KDNuggets 博客中文翻译(一)
原文:KDNuggets
协议:CC BY-NC-SA 4.0
使用 Python、SpaCy 和 Streamlit 构建结构化金融新闻源
原文:www.kdnuggets.com/2021/09/-structured-financial-newsfeed-using-python-spacy-and-streamlit.html
评论
由 Harshit Tyagi,数据科学讲师 | 导师 | YouTuber
![使用 Python、SpaCy 和 Streamlit 构建结构化金融新闻源]()
自然语言处理的一个非常有趣且广泛使用的应用是命名实体识别(NER)。
从原始和非结构化数据中获取洞察至关重要。上传文档并从中提取重要信息被称为信息检索。
信息检索一直是自然语言处理中的一项主要任务/挑战。命名实体识别(或命名实体链接)在多个领域(如金融、药品、电子商务等)中用于信息检索目的。
在这个教程帖子中,我将展示你如何利用 NEL 开发一个自定义的股票市场新闻源,列出互联网上的热门股票。
先决条件
没有特别的先决条件。你可能需要对 Python 和 NLP 的基本任务(如分词、词性标注、依存解析等)有一些了解。
我将详细介绍重要的部分,所以即使你是完全的初学者,也能理解发生了什么。
所以,让我们开始吧,跟着做,你将会有一个简洁的股票新闻源,你可以开始研究了。
你需要的工具/设置:
-
Google Colab 用于数据和 SpaCy 库的初步测试和探索。
-
使用 VS Code(或任何编辑器)来编写 Streamlit 应用程序。
-
股票市场信息(新闻)的来源,我们将对其进行 NER 和后续的 NEL。
-
需要一个虚拟的 Python 环境(我使用的是 conda),以及 Pandas、SpaCy、Streamlit 和 Streamlit-Spacy(如果你想展示一些 SpaCy 渲染结果的话)等库。
目标
本项目的目标是学习并应用命名实体识别,提取重要的实体(在我们的示例中为上市公司),然后使用知识库(Nifty500 公司名单)将每个实体与一些信息进行链接。
我们将从互联网上的 RSS 源获取文本数据,提取热门股票的名称,然后获取这些股票的市场价格数据,以在对这些股票采取任何操作之前测试新闻的真实性。
注意:命名实体识别可能不是最前沿的问题,但在行业中有许多应用。
继续使用 Google Colab 进行实验和测试:
第一步:提取热门股票新闻数据
为了获得可靠的真实股市新闻,我将使用Economic Times和Money Control RSS 源进行本教程,但你也可以使用/添加你所在国家的 RSS 源或 Twitter/Telegram(群组)数据,以使你的源更具信息性/准确性。
机会是巨大的。本教程应作为应用 NEL 构建不同领域应用程序的垫脚石,解决不同类型的信息检索问题。
如果你查看 RSS 源,它看起来像这样:
![]()
economictimes.indiatimes.com/markets/rssfeeds/1977021501.cms
我们的目标是从这个 RSS 源中获取文本标题,然后使用 SpaCy 提取标题中的主要实体。
标题位于 XML 的
标签中。</p>
<p>首先,我们需要捕获整个 XML 文档,可以使用<code>**requests**</code>库来完成。确保你在 colab 的运行时环境中安装了这些包。</p>
<p>你可以运行以下命令来从 colab 的代码单元中安装几乎任何包:</p>
<pre><code class="language-py">!pip install <package_name>
</code></pre>
<p>发送一个<code>GET</code>请求到提供的链接以获取 XML 文档。</p>
<pre><code class="language-py">import requestsresp = requests.get("https://economictimes.indiatimes.com/markets/stocks/rssfeeds/2146842.cms")
</code></pre>
<p>运行单元以检查响应对象中得到的内容。</p>
<p>它应该会给你一个带有 HTTP 代码 200 的成功响应,如下所示:</p>
<p><img src="https://kdn.flygon.net/docs/img/32fa6a5235798fcfe47128fcc891a836.png" alt="" loading="lazy"></p>
<p>现在你有了这个响应对象,我们可以将其内容传递给 BeautifulSoup 类来解析 XML 文档,如下所示:</p>
<pre><code class="language-py">from bs4 import BeautifulSoupsoup = BeautifulSoup(resp.content, features='xml')
soup.findAll('title')
</code></pre>
<p>这将给你一个包含所有标题的 Python 列表:</p>
<p><img src="https://kdn.flygon.net/docs/img/d243f2acf112117879f8e373ee8221c3.png" alt="" loading="lazy"></p>
<p>图片由作者提供</p>
<p>太棒了,我们已经得到了文本数据,我们将使用 NLP 从中提取主要实体(在本例中是上市公司)。</p>
<p>现在是将 NLP 应用到实践中的时候了。</p>
<h2 id="第-2-步从标题中提取实体">第 2 步:从标题中提取实体</h2>
<p>这是激动人心的部分。我们将使用来自<code>**spaCy**</code>库的<strong>预训练核心语言模型</strong>来提取标题中的主要实体。</p>
<p>关于 spaCy 和核心模型的简要介绍。</p>
<p><strong>spaCy</strong>是一个开源 NLP 库,以超快的速度处理文本数据。它是 NLP 研究中的领先库,被广泛用于企业级应用中。spaCy 以其适应问题的能力而闻名,并且支持超过 64 种语言,能够很好地与 TensorFlow 和 PyTorch 兼容。</p>
<p>说到核心模型,spaCy 具有两个主要类别的预训练语言模型,这些模型在不同大小的文本数据上进行训练,以提供最先进的推断。</p>
<ol>
<li>
<p>核心模型——用于通用的基础 NLP 任务。</p>
</li>
<li>
<p>起始模型——用于需要迁移学习的特定应用程序。我们可以利用模型的学习权重来微调我们的自定义模型,而无需从头开始训练模型。</p>
</li>
</ol>
<p>由于我们在这个教程中的用例是基本的,我们将继续使用 <code>en_core_web_sm</code> 核心模型管道。</p>
<p>那么,让我们将它加载到笔记本中:</p>
<pre><code class="language-py">nlp = spacy.load("en_core_web_sm")
</code></pre>
<p><em><strong>注意:</strong></em> Colab 已经为我们下载了这个模型,但如果你尝试在本地系统中运行,你需要使用以下命令首先下载模型:</p>
<pre><code class="language-py">python -m spacy [download](https://spacy.io/api/cli#download) en_core_web_sm
</code></pre>
<p><code>en_core_web_sm</code> 基本上是一个针对 CPU 优化的英语管道,具有以下组件:</p>
<ul>
<li>
<p>tok2vec — 将令牌转换为向量(对文本数据进行标记化),</p>
</li>
<li>
<p>tagger — 为每个令牌添加相关的元数据。spaCy 利用一些统计模型来预测每个令牌的词性(POS)。更多信息请参见 <a href="https://spacy.io/models/en" target="_blank">文档</a>。</p>
</li>
<li>
<p>parser — 依赖解析器在令牌之间建立关系。</p>
</li>
<li>
<p>其他组件包括 senter、ner、attribute_ruler、lemmatizer。</p>
</li>
</ul>
<p>现在,为了测试这个模型能为我们做什么,我会将一个单独的标题传递给实例化的模型,然后检查句子的不同部分。</p>
<pre><code class="language-py"># make sure you extract the text out of <title> tagsprocessed_hline = nlp(headlines[4].text)
</code></pre>
<p>该管道执行从标记化到命名实体识别(NER)的所有任务。这里我们首先得到令牌:</p>
<p><img src="https://kdn.flygon.net/docs/img/6d2917dbe55b3aaa0813afa881b488a9.png" alt="" loading="lazy"></p>
<p>图片来源于作者</p>
<p>你可以使用 <code>pos_</code> 属性查看标记的词性。</p>
<p><img src="https://kdn.flygon.net/docs/img/5efb57780795368a90a99a8bafe56987.png" alt="" loading="lazy"></p>
<p>图片来源于作者</p>
<p>每个令牌都带有一些元数据。例如,“Trade”是专有名词,“Setup”是名词,“:`” 是标点符号,等等。所有标签的完整列表可以在 <a href="https://spacy.io/models/en" target="_blank">这里</a> 找到。</p>
<p>然后,你可以通过查看依赖图来了解它们之间的关系,使用 <code>dep_</code> 属性:</p>
<p><img src="https://kdn.flygon.net/docs/img/45aabe9dbacbb7638e622b37d4f2b7a8.png" alt="" loading="lazy"></p>
<p>图片来源于作者</p>
<p>这里,“Trade”是复合词,“Setup”是根词,“Nifty”是同位语修饰语。再次说明,所有语法标签可以在 <a href="https://spacy.io/models/en" target="_blank">这里</a> 找到。</p>
<p>你还可以使用以下的 displacy <code>render()</code> 方法来可视化令牌之间的关系依赖:</p>
<pre><code class="language-py">spacy.displacy.render(processed_hline, style='dep',jupyter=True, options={'distance': 120})
</code></pre>
<p>这将生成如下图表:</p>
<p><img src="https://kdn.flygon.net/docs/img/aaf67d47e41b6990f01d0a7e67f61cc6.png" alt="" loading="lazy"></p>
<p>图片来源于作者</p>
<h2 id="实体提取">实体提取</h2>
<p>要查看句子的主要实体,你可以在同一代码中将 <code>**'ent’**</code> 作为样式传递:</p>
<p><img src="https://kdn.flygon.net/docs/img/aca72aeee53f1c5d7988bf6430bc89e4.png" alt="" loading="lazy"></p>
<p>图片来源于作者 — 我使用了另一个标题,因为我们上面用的那个没有任何实体。</p>
<p>我们对不同的实体有不同的标签,例如“day”有 DATE 标签,“Glasscoat”有 GPE 标签,可以是国家/城市/州。我们主要寻找带有 ORG 标签的实体,这些标签能给我们公司、机构、组织等信息。</p>
<p>我们现在能够从文本中提取实体。让我们来提取所有标题中的组织实体。</p>
<p>这将返回如下的公司列表:</p>
<p><img src="https://kdn.flygon.net/docs/img/ea49df1fea8fe173af6aa627ea237b75.png" alt="" loading="lazy"></p>
<p>图片来源于作者</p>
<p>很简单,对吧?</p>
<p>这就是 spaCy 的魔力!</p>
<p>下一步是查找所有这些公司在知识库中,以提取该公司的正确股票符号,然后使用像 yahoo-finance 这样的库提取市场详情,如价格、收益等。</p>
<h2 id="第三步--命名实体链接">第三步 — 命名实体链接</h2>
<p>了解市场上哪些股票在活跃,并在你的仪表板上获取其详细信息是这个项目的目标。</p>
<p>我们有公司名称,但为了获取它们的交易详情,我们需要公司的交易股票符号。</p>
<p>由于我在提取印度公司的详细信息和新闻,我将使用<a href="https://www1.nseindia.com/products/content/equities/indices/nifty_500.htm" target="_blank">Nifty 500 公司(一个 CSV 文件)</a>的外部数据库。</p>
<p>对于每家公司,我们将使用 pandas 在公司列表中查找它,然后使用<a href="https://pypi.org/project/yfinance/" target="_blank">yahoo-finance</a>库捕获股票市场统计数据。</p>
<p>图片由作者提供</p>
<p>你应该注意到的一点是,我在将每个股票符号传递给<code>yfinance</code>库的<code>Ticker</code>类之前,添加了一个<code>.NS</code>后缀。这是因为印度 NSE 股票符号在<code>yfinance</code>中以<code>.NS</code>后缀存储。</p>
<p>之后,流行的股票将会出现在如下的数据框中:</p>
<p><img src="https://kdn.flygon.net/docs/img/8a464b3bde7133a42af081ddc2a1cce0.png" alt="" loading="lazy"></p>
<p>图片由作者提供</p>
<p>太好了!这是不是很棒?这样一个简单却深刻的应用程序,可以帮助你找到正确的股票方向。</p>
<p>现在,为了使其更易于访问,我们可以使用 Streamlit 将刚刚编写的代码创建为 Web 应用程序。</p>
<h2 id="第四步--使用-streamlit-构建-web-应用程序">第四步 — 使用 Streamlit 构建 Web 应用程序</h2>
<p>该是移动到编辑器,创建一个新项目和虚拟环境来进行 NLP 应用程序的时候了。</p>
<p>开始使用 Streamlit 对于这样的演示数据应用程序非常简单。确保你已经安装了 streamlit。</p>
<pre><code class="language-py">pip install Streamlit
</code></pre>
<p>现在,让我们创建一个名为 app.py 的新文件,并开始编写功能代码以准备应用程序。</p>
<p>在顶部导入所有所需的库。</p>
<pre><code class="language-py">import pandas as pdimport requestsimport spacyimport streamlit as stfrom bs4 import BeautifulSoupimport yfinance as yf
</code></pre>
<p>给你的应用程序添加一个标题:</p>
<pre><code class="language-py">st.title('Buzzing Stocks :zap:')
</code></pre>
<p>通过在终端中运行<code>streamlit run app.p</code>y 来测试你的应用程序。它应该会在你的 Web 浏览器中打开一个应用程序。</p>
<p>我添加了一些额外的功能,以从多个来源捕获数据。现在,你可以将你选择的 RSS 源 URL 添加到应用程序中,数据将被处理,趋势股票将在数据框中显示出来。</p>
<p>要访问完整的代码库,你可以查看我的仓库:</p>
<p><strong><a href="https://github.com/dswh/NER_News_Feed" target="_blank">GitHub - dswh/NER_News_Feed</a></strong></p>
<p>你可以添加多个样式元素、不同的数据源和其他类型的处理,以提高其效率和实用性。</p>
<p>我当前状态下的应用程序看起来像横幅中的图片。</p>
<p>如果你想逐步跟随我,请在这里观看我编写这个应用程序的过程:</p>
<h2 id="下一步">下一步!</h2>
<p>除了选择一个金融应用案例外,你也可以选择其他你喜欢的应用。医疗保健、电子商务、研究等等。所有行业都需要处理文档并提取和链接重要实体。尝试另一个想法。</p>
<p>一个简单的想法是提取研究论文中所有重要的实体,然后使用谷歌搜索 API 创建一个知识图谱。</p>
<p>此外,如果你想将股票新闻推送应用提升到另一个水平,你还可以添加一些交易算法来生成买卖信号。</p>
<p>我鼓励你放飞你的想象力。</p>
<h2 id="如何与我联系">如何与我联系!</h2>
<p>如果你喜欢这篇文章并想看到更多类似内容,你可以订阅<a href="https://dswharshit.substack.com/publish/settings#twitter-account" target="_blank"><strong>我的新闻通讯</strong></a><strong>或</strong><a href="https://www.youtube.com/channel/UCH-xwLTKQaABNs2QmGxK2bQ" target="_blank"><strong>我的 YouTube 频道</strong></a>,我会继续分享这样有用且快捷的项目。</p>
<p>如果你是刚开始编程的人或想进入数据科学或机器学习领域,你可以查看我在<a href="https://www.wiplane.com/p/foundations-for-data-science-ml" target="_blank"><strong>WIP Lane Academy</strong></a><strong>的课程</strong>。</p>
<p>感谢 Elliot Gunn。</p>
<p><strong>简介:<a href="https://www.linkedin.com/in/tyagiharshit/" target="_blank">Harshit Tyagi</a></strong> 是一位具有综合网页技术和数据科学(即全栈数据科学)经验的工程师。他已经指导了超过 1000 名 AI/网页/数据科学的求职者,并设计了数据科学和机器学习工程学习课程。此前,Harshit 与耶鲁大学、麻省理工学院和加州大学洛杉矶分校的研究科学家一起开发了数据处理算法。</p>
<p><a href="https://dswharshit.medium.com/d19736fdd70c" target="_blank">原文</a>. 经许可转载。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p>2021 年数据科学学习路线图</p>
</li>
<li>
<p>机器学习如何利用线性代数解决数据问题</p>
</li>
<li>
<p>学习数据科学和机器学习:路线图后的第一步</p>
</li>
</ul>
<hr>
<h2 id="我们的前三个课程推荐">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业道路。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能。</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织进行 IT 维护。</p>
<hr>
<h3 id="更多相关内容">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/06/structured-approach-building-machine-learning-model.html" target="_blank">构建机器学习模型的结构化方法</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/11/getting-started-spacy-nlp.html" target="_blank">使用 spaCy 进行 NLP 入门</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/01/natural-language-processing-spacy.html" target="_blank">使用 spaCy 进行自然语言处理</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/02/deploying-streamlit-webapp-heroku-dagshub.html" target="_blank">使用 DAGsHub 将 Streamlit WebApp 部署到 Heroku</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/10/simple-question-answering-web-app-hugging-face-pipelines.html" target="_blank">使用 HuggingFace Pipelines 和 Streamlit 回答问题</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/11/diy-automated-machine-learning-app.html" target="_blank">使用 Streamlit 进行 DIY 自动化机器学习</a></p>
</li>
</ul>
<h1 id="人工智能">=<mark>人工智能</mark>=</h1>
<h1 id="在边缘-ai-应用中最大化性能">在边缘 AI 应用中最大化性能</h1>
<blockquote>
<p><a href="https://www.kdnuggets.com/maximize-performance-in-edge-ai-applications" target="_blank"><code>www.kdnuggets.com/maximize-performance-in-edge-ai-applications</code></a></p>
</blockquote>
<p>随着 AI 从云端迁移到边缘,我们看到这项技术在不断扩展的应用场景中得到使用——从异常检测到包括智能购物、监控、机器人技术和工厂自动化的应用。因此,没有一种通用的解决方案。但随着摄像头启用设备的快速增长,AI 已被广泛应用于分析实时视频数据,以自动化视频监控,提升安全性,提高操作效率,并提供更好的客户体验,最终在其行业中获得竞争优势。为了更好地支持视频分析,你必须了解优化边缘 AI 部署系统性能的策略。</p>
<h1 id="优化-ai-系统性能的策略包括">优化 AI 系统性能的策略包括</h1>
<ul>
<li>选择合适大小的计算引擎,以满足或超越所需的性能水平。对于 AI 应用,这些计算引擎必须执行整个视觉管道的功能(即,视频的前处理和后处理、神经网络推理)。</li>
</ul>
<p>可能需要一个专用的 AI 加速器,无论是独立的还是集成在 SoC 中(而不是在 CPU 或 GPU 上运行 AI 推理)。</p>
<ul>
<li>
<p>理解吞吐量和延迟之间的区别;其中吞吐量是系统中数据处理的速率,而延迟则衡量数据通过系统的处理延迟,并且通常与实时响应性相关。例如,系统可以以每秒 100 帧的速度生成图像数据(吞吐量),但图像通过系统的时间是 100 毫秒(延迟)。</p>
</li>
<li>
<p>考虑未来轻松扩展 AI 性能以适应不断增长的需求、变化的要求和不断发展的技术(例如,更先进的 AI 模型以提高功能性和准确性)。你可以通过使用模块化格式的 AI 加速器或额外的 AI 加速器芯片来实现性能扩展。</p>
</li>
</ul>
<h1 id="理解可变-ai-性能要求">理解可变 AI 性能要求</h1>
<p>实际的性能要求依赖于应用。通常,可以预期对于视频分析,系统必须处理来自摄像头的数据流,速率为每秒 30-60 帧,分辨率为 1080p 或 4k。一台 AI 启用的摄像头将处理单个流;一个边缘设备将并行处理多个流。在任何情况下,边缘 AI 系统必须支持预处理功能,将摄像头的传感器数据转换为符合 AI 推理部分输入要求的格式(见图 1)。</p>
<p>预处理功能接收原始数据,执行如调整大小、归一化和颜色空间转换等任务,然后将输入数据提供给运行在 AI 加速器上的模型。预处理可以使用高效的图像处理库,如 OpenCV,以减少预处理时间。后处理涉及分析推理的输出。它使用如非极大值抑制(NMS 解释大多数目标检测模型的输出)和图像显示等任务生成可操作的见解,如边界框、类别标签或置信度分数。</p>
<p><img src="https://kdn.flygon.net/docs/img/00e9b9c92eb05e73b077e71869076f03.png" alt="最大化边缘 AI 应用的性能" loading="lazy"></p>
<p>图 1. 对于 AI 模型推理,预处理和后处理功能通常在应用处理器上执行。</p>
<p>AI 模型推理可能面临额外的挑战,即每帧处理多个神经网络模型,具体取决于应用的能力。计算机视觉应用通常涉及多个 AI 任务,需要多个模型的流水线。此外,一个模型的输出通常是下一个模型的输入。换句话说,应用中的模型通常彼此依赖,并且必须按顺序执行。要执行的模型集合可能不是静态的,甚至可能在每帧之间动态变化。</p>
<p>运行多个模型动态的挑战需要一个外部 AI 加速器,该加速器需配备专用且足够大的内存来存储这些模型。由于 SoC 中共享内存子系统和其他资源的限制,SoC 内部集成的 AI 加速器通常无法管理多模型工作负载。</p>
<p>例如,基于运动预测的物体跟踪依赖于连续检测来确定一个向量,这个向量用于识别未来位置的跟踪物体。由于缺乏真正的重识别能力,这种方法的效果有限。使用运动预测时,物体的轨迹可能因错过检测、遮挡或物体暂时离开视野而丢失。一旦丢失,就无法重新关联物体的轨迹。增加重识别功能可以解决这个限制,但需要一个视觉外观嵌入(即图像指纹)。外观嵌入需要第二个网络来通过处理包含在第一个网络检测到的物体边界框内的图像来生成特征向量。这个嵌入可以用来重新识别物体,无论时间或空间如何。由于必须为视野中的每个检测到的物体生成嵌入,因此随着场景变得更加繁忙,处理要求也会增加。带有重识别的物体跟踪需要在执行高精度/高分辨率/高帧率检测和保留足够的开销以便嵌入可扩展性之间进行仔细权衡。解决处理需求的一种方法是使用专用的 AI 加速器。如前所述,SoC 的 AI 引擎可能会受到共享内存资源不足的影响。模型优化也可以用来降低处理需求,但可能会影响性能和/或精度。</p>
<h1 id="不要让系统级开销限制-ai-性能">不要让系统级开销限制 AI 性能</h1>
<p>在智能摄像头或边缘设备中,集成的 SoC(即主处理器)获取视频帧并执行我们之前描述的预处理步骤。这些功能可以由 SoC 的 CPU 核心或 GPU(如果有的话)来执行,也可以由 SoC 中的专用硬件加速器(例如图像信号处理器)来完成。在这些预处理步骤完成后,集成在 SoC 中的 AI 加速器可以直接访问系统内存中的量化输入,或者在离散 AI 加速器的情况下,输入则通过 USB 或 PCIe 接口传递进行推理。</p>
<p>集成 SoC 可以包含一系列计算单元,包括 CPU、GPU、AI 加速器、视觉处理器、视频编码器/解码器、图像信号处理器(ISP)等。这些计算单元共享相同的内存总线,从而访问相同的内存。此外,CPU 和 GPU 可能还需要在推理中发挥作用,并且这些单元在部署系统中将忙于运行其他任务。这就是我们所说的系统级开销(见图 2)。</p>
<p>许多开发人员错误地评估了 SoC 内置 AI 加速器的性能,而没有考虑系统级开销对整体性能的影响。例如,考虑在 SoC 中运行一个 50 TOPS 的 AI 加速器上的 YOLO 基准测试,可能会得到 100 次推断/秒 (IPS) 的基准结果。但在实际部署的系统中,所有其他计算单元都在活动时,这 50 TOPS 可能会减少到约 12 TOPS,而整体性能只会得到 25 IPS,假设使用了宽松的 25% 利用率因素。系统开销始终是一个因素,特别是当平台持续处理视频流时。相反,使用离散 AI 加速器(例如,Kinara Ara-1、Hailo-8、Intel Myriad X),系统级利用率可能会超过 90%,因为一旦主 SoC 启动推断功能并传输 AI 模型的输入数据,加速器会自主运行,利用其专用内存访问模型权重和参数。</p>
<p><img src="https://kdn.flygon.net/docs/img/169f84e82b6cf6d3a162e4e1d5f12db8.png" alt="在边缘 AI 应用中最大化性能" loading="lazy"></p>
<p>图 2. 共享内存总线将决定系统级性能,此处显示了估计值。实际值将根据你的应用使用模型和 SoC 的计算单元配置有所不同。</p>
<h1 id="边缘的视频分析需要低延迟">边缘的视频分析需要低延迟</h1>
<p>到目前为止,我们讨论了以每秒帧数和 TOPS 作为衡量标准的 AI 性能。但低延迟是提供系统实时响应的另一个重要要求。例如,在游戏中,低延迟对于无缝和响应迅速的游戏体验至关重要,尤其是在动作控制游戏和虚拟现实 (VR) 系统中。在自动驾驶系统中,低延迟对于实时物体检测、行人识别、车道检测和交通标志识别至关重要,以避免影响安全。自动驾驶系统通常要求从检测到实际动作的端到端延迟小于 150 毫秒。类似地,在制造业中,低延迟对实时缺陷检测、异常识别和机器人指导至关重要,依赖于低延迟视频分析以确保高效操作并减少生产停机时间。</p>
<p>一般来说,视频分析应用中的延迟有三个组成部分(图 3):</p>
<ul>
<li>
<p>数据捕获延迟是指从相机传感器捕获视频帧到帧可用于分析系统处理的时间。你可以通过选择具有快速传感器和低延迟处理器的相机、选择最佳帧率和使用高效的视频压缩格式来优化这个延迟。</p>
</li>
<li>
<p>数据传输延迟是指从相机捕获并压缩的视频数据传输到边缘设备或本地服务器的时间。这包括每个端点发生的网络处理延迟。</p>
</li>
<li>
<p>数据处理延迟是指边缘设备执行视频处理任务的时间,如帧解压和分析算法(例如,基于运动预测的物体跟踪、人脸识别)。正如前面提到的,对于需要在每个视频帧上运行多个 AI 模型的应用程序,处理延迟尤为重要。</p>
</li>
</ul>
<p><img src="https://kdn.flygon.net/docs/img/7f4b95b9683367052948b86bce43b23a.png" alt="最大化边缘 AI 应用中的性能" loading="lazy"></p>
<p>图 3. 视频分析管道包括数据捕获、数据传输和数据处理。</p>
<p>数据处理延迟可以通过使用设计为最小化芯片上数据移动和计算与各种内存层次之间数据移动的 AI 加速器来优化。此外,为了提高延迟和系统级效率,架构必须支持模型之间的零(或接近零)切换时间,以更好地支持我们之前讨论的多模型应用。另一个提升性能和延迟的因素与算法灵活性有关。换句话说,一些架构仅针对特定 AI 模型优化行为,但随着 AI 环境的迅速变化,每隔一天似乎就有新的高性能和更高精度的模型出现。因此,选择一种对模型拓扑、操作符和大小没有实际限制的边缘 AI 处理器。</p>
<p>在边缘 AI 设备中,最大化性能需要考虑许多因素,包括性能和延迟要求以及系统开销。成功的策略应该考虑使用外部 AI 加速器,以克服 SoC 的 AI 引擎中的内存和性能限制。</p>
<p><strong><a href="https://www.linkedin.com/in/c-h-chee/" target="_blank">C.H. Chee</a></strong> 是一位成功的产品营销和管理高管,Chee 在推广半导体行业的产品和解决方案方面具有广泛经验,专注于基于视觉的 AI、连接性和视频接口,涵盖企业和消费市场。作为一名企业家,Chee 联合创办了两家视频半导体初创公司,这些公司后来被一家上市半导体公司收购。Chee 领导过产品营销团队,喜欢与专注于取得出色成果的小团队合作。</p>
<h3 id="更多相关信息">更多相关信息</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/maximize-productivity-data-scientist-organizing.html" target="_blank">通过组织工作最大化您的数据科学家生产力</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/bay-path-maximize-value-online-masters-data-science.html" target="_blank">通过第三名最佳在线数据硕士课程最大化您的价值…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/10/machine-learning-edge.html" target="_blank">边缘上的机器学习</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/qualcomm-windows-on-snapdragon-brings-hybrid-ai-to-apps-at-the-edge" target="_blank">Windows on Snapdragon 将混合 AI 引入边缘应用</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/04/introducing-tpu-v4-googles-cutting-edge-supercomputer-large-language-models.html" target="_blank">介绍 TPU v4:谷歌前沿超级计算机用于大型语言模型</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/the-promise-of-edge-ai-and-approaches-for-effective-adoption" target="_blank">边缘 AI 的承诺及其有效采纳的方法</a></p>
</li>
</ul>
<h1 id="我们可以期待-gpt-5-带来什么">我们可以期待 GPT-5 带来什么?</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2023/06/expect-gpt5.html" target="_blank"><code>www.kdnuggets.com/2023/06/expect-gpt5.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/6068774983714942e1d98cd6dfd25fc5.png" alt="我们可以期待 GPT-5 带来什么?" loading="lazy"></p>
<p>编辑提供的图片</p>
<p>跟上 AI 和技术的快速发展可能看起来非常困难。每周或每月,总会有新的东西出现,现在你又在这里学习新的内容!</p>
<p>这次是 GPT-5。</p>
<p>GPT-4 于 2023 年 3 月发布,自那时以来,大家一直在等待 GPT-5 的发布。Siqi Chen 在 3 月 27 日<a href="https://twitter.com/blader/status/1640217165822578688" target="_blank">发推</a>称“GPT-5 计划在今年 12 月完成训练。”然而,OpenAI 首席执行官 Sam Altman 在 4 月的<a href="https://www.imaginationinaction.co/the-future-of-business-with-ai" target="_blank">MIT 活动</a>上被问及 GPT-5 时澄清道,“我们不会,也不会在一段时间内发布”。</p>
<p>这就澄清了这一点。然而,一些专家建议 OpenAI 在 2023 年第三季度或第四季度发布 GPT-4.5,作为 GPT-4 和 GPT-5 之间的一个中间版本。当前模型总是在不断改进,这可能成为 GPT-4.5 的一个潜在发布。许多人认为 GPT-4.5 具备多模态能力,这在 2023 年 3 月的 GPT-4 开发者直播中已有展示。</p>
<p>尽管对 GPT-5 有很高的期望,GPT-4 仍然需要解决一些问题。例如,GPT-4 的推理时间非常长,同时运行成本也很高。还有其他挑战,比如访问 GPT-4 的 API。</p>
<p>尽管还有很多工作要做,但我们可以说的是,每一次 GPT 的发布都推动了 AI 技术及其能力的边界。AI 爱好者们对探索 GPT-5 的突破性特性感到兴奋。</p>
<p>那么我们可以期待 GPT-5 带来哪些功能呢?让我们来了解一下。</p>
<h1 id="减少幻觉">减少幻觉</h1>
<p>这全关乎信任,这是大多数用户不相信 AI 模型的主要原因。例如,GPT-4 在内部事实评估中的得分比 GPT-3.5 高 40%,如下面的图片所示。这意味着 GPT-4 在回应不允许的内容方面的可能性更小,产生事实性回应的可能性比 GPT-3.5 高 40%。</p>
<p>随着新版本不断改进当前挑战,据说 GPT-5 将把幻觉减少到 10%以下,使大型语言模型(LLM)更值得信赖。</p>
<p><img src="https://kdn.flygon.net/docs/img/6dbc33e2d097d20a1a2e0b6d1bb2eecb.png" alt="我们可以期待 GPT-5 带来什么?" loading="lazy"></p>
<p>图片来源于<a href="https://openai.com/research/gpt-4" target="_blank">OpenAI</a></p>
<h1 id="计算效率">计算效率</h1>
<p>如前所述,GPT-4 的计算成本非常高,每个 token $0.03。这与 GPT-3.5 的$0.002 成本相比差距巨大。GPT-4 在一万亿参数数据集和基础设施上训练,反映了其成本。</p>
<p>而谷歌的 PaLM 2 模型仅在 3400 亿参数上进行训练,并且性能高效。如果 OpenAI 计划与谷歌的 PaLM 2 竞争,他们需要寻找降低成本和缩小 GPT-4 参数规模的方法,同时保持性能。</p>
<p>另一个需要关注的方面是更好的推理时间,即深度学习模型预测新数据所需的时间。GPT-4 的功能和插件越多,计算效率也就越高。开发者们已经向 OpenAI 抱怨 GPT-4 的 API 经常停止响应,这迫使他们使用 GPT-3.5。</p>
<p>考虑到所有这些,我们可以期待 OpenAI 通过推出更小、更便宜、更高效的 GPT-5 来克服这些挑战。</p>
<h1 id="多感官">多感官</h1>
<p>在 GPT-4 发布之前,很多人对其多模态能力感到疯狂。尽管这尚未添加到 GPT-4 中,但这可能是 GPT-5 出现并真正成为明星的地方,使其真正实现多模态。</p>
<p>我们不仅可以期待它处理图像和文本,还可以处理音频、视频、温度等更多内容。萨姆·奥特曼在一次采访中表示<em>“我非常期待看到当我们能够处理视频时会发生什么,世界上有很多视频内容。很多事情用视频学习比用文本更容易。”</em></p>
<p>增加可以用来使对话更具动态性和互动性的数据类型。多模态能力将是通向人工通用智能(AGI)的最快途径。</p>
<h1 id="长期记忆">长期记忆</h1>
<p>GPT-4 的最大令牌长度为 32 千个令牌,这在当时令人印象深刻。但随着世界上不断推出新模型,我们已经有如 Story Writer 这样的模型能够输出 65 千个令牌。</p>
<p>为了跟上当前的竞争,我们可以期待 GPT-5 引入更长的上下文长度,使用户能够拥有能够记住他们的个性和历史多年之久的 AI 朋友。</p>
<h1 id="改进的上下文理解">改进的上下文理解</h1>
<p>作为一个大型语言模型(LLM),我们可以期待的第一件事是对上下文理解能力的提升。如果我们将其与上面提到的长期记忆结合起来,GPT-5 可能具有在长时间对话中保持上下文的潜力。作为用户,你将获得更多量身定制且符合要求的有意义的回应。</p>
<p>随之而来的是对语言的更高级理解,其中自然语言的主要组成部分是情感。GPT-5 在上下文理解方面的潜在能力可以使其更具同理心,并生成适当的回复以继续参与对话。</p>
<h1 id="总结">总结</h1>
<p>关于 GPT-5 潜在能力还有很多未知,我们要等到发布时才能了解更多信息。本文基于 GPT-4 和 GPT-3.5 目前面临的挑战,以及 OpenAI 如何利用这些障碍克服困难,推出高性能的 GPT-5。</p>
<p><strong><a href="https://www.linkedin.com/in/nisha-arya-ahmed/" target="_blank">尼莎·阿利亚</a></strong> 是一位数据科学家、自由技术写作人以及 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能在延长人类寿命方面的不同应用方式。作为一个热衷学习的人,她寻求扩展自己的技术知识和写作技能,同时帮助指导他人。</p>
<h3 id="更多相关话题">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2023/06/2023-ai-index-report-ai-trends-expect-future.html" target="_blank">2023 年 AI 指数报告:未来我们可以预期的 AI 趋势</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/01/expect-career-path-data-scientist.html" target="_blank">作为数据科学家的职业发展预期</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/11/expect-ai-quality-trends-2023.html" target="_blank">2023 年人工智能质量趋势的预期</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/02/data-scientists-expect-flawed-advice-google-bard.html" target="_blank">数据科学家为何期望从 Google Bard 得到有缺陷的建议</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/04/odsc-15-trending-mlops-talks-access-free-odsc-east-2022.html" target="_blank">ODSC East 2022 免费访问的 15 个热门 MLOps 讲座</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/04/artificial-intelligence-transform-data-integration.html" target="_blank">人工智能如何改变数据集成</a></p>
</li>
</ul>
<h1 id="什么是谷歌-ai-bard">什么是谷歌 AI Bard?</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2023/03/google-ai-bard.html" target="_blank"><code>www.kdnuggets.com/2023/03/google-ai-bard.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/3c02d03924e5411c0f94ae7aa8583537.png" alt="什么是谷歌 AI Bard?" loading="lazy"></p>
<p>作者提供的图片</p>
<p>当大家都在疯狂讨论 ChatGPT 时,谷歌突然发布了他们自己实验性的 AI 驱动聊天机器人 - 谷歌 Bard。你可以看到竞争非常激烈,谷歌需要作出回应。但这是否是对 ChatGPT 的回应,还是谷歌 Bard 已在筹备中?</p>
<hr>
<h2 id="我们的前三个课程推荐-1">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业的快车道。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你组织的 IT</p>
<hr>
<h1 id="大揭密谷歌-ai-bard">大揭密:谷歌 AI Bard</h1>
<p>所以现在我们知道谷歌 Bard 是谷歌对 OpenAI 的 ChatGPT 的回应。让我们进一步了解它。它具有相同的主要特点 - 它是一个人工智能聊天机器人。它能够以对话的方式回应不同的查询。</p>
<p>它利用网络上的信息,提供高质量、最新且易于用户理解的回应。谷歌 Bard 结合了机器学习和自然语言处理(NLP)来为用户提供这些高质量而现实的回应。</p>
<p>谷歌 Bard 旨在将其增强到谷歌的搜索工具中,并为企业提供自动化支持和其他可以完成的类似人类的交互任务。必应已经将 ChatGPT 融入其网站,实现了更好的搜索、浏览和聊天体验。</p>
<p>除了作为谷歌搜索工具的一部分外,它还可以集成到网站、消息平台、桌面和移动应用程序等更多领域。这一切将在他们有限的测试服务完成后提供。你可以通过查看下面的谷歌互动图像了解这一点:</p>
<p><img src="https://kdn.flygon.net/docs/img/f1fcc338b827587649a9eb5dfef5af16.png" alt="什么是谷歌 AI Bard?" loading="lazy"></p>
<p>图片由 <a href="https://blog.google/technology/ai/bard-google-ai-search-updates/" target="_blank">谷歌</a> 提供</p>
<h1 id="它是如何工作的">它是如何工作的?</h1>
<p>谷歌的知识图谱是他们连接信息的一种方式。知识图谱卡片包含与特定搜索相关的背景信息。谷歌希望 Bard 与知识图谱卡片协调工作,然而,Bard 对 NORA 问题做出回应。NORA 代表“没有唯一正确答案”。</p>
<p>为了使其有效,Bard 使用了 <a href="https://blog.google/technology/ai/lamda/" target="_blank">LaMDA</a>,一个对话应用语言模型,以更好地理解请求/问题并应用上下文。然后,Bard 利用网络从各种信息中提取内容来形成回答。接着,这些内容被转换成你通常与人类进行的对话回应。</p>
<h2 id="什么是-lamda">什么是 LaMDA?</h2>
<p>两年前,Google 揭示了他们的对话应用语言模型(LaMDA)。</p>
<p>Google 的语言模型 LaMDA 基于 Transformer,这是一种 Google Research 在 2017 年发明的神经网络架构。它还结合了多模态用户意图、强化学习和建议。</p>
<p>该模型经过训练以阅读和理解文字,从句子到段落。然后,它会利用这些理解寻找关系,以预测下一个可能出现的词。我们可以说 LaMDA 是一种统计方法,因为它基于之前的词预测未来的词。这使得聊天机器人能够以流畅的方式进行对话,从一个话题转到另一个话题。</p>
<p>LaMDA 的主要优点是它使用更少的计算资源,允许可扩展性,并提供更有效的反馈系统,这由 Google 自身的内部测试完成。</p>
<h1 id="我如何使用-google-bard">我如何使用 Google Bard?</h1>
<p>在撰写本文时,Google Bard 目前仅对有限的测试人员开放。然而,近期有计划使其变得更加可及。</p>
<p>如果你是这些测试人员之一,可以通过打开 Google 应用程序,点击聊天机器人图标,开始对话或提出请求来使用 Google Bard。</p>
<p>Google 已达到其测试小组的限制,将不再接受申请。在此期间,Google 旨在优化 Bard 的准确性、质量和速度。</p>
<h1 id="google-bard-与-chatgpt-的比较">Google Bard 与 ChatGPT 的比较</h1>
<p>现在我们对 Google Bard 有了很好的理解和范围,那么 Google Bard 和 OpenAI 的 ChatGPT 有什么区别呢?</p>
<p>如果你需要快速了解 ChatGPT,请阅读:ChatGPT: 一切你需要知道的</p>
<p>那么,让我们深入了解一下 Google Bard 和 ChatGPT 之间的区别。</p>
<p><img src="https://kdn.flygon.net/docs/img/55aee3d250b6779f3658c8793392d934.png" alt="What is Google AI Bard" loading="lazy"></p>
<p>图片由作者提供</p>
<h1 id="结论">结论</h1>
<p>看到 Google 在 Bard 方面有什么新进展会很有趣。它会比 ChatGPT 更有效吗?</p>
<p>如果你想看看 Google Bard 和 ChatGPT 之间的回应差异,可以查看亚利桑那大学助理教授 Henk van Ess 对 Bard AI 和 ChatGPT 的比较:<a href="https://twitter.com/henkvaness/status/1614092390968750081?ref_src=twsrc%5Etfw%7Ctwcamp%5Etweetembed%7Ctwterm%5E1614092390968750081%7Ctwgr%5Eac6d1ef7bfc34f19fdd07c84dc7088ee4f76e514%7Ctwcon%5Es1_&ref_url=https%3A%2F%2Fparametric-architecture.com%2Fwhat-is-the-difference-between-google-bard-ai-and-open-ai-chatgpt%2F" target="_blank">ChatGPT 是否对 Google 构成威胁?</a></p>
<p>如果你有机会使用 Google Bard 测试版服务,请在评论中告诉我们你的想法。</p>
<p><strong><a href="https://www.linkedin.com/in/nisha-arya-ahmed/" target="_blank">Nisha Arya</a></strong> 是一名数据科学家,自由技术写作者,以及 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程以及与数据科学相关的理论知识。她还希望探索人工智能如何/可以提升人类生命的延续性。作为一个热衷学习的人,她寻求拓宽自己的技术知识和写作技能,同时帮助他人。</p>
<h3 id="更多相关主题">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2023/02/data-scientists-expect-flawed-advice-google-bard.html" target="_blank">为何数据科学家期望从 Google Bard 获得有缺陷的建议</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/03/chatgpt-google-bard-comparison-technical-differences.html" target="_blank">ChatGPT 与 Google Bard:技术差异的比较</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/04/8-opensource-alternative-chatgpt-bard.html" target="_blank">8 个开源 ChatGPT 和 Bard 替代品</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/super-bard-ai-better.html" target="_blank">超级 Bard:无所不能的 AI,且表现更优</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/top-10-tools-detecting-chatgpt-gpt4-bard-llms.html" target="_blank">检测 ChatGPT、GPT-4、Bard 和 Claude 的十大工具</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/bard-data-science-cheat-sheet.html" target="_blank">Bard 数据科学备忘单</a></p>
</li>
</ul>
<h1 id="人工智能不是来取代我们的">人工智能不是来取代我们的</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2023/02/ai-replace-us.html" target="_blank"><code>www.kdnuggets.com/2023/02/ai-replace-us.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/286adf42748b3b2a94b21e250cdf1c4f.png" alt="人工智能不是来取代我们的" loading="lazy"></p>
<p>作者提供的图片</p>
<p>当我听说人工智能能够写出体面的代码时,我不得不承认,我的脊背有些发凉。每天似乎都有新的职业受到人工智能的威胁。SEO 博客作者都在提心吊胆。艺术家们则惊恐地看着用户涌向 Midjourney 的 Discord 服务器。现在还有这个。</p>
<hr>
<h2 id="我们的三大课程推荐">我们的三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织在 IT 领域</p>
<hr>
<p><img src="https://kdn.flygon.net/docs/img/5b1e79293e87a0eb9b89faf5e723328c.png" alt="人工智能不是来取代我们的" loading="lazy"></p>
<p>Chat GPT 的截图</p>
<p>我一直主张技术不会消除工作,而是增加工作。是的,文字处理器使打字员变得过时。在此之前,汽车使马车司机变得过时。但尽管技术快速涌入,工作岗位——好工作、有趣的工作、引人入胜的工作——的整体数量还是在增加。</p>
<p>数据与我的直觉一致。世界经济论坛<a href="https://www.weforum.org/agenda/2020/10/dont-fear-ai-it-will-lead-to-long-term-job-growth/" target="_blank">估计</a>到 2025 年技术将增加 1200 万个工作岗位。经济历史学家詹姆斯·贝森<a href="https://hbr.org/2015/04/how-technology-has-affected-wages-for-the-last-200-years" target="_blank">建议</a>过去两个世纪工资的部分上涨得益于生产的增长,而这又归功于自动化和技术的发展。</p>
<p>但这是我第一次面对自己被取代的可能性。ChatGPT 可以写代码。</p>
<p>这是否意味着人工智能最终会取代我们?</p>
<p>我相信这不仅不太可能,而且是不可能的,这要归功于人工智能的训练方式。有些技能(例如这些<a href="https://www.stratascratch.com/blog/what-skills-do-you-need-as-a-data-scientist/" target="_blank">数据科学技能</a>)无论技术多么先进,人工智能都无法取代。</p>
<h1 id="什么技能是不可替代的为什么">什么技能是不可替代的,为什么?</h1>
<p>人工智能永远不会有创造力。人工智能永远不会有创新性。人工智能永远无法进行推理、思考或争论。</p>
<p>目前,它只是一个非常有能力的模仿者。人工智能可以<a href="https://medium.com/mlearning-ai/stop-calling-everything-ai-4c500cce8575" target="_blank">模式匹配</a>,并且做得非常好。但它无法完成那些使人类工人和人脑如此宝贵的事情。</p>
<p>为什么会这样?考虑一下人工智能生成图像的过程作为例子。Midjourney 已经在来自网络各个部分的数百万张图像上进行了训练。每张图像都有一些关联的文字。一个笑容灿烂的女性图像会被描述为“笑容灿烂的女性”。一件拉斐尔风格的艺术作品会被描述为名字、风格和画作内容。</p>
<p>当你要求 Midjourney 生成一幅笑容灿烂的女性拉斐尔风格的画作时,它会将所有的训练数据放入一个搅拌机中,然后输出一个综合结果。这并不具有创新性或创造性。人工智能并没有“思考”或“推理”来创建那个图像。它只是使用模式识别来跟随你的提示。</p>
<p><img src="https://kdn.flygon.net/docs/img/21ce47c9d46ddb97270b42c585069fb8.png" alt="人工智能不是来取代我们的" loading="lazy"></p>
<p>由 Midjourney 创建的图像 | 提示:笑容灿烂的女性,拉斐尔风格,画作</p>
<p><a href="https://www.theguardian.com/music/2023/jan/17/this-song-sucks-nick-cave-responds-to-chatgpt-song-written-in-style-of-nick-cave" target="_blank">Nick Cave 对 ChatGPT 用他的风格创作的歌曲感到厌恶</a>。在解释原因时,他理解到 ChatGPT 所做的是“模仿,或者复制,或者模仿的拼贴”。这正是写好歌曲所不具备的。然后他解释了它是什么:“这是一种自我谋杀的行为,它摧毁了一个人过去所努力创造的一切。正是那些危险的、令人心跳骤停的离经叛道,才将艺术家推向超越他们所认知的自我的极限。”在这方面,我认为 Nick Cave 解释了人类与人工智能之间的区别。我理解的意思是,我们应该区分生成和创造。所有人工智能做的只是生成,而人类则有创造的能力。</p>
<p>看来 ChatGPT 同意 Nick 的观点!我让它写一篇关于人工智能是否会被用来取代软件工程师的博客文章。它可以吸收成千上万篇关于这个主题的博客文章,并输出最接近的内容。它并没有考虑你的问题,也没有思考如何最佳回应。它只是使用训练数据来完成你的提示。</p>
<p>ChatGPT 说得最好:</p>
<p><img src="https://kdn.flygon.net/docs/img/c67c738b191ec2d32633a6732af3eb6b.png" alt="人工智能不是来取代我们的" loading="lazy"></p>
<p>来自 ChatGPT 的图像</p>
<p>这意味着,按照目前的使用和训练方式,人工智能永远无法真正生成独特的艺术作品。它永远无法产生原创思想或分享独特且个人化的经历。它也不能成为一名软件工程师。</p>
<p>它能做的只是消费和反复输出。</p>
<p>这也是为什么人工智能有时会犯错,比如给人手添加过多的手指,或者在博客文章中提供错误的信息/虚假的报告。它不能知道什么是对的,什么是错的,只能知道它所消费的内容。</p>
<h1 id="它可以用于什么">它可以用于什么?</h1>
<p>尽管如此,我确实发现 AI 当前的应用场景令人印象深刻且有价值。除了编写 Python 代码生成五个随机数字之外,AI 还能做更多的事情。大多数这些技能都属于“让我的工作更有趣且少些枯燥”的范畴。</p>
<p>例如,我们雇用的博客作者常常花费大量时间优化博客帖子以便于搜索引擎。(我们这样做是为了帮助感兴趣的读者更容易找到我们的博客帖子。)这可能有点枯燥。我们的作者喜欢专注于使博客帖子有趣、信息丰富和有趣。确保博客帖子具有优化的关键词数量以便于读者发现,则少了一些乐趣。</p>
<p>AI 也已经用于拼写检查。例如,Grammarly <a href="https://www.grammarly.com/blog/how-grammarly-uses-ai/#:~:text=Grammarly's%20products%20are%20powered%20by,processing%20to%20improve%20your%20writing." target="_blank">使用</a> 相同的模式匹配能力来确保你写的内容符合它所学的规范。</p>
<p>你也可以用 AI 来进行研究。它在整合和传达信息方面非常有效,因为它已经扫描了比任何人一生中能阅读的文本还要多的内容。例如,ChatGPT 可以向我解释相机是如何工作的,飞机是如何飞行的,甚至是量子力学。</p>
<p>最后,软件工程师和数据科学家可能依赖 AI 来调试他们编写的代码。我们都使用过 StackOverflow。可以把 AI 看作是一个阅读过所有问题和答案的 StackOverflow 助手,能够将发现汇总成一个简单的回答。</p>
<p>事实是,如果 AI 能够取代你的工作,这意味着你原本做的工作相当琐碎。AI 的当前版本应该能让你腾出时间做更多令人兴奋、智力密集或基于技能的工作。</p>
<h1 id="ai-可以并且应该增强人类工作">AI 可以并且应该增强人类工作</h1>
<p>有一个领域,AI 不仅可以自动化你工作流程中的基本步骤,还能使人类的工作变得更好。那就是医疗领域。</p>
<p>AI 可以处理大量数据并发现模式,因此在帮助医疗专业人员做出诊断方面特别出色。尽管大多数临床医生仍然更喜欢与患者交谈以全面了解症状,但 AI 助手可以监测血压并将症状与潜在疾病进行匹配。</p>
<p>医疗领域的 AI 仍然有些争议,自从 IBM 购买了可以击败《危险边缘》竞赛者的“Watson” AI 并试图用它来诊断患者之后。最终,这款 AI 在处理复杂的患者档案时遇到了麻烦,无法做出可靠的诊断。但随着 AI 在处理复杂和多样的信息源方面变得越来越出色,以及临床医生越来越习惯依赖 AI 来解释医学扫描和症状,这将是 AI 能够发挥作用并挽救生命的一个领域。</p>
<h1 id="所以ai-会抢你的工作吗">所以,AI 会抢你的工作吗?</h1>
<p>当我开始与 AI 技术互动时,我很快就克服了我的震惊。我使用得越多,越能清楚地看出作为一个拥有大脑的人,我的工作是 AI 无法替代的。AI 永远无法像我一样解决问题,也无法像我一样讲述个人经历。</p>
<p>在我看来,AI 并不是为了取代我们而来的。它是为了帮助我们。如果它能取代你,那么你应该尽快在简历中添加一些额外的技能。</p>
<p><strong><a href="https://www.stratascratch.com" target="_blank">内特·罗西迪</a></strong> 是一位数据科学家,专注于产品战略。他也是一名兼职教授,教授分析学,并且是 <a href="https://www.stratascratch.com/" target="_blank">StrataScratch</a> 的创始人,该平台帮助数据科学家通过顶级公司提供的真实面试问题来准备面试。你可以在 <a href="https://twitter.com/StrataScratch" target="_blank">Twitter: StrataScratch</a> 或 <a href="https://www.linkedin.com/in/nathanrosidi/" target="_blank">LinkedIn</a> 上与他联系。</p>
<h3 id="更多相关话题-1">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2023/03/manning-fear-not-ai-coding-help-you.html" target="_blank">别害怕,因为 AI 编程来帮助你了!</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/04/deepmind-alphacode-replace-programmers.html" target="_blank">DeepMind 的 AlphaCode 会取代程序员吗?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/06/chatgpt-replace-data-scientists.html" target="_blank">ChatGPT 会取代数据科学家吗?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/will-ai-replace-humanity" target="_blank">AI 会取代人类吗?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/top-8-ai-search-engine-that-you-should-replace-with-google" target="_blank">你应该用什么来替代 Google 的 8 个 AI 搜索引擎</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/07/ai-tools-along-skills-make-10000-monthly-bs.html" target="_blank">这里是我用的 AI 工具以及我的技能,帮助我每月赚取 $10,000…</a></p>
</li>
</ul>
<h1 id="机器学习并不像你的大脑第六部分精确突触权重的重要性及其快速设置的能力">机器学习并不像你的大脑第六部分:精确突触权重的重要性及其快速设置的能力</h1>
<blockquote>
<p><a href="https://www.kdnuggets.com/2022/08/machine-learning-like-brain-part-6-importance-precise-synapse-weights-ability-set-quickly.html" target="_blank"><code>www.kdnuggets.com/2022/08/machine-learning-like-brain-part-6-importance-precise-synapse-weights-ability-set-quickly.html</code></a></p>
</blockquote>
<p>据我们所知,突触的权重只能通过连接它的两个神经元的近乎同时的发放来改变。这完全与机器学习反向传播算法的基本架构相悖。</p>
<p>你可以把反向传播想象成一个坐在神经网络旁边的小人,他查看网络输出,将其与期望输出进行比较,然后为网络中的突触指示新的权重。在生物系统中,没有机制可以指示任何特定突触的权重。你可以尝试通过发放连接的两个神经元来增加突触权重,但也没有办法做到这一点。你不能仅仅要求发放神经元 1000 和 1001 来增加它们之间的突触,因为没有办法在网络中发放特定的神经元。</p>
<p>我们确定的唯一调整突触权重的机制被称为赫布学习。它是一个常被俏皮地表述为“同时发放的神经元会连接在一起”的机制。但正如所有生物学现象一样,它并不那么简单。在“突触可塑性”的研究中,得到的曲线如图所示,表明要增强连接源神经元和目标神经元的突触,源神经元需要在目标神经元之前稍微发放。要减少突触权重,目标神经元必须在源神经元之前稍微发放。这在整体上是有意义的,因为如果一个神经元对另一个神经元的发放有贡献,那么连接这两个神经元的突触应该被加强,反之亦然。</p>
<p>图中还有一些需要注意的问题。首先,尽管整体概念在图 B 中进行了总结,图 A 显示了观察数据中大量的散布。这意味着,将突触设定为任何特定值的能力非常有限,这一点已通过模拟得到确认。</p>
<p>你还可以观察到,要对突触权重进行任何实质性的改变需要多次重复。即使在理论环境中(没有干扰的情况下),你也可以得出结论:对突触值的精确度要求越高,设定它所需的时间就越长。例如,如果你希望一个突触有 256 种不同的值之一,你可以定义每对增强性尖峰将权重增加 1/256。可能需要 256 对尖峰(到源头和目标)才能设置权重。在生物神经元的缓慢速度下,这将需要整整一秒钟。</p>
<p>想象一下构建一台计算机,其中单个字节的内存写入需要大约一秒钟。此外,设想需要支持电路来设置一个值 x,安排准确的 x 次脉冲到源神经元和目标神经元。这假设它从 0 的权重开始,这又是另一个问题,因为没有办法知道任何突触的当前权重。最后,想象一下网络中的任何使用如何修改突触权重,使得这样的系统无论如何都无法存储准确的值。在特定突触中存储特定值的整个概念完全不切实际。</p>
<p>还有另一种看法更为合理。考虑将突触视为一个二进制设备,值为 0 或 1(或者在抑制突触的情况下为-1)。现在,突触的特定权重代表了该突触的重要性以及遗忘它所代表的数据位的可能性。如果我们考虑神经元发射脉冲(可能是 5 次),那么任何超过 0.2 的权重代表 1,任何低于 0.2 的权重代表 0。这样的系统可以在一次脉冲中学习,并且对内存内容的随机变化具有免疫力。这是一个完全合理的情景,但它与现代机器学习方法完全相悖。</p>
<blockquote>
<p>到目前为止,集中讨论了 ML 和感知机可以做到而神经元不能做到的事情,我将在本系列的第七部分扭转局面,描述一些神经元特别擅长的事情。</p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/69031318b3e16f9c8fe2bf85cbd61f7d.png" alt="机器学习不像你的大脑 第六部分:精确突触权重的重要性及其快速设置能力" loading="lazy"></p>
<p>图 A:显示源神经元和目标神经元的相对脉冲时间如何影响突触权重。图 B:一个理想化的 Hebbian 学习在仿真中可用的表示。<em>摘自:Piochon, Claire & Kruskal, Peter & Maclean, Jason & Hansel, Christian. (2012). 小脑回路中的非 Hebbian 脉冲时间依赖性可塑性。神经回路前沿。6. 124. 10.3389/fncir.2012.00124.</em></p>
<p>欲了解更多信息,请访问 <a href="https://www.youtube.com/watch?v=jdaAKy-XkA0" target="_blank"><code>www.youtube.com/watch?v=jdaAKy-XkA0</code></a></p>
<p><strong><a href="https://futureai.guru/Founder.aspx" target="_blank">查尔斯·西蒙</a></strong> 是一位全国知名的企业家和软件开发者,也是 FutureAI 的首席执行官。西蒙是《计算机会反叛吗?:为人工智能的未来做准备》的作者,以及 Brain Simulator II 的开发者,这是一个 AGI 研究软件平台。欲了解更多信息,<a href="https://futureai.guru/Founder.aspx" target="_blank">请访问这里</a>。</p>
<h3 id="更多相关主题-1">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/06/machine-learning-like-brain-part-4-neuron-limited-ability-represent-precise-values.html" target="_blank">机器学习不像你的大脑 第四部分:神经元的……</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/04/machine-learning-like-brain-part-one-neurons-slow-slow-slow.html" target="_blank">机器学习不像你的大脑 第一部分:神经元很慢,……</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/05/machine-learning-like-brain-part-two-perceptrons-neurons.html" target="_blank">机器学习不像你的大脑 第二部分:感知器与神经元</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/06/machine-learning-like-brain-part-3-fundamental-architecture.html" target="_blank">机器学习不像你的大脑 第三部分:基本架构</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/07/machine-learning-like-brain-part-5-biological-neurons-cant-summation-inputs.html" target="_blank">机器学习不像你的大脑 第五部分:生物神经元</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/08/machine-learning-like-brain-part-seven-neurons-good.html" target="_blank">机器学习不像你的大脑 第七部分:神经元的作用</a></p>
</li>
</ul>
<h1 id="欧洲-ai-法案简化版">欧洲 AI 法案:简化版</h1>
<blockquote>
<p>译文:<a href="https://www.kdnuggets.com/2022/06/european-ai-act-simplified-breakdown.html" target="_blank"><code>www.kdnuggets.com/2022/06/european-ai-act-simplified-breakdown.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/f0cd864b550e859c6532a6301665122c.png" alt="欧洲 AI 法案:简化版" loading="lazy"></p>
<p><a href="https://unsplash.com/@sasun1990" target="_blank">Sasun Bughdaryan</a> via Unsplash</p>
<p>2020 年 2 月 19 日,发布了一份关于 AI 的白皮书——“欧洲卓越与信任的方法”。随后,在 2021 年 4 月 21 日,欧洲委员会发布了关于 AI 使用法案的立法。</p>
<hr>
<h2 id="我们的前三个课程推荐-2">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织的 IT 需求</p>
<hr>
<p>根据欧盟的说法,一些 AI 系统非常复杂、不可预测且非常不透明。他们的目标是确保这些不同类型的 AI 系统符合基本权利并提供信任,同时减少市场碎片化。</p>
<p>《法律》的主要目标是:</p>
<ul>
<li>
<p>欧洲市场上的 AI 系统是安全的。</p>
</li>
<li>
<p>这些 AI 系统尊重欧盟的价值观和公民权利。</p>
</li>
<li>
<p>这些 AI 系统确保法律确定性,以帮助促进 AI 的投资和创新。</p>
</li>
<li>
<p>这些 AI 系统值得信赖,以确保市场不会失败。</p>
</li>
<li>
<p>它改进了现有的安全性和权利要求立法。</p>
</li>
</ul>
<p>然而,这项法律可能不仅适用于欧盟;其他国家已经开始探索提供更透明 AI 系统的新方法。2021 年 9 月,巴西通过了一项创建法律框架的法案。</p>
<h1 id="ai-风险框架">AI 风险框架</h1>
<p>该法律将这些 AI 系统分类为四个风险领域:不可接受风险、高风险、有限风险和最低或无风险。</p>
<h2 id="最低或无风险">最低或无风险</h2>
<p>这允许使用低风险或无风险的 AI 系统,没有限制。虽然没有任何限制,但 AI 系统的提供者必须遵守自愿的行为规范。委员会预测,大多数 AI 系统将归入“低风险或无风险”类别。</p>
<p>这些类型的 AI 系统包括垃圾邮件过滤。</p>
<h2 id="有限风险">有限风险。</h2>
<p>这些 AI 系统也被允许,但需提供更深入的信息和更高的透明度,如技术文档。他们也可以选择遵守自愿的行为规范。</p>
<p>这些类型的 AI 系统包括聊天机器人。</p>
<h2 id="高风险">高风险</h2>
<p>这些是最具风险的人工智能系统,尽管允许使用,但它们必须符合要求和事前/事后合规评估。在系统投入市场前需进行合规评估。</p>
<p>这些人工智能系统将会是:</p>
<ul>
<li>
<p>人工智能系统被用作产品安全组件,例如医疗设备</p>
</li>
<li>
<p>独立的高风险人工智能系统,例如执法系统</p>
</li>
</ul>
<h2 id="不可接受的风险">不可接受的风险</h2>
<p>这些类型的人工智能系统完全禁止,因为它们已知对人们的安全和权利构成‘不可接受的风险’。</p>
<p>例如对儿童或精神残疾人士的剥削。这可能通过包含集成语音助手的玩具娃娃,促使用户进行危险行为。</p>
<h1 id="高风险人工智能系统的要求">高风险人工智能系统的要求</h1>
<p>高风险人工智能系统由于其要求而面临最大的风险。这些要求包括</p>
<p><strong>数据和数据治理</strong> - 确保这些人工智能系统使用高质量的相关和代表性数据</p>
<p><strong>文档和记录保存</strong> - 创建文档和记录功能以帮助追踪和审计,同时确保人工智能系统的合规性。</p>
<p><strong>透明度和用户信息提供</strong> - 向用户提供信息,例如如何使用系统以确保透明度。</p>
<p><strong>人工监督</strong> - 在人工智能系统的构建阶段以及实施阶段,人工干预是至关重要的。</p>
<p><strong>强健、准确、网络安全</strong> - 这些元素对任何人工智能系统都至关重要,以保护企业和用户。</p>
<h1 id="罚款处罚">罚款/处罚</h1>
<p>从公司到这些人工智能系统的制造商再到分销商,都可能面临严重的罚款。这些罚款分为三个级别,具体取决于违规的严重性。</p>
<h2 id="高达-1000-万欧元">高达 1000 万欧元</h2>
<p>这是《人工智能法》中规定的最低罚款级别。这可能是由于向当局提供了不完整或虚假的信息。罚款金额可能高达<strong>1000 万欧元</strong>或公司全球年营业额的 2%。</p>
<h2 id="高达-2000-万欧元">高达 2000 万欧元</h2>
<p>这是下一个潜在的罚款,可能是由于人工智能系统要求的违反。例如,缺乏提供透明度的技术文档。罚款金额可能高达 2000 万欧元或公司全球年营业额的 4%。</p>
<h2 id="高达-3000-万欧元">高达 3000 万欧元</h2>
<p>这是最高的罚款金额,可能由于使用了禁止的人工智能系统或系统质量未达到标准。罚款金额可能高达 3000 万欧元或公司全球年营业额的 6%。</p>
<h1 id="结论-1">结论</h1>
<p>尽管还有更多内容需要审查,一切尚未确定,但《人工智能法案》已经引起了很多关注。对企业、制造商和分销商,无论是在欧盟内部还是外部,都是如此。《人工智能法案》的目的是确保欧盟在人工智能领域的卓越,提供正确的条件以促进人工智能的发展,并确保人工智能系统对人类有益。</p>
<p><strong><a href="https://www.linkedin.com/in/nisha-arya-ahmed/" target="_blank">Nisha Arya</a></strong> 是一名数据科学家和自由职业技术写作人员。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探索人工智能如何有助于人类寿命的不同方式。她是一位热衷于学习的人,寻求扩展自己的技术知识和写作技能,同时帮助指导他人。</p>
<h3 id="更多相关话题-2">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/sql-simplified-crafting-modular-and-understandable-queries-with-ctes" target="_blank">SQL 简化:使用 CTE 制作模块化和易于理解的查询</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/data-scientist-breakdown-skills-certifications-and-salary" target="_blank">数据科学家细分:技能、认证和薪资</a></p>
</li>
</ul>
<h1 id="ai-有自己的蝙蝠侠吗">AI 有自己的蝙蝠侠吗?</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2022/05/ai-get-batman.html" target="_blank"><code>www.kdnuggets.com/2022/05/ai-get-batman.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/bc52e9e7aecb8f2bc5f7292573f138d2.png" alt="AI 有自己的蝙蝠侠吗?" loading="lazy"></p>
<p>图片由<a href="https://unsplash.com/@michael_marais?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Michael Marais</a>拍摄,来自<a href="https://unsplash.com/s/photos/digital-batman%3F?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Unsplash</a></p>
<p>每个轰动一时的故事都有一个英雄和一个反派,AI 范式也不例外。随着 AI 和数据的发展以及在我们日常生活中扮演越来越重要的角色,AI 多年来一直需要发出蝙蝠信号。你知道这个故事 - 数百万的投资却回报甚微。</p>
<hr>
<h2 id="我们的前三大课程推荐">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业的捷径</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织 IT 工作</p>
<hr>
<p>要理解英雄的角色,重要的是注意到阻碍 AI 充分发挥潜力的反派。对于 AI 来说,反派是<em>双面派</em>。虽然数据是构建可靠且强大的 AI 模型的关键组成部分,但数据也是 AI 采纳的主要障碍之一。</p>
<p><a href="https://www.gartner.com/smarterwithgartner/3-barriers-to-ai-adoption" target="_blank">根据 Gartner</a>,数据质量和数量的缺乏是 AI 采纳的一些最大障碍。成功的 AI 项目需要大量的数据来获取最佳应对情况的信息。没有足够的数据或新场景与过去的数据不匹配时,AI 可能会出现问题。情况越复杂,AI 现有的数据越可能不够。</p>
<p>起初训练和完善 AI 模型所需的数据量并不总是明确的。隐私问题也可能使得获取所需数据变得困难。</p>
<h1 id="引入合成数据">引入合成数据</h1>
<p>在视觉领域,合成数据在创建更具能力和伦理的 AI 模型方面显示出潜力。合成数据是计算机生成的图像数据,用于模拟现实世界。视觉特效行业的技术与生成神经网络结合,以创建广泛、多样化且真实感强的标记图像数据。合成数据集是人工创建的,而不是通过现实世界数据生成的,从而使训练数据的开发成本和时间大大降低。像布鲁斯·韦恩一样,合成数据也有许多巧妙的应用。</p>
<h1 id="穿斗篷的十字军">穿斗篷的十字军</h1>
<p>目前,大多数人工智能系统依赖于“监督学习”,即人工标记并有效地教导人工智能如何解释图像的过程。这个过程既耗时又耗费资源,并且存在根本性限制,因为人类无法扩展,更重要的是,无法标记如 3D 位置、交互等关键属性。此外,关于人工智能的群体偏见和消费者隐私的担忧不断增加,使得获取具有代表性的人类数据变得越来越困难。</p>
<p>对于以消费者为中心的应用程序,如智能手机和智能家居,确保隐私至关重要。合成数据最终可以消除在构建以消费者为中心的应用程序中使用真实人类的需求。由于合成数据是人工生成的,这消除了许多传统数据集收集过程中存在的偏见和隐私问题。</p>
<h1 id="比子弹还快">比子弹还快</h1>
<p>捕获和准备真实世界数据用于模型训练是一个漫长且繁琐的过程。对于复杂的计算机视觉系统,如自动驾驶汽车、机器人或卫星图像,部署所需的硬件可能非常昂贵。一旦数据被捕获,人类需要标记和注释关键特征,这容易出错且成本高昂。</p>
<p>合成数据能够按需提供数据,从而降低计算机视觉模型和产品的成本并加快市场速度。它比传统的人工标注真实数据的方法快和便宜几个数量级,并将加速新型更强大模型在各行业的部署。</p>
<h1 id="针对新兴技术的强大模型">针对新兴技术的强大模型</h1>
<p>如同蝙蝠侠的能力一样,合成数据的能力超越了普通公民。如前所述,人类在准确标记帮助计算机视觉系统解释周围世界的关键属性方面有限。公司受制于足够多样化和准确标记的人类数据集的可用性。目前,获取和标记图像数据的时间和成本巨大。这种方法的根本限制在于,人类工作者无法标记公司可能感兴趣的所有属性。</p>
<p>与需要手动标记的真实数据不同,合成数据是人工生成并标记的,模拟真实世界。合成数据方法提供的关于 3D 位置、深度和新传感器系统的新标签将允许开发适用于自主、机器人和 AR/VR/元宇宙等应用的新型更强大的模型。</p>
<h1 id="适用于所有人的超级英雄">适用于所有人的超级英雄</h1>
<p>人工智能系统可能包含固有的偏见,这会影响到人群的各个群体。驱动人工智能模型的数据集可能在某些数据类别上不平衡,并且某些群体可能被过度或不足代表。这可能导致人工智能数据集中的性别、种族和年龄偏见。引入合成数据。</p>
<p>合成数据并非从现实世界事件或现象中提取,而是部分或完全人工生成的。如果数据集不够多样或庞大,人工智能生成的数据可以填补空白,形成更全面、公正的数据集。这使得人工智能科学家能够创建平衡的数据集,帮助组织满足监管和合规要求,并构建更公平且具有伦理的人工智能系统。</p>
<p>世界将需要强大且具有伦理的人工智能系统来支持未来的应用。自动驾驶的车辆将把旅行者送往机场,虚拟工作会议将在元宇宙中进行,或者送货机器人将送来本周的食品,这些都将依赖于由庞大数据集驱动的计算机视觉应用。合成数据的超能力将在确保这些数据集具有伦理性、公正性、经济性和鲁棒性方面发挥至关重要的作用。</p>
<p><strong><a href="https://www.linkedin.com/in/yasharbehzadi/" target="_blank">Yashar Behzadi, Ph.D.</a></strong> 是 Synthesis AI 的首席执行官兼创始人。他是一位经验丰富的企业家,在人工智能、医疗技术和物联网市场上建立了变革性的企业。</p>
<h3 id="更多相关主题-2">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/kmeans-clustering-algorithm-work.html" target="_blank">什么是 K-Means 聚类及其算法如何工作?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/stop-chatgpt-get-ahead-99-users.html" target="_blank">停止在 ChatGPT 上做这些事情,并超越 99%的用户</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/02/data-mesh-distributed-data-architecture.html" target="_blank">数据网格及其分布式数据架构</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n07.html" target="_blank">KDnuggets™ 新闻 22:n07, 2 月 16 日: 如何学习机器数学…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/03/simpson-paradox-implications-data-science.html" target="_blank">辛普森悖论及其在数据科学中的影响</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/03/berksonjekel-paradox-importance-data-science.html" target="_blank">伯克森-杰克尔悖论及其对数据科学的重要性</a></p>
</li>
</ul>
<h1 id="职业发展">=<mark>职业发展</mark>=</h1>
<h1 id="5-个需求高但未得到足够认可的-it-职位">5 个需求高但未得到足够认可的 IT 职位</h1>
<blockquote>
<p>原文: <a href="https://www.kdnuggets.com/5-it-jobs-that-are-high-in-demand-but-dont-get-enough-recognition" target="_blank"><code>www.kdnuggets.com/5-it-jobs-that-are-high-in-demand-but-dont-get-enough-recognition</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/124a5cd22a9c8afef6d6d816bdf376bd.png" alt="2024 年 IT 职位" loading="lazy"></p>
<p>作者提供的图片</p>
<p>当人们考虑进入技术领域时,他们通常会追求高度技术性的工作,如软件工程或数据科学。然而,技术领域的发展是由不同领域的不同专家共同推动的。</p>
<hr>
<h2 id="我们的前三个课程推荐-3">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业轨道。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析能力</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织在 IT 方面</p>
<hr>
<p>虽然软件工程师和数据科学家是许多组织的基础,但其他利益相关者将组织凝聚在一起,使其成功。</p>
<h2 id="it-支持">IT 支持</h2>
<p>链接: <a href="https://imp.i384100.net/9gX7R3" target="_blank">谷歌 IT 支持专业证书</a></p>
<p>级别: 初学者</p>
<p>时长: 6 个月,每周 10 小时</p>
<p>IT 支持在技术领域中非常重要。他们的主要职责是安装和配置计算机系统,诊断硬件和软件故障以及解决技术和应用问题 - 这些问题在技术行业中经常发生。</p>
<p>在谷歌提供的这门课程中,你将获得成功进入初级 IT 职位所需的技能,并学习执行日常 IT 支持任务,包括计算机组装、无线网络、程序安装和客户服务。你还将学习如何提供端到端的客户支持,从识别问题到故障排除和调试,并使用包括 Linux、域名系统、命令行界面和二进制代码在内的系统。</p>
<h2 id="网络安全">网络安全</h2>
<p>链接: <a href="https://imp.i384100.net/jrv9k0" target="_blank">谷歌网络安全专业证书</a></p>
<p>级别: 初学者</p>
<p>时长: 6 个月,每周 7 小时</p>
<p>我会一直说这一点, <a href="https://www.kdnuggets.com/the-world-needs-more-cyber-security-analysts" target="_blank">世界需要更多的网络安全分析师。</a> 网络安全分析师的主要职责是保护组织的网络和系统免受攻击。</p>
<p>在 Google 提供的课程中,你将了解网络安全实践的重要性及其对组织的影响,识别常见的风险、威胁和漏洞,以及减轻这些问题的技术。你将学习如何使用安全信息和事件管理(SIEM)工具保护网络、设备、人员和数据免受未经授权的访问和网络攻击,并获得 Python、Linux 和 SQL 的实际操作经验。</p>
<h2 id="云解决方案架构师">云解决方案架构师</h2>
<p>链接:<a href="https://imp.i384100.net/AWbvJo" target="_blank">AWS 云解决方案架构师专业证书</a></p>
<p>级别:中级</p>
<p>时长:2 个月,每周 10 小时</p>
<p>云计算与安全是 IT 领域中需求量最大的领域之一,目前 AWS 平台是全球使用最广泛的云平台。</p>
<p>在 AWS 提供的课程中,你将学习如何在何时以及如何应用关键的 AWS 服务(计算、存储、数据库、网络、监控和安全)做出明智的决策。你还将学习设计架构解决方案,无论是为了成本、性能和/或运营卓越,以应对常见的业务挑战。同时,还将学习以安全且可扩展的方式创建和操作数据湖,将数据导入并组织到数据湖中,以及优化性能和成本。</p>
<p>最后但同样重要的是,你将为认证考试做准备,识别每个领域的优势和不足,并制定识别错误回答的策略。</p>
<h2 id="项目管理">项目管理</h2>
<p>链接:<a href="https://imp.i384100.net/ZQZM9X" target="_blank">Google 项目管理:专业证书</a></p>
<p>级别:初级</p>
<p>时长:6 个月,每周 10 小时</p>
<p>在技术领域,项目经理的价值极高。他们负责管理信息技术项目的时间表和预算,以确保实施过程的顺利。</p>
<p>在 Google 提供的课程中,你将深入了解成功担任初级项目管理角色所需的实践和技能。你还将学习如何在项目的各个阶段创建有效的项目文档和成果物,以及敏捷项目管理的基础知识,重点是实施 Scrum 事件、构建 Scrum 成果物和理解 Scrum 角色。</p>
<h2 id="技术营销">技术营销</h2>
<p>链接:<a href="https://imp.i384100.net/EK3Mo2" target="_blank">Google 数字营销与电子商务专业证书</a></p>
<p>级别:初级</p>
<p>时长:6 个月,每周 10 小时</p>
<p>当你的公司已经开发出 10/10 的产品并且它在正常运行时,这是很棒的。但是如果你没有营销专家来推动公司成功,那么你将没有销售或潜在客户。</p>
<p>在 Google 提供的课程中,你将学习数字营销和电子商务的基础知识,以获得进入初级职位所需的技能。你将了解如何通过搜索和电子邮件等数字营销渠道吸引和参与客户,并通过分析衡量营销表现和呈现见解。</p>
<h2 id="总结-1">总结</h2>
<p>技术行业不仅需要高技能的专业人士来构建产品。它们还需要一个拥有广泛技能的完整生态系统,以将你的最终产品推向市场。</p>
<p><a href="https://www.linkedin.com/in/nisha-arya-ahmed/" target="_blank"></a><strong><a href="https://www.linkedin.com/in/nisha-arya-ahmed/" target="_blank">Nisha Arya</a></strong> 是一名数据科学家、自由技术作家、以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。Nisha 涵盖了广泛的主题,并希望探索人工智能如何有利于人类寿命的不同方式。作为一个热衷学习者,Nisha 希望拓宽她的技术知识和写作技能,同时帮助指导他人。</p>
<h3 id="更多相关内容-1">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/7-platforms-for-getting-high-paying-data-science-jobs" target="_blank">获得高薪数据科学职位的 7 个平台</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/4-entry-level-certificates-from-microsoft-to-land-in-demand-jobs" target="_blank">微软的 4 个入门级证书助你获得热门职位</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/how-to-get-into-data-analytics.html" target="_blank">如何在没有相关学位的情况下进入数据分析领域</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/01/transfer-learning-image-recognition-natural-language-processing.html" target="_blank">图像识别和自然语言处理的迁移学习</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/10/evolution-speech-recognition-metrics.html" target="_blank">语音识别指标的演变</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/mlops-mess-expected.html" target="_blank">MLOps 乱象,但这是可以预期的</a></p>
</li>
</ul>
<h1 id="科技行业各领域的热门-google-认证">科技行业各领域的热门 Google 认证</h1>
<blockquote>
<p>链接:<a href="https://www.kdnuggets.com/popular-google-certification-for-all-areas-in-the-tech-industry" target="_blank"><code>www.kdnuggets.com/popular-google-certification-for-all-areas-in-the-tech-industry</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/811c6d98cd331674c216a76bd1e68622.png" alt="XXX" loading="lazy"></p>
<p>图片由作者提供</p>
<p>当人们说他们在科技行业工作时,许多人假设他们是软件工程师,掌握 3 种不同的编程语言,并能在一夜之间构建应用程序。但科技行业远不止这些。</p>
<p>随着科技的不断发展,我们不仅需要软件工程师和数据科学家,还需要网络安全分析师、市场营销人员、设计专业人士等。如果你正在寻找职业转型,但希望保持选项开放而不涉及编码,继续阅读……</p>
<h2 id="数据分析">数据分析</h2>
<p>链接:<a href="https://imp.i384100.net/q43M5g" target="_blank">Google 数据分析专业认证</a></p>
<p>对于那些有兴趣处理数据、准备数据并分析数据以进行决策的人,我们从最技术性的开始。</p>
<p>Google 数据分析专业认证使你能够理解关联数据分析师使用的实践和过程。你将学习如何清理数据、分析数据,并使用 SQL、R 编程和 Tableau 等工具创建可视化。</p>
<p>随着我们理解数据的价值,我们也明白数据分析师的价值将继续增长。</p>
<h2 id="项目管理-1">项目管理</h2>
<p>链接:<a href="https://imp.i384100.net/rQPyjv" target="_blank">Google 项目管理专业认证</a></p>
<p>科技行业发展迅速,每天都有新的项目发布。这就是我介绍项目管理及其在任何行业中重要性的地方。如果没有项目管理,许多新工具可能无法部署,让我们能够使用它们。</p>
<p>项目管理是应用过程、方法、技能、知识和经验以实现特定目标,确保项目成功。在这个 Google 项目管理专业认证中,你将学习如何有效记录项目,了解 Agile 项目管理、Scrum 的基础,并实践战略沟通,提升你的问题解决能力。</p>
<h2 id="网络安全-1">网络安全</h2>
<p>链接:<a href="https://imp.i384100.net/g1E7vA" target="_blank">Google 网络安全专业认证</a></p>
<p>数据是新的黄金,就像黄金一样,组织也有相应的流程和工具来确保其安全。</p>
<p>在这个 Google 网络安全专业认证中,你将学习最佳网络安全实践及其对组织的影响。你将识别常见的风险和漏洞,并应用技术来缓解这些问题。</p>
<p>网络安全全在于保护,因此深入了解保护网络、设备、数据和人员的各种工具,以及使用 Python、Linux 和 SQL 的实践经验。</p>
<h2 id="it-支持-1">IT 支持</h2>
<p>链接:<a href="https://imp.i384100.net/5gNGX2" target="_blank">Google IT 支持专业认证</a></p>
<p>科技行业内容丰富。它就像从零开始建造一座房子,每个承包商都负责确保不同层级始终符合他们专业领域的黄金标准。这就是 IT 支持的作用所在。</p>
<p>在这个 Google IT 支持专业认证中,你将了解 IT 支持日常处理的任务,包括计算机组装、无线网络、安装和客户服务。你还将学习如何识别问题,利用如 Linux、域名系统、命令行界面和二进制代码等工具进行故障排除和调试。</p>
<h2 id="市场营销与电子商务">市场营销与电子商务</h2>
<p>链接: <a href="https://imp.i384100.net/nLQ6kA" target="_blank">Google 的市场营销与电子商务专业认证</a></p>
<p>你有软件工程师在构建产品。你有数据分析师在分析数据。你有项目经理确保产品顺利投入生产。你有网络安全和 IT 支持确保一切顺利运行,组织不受攻击。那么一切都准备好了,现在怎么办?</p>
<p>销售产品。确保每个人都知道它。通过这个伟大的产品赚取收入!这就是 Google 的市场营销与电子商务专业认证发挥作用的地方。</p>
<p>你将学习数字营销和电子商务的基础知识,以及如何通过各种数字营销渠道吸引和吸引客户。接着,你将学习如何通过分析来衡量这些渠道的表现,并提供见解。</p>
<h2 id="总结一下">总结一下</h2>
<p>一个行业,有 5 种潜在的可能性来帮助你打开大门。所有这些专业人士都是必需的,并构成了组织成功的基础。</p>
<p>科技世界将继续增长,与此同时,还有更多领域和部门可以让你转型进入。</p>
<p>今天就开始学习吧!</p>
<p><a href="https://www.linkedin.com/in/nisha-arya-ahmed/" target="_blank"></a><strong><strong><a href="https://www.linkedin.com/in/nisha-arya-ahmed/" target="_blank">Nisha Arya</a></strong></strong> 是一名数据科学家、自由技术作家,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及数据科学的理论知识。Nisha 涉及广泛的话题,并希望探索人工智能如何有利于人类生命的延续。作为一个热衷学习者,Nisha 希望拓宽她的技术知识和写作技能,同时帮助指导他人。</p>
<h3 id="更多相关内容-2">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/advance-your-tech-career-with-these-3-popular-certificates" target="_blank">通过这三个热门证书推进你的科技职业</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/07/celebrating-women-leadership-roles-tech-industry.html" target="_blank">庆祝科技行业的女性领导角色</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/the-ultimate-roadmap-to-becoming-specialised-in-the-tech-industry" target="_blank">成为科技行业专业人士的终极路线图</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/the-impact-of-ai-on-the-tech-industry" target="_blank">人工智能对科技行业的影响</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/02/layoffs-tech.html" target="_blank">科技行业的裁员潮怎么回事?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/01/google-data-analytics-certification-review-2023.html" target="_blank">2023 年 Google 数据分析认证评测</a></p>
</li>
</ul>
<h1 id="科技裁员的原因是什么">科技裁员的原因是什么?</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2023/02/layoffs-tech.html" target="_blank"><code>www.kdnuggets.com/2023/02/layoffs-tech.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/08f1e388bbcc94aefd755135f2de6419.png" alt="科技裁员风波" loading="lazy"></p>
<p>作者提供的图片</p>
<p>如果你在科技行业,你可能享受了一个辉煌的十年。数据科学是最炙手可热的工作。每位大学教授都告诉你,你的技能将让你保持就业,直到世界末日。每个<a href="https://www.stratascratch.com/blog/11-best-companies-to-work-for-as-a-data-scientist/" target="_blank">公司都需要数据科学家</a>,这些职位暂时不会消失。</p>
<hr>
<h2 id="我们的前三个课程推荐-4">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业之路。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析能力</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你组织的 IT 需求</p>
<hr>
<p>除非你最近打开了报纸或查看了头条新闻,否则你会知道这并不完全准确。Twitter、Meta、Netflix、Microsoft 和其他数十家科技公司最近都进行了大规模裁员。那些避免裁员的公司也实施了招聘冻结。总体来看,2022 年几乎有 9 万名科技行业的员工被裁员。</p>
<p>在 2023 年的前几周,另有 16,000 人被裁员,<a href="https://news.crunchbase.com/startups/tech-layoffs-2023/" target="_blank">根据</a> Crunchbase 的数据。</p>
<p>突然间,最热门的就业市场变得冷却了不少。</p>
<p>大型科技公司发生了什么?如果你在科技行业,未来会怎样?你应该担心吗,还是考虑换个职业?</p>
<p>这篇文章将回答所有这些问题及更多内容。剧透:如果你在科技行业,你的技能仍然很受欢迎。</p>
<h1 id="我们是如何到达这里的">我们是如何到达这里的?</h1>
<p>解释科技裁员的因素有几个,不过很难确定这些因素中有多少具体导致了裁员。</p>
<p>首先,科技公司前所未有的增长速度一直有些不可持续。COVID 使得许多电子商务和广告基础公司经历了快速增长,但消费者开始恢复正常后,这种增长难以维持。</p>
<p>在经历了十年的高估、过度招聘和风投补贴增长后,裁员的“报应”终于到来了。</p>
<p>其次,正如你无疑已经厌倦听到的那样,目前经济形势很奇怪。供应链问题层出不穷。通货膨胀高得离谱。地缘政治动荡。这一切导致科技行业的增长放缓——足够让科技公司开始恐慌。</p>
<p>第三,来自多个方面的压力。以 Twitter 为例,目前在埃隆·马斯克的不可预测和混乱的领导下。马斯克对员工数量进行了大幅削减,截至目前,Twitter 仍在运营(尽管有些故障)。这一成功让其他公司董事会质疑,为什么他们要支付如此多员工的薪水,而 Twitter 证明了在员工数量削减一半的情况下仍能运作。</p>
<p>还有一种社会传染的因素。斯坦福大学商学院教授杰弗里·费弗认为,模仿行为可能是导致我们现在看到的许多裁员的原因。“会有科技衰退吗?有。估值有泡沫吗?绝对有。Meta 过度招聘了吗?可能。但这就是他们裁员的原因吗?当然不是。Meta 有很多钱。这些公司都在赚钱。他们这样做是因为其他公司也在这样做,”费弗 <a href="https://news.stanford.edu/2022/12/05/explains-recent-tech-layoffs-worried/#:~:text=It%20is%20estimated%20that%20in,and%20starts%20ups%20as%20well." target="_blank">告诉</a> 斯坦福新闻记者梅丽莎·德·维特。</p>
<h1 id="了解科技裁员的全貌">了解科技裁员的全貌</h1>
<p>让我们深入了解一下多个大型科技公司就业情况究竟发生了什么。</p>
<h2 id="metafacebook">Meta(Facebook)</h2>
<p><img src="https://kdn.flygon.net/docs/img/d5f7d4541ecee7933693fd103a972277.png" alt="科技裁员的情况如何?" loading="lazy"></p>
<p>图片来源:作者</p>
<p>Meta <a href="https://www.cnbc.com/2022/11/09/meta-to-lay-off-more-than-11000-thousand-employees.html" target="_blank">报告</a>称 2022 年 11 月裁员 11,000 人,影响了 13%的员工。这些裁员几乎影响了公司的每个领域,尤其是招聘,因为 Meta 还计划在 2023 年第一季度冻结招聘,并在此后减缓招聘速度。</p>
<p>大多数专家一致认为,这一现象的主要原因是 Meta 在其元宇宙上的巨大支出。此外,2022 年最后两个季度的广告收入下降。由于 Meta 的成本在第三季度同比增长了 19%,达到了 221 亿美元,收入无法跟上。</p>
<p>然而,在 Q3 财报的分析师电话会议上,马克·扎克伯格宣布“某些团队将显著增长”,以试图“将[Meta]的投资集中在少数几个高优先级的增长领域”。</p>
<p>那些领域可能是什么呢?</p>
<p>查阅 <a href="https://www.linkedin.com/jobs/search/?currentJobId=3407318955&f_C=10667&keywords=meta" target="_blank">LinkedIn</a>、<a href="https://www.indeed.com/jobs?q=meta&l=&from=searchOnHP&vjk=6703eebaf3ff06cb" target="_blank">Indeed</a> 和 Meta 自己的 <a href="https://www.metacareers.com/jobs/?sub_teams%5B0%5D=Data%20Science" target="_blank">招聘页面</a>,这些成千上万的新职位大多出现在科技行业。Meta 正在招聘数据科学家、研究员、分析师和工程师。</p>
<h2 id="微软">微软</h2>
<p><img src="https://kdn.flygon.net/docs/img/c9dbe2ebe80b9e3f8b6f843fcc801ef1.png" alt="科技裁员的情况如何?" loading="lazy"></p>
<p>图片来源:作者</p>
<p>微软进行了非常小规模的裁员,<a href="https://www.cnbc.com/2022/10/18/microsoft-confirms-job-cuts-after-calling-for-growth-to-slow.html" target="_blank">据报道</a> 这次裁员影响了不到 1% 的员工。</p>
<p>这次裁员的原因很简单:2022 年第三季度的收入增长是过去五年来最慢的。</p>
<p>我想稍微提一下,收入仍然 <em>增长</em>。只是增长的速度减慢了。</p>
<p><a href="https://www.linkedin.com/jobs/search/?currentJobId=3431685212&f_C=1035&f_I=4&geoId=103644278&keywords=microsoft%20data%20science&location=United%20States&refresh=true&sortBy=R&start=50" target="_blank">LinkedIn</a> 报道称微软仍在科技招聘网站上招聘数千个职位,包括研究、机器学习和数据科学领域。 <a href="https://www.indeed.com/jobs?q=microsoft&l=&vjk=31184bbb269d0be0" target="_blank">Indeed</a> 和微软的招聘 <a href="https://careers.microsoft.com/us/en/" target="_blank">网站</a> 也证实了这一点。</p>
<h2 id="netflix">Netflix</h2>
<p><img src="https://kdn.flygon.net/docs/img/83a3692b8d5a790cc9af5b41277c149e.png" alt="科技裁员情况如何?" loading="lazy"></p>
<p>图片来源:作者</p>
<p>流媒体巨头在过去几年面临了独特的困难,科技泡沫暂且不提。在 2022 年 5 月,Netflix 报告了十年来的首次用户流失。因此,公司 <a href="https://www.nytimes.com/2022/06/23/business/media/netflix-layoffs.html" target="_blank">进行了</a> 450 人的裁员。</p>
<p>尽管有这些裁员,Netflix 仍在其 <a href="https://jobs.netflix.com/search?team=Data%20Science%20and%20Engineering" target="_blank">内部招聘网站</a> 上提供多个数据科学和工程职位。LinkedIn <a href="https://www.linkedin.com/jobs/search/?currentJobId=3434154134&f_C=165158&f_I=6&geoId=103644278&keywords=netflix&location=United%20States&refresh=true&sortBy=R" target="_blank">显示</a> 有 200 个职位空缺,其中一些在分析师/数据科学领域, <a href="https://www.indeed.com/jobs?q=netflix&l=&vjk=01d1bb644bd70fde" target="_blank">Indeed</a> 也显示了类似的职位。</p>
<h2 id="亚马逊">亚马逊</h2>
<p><img src="https://kdn.flygon.net/docs/img/355a0482fd44254b362ba0c0fcc7e6e0.png" alt="科技裁员情况如何?" loading="lazy"></p>
<p>图片来源:作者</p>
<p>这家电商巨头 <a href="https://www.wsj.com/articles/amazon-to-lay-off-over-17-000-workers-more-than-first-planned-11672874304" target="_blank">裁员</a> 了 18,000 人。然而,裁员主要集中在公司员工。裁员影响了该部门大约 5% 的员工和其全部员工的 1.2%。公司将此归因于疫情期间大规模扩张带来的压力。</p>
<p>目前的就业前景并没有那么严峻。 <a href="https://www.indeed.com/jobs?q=amazon+engineer&l=&sc=0fcckey%3Acaff23281376b83d%2Cq%3Aengineer%3B&vjk=acf3bc3be40d827b" target="_blank">Indeed</a>、<a href="https://www.linkedin.com/jobs/search/?currentJobId=3427079410&f_C=1586&f_I=6&geoId=103644278&keywords=data%20scientist&location=United%20States&refresh=true&sortBy=R" target="_blank">LinkedIn</a> 和亚马逊的 <a href="https://www.amazon.jobs/en/job_categories/software-development" target="_blank">网站</a> 显示了许多科技行业的职位机会。</p>
<h2 id="推特">推特</h2>
<p><img src="https://kdn.flygon.net/docs/img/968f86761c34664a171819fd633f508b.png" alt="科技裁员情况如何?" loading="lazy"></p>
<p>作者提供的图片</p>
<p>Twitter 可能是报道最多的裁员来源,原因在于 Twitter 上的记者与新管理层之间的敌意。Twitter 因新任 CEO 埃隆·马斯克的任性裁员超过了其 7,500 人的一半员工。</p>
<p>马斯克<a href="https://www.cnn.com/2022/11/03/tech/twitter-layoffs/index.html" target="_blank">报道</a>Twitter 每天损失超过 400 万美元,迫使其“别无选择”只能裁员约 3,700 名员工,包括信任与安全团队、内容审核团队以及 Twitter 总部的<a href="https://www.nytimes.com/2022/12/29/technology/twitter-elon-musk.html" target="_blank">清洁工</a>。</p>
<p>与名单上的其他公司不同,Twitter 的独特之处在于公司内没有任何职位空缺。Twitter 的职业<a href="https://careers.twitter.com/" target="_blank">网站</a>上只有 24 个职位空缺,全部仅供“未来考虑”。<a href="https://www.linkedin.com/company/twitter/jobs/" target="_blank">LinkedIn</a>和<a href="https://www.indeed.com/jobs?q=twitter&l=" target="_blank">Indeed</a>也显示一样。</p>
<h2 id="其他科技公司">其他科技公司</h2>
<p>这五个例子无疑是最大的和最知名的,但并非唯一的裁员科技公司。其他裁员的公司还包括 Snap(<a href="https://www.theverge.com/2022/8/30/23329301/snap-layoffs-20-percent-employees-snapchat" target="_blank">20%的员工</a>)、Salesforce(<a href="https://www.nytimes.com/2023/01/04/technology/salesforce-layoffs.html" target="_blank">裁员 9,090 人</a>)、Zillow(25%的员工)以及更多公司。</p>
<p>这是<a href="https://layoffs.fyi" target="_blank">layoffs.fyi 的图表</a>,展示了 2022 年和 2023 年科技行业的裁员情况。</p>
<p><img src="https://kdn.flygon.net/docs/img/147140b68094f61def0a069faf5c90c2.png" alt="What's With All the Layoffs in Tech?" loading="lazy"></p>
<p>来源:<a href="https://layoffs.fyi/" target="_blank">layoffs.fyi</a></p>
<p>我喜欢<a href="https://layoffs.fyi/" target="_blank">他们的表格</a>,展示了自 COVID-19 开始以来裁员的 1,910 家公司。如果你想了解得更清楚,我推荐你查看一下。</p>
<p>或者,更好的是,这里有可视化的数据。</p>
<p><img src="https://kdn.flygon.net/docs/img/de3b638682ac0a39d6cc152a660942c8.png" alt="What's With All the Layoffs in Tech?" loading="lazy"></p>
<p>来源:<a href="https://layoffs.fyi/" target="_blank">layoffs.fyi</a></p>
<h1 id="该怎么做呢">该怎么做呢?</h1>
<p>如果你仔细阅读了这篇文章,我希望你能了解到三件事:</p>
<ul>
<li>
<p><strong>裁员已经影响了许多科技公司</strong>。如果你<em>被</em>裁员了,这与您的技能水平或能力无关。只是现在的市场情况。</p>
</li>
<li>
<p><strong>裁员</strong> <em><strong>并未</strong></em> <strong>过分针对技术员工</strong>。也就是说,科技公司在裁员时要么对所有员工都采取行动,要么在非工程、分析、数据科学等领域进行裁员。</p>
</li>
<li>
<p><strong>大多数这些公司仍在招聘技术职位</strong>,Twitter 是一个显著的例外。</p>
</li>
</ul>
<p>如果你在科技行业,由于科技公司在努力调整方向,你可能会被裁员,这并非完全由于你的过错。但仍然有很多机会。</p>
<p>那么你该怎么做呢?</p>
<p>确保你不会长时间失业的最佳措施就是<strong>保持你的面试技巧敏锐</strong>。我建议查看像我们自己的<a href="https://www.stratascratch.com/?utm_source=blog&utm_medium=click&utm_campaign=kdn+tech+layoffs" target="_blank">StrataScratch</a>这样的平台,它会帮助你练习常见的面试问题,包括编码和非编码问题。</p>
<p>你也可以参加像<a href="https://www.kaggle.com/competitions" target="_blank">Kaggle</a>或<a href="https://leetcode.com/problemset/all/" target="_blank">Leetcode</a>这样的网站上的编码竞赛,这是提高或保持你的<a href="https://www.stratascratch.com/blog/what-skills-do-you-need-as-a-data-scientist/?utm_source=blog&utm_medium=click&utm_campaign=kdn+tech+layoffs" target="_blank">数据科学技能</a>的好方法。Hackerrank 还提供了一个很棒的面试<a href="https://www.hackerrank.com/dashboard" target="_blank">准备工具包</a>,如果你很久没参加技术面试了,这可能会很有用。它还提供 Python 和问题解决等有价值的数据科学技能的认证。</p>
<p>最后,我建议花点时间审视一下你的网络。更新你的 LinkedIn,并向你在其他公司可能有的老联系人发送信息,提议见面。很多就业机会不仅依赖于你知道什么,而更在于你认识谁。</p>
<h1 id="最终想法">最终想法</h1>
<p>在所有关于裁员的恐慌中,我觉得<a href="https://www.marketwatch.com/story/the-best-job-in-america-pays-over-120-000-a-year-offers-low-stress-healthy-work-life-balance-and-its-workers-are-in-high-demand-11673327726" target="_blank">这篇文章</a>来自 MarketWatch 非常有趣。你能猜到他们称为“美国最佳职位”的是什么吗?</p>
<p>这是一个软件工程师。</p>
<p>所以说,很容易被关于裁员的坏消息所困扰并担心你的未来就业。我想重申,如果你发现自己被裁员,那不是因为你的问题,而是因为市场正在降温。</p>
<p>与其担心是否会被裁员,不如采取行动提高从一个技术职位直接跳槽到另一个的机会。</p>
<p>尽管头条新闻可能会这样说,但职位板证明许多公司仍然需要熟练的技术员工。</p>
<p><strong><a href="https://www.stratascratch.com" target="_blank">Nate Rosidi</a></strong> 是一位数据科学家,专注于产品策略。他也是一名讲授分析学的兼职教授,并且是<a href="https://www.stratascratch.com/" target="_blank">StrataScratch</a>,一个帮助数据科学家准备面试的平台注册者。可以在<a href="https://twitter.com/StrataScratch" target="_blank">Twitter: StrataScratch</a>或<a href="https://www.linkedin.com/in/nathanrosidi/" target="_blank">LinkedIn</a>上与他联系。</p>
<h3 id="了解更多主题">了解更多主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/the-surge-in-tech-layoffs-2024-who-to-blame" target="_blank">2024 年技术裁员激增:谁该负责?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/popular-google-certification-for-all-areas-in-the-tech-industry" target="_blank">科技行业所有领域的热门谷歌认证</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/09/collections-python.html" target="_blank">Python 中的所有集合</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/super-bard-ai-better.html" target="_blank">超级巴德:能够做所有事情且更出色的 AI</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/08/mads-5-skills-marketing-analytics-data-science-pros-need-today.html" target="_blank">今天所有市场营销分析和数据科学专业人士需要的 5 项技能</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/if-you-want-to-master-generative-ai-ignore-all-but-two-tools" target="_blank">如果你想精通生成式 AI,请忽略所有(除了两个)工具</a></p>
</li>
</ul>
<h1 id="kdnuggets-新闻-21n4812-月-22-日使用管道编写干净的-python-代码成为伟大数据科学家所需的-5-项关键技能">KDnuggets™ 新闻 21:n48,12 月 22 日:使用管道编写干净的 Python 代码;成为伟大数据科学家所需的 5 项关键技能</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2021/n48.html" target="_blank"><code>www.kdnuggets.com/2021/n48.html</code></a></p>
</blockquote>
<p>特性 | 产品 | 教程 | 观点 | 排行榜 | 职位 | <a href="https://www.kdnuggets.com/news/submissions.html" target="_blank">提交博客</a> | 本周图片</p>
<p>本周 KDnuggets:使用管道编写干净的 Python 代码;成为伟大数据科学家所需的 5 项关键技能;将机器学习算法完整部署到实时生产环境;成功数据科学家的 5 个特征;学习数据科学统计的最佳资源;以及更多精彩内容。</p>
<p>KDnuggets <a href="https://www.kdnuggets.com/2021/11/top-blogs-reward-program-resumes.html" target="_blank"><strong>顶级博客奖励计划</strong></a> 每月向顶级博客作者支付奖励。接受转载,但原创投稿的转载率是 3 倍。阅读我们的 <a href="https://www.kdnuggets.com/news/submissions.html" target="_blank"><strong>指南</strong></a> 并先提交你的博客到 KDnuggets!</p>
<p>特性</p>
<ul>
<li>
<p>**<img src="https://kdn.flygon.net/docs/img/write-clean-python-code-pipes.html" alt="金博客使用管道编写干净的 Python 代码**" loading="lazy">,作者:Khuyen Tran</p>
</li>
<li>
<p>**<img src="https://kdn.flygon.net/docs/img/5-key-skills-needed-become-great-data-scientist.html" alt="银博客成为伟大数据科学家所需的 5 项关键技能**" loading="lazy">,作者:Sharan Kumar Ravindran</p>
</li>
<li>
<p><strong>将机器学习算法完整部署到实时生产环境</strong>,作者:Graham Harrison</p>
</li>
<li>
<p><strong>成功数据科学家的 5 个特征</strong>,作者:Matthew Mayo</p>
</li>
<li>
<p><strong>学习数据科学统计的最佳资源</strong>,作者:Springboard</p>
</li>
</ul>
<p>产品,服务</p>
<ul>
<li><strong>利用 AI 和分析引擎更快地准备时间序列数据</strong>,作者:PI.EXCHANGE</li>
</ul>
<p>教程,概述</p>
<ul>
<li>
<p><strong>每位数据科学家都应了解的三个 R 库(即使你使用 Python)</strong>,作者:Terence Shin</p>
</li>
<li>
<p><strong>如何加速 XGBoost 模型训练</strong>,作者:Michael Galarnyk</p>
</li>
<li>
<p><strong>云机器学习透视:2021 年的惊喜与 2022 年的预测</strong>,作者:George Vyshnya</p>
</li>
<li>
<p><strong>如何在没有合适学位的情况下进入数据分析领域</strong>,作者:Zulie Rane</p>
</li>
</ul>
<p>观点</p>
<ul>
<li>
<p><strong>我如何在 14 年里将薪资提升 14 倍</strong>,作者:Leon Wei</p>
</li>
<li>
<p><strong>2022 年及以后 10 大 AI 与数据分析趋势</strong>,作者:David Pool</p>
</li>
<li>
<p><strong>聊天机器人转型:从失败到未来</strong>,作者:Lubo Smid</p>
</li>
<li>
<p><strong>为什么我们总是需要人类来训练 AI——有时是实时的</strong>,作者:Shoma Kimura</p>
</li>
</ul>
<p>最新故事</p>
<ul>
<li>
<p><strong>2021 年十大故事:我们不需要数据科学家,我们需要数据工程师;成为数据科学家的指南(逐步方法);我如何在 18 个月内将收入翻倍</strong>,作者:Gregory Piatetsky</p>
</li>
<li>
<p><strong>最新故事,12 月 13-19 日:使用管道编写清晰的 Python 代码</strong>,作者:KDnuggets</p>
</li>
</ul>
<p>职位</p>
<ul>
<li>
<p>查看我们最近的 AI、分析、数据科学、机器学习职位</p>
</li>
<li>
<p>你可以在 KDnuggets 的职位页面上免费发布与 AI、大数据、数据科学或机器学习相关的行业或学术职位,详细信息请发送电子邮件至 kdnuggets.com/jobs</p>
</li>
</ul>
<p>本周图片</p>
<blockquote>
<p>![成为伟大的数据科学家所需的 5 项关键技能</p>
<p><a href="https://www.kdnuggets.com/2021/12/5-key-skills-needed-become-great-data-scientist.html" target="_blank">成为伟大的数据科学家所需的 5 项关键技能</a></p>
</blockquote>
<h3 id="更多相关主题-3">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/write-clean-python-code-pipes.html" target="_blank">使用管道编写清晰的 Python 代码</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-key-skills-needed-become-great-data-scientist.html" target="_blank">成为伟大的数据科学家所需的 5 项关键技能</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/04/low-code-developers-still-needed.html" target="_blank">低代码:开发人员仍然需要吗?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n09.html" target="_blank">KDnuggets™新闻 22:n09,3 月 2 日:讲述一个伟大的数据故事:A…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n01.html" target="_blank">KDnuggets™新闻 22:n01,1 月 5 日:跟踪和可视化的 3 个工具…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/data-science-make-clean-energy-equitable.html" target="_blank">利用数据科学让清洁能源更加公平</a></p>
</li>
</ul>
<h1 id="构建有效的数据分析团队和项目生态系统以实现成功">构建有效的数据分析团队和项目生态系统以实现成功</h1>
<blockquote>
<p>网址:<a href="https://www.kdnuggets.com/2021/04/build-effective-data-analytics-team-project-ecosystem-success.html" target="_blank"><code>www.kdnuggets.com/2021/04/build-effective-data-analytics-team-project-ecosystem-success.html</code></a></p>
</blockquote>
<p>评论</p>
<p><strong>作者:<a href="https://www.linkedin.com/in/randy-runtsch-73a197/" target="_blank">Randy Runtsch</a>,数据分析师</strong></p>
<h3 id="介绍">介绍</h3>
<hr>
<h2 id="我们的前三大课程推荐-1">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速入门网络安全职业。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升您的数据分析水平</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持您的组织在 IT 领域</p>
<hr>
<p>在长期的软件开发、信息安全和数据分析职业生涯中,我观察到大型、复杂和令人不知所措的项目有可能无法满足利益相关者的需求,除非它们得到极其出色的管理。相反,我参与的大多数成功的数据分析项目规模、团队规模和时间线都很小。它们通常在几天、几周或几个月内完成,并且通常能满足最终用户的需求。</p>
<p>高效的管理、敏捷的实践、熟练的从业者、强大的工具、标准和指南可以结合起来创建一个数据分析生态系统,从而实现短项目周期和有用的解决方案。以下部分描述了我的团队开发和利用的一些组织、项目和数据分析特质与技术。虽然我们在大型企业的风险管理和内部审计职能中构建了数据分析程序,但你也许可以将这些技术应用于你的工作环境中。</p>
<h3 id="良好的管理与领导力">良好的管理与领导力</h3>
<p>在我 34 年的软件开发和数据分析工作经历中,我观察到许多管理和领导风格,无论好坏。我最近在与一位创建框架并指导我们团队在大型企业中建立成功的部门数据分析程序的经理合作时,取得了显著的成功。根据经验和观察,以下是他和其他杰出领导者帮助个人、团队和项目成功的一些特质和行动:</p>
<ul>
<li>
<p>为项目设定目标,并管理项目及团队以实现这些目标。</p>
</li>
<li>
<p>确定所需的能力,招聘和培训员工以满足这些需求。</p>
</li>
<li>
<p>与内部和外部组织合作,分享和学习最佳实践。</p>
</li>
<li>
<p>提供符合需求的强大软件工具。</p>
</li>
<li>
<p>作为与高层管理沟通的桥梁。</p>
</li>
<li>
<p>与团队及其成员合作并关心他们,但不要过于强势。</p>
</li>
<li>
<p>确保实施并遵循基本但足够的标准、指南和程序。</p>
</li>
<li>
<p>为成长和成就建立节奏。</p>
</li>
<li>
<p>尊重每个团队成员的时间和专注需求。</p>
</li>
</ul>
<h3 id="招聘和发展技能与知识">招聘和发展技能与知识</h3>
<p>几年前,我参加了一个数据分析会议,一位讲者描述了她作为数据科学家所需的一些技能。她表示,执行她的工作需要超过 200 项技能。确实,创建成功的数据分析解决方案要求分析师具备许多才能。为了招聘和培养具备所需技能和知识的分析师,你和你的管理层可以考虑以下步骤:</p>
<ol>
<li>
<p><strong>编写引人注目的职位描述和招聘启事</strong>——制定职位描述和招聘启事,描述成功候选人必须具备的技能和知识。同时,列出员工在职期间需要发展的技能和知识。</p>
</li>
<li>
<p><strong>招聘具有专业知识和良好潜力的数据分析师</strong>——运用职位描述和招聘启事,招聘具备所需技能和知识,并具有发展额外所需技能的能力和潜力的分析师。</p>
</li>
<li>
<p><strong>识别学习资源</strong>——创建课程和教程的列表,以帮助数据分析师发展在其职位上取得成功所需的技能和知识。</p>
</li>
<li>
<p><strong>评估技能</strong>——评估团队及其成员的优势和劣势,识别发展和成长需求,将每个数据分析师的技能和知识与职位描述以及深入的能力列表进行对比。</p>
</li>
<li>
<p><strong>培训分析师</strong>——确保工作单位的预算和时间表允许资金和时间用于数据分析师完成培训,以发展所需的技能和知识。根据技能评估结果,确保分析师参加学习资源列表中定义的培训。</p>
</li>
</ol>
<h3 id="保持项目团队小型化">保持项目团队小型化</h3>
<p>复杂的项目与大型团队可能会因为管理不善而陷入困境。尽量保持每个项目的规模和范围较小,并将团队规模限制为一到三名最终用户和一名主数据分析师,可能有助于项目的成功。对于复杂项目,团队可以增加数据分析师,以便通过分工或互补技能来提升项目效益。对于大型或复杂项目,你可能希望指派一名项目经理与团队合作,识别和管理任务、时间表、风险和问题。最后,在需要时寻求项目业务领域的主题专家(SME)。</p>
<h3 id="采用敏捷实践">采用敏捷实践</h3>
<p>项目团队,特别是在软件开发中,通常会应用<a href="https://en.wikipedia.org/wiki/Agile_software_development" target="_blank">敏捷开发方法</a>,例如 Scrum 或 Kanban,来组织任务并快速推进。我的团队有效地使用了在 Microsoft OneNote 中开发的 Kanban Board,以便在频繁的站会中跟踪和沟通任务。它由一页上的三个列组成。每个任务从“准备工作”移动到“进行中”时,任务开始,从“进行中”到“完成”时,任务结束。</p>
<p><img src="https://kdn.flygon.net/docs/img/733e7d4d00b278a745be900827a2ce25.png" alt="示例看板" loading="lazy"></p>
<p>简单的 Kanban Board 可以用来管理项目任务。图像由作者提供。</p>
<h3 id="确定简洁的范围目标和时间表">确定简洁的范围、目标和时间表</h3>
<p>与最终用户、团队成员和经理在项目生命周期中的对话对于建立并保持商定的简洁范围、目标和时间表至关重要。通过保持项目紧凑,我在一周到三个月长的项目中都取得了一致的成功。</p>
<p>如果项目庞大且复杂,可以考虑将其拆分成更小的子项目,每个子项目具有有限的范围、目标和时间表。</p>
<h3 id="将合理数量的竞争项目和任务分配给数据分析师">将合理数量的竞争项目和任务分配给数据分析师</h3>
<p>一些研究人员发现,当<a href="https://en.wikipedia.org/wiki/Human_multitasking" target="_blank">多任务处理</a>时,人类表现会受到影响。分配给个人的多个项目或任务可能会适得其反。此外,虽然技能和任务多样性是可以提高个人满意度和表现的工作因素(见<a href="https://en.wikipedia.org/wiki/Job_characteristic_theory" target="_blank">job characteristics theory</a>),但分配给工人的项目或任务数量应合理,以便工人能够成功并完成所有任务。</p>
<h3 id="平衡团队合作与自主性">平衡团队合作与自主性</h3>
<p>在一个运作良好的团队中工作可以带来许多好处,例如:</p>
<ul>
<li>
<p>团队成员可以互补彼此的技能。</p>
</li>
<li>
<p>团队成员可以相互鼓励并推动前进。</p>
</li>
<li>
<p>团队成员可以共享想法并进行头脑风暴,以确定解决方案。</p>
</li>
<li>
<p>团队的生产力可能会超过其各部分的总和。</p>
</li>
</ul>
<p>对于有效团队合作的好处毋庸置疑。另一方面,一些类型的工作,如数据分析、编程和写作,通常最好由那些半自主工作的个人完成,这些个人通常会收到团队成员的反馈。他们的工作需要专注和有限的干扰。</p>
<h3 id="采用并掌握强大且多功能的工具和语言">采用并掌握强大且多功能的工具和语言</h3>
<p>数据分析师应该配备强大且多功能的数据分析工具,以满足他们的需求。通过这种方法,分析师可以利用每个工具的功能,发展能力和最佳实践。以下部分描述了我的当前团队在数据分析项目中使用的每个软件包。</p>
<p><strong>Alteryx Designer</strong> — 根据 Alteryx 的网站,Designer 可用于“自动化分析的每一步,包括数据准备、数据融合、报告、预测分析和数据科学。”虽然单用户许可证的费用高达数千美元,但它是一个强大的数据分析和数据科学工具。我的团队使用它来创建和运行工作流,这些工作流输入数据、转换和准备数据,并以多种格式输出数据。分析师可以快速轻松地创建功能强大且运行迅速的工作流。</p>
<p><strong>Tableau</strong> — Tableau 软件创建了一个强大且可能是最受欢迎的商业智能和数据可视化平台。我的团队使用 Tableau Desktop 连接数据源,开发可视化工作表和仪表板。然后,我们将可视化内容发布到 Tableau Server,最终用户可以查看和互动。</p>
<p><strong>Python</strong> — Python 是一种用户友好且强大的编程语言,在数据分析师和数据科学家中非常受欢迎。与同样受数据科学家青睐的以统计为中心的 R 语言不同,Python 是一种通用编程语言。它是免费的且易于学习。分析师可以通过自由提供的库扩展 Python 的功能,例如 <a href="https://numpy.org/" target="_blank">NumPy</a> 和 <a href="https://www.tensorflow.org/" target="_blank">TensorFlow</a>。</p>
<p><img src="https://kdn.flygon.net/docs/img/97d73110a0c3533bf26244052660e4a0.png" alt="Python 编程语言" loading="lazy"></p>
<p>Python 编程语言代码示例。图片来自作者。</p>
<p><strong>SQL</strong> — 结构化查询语言(SQL)是用于实现、操作和查询存储在关系数据库管理系统(RDBMS)中的结构化数据的标准语言。它包括多个子语言。通过数据查询语言(DQL),分析师可以查询和检索数据库表中的数据。RDBMS 数据库在全球企业中存储大量数据集。</p>
<p><img src="https://kdn.flygon.net/docs/img/58b54b30f73ec759558018dc2e1280e4.png" alt="SQL — 结构化查询语言" loading="lazy"></p>
<p>SQL(结构化查询语言)代码示例。图片来自作者。</p>
<p><strong>Microsoft SQL Server Management Studio (SSMS)</strong> — SSMS 是微软的集成开发环境(IDE),用于管理和查询在 SQL Server RDBMS 中实现的数据库。免费且易于学习,我使用 SSMS 创建和运行 SQL 代码以查询包含所需数据的数据库。</p>
<p><img src="https://kdn.flygon.net/docs/img/0934460dee0427e02aa123e29732e678.png" alt="Microsoft SQL Server Management Studio (SSMS)" loading="lazy"></p>
<p>SQL Server Management Studio (SSMS) 用于管理 Microsoft SQL Server 数据库和 SQL 代码。图片来自作者。</p>
<p><strong>Rapid SQL</strong> — Rapid SQL 是一个类似于 SSMS 的集成开发环境,用于开发 SQL 查询以访问存储在 Oracle、SQL Server、DB2 和 SAP Sybase 数据库中的数据。我使用 Rapid SQL 从 DB2 或 Oracle 数据库中获取数据。</p>
<p><strong>微软 Visual Studio</strong> — Visual Studio 是微软的旗舰集成开发环境(IDE)。我使用 Visual Studio Professional 来创建用 Python 和其他编程语言编写的应用程序。它的编辑器功能强大,具有语法高亮功能。 <a href="https://visualstudio.microsoft.com/vs/community/" target="_blank">Visual Studio Community 2019</a> 是一个免费的 IDE 版本,可能满足你的需求。微软的 Visual Studio Code(VS Code)是另一个受程序员和数据分析师欢迎的免费 IDE。</p>
<p><img src="https://kdn.flygon.net/docs/img/72e8cabf73f23b02a4c7c3e7f006604c.png" alt="微软 Visual Studio" loading="lazy"></p>
<p>微软 Visual Studio Professional 是一个集成开发环境(IDE),用于编写程序和开发应用程序。图像由作者提供。</p>
<p><strong>微软 Excel</strong> — Excel 无疑是一个普遍使用、有用、强大且有时不可或缺的工具。我使用 Excel 工作簿作为项目数据源和输出,以创建小型数据集,进行必要的数据清洗和计算等。像 Excel 这样的电子表格应用程序在任何数据分析或数据科学工作中都是一项重要工具。</p>
<p><img src="https://kdn.flygon.net/docs/img/f52e18b877bde25ad9b66b0d8602f981.png" alt="微软 Excel" loading="lazy"></p>
<p>电子表格应用程序,如微软 Excel,是多功能的数据分析工具。图像由作者提供。</p>
<h3 id="制定基本标准指南和程序">制定基本标准、指南和程序</h3>
<p>对数据分析项目应用简明的标准和指南可以提高生产力以及工作产品的维护和共享。以下是指导我工作的标准和指南类型。</p>
<p><strong>命名标准</strong> — 对文件夹、文件、数据库表、列和字段等项进行标准化命名,使得在多个工作产品中一致命名和查找工作产品变得容易。</p>
<p><strong>文件夹结构标准和模板</strong> — 使用统一的文件夹结构可以使设置新项目和查找文件夹及文件变得容易。我的团队使用以下文件夹结构模板来组织和存储所有数据分析项目的工作产品:</p>
<ul>
<li>
<p>项目名称(将此值更改为项目名称)</p>
</li>
<li>
<p>alteryx_workflows</p>
</li>
<li>
<p>数据</p>
</li>
<li>
<p>文档</p>
</li>
<li>
<p>python_programs</p>
</li>
<li>
<p>sql_scripts</p>
</li>
<li>
<p>tableau_workbooks</p>
</li>
</ul>
<p>文件夹结构会根据每个项目的需求扩展和收缩。</p>
<p><strong>编码标准</strong> — 编码标准对编程的作用就像语法对英语散文的作用一样。它们帮助我们组织和清晰一致地传达思想。我曾参与的数据分析和软件开发团队受益于记录的编码规范。在项目中应用这些标准可以使每个代码模块更易于原作者编写,并且任何团队成员都可以更容易地阅读、理解、增强和维护。以下是我的团队用于指导工作的部分编码标准的描述。</p>
<ul>
<li>
<p><strong>类、变量和函数命名规范</strong> — 为了可读性,我们决定将所有类、函数和变量名称创建为小写字母,每个单词或缩写之间用下划线(“_”)分隔。每个类和变量名称描述它存储的值类型,而每个函数名称描述函数对哪些值或对象执行什么操作。例如,存储人名的变量可以叫做 person_name 或 person_nm。一个从数据库中检索人名列表的函数可以叫做 get_person_names()。</p>
</li>
<li>
<p><strong>代码模块前言</strong> — 我们在每个模块开头加入文本以描述其目的。为了帮助可能维护该模块的其他编码人员,我们添加了额外的信息,例如作者的名字、数据库连接字符串、文件位置和更改日志。</p>
</li>
<li>
<p><strong>注释</strong> — 尽管有些人说代码自我文档化,但我相信,恰当的注释可以帮助编码人员组织思路,并帮助需要维护或增强代码的其他人更快地理解它。例如,在开始时,我描述一个函数对什么数据做了什么。我还在每个执行任务的代码逻辑分组之前添加简要注释。</p>
</li>
<li>
<p><strong>空白</strong> — 为了使代码更易读,我在每个函数、每组变量定义和每个执行特定任务的代码块之间插入空行。</p>
</li>
<li>
<p><strong>简洁的函数范围和可见大小</strong> — 与空白一样,我限制每个函数的内容,以便更容易编码、理解、维护和扩展。我努力保持每个函数简单,并尝试使其内容在编辑器中可见(例如,跨 80 个字符和向下 40 行)。</p>
</li>
</ul>
<p><strong>可视化样式指南</strong> — 尽管编码标准可以帮助程序员理解、编写和维护代码,但可视化样式指南可以帮助数据分析师开发一致、有用和有意义的视觉效果。它们还可以通过提供一致、设计良好、易于理解和用户友好的视觉效果来使数据分析项目中的最终用户受益。以下是我的团队采纳的一些视觉样式指南。</p>
<ul>
<li>
<p><strong>品牌标准</strong> — 我们公司的品牌管理部门已确定了一组一致的字体、颜色和视觉设计风格及组件。我们将这些纳入我们的可视化指南,以增加专业性和一致性,并帮助最终用户获得熟悉的用户界面风格。</p>
</li>
<li>
<p><strong>字体</strong> — 我们公司设计了一种字体,当可用时我们将使用它。否则,我们的数据分析产品将默认使用 Ariel 字体。</p>
</li>
<li>
<p><strong>颜色</strong> — 我们公司的品牌标准包括一个小的色彩调色板。我们在可能的情况下将这些颜色应用于图表、图形和仪表板。我们还尽量限制在任何图表、图形或仪表板上使用的颜色数量,以保持视觉上的愉悦。</p>
</li>
<li>
<p><strong>标题、头部和标签</strong>——我们的指南描述了文本元素(如仪表板标题、图表和图形头部、列、过滤器和图例)应用的标准位置、字体、大小和颜色。</p>
</li>
<li>
<p><strong>视觉组件的摆放</strong>——与文本一样,我们的指南描述了仪表板上元素(如图表和图形、过滤器和图例)的标准位置。</p>
</li>
</ul>
<h3 id="摘要">摘要</h3>
<p>构建一个有效的数据分析团队并不容易,该团队需要定期构建和交付数据分析解决方案,为终端用户提供洞察力并帮助他们做出决策。但是,运用我在软件开发和数据分析领域长期积累的经验和有效实践,可能会帮助你取得成功。</p>
<p><strong>简历:<a href="https://www.linkedin.com/in/randy-runtsch-73a197/" target="_blank">Randy Runtsch</a></strong> 是一名数据分析师、软件开发人员、作家、摄影师、骑行者和冒险家。他和他的妻子住在美国明尼苏达州东南部。请关注 Randy 即将发布的关于公共数据集推动数据分析解决方案、编程、数据分析、自行车旅行、啤酒等方面的文章。</p>
<p><a href="https://towardsdatascience.com/how-to-set-up-a-data-analytics-team-and-project-ecosystem-for-success-100e14067e77" target="_blank">原文</a>。经许可转载。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p>数据科学团队模型:国际象棋与跳棋</p>
</li>
<li>
<p>在小公司构建数据科学团队的六个建议</p>
</li>
<li>
<p>数据科学家缺失的团队</p>
</li>
</ul>
<h3 id="更多相关内容-3">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/10/build-data-science-enablement-team-complete-guide.html" target="_blank">如何建立数据科学赋能团队:完整指南</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/ultimate-opensource-large-language-model-ecosystem.html" target="_blank">终极开源大型语言模型生态系统</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/08/free-book-build-reproducible-maintainable-data-science-project.html" target="_blank">构建可复现且易维护的数据科学项目:一本免费的指南…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/01/context-consistency-collaboration-essential-data-science-success.html" target="_blank">背景、一致性和协作对数据科学的成功至关重要</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2024/07/astronomer/data-orchestration-the-dividing-line-between-generative-ai-success-and-failure" target="_blank">数据编排:生成式 AI 成功与失败的分界线…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/10/nwu-data-science-methods-drive-business-success" target="_blank">数据科学方法推动商业成功</a></p>
</li>
</ul>
<h1 id="kdnuggets-新闻-20n42-11-月-4-日-数据科学数据可视化和机器学习的顶级-python-库掌握时间序列分析">KDnuggets™ 新闻 20:n42, 11 月 4 日: 数据科学、数据可视化和机器学习的顶级 Python 库;掌握时间序列分析</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2020/n42.html" target="_blank"><code>www.kdnuggets.com/2020/n42.html</code></a></p>
</blockquote>
<p>特性 | 新闻 | 教程 | 观点 | 顶级 | 招聘 | 提交博客 | 本周图片</p>
<p>数据科学家可以从 2020 年美国总统选举中学到什么?结果尚未确定,但似乎几个摇摆州的民调高估了民主党选票,就像 2016 年一样。准确预测人类行为是困难的,而在摇摆州预测选举结果时,即使是微小的错误(例如 48%而非 52%)也变得极为重要。请考虑这些可能性,检查预测假设,并尝试使用不同的数据来源以减少误差。GP</p>
<p>特性</p>
<ul>
<li>
<p><strong>数据科学、数据可视化和机器学习的顶级 Python 库</strong></p>
</li>
<li>
<p><strong>在专家的帮助下掌握时间序列分析</strong></p>
</li>
<li>
<p><strong>解释可解释的人工智能:一种两阶段方法</strong></p>
</li>
<li>
<p><strong>数据科学家缺失的团队</strong></p>
</li>
<li>
<p><strong>数据科学家还是机器学习工程师?哪个职业选择更好?</strong></p>
</li>
</ul>
<p>新闻</p>
<ul>
<li>
<p><strong>迁移敏感数据到云端的七个步骤:数据团队指南</strong></p>
</li>
<li>
<p><strong>与 Stefan Jansen 探讨机器学习在算法交易中的重要性</strong></p>
</li>
</ul>
<p>教程,概述</p>
<ul>
<li>
<p><strong>实用统计推理的 10 个原则</strong></p>
</li>
<li>
<p><strong>使用 BERT 进行主题建模</strong></p>
</li>
<li>
<p><strong>微软和谷歌开源了基于他们深度学习训练工作的这些框架</strong></p>
</li>
<li>
<p><strong>如何理解强化学习代理?</strong></p>
</li>
<li>
<p>**<img src="https://kdn.flygon.net/docs/img/building-neural-networks-pytorch-google-colab.html" alt="银色博客在 Google Colab 中使用 PyTorch 构建神经网络**" loading="lazy"></p>
</li>
<li>
<p><strong>处理机器学习中的不平衡数据</strong></p>
</li>
<li>
<p><strong>AI 简介,更新版</strong></p>
</li>
<li>
<p><strong>停止从命令行运行 Jupyter 笔记本</strong></p>
</li>
</ul>
<p>观点</p>
<ul>
<li>
<p><strong>当良好的数据分析未能产生你期望的结果时</strong></p>
</li>
<li>
<p><strong>克服 AI 中的种族偏见</strong></p>
</li>
<li>
<p><strong>你不再需要使用 Docker</strong></p>
</li>
</ul>
<p>热门故事,推文</p>
<ul>
<li>
<p><strong>热门故事, 10 月 26 日 - 11 月 1 日: 如何成为数据科学家:逐步指南;PerceptiLabs — TensorFlow 的图形用户界面和可视化 API</strong></p>
</li>
<li>
<p><strong>KDnuggets 热门推文, 10 月 21-27 日: #机器学习可以恢复失传的语言</strong></p>
</li>
</ul>
<p>职位</p>
<ul>
<li>
<p>查看我们最近的 AI、分析、数据科学、机器学习职位</p>
</li>
<li>
<p>你可以在 KDnuggets 的招聘页面上免费发布与 AI、大数据、数据科学或机器学习相关的行业或学术职位,邮箱 - 详情请见 kdnuggets.com/jobs</p>
</li>
</ul>
<p>本周图片</p>
<blockquote>
<p><img src="https://kdn.flygon.net/docs/img/top-python-libraries-data-science-data-visualization-machine-learning.html" alt="数据科学、数据可视化、机器学习的顶级 Python 库数据科学、数据可视化、机器学习的顶级 Python 库;" loading="lazy"></p>
</blockquote>
<h3 id="更多相关话题-3">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/n26.html" target="_blank">KDnuggets 新闻, 6 月 29 日: 数据科学的 20 个基本 Linux 命令…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n05.html" target="_blank">KDnuggets™新闻 22:n05, 2 月 2 日: 掌握机器学习的 7 个步骤…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2020/11/top-python-libraries-data-science-data-visualization-machine-learning.html" target="_blank">数据科学、数据可视化等领域的前 38 个 Python 库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/06/market-data-news-time-series-analysis.html" target="_blank">市场数据和新闻:时间序列分析</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/revamping-data-visualization-mastering-timebased-resampling-in-pandas" target="_blank">重塑数据可视化:掌握 Pandas 中的时间基础重采样</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/08/times-series-analysis-arima-models-python.html" target="_blank">时间序列分析:Python 中的 ARIMA 模型</a></p>
</li>
</ul>
<h1 id="kdnuggets-新闻-20n41-10-月-28-日初级和高级数据科学家的区别不存在公民数据科学家这一说">KDnuggets™ 新闻 20:n41, 10 月 28 日:初级和高级数据科学家的区别;不存在公民数据科学家这一说</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2020/n41.html" target="_blank"><code>www.kdnuggets.com/2020/n41.html</code></a></p>
</blockquote>
<p>特征 | 新闻 | 教程 | 意见 | 热门 | 职业 | 提交博客 | 本周图片</p>
<p>本周在 KDnuggets:初级和高级数据科学家的区别;“公民数据科学家”不是通往新职业的捷径;成为数据科学家的逐步指南;加入大数据革命;了解 DeepMind 依赖的统计方法以构建公平的机器学习模型;以及更多内容!</p>
<p>特征</p>
<ul>
<li>
<p><strong>初级和高级数据科学家之间未说出的区别</strong></p>
</li>
<li>
<p><strong>不存在公民数据科学家这一说</strong></p>
</li>
<li>
<p><strong>如何成为数据科学家:逐步指南</strong></p>
</li>
<li>
<p><strong>告别大数据。你好,大数据!</strong></p>
</li>
<li>
<p><strong>DeepMind 依赖这种旧的统计方法来构建公平的机器学习模型</strong></p>
</li>
</ul>
<p>新闻</p>
<ul>
<li><strong>PerceptiLabs - TensorFlow 的 GUI 和视觉 API</strong></li>
</ul>
<p>教程,概述</p>
<ul>
<li>
<p><strong>计算机视觉路线图</strong></p>
</li>
<li>
<p><strong>在 AWS 上使用 Docker Swarm、Traefik 和 Keycloak 部署安全且可扩展的 Streamlit 应用程序</strong></p>
</li>
<li>
<p><strong>使用机器学习和 R 进行行为分析:免费电子书</strong></p>
</li>
<li>
<p><strong>你应该为你的 QA 任务使用哪个版本的 BERT?</strong></p>
</li>
<li>
<p><strong>10 项被低估的 Python 技能</strong></p>
</li>
</ul>
<p>意见</p>
<ul>
<li>
<p><strong>人工智能能学习人类价值观吗?</strong></p>
</li>
<li>
<p><strong>获取数据科学职位比以往任何时候都更难 - 如何将其转变为你的优势</strong></p>
</li>
<li>
<p><strong>对有志成为数据科学家的建议</strong></p>
</li>
<li>
<p><strong>自动化如何改善数据科学家的角色</strong></p>
</li>
<li>
<p><strong>软件 2.0 成形</strong></p>
</li>
<li>
<p><strong>人工智能的伦理</strong></p>
</li>
</ul>
<p>热门故事,推文</p>
<ul>
<li>
<p><strong>2023 年 10 月 19-25 日 热门故事:如何在面试中解释关键机器学习算法;自然语言处理路线图</strong></p>
</li>
<li>
<p><strong>2023 年 10 月 14-20 日 KDnuggets 热门推文:神经网络背后的数学介绍</strong></p>
</li>
</ul>
<p>职业</p>
<ul>
<li>
<p>查看我们最近的 AI、分析、数据科学、机器学习职位</p>
</li>
<li>
<p>你可以在 KDnuggets 的职位页面上发布与 AI、大数据、数据科学或机器学习相关的免费简短职位信息,邮箱 - 详细信息请见 kdnuggets.com/jobs</p>
</li>
</ul>
<p>本周图片</p>
<blockquote>
<p><img src="https://kdn.flygon.net/docs/img/no-citizen-data-scientist.html" alt="没有公民数据科学家的这种事> > 来自《没有公民数据科学家的这种事》" loading="lazy"></p>
</blockquote>
<h3 id="更多相关主题-4">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/junior-senior-data-scientist-salary-difference.html" target="_blank">初级与高级数据科学家薪资:有什么区别?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/difference-data-analysts-data-scientists.html" target="_blank">数据分析师与数据科学家之间的区别是什么?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/08/difference-training-testing-data-machine-learning.html" target="_blank">机器学习中训练数据与测试数据的区别</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/11/efficiency-spells-difference-biological-neurons-artificial-counterparts.html" target="_blank">效率是生物神经元与…的区别</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/02/difference-sql-object-relational-mapping-orm.html" target="_blank">SQL 与对象关系映射(ORM)之间的区别是什么?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/08/difference-l1-l2-regularization.html" target="_blank">L1 与 L2 正则化的区别</a></p>
</li>
</ul>
<h1 id="简历">=<mark>简历</mark>=</h1>
<h1 id="kdnuggets-新闻-21n4010-月-20-日你需要的-20-个-python-包用于机器学习和数据科学通过项目展示来赢得数据科学面试">KDnuggets™ 新闻 21:n40,10 月 20 日:你需要的 20 个 Python 包用于机器学习和数据科学;通过项目展示来赢得数据科学面试</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2021/n40.html" target="_blank"><code>www.kdnuggets.com/2021/n40.html</code></a></p>
</blockquote>
<p>特性 | 产品 | 教程 | 观点 | 排行榜 | 职位 | <a href="https://www.kdnuggets.com/news/submissions.html" target="_blank">提交博客</a> | 本周图片</p>
<p>本周在 KDnuggets 上:你需要的 20 个 Python 包用于机器学习和数据科学;如何通过参与项目在数据科学面试中脱颖而出;部署你的第一个机器学习 API;使用 5 行代码进行实时图像分割;什么是聚类,它是如何工作的?以及更多内容。</p>
<p>请考虑 <a href="https://www.kdnuggets.com/news/submissions.html" target="_blank"><strong>提交</strong></a> 一篇原创博客到 KDnuggets!</p>
<p>特性</p>
<ul>
<li>
<p><strong>你需要的 20 个 Python 包用于机器学习和数据科学</strong>,作者 Sandro Luck</p>
</li>
<li>
<p>**<img src="https://kdn.flygon.net/docs/img/ace-data-science-interview-portfolio-projects.html" alt="银色博客如何通过参与项目来在数据科学面试中脱颖而出**" loading="lazy">,作者 Abid Ali Awan</p>
</li>
<li>
<p>**<img src="https://kdn.flygon.net/docs/img/deploying-first-machine-learning-api.html" alt="银色博客部署你的第一个机器学习 API**" loading="lazy">,作者 Abid Ali Awan</p>
</li>
<li>
<p><strong>使用 5 行代码进行实时图像分割</strong>,作者 Ayoola Olafenwa</p>
</li>
<li>
<p><strong>什么是聚类,它是如何工作的?</strong>,作者 Satoru Hayasaka</p>
</li>
</ul>
<p>产品、服务</p>
<ul>
<li>
<p><strong>2021 年数据工程师薪资报告分享快速发展的市场见解</strong>,作者 Burtch Works</p>
</li>
<li>
<p><strong>向西北大学数据科学专家学习</strong>,作者 Northwestern</p>
</li>
<li>
<p><strong>Hasura 如何通过 PostHog 将转化率提高了 20%</strong>,作者 PostHog</p>
</li>
<li>
<p><strong>亚马逊 Web 服务网络研讨会:利用数据集创建以客户为中心的策略并改善业务成果</strong>,作者 Roidna</p>
</li>
<li>
<p><strong>知识图谱论坛:技术生态系统和商业应用</strong>,作者 Ontotext</p>
</li>
</ul>
<p>教程、概述</p>
<ul>
<li>
<p><strong>构建多模态模型:使用 widedeep Pytorch 包</strong>,作者 Rajiv Shah</p>
</li>
<li>
<p><strong>AI 新计算范式:处理内存中的处理(PIM)架构</strong>,作者 Nam Sung Kim</p>
</li>
<li>
<p><strong>如何使用自动 bootstrap 方法计算机器学习中性能指标的置信区间</strong>,作者 David B Rosen (PhD)</p>
</li>
<li>
<p><strong>2022 年最实用的数据科学技能</strong>,作者:Terence Shin</p>
</li>
<li>
<p><strong>生产环境中服务机器学习模型:常见模式</strong>,作者:Mo, Oakes & Galarnyk</p>
</li>
<li>
<p><strong>如何用 KNIME Analytics 平台在三步内创建互动式仪表板</strong>,作者:Emilio Silvestri</p>
</li>
</ul>
<p>意见</p>
<ul>
<li>
<p><strong>避免这五种行为,让你看起来像个数据新手</strong>,作者:Tessa Xie</p>
</li>
<li>
<p><strong>我们的算法迷恋如何破坏了计算机视觉:以及合成计算机视觉如何修复它</strong>,作者:Paul Pop</p>
</li>
<li>
<p><strong>你的工作会被机器取代吗?</strong>,作者:Martin Perry</p>
</li>
<li>
<p><strong>数据专业人士如何在忙碌时依然令人印象深刻</strong>,作者:Devin Partida</p>
</li>
</ul>
<p>头条新闻</p>
<ul>
<li>
<p><strong>10 月 11 日至 17 日头条:使用 SQL 查询你的 Pandas 数据框</strong>,作者:KDnuggets</p>
</li>
<li>
<p><strong>KDnuggets 2021 年 9 月最佳博客奖励</strong>,作者:Gregory Piatetsky</p>
</li>
</ul>
<p>职位</p>
<ul>
<li>
<p>查看我们最新的 AI、分析、数据科学、机器学习职位</p>
</li>
<li>
<p>你可以在 KDnuggets 招聘页面上发布与 AI、大数据、数据科学或机器学习相关的免费短期职位信息,详情请通过电子邮件联系 - 请参阅 kdnuggets.com/jobs</p>
</li>
</ul>
<p>本周图像</p>
<blockquote>
<p>![使用 5 行代码进行实时图像分割</p>
<p><a href="https://www.kdnuggets.com/2021/10/real-time-image-segmentation-5-lines-code.html" target="_blank">使用 5 行代码进行实时图像分割</a></p>
</blockquote>
<h3 id="更多相关内容-4">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/n03.html" target="_blank">KDnuggets™ 新闻 22:n03,1 月 19 日:深入了解 13 个数据…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n37.html" target="_blank">KDnuggets 新闻,9 月 21 日:7 个机器学习作品集项目…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/5-free-university-courses-to-ace-coding-interviews" target="_blank">5 门免费的大学课程助力编程面试</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/12/7-super-cheat-sheets-need-ace-machine-learning-interview.html" target="_blank">7 张超级备忘单助力机器学习面试</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/10/10-cheat-sheets-need-ace-data-science-interview.html" target="_blank">10 张你需要的备考数据科学面试的备忘单</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/09/7-machine-learning-portfolio-projects-boost-resume.html" target="_blank">7 个机器学习作品集项目提升简历</a></p>
</li>
</ul>
<h1 id="kdnuggets新闻-20n4110-月-28-日初级和高级数据科学家的区别没有所谓的公民数据科学家">KDnuggets™新闻 20:n41,10 月 28 日:初级和高级数据科学家的区别;没有所谓的公民数据科学家</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2020/n41.html" target="_blank"><code>www.kdnuggets.com/2020/n41.html</code></a></p>
</blockquote>
<p>特性 | 新闻 | 教程 | 观点 | 头条 | 招聘 | 提交博客 | 本周图片</p>
<p>本周在 KDnuggets:初级和高级数据科学家之间的区别;“公民数据科学家”并不是通往新职业的快速通道;成为数据科学家的逐步指南;加入大数据革命;了解 DeepMind 依赖的统计方法以构建公平的机器学习模型;等等!</p>
<p>特性</p>
<ul>
<li>
<p><strong>初级和高级数据科学家之间的未说出的区别</strong></p>
</li>
<li>
<p><strong>没有所谓的公民数据科学家</strong></p>
</li>
<li>
<p><strong>如何成为数据科学家:逐步指南</strong></p>
</li>
<li>
<p><strong>告别大数据。你好,大规模数据!</strong></p>
</li>
<li>
<p><strong>DeepMind 依赖这种旧的统计方法来构建公平的机器学习模型</strong></p>
</li>
</ul>
<p>新闻</p>
<ul>
<li><strong>PerceptiLabs - TensorFlow 的 GUI 和可视化 API</strong></li>
</ul>
<p>教程,概述</p>
<ul>
<li>
<p><strong>计算机视觉的路线图</strong></p>
</li>
<li>
<p><strong>在 AWS 上使用 Docker Swarm、Traefik 和 Keycloak 部署安全且可扩展的 Streamlit 应用</strong></p>
</li>
<li>
<p><strong>使用机器学习和 R 进行行为分析:免费电子书</strong></p>
</li>
<li>
<p><strong>你应该为 QA 任务使用哪种 BERT 变体?</strong></p>
</li>
<li>
<p><strong>10 种被低估的 Python 技能</strong></p>
</li>
</ul>
<p>观点</p>
<ul>
<li>
<p><strong>人工智能能否学习人类价值观?</strong></p>
</li>
<li>
<p><strong>获取数据科学工作比以往任何时候都难——如何将其转化为你的优势</strong></p>
</li>
<li>
<p><strong>对有志数据科学家的建议</strong></p>
</li>
<li>
<p><strong>自动化如何改善数据科学家的角色</strong></p>
</li>
<li>
<p><strong>软件 2.0 逐渐成型</strong></p>
</li>
<li>
<p><strong>人工智能的伦理</strong></p>
</li>
</ul>
<p>头条新闻,推文</p>
<ul>
<li>
<p><strong>头条新闻,10 月 19-25 日:如何在面试中解释关键机器学习算法;自然语言处理的路线图</strong></p>
</li>
<li>
<p><strong>Top KDnuggets 推文,10 月 14-20 日:神经网络背后的数学介绍</strong></p>
</li>
</ul>
<p>招聘</p>
<ul>
<li>
<p>查看我们最近的人工智能、分析、数据科学、机器学习职位</p>
</li>
<li>
<p>您可以在 KDnuggets 职位页面上免费发布与人工智能、大数据、数据科学或机器学习相关的行业或学术职位信息,发送邮件 - 详细信息请见 kdnuggets.com/jobs</p>
</li>
</ul>
<p>本周图像</p>
<blockquote>
<p>![根本不存在公民数据科学家</p>
<p>来自《根本不存在公民数据科学家》</p>
</blockquote>
<h3 id="更多相关内容-5">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/junior-senior-data-scientist-salary-difference.html" target="_blank">初级与高级数据科学家薪资:有什么区别?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/difference-data-analysts-data-scientists.html" target="_blank">数据分析师与数据科学家的区别是什么?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/08/difference-training-testing-data-machine-learning.html" target="_blank">机器学习中训练数据与测试数据的区别</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/11/efficiency-spells-difference-biological-neurons-artificial-counterparts.html" target="_blank">效率决定生物神经元与…之间的区别</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/02/difference-sql-object-relational-mapping-orm.html" target="_blank">SQL 与对象关系映射(ORM)的区别是什么?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/08/difference-l1-l2-regularization.html" target="_blank">L1 与 L2 正则化的区别</a></p>
</li>
</ul>
<h1 id="kdnuggets-新闻-20n256-月-24-日你应该了解的-pytorch-基础知识提升数据科学技能的免费数学课程">KDnuggets™ 新闻 20:n25,6 月 24 日:你应该了解的 PyTorch 基础知识;提升数据科学技能的免费数学课程</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2020/n25.html" target="_blank"><code>www.kdnuggets.com/2020/n25.html</code></a></p>
</blockquote>
<p>特点 | 教程 | 意见 | 头条 | 职位 | 提交博客 | 本周图片</p>
<p>本周在 KDnuggets:学习 PyTorch 基础知识;寻找数学课程以提升数据科学技能;阅读关于分类项目的温和逐步指南;了解机器学习和计算机视觉如何用于作物病害检测;还有更多内容。</p>
<p>安息吧,Tom Fawcett。</p>
<p>特点</p>
<ul>
<li>
<p>**<img src="https://kdn.flygon.net/docs/img/fundamentals-pytorch.html" alt="Silver Blog 你应该了解的 PyTorch 最重要基础**" loading="lazy"></p>
</li>
<li>
<p><strong>4 个免费数学课程,提升你的数据科学技能</strong></p>
</li>
<li>
<p><strong>机器学习中的分类项目:温和的逐步指南</strong></p>
</li>
<li>
<p><strong>使用机器学习和计算机视觉进行作物病害检测</strong></p>
</li>
<li>
<p><strong>纪念 Tom Fawcett</strong></p>
</li>
</ul>
<p>教程,概述</p>
<ul>
<li>
<p><strong>使用 TensorFlow 数据集和 TensorBoard 的 TensorFlow 建模管道</strong></p>
</li>
<li>
<p><strong>人工智能中的偏见:入门指南</strong></p>
</li>
<li>
<p><strong>Dask 中的机器学习</strong></p>
</li>
<li>
<p><strong>如何处理数据集中的缺失值</strong></p>
</li>
<li>
<p><strong>基因组预测中的图机器学习</strong></p>
</li>
<li>
<p><strong>什么是情感人工智能,它为何重要?</strong></p>
</li>
<li>
<p><strong>modelStudio 和互动解释性模型分析的语法</strong></p>
</li>
<li>
<p><strong>使用 Tensorflow.js 实现计算机视觉应用的 6 个简单步骤</strong></p>
</li>
<li>
<p><strong>LightGBM:一种高效的梯度提升决策树</strong></p>
</li>
<li>
<p><strong>使用 AWS Sagemaker 一步步构建狗种分类器</strong></p>
</li>
</ul>
<p>意见</p>
<ul>
<li><strong>不要点击这个(如何识别深伪造视频和人工智能生成的文本)</strong></li>
</ul>
<p>头条新闻,推文</p>
<ul>
<li>
<p><strong>头条新闻,6 月 15-21 日:使用 Python 的简单语音转文本;谷歌 Colab 深度学习完全指南</strong></p>
</li>
<li>
<p><strong>KDnuggets 精选推文,6 月 10-16 日:#机器学习的博弈论速成课:经典与新思想</strong></p>
</li>
</ul>
<p>职位</p>
<ul>
<li>
<p>查看我们最新的 人工智能,分析,数据科学,机器学习职位</p>
</li>
<li>
<p>你可以在 KDnuggets 工作页面上免费发布与 AI、大数据、数据科学或机器学习相关的行业或学术职位,电子邮件 - 详情请见 kdnuggets.com/jobs</p>
</li>
</ul>
<p>本周图片</p>
<blockquote>
<p><img src="https://kdn.flygon.net/docs/img/fundamentals-pytorch.html" alt="你应该知道的 PyTorch 最重要的基础知识> > 从你应该知道的 PyTorch 最重要的基础知识" loading="lazy"></p>
</blockquote>
<h3 id="更多相关话题-4">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/n03.html" target="_blank">KDnuggets™ 新闻 22:n03, 1 月 19 日:深入探讨 13 个数据…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n15.html" target="_blank">KDnuggets 新闻,4 月 13 日:数据科学家应该了解的 Python 库…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n18.html" target="_blank">KDnuggets 新闻,5 月 4 日:9 门免费的哈佛课程学习数据…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n07.html" target="_blank">KDnuggets™ 新闻 22:n07, 2 月 16 日:如何学习机器…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/boost-your-data-science-skills-the-essential-sql-certifications-you-need" target="_blank">提升你的数据科学技能:你需要的必备 SQL 认证</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/03/overcome-fear-learn-math-data-science.html" target="_blank">如何克服数学恐惧并学习数据科学中的数学</a></p>
</li>
</ul>
<h1 id="人工智能中的偏见入门">人工智能中的偏见:入门</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2020/06/bias-ai-primer.html" target="_blank"><code>www.kdnuggets.com/2020/06/bias-ai-primer.html</code></a></p>
</blockquote>
<p>评论</p>
<p>人工智能中的偏见现在和以前一样重要;它一直是一个重要的话题,但随着时间的推移,它似乎获得了更多的关注,这也是它应得的关注。人工智能偏见及其相关的伦理、包容性和多样性概念不再是相关课程和文本中的附带话题,而是如斯坦福的 CS224n: 自然语言处理与深度学习 这样的课程中的核心和早期话题,还有即将出版的 Fast.ai 的书籍《Deep Learning for Coders with fastai and PyTorch》仅举两个具体的例子。</p>
<p>除了越来越多的从业者在日常工作中逐渐关注和包含人工智能偏见和伦理问题,许多研究人员今天也在做出有针对性且非常有意识的影响。<a href="http://m-mitchell.com/" target="_blank">玛格丽特·米切尔</a> 是从事这一领域的研究人员之一。米切尔(<a href="https://twitter.com/mmitchell_ai" target="_blank">@mmitchell_ai</a>)是谷歌研究与机器智能组的高级研究科学家。根据她的 <a href="http://m-mitchell.com/" target="_blank">网站</a>,她的工作内容如下:</p>
<blockquote>
<hr>
<h2 id="我们的前三个课程推荐-5">我们的前三个课程推荐</h2>
<h2 id="_"></h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织的 IT</p>
<hr>
<p>我的研究通常涉及视觉-语言和基础语言生成,专注于如何将人工智能发展到积极的目标。这包括帮助计算机根据它们可以处理的内容进行沟通的研究,以及从人工智能的最新技术中创建辅助和临床技术的项目。</p>
</blockquote>
<p>尽管玛格丽特的工作显然超越了基础,她确实在斯坦福 CS224n: 自然语言处理与深度学习的 <a href="https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/" target="_blank">2019 年冬季课程</a> 上进行了关于人工智能偏见的话题介绍,相关幻灯片可在课程网站上获得。这些幻灯片(及演讲)的标题为 <strong><a href="https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/slides/cs224n-2019-lecture19-bias.pdf" target="_blank">人工智能的视觉和语言中的偏见</a></strong>,是对那些对人工智能偏见和伦理感兴趣但缺乏入门点的人们的绝佳资源。</p>
<p><img src="https://kdn.flygon.net/docs/img/42f68e7509eca52bef16da16150e573b.png" alt="Figure" loading="lazy"></p>
<p><strong>图 1.</strong> 公平性与包容性的评估:混淆矩阵(来自 Margaret Mitchell 的 <a href="https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/slides/cs224n-2019-lecture19-bias.pdf" target="_blank">人工智能视觉与语言中的偏见幻灯片</a>)。</p>
<p>讲座是一次自成一体的自然语言处理与深度学习课程(尽管涵盖了语言、视觉以及更多的“通用” AI),可以在一个场合中轻松消化,无论是通过幻灯片本身还是配套的讲座视频(见下文)。</p>
<p>首先,幻灯片涵盖了(毫不意外地)多种特定的偏见及其如何影响 AI 系统的不同方面,包括人类报告偏见、数据中的偏见、解释偏见、算法偏见等。还涉及了一些密切相关的概念,如原型理论的影响、公平性与包容性、反馈回路以及不公正的 AI 结果等。此外,还讨论了诸如从面部图像预测犯罪等有争议(甚至更糟糕)的项目,以及它们的缺陷和偏见。</p>
<p>讲座中强调了人类在 AI 偏见中的角色。AI 绝非一个孤立的、自成体系的技术,它与开发、训练、整理数据、操作及获取洞察的人员直接相关,反映了这些构建和互动的人的特质。正如 Mitchell 所说,“[我们要影响 AI 的发展方式]”,并给出了具体的例子说明如何做到这一点。</p>
<p><img src="https://kdn.flygon.net/docs/img/54810b601491dd74cad9c3fda41f1715.png" alt="图" loading="lazy"></p>
<p><strong>图 2.</strong> 数据中的人类偏见以及数据收集和注释中的人类偏见示例(来自 Margaret Mitchell 的 <a href="https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/slides/cs224n-2019-lecture19-bias.pdf" target="_blank">人工智能视觉与语言中的偏见幻灯片</a>)。</p>
<p>如前所述,幻灯片的内容也在 Mitchell 的课堂讲座视频中涵盖,这段视频也免费向所有人开放(见下文),你可以在一个小时的讲座中听到作者对幻灯片内容的详细解释。</p>
<p>AI 偏见是一个广泛的研究领域。然而,更重要的是,虽然它可以被视为一个值得深入探讨的独立实体,但非专家在总体 AI 相关背景中也需要考虑偏见。简而言之,人工智能中的偏见是所有人,包括利益相关者和非利益相关者、技术人员和非技术人员,从研究人员到工程师、从实践者到产品设计师等都需要关注的问题。</p>
<p>每个人都应尽力将 AI 建设得尽可能无偏见。因此,深入了解 AI 偏见的相关问题是每个人的必修课,而 Margaret Mitchell 的幻灯片和讲座是一个很好的起点。</p>
<p><strong>相关</strong>:</p>
<ul>
<li>
<p>谷歌开源 TFCO 以帮助构建公平的机器学习模型</p>
</li>
<li>
<p>最佳深度学习 NLP 课程免费</p>
</li>
<li>
<p>将伦理应用于人工智能的 5 种方法</p>
</li>
</ul>
<h3 id="更多相关内容-6">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2020/09/understanding-bias-variance-trade-off-3-minutes.html" target="_blank">3 分钟理解偏差-方差权衡</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/03/dealing-position-bias-recommendations-search.html" target="_blank">处理推荐和搜索中的位置偏差</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/08/biasvariance-tradeoff.html" target="_blank">偏差-方差权衡</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/introduction-to-statistics-statology-primer" target="_blank">统计学入门:Statology 入门</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/probability-statology-primer" target="_blank">概率:Statology 入门</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/describing-data-statology-primer" target="_blank">数据描述:Statology 入门</a></p>
</li>
</ul>
<h1 id="google-开源了-mobilenetv3并提出了改进移动计算机视觉模型的新思路">Google 开源了 MobileNetV3,并提出了改进移动计算机视觉模型的新思路</h1>
<blockquote>
<p>译文:<a href="https://www.kdnuggets.com/2019/12/google-open-sources-mobilenetv3-improve-mobile-computer-vision-models.html" target="_blank"><code>www.kdnuggets.com/2019/12/google-open-sources-mobilenetv3-improve-mobile-computer-vision-models.html</code></a></p>
</blockquote>
<p>评论 <img src="https://kdn.flygon.net/docs/img/0665646a2b72f0810caf185893592b3e.png" alt="图" loading="lazy"></p>
<p>移动深度学习正成为人工智能(AI)领域中最活跃的研究领域之一。设计能够在移动运行时高效执行的深度学习模型需要重新思考许多神经网络架构范式。移动深度学习模型需要平衡复杂神经网络结构的准确性与移动运行时的性能限制。在移动深度学习的领域中,计算机视觉仍然是最具挑战性的领域之一。2017 年,<a href="https://ai.googleblog.com/2017/06/mobilenets-open-source-models-for.html" target="_blank">Google 介绍了 MobileNets</a>,这是一个基于 TensorFlow 的计算机视觉模型系列。<a href="https://arxiv.org/abs/1905.02244" target="_blank">MobileNets 的最新架构在几天前揭晓</a>,其中包含了一些有趣的改进移动计算机视觉模型的想法。</p>
<hr>
<h2 id="我们的前三大课程推荐-2">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你组织的 IT 需求</p>
<hr>
<p>MobileNetV3 是驱动许多流行移动应用图像分析功能的架构的第三个版本。该架构也被纳入了流行的框架,如 TensorFlow Lite。MobileNets 需要仔细平衡计算机视觉和深度学习的一般进展与移动环境的限制。Google 定期发布 MobileNets 架构的更新,这些更新融入了一些深度学习领域最具创新性的想法。</p>
<h3 id="mobilenetv1">MobileNetV1</h3>
<p><a href="https://arxiv.org/abs/1704.04861" target="_blank">MobileNets 的第一个版本</a> 于 2017 年春季发布。其核心思想是引入一系列基于 TensorFlow 的计算机视觉模型,这些模型在考虑到设备或嵌入式应用资源受限的情况下最大化准确性。从概念上讲,MobileNetV1 旨在实现两个基本目标,以构建以移动为优先的计算机视觉模型:</p>
<ul>
<li>
<p><strong>更小的模型尺寸</strong>:更少的参数数量</p>
</li>
<li>
<p><strong>更小的复杂性</strong>:更少的乘法和加法</p>
</li>
</ul>
<p>根据这些原则,MobileNetV1 是小型、低延迟、低功耗的模型,参数化以满足各种使用场景的资源限制。它们可以用于分类、检测、嵌入和分割。</p>
<p><img src="https://kdn.flygon.net/docs/img/8fd54267b04b8152578bce676a516a38.png" alt="" loading="lazy"></p>
<p>MobileNetV1 的核心架构基于一个精简的架构,使用深度可分离卷积来构建轻量级深度神经网络。在神经网络架构方面,深度可分离卷积是一个深度卷积,后跟一个逐点卷积,如下图所示。在 MobileNetV1 中,深度卷积对每个输入通道应用一个滤波器。逐点卷积随后对深度卷积的输出应用 1×1 卷积进行组合。标准卷积在一步中既滤波又组合输入,深度可分离卷积则将其拆分为两个层,一个用于滤波,另一个用于组合。</p>
<p><img src="https://kdn.flygon.net/docs/img/eab2ecda2c05b8425c766c78bb1a5873.png" alt="" loading="lazy"></p>
<p>第一个 MobileNetV1 实现被包含在<a href="https://github.com/tensorflow/models/blob/master/research/slim/README.md" target="_blank">TensorFlow-Slim 图像分类库</a>中。随着基于这一新范式的新移动应用的开发,出现了改进整体架构的新想法。</p>
<h3 id="mobilenetv2">MobileNetV2</h3>
<p>MobileNet 架构的第二个版本<a href="https://arxiv.org/abs/1801.04381" target="_blank">在 2018 年初发布</a>。MobileNetV2 基于其前身的一些理念,并结合了新的想法,以优化架构用于分类、物体检测和语义分割等任务。从架构的角度来看,MobileNetV2 引入了两个新特性:</p>
<ol>
<li>
<p>层之间的线性瓶颈</p>
</li>
<li>
<p>瓶颈之间的 shortcut 连接<a href="https://ai.googleblog.com/2018/04/mobilenetv2-next-generation-of-on.html#1" target="_blank">1</a>。基本结构如下图所示。</p>
</li>
</ol>
<p>MobileNetV2 的核心思想是瓶颈编码模型的中间输入和输出,而内层封装了模型从像素等低层次概念到图像类别等高层次描述符的转换能力。最后,与传统的残差连接一样,shortcut 连接实现了更快的训练和更好的准确性。</p>
<p><img src="https://kdn.flygon.net/docs/img/fb540d2a4d751f9040afe0288cced2ae.png" alt="" loading="lazy"></p>
<h3 id="mobilenetsv3">MobileNetsV3</h3>
<p>对 MobileNets 架构的最新改进总结 <a href="https://arxiv.org/abs/1905.02244" target="_blank">在今年八月发布的一篇研究论文中</a>。MobileNetV3 的主要贡献是使用 AutoML 寻找给定问题的最佳神经网络架构。这与以前版本架构的手工设计形成对比。具体而言,MobileNetV3 利用两种 AutoML 技术: <a href="https://ai.google/research/pubs/pub47217/" target="_blank">MnasNet</a> 和 <a href="https://arxiv.org/pdf/1804.03230" target="_blank">NetAdapt</a>。MobileNetV3 首先使用 MnasNet 搜索粗略架构,MnasNet 使用强化学习从离散选择集中选择最佳配置。之后,模型使用 NetAdapt 进行架构微调,NetAdapt 是一种补充技术,通过小幅度减小来修剪未充分利用的激活通道。</p>
<p>MobileNetV3 的另一个新颖想法是将一个 <a href="https://arxiv.org/abs/1709.01507" target="_blank">squeeze-and-excitation</a> 块融入核心架构中。squeeze-and-excitation 块的核心思想是通过显式建模卷积特征通道之间的相互依赖关系来提高网络生成表示的质量。为此,我们提出了一种机制,允许网络进行特征重新校准,从而可以学习使用全局信息来有选择地强调有用特征并抑制不太有用的特征。在 MobileNetV3 的情况下,架构扩展了 MobileNetV2,融入了 squeeze-and-excitation 块作为搜索空间的一部分,最终得到了更为强健的架构。</p>
<p><img src="https://kdn.flygon.net/docs/img/2fa97817013f78283082bc74622c6084.png" alt="" loading="lazy"></p>
<p>MobileNetV3 的一个有趣优化是重新设计了架构中一些昂贵的层。MobileNetV2 中的一些层对模型的准确性至关重要,但也引入了令人担忧的延迟水平。通过进行一些基本优化,MobileNetV3 能够在不牺牲准确性的情况下,移除前代架构中的三个昂贵层。</p>
<p><img src="https://kdn.flygon.net/docs/img/3ed6adaa7ac831b133ecc63361ecde38.png" alt="" loading="lazy"></p>
<p>MobileNetV3 相比以前的架构显示出了显著的改进。例如,在目标检测任务中,MobileNetV3 的延迟减少了 25%,同时保持了与以前版本相同的准确性。分类任务中也观察到了类似的改进,如下图所示:</p>
<p><img src="https://kdn.flygon.net/docs/img/f78c50eca956c18cfbc8df1d9fc489a3.png" alt="" loading="lazy"></p>
<p>MobileNets 仍然是移动计算机视觉中最先进的架构之一。将 AutoML 纳入 MobileNetV3 无疑开启了许多我们之前未曾想到的有趣架构。<a href="https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet" target="_blank">MobileNets 的最新版本可在 GitHub 上找到</a>,MobileNetV3 的实现包括在 <a href="https://github.com/tensorflow/models/tree/master/research/object_detection" target="_blank">Tensorflow 目标检测 API</a> 中。</p>
<p><a href="https://towardsdatascience.com/google-open-sources-mobilenetv3-with-new-ideas-to-improve-mobile-computer-vision-models-bfba8967a7f1" target="_blank">原文</a>。经许可转载。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p>K-Means 聚类下的图像分割简介</p>
</li>
<li>
<p>在 TensorFlow 中比较 MobileNet 模型</p>
</li>
<li>
<p>谷歌、优步和 Facebook 的开源项目,用于数据科学和 AI</p>
</li>
</ul>
<h3 id="更多相关主题-5">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/dinov2-selfsupervised-computer-vision-models-meta-ai.html" target="_blank">DINOv2: Meta AI 的自监督计算机视觉模型</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/01/tensorflow-computer-vision-transfer-learning-made-easy.html" target="_blank">TensorFlow 在计算机视觉中的应用 - 迁移学习变得简单</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2024/01/mlm-discover-the-world-of-computer-vision-ebook" target="_blank">发现计算机视觉的世界:介绍 MLM 的最新…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/5-applications-computer-vision.html" target="_blank">计算机视觉的 5 个应用</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/05/6-things-need-know-data-management-matters-computer-vision.html" target="_blank">关于数据管理你需要知道的 6 件事及其重要性…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n10.html" target="_blank">KDnuggets 新闻 2022 年 3 月 9 日:在 5… 内构建机器学习 Web 应用</a></p>
</li>
</ul>
<h1 id="ds">=<mark>DS</mark>=</h1>
<h1 id="免费学习斯坦福大学的计算机科学中的概率学">免费学习斯坦福大学的计算机科学中的概率学</h1>
<blockquote>
<p>译文:<a href="https://www.kdnuggets.com/learn-probability-in-computer-science-with-stanford-university-for-free" target="_blank"><code>www.kdnuggets.com/learn-probability-in-computer-science-with-stanford-university-for-free</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/9b658529e2f6f9138e1c2f7872c64f1d.png" alt="免费学习斯坦福大学的计算机科学中的概率学" loading="lazy"></p>
<p>图片由作者提供</p>
<p>对于那些深入计算机科学领域或需要刷新概率知识的人来说,你们将会大有收获。斯坦福大学最近更新了其 <a href="https://www.youtube.com/playlist?list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg" target="_blank">YouTube 播放列表</a> 的 CS109 课程,增加了新内容!</p>
<hr>
<h2 id="我们的前三个课程推荐-6">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织的 IT</p>
<hr>
<p>该播放列表包含 29 节讲座,为你提供概率理论基础的黄金标准知识、概率理论中的基本概念、分析概率的数学工具,并最终结束于数据分析和机器学习。</p>
<p>那么让我们直接开始吧……</p>
<h1 id="讲座-1计数">讲座 1:计数</h1>
<p>链接: <a href="https://www.youtube.com/watch?v=2MuDZIAzBMY&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=1" target="_blank">计数</a></p>
<p>了解概率的历史及其如何帮助我们实现现代人工智能,包括开发人工智能系统的实际例子。理解核心计数阶段,包括使用“步骤”和“或”的计数。这涵盖了诸如人工神经网络等领域,以及研究人员如何利用概率构建机器。</p>
<h1 id="讲座-2组合数学">讲座 2:组合数学</h1>
<p>链接: <a href="https://www.youtube.com/watch?v=ag4Ei15CG0c&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=2" target="_blank">组合数学</a></p>
<p>第二讲深入探讨更严肃的计数——这称为组合数学。组合数学是计数和排列的数学。深入了解<em>n</em>个对象的计数任务,包括排序对象(排列)、选择<em>k</em>个对象(组合)和将对象放入<em>r</em>个桶中。</p>
<h1 id="讲座-3什么是概率">讲座 3:什么是概率?</h1>
<p>链接: <a href="https://www.youtube.com/watch?v=EGgMCE2AgyU&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=3" target="_blank">什么是概率?</a></p>
<p>课程在这里真正开始深入探讨概率。学习概率的核心规则,并通过各种示例了解这些规则,并稍微涉及 Python 编程语言及其在概率中的应用。</p>
<h1 id="讲座-4概率与贝叶斯">讲座 4:概率与贝叶斯</h1>
<p>链接:<a href="https://www.youtube.com/watch?v=NHRoXvPaZqY&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=4" target="_blank">概率与贝叶斯</a></p>
<p>在这节讲座中,你将深入学习如何使用条件概率、链式法则、全概率法则和贝叶斯定理。</p>
<h1 id="讲座-5独立性">讲座 5:独立性</h1>
<p>链接:<a href="https://www.youtube.com/watch?v=zTJDZ2wmaRU&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=6" target="_blank">独立性</a></p>
<p>在这节讲座中,你将学习概率如何在互斥和独立的情况下应用,使用 AND/OR。讲座将通过各种示例帮助你很好地掌握这些概念。</p>
<h1 id="讲座-6随机变量与期望">讲座 6:随机变量与期望</h1>
<p>链接:<a href="https://www.youtube.com/watch?v=8QCg2ur-3fo&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=6" target="_blank">随机变量与期望</a></p>
<p>基于之前的讲座和你对条件概率及独立性的知识,这节讲座将深入随机变量,使用并生成随机变量的概率质量函数,并能够计算期望值。</p>
<h1 id="讲座-7方差-伯努利-二项分布">讲座 7:方差 伯努利 二项分布</h1>
<p>链接:<a href="https://www.youtube.com/watch?v=I2UBspTNAG0&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=7" target="_blank">方差 伯努利 二项分布</a></p>
<p>现在你将利用你的知识解决越来越难的问题。你在这节讲座中的目标是识别和使用二项随机变量、伯努利随机变量,并能够计算随机变量的方差。</p>
<h1 id="讲座-8泊松分布">讲座 8:泊松分布</h1>
<p>链接:<a href="https://www.youtube.com/watch?v=QV3IRiG6dVs&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=8" target="_blank">泊松分布</a></p>
<p>泊松分布在你有一个速率并且关心事件发生次数时非常有用。你将学习如何在不同方面使用它,并结合 Python 代码示例。</p>
<h1 id="讲座-9连续随机变量">讲座 9:连续随机变量</h1>
<p>链接:<a href="https://www.youtube.com/watch?v=OFgBn4rQkqc&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=9" target="_blank">连续随机变量</a></p>
<p>本讲座的目标包括熟练使用新的离散随机变量,积分密度函数以获得概率,以及使用累积分布函数以获得概率。</p>
<h1 id="讲座-10正态分布">讲座 10:正态分布</h1>
<p>链接:<a href="https://www.youtube.com/watch?v=rpB_NNXiWlM&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=10" target="_blank">正态分布</a></p>
<p>你可能之前听说过正态分布,在这节讲座中,你将了解正态分布的简要历史、它的定义、为什么它重要以及实际例子。</p>
<h1 id="讲座-11联合分布">讲座 11:联合分布</h1>
<p>链接:<a href="https://www.youtube.com/watch?v=8Il2M7kbQSc&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=11" target="_blank">联合分布</a></p>
<p>在之前的讲座中,你最多处理了 2 个随机变量,下一步学习将是处理任意数量的随机变量。</p>
<h1 id="讲座-12推断">讲座 12:推断</h1>
<p>链接:<a href="https://www.youtube.com/watch?v=fvgQBAsg5Zo&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=12" target="_blank">推断</a></p>
<p>本讲座的学习目标是如何使用多项式,理解对数概率的实用性,并能够使用贝叶斯定理与随机变量。</p>
<h1 id="讲座-13-推断-ii">讲座 13: 推断 II</h1>
<p>链接: <a href="https://www.youtube.com/watch?v=d0ImA7m4BEg&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=13" target="_blank">推断 II</a></p>
<p>学习目标继续延续上节课,结合贝叶斯定理与随机变量。</p>
<h1 id="讲座-14-建模">讲座 14: 建模</h1>
<p>链接: <a href="https://www.youtube.com/watch?v=q9lk8l8P-E4&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=14" target="_blank">建模</a></p>
<p>在本讲座中,你将把迄今为止学到的所有知识与现实问题——概率建模结合起来。这是将一堆随机变量一起随机处理。</p>
<h1 id="讲座-15-一般推断">讲座 15: 一般推断</h1>
<p>链接: <a href="https://www.youtube.com/watch?v=c0QGjtu9GZg&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=15" target="_blank">一般推断</a></p>
<p>你将深入探讨一般推断,特别是学习一种称为拒绝采样的算法。</p>
<h1 id="讲座-16-beta">讲座 16: Beta</h1>
<p>链接: <a href="https://www.youtube.com/watch?v=aOhk9mFrHdU&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=16" target="_blank">Beta</a></p>
<p>本讲座将深入探讨用于解决现实世界问题的概率随机变量。Beta 是一种概率分布,其范围在 0 和 1 之间。</p>
<h1 id="讲座-17-添加随机变量">讲座 17: 添加随机变量</h1>
<p>链接: <a href="https://www.youtube.com/watch?v=UEyHbI9FRtM&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=17" target="_blank">添加随机变量 I</a></p>
<p>在课程的这一部分,你将学习深入理论,而随机变量的添加是如何获得概率理论结果的介绍。</p>
<h1 id="讲座-18-中央极限定理">讲座 18: 中央极限定理</h1>
<p>链接: <a href="https://www.youtube.com/watch?v=6Q9wT6JGMMM&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=18" target="_blank">中央极限定理</a></p>
<p>在本讲座中,你将深入中央极限定理,这是概率中的一个重要元素。你将通过实际例子来掌握这个概念。</p>
<h1 id="讲座-19-自助法与-p-值">讲座 19: 自助法与 P 值</h1>
<p>链接: <a href="https://www.youtube.com/watch?v=NXJwyPT1vsc&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=19" target="_blank">自助法与 P 值 I</a></p>
<p>你现在将进入不确定性理论、采样和自助法,这些都是受到中央极限定理启发的。你将通过实际例子进行学习。</p>
<h1 id="讲座-20-算法分析">讲座 20: 算法分析</h1>
<p>链接: <a href="https://www.youtube.com/watch?v=Ht9yUPtppwY&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=20" target="_blank">算法分析</a></p>
<p>在本讲座中,你将深入计算机科学,深入理解算法分析,即寻找算法的计算复杂度的过程。</p>
<h1 id="讲座-21-最大似然估计-mle">讲座 21: 最大似然估计 (M.L.E.)</h1>
<p>链接: <a href="https://www.youtube.com/watch?v=utFEufMXHgw&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=21" target="_blank">最大似然估计 (M.L.E.)</a></p>
<p>本讲座将深入探讨参数估计,这将为你提供更多关于机器学习的知识。在这里,你将把概率的知识应用到机器学习和人工智能中。</p>
<h1 id="讲座-22-map">讲座 22: M.A.P.</h1>
<p>链接: <a href="https://www.youtube.com/watch?v=sL1zOr-P4xc&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=22" target="_blank">M.A.P.</a></p>
<p>我们仍然处于探讨概率核心原理及其在机器学习中的应用阶段。在本讲座中,你将关注机器学习中涉及概率和随机变量的参数。</p>
<h1 id="讲座-23-朴素贝叶斯">讲座 23: 朴素贝叶斯</h1>
<p>链接: <a href="https://www.youtube.com/watch?v=yqF3DvDVpvw&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=23" target="_blank">朴素贝叶斯</a></p>
<p>朴素贝叶斯是你将深入学习的第一个机器学习算法。你将学习关于参数估计的理论,然后将进一步探讨像朴素贝叶斯这样的核心算法如何引发像神经网络这样的概念。</p>
<h1 id="讲座-24-逻辑回归">讲座 24: 逻辑回归</h1>
<p>链接: <a href="https://www.youtube.com/watch?v=ILqZWvDWKEc&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=24" target="_blank">逻辑回归</a></p>
<p>在这次讲座中,你将深入了解第二个算法——逻辑回归,该算法用于分类任务,你还将进一步学习相关内容。</p>
<h1 id="讲座-25-深度学习">讲座 25: 深度学习</h1>
<p>链接: <a href="https://www.youtube.com/watch?v=MSfI6TTgyl4&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=25" target="_blank">深度学习</a></p>
<p>随着你开始深入了解机器学习,本讲座将根据你已学到的内容更详细地讲解深度学习。</p>
<h1 id="讲座-26-公平性">讲座 26: 公平性</h1>
<p>链接: <a href="https://www.youtube.com/watch?v=cbzwbr5H_LA&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=26" target="_blank">公平性</a></p>
<p>我们生活在一个机器学习被应用于日常生活的世界中。在本讲座中,你将探讨机器学习的公平性,重点关注伦理问题。</p>
<h1 id="讲座-27-高级概率">讲座 27: 高级概率</h1>
<p>链接: <a href="https://www.youtube.com/watch?v=BquE8Z9htws&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=27" target="_blank">高级概率</a></p>
<p>你已经学习了很多关于概率的基础知识,并在不同场景中应用了它,以及它与机器学习算法的关系。下一步是对概率有更深入的了解。</p>
<h1 id="讲座-28-概率的未来">讲座 28: 概率的未来</h1>
<p>链接: <a href="https://www.youtube.com/watch?v=SoXygq5LtiM&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=28" target="_blank">概率的未来</a></p>
<p>本讲座的学习目标是了解概率的应用及其能够解决的各种问题。</p>
<h1 id="讲座-29-最终回顾">讲座 29: 最终回顾</h1>
<p>链接: <a href="https://www.youtube.com/watch?v=yyKSsjRt42o&list=PLoROMvodv4rOpr_A7B9SriE_iZmkanvUg&index=29" target="_blank">最终回顾</a></p>
<p>最后但同样重要的是最后一讲。你将回顾所有其他 28 讲,并处理任何不确定的问题。</p>
<h1 id="总结-2">总结</h1>
<p>寻找适合学习旅程的优质材料可能很困难。这些计算机科学课程材料非常出色,可以帮助你掌握那些你不确定或需要复习的概率概念。</p>
<p><a href="https://www.linkedin.com/in/nisha-arya-ahmed/" target="_blank"></a><strong><strong><a href="https://www.linkedin.com/in/nisha-arya-ahmed/" target="_blank">Nisha Arya</a></strong></strong> 是一位数据科学家、自由技术作家,同时也是 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。Nisha 涉及广泛的主题,并希望探索人工智能如何促进人类寿命的不同方式。作为一个热衷学习者,Nisha 寻求拓宽她的技术知识和写作技能,同时帮助指导他人。</p>
<h3 id="相关话题">相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/5-free-stanford-university-courses-to-learn-data-science" target="_blank">5 门免费斯坦福大学数据科学课程</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/5-free-university-courses-to-learn-computer-science" target="_blank">5 门免费大学计算机科学课程</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/learn-computer-science-with-princeton-university-for-free" target="_blank">免费学习普林斯顿大学计算机科学课程!</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n27.html" target="_blank">KDnuggets 新闻,7 月 6 日:12 个必备数据科学 VSCode…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/a-collection-of-free-data-science-courses-from-harvard-stanford-mit-cornell-and-berkeley" target="_blank">哈佛、斯坦福等高校的免费数据科学课程合集</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/02/importance-probability-data-science.html" target="_blank">概率在数据科学中的重要性</a></p>
</li>
</ul>
<h1 id="数据成熟度金字塔从报告到主动智能数据平台">数据成熟度金字塔:从报告到主动智能数据平台</h1>
<blockquote>
<p>译文:<a href="https://www.kdnuggets.com/the-data-maturity-pyramid-from-reporting-to-a-proactive-intelligent-data-platform" target="_blank"><code>www.kdnuggets.com/the-data-maturity-pyramid-from-reporting-to-a-proactive-intelligent-data-platform</code></a></p>
</blockquote>
<p>如今,组织比以往任何时候都更加依赖数据来做出明智的决策并获得竞争优势。成为数据驱动型组织的过程包括逐步提升数据能力,利用人工智能和机器学习技术,并采用健全的数据治理实践。</p>
<p>本文详细探讨了这些步骤——从报告和数据治理,到作为人工智能/机器学习基础的数据产品以及主动智能数据平台(PIDP)。我们还深入了解了数据工程师在这一过程中的角色。</p>
<hr>
<h2 id="我们的前三大课程推荐-3">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业道路。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升您的数据分析能力</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持您组织的 IT</p>
<hr>
<h1 id="企业环境中的数据成熟度">企业环境中的数据成熟度</h1>
<p>在企业环境中,可以区分多个数据成熟度层级,表示公司在利用数据资产方面的不同进展程度。在这种背景下,数据成熟度模型的概念自然地以一个由不同层级组成的分层金字塔形式出现。此外,朝着更高数据成熟度的过程是一个不断改进的周期,不仅旨在达到越来越高级别,还要完善和优化已达到的能力。</p>
<p><img src="https://kdn.flygon.net/docs/img/152198039203aaa933d1eff0f323309c.png" alt="数据成熟度金字塔:从报告到主动智能数据平台" loading="lazy"></p>
<p>金字塔让我们可以同时展示两个特征:</p>
<ol>
<li>
<p>每个后续层级都位于前一个层级之上;</p>
</li>
<li>
<p>下一个层级的扩展不可避免地导致下层级的扩展。</p>
</li>
</ol>
<p>这意味着随着数据产品在组织中的演变,数据管理中的方法和技术也会得到改善。数据的信任度、可发现性、安全性、一致性和其他特征可能会逐步提升,从而在每个层级上实现改进。</p>
<p>让我们描述一个公司在采用和实施人工智能和机器学习的过程中。</p>
<p>我们有一家电信公司:</p>
<ul>
<li>
<p>对来自各种来源的企业数据有深入理解;</p>
</li>
<li>
<p>维护可靠且一致的企业级报告;</p>
</li>
<li>
<p>使用依赖于实时数据的营销活动管理系统。</p>
</li>
</ul>
<p>公司决定实施一个先进的 AI/ML 驱动系统,以为客户提供最佳的下一个计划。这一举措解锁了数据利用的新层级,同时也改进了金字塔的所有前置层级:它带来了用于报告的新数据,引入了有关数据安全和合规性的全新挑战,并提供了有关营销的宝贵洞察。</p>
<p>请考虑任何数据计划不一定需要从底部开始——一旦你的组织在某一层级上变得足够熟练,你就可以进入下一层级。然而,金字塔中的一些层级可能处于完全不同的数据转型阶段。例如,你的组织可能决定从 AI 领域开始数据转型,因为从商业角度看这似乎是最大的机会。</p>
<p>假设你的组织希望利用 AI 和 ML 快速找到最便宜的机票,同时考虑到火车和巴士转乘以及其他旅行细节。解决这个问题需要一个相当具体且有限的数据集。然而,组织中的报告或数据管理水平可能还未发展到能够支持这个功能。此时,你并不是在处理数据金字塔,因为前两层不能作为 AI/ML 的基础——你的 AI/ML 层是漂浮的。建立“漂浮”的分析系统极其困难,但作为加速市场时间并迅速测试特定 AI 用例的手段是可能的。基础金字塔层的高级开发可能会被延迟,但系统最终会达到其最终且可持续的金字塔形态。</p>
<h1 id="数据驱动能力与竞争优势">数据驱动能力与竞争优势</h1>
<p>讨论提高数据成熟度的好处时,重要的是要注意到,你提高数据成熟度的程度越高,获得的回报也会越大。简单来说,你当前的数据成熟度水平越高,即使是下一步的小改进也会带来更多的价值。这种收益的快速增长类似于所描述的“<a href="https://en.m.wikipedia.org/wiki/Exponential_function" target="_blank">指数函数</a>”,其增长率与当前测量的状态相关。</p>
<p>在分析系统中,这种关系很容易察觉。每个后续层级可以并且应该建立在前一个层级之上,同时解锁完全新的好处和功能,这些在早期阶段是无法获得的。</p>
<p><img src="https://kdn.flygon.net/docs/img/ff7acb1557ef25754f50b405804adc5f.png" alt="数据成熟度金字塔:从报告到主动智能数据平台" loading="lazy"></p>
<p><em>图 2</em>。数据驱动能力与数据成熟度各级别间的竞争优势相关性</p>
<p>为了演示这个过程,我们假设你的组织开发了一个新的数据产品——一个用于电子商务平台的客户推荐引擎。该引擎处理历史客户行为数据,为用户提供个性化的产品推荐。最初,系统是基于规则的,依赖于预定义的启发式方法来进行推荐。</p>
<p>在过渡到 AI/ML 级别时,团队决定实施一个机器学习模型。例如,一个协同过滤模型,或一个基于深度学习的推荐系统。该模型可以分析大量数据,识别数据中的复杂模式,并为每个用户提供准确且个性化的产品推荐。</p>
<p>随着推荐系统的部署,它继续从用户互动中收集更多数据。用户与平台的互动越多,系统积累的数据也就越多。这种数据增长使得机器学习模型可以不断学习和完善其推荐,从而使推荐引擎的准确性和效果不断提高。</p>
<p><strong>注意:</strong> 这些过渡中的每一个将在后面更详细地讨论。在这一阶段,请记住,每次过渡到新的成熟度水平都会带来系统复杂性的整体增长。这种增长意味着使用新工具、获得新团队技能、在系统和团队之间建立额外的连接(同时避免孤岛效应),最重要的是,获得竞争优势。你的组织在每个级别上获得更多的好处,而你的竞争对手则落后。</p>
<p>复杂系统的开发难度本质上高于简单系统。此外,并不是所有公司都有资源来管理从构思到实施,再到大规模采纳和支持的整个开发过程。</p>
<p>想象一个供应链管理公司,它实施了几个机器学习模型来预测需求、优化库存和识别物流中的低效。拥有这样一个利用先进分析和预测洞察的数据和 AI/ML 驱动的解决方案是一个巨大的竞争优势。</p>
<p>现在,我们假设公司希望向具有生成性 AI 能力的主动智能数据平台(PIDP)迈进一步。这样的系统将从识别数据中的风险和机会,演变为根据这些数据主动生成可操作的计划,利用<a href="https://provectus.com/blog/comparison-large-language-models-biomedical-domain/" target="_blank">大型语言模型(LLMs)</a>。现在,系统不仅仅是通知利益相关者潜在问题或提供洞察,而是为他们提供智能、精心制定的行动计划。生成性 AI 可以用来启动流程、调用内部或第三方 API,甚至自主执行生成的计划。</p>
<p>在我们的供应链管理系统的情况下,这种转变不仅可以使其预测潜在的库存短缺,还可以主动与供应商互动、下订单并协调物流,所有这些都能实时完成,无需人工干预。这样的系统可以评估结果,从中学习,并优化其下一步行动。人类反馈仍然至关重要,确保与战略目标对齐,并确保持续改进。</p>
<p>将生成式 AI 纳入主动智能数据平台不仅仅是技术上的飞跃——它是战略性的转型。在供应链领域,这可能意味着缩短交货时间、减少缺货情况和最大化资产利用率,这些都转化为实际的商业价值。</p>
<p>当竞争对手在处理规则驱动系统或传统机器学习算法时,一家在 PIDP 水平运营的公司正以其灵活性和前瞻性应对现代供应链的复杂性,这使其与众不同。</p>
<p>让我们更详细地探讨数据金字塔的每个层级,以了解其在从报告到 PIDP 的旅程中的角色。</p>
<h1 id="第-1-层---报告">第 1 层 - 报告</h1>
<p><img src="https://kdn.flygon.net/docs/img/42b318f2e3fe3da67a4dbd2f39a17642.png" alt="数据成熟度金字塔:从报告到主动智能数据平台" loading="lazy"></p>
<p>报告是数据工程师的重要领域。它涉及设计和构建可以作为分析和其他数据驱动子系统和解决方案基础的数据平台。数据工程师负责建立强大的数据管道和基础设施,这些管道和基础设施可以高效、安全地收集、存储和处理数据。这些基础数据平台使数据工程师能够确保企业的数据易于访问、组织良好,并为进一步的分析和报告做好准备。</p>
<p>为了增加一些历史背景,考虑到仅仅五年前,使用实时工具表明数据平台更成熟,相比于批处理平台。今天,除了一些例外,界限变得更加模糊。批处理和流处理的复杂性差别不大;唯一的例外是数据血缘、安全性和发现——通常在我们所说的数据治理中。在这些领域,由于实时处理发生了许多变化,并期望在不久的将来有更多改进。</p>
<p>尽管如此,从几乎所有来源实现接近实时的数据集成是可能的,事件网关是保持数据一致性吸收的合适选择。对于在组织中数据量显著大于其他数据源的少数数据源,可能更倾向于批量处理。例如,对于一家中型在线公司,Google Analytics 的原始数据可能占到所有处理数据的一半。是否值得以与事务系统数据相同的速度处理这些数据,可能会带来高昂的成本,这是值得讨论的。然而,随着技术的进步,批处理和实时处理之间的选择需求可能会减少。</p>
<p>与批处理相比,实时数据产品在数据治理能力和实时数据处理的维护开销方面仍存在显著差距。因此,建议仅在有限的使用场景中依赖实时数据处理,例如广告竞价或欺诈检测,其中数据的新鲜度比<a href="https://provectus.com/data-quality-assurance/" target="_blank">数据质量</a>更为重要。</p>
<p>一些产品比起速度,更从较高水平的透明度和质量中获益。它们可以依靠微批次的数据处理,或采用传统的批处理模式(例如财务报告)。欲了解更多信息,请阅读<a href="https://www.linkedin.com/posts/danwtaylor_data-platform-strategy-activity-7005887490276392960-CfcJ/" target="_blank">Dan Taylor 在 LinkedIn 上的文章</a>。</p>
<h1 id="第二级---数据治理倡议">第二级 - 数据治理倡议</h1>
<p><img src="https://kdn.flygon.net/docs/img/dc5e5bb5b6674a2e05c218aec025ba9e.png" alt="数据成熟度金字塔:从报告到主动智能数据平台" loading="lazy"></p>
<p>数据治理是一个广泛的术语,定义各异。但如果我们尝试大致描述数据治理倡议,我们最终会涉及其组件、特性和实践,例如:数据发现、数据建模、数据词汇表、数据质量、数据溯源、数据安全以及<a href="https://www.gartner.com/en/information-technology/glossary/master-data-management-mdm" target="_blank">主数据管理(MDM)</a>。</p>
<p>过渡到有意识和系统的数据治理实践可以带来惊人的数据素养、速度、可靠性和安全性提升。这些只是从简单报告转向企业数据管理系统时实现的好处的一部分。</p>
<p>对数据民主化的需求不可避免地增加了对更高效数据访问管理的要求。在公司层面统一度量标准导致了需要创建词汇表、统一报告、管理数据碎片和重复等,这些都帮助节省了在特定用例中处理和使用数据的时间。这些数据解决方案和产品推动了数据发现的需求,以及更详细的目录和数据使用。</p>
<p>在数据治理层面,数据工程师通常与软件开发团队紧密合作,以构建和维护像参考数据管理工具这样的系统。数据可观测性工具如<a href="https://openlineage.io/" target="_blank">OpenLineage</a>也是如此。理想情况下,它应成为所有类型的数据治理计划的统一平台,例如,<a href="https://opendatadiscovery.org/" target="_blank">开放数据发现平台</a>旨在成为的那样。</p>
<h1 id="level-3---数据产品">Level 3 - 数据产品</h1>
<p><img src="https://kdn.flygon.net/docs/img/064cf2f3daaf6826eb317cd077d0d384.png" alt="数据成熟度金字塔:从报告到主动智能数据平台" loading="lazy"></p>
<p>基本数据产品不涉及任何 AI/ML 技术和用例。它们通常也不需要高级分析。因为广泛的问题和任务可以仅通过使用存储在企业数据平台中的合并数据来解决。这些包括:</p>
<ul>
<li>
<p>几乎所有对历史数据的操作;</p>
</li>
<li>
<p>交易系统通过移除数据负载来支持这一点;</p>
</li>
<li>
<p>在大量数据上进行高速度、大规模的计算。</p>
</li>
</ul>
<p>举一些更具体的例子,这些是用于销售与市场系统、A/B 测试、计费系统等的系统和工具。</p>
<p>在数据产品阶段,软件和应用开发团队也发挥着重要作用。在考虑业务目标的同时,与他们沟通数据产品的技术方面是成功利用数据进行任何用例的关键。</p>
<p>请注意,API 或端到端解决方案的开发应始终作为企业开发的一部分。跨职能开发团队可以带来最大的利益,并且在数据相关的方面,讨论<a href="https://www.datamesh-architecture.com/" target="_blank">Data Mesh</a>的概念是有意义的。</p>
<p>Data Mesh 革新了组织管理数据的方式。Data Mesh 鼓励组织将数据视为一种产品,而不是将其看作一个整体实体。通过这种方式,它分散了数据所有权,并帮助团队开发和维护自己的数据产品,从而减少了瓶颈和对集中数据团队的依赖。</p>
<h1 id="level-4---ai-和-ml-解决方案">Level 4 - AI 和 ML 解决方案</h1>
<p><img src="https://kdn.flygon.net/docs/img/6876d4fbaabac2864ae5742ed3d87f01.png" alt="数据成熟度金字塔:从报告到主动智能数据平台" loading="lazy"></p>
<p>AI 是新电力。但我们仍处于过渡时期:AI 的潜力是显而易见的,但并不是所有公司都已<em>足够</em>彻底地改革其商业模式,以便全方位、大规模地利用 AI。</p>
<p>正如<a href="https://www.linkedin.com/posts/teradata_the-disruptive-economics-of-ai-activity-7082674552555659265-Ud8S?utm_source=share&utm_medium=member_desktop" target="_blank">斯蒂芬·布罗布斯特的演讲</a>中所完美描述的那样,AI 的主要价值将在 AI 无处不在时实现。到目前为止,最终受益者并没有关注到普遍性因素,常常试图解决无法带入现实世界的用例。</p>
<p>从数据工程的角度来看,AI 由数据驱动。这就是为什么我们应该始终记住 <a href="https://www.linkedin.com/posts/pau-labarta-bajo-4432074b_machinelearning-mlops-realworldml-activity-7100041296811089921-4UM8?utm_source=share&utm_medium=member_desktop" target="_blank">特征存储和 ML 模型运营化</a> —— 这些组件有助于持续不断地将数据转化为生产中的 AI/ML 解决方案。更详细地说,这些组件及相关角色在 Databricks 的 <a href="https://www.databricks.com/resources/ebook/the-big-book-of-mlops" target="_blank">《MLOps 大全》</a> 中进行了描述。这本全面的指南详细阐述了五个关键角色——数据工程师、数据科学家、ML 工程师、业务利益相关者、数据治理官——及其在七个关键流程中的相互作用——数据准备、探索性数据分析(EDA)、特征工程、模型训练、模型验证、部署和监控。</p>
<p>还值得记住的是,AI 的全部潜力只有在其模块与公司的整体基础设施、流程甚至文化相整合时才能真正实现。当各种系统和个人无缝地协作成为一个统一的整体时,这时向主动智能数据平台的过渡才开始在整个组织中变得有意义。</p>
<h1 id="第五级---主动智能数据平台pidp">第五级 - 主动智能数据平台(PIDP)</h1>
<p><img src="https://kdn.flygon.net/docs/img/f47fd91e3a7afff55ba41b6172ded00b.png" alt="数据成熟度金字塔:从报告到主动智能数据平台" loading="lazy"></p>
<p>主动智能数据平台(PIDP)是数据成熟度金字塔的顶层。其核心涉及将 AI/ML 技术和高级分析无缝集成到业务常规(BAU)流程中,遍及整个组织。</p>
<p>让我们在最近出现的 AI 细分领域之一——生成式 AI 的背景下,仔细看看 PIDP。具体来说,我们将探讨三个领域——数字双胞胎、控制塔和指挥中心——其中 <a href="https://provectus.com/the-cxo-guide-to-generative-ai-threats-and-opportunities/" target="_blank">生成式 AI 的变革潜力</a> 最为明显。</p>
<p>考虑到大型工厂开发其设施的数字双胞胎以提高运营效率。在这样的先进设置中,尽管操作员拥有所有必需的控制,但面临着持续决策的巨大挑战。引入一个可以通过自然语言与数字双胞胎进行沟通的生成式 AI 代理,可以简化和自动化例行任务、风险评估、机会分析,并帮助做出明智的决策。</p>
<p>类似地,在电信行业,<a href="https://www.ibm.com/topics/control-towers" target="_blank">控制塔</a>适应了全球运营商在优化、及时问题检测和事故预防方面的投资趋势。这些中心接收来自不同权威层级的大量数据。人工操作员承担着高技能和信息充足的责任,以便有效管理任务。将生成式人工智能纳入其中,可以减轻他们操作中的常规和复杂方面。</p>
<p>现在,考虑指挥中心,尤其是在供应链领域。这里的运营决策通常需要多部门协作,例如供应链部门、财务和法律部门等。这些团队具有不同的专业知识和部分见解,应当共同决定其行动。在这种背景下,生成式人工智能作为统一企业管理平台的一部分的效用变得显而易见。这些生成式 AI 模型可以识别风险和机会,评估其全企业范围的影响,分析潜在解决方案等等。</p>
<p>数据在这些领域中扮演着关键角色。它是缠绕整个组织的皇冠,使其像钟表一样顺利运作。</p>
<p>PIDP 是一个强大的工具,使组织能够主动应对挑战,做出数据驱动的决策,并保持竞争优势。</p>
<p>在这个阶段,数据工程师的角色是最重要的,同时也可能不那么显眼。由于公司已经从数据驱动的产品中获得主要好处,将人工智能无缝地集成到决策过程中,从简单的分析仪表板到公司各部门之间的协调互动,是关键。组织从依赖数据的原始实用应用演变为能够在非专业、非技术环境中顺利推动商业价值的易用应用。</p>
<p>然而,重要的是要理解,在这个阶段,几乎每个节点中的链接都是数据,它的管理和处理。这当然是数据工程师工作的主要优点。</p>
<h1 id="结论-2">结论</h1>
<p>实现主动智能数据平台的旅程具有挑战性,但对于寻求在数据和人工智能驱动的世界中蓬勃发展的现代组织来说至关重要。通过逐步提升数据成熟度水平、拥抱数据驱动的能力、建立强大的数据治理举措以及利用人工智能和机器学习的潜力,组织可以解锁一系列关键的竞争优势,保持领先地位。</p>
<p>主动智能数据平台代表了这一旅程的顶点,也是数据成熟度金字塔的最终层级。它可以赋能组织在快速变化的商业环境中引领、创新和成功。</p>
<p><strong><a href="https://www.linkedin.com/in/ramandamayeu/?locale=en_US" target="_blank">拉曼·达马耶乌</a></strong> 擅长传统数据仓库和最新的云解决方案。作为数据治理的热情倡导者,拉曼对类似于开放数据发现的平台情有独钟。在 Provectus,他不断推动数据驱动的项目向前发展,帮助行业迈向数据处理的下一个水平。</p>
<h3 id="了解更多相关主题">了解更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/data-maturity-the-cornerstone-of-ai-enabled-innovation" target="_blank">数据成熟度:AI 驱动创新的基石</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/02/making-intelligent-document-processing-smarter-part-1.html" target="_blank">让智能文档处理更智能:第一部分</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/04/ethics-ai-navigating-future-intelligent-machines.html" target="_blank">人工智能伦理:导航智能机器的未来</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n20.html" target="_blank">KDnuggets 新闻,5 月 18 日:5 个免费机器学习托管平台</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/05/5-key-components-data-sharing-platform.html" target="_blank">数据共享平台的 5 个关键组件</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/02/qdrant-open-source-vector-search-engine-managed-cloud-platform.html" target="_blank">Qdrant:具有托管云平台的开源向量搜索引擎</a></p>
</li>
</ul>
<h1 id="numpy-和-pandas-介绍">Numpy 和 Pandas 介绍</h1>
<blockquote>
<p>译文:<a href="https://www.kdnuggets.com/introduction-to-numpy-and-pandas" target="_blank"><code>www.kdnuggets.com/introduction-to-numpy-and-pandas</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/4d9285217a1b6e8662caf239c11bade7.png" alt="Numpy 和 Pandas 介绍" loading="lazy"></p>
<p>插图由作者提供。来源:Flaticon</p>
<p>Python 是你在数据科学领域遇到的最受欢迎的语言,因为它简单,社区庞大,并且有大量的开源库。</p>
<hr>
<h2 id="我们的三大课程推荐-1">我们的三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 加速进入网络安全职业</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析能力</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织的 IT</p>
<hr>
<p>如果你正在进行一个数据科学项目,Python 包将让你的工作更加轻松,因为你只需几行代码就能完成复杂的操作,如数据处理和应用机器学习/深度学习模型。</p>
<p>当开始你的数据科学之旅时,建议先学习两个最有用的 Python 包:NumPy 和 Pandas。在这篇文章中,我们将介绍这两个库。让我们开始吧!</p>
<h1 id="什么是-numpy">什么是 NumPy?</h1>
<p>NumPy 代表 Numerical Python(数值计算的 Python),用于高效计算数组和矩阵,在机器学习模型的幕后进行运算。NumPy 的构建块是数组,它是一种与列表非常相似的数据结构,不同之处在于它提供了大量的数学函数。换句话说,NumPy 数组是一个多维数组对象。</p>
<h2 id="创建-numpy-数组">创建 NumPy 数组</h2>
<p>我们可以使用列表或列表的列表来定义 NumPy 数组:</p>
<pre><code class="language-py">import numpy as np
l = [[1,2,3],[4,5,6],[7,8,9]]
numpy_array = np.array(l)
numpy_array
</code></pre>
<pre><code class="language-py">array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
</code></pre>
<p>与列表的列表不同,我们可以通过在每一行之间添加缩进来可视化 3X3 矩阵。此外,NumPy 提供了 40 多个内置函数用于数组创建。</p>
<p>要创建一个填充零的数组,可以使用函数 <code>np.zeros</code>,只需指定你所需的形状:</p>
<pre><code class="language-py">zeros_array = np.zeros((3,4))
zeros_array
</code></pre>
<pre><code class="language-py">array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
</code></pre>
<p>同样,我们也可以创建一个填充一的数组:</p>
<pre><code class="language-py">ones_array = np.ones((3,4))
ones_array
</code></pre>
<pre><code class="language-py">array([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
</code></pre>
<p>还可以创建单位矩阵,它是一个方阵,主对角线上的元素为 1,其他位置的元素为 0:</p>
<pre><code class="language-py">identity_array = np.identity(3)
identity_array
</code></pre>
<pre><code class="language-py">array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
</code></pre>
<p>此外,NumPy 提供了不同的函数来创建随机数组。要创建一个填充了从 [0,1] 区间均匀分布的随机样本的数组,我们只需使用函数 <code>np.random.rand</code>:</p>
<pre><code class="language-py">random_array = np.random.rand(3,4)
random_array
</code></pre>
<pre><code class="language-py">array([[0.84449279, 0.71146992, 0.48159787, 0.04927379],
[0.03428534, 0.26851667, 0.65718662, 0.52284251],
[0.1380207 , 0.91146148, 0.74171469, 0.57325424]])
</code></pre>
<p>类似于之前的函数,我们可以定义一个包含随机值的数组,但这次的值来自标准正态分布:</p>
<pre><code class="language-py">randn_array = np.random.randn(10)
randn_array
</code></pre>
<pre><code class="language-py">array([-0.68398432, -0.25466784, 0.27020797, 0.29632334, -0.20064897,
0.7988508 , 1.34759319, -0.41418478, -0.35223377, -0.10282884])
</code></pre>
<p>如果我们有兴趣构建一个包含随机整数的数组,这些整数属于区间 [low, high),我们只需使用函数 <code>np.random.randint</code>:</p>
<pre><code class="language-py">randint_array = np.random.randint(1,20,20)
randint_array
</code></pre>
<pre><code class="language-py">array([14, 3, 1, 2, 17, 15, 5, 17, 18, 9, 4, 19, 14, 14, 1, 10, 17,
19, 4, 6])
</code></pre>
<h2 id="索引和切片">索引和切片</h2>
<p>除了用于数组创建的内置函数之外,NumPy 的另一个优点是可以使用一组方括号从数组中选择元素。例如,我们可以尝试获取矩阵的第一行:</p>
<pre><code class="language-py">a1 = np.array([[1,2,3],[4,5,6]])
a1[0]
</code></pre>
<pre><code class="language-py">array([1, 2, 3])
</code></pre>
<p>假设我们想选择第一行的第三个元素。在这种情况下,我们需要指定两个索引,即行的索引和列的索引:</p>
<pre><code class="language-py">print(a1[0,2]) #3
</code></pre>
<p>另一种方法是使用<code>a1[0][2]</code>,但这被认为效率较低,因为它首先创建包含第一行的数组,然后从该行中选择元素。</p>
<p>此外,我们还可以使用方括号中的语法<code>start:stop:step</code>从矩阵中切片,其中 stop 索引不包含在内。例如,我们再次选择第一行,但只取前两个元素:</p>
<pre><code class="language-py">print(a1[0,0:2])
</code></pre>
<pre><code class="language-py">[1 2]
</code></pre>
<p>如果我们希望选择所有行,但只提取每行的第一个元素:</p>
<pre><code class="language-py">print(a1[:,0])
</code></pre>
<pre><code class="language-py">[1 4]
</code></pre>
<p>除了整数数组索引之外,还有布尔数组索引来选择数组中的元素。假设我们只想要满足以下条件的元素:</p>
<pre><code class="language-py">a1>5
</code></pre>
<pre><code class="language-py">array([[False, False, False],
[False, False, True]])
</code></pre>
<p>如果我们根据这个条件过滤数组,输出将只显示<code>True</code>元素:</p>
<pre><code class="language-py">a1[a1>5]
</code></pre>
<pre><code class="language-py">array([6])
</code></pre>
<h2 id="数组操作">数组操作</h2>
<p>在数据科学项目中,通常需要将数组重塑为新的形状而不改变数据。</p>
<p>例如,我们从一个 2X3 的数组开始。如果我们不确定数组的形状,可以使用属性<code>shape</code>来帮助我们:</p>
<pre><code class="language-py">a1 = np.array([[1,2,3],[4,5,6]])
print(a1)
print('Shape of Array: ',a1.shape)
</code></pre>
<pre><code class="language-py">[[1 2 3]
[4 5 6]]
Shape of Array: (2, 3)
</code></pre>
<p>要将数组重塑为 3X2 的维度,我们可以简单地使用<code>reshape</code>函数:</p>
<pre><code class="language-py">a1 = a1.reshape(3,2)
print(a1)
print('Shape of Array: ',a1.shape)
</code></pre>
<pre><code class="language-py">[[1 2]
[3 4]
[5 6]]
Shape of Array: (3, 2)
</code></pre>
<p>另一种常见情况是将多维数组转化为一维数组。这可以通过将-1 指定为形状来实现:</p>
<pre><code class="language-py">a1 = a1.reshape(-1)
print(a1)
print('Shape of Array: ',a1.shape)
</code></pre>
<pre><code class="language-py">[1 2 3 4 5 6]
Shape of Array: (6,)
</code></pre>
<p>也可能出现需要获得转置数组的情况:</p>
<pre><code class="language-py">a1 = np.array([[1,2,3,4,5,6]])
print('Before shape of Array: ',a1.shape)
a1 = a1.T
print(a1)
print('After shape of Array: ',a1.shape)
</code></pre>
<pre><code class="language-py">Before shape of Array: (1, 6)
[[1]
[2]
[3]
[4]
[5]
[6]]
After shape of Array: (6, 1)
</code></pre>
<p>同样,你可以使用<code>np.transpose(a1)</code>应用相同的变换。</p>
<h2 id="数组乘法">数组乘法</h2>
<p>如果你尝试从头构建机器学习算法,你肯定需要计算两个数组的矩阵乘积。这可以使用<code>np.matmul</code>函数来完成,当数组具有多于 1 维时:</p>
<pre><code class="language-py">a1 = np.array([[1,2,3],[4,5,6]])
a2 = np.array([[1,2],[4,5],[7,8]])
print('Shape of Array a1: ',a1.shape)
print('Shape of Array a2: ',a2.shape)
a3 = np.matmul(a1,a2)
# a3 = a1 @ a2
print(a3)
print('Shape of Array a3: ',a3.shape)
</code></pre>
<pre><code class="language-py">Shape of Array a1: (2, 3)
Shape of Array a2: (3, 2)
[[30 36]
[66 81]]
Shape of Array a3: (2, 2)
</code></pre>
<p><code>@</code>可以是<code>np.matmul</code>的一个更简短的替代方案。</p>
<p>如果你将一个矩阵与一个标量相乘,<code>np.dot</code>是最好的选择:</p>
<pre><code class="language-py">a1 = np.array([[1,2,3],[4,5,6]])
a3 = np.dot(a1,2)
# a3 = a1 * 2
print(a3)
print('Shape of Array a3: ',a3.shape)
</code></pre>
<pre><code class="language-py">[[ 2 4 6]
[ 8 10 12]]
Shape of Array a3: (2, 3)
</code></pre>
<p>在这种情况下,*是<code>np.dot</code>的一个更简短的替代方案。</p>
<h2 id="数学函数">数学函数</h2>
<p>NumPy 提供了大量的数学函数,例如三角函数、舍入函数、指数、对数等。你可以在<a href="https://numpy.org/doc/stable/reference/routines.math.html" target="_blank">这里</a>找到完整列表。我们将展示你可以应用于问题的最重要的函数。</p>
<p>指数和自然对数无疑是最流行和最知名的变换:</p>
<pre><code class="language-py">a1 = np.array([[1,2,3],[4,5,6]])
print(np.exp(a1))
</code></pre>
<pre><code class="language-py">[[ 2.71828183 7.3890561 20.08553692]
[ 54.59815003 148.4131591 403.42879349]]
</code></pre>
<pre><code class="language-py">a1 = np.array([[1,2,3],[4,5,6]])
print(np.log(a1))
</code></pre>
<pre><code class="language-py">[[0\. 0.69314718 1.09861229]
[1.38629436 1.60943791 1.79175947]]
</code></pre>
<p>如果我们想要在一行代码中提取最小值和最大值,我们只需调用以下函数:</p>
<pre><code class="language-py">a1 = np.array([[1,2,3],[4,5,6]])
print(np.min(a1),np.max(a1)) # 1 6
</code></pre>
<p>我们还可以计算数组中每个元素的平方根:</p>
<pre><code class="language-py">a1 = np.array([[1,2,3],[4,5,6]])
print(np.sqrt(a1))
</code></pre>
<pre><code class="language-py">[[1\. 1.41421356 1.73205081]
[2\. 2.23606798 2.44948974]]
</code></pre>
<h1 id="什么是-pandas">什么是 Pandas?</h1>
<p>Pandas 基于 Numpy 构建,并且对于数据集的操作非常有用。主要有两个数据结构:<strong>Series</strong> 和 <strong>Dataframe</strong>。Series 是值的序列,而 Dataframe 是一个具有行和列的表。换句话说,Series 是 Dataframe 的一列。</p>
<h2 id="创建-series-和-dataframe">创建 Series 和 Dataframe</h2>
<p>要构建 Series,我们只需将值列表传递给该方法:</p>
<pre><code class="language-py">import pandas as pd
type_house = pd.Series(['Loft','Villa'])
type_house
</code></pre>
<pre><code class="language-py">0 Loft
1 Villa
dtype: object
</code></pre>
<p>我们可以通过传递一个对象字典来创建 Dataframe,其中键对应于列名,值是列的条目:</p>
<pre><code class="language-py">df = pd.DataFrame({'Price': [100000, 300000], 'date_construction': [1960, 2010]})
df.head()
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/ecf9e9823371257d8e1f15f42963a68e.png" alt="Numpy 和 Pandas 介绍" loading="lazy"></p>
<p>一旦创建了 Dataframe,我们可以检查每列的类型:</p>
<pre><code class="language-py">type(df.Price),type(df.date_construction)
</code></pre>
<pre><code class="language-py">(pandas.core.series.Series, pandas.core.series.Series)
</code></pre>
<p>应该很清楚,列是类型为 Series 的数据结构。</p>
<h2 id="汇总函数">汇总函数</h2>
<p>从现在开始,我们将通过使用 <a href="https://www.kaggle.com/competitions/bike-sharing-demand/data" target="_blank">Kaggle</a> 上的共享单车数据集展示 Pandas 的潜力。我们可以通过以下方式导入 CSV 文件:</p>
<pre><code class="language-py">df = pd.read_csv('/kaggle/input/bike-sharing-demand/train.csv')
df.head()
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/0d11d85db19fc26aa564d36008ea5cc5.png" alt="Numpy 和 Pandas 介绍" loading="lazy"></p>
<p>Pandas 不仅允许读取 CSV 文件,还可以读取 Excel 文件、JSON、Parquet 和其他类型的文件。你可以在 <a href="https://pandas.pydata.org/docs/user_guide/io.html" target="_blank">这里</a> 找到完整的列表。</p>
<p>从输出中,我们可以查看 Dataframe 的前五行。如果我们想显示数据集的最后四行,可以使用 tail() 方法:</p>
<pre><code class="language-py">df.tail(4)
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/53ee43d7a9555e510045420dbf549c24.png" alt="Numpy 和 Pandas 介绍" loading="lazy"></p>
<p>少量的行不足以对我们拥有的数据有一个良好的了解。开始分析的一个好方法是查看数据集的形状:</p>
<pre><code class="language-py">df.shape #(10886, 12)
</code></pre>
<p>我们有 10886 行和 12 列。你想看看列名吗?这样做非常直观:</p>
<pre><code class="language-py">df.columns
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/d5ded607aa035f041cf4e7328325dae0.png" alt="Numpy 和 Pandas 介绍" loading="lazy"></p>
<p>有一个方法可以将所有这些信息可视化为一个独特的输出:</p>
<pre><code class="language-py">df.info()
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/0b6daa6485f620c6173f6cc61c6c1b9a.png" alt="Numpy 和 Pandas 介绍" loading="lazy"></p>
<p>如果我们想显示每列的统计信息,可以使用 describe 方法:</p>
<pre><code class="language-py">df.describe()
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/0b6daa6485f620c6173f6cc61c6c1b9a.png" alt="Numpy 和 Pandas 介绍" loading="lazy"></p>
<p>从分类字段中提取信息也很重要。我们可以找到季节列的唯一值和唯一值的数量:</p>
<pre><code class="language-py">df.season.unique(),df.season.nunique()
</code></pre>
<p>输出:</p>
<pre><code class="language-py">(array([1, 2, 3, 4]), 4)
</code></pre>
<p>我们可以看到这些值是 1, 2, 3, 4。然后,有四个可能的值。这个验证对于理解分类变量和防止列中可能存在的噪声至关重要。</p>
<p>要显示每个级别的频率,我们可以使用 value_counts() 方法:</p>
<pre><code class="language-py">df.season.value_counts()
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/30588d72e21e5a5a3b8da79ec6f3ab5e.png" alt="Numpy 和 Pandas 介绍" loading="lazy"></p>
<p>最后一步应该是检查每列中的缺失值:</p>
<pre><code class="language-py">df.isnull().sum()
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/1112e0adcd43a5777614d16ab161b33b.png" alt="Numpy 和 Pandas 介绍" loading="lazy"></p>
<p>幸运的是,我们在这些字段中没有任何缺失值。</p>
<h2 id="索引和切片-1">索引和切片</h2>
<p>像在 NumPy 中一样,可以基于索引选择数据。数据框有两种主要方法来获取条目:</p>
<ul>
<li>
<p>iloc 根据整数位置选择元素</p>
</li>
<li>
<p>loc 根据标签或布尔数组来获取项目。</p>
</li>
</ul>
<p>要选择第一行,iloc 是最佳选择:</p>
<pre><code class="language-py">df.iloc[0]
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/5b4c811da0db3c7c02de9e04d91ef4a1.png" alt="Numpy 和 Pandas 介绍" loading="lazy"></p>
<p>如果我们想选择所有行和仅第二列,可以这样做:</p>
<pre><code class="language-py">df.iloc[:,1]
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/940e13e075bc84df46d4988047368286.png" alt="Numpy 和 Pandas 介绍" loading="lazy"></p>
<p>也可以同时选择更多列:</p>
<pre><code class="language-py">df.iloc[0:3,[0,1,2,5]]
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/be70da37fefd58159edef0c8d913171d.png" alt="Numpy 和 Pandas 介绍" loading="lazy"></p>
<p>基于索引选择列会变得复杂。指定列名会更好。这可以通过 loc 实现:</p>
<pre><code class="language-py">df.loc[0:3,['datetime','season','holiday','temp']]
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/b4ca1e4cc33c49bdf7e4cb96706ee049.png" alt="Numpy 和 Pandas 介绍" loading="lazy"></p>
<p>类似于 NumPy,可以根据条件筛选数据框。例如,我们想返回所有天气等于 1 的行:</p>
<pre><code class="language-py">df[df.weather==1]
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/1d7ea3bb858a6b861929e5c6a7e7199b.png" alt="Numpy 和 Pandas 介绍" loading="lazy"></p>
<p>如果我们想返回特定列的输出,可以使用 loc:</p>
<pre><code class="language-py">df.loc[df.weather==1,['season','holiday']]
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/be08c2d2a1391b4c57ab4c85f15fc5c7.png" alt="Numpy 和 Pandas 介绍" loading="lazy"></p>
<h2 id="创建新变量">创建新变量</h2>
<p>创建新变量对从数据中提取更多信息和提高可解释性有着巨大的影响。我们可以基于 workingday 的值创建一个新的分类变量:</p>
<pre><code class="language-py">df['workingday_c'] = df['workingday'].apply(lambda x: 'work' if x==1 else 'relax')
df[['workingday','workingday_c']].head()
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/e31b23b47f15b78e19eb3c7a55685288.png" alt="Numpy 和 Pandas 介绍" loading="lazy"></p>
<p>如果有多个条件,最好使用字典和 map 方法来映射这些值:</p>
<pre><code class="language-py">diz_season = {1:'winter',2:'spring',3:'summer',4:'fall'}
df['season_c'] = df['season'].map(lambda x: diz_season[x])
df[['season','season_c']].head()
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/4825bbefe7d7360444b81e2701f00e71.png" alt="Numpy 和 Pandas 介绍" loading="lazy"></p>
<h2 id="分组和排序">分组和排序</h2>
<p>你可能希望基于分类列对数据进行分组。这可以通过 groupby 实现:</p>
<pre><code class="language-py">df.groupby('season_c').agg({'count':['median','max']})
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/366b3cb7d9211cbfea8f37bb6b5edb11.png" alt="Numpy 和 Pandas 介绍" loading="lazy"></p>
<p>对于每个季节的级别,我们可以观察到租赁自行车的中位数和最大数量。没有基于列排序的情况下,这个输出可能会令人困惑。我们可以使用 sort_values()方法来完成这项工作:</p>
<pre><code class="language-py">df.groupby('season_c').agg({'count':['median','max']}).reset_index().sort_values(by=('count', 'median'),ascending=False)
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/eb593e2ce6bfeaea8f5adea326c27bd8.png" alt="Numpy 和 Pandas 介绍" loading="lazy"></p>
<p>现在,输出更有意义了。我们可以推断出,夏季租赁自行车的数量最高,而冬季则不适合租赁自行车。</p>
<h1 id="结束语">结束语</h1>
<p>就这些了!希望你觉得这份指南对学习 NumPy 和 Pandas 的基础知识有所帮助。它们通常是分开学习的,但理解 NumPy 再学习 Pandas(Pandas 建立在 NumPy 之上)可能会很有启发。</p>
<p>这篇教程中肯定有一些方法没有覆盖,但目标是涵盖这两个库中最重要和最流行的方法。代码可以在 <a href="https://www.kaggle.com/code/eugeniaanello/introduction-to-numpy-and-pandas" target="_blank">Kaggle</a> 上找到。感谢阅读!祝您有美好的一天!</p>
<p><strong><a href="https://www.linkedin.com/in/eugenia-anello/" target="_blank">尤金尼亚·安内洛</a></strong> 目前是意大利帕多瓦大学信息工程系的研究员。她的研究项目专注于结合异常检测的持续学习。</p>
<h3 id="更多相关内容-7">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2023/08/beyond-numpy-pandas-unlocking-potential-lesserknown-python-libraries.html" target="_blank">超越 NumPy 和 Pandas:解锁鲜为人知的 Python 库的潜力</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/numpy-with-pandas-for-more-efficient-data-analysis" target="_blank">使用 Pandas 进行更高效的数据分析的 NumPy</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2020/06/introduction-pandas-data-science.html" target="_blank">数据科学中的 Pandas 入门</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2019/06/select-rows-columns-pandas.html" target="_blank">如何使用 [ ], .loc, iloc, .at… 在 Pandas 中选择行和列</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/01/pandas-one-liners-data-access-manipulation-management.html" target="_blank">10 个 Pandas 一行代码实现数据访问、处理和管理</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/7-steps-to-mastering-data-wrangling-with-pandas-and-python" target="_blank">掌握 Pandas 和 Python 数据处理的 7 个步骤</a></p>
</li>
</ul>
<h1 id="数据从哪里来">数据从哪里来?</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2022/08/data-come.html" target="_blank"><code>www.kdnuggets.com/2022/08/data-come.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/e899c471bc6b4a00bde74806b6cf467b.png" alt="数据从哪里来?" loading="lazy"></p>
<p>图片由<a href="https://www.pexels.com/photo/software-engineer-standing-beside-server-racks-1181354/" target="_blank">Christina Morillo</a>提供</p>
<p>数据正在以越来越快的速度推动世界前进。它被用于辅助机器学习,优化人工智能驱动的计算机,并以惊人的准确性预测未来结果。我们的现代时代仍由数据推动的持续技术突破所定义。原始数据是新技术的指引,并帮助将新进展与现实和日常功能保持一致。</p>
<hr>
<h2 id="我们的前三个课程推荐-7">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升您的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持您的组织的 IT 需求</p>
<hr>
<p>数据让我们更好地掌控自己的生活。无论是为公共政策提供信息、优化自动驾驶车辆、预测我们何时需要订购手部清洁剂,还是在社交媒体上提供相关内容建议,数据都能帮助我们回答生活中的问题,往往是在我们意识到这些问题之前!</p>
<p>由于其作为商业智能的一种强大形式,<a href="https://online.maryville.edu/blog/future-big-data/#:~:text=Big%20data%20and%20analytics%20provide,they%20can%20address%20them%20systematically." target="_blank">消费者数据是无价的</a>,对几乎每家公司来说都极其重要。数据对于那些利用机器学习技术的科技公司尤为宝贵。原始数据可以通过利用机器学习对现实生活的“学习”来增强软件的能力。</p>
<p>与人类不同,机器学习工具无需休息,因此人工智能计算机成为许多未来科学发现的源泉似乎是不可避免的。一个雄心勃勃的科技初创公司如何才能最好地获得大量数据并保持控制?</p>
<p>在本文中,我们将讨论收集或接收数据的五种主要方式,无论是为了优化人工智能驱动的机器,还是简单地预测未来的消费者需求。</p>
<h1 id="原始数据从哪里来">原始数据从哪里来?</h1>
<p>数据存在于我们周围,但为特定项目收集和组织数据有时可能令人不知所措。以下是原始数据的五大常见来源。</p>
<h2 id="1-公开可用的数据">1. 公开可用的数据</h2>
<p>我们将从最明显的数据来源开始——公共数据,这些数据可以在政府记录或其他公共数据库中找到,如 Facebook、LinkedIn 或 Google。公共数据是任何公开的信息,例如报纸报道、城市人口普查信息或选民登记名单。随着我们的社会不断将更多技术融入日常生活,关于人们的数据只会继续增长。</p>
<p>例如,<a href="https://phys.org/news/2022-07-machine-learning-algorithm-racial-makeup-neighborhoods.html" target="_blank">最近的一项研究显示</a>,通过美国人口普查局收集的信息可以准确预测社区的人口变化,这可能会减少劳动力密集的上门普查调查的需求。虽然这是一个无害的例子,但其他收集公共数据的技术改进,例如面部识别技术,仍然是有争议的数据收集方式,因此很少使用。</p>
<p>无论你是在通过 Twitter 进行情感分析,还是使用本地人口统计数据来建立初步的数据模型,公共数据都可以作为有用的基础。虽然这是你研究或项目的一个良好起点,但它也使得你的数据模型更容易被复制。统计数据显示,<a href="https://www.invoca.com/blog/retail-marketing-statistics" target="_blank">81%的零售商</a>收集大量数据以帮助他们的营销和发展。</p>
<p>使用公共数据可以使你的模型更加通用,但也可以带来一种透明度,这对你的项目是有利的。例如,<a href="https://cryptowallet.com/academy/how-to-buy-crypto-sweden/" target="_blank">像比特币这样的加密货币</a>在一个无权限、所有人都可以访问的公共区块链上交易,但交易依然非常安全。</p>
<h2 id="2-使用你软件的数据">2. 使用你软件的数据</h2>
<p>既然你已经有了基于公开数据的模型,现在是时候用更具体的数据进行微调了。</p>
<p>用于机器学习或开发人工智能程序的最佳数据是与你的程序或用户类型特定的数据。例如,自动驾驶汽车会不断收集来自驾驶员的数据以增强其自主驾驶能力。对话式 AI 聊天机器人依赖数据输入和用户行为来提升其回复请求和准确回答问题的能力。</p>
<p>这种收集数据的方法极为相关,因为它非常具体。例如,如果你在为一家金融公司开发一个人工智能驱动的搜索数据库,你可以使用公开的金融数据来开始构建数据库的基础。然而,为了真正完善数据库,使其能够定制化地应对金融部门中出现的各种问题和查询,该软件需要依靠与用户的互动来进行学习。这就是为什么人工智能驱动的软件可能一开始显得笨拙或无关紧要,而在频繁使用后变得更加准确和高效。</p>
<h2 id="3-人工输入">3. 人工输入</h2>
<p>另一种数据收集的方法来源于人工输入。在这种方法中,经过培训的操作员或工程师在设计或应用程序时,同时进行数据收集。在系统操作时手动监督和控制,开发人员可以在开发新模型的原型时同时收集现实世界的数据。系统可能一开始由操作员控制 70%,自主 30%,但一旦收集到足够的数据,并且人工智能得到增强,系统可能会在“学习”如何行为的过程中进展到 95%自主。</p>
<p>自驾车,例如,在成为完全自主之前经历 5 个阶段。汽车从最基本的自驾功能开始——例如检测前方车辆并刹车、保持车道内直行或维持某一速度。这些功能依赖于摄像头和传感器,这些也在收集关于驾驶行为、社区和常见障碍的数据方面发挥重要作用。</p>
<h2 id="4-数据收集">4. 数据收集</h2>
<p>一种更为传统的数据收集形式,“暴力数据采集”仍然是一种有效的方法。这是指数据是有目的地收集的,而不是从公开数据中获取或作为产品测试或开发的一部分。例如,一个城市普查员可能会逐户核实信息关于居住在那里的市民。类似地,一辆勘测车可以被指派在社区周围行驶,以收集图像用于创建高清地图。</p>
<p>在这两种情况下,主要目标是数据收集。寻找模式和使用数据是在之后的步骤——没有人为或人工智能的干预来使数据有意义。虽然这种方法耗时且劳动密集,但这种艰难获得的数据对竞争者来说可能难以复制。</p>
<h2 id="5-购买数据集">5. 购买数据集</h2>
<p>公司获得高质量数据的一种越来越受欢迎的方法是直接从一个可信赖的公司购买数据集。在购买数据用于模型时,你无法控制所获得数据的类型或质量,并且总有可能这些数据会过时或与你的项目不相关。</p>
<p>然而,这是一种快速而简单的方式来获取你开始训练程序所需的数据。使用这种方法获取数据的公司应当研究他们购买的数据来源公司、数据的来源以及数据的收集方式,以确认这些数据是否符合他们的需求再进行购买。</p>
<h1 id="结论-3">结论</h1>
<p>数据无处不在,并将<a href="https://www.forbes.com/sites/forbestechcouncil/2022/04/28/data-is-the-new-business-fuel-but-it-requires-sound-risk-management/" target="_blank">继续推动技术增长</a>在我们的社会中。随着人工智能和机器学习,特别是,推动我们进入一个令人兴奋的新纪元,我们将看到来自科技公司的高质量和实时数据需求日益增加。</p>
<p>如果你在寻找自己项目的数据,最近改版的 KDnuggets 精心挑选的<a href="https://www.kdnuggets.com/datasets/index.html" target="_blank">数据科学、机器学习、人工智能和分析的数据集</a>是一个很好的起点。</p>
<p><strong><a href="http://nahlawrites.com/" target="_blank">Nahla Davies</a></strong> 是一名软件开发人员和技术作家。在全职从事技术写作之前,她曾管理——其中包括许多有趣的事情——担任一家《财富》5000 公司体验式品牌机构的首席程序员,该机构的客户包括三星、时代华纳、Netflix 和索尼。</p>
<h3 id="更多相关话题-5">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/n46.html" target="_blank">KDnuggets 新闻,11 月 30 日:什么是切比雪夫定理及其如何…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/what-does-a-data-scientist-do.html" target="_blank">数据科学家做什么?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/long-take-learn-data-science-fundamentals.html" target="_blank">学习数据科学基础知识需要多长时间?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/11/chebychev-theorem-apply-data-science.html" target="_blank">什么是切比雪夫定理及其如何应用于数据科学?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/what-is-data-lineage-and-why-does-it-matter" target="_blank">数据血统是什么?为什么它很重要?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/07/random-forest-algorithm-need-normalization.html" target="_blank">随机森林算法是否需要归一化?</a></p>
</li>
</ul>
<h1 id="10-种高级-git-技巧">10 种高级 Git 技巧</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/10-advanced-git-techniques" target="_blank"><code>www.kdnuggets.com/10-advanced-git-techniques</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/25cf21f99ae6ce54a3340ab056432ef1.png" alt="10 种高级 Git 技巧" loading="lazy"></p>
<p>图片来自作者</p>
<p>是否曾想过如何在使用 Git 时在经理面前显得像个专家?在这篇文章中,我们将学习 10 种高级 Git 技巧和快捷方式,使你在版本控制、维护和共享代码时更加高效。</p>
<hr>
<h2 id="我们的前-3-个课程推荐">我们的前 3 个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织在 IT 方面</p>
<hr>
<p>你可能已经知道了使用 Git 进行提交、推送、拉取和分支的基础知识。但还有许多鲜为人知的命令和功能可以提升你的技能。阅读完这些,你将掌握一些炫酷的技巧,令同事对你的 Git 熟练度刮目相看。</p>
<h1 id="1-添加--提交">1. 添加 & 提交</h1>
<p>你已经多次以这种方式添加和提交文件,但如果我告诉你可以使用 <code>-am</code> 标志在一行内完成呢?</p>
<pre><code class="language-py">$ git add .
$ git commit -m "new project"
</code></pre>
<p>尝试使用这个命令,它会添加文件更改并使用消息创建提交。</p>
<pre><code class="language-py">$ git commit -am "new project"
</code></pre>
<pre><code class="language-py">[master 17d7675] new project
4 files changed, 2 insertions(+), 1 deletion(-)
</code></pre>
<h1 id="2-修改">2. 修改</h1>
<p>你可以使用 <code>--amend</code> 标志重命名当前的提交信息,并写入新信息。这将帮助你处理意外的提交信息。</p>
<pre><code class="language-py">$ git commit --amend -m "Love"
</code></pre>
<pre><code class="language-py">[master 7b7f891] Love
Date: Mon Jan 22 17:57:58 2024 +0500
4 files changed, 2 insertions(+), 1 deletion(-)
</code></pre>
<p>你可以在将当前提交推送到远程仓库之前包含额外的更改。为此,你需要添加文件更改,然后使用 <code>--amend</code> 标志提交。要保留之前的提交信息,只需使用 <code>--no-edit</code> 标志。</p>
<pre><code class="language-py">$ git add .
$ git commit --amend --no-edit
</code></pre>
<pre><code class="language-py">[master f425059] Love
Date: Mon Jan 22 17:57:58 2024 +0500
6 files changed, 2 insertions(+), 34 deletions(-)
</code></pre>
<h1 id="3-覆盖远程历史记录">3. 覆盖远程历史记录</h1>
<p>如果你想推送本地提交并覆盖远程历史记录而不处理解决问题,你可以使用 <code>--force</code> 标志。然而,重要的是要注意,使用强制标志并不推荐,应该仅在你完全确定自己的操作时使用。请记住,使用强制标志将重写远程历史记录。</p>
<pre><code class="language-py">$ git push origin master --force
</code></pre>
<pre><code class="language-py">Enumerating objects: 7, **done**.
Counting objects: 100% (7/7), **done**.
Delta compression using up to 16 threads
Compressing objects: 100% (4/4), **done**.
Writing objects: 100% (4/4), 357 bytes | 357.00 KiB/s, **done**.
Total 4 (delta 2), reused 0 (delta 0), pack-reused 0
remote: Resolving deltas: 100% (2/2), completed with 2 local objects.
To https://github.com/kingabzpro/VSCode-DataCamp.git
8f184d5..f425059 master -> master
</code></pre>
<h1 id="4-撤销">4. 撤销</h1>
<p>要在 Git 中撤销一次提交,你可以使用 <code>revert</code> 命令。然而,这个命令不会删除任何提交。相反,它会创建一个新提交,撤销原始提交所做的更改。</p>
<p>我们将使用 <code>log</code> 命令和 <code>--oneline</code> 标志以更简洁的形式查看提交历史。</p>
<pre><code class="language-py">$ git log --oneline
</code></pre>
<pre><code class="language-py">f425059 (HEAD -> master, origin/master) Love
8f184d5 first commit
</code></pre>
<p>要恢复到以前的提交,我们使用 <code>git revert</code> 命令,后面跟上提交 ID。这会创建一个新提交,包含以前提交的更改。</p>
<pre><code class="language-py">$ git revert 8f184d5
</code></pre>
<h1 id="5-codespace">5. Codespace</h1>
<p>你想提高在 GitHub 上的生产力吗?使用 GitHub Code Spaces,你现在可以直接在浏览器中编辑和运行代码。</p>
<p>要访问此功能,只需导航到你喜欢的仓库,按下键盘上的句点键(“.”),系统将重定向到 VSCode UI。</p>
<p><img src="https://kdn.flygon.net/docs/img/eda67b5669fef0b6619e8501be3e8d39.png" alt="10 种高级 Git 技巧" loading="lazy"></p>
<p>图片来自作者</p>
<p>你可以对代码进行更改并推送到远程仓库。然而,如果你想在终端中运行代码,你需要在云中运行 Codespace。免费版本提供了一个很好的选项,可以在浏览器中运行你的 Python 代码。这不是很棒吗?我今天才发现这个。</p>
<p><img src="https://kdn.flygon.net/docs/img/0cab25164ac9919bc0dcfd7d22fd2190.png" alt="10 种高级 Git 技巧" loading="lazy"></p>
<p>图片来自作者</p>
<h1 id="6-存储">6. 存储</h1>
<p>在处理项目时,你可以将文件添加到暂存区,然后提交以保存当前进度。然而,还有另一种方法可以轻松保存你的工作,那就是使用 <code>stash</code> 命令。当你使用 <code>stash</code> 时,你可以保存当前进度,而无需将其添加到暂存区或提交。这允许你保存进度并在需要时恢复。</p>
<p>我们将通过提供一个名称并将其存储来保存当前进度。</p>
<pre><code class="language-py">$ git stash save new-idea
</code></pre>
<pre><code class="language-py">Saved working directory and index state On master: new-idea
</code></pre>
<p>你可以查看你的 stash 列表,并记下对应的索引以便检索。</p>
<pre><code class="language-py">$ git stash list
</code></pre>
<pre><code class="language-py">stash@{0}: On master: new-idea
</code></pre>
<p>我们的“新想法”存储在索引 0 中。要检索它,请使用以下命令:</p>
<pre><code class="language-py">$ git stash apply 0
</code></pre>
<pre><code class="language-py">On branch master
Your branch is up to date with 'origin/master'.
</code></pre>
<h1 id="7-重命名分支">7. 重命名分支</h1>
<p>你可以将默认分支名称重命名为更合适的名称。在这种情况下,我们将“master”重命名为“main”。</p>
<pre><code class="language-py">$ git branch -M main
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/78efe97dc4d0a4a1ab5bafdd5854a44d.png" alt="10 种高级 Git 技巧" loading="lazy"></p>
<p>你可以使用以下命令验证更改:</p>
<pre><code class="language-py">$ git status
</code></pre>
<pre><code class="language-py">On branch main
Your branch is up to date with 'origin/master'.
</code></pre>
<h1 id="8-装饰日志">8. 装饰日志</h1>
<p>如果你想查看当前仓库中所有提交的详细历史记录,你可以使用 <code>git log</code> 命令。然而,输出可能难以阅读。为了使其更易读,你可以使用 <code>graph</code>、<code>decorate</code> 和 <code>oneline</code> 标志。这将显示多个分支中的更改及其合并情况。</p>
<pre><code class="language-py">$ git log --graph --decorate --oneline
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/9de6dc561076347a289db767e7758a57.png" alt="10 种高级 Git 技巧" loading="lazy"></p>
<h1 id="9-切换回分支">9. 切换回分支</h1>
<p>在多个场合,我已经切换到一个新分支并忘记了之前分支的名称。因此,我不得不使用 <code>git branch -a</code> 命令查看分支名称列表。然而,使用 <code>git checkout</code> 命令后的破折号“-”有更简单的方法返回到原始分支。</p>
<p>我们将首先创建一个新的 Git 分支“neo”。</p>
<pre><code class="language-py">$ git branch neo
</code></pre>
<p>我们将切换到“neo”分支。</p>
<pre><code class="language-py">$ git checkout neo
</code></pre>
<pre><code class="language-py">Switched to branch 'neo'
</code></pre>
<p>要返回到原始分支,我们将使用以下命令:</p>
<pre><code class="language-py">$ git checkout -
</code></pre>
<pre><code class="language-py">Switched to branch 'main'
</code></pre>
<h1 id="10-复制远程更改">10. 复制远程更改</h1>
<p>我们已经了解了如何覆盖远程仓库。现在,让我们学习如何使用远程仓库覆盖本地仓库。</p>
<p>我们将使用 <code>fetch</code> 命令从远程仓库获取最新更改。</p>
<pre><code class="language-py">$ git fetch origin
</code></pre>
<p>接下来,我们将使用带有'hard'标志的'reset'命令来用远程版本覆盖任何本地更改。请注意,这将永久丢弃任何本地更改。</p>
<pre><code class="language-py">$ git reset --hard origin/master
</code></pre>
<pre><code class="language-py">HEAD is now at f425059 Love
</code></pre>
<p>如果仍然有未跟踪的文件,可以使用以下命令将其删除:</p>
<pre><code class="language-py">$ git clean -df
</code></pre>
<h1 id="结论-4">结论</h1>
<p>我受到 Fireship 的<a href="https://www.youtube.com/watch?v=ecK3EnyGD8o&list=WL&index=1" target="_blank">YouTube 视频</a>的启发而写了这篇文章。我钦佩创作者能够以简单的方式解释复杂的主题。通过跟随他的方法,我学到了很多关于 Git 的功能。</p>
<p>在本文中,我们介绍了对于从事协作数据项目的数据科学家和软件工程师至关重要的高级 Git 技术。掌握这些技巧可以帮助你避免事故并更快地解决问题。</p>
<p>希望你觉得这个博客有用。如果你希望阅读更多关于数据科学世界中常用工具的简明信息,请告诉我。</p>
<p><a href="https://www.polywork.com/kingabzpro" target="_blank"></a><strong><strong><a href="https://www.polywork.com/kingabzpro" target="_blank">Abid Ali Awan</a></strong></strong> (<a href="https://www.linkedin.com/in/1abidaliawan" target="_blank">@1abidaliawan</a>) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一种 AI 产品,以帮助面临心理健康问题的学生。</p>
<h3 id="相关主题">相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/06/14-essential-git-commands-data-scientists.html" target="_blank">数据科学家必备的 14 条 Git 命令</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n39.html" target="_blank">KDnuggets 新闻,10 月 5 日:初学者的顶级免费 Git GUI 客户端 •…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/11/git-data-science-cheatsheet.html" target="_blank">数据科学的 Git 备忘单</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/10/top-free-git-gui-clients-beginners.html" target="_blank">初学者的顶级免费 Git GUI 客户端</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/06/advanced-feature-selection-techniques-machine-learning-models.html" target="_blank">机器学习模型的高级特征选择技术</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/3-research-driven-advanced-prompting-techniques-for-llm-efficiency-and-speed-optimization" target="_blank">3 种基于研究的高级提示技术以提高 LLM 效率…</a></p>
</li>
</ul>
<h1 id="10-个计算机视觉-ai-项目创意">10 个计算机视觉 AI 项目创意</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2021/11/10-ai-project-ideas-computer-vision.html" target="_blank"><code>www.kdnuggets.com/2021/11/10-ai-project-ideas-computer-vision.html</code></a></p>
</blockquote>
<p>评论</p>
<p><strong>作者:<a href="https://www.projectpro.io/projects" target="_blank">Manika Nagpal</a>,ProjectPro 技术内容分析师</strong>。</p>
<p><img src="https://kdn.flygon.net/docs/img/bd592b25bcf73236dcd0632859c1a5c3.png" alt="" loading="lazy"></p>
<blockquote>
<hr>
<h2 id="我们的前三名课程推荐">我们的前三名课程推荐</h2>
<h2 id="_-1"></h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你所在组织的 IT 工作</p>
<hr>
<p><em>“人工智能是让机器做那些人类做起来需要智慧的事情的科学。” -- 马文·明斯基,麻省理工学院人工智能实验室的共同创始人。</em></p>
</blockquote>
<p>上面的引用很好地总结了人工智能(AI)的美妙之处。使用 AI 自动化简单任务,使人类能够投入解决更具挑战性的问题。这就是为什么尽管技术仍处于起步阶段,我们都看到 AI 获得了广泛关注。通过查看 Gartner 最近的调查可以很容易地确认这一点,该调查显示 <a href="https://www.gartner.com/en/newsroom/press-releases/2020-06-22-gartner-identifies-top-10-data-and-analytics-technolo" target="_blank">到 2024 年底,75% 的组织将从试点阶段转向 AI 的实际应用。</a></p>
<p>人工智能技术,如机器学习、深度学习、自然语言处理等,允许用户从数据中得出有见地的结论,这些结论是以往无法揭示的。它们还使个人能够对特定参数做出预测,从而为未来做好准备。而且,请不要把数据集仅仅看作是一组数字。过去那样的日子已经一去不复返。随着 AI 技术的进步,从图像和文本中提取信息已经变得可能。</p>
<p>处理利用数据图像和视频潜力的 AI 分支称为计算机视觉。计算机视觉(CV)有许多令人兴奋的应用,在这篇博客中,我们将列出 <a href="https://bit.ly/3ChPXgS" target="_blank">CV 爱好者可以从事的 AI 项目创意</a>。这些项目创意已根据经验水平分为不同类别,方便你根据行业经验进行浏览。</p>
<ul>
<li>
<p>适合初学者的计算机视觉 AI 项目</p>
</li>
<li>
<p>适合中级专业人士的计算机视觉 AI 项目</p>
</li>
<li>
<p>挑战性的计算机视觉 AI 项目,适合专家</p>
</li>
</ul>
<h2 id="适合初学者的计算机视觉-ai-项目">适合初学者的计算机视觉 AI 项目</h2>
<h3 id="1-人脸识别应用">1) 人脸识别应用</h3>
<p>面部识别是一个有趣的计算机视觉应用,大多数初学者喜欢构建它。想象一下,一个能够查看你的照片并用你的名字识别你应用程序,听起来很酷,对吧?有了如此多的计算机视觉库,创建这样的应用程序并不像你想象的那么困难。</p>
<p><img src="https://kdn.flygon.net/docs/img/127ac8de9ecec49227fedc41a586c227.png" alt="" loading="lazy"></p>
<p><strong>解决方案方法:</strong> 使用 Haar Cascade 分类器在 Python 中构建面部识别系统是相当简单的。这是一个经过预训练的模型,可以检测给定图像中是否存在面孔。你可以使用该模型在图像中定位面孔,然后使用 KNN 机器学习算法来估计它与另一张面孔的相似度。</p>
<p><strong>数据集:</strong> 使用<a href="http://vision.ucsd.edu/content/yale-face-database" target="_blank">耶鲁面部数据库</a>进行此项目,该数据库包含 15 个人的 165 张灰度图像。</p>
<p><strong>用例:</strong> 面部识别被广泛用作安全功能,例如在手机锁屏上,以防止随机人员解锁。</p>
<h3 id="2-口罩检测">2) 口罩检测</h3>
<p>随着中国<a href="https://medicalxpress.com/news/2021-10-flights-cancelled-schools-china-virus.html" target="_blank">再次关闭学校并取消航班以应对最近的冠状病毒病例激增</a>,全球公民感到担忧。我们现在都知道,保持至少 2 米的物理距离和佩戴口罩是控制病毒传播的两个主要步骤。然而,我们仍然看到很多人在公共场所没有佩戴口罩。解决这个问题的一种方法是使用计算机视觉(CV)构建一个能够检测未佩戴口罩人员的系统。</p>
<p><img src="https://kdn.flygon.net/docs/img/6bb6ce8d93167d7463338f793abb276d.png" alt="" loading="lazy"></p>
<p><strong>解决方案方法:</strong> 使用像 ImageNet 这样的 CNN 模型并训练它学习带口罩的面孔和不带口罩的面孔之间的区别。达到一定准确度后,下一步是检测给定图像中的面部特征。最后,应用该模型测试是否佩戴了口罩。</p>
<p><strong>数据集:</strong> 你可以使用 Prajna Bhandary 提供的<a href="https://github.com/prajnasb/observations" target="_blank">COVID-19 图像数据集</a>进行此项目,该数据集包含 690 张佩戴口罩的人员图像和 686 张未佩戴口罩的人员图像。</p>
<p><strong>用例:</strong> 这个模型可以部署在公共场所,以确保未佩戴口罩的人被罚款。</p>
<h3 id="3-狗与猫分类项目">3) 狗与猫分类项目</h3>
<p>这个项目的目标是学习使用计算机视觉进行图像分类。这是一个有趣的计算机视觉项目创意,适合初学者,他们将训练一个<a href="https://bit.ly/3vL8wHv" target="_blank">深度学习算法</a>来区分狗和猫的图像。</p>
<p><img src="https://kdn.flygon.net/docs/img/1a0ac056ac5c6c699b01be33c0b9a5e6.png" alt="" loading="lazy"></p>
<p><strong>解决方案方法:</strong> 对于这个问题,你可以使用 TensorFlow 和 Keras 在 Python 中从头构建一个简单的 CNN 模型,并训练它学习猫和狗的特征。作为替代方案,你也可以使用像 VGG-16 这样的简单 CNN 模型自动区分这两种动物。</p>
<p><strong>数据集:</strong> <a href="https://www.kaggle.com/c/dogs-vs-cats/data" target="_blank">Kaggle 上的狗与猫数据集</a></p>
<p><strong>用例:</strong> 这个项目的最佳学习方式是了解如何使用 TensorFlow 和 Keras 库在 Python 中从零开始构建卷积神经网络(CNN)模型。</p>
<h3 id="4-点击自拍系统">4) 点击自拍!系统</h3>
<p>自拍现在已成为 Z 世代的爱好!他们学习的速度更快,因为他们属于从出生起就见证了智能手机无处不在的那一代。而且,他们中的大多数人不犹豫地与朋友分享他们在社交媒体上学到的东西。因此,我们为我们的 Z 世代提出了一个出色的计算机视觉项目创意,制作一个自动自拍系统,当人看向镜头并微笑时自动拍照。</p>
<p><img src="https://kdn.flygon.net/docs/img/cd48de171541a859fa75d45173348116.png" alt="" loading="lazy"></p>
<p><strong>解决方案方法:</strong> 对于这个项目,你可以使用像 VGG-16 这样的卷积神经网络模型,训练它以区分微笑脸和非微笑脸。一旦你获得了较好的准确率,就可以用你的图像测试模型。之后,你可以使用 OpenCV 库在每一帧实时摄像机画面上实现该模型,并在检测到微笑脸时触发摄像机拍摄画面。确保在每次测试和训练模型之前进行人脸检测。</p>
<p><strong>数据集:</strong> <a href="https://www.kaggle.com/ghousethanedar/smiledetection" target="_blank">Kaggle 上的笑脸检测数据集</a></p>
<p><strong>用例:</strong> Z 世代不仅可以用它来拍摄自拍照,许多进行活动的数字营销团队(例如,如果用户在社交媒体上分享评论便赠送免费样品的活动)也可以从中受益。</p>
<h2 id="适用于中级专业人士的计算机视觉-ai-项目">适用于中级专业人士的计算机视觉 AI 项目</h2>
<h3 id="5-文本识别系统">5) 文本识别系统</h3>
<p>访问一个语言与你不同的外国可以是挑战性的。但这不应该阻止你探索这些地方并体验那些国家可能提供的文化。幸运的是,借助计算机视觉技术,旅行体验已经大大改善。其原因之一就是其在文本识别系统中的应用,这些系统可以读取任何语言并将其翻译为用户指定的语言。</p>
<p><img src="https://kdn.flygon.net/docs/img/4aeb3737b548b4bcccefc134562fa646.png" alt="" loading="lazy"></p>
<p><strong>解决方案方法:</strong> 对于这个项目,主要任务是光学字符识别(OCR),你可以使用谷歌的 Tesseract 以及像 YOLO v4 这样的目标检测模型。你可以下载预训练的 YOLO 权重,然后用它创建自定义目标检测模型。之后,使用 LabelImg 对图像进行注释以供训练。接下来,使用注释图像训练 YOLO 模型。此外,使用 Pytessaract 库从测试图像中提取文本,然后预测文本。</p>
<p><strong>数据集:</strong> <a href="https://www.kaggle.com/eabdul/textimageocr" target="_blank">Kaggle 上的文本-图像-OCR 数据集</a></p>
<p><strong>用例:</strong> 实现这个项目用于语言翻译应用。</p>
<h3 id="6-使用-mnist-的数字识别器">6) 使用 MNIST 的数字识别器</h3>
<p>MNIST 数据集在数据科学社区中非常受欢迎。它包含手写数字的图像,并通过 NIST 重新采样创建。MNIST 数据集大约有 70,000 张 28 x 28 像素的黑白图像。在这个项目中,可以使用这个数据集构建一个数字识别系统。</p>
<p><img src="https://kdn.flygon.net/docs/img/31026eabb6f3abc21f08c10f1d80afbb.png" alt="" loading="lazy"></p>
<p><strong>解决方案:</strong> 这个项目的首要任务是正确分析 MNIST 数据集。这将帮助我们理解数据在应用任何算法之前需要如何预处理。一旦分析和预处理完成,就可以设计一个用于分类数字的 CNN 模型(在 Python 中)。在达到一定准确度后,可以用测试图像来测试模型。可以使用混淆矩阵来深入可视化模型的性能。</p>
<p><strong>数据集:</strong> <a href="http://yann.lecun.com/exdb/mnist/" target="_blank">Yann LeCun、Corinna Cortes 和 Chris Burges 的 MNIST 手写数字数据库</a></p>
<p><strong>使用案例:</strong> 这个项目可以扩展到构建一个读取不同语言手写文本并将其转换为数字信息的应用程序。然后,可以应用语言翻译技术将其转换为所需语言。</p>
<h3 id="7-图像着色">7) 图像着色</h3>
<p>看着那些旧的灰度图像,我们中的许多人很难想象当时捕捉到的颜色。为了减轻我们的痛苦,计算机视觉技术提供了完美的解决方案,因为可以利用它来创建智能图像着色系统。</p>
<p><img src="https://kdn.flygon.net/docs/img/d5f612b96ec7ec723e72901a46e42a80.png" alt="" loading="lazy"></p>
<p><strong>解决方案:</strong> 实现这个项目想法时,可以使用 VGG-16 模型。在初始化模型参数后,使用<em>ImageDataGenerator</em>来重新缩放图像。接下来,将 RGB 格式转换为 LAB 格式。然后,使用 Keras 创建一个用于自动编码器的顺序模型,并用测试图像测试其性能。</p>
<p><strong>数据集:</strong> <a href="https://www.kaggle.com/arnaud58/landscape-pictures" target="_blank">Kaggle 上的风景图片</a></p>
<p><strong>使用案例:</strong> 这个项目可以用来为旧的历史图像上色,以获取更多信息。</p>
<h2 id="挑战性-ai-计算机视觉项目专家篇">挑战性 AI 计算机视觉项目(专家篇)</h2>
<h3 id="8-社交距离追踪器">8) 社交距离追踪器</h3>
<p>社交距离,即人与人之间保持两米的物理距离,是对抗冠状病毒的最佳预防措施之一。该病毒致命,如果市民希望未来不再出现偶尔的封锁,必须遵守社交距离规范。计算机视觉技术可以提供很大帮助,因为可以用来构建一个系统,以估算给定画面中任何两个个体之间的距离。</p>
<p><img src="https://kdn.flygon.net/docs/img/d689e3a161a24a159428054c199879b8.png" alt="" loading="lazy"></p>
<p><strong>解决方案:</strong> 这个项目的第一步将是使用目标检测模型如 Faster RCNN,并训练它识别画面中的人。一旦完成,你需要设置像素的比例,并使用该比例将像素距离转换为实际距离。如果距离小于 2 米,屏幕上应弹出警告信息。</p>
<p><strong>数据集:</strong> <a href="https://pavisdata.iit.it/data/datasets/social_distancing/social_distancing_dataset.zip" target="_blank">社交距离数据集</a></p>
<p><strong>用例:</strong> 这个项目可以在机场、公交车站、市场等公共场所部署,以确保社交距离。</p>
<h3 id="9-停车管理系统">9) 停车管理系统</h3>
<p>我们许多人不喜欢在长队中等待停车位的分配。但现在我们拥有计算机视觉技术,预计长队很快就会消失。这主要是因为我们可以利用人工智能技术创建一个自动停车系统,在该系统中,汽车会自动停放。</p>
<p><img src="https://kdn.flygon.net/docs/img/426fba5de621de3399492a3e559cbc12.png" alt="" loading="lazy"></p>
<p><strong>解决方案:</strong> 该项目将包括几个小项目,如车牌识别、车辆识别、路径识别和自动扣费系统。对于前三个项目,你可以使用目标检测模型并训练它识别车辆车牌及其型号。之后,利用计算机视觉来导航车辆的路径。下一步是扫描记录。</p>
<p><strong>数据集:</strong> 我们建议你花时间构建自己的数据集,特别是针对这个项目。对于试验方法,你可以使用<a href="https://www.kaggle.com/jessicali9530/stanford-cars-dataset" target="_blank">斯坦福汽车数据集</a>和<a href="https://www.kaggle.com/andrewmvd/car-plate-detection" target="_blank">汽车车牌检测</a>,这两个数据集在 Kaggle 上可以找到。</p>
<p><strong>用例:</strong> 这个项目可以在商场、地铁站等地方实施,以加快停车过程。</p>
<h3 id="10-自动考勤系统">10) 自动考勤系统</h3>
<p>在机构中维护员工/学生的实体记录有时会因为所需空间而变得困难。多亏了 IT 行业的发展,基于软件的考勤系统现在变得易于获取。这些系统使得信息可以数字化存储,这比登记册方便高效得多。然而,AI 专家希望通过计算机视觉使考勤系统更顺畅和自动化。这样的系统将捕捉个人的面部,并扫描先前存储的记录来识别该人。一旦面部与记录中的某个匹配,它将自动标记该人出勤。</p>
<p><img src="https://kdn.flygon.net/docs/img/a55b64b60b27123738ad77d826b3d20a.png" alt="" loading="lazy"></p>
<p><strong>解决方案方法:</strong> 第一步是让 CNN 模型学习识别必须打卡的人员。之后,通过提交某个人的图像并对其进行人脸检测来测试系统的性能。接下来,使用训练好的 CNN 模型来识别该人员。一旦识别出一个人,更新其记录,将其标记为数据库中的“出席”。</p>
<p><strong>数据集:</strong> 为这个项目创建一个自己的数据集会更有趣。否则,你可以使用<a href="http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html" target="_blank">CelebA 数据集</a>。</p>
<p><strong>用例:</strong> 各种公司可以利用这个项目来自动化他们的考勤系统。</p>
<p>如果你对探索人工智能的激动人心的领域感兴趣,我们建议你尝试一些项目。如果你不知道从哪里开始,可以查看这些<a href="https://bit.ly/2ZnGV3I" target="_blank">带有源代码的解决过的端到端数据科学和机器学习项目</a>,以开启你的学习之旅。</p>
<p><strong>相关内容:</strong></p>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/09/computer-vision-agriculture.html" target="_blank">农业中的计算机视觉</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/08/open-source-datasets-computer-vision.html" target="_blank">计算机视觉的开源数据集</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/02/deep-learning-based-real-time-video-processing.html" target="_blank">基于深度学习的实时视频处理</a></p>
</li>
</ul>
<h3 id="更多相关话题-6">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/01/tensorflow-computer-vision-transfer-learning-made-easy.html" target="_blank">计算机视觉中的 TensorFlow - 轻松实现迁移学习</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2024/01/mlm-discover-the-world-of-computer-vision-ebook" target="_blank">探索计算机视觉的世界:介绍 MLM 最新的……</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/5-applications-computer-vision.html" target="_blank">计算机视觉的 5 种应用</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/05/6-things-need-know-data-management-matters-computer-vision.html" target="_blank">你需要了解的 6 件数据管理相关的事情及其重要性……</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n10.html" target="_blank">KDnuggets 新闻 2022 年 3 月 9 日:在 5 天内构建机器学习 Web 应用程序……</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/dinov2-selfsupervised-computer-vision-models-meta-ai.html" target="_blank">DINOv2:Meta AI 的自监督计算机视觉模型</a></p>
</li>
</ul>
<h1 id="人工智能大数据和数据科学的-10-种算法类别">人工智能、大数据和数据科学的 10 种算法类别</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2016/07/10-algorithm-categories-data-science.html" target="_blank"><code>www.kdnuggets.com/2016/07/10-algorithm-categories-data-science.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/3d9c022da2d331bb56691a9617b91b90.png" alt="c" loading="lazy"> 评论</p>
<p><strong>作者:Chris Pehura, C-SUITE DATA</strong>。</p>
<p><img src="https://kdn.flygon.net/docs/img/0dde194b818ff3615570abe6796879bb.png" alt="大数据全景" loading="lazy"></p>
<hr>
<h2 id="我们的前三大课程推荐-4">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业轨道。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织 IT 需求</p>
<hr>
<p>算法会取代我们的工作吗?是的,是的,确实会……这反而是一件好事。</p>
<p>算法是一系列带有规则的步骤,帮助我们解决问题并实现目标。当我们以正确的方式构建这些步骤和规则时,我们可以自动化算法来建立人工智能(A.I.)。正是这种 A.I.帮助我们进行繁重的分析工作,使我们可以专注于我们擅长的事情……即我们被聘用来做的事情。</p>
<p>人工智能正在改变我们的工作、工作方式和商业文化。人工智能帮助我们发现并专注于使我们的人力资本优秀的关键专业知识。但是,在工作场所使用人工智能确实会变得复杂。因为用于实施人工智能的算法有不同的层次,每个层次的使用和影响都不同。为了更好地平衡我们的人力资本和人工智能资本,以下是用于实施人工智能、大数据和数据科学的十大算法类别。</p>
<ol>
<li>
<p><strong>计算器。</strong> 这些算法使用由简单规则指导的小型重复步骤来处理复杂问题。我们提供数据给这些算法,它们就会给出答案。如果我们不满意这个答案,我们会提供更多数据来细化它。计算器擅长于客户分类、项目时间估算以及分析调查数据以了解我们的商业文化。</p>
</li>
<li>
<p><strong>指导者。</strong> 这些算法通过基于成功的历史行动提供预测、排名和成功可能性,来指导我们如何最佳地导航政策、流程或工作流程。指导者擅长协调需要理解和执行风险管理、战略变革以及复杂项目管理的许多动态部分。</p>
</li>
<li>
<p><strong>顾问。</strong> 这些算法通过提供基于历史模式的预测、排名和成功可能性来建议我们最佳选项。顾问擅长于决策、规划和风险缓解方面的建议。</p>
</li>
<li>
<p><strong>预测者。</strong> 这些算法通过使用小的可重复决策和判断来解释历史行为和事件,从而预测未来的人类行为和事件。预测者在商业规划、市场预测、品牌管理、健康诊断以及预测消费者行为、品牌吸引力、欺诈、市场机会、天气事件和疾病爆发方面表现出色。</p>
</li>
<li>
<p><strong>战术家。</strong> 这些算法<strong>战术性</strong>地预测短期行为并做出相应反应。它们通过应用短期战术规则的组合以及对相关人员的信息来实现这一点。战术家擅长平衡供应链、系统性能、人力资源负荷和装配线。</p>
</li>
<li>
<p><strong>战略家。</strong> 这些算法<strong>战略性</strong>地预测行为并进行相应规划。战略家超越数据,揭示洞察和创新机会。它们通过应用短期和长期战略规则的组合以及对相关人员及其在各种环境中反应的信息来实现这一点。战略家擅长预测市场需求、客户流失、人类生产力和员工流失。</p>
</li>
<li>
<p><strong>提升者。</strong> 这些算法通过自动化我们单调重复的工作来帮助我们,使我们能够专注于我们被聘用来做的工作。这些算法拥有一些专业知识,使它们能够进行我们的分析性重负担。提升者擅长分析和识别可重复的模式和规范中的差距、欺诈、风险、改进、转型、机会和创新。</p>
</li>
<li>
<p><strong>合作伙伴。</strong> 这些算法能够发挥我们最佳的潜力。它们在我们的领域拥有大量的专业知识,使我们能够更高效、更专注。合作伙伴擅长给我们提供建议、培训、保持市场变化的更新,并且协调我们及我们的工作日常、季度和年度活动。合作伙伴理解我们的行为,从我们何时该吃午餐到空调需要设置的温度。</p>
</li>
<li>
<p><strong>认可者。</strong> 这些算法在多个领域拥有专业知识,允许我们小组完成所有基础分析工作。一旦算法完成分析,我们每个人根据自己的专业知识审查工作,然后<strong>认可</strong>这些工作。认可者擅长通过深入分析构建全局,并从各个角度审视问题。它们对商业规划、战略变革和文化变革非常有用。</p>
</li>
<li>
<p><strong>管理者。</strong> 这些算法对我们的业务运作具有关键的专业知识。它们管理我们和我们的工作,以保持我们和业务的健康、生产力和财务稳定。这些算法协调我们和其他所有算法,帮助我们实现战略性的长期目标。</p>
</li>
</ol>
<p><strong>个人简介: <a href="https://www.linkedin.com/in/chrispehura" target="_blank">Chris Pehura</a></strong> 是一名管理顾问,专注于数据,帮助财富 100/1000 公司从战略上演变和重塑其业务,以最大化收入增长。通过重新调整、彻底改革、从顶层到底层和从底层到顶层重建,他将领导者、战略和解决方案整合并巩固到组织的各个方面。</p>
<p><a href="http://bizcatalyst360.com/10-algorithm-categories-for-a-i-big-data-and-data-science/" target="_blank">原文</a>。经许可转载。</p>
<p><strong>相关内容:</strong></p>
<ul>
<li>
<p>前 10 名数据挖掘算法解析</p>
</li>
<li>
<p>算法经济与容器如何改变应用程序</p>
</li>
<li>
<p>为什么从零开始实现机器学习算法?</p>
</li>
</ul>
<h3 id="更多主题">更多主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/n30.html" target="_blank">KDnuggets 新闻,7 月 27 日:AIoT 革命:AI 和物联网如何…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/kmeans-clustering-algorithm-work.html" target="_blank">什么是 K 均值聚类及其算法如何工作?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n15.html" target="_blank">KDnuggets 新闻,4 月 13 日:数据科学家应关注的 Python 库…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2020/01/decision-tree-algorithm-explained.html" target="_blank">决策树算法解析</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/deployment-machine-learning-algorithm-live-production-environment.html" target="_blank">机器学习算法的完整端到端部署…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/07/ml-algorithm-choose.html" target="_blank">解锁选择完美机器学习算法的秘密!</a></p>
</li>
</ul>
<h1 id="机器学习工程师需要了解的-10-种算法">机器学习工程师需要了解的 10 种算法</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2016/08/10-algorithms-machine-learning-engineers.html/2" target="_blank"><code>www.kdnuggets.com/2016/08/10-algorithms-machine-learning-engineers.html/2</code></a></p>
</blockquote>
<p><strong>6. 集成方法</strong>:</p>
<hr>
<h2 id="我们的前三名课程推荐-1">我们的前三名课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业轨道</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织进行 IT 工作</p>
<hr>
<p>集成方法是学习算法,通过构建一组分类器,并通过对它们的预测进行加权投票来对新数据点进行分类。最初的集成方法是贝叶斯平均,但近年来的算法包括错误修正输出编码、袋装法和提升法。</p>
<p><img src="https://kdn.flygon.net/docs/img/ae82076c4e349b08aab3c861330ef1d9.png" alt="" loading="lazy"></p>
<p><em>集成学习机器学习算法</em>那么集成方法如何工作,它们为什么优于单一模型?</p>
<ul>
<li>
<p>它们平衡偏差:如果你将一堆倾向于民主的民调和倾向于共和的民调进行平均,你将得到一个没有倾向于任何一方的平均值。</p>
</li>
<li>
<p>它们减少了方差:一组模型的综合意见比单一模型的意见噪声更少。在金融领域,这被称为多样化——一个包含多只股票的混合投资组合的波动性远低于仅仅一只股票。这就是为什么你的模型在有更多数据点时表现更好,而不是更少数据点。</p>
</li>
<li>
<p>它们不容易过拟合:如果你有一些没有过拟合的个体模型,并且你以简单的方式(如平均、加权平均、逻辑回归)结合每个模型的预测,那么就不会出现过拟合的情况。</p>
</li>
</ul>
<h2 id="无监督学习算法">无监督学习算法</h2>
<h3 id="7聚类算法"><strong>7. 聚类算法</strong>:</h3>
<p>聚类任务是将一组对象分组,使得同一组(<em>簇</em>)中的对象比其他组中的对象更相似。</p>
<p><img src="https://kdn.flygon.net/docs/img/eff8f346195e69945fd942ac2ac1d113.png" alt="" loading="lazy"></p>
<p><em>聚类算法</em>每种聚类算法都是不同的,以下是其中的一些:</p>
<ul>
<li>
<p>基于质心的算法</p>
</li>
<li>
<p>基于连通性的算法</p>
</li>
<li>
<p>基于密度的算法</p>
</li>
<li>
<p>概率性</p>
</li>
<li>
<p>维度减少</p>
</li>
<li>
<p>神经网络 / 深度学习</p>
</li>
</ul>
<h3 id="8主成分分析"><strong>8. 主成分分析</strong>:</h3>
<p>PCA 是一种统计程序,通过使用正交变换,将可能相关变量的观察值转换为称为主成分的线性无关变量的值集合。</p>
<p><img src="https://kdn.flygon.net/docs/img/7ff77e947d89208847cbbfcf74dd1f6f.png" alt="" loading="lazy"></p>
<p><em>主成分分析</em> PCA 的一些应用包括压缩、简化数据以便于学习、可视化。注意,在决定是否使用 PCA 时,领域知识非常重要。数据噪声较大的情况下(PCA 的所有成分都有相当高的方差),PCA 不适用。</p>
<h3 id="9-奇异值分解"><strong>9. 奇异值分解</strong>:</h3>
<p>在线性代数中,SVD 是对实复矩阵的分解。对于给定的 <em>m * n</em> 矩阵 M,存在一种分解使得 M = UΣV,其中 U 和 V 是单位矩阵,Σ 是对角矩阵。</p>
<p><img src="https://kdn.flygon.net/docs/img/8ef41c71a9c41fc56d51c1d96a6dbdf6.png" alt="" loading="lazy"></p>
<p><em>奇异值分解</em> PCA 实际上是 SVD 的一种简单应用。在计算机视觉中,最早的面部识别机器学习算法使用 PCA 和 SVD 将面部表示为“特征脸”的线性组合,进行降维,然后通过简单的方法匹配面部身份;尽管现代方法更为复杂,但许多方法仍然依赖于类似的技术。</p>
<h3 id="10-独立成分分析"><strong>10. 独立成分分析</strong>:</h3>
<p>ICA 是一种统计技术,用于揭示隐藏在一组随机变量、测量值或信号背后的因素。ICA 为观察到的多变量数据定义了生成模型,这些数据通常以大型样本数据库的形式提供。</p>
<p>在模型中,数据变量被假设为某些未知潜在变量的线性混合,且混合系统也是未知的。潜在变量被假设为非高斯且相互独立,它们被称为观察数据的独立成分。</p>
<p><img src="https://kdn.flygon.net/docs/img/5eb17ad61ae0a155144e13ef119da9f9.png" alt="" loading="lazy"></p>
<p><em>独立成分分析</em> ICA 与 PCA 相关,但它是一种更强大的技术,能够在这些经典方法完全失败时找到来源的潜在因素。其应用包括数字图像、文档数据库、经济指标和心理测量。</p>
<p>现在,运用你对 AI 算法的理解,创建更好的机器学习应用,改善人们的体验。</p>
<p><strong>简介: <a href="https://www.linkedin.com/in/khanhnamle94" target="_blank">James Le</a></strong> 是 New Story Charity 的产品实习生,同时也是 Denison University 的计算机科学与通信专业学生。</p>
<p><a href="https://gab41.lab41.org/the-10-algorithms-machine-learning-engineers-need-to-know-f4bb63f5b2fa" target="_blank">原文</a>。经许可转载。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p>AI、大数据和数据科学的 10 种算法类别</p>
</li>
<li>
<p>前 10 大数据挖掘算法,详解</p>
</li>
<li>
<p>机器学习关键术语,详解</p>
</li>
</ul>
<h3 id="相关主题-1">相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/build-solid-data-team.html" target="_blank">建立一个稳固的数据团队</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/write-clean-python-code-pipes.html" target="_blank">使用管道编写干净的 Python 代码</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/three-r-libraries-every-data-scientist-know-even-python.html" target="_blank">每个数据科学家都应该知道的三个 R 库(即使你使用 Python)</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/02/dont-need-data-scientists-need-data-engineers.html" target="_blank">我们不需要数据科学家,我们需要数据工程师</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/stop-learning-data-science-find-purpose.html" target="_blank">停止学习数据科学以寻找目标,并寻找目标来……</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/springboard-top-resources-learn-data-science-statistics.html" target="_blank">学习数据科学的统计学顶级资源</a></p>
</li>
</ul>
<h1 id="2020-年-10-个惊人的机器学习项目">2020 年 10 个惊人的机器学习项目</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2021/03/10-amazing-machine-learning-projects-2020.html" target="_blank"><code>www.kdnuggets.com/2021/03/10-amazing-machine-learning-projects-2020.html</code></a></p>
</blockquote>
<p>评论</p>
<p><strong>由 <a href="https://www.linkedin.com/in/anupamchugh/?originalSubdomain=in" target="_blank">Anupam Chugh</a>,iOS 开发者 | Medium 撰稿人 | BITS Pilani</strong>。</p>
<p><img src="https://kdn.flygon.net/docs/img/3f52c957b761c877d775d26e30aff7ad.png" alt="" loading="lazy"></p>
<p><em>照片由 <a href="https://unsplash.com/@plhnk?utm_source=medium&utm_medium=referral" target="_blank">Paul Hanaoka</a> 提供,来源于 <a href="https://unsplash.com/?utm_source=medium&utm_medium=referral" target="_blank">Unsplash</a>。</em></p>
<p>在过去的一年里,机器学习社区发生了很多事情。这里是最受欢迎和最具趋势的开源研究项目、演示和原型的巡礼。它涵盖了从照片编辑到自然语言处理到使用“无代码”训练模型的各个方面,希望它们能激发你在今年构建令人惊叹的人工智能产品。你还可以在 <a href="https://www.kdnuggets.com/2020/03/20-machine-learning-datasets-project-ideas.html" target="_blank">这里找到更多机器学习项目</a>。</p>
<h3 id="1-背景抠像-v2">1. 背景抠像 v2</h3>
<p><a href="https://github.com/PeterL1n/BackgroundMattingV2" target="_blank">背景抠像 v2</a> 受到受欢迎的 <a href="https://github.com/senguptaumd/Background-Matting" target="_blank">The World is Your Green Screen</a> 开源项目的启发,展示了如何实时去除或更改背景。它提供了更好的性能(4K 下 30fps 和 FHD 下 60fps),并且可以与流行的视频会议应用 Zoom 一起使用。</p>
<p>该技术使用额外捕获的背景帧,并将其用于恢复 alpha 遮罩和前景层。为了实时处理高分辨率图像,使用了两个神经网络。</p>
<p>如果你想在保留背景的同时从视频中去除一个人,这个项目肯定会很有帮助。</p>
<p><img src="https://kdn.flygon.net/docs/img/1435d1a137c845cb8869e71ab8c659e4.png" alt="" loading="lazy"></p>
<p><em><a href="https://github.com/PeterL1n/BackgroundMattingV2" target="_blank">演示</a></em></p>
<h3 id="2-skyar">2. SkyAR</h3>
<p>这里还有另一个 <a href="https://github.com/jiupinjia/SkyAR" target="_blank">惊人项目</a>,它进行视频天空替换和协调,能够自动生成现实且戏剧性的天空背景,并具有可控的风格。</p>
<p>基于 Pytorch,该项目部分采纳了 <a href="https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix" target="_blank">pytorch-CycleGAN-and-pix2pix</a> 项目的代码,利用天空抠像、通过光流进行运动估计和图像混合,在实时视频中提供艺术背景。</p>
<p>上述开源项目在电影和视频游戏中具有令人难以置信的潜力,例如添加假雨/晴天等。</p>
<p><img src="https://kdn.flygon.net/docs/img/3bc9c3a96cc41e80586e3d9beb560565.png" alt="" loading="lazy"></p>
<p><em><a href="https://github.com/jiupinjia/SkyAR" target="_blank">源代码</a></em></p>
<h3 id="3-animegan-v2">3. AnimeGAN v2</h3>
<p>将照片卡通化总是一个有趣的机器学习项目。不是吗?</p>
<p><a href="https://github.com/TachibanaYoshino/AnimeGANv2" target="_blank">这个项目,AnimeGANv2</a>,是 AnimeGAN 的改进版。它结合了神经风格迁移和生成对抗网络(GAN),以完成任务,同时确保防止高频伪影的生成。</p>
<p><img src="https://kdn.flygon.net/docs/img/5a5ba524f25ffc40b2aa668f4c28ac20.png" alt="" loading="lazy"></p>
<p><em><a href="https://github.com/TachibanaYoshino/AnimeGANv2" target="_blank">来源</a></em></p>
<h3 id="4-txtai">4. txtai</h3>
<p>AI 优化的搜索引擎和 QA 聊天机器人始终是当下的需求。这正是这个<a href="https://github.com/neuml/txtai" target="_blank">项目</a>所做的。</p>
<p>通过使用<a href="https://github.com/UKPLab/sentence-transformers" target="_blank">sentence-transformers</a>、<a href="https://github.com/huggingface/transformers" target="_blank">transformers</a>和<a href="https://github.com/facebookresearch/faiss" target="_blank">faiss</a>,<em>txtai</em>构建了一个用于上下文搜索和抽取式问答的 AI 驱动引擎。</p>
<p>实质上,<em>txtai</em>支持构建文本索引以执行相似性搜索,并创建基于抽取式问答的系统。</p>
<p><img src="https://kdn.flygon.net/docs/img/a16e86b8346cb4fa5783f15b0dcd66d9.png" alt="" loading="lazy"></p>
<p><em><a href="https://github.com/neuml/txtai" target="_blank">来源</a></em></p>
<h3 id="5-让旧照片重获新生">5. 让旧照片重获新生</h3>
<p>接下来,我们有<a href="https://github.com/microsoft/Bringing-Old-Photos-Back-to-Life" target="_blank">微软最新的照片修复项目</a>,该项目能自动修复损坏的照片。</p>
<p>具体而言,它通过利用划痕检测、面部增强和其他技术,通过 PyTorch 中的深度学习实现,恢复受复杂退化影响的旧照片。</p>
<p>根据他们的<a href="https://arxiv.org/abs/2004.09484" target="_blank">研究论文</a>:“我们训练了两个变分自编码器(VAEs),分别将旧照片和干净照片转换到两个潜在空间。这两个潜在空间之间的转换通过合成配对数据进行学习。这种转换对真实照片的泛化效果很好,因为在紧凑的潜在空间中缩小了领域间隙。此外,为了解决混合在一张旧照片中的多种退化情况,我们设计了一个全球分支,带有一个部分非局部块,针对结构化缺陷,如划痕和灰尘斑点,以及一个局部分支,针对非结构化缺陷,如噪声和模糊。”</p>
<p>该模型显然超越了传统的最先进方法,下面的演示就是明证:</p>
<p><img src="https://kdn.flygon.net/docs/img/7502992766a95abae6bf0fb4ab995793.png" alt="" loading="lazy"></p>
<p><em><a href="https://github.com/microsoft/Bringing-Old-Photos-Back-to-Life" target="_blank">来源</a></em></p>
<h3 id="6-avatarify">6. Avatarify</h3>
<p>Deepfake 项目在机器学习和 AI 社区引起了轰动。<a href="https://github.com/alievk/avatarify" target="_blank">这个项目</a>展示了一个经典的例子,它让你在实时视频会议应用中创建逼真的头像。</p>
<p>基本上,它使用了<a href="https://github.com/AliaksandrSiarohin/first-order-model" target="_blank">First Order Model</a>来从视频中提取动作,并通过使用光流将其应用到目标头像图像中。这样,你可以在虚拟相机上生成头像,甚至可以给经典画作动画。从埃隆·马斯克到蒙娜丽莎,你可以尽情模仿任何人以获取乐趣!</p>
<p><img src="https://kdn.flygon.net/docs/img/412d871fc0044077dd343e16aa7b8818.png" alt="" loading="lazy"></p>
<p><em><a href="https://github.com/alievk/avatarify" target="_blank">来源</a></em></p>
<h3 id="7-pulse">7. Pulse</h3>
<p>这是一个展示如何从低分辨率图像生成真实面部图像的 AI 模型。</p>
<p><a href="https://github.com/adamian98/pulse" target="_blank">PULSE</a>,即自监督照片超分辨率通过生成模型的潜在空间探索,提供了基于创建真实 SR 图像的超分辨率问题的替代公式,该公式还可以正确地缩小回去。</p>
<p><img src="https://kdn.flygon.net/docs/img/7b36a047fadef9dbce49c48ac10b9d79.png" alt="" loading="lazy"></p>
<p><em><a href="https://www.reddit.com/r/MachineLearning/comments/hciw10/r_wolfenstein_and_doom_guy_upscaled_into/" target="_blank">来源</a></em></p>
<h3 id="8-pixel2style2pixel">8. pixel2style2pixel</h3>
<p>基于<a href="https://arxiv.org/abs/2008.00951" target="_blank">研究论文</a>《Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation》,这个<a href="https://github.com/eladrich/pixel2style2pixel" target="_blank">项目</a>使用了 Pixel2Pixel 框架,旨在通过使用相同的架构来解决各种图像到图像的任务,以避免任何可能的局部偏差。</p>
<p>基于一种新颖的编码器网络,该网络可以训练以将面部图像对齐到正面姿势、条件图像合成,并创建超分辨率图像。</p>
<p>从将几乎真实的人物从卡通图片生成到将素描或面部分割转换为照片级真实图像,你可以用这个做很多事情。</p>
<p><img src="https://kdn.flygon.net/docs/img/834aff9037b95b8487794ad63162005d.png" alt="" loading="lazy"></p>
<p><em><a href="https://www.reddit.com/r/MachineLearning/comments/jcuch4/p_creating_real_versions_of_pixar_characters/" target="_blank">来源</a></em></p>
<h3 id="9-igel">9. igel</h3>
<p>可能由于预算问题或缺乏明确的愿景,但找到具有相关机器学习专长的人始终是初创公司的挑战。尤其是因为这个领域总是不断进步的。</p>
<p>因此,最近出现了大量无代码机器学习平台,例如 Google 和 Apple 也发布了自己的工具集,以便快速训练模型。</p>
<p>这个令人愉快的开源机器学习项目正是通过允许你训练/拟合、测试和使用模型而无需编写代码来实现这一点的。虽然 GUI 拖放版本仍在开发中,但你可以通过该项目的命令行工具实现很多功能:</p>
<pre><code class="language-py">//train or fit a model
igel fit -dp 'path_to_your_csv_dataset.csv' -yml 'path_to_your_yaml_file.yaml'
//evaluate
igel evaluate -dp 'path_to_your_evaluation_dataset.csv'
//predict
igel predict -dp 'path_to_your_test_dataset.csv'
</code></pre>
<p>还有一个单一命令<em>igel experiment</em>来结合所有阶段:训练、评估和预测。有关更多详细信息,请参阅<a href="https://github.com/nidhaloff/igel" target="_blank">文档</a>。</p>
<p><img src="https://kdn.flygon.net/docs/img/9e342cb444bf3fe98419e7df56f89344.png" alt="" loading="lazy"></p>
<p><em><a href="https://github.com/nidhaloff/igel" target="_blank">来源</a></em></p>
<h3 id="10-pose-animator">10. Pose Animator</h3>
<p>最后但同样重要的是,我们有一个网页动画工具。基本上,<a href="https://github.com/yemount/pose-animator/" target="_blank">这个项目</a>使用 PoseNet 和 FaceMesh 地标结果,通过利用一些 TensorFlow.js 模型,将 SVG 矢量图像赋予生命。</p>
<p>你可以通过以下方式为自己的设计或骨架图像添加动画:</p>
<p><img src="https://kdn.flygon.net/docs/img/3a60e2cfad90130d1aad605af380ecd9.png" alt="" loading="lazy"></p>
<p><em><a href="https://github.com/yemount/pose-animator/" target="_blank">来源</a></em></p>
<p><a href="https://medium.com/better-programming/the-top-10-trending-machine-learning-projects-of-2020-d923bf31abb7" target="_blank">原始文章</a>。经许可转载。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2020/12/2020-amazing-ai-papers.html" target="_blank">2020 年:充满惊人 AI 论文的一年 — 评述</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2020/03/20-machine-learning-datasets-project-ideas.html" target="_blank">20+机器学习数据集和项目想法</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/01/machine-learning-algorithms-2021.html" target="_blank">2021 年你应该知道的所有机器学习算法</a></p>
</li>
</ul>
<hr>
<h2 id="我们的前三大课程推荐-5">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析能力</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织进行 IT 工作</p>
<hr>
<h3 id="更多相关话题-7">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/stop-learning-data-science-find-purpose.html" target="_blank">停止学习数据科学以寻找目标,找到目标去…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/springboard-top-resources-learn-data-science-statistics.html" target="_blank">学习数据科学统计的最佳资源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/9b-ai-failure-examined.html" target="_blank">一个 90 亿美元的 AI 失败,进行审查</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-characteristics-successful-data-scientist.html" target="_blank">成功数据科学家的 5 个特征</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/makes-python-ideal-programming-language-startups.html" target="_blank">是什么使 Python 成为初创公司的理想编程语言</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/three-r-libraries-every-data-scientist-know-even-python.html" target="_blank">每个数据科学家都应该知道的三个 R 库(即使你使用 Python)</a></p>
</li>
</ul>
<h1 id="2023-年你应该了解的-10-个令人惊叹的机器学习可视化">2023 年你应该了解的 10 个令人惊叹的机器学习可视化</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2022/11/10-amazing-machine-learning-visualizations-know-2023.html" target="_blank"><code>www.kdnuggets.com/2022/11/10-amazing-machine-learning-visualizations-know-2023.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/94707c4df6887d0528c7e4b23ee48ee8.png" alt="2023 年你应该了解的 10 个令人惊叹的机器学习可视化" loading="lazy"></p>
<p>图片由编辑提供</p>
<p>数据可视化在机器学习中发挥着重要作用。</p>
<hr>
<h2 id="我们的三大课程推荐-2">我们的三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析能力</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织 IT</p>
<hr>
<p>数据可视化在机器学习中的使用场景包括:</p>
<ul>
<li>
<p>超参数调优</p>
</li>
<li>
<p>模型性能评估</p>
</li>
<li>
<p>验证模型假设</p>
</li>
<li>
<p>查找异常值</p>
</li>
<li>
<p>选择最重要的特征</p>
</li>
<li>
<p>识别特征之间的模式和关联</p>
</li>
</ul>
<p>直接与上述机器学习关键点相关的可视化称为 <em><strong>机器学习可视化</strong></em>。</p>
<p>创建机器学习可视化有时是一个复杂的过程,因为即使在 Python 中也需要编写大量代码。但幸好,有了 Python 的开源 <strong>Yellowbrick</strong> 库,即使是复杂的机器学习可视化也可以用更少的代码创建。该库扩展了 Scikit-learn API,并提供了 Scikit-learn 未提供的高级可视化诊断功能。</p>
<p>今天,我将详细讨论以下几种机器学习可视化类型、它们的使用场景以及 Yellowbrick 的实现。</p>
<h1 id="yellowbrick--快速入门">Yellowbrick — 快速入门</h1>
<h2 id="安装">安装</h2>
<p>可以通过运行以下命令之一来安装 Yellowbrick。</p>
<ul>
<li><strong>pip</strong> 包安装器:</li>
</ul>
<pre><code class="language-py">pip install yellowbrick
</code></pre>
<ul>
<li><strong>conda</strong> 包安装器:</li>
</ul>
<pre><code class="language-py">conda install -c districtdatalabs yellowbrick
</code></pre>
<h2 id="使用-yellowbrick">使用 Yellowbrick</h2>
<p>Yellowbrick 可视化工具具有类似 Scikit-learn 的语法。可视化工具是一个从数据中学习以生成可视化的对象。它通常与 Scikit-learn 估计器一起使用。要训练可视化工具,我们调用它的 fit() 方法。</p>
<h2 id="保存图形">保存图形</h2>
<p>要保存使用 Yellowbrick 可视化工具创建的图形,我们调用 show() 方法如下。这将把图形保存为磁盘上的 PNG 文件。</p>
<pre><code class="language-py">visualizer.show(outpath="name_of_the_plot.png")
</code></pre>
<h1 id="1-主成分图">1. 主成分图</h1>
<h2 id="使用">使用</h2>
<p>主成分图通过 2D 或 3D 散点图可视化高维数据。因此,这种图对于识别高维数据中的重要模式极为有用。</p>
<h2 id="yellowbrick-实现">Yellowbrick 实现</h2>
<p>使用传统方法创建此图复杂且耗时。我们需要先对数据集应用 PCA,然后使用 matplotlib 库创建散点图。</p>
<p>相反,我们可以使用 Yellowbrick 的 PCA 可视化器类来实现相同的功能。它利用主成分分析方法,减少数据集的维度,并用 2 或 3 行代码创建散点图!我们只需要在 PCA() 类中指定一些关键字参数即可。</p>
<p>让我们通过一个例子进一步理解这一点。在这里,我们使用<em>breast_cancer</em>数据集(请参见<a href="https://towardsdatascience.com/10-amazing-machine-learning-visualizations-you-should-know-in-2023-528282940582#6fde" target="_blank">Citation</a>,该数据集具有 30 个特征和 569 个样本,分为两个类别(<em>Malignant</em>和<em>Benign</em>)。由于数据的高维度(30 个特征),除非对数据集应用 PCA,否则无法在二维或三维散点图中绘制原始数据。</p>
<p>以下代码解释了我们如何利用 Yellowbrick 的 PCA 可视化器创建一个 30 维数据集的二维散点图。</p>
<p>作者提供的代码</p>
<p><img src="https://kdn.flygon.net/docs/img/045f880cb835bfa38de67690ac085953.png" alt="2023 年你应该知道的 10 个惊人的机器学习可视化" loading="lazy"></p>
<p>主成分图 — 2D|作者提供的图像</p>
<p>我们还可以通过在 PCA() 类中设置<code>projection=3</code>来创建三维散点图。</p>
<p>作者提供的代码</p>
<p><img src="https://kdn.flygon.net/docs/img/f7228111c3dc766f74a9566110390476.png" alt="2023 年你应该知道的 10 个惊人的机器学习可视化" loading="lazy"></p>
<p>主成分图 — 3D|作者提供的图像</p>
<p>PCA 可视化器的最重要参数包括:</p>
<ul>
<li>
<p><strong>scale:</strong> bool,默认为<code>True</code>。这表示数据是否应该进行缩放。我们应该在运行 PCA 之前对数据进行缩放。了解更多信息<a href="https://rukshanpramoditha.medium.com/principal-component-analysis-18-questions-answered-4abd72041ccd#f853" target="_blank">这里</a>。</p>
</li>
<li>
<p><strong>projection:</strong> int,默认为 2。当<code>projection=2</code>时,创建一个二维散点图。当<code>projection=3</code>时,创建一个三维散点图。</p>
</li>
<li>
<p><strong>classes:</strong> list,默认为<code>None</code>。这表示 y 中每个类别的类标签。类别名称将作为图例的标签。</p>
</li>
</ul>
<h1 id="2-验证曲线">2. 验证曲线</h1>
<h2 id="使用方法">使用方法</h2>
<p>验证曲线绘制了<em>单个</em>超参数对训练集和验证集的影响。通过查看曲线,我们可以确定模型在指定超参数值下的过拟合、欠拟合和适中情况。当需要同时调整多个超参数时,不能使用验证曲线。此时,可以使用网格搜索或随机搜索。</p>
<h2 id="yellowbrick-实现-1">Yellowbrick 实现</h2>
<p>使用传统方法创建验证曲线复杂且耗时。相反,我们可以使用 Yellowbrick 的 ValidationCurve 可视化器。</p>
<p>在 Yellowbrick 中绘制验证曲线时,我们将使用相同的<em>breast_cancer</em>数据集(请参见<a href="https://towardsdatascience.com/10-amazing-machine-learning-visualizations-you-should-know-in-2023-528282940582#6fde" target="_blank">Citation</a>)。我们将绘制<strong>max_depth</strong>超参数在随机森林模型中的影响。</p>
<p>以下代码解释了如何利用 Yellowbrick 的 ValidationCurve 可视化工具使用<em>breast_cancer</em>数据集创建验证曲线。</p>
<p>代码由作者提供</p>
<p><img src="https://kdn.flygon.net/docs/img/150429e016c8884c12190c126762d4e9.png" alt="2023 年你应该知道的 10 个惊人的机器学习可视化" loading="lazy"></p>
<p>验证曲线|图片由作者提供</p>
<p>模型在<strong>max_depth</strong>值为 6 之后开始过拟合。当<code>max_depth=6</code>时,模型很好地拟合了训练数据,并且在新的未见数据上也具有良好的泛化能力。</p>
<p>ValidationCurve 可视化工具的最重要参数包括:</p>
<ul>
<li>
<p><strong>estimator:</strong> 这可以是任何 Scikit-learn 机器学习模型,如决策树、随机森林、支持向量机等。</p>
</li>
<li>
<p><strong>param_name:</strong> 这是我们希望监控的超参数的名称。</p>
</li>
<li>
<p><strong>param_range:</strong> 这包括<em>param_name</em>的可能值。</p>
</li>
<li>
<p><strong>cv:</strong> int,定义交叉验证的折数。</p>
</li>
<li>
<p><strong>scoring:</strong> 字符串,包含模型的评分方法。对于分类,<em>accuracy</em> 是首选。</p>
</li>
</ul>
<h1 id="3-学习曲线">3. 学习曲线</h1>
<h2 id="用法">用法</h2>
<p>学习曲线绘制了训练和验证错误或准确率与迭代次数或训练实例数的关系。你可能认为学习曲线和验证曲线看起来一样,但学习曲线的 x 轴绘制了迭代次数,而验证曲线的 x 轴绘制了超参数的值。</p>
<p>学习曲线的用途包括:</p>
<ul>
<li>
<p>学习曲线用于检测模型的<em>欠拟合</em>、<em>过拟合</em>和<em>正好合适</em>条件。</p>
</li>
<li>
<p>学习曲线用于识别在寻找神经网络或机器学习模型的最佳学习率时的<em>慢收敛</em>、<em>振荡</em>、<em>振荡且发散</em>以及<em>适当收敛</em>场景。</p>
</li>
<li>
<p>学习曲线用于查看我们的模型从增加更多训练数据中获益多少。以这种方式使用时,x 轴显示训练实例的数量。</p>
</li>
</ul>
<h2 id="yellowbrick-实现-2">Yellowbrick 实现</h2>
<p>使用传统方法创建学习曲线复杂且耗时。相反,我们可以使用 Yellowbrick 的 LearningCurve 可视化工具。</p>
<p>为了在 Yellowbrick 中绘制学习曲线,我们将使用相同的<em>breast_cancer</em>数据集构建一个支持向量分类器(见<a href="https://towardsdatascience.com/10-amazing-machine-learning-visualizations-you-should-know-in-2023-528282940582#6fde" target="_blank">Citation</a>)。</p>
<p>以下代码解释了如何利用 Yellowbrick 的 LearningCurve 可视化工具使用<em>breast_cancer</em>数据集创建验证曲线。</p>
<p>代码由作者提供</p>
<p><img src="https://kdn.flygon.net/docs/img/3d6f70a3ea545013b87705ed288eedf1.png" alt="2023 年你应该知道的 10 个惊人的机器学习可视化" loading="lazy"></p>
<p>学习曲线|图片由作者提供</p>
<p>模型从增加更多训练实例中不会获得收益。模型已经用 569 个训练实例进行了训练。175 个训练实例之后,验证准确率没有改善。</p>
<p>LearningCurve 可视化工具的最重要参数包括:</p>
<ul>
<li>
<p><strong>estimator:</strong> 这可以是任何 Scikit-learn 机器学习模型,例如决策树、随机森林、支持向量机等。</p>
</li>
<li>
<p><strong>cv:</strong> int,定义交叉验证的折数。</p>
</li>
<li>
<p><strong>scoring:</strong> 字符串,包含模型的评分方法。对于分类任务,<em>准确率</em> 是首选。</p>
</li>
</ul>
<h1 id="4-肘部图">4. 肘部图</h1>
<h2 id="使用方法-1">使用方法</h2>
<p>肘部图用于选择 K-Means 聚类中的最佳簇数。模型在肘部图中肘部出现的位置拟合最佳。肘部是图表上的拐点。</p>
<h2 id="yellowbrick-实现-3">Yellowbrick 实现</h2>
<p>使用传统方法创建肘部图复杂且耗时。相反,我们可以使用 Yellowbrick 的 KElbowVisualizer。</p>
<p>要在 Yellowbrick 中绘制学习曲线,我们将使用 <em>iris</em> 数据集构建一个 K-Means 聚类模型(见文末的 <a href="https://towardsdatascience.com/10-amazing-machine-learning-visualizations-you-should-know-in-2023-528282940582#2bc7" target="_blank">Citation</a>)。</p>
<p>以下代码解释了我们如何利用 Yellowbrick 的 KElbowVisualizer 使用 <em>iris</em> 数据集创建肘部图。</p>
<p>作者提供的代码</p>
<p><img src="https://kdn.flygon.net/docs/img/3cde2829e689c0b5be926da3a47f32b6.png" alt="2023 年你应该知道的 10 个令人惊叹的机器学习可视化" loading="lazy"></p>
<p>肘部图|作者提供的图片</p>
<p><em>肘部</em> 发生在 k=4(用虚线标注)。图表显示模型的最佳簇数是 4。换句话说,模型在 4 个簇时拟合得很好。</p>
<p>KElbowVisualizer 的最重要参数包括:</p>
<ul>
<li>
<p><strong>estimator:</strong> K-Means 模型实例</p>
</li>
<li>
<p><strong>k:</strong> int 或元组。如果是整数,它将计算范围为 (2, k) 内的簇的分数。如果是元组,它将计算给定范围内的簇的分数,例如 (3, 11)。</p>
</li>
</ul>
<h1 id="5-轮廓图">5. 轮廓图</h1>
<h2 id="使用方法-2">使用方法</h2>
<p>轮廓图用于选择 K-Means 聚类中的最佳簇数,同时也可以检测簇的不平衡。与肘部图相比,这种图提供了更准确的结果。</p>
<h2 id="yellowbrick-实现-4">Yellowbrick 实现</h2>
<p>使用传统方法创建肘部图复杂且耗时。相反,我们可以使用 Yellowbrick 的 SilhouetteVisualizer。</p>
<p>要在 Yellowbrick 中创建轮廓图,我们将使用 <em>iris</em> 数据集构建一个 K-Means 聚类模型(见文末的 <a href="https://towardsdatascience.com/10-amazing-machine-learning-visualizations-you-should-know-in-2023-528282940582#2bc7" target="_blank">Citation</a>)。</p>
<p>以下代码块解释了我们如何利用 Yellowbrick 的 SilhouetteVisualizer 使用 <em>iris</em> 数据集和不同的 k(簇数)值创建轮廓图。</p>
<p><strong>k=2</strong></p>
<p>作者提供的代码</p>
<p><img src="https://kdn.flygon.net/docs/img/f703ccc9d7dcd76127416d55263c8354.png" alt="2023 年你应该知道的 10 个令人惊叹的机器学习可视化" loading="lazy"></p>
<p>具有 2 个簇的轮廓图(k=2)|作者提供的图片</p>
<p>通过改变 KMeans() 类中的簇数,我们可以在不同的时间执行上述代码,以创建当 k=3、k=4 和 k=5 时的轮廓图。</p>
<p><strong>k=3</strong></p>
<p><img src="https://kdn.flygon.net/docs/img/8903414955555e93c6cee0a303ae8a93.png" alt="2023 年你应该知道的 10 种惊人的机器学习可视化" loading="lazy"></p>
<p>|具有 3 个聚类(k=3)的轮廓图|作者提供的图像</p>
<p><strong>k=4</strong></p>
<p><img src="https://kdn.flygon.net/docs/img/dda9337e16726fee4d16d7da155015ce.png" alt="2023 年你应该知道的 10 种惊人的机器学习可视化" loading="lazy"></p>
<p>具有 4 个聚类(k=4)的轮廓图|作者提供的图像</p>
<p><strong>k=5</strong></p>
<p><img src="https://kdn.flygon.net/docs/img/31a7712a95ab447641da039dfce5e61d.png" alt="2023 年你应该知道的 10 种惊人的机器学习可视化" loading="lazy"></p>
<p>具有 4 个聚类(k=5)的轮廓图|作者提供的图像</p>
<p>轮廓图包含每个聚类一个刀形。每个刀形由表示聚类中所有数据点的条形创建。因此,刀形的宽度表示聚类中所有实例的数量。条形的长度表示每个实例的轮廓系数。虚线表示轮廓评分 — 来源:<a href="https://medium.com/mlearning-ai/k-means-clustering-with-scikit-learn-e2af706450e4" target="_blank"><em>实践 K-Means 聚类</em></a>(由我撰写)。</p>
<p>刀形宽度大致相等的图告诉我们聚类是平衡的,并且每个聚类中的实例数量大致相同 — 这是 K-Means 聚类中最重要的假设之一。</p>
<p>当刀形图中的条形延伸到虚线时,聚类被良好分隔 — 这是 K-Means 聚类中的另一个重要假设。</p>
<p>当 k=3 时,聚类平衡且良好分隔。因此,在我们的示例中,最佳的聚类数量是 3。</p>
<p>SilhouetteVisualizer 的最重要参数包括:</p>
<ul>
<li>
<p><strong>估计器:</strong>K-Means 模型实例</p>
</li>
<li>
<p><strong>颜色:</strong> 字符串,用于每个刀形的颜色集合。‘yellowbrick’或 Matplotlib 的颜色映射字符串之一,如‘Accent’,‘Set1’,等。</p>
</li>
</ul>
<h1 id="6-类别不平衡图">6. 类别不平衡图</h1>
<h2 id="用法-1">用法</h2>
<p>类别不平衡图检测分类数据集中目标列中的类别不平衡。</p>
<p>类别不平衡发生在一个类别的实例数量显著多于另一个类别时。例如,涉及垃圾邮件检测的数据集中,“非垃圾邮件”类别有 9900 个实例,而“垃圾邮件”类别只有 100 个实例。模型将无法捕捉到少数类别(<em>垃圾邮件</em>类别)。因此,当发生类别不平衡时,模型在预测少数类别时将不准确 — 来源:<a href="https://rukshanpramoditha.medium.com/top-20-machine-learning-and-deep-learning-mistakes-that-secretly-happen-behind-the-scenes-e211e056c867" target="_blank"><em>揭示机器学习和深度学习中的 20 个常见错误</em></a>(由我撰写)。</p>
<h2 id="yellowbrick-实现-5">Yellowbrick 实现</h2>
<p>使用传统方法创建类别不平衡图复杂且耗时。相反,我们可以使用 Yellowbrick 的 ClassBalance 可视化工具。</p>
<p>要在 Yellowbrick 中绘制类别不平衡图,我们将使用<em>breast_cancer</em>数据集(分类数据集,详见<a href="https://towardsdatascience.com/10-amazing-machine-learning-visualizations-you-should-know-in-2023-528282940582#6fde" target="_blank">Citation</a>)。</p>
<p>以下代码解释了我们如何利用 Yellowbrick 的 ClassBalance 可视化工具使用<em>breast_cancer</em>数据集创建类别不平衡图。</p>
<p>代码由作者提供</p>
<p><img src="https://kdn.flygon.net/docs/img/bef8df00aabfd074c350c6f16747c0a6.png" alt="2023 年你应该了解的 10 个惊人机器学习可视化" loading="lazy"></p>
<p>类别不平衡图|作者提供的图像</p>
<p>在<em>恶性</em>类别中有超过 200 个实例,在<em>良性</em>类别中有超过 350 个实例。因此,尽管这些实例在两个类别之间分布不均,但我们在这里看不到明显的类别不平衡。</p>
<p>ClassBalance 可视化工具的最重要参数包括:</p>
<ul>
<li><strong>labels:</strong> 列表,目标列中唯一类别的名称。</li>
</ul>
<h1 id="7-残差图">7. 残差图</h1>
<h2 id="用法-2">用法</h2>
<p>线性回归中的残差图用于通过分析回归模型中误差的方差来确定残差(观察值-预测值)是否不相关(独立)。</p>
<p>残差图是通过绘制残差与预测值的关系来创建的。如果预测值与残差之间存在任何模式,表明拟合的回归模型不完美。如果点在 x 轴周围随机分布,说明回归模型与数据拟合良好。</p>
<h2 id="yellowbrick-实现-6">Yellowbrick 实现</h2>
<p>使用传统方法创建残差图复杂且耗时。相反,我们可以使用 Yellowbrick 的 ResidualsPlot 可视化工具。</p>
<p>要在 Yellowbrick 中绘制残差图,我们将使用<em>Advertising</em>(<a href="https://drive.google.com/file/d/1-1MgAOHbTI5DreeXObN6KLcSka6LS9G-/view?usp=share_link" target="_blank">Advertising.csv</a>,详见<a href="https://towardsdatascience.com/10-amazing-machine-learning-visualizations-you-should-know-in-2023-528282940582#8bd8" target="_blank">Citation</a>)数据集。</p>
<p>以下代码解释了我们如何利用 Yellowbrick 的 ResidualsPlot 可视化工具使用<em>Advertising</em>数据集创建残差图。</p>
<p>代码由作者提供</p>
<p><img src="https://kdn.flygon.net/docs/img/43a4c0ed19f3dfa9bb5268674da76344.png" alt="2023 年你应该了解的 10 个惊人机器学习可视化" loading="lazy"></p>
<p>残差图|作者提供的图像</p>
<p>我们可以清楚地看到残差图中预测值与残差之间存在某种非线性模式。拟合的回归模型不完美,但足够好。</p>
<p>ResidualsPlot 可视化工具的最重要参数包括:</p>
<ul>
<li>
<p><strong>estimator:</strong> 这可以是任何 Scikit-learn 回归器。</p>
</li>
<li>
<p><strong>hist:</strong> 布尔值,默认为<code>True</code>。是否绘制残差的直方图,用于检查另一个假设——残差大致呈正态分布,均值为 0,标准差固定。</p>
</li>
</ul>
<h1 id="8-预测误差图">8. 预测误差图</h1>
<h2 id="用法-3">用法</h2>
<p>预测误差图在回归分析中是一种图形方法,用于评估回归模型。</p>
<p>预测误差图是通过将预测值与实际目标值进行比较来创建的。</p>
<p>如果模型的预测非常准确,点应该落在 45 度线上的。如果不准确,点则会分散在这条线周围。</p>
<h2 id="yellowbrick-实现-7">Yellowbrick 实现</h2>
<p>使用传统方法创建预测误差图既复杂又耗时。相反,我们可以使用 Yellowbrick 的 PredictionError 可视化工具。</p>
<p>要在 Yellowbrick 中绘制预测误差图,我们将使用<em>Advertising</em>(<a href="https://drive.google.com/file/d/1-1MgAOHbTI5DreeXObN6KLcSka6LS9G-/view?usp=share_link" target="_blank">Advertising.csv</a>,详见末尾的<a href="https://towardsdatascience.com/10-amazing-machine-learning-visualizations-you-should-know-in-2023-528282940582#8bd8" target="_blank">Citation</a>)数据集。</p>
<p>以下代码解释了如何利用 Yellowbrick 的 PredictionError 可视化工具来创建一个使用<em>Advertising</em>数据集的残差图。</p>
<p>作者代码</p>
<p><img src="https://kdn.flygon.net/docs/img/975ad64ede24ec65172ffdc5e307d90c.png" alt="2023 年你应该知道的 10 个令人惊叹的机器学习可视化" loading="lazy"></p>
<p>预测误差图|作者图像</p>
<p>点并没有完全落在 45 度线上的,但模型足够好。</p>
<p>PredictionError 可视化工具的最重要参数包括:</p>
<ul>
<li>
<p>**estimator: ** 这可以是任何 Scikit-learn 回归器。</p>
</li>
<li>
<p>**identity: ** 布尔值,默认<code>True</code>。是否绘制 45 度线。</p>
</li>
</ul>
<h1 id="9-库克距离图">9. 库克距离图</h1>
<h2 id="使用方法-3">使用方法</h2>
<p>库克距离衡量了实例对线性回归的影响。具有大影响的实例被视为异常值。具有大量异常值的数据集在没有预处理的情况下不适合进行线性回归。简而言之,库克距离图用于检测数据集中的异常值。</p>
<h2 id="yellowbrick-实现-8">Yellowbrick 实现</h2>
<p>使用传统方法创建库克距离图既复杂又耗时。相反,我们可以使用 Yellowbrick 的 CooksDistance 可视化工具。</p>
<p>要在 Yellowbrick 中绘制库克距离图,我们将使用<em>Advertising</em>(<a href="https://drive.google.com/file/d/1-1MgAOHbTI5DreeXObN6KLcSka6LS9G-/view?usp=share_link" target="_blank">Advertising.csv</a>,详见末尾的<a href="https://towardsdatascience.com/10-amazing-machine-learning-visualizations-you-should-know-in-2023-528282940582#8bd8" target="_blank">Citation</a>)数据集。</p>
<p>以下代码解释了如何利用 Yellowbrick 的 CooksDistance 可视化工具来创建一个使用<em>Advertising</em>数据集的库克距离图。</p>
<p>作者代码</p>
<p><img src="https://kdn.flygon.net/docs/img/61959f47735e7883841325fbb5347350.png" alt="2023 年你应该知道的 10 个令人惊叹的机器学习可视化" loading="lazy"></p>
<p>库克距离图|作者图像</p>
<p>有一些观察点延伸出了阈值(水平红色)线。这些是异常值。因此,我们应该在构建回归模型之前对数据进行准备。</p>
<p>CooksDistance 可视化工具的最重要参数包括:</p>
<ul>
<li>**draw_threshold: ** 布尔值,默认<code>True</code>。是否绘制阈值线。</li>
</ul>
<h1 id="10-特征重要性图">10. 特征重要性图</h1>
<h2 id="使用方法-4">使用方法</h2>
<p>特征重要性图用于选择产生 ML 模型所需的最小重要特征。由于并非所有特征对模型的贡献相同,我们可以从模型中删除不重要的特征。这将减少模型的复杂性。简单的模型容易训练和解释。</p>
<p>特征重要性图可视化每个特征的相对重要性。</p>
<h2 id="yellowbrick-实现-9">Yellowbrick 实现</h2>
<p>使用传统方法创建特征重要性图复杂且耗时。相反,我们可以使用 Yellowbrick 的 FeatureImportances 可视化工具。</p>
<p>要在 Yellowbrick 中绘制特征重要性图,我们将使用<em>breast_cancer</em>数据集(见<a href="https://towardsdatascience.com/10-amazing-machine-learning-visualizations-you-should-know-in-2023-528282940582#6fde" target="_blank">Citation</a>),该数据集包含 30 个特征。</p>
<p>以下代码解释了如何利用 Yellowbrick 的 FeatureImportances 可视化工具使用 <em>breast_cancer</em> 数据集创建特征重要性图。</p>
<p>作者提供的代码</p>
<p><img src="https://kdn.flygon.net/docs/img/c9298cfb81fbeec3ff251f21569db3b8.png" alt="2023 年你应该知道的 10 种惊人的机器学习可视化" loading="lazy"></p>
<p>特征重要性图 | 作者提供的图片</p>
<p>数据集中的所有 30 个特征对模型的贡献并不相同。我们可以从数据集中删除条形较小的特征,并使用选定的特征重新拟合模型。</p>
<p>特征重要性可视化工具的最重要参数包括:</p>
<ul>
<li>
<p><strong>estimator:</strong> 任何支持 <code>feature_importances_</code> 属性或 <code>coef_</code> 属性的 Scikit-learn 估算器。</p>
</li>
<li>
<p><strong>relative:</strong> bool,默认为 <code>True</code>。是否将相对重要性绘制为百分比。如果为 <code>False</code>,则显示特征重要性的原始数值分数。</p>
</li>
<li>
<p><strong>absolute:</strong> bool,默认为 <code>False</code>。是否仅考虑系数的大小,忽略负号。</p>
</li>
</ul>
<h1 id="ml-可视化工具的用途总结">ML 可视化工具的用途总结</h1>
<ol>
<li>
<p><strong>主成分图:</strong> <em>PCA()</em>,用法 — 将高维数据可视化为 2D 或 3D 散点图,可用于识别高维数据中的重要模式。</p>
</li>
<li>
<p><strong>验证曲线:</strong> <em>ValidationCurve()</em>,用法 — 绘制 <em>单一</em> 超参数对训练集和验证集的影响。</p>
</li>
<li>
<p><strong>学习曲线:</strong> <em>LearningCurve()</em>,用法 — 检测模型的 <em>欠拟合</em>、<em>过拟合</em> 和 <em>适中</em> 条件,识别 <em>收敛缓慢</em>、<em>震荡</em>、<em>震荡并发散</em> 和 <em>适当收敛</em> 情景,显示我们的模型从增加更多训练数据中获益多少。</p>
</li>
<li>
<p><strong>肘部图:</strong> <em>KElbowVisualizer()</em>,用法 — 选择 K-Means 聚类中的最佳簇数。</p>
</li>
<li>
<p><strong>轮廓图:</strong> <em>SilhouetteVisualizer()</em>,用法 — 选择 K-Means 聚类中的最佳簇数,检测 K-Means 聚类中的簇不平衡。</p>
</li>
<li>
<p><strong>类别不平衡图:</strong> <em>ClassBalance()</em>,用法 — 检测分类数据集中目标列的类别不平衡。</p>
</li>
<li>
<p><strong>Residuals Plot:</strong> <em>ResidualsPlot()</em>, 用法 — 通过分析回归模型中误差的方差,确定残差(观察值-预测值)是否不相关(独立)。</p>
</li>
<li>
<p><strong>Prediction Error Plot:</strong> <em>PredictionError()</em>, 用法 — 用于评估回归模型的图形方法。</p>
</li>
<li>
<p><strong>Cook's Distance Plot:</strong> <em>CooksDistance()</em>, 用法 — 基于实例的 Cook 距离检测数据集中的异常值。</p>
</li>
<li>
<p><strong>Feature Importances Plot:</strong> <em>FeatureImportances()</em>, 用法 — 根据每个特征的相对重要性选择所需的最少重要特征,以生成一个机器学习模型。</p>
</li>
</ol>
<p>这就是今天帖子的结束。</p>
<blockquote>
<p>如果你有任何问题或反馈,请告诉我。</p>
</blockquote>
<h2 id="乳腺癌数据集信息">乳腺癌数据集信息</h2>
<ul>
<li>
<p>**Citation: **Dua, D. 和 Graff, C.(2019)。UCI Machine Learning Repository [<a href="http://archive.ics.uci.edu/ml" target="_blank">http://archive.ics.uci.edu/ml</a>]。加州欧文:加州大学信息与计算机科学学院。</p>
</li>
<li>
<p>**Source: **<a href="https://archive.ics.uci.edu/ml/datasets/breast+cancer+wisconsin+(diagnostic)" target="_blank"><code>archive.ics.uci.edu/ml/datasets/breast+cancer+wisconsin+(diagnostic)</code></a></p>
</li>
<li>
<p>**License: **<em>威廉·H·沃尔伯格博士</em>(普通外科系)。</p>
<p>威斯康星大学的<em>W. Nick Street</em>(计算机科学系)。</p>
<p>威斯康星大学的<em>Olvi L. Mangasarian</em>(计算机科学系,威斯康星大学)拥有此数据集的版权。Nick Street 在<em>Creative Commons Attribution 4.0 International License</em>(<a href="https://creativecommons.org/licenses/by/4.0/" target="_blank"><strong>CC BY 4.0</strong></a>)下将此数据集捐赠给公众。你可以在<a href="https://rukshanpramoditha.medium.com/dataset-and-software-license-types-you-need-to-consider-d20965ca43dc#6ade" target="_blank">这里</a>了解更多关于不同数据集许可证类型的信息。</p>
</li>
</ul>
<h2 id="鸢尾花数据集信息">鸢尾花数据集信息</h2>
<ul>
<li>
<p>**Citation: **Dua, D. 和 Graff, C.(2019)。UCI Machine Learning Repository [<a href="http://archive.ics.uci.edu/ml" target="_blank">http://archive.ics.uci.edu/ml</a>]。加州欧文:加州大学信息与计算机科学学院。</p>
</li>
<li>
<p>**Source: **<a href="https://archive.ics.uci.edu/ml/datasets/iris" target="_blank"><code>archive.ics.uci.edu/ml/datasets/iris</code></a></p>
</li>
<li>
<p>**License: <em><em><em>R.A.费舍尔</em>拥有此数据集的版权。Michael Marshall 在</em>Creative Commons Public Domain Dedication License</em>(<a href="https://creativecommons.org/share-your-work/public-domain/cc0" target="_blank"><strong>CC0</strong></a>)下将此数据集捐赠给公众。你可以在<a href="https://rukshanpramoditha.medium.com/dataset-and-software-license-types-you-need-to-consider-d20965ca43dc#6ade" target="_blank">这里</a>了解更多关于不同数据集许可证类型的信息。</p>
</li>
</ul>
<h2 id="广告数据集信息">广告数据集信息</h2>
<ul>
<li>
<p><strong>Source:</strong> <a href="https://www.kaggle.com/datasets/sazid28/advertising.csv" target="_blank"><code>www.kaggle.com/datasets/sazid28/advertising.csv</code></a></p>
</li>
<li>
<p>**License: **此数据集在<em>Creative Commons Public Domain Dedication License</em>(<a href="https://creativecommons.org/share-your-work/public-domain/cc0" target="_blank"><strong>CC0</strong></a>)下公开提供。你可以在<a href="https://rukshanpramoditha.medium.com/dataset-and-software-license-types-you-need-to-consider-d20965ca43dc#6ade" target="_blank">这里</a>了解更多关于不同数据集许可证类型的信息。</p>
</li>
</ul>
<h2 id="参考资料">参考资料</h2>
<ul>
<li>
<p><a href="https://www.scikit-yb.org/en/latest/" target="_blank"><code>www.scikit-yb.org/en/latest/</code></a></p>
</li>
<li>
<p><a href="https://www.scikit-yb.org/en/latest/quickstart.html" target="_blank"><code>www.scikit-yb.org/en/latest/quickstart.html</code></a></p>
</li>
<li>
<p><a href="https://www.scikit-yb.org/en/latest/api/index.html" target="_blank"><code>www.scikit-yb.org/en/latest/api/index.html</code></a></p>
</li>
</ul>
<p><strong><a href="https://www.linkedin.com/in/rukshan-manorathna-700a3916b/" target="_blank">Rukshan Pramoditha</a></strong> (<a href="https://rukshanpramoditha.medium.com/" target="_blank">@rukshanpramoditha</a>) 拥有工业统计学的学士学位。自 2020 年以来支持数据科学教育。Medium 上排名前 50 的数据科学/人工智能/机器学习作家。他撰写过关于数据科学、机器学习、深度学习、神经网络、Python 和数据分析的文章。他有将复杂话题转化为有价值且易于理解内容的卓越记录。</p>
<p><a href="https://towardsdatascience.com/10-amazing-machine-learning-visualizations-you-should-know-in-2023-528282940582" target="_blank">原文</a>。经许可转载。</p>
<h3 id="更多相关主题-6">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/12/make-amazing-visualizations-python-graph-gallery.html" target="_blank">使用 Python 图形库制作惊人的可视化</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/5-amazing-free-llms-playgrounds-you-need-to-try-in-2023" target="_blank">2023 年你需要尝试的 5 个惊人且免费的 LLMs 游乐场</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/03/5-machine-learning-skills-every-machine-learning-engineer-know-2023.html" target="_blank">每个机器学习工程师应掌握的 5 项机器学习技能…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n15.html" target="_blank">KDnuggets 新闻,4 月 13 日:数据科学家应了解的 Python 库…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/best-automl-frameworks-2023.html" target="_blank">2023 年你应考虑的顶级 AutoML 框架</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/04/top-19-skills-need-know-2023-data-scientist.html" target="_blank">2023 年成为数据科学家所需掌握的 19 项技能</a></p>
</li>
</ul>
<h1 id="10-个基础统计概念简明易懂">10 个基础统计概念简明易懂</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/10-basic-statistical-concepts-in-plain-english" target="_blank"><code>www.kdnuggets.com/10-basic-statistical-concepts-in-plain-english</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/c8548e744fe68e3e5fe24148dbc3556e.png" alt="10 个基础统计概念简明易懂" loading="lazy"></p>
<p>图片来源:作者</p>
<p>统计学在数据科学、商业、社会科学等众多领域中发挥着关键作用。然而,许多基础统计概念对于没有强数学背景的初学者来说可能显得复杂和令人生畏。本文将用简单、非技术性的术语介绍 10 个基础统计概念,旨在以易于理解的方式传达这些概念。</p>
<hr>
<h2 id="我们的前三个课程推荐-8">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速通道进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升您的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持您的组织的 IT 需求</p>
<hr>
<h1 id="1-概率分布">1. 概率分布</h1>
<p>概率分布显示了在一个过程中不同结果发生的可能性。例如,假设我们有一个袋子,里面有相等数量的红色、蓝色和绿色玻璃珠。如果我们随机抽取玻璃珠,概率分布会告诉我们抽到每种颜色的几率。它会显示出得到红色、蓝色或绿色的机会都是相等的 1/3,即 33%的概率。许多现实世界的数据往往可以使用已知的概率分布进行建模,尽管这并非总是如此。</p>
<h1 id="2-假设检验">2. 假设检验</h1>
<p>假设检验允许我们基于数据做出声明,类似于法庭审判旨在根据现有证据证明罪或无罪。我们从一个假设或声明开始,称为原假设。然后我们检查观察到的数据是否支持或反驳这个声明,并在一定的置信水平内进行判断。例如,一家制药公司可能声称他们的新药比现有药物更快缓解疼痛。研究人员可以通过分析临床试验结果来测试这一声明。根据数据,他们可以在证据不足的情况下拒绝这一声明,或者无法拒绝原假设,表明没有足够的证据证明新药不会更快缓解疼痛。</p>
<h1 id="3-置信区间">3. 置信区间</h1>
<ul>
<li>当从总体中抽取数据时,置信区间提供了一个值的范围,在这个范围内我们可以合理地确定总体的真实均值所在。例如,如果我们说一个国家的男性平均身高是 172 厘米,95%的置信区间为 170 厘米到 174 厘米,那么我们有 95%的信心认为所有男性的平均身高在 170 厘米到 174 厘米之间。通常,置信区间随着样本量的增大而变小,假设其他因素如变异性保持不变。</li>
</ul>
<h1 id="4-回归分析">4. 回归分析</h1>
<ul>
<li>回归分析帮助我们理解一个变量的变化如何影响另一个变量。例如,我们可以分析数据来查看广告支出如何影响销售。回归方程量化了这种关系,使我们能够基于预计的广告支出来预测未来的销售情况。在两个变量之外,多重回归包括多个解释变量,以隔离它们对结果变量的个别影响。</li>
</ul>
<h1 id="5-方差分析anova">5. 方差分析(ANOVA)</h1>
<ul>
<li>方差分析(ANOVA)让我们比较多个组的均值,以查看它们是否存在显著差异。例如,零售商可能会测试三种包装设计的客户满意度。通过分析调查评分,ANOVA 可以确认三组之间的满意度是否有所不同。如果存在差异,说明并非所有设计都能带来相同的满意度。这一洞察有助于选择最佳包装。</li>
</ul>
<h1 id="6-p-值">6. P 值</h1>
<ul>
<li>P 值指示在假设零假设为真的情况下,获得至少与观察数据一样极端结果的概率。较小的 P 值提供了强有力的证据来反对零假设,因此你可以考虑拒绝零假设,支持备择假设。回到临床试验的例子,当比较新药与标准药物的止痛效果时,较小的 P 值表明新药确实有更快的作用。</li>
</ul>
<h1 id="7-贝叶斯统计">7. 贝叶斯统计</h1>
<ul>
<li>频率统计仅依赖数据,而贝叶斯统计则结合了现有信念和新的证据。随着我们获取更多数据,我们更新我们的信念。例如,假设根据预测今天降雨的概率是 50%。如果我们随后发现天空中有乌云,贝叶斯定理告诉我们如何基于新的证据将这一概率更新为 70%。贝叶斯方法计算上可能较为复杂,但在数据科学的某些方面颇受欢迎。</li>
</ul>
<h1 id="8-标准差">8. 标准差</h1>
<ul>
<li>标准差量化了数据与均值的离散程度。低标准差意味着数据点集中在均值附近,而高标准差表示更大的变异。例如,85、88、89、90 的测试分数的标准差低于 60、75、90、100 的分数。标准差在统计学中非常有用,并且是许多分析的基础。</li>
</ul>
<h1 id="9-相关系数">9. 相关系数</h1>
<p>相关系数测量两个变量线性关系的强度,从 -1 到 +1。接近 +/-1 的值表示强相关,而接近 0 的值则表示弱相关。例如,我们可以计算房屋面积和价格之间的相关性。强正相关意味着较大的房屋往往有更高的价格。需要注意的是,尽管相关性衡量了关系,但它并不意味着一个变量导致另一个变量的发生。大家一起:<em>相关性不意味着因果关系!</em></p>
<h1 id="10-中心极限定理">10. 中心极限定理</h1>
<p>中心极限定理在样本量大时更为准确,它表明当我们从一个总体中抽取样本并计算样本均值时,这些均值遵循正态分布模式,无论原始分布如何。例如,如果我们对一组人的电影偏好进行调查,绘制每组的平均值并重复这一过程,这些平均值会形成一个钟形曲线,即使个体意见各异。</p>
<p>理解统计概念提供了一个分析的视角,通过这个视角我们可以开始解读数据,从而做出明智的、基于证据的决策。不论是在数据科学、商业、学校还是我们的日常生活中,统计学都是一套强大的工具,可以为我们提供关于世界如何运作的看似无尽的洞察。我希望这篇文章能够为你提供这些概念的直观而全面的介绍。</p>
<p><a href="https://www.linkedin.com/in/mattmayo13/" target="_blank"></a><strong><strong><a href="https://www.kdnuggets.com/wp-content/uploads/./profile-pic.jpg" target="_blank">马修·梅奥</a></strong></strong> (<a href="https://twitter.com/mattmayo13" target="_blank"><strong>@mattmayo13</strong></a>) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为<a href="https://www.kdnuggets.com/" target="_blank">KDnuggets</a>和<a href="https://www.statology.org/" target="_blank">Statology</a>的主编,以及<a href="https://machinelearningmastery.com/" target="_blank">Machine Learning Mastery</a>的贡献编辑,马修旨在让复杂的数据科学概念变得易于理解。他的职业兴趣包括自然语言处理、语言模型、机器学习算法以及探索新兴人工智能。他的使命是让数据科学社区的知识普及化。马修从 6 岁开始编程。</p>
<h3 id="更多相关话题-8">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2020/06/8-basic-statistics-concepts.html" target="_blank">数据科学的 8 个基础统计概念</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/back-to-basics-week-2-database-sql-data-management-and-statistical-concepts" target="_blank">基础知识回顾第 2 周:数据库、SQL、数据管理及其他</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2020/05/5-concepts-gradient-descent-cost-function.html" target="_blank">你应该了解的 5 个梯度下降和成本函数概念</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/01/concepts-know-getting-transformer.html" target="_blank">你在了解 Transformers 之前应该知道的概念</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/02/not-so-sexy-sql-concepts-stand-out.html" target="_blank">那些不那么性感但能让你脱颖而出的 SQL 概念</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/11/7-sql-concepts-needed-data-science.html" target="_blank">数据科学中你应该知道的 7 个 SQL 概念</a></p>
</li>
</ul>
<h1 id="2020-年最佳机器学习课程">2020 年最佳机器学习课程</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2020/10/10-best-machine-learning-courses-2020.html" target="_blank"><code>www.kdnuggets.com/2020/10/10-best-machine-learning-courses-2020.html</code></a></p>
</blockquote>
<p>评论</p>
<p><strong>由 <a href="https://medium.com/@ahmadbinshafiq" target="_blank">Ahmad Bin Shafiq</a>,机器学习学生</strong>。</p>
<p><img src="https://kdn.flygon.net/docs/img/b7eb044cac8a7afa4e1ae358ab893c0f.png" alt="" loading="lazy"></p>
<p><em>照片由 <a href="https://unsplash.com/@photoshobby?utm_source=medium&utm_medium=referral" target="_blank">Photos Hobby</a> 提供,来自 <a href="https://unsplash.com/?utm_source=medium&utm_medium=referral" target="_blank">Unsplash</a>。</em></p>
<h3 id="实用动手课程理论较少">实用/动手课程,理论较少</h3>
<p><strong>1) <a href="https://course.fast.ai/" target="_blank">面向编码者的实用深度学习 FAST.AI</a></strong></p>
<p><img src="https://kdn.flygon.net/docs/img/b3c358295b017037b78fa0afc15eed17.png" alt="" loading="lazy"></p>
<p><strong>价格:</strong> 免费</p>
<p><strong>授课教师:</strong> 这是互联网上最著名和实用的课程之一,由杰里米·霍华德(Jeremy Howard)教授,他是旧金山大学的研究科学家,<a href="https://wamri.ai/" target="_blank">WAMRI</a>主席,还是 platform.ai 的首席科学家。他曾是数据科学平台 <a href="https://www.kaggle.com/" target="_blank">Kaggle</a> 的总统和首席科学家,并连续两年在国际机器学习竞赛中排名第一。</p>
<p><strong>课程成果:</strong> 该课程是深度学习的动手入门,你将直接通过构建最先进的分类器来深入学习深度学习。你将学习许多深度学习的实际方面,而无需了解其底层理论。</p>
<p><strong>2) <a href="https://www.fast.ai/2019/07/08/fastai-nlp/" target="_blank">Fast.ai 的自然语言处理代码优先入门</a></strong></p>
<p><img src="https://kdn.flygon.net/docs/img/10925c74e8baa9ed55511b4b9200595a.png" alt="" loading="lazy"></p>
<p><strong>价格:</strong> 免费</p>
<p><strong>授课教师:</strong> <a href="https://www.youtube.com/channel/UC_pSCYWbMn4JcsxbWOzkgEQ" target="_blank">Rachel Thomas</a> 是美国计算机科学家,旧金山大学应用数据伦理中心的创始主任。她与杰里米·霍华德共同创立了 fast.ai。</p>
<p><strong>课程成果:</strong> 本课程是 NLP 的动手入门,你将首先根据课程名称编码一个实用的 NLP 应用,然后逐渐深入理解其底层理论。</p>
<p>涵盖的应用包括主题建模、分类(识别评论的情感是正面还是负面)、语言建模和翻译。课程讲授传统 NLP 主题(包括正则表达式、SVD、朴素贝叶斯、分词)和近期的神经网络方法(包括 RNN、seq2seq、注意力机制和变换器架构),并且涉及紧迫的伦理问题,如偏见和虚假信息。</p>
<p><strong>3) <a href="https://www.udemy.com/course/python-for-data-science-and-machine-learning-bootcamp/" target="_blank">数据科学与机器学习 Python 训练营</a></strong></p>
<p><img src="https://kdn.flygon.net/docs/img/2966fb3651a6fcfc3f8528bb4d69374c.png" alt="" loading="lazy"></p>
<p><strong>价格:</strong> $129(促销价 $10-$20)</p>
<p><strong>讲师:</strong>Jose Marcial Portilla 拥有圣克拉拉大学的机械工程学士和硕士学位,并在数据科学和编程领域有多年的专业讲师和培训师经验。他在微流体学、材料科学和数据科学技术等领域有出版物和专利。</p>
<p><strong>评分:</strong>4.6*</p>
<p><strong>课程成果:</strong>本课程是对机器学习和数据科学的非常实用的介绍。它不假设任何先前的知识,从教授基础的 Python 到 Numpy Pandas 开始,然后教授使用 Python 的机器学习,通过 scikit-learn 进行学习,接着涉及自然语言处理和 Tensorflow,以及通过 Spark 进行大数据处理。</p>
<p>这绝对是最好的课程之一,因为 Jose 是一位非常优秀的讲师。</p>
<p><strong>4) <a href="https://www.coursera.org/professional-certificates/tensorflow-in-practice" target="_blank">DeepLearning.AI TensorFlow 开发者专业证书</a></strong></p>
<p><img src="https://kdn.flygon.net/docs/img/1602d39fb6951ac97f4d72fc97422c50.png" alt="" loading="lazy"></p>
<p><strong>价格:</strong>$49/月</p>
<p><strong>讲师:</strong><a href="https://www.coursera.org/professional-certificates/tensorflow-in-practice#instructors" target="_blank">Laurence Moroney</a> 是 Google 的开发者倡导者,专注于使用 TensorFlow 进行人工智能工作。他也是许多书籍的作者。</p>
<p><strong>评分:</strong>4.7*</p>
<p><strong>课程成果:</strong>在这个动手实践的四课程专业证书项目中,你将学习使用 TensorFlow 构建可扩展的 AI 驱动应用程序所需的工具。Lawrence 将从 TensorFlow 的基础知识开始教学,逐步进展到使用 TensorFlow 的前沿应用。</p>
<p><strong>5) <a href="https://www.datacamp.com/tracks/data-scientist-with-python" target="_blank">数据营数据科学路径</a></strong></p>
<p><img src="https://kdn.flygon.net/docs/img/e62b53a331ecc41cc4bd3413f68ccc93.png" alt="" loading="lazy"></p>
<p><strong>价格:</strong>$25/月或$300/年</p>
<p><strong>讲师:</strong>多位行业专家</p>
<p><strong>课程成果:</strong>即使没有编程基础,你也会从零开始学习编程,然后逐步掌握高级库和框架。每节课都有一些练习或任务。此外,你还可以访问数据营的项目,这将提升你的编程经验和简历。</p>
<h3 id="理论课程较少实际操作">理论课程较少实际操作</h3>
<p><strong>1) <a href="https://coursera.org/learn/machine-learning/" target="_blank">斯坦福大学的机器学习课程</a></strong></p>
<p><img src="https://kdn.flygon.net/docs/img/a6c5e16fd27ce025ccbddb8694138930.png" alt="" loading="lazy"></p>
<p><strong>价格:</strong>$80</p>
<p><strong>讲师:</strong>Andrew Ng 是 Landing AI 的 CEO/创始人;Coursera 的联合创始人;斯坦福大学的兼职教授;曾任百度首席科学家,并且是 Google Brain 的创始首席。</p>
<p><strong>评分:</strong>4.9</p>
<p><strong>课程成果:</strong>你将学习所有著名机器学习算法的基础理论,从监督学习到无监督学习。你还将有机会在 MATLAB/Octave 中从零开始编写这些算法。</p>
<p><strong>2) <a href="https://www.coursera.org/specializations/deep-learning" target="_blank">深度学习专业化课程</a></strong></p>
<p><img src="https://kdn.flygon.net/docs/img/860cfd24e1b70ccfb9a861dfb88d04c6.png" alt="" loading="lazy"></p>
<p><strong>价格:</strong>$49/月</p>
<p><strong>讲师:</strong>Andrew Ng</p>
<p><strong>评分:</strong>4.8*</p>
<p><strong>课程成果:</strong> 这门五部分的专业课程将教你深度学习的基本理论,从单层网络到多层密集网络,从 CNN 的基础知识到使用 YOLO 进行目标检测的理论,从 RNN 的基础知识到情感分析。</p>
<p>本课程还将介绍诸如 Tensorflow 或 Keras 等深度学习框架的基础知识。</p>
<p><strong>3) <a href="https://www.youtube.com/watch?v=NfnWJUyUJYU&list=PLkt2uSq6rBVctENoVBg1TpCC7OQi31AlC&ab_channel=AndrejKarpathy" target="_blank">CS231n by Andrej Karpathy</a></strong></p>
<p><img src="https://kdn.flygon.net/docs/img/115c8f3355f7608f2c672d3ce7adb847.png" alt="" loading="lazy"></p>
<p><strong>价格:</strong> 免费</p>
<p><strong>授课教师:</strong> <strong>Andrej Karpathy</strong>,特斯拉的 AI 高级总监,领导负责自动驾驶系统中所有神经网络的团队。他曾是 <a href="http://openai.com/" target="_blank">OpenAI</a> 的研究科学家,专注于计算机视觉中的深度学习、生成建模和强化学习。他获得了斯坦福大学的博士学位。</p>
<p><strong>课程成果:</strong> 本课程深入探讨了深度学习架构的细节,重点学习这些任务的端到端模型,特别是图像分类。学生将学习实现、训练和调试自己的神经网络,并深入了解计算机视觉领域的前沿研究。重点是教会如何设置图像识别问题、学习算法(例如反向传播)、训练的实用工程技巧以及网络的微调。</p>
<p><strong>4) <a href="https://www.youtube.com/watch?v=OgK8JFjkSto&list=PLTKMiZHVd_2KyGirGEvKlniaWeLOHhUF3&ab_channel=SebastianRaschka" target="_blank">Stat 451: Introduction to Machine Learning</a></strong></p>
<p><img src="https://kdn.flygon.net/docs/img/ac6c72fdf7511855f44999a6402d1161.png" alt="" loading="lazy"></p>
<p><strong>价格:</strong> 免费</p>
<p><strong>授课教师:</strong> <a href="https://www.youtube.com/channel/UC_CzsS7UTjcxJ-xXp1ftxtA" target="_blank">Sebastian Raschka</a> 是威斯康星大学麦迪逊分校的统计学助理教授,专注于机器学习和深度学习研究。</p>
<p><strong>课程成果:</strong> 你将学习所有著名机器学习算法的基本理论,从神经网络到监督学习和无监督学习。</p>
<p>本课程最初由 Sebastian 博士在威斯康星大学麦迪逊分校授课。</p>
<p><strong>5) <a href="http://introtodeeplearning.com/" target="_blank">MIT Introduction to Deep Learning | 6.S191</a></strong></p>
<p><img src="https://kdn.flygon.net/docs/img/d2e8d36c669a590bb578e55b1f4f8141.png" alt="" loading="lazy"></p>
<p><strong>价格:</strong> 免费</p>
<p><strong>授课教师:</strong> Ava Soleimany 是哈佛大学生物物理学博士生,同时在麻省理工学院工作,与 Sangeeta Bhatia 一起在 Koch Integrative Cancer Research Institute 工作,并获得 NSF 研究生奖学金的资助。</p>
<p>Alexander Amini 是麻省理工学院的博士生,隶属于 <a href="http://www.csail.mit.edu/" target="_blank">计算机科学与人工智能实验室(CSAIL)</a>,与 <a href="http://danielarus.csail.mit.edu/" target="_blank">Prof. Daniela Rus</a> 一起工作。他是 NSF 奖学金获得者,并在麻省理工学院完成了电气工程与计算机科学的学士和硕士学位,辅修数学。</p>
<p><strong>课程成果:</strong>6.S191 是 MIT 官方的深度学习方法入门课程,应用于计算机视觉、自然语言处理、生物学等领域!学生将获得深度学习算法的基础知识。</p>
<p>学生还将获得在 TensorFlow 中构建神经网络的实践经验。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2020/09/online-courses-better-data-scientist.html" target="_blank">成为更优秀数据科学家必须参加的在线课程</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2020/09/online-certificates-ai-data-science-machine-learning-top.html" target="_blank">顶尖大学的人工智能、数据科学、机器学习在线证书/课程</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2020/09/machine-learning-from-scratch-free-online-textbook.html" target="_blank">从零开始的机器学习:免费在线教材</a></p>
</li>
</ul>
<hr>
<h2 id="我们的前三大课程推荐-6">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业轨道。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持组织的 IT</p>
<hr>
<h3 id="了解更多主题-1">了解更多主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/mozart-best-etl-tools-2021.html" target="_blank">2021 年最佳 ETL 工具</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-key-skills-needed-become-great-data-scientist.html" target="_blank">成为优秀数据科学家所需的 5 项关键技能</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/6-predictive-models-every-beginner-data-scientist-master.html" target="_blank">每个初学者数据科学家应掌握的 6 种预测模型</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/stop-learning-data-science-find-purpose.html" target="_blank">停止学习数据科学以寻找目的,并寻找目的以…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/springboard-top-resources-learn-data-science-statistics.html" target="_blank">数据科学统计学习的最佳资源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-characteristics-successful-data-scientist.html" target="_blank">成功数据科学家的 5 个特征</a></p>
</li>
</ul>
<h1 id="数据科学家必读的-10-本最佳机器学习教科书">数据科学家必读的 10 本最佳机器学习教科书</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2020/04/10-best-machine-learning-textbooks-data-scientists.html" target="_blank"><code>www.kdnuggets.com/2020/04/10-best-machine-learning-textbooks-data-scientists.html</code></a></p>
</blockquote>
<p>评论</p>
<p><strong>作者:<a href="https://lionbridge.ai/articles/" target="_blank">Daniel Smith</a>,Lionbridge</strong></p>
<p><img src="https://kdn.flygon.net/docs/img/425eab5030a55a8078bf984a2d57e299.png" alt="Lionbridge AI ML 书籍" loading="lazy"></p>
<hr>
<h2 id="我们的前三大课程推荐-7">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织的 IT 工作</p>
<hr>
<p>机器学习作为一个首次接触的主题可能令人畏惧。这个术语涵盖了许多领域、研究主题和商业用例,可能很难知道从哪里开始。为了解决这个问题,通常可以转向介绍新研究领域基本原理的教科书。这对于人工智能和机器学习尤为适用,特别是如果你有统计或编程背景时。与我们<em>介绍训练数据</em>的在线文章配合使用,它们可以成为学习和成长的强大工具之一。</p>
<p>在本文中,我们将展示一些该领域最好的教科书。这些教科书在大学课程中被频繁使用,且受到教授和工程师的推荐,为你提供了对人工智能广阔世界的经验证介绍。即使你在机器学习方面有丰富经验,翻阅这些教科书也能让你得到很好的复习。毕竟,总有新的知识值得学习。</p>
<p><strong>深度学习</strong></p>
<p>Ian Goodfellow、Yoshua Bengio 和 Aaron Courville</p>
<p><strong><img src="https://kdn.flygon.net/docs/img/8f026f51d8d2c37d9606aa0eb05b82e2.png" alt="" loading="lazy">ISBN:</strong> 978-0262035613</p>
<p><strong>购买本书:</strong>在 Amazon <a href="https://www.amazon.com/dp/0262035618/" target="_blank">这里</a>,或在<a href="https://www.deeplearningbook.org/" target="_blank">这里</a>免费阅读全文。</p>
<p>在深度学习方面,这本书是最好的入门选择。这本全面的教科书提供了你开始自己工作的所需的一般知识和数学基础。<em>Deep Learning</em>得到了机器学习领域众多知名人士的认可,从 Geoffrey Hinton 到 Yann LeCun,它包含了对研究和工业领域的有用信息。</p>
<p><strong>人工智能:现代方法</strong></p>
<p>Stuart J. Russell 和 Peter Norvig</p>
<p><strong><img src="https://kdn.flygon.net/docs/img/903df30131e172273df3b91bdddc2acf.png" alt="" loading="lazy">ISBN:</strong> 978-9332543515</p>
<p><strong>购买本书:</strong> 在 Amazon 上<a href="https://www.amazon.com/Artificial-Intelligence-Approach-Stuart-Russell/dp/9332543518/" target="_blank">这里</a>。</p>
<p>Russell 和 Norvig 的书是众多大学级人工智能课程的基石。特别适合初学者,<em>人工智能</em>提供了对该领域的全面介绍和几个关键研究主题的概述,逐步讲解了智能体如何做出决策,并深入解释了神经网络。如果你只拥有一本关于人工智能的书,这本就是你需要的。</p>
<p><strong>统计学习要素:数据挖掘、推断与预测</strong></p>
<p>Trevor Hastie, Robert Tibshirani, 和 Jerome Friedman</p>
<p><strong><img src="https://kdn.flygon.net/docs/img/bed4aaae76a03612c5705e0525889d2d.png" alt="" loading="lazy">ISBN:</strong> 978-0387848570</p>
<p><strong>购买本书:</strong> 在 Amazon 上<a href="https://www.amazon.com/dp/0387848576?" target="_blank">这里</a>。</p>
<p>一直以来深受机器学习爱好者的喜爱</p>
<h3 id="发现我们如何改进你的模型">发现我们如何改进你的模型</h3>
<p>e 学习社区,<em>统计学习要素</em>在其概念框架内涵盖了广泛的主题。它既可以作为神经网络、随机森林和测试方法等主题的入门书,也可以作为参考书。然而,这本书也以一种鼓励读者自己探索的风格编写。通过这种方式,它不仅是一本介绍书,还鼓励技能的发展,这对未来的机器学习职业生涯非常有用。最新版本于 2013 年发布。</p>
<p><strong>百页机器学习书</strong></p>
<p>Andriy Burkov</p>
<p><strong><img src="https://kdn.flygon.net/docs/img/b25e2dab58e0fb7ae8ac2ebe18d5bd70.png" alt="" loading="lazy">ISBN:</strong> 978-1999579500</p>
<p><strong>购买本书:</strong> 在 Amazon 上<a href="https://www.amazon.com/Hundred-Page-Machine-Learning-Book/dp/199957950X/" target="_blank">这里</a>,或在书籍网站上阅读各种章节的扩展版本<a href="http://themlbook.com/wiki/doku.php" target="_blank">这里</a>。</p>
<p>这个项目始于对作者的 LinkedIn 挑战,后来发展成了一本机器学习畅销书。正如书名所示,它是目前市面上最简明的领域介绍之一。然而,Burkov 没有回避必要的数学,将理论和实践挤进了极小的平装本中。凭借其广泛的话题覆盖和机器学习领域思想领袖的推荐,这本短小的书应该出现在所有机器学习新手的书架上。</p>
<p><strong>模式识别与机器学习</strong></p>
<p>Christopher M. Bishop</p>
<p><strong><img src="https://kdn.flygon.net/docs/img/c5bda26eacee1c8ae467b7d3e56db555.png" alt="" loading="lazy">ISBN:</strong> 978-0387310732</p>
<p><strong>购买本书:</strong> 在 Amazon 上<a href="https://www.amazon.com/dp/0387310738?" target="_blank">这里</a>。</p>
<p>Bishop 的书自 2006 年首次出版以来一直是重要的大学教材。尽管它假设读者已具备一定的线性代数和多变量微积分知识,但它是希望理解机器学习背后统计技术的任何人的关键参考点。书中还包括一个测试和大量问题,以巩固你所学到的知识。</p>
<p><strong>应用预测建模</strong></p>
<p>Max Kuhn 和 Kjell Johnson</p>
<p><strong><img src="https://kdn.flygon.net/docs/img/f2d0e5abe38a7b82ec883774dd2064e1.png" alt="" loading="lazy">ISBN:</strong> 978-1461468486</p>
<p><strong>购买书籍:</strong> 在亚马逊上<a href="https://www.amazon.com/dp/1461468485?" target="_blank">这里</a>。</p>
<p>Kuhn 和 Johnson 的书对于任何希望了解预测模型和建模过程的学生或开发人员来说都是一个很好的选择。它从头开始覆盖预测建模过程,从数据预处理开始,逐步讲解回归和分类技术。它专注于解决实际问题,使用动手示例,并为每个阶段提供相应的 R 代码。书中每章还包含一系列问题,旨在帮助读者应用所学知识。</p>
<p><strong>机器学习</strong></p>
<p>Tom M. Mitchell</p>
<p><strong><img src="https://kdn.flygon.net/docs/img/950252bba4ac436f751820afb5ec9a6d.png" alt="" loading="lazy">ISBN:</strong> 978-0070428072</p>
<p><strong>购买书籍:</strong> 在亚马逊上<a href="https://www.amazon.com/dp/0070428077?" target="_blank">这里</a>,或阅读可能的第二版草稿<a href="http://www.cs.cmu.edu/~tom/NewChapters.html" target="_blank">这里</a>。</p>
<p><em>机器学习</em>是一本简明的文本,为机器学习基础提供了很好的介绍。从神经网络到贝叶斯学习,Mitchell 以较高的水平解释了各种概念和算法。虽然它不包含太多教程或实现建议,但它应能为你提供一个坚实的基础,以便进行更深入的研究。</p>
<p><strong>Python 机器学习</strong></p>
<p>Sebastian Raschka 和 Vahid Mirjalili</p>
<p><strong><img src="https://kdn.flygon.net/docs/img/37764aaef0df9b94f0362d457c9c82d9.png" alt="" loading="lazy">ISBN:</strong> 978-1783555130</p>
<p><strong>购买书籍:</strong> 在亚马逊上<a href="https://www.amazon.com/Python-Machine-Learning-scikit-learn-TensorFlow/dp/1787125939/" target="_blank">这里</a>。</p>
<p>对于那些希望直接进入编程的人,语言特定的机器学习介绍可能非常有用。<em>Python 机器学习</em>是对这一主题进行更技术性介绍的绝佳选择。该书解释了如何实现一系列流行的机器学习算法,特别关注使用 scikit-learn 进行实现。这是那些希望提高算法开发理解的人的绝佳选择。</p>
<p><strong>动手实践机器学习与 Scikit-Learn 和 TensorFlow:构建智能系统的概念、工具和技术</strong></p>
<p>Aurélien Géron</p>
<p><strong><img src="https://kdn.flygon.net/docs/img/2d0ecc2a222e581a580c0a6179976799.png" alt="" loading="lazy">ISBN:</strong> 978-1491962299</p>
<p><strong>购买书籍:</strong> 在亚马逊上<a href="https://www.amazon.com/Hands-Machine-Learning-Scikit-Learn-TensorFlow/dp/1491962291" target="_blank">这里</a>。</p>
<p>这本实用的书籍专注于教程序员如何使用 scikit-learn 和 TensorFlow 框架来实现机器学习程序。Géron 的解释依靠实例和练习,帮助你学习从线性回归到深度神经网络的一系列技术。虽然理论较少,但如果你的主要目标是快速直观地学习如何构建自己的机器学习算法,这本书是值得寻找的绝佳选择。</p>
<p><strong>Speech and Language Processing</strong></p>
<p>丹尼尔·朱拉夫斯基 和 詹姆斯·H·马丁</p>
<p><strong><img src="https://kdn.flygon.net/docs/img/d5a5f85d6acdce2349887c758c80740e.png" alt="" loading="lazy">ISBN:</strong> 978-0131873216</p>
<p><strong>购买书籍</strong>: 在亚马逊 <a href="https://www.amazon.com/Speech-Language-Processing-Daniel-Jurafsky/dp/0131873210" target="_blank">这里</a>。</p>
<p>对于那些有一点基础知识的人,还有一些很棒的教科书可以提供对特定机器学习领域的全面介绍。如果这是你的目标,我们推荐《<em>Speech and Language Processing</em>》。这本书被多位专家推荐,是任何对自然语言处理感兴趣的人的信息宝库。它涵盖了语言技术的广泛领域,将传统上各不相同的课程中的理念加以统一。重点介绍实际应用,这本书是了解语音和语言处理可能性的绝佳入门书籍。</p>
<p>通过阅读这些教科书的组合,你一定能建立起扎实的机器学习知识基础,并形成一个可以反复查阅的参考资料库。即使你只读了一本,所取得的进展也会激励你继续学习、提升和产生影响。</p>
<p>一旦你准备好并能够创建自己的机器学习算法,千万不要忘记数据对于你项目的成功至关重要。从图像标注到本体创建,Lionbridge 是一个经验丰富的数据提供商,为需要可信数据集的研究人员、工程师和企业提供服务。对于全面的标注和可靠的基础数据,请依赖我们处理你的所有标注需求。</p>
<h3 id="了解我们如何改善你的模型">了解我们如何改善你的模型</h3>
<h3 id="立即联系我们"><a href="https://lionbridge.ai/contact-sales/" target="_blank">立即联系我们</a></h3>
<p><strong>个人简介</strong>: <strong><a href="https://lionbridge.ai/articles/" target="_blank">丹尼尔·史密斯</a></strong> 是 Lionbridge 网站营销团队的一员,撰写各种内容。</p>
<p><a href="https://lionbridge.ai/articles/10-best-machine-learning-textbooks-all-data-scientists-should-read/" target="_blank">原文</a>。经许可转载。</p>
<p><strong>相关内容:</strong></p>
<ul>
<li>
<p>10 篇必读的机器学习文章(2020 年 3 月)</p>
</li>
<li>
<p>24 本最佳(且免费的)理解机器学习的书籍</p>
</li>
<li>
<p>每位数据科学家都应该阅读的 5 篇关于 CNN 的论文</p>
</li>
</ul>
<h3 id="更多相关话题-9">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2023/07/textbooks-all-you-need-revolutionary-approach-ai-training.html" target="_blank">教材是你所需的一切:一种革命性的 AI 培训方法</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/generative-agent-research-papers-you-should-read" target="_blank">你应该阅读的生成代理研究论文</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/04/machine-learning-books-need-read-2022.html" target="_blank">2022 年你需要阅读的机器学习书籍</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n17.html" target="_blank">KDnuggets 新闻,4 月 27 日:论文与代码的简要介绍;…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/03/top-machine-learning-papers-read-2023.html" target="_blank">2023 年值得阅读的顶级机器学习论文</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/5-machine-learning-papers-to-read-in-2024" target="_blank">2024 年值得阅读的 5 篇机器学习论文</a></p>
</li>
</ul>
<h1 id="数据科学家数据分析师的-10-个最佳移动应用">数据科学家/数据分析师的 10 个最佳移动应用</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2018/10/10-best-mobile-apps-data-scientist.html" target="_blank"><code>www.kdnuggets.com/2018/10/10-best-mobile-apps-data-scientist.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/3d9c022da2d331bb56691a9617b91b90.png" alt="c" loading="lazy"> 评论</p>
<p><strong>由 <a href="https://www.linkedin.com/in/premjithbpk" target="_blank">Premjith Purushothaman</a> 提供</strong></p>
<p><img src="https://kdn.flygon.net/docs/img/508ed745d4663485ec304297d8598c0c.png" alt="10 个实用的移动应用图 1" loading="lazy"></p>
<p>数据科学和机器学习正不断发展,改变着你周围的世界。你无需全天候携带笔记本电脑或 PC 就能在工作场所中表现出色。是时候从日常工作中休息一下,采纳更快的学习策略。解决方案很简单,只需切换到移动应用。</p>
<p>你知道你可以在智能手机上运行 Python 吗?</p>
<p>是的!移动应用已经对我们的学习方法产生了巨大影响。那些难以理解的学科,现在可以通过手机或平板中的图片和故事来教授。无论你是在旅行中还是在其他地方,你都可以随时获取它们。</p>
<p>在这个博客中,我们分享了一些可以提升你关键数据科学和分析技能的有价值应用。这些应用可以提升你的听力能力、逻辑技能、基本领导能力等,效果超出我们的预期。</p>
<p>我们将这些移动应用分类整理,我们都了解自己的弱点,因此这个博客将帮助你瞄准关键点。这些 Android 应用在 Google Play 商店中可以免费下载。</p>
<p><img src="https://kdn.flygon.net/docs/img/df54012179d75c3893dfafc35cae5269.png" alt="10 个实用的移动应用图 2" loading="lazy"></p>
<ol>
<li><strong>Elevate(下载量 – 100 万)</strong></li>
</ol>
<p>Elevate 是一个个性化的大脑训练程序,旨在提升你的智力技能。你的大脑训练课程包括每天 3 个练习。活动是根据之前的表现选择的。如果你在某些方面较弱,你可以更频繁地见到这些活动。这个应用有不同的训练程序,但在免费版中并不可用。总体来说,它成功地提供了令人振奋的知识。</p>
<ol>
<li><strong>Lumosity(下载量 – 1000 万)</strong></li>
</ol>
<p>Lumosity 是一个个性化的大脑训练程序,也支持游戏。这些游戏足以挑战你的核心推理能力。这个应用将帮助你提高阅读、写作、数学和逻辑能力。个性化的训练程序非常有趣且上瘾。每天你会得到 3 个大脑训练练习。更多练习也可以通过付费获得。</p>
<ol>
<li><strong>Neuronation(下载量 – 500 万)</strong></li>
</ol>
<p>Neurontin 是一款用于改善大脑活动的健康应用。它可以帮助提高记忆力、智力和逻辑思维。它包含了一系列不同的活动,并设计了大约 60 个程序。它还允许你挑战你的朋友,并每周监控你的表现。如果你真的定期使用这些应用,它可能会改变你的生活。</p>
<ol>
<li><strong>Math Workout(下载量 – 500 万)</strong></li>
</ol>
<p>想要在数字方面表现出色吗?这个应用程序将帮助你做到这一点。这个应用将在生活的不同阶段提供帮助。简而言之,你应该提高你的心理数学技能。训练你的大脑以便能在指尖上进行数值计算。这是一个初级应用。它有趣的活动可以帮助你获得数字直觉。</p>
<ol>
<li><strong>QPython(下载量 – 50 万)</strong></li>
</ol>
<p>QPython 帮助你在手机上运行 Python。它帮助你的安卓设备运行 Python 内容和任务。它与 Python 2.7 兼容最佳,并且是一个高评分的应用。它包括 Python 解释器、编辑器以及 Android 的 SL4A 库。它还包含有用的 Python 库。它还可以从 QR 代码中执行 Python 代码和文件。</p>
<p><img src="https://kdn.flygon.net/docs/img/9819aa21b5b0952cf62d8afc6d3fe2c3.png" alt="10 个实用的移动应用图 3" loading="lazy"></p>
<ol>
<li><strong>Learn Python(下载量 – 1 万)</strong></li>
</ol>
<p>你不再需要你的电脑来学习 Python。这是一个针对安卓手机的 Python 教程。这个教程涵盖了 Python 的基础知识、数据类型、控制结构模块等。为了提高学习体验,这个教程还包括了真假题、混乱谜题和问答。对于对 Python 感兴趣的人来说,这是一个很好的起点。</p>
<ol>
<li><strong>R Programming(下载量 – 1 万)</strong></li>
</ol>
<p>就像 Python 一样,你也可以在你的 Android 设备上学习 R。这个应用程序向你介绍了 R 编程的基础。可以把它看作是 R 的一个简化版本。这个应用最适合初学者。它包含了向量、函数、矩阵、因子、数据框、列表等内容。</p>
<ol>
<li><strong>Basic Statistics(下载量 – 5 万)</strong></li>
</ol>
<p>这个应用程序是为数据科学/分析的新手设计的。将此应用视为在不同统计度量(如图表和频率分布、数据描述、假设检验等)上的一种提升。如果你正在准备考试,这可能是一个完美的指南。</p>
<ol>
<li><strong>Probability Distributions(下载量 – 5 万)</strong></li>
</ol>
<p>在掌握统计学基础之后,这款应用将是下一个最佳选择。这个应用让你可以在你的安卓设备上处理复杂的功能。你应该熟悉像二项分布这样的概率分布。</p>
<ol>
<li><strong>Udacity(下载量 – 100 万)</strong></li>
</ol>
<p>Udacity 应用提供了各种各样的课程。由于它是一个移动应用,你可以在移动设备上进行课程学习。无论是在网站上还是在移动应用上,没有任何区别。应用的界面设计得体且简单易用。</p>
<p>可能很难将所有 10 个应用程序下载到你的安卓设备上。随着<a href="https://mindster.in/mobile-app-development-services" target="_blank">移动应用开发</a>领域的繁荣,每天都有更多的应用程序推出以满足用户需求。为了从这些应用程序中获益,你应该每天尽量挤出一些时间进行培训练习。</p>
<p><strong>个人简介</strong>: <a href="https://www.linkedin.com/in/premjithbpk" target="_blank">Premjith Purushothaman</a> 是一位前移动应用开发者,目前专注于数字营销。他希望与拥有相同兴趣和动机的人一起工作。他总是深入挖掘具有技术洞察力的直观知识。</p>
<p><strong>相关内容:</strong></p>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2018/10/why-call-myself-data-scientist.html" target="_blank">为什么我称自己为数据科学家?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2018/09/how-many-data-scientists-are-there.html" target="_blank">有多少数据科学家?是否存在短缺?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2018/08/what-data-scientists-want.html" target="_blank">数据科学家想要什么?</a></p>
</li>
</ul>
<hr>
<h2 id="我们的前三个课程推荐-9">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析水平</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织 IT 需求</p>
<hr>
<h3 id="更多相关内容-8">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/build-solid-data-team.html" target="_blank">建立一个坚实的数据团队</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/write-clean-python-code-pipes.html" target="_blank">使用管道编写干净的 Python 代码</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/mozart-best-etl-tools-2021.html" target="_blank">2021 年最佳 ETL 工具</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/12/artificial-intelligence-change-mobile-apps.html" target="_blank">人工智能将如何改变移动应用</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-key-skills-needed-become-great-data-scientist.html" target="_blank">成为优秀数据科学家所需的 5 项关键技能</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/6-predictive-models-every-beginner-data-scientist-master.html" target="_blank">每个初学者数据科学家应掌握的 6 个预测模型</a></p>
</li>
</ul>
<h1 id="每个数据工程师都应该知道的-10-个内置-python-模块">每个数据工程师都应该知道的 10 个内置 Python 模块</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/10-built-in-python-modules-every-data-engineer-should-know" target="_blank"><code>www.kdnuggets.com/10-built-in-python-modules-every-data-engineer-should-know</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/6e455bb9f0812cffe77fc8a0247e588f.png" alt="每个数据工程师都应该知道的 10 个内置 Python 模块" loading="lazy"></p>
<p>作者提供的图像</p>
<p>Python 是你作为数据工程师将使用的编程语言之一。作为数据工程师,你应该熟悉许多 <a href="https://www.kdnuggets.com/7-python-libraries-every-data-engineer-should-know" target="_blank">Python 库</a>。但 Python 的标准库中包含了用于各种相关任务的强大模块,从文件操作到数据序列化、文本处理等。</p>
<hr>
<h2 id="我们的前-3-个课程推荐-1">我们的前 3 个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织的 IT</p>
<hr>
<p>本文汇编了一些对数据工程最有帮助的内置 Python 模块,具体包括以下内容:</p>
<ul>
<li>
<p>文件和目录管理</p>
</li>
<li>
<p>数据处理和序列化</p>
</li>
<li>
<p>数据库交互</p>
</li>
<li>
<p>文本处理</p>
</li>
<li>
<p>日期和时间操作</p>
</li>
<li>
<p>系统交互</p>
</li>
</ul>
<p>让我们开始吧。</p>
<p><img src="https://kdn.flygon.net/docs/img/e7ddd9abf64a5e3813f724b2f64dd6e4.png" alt="python-modules-de" loading="lazy"></p>
<p>数据工程的内置 Python 模块 | 作者提供的图像</p>
<h2 id="1-os">1. os</h2>
<p><a href="https://docs.python.org/3/library/os.html" target="_blank">os</a> 模块是你与操作系统交互的首选工具。它使你能够执行各种任务,如文件路径操作、目录管理和处理环境变量。</p>
<p>你可以使用 os 模块的功能执行以下数据工程任务:</p>
<ul>
<li>
<p>自动创建和删除用于临时或输出数据存储的目录</p>
</li>
<li>
<p>在不同目录中组织大型数据集时操作文件路径</p>
</li>
<li>
<p>处理环境变量以管理数据管道中的配置设置</p>
</li>
</ul>
<p><a href="https://www.youtube.com/watch?v=tJxcKyFMTGo" target="_blank">OS 模块 - 使用底层操作系统功能</a>,由 Corey Schafer 制作的教程,涵盖了 os 模块的所有功能。</p>
<h2 id="2-pathlib">2. pathlib</h2>
<p><a href="https://docs.python.org/3/library/pathlib.html" target="_blank">pathlib</a> 模块提供了一种更现代和面向对象的处理文件系统路径的方法。它允许通过直观且可读的语法轻松操作文件和目录路径,使其成为文件管理任务的最爱。</p>
<p>pathlib 模块在以下数据工程任务中非常有用:</p>
<ul>
<li>
<p>精简迭代和验证大型数据集的过程</p>
</li>
<li>
<p>在 ETL(提取、转换、加载)过程中简化移动或复制文件时路径的管理</p>
</li>
<li>
<p>确保跨平台兼容性,特别是在多环境数据工程工作流中</p>
</li>
</ul>
<p>这里有几个教程涵盖了 pathlib 模块的基础知识:</p>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/how-to-navigate-the-filesystem-with-pythons-pathlib" target="_blank">如何使用 Python 的 Pathlib 导航文件系统</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/organize-search-and-back-up-files-with-pythons-pathlib" target="_blank">用 Python 的 Pathlib 组织、搜索和备份文件</a></p>
</li>
</ul>
<h2 id="3-shutil">3. shutil</h2>
<p><a href="https://docs.python.org/3/library/shutil.html" target="_blank">shutil</a> 模块用于常见的高级文件操作,包括复制、移动和删除文件及目录。它非常适合处理涉及大量数据集或多个文件的任务。</p>
<p>在数据工程项目中,shutil 可以帮助:</p>
<ul>
<li>
<p>高效地在不同存储位置之间移动或复制大型数据集</p>
</li>
<li>
<p>自动清理处理数据后的临时文件和目录</p>
</li>
<li>
<p>在处理或分析之前创建关键数据集的备份</p>
</li>
</ul>
<p><a href="https://www.youtube.com/watch?v=sXzezIK0d7c" target="_blank">shutil: 终极 Python 文件管理工具包</a> 是一个关于 shutil 的全面教程。</p>
<h2 id="4-csv">4. csv</h2>
<p><a href="https://docs.python.org/3/library/csv.html" target="_blank">csv</a> 模块对于处理 CSV 文件至关重要,CSV 是一种常见的数据存储和交换格式。它提供了读取和写入 CSV 文件的工具,并且可以自定义处理不同 CSV 格式的选项。</p>
<p>这里有一些你可以使用 csv 模块完成的任务:</p>
<ul>
<li>
<p>作为 ETL 管道的一部分解析和处理大型 CSV 文件</p>
</li>
<li>
<p>将 CSV 数据转换为其他格式,例如 JSON 或数据库表</p>
</li>
<li>
<p>将处理或转换的数据写回 CSV 格式以供下游应用程序使用</p>
</li>
</ul>
<p><a href="https://www.youtube.com/watch?v=q5uM4VKywbA" target="_blank">CSV 模块 - 如何读取、解析和写入 CSV 文件</a> 是使用 csv 模块的好参考。</p>
<h2 id="5-json">5. json</h2>
<p>内置的 <a href="https://docs.python.org/3/library/json.html" target="_blank">json</a> 模块是处理 JSON 数据的首选——在处理 Web 服务和 API 时很常见。它允许你将 Python 对象序列化和反序列化为 JSON 字符串,使你的应用程序和外部系统之间的数据交换变得简单。</p>
<p>你将使用 json 模块来:</p>
<ul>
<li>
<p>无缝地将 API 响应转换为 Python 对象以进行进一步处理</p>
</li>
<li>
<p>以结构化格式存储配置信息或元数据</p>
</li>
<li>
<p>处理在大数据应用中常见的复杂嵌套数据结构</p>
</li>
</ul>
<p><a href="https://www.youtube.com/watch?v=9N6a-VLBa2I" target="_blank">使用 json 模块处理 JSON 数据</a> 将帮助你学习如何在 Python 中处理 JSON。</p>
<h2 id="6-pickle">6. pickle</h2>
<p><a href="https://docs.python.org/3/library/pickle.html" target="_blank">pickle</a> 模块用于将 Python 对象序列化和反序列化为二进制格式。它特别适合于将复杂的数据结构,如列表、字典或自定义对象,保存到磁盘并在需要时重新加载。</p>
<p>pickle 模块适用于以下任务:</p>
<ul>
<li>
<p>缓存转换后的数据以加速数据管道中的重复任务</p>
</li>
<li>
<p>持久化训练的模型或数据转换步骤以保证可重复性</p>
</li>
<li>
<p>在处理阶段之间存储和重新加载复杂配置或数据集</p>
</li>
</ul>
<p><a href="https://www.youtube.com/watch?v=2Tw39kZIbhs" target="_blank">Python Pickle 模块用于保存对象(序列化)</a> 是一篇简短但有用的教程,讲解了 pickle 模块。</p>
<h2 id="7-sqlite3">7. sqlite3</h2>
<p><a href="https://docs.python.org/3/library/sqlite3.html" target="_blank">sqlite3</a> 模块提供了一个简单的接口用于操作 SQLite 数据库,这些数据库轻量且自包含。这个模块非常适合那些需要结构化数据存储但不想使用数据库服务器的项目。</p>
<ul>
<li>
<p>在将 ETL 管道扩展到完整的数据库系统之前进行原型设计</p>
</li>
<li>
<p>存储元数据、记录信息或在数据处理过程中保存中间结果</p>
</li>
<li>
<p>快速查询和管理结构化数据,无需设置数据库服务器</p>
</li>
</ul>
<p><a href="https://www.kdnuggets.com/a-guide-to-working-with-sqlite-databases-in-python" target="_blank">在 Python 中使用 SQLite 数据库的指南</a> 是一篇全面的教程,帮助你入门 SQLite 数据库的使用。</p>
<h2 id="8-datetime">8. datetime</h2>
<p>在处理真实世界数据集时,处理日期和时间是非常常见的。<a href="https://docs.python.org/3/library/datetime.html" target="_blank">datetime</a> 模块帮助你在应用程序中管理日期和时间数据。</p>
<p>它提供了用于处理日期、时间和时间间隔的工具,并支持日期字符串的格式化和解析,具体包括:</p>
<ul>
<li>
<p>解析和格式化日志或事件数据中的时间戳</p>
</li>
<li>
<p>管理日期范围和计算时间间隔,当处理真实世界的数据集时</p>
</li>
</ul>
<p><a href="https://www.youtube.com/watch?v=eirjjyP2qcQ" target="_blank">Datetime 模块 - 如何处理日期、时间、时间差和时区</a> 是一篇极好的教程,帮助你学习所有关于 datetime 模块的知识。</p>
<h2 id="9-re">9. re</h2>
<p><a href="https://docs.python.org/3/library/re.html" target="_blank">re</a> 模块提供了强大的工具来处理正则表达式,这对文本处理至关重要。它使你能够根据复杂的模式搜索、匹配和操控字符串,这使其在数据清洗、验证和转换任务中不可或缺。</p>
<ul>
<li>
<p>从日志、原始数据或非结构化文本中提取特定模式</p>
</li>
<li>
<p>验证数据格式,如日期、电子邮件或电话号码,在 ETL 过程中</p>
</li>
<li>
<p>清理原始文本数据以便进一步分析</p>
</li>
</ul>
<p>你可以参考 <a href="https://www.youtube.com/watch?v=K8L6KVGG-7o" target="_blank">re 模块 - 如何编写和匹配正则表达式 (Regex)</a> 来详细学习使用内置的 re 模块。</p>
<h2 id="10-subprocess">10. subprocess</h2>
<p><a href="https://docs.python.org/3/library/subprocess.html" target="_blank">subprocess</a> 模块是一个强大的工具,用于在 Python 脚本中运行 shell 命令和与系统 shell 交互。</p>
<p>这对于自动化系统任务、调用命令行工具或捕获来自外部进程的输出至关重要,例如:</p>
<ul>
<li>
<p>自动化执行 shell 脚本或数据处理命令</p>
</li>
<li>
<p>从命令行工具捕获输出以集成到 Python 工作流中</p>
</li>
<li>
<p>组织涉及多个工具和命令的复杂数据处理管道</p>
</li>
</ul>
<p><a href="https://www.youtube.com/watch?v=2Fp1N6dof0Y" target="_blank">使用 Subprocess 模块调用外部命令</a> 是一个关于如何开始使用 subprocess 模块的教程。</p>
<h2 id="总结-3">总结</h2>
<p>希望你发现这篇关于 Python 内置模块在数据工程中的总结有帮助。</p>
<p>这些模块可以成为你数据工程工具包中的良好补充——提供处理各种任务所需的基本功能,而无需依赖外部库。</p>
<p>如果你对数据工程的 Python 库感兴趣,可以阅读 <a href="https://www.kdnuggets.com/7-python-libraries-every-data-engineer-should-know" target="_blank">7 Python Libraries Every Data Engineer Should Know</a>。</p>
<p><strong><a href="https://twitter.com/balawc27" target="_blank"></a></strong><a href="https://www.kdnuggets.com/wp-content/uploads/bala-priya-author-image-update-230821.jpg" target="_blank">Bala Priya C</a>**** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正通过撰写教程、操作指南、观点文章等方式,学习并与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。</p>
<h3 id="更多相关主题-7">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/7-python-libraries-every-data-engineer-should-know" target="_blank">7 Python Libraries Every Data Engineer Should Know</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/03/5-machine-learning-skills-every-machine-learning-engineer-know-2023.html" target="_blank">每个机器学习工程师应该具备的 5 种机器学习技能</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/tools-every-ai-engineer-should-know-a-practical-guide" target="_blank">每个 AI 工程师应该知道的工具:实用指南</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n21.html" target="_blank">KDnuggets 新闻,5 月 25 日:每个…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/05/6-python-machine-learning-tools-every-data-scientist-know.html" target="_blank">每个数据科学家应该了解的 6 种 Python 机器学习工具</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-python-libraries-every-data-scientist-should-know" target="_blank">每个数据科学家应该知道的 10 个 Python 库</a></p>
</li>
</ul>
<h1 id="10-chatgpt-插件数据科学备忘单">10 ChatGPT 插件数据科学备忘单</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2023/06/10-chatgpt-plugins-data-science-cheat-sheet.html" target="_blank"><code>www.kdnuggets.com/2023/06/10-chatgpt-plugins-data-science-cheat-sheet.html</code></a></p>
</blockquote>
<h1 id="数据科学插件">数据科学插件</h1>
<hr>
<h2 id="我们的前三个课程推荐-10">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析能力</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织 IT</p>
<hr>
<p>ChatGPT 正在帮助我们所有人,包括数据科学家,在更短的时间内提高生产力。ChatGPT 的初始使用案例和能力令人瞩目,随着时间的推移情况只会变得更好。现在 ChatGPT 用户可以广泛使用插件,我们认为是时候指出哪些插件适合数据人员检查和利用了。</p>
<p><a href="https://www.kdnuggets.com/publications/sheets/10_ChatGPT_Plugins_for_Data_Science_Cheat_Sheet_KDnuggets.pdf" target="_blank"></a></p>
<p><img src="https://www.kdnuggets.com/publications/sheets/10_ChatGPT_Plugins_for_Data_Science_Cheat_Sheet_KDnuggets.pdf" alt="10 ChatGPT 插件数据科学备忘单" loading="lazy"></p>
<blockquote>
<p>ChatGPT 插件是有价值的第三方应用程序,可以轻松集成到 ChatGPT 平台中,以实现自动化和增强其功能。你可以简化工作流程、自动化任务并向平台添加新功能。</p>
</blockquote>
<p>要了解我们认为最适合数据科学的 10 个 ChatGPT 插件的概述,请查看我们最新的备忘单,名为 10 ChatGPT 插件数据科学备忘单。</p>
<p>你会发现用于编码、分析、网页搜索、文档查询等的插件。</p>
<p>现在就查看,并请继续关注以获取更多信息。</p>
<h3 id="更多相关话题-10">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2023/06/chatgpt-plugins-everything-need-know.html" target="_blank">ChatGPT 插件:你需要知道的一切</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/03/chatgpt-data-science-cheat-sheet.html" target="_blank">ChatGPT 数据科学备忘单</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/06/chatgpt-data-science-interviews-cheat-sheet.html" target="_blank">ChatGPT 数据科学面试备忘单</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/01/chatgpt-cheat-sheet.html" target="_blank">ChatGPT 备忘单</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/machine-learning-chatgpt-cheat-sheet.html" target="_blank">使用 ChatGPT 的机器学习备忘单</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-chatgpt-projects-cheat-sheet" target="_blank">10 ChatGPT 项目备忘单</a></p>
</li>
</ul>
<h1 id="10-chatgpt-项目备忘单">10 ChatGPT 项目备忘单</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/10-chatgpt-projects-cheat-sheet" target="_blank"><code>www.kdnuggets.com/10-chatgpt-projects-cheat-sheet</code></a></p>
</blockquote>
<h1 id="你需要的脱颖而出的要素">你需要的脱颖而出的要素</h1>
<hr>
<h2 id="我们的前三个课程推荐-11">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业轨道。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你所在组织的 IT</p>
<hr>
<p><a href="https://chat.openai.com/" target="_blank">ChatGPT</a> 正在迅速改变人工智能能力的游戏规则。KDnuggets 的 <a href="https://www.kdnuggets.com/publications/sheets/KDnuggets_10_ChatGPT_Projects_Cheat_Sheet.pdf" target="_blank">最新备忘单</a> 提供了一个实用的指南,介绍了 10 个令人兴奋的动手项目,展示了如何利用 ChatGPT 进行各种数据科学工作流。从构建 AI 助手和 Web 应用程序到生成 PowerPoint 演示文稿,这些项目提供了跨机器学习、自然语言处理和全栈开发的实际示例。</p>
<p><a href="https://www.kdnuggets.com/publications/sheets/KDnuggets_10_ChatGPT_Projects_Cheat_Sheet.pdf" target="_blank"></a></p>
<p><img src="https://www.kdnuggets.com/publications/sheets/KDnuggets_10_ChatGPT_Projects_Cheat_Sheet.pdf" alt="10 ChatGPT 项目备忘单" loading="lazy"></p>
<p>备忘单链接到每个项目的教程,逐步讲解如何利用 ChatGPT 的对话提示进行实现。高亮部分包括使用 ChatGPT 进行贷款批准分类器模型、简历解析器、实时语言翻译器、探索性数据分析,甚至将其功能集成到 Google Sheets 中。无论你是 ChatGPT 的新手还是希望推动其边界,这些项目合集都作为一个发射台,提升生产力并加速 AI 辅助开发。</p>
<blockquote>
<p>高亮部分包括使用 ChatGPT 进行贷款批准分类器模型、简历解析器、实时语言翻译器、探索性数据分析,甚至将其功能集成到 Google Sheets 中。</p>
</blockquote>
<p>通过 Python、React 等代码示例,这些精心挑选的项目允许你动手实验 ChatGPT 的潜力。它们提供了将理论知识与实践经验相结合的理想方式。随着 ChatGPT 的快速演进,像这样的备忘单为数据科学家提供了一个轻松的参考,以解锁其可能性并将 AI 集成到工作流中。这是任何希望提升 ChatGPT 技能的从业者必备的指南。</p>
<p><a href="https://www.kdnuggets.com/publications/sheets/KDnuggets_10_ChatGPT_Projects_Cheat_Sheet.pdf" target="_blank">立即查看</a>,并及时关注更多内容。</p>
<h3 id="更多相关内容-9">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2023/01/chatgpt-cheat-sheet.html" target="_blank">ChatGPT 秘籍</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/machine-learning-chatgpt-cheat-sheet.html" target="_blank">ChatGPT 与机器学习秘籍</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/03/chatgpt-data-science-cheat-sheet.html" target="_blank">ChatGPT 在数据科学中的秘籍</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/06/chatgpt-data-science-interviews-cheat-sheet.html" target="_blank">ChatGPT 在数据科学面试中的秘籍</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/06/10-chatgpt-plugins-data-science-cheat-sheet.html" target="_blank">10 个用于数据科学的 ChatGPT 插件秘籍</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/the-kdnuggets-2023-cheat-sheet-collection" target="_blank">KDnuggets 2023 秘籍集合</a></p>
</li>
</ul>
<h1 id="10-个你需要掌握的数据科学面试备忘单">10 个你需要掌握的数据科学面试备忘单</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2022/10/10-cheat-sheets-need-ace-data-science-interview.html" target="_blank"><code>www.kdnuggets.com/2022/10/10-cheat-sheets-need-ace-data-science-interview.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/430e6760ca9272e9d5015baa08057d78.png" alt="10 个你需要掌握的数据科学面试备忘单" loading="lazy"></p>
<p>图片来源:作者</p>
<p>这 10 个备忘单适用于初学者、学生、求职者和专业人士。这些是我的最爱,它们经过精心挑选,以便你不必为数据科学的每个子类别寻找最佳备忘单。</p>
<hr>
<h2 id="我们的前三个课程推荐-12">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织进行 IT 工作</p>
<hr>
<p>备忘单是救命稻草。在我准备数据科学和机器学习面试时,它们帮助了我多次。我只花了 30 分钟就复习了所有旧但必要的概念,为任何技术问题做好准备。</p>
<p><strong>备忘单列表包括:</strong></p>
<ol>
<li>
<p>SQL</p>
</li>
<li>
<p>网络爬虫</p>
</li>
<li>
<p>统计学</p>
</li>
<li>
<p>数据清洗</p>
</li>
<li>
<p>数据可视化</p>
</li>
<li>
<p>商业智能</p>
</li>
<li>
<p>机器学习</p>
</li>
<li>
<p>深度学习</p>
</li>
<li>
<p>自然语言处理</p>
</li>
<li>
<p>超级备忘单。</p>
</li>
</ol>
<p><strong>注意:</strong> 有些备忘单是可下载的 PDF 文件,有些是基于 HTML 的,有些则以博客风格编写。</p>
<h1 id="sql">SQL</h1>
<p><img src="https://kdn.flygon.net/docs/img/cd34c75c067988306596c4eccf85e2fa.png" alt="10 个你需要掌握的数据科学面试备忘单" loading="lazy"></p>
<p><a href="https://www.dataquest.io/blog/sql-cheat-sheet/" target="_blank">Dataquest</a> 提供的备忘单示例</p>
<p><a href="https://www.dataquest.io/blog/sql-cheat-sheet/" target="_blank">SQL</a> 由 Dataquest 提供,是一份博客风格的备忘单。它将为你提供 SQL 基本查询的概述。</p>
<ul>
<li>
<p><strong>基础知识:</strong> 选择行和列、注释以及限制</p>
</li>
<li>
<p><strong>连接:</strong> 内连接、左连接、右连接和外连接</p>
</li>
<li>
<p><strong>复杂查询:</strong> 子查询、字符串匹配、案例、With 子句、创建和删除视图、并集、交集和链式查询</p>
</li>
</ul>
<p>作为一名数据科学家,你必须了解这些功能和命令,以通过 SQL 编码面试。即使在之后,它们也将是你工作生活中的重要组成部分。提取特定数据、创建管道、处理数据以及使用 SQL 命令和复杂查询进行分析。</p>
<h1 id="网络爬虫">网络爬虫</h1>
<p><img src="https://kdn.flygon.net/docs/img/262aa9cfa2db7702a937a0133f6dc8bc.png" alt="10 个你需要掌握的数据科学面试备忘单" loading="lazy"></p>
<p>图片来源:<a href="https://frank-andrade.medium.com/" target="_blank">Frank Andrade</a></p>
<p><a href="https://medium.com/geekculture/web-scraping-cheat-sheet-2021-python-for-web-scraping-cad1540ce21c" target="_blank">网络爬虫</a> 由 Frank Andrade 提供,是一个基于博客的备忘单,涵盖了网络爬虫的所有基础知识以及如何利用它创建自动化网页爬虫。对于数据专业人士来说,掌握网络爬虫技能是一个加分项。它将帮助他们从基于 HTML 的网站和 API 中收集数据。</p>
<p><strong>你将学习到:</strong></p>
<ol>
<li>
<p>网络爬虫的 HTML</p>
</li>
<li>
<p>Beautiful Soup</p>
</li>
<li>
<p>XPath</p>
</li>
<li>
<p>Selenium</p>
</li>
<li>
<p>Scrapy</p>
</li>
<li>
<p>网络爬虫的 Python 基础</p>
</li>
</ol>
<p>备忘单包含易于遵循的代码示例和可视化辅助。你可以学习各种网络爬虫 Python 库的函数,并自动化你的工作流程。</p>
<h1 id="统计学">统计学</h1>
<p><img src="https://kdn.flygon.net/docs/img/7c85cd0b94bd96f4a2594502fb2165ed.png" alt="10 Cheat Sheets You Need To Ace Data Science Interview" loading="lazy"></p>
<p>来自 <a href="https://stanford.edu/~shervine/teaching/cme-106/cheatsheet-statistics" target="_blank">stanford.edu</a> 的备忘单示例</p>
<p><a href="https://stanford.edu/~shervine/teaching/cme-106/cheatsheet-statistics" target="_blank">统计学</a> 由 stanford.edu 提供,是一个基于 HTML 的备忘单。它涵盖了所有统计概念,包括数学公式和可视化示例(如果可能的话)。</p>
<p><strong>它被分为 5 个核心部分:</strong></p>
<ol>
<li>
<p>参数估计</p>
</li>
<li>
<p>置信区间</p>
</li>
<li>
<p>假设检验</p>
</li>
<li>
<p>回归分析</p>
</li>
<li>
<p>相关性分析</p>
</li>
</ol>
<p>在技术工作展示中,你需要用统计术语支持你的论点。阅读备忘单 5 分钟将帮助你记住核心术语和公式。</p>
<h1 id="pandas-数据处理">Pandas 数据处理</h1>
<p><img src="https://kdn.flygon.net/docs/img/a5b807bd1b497745d77d80ce25215b44.png" alt="10 Cheat Sheets You Need To Ace Data Science Interview" loading="lazy"></p>
<p>来自 <a href="https://datacamp-community-prod.s3.amazonaws.com/d4efb29b-f9c6-4f1c-8c98-6f568d88b48f" target="_blank">DataCamp</a> 的备忘单示例</p>
<p><a href="https://datacamp-community-prod.s3.amazonaws.com/d4efb29b-f9c6-4f1c-8c98-6f568d88b48f" target="_blank">Pandas 数据处理</a> 由 DataCamp 提供,是一个基于 PDF 的单页备忘单。它包含各种数据处理技术的代码和可视化示例。</p>
<ol>
<li>
<p><strong>重塑数据:</strong> 数据透视、透视表、堆叠和拆分以及熔化</p>
</li>
<li>
<p><strong>迭代</strong></p>
</li>
<li>
<p><strong>处理缺失数据</strong></p>
</li>
<li>
<p><strong>高级索引:</strong> 重新索引、设置和取消设置索引以及多级索引。</p>
</li>
<li>
<p><strong>重复数据</strong></p>
</li>
<li>
<p><strong>分组数据</strong></p>
</li>
<li>
<p><strong>合并表格:</strong> 合并、连接和串联</p>
</li>
<li>
<p><strong>日期</strong></p>
</li>
<li>
<p><strong>可视化</strong></p>
</li>
</ol>
<p>这是一个很好的资源,可以复习 pandas 库的所有核心功能。</p>
<h1 id="数据可视化">数据可视化</h1>
<p><img src="https://kdn.flygon.net/docs/img/7000ab3638f17ae105aa8abb71b8f93b.png" alt="10 Cheat Sheets You Need To Ace Data Science Interview" loading="lazy"></p>
<p>来自 <a href="https://www.datacamp.com/cheat-sheet/data-viz-cheat-sheet" target="_blank">DataCamp</a> 的图像</p>
<p><a href="https://www.datacamp.com/cheat-sheet/data-viz-cheat-sheet" target="_blank">数据可视化</a> 由 DataCamp 提供,是理解数据可视化及其使用时机的最佳备忘单。它是一个混合型(博客+PDF)备忘单,涵盖了数据可视化的所有基本概念。</p>
<p><strong>你将学习到:</strong></p>
<ol>
<li>
<p>如何捕捉趋势</p>
</li>
<li>
<p>如何可视化关系</p>
</li>
<li>
<p>部分到整体图表</p>
</li>
<li>
<p>如何可视化单一值</p>
</li>
<li>
<p>如何捕捉分布</p>
</li>
<li>
<p>可视化流程</p>
</li>
</ol>
<p>你可以将所有核心概念作为博客阅读或下载 PDF 文件。你会惊讶于这些对于图表选择的必要性。</p>
<h1 id="tableau-商业智能">Tableau 商业智能</h1>
<p><img src="https://kdn.flygon.net/docs/img/97dac66626fb27b77e7da9f0b19fd498.png" alt="你需要的 10 个备忘单以通过数据科学面试" loading="lazy"></p>
<p>备忘单示例来自 <a href="https://www.learnovita.com/tableau-cheat-sheet-tutorial" target="_blank">learnovita.com</a></p>
<p><a href="https://www.learnovita.com/tableau-cheat-sheet-tutorial" target="_blank">Tableau</a>由 learnovita.com 提供,是一个基于博客的备忘单。它涵盖了所有基本功能、数据类型、可视化类型和命令。</p>
<p>它包括:</p>
<ol>
<li>
<p>数据源</p>
</li>
<li>
<p>数据提取</p>
</li>
<li>
<p>数据连接</p>
</li>
<li>
<p>数据融合</p>
</li>
<li>
<p>操作符</p>
</li>
<li>
<p>LOD 表达式</p>
</li>
<li>
<p>排序</p>
</li>
<li>
<p>过滤器</p>
</li>
<li>
<p>图表</p>
</li>
</ol>
<p>Tableau 是商业智能领域最著名的工具。它将帮助你通过几次点击进行数据分析、可视化和整理。此外,你可以在几分钟内创建故事和仪表板。在数据分析和数据科学相关工作中对此需求很高。</p>
<blockquote>
<p>“为了获取这些备忘单的最大效果,我建议你将此页面收藏,并回顾所有备忘单。浏览所有 API、命令和技术术语只需 30 分钟。”</p>
</blockquote>
<h1 id="机器学习">机器学习</h1>
<p><img src="https://kdn.flygon.net/docs/img/119a094daadb7a2ba3996e2317f68057.png" alt="你需要的 10 个备忘单以通过数据科学面试" loading="lazy"></p>
<p>备忘单示例来自 <a href="https://datacamp-community-prod.s3.amazonaws.com/eb807da5-dce5-4b97-a54d-74e89f14266b" target="_blank">DataCamp</a></p>
<p><a href="https://datacamp-community-prod.s3.amazonaws.com/eb807da5-dce5-4b97-a54d-74e89f14266b" target="_blank">使用 Scikit-Learn 的机器学习</a>由 DataCamp 提供,是一个基于 PDF 的备忘单,将帮助你复习所有数据处理和建模的函数和命令。</p>
<p><strong>你将学习 Scikit-Learn 的 API:</strong></p>
<ol>
<li>
<p>数据加载</p>
</li>
<li>
<p>预处理</p>
</li>
<li>
<p>数据拆分</p>
</li>
<li>
<p>构建模型</p>
</li>
<li>
<p>模型训练</p>
</li>
<li>
<p>预测</p>
</li>
<li>
<p>模型评估</p>
</li>
<li>
<p>模型调优</p>
</li>
</ol>
<p>这个备忘单在编程考试、技术面试或仅仅是复习命令以运行简单的机器学习任务时非常方便。</p>
<h1 id="深度学习">深度学习</h1>
<p><img src="https://kdn.flygon.net/docs/img/e5f59edba8c663d9e92ae273aaef8065.png" alt="你需要的 10 个备忘单以通过数据科学面试" loading="lazy"></p>
<p>备忘单示例来自 <a href="https://datacamp-community-prod.s3.amazonaws.com/af9bb467-170d-41c9-a0bd-26e675384c4e" target="_blank">DataCamp</a></p>
<p><a href="https://datacamp-community-prod.s3.amazonaws.com/af9bb467-170d-41c9-a0bd-26e675384c4e" target="_blank">使用 Keras 的深度学习</a>由 DataCamp 提供,是一个基于 PDF 的备忘单,可以用来回顾所有的 Keras 函数,包括数据预处理和神经网络。</p>
<p><strong>它将帮助你:</strong></p>
<ol>
<li>
<p>加载默认数据集</p>
</li>
<li>
<p>预处理</p>
</li>
<li>
<p>神经网络模型架构</p>
</li>
<li>
<p>预测</p>
</li>
<li>
<p>模型检查</p>
</li>
<li>
<p>模型编译</p>
</li>
<li>
<p>模型训练和评估</p>
</li>
<li>
<p>模型保存和加载</p>
</li>
<li>
<p>微调</p>
</li>
</ol>
<p>这是一个基于代码的备忘单,假设你了解构建和训练神经网络的基础知识。你只需一瞥便能理解各种函数,这将帮助你在编程面试和家庭作业中。</p>
<h1 id="自然语言处理">自然语言处理</h1>
<p><img src="https://kdn.flygon.net/docs/img/1b18323bca9f21c5f31fa7994d46b3de.png" alt="你需要的 10 个数据科学面试备忘单" loading="lazy"></p>
<p>来自<a href="https://github.com/janlukasschroeder/nlp-cheat-sheet-python" target="_blank">janlukasschroeder</a>的备忘单示例</p>
<p><a href="https://github.com/janlukasschroeder/nlp-cheat-sheet-python" target="_blank">NLP</a>由<a href="https://github.com/janlukasschroeder" target="_blank">janlukasschroeder</a>提供,是一本独一无二的自然语言处理(NLP)备忘单。这是一份基于 GitHub 的备忘单,其中所有内容都使用 Markdown 格式在 README.md 文件中创建。</p>
<p><strong>你将学到:</strong></p>
<ol>
<li>
<p>词嵌入</p>
</li>
<li>
<p>停用词</p>
</li>
<li>
<p>范围</p>
</li>
<li>
<p>分词</p>
</li>
<li>
<p>词块与词块化</p>
</li>
<li>
<p>词性标注(POS)</p>
</li>
<li>
<p>BILUO 标注</p>
</li>
<li>
<p>词干提取</p>
</li>
<li>
<p>词形还原</p>
</li>
<li>
<p>句子检测</p>
</li>
<li>
<p>依赖解析</p>
</li>
<li>
<p>命名实体识别(NER)</p>
</li>
<li>
<p>文本分类</p>
</li>
<li>
<p>相似度</p>
</li>
<li>
<p>N-grams</p>
</li>
<li>
<p>可视化</p>
</li>
<li>
<p>核函数</p>
</li>
<li>
<p>文本摘要</p>
</li>
<li>
<p>情感分析</p>
</li>
<li>
<p>莱文斯坦距离</p>
</li>
<li>
<p>马尔可夫决策过程</p>
</li>
<li>
<p>概率以丢弃词语以减少噪音</p>
</li>
</ol>
<p>它包含了你想了解的 NLP 基础知识和语言应用。你还将学习各种神经网络架构、损失函数、优化器和正则化器。如果你喜欢这份备忘单,给它一个星标。</p>
<h1 id="超级备忘单">超级备忘单</h1>
<p><img src="https://kdn.flygon.net/docs/img/8838b4f7975e980d5b7d77fc80e5bec3.png" alt="你需要的 10 个数据科学面试备忘单" loading="lazy"></p>
<p>来自<a href="https://github.com/ml874/Data-Science-Cheatsheet/blob/master/data-science-cheatsheet.pdf" target="_blank">GitHub</a>的备忘单示例</p>
<p><a href="https://github.com/ml874/Data-Science-Cheatsheet/blob/master/data-science-cheatsheet.pdf" target="_blank">超级数据科学</a>由<a href="https://github.com/ml874" target="_blank">马弗里克·林</a>提供,是一本基于 PDF 的多页备忘单,也是我最喜欢的。它涵盖了从算法到 SQL 的所有主题。备忘单纯粹是理论性的,包含数学和视觉辅助。</p>
<p><strong>它包含各种类别:</strong></p>
<ol>
<li>
<p>概率</p>
</li>
<li>
<p>统计学</p>
</li>
<li>
<p>数据类型</p>
</li>
<li>
<p>数据清理</p>
</li>
<li>
<p>特征工程</p>
</li>
<li>
<p>统计分析</p>
</li>
<li>
<p>分布</p>
</li>
<li>
<p>模型评估指标</p>
</li>
<li>
<p>线性回归</p>
</li>
<li>
<p>距离方法</p>
</li>
<li>
<p>最近邻分类</p>
</li>
<li>
<p>聚类</p>
</li>
<li>
<p>机器学习</p>
</li>
<li>
<p>深度学习</p>
</li>
<li>
<p>大数据</p>
</li>
<li>
<p>图论</p>
</li>
<li>
<p>SQL</p>
</li>
</ol>
<p>如果你像我一样懒惰,我想你会喜欢一次性复习所有内容,并对面试充满信心。我并不是说你应该忽视上述所有内容。这十项都是你在数据科学、数据分析或机器学习面试中成功所必需的,尤其是基于 HTML 和博客文章的内容。</p>
<p><strong><a href="https://www.polywork.com/kingabzpro" target="_blank">Abid Ali Awan</a></strong> (<a href="https://twitter.com/1abidaliawan" target="_blank">@1abidaliawan</a>) 是一位认证的数据科学专家,热爱构建机器学习模型。目前,他专注于内容创作,撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,帮助那些在精神疾病方面挣扎的学生。</p>
<h3 id="更多相关主题-8">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/12/7-super-cheat-sheets-need-ace-machine-learning-interview.html" target="_blank">7 份超级备忘单助你在机器学习面试中表现出色</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/top-7-essential-cheat-sheets-to-ace-your-data-science-interview" target="_blank">7 份必备备忘单助你在数据科学面试中脱颖而出</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/5-super-helpful-sql-cheat-sheets-you-cant-miss" target="_blank">5 份超级有用的 SQL 备忘单你不能错过!</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-statistics-questions-to-ace-your-data-science-interview" target="_blank">10 个统计学问题助你在数据科学面试中脱颖而出</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n06.html" target="_blank">KDnuggets™ 新闻 22:n06,2 月 9 日:数据科学编程…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n23.html" target="_blank">KDnuggets 新闻,6 月 8 日:21 份数据科学备忘单…</a></p>
</li>
</ul>
<h1 id="10-种最常见的数据质量问题及其解决方法">10 种最常见的数据质量问题及其解决方法</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2022/11/10-common-data-quality-issues-fix.html" target="_blank"><code>www.kdnuggets.com/2022/11/10-common-data-quality-issues-fix.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/526076380be505349c1a76723d549a51.png" alt="10 种最常见的数据质量问题及其解决方法" loading="lazy"></p>
<p>图片来源:作者</p>
<h1 id="介绍-1">介绍</h1>
<hr>
<h2 id="我们的前三大课程推荐-8">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析能力</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织的 IT</p>
<hr>
<p>数据已经成为全球所有企业的核心。组织高度依赖数据资产进行决策,但不幸的是,“100%干净准确的数据”并不存在。数据受到许多因素的影响,这些因素恶化了数据的质量。专家表示,对抗数据问题的最佳方法是识别其根本原因,并引入新流程以提高数据质量。本文涵盖了企业面临的常见数据质量问题以及如何最佳解决这些问题。在我们深入探讨之前,让我们首先了解一下这些问题的知识为何重要,以及它们对业务活动的影响。</p>
<h1 id="为什么数据质量很重要">为什么数据质量很重要?</h1>
<p><strong>什么是数据质量?</strong> 数据质量指的是数据当前状态的衡量,包括完整性、准确性、可靠性、相关性和及时性等特征。数据质量问题表示存在损害上述特征的缺陷。数据只有在高质量的情况下才有价值。数据质量差的一些后果包括:</p>
<ul>
<li>
<p>决策失误</p>
</li>
<li>
<p>生产力下降</p>
</li>
<li>
<p>不准确的分析导致声誉受损</p>
</li>
<li>
<p>客户不满意和收入损失</p>
</li>
<li>
<p>错误的商业计划</p>
</li>
</ul>
<h1 id="常见的数据质量问题">常见的数据质量问题</h1>
<h2 id="1-人为错误">1) 人为错误</h2>
<p>即使有所有的自动化,数据仍然在各种网络界面上输入。因此,很可能出现<strong>打字错误</strong>,导致数据不准确。这种数据输入既可能由客户完成,也可能由员工完成。客户可能会将正确的数据写入错误的数据字段。类似地,员工在处理或迁移数据时也可能犯错。专家建议自动化过程,以减少人工数据捕获的参与。一些可能有助于这方面的步骤包括:</p>
<ul>
<li>
<p>使用数据质量工具进行实时表单验证</p>
</li>
<li>
<p>对员工进行适当的培训</p>
</li>
<li>
<p>使用明确的列表锁定客户可以输入的内容</p>
</li>
</ul>
<h2 id="2-数据重复">2) 数据重复</h2>
<p>目前,数据来自多个渠道,在合并时容易产生重复数据。这会导致相同记录的多个变体,从而提供扭曲的分析结果和不正确的见解。预算也会在这些重复记录上浪费。你可以使用<strong>数据重复工具</strong>来查找类似的记录并将其标记为重复。另一个可能有帮助的技术是标准化数据字段,并对数据输入进行严格的验证检查。</p>
<h2 id="3-数据不一致">3) 数据不一致</h2>
<p>多个数据源中的相同信息不匹配可能导致数据不一致。数据的一致性对于正确利用数据至关重要。不一致可能源于不同的单位和语言。例如,距离可能以公里为单位表示,而实际上需要的是米。这会干扰所有业务操作,需要在源头解决,以确保数据管道提供可信的数据。因此,在迁移之前需要进行所有必要的转换,并引入<strong>有效性约束</strong>。对数据质量的持续监控也可以帮助你识别这些不一致性。</p>
<h2 id="4-数据不准确和丢失">4) 数据不准确和丢失</h2>
<p>不准确的数据会严重影响决策,使企业难以实现目标。这很难识别,因为格式、单位和语言都是正确的,但可能会有拼写错误或丢失的数据,使其变得不准确。数据完整性丧失和数据漂移(随时间发生的意外变化)也表明数据不准确。我们需要通过使用各种数据管理和数据质量工具,在数据生命周期的早期阶段追踪这些问题。这些工具应该足够智能,能够通过自动<strong>排除不完整条目</strong>并生成警报来发现这些问题。</p>
<h2 id="5-使用错误的公式">5) 使用错误的公式</h2>
<p>在实际操作中,数据集中的许多字段可能是通过其他字段计算得出的,以提取有意义的信息。这些字段被称为<strong>计算字段</strong>。例如,年龄是从出生日期推导出来的。每当添加新记录时,这些公式会自动计算,使用错误的公式会使该字段的内容不准确。违反这些规则和逻辑会导致数据无效。<strong>测试</strong>系统的各个阶段可以帮助你解决这个问题。</p>
<h2 id="6-数据过载">6) 数据过载</h2>
<p>大量的数据涌入系统会掩盖关键见解,并添加不相关的数据。捕获、组织和排序这些数据的额外开销不仅是一个昂贵的过程,而且效果也不佳。这种数据负担使得分析趋势和模式、识别异常值以及进行变更变得困难,因为这需要大量时间。来自不同来源的数据需要通过<strong>过滤掉不相关数据</strong>来清理,并进行适当的组织。这种技术确保了数据的相关性和完整性。</p>
<h2 id="7-数据停机">7) 数据停机</h2>
<p>当数据处于部分、错误或不准确状态时,这被称为数据停机时间。这对依赖行为数据来运行操作的数据驱动型组织来说,成本极高。导致数据停机时间的一些常见因素包括架构的意外变化、迁移问题、网络或服务器故障、数据不兼容等。但重要的是要持续测量停机时间,并通过自动化解决方案将其最小化。通过引入<strong>数据可观察性</strong>从源头到消费点可以消除停机时间。数据可观察性是组织理解数据健康状况并通过采用最佳实践进行改善的能力。此外,公司应引入服务水平协议(SLA),以追究数据团队的责任。</p>
<h2 id="8-隐藏数据">8) 隐藏数据</h2>
<p>经验快速增长的公司也会快速积累数据。他们只使用收集数据的一部分,将剩余的数据转储到不同的数据仓库。这被称为隐藏数据,因为尽管它有助于优化流程并提供有价值的见解,但却未被使用。大多数公司没有一个连贯且集中化的数据收集方法,这导致了隐藏数据的产生。<strong>集中管理你的数据</strong>是克服这个问题的最佳方法。</p>
<h2 id="9-过时数据">9) 过时数据</h2>
<p>数据可能会非常快速地过时,导致数据衰退。数据描述的对象发生变化,但这些变化在计算机中未被察觉。例如,如果一个人已经更改了他的字段,但数据库仍显示过时的数据。这种数据与现实不匹配的问题会恶化数据质量。<strong>设置提醒以审查和更新你的数据</strong>,以确保它不会过时和陈旧。</p>
<h2 id="10-数据素养不足">10) 数据素养不足</h2>
<p>尽管做了所有努力,如果组织团队没有数据素养,他们将做出不正确的数据质量假设。理解数据属性并不简单,因为同一字段在不同记录中可能有不同的含义。能够可视化更新的影响以及每个属性的含义是经验的积累。应组织<strong>数据素养培训课程</strong>,以向所有参与数据工作的团队解释数据。</p>
<h1 id="结论-5">结论</h1>
<p>本文涵盖了您可以从根本上解决的最常见的数据质量问题,以防止未来的损失。请记住,数据本身不会有价值,除非你让它变得有价值。希望您喜欢阅读这篇文章。请随时在评论区分享您的想法或反馈。</p>
<p><strong><a href="https://www.linkedin.com/in/kanwal-mehreen1" target="_blank">Kanwal Mehreen</a></strong> 是一名有志的软件开发者,对数据科学和人工智能在医学中的应用充满兴趣。Kanwal 被选为 2022 年亚太地区的 Google Generation Scholar。Kanwal 喜欢通过撰写关于热门话题的文章来分享技术知识,并热衷于提升女性在科技行业中的代表性。</p>
<h3 id="更多相关内容-10">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2023/01/overcome-data-quality-issues-great-expectations.html" target="_blank">用伟大的期望克服数据质量问题</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/03/data-quality-dimensions-assuring-data-quality-great-expectations.html" target="_blank">数据质量维度:用伟大的期望确保你的数据质量</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/03/key-issues-associated-classification-accuracy.html" target="_blank">分类准确性相关的关键问题</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/5-common-data-science-mistakes-and-how-to-avoid-them" target="_blank">5 个常见的数据科学错误及如何避免它们</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/5-common-python-gotchas-and-how-to-avoid-them" target="_blank">5 个常见的 Python 陷阱(及如何避免它们)</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/01/data-quality-good-bad-ugly.html" target="_blank">数据质量:好、坏、丑</a></p>
</li>
</ul>
<h1 id="2024-年数据分析师面试问题">2024 年数据分析师面试问题</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/10-data-analyst-interview-questions-to-land-a-job-in-2024" target="_blank"><code>www.kdnuggets.com/10-data-analyst-interview-questions-to-land-a-job-in-2024</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/716921bcff4be138800b58213311ead0.png" alt="2024 年数据分析师面试问题" loading="lazy"></p>
<p>作者提供的图片</p>
<p>作为一个初级数据分析师候选人,求职过程可能会感觉像是一个无休止的过程。</p>
<hr>
<h2 id="我们的三大课程推荐-3">我们的三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速开启网络安全职业生涯</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持组织的 IT 需求</p>
<hr>
<p>我在职业生涯初期申请了无数的数据分析师面试,常常感到迷茫和困惑。</p>
<p>我经常遇到边缘案例、业务问题和棘手的技术问题,每次面试之后,我都会感到信心动摇。</p>
<p>然而,在行业中工作了 4 年并帮助进行初级面试后,我对雇主在数据分析师候选人中寻找的东西有了更多了解。</p>
<p>在本文中,我们将深入探讨通常有三个重点领域——技术专长、业务问题解决以及软技能。</p>
<p>每一轮面试都会涵盖这些广泛领域的某些方面,尽管每个雇主对不同技能的重视程度不同。</p>
<p>例如,管理咨询公司非常看重演讲技能。他们想知道你是否能将复杂的技术见解呈现给商业利益相关者。</p>
<p>在这种情况下,你的软技能和解决问题的能力比技术技能更被重视。他们更关心你是否能够向利益相关者解释假设检验的结果,而不是你编写的 Python 代码是否干净。</p>
<p>相反,基于产品的公司或科技初创公司往往更重视技术技能。他们经常测试你的编码能力、执行 ETL 任务的能力以及按时完成交付物的能力。</p>
<p>不过我扯远了。</p>
<p>你来到这里是为了了解如何获得数据分析师的职位,所以让我们直接深入探讨你在面试过程中可能遇到的问题。</p>
<h2 id="第一轮数据分析师技术面试">第一轮:数据分析师技术面试</h2>
<p>通常,初级数据分析师面试的第一轮包括一系列技术问题。</p>
<p>这是一个计时的技术测试或家庭作业——其结果将用于决定你是否能进入下一轮。</p>
<p>这是你在这一轮面试中可以预期的一些问题,并附有如何回答的示例:</p>
<h3 id="1-什么是假设检验">1. 什么是假设检验?</h3>
<p><strong>样本答案:</strong></p>
<p>假设检验是一种用于根据样本数据集来识别和决策总体参数的技术。</p>
<p>它始于制定原假设(H0),原假设代表没有效应的默认假设。</p>
<p>然后选择一个显著性水平,通常为 0.05 或 0.10。这是原假设将被拒绝的概率阈值。</p>
<p>然后应用统计检验,如 T 检验、ANOVA 或卡方检验,以使用样本数据测试初始假设。</p>
<p>然后计算检验统计量以及 p 值,p 值是指在原假设下观察到检验结果的概率。</p>
<p>如果 p 值低于显著性水平,则可以拒绝原假设,并有足够的证据支持备择假设。</p>
<h3 id="2-t-检验和卡方检验之间的区别是什么何时使用它们">2. T 检验和卡方检验之间的区别是什么,何时使用它们?</h3>
<p><strong>样本答案:</strong></p>
<p>T 检验和卡方检验是用于比较不同数据组分布的统计技术。它们用于不同的场景。</p>
<ul>
<li>
<p>T 检验:此检验用于比较两组定量数据的均值,并评估它们是否在统计上存在显著差异。</p>
</li>
<li>
<p>卡方检验:此检验用于比较分类数据的分布,以检查变量是否相互关联。</p>
</li>
</ul>
<p>以下是我会使用每种检验情况的描述:</p>
<ul>
<li>
<p>T 检验:假设我们想了解广告对产品销售的影响。我们会使用配对 T 检验来比较广告前后产品销售的均值。</p>
</li>
<li>
<p>卡方检验:如果你在销售一种产品,并想测量性别与个人是否喜欢该产品之间的关系,可以使用卡方检验。</p>
</li>
</ul>
<h3 id="3-你如何处理数据集中的缺失数据">3. 你如何处理数据集中的缺失数据?</h3>
<p><strong>样本答案:</strong></p>
<p>处理数据集中的缺失数据有多种方法,具体取决于问题陈述和变量的分布。一些常见的方法包括:</p>
<ul>
<li>
<p>删除:如果只有少量缺失数据点且看起来是随机的,可以简单地从数据集中删除这些整行数据。</p>
</li>
<li>
<p>填充:根据底层变量分布,可以选择用均值、中位数或众数填充缺失值。例如,如果特征是正态分布的,可以使用均值来保持数据的整体分布。</p>
</li>
<li>
<p>前向/后向填充:在时间序列数据中,缺失值通常由前一个或下一个数据点填充。</p>
</li>
</ul>
<h3 id="4-你如何检测和处理数据集中的异常值">4. 你如何检测和处理数据集中的异常值?</h3>
<p><strong>样本答案:</strong></p>
<p>为了检测异常值,我会使用箱线图可视化变量,以识别图表“胡须”外的点。</p>
<p>我还会计算每个变量的 Z 分数,并将 Z 分数为+3 或-3 的数据点识别为异常值。</p>
<p>为了减少异常值的影响,我会使用像 Scikit-Learn 中的 RobustScaler() 这样的函数来转换数据集,该函数根据分位数范围对数据进行缩放。</p>
<p>我还可能使用像对数、平方根或 BoxCox 转换这样的转换来规范变量的分布。</p>
<h3 id="5-解释-sql-中-where-和-having-子句的区别">5. 解释 SQL 中 “Where” 和 “Having” 子句的区别。</h3>
<p><strong>示例回答:</strong></p>
<p>“Where” 子句用于根据单独条件过滤表中的行,并在进行任何分组之前应用。</p>
<p>相比之下,“Having” 子句用于在表格聚合之后筛选记录,只能与 “Group By” 子句一起使用。</p>
<h3 id="6-如果表-1-有-100-条记录表-2-有-200-条记录那么从这些表之间的内连接中你期望的记录范围是什么">6. 如果表 1 有 100 条记录,表 2 有 200 条记录,那么从这些表之间的内连接中你期望的记录范围是什么?</h3>
<p><strong>示例回答:</strong></p>
<p>内连接只返回表之间具有匹配值的记录。如果数据集中没有匹配值,内连接的结果可能是 0\。</p>
<p>如果表 1 和表 2 之间的所有行都匹配,那么查询将返回表 1 中的记录总数,即 100。</p>
<p>因此,这些表之间的内连接所期望的记录范围是 0 到 100。</p>
<h3 id="准备数据分析师的技术面试">准备数据分析师的技术面试</h3>
<p>注意,上述问题围绕数据预处理与分析、SQL 和统计学展开。</p>
<p>在某些情况下,你可能会获得一个 ER 图和一些表,并被要求当场编写 SQL 查询。你甚至可能被期望进行配对编程,你将获得一个数据集并需要与面试官一起解决一个问题。</p>
<p>这里有一些资源可以帮助你在技术 SQL 面试中脱颖而出:</p>
<p>1. <a href="https://youtu.be/TNNRBYsijeE?si=JbelGUv_z37BDuTm" target="_blank">如何在 2024 年学习 SQL 进行数据分析</a></p>
<p>2. <a href="https://youtu.be/7mz73uXD9DA?si=LYOl_sWAjd2gWZvL" target="_blank">4 小时内学习 SQL 进行数据分析</a></p>
<h2 id="第二轮数据分析师面试商业问题解决">第二轮:数据分析师面试——商业问题解决</h2>
<p>假设你已经通过了技术面试。</p>
<p>这意味着你满足了雇主的技术要求,现在离获得这份工作更近一步。</p>
<p>但你还没有完全摆脱困境。</p>
<p>大多数数据分析师面试包括案例研究型的问题,你将获得一个数据集,并被要求分析它以解决商业问题。</p>
<p>这是你可能在数据分析师面试中遇到的一个案例研究型问题的示例:</p>
<h3 id="你将如何评估市场营销活动的成功">你将如何评估市场营销活动的成功?</h3>
<p><strong>商业案例:</strong> 我们正在启动一个市场营销活动,以增加产品销售和品牌知名度。该活动将包括店内促销和在线广告的混合。你将如何评估它的成功?</p>
<p>这是对上述问题的示例回答,概述了在面对上述情景时可能采取的每一步:</p>
<ul>
<li>
<p>步骤 1:为了评估这次营销活动的成功,我们首先必须定义成功指标,如销售增长、店内客流量增加和客户参与度提升。</p>
</li>
<li>
<p>步骤 2:收集在线广告活动和店内出勤的数据。</p>
</li>
<li>
<p>步骤 3:将当前的指标,如店内客流量,与营销活动启动前的类似指标进行比较。</p>
</li>
<li>
<p>步骤 4:使用配对 T 检验等方法评估转化率或销售额是否有统计学意义上的改善。对于比例,如点击率,可以实施卡方检验。</p>
</li>
<li>
<p>步骤 5:对广告创意和社交媒体帖子进行 A/B 测试,以识别影响销售和转化的最有效因素。</p>
</li>
</ul>
<h3 id="准备数据分析师问题解决面试">准备数据分析师问题解决面试</h3>
<p>类似于技术面试,这可能是一个现场问题,你会被呈现问题陈述,需要制定解决方案的步骤。</p>
<p>或者这可能是一个需要大约一周完成的家庭作业评估。</p>
<p>无论如何,为这一轮做最好的准备方式就是练习。</p>
<p>这里是一些我推荐的学习资源,帮助你在数据分析师面试的这一轮中取得成功:</p>
<p>1. <a href="https://youtu.be/sjub3tYLHDc?si=BzzxSSQGfKAb5ZUO" target="_blank">如何解决数据分析案例研究问题</a></p>
<p>2. <a href="https://youtu.be/uJO4ZMB4QZw?si=Uccl0jNscOna2DVj" target="_blank">数据分析师案例研究面试</a></p>
<h2 id="第三轮数据分析师面试软技能与文化适配">第三轮:数据分析师面试 — 软技能与文化适配</h2>
<p>很多人对面试中的软技能轮次不太在意。</p>
<p>这是候选人确信自己即将得到录用的时候——因为他们已经通过了最“困难”的面试轮次。</p>
<p>但不要过于自信。</p>
<p>我见过许多有潜力的候选人因为态度不对或不符合公司文化而被拒绝。</p>
<p>尽管面试的这一部分无法像前几轮那样量化,主要基于你给面试官留下的印象,但它常常是决定公司是否选择你的关键因素。</p>
<p>这里是你在面试过程中可能会遇到的一些问题:</p>
<h3 id="1-描述一次你向非技术利益相关者解释技术概念的经历">1. 描述一次你向非技术利益相关者解释技术概念的经历。</h3>
<p><strong>示例回答:</strong></p>
<p>在我之前的角色中,我曾被要求向营销团队展示复杂的概念。</p>
<p>他们想了解我们的新客户细分模型是如何工作的,以及如何使用它来提高活动表现。</p>
<p>我开始通过视觉辅助工具来说明每个概念。我还为每个客户细分创建了角色,为每个用户组分配了名字,以使其对利益相关者更易于理解。</p>
<p>营销团队清楚理解了细分模型背后的价值,并在随后的活动中使用了它,这导致销售额提高了 15%。</p>
<p>注:如果你没有任何经验且这是你申请的第一个数据分析师职位,那么你可以提供一个你在未来遇到这种情况时的应对方式示例。</p>
<h3 id="2-能否告诉我你最近做的一个数据分析项目">2. 能否告诉我你最近做的一个数据分析项目?</h3>
<p><strong>示例答案:</strong></p>
<p>在我最新的数据分析项目中,我分析了我国数据相关工作所需的各种技能的需求。</p>
<p>我通过抓取 5,000 个职位列表收集数据,并在 Python 中对这些数据进行了预处理。</p>
<p>然后,我识别了这些职位列表中的显著术语,如“Python”,“SQL”和“沟通”。</p>
<p>最终,我建立了一个 Tableau 仪表板,显示了每项技能在这些职位列表中出现的频率。</p>
<p>我写了一篇文章,解释了我从这个项目中得到的发现,并将我的代码上传到了 GitHub。</p>
<h3 id="3-在你看来数据分析师应该具备的最重要的特质是什么为什么">3. 在你看来,数据分析师应该具备的最重要的特质是什么,为什么?</h3>
<p><strong>示例答案:</strong></p>
<p>我认为数据分析师最重要的特质是好奇心。</p>
<p>在我所有过去的项目中,我都因为好奇心驱动着去学习我所呈现的数据。</p>
<p>我第一个数据分析项目,例如,是纯粹出于好奇心。我想了解好莱坞女性代表性是否随着时间的推移而有所改善,以及性别动态如何随时间变化。</p>
<p>在收集和探索数据后,我发现女性导演的电影通常评分低于男性导演的电影。</p>
<p>我不仅停留在表面分析上,还想弄清楚为什么会这样。</p>
<p>我通过收集这些电影的类型进行了进一步分析,并更好地理解了目标受众,发现我的数据集中女性导演的电影因集中在评分较低的类型中而评分较低。</p>
<p>这是一种相关性,而不是因果关系。</p>
<p>我认为发现这些见解并深入挖掘观察到的趋势需要一个有好奇心的人,而不是仅仅接受表面价值。</p>
<h3 id="准备数据分析师行为面试">准备数据分析师行为面试</h3>
<p>我建议事先将一些问题的答案写下来——就像你在其他面试轮次中会做的那样。</p>
<p>文化和个人适配对招聘经理来说非常重要,因为一个不遵守团队运作方式的个人可能会在之后造成摩擦。</p>
<p>你必须研究公司的文化和整体方向,并了解这些是否与你的整体目标一致。</p>
<p>例如,如果公司的环境节奏快,每个人都在从事前沿技术,那么评估一下这里是否是你能蓬勃发展的地方。</p>
<p>如果你是一个想要跟上行业趋势、尽可能多地学习并迅速晋升的人,那么这里是适合你的地方。</p>
<p>确保将这一信息传达给你的面试官,他们可能也拥有类似的抱负和对成长的热情。</p>
<p>同样,如果你是那种喜欢咨询环境的人,因为你喜欢客户工作并向非技术利益相关者分解解决方案,那么找到一家与你的技能相匹配并能够传达信息的公司。</p>
<p>简而言之,发挥你的优势,并确保它们传达给雇主。</p>
<p>虽然这听起来可能过于简单,但这比只是盲目申请 Indeed 上看到的每个空缺职位要好,并且不明白为什么在求职中无所进展。</p>
<h2 id="10-个数据分析师面试问题以获得工作下一步">10 个数据分析师面试问题以获得工作——下一步</h2>
<p>如果你能跟到这里,恭喜你!</p>
<p>你现在了解了数据分析师面试中问到的 3 种问题,并且对雇主在寻找初级候选人时的要求有了深入了解。</p>
<p>以下是一些潜在的下一步措施,能提高你获得该领域工作的机会:</p>
<h3 id="1-创建项目">1. 创建项目</h3>
<p>项目是让你在众多候选人中脱颖而出并开始获得工作机会的好方法。你可以观看<a href="https://youtu.be/sPPFDBUJzA0?si=Qzr3c4uz-DLL6Zec" target="_blank">这个视频</a>来了解如何创建项目以获得该领域的第一份工作。</p>
<h3 id="2-构建个人网站">2. 构建个人网站</h3>
<p>我还建议建立一个个人网站,以展示你的所有工作。这将提升你的可见性,并最大化你获得数据分析师职位的机会。</p>
<p>如果你不知道从哪里开始,我有一个<a href="https://youtu.be/jtfwcyDAcvE?si=c98TcaFtzHP9fW4l" target="_blank">视频教程,教你从零开始用 ChatGPT 构建个人网站</a>。</p>
<h3 id="3-提升你的技术技能">3. 提升你的技术技能</h3>
<p>温习如统计学、数据可视化、SQL 和编程等技能。关于这些主题,有许多资源更详细地介绍了它们,我最喜欢的包括<a href="https://www.youtube.com/c/lukebarousse" target="_blank">Luke Barousse 的 YouTube 频道</a>、<a href="https://www.w3schools.com/sql/" target="_blank">W3Schools</a>和<a href="https://www.youtube.com/@statquest" target="_blank">StatQuest</a>。</p>
<p> </p>
<p> </p>
<p><a href="https://linktr.ee/natasshaselvaraj" target="_blank"></a><strong><a href="https://linktr.ee/natasshaselvaraj" target="_blank">Natassha Selvaraj</a></strong> 是一位自学成才的数据科学家,热衷于写作。Natassha 撰写所有与数据科学相关的内容,是所有数据主题的真正大师。你可以在<a href="https://www.linkedin.com/in/natassha-selvaraj-33430717a/" target="_blank">LinkedIn</a>与她联系,或查看她的<a href="https://www.youtube.com/@natassha_ds" target="_blank">YouTube 频道</a>。</p>
<h3 id="更多相关内容-11">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/5-data-analyst-projects-to-land-a-job-in-2024" target="_blank">2024 年获得数据分析师职位的 5 个项目</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/free-data-science-interview-book-to-land-your-dream-job" target="_blank">免费数据科学面试书籍,助你获得理想工作</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/01/unable-land-data-science-job.html" target="_blank">无法找到数据科学工作?原因在这里</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n05.html" target="_blank">KDnuggets™新闻 22:n05,2 月 2 日:掌握机器学习的 7 个步骤…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/05/data-science-projects-land-job-2022.html" target="_blank">2022 年将帮助你获得工作的数据科学项目</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/10/data-science-portfolio-land-job-2022.html" target="_blank">2022 年将帮助你获得工作的数据科学作品集</a></p>
</li>
</ul>
<h1 id="每个初学者都应该学习的-10-个必备-devops-工具">每个初学者都应该学习的 10 个必备 DevOps 工具</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/10-essential-devops-tools-every-beginner-should-learn" target="_blank"><code>www.kdnuggets.com/10-essential-devops-tools-every-beginner-should-learn</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/4fcdcd259d2d94b180d4fe59878c0edd.png" alt="每个初学者都应该学习的 10 个必备 DevOps 工具封面照片" loading="lazy"></p>
<p>作者提供的图片 | ChatGPT & Canva</p>
<p>DevOps(开发运维)和 MLOps(机器学习运维)几乎是一样的,并且共享各种工具。作为 DevOps 工程师,你将负责部署、维护和监控应用程序,而作为 MLOps 工程师,你则负责将制造模型部署、管理并投入生产。因此,学习 DevOps 工具是有益的,它为你打开了广泛的就业机会。DevOps 指的是一组旨在提高公司交付应用程序和服务的速度和效率的实践和工具。</p>
<hr>
<h2 id="我们的前-3-个课程推荐-2">我们的前 3 个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业轨道。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织的 IT</p>
<hr>
<p>在本博客中,你将学习关于版本控制、CI/CD、测试、自动化、容器化、工作流编排、云计算、IT 管理以及生产环境应用程序监控的基本且流行的工具。</p>
<h2 id="1-git">1. Git</h2>
<p>Git 是现代软件开发的基石。它是一种分布式版本控制工具,允许多个开发者在同一代码库上协作而不会互相干扰。如果你刚开始接触软件开发,了解 Git 是基础。</p>
<p>了解 14 个必备的 Git 命令,用于版本控制和数据科学项目协作。</p>
<h2 id="2-github-actions">2. GitHub Actions</h2>
<p>GitHub Actions 简化了软件工作流的自动化,使你可以通过几行代码直接从 GitHub 构建、测试和部署代码。作为 DevOps 工程的核心功能,掌握持续集成和持续开发(CI/CD)对成功至关重要。通过学习自动化工作流、生成日志和排除故障,你将显著提升你的就业前景。</p>
<p>记住,运营相关的职业主要还是看经验和作品集。</p>
<p>通过学习 GitHub Actions 初学者指南来了解如何自动化机器学习的训练和评估。</p>
<h2 id="3-selenium">3. Selenium</h2>
<p>Selenium 是一个强大的工具,主要用于自动化网页浏览器交互,使你能够高效地测试你的网页应用。只需几行代码,你就可以利用 Selenium 控制网页浏览器、模拟用户交互,并对网页应用进行自动化测试,确保其功能、可靠性和性能。</p>
<h2 id="4-linux">4. Linux</h2>
<p>由于许多服务器使用 Linux,理解这个操作系统可能至关重要。Linux 命令和脚本构成了 DevOps 世界中许多操作的基础,从基本的文件操作到自动化整个工作流程。事实上,许多经验丰富的开发者在数据加载、操作、自动化、日志记录以及众多其他任务中,严重依赖 Linux 脚本,特别是 Bash。</p>
<p>通过查看 数据科学的 Linux 快捷方式,了解最常用的 Linux 命令。</p>
<h2 id="5-云平台">5. 云平台</h2>
<p>熟悉 AWS、Azure 或 Google Cloud Platform 等云平台对于获得行业职位至关重要。我们每天使用的大多数服务和应用都是部署在云上的。</p>
<p>云平台提供的服务可以帮助你部署、管理和扩展应用。通过掌握云平台,你将能够利用可扩展性、灵活性和成本效益的优势,使你在就业市场上成为极受欢迎的专业人士。</p>
<p>开始阅读 初学者云计算指南,了解云计算的工作原理、主要云平台以及应用。</p>
<h2 id="6-docker">6. Docker</h2>
<p>Docker 是一个旨在简化应用创建、部署和运行的工具,通过使用容器实现。容器允许开发者将应用及其所需的所有部分(如库和其他依赖项)打包在一起,作为一个整体进行发布。</p>
<p>通过阅读 数据科学家的 Docker 教程 了解更多关于 Docker 的信息。</p>
<h2 id="7-kubernetes">7. Kubernetes</h2>
<p>Kubernetes 是一个强大的容器编排工具,自动化容器的部署、扩展和管理,适用于各种环境。作为 DevOps 工程师,掌握 Kubernetes 对于高效地扩展、分发和管理容器化应用至关重要,以确保高可用性、可靠性和性能。</p>
<p>阅读 Kubernetes 实战:第二版 书籍,了解部署和管理云原生应用的必备工具。</p>
<h2 id="8-prometheus">8. Prometheus</h2>
<p>Prometheus 是一个开源的监控和警报工具包,最初由 SoundCloud 开发。它使您能够监控广泛的指标并实时接收警报,为系统的性能和健康提供无与伦比的洞察。通过学习 Prometheus,您将能够快速识别问题,优化系统效率,并确保高正常运行时间和可用性。</p>
<h2 id="9-terraform">9. Terraform</h2>
<p>Terraform 是一个开源的基础设施即代码(IaC)工具,由 HashiCorp 开发,它使您能够轻松、精准地在多个云环境和内部部署环境中配置、管理和版本化基础设施资源。它支持广泛的现有服务提供商以及自定义的内部解决方案,使您能够安全、高效、一致地创建、修改和跟踪基础设施变更。</p>
<h2 id="10-ansible">10. Ansible</h2>
<p>Ansible 是一个简单但强大的 IT 自动化引擎,能够简化配置管理、应用程序部署、编排以及许多其他 IT 过程。通过自动化重复任务、部署应用程序和管理跨多种环境的配置——包括云环境、内部部署和混合基础设施——Ansible 使用户能够提高效率、减少错误并改善整体 IT 灵活性。</p>
<h2 id="结论-6">结论</h2>
<p>学习这些工具只是您在 DevOps 世界中的旅程的起点。请记住,DevOps 不仅仅是工具,它还涉及创造一种重视协作、持续改进和创新的文化。通过掌握这些工具,您将为在 DevOps 领域的成功职业生涯奠定坚实的基础。所以,今天就开始你的旅程,迈出迈向高薪和令人兴奋的职业的第一步吧。</p>
<p><a href="https://www.polywork.com/kingabzpro" target="_blank"></a><strong><strong><a href="https://www.polywork.com/kingabzpro" target="_blank">Abid Ali Awan</a></strong></strong> (<a href="https://www.linkedin.com/in/1abidaliawan" target="_blank">@1abidaliawan</a>) 是一位认证的数据科学专业人士,他热爱构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一款 AI 产品,以帮助那些遭受心理疾病困扰的学生。</p>
<h3 id="更多相关话题-11">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/n01.html" target="_blank">KDnuggets™ 新闻 22:n01,1 月 5 日:跟踪和可视化的 3 种工具…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/6-predictive-models-every-beginner-data-scientist-master.html" target="_blank">每个初学者数据科学家都应该掌握的 6 种预测模型</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/03/corise-unlock-potential-with-this-free-devops-crash-course.html" target="_blank">利用这个免费的 DevOps 快速入门课程释放你的潜力</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-essential-pandas-functions-every-data-scientist-should-know" target="_blank">每个数据科学家都应知道的 10 个基本 Pandas 函数</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/05/6-python-machine-learning-tools-every-data-scientist-know.html" target="_blank">每位数据科学家都应该了解的 6 款 Python 机器学习工具</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n21.html" target="_blank">KDnuggets 新闻,5 月 25 日:每位数据科学家都应该了解的 6 款 Python 机器学习工具</a></p>
</li>
</ul>
<h1 id="每个数据科学家都应该知道的-10-个基本-pandas-函数">每个数据科学家都应该知道的 10 个基本 Pandas 函数</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/10-essential-pandas-functions-every-data-scientist-should-know" target="_blank"><code>www.kdnuggets.com/10-essential-pandas-functions-every-data-scientist-should-know</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/5b9d1f3a3bddc655a852e9e6325de10e.png" alt="每个数据科学家都应该知道的 10 个基本 Pandas 函数" loading="lazy"></p>
<p>作者图片</p>
<p>在今天的数据驱动世界中,数据分析和洞察帮助你最大化利用数据,并帮助你做出更好的决策。从公司的角度来看,它提供了<strong>竞争优势</strong>并使整个过程<strong>个性化</strong>。</p>
<hr>
<h2 id="我们的前-3-个课程推荐-3">我们的前 3 个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业轨道。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你所在组织的 IT 工作</p>
<hr>
<p>本教程将深入探讨功能强大的 Python 库<code>pandas</code>,我们将讨论该库中对数据分析最重要的函数。由于其简洁性和高效性,初学者也可以跟随本教程。如果你的系统中没有安装 Python,你可以使用 Google Colaboratory。</p>
<h1 id="数据导入">数据导入</h1>
<p>你可以从<a href="https://www.kaggle.com/datasets/kyanyoga/sample-sales-data" target="_blank">这个链接</a>下载数据集。</p>
<pre><code class="language-py">import pandas as pd
df = pd.read_csv("kaggle_sales_data.csv", encoding="Latin-1") # Load the data
df.head() # Show first five rows
</code></pre>
<p>输出:</p>
<p><img src="https://kdn.flygon.net/docs/img/d79b9cd89e2e2614e17e2e8a99aa9b62.png" alt="每个数据科学家都应该知道的 10 个基本 Pandas 函数" loading="lazy"></p>
<h1 id="数据探索">数据探索</h1>
<p>在本节中,我们将讨论各种函数,这些函数帮助你更好地了解你的数据。例如查看数据或获取均值、平均值、最小值/最大值,或获取数据框的信息。</p>
<h2 id="1-数据查看">1. 数据查看</h2>
<ol>
<li><code>df.head()</code>: 显示样本数据的前五行</li>
</ol>
<p><img src="https://kdn.flygon.net/docs/img/d79b9cd89e2e2614e17e2e8a99aa9b62.png" alt="每个数据科学家都应该知道的 10 个基本 Pandas 函数" loading="lazy"></p>
<ol>
<li><code>df.tail()</code>: 显示样本数据的最后五行</li>
</ol>
<p><img src="https://kdn.flygon.net/docs/img/11a952ce9450215dabe3acb59b2a344f.png" alt="每个数据科学家都应该知道的 10 个基本 Pandas 函数" loading="lazy"></p>
<ol>
<li><code>df.sample(n)</code>: 显示样本数据中的随机 n 行</li>
</ol>
<pre><code class="language-py">df.sample(6)
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/7b7e1f56d911ce767f3df3385e0e61e0.png" alt="每个数据科学家都应该知道的 10 个基本 Pandas 函数" loading="lazy"></p>
<ol>
<li><code>df.shape</code>: 显示样本数据的行和列(维度)。</li>
</ol>
<pre><code class="language-py">(2823, 25)
</code></pre>
<p>这意味着我们的数据集有 2823 行,每行包含 25 列。</p>
<h2 id="2-统计">2. 统计</h2>
<p>本节包含帮助你对数据进行统计分析的函数,如平均值、最小值/最大值和四分位数。</p>
<ol>
<li><code>df.describe()</code>: 获取样本数据每列的基本统计信息</li>
</ol>
<p><img src="https://kdn.flygon.net/docs/img/26a4cc20855be9b53a3812ffb86f3d54.png" alt="每个数据科学家都应该知道的 10 个基本 Pandas 函数" loading="lazy"></p>
<ol>
<li>
<p><code>df.info()</code>:获取有关使用的各种数据类型以及每列的非空计数的信息。<img src="https://kdn.flygon.net/docs/img/75fbc353acfeb83d103c3cdf5deffe0c.png" alt="每个数据科学家都应该知道的 10 个基本 Pandas 函数" loading="lazy"></p>
</li>
<li>
<p><code>df.corr()</code>:这可以给你数据框中所有整数列之间的相关性矩阵。</p>
</li>
</ol>
<p><img src="https://kdn.flygon.net/docs/img/2445c39af0961c103748b8b8d02caa9b.png" alt="每个数据科学家都应该知道的 10 个基本 Pandas 函数" loading="lazy"></p>
<ol>
<li><code>df.memory_usage()</code>:它将告诉你每列消耗的内存量。</li>
</ol>
<p><img src="https://kdn.flygon.net/docs/img/3e839015446ba7995150125406872e8c.png" alt="每个数据科学家都应该知道的 10 个基本 Pandas 函数" loading="lazy"></p>
<h2 id="3-数据选择">3. 数据选择</h2>
<p>你也可以选择任何特定行、列,甚至多个列的数据。</p>
<ol>
<li><code>df.iloc[row_num]</code>:它将根据索引选择特定的行。</li>
</ol>
<p>例如,</p>
<pre><code class="language-py">df.iloc[0]
</code></pre>
<ol>
<li><code>df[col_name]</code>:它将选择特定的列。</li>
</ol>
<p>例如,</p>
<pre><code class="language-py">df["SALES"]
</code></pre>
<p>输出:</p>
<p><img src="https://kdn.flygon.net/docs/img/7bfdc756624e7dba11afbf920aa4416c.png" alt="每个数据科学家都应该知道的 10 个基本 Pandas 函数" loading="lazy"></p>
<ol>
<li><code>df[[‘col1’, ‘col2’]]</code>:这将选择给定的多个列。</li>
</ol>
<p>例如,</p>
<pre><code class="language-py">df[["SALES", "PRICEEACH"]]
</code></pre>
<p>输出:</p>
<p><img src="https://kdn.flygon.net/docs/img/6c6c93d46e098f967d6c8876a3a30720.png" alt="每个数据科学家都应该知道的 10 个基本 Pandas 函数" loading="lazy"></p>
<h1 id="4-数据清洗">4. 数据清洗</h1>
<p>这些函数用于处理缺失数据。数据中的某些行包含空值和垃圾值,这可能会影响我们训练模型的性能。因此,最好纠正或删除这些缺失值。</p>
<ol>
<li>
<p><code>df.isnull()</code>:这将识别数据框中的缺失值。</p>
</li>
<li>
<p><code>df.dropna()</code>:这将删除包含任何列中缺失值的行。</p>
</li>
<li>
<p><code>df.fillna(val)</code>:这将用<code>val</code>填充缺失值。</p>
</li>
<li>
<p><code>df[‘col’].astype(new_data_type)</code>:它可以将选定列的数据类型转换为不同的数据类型。</p>
</li>
</ol>
<p>例如,</p>
<pre><code class="language-py">df["SALES"].astype(int)
</code></pre>
<p>我们将 SALES 列的数据类型从浮点型转换为整型。</p>
<p><img src="https://kdn.flygon.net/docs/img/c2af723905b1b39d25f62feda6a3c85e.png" alt="每个数据科学家都应该知道的 10 个基本 Pandas 函数" loading="lazy"></p>
<h1 id="5-数据分析">5. 数据分析</h1>
<p>在这里,我们将使用一些数据分析中的有用函数,如分组、排序和过滤。</p>
<ol>
<li><strong>聚合函数:</strong></li>
</ol>
<p>你可以按列名对列进行分组,然后应用一些聚合函数,如总和、最小/最大、平均等。</p>
<pre><code class="language-py">df.groupby("col_name_1").agg({"col_name_2": "sum"})
</code></pre>
<p>例如,</p>
<pre><code class="language-py">df.groupby("CITY").agg({"SALES": "sum"})
</code></pre>
<p>它将给出每个城市的总销售额。</p>
<p><img src="https://kdn.flygon.net/docs/img/b6a28433c28fec9ab8c4e84cd630cb16.png" alt="每个数据科学家都应该知道的 10 个基本 Pandas 函数" loading="lazy"></p>
<p>如果你想一次应用多个聚合,可以像这样编写它们。</p>
<p>例如,</p>
<pre><code class="language-py">aggregation = df.agg({"SALES": "sum", "QUANTITYORDERED": "mean"})
</code></pre>
<p>输出:</p>
<pre><code class="language-py">SALES 1.003263e+07
QUANTITYORDERED 3.509281e+01
dtype: float64
</code></pre>
<ol>
<li><strong>数据过滤:</strong></li>
</ol>
<p>我们可以根据特定值或条件过滤行中的数据。</p>
<p>例如,</p>
<pre><code class="language-py">df[df["SALES"] > 5000]
</code></pre>
<p>显示销售额大于 5000 的行。</p>
<p>你也可以使用<code>query()</code>函数来过滤数据框。它将生成类似的输出。</p>
<p>例如,</p>
<pre><code class="language-py">df.query("SALES" > 5000)
</code></pre>
<ol>
<li><strong>数据排序:</strong></li>
</ol>
<p>你可以根据特定列对数据进行排序,可以选择升序或降序。</p>
<p>例如,</p>
<pre><code class="language-py">df.sort_values("SALES", ascending=False) *# Sorts the data in descending order*
</code></pre>
<ol>
<li><strong>Pivot Tables:</strong></li>
</ol>
<p>我们可以创建透视表,通过特定的列来汇总数据。当你只想考虑某些列的效果时,这非常有用。</p>
<p>例如,</p>
<pre><code class="language-py">pd.pivot_table(df, values="SALES", index="CITY", columns="YEAR_ID", aggfunc="sum")
</code></pre>
<p>让我为你解释一下。</p>
<ol>
<li>
<p><code>values</code>: 它包含你想要填充表格单元格的列。</p>
</li>
<li>
<p><code>index</code>: 使用的列将成为透视表的行索引,该列的每个唯一类别将成为透视表中的一行。</p>
</li>
<li>
<p><code>columns</code>: 它包含透视表的标题,每个唯一的元素将成为透视表中的一列。</p>
</li>
<li>
<p><code>aggfunc</code>: 这是我们之前讨论过的聚合函数。</p>
</li>
</ol>
<p>输出:</p>
<p><img src="https://kdn.flygon.net/docs/img/d67238d9c896a542aa9d396700b9f2da.png" alt="10 Essential Pandas Functions Every Data Scientist Should Know" loading="lazy"></p>
<p>该输出显示了一个图表,描述了某个城市在特定年份的总销售额。</p>
<h2 id="6-combining-data-frames">6. Combining Data Frames</h2>
<p>我们可以水平或垂直地组合和合并多个数据框。它会连接两个数据框并返回一个合并后的数据框。</p>
<p>例如,</p>
<pre><code class="language-py">combined_df = pd.concat([df1, df2])
</code></pre>
<p>你可以基于一个公共列合并两个数据框。这在你想要结合两个具有共同标识符的数据框时非常有用。</p>
<p>例如,</p>
<pre><code class="language-py">merged_df = pd.merge(df1, df2, on="common_col")
</code></pre>
<h2 id="7-applying-custom-functions">7. Applying Custom Functions</h2>
<p>你可以根据需要在行或列中应用自定义函数。</p>
<p>例如,</p>
<pre><code class="language-py">def cus_fun(x):
return x * 3
df["Sales_Tripled"] = df["SALES"].apply(cus_fun, axis=0)
</code></pre>
<p>我们编写了一个自定义函数,将每行的销售额三倍化。<code>axis=0</code> 表示我们想在列上应用自定义函数,<code>axis=1</code> 表示我们想在行上应用该函数。</p>
<p>在之前的方法中,你必须编写一个单独的函数,然后通过 apply() 方法调用它。Lambda 函数帮助你在 apply() 方法内部使用自定义函数。让我们看看如何做到这一点。</p>
<pre><code class="language-py">df["Sales_Tripled"] = df["SALES"].apply(lambda x: x * 3)
</code></pre>
<p><strong>Applymap:</strong></p>
<p>我们还可以在一行代码中将自定义函数应用于数据框的每个元素。但要记住,这适用于数据框中的所有元素。</p>
<p>例如,</p>
<pre><code class="language-py">df = df.applymap(lambda x: str(x))
</code></pre>
<p>它将数据框中所有元素的数据类型转换为字符串。</p>
<h2 id="8-time-series-analysis">8. Time Series Analysis</h2>
<p>在数学中,时间序列分析指的是分析在特定时间间隔内收集的数据,而 pandas 提供了执行这种分析的函数。</p>
<p><strong>Conversion to DateTime Object Model:</strong></p>
<p>我们可以将日期列转换为 datetime 格式,以便更轻松地进行数据操作。</p>
<p>例如,</p>
<pre><code class="language-py">df["ORDERDATE"] = pd.to_datetime(df["ORDERDATE"])
</code></pre>
<p>输出:</p>
<p><img src="https://kdn.flygon.net/docs/img/a933247c8865091fab44e9faee45a572.png" alt="10 Essential Pandas Functions Every Data Scientist Should Know" loading="lazy"></p>
<p><strong>Calculate Rolling Average:</strong></p>
<p>使用此方法,我们可以创建一个滚动窗口来查看数据。我们可以指定任何大小的滚动窗口。如果窗口大小为 5,则表示在该时间点上为 5 天的数据窗口。它可以帮助你消除数据中的波动,并帮助识别随时间变化的模式。</p>
<p>例如,</p>
<pre><code class="language-py">rolling_avg = df["SALES"].rolling(window=5).mean()
</code></pre>
<p>输出:</p>
<p><img src="https://kdn.flygon.net/docs/img/abc0fcfe99ec1b44500b14254819a941.png" alt="每个数据科学家都应了解的 10 个 Pandas 函数" loading="lazy"></p>
<h2 id="9-交叉表">9. 交叉表</h2>
<p>我们可以对表中的两个列执行交叉表分析。它通常是一个频率表,显示各种类别的出现频率。这可以帮助你理解不同地区类别的分布。</p>
<p>例如,</p>
<p>获取 <code>COUNTRY</code> 和 <code>DEALSIZE</code> 之间的交叉表。</p>
<pre><code class="language-py">cross_tab = pd.crosstab(df["COUNTRY"], df["DEALSIZE"])
</code></pre>
<p>它可以显示按不同国家排序的订单大小(‘DEALSIZE’)。</p>
<p><img src="https://kdn.flygon.net/docs/img/9a1c4e7d37d6d2b05a2dd65f04fc5191.png" alt="每个数据科学家都应了解的 10 个 Pandas 函数" loading="lazy"></p>
<h2 id="10-处理离群值">10. 处理离群值</h2>
<p>数据中的离群值指的是某个点远远超出平均范围。让我们通过一个例子来理解它。假设你有 5 个点,例如 3、5、6、46、8。我们可以明确地说,数字 46 是一个离群值,因为它远远超出了其余点的平均值。这些离群值可能导致错误的统计数据,应该从数据集中移除。</p>
<p>在这里,pandas 帮助找到这些潜在的离群值。我们可以使用一种叫做四分位数间距(IQR)的方法,这是一种常见的找到和处理这些离群值的方法。如果你想了解这个方法的更多信息,你可以 <a href="https://byjus.com/maths/interquartile-range/" target="_blank">这里</a> 阅读更多内容。</p>
<p>让我们看看如何使用 pandas 来实现这个目标。</p>
<pre><code class="language-py">Q1 = df["SALES"].quantile(0.25)
Q3 = df["SALES"].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df[(df["SALES"] < lower_bound) | (df["SALES"] > upper_bound)]
</code></pre>
<p>Q1 是第一个四分位数,表示数据的第 25 百分位数,而 Q3 是第三个四分位数,表示数据的第 75 百分位数。</p>
<p><code>lower_bound</code> 变量存储用于查找潜在离群值的下界。它的值设置为 Q1 下方 IQR 的 1.5 倍。同样,<code>upper_bound</code> 计算上界,即 Q3 上方 IQR 的 1.5 倍。</p>
<p>然后,你需要筛选出低于下界或高于上界的离群值。</p>
<p><img src="https://kdn.flygon.net/docs/img/a2be5a948c74f1e0280dcc7c21115dba.png" alt="每个数据科学家都应了解的 10 个 Pandas 函数" loading="lazy"></p>
<h1 id="总结一下-1">总结一下</h1>
<p>Python pandas 库使我们能够执行高级数据分析和操作。这些只是其中的一些功能。你可以在 <a href="https://dataanalysispython.readthedocs.io/en/latest/" target="_blank">这</a> pandas 文档中找到更多工具。一个重要的事情是,技术的选择可以根据你的需求和使用的数据集而有所不同。</p>
<p><strong><a href="https://www.linkedin.com/in/aryan-garg-1bbb791a3/" target="_blank"></a></strong><a href="https://www.linkedin.com/in/aryan-garg-1bbb791a3/" target="_blank">Aryan Garg</a>** 是一名 B.Tech. 电气工程专业的学生,目前在本科最后一年。他对 Web 开发和机器学习领域感兴趣。他已经追求了这一兴趣,并渴望在这些方向上进一步发展。**</p>
<h3 id="更多相关内容-12">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/n03.html" target="_blank">KDnuggets™ News 22:n03, Jan 19: 深入了解 13 个数据…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n21.html" target="_blank">KDnuggets 新闻,5 月 25 日:每个 Python 机器学习工具的 6 个必备工具</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/05/6-python-machine-learning-tools-every-data-scientist-know.html" target="_blank">每个数据科学家都应该了解的 6 个 Python 机器学习工具</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/01/12-docker-commands-every-data-scientist-know.html" target="_blank">每个数据科学家都应该了解的 12 个 Docker 命令</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/tools-every-data-scientist-should-know-a-practical-guide" target="_blank">每个数据科学家都应该了解的工具:实用指南</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-python-libraries-every-data-scientist-should-know" target="_blank">每个数据科学家都应该了解的 10 个 Python 库</a></p>
</li>
</ul>
<h1 id="数据科学的-10-个基本-sql-命令">数据科学的 10 个基本 SQL 命令</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2022/10/10-essential-sql-commands-data-science.html" target="_blank"><code>www.kdnuggets.com/2022/10/10-essential-sql-commands-data-science.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/93b5f1ae3a5afebae36da396cd2653c7.png" alt="数据科学的 10 个基本 SQL 命令" loading="lazy"></p>
<p>图片由作者提供</p>
<p>这是学习 SQL 命令的新一天,这些命令将帮助你在数据科学职业中。你将使用 SQL 查询来提取、保存和修改数据库以满足你的需求。</p>
<hr>
<h2 id="我们的前三课程推荐">我们的前三课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织 IT</p>
<hr>
<p>那么,是什么阻止你学习提取数据和在 SQL 数据库上执行快速分析的最常用命令呢?</p>
<p>在这篇文章中,我们将通过使用<a href="https://www.programiz.com/sql/online-compiler/" target="_blank">在线 SQL 编辑器</a>学习基本 SQL 命令及代码示例。它允许用户在线运行查询而不会遇到问题。该平台提供了一个编辑器和三个用于练习的 SQL 表。数据库包括三个表:<strong>Customers</strong>、<strong>Orders</strong>和<strong>Shippings</strong>。</p>
<ol>
<li>
<p>选择</p>
</li>
<li>
<p>唯一</p>
</li>
<li>
<p>条件</p>
</li>
<li>
<p>LIKE</p>
</li>
<li>
<p>按顺序排列</p>
</li>
<li>
<p>作为</p>
</li>
<li>
<p>连接</p>
</li>
<li>
<p>UNION</p>
</li>
<li>
<p>按组</p>
</li>
<li>
<p>CASE</p>
</li>
</ol>
<h1 id="选择">选择</h1>
<p>SELECT 命令允许我们从表中提取选择的或所有列。这是 SQL 查询的基本构建块。</p>
<p>在我们的例子中,我们使用<code>*</code>从<strong>Customer</strong>表中显示所有列。</p>
<pre><code class="language-py">SELECT *
FROM Customers;
</code></pre>
<table>
<thead>
<tr>
<th><strong>客户编号</strong></th>
<th><strong>名</strong></th>
<th><strong>姓</strong></th>
<th><strong>年龄</strong></th>
<th><strong>国家</strong></th>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>John</td>
<td>Doe</td>
<td>31</td>
<td>美国</td>
</tr>
<tr>
<td>2</td>
<td>Robert</td>
<td>Luna</td>
<td>22</td>
<td>美国</td>
</tr>
<tr>
<td>3</td>
<td>David</td>
<td>Robinson</td>
<td>22</td>
<td>英国</td>
</tr>
<tr>
<td>4</td>
<td>John</td>
<td>Reinhardt</td>
<td>25</td>
<td>英国</td>
</tr>
<tr>
<td>5</td>
<td>Betty</td>
<td>Doe</td>
<td>28</td>
<td>阿联酋</td>
</tr>
</tbody>
</table>
<p>在第二个示例中,我们只展示了<strong>Customers</strong>表中的三列。你可以输入用逗号“,”分隔的列名,并以<strong>FROM</strong>命令和表名结束。</p>
<pre><code class="language-py">SELECT first_name,
last_name,
country
FROM Customers;
</code></pre>
<table>
<thead>
<tr>
<th><strong>名</strong></th>
<th><strong>姓</strong></th>
<th><strong>国家</strong></th>
</tr>
</thead>
<tbody>
<tr>
<td>John</td>
<td>Doe</td>
<td>美国</td>
</tr>
<tr>
<td>Robert</td>
<td>Luna</td>
<td>美国</td>
</tr>
<tr>
<td>David</td>
<td>Robinson</td>
<td>英国</td>
</tr>
<tr>
<td>John</td>
<td>Reinhardt</td>
<td>英国</td>
</tr>
<tr>
<td>Betty</td>
<td>Doe</td>
<td>阿联酋</td>
</tr>
</tbody>
</table>
<h1 id="唯一">唯一</h1>
<p>DISTINCT 用于显示列中的唯一值。它现在只显示一个 John,而不是两个 John。</p>
<pre><code class="language-py">SELECT DISTINCT first_name
FROM Customers;
</code></pre>
<table>
<thead>
<tr>
<th><strong>名</strong></th>
</tr>
</thead>
<tbody>
<tr>
<td>John</td>
</tr>
<tr>
<td>Robert</td>
</tr>
<tr>
<td>David</td>
</tr>
<tr>
<td>Betty</td>
</tr>
</tbody>
</table>
<h1 id="条件">条件</h1>
<p>WHERE 命令用于条件和过滤。我们将过滤表以显示年龄大于 25 的客户。除了大于,你还可以使用小于<strong><</strong>、小于或等于<strong><=</strong>、大于或等于<strong>>=</strong>和等于<strong>=</strong>。</p>
<pre><code class="language-py">SELECT *
FROM Customers
WHERE age > 25;
</code></pre>
<p>结果显示我们只有两个年龄大于 25 的客户。</p>
<table>
<thead>
<tr>
<th><strong>customer_id</strong></th>
<th><strong>first_name</strong></th>
<th><strong>last_name</strong></th>
<th><strong>age</strong></th>
<th><strong>country</strong></th>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>John</td>
<td>Doe</td>
<td>31</td>
<td>美国</td>
</tr>
<tr>
<td>5</td>
<td>Betty</td>
<td>Doe</td>
<td>28</td>
<td>阿联酋</td>
</tr>
</tbody>
</table>
<p>你还可以使用<strong>AND</strong>、<strong>OR</strong>、<strong>BETWEEN</strong>和<strong>IN</strong>来组合两个或多个条件。在我们的案例中,我们正在寻找年龄大于 25 的美国客户。</p>
<pre><code class="language-py">SELECT *
FROM Customers
WHERE age > 25
AND country == 'USA';
</code></pre>
<table>
<thead>
<tr>
<th><strong>customer_id</strong></th>
<th><strong>first_name</strong></th>
<th><strong>last_name</strong></th>
<th><strong>age</strong></th>
<th><strong>country</strong></th>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>John</td>
<td>Doe</td>
<td>31</td>
<td>美国</td>
</tr>
</tbody>
</table>
<h1 id="like">LIKE</h1>
<p>LIKE 命令用于字符串过滤。你提供表达式,它将用来查找匹配该表达式的值。例如,如果你想要所有以 J 开头的名字,可以使用“J%”。要查找以 J 结尾的名字,我们将使用“%J”。这很简单。</p>
<pre><code class="language-py">SELECT *
FROM Customers
WHERE first_name LIKE "J%";
</code></pre>
<table>
<thead>
<tr>
<th><strong>customer_id</strong></th>
<th><strong>first_name</strong></th>
<th><strong>last_name</strong></th>
<th><strong>age</strong></th>
<th><strong>country</strong></th>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>John</td>
<td>Doe</td>
<td>31</td>
<td>美国</td>
</tr>
<tr>
<td>4</td>
<td>John</td>
<td>Reinhardt</td>
<td>25</td>
<td>英国</td>
</tr>
</tbody>
</table>
<p>尝试查找<strong>first_name</strong>以“J”开头且<strong>last_name</strong>以“e”结尾的客户。你可以通过阅读 SQL LIKE 操作符示例教程来了解更多创建表达式的其他方法。</p>
<pre><code class="language-py">SELECT *
FROM Customers
WHERE first_name LIKE "J%"
OR last_name LIKE "%e";
</code></pre>
<table>
<thead>
<tr>
<th><strong>customer_id</strong></th>
<th><strong>first_name</strong></th>
<th><strong>last_name</strong></th>
<th><strong>age</strong></th>
<th><strong>country</strong></th>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>John</td>
<td>Doe</td>
<td>31</td>
<td>美国</td>
</tr>
<tr>
<td>4</td>
<td>John</td>
<td>Reinhardt</td>
<td>25</td>
<td>英国</td>
</tr>
<tr>
<td>5</td>
<td>Betty</td>
<td>Doe</td>
<td>28</td>
<td>阿联酋</td>
</tr>
</tbody>
</table>
<h1 id="order-by">ORDER BY</h1>
<p>ORDER BY 用于对查询结果进行排序。我们使用 ORDER BY 对结果进行基于<strong>first_name</strong>的升序排序。</p>
<pre><code class="language-py">SELECT *
FROM Customers
ORDER BY first_name;
</code></pre>
<table>
<thead>
<tr>
<th><strong>customer_id</strong></th>
<th><strong>first_name</strong></th>
<th><strong>last_name</strong></th>
<th><strong>age</strong></th>
<th><strong>country</strong></th>
</tr>
</thead>
<tbody>
<tr>
<td>5</td>
<td>Betty</td>
<td>Doe</td>
<td>28</td>
<td>阿联酋</td>
</tr>
<tr>
<td>3</td>
<td>David</td>
<td>Robinson</td>
<td>22</td>
<td>英国</td>
</tr>
<tr>
<td>1</td>
<td>John</td>
<td>Doe</td>
<td>31</td>
<td>美国</td>
</tr>
<tr>
<td>4</td>
<td>John</td>
<td>Reinhardt</td>
<td>25</td>
<td>英国</td>
</tr>
<tr>
<td>2</td>
<td>Robert</td>
<td>Luna</td>
<td>22</td>
<td>美国</td>
</tr>
</tbody>
</table>
<p>你可以尝试使用<strong>DESC</strong>在末尾对结果进行降序排序。</p>
<pre><code class="language-py">SELECT *
FROM Customers
ORDER BY first_name DESC;
</code></pre>
<table>
<thead>
<tr>
<th><strong>customer_id</strong></th>
<th><strong>first_name</strong></th>
<th><strong>last_name</strong></th>
<th><strong>age</strong></th>
<th><strong>country</strong></th>
</tr>
</thead>
<tbody>
<tr>
<td>2</td>
<td>Robert</td>
<td>Luna</td>
<td>22</td>
<td>美国</td>
</tr>
<tr>
<td>1</td>
<td>John</td>
<td>Doe</td>
<td>31</td>
<td>美国</td>
</tr>
<tr>
<td>4</td>
<td>John</td>
<td>Reinhardt</td>
<td>25</td>
<td>英国</td>
</tr>
<tr>
<td>3</td>
<td>David</td>
<td>Robinson</td>
<td>22</td>
<td>英国</td>
</tr>
<tr>
<td>5</td>
<td>Betty</td>
<td>Doe</td>
<td>28</td>
<td>阿联酋</td>
</tr>
</tbody>
</table>
<h1 id="as">AS</h1>
<p>AS 命令用于创建别名或重命名列名。在下面的示例中,我们将“customer_id”重命名为“ID”,将“first_name”重命名为“Name”。</p>
<pre><code class="language-py">SELECT customer_id AS ID,
first_name AS Name
FROM Customers;
</code></pre>
<table>
<thead>
<tr>
<th><strong>ID</strong></th>
<th><strong>Name</strong></th>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>John</td>
</tr>
<tr>
<td>2</td>
<td>Robert</td>
</tr>
<tr>
<td>3</td>
<td>David</td>
</tr>
<tr>
<td>4</td>
<td>John</td>
</tr>
<tr>
<td>5</td>
<td>Betty</td>
</tr>
</tbody>
</table>
<h1 id="join">JOIN</h1>
<p>你将联接多个表进行数据分析,这非常简单。只需在第一个表后使用<strong>LEFT JOIN</strong>、<strong>INNER JOIN</strong>、<strong>RIGHT JOIN</strong>或<strong>FULL JOIN</strong>。写下第二个表的名称,然后跟上<strong>ON</strong>来在特定列上联接表。在我们的案例中,两个表都有一个名为<strong>customer_id</strong>的公共列。我们将使用“==”符号联接这两个表的列名。</p>
<pre><code class="language-py">SELECT first_name,
item,
amount
FROM Customers
LEFT JOIN Orders
ON Customers.customer_id == Orders.customer_id
</code></pre>
<table>
<thead>
<tr>
<th><strong>first_name</strong></th>
<th><strong>item</strong></th>
<th><strong>amount</strong></th>
</tr>
</thead>
<tbody>
<tr>
<td>John</td>
<td>Keyboard</td>
<td>400</td>
</tr>
<tr>
<td>Robert</td>
<td>Mousepad</td>
<td>250</td>
</tr>
<tr>
<td>David</td>
<td>Monitor</td>
<td>12000</td>
</tr>
<tr>
<td>John</td>
<td>Keyboard</td>
<td>400</td>
</tr>
<tr>
<td>John</td>
<td>Mouse</td>
<td>300</td>
</tr>
<tr>
<td>Betty</td>
<td></td>
<td></td>
</tr>
</tbody>
</table>
<h1 id="union">UNION</h1>
<p>UNION 用于将两个查询结果一起显示。在这个例子中,我们将<strong>Customer</strong>表中的“first_name”显示为“Name_item”,并将<strong>Orders</strong>表中的“item”一起显示。</p>
<p><strong>注意:</strong> 确保两个查询显示相同数量的列。</p>
<pre><code class="language-py">SELECT first_name AS Name_item
FROM Customers
UNION
SELECT item
FROM Orders
</code></pre>
<p>如你所见,结果包含了<strong>Customers</strong>表中的 first_name 和 <strong>Orders</strong> 表中的 item。列按 A-Z 排序。</p>
<table>
<thead>
<tr>
<th><strong>Name_item</strong></th>
</tr>
</thead>
<tbody>
<tr>
<td>Betty</td>
</tr>
<tr>
<td>David</td>
</tr>
<tr>
<td>John</td>
</tr>
<tr>
<td>Keyboard</td>
</tr>
<tr>
<td>Monitor</td>
</tr>
<tr>
<td>Mouse</td>
</tr>
<tr>
<td>Mousepad</td>
</tr>
<tr>
<td>Robert</td>
</tr>
</tbody>
</table>
<h1 id="group-by">GROUP BY</h1>
<p>GROUP BY 命令在数据分析任务中经常使用。你可以对任意列进行分组,从而更好地理解数据分布。</p>
<p>GROUP BY 需要聚合函数:</p>
<ul>
<li>
<p>COUNT: 总行数</p>
</li>
<li>
<p>SUM: 所有值的总和</p>
</li>
<li>
<p>MAX: 最大值</p>
</li>
<li>
<p>MIN: 最小值</p>
</li>
<li>
<p>AVG: 平均值</p>
</li>
</ul>
<p>你可以使用聚合函数和 GROUP BY 将列中的值合并为类别。在下面的示例中,我们将对金额进行 SUM 聚合,并按 item 名称进行分组。</p>
<pre><code class="language-py">SELECT item,
SUM(amount)
FROM Orders
GROUP BY item
</code></pre>
<p>单个键盘的价格是 400,我们售出了 2 个键盘。它将其加总显示为 800。我知道这是一个简单的例子,但这是一个开始。</p>
<table>
<thead>
<tr>
<th><strong>item</strong></th>
<th><strong>SUM(amount)</strong></th>
</tr>
</thead>
<tbody>
<tr>
<td>Keyboard</td>
<td>800</td>
</tr>
<tr>
<td>Monitor</td>
<td>12000</td>
</tr>
<tr>
<td>Mouse</td>
<td>300</td>
</tr>
<tr>
<td>Mousepad</td>
<td>250</td>
</tr>
</tbody>
</table>
<h1 id="case">CASE</h1>
<p>CASE 命令类似于 Python 或其他语言中的<strong>if-else 语句</strong>。我们将用它来根据条件创建类别。</p>
<p>如果金额小于 1000,返回 ‘Low’,否则返回 ‘High’。</p>
<p>该命令以<strong>CASE</strong>开头,以<strong>END</strong>和列名结尾。</p>
<p><strong>If</strong> 被替换为 <strong>WHEN</strong>,<strong>else</strong> 被替换为 <strong>ELSE</strong>。</p>
<pre><code class="language-py">SELECT item,
amount,
CASE
WHEN amount < 1000 THEN 'Low'
ELSE 'High'
END AS Priority
FROM Orders;
</code></pre>
<table>
<thead>
<tr>
<th><strong>item</strong></th>
<th><strong>amount</strong></th>
<th><strong>Priority</strong></th>
</tr>
</thead>
<tbody>
<tr>
<td>Keyboard</td>
<td>400</td>
<td>Low</td>
</tr>
<tr>
<td>Mouse</td>
<td>300</td>
<td>Low</td>
</tr>
<tr>
<td>Monitor</td>
<td>12000</td>
<td>High</td>
</tr>
<tr>
<td>Keyboard</td>
<td>400</td>
<td>Low</td>
</tr>
<tr>
<td>Mousepad</td>
<td>250</td>
<td>Low</td>
</tr>
</tbody>
</table>
<p><strong><a href="https://www.polywork.com/kingabzpro" target="_blank">Abid Ali Awan</a></strong> (<a href="https://twitter.com/1abidaliawan" target="_blank">@1abidaliawan</a>) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为那些受精神疾病困扰的学生构建人工智能产品。</p>
<h3 id="相关主题更多内容">相关主题更多内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/07/16-essential-dvc-commands-data-science.html" target="_blank">数据科学的 16 个基本 DVC 命令</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/06/14-essential-git-commands-data-scientists.html" target="_blank">数据科学家的 14 个基本 Git 命令</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/01/12-essential-commands-streamlit.html" target="_blank">Streamlit 的 12 个基本命令</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n26.html" target="_blank">KDnuggets 新闻,6 月 29 日:数据科学的 20 个基本 Linux 命令…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/06/20-basic-linux-commands-data-science-beginners.html" target="_blank">数据科学初学者的 20 个基本 Linux 命令</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/01/12-docker-commands-every-data-scientist-know.html" target="_blank">每位数据科学家都应了解的 12 个 Docker 命令</a></p>
</li>
</ul>
<h1 id="10-个顶级大学的免费机器学习课程">10 个顶级大学的免费机器学习课程</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2023/02/10-free-machine-learning-courses-top-universities.html" target="_blank"><code>www.kdnuggets.com/2023/02/10-free-machine-learning-courses-top-universities.html</code></a></p>
</blockquote>
<p>机器学习是一个快速发展的领域,正在革新许多行业,包括医疗保健、金融和技术。凭借其分析大量数据并进行预测和决策的能力,机器学习是任何有意从事数据科学或人工智能职业的人的必备技能。</p>
<p>如果你想深入了解机器学习,那么你很幸运!网上有许多高质量的课程,由世界顶级大学提供。在本文中,我们将向你介绍 10 个来自顶级大学的免费机器学习课程。这些课程涵盖了从机器学习基础到更高级的技术,适合各个级别的学习者。无论你是想开始学习机器学习的初学者,还是想深化知识的经验丰富的数据科学家,你肯定会在这个列表中找到感兴趣的内容。那么,让我们开始吧!</p>
<hr>
<h2 id="我们的前三个课程推荐-13">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业的快车道。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织 IT</p>
<hr>
<p><img src="https://kdn.flygon.net/docs/img/820f68cb9d6c1b4ea6c5193efee0fa9f.png" alt="10 个顶级大学的免费机器学习课程" loading="lazy"></p>
<p>照片由 <a href="https://unsplash.com/ja/@datingscout?utm_source=medium&utm_medium=referral" target="_blank">Datingscout</a> 拍摄,来源于 <a href="https://unsplash.com?utm_source=medium&utm_medium=referral" target="_blank">Unsplash</a></p>
<h1 id="1-机器学习导论---uc-berkeley">1. 机器学习导论 - UC Berkeley</h1>
<p><strong>课程链接:</strong> <a href="https://lnkd.in/dChzX6dZ" target="_blank"><code>lnkd.in/dChzX6dZ</code></a></p>
<p>第一门课程是 UC Berkeley 提供的机器学习导论课程。这门课程是对机器学习领域的非常好的入门介绍,尤其适合初学者。它涵盖了每个机器学习任务中最重要的机器学习算法,如:</p>
<ul>
<li>
<p>分类:支持向量机(SVM)、高斯判别分析(线性判别分析 LDA 和二次判别分析 QDA)、逻辑回归、决策树、神经网络、卷积神经网络、提升方法和 K 近邻。</p>
</li>
<li>
<p>回归:最小二乘线性回归、逻辑回归、多项式回归、岭回归、Lasso。</p>
</li>
<li>
<p>聚类:<em>k</em>-均值聚类、层次聚类、谱图聚类。</p>
</li>
</ul>
<p>如果你是初学者并希望在机器学习基础概念方面建立坚实的基础,这门课程将是一个完美的选择。</p>
<p><strong>预计时长:</strong> 30 小时</p>
<p><strong>讲师:</strong> <a href="http://www.cs.berkeley.edu/~jrs" target="_blank"><strong>Jonathan Shewchuk</strong></a></p>
<p><strong>难度等级:</strong> 初学者</p>
<p><strong>课程材料:</strong></p>
<ul>
<li>
<p><a href="https://people.eecs.berkeley.edu/~jrs/189/#:~:text=Spring%202022.-,Lectures,-Now%20available%3A" target="_blank">讲义</a></p>
</li>
<li>
<p><a href="https://people.eecs.berkeley.edu/~jrs/189/#:~:text=or%20eTextbook.-,Homework%20and%20Exams,-You%20have%20a" target="_blank">作业与考试</a></p>
</li>
</ul>
<h1 id="2-机器学习简介---卡内基梅隆大学">2. 机器学习简介 - 卡内基梅隆大学</h1>
<p><strong>课程链接:</strong> <a href="https://lnkd.in/dH8ktatw" target="_blank"><code>lnkd.in/dH8ktatw</code></a></p>
<p>第二门课程也是由卡内基梅隆大学提供的入门级机器学习课程。这门课程以理论和实践两种方式涵盖了更多的机器学习算法。课程内容包括最重要的机器学习算法,如贝叶斯网络、决策树学习、支持向量机、统计学习方法、无监督学习算法、深度学习简介和强化学习。</p>
<p>此外,课程还涵盖了重要概念,如 PAC 学习框架、贝叶斯学习方法、基于边际的学习和奥卡姆剃刀。</p>
<p>这门课程旨在为你提供在机器学习领域研究或工作的人员目前所需的全面基础,包括方法论、技术、数学和算法。</p>
<p><strong>预计时长:</strong> 50 小时</p>
<p><strong>讲师:</strong> <a href="http://www.cs.cmu.edu/~tom" target="_blank">Tom Mitchell</a> & <a href="http://www.cs.cmu.edu/~ninamf/" target="_blank">Maria-Florina Balcan</a></p>
<p><strong>难度等级:</strong> 初学者</p>
<p><strong>课程材料:</strong></p>
<ul>
<li>
<p><a href="http://www.cs.cmu.edu/~ninamf/courses/601sp15/homeworks.shtml" target="_blank">作业</a></p>
</li>
<li>
<p><a href="http://www.cs.cmu.edu/~ninamf/courses/601sp15/projects.html" target="_blank">项目</a></p>
</li>
<li>
<p><a href="http://www.cs.cmu.edu/~ninamf/courses/601sp15/lectures.shtml" target="_blank">视频与幻灯片</a></p>
</li>
</ul>
<h1 id="3-机器学习---斯坦福大学">3. 机器学习 - 斯坦福大学</h1>
<p><strong>课程链接:</strong> <a href="https://lnkd.in/d4FzSKpJ" target="_blank"><code>lnkd.in/d4FzSKpJ</code></a></p>
<p>第三门课程是著名的 Andrew Ng 的机器学习课程,授课于斯坦福大学。这门课程专注于理论和实践的机器学习技术。你不仅会理解最重要的机器学习算法,还将学习如何从头构建和实现它们。最后,你将了解一些行业最佳实践,涉及机器学习和人工智能的创新。</p>
<p><strong>注意:该课程在 Coursera 上有一个新版本,由 Andrew Ng 教授授课。你可以在这里找到它。</strong></p>
<p><strong>预计时长:</strong> 60 小时</p>
<p><strong>讲师:</strong> Andrew Ng</p>
<p><strong>难度等级:</strong> 初学者</p>
<p><strong>课程材料:</strong></p>
<ul>
<li>
<p><a href="http://www.holehouse.org/mlclass/" target="_blank">课程页面</a></p>
</li>
<li>
<p><a href="https://www.youtube.com/playlist?list=PLLssT5z_DsK-h9vYZkQkYNWcItqhlRJLN" target="_blank">视频</a></p>
</li>
<li>
<p><a href="https://www.coursera.org/learn/machine-learning" target="_blank">Coursera 页面</a></p>
</li>
</ul>
<h1 id="4-机器学习与数据挖掘---加州理工学院">4. 机器学习与数据挖掘 - 加州理工学院</h1>
<p><strong>课程链接:</strong> <a href="https://lnkd.in/dUhbEyBx" target="_blank"><code>lnkd.in/dUhbEyBx</code></a></p>
<p>第四门课程是加州理工学院的《机器学习与数据挖掘》课程。这门课程涵盖了机器学习和数据挖掘中最流行的方法,更侧重于建立对这些方法在实践中应用的深入理解。此外,它还涵盖了一些最新的研究进展,例如深度生成模型。</p>
<p><strong>估计时长:</strong> 30 小时</p>
<p><strong>讲师:</strong> <a href="http://www.yisongyue.com/" target="_blank">岳一松</a></p>
<p><strong>难度级别:</strong></p>
<p><strong>课程材料:</strong></p>
<ul>
<li>
<p><a href="http://www.yisongyue.com/courses/cs155/2017_winter/" target="_blank">课程页面</a></p>
</li>
<li>
<p><a href="https://www.youtube.com/playlist?list=PLuz4CTPOUNi6BfMrltePqMAHdl5W33-bC" target="_blank">视频(2017)</a></p>
</li>
<li>
<p><a href="http://www.yisongyue.com/courses/cs155/2017_winter/#:~:text=Lectures%20%26%20Recitation%20Schedule" target="_blank">幻灯片</a></p>
</li>
<li>
<p><a href="http://www.yisongyue.com/courses/cs155/2017_winter/#:~:text=throughout%20the%20course.-,Assignments,-Homework%20LaTeX%20template" target="_blank">作业</a></p>
</li>
</ul>
<h1 id="5-数据学习---加州理工学院">5. 数据学习 - 加州理工学院</h1>
<p><strong>课程链接:</strong> <a href="https://lnkd.in/d4zZZJ5h" target="_blank"><code>lnkd.in/d4zZZJ5h</code></a></p>
<p>本列表中的第五门课程是加州理工学院的《数据学习》课程。这门课程以故事般的方式更侧重于学习理论,涵盖了学习是什么、机器能否学习以及如何学习等主题。它还平衡了理论和实践,并涵盖了机器学习的重要数学基础。</p>
<p><strong>估计时长:</strong> 30 小时</p>
<p><strong>讲师:</strong> 亚瑟·阿布-莫斯塔法教授</p>
<p><strong>难度级别:</strong> 初学者</p>
<p><strong>课程材料:</strong></p>
<ul>
<li>
<p><a href="https://home.work.caltech.edu/telecourse.html" target="_blank">课程页面</a></p>
</li>
<li>
<p><a href="https://www.youtube.com/playlist?list=PLD63A284B7615313A" target="_blank">视频</a></p>
</li>
<li>
<p><a href="https://work.caltech.edu/lectures.html#:~:text=Place%20the%20mouse%20on%20a%20lecture%20title%20for%20a%20short%20description" target="_blank">幻灯片</a></p>
</li>
</ul>
<h1 id="6-智能系统机器学习---康奈尔大学">6. 智能系统机器学习 - 康奈尔大学</h1>
<p><strong>课程链接:</strong> <a href="https://lnkd.in/dtSjQ22i" target="_blank"><code>lnkd.in/dtSjQ22i</code></a></p>
<p>本列表中的第六门课程是康奈尔大学的《智能系统机器学习》课程。这门课程将广泛介绍机器学习领域,并介绍一些最重要的机器学习算法和概念,帮助你开启机器学习之旅。</p>
<p><strong>估计时长:30 小时</strong></p>
<p><strong>讲师:</strong> <a href="http://kilian.cs.cornell.edu/" target="_blank">基利安·温伯格</a></p>
<p><strong>难度级别:初学者</strong></p>
<p><strong>课程材料:</strong></p>
<ul>
<li><a href="https://www.youtube.com/playlist?list=PLl8OlHZGYOQ7bkVbuRthEsaLr7bONzbXS" target="_blank">视频</a></li>
</ul>
<h1 id="7-大规模机器学习---多伦多大学">7. 大规模机器学习 - 多伦多大学</h1>
<p><strong>课程链接:</strong> <a href="http://www.cs.toronto.edu/~rsalakhu/STA4273_2015/" target="_blank"><code>lnkd.in/dv8-7EFE</code></a></p>
<p>我们列表中的第七门课程是由多伦多大学提供的大规模机器学习课程。这门课程更为高级,旨在为具有一定数学成熟度的研究生设计。课程从回归和分类的线性方法等基本机器学习方法开始,然后深入探讨统计机器学习方法,如贝叶斯网络、马尔可夫随机场及更多高级方法。</p>
<p><strong>预计时长:20 小时</strong></p>
<p><strong>讲师:</strong> <a href="https://video-archive.fields.utoronto.ca/list/speaker/8265-452-716" target="_blank">拉斯·萨拉赫乌丁诺夫</a></p>
<p><strong>难度等级:</strong> 高级</p>
<p><strong>课程材料:</strong></p>
<ul>
<li>
<p><a href="http://www.cs.toronto.edu/~rsalakhu/STA4273_2015/" target="_blank">课程页面</a></p>
</li>
<li>
<p><a href="https://video-archive.fields.utoronto.ca/list/event/283" target="_blank">视频</a></p>
</li>
<li>
<p><a href="http://www.cs.toronto.edu/~rsalakhu/STA4273_2015/assignments.html" target="_blank">作业与项目</a></p>
</li>
</ul>
<h1 id="8-大数据机器学习---卡内基梅隆大学">8. 大数据机器学习 - 卡内基梅隆大学</h1>
<p><strong>课程链接:</strong> <a href="https://www.youtube.com/@user-yd6im1cq5k/about" target="_blank"><code>www.youtube.com/@user-yd6im1cq5k/about</code></a></p>
<p>列表中的第八门课程是卡内基梅隆大学的大数据机器学习课程。这门课程以更深刻的方式处理与之前课程类似的问题。它关注如何构建能够处理大数据集的机器学习系统。处理大数据集具有几个困难,例如:</p>
<ul>
<li>
<p>计算和训练模型非常昂贵</p>
</li>
<li>
<p>难以可视化和理解</p>
</li>
<li>
<p>大数据集在不同的学习方法中表现出不同的行为,影响最准确的预测。</p>
</li>
</ul>
<p>基于处理大数据集需要不同的可扩展学习技术,包括:</p>
<ul>
<li>
<p>流式学习技术</p>
</li>
<li>
<p>并行基础设施,如 map-reduce</p>
</li>
<li>
<p>特征哈希和布隆过滤器用于减少学习方法的内存需求。</p>
</li>
</ul>
<p><strong>预计时长:40 小时</strong></p>
<p><strong>讲师:</strong> 威廉·科恩</p>
<p><strong>难度等级:高级</strong></p>
<p><strong>课程材料:</strong></p>
<ul>
<li>
<p><a href="http://curtis.ml.cmu.edu/w/courses/index.php/Main_Page" target="_blank">课程页面</a></p>
</li>
<li>
<p><a href="https://www.youtube.com/@user-yd6im1cq5k/videos" target="_blank">视频</a></p>
</li>
</ul>
<h1 id="9-机器学习与统计推断基础---加州理工学院">9. 机器学习与统计推断基础 - 加州理工学院</h1>
<p><strong>课程链接:</strong> <a href="http://tensorlab.cms.caltech.edu/users/anima/cms165-2020.html" target="_blank"><code>tensorlab.cms.caltech.edu/users/anima/cms165-2020.html#</code></a></p>
<p>第九门课程是由加州理工学院提供的机器学习与统计推断基础课程。该课程涵盖了机器学习和统计推断的核心概念。涵盖的机器学习概念包括:</p>
<ul>
<li>
<p>谱方法</p>
</li>
<li>
<p>非凸优化</p>
</li>
<li>
<p>概率模型</p>
</li>
<li>
<p>表示理论</p>
</li>
</ul>
<p>涵盖的统计推断主题包括:</p>
<ul>
<li>
<p>检测与估计</p>
</li>
<li>
<p>充分统计量</p>
</li>
<li>
<p>克拉默-拉奥界限</p>
</li>
<li>
<p>拉奥-布莱克威尔理论</p>
</li>
<li>
<p>变分推断</p>
</li>
</ul>
<p>课程假设你对分析、概率、统计和基本编程感到舒适。</p>
<p><strong>预计时长:30 小时</strong></p>
<p><strong>难度等级:初学者</strong></p>
<p><strong>课程材料:</strong></p>
<ul>
<li>
<p><a href="https://www.youtube.com/playlist?list=PLVNifWxslHCDlbyitaLLYBOAEPbmF1AHg" target="_blank">视频</a></p>
</li>
<li>
<p><a href="http://tensorlab.cms.caltech.edu/users/anima/cms165-2020.html#:~:text=1pm%20ANB%20105-,Lectures,-Lecture%20videos%20can" target="_blank">讲义</a></p>
</li>
<li>
<p><a href="http://tensorlab.cms.caltech.edu/users/anima/cms165-2020.html#:~:text=sdai%40caltech.edu-,Assignments,-Assignment%201" target="_blank">作业</a></p>
</li>
</ul>
<h1 id="10-机器学习的算法方面---mit">10. 机器学习的算法方面 - MIT</h1>
<p><strong>课程链接:</strong> <a href="https://ocw.mit.edu/courses/18-409-algorithmic-aspects-of-machine-learning-spring-2015/" target="_blank">https://ocw.mit.edu/courses/18-409-algorithmic-aspects-of-machine-learning-spring-2015/</a></p>
<p>这个列表中的第十个也是最后一个课程是麻省理工学院的《机器学习的算法方面》课程。该课程围绕机器学习中的算法问题进行结构化。现代机器学习系统总是建立在没有可证明保证的算法之上,何时以及为什么这些算法有效仍然是一个辩论的话题。在这门课程中,重点将是设计可以严格分析其性能的算法,针对基本的机器学习问题。</p>
<p><strong>讲师:</strong> <a href="https://ocw.mit.edu/search?q=Prof.+Ankur+Moitra" target="_blank"><strong>安库尔·莫伊特拉教授</strong></a></p>
<p><strong>预计时长:</strong> 50 小时</p>
<p><strong>难度等级:</strong> 初学者</p>
<p><strong>课程材料:</strong></p>
<ul>
<li>
<p><a href="https://ocw.mit.edu/courses/18-409-algorithmic-aspects-of-machine-learning-spring-2015/" target="_blank">课程页面</a></p>
</li>
<li>
<p><a href="https://www.youtube.com/playlist?list=PLB3sDpSRdrOvI1hYXNsa6Lety7K8FhPpx" target="_blank">课程视频</a></p>
</li>
</ul>
<p>总结来说,网络上有许多免费的机器学习课程,来自世界上一些顶尖大学。这些课程涵盖了从机器学习基础到更高级的技术等各种主题,适合各个水平的学习者。无论你是刚刚开始学习机器学习的初学者,还是希望深入知识的经验丰富的数据科学家,你肯定能在这 10 个免费的机器学习课程列表中找到感兴趣的内容。通过利用这些资源,你可以学习到宝贵的技能和知识,帮助你在快速发展的机器学习领域中取得成功。</p>
<p><strong><a href="https://www.linkedin.com/in/youssef-hosni-b2960b135" target="_blank">尤瑟夫·拉法特</a></strong> 是一名计算机视觉研究员和数据科学家。他的研究专注于为医疗保健应用开发实时计算机视觉算法。他还在营销、金融和医疗保健领域担任了超过 3 年的数据科学家。</p>
<h3 id="更多相关主题-9">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/5-free-artificial-intelligence-courses-from-top-universities" target="_blank">来自顶尖大学的 5 个免费人工智能课程</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/08/best-courses-ai-universities-youtube-playlists.html" target="_blank">大学提供的人工智能最佳课程(YouTube 播放列表)</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n48.html" target="_blank">KDnuggets 新闻,12 月 14 日:3 个免费的机器学习课程…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/02/top-5-free-machine-learning-courses.html" target="_blank">顶级 5 个免费的机器学习课程</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/top-5-free-machine-learning-courses-to-level-up-your-skills" target="_blank">提升技能的前 5 名免费机器学习课程</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/free-courses-that-are-actually-free-ai-ml-edition" target="_blank">真正免费的课程:人工智能与机器学习版</a></p>
</li>
</ul>
<h1 id="10-本机器学习和数据科学必读的免费书籍">10 本机器学习和数据科学必读的免费书籍</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2017/04/10-free-must-read-books-machine-learning-data-science.html" target="_blank"><code>www.kdnuggets.com/2017/04/10-free-must-read-books-machine-learning-data-science.html</code></a></p>
</blockquote>
<p>有什么比用一些免费的机器学习和数据科学电子书来享受这个春天的天气更好的方式呢?对吧?对吧?</p>
<p>这是一个快速收集的书单,帮助你在良好的起点上开始学习。书单从统计学基础开始,进入机器学习基础,进而探讨几个更宏观的标题,快速了解一两个高级话题,并以一些综合的内容结尾。经典与现代书籍的混合,希望你能在这里找到一些对你来说新的且有趣的内容。</p>
<hr>
<h2 id="我们的三大课程推荐-4">我们的三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业的捷径。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析水平</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织的 IT</p>
<hr>
<p><img src="https://kdn.flygon.net/docs/img/daaaa35cb07263fa738d353747ec317b.png" alt="免费书籍!" loading="lazy"></p>
<p><strong>1. <a href="http://www.greenteapress.com/thinkstats/" target="_blank">思考统计:程序员的概率与统计</a></strong></p>
<p>作者:Allen B. Downey</p>
<blockquote>
<p>《思考统计》是为 Python 程序员介绍概率和统计的书籍。</p>
<p>《思考统计》强调了可以用来探索真实数据集和回答有趣问题的简单技巧。书中使用了来自国家卫生研究院的数据进行案例研究。鼓励读者使用真实数据集进行项目。</p>
</blockquote>
<p><strong>2. <a href="http://camdavidsonpilon.github.io/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers/" target="_blank">概率编程与贝叶斯方法</a></strong></p>
<p>作者:Cam Davidson-Pilon</p>
<blockquote>
<p>从计算/理解优先、数学次之的角度介绍贝叶斯方法和概率编程。</p>
<p>贝叶斯方法是推理的自然方法,但在读者面前常常被缓慢的数学分析所遮蔽。典型的贝叶斯推理文本涉及两到三章的概率理论,然后才介绍贝叶斯推理。不幸的是,由于大多数贝叶斯模型的数学不可处理,读者只能看到简单的人工示例。这可能会让用户对贝叶斯推理感到无所谓。事实上,这曾是作者自己的看法。</p>
</blockquote>
<p><strong>3. <a href="http://www.cs.huji.ac.il/~shais/UnderstandingMachineLearning/" target="_blank">理解机器学习:从理论到算法</a></strong></p>
<p>作者:Shai Shalev-Shwartz 和 Shai Ben-David</p>
<blockquote>
<p>机器学习是计算机科学中发展最快的领域之一,具有广泛的应用。本教材旨在以原则性的方式介绍机器学习及其提供的算法范式。书中对机器学习基础理论和将这些原理转化为实际算法的数学推导进行了理论性的描述。在介绍基本概念后,本书覆盖了之前教材未涉及的大量核心主题,包括学习的计算复杂性、凸性和稳定性概念;重要的算法范式,如随机梯度下降、神经网络和结构化输出学习;以及新兴的理论概念,如 PAC-Bayes 方法和基于压缩的界限。</p>
</blockquote>
<p><strong>4. <a href="http://statweb.stanford.edu/~tibs/ElemStatLearn/printings/ESLII_print10.pdf" target="_blank">统计学习的要素</a></strong></p>
<p>作者:Trevor Hastie, Robert Tibshirani 和 Jerome Friedman</p>
<blockquote>
<p>本书在一个共同的概念框架中描述了这些领域的重要思想。虽然方法是统计性的,但重点在于概念而非数学。书中给出了许多例子,并大量使用了彩色图形。它应成为统计学家和任何对科学或工业中的数据挖掘感兴趣的人士的宝贵资源。书中的内容涵盖广泛,从监督学习(预测)到无监督学习,许多主题包括神经网络、支持向量机、分类树和提升——这是任何书籍中对这一主题的首次全面处理。</p>
</blockquote>
<p><strong>5. <a href="http://www-bcf.usc.edu/~gareth/ISL/" target="_blank">带有 R 应用的统计学习简介</a></strong></p>
<p>作者:Gareth James, Daniela Witten, Trevor Hastie 和 Robert Tibshirani</p>
<blockquote>
<p>本书介绍了统计学习方法,主要面向本科高年级学生、硕士生和非数学科学领域的博士生。书中还包含了多个 R 实验室的详细解释,讲解了如何在实际环境中实施各种方法,对于从事数据科学工作的实践者来说,应该是一个宝贵的资源。</p>
</blockquote>
<p><strong>6. <a href="https://www.cs.cornell.edu/jeh/book.pdf" target="_blank">数据科学基础</a></strong></p>
<p>作者:Avrim Blum, John Hopcroft, 和 Ravindran Kannan</p>
<blockquote>
<p>虽然传统的计算机科学领域仍然非常重要,但未来的研究人员将越来越多地涉及使用计算机理解和提取来自大量数据的可用信息,而不仅仅是如何在特定明确的问题上使计算机变得有用。考虑到这一点,我们编写了这本书,以覆盖未来 40 年可能有用的理论,就像对自动机理论、算法及相关主题的理解在过去 40 年中给学生带来了优势一样。</p>
</blockquote>
<p><strong>7. <a href="http://guidetodatamining.com/" target="_blank">程序员的数据挖掘指南:数字化古老的艺术</a></strong></p>
<p>作者:<strong>罗恩·扎卡斯基</strong></p>
<blockquote>
<p>本指南采用“做中学”的方法。与其被动地阅读书籍,我鼓励你通过练习和实验我提供的 Python 代码来积极参与。我希望你能主动尝试并编程数据挖掘技术。这本教科书分为一系列逐步递进的小步骤,直到你完成书本时,你已经奠定了理解数据挖掘技术的基础。</p>
</blockquote>
<p><strong>8. <a href="http://mmds.org/" target="_blank">大规模数据集挖掘</a></strong></p>
<p>作者:<strong>朱尔·莱斯科维奇</strong>、<strong>安南德·拉贾拉曼</strong> 和 <strong>杰夫·乌尔曼</strong></p>
<blockquote>
<p>本书基于斯坦福计算机科学课程 CS246:大规模数据集挖掘(和 CS345A:数据挖掘)。</p>
<p>本书像课程一样,设计为本科计算机科学水平,无需正式的先修条件。为了支持更深入的探索,大多数章节都附有进一步阅读的参考资料。</p>
</blockquote>
<p><strong>9. <a href="http://www.deeplearningbook.org/" target="_blank">深度学习</a></strong></p>
<p>作者:<strong>伊恩·古德费洛</strong>、<strong>约书亚·本吉奥</strong> 和 <strong>亚伦·库维尔</strong></p>
<blockquote>
<p>《深度学习》教科书旨在帮助学生和从业者进入机器学习领域,特别是深度学习。该书的在线版本现已完成,并将继续免费在线提供。</p>
</blockquote>
<p><strong>10. <a href="http://www.mlyearning.org/" target="_blank">机器学习的渴望</a></strong></p>
<p>作者:<strong>安德鲁·吴</strong></p>
<blockquote>
<p>AI、机器学习和深度学习正在改变众多行业。但是,构建机器学习系统需要你做出实际的决策:</p>
<ul>
<li>你是否应该收集更多的训练数据?</li>
<li></li>
<li>你是否应该使用端到端的深度学习?</li>
<li></li>
<li>你如何处理训练集与测试集不匹配的问题?</li>
<li></li>
<li>还有更多。</li>
<li></li>
</ul>
<p>历史上,学习如何做出这些“策略”决策的唯一途径是多年的研究生课程或公司实习。我正在撰写一本书,帮助你快速掌握这项技能,使你在构建 AI 系统方面变得更出色。</p>
</blockquote>
<p><strong>相关</strong>:</p>
<ul>
<li>
<p>数据爱好者必读的十大书籍</p>
</li>
<li>
<p>进入数据科学或大数据职业之前要读的 5 本电子书</p>
</li>
<li>
<p>进入机器学习职业之前要读的 5 本电子书</p>
</li>
</ul>
<h3 id="更多相关话题-12">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/build-solid-data-team.html" target="_blank">建立一个强大的数据团队</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/write-clean-python-code-pipes.html" target="_blank">使用管道编写干净的 Python 代码</a></p>
</li>
<li>
<p>[停止学习数据科学,找到目标,再找目标...] (<a href="https://www.kdnuggets.com/2021/12/stop-learning-data-science-find-purpose.html" target="_blank">https://www.kdnuggets.com/2021/12/stop-learning-data-science-find-purpose.html</a>)</p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/springboard-top-resources-learn-data-science-statistics.html" target="_blank">学习数据科学统计的顶级资源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-characteristics-successful-data-scientist.html" target="_blank">成功数据科学家的 5 个特征</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-key-skills-needed-become-great-data-scientist.html" target="_blank">成为优秀数据科学家所需的 5 项关键技能</a></p>
</li>
</ul>
<h1 id="10-个免费的机器学习和数据科学必看课程">10 个免费的机器学习和数据科学必看课程</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2018/11/10-free-must-see-courses-machine-learning-data-science.html" target="_blank"><code>www.kdnuggets.com/2018/11/10-free-must-see-courses-machine-learning-data-science.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/3d9c022da2d331bb56691a9617b91b90.png" alt="c" loading="lazy"> 评论</p>
<p>这是一个免费的机器学习和数据科学课程集合,适合开启你的冬季学习季节。课程涵盖从入门机器学习到深度学习、自然语言处理及更多领域。</p>
<p>如果在阅读此列表后,你希望获得更多免费的优质策划学习资料,请查看下面的相关帖子。</p>
<hr>
<h2 id="我们的三大课程推荐-5">我们的三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持组织中的 IT</p>
<hr>
<p><img src="https://kdn.flygon.net/docs/img/1cb320c1836423482d47065338288c63.png" alt="Post header image" loading="lazy"></p>
<p><strong>1. <a href="https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-0002-introduction-to-computational-thinking-and-data-science-fall-2016/" target="_blank">计算思维与数据科学导论</a></strong></p>
<p>麻省理工学院</p>
<blockquote>
<p>6.0002 是 6.0001《计算机科学与 Python 编程导论》的续集,旨在为编程经验较少或没有编程经验的学生提供课程。课程旨在帮助学生理解计算在解决问题中所起的作用,并帮助学生,无论其主修专业如何,建立对编写小程序以实现有用目标的能力的自信。课程使用 Python 3.5 编程语言。</p>
</blockquote>
<p><strong>2. <a href="http://cs229.stanford.edu/" target="_blank">机器学习</a></strong></p>
<p>斯坦福大学</p>
<blockquote>
<p>这门课程提供了机器学习和统计模式识别的广泛介绍。主题包括:监督学习(生成式/判别式学习,参数化/非参数化学习,神经网络,支持向量机);无监督学习(聚类,降维,核方法);学习理论(偏差/方差权衡;VC 理论;大间隔);强化学习和自适应控制。课程还将讨论机器学习的最新应用,如机器人控制、数据挖掘、自动导航、生物信息学、语音识别以及文本和网页数据处理。</p>
</blockquote>
<p><strong>3. <a href="https://course.fast.ai/ml" target="_blank">为编码者介绍机器学习!</a></strong></p>
<p>fast.ai</p>
<blockquote>
<p>课程大约有 24 小时的内容,你应该计划每周花费大约 8 小时,持续 12 周来完成这些材料。该课程基于在旧金山大学为<a href="https://www.usfca.edu/arts-sciences/graduate-programs/data-science" target="_blank">数据科学硕士项目</a>录制的课程。我们假设你至少有一年的编程经验,并且要么记得你在高中数学中学到的知识,要么准备进行一些独立学习以刷新你的知识。</p>
</blockquote>
<p><strong>4. <a href="https://developers.google.com/machine-learning/crash-course/" target="_blank">机器学习速成课程</a></strong></p>
<p>谷歌</p>
<blockquote>
<p>准备开始练习机器学习了吗?通过速成课程学习并应用基本的机器学习概念,参与 Kaggle 竞赛获得实际经验,或访问 Learn with Google AI 探索完整的培训资源库。</p>
</blockquote>
<p><strong>5. <a href="http://introtodeeplearning.com/" target="_blank">深度学习简介</a></strong></p>
<p>麻省理工学院</p>
<blockquote>
<p>一门介绍深度学习方法的课程,应用于机器翻译、图像识别、游戏玩法、图像生成等。该课程包括 TensorFlow 实验室和同行头脑风暴,并结合讲座。课程最后将提出项目建议,并获得来自工作人员和行业赞助商小组的反馈。</p>
</blockquote>
<p><strong>6. <a href="https://course.fast.ai/" target="_blank">实用深度学习:程序员第一部分</a></strong></p>
<p>fast.ai</p>
<blockquote>
<p>欢迎参加 fast.ai 2018 版的 7 周课程“实用深度学习:程序员第一部分”,由 Jeremy Howard(Kaggle 连续两年排名第一的竞争者和 Enlitic 创始人)教授。学习如何构建最先进的模型,无需研究生级别的数学,但也不降低任何难度。还有一件事... 这完全免费!而且有一个由数千名其他学习者组成的社区,随时准备帮助你进行学习——如果你需要帮助,或只是想与其他深度学习学习者聊天,请前往 forums.fast.ai。</p>
</blockquote>
<p><em>请注意,这门课程还有第二部分:<a href="https://course.fast.ai/part2.html" target="_blank">前沿深度学习:程序员第二部分</a></em></p>
<p><strong>7. <a href="https://github.com/yandexdataschool/nlp_course" target="_blank">自然语言处理</a></strong></p>
<p>Yandex 数据学校</p>
<blockquote>
<p><img src="https://kdn.flygon.net/docs/img/c359d9fe852c8a85ae94056cbab5ecb2.png" alt="" loading="lazy"></p>
</blockquote>
<p><strong>8. <a href="https://web.stanford.edu/class/cs124/" target="_blank">从语言到信息</a></strong></p>
<p>斯坦福大学</p>
<blockquote>
<p>在线世界中有大量的非结构化信息,形式包括语言和社交网络。学习如何理解这些信息以及如何通过语言与人互动,从回答问题到提供建议!</p>
</blockquote>
<p><strong>9. <a href="https://github.com/yandexdataschool/Practical_RL" target="_blank">实用强化学习</a></strong></p>
<p>Yandex 数据学校</p>
<blockquote>
<p>一门关于强化学习的课程。</p>
<ul>
<li><strong>为好奇心优化。</strong> 对于所有没有详细覆盖的材料,都有更多信息和相关材料的链接(D.Silver/Sutton/博客/其他)。如果你想深入探究,作业将会有额外的奖励部分。</li>
<li></li>
<li><strong>实用性优先。</strong> 解决强化学习问题中所有关键内容都值得提及。我们不会回避讨论技巧和启发式方法。每个主要的想法都应该有一个实验室,让你在实际问题中“感受”它。</li>
</ul>
</blockquote>
<p><strong>10. <a href="https://github.com/fastai/numerical-linear-algebra/blob/master/README.md" target="_blank">编程人员的计算线性代数</a></strong></p>
<p>fast.ai</p>
<blockquote>
<p>这门课程聚焦于一个问题:<strong>我们如何以可接受的速度和准确性进行矩阵计算?</strong></p>
<p>这门课程在旧金山大学的分析学硕士项目中教授,时间是 2017 年夏季(针对正在学习成为数据科学家的研究生)。课程使用 Python 和 Jupyter Notebooks 进行教学,大多数课程使用 Scikit-Learn 和 Numpy 库,少部分课程使用 Numba(一个将 Python 编译为 C 以提高性能的库)和 PyTorch(GPU 上的 Numpy 替代品)。</p>
</blockquote>
<p><strong>相关</strong>:</p>
<ul>
<li>
<p>10 本机器学习和数据科学必读免费书籍</p>
</li>
<li>
<p>10 本机器学习和数据科学的更多必读免费书籍</p>
</li>
<li>
<p>5 门关于人工智能入门的免费课程</p>
</li>
</ul>
<h3 id="更多相关主题-10">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-key-skills-needed-become-great-data-scientist.html" target="_blank">成为优秀数据科学家所需的 5 项关键技能</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/6-predictive-models-every-beginner-data-scientist-master.html" target="_blank">每位初学者数据科学家应该掌握的 6 种预测模型</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/mozart-best-etl-tools-2021.html" target="_blank">2021 年最佳 ETL 工具</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/stop-learning-data-science-find-purpose.html" target="_blank">停止学习数据科学以寻找目的,并以目的去…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/springboard-top-resources-learn-data-science-statistics.html" target="_blank">学习数据科学统计学的最佳资源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/build-solid-data-team.html" target="_blank">建立一个扎实的数据团队</a></p>
</li>
</ul>
<h1 id="10-个免费必修的数据科学课程">10 个免费必修的数据科学课程</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/10-free-must-take-data-science-courses-to-get-started" target="_blank"><code>www.kdnuggets.com/10-free-must-take-data-science-courses-to-get-started</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/96dbcdd9ba94612885f34259f755e1d1.png" alt="10 个免费必修的数据科学课程" loading="lazy"></p>
<p>图片由 Ideogram.ai 生成</p>
<p>你是数据科学初学者并想开始你的数据科学家职业生涯吗?或者你之前学过这些内容,需要复习一下?那么,你刚刚读到了完美的文章!</p>
<hr>
<h2 id="我们的前三个课程推荐-14">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织的 IT 工作</p>
<hr>
<p>目前有许多免费的数据科学课程,这可能需要大量时间和技能。因此,这篇文章将指导你选择正确的免费课程来优化你的学习。</p>
<p>这些课程是什么?让我们来看看。</p>
<h2 id="1-ibm-数据科学简介">1. IBM: 数据科学简介</h2>
<p>在你跳入数据科学领域之前,你必须了解这个领域的内容。通过对工作职责和职位要求的良好理解,你可能会在未来获得更多收益。</p>
<p>这就是为什么他首先必须参加一个能够介绍数据科学重要性的课程: <a href="https://www.edx.org/learn/data-science/ibm-introduction-to-data-science" target="_blank">IBM: 数据科学简介</a> 课程。</p>
<p>在这门课程中,你将学习必要的知识,如数据科学的定义、数据科学家做什么、通常使用的工具、成功所需的技能以及数据科学家在商业中的角色。</p>
<p>这是一个短期课程,为你未来的职业生涯奠定基础。</p>
<h2 id="2-完全初学者的数据科学介绍">2. 完全初学者的数据科学介绍</h2>
<p>让我们继续学习,这次深入学习数据科学概念。你可能已经理解了数据科学是什么以及它如何运作,但还有一些概念你必须学习。</p>
<p>在 <a href="https://www.udemy.com/course/intro2dseng/" target="_blank">完全初学者的数据科学介绍</a> 中,你将学习更多关于数据科学应用、机器学习概念以及数据科学与类似数据角色之间的区别。</p>
<p>这也是一个短期课程,完成大约需要一天时间,但学得好,它可以很好地支持你的职业生涯。</p>
<h2 id="3-统计学介绍">3. 统计学介绍</h2>
<p>数据科学领域与统计学密不可分。虽然它们是不同的概念,但由于统计技术在数据科学中的应用,它们紧密相连。这就是为什么我们需要学习统计学,以便在数据科学领域取得成功。</p>
<p><a href="https://www.coursera.org/learn/stanford-statistics" target="_blank">斯坦福大学的统计学导论课程</a>将向你介绍统计思维,这对于学习数据和与他人分享见解至关重要。在这门课程中,你将学习所有基本的统计概念,如描述统计、推断统计、概率、重抽样、回归等。</p>
<p>对初学者来说,这可能是一个相当具有挑战性的课程,但你可以慢慢进行,这将对你的数据科学职业生涯有极大帮助。</p>
<h2 id="4-python-数据科学ai-和开发">4. Python 数据科学、AI 和开发</h2>
<p>一旦你对数据科学领域有了深入的了解,就该投入到技术技能的学习中了。</p>
<p>在现代时代,数据科学现在与编程语言密不可分,因为它允许用户加速世界的进程。这就是为什么我们将从学习数据科学技能的基础开始:Python 编程。</p>
<p><a href="https://www.coursera.org/learn/python-for-applied-data-science-ai" target="_blank">IBM 的数据科学、AI 和开发 Python 课程</a> 是你学习 Python 的完美课程,这在数据科学领域是必需的。通过学习五个不同的模块,你将掌握所有基础知识,包括 Python 基础、数据结构、如何使用 Python 处理数据和 API。</p>
<p>这是一个自定进度的课程,你可以花费几周时间来掌握基础知识。</p>
<h2 id="5-机器学习全课程">5. 机器学习全课程</h2>
<p>有了 Python 知识,我们来深入了解机器学习。机器学习已成为数据科学家解决业务问题的必备工具。因此,我们必须更加了解机器学习的概念。</p>
<p>在 <a href="http://freecodecamp.org" target="_blank">Machine Learning for Everybody – Full Course by freecodecamp.org</a> 中,你将由经验丰富的讲师学习概念,并了解模型如何在 Python 中运作。主要收获是对机器学习概念的理解,而不是实践操作,因此你应该专注于学习这些概念。</p>
<p>这是一个短期课程,你可以尝试在一天内完成,但应在各个阶段花时间理解课程内容。</p>
<h2 id="6-使用-python-进行数据科学导论">6. 使用 Python 进行数据科学导论</h2>
<p>在编程技能作为基础之后,我们将更深入地学习如何使用 Python 进行数据科学。在下一个课程中,我们将学习 <a href="https://www.edx.org/learn/data-science/harvard-university-introduction-to-data-science-with-python" target="_blank">哈佛大学的 Python 数据科学导论</a>。</p>
<p>该课程适用于那些想要深入了解数据科学但已经具备最低限度的 Python 编程知识的人。这不是一个学习 Python 的课程,而是关于如何在数据科学工作中使用 Python 的课程。</p>
<p>这是因为许多课程涉及了 Python 在数据科学领域的实际应用,比如使用统计学习、模型开发、模型选择以及开发你的第一个数据科学项目。</p>
<p>如果你完成了这门课程,它可以作为你的第一个数据科学作品集。</p>
<h2 id="7-使用-scikit-learn-在-python-中进行机器学习">7. 使用 scikit-learn 在 Python 中进行机器学习</h2>
<p>你应该学习的下一个课程是 <a href="https://www.fun-mooc.fr/en/courses/machine-learning-python-scikit-learn/" target="_blank">来自 Inria 的 Python 中的机器学习与 scikit-learn</a>。这是一个入门级课程,旨在帮助你开发机器学习模型,但仍然需要理解编程和机器学习概念。</p>
<p>预测机器学习模型是数据科学家重要的工具,这门课程将教你开发它所需的所有基础知识。使用流行的 Scikit-Learn 库,课程将指导你创建管道、开发最佳模型、调整模型并评估模型。</p>
<p>课程是自定进度的,你可以花时间完成它。</p>
<h2 id="8-学习-sql-基础知识以专注于数据科学">8. 学习 SQL 基础知识以专注于数据科学</h2>
<p>Python 并不是数据科学家应该掌握的唯一编程语言。随着公司数据存储方式的变化,SQL 在数据角色中的重要性变得更加突出。这意味着数据科学家需要理解 SQL 进行数据查询。</p>
<p><a href="https://www.coursera.org/specializations/learn-sql-basics-data-science" target="_blank">从 UC Davis 学习 SQL 基础知识以专注于数据科学</a> 是学习 SQL 的合适课程,它适合任何没有编程技能的初学者。</p>
<p>该课程包含四个模块,难度逐步增加。你将从 SQL 基础知识开始学习,接着了解更多关于使用 SQL 进行数据处理和分析的内容。你还会学习如何使用分布式计算,并最终开发你的 SQL 项目。</p>
<p>完成这门课程将把你的职业生涯提升到一个新的水平,所以不要错过它。</p>
<h2 id="9-数据可视化入门">9. 数据可视化入门</h2>
<p>对于数据科学家来说,将结果传达给观众和结果本身一样重要。如果你不能让观众理解你的数据科学项目并说服利益相关者项目的重要性,那么这就等于一个失败的项目。</p>
<p>数据可视化是一种比展示原始数据更具美感和更友好的方式来展示你的结果。<a href="https://www.simplilearn.com/free-data-visualization-course-online-skillup" target="_blank">Simplilearn 的数据可视化入门</a>是学习如何可视化数据的一个很好的起点。</p>
<p>这门课程将教你数据可视化原则,如何用可视化进行沟通,以及如何使用多个可视化工具,如 PowerBI、Excel 和 Matplotlib。</p>
<p>这是一个短期课程,但如果你学得好,它可能会很有效。</p>
<h2 id="10-传达数据科学结果">10. 传达数据科学结果</h2>
<p>我们最后要学习的课程是如何进行沟通,尤其是与利益相关者和非技术观众的沟通。这是一项每位数据科学家都需要掌握的关键软技能,因为这是数据科学工作的一部分。</p>
<p>我们可能拥有数据科学的技术技能和优秀的成果,但错误的沟通可能会导致灾难性的项目。由<a href="https://www.coursera.org/learn/data-results" target="_blank">华盛顿大学提供的数据科学结果沟通课程</a>是必要的。</p>
<p>该课程将教你如何有效地可视化数据结果、数据科学项目中的隐私和伦理问题,以及数据科学的可重复性和云计算。通过学习这些技能,你一定能够在职业生涯中脱颖而出。</p>
<h2 id="结论-7">结论</h2>
<p>上述课程建议从头到尾逐一学习,但可以根据需要选择学习。文章的关键点在于,免费课程是必须学习的,因为它们教会你成为数据科学家所需的技能。</p>
<p>享受这个过程,并相信你可以成为一名数据科学家。</p>
<p><strong><a href="https://www.linkedin.com/in/cornellius-yudha-wijaya/" target="_blank"></a></strong><a href="https://www.linkedin.com/in/cornellius-yudha-wijaya/" target="_blank">Cornellius Yudha Wijaya</a>**** 是一位数据科学助理经理和数据撰稿人。他在全职工作于 Allianz Indonesia 的同时,喜欢通过社交媒体和写作分享 Python 和数据技巧。Cornellius 撰写了各种 AI 和机器学习主题的文章。</p>
<h3 id="更多相关内容-13">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/07/sphere-upskilling-data-vis-matters.html" target="_blank">为何提升数据可视化技能很重要(& 如何开始)</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/federated-learning-collaborative-machine-learning-tutorial-get-started.html" target="_blank">联邦学习:协作机器学习教程…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/08/sphere-3-benefits-ab-testing-get-started.html" target="_blank">A/B 测试的 3 个好处(+如何开始)</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/08/7-beginnerfriendly-projects-get-started-chatgpt.html" target="_blank">7 个适合初学者的项目,让你快速入门 ChatGPT</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/short-and-fun-courses-to-get-you-up-to-speed-about-generative-ai" target="_blank">短小有趣的课程,让你快速了解生成 AI</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/10/get-running-sql-list-free-learning-resources.html" target="_blank">如何快速入门 SQL - 免费学习资源列表</a></p>
</li>
</ul>
<h1 id="10-个学习-llm-的免费资源">10 个学习 LLM 的免费资源</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/10-free-resources-to-learn-llms" target="_blank"><code>www.kdnuggets.com/10-free-resources-to-learn-llms</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/95b5bc098d5be3f548fcc507b3d2db76.png" alt="10 个学习 LLM 的免费资源。" loading="lazy"></p>
<p>作者提供的图片</p>
<p>在上一篇文章中,我解释了如何 <a href="https://www.kdnuggets.com/5-steps-to-learn-ai-for-free-in-2024" target="_blank">人工智能是未来的技能</a>,这些职位的年薪高达 $375,000。</p>
<hr>
<h2 id="我们的前三大课程推荐-9">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业的捷径。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织在 IT 方面</p>
<hr>
<p>大语言模型(LLMs)已成为人工智能的核心关注点,现在几乎每个数据驱动的角色都需要对这些算法有一些基础了解。</p>
<p>无论你是希望扩展技能的开发者、数据从业者,还是想转行进入人工智能领域的专业人士,了解 LLM 在当前就业市场中都能为你带来巨大的收益。</p>
<p>在这篇文章中,我将为你提供 10 个帮助你了解大语言模型的免费资源。</p>
<h2 id="1-大语言模型简介-由-andrej-karpathy">1. <strong>大语言模型简介</strong> 由 Andrej Karpathy</h2>
<p>如果你是人工智能领域的完全初学者,我建议你从这个 <a href="https://youtu.be/zjkBMFhNj_g?si=n7PqV1sHe1npNYyI" target="_blank">一小时的 YouTube 教程</a> 开始,讲解了 LLM 的工作原理。</p>
<p>到视频结束时,你将理解 LLM 的工作原理、LLM 扩展法则、模型微调、多模态性和 LLM 定制化。</p>
<h2 id="2-微软初学者的生成式-ai">2. <strong>微软初学者的生成式 AI</strong></h2>
<p><a href="https://microsoft.github.io/generative-ai-for-beginners/#/" target="_blank">生成式 AI 初学者</a> 是一门 18 课的课程,将教你关于构建生成式 AI 应用程序的一切。</p>
<p>从最基本的开始——你将首先了解生成式 AI 和 LLM 的概念,然后进展到诸如提示工程和 LLM 选择等主题。</p>
<p>接着,你将学习如何使用低代码工具、RAGs 和 AI 代理来构建 LLM 驱动的应用程序。</p>
<p>课程还将教你如何微调 LLM 和保护你的 LLM 应用程序。</p>
<p>你可以跳过模块,选择对你的学习目标最相关的课程。</p>
<h2 id="3-利用-llm-的生成式-ai-由-deeplearningai">3. <strong>利用 LLM 的生成式 AI</strong> 由 Deeplearning.AI</h2>
<p><a href="https://www.deeplearning.ai/courses/generative-ai-with-llms/" target="_blank">利用 LLM 的生成式 AI</a> 是一门关于语言模型的课程,需要大约 3 周的全日制学习。</p>
<p>这个学习资源涵盖了 LLM 的基础知识、变换器架构和提示工程。</p>
<p>你还将学习如何在 AWS 上微调、优化和部署语言模型。</p>
<h2 id="4-hugging-face-nlp-课程">4. Hugging Face NLP 课程</h2>
<p>Hugging Face 是一家领先的 NLP 公司,提供库和模型,允许你构建机器学习应用程序。他们让普通用户也能轻松构建 AI 应用程序。</p>
<p><a href="https://huggingface.co/learn/nlp-course/chapter1/1" target="_blank">Hugging Face 的 NLP 学习轨迹</a>涵盖了变换器架构、LLM 的工作原理以及他们生态系统中可用的数据集和分词器库。</p>
<p>你将学习如何微调数据集,并使用 Transformers 库和 Hugging Face 的管道执行文本总结、问答和翻译等任务。</p>
<h2 id="5-cohere-的-llm-大学">5. Cohere 的 LLM 大学</h2>
<p><a href="https://cohere.com/llmu" target="_blank">LLM 大学</a>是一个涵盖 NLP 和 LLM 相关概念的学习平台。</p>
<p>与之前的课程类似,你将从学习 LLM 的基础和架构开始,逐渐深入到更高级的概念,如提示工程、微调和 RAGs。</p>
<p>如果你已经有一些 NLP 的知识,你可以直接跳过基础模块,跟随更高级的教程。</p>
<h2 id="6-ineuron-的基础生成性-ai">6. iNeuron 的基础生成性 AI</h2>
<p><a href="https://ineuron.ai/course/generative-ai-community-edition" target="_blank">基础生成性 AI</a>是一个免费的两周课程,涵盖生成性 AI、Langchain、向量数据库、开源语言模型和 LLM 部署的基础知识。</p>
<p>每个模块大约需要两小时完成,建议每个模块在一天内完成。</p>
<p>在课程结束时,你将学会使用语言模型实现一个端到端的医疗聊天机器人。</p>
<h2 id="7-krish-naik-的自然语言处理">7. <strong>Krish Naik</strong> 的自然语言处理</h2>
<p><a href="https://youtube.com/playlist?list=PLZoTAELRMXVNNrHSKv36Lr3_156yCo6Nn&si=bj9Mbj03Lv813ASu" target="_blank">这个 YouTube 上的 NLP 播放列表</a>涵盖了诸如分词、文本预处理、RNN 和 LSTM 等概念。</p>
<p>这些主题是理解现代大型语言模型如何工作的先决条件。</p>
<p>完成这门课程后,你将了解构成 NLP 基础的不同文本处理技术。</p>
<p>你还将理解顺序 NLP 模型的工作原理和实施过程中遇到的挑战,这最终导致了更高级的 LLM 的发展,如 GPT 系列。</p>
<h2 id="额外的-llm-学习资源">额外的 LLM 学习资源</h2>
<p>一些额外的学习 LLM 资源包括:</p>
<h4 id="1-带代码的论文">1. 带代码的论文</h4>
<p><a href="https://paperswithcode.com/" target="_blank">带代码的论文</a>是一个将机器学习研究论文与代码结合的平台,使你更容易跟上该领域的最新发展以及实际应用。</p>
<h4 id="2-注意力机制即一切">2. 注意力机制即一切</h4>
<p>为了更好地理解变换器架构(如 BERT 和 GPT 等最先进语言模型的基础),我推荐阅读研究论文<a href="https://arxiv.org/abs/1706.03762" target="_blank">《注意力机制即一切》</a>。</p>
<p>这将帮助你更好地理解 LLM 的工作原理以及为什么基于变换器的模型比之前的最先进模型表现更好。</p>
<h4 id="3-llm-powerhouse">3. LLM-PowerHouse</h4>
<p>这是一个 <a href="https://github.com/ghimiresunil/LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing" target="_blank">GitHub 仓库</a>,它整理了 LLM 教程、最佳实践和代码。</p>
<p>这是一个关于语言模型的全面指南 —— 包括 LLM 架构的详细解释、模型微调和部署的教程,以及可以直接用于你自己 LLM 应用程序的代码片段。</p>
<h2 id="10-个学习-llm-的免费资源--关键要点">10 个学习 LLM 的免费资源 — 关键要点</h2>
<p>目前有大量的资源可以用来学习 LLM,我已将最有用的资源整理到本文中。</p>
<p>本文中引用的大多数学习材料需要一些编程和机器学习的知识。如果你没有这些领域的背景,我建议查看以下资源:</p>
<ul>
<li>
<p><a href="https://youtu.be/NRKCLqIREMM?si=06RBssHOy-XsQTPN" target="_blank">如何在 2024 年学习编程</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/5-free-university-courses-to-learn-machine-learning" target="_blank">学习机器学习的 5 门免费大学课程</a></p>
</li>
</ul>
<p> </p>
<p> </p>
<p><a href="https://linktr.ee/natasshaselvaraj" target="_blank"></a><strong><a href="https://linktr.ee/natasshaselvaraj" target="_blank">Natassha Selvaraj</a></strong> 是一位自学成才的数据科学家,对写作充满热情。Natassha 撰写有关数据科学的所有内容,是数据主题的真正大师。你可以在 <a href="https://www.linkedin.com/in/natassha-selvaraj-33430717a/" target="_blank">LinkedIn</a> 上与她联系或查看她的 <a href="https://www.youtube.com/@natassha_ds" target="_blank">YouTube 频道</a>。</p>
<h3 id="更多相关内容-14">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/top-3-free-resources-learn-linear-algebra-machine-learning.html" target="_blank">学习机器学习的前 3 个免费资源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2024/03/365datascience-best-free-resources-learn-data-analysis-data-science" target="_blank">学习数据分析和数据科学的最佳免费资源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/02/top-free-resources-learn-chatgpt.html" target="_blank">学习 ChatGPT 的顶级免费资源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/12/springboard-best-data-science-resources-bootcamp-courses-learn-data-science-new-year" target="_blank">最佳数据科学资源、训练营和课程…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/easily-integrate-llms-into-your-scikit-learn-workflow-with-scikit-llm" target="_blank">使用 Scikit-LLM 轻松将 LLM 集成到你的 Scikit-learn 工作流中</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/05/free-university-data-science-resources.html" target="_blank">免费的大学数据科学资源</a></p>
</li>
</ul>
<h1 id="10-个免费的顶级机器学习课程">10 个免费的顶级机器学习课程</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2019/12/10-free-top-notch-courses-machine-learning.html" target="_blank"><code>www.kdnuggets.com/2019/12/10-free-top-notch-courses-machine-learning.html</code></a></p>
</blockquote>
<p>评论</p>
<p>假期将至,如果你在家人、朋友和同事之间的活动中找不到消遣时间,何不利用这些优质的免费在线课程呢?</p>
<p>这是一个包含免费优质在线机器学习课程的集合,来自一些受尊敬的大学以及其他在线平台。无论你是寻找入门课程还是更高级的主题,理论课程还是实践课程,或者是一般性主题还是特定主题,这里的课程都应该能够满足你年末学习的需求。查看下面的课程,今天就开始学习新的知识吧。</p>
<p>别忘了查看底部的相关帖子,获取更多免费的机器学习课程。</p>
<p><img src="https://kdn.flygon.net/docs/img/8dfad3f9ae6e1ffd076a5b0c8ebc35be.png" alt="图像" loading="lazy"></p>
<p>来源: <a href="https://cedar.buffalo.edu/~srihari/CSE574/" target="_blank">机器学习简介(布法罗大学)</a></p>
<p><strong>1. <a href="https://www.springboard.com/resources/learning-paths/machine-learning-python/" target="_blank">Python 中的机器学习</a></strong></p>
<p>Springboard</p>
<blockquote>
<p>机器学习是过去十年中最热门的新技术之一,正在改变从消费电子到医疗保健,再到零售等领域。这导致许多学生和在职专业人士对这一行业产生了强烈的好奇。</p>
<p>如果你是一名技术专业人士,比如软件开发者、业务分析师,甚至是产品经理,你可能会对机器学习如何改变你的工作方式和推动你的职业发展感到好奇。然而,作为一名忙碌的专业人士,你可能也在寻找一种既严格又实用,同时又简洁快速的机器学习理解方式。本教程将帮助你实现这些目标。</p>
</blockquote>
<p><strong>2. <a href="https://cedar.buffalo.edu/~srihari/CSE574/" target="_blank">机器学习简介</a></strong></p>
<p>布法罗大学</p>
<blockquote>
<p>机器学习是一个关于设计可以从示例中学习的机器的激动人心的话题。课程涵盖了机器学习所需的理论、原则和算法。这些方法基于统计学和概率学——这些已经成为设计展现人工智能的系统的核心。</p>
<p>参考教材包括 Chris Bishop 的《模式识别与机器学习》(Springer 2006)、Daphne Koller 和 Nir Friedman 的《概率图模型》(MIT Press 2009)以及 Goodfellow、Bengio 和 Courville 的《深度学习》(MIT Press 2016)。</p>
</blockquote>
<p><strong>3. <a href="https://practicalai.me/" target="_blank">实用 AI: 机器学习的实用方法</a></strong></p>
<p>practicalAI</p>
<blockquote>
<p><img src="https://kdn.flygon.net/docs/img/7bd1e88d7ae3b9a459c5afe79b136e8c.png" alt="图像" loading="lazy"></p>
</blockquote>
<p><strong>4. <a href="https://github.com/machinelearningmindset/machine-learning-course" target="_blank">一个 Python 的机器学习课程</a></strong></p>
<p>机器学习思维模式</p>
<blockquote>
<p>机器学习作为人工智能的工具,是最广泛采用的科学领域之一。大量文献已经发布关于机器学习的内容。该项目的目的是通过使用 Python 提供机器学习的最重要方面,呈现一系列简单而全面的教程。在这个项目中,我们使用了许多不同的知名机器学习框架,如 Scikit-learn,来构建我们的教程。</p>
</blockquote>
<p><strong>5. <a href="http://www.cs.cornell.edu/courses/cs4780/2018fa/syllabus/index.html" target="_blank">智能系统的机器学习</a></strong></p>
<p>康奈尔大学</p>
<blockquote>
<p>机器学习领域关注的问题是如何构建能够随着经验自动改进的计算机程序。近年来,许多成功的机器学习应用已经开发出来,从学习检测欺诈信用卡交易的数据挖掘程序,到学习用户阅读偏好的信息过滤系统,再到学习驾驶的自主车辆。此外,该领域的理论和算法也取得了重要进展。本课程将提供对机器学习领域的广泛介绍。先决条件:CSE 241 及足够的数学基础(矩阵代数、概率论/统计学、多变量微积分)。讲师将举行一场家庭考试(关于基本数学知识),考试截止日期为 1 月 30 日。</p>
</blockquote>
<p><strong>6. <a href="https://cedar.buffalo.edu/~srihari/CSE676/index.html" target="_blank">深度学习</a></strong></p>
<p>布法罗大学</p>
<blockquote>
<p>深度学习算法学习数据的多层次表示,每一层以层级方式解释数据。这些算法在揭示数据中潜在结构方面非常有效,例如区分类别的特征。它们在许多人工智能问题中取得了成功,包括图像分类、语音识别和自然语言处理。该课程将通过讲座和项目进行教学,内容将涵盖基本理论、应用范围及从非常大的数据集中学习。课程将涉及与深度学习相关的连接主义架构,例如基础神经网络、卷积神经网络和递归神经网络。主要重点将是训练和优化这些架构的方法,以及如何有效地进行推理。学生将被鼓励使用开源软件库,如 Tensorflow。</p>
</blockquote>
<p><strong>7. <a href="http://www.scs.ryerson.ca/~kosta/CP8309-F2018/index.html" target="_blank">计算机视觉中的深度学习</a></strong></p>
<p>赖尔森大学</p>
<blockquote>
<p>计算机视觉被广泛定义为从一张或多张图像中恢复世界的有用属性。近年来,深度学习作为解决计算机视觉任务的强大工具逐渐显现。本课程将涵盖深度学习和计算机视觉交叉领域的一系列基础主题。</p>
</blockquote>
<p><strong>8. <a href="https://interpretable-ml-class.github.io/" target="_blank">机器学习中的可解释性与解释性</a></strong></p>
<p>哈佛大学</p>
<blockquote>
<p>随着机器学习模型越来越多地被用于帮助决策者在高风险环境中,如医疗保健和刑事司法,确保决策者(最终用户)正确理解并信任这些模型的功能变得尤为重要。该研究生课程旨在使学生熟悉解释性和可解释性机器学习的新进展。在本课程中,我们将回顾该领域的重要论文,理解模型解释性和可解释性的概念,详细讨论不同类型的可解释模型(例如,基于原型的方法、稀疏线性模型、基于规则的技术、广义加性模型)、后置解释(黑箱解释,包括反事实解释和显著性图),并探索解释性与因果关系、调试和公平性的关系。课程还将强调各种可以从模型解释性中获得巨大收益的应用,包括刑事司法和医疗保健。</p>
</blockquote>
<p><em>编辑注:课程在撰写时正在进行中,并非所有资源都已在线提供。</em></p>
<p><strong>9. <a href="https://www.cs.bgu.ac.il/~elhadad/nlp19.html" target="_blank">自然语言处理中的主题</a></strong></p>
<p>内盖夫本-古里安大学</p>
<blockquote>
<p>这门课程是自然语言处理的入门课程。课程的主要目标是学习如何开发能够在自然语言上执行智能任务的实用计算机系统:分析、理解和生成书面文本。这个任务需要从多个领域学习材料:语言学、机器学习和统计分析,以及核心的自然语言技术。</p>
</blockquote>
<p><strong>10. <a href="https://cedar.buffalo.edu/~srihari/CSE674/" target="_blank">概率图模型课程</a></strong></p>
<p>布法罗大学</p>
<blockquote>
<p>概率图模型是概率分布的图形表示。这些模型在表示许多科学和工程应用中遇到的复杂概率分布方面非常灵活。它们现在已成为设计展现高级人工智能的系统(如深度学习的生成模型)的关键。</p>
<p>课程涵盖了与概率图模型相关的理论、原理和算法。讨论了有向图模型(贝叶斯网络)和无向图模型(马尔可夫网络),包括表示、推理和学习。</p>
</blockquote>
<p><strong>相关</strong>:</p>
<ul>
<li>
<p>10 门必看的免费机器学习和数据科学课程</p>
</li>
<li>
<p>另 10 门必看的免费机器学习和数据科学课程</p>
</li>
<li>
<p>另 10 门必看的免费机器学习和数据科学课程</p>
</li>
</ul>
<h3 id="更多相关内容-15">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-key-skills-needed-become-great-data-scientist.html" target="_blank">成为优秀数据科学家所需的 5 项关键技能</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/6-predictive-models-every-beginner-data-scientist-master.html" target="_blank">每个初学者数据科学家应该掌握的 6 种预测模型</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/mozart-best-etl-tools-2021.html" target="_blank">2021 年最佳 ETL 工具</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/springboard-top-resources-learn-data-science-statistics.html" target="_blank">学习数据科学统计学的顶级资源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/stop-learning-data-science-find-purpose.html" target="_blank">停止学习数据科学以寻找目标,并寻找目标去…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/build-solid-data-team.html" target="_blank">建立一个强大的数据团队</a></p>
</li>
</ul>
<h1 id="掌握计算机科学的-10-个-github-资源库">掌握计算机科学的 10 个 GitHub 资源库</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/10-github-repositories-to-master-computer-science" target="_blank"><code>www.kdnuggets.com/10-github-repositories-to-master-computer-science</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/7e854be82ea681654b737a10d1a78f36.png" alt="掌握计算机科学的 10 个 GitHub 资源库" loading="lazy"></p>
<p>图片由 DALLE-3 生成</p>
<p>从零开始学习计算机科学可能相当困难,你可能会在开始之前感到气馁。然而,GitHub 上的开源社区创建了大量资源,可以指导你完成这段旅程。在这篇博客文章中,我们将探讨 10 个重要的 GitHub 资源库,帮助你学习必要的概念和工具,以掌握计算机科学并在顶级科技公司获得职位。</p>
<hr>
<h2 id="我们的前三个课程推荐-15">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升您的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持您的组织 IT</p>
<hr>
<h1 id="1-开发者路线图">1. 开发者路线图</h1>
<p><strong>链接:</strong> <a href="https://github.com/kamranahmedse/developer-roadmap" target="_blank">kamranahmedse/developer-roadmap</a></p>
<p>该资源库包含社区驱动的路线图,已在开发者中越来越受欢迎,提供了交互式和全面的学习各种技术和编程语言的指南。</p>
<p>这些路线图涵盖了广泛的主题,包括前端、后端、DevOps、全栈、计算机科学、数据结构、人工智能、数据科学、MLOps、质量保证、Python、软件架构、游戏开发、软件设计、JavaScript、TypeScript、C++等。</p>
<h1 id="2-计算机科学学位课程">2. 计算机科学学位课程</h1>
<p><strong>链接:</strong> ossu/computer-science</p>
<p>开源社会大学(OSSU)提供了一个免费的、全面的、社区驱动的计算机科学课程,提供了对计算机科学基本概念的完整教育。该课程根据领先大学本科计算机科学专业的学位要求设计,由麻省理工学院、哈佛大学和普林斯顿大学等著名学府的教授授课。</p>
<p>课程涵盖了编程语言、算法、数据结构、操作系统、计算机架构和软件工程等基本主题,并提供了高级选修课程以供专业化。</p>
<h1 id="3-freecodecamp">3. freeCodeCamp</h1>
<p><strong>链接:</strong> <a href="https://github.com/freeCodeCamp/freeCodeCamp" target="_blank">freeCodeCamp/freeCodeCamp</a></p>
<p>freeCodeCamp 是一个提供各种计算机技术免费课程和教程的平台。它还为想要学习编码技能的个人提供了友好和支持的社区。freeCodeCamp 由一家慈善组织运营,旨在帮助数百万成年人转型进入技术职业。</p>
<p>该资源提供了一个全面且自定进度的全栈网页开发和机器学习课程,包含数千个互动编码挑战,以提高编码能力。</p>
<h1 id="4-系统设计基础">4. 系统设计基础</h1>
<p><strong>链接:</strong> <a href="https://github.com/donnemartin/system-design-primer" target="_blank">donnemartin/system-design-primer</a></p>
<p>该资源库作为学习系统设计原则和准备系统设计面试的全面资源。它由 Donne Martin 维护,他是一名曾在 Amazon 和 Google 等公司工作的软件工程师。</p>
<p>它涵盖了设计大型系统相关的广泛主题,包括:系统设计基础、分布式系统的关键特征、系统设计问题、Anki 闪卡,以及系统设计面试问题及其解决方案。</p>
<h1 id="5-免费编程书籍">5. 免费编程书籍</h1>
<p><strong>链接:</strong> <a href="https://github.com/EbookFoundation/free-programming-books" target="_blank">EbookFoundation/free-programming-books</a></p>
<p>这是一个由社区驱动的项目,旨在提供一份精选的高质量编程书籍列表,这些书籍可以免费访问和下载,涵盖了广泛的编程语言、框架和相关主题。</p>
<p>该资源库提供英语和其他语言(如阿拉伯语、韩语、意大利语、泰米尔语等)的免费书籍。还提供额外资源,如各种编程语言的多语言课程、互动编程资源、播客和编程练习场。</p>
<h1 id="6-令人惊叹的计算机科学机会">6. 令人惊叹的计算机科学机会</h1>
<p><strong>链接:</strong> <a href="https://github.com/anu0012/awesome-computer-science-opportunities" target="_blank">anu0012/awesome-computer-science-opportunities</a></p>
<p>这是一个为学生和专业人士提供的令人惊叹的计算机科学机会和资源列表。</p>
<p>它涵盖了广泛的主题,包括竞争编程平台、网页开发教程、移动开发课程、DevOps 训练营、数据科学竞赛、人工智能资源、计算机科学基础、开源项目、网络安全博客、在线课程(MOOCs)、奖学金和助学金、编程事件和黑客马拉松、学生包等一般机会,以及由社区驱动的演示项目。</p>
<p>该列表旨在提供一个全面的有价值资源集合,以帮助个人学习、练习并在计算机科学的各个领域中脱颖而出。</p>
<h1 id="7-编码面试大学">7. 编码面试大学</h1>
<p><strong>链接:</strong> <a href="https://github.com/jwasham/coding-interview-university" target="_blank">jwasham/coding-interview-university</a></p>
<p>这个库包含了一个成为大型公司软件工程师的学习计划,由 jwasham 编写。它是为那些没有正规计算机科学教育或学位的个人准备的,就像作者一样。</p>
<p>学习计划内容全面,旨在覆盖大学计算机科学课程中通常教授的大部分重要主题,重点关注数据结构、算法和编码面试准备。</p>
<p>它提供了一种结构化的方法,包括目录、每日计划、编码实践和学习主题列表。</p>
<h1 id="8-自建-x">8. 自建 X</h1>
<p><strong>链接:</strong> <a href="https://github.com/codecrafters-io/build-your-own-x" target="_blank">codecrafters-io/build-your-own-x</a></p>
<p>这是一个包含详细步骤指南的库,用于从头开始重建各种技术。它旨在通过从基础构建技术来提供学习和理解不同技术的好方法。</p>
<p>这个库被分为不同的类别,每个类别关注特定类型的技术,如 3D 渲染器、增强现实、命令行工具、数据库、Docker、游戏、Git 等。每个类别包含指向教程、文章和资源的链接,这些资源指导用户从头开始构建各种技术。</p>
<h1 id="9-公共-api">9. 公共 API</h1>
<p><strong>链接:</strong> <a href="https://github.com/public-apis/public-apis" target="_blank">public-apis/public-apis</a></p>
<p>公共 API 是一个策划的免费 API 列表,开发者可以轻松地探索并将其集成到自己的项目中。这些 API 涵盖了从动物和娱乐到金融和健康等各种类别,提供了数据和服务,这些数据和服务否则会耗费时间并且成本高昂。</p>
<p>使用公共 API 的一个关键优势是能够快速增强产品功能并快速构建 MVP。例如,如果你正在构建一个与汽车相关的应用程序,你可以无缝集成提供不同类型汽车信息的公共 API。这不仅节省了开发时间,还确保用户可以访问准确和最新的数据。</p>
<h1 id="10-精选列表">10. 精选列表</h1>
<p><strong>链接:</strong> <a href="https://github.com/sindresorhus/awesome" target="_blank">sindresorhus/awesome</a></p>
<p>这是一个在 GitHub 上策划的精彩列表,涵盖了各种有趣的主题。这些列表包含了按平台、编程语言、开发工具等类别组织的资源。</p>
<p>精选列表是一个巨大的社区项目,社区成员创建拉取请求并更新现有列表。它是你学习计算机科学各种工具和概念时唯一需要的资源。精选列表对于希望构建耐用且安全应用程序的专业人士也非常有用。</p>
<h1 id="最终想法-1">最终想法</h1>
<p>无论你是新手还是领域专家,这些资源都旨在满足不同的技能水平和兴趣。它们不仅在基本计算机科学概念上建立了坚实的基础,还提供了专业化和探索前沿技术的路线图。</p>
<p>这些 GitHub 仓库的真正力量在于其协作性质。它们由全球热情的开发者和教育者维护和贡献,确保内容保持最新、相关且不断发展。</p>
<p><a href="https://www.polywork.com/kingabzpro" target="_blank"></a><strong><strong><a href="https://www.polywork.com/kingabzpro" target="_blank">Abid Ali Awan</a></strong></strong> (<a href="https://www.linkedin.com/in/1abidaliawan" target="_blank">@1abidaliawan</a>) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理疾病困扰的学生构建 AI 产品。</p>
<h3 id="了解更多相关信息">了解更多相关信息</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-data-science" target="_blank">掌握数据科学的 10 个 GitHub 仓库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-machine-learning" target="_blank">掌握机器学习的 10 个 GitHub 仓库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-data-engineering" target="_blank">掌握数据工程的 10 个 GitHub 仓库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-mlops" target="_blank">掌握 MLOps 的 10 个 GitHub 仓库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-python" target="_blank">掌握 Python 的 10 个 GitHub 仓库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-sql" target="_blank">掌握 SQL 的 10 个 GitHub 仓库</a></p>
</li>
</ul>
<h1 id="10-个-github-仓库来掌握数据科学">10 个 GitHub 仓库来掌握数据科学</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/10-github-repositories-to-master-data-science" target="_blank"><code>www.kdnuggets.com/10-github-repositories-to-master-data-science</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/26351554432cbb62cb54038e9c1eb60b.png" alt="10 个 GitHub 仓库来掌握数据科学" loading="lazy"></p>
<p>图像由 ChatGPT 生成</p>
<p>通过课程或 YouTube 视频学习数据科学可能会变得单调,因为这通常涉及被动地接受信息。你没有动手操作、进行实验或实际构建任何东西。你只是从屏幕上吸收内容。但是,如果我告诉你有一种更具互动性和有效的方法来掌握数据科学工具和概念,你会不会感兴趣?没错。今天,我们将探索 10 个 GitHub 仓库,它们将通过互动课程、书籍、指南、代码示例、项目、基于顶级大学课程的免费课程、面试问题和最佳实践,帮助你掌握数据科学概念。</p>
<hr>
<h2 id="我们的三大课程推荐-6">我们的三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你所在组织的 IT 工作</p>
<hr>
<h2 id="1-virgilio你的数据科学导师">1. Virgilio:你的数据科学导师</h2>
<p><strong>仓库:</strong> <a href="https://github.com/virgili0/Virgilio" target="_blank">virgili0/Virgilio</a></p>
<p>Virgilio 是一个全面的数据科学电子学习指南和导师。它提供了结构化的内容、教程和资源,帮助你在数据科学的广阔领域中导航,是初学者的绝佳起点。</p>
<p>它提供了一个互动网站,将教授你统计学和 Python 的基础知识。它将帮助你学习数据科学项目中的各个步骤。你将学习机器学习模型、数据处理和可视化技术、自动化等。</p>
<h2 id="2-python-数据科学手册">2. Python 数据科学手册</h2>
<p><strong>仓库:</strong> <a href="https://github.com/jakevdp/PythonDataScienceHandbook" target="_blank">jakevdp/PythonDataScienceHandbook</a></p>
<p>这个仓库包含了《Python 数据科学手册》的完整文本,以 Jupyter Notebooks 的形式提供。你可以免费阅读这本书,甚至可以在 Google Colab 上运行笔记本,实时体验各种数据科学任务。它涵盖了 Python 中的重要数据科学库,如 NumPy、pandas、Matplotlib、Scikit-Learn 等。它是一个很好的起点。</p>
<h2 id="3-数据科学入门">3. 数据科学入门</h2>
<p><strong>仓库:</strong> <a href="https://github.com/microsoft/Data-Science-For-Beginners" target="_blank">microsoft/Data-Science-For-Beginners</a></p>
<p>这个微软的仓库提供了一个为期 10 周、包含 20 节课的课程,专为初学者设计。它提供了全面的课程和动手项目,以建立扎实的数据科学概念和技术基础。</p>
<p>每一节课包括一个草图笔记、补充视频、课前热身测验、书面课程、指南、知识检查、挑战、补充阅读、作业和课后测验。</p>
<h2 id="4-数据科学-ipython-笔记本">4. 数据科学 IPython 笔记本</h2>
<p><strong>仓库:</strong> <a href="https://github.com/donnemartin/data-science-ipython-notebooks" target="_blank">donnemartin/data-science-ipython-notebooks</a></p>
<p>这个仓库包括一系列 Jupyter 笔记本,涵盖了各种数据科学主题,包括深度学习、机器学习、数据分析和 Python 基础知识。它是一个宝贵的实践学习资源。内容根据工具如 scikit-learn、scipy、pandas、matplotlib、numpy、python-data、spark 等进行分类。</p>
<h2 id="5-应用机器学习">5. 应用机器学习</h2>
<p><strong>仓库:</strong> <a href="https://github.com/eugeneyan/applied-ml" target="_blank">eugeneyan/applied-ml</a></p>
<p>这个仓库专注于应用机器学习,提供公司分享的真实数据科学和机器学习工作的论文和技术博客。它是学习如何在生产环境中实现机器学习的优秀资源。</p>
<p>课程列表根据主题进行分类,如数据质量、数据工程、特征存储、分类、回归、预测、推荐、搜索与排序等。它主要关注机器学习以及如何实施机器学习项目。</p>
<h2 id="6-免费自学数据科学的路径">6. 免费自学数据科学的路径</h2>
<p><strong>仓库:</strong> <a href="https://github.com/ossu/data-science" target="_blank">ossu/data-science</a></p>
<p>这个仓库提供了一个全面的自学数据科学课程。它包括免费的课程、教科书和资源的链接,涵盖了从基础数学到高级机器学习的所有内容。</p>
<p>你应该阅读我的博客,免费报名数据科学本科课程,该博客涵盖了课程的各个方面,并解释了如何报名并开始学习。</p>
<h2 id="7-开源数据科学硕士">7. 开源数据科学硕士</h2>
<p><strong>仓库:</strong> <a href="https://github.com/datasciencemasters/go" target="_blank">datasciencemasters/go</a></p>
<p>这个仓库提供了一个全面的开源课程,旨在为学生准备入门级的数据科学家角色。其目标是提供高质量的、免费的教育资源,与最著名的付费课程的材料相媲美。通过利用开源材料,这个课程确保初学者可以在没有经济障碍的情况下获得最好的学习资源。</p>
<h2 id="8-极好的数据科学">8. 极好的数据科学</h2>
<p><strong>仓库:</strong> <a href="https://github.com/academic/awesome-datascience" target="_blank">academic/awesome-datascience</a></p>
<p>该仓库是一个精心策划的优秀数据科学资源列表,包括教程、书籍、软件和工具。它是任何希望学习并将数据科学应用于实际问题的人的首选参考。除了资源列表外,它还解释了如何开始数据科学职业生涯。我建议你将其收藏,以便在发现新工具或学习新概念时使用。它由开源社区维护,确保你获取最新的、最前沿的信息。</p>
<h2 id="9-数据科学面试问题与答案">9. 数据科学面试问题与答案</h2>
<p><strong>Repository:</strong> <a href="https://github.com/alexeygrigorev/data-science-interviews" target="_blank">alexeygrigorev/data-science-interviews</a></p>
<p>准备数据科学职位面试吗?该仓库提供了一系列数据科学面试问题及其答案。这是了解可能遇到的问答类型并准备回答的绝佳资源。</p>
<p>该仓库分为两个部分:理论和技术问题。总体而言,它涵盖了关于 SQL、Python、分类、正则化、特征选择、决策树等的问答。</p>
<h2 id="10-cookiecutter-数据科学">10. Cookiecutter 数据科学</h2>
<p><strong>Repository:</strong> <a href="https://github.com/drivendataorg/cookiecutter-data-science" target="_blank">drivendataorg/cookiecutter-data-science</a></p>
<p>该仓库提供了一个标准化的数据科学项目结构。它有助于确保你的项目有条理、可重复和可共享,并遵循数据科学工作的最佳实践。</p>
<p>拥有一个结构良好的数据科学项目模板可以显著减轻与协作和可重复性相关的许多挑战。它不仅通过提供一致的框架来简化团队合作,还增强了你修复错误和解决问题的能力。</p>
<h2 id="最终想法-2">最终想法</h2>
<p>无论你是希望打下坚实基础的初学者,还是寻求扩展知识的经验丰富的从业者,这些 10 个仓库都提供了有价值的内容,以提升你在数据科学领域的技能和专业知识。它们包括教程、互动书籍、课程、项目代码示例、免费资源、研究论文、项目模板、大学课程等。只需将其收藏,以便在学习新工具或概念时使用。</p>
<p><a href="https://www.polywork.com/kingabzpro" target="_blank"></a><strong><strong><a href="https://www.polywork.com/kingabzpro" target="_blank">Abid Ali Awan</a></strong></strong> (<a href="https://www.linkedin.com/in/1abidaliawan" target="_blank">@1abidaliawan</a>) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些在精神健康方面挣扎的学生。</p>
<h3 id="更多相关信息-1">更多相关信息</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-computer-science" target="_blank">掌握计算机科学的 10 个 GitHub 代码库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-data-engineering" target="_blank">掌握数据工程的 10 个 GitHub 代码库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-machine-learning" target="_blank">掌握机器学习的 10 个 GitHub 代码库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-mlops" target="_blank">掌握 MLOps 的 10 个 GitHub 代码库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-python" target="_blank">掌握 Python 的 10 个 GitHub 代码库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-sql" target="_blank">掌握 SQL 的 10 个 GitHub 代码库</a></p>
</li>
</ul>
<h1 id="掌握机器学习">掌握机器学习</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/10-github-repositories-to-master-machine-learning" target="_blank"><code>www.kdnuggets.com/10-github-repositories-to-master-machine-learning</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/7e833e7a197747081dd4329a93924f24.png" alt="掌握机器学习的 10 个 GitHub 仓库" loading="lazy"></p>
<p>图像由 DALLE-3 生成</p>
<p>掌握机器学习 (ML) 可能会让人感到压倒性,但有了合适的资源,这会变得更加可管理。GitHub,这个平台广泛用于代码托管,拥有许多对学习者和从业者都有价值的仓库。在这篇文章中,我们回顾了 10 个必备的 GitHub 仓库,它们提供了从初学者友好的教程到高级机器学习工具的各种资源。</p>
<hr>
<h2 id="我们的前三个课程推荐-16">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持组织的 IT 部门</p>
<hr>
<h1 id="1-microsoft-的-ml-for-beginners">1. Microsoft 的 ML-For-Beginners</h1>
<p><strong>Repository:</strong> <a href="https://github.com/microsoft/ML-For-Beginners" target="_blank">microsoft/ML-For-Beginners</a></p>
<p>这个为期 12 周的全面课程提供了 26 节课和 52 次测验,是新手的理想起点。它为没有机器学习经验的初学者提供了一个起点,旨在使用 Scikit-learn 和 Python 建立核心能力。</p>
<p>每节课都包括补充材料,包括前测和后测、书面说明、解决方案、作业和其他资源,以补充实践活动。</p>
<h1 id="2-ml-youtube-courses">2. ML-YouTube-Courses</h1>
<p><strong>Repository:</strong> <a href="https://github.com/dair-ai/ML-YouTube-Courses" target="_blank">dair-ai/ML-YouTube-Courses</a></p>
<p>这个 GitHub 仓库作为优质机器学习课程的策划索引,汇集了来自 Clatech、斯坦福大学和 MIT 等提供者的 ML 教程、讲座和教育系列的链接,集中在一个位置,方便感兴趣的学习者找到符合他们需求的视频 ML 内容。</p>
<p>如果你想免费并按自己的时间学习,这是你唯一需要的仓库。</p>
<h1 id="3-机器学习的数学">3. 机器学习的数学</h1>
<p><strong>Repository:</strong> <a href="https://github.com/mml-book/mml-book.github.io" target="_blank">mml-book/mml-book.github.io</a></p>
<p>数学是机器学习的核心,而这个仓库作为书籍《机器学习中的数学》的配套网页。该书激励读者学习机器学习所需的数学概念。作者的目标是提供理解先进机器学习技术所需的数学技能,而不是涵盖这些技术本身。</p>
<p>它涵盖了线性代数、解析几何、矩阵分解、向量分析、概率、分布、连续优化、线性回归、PCA、高斯混合模型和 SVM。</p>
<h1 id="4-mit-深度学习书籍">4. MIT 深度学习书籍</h1>
<p><strong>仓库:</strong> <a href="https://github.com/janishar/mit-deep-learning-book-pdf" target="_blank">janishar/mit-deep-learning-book-pdf</a></p>
<p>深度学习教材是一个全面的资源,旨在帮助学生和从业者进入机器学习领域,特别是深度学习。该书于 2016 年出版,提供了在驱动人工智能最近进展的机器学习技术方面的理论和实践基础。</p>
<p>MIT 深度学习书籍的在线版本现在已经完成,并将继续免费在线提供,为人工智能教育的普及做出宝贵贡献。</p>
<p>这本书深入涵盖了广泛的主题,包括深度前馈网络、正则化、优化算法、卷积网络、序列建模和实际方法论。</p>
<h1 id="5-机器学习-zoomcamp">5. 机器学习 ZoomCamp</h1>
<p><strong>仓库:</strong> <a href="https://github.com/DataTalksClub/machine-learning-zoomcamp" target="_blank">DataTalksClub/machine-learning-zoomcamp</a></p>
<p>机器学习 ZoomCamp 是一个免费的四个月在线训练营,提供机器学习工程的全面介绍。对于那些认真想要提升自己职业生涯的人来说,这个项目指导学生完成实际的机器学习项目,涵盖了回归、分类、评估指标、模型部署、决策树、神经网络、Kubernetes 和 TensorFlow Serving 等基本概念。</p>
<p>在课程期间,参与者将获得实际经验,涉及深度学习、无服务器模型部署和集成技术。课程以两个顶点项目作为结束,让学生展示他们新获得的技能。</p>
<h1 id="6-机器学习教程">6. 机器学习教程</h1>
<p><strong>仓库:</strong> <a href="https://github.com/ujjwalkarn/Machine-Learning-Tutorials" target="_blank">ujjwalkarn/Machine-Learning-Tutorials</a></p>
<p>这个仓库是关于机器学习和深度学习的教程、文章和其他资源的集合。它涵盖了广泛的主题,如 Quora、博客、访谈、Kaggle 比赛、备忘单、深度学习框架、自然语言处理、计算机视觉、各种机器学习算法和集成技术。</p>
<p>该资源旨在提供理论和实践知识,包含代码示例和使用案例描述。它是一个综合性的学习工具,提供了多方面的方法来接触机器学习领域。</p>
<h1 id="7-极好的机器学习资源">7. 极好的机器学习资源</h1>
<p><strong>仓库:</strong> <a href="https://github.com/josephmisiti/awesome-machine-learning" target="_blank">josephmisiti/awesome-machine-learning</a></p>
<p>极好的机器学习资源是一个精心策划的机器学习框架、库和软件的列表,适合那些希望探索该领域各种工具和技术的人。它涵盖了从 C++到 Go 等多种编程语言的工具,并进一步划分为包括计算机视觉、强化学习、神经网络和通用机器学习在内的不同机器学习类别。</p>
<p>极好的机器学习资源是一个全面的资源,面向机器学习从业者和爱好者,涵盖了从数据处理和建模到模型部署和生产化的所有内容。该平台便于比较不同选项,帮助用户找到最适合其特定项目和目标的方案。此外,得益于社区的贡献,仓库始终保持最新,涵盖了各种编程语言中的最新机器学习软件。</p>
<h1 id="8-斯坦福-cs-229-机器学习-vip-备忘单">8. 斯坦福 CS 229 机器学习 VIP 备忘单</h1>
<p><strong>仓库:</strong> <a href="https://github.com/afshinea/stanford-cs-229-machine-learning" target="_blank">afshinea/stanford-cs-229-machine-learning</a></p>
<p>这个仓库提供了斯坦福 CS 229 课程中涵盖的机器学习概念的简明参考和复习资料。它旨在将所有重要概念整合成 VIP 备忘单,涵盖监督学习、无监督学习和深度学习等主要主题。该仓库还包含 VIP 复习资料,突出概率、统计学、代数和微积分的先决条件。此外,还有一个超级 VIP 备忘单,将所有这些概念汇总成一个终极参考,以供学习者随时查阅。</p>
<p>通过将这些关键点、定义和技术概念结合在一起,目标是帮助学习者全面掌握 CS 229 中的机器学习主题。这些备忘单能将讲座和教科书材料中的重要概念总结成简明的参考,以备技术面试之用。</p>
<h1 id="9-机器学习面试">9. 机器学习面试</h1>
<p><strong>仓库:</strong> <a href="https://github.com/khangich/machine-learning-interview" target="_blank">khangich/machine-learning-interview</a></p>
<p>它提供了一个全面的学习指南和资源,以帮助准备在 Facebook、Amazon、Apple、Google、Microsoft 等大型科技公司进行的机器学习工程和数据科学面试。</p>
<p><strong>涵盖的关键主题:</strong></p>
<ul>
<li>
<p>LeetCode 问题按类型分类(SQL、编程、统计学)。</p>
</li>
<li>
<p>机器学习基础,如逻辑回归、KMeans、神经网络。</p>
</li>
<li>
<p>深度学习概念,从激活函数到递归神经网络(RNNs)。</p>
</li>
<li>
<p>机器学习系统设计,包括技术债务和机器学习规则的论文</p>
</li>
<li>
<p>经典机器学习论文阅读。</p>
</li>
<li>
<p>机器学习生产挑战,如 Uber 的扩展和生产中的深度学习</p>
</li>
<li>
<p>常见的机器学习系统设计面试问题,例如视频/推荐、欺诈检测。</p>
</li>
<li>
<p>YouTube、Instagram 推荐的示例解决方案和架构。</p>
</li>
</ul>
<p>本指南整合了顶级专家如 Andrew Ng 的资料,并包括了在顶尖公司面试中真实的面试问题。它旨在提供一份学习计划,以便在各大科技公司中赢得机器学习面试。</p>
<h1 id="10-了不起的生产机器学习">10. 了不起的生产机器学习</h1>
<p><strong>仓库:</strong> <a href="https://github.com/EthicalML/awesome-production-machine-learning" target="_blank">EthicalML/awesome-production-machine-learning</a></p>
<p>本仓库提供了一个经过整理的开源库列表,以帮助在生产环境中部署、监控、版本控制、扩展和保护机器学习模型。它涵盖了生产机器学习的各个方面,包括:</p>
<ol>
<li>
<p>解释预测与模型</p>
</li>
<li>
<p>隐私保护机器学习</p>
</li>
<li>
<p>模型与数据版本控制</p>
</li>
<li>
<p>模型训练编排</p>
</li>
<li>
<p>模型服务与监控</p>
</li>
<li>
<p>自动化机器学习</p>
</li>
<li>
<p>数据管道</p>
</li>
<li>
<p>数据标注</p>
</li>
<li>
<p>元数据管理</p>
</li>
<li>
<p>计算分发</p>
</li>
<li>
<p>模型序列化</p>
</li>
<li>
<p>优化计算</p>
</li>
<li>
<p>数据流处理</p>
</li>
<li>
<p>异常值与异常检测</p>
</li>
<li>
<p>特征存储</p>
</li>
<li>
<p>对抗性鲁棒性</p>
</li>
<li>
<p>数据存储优化</p>
</li>
<li>
<p>数据科学笔记本</p>
</li>
<li>
<p>神经搜索</p>
</li>
<li>
<p>以及更多。</p>
</li>
</ol>
<h1 id="结论-8">结论</h1>
<p>无论你是初学者还是经验丰富的机器学习从业者,这些 GitHub 仓库提供了大量的知识和资源,以加深你对机器学习的理解和技能。从基础数学到高级技术和实际应用,这些仓库是任何认真对待掌握机器学习的人的必备工具。</p>
<p><a href="https://www.polywork.com/kingabzpro" target="_blank"></a><strong><strong><a href="https://www.polywork.com/kingabzpro" target="_blank">Abid Ali Awan</a></strong></strong> (<a href="https://www.linkedin.com/in/1abidaliawan" target="_blank">@1abidaliawan</a>) 是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些面临心理健康问题的学生。</p>
<h3 id="更多相关内容-16">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-mlops" target="_blank">掌握 MLOps 的 10 个 GitHub 仓库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-computer-science" target="_blank">掌握计算机科学的 10 个 GitHub 仓库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-data-engineering" target="_blank">掌握数据工程的 10 个 GitHub 仓库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-python" target="_blank">掌握 Python 的 10 个 GitHub 仓库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-sql" target="_blank">掌握 SQL 的 10 个 GitHub 仓库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-data-science" target="_blank">掌握数据科学的 10 个 GitHub 代码库</a></p>
</li>
</ul>
<h1 id="十个-github-仓库助你掌握-mlops">十个 GitHub 仓库,助你掌握 MLOps</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/10-github-repositories-to-master-mlops" target="_blank"><code>www.kdnuggets.com/10-github-repositories-to-master-mlops</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/75eefa573aa298eeafd2df2d57ca1f5b.png" alt="十个 GitHub 仓库,助你掌握 MLOps" loading="lazy"></p>
<p>作者提供的图片</p>
<p>对于那些希望有效地部署、监控和维护其生产环境中的 ML 模型的人来说,掌握 MLOps(机器学习运维)变得越来越重要。MLOps 是一套旨在融合 ML 系统开发(Dev)和 ML 系统运维(Ops)的实践。幸运的是,开源社区创建了大量资源来帮助初学者掌握这些概念和工具。</p>
<hr>
<h2 id="我们的三大课程推荐-7">我们的三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速入门网络安全职业</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析能力</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织进行 IT 服务</p>
<hr>
<p>以下是十个对掌握 MLOps 至关重要的 GitHub 仓库:</p>
<h1 id="1-mlops-basics">1. MLOps-Basics</h1>
<p><strong>GitHub 链接:</strong> <a href="https://github.com/graviraja/MLOps-Basics" target="_blank">graviraja/MLOps-Basics</a></p>
<p>这是一个为期 9 周的学习计划,旨在帮助你掌握与模型监控、配置、数据版本控制、模型打包、Docker、GitHub Actions 和 AWS 云相关的各种概念和工具。你将学习如何构建一个端到端的 MLOps 项目,每周将专注于一个特定主题,以帮助你实现这个目标。</p>
<h1 id="2-mlops-示例由-microsoft-提供">2. MLOps 示例由 Microsoft 提供</h1>
<p><strong>GitHub 链接:</strong> <a href="https://github.com/microsoft/MLOps" target="_blank">microsoft/MLOps</a></p>
<p>这个仓库提供了 MLOps 的端到端示例和解决方案。它展示了使用 Azure 机器学习实施 ML 工作流的不同端到端场景,并且集成了 GitHub 和其他 Azure 服务,如数据工厂和 DevOps。</p>
<h1 id="3-made-with-ml">3. Made-With-ML</h1>
<p><strong>GitHub 链接:</strong> <a href="https://github.com/GokuMohandas/Made-With-ML" target="_blank">GokuMohandas/Made-With-ML</a></p>
<p>如果你在寻找 MLOps 的端到端示例和解决方案,这个仓库可以满足你的需求。它包含了多种场景,展示了如何使用 Azure 机器学习来实现 ML 工作流的运维。此外,它还集成了其他 Azure 服务,如数据工厂和 DevOps,以及 GitHub。</p>
<h1 id="4-awesome-mlops">4. Awesome MLOPs</h1>
<p><strong>GitHub 链接:</strong> <a href="https://github.com/Pythondeveloper6/Awesome-MLOPS" target="_blank">Pythondeveloper6/Awesome-MLOPS</a></p>
<p>该仓库包含各种在线免费资源的链接,这些资源包括 YouTube 视频、职业路线图、需要关注的 LinkedIn 账户、书籍、博客、免费和付费课程、社区、项目和工具。你几乎可以在一个地方找到与 MLOps 相关的所有内容,因此你无需在网上搜索各种信息,只需访问该仓库即可学习。</p>
<h1 id="5-mlops-指南">5. MLOps 指南</h1>
<p><strong>GitHub 链接:</strong> <a href="https://github.com/mlops-guide/mlops-guide.github.io" target="_blank">mlops-guide/mlops-guide.github.io</a></p>
<p>该仓库将带你到一个托管在 GitHub 上的静态网站,帮助项目和公司构建更可靠的 MLOps 环境。它涵盖了 MLOps 的原则、实施指南和项目工作流程。</p>
<h1 id="6-极好的-mlops-工具">6. 极好的 MLOps 工具</h1>
<p><strong>GitHub 链接:</strong> <a href="https://github.com/kelvins/awesome-mlops" target="_blank">kelvins/awesome-mlops</a></p>
<p>该仓库包含了一系列 MLOps 工具,可用于 AutoML、机器学习的 CI/CD、Cron 任务监控、数据目录、数据丰富、数据探索、数据管理、数据处理、数据验证、数据可视化、漂移检测、特征工程、特征存储、超参数调整、知识共享、机器学习平台、模型公平性与隐私、模型解释性、模型生命周期、模型服务、模型测试与验证、优化工具、简化工具以及可视分析和调试。</p>
<h1 id="7-dtu-的-mlops">7. DTU 的 MLOps</h1>
<p><strong>GitHub 链接:</strong> <a href="https://github.com/SkafteNicki/dtu_mlops" target="_blank">SkafteNicki/dtu_mlops</a></p>
<p>这是 DTU <a href="https://kurser.dtu.dk/course/02476" target="_blank">课程 02476</a> 的一个仓库,其中包括机器学习操作课程的练习和附加材料。课程持续三周,涵盖开发实践、可重复性、自动化、云服务、部署以及监控和扩展等高级主题。</p>
<h1 id="8-goku-mohandas-的-mlops-课程">8. Goku Mohandas 的 MLOps 课程</h1>
<p><strong>GitHub 链接:</strong> <a href="https://github.com/GokuMohandas/mlops-course" target="_blank">GokuMohandas/mlops-course</a></p>
<p>该课程专注于教授学生如何设计、开发、部署和迭代生产级 ML 应用,使用最佳实践,扩展 ML 工作负载,集成 MLOps 组件,并创建 CI/CD 工作流以实现持续改进和无缝部署。</p>
<h1 id="9-mlops-zoomcamp">9. MLOps ZoomCamp</h1>
<p><strong>GitHub 链接:</strong> DataTalksClub/mlops-zoomcamp</p>
<p>这是我最喜欢的通过构建项目来学习新概念的课程之一。DataTalks.Club 的 MLOps 课程教授了将机器学习服务投入生产的实际方面,从训练和实验到模型部署和监控。课程旨在帮助数据科学家、ML 工程师、软件工程师和数据工程师学习如何实现机器学习工作流程。</p>
<h1 id="10-无服务器-ml-课程">10. 无服务器 ML 课程</h1>
<p><strong>GitHub 链接:</strong> <a href="https://github.com/featurestoreorg/serverless-ml-course" target="_blank">featurestoreorg/serverless-ml-course</a></p>
<p>这门课程专注于开发具有无服务器能力的完整机器学习系统。它允许开发者创建预测服务,而不需要在 Kubernetes 或云计算方面的专业知识。他们可以通过编写 Python 程序和使用无服务器功能、推理管道、特征存储和模型注册表来实现。</p>
<h1 id="结论-9">结论</h1>
<p>掌握 MLOps 对确保机器学习项目在生产中的可靠性、可扩展性和效率至关重要。上述存储库提供了丰富的知识、实用的示例和关键工具,帮助你有效理解和应用 MLOps 原则。无论你是希望入门的新手,还是寻求深化知识的经验丰富的从业者,这些资源都能为你提供宝贵的见解和指导,助你在掌握 MLOps 的旅程中取得成功。</p>
<p>请查看名为 <a href="https://aigents.co/learn?search=mlops" target="_blank">Travis</a> 的 AI 学习平台,它可以帮助你更快地掌握 MLOps 及其概念。Travis 生成关于主题的解释,你可以提出后续问题。此外,它提供了指向 Medium、Substacks、独立博客、官方文档和书籍的顶级出版物上发布的博客和教程的链接,方便你进行自己的研究。</p>
<p><a href="https://www.polywork.com/kingabzpro" target="_blank"></a><strong><strong><a href="https://www.polywork.com/kingabzpro" target="_blank">Abid Ali Awan</a></strong></strong> (<a href="https://www.linkedin.com/in/1abidaliawan" target="_blank">@1abidaliawan</a>) 是一名认证的数据科学专业人士,他热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理健康问题的学生开发 AI 产品。</p>
<h3 id="相关主题-2">相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2023/02/learn-mlops-github-repositories.html" target="_blank">从这些 GitHub 存储库中学习 MLOps</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-machine-learning" target="_blank">掌握机器学习的 10 个 GitHub 存储库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-computer-science" target="_blank">掌握计算机科学的 10 个 GitHub 存储库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-data-engineering" target="_blank">掌握数据工程的 10 个 GitHub 存储库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-python" target="_blank">掌握 Python 的 10 个 GitHub 存储库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-sql" target="_blank">掌握 SQL 的 10 个 GitHub 存储库</a></p>
</li>
</ul>
<h1 id="精通-python-的-10-个-github-库">精通 Python 的 10 个 GitHub 库</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/10-github-repositories-to-master-python" target="_blank"><code>www.kdnuggets.com/10-github-repositories-to-master-python</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/41dd40a0afbe85425f627034c8ab9672.png" alt="精通 Python 的 10 个 GitHub 库" loading="lazy"></p>
<p>作者提供的图片</p>
<p>我们都知道免费的 Python 课程是学习这门语言的最佳方式,但你是否曾经查看过 GitHub 平台上的学习资源和项目?从课程中学习很棒,但通过实际项目和开源库进行实践可以将你的 Python 技能提升到一个新的水平。</p>
<hr>
<h2 id="我们的前三个课程推荐-17">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织的 IT 需求</p>
<hr>
<p>在这篇博客中,我们将介绍 10 个重要的 GitHub 库,帮助你精通 Python,并为你的职业生涯提供必备经验。这些库提供了丰富的知识,从适合初学者的教程到高级编码挑战,涵盖了广泛的主题,如网页开发、数据分析、机器学习等。</p>
<h1 id="1-asabeneh30-days-of-python">1. Asabeneh/30-Days-Of-Python</h1>
<p><a href="https://github.com/Asabeneh/30-Days-Of-Python" target="_blank">Asabeneh/30-Days-Of-Python</a> 通过为期一个月的挑战来开启你的 Python 学习之旅。该库为初学者设计,介绍了 Python 基础知识,并逐步深入到更复杂的主题,如统计学、数据分析、网页开发和数据库管理。每天花费几个小时,你将获得扎实的 Python 基础,为你转入任何技术岗位铺平道路。</p>
<h1 id="2-trekhleblearn-python">2. trekhleb/learn-python</h1>
<p><a href="https://github.com/trekhleb/learn-python" target="_blank">trekhleb/learn-python</a> 是一个全面的资源,强调通过破解学习 Python。它涵盖了广泛的 Python 函数和最佳实践,适合不同水平的学习者。你可以修改或添加代码来查看其工作原理,并使用断言进行测试。这种互动式学习方法允许你添加和删除代码,以测试其是否正常工作,帮助你提升学习体验。</p>
<h1 id="3-avik-jain100-days-of-ml-code">3. Avik-Jain/100-Days-Of-ML-Code</h1>
<p>对于那些希望深入了解 Python 机器学习的用户,<a href="https://github.com/Avik-Jain/100-Days-Of-ML-Code" target="_blank">Avik-Jain/100-Days-Of-ML-Code</a> 提供了一种结构化的方法来掌握机器学习的基础。在 100 天内,它介绍了机器学习中的关键概念和算法,并利用 Python 进行实际实现。这个仓库非常适合希望转型为机器学习工程师的程序员。</p>
<h1 id="4-realpythonpython-guide">4. realpython/python-guide</h1>
<p><a href="https://github.com/realpython/python-guide/tree/master" target="_blank">realpython/python-guide</a> 是一本免费提供在 GitHub 上的《Python 路书》。该指南包含了最佳实践和 Python 在各种场景中的应用。它提供了从设置和安装到高级主题如网页开发和机器学习的指导。《Python 路书》是开发者提升 Python 技能的宝贵资源。</p>
<h1 id="5-zhiwehupython-programming-exercises">5. zhiwehu/Python-programming-exercises</h1>
<p><a href="https://github.com/zhiwehu/Python-programming-exercises" target="_blank">zhiwehu/Python-programming-exercises</a> 挑战你的是一个包含 100 多个 Python 练习的集合,从简单到困难不等。它旨在测试和提高你的 Python 问题解决能力。这个仓库非常适合那些希望练习编码并为编码面试做准备的学习者。</p>
<h1 id="6-geekcomputerspython">6. geekcomputers/Python</h1>
<p><a href="https://github.com/geekcomputers/Python" target="_blank">geekcomputers/Python</a> 是一个包含各种 Python 脚本的代码库,展示了使用 Python 编程可以构建的不同内容。从简单的脚本到复杂的项目,它提供了一个实际的视角,说明了 Python 如何用于自动化任务,并作为初学者入门 Python 的教育示例。</p>
<h1 id="7-practical-tutorialsproject-based-learning">7. practical-tutorials/project-based-learning</h1>
<p><a href="https://github.com/practical-tutorials/project-based-learning?tab=readme-ov-file#python" target="_blank">practical-tutorials/project-based-learning</a> 仓库是一个宝贵的资源,提供了各种编程语言的基于项目的教程链接,特别关注 Python。</p>
<p>通过基于项目的方法学习是一种有效的方式,可以将 Python 概念应用到现实世界的场景中。此外,它还可以帮助你建立开发者作品集,并获得经验,从而确保你的第一份工作。</p>
<h1 id="8-avinashkranjanamazing-python-scripts">8. avinashkranjan/Amazing-Python-Scripts</h1>
<p><a href="https://github.com/avinashkranjan/Amazing-Python-Scripts" target="_blank">avinashkranjan/Amazing-Python-Scripts</a> 仓库是一个汇集了各种 Python 脚本的集合,这些脚本可以帮助自动化任务、执行网页抓取等。这个资源对那些想要独立完成小项目的学生特别有用,因为有很多选择。此外,这些脚本也可以帮助构建更复杂的项目。</p>
<h1 id="9-thealgorithmspython">9. TheAlgorithms/Python</h1>
<p>如果你对算法感兴趣,<a href="https://github.com/TheAlgorithms/Python" target="_blank">TheAlgorithms/Python</a>是一个很好的仓库。它提供了各种算法和数据结构的 Python 实现,提供了全面的算法学习体验。这个仓库非常适合那些希望探索计算机科学基础和竞争编程的人。然而,请注意,这些实现仅用于学习目的,可能不如 Python 标准库中的实现高效。</p>
<h1 id="10-vintaawesome-python">10. vinta/awesome-python</h1>
<p>最后,<a href="https://github.com/vinta/awesome-python" target="_blank">vinta/awesome-python</a>仓库是一个收集了卓越 Python 框架、库、软件和资源的集合。它是探索 Python 工具和库的绝佳来源,能够帮助你完成项目和学习之旅。无论你寻找的是 Web 框架、数据分析工具,还是与 Python 相关的任何东西,你都可能在这里找到。</p>
<h1 id="结论-10">结论</h1>
<p>这 10 个 GitHub 仓库向你介绍了 Python 编程的世界,涵盖了从基础到高级的主题,包括互动学习、基于项目的学习和基于练习的学习。通过探索这些仓库,你可以建立 Python 的坚实基础,发展解决问题的技能,并参与实际项目以积累经验。记住,学习 Python 的旅程是持续不断且不断发展的,这些仓库只是开始!</p>
<p><a href="https://www.polywork.com/kingabzpro" target="_blank"></a><strong><strong><a href="https://www.polywork.com/kingabzpro" target="_blank">Abid Ali Awan</a></strong></strong> (<a href="https://www.linkedin.com/in/1abidaliawan" target="_blank">@1abidaliawan</a>)是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为那些与心理疾病斗争的学生构建 AI 产品。</p>
<h3 id="更多相关话题-13">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-machine-learning" target="_blank">掌握机器学习的 10 个 GitHub 仓库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-computer-science" target="_blank">掌握计算机科学的 10 个 GitHub 仓库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-data-engineering" target="_blank">掌握数据工程的 10 个 GitHub 仓库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-mlops" target="_blank">掌握 MLOps 的 10 个 GitHub 仓库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-sql" target="_blank">掌握 SQL 的 10 个 GitHub 仓库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-data-science" target="_blank">掌握数据科学的 10 个 GitHub 仓库</a></p>
</li>
</ul>
<h1 id="十大-github-库掌握-sql">十大 GitHub 库掌握 SQL</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/10-github-repositories-to-master-sql" target="_blank"><code>www.kdnuggets.com/10-github-repositories-to-master-sql</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/39ed048c2ff774b8625fa3fc97c8df9f.png" alt="10 GitHub Repositories to Master SQL cover" loading="lazy"></p>
<p>图片由作者提供 | ChatGPT & Canva</p>
<p>掌握 SQL 是任何追求 IT 职业的人的基本技能,无论你是希望成为开发者、数据科学家、IT 经理还是机器学习工程师。在当今数据驱动的世界中,能够有效使用 SQL 访问和管理数据库是一个基本要求。</p>
<hr>
<h2 id="我们的三大课程推荐-8">我们的三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析水平</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你所在组织的 IT</p>
<hr>
<p>在这篇博客文章中,我们将深入探讨十大 GitHub 库,这些库可以帮助你入门 SQL 和数据库管理,并将你的技能提升到更高水平。这个列表适合寻求提升数据处理技能的初学者和专业人士。</p>
<h2 id="1-sql-101-由-s-shemmee-提供">1. SQL 101 由 s-shemmee 提供</h2>
<p><a href="https://github.com/s-shemmee/SQL-101" target="_blank">SQL 101</a>库提供了逐步教程、实际示例和练习。这个指南是你掌握基础知识并释放 SQL 数据力量的入口。</p>
<p>你将学习关于查询数据、修改数据、数据类型和约束、连接和关系、聚合和分组、子查询和视图、索引和性能优化、事务和并发控制以及高级主题。</p>
<h2 id="2-由-webdevsimplified-提供的-learn-sql">2. 由 WebDevSimplified 提供的 Learn SQL</h2>
<p><a href="https://github.com/WebDevSimplified/Learn-SQL" target="_blank">学习 SQL</a>库提供了一系列针对初学者的练习题和解决方案。12 个练习将帮助巩固学习并增强有效处理 SQL 查询的信心。</p>
<h2 id="3-sql-大师课程由-datawithdanny-提供">3. SQL 大师课程由 datawithdanny 提供</h2>
<p><a href="https://github.com/datawithdanny/sql-masterclass" target="_blank">SQL 大师课程</a>是一个全面的在线课程,旨在将学习者从 SQL 技能的初学者提升到高级水平。这个库提供了结构化的学习路径,包括实践练习、真实世界的例子和测验,帮助学生掌握 SQL 查询和数据分析的艺术。</p>
<h2 id="4-sql-map-由-sqlmapproject-提供">4. SQL Map 由 sqlmapproject 提供</h2>
<p><a href="https://github.com/sqlmapproject/sqlmap" target="_blank">sqlmap</a> 是一个自动化 SQL 注入和数据库接管工具,提供了关于数据库系统漏洞的见解。通过学习这个工具,你可以简化测试数据库服务器的过程,获得关于数据库系统漏洞的宝贵见解,并保护你的服务器免受未知的恶意攻击。</p>
<h2 id="5-sql-server-samples-by-microsoft">5. SQL Server Samples by Microsoft</h2>
<p><a href="https://github.com/microsoft/sql-server-samples" target="_blank">SQL Server Samples</a> 仓库包含了 SQL Server、Azure SQL 数据库和其他微软数据库技术的代码示例,提供了丰富的学习资源和实际例子。</p>
<h2 id="6-sql-music-store-analysis-project-by-rishabhnmishra">6. SQL Music Store Analysis Project by rishabhnmishra</h2>
<p><a href="https://github.com/rishabhnmishra/SQL_Music_Store_Analysis" target="_blank">SQL Music Store Analysis</a> 是一个初学者项目,教你如何分析音乐播放列表的 PostgresQL 数据库。它包括一个关于使用该项目和执行各种数据分析的 YouTube 教程。</p>
<h2 id="7-data-engineering-zoomcamp-by-datatalksclub">7. Data Engineering Zoomcamp by DataTalksClub</h2>
<p><a href="https://github.com/DataTalksClub/data-engineering-zoomcamp" target="_blank">Data Engineering Zoomcamp</a> 提供了一个动手学习数据工程的体验,通过视频教程、测验、项目和同行评估来装备学生实际技能。</p>
<p>该仓库涵盖了诸如容器化和基础设施即代码、工作流编排、数据摄取、数据仓库、分析工程、批处理和流处理等重要主题。</p>
<h2 id="8-sql-server-kit-by-ktaranov">8. SQL Server Kit by ktaranov</h2>
<p><a href="https://github.com/ktaranov/sqlserver-kit" target="_blank">SQL Server Kit</a> 仓库包含了许多有用的链接、博客、视频、播客、课程、脚本、工具和微软 SQL Server 数据库的最佳实践。它是一个开发人员和工程师寻找优化 SQL Server 和学习新 SQL 概念的宝贵资源。</p>
<h2 id="9-awesome-db-tools-by-mgramin">9. Awesome DB Tools by mgramin</h2>
<p><a href="https://github.com/mgramin/awesome-db-tools" target="_blank">Awesome DB Tools</a> 是一个集合了实用和前沿工具的资源库,简化了 DBAs、DevOps、开发人员和日常用户与数据库的互动。</p>
<p>该列表包括 IDE、GUI、CLI、模式、API、应用平台、备份、克隆、监控、测试、HA/故障转移/分片、Kubernetes、配置调整、DevOps、报告、分发、安全、SQL 和数据管理工具。</p>
<h2 id="10-sql-for-wary-data-scientists-by-gvwilson">10. SQL for Wary Data Scientists by gvwilson</h2>
<p><a href="https://github.com/gvwilson/sql-tutorial" target="_blank">SQL for Wary Data Scientists</a> 这本书提供了一个针对数据科学家的互动式 SQL 入门教程。它涵盖了诸如管理命令、聚合、聚合函数、交叉连接、异或、过滤、完全外连接、分组、内存数据库、包含或、连接、连接条件、左外连接、空值、查询、右外连接、三值逻辑和墓碑等主题。</p>
<h2 id="结论-11">结论</h2>
<p>这 10 个 GitHub 仓库提供了从初学者教程到高级练习和全面课程的广泛材料。学习 SQL 变得简单而免费。你只需要努力工作并保持坚持,便能迅速成为数据专业人士。博客中提到的资源将帮助你了解新工具、构建数据库、访问数据、管理数据库系统以及进行数据分析。内容不仅限于文本,你还可以通过互动网站、书籍、视频教程和练习进行学习。</p>
<p><a href="https://www.polywork.com/kingabzpro" target="_blank"></a><strong><strong><a href="https://www.polywork.com/kingabzpro" target="_blank">Abid Ali Awan</a></strong></strong> (<a href="https://www.linkedin.com/in/1abidaliawan" target="_blank">@1abidaliawan</a>) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一款 AI 产品,帮助那些遭受心理健康问题的学生。</p>
<h3 id="更多相关话题-14">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-machine-learning" target="_blank">10 个 GitHub 仓库来掌握机器学习</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-computer-science" target="_blank">10 个 GitHub 仓库来掌握计算机科学</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-data-engineering" target="_blank">10 个 GitHub 仓库来掌握数据工程</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-data-science" target="_blank">10 个 GitHub 仓库来掌握数据科学</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-statistics" target="_blank">10 个 GitHub 仓库来掌握统计学</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-mlops" target="_blank">10 个 GitHub 仓库来掌握 MLOps</a></p>
</li>
</ul>
<h1 id="10-个-github-仓库来掌握统计学">10 个 GitHub 仓库来掌握统计学</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/10-github-repositories-to-master-statistics" target="_blank"><code>www.kdnuggets.com/10-github-repositories-to-master-statistics</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/c04f5dbd373659270ba453c387b00b55.png" alt="10 个 GitHub 仓库来掌握统计学" loading="lazy"></p>
<p>图片由 ChatGPT 生成</p>
<p>学习统计学是成为数据科学家、数据分析师或甚至 AI 工程师的核心部分。现代技术中使用的大多数机器学习模型都是统计模型。因此,对统计学有深入的理解将使你更容易学习和构建先进的 AI 技术。</p>
<hr>
<h2 id="我们的前三大课程推荐-10">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析能力</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织 IT</p>
<hr>
<p>在这篇博客中,我们将探索 10 个 GitHub 仓库,帮助你掌握统计学。这些仓库包括代码示例、书籍、Python 库、指南、文档和视觉学习材料。</p>
<h2 id="1-数据科学家实用统计学">1. 《数据科学家实用统计学》</h2>
<p><strong>仓库:</strong> <a href="https://github.com/gedeck/practical-statistics-for-data-scientists" target="_blank">gedeck/practical-statistics-for-data-scientists</a></p>
<p>这个仓库提供了来自《数据科学家实用统计学》一书的实际示例和代码片段,涵盖了基本的统计技术和概念。对于希望将统计方法应用于实际场景的数据科学家来说,这是一个很好的起点。</p>
<p>书中的代码仓库包含了适当的 R 和 Python 代码示例。如果你习惯了 Jupyter Notebook 风格的编码,它还提供了类似的 Python 和 R 的 Jupyter Notebook 示例。</p>
<h2 id="2-黑客的概率编程和贝叶斯方法">2. 《黑客的概率编程和贝叶斯方法》</h2>
<p><strong>仓库:</strong> <a href="https://github.com/CamDavidsonPilon/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers" target="_blank">CamDavidsonPilon/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers</a></p>
<p>这个仓库提供了使用 Python 的贝叶斯方法的互动式实践介绍。内容以 Jupyter 笔记本形式呈现,通过 nbviewer 展示,使得跟随关于贝叶斯模型和概率编程的理论及 Python 代码变得更加容易。</p>
<p>这本互动书籍包括对贝叶斯方法的介绍,Python 的 PyMC 库入门,马尔科夫链蒙特卡罗,大数法则,损失函数等内容。</p>
<h2 id="3-statsmodelspython-中的统计建模和计量经济学">3. Statsmodels:Python 中的统计建模和计量经济学</h2>
<p><strong>仓库:</strong> <a href="https://github.com/statsmodels/statsmodels" target="_blank">statsmodels/statsmodels</a></p>
<p>Statsmodels 是一个强大的 Python 统计建模和计量经济学库。该仓库包括了执行各种统计测试、线性模型、时间序列分析等的全面文档和示例。我们可以使用这些文档中的示例来学习如何执行各种统计分析,包括时间序列分析、生存分析、多元分析、线性回归等。</p>
<h2 id="4-tensorflow-概率">4. 《TensorFlow 概率》</h2>
<p><strong>仓库:</strong> <a href="https://github.com/tensorflow/probability" target="_blank">tensorflow/probability</a></p>
<p>TensorFlow Probability 是一个用于 TensorFlow 中的概率推理和统计分析的库。它扩展了 TensorFlow 核心库,提供了构建和训练概率模型的工具,是那些希望将深度学习与统计建模结合的人的极佳资源。</p>
<p>文档包含了线性混合效应模型、分层线性模型、概率主成分分析、贝叶斯神经网络等示例。</p>
<h2 id="5-概率与统计烹饪书">5. 《概率与统计烹饪书》</h2>
<p><strong>仓库:</strong> <a href="https://github.com/mavam/stat-cookbook" target="_blank">mavam/stat-cookbook</a></p>
<p>该仓库是一个解决常见统计问题的食谱集合,为各种统计任务提供快速解决方案和示例,作为一个有用的参考。它提供了有关概率和统计的简明指导,包括连续分布、概率理论、随机变量、期望、方差和不等式等概念。你可以使用 make 命令本地访问食谱或下载 PDF 文件。该仓库还包括各种统计概念的 LaTeX 文件。</p>
<h2 id="6-看到理论">6. 《看到理论》</h2>
<p><strong>仓库:</strong> <a href="https://github.com/seeingtheory/Seeing-Theory" target="_blank">seeingtheory/Seeing-Theory</a></p>
<p>《看到理论》是一个概率和统计的视觉介绍。该仓库包括互动可视化和解释,使复杂的统计概念变得更易于理解,尤其适合视觉学习者。</p>
<p>这是一本高度互动的初学者书籍,涵盖了各种主题,如基础概率、复合概率、概率分布、频率推断、贝叶斯推断和回归分析。</p>
<h2 id="7-python-统计数学">7. 《Python 统计数学》</h2>
<p><strong>仓库:</strong> <a href="https://github.com/tirthajyoti/Stats-Maths-with-Python" target="_blank">tirthajyoti/Stats-Maths-with-Python</a></p>
<p>该仓库包含了涵盖一般统计学、数学编程和使用 Python 的科学计算的脚本和 Jupyter 笔记本。对于那些希望提升统计和数学编程技能的人来说,这是一个宝贵的资源。</p>
<p>它包括贝叶斯规则、布朗运动、假设检验、线性回归等示例。</p>
<h2 id="8-概率统计与机器学习的-python">8. 《概率、统计与机器学习的 Python》</h2>
<p><strong>代码库:</strong> <a href="https://github.com/unpingco/Python-for-Probability-Statistics-and-Machine-Learning" target="_blank">unpingco/Python-for-Probability-Statistics-and-Machine-Learning</a></p>
<p>该代码库包含了《Python for Probability, Statistics, and Machine Learning》一书中的代码示例和 Jupyter 笔记本,涵盖了从基本概率和统计到高级机器学习技术的广泛主题。</p>
<p>在“chapters”文件夹内,有三个子文件夹,包含了关于统计学、概率论和机器学习的 Jupyter 笔记本。每个笔记本都包括代码、输出和描述,解释了方法论、代码和结果。</p>
<h2 id="9-概率与统计-vip-备忘单">9. 概率与统计 VIP 备忘单</h2>
<p><strong>代码库:</strong> <a href="https://github.com/shervinea/stanford-cme-106-probability-and-statistics" target="_blank">shervinea/stanford-cme-106-probability-and-statistics</a></p>
<p>该代码库包含斯坦福大学工程师概率与统计课程的 VIP 备忘单。这些备忘单提供了关键概念和公式的简明总结,是学生和专业人士的实用参考。</p>
<p>这是一个流行的备忘单,涵盖了条件概率、随机变量、参数估计、假设检验等主题。</p>
<h2 id="10-机器学习基础数学">10. 机器学习基础数学</h2>
<p><strong>代码库:</strong> <a href="https://github.com/hrnbot/Basic-Mathematics-for-Machine-Learning" target="_blank">hrnbot/Basic-Mathematics-for-Machine-Learning</a></p>
<p>理解数学基础对掌握机器学习和统计学至关重要。该代码库旨在揭示数学的奥秘,并通过 Python Jupyter 笔记本帮助你学习代数、微积分、统计学、概率论、向量和矩阵的基础知识。</p>
<h2 id="终极思考">终极思考</h2>
<p>在 GitHub 上分享的学习资源由专家和开源社区创建,旨在分享知识,为数据科学和统计领域的初学者铺平更容易的学习道路。你将通过阅读理论、解决代码示例、理解数学概念、构建项目、进行各种分析和探索流行的统计工具来学习统计学。所有这些内容都在上述 GitHub 代码库中涵盖。这些资源是免费的,任何人都可以参与改进它们。所以,继续学习并构建惊人的事物。</p>
<p><a href="https://www.polywork.com/kingabzpro" target="_blank"></a><strong><strong><a href="https://www.polywork.com/kingabzpro" target="_blank">Abid Ali Awan</a></strong></strong> (<a href="https://www.linkedin.com/in/1abidaliawan" target="_blank">@1abidaliawan</a>) 是一位认证数据科学专家,热衷于构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理健康问题的学生打造一个 AI 产品。</p>
<h3 id="了解更多">了解更多</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-machine-learning" target="_blank">掌握机器学习的 10 个 GitHub 仓库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-computer-science" target="_blank">掌握计算机科学的 10 个 GitHub 仓库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-data-engineering" target="_blank">掌握数据工程的 10 个 GitHub 仓库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-mlops" target="_blank">掌握 MLOps 的 10 个 GitHub 仓库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-python" target="_blank">掌握 Python 的 10 个 GitHub 仓库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/10-github-repositories-to-master-sql" target="_blank">掌握 SQL 的 10 个 GitHub 仓库</a></p>
</li>
</ul>
<h1 id="10-个适合有志数据科学家的优秀-python-资源">10 个适合有志数据科学家的优秀 Python 资源</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2019/09/10-great-python-resources-aspiring-data-scientists.html" target="_blank"><code>www.kdnuggets.com/2019/09/10-great-python-resources-aspiring-data-scientists.html</code></a></p>
</blockquote>
<p>评论<img src="https://kdn.flygon.net/docs/img/028778782d18a1ada83470e2f1627872.png" alt="头图" loading="lazy"></p>
<p>Python 是数据科学中使用最广泛的语言之一,还是一个<a href="https://spectrum.ieee.org/computing/software/the-top-programming-languages-2019" target="_blank">极受欢迎的通用编程语言</a>。</p>
<hr>
<h2 id="我们的前三大课程推荐-11">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织 IT</p>
<hr>
<p>许多潜在的数据科学家首先面临的问题是,当开始涉足数据科学时,哪种编程语言可能是他们的选择。如果你没有现成的编程技能,这个问题会更加复杂。如果你能对 Python 有一个深入的理解(如果你的数据科学编程工具是其他语言,则替换为该语言),那将更好,但许多新手发现自己在编程一般或 Python 更具体的领域,几乎是从零开始。</p>
<p>这是一个包含 10 个有趣资源的集合,以文章和教程的形式,旨在为新手数据科学家提供洞察和实用指导。请注意,这些资源不是数据科学教程,而是涵盖边缘相关的主题和一般 Python 编程知识。</p>
<p>所以在此不再赘述,按无特定顺序,以下是 10 个旨在帮助你更好地学习 Python 的资源。</p>
<p><strong>1. <a href="https://www.freecodecamp.org/news/an-a-z-of-useful-python-tricks-b467524ee747/" target="_blank">有用的 Python 技巧 A-Z</a></strong></p>
<blockquote>
<p>我每天都使用 Python,它是我作为数据科学家工作的重要组成部分。在这个过程中,我掌握了一些有用的技巧和窍门。</p>
<p>在这里,我以 A-Z 格式分享了一些技巧。</p>
<p>这些“技巧”大多是我在日常工作中使用或偶然发现的。一些是我在浏览 Python 标准库文档时发现的,还有一些是在搜索 PyPi 时发现的。</p>
</blockquote>
<p><strong>2. <a href="https://github.com/arogozhnikov/python3_with_pleasure" target="_blank">愉快地迁移到 Python 3</a></strong></p>
<blockquote>
<p>Python 成为了机器学习和其他以数据为主的科学领域的主流语言;它拥有各种深度学习框架和成熟的数据处理与可视化工具。</p>
<p>然而,Python 生态系统在 Python 2 和 Python 3 中共存,Python 2 在数据科学家中仍被使用。到 2019 年底,科学堆栈将停止支持 Python2. 至于 numpy,2018 年后,任何新的功能发布将仅支持 Python3. <em>更新(2018 年 9 月):pandas、matplotlib、ipython、jupyter notebook 和 jupyter lab 现在也同样适用</em>。</p>
<p>为了使过渡不那么令人沮丧,我收集了一些你可能会觉得有用的 Python 3 特性。</p>
</blockquote>
<p><strong>3. <a href="https://hackernoon.com/learn-functional-python-in-10-minutes-to-2d1651dece6f" target="_blank">10 分钟掌握函数式 Python</a></strong></p>
<blockquote>
<p>在本文中,你将学习什么是函数式范式以及如何在 Python 中使用函数式编程。你还将了解列表推导式和其他形式的推导式。</p>
</blockquote>
<p><strong>4. <a href="https://insights.dice.com/2019/04/23/asynchronous-programming-python-walkthrough/" target="_blank">Python 异步编程:一个全面指南</a></strong></p>
<blockquote>
<p>在 asyncio(有时写作 async IO)之前,Python 使用了基于生成器的协程;Python 3.10 移除了这些协程。asyncio 模块在 Python 3.4 中引入,async/await 则在 3.5 中加入。</p>
<p>这里有几个你应该了解的异步概念:协程和任务。我们先来看一下协程。</p>
</blockquote>
<p><strong>5. <a href="https://www.toptal.com/python/top-10-mistakes-that-python-programmers-make" target="_blank">有问题的 Python 代码:Python 开发者最常犯的 10 个错误</a></strong></p>
<blockquote>
<p>Python 简单易学的语法可能会误导 Python 开发者——特别是那些对语言较新的开发者——忽视其一些细微之处,并低估了 Python 语言的多样性和强大功能。</p>
<p>鉴于这一点,本文呈现了一个“前 10”列表,列出了即使是一些更高级的 Python 开发者也可能会犯的一些微妙且难以发现的错误。</p>
</blockquote>
<p><strong>6. <a href="https://realpython.com/primer-on-python-decorators/" target="_blank">Python 装饰器入门</a></strong></p>
<blockquote>
<p>在本教程中,我们将了解装饰器是什么,以及如何创建和使用它们。装饰器提供了一种简单的语法来调用高阶函数。</p>
<p>根据定义,装饰器是一个函数,它接受另一个函数,并在不显式修改后者函数的情况下扩展其行为。</p>
</blockquote>
<p><strong>7. <a href="https://python.swaroopch.com/data_structures.html" target="_blank">Python 入门 - 数据结构</a></strong></p>
<blockquote>
<p>数据结构基本上就是这些 - 它们是可以将一些数据放在一起的结构。换句话说,它们用于存储相关数据的集合。</p>
<p>Python 有四种内置数据结构——<em>列表、元组、字典</em> 和 <em>集合</em>。我们将看看如何使用它们,以及它们如何使我们的生活更轻松。</p>
</blockquote>
<p><strong>8. <a href="https://realpython.com/get-started-with-django-1/" target="_blank">Django 入门教程 第一部分:构建一个作品集应用</a></strong></p>
<blockquote>
<p>Django 是一个功能齐全的 Python 网络框架,可以用来构建复杂的网络应用程序。在本教程中,你将通过示例学习 Django。你将按照步骤创建一个功能完整的网络应用程序,同时了解框架的一些重要特性及其如何协同工作。</p>
<p>在本系列的后续文章中,你将看到如何利用 Django 的更多功能构建更复杂的网站,这些内容会超出本教程的范围。</p>
</blockquote>
<p><strong>9. <a href="https://towardsdatascience.com/a-beginners-guide-to-python-for-data-science-60ef022b7b67" target="_blank">数据科学初学者的 Python 指南</a></strong></p>
<blockquote>
<p>一些编程语言在数据科学的核心中占据重要位置。Python 就是其中之一。它是数据科学的一个重要组成部分,反之亦然。实际上,要详细解释这一点将会非常漫长。</p>
<p>首先,Python 提供了强大的功能来处理数学、统计和科学函数。在数据科学应用中,它提供了广泛的库来处理这些问题。更不用说它是开源的、解释型的、高级工具了!</p>
</blockquote>
<p><strong>10. <a href="https://www.simplilearn.com/why-python-is-essential-for-data-analysis-article" target="_blank">为什么 Python 对数据分析至关重要</a></strong></p>
<blockquote>
<p>Python 是一种通用编程语言,这意味着它可以用于开发网络和桌面应用程序。它在复杂的数值和科学应用开发中也很有用。由于这种多样性,Python 成为世界上增长最快的编程语言之一也就不足为奇了。</p>
<p>那么 Python 如何与数据分析相结合呢?我们将详细探讨为什么这门多功能编程语言对任何希望从事数据分析工作的人来说都是必不可少的,或者对那些寻找提升技能途径的人来说很重要。了解这些之后,你将更清楚为什么应该选择 Python 进行数据分析。</p>
</blockquote>
<p><strong>相关内容</strong>:</p>
<ul>
<li>
<p>10 个更多必看免费课程,适用于机器学习和数据科学</p>
</li>
<li>
<p>10 本机器学习和数据科学必读的免费书籍</p>
</li>
<li>
<p>另外 10 本机器学习和数据科学必读的免费书籍</p>
</li>
</ul>
<h3 id="更多相关内容-17">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/write-clean-python-code-pipes.html" target="_blank">使用管道编写干净的 Python 代码</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/build-solid-data-team.html" target="_blank">建立一个强大的数据团队</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/springboard-top-resources-learn-data-science-statistics.html" target="_blank">数据科学学习统计的顶级资源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-key-skills-needed-become-great-data-scientist.html" target="_blank">成为优秀数据科学家所需的五项关键技能</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/three-r-libraries-every-data-scientist-know-even-python.html" target="_blank">每个数据科学家都应该了解的三个 R 库(即使你使用 Python)</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/makes-python-ideal-programming-language-startups.html" target="_blank">是什么让 Python 成为初创公司的理想编程语言</a></p>
</li>
</ul>
<h1 id="10-个在-chatgpt-时代建立深科技初创公司的障碍">10 个在 ChatGPT 时代建立深科技初创公司的障碍</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2023/04/10-hurdles-building-deep-tech-startup-age-chatgpt.html" target="_blank"><code>www.kdnuggets.com/2023/04/10-hurdles-building-deep-tech-startup-age-chatgpt.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/823b57db545fb4088af331a2335c1963.png" alt="10 个在 ChatGPT 时代建立深科技初创公司的障碍" loading="lazy"></p>
<p>图片由编辑提供</p>
<p>深科技初创公司面临着与其他科技公司不同的一系列挑战,这使得创始人和投资者必须做好更加复杂和苛刻的旅程的准备。</p>
<hr>
<h2 id="我们的前三名课程推荐-2">我们的前三名课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升您的数据分析水平</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持您的组织在 IT 领域</p>
<hr>
<p>AI 和 ML 在这些公司中发挥了关键作用,使它们能够分析大量数据、识别模式并开发先进的解决方案,同时市场营销却退居一旁。</p>
<p>大型语言模型(LLMs),如 GPT-4,正在革新自然语言处理、药物发现和个性化医学。LLMs 还可以促进与用户的对话,使医疗提供者能够开发提供心理健康支持、回答患者问题甚至提供治疗干预的聊天机器人。通过利用 AI 的力量,这些前沿技术有可能改变心理健康护理的未来,并改善全球数百万人的生活。</p>
<p>在创建了之前的科技公司 Bright Box 并在 2017 年以 7500 万美元出售后,我发现自己在新的公司 Brainify.ai 中面临不同的环境,该公司旨在通过利用 AI/ML 驱动的 EEG 生物标志物预测,将新药批准的可能性提高 80% 并减少研发成本。</p>
<h1 id="技术复杂性">技术复杂性</h1>
<p>深科技初创公司通常致力于前沿技术,这些技术在科学上非常复杂,需要对基础原理有深入的理解。这需要领域内具有专业知识的专家参与,这可能难以找到和留住。</p>
<h1 id="长期开发周期">长期开发周期</h1>
<p>开发和验证新技术可能需要相当长的时间。这可能导致较长的开发周期和市场进入延迟,这对资源有限的初创公司尤其具有财务挑战。</p>
<p><img src="https://kdn.flygon.net/docs/img/3d3278748c54704b98198d6470dc3d1e.png" alt="10 个在 ChatGPT 时代建立深科技初创公司的障碍" loading="lazy"></p>
<p>图片来自 Unsplash</p>
<h1 id="高风险性质">高风险性质</h1>
<p>由于科学研究和开发中固有的不确定性,深科技初创企业往往面临更高的失败风险。投资者可能对资助这些企业持更谨慎的态度,这使得深科技初创企业更难获得资金。</p>
<h1 id="监管障碍">监管障碍</h1>
<p>深科技初创企业可能会在高度监管的行业中运营,例如医疗保健、生物技术或能源。应对复杂的监管要求和获得必要的批准可能耗时且资源密集。</p>
<h1 id="知识产权ip保护">知识产权(IP)保护</h1>
<p>深科技初创企业通常依赖于有价值的知识产权(IP)来维持其竞争优势。通过专利和其他法律机制保护这些知识产权可能具有挑战性、昂贵,并且对初创企业的成功至关重要。</p>
<h1 id="深科技初创企业的市场营销策略">深科技初创企业的市场营销策略</h1>
<p>作为一名经验丰富的企业家,在深科技初创企业中,最具挑战性的方面之一就是市场营销方式的差异。在深科技领域,大量时间花费在隐秘阶段,专注于研发,然后才会推广任何产品或服务。与其他行业不同,在其他行业中,市场营销可以在产品开发过程中早早开始,而深科技初创企业必须谨慎行事,确保任何提出的主张都经过科学验证和证明。</p>
<p>这意味着我不得不采取更为保守的营销策略,仅在我们达到特定里程碑或对我们的技术有了特定信心的阈值后才推广我们的产品。维护我们在科学界以及潜在投资者和客户中的声誉至关重要,因为在这一领域,可信度是关键。任何过早或未经证实的主张都可能迅速损害我们的声誉,并阻碍我们在长期内取得成功的能力。</p>
<p><img src="https://kdn.flygon.net/docs/img/865b03c3622245541d0fb3027c4d1457.png" alt="构建深科技初创企业的 10 大挑战" loading="lazy"></p>
<p>图片来自 Unsplash</p>
<h1 id="准确沟通">准确沟通</h1>
<p>在围绕我们的技术建立兴奋感与确保我们仅传达准确和可验证的信息之间找到微妙的平衡,一直是经营深科技初创企业的特别具有挑战性的方面。</p>
<h1 id="广泛的研究">广泛的研究</h1>
<p>深科技初创企业的主要区分因素在于广泛的研究活动、高风险和初期开发阶段的不确定性。最初,通常无法知道初创企业的科学基础是否可能。</p>
<h1 id="科学失败的高风险">科学失败的高风险</h1>
<p>这与典型的科技初创企业形成对比,后者的重点更多在于产品市场契合度和执行策略。换句话说,对于科技初创企业而言,重点在于业务如何开展,而不是是否可行。而深科技初创企业由于研究活动的固有性质和涉及的不确定性,面临着更高的科学失败风险。</p>
<h1 id="验证后的资金筹集">验证后的资金筹集</h1>
<p>为我们的初创公司获得资金始于 Mariam Khayaredinova(首席执行官兼联合创始人)和我个人的 25 万美元投资。我们希望首先验证解决方案的需求并评估实现目标的可能性。一旦我们对创意的潜力有信心,我们决定从天使投资者那里筹集更多资本。凭借我之前的退出经验和我们强大的业绩记录,我们成功从天使投资者那里获得了约 100 万美元,并从创始团队获得了额外的 35 万美元。</p>
<p>目前,我们正在证明市场适配性,展示我们技术的可扩展性,并向投资者展示潜在的丰厚回报。保持对最新进展和新兴机会的关注至关重要。深度技术领域不断发展,因此了解挑战和可能性对成功至关重要。</p>
<p><strong><a href="https://www.linkedin.com/in/ivanmishanin/" target="_blank">Ivan Mishanin</a></strong> 是 Brainify.ai 的联合创始人兼首席运营官,该平台致力于用于精神病学的新治疗开发的 AI/ML 生物标志物。他之前的科技公司 Bright Box 被苏黎世保险集团以 7500 万美元收购。</p>
<h3 id="了解更多此话题">了解更多此话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/12-tips-data-analyst-to-co-founder.html" target="_blank">12 条建议:从数据分析师到初创公司联合创始人</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/06/data-scientists-still-needed-age-generative-ai.html" target="_blank">生成 AI 时代的数据科学家仍然需要吗?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/understanding-data-privacy-in-the-age-of-ai" target="_blank">理解 AI 时代的数据隐私</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/building-microservice-for-multichat-backends-using-llama-and-chatgpt" target="_blank">使用 Llama 和 ChatGPT 构建多聊天后台的微服务</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/03/visual-chatgpt-microsoft-combine-chatgpt-vfms.html" target="_blank">Visual ChatGPT: 微软结合 ChatGPT 和 VFM</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/07/chatgpt-cli-transform-commandline-interface-chatgpt.html" target="_blank">ChatGPT CLI: 将你的命令行界面转变为 ChatGPT</a></p>
</li>
</ul>
<h1 id="10-个-jupyter-notebook-小技巧和窍门">10 个 Jupyter Notebook 小技巧和窍门</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2023/06/10-jupyter-notebook-tips-tricks-data-scientists.html" target="_blank"><code>www.kdnuggets.com/2023/06/10-jupyter-notebook-tips-tricks-data-scientists.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/85e8a7853e673a63f605937b572ab719.png" alt="10 个 Jupyter Notebook 小技巧和窍门" loading="lazy"></p>
<p>图片由作者提供</p>
<p>无论你是初学者还是数据专业人士,你一定使用过 Jupyter Notebook,并发现运行 Python 代码并以报告格式可视化输出是多么简单。</p>
<hr>
<h2 id="我们的前三大课程推荐-12">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织的 IT</p>
<hr>
<p>但是,如果我告诉你可以提升你的 Jupyter 开发体验呢?在这篇文章中,我们将学习 10 个 Jupyter Notebook 小技巧,以提升数据专业人员的生产力和性能。</p>
<h1 id="1-键盘快捷键">1. 键盘快捷键</h1>
<p>键盘快捷键对于执行重复任务和节省时间非常重要。你可以通过<strong>帮助 > 键盘快捷键</strong>或按<strong>H</strong>键了解所有默认的键盘快捷键。</p>
<p>访问命令的最简单和最流行的方法是类似于 VSCode 的命令面板。你可以按<strong>Ctrl + Shift + P</strong> 调出命令面板。它允许你搜索和执行命令,或滚动浏览所有命令以发现你想运行的命令。</p>
<p><img src="https://kdn.flygon.net/docs/img/e043ed190771badd5dcc05a40198b306.png" alt="10 个 Jupyter Notebook 小技巧和窍门" loading="lazy"></p>
<p>动图由作者提供</p>
<h1 id="2-ipython-魔法命令">2. IPython 魔法命令</h1>
<p>你可以在 Jupyter Notebook 中访问所有 IPython 魔法命令。这些命令为你执行代码提供了额外的功能。</p>
<p>例如,你可以使用<code>%%time</code> 魔法命令来显示单元格的执行时间。在我们的例子中,代码运行了 1000 次需要 1.09 秒。</p>
<pre><code class="language-py">%%time
import time
for i in range(1_000):
time.sleep(0.001)
</code></pre>
<pre><code class="language-py">CPU times: user 10.2 ms, sys: 1.68 ms, total: 11.9 ms
Wall time: 1.09 s
</code></pre>
<p>你可以通过运行<code>%lsmagic</code>命令或查看<a href="https://ipython.readthedocs.io/en/stable/interactive/magics.html" target="_blank">内置魔法命令</a>来了解所有可用的魔法命令。</p>
<p>常用命令列表:</p>
<ul>
<li>
<p><strong>%env</strong> 用于设置环境变量。</p>
</li>
<li>
<p><strong>%run</strong> 用于执行 Python 代码。</p>
</li>
<li>
<p><strong>%store</strong> 用于在多个笔记本之间访问变量。</p>
</li>
<li>
<p><strong>%%time</strong> 显示单元格的执行时间。</p>
</li>
<li>
<p><strong>%%writefile</strong> 将单元格的内容保存到一个文件中。</p>
</li>
<li>
<p><strong>%pycat</strong> 显示外部文件的内容。</p>
</li>
<li>
<p><strong>%pdb</strong> 用于调试。</p>
</li>
<li>
<p><strong>%matplotlib inline</strong> 用于抑制函数在最后一行的输出。</p>
</li>
</ul>
<h1 id="3-执行-shell-命令">3. 执行 Shell 命令</h1>
<p>你可以在 Jupyter Notebook 单元格中使用 <code>!</code> 运行 Shell 和 Bash 命令,如下所示。这为你提供了额外的能力来运行 Unix 或 Linux 基于的命令和工具。</p>
<pre><code class="language-py">!git push origin
</code></pre>
<p>此命令最常见的用途是即时安装 Python 包。</p>
<pre><code class="language-py">!pip install numpy
</code></pre>
<p>你还可以使用 Magic 命令 <code>%pip</code> 安装 Python 包</p>
<pre><code class="language-py">%pip install numpy
</code></pre>
<h1 id="4-使用-latex-公式">4. 使用 LaTeX 公式</h1>
<p>在创建数据分析报告时,你需要提供统计或数学方程式,Jupyter Notebook 允许你使用 Latex 公式呈现复杂的方程。</p>
<p>只需创建一个 Markdown 单元格,并用美元符号 $ 包围你的 Latex 公式,如下所示。</p>
<pre><code class="language-py">$\int \frac{1}{x} dx = \ln \left| x \right| + C$
</code></pre>
<p><strong>输出:</strong></p>
<p><img src="https://kdn.flygon.net/docs/img/9da1a9309898fbbc43f627da39c1b316.png" alt="数据科学家的 10 个 Jupyter Notebook 小贴士和技巧" loading="lazy"></p>
<h1 id="5-为-jupyter-notebook-安装其他内核">5. 为 Jupyter Notebook 安装其他内核</h1>
<p>我们都知道 Python 内核,但你也可以安装其他内核,并用任何语言运行代码。</p>
<p>例如,如果你想在 Jupyter Notebook 中运行 R 编程语言,你需要安装 R 并在 R 环境中安装 IRkernel。</p>
<pre><code class="language-py">install.packages('IRkernel')
IRkernel::installspec()
</code></pre>
<p>或者,如果你已经安装了 Anaconda,你可以在终端中运行下面的命令来为 Jupyter Notebook 设置 R。</p>
<pre><code class="language-py">conda install -c r r-essentials
</code></pre>
<p>对于 Julia 语言爱好者,我创建了一个简单的指南 如何在 Jupyter Notebook 中设置 Julia。</p>
<h1 id="6-从不同内核运行代码">6. 从不同内核运行代码</h1>
<p>你还可以通过使用 Magic 命令在 Python Jupyter Notebook 中从多个内核运行代码,例如:</p>
<ul>
<li>
<p>%%bash</p>
</li>
<li>
<p>%%html</p>
</li>
<li>
<p>%%javascript</p>
</li>
<li>
<p>%%perl</p>
</li>
<li>
<p>%%python3</p>
</li>
<li>
<p>%%ruby</p>
</li>
</ul>
<p>在这个例子中,我们将尝试使用 <code>%%HTML</code> Magic 命令在 Python 内核中运行 HTML 代码。</p>
<pre><code class="language-py">%%HTML
<html>
<body>
<h1>Hello World</h1>
<p>Welcome to my website</p>
</body>
</html>
</code></pre>
<p><strong>输出:</strong></p>
<p><img src="https://kdn.flygon.net/docs/img/3a7621c33853a6d4f034a296742bc574.png" alt="数据科学家的 10 个 Jupyter Notebook 小贴士和技巧" loading="lazy"></p>
<p>类似于 <code>!</code>,你可以使用 <code>%%script</code> 运行 Shell 脚本,这允许你运行安装在机器上的所有内核。例如,你可以运行 R 脚本。</p>
<pre><code class="language-py">%%script R --no-save
print("KDnuggets")
</code></pre>
<p><strong>输出:</strong></p>
<pre><code class="language-py">> print("KDnuggets")
[1] "KDnuggets"
>
</code></pre>
<h1 id="7-多光标支持">7. 多光标支持</h1>
<p>你可以使用多个光标来编辑多个变量和语法或添加多行代码。要创建多个光标,你需要在按住 <strong>Alt</strong> 键的同时点击并拖动鼠标。</p>
<p><img src="https://kdn.flygon.net/docs/img/043f93d8a84e70064674ef0bb87f96cf.png" alt="数据科学家的 10 个 Jupyter Notebook 小贴士和技巧" loading="lazy"></p>
<p>作者提供的 GIF</p>
<h1 id="8-输出图像视频和音频">8. 输出图像、视频和音频</h1>
<p>你可以在不安装额外的 Python 包的情况下显示图像、视频和音频。</p>
<p>你只需导入 <code>IPython.display</code> 即可获取图像、视频和音频功能。这在处理非结构化数据集和机器学习应用时非常有用。</p>
<p><img src="https://kdn.flygon.net/docs/img/f44688dadc402fa0a35953e1d4318f84.png" alt="数据科学家的 10 个 Jupyter Notebook 小贴士和技巧" loading="lazy"></p>
<p>作者提供的图片</p>
<h1 id="9-处理大型数据">9. 处理大型数据</h1>
<p>你可以通过使用 <a href="https://github.com/ipython/ipyparallel" target="_blank">IPython Parallel</a> 库处理和查询大型数据集。它是用于控制 IPython 进程集群的 CLI 脚本集合,基于 Jupyter 协议构建。</p>
<p>此外,你还可以使用 <a href="https://github.com/jupyter-incubator/sparkmagic" target="_blank">sparkmagic</a> 命令来使用 PySpark 会话。</p>
<p>查看 sparkmagic 仓库中的示例。</p>
<pre><code class="language-py">%%spark -c sql -o df_employee--maxrows 5
SELECT * FROM employee
</code></pre>
<p><strong>输出:</strong></p>
<pre><code class="language-py"> age name
0 40.0 abid
1 20.0 Matt
2 36.0 Chris
</code></pre>
<h1 id="10-分享笔记本">10. 分享笔记本</h1>
<p>分享报告或代码源及其输出非常重要,你可以通过多种方式实现:</p>
<ol>
<li>
<p>使用 <strong>文件 > 另存为 > HTML</strong> 将笔记本转换为 HTML 文件。</p>
</li>
<li>
<p>使用 <strong>文件 > 另存为 > PDF</strong> 将笔记本保存为 PDF 文件。</p>
</li>
<li>
<p>将笔记本保存为 Markdown <strong>文件 > 另存为 > Markdown</strong>。</p>
</li>
<li>
<p>使用 <a href="https://www.dataquest.io/blog/how-to-setup-a-data-science-blog/" target="_blank">Pelican</a> 创建博客。</p>
</li>
<li>
<p>将 .ipynb 文件上传到 <a href="https://colab.research.google.com/" target="_blank">Google Colab</a> 并在同事之间分享。</p>
</li>
<li>
<p>使用 <a href="https://gist.github.com/" target="_blank">GitHub Gits</a> 与公众分享笔记本文件。</p>
</li>
<li>
<p>将你的文件托管在云端或外部服务器上,并使用 <a href="https://nbviewer.org/" target="_blank">nbviewer</a> 渲染笔记本。</p>
</li>
</ol>
<p>希望你觉得我列出的 10 个 Jupyter Notebook 技巧对你有帮助。如果你有任何额外的建议或技巧想要分享,请在下方评论中告诉我。感谢阅读。</p>
<p><strong><a href="https://www.polywork.com/kingabzpro" target="_blank">Abid Ali Awan</a></strong> (<a href="https://twitter.com/1abidaliawan" target="_blank">@1abidaliawan</a>) 是一位认证数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助面临心理健康问题的学生。</p>
<h3 id="相关主题-3">相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/python-in-finance-real-time-data-streaming-within-jupyter-notebook" target="_blank">金融中的 Python:Jupyter Notebook 内的实时数据流</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/5-free-templates-for-data-science-projects-on-jupyter-notebook" target="_blank">5 个 Jupyter Notebook 数据科学项目的免费模板</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/11/setup-julia-jupyter-notebook.html" target="_blank">如何在 Jupyter Notebook 上设置 Julia</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/jupyter-notebook-magic-methods-cheat-sheet" target="_blank">Jupyter Notebook 魔法方法速查表</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/05/sas-quick-data-science-tips-tricks-learn.html" target="_blank">快速数据科学技巧和窍门来学习 SAS</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/12-vscode-tips-tricks-python-development.html" target="_blank">12 个用于 Python 开发的 VSCode 技巧和窍门</a></p>
</li>
</ul>
<h1 id="2022-年及以后-10-个关键-ai-与数据分析趋势">2022 年及以后 10 个关键 AI 与数据分析趋势</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2021/12/10-key-ai-trends-for-2022.html" target="_blank"><code>www.kdnuggets.com/2021/12/10-key-ai-trends-for-2022.html</code></a></p>
</blockquote>
<p>评论</p>
<p><strong>作者:<a href="https://www.smarter.ai/" target="_blank">David Pool</a>,<a href="https://www.smarter.ai/" target="_blank">Smarter.ai</a> 的联合创始人及 CAIO</strong></p>
<p><img src="https://kdn.flygon.net/docs/img/91ff2f53f9a49256f2f23c87bf7cfbfd.png" alt="" loading="lazy"></p>
<hr>
<h2 id="我们的前三个课程推荐-18">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速开启网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你所在组织的 IT</p>
<hr>
<p>全球大流行改变了我们的交易方式。随着世界大部分地区转向在线,电子商务、云计算和增强的网络安全措施只是评估当前数据分析趋势的冰山一角。</p>
<p>管理风险和控制成本一直是企业的重要考虑因素。然而,能够有效分析数据的正确机器学习技术正在成为任何希望获得竞争优势的公司至关重要的条件。</p>
<p><strong>为什么趋势对模型创作者重要?</strong></p>
<p>我们对 2022 年及以后数据分析趋势的总结应该能给创作者一个关于行业发展方向的良好概念。</p>
<p>通过保持对数据科学趋势的关注,并调整他们的模型以符合当前标准,创作者可以使他们的工作真正变得不可或缺。无论这些数据分析趋势是否激励你构思新的模型,还是更新你工具箱中的现有模型,完全取决于你自己。</p>
<h3 id="创作者经济进入-ai-领域想象一下类似于-airbnb-的-ai-工具市场">创作者经济进入 AI 领域:想象一下类似于 Airbnb 的 AI 工具市场</h3>
<p>随着计算机游戏领域的趋势,用户生成内容(UGC)作为游戏平台的重要组成部分实现了货币化,我们也看到了类似的货币化发生在数据科学领域。这从简单的模型开始,如分类、回归和聚类模型,这些模型都被重新利用并上传到专门的平台。这些模型随后会提供给希望自动化日常业务数据和流程的全球商业用户市场。</p>
<p>这将很快被深度模型工件所取代,如卷积网络、GAN 和自编码器,这些模型经过调整并应用于解决商业问题。这些模型旨在由商业分析师而非数据科学家团队安全使用。</p>
<p>数据科学家以咨询工作形式出售他们的技能和经验,或将模型上传到代码库,这并不新鲜。然而,2022 年将通过双面市场实现这些技能的货币化,使得单个模型可以进入全球市场。</p>
<p>想象一下 AI 版的 Airbnb。</p>
<h3 id="环境-ai-成为关注焦点">环境 AI 成为关注焦点</h3>
<p>尽管大多数研究无可厚非地集中在推动复杂性边界上,但现实是,训练和运行复杂模型对环境的影响可能很大。</p>
<p>预测到 2040 年,数据中心将占全球 CO2 排放量的 15%,而 2019 年的一项研究论文《深度学习的能源考虑》发现,训练一个自然语言翻译模型的 CO2 排放量相当于四辆家庭轿车在其生命周期内的排放量。显然,训练越多,CO2 释放越多。</p>
<p>随着对环境影响理解的加深,组织们正在探索减少碳足迹的方法。虽然我们现在可以利用 AI 提高数据中心的效率,但世界应当期待看到更多对简单模型的关注,这些简单模型在解决特定问题时能与复杂模型一样表现出色。</p>
<p>实际上,当一个简单的贝叶斯模型使用的数据、训练和计算能力远远少于 10 层卷积神经网络却表现同样良好时,我们为何还要使用复杂的 10 层卷积神经网络?“模型效率”将成为环境 AI 的代名词,因为创作者们专注于构建简单、高效且易用的模型,而这些模型不会对地球造成巨大负担。</p>
<h3 id="超参数化模型成为大型科技公司的超级游艇">超参数化模型成为大型科技公司的超级游艇</h3>
<p>不同于穆斯克和贝索斯的太空科技竞赛,大型科技公司也有他们自己令人兴奋的竞赛:<strong>谁拥有最大的深度学习模型</strong>?</p>
<p><img src="https://kdn.flygon.net/docs/img/9389962a5dbd807a920523666397ce74.png" alt="" loading="lazy"></p>
<p>在过去 3 年中,最大模型的参数数量从 2018 年的 9400 万增长到了 2021 年的惊人 1.6 万亿,谷歌、Facebook、微软、OpenAI 等公司不断推升复杂性边界。</p>
<p>如今,这些数万亿的参数是基于语言的,允许数据科学家构建能够详细理解语言的模型,使模型能够撰写人类水平的文章、报告和翻译。它们甚至能编写代码、开发食谱,并理解上下文中的讽刺和讽刺。</p>
<p>从 2021 年开始,我们可以期待视觉模型在无需庞大数据集的情况下实现类似的人类水平表现。例如,你可以只给幼儿展示一次巧克力,他们每次看到巧克力时都会认识它,而无需重新训练!</p>
<p>创作者们已经开始将这些模型应用于具体的机会。其中一个最为显著的例子来自游戏开发者 Dungeon.AI,他们基于 1970 年代的风靡游戏《龙与地下城》开发了一系列幻想游戏。这些逼真的世界基于 1750 亿参数的模型 GPT-3。我们预计创作者们会在特定领域看到更多这种活动,比如理解法律文本、撰写广告文案或将图像或视频分类到特定组中。</p>
<h3 id="数字协作工人的增强型工作队伍">数字协作工人的增强型工作队伍</h3>
<p>随着认知技术和机器学习模型在全球范围内被企业越来越多地采用,机械化的行政工作和将琐碎任务分配给人工劳动力的时代正逐渐消失。</p>
<p>取而代之的是,企业选择了一种增强型劳动力模型,使人类和机器人并肩工作。这一技术进步使工作具有可扩展性和优先级,赋予人类以消费者为首要任务的能力。</p>
<p>尽管创建增强型劳动力无疑是创作者需要关注的数据分析趋势之一,但部署正确的人工智能并解决自动化带来的任何初期问题是一个重大挑战。此外,面对统计数据称到 2025 年每三份工作中就有一份将被机器人取代,员工们自然对这一趋势不太热衷。[1]</p>
<p>这些担忧在某种程度上是有效的,但也有一种有根据的信念认为,机器学习和自动化将仅仅提升员工的生活,使他们能够更快、更无不确定性地做出关键决策。尽管存在潜在缺点,增强型劳动力使个人可以花更多时间进行质量保证和客户服务,同时在复杂的业务问题出现时解决它们。[2]</p>
<p>随着众多公司热衷于将机器人流程自动化(RPA)、机器学习和认知增强作为未来建模的一部分,这也是所有有志数据分析师应了解的人工智能趋势之一。</p>
<h3 id="改善网络安全">改善网络安全</h3>
<p>随着大多数企业在疫情期间被迫投资于增加在线存在感,提高网络安全已成为 2021 年最重要的数据分析趋势之一。</p>
<p>单次网络攻击可以完全扰乱一个企业,但企业如何在没有巨大的成本和时间投入的情况下追踪潜在的失败点?这个燃眉之急的答案在于优秀的建模和对风险的理解。人工智能快速且准确的数据分析能力意味着可以进行更深入的风险建模和威胁感知。</p>
<p>与人类不同,机器学习模型能够以快速的速度处理数据,提供保持威胁控制的洞察而无需太多外部输入。根据 IBM 对网络安全的人工智能分析,这项技术可以收集从恶意文件到不利 IP 地址的所有信息,使企业能够比以前快多达 60 倍地应对威胁。[3] 由于遏制一次数据泄露的平均成本为 11.2 亿美元,投资优秀的网络安全建模是企业不应忽视的事情。[4]</p>
<p>总之,通过保持网络安全以应对这一数据分析趋势,企业可以更好地保护其底线。</p>
<h3 id="低代码和无代码人工智能">低代码和无代码人工智能</h3>
<p>由于全球范围内可用的数据科学家如此稀缺,使非专家能够从预定义的组件中创建可操作的应用程序,使低代码和无代码人工智能成为近年来在行业中出现的最具民主性的趋势之一。</p>
<p>实质上,这种人工智能方法几乎不需要编程,允许任何人“使用简单的构建块来根据需求定制应用程序。”[5]</p>
<p>最近的趋势表明,数据科学家和工程师的就业市场极为积极,LinkedIn 的就业报告称,在未来 5 年内,大约<a href="https://business.linkedin.com/talent-solutions/resources/talent-acquisition/jobs-on-the-rise-us#digital" target="_blank">全球将创造 1.5 亿个技术职位</a>。考虑到超过 83%的企业现在将人工智能视为保持相关性的关键因素,这也就不足为奇了。</p>
<p>然而,在当前的环境下,对人工智能相关服务的强烈需求根本无法得到满足。更重要的是,超过 60%的人工智能顶尖人才被科技和金融行业抢走,导致其他行业几乎没有潜在的员工可供使用。[6]</p>
<p>因此,创建低代码和无代码人工智能解决方案,使企业能够在没有数据专家的情况下进行竞争,是保持行业开放和具有竞争力的关键。</p>
<h3 id="云计算的崛起">云计算的崛起</h3>
<p>疫情使得云计算的转型成为近年来出现的最不可避免的数据分析趋势之一。面对比以往更多的数据,通过云端共享和管理数字服务已经被全球的企业迅速采纳。</p>
<p><img src="https://kdn.flygon.net/docs/img/5d6452311507fd22500606c58b1cacd8.png" alt="" loading="lazy"></p>
<p>机器学习平台将数据带宽需求提升到一个新水平,但云计算的崛起使得完成工作更快,并具有公司级别的可见性。鉴于 94%的企业已经使用云服务,并且公共云基础设施预计到 2021 年底将增长 35%,未能利用云计算的公司将会被甩在后面。[7]</p>
<p>云计算能够保持数据安全、保护企业免受网络攻击并提升可扩展性,其好处多于坏处,使其成为创作者在未来几年需要关注的关键数据分析趋势之一。</p>
<h3 id="小数据与可扩展人工智能">小数据与可扩展人工智能</h3>
<p>随着全球越来越多地转向线上,能够创建响应更广泛数据集的可扩展人工智能比以往任何时候都更为重要。虽然快速到达的大数据仍然对创建有效的人工智能模型至关重要,但真正为客户分析增值的是小数据。这并不是说大数据没有价值,而是从如此庞大的数据集中提取有意义的趋势几乎是不可能的。</p>
<p>如你所料,小数据由少量数据类型组成,这些数据类型包含足够的信息来测量模式,但不会让公司感到 overwhelmed。通过从具体案例中提取见解,营销人员可以更有效地建模消费者行为,并通过个性化将其发现转化为销售增长。[8]</p>
<h3 id="改进的数据来源">改进的数据来源</h3>
<p>由 Boris Glavic 定义为“关于数据的来源和创建过程的信息,”[9] 数据来源是保持工业生产数据可靠的数据科学趋势之一。</p>
<p>为了保持盈利,企业需要能够信任用于营销和广告目的的数据。虽然有大量数据是好的,但只有在正确分析的情况下才有用。不准确的预测和糟糕的数据管理会严重影响企业,但随着时间的推移,机器学习模型的改进已使这一问题减少。</p>
<p>现在能够使用针对性的算法,这些模型可以确定哪些数据集应被使用,哪些应被丢弃。对于数据分析师来说,跟踪智能特性并保持所有文件的最新状态应该使相关数据更容易被筛选出来。</p>
<h3 id="迁移到-python-和工具">迁移到 Python 和工具</h3>
<p>Python 通过其简单的语言和语法提供更用户友好的编码方式,是一种引领科技行业的高级编程语言。</p>
<p>尽管 R 不太可能在数据科学领域消失,<a href="https://towardsdatascience.com/python-vs-r-whats-best-for-machine-learning-93432084b480" target="_blank">Python 被全球企业视为更易获取的工具</a>,因为它优先考虑逻辑代码和可读性。与主要用于统计计算和图形的 R 不同,Python 可以轻松用于机器学习,因为它比其前身更深入地收集和分析数据。</p>
<p>使用 Python 在可扩展的生产环境中,能给数据分析师带来优势,这是数据科学中的一种趋势,新兴创作者不应忽视。</p>
<h3 id="深度学习和自动化">深度学习和自动化</h3>
<p>深度学习与机器学习相关,但其算法受人脑神经通路的启发。对于企业而言,使用这种技术确保了准确的预测和易于理解的有用模型。[10]</p>
<p>虽然深度学习并不适用于每个行业,但该机器学习子领域中使用的神经网络改进了自动化,使企业能够在较少人工干预的情况下进行高度分析。</p>
<p>从数字助手到<a href="https://blogs.edf.org/energyexchange/2017/08/09/shell-becomes-latest-oil-and-gas-company-to-test-smart-methane-sensors/" target="_blank">壳牌在墨西哥湾现代化的智能传感器</a>,深度学习和自动化的应用是将高质量数据转化为保证的顶线增长的 AI 趋势之一。</p>
<h3 id="实时数据">实时数据</h3>
<p><img src="https://kdn.flygon.net/docs/img/457a15051e1edc261cf2f82f33bd7c82.png" alt="" loading="lazy"></p>
<p>能够实时评估数据是近年来最令人兴奋的数据分析趋势之一。<a href="https://www.smarter.ai/blog/sentiment_evaluation" target="_blank">情感分析和实时自动化测试</a> 在 2021 年变得越来越受企业欢迎,公司利用数据进展实时评估消费者行为。实时分析允许在问题出现时立即进行调整和更改,使企业更加主动。</p>
<p>根据研究和咨询公司 Gartner 的数据,到 2022 年,将有超过 50% 的新业务系统使用实时数据来改善决策。[11] 这不仅会改善客户体验,提高企业利润率,而且实时数据还是消除与历史、本地数据报告相关成本的数据分析趋势之一。</p>
<h3 id="从-dataops-转向-xops">从 DataOps 转向 XOps</h3>
<p>在现代世界中,企业拥有如此多的数据,手动处理显然是不切实际的。</p>
<p>尽管 DataOps 在数据收集和评估方面效率很高,但向更复杂的 XOps 转变被证明是明年的顶级数据分析趋势之一。为了进一步支持这一观点,Gartner 确认了 XOps 的重要性,称其是<a href="https://www.gartner.com/smarterwithgartner/gartner-top-10-data-and-analytics-trends-for-2021" target="_blank">将数据处理过程结合起来以获得更前沿的数据科学方法</a>的有效方式。</p>
<p>你可能已经熟悉 DataOps,但如果你对一个新术语感到困惑,让我们来为你解答。</p>
<p>根据 Salt Project 的数据管理专家,XOps 是一个“涵盖所有 IT 学科和责任的总称,描述了所有 IT 操作的通用术语。”[12] 它包括 DataOps、MLOps、ModelOps、AIOps 和 PlatformOps,采用多方面的方法来提高效率,实现自动化,并缩短多个行业的开发周期。</p>
<p>通过整合这些程序,企业可以利用最新的 IT 软件,使数据调查变得无缝,从而节省时间、精力和金钱。</p>
<h3 id="未来的数据分析趋势关键要点是什么">未来的数据分析趋势:关键要点是什么?</h3>
<p>2021 年的数据科学趋势极为进步,证明准确且易于消化的数据对企业来说比以往任何时候都更有价值。</p>
<p>然而,数据分析趋势永远不会静止,因为可供企业使用的数据量不断增长。这使得找到对所有企业都有效的数据处理方法成为一个持续的挑战。</p>
<p>随着可访问性、民主化和自动化成为数据行业未来的关键优先事项,创作者应当致力于保持其模型易于理解,并且在可能的情况下做到未来-proof。</p>
<p>[1] Joshua Barajas,《Gartner 称智能机器人将在 2025 年前占据三分之一的工作岗位》,PBS,最后修改于 2014 年 10 月 7 日,<a href="https://www.pbs.org/newshour/economy/smart-robots-will-take-third-jobs-2025-gartner-says" target="_blank">https://www.pbs.org/newshour/economy/smart-robots-will-take-third-jobs-2025-gartner-says</a></p>
<p>[2] Bill Cline, Maureen Brady, David Montes, Chris Foster, Catia Davim, KPMG,《增强型劳动力》,<a href="https://home.kpmg/xx/en/home/insights/2018/06/augmented-workforce-fs.html" target="_blank">https://home.kpmg/xx/en/home/insights/2018/06/augmented-workforce-fs.html</a></p>
<p>[3] IBM,《更智能的网络安全中的人工智能》,最后修改于 2021 年 10 月 4 日,<a href="https://www.ibm.com/uk-en/security/artificial-intelligence" target="_blank">https://www.ibm.com/uk-en/security/artificial-intelligence</a></p>
<p>[4] IBM 公司,《超越炒作:你 SOC 中的人工智能》,2020 年 7 月,<a href="https://www.ibm.com/downloads/cas/9EDONM6M" target="_blank">https://www.ibm.com/downloads/cas/9EDONM6M</a></p>
<p>[5] Anton Vaisbud,《企业中的低代码人工智能》,最后修改于 2021 年 2 月 26 日,<a href="https://towardsdatascience.com/low-code-ai-in-enterprise-benefits-and-use-cases-b9692ee13168" target="_blank">https://towardsdatascience.com/low-code-ai-in-enterprise-benefits-and-use-cases-b9692ee13168</a></p>
<p>[6] David Kelnar,《人工智能现状:2019 年的分歧》,MMC Ventures,最后修改于 2019 年 3 月 5 日, <a href="https://www.stateofai2019.com/introduction" target="_blank"><code>www.stateofai2019.com/introduction</code></a></p>
<p>[7] Nick Galov,《2021 年云计算采纳统计数据》,最后修改于 2021 年 8 月 1 日,<a href="https://hostingtribunal.com/blog/cloud-adoption-statistics/" target="_blank">https://hostingtribunal.com/blog/cloud-adoption-statistics/</a></p>
<p>[8] Shane Hill,《忘记“大数据”吧:真正创造价值的是小数据》,最后修改于 2020 年 10 月 13 日,<a href="https://techmonitor.ai/ai/small-data-not-big-data" target="_blank">https://techmonitor.ai/ai/small-data-not-big-data</a></p>
<p>[9] Boris Glavic,《大数据溯源:挑战与基准测试的影响》,《指定大数据基准》,2014 年,第 8163 卷,摘要</p>
<p>[10] IBM 云教育,《深度学习》,最后修改于 2020 年 5 月 1 日,<a href="https://www.ibm.com/cloud/learn/deep-learning" target="_blank">https://www.ibm.com/cloud/learn/deep-learning</a></p>
<p>[11] Susan Moore,《2019 年 Gartner 十大数据与分析趋势》,最后修改于 2019 年 11 月 5 日,<a href="https://www.gartner.com/smarterwithgartner/gartner-top-10-data-analytics-trends" target="_blank">https://www.gartner.com/smarterwithgartner/gartner-top-10-data-analytics-trends</a></p>
<p>[12] Rhett Glauser,《什么是 XOps?》,最后修改于 2020 年 5 月 6 日,<a href="https://saltproject.io/what-is-xops/" target="_blank">https://saltproject.io/what-is-xops/</a></p>
<p><a href="https://www.smarter.ai/blog/key-data-analysis-trends-for-2022-and-beyond" target="_blank">原文</a>。经许可转载。</p>
<p><strong>个人简介:</strong> <a href="https://www.linkedin.com/in/david-pool-93758571/" target="_blank">David Pool</a> 是一位商业导向的经验丰富的企业家,专注于人工智能、机器学习、数据分析和商业智能。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/cloud-ml-perspective-surprises-2021-projections-2022.html" target="_blank">云机器学习透视:2021 年的惊喜与 2022 年的预测</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/developments-predictions-data-science-analytics-industry.html" target="_blank">数据科学与分析行业 2021 年主要发展及 2022 年关键趋势</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/trends-ai-data-science-ml-technology.html" target="_blank">2021 年主要发展与 2022 年人工智能、数据科学、机器学习技术的关键趋势</a></p>
</li>
</ul>
<h3 id="更多相关主题-11">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/developments-predictions-ai-machine-learning-data-science-research.html" target="_blank">人工智能、分析、机器学习、数据科学、深度学习……</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/developments-predictions-data-science-analytics-industry.html" target="_blank">2021 年数据科学与分析行业主要发展及关键…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/trends-ai-data-science-ml-technology.html" target="_blank">2021 年主要发展及 2022 年人工智能、数据科学的关键趋势</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/08/5-key-data-science-trends-analytics-trends.html" target="_blank">5 个关键数据科学趋势及分析趋势</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/nvidia-0317-top-ai-data-science-tools-techniques-2022-beyond.html" target="_blank">2022 年及以后顶尖的人工智能与数据科学工具和技术</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/12/key-data-science-machine-learning-ai-analytics-developments-2022.html" target="_blank">2022 年数据科学、机器学习、人工智能及分析领域的重要发展</a></p>
</li>
</ul>
<h1 id="成为数据科学家你需要了解的十种机器学习算法">成为数据科学家你需要了解的十种机器学习算法</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2018/04/10-machine-learning-algorithms-data-scientist.html/2" target="_blank"><code>www.kdnuggets.com/2018/04/10-machine-learning-algorithms-data-scientist.html/2</code></a></p>
</blockquote>
<h3 id="6-前馈神经网络">6. 前馈神经网络</h3>
<p>这些基本上是多层逻辑回归分类器。多个由非线性激活函数(sigmoid、tanh、relu + softmax 和新的 selu)分隔的权重层。它们的另一个常见名称是多层感知机。FFNN 可以用于分类和作为自编码器进行无监督特征学习。</p>
<p><img src="https://kdn.flygon.net/docs/img/b73e7922fae61090203dc0ec473f9f81.png" alt="machine learning algorithms" loading="lazy"></p>
<p>多层感知机</p>
<p><img src="https://kdn.flygon.net/docs/img/1e53aeab5704a84516b7e95581213348.png" alt="machine learning algorithms" loading="lazy"></p>
<p>FFNN 作为自编码器</p>
<p>FFNN 可以用于训练分类器或作为自编码器提取特征</p>
<p><strong>库:</strong></p>
<p><a href="http://scikit-learn.org/stable/modules/generated/sklearn.neural_network.MLPClassifier.html#sklearn.neural_network.MLPClassifier" target="_blank"><code>scikit-learn.org/stable/modules/generated/sklearn.neural_network.MLPClassifier.html#sklearn.neural_network.MLPClassifier</code></a></p>
<p><a href="http://scikit-learn.org/stable/modules/generated/sklearn.neural_network.MLPRegressor.html" target="_blank"><code>scikit-learn.org/stable/modules/generated/sklearn.neural_network.MLPRegressor.html</code></a></p>
<p><a href="https://github.com/keras-team/keras/blob/master/examples/reuters_mlp_relu_vs_selu.py" target="_blank"><code>github.com/keras-team/keras/blob/master/examples/reuters_mlp_relu_vs_selu.py</code></a></p>
<p><strong>入门教程:</strong></p>
<p><a href="http://www.deeplearningbook.org/contents/mlp.html" target="_blank"><code>www.deeplearningbook.org/contents/mlp.html</code></a></p>
<p><a href="http://www.deeplearningbook.org/contents/autoencoders.html" target="_blank"><code>www.deeplearningbook.org/contents/autoencoders.html</code></a></p>
<p><a href="http://www.deeplearningbook.org/contents/representation.html" target="_blank"><code>www.deeplearningbook.org/contents/representation.html</code></a></p>
<h3 id="7-卷积神经网络convnets">7. 卷积神经网络(Convnets)</h3>
<p>几乎所有世界上最先进的基于视觉的机器学习结果都是通过卷积神经网络实现的。它们可以用于图像分类、目标检测或图像分割。由 Yann Lecun 在 80 年代末 90 年代初发明,卷积神经网络具有作为层级特征提取器的卷积层。你也可以在文本中使用它们(甚至在图形中)。</p>
<p><img src="https://kdn.flygon.net/docs/img/4b9d7421c900673e7f954c1822d35b4d.png" alt="" loading="lazy"></p>
<p>使用卷积神经网络进行最先进的图像和文本分类、目标检测、图像分割。</p>
<p><strong>库:</strong></p>
<p><a href="https://developer.nvidia.com/digits" target="_blank"><code>developer.nvidia.com/digits</code></a></p>
<p><a href="https://github.com/kuangliu/torchcv" target="_blank"><code>github.com/kuangliu/torchcv</code></a></p>
<p><a href="https://github.com/chainer/chainercv" target="_blank"><code>github.com/chainer/chainercv</code></a></p>
<p><a href="https://keras.io/applications/" target="_blank"><code>keras.io/applications/</code></a></p>
<p><strong>入门教程:</strong></p>
<p><a href="http://cs231n.github.io/" target="_blank"><code>cs231n.github.io/</code></a></p>
<p><a href="https://adeshpande3.github.io/A-Beginner's-Guide-To-Understanding-Convolutional-Neural-Networks/" target="_blank"><code>adeshpande3.github.io/A-Beginner%27s-Guide-To-Understanding-Convolutional-Neural-Networks/</code></a></p>
<h3 id="8-循环神经网络rnns">8. 循环神经网络(RNNs):</h3>
<p>RNN 通过在时间 t 应用相同的权重集合到汇聚状态和输入上来对序列建模(给定一个序列在时间 0..t..T 有输入,并且在每个时间 t 都有一个隐藏状态,该状态是 RNN 的 t-1 步骤的输出)。纯 RNN 现在很少使用,但像 LSTM 和 GRU 这样的对比模型在大多数序列建模任务中处于最前沿。</p>
<p><img src="https://kdn.flygon.net/docs/img/9df42b9af4a17bfb507f092586a6b63f.png" alt="机器学习算法" loading="lazy"></p>
<p>RNN(如果这里有一个密集连接单元和非线性,现代的 f 通常是 LSTM 或 GRU)。LSTM 单元用来代替纯 RNN 中的普通密集层。</p>
<p><img src="https://kdn.flygon.net/docs/img/a2e8504e97e3117fc1659842b6a95898.png" alt="机器学习算法" loading="lazy"></p>
<p>使用 RNN 进行任何序列建模任务,特别是文本分类、机器翻译、语言建模</p>
<p><strong>库:</strong></p>
<p><a href="https://github.com/tensorflow/models" target="_blank"><code>github.com/tensorflow/models</code></a>(这里有很多来自 Google 的酷炫 NLP 研究论文)</p>
<p><a href="https://github.com/wabyking/TextClassificationBenchmark" target="_blank"><code>github.com/wabyking/TextClassificationBenchmark</code></a></p>
<p><a href="http://opennmt.net/" target="_blank"><code>opennmt.net/</code></a></p>
<p><strong>入门教程:</strong></p>
<p><a href="http://cs224d.stanford.edu/" target="_blank"><code>cs224d.stanford.edu/</code></a></p>
<p><a href="http://www.wildml.com/category/neural-networks/recurrent-neural-networks/" target="_blank"><code>www.wildml.com/category/neural-networks/recurrent-neural-networks/</code></a></p>
<p><a href="http://colah.github.io/posts/2015-08-Understanding-LSTMs/" target="_blank"><code>colah.github.io/posts/2015-08-Understanding-LSTMs/</code></a></p>
<h3 id="9-条件随机场crfs">9. 条件随机场(CRFs)</h3>
<p>CRF 可能是概率图模型(PGMs)家族中最常用的模型。它们用于像 RNN 这样的序列建模,也可以与 RNN 结合使用。在神经机器翻译系统出现之前,CRF 是最先进的技术,在许多小数据集的序列标记任务中,它们仍然比 RNN 表现更好,因为 RNN 需要更多的数据来进行泛化。CRF 也可以用于其他结构化预测任务,如图像分割等。CRF 对序列中的每个元素(比如一个句子)进行建模,使得邻近元素影响序列中某个组件的标签,而不是所有标签彼此独立。</p>
<p>使用 CRF 对序列进行标记(在文本、图像、时间序列、DNA 等中)</p>
<p><strong>库:</strong></p>
<p><a href="https://sklearn-crfsuite.readthedocs.io/en/latest/" target="_blank"><code>sklearn-crfsuite.readthedocs.io/en/latest/</code></a></p>
<p><strong>入门教程:</strong></p>
<p><a href="http://blog.echen.me/2012/01/03/introduction-to-conditional-random-fields/" target="_blank"><code>blog.echen.me/2012/01/03/introduction-to-conditional-random-fields/</code></a></p>
<p>Hugo Larochelle 在 YouTube 上的 7 部分讲座系列:<a href="https://www.youtube.com/watch?v=GF3iSJkgPbA" target="_blank"><code>www.youtube.com/watch?v=GF3iSJkgPbA</code></a></p>
<h3 id="10-决策树">10. 决策树</h3>
<p>假设我拿到一个包含各种水果数据的 Excel 表格,我需要判断哪些看起来像苹果。我会问一个问题:“哪些水果是红色且圆形的?”然后将所有水果根据是否回答“是”或“否”来分类。现在,所有红色且圆形的水果可能不是苹果,而所有苹果也不一定是红色和圆形的。所以,我会对红色和圆形的水果问一个问题:“哪些水果有红色或黄色的色调?”对非红色和圆形的水果问:“哪些水果是绿色且圆形的?”根据这些问题,我可以较为准确地判断哪些是苹果。这种问题级联就是决策树。然而,这只是基于我的直觉的决策树。直觉无法处理高维和复杂的数据。我们必须通过查看标记的数据自动生成问题级联。这就是基于机器学习的决策树所做的。早期版本如 CART 树曾用于简单数据,但随着数据集的增大和复杂化,需要用更好的算法来解决偏差-方差权衡。现在常用的两种决策树算法是随机森林(在属性的随机子集上构建不同的分类器并将它们结合输出)和提升树(训练一系列级联的树,每棵树都纠正其下方树的错误)。</p>
<p>决策树可用于分类数据点(甚至回归)</p>
<p><strong>库</strong></p>
<p><a href="http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html" target="_blank"><code>scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html</code></a></p>
<p><a href="http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html" target="_blank"><code>scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html</code></a></p>
<p><a href="http://xgboost.readthedocs.io/en/latest/" target="_blank"><code>xgboost.readthedocs.io/en/latest/</code></a></p>
<p><a href="https://catboost.yandex/" target="_blank"><code>catboost.yandex/</code></a></p>
<h3 id="入门教程">入门教程</h3>
<p><a href="http://xgboost.readthedocs.io/en/latest/model.html" target="_blank"><code>xgboost.readthedocs.io/en/latest/model.html</code></a></p>
<p><a href="https://arxiv.org/abs/1511.05741" target="_blank"><code>arxiv.org/abs/1511.05741</code></a></p>
<p><a href="https://arxiv.org/abs/1407.7502" target="_blank"><code>arxiv.org/abs/1407.7502</code></a></p>
<p><a href="http://education.parrotprediction.teachable.com/p/practical-xgboost-in-python" target="_blank"><code>education.parrotprediction.teachable.com/p/practical-xgboost-in-python</code></a></p>
<p><strong>TD 算法(推荐使用)</strong></p>
<p>如果你仍在疑惑这些方法如何解决像 DeepMind 那样击败围棋世界冠军的任务,其实它们不能。我们之前讨论的 10 种算法都是模式识别算法,而不是策略学习算法。要学习解决多步骤问题的策略,比如赢得棋局或玩 Atari 游戏,我们需要让一个智能体在世界中自由探索,并从它所面临的奖励/惩罚中学习。这种机器学习方法被称为强化学习。最近很多(但不是全部)领域的成功都是将卷积神经网络(Convnet)或长短期记忆网络(LSTM)的感知能力与一种称为时间差分学习(Temporal Difference Learning)的算法集合结合的结果。这些算法包括 Q-Learning、SARSA 及其他变种。这些算法聪明地运用了 Bellman 方程,以获得一个可以通过智能体从环境中获得的奖励进行训练的损失函数。</p>
<p>这些算法主要用于自动玩游戏 😄,也用于语言生成和目标检测的其他应用。</p>
<p><strong>库:</strong></p>
<p><a href="https://github.com/keras-rl/keras-rl" target="_blank"><code>github.com/keras-rl/keras-rl</code></a></p>
<p><a href="https://github.com/tensorflow/minigo" target="_blank"><code>github.com/tensorflow/minigo</code></a></p>
<p><strong>入门教程:</strong></p>
<p>获取免费的 Sutton 和 Barto 书籍: <a href="https://web2.qatar.cmu.edu/~gdicaro/15381/additional/SuttonBarto-RL-5Nov17.pdf" target="_blank"><code>web2.qatar.cmu.edu/~gdicaro/15381/additional/SuttonBarto-RL-5Nov17.pdf</code></a></p>
<p>观看 David Silver 的课程: <a href="https://www.youtube.com/watch?v=2pWv7GOvuf0" target="_blank"><code>www.youtube.com/watch?v=2pWv7GOvuf0</code></a></p>
<p>这些是你可以学习的 10 种机器学习算法,以成为数据科学家。</p>
<p>你还可以在 <a href="https://blog.paralleldots.com/data-science/lesser-known-machine-learning-libraries-part-ii/" target="_blank">这里</a> 阅读有关机器学习库的文章。</p>
<p>我们希望你喜欢这篇文章。请 <a href="http://user.apis.paralleldots.com/signing-up?utm_source=blog&utm_medium=chat&utm_campaign=paralleldots_blog" target="_blank">注册</a> 一个免费的 ParallelDots 账户,开始你的 AI 之旅。你还可以在 <a href="https://www.paralleldots.com/ai-apis" target="_blank">这里</a> 查看 ParallelDots AI API 的演示。</p>
<p><a href="https://blog.paralleldots.com/data-science/machine-learning/ten-machine-learning-algorithms-know-become-data-scientist/" target="_blank">原文</a>。经授权转载。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2018/03/top-20-deep-learning-papers-2018.html" target="_blank">2018 年深度学习前 20 篇论文</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2018/03/hierarchical-classification.html" target="_blank">层次分类 – 一种预测数千种可能类别的有用方法</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2017/12/10-deep-learning-methods-ai-practitioners-need-apply.html" target="_blank">AI 从业者需要应用的 10 种深度学习方法</a></p>
</li>
</ul>
<hr>
<h2 id="我们的前三大课程推荐-13">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全认证</a> - 快速开启网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织在 IT 领域</p>
<hr>
<h3 id="更多相关话题-15">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/three-r-libraries-every-data-scientist-know-even-python.html" target="_blank">每个数据科学家都应该知道的三个 R 库(即使你使用 Python)</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-characteristics-successful-data-scientist.html" target="_blank">成功数据科学家的 5 个特征</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/stop-learning-data-science-find-purpose.html" target="_blank">停止学习数据科学以寻找目标,并通过寻找目标来……</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/springboard-top-resources-learn-data-science-statistics.html" target="_blank">学习数据科学统计的顶级资源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-key-skills-needed-become-great-data-scientist.html" target="_blank">成为一名伟大的数据科学家所需的 5 项关键技能</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/9b-ai-failure-examined.html" target="_blank">100 亿美元的 AI 失败,剖析</a></p>
</li>
</ul>
<h1 id="10-个机器学习模型训练中的错误">10 个机器学习模型训练中的错误</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2021/07/10-machine-learning-model-training-mistakes.html" target="_blank"><code>www.kdnuggets.com/2021/07/10-machine-learning-model-training-mistakes.html</code></a></p>
</blockquote>
<p>评论</p>
<p><strong>作者:<a href="https://www.linkedin.com/in/sandeepuc/" target="_blank">Sandeep Uttamchandani, Ph.D.</a>,既是产品/软件开发者(工程副总裁),也是企业范围内数据/AI 项目的领导者(首席数据官)</strong></p>
<p><img src="https://kdn.flygon.net/docs/img/70a570ad807374cd4dd6269c8abf20d0.png" alt="Mistakes header" loading="lazy"></p>
<p>图片来自<a href="https://pixabay.com/users/tumisu-148124/?utm_source=link-attribution&utm_medium=referral&utm_campaign=image&utm_content=1966448" target="_blank">Tumisu</a>的<a href="https://pixabay.com/?utm_source=link-attribution&utm_medium=referral&utm_campaign=image&utm_content=1966448" target="_blank">Pixabay</a></p>
<p>机器学习模型训练是整个模型构建过程中最耗时和资源的部分。训练本质上是迭代的,但在某些迭代过程中,错误可能会渗入。在这篇文章中,我分享了机器学习模型训练中的十个致命错误——这些错误是最常见的,也是最容易被忽视的。</p>
<h2 id="机器学习模型训练的十个致命错误">机器学习模型训练的十个致命错误</h2>
<h3 id="1-在模型未收敛时盲目增加轮次"><strong>1. 在模型未收敛时盲目增加轮次</strong></h3>
<p>在模型训练过程中,有时损失-轮次图表会反复波动,不论轮次多少都似乎无法收敛。没有万能的解决方案,因为需要调查多个根本原因——不良训练样本、缺失的真值、变化的数据分布、过高的学习率。我见过的最常见原因是不良训练样本,涉及异常数据与不正确标签的组合。</p>
<h3 id="2-未对训练数据集进行随机打乱">2. <strong>未对训练数据集进行随机打乱</strong></h3>
<p>有时,模型似乎正在收敛,但突然损失值显著增加,即损失值在减少后突然显著增加。这种损失爆炸有多种原因。我见过的最常见原因是数据中的离群值没有均匀分布/打乱。打乱一般来说是一个重要步骤,包括在损失表现出重复步进函数行为的模式中。</p>
<h3 id="3-在多类别分类中不优先考虑特定类别的度量准确性">3. <strong>在多类别分类中,不优先考虑特定类别的度量准确性</strong></h3>
<p>对于多类别预测问题,除了跟踪总体分类准确性外,通常还需优先考虑特定类别的准确性,并逐步改进模型。例如,在对不同类型的欺诈交易进行分类时,根据业务需求,专注于提高特定类别(如外国交易)的召回率。</p>
<h3 id="4-假设特异性会导致模型准确性降低">4. <strong>假设特异性会导致模型准确性降低</strong></h3>
<p>与其构建一个通用模型,不如想象为特定地理区域或特定用户画像构建模型。特定性会使数据更加稀疏,但可能会提高对这些特定问题的准确性。在调优过程中,探索特定性和稀疏性的权衡是很重要的。</p>
<h3 id="5-忽视预测偏差">5. <strong>忽视预测偏差</strong></h3>
<p>预测偏差是预测平均值和数据集中标签平均值之间的差异。预测偏差是模型问题的早期指标。较大的非零预测偏差表明模型中存在某个地方的错误。关于广告点击率的一个有趣的 <a href="https://research.fb.com/wp-content/uploads/2016/11/practical-lessons-from-predicting-clicks-on-ads-at-facebook.pdf" target="_blank">Facebook 论文</a>。通常,偏差在预测桶之间的测量是有用的。</p>
<h3 id="6-仅仅依靠模型准确率就称之为成功">6. <strong>仅仅依靠模型准确率就称之为成功</strong></h3>
<p>95% 的准确率意味着 100 次预测中有 95 次是正确的。在数据集中存在类别不平衡的情况下,准确率是一个有缺陷的指标。应该深入调查诸如精准度/召回率等指标,以及它们如何与整体用户指标(如垃圾邮件检测、肿瘤分类等)相关联。</p>
<h3 id="7-不了解正则化-λ-的影响">7. <strong>不了解正则化 λ 的影响</strong></h3>
<p>λ 是在简单性和训练数据拟合之间取得平衡的关键参数。高 λ → 简单模型 → 可能欠拟合。低 λ → 复杂模型 → 可能对数据过拟合(无法推广到新数据)。理想的 λ 值是能够很好地推广到以前未见过的数据的值:依赖数据并需要分析。</p>
<h3 id="8-重复使用相同的测试集">8. 重复使用相同的测试集</h3>
<p>使用相同数据进行参数和超参数设置的次数越多,对结果实际推广能力的信心就越小。重要的是收集更多的数据,并不断增加测试和验证集。</p>
<h3 id="9-未关注神经网络中的初始化值"><strong>9. 未关注神经网络中的初始化值</strong></h3>
<p>鉴于神经网络中的非凸优化,<a href="https://www.deeplearning.ai/ai-notes/initialization/" target="_blank">初始化很重要</a>。</p>
<h3 id="10-假设错误标签总是需要修复">10. 假设错误标签总是需要修复</h3>
<p>当发现错误标签时,可能会很想立即修复它们。首先分析误分类示例的根本原因是很重要的。通常,由于标签错误引起的错误可能只占很小的比例。可能存在更大的机会来更好地训练针对特定数据片段的模型,这些数据片段可能是主要的根本原因。</p>
<p>总结来说,避免这些错误可以让你在大多数其他团队中脱颖而出。将这些作为你的流程检查清单。</p>
<p><strong>简介: <a href="https://www.linkedin.com/in/sandeepuc/" target="_blank">Sandeep Uttamchandani, Ph.D.</a></strong>: 数据 + 人工智能/机器学习 -- 既是产品/软件构建者(工程副总裁)也是企业范围内数据/人工智能项目的领导者(首席数据官) | O'Reilly 图书作者 | DataForHumanity 创始人(非营利组织)</p>
<p><a href="https://betterprogramming.pub/10-deadly-sins-of-ml-model-training-a5046c1f5094" target="_blank">原文</a>。经授权转载。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p>如何判断你的机器学习模型是否过拟合</p>
</li>
<li>
<p>使用 PyCaret 编写和训练你自己的自定义机器学习模型</p>
</li>
<li>
<p>如何在 20 天内破坏一个模型——关于生产模型分析的教程</p>
</li>
</ul>
<hr>
<h2 id="我们的三大课程推荐-9">我们的三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速入门网络安全职业。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织 IT 需求</p>
<hr>
<h3 id="更多相关话题-16">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/synthetic-data-overcome-data-shortages-machine-learning-model-training.html" target="_blank">如何使用合成数据克服机器学习中的数据短缺问题</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/speed-xgboost-model-training.html" target="_blank">如何加快 XGBoost 模型训练速度</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/manning-software-mistakes-tradeoffs-book.html" target="_blank">软件错误与权衡:Tomasz Lelek 的新书及…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/06/mistakes-newbie-data-scientists-avoid.html" target="_blank">新手数据科学家应避免的错误</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/03/3-mistakes-could-affecting-accuracy-data-analytics.html" target="_blank">可能影响数据分析准确性的 3 个错误</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/avoid-these-5-common-mistakes-every-novice-in-ai-makes" target="_blank">避免这 5 个每位 AI 新手都会犯的常见错误</a></p>
</li>
</ul>
<h1 id="程序员的-10-个数学概念">程序员的 10 个数学概念</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/10-math-concepts-for-programmers" target="_blank"><code>www.kdnuggets.com/10-math-concepts-for-programmers</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/358edaf91e6f8731743400c660270521.png" alt="程序员的 10 个数学概念" loading="lazy"></p>
<p>作者提供的图片</p>
<p>随着对程序员需求的增加,供应自然会因更多人进入行业而增加。然而,这个行业竞争激烈。为了持续提升自己,提升技能并增加薪资——你需要证明自己是一个高效的程序员。你可以通过学习那些别人通常不知道的东西来做到这一点。</p>
<hr>
<h2 id="我们的前三名课程推荐-3">我们的前三名课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业道路。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织的 IT 需求</p>
<hr>
<p>许多人进入编程行业时以为不需要了解背后的数学。虽然这在某种程度上是对的,但理解编程背后的逻辑数学概念会让你成为一个更高效的程序员。</p>
<p>怎么做?通过理解你在做什么以及发生了什么。就是这样。</p>
<p>那么,让我们直接进入主题吧。程序员的十大数学概念是什么?</p>
<h1 id="布尔代数">布尔代数</h1>
<p>布尔代数源于代数。我想这很明显。如果你是程序员或正在成为程序员的路上,你可能已经知道什么是布尔代数。如果没有,我会迅速定义一下。</p>
<p>布尔值是一种数据类型/二元变量,它只有两个可能的值,例如 0(假)或 1(真)。布尔数据类型由布尔代数支持,其中变量的值称为真值,即真和假。在处理布尔代数时,你可以使用三种运算符:</p>
<ul>
<li>
<p>连词或 AND 操作</p>
</li>
<li>
<p>离散或 OR 操作</p>
</li>
<li>
<p>否定或 Not 操作</p>
</li>
</ul>
<p>这些可以通过维恩图来直观表示,以帮助你更好地理解输出。布尔代数由 6 条定律组成:</p>
<ul>
<li>
<p>交换律</p>
</li>
<li>
<p>结合律</p>
</li>
<li>
<p>分配律</p>
</li>
<li>
<p>AND 定律</p>
</li>
<li>
<p>OR 定律</p>
</li>
<li>
<p>否定律</p>
</li>
</ul>
<h1 id="数字系统">数字系统</h1>
<p>计算机理解数字,这就是为什么它们需要数字系统。数字系统是用于表示数字的书写系统。例如,你有以下四种最常见的数字系统类型:</p>
<ol>
<li>
<p>十进制数字系统(基数 10)</p>
</li>
<li>
<p>二进制数字系统(基数 2)</p>
</li>
<li>
<p>八进制数字系统(基数 8)</p>
</li>
<li>
<p>十六进制数字系统(基数 16)</p>
</li>
</ol>
<p>计算机使用基数 2 的数字系统,其中可能的数字是 0 和 1。Base64 也用于将二进制数据编码为字符串格式。</p>
<h1 id="浮点数">浮点数</h1>
<p>进一步了解数字,我们有浮点数。浮点数是一种表示实数近似值的变量数据类型。浮点数是小数点位置可以移动或“浮动”的数字,而不是固定在一个位置。这允许开发人员在范围和精度之间进行权衡。</p>
<p>为什么要近似?计算机的空间有限,要么是 32 位(单精度),要么是 64 位(双精度)。64 位是 Python 和 JavaScript 等编程语言的默认值。浮点数的示例有 1.29、87.565 和 9038724.2。它可以是带小数点的正数或负数。</p>
<h1 id="对数">对数</h1>
<p>也称为对数,是一个数学概念,利用指数的逆操作来回答问题。那么为什么对数对程序员很重要?因为它简化了复杂的数学计算。例如,1000 = 10⁴ 也可以写成 4 = log10 1000。</p>
<p>基数是一个需要自身相乘的数学对象。指数是一个数字,它表示基数需要自身相乘多少次。因此,对数是一个指数,它指示一个基数必须提高到什么幂才能得到一个给定的数字。</p>
<p>当对数使用基数 2 时,它是二进制对数;如果基数是 10,则是常用对数。</p>
<h1 id="集合论">集合论</h1>
<p>集合是一个无序的唯一值集合,这些值之间不需要有任何关系。集合只能包含唯一的项目,不能包含相同的项目两次或更多次。</p>
<p>例如,Excel 文件或数据库包含具有一组唯一行的表。这是一种离散数学,因为这些结构可以有有限数量的元素。集合论的目标是理解值的集合及其相互之间的关系。这通常用于数据分析师、SQL 专家和数据科学家。</p>
<p>你可以通过以下方式进行:</p>
<ul>
<li>
<p>内连接或交集 – 返回一个包含两个集合中都存在的元素的集合。</p>
</li>
<li>
<p>外连接或并集 – 返回两个集合中的所有元素。</p>
</li>
<li>
<p>全部并集 – 与外连接操作符相同,但它会包含所有重复项。</p>
</li>
<li>
<p>除了或减去 – 减去 B 的 A 是一个包含 A 集合中不属于 B 集合的元素的集合。</p>
</li>
</ul>
<h1 id="组合数学">组合数学</h1>
<p>组合数学是计算事物数量以获得结果,并通过模式理解有限结构的某些属性的艺术。编程的核心是解决问题,而组合数学是我们可以排列对象以研究这些有限离散结构的方法。</p>
<p>组合数学公式是排列与组合的结合。</p>
<ul>
<li>
<p>排列是将一个集合安排成某种顺序或序列的行为。</p>
</li>
<li>
<p>组合是选择一个集合中的值,不考虑顺序。</p>
</li>
</ul>
<h1 id="图论">图论</h1>
<p>正如你所知道的,图是值的可视化表示,这些值可以相互连接。对于数据,这些值由于变量而连接,在图论中称为链接。</p>
<p>图论是研究图中边和顶点之间关系的学科。这使我们能够通过顶点(也称为节点)和边(也称为线)之间的对关系来创建对象对。图表示为一对 G(V, E),其中 V 代表有限集合的顶点,E 代表有限集合的边。</p>
<h1 id="复杂度理论">复杂度理论</h1>
<p>复杂度理论是研究算法运行所需的时间和内存量随输入大小变化的函数。复杂度有两种类型:</p>
<ul>
<li>
<p>空间复杂度 - 一个算法运行所需的内存量。</p>
</li>
<li>
<p>时间复杂度 - 一个算法运行所需的时间量。</p>
</li>
</ul>
<p>更多的人关注时间复杂度,因为我们可以重用算法的内存。对于时间复杂度,衡量的最佳方式是考虑算法执行的操作次数。算法是通过 if 语句和循环构建的,因此为了减少时间消耗,你需要使用具有尽可能少的 if 语句和循环的代码。</p>
<p>复杂度理论使用大 O 符号来帮助描述和提供对算法限制行为的更好理解。它用于根据输入大小的变化来分类算法。</p>
<h1 id="统计学-1">统计学</h1>
<p>啊,统计学。如果你想进入人工智能领域,你需要了解统计学。人工智能和机器学习是统计学的别名。统计编程用于解决数据密集型问题,例如 ChatGPT。ChatGPT 的响应完全基于与用户提供的提示匹配的概率。</p>
<p>在统计编程中,你需要学习的不仅仅是均值、中位数和众数。你还需要了解偏差、协方差和贝叶斯定理。作为程序员,你会遇到任务并意识到你在问这是线性回归问题还是逻辑回归问题。理解这两者之间的区别将帮助你确定手头的任务类型。</p>
<h1 id="线性代数">线性代数</h1>
<p>你可能在学校学习过线性代数,也可能没有。线性代数非常重要,并广泛用于计算机图形学和深度学习。为了掌握线性代数,你需要理解这三个词:</p>
<ul>
<li>
<p>标量 - 单个数值</p>
</li>
<li>
<p>向量 - 一维数组或数字列表</p>
</li>
<li>
<p>矩阵 - 二维数组或网格</p>
</li>
</ul>
<p>向量可以表示 3D 空间中的点和方向,而矩阵可以表示这些向量发生的变换。</p>
<h1 id="总结-4">总结</h1>
<p>本文为你提供了改进编程职业的十大数学概念的快速概述。学习这些复杂的内容不仅能使你的日常工作更加顺畅且易于理解,还可以向雇主展示你的潜力。</p>
<p>如果你正在寻找一本免费的书籍来帮助你,可以查看:机器学习数学:免费电子书</p>
<p><strong><a href="https://www.linkedin.com/in/nisha-arya-ahmed/" target="_blank">尼莎·阿利亚</a></strong> 是一名数据科学家、自由技术作家以及 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何促进人类寿命的各种方式。作为一个热衷学习者,她寻求扩展她的技术知识和写作技能,同时帮助指导他人。</p>
<h3 id="主题深入了解">主题深入了解</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/03/overcome-fear-learn-math-data-science.html" target="_blank">如何克服对数学的恐惧并学习数据科学数学</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/04/deepmind-alphacode-replace-programmers.html" target="_blank">DeepMind 的 AlphaCode 会取代程序员吗?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2020/05/5-concepts-gradient-descent-cost-function.html" target="_blank">你需要知道的 5 个梯度下降和成本函数概念</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2020/06/8-basic-statistics-concepts.html" target="_blank">数据科学的 8 个基础统计概念</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/01/concepts-know-getting-transformer.html" target="_blank">你在接触 Transformers 之前需要知道的概念</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/02/not-so-sexy-sql-concepts-stand-out.html" target="_blank">那些不起眼但让你脱颖而出的 SQL 概念</a></p>
</li>
</ul>
<h1 id="作为数据科学初学者你应该避免的-10-个错误">作为数据科学初学者,你应该避免的 10 个错误</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2021/06/10-mistakes-avoid-data-science-beginner.html" target="_blank"><code>www.kdnuggets.com/2021/06/10-mistakes-avoid-data-science-beginner.html</code></a></p>
</blockquote>
<p>评论</p>
<p><strong>由 <a href="https://www.linkedin.com/in/isabelleflueckiger/" target="_blank">Isabelle Flückiger</a>,高级主管 | 国际顾问 | 演讲者 | 思想领袖 | 学习领导力 | 讲师 | 创业顾问</strong></p>
<p><img src="https://kdn.flygon.net/docs/img/2169d4bfb6654f40f26ffa98c6e07a3e.png" alt="" loading="lazy"></p>
<p>图片由 <a href="https://pixabay.com/users/stevepb-282134/" target="_blank">Steve Buissinne</a> 提供,来自 <a href="https://pixabay.com/photos/slip-up-danger-careless-slippery-709045/" target="_blank">Pixabay</a></p>
<hr>
<h2 id="我们的前三名课程推荐-4">我们的前三名课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业轨道。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析能力</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织的 IT</p>
<hr>
<p>数据科学正在取得成功。全球成千上万的学生报名参加在线课程,甚至数据科学硕士项目。</p>
<p>数据科学领域是一个竞争激烈的市场,特别是在获得大科技公司(所谓的)梦想职位时。好消息是,你可以通过充分准备获得这种职位的竞争优势。</p>
<p>另一方面,有(过多的)MOOC、硕士项目、训练营、博客、视频和数据科学学院。作为初学者,你会感到迷茫。我应该参加哪个课程?我应该学习哪些主题?我需要关注哪些方法?我必须学习哪些工具和编程语言?</p>
<p>事实上,每个数据科学家都有她/他的个性化学习之旅,并且对这种学习路径存在偏见。因此,在不了解你的情况下,很难说出最适合你的方法。</p>
<p>但所有数据科学家都反复犯一些共同的错误。即使知道这些错误,你也无法完全避免它们,但最终可以更早地停止这些错误,并更快地回到成功的道路上。</p>
<p>基于我在数据科学领域超过 20 年的经验,领导最多 150 人的团队,并且仍在全球领先大学之一兼职讲授课程,我为你总结了避免常见错误的核心要点,以帮助你更快实现梦想。</p>
<p>错误按初学者数据科学家的学习进度排序。</p>
<h3 id="1-在你最终开始之前花费过多时间评估各种不同类型和选项的课程或者最终从未开始"><strong>#1 在你最终开始之前花费过多时间评估各种不同类型和选项的课程——或者最终从未开始</strong></h3>
<p>我知道你被所有课程搞得不知所措,并且你尝试不犯任何错误。你想有效地投资时间和金钱,并选择承诺最快和最佳成功的方法。</p>
<p>不幸的是,没有像在任何技术和科学领域那样的即时成功,为了获得最佳成功,你将没有任何比较。</p>
<p>事实是,如今所有成熟的平台、学院和机构都有很好的课程。所以,不要过度考虑和分析课程。勇敢地选择一个,完成该课程,然后再选择另一个。</p>
<p>最关键的方面是开始和实践。你不能在这里犯错,因为你既不知道你的旅程,也不知道选择另一条路会有什么不同。没有人能告诉你这一点。完毕。</p>
<p>也重要的是要认识到学习是循环的,而非线性的。学习一门数据科学课程并不排除你同时学习另一门课程。</p>
<p>尽管有多年的经验,我仍然进行数据科学、机器学习和人工智能培训。在每一门看似“简单”的入门课程中,我都会发现一个新的方面和新的视角。这正是成为一个高需求的数据科学家的关键。就是理解一个主题的所有不同视角。</p>
<h3 id="2-你想一次性学习过多的方法和工具而不是逐个学习和理解这些方法"><strong>#2 你想一次性学习过多的方法和工具,而不是逐个学习和理解这些方法</strong></h3>
<p>许多有志于数据科学的人员认为,简历上列出尽可能多的方法有助于更快找到工作。但事实正好相反。当申请工作时,如果你只开始学习数据科学六个月,对于每个招聘人员来说,很明显这只是空谈,没有实质内容。</p>
<p>如果我们看回归模型,有很多书籍专门讲回归。回归类型超过 50 种,每种都有不同的前提条件。因此,简历上只写“回归”并不能说明问题。此外,回归模型仍然是应用中最重要的模型,并且为数据科学的一般理解奠定基础。</p>
<p>你必须理解一个方法解决了什么;假设是什么;参数是什么意思;有哪些陷阱;等等。</p>
<p>根据简历和回归知识的描述,每个经验丰富的招聘人员——或如今的招聘算法——都可以识别你理解的深度。</p>
<p>只有对少数几种方法有深入的知识和经验,比知道很多方法但没有实质内容要好。</p>
<h3 id="3-你从头开始编写所有代码因为你认为这有助于你更好更快地编程"><strong>#3 你从头开始编写所有代码,因为你认为这有助于你更好、更快地编程</strong></h3>
<p>开始编码时,人们认为必须尽快开始编码和重新编程尽可能多的算法。同样,你应该专注于理解一些算法,而不是数量。</p>
<p>首先,你需要了解编码的前提条件:线性代数、数学归纳法、离散数学、几何学——是的,这些是优秀程序员的强项,但数据科学家常常忽视,统计学和概率论、微积分、布尔代数和图论。</p>
<p>我并不是通过更多编码变得更好和更快。我通过理解数学基础、审查他人的代码以及在不同数据和问题上运行和测试代码变得擅长编程。</p>
<p>是的,编码很重要,但更重要的是理解代码的(优秀)架构。这只能通过审查其他代码来学习。</p>
<p>一个事实是,代码越来越成为商品,甚至有无代码工具。差异将不再是能编码和不能编码之间,而是理解其架构和不理解之间。</p>
<p>我给你另一个例子:我假设你已经使用过 TensorFlow。但你了解它是什么吗?它做了什么?为什么它叫做“TensorFlow”?你知道什么是张量吗?不仅仅是张量积的机械计算,而是它在几何上的意义是什么?</p>
<h3 id="4-通过学习理论你认为自己知道了一切但却缺乏足够的实践经验"><strong>#4 通过学习理论,你认为自己知道了一切,但却缺乏足够的实践经验</strong></h3>
<p>学习数据科学是试错的过程。只有当你尽可能多地积累经验,犯错并解决问题时,你才会获得更深刻的理解。</p>
<p>理论是可以接受的且至关重要。你需要对基础知识有一定的理解。</p>
<p>不幸的是,在实践中,它很少像理论中那样运作。相反,它往往恰恰是你学到的不应该这样做的方式。</p>
<p>所以,你必须从头开始,使用实际的例子。通常,你会觉得还没准备好进行实践工作:基础知识不够或编程经验不足。</p>
<p>但我强烈建议:即使你觉得还没准备好做练习,也要从头开始。这不需要是一个全天或一周的项目。一个小的 1-2 小时项目就足够了。</p>
<p>你可以从像 RapidMiner 或 KNIME 这样的无代码工具开始,或者使用别人的代码并进行应用。例如,使用一个简单的情感分析代码来分析推文或产品描述。然后,你可以开始修改代码以适用于其他例子并比较结果。</p>
<p>当你作为小孩学习说话时,你是从单个词或两三个词的表达开始的。一步一步地,你建立了对语言的感觉。数据科学中的实践经验也是如此。</p>
<p>专家提示:学习是循环的。所以,保存你的工作。以后你可以回来,改进它,上传到 GitHub,并使用 Tableau 添加可视化。</p>
<h3 id="5-你认为认证是获得数据科学工作的一种竞争优势"><strong>#5 你认为认证是获得数据科学工作的一种竞争优势</strong></h3>
<p>认证是可以的。有很多声音告诉你不要做认证。但它们可以作为一种动力,并且最终它们可以正式展示你的进步和学习的渴望。我仍然会做证书。这没什么错,当你投入时间时,获得证书是合理的。</p>
<p>但这在市场上并不具备差异化。事实上,有成千上万的人拥有相同的证书。所以,要拥有竞争优势,你必须超越这些。</p>
<p>例如,我的一位学生找我寻求在金融领域实习的支持。他想应用所学知识,了解数据科学团队的文化和合作。我能帮他安排在一家银行实习,他将以此作为学期论文。是的,同时进行学习、实习和学期论文确实很有压力。但这将为他提供无价的竞争优势。</p>
<h3 id="6-你担心其他人的看法而不是基于事实建立自己的观点"><strong>#6 你担心其他人的看法,而不是基于事实建立自己的观点</strong></h3>
<p>大多数有志成为数据科学家的人士担心其他数据科学家的看法。听到的争论越多,他们就越困惑。尽管困惑是通向清晰的必经之路,但它不应成为常态。</p>
<p>每个数据科学家都是一个具有个人经验、学习历程和职业路径的个体。我常说,“如果你有两个数据科学家在一个房间里,你就有至少四种不同的观点。”</p>
<p>采纳意见作为灵感和寻找信息的指导是好的,但不应将其视为信息本身。</p>
<p>寻找确凿的事实。得出逻辑结论,验证,并再次更新。这是成功推进数据科学职业生涯的重要技能。</p>
<h3 id="7-不关心业务和领域知识"><strong>#7 不关心业务和领域知识</strong></h3>
<p>许多数据科学家认为他们可以将方法应用于每一个问题和行业,但从超过 20 年的经验来看,我可以告诉你这是错误的。</p>
<p>我常常看到数据科学家向业务人员展示发现,而他们的反应是,“哦,我们已经知道这个了。我们需要的是‘为什么会这样’和‘如何解决’。或者在最坏的情况下,是‘这完全是胡说八道,因为这不是我们业务的运作方式。’哗啦!</p>
<p>拥有领域知识比掌握所有花哨的方法更为重要。数据科学家解决的是业务问题,而非技术问题。通过解决业务问题,你为公司的业务带来价值,而你所能带来的价值仅限于你的解决方案的价值。只有了解业务,你才能成功完成这项任务。</p>
<p>我在许多不同的行业工作过。每次在开始与业务接触之前,我都会大量阅读有关该行业的资料。</p>
<ul>
<li>
<p>我从维基百科开始,了解了整体情况和相关公司。</p>
</li>
<li>
<p>我查看了行业前 10 家公司年度报告和投资者关系信息。</p>
</li>
<li>
<p>我阅读了过去几年关于这个行业和公司的所有新闻文章。</p>
</li>
<li>
<p>我联系了在这个行业工作的 LinkedIn 联系人。</p>
</li>
</ul>
<p>只有到那时,我才开始与业务互动。</p>
<p>你的一半学习内容应包括行业和商业知识的发展。</p>
<h3 id="8-你没有持续和一致地学习和进修"><strong>#8 你没有持续和一致地学习和进修</strong></h3>
<p>很容易因为不理解主题而分心或早早放弃。学习数据科学是一个马拉松,而不是短跑。因此,建立一个持续和一致的学习例程至关重要。就像马拉松训练一样,你每天都在小单位进行训练。</p>
<p>如前所述,学习是循环的。曾经学习过的主题并不意味着你已经掌握它。</p>
<p>举个例子。在数学金融课程中,我必须学习许多极限定理。考试非常成功,我确信我理解了它们。但七年后,当我需要审查复杂结构金融产品的估值代码时,才恍若顿悟,意识到直到那时我才真正理解它。</p>
<p>因此,每天,或至少每周,预留几个小时用于学习。这无关你是有抱负的还是已经是高级数据科学家。</p>
<p>学习应包括新的数据科学主题、从不同视角(例如另一个课程或书籍)学习过的主题、新技术和技术趋势、行业和商业知识、数据可视化和数据讲故事,以及数据应用。</p>
<p>这增加了层层理解,在面试中,你将能够通过从不同角度展示整体视图来给出令人信服的回答。</p>
<h3 id="9-数据讲故事不足"><strong>#9 数据讲故事不足</strong></h3>
<p>在数据科学工作中,你将主要把你的发现传达给非技术人员,特别是业务人员。而业务部门为你的工作提供资金。如果没有他们的支持,你的工作和数据科学团队将不存在。</p>
<p>你的工作是为业务创造价值,而不是仅仅为了应用而应用华丽的方法。</p>
<p>我有一个朋友是全球一家银行的数据科学负责人。当他们招聘数据科学家时,他们会提前两周发送一个数据集,并要求做一个 20 分钟的演讲。没有进一步的指导。他们想看到讲故事的能力。他们不关心使用的方法——除非候选人对所用方法讲出绝对无稽之谈。他们想看到的是,首先是商业问题的框架及其解决的重要性。其次,应该解决什么,最后,如何解决以及在商业环境中的结果。“这是我们整天最重要的工作。候选人不必在这方面完美,但必须展示她/他理解我们工作的重点。”</p>
<p>所以,学习数据讲故事——甚至有免费的课程——并学习在商业背景下的数据可视化。</p>
<h3 id="10-自学而不与数据科学社区互动"><strong>#10 自学而不与数据科学社区互动</strong></h3>
<p>许多人认为可以通过自己的努力学习数据科学。其他数据科学家被视为竞争者,人们不愿意交换知识。</p>
<p>但仅在你选择的世界中阅读和学习是高度偏颇的,许多关于某一主题或方法的观点被遗漏了。此外,关于某个话题的开放讨论和获得辩论经验的机会也缺失了——这是任何数据科学家都需要的技能。</p>
<p>任何有经验的招聘人员都知道在一两个问题之后,你是一个单打独斗的人,还是有一个活跃的网络帮助你获取知识。这对公司有益,并提高了你的市场价值和需求。</p>
<p>因此,发展一个网络至关重要。这可以通过参加训练营、黑客马拉松和 Meetup 会议来实现。</p>
<p>现在,你理论上知道了应该避免什么。</p>
<p>这些错误中的任何一个都可能成为你数据科学工作的障碍。</p>
<p>我知道你仍然会犯这些错误。我也不例外。人们天性会认为“我与众不同”——尽管数据却显示相反。但意识到这些潜在的错误将帮助你更快地调整路径,从而更有效地成为一个受欢迎的数据科学家。</p>
<h3 id="你喜欢我的故事吗这里可以找到更多"><strong>你喜欢我的故事吗?这里可以找到更多。</strong></h3>
<p><a href="https://towardsdatascience.com/hands-on-step-by-step-guidance-to-grow-your-job-opportunities-fe0c757fb966" target="_blank"><strong>逐步指导以提升你的就业机会</strong></a></p>
<p>如何战略性地利用 Meetup 会议来获得你梦想的数据科学工作</p>
<p><a href="https://towardsdatascience.com/the-ultimate-guide-on-the-data-science-micromasters-programs-on-edx-2020-2021-db7646381387" target="_blank"><strong>2021 年 edX 数据科学微硕士项目终极指南</strong></a></p>
<p>你应该选择哪六个项目中的哪个?</p>
<p><a href="https://towardsdatascience.com/the-top-technology-trends-and-their-impact-on-data-science-machine-learning-and-ai-f6223b496efa" target="_blank"><strong>科技趋势及其对数据科学、机器学习和人工智能的影响</strong></a></p>
<p>为你和你的职业制定的行动计划</p>
<p><strong>个人简介:<a href="https://www.linkedin.com/in/isabelleflueckiger/" target="_blank">Isabelle Flückiger</a></strong> 是一位高级执行官,具有国际 C 级顾问经验,专注于端到端数字、数据和新技术转型项目,具有银行、保险、化学品、公用事业和制药/生命科学等关键行业经验。</p>
<p><a href="https://towardsdatascience.com/10-mistakes-you-should-avoid-as-a-data-science-beginner-ec1b14ea1bcd" target="_blank">原文</a>。经许可转载。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p>如何在 6 个月内找到数据分析工作</p>
</li>
<li>
<p>初学者的十大数据科学项目</p>
</li>
<li>
<p>数据科学在 10 年内不会灭绝,你的技能可能会</p>
</li>
</ul>
<h3 id="更多相关话题-17">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/06/mistakes-newbie-data-scientists-avoid.html" target="_blank">新手数据科学家应该避免的错误</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/5-common-data-science-mistakes-and-how-to-avoid-them" target="_blank">5 个常见的数据科学错误及如何避免它们</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/avoid-these-5-common-mistakes-every-novice-in-ai-makes" target="_blank">避免这 5 个每个 AI 初学者常犯的错误</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/04/top-5-reasons-avoid-data-science-career.html" target="_blank">避免数据科学职业的前 5 个理由</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/3-courses-you-should-consider-if-you-want-to-become-a-data-analyst" target="_blank">如果你想成为数据分析师,应该考虑的 3 门课程</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/6-predictive-models-every-beginner-data-scientist-master.html" target="_blank">每个初学者数据科学家应掌握的 6 种预测模型</a></p>
</li>
</ul>
<h1 id="10-种现代数据工程工具">10 种现代数据工程工具</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2022/07/10-modern-data-engineering-tools.html" target="_blank"><code>www.kdnuggets.com/2022/07/10-modern-data-engineering-tools.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/205bb98778b4f3de928d05254dab6fd2.png" alt="10 Modern Data Engineering Tools" loading="lazy"></p>
<p>图片由作者提供</p>
<h1 id="dbt">dbt</h1>
<hr>
<h2 id="我们的前三名课程推荐-5">我们的前三名课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google Cybersecurity Certificate</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google Data Analytics Professional Certificate</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT Support Professional Certificate</a> - 支持你组织的 IT</p>
<hr>
<p><img src="https://kdn.flygon.net/docs/img/1c396fe093c7be7ca0feef257dca3eb9.png" alt="dbt" loading="lazy"></p>
<p><a href="https://github.com/dbt-labs/dbt-core" target="_blank">dbt</a> 允许数据工程师使用 SQL 在仓库中建模和转换数据。它负责 <a href="https://www.ibm.com/cloud/learn/etl" target="_blank">ETL</a> 的转换部分。</p>
<p>你可以使用 SQL 选择命令开发模型,进行测试、文档编写,并在安全的开发环境中部署。dbt 促进了 Git 支持的版本控制和团队协作。</p>
<blockquote>
<p>按照 <a href="https://www.youtube.com/watch?v=5rNquRnNb4E" target="_blank">Intro to Data Build Tool (dbt)</a> 教程创建你的第一个 dbt 项目。</p>
</blockquote>
<h1 id="airflow">Airflow</h1>
<p><img src="https://kdn.flygon.net/docs/img/5fb3b60142dea1bf8076d350066d65b3.png" alt="Airflow" loading="lazy"></p>
<p><a href="https://airflow.apache.org/" target="_blank">Apache Airflow</a> 是一个平台,允许数据工程师创建、调度和监控工作流。工作流可以是复杂的数据管道,由有向无环图(DAGs)任务组成。Airflow 会确保每个作业在特定时间以正确的顺序执行,并获得所需的资源。你还可以通过图形用户界面(GUI)监控和解决问题。</p>
<blockquote>
<p>通过参加 <a href="https://www.youtube.com/watch?v=K9AnJ9_ZAXE" target="_blank">Airflow 初学者课程</a> 了解更多关于 Airflow 的信息。</p>
</blockquote>
<h1 id="snowflake">Snowflake</h1>
<p><img src="https://kdn.flygon.net/docs/img/7232313dcae418450bdaf252cbffd367.png" alt="Snowflake" loading="lazy"></p>
<p><a href="https://www.snowflake.com/" target="_blank">Snowflake</a> 是一个企业级云数据仓库。它允许数据工程师存储数据并执行分析任务,如 ETL。它会自动调整资源的规模,以优化成本而不牺牲性能。</p>
<p>Snowflake 包括托管基础设施、可扩展性、自动集群,并与 JavaScript、Python 和 R 等著名编程语言集成。它具有三层架构:数据库存储、查询处理和云服务。</p>
<blockquote>
<p>通过在 YouTube 上观看 <a href="https://www.youtube.com/watch?v=xojAXXRo_S0" target="_blank">简单教程</a> 了解更多关于 Snowflake 的信息。</p>
</blockquote>
<h1 id="bigquery">BigQuery</h1>
<p><img src="https://kdn.flygon.net/docs/img/56803a0c1d365a795d6822b18be03adf.png" alt="BigQuery" loading="lazy"></p>
<p><a href="https://cloud.google.com/bigquery/" target="_blank">BigQuery</a> 是一个无服务器的云数据仓库,专为大数据集设计。在 BigQuery 中构建数据湖变得简单、快速且成本效益高。与 Data Studio 的集成允许数据工程师快速简单地可视化处理后的数据表。它包括 <a href="https://cloud.google.com/bigquery-ml/docs/" target="_blank">BigQuery ML</a>、<a href="https://cloud.google.com/bigquery/docs/geospatial-intro" target="_blank">地理空间分析</a>、<a href="https://cloud.google.com/bigquery/docs/bi-engine-intro" target="_blank">BigQuery BI 引擎</a> 和 <a href="https://cloud.google.com/blog/products/g-suite/connected-sheets-is-generally-available" target="_blank">连接的 Google Sheets</a>。</p>
<p>BigQuey 允许你运行 PB 级别的 SQL 分析查询,以获得关键的商业洞察。</p>
<blockquote>
<p>通过关注 <a href="https://www.youtube.com/watch?v=woU1YYlSR7o" target="_blank">Google Big Query</a> 在 YouTube 上的教程来了解更多关于 BigQuey 的信息。</p>
</blockquote>
<h1 id="metabase">Metabase</h1>
<p><img src="https://kdn.flygon.net/docs/img/384c0e1b53301bee6564bdef3c49d71c.png" alt="Metabase" loading="lazy"></p>
<p><a href="https://github.com/metabase/metabase" target="_blank">Metabase</a> 是一个开源 BI(商业智能)工具,可以让你的团队提问并从数据中学习。你可以运行复杂的 SQL 查询,构建交互式仪表板,创建数据模型,设置警报和仪表板订阅。它还允许你分析数据仓库中的数据。Metabase 在开发者中相当受欢迎,在 GitHub 上有 29k 星。</p>
<blockquote>
<p>通过关注 <a href="https://www.youtube.com/watch?v=4bNp906oOhs" target="_blank">Metabase</a> 在 YouTube 上的教程来了解更多信息。</p>
</blockquote>
<h1 id="google-cloud-storage-gcs">Google Cloud Storage (GCS)</h1>
<p><img src="https://kdn.flygon.net/docs/img/29b5b00778d7cea4e17a9f8fb7cbcf68.png" alt="Google Cloud Storage (GCS)" loading="lazy"></p>
<p><a href="https://cloud.google.com/storage/docs/introduction" target="_blank">Google Cloud Storage</a> 是安全且可扩展的对象存储,允许你保存图像、文档、电子表格、音频、视频甚至网站。你可以享受无限的存储空间,费用取决于你的使用情况。这对初创企业和中小企业非常有利。对象是存储在称为桶的容器中的不可变文件。桶与项目关联,你可以将项目分组到组织中。</p>
<blockquote>
<p>通过关注 <a href="https://www.youtube.com/watch?v=TVRsSiGJQvk" target="_blank">Google Cloud Storage</a> 在 YouTube 上的教程来了解更多信息。</p>
</blockquote>
<h1 id="postgresql">PostgreSQL</h1>
<p><img src="https://kdn.flygon.net/docs/img/8feb694b707b7a8214e1cba5f341cd71.png" alt="PostgreSQL" loading="lazy"></p>
<p><a href="https://www.postgresql.org/about/" target="_blank">PostgreSQL</a> 是一个开源数据库,既可靠又灵活。它支持关系型和非关系型数据库。PostgreSQL 是最符合标准、稳定且成熟的关系型数据库。它提供性能优化和可扩展性,支持并发,支持多种编程语言,以及灾难恢复管理。</p>
<blockquote>
<p>通过关注 <a href="https://www.youtube.com/watch?v=qw--VYLpxG4" target="_blank">Learn PostgreSQL</a> 在 YouTube 上的教程来了解更多信息。</p>
</blockquote>
<h1 id="terraform">Terraform</h1>
<p><img src="https://kdn.flygon.net/docs/img/e690bb6a28b404b1d1be436a97186da0.png" alt="Terraform" loading="lazy"></p>
<p><a href="https://www.terraform.io/intro" target="_blank">Terraform</a>是由 HashiCorp 开发的开源 IaC(基础设施即代码)工具,允许你使用配置文件定义云资源和本地资源。这些文件可以进行版本控制、重用和共享。它使数据工程师能够对基础设施进行编码,并实施最佳的 DevOps 实践,如版本控制、持续集成和持续开发。</p>
<p>数据工程师可以在多个云平台上定义资源,创建和监控执行计划,最后按照正确的顺序执行操作。</p>
<blockquote>
<p>通过观看<a href="https://www.youtube.com/watch?v=SLB_c_ayRMo" target="_blank">Terraform 课程 - 自动化你的 AWS 云基础设施</a>教程,了解更多信息。</p>
</blockquote>
<h1 id="kafka">Kafka</h1>
<p><img src="https://kdn.flygon.net/docs/img/60d896c649f5eae316f1fa88abd14a0c.png" alt="Kafka" loading="lazy"></p>
<p><a href="https://kafka.apache.org/" target="_blank">Apache Kafka</a>是一个开源事件流平台,允许数据工程师创建高性能的数据管道、流式分析和数据集成。超过 80%的财富 100 强公司使用它来构建实时流数据管道和应用程序。Kafka 允许应用程序高效且持久地发布和消费大量记录流。它具有高吞吐量、低延迟和容错能力。</p>
<blockquote>
<p>通过观看<a href="https://www.youtube.com/watch?v=daRykH67_qs" target="_blank">学习 Kafka | Intellipaat</a>教程,了解更多信息。</p>
</blockquote>
<h1 id="spark">Spark</h1>
<p><img src="https://kdn.flygon.net/docs/img/7572bbf541413de68dfc4551689f3b79.png" alt="Spark" loading="lazy"></p>
<p><a href="https://spark.apache.org/" target="_blank">Apache Spark™</a>是一个开源的多语言数据处理引擎,适用于大规模数据集。它允许你在单节点或集群上运行数据工程、数据科学和机器学习过程。</p>
<p><strong>Spark 的主要特点:</strong></p>
<ul>
<li>
<p>使用首选编程语言(Scala、Java、Python 和 R)进行批处理/流处理数据</p>
</li>
<li>
<p>快速的 SQL 分析</p>
</li>
<li>
<p>在 PB 级数据上进行探索性数据分析</p>
</li>
<li>
<p>开发和部署可扩展的机器学习解决方案</p>
</li>
</ul>
<blockquote>
<p>通过观看<a href="https://www.youtube.com/watch?v=_C8kWso4ne4" target="_blank">PySpark</a>教程,了解更多信息。</p>
</blockquote>
<h1 id="结论-12">结论</h1>
<p>数据工程是增长最快、薪资最高的职业之一。美国顶尖科技公司每年支付给合格的数据工程师的薪资超过 177,000 美元 - <a href="https://www.indeed.com/career/data-engineer/salaries" target="_blank">indeed.com</a>。要在数据工程领域成长,你必须学习和掌握需求量大的工具。</p>
<p>我仍在学习数据工程及其对数据驱动型公司的重要性。我提到的工具列表是由在顶尖科技公司工作的经验丰富的数据工程师使用的。</p>
<p>如果你是数据工程领域的新手,完成<a href="https://github.com/DataTalksClub/data-engineering-zoomcamp" target="_blank">data engineering zoomcamp</a>以了解工具、最佳实践和理论。这个 zoomcamp 将帮助你理解这些工具如何在典型的数据工程项目中协同工作。</p>
<p><strong><a href="https://www.polywork.com/kingabzpro" target="_blank">Abid Ali Awan</a></strong> (<a href="https://twitter.com/1abidaliawan" target="_blank">@1abidaliawan</a>) 是一名认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一种 AI 产品,帮助那些与心理疾病作斗争的学生。</p>
<h3 id="了解更多相关主题-1">了解更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/n28.html" target="_blank">KDnuggets 新闻,7 月 13 日:数据科学中的线性代数;10 种现代…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/bayesian-thinking-in-modern-data-science" target="_blank">现代数据科学中的贝叶斯思维</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/12/sphere-learn-modern-forecasting-techniques-help-predict-future-business-outcomes.html" target="_blank">学习现代预测技术,帮助预测未来业务结果…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/11/packt-tackle-computer-science-problems-fundamental-modern-algorithms-machine-learning" target="_blank">使用基础和现代算法解决计算机科学问题</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/7-modern-sql-database-you-must-know-in-2024" target="_blank">2024 年必须知道的 7 种现代 SQL 数据库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/digital-transformation-playbook-for-modern-businesses" target="_blank">现代企业的数字化转型手册</a></p>
</li>
</ul>
<h1 id="10-本更多必读的免费机器学习和数据科学书籍">10 本更多必读的免费机器学习和数据科学书籍</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2018/05/10-more-free-must-read-books-for-machine-learning-and-data-science.html" target="_blank"><code>www.kdnuggets.com/2018/05/10-more-free-must-read-books-for-machine-learning-and-data-science.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/3d9c022da2d331bb56691a9617b91b90.png" alt="c" loading="lazy"> 评论</p>
<p>现在是时候开始另一个免费的机器学习和数据科学书籍的合集,来启动你的夏季学习季节了。因为这确实是个趋势,对吧?</p>
<p>如果在阅读完这个列表后,你发现自己还想要更多免费的优质精选书籍,请查看本系列的前一版或下面的相关帖子。</p>
<hr>
<h2 id="我们的前三大课程推荐-14">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速入门网络安全职业。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析能力</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织的 IT 工作</p>
<hr>
<p><img src="https://kdn.flygon.net/docs/img/76a9e1c81c124bd744844e1bfe915b28.png" alt="Post header image" loading="lazy"></p>
<p><strong>1. <a href="https://github.com/jakevdp/PythonDataScienceHandbook" target="_blank">Python 数据科学手册</a></strong></p>
<p>作者:Jake VanderPlas</p>
<blockquote>
<p>这本书介绍了在 Python 中处理数据所需的核心库:特别是 IPython、NumPy、Pandas、Matplotlib、Scikit-Learn 及相关包。假设你对 Python 语言有所了解;如果你需要快速了解语言本身,请参阅免费的伴随项目,<a href="https://github.com/jakevdp/WhirlwindTourOfPython" target="_blank">Python 速览</a>:这是一个快速介绍 Python 语言的项目,旨在面向研究人员和科学家。</p>
</blockquote>
<p><strong>2. <a href="http://neuralnetworksanddeeplearning.com/" target="_blank">神经网络与深度学习</a></strong></p>
<p>作者:Michael Nielsen</p>
<blockquote>
<p><em>《神经网络与深度学习》</em> 是一本免费的在线书籍。该书将教你关于:</p>
<ul>
<li>神经网络,一种美丽的生物启发编程范式,使计算机能够从观察数据中学习</li>
<li></li>
<li>深度学习,一套强大的技术,用于神经网络中的学习</li>
<li></li>
</ul>
<p>神经网络和深度学习目前为许多图像识别、语音识别和自然语言处理问题提供了最佳解决方案。这本书将教你许多神经网络和深度学习背后的核心概念。</p>
</blockquote>
<p><strong>3. <a href="http://greenteapress.com/wp/think-bayes/" target="_blank">Think Bayes</a></strong></p>
<p>作者:Allen B. Downey</p>
<blockquote>
<p><em>Think Bayes</em> 是一本使用计算方法介绍贝叶斯统计的书籍。</p>
<p>本书以及<em>Think X</em>系列的其他书籍的前提是,如果你知道如何编程,你可以利用这个技能学习其他主题。</p>
<p>大多数关于贝叶斯统计的书籍使用数学符号,并通过微积分等数学概念来呈现思想。本书则使用 Python 代码而非数学,并用离散近似代替连续数学。因此,本书中原本在数学书中是积分的内容变成了求和,而对概率分布的大部分操作则是简单的循环。</p>
</blockquote>
<p><strong>4. <a href="http://www.kareemalkaseer.com/books/ml" target="_blank">机器学习与大数据</a></strong></p>
<p>作者:Kareem Alkaseer</p>
<blockquote>
<p>这是一个进行中的项目,我会在时间允许的情况下进行更新。其目的是在理论与实现之间取得平衡,使软件工程师能够舒适地实现机器学习模型,而不必过于依赖库。大多数时候,一个模型或技术的概念是简单或直观的,但常常在细节或术语中被迷失。此外,大多数现有库能够解决当前问题,但它们被视为黑箱,并且它们通常具有自己的抽象和架构,这些隐藏了基本概念。本书的尝试是使这些基本概念更加清晰。</p>
</blockquote>
<p><strong>5. <a href="https://web.stanford.edu/~hastie/StatLearnSparsity/" target="_blank">稀疏统计学习:套索与推广</a></strong></p>
<p>作者:Trevor Hastie, Robert Tibshirani, Martin Wainwright</p>
<blockquote>
<p>在过去的十年中,计算和信息技术经历了爆炸性增长。随之而来的是大量的数据,涉及医学、生物学、金融和市场营销等各个领域。本书描述了这些领域中的重要思想,采用了一个共同的概念框架。</p>
</blockquote>
<p><strong>6. <a href="https://leanpub.com/LittleInferenceBook" target="_blank">数据科学的统计推断</a></strong></p>
<p>作者:Brian Caffo</p>
<blockquote>
<p>本书作为 <a href="https://www.coursera.org/course/statinference" target="_blank">统计推断</a> Coursera 课程的配套书籍,同时也是 <a href="https://www.coursera.org/specialization/jhudatascience/1?utm_medium=courseDescripTop" target="_blank">数据科学专业化</a> 的一部分。然而,即使你没有参加课程,本书也基本可以独立使用。本书的一个有用组成部分是由 YouTube 视频组成的 Coursera 课程。</p>
<p>本书旨在为统计推断这一重要领域提供一种低成本的入门介绍。目标读者是那些在数值和计算方面有一定基础的学生,他们希望将这些技能应用于数据科学或统计学。本书作为一系列 markdown 文档在 github 上免费提供,并以更便捷的格式(epub, mobi)在 LeanPub 和零售商店销售。</p>
</blockquote>
<p><strong>7. <a href="http://stanford.edu/~boyd/cvxbook/" target="_blank">凸优化</a></strong></p>
<p>作者:Stephen Boyd 和 Lieven Vandenberghe</p>
<blockquote>
<p>本书涉及凸优化,这是一类特殊的数学优化问题,包括最小二乘法和线性规划问题。众所周知,最小二乘法和线性规划问题具有相当完整的理论,出现在各种应用中,并且可以非常高效地进行数值求解。本书的基本观点是,对于更大的凸优化问题类,也是如此。</p>
</blockquote>
<p><strong>8. <a href="https://www.nltk.org/book/" target="_blank">用 Python 进行自然语言处理</a></strong></p>
<p>作者:斯蒂文·伯德、伊万·克莱因和爱德华·洛珀</p>
<blockquote>
<p>这是一本关于自然语言处理的书。所谓“自然语言”,是指人类用于日常交流的语言;例如英语、印地语或葡萄牙语。与编程语言和数学符号等人工语言相比,自然语言随着代际传承而演变,并且难以用明确的规则来界定。我们将自然语言处理——或简称 NLP——广泛理解为对自然语言的任何计算机操作。</p>
<p>...</p>
<p>本书基于 Python 编程语言,并结合了一个名为<em>自然语言工具包(NLTK)</em>的开源库。</p>
</blockquote>
<p><strong>9. <a href="https://automatetheboringstuff.com/" target="_blank">用 Python 自动化无聊的工作</a></strong></p>
<p>作者:阿尔·斯维加特</p>
<blockquote>
<p>如果你曾花费几个小时来重命名文件或更新数百个电子表格单元格,你知道这类任务是多么乏味。但如果你可以让你的计算机为你完成这些任务呢?</p>
<p>在《用 Python 自动化无聊的工作》中,你将学习如何使用 Python 编写程序,在几分钟内完成手动操作需要几个小时的任务——无需先前的编程经验。一旦你掌握了编程基础,你将能够创建 Python 程序,轻松实现有用且令人印象深刻的自动化功能。</p>
</blockquote>
<p><strong>10. <a href="http://dmml.asu.edu/smm/" target="_blank">社交媒体挖掘:导论</a></strong></p>
<p>作者:雷扎·扎法拉尼、穆罕默德·阿里·阿巴西和刘欢</p>
<blockquote>
<p>在过去十年中,社交媒体的增长彻底改变了个人互动和行业运营的方式。个人通过社交媒体互动、分享和消费内容,以前所未有的速度生成数据。理解和处理这种新类型的数据,以提取可操作的模式,给跨学科研究、创新算法和工具开发带来了挑战和机遇。《社交媒体挖掘》将社交媒体、社交网络分析和数据挖掘整合在一起,为学生、从业者、研究人员和项目经理提供了一个方便而连贯的平台,以理解社交媒体挖掘的基础和潜力。</p>
</blockquote>
<p><strong>相关</strong>:</p>
<ul>
<li>
<p>10 本免费必读的机器学习和数据科学书籍</p>
</li>
<li>
<p>数据爱好者的十大必备书籍</p>
</li>
<li>
<p>在进入机器学习职业之前需要阅读的 5 本电子书</p>
</li>
</ul>
<h3 id="更多相关话题-18">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/build-solid-data-team.html" target="_blank">建立一个强大的数据团队</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/write-clean-python-code-pipes.html" target="_blank">使用管道编写干净的 Python 代码</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/stop-learning-data-science-find-purpose.html" target="_blank">停止学习数据科学以寻找目标,并寻找目标去…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/springboard-top-resources-learn-data-science-statistics.html" target="_blank">学习数据科学所需的顶级统计资源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-characteristics-successful-data-scientist.html" target="_blank">成功数据科学家的 5 个特征</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-key-skills-needed-become-great-data-scientist.html" target="_blank">成为优秀数据科学家所需的 5 项关键技能</a></p>
</li>
</ul>
<h1 id="10-门必看的免费机器学习和数据科学课程">10 门必看的免费机器学习和数据科学课程</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2018/12/10-more-free-must-see-courses-machine-learning-data-science.html" target="_blank"><code>www.kdnuggets.com/2018/12/10-more-free-must-see-courses-machine-learning-data-science.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/3d9c022da2d331bb56691a9617b91b90.png" alt="c" loading="lazy"> 评论</p>
<p>我们最后的集合 的免费机器学习和数据科学课程受到了好评,所以为什么不再编制一个呢?这里有 10 门课程,帮助你度过寒冬学习季。课程涵盖从入门机器学习到深度学习,再到自然语言处理及其他领域。</p>
<p>这份合集得益于哥伦比亚大学、克拉科夫理工大学、麻省理工学院、加州大学伯克利分校、华盛顿大学、威斯康星大学麦迪逊分校以及 Yandex 数据学校的支持。</p>
<hr>
<h2 id="我们的-3-大课程推荐">我们的 3 大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织 IT</p>
<hr>
<p>如果在阅读了这个列表后,你还希望获得更多免费优质的学习材料,请查看下面相关的帖子。</p>
<p><img src="https://kdn.flygon.net/docs/img/536fc11b539a26d0daebb9d5af9539d0.png" alt="" loading="lazy"></p>
<p><strong>1. <a href="https://courses.cs.washington.edu/courses/cse546/17au/" target="_blank">机器学习</a></strong></p>
<p>华盛顿大学</p>
<blockquote>
<p>本课程旨在提供机器学习基本方法和算法的全面基础。课程主题包括经典统计学、机器学习、数据挖掘、贝叶斯统计和优化。</p>
<p>先决条件:进入该课程的学生应对编程感到舒适,并且应具备线性代数、概率、统计和算法的预备知识。</p>
</blockquote>
<p><strong>2. <a href="http://pages.stat.wisc.edu/~sraschka/teaching/stat479-fs2018/" target="_blank">机器学习</a></strong></p>
<p>威斯康星大学麦迪逊分校</p>
<blockquote>
<p>本课程将涵盖机器学习的关键概念,包括分类、回归分析、聚类和降维。学生将学习机器学习算法背后的基本数学概念,但本课程同样注重使用来自 Python 编程生态系统的开源库进行机器学习算法的实际应用。</p>
</blockquote>
<p><strong>3. <a href="https://github.com/jstray/lede-algorithms/blob/master/README.md" target="_blank">算法(新闻学)</a></strong></p>
<p>哥伦比亚大学</p>
<blockquote>
<p>这是一个关于新闻中的算法数据分析的课程,也涉及社会中使用的算法的新闻分析。主要主题包括文本处理、高维数据可视化、回归、机器学习、算法偏见与问责、蒙特卡罗模拟和选举预测。</p>
<p>所有编码工作都在 Python 中完成,使用 Pandas、matplotlib、scikit learn。</p>
</blockquote>
<p><strong>4. <a href="https://github.com/yandexdataschool/Practical_DL/tree/master" target="_blank">实用深度学习</a></strong></p>
<p>Yandex 数据学校</p>
<blockquote>
<p><img src="https://kdn.flygon.net/docs/img/ef9a12874418cab4a3af27b666645b5c.png" alt="Yandex DL 课程" loading="lazy"></p>
</blockquote>
<p><strong>5. <a href="http://ondata.blog/big-data-in-30-hours/" target="_blank">30 小时大数据</a></strong></p>
<p>克拉科夫技术大学</p>
<blockquote>
<p>本技术性、实践性的课程旨在向技术人员(包括企业、学术界或学生)介绍实用的数据工程和数据科学,通过 15 节课(每节 2 小时)。所有主题都通过实例进行讲解,学生需立即使用命令行或图形用户界面工具进行操作。</p>
<p>先决条件:参与者需要具备技术背景,通晓一般编程和操作系统,对 Linux shell、数据库和 SQL 有基本了解。讲座 9-15 需要具备 Python 的工作知识。</p>
</blockquote>
<p><em>请注意,本课程仍在开发中,并非所有课程都已完成。</em></p>
<p><strong>6. <a href="https://sites.google.com/view/deep-rl-bootcamp/lectures" target="_blank">深度强化学习训练营</a></strong></p>
<p>加州大学伯克利分校(及其他)</p>
<blockquote>
<p>强化学习考虑的是学习行动的问题,并有望为下一代 AI 系统提供动力,这些系统需要超越输入输出模式识别(目前已足够用于语音、视觉、机器翻译),而必须生成智能行为。示例应用领域包括机器人技术、营销、对话、HVAC、优化医疗保健和供应链。</p>
<p>这个为期两天的训练营将通过讲座和实践实验室课程教你深度强化学习的基础,以便你能够使用这些技术构建新的令人着迷的应用,并可能推进算法的前沿。</p>
</blockquote>
<p><strong>7. <a href="https://courses.cs.washington.edu/courses/cse573/17wi/" target="_blank">人工智能导论</a></strong></p>
<p>华盛顿大学</p>
<blockquote>
<p><img src="https://kdn.flygon.net/docs/img/6fc875eea7118d7f732504195050240b.png" alt="UW 人工智能导论" loading="lazy"></p>
</blockquote>
<p><strong>8. <a href="https://ocw.mit.edu/resources/res-9-003-brains-minds-and-machines-summer-course-summer-2015/" target="_blank">大脑、心智与机器暑期课程</a></strong></p>
<p>麻省理工学院</p>
<blockquote>
<p>本课程探讨了智能的问题——其本质、大脑如何产生智能以及如何在机器中复制智能——采用一种综合认知科学(研究心理),神经科学(研究大脑)以及计算机科学和人工智能(研究开发智能机器所需的计算)的方式。材料来源于每年在海洋生物实验室举办的“大脑、心智与机器”暑期课程。</p>
</blockquote>
<p><strong>9. <a href="https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-046j-design-and-analysis-of-algorithms-spring-2015/" target="_blank">算法设计与分析</a></strong></p>
<p>麻省理工学院</p>
<blockquote>
<p>这是一个中级算法课程,重点教授高效算法的设计和分析技术,强调应用方法。主题包括分治法、随机化、动态规划、贪心算法、增量改进、复杂性和密码学。</p>
</blockquote>
<p><strong>10. <a href="https://courses.cs.washington.edu/courses/cse517/17wi/" target="_blank">自然语言处理</a></strong></p>
<p>华盛顿大学</p>
<blockquote>
<p><img src="https://kdn.flygon.net/docs/img/09effd520b11e23d85590b5a60a3a4b2.png" alt="UW NLP POS" loading="lazy"></p>
</blockquote>
<p><strong>相关:</strong></p>
<ul>
<li>
<p>10 个免费必看的机器学习和数据科学课程</p>
</li>
<li>
<p>10 本免费必读的机器学习和数据科学书籍</p>
</li>
<li>
<p>10 本免费必读的机器学习和数据科学书籍</p>
</li>
</ul>
<h3 id="更多相关主题-12">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-key-skills-needed-become-great-data-scientist.html" target="_blank">成为优秀数据科学家所需的 5 项关键技能</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/6-predictive-models-every-beginner-data-scientist-master.html" target="_blank">每个初学者数据科学家应该掌握的 6 种预测模型</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/mozart-best-etl-tools-2021.html" target="_blank">2021 年最佳 ETL 工具</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/stop-learning-data-science-find-purpose.html" target="_blank">停止学习数据科学以寻找目标,并通过寻找目标来……</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/springboard-top-resources-learn-data-science-statistics.html" target="_blank">学习数据科学统计学的最佳资源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/build-solid-data-team.html" target="_blank">建立一个坚实的数据团队</a></p>
</li>
</ul>
<h1 id="10-篇必读的机器学习文章2020-年-3-月">10 篇必读的机器学习文章(2020 年 3 月)</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2020/04/10-must-read-machine-learning-articles-march-2020.html" target="_blank"><code>www.kdnuggets.com/2020/04/10-must-read-machine-learning-articles-march-2020.html</code></a></p>
</blockquote>
<p>评论<img src="https://kdn.flygon.net/docs/img/db547271a7cdaa034c25589ff7d9e8ee.png" alt="图示" loading="lazy"></p>
<p>虽然 COVID-19 正在主导全球新闻,但值得注意的是,在机器学习领域,许多公司仍在照常运营。当然,现在几乎每个人都采取了一些措施来抗击冠状病毒的传播。然而,许多研究人员仍在努力保持 AI 领域的进展和创新。</p>
<p>本列表将展示一些最近在机器学习领域的工作和发现,以及初学者和中级数据科学家的指南和资源。</p>
<h3 id="机器学习新闻">机器学习新闻</h3>
<p><img src="https://kdn.flygon.net/docs/img/af107097a70e7419c9a8f6bd905a2687.png" alt="图示" loading="lazy"></p>
<ol>
<li>
<p><a href="https://venturebeat.com/2020/03/11/google-launches-cloud-ai-platform-pipelines-in-beta-to-simplify-machine-learning-development/" target="_blank">谷歌推出 Cloud AI 平台管道</a> — 本文介绍了谷歌 Cloud AI 平台的测试版发布,以帮助机器学习开发。公司描述其平台为一个简单易安装的机器学习工作流环境。</p>
</li>
<li>
<p><a href="https://www.technologyreview.com/s/615311/implant-machine-learning-amputees-control-prosthetic-hands-ai/" target="_blank">AI 植入体让截肢者控制义肢</a> — 来源于 MIT Technology Review,本文概述了一项惊人的研究,帮助截肢者更好地控制其义肢的运动。研究共同负责人保罗·塞德纳教授表示,初步校准后“思维与运动之间没有差距。”</p>
</li>
<li>
<p><a href="https://aibusiness.com/how-ai-is-changing-the-video-game-industry-an-era-of-augmentation-and-synthetic-media/" target="_blank">AI 正在改变视频游戏产业 — 增强与合成媒体时代</a> — 正如标题所示,本文解释了 AI 和游戏产业的现状。它详细讨论了 AI 中具有巨大潜力改善视频游戏的领域,如增强现实和生成 AI 模型。</p>
</li>
<li>
<p><a href="https://www.androidcentral.com/ai-breakthrough-could-significantly-improve-oculus-quest-rendering-power" target="_blank">AI 突破可能显著提升 Oculus Quest 性能</a> — Oculus 是虚拟现实消费市场的先锋之一,自 2014 年被 Facebook 收购以来发展迅速。它们的增长很大程度上可能归功于 Oculus Quest,这是首批无绳独立 VR 游戏系统之一。本文解释了一个 AI 突破如何在不更换硬件的情况下将 Quest 的图形能力提升高达 67%。</p>
</li>
</ol>
<h3 id="ml-指南与特征文章">ML 指南与特征文章</h3>
<p><img src="https://kdn.flygon.net/docs/img/dc02cd478205e4def7302272c445e465.png" alt="图示" loading="lazy"></p>
<ol start="5">
<li>
<p><a href="https://towardsdatascience.com/intro-to-fastai-installation-and-building-our-first-classifier-938e95fd97d3" target="_blank">FastAI 入门</a> —— 在这篇指南中,数据科学学生 <a href="https://towardsdatascience.com/@radecicdario?source=post_page-----938e95fd97d3----------------------" target="_blank">Dario Radečić</a> 对 Fast AI 进行了很好的概述,这是一个广泛使用的机器学习库。该指南详细解释了如何使用 Fast AI 处理 MNIST 数据集,逐步讲解了整个过程。</p>
</li>
<li>
<p><a href="https://lionbridge.ai/articles/difference-between-cnn-and-rnn/" target="_blank">CNN 和 RNN 之间的区别是什么?</a> —— 这篇机器学习基础指南简要介绍了卷积神经网络和递归神经网络。它解释了这两种神经网络在计算机视觉和自然语言处理中的应用以及它们之间的基本区别。</p>
</li>
<li>
<p><a href="https://blog.getcangler.com/the-future-of-data-analytics-5-predictions-for-where-we-are-headed" target="_blank">数据分析的未来</a> —— 公司将如何利用我们的数据?我们能否利用数据改善教育系统?从预测分析的道德伦理到教育和虚拟助手,本文简要展望了数据分析的未来。</p>
</li>
<li>
<p><a href="https://hackernoon.com/4-social-media-data-mining-techniques-to-help-grow-your-online-business-o6ch32q4" target="_blank">社交媒体数据挖掘技术</a> —— 数据挖掘和数据收集是非常广泛的研究领域,现今被许多企业所应用。本文简要介绍了社交媒体中的数据挖掘及其如何帮助发展在线业务。</p>
</li>
</ol>
<h3 id="机器学习资源">机器学习资源</h3>
<ol start="9">
<li>
<p><a href="https://datasetsearch.research.google.com/" target="_blank">Google 数据集搜索</a> —— 虽然这个专门用于数据集的搜索引擎已经在谷歌的开发日程中存在了一段时间,但它终于在今年早些时候推出了正式版。正如 <a href="https://towardsdatascience.com/google-just-published-25-million-free-datasets-d83940e24284" target="_blank">Towards Data Science</a> 报道的那样,Google 数据集搜索使你可以访问超过 2500 万个开放数据集。</p>
</li>
<li>
<p><a href="https://lionbridge.ai/datasets/coronavirus-datasets-from-every-country/" target="_blank">来自每个国家的冠状病毒数据集</a> —— 随着 COVID-19 几乎占据了每个人的思维,这个数据集聚合器每周更新,随着新数据集的发布不断添加。这个列表上的许多数据集每天更新。</p>
</li>
</ol>
<p>正如你所看到的,每天在机器学习领域仍有大量的工作正在进行。我们希望你从这些 AI 新闻文章中获得了一些新的见解,或者从某些指南中学到了新知识。</p>
<p>欲了解更多机器学习新闻和指南,不要忘记关注我在 <a href="https://hackernoon.com/@limarc2000" target="_blank">Hacker Noon</a>、<a href="https://twitter.com/AmbalinaLimarc" target="_blank">Twitter</a> 和 <a href="http://jpbound.com/" target="_blank">我的个人博客</a>。</p>
<p><strong>简介: <a href="https://www.linkedin.com/in/limarc-ambalina-11604371/" target="_blank">Limarc Ambalina</a></strong> 是一位驻东京的作家,专注于人工智能、技术和流行文化。他曾为多个出版物撰写文章,包括 Hacker Noon、Japan Today 和 Towards Data Science。</p>
<p><a href="https://towardsdatascience.com/10-must-read-machine-learning-articles-march-2020-80da9c380981" target="_blank">原文</a>。转载已获许可。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p>介绍 MIDAS:图形异常检测的新基准</p>
</li>
<li>
<p>如何在 3 个简单步骤中对任何 Python 脚本进行超参数调整</p>
</li>
<li>
<p>使用随机森林®而不是神经网络的 3 个理由:比较机器学习与深度学习</p>
</li>
</ul>
<hr>
<h2 id="我们的-3-个课程推荐">我们的 3 个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速通道进入网络安全职业。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析能力</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你所在组织的 IT</p>
<hr>
<h3 id="更多相关主题-13">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-key-skills-needed-become-great-data-scientist.html" target="_blank">成为一名优秀数据科学家所需的 5 项关键技能</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/6-predictive-models-every-beginner-data-scientist-master.html" target="_blank">每个初学数据科学者应掌握的 6 个预测模型</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/mozart-best-etl-tools-2021.html" target="_blank">2021 年最佳 ETL 工具</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/stop-learning-data-science-find-purpose.html" target="_blank">停止学习数据科学以寻找目标,寻找目标以…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/springboard-top-resources-learn-data-science-statistics.html" target="_blank">学习数据科学统计的顶级资源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-characteristics-successful-data-scientist.html" target="_blank">成功数据科学家的 5 个特征</a></p>
</li>
</ul>
<h1 id="实用统计推理的-10-个原则">实用统计推理的 10 个原则</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2020/11/10-principles-practical-statistical-reasoning.html" target="_blank"><code>www.kdnuggets.com/2020/11/10-principles-practical-statistical-reasoning.html</code></a></p>
</blockquote>
<p>评论</p>
<p><strong><a href="https://www.linkedin.com/in/neil-chandarana-369b3957/" target="_blank">Neil Chandarana</a>,机器学习</strong></p>
<p><img src="https://kdn.flygon.net/docs/img/5afa0789466c7c2ba17970d60068d365.png" alt="图" loading="lazy"></p>
<p><a href="https://unsplash.com/@andreasbruecker?utm_source=medium&utm_medium=referral" target="_blank">Andreas Brücker</a>拍摄的照片,来自<a href="https://unsplash.com/?utm_source=medium&utm_medium=referral" target="_blank">Unsplash</a></p>
<hr>
<h2 id="我们的前三个课程推荐-19">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业轨道。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你所在组织的 IT 需求</p>
<hr>
<p>成功应用统计学(数据科学)有两个核心方面:</p>
<ol>
<li>
<p>领域知识。</p>
</li>
<li>
<p>统计方法论。</p>
</li>
</ol>
<p>由于这一领域的高度专业性,任何书籍或文章都很难同时传达两者之间的详细和准确的描述。通常,人们可以阅读两种类型的材料:</p>
<ol>
<li>
<p>关于统计方法的广泛信息,其中得出的结论是普遍适用的,但并不具体。</p>
</li>
<li>
<p>详细的统计方法,其中得出的结论仅在特定领域内有用。</p>
</li>
</ol>
<p>在自己做数据科学项目的 3 年和在交易所操作数据的 3.5 年后,还有一个额外的学习类别。它与上述同样有用,我将其融入到<strong>每一个</strong>项目/副业/咨询工作中…</p>
<p><strong>实用统计推理</strong></p>
<p>我创造了这个术语,因为我不知道该如何称呼这个类别。然而,它涵盖了:</p>
<ul>
<li>
<p>应用统计学/数据科学的性质和目标。</p>
</li>
<li>
<p>适用于所有应用的原则</p>
</li>
<li>
<p>改进结论的实际步骤/问题</p>
</li>
</ul>
<p>如果你有应用统计方法的经验,我鼓励你利用你的经验来阐明和批评以下原则。如果你从未尝试过实施统计模型,可以尝试一下,然后再回来。不要把以下内容看作是需要记住的清单。如果你能与自己的经验相关联,你将获得最佳的信息综合。</p>
<p>以下原则帮助我提高了分析的效率和结论的清晰度。我希望你也能从中获益。</p>
<h3 id="1--数据质量很重要"><strong>1 — 数据质量很重要</strong></h3>
<p>低<strong>数据质量</strong>通过更复杂的分析能够纠正的程度是有限的。值得完成的实际检查包括:</p>
<ul>
<li>
<p><em>对逻辑上不一致或与各变量可能出现的范围先前信息相冲突的值进行视觉/自动检查。例如极端值、变量类型。</em></p>
</li>
<li>
<p><em>分布频率。</em></p>
</li>
<li>
<p><em>进行成对散点图以低层次检查共线性。</em></p>
</li>
<li>
<p><em>缺失观察值(0, 99, None, NaN 值)。</em></p>
</li>
<li>
<p><em>质疑收集方法是否存在因不一致引入的偏差,例如观察者之间的差异。</em></p>
</li>
</ul>
<h3 id="2--批评变异"><strong>2 — 批评变异</strong></h3>
<p>在几乎所有问题中,你都会处理<strong>未控制的变异</strong>。对这种变异的态度应根据这种变异是否是研究系统的固有部分或是否代表实验误差来有所不同。在这两种情况下,我们都考虑变异的分布,但动机不同:</p>
<ul>
<li>
<p><strong>固有变异:</strong>我们对分布形式的细节感兴趣。</p>
</li>
<li>
<p><strong>误差变异:</strong>我们对如果消除了误差会观察到的内容感兴趣。</p>
</li>
</ul>
<h3 id="3--选择合理的分析深度"><strong>3 — 选择合理的分析深度</strong></h3>
<p>尝试将分析深度独立于可用数据量或可用技术来考虑。仅仅因为数据收集容易/便宜,并不意味着数据是相关的。方法和技术也一样。合理选择的分析深度支持明确的结论,明确的结论支持更好的决策。</p>
<h3 id="4--理解数据结构"><strong>4 — 理解数据结构</strong></h3>
<p><strong>数据量</strong>涉及个体的数量和每个个体的变量数量。<strong>数据结构 = 数据量 + 个体分组。</strong>大多数数据集呈现以下形式:</p>
<ul>
<li>
<p>有许多个体。</p>
</li>
<li>
<p>对每个个体,观察到多个变量。</p>
</li>
<li>
<p>个体被认为是相互独立的。</p>
</li>
</ul>
<p>鉴于这种形式,回答以下问题将缩短得出有意义结论的路径。</p>
<ul>
<li>
<p><em>什么应被视为一个个体?</em></p>
</li>
<li>
<p><em>个体是否以需要纳入分析的方式分组/关联?</em></p>
</li>
<li>
<p><em>每个个体测量了哪些变量?</em></p>
</li>
<li>
<p><em>是否缺少任何观察值?可以做什么来替代/估计这些值?</em></p>
</li>
</ul>
<p>注意:小数据集可以轻松检查数据结构,而大数据集可能只能对结构的少部分进行分析。将这一点纳入你的分析中,并根据需要花费时间。</p>
<h3 id="5--统计分析的-4-个阶段"><strong>5 — 统计分析的 4 个阶段</strong></h3>
<ol>
<li>
<p><strong>初步数据处理。</strong>意图 = 检查数据质量、结构和数量,并将数据汇总为详细分析的形式。</p>
</li>
<li>
<p><strong>初步分析。</strong>意图 = 明确数据的形式,并建议定量分析的方向(图表、表格)。</p>
</li>
<li>
<p><strong>定量分析。</strong>意图 = 提供结论的基础。</p>
</li>
<li>
<p><strong>结论展示。</strong>意图 = 准确、简洁、清晰的结论,并具有领域解释。</p>
</li>
</ol>
<p>…但这些阶段存在一些警告:</p>
<ul>
<li>
<p>阶段的划分是有用的,但不是严格的。初步分析可能得出明确结论,而最终分析可能揭示意外的差异,需要重新考虑分析的整体基础。</p>
</li>
<li>
<p>在给定清理过的数据集时跳过 1。</p>
</li>
<li>
<p>在已有大量现有分析的领域中跳过 2。</p>
</li>
</ul>
<h3 id="6--输出是什么"><strong>6 — 输出是什么?</strong></h3>
<p>记住,统计分析只是更大决策过程中的一个步骤。<strong>向决策者展示结论</strong>对任何分析的有效性至关重要:</p>
<ul>
<li>
<p>结论风格应根据观众调整。</p>
</li>
<li>
<p>用对关键非技术读者合理的形式解释分析的广泛策略。</p>
</li>
<li>
<p>包括结论和数据之间的直接链接。</p>
</li>
<li>
<p>以简单方式呈现复杂分析的努力是值得的。然而,请注意,简单性是主观的,并与熟悉度相关。</p>
</li>
</ul>
<h3 id="7--适当的分析风格"><strong>7 — 适当的分析风格</strong></h3>
<p>从技术角度看,<strong>分析风格</strong>指的是如何建模关注的基础系统:</p>
<ul>
<li>
<p><strong>概率/推断性:</strong> 得出受不确定性影响的结论,通常是数值的。</p>
</li>
<li>
<p><strong>描述性:</strong> 旨在总结数据,通常是图形化的。</p>
</li>
</ul>
<p>适当的分析风格有助于保持关注。早点考虑,它将减少返回到耗时数据处理步骤的需求。</p>
<h3 id="8--计算考虑-只是有时是一个问题"><strong>8 — 计算考虑</strong> 只是有时是一个问题</h3>
<p>技术选择渗透到应用统计分析的各个方面,包括:</p>
<ul>
<li>
<p>原始数据的组织和存储。</p>
</li>
<li>
<p>结论的安排。</p>
</li>
<li>
<p>实施主要分析/分析。</p>
</li>
</ul>
<p>那么,什么时候应该引起注意呢?</p>
<ul>
<li>
<p><strong>大规模调查 + 大数据</strong> = 如果现有工具无法实现灵活性和性能,值得将资源投入到定制程序/库中。</p>
</li>
<li>
<p><strong>大规模调查 + 小数据</strong> = 计算考虑不重要。</p>
</li>
<li>
<p><strong>小规模调查 + 大数据</strong> = 定制程序不可行,灵活和通用程序/库的可用性至关重要。</p>
</li>
<li>
<p><strong>小规模调查 + 小数据</strong> = 计算考虑不重要。</p>
</li>
</ul>
<h3 id="9--设计良好的调查"><strong>9 — 设计良好的调查</strong></h3>
<p>尽管可以在多种调查类型中使用各种统计方法,但结果的解释将根据<strong>调查设计</strong>有所不同:</p>
<ul>
<li>
<p><strong>实验</strong> = 系统由调查者设置和控制。可以自信地将明显的差异归因于变量。</p>
</li>
<li>
<p><strong>观察性研究</strong> = 调查者对数据收集没有控制,只有监控数据质量。真正的解释变量可能缺失,难以自信地得出结论。</p>
</li>
<li>
<p><strong>样本调查</strong> = 由调查者控制的方法(随机化)从总体中抽取的样本。对总体的描述性属性可以得出可靠结论,但解释变量如上所述受限。</p>
</li>
<li>
<p><strong>受控前瞻性研究</strong> = 由研究者选择的样本,解释变量被测量并随着时间的推移进行跟踪。具有实验的一些优点,但实际上不可能测量所有解释变量。</p>
</li>
<li>
<p><strong>受控回顾性研究</strong> = 现有数据集,适当地处理解释变量。</p>
</li>
</ul>
<p>注意:调查设计的一个重要方面是区分反应变量和解释变量。</p>
<h3 id="10--调查的目的"><strong>10 — 调查的目的</strong></h3>
<p>显然,调查的目的很重要。但你应该如何考虑目的呢?</p>
<p>首先,目标的一般定性区分:</p>
<ul>
<li>
<p><strong>解释性:</strong> 增强理解。任意选择适合的模型是危险的。</p>
</li>
<li>
<p><strong>预测性:</strong> 主要的实际用途。容易在适合的模型中任意选择。</p>
</li>
</ul>
<p>调查的具体目的可能表明,分析应该集中在研究系统的某个特定方面。这也影响到结论的类型和结论的呈现方式。</p>
<p>目的可能决定了结论的有效期。如果观察到变量之间关系的变化,任何完全基于经验选择的模型都会面临风险。</p>
<h3 id="结语">结语</h3>
<p>几乎生活中的所有任务都可以从这个框架来考虑:</p>
<p>输入 -> 系统 -> 输出</p>
<p>然后工作就变成了定义框架的每个方面。</p>
<p>实用统计推理涉及到“系统”。系统的某些部分无法脱离上下文来确定。有些部分可以。实用统计推理实际上只是能够轻松且熟练地定义你的“系统”的能力。这种能力绝对不仅限于这些原则。</p>
<p><em>如果你想看到编程/数据科学方面的副业展示在你面前,请查看我的</em><a href="https://www.youtube.com/watch?v=s4cQMryKwqA&t=324s" target="_blank"><em>YouTube 频道</em></a><em>,我在其中发布了完整的 Python 构建过程。</em></p>
<p><em>目标是激励和合作,所以请与我联系!</em></p>
<p><strong>简介:<a href="https://www.linkedin.com/in/neil-chandarana-369b3957/" target="_blank">Neil Chandarana</a></strong> 从事机器学习工作,并且是前期权交易员。他正在从事改善生活和增强人类生活体验的项目,并且<a href="https://www.youtube.com/watch?v=s4cQMryKwqA&t=7054s" target="_blank">喜欢分享他的想法</a>。</p>
<p><a href="https://towardsdatascience.com/10-principles-of-practical-statistical-reasoning-3071d360d255" target="_blank">原文</a>。经许可转载。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p>联合分析:入门</p>
</li>
<li>
<p>使用 Python 进行探索性数据分析</p>
</li>
<li>
<p>类固醇中的探索性数据分析</p>
</li>
</ul>
<h3 id="更多相关话题-19">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2023/06/orca-llm-reasoning-processes-chatgpt.html" target="_blank">Orca LLM:模拟 ChatGPT 的推理过程</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/react-reasoning-and-acting-augments-llms-with-tools" target="_blank">ReAct,推理与行动通过工具增强了 LLMs!</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/enhancing-llm-reasoning-unveiling-chain-of-code-prompting" target="_blank">增强 LLM 推理:揭示代码链提示</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/thought-propagation-an-analogical-approach-to-complex-reasoning-with-large-language-models" target="_blank">思想传播:复杂推理的类比方法…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/data-management-principles-for-data-science" target="_blank">数据科学的数据管理原则</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/practical-statistics-data-scientists.html" target="_blank">数据科学实用统计学</a></p>
</li>
</ul>
<h1 id="10-个我们都应该知道的-python-代码片段">10 个我们都应该知道的 Python 代码片段</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2021/06/10-python-code-snippets.html" target="_blank"><code>www.kdnuggets.com/2021/06/10-python-code-snippets.html</code></a></p>
</blockquote>
<p>评论</p>
<p><strong>由<a href="https://www.linkedin.com/in/pralabh-saxena-05/" target="_blank">Pralabh Saxena</a>, 软件开发者</strong></p>
<p><img src="https://kdn.flygon.net/docs/img/379ec36e37093fcf44efcc85755bd900.png" alt="图示" loading="lazy"></p>
<p>图片由<a href="https://pixabay.com/users/johnsonmartin-724525/?utm_source=link-attribution&utm_medium=referral&utm_campaign=image&utm_content=1084923" target="_blank">Johnson Martin</a>提供,来源于<a href="https://pixabay.com/?utm_source=link-attribution&utm_medium=referral&utm_campaign=image&utm_content=1084923" target="_blank">Pixabay</a></p>
<hr>
<h2 id="我们的三大课程推荐-10">我们的三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织 IT</p>
<hr>
<p>近年来,Python 的用户群体增长巨大。初学者程序员由于其简单的语法和应用选择了 Python 作为他们的第一语言。</p>
<p>在这篇文章中,我将分享一些可以用来解决日常问题的 Python 代码片段。让我们开始吧!</p>
<h3 id="1-合并两个字典">1. 合并两个字典</h3>
<p>在<code>Python 3.5</code>之后,合并多个字典变得更简单了。我们可以使用<code>(**)</code>操作符在一行中合并多个字典。只需将字典传递到{}中,并使用(**)操作符即可完成。</p>
<blockquote>
<p>语法:</p>
</blockquote>
<pre><code class="language-py">Output:Merged dictionary: {'name': 'Joy', 'age': 25, 'city': 'New York'}
</code></pre>
<h3 id="2-链式比较">2. 链式比较</h3>
<p>这段代码允许你在一行中进行多种比较操作。</p>
<pre><code class="language-py">Output:True
False
</code></pre>
<h3 id="3-打印字符串-n-次">3. 打印字符串 N 次</h3>
<p>我们可以使用这段代码在不使用任何循环的情况下输出一个字符串 N 次。</p>
<pre><code class="language-py">Output:
Hello!Hello!Hello!Hello!Hello!
</code></pre>
<h3 id="4-检查文件是否存在">4. 检查文件是否存在</h3>
<p>在进行文件处理及其他操作时,了解我们使用的文件是否存在是很重要的。使用这段代码,我们可以知道文件是否存在于我们的目录或指定路径中。</p>
<pre><code class="language-py">Output:Does file exist: False
</code></pre>
<h3 id="5-获取列表中的最后一个元素">5. 获取列表中的最后一个元素</h3>
<p>我们可以使用以下方法从列表中检索最后一个元素。</p>
<h3 id="6-列表推导">6. 列表推导</h3>
<p>列表推导可以用来基于现有列表的元素在一行代码中创建一个新列表。</p>
<pre><code class="language-py">Output:Vowels are: ['i', 'i', 'o', 'e', 'a', 'o', 'i']
</code></pre>
<h3 id="7-计算代码执行时间">7. 计算代码执行时间</h3>
<p>我们可以使用<code>time</code>库来计算执行特定代码所需的时间。</p>
<pre><code class="language-py">Output:Sum: 45
Time: 0.0009965896606445312
</code></pre>
<h3 id="8-查找出现频率最高的元素">8. 查找出现频率最高的元素</h3>
<p>这段代码返回列表中出现频率最高的项。</p>
<pre><code class="language-py">Output:most frequent item is: 2
</code></pre>
<h3 id="9-将两个列表转换为字典">9. 将两个列表转换为字典</h3>
<p>这个代码片段可以用来将两个列表转换成字典。在这个方法中,我们将两个列表作为输入值。第一个列表将作为字典的键,另一个列表中的值将作为字典的值。</p>
<pre><code class="language-py">Output:{1: 'one', 2: 'two', 3: 'three'}
</code></pre>
<h3 id="10-错误处理">10. 错误处理</h3>
<p>与其他编程语言一样,Python 也提供了使用 <code>try</code>、<code>except</code> 和 <code>finally</code> 块来处理异常的方法。</p>
<pre><code class="language-py">Output:Can not divide by zero
Executing finally block
</code></pre>
<h3 id="结论-13">结论</h3>
<p>本文到此为止。我们讨论了一些我认为非常有用的代码片段,这些片段可以用于日常问题。你可以在日常编程和竞赛编程问题中使用这些片段,以加快工作速度并提高代码效率。</p>
<p>感谢阅读!</p>
<p>欲了解更多 12 个代码片段,<a href="https://levelup.gitconnected.com/22-code-snippets-that-every-python-programmer-must-learn-b7f7ec35e9df" target="_blank">请参见原文</a>。</p>
<h3 id="提升编码能力">提升编码能力</h3>
<p>感谢你成为我们社区的一部分! <a href="https://www.youtube.com/channel/UC3v9kBR_ab4UHXXdknz8Fbg?sub_confirmation=1" target="_blank">订阅我们的 YouTube 频道</a> 或加入 <a href="https://skilled.dev/" target="_blank"><strong>Skilled.dev 编程面试课程</strong></a>。</p>
<p><a href="https://skilled.dev/" target="_blank"><strong>编程面试问题 + 拿到开发工作 | Skilled.dev</strong></a></p>
<p>掌握编程面试的课程</p>
<p><strong>简历:<a href="https://www.linkedin.com/in/pralabh-saxena-05/" target="_blank">Pralabh Saxena</a></strong> 是一名拥有 1 年经验的软件开发者。Pralabh <a href="https://pralabhsaxena.medium.com/" target="_blank">撰写文章</a> 主题包括 Python、机器学习、数据科学和 SQL。</p>
<p><a href="https://levelup.gitconnected.com/22-code-snippets-that-every-python-programmer-must-learn-b7f7ec35e9df" target="_blank">原文</a>。转载许可。</p>
<p><strong>相关内容:</strong></p>
<ul>
<li>
<p>数据科学家,你需要学会编程</p>
</li>
<li>
<p>如何使 Python 代码运行得极快</p>
</li>
<li>
<p>如何排查 Python 中的内存问题</p>
</li>
</ul>
<h3 id="更多相关主题-14">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/n15.html" target="_blank">KDnuggets 新闻,4 月 13 日:数据科学家应知的 Python 库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n01.html" target="_blank">KDnuggets™ 新闻 22:n01, 1 月 5 日:跟踪和可视化的 3 种工具…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/04/python-libraries-data-scientists-know-2022.html" target="_blank">2022 年数据科学家应知的 Python 库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/three-r-libraries-every-data-scientist-know-even-python.html" target="_blank">每位数据科学家都应知道的三个 R 库(即使你使用 Python)</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/05/6-python-machine-learning-tools-every-data-scientist-know.html" target="_blank">每位数据科学家都应了解的 6 种 Python 机器学习工具</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n21.html" target="_blank">KDnuggets 新闻,5 月 25 日:6 种 Python 机器学习工具</a></p>
</li>
</ul>
<h1 id="每个数据科学家都应该知道的-10-个-python-库">每个数据科学家都应该知道的 10 个 Python 库</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/10-python-libraries-every-data-scientist-should-know" target="_blank"><code>www.kdnuggets.com/10-python-libraries-every-data-scientist-should-know</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/10e6881683f95a8507ae28d86040e4b9.png" alt="python-libs-fimg" loading="lazy"></p>
<p>图片由作者提供</p>
<p>如果你想在数据领域发展,你可能知道 Python 是数据科学的首选语言。除了易于学习,Python 还拥有丰富的库,可以用几行代码完成任何数据科学任务。</p>
<hr>
<h2 id="我们的三大课程推荐-11">我们的三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 加速进入网络安全领域的职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你所在组织的 IT 工作</p>
<hr>
<p>所以无论你是刚开始成为数据科学家,还是希望转行数据领域,学习使用这些库都将非常有帮助。在这篇文章中,我们将探讨一些数据科学必知的 Python 库。</p>
<p>我们特别关注用于数据分析和可视化的 Python 库、网页抓取、API 的使用、机器学习等。让我们开始吧。</p>
<p><img src="https://kdn.flygon.net/docs/img/482a1472b6fea19a62d7f52c2027b307.png" alt="py-ds-libraries" loading="lazy"></p>
<p>Python 数据科学库 | 图片由作者提供</p>
<h2 id="1-pandas">1. Pandas</h2>
<p><a href="https://pandas.pydata.org/" target="_blank">Pandas</a>是你在进行数据分析时首先接触的库之一。Series 和 dataframes,这两个 pandas 的关键数据结构,简化了操作结构化数据的过程。</p>
<p>你可以使用 pandas 进行数据清理、转换、合并和连接,因此它对数据预处理和分析都很有帮助。</p>
<p>让我们来了解一下 pandas 的关键特性:</p>
<ul>
<li>
<p>Pandas 提供了两种主要的数据结构:Series(单维)和 DataFrame(二维),它们允许轻松操作结构化数据。</p>
</li>
<li>
<p>处理缺失数据、过滤数据以及执行各种操作以清理和预处理数据集的函数和方法</p>
</li>
<li>
<p>用于以灵活和高效的方式合并、连接和拼接数据集的函数</p>
</li>
<li>
<p>专门处理时间序列数据的函数,使处理时间数据更加容易</p>
</li>
</ul>
<p>这门来自 Kaggle 的<a href="https://www.kaggle.com/learn/pandas" target="_blank">短课程</a>将帮助你开始使用 pandas 进行数据分析。</p>
<h2 id="2-matplotlib">2. Matplotlib</h2>
<p>你必须超越分析,进行数据可视化才能理解数据。<a href="https://matplotlib.org/" target="_blank">Matplotlib</a>是你在转向其他库如 Seaborn、Plotly 等之前接触的第一个数据可视化库。</p>
<p>它是可自定义的(尽管需要一些努力),适用于从简单的折线图到更复杂的可视化的各种绘图任务。一些功能包括:</p>
<ul>
<li>
<p>简单的可视化,如折线图、条形图、直方图、散点图等。</p>
</li>
<li>
<p>可自定义的图表,对图形的每个方面(如颜色、标签和尺度)具有相当细致的控制。</p>
</li>
<li>
<p>与 Pandas 和 NumPy 等其他 Python 库良好配合,使得可视化存储在数据框和数组中的数据变得更容易。</p>
</li>
</ul>
<p><a href="https://matplotlib.org/stable/tutorials/index.html" target="_blank">Matplotlib 教程</a>应能帮助你开始绘图。</p>
<h2 id="3-seaborn">3. Seaborn</h2>
<p><a href="https://seaborn.pydata.org/" target="_blank">Seaborn</a> 建立在 Matplotlib 之上(它是更易用的 Matplotlib),专为统计和简化的数据可视化而设计。它通过高层接口简化了复杂可视化的创建过程,并与 pandas 数据框良好集成。</p>
<p>Seaborn 具有:</p>
<ul>
<li>
<p>内置主题和颜色调色板,在不费太多力气的情况下改善图表</p>
</li>
<li>
<p>创建有用的可视化功能,如小提琴图、配对图和热图</p>
</li>
</ul>
<p>Kaggle 上的<a href="https://www.kaggle.com/learn/data-visualization" target="_blank">数据可视化微课程</a>将帮助你快速上手 Seaborn。</p>
<h2 id="4-plotly">4. Plotly</h2>
<p>当你对使用 Seaborn 感到自如时,可以学习使用<a href="https://plotly.com/graphing-libraries/" target="_blank">Plotly</a>,这是一个用于创建互动数据可视化的 Python 库。</p>
<p>除了各种图表类型外,使用 Plotly,你可以:</p>
<ul>
<li>
<p>创建交互式图表</p>
</li>
<li>
<p>使用 Plotly Dash 构建网页应用和数据仪表板</p>
</li>
<li>
<p>将图表导出为静态图像、HTML 文件,或嵌入到网页应用中</p>
</li>
</ul>
<p>指南<a href="https://plotly.com/python/plotly-fundamentals/" target="_blank">Plotly Python 开源绘图库基础</a>将帮助你熟悉使用 Plotly 进行绘图。</p>
<h2 id="5-requests">5. Requests</h2>
<p>你通常需要通过发送 HTTP 请求从 API 获取数据,对于此目的可以使用<a href="https://requests.readthedocs.io/" target="_blank">Requests</a>库。</p>
<p>它使用简单,使从 API 或网页获取数据变得轻而易举,具有开箱即用的会话管理、身份验证等支持。使用 Requests,你可以:</p>
<ul>
<li>
<p>发送 HTTP 请求,包括 GET 和 POST 请求,以与网络服务进行交互</p>
</li>
<li>
<p>管理和保持设置 across requests,例如 cookies 和 headers</p>
</li>
<li>
<p>使用各种身份验证方法,包括基本认证和 OAuth</p>
</li>
<li>
<p>处理超时、重试和错误以确保可靠的网页交互</p>
</li>
</ul>
<p>你可以参考<a href="https://requests.readthedocs.io/en/latest/" target="_blank">Requests 文档</a>来获取简单和高级的使用示例。</p>
<h2 id="6-beautiful-soup">6. Beautiful Soup</h2>
<p>网络爬虫是数据科学家的必备技能,<a href="https://beautiful-soup-4.readthedocs.io/en/latest/" target="_blank">Beautiful Soup</a>是所有网络爬虫相关操作的首选库。获取数据后,可以使用 Beautiful Soup 来导航和搜索解析树,轻松定位和提取所需的信息。</p>
<p>因此,Beautiful Soup 通常与 Requests 库一起使用来获取和解析网页。你可以:</p>
<ul>
<li>
<p>解析 HTML 文档以查找特定信息</p>
</li>
<li>
<p>使用 Python 风格的惯用语在解析树中导航和搜索,以提取特定数据</p>
</li>
<li>
<p>查找和修改文档中的标签和属性</p>
</li>
</ul>
<p><a href="https://www.kdnuggets.com/mastering-web-scraping-with-beautifulsoup" target="_blank">掌握 BeautifulSoup 的网络爬虫</a>是学习 Beautiful Soup 的全面指南。</p>
<h2 id="7-scikit-learn">7. Scikit-Learn</h2>
<p><a href="https://scikit-learn.org/" target="_blank">Scikit-Learn</a>是一个机器学习库,提供了用于分类、回归、聚类和降维的现成算法实现。它还包括模型选择、预处理和评估的模块,使其成为构建和评估机器学习模型的实用工具。</p>
<p>Scikit-Learn 库还具有专门的模块用于:</p>
<ul>
<li>
<p>数据预处理,例如缩放、标准化和编码类别特征</p>
</li>
<li>
<p>模型选择和超参数调优</p>
</li>
<li>
<p>模型评估</p>
</li>
</ul>
<p><a href="https://www.youtube.com/watch?v=hDKCxebp88A" target="_blank">使用 Python 和 Scikit-Learn 进行机器学习 - 完整课程</a>是一个学习使用 Scikit-Learn 构建机器学习模型的好资源。</p>
<h2 id="8-statsmodels">8. Statsmodels</h2>
<p><a href="https://www.statsmodels.org/" target="_blank">Statsmodels</a>是一个专注于统计建模的库。它提供了一系列用于估计统计模型、执行假设检验和数据探索的工具。如果你想探索计量经济学和其他需要严谨统计分析的领域,Statsmodels 特别有用。</p>
<p>你可以使用 statsmodels 进行估计、统计测试等。Statsmodels 提供了以下功能:</p>
<ul>
<li>
<p>用于总结和探索数据集以获得建模前的见解的函数</p>
</li>
<li>
<p>不同类型的统计模型,包括线性回归、广义线性模型和时间序列分析</p>
</li>
<li>
<p>一系列统计测试,包括 t 检验、卡方检验和非参数检验</p>
</li>
<li>
<p>用于诊断和验证模型的工具,包括残差分析和拟合优度测试</p>
</li>
</ul>
<p><a href="https://www.statsmodels.org/stable/gettingstarted.html" target="_blank">入门指南 - statsmodels</a>应该能帮助你学习这个库的基础知识。</p>
<h2 id="9-xgboost">9. XGBoost</h2>
<p><a href="https://xgboost.readthedocs.io/" target="_blank">XGBoost</a> 是一个优化的梯度提升库,旨在提供高性能和高效率。它广泛用于机器学习竞赛和实际应用中。XGBoost 适用于各种任务,包括分类、回归和排序,并包含正则化和跨平台集成功能。</p>
<p>XGBoost 的一些特性包括:</p>
<ul>
<li>
<p>先进的提升算法实现,可用于分类、回归和排序问题。</p>
</li>
<li>
<p>内置正则化以防止过拟合并提高模型泛化能力。</p>
</li>
</ul>
<p><a href="https://www.kaggle.com/code/dansbecker/xgboost" target="_blank">XGBoost</a> 在 Kaggle 上的教程是一个熟悉 XGBoost 的好地方。</p>
<h2 id="10-fastapi">10. <strong>FastAPI</strong></h2>
<p>到目前为止,我们已经看过了 Python 库。让我们以构建 API 的框架——<strong>FastAPI</strong> 来结束。</p>
<p><a href="https://fastapi.tiangolo.com/" target="_blank">FastAPI</a> 是一个用于用 Python 构建 API 的 web 框架。它非常适合创建用于服务机器学习模型的 API,提供了一种强大而高效的方式来部署数据科学应用。</p>
<ul>
<li>
<p>FastAPI 易于使用和学习,允许快速开发 API。</p>
</li>
<li>
<p>提供对异步编程的全面支持,使其适合处理多个同时连接。</p>
</li>
</ul>
<p><a href="https://www.kdnuggets.com/fastapi-tutorial-build-apis-with-python-in-minutes" target="_blank">FastAPI 教程:在几分钟内用 Python 构建 API</a> 是一个全面的教程,可以帮助你学习用 FastAPI 构建 API 的基础知识。</p>
<h2 id="总结-5">总结</h2>
<p>我希望你发现这个数据科学库的汇总对你有所帮助。如果有一个要点,那就是这些 Python 库是你数据科学工具箱中有用的补充。</p>
<p>我们已经介绍了涵盖各种功能的 Python 库——从数据处理和可视化到机器学习、网页抓取和 API 开发。如果你对数据工程中的 Python 库感兴趣,你可能会觉得<a href="https://www.kdnuggets.com/7-python-libraries-every-data-engineer-should-know" target="_blank">每个数据工程师都应该知道的 7 个 Python 库</a>很有帮助。</p>
<p><strong><a href="https://twitter.com/balawc27" target="_blank"></a></strong><a href="https://www.kdnuggets.com/wp-content/uploads/bala-priya-author-image-update-230821.jpg" target="_blank">Bala Priya C</a>** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正致力于通过撰写教程、操作指南、观点文章等方式向开发者社区学习和分享她的知识。Bala 还制作了引人入胜的资源概述和编码教程。**</p>
<h3 id="更多相关内容-18">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/three-r-libraries-every-data-scientist-know-even-python.html" target="_blank">每个数据科学家都应该知道的三个 R 库(即使你使用 Python)</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/7-python-libraries-every-data-engineer-should-know" target="_blank">每个数据工程师都应该知道的 7 个 Python 库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n15.html" target="_blank">KDnuggets 新闻,4 月 13 日:数据科学家应该了解的 Python 库…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n21.html" target="_blank">KDnuggets 新闻,5 月 25 日:每个数据科学家都应该了解的 6 种 Python 机器学习工具…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/05/6-python-machine-learning-tools-every-data-scientist-know.html" target="_blank">每个数据科学家都应该了解的 6 种 Python 机器学习工具</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/04/python-libraries-data-scientists-know-2022.html" target="_blank">数据科学家在 2022 年应该知道的 Python 库</a></p>
</li>
</ul>
<h1 id="10-个-python-初学者技能">10 个 Python 初学者技能</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2020/12/10-python-skills-beginners.html" target="_blank"><code>www.kdnuggets.com/2020/12/10-python-skills-beginners.html</code></a></p>
</blockquote>
<p>评论</p>
<p><strong>由<a href="https://twitter.com/Nicole_Janeway" target="_blank">Nicole Janeway Bills</a>,Atlas Research 的数据科学家</strong></p>
<p><img src="https://kdn.flygon.net/docs/img/ba61ff76a6f3e7f068178f3d16e421ad.png" alt="图示" loading="lazy"></p>
<p>图片来源:<a href="https://unsplash.com/@shebster_07?utm_source=medium&utm_medium=referral" target="_blank">Shelby Miller</a> 于<a href="https://unsplash.com/?utm_source=medium&utm_medium=referral" target="_blank">Unsplash</a></p>
<hr>
<h2 id="我们的三大课程推荐-12">我们的三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业道路。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析能力</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你在 IT 领域的组织</p>
<hr>
<p>借助 Python 直观、人性化的语法,任何人都可以利用科学计算的强大功能。Python 已成为数据科学和机器学习的标准语言,并且在<a href="https://insights.stackoverflow.com/survey/2020#most-loved-dreaded-and-wanted" target="_blank">Stack Overflow 的 2020 开发者调查</a>中被评为<strong>最受喜爱的前三种</strong>语言。</p>
<p>如果你是这个备受喜爱的编程语言的<em>新手</em>,这里有十个技巧可以促进你的 Python 技能发展。你可以在这个<a href="https://colab.research.google.com/drive/1K2oWzxzYbura4VqrntsZimnWqQex_c38?usp=sharing" target="_blank"><strong>Google Colab</strong> <strong>笔记本</strong></a>中跟随(此外,<a href="https://youtu.be/aaebOpi1kik?t=24" target="_blank">一个 Google Colab 的简短视频介绍</a>)。</p>
<h3 id="10--列表推导">#10 — 列表推导</h3>
<p>列表推导是一种简单的单行语法,用于处理列表,它允许你访问并对列表中的单个元素执行操作。</p>
<p>语法由包含如<code>print(plant)</code>的表达式的括号组成,后跟一个<code>for</code>和/或<code>if</code>子句。</p>
<p>将打印:</p>
<pre><code class="language-py">boat orchid
dancing-lady orchid
nun's hood orchid
chinese ground orchid
vanilla orchid
tiger orchid
</code></pre>
<p>(注:列表推导末尾的分号将抑制打印 Jupyter Notebook 单元格最后一行的输出。这样,Jupyter Notebook 不会打印<code>None</code>列表。)</p>
<h3 id="9--单行-if-语句">#9 — 单行 if 语句</h3>
<p>除了前面的技巧,单行 if 可以帮助你使代码更简洁。</p>
<p>假设我们决定我们有兴趣识别植物是否为兰花。使用单行 if,我们从测试条件为真时我们希望输出的值开始。</p>
<p>这段代码将单行 if 与列表推导结合,用于在植物是兰花时输出 1,否则输出 0。</p>
<pre><code class="language-py">[1 if 'orchid' in plant else 0 for plant in greenhouse]
</code></pre>
<p>将输出:</p>
<pre><code class="language-py">[1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0]
</code></pre>
<p>这个列表本身可能不那么有趣,但与下一个提示结合使用时,我们将看到单行 if 的实际应用。</p>
<h3 id="8--将-lambda-应用到数据框列">#8 — 将 lambda 应用到数据框列</h3>
<p>Pandas 数据框是一个可以存储表格数据的结构,类似于 Python 中的 Excel。 <code>[lambda](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.apply.html)</code> 是一个关键字,它提供了对表格中值执行操作的快捷方式。</p>
<p>假设我们有一个关于我们温室植物的信息表:</p>
<p>打印这个数据框将显示如下内容:</p>
<p><img src="https://kdn.flygon.net/docs/img/a982949fc7ad6d5bfff5ec78ee0e8cd8.png" alt="帖子图片" loading="lazy"></p>
<p>假设我们想知道某种植物是否喜欢某位德国古典作曲家。</p>
<pre><code class="language-py">data[‘music’].apply(lambda x: 1 if x == ‘bach’ else 0)
</code></pre>
<p>将输出:</p>
<p><img src="https://kdn.flygon.net/docs/img/dbc32c3e80ae972422484e9c406bc9ae.png" alt="帖子图片" loading="lazy"></p>
<p>其中第一列是数据框索引,第二列是表示单行 if 输出的系列。</p>
<p><code>lambda</code> 代表一个 “<a href="https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.apply.html" target="_blank">匿名函数</a>” 。它允许我们在数据框中的值上执行操作,而无需创建正式的函数——即,包含 <code>def</code> 和 <code>return</code> 语句的函数,稍后我们将看到。</p>
<h3 id="7-将条件应用于多个列">#7— 将条件应用于多个列</h3>
<p>假设我们想要识别哪些喜欢巴赫的植物也需要充足的阳光,这样我们可以将它们一起安排在温室中。</p>
<p>首先,我们使用 <code>def</code> 关键字创建一个函数,并给它一个用下划线连接单词的名称(例如 sunny_shelf)。恰当地,这种命名约定被称为 <a href="https://www.python.org/dev/peps/pep-0008/#function-and-variable-names" target="_blank">蛇形命名法</a> ????</p>
<p>函数 sunny_shelf 接受两个参数作为输入——检查“充足阳光”的列和检查“巴赫”的列。该函数输出这两个条件是否都为真。</p>
<p>在第 4 行,我们对数据框应用了 <a href="https://chrisalbon.com/python/data_wrangling/pandas_apply_operations_to_dataframes/" target="_blank">.apply()</a> 函数,并指定了应作为参数传递的列。 <code>axis=1</code> 告诉 pandas 应该在列上评估该函数(而不是 <code>axis=0</code>,它在行上进行评估)。我们将 .apply() 函数的输出分配给一个名为‘new_shelf’的新数据框列。</p>
<p>或者,我们可以使用 <a href="https://numpy.org/doc/stable/reference/generated/numpy.where.html" target="_blank">np.where()</a> 函数达到相同的目的:</p>
<p>这个 <a href="https://numpy.org/doc/stable/reference/generated/numpy.where.html" target="_blank">来自 numpy 库的函数</a> 检查上述指定的两个条件(即植物是否喜欢充足的阳光和德式古典音乐),并将结果分配给‘new_shelf’列。</p>
<p><em>有关</em><a href="https://chrisalbon.com/python/data_wrangling/pandas_apply_operations_to_dataframes/" target="_blank"><em>.apply()</em></a><em>、</em><a href="https://chrisalbon.com/python/data_wrangling/pandas_create_column_using_conditional/" target="_blank"><em>np.where()</em></a><em>以及其他极其有用的代码片段,请查看</em><a href="https://chrisalbon.com/" target="_blank"><em>Chris Albon 的博客</em></a><em>。</em></p>
<h3 id="6-拆分长代码行">#6— 拆分长代码行</h3>
<p>顺便说一下,你可以将括号、方括号或大括号内的任何语句拆分到多行,以避免单行过长。我们在初始化温室列表、创建植物数据框和使用 np.where()函数时见过这种情况。</p>
<p>根据<a href="https://www.python.org/dev/peps/pep-0008/#maximum-line-length" target="_blank">PEP8</a> Python 风格指南:</p>
<blockquote>
<p>包装长行的首选方式是使用 Python 在括号、方括号和大括号中的隐式行续接。</p>
</blockquote>
<h3 id="5--读取csv-并设置索引">#5 — 读取.csv 并设置索引</h3>
<p>现在让我们扩展温室,以便有更多实际数据可用。我们将通过导入一个包含植物数据的.csv 来实现。<a href="https://docs.google.com/spreadsheets/d/14DTM1iEJtRBNDpayc3P-qUY0Bo2O1SVxxdi96dJmaXk/edit?usp=sharing" target="_blank">通过访问此数据集进行跟踪</a>。</p>
<p>假设表中包含一个唯一的植物标识符,我们希望将其用作 DataFrame 中的索引。我们可以使用 index_col 参数来设置。</p>
<pre><code class="language-py">data = pd.read_csv('greenhouse.csv', index_col='plant_id')
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/2157af16fe911a6deb834b7c8c4305fc.png" alt="Image for post" loading="lazy"></p>
<p><em>有关探索性数据分析(EDA)的基础知识及其他 9 个有用的 Python 技巧,请查看这篇文章:</em></p>
<p><a href="https://towardsdatascience.com/10-underrated-python-skills-dfdff5741fdf" target="_blank"><strong>10 个被低估的 Python 技能</strong></a></p>
<p>提升你的数据科学技能,运用这些技巧改进 Python 编码,提升 EDA、目标分析、特征…</p>
<h3 id="4-格式化为货币">#4— 格式化为货币</h3>
<p>我们到底在这些植物上花了多少钱?让我们将此计算的输出格式化为货币。</p>
<pre><code class="language-py">‘${:,.2f}’.format(data[‘price’].sum())
</code></pre>
<p>将输出:</p>
<pre><code class="language-py">'$15,883.66'
</code></pre>
<p>逗号分隔符使我们能够轻松查看到目前为止花费了多少现金。</p>
<h3 id="3--创建透视表">#3 — 创建透视表</h3>
<p>接下来,假设我们想查看每种植物的花费。我们可以使用<a href="https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.pivot_table.html" target="_blank">pd.pivot_table()</a>或<a href="https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.groupby.html" target="_blank">.groupby()</a>进行聚合透视。</p>
<pre><code class="language-py">pd.pivot_table(data, index=’plant’, values=’price’, aggfunc=np.sum)
</code></pre>
<p>或</p>
<pre><code class="language-py">data[[‘plant’,’price’]].groupby(by=’plant’).sum()
</code></pre>
<p>无论哪种方法都将输出以下内容:</p>
<p><img src="https://kdn.flygon.net/docs/img/cf5e611fb31f1bcb8d38f87f6012f898.png" alt="Image for post" loading="lazy"></p>
<p>我们还可以使用任何方法指定多级透视表。</p>
<p>检查<code>piv.equals(piv0)</code>会返回 True。</p>
<p>结果 DataFrame 如下所示:</p>
<p><img src="https://kdn.flygon.net/docs/img/91b468e39116151aa4717c030a776c21.png" alt="Image for post" loading="lazy"></p>
<h3 id="2-计算总百分比">#2— 计算总百分比</h3>
<p>想知道每种植物对温室总成本的贡献吗?将每个值除以所有行的总和,并将该结果分配给一个名为‘perc’的新列:</p>
<pre><code class="language-py">piv['perc'] = piv['price'].div(piv['price'].sum(axis=0))
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/edd7bf84823eb44cf98942f40d67b2d1.png" alt="Image for post" loading="lazy"></p>
<h3 id="1--按多个列排序">#1 — 按多个列排序</h3>
<p>最后,让我们对 DataFrame 进行排序,使兰花排在顶部,植物按价格降序排列。</p>
<pre><code class="language-py">piv.sort_values([‘orchid’,’price’], ascending=False)
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/2d57a1d43fffb464e49eebd69eb27617.png" alt="帖子图片" loading="lazy"></p>
<h3 id="摘要-1">摘要</h3>
<p>在这篇文章中,我们介绍了 10 种对初学者数据科学家可能有用的 Python 技能。这些技巧包括:</p>
<ul>
<li>
<p><a href="https://towardsdatascience.com/10-python-skills-beginners-3066305f0d3c#f070" target="_blank">列表推导 (#10)</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/10-python-skills-beginners-3066305f0d3c#e7ec" target="_blank">单行 if 语句 (#9)</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/10-python-skills-beginners-3066305f0d3c#8169" target="_blank">对 DataFrame 列应用 lambda (#8)</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/10-python-skills-beginners-3066305f0d3c#52d6" target="_blank">对多个列应用条件 (#7)</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/10-python-skills-beginners-3066305f0d3c#2f45" target="_blank">拆分长代码行 (#6)</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/10-python-skills-beginners-3066305f0d3c#cad2" target="_blank">读取.csv 并设置索引 (#5)</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/10-python-skills-beginners-3066305f0d3c#12e9" target="_blank">格式化为货币 (#4)</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/10-python-skills-beginners-3066305f0d3c#727c" target="_blank">创建透视表 (#3)</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/10-python-skills-beginners-3066305f0d3c#d991" target="_blank">计算总数的百分比 (#2)</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/10-python-skills-beginners-3066305f0d3c#69c2" target="_blank">按多个列排序</a> (#1)</p>
</li>
</ul>
<p><a href="https://colab.research.google.com/drive/1K2oWzxzYbura4VqrntsZimnWqQex_c38?usp=sharing" target="_blank">在这里访问 <strong>Colab 笔记本</strong></a>,并 <a href="https://docs.google.com/spreadsheets/d/14DTM1iEJtRBNDpayc3P-qUY0Bo2O1SVxxdi96dJmaXk/edit?usp=sharing" target="_blank">在这里访问 <strong>温室数据集</strong></a>。</p>
<p>我希望这篇文章能帮助你作为新数据科学家提升技能。感谢让我在一篇文章中分享我最喜欢的两个事物——Python 和园艺。</p>
<p><strong>如果你喜欢这个故事</strong>,请查看 <a href="https://towardsdatascience.com/10-underrated-python-skills-dfdff5741fdf" target="_blank"><strong>10 个被低估的 Python 技能</strong></a> 和 <a href="https://towardsdatascience.com/10-python-skills-419e5e4c4d66" target="_blank"><strong>10 个在培训班上未教的 Python 技能</strong></a>。关注我在 <a href="https://medium.com/@nicolejaneway" target="_blank">Medium</a>, <a href="http://www.linkedin.com/in/nicole-janeway-bills" target="_blank">LinkedIn</a>, <a href="https://www.youtube.com/channel/UCO6JE24WY82TKabcGI8mA0Q?view_as=subscriber" target="_blank">YouTube</a> 和 <a href="https://twitter.com/Nicole_Janeway" target="_blank">Twitter</a>上的更多数据科学技能提升创意。</p>
<h3 id="更多数据科学家的优秀资源">更多数据科学家的优秀资源</h3>
<p><a href="https://towardsdatascience.com/best-data-science-certification-4f221ac3dbe3" target="_blank"><strong>你从未听说过的最佳数据科学认证</strong></a></p>
<p>实用的数据策略培训指南。</p>
<p><a href="https://towardsdatascience.com/must-read-data-science-papers-487cce9a2020" target="_blank"><strong>5 篇必读的数据科学论文(及其使用方法)</strong></a></p>
<p>基础思想,帮助你在数据科学领域保持领先。</p>
<p><a href="https://towardsdatascience.com/data-analyst-vs-data-scientist-2534fc1057c3" target="_blank"><strong>数据分析师、数据科学家和机器学习工程师之间的区别是什么?</strong></a></p>
<p>通过赛跑比赛的类比来探讨这些常见职位名称之间的区别。</p>
<p><a href="https://towardsdatascience.com/model-selection-and-deployment-cf754459f7ca" target="_blank"><strong>如何让你的数据科学项目具备未来适应性</strong></a></p>
<p>机器学习模型选择与部署的 5 个关键要素</p>
<p><a href="https://towardsdatascience.com/data-science-planning-c0649c52f867" target="_blank"><strong>你的机器学习模型可能会失败吗?</strong></a></p>
<p>规划过程中需要避免的 5 个失误</p>
<p><strong>个人简介: <a href="http://www.linkedin.com/in/nicole-janeway-bills" target="_blank">妮可·贾纳威·比尔斯</a></strong> 是一名拥有商业和联邦咨询经验的机器学习工程师。妮可精通 Python、SQL 和 Tableau,在自然语言处理(NLP)、云计算、统计测试、定价分析和 ETL 过程方面有业务经验,旨在利用这些背景将数据与业务成果连接起来,并继续发展技术技能。</p>
<p><a href="https://towardsdatascience.com/10-python-skills-beginners-3066305f0d3c" target="_blank">原文</a>。经许可转载。</p>
<p><strong>相关内容:</strong></p>
<ul>
<li>
<p>10 个被低估的 Python 技能</p>
</li>
<li>
<p>6 个月数据科学家的 6 条经验教训</p>
</li>
<li>
<p>fastcore:一个被低估的 Python 库</p>
</li>
</ul>
<h3 id="更多相关主题-15">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/09/7-tips-python-beginners.html" target="_blank">7 个 Python 初学者的技巧</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/11/7-python-projects-beginners.html" target="_blank">7 个适合初学者的 Python 项目</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/how-to-write-efficient-python-code-a-tutorial-for-beginners" target="_blank">如何编写高效的 Python 代码:初学者教程</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/convert-python-dict-to-json-a-tutorial-for-beginners" target="_blank">将 Python 字典转换为 JSON:初学者教程</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/5-free-python-courses-for-data-science-beginners" target="_blank">5 个适合数据科学初学者的免费 Python 课程</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/convert-bytes-to-string-in-python-a-tutorial-for-beginners" target="_blank">将字节转换为字符串的 Python 教程:初学者指南</a></p>
</li>
</ul>
<h1 id="10-个-python-技能训练营中不会教你">10 个 Python 技能,训练营中不会教你</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2020/12/10-python-skills-dont-teach-bootcamp.html" target="_blank"><code>www.kdnuggets.com/2020/12/10-python-skills-dont-teach-bootcamp.html</code></a></p>
</blockquote>
<p>评论<img src="https://kdn.flygon.net/docs/img/3d7f5b23b52139faf90e6068dd2fd7cb.png" alt="图像" loading="lazy"></p>
<p>图片由<em><a href="https://www.pexels.com/@sandy-torchon-2229511?utm_content=attributionCopyText&utm_medium=referral&utm_source=pexels" target="_blank">Sandy Torchon*</a> 在</em><a href="https://www.pexels.com/photo/people-riding-the-roller-coaster-3973555/?utm_content=attributionCopyText&utm_medium=referral&utm_source=pexels" target="_blank">Pexels*</a>上拍摄</p>
<p>数据科学训练营非常有趣,但他们没有时间教你所有的内容。</p>
<p>编程训练营的经历就像是去游乐园(虽然那里的一些陌生人可能会成为你的好朋友)。当过山车启动时,它要求你全神贯注。在一阵阵的紧张间隙中,你将有机会喘口气——交流故事、推荐和想法。</p>
<p>通过这 10 个 Python 技能,重新体验学习新事物的兴奋感,这些技能在训练营中不会教你。</p>
<h3 id="10--设置-dataframe-显示选项">#10 — 设置 DataFrame 显示选项</h3>
<p>在 Jupyter Notebook 中更改 pandas DataFrames 的显示方式非常简单。我通常将这段代码包含在与我的导入语句相同的单元格中:</p>
<p>使用这些设置,我可以完全读取可能包含大量文本的单元格。我不必担心过长的数据框,但可以随心所欲地左右滚动。</p>
<p>玩转这些选项,找到适合你的设置。更多信息,你可以查看 pandas 文档中的这一部分<a href="https://pandas.pydata.org/pandas-docs/stable/user_guide/options.html" target="_blank">这里</a>。</p>
<h3 id="9--更改-pandas-显示数字的方式">#9 — 更改 pandas 显示数字的方式</h3>
<p>如果你想更改 DataFrames 中数字的显示方式,可以使用这些方便的选项来舍入尾随的小数。</p>
<pre><code class="language-py">pd.set_option(‘precision’, 2) # Round to two decimal points
</code></pre>
<p>第二个选项还提供了在较大的数字之间使用逗号分隔符的功能:</p>
<pre><code class="language-py">pd.options.display.float_format = ‘{:,.2f}’.format
</code></pre>
<h3 id="8--导入-excel-工作簿并附加表单名称">#8 — 导入 Excel 工作簿并附加表单名称</h3>
<p>如果你正在读取一个包含多个表单的工作簿,可以使用以下方法将它们全部导入一个数据框:</p>
<pre><code class="language-py">df = pd.concat(pd.read_excel('Ticket_Sales_Total.xlsx', sheet_name=**None**), ignore_index=**True**)
</code></pre>
<p><a href="https://pbpython.com/pandas-excel-tabs.html" target="_blank">这个技巧有效</a>,当你的数据使用相同的表头且没有其他信息可以从表单名称中获得时。</p>
<p>另外,如果你想读取表单并保留一些来自表单名称的信息,可以使用下面的函数。</p>
<p>在第 15 行,pandas 创建了一个新列(‘sheet’),其值为表单名称的最后一个单词。如果 Ticket_Sales_Total.xlsx 中的表单名称为 <em>Ticket Sales 2017</em>、<em>Ticket Sales 2018</em> 和 <em>Ticket Sales 2019</em>,那么 read_excel_sheets() 函数将为每一行附加来自表单名称的相关年份。</p>
<p><em>感谢</em><a href="https://www.caktusgroup.com/blog/2019/08/13/import-multiple-excel-sheets-pandas/" target="_blank"><em>Colin Copland</em></a><em>的这个小提示!</em></p>
<h3 id="7--检查-pandas-行的随机选择">#7 — 检查 pandas 行的随机选择</h3>
<p>与其仅查看 dataframe 的 <code>.head()</code> 或 <code>.tail()</code>,你可以通过以下方式查看随机行的选择:</p>
<pre><code class="language-py">df.sample(n)
</code></pre>
<p>这很有用,因为在一个排序的数据框中,异常记录可能会出现在头部或尾部,从而导致在 <a href="https://towardsdatascience.com/10-underrated-python-skills-dfdff5741fdf" target="_blank">进行探索性数据分析(EDA)</a> 时产生扭曲的视角。</p>
<p>关于 pandas 的示例项目,请查看:</p>
<p><a href="https://medium.com/atlas-research/ner-for-clinical-text-7c73caddd180" target="_blank"><strong>临床文本中的命名实体识别</strong></a></p>
<p>使用 pandas 将 2011 年的 i2b2 数据集重新格式化为 CoNLL 格式,以用于自然语言处理(NLP)。</p>
<h3 id="第-6-步--利用预测力评分代替相关性">第 6 步 — 利用预测力评分代替相关性</h3>
<p><a href="https://github.com/8080labs/ppscore" target="_blank">预测力评分</a> 是由 <a href="https://medium.com/u/6ed760f28120?source=post_page-----419e5e4c4d66--------------------------------" target="_blank">弗洛里安·维茨霍雷克</a> 和 <a href="https://8080labs.com/" target="_blank">8080 Labs</a> 团队开发的,目的是改进相关性度量。</p>
<p><strong>相关性有限</strong>,因为它会忽略 <em>非线性</em> 关系(例如,绘制每日温度和主题公园门票销售的二次关系图,或表示游乐设施票价与排队人数的阶跃函数,或者在“猜测你的体重”嘉年华游戏中使用的高斯函数)。任何与 <em>分类</em> 变量相关的关系也会被相关性矩阵遗漏。</p>
<p>此外,相关性缺乏提供关系 <em>不对称性</em> 信息的能力。例如,知道一个顾客最喜欢的公园部分可能不能预测他们最喜欢的游乐设施,但知道他们最喜欢的游乐设施会更强地预测他们最喜欢的公园部分。</p>
<p>相比之下,预测力评分可以检测非线性效应,自动编码分类变量,并量化不对称性。它计算列对之间的预测关系,并提供从 0 到 1 的评分。</p>
<p>使用方法,只需 <code>import ppscore as pps</code> 并调用 <code>pps.matrix(df)</code>。</p>
<p><a href="https://towardsdatascience.com/best-data-science-certification-4f221ac3dbe3" target="_blank"><strong>你从未听说过的最佳数据科学认证</strong></a></p>
<p>关于数据战略中最有价值的培训的实用指南。</p>
<h3 id="-第-5-步--创建一个包"># 第 5 步 — 创建一个包</h3>
<p>模块有助于将可重用的代码,如 Python 函数、变量和类进行模块化。以这种方式进行组织可以使代码更易于理解和使用。</p>
<blockquote>
<p>对我来说,这是数据科学家提高生产力的最大助力。它使你能够更快地工作,减少错误。而且,通过编写包,你还可以提升你的编码技能。— <a href="https://medium.com/u/4953633c3102?source=post_page-----419e5e4c4d66--------------------------------" target="_blank">亚当·沃塔瓦</a></p>
</blockquote>
<p>一个包将包含一个或多个相关模块。我们可以创建一个名为 mythemepark 的包,步骤如下:</p>
<p>第一步 — 创建一个名为 MyThemePark 的新文件夹。</p>
<p>第 2 步——在 MyThemepark 内部创建一个名为 mythemepark 的子文件夹。</p>
<p>第 3 步——使用像<a href="https://atom.io/" target="_blank">atom</a>这样的 Python IDE,创建模块 greet_visitors.py(用于提供欢迎游客进入公园的代码)、functions.py(提供操作各种游乐设施和游戏的代码)和 classes.py(提供可以实例化新对象(如娱乐设施、商店、促销等)的模板)。</p>
<p>备注:</p>
<ul>
<li>
<p>确保你使用这些<a href="https://www.python.org/dev/peps/pep-0008/#package-and-module-names" target="_blank">PEP8 包和模块命名约定</a>。</p>
</li>
<li>
<p>包曾经需要有一个 <strong>init</strong>.py 文件,但随着<a href="https://www.python.org/dev/peps/pep-0420/#rationale" target="_blank">命名空间包</a>的引入,现在不再需要这样做。</p>
</li>
</ul>
<h3 id="4-检查包的大小">#4— 检查包的大小</h3>
<p>在 pip 安装了运行主题公园所需的所有依赖项后,你的 SSD 可能会有些混乱。检查已安装包的大小将帮助你了解哪些包占用最多空间。然后,你可以决定哪些包“带来快乐”,并适当进行<a href="https://konmari.com/" target="_blank">KonMari</a>整理。</p>
<p>要找到 Linux 机器上已安装包的路径,请输入:</p>
<pre><code class="language-py">pip3 show "some_package" | grep "Location:"
</code></pre>
<p>这将返回 path/to/all/packages。类似于:/Users/yourname/opt/anaconda3/lib/python3.7/site-packages</p>
<p>将该文件路径插入到以下命令中:</p>
<pre><code class="language-py">du -h path/to/all/packages
</code></pre>
<p>其中<code>du</code>报告文件系统的磁盘空间使用情况。</p>
<p>这段代码将输出每个包的大小。最后一行输出将包含所有包的总大小。</p>
<p><a href="https://towardsdatascience.com/10-underrated-python-skills-dfdff5741fdf" target="_blank"><strong>10 个被低估的 Python 技能</strong></a></p>
<p>使用这些技巧提升你的数据科学技能,以改善 Python 编码以进行更好的 EDA、目标分析、特征…</p>
<h3 id="3--检查内存使用">#3 — 检查内存使用</h3>
<p>如同优化工作空间一样,检查<a href="https://stackoverflow.com/questions/40993626/list-memory-usage-in-ipython-and-jupyter" target="_blank">代码组件的内存使用</a>也可能很有用。你可以使用 Python 的<a href="https://docs.python.org/3/library/sys.html#sys.getsizeof" target="_blank">sys.getsizeof</a>方法,通过实现以下代码来做到这一点:</p>
<h3 id="2-提升你的命令行工具">#2— 提升你的命令行工具</h3>
<p><a href="https://click.palletsprojects.com/en/7.x/" target="_blank">Click</a>是一个 Python 命令行工具,使你能够为 bash shell 创建直观的程序和接口。Click 支持选项对话框、用户提示、确认请求、环境变量值等。</p>
<p>这是一个示例脚本,用于向游乐设施操作员请求密码:</p>
<p>将输出:</p>
<pre><code class="language-py">$ encrypt
Password:
Repeat for confirmation:
</code></pre>
<h3 id="1--检查所有内容是否符合-pep8-规范">#1 — 检查所有内容是否符合 PEP8 规范</h3>
<p><a href="https://github.com/alexandercbooth/nblint" target="_blank">nblint 包</a>允许你在 Jupyter Notebook 中运行 pycodestyle 引擎。这将检查你的代码(即代码规范检查)使用 pycodestyle 引擎。</p>
<p>Linting 突出显示你 Python 代码中的任何语法或风格问题,使其更不容易出错,并且对你的同事更具可读性。Linting 工具最早由 1978 年的沮丧调试者引入,这个做法确实得名于从干衣机中取出的衣物上去除小块杂布的行为。</p>
<h3 id="附加清理-conda-缓存">附加:清理 conda 缓存</h3>
<p>首先,简要说明一下<code>pip</code>和<code>conda</code>之间的区别。 <a href="https://pip.pypa.io/en/stable/" target="_blank">pip</a> 是 Python 包装权威机构推荐的用于从 Python 包索引 <a href="https://pypi.org/" target="_blank">PyPI</a> 安装软件包的工具。 <a href="https://conda.io/docs/" target="_blank">conda</a> 是来自 <a href="https://repo.anaconda.com/" target="_blank">Anaconda</a> 的跨平台包和环境管理器。</p>
<p>一般来说,混合使用 pip 和 conda 包管理器是不明智的。这是因为这两个管理器之间没有沟通——这可能会导致软件包冲突。考虑在虚拟环境中专门使用 pip <a href="https://towardsdatascience.com/10-underrated-python-skills-dfdff5741fdf" target="_blank">除非你准备好使用 conda</a>。</p>
<p>我们已经介绍了如何清理你用 pip 安装的软件包——这里是移除 conda 安装的软件包的说明。如果你一直在使用 conda 包管理器,你可以通过使用以下代码来释放空间:</p>
<pre><code class="language-py">conda clean --all
</code></pre>
<h3 id="总结-6">总结</h3>
<p>再次回顾一下我们在本文中涵盖的十个提示:</p>
<ul>
<li>
<p><a href="https://towardsdatascience.com/10-python-skills-419e5e4c4d66#9907" target="_blank">设置 DataFrame 显示选项 (#10)</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/10-python-skills-419e5e4c4d66#c5b0" target="_blank">更改 pandas 显示数字的方式 (#9)</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/10-python-skills-419e5e4c4d66#1282" target="_blank">导入 Excel 工作簿并附加工作表名称 (#8)</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/10-python-skills-419e5e4c4d66#3346" target="_blank">检查熊猫行的随机选择 (#7)</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/10-python-skills-419e5e4c4d66#c2df" target="_blank">利用预测能力分数代替相关性 (#6)</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/10-python-skills-419e5e4c4d66#fb56" target="_blank">创建一个软件包 (#5)</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/10-python-skills-419e5e4c4d66#531b" target="_blank">检查软件包的大小 (#4)</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/10-python-skills-419e5e4c4d66#5407" target="_blank">检查内存使用 (#3)</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/10-python-skills-419e5e4c4d66#35ba" target="_blank">提升你的命令行工具 (#2)</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/10-python-skills-419e5e4c4d66#4ec5" target="_blank">检查所有内容是否符合 PEP8 (#1)</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/10-python-skills-419e5e4c4d66#9d53" target="_blank">清理 conda 缓存</a></p>
</li>
</ul>
<p><strong>如果你喜欢这篇文章</strong>,请在 <a href="https://medium.com/@nicolejaneway" target="_blank">Medium</a>、 <a href="http://www.linkedin.com/in/nicole-janeway-bills" target="_blank">LinkedIn</a>、 <a href="https://www.youtube.com/channel/UCO6JE24WY82TKabcGI8mA0Q?view_as=subscriber" target="_blank">YouTube</a> 和 <a href="https://twitter.com/Nicole_Janeway" target="_blank">Twitter</a> 上关注我,以获取更多提升数据科学技能的想法。</p>
<h3 id="继续提升你的技能">继续提升你的技能</h3>
<p><a href="https://towardsdatascience.com/10-python-skills-beginners-3066305f0d3c" target="_blank"><strong>10 个适合初学者的 Python 技能</strong></a></p>
<p>Python 是增长最快、最受喜爱的编程语言。通过这些数据科学技巧入门。</p>
<p><a href="https://towardsdatascience.com/10-underrated-python-skills-dfdff5741fdf" target="_blank"><strong>10 个被低估的 Python 技能</strong></a></p>
<p>通过这些技巧提升你的数据科学技能,改进你的 Python 编码以优化 EDA、目标分析、特征…</p>
<p><a href="https://nicolejaneway.medium.com/how-to-ace-the-aws-cloud-practitioner-certification-with-minimal-effort-39f10f43146" target="_blank"><strong>如何以最小的努力通过 AWS Cloud Practitioner 认证</strong></a></p>
<p>预测:阴天,100% 可能第一次尝试就通过。</p>
<p><a href="https://towardsdatascience.com/model-selection-and-deployment-cf754459f7ca" target="_blank"><strong>如何使你的数据科学项目具有未来适应性</strong></a></p>
<p>5 个关键的 ML 模型选择和部署元素</p>
<p><a href="https://towardsdatascience.com/walkthrough-mapping-gis-data-in-python-92c77cd2b87a" target="_blank"><strong>逐步指南:在 Python 中映射 GIS 数据</strong></a></p>
<p>通过 GeoPandas DataFrames 和 Google Colab 提高你对地理空间信息的理解</p>
<p><strong>简介: <a href="http://www.linkedin.com/in/nicole-janeway-bills" target="_blank">尼科尔·詹纳威·比尔斯</a></strong> 是一位拥有商业和联邦咨询经验的机器学习工程师。精通 Python、SQL 和 Tableau,尼科尔在自然语言处理(NLP)、云计算、统计测试、定价分析和 ETL 过程方面具有商业经验,并旨在利用这些背景将数据与业务成果联系起来,并继续发展技术技能。</p>
<p><a href="https://towardsdatascience.com/10-python-skills-419e5e4c4d66" target="_blank">原始</a>。已获转载许可。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p>10 个适合初学者的 Python 技能</p>
</li>
<li>
<p>10 个被低估的 Python 技能</p>
</li>
<li>
<p>你从未听说过的最佳数据科学认证</p>
</li>
</ul>
<hr>
<h2 id="我们的前三大课程推荐-15">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织的 IT</p>
<hr>
<h3 id="更多相关内容-19">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/large-language-models-work.html" target="_blank">大型语言模型是什么?它们如何工作?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/foundation-models-work.html" target="_blank">基础模型是什么?它们如何工作?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/06/vector-databases-important-llms.html" target="_blank">向量数据库是什么?它们为何对 LLMs 重要?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/your-features-are-important-it-doesnt-mean-they-are-good" target="_blank">你的特性重要吗?这并不意味着它们是好的</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/09/best-data-science-bootcamp-degree-online-course.html" target="_blank">哪个更好:数据科学训练营 vs 学位 vs 在线课程</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/06/free-full-stack-llm-bootcamp.html" target="_blank">免费全栈 LLM 训练营</a></p>
</li>
</ul>
<h1 id="10-个-python-统计函数">10 个 Python 统计函数</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/10-python-statistical-functions" target="_blank"><code>www.kdnuggets.com/10-python-statistical-functions</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/dbee76aec2f97bf997f9faf6e6be977d.png" alt="10 Python 统计函数" loading="lazy"></p>
<p>图片由 <a href="https://www.freepik.com/free-photo/top-view-office-desk-with-growth-chart-glasses_11383330.htm#fromView=search&page=1&position=24&uuid=a78a7cd4-2cc8-4097-878b-62664fe9c5e1" target="_blank">freepik</a> 提供</p>
<p>统计函数是从原始数据中提取有意义洞察的基石。Python 为统计学家和数据科学家提供了强大的工具包,用于理解和分析数据集。像 NumPy、Pandas 和 SciPy 这样的库提供了全面的函数套件。本指南将深入探讨这三个库中 10 个必备的统计函数。</p>
<hr>
<h2 id="我们的前三个课程推荐-20">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升您的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持您的组织的 IT 需求</p>
<hr>
<h2 id="统计分析库">统计分析库</h2>
<p>Python 提供了许多专门用于统计分析的库。其中三个最广泛使用的是 NumPy、Pandas 和 SciPy stats。</p>
<ul>
<li>
<p><strong>NumPy:</strong> 是 Numerical Python 的缩写,这个库提供了对数组、矩阵以及各种数学函数的支持。</p>
</li>
<li>
<p><strong>Pandas:</strong> Pandas 是一个数据操作和分析库,适用于处理表格和时间序列数据。它建立在 NumPy 之上,并添加了数据操作的额外功能。</p>
</li>
<li>
<p><strong>SciPy stats:</strong> 是 Scientific Python 的缩写,这个库用于科学和技术计算。它提供了大量的概率分布、统计函数和假设检验。</p>
</li>
</ul>
<p>Python 库在使用之前必须下载并导入到工作环境中。要安装库,请使用终端和 pip install 命令。安装完成后,可以通过 import 语句将其加载到 Python 脚本或 Jupyter notebook 中。NumPy 通常导入为 <code>np</code>,Pandas 导入为 <code>pd</code>,通常只从 SciPy 中导入 stats 模块。</p>
<pre><code class="language-py">pip install numpy
pip install pandas
pip install scipy
import numpy as np
import pandas as pd
from scipy import stats
</code></pre>
<p>在使用多个库可以计算不同函数的情况下,将显示每个库的示例代码。</p>
<h2 id="1-均值平均数">1. 均值(平均数)</h2>
<p>均值,也称为平均数,是最基本的统计测量。它提供了一组数字的中心值。从数学上讲,它是所有值的总和除以值的数量。</p>
<pre><code class="language-py">mean_numpy = np.mean(data)
mean_pandas = pd.Series(data).mean()
</code></pre>
<h2 id="2-中位数">2. 中位数</h2>
<p>中位数是另一种集中趋势的度量。它通过报告将所有值按顺序排列后数据集中的中间值来计算。与均值不同,它不受离群值的影响。这使得它在偏斜分布中成为一种更稳健的度量。</p>
<pre><code class="language-py">median_numpy = np.median(data)
median_pandas = pd.Series(data).median()
</code></pre>
<h2 id="3-标准差">3. 标准差</h2>
<p>标准差是衡量一组值的变异程度或离散程度的指标。它通过每个数据点与均值之间的差异来计算。较低的标准差表示数据集中的值趋向于接近均值,而较大的标准差表示值分布较为分散。</p>
<pre><code class="language-py">std_numpy = np.std(data)
std_pandas = pd.Series(data).std()
</code></pre>
<h2 id="4-百分位数">4. 百分位数</h2>
<p>百分位数表示值在数据集中相对的排名,当所有数据按顺序排列时。例如,第 25 百分位数是低于 25%数据的值。中位数从技术上定义为第 50 百分位数。</p>
<p>百分位数是使用 NumPy 库计算的,必须在函数中包含感兴趣的具体百分位数。在示例中计算了第 25、第 50 和第 75 百分位数,但从 0 到 100 的任何百分位数值都是有效的。</p>
<pre><code class="language-py">percentiles = np.percentile(data, [25, 50, 75])
</code></pre>
<h2 id="5-相关性">5. 相关性</h2>
<p>两个变量之间的相关性描述了它们关系的强度和方向。这是指一个变量在另一个变量变化时发生变化的程度。相关系数的范围是-1 到 1,其中-1 表示完全负相关,1 表示完全正相关,0 表示变量之间没有线性关系。</p>
<pre><code class="language-py">corr_numpy = np.corrcoef(x, y)
corr_pandas = pd.Series(x).corr(pd.Series(y))
</code></pre>
<h2 id="6-协方差">6. 协方差</h2>
<p>协方差是一个统计度量,表示两个变量共同变化的程度。它不像相关性那样提供关系的强度,但提供了变量之间关系的方向。它也是许多统计方法的关键,这些方法研究变量之间的关系,例如主成分分析。</p>
<pre><code class="language-py">cov_numpy = np.cov(x, y)
cov_pandas = pd.Series(x).cov(pd.Series(y))
</code></pre>
<h2 id="7-偏度">7. 偏度</h2>
<p>偏度衡量连续变量分布的非对称性。零偏度表示数据对称分布,例如正态分布。偏度有助于识别数据集中的潜在离群值,且建立对称性是某些统计方法和变换的要求。</p>
<pre><code class="language-py">skew_scipy = stats.skew(data)
skew_pandas = pd.Series(data).skew()
</code></pre>
<h2 id="8-峰度">8. 峰度</h2>
<p>偏度常与峰度一起使用,峰度描述了分布的尾部相对于正态分布的面积多少。它用于指示离群值的存在,并描述分布的整体形状,例如是否高度尖锐(称为尖峰型)或更为平坦(称为平峰型)。</p>
<pre><code class="language-py">kurt_scipy = stats.kurtosis(data)
kurt_pandas = pd.Series(data).kurt()
</code></pre>
<h2 id="9-t-检验">9. T 检验</h2>
<p>t 检验是一种统计检验,用于确定两组均值之间是否存在显著差异。或者,在单样本 t 检验的情况下,它可以用来确定样本的均值是否显著不同于预定的总体均值。</p>
<p>该测试使用 SciPy 库中的 stats 模块运行。测试提供了两个输出,t 统计量和 p 值。通常,如果 p 值小于 0.05,则结果被认为在统计上显著,表明两个均值彼此不同。</p>
<pre><code class="language-py">t_test, p_value = stats.ttest_ind(data1, data2)
onesamp_t_test, p_value = stats.ttest_1samp(data, popmean = 0)
</code></pre>
<h2 id="10-卡方检验">10. 卡方检验</h2>
<p>卡方检验用于确定两个分类变量之间是否存在显著的关联,例如职位和性别。该检验同样使用 SciPy 库中的 stats 模块,并需要输入观察数据和期望数据。与 t 检验类似,输出提供了卡方检验统计量和 p 值,可以与 0.05 进行比较。</p>
<pre><code class="language-py">chi_square_test, p_value = stats.chisquare(f_obs=observed, f_exp=expected)
</code></pre>
<h2 id="总结-7">总结</h2>
<p>本文重点介绍了 Python 中的 10 个关键统计函数,但在各种包中还有许多其他函数可用于更具体的应用。利用这些统计和数据分析工具,可以从数据中获得强大的洞察力。</p>
<p><a href="https://www.linkedin.com/in/mehrnazsiavoshi/" target="_blank"></a><strong><a href="https://www.linkedin.com/in/mehrnazsiavoshi/" target="_blank">Mehrnaz Siavoshi</a></strong>拥有数据分析硕士学位,是一名全职生物统计学家,专注于复杂的机器学习开发和医疗保健统计分析。她有 AI 经验,并在 People 大学教授生物统计学和机器学习课程。</p>
<h3 id="更多相关主题-16">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/10/statistical-functions-python.html" target="_blank">Python 中的统计函数</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/01/python-lambda-functions-explained.html" target="_blank">Python Lambda 函数解释</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/08/4-python-itertools-filter-functions-probably-didnt-know.html" target="_blank">你可能不知道的 4 个 Python Itertools 筛选函数</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/5-tips-for-writing-better-python-functions" target="_blank">提高 Python 函数编写质量的 5 个技巧</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/07/introduction-statistical-learning-python-edition-free-book.html" target="_blank">统计学习导论,Python 版:免费书籍</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/12/momentgenerating-functions.html" target="_blank">什么是矩生成函数?</a></p>
</li>
</ul>
<h1 id="今天你应该学习的-10-个-python-技巧和窍门">今天你应该学习的 10 个 Python 技巧和窍门</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2020/01/10-python-tips-tricks-learn-today.html" target="_blank"><code>www.kdnuggets.com/2020/01/10-python-tips-tricks-learn-today.html</code></a></p>
</blockquote>
<p>comments<img src="https://kdn.flygon.net/docs/img/1ef0f4e1d43dc885d3291909d85ff6ef.png" alt="Figure" loading="lazy"></p>
<p>照片来自<a href="https://unsplash.com/@rifqialiridho?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Rifqi Ali Ridho</a>在<a href="https://unsplash.com/s/photos/paintbrush?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Unsplash</a></p>
<p>根据 Stack Overflow 的数据,Python 是增长最快的编程语言。最新的<a href="https://www.whatech.com/development/press-release/442278-why-developers-vote-python-as-the-best-application-programming-language" target="_blank">Forbes 报告</a>指出,Python 去年增长了 456%。Netflix 使用 Python,IBM 使用 Python,还有数百家公司也使用 Python。不要忘了 Dropbox,Dropbox 也是用 Python 创建的。根据<a href="https://insights.dice.com/2016/02/01/whats-hot-and-not-in-tech-skills/" target="_blank">DICE 的研究</a>,Python 也是最热门的技能之一,并且是全球最受欢迎的编程语言之一,基于<a href="https://pypl.github.io/PYPL.html" target="_blank">编程语言流行指数</a>。</p>
<p>与其他编程语言相比,Python 提供的一些优势包括:</p>
<ol>
<li>
<p>与主要平台和操作系统兼容</p>
</li>
<li>
<p>许多开源框架和工具</p>
</li>
<li>
<p>可读性和可维护性高的代码</p>
</li>
<li>
<p>强大的标准库</p>
</li>
<li>
<p>标准的测试驱动开发</p>
</li>
</ol>
<h3 id="python-技巧和窍门">Python 技巧和窍门</h3>
<p>在这篇文章中,我将介绍 10 个有用的代码技巧和窍门,帮助你完成日常任务。所以,不再耽搁,让我们开始吧。</p>
<h3 id="1-连接字符串">1. 连接字符串</h3>
<p>当你需要连接一个字符串列表时,可以通过<em>for 循环</em>逐个添加每个元素。然而,这种方法效率非常低,尤其是当列表很长时。在 Python 中,字符串是不可变的,因此每对连接都需要将左右字符串复制到新的字符串中。</p>
<p>更好的方法是使用<code>join()</code>函数,如下所示:</p>
<pre><code class="language-py">characters = ['p', 'y', 't', 'h', 'o', 'n']
word = "".join(characters)
print(word) # python
</code></pre>
<h3 id="2-使用列表推导式">2. 使用列表推导式</h3>
<p>列表推导式用于从其他可迭代对象创建新列表。由于列表推导式返回列表,它们包含一个括号,括号内是对每个元素执行的表达式,配合<code>for</code>循环迭代每个元素。列表推导式更快,因为它经过优化,Python 解释器能在循环时识别出可预测的模式。</p>
<p>作为一个示例,让我们使用列表推导式找出前五个整数的平方。</p>
<pre><code class="language-py">m = [x ** 2 for x in range(5)]
print(m) # [0, 1, 4, 9, 16]
</code></pre>
<p>现在我们来使用列表推导式找出两个列表中的共同数字</p>
<pre><code class="language-py">list_a = [1, 2, 3, 4]
list_b = [2, 3, 4, 5]
common_num = [a for a in list_a for b in list_b if a == b]
print(common_num) # [2, 3, 4]
</code></pre>
<h3 id="3-使用enumerate迭代">3. 使用<code>enumerate()</code>迭代</h3>
<p><code>enumerate()</code>方法为可迭代对象添加计数器,并以枚举对象的形式返回。</p>
<p>让我们解决一个经典的编码面试题,广为人知的 Fizz Buzz 问题。</p>
<blockquote>
<p>编写一个程序,打印列表中的数字,对于‘3’的倍数,打印“fizz”代替数字,对于‘5’的倍数,打印“buzz”,对于 3 和 5 的倍数,打印“fizzbuzz”。</p>
</blockquote>
<pre><code class="language-py">numbers = [30, 42, 28, 50, 15]
for i, num in enumerate(numbers):
if num % 3 == 0 and num % 5 == 0:
numbers[i] = 'fizzbuzz'
elif num % 3 == 0:
numbers[i] = 'fizz'
elif num % 5 == 0:
numbers[i] = 'buzz'
print(numbers) # ['fizzbuzz', 'fizz', 28, 'buzz', 'fizzbuzz']
</code></pre>
<h3 id="4-在处理列表时使用-zip">4. 在处理列表时使用 ZIP</h3>
<p>假设你被要求将几个相同长度的列表合并并打印结果?这里有一个利用<code>zip()</code>的通用方法来获取所需结果,如下面的代码所示:</p>
<pre><code class="language-py">countries = ['France', 'Germany', 'Canada']
capitals = ['Paris', 'Berlin', 'Ottawa']
for country, capital in zip(countries,capitals):
print(country, capital) # France Paris
Germany Berlin
Canada Ottawa
</code></pre>
<h3 id="5-使用-itertools">5. 使用 itertools</h3>
<p>Python 的<code>itertools</code>模块是处理迭代器的工具集合。<code>itertools</code>有多个工具用于生成可迭代的输入数据序列。这里我将以<code>itertools.combinations()</code>为例。<code>itertools.combinations()</code>用于构建组合。这些组合也是输入值的所有可能分组。</p>
<p>让我们用一个实际的例子来说明上述观点。</p>
<blockquote>
<p>假设有四支队伍参加比赛。在联赛阶段,每支队伍都要与其他每支队伍比赛。你的任务是生成所有可能的比赛对阵。</p>
</blockquote>
<p>让我们看看下面的代码:</p>
<pre><code class="language-py">import itertools
friends = ['Team 1', 'Team 2', 'Team 3', 'Team 4']
list(itertools.combinations(friends, r=2)) # [('Team 1', 'Team 2'), ('Team 1', 'Team 3'), ('Team 1', 'Team 4'), ('Team 2', 'Team 3'), ('Team 2', 'Team 4'), ('Team 3', 'Team 4')]
</code></pre>
<p>重要的一点是,值的顺序并不重要。因为<code>('Team 1', 'Team 2')</code>和<code>('Team 2', 'Team 1')</code>表示的是相同的组合,输出列表中只会包含其中一个。类似地,我们还可以使用<code>itertools.permutations()</code>以及模块中的其他函数。作为更完整的参考,请查看<a href="https://medium.com/@jasonrigden/a-guide-to-python-itertools-82e5a306cdf8" target="_blank">这个精彩的教程</a>。</p>
<h3 id="6-使用-python-集合">6. 使用 Python 集合</h3>
<p>Python 集合是容器数据类型,包括列表、集合、元组和字典。collections 模块提供了高性能的数据类型,可以增强你的代码,使其更加简洁易懂。collections 模块提供了很多函数。为了演示,我将使用<code>Counter()</code>函数。</p>
<p><code>Counter()</code>函数接受一个可迭代对象,如列表或元组,并返回一个 Counter 字典。字典的键将是可迭代对象中存在的唯一元素,而每个键的值将是可迭代对象中该元素的计数。</p>
<p>要创建一个<code>counter</code>对象,将一个可迭代对象(列表)传递给<code>Counter()</code>函数,如下面的代码所示。</p>
<pre><code class="language-py">from collections import Countercount = Counter(['a','b','c','d','b','c','d','b'])
print(count) # Counter({'b': 3, 'c': 2, 'd': 2, 'a': 1})
</code></pre>
<p>作为更完整的参考,请查看我的<a href="https://towardsdatascience.com/a-hands-on-guide-to-python-collections-aa350cb399e3" target="_blank">python collections tutorial</a>。</p>
<h3 id="7-将两个列表转换为字典">7. 将两个列表转换为字典</h3>
<p>假设我们有两个列表,一个列表包含学生的名字,另一个列表包含他们的分数。让我们看看如何将这两个列表转换为一个字典。使用 zip 函数,可以通过下面的代码完成:</p>
<pre><code class="language-py">students = ["Peter", "Julia", "Alex"]
marks = [84, 65, 77]
dictionary = dict(zip(students, marks))
print(dictionary) # {'Peter': 84, 'Julia': 65, 'Alex': 77}
</code></pre>
<h3 id="8-使用-python-生成器">8. 使用 Python 生成器</h3>
<p>生成器函数允许你声明一个像迭代器一样工作的函数。它们允许程序员以一种快速、简单、清晰的方式创建迭代器。让我们举一个例子来解释这个概念。</p>
<blockquote>
<p>假设你需要计算前 100000000 个完美平方数的和,从 1 开始。</p>
</blockquote>
<p>看起来很简单,对吧?这可以使用列表推导式轻松完成,但问题是输入数据量很大。例如,我们来看下面的代码:</p>
<pre><code class="language-py">t1 = time.clock()
sum([i * i for i in range(1, 100000000)])
t2 = time.clock()
time_diff = t2 - t1
print(f"It took {time_diff} Secs to execute this method") # It took 13.197494000000006 Secs to execute this method
</code></pre>
<p>当我们增加需要求和的完美数字时,我们会发现由于计算时间较长,这种方法不可行。此时,Python 生成器可以派上用场。通过将方括号替换为圆括号,我们将列表推导式改为生成器表达式。现在让我们计算所需的时间:</p>
<pre><code class="language-py">t1 = time.clock()
sum((i * i for i in range(1, 100000000)))
t2 = time.clock()
time_diff = t2 - t1
print(f"It took {time_diff} Secs to execute this method") # It took 9.53867000000001 Secs to execute this method
</code></pre>
<p>正如我们所见,所需的时间已大大减少。对于更大的输入,这种效果会更加明显。</p>
<p>欲了解更全面的参考资料,请查看我的文章 <a href="https://towardsdatascience.com/reduce-memory-usage-and-make-your-python-code-faster-using-generators-bd79dbfeb4c" target="_blank">使用生成器减少内存使用并加快 Python 代码速度</a>。</p>
<h3 id="9-从函数返回多个值">9. 从函数返回多个值</h3>
<p>Python 能够从函数调用中返回多个值,这是许多其他流行编程语言所缺乏的。在这种情况下,返回值应该是一个用逗号分隔的值列表,Python 会构建一个 <em>元组</em> 并将其返回给调用者。以下代码为示例:</p>
<pre><code class="language-py">
def multiplication_division(num1, num2):
return num1*num2, num1/num2
product, division = multiplication_division(15, 3)
print("Product=", product, "Quotient =", division) # Product= 45 Quotient = 5.0
</code></pre>
<h3 id="10-使用-sorted-函数">10. 使用 <code>sorted()</code> 函数</h3>
<p>在 Python 中,使用内置方法 <code>sorted()</code> 排序任何序列非常简单,<code>sorted()</code> 会为你完成所有的繁重工作。<code>sorted()</code> 可以对任何序列(列表、元组)进行排序,并始终返回一个元素按排序顺序排列的列表。我们来看一个示例,将数字列表按升序排序。</p>
<pre><code class="language-py">sorted([3,5,2,1,4]) # [1, 2, 3, 4, 5]
</code></pre>
<p>以另一个示例为例,我们将一个字符串列表按降序排序。</p>
<pre><code class="language-py">sorted(['france', 'germany', 'canada', 'india', 'china'], reverse=True) # ['india', 'germany', 'france', 'china', 'canada']
</code></pre>
<h3 id="结论-14">结论</h3>
<p>在这篇文章中,我介绍了 10 个 Python 技巧和窍门,可以作为你日常工作的参考。希望你喜欢这篇文章。敬请关注我的下一篇文章,“加速 Python 代码的技巧与窍门”。</p>
<h3 id="参考文献进一步阅读">参考文献/进一步阅读</h3>
<p><a href="https://github.com/30-seconds/30-seconds-of-python" target="_blank">30-seconds/30-seconds-of-python</a></p>
<p>精选有用的 Python 代码片段,你可以在 30 秒或更短时间内理解。欢迎贡献…</p>
<p><a href="https://medium.com/towards-artificial-intelligence/50-python-3-tips-tricks-e5dbe05212d7" target="_blank">50+ Python 3 技巧与窍门</a></p>
<p>这些 Python 精华将使你的代码变得美观而优雅</p>
<p><a href="https://medium.com/@jasonrigden/a-guide-to-python-itertools-82e5a306cdf8" target="_blank">Python Itertools 指南</a></p>
<p>这些可迭代对象比你想象的要强大得多。</p>
<h3 id="联系方式">联系方式</h3>
<p>如果你想保持更新我的最新文章和项目,请 <a href="https://medium.com/@abhinav.sagar" target="_blank">在 Medium 上关注我</a>。以下是我的一些联系方式:</p>
<ul>
<li>
<p><a href="https://abhinavsagar.github.io/" target="_blank">个人网站</a></p>
</li>
<li>
<p><a href="https://in.linkedin.com/in/abhinavsagar4" target="_blank">Linkedin</a></p>
</li>
<li>
<p><a href="https://medium.com/@abhinav.sagar" target="_blank">Medium Profile</a></p>
</li>
<li>
<p><a href="https://github.com/abhinavsagar" target="_blank">GitHub</a></p>
</li>
<li>
<p><a href="https://www.kaggle.com/abhinavsagar" target="_blank">Kaggle</a></p>
</li>
</ul>
<p>祝阅读愉快,学习愉快,编码愉快!</p>
<p><strong>个人简介:<a href="https://www.linkedin.com/in/abhinavsagar4" target="_blank">Abhinav Sagar</a></strong> 是 VIT Vellore 的四年级本科生。他对数据科学、机器学习及其在实际问题中的应用感兴趣。</p>
<p><a href="https://towardsdatascience.com/10-python-tips-and-tricks-you-should-learn-today-a05c23a39dc5" target="_blank">原创</a>。经授权转载。</p>
<p><strong>相关内容:</strong></p>
<ul>
<li>
<p>Python 列表和列表操作</p>
</li>
<li>
<p>Python 字典和字典方法</p>
</li>
<li>
<p>为什么 Python 是数据科学中最受欢迎的语言之一?</p>
</li>
</ul>
<hr>
<h2 id="我们的前三个课程推荐-21">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织进行 IT 管理</p>
<hr>
<h3 id="更多相关话题-20">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/three-r-libraries-every-data-scientist-know-even-python.html" target="_blank">每个数据科学家都应该了解的三个 R 库(即使你使用 Python)</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/stop-learning-data-science-find-purpose.html" target="_blank">停止学习数据科学以寻找目标,并寻找目标以……</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/makes-python-ideal-programming-language-startups.html" target="_blank">是什么让 Python 成为初创企业理想的编程语言</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/9b-ai-failure-examined.html" target="_blank">分析$9B AI 失败案例</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/springboard-top-resources-learn-data-science-statistics.html" target="_blank">学习数据科学统计的最佳资源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-characteristics-successful-data-scientist.html" target="_blank">成功数据科学家的 5 个特征</a></p>
</li>
</ul>
<h1 id="数据科学自学的-10-个资源">数据科学自学的 10 个资源</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2021/02/10-resources-data-science-self-study.html" target="_blank"><code>www.kdnuggets.com/2021/02/10-resources-data-science-self-study.html</code></a></p>
</blockquote>
<p>评论</p>
<p><img src="https://kdn.flygon.net/docs/img/ceb8961dbef1c6c10a4966f0d40ce033.png" alt="" loading="lazy"></p>
<p><em>照片由<a href="https://unsplash.com/@element5digital?utm_source=medium&utm_medium=referral" target="_blank">Element5 Digital</a>提供,来源于<a href="https://unsplash.com?utm_source=medium&utm_medium=referral" target="_blank">Unsplash</a>。</em></p>
<hr>
<h2 id="我们的前三名课程推荐-6">我们的前三名课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织 IT 需求</p>
<hr>
<p>数据科学有两种基本路径:传统大学学位路径和自学路径。</p>
<p><strong>传统的大学学位路径:</strong> 一些顶级大学提供传统的研究生级数据科学项目。由于这些是研究生级课程,大多数要求具有物理学、数学、会计、商业、计算机科学或工程等分析领域的本科学位。这些课程通常需要 3 到 4 个学期的时间,适合全日制学习。传统课程有不同的类型,例如:数据科学硕士、数据分析硕士或商业分析硕士。传统面对面的课程学费范围可能在$15,000 到$40,000 之间,不包括生活费用。对于在线数据科学硕士课程,费用可能在$12,000 到$40,000 之间。下面的链接探讨了欧洲和美国/加拿大的顶级 MS 学位,包含排名、学费等信息。</p>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2020/09/best-online-masters-data-science-analytics-online.html" target="_blank">最佳在线分析、商业分析、数据科学硕士课程 – 更新版</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2019/05/best-masters-data-science-analytics-us-canada.html" target="_blank">美国/加拿大最佳分析、商业分析、数据科学硕士课程</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2019/04/best-masters-data-science-analytics-europe.html" target="_blank">2019 年欧洲最佳数据科学与分析硕士课程</a></p>
</li>
</ul>
<p><strong>自学路径:</strong> 如果你愿意,可以在大学(或研究生院)投入四年时间。这将使你对数据科学领域有更深入的理解,但如果你的情况不允许你获得大学学位,你可以通过自学(有一定的热情和投入)来学习数据科学。像 edX、Coursera、DataCamp、Udacity 和 Udemy 等平台上有许多优秀的数据科学课程。只要投入一些时间,你就可以通过这些课程学习数据科学的基础知识。因此,自学路径相比于大学学位路径非常经济实惠。</p>
<p>在这篇博客中,我们讨论了 10 个用于数据科学自学的资源。这些资源被分为 3 个主要类别:(A)构建基础知识的资源;(B)数据科学实践的资源;和(C)网络和持续学习的资源。</p>
<h3 id="a-构建基础知识的资源">A. 构建基础知识的资源</h3>
<p>你数据科学之旅的第一步是建立对基本数据科学概念的强大知识。以下讨论的资源有助于学习基本概念。</p>
<p><em><strong>1. 大规模开放在线课程 (MOOCs)</strong></em></p>
<p>对数据科学从业者需求的增加催生了大量的大规模开放在线课程(MOOCs)。最受欢迎的 MOOC 提供者包括以下几家:</p>
<ul>
<li>
<p><strong>edX</strong>: <a href="https://www.edx.org/" target="_blank"><code>www.edx.org/</code></a></p>
</li>
<li>
<p><strong>Coursera</strong>: <a href="https://www.coursera.org/" target="_blank"><code>www.coursera.org/</code></a></p>
</li>
<li>
<p><strong>DataCamp</strong>: <a href="https://www.datacamp.com/" target="_blank"><code>www.datacamp.com/</code></a></p>
</li>
<li>
<p><strong>Udemy</strong>: <a href="https://www.udemy.com/" target="_blank"><code>www.udemy.com/</code></a></p>
</li>
<li>
<p><strong>Udacity</strong>: <a href="https://www.udacity.com/" target="_blank"><code>www.udacity.com/</code></a></p>
</li>
<li>
<p><strong>Lynda</strong>: <a href="https://www.lynda.com/" target="_blank"><code>www.lynda.com/</code></a></p>
</li>
</ul>
<p>如果你打算参加这些课程,请记住,有些 MOOCs 是 100% 免费的,而有些则需要你支付订阅费(每门课程的费用可能从 $50 到 $200 或更多,具体取决于平台)。请记住,获得任何学科的专业知识需要大量的时间和精力。因此,不要急于求成。确保如果你决定注册课程,你应该准备好完成整个课程,包括所有作业和家庭作业。一些测验和家庭作业可能会相当具有挑战性。然而,记住如果你不挑战自己,你将无法在知识和技能上成长。</p>
<p>我自己完成了许多数据科学 MOOCs,以下是我最喜欢的 3 个数据科学专业课程。</p>
<p><a href="https://www.edx.org/professional-certificate/harvardx-data-science" target="_blank"><strong>数据科学专业证书</strong></a> <strong>(HarvardX,通过 edX)</strong></p>
<p>包含以下课程,全部使用 R 进行教学(你可以免费试听课程或购买认证证书):</p>
<ul>
<li>
<p>数据科学:R 基础;</p>
</li>
<li>
<p>数据科学:可视化;</p>
</li>
<li>
<p>数据科学:概率;</p>
</li>
<li>
<p>数据科学:推断与建模;</p>
</li>
<li>
<p>数据科学:生产力工具;</p>
</li>
<li>
<p>数据科学:数据清理;</p>
</li>
<li>
<p>数据科学:线性回归;</p>
</li>
<li>
<p>数据科学:机器学习;</p>
</li>
<li>
<p>数据科学:综合项目</p>
</li>
</ul>
<p><a href="https://www.edx.org/micromasters/gtx-analytics-essential-tools-and-methods" target="_blank"><strong>分析:基本工具和方法</strong></a> <strong>(由 Georgia TechX 提供,通过 edX 平台)</strong></p>
<p>包括以下课程,所有课程均使用 R、Python 和 SQL 教授(您可以免费审计或购买经过验证的证书):</p>
<ul>
<li>
<p>分析建模导论;</p>
</li>
<li>
<p>数据分析计算基础;</p>
</li>
<li>
<p>商业数据分析。</p>
</li>
</ul>
<p><a href="https://www.coursera.org/specializations/data-science-python" target="_blank"><strong>Python 数据科学应用专业化</strong></a> <strong>(由密歇根大学提供,通过 Coursera 平台)</strong></p>
<p>包括以下课程,所有课程均使用 Python 教授(您可以免费审计大多数课程,有些课程需要购买经过验证的证书):</p>
<ul>
<li>
<p>在 Python 中数据科学导论;</p>
</li>
<li>
<p>在 Python 中应用绘图、制图和数据表示;</p>
</li>
<li>
<p>《在 Python 中应用机器学习》;</p>
</li>
<li>
<p>在 Python 中应用文本挖掘;</p>
</li>
<li>
<p>在 Python 中应用社会网络分析</p>
</li>
</ul>
<p><em><strong>2. 从教科书中学习</strong></em></p>
<p>从教科书中学习可以提供比在线课程更精细和深入的知识。这本书提供了对数据科学和机器学习的绝佳介绍,包含代码:《Python 机器学习》由 Sebastian Raschka 编写。 <a href="https://github.com/rasbt/python-machine-learning-book-3rd-edition" target="_blank"><code>github.com/rasbt/python-machine-learning-book-3rd-edition</code></a></p>
<p><img src="https://kdn.flygon.net/docs/img/f17fae37f4471e5e35fe228288451ca1.png" alt="" loading="lazy"></p>
<p>作者以非常易于理解的方式解释了机器学习的基本概念。此外,书中包含了代码,您可以实际使用这些代码进行练习并建立自己的模型。我个人发现这本书在我的数据科学旅程中非常有用。我会推荐这本书给任何数据科学的有志之士。只需具备基本的线性代数和编程技能即可理解本书。</p>
<p>还有很多其他优秀的数据科学教科书,如 Wes McKinney 的《<a href="https://sushilapalwe.files.wordpress.com/2018/04/python-for-data-analytics-book.pdf" target="_blank">Python 数据分析</a>》、Kuhn 和 Johnson 的《<a href="https://vuquangnguyen2016.files.wordpress.com/2018/03/applied-predictive-modeling-max-kuhn-kjell-johnson_1518.pdf" target="_blank">应用预测建模</a>》以及 Ian H. Witten、Eibe Frank 和 Mark A. Hall 的《<a href="https://www.wi.hs-wismar.de/~cleve/vorl/projects/dm/ss13/HierarClustern/Literatur/WittenFrank-DM-3rd.pdf" target="_blank">数据挖掘:实用机器学习工具与技术</a>》。</p>
<p><em><strong>3. YouTube</strong></em></p>
<p>YouTube 上包含了许多教育视频和教程,可以教授数据科学所需的基本数学和编程技能,以及一些适合初学者的数据科学教程。简单的搜索可以找到许多视频教程和讲座。我在 YouTube 上最喜欢的三个课程是:</p>
<ul>
<li>
<p><a href="https://www.youtube.com/playlist?list=PL49CF3715CB9EF31D" target="_blank">Gilbert Strang 的线性代数</a></p>
</li>
<li>
<p><a href="https://www.youtube.com/playlist?list=PLtBw6njQRU-rwp5__7C0oIVt26ZgjG9NI" target="_blank">Alexander Amini 的深度学习介绍</a></p>
</li>
<li>
<p><a href="https://www.youtube.com/playlist?list=PLRJdqdXieSHMtmKxr4s78F7U88l-SawAj" target="_blank">John Guttag 和 Eric Grimson 的计算思维与数据科学介绍</a></p>
</li>
</ul>
<p><em><strong>4. 可汗学院</strong></em></p>
<p>可汗学院也是学习数据科学所需的基础数学、统计学、微积分和线性代数技能的好网站。这对那些对数据科学感兴趣但没有所需定量背景的个人来说应该是一个很好的资源。</p>
<h3 id="b-数据科学实践资源">B. 数据科学实践资源</h3>
<p>由于数据科学是一个实践性强的领域,单靠课程获得的学术知识不足以使你成为数据科学家。你需要将知识应用于实际的数据科学项目中,以便成为数据科学从业者。以下平台将帮助你通过将知识应用于实际问题来磨练数据科学技能。</p>
<p><em><strong>5. Kaggle</strong></em></p>
<p><a href="https://www.kaggle.com/" target="_blank">Kaggle</a> 是世界上最大的 数据科学社区,提供强大的工具和资源,帮助你实现数据科学目标。Kaggle 允许用户查找和发布数据集、在基于网络的数据科学环境中探索和构建模型、与其他数据科学家和机器学习工程师合作,并参加解决数据科学挑战的竞赛。在这个平台上,你可以访问 <a href="https://www.kaggle.com/datasets" target="_blank">数据集</a>、<a href="https://www.kaggle.com/learn/overview" target="_blank">课程</a>、<a href="https://www.kaggle.com/notebooks" target="_blank">笔记本</a> 和 <a href="https://www.kaggle.com/competitions" target="_blank">竞赛</a>。当你参与 Kaggle 项目和竞赛时,你在数据科学方面的知识和经验将不断增长。Kaggle 也是与其他数据科学从业者和爱好者网络互动的绝佳平台。</p>
<p><em><strong>6. 实习</strong></em></p>
<p>实习提供了在数据科学项目中工作的绝佳机会。许多公司为学生提供实习机会,实习期从几个月到一年不等。数据科学实习通常通过像 indeed.com 或 LinkedIn Jobs 这样的平台注册。</p>
<h3 id="c-网络和持续学习资源">C. 网络和持续学习资源</h3>
<p>由于数据科学领域因技术进步而不断发展,因此持续学习在数据科学中至关重要。与其他数据科学家建立合作网络将使你始终保持领先。以下平台是出色的网络和持续学习资源。</p>
<p><em><strong>7. 媒介</strong></em></p>
<p><a href="https://medium.com/" target="_blank">Medium</a> 现在被认为是学习数据科学和建立网络的最快增长的平台之一。如果你有兴趣使用这个平台进行数据科学自学,第一步是创建一个 Medium 账户。你可以创建一个免费账户或会员账户。免费账户每月可以访问的会员文章数量有限。会员账户需要每月支付 $5 或每年 $50 的订阅费。了解更多关于成为 Medium 会员的信息,请访问:<a href="https://medium.com/membership" target="_blank"><code>medium.com/membership</code></a>。</p>
<p>使用会员账户,你将可以无限制地访问 Medium 上的文章和出版物。Medium 有几个数据科学出版物,可以帮助你了解该领域的新发展,并与其他数据科学家或有志者建立联系。Medium 上的两大数据科学出版物是 <a href="https://towardsdatascience.com/" target="_blank">Towards Data Science</a> 和 <a href="https://pub.towardsai.net/" target="_blank">Towards AI</a>。每天,Medium 上都会发布涵盖数据科学、机器学习、数据可视化、编程、人工智能等主题的新文章。通过 Medium 网站上的搜索工具,你可以访问许多文章和教程,涵盖从基础到高级的各种数据科学主题。</p>
<p><em><strong>8. LinkedIn</strong></em></p>
<p>LinkedIn 是一个出色的网络平台。LinkedIn 上有几个数据科学小组和组织,你可以加入,如 Towards AI、DataScienceHub、Towards data science、KDnuggets 等。你还可以在这个平台上关注该领域的顶尖领导者。</p>
<p><em><strong>9. KDnuggets</strong></em></p>
<p><a href="https://www.kdnuggets.com/" target="_blank">KDnuggets</a> 是一个领先的网站,专注于<strong>人工智能、分析、大数据、数据挖掘、数据科学和机器学习</strong>。在这个网站上,你可以找到数据科学领域的重要教育工具和资源,以及职业发展工具。</p>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/news/index.html" target="_blank">博客/新闻</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/opinions/index.html" target="_blank">意见</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/tutorials/index.html" target="_blank">教程</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/news/top-stories.html" target="_blank">头条新闻</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/companies/index.html" target="_blank">公司</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/courses/index.html" target="_blank">课程</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/datasets/index.html" target="_blank">数据集</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/education/index.html" target="_blank">教育</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/meetings/index.html" target="_blank">活动(在线)</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/jobs/index.html" target="_blank">职位</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/software/index.html" target="_blank">软件</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/webcasts/index.html" target="_blank">网络研讨会</a></p>
</li>
</ul>
<p><em><strong>10. GitHub</strong></em></p>
<p>GitHub 包含了多个关于数据科学和机器学习的教程和项目。除了作为数据科学教育的极佳资源外,GitHub 还是一个出色的<a href="https://towardsdatascience.com/how-to-organize-your-data-science-project-dd6599cf000a" target="_blank">项目组织</a>和作品集建设平台。有关如何在 GitHub 上创建数据科学作品集的更多信息,请参阅以下文章:<a href="https://www.kdnuggets.com/2021/01/build-data-science-portfolio.html" target="_blank">利用这些平台打造脱颖而出的作品集</a>。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/01/learn-data-science-free-2021.html" target="_blank">2021 年免费学习数据科学</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/01/data-science-learning-journey.html" target="_blank">我迄今为止的数据科学学习历程</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2020/12/simplilearn-top-9-data-science-courses-online.html" target="_blank">在线学习数据科学的 9 大课程</a></p>
</li>
</ul>
<h3 id="更多相关主题-17">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2023/12/springboard-best-data-science-resources-bootcamp-courses-learn-data-science-new-year" target="_blank">最佳数据科学资源、训练营和课程…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2024/03/365datascience-best-free-resources-learn-data-analysis-data-science" target="_blank">学习数据分析和数据科学的最佳免费资源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/01/best-learning-resources-data-science-2022.html" target="_blank">2022 年数据科学学习的最佳资源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/springboard-top-resources-learn-data-science-statistics.html" target="_blank">学习数据科学统计学的顶级资源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/04/data-science-interview-guide-part-2-interview-resources.html" target="_blank">数据科学面试指南 - 第二部分:面试资源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/05/free-university-data-science-resources.html" target="_blank">免费的大学数据科学资源</a></p>
</li>
</ul>
<h1 id="10-个简单技巧加速你在-python-中的数据分析">10 个简单技巧加速你在 Python 中的数据分析</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2019/07/10-simple-hacks-speed-data-analysis-python.html" target="_blank"><code>www.kdnuggets.com/2019/07/10-simple-hacks-speed-data-analysis-python.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/3d9c022da2d331bb56691a9617b91b90.png" alt="c" loading="lazy"> 评论</p>
<p><strong>由<a href="https://www.linkedin.com/in/parul-pandey-a5498975/" target="_blank">Parul Pandey</a>,数据科学爱好者</strong></p>
<p><img src="https://kdn.flygon.net/docs/img/fd6d112577937ab23fd45ef60708771e.png" alt="图示" loading="lazy"></p>
<p><a href="https://pixabay.com/images/id-2123970/" target="_blank">来源</a></p>
<p>提示和技巧,尤其是在编程世界中,非常有用。有时一个小技巧既能节省时间又能拯救生命。一个小小的快捷方式或附加功能有时可以成为上天的恩赐,并能显著提升生产力。所以,这里有一些我用过并汇编在这篇文章中的我最喜欢的提示和技巧。有些可能比较常见,有些可能较新,但我相信下次你做数据分析项目时,它们会非常有用。</p>
<h3 id="1-对-pandas-数据框进行分析">1. 对 pandas 数据框进行分析</h3>
<p><strong>Profiling</strong> 是一个帮助我们理解数据的过程,<a href="https://github.com/pandas-profiling/pandas-profiling" target="_blank"><strong>Pandas Profiling</strong></a> 是一个完全实现这一点的 Python 包。它是进行 Pandas 数据框探索性数据分析的简单而快速的方法。pandas 的<code>df.describe()</code>和<code>df.info()functions</code>通常作为 EDA 过程的第一步。然而,它仅提供数据的非常基本概述,在大型数据集的情况下帮助不大。另一方面,Pandas Profiling 函数通过<code>df.profile_report()</code>扩展了 pandas DataFrame,实现了快速数据分析。它用一行代码显示大量信息,并且是一个交互式 HTML 报告。</p>
<p>对于给定的数据集,pandas profiling 包计算以下统计数据:</p>
<p><img src="https://kdn.flygon.net/docs/img/ecad56550efebb2dc30e3909e2bb1bb0.png" alt="图示" loading="lazy"></p>
<p>Pandas Profiling 包计算的统计数据。</p>
<p><strong>安装</strong></p>
<pre><code class="language-py">pip install pandas-profiling
or
conda install -c anaconda pandas-profiling
</code></pre>
<p><strong>使用</strong></p>
<p>让我们使用经典的泰坦尼克号数据集来演示这个多功能的 Python 分析器的能力。</p>
<pre><code class="language-py">#importing the necessary packages
import pandas as pd
import pandas_profiling
# Depreciated: pre 2.0.0 version
df = pd.read_csv('titanic/train.csv')
pandas_profiling.ProfileReport(df)
</code></pre>
<p>编辑:在这篇文章发布后一周,Pandas-Profiling 推出了一个重大升级 - 版本 2.0.0。语法有所变化,实际上功能已包含在 pandas 中,报告也变得更加全面。以下是最新的使用语法:</p>
<p><strong>使用</strong></p>
<p>要在 Jupyter 笔记本中显示报告,请运行:</p>
<pre><code class="language-py">#Pandas-Profiling 2.0.0
df.profile_report()
</code></pre>
<p>这行代码就是你需要在 Jupyter 笔记本中显示数据分析报告的全部。报告非常详细,包括必要的图表。</p>
<p><img src="https://kdn.flygon.net/docs/img/888ec5d1b8d79beed629d4f3b31f4964.png" alt="" loading="lazy"></p>
<p>报告还可以导出为<strong>交互式 HTML 文件</strong>,代码如下。</p>
<pre><code class="language-py">profile = df.profile_report(title='Pandas Profiling Report')
profile.to_file(outputfile="Titanic data profiling.html")
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/77cd5dac107d830fa64b1e36488a7840.png" alt="" loading="lazy"></p>
<p>请参阅<a href="https://pandas-profiling.github.io/pandas-profiling/docs/" target="_blank">文档</a>以获取更多详细信息和示例。</p>
<h3 id="2-为-pandas-图表添加交互性">2. 为 pandas 图表添加交互性</h3>
<p><strong>Pandas</strong>有一个内置的<code>.plot()</code>函数作为 DataFrame 类的一部分。然而,使用该函数生成的可视化图表不具备交互性,这使得它们的吸引力降低。相反,<code>pandas.DataFrame.plot()</code>函数绘制图表的便利性也不可忽视。如果我们能在不对代码进行重大修改的情况下,使用 pandas 绘制类似于 plotly 的交互式图表,那会怎么样呢?实际上,你可以借助<a href="https://github.com/santosjorge/cufflinks" target="_blank"><strong>Cufflinks</strong></a>库来实现这一点<strong>。</strong></p>
<p>Cufflinks 库将<a href="https://www.plot.ly/" target="_blank"><strong>plotly</strong></a>的强大功能与<a href="http://pandas.pydata.org/" target="_blank">pandas</a>的灵活性结合起来,方便绘图。现在,让我们看看如何安装这个库并在 pandas 中使用它。</p>
<p><strong>安装</strong></p>
<pre><code class="language-py">pip install plotly # Plotly is a pre-requisite before installing cufflinks
pip install cufflinks
</code></pre>
<p><strong>用法</strong></p>
<pre><code class="language-py">#importing Pandas
import pandas as pd
#importing plotly and cufflinks in offline mode
import cufflinks as cf
import plotly.offline
cf.go_offline()
cf.set_config_file(offline=False, world_readable=True)
</code></pre>
<p>现在是时候让魔法在 Titanic 数据集中展开了。</p>
<pre><code class="language-py">df.iplot()
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/35469750ef51f65125c84e1eb17fbde7.png" alt="图示" loading="lazy"><img src="https://kdn.flygon.net/docs/img/6fb0c52d10aa70787737d7598b62dd47.png" alt="图示" loading="lazy"></p>
<p>XXX</p>
<p><strong>df.iplot() 与 df.plot()</strong></p>
<p>右侧的可视化展示了静态图表,而左侧的图表则是交互式的,并且更加详细,所有这些都没有对语法进行任何重大更改。</p>
<p><a href="https://github.com/santosjorge/cufflinks/blob/master/Cufflinks%20Tutorial%20-%20Pandas%20Like.ipynb" target="_blank"><strong>点击这里</strong></a>获取更多示例。</p>
<h3 id="3-一点魔法">3. 一点魔法</h3>
<p><strong>魔法命令</strong>是 Jupyter Notebooks 中的一组便利函数,旨在解决标准数据分析中的一些常见问题。你可以使用<code>%lsmagic</code>查看所有可用的魔法命令。</p>
<p><img src="https://kdn.flygon.net/docs/img/bb157a69505a727331e7366042d0f033.png" alt="图示" loading="lazy"></p>
<p>所有可用魔法函数的列表</p>
<p>魔法命令有两种类型:<em><strong>行魔法</strong></em>,由单个<code>%</code>字符前缀,并在单行输入上操作;和<em><strong>单元格魔法</strong></em>,由双<code>%%</code>前缀标识,并在多行输入上操作。如果设置为 1,魔法函数可以在不输入初始%符号的情况下调用。</p>
<p>让我们看看一些可能在常见数据分析任务中有用的功能:</p>
<ul>
<li><strong>% pastebin</strong></li>
</ul>
<p>%pastebin 将代码上传到<a href="https://en.wikipedia.org/wiki/Pastebin" target="_blank">Pastebin</a>并返回网址。Pastebin 是一个在线内容托管服务,我们可以在这里存储纯文本如源代码片段,然后将网址分享给他人。实际上,Github gist 也类似于<strong>pastebin</strong>,尽管有版本控制。</p>
<p>考虑一个名为<code>file.py</code>的 Python 脚本,内容如下:</p>
<pre><code class="language-py">#file.py
def foo(x):
return x
</code></pre>
<p>在 Jupyter Notebook 中使用<strong>%pastebin</strong>会生成一个 pastebin 网址。</p>
<p><img src="https://kdn.flygon.net/docs/img/0bca3617a36ba8b44974f606609fe544.png" alt="" loading="lazy"></p>
<ul>
<li><strong>%matplotlib notebook</strong></li>
</ul>
<p><code> %matplotlib inline</code> 函数用于在 Jupyter notebook 中渲染静态 matplotlib 图表。尝试将<code>inline</code>部分替换为<code>notebook</code>,以便获得可缩放和可调整大小的图表。确保在导入 matplotlib 库之前调用该函数。</p>
<p><img src="https://kdn.flygon.net/docs/img/e30c44c157cb07da81eb12798ac203e4.png" alt="" loading="lazy"></p>
<p><strong>%matplotlib inline 与 %matplotlib notebook</strong></p>
<ul>
<li><strong>%run</strong></li>
</ul>
<p><code> %run</code> 函数在笔记本中运行 Python 脚本。</p>
<pre><code class="language-py">%run file.py
</code></pre>
<ul>
<li><strong>%%writefile</strong></li>
</ul>
<p><code>%%writefile</code> 将单元格的内容写入文件。这里的代码将被写入名为 <strong>foo.py</strong> 的文件,并保存在当前目录中。</p>
<p><img src="https://kdn.flygon.net/docs/img/ab331460839793d1854a8a282d532412.png" alt="" loading="lazy"></p>
<ul>
<li><strong>%%latex</strong></li>
</ul>
<p><code>%%latex</code> 函数将单元格内容渲染为 LaTeX。这对于在单元格中书写数学公式和方程非常有用。</p>
<p><img src="https://kdn.flygon.net/docs/img/9523100bf882a6a7340a0a3dbbc4c4df.png" alt="" loading="lazy"></p>
<h3 id="4-查找和消除错误">4. 查找和消除错误</h3>
<p><strong>交互式调试器</strong> 也是一个魔法函数,但我将其分为一个独立的类别。如果在运行代码单元时遇到异常,请在新行中输入 <code> %debug</code> 并运行。这将打开一个交互式调试环境,将你带到发生异常的位置。你还可以检查程序中分配的变量的值,并在这里执行操作。要退出调试器,请按 <code>q</code>。</p>
<p><img src="https://kdn.flygon.net/docs/img/24de249f6095d5a6ecbcbc1f052e60c1.png" alt="" loading="lazy"></p>
<h3 id="5-打印也可以很漂亮">5. 打印也可以很漂亮</h3>
<p>如果你想生成美观的数据结构表示, <a href="https://docs.python.org/2/library/pprint.html" target="_blank"><strong>pprint</strong></a> 是首选模块。它在打印字典或 JSON 数据时特别有用。让我们来看一个使用 <code>print</code> 和 <code>pprint</code> 显示输出的示例。</p>
<p><img src="https://kdn.flygon.net/docs/img/c36d818c9468452dd36ae1d2361ac7c5.png" alt="" loading="lazy"></p>
<p><img src="https://kdn.flygon.net/docs/img/581e71757069ecf7f135bb2ee7d558f3.png" alt="" loading="lazy"></p>
<h3 id="6-使提示框突出显示">6. 使提示框突出显示</h3>
<p>我们可以在 Jupyter Notebooks 中使用警告/提示框来突出显示重要内容或需要引起注意的事项。提示框的颜色取决于指定的警告类型。只需在需要突出显示的单元格中添加以下任何或所有代码。</p>
<ul>
<li><strong>蓝色警告框:信息</strong></li>
</ul>
<pre><code class="language-py"><div class="alert alert-block alert-info">
<b>Tip:</b> Use blue boxes (alert-info) for tips and notes.
If it’s a note, you don’t have to include the word “Note”.
</div>
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/d080781aae3d7cf705c4071a03469d8a.png" alt="" loading="lazy"></p>
<ul>
<li><strong>黄色警告框:警告</strong></li>
</ul>
<pre><code class="language-py"><div class="alert alert-block alert-warning">
<b>Example:</b> Yellow Boxes are generally used to include additional examples or mathematical formulas.
</div>
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/eefcb6bfb4fbbb7da2ae310aa31054a5.png" alt="" loading="lazy"></p>
<ul>
<li><strong>绿色警告框:成功</strong></li>
</ul>
<pre><code class="language-py"><div class="alert alert-block alert-success">
Use green box only when necessary like to display links to related content.
</div>
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/153e8056a7699e171ab93196f8b03755.png" alt="" loading="lazy"></p>
<ul>
<li><strong>红色警告框:危险</strong></li>
</ul>
<pre><code class="language-py"><div class="alert alert-block alert-danger">
It is good to avoid red boxes but can be used to alert users to not delete some important part of code etc.
</div>
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/b5b69b493eebb5ea48fc5abacbf6d805.png" alt="" loading="lazy"></p>
<h3 id="7-打印单元格的所有输出">7. 打印单元格的所有输出</h3>
<p>设想一个包含以下代码行的 Jupyter Notebook 单元格:</p>
<pre><code class="language-py">In [1]: 10+5
11+6
</code></pre>
<pre><code class="language-py">Out [1]: 17
</code></pre>
<p>这是一个单元格的正常属性,只有最后一个输出会被打印,而对于其他输出,我们需要添加 <code>print()</code> 函数。实际上,我们只需在笔记本顶部添加以下代码片段,就可以打印所有输出。</p>
<pre><code class="language-py">from IPython.core.interactiveshell import InteractiveShell InteractiveShell.ast_node_interactivity = "all"
</code></pre>
<p>现在所有输出会一个接一个地打印出来。</p>
<pre><code class="language-py">In [1]: 10+5
11+6
12+7
</code></pre>
<pre><code class="language-py">Out [1]: 15
Out [1]: 17
Out [1]: 19
</code></pre>
<p>要恢复到原始设置:</p>
<pre><code class="language-py">InteractiveShell.ast_node_interactivity = "last_expr"
</code></pre>
<h3 id="8-使用-i-选项运行-python-脚本">8. 使用 'i' 选项运行 Python 脚本</h3>
<p>从命令行运行 Python 脚本的典型方法是:<code>python hello.py</code>。然而,如果在运行相同脚本时添加 <code>-i</code>,例如 <code>python -i hello.py</code>,则会提供更多的优势。让我们看看如何。</p>
<ul>
<li>首先,一旦程序结束,Python 不会退出解释器。因此,我们可以检查变量的值和程序中定义的函数的正确性。</li>
</ul>
<p><img src="https://kdn.flygon.net/docs/img/33e2cac27f652736f64b43036e92ab3e.png" alt="" loading="lazy"></p>
<ul>
<li>其次,我们可以轻松调用 Python 调试器,因为我们仍然在解释器中:</li>
</ul>
<pre><code class="language-py">import pdb
pdb.pm()
</code></pre>
<p>这将把我们带到发生异常的位置,然后我们可以进一步处理代码。</p>
<p><img src="https://kdn.flygon.net/docs/img/82537e7c997adffd53bbede48ac08569.png" alt="图片" loading="lazy"></p>
<p><em>原始的</em><a href="http://www.bnikolic.co.uk/blog/python-running-cline.html" target="_blank"><em>来源</em></a>*。</p>
<h3 id="9-自动注释代码">9. 自动注释代码</h3>
<p><code>Ctrl/Cmd + /</code> 会自动将所选行注释掉。再次按下组合键将取消注释该行代码。</p>
<p><img src="https://kdn.flygon.net/docs/img/33a4882d98f017683aa1128f5fcd85b2.png" alt="" loading="lazy"></p>
<h3 id="10-删除是人的本能恢复是神圣的">10. 删除是人的本能,恢复是神圣的</h3>
<p>你是否曾在 Jupyter Notebook 中不小心删除了一个单元格?如果是,那么这里有一个快捷键可以撤销该删除操作。</p>
<ul>
<li>
<p>如果你删除了一个单元格的内容,可以通过按 <code>CTRL/CMD+Z</code> 容易地恢复它。</p>
</li>
<li>
<p>如果需要恢复整个删除的单元格,可以按 <code>ESC+Z</code> 或 <code>EDIT > Undo Delete Cells</code></p>
</li>
</ul>
<p><img src="https://kdn.flygon.net/docs/img/121ab7f8c18f4fdea8ee2f6afc370c82.png" alt="" loading="lazy"></p>
<h3 id="结论-15">结论</h3>
<p>在这篇文章中,我列出了在使用 Python 和 Jupyter Notebooks 时总结的主要技巧。我相信它们会对你有帮助,你也会从中获得一些收获。祝编程愉快!</p>
<p><strong>个人简介: <a href="https://www.linkedin.com/in/parul-pandey-a5498975/" target="_blank">Parul Pandey</a></strong> 是一位数据科学爱好者,常为数据科学相关出版物如 Towards Data Science 撰写文章。</p>
<p><a href="https://towardsdatascience.com/10-simple-hacks-to-speed-up-your-data-analysis-in-python-ec18c6396e6b" target="_blank">原文</a>。经许可转载。</p>
<p><strong>相关内容:</strong></p>
<ul>
<li>
<p>使用‘What-If Tool’调查机器学习模型</p>
</li>
<li>
<p>使用 Matplotlib 制作动画</p>
</li>
<li>
<p>PyViz:简化 Python 中的数据可视化过程</p>
</li>
</ul>
<hr>
<h2 id="我们的三大课程推荐-13">我们的三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析能力</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织 IT</p>
<hr>
<h3 id="更多相关话题-21">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/10/3-simple-ways-speed-python-code.html" target="_blank">加速 Python 代码的 3 种简单方法</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/04/rapids-cudf-speed-next-data-science-workflow.html" target="_blank">RAPIDS cuDF 加速您的下一个数据科学工作流程</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/5-python-tips-for-data-efficiency-and-speed" target="_blank">提高数据效率和速度的 5 个 Python 技巧</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/08/speed-sql-queries-indexes-python-edition.html" target="_blank">如何使用索引加速 SQL 查询【Python 版】</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/how-to-speed-up-python-code-with-caching" target="_blank">如何通过缓存加速 Python 代码</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/how-to-speed-up-python-pandas-by-over-300x" target="_blank">如何将 Python Pandas 的速度提高超过 300 倍</a></p>
</li>
</ul>
<h1 id="数据科学家需要掌握的-10-种统计技术">数据科学家需要掌握的 10 种统计技术</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2017/11/10-statistical-techniques-data-scientists-need-master.html/2" target="_blank"><code>www.kdnuggets.com/2017/11/10-statistical-techniques-data-scientists-need-master.html/2</code></a></p>
</blockquote>
<p><strong><strong>6 — 维度缩减:</strong></strong></p>
<p>维度缩减将估计<em>p + 1</em>个系数的问题简化为估计<em>M + 1</em>个系数的简单问题,其中<em>M < p</em>。这通过计算<em>M</em>个不同的<em>线性组合</em>,或<em>投影</em>来实现。然后,这些<em>M</em>个投影被用作预测变量,通过最小二乘法拟合一个线性回归模型。处理此任务的 2 种方法是<em>主成分回归</em>和<em>偏最小二乘</em>。</p>
<p><img src="https://kdn.flygon.net/docs/img/aaf5c3c81c82d9b597e23931df90d35b.png" alt="" loading="lazy"></p>
<ul>
<li>
<p>可以将<strong>主成分回归</strong>描述为从大量变量中派生出低维特征集的一种方法。数据的<em>第一个</em>主成分方向是观测值变化最大的方向。换句话说,第一个主成分是一条尽可能贴合数据的直线。可以拟合<em>p</em>个不同的主成分。第二个主成分是与第一个主成分不相关的变量的线性组合,并在此约束下具有最大的方差。其理念是主成分通过在随后的正交方向上使用数据的线性组合来捕捉数据中的最大方差。通过这种方式,我们还可以结合相关变量的影响,从现有数据中获取更多信息,而在常规最小二乘法中,我们则需要丢弃一个相关变量。</p>
</li>
<li>
<p>我们上面描述的 PCR 方法涉及识别最佳表示预测变量的<em>X</em>的线性组合。这些组合(<em>方向</em>)是以无监督的方式识别的,因为响应<em>Y</em>未用于帮助确定主成分方向。也就是说,响应<em>Y</em>并不<em>监督</em>主成分的识别,因此没有保证最佳解释预测变量的方向也是预测响应的最佳方向(尽管这通常被假设)。<strong>偏最小二乘</strong>(PLS)是 PCR 的<em>有监督</em>替代方法。与 PCR 一样,PLS 也是一种维度缩减方法,它首先识别出原始特征的线性组合的新特征集,然后通过最小二乘法对新的<em>M</em>个特征拟合线性模型。然而,与 PCR 不同的是,PLS 利用响应变量来识别新特征。</p>
</li>
</ul>
<p><strong><strong>7 — 非线性模型:</strong></strong></p>
<p>在统计学中,非线性回归是一种回归分析方法,其中观测数据通过一个非线性组合的模型参数的函数来建模,并且依赖于一个或多个自变量。这些数据通过逐步逼近的方法进行拟合。以下是处理非线性模型的一些重要技术:</p>
<ul>
<li>
<p>如果一个实数上的函数可以写成区间指示函数的有限线性组合,那么这个函数被称为<strong>阶跃函数</strong>。非正式地说,阶跃函数是一个分段常数函数,只有有限多个区间。</p>
</li>
<li>
<p><strong>分段函数</strong> 是由多个子函数定义的函数,每个子函数适用于主函数定义域的某个区间。分段实际上是一种表达函数的方式,而不是函数本身的特性,但经过额外的限定,它可以描述函数的性质。例如,<strong>分段多项式</strong>函数是一个在每个子域上都是多项式的函数,但每个子域上的多项式可能不同。</p>
</li>
</ul>
<p><img src="https://kdn.flygon.net/docs/img/594bd23c68d30b0aa895e2e2b83540c7.png" alt="" loading="lazy"></p>
<ul>
<li>
<p><strong>样条函数</strong> 是一种由多项式分段定义的特殊函数。在计算机图形学中,样条函数指的是分段的多项式参数曲线。样条函数因其构造的简单性、评估的便利性和准确性,以及通过曲线拟合和交互式曲线设计来逼近复杂形状的能力而受到欢迎。</p>
</li>
<li>
<p><strong>广义加性模型</strong>是一种广义线性模型,其中线性预测变量依赖于某些预测变量的未知平滑函数,重点在于对这些平滑函数进行推断。</p>
</li>
</ul>
<p><strong><strong>8 — 基于树的方法:</strong></strong></p>
<p>基于树的方法既可以用于回归问题,也可以用于分类问题。这些方法涉及将预测变量空间划分为若干个简单区域。由于用于划分预测变量空间的分割规则可以用树来总结,这些方法被称为<strong>决策树</strong>方法。以下这些方法生成多个树,然后将它们结合以得出单一的共识预测。</p>
<ul>
<li>
<p><strong>Bagging</strong> 是通过对原始数据集生成额外的数据进行训练,以重复组合的方式减少预测的方差,从而产生与原始数据具有相同规模/大小的多步骤数据。通过增加训练集的规模,无法提升模型的预测能力,只能减少方差,从而将预测值精确调整至预期结果。</p>
</li>
<li>
<p><strong>提升</strong> 是一种使用多个不同模型计算输出,然后使用加权平均的方法来平均结果的方式。通过调整加权公式来结合这些方法的优缺点,你可以为更广泛的输入数据提供良好的预测能力,利用不同的精确调优模型。</p>
</li>
</ul>
<p><img src="https://kdn.flygon.net/docs/img/8564dca67fc55bd7baf8ab9137185528.png" alt="" loading="lazy"></p>
<ul>
<li><strong>随机森林</strong>算法实际上与袋装方法非常相似。这里,你会从训练集中抽取随机的自助样本。然而,除了自助样本,你还会抽取一个特征的随机子集来训练个体决策树;在袋装方法中,你会给每棵树提供完整的特征集。由于随机特征选择,你使得树之间相对独立于常规袋装方法,这通常会导致更好的预测性能(由于更好的方差-偏差权衡),而且也更快,因为每棵树只从特征的子集学习。</li>
</ul>
<p><strong><strong>9 — 支持向量机:</strong></strong></p>
<p><img src="https://kdn.flygon.net/docs/img/cce76979f7f43d567a5ca6b735d0d831.png" alt="" loading="lazy"></p>
<p>支持向量机(SVM)是一种分类技术,被列在机器学习的监督学习模型下。通俗来说,它涉及到寻找一个超平面(二维中的直线,三维中的平面,以及更高维中的超平面),该超平面能以最大的间隔最好地分离两类点。本质上,这是一个约束优化问题,在约束条件下最大化间隔,即完美分类数据(硬间隔)。</p>
<p>支持这个超平面的数据点称为“支持向量”。在上图中,填充的蓝色圆圈和两个填充的方块就是支持向量。对于两个类别的数据不能线性可分的情况,这些点会被投影到一个扩展(更高维)空间,在那里可能会实现线性分离。涉及多个类别的问题可以被拆解为多个一对一或一对其余的二分类问题。</p>
<p><strong><strong>10 — 无监督学习:</strong></strong></p>
<p>到目前为止,我们只讨论了监督学习技术,其中组是已知的,算法所提供的经验是实际实体与它们所属组之间的关系。当数据的组(类别)未知时,可以使用另一组技术。这些技术被称为无监督学习,因为它由学习算法去找出提供的数据中的模式。聚类是无监督学习的一个例子,其中不同的数据集被聚类成紧密相关的组。以下是最广泛使用的无监督学习算法列表:</p>
<p><img src="https://kdn.flygon.net/docs/img/61f3908308615b6f22c03bc7ae8be331.png" alt="" loading="lazy"></p>
<ul>
<li>
<p><strong>主成分分析</strong>帮助通过识别具有最大方差且互不相关的特征线性组合,生成数据集的低维表示。这种线性维度技术可能有助于在无监督设置中理解变量之间的潜在交互。</p>
</li>
<li>
<p><strong>k 均值聚类</strong>:根据与簇中心的距离将数据划分为 k 个不同的簇。</p>
</li>
<li>
<p><strong>层次聚类</strong>: 通过创建聚类树构建多级聚类层次。</p>
</li>
</ul>
<ul>
<li>这是一些基本统计技术的简介,旨在帮助数据科学项目经理或高管更好地理解数据科学团队内部的运作。事实上,一些数据科学团队纯粹通过 Python 和 R 库运行算法。他们中的大多数甚至不需要考虑基础数学。然而,能够理解统计分析的基础知识可以为你的团队提供更好的方法。深入了解最小的部分可以更轻松地进行操作和抽象。希望这个基本的数据科学统计指南能给你提供一个不错的理解!</li>
</ul>
<p><em>附注: 你可以从</em><a href="https://github.com/khanhnamle1994/statistical-learning" target="_blank"><em>我的 GitHub 源码在这里</em></a><em>获取所有讲座幻灯片和 RStudio 会议记录。感谢你们的热烈回应!</em></p>
<p><strong>个人简介: <a href="https://www.linkedin.com/in/khanhnamle94/" target="_blank">詹姆斯·李</a></strong> 目前正在申请 2018 年秋季入学的美国计算机科学硕士项目。他计划的研究将集中在机器学习和数据挖掘方面。同时,他作为自由职业全栈 Web 开发人员工作。</p>
<p><a href="https://towardsdatascience.com/the-10-statistical-techniques-data-scientists-need-to-master-1ef6dbd531f7" target="_blank">原文</a>。经许可转载。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p>机器学习工程师需知的 10 种算法</p>
</li>
<li>
<p>前 10 大数据挖掘算法解析</p>
</li>
<li>
<p>初学者的前 10 大机器学习算法</p>
</li>
</ul>
<h3 id="相关话题-1">相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/6-predictive-models-every-beginner-data-scientist-master.html" target="_blank">每个初学者数据科学家应掌握的 6 种预测模型</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/build-solid-data-team.html" target="_blank">建立稳固的数据团队</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/write-clean-python-code-pipes.html" target="_blank">使用管道编写干净的 Python 代码</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-key-skills-needed-become-great-data-scientist.html" target="_blank">成为伟大数据科学家所需的 5 项关键技能</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/mozart-best-etl-tools-2021.html" target="_blank">2021 年最佳 ETL 工具</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/stop-learning-data-science-find-purpose.html" target="_blank">停止学习数据科学,寻找目的,然后…</a></p>
</li>
</ul>
<h1 id="10-个统计学问题助你在数据科学面试中脱颖而出">10 个统计学问题助你在数据科学面试中脱颖而出</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/10-statistics-questions-to-ace-your-data-science-interview" target="_blank"><code>www.kdnuggets.com/10-statistics-questions-to-ace-your-data-science-interview</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/545e41c9df4e9562c1714364ab85cc47.png" alt="数据科学统计学面试问题" loading="lazy"></p>
<p>图片来源于作者</p>
<p>我是一名拥有计算机科学背景的数据科学家。</p>
<hr>
<h2 id="我们的前三个课程推荐-22">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织 IT 部门</p>
<hr>
<p>我熟悉数据结构、面向对象编程和数据库管理,因为在大学里我学了这些概念三年。</p>
<p>然而,当进入数据科学领域时,我注意到一个显著的技能差距。</p>
<p>我没有在几乎所有数据科学职位中所需的数学或统计学背景。</p>
<p>我参加了一些统计学的在线课程,但似乎没有真正掌握。</p>
<p>大多数程序要么非常基础并且针对高级管理人员,要么详细且建立在我没有的前置知识上。</p>
<p>我花时间在互联网上搜索资源,以更好地理解诸如假设检验和置信区间等概念。</p>
<p>在面试多个数据科学职位后,我发现大多数统计学面试问题遵循类似的模式。</p>
<p>在本文中,我将列出我在数据科学面试中遇到的 10 个最流行的统计学问题,并附上这些问题的样本答案。</p>
<h2 id="问题-1什么是-p-值">问题 1:什么是 p 值?</h2>
<p>答案:在零假设为真的情况下,p 值是你观察到的结果至少极端的结果的概率。</p>
<p>p 值通常用于确定统计测试的结果是否显著。简单来说,p 值告诉我们是否有足够的证据来拒绝零假设。</p>
<h2 id="问题-2解释统计功效的概念">问题 2:解释统计功效的概念</h2>
<p>答案:如果你进行统计测试以检测是否存在效果,统计功效是测试准确检测该效果的概率。</p>
<p>这里是一个简单的例子来解释这个问题:</p>
<p>假设我们对 100 人的测试组进行广告投放,并获得了 80 次转化。</p>
<p>零假设是广告对转化次数没有影响。然而,实际上广告对销售量有显著影响。</p>
<p>统计功效是你准确拒绝零假设并实际检测到效应的概率。较高的统计功效表示测试能更好地检测到效应(如果存在的话)。</p>
<h2 id="问题-3你如何向非技术性利益相关者描述置信区间">问题 3:你如何向非技术性利益相关者描述置信区间?</h2>
<p>我们使用之前相同的示例,其中对 100 人的样本进行广告测试并获得了 80 次转换。</p>
<p>我们提供一个范围而不是说转换率是 80%,因为我们不知道真实的总体行为如何。换句话说,如果我们取无限多个样本,我们会看到多少次转换?</p>
<p>这里是一个仅根据我们从样本中获得的数据可能会说的示例:</p>
<p>“如果我们对一个更大的人群进行这个广告测试,我们有 95%的信心转换率会在 75%到 88%之间。”</p>
<p>我们使用这个范围,因为我们不知道总人口的反应,只能根据我们的测试组生成一个估计,而这只是一个样本。</p>
<h2 id="问题-4参数检验和非参数检验有什么区别">问题 4:参数检验和非参数检验有什么区别?</h2>
<p>参数检验假设数据集遵循某种潜在分布。进行参数检验时最常见的假设是数据呈正态分布。</p>
<p>参数检验的示例包括 ANOVA、T 检验、F 检验和卡方检验。</p>
<p>然而,非参数检验不会对数据集的分布做任何假设。如果你的数据集不是正态分布的,或者包含等级或异常值,选择非参数检验是明智的。</p>
<h2 id="问题-5协方差和相关性有什么区别">问题 5:协方差和相关性有什么区别?</h2>
<p>协方差测量变量之间线性关系的方向。相关性测量这种关系的强度和方向。</p>
<p>尽管相关性和协方差都能提供特征关系的类似信息,但它们之间的主要区别在于尺度。</p>
<p>相关性范围在-1 和+1 之间。它是标准化的,容易让你理解特征之间是否存在正相关或负相关关系以及这种效应的强度。另一方面,协方差以与因变量和自变量相同的单位显示,这可能使其解释起来稍微困难一些。</p>
<h2 id="问题-6你如何分析和处理数据集中的异常值">问题 6:你如何分析和处理数据集中的异常值?</h2>
<p>有几种方法可以检测数据集中的异常值。</p>
<ul>
<li>
<p>视觉方法:可以通过箱型图和散点图等图表直观地识别异常值。箱型图中位于“胡须”之外的点通常是异常值。使用散点图时,异常值可以被检测为在可视化中远离其他数据点的点。</p>
</li>
<li>
<p>非视觉方法:一种非视觉技术用于检测异常值是 Z 分数。Z 分数通过从均值中减去一个值并除以标准差来计算。这告诉我们一个值距离均值有多少标准差。超过或低于均值 3 个标准差的值被认为是异常值。</p>
</li>
</ul>
<h2 id="问题-7区分单尾检验和双尾检验">问题 7:区分单尾检验和双尾检验。</h2>
<p>单尾检验检查一个方向上是否存在关系或效果。例如,广告投放后,你可以使用单尾检验来检查是否有积极的影响,即销售的增加。这是一个右尾检验。</p>
<p>双尾检验检查两种方向上的关系可能性。例如,如果所有公立学校实施了一种新的教学风格,双尾检验将评估是否存在分数的显著增加或减少。</p>
<h2 id="问题-8在以下场景中你会选择实施哪个统计检验">问题 8:在以下场景中,你会选择实施哪个统计检验?</h2>
<p>一家在线零售商希望评估新广告活动的效果。他们收集了广告发布前后 30 天的每日销售数据。公司希望确定广告是否对每日销售产生了显著影响。</p>
<p>选项:</p>
<p>A) 卡方检验</p>
<p>B) 配对 t 检验</p>
<p>C) 单因素方差分析</p>
<p>d) 独立样本 t 检验</p>
<p><strong>答案</strong>:要评估新广告活动的效果,我们应该使用配对 t 检验。</p>
<p>配对 t 检验用于比较两个样本的均值,并检查差异是否具有统计学意义。</p>
<p>在这种情况下,我们比较的是广告投放前后的销售数据,比较的是同一组数据的变化,因此我们使用配对 t 检验而不是独立样本 t 检验。</p>
<h2 id="问题-9什么是卡方独立性检验">问题 9:什么是卡方独立性检验?</h2>
<p>卡方独立性检验用于检查观察结果和预期结果之间的关系。该检验的零假设(H0)是任何观察到的特征差异纯粹是由于偶然。</p>
<p>简而言之,这种检验可以帮助我们确定两个分类变量之间的关系是否由于偶然,或者是否存在统计学上的显著关联。</p>
<p>例如,如果你想测试性别(男性与女性)和冰淇淋口味偏好(香草与巧克力)之间是否存在关系,可以使用卡方独立性检验。</p>
<h2 id="问题-10解释回归模型中的正则化概念">问题 10:解释回归模型中的正则化概念。</h2>
<p>正则化是一种通过添加额外信息来减少过拟合的技术,使模型能够更好地适应和概括尚未训练的数据集。</p>
<p>在回归分析中,有两种常用的正则化技术:岭回归和套索回归。</p>
<p>这些模型通过向回归模型添加惩罚项来稍微改变回归模型的误差方程。</p>
<p>对于岭回归而言,惩罚项与系数的平方和相乘。这意味着系数较大的模型受到的惩罚更重。而在套索回归中,惩罚项与系数的绝对值和相乘。</p>
<p>尽管这两种方法的主要目标都是在最小化模型误差的同时缩小系数的大小,但岭回归对大系数的惩罚更重。</p>
<p>另一方面,套索回归对每个系数施加了一个常量惩罚,这意味着在某些情况下,系数可能会收缩到零。</p>
<h2 id="10-道统计学问题助你通过数据科学面试接下来的步骤">10 道统计学问题,助你通过数据科学面试——接下来的步骤</h2>
<p>如果你已经跟进到现在,恭喜你!</p>
<p>你现在对数据科学面试中出现的统计问题有了很好的掌握。</p>
<p>作为下一步,我建议你参加一个在线课程来复习这些概念并将其付诸实践。</p>
<p>这里是一些我发现有用的统计学习资源:</p>
<ul>
<li>
<p><a href="https://www.youtube.com/@statquest/videos" target="_blank">StatQuest</a></p>
</li>
<li>
<p><a href="https://www.youtube.com/@krishnaik06" target="_blank">Krish Naik 的 YouTube 频道</a></p>
</li>
<li>
<p><a href="https://www.edx.org/learn/python/stanford-university-statistical-learning-with-python" target="_blank">edX 上的统计学习</a></p>
</li>
</ul>
<p>最终课程可以在 edX 上免费审计,而前两个资源是广泛涵盖统计学和机器学习的 YouTube 频道。</p>
<p> </p>
<p> </p>
<p><a href="https://linktr.ee/natasshaselvaraj" target="_blank"></a><strong><a href="https://linktr.ee/natasshaselvaraj" target="_blank">Natassha Selvaraj</a></strong> 是一位自学成才的数据科学家,对写作充满热情。Natassha 关注所有与数据科学相关的内容,是所有数据主题的真正大师。你可以通过 <a href="https://www.linkedin.com/in/natassha-selvaraj-33430717a/" target="_blank">LinkedIn</a> 与她联系,或查看她的 <a href="https://www.youtube.com/@natassha_ds" target="_blank">YouTube 频道</a>。</p>
<h3 id="更多相关话题-22">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/top-7-essential-cheat-sheets-to-ace-your-data-science-interview" target="_blank">通过数据科学面试的 7 张必备备忘单</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/10/10-cheat-sheets-need-ace-data-science-interview.html" target="_blank">你需要的 10 张备忘单来通过数据科学面试</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/12/7-super-cheat-sheets-need-ace-machine-learning-interview.html" target="_blank">你需要的 7 张超级备忘单来通过机器学习面试</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/06/24-sql-questions-might-see-next-interview.html" target="_blank">24 道你可能会在下一次面试中遇到的 SQL 问题</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n18.html" target="_blank">KDnuggets 新闻,5 月 4 日:9 门免费的哈佛课程学习数据…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/01/answer-data-science-coding-interview-questions.html" target="_blank">如何回答数据科学编码面试问题</a></p>
</li>
</ul>
<h1 id="你可能不知道的-10-件关于-scikit-learn-的事">你可能不知道的 10 件关于 Scikit-Learn 的事</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2020/09/10-things-know-scikit-learn.html" target="_blank"><code>www.kdnuggets.com/2020/09/10-things-know-scikit-learn.html</code></a></p>
</blockquote>
<p>评论</p>
<p><strong>作者:<a href="https://www.linkedin.com/in/rebecca-vickery-20b94133/" target="_blank">Rebecca Vickery</a>,数据科学家</strong></p>
<p><img src="https://kdn.flygon.net/docs/img/cbdc641473704432ff7792a819e0fc6d.png" alt="图示" loading="lazy"></p>
<p>图片由 <a href="https://unsplash.com/@sanfrancisco?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Sasha • Stories</a> 提供,来源于 <a href="https://unsplash.com/s/photos/crystal-ball?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Unsplash</a></p>
<hr>
<h2 id="我们的前三名课程推荐-7">我们的前三名课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业的捷径。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析能力</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织进行 IT 工作</p>
<hr>
<p>Scikit-learn 是最广泛使用的 Python 机器学习库之一。它提供了一个标准化且简单的接口用于数据预处理、模型训练、优化和评估。</p>
<p>该项目起初是由 David <a href="https://en.wikipedia.org/wiki/David_Cournapeau" target="_blank">Cournapeau</a> 开发的 Google 夏季编程项目,并于 2010 年首次公开发布。自创建以来,该库已发展成一个丰富的机器学习模型开发生态系统。</p>
<p>随着时间的推移,该项目开发了许多实用的功能和能力,提升了其易用性。在本文中,我将介绍你可能不知道的 10 个最有用的功能。</p>
<h3 id="1-scikit-learn-内置了数据集">1. Scikit-learn 内置了数据集</h3>
<p>Scikit-learn API 内置了各种<a href="https://scikit-learn.org/stable/datasets/index.html" target="_blank"><strong>玩具数据集和真实数据集</strong></a>。这些数据集可以通过一行代码访问,非常适合学习或快速尝试新功能。</p>
<p>你还可以使用<a href="https://scikit-learn.org/stable/datasets/index.html#generated-datasets" target="_blank"><strong>生成器</strong></a>轻松生成合成数据集,包括回归的 <code>make_regression()</code>、聚类的 <code>make_blobs()</code> 和分类的 <code>make_classification()</code>。</p>
<p>所有加载工具都提供了将数据拆分成 X(特征)和 y(目标)的选项,以便可以直接用于训练模型。</p>
<h3 id="2-第三方公共数据集也很容易获得">2. 第三方公共数据集也很容易获得</h3>
<p>如果你希望通过 Scikit-learn 直接访问更多种类的公开数据集,有一个方便的函数可以让你直接从<a href="https://www.openml.org/home" target="_blank">openml.org</a>网站导入数据。这个网站包含了超过 21,000 个用于机器学习项目的多样化数据集。</p>
<h3 id="3-有现成的分类器用于训练基线模型">3. 有现成的分类器用于训练基线模型</h3>
<p>在为项目开发机器学习模型时,首先创建一个基线模型是明智的。这个模型本质上应该是一个“虚拟”模型,例如总是预测最常见的类别。这样可以为你的“智能”模型提供一个基准,以确保它的表现优于随机结果。</p>
<p>Scikit-learn 包含一个<code>[**DummyClassifier()**](https://scikit-learn.org/stable/modules/generated/sklearn.dummy.DummyClassifier.html)</code>用于分类任务和一个<code>**DummyRegressor()**</code>用于回归问题。</p>
<h3 id="4-scikit-learn-具有自己的绘图-api">4. Scikit-learn 具有自己的绘图 API</h3>
<p>Scikit-learn 具有内置的<a href="https://scikit-learn.org/stable/developers/plotting.html" target="_blank"><strong>绘图 API</strong></a>,允许你在不导入其他库的情况下可视化模型性能。包括以下绘图工具;偏依赖图、混淆矩阵、精确度-召回曲线和 ROC 曲线。</p>
<pre><code class="language-py">
import matplotlib.pyplot as plt
from sklearn import metrics, model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
clf = RandomForestClassifier(random_state=0)
clf.fit(X_train, y_train)
metrics.plot_roc_curve(clf, X_test, y_test)
plt.show()
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/adae73e95dd662f04474adbc8c32218a.png" alt="Image for post" loading="lazy"></p>
<h3 id="5-scikit-learn-具有内置的特征选择方法">5. Scikit-learn 具有内置的特征选择方法</h3>
<p>提高模型性能的一种技术是仅使用最佳特征集进行训练或去除冗余特征。这个过程被称为特征选择。</p>
<p>Scikit-learn 提供了许多函数来执行<a href="https://scikit-learn.org/stable/modules/classes.html#module-sklearn.feature_selection" target="_blank"><strong>特征选择</strong></a>。一个例子是<code>[**SelectPercentile()**](https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.SelectPercentile.html#sklearn.feature_selection.SelectPercentile)</code>。该方法基于选定的统计方法为评分选择表现最好的 X 百分位特征。</p>
<h3 id="6-pipelines-允许你将机器学习工作流中的所有步骤链式组合在一起">6. Pipelines 允许你将机器学习工作流中的所有步骤链式组合在一起</h3>
<p>除了提供广泛的机器学习算法外,Scikit-learn 还提供了一系列用于数据预处理和转换的函数。为了促进机器学习工作流的可重复性和简便性,Scikit-learn 创建了<a href="https://scikit-learn.org/stable/modules/generated/sklearn.pipeline.Pipeline.html" target="_blank"><strong>pipelines</strong></a>,允许你将多个预处理步骤与模型训练阶段链式组合。</p>
<p>管道将工作流中的所有步骤作为一个单一实体存储,可以通过 fit 和 predict 方法调用。当你在管道对象上调用 fit 方法时,预处理步骤和模型训练会自动执行。</p>
<h3 id="7-使用-columntransformer你可以对不同的特征应用不同的预处理">7. 使用 ColumnTransformer,你可以对不同的特征应用不同的预处理</h3>
<p>在许多数据集中,你会遇到需要不同预处理步骤的各种特征。例如,你可能有类别型数据和数值型数据的混合,可能需要通过独热编码将类别数据转换为数值,并对数值变量进行缩放。</p>
<p>Scikit-learn 管道中有一个叫 <a href="https://scikit-learn.org/stable/modules/generated/sklearn.compose.ColumnTransformer.html#sklearn.compose.ColumnTransformer" target="_blank"><strong>ColumnTransformer</strong></a> 的函数,它允许你通过索引或指定列名轻松指定应用最合适的预处理的列。</p>
<h3 id="8-你可以轻松输出管道的-html-表示">8. 你可以轻松输出管道的 HTML 表示</h3>
<p>管道往往会变得相当复杂,特别是在处理实际数据时。因此,Scikit-learn 提供了一种方法来输出 <a href="https://scikit-learn.org/stable/modules/compose.html#visualizing-composite-estimators" target="_blank"><strong>HTML 图示</strong></a> 以显示管道中的步骤非常方便。</p>
<p><img src="https://kdn.flygon.net/docs/img/5427a5b0ffaa48ee38798396281e2b25.png" alt="文章配图" loading="lazy"></p>
<h3 id="9-有一个绘图函数用于可视化树">9. 有一个绘图函数用于可视化树</h3>
<p><code> [**plot_tree()**](https://scikit-learn.org/stable/modules/generated/sklearn.tree.plot_tree.html)</code> 函数允许你创建决策树模型中步骤的图示。</p>
<p><img src="https://kdn.flygon.net/docs/img/e02b4283a42a67f179b6df6016b20cb4.png" alt="文章配图" loading="lazy"></p>
<h3 id="10-有许多第三方库可以扩展-scikit-learn-的功能">10. 有许多第三方库可以扩展 Scikit-learn 的功能</h3>
<p>许多第三方库可以与 Scikit-learn 配合使用,并扩展其功能。</p>
<p>两个示例包括 <a href="http://contrib.scikit-learn.org/category_encoders/" target="_blank"><strong>category-encoders</strong></a> 库,它提供了更多的类别特征预处理方法,以及 <a href="https://eli5.readthedocs.io/en/latest/" target="_blank"><strong>ELI5</strong></a> 包,用于更好的模型解释。</p>
<p>这两个包也可以直接在 Scikit-learn 管道中使用。</p>
<p>感谢阅读!</p>
<p><a href="https://mailchi.mp/ce8ccd91d6d5/datacademy-signup" target="_blank"><strong>我每月发送一次通讯,如果你想加入,请通过这个链接注册。期待成为你学习旅程的一部分!</strong></a></p>
<p><strong>简历: <a href="https://www.linkedin.com/in/rebecca-vickery-20b94133/" target="_blank">Rebecca Vickery</a></strong> 正通过自学数据科学。现任 Holiday Extras 数据科学家。alGo 联合创始人。</p>
<p><a href="https://towardsdatascience.com/10-things-you-didnt-know-about-scikit-learn-cccc94c50e4f" target="_blank">原始链接</a>。经授权转载。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p>可解释机器学习的 Python 库</p>
</li>
<li>
<p>数据科学的五个命令行工具</p>
</li>
<li>
<p>每位数据科学家都应该知道的命令行基础知识</p>
</li>
</ul>
<h3 id="更多相关话题-23">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/09/7-things-didnt-know-could-low-code-tool.html" target="_blank">你不知道的低代码工具的 7 件事</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/07/sas-3-things-didnt-know-sas-academy-data-science.html" target="_blank">你不知道的 SAS 数据科学学院的 3 件事</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/08/4-python-itertools-filter-functions-probably-didnt-know.html" target="_blank">你可能不知道的 4 个 Python Itertools 过滤函数</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/05/6-things-need-know-data-management-matters-computer-vision.html" target="_blank">关于数据管理你需要知道的 6 件事及其重要性…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/08/things-know-scaling-web-datadriven-product.html" target="_blank">扩展你的 Web 数据驱动产品时你应该知道的事</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/08/5-things-need-know-building-llm-applications.html" target="_blank">构建 LLM 应用时需要知道的 5 件事</a></p>
</li>
</ul>
<h1 id="10-个被低估的机器学习-python-包">10 个被低估的机器学习 Python 包</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2021/01/10-underappreciated-python-packages-machine-learning-practitioners.html" target="_blank"><code>www.kdnuggets.com/2021/01/10-underappreciated-python-packages-machine-learning-practitioners.html</code></a></p>
</blockquote>
<p>comments</p>
<p><strong>由<a href="https://vinayprabhu.github.io/" target="_blank">Vinay Uday Prabhu</a>,UnifyID Inc.首席科学家</strong></p>
<p><img src="https://kdn.flygon.net/docs/img/581c9aff740dcd71f1784a23ed38d159.png" alt="Figure" loading="lazy"></p>
<p>这里列出的所有 PyPi 包的汇编</p>
<hr>
<h2 id="我们的前三名课程推荐-8">我们的前三名课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持您组织的 IT</p>
<hr>
<blockquote>
<p>TL-DR: 精心策划的资源:</p>
<p>????????: <a href="https://github.com/vinayprabhu/Favorite_PyPi_2020" target="_blank">Github Repo</a> 其中包含所有图像、代码和图表</p>
<p>???????? : <a href="https://github.com/vinayprabhu/Favorite_PyPi_2020/blob/main/PyPi_2020_collage.pdf" target="_blank">带有可点击链接的 PDF 汇编</a></p>
<p>????????: <a href="https://github.com/vinayprabhu/Favorite_PyPi_2020/blob/main/Colab_Pypi_Top10.ipynb" target="_blank">Colab 笔记本</a></p>
<p>????????: <a href="https://github.com/vinayprabhu/Favorite_PyPi_2020/blob/main/Top_Pypi_2020.html" target="_blank">HTML 文档</a></p>
<p>????????: <a href="https://github.com/vinayprabhu/Favorite_PyPi_2020/blob/main/Top_Pypi_2020.pdf" target="_blank">PDF 格式的笔记本</a></p>
</blockquote>
<h3 id="引言">引言</h3>
<blockquote>
<p><em>“开源的力量就是人民的力量。人民统治”:</em><em><strong>Philippe Kahn</strong></em></p>
</blockquote>
<p>自从我的博士研究主要涉及在<strong>R</strong>(以及坦白说<strong>Octave/MATLAB</strong>)中进行统计分析以来,我就坚定地拥抱了 Python 作为机器学习者/数据科学家/ <em>插入最新职业热词</em>的通用语言。</p>
<p>我的日常工作流程涉及<em>快速</em> <em>响应</em>混乱现实数据的变化,尽管这些数据常常打破了天真的假设。对我而言,研究生院与工业界之间的一个主要区别是征服内心那个驱使你从零开始实现算法的自我。 一旦过了<em>白板/假设建立阶段</em>,我会迅速浏览<a href="https://pypi.org/" target="_blank">PyPi 仓库</a>检查是否已经有相关模块。这通常接着是</p>
<p>*<em>>></em> pip install <em>PACKAGE_NAME</em>***仪式,结果,我发现自己站在开源巨人的肩膀上,利用他们的精心工作来扩展<a href="https://en.wikipedia.org/wiki/DIKW_pyramid" target="_blank">DIKW 金字塔</a>。</p>
<p>我撰写了这篇博客文章,以<em>认可、庆祝并且是,宣传</em>,一些令人惊叹和<em>被低估的</em> PyPi 包,这些包是我过去一年使用的;我强烈认为它们值得我们社区更多的关注和喜爱。这也是我对开源学者的汗水贡献的一次谦逊致敬,这些贡献常常被埋没在<em>pip install</em>命令中。</p>
<p>关于子领域偏差的警告:<em>这篇文章专注于涉及</em><em><strong>神经网络/深度学习</strong></em><em>的机器学习管道。我计划在不久的将来撰写类似专题的博客文章,如时间序列分析和人体运动学分析。</em>✌️</p>
<p>接下来是涵盖的 10 个 PyPi 包的基本介绍:</p>
<p>a) <strong>神经网络架构规范和训练</strong>:<em>NSL-tf</em>、<em>Kymatio</em> 和 <em>LARQ</em></p>
<p>b) <strong>训练后校准和性能基准测试</strong>:<em>NetCal</em>、<em>PyEER</em> 和 <em>Baycomp</em>。</p>
<p>c) <strong>实际部署前的压力测试</strong>:<em>PyOD</em>、<em>HyPPO</em> 和 <em>Gradio</em> d) <strong>文档/传播</strong>:<em>Jupyter_to_medium</em></p>
<h3 id="0-安装上述提到的包-">0: 安装上述提到的包 😃</h3>
<pre><code class="language-py">!pip install --quiet neural-structured-learning
!pip install --quiet larq larq-zoo
!pip install --quiet kymatio
!pip install --quiet netcal
!pip install --quiet baycomp
!pip install --quiet pyeer
!pip install --quiet pyod
!pip install --quiet hyppo
!pip install --quiet gradio
!pip install --quiet jupyter_to_medium
</code></pre>
<h3 id="a-神经网络架构规范和训练nsl-tfkymatio-和-larq">A) 神经网络架构规范和训练:<em>NSL-tf</em>、<em>Kymatio</em> 和 <em>LARQ</em></h3>
<h3 id="1-神经结构学习---tensorflow">1: <a href="https://www.tensorflow.org/neural_structured_learning" target="_blank">神经结构学习 - Tensorflow</a>:</h3>
<p>大多数现成的机器学习分类算法的核心存在<em><strong>i.i.d. 谬论</strong></em>。简而言之,算法设计基于样本在训练集(以及测试集)中是独立且同分布的假设。然而,实际上这很少成立,样本之间存在可以利用的相关性,以实现更好的准确性和解释性。在广泛的应用场景中(见图-1),这些相关性通过一个底层图(G(V,E))被捕获,该图可以是共同挖掘的或统计推断的。例如,如果你正在执行文本推文的情感检测,底层的关注者-被关注者社交图提供了建模<em>社交</em> <em>背景</em>的关键线索,这些背景是推文发布的背景信息。这种社交邻域信息可以被用来执行网络辅助分类,这对防范文本唯一的缺陷如讽刺误检和话题标签劫持至关重要。</p>
<p><img src="https://kdn.flygon.net/docs/img/2944877f0d45bad5f74fd27be3bb672f.png" alt="图示" loading="lazy"></p>
<p>图-1:在线信息图示例</p>
<p>我的<a href="https://kilthub.cmu.edu/articles/thesis/Network_Aided_Classification_and_Detection_of_Data/7430012/1" target="_blank"><strong>博士论文</strong></a>题为“网络辅助的数据分类与检测”字面上探讨了这种图增强机器学习的科学和<em>算法</em>,看到 Tensorflow 发布了<a href="https://www.tensorflow.org/neural_structured_learning" target="_blank"><strong>神经结构学习</strong></a>框架,以及一系列精心制作的教程(YouTube <a href="https://www.youtube.com/watch?v=N_IS3x5wFNI&list=PLS6Lwe0CFTqbS8WxxPmil0mCjAHZ0rD1x&ab_channel=TensorFlow" target="_blank">播放列表</a>),还有一个易于跟随的<a href="https://colab.research.google.com/drive/1yidXh-kM6fMi5c0yEXonvG4GFdcDO0-d#scrollTo=gRfU8T3BTYep&line=2&uniqifier=1" target="_blank"><strong>NSL 示例 colab-notebook</strong></a>,让我感到非常振奋。</p>
<p>在下面的示例单元格中,我们在对抗性环境中训练一个 NSL 增强的神经网络用于标准 MNIST 数据集。</p>
<pre><code class="language-py">import tensorflow as tf
import neural_structured_learning as nsl
import numpy as np
import matplotlib.pyplot as plt
# Prepare data.
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# Create a base model -- sequential, functional, or subclass.
model = tf.keras.Sequential([
tf.keras.Input((28, 28), name='feature'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
# Wrap the model with adversarial regularization.
adv_config = nsl.configs.make_adv_reg_config(multiplier=0.2, adv_step_size=0.05)
adv_model = nsl.keras.AdversarialRegularization(model, adv_config=adv_config)
# Compile, train, and evaluate.
adv_model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
adv_model.fit({'feature': x_train, 'label': y_train}, batch_size=32, epochs=5)
adv_model.evaluate({'feature': x_test, 'label': y_test})Epoch 1/5
1875/1875 [==============================] - 39s 2ms/step - loss: 0.5215 - sparse_categorical_crossentropy: 0.4292 - sparse_categorical_accuracy: 0.8781 - scaled_adversarial_loss: 0.0924
Epoch 2/5
1875/1875 [==============================] - 4s 2ms/step - loss: 0.1447 - sparse_categorical_crossentropy: 0.1171 - sparse_categorical_accuracy: 0.9663 - scaled_adversarial_loss: 0.0276
Epoch 3/5
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0944 - sparse_categorical_crossentropy: 0.0758 - sparse_categorical_accuracy: 0.9770 - scaled_adversarial_loss: 0.0186
Epoch 4/5
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0672 - sparse_categorical_crossentropy: 0.0536 - sparse_categorical_accuracy: 0.9840 - scaled_adversarial_loss: 0.0137
Epoch 5/5
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0532 - sparse_categorical_crossentropy: 0.0421 - sparse_categorical_accuracy: 0.9876 - scaled_adversarial_loss: 0.0111
313/313 [==============================] - 1s 2ms/step - loss: 0.0940 - sparse_categorical_crossentropy: 0.0751 - sparse_categorical_accuracy: 0.9761 - scaled_adversarial_loss: 0.0189
***[0.09399436414241791,
0.07509651780128479,
0.9761000275611877,
0.018897896632552147]***Y_pred_test=adv_model.predict({'feature': x_test, 'label': y_test})
Y_pred_test.shape***(10000, 10)***
</code></pre>
<h3 id="2-kymatio-python-中的小波散射">2: Kymatio: Python 中的小波散射</h3>
<p>这是机器学习中最好的(或最糟糕的?)秘密之一:<em><strong>很多简单的数据集(如 x-mnist 家族 / cats-v-dogs / Hot-Dog 分类)不需要反向传播/SGD 训练技巧</strong></em>。</p>
<p>这些类别足够可分,且架构引导的区分能力足够高,通过使用<a href="https://arxiv.org/pdf/1911.07418.pdf" target="_blank"><strong>Grassmannian 码本</strong></a>或小波滤波器进行仔细初始化,然后进行“最后一层”超平面学习(使用标准回归技术)应该足以获得一个高准确率的分类器。</p>
<p>在这方面,<a href="https://www.kymat.io/" target="_blank"><strong>Kymatio</strong></a>在小波滤波器领域发挥了类似凯撒的角色,将所有以前孤立的项目如 <code>ScatNet</code>、<code>scattering.m</code>、<code>PyScatWave</code>、<code>WaveletScattering.jl</code> 和 <code>PyScatHarm</code> 整合成一个易于使用的整体便携框架,能够无缝地在六对前端-后端中工作:NumPy (CPU)、scikit-learn (CPU)、纯 PyTorch (CPU 和 GPU)、PyTorch+scikit-cuda (GPU)、TensorFlow (CPU 和 GPU) 以及 Keras (CPU 和 GPU)。</p>
<p>在下面的示例单元格中,我们使用内建的 Scattering2D 类来训练另一个 MNIST 神经网络,该网络在 15 个训练周期中达到了 92.84% 的准确率。这个软件包文档非常完善,包含了大量有趣的示例,如使用 1D 变换的<a href="https://www.kymat.io/gallery_1d/plot_classif_torch.html#sphx-glr-gallery-1d-plot-classif-torch-py" target="_blank"><strong>口语数字录音分类</strong></a>和<a href="https://www.kymat.io/gallery_3d/scattering3d_qm7_torch.html#sphx-glr-gallery-3d-scattering3d-qm7-torch-py" target="_blank"><strong>3D 变换量子化学回归</strong></a>。</p>
<pre><code class="language-py"># 1: Importsfrom tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Flatten, Dense
from kymatio.keras import Scattering2D
# Above, we import the Scattering2D class from the kymatio.keras package.# 2: Model definitioninputs = Input(shape=(28, 28))
x = Scattering2D(J=3, L=8)(inputs)
x = Flatten()(x)
x_out = Dense(10, activation='softmax')(x)
model_kymatio = Model(inputs, x_out)
print(model_kymatio.summary())# 3: Compile and trainmodel_kymatio.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])# We then train the model_kymatio using model_kymatio.fit on a subset of the MNIST data.
model_kymatio.fit(x_train[:10000], y_train[:10000], epochs=15,
batch_size=64, validation_split=0.2)
# Finally, we evaluate the model_kymatio on the held-out test data.model_kymatio.evaluate(x_test, y_test)Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 28, 28)] 0
_________________________________________________________________
scattering2d (Scattering2D) (None, 217, 3, 3) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 1953) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 19540
=================================================================
Total params: 19,540
Trainable params: 19,540
Non-trainable params: 0
_________________________________________________________________
313/313 [==============================] - 36s 114ms/step - loss: 0.6448 - accuracy: 0.9285***[0.6448228359222412, 0.9284999966621399]***
</code></pre>
<h3 id="3-larq"><a href="https://docs.larq.dev/zoo/tutorials/" target="_blank">3: LARQ</a></h3>
<p>去年十二月,在温哥华的 NEURIPS-2019 上,我遇到了 LARQ 的开发者,他们展示了他们的新开源 Python 库,用于训练二值化神经网络 (BNNs),同时展示了他们的论文海报,论文标题为<a href="https://papers.nips.cc/paper/2019/file/9ca8c9b0996bbf05ae7753d34667a6fd-Paper.pdf" target="_blank"><em>潜在权重不存在:重新思考二值化</em></a>。</p>
<p>神经网络优化。虽然对于资源受限的设备部署模型压缩似乎有很多兴趣(<a href="https://awesomeopensource.com/projects/model-compression" target="_blank">这里有 42 个</a>!),但从零开始训练快速且简约的二值神经网络似乎是一个许多人在一开始就忽略的选项。</p>
<p>LARQ 包应有助于改变这一情况,考虑到其易用性、快速推断(卷积操作转变为使用二值权重的 xor/位移)、出色的文档和大量的架构示例,用户可以通过完整的模型<em><a href="https://docs.larq.dev/zoo/" target="_blank">zoo</a></em>进行修改。今年,我个人使用 LARQ 发布了关于<em><a href="https://matthewmcateer.me/posts/bnn-nst/" target="_blank">风格迁移</a></em>和一个<em><a href="https://pml4dc.github.io/iclr2020/papers/PML4DC2020_32.pdf" target="_blank">40 kB BiPedalNet 模型</a></em>的工作,使用这个工具包总是非常顺利。除了<em><a href="https://docs.larq.dev/zoo/" target="_blank">Zoo</a></em>,该包还配备了一个高度优化的<em><a href="https://docs.larq.dev/compute-engine/" target="_blank">计算引擎</a></em>,<em>目前支持各种移动平台,已在 Pixel 1 手机和 Raspberry Pi 上进行基准测试,还提供了一个为支持的指令集开发的手工优化的 TensorFlow Lite 自定义操作集合,这些操作是用内联汇编或 C++通过编译器内建函数开发的。</em></p>
<p>在下面的示例代码单元中,我们训练了一个 13.19 KB 的 BNN,它在 MNIST 数据集上经过 6 个周期达到了 98.31%,并演示了如何轻松地从 LARQ-zoo 中提取一个 SOTA 预训练的<em>QuickNet</em>模型并进行推断。</p>
<pre><code class="language-py">import larq as lq
# MODEL DEFINITION (All quantized layers except the first will use the same options)kwargs = dict(input_quantizer="ste_sign",
kernel_quantizer="ste_sign",
kernel_constraint="weight_clip")model_bnn = tf.keras.models.Sequential()# In the first layer we only quantize the weights and not the input
model_bnn.add(lq.layers.QuantConv2D(32, (3, 3),
kernel_quantizer="ste_sign",
kernel_constraint="weight_clip",
use_bias=False,
input_shape=(28, 28, 1)))
model_bnn.add(tf.keras.layers.MaxPooling2D((2, 2)))
model_bnn.add(tf.keras.layers.BatchNormalization(scale=False))model_bnn.add(lq.layers.QuantConv2D(64, (3, 3), use_bias=False, **kwargs))
model_bnn.add(tf.keras.layers.MaxPooling2D((2, 2)))
model_bnn.add(tf.keras.layers.BatchNormalization(scale=False))model_bnn.add(lq.layers.QuantConv2D(64, (3, 3), use_bias=False, **kwargs))
model_bnn.add(tf.keras.layers.BatchNormalization(scale=False))
model_bnn.add(tf.keras.layers.Flatten())model_bnn.add(lq.layers.QuantDense(64, use_bias=False, **kwargs))
model_bnn.add(tf.keras.layers.BatchNormalization(scale=False))
model_bnn.add(lq.layers.QuantDense(10, use_bias=False, **kwargs))
model_bnn.add(tf.keras.layers.BatchNormalization(scale=False))
model_bnn.add(tf.keras.layers.Activation("softmax"))# MODEL DEFINITON AND TRAINING print(lq.models.summary(model_bnn))
model_bnn.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])x_train_bnn = x_train.reshape((60000, 28, 28, 1))
x_test_bnn = x_test.reshape((10000, 28, 28, 1))
model_bnn.fit(x_train_bnn,y_train, batch_size=64, epochs=6)test_loss, test_acc = model_bnn.evaluate(x_test_bnn, y_test)
print(f"Test accuracy {test_acc * 100:.2f} %")
+sequential_1 summary--------------------------+
| Total params 93.6 k |
| Trainable params 93.1 k |
| Non-trainable params 468 |
| Model size 13.19 KiB |
| Model size (8-bit FP weights) 11.82 KiB |
| Float-32 Equivalent 365.45 KiB |
| Compression Ratio of Memory 0.04 |
| Number of MACs 2.79 M |
| Ratio of MACs that are binarized 0.9303 |
+----------------------------------------------+
***None
313/313 [==============================] - 1s 2ms/step - loss: 0.3632 - accuracy: 0.9831
Test accuracy 98.31 %***Y_pred_bnn = model_bnn.predict(x_test_bnn)
y_pred_bnn=np.argmax(Y_pred_bnn,axis=1)
(y_pred_bnn==y_test).mean()***0.9831***import tensorflow_datasets as tfds
import larq_zoo as lqz
from urllib.request import urlopen
from PIL import Image
#####################################img_path = "https://raw.githubusercontent.com/larq/zoo/master/tests/fixtures/elephant.jpg"with urlopen(img_path) as f:
img = Image.open(f).resize((224, 224))x = tf.keras.preprocessing.image.img_to_array(img)
x = lqz.preprocess_input(x)
x = np.expand_dims(x, axis=0)
model = lqz.sota.QuickNet(weights="imagenet")
preds = model.predict(x)
pred_dec=lqz.decode_predictions(preds, top=5)[0]
print(f'Top-5 predictions: {pred_dec}')#####################################pred_dec=lqz.decode_predictions(preds, top=5)[0]
plt.imshow(img)
plt.title(f'Top prediction:\n {pred_dec[0]}');***Top-5 predictions: [('n02504458', 'African_elephant', 0.7053231), ('n01871265', 'tusker', 0.2933379), ('n02504013', 'Indian_elephant', 0.001338586), ('n02408429', 'water_buffalo', 7.938418e-08), ('n01704323', 'triceratops', 7.2361296e-08)]***
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/a6780fad5a800441cfe7fcb83d032f80.png" alt="png" loading="lazy"></p>
<h3 id="b-训练后校准和性能基准测试netcalpyeer-和-baycomp">B) 训练后校准和性能基准测试:NetCal、PyEER 和 BayComp</h3>
<p>在本节中,我们将查看在训练后、部署前场景中有用的包,其中从业者的目标是校准预训练模型的输出,并严格基准测试多个适合部署的模型的性能。</p>
<h3 id="1-netcal"><a href="https://pypi.org/project/netcal/" target="_blank">1: Netcal</a>:</h3>
<p><img src="https://kdn.flygon.net/docs/img/32e6d40a03a71407982fa90300c831bc.png" alt="图" loading="lazy"></p>
<p>图-2:缩放与分箱与缩放-分箱。‘B’表示模型的不同概率数</p>
<p>输出。来源:<a href="https://arxiv.org/pdf/1909.10155.pdf" target="_blank"><code>arxiv.org/pdf/1909.10155.pdf</code></a></p>
<p>我常常看到机器学习从业者误认为输出的<em>softmax</em>值和概率是等同的。它们远非如此!它们在(0,1]空间中的共存使它们伪装成概率,但‘原始’softmax 值,嗯,可以说是‘<a href="https://arxiv.org/pdf/1706.04599.pdf" target="_blank">未校准</a>’。因此,训练后校准是深度学习中快速增长的工作领域,这里提出的技术大致分为三类(见图-2):</p>
<ul>
<li>
<p>分箱(例如:直方图分箱、等距回归、贝叶斯分箱到分位数(BBQ)、近似等距回归集成(ENIR))</p>
</li>
<li>
<p>缩放(例如: Logistic 校准/Platt 缩放,温度缩放,Beta 校准)</p>
</li>
<li>
<p><a href="https://arxiv.org/pdf/1909.10155.pdf" target="_blank">混合缩放-分箱</a> (Python 库: <a href="https://pypi.org/project/uncertainty-calibration" target="_blank"><code>pypi.org/project/uncertainty-calibration</code></a>)</p>
</li>
</ul>
<p>关于上述所有分箱和缩放技术,具有极好编写文档的实现可以在 NetCal 中找到。该包还包括生成可靠性图和估计校准误差指标(如期望/最大/平均校准误差)的原语。</p>
<p>在下面的单元格中,我们使用从上述 NSL 训练模型获得的 MNIST 测试集上的 softmax 值来演示温度缩放校准和可靠性图生成例程的使用。</p>
<pre><code class="language-py"># In case you also want to try the scaling-binning calibration: #!pip3 install git+https://github.com/p-lambda/verified_calibration.git # PyPi--> Kaputfrom netcal.scaling import TemperatureScaling
import matplotlib.pyplot as plt
### Initialize and transform
temperature = TemperatureScaling()
temperature.fit(Y_pred_test, y_test)
calibrated = temperature.transform(Y_pred_test)
### Visualization
fig, axes = plt.subplots(nrows=1, ncols=2,figsize=(10,4))
axes[0].matshow(Y_pred_test.T,aspect='auto', cmap='jet')
axes[0].set_title("Original Uncalibrated softmax")
axes[0].set_xlabel("Test image index (10k images)")
axes[0].set_ylabel("Class index")
# axes[0].set_xticks([])
axes[1].matshow(calibrated.T,aspect='auto', cmap='jet')
axes[1].set_title("T-scaled softmax")
axes[1].set_xlabel("Test image index (10k images)")
# axes[1].set_xticks([])
plt.tight_layout()
plt.show()
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/d5cc7402f1bff615fa0059bf41206c80.png" alt="png" loading="lazy"></p>
<pre><code class="language-py">y_pred_nsl=np.argmax(Y_pred_test,axis=1)
ind_correct=np.where(y_pred_nsl==y_test)[0]
ind_wrong=np.where(y_pred_nsl!=y_test)[0]plt.figure(figsize=(10,4))
for i in range(5):
plt.subplot(1,5,i+1)
ind_i=ind_correct[i]
plt.imshow(x_test[ind_i],cmap='gray_r')
class_pred_i=np.argmax(Y_pred_test[ind_i,:])
softmax_uncalib_i=str(np.round(Y_pred_test[ind_i,class_pred_i],3))
softmax_calib_i=str(np.round(calibrated[ind_i,class_pred_i],3))
plt.title(f'{class_pred_i} | {softmax_uncalib_i} | {softmax_calib_i}')
plt.tight_layout()
plt.suptitle('Correct predictions \n Class | Uncalibrated | Calibrated');
#############################################
plt.figure(figsize=(10,4))
for i in range(5):
plt.subplot(1,5,i+1)
ind_i=ind_wrong[i]
plt.imshow(x_test[ind_i],cmap='gray_r')
class_pred_i=np.argmax(Y_pred_test[ind_i,:])
softmax_uncalib_i=str(np.round(Y_pred_test[ind_i,class_pred_i],3))
softmax_calib_i=str(np.round(calibrated[ind_i,class_pred_i],3))
plt.title(f'{class_pred_i} | {softmax_uncalib_i} | {softmax_calib_i}')
plt.tight_layout()
plt.suptitle('Wrong predictions \n Class | Uncalibrated | Calibrated');
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/69889862580274b1cdc38edc66102162.png" alt="png" loading="lazy"></p>
<p><img src="https://kdn.flygon.net/docs/img/daa5d781ae7379488957133f289260c2.png" alt="png" loading="lazy"></p>
<pre><code class="language-py">from netcal.presentation import ReliabilityDiagram
n_bins = 10
diagram = ReliabilityDiagram(n_bins)
diagram.plot(Y_pred_test, y_test) # visualize miscalibration of uncalibrated
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/af4846a01cfe622db1c26cb4d13f6a83.png" alt="png" loading="lazy"></p>
<h3 id="2-baycomp-你认为你有一个更好的分类器吗"><a href="https://baycomp.readthedocs.io/" target="_blank">2: Baycomp</a>: 你认为你有一个更好的分类器吗?</h3>
<p>一个被低估的难题是,机器学习从业者以及在某些方面,研究论文审稿人,如何严格确定一个分类器模型相对于其他模型的预测优势。像 <a href="https://paperswithcode.com/" target="_blank">Papers with code</a> 这样的平台通过错误地将 top-1 准确度指标(见下图)作为决定性度量,进一步传播了这种模型排名的误区。</p>
<p><img src="https://kdn.flygon.net/docs/img/1a89fad6cb754f68e51ad5bae2408900.png" alt="Figure" loading="lazy"></p>
<p>来源: <a href="https://paperswithcode.com/sota/image-classification-on-inaturalist-2018" target="_blank"><code>paperswithcode.com/sota/image-classification-on-inaturalist-2018</code></a></p>
<p>那么,考虑到两个具有类似工程开销的分类模型,你如何选择其中一个而不是另一个?通常,我们有一个标准基准数据集(或一组数据集),作为分类器竞争的测试平台。在获得‘<em>该数据集空间的原始准确度指标</em>’后,统计思维的机器学习者可能会倾向于使用来自频率学派零假设显著性测试(NHST)框架的工具来确定哪个分类器‘更好’。然而,如 <a href="https://www.jmlr.org/papers/volume18/16-305/16-305.pdf" target="_blank">这里</a> 所述,“<em>许多科学领域意识到频率学推理的局限性,在最激进的情况下甚至禁止在出版物中使用它</em>”。</p>
<p>Baycomp 在这种背景下出现,提供了一个 <em><strong>用于比较分类器的贝叶斯框架</strong></em>。该库帮助计算三个概率:</p>
<ul>
<li>
<p>P_left: 第一个分类器比第二个分类器具有更高准确度得分的概率。</p>
</li>
<li>
<p>P_rope: 差异在实际等效区域(rope)内的概率</p>
</li>
<li>
<p>P_right: 第二个分类器具有更高得分的概率。</p>
</li>
</ul>
<p><strong>实用等效区域</strong>(rope)由机器学习者指定,该学习者对在部署领域中可以安全假设为<em>等效</em>的内容非常熟悉。</p>
<p>在下面的示例单元中,我们考虑了一个合成示例,其中包括两个紧密竞争的分类器以及我们刚刚使用 NSL-TF 和 LARQ-BNN 框架在 MNIST 数据集上训练的两个分类器。</p>
<pre><code class="language-py"># Helper function to plot the accuracies
def bar_plt2(acc_1,acc_2,label_1='Legacy classifier',label_2='New classifier',X_LABELS=['default'],Category_x='Dataset'):
# set width of bar
if(X_LABELS==['default']):
X_LABELS=list(string.ascii_uppercase[0:len(acc_1)])
barWidth = 0.25
# Set position of bar on X axis
r1 = np.arange(len(acc_1))
r2 = [x + barWidth for x in r1]
# Make the plot
plt.bar(r1, acc_1, color='#7f6d5f', width=barWidth, edgecolor='white', label=label_1)
plt.bar(r2, acc_2, color='#557f2d', width=barWidth, edgecolor='white', label=label_2)
# Add xticks on the middle of the group bars
plt.xlabel(Category_x, fontweight='bold')
plt.xticks([r + barWidth for r in range(len(acc_1))],X_LABELS)
plt.title('Accuracy comparison of the two classifiers')
# Create legend & Show graphic
plt.legend()
plt.show()
return Noneimport string
from baycomp import *
# First, let us generate two synthetic classifier accuracy vectors across 10 hypothetical datasets.
# Accuracies obtained by a legacy classifier
classifier_legacy_acc=np.random.randint(80,85,size=(10))
mean_legacy=np.mean(classifier_legacy_acc)
# Accuracies obtained by a new-proposed classifier
classifier_new_acc=np.random.randint(80,87,size=(10))
mean_new=np.mean(classifier_new_acc)
print(f'The mean accuracies of the two classifiers are: {mean_legacy} and {mean_new}')
bar_plt2(classifier_legacy_acc,classifier_new_acc)The mean accuracies of the two classifiers are: 82.0 and 81.8
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/2d6d7dda04dc122e5edcebdba65f2f69.png" alt="png" loading="lazy"></p>
<pre><code class="language-py">print('$p_{left}, p_{rope},p_{right}$ using the two_on_multiple function: ')
print(two_on_multiple(classifier_legacy_acc, classifier_new_acc, rope=1))
# With some additional arguments, the function can also plot the posterior distribution from
# which these probabilities came.
# Tests are packed into test classes.
# The above call is equivalent to
print('$p_{left}, p_{rope},p_{right}$ using the SignedRankTest.probs function: ')
print(SignedRankTest.probs(classifier_legacy_acc, classifier_new_acc, rope=1))
# and to get a plot, we call
print(SignedRankTest.plot(classifier_legacy_acc, classifier_new_acc, rope=1, names=("Legacy-SRT", "New-SRT")))
# To switch to another test, use another class:
SignTest.probs(classifier_legacy_acc, classifier_new_acc, rope=1)
# Finally, we can construct and query sampled posterior distributions.
posterior = SignedRankTest(classifier_legacy_acc, classifier_new_acc, rope=1)
print(posterior.probs())
posterior.plot(names=("legacy-Post", "new-Post"))$p_{left}, p_{rope},p_{right}$ using the two_on_multiple function:
(0.28222, 0.4604, 0.25738)
$p_{left}, p_{rope},p_{right}$ using the SignedRankTest.probs function:
***(0.28056, 0.46356, 0.25588)***
######################################################
acc_bnn=np.zeros(10)
acc_nsl=np.zeros(10)
for c in range(10):
mask_c=y_test==c
acc_bnn[c]= (y_pred_bnn[mask_c]==c).mean()
acc_nsl[c]= (y_pred_nsl[mask_c]==c).mean()
bar_plt2(acc_nsl,acc_bnn,label_1='NSL',label_2='BNN',X_LABELS=list(np.arange(10).astype(str)),Category_x='MNIST digit classes')
posterior = SignedRankTest(acc_nsl, acc_bnn, rope=0.005)
print(posterior.probs())
posterior.plot(names=("NSL", "BNN"))
***(0.0, 0.2846, 0.7154)***
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/c2a73cc8cfd3d6f173d37301cacecd95.png" alt="png" loading="lazy"></p>
<p><img src="https://kdn.flygon.net/docs/img/91a01fb33e6680632e0490584b6e874d.png" alt="图" loading="lazy"></p>
<p>使用 baycomp 比较分类器 +NSL 与 BNN 分类器在 MNIST 数据集上的比较</p>
<p><em><strong>重要警告</strong></em>:<em>有关机器学习中预测准确性崇拜的相关但不同的讨论。这</em><a href="https://plato.stanford.edu/entries/prediction-accommodation/#:~:text=The%20view%20that%20predictions%20are,when%20predicted%20than%20when%20accommodated." target="_blank"><em>预测主义与适应辩论</em></a><em>在科学中自 19 世纪的约翰·赫歇尔和威廉·惠更斯时代以来一直在演变。</em></p>
<h3 id="3-pyeer"><a href="https://pypi.org/project/pyeer/" target="_blank">3: PyEER</a></h3>
<p><img src="https://kdn.flygon.net/docs/img/fe59eb7b9ce52d039f05b4232f0ce982.png" alt="图" loading="lazy"></p>
<p>PyEER 中可用的方法广泛</p>
<p>比较两个分类器的另一种方法,特别是在解决二元身份验证问题的背景下(而非<em>监控</em>而是<em>身份验证</em>),是通过绘制比较检测错误权衡(DET)和接收器操作特性(ROC)图。PyEER 在这方面是绝对的杰作,因为它不仅可以绘制相关图形,还能自动生成指标报告和估算 EER 最佳阈值。在下面的示例单元中,我们比较了即将在下一节介绍的角度基础异常检测器(ABOD)和 KNN 内点-外点检测器二元分类器。</p>
<pre><code class="language-py">from pyeer.eer_info import get_eer_stats
from pyeer.report import generate_eer_report, export_error_rates
from pyeer.plot import plot_eer_stats
# Gather up all the 'Genuine scores' and the 'impostor scores'
gscores_abod=y_test_proba_abod[y_test_ood==0,0]
iscores_abod=y_test_proba_abod[y_test_ood==1,0]
gscores_knn=y_test_proba_knn[y_test_ood==0,0]
iscores_knn=y_test_proba_knn[y_test_ood==1,0]
# Calculating stats for classifier A
stats_abod = get_eer_stats(gscores_abod, iscores_abod)
# Calculating stats for classifier B
stats_knn = get_eer_stats(gscores_knn, iscores_knn)
print(f'EER-KNN = {stats_knn.eer}, EER-ABOD = {stats_abod.eer}')
plot_eer_stats([stats_abod, stats_knn], ['ABOD', 'KNN'])##############################
import matplotlib.image as mpimg
img1 = mpimg.imread('DET.png')
img2 = mpimg.imread('ROC.png')
plt.figure(figsize=(9,4))
plt.subplot(121)
plt.imshow(img1)
plt.subplot(122)
plt.imshow(img2)
plt.show()EER-KNN = 0.0, EER-ABOD = 0.008333333333333333
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/96d46c201082e58e04fc232d1fa08fb2.png" alt="png" loading="lazy"></p>
<h3 id="c-现实世界部署前的压力测试pyodhyppo-和-gradio">C: 现实世界部署前的压力测试:PyOD、HyPPO 和 Gradio</h3>
<p><img src="https://kdn.flygon.net/docs/img/17ec9df55fe6dd212daf2484e5a6f557.png" alt="图" loading="lazy"></p>
<p>OOD 易感性的全景:访问 SVG <a href="https://matthew-mcateer.github.io/oodles-of-oods/" target="_blank">这里</a></p>
<p>对于外部分布(OOD)样本造成的自信错误预测,目前是从理论论文过渡到现实世界部署中最严重的障碍之一,因为输入没有从所谓的<em>训练流形</em>中获得保证。在与<a href="https://matthew-mcateer.github.io/oodles-of-oods/" target="_blank">Matthew McAteer</a>的联合项目中,我创建了一个易感性全景(见上图),这应该能够帮助机器学习者覆盖与他们的模型相关的广泛特定易感性向量。</p>
<p>虽然没有银弹(可能永远也不会有——见 <a href="https://arxiv.org/pdf/1802.08686.pdf" target="_blank">这篇</a> 和 <a href="https://arxiv.org/abs/1809.02104" target="_blank">这篇</a>),但很难反对在你的管道中加入 OOD 模型正则化和 OOD 检测模块。</p>
<p>关于 OOD 检测,我认为 ML 社区有三项近期努力被低估了。</p>
<p>前两个, <em>PyOD</em> 和 <em>HyPPO</em>,在进行推理前有助于预筛选输入,而第三个,Gradio,是一个出色的人机交互白帽压力测试工具,补充了如 <a href="https://dynabench.org/" target="_blank">Dynabench</a> 这样的 FAIR 努力。</p>
<h3 id="1-pyod"><a href="https://pyod.readthedocs.io/en/latest/" target="_blank">1: PYOD</a></h3>
<p><img src="https://kdn.flygon.net/docs/img/f1cb5578bfaf5d746d6dc6a33256602b.png" alt="图示" loading="lazy"></p>
<p>来源:<a href="https://www.jmlr.org/papers/volume20/19-011/19-011.pdf" target="_blank"><code>www.jmlr.org/papers/volume20/19-011/19-011.pdf</code></a></p>
<p>PyOD 可以说是最全面和可扩展的异常检测 Python 工具包,包含了 30 多种检测算法的实现!</p>
<p>学生维护的 PyPi 包能够结合软件工程最佳实践,这确保了实现的模型类都经过了单元测试、跨平台持续集成、代码覆盖率和代码可维护性检查,这种情况比较少见。这与清晰统一的 API、详细的文档以及即时(JIT)编译执行相结合,使得学习不同技术和实际使用变得异常轻松。作者在仔细并行化方面投入的努力,使得异常检测代码不仅非常快速且可扩展,而且在 <em>Python 2 和 3 及主要操作系统(Windows、Linux 和 MacOS)</em> 上也无缝兼容。</p>
<p>在下面的示例单元格中,我们训练并可视化了两个内点-外点检测器二元分类器在一个合成数据集上的结果:角度基础异常检测器(ABOD)和 KNN 异常检测器。</p>
<pre><code class="language-py">from pyod.models.abod import ABOD
from pyod.models.knn import KNN # kNN detector
from pyod.utils.data import generate_data
from pyod.utils.data import evaluate_print
from pyod.utils.example import visualize
# Generate sample data with pyod.utils.data.generate_data():contamination = 0.4 # percentage of outliers
n_train = 200 # number of training points
n_test = 100 # number of testing pointsX_train_ood, y_train_ood, X_test_ood, y_test_ood = generate_data(n_train=n_train, n_test=n_test, contamination=contamination)
##### 1: ABOD
clf_name_1 = 'ABOD'
clf_abod = ABOD(method="fast") # initialize detector
clf_abod.fit(X_train_ood)y_train_pred_abod = clf_abod.predict(X_train_ood) # binary labels
y_test_pred_abod = clf_abod.predict(X_test_ood) # binary labelsy_test_scores_abod = clf_abod.decision_function(X_test_ood) # raw outlier scores
y_test_proba_abod = clf_abod.predict_proba(X_test_ood) # outlier probabilityevaluate_print("ABOD", y_test_ood, y_test_scores_abod) # performance evaluation####### 2 : KNN
clf_knn = KNN() # initialize detector
clf_knn.fit(X_train_ood)y_train_pred_knn = clf_knn.predict(X_train_ood) # binary labels
y_test_pred_knn = clf_knn.predict(X_test_ood) # binary labelsy_test_scores_knn = clf_knn.decision_function(X_test_ood) # raw outlier scores
y_test_proba_knn = clf_knn.predict_proba(X_test_ood) # outlier probabilityevaluate_print("KNN", y_test_ood, y_test_scores_knn) # performance evaluationABOD ROC:0.9992, precision @ rank n:0.975
KNN ROC:1.0, precision @ rank n:1.0
</code></pre>
<p>现在,让我们可视化结果:</p>
<pre><code class="language-py"># ABOD Performance
visualize("ABOD", X_train_ood, y_train_ood, X_test_ood, y_test_ood, y_train_pred_abod,
y_test_pred_abod, show_figure=True, save_figure=False)
# KNN Performance;
visualize("KNN", X_train_ood, y_train_ood, X_test_ood, y_test_ood, y_train_pred_knn,
y_test_pred_knn, show_figure=True, save_figure=False)
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/b1e03b0842cef601d3e1bd7dce0867b8.png" alt="图示" loading="lazy"></p>
<p>ABOD 与 KNN 在异常检测中的对比</p>
<h3 id="2-hyppo"><a href="https://hyppo.neurodata.io/index.html" target="_blank">2: Hyppo</a>:</h3>
<p>目睹深度学习社区普遍存在这种集体遗忘现象,继续将 OOD 易感性视为一种独特的“深度神经网络”缺陷,似乎需要一个深度学习解决方案,而完全忽视了统计学社区已经探索过的一系列方法和解决方案,这有些令人困惑。</p>
<p>有人可能会认为,按定义,OOD(异常检测)属于多变量假设检验框架的范畴,因此看到深度学习 OOD 论文没有将其炫目的新深度方法与可能存在的传统假设检验算法进行基准测试,实在令人沮丧。在这种背景下,我们现在介绍 HYPPO。</p>
<p>HYPPO(<strong>HYP</strong>othesis Testing in <strong>P</strong>yth<strong>O</strong>n,发音为“Hippo”)可以说是由<a href="https://neurodata.io/" target="_blank">NEURODATA</a>社区生产的最全面的开源多变量假设检验软件包。在下图中,我们可以看到这个包中实现的模块的全景,涵盖了合成数据生成(具有 20 种依赖结构!)、独立性测试、K 样本测试以及时间序列测试。</p>
<p><img src="https://kdn.flygon.net/docs/img/a278d6ff3db81a5ad235291b15bde662.png" alt="图" loading="lazy"></p>
<p>Hyppo 中实现的算法全景</p>
<p>在下面的示例单元格中,我们看到使用 K-Sample-Distance Correlation(或称“Dcorr”)测试来检验 PyOD 中 generate_data()模块生成的内外分布数据。在深度学习环境中,我们可以在输入层级别或特征嵌入空间中部署这些测试,以估计输出的 softmax 值是否值得进一步在推理管道中处理。</p>
<pre><code class="language-py">from hyppo.ksample import KSample
samp_in_train= X_train_ood[y_train_ood==0]
samp_out_train= X_train_ood[y_train_ood==1]
samp_in_test= X_test_ood[y_test_ood==0]
samp_out_test= X_test_ood[y_test_ood==1]
stat_in_out, pvalue_in_out = KSample("Dcorr").test(samp_in_train, samp_out_test)
print(f'In-train v/s Out-test \n Energy test statistic: {stat_in_out}. Energy p-value: {pvalue_in_out}')
stat_out_in, pvalue_out_in = KSample("Dcorr").test(samp_in_test, samp_out_train)
print(f'In-test v/s Out-train \n Energy test statistic: {stat_out_in}. Energy p-value: {pvalue_out_in}')
stat_in_in, pvalue_in_in = KSample("Dcorr").test(samp_in_train, samp_in_test)
print(f'In-train v/s In-test \n Energy test statistic: {stat_in_in}. Energy p-value: {pvalue_in_in}')
stat_out_out, pvalue_out_out = KSample("Dcorr").test(samp_out_train, samp_out_test)
print(f'Out-train v/s Out-test \n Energy test statistic: {stat_out_out}. Energy p-value: {pvalue_out_out}')In-train v/s Out-test
Energy test statistic: 0.8626341445137959\. Energy p-value: 4.357148137679374e-32
In-test v/s Out-train
Energy test statistic: 0.7584832208162725\. Energy p-value: 4.0495216242247524e-25
In-train v/s In-test
Energy test statistic: -0.005691336487203311\. Energy p-value: 1.0
Out-train v/s Out-test
Energy test statistic: 0.006631965940452427\. Energy p-value: 0.18021672902891694
</code></pre>
<h3 id="3-gradio"><a href="https://gradio.app/ml_examples" target="_blank">3: Gradio</a>:</h3>
<p><img src="https://kdn.flygon.net/docs/img/f63344218fef2c36bef52b79235e381e.png" alt="图" loading="lazy"></p>
<p>Gradio 的显著性裁剪算法:<a href="http://saliency-model.gradiohub.com/" target="_blank"><code>saliency-model.gradiohub.com/</code></a></p>
<p>迄今为止,与刚刚训练的模型交互所需的良好 GUI 通常需要大量的 JavaScript 前端技巧或 Heroku-Flask 路线,这可能会使算法的重点分散。</p>
<p>借助 Gradio,可以用不到 10 行 Python 代码快速启动一个 GUI,包含文本输入、图像输入(配备了出色的 Toast-UI 图像编辑器)和一个素描板!</p>
<p>在过去的一年里,我在工作流程中大量使用了 Gradio,用它来调查 Twitter 的显著性裁剪算法为何会产生如此种族偏见的结果(见左图),以及为什么 Onions 会触发<a href="https://www.bbc.com/news/54467384" target="_blank">facebook</a>上的 NSFW 过滤器(见下方推文)。</p>
<p><a href="https://github.com/vinayprabhu/Crimes_of_Vision_Datasets/blob/master/Notebooks/Notebook_5b_Onion_Gradio_NSFW.ipynb" target="_blank">NSFW-Onion</a>的灾难。Colab 笔记本:<a href="https://github.com/vinayprabhu/Crimes_of_Vision_Datasets/blob/master/Notebooks/Notebook_5b_Onion_Gradio_NSFW.ipynb" target="_blank"><code>github.com/vinayprabhu/Crimes_of_Vision_Datasets/blob/master/Notebooks/Notebook_5b_Onion_Gradio_NSFW.ipynb</code></a></p>
<p>在下面的示例单元格中,我们展示了两个简单的示例,使用 Gradio 启动 UI,以对我们刚刚训练的 MNIST 分类 BNN 模型进行压力测试,并演示了使用 InceptionV3 模型进行图像分类的简便性。Gradio 团队还迅速添加了解释性和嵌入可视化工具,并实现了 SOTA 的<a href="https://gradio.app/g/dawoodkhan82/dan" target="_blank">盲超分辨率</a>和<a href="https://gradio.app/g/BackgroundMattingV2" target="_blank">实时高分辨率背景抠图</a> UI!</p>
<pre><code class="language-py">import gradio as gr
import requests
inception_net = tf.keras.applications.InceptionV3() # load the model
# Download human-readable labels for ImageNet.
response = requests.get("https://git.io/JJkYN")
labels = response.text.split("\n")
def classify_image(inp):
print(inp.shape)
inp = inp.reshape((-1, 299, 299, 3))
inp = tf.keras.applications.inception_v3.preprocess_input(inp)
prediction = inception_net.predict(inp).flatten()
return {labels[i]: float(prediction[i]) for i in range(1000)}
image = gr.inputs.Image(shape=(299, 299, 3))
label = gr.outputs.Label(num_top_classes=3)
gr.Interface(fn=classify_image, inputs=image, outputs=label, capture_session=True).launch()import gradio as gr
import requests
# EXAMPLE-1:We use the LARQ trained BNN to launch an interactive UI that facilitates a sktechpad inoput and prediction
def classify(image):
print(image.shape)
prediction = model_bnn.predict(image.reshape((-1,28,28,1))).tolist()[0]
return {str(i): prediction[i] for i in range(10)}
sketchpad = gr.inputs.Sketchpad()
label = gr.outputs.Label(num_top_classes=3)
gr.Interface(fn=classify, inputs=sketchpad, outputs=label, capture_session=True).launch()# EXAMPLE-2:Image-classifcation with InceptionNet-V3inception_net = tf.keras.applications.InceptionV3() # load the model
# Download human-readable labels for ImageNet.
response = requests.get("https://git.io/JJkYN")
labels = response.text.split("\n")
def classify_image(inp):
print(inp.shape)
inp = inp.reshape((-1, 299, 299, 3))
inp = tf.keras.applications.inception_v3.preprocess_input(inp)
prediction = inception_net.predict(inp).flatten()
return {labels[i]: float(prediction[i]) for i in range(1000)}
image = gr.inputs.Image(shape=(299, 299))
label = gr.outputs.Label(num_top_classes=3)
gr.Interface(fn=classify_image, inputs=image, outputs=label, capture_session=True).launch()
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/9b5d730fae41a829217dfe3fbcc4ab6c.png" alt="图" loading="lazy"></p>
<p>Gradio MNIST 分类与草图输入<img src="https://kdn.flygon.net/docs/img/ead2537d8637878a263a7c0101d030a7.png" alt="图示" loading="lazy"></p>
<p>Gradio 图像分类(InceptionV3)与图像输入</p>
<h3 id="d-文档传播">D) 文档/传播:</h3>
<h3 id="1-jupyter_to_medium">1) Jupyter_to_medium:</h3>
<p><img src="https://kdn.flygon.net/docs/img/45bb652f1b909dd4c89ef395ee1ae867.png" alt="图示" loading="lazy"></p>
<p>示例图像。来源:<a href="https://www.dexplo.org/jupyter_to_medium/" target="_blank"><code>www.dexplo.org/jupyter_to_medium/</code></a></p>
<p><em>Jupyter_to_medium 包</em> 的视频教程</p>
<p>最后但同样重要的是,我使用了<em>Jupyter_to_medium</em> PyPi 包来撰写本博客文章,来源于它的<a href="https://github.com/vinayprabhu/Favorite_PyPi_2020" target="_blank">source notebook</a>! 正如你们中的许多人可能经历过的,将你的 Jupyter/Colab 笔记本转换为可读的博客文章涉及到痛苦的复制粘贴、代码截图和插件花招。自从这个改变游戏规则的包发布以来,这些问题已经成为过去。</p>
<p>这个过程非常简单:pip 安装,完成笔记本,选择文件→‘部署为’,插入来自 medium 的集成令牌,然后进行最终编辑/美化(如有必要)。</p>
<p>最后,我要感谢那些创造了这些精彩 PyPi 包的杰出研究人员和工程师。在即将到来的博客文章中,我计划涵盖与特定主题相关的包,如时间序列分析和降维。这里有一张回顾图片,总结了上述探索的包。</p>
<p><img src="https://kdn.flygon.net/docs/img/b0ff25585442b78ff440f70a0a846a2b.png" alt="图示" loading="lazy"></p>
<p>本博客文章中涵盖的 PyPi 生态系统回顾</p>
<p>希望你们中的一些人在机器学习冒险中能发现这篇博客文章有所帮助。祝好运,并祝大家 2021 年快乐高效 ????</p>
<p>随时欢迎对内容/错误/坏链进行反馈。你可以通过<a href="https://www.linkedin.com/in/vinay-prabhu-84619785/" target="_blank">Linkedin</a>或<a href="https://twitter.com/vinayprabhu" target="_blank">Twitter</a>与我联系 ????</p>
<p><strong>个人简介:<a href="https://vinayprabhu.github.io/" target="_blank">Vinay Uday Prabhu</a></strong> 是 UnifyID Inc. 的首席科学家。</p>
<p><a href="https://towardsdatascience.com/most-useful-machine-learning-pypi-packages-of-2020-a0ec6678ce22" target="_blank">原文</a>。已获许可转载。</p>
<p><strong>相关内容:</strong></p>
<ul>
<li>
<p>数据科学作为产品 – 为什么这么难?</p>
</li>
<li>
<p>生成美丽的神经网络可视化</p>
</li>
<li>
<p>使用 Pomegranate 进行快速直观的统计建模</p>
</li>
</ul>
<h3 id="更多相关话题-24">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-key-skills-needed-become-great-data-scientist.html" target="_blank">成为出色数据科学家所需的 5 个关键技能</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/6-predictive-models-every-beginner-data-scientist-master.html" target="_blank">每个初学数据科学家都应该掌握的 6 种预测模型</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/mozart-best-etl-tools-2021.html" target="_blank">2021 年最佳 ETL 工具</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/write-clean-python-code-pipes.html" target="_blank">使用管道编写干净的 Python 代码</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/makes-python-ideal-programming-language-startups.html" target="_blank">是什么使得 Python 成为初创公司理想的编程语言</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/three-r-libraries-every-data-scientist-know-even-python.html" target="_blank">每个数据科学家都应该知道的三大 R 库(即使你使用 Python)</a></p>
</li>
</ul>
<h1 id="10-个被低估的-python-技能">10 个被低估的 Python 技能</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2020/10/10-underrated-python-skills.html" target="_blank"><code>www.kdnuggets.com/2020/10/10-underrated-python-skills.html</code></a></p>
</blockquote>
<p>评论 <img src="https://kdn.flygon.net/docs/img/ba293eb99023d78b02241f8edbd8dc5d.png" alt="图" loading="lazy"></p>
<p>照片由<a href="https://www.pexels.com/@roseleon?utm_content=attributionCopyText&utm_medium=referral&utm_source=pexels" target="_blank">杰曼·乌林瓦</a>提供,来源于<a href="https://www.pexels.com/photo/photo-of-woman-leaning-on-wooden-fence-3321584/?utm_content=attributionCopyText&utm_medium=referral&utm_source=pexels" target="_blank">Pexels</a>。</p>
<hr>
<h2 id="我们的前三个课程推荐-23">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业的快车道。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析能力</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你组织的 IT 需求</p>
<hr>
<p>在 2012 年的一篇文章中,<em><a href="https://hbr.org/2012/10/data-scientist-the-sexiest-job-of-the-21st-century" target="_blank">哈佛商业评论</a></em>描绘了<a href="https://medium.com/atlas-research/data-science-team-eae84b1af65d" target="_blank">data science teams</a>从数据中轻松创建可操作信息的愿景。</p>
<p>虽然这还不是<em>海滩救护队</em>,但数据科学是一个充满活力的领域,具有从组织的顶级战略资产——优良的数据基础设施中产生有价值见解的巨大潜力。</p>
<p>为了帮助你的数据科学工作,这里有<strong>十个被低估的 Python 技能</strong>。掌握这些能力会——我敢说——使你成为一个更具吸引力的数据科学家。我们的团队兼具美貌与智慧,同时推动极限,拯救处于危险中的人,并做出英雄般的行为。所以让我们开始吧。</p>
<h3 id="10--设置虚拟环境">#10 — 设置虚拟环境</h3>
<p>虚拟环境为你的 Python 项目设置了一个隔离的工作空间。无论你是独立工作还是与合作伙伴一起工作,拥有一个虚拟环境都有以下好处:</p>
<ol>
<li>
<p>避免包冲突</p>
</li>
<li>
<p>提供清晰的视角,查看包的安装位置</p>
</li>
<li>
<p>确保项目中使用的包版本的一致性</p>
</li>
</ol>
<p>使用虚拟环境允许你(和你的团队成员)为不同的项目拥有不同的依赖项。在虚拟环境中,你可以测试安装包而不会污染系统安装。</p>
<p><img src="https://kdn.flygon.net/docs/img/b3c5e42fdd2745052866edb39f1db8f3.png" alt="图" loading="lazy"></p>
<p>“我有点喜欢这里。它很私密。”——<em>《神秘博士》</em>的杰米·海涅曼。照片由<a href="https://unsplash.com/@nasa?utm_source=medium&utm_medium=referral" target="_blank">NASA</a>提供,来源于<a href="https://unsplash.com/?utm_source=medium&utm_medium=referral" target="_blank">Unsplash</a>。</p>
<p>部署 <a href="https://docs.python.org/3/library/venv.html" target="_blank">venv 模块</a> 对于避免后续问题非常有帮助,所以在开始你的项目时不要跳过这一步。</p>
<p><a href="https://avilpage.com/2020/02/reduce-python-package-footprint.html" target="_blank"><em>了解更多</em></a><em>:通过设置一个包含最常用科学计算包的虚拟环境来节省空间——并避免在不同位置安装相同版本的多个包。然后将该公共环境作为 .pth 文件分享给项目特定环境。</em></p>
<h3 id="9--按照-pep8-标准进行注释">#9 — 按照 PEP8 标准进行注释</h3>
<p>编写好的注释可以提高自信心和协作能力。在 Python 中,这意味着遵循 <a href="https://www.python.org/dev/peps/pep-0008/#comments" target="_blank">PEP8</a> 风格指南。</p>
<p>注释应该是声明性的,例如:</p>
<pre><code class="language-py"># Fix issue with utf-8 parsing
</code></pre>
<p><strong>不</strong> <code># 修复问题</code></p>
<p>下面是一个包含 <a href="https://www.python.org/dev/peps/pep-0257/" target="_blank">docstring</a> 的示例,这是一种特殊类型的注释,用于解释函数的目的:</p>
<pre><code class="language-py">def persuasion():
"""Attempt to get point across."""
print('Following this advice about writing proper Python comments will make you popular at parties')
</code></pre>
<p>Docstrings 特别有用,因为你的 IDE 会识别这个字符串文字作为与类相关的定义。在 Jupyter Notebook 中,你可以通过将光标放在函数的末尾,并同时按下 Shift 和 Tab 来查看函数的 docstring。</p>
<h3 id="8--查找好的实用代码">#8 — 查找好的实用代码</h3>
<p>你一定听过“站在巨人的肩膀上”这个表达。Python 是一个资源极其丰富的语言。通过认识到你不必单打独斗,你可以并且应该重用前人编写的实用代码,从而加速你的数据科学发现。</p>
<p>一个很好的实用代码来源是 <a href="https://chrisalbon.com/" target="_blank">Chris Albon</a> 的博客,他是 <a href="https://machinelearningflashcards.com/" target="_blank">机器学习闪卡</a> 的创建者,这些闪卡装饰了我家办公室/卧室的墙壁。他的网站首页提供了数百个代码片段,以加速你在 Python 中的工作流程。</p>
<p>例如,Chris 向我们展示了如何<a href="https://chrisalbon.com/python/data_wrangling/pandas_apply_function_by_group/" target="_blank">对数据框应用函数</a>(例如 pandas 的滚动均值 — .rolling()),按组进行:</p>
<pre><code class="language-py">df.groupby('lifeguard_team')['lives_saved'].apply(**lambda** x:x.rolling(center=False,window=**2**).mean())
</code></pre>
<p>这段代码输出一个数据框,其中包含每两行的滚动平均值,并在 .groupby() 语句的第一部分中对每个组重新开始。</p>
<h3 id="7--使用-pandas-profiling-进行自动化-eda">#7 — 使用 pandas-profiling 进行自动化 EDA</h3>
<p>使用 <a href="https://pandas-profiling.github.io/pandas-profiling/docs/master/rtd/" target="_blank">panda-profiling 工具包</a> 自动化你的探索性数据分析。EDA 是任何数据科学项目的关键阶段零。它通常涉及基本的统计分析以及查看特征之间的相关性。</p>
<p><img src="https://kdn.flygon.net/docs/img/bd116b9e8b1cb1526e8dc790ff4e27fc.png" alt="图示" loading="lazy"></p>
<p><a href="https://pandas-profiling.github.io/pandas-profiling/docs/master/rtd/" target="_blank">pandas-profiling</a>来救援。照片由<a href="https://unsplash.com/@neonbrand?utm_source=medium&utm_medium=referral" target="_blank">NeONBRAND</a>拍摄,来自<a href="https://unsplash.com/?utm_source=medium&utm_medium=referral" target="_blank">Unsplash</a></p>
<p>本文带你通过标准的‘手动’数据探索方法,并将其与 pandas-profiling 库创建的自动报告进行比较:</p>
<p><a href="https://towardsdatascience.com/a-better-eda-with-pandas-profiling-e842a00e1136" target="_blank"><strong>通过 Pandas-profiling 改进 EDA</strong></a></p>
<p>探索性数据分析已死,万岁 Pandas-profiling!用更少的努力完美概述你的数据。</p>
<h3 id="6--使用-qcut-改进目标分析">#6 — 使用 qcut 改进目标分析</h3>
<p>在这段关于改善机器学习工作流的优秀视频中,<a href="https://rebeccabilbro.github.io/" target="_blank">Rebecca Bilbro</a>提供了明智的建议,即在进行特征分析之前,先查看你的目标列。</p>
<p><a href="https://amzn.to/3jVSt31" target="_blank">从终点开始思考</a>——这种方式可以在开始预测或分类之前,帮助你对目标变量有一个扎实的理解。采用这种方法有助于你提前识别可能棘手的问题(例如,<a href="https://towardsdatascience.com/how-to-handle-smote-data-in-imbalanced-classification-problems-cf4b86e8c6a1" target="_blank">类别不平衡</a>)。</p>
<p>如果你正在处理一个连续变量,将你的值进行分箱可能会很有用。使用 5 个箱子可以利用帕累托原则。要创建五分位数,只需使用 pandas 的 q-cut 函数:</p>
<pre><code class="language-py">amount_quintiles = pd.qcut(df.amount, q**=**5)
</code></pre>
<p>每个区间将包含你数据集的 20%。将目标变量的最高五分位数与最低五分位数进行比较通常会得到有趣的结果。这种技术是确定目标变量中顶尖(或底层)表现者可能存在异常的良好起点。</p>
<p>要进一步学习,也可以查看 Rebecca 在<a href="https://medium.com/u/d6aacbc643bf?source=post_page-----dfdff5741fdf--------------------------------" target="_blank">Women Who Code DC</a>职业系列中的表现,由我亲自采访:</p>
<h3 id="5--在特征分析中添加可视化">#5 — 在特征分析中添加可视化</h3>
<p>可视化不仅仅用于商业智能仪表盘。在你调查新数据集时,加入一些有用的图表和图形可以加快洞察的速度。</p>
<p><img src="https://kdn.flygon.net/docs/img/858e48f6026a85e3197de99e0630665d.png" alt="图像" loading="lazy"></p>
<p><a href="https://seaborn.pydata.org/examples/index.html" target="_blank">Seaborn 示例图库</a></p>
<p>有许多可能的方法可以使用数据可视化来提升你的分析能力。一些资源供你探索:</p>
<ul>
<li>
<p><a href="https://seaborn.pydata.org/examples/index.html" target="_blank">Seaborn 示例图库</a></p>
</li>
<li>
<p><a href="https://docs.bokeh.org/en/latest/docs/gallery.html#notebook-examples" target="_blank">Bokeh notebook 示例</a></p>
</li>
<li>
<p><a href="https://www.scikit-yb.org/en/latest/gallery.html" target="_blank">Yellowbrick 图库</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/the-most-useful-ml-tools-2020-e41b54061c58" target="_blank">数据探索的 Streamlet</a>(感谢 <a href="https://medium.com/u/a0eb4622a0ca?source=post_page-----dfdff5741fdf--------------------------------" target="_blank">Ian Xiao</a> 提供这个提示!)</p>
</li>
<li>
<p><a href="https://towardsdatascience.com/new-data-science-f4eeee38d8f6" target="_blank">Tableau 入门指南</a></p>
</li>
</ul>
<h3 id="4--测量和优化运行时间">#4 — 测量和优化运行时间</h3>
<p>数据科学家有点以“修补匠”著称。但随着该领域 <a href="https://towardsdatascience.com/must-read-data-science-papers-487cce9a2020" target="_blank">越来越接近软件工程</a>,对简洁、高性能代码的需求增加了。程序的性能应在时间、空间和磁盘使用方面进行评估——这些是可扩展性能的关键。</p>
<p>Python 提供了一些 <a href="https://docs.python.org/3/library/profile.html" target="_blank">性能分析工具</a> 来展示你的代码在哪里花费时间。为了支持函数运行时的监控,Python 提供了 <a href="https://docs.python.org/3/library/timeit.html" target="_blank">timeit</a> 函数。</p>
<pre><code class="language-py">**%%**timeitfor i in range(100000):
i **=** i******3
</code></pre>
<p>在使用 pandas 时改进代码的一些快速技巧:</p>
<ol>
<li>
<p>按照 pandas 预期的方式使用:不要循环遍历数据框的行——改用 <a href="https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.apply.html" target="_blank">apply</a> 方法</p>
</li>
<li>
<p>利用 <a href="https://numpy.org/" target="_blank">NumPy</a> 数组实现更高效的编码</p>
</li>
</ol>
<h3 id="3-简化时间序列分析">#3— 简化时间序列分析</h3>
<p>处理时间序列可能会让人感到畏惧。我的训练营讲师在准备讲解这个主题的那一天,面带忧虑的神情出现在课堂上。</p>
<p>幸运的是,<a href="https://pypi.org/project/dtw-python/" target="_blank">dtw-python 包</a> 提供了一种直观的方式来比较时间序列。简言之,动态时间规整计算不同长度的两个数组或时间序列之间的距离。</p>
<p><img src="https://kdn.flygon.net/docs/img/f4202b263fce926a090125ce560d0299.png" alt="图" loading="lazy"></p>
<p>通过 <a href="https://www.jstatsoft.org/article/view/v031i07" target="_blank">The dtw Package</a> 对齐两个时间序列</p>
<p>首先,DTW 拉伸和/或压缩可能长度不同的序列,使它们尽可能地相似。借用一个语音识别的例子,使用这种技术可以帮助算法识别“now”和“nowwwwwwww”是相同的词,无论是由急躁的成年人还是暴躁的幼儿说的。经过转换后,包计算对齐后的单个元素之间的距离。</p>
<p>了解更多:</p>
<ul>
<li>
<p><a href="https://www.jstatsoft.org/article/view/v031i07" target="_blank">在此下载论文</a>(最初在 R 中实现,但同样适用于 Python)</p>
</li>
<li>
<p><a href="https://scholar.google.it/scholar?oi=bibs&hl=it&cites=5151555337428350289" target="_blank">在这里阅读用例</a></p>
</li>
<li>
<p>在 Google Colab 上自己试验 DTW Python,点击 <a href="https://colab.research.google.com/drive/1-fbhBlKRrEG8jkqoBAWOAzWaOarDQcDp?usp=sharing" target="_blank">这里</a> 和 <a href="https://colab.research.google.com/github/nipunbatra/blog/blob/master/_notebooks/2014-05-01-dtw.ipynb" target="_blank">这里</a>。</p>
</li>
</ul>
<h3 id="2--设置-ml-flow-进行实验跟踪">#2 — 设置 ML Flow 进行实验跟踪</h3>
<p><a href="https://mlflow.org/docs/latest/index.html" target="_blank">ML Flow</a> 支持跟踪参数、代码版本、度量和输出文件。MlflowClient 函数创建和管理实验、管道运行和模型版本。使用 <code>mlflow.log_artifact</code>、<code>.log_metric()</code> 和 <code>.log_param()</code> 记录工件(例如数据集)、度量和超参数。</p>
<p>你可以通过 <code>mlflow ui</code> 命令在本地主机浏览器中轻松查看所有实验的元数据和结果。</p>
<p>另外,查看这个关于数据科学工作流的完整指南:</p>
<p><a href="https://medium.com/atlas-research/model-selection-d190fb8bbdda" target="_blank"><strong>模型选择综合指南</strong></a></p>
<p>选择正确算法的系统化方法。</p>
<h3 id="1--理解-__main__-函数">#1 — 理解 <code>__main__</code> 函数</h3>
<p>使用 <code>if __name__ == '__main__'</code> 提供了从命令行执行代码或将代码作为包导入到交互环境中的灵活性。这个条件语句控制程序在特定上下文中如何执行。</p>
<p>你应该预期到,作为可执行文件运行代码的用户,其目标与将代码作为包导入的用户不同。<code>if __name__ == '__main__'</code> 语句提供了基于代码执行环境的控制流。</p>
<ul>
<li>
<p><code>__name__</code> 是模块全局命名空间中的一个特殊变量。</p>
</li>
<li>
<p>它具有一个由 Python 设置的 <code>repr()</code> 方法。</p>
</li>
<li>
<p><code>repr(__name__)</code> 的值取决于执行上下文。</p>
</li>
<li>
<p>从命令行中,<code>repr(__name__)</code> 的值为 '<strong>main</strong>' —— 因此 if 块中的任何代码都会运行。</p>
</li>
<li>
<p>作为包导入时,<code>repr(__name__)</code> 的值为导入的名称 —— 因此 if 块中的代码将 <em>不会</em> 执行。</p>
</li>
</ul>
<p>为什么这很有帮助?因为从命令行运行代码的人会有立即执行函数的意图。这可能与将你的包作为工具代码导入到 Jupyter Notebook 的用户的意图不同。</p>
<p>在 <code>if __name__ == '__main__'</code> 中,你应该创建一个名为 <code>main()</code> 的函数,其中包含你想要运行的代码。在各种编程语言中,主函数提供了执行的入口点。在 Python 中,我们仅通过约定将此函数命名为 <code>main()</code> —— 与底层语言不同,Python 并不赋予主函数任何特殊意义。然而,通过使用标准术语,我们让其他程序员知道这个函数代表了完成脚本主要任务的起点。</p>
<p>与其在 <code>main()</code> 中包含完成任务的代码块,不如让主函数调用模块中存储的其他函数。有效的模块化允许用户按需重用代码的各个方面。</p>
<p>你模块化的程度取决于你自己 —— 更多的函数意味着更多的灵活性和更容易重用,但也可能使你的包在人类浏览函数之间的逻辑断裂时更难阅读和理解。</p>
<h3 id="额外提示知道何时不使用-python">额外提示:知道何时不使用 Python。</h3>
<p>作为一名全职 Python 程序员,有时我会想我是否过于依赖这个科学计算工具。Python 是一种令人愉快的语言。它简单易用且维护成本低,其动态结构非常适合数据科学探索的性质。</p>
<p>不过,Python 绝对不是解决广泛定义的机器学习工作流程中每个方面的最佳工具。例如:</p>
<ul>
<li>
<p>SQL 对于将数据转移到<a href="https://towardsdatascience.com/data-warehouse-68ec63eecf78" target="_blank">data warehouse</a>的 ETL 过程至关重要,在那里数据可以被<a href="https://towardsdatascience.com/data-analyst-vs-data-scientist-2534fc1057c3" target="_blank">data analysts and data scientists</a>查询。</p>
</li>
<li>
<p><a href="https://towardsdatascience.com/java-for-data-science-f64631fdda12" target="_blank">Java</a> 可能有助于构建数据管道组件,如数据摄取和清理工具(例如,使用<a href="https://pdfbox.apache.org/" target="_blank">Apache PDFBox</a>解析 PDF 文档中的文本)。</p>
</li>
<li>
<p>Julia 正在作为一种飞速发展的 Python 替代品在数据科学中崭露头角。</p>
</li>
<li>
<p>Scala 通常用于大数据和模型服务。</p>
</li>
</ul>
<p>在由<a href="https://medium.com/u/ca095fd8e66c?source=post_page-----dfdff5741fdf--------------------------------" target="_blank">The TWIML AI Podcast</a>主办的圆桌讨论中,专家们探讨了他们所选择的编程语言的数据科学应用。</p>
<p>听到一个<a href="https://burakkanber.com/blog/machine-learning-in-other-languages-introduction/" target="_blank">JavaScript dev</a>谈论使用这种通常以网页开发为中心的语言进行机器学习的潜力有些奇怪。但这很大胆也很有创意——它有可能通过<a href="https://towardsdatascience.com/must-read-data-science-papers-487cce9a2020" target="_blank">打破障碍</a>在机器学习和传统软件开发之间实现数据科学的民主化。</p>
<p>目前,JavaScript 拥有数量上的优势:68%的开发者使用 JavaScript,而使用 Python 的仅为 44%,根据<a href="https://insights.stackoverflow.com/survey/2020" target="_blank">2020 年 Stack Overflow 开发者调查</a>。只有 1%使用 Julia,但预计这一比例将迅速变化。更多的 ML 开发者是否意味着更多的竞争、更多的见解,甚至更多的 arXiv 论文?这更是提升你 Python 技能的理由。</p>
<h3 id="总结-8">总结</h3>
<p>在这篇文章中,我们介绍了 10 个可能被忽视的 Python 技能,这些技巧包括:</p>
<ul>
<li>
<p><a href="https://towardsdatascience.com/10-underrated-python-skills-dfdff5741fdf#eeab" target="_blank">为你的项目创建虚拟环境 (#10)</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/10-underrated-python-skills-dfdff5741fdf#bd0a" target="_blank">根据 Python 风格指南进行注释 (#9)</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/10-underrated-python-skills-dfdff5741fdf#aa14" target="_blank">寻找实用代码而不是重新发明轮子 (#8)</a></p>
</li>
<li>
<ul>
<li><a href="https://towardsdatascience.com/10-underrated-python-skills-dfdff5741fdf#1f2a" target="_blank">改进你的 EDA</a>、<a href="https://towardsdatascience.com/10-underrated-python-skills-dfdff5741fdf#fb33" target="_blank">目标分析</a> 和 <a href="https://towardsdatascience.com/10-underrated-python-skills-dfdff5741fdf#c257" target="_blank">特征分析</a> (#7, 6, 5)</li>
</ul>
</li>
<li>
<ul>
<li><a href="https://towardsdatascience.com/10-underrated-python-skills-dfdff5741fdf#0e56" target="_blank">基于运行时优化编写更高效的代码 (#4)</a></li>
</ul>
</li>
<li>
<p><a href="https://towardsdatascience.com/10-underrated-python-skills-dfdff5741fdf#2f9e" target="_blank">使用动态时间规整进行时间序列分析 (#3)</a></p>
</li>
<li>
<ul>
<li><a href="https://towardsdatascience.com/10-underrated-python-skills-dfdff5741fdf#8022" target="_blank">使用 ML Flow 进行实验跟踪 (#2)</a></li>
</ul>
</li>
<li>
<ul>
<li><a href="https://towardsdatascience.com/10-underrated-python-skills-dfdff5741fdf#73b1" target="_blank">加入主函数以增强包的灵活性 (#1)</a></li>
</ul>
</li>
</ul>
<ul>
<li>
<p>我希望这篇文章能为你在数据科学实践中提供一些新的学习内容。</p>
</li>
<li>
<p><a href="https://giphy.com/gifs/baywatch-90s-nostalgia-dARiojBIBC9zJVEMQV" target="_blank">通过 GIPHY</a></p>
</li>
<li>
<p><strong>如果你喜欢这篇文章</strong>,可以在 <a href="https://medium.com/@nicolejaneway" target="_blank">Medium</a>、<a href="http://www.linkedin.com/in/nicole-janeway-bills" target="_blank">LinkedIn</a>、<a href="https://www.youtube.com/channel/UCO6JE24WY82TKabcGI8mA0Q?view_as=subscriber" target="_blank">YouTube</a> 和 <a href="https://twitter.com/Nicole_Janeway" target="_blank">Twitter</a> 上关注我,获取更多提升数据科学技能的想法。注册以在“<a href="https://page.co/ahje9p" target="_blank"><strong>提升你在 2020 年最后几个月数据科学的资源</strong></a>”发布时获得通知。</p>
</li>
<li>
<p><strong>免责声明</strong>:本文中的任何书籍链接都是附属链接。感谢你对我 Medium 写作的支持。</p>
</li>
<li>
<p><strong>你认为哪些 Python 技能被低估了?</strong> 请在评论中告诉我。</p>
</li>
</ul>
<h3 id="----提升你-python-技能的项目">- 提升你 Python 技能的项目</h3>
<ul>
<li>
<p><a href="https://medium.com/atlas-research/ner-for-clinical-text-7c73caddd180" target="_blank"><strong>临床文本的命名实体识别</strong></a></p>
</li>
<li>
<p>使用 pandas 将 2011 年 i2b2 数据集重新格式化为 CoNLL 格式,以用于自然语言处理(NLP)。</p>
</li>
<li>
<p><a href="https://towardsdatascience.com/build-full-stack-ml-12-hours-50c310fedd51" target="_blank"><strong>12 小时 ML 挑战</strong></a></p>
</li>
<li>
<p>如何使用 Streamlit 和 DevOps 工具构建和部署 ML 应用</p>
</li>
<li>
<p><a href="https://towardsdatascience.com/walkthrough-mapping-gis-data-in-python-92c77cd2b87a" target="_blank"><strong>教程:在 Python 中映射 GIS 数据</strong></a></p>
</li>
<li>
<p>通过 GeoPandas DataFrames 和 Google Colab 提高你对地理空间信息的理解</p>
</li>
<li>
<p><a href="https://medium.com/@maxtingle/getting-started-with-spotifys-api-spotipy-197c3dc6353b" target="_blank"><strong>快速入门 Spotify 的 API 与 Spotipy</strong></a></p>
</li>
<li>
<p>数据科学家的快速入门指南:导航 Spotify 的 Web API 并使用 Spotipy Python 访问数据…</p>
</li>
<li>
<p><strong>个人简介:<a href="https://www.linkedin.com/in/nicole-janeway-bills/" target="_blank">Nicole Janeway Bills</a></strong> 是一位具有商业和联邦咨询经验的数据科学家。她帮助组织利用其最宝贵的资产:一个简单且稳健的数据策略。<a href="https://page.co/ahje9p" target="_blank"><strong>注册获取更多她的写作</strong></a>。</p>
</li>
</ul>
<p><a href="https://towardsdatascience.com/10-underrated-python-skills-dfdff5741fdf" target="_blank">原文</a>. 经许可转载。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p>fastcore: 一个被低估的 Python 库</p>
</li>
<li>
<p>数据科学基础:你需要知道的 10 项关键技能</p>
</li>
<li>
<p>我如何在 8 个月内提升我的数据科学技能</p>
</li>
</ul>
<h3 id="更多相关话题-25">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/novice-to-ninja-why-your-python-skills-matter-in-data-science" target="_blank">从新手到高手:为什么你的 Python 技能在数据科学中至关重要</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-key-skills-needed-become-great-data-scientist.html" target="_blank">成为优秀数据科学家所需的 5 项关键技能</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/07/ai-tools-along-skills-make-10000-monthly-bs.html" target="_blank">这里是我使用的 AI 工具以及我的技能来赚取$10,000…</a></p>
</li>
<li>
<p>数据科学基础:你需要知道的 10 项关键技能</p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/03/9-skills-become-data-engineer.html" target="_blank">成为数据工程师所需的 9 项技能</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/01/humbling-improve-data-science-skills.html" target="_blank">为什么谦逊会提升你的数据科学技能</a></p>
</li>
</ul>
<h1 id="10-个隐私保护合成数据的使用案例">10 个隐私保护合成数据的使用案例</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2020/08/10-use-cases-privacy-preserving-synthetic-data.html" target="_blank"><code>www.kdnuggets.com/2020/08/10-use-cases-privacy-preserving-synthetic-data.html</code></a></p>
</blockquote>
<p>评论</p>
<p><strong>由 <a href="https://medium.com/@Elise_Deux" target="_blank">Elise Devaux</a> 和 <a href="http://www.statice.ai/" target="_blank">Statice</a> 提供</strong></p>
<p>快速发展的数据保护法律正在不断重塑数据格局。组织克服敏感数据使用限制并保护客户隐私的能力将成为未来成功企业的关键驱动力。本博客介绍了十个隐私保护合成数据的具体应用,可能帮助企业保持竞争优势:</p>
<ul>
<li>
<p>云迁移</p>
</li>
<li>
<p>内部数据共享</p>
</li>
<li>
<p>数据保留</p>
</li>
<li>
<p>数据分析</p>
</li>
<li>
<p>数据测试</p>
</li>
<li>
<p>AI/ML 模型训练</p>
</li>
<li>
<p>第三方数据共享</p>
</li>
<li>
<p>产品开发</p>
</li>
<li>
<p>数据货币化</p>
</li>
<li>
<p>数据发布</p>
</li>
</ul>
<hr>
<h2 id="我们的前三课程推荐-1">我们的前三课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升您的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持您的组织 IT</p>
<hr>
<p>在适当的隐私保障下,隐私保护合成数据是一种匿名化数据。因此,它不属于个人数据保护法律的范围。这反过来减少了组织在使用敏感数据时的限制,同时保护了个人隐私。正如我们将在以下使用案例中看到的,它在监管严格的行业中尤为有价值。</p>
<h3 id="合成数据的价值创造生命周期">合成数据的价值创造生命周期</h3>
<p>数据正日益成为推动企业价值和增长的核心元素。在几乎每个数据孤岛和数据生命周期的每个阶段,企业都有能力生成价值。然而,数据在组织内部几乎没有流动,受到繁重的合规性和数据治理流程的阻碍。因此,合成数据在数据生命周期中的使用被拓展。从数据集成到数据传播,它提供了利用数据的另一种选择。</p>
<p><img src="https://kdn.flygon.net/docs/img/e88d053b4aa4638cdcc86f382880c3fb.png" alt="图示" loading="lazy"></p>
<p>随着数据通过收集、集成、处理和传播阶段,企业可以生成价值。然而,由于严格的隐私法规,大部分潜在价值仍未被挖掘。</p>
<p><strong>1. 云迁移</strong></p>
<p>将敏感数据迁移到云基础设施涉及复杂的合规流程。确保数据安全,同时保证其在未来使用中的完整性,可能既耗时又昂贵,甚至在某些情况下不可能。由于它嵌入了隐私设计原则,Statice 的合成数据使企业能够更轻松地将样本或完整数据资产迁移到云环境中。这为企业节省了时间和金钱,并提升了数据灵活性。</p>
<p><strong>2. 内部数据共享</strong></p>
<p>隐私流程和内部控制会减缓,有时阻碍组织内理想数据流的实现。获取内部数据可能需要几周,甚至更长时间,特别是当不清楚需要哪些数据点时。使用合成数据样本或完整数据集,能够使企业摆脱获取敏感数据时遇到的障碍。它们可以更快地共享内部来源和汇总数据,从而提高利用数据的能力。</p>
<p><strong>3. 数据保留</strong></p>
<p>数据保留的规定在过去十年里一直是欧洲的热点话题。今天,<a href="https://gdpr-info.eu/art-5-gdpr/" target="_blank">GDPR 坚持</a>限制企业存储个人数据的时间和数量。此外,各国法律通常对某些性质的数据,如电信或银行信息,进行保留管理。问题在于,某些分析需要更长时间的数据存储,这会违反这些规定。例如,年度季节性分析需要至少两年的数据。在这种情况下,合成数据提供了一种遵守数据保留法律的方式,同时实现其他方式无法进行的长期分析。</p>
<p><strong>4. 数据测试</strong></p>
<p>在测试环境中,缺乏有用的测试数据可能会减缓新系统的开发并阻碍现实测试。同样,合成数据提供了一种替代生产数据的方式。由于它模仿了生产数据的统计特性,合成数据可用于测试新产品和服务、验证模型或测试性能。这种资源易于快速获取,允许更大的数据灵活性和更快的软件开发上线时间。</p>
<p><strong>5. 数据分析</strong></p>
<p>一方面,使用部分遮蔽的数据可能会影响分析质量,并且<a href="https://www.statice.ai/post/the-truth-about-anonymous_data" target="_blank">存在强烈的重新识别风险</a>。另一方面,获取数据二次使用的系统同意是一个繁琐的过程,特别是考虑到当前的数据量和对数据处理的消费者情绪。隐私保护的合成数据帮助平衡隐私和实用性的困境。企业可以对以隐私保护方式生成的合成数据进行分析,而无需担心隐私或质量问题。这反过来帮助数据驱动的企业做出更好的决策。</p>
<p><strong>6. AI/ML 模型训练</strong></p>
<p>同样,寻找大量合规数据以训练机器学习模型在许多行业中都是一个挑战。使用隐私保护合成数据来驱动机器学习模型可以是一种更具可扩展性的方法,同时也保护数据隐私。多个企业已经<a href="https://www.statice.ai/post/future-proofing-data-operations-successful-insurance-mobiliere" target="_blank">验证了隐私保护机器学习的使用</a>,在使用合成数据构建和训练模型时产生了有意义的结果。这是企业以安全的方式扩展机器学习使用及其利益的机会。</p>
<p><strong>7. 产品开发</strong></p>
<p>数据是产品和服务开发的关键资源。一旦隐私保护合成数据在企业仓库中可用,工程师和数据科学家可以轻松访问和使用这些数据。企业可以创建并提供不构成隐私泄露的数据仓库,为产品和服务开发提供资源。这反过来为他们带来价值,因为他们能够利用现有数据进行开发和创新。</p>
<p><strong>8. 数据货币化</strong></p>
<p>向第三方打包和销售数据现在受到严格监管。隐私保护合成数据提供了一种从数据流中构建收入的机会,这些数据流在正常情况下过于敏感而无法用于此类目的。组织可以随意构建新的数据衍生收入流,而不会冒着侵犯个人隐私的风险。</p>
<p><strong>9. 数据共享</strong></p>
<p>与第三方交换数据是推动企业创新的重要因素。但无论是与客户共享分析数据、与合作伙伴共同开发产品,还是向离岸站点发送数据,企业往往都面临敏感数据共享的固有挑战。为了避免这些耗时的过程并提高灵活性,企业可以使用<strong>隐私保护合成数据</strong>。</p>
<p><strong>10. 数据发布</strong></p>
<p>对于举办黑客马拉松或寻求与外部利益相关者共享数据的企业来说,确保没有个人信息被泄露至关重要。臭名昭著的 Netflix 奖案例说明了发布匿名化不充分数据的风险。使用隐私保护合成数据,企业能够确保保护个人隐私。</p>
<p>在当今高度监管的环境中,企业必须找到解锁数据价值的方法,以保持竞争力。隐私保护合成数据是使用敏感数据的安全合规替代方案,能够为企业提供显著的竞争优势。从内部数据共享到数据货币化,企业可以创造额外的价值,这在竞争激烈的市场中可能是决定性的。</p>
<p><strong>简介: <a href="https://medium.com/@Elise_Deux" target="_blank">Elise Devaux</a></strong> (<strong><a href="https://twitter.com/elise_deux" target="_blank">@elise_deux</a></strong>) 是一位技术爱好者兼数字营销经理,现任职于 <a href="http://www.statice.ai/" target="_blank">Statice</a>,一家专注于合成数据作为隐私保护解决方案的初创公司。</p>
<p><a href="https://www.statice.ai/post/10-use-cases-synthetic-data" target="_blank">原文</a>。转载自有权限。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p>应对 2020 年数据隐私和安全法律的 10 个步骤</p>
</li>
<li>
<p>Scikit-Learn 和更多工具用于机器学习的合成数据集生成</p>
</li>
<li>
<p>合成数据生成:新数据科学家必备的技能</p>
</li>
</ul>
<h3 id="更多相关话题-26">更多相关话题</h3>
<ul>
<li>
<p>[如何利用合成数据克服机器学习模型训练中的数据短缺]<a href="https://www.kdnuggets.com/2022/03/synthetic-data-overcome-data-shortages-machine-learning-model-training.html" target="_blank">https://www.kdnuggets.com/2022/03/synthetic-data-overcome-data-shortages-machine-learning-model-training.html</a>)</p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/08/dss-machine-learning-enterprise-cases-challenges.html" target="_blank">企业中的机器学习:应用案例与挑战</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/03/nosql-databases-cases.html" target="_blank">NoSQL 数据库及其应用案例</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/5-use-cases-of-dalle-3" target="_blank">DALLE-3 的 5 个应用案例</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/vector-databases-in-ai-and-llm-use-cases" target="_blank">AI 和 LLM 使用案例中的向量数据库</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/tonic-high-fidelity-synthetic-data-engineers-scientists-alike.html" target="_blank">为数据工程师和数据科学家提供的高保真合成数据</a></p>
</li>
</ul>
<h1 id="10-个最常用的-tableau-函数">10 个最常用的 Tableau 函数</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2022/08/10-used-tableau-functions.html" target="_blank"><code>www.kdnuggets.com/2022/08/10-used-tableau-functions.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/919b39bcb780833ea0abff000316c293.png" alt="10 个最常用的 Tableau 函数" loading="lazy"></p>
<p>图片作者 | <a href="https://carbon.now.sh/" target="_blank">Carbon</a></p>
<p><a href="https://help.tableau.com/current/pro/desktop/en-us/functions.htm" target="_blank">Tableau 函数</a> 为商业智能开发人员提供了额外的功能,以推动复杂分析和执行数学计算。它用于增强字符串、数字、日期和地理数据字段。</p>
<hr>
<h2 id="我们的前-3-个课程推荐-4">我们的前 3 个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织的 IT</p>
<hr>
<p>我们将学习最常用的 10 个 Tableau 函数,用于商业智能测试和开发。这些函数将帮助你理解 Tableau 不仅仅是一个拖放的华丽工具。</p>
<h1 id="min-和-max">MIN 和 MAX</h1>
<p><strong>MAX</strong> 函数将返回两个参数中的最高值。它也可以应用于数据字段,如下所示。</p>
<pre><code class="language-py">MAX([Sales],[Profit])
</code></pre>
<p><strong>示例:</strong></p>
<pre><code class="language-py">MAX(10,17) = 17
</code></pre>
<p>对于<strong>MIN</strong>,则相反。该函数将返回两个参数中最低的值。参数可以是数据字段或整数。</p>
<pre><code class="language-py">MIN([Sales],[Profit])
</code></pre>
<p><strong>示例:</strong></p>
<pre><code class="language-py">MIN(14,17) = 14
</code></pre>
<h1 id="replace">REPLACE</h1>
<p><strong>REPLACE</strong> 函数可以应用于字符串数据字段和字符串。它需要三个参数:</p>
<ul>
<li>
<p><strong>string</strong>:可以是字符串数据字段或字符串。</p>
</li>
<li>
<p><strong>substring</strong>:是你想更改的词或字母。</p>
</li>
<li>
<p><strong>replacement</strong>:一个将替换子字符串的字符串。</p>
</li>
</ul>
<pre><code class="language-py">REPLACE(string, substring, replacement)
</code></pre>
<p><strong>示例:</strong></p>
<pre><code class="language-py">REPLACE("Abid Ali", "Ali", "Awan") = "Abid Awan"
</code></pre>
<h1 id="datediff">DATEDIFF</h1>
<p>用于查找两个日期字段之间的差异。你可以提取周、天、月和年的差异。</p>
<p>该函数需要 4 个参数:</p>
<ul>
<li>
<p><strong>date_part</strong>:是一个日期单位,用于返回两个日期之间的差异。</p>
</li>
<li>
<p><strong>date1 和 date2</strong>:是日期字段</p>
</li>
<li>
<p><strong>start_of_week</strong>:可以是星期一、星期日或星期二。这取决于你的需求。</p>
</li>
</ul>
<pre><code class="language-py">DATEDIFF(date_part, date1, date2, [start_of_week])
</code></pre>
<p><strong>示例:</strong></p>
<pre><code class="language-py">DATEDIFF('week', #2019-10-22#, #2019-10-24#, 'monday')= 1
</code></pre>
<h1 id="datename-和-datepart">DATENAME 和 DATEPART</h1>
<p><strong>DATENAME</strong> 用于返回日期数据字段中的 date_part 字符串。我们可以提取日期的天、年、周和月。</p>
<ul>
<li>
<p><strong>date_part</strong>:是应用于日期的日期单位</p>
</li>
<li>
<p><strong>date</strong>:是一个日期字段或字符串。</p>
</li>
<li>
<p><strong>start_of_week</strong>:日子被视为一周的第一天</p>
</li>
</ul>
<pre><code class="language-py">DATENAME(date_part, date, [start_of_week])
</code></pre>
<p><strong>示例:</strong></p>
<pre><code class="language-py">DATENAME('month', #2020-03-25#) = "March"
</code></pre>
<p>代替返回字符串形式的月份名称,<strong>DATEPART</strong> 用于以整数形式从日期中提取日期部分。我们可以用它进行复杂的计算。</p>
<pre><code class="language-py">DATEPART(date_part, date, [start_of_week])
</code></pre>
<p><strong>示例:</strong></p>
<pre><code class="language-py">DATEPART('month', #2020-03-25#) = 3
</code></pre>
<h1 id="类型转换">类型转换</h1>
<p>这是 Tableau 中使用最广泛的函数,我用它来将字符串转换为日期、整数转换为字符串、字符串转换为浮点数以及日期解析。</p>
<p>以下是类型转换函数的列表:</p>
<ul>
<li>
<p>DATE(expression)</p>
</li>
<li>
<p>DATETIME(expression)</p>
</li>
<li>
<p>DATEPARSE(format, string)</p>
</li>
<li>
<p>FLOAT(expression)</p>
</li>
<li>
<p>INT(expression)</p>
</li>
<li>
<p>STR(expression)</p>
</li>
</ul>
<h1 id="if-和-else">IF 和 ELSE</h1>
<p>Tableau 具有简单的条件函数。你可以像 Python 一样执行 If else 语句。只需确保在语句末尾添加“<strong>END</strong>”以结束语句。</p>
<p>我使用<strong>IF</strong> 和 <strong>ELSE</strong> 语句来创建分类和绘制时间序列图。</p>
<pre><code class="language-py">IF <expr> THEN <then> ELSE <else> END
</code></pre>
<p><strong>示例:</strong></p>
<pre><code class="language-py">If [Profit] > 0 THEN 'Profitable' ELSE 'Loss' END
</code></pre>
<h1 id="and-和-or">AND 和 OR</h1>
<p>对于高级逻辑函数,你还可以添加<strong>AND</strong> 和 <strong>OR</strong> 命令来扩展表达式。</p>
<pre><code class="language-py">IF <expr1> AND <expr2> THEN <then> END
</code></pre>
<p><strong>示例:</strong></p>
<pre><code class="language-py">IF (ATTR([Market]) = "South Asia" AND SUM([Sales]) > [Emerging Threshold] )THEN "Well Performing"
</code></pre>
<h1 id="case-1">CASE</h1>
<p>类似于<strong>IF</strong> 和 <strong>ELSE</strong> 语句,你可以使用<strong>CASE</strong> 来创建逻辑函数。你可以将其应用于数据字段,并根据表达式创建多个分类。</p>
<pre><code class="language-py">CASE <expression> WHEN <value1> THEN <return1> WHEN <value2> THEN <return2> ... ELSE <default return> END
</code></pre>
<p><strong>示例:</strong></p>
<p>以下脚本用于将“Language”字符串字段转换为整数。如果值是<strong>English</strong>,它将返回<strong>1</strong>;对于<strong>Urdu</strong>,返回<strong>2</strong>;对于其他任何值,返回<strong>3</strong>。</p>
<pre><code class="language-py">CASE [Language] WHEN 'English' THEN 1 WHEN 'Urdu' THEN 2 ELSE 3 END
</code></pre>
<h1 id="lookup">LOOKUP</h1>
<p><strong>LOOKUP</strong> 用于在数据集中创建偏移。我主要使用这个函数来创建时间序列预测和分析。</p>
<p>需要一个数据字段和一个整数形式的偏移参数。</p>
<pre><code class="language-py">LOOKUP(expression, [offset])
</code></pre>
<p><strong>示例:</strong></p>
<p>通过使用以下命令,我们将<strong>Profit</strong> 偏移了 2。现在,我们可以看到来自未来两个季度的销售值。</p>
<pre><code class="language-py">LOOKUP(SUM([Profit]), 2)
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/371480ae60cecfbb1da2cf2563a476ad.png" alt="Tableau LOOKUP 函数" loading="lazy"></p>
<p>图片来自 <a href="https://help.tableau.com/current/pro/desktop/en-us/functions_functions_tablecalculation.htm" target="_blank">Tableau</a></p>
<h1 id="tabpy">TabPy</h1>
<p><a href="https://github.com/tableau/TabPy" target="_blank">TabPy</a> 允许用户在 Tableau 中运行 Python 脚本。你可以使用 <code>pip install tabpy</code> 安装它,并通过在终端中输入 <code>tabpy</code> 来运行服务器。有关 Tabpy 安装的更多信息,请参见 <a href="https://www.datacamp.com/tutorial/getting-started-with-tabpy" target="_blank">TabyPy 教程</a>。</p>
<p>你可以使用:</p>
<ul>
<li>
<p>SCRIPT_BOOL</p>
</li>
<li>
<p>SCRIPT_INT</p>
</li>
<li>
<p>SCRIPT_REAL</p>
</li>
<li>
<p>SCRIPT_STR</p>
</li>
</ul>
<p>每个命令都需要带有参数和参数列表的 Python 脚本。</p>
<pre><code class="language-py">SCRIPT_REAL(Python Script, argument 1, argument 2, ...)
</code></pre>
<p><strong>示例:</strong></p>
<p>我们将创建一个相关性函数,它接受<strong>Sales</strong> 和 <strong>Profit</strong> 字段,并返回相关系数。如你所见,<strong>_arg1</strong> 和 <strong>_arg2</strong> 是<strong>Sales</strong> 和 <strong>Profit</strong> 的占位符。</p>
<pre><code class="language-py">SCRIPT_REAL("import numpy as np
return np.corrcoef(_arg1,_arg2)[0,1]",
SUM([Sales]),SUM([Profit]))
</code></pre>
<p>类似地,你可以将 Python 函数部署到 TabPy 服务器,并使用相同的脚本进行访问。阅读 <a href="https://www.datacamp.com/tutorial/tabpy-tutorial-deploying-python-functions-and-prophet-forecasting-model" target="_blank">TabPy 教程:部署 Python 函数和 Prophet 预测模型</a> 了解有关部署 Python 函数的更多信息。</p>
<p>以<strong>“return tabpy.query(<function name>, lists or arguments)[‘response’]”</strong> 开头的 TabPy 查询脚本</p>
<pre><code class="language-py">SCRIPT_REAL(TabPy Query Script, argument 1, argument 2, ...)
</code></pre>
<p><strong>示例:</strong></p>
<p>我们通过添加函数名(<strong>pcc</strong>)、参数占位符和参数来访问 Pearson 相关系数函数。</p>
<pre><code class="language-py">SCRIPT_REAL("return tabpy.query('pcc',_arg1, _arg2)['response']",
SUM([Sales]),SUM([Profit]))
</code></pre>
<blockquote>
<p>通过阅读官方<a href="https://help.tableau.com/current/pro/desktop/en-us/functions.htm" target="_blank">文档</a>了解更多关于 Tableau 函数的信息。</p>
</blockquote>
<p><strong><a href="https://www.polywork.com/kingabzpro" target="_blank">Abid Ali Awan</a></strong> (<a href="https://twitter.com/1abidaliawan" target="_blank">@1abidaliawan</a>) 是一位认证数据科学专业人员,热爱构建机器学习模型。 目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。 Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些面临心理健康问题的学生构建一个 AI 产品。</p>
<h3 id="更多相关主题-18">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/n31.html" target="_blank">KDnuggets 新闻,8 月 3 日:10 个最常用的 Tableau 函数 • 是…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/05/create-efficient-combined-data-sources-tableau.html" target="_blank">使用 Tableau 创建高效的组合数据源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/06/prepare-data-effective-tableau-power-bi-dashboards.html" target="_blank">为有效的 Tableau 和 Power BI 仪表板准备数据</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/06/primary-supervised-learning-algorithms-used-machine-learning.html" target="_blank">机器学习中使用的主要监督学习算法</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/07/used-chatgpt-every-day-5-months-hidden-gems-change-life.html" target="_blank">我每天使用 ChatGPT 五个月。这里有一些隐藏的宝石……</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2024/01/pecan-llms-used-alone-cant-address-companys-predictive-needs" target="_blank">为何单独使用 LLM 无法满足你公司预测需求</a></p>
</li>
</ul>
<h1 id="10-个对-python-开发者有用的机器学习实践">10 个对 Python 开发者有用的机器学习实践</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2020/05/10-useful-machine-learning-practices-python-developers.html" target="_blank"><code>www.kdnuggets.com/2020/05/10-useful-machine-learning-practices-python-developers.html</code></a></p>
</blockquote>
<p>评论</p>
<p><strong>由<a href="https://www.linkedin.com/in/bhavsarpratik/" target="_blank">Pratik Bhavsar</a>,远程 NLP 工程师</strong>。</p>
<p>有时作为数据科学家,我们会忘记我们是因为什么而被雇佣的。我们主要是开发者,然后是研究人员,再然后可能是数学家。我们的首要责任是快速开发无错误的解决方案。</p>
<blockquote>
<hr>
<h2 id="我们的前三个课程推荐-24">我们的前三个课程推荐</h2>
<h2 id="_-2"></h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析能力</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织的 IT</p>
<hr>
<p>仅仅因为我们能创建模型,并不意味着我们是神。这并不赋予我们编写糟糕代码的自由。</p>
</blockquote>
<p>自从开始以来,我犯了许多错误,并想分享我认为<strong>ML 工程</strong>中最常见的技能。在我看来,这也是当前行业中<em><strong>最缺乏的技能</strong></em>。</p>
<p><em>我称他们为<strong>软件文盲</strong>数据科学家,因为很多人是非计算机科学专业的 Coursera 培训工程师。而我自己也曾是那样的人。</em> <em>????</em></p>
<p>如果要在一位出色的数据科学家和一位出色的 ML 工程师之间选择,我会选择后者。</p>
<p>让我们开始吧。</p>
<h3 id="1-学会编写抽象类">1. 学会编写抽象类</h3>
<p>一旦你开始编写抽象类,你会发现它可以为你的代码库带来多少清晰度。它们强制执行相同的方法和方法名称。如果许多人在同一个项目上工作,每个人开始编写不同的方法。这可能会造成无效的混乱。</p>
<h3 id="2-在顶部固定你的种子">2. 在顶部固定你的种子</h3>
<p>实验的可重复性是非常重要的,种子是我们的敌人。抓住它。否则,它会导致训练/测试数据的不同划分以及神经网络中权重的不同初始化。这会导致结果不一致。</p>
<h3 id="3-从几行开始">3. 从几行开始</h3>
<p>如果你的数据过大,并且你在代码的后期部分工作,比如清洗数据或建模,使用<strong>nrows</strong>来避免每次都加载大量数据。当你只想测试代码而不是实际运行整个程序时,使用这个选项。</p>
<p><em>这在你的本地 PC 配置不足以处理数据量时非常适用,但你仍然喜欢在本地使用 Jupyter/VS code/Atom 进行开发。</em></p>
<blockquote>
<p>df_train = pd.read_csv(‘train.csv’,<em><strong>nrows=1000</strong></em><em>)</em></p>
</blockquote>
<h3 id="4-预期失败成熟开发者的标志">4. 预期失败(成熟开发者的标志)</h3>
<p>始终检查数据中的 NA,因为这些会在以后导致问题。即使当前数据中没有,也不意味着未来的重训练循环中不会出现。因此,仍然要保持检查。????</p>
<blockquote>
<p><em>print(len(df))</em></p>
<p><em>df.isna().sum()</em></p>
<p><em>df.dropna()</em></p>
<p><em>print(len(df))</em></p>
</blockquote>
<h3 id="5展示处理进度">5. 展示处理进度</h3>
<p>当你处理大数据时,知道处理所需的时间以及我们在整个处理中的进展是很好的。</p>
<p>选项 1 — tqdm</p>
<p>选项 2 — fastprogress</p>
<p><img src="https://kdn.flygon.net/docs/img/8fffa61e7c05e72079c7455b78f715ef.png" alt="" loading="lazy"></p>
<h3 id="6-pandas-可能会很慢">6. Pandas 可能会很慢</h3>
<p>如果你使用过 pandas,你知道它有时会很慢——尤其是 groupby。与其绞尽脑汁寻找‘优秀’的加速方案,不如通过改变一行代码直接使用 modin。</p>
<blockquote>
<p><em>import modin.pandas as pd</em></p>
</blockquote>
<h3 id="7-计时函数">7. 计时函数</h3>
<p>不是所有的函数都是一样的。</p>
<p>即使整个代码运行正常,也不意味着你写了出色的代码。一些软性错误实际上会让你的代码变慢,因此有必要找到它们。使用这个装饰器来记录函数的运行时间。</p>
<h3 id="8-不要在云上烧钱">8. 不要在云上烧钱</h3>
<p>没有人喜欢浪费云资源的工程师。</p>
<p>我们的一些实验可能会运行几个小时。很难跟踪并在完成时关闭云实例。我自己也犯过错误,也看到过有人让实例开几天。</p>
<p><em>这发生在我们在周五工作,留下东西在运行,周一才意识到。</em> <em>????</em></p>
<p>只需在执行结束时调用此函数,你的屁股将再也不会着火了!</p>
<p>但将主代码包裹在<em><strong>try</strong></em>中,再将此方法包裹在<em><strong>except</strong></em>中——这样,如果发生错误,服务器不会继续运行。是的,我也处理过这些情况。????</p>
<p>我们要负点责任,不要生成二氧化碳。????</p>
<h3 id="9-创建并保存报告">9. 创建并保存报告</h3>
<p>在建模的特定阶段之后,所有伟大的见解都仅来自错误和指标分析。确保为自己和经理创建并保存格式良好的报告。</p>
<p>反正,管理层喜欢报告,对吧?????</p>
<h3 id="10-编写出色的-api">10. 编写出色的 API</h3>
<p>一切以坏结局收尾的都是坏的。</p>
<p>你可以做很好的数据清洗和建模,但最终仍然可能造成巨大的混乱。我与许多人的经验告诉我,很多人对如何编写好的 API、文档和服务器设置不清楚。</p>
<p><em>下面是经典机器学习和深度学习部署在负载不高的情况下的一个好方法——比如 1000/min。</em></p>
<p>组合见 — Fastapi + uvicorn</p>
<ul>
<li>
<p><strong>最快</strong>— 使用<strong>fastapi</strong>编写 API,因为它在 I/O 绑定方面是最快的,如 <a href="https://www.techempower.com/benchmarks/#section=test&runid=7464e520-0dc2-473d-bd34-dbdfd7e85911&hw=ph&test=query&l=zijzen-7" target="_blank">this</a>所示,原因在 <a href="https://fastapi.tiangolo.com/benchmarks/" target="_blank">这里</a>中解释。</p>
</li>
<li>
<p><strong>文档</strong>— 使用 fastapi 编写 API 为我们提供了<strong>免费文档</strong>,并且测试端点位于 http:url/docs → 随着代码的更改,由 fastapi 自动生成和更新</p>
</li>
<li>
<p><strong>工作者</strong>— 使用<strong>uvicorn</strong>部署 API</p>
</li>
</ul>
<p>运行这些命令以使用 4 个工作进程进行部署。通过负载测试优化工作进程的数量。</p>
<blockquote>
<p><em>pip install fastapi uvicorn</em></p>
<p><em>uvicorn main:app --workers 4 --host 0.0.0.0 --port 8000</em></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/adfb99e05cdbe7f2c47a07e63475684e.png" alt="" loading="lazy"></p>
<p><a href="https://medium.com/modern-nlp/10-great-ml-practices-for-python-developers-b089eefc18fc" target="_blank">原文</a>。经许可转载。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2020/05/coding-habits-data-scientists.html" target="_blank">数据科学家的编码习惯</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2019/07/12-things-learned-machine-learning-engineer.html" target="_blank">作为机器学习工程师的第一年中学到的 12 件事</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2018/08/programming-best-practices-data-science.html" target="_blank">数据科学的编程最佳实践</a></p>
</li>
</ul>
<h3 id="更多相关话题-27">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/01/developers-python-machine-learning-projects.html" target="_blank">为什么越来越多的开发者使用 Python 进行机器学习项目?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/04/low-code-developers-still-needed.html" target="_blank">低代码:开发者还需要吗?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/11/3-useful-python-automation-scripts.html" target="_blank">3 个有用的 Python 自动化脚本</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/12/4-useful-intermediate-sql-queries-data-science.html" target="_blank">4 个有用的中级 SQL 查询用于数据科学</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n47.html" target="_blank">KDnuggets 新闻,12 月 7 日:揭示十大数据科学误区 • 4…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/02/bash-scripts-data-science.html" target="_blank">5 个真正有用的 Bash 脚本用于数据科学</a></p>
</li>
</ul>
<h1 id="获取数据科学项目的-10-个精彩网站">获取数据科学项目的 10 个精彩网站</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2023/04/10-websites-get-amazing-data-data-science-projects.html" target="_blank"><code>www.kdnuggets.com/2023/04/10-websites-get-amazing-data-data-science-projects.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/644f17714f0cd549f139e1eeec910389.png" alt="获取数据科学项目的 10 个精彩网站" loading="lazy"></p>
<p>作者提供的图片</p>
<p>“有人真的会关心花萼长度吗?”几天前,我的朋友在喝咖啡时向我抱怨。她指的是 R 语言中内置的<code>iris</code>数据集,这个数据集早在 1936 年就首次出现了。“为什么大学教授总是用糟糕、无聊、毫无意义的数据来教我们数据科学,而外面有这么多很棒的数据适合数据科学项目呢?”</p>
<hr>
<h2 id="我们的前三名课程推荐-9">我们的前三名课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织的 IT 工作</p>
<hr>
<p>她说得对。当你的数据对你来说无聊或毫无意义时,确实很难激励自己学习数据科学,或者进行<a href="https://www.stratascratch.com/blog/19-data-science-project-ideas-for-beginners/?utm_source=blog&utm_medium=click&utm_campaign=kdn+data+for+ds+projects" target="_blank">数据科学项目</a>。我知道在找到一些吸引我的有趣数据之前,我也曾很难激励自己学习数据科学。</p>
<p>在这篇文章中,我将详细介绍 10 个出色的网站,你可以从中获取一些非常棒的数据用于数据科学项目。目的是展示各种可能吸引你的数据。最终,这些网站应该能帮助你找到感兴趣的数据,完成一个酷炫的数据科学项目,并用它来获得一份工作。</p>
<h1 id="我是如何审查这些数据来源的">我是如何审查这些数据来源的?</h1>
<p>如果你在这篇文章中看到一个网站,那是因为它包含的数据是:</p>
<ul>
<li>
<p>免费提供。你无需为此付费。</p>
</li>
<li>
<p>面向社区的。这不仅仅是一个文件;还会有一些评论和解释。</p>
</li>
<li>
<p>很酷。这是某人会关心的东西。也许是你!</p>
</li>
<li>
<p>相对干净。你将有机会练习数据科学的有趣部分——分析、可视化、共享等。</p>
</li>
<li>
<p>语言无关。你可以用 Python、R、SQL 或任何你喜欢的语言来挖掘这些数据。</p>
</li>
</ul>
<h1 id="获取你数据科学项目的超赞数据的-10-个网站">获取你数据科学项目的超赞数据的 10 个网站</h1>
<p>让我们深入探讨一下找到你真正关心并希望用数据科学进行探索的最佳网站。</p>
<table>
<thead>
<tr>
<th>Google 数据集搜索</th>
<th>范围广泛,质量参差不齐</th>
</tr>
</thead>
<tbody>
<tr>
<td>Kaggle</td>
<td>更有限,但有大量背景和社区支持</td>
</tr>
<tr>
<td>KDNuggets</td>
<td>专门针对 AI、机器学习、数据科学</td>
</tr>
<tr>
<td>政府网站</td>
<td>种类繁多,学习资源</td>
</tr>
<tr>
<td>Pudding.cool</td>
<td>流行文化,论文</td>
</tr>
<tr>
<td>538</td>
<td>体育,政治,干净的数据</td>
</tr>
<tr>
<td>Tidy Tuesdays</td>
<td>杂乱数据,优秀社区</td>
</tr>
<tr>
<td>GitHub</td>
<td>大量可搜索的数据,有评论,质量不一</td>
</tr>
<tr>
<td>Buzzfeed</td>
<td>流行文化,论文,严谨的科学</td>
</tr>
<tr>
<td>Awesome Public Datasets</td>
<td>种类繁多,仅数据集,无评论</td>
</tr>
</tbody>
</table>
<h2 id="1-google-数据集搜索">1. Google 数据集搜索</h2>
<p>我有点作弊,因为这其实不是一个数据集网站,而是一个数据集的搜索引擎。但它太棒了,不得不包括在内。</p>
<p>Google 的 <a href="https://datasetsearch.research.google.com/" target="_blank">数据集搜索</a> 就像 Google,但用于数据集。你输入查询,Google 就会返回所有相关的数据显示。</p>
<p>例如,搜索“猫”会带来超过一百个数据集,包括一个 <a href="https://www.kaggle.com/datasets/crawford/cat-dataset" target="_blank">数据集</a> 含有超过 9,000 张猫的图片。</p>
<p><img src="https://kdn.flygon.net/docs/img/991d47518760898364cf5dcce73e44c2.png" alt="获取数据科学项目的绝佳数据的 10 个网站" loading="lazy"></p>
<p>来源: <a href="https://datasetsearch.research.google.com/search?src=0&query=cats&docid=L2cvMTFqY2tkNTI3MQ%3D%3D" target="_blank">Google 数据集搜索</a></p>
<p>我喜欢这个网站的原因:</p>
<ul>
<li>
<p>它非常多才多艺。你几乎肯定会找到你感兴趣的东西。</p>
</li>
<li>
<p>它即时可用。这个网站包含了使用过这个数据集的其他论文,因此你可以看到其他人已经用这些数据做了什么有趣的事情。</p>
</li>
<li>
<p>你可以切换到仅包含免费数据集的选项。</p>
</li>
<li>
<p>它为你提取了上下文,所以你可以得到一些关于数据集的解释以及为什么要收集它的原因。</p>
</li>
</ul>
<p>这是一个很好的起点。</p>
<h2 id="2-kaggle">2. Kaggle</h2>
<p><a href="https://www.kaggle.com/datasets" target="_blank">Kaggle 数据集</a> 也是一个搜索引擎,但它更有限也更集中。</p>
<p>这比较有限,因为它仅包含人们在 Kaggle 上发布的数据集。但它更有针对性,因为这些数据集不仅仅是 Google 抓取的随机数据集。Kaggle 是数据科学竞赛的家园,因此它收集的数据集与数据科学极为相关。</p>
<p>这使你能够根据你的特定兴趣进行筛选。例如,如果我用“计算机视觉”过滤器搜索“猫”,我可以找到那个相同的猫数据集。</p>
<p><img src="https://kdn.flygon.net/docs/img/f1d66a29e6dc26fb3e188fe65564c850.png" alt="获取数据科学项目的绝佳数据的 10 个网站" loading="lazy"></p>
<p>来源: <a href="https://www.kaggle.com/datasets?search=cats&tags=13207-Computer+Vision" target="_blank">Kaggle 数据集</a></p>
<p>我喜欢这个网站的原因:</p>
<ul>
<li>
<p>社区方面非常强大。点击那个猫数据集会显示 <a href="https://www.kaggle.com/datasets/crawford/cat-dataset/discussion" target="_blank">其他六个人</a> 提出关于数据集的问题——并得到答案。</p>
</li>
<li>
<p>有很多示例项目。你还可以查看 <a href="https://www.kaggle.com/code/steubk/i-tawt-i-taw-a-puddy-tat" target="_blank">其他人构建</a> 或围绕这些数据进行编码的内容。</p>
</li>
<li>
<p>你也可以反过来做——查看他们的 <a href="https://www.kaggle.com/competitions" target="_blank">竞赛</a> 并看看是否有你感兴趣的内容,然后使用附带的数据集。</p>
</li>
</ul>
<h2 id="3-kdnuggets">3. KDNuggets</h2>
<p>这可能会让你感到惊讶,但 KDNuggets 策划了一个 <a href="https://worlddata.ai/partners/kdnuggets" target="_blank">很棒的数据集</a> 。这些数据集专门用于数据科学、机器学习、人工智能和分析,因此它们</p>
<p>这些网站中许多并不是 KDNuggets 独有的,但这是一个值得浏览的好列表。值得注意的是,当你注册成为 KDNuggets 的电子邮件订阅者时,你还可以访问 <a href="https://worlddata.ai/partners/kdnuggets" target="_blank">World Data AI</a>,它包含 35 亿个数据集。</p>
<p><img src="https://kdn.flygon.net/docs/img/996cc165882611f7bc344eb8419c6dd3.png" alt="10 个网站获取惊人的数据用于数据科学项目" loading="lazy"></p>
<p>来源: KDnuggets 数据集</p>
<p>我喜欢这个网站的原因:</p>
<ul>
<li>
<p>针对数据科学的数据。这些数据集中的许多是为了其他目的而整理的,但它们都在这里,特别是因为它们对人工智能、机器学习和数据科学很有用。</p>
</li>
<li>
<p>每个数据集的简要描述。只是一些背景信息,以帮助你决定它是否适合你。</p>
</li>
</ul>
<h2 id="4-政府网站">4. 政府网站</h2>
<p>我可以很容易地将这个获取数据集的网站列表扩展到大约一百万个,只需逐一列出我喜欢用来获取数据的政府网站。我不会这样做。相反,我会在这里提供一个小列表:</p>
<ul>
<li>
<p><a href="http://datasf.org/" target="_blank"><code>datasf.org/</code></a></p>
</li>
<li>
<p><a href="http://data.gov.uk/" target="_blank"><code>data.gov.uk</code></a></p>
</li>
<li>
<p><a href="https://www.usa.gov/About/developer-resources/1usagov.shtml" target="_blank"><code>www.usa.gov/About/developer-resources/1usagov.shtml</code></a></p>
</li>
<li>
<p><a href="http://www.census.gov/" target="_blank"><code>www.census.gov/data/datasets.html</code></a></p>
</li>
</ul>
<p>各国政府不断收集数据以进行研究,许多政府会将这些数据在线发布。</p>
<p><img src="https://kdn.flygon.net/docs/img/2736295bbc7172bc2d99146b3baf5d2d.png" alt="10 个网站获取惊人的数据用于数据科学项目" loading="lazy"></p>
<p>来源: <a href="https://www.census.gov/data.html" target="_blank">美国人口普查局</a></p>
<p>我喜欢这些网站的原因:</p>
<ul>
<li>
<p>数据用于研究,所以通常很干净且组织良好。</p>
</li>
<li>
<p>数据有实际的使用案例。有人为了一个真实的、与政府相关的原因收集了这些数据。</p>
</li>
<li>
<p>通常这些数据非常新鲜。</p>
</li>
<li>
<p>数据背后常常有一些有趣的故事。</p>
</li>
<li>
<p>许多政府已经投入资源来展示如何访问或使用数据,例如 <a href="https://www.census.gov/data/academy.html" target="_blank">人口普查局</a>。</p>
</li>
</ul>
<h2 id="5-puddingcool">5. Pudding.cool</h2>
<p>如果你喜欢数据中加入一些流行文化的元素,可以查看 Pudding.cool。这个网站探讨了各种话题,如 <a href="https://pudding.cool/2017/05/song-repetition/" target="_blank">重复的流行歌词</a>、<a href="https://pudding.cool/2018/08/pockets/" target="_blank">女性口袋</a>,以及 <em>生活大爆炸</em> 如何被中国政府 <a href="https://pudding.cool/2022/08/censorship/" target="_blank">审查</a>。</p>
<p>这更像是一个数字杂志,撰写关于文化的长篇文章,同时展示大量数据。我把它包括在这里,因为他们讲述了很棒的故事,并<a href="https://github.com/the-pudding/data" target="_blank">分享他们的数据</a>。</p>
<p><img src="https://kdn.flygon.net/docs/img/fe5b35eb9f1fa2190120282a2b7559aa.png" alt="10 Websites to Get Amazing Data for Data Science Projects" loading="lazy"><img src="https://kdn.flygon.net/docs/img/0499ede6b9e8fdc7efe685b975b4a1bb.png" alt="10 Websites to Get Amazing Data for Data Science Projects" loading="lazy"></p>
<p>来源:<a href="https://pudding.cool/2023/01/lit-canon/" target="_blank">The Pudding</a></p>
<p>我喜欢这个网站的原因:</p>
<ul>
<li>
<p>超棒、有趣的数据。</p>
</li>
<li>
<p>分享数据和脚本。</p>
</li>
<li>
<p>许多你在现实生活中可能关心的事情。</p>
</li>
</ul>
<h2 id="6-538">6. 538</h2>
<p>另一个以论文为驱动的流行文化网站,提供<a href="https://data.fivethirtyeight.com/" target="_blank">自由获取的数据</a>供你挖掘。他们更多关注体育和政治。虽然数据驱动性较少,但我将其列入这个名单,因为它仍然策划和分享数据集。</p>
<p><img src="https://kdn.flygon.net/docs/img/f0450670e7a3db4401e196d36a8ee06b.png" alt="10 Websites to Get Amazing Data for Data Science Projects" loading="lazy"></p>
<p>来源:<a href="https://data.fivethirtyeight.com/" target="_blank">FiveThirtyEight Data</a></p>
<p>我喜欢这个网站的原因:</p>
<ul>
<li>
<p>智能的故事,配以数据支持,你可以深入研究。</p>
</li>
<li>
<p>数据以干净的 CSV 格式呈现。</p>
</li>
<li>
<p>数据源高度可靠。</p>
</li>
</ul>
<h2 id="7-tidy-tuesdays">7. Tidy Tuesdays</h2>
<p>现在,现实情况是数据通常并不整洁。<a href="https://github.com/rfordatascience/tidytuesday" target="_blank">Tidy Tuesdays</a> 并不完全是一个数据集网站,而是一个每周活动和社区,强调使用数据科学探索不整洁的数据。</p>
<p>每周都有新的数据集发布。参与者被鼓励在 GitHub 和 Twitter 上分享他们的清理技术和可视化成果。</p>
<p><img src="https://kdn.flygon.net/docs/img/25af76dd949d9edfc8661c0c5a0c2d0d.png" alt="10 Websites to Get Amazing Data for Data Science Projects" loading="lazy"></p>
<p>来源:<a href="https://github.com/z3tt/TidyTuesday" target="_blank">TidyTuesday GitHub</a></p>
<p>我喜欢这个网站的原因:</p>
<ul>
<li>
<p>社区非常棒。每周你都会学到一些新东西。</p>
</li>
<li>
<p>非常方便。无需费劲去寻找数据集。每周都有新的数据发布。</p>
</li>
<li>
<p>具有挑战性的、不整洁的数据。你在现实生活中获得的数据很少会像列表中的其他数据那样经过整理。Tidy Tuesdays 帮助你学习如何处理混乱的数据。</p>
</li>
</ul>
<h2 id="8-github">8. GitHub</h2>
<p>GitHub 是大量数据的家园。你可以轻松搜索、筛选和下载数据进行自己的尝试。然而,数据质量差异很大。因为任何人都可以上传数据,它的状态可能并不总是很好。</p>
<p>尽管如此,我觉得这些好处弥补了这些缺点。</p>
<p><img src="https://kdn.flygon.net/docs/img/222068f7954301169d2d49cce1b24828.png" alt="10 Websites to Get Amazing Data for Data Science Projects" loading="lazy"></p>
<p>来源:<a href="https://github.com/search?q=cat+data" target="_blank">GitHub Cat Data</a></p>
<p>我喜欢这个网站的原因:</p>
<ul>
<li>
<p>你可以按语言过滤,例如 Python、Javascript 或其他。</p>
</li>
<li>
<p>数据量非常庞大。</p>
</li>
<li>
<p>通常数据会附带一些评论或代码供你查看。</p>
</li>
</ul>
<h2 id="9-buzzfeed">9. Buzzfeed</h2>
<p>Buzzfeed 不仅仅是通过让你制作沙拉来评论人类状况的测验。尽管这一点可能不那么为人所知,但 Buzzfeed 也做了很多<a href="https://github.com/BuzzFeedNews" target="_blank">优质数据新闻</a>。</p>
<p>一切都是开源的。</p>
<p><img src="https://kdn.flygon.net/docs/img/42bc2d7f1c6274748f2bffd92d1949a5.png" alt="10 个获取惊人数据的网站" loading="lazy"></p>
<p>来源:<a href="https://github.com/BuzzFeedNews/everything#data-and-analyses" target="_blank">BuzzFeed News GitHub</a></p>
<p>我喜欢这个网站的原因:</p>
<ul>
<li>
<p>有趣的数据,经过预处理,并附有形式良好的文章评论。</p>
</li>
<li>
<p>更加复杂的主题。重点是政治和健康等更复杂的主题,但还有很多其他内容。</p>
</li>
</ul>
<h2 id="10-极好的公开数据集">10. 极好的公开数据集</h2>
<p>我将以一个相当自解释的标题结束这份列表:<a href="https://github.com/awesomedata/awesome-public-datasets" target="_blank">极好的公开数据集</a>。这个仓库在 GitHub 上,包含(主要是)免费的数据集供你探索。它们来自在线数据集、用户建议和研究论文。</p>
<p><img src="https://kdn.flygon.net/docs/img/7b1bb9860760df39f5ffc086255c55c3.png" alt="10 个获取惊人数据的网站" loading="lazy"></p>
<p>来源:<a href="https://github.com/awesomedata/awesome-public-datasets/blob/master/README.rst" target="_blank">极好的公开数据集 GitHub</a></p>
<p>我喜欢这个网站的原因:</p>
<ul>
<li>
<p>你可以加入一个<a href="https://awesomedataworld.slack.com/" target="_blank">Slack 群组</a>!</p>
</li>
<li>
<p>主题种类繁多。农业、金融、博物馆。你一定能找到让你感兴趣的内容。</p>
</li>
<li>
<p>精心策划。这些数据集质量很高。</p>
</li>
</ul>
<h1 id="这些网站提供惊人的数据科学数据集">这些网站提供惊人的数据科学数据集</h1>
<p>深入挖掘,你不仅会发现可以让你入门的数据,还会找到社区、灵感和你可以用来学习和成长的数据科学代码。</p>
<p>有如此多的数据可供使用,你不应感到将就。总是寻找那些激发你灵感或让你兴奋的数据。希望这份列表能给你一些起点。</p>
<p><strong><a href="https://www.stratascratch.com" target="_blank">Nate Rosidi</a></strong> 是一位数据科学家和产品战略专家。他还担任分析课程的兼职教授,并且是<a href="https://www.stratascratch.com/" target="_blank">StrataScratch</a>的创始人,该平台帮助数据科学家通过顶级公司的真实面试问题来为面试做准备。可以在<a href="https://twitter.com/StrataScratch" target="_blank">Twitter: StrataScratch</a>或<a href="https://www.linkedin.com/in/nathanrosidi/" target="_blank">LinkedIn</a>上与他联系。</p>
<h3 id="相关话题-2">相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/06/octoparse-scrape-images-easily-websites-nocoding-way.html" target="_blank">无编码方式轻松抓取网站上的图片</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/11/10-amazing-machine-learning-visualizations-know-2023.html" target="_blank">2023 年你应该了解的 10 个惊人机器学习可视化</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/12/make-amazing-visualizations-python-graph-gallery.html" target="_blank">用 Python 图表画廊制作惊人可视化</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/5-amazing-free-llms-playgrounds-you-need-to-try-in-2023" target="_blank">2023 年你必须尝试的 5 个令人惊叹且免费的 LLM 游乐场</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/08/7-beginnerfriendly-projects-get-started-chatgpt.html" target="_blank">7 个适合初学者的 ChatGPT 项目</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/02/first-job-data-science-without-work-experience.html" target="_blank">如何在没有工作经验的情况下获得数据科学领域的第一份工作</a></p>
</li>
</ul>
<h1 id="100-个关于分析大数据数据挖掘数据科学机器学习的活跃博客">100 个关于分析、大数据、数据挖掘、数据科学、机器学习的活跃博客</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2016/03/100-active-blogs-analytics-big-data-science-machine-learning.html" target="_blank"><code>www.kdnuggets.com/2016/03/100-active-blogs-analytics-big-data-science-machine-learning.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/3d9c022da2d331bb56691a9617b91b90.png" alt="c" loading="lazy"> 评论</p>
<p>这里有大约 100 个活跃且定期更新的博客,按字母顺序列出。另见 KDnuggets 完整博客列表</p>
<p><img src="https://kdn.flygon.net/docs/img/blogs.html" alt="Blogs-data-science-big-data-analytics" loading="lazy"></p>
<ul>
<li>
<p><img src="https://kdn.flygon.net/docs/img/0a3ee464311a60a6bfa057b91b75a749.png" alt="new" loading="lazy"> <a href="http://www.3blades.io/blog/" target="_blank">3Blades</a> 云中的数据分析。</p>
</li>
<li>
<p><a href="https://abbottanalytics.blogspot.com/" target="_blank">Abbott Analytics(Dean Abbott 和 Will Dwinnell)</a> 提供数据挖掘和预测分析中的技巧、窍门和评论,包括数据预处理、可视化、建模和模型部署。</p>
</li>
<li>
<p><a href="http://www.analyticsvidhya.com/blog/" target="_blank">Analytics Vidhya 博客</a> 涵盖分析技能的发展、分析行业最佳实践等内容。</p>
</li>
<li>
<p><a href="http://www.thejuliagroup.com/blog/" target="_blank">Ann Maria 博客</a>,由在线统计教育公司 The Julia Group 的总裁<strong>AnnMaria De Mars</strong>博士撰写。</p>
</li>
<li>
<p><a href="https://webanalysis.blogspot.com/" target="_blank">Anil Batra 的网络分析(分析)</a>,在线广告和行为定向博客</p>
</li>
<li>
<p><img src="https://kdn.flygon.net/docs/img/0a3ee464311a60a6bfa057b91b75a749.png" alt="new" loading="lazy"> <a href="https://annalyzin.wordpress.com/" target="_blank">Annalyzin</a>,面向外行的分析,提供教程和实验,由 Annalyn Ng 撰写。</p>
</li>
<li>
<p><a href="http://www.arilamstein.com/blog" target="_blank">Ari Lamstein 博客</a>,涵盖开放数据、地图制作、R 语言等内容。</p>
</li>
<li>
<p><a href="http://www.bzst.com/" target="_blank">商业。统计。技术</a>,由印度海得拉巴印度商学院统计学教授<strong>Galit Shmueli</strong>撰写。</p>
</li>
<li>
<p><a href="http://www.beyondtheboxscore.com/" target="_blank">超越得分框</a> 一个利用统计数据分析棒球比赛的博客。</p>
</li>
<li>
<p><a href="https://datacreators.wordpress.com/" target="_blank">从大数据到大利润</a>,由<strong>Russell Walker</strong>教授撰写,西北大学。</p>
</li>
<li>
<p><a href="https://blogstats.wordpress.com/" target="_blank">统计博客</a> 由 Armin Grossenbacher 撰写,主要面向统计机构的专业网络。</p>
</li>
<li>
<p><a href="http://practicalanalytics.wordpress.com/" target="_blank">商业分析(实用分析)博客</a> 由 Ravi Kalakota 撰写。</p>
</li>
<li>
<p><a href="http://www.bzst.com/" target="_blank">商业。统计。技术</a> 博客由印度海得拉巴印度商学院统计学教授<strong>Galit Shmueli</strong>撰写。</p>
</li>
<li>
<p><a href="http://www.calculatedriskblog.com/" target="_blank">Calculated Risk</a>,财经与经济</p>
</li>
<li>
<p><a href="http://blog.cluster-text.com/" target="_blank">Clustify 博客</a>,涵盖电子发现、预测编码、文档聚类、技术和软件开发。</p>
</li>
<li>
<p><a href="http://cooldata.wordpress.com/" target="_blank">CoolData</a> 由 Kevin MacDonell 撰写,涉及分析、预测建模以及与筹款相关的酷数据。</p>
</li>
<li>
<p><a href="http://www.dataminingblog.com/" target="_blank">数据挖掘研究博客</a>由 Sandro Saitta 主办,涵盖数据挖掘研究问题、近期应用、重要事件、领先人物访谈、当前趋势、书评等。</p>
</li>
<li>
<p><a href="http://datamining.typepad.com/data_mining/" target="_blank">数据挖掘:文本挖掘、可视化和社交媒体</a>由 Matthew Hurst 撰写。</p>
</li>
<li>
<p><a href="http://datascience101.wordpress.com/" target="_blank">数据科学 101</a>由 Ryan Swanstrom 撰写,讨论成为数据科学家的过程。</p>
</li>
<li>
<p><a href="http://www.becomingadatascientist.com/" target="_blank">数据科学 Renee</a>,由 Renee M. P. Teate 撰写,讨论成为数据科学家的过程。</p>
</li>
<li>
<p><a href="http://www.datatau.com/" target="_blank">Data Tau</a> 一份由读者提交的有趣文章列表。</p>
</li>
<li>
<p><a href="http://www.decisionstats.com/" target="_blank">DecisionStats</a>由 Ajay Ohri 主办,DECISIONSTATS 创始人,著有《R for Business Analytics》和《R for Cloud Computing》。</p>
</li>
<li>
<p><a href="https://diffuseprior.wordpress.com/" target="_blank">DiffusePrior</a>由 Alan Fernihough 撰写,讨论在计量经济学研究中使用 R。</p>
</li>
<li>
<p><a href="http://blog.dominodatalab.com/" target="_blank">Domino Data Lab</a>关于创业公司、数据科学、R 和 Python。</p>
</li>
<li>
<p><a href="http://www.datagenetics.com/blog.html" target="_blank">数据遗传学</a></p>
</li>
<li>
<p><a href="http://www.deep-data-mining.com/" target="_blank">深度数据挖掘博客</a>,由 Jay Zhou 主办,主要关注数据挖掘的技术方面。</p>
</li>
<li>
<p><a href="http://bigdatablog.emc.com/" target="_blank">EMC 大数据博客</a>,由 Mona Patel 撰写,EMC 的大数据解决方案营销。</p>
</li>
<li>
<p><a href="http://errorstatistics.com/" target="_blank">误差统计哲学</a>由弗吉尼亚理工大学的统计哲学家 Deborah G. Mayo 撰写。</p>
</li>
<li>
<p><a href="https://www.facebook.com/data?_rdr=p" target="_blank">Facebook 数据科学博客</a>,Facebook 数据科学家提供的有趣见解的官方博客。</p>
</li>
<li>
<p><a href="http://fbhalper.wordpress.com/" target="_blank">Fern Halper 的《数据使世界运转》</a>,主要关注商业和文本分析。</p>
</li>
<li>
<p><a href="https://fivethirtyeight.com/" target="_blank">FiveThirtyEight</a>,由 Nate Silver 及其团队撰写,通过图表和饼图从统计学角度看待从政治到科学再到体育的一切。</p>
</li>
<li>
<p><a href="http://freakonometrics.hypotheses.org/" target="_blank">怪诞计量学</a> – Charpentier,一位数学教授,提供了一系列通常易于理解的统计学主题帖子,同时具备良好的幽默感。</p>
</li>
<li>
<p><a href="http://www.freakonomics.com/blog/" target="_blank">怪诞经济学博客</a>,由 Steven Levitt 和 Stephen J. Dubner 撰写。</p>
</li>
<li>
<p><a href="http://fastml.com/" target="_blank">FastML</a>,涵盖机器学习和数据科学的实际应用。</p>
</li>
<li>
<p><a href="http://flowingdata.com/" target="_blank">FlowingData</a>,Nathan Yau 的可视化和统计网站。</p>
</li>
<li>
<p><a href="https://glinden.blogspot.com/" target="_blank">Greg 的极客之旅</a>,探索个性化信息的未来。</p>
</li>
<li>
<p><a href="http://harvarddatascience.com/" target="_blank">哈佛数据科学</a>,关于统计计算和可视化的思考。</p>
</li>
<li>
<p><img src="https://kdn.flygon.net/docs/img/0a3ee464311a60a6bfa057b91b75a749.png" alt="new" loading="lazy"> <a href="https://community.havenondemand.com/t5/Blog/bg-p/blog_iod#" target="_blank">HPE Haven OnDemand 开发者社区博客</a>。</p>
</li>
<li>
<p><img src="https://kdn.flygon.net/docs/img/0a3ee464311a60a6bfa057b91b75a749.png" alt="new" loading="lazy"> <a href="https://community.dev.hpe.com/t5/Vertica-Blog/bg-p/bigdata_blog_vertica#" target="_blank">HPE Vertica 开发者社区博客</a>。</p>
</li>
<li>
<p><a href="http://hunch.net/" target="_blank">Hunch.net</a>,由<strong>约翰·兰福德</strong>主办,涵盖机器学习理论与实践的交汇点。</p>
</li>
<li>
<p><a href="http://robjhyndman.com/hyndsight/" target="_blank">Hyndsight</a> 由<strong>罗布·亨德曼</strong>主办,涉及预测、数据可视化和函数数据。</p>
</li>
<li>
<p><a href="http://www.ibmbigdatahub.com/blog" target="_blank">IBM 大数据中心博客</a>,来自 IBM 思想领袖的博客。</p>
</li>
<li>
<p><a href="http://www.insightdatascience.com/blog/" target="_blank">Insight 数据科学博客</a> 由 Insight 数据科学研究员项目的校友主办,关注数据科学中的最新趋势和话题。</p>
</li>
<li>
<p><a href="http://www.informationisbeautiful.net/blog/" target="_blank">信息之美</a>,由独立数据记者和信息设计师<strong>大卫·麦坎德莱斯</strong>创办,他也是《信息之美》一书的作者。</p>
</li>
<li>
<p><a href="http://jeffjonas.typepad.com/" target="_blank">杰夫·乔纳斯博客</a>,关于隐私和信息时代的想法与资源。</p>
</li>
<li>
<p><a href="http://jtonedm.com/" target="_blank">JT 的 EDM</a>,<strong>詹姆斯·泰勒</strong>讨论一切决策管理。</p>
</li>
<li>
<p><a href="http://www.juiceanalytics.com/writing/" target="_blank">Juice Analytics</a> 关于分析和可视化。</p>
</li>
<li>
<p><a href="https://blog.kaggle.com/" target="_blank">Kaggle 博客 “No Free Hunch”</a>,涵盖 Kaggle 数据科学和机器学习竞赛。</p>
</li>
<li>
<p><a href="https://lovestats.wordpress.com/" target="_blank">爱统计博客</a> 由<strong>安妮</strong>主办,她是一位市场研究方法学家,博客内容包括抽样、调查、统计、图表等。</p>
</li>
<li>
<p><a href="http://learninglover.com/blog/" target="_blank">学习爱好者</a> 关于编程、算法,并附有一些用于学习的闪卡。</p>
</li>
<li>
<p><a href="https://bickson.blogspot.com/" target="_blank">大规模机器学习及其他</a>,由<strong>丹尼·比克森</strong>主办,创办了 GraphLab,一个获奖的大规模开源项目。</p>
</li>
<li>
<p><img src="https://kdn.flygon.net/docs/img/0a3ee464311a60a6bfa057b91b75a749.png" alt="new" loading="lazy"> <a href="http://lazyprogrammer.me/" target="_blank">懒程序员</a> 关注大数据、数据科学和初创公司编程的最新动态。</p>
</li>
<li>
<p><a href="http://blog.minethatdata.com/" target="_blank">MineThatData 博客</a> 由<strong>凯文·希尔斯特罗姆</strong>主办,讨论多渠道营销和数据库营销。</p>
</li>
<li>
<p><a href="http://www.metabrown.com/blog/" target="_blank">元分析</a> 提供广泛的类别供探索!分析带到银行——<strong>Meta S. Brown</strong>关于预测分析。</p>
</li>
<li>
<p><a href="http://machinelearningmastery.com/blog/" target="_blank">机器学习大师</a> 由<strong>杰森·布朗利</strong>主办,涉及编程与机器学习。</p>
</li>
<li>
<p><a href="http://www.machinedlearnings.com/" target="_blank">机器学习</a> 由<strong>保罗·迈内罗</strong>主办,来自微软云与信息服务实验室。</p>
</li>
<li>
<p><a href="http://www.mattcutts.com/blog/" target="_blank">Matt Cutts: 小工具、谷歌与 SEO 博客</a></p>
</li>
<li>
<p><a href="http://net-savvy.com/executive/" target="_blank">网络精英</a>,<strong>内森·吉利亚特</strong>的社交媒体分析博客。</p>
</li>
<li>
<p><a href="http://nuit-blanche.blogspot.in/" target="_blank">Nuit Blanche</a> 由<strong>伊戈尔·卡龙</strong>主办,专注于压缩感知、先进矩阵分解技术、机器学习。</p>
</li>
<li>
<p><a href="http://junkcharts.typepad.com/numbersruleyourworld/" target="_blank">数字统治你的世界</a>,由<strong>凯泽·冯</strong>主办。</p>
</li>
</ul>
<h3 id="了解更多主题-2">了解更多主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/04/write-engaging-technical-blogs.html" target="_blank">如何编写引人入胜的技术博客</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/time-100-ai-the-most-influential" target="_blank">时代 100 AI: 最具影响力?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/5-free-courses-on-ai-and-chatgpt-to-take-you-from-0-100" target="_blank">5 门免费的人工智能和 ChatGPT 课程,带你从 0 到 100</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/06/data-mining-different-machine-learning.html" target="_blank">数据挖掘与机器学习有什么不同?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/developments-predictions-ai-machine-learning-data-science-research.html" target="_blank">人工智能、分析、机器学习、数据科学、深度学习……</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/01/mwiti-solid-plan-learning-data-science-machine-learning-deep-learning.html" target="_blank">学习数据科学、机器学习和深度学习的坚实计划</a><br>
??、分析、机器学习、数据科学、深度学习……](<a href="https://www.kdnuggets.com/2021/12/developments-predictions-ai-machine-learning-data-science-research.html" target="_blank">https://www.kdnuggets.com/2021/12/developments-predictions-ai-machine-learning-data-science-research.html</a>)</p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/01/mwiti-solid-plan-learning-data-science-machine-learning-deep-learning.html" target="_blank">学习数据科学、机器学习和深度学习的全面计划</a></p>
</li>
</ul>
<h1 id="kdnuggets-新闻-21n48-12-月-22-日使用管道编写干净的-python-代码成为优秀数据科学家的-5-项关键技能">KDnuggets™ 新闻 21:n48, 12 月 22 日:使用管道编写干净的 Python 代码;成为优秀数据科学家的 5 项关键技能</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2021/n48.html" target="_blank"><code>www.kdnuggets.com/2021/n48.html</code></a></p>
</blockquote>
<p>特点 | 产品 | 教程 | 意见 | 顶级 | 职位 | <a href="https://www.kdnuggets.com/news/submissions.html" target="_blank">提交博客</a> | 本周图片</p>
<p>本周在 KDnuggets:使用管道编写干净的 Python 代码;成为优秀数据科学家的 5 项关键技能;将机器学习算法完整端到端地部署到实时生产环境中;成功数据科学家的 5 个特征;学习数据科学统计的顶级资源;还有更多。</p>
<p>KDnuggets <a href="https://www.kdnuggets.com/2021/11/top-blogs-reward-program-resumes.html" target="_blank"><strong>顶级博客奖励计划</strong></a>将每月向顶级博客的作者支付报酬。接受转载,但原创投稿的转载率为 3 倍。阅读我们的 <a href="https://www.kdnuggets.com/news/submissions.html" target="_blank"><strong>指南</strong></a>并将你的博客首先提交给 KDnuggets!</p>
<p>特点</p>
<ul>
<li>
<p>**<img src="https://kdn.flygon.net/docs/img/write-clean-python-code-pipes.html" alt="Gold Blog 使用管道编写干净的 Python 代码**" loading="lazy">,作者:Khuyen Tran</p>
</li>
<li>
<p>**<img src="https://kdn.flygon.net/docs/img/5-key-skills-needed-become-great-data-scientist.html" alt="Silver Blog 成为优秀数据科学家的 5 项关键技能**" loading="lazy">,作者:Sharan Kumar Ravindran</p>
</li>
<li>
<p><strong>将机器学习算法完整端到端地部署到实时生产环境中</strong>,作者:Graham Harrison</p>
</li>
<li>
<p><strong>成功数据科学家的 5 个特征</strong>,作者:Matthew Mayo</p>
</li>
<li>
<p><strong>学习数据科学统计的顶级资源</strong>,作者:Springboard</p>
</li>
</ul>
<p>产品,服务</p>
<ul>
<li><strong>利用 AI 和分析引擎更快地准备时间序列数据</strong>,作者:PI.EXCHANGE</li>
</ul>
<p>教程,概述</p>
<ul>
<li>
<p><strong>每个数据科学家都应该知道的三个 R 库(即使你使用 Python)</strong>,作者:Terence Shin</p>
</li>
<li>
<p><strong>如何加速 XGBoost 模型训练</strong>,作者:Michael Galarnyk</p>
</li>
<li>
<p><strong>云机器学习透视:2021 年的惊喜,2022 年的预测</strong>,作者:George Vyshnya</p>
</li>
<li>
<p><strong>如何在没有相关学位的情况下进入数据分析领域</strong>,作者:Zulie Rane</p>
</li>
</ul>
<p>意见</p>
<ul>
<li>
<p><strong>作为数据分析/科学专业人士,我在 14 年内将薪水提高了 14 倍</strong>,作者:Leon Wei</p>
</li>
<li>
<p><strong>2022 年及以后 10 大 AI 与数据分析趋势</strong>,作者:David Pool</p>
</li>
<li>
<p><strong>聊天机器人转型:从失败到未来</strong>,作者:Lubo Smid</p>
</li>
<li>
<p><strong>为什么我们始终需要人类来训练 AI——有时是实时的</strong>,作者:Shoma Kimura</p>
</li>
</ul>
<p>热点新闻</p>
<ul>
<li>
<p><strong>2021 年最佳故事:我们不需要数据科学家,我们需要数据工程师;成为数据科学家的指南(逐步方法);如何在 18 个月内将我的收入提高三倍</strong>,作者:Gregory Piatetsky</p>
</li>
<li>
<p><strong>本周热点新闻,12 月 13 日至 19 日:使用管道编写干净的 Python 代码</strong>,作者:KDnuggets</p>
</li>
</ul>
<p>职位</p>
<ul>
<li>
<p>查看我们近期的 AI、分析、数据科学、机器学习职位</p>
</li>
<li>
<p>你可以在 KDnuggets 的职位页面免费发布与 AI、大数据、数据科学或机器学习相关的行业或学术职位,详细信息请见 kdnuggets.com/jobs</p>
</li>
</ul>
<p>本周图片</p>
<blockquote>
<p></p>
</blockquote>
<h3 id="更多相关话题-28">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/write-clean-python-code-pipes.html" target="_blank">使用管道编写干净的 Python 代码</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-key-skills-needed-become-great-data-scientist.html" target="_blank">成为优秀数据科学家所需的 5 项关键技能</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/04/low-code-developers-still-needed.html" target="_blank">低代码:开发者仍然需要吗?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n09.html" target="_blank">KDnuggets™ 新闻 22:n09,3 月 2 日:讲述一个精彩的数据故事:A…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n01.html" target="_blank">KDnuggets™ 新闻 22:n01,1 月 5 日:追踪和可视化的 3 种工具…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/data-science-make-clean-energy-equitable.html" target="_blank">使用数据科学使清洁能源更加公平</a></p>
</li>
</ul>
<h1 id="作为数据科学家工作的-11-家最佳公司">作为数据科学家工作的 11 家最佳公司</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2021/12/11-best-companies-work-data-scientist.html" target="_blank"><code>www.kdnuggets.com/2021/12/11-best-companies-work-data-scientist.html</code></a></p>
</blockquote>
<p><strong>作者 <a href="http://www.stratascratch.com/" target="_blank">Zulie Rane</a>,自由撰稿人和编码爱好者</strong></p>
<p><img src="https://kdn.flygon.net/docs/img/c14e5d84e9e2fda1b8f51a084d74df61.png" alt="作为数据科学家工作的 11 家最佳公司" loading="lazy"></p>
<hr>
<h2 id="我们的前三大课程推荐-16">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业的快车道。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析能力</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织的 IT 需求</p>
<hr>
<p>自 1960 年代以来,大数据在全球扎根并扩展。据<a href="https://www.oracle.com/big-data/what-is-big-data/" target="_blank">Oracle</a>介绍,大数据是指“包含更大种类的数据,数据量不断增加,且速度更快。” 随着大数据的到来,我们现在拥有庞大而复杂的数据集,可以为比以往更多的商业问题提供见解。数据科学公司在各个行业中不断涌现,以分析这些数据以获取商业洞察。</p>
<p>所有这些商业机会直接转化为就业机会。尽管很少有大学提供数据科学项目,但这个行业正在以极大的热情增长。市场上有大量的数据科学公司,几乎每个重要公司都会有一些数据科学家在工作。Bernhardt Schroeder 在<a href="https://www.forbes.com/sites/bernhardschroeder/2021/06/11/the-data-analytics-profession-and-employment-is-exploding-three-trends-that-matter/?sh=5fea28f33f81" target="_blank">Forbes</a>中报道,根据美国劳工统计局的数据,美国的数据科学行业到 2026 年将增长 28%。数据科学领域有大量的空缺职位,因此如果你拥有相关技能和兴趣,你几乎可以随意选择。哪些是最适合的数据科学公司?你如何确定哪家最适合你?</p>
<p>当你想要<a href="https://www.stratascratch.com/blog/how-to-become-a-data-scientist-from-scratch/" target="_blank">成为数据科学家</a>时,大多数人首先会想到谷歌的数据科学职位,或者希望在脸书找到一份工作。我们有<a href="https://www.stratascratch.com/blog/ultimate-guide-to-the-top-5-data-science-companies/" target="_blank">顶级 5 家数据科学公司终极指南</a>,在其中我们讨论了这些大型科技公司中的数据科学角色。当然,这些都是经典的数据科学雇主,但这个列表旨在超越常规和预期。我想为你提供一些出色的、可能被低估的选择,以<a href="https://www.stratascratch.com/blog/how-to-get-a-data-science-job-the-ultimate-guide/" target="_blank">获得数据科学家的职位</a>。</p>
<h2 id="什么让一家数据科学公司成为最佳">什么让一家数据科学公司成为最佳?</h2>
<p>当谈到寻找最适合的数据科学公司时,有很多因素需要考虑。你可能更喜欢较小的数据科学公司、某个行业的数据科学工作,或者你可能有地理限制。我个人更喜欢以客户为中心的公司,有很大的空间来探索自己的数据科学兴趣,但每个人都不同!我将带你了解我认为作为数据科学家工作的最佳公司。我考虑了薪酬、工作/生活平衡以及在行业中的重要性——工作的酷炫程度。最后,我根据公司规模将它们分成了几个类别。</p>
<p>让我们深入了解最佳的数据科学公司吧。</p>
<p><img src="https://kdn.flygon.net/docs/img/d4e4d580afa7f8b6d1feb87f223f414c.png" alt="作为数据科学家工作的 11 家公司" loading="lazy"></p>
<h2 id="作为数据科学家的最佳公司大型公司">作为数据科学家的最佳公司:大型公司</h2>
<h3 id="1-微软">1. 微软</h3>
<p>微软有很多很酷的数据科学项目和产品。虽然它们被认为是企业和消费者软件公司,但微软仍然是一个强大的数据科学公司。举个例子,他们有一个叫做<a href="https://www.microsoft.com/en-us/ai/ai-for-earth" target="_blank">AI for Earth</a>的项目,将他们的云和 AI 工具交到那些致力于改善环境的人手中。他们开发开源工具、数据、API 和模型,以支持可持续发展技术的开发。他们还有<a href="https://www.microsoft.com/en-us/ai/ai-for-accessibility" target="_blank">AI for Accessibility</a>项目,旨在缩小“<a href="https://blogs.microsoft.com/ai/shrinking-the-data-desert/" target="_blank">数据沙漠</a>”,填补残疾人士 AI 数据集的空白。</p>
<p>除了令人钦佩的研究和开源项目外,微软还有广泛的产品线,包括面向消费者、企业和开发者的产品。你可以参与从 Microsoft Word 到 Xbox 的产品。由于有如此多样的终端用户和产品,你可能会找到一个适合你兴趣的领域,或者通过内部调动尝试几个不同的产品领域。</p>
<p>他们在全球范围内有许多数据、分析和 AI<a href="https://careers.microsoft.com/us/en/data-analytics-and-ai" target="_blank">职位空缺</a>。你可以选择专注于纯数据科学角色、优化销售策略,或者作为一名专注于数据科学的软件工程师。项目的多样性使微软成为最佳数据科学公司之一。许多团队有不同的需求和工作机会,所以自己查看一下是否有你感兴趣的产品领域或团队。如果你对这条职业道路感兴趣,可以查看<a href="https://www.stratascratch.com/blog/microsoft-data-scientist-position-guide/" target="_blank">如何成为微软数据科学家的综合指南</a>。</p>
<h3 id="2-亚马逊">2. 亚马逊</h3>
<p>亚马逊早已不再只是一个在线书店,它是数据科学家工作的最佳场所之一。(我们有一份<a href="https://www.stratascratch.com/blog/amazon-data-scientist-position-guide/" target="_blank">如何成为亚马逊数据科学家的指南</a>。)亚马逊网络服务(AWS)是云服务行业中最大的单一市场份额持有者。在数据科学公司中,亚马逊是一家强大的公司,雇用数据科学家以提供机器学习和数据科学解决方案以及 AWS 云服务。</p>
<p>除了其以 AWS 为中心的数据科学服务,亚马逊还为在线零售客户提供反欺诈产品,这些产品利用机器学习在其大量交易中检测欺诈行为。</p>
<p>考虑到亚马逊通过其电子商务业务生成和收集的大量数据,亚马逊掌握了很多非常有趣和信息丰富的数据。你不想获得这些数据吗?亚马逊有大量的<a href="https://www.amazon.jobs/en/job_categories/data-science" target="_blank">开放数据科学职位</a>,涵盖了从优化供应链到预测需求等领域。对于数据科学家来说,亚马逊有大量引人入胜的问题需要解决。</p>
<h3 id="3-airbnb">3. Airbnb</h3>
<p>Airbnb 付出了大量努力来革新旅游行业。Airbnb 充分利用了数据科学家。其前数据科学主管曾表示,Airbnb“将数据视为客户的声音,将数据科学视为对这些声音的解读。”我发现以客户为中心的公司工作非常愉快。做出的决策有目的和逻辑,旨在惠及客户和企业。</p>
<p>Airbnb 利用数据科学来改进其服务和搜索,还改进了招聘实践。他们使用数据科学来分析并消除自身招聘行为中的偏见。数据科学公司可以将其大量知识应用于内部流程,Airbnb 就是一个很好的例子。他们的自我反思和批评文化是我认为 Airbnb 是最佳数据科学公司之一的原因。</p>
<p>Airbnb 的数据科学还有另一个有趣的地方,那就是他们在金融、信任和客户体验方面有开放的数据科学职位。由于关注领域如此广泛,数据科学家可以在 Airbnb 内部移动,接触到许多不同的行业。我总是认为提前计划并考虑你的下三步是个好主意。在 Airbnb 担任数据科学家可能会引导你进入金融科技公司、安全领域或更面向客户的角色,因此如果你对这些感兴趣,可以查看 Airbnb 的开放数据科学职位<a href="https://careers.airbnb.com/" target="_blank">列表</a>,找到适合你兴趣的职位。</p>
<h3 id="4-nvidia">4. Nvidia</h3>
<p>有数据科学公司,然后是 Nvidia。Nvidia 定义了“<a href="https://www.nvidia.com/en-us/deep-learning-ai/solutions/data-analytics/" target="_blank">加速分析</a>”,这种分析通过使用 GPU,比如他们的 NVIDIA DGX A100s,使数据处理速度提高多达 20 倍,并且无需重新构建。在商业世界中,时间就是金钱,这些优化带来了 Nvidia 显卡的巨大成功。他们让数据科学家与最前沿的芯片和显卡合作,优化这些设备以处理大量数据。</p>
<p>在 Nvidia,你有机会提升全球数据科学家的工作效率。你可以对数据科学工作的效率产生乘数效应,这也是为什么 Nvidia 是最好的数据科学公司之一——你有极高的影响力和成就感。</p>
<p>Nvidia 还向客户提供数据科学咨询,并在内部使用数据科学来优化开发产品的受欢迎程度。作为一家大型公司,他们有数百个开放的数据科学<a href="https://nvidia.wd5.myworkdayjobs.com/NVIDIAExternalCareerSite/4/refreshFacet/318c8bb6f553100021d223d9780d30be" target="_blank">职位</a>,涵盖从数据架构师到数据生成工程师等多个角色。</p>
<h3 id="5-oracle">5. Oracle</h3>
<p>Oracle 有一个非常<a href="https://www.oracle.com/business-analytics/analytics-platform/" target="_blank">酷的云平台</a>,使他们的客户能够通过机器学习模型、可视化和预测分析来利用数据。作为开发这个平台的数据科学家,你将开发所有这些出色的模型和工具,供最终用户应用于他们的数据。</p>
<p>这个分析<a href="https://www.oracle.com/business-analytics/analytics-platform/" target="_blank">平台</a>拥有“嵌入的机器学习和自然语言处理技术,[帮助提高生产力]”。这种工作给你提供了一个极好的机会来改善客户的(工作)生活质量。你可以从事广告工作、设计数据科学驱动的产品、寻找组织和分析非结构化数据的新方法,或在噪声中寻找意义。</p>
<p>Oracle 有成千上万的数据科学<a href="https://eeho.fa.us2.oraclecloud.com/hcmUI/CandidateExperience/en/sites/CX_1/requisitions?keyword=data%20science&location=United%20States&locationId=300000000149325&locationLevel=country" target="_blank">职位</a>,涵盖了几乎所有内部部门,适用于各种经验水平。鉴于开放的数据科学职位数量之多,Oracle 是寻找在多个领域获得声誉和经验的数据科学公司中最好的选择之一。</p>
<h3 id="6-达美航空">6. 达美航空</h3>
<p>你可能不会立刻想到总部位于亚特兰大的航空公司,但<strong>达美航空</strong>确实应被考虑在数据科学公司之列。达美航空在决策科学中应用机器学习,“这种规模在航空公司中前所未有”。凭借对达美历史数据的访问,达美的数据显示科学家模拟操作挑战,以找出能够最小化客户影响的解决方案。作为一个对许多航空公司的无能感到沮丧的人,发现有公司转向数据的力量来优化客户体验真是令人耳目一新。</p>
<p>作为世界上最繁忙的机场——哈茨菲尔德-杰克逊国际机场的主要航空公司,效率和优化是达美航空的关键目标。达美有大量开放的数据科学<a href="https://delta.dejobs.org/jobs/?q=data+science" target="_blank">职位</a>,但绝大多数职位位于乔治亚州的亚特兰大。达美确实是东南部最佳数据科学公司之一。你的工作可能涵盖从健康分析到运营决策科学到数据策略师的各种领域。谈到多样性!</p>
<h2 id="数据科学家最佳工作公司中型和小型公司">数据科学家最佳工作公司:中型和小型公司</h2>
<p><img src="https://kdn.flygon.net/docs/img/61c11e7d7e4db24a67d88bba58202506.png" alt="数据科学家最佳工作公司" loading="lazy"></p>
<h3 id="7-splunk">7. Splunk</h3>
<p>Splunk 的主要产品是一个<a href="https://www.splunk.com/en_us/platform/platform-operations-overview.html" target="_blank">中央数据平台</a>,允许用户以安全的方式监控、调查、分析和处理数据,以提高运营效率。他们的机器学习内置功能包括异常检测、预测、事件聚类和预测分析。就数据科学公司而言,如果你对硬核机器学习模型充满热情,Splunk 将非常适合你。</p>
<p>他们的中央数据平台允许在多云环境中进行数据流。Splunk 的平台还具备对数据进行实时搜索的能力,适用于结构化和非结构化数据。查看 Splunk 的开放数据科学职位<a href="https://www.splunk.com/en_us/careers/search-jobs.html?keyword=data%20science" target="_blank">这里</a>。</p>
<h3 id="8-cloudera">8. Cloudera</h3>
<p>作为自称的“混合云公司”,Cloudera 允许客户结合私人和公共云。这意味着你可以混合内部和外部数据,为客户提供更强大的洞察。Cloudera 在数据科学公司中因其强大且可扩展的云数据平台而独树一帜。他们的 Cloudera 数据平台(CDP)混合云运行在客户端的数据所在位置,从而实现更快的工作速度和更高的安全性。</p>
<p>Cloudera 的数据科学家更注重数据管理和他们的机器学习平台,因此如果你对这些领域感兴趣,可以查看<a href="https://www.cloudera.com/careers/careers-listing.html" target="_blank">这里</a>。</p>
<h3 id="9-分子">9. 分子</h3>
<p>Numerator 是专注于电子商务客户洞察的数据科学公司之一。他们旨在提供“帮助你针对消费者而非人口统计数据进行市场营销”的洞察。Numerator 专注于其产品易于实施,并声称其产品可以在购买后 72 小时内发布。</p>
<p>Numerator 是最大的、最具多样性的消费者购买面板。他们提供大量数据,并付出额外努力进行分析。数据科学家们直接从消费者那里收集数据并进行分析,以为 Numerator 的客户提供洞察。Numerator 喜欢让他们的数据科学家尽可能自主地工作,因此你可以从项目的起始阶段到生产阶段主导项目。如果你喜欢处理无结构的工作和开放性问题,Numerator 是最佳的数据科学公司之一。查看<a href="https://www.numerator.com/join-our-team" target="_blank">Numerator 的职业门户</a>,了解你可以提供有价值市场分析的机会。</p>
<h3 id="10-teradata">10. Teradata</h3>
<p>与 Cloudera 类似,Teradata 是一个混合云平台,允许你将公共云(如 Azure 和 AWS)与本地解决方案混合使用。像许多数据科学公司一样,Teradata 还提供咨询团队帮助企业客户最大化使用其解决方案的好处。</p>
<p>他们的主要产品 Vantage 是一款包括<a href="https://www.teradata.com/Blogs/A-Day-in-the-Life-of-a-Data-Scientist-with-Teradata-Vantage" target="_blank">集成分析功能</a>的软件,能够在多个混合平台上执行以提供大规模的洞察。</p>
<p>你可以在高度并行和高效的分布环境中扩展所提供的分析功能(机器学习、统计、文本等)。Teradata 采用学术方法进行工作和验证,因此鼓励申请专利、在期刊上发表论文和参加会议。如果你喜欢在数据领域大展拳脚,Teradata 可以为你提供一个优秀的专业社区以及提升数据科学家职业的联系。</p>
<p>Teradata 在全球范围内有 <a href="https://teradata.dejobs.org/data-scientist/jobs-in/" target="_blank">职位</a>,他们甚至还有一个非常酷的角色——“数据科学家算法开发工程师”。如果你希望将对数据的热情与对算法和优化的深入知识结合起来,Teradata 是最好的数据科学公司之一。</p>
<h3 id="11-databricks">11. Databricks</h3>
<p>Databricks 的 <a href="https://databricks.com/product/data-lakehouse" target="_blank">Lakehouse</a> 平台是数据湖和数据仓库的结合体。他们旨在像数据湖一样具有成本效益,同时提供数据仓库通常关联的高端数据管理和性能。</p>
<p>他们希望消除数据孤岛,将分析、数据科学和机器学习融为一体。Lakehouse 基于开源平台构建,以最大化其可用性和灵活性。数据科学公司可能对其专有系统和软件非常保护,因此我认为 Databricks 选择在开源平台上构建其主要产品相当酷。</p>
<p>他们公开的数据科学家职位招聘具有很大的 <a href="https://databricks.com/company/careers/open-positions" target="_blank">机会</a> 影响力,因为其职责包括塑造他们数据科学解决方案的方向,包括“预测、产品分析、客户流失预测和洞察、分段和推荐”。你还可以在公司层面代表数据科学,并推动数据驱动的思维方式。</p>
<p>他们拥有数据解决方案架构师、机器学习平台工程师、分布式数据系统工程师,以及许多与数据科学相关的职位。</p>
<h3 id="关于数据科学家的最佳公司最终想法">关于数据科学家的最佳公司最终想法</h3>
<p>有很多公司雇佣数据科学家。数据科学工作通常涉及机器学习或数据科学的专有平台,或者将数据科学应用于其他行业。最适合你的公司和职位取决于你的兴趣所在。</p>
<p>如果你对环境有极大的热情,你可能会想作为数据科学家参与微软的 <a href="https://www.microsoft.com/en-us/ai/ai-for-earth" target="_blank">AI for Earth</a> 项目。然而,如果你对纯数据充满热情并对电子商务感兴趣,Numerator 可能更适合你。</p>
<p>好消息是你有很多选择。如果你没有正式学习计算机科学或数据科学,我认为继续留在你现在的行业并寻找数据科学职位是个好主意。你现有的背景知识会给你带来相对于不了解该行业的其他数据科学家的优势。</p>
<p><strong>简介:<a href="http://www.stratascratch.com/" target="_blank">Zulie Rane</a></strong> 是一位自由撰稿人和编程爱好者。</p>
<p><a href="https://www.stratascratch.com/blog/11-best-companies-to-work-for-as-a-data-scientist/" target="_blank">原文</a>。经许可转载。</p>
<h3 id="更多相关话题-29">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2023/07/mostly-data-access-severely-lacking-synthetic-data-help.html" target="_blank">大多数公司在数据访问方面严重不足,71%的人认为……</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/05/6-highest-paying-companies-data-scientists.html" target="_blank">数据科学家薪资最高的 6 家公司</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/hard-get-faang-companies.html" target="_blank">进入 FAANG 公司有多难</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/top-companies-in-india-to-consider-for-employment" target="_blank">印度顶尖公司就业推荐</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/08/data-scientists-data-engineers-work-together.html" target="_blank">数据科学家与数据工程师如何协作?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/09/datacamp-learn-different-data-visualizations-work.html" target="_blank">学习不同的数据可视化效果</a></p>
</li>
</ul>
<h1 id="11-个最佳数据科学教育平台">11 个最佳数据科学教育平台</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2021/08/11-best-data-science-education-platforms.html" target="_blank"><code>www.kdnuggets.com/2021/08/11-best-data-science-education-platforms.html</code></a></p>
</blockquote>
<p>评论</p>
<p><strong>由<a href="https://www.linkedin.com/in/zulie-rane-2a225a185/" target="_blank">Zulie Rane</a>,自由撰稿人和编程爱好者</strong>。</p>
<p><img src="https://kdn.flygon.net/docs/img/d80dccb60db2f2e305a25042b21d77c3.png" alt="" loading="lazy"></p>
<p>现在是 2021 年,数据科学仍然是你可以从事的最激动人心且最有前景的职业之一。此外,你完全可以在闲暇时通过一些最好的在线数据科学教育平台来学习你所需的所有技能。</p>
<p>如果你梦想<a href="https://www.stratascratch.com/blog/how-to-become-a-data-scientist-from-scratch/" target="_blank">成为数据科学家</a>,这对你来说是个好消息,难道你不想吗?你能获得<a href="https://www.stratascratch.com/blog/how-much-do-data-scientists-make/" target="_blank">六位数的平均薪资</a>,工作满意度高,而且这是一个<a href="https://brainstation.io/career-guides/is-data-science-a-good-career" target="_blank">稳定的职业</a>并且有很多晋升机会。这一切都在你的掌握之中。你只需确保你在寻找<a href="https://www.stratascratch.com/blog/4-features-to-look-for-in-educational-platforms/" target="_blank">教育平台的正确特性</a>。</p>
<p>根据你在最佳数据科学教育平台中寻找的内容,你可能希望找到一个针对初学者的平台,涵盖基础知识,提供特定语言如 Python,或帮助你获得特定的职位面试。</p>
<p>这些是根据你在职业生涯中最重要的方面,为你挑选的十一大全球最佳数据科学教育平台。</p>
<h2 id="1-最佳数据科学教育平台针对初学者mode">1. 最佳数据科学教育平台<em>针对初学者</em>:Mode</h2>
<p><img src="https://kdn.flygon.net/docs/img/14164186eeb706a9fff85c1fee7ffb30.png" alt="" loading="lazy"></p>
<p>许多即将成为数据科学家的人从零开始。这意味着,适合你的最佳数据科学教育平台是那些针对没有编程经验的人、可能不知道自己想做什么的职业新人,以及不熟悉众多潜在语言的人。</p>
<p>我真的很喜欢<a href="https://mode.com/" target="_blank">Mode</a>作为初学者的数据科学教育平台。它的优势在于它不会试图做所有事情。它有一系列直接的 Python 和 SQL 教程,这两种语言都是刚刚涉足数据科学的人首选的语言。</p>
<p>对于那些希望在非常基础的层面上学习<a href="https://www.stratascratch.com/blog/top-5-data-science-programming-languages/" target="_blank">编程语言</a>和分析的初学者数据科学家来说,这是最佳的数据科学教育平台。这个平台将帮助你掌握这两种语言的入门技能。通过他们的 Python 教程,重点是商业数据。对于 SQL,你将经历回答基于数据的问题的过程。你无需任何编程语言就可以开始。</p>
<p>它也是完全免费的。他们的商业模式面向企业客户,他们希望通过教授你基础知识,也许当你成为数据科学家时,你会记住这些知识。</p>
<p>一旦你充分利用了 Mode Analytics,你可以进一步寻找新的平台来提升和加深你的<a href="https://www.stratascratch.com/blog/most-in-demand-data-science-technical-skills/" target="_blank">data science skills</a>。</p>
<h2 id="2-最佳数据科学教育平台-对于有经验的用户stratascratch">2. 最佳数据科学教育平台 <em>对于有经验的用户</em>:StrataScratch</h2>
<p><img src="https://kdn.flygon.net/docs/img/9bc679040bcbc5b3c574e00fd408be2f.png" alt="" loading="lazy"></p>
<p>如果你已经了解一些数据科学知识,知道自己想要什么样的工作,甚至知道自己想要在哪家公司工作,StrataScratch 是最适合你的数据科学教育平台。该平台提供了实际的<a href="https://www.stratascratch.com/blog/data-science-interview-guide-questions-from-80-different-companies/" target="_blank">data science interview questions</a>,涵盖了从简单到困难的不同层次,来自特定公司,使用特定语言。你可以找到各种难度的问题,比如使用 Python 的困难 Amazon 面试问题(见<a href="https://platform.stratascratch.com/coding/10319-monthly-percentage-difference?python=1" target="_blank">这里</a>),Uber 的中等难度业务案例问题(如<a href="https://platform.stratascratch.com/technical/2014-determining-origin-city" target="_blank">this one</a>),以及介于两者之间的任何问题。</p>
<p>这个庞大的问题库使其成为一个更好的数据科学教育平台,适合那些已经了解数据科学领域的人。如果你是新手,可能会感到不知所措。经验丰富的数据科学求职者可以通过有针对性的方法从中获取更多的价值。</p>
<p>StrataScratch 采用了增值模式。一些问题是免费的,但大多数优质问题需要付费。这个数据科学教育平台的终身订阅费用为 199 美元,月费 29 美元,年费 99 美元。</p>
<h2 id="3-最佳数据科学教育平台-对于特定语言udemy">3. 最佳数据科学教育平台 <em>对于特定语言</em>:Udemy</h2>
<p><img src="https://kdn.flygon.net/docs/img/bab27864090b80ee390ed0774eef5f10.png" alt="" loading="lazy"></p>
<p>也许你对数据科学有基本了解,或者你已经掌握了像 Python 这样的数据科学语言的基础。如果你想学习特定语言,最适合你的数据科学教育平台是<a href="http://udemy.com/" target="_blank">Udemy</a>。</p>
<p>Udemy 是一个在线学习平台,提供各种技能的课程,但他们有很多非常受欢迎的语言课程。超过 500 万名学习者参加了他们的数据科学<a href="https://www.udemy.com/topic/data-science/" target="_blank">courses</a>,你肯定能找到适合你的课程。</p>
<p>我推荐 Udemy 作为特定语言的最佳数据科学教育平台的原因是 Udemy 的强项在于专业化。虽然他们确实提供涵盖更广泛主题的课程,如“数据科学 101”和“可视化”,但他们拥有特定领域的专家讲师,并且教授你该语言的非常具体的技能。Udemy 为你能想象的几乎所有语言提供了有才华的个别教师。例如,你可以上像“用 Python 进行机器学习、数据科学和深度学习”这样具体的课程,由专家 Frank Kane 教授。</p>
<p>Udemy 课程不是免费的,但如果你知道你想学习的语言,价格点是合理的。只需搜索你想学习的语言,看看有什么选择。</p>
<h2 id="4-最佳数据科学教育平台-针对特定工作hackerrank">4. 最佳数据科学教育平台 <em>针对特定工作</em>:HackerRank</h2>
<p><img src="https://kdn.flygon.net/docs/img/1f4970493b58bbdfa182c80c89961766.png" alt="" loading="lazy"></p>
<p>与语言类似,一些有志于成为数据科学家的人不需要基础知识——他们希望找到一个可以教他们特定工作的技能的平台。如果你有一个公司或职位在心中,最适合你的数据科学教育平台是 <a href="https://www.hackerrank.com/" target="_blank">HackerRank</a>。</p>
<p>HackerRank 是一个非常以社区为导向的数据科学教育平台。它最初是为了帮助公司进行面试而建立的,后来扩展成了一个程序员平台。HackerRank 提供了计算机科学各个领域的问题,比如算法、机器学习或人工智能。</p>
<p>由于它是为公司而非面试官而建造的,这使其成为一个极好的数据科学教育平台,可以找到并申请工作,同时练习在你寻找的工作中高度重视的技能。</p>
<p>由于其盈利方式是通过企业客户,它对像你我这样的程序员是免费的。</p>
<h2 id="5-最佳-免费-数据科学教育平台exercism">5. 最佳 <em>免费</em> 数据科学教育平台:Exercism</h2>
<p><img src="https://kdn.flygon.net/docs/img/4f94fe5f5516d94ef9d7c432ce75f948.png" alt="" loading="lazy"></p>
<p>你会发现这个列表中已经有两个免费的选项,所以你可能会想知道为什么这个特定的数据科学教育平台作为免费选项如此出色。</p>
<p>事实是,市场上有很多“免费”的数据科学教育平台,这些平台实际上只是便宜的方式来收集电子邮件用于追加销售,或者是为公司而非程序员建设的,偶然间提供了数据科学教育平台。</p>
<p><a href="https://exercism.io/" target="_blank">Exercism</a> 不属于这些。这个数据科学教育平台提供了 50 多个语言轨迹,大量的问题,专门为数据科学家设计,并且永久免费。Exercism 并非营利机构——他们的使命是提高经济和社会流动性,所以你知道它会高质量且永远免费。</p>
<h2 id="6-最佳数据科学教育平台-针对动手学习者leetcode">6. 最佳数据科学教育平台 <em>针对动手学习者</em>:LeetCode</h2>
<p><img src="https://kdn.flygon.net/docs/img/e2f8221e9f638d741810c7c7d96832b2.png" alt="" loading="lazy"></p>
<p>对于你来说,最佳的数据科学教育平台还取决于你的学习风格和时间安排。如果你喜欢动手操作的互动实践,那么<a href="https://leetcode.com/" target="_blank">Leetcode</a>在这些选项中是最适合你的数据科学教育平台。</p>
<p>这个平台高度互动,提供了大量针对你选择的难度级别的不同问题和挑战。它们提供基础课程,例如<a href="https://leetcode.com/explore/learn/card/fun-with-arrays/" target="_blank">数组 101</a>,以及每月的<a href="https://leetcode.com/explore/challenge/card/december-leetcoding-challenge/" target="_blank">challenges</a>来测试你的技能。我选择它们作为最佳的实践学习平台,因为你需要实际输入代码并进行操作。这些挑战提供了社区元素(如果那种东西能激励你工作的压力也在其中!)。</p>
<p>这个数据科学教育平台采用了增值模式——有大量免费内容,但许多更好和更有价值的问题和指南需要付费才能访问。高级版的费用为每月$35 或每年$159。</p>
<h2 id="7-最佳数据科学教育平台-基础知识qvault">7. 最佳数据科学教育平台 <em>基础知识</em>:Qvault</h2>
<p><img src="https://kdn.flygon.net/docs/img/36965f4d8d4c69c9675c45420c175dd8.png" alt="" loading="lazy"></p>
<p>人们在追求数据科学职业时最大的错误之一就是忽视基础知识。许多有志的数据科学家甚至不理解他们的硬件、计算理论和网页开发的基本知识,尽管这些元素都是数据科学的基础。你可能能在面试中回答一个<a href="https://www.stratascratch.com/blog/data-science-coding-interview-questions-with-5-technical-concepts/" target="_blank">data science coding question</a>但因为你不理解数据科学和计算机科学的基本构建块而被卡住。</p>
<p>对于掌握这些关键基础知识的最佳数据科学教育平台是<a href="https://qvault.io/" target="_blank">Qvault</a>。它们提供 Go、JavaScript、大 O 算法、函数式编程和数据结构的课程。</p>
<p>该数据科学教育平台的定价相对较为实惠。免费的基础计划包括阅读访问课程材料和一些沙盒访问权限,而每月$8 的专业版提供即时代码验证和问题的完整解决方案。</p>
<h2 id="8-最佳数据科学教育平台-认证coursera">8. 最佳数据科学教育平台 <em>认证</em>:Coursera</h2>
<p><img src="https://kdn.flygon.net/docs/img/a43463369c6e34667e1ccb4b7df8df22.png" alt="" loading="lazy"></p>
<p>现代公案:如果你参加了数据科学课程却没有获得证书,这一切发生了吗?证书可以是你简历中的有价值补充。当你申请数据科学领域的工作时,你需要知道公司不一定在寻找学位,但他们在寻找你知道自己在做什么的证明。证书将为你完成这一任务。</p>
<p><a href="https://www.coursera.org/" target="_blank">Coursera</a> 是一个在线数据科学教育平台,提供来自各地的课程,因此很容易找到符合你需求的课程,无论是价格还是内容方面。Coursera 提供来自哈佛、约翰·霍普金斯以及其他知名数据科学机构的课程。</p>
<p>Coursera 是获得认证的最佳数据科学教育平台,因为它正是为此而建立的。Coursera 与大学及其他组织合作,提供在线课程和认证(甚至学位)。价格因你选择的认证机构而异,可能高达数千美元,但他们也提供一些<a href="https://www.coursera.org/courses?query=free" target="_blank">免费课程</a>,如果你预算有限,这些课程是一个很好的起点。</p>
<h2 id="9-最佳-自我驱动型-数据科学教育平台databricks-书籍">9. 最佳 <em>自我驱动型</em> 数据科学教育平台:Databricks 书籍</h2>
<p><img src="https://kdn.flygon.net/docs/img/6f6ed2de531145c56f95d686ac4b319b.png" alt="" loading="lazy"></p>
<p>没有什么比一本书更能激发自我驱动了。虽然“数据科学教育平台”让人联想到在线资源,但探索实体世界也无妨。Databricks 向企业客户销售一个“开放统一的数据和 AI 平台”,但他们也提供一本完全免费的<a href="https://databricks.com/p/ebook/the-big-book-of-data-science-use-cases-nurture?gclid=CjwKCAjwpMOIBhBAEiwAy5M6YNwKfp2iE0aJEwU5FZxS6me1DeqbsrUQxCaIS6RVa7Qi0sWRYqmy9hoCoXgQAvD_BwE&utm_medium=cpc&utm_source=google&utm_campaign=11365079224&utm_offer=p_ebook_the-big-book-of-data-science-use-cases&utm_content=ebook&utm_term=%2Bdata%20%2Bscience%20%2Bplatform" target="_blank">可下载教科书</a>,名为《数据科学用例大全》。它包含了来自 Comcast、Regeneron 和 Nationwide 的代码示例、笔记本和用例。对于自我驱动的学习者来说,这是最适合自主学习的资源。</p>
<p>这本书自然与 Databricks 产品相关,但它仍然是一个非常有用的资源,帮助你学习具有实际应用的数据科学。</p>
<h2 id="10-最佳-讲座型-数据科学教育平台exponent">10. 最佳 <em>讲座型</em> 数据科学教育平台:Exponent</h2>
<p><img src="https://kdn.flygon.net/docs/img/c11e852d7ff7b60f7038b4c935a556fe.png" alt="" loading="lazy"></p>
<p>有些人喜欢在观看讲座时学习数据科学。讲座很棒——你可以做笔记,也可以在做其他事情时观看,比如做饭或刺绣。对于讲座爱好者来说,最好的数据科学教育平台是 Exponent。</p>
<p>Exponent 拥有大量视频和讲座,适合喜欢通过讲座内容消化学习的人。与 StrataScratch 一样,它们以面试为导向,提供对<a href="https://www.stratascratch.com/blog/ultimate-guide-to-the-top-5-data-science-companies/" target="_blank">FAANG 公司</a>等数据科学巨头面试问题的答疑视频。</p>
<p>它们最初作为产品管理指南,但也有一些对数据科学家有价值的信息。虽然这个库没有他们其他的<a href="https://www.stratascratch.com/blog/data-scientist-career-path-from-novice-to-first-job/" target="_blank">职业路径</a>那么全面,但你可以<a href="https://www.tryexponent.com/courses?roles=career_ds&src=nav" target="_blank">在这里查看</a>,发现有大量的视频内容供有志的数据科学家学习。也许在此过程中,你会发现自己对产品管理、系统工程或其他完全不同的领域产生了兴趣。</p>
<p>他们提供的月度订阅价格为$79/月(如果年付则为$17/月)。虽然价格确实偏高,但如果你在 Facebook 找到数据科学工作,这笔花费绝对值得。</p>
<h2 id="11-最佳数据科学教育平台终极总结">11: 最佳数据科学教育平台终极总结</h2>
<p>如果我上面评审的十个数据科学教育平台都没有引起你的兴趣,幸运的是,几乎有无限的数据科学学习潜力。你可以在图书馆、YouTube 或当地社区学院寻找免费的或便宜的学习方式。GitHub 上充满了你可以检查和学习的项目和开源代码。数据科学社区整体上是开放的,并且非常欢迎新成员的加入。</p>
<p>互联网在某种程度上是一个自我数据科学教育的平台。根据你的兴趣,你可以利用上述资源混合搭配,制定自己的数据科学课程。毕竟,如果你想成为数据科学家,我知道你已经有了动力、智慧,并且愿意付出努力来实现目标。希望这份数据科学教育平台的清单能为你指引正确的方向。</p>
<h3 id="2021-年最佳数据科学教育平台取决于你从中需要什么">2021 年最佳数据科学教育平台取决于你从中需要什么。</h3>
<p>对数据科学家的需求只会增加——最近的<a href="https://techhub.dice.com/Dice-Q2-Tech-Job-Report.html" target="_blank">Dice 报告</a>表明,数据科学家的需求在多个行业中实际上增长了 50%——而合格的数据科学家供应仍然不足,因此你还有机会加入数据科学的行列。</p>
<p>这就是为什么许多公司接受不那么正式的教育。如果你想在有利时机进入数据科学领域,可以查看 2021 年 11 个最佳数据科学教育平台,看看哪个平台最适合你。</p>
<p><a href="https://www.stratascratch.com/blog/the-11-best-data-science-platforms/" target="_blank">原文</a>。经许可转载。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/08/7-reasons-degree-data-science.html" target="_blank">你应该获得数据科学正式学位的 7 个理由</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/07/google-advice-learning-data-science.html" target="_blank">谷歌研究总监对数据科学学习的建议</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/07/learning-path-data-scientist.html" target="_blank">成为数据科学家的学习路径</a></p>
</li>
</ul>
<hr>
<h2 id="我们的前三大课程推荐-17">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯的捷径。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织在 IT 领域</p>
<hr>
<h3 id="更多相关话题-30">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/11/ai-education-gap-close.html" target="_blank">人工智能教育差距及如何弥合</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/04/5-ways-ai-impacting-stem-education-2023.html" target="_blank">2023 年人工智能对 STEM 教育的影响方式</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/chatgpt-education-friend-foe.html" target="_blank">ChatGPT 在教育中的角色:朋友还是敌人?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/7-best-cloud-database-platforms" target="_blank">7 个最佳云数据库平台</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/01/7-best-platforms-practice-sql.html" target="_blank">7 个最佳 SQL 练习平台</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/7-best-platforms-to-practice-python" target="_blank">7 个最佳 Python 练习平台</a></p>
</li>
</ul>
<h1 id="11-个最佳实践云迁移和数据迁移到-aws-云">11 个最佳实践:云迁移和数据迁移到 AWS 云</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2023/04/11-best-practices-cloud-data-migration-aws-cloud.html" target="_blank"><code>www.kdnuggets.com/2023/04/11-best-practices-cloud-data-migration-aws-cloud.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/f26dd0ba7cfe59c42bc0f671f1ff5a5c.png" alt="11 个最佳实践:云迁移和数据迁移到 AWS 云" loading="lazy"></p>
<p>图片来源:编辑</p>
<p>我们的一位客户——<strong>Ubicquia——智能物联网智能城市解决方案提供商</strong>,由于最终客户对合规性、治理和安全性的要求,想将他们的工作负载从某个公共云平台迁移到 AWS。作为他们的实施合作伙伴,Anblicks 帮助完成了这次迁移,提高了云基础设施的连接性、可靠性、性能、可扩展性和成本效率。它还提供了访问 AWS 各种托管服务的机会,帮助团队更快地交付产品,并满足合规要求。</p>
<hr>
<h2 id="我们的前三个课程推荐-25">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升您的数据分析技能。</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持您的组织的 IT 需求。</p>
<hr>
<p>在今天的数字化环境中,大多数企业越来越倾向于通过<a href="https://www.anblicks.com/services/data-analytics/data-platform-migration" target="_blank">云迁移服务来提升运营</a>,以保持竞争优势。采用云解决方案带来了众多好处,包括提高实时性能、可扩展性、灵活性和成本效益。通过利用云服务,企业可以访问先进的工具和技术,这些工具和技术可以简化操作、增强协作,并提供更好的客户体验。此外,基于云的解决方案还提供了增强的数据安全性、灾难恢复和业务连续性能力,使其成为各类企业和行业的首选。</p>
<p>尽管云迁移服务提供了众多好处,但企业在迁移过程中面临一些常见挑战。要克服这些挑战,必须遵循最佳实践,例如评估当前基础设施、自动化流程、从小处开始、评估迁移服务的局限性、在迁移过程中进行优化、使用安全且合规的数据迁移技术,并进行全面测试。</p>
<h1 id="11-个最佳实践云迁移和数据迁移到-aws-云-1">11 个最佳实践:云迁移和数据迁移到 AWS 云</h1>
<p>本文包括了一份从我们迁移到 AWS 云的过程中总结的<strong>最佳实践</strong>清单。为了确保平稳过渡并减少对操作的干扰,您可以在迁移实施过程中利用这些措施。</p>
<h2 id="1-评估">1. 评估</h2>
<p>迁移前的架构评估不仅应包括对现有硬件、软件系统以及网络和数据存储配置的审查。在确定目标架构之前,评估人员应评估应用程序和基础设施的可用性、可维护性、安全性、可扩展性和性能要求。在评估过程中识别的任何瓶颈有助于确定改进领域,并在迁移期间进行必要的更改或升级。在迁移计划中优先考虑应用程序可以通过评估每个应用程序的业务需求并确定其关键性水平来实现。AWS 应用发现服务就是一个例子,可以帮助在将工作负载迁移到 AWS 云之前发现您的资产。</p>
<p>评估数据源的因素,如数据大小、结构、格式和与目标系统的兼容性,对于确定最佳迁移方法以及发现数据迁移过程中可能出现的潜在问题至关重要。例如,您可能需要为大数据集使用与小数据集不同的迁移策略。对于数据丢失预防至关重要的系统,持续复制到目标系统直到切换完成的迁移方式将是必需的。此外,如果数据是专有格式的,您可能需要在迁移之前将其转换为目标系统兼容的更通用格式。例如,AWS DMS 服务提供的迁移前评估报告可以帮助识别在源数据迁移到 AWS RDS 期间可能出现的兼容性问题。</p>
<h2 id="2-网络管理">2. 网络管理</h2>
<p>规划您的网络架构,并考虑使用 AWS 虚拟私有云(VPC)来实现安全和隔离的网络环境。使用 AWS Direct Connect 或 VPN 连接建立您本地网络与 AWS 环境之间的安全可靠连接。实施网络监控和流量分析工具,以识别和解决网络性能问题。</p>
<h2 id="3-迁移成本">3. 迁移成本</h2>
<p>分析您现有的基础设施,并找出可以降低成本的领域,例如使用预留实例或利用 AWS 定价模型如抢占实例。使用自动化工具以减少手动操作,降低整体迁移成本。</p>
<p>实施一个包括定期监控和优化 AWS 资源的云成本管理策略,以避免意外开支。</p>
<h2 id="4-自动化">4. 自动化</h2>
<p>类似于自动化可以帮助其他领域一样,它也可以简化迁移过程并减少错误的可能性。通过自动化任务如数据转移和应用部署,你可以提高迁移的整体效率。利用 AWS 服务如 AWS DataSync、AWS Database Migration Service 和 AWS Application and Server Migration Services。这些服务可以帮助提高迁移的整体效率,并使数据和应用迁移到云端变得更容易。</p>
<h2 id="5-从小规模开始">5. 从小规模开始</h2>
<p>从小部分数据和有限数量的应用程序开始,可能是迁移到任何云端的好方法。通过这样做,你可以评估迁移过程,检测可能的问题,并验证其是否按预期运行。这种方法还可以帮助你完善迁移过程,并在全量迁移之前进行必要的调整。此外,从小规模开始还可以帮助你熟悉完成成功迁移所需的过程、工具和资源。通过分阶段的方法,你可以降低风险并最小化迁移过程中的停机时间。</p>
<h2 id="6-评估迁移服务的限制">6. 评估迁移服务的限制</h2>
<p>虽然有众多迁移服务,但重要的是要注意每个服务可能有其限制和前提条件。因此,务必仔细评估服务的功能,以确保它符合你迁移的具体要求。此外,在规划迁移时,考虑网络带宽、数据大小和复杂性以及整体迁移时间线等因素也很重要。</p>
<p>2017 年,全球教育公司 Pearson 在云迁移过程中经历了重大挑战。迁移导致了显著的停机时间和服务中断,导致了客户投诉和收入损失。</p>
<h2 id="7-在迁移过程中进行优化">7. 在迁移过程中进行优化</h2>
<p>云迁移允许你的组织在过程中优化成本和资源。在发现阶段识别出不再需要的资源和应用程序。丢弃这些未使用的资源可以节省成本。此外,分析师可以检查历史资源使用情况,并指出哪些资源被低估使用。你可以在迁移到云端时缩减这些资源,以实现成本优化。</p>
<p>此外,尽可能利用 AWS 托管服务的优势是合理的。AWS 为许多应用程序提供托管服务,如数据库、缓存等。这些服务本质上具有高可用性、可扩展性和安全性。此外,这些服务的升级由 AWS 处理,从而减少了管理资源所需的行政工作。</p>
<h2 id="8-使用安全且合规的数据迁移技术">8. 使用安全且合规的数据迁移技术</h2>
<p>数据安全和合规性是迁移到云时的关键考虑因素。AWS 提供各种服务来帮助保护静态数据和传输中的数据。例如,Amazon S3、RDS 以及许多其他服务提供静态数据的加密选项。虽然这满足了迁移后的合规要求,但同样重要的是要安全地将数据从现有数据源迁移到云。在数据迁移过程中,存储解决方案和服务不应公开或开放给更广泛的网络,只应允许来自目标云系统的访问。使用传输加密还增加了一层额外的安全保障。</p>
<h2 id="9-监控">9. 监控</h2>
<p>使用 AWS 监控工具,如 Amazon CloudWatch,来跟踪资源利用情况、检测潜在问题,并根据预定义的阈值触发警报。然后实施集中式日志记录,以收集和分析 AWS 环境中的日志数据。</p>
<p>使用性能测试工具来确保你的应用程序和工作负载在新的云环境中运行最佳。</p>
<h2 id="10-治理">10. 治理</h2>
<p>定义管理 AWS 环境中访问、权限和安全的政策和程序是重要的。实施安全最佳实践,如 SSO、多因素认证和加密,以保护你在云中的数据和基础设施。使用 AWS 服务限制来控制 AWS 资源的使用,防止意外超支。</p>
<h2 id="11-综合测试">11. 综合测试</h2>
<p>在迁移后进行彻底的验证是重要的,以确保所有应用程序和数据都已成功转移并正常工作。这个过程包括对数据完整性、性能和安全措施的全面测试,<em>最终目标</em>是建立一个稳定和安全的系统。确保迁移系统无错误或问题的一种方法是生成并执行系统上的测试用例。在测试阶段,制定回滚计划也是一种良好的做法,以防出现任何问题。</p>
<h1 id="总结-9">总结</h1>
<p>如果迁移到云的过程不正确,它可能变得复杂且耗时。但它带来了显著的好处,如提高性能、可扩展性、成本节约和安全性。通过遵循 AWS 迁移框架的最佳实践——<strong>评估、动员、迁移与现代化</strong>,我们可以确保为我们的组织实现顺利而成功的迁移。此外,彻底了解新的云平台并利用 AWS 提供的各种服务和功能来优化你的工作负载也是至关重要的。云迁移对希望改善基础设施并在今天的市场中保持竞争力的组织来说具有重要价值。</p>
<p><strong><a href="https://www.linkedin.com/in/tvarughese/" target="_blank">Tonu Varughese</a></strong> 是一位高度熟练的高级 DevOps 工程师,拥有超过 12 年的技术行业经验。他专注于云计算、DevOps 实践和 Linux 管理。他在为各种组织设计、实施和维护稳健且可扩展的基础设施方面有着可靠的业绩记录。</p>
<h3 id="更多相关内容-20">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2023/02/data-warehousing-etl-best-practices.html" target="_blank">数据仓库和 ETL 最佳实践</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/integrating-chatgpt-data-science-workflows-tips-best-practices.html" target="_blank">将 ChatGPT 融入数据科学工作流程:技巧与最佳实践</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/04/mlops-best-practices-apply.html" target="_blank">MLOps:最佳实践及其应用方法</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/01/setup-jupyterhub-tljh-aws-ec2.html" target="_blank">在 AWS EC2 上设置和使用 JupyterHub (TLJH)</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/04/data-visualization-best-practices-resources-effective-communication.html" target="_blank">数据可视化最佳实践与有效沟通资源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/06/5-best-practices-data-science-team-collaboration.html" target="_blank">数据科学团队协作的 5 个最佳实践</a></p>
</li>
</ul>
<h1 id="完整-eda探索性数据分析的-11-个必备代码块">完整 EDA(探索性数据分析)的 11 个必备代码块</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2021/03/11-essential-code-blocks-exploratory-data-analysis.html" target="_blank"><code>www.kdnuggets.com/2021/03/11-essential-code-blocks-exploratory-data-analysis.html</code></a></p>
</blockquote>
<p>评论</p>
<p><strong>由<a href="https://www.linkedin.com/in/suemnjeri/" target="_blank">Susan Maina</a>,对数据充满热情,机器学习爱好者,<a href="https://medium.com/@suemnjeri" target="_blank">Medium 作者</a></strong></p>
<p>探索性数据分析,或称 EDA,是<a href="https://www.datasciencegraduateprograms.com/the-data-science-process/" target="_blank">data science process</a>的第一步之一。它涉及尽可能多地了解数据,同时不花费过多时间。在这里,你可以对数据有直观和高层次的实际理解。在这个过程中结束时,你应该对数据集的结构、一些清理思路、目标变量以及可能的建模技术有一个大致的了解。</p>
<p>在大多数问题中,有一些通用策略可以快速执行 EDA。在这篇文章中,我将使用来自 kaggle 的<a href="https://www.kaggle.com/dansbecker/melbourne-housing-snapshot" target="_blank">墨尔本住房快照数据集</a>来演示你可以用来进行满意的探索性数据分析的 11 个代码块。该数据集包括<code>Address</code>、房地产的<code>Type</code>、<code>Suburb</code>、销售<code>Method</code>、<code>Rooms</code>、<code>Price</code>、房地产代理<code>(SellerG)</code>、<code>Date</code>、<code>Distance</code>与 CBD 的距离。你可以通过<a href="https://www.kaggle.com/dansbecker/melbourne-housing-snapshot/download" target="_blank">这里</a>下载数据集跟随学习。</p>
<p>第一步是导入所需的库。我们需要<a href="https://en.wikipedia.org/wiki/Pandas_(software)" target="_blank">Pandas</a>、<a href="https://towardsdatascience.com/4-fundamental-numpy-properties-every-data-scientist-must-master-c906236eb44b" target="_blank">Numpy</a>、<a href="https://en.wikipedia.org/wiki/Matplotlib" target="_blank">matplotlib</a>和<a href="https://seaborn.pydata.org/" target="_blank">seaborn</a>。为了确保所有列都显示出来,请使用<code>pd.set_option(’display.max_columns’, 100)</code>。默认情况下,pandas 显示 20 列并隐藏其余列。</p>
<pre><code class="language-py">import pandas as pd
pd.set_option('display.max_columns',100)import numpy as npimport matplotlib.pyplot as plt
%matplotlib inlineimport seaborn as sns
sns.set_style('darkgrid')
</code></pre>
<p>Panda 的<code>pd.read_csv(path)</code>将 csv 文件读取为 DataFrame。</p>
<pre><code class="language-py">data = pd.read_csv('melb_data.csv')
</code></pre>
<h3 id="基本数据集探索">基本数据集探索</h3>
<p><strong>1. DataFrame 的形状(维度)</strong></p>
<p>Pandas DataFrame 的<code>.shape</code>属性提供数据的整体结构。它返回一个<a href="https://towardsdatascience.com/ultimate-guide-to-lists-tuples-arrays-and-dictionaries-for-beginners-8d1497f9777c" target="_blank">tuple</a>的长度为 2,表示数据集中有多少行观察值和列。</p>
<pre><code class="language-py">data.shape### Results
(13580, 21)
</code></pre>
<p>我们可以看到数据集有 13,580 个观察值和 21 个特征,其中一个特征是目标变量。</p>
<p><strong>2. 各列的数据类型</strong></p>
<p>DataFrame 的<code>.dtypes</code>属性显示各列的数据类型,作为 Panda 的<a href="https://www.geeksforgeeks.org/python-pandas-series/" target="_blank">Series</a>(Series 表示一个值及其索引的列)。</p>
<pre><code class="language-py">data.dtypes### Results
Suburb object
Address object
Rooms int64
Type object
Price float64
Method object
SellerG object
Date object
Distance float64
Postcode float64
Bedroom2 float64
Bathroom float64
Car float64
Landsize float64
BuildingArea float64
YearBuilt float64
CouncilArea object
Lattitude float64
Longtitude float64
Regionname object
Propertycount float64
dtype: object
</code></pre>
<p>我们观察到数据集中具有<strong>分类</strong>(对象)和<strong>数值</strong>(浮点数和整数)特征的组合。此时,我回到 Kaggle 页面以了解列及其含义。请查看使用<a href="https://www.datawrapper.de/" target="_blank">Datawrapper</a>创建的列及其定义的表格<a href="https://datawrapper.dwcdn.net/hHuXG/4/" target="_blank">这里</a>。</p>
<p>注意事项:</p>
<ul>
<li>应该是分类的数值特征,反之亦然。</li>
</ul>
<p>从快速分析来看,我没有发现数据类型的任何不匹配。这是有道理的,因为此数据集版本是原始<a href="https://www.kaggle.com/anthonypino/melbourne-housing-market" target="_blank">墨尔本数据</a>的清理快照。</p>
<p><strong>3. 显示几行数据</strong></p>
<p>Pandas DataFrame 提供了非常方便的函数来显示几个观察值。<code>data.head()</code>显示前 5 个观察值,<code>data.tail()</code>显示最后 5 个,<code>data.sample()</code>从数据集中随机选择一个观察值。你可以使用<code>data.sample(5)</code>显示 5 个随机观察值。</p>
<pre><code class="language-py">data.head()
data.tail()
data.sample(5)
</code></pre>
<p>注意事项:</p>
<ul>
<li>
<p>你能理解列名吗?它们有意义吗?(如有需要,请再次检查变量定义)</p>
</li>
<li>
<p>这些列中的值有意义吗?</p>
</li>
<li>
<p>是否发现了显著的缺失值(NaN)?</p>
</li>
<li>
<p>分类特征有哪些类别?</p>
</li>
</ul>
<p>我的见解:<code>Postcode</code>和<code>Propertycount</code>特征均根据<code>Suburb</code>特征发生了变化。此外,<code>BuildingArea</code>和<code>YearBuilt</code>存在显著的缺失值。</p>
<h3 id="分布">分布</h3>
<p>这指的是特征中值的分布情况,或它们出现的频率。对于数值特征,我们将查看特定列中数字组出现的次数,而对于分类特征,则查看每列的类别及其频率。我们将使用<strong>图形</strong>和实际的汇总<strong>统计</strong>。图形使我们能够整体了解分布,而统计数据提供了实际数字。这两种策略都推荐使用,因为它们相辅相成。</p>
<h3 id="数值特征">数值特征</h3>
<p><strong>4. 绘制每个数值特征</strong></p>
<p>我们将使用 Pandas <a href="https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.hist.html" target="_blank">直方图</a>。直方图将数字分组到范围(或区间)中,柱子的高度显示该范围内的数字数量。<code>df.hist()</code>在网格中绘制数据的数值特征的直方图。我们还将提供<code>figsize</code>和<code>xrot</code>参数,以增加网格大小并将 x 轴旋转 45 度。</p>
<pre><code class="language-py">data.hist(figsize=(14,14), xrot=45)
plt.show()
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/96dad936f185d8266d880b0fd7a70289.png" alt="Image for post" loading="lazy"></p>
<p>作者的直方图</p>
<p>注意事项:</p>
<ul>
<li>
<p>可能无法解释的异常值或可能是测量错误</p>
</li>
<li>
<p>应该是分类的数值特征。例如,<code>Gender</code>由 1 和 0 表示。</p>
</li>
<li>
<p>不合理的边界值,如百分比值> 100。</p>
</li>
</ul>
<p>从直方图中,我注意到<code>BuildingArea</code>和<code>LandSize</code>在右侧有潜在的异常值。我们的目标特征<code>Price</code>也高度偏向右侧。我还注意到<code>YearBuilt</code>非常偏向左侧,边界从 1200 年开始,这很奇怪。让我们继续查看汇总统计信息以获得更清晰的图像。</p>
<p><strong>5. 数值特征的汇总统计信息</strong></p>
<p>现在我们对数值特征有了直观的了解,我们将查看实际统计数据,使用<code>df.describe()</code>显示其汇总统计信息。</p>
<pre><code class="language-py">data.describe()
</code></pre>
<p>我们可以看到每个数值特征的<em>count</em>(值的数量)、<em>mean</em>(均值)、<em>std</em>(标准差)、<em>minimum</em>(最小值)、<em>25th</em>(25 百分位数)、<em>50th</em>(50 百分位数或中位数)、<em>75th</em>(75 百分位数)和<em>maximum</em>(最大值)。从 count 中我们还可以识别出具有<strong>缺失值</strong>的特征;它们的数量与数据集的总行数不相等。这些特征是<code>Car</code>、<code>LandSize</code>和<code>YearBuilt</code>。</p>
<p>我注意到<code>LandSize</code>和<code>BuildingArea</code>的最小值为 0。我们还看到<code>Price</code>的范围从 85,000 到 9,000,000,这是一个很大的范围。我们将在项目后续的详细分析中探索这些列。</p>
<p>然而,查看<code>YearBuilt</code>特征时,我们注意到最小年份为 1196。这可能是数据输入错误,将在清理过程中删除。</p>
<h3 id="分类特征">分类特征</h3>
<p><strong>6. 分类特征的汇总统计信息</strong></p>
<p>对于分类特征,重要的是在绘制图形之前展示汇总统计信息,因为某些特征有很多独特的类别(如我们将看到的<code>Address</code>),如果在 countplot 上进行可视化,这些类别将变得难以阅读。</p>
<p>要检查仅分类特征的汇总统计信息,我们将使用<code>df.describe(include='object')</code></p>
<pre><code class="language-py">data.describe(include='object')
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/ecd1ed1297aea86ac40705b14a1767b3.png" alt="Image for post" loading="lazy"></p>
<p>作者分类汇总统计</p>
<p>这个表格与数值特征的表格略有不同。在这里,我们获得每个特征的<em>count</em>(值的数量)、<em>unique</em>(唯一类别的数量)、<em>top</em>(最频繁的类别)以及该类别在数据集中出现的<em>frequently</em>(频率)。</p>
<p>我们注意到一些类别有很多独特的值,例如<code>Address</code>,其次是<code>Suburb</code>和<code>SellerG</code>。根据这些发现,我将仅绘制具有 10 个或更少独特类别的列。我们还注意到<code>CouncilArea</code>有缺失值。</p>
<p><strong>7. 绘制每个分类特征</strong></p>
<p>根据上述统计数据,我们注意到<code>Type</code>、<code>Method</code>和<code>Regionname</code>有少于 10 个类别,可以有效地进行可视化。我们将使用<a href="https://seaborn.pydata.org/generated/seaborn.countplot.html" target="_blank">Seaborn countplot</a>绘制这些特征,它类似于分类变量的直方图。countplot 中的每一条柱子代表一个独特的类别。</p>
<p>我创建了一个<a href="https://towardsdatascience.com/a-gentle-introduction-to-flow-control-loops-and-list-comprehensions-for-beginners-3dbaabd7cd8a" target="_blank">For loop</a>。对于每个分类特征,将显示一个计数图以展示该特征的类别分布。行<code>df.select_dtypes(include=’object’)</code>选择分类列及其值并显示它们。我们还将包括一个<a href="https://towardsdatascience.com/a-gentle-introduction-to-flow-control-loops-and-list-comprehensions-for-beginners-3dbaabd7cd8a" target="_blank">If-statement</a>,以便仅选择包含 10 个或更少类别的三列,使用行<code>Series.nunique() < 10</code>。阅读<code>.nunique()</code>文档<a href="https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.nunique.html" target="_blank">这里</a>。</p>
<pre><code class="language-py">for column in data.select_dtypes(include='object'):
if data[column].nunique() < 10:
sns.countplot(y=column, data=data)
plt.show()
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/6208f79308cff63d0955c7b208e98d23.png" alt="Image for post" loading="lazy"></p>
<p>按作者绘制的计数图</p>
<p>注意事项:</p>
<ul>
<li>
<p>稀疏类别可能会影响模型的性能。</p>
</li>
<li>
<p>类别标记错误,例如两个完全相同的类别只有细微的拼写差异。</p>
</li>
</ul>
<p>我们注意到<code>Regionname</code>有一些稀疏类别,这些类别在建模过程中可能需要合并或重新分配。</p>
<h3 id="分组和分段">分组和分段</h3>
<p>分段允许我们切割数据并观察分类特征与数值特征之间的关系。</p>
<p><strong>8. 按分类特征对目标变量进行分段。</strong></p>
<p>在这里,我们将比较目标特征<code>Price</code>与主要分类特征<code>(Type</code>、<code>Method</code>和<code>Regionname)</code>的各个类别之间的差异,并观察<code>Price</code>如何随类别变化。</p>
<p>我们使用了<a href="https://seaborn.pydata.org/generated/seaborn.boxplot.html" target="_blank">Seaborn boxplot</a>,它绘制了<code>Price</code>在分类特征的各个类别中的分布。该<a href="https://www.geeksforgeeks.org/how-to-show-mean-on-boxplot-using-seaborn-in-python/" target="_blank">教程</a>清晰地解释了箱线图的特征。两端的点表示离群值。</p>
<p><img src="https://kdn.flygon.net/docs/img/6abcbbcd16f872b135829f01e2cd5947.png" alt="Image for post" loading="lazy"></p>
<p>图片来自<a href="https://www.geeksforgeeks.org/how-to-show-mean-on-boxplot-using-seaborn-in-python/" target="_blank">www.geekeforgeeks.org</a></p>
<p>我再次使用了一个<em>for loop</em>来绘制每个分类特征与<code>Price</code>的箱线图。</p>
<pre><code class="language-py">for column in data.select_dtypes(include=’object’):
if data[column].nunique() < 10:
sns.boxplot(y=column, x=’Price’, data=data)
plt.show()
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/6db28afbda3105515549d150ba4db0a9.png" alt="Image for post" loading="lazy"></p>
<p>按作者绘制的箱线图</p>
<p>注意事项:</p>
<ul>
<li>哪些类别对目标变量的影响最大。</li>
</ul>
<p>注意到<code>Price</code>在之前看到的<code>Regionname</code>的 3 个稀疏类别中仍然分布稀疏,这进一步支持了我们对这些类别的论点。</p>
<p>还注意到<code>SA</code>类别(出现频率最低的<code>Method</code>类别)指令价格很高,几乎与最频繁出现的类别<code>S.</code>相似。</p>
<p><strong>9. 按每个分类特征对数值特征进行分组。</strong></p>
<p>在这里,我们将看到所有其他数值特征(不仅仅是 <code>Price</code>)如何随每个类别特征变化,通过总结各类别的数值特征来实现。我们使用 <a href="https://www.shanelynn.ie/summarising-aggregation-and-grouping-data-in-python-pandas/" target="_blank">Dataframe 的 groupby</a> 函数按类别分组数据,并计算各种数值特征的指标(如 <em>均值</em>、<em>中位数</em>、<em>最小值</em>、<em>标准差</em> 等)。</p>
<p>对于只有 3 个类别特征且类别少于 10 的情况,我们对数据进行分组,然后计算数值特征的 <code>mean</code>。我们使用 <code>display()</code>,这比 <code>print()</code> 结果更清晰。</p>
<pre><code class="language-py">for column in data.select_dtypes(include='object'):
if data[column].nunique() < 10:
display(data.groupby(column).mean())
</code></pre>
<p>我们可以比较 <code>Type,</code> <code>Method</code> 和 <code>Regionname</code> 类别在数值特征上的分布情况。</p>
<h3 id="数值特征与其他数值特征之间的关系">数值特征与其他数值特征之间的关系</h3>
<p><strong>10. 不同数值特征的相关性矩阵</strong></p>
<p><a href="https://www.mathsisfun.com/data/correlation.html" target="_blank">相关性</a>是一个介于 -1 和 1 之间的值,表示两个不同特征的值如何同时变化。<em>正相关</em>意味着当一个特征增加时,另一个特征也会增加,而<em>负相关</em>则表示一个特征增加时另一个特征减少。接近 0 的相关性表示<em>弱</em>关系,而接近 -1 或 1 则表示<em>强</em>关系。</p>
<p><img src="https://kdn.flygon.net/docs/img/88d80dd2671a58f0c17cab9179306523.png" alt="Image for post" loading="lazy"></p>
<p>图片来自 <a href="http://www.edugyan.in/2017/02/correlation-coefficient.html" target="_blank">edugyan.in</a></p>
<p>我们将使用 <code>df.corr()</code> 计算数值特征之间的 <a href="https://machinelearningmastery.com/how-to-use-correlation-to-understand-the-relationship-between-variables/" target="_blank">相关性</a>,并返回一个 DataFrame。</p>
<pre><code class="language-py">corrs = data.corr()
corrs
</code></pre>
<p>现在这可能意义不大,所以让我们绘制一个热力图来可视化相关性。</p>
<p><strong>11. 相关性的热力图</strong></p>
<p>我们将使用 <a href="https://seaborn.pydata.org/generated/seaborn.heatmap.html" target="_blank">Seaborn 热力图</a> 将网格绘制为矩形的颜色编码矩阵。我们使用 <code>sns.heatmap(corrs, cmap='RdBu_r', annot=True)</code>。</p>
<p><code>cmap='RdBu_r'</code> 参数告诉热力图使用什么颜色调色板。高正相关性显示为 <em>深红色</em>,高负相关性显示为 <em>深蓝色</em>。接近白色表示弱关系。阅读 <a href="https://medium.com/@morganjonesartist/color-guide-to-seaborn-palettes-da849406d44f" target="_blank">这个</a> 好教程获取其他颜色调色板。<code>annot=True</code> 包括了相关性值在框中,便于阅读和解释。</p>
<pre><code class="language-py">plt.figure(figsize=(10,8))
sns.heatmap(corrs, cmap='RdBu_r', annot=True)
plt.show()
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/be9b497b0f0a6f548ea07f4e89e75e6c.png" alt="Image for post" loading="lazy"></p>
<p>作者制作的热力图</p>
<p>需要注意的事项:</p>
<ul>
<li>
<p>强相关的特征;要么是深红色(正相关),要么是深蓝色(负相关)。</p>
</li>
<li>
<p>目标变量;如果它与其他特征有强正相关或负相关关系。</p>
</li>
</ul>
<p>我们注意到<code>Rooms</code>、<code>Bedrooms2</code>、<code>Bathrooms</code>和<code>Price</code>之间有强正相关关系。另一方面,<code>Price</code>作为我们的目标特征,与<code>YearBuilt</code>有稍微弱<em>负</em>相关关系,与<code>Distance</code>从 CBD 的距离有更弱的<em>负</em>相关关系。</p>
<p>在这篇文章中,我们探讨了墨尔本数据集,并对其结构及特征有了初步了解。在这一阶段,我们不需要做到 100%的全面,因为在未来的阶段,我们会更详细地探索数据。你可以在 Github 上获得完整的代码,<a href="https://github.com/suemnjeri/medium-articles/blob/main/melbourne/EDA_melbourne_for_medium.ipynb" target="_blank">点击这里</a>。我将很快上传数据集清理的概念。</p>
<p><strong>简介: <a href="https://www.linkedin.com/in/suemnjeri/" target="_blank">苏珊·梅纳</a></strong> 对数据充满热情,是机器学习爱好者,<a href="https://medium.com/@suemnjeri" target="_blank">Medium 上的作者</a>。</p>
<p><a href="https://towardsdatascience.com/11-simple-code-blocks-for-complete-exploratory-data-analysis-eda-67c2817f56cd" target="_blank">原始内容</a>。经许可转载。</p>
<p><strong>相关内容:</strong></p>
<ul>
<li>
<p>仅用两行代码进行强大的探索性数据分析</p>
</li>
<li>
<p>Pandas Profiling: 一行代码实现 EDA</p>
</li>
<li>
<p>一行代码进行统计和视觉探索性数据分析</p>
</li>
</ul>
<hr>
<h2 id="我们的-3-个顶级课程推荐">我们的 3 个顶级课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析能力</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织在 IT 领域</p>
<hr>
<h3 id="更多相关主题-19">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/new-ways-sharing-code-blocks.html" target="_blank">数据科学家共享代码块的新方法</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/06/data-scientist-essential-guide-exploratory-data-analysis.html" target="_blank">数据科学家探索性数据分析的必备指南</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/04/ace-data-science-assessment-test-automatic-eda-tools.html" target="_blank">如何通过使用自动 EDA 工具来成功应对数据科学评估测试</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/collection-of-guides-on-mastering-sql-python-data-cleaning-data-wrangling-and-exploratory-data-analysis" target="_blank">掌握 SQL、Python、数据清理、数据处理等的指南汇总</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/exploratory-data-analysis-techniques-unstructured-data.html" target="_blank">非结构化数据的探索性数据分析技术</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/7-steps-to-mastering-exploratory-data-analysis" target="_blank">掌握探索性数据分析的 7 个步骤</a></p>
</li>
</ul>
<h1 id="2022-年最实用的-11-项数据科学技能">2022 年最实用的 11 项数据科学技能</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2021/10/11-most-practical-data-science-skills-2022.html" target="_blank"><code>www.kdnuggets.com/2021/10/11-most-practical-data-science-skills-2022.html</code></a></p>
</blockquote>
<p>评论</p>
<p><img src="https://kdn.flygon.net/docs/img/8b878beaa6080cb3fb87408ac1b8c278.png" alt="" loading="lazy"></p>
<p>许多“数据科学入门”课程和文章,包括我自己的,往往强调统计学、数学和编程等基础技能。然而,最近我通过自己的经历发现,这些基础技能可能很难转化为使你具备就业能力的实际技能。</p>
<hr>
<h2 id="我们的前-3-个课程推荐-5">我们的前 3 个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全领域的职业轨道。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你所在组织的 IT</p>
<hr>
<p>因此,我想创建一个<strong>独特的</strong>、<strong>实用的</strong>技能列表,使你<strong>具备就业能力</strong>。</p>
<p>我提到的前四项技能对于任何数据科学家都是绝对关键的,无论你专注于什么。以下技能(5–11)都是重要的技能,但根据你的专长,它们的使用情况会有所不同。</p>
<p>例如,如果你主要在统计学方面扎根,你可能会花更多时间在推断统计上。相反,如果你对文本分析更感兴趣,你可能会花更多时间学习自然语言处理,或者如果你对决策科学感兴趣,你可能会专注于解释性建模。你懂的。</p>
<p>话虽如此,让我们深入探讨我认为的 11 项最实用的数据科学技能:</p>
<h3 id="1-编写-sql-查询与构建数据管道">1. 编写 SQL 查询与构建数据管道</h3>
<p>学会编写健壮的 SQL 查询,并在像 Airflow 这样的工作流管理平台上调度它们,将使你作为数据科学家非常抢手,这就是为什么它是第 1 点。</p>
<p>为什么?原因有很多:</p>
<ol>
<li>
<p><strong>灵活性</strong>:公司喜欢不仅仅能建模数据的数据科学家。公司<strong>非常喜欢</strong>全栈数据科学家。如果你能介入并帮助构建核心数据管道,你将能够改进所收集的见解,构建更强的报告,并最终让每个人的工作变得更轻松。</p>
</li>
<li>
<p><strong>独立性:</strong> 有时你会需要一个模型或数据科学项目所需的表格或视图,而这些表格或视图并不存在。能够为你的项目编写健壮的管道,而不是依赖数据分析师或数据工程师,将为你节省时间,并使你更有价值。</p>
</li>
</ol>
<p>因此,作为数据科学家,你<strong>必须</strong>精通 SQL。这没有例外。</p>
<p><strong>资源</strong></p>
<ul>
<li>
<p><a href="https://towardsdatascience.com/a-complete-15-week-curriculum-to-master-sql-for-data-science-999e690033e4" target="_blank">一个完整的 15 周课程,掌握数据科学中的 SQL</a></p>
</li>
<li>
<p><a href="https://mode.com/sql-tutorial/" target="_blank">Mode SQL 教程</a></p>
</li>
</ul>
<h3 id="2-数据处理--特征工程">2. 数据处理 / 特征工程</h3>
<p>无论你是在构建模型、探索新特征,还是进行深入分析,你都需要知道如何处理数据。</p>
<p><strong>数据处理</strong>指的是将数据从一种格式转换成另一种格式。</p>
<p><strong>特征工程</strong>是一种数据处理,但特别指的是从原始数据中提取<strong>特征</strong>。</p>
<p>你如何处理数据并不一定重要,无论是使用 Python 还是 SQL,但你应该能够以你喜欢的方式处理数据(当然是在可能的范围内)。</p>
<p><strong>资源</strong></p>
<ul>
<li>
<p><a href="https://towardsdatascience.com/feature-engineering-for-machine-learning-3a5e293a5114" target="_blank">机器学习的特征工程基础技术</a></p>
</li>
<li>
<p><a href="https://machinelearningmastery.com/discover-feature-engineering-how-to-engineer-features-and-how-to-get-good-at-it/" target="_blank">发现特征工程,如何工程化特征以及如何做得更好 - 机器学习精粹</a></p>
</li>
</ul>
<h3 id="3-版本控制--github">3. 版本控制 / GitHub</h3>
<p>当我说“版本控制”时,我特指<strong>GitHub</strong>和<strong>Git</strong>。Git 是全球主要的版本控制系统,而 GitHub 本质上是一个基于云的文件和文件夹存储库。</p>
<p>尽管 Git 一开始不是最直观的技能,但它对于几乎所有与编码相关的角色都是必需的。为什么?</p>
<ul>
<li>
<p>它允许你与他人并行协作和处理项目</p>
</li>
<li>
<p>它跟踪你代码的所有版本(以防你需要恢复到旧版本)</p>
</li>
</ul>
<p>花时间学习 Git。这将对你大有裨益!</p>
<h3 id="4-讲故事即沟通">4. 讲故事(即沟通)</h3>
<p>构建一个视觉上令人惊叹的仪表盘或一个准确率超过 95%的复杂模型是一回事。但如果你不能将项目的价值传达给他人,你将得不到应有的认可,最终,你的职业成功也不会如你所期望的那样。</p>
<p>讲故事指的是你如何传达你的见解和模型。从概念上讲,如果你把它想象成一本图画书,见解/模型就是图片,而“讲故事”指的是连接所有图片的叙述。</p>
<p>在科技领域,讲故事和沟通是被严重低估的技能。从我在职业生涯中的观察来看,这项技能区分了初级人员与高级人员和管理者。</p>
<h3 id="5-回归分类">5. 回归/分类</h3>
<p>构建回归和分类模型,即预测模型,并不是你<strong>总是</strong>需要做的事情,但如果你是数据科学家,雇主会期望你掌握这方面的知识。</p>
<p>即使这不是你经常做的事情,你也必须擅长,因为你希望能够构建高性能的模型。举个例子,到目前为止,我只将两个机器学习模型投入生产,但它们是对业务有重大影响的关键模型。</p>
<p>因此,你应该对数据准备技术、增强算法、超参数调优和模型评估指标有一个良好的理解。</p>
<p><strong>资源</strong></p>
<ul>
<li>
<p><a href="https://towardsdatascience.com/all-machine-learning-algorithms-you-should-know-in-2021-2e357dd494c7" target="_blank">2021 年你应该知道的所有机器学习算法</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/how-to-prepare-your-data-for-your-machine-learning-model-b4c9fd4e7ea" target="_blank">如何为机器学习模型准备数据</a></p>
</li>
</ul>
<h3 id="6-可解释的人工智能--可解释的机器学习">6. 可解释的人工智能 / 可解释的机器学习</h3>
<p>由于这些模型如何根据其输入生成预测并不清楚,许多机器学习算法曾经被视为“黑箱”。现在,由于可解释机器学习技术的广泛采用,如 SHAP 和 LIME,这种情况正在改变。</p>
<p>SHAP 和 LIME 是两种技术,它们不仅告诉你每个特征的重要性,还展示对模型输出的影响,类似于线性回归方程中的系数。</p>
<p>使用 SHAP 和 LIME,你可以创建解释性模型,同时更好地传达你预测模型背后的逻辑。</p>
<p><strong>资源</strong></p>
<ul>
<li>
<p><a href="https://towardsdatascience.com/shap-explain-any-machine-learning-model-in-python-24207127cad7" target="_blank">SHAP:在 Python 中解释任何机器学习模型</a></p>
</li>
<li>
<p><a href="https://towardsdatascience.com/understanding-model-predictions-with-lime-a582fdff3a3b" target="_blank">使用 LIME 理解模型预测</a></p>
</li>
</ul>
<h3 id="7-ab-测试实验">7. A/B 测试(实验)</h3>
<p>A/B 测试是一种实验形式,你比较两个不同的组,以根据给定指标查看哪一个表现更好。</p>
<p>A/B 测试可以说是企业界最实用和广泛使用的统计概念。为什么?A/B 测试允许你将数百或数千个小的改进累积起来,从而在时间推移中实现显著的变化和改进。</p>
<p>如果你对数据科学的统计方面感兴趣,那么 A/B 测试是必不可少的,需要理解和学习。</p>
<p><strong>资源</strong></p>
<ul>
<li><a href="https://towardsdatascience.com/a-b-testing-a-complete-guide-to-statistical-testing-e3f1db140499" target="_blank">A/B 测试——统计测试的完整指南</a></li>
</ul>
<h3 id="8-聚类">8. 聚类</h3>
<p>就个人而言,我在职业生涯中没有使用过聚类,但这是数据科学的一个核心领域,每个人至少应该对此有所了解。</p>
<p>聚类有许多有用的方面。你可以发现不同的客户细分,可以使用聚类来标记未标记的数据,甚至可以使用聚类来寻找模型的截断点。</p>
<p>下面是一些涵盖你应该了解的最重要的聚类技术的资源。</p>
<p><strong>资源</strong></p>
<ul>
<li>
<p><a href="https://towardsdatascience.com/the-5-clustering-algorithms-data-scientists-need-to-know-a36d136ef68" target="_blank">数据科学家需要了解的 5 种聚类算法</a></p>
</li>
<li>
<p><a href="https://machinelearningmastery.com/clustering-algorithms-with-python/" target="_blank">Python 中的 10 种聚类算法 - 机器学习大师</a></p>
</li>
</ul>
<h3 id="9-推荐系统">9. 推荐系统</h3>
<p>虽然我到现在为止还没有建立过推荐系统(但未来可能会有),但它是数据科学中最实际的应用之一。推荐系统之所以如此强大,是因为它们能够推动收入和利润。事实上,<a href="https://rejoiner.com/resources/amazon-recommendations-secret-selling-online/#:~:text=%E2%80%9CJudging%20by%20Amazon%27s%20success%2C%20the,the%20same%20time%20last%20year." target="_blank">亚马逊声称 2019 年因其推荐系统提升了 29%的销售额</a>。</p>
<p>因此,如果你曾在需要做出<strong>选择</strong>且<strong>选项非常多</strong>的公司工作,推荐系统可能是一个值得探索的有用应用。</p>
<h3 id="10-自然语言处理nlp">10. 自然语言处理(NLP)</h3>
<p>自然语言处理(NLP),即自然语言处理,是人工智能的一个分支,专注于文本和语音。与机器学习不同,我认为 NLP 还远未成熟,这也是它如此有趣的原因。</p>
<p>自然语言处理有很多应用场景……</p>
<ul>
<li>
<p>它可以用于情感分析,以了解人们对某个业务或业务产品的看法。</p>
</li>
<li>
<p>它可以通过区分正面和负面评论来监控公司的社交媒体。</p>
</li>
<li>
<p>自然语言处理是构建聊天机器人和虚拟助手的核心</p>
</li>
<li>
<p>自然语言处理还用于文本提取(筛选文档)</p>
</li>
</ul>
<p>总的来说,自然语言处理(NLP)在数据科学领域是一个非常有趣且有用的细分领域。</p>
<p><strong>资源</strong></p>
<ul>
<li><a href="https://www.projectpro.io/article/10-nlp-techniques-every-data-scientist-should-know/415" target="_blank">每个数据科学家都应该知道的 10 种 NLP 技术</a></li>
</ul>
<h3 id="11-指标开发">11. 指标开发</h3>
<p>最近,数据科学家已经承担了指标开发的责任,因为指标的呈现依赖于 1)计算指标所需的数据和 2)计算和输出指标的代码。</p>
<p>指标开发涉及几个方面:</p>
<ol>
<li>
<p>这涉及选择团队或部门应使用的正确指标,以帮助他们监控目标。</p>
</li>
<li>
<p>这涉及澄清和建立任何需要做出的假设,以确保指标有效。</p>
</li>
<li>
<p>这涉及开发指标、编写代码,并建立一个周期性监控指标的管道。</p>
</li>
</ol>
<p>我希望这能帮助指导你的学习,并为即将到来的一年提供一些方向。有很多东西要学,所以我建议你选择几个对你最有兴趣的技能,然后从那里开始。</p>
<p>请记住,这更多是基于轶事经验的观点文章,所以你可以根据自己的需要取舍。但一如既往,我祝你学习顺利!</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/09/data-scientists-data-engineering-skills.html" target="_blank">没有数据工程技能的数据科学家将面临严峻现实</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/09/3-important-lessons-data-science-career.html" target="_blank">我在数据科学职业生涯三年中学到的三个最重要的教训</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/06/data-science-not-becoming-extinct-10-years.html" target="_blank">数据科学在未来 10 年不会消失,但你的技能可能会</a></p>
</li>
</ul>
<h3 id="了解更多相关话题">了解更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/08/indemand-artificial-intelligence-skills-learn-2022.html" target="_blank">2022 年最受欢迎的人工智能技能学习指南</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n13.html" target="_blank">KDnuggets 新闻 3 月 30 日:最受欢迎的编程入门…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n11.html" target="_blank">KDnuggets 新闻 2022 年 3 月 16 日:学习数据科学基础及 5 个…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/01/best-learning-resources-data-science-2022.html" target="_blank">2022 年数据科学最佳学习资源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n05.html" target="_blank">KDnuggets™新闻 22:n05,2 月 2 日:掌握机器学习的 7 个步骤…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/02/scaler-8-best-data-science-courses-enroll-2022-steep-career-advancement.html" target="_blank">2022 年报名的 8 个最佳数据科学课程,助力职业快速提升</a></p>
</li>
</ul>
<h1 id="每个程序员都应该知道的-11-个-python-魔法方法">每个程序员都应该知道的 11 个 Python 魔法方法</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/11-python-magic-methods-every-programmer-should-know" target="_blank"><code>www.kdnuggets.com/11-python-magic-methods-every-programmer-should-know</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/c6e4055e8f998e4027bd282946ee7fbd.png" alt="每个程序员都应该知道的 11 个 Python 魔法方法" loading="lazy"></p>
<p>作者提供的图片</p>
<p>在 Python 中,魔法方法帮助你在 Python 类中模拟内置函数的行为。这些方法有前后双下划线(__),因此也称为<strong>双下划线方法</strong>。</p>
<p>这些魔法方法还帮助你在 Python 中实现运算符重载。你可能见过这样的例子。例如,使用乘法运算符*与两个整数相乘会得到乘积。而与字符串和整数<code>k</code>一起使用,则会得到重复<code>k</code>次的字符串:</p>
<pre><code class="language-py"> >>> 3 * 4
12
>>> 'code' * 3
'codecodecode'
</code></pre>
<p>在这篇文章中,我们将通过创建一个简单的二维向量<code>Vector2D</code>类来深入探讨 Python 中的魔法方法。</p>
<p>我们将从你可能熟悉的方法开始,逐步构建更有用的魔法方法。</p>
<p>让我们开始编写一些魔法方法吧!</p>
<h1 id="1-init">1. <strong>init</strong></h1>
<p>考虑以下<code>Vector2D</code>类:</p>
<pre><code class="language-py">class Vector2D:
pass
</code></pre>
<p>一旦你创建了一个类并实例化一个对象,你可以这样添加属性:<code>obj_name.attribute_name = value</code>。</p>
<p>然而,与其手动为你创建的每个实例添加属性(这当然毫无趣味!),你需要一种方法来初始化这些属性。</p>
<p>为此,你可以定义<code>__init__</code>方法。让我们为我们的<code>Vector2D</code>类定义<code>__init__</code>方法:</p>
<pre><code class="language-py">class Vector2D:
def __init__(self, x, y):
self.x = x
self.y = y
v = Vector2D(3, 5)
</code></pre>
<h1 id="2-repr">2. <strong>repr</strong></h1>
<p>当你尝试检查或打印你实例化的对象时,你会发现没有得到任何有用的信息。</p>
<pre><code class="language-py">v = Vector2D(3, 5)
print(v)
</code></pre>
<pre><code class="language-py">Output >>> <__main__.Vector2D object at 0x7d2fcfaf0ac0>
</code></pre>
<p>这就是为什么你应该添加一个表示字符串,即对象的字符串表示。为此,请添加一个<code>__repr__</code>方法,如下所示:</p>
<pre><code class="language-py">class Vector2D:
def __init__(self, x, y):
self.x = x
self.y = y
def __repr__(self):
return f"Vector2D(x={self.x}, y={self.y})"
v = Vector2D(3, 5)
print(v)
</code></pre>
<pre><code class="language-py">Output >>> Vector2D(x=3, y=5)
</code></pre>
<p><code>__repr__</code>应该包含创建类实例所需的所有属性和信息。<code>__repr__</code>方法通常用于调试目的。</p>
<h1 id="3-str">3. <strong>str</strong></h1>
<p><code>__str__</code>也用于添加对象的字符串表示。通常,<code>__str__</code>方法用于向类的最终用户提供信息。</p>
<p>让我们为我们的类添加一个<code>__str__</code>方法:</p>
<pre><code class="language-py">class Vector2D:
def __init__(self, x, y):
self.x = x
self.y = y
def __str__(self):
return f"Vector2D(x={self.x}, y={self.y})"
v = Vector2D(3, 5)
print(v)
</code></pre>
<pre><code class="language-py">Output >>> Vector2D(x=3, y=5)
</code></pre>
<p>如果没有<code>__str__</code>的实现,它将回退到<code>__repr__</code>。因此,对于你创建的每个类,你至少应该添加一个<code>__repr__</code>方法。</p>
<h1 id="4-eq">4. <strong>eq</strong></h1>
<p>接下来,让我们添加一个方法来检查任何两个<code>Vector2D</code>类对象的相等性。如果两个向量对象的 x 和 y 坐标相同,则它们是相等的。</p>
<p>现在创建两个<code>Vector2D</code>对象,x 和 y 值相等,并比较它们的相等性:</p>
<pre><code class="language-py">v1 = Vector2D(3, 5)
v2 = Vector2D(3, 5)
print(v1 == v2)
</code></pre>
<p>结果是 False。因为默认情况下,比较检查内存中对象 ID 的相等性。</p>
<pre><code class="language-py">Output >>> False
</code></pre>
<p>让我们添加<code>__eq__</code>方法来检查相等性:</p>
<pre><code class="language-py">class Vector2D:
def __init__(self, x, y):
self.x = x
self.y = y
def __repr__(self):
return f"Vector2D(x={self.x}, y={self.y})"
def __eq__(self, other):
return self.x == other.x and self.y == other.y
</code></pre>
<p>现在,相等性检查应该按预期工作:</p>
<pre><code class="language-py">v1 = Vector2D(3, 5)
v2 = Vector2D(3, 5)
print(v1 == v2)
</code></pre>
<pre><code class="language-py">Output >>> True
</code></pre>
<h1 id="5-len">5. <strong>len</strong></h1>
<p>Python 内置的 <code>len()</code> 函数帮助你计算内置可迭代对象的长度。假设对于一个向量,长度应返回向量包含的元素数量。</p>
<p>那么让我们为 <code>Vector2D</code> 类添加一个 <code>__len__</code> 方法:</p>
<pre><code class="language-py">class Vector2D:
def __init__(self, x, y):
self.x = x
self.y = y
def __repr__(self):
return f"Vector2D(x={self.x}, y={self.y})"
def __len__(self):
return 2
v = Vector2D(3, 5)
print(len(v))
</code></pre>
<p>所有 <code>Vector2D</code> 类的对象长度为 2:</p>
<pre><code class="language-py">Output >>> 2
</code></pre>
<h1 id="6-add">6. <strong>add</strong></h1>
<p>现在让我们考虑一下我们在向量上执行的常见操作。让我们添加魔法方法来加减任意两个向量。</p>
<p>如果你直接尝试添加两个向量对象,你将遇到错误。因此,你应该添加一个 <code>__add__</code> 方法:</p>
<pre><code class="language-py">class Vector2D:
def __init__(self, x, y):
self.x = x
self.y = y
def __repr__(self):
return f"Vector2D(x={self.x}, y={self.y})"
def __add__(self, other):
return Vector2D(self.x + other.x, self.y + other.y)
</code></pre>
<p>你现在可以像这样添加任意两个向量:</p>
<pre><code class="language-py">v1 = Vector2D(3, 5)
v2 = Vector2D(1, 2)
result = v1 + v2
print(result)
</code></pre>
<pre><code class="language-py">Output >>> Vector2D(x=4, y=7)
</code></pre>
<h1 id="7-sub">7. <strong>sub</strong></h1>
<p>接下来,让我们添加一个 <code>__sub__</code> 方法来计算 <code>Vector2D</code> 类中任意两个对象之间的差异:</p>
<pre><code class="language-py">class Vector2D:
def __init__(self, x, y):
self.x = x
self.y = y
def __repr__(self):
return f"Vector2D(x={self.x}, y={self.y})"
def __sub__(self, other):
return Vector2D(self.x - other.x, self.y - other.y)
</code></pre>
<pre><code class="language-py">v1 = Vector2D(3, 5)
v2 = Vector2D(1, 2)
result = v1 - v2
print(result)
</code></pre>
<pre><code class="language-py">Output >>> Vector2D(x=2, y=3)
</code></pre>
<h1 id="8-mul">8. <strong>mul</strong></h1>
<p>我们还可以定义一个 <code>__mul__</code> 方法来定义对象之间的乘法。</p>
<p>让我们实现处理</p>
<ul>
<li>
<p>标量乘法:向量与标量的乘法</p>
</li>
<li>
<p>内积:两个向量的点积</p>
</li>
</ul>
<pre><code class="language-py">class Vector2D:
def __init__(self, x, y):
self.x = x
self.y = y
def __repr__(self):
return f"Vector2D(x={self.x}, y={self.y})"
def __mul__(self, other):
# Scalar multiplication
if isinstance(other, (int, float)):
return Vector2D(self.x * other, self.y * other)
# Dot product
elif isinstance(other, Vector2D):
return self.x * other.x + self.y * other.y
else:
raise TypeError("Unsupported operand type for *")
</code></pre>
<p>现在我们将举几个例子来看看 <code>__mul__</code> 方法的实际效果。</p>
<pre><code class="language-py">v1 = Vector2D(3, 5)
v2 = Vector2D(1, 2)
# Scalar multiplication
result1 = v1 * 2
print(result1)
# Dot product
result2 = v1 * v2
print(result2)
</code></pre>
<pre><code class="language-py">Output >>>
Vector2D(x=6, y=10)
13
</code></pre>
<h1 id="9-getitem">9. <strong>getitem</strong></h1>
<p><code>__getitem__</code> 魔法方法允许你对对象进行索引,并使用熟悉的方括号 [ ] 语法访问属性或属性切片。</p>
<p>对于 <code>Vector2D</code> 类的对象 <code>v</code>:</p>
<ul>
<li>
<p><code>v[0]</code>:x 坐标</p>
</li>
<li>
<p><code>v[1]</code>:y 坐标</p>
</li>
</ul>
<p>如果你尝试通过索引访问,会遇到错误:</p>
<pre><code class="language-py">v = Vector2D(3, 5)
print(v[0],v[1])
</code></pre>
<pre><code class="language-py">---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-6-3fbbbf13d881>in <cell line:="">()
----> 1 print(v[0],v[1])
TypeError: 'Vector2D' object is not subscriptable</cell></ipython-input-6-3fbbbf13d881>
</code></pre>
<p>让我们实现 <code>__getitem__</code> 方法:</p>
<pre><code class="language-py">class Vector2D:
def __init__(self, x, y):
self.x = x
self.y = y
def __repr__(self):
return f"Vector2D(x={self.x}, y={self.y})"
def __getitem__(self, key):
if key == 0:
return self.x
elif key == 1:
return self.y
else:
raise IndexError("Index out of range")
</code></pre>
<p>你现在可以使用它们的索引访问元素,如下所示:</p>
<pre><code class="language-py">v = Vector2D(3, 5)
print(v[0])
print(v[1])
</code></pre>
<pre><code class="language-py">Output >>>
3
5
</code></pre>
<h1 id="10-call">10. <strong>call</strong></h1>
<p>通过实现 <code>__call__</code> 方法,你可以像调用函数一样调用对象。</p>
<p>在 <code>Vector2D</code> 类中,我们可以实现一个 <code>__call__</code> 方法来按给定因子缩放向量:</p>
<pre><code class="language-py">class Vector2D:
def __init__(self, x, y):
self.x = x
self.y = y
def __repr__(self):
return f"Vector2D(x={self.x}, y={self.y})"
def __call__(self, scalar):
return Vector2D(self.x * scalar, self.y * scalar)
</code></pre>
<p>所以,如果你现在调用 3,你将得到按 3 的因子缩放的向量:</p>
<pre><code class="language-py">v = Vector2D(3, 5)
result = v(3)
print(result)
</code></pre>
<pre><code class="language-py">Output >>> Vector2D(x=9, y=15)
</code></pre>
<h1 id="11-getattr">11. <strong>getattr</strong></h1>
<p><code>__getattr__</code> 方法用于获取对象的特定属性值。</p>
<p>在这个示例中,我们可以添加一个 <code>__getattr__</code> 方法,该方法在计算 向量的大小(L2 范数) 时被调用:</p>
<pre><code class="language-py">class Vector2D:
def __init__(self, x, y):
self.x = x
self.y = y
def __repr__(self):
return f"Vector2D(x={self.x}, y={self.y})"
def __getattr__(self, name):
if name == "magnitude":
return (self.x ** 2 + self.y ** 2) ** 0.5
else:
raise AttributeError(f"'Vector2D' object has no attribute '{name}'")
</code></pre>
<p>让我们验证一下这是否按预期工作:</p>
<pre><code class="language-py">v = Vector2D(3, 4)
print(v.magnitude)
</code></pre>
<pre><code class="language-py">Output >>> 5.0
</code></pre>
<h1 id="结论-16">结论</h1>
<p>本教程到此结束!希望你学会了如何为你的类添加魔法方法,以模拟内置函数的行为。</p>
<p>我们已经介绍了一些最有用的魔法方法。但这并不是一个详尽无遗的列表。为了进一步了解,请创建一个你选择的 Python 类,并根据所需功能添加魔法方法。继续编程!</p>
<p><strong><a href="https://twitter.com/balawc27" target="_blank"></a></strong><a href="https://www.kdnuggets.com/wp-content/uploads/bala-priya-author-image-update-230821.jpg" target="_blank">Bala Priya C</a>** 是来自印度的开发人员和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正致力于通过撰写教程、操作指南、评论文章等方式学习和分享知识。Bala 还创建引人入胜的资源概述和编码教程。**</p>
<hr>
<h2 id="我们的三大课程推荐-14">我们的三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织在 IT 方面</p>
<hr>
<h3 id="更多相关内容-21">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/python-fstrings-magic-5-gamechanging-tricks-every-coder-needs-to-know" target="_blank">Python f-Strings 魔法:每个程序员需要知道的 5 个改变游戏规则的技巧</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/understanding-pythons-iteration-and-membership-a-guide-to-__contains__-and-__iter__-magic-methods" target="_blank">理解 Python 的迭代与成员资格:<strong>contains</strong> 和 <strong>iter</strong> 魔法方法指南</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/jupyter-notebook-magic-methods-cheat-sheet" target="_blank">Jupyter Notebook 魔法方法备忘单</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/05/6-python-machine-learning-tools-every-data-scientist-know.html" target="_blank">每个数据科学家都应该了解的 6 个 Python 机器学习工具</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/three-r-libraries-every-data-scientist-know-even-python.html" target="_blank">每个数据科学家都应该知道的三大 R 库(即使你使用 Python)</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n21.html" target="_blank">KDnuggets 新闻,5 月 25 日:每个……的 6 个 Python 机器学习工具</a></p>
</li>
</ul>
<h1 id="11-个关于数据工程师的问题职业的内容是什么未来的发展方向如何">11 个关于数据工程师的问题:职业的内容是什么?未来的发展方向如何?</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2022/10/11-questions-data-engineers-profession-heading.html" target="_blank"><code>www.kdnuggets.com/2022/10/11-questions-data-engineers-profession-heading.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/b856e63f4a1f334d58b08c3eeb89d27d.png" alt="11 个关于数据工程师的问题:职业的内容是什么?未来的发展方向如何?" loading="lazy"></p>
<p>我于 2017 年从开发转向数据工程。在此之前,我在桌面开发、后台(主要是 Java)以及一些前端开发方面工作了十年。尽管我有强大的 IT 经验,但一开始搞清楚数据工程师做什么、他们与数据库管理员有何不同、他们如何与数据分析相关联以及他们与大数据有什么关系并不容易。</p>
<hr>
<h2 id="我们的前三个课程推荐-26">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升您的数据分析能力</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持您的组织的 IT 需求</p>
<hr>
<p>正是“大数据”这一术语的魅力决定了我现在所做的事情(这个 <a href="https://aws.amazon.com/big-data/what-is-big-data/" target="_blank">链接</a> 提供了大数据的一个成熟定义,包含“三位一体:体量、种类、速度”+ 亚马逊 AWS 的一个信息性视频)。对我而言,大数据领域看起来像是一个我必须接受的挑战。</p>
<p>我对分布式系统、可扩展技术和云计算越来越感兴趣,并参加了分析相关大数据产品(如 Hadoop、Kafka、Spark 等)的会议。周围出现了与大数据相关的同事,我向他们提出了很多问题。有时我收到的回答并不完全清楚,这进一步激发了我的好奇心。</p>
<p><img src="https://kdn.flygon.net/docs/img/4f2904e6120b12a8c96507b8c72c6a7d.png" alt="11 个关于数据工程师的问题:职业的内容是什么?未来的发展方向如何?" loading="lazy"></p>
<p><em>Hadoop 的首次发布——这是一个公开可用的平台,用于存储和处理来自分布式来源的数据阵列,计算量达到 PB 级——发生在 2006 年。很快,商业界开始认为大数据在实践中是适用的。接下来的十年,大多数</em> <a href="https://hbr.org/2012/10/big-data-the-management-revolution" target="_blank"><em>商业媒体</em></a> <em>称大数据无异于一场“革命”和“一次政变”。</em></p>
<p>然而,在过去的两三年里,大数据的神奇影响力减弱了:数据工程实际上已经吸收了这个领域,并使其在 IT 专家中变得普遍。大数据无处不在,如果今天商业数据不是“大数据”,那么明天它将变成“大数据”。与此同时,对数据职业的关注只增不减,它们的需求量不亚于例如 Java 开发人员。此外,数据工程师的平均薪资高于后端开发人员(数据科学家更被重视,为什么我们稍后会在本文中理解)。</p>
<p>今天,我看到身边的开发人员和其他 IT 专家对数据工程有着与我 6-7 年前相同的问题。在这里,我试图以一种易于理解的方式回答最常见的问题。我不假装涵盖所有内容,并且完全理解其他人已经更全面和有趣地描述了某些职业方面——这就是为什么文本中有这么多链接。</p>
<p>我希望我的回答对初学数据工程的人员和任何对数据工程感兴趣的人有所帮助。</p>
<h1 id="简而言之谁是数据工程师">简而言之:谁是数据工程师?</h1>
<p>数据工程师是一个使数据对客户可用的人。为此,数据工程师准确了解如何收集所需的数据,并设置一个可能包括以下内容的流程:</p>
<ul>
<li>
<p>数据收集:银行交易、忠诚度系统注册、客户地理位置、飞机上的传感器读数等;</p>
</li>
<li>
<p>清理数据中的错误和重复——确保所需的数据质量;</p>
</li>
<li>
<p>数据转换和聚合;</p>
</li>
<li>
<p>数据存储;</p>
</li>
<li>
<p>按客户要求的正确和快速交付。</p>
</li>
</ul>
<p>这里的关键概念是数据仓库:我们将数据上传到其中,在那里进行转换,然后从中卸载以进行分析。通常,存储是关系型的,但与<a href="https://cloud.google.com/learn/what-are-transactional-databases" target="_blank">事务数据库管理系统</a>不同,它用于分析负载(<a href="https://www.guru99.com/online-analytical-processing.html" target="_blank">OLAP</a>)。</p>
<p>这是什么意思?事务负载的特点是写入和读取的数据量相对较小,同时用户数量可能较多。分析负载的情况正好相反:写入和读取的数据量很大,同时用户数量有限。这是职业的一个细微差别。</p>
<p>建模仓库有很多选项,例如经典的、<a href="https://www.geeksforgeeks.org/difference-between-kimball-and-inmon/" target="_blank">Kimball 或 Inmon 组织</a>,或更现代的方法,如 <a href="https://en.wikipedia.org/wiki/Data_vault_modeling" target="_blank">Data Vault</a>。还有一些非严格关系型的存储选项,如数据湖或 <a href="https://www.databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html#:~:text=A%20lakehouse%20is%20a%20new,cloud%20storage%20in%20open%20formats." target="_blank">Lakehouse</a>——对于这些,您需要建立独立的数据收集管道,并进行预处理和加载到存储中。</p>
<p>存储的选择、数据处理工具、数据处理速度和扩展能力都是数据工程师的关注点。数据管理员通常负责确保配置的管道在一个月、一年及更长时间内无中断地运行。这个人解决问题并提高生产力。大多数数据工程师也能做到这一点,但理想情况下这并不是他们的责任。</p>
<p>数据在提供后如何使用,理想情况下也不应该是数据工程师的关注点。主要的任务是将存储适应于日常负载和数据类型。</p>
<h1 id="数据工程师与数据分析师有何关系">数据工程师与数据分析师有何关系?</h1>
<p>记住,数据工程师使数据可访问。他们从各种来源收集数据,系统化数据,处理数据,并说:“这是数据,需要的人请从这里取。”例如,业务用户,如经理,可以获取这些数据。但理想情况下,数据分析师会首先获取数据。</p>
<p>数据分析师的任务是解读和可视化数据,以找出可以提取的商业价值。数据分析师利用数据中的模式来回答业务问题,做出预测并提供建议。我们可以说数据分析师直接影响商业决策。</p>
<p>相应地,数据分析师为数据工程师设定任务,例如从哪里获取分析数据、需要清理什么、需要修正什么。有时数据工程师会进行数据的初步解读,而数据分析师会准备自己的数据。但通常这些职能并不重叠。然而,高级数据分析师理解非结构化数据,知道如何编写复杂的 SQL 查询,并用 R 或 Python 编写少量代码。</p>
<p>一般来说,数据工程师可以稍微像数据分析师,反之亦然。如果数据分析师仅使用 Excel 数据透视表,那么他或她与数据工程没有关系。</p>
<h1 id="数据工程师与-bi-工程师相比如何">数据工程师与 BI 工程师相比如何?</h1>
<p>BI 工程师的重点是报告。对于大型客户,BI 工程师决定使用哪些 BI 工具,如 Tableau、Qlik、Power BI、Looker、Sisense 等,并进行配置。多亏了 BI 工程师,公司经理可以实时查看公司情况的可视化仪表盘:在 10 秒内就能清楚地了解公司的弱点。如果经理希望,他们可以将报告转换为演示文稿。</p>
<p>那么,谁来配置必要数据的交付到 BI 系统呢?没错,是数据工程师。</p>
<p>然而,在数据集较小的小公司中——没有像 MySQL 或 Oracle 这样的平台或基础平台——BI 工程师独立配置数据管道。总的来说,从技能角度来看,BI 工程师是数据工程师和数据分析师的混合体:这个人理解数据集成、处理和数据分析的基础知识,并能将知识应用于实践。</p>
<p>另一方面,几乎任何数据工程师都会在 Tableau 中构建仪表盘,即使他或她没有足够的经验来了解即使是最常见的 BI 系统的所有可能性。此外,任何系统都有生命周期,包括 BI 系统——它们在不断演变,需要监控和更新。数据工程师通常没有时间处理这些,但监控和更新系统是 BI 工程师的优先任务。</p>
<h1 id="数据工程师与数据科学家有什么共同点">数据工程师与数据科学家有什么共同点?</h1>
<p>简而言之,他们几乎没有共同之处,除了数据工程师(现在你会有既视感)设置了数据科学家所需的数据管道。数据科学家主要需要这些数据来训练使用神经网络和机器学习算法的模型。</p>
<p>模型在商业中用于预测和自动响应。例如,它们可以为经纪公司提供买卖苹果股票的建议。</p>
<p>数据科学家的专业领域包括 AI、ML 和 DL。即使是高级数据工程师也很少在工作中接触这些。除了编程技能,数据科学家还必须具备强大的数学技能和统计知识。</p>
<p>所以,数据工程师既有点数据管理员、数据分析师,又有点 BI 工程师。数据分析师、BI 工程师和数据管理员也可以有点数据工程师的特质。而数据科学家则是一个独立的领域:他们有不同的生产周期、不同的理论基础和资格要求。</p>
<h1 id="数据工程师实习生需要具备什么能力初级工程师呢">数据工程师实习生需要具备什么能力?初级工程师呢?</h1>
<p>我建议新手数据工程师不要忽视理论基础——关系代数和分布式计算。</p>
<p>初学者需要弄清楚什么是 ETL 和 ELT,以及它们之间的 <a href="https://www.qlik.com/us/etl/etl-vs-elt" target="_blank">区别</a>,除了“提取、转换和加载”这几个词的不同顺序。他们还需要理解 <a href="https://www.mongodb.com/nosql-explained/nosql-vs-sql" target="_blank">SQL 和 NoSQL 的区别</a>。他们必须熟悉数据工程任务的类别,并至少在每一类别中拆解一个主流工具:</p>
<ul>
<li>
<p>数据存储;</p>
</li>
<li>
<p>分布式数据处理;</p>
</li>
<li>
<p>编排。</p>
</li>
</ul>
<p>了解 <a href="https://www.guru99.com/software-development-life-cycle-tutorial.html" target="_blank">软件开发生命周期</a> 也很有用:需求如何收集和文档化,以及软件如何开发、测试和实施。展望未来,许多数据工程师编写代码和自动化测试,换句话说,他们在没有测试人员的情况下完成工作。</p>
<p>数据工程师与客户直接沟通的频率相当高,绕过了业务分析师。这就是我目前项目中的情况:数据工程师独立将任务从业务语言翻译成技术语言。这意味着从一开始就应对数据业务需求有共同的理解,以及银行、医疗、零售、电信、保险公司和旅游业如何使用这些数据。没有高级的软技能和良好的英语口语是不行的。你的英语水平至少需要达到中级。</p>
<h1 id="我在哪里可以找到有关数据工程的信息">我在哪里可以找到有关数据工程的信息?</h1>
<p>开始时,你可以阅读数据工程技术和工具创建者的英文博客。本文中的大多数链接都指向像 MongoDB、Qlik、AWS 等博客。</p>
<p>如果你已经选择了一个要精通的平台,查看供应商的培训材料是有意义的。像 <a href="https://www.snowflake.com/" target="_blank">Snowflake</a> 和 <a href="https://www.databricks.com/" target="_blank">Databricks</a> 这样的主流、自给自足的平台提供了大量高质量的各种复杂程度的材料,适合初学者、中级人员和架构师。当然,它们也会强调自己的产品。</p>
<p>数据工程师有自己的宝典 — <a href="https://www.amazon.com/DAMA-DMBOK-Data-Management-Body-Knowledge/dp/1634622340" target="_blank">DMBOK</a>(数据管理知识体系)。这里描述了标准化的数据管理方法和最佳实践。</p>
<p><img src="https://kdn.flygon.net/docs/img/4f2904e6120b12a8c96507b8c72c6a7d.png" alt="11 个关于数据工程师的问题:这份职业是干什么的,未来发展方向如何?" loading="lazy"></p>
<p>这本严肃且可能有些枯燥的书适用于高级及以上水平。初学者可以将其作为参考。DMBOK 将突出值得探索的领域 —— 然后你可以去供应商的博客,那里以更有趣和易懂的方式描述了所有内容。</p>
<h1 id="数据工程师是否需要会编程">数据工程师是否需要会编程?</h1>
<p>许多数据工程师懂得编写代码。绝大多数客户期望数据工程师至少在脚本层面上熟练掌握 SQL 和这些语言中的一种:Python、Scala、Java、JavaScript、C#。</p>
<p>我们中的一些人使用低代码平台,通过现成工具组装数据管道(<a href="https://www.gartner.com/reviews/market/data-integration-tools" target="_blank">数据集成工具</a>)。在这种情况下,他们有时被称为 ETL 开发人员、数据集成工程师或其他称谓。基本上,这些人也是数据工程师,只是专注于数据集成。</p>
<p>他们可能不知道一些职业的细节。例如,如果需要将生产力提高 10 倍,如果没有提供具体的扩展工具并说:“做这个”,将会遇到困难。</p>
<p>总而言之,即使你只会最低水平的编程,也可以成为数据工程师。同时,一个只会 C#脚本的数据工程师仍然可以达到高级水平甚至更高——就像一个不懂编程的 QA 工程师(与 QAA 不同)一样。</p>
<h1 id="人们在进入数据工程领域之前来自哪里哪些领域在成为数据工程师时最容易">人们在进入数据工程领域之前来自哪里?哪些领域在成为数据工程师时最容易?</h1>
<p>我只能谈论我个人朋友和同事的经历,这并不一定反映整体情况。我只偶尔遇到完全“从零”进入这个职业的人——大多数人都是开发人员或数据专家。此外,我不知道 DevOps 工程师转行做数据工程师的案例。也许他们比其他 IT 职业更热爱自己的工作,并且同样非常受欢迎。</p>
<p>许多数据工程师起初是数据库管理员或数据分析师。他们已经知道 SQL、BI,并且理解如何处理数据。以这样的背景,在多个领域中,你可以在六个月内完全解决数据工程师的任务。</p>
<p>我可以假设,对于一个了解 Java 和/或 Python 的后端开发人员来说,成为数据工程师更容易、更快。如果你了解 Scala、Airflow 或 Spark,那么你真的很有优势。</p>
<h1 id="与客户工作的一个简单例子是什么">与客户工作的一个简单例子是什么?</h1>
<p>几乎所有公司都有数据库,他们时不时地使用它:他们在其中上传某些内容,卸载其他内容,并根据需求以某种方式使用数据库。例如,一个 Python 开发人员编写平台,一个业务分析师和市场营销人员分析数据,有时还需要连接系统管理员。当显然需要系统化的方法并且工作量足够多到需要一个整个人时,就会呼叫数据工程师来帮忙。</p>
<p>他们来找我们,说:“我们有自己的数据库,但它承受不了这种负载。我们需要一个存储解决方案,可以放置所有内容,并进行大而重的请求”(顺便提一下,还有反向情况:存储空间负载不足,你需要找出如何处理它)。</p>
<p>好的,我们理解数据需要转移到内部存储并使其可用。为了提高允许的负载,你需要进行扩展。我们澄清细节:我们需要验证数据,还是数据本身已经是干净的?我们需要多频繁地更新/处理数据——一天做一次就足够,还是这个过程是持续的?可能会有几十个类似的要求。</p>
<p>收集需求后,我们进入系统设计阶段。我们展示将如何在技术上解决问题,使用哪种技术栈。有时客户对自己的决定不确定——这种情况下,我们会展示备选方案,并描述每个方案的优缺点。也有可能客户愿意超出预算,只要他们看到对业务更有用的选项。</p>
<p>我们必须让业务方能够理解,并使用他们的语言。如果客户在技术上很成熟,并且非常了解<a href="https://www.mongodb.com/databases/data-lake-vs-data-warehouse-vs-database" target="_blank">数据仓库与数据湖的区别</a>,那么我们就提供更多的技术细节。如果不是,我们则关注基本问题:成本是多少,存储的安全性如何,以及切换到其他供应商解决方案的难易程度。</p>
<p>我们一定会讨论在紧急情况下的行动方案,以及这种响应所需的时间。</p>
<h1 id="数据工程师的职业轨迹是什么样的在哪些方面可以成长">数据工程师的职业轨迹是什么样的?在哪些方面可以成长?</h1>
<p>和几乎所有职业一样,成长可以是扩展性的(横向增长),也可以是深入性的(纵向深入)。你可以精通一个技术栈,成为一个被视为半神般的专家,求助时大家都找你。当其他人无法解决时,你可以被求助。你也可以提升你的管理技能,成为团队领导等。</p>
<p><img src="https://kdn.flygon.net/docs/img/0a0c02e1666d1e110cd7f63ee015cdc2.png" alt="关于数据工程师的 11 个问题:这个职业是什么,未来会发展到哪里?" loading="lazy"></p>
<p><em>美国数据工程师的职业发展轨迹,</em> <a href="https://www.glassdoor.com/Career/how-to-become-big-data-engineer_KO14,31.htm" target="_blank"><em>根据 Glassdoor</em></a></p>
<p>数据工程师的发展路径以及对数据工程师的要求因公司而异。在我的公司,职业阶梯如下:数据工程师?团队领导数据工程师?数据技术架构师?数据解决方案架构师(DSA)。</p>
<p><strong>数据工程师。</strong> 了解数据管理的基础知识:数据建模、ELT/ETL、数据质量、数据仓库/湖模型、分布式系统。能熟练使用至少一种技术栈:AWS、Azure、Snowflake、Apache Hadoop 等。要求掌握 SQL,并至少掌握一种编程语言:Scala、Python、Java、C#。</p>
<p><strong>团队领导数据工程师。</strong> 此人对数据管理和工程的基础知识有较高的了解。具备较强的沟通和解决问题的能力。知道如何管理项目、交付和变更。</p>
<p><strong>数据技术架构师。</strong> 通常,这个人是渴望担任 DSA 职位的人,但缺乏经验和技术博学。他或她至少精通一个技术栈,并且能够在 DSA 的指导下处理解决方案实施的技术细节。</p>
<p><strong>数据解决方案架构师。</strong> 数据管理和数据工程的专家。此人了解当前的数据处理技术,能够快速掌握新技术。此人具备领导力、项目和变更管理技能,以及工程管理能力,如团队和技术部门管理。</p>
<p>大型 IT 公司经常创建技能中心来发展硬技能和软技能。例如,现在 DataArt 中几乎有 200 名数据专家,其中几个人在卓越中心(包括我)。我们的主要目标是帮助同事选择他们希望在职业上成长的方向,并帮助他们掌握新技术。我们为数据专家提供机会,通过担任导师、演讲者、技术专家和客户服务专家,充分发挥他们的潜力。</p>
<h1 id="职业在如何变化有什么趋势">职业在如何变化?有什么趋势?</h1>
<p>在我看来,越来越多的关注被放在数据管理上,即 <a href="https://blog.hubspot.com/website/data-governance" target="_blank">数据治理</a>。以前,公司可以将数据倾倒到数据湖中,最终这些数据湖变成了“数据沼泽”:一些难以理解的数据,很难搞清楚是谁放了什么,以及为什么。现在,在架构层面,这家公司从不同的角度考虑数据管理,并描述如何确保 <a href="https://www.sisense.com/glossary/data-quality/" target="_blank">数据质量</a>,以及如何处理元数据、主数据和参考数据等。这比建立一个 ETL 流水线要困难得多。</p>
<p>其中一个趋势是转向云管理系统。也就是说,我们不在本地部署系统,而是购买一个已经组装好的云系统。我们可以拥有至少 10,000 台机器的请求池,但完全不需要考虑如何分配和扩展。</p>
<p>这种无服务器的趋势对数据工程来说是非常重要的。因此,大数据失去了它的神奇魅力,因为大数据主要涉及水平扩展。由于云技术,数据工程师的重点从扩展转向了数据管理。<strong>从概念上讲,现在更正确的提问不是如何处理大数据,而是如何全面管理数据</strong>。</p>
<p>技术的数量被夸大了,类似工具的数量越来越多。几乎不可能找到技术栈完全匹配的专家。这意味着,例如,任何级别的数据工程师都必须在实践中获取必要的知识,这很正常。</p>
<p><strong><a href="https://ru.linkedin.com/in/ilia-moshkov-a37364172" target="_blank">伊利亚·莫什科夫</a></strong> 是高级数据工程师,并且是 DataArt 数据卓越中心的成员</p>
<h3 id="更多相关主题-20">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/generative-ai-specialisation-courses-from-ibm-for-every-profession" target="_blank">IBM 针对各行各业的生成式人工智能专业课程</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/tonic-high-fidelity-synthetic-data-engineers-scientists-alike.html" target="_blank">高保真合成数据,适用于数据工程师和数据科学家</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/08/data-scientists-data-engineers-work-together.html" target="_blank">数据科学家和数据工程师如何协作?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/08/corise-land-ml-job-advice-engineers-meta-google-brain-sap.html" target="_blank">如何获得机器学习职位:来自 Meta、Google Brain 和 SAP 工程师的建议</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/02/dont-need-data-scientists-need-data-engineers.html" target="_blank">我们不需要数据科学家,我们需要数据工程师</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/02/5-sql-visualization-tools-data-engineers.html" target="_blank">5 款适用于数据工程师的 SQL 可视化工具</a></p>
</li>
</ul>
<h1 id="kdnuggets-新闻-21n4010-月-20-日你需要的-20-个-python-包用于机器学习和数据科学通过投资组合项目应对数据科学面试">KDnuggets™ 新闻 21:n40,10 月 20 日:你需要的 20 个 Python 包用于机器学习和数据科学;通过投资组合项目应对数据科学面试</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2021/n40.html" target="_blank"><code>www.kdnuggets.com/2021/n40.html</code></a></p>
</blockquote>
<p>特性 | 产品 | 教程 | 观点 | 排行 | 招聘 | <a href="https://www.kdnuggets.com/news/submissions.html" target="_blank">提交博客</a> | 本周图片</p>
<p>本周 KDnuggets:你需要的 20 个 Python 包用于机器学习和数据科学;如何通过处理投资组合项目来应对数据科学面试;部署你的第一个机器学习 API;实时图像分割,使用 5 行代码;什么是聚类及其工作原理?;以及更多精彩内容。</p>
<p>请考虑 <a href="https://www.kdnuggets.com/news/submissions.html" target="_blank"><strong>提交</strong></a> 一篇原创博客到 KDnuggets!</p>
<p>特性</p>
<ul>
<li>
<p><strong>你需要的 20 个 Python 包用于机器学习和数据科学</strong>,作者:Sandro Luck</p>
</li>
<li>
<p>**<img src="https://kdn.flygon.net/docs/img/ace-data-science-interview-portfolio-projects.html" alt="银色博客如何通过处理投资组合项目来应对数据科学面试**" loading="lazy">,作者:Abid Ali Awan</p>
</li>
<li>
<p>**<img src="https://kdn.flygon.net/docs/img/deploying-first-machine-learning-api.html" alt="银色博客部署你的第一个机器学习 API**" loading="lazy">,作者:Abid Ali Awan</p>
</li>
<li>
<p><strong>实时图像分割,使用 5 行代码</strong>,作者:Ayoola Olafenwa</p>
</li>
<li>
<p><strong>什么是聚类及其工作原理?</strong>,作者:Satoru Hayasaka</p>
</li>
</ul>
<p>产品,服务</p>
<ul>
<li>
<p><strong>2021 数据工程师薪资报告分享了对迅速发展的市场的见解</strong>,作者:Burtch Works</p>
</li>
<li>
<p><strong>向西北大学的数据科学专家学习</strong>,作者:Northwestern</p>
</li>
<li>
<p><strong>Hasura 如何通过 PostHog 提高 20%的转化率</strong>,作者:PostHog</p>
</li>
<li>
<p><strong>亚马逊网络服务网络研讨会:利用数据集创建以客户为中心的战略并改善业务结果</strong>,作者:Roidna</p>
</li>
<li>
<p><strong>知识图谱论坛:技术生态系统与业务应用</strong>,作者:Ontotext</p>
</li>
</ul>
<p>教程,概述</p>
<ul>
<li>
<p><strong>构建多模态模型:使用 widedeep Pytorch 包</strong>,作者:Rajiv Shah</p>
</li>
<li>
<p><strong>AI 的新计算范式:内存处理(PIM)架构</strong>,作者:Nam Sung Kim</p>
</li>
<li>
<p><strong>如何使用自动引导法计算机器学习中性能指标的置信区间</strong>,作者:David B Rosen(博士)</p>
</li>
<li>
<p><strong>2022 年最实用的数据科学技能</strong>,作者:特伦斯·申</p>
</li>
<li>
<p><strong>生产中服务 ML 模型:常见模式</strong>,作者:莫、奥克斯与加拉尼克</p>
</li>
<li>
<p><strong>如何使用 KNIME Analytics Platform 在三步内创建交互式仪表板</strong>,作者:埃米利奥·西尔维斯特里</p>
</li>
</ul>
<p>观点</p>
<ul>
<li>
<p><strong>避免这五种行为,让你看起来像数据新手</strong>,作者:特莎·谢</p>
</li>
<li>
<p><strong>我们对算法的痴迷如何破坏了计算机视觉:以及合成计算机视觉如何修复它</strong>,作者:保罗·波普</p>
</li>
<li>
<p><strong>你的工作会被机器取代吗?</strong>,作者:马丁·佩里</p>
</li>
<li>
<p><strong>即使在忙碌时如何让数据专业人士留下深刻印象</strong>,作者:德文·帕提达</p>
</li>
</ul>
<p>头条新闻</p>
<ul>
<li>
<p><strong>头条新闻,10 月 11-17:使用 SQL 查询你的 Pandas DataFrames</strong>,作者:KDnuggets</p>
</li>
<li>
<p><strong>KDnuggets 2021 年 9 月最佳博客奖励</strong>,作者:格雷戈里·皮亚特斯基</p>
</li>
</ul>
<p>职位</p>
<ul>
<li>
<p>查看我们最近的 AI、分析、数据科学、机器学习职位</p>
</li>
<li>
<p>你可以在 KDnuggets 职位页面免费发布与 AI、大数据、数据科学或机器学习相关的行业或学术职位,详细信息请通过电子邮件查看 kdnuggets.com/jobs</p>
</li>
</ul>
<p>本周图片</p>
<blockquote>
<p>![实时图像分割,只需 5 行代码</p>
<p><a href="https://www.kdnuggets.com/2021/10/real-time-image-segmentation-5-lines-code.html" target="_blank">实时图像分割,只需 5 行代码</a></p>
</blockquote>
<h3 id="更多相关话题-31">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/n03.html" target="_blank">KDnuggets™ 新闻 22:n03,1 月 19 日:深入分析 13 个数据…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n37.html" target="_blank">KDnuggets 新闻,9 月 21 日:7 个机器学习项目…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/5-free-university-courses-to-ace-coding-interviews" target="_blank">5 门免费大学课程助你通过编码面试</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/12/7-super-cheat-sheets-need-ace-machine-learning-interview.html" target="_blank">7 张超级备忘单助你通过机器学习面试</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/10/10-cheat-sheets-need-ace-data-science-interview.html" target="_blank">10 张你需要的备忘单以通过数据科学面试</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/09/7-machine-learning-portfolio-projects-boost-resume.html" target="_blank">7 个机器学习项目提升简历</a></p>
</li>
</ul>
<h1 id="kdnuggets-新闻-21n349-月-8-日您用-python-读取-excel-文件吗有一种快-1000-倍的方法假设检验详解">KDnuggets™ 新闻 21:n34,9 月 8 日:您用 Python 读取 Excel 文件吗?有一种快 1000 倍的方法;假设检验详解</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2021/n34.html" target="_blank"><code>www.kdnuggets.com/2021/n34.html</code></a></p>
</blockquote>
<p>特点 | 产品 | 教程 | 观点 | 排行 | 职位 | <a href="https://www.kdnuggets.com/news/submissions.html" target="_blank">提交博客</a> | 本周图片</p>
<p>本周在 KDnuggets:您用 Python 读取 Excel 文件吗?有一种快 1000 倍的方法;假设检验详解;数据科学备忘单 2.0;我最近遇到的 6 个酷炫 Python 库;2021 年学习自然语言处理的最佳资源;还有更多。</p>
<p>我们新的<a href="https://www.kdnuggets.com/2021/04/kdnuggets-top-authors-reward-program.html" target="_blank"><strong>KDnuggets 顶级博客奖励计划</strong></a>将奖励顶级博客的作者 - 查看<a href="https://www.kdnuggets.com/2021/04/kdnuggets-top-authors-reward-program.html" target="_blank">详情</a>。接受转载,但我们更喜欢原创投稿,奖励是转载的 3 倍。</p>
<p>特点</p>
<ul>
<li>
<p>**<img src="https://kdn.flygon.net/docs/img/excel-files-python-1000x-faster-way.html" alt="金博客您用 Python 读取 Excel 文件吗?有一种快 1000 倍的方法**" loading="lazy">,作者:Nicolas Vandeput</p>
</li>
<li>
<p>**<img src="https://kdn.flygon.net/docs/img/hypothesis-testing-explained.html" alt="金博客假设检验详解**" loading="lazy">,作者:Angelica Lo Duca</p>
</li>
<li>
<p>**<img src="https://kdn.flygon.net/docs/img/data-science-cheat-sheet.html" alt="银博客数据科学备忘单 2.0**" loading="lazy">,作者:Aaron Wang</p>
</li>
<li>
<p><strong>我最近遇到的 6 个酷炫 Python 库</strong>,作者:Dhilip Subramanian</p>
</li>
<li>
<p><strong>2021 年学习自然语言处理的最佳资源</strong>,作者:Aqsa Zafar</p>
</li>
</ul>
<p>产品,服务</p>
<ul>
<li>
<p><strong>未来系列 | 探索人工智能的未来</strong>,作者:Altair</p>
</li>
<li>
<p><strong>电子书:实用指南,用于在云中使用第三方数据</strong>,作者:Roidna</p>
</li>
<li>
<p><strong>验证您的数据和分析技能的热门认证</strong>,作者:SAS</p>
</li>
</ul>
<p>教程,概述</p>
<ul>
<li>
<p><strong>如何为数据科学项目创建惊艳的 Web 应用程序</strong>,作者:Murallie Thuwarakesh</p>
</li>
<li>
<p><strong>快速 AutoML 与 FLAML + Ray Tune</strong>,作者:Wu, Wang, Baum, Liaw & Galarnyk</p>
</li>
<li>
<p><strong>使用 Gretel 和 Apache Airflow 构建合成数据管道</strong>,作者:Drew Newberry</p>
</li>
<li>
<p><strong>机器学习在移动应用开发中的好处是什么?</strong>,作者:Ria Katiyar</p>
</li>
<li>
<p><strong>电子书:用 R 学习数据科学 - 免费下载</strong>,作者:Narayana Murthy</p>
</li>
<li>
<p><strong>关于吴道 2.0 的五个关键事实:迄今为止最大规模的 Transformer 模型</strong>,作者 Jesus Rodriguez</p>
</li>
<li>
<p><strong>机器学习如何利用线性代数解决数据问题</strong>,作者 Harshit Tyagi</p>
</li>
</ul>
<p>观点</p>
<ul>
<li>
<p><strong>如何解决现实世界中的机器学习问题</strong>,作者 Pau Labarta Bajo</p>
</li>
<li>
<p><strong>反脆弱性与机器学习</strong>,作者 Prad Upadrashta</p>
</li>
<li>
<p><strong>OpenAI Codex 背后的 5 个迷人挑战:你不知道的关于构建 Codex 的挑战</strong>,作者 Jesus Rodriguez</p>
</li>
</ul>
<p>热门故事</p>
<ul>
<li><strong>热门故事,8 月 30 日 - 9 月 5 日:你用 Python 阅读 Excel 文件吗?有 1000 倍更快的方法;假设检验解释</strong>,作者 KDnuggets</li>
</ul>
<p>职位</p>
<ul>
<li>
<p>查看我们最近的 人工智能、分析、数据科学、机器学习职位</p>
</li>
<li>
<p>你可以在 KDnuggets 的招聘页面上免费发布与人工智能、大数据、数据科学或机器学习相关的行业或学术职位,邮箱 - 详情请见 kdnuggets.com/jobs</p>
</li>
</ul>
<p>本周图片</p>
<blockquote>
<p>![假设检验解释</p>
<p><a href="https://www.kdnuggets.com/2021/09/hypothesis-testing-explained.html" target="_blank">假设检验解释</a></p>
</blockquote>
<h3 id="更多相关话题-32">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/hypothesis-testing-and-ab-testing" target="_blank">假设检验与 A/B 测试</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/09/hypothesis-testing-explained.html" target="_blank">假设检验解释</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/02/hypothesis-testing-data-science.html" target="_blank">数据科学中的假设检验</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/08/way-bridge-mlops-tools-gap.html" target="_blank">是否有办法弥合 MLOps 工具的差距?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/piexchange-faster-way-prepare-timeseries-data-ai-analytics-engine.html" target="_blank">利用 AI 和分析引擎更快地准备时间序列数据</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n17.html" target="_blank">KDnuggets 新闻,4 月 27 日:关于 Papers With Code 的简要介绍;…</a></p>
</li>
</ul>
<h1 id="12-个最具挑战性的数据科学面试问题">12 个最具挑战性的数据科学面试问题</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2022/07/12-challenging-data-science-interview-questions.html" target="_blank"><code>www.kdnuggets.com/2022/07/12-challenging-data-science-interview-questions.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/35f3347974695925256b93e3f2cb0b64.png" alt="12 个最具挑战性的数据科学面试问题" loading="lazy"></p>
<p>图片来源 | Canva Pro</p>
<p>如果你问我,招聘经理并不在意正确答案。他们希望评估你的工作经验、技术知识和逻辑思维。此外,他们寻找的是既了解业务又掌握技术的 数据科学家。</p>
<p>例如,在与一家顶级电信公司的面试中,我被要求提出一个新的数据科学产品。我建议使用一个开源解决方案,并让社区参与到项目中。我解释了我的思路以及如何通过向付费客户提供高级服务来实现产品的货币化。</p>
<p>我收集了 12 个最具挑战性的数据科学面试问题及其答案。这些问题被分为三部分:情境问题、数据分析和机器学习,以涵盖所有方面。</p>
<p>你也可以查看完整的数据科学面试合集:第一部分 和 第二部分。该合集包含了关于数据科学所有子类别的数百个问题。</p>
<h1 id="情境面试问题">情境面试问题</h1>
<h2 id="1-你做过的最具挑战性的数据科学项目是什么">1) 你做过的最具挑战性的数据科学项目是什么?</h2>
<p>你不必过于担心。招聘经理想评估你处理复杂项目的经验。</p>
<p>从项目名称和简短描述开始。然后,解释为什么这个项目具有挑战性以及你是如何克服这些挑战的。关键在于细节、工具、方法论、术语、创新思维和奉献精神。</p>
<p>在面试前回顾你最近的五个项目是一个好习惯。这将帮助你准备谈话要点、业务用例、工具和数据科学方法论。</p>
<h2 id="2-如果我们给你一个随机的数据集你会如何判断它是否符合业务需求">2) 如果我们给你一个随机的数据集,你会如何判断它是否符合业务需求?</h2>
<p>这不是一个完整的问题,可能会让面试者感到困惑。你需要询问业务用例以及基准指标的额外信息。在那之后,你可以开始分析数据和业务用例。你将需要解释统计算法来分析数据的可靠性和质量。之后,将其与业务用例匹配,并说明它如何改进现有系统。</p>
<p>记住,这个问题主要是评估你的批判性思维能力和处理随机数据集的准备情况。解释你的思路并得出结论。</p>
<h2 id="3-你将如何利用你的机器学习技能来创造收入">3) 你将如何利用你的机器学习技能来创造收入?</h2>
<p>这是一个棘手的问题,你应该准备好相关的数据和机器学习如何为多个公司创造收入的案例。</p>
<p>如果你对数字不太了解,也不用担心。有多种方法可以解决这个问题。机器学习用于预测股价、诊断疾病、多语言客户服务和电子商务推荐系统。</p>
<p>你需要告诉他们你在某一特定领域的专业知识,并将其与公司的使命匹配。如果公司是金融科技公司,你可以提出欺诈检测、预测增长、威胁检测和政策推荐系统等建议。</p>
<h1 id="数据分析-1">数据分析</h1>
<h2 id="4-我们为什么使用-ab-测试">4) 我们为什么使用 A/B 测试?</h2>
<p>A/B 测试是一种用于随机实验的统计假设检验,涉及两个变量 A 和 B。它主要用于用户体验研究,通过分析用户对两个不同版本的产品的反应。</p>
<p>在数据科学中,它用于测试公司内各种机器学习模型的生产和数据驱动解决方案分析。</p>
<p><img src="https://kdn.flygon.net/docs/img/b54efd528e1f1dc1a18f6dc75789b7f1.png" alt="我们为什么使用 A/B 测试?" loading="lazy"></p>
<p>图片来源于 <a href="https://www.optimizely.com/optimization-glossary/ab-testing/" target="_blank">Optimizely</a></p>
<h2 id="5-写一个-sql-查询列出所有订单及客户信息">5) 写一个 SQL 查询,列出所有订单及客户信息。</h2>
<p>面试官会提供关于数据库表的额外信息,例如<strong>Customers</strong>表具有<em>ID</em>和<em>Name</em>数据字段,而<strong>Orders</strong>表具有<em>ID</em>、<em>CUSTOMER</em>和<em>VALUE</em>字段。</p>
<p>我们将通过<em>ID</em>和<em>CUSTOMER</em>列连接两个表,并显示<em>ID</em>、<em>Name</em>作为客户名称,以及<em>VALUE</em>。</p>
<pre><code class="language-py">SELECT a.ID,
a.Name as Customer Name,
b.VALUE
FROM Customers as a
LEFT JOIN Orders as b
ON a.ID = b.CUSTOMER
</code></pre>
<p>上面的例子很简单。你必须为复杂的 SQL 查询做好准备,以通过面试环节。查看 Nate 最近的博客 你可能在下次面试中看到的 24 个 SQL 问题。</p>
<h2 id="6-马尔科夫链是什么">6) 马尔科夫链是什么?</h2>
<p>马尔科夫链是一种通过概率方法从一个状态转换到另一个状态的模型。它定义了基于当前状态和经过的时间,转换到未来状态的概率。马尔科夫链被广泛应用于信息理论、搜索引擎和语音识别。通过阅读 <a href="https://brilliant.org/wiki/markov-chains/" target="_blank">Brilliant Math’s</a> 维基页面来了解更多信息。</p>
<p><img src="https://kdn.flygon.net/docs/img/e8c5682b722d264ef512bd38abd91a61.png" alt="马尔科夫链是什么?" loading="lazy"></p>
<p>图片来源于 <a href="https://brilliant.org/wiki/markov-chains/" target="_blank">Brilliant Math & Science Wiki</a></p>
<h2 id="7-如何处理异常值">7) 如何处理异常值?</h2>
<p>简单的解决方案是丢弃异常值,因为它们会影响整体数据分析。但在这样做之前,请确保你的数据集足够大,并且你要移除的值确实是垃圾。垃圾指的是这些值是由于错误而被添加的。</p>
<p>除此之外,你还可以:</p>
<ul>
<li>
<p>归一化数据</p>
</li>
<li>
<p>应用 MinMaxScaler 或 StandardScaler。</p>
</li>
<li>
<p>使用不受异常值影响的算法,例如随机森林。</p>
</li>
</ul>
<p><img src="https://kdn.flygon.net/docs/img/711bfe27c3a0426caea965a4b857b8a0.png" alt="如何处理异常值?" loading="lazy"></p>
<p>图片来源于 <a href="http://dataanalyticsedge.com/2021/01/22/outlier-detection-and-treatment/" target="_blank">dataanalyticsedge</a></p>
<h1 id="机器学习-1">机器学习</h1>
<h2 id="8-什么是-tf-idf">8) 什么是 TF-IDF?</h2>
<p>TF-IDF(词频逆文档频率)用于计算一个词在文本序列或语料库中的相关性。在文本索引过程中,它评估文档或语料库中每个术语的值。它通常用于文本向量化,将一行或一句话转换为数值,并用于 NLP(自然语言处理)任务。</p>
<p><img src="https://kdn.flygon.net/docs/img/3633066195b3f037da44aa629ef9c403.png" alt="TF-IDF 是什么?" loading="lazy"></p>
<p>图片由 <a href="https://3.bp.blogspot.com/-u928a3xbrsw/UukmRVX_JzI/AAAAAAAAAKE/wIhuNmdQb7E/s1600/td-idf-graphic.png" target="_blank">filotechnologia.blogspot</a> 提供</p>
<h2 id="9-误差与残差有什么区别">9) 误差与残差有什么区别?</h2>
<p><strong>误差</strong>是观察值与其理论值之间的差异。通常是由数据生成过程(DGP)生成的未观察到的值。</p>
<p><strong>残差</strong>是观察值与由模型生成的预测值之间的差异。</p>
<h2 id="10-梯度下降方法是否总是收敛到相似的点">10) 梯度下降方法是否总是收敛到相似的点?</h2>
<p>不一定。它很容易陷入局部最小值或最优点。如果有多个局部最优点,其收敛性取决于数据和初始条件。很难达到全局最小值。</p>
<h2 id="11-滑动窗口法用于时间序列预测是什么">11) 滑动窗口法用于时间序列预测是什么?</h2>
<p>滑动窗口法也称为滞后法,其中之前的时间步骤用作输入,下一时间步骤用作输出。之前的步骤取决于 <strong>窗口宽度</strong>,即之前步骤的数量。滑动窗口法在单变量预测中相当有名。它将时间序列数据集转换为监督学习问题。</p>
<p>例如,如果序列是 [45,96,105,108,130,140,160,190,220,250,300,400] 且 <strong>窗口宽度</strong> 是 <strong>三</strong>。输出将如下所示:</p>
<table>
<thead>
<tr>
<th><strong>X</strong></th>
<th><strong>y</strong></th>
</tr>
</thead>
<tbody>
<tr>
<td>45,96,105</td>
<td>108</td>
</tr>
<tr>
<td>96,105,108</td>
<td>130</td>
</tr>
<tr>
<td>105,108,130</td>
<td>140</td>
</tr>
<tr>
<td>108,130,140</td>
<td>160</td>
</tr>
<tr>
<td>…</td>
<td>…</td>
</tr>
</tbody>
</table>
<h2 id="12-如何避免模型的过拟合">12) 如何避免模型的过拟合?</h2>
<p>过拟合发生在你的模型在训练集和验证集上表现良好,但在未见过的测试集上表现不佳时。</p>
<p><img src="https://kdn.flygon.net/docs/img/bd46b8d1dccb96ac227c4334a0b4be42.png" alt="如何避免模型的过拟合?" loading="lazy"></p>
<p>图片由 <a href="https://medium.com/analytics-vidhya/7-ways-to-avoid-overfitting-9ff0e03554d3" target="_blank">Ilyes Talbi</a> 提供</p>
<p>我们可以通过以下方式避免过拟合:</p>
<ul>
<li>
<p>保持模型简单</p>
</li>
<li>
<p>避免训练过长的轮次</p>
</li>
<li>
<p>特征工程</p>
</li>
<li>
<p>使用交叉验证技术</p>
</li>
<li>
<p>使用正则化技术</p>
</li>
<li>
<p>使用 <a href="https://shap.readthedocs.io/en/latest/index.html" target="_blank">Shap</a> 进行模型评估</p>
</li>
</ul>
<h2 id="参考">参考</h2>
<ul>
<li>
<p><a href="https://www.simplilearn.com/tutorials/data-science-tutorial/data-science-interview-questions" target="_blank">2022 年前 80 名数据科学面试问题及答案 | Simplilearn</a></p>
</li>
<li>
<p><a href="https://www.springboard.com/blog/data-science/data-science-interview-questions/" target="_blank">87 个常见数据科学面试问题 (springboard.com)</a></p>
</li>
<li>
<p><a href="https://intellipaat.com/blog/interview-question/nlp-interview-questions/" target="_blank">2022 年前 30 名 NLP 面试问题及答案 - Intellipaat</a></p>
</li>
<li>
<p><a href="https://www.indeed.com/career-advice/interviewing/data-science-interview-questions" target="_blank">2022 年 9 个数据科学面试问题及答案 | Indeed.com</a></p>
</li>
<li>
<p><a href="https://www.mlstack.cafe/blog/time-series-interview-questions" target="_blank">23 个时间序列面试问题(已回答)ML 开发者必须知道 | MLStack.Cafe</a></p>
</li>
</ul>
<p><strong><a href="https://www.polywork.com/kingabzpro" target="_blank">Abid Ali Awan</a></strong> (<a href="https://twitter.com/1abidaliawan" target="_blank">@1abidaliawan</a>) 是一位认证的数据科学专家,热衷于构建机器学习模型。目前,他专注于内容创作,撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,帮助那些遭受心理健康问题的学生。</p>
<h3 id="相关阅读">相关阅读</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/how-multimodality-makes-llm-alignment-more-challenging" target="_blank">多模态如何使 LLM 对齐更加具有挑战性</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/04/post-gpt4-answering-asked-questions-ai.html" target="_blank">GPT-4 之后:回答关于 AI 的常见问题</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n18.html" target="_blank">KDnuggets 新闻,5 月 4 日:9 门免费哈佛课程,助你学习数据…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/01/answer-data-science-coding-interview-questions.html" target="_blank">如何回答数据科学编码面试问题</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/04/15-python-coding-interview-questions-must-know-data-science.html" target="_blank">15 个你必须知道的 Python 编码面试问题,适用于数据科学</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/09/24-ab-testing-interview-questions-data-science-interviews-crack.html" target="_blank">数据科学面试中的 24 个 A/B 测试面试问题及解答</a></p>
</li>
</ul>
<h1 id="每个数据科学家应知道的-12-个-docker-命令">每个数据科学家应知道的 12 个 Docker 命令</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2023/01/12-docker-commands-every-data-scientist-know.html" target="_blank"><code>www.kdnuggets.com/2023/01/12-docker-commands-every-data-scientist-know.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/e346bd1486a4f74e575375cb7ebddacf.png" alt="每个数据科学家应知道的 12 个 Docker 命令" loading="lazy"></p>
<p>作者提供的图片</p>
<p>从事数据科学项目总是令人兴奋的。然而,这也并非没有挑战。每个项目都需要你安装一长串(可能)库及其特定版本。因此,理清项目的依赖关系可能相当具有挑战性。这时 <strong>Docker</strong> 可以提供帮助。</p>
<hr>
<h2 id="我们的前三名课程推荐-10">我们的前三名课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google Cybersecurity Certificate</a> - 加入网络安全领域的快车道</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google Data Analytics Professional Certificate</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT Support Professional Certificate</a> - 支持你的组织的 IT 工作</p>
<hr>
<p>Docker 是一种流行的容器化技术。使用 Docker,你可以将你的数据科学应用程序——包括代码和所需的依赖项——打包成一个称为 <strong>镜像</strong> 的可移植工件。因此,Docker 促进了开发环境的复制,使本地开发变得轻而易举。</p>
<p>以下是一些关键的 Docker 命令,它们在你进行下一个项目时会非常有用。我们将使用来自 <a href="https://hub.docker.com/" target="_blank">Docker Hub</a> 的镜像,这是一个非常流行的平台,用于查找、共享和管理容器镜像。</p>
<h1 id="1-docker-pull">1. docker pull</h1>
<p>要从 Docker Hub 拉取镜像,你可以运行 <code>docker pull</code> 命令,如下所示:</p>
<pre><code class="language-py">docker pull <name-of-the-image>
</code></pre>
<p>例如,要从 Docker Hub 拉取 Python 镜像,你可以运行以下命令:</p>
<pre><code class="language-py">docker pull python
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/34e7c97e5edabc29da75c888a3b9befe.png" alt="每个数据科学家应知道的 12 个 Docker 命令" loading="lazy"></p>
<p>默认情况下,此命令拉取可用的 <em>最新</em> 版本的镜像。你可以 <em>选择性地</em> 添加标签以拉取特定版本的镜像。</p>
<blockquote>
<p><strong>注意</strong>:如果你想以非超级用户权限运行 Docker 命令,可以创建 <code>docker</code> 组并将用户添加到该组中。</p>
</blockquote>
<h1 id="2-docker-images">2. docker images</h1>
<p>要查看所有已下载的镜像列表,你可以运行 <code>docker images</code> 命令。</p>
<pre><code class="language-py">docker images
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/2c0234a7a6767d6dce9bc0389c96e2d4.png" alt="每个数据科学家应知道的 12 个 Docker 命令" loading="lazy"></p>
<h1 id="3-docker-run">3. docker run</h1>
<p>你可以使用 docker run 命令从下载的镜像启动一个容器。下载镜像后,你可以启动一个 docker 容器,即镜像的运行实例,如下所示:</p>
<pre><code class="language-py">docker run <name-of-the-image>
docker run [options] <name-of-the-image>
</code></pre>
<p>例如,你可以使用 -i 选项在启动容器时启动一个交互式 Python REPL,而 -t 选项分配一个伪终端,如下所示:</p>
<p><img src="https://kdn.flygon.net/docs/img/7baf6b74b34c36c7f859df5a01f25cda.png" alt="12 Docker Commands Every Data Scientist Should Know" loading="lazy"></p>
<p>镜像是一个可移植的工件,容器是该镜像的运行实例。这意味着你可以从单个 Docker 镜像运行多个容器。</p>
<p><img src="https://kdn.flygon.net/docs/img/a640a18ff7397b92ed31916cd71e9ffa.png" alt="12 Docker Commands Every Data Scientist Should Know" loading="lazy"></p>
<p>图片作者</p>
<h1 id="4-docker-ps">4. docker ps</h1>
<p>你可以运行 <code>docker ps</code> 命令来获取所有运行中的容器的列表。</p>
<pre><code class="language-py">docker ps
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/9bba5e921e73f949cb50daad4db825d2.png" alt="12 Docker Commands Every Data Scientist Should Know" loading="lazy"></p>
<p>请注意,每个 Docker 容器都有一个 <code>CONTAINER ID</code>。在接下来的几分钟内,我们将学习 Docker 命令来停止和重启容器、检查日志等。我们将在这些命令中使用特定容器的 <code>CONTAINER ID</code>。</p>
<p>假设你在之前的会话中运行了一个容器,并且该容器现在不再运行。在这种情况下,你可以运行带有 <code>-a</code> 选项的 <code>docker ps</code> 命令。这将列出所有容器:当前运行的容器以及之前停止的容器。</p>
<pre><code class="language-py">docker ps -a
</code></pre>
<h1 id="5-docker-stop">5. docker stop</h1>
<p>有时你可能需要停止一个正在运行的容器。要做到这一点,请运行 <code>docker stop</code> 命令。</p>
<pre><code class="language-py">docker stop <CONTAINER ID>
</code></pre>
<h1 id="6-docker-start">6. docker start</h1>
<p>你可以使用 <code>docker start</code> 命令来重启之前停止的容器。你可以运行 <code>docker ps -a</code> 命令,获取容器 ID,然后在 <code>docker start</code> 命令中使用该 ID 来重启容器。</p>
<pre><code class="language-py">docker start <CONTAINER ID>
</code></pre>
<h1 id="7-docker-rmi">7. docker rmi</h1>
<p>要移除特定的镜像,可以运行 <code>docker rmi</code> 命令。</p>
<pre><code class="language-py">docker rmi <name-of-the-image>
</code></pre>
<p>运行此命令会从本地开发环境中移除镜像。下次你想从该镜像启动容器时,需要从 DockerHub 拉取镜像。</p>
<h1 id="8-docker-rm">8. docker rm</h1>
<p>要从开发环境中永久移除一个容器,你可以运行 <code>docker rm</code> 命令。但是,建议确保容器已停止后再尝试移除它。</p>
<pre><code class="language-py">docker rm <CONTAINER ID>
</code></pre>
<h1 id="9-docker-logs">9. docker logs</h1>
<p><code>docker logs</code> 命令在调试容器时特别有用。</p>
<pre><code class="language-py">docker logs <CONTAINER ID>
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/6d8afbc8cd76bee3aed7626fe3bc81ca.png" alt="12 Docker Commands Every Data Scientist Should Know" loading="lazy"></p>
<h1 id="10-docker-exec">10. docker exec</h1>
<p>使用 <code>docker exec</code> 命令,你可以在运行中的容器内执行命令。</p>
<pre><code class="language-py">docker exec <CONTAINER ID> <COMMAND> <ARGS>
</code></pre>
<blockquote>
<p><strong>亲自尝试</strong>:作为一个快速练习,总结你所学的内容,从 Docker Hub 拉取 <a href="https://hub.docker.com/_/bash" target="_blank">官方 Bash 镜像</a>。接下来,尝试在启动容器时启动一个交互式终端会话,并运行一个基本的 Bash 命令。</p>
</blockquote>
<h1 id="11-docker-version">11. docker version</h1>
<p>要检查工作环境中安装的 docker 版本,运行 <code>docker version</code> 命令:</p>
<pre><code class="language-py">docker version
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/ce3c19af81f81817ef1bdd81ae887d37.png" alt="12 Docker Commands Every Data Scientist Should Know" loading="lazy"></p>
<h1 id="12-docker-info">12. docker info</h1>
<p><code>docker info</code> 命令提供了有关系统范围内 Docker 安装的更详细信息。</p>
<pre><code class="language-py">docker info
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/8963e50a7b615b55bbac24a6e3f7385f.png" alt="每个数据科学家都应该知道的 12 个 Docker 命令" loading="lazy"></p>
<p>docker info 的输出(截断)</p>
<h1 id="结论-17">结论</h1>
<p>希望你觉得这个关于必备 Docker 命令的教程对你有帮助。一旦你熟悉了 Docker,你可以尝试将你的 Python 和数据科学应用程序 Docker 化。然后,你可以将应用程序的镜像推送到 DockerHub。其他开发者将能够拉取你的镜像并在他们的工作环境中启动容器——这一切只需一个命令。</p>
<p><strong><a href="https://twitter.com/balawc27" target="_blank">Bala Priya C</a></strong> 是一位技术作家,喜欢创建长篇内容。她的兴趣领域包括数学、编程和数据科学。她通过编写教程、操作指南等,向开发者社区分享她的学习经验。</p>
<h3 id="更多相关话题-33">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/n26.html" target="_blank">KDnuggets 新闻,6 月 29 日:数据科学的 20 个基础 Linux 命令…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/06/14-essential-git-commands-data-scientists.html" target="_blank">数据科学家的 14 个必备 Git 命令</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/06/20-basic-linux-commands-data-science-beginners.html" target="_blank">数据科学初学者的 20 个基础 Linux 命令</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/07/16-essential-dvc-commands-data-science.html" target="_blank">数据科学的 16 个必备 DVC 命令</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/10/10-essential-sql-commands-data-science.html" target="_blank">数据科学的 10 个必备 SQL 命令</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/01/12-essential-commands-streamlit.html" target="_blank">Streamlit 的 12 个必备命令</a></p>
</li>
</ul>
<h1 id="12-个-streamlit-必备命令">12 个 Streamlit 必备命令</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2023/01/12-essential-commands-streamlit.html" target="_blank"><code>www.kdnuggets.com/2023/01/12-essential-commands-streamlit.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/1e8fec6012e6c352b7fbfc5cb479dd3d.png" alt="12 个 Streamlit 必备命令" loading="lazy"></p>
<p>作者提供的图像</p>
<h1 id="1-write">1. write</h1>
<hr>
<h2 id="我们的前三个课程推荐-27">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析水平</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织的 IT</p>
<hr>
<p><a href="https://docs.streamlit.io/library/api-reference/write-magic/st.write" target="_blank">st.write</a> 不仅仅是一个打印函数来显示文本和数字。你可以用它来显示 pandas DataFrame、错误、字典、交互式可视化和 Keras 模型。</p>
<pre><code class="language-py">st.write(*args, unsafe_allow_html=False, **kwargs)
</code></pre>
<p>就像打印一样,你需要提供字符串/数字或对象。</p>
<p><img src="https://kdn.flygon.net/docs/img/82c030d364269709be19e8f3d135b359.png" alt="12 个 Streamlit 必备命令" loading="lazy"></p>
<p>来自 Streamlit API 参考</p>
<p><strong>注意:</strong> 你还可以使用 <code>st.title</code>、<code>st.header</code>、<code>st.header</code>、<code>st.code</code> 和 <code>st.latex</code> 来显示各种类型的文本元素。</p>
<h1 id="2-markdown">2. markdown</h1>
<p>如果你熟悉 Markdown,那么 <a href="https://docs.streamlit.io/library/api-reference/text/st.markdown" target="_blank">st.markdown</a> 是你的好帮手。它将帮助你显示图像、文本、标题等。</p>
<pre><code class="language-py">st.markdown(body, unsafe_allow_html=False)
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/8288e66146abf1e69f07fa73215b8cd0.png" alt="12 个 Streamlit 必备命令" loading="lazy"></p>
<p>来自 Streamlit API 参考</p>
<h1 id="3-dataframe">3. dataframe</h1>
<p>你可以使用 <a href="https://docs.streamlit.io/library/api-reference/data/st.dataframe" target="_blank">st.dataframe</a> 来显示 pandas DataFrame 和 Styler、pyarrow 表、NumPy 数组、PySpark DataFrame 和 Snowpark DataFrame 和表格。该函数允许你自定义表格,通过调整宽度和高度,并使用 pandas styler 进行样式设置。</p>
<pre><code class="language-py">st.dataframe(data=None, width=None, height=None, *, use_container_width=False)
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/6cccc930792f1b4a315b90be6f77f782.png" alt="12 个 Streamlit 必备命令" loading="lazy"></p>
<p>来自 Streamlit API 参考</p>
<h1 id="4-metric">4. metric</h1>
<p>如果你创建了仪表盘,你会知道显示 KPI 和关键性能指标的重要性。</p>
<p><a href="https://docs.streamlit.io/library/api-reference/data/st.metric" target="_blank">st.metric</a> 命令使显示各种指标变得容易,并带有 delta 指示器。你还可以使用 <a href="https://docs.streamlit.io/library/api-reference/layout/st.columns" target="_blank">st.columns</a> 显示多个指标。</p>
<pre><code class="language-py">st.metric(label, value, delta=None, delta_color="normal", help=None)
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/4fb20ead02390a5b95cb27dd6e1896d1.png" alt="12 个 Streamlit 必备命令" loading="lazy"></p>
<p>来自 Streamlit API 参考</p>
<h1 id="5-line_chart">5. line_chart</h1>
<p>Streamlit 还具有其可视化命令,这是 st.altair_chart 的语法糖。你可以使用 <a href="https://docs.streamlit.io/library/api-reference/charts/st.line_chart" target="_blank">st.line_chart</a> 在几秒钟内显示折线图。它比 st.altair_chart 更易于使用,因为它使用数据的列和索引来确定图表的规范。</p>
<pre><code class="language-py">st.line_chart(data=None, *, x=None, y=None, width=0, height=0, use_container_width=True)
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/f9d3af969aba9ef033c0e6436f289f3d.png" alt="12 个 Streamlit 的基本命令" loading="lazy"></p>
<p>图片来自 Streamlit API 参考</p>
<h1 id="6-matplotlib">6. matplotlib</h1>
<p><a href="https://docs.streamlit.io/library/api-reference/charts/st.pyplot" target="_blank">st.pyplot</a> 显示 matplotlib.pyplot 图形。你可以用它来显示各种图表,并像在 Jupyter Notebook 中一样自定义它们。</p>
<pre><code class="language-py">st.pyplot(fig=None, clear_figure=None, **kwargs)
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/4d59fd43cf997e62b45abc1e92f06452.png" alt="12 个 Streamlit 的基本命令" loading="lazy"></p>
<p>图片来自 Streamlit API 参考</p>
<p><strong>注意:</strong> 你还可以使用 st.altair_chart、st.vega_lite_chart、st.plotly_chart、st.pydeck_chart、st.graphviz_chart 和 st.map 来显示交互式可视化图表。</p>
<h1 id="7-文本输入">7. 文本输入</h1>
<p><a href="https://docs.streamlit.io/library/api-reference/widgets/st.text_input" target="_blank">st.text_input</a> 显示单行文本输入控件。你可以用它来向函数提供用户输入,使你的 web 应用程序更具互动性和可定制性。它通常用于 NLP 和机器学习任务。</p>
<pre><code class="language-py">st.text_input(label, value="", max_chars=None, key=None, type="default", help=None, autocomplete=None, on_change=None, args=None, kwargs=None, *, placeholder=None, disabled=False, label_visibility="visible")
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/411d596687f3b914e8dc1b48bd3e31a6.png" alt="12 个 Streamlit 的基本命令" loading="lazy"></p>
<p>图片来自 Streamlit API 参考</p>
<h1 id="8-选择框">8. 选择框</h1>
<p>除了文本输入,你还可以使用 <a href="https://docs.streamlit.io/library/api-reference/widgets/st.selectbox" target="_blank">st.selectbox</a> 小部件,并向用户提供选项。这将改善用户体验,因为他们可以通过选择不同的选项进行操作。</p>
<pre><code class="language-py">st.selectbox(label, options, index=0, format_func=special_internal_function, key=None, help=None, on_change=None, args=None, kwargs=None, *, disabled=False, label_visibility="visible")
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/5099a89e2ddfc7a7c177a34424415f6f.png" alt="12 个 Streamlit 的基本命令" loading="lazy"></p>
<p>图片来自 Streamlit API 参考</p>
<p><strong>注意:</strong> 你还可以使用 st.button、st.download_button、st.checkbox、st.radio、st.slider、st.number_input、st.text_area、st.date_input、st.time_input、st.file_uploader、st.camera_input 和 st.color_picker 作为输入控件。</p>
<h1 id="9-图像">9. 图像</h1>
<p>要显示图像,你需要使用 PIL 打开图像,并将对象提供给 <a href="https://docs.streamlit.io/library/api-reference/media/st.image" target="_blank">st.image</a>。这些函数接受 Numpy ndarray 来显示各种图像。</p>
<pre><code class="language-py">st.image(image, caption=None, width=None, use_column_width=None, clamp=False, channels="RGB", output_format="auto")
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/af9996a0328149831679df80c6c93116.png" alt="12 个 Streamlit 的基本命令" loading="lazy"></p>
<p>图片来自 Streamlit API 参考</p>
<p><strong>注意:</strong> 你还可以使用 st.audio 和 st.video 来收听音频和观看视频。</p>
<h1 id="10-进度">10. 进度</h1>
<p><a href="https://docs.streamlit.io/library/api-reference/status/st.progress" target="_blank">st.progress</a> 是一项了不起的功能。你可以通过查看进度条来估计时间,而不是等待一个未知的时间段。这将改善用户体验。</p>
<pre><code class="language-py">st.progress(value)
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/3f63e859337f24e8fd5edb6ce28102b8.png" alt="12 个 Streamlit 的基本命令" loading="lazy"></p>
<p>图片来自 Streamlit API 参考</p>
<p><strong>注意:</strong> 你还可以使用 <a href="https://docs.streamlit.io/library/api-reference/status" target="_blank">status elements</a> 来显示旋转器、警告、错误、信息、成功和异常。</p>
<h1 id="11-sidebar">11. sidebar</h1>
<p><a href="https://docs.streamlit.io/library/api-reference/layout/st.sidebar" target="_blank">st.sidebar</a> 是自定义布局和容器的一部分。它用于分析和机器学习应用。它还为你提供了更多空间来添加用户选项。</p>
<pre><code class="language-py">with st.sidebar:
st.[element_name]
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/442e418b74ae8f006dd8715b75f6fa9f.png" alt="Streamlit 的 12 个基本命令" loading="lazy"></p>
<p>图片来自 Streamlit API 参考</p>
<p><strong>注意:</strong> 你还可以使用 <a href="https://docs.streamlit.io/library/api-reference/layout" target="_blank">Layouts and Containers</a> 来自定义标签页、容器、列和扩展器。</p>
<h1 id="12-cache">12. cache</h1>
<p><a href="https://docs.streamlit.io/library/api-reference/performance/st.cache" target="_blank">st.cache</a> 是处理大数据集和机器学习模型时的最佳伙伴。它是一个函数装饰器,用于记忆函数执行并节省时间。</p>
<pre><code class="language-py">st.cache(func=None, persist=False, allow_output_mutation=False, show_spinner=True, suppress_st_warning=False, hash_funcs=None, max_entries=None, ttl=None)
</code></pre>
<pre><code class="language-py">@st.cache(persist=True)
def fetch_and_clean_data(url):
# Fetch data from URL here, and then clean it up.
return data
</code></pre>
<h1 id="结论-18">结论</h1>
<p>你可以使用这些命令来创建数据分析仪表板、机器学习演示、Web 应用程序,甚至创建你的个人作品网站。如果你寻找灵感,可以看看社区创建和分享的 <a href="https://streamlit.io/gallery" target="_blank">Gallery</a>。</p>
<p>在这篇文章中,我们介绍了 12 个最基本的 Streamlit 命令,如果你想了解所有命令,可以查看 <a href="https://docs.streamlit.io/library/cheatsheet" target="_blank">Streamlit Cheat Sheet</a>。我们已经了解了文本、数据框、可视化、指标、输入和小部件、布局以及实用命令。</p>
<p>如果你喜欢我的工作,请在社交媒体上分享,或者如果你对 Streamlit 有任何问题,可以通过 <a href="https://www.linkedin.com/in/1abidaliawan/" target="_blank">LinkedIn</a> 联系我。</p>
<p><strong><a href="https://www.polywork.com/kingabzpro" target="_blank">Abid Ali Awan</a></strong> (<a href="https://twitter.com/1abidaliawan" target="_blank">@1abidaliawan</a>) 是一名认证的数据科学专家,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理健康问题的学生开发一个 AI 产品。</p>
<h3 id="更多相关内容-22">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/06/14-essential-git-commands-data-scientists.html" target="_blank">数据科学家的 14 个基本 Git 命令</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/07/16-essential-dvc-commands-data-science.html" target="_blank">数据科学的 16 个基本 DVC 命令</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/10/10-essential-sql-commands-data-science.html" target="_blank">数据科学的 10 个基本 SQL 命令</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/06/20-basic-linux-commands-data-science-beginners.html" target="_blank">数据科学初学者的 20 个基本 Linux 命令</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n26.html" target="_blank">KDnuggets 新闻,6 月 29 日:20 个基本的 Linux 命令用于数据科学……</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/01/12-docker-commands-every-data-scientist-know.html" target="_blank">每位数据科学家都应该知道的 12 个 Docker 命令</a></p>
</li>
</ul>
<h1 id="12-个数据科学必备的-vscode-扩展">12 个数据科学必备的 VSCode 扩展</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2022/07/12-essential-vscode-extensions-data-science.html" target="_blank"><code>www.kdnuggets.com/2022/07/12-essential-vscode-extensions-data-science.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/17e50825f5c5f246cac15911b1dc94da.png" alt="12 Essential VSCode Extensions for Data Science" loading="lazy"></p>
<p>图片作者</p>
<p><a href="https://code.visualstudio.com/" target="_blank">Visual Studio Code</a> (VSCode) 是一个免费的集成开发环境(IDE)。它在开发人员和数据从业者中很受欢迎。VSCode 提供丰富的功能、扩展(插件)、<strong>内置</strong> <strong>Git</strong>、运行和调试代码的能力以及对工作区的完全自定义。你可以在不离开应用程序的情况下构建、测试、部署和监控你的数据科学应用程序。</p>
<p>我尝试过多个 IDE,坦白说,我发现 VSCode 最好,因为它提供了一个轻量级、强大且可定制的工作环境。这个 IDE 最大的优点是拥有大量适用于各种 IT 专业人士的扩展。</p>
<p>在这篇博客中,我们将学习对我的工作区至关重要的扩展。</p>
<p><strong>列表的快速回顾:</strong></p>
<ol>
<li>
<p>GitHub Copilot</p>
</li>
<li>
<p>Python</p>
</li>
<li>
<p>Pylance</p>
</li>
<li>
<p>Python Indent</p>
</li>
<li>
<p>Indent-rainbow</p>
</li>
<li>
<p>Jupyter</p>
</li>
<li>
<p>Jupyter Notebook 渲染器</p>
</li>
<li>
<p>R</p>
</li>
<li>
<p>Julia</p>
</li>
<li>
<p>DVC</p>
</li>
<li>
<p>GitLens</p>
</li>
<li>
<p>Todo MD</p>
</li>
</ol>
<h1 id="1-github-copilot">1. GitHub Copilot</h1>
<p><a href="https://marketplace.visualstudio.com/items?itemName=GitHub.copilot" target="_blank">GitHub Copilot</a> 是你的 AI 助手。它会建议一行或整个函数。GitHub Copilot 使用 OpenAI Codex 提供实时建议。这个扩展的最佳部分是它会根据用户的行为进行学习。每当我需要编写类似的 Python 脚本时,它会建议 <strong>注释</strong>、<strong>函数</strong> 和 <strong>文档字符串</strong>。我只需按下“Tab”键即可。</p>
<p>今天就 <a href="https://copilot.github.com/" target="_blank">注册</a> 以获得技术预览。</p>
<h1 id="2-python">2. Python</h1>
<p><a href="https://marketplace.visualstudio.com/items?itemName=ms-python.python" target="_blank">Python</a> 扩展提供了语言支持,如代码检查、调试、代码导航、代码格式化、重构、变量查看器和测试查看器。它会自动安装 Pylance 和 Jupyter 扩展,以为你提供最佳的 Python 文件和 <strong>Jupyter Notebook</strong> 文件体验。</p>
<h1 id="3-pylance">3. Pylance</h1>
<p><a href="https://marketplace.visualstudio.com/items?itemName=ms-python.vscode-pylance" target="_blank">Pylance</a> 与 Python 扩展提供了超级增强的语言支持。它会提供参数建议、代码补全、自动导入、类型检查和语义高亮。它被高度推荐,因为它将我的 Python 开发体验提高了 <strong>2X</strong>。Pylance 远不止是 Python 的自动补全功能。</p>
<h1 id="4-python-indent">4. Python Indent</h1>
<p><a href="https://marketplace.visualstudio.com/items?itemName=KevinRose.vsc-python-indent" target="_blank">Python Indent</a> 是你一直知道你需要的扩展。每当你输入一行代码并按下 <strong>Enter</strong> 时,它将为你提供正确的 Python 缩进。它与括号对、悬挂缩进、关键字和扩展注释一起工作。</p>
<h1 id="5-indent-rainbow">5. Indent-rainbow</h1>
<p><a href="https://marketplace.visualstudio.com/items?itemName=oderwat.indent-rainbow" target="_blank">Indent-rainbow</a> 带来了<strong>HTML</strong>和 Python 编码世界的宁静。我现在可以看到干净且组织良好的缩进。这款扩展帮助我快速调试代码并编写有效的代码。Indent-rainbow 为文本前的缩进上色,每一步交替使用四种颜色。</p>
<h1 id="6-jupyter">6. Jupyter</h1>
<p><a href="https://marketplace.visualstudio.com/items?itemName=ms-toolsai.jupyter" target="_blank">Jupyter</a> 让你可以在 VScode 中编辑、运行和保存 Python Jupyter Notebook。它简单易用,支持所有编程语言,例如<strong>Julia</strong>、<strong>R</strong>、<strong>Scala</strong>和<strong>SQL</strong>。它将 Jupyter 功能与 VSCode 扩展结合起来,提供终极的 Python 开发体验。Jupyter 包含快速的 <code>.ipynb</code> 文件加载、<strong>notebook diff-tool</strong>、Python 和 Pylance 集成,以及代码折叠功能。</p>
<p>我强烈推荐你在 VSCode 中使用 Jupyter Notebook。</p>
<h1 id="7-jupyter-notebook-renderers">7. Jupyter Notebook Renderers</h1>
<p><a href="https://marketplace.visualstudio.com/items?itemName=ms-toolsai.jupyter-renderers" target="_blank">Jupyter Notebook Renderers</a> 与 Jupyter 扩展配合使用,提供交互式数据可视化。对于数据分析师、数据科学家和数据工程师来说,这是一个必备的扩展,能够可视化 Plotly、Vega、Bokeh、GIF、PNG、SVG 和 JPEG 输出。</p>
<h1 id="8-r">8. R</h1>
<p><a href="https://marketplace.visualstudio.com/items?itemName=REditorSupport.r" target="_blank">R</a> 扩展提供丰富的语言支持。如果你是数据分析师或研究人员,你一定对 R 语言及其生态系统有所了解。VSCode 扩展通过提供语法高亮、代码分析、R 终端和对<strong>R Markdown</strong>的支持来增强你的体验。它还允许你查看数据、图表和变量。</p>
<h1 id="9-julia">9. Julia</h1>
<p><a href="https://marketplace.visualstudio.com/items?itemName=julialang.language-julia" target="_blank">Julia</a> 扩展提供类似于 Python 和 R 的语言支持。在我看来,Julia 是机器学习和数据科学的未来。这个扩展带有语法高亮、代码片段、<strong>Julia REPL</strong>、代码补全、linter、悬停帮助和调试功能。类似于 R,它提供了绘图画廊、表格数据的网格查看器,以及测试、构建和基准测试程序的能力。</p>
<h1 id="10-dvc">10. DVC</h1>
<p><a href="https://marketplace.visualstudio.com/items?itemName=Iterative.dvc" target="_blank">DVC</a> 是一个新的扩展,我认为是<strong>MVP</strong>,用于版本控制和跟踪你的机器学习实验。每个数据团队都依赖它来对数据集进行版本控制,以确保可重现性。除了数据,你还可以对元数据、图表、模型进行版本控制,跟踪和存储实验,创建数据和 ML 管道,并像使用 Git 一样共享。该扩展提供了实验跟踪、仪表板、实时跟踪和基于 GUI 的数据管理功能。</p>
<p>DVC 扩展使大文件版本控制变得更简单和容易。</p>
<h1 id="11-gitlens">11. GitLens</h1>
<p><a href="https://marketplace.visualstudio.com/items?itemName=eamodio.gitlens" target="_blank">GitLens</a> 让你的 Git 仓库生动起来。你可以使用交互式用户界面执行所有与 Git 相关的任务,而不是在终端中输入脚本。它包括修订导航、<strong>当前行责任</strong>、<strong>作者</strong>、<strong>文件</strong> <strong>注释</strong>、侧边栏视图、Git 命令面板和可定制的菜单和工具栏。通过提供视觉创作、无缝团队协作和分析项目进展的能力,它提升了你的开发体验。</p>
<h1 id="12-todo-md">12. Todo MD</h1>
<p><a href="https://marketplace.visualstudio.com/items?itemName=usernamehw.todo-md" target="_blank">Todo MD</a> 是最佳任务跟踪扩展。你可以找到多个可能对你的特定开发环境有帮助的待办事项扩展,但 Todo MD 允许你设置优先任务,跟踪日常任务、项目、标签和上下文。通过使用 <strong>Markdown</strong> 语法,你可以创建带有特殊标签的任务列表,例如“逾期”或筛选与你的特定简单标签和特殊标签相关的任务。</p>
<p>我用它来跟踪我的重复任务。例如,运行和自动化用于编辑任务的 Python 脚本。</p>
<h1 id="结论-19">结论</h1>
<p>如果你更关注数据科学解决方案的开发和部署,推荐使用其他扩展,如 <a href="https://marketplace.visualstudio.com/items?itemName=GitHub.vscode-pull-request-github" target="_blank">GitHub Pull Requests and Issues</a>、<a href="https://marketplace.visualstudio.com/items?itemName=ms-azuretools.vscode-docker" target="_blank">Docker</a> 和 <a href="https://marketplace.visualstudio.com/items?itemName=ms-kubernetes-tools.vscode-kubernetes-tools" target="_blank">Kubernetes</a>。我提到的这些扩展对我来说是日常构建、测试和运行 Python 脚本的必要工具。</p>
<p>如果你有更好的数据科学扩展建议,请在评论中提到。我一直在寻求通过用更好的替代方案替换旧扩展来改进我的工作空间。我目前正在寻找使用 <strong>GitHub Actions</strong> 自动化我的工作流程,并且我对建议持开放态度。</p>
<p><strong><a href="https://www.polywork.com/kingabzpro" target="_blank">Abid Ali Awan</a></strong> (<a href="https://twitter.com/1abidaliawan" target="_blank">@1abidaliawan</a>) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为面临心理疾病困扰的学生开发 AI 产品。</p>
<hr>
<h2 id="我们的前三大课程推荐-18">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析水平</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你们组织的 IT 工作</p>
<hr>
<h3 id="更多相关话题-34">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/n27.html" target="_blank">KDnuggets 新闻,7 月 6 日:12 个必备的数据科学 VSCode…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/top-7-alternatives-to-vscode-for-data-science" target="_blank">数据科学领域 VSCode 的 7 大替代方案</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/12-vscode-tips-tricks-python-development.html" target="_blank">12 个针对 Python 开发的 VSCode 技巧和窍门</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/n24.html" target="_blank">KDnuggets 新闻,7 月 5 日:一个糟糕的数据科学项目 • 10 个 AI…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/06/ai-chrome-extensions-data-scientists-cheat-sheet.html" target="_blank">AI Chrome 扩展程序为数据科学家提供的备忘单</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/04/6-chatgpt-mindblowing-extensions-anywhere.html" target="_blank">6 个让人惊叹的 ChatGPT 扩展程序,适用于任何地方</a></p>
</li>
</ul>
<h1 id="12-位启发性的女性数据科学家大数据">12 位启发性的女性数据科学家,大数据</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2016/04/12-inspiring-women-in-data-science-big-data.html" target="_blank"><code>www.kdnuggets.com/2016/04/12-inspiring-women-in-data-science-big-data.html</code></a></p>
</blockquote>
<p>STEM 领域——科学、技术、工程和数学——的女性不足已经有很多文献记录,这些数据可能令人沮丧。例如,1960 年,女性占计算机和数学职业中的员工的 27%。但根据 <a href="http://www.aauw.org/research/solving-the-equation/" target="_blank">2015 年的美国人口普查数据分析</a>,这一比例在 2013 年下降至 26%,而在过去几十年中,女性参与整体劳动力的比例却有所增加。</p>
<p>有许多成功且杰出的女性,成为了有志于数据科学家的灵感来源。以下是一些曾在 Strata + Hadoop 大数据女性午餐会和斯坦福大学数据科学女性会议上发言的女性。</p>
<hr>
<h2 id="我们的前三大课程推荐-19">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织的 IT</p>
<hr>
<p><img src="https://kdn.flygon.net/docs/img/eebd6b12351cd5288a0db244cb18fd0e.png" alt="inspiring-women-in-data-science" loading="lazy"></p>
<ol>
<li>
<p><a href="https://icme.stanford.edu/people/karen-matthys" target="_blank">凯伦·马蒂斯</a>,斯坦福计算与数学工程研究所的外部合作伙伴执行董事。她正在推广下一个活动、奖学金,并致力于 30by30 活动,该活动的目标是到 2030 年,将所有组织中计算机科学和工程职位上的女性比例提高到 30%。</p>
</li>
<li>
<p><a href="https://jilldyche.com/" target="_blank">吉尔·戴奇</a>,SAS Institute 的最佳实践副总裁。她著有几本书,包括最新的一本《新 IT:技术领导者如何在数字时代推动商业战略》。戴奇目前正在从事一个副项目,即一本电子书,倡导对动物收容所实践进行简单改进,以提高宠物领养率。</p>
</li>
<li>
<p><a href="https://www.linkedin.com/in/yanbingli" target="_blank">颜冰</a>,VMware 存储和可用性部门的副总裁兼总经理。虽然她并不完全是大数据专家,颜冰在大数据女性会议上谈到了关注点和职业目标——以及她如何调整在 VMware 追求的角色,以实现成为大公司 CEO 的更大战略目标。她在午餐会上告诉与会者:“我们需要非常意识到,不总是依赖最轻松的路径。”</p>
</li>
<li>
<p><a href="https://twitter.com/jeggers" target="_blank">贾娜·埃格斯</a>,Nara Logics 的首席执行官。她是 Nara Logics 的首席执行官,该公司利用新的神经科学发现来在计算机上建模数据。她曾经营和管理过多家公司,曾担任 Intuit 的创新实验室主任和 QuickBase 的总经理,并且还担任过分析师。</p>
</li>
<li>
<p><a href="https://hrdag.org/people/megan-price-phd/" target="_blank">梅根·普赖斯</a>,Human Rights Data Analysis Group 的执行董事。她的组织利用统计分析揭示证据,以推动行动和改变。该组织在包括危地马拉、哥伦比亚和叙利亚在内的多个项目中开展工作。在叙利亚项目中,普赖斯担任首席统计师,并撰写了两份由联合国人权事务高级专员办事处委托的有关该国记录死亡的最新报告。她是卡内基梅隆大学人权科学中心的研究员,并获得生物统计学博士学位。</p>
</li>
<li>
<p><a href="https://twitter.com/nehanarkhede" target="_blank">内哈·纳尔赫德</a>,Confluent 的联合创始人兼 CTO。纳尔赫德是 Confluent 的共同创始人之一,该公司开发了一种流行的大数据工具,能够实现实时流数据处理——Apache Kafka。纳尔赫德和她的共同创始人最初在 LinkedIn 工作时开发了这项技术。</p>
</li>
<li>
<p><a href="https://twitter.com/ImAmyO" target="_blank">艾米·奥康纳</a>,Cloudera 的大数据传播者。她于 2013 年加入 Hadoop 分发商 Cloudera,此前在诺基亚担任大数据高级总监。在 Cloudera 的角色中,她为客户提供引入和采纳大数据解决方案的建议。她拥有康涅狄格大学的电气工程学士学位和东北大学的 MBA 学位。</p>
</li>
<li>
<p><a href="https://twitter.com/mrogati" target="_blank">莫尼卡·罗加提</a>,Data Collective 的股权合伙人,同时在 Advisor 和 Insight Data Science 担任顾问。莫尼卡曾是穿戴设备公司 Jawbone 的数据副总裁,也曾是 LinkedIn 的数据科学家。如今,她专注于为 Data Collective 风险投资集团提供技术尽职调查和建议,并担任 Insight Data Science Fellow Program 的顾问,该项目是一个旨在弥合学术界与数据科学职业之间差距的博士后培训奖学金项目。</p>
</li>
<li>
<p><a href="https://www.linkedin.com/in/jennifer-chayes-6328145" target="_blank">詹妮弗·图尔·查耶斯</a> 是微软研究院的杰出科学家和常务董事。她在 2015 年 11 月的斯坦福大学首届女性数据科学会议上进行了演讲。查耶斯在 2015 年 11 月斯坦福大学女性大数据活动的职业发展小组讨论中表示:“你不应该让对自己能力的恐惧,或者对自己可能是冒名顶替者的恐惧,影响你所做的决策。你应该把那部分脑袋放在一边,感谢它的存在,然后忽略它。我们每个人都有那部分脑袋,如果我听从了那部分脑袋,我的人生将会非常无聊。” 查耶斯拥有普林斯顿大学数学物理学博士学位。</p>
</li>
<li>
<p><a href="https://www.linkedin.com/in/caitlinsmallwood" target="_blank">凯特琳·斯莫尔伍德</a>,Netflix 科学与算法副总裁。她领导着这家数字娱乐公司的一组高级数学家、数据科学家和统计学家。她的团队专注于预测建模、算法研究与原型设计,以及公司内其他深度分析。她的职业生涯包括在雅虎担任数据解决方案总监,以及在普华永道担任定量咨询高级经理。</p>
</li>
<li>
<p><a href="https://www.linkedin.com/in/carrie-grimes-4b61138" target="_blank">凯瑞·格莱姆斯</a>,谷歌的杰出工程师。格莱姆斯在谷歌度过了她的职业生涯,目前在技术学院小组工作,负责数据驱动的资源规划、成本分析和分布式集群管理软件。格莱姆斯拥有斯坦福大学统计学博士学位和哈佛大学人类学学士学位。</p>
</li>
<li>
<p><a href="https://www.linkedin.com/in/kelly-thompson-9836204" target="_blank">凯莉·汤普森</a>,沃尔玛电子商务全球类别发展和商品解决方案高级副总裁。汤普森负责沃尔玛的战略、结构和运营模式,将商品销售与数据和分析结合起来。沃尔玛是世界上最大的公司之一,人们通常认为大公司反应迟缓,但汤普森表示,她的组织实际上正在这家大公司内部建立更具敏捷性的团队。</p>
</li>
</ol>
<p>基于<a href="http://www.informationweek.com/big-data/big-data-analytics/12-inspiring-women-in-data-science-big-data--/d/d-id/1325032" target="_blank">InformationWeek 幻灯片</a>。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p>在你准备好数据科学之前,停止招聘数据科学家</p>
</li>
<li>
<p>我们需要更多女性进入大数据领域的 4 个理由</p>
</li>
<li>
<p>女性分析书籍作者 – 元列表</p>
</li>
</ul>
<h3 id="相关主题-4">相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/01/story-women-data-science-wids-datathon.html" target="_blank">女性数据科学家(WiDS)数据竞赛的故事</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/women-world-data.html" target="_blank">数据世界中的女性</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/03/8-women-ai-striving-humanize-world.html" target="_blank">8 位致力于人性化世界的女性 AI 专家</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/07/celebrating-women-leadership-roles-tech-industry.html" target="_blank">庆祝科技行业女性领导者</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/how-big-data-is-saving-lives-in-real-time-iov-data-analytics-helps-prevent-accidents" target="_blank">大数据如何实时拯救生命:IoV 数据分析帮助…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/06/big-data-analytics-crucial-business-intelligence.html" target="_blank">大数据分析:为何它对商业智能如此重要?</a></p>
</li>
</ul>
<h1 id="12-个技巧从数据分析师到创业联合创始人">12 个技巧:从数据分析师到创业联合创始人</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2021/12/12-tips-data-analyst-to-co-founder.html" target="_blank"><code>www.kdnuggets.com/2021/12/12-tips-data-analyst-to-co-founder.html</code></a></p>
</blockquote>
<p>评论</p>
<p><strong>作者:<a href="https://twitter.com/rzykov" target="_blank">Roman Zykov</a>,数据科学家和 TopDataLab 创始人</strong>。</p>
<p><img src="https://kdn.flygon.net/docs/img/35070e880b2fd0609156e10fcb1d68ab.png" alt="" loading="lazy"></p>
<hr>
<h2 id="我们的前三大课程推荐-20">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析水平</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织在 IT 领域</p>
<hr>
<p>在我的职业生涯早期,作为数据分析师的我,像许多人一样,梦想做一些对人们有重大价值的事情。我想要有创意。我想要感受到自己工作的成果,而不仅仅是研究数据。我在几家初创公司工作了十年,然后于 2012 年共同创办了一家电子商务推荐服务公司。在 2020 年疫情期间,我休假了一年——写了一本书,在亚马逊上发布,并在 2021 年夏天完全离开了那家成功的公司(正现金流,150 多名员工分布在俄罗斯、欧洲和南美)。现在我正在从零开始开发下一个项目。</p>
<p>我决定分享一些对我当初创业时非常有用的技巧。此帖补充了我书中的第十二章(“挑战与创业”)。<a href="https://topdatalab.com/book" target="_blank">书籍</a> [3]。</p>
<p><strong>为一个客户创建一个产品创意。</strong> 首先,有了创意,然后是产品。如果你有一个创意,最好的测试方法是将其实施在你当前的工作中,为公司带来利益。例如,我的项目在我和我的伙伴们创建公司之前就已经诞生。我在还在职时就作为副业开发了推荐系统。所以我立刻知道该怎么做,特别是在最初阶段。我可以闭着眼睛创建一个最小可行产品(MVP)。</p>
<p><strong>找到廉价地将产品扩展到成千上万客户的方法</strong>(理解工程)。能够以最小的努力扩展产品至关重要。为此,你需要学习将模型投入生产的实践。除了 Python 和 SQL,了解一些编译编程语言(Java, Scala, C#, C++)是个好主意。了解如何使用不同类型的数据库和 Hadoop 也很有帮助。我发现参观 Netflix 办公室非常有帮助,在那里我获得了一些关于开源软件和 Hadoop 的建议。我花了大约六个月的时间来学习和实施 Hadoop。我还在 O'Reilly STRATA 会议的视频中听说了 Spark。我们是最早在生产中实施 Spark 的团队之一。</p>
<p><strong>做少些长期研究,多做些业务</strong>。在初创公司,你必须非常迅速地行动,同时获得保证的结果。假设你在两个机器学习算法之间做选择。第一个算法难以开发,但理论上能提供更好的结果。第二个算法简单,但指标一般——作为第一步,我总是会选择简单的那个。是的,你可以将第一个算法放在假设的待办事项中,但你可能会在几个月后改变它。</p>
<p>我花了两年时间在一个短期推荐算法上 [4]。我们做了很多复杂的事情。最终,最简单的算法版本赢得了所有的 A/B 测试。尝试找到完美的算法对我来说是浪费时间。</p>
<p><strong>理论与实践并不总是相同的。</strong> 我过去十年一直在为电子商务开发推荐算法。关于这个主题的科学文章使用标准指标(Precision, Recall, Novelty, Diversity [2])。看起来,拿一篇科学论文然后去做。这种方法在计算机视觉领域效果很好,但在我的领域却不适用。购买是一个延迟事件。买家可能在几个小时甚至几天后才进行购买。因此,准确性指标 [1] 与访客转化为买家的之间没有直接的关联。</p>
<p>另一个问题是 — 推荐算法会改变用户行为。当你在用户的过去行为日志上进行离线测试时 — 你没有考虑这一点。这一因素也对在 A/B 测试中预测在线表现的误差有所贡献。</p>
<p><strong>正确获取指标是成功的关键。</strong> 看起来,选择一个标准指标来衡量你的机器学习模型,一切都会顺利。然而,事实并非如此。你听说过医疗保健中的分类指标问题吗?例如,你有两种不同的 COVID PCR 测试:</p>
<ul>
<li>
<p>test A yields more false positives</p>
</li>
<li>
<p>test B yield more false negatives</p>
</li>
</ul>
<p>测试 A 将把更多健康的人送入隔离,这将造成经济损害。测试 B 将漏掉更多病人,他们会传播疾病。测试的选择是一个复杂的问题,这将取决于具体情况。在 A/B 测试两个不同算法后,你也会面临同样的选择。例如,我在推荐系统中遇到过这样的情况:算法改进了商业指标,但推荐内容的视觉效果却变差了。这样的“改进”很难向客户推销。</p>
<p><strong>全职专注比在晚上做初创公司更好</strong>。我曾经在晚上和周末编程。我甚至买了第二台笔记本电脑,带到现在的工作中,以便有时也能在那里编程。工作后的晚上我很疲倦,所以写的代码中有很多错误。第二天我不得不修复这些错误。有些错误我甚至是在几年后才发现的。因此,尽量找到全身心投入项目的机会。这将为你节省大量精力和时间。</p>
<p><strong>专业经验的重要性</strong>。有了它,成功更容易而不需要吸引大量投资。但如果缺乏经验,你将不得不花费更多的钱。因此,最好在积极发展的公司中工作以学习更多。我以前的老板曾给过我这样的建议。如果你也曾在潜在客户的另一侧工作过,你将更容易理解他们的需求。大家都知道,客户在产品访谈中不会告诉你所有事情。许多问题甚至对客户自己来说都很难理解。我在电子商务中作为分析师的经验对我帮助很大。我基于在那里获得的知识创建了我的第一个初创公司。</p>
<p><strong>B2B 初创公司比 B2C 初创公司更有可能成功</strong>。B2B 需要的投资较少,员工数量也较少,而且平均交易额要高得多。在 B2B 中,你需要获得的客户数量远少于 B2C 才能实现盈亏平衡。</p>
<p><strong>不要盲目模仿</strong>。复制其他公司,尤其是 FAANG 公司的做法很容易。你的公司和内部文化是独特的。简单地将任何标准如开发、ML 模型部署或产品的模板拼凑在一起是不行的。你更可能根据常识和适合你的情况制定自己的规则。</p>
<p><strong>云计算更适合初创阶段</strong>。现在云计算就像一个乐高构建器——你不必考虑硬件和软件问题,而且扩展相对简单。我在租用的硬件上做了第一个项目,部署了 Hadoop 并设置了所有计算算法。我立即在云中开始了第二个项目,花费的时间少得多。</p>
<p><strong>客户希望增加销售额而不是获得数据分析</strong>。分析产品比起提升客户销售的系统要复杂得多。如果这种效果也容易检查,例如在 Google Analytics 中,那么你的产品将会非常畅销。这就是为什么我没有创建一个分析项目,而是直接去数据能够直接增加销售的地方——例如推荐系统。</p>
<p><strong>自助分析。</strong> 尝试在公司中培养自助分析的文化。没有人喜欢被一连串可以用“计算器”完成的任务轰炸。这些是员工可以通过两三次鼠标点击完成的基本任务。你需要满足三个条件才能摆脱这些任务:</p>
<ul>
<li>
<p>用户友好的互动分析系统(OLAP、Tableau、Metabase)。</p>
</li>
<li>
<p>最低的数据质量水平。</p>
</li>
<li>
<p>经过培训的用户。</p>
</li>
</ul>
<p>在这三个领域投入努力。即使在发展非常迅速的初创环境中,这也会获得很好的回报。</p>
<h3 id="参考资料-1">参考资料</h3>
<p>[1] Marco Rossetti, Fabio Stella, Markus Zanker, <a href="https://medium.com/r/?url=https%3A%2F%2Fwww.youtube.com%2Fwatch%3Fv%3DHEsG5rTaPwE" target="_blank">RecSys 2016:论文会话 1——对比离线和在线推荐评估结果</a> (2016).</p>
<p>[2] Paolo Cremonesi, Yehuda Koren, Roberto Turrin, <a href="https://www.researchgate.net/publication/221141030_Performance_of_recommender_algorithms_on_top-N_recommendation_tasks" target="_blank">推荐算法在 Top-N 推荐任务中的表现</a> (2010).</p>
<p>[3] Roman Zykov, <a href="https://topdatalab.com/book" target="_blank">Roman 的数据科学:如何将数据货币化</a> (2021).</p>
<p>[4] Maxim Borisyak, Roman Zykov, Artem Noskov, <a href="https://arxiv.org/abs/1507.07382" target="_blank">Kullback-Leibler 散度在短期用户兴趣检测中的应用</a> (2015).</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2019/08/elevator-pitch-data-science-startup.html" target="_blank">为你的数据科学初创公司打造电梯演讲</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/05/vc-pitch-deck-open-source-elt-platform.html" target="_blank">如何向风险投资公司推介:我们用来筹集资金的演示文稿</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2020/05/six-ways-data-scientists-succeed-startup.html" target="_blank">数据科学家在初创公司成功的六种方法</a></p>
</li>
</ul>
<h3 id="相关话题-3">相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2023/04/10-hurdles-building-deep-tech-startup-age-chatgpt.html" target="_blank">在 ChatGPT 时代构建深科技初创公司的 10 个难题</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/navigating-data-science-job-titles-data-analyst-vs-data-scientist-vs-data-engineer" target="_blank">数据科学职位名称导航:数据分析师 vs 数据科学家…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/01/data-scientist-data-analyst-data-engineer.html" target="_blank">数据科学家 vs 数据分析师 vs 数据工程师</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/data-analyst-data-strategist-career-path-making-impact.html" target="_blank">从数据分析师到数据战略师:影响力职业路径</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/08/datacamp-preparing-data-analyst-interview.html" target="_blank">准备数据分析师面试</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/10/datacamp-data-driven-faster-analyst-takeover.html" target="_blank">通过 DataCamp 的分析师接管更快地实现数据驱动</a></p>
</li>
</ul>
<h1 id="12-个-vscode-的-python-开发技巧和窍门">12 个 VSCode 的 Python 开发技巧和窍门</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2023/05/12-vscode-tips-tricks-python-development.html" target="_blank"><code>www.kdnuggets.com/2023/05/12-vscode-tips-tricks-python-development.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/d56491937200bf93c18bde6c0c7a9966.png" alt="12 个 VSCode 的 Python 开发技巧和窍门" loading="lazy"></p>
<p>图片由作者提供</p>
<p><a href="https://code.visualstudio.com/" target="_blank">Visual Studio Code</a> (VSCode) 是一个流行的 Python 开发集成开发环境 (IDE)。它快速且拥有丰富的功能,使开发体验变得有趣且轻松。</p>
<hr>
<h2 id="我们的前三大课程推荐-21">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织 IT</p>
<hr>
<p>VSCode 的 Python 扩展是我将其用于所有工作相关任务的主要原因之一。它为你提供了语法自动补全、代码检查、单元测试、Git、调试、笔记本、编辑工具,并能够自动化大多数任务。你可以通过按键盘快捷键或点击几个按钮来代替手动操作。</p>
<p>在这篇文章中,我们将学习如何将 VSCode 提升到一个新水平,并提高在构建 Python 软件和解决方案方面的生产力。</p>
<blockquote>
<p><strong>注意:</strong> 如果你是 VSCode 的新手,并且想学习所有基础知识,请阅读 <a href="https://www.datacamp.com/tutorial/setting-up-vscode-python" target="_blank">设置 VSCode 以进行 Python 开发</a> 教程,以了解关键功能。</p>
</blockquote>
<h1 id="1-命令行">1. 命令行</h1>
<p>你可以通过 <strong>终端</strong> 或 <strong>Bash</strong> 使用 CLI 命令启动 VSCode。</p>
<ol>
<li>
<p>在当前目录中打开 VSCode: <code>code .</code></p>
</li>
<li>
<p>在最近使用的窗口中,在当前目录中打开 VSCode: <code>code -r .</code></p>
</li>
<li>
<p>创建一个新窗口: <code>code -n</code></p>
</li>
<li>
<p>打开文件差异编辑器 VSCode: <code>code --diff <file1> <file2></code></p>
</li>
</ol>
<h1 id="2-命令面板">2. 命令面板</h1>
<p>根据当前上下文访问所有可用的命令和快捷键。你可以通过使用键盘快捷键来启动命令面板:<strong>Ctrl+Shift+P</strong>。之后,你可以输入相关的关键词以访问特定命令。</p>
<p><img src="https://kdn.flygon.net/docs/img/6691a56d9145e6d6205ccdd4c1e1e215.png" alt="12 个 VSCode 的 Python 开发技巧和窍门" loading="lazy"></p>
<p>图片由作者提供</p>
<h1 id="3-键盘快捷键">3. 键盘快捷键</h1>
<p>什么比命令面板更好呢?键盘快捷键。你可以根据需要修改键盘快捷键,或者通过阅读 <a href="https://code.visualstudio.com/shortcuts/keyboard-shortcuts-windows.pdf" target="_blank">键盘快捷键</a> 参考表来了解默认的键盘快捷键。</p>
<p>键盘快捷键将帮助我们直接访问命令,而不是滚动浏览命令面板选项。</p>
<h1 id="4-错误和警告">4. 错误和警告</h1>
<p>通过使用键盘快捷键<strong>Ctrl+Shift+M</strong>快速访问错误和警告,并通过点击警告或按<strong>F8</strong>或<strong>Shift+F8</strong>键在它们之间循环。</p>
<p><img src="https://kdn.flygon.net/docs/img/df565eb6396d6d31e05fe0b77709f091.png" alt="12 VSCode 技巧与窍门" loading="lazy"></p>
<p>图片由作者提供</p>
<h1 id="5-完全可定制的开发环境">5. 完全可定制的开发环境</h1>
<p>你可以自定义主题、图标、键盘快捷键、调试设置、字体、代码检查和代码片段。VSCode 是一个完全可定制的开发环境,允许你甚至创建自己的扩展。</p>
<h1 id="6-扩展">6. 扩展</h1>
<p>Python 的 VSCode 扩展可以提升开发体验,并使你更高效。这不仅仅关乎生产力,还关乎视觉效果。大多数流行的 Python 扩展在<a href="https://marketplace.visualstudio.com/vscode" target="_blank">Visual Studio Marketplace</a>上提供带有统计数据和图表的互动 GUI。</p>
<p><img src="https://kdn.flygon.net/docs/img/9e46e9562e4c069d8614ba670a58be0f.png" alt="12 VSCode 技巧与窍门" loading="lazy"></p>
<p>图片由作者提供</p>
<p>查看我列出的 12 个数据科学必备 VSCode 扩展,这些扩展会使 VSCode 成为一个超级应用,你可以在不离开应用的情况下执行所有数据科学任务。</p>
<h1 id="7-jupyter-notebook">7. Jupyter Notebook</h1>
<p>让你进行数据分析和机器学习实验的最重要的扩展是<a href="https://marketplace.visualstudio.com/items?itemName=ms-toolsai.jupyter" target="_blank">Jupyter Notebook</a>扩展。</p>
<p><img src="https://kdn.flygon.net/docs/img/08a72d7072aa5adc56e54164aadf3797.png" alt="12 VSCode 技巧与窍门" loading="lazy"></p>
<p>图片由作者提供</p>
<p>这个扩展被高度推荐给数据科学家,用于执行数据科学实验和构建生产级代码。</p>
<h1 id="8-多光标选择">8. 多光标选择</h1>
<p>多光标选择在你需要对同一实例进行多个编辑时是一个救命工具。</p>
<ul>
<li>
<p>使用<strong>Alt+Click</strong>添加多个光标点</p>
</li>
<li>
<p>要将光标设置在上方,请使用<strong>Ctrl+Alt+Up</strong>,设置在下方请使用<strong>Ctrl+Alt+Down</strong></p>
</li>
<li>
<p>使用<strong>Ctrl+Shift+L</strong>将额外的光标添加到当前选择的所有出现位置</p>
</li>
</ul>
<p><img src="https://kdn.flygon.net/docs/img/bd7771da69ea36c2c2de21e1ce3298fe.png" alt="12 VSCode 技巧与窍门" loading="lazy"></p>
<p>图片来自<a href="https://code.visualstudio.com/docs/getstarted/tips-and-tricks#_editing-hacks" target="_blank">Visual Studio Code</a></p>
<h1 id="9-搜索和修改">9. 搜索和修改</h1>
<p>我知道这是一个简单的功能,但当你在文件中的不同位置编辑类似的变量、参数和参数时,它非常方便。你可以逐一搜索和替换它们,也可以一次性替换所有。</p>
<p>要重命名符号或参数,请选择该符号并按下<strong>F2</strong>键。</p>
<p><img src="https://kdn.flygon.net/docs/img/e2ca942c060646b77dbc6cc6f7a194d7.png" alt="12 VSCode 技巧与窍门" loading="lazy"></p>
<p>图片由作者提供</p>
<h1 id="10-内置-git-集成">10. 内置 Git 集成</h1>
<p>这是一种内置集成,允许你通过点击几个按钮来执行所有与 Git 相关的任务,而不是在 CLI 中输入 Git 命令。你可以通过与用户友好的 GUI 互动来可视化历史记录、查看差异并创建新分支。这甚至比 GitHub Desktop 应用程序还要简单。</p>
<p><img src="https://kdn.flygon.net/docs/img/d5baf03cb92e6ea30262df84fa0d0b88.png" alt="12 个 Python 开发的 VSCode 提示与技巧" loading="lazy"></p>
<p>图片由作者提供</p>
<h1 id="11-代码片段">11. 代码片段</h1>
<p>代码片段就像自动补全,但你可以对其进行更多控制。你可以为重复的代码模式创建自定义代码片段。你可以输入一个单词,它将自动填充其余部分,而不是创建一个 Python 函数。</p>
<p>要创建自定义代码片段,请选择 <strong>文件</strong> > <strong>首选项</strong> > <strong>配置用户代码片段</strong>,然后选择语言。</p>
<p><img src="https://kdn.flygon.net/docs/img/4aa463f8d0cbd5c05123b729ce6d611b.png" alt="12 个 Python 开发的 VSCode 提示与技巧" loading="lazy"></p>
<p>图片由作者提供</p>
<h1 id="12-github-copilot">12. GitHub Copilot</h1>
<p>每个人都在谈论 ChatGPT 的代码建议,但 <a href="https://github.com/features/copilot" target="_blank">GitHub Copilot</a> 已经存在了两年多,它在理解用户行为和帮助他们快速高效地编写代码方面越来越出色。GitHub Copilot 基于 GPT-3,通过建议代码行或整个函数来提升开发体验。</p>
<p><img src="https://kdn.flygon.net/docs/img/194ddde6045ff3760d349ac8b8c67652.png" alt="12 个 Python 开发的 VSCode 提示与技巧" loading="lazy"></p>
<p>图片来自 <a href="https://github.com/features/copilot" target="_blank">GitHub Copilot</a></p>
<p><strong><a href="https://www.polywork.com/kingabzpro" target="_blank">Abid Ali Awan</a></strong> (<a href="https://twitter.com/1abidaliawan" target="_blank">@1abidaliawan</a>) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些在心理健康方面挣扎的学生。</p>
<h3 id="更多相关内容-23">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/n27.html" target="_blank">KDnuggets 新闻,7 月 6 日:12 个必备的数据科学 VSCode…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/07/12-essential-vscode-extensions-data-science.html" target="_blank">12 个必备的 VSCode 扩展插件</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/top-7-alternatives-to-vscode-for-data-science" target="_blank">数据科学领域 VSCode 的 7 个最佳替代品</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/06/10-jupyter-notebook-tips-tricks-data-scientists.html" target="_blank">10 个 Jupyter Notebook 的提示和技巧</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/05/sas-quick-data-science-tips-tricks-learn.html" target="_blank">快速学习 SAS 的数据科学提示和技巧</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/tips-tricks-deploying-dl-webapps-heroku.html" target="_blank">在 Heroku 云上部署深度学习 Web 应用的技巧和窍门</a></p>
</li>
</ul>
<h1 id="什么是-etl">什么是 ETL?</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2021/04/whats-etl.html" target="_blank"><code>www.kdnuggets.com/2021/04/whats-etl.html</code></a></p>
</blockquote>
<p>评论</p>
<p><strong>由 <a href="https://www.linkedin.com/in/omahmood/" target="_blank">Omer Mahmood</a>,Google 云客户工程、CPG 和旅游部门负责人</strong></p>
<p>在我上一篇文章中,<a href="https://towardsdatascience.com/whats-mlops-5bf60dd693dd" target="_blank">我讨论了将机器学习(ML)模型投入生产的意义</a>,并介绍了 MLOps 的概念。这次我们将探讨数据科学步骤的另一端,即 <a href="https://cloud.google.com/solutions/machine-learning/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning#data_science_steps_for_ml" target="_blank">数据提取和集成</a>。</p>
<hr>
<h2 id="我们的前三大课程推荐-22">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">Google 网络安全证书</a> - 快速进入网络安全职业生涯</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">Google 数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">Google IT 支持专业证书</a> - 支持你的组织的 IT</p>
<hr>
<h3 id="tldr">TL;DR</h3>
<p>ETL 代表 <em>提取-转换-加载</em>,它通常涉及从一个或多个来源移动数据,进行一些更改,然后将其加载到新的单一目标中。</p>
<ul>
<li>
<p>在大多数公司中,<strong>数据往往是孤立的</strong>,以各种格式存储,通常是不准确或不一致的</p>
</li>
<li>
<p>如果我们希望能够轻松分析并从数据中获得洞察,或者 <strong>使用它</strong> <strong>进行数据科学</strong>,这种情况远非理想。</p>
</li>
</ul>
<h3 id="-我们如何走到这里">???????? 我们如何走到这里</h3>
<p>大多数 ML 算法需要大量的训练数据,以生成能够做出准确预测的模型。它们还需要良好的训练数据,代表我们试图解决的问题。</p>
<p>为了强化这一点,我遇到一个很好的例子,类似于 ‘<a href="https://en.wikipedia.org/wiki/Maslow%27s_hierarchy_of_needs" target="_blank">马斯洛需求层次</a>’,突显了数据收集和存储在数据科学中的重要性:</p>
<p><img src="https://kdn.flygon.net/docs/img/122661a46d4ddd1a9208b838242c391b.png" alt="数据科学需求层次" loading="lazy"></p>
<p><em>图 1: 数据科学需求层次金字塔,来源:“AI 需求层次” MONICA ROGATI[1]</em></p>
<p>金字塔底部是收集正确的数据的基本需求,包括正确的格式、系统和数量。</p>
<blockquote>
<p><strong>任何 AI 和 ML 的应用效果都将取决于所收集数据的质量。</strong></p>
</blockquote>
<p>所以,假设你已经 <a href="https://developers.google.com/machine-learning/problem-framing" target="_blank">框定了问题并确定它适合 ML</a>。你知道你需要什么数据,至少在开始实验时需要的数据。但不幸的是,它们分散在不同的系统中,遍布整个组织。</p>
<p>下一步是弄清楚如何将数据汇总、按需转换,然后将其作为单一的集成数据集放置到某个地方。只有当数据可访问时,你才能开始探索数据、进行特征工程和模型训练——这就是我们友好的缩写 ETL 的用武之地!</p>
<h3 id="-这怎么运作">???? 这怎么运作?</h3>
<p>为了让它更具体一些,我们用一个现代的实际 ETL 示例。</p>
<p>想象你是一个使用销售力量(SalesForce)这样的客户关系管理(CRM)系统来跟踪注册客户的在线零售商。</p>
<p>你还使用了像 Stripe 这样的支付处理器来处理并存储通过你的网站完成的销售交易的详细信息。</p>
<p>假设你的目标是通过使用客户历史购买数据来提高转化率,从而在客户浏览你的网站时提供更好的产品推荐。</p>
<p>你当然可以使用机器学习模型来驱动推荐引擎实现这个目标。但问题是,你需要的数据存在于两个不同的系统中。我们案例中的解决方案是使用 ETL 过程来提取、转换并将它们合并到数据仓库中:</p>
<p><img src="https://kdn.flygon.net/docs/img/f5f3cdce7d52dd69603d6bf8334d1f00.png" alt="说明 ETL 过程的图示" loading="lazy"></p>
<p><em>图 2:使用 ETL 将数据从不同来源移动到数据仓库的过程。图示作者提供。</em></p>
<p>让我们分析一下上面的图示:</p>
<p><strong>1. 提取</strong> — 这个过程涉及从我们的两个来源(SalesForce 和 Stripe)中检索数据。一旦数据被检索,ETL 工具将把它加载到一个准备进行下一步的暂存区。</p>
<p><strong>2. 转换</strong> — 这是一个关键步骤,因为它处理数据如何被集成的具体细节。任何数据的清理、重新格式化、去重和混合都在这里进行,然后才能继续向下处理。</p>
<p>在我们的例子中,假设在一个系统中,客户记录以“凯文·里夫斯”存储,而在另一个系统中,这个客户记录以“基努·里维斯”存储。</p>
<p>假设我们知道这是同一个客户(基于他们的送货地址),但系统仍需对这两个记录进行对账,以避免重复记录的出现。</p>
<p>➡️ ETL 框架和工具为我们提供了自动化这种转化所需的逻辑,并且可以应对许多其他场景。</p>
<p><strong>3. 加载</strong> — 涉及将传入的数据成功插入到目标数据库、数据存储,或者在我们的例子中是数据仓库中。</p>
<p><strong>所以,我们已经收集了数据,通过 ETL 管道整合了它,并将其加载到一个可供数据科学使用的地方。</strong></p>
<p>???? **<em>附注</em> **????</p>
<p><strong>ETL 与 ELT</strong></p>
<p>你可能还遇到过“ELT”这个术语。提取、加载和转换(ELT)与 ETL 的区别仅在于转换发生的位置。在 ELT 过程中,数据转换发生在目标数据存储中。</p>
<p>这可以通过去除有时作为独立或中间阶段系统的数据转换来简化架构。另一个优势是,你可以从通常存在于云数据仓库等目的地的额外规模和计算性能中受益。</p>
<p>???? <em><strong>附注</strong></em>????</p>
<h3 id="-常见挑战">???? 常见挑战</h3>
<p>好的,这些 ETL 的内容听起来很简单,对吧?这里有一些需要注意的‘陷阱’:</p>
<h3 id="️-扩展">☄️ 扩展</h3>
<p>根据 IDC 的报告,到 2025 年企业产生的数据量预计将增长至 175 泽字节[2]。因此,你应该确保选择的 ETL 工具能够满足当前及未来的需求。你现在可能以批量方式移动数据,但这会一直是这样吗?你可以并行运行多少作业?</p>
<p><strong>迁移到云端是未来保障 ETL 过程的一个相当安全的选择</strong>——通过访问理论上无限的存储和计算能力,同时减少 IT 资本支出。</p>
<h3 id="-数据准确性">???? 数据准确性</h3>
<p>另一个大的 ETL 挑战是确保你转换的数据是准确和完整的。手动编码和更改或未计划和测试 ETL 作业可能会引入错误,包括加载重复数据、丢失数据和其他问题。</p>
<p>ETL 工具确实会减少手动编码的需要,并帮助减少错误。数据准确性测试可以帮助发现不一致和重复,监控功能可以帮助识别处理不兼容数据类型和其他数据管理问题的情况。</p>
<h3 id="-数据源的多样性">???? 数据源的多样性</h3>
<p>数据的体量在增长。但更重要的是,数据的复杂性也在增加。一家企业可能需要处理来自数百甚至数千个数据源的多样化数据。这些数据源可以包括结构化和半结构化源、实时源、平面文件、CSV、对象桶、流数据源以及未来可能出现的新数据源。</p>
<p>一些数据最好批量转换,而对于其他数据,流式、持续的数据转换效果更佳。</p>
<p>制定应对不同数据源的策略是关键。一些现代 ETL 工具可以在一个地方支持多种数据源,包括批处理和流处理。</p>
<h3 id="️-那么我该如何开始">????????♀️ 那么我该如何开始?</h3>
<p>到这一步,你应该对为什么以及何时需要在数据科学工作流中使用 ETL 有一个清晰的了解。我们还涵盖了在开始考虑 ETL 过程时需要注意的常见挑战。</p>
<p>我将结束于一个简单的 ETL 工具选择方法,以及一些其他有用的资源。</p>
<h3 id="️-我应该使用哪个-etl-工具何时使用">????????♀️ 我应该使用哪个 ETL 工具,何时使用?</h3>
<p>所以我们理解 ETL 过程中的情况,但在更实际的层面上这意味着什么?</p>
<p><strong>你需要设计一个明确描述的 ETL 管道:</strong></p>
<ul>
<li>
<p>从哪些数据源中提取数据以及如何连接到这些数据源</p>
</li>
<li>
<p>在获取数据后需要进行哪些转换,最后</p>
</li>
<li>
<p>管道完成后数据的加载位置</p>
</li>
</ul>
<p>ETL 管道可以通过基于代码的框架来表达,或者现在更流行的选择是使用提供“拖放”用户界面的 ETL 工具,以视觉方式定义管道中的步骤。</p>
<p>一旦你实现了 ETL 管道,它通常需要在某个地方运行,即使用一个 ETL 工具来执行你的管道,并且一个提供临时存储和转换数据所需资源的环境。</p>
<p>我尝试在下面的图表中简化决策步骤(点击放大):</p>
<p><img src="https://kdn.flygon.net/docs/img/406a4f7f5ff78624116a03ded80efbe0.png" alt="决定使用哪个 ETL 工具和何时使用的决策树" loading="lazy"></p>
<p><em>图 3: 选择哪个 ETL 工具以及何时使用。作者插图。</em></p>
<p><strong>注意: 这张决策树绝不是详尽无遗的列表; 你需要做出的决策、框架或可用产品。</strong></p>
<p>确实,对于每一个中间 ETL 步骤,都有数十种开源和专有的解决方案。从编排到调度——我们无法在这里涵盖所有内容。</p>
<p>这篇文章的目的是作为进入 ETL 世界的跳板!祝你在数据集成的旅程中好运!????</p>
<h3 id="-有用的资源和进一步阅读">???? 有用的资源和进一步阅读</h3>
<p><strong>链接</strong></p>
<ul>
<li>
<p><a href="https://developers.google.com/machine-learning/data-prep" target="_blank">机器学习的数据准备和特征工程</a></p>
</li>
<li>
<p><a href="https://www.gartner.com/reviews/market/data-integration-tools" target="_blank">Gartner — 数据集成工具评论与评级</a></p>
</li>
</ul>
<p><strong><strong>书籍</strong></strong></p>
<ul>
<li>
<p><a href="https://amzn.to/3qNtT85" target="_blank">数据仓库 ETL 工具包</a>: 提取、清理、整理和交付数据的实用技术, Wiley, 作者: Ralph Kimball, Joe Caserta</p>
</li>
<li>
<p><a href="https://amzn.to/3qNHrQT" target="_blank">流处理系统</a>: 大规模数据处理的什么、哪里、何时和如何, O’Reilly, 作者: Tyler Akidau, Slava Chernyak, Reuven Lax</p>
</li>
</ul>
<p><strong><strong>数据无关的 ETL 工具</strong></strong></p>
<ul>
<li>
<p><a href="https://fivetran.com/" target="_blank">Fivetran</a></p>
</li>
<li>
<p><a href="https://www.stitchdata.com/" target="_blank">Stitch</a></p>
</li>
</ul>
<h3 id="-参考文献"><strong>???? 参考文献</strong></h3>
<p>[1] 人工智能需求层次结构, Monica Rogati</p>
<p><a href="https://hackernoon.com/the-ai-hierarchy-of-needs-18f111fcc007" target="_blank"><code>hackernoon.com/the-ai-hierarchy-of-needs-18f111fcc007</code></a></p>
<p>[2] 175 Zettabytes By 2025, Forbes, Tom Coughlin</p>
<p><a href="https://www.forbes.com/sites/tomcoughlin/2018/11/27/175-zettabytes-by-2025/?sh=6a5d2e7a5459" target="_blank"><code>www.forbes.com/sites/tomcoughlin/2018/11/27/175-zettabytes-by-2025/?sh=6a5d2e7a5459</code></a></p>
<p><strong>简介: <a href="https://www.linkedin.com/in/omahmood/" target="_blank">Omer Mahmood</a></strong> 是 Google 的云客户工程、消费品和旅游部门负责人。</p>
<p><a href="https://towardsdatascience.com/whats-etl-b4903a57f8ce" target="_blank">原文</a>. 经许可转载。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p>介绍 dbt,ETL 和 ELT 的颠覆者</p>
</li>
<li>
<p>数据工程师的角色正在变化</p>
</li>
<li>
<p>为什么 ETL 的未来不是 ELT,而是 EL(T)</p>
</li>
</ul>
<h3 id="更多相关话题-35">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/mozart-best-etl-tools-2021.html" target="_blank">2021 年最佳 ETL 工具</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/stop-learning-data-science-find-purpose.html" target="_blank">停止学习数据科学以寻找目标,并以寻找目标来……</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/9b-ai-failure-examined.html" target="_blank">一个 90 亿美元的人工智能失败案例,深入分析</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/springboard-top-resources-learn-data-science-statistics.html" target="_blank">数据科学学习统计的最佳资源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/5-characteristics-successful-data-scientist.html" target="_blank">成功数据科学家的 5 个特征</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/makes-python-ideal-programming-language-startups.html" target="_blank">是什么让 Python 成为初创公司理想的编程语言</a></p>
</li>
</ul>
<h1 id="数据科学领域最具影响力的-123-人">数据科学领域最具影响力的 123 人</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2015/09/123-influential-people-data-science.html" target="_blank"><code>www.kdnuggets.com/2015/09/123-influential-people-data-science.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/3d9c022da2d331bb56691a9617b91b90.png" alt="c" loading="lazy"> 评论</p>
<p><strong>作者:Alex Salkever</strong>,(Silk.co)。</p>
<p>数据科学显然是一个热门领域。就像大多数极客的迷因一样,社交媒体的热点集中在 Twitter 上。很多公司都在这一领域推出了新产品。但是,谁是真正的影响者?他们在 Twitter 上的行为如何?我们转向了<a href="https://twitter.com/marshallk" target="_blank">Marshall Kirkpatrick</a>的影响者映射和营销工具<a href="http://www.getlittlebird.com/" target="_blank">Little Bird</a>来生成一个列表并进行一些分析。它作为一种获取网络中不显而易见的影响者见解的方式,正在获得<a href="http://www.walkersands.com/Blog/little-bird-influencer-engagement-tool-review/" target="_blank">热评</a>。</p>
<hr>
<h2 id="我们的前三大课程推荐-23">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速入门网络安全职业。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升您的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持您的组织的 IT 需求</p>
<hr>
<p>与简单的关注者数量不同,Little Bird 通过测量影响者转发其他影响者的频率和网络活动的密度来构建真实的影响者网络图。这些数据会转化为他们所谓的“影响者评分”。这不是一个完美的方法,但它相对可靠,能够为赋予上下文相关性和真正的影响者地位提供一种方法,而不仅仅是计算推文数量。</p>
<p>要设置 Little Bird 以运行您主题的影响者图,您需要提供一 handful 个您知道在您关注的领域中是影响者的账户。我们输入了六个我们知道的严重影响者的 Twitter 账号(包括 Hilary Mason、KDnuggets 和 DataScienceCentral),然后让 Little Bird 进行网络分析和指标计算。Little Bird 从全球返回了 123 个影响者。</p>
<p>这是一个很棒的列表,有很多有趣的分析空间。通过从 Little Bird 导出的电子表格,我将<a href="http://most-influential-data-science-accounts-on.silk.co/?utm_type=GuestBlog&utm_campaign=KDN&utm_source=LittleBird" target="_blank">数据上传到 Silk.co 的在线数据和网站发布平台</a>。以下是我们的发现。</p>
<p><strong>数据科学领域前 10 名内部人士:Hilary、KDnuggets 和 Kaggle 领跑</strong></p>
<p><img src="https://kdn.flygon.net/docs/img/bc9cf00c57db3fd478282b912cc49c84.png" alt="littlebird-data-science-influencers" loading="lazy"></p>
<p>在前 10 名数据科学影响者中,只有两人获得了 50 或以上的 Insider Score。影响者类型相对分散,包括从业者、公司账户、媒体来源、风险投资公司,甚至还有一个数据科学专注的非政府组织。</p>
<p>数据来源于 most-influential-data-science-accounts-on.silk.co</p>
<p><img src="https://kdn.flygon.net/docs/img/effdf521aa05ecb853daf1e7d6f95415.png" alt="littlebird-data-science-score-top10" loading="lazy"></p>
<p><strong>截至 2015 年 9 月 15 日的前 10 名数据科学影响者按得分排序。</strong></p>
<p>北美账户主导了最具影响力的影响者</p>
<p>我们查看了 Little Bird 分配了 10 分或更高的 Insider Score 的 Twitter 账户。其中 84%位于北美。欧洲和欧盟地区国家占 12%。结论?数据科学的影响力主要集中在北美。</p>
<p>数据来源于 most-influential-data-science-accounts-on.silk.co</p>
<p><strong>Insider 影响力的长尾</strong></p>
<p>当映射在影响者的 Insider Scores 分布时,显示出经典的“长尾”特征,即少量高度影响力的账户,一小部分中等影响力的账户,然后是大量影响力显著较低的账户。实际上,大部分账户的“Insider Score”实际上为 0。</p>
<p>数据来源于 most-influential-data-science-accounts-on.silk.co</p>
<p>你可以在 <a href="http://most-influential-data-science-accounts-on.silk.co/?utm_type=GuestBlog&utm_campaign=KDN&utm_source=LittleBird" target="_blank">Silk “最具影响力的数据科学账户</a>” 上探索和发现更多的相关性。请随意试用。你也可以始终以表格格式查看所有数据。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p>10 位你需要了解的预测分析影响者</p>
</li>
<li>
<p>数据科学学位——分析与可视化</p>
</li>
<li>
<p>前大数据影响者和品牌</p>
</li>
<li>
<p>2014 年最具影响力的大数据影响者,依据 HadoopSphere</p>
</li>
</ul>
<h3 id="更多相关主题-21">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/time-100-ai-the-most-influential" target="_blank">时代 100 AI:最具影响力?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/people-fail-learn-programming.html" target="_blank">为什么大多数人无法学会编程?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/people-management-ai-building-highvelocity-ai-teams.html" target="_blank">AI 的人才管理:建立高效能的 AI 团队</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/09/efforts-people-analytics-worth-outcome.html" target="_blank">人力分析的努力是否值得结果?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/07/12-challenging-data-science-interview-questions.html" target="_blank">12 个最具挑战性的数据科学面试问题</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/07/mostly-data-access-severely-lacking-synthetic-data-help.html" target="_blank">数据访问在大多数公司中严重不足,71%的人认为……</a></p>
</li>
</ul>
<h1 id="mlops-概述">MLOps 概述</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2021/03/overview-mlops.html" target="_blank"><code>www.kdnuggets.com/2021/03/overview-mlops.html</code></a></p>
</blockquote>
<p>评论</p>
<p><strong>由<a href="https://www.aiperspectives.com/" target="_blank">Steve Shwartz</a>,AI 作者、投资者和连续创业者</strong>。</p>
<p><img src="https://kdn.flygon.net/docs/img/48afb2bff1fb2e3e30045c24f69e1f4c.png" alt="" loading="lazy"></p>
<hr>
<h2 id="我们的前三大课程推荐-24">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织 IT 部门</p>
<hr>
<p><em>图片来源:iStockPhoto / NanoStockk</em></p>
<p>通常需要相当的数据科学专业知识来创建数据集并构建特定应用的模型。但仅仅构建一个好的模型通常是不够的。实际上,远远不够。如下面所示,开发和测试模型只是第一步。</p>
<p><img src="https://kdn.flygon.net/docs/img/2c877ece7473a610986f63f263699983.png" alt="" loading="lazy"></p>
<p><em>机器学习模型生命周期。</em></p>
<p>机器学习操作(MLOps)是使该模型有用的所有其他要求,包括自动化开发和部署管道、监控、生命周期管理和治理的能力,如上所示。让我们逐一探讨这些内容。</p>
<h3 id="自动化管道">自动化管道</h3>
<p>创建生产级 ML 系统需要多个步骤:首先,数据必须经过一系列转换。然后,模型进行训练。通常,这需要对不同的网络架构和超参数进行实验。经常需要返回数据,尝试不同的特征。接下来,模型必须通过单元测试和集成测试进行验证。它需要通过数据和模型偏差以及可解释性的测试。最后,它被部署到公共云、内部环境或混合环境中。此外,过程中某些步骤可能需要审批流程。</p>
<p>如果这些步骤每一步都手动执行,开发过程通常会很慢且容易出错。幸运的是,许多 MLOps 工具存在,可以自动化这些步骤,从数据转换到端到端部署。当需要重新训练时,它是一个自动化、可靠且可重复的过程。</p>
<h3 id="监控">监控</h3>
<p>ML 模型在首次部署时往往表现良好,但随着时间推移效果会逐渐下降。正如 Forrester 分析师 Dr. Kjell Carlsson <a href="https://go.forrester.com/blogs/no-deploy-no-joy-leverage-modelops-to-operationalize-ai-and-machine-learning/" target="_blank">所说</a>:“AI 模型就像隔离中的六岁孩子:它们需要持续关注……否则,某些东西会坏掉。”</p>
<p>部署时包括各种监控类型至关重要,这样当问题发生时,ML 团队可以收到警报。性能可能因基础设施问题如 CPU 或内存不足而下降。当作为模型输入的自变量的真实数据开始呈现与训练数据不同的特征时,性能也可能下降,这种现象称为数据漂移。</p>
<p>同样,由于现实条件的变化,模型可能变得不再适用,这种现象称为概念漂移。例如,许多关于客户和供应商行为的预测模型在 COVID-19 疫情中发生了剧烈变化。</p>
<p>一些公司还监控替代模型(例如,不同的网络架构或不同的超参数),以查看这些“挑战者”模型是否有更好的表现。</p>
<p>通常,为模型做出的决策设置保护措施是合理的。这些保护措施是简单的规则,可以触发警报、阻止决策或将决策放入需要人工审批的工作流程中。</p>
<h3 id="生命周期管理">生命周期管理</h3>
<p>当模型性能因数据或模型漂移开始下降时,需要进行模型再训练,甚至可能需要重新架构模型。然而,数据科学团队不应从头开始。在开发原始模型时,或许在之前的再架构中,他们已经测试了许多架构、超参数和特性。记录所有这些先前的实验(和结果)至关重要,以便数据科学团队不必从头再来。这也对数据科学团队成员之间的沟通和协作至关重要。</p>
<h3 id="治理">治理</h3>
<p>机器学习模型被用于许多影响人们的应用场景,如银行贷款决策、医疗诊断和招聘/解雇决策。机器学习模型在决策中的使用受到批评的原因有两个:首先,这些模型可能存在偏见,尤其是当训练数据导致模型基于种族、肤色、民族、国籍、宗教、性别、性取向或其他受保护类别进行歧视时。其次,这些模型往往是黑箱,无法解释其决策过程。</p>
<p>因此,使用基于机器学习的决策制定的组织面临着确保其模型不歧视且能够解释其决策的压力。许多 MLOps 供应商正在结合基于学术研究的工具(例如,<a href="https://arxiv.org/pdf/1705.07874.pdf" target="_blank">SHAP</a>和<a href="https://arxiv.org/pdf/1610.02391.pdf" target="_blank">Grad-CAM</a>),帮助解释模型决策,并使用各种技术来确保数据和模型不带有偏见。此外,他们还在监控协议中加入了偏见和可解释性测试,因为模型可能会随着时间的推移变得有偏见或失去解释能力。</p>
<p>组织还需要建立信任,并开始确保持续的性能、无偏见和可解释性是可审计的。这要求建立模型目录,不仅记录所有的数据、参数和架构决策,还要记录每个决策,并提供可追溯性,以便确定每个决策所使用的数据、模型和参数,何时对模型进行再训练或其他修改,以及谁做了每个更改。审计人员还需要能够重复历史交易,并使用“假设”场景测试模型决策的边界。</p>
<p>安全和数据隐私也是使用机器学习的组织面临的关键问题。必须确保个人信息得到保护,并且基于角色的数据访问能力至关重要,尤其是对于受监管的行业。</p>
<p>世界各国政府也在迅速采取行动,对影响人们的机器学习决策进行监管。欧盟通过其 GDPR 和 CRD IV 规章走在了前列。在美国,包括美国联邦储备银行和 FDA 在内的多个监管机构已经为金融和医疗决策的机器学习决策制定了规章。更全面的法律《2020 年数据问责和透明度法案》计划于 2021 年提交国会审议。法规可能会发展到 CEO 需要对其机器学习模型的可解释性和无偏见性进行签字确认的程度。</p>
<h3 id="机器学习运维领域">机器学习运维领域</h3>
<p>随着我们进入 2021 年,机器学习运维市场正在爆炸性增长。根据分析公司 Cognilytica 的数据,预计到 2025 年将成为一个 <a href="https://www.cognilytica.com/2020/04/02/infographic-the-rapid-growth-of-mlops/" target="_blank">$40 亿市场</a>。</p>
<p>机器学习运维领域有大玩家也有小玩家。主要的机器学习平台供应商,如 Amazon、Google、Microsoft、IBM、Cloudera、Domino、DataRobot 和 H2O,正将机器学习运维能力融入其平台中。根据 Crunchbase 的数据,机器学习运维领域有 35 家私营公司已筹集了 180 万美元到 10 亿美元的融资,并在 LinkedIn 上有 3 到 2800 名员工:</p>
<table>
<thead>
<tr>
<th></th>
<th><strong>融资(百万美元)</strong></th>
<th><strong>员工数量</strong></th>
<th><strong>描述</strong></th>
</tr>
</thead>
<tbody>
<tr>
<td>Cloudera</td>
<td>1000</td>
<td>2803</td>
<td>Cloudera 提供一个企业数据云,适用于任何数据,从边缘到人工智能。</td>
</tr>
<tr>
<td>Databricks</td>
<td>897</td>
<td>1757</td>
<td>Databricks 是一个软件平台,帮助客户统一其业务、数据科学和数据工程方面的分析。</td>
</tr>
<tr>
<td>DataRobot</td>
<td>750</td>
<td>1105</td>
<td>DataRobot 将 AI 技术和 ROI 使能服务带给全球企业。</td>
</tr>
<tr>
<td>Dataiku</td>
<td>246</td>
<td>556</td>
<td>Dataiku 作为一个企业人工智能和机器学习平台运营。</td>
</tr>
<tr>
<td>Alteryx</td>
<td>163</td>
<td>1623</td>
<td>Alteryx 通过统一分析、数据科学和自动化流程来加速数字化转型。</td>
</tr>
<tr>
<td>H2O</td>
<td>151</td>
<td>257</td>
<td>H2O.ai 是 AI 和自动化机器学习的开源领导者,使命是让 AI 对所有人开放</td>
</tr>
<tr>
<td>Domino</td>
<td>124</td>
<td>232</td>
<td>Domino 是全球领先的企业数据科学平台,为超过 20% 的《财富》100 强公司提供数据科学支持</td>
</tr>
<tr>
<td>Iguazio</td>
<td>72</td>
<td>83</td>
<td>Iguazio 数据科学平台使你能够以规模和实时开发、部署和管理 AI 应用程序</td>
</tr>
<tr>
<td>Explorium.ai</td>
<td>50</td>
<td>96</td>
<td>Explorium 提供一个数据科学平台,支持增强的数据发现和特征工程</td>
</tr>
<tr>
<td>Algorithmia</td>
<td>38</td>
<td>63</td>
<td>Algorithmia 是一个机器学习模型部署和管理解决方案,自动化组织的 MLOps</td>
</tr>
<tr>
<td>Paperspace</td>
<td>23</td>
<td>37</td>
<td>Paperspace 支持基于 GPU 的下一代应用程序</td>
</tr>
<tr>
<td>Pachyderm</td>
<td>21</td>
<td>32</td>
<td>Pachyderm 是一个企业级数据科学平台,使可解释、可重复和可扩展的 AI/ML 成为现实</td>
</tr>
<tr>
<td>Weights and Biases</td>
<td>20</td>
<td>58</td>
<td>Weights and Biases 是用于实验跟踪、提升模型性能和结果协作的工具</td>
</tr>
<tr>
<td>OctoML</td>
<td>19</td>
<td>37</td>
<td>OctoML 正在改变开发人员优化和部署机器学习模型以满足 AI 需求的方式</td>
</tr>
<tr>
<td>Arthur AI</td>
<td>18</td>
<td>28</td>
<td>Arthur AI 是一个监控机器学习模型生产力的平台</td>
</tr>
<tr>
<td>Truera</td>
<td>17</td>
<td>26</td>
<td>Truera 提供一个模型智能平台,帮助企业分析机器学习</td>
</tr>
<tr>
<td>Snorkel AI</td>
<td>15</td>
<td>39</td>
<td>Snorkel AI 专注于通过 Snorkel Flow 使 AI 实用:一个以数据为中心的企业 AI 平台</td>
</tr>
<tr>
<td>Seldon.io</td>
<td>14</td>
<td>48</td>
<td>机器学习部署平台</td>
</tr>
<tr>
<td>Fiddler Labs</td>
<td>13</td>
<td>46</td>
<td>Fiddler 使用户能够创建透明、可解释和易于理解的 AI 解决方案</td>
</tr>
<tr>
<td>run.ai</td>
<td>13</td>
<td>26</td>
<td>Run:AI 开发了一种自动化分布式训练技术,可以虚拟化并加速深度学习</td>
</tr>
<tr>
<td>ClearML (Allegro)</td>
<td>11</td>
<td>29</td>
<td>ML / DL 实验管理器和 ML-Ops 开源解决方案,端到端产品生命周期管理企业解决方案</td>
</tr>
<tr>
<td>Verta</td>
<td>10</td>
<td>15</td>
<td>Verta 构建软件基础设施,帮助企业数据科学和机器学习(ML)团队开发和部署 ML 模型</td>
</tr>
<tr>
<td>cnvrg.io</td>
<td>8</td>
<td>38</td>
<td>cnvrg.io 是一个全栈数据科学平台,帮助团队管理模型并构建自适应机器学习管道</td>
</tr>
<tr>
<td>Datatron</td>
<td>8</td>
<td>19</td>
<td>Datatron 提供一个统一的模型治理(管理)平台,适用于所有生产中的 ML、AI 和数据科学模型</td>
</tr>
<tr>
<td>Comet</td>
<td>7</td>
<td>19</td>
<td>Comet.ml 是一个机器学习平台,旨在帮助 AI 从业者和团队构建可靠的机器学习模型</td>
</tr>
<tr>
<td>ModelOp</td>
<td>6</td>
<td>39</td>
<td>监管、监控和管理企业中的所有模型</td>
</tr>
<tr>
<td>WhyLabs</td>
<td>4</td>
<td>15</td>
<td>WhyLabs 是 AI 可观察性和监控公司</td>
</tr>
<tr>
<td>Arize AI</td>
<td>4</td>
<td>14</td>
<td>Arize AI 提供一个平台,用于解释和排查生产中的 AI</td>
</tr>
<tr>
<td>DarwinAI</td>
<td>4</td>
<td>31</td>
<td>DarwinAI 的生成合成 'AI 构建 AI' 技术实现了优化和可解释的深度学习。</td>
</tr>
<tr>
<td>Mona</td>
<td>4</td>
<td>11</td>
<td>Mona 是一个用于数据和 AI 驱动系统的 SaaS 监控平台。</td>
</tr>
<tr>
<td>Valohai</td>
<td>2</td>
<td>13</td>
<td>您的托管机器学习平台,让数据科学家能够构建、部署和跟踪机器学习模型。</td>
</tr>
<tr>
<td>Modzy</td>
<td>0</td>
<td>31</td>
<td>安全的 ModelOps 平台,用于发现、部署、管理和治理大规模的机器学习——更快实现价值。</td>
</tr>
<tr>
<td>Algomox</td>
<td>0</td>
<td>17</td>
<td>激发您的 AI 转型</td>
</tr>
<tr>
<td>Monitaur</td>
<td>0</td>
<td>8</td>
<td>Monitaur 是一家提供审计、透明度和治理的软件公司,专注于使用机器学习软件的公司。</td>
</tr>
<tr>
<td>Hydrosphere.io</td>
<td>0</td>
<td>3</td>
<td>Hydrosphere.io 是一个用于 AI/ML 操作自动化的平台</td>
</tr>
</tbody>
</table>
<p>这些公司中的许多专注于 MLOps 的一个细分领域,如自动化管道、监控、生命周期管理或治理。<a href="https://www.oreilly.com/radar/why-best-of-breed-is-a-better-choice-than-all-in-one-platforms-for-data-science/" target="_blank">一些人认为</a> 使用多个最佳产品的 MLOps 产品比单一平台更适合数据科学项目。有些公司正在为特定垂直领域构建 MLOps 产品。例如,<a href="https://monitaur.ai/" target="_blank">Monitaur</a> 将自己定位为能够与任何平台协作的最佳治理解决方案。Monitaur 还为受监管的行业(首先是保险)构建了行业特定的 MLOps 治理能力。(完全披露:我是一位 Monitaur 的投资者)。</p>
<p>还有许多开源的 MLOps 项目,包括:</p>
<ul>
<li>
<p><strong>MLFlow</strong> 管理 ML 生命周期,包括实验、可重复性和部署,并包括一个模型注册中心。</p>
</li>
<li>
<p><strong>DVC</strong> 管理 ML 项目的版本控制,使其可分享和可重复。</p>
</li>
<li>
<p><strong>Polyaxon</strong> 具有实验、生命周期自动化、协作和部署的能力,并包括一个模型注册中心。</p>
</li>
<li>
<p><strong>Metaflow</strong> 是 Netflix 以前的项目,用于管理自动化管道和部署。</p>
</li>
<li>
<p><strong>Kubeflow</strong> 具有 Kubernetes 容器中的工作流自动化和部署能力。</p>
</li>
</ul>
<p>2021 年承诺将是 MLOps 的一个有趣年份。我们可能会看到快速增长、巨大的竞争,以及最可能的一些整合。</p>
<p><strong>Bio:</strong> <a href="https://www.linkedin.com/in/steveshwartz/" target="_blank">Steve Shwartz</a> (<a href="https://twitter.com/sshwartz" target="_blank">@sshwartz</a>) 多年前在耶鲁大学开始他的 AI 职业生涯,是一位成功的连续创业者和投资者,并著有《邪恶机器人、致命计算机及其他神话:关于 AI 和人类未来的真相》。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/03/machine-learning-model-monitoring-checklist.html" target="_blank">机器学习模型监控检查表:7 个跟踪项</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/01/mlops-effective-ai-strategy.html" target="_blank">如何使用 MLOps 进行有效的 AI 策略</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/01/mlops-model-monitoring-101.html" target="_blank">MLOps:模型监控基础</a></p>
</li>
</ul>
<h3 id="更多相关话题-36">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/02/design-patterns-machine-learning-mlops.html" target="_blank">MLOps 中的机器学习设计模式</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/mlops-mess-expected.html" target="_blank">MLOps 是一团糟,但这在意料之中</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/08/comprehensive-guide-mlops.html" target="_blank">MLOps 综合指南</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/02/ploomber-kubeflow-mlops-easier.html" target="_blank">Ploomber 与 Kubeflow:让 MLOps 更加简单</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/domino-connect-data-science-community-nyc-mlops-conference.html" target="_blank">在纽约的 Rev 3 上与数据科学社区联系,全球第一…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/mlops-engineer.html" target="_blank">什么是 MLOps 工程师?</a></p>
</li>
</ul>
<h1 id="kdnuggets-新闻-20n4110-月-28-日初级与高级数据科学家的区别没有所谓的公民数据科学家">KDnuggets™ 新闻 20:n41,10 月 28 日:初级与高级数据科学家的区别;没有所谓的公民数据科学家</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2020/n41.html" target="_blank"><code>www.kdnuggets.com/2020/n41.html</code></a></p>
</blockquote>
<p>特性 | 新闻 | 教程 | 观点 | 热门 | 招聘 | 提交博客 | 本周图片</p>
<p>本周在 KDnuggets:初级与高级数据科学家的区别;“公民数据科学家”不是进入新职业的捷径;成为数据科学家的分步指南;加入大规模数据革命;了解 DeepMind 构建公平机器学习模型所依赖的统计方法;以及更多!</p>
<p>特性</p>
<ul>
<li>
<p><strong>初级和高级数据科学家之间未言明的区别</strong></p>
</li>
<li>
<p><strong>没有所谓的公民数据科学家</strong></p>
</li>
<li>
<p><strong>如何成为数据科学家:一步步指南</strong></p>
</li>
<li>
<p><strong>告别大数据。你好,大规模数据!</strong></p>
</li>
<li>
<p><strong>DeepMind 依赖这种古老的统计方法来构建公平的机器学习模型</strong></p>
</li>
</ul>
<p>新闻</p>
<ul>
<li><strong>PerceptiLabs - TensorFlow 的 GUI 和视觉 API</strong></li>
</ul>
<p>教程,概述</p>
<ul>
<li>
<p><strong>计算机视觉路线图</strong></p>
</li>
<li>
<p><strong>使用 Docker Swarm、Traefik 和 Keycloak 在 AWS 上部署安全且可扩展的 Streamlit 应用程序</strong></p>
</li>
<li>
<p><strong>使用机器学习和 R 进行行为分析:免费的电子书</strong></p>
</li>
<li>
<p><strong>你应该使用哪种 BERT 变体来处理你的 QA 任务?</strong></p>
</li>
<li>
<p><strong>10 个被低估的 Python 技能</strong></p>
</li>
</ul>
<p>观点</p>
<ul>
<li>
<p><strong>AI 能否学习人类价值观?</strong></p>
</li>
<li>
<p><strong>获取数据科学职位比以往更困难——如何将其转化为你的优势</strong></p>
</li>
<li>
<p><strong>对有志数据科学家的建议</strong></p>
</li>
<li>
<p><strong>自动化如何改善数据科学家的角色</strong></p>
</li>
<li>
<p><strong>软件 2.0 成型</strong></p>
</li>
<li>
<p><strong>AI 的伦理</strong></p>
</li>
</ul>
<p>热门新闻,推文</p>
<ul>
<li>
<p><strong>10 月 19-25 日热门新闻:如何在面试中解释关键的机器学习算法;自然语言处理路线图</strong></p>
</li>
<li>
<p><strong>KDnuggets 顶级推文,10 月 14-20 日:神经网络背后的数学介绍</strong></p>
</li>
</ul>
<p>招聘</p>
<ul>
<li>
<p>查看我们最近的 AI、分析、数据科学、机器学习职位</p>
</li>
<li>
<p>你可以在 KDnuggets 招聘页面上免费发布与 AI、大数据、数据科学或机器学习相关的行业或学术职位,电子邮件 - 详情见 kdnuggets.com/jobs</p>
</li>
</ul>
<p>本周图片</p>
<blockquote>
<p><img src="https://kdn.flygon.net/docs/img/no-citizen-data-scientist.html" alt="没有公民数据科学家> > 来源于《没有公民数据科学家》" loading="lazy"></p>
</blockquote>
<h3 id="更多相关主题-22">更多相关主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/junior-senior-data-scientist-salary-difference.html" target="_blank">初级与高级数据科学家薪资:有什么区别?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/difference-data-analysts-data-scientists.html" target="_blank">数据分析师和数据科学家的区别是什么?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/08/difference-training-testing-data-machine-learning.html" target="_blank">机器学习中训练数据与测试数据的区别</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/11/efficiency-spells-difference-biological-neurons-artificial-counterparts.html" target="_blank">效率决定了生物神经元与……的区别</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/02/difference-sql-object-relational-mapping-orm.html" target="_blank">SQL 与面向对象关系映射(ORM)的区别是什么?</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/08/difference-l1-l2-regularization.html" target="_blank">L1 与 L2 正则化的区别</a></p>
</li>
</ul>
<h1 id="kdnuggets-新闻-20n369-月-23-日新投票你在-2020-年使用最多的-python-ide--编辑器是什么自动化你的-python-项目的每一个方面">KDnuggets™ 新闻 20:n36,9 月 23 日:新投票:你在 2020 年使用最多的 Python IDE / 编辑器是什么?;自动化你的 Python 项目的每一个方面</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2020/n36.html" target="_blank"><code>www.kdnuggets.com/2020/n36.html</code></a></p>
</blockquote>
<p>特性 | 新闻 | 教程 | 意见 | 排行 | 职位 | 提交博客 | 本周图片</p>
<p>最新的 KDnuggets 投票询问了你在 2020 年使用最多的 Python IDE / 编辑器是什么。 立即投票!</p>
<p>本周还包括:自动化你的 Python 项目的每一个方面;Autograd: 你未曾使用过的最佳机器学习库?;从头开始用 Python 实现深度学习库;顶级大学的人工智能、数据科学、机器学习在线证书/课程;神经网络能展示想象力吗?DeepMind 认为它们可以;还有更多。</p>
<p>特性</p>
<ul>
<li>
<p><strong>新投票:你在 2020 年使用最多的 Python IDE / 编辑器是什么?</strong></p>
</li>
<li>
<p>**<img src="https://kdn.flygon.net/docs/img/automating-every-aspect-python-project.html" alt="金牌博客自动化你的 Python 项目的每一个方面**" loading="lazy"></p>
</li>
<li>
<p>**<img src="https://kdn.flygon.net/docs/img/autograd-best-machine-learning-library-not-using.html" alt="银牌博客 Autograd: 你未曾使用过的最佳机器学习库?**" loading="lazy"></p>
</li>
<li>
<p><strong>从头开始用 Python 实现深度学习库</strong></p>
</li>
<li>
<p><strong>顶级大学的人工智能、数据科学、机器学习在线证书/课程</strong></p>
</li>
<li>
<p><strong>神经网络能展示想象力吗?DeepMind 认为它们可以</strong></p>
</li>
</ul>
<p>新闻</p>
<ul>
<li>
<p><strong>Mathworks 深度学习工作流程:技巧、窍门及常被忽视的步骤</strong></p>
</li>
<li>
<p><strong>Coursera 的“人人可学的机器学习”满足了未满足的培训需求</strong></p>
</li>
</ul>
<p>教程,概述</p>
<ul>
<li>
<p><strong>从零开始的机器学习:免费在线教科书</strong></p>
</li>
<li>
<p><strong>用一行代码进行统计和可视化探索性数据分析</strong></p>
</li>
<li>
<p><strong>什么是辛普森悖论以及如何自动检测它</strong></p>
</li>
<li>
<p><strong>生成式与判别式机器学习模型的内部指南</strong></p>
</li>
</ul>
<p>意见</p>
<ul>
<li>
<p><strong>预测分析在劳动行业中的潜力</strong></p>
</li>
<li>
<p><strong>我是一名数据科学家,不仅仅是处理你数据的小手</strong></p>
</li>
<li>
<p><strong>阿根廷作家和匈牙利数学家能教会我们关于机器学习过拟合的什么</strong></p>
</li>
<li>
<p><strong>如何在数据过载时代有效获取消费者洞察</strong></p>
</li>
<li>
<p><strong>不受欢迎的观点 - 数据科学家应该更具端到端能力</strong></p>
</li>
</ul>
<p>热点新闻,推文</p>
<ul>
<li>
<p><strong>热点新闻,9 月 14-20 日:自动化你 Python 项目的每一个方面;深度学习最重要的理念</strong></p>
</li>
<li>
<p><strong>KDnuggets 顶级推文,9 月 9-15 日:你会以每月 49 美元注册#Google 大学吗?这里是@Kaggle 的国际替代方案</strong></p>
</li>
</ul>
<p>职位</p>
<ul>
<li>
<p>查看我们最近的人工智能、分析、数据科学、机器学习职位</p>
</li>
<li>
<p>你可以在 KDnuggets 招聘页面上免费发布与人工智能、大数据、数据科学或机器学习相关的行业或学术职位,发送电子邮件 - 详细信息请见 kdnuggets.com/jobs</p>
</li>
</ul>
<p>本周图片</p>
<blockquote>
<p><img src="https://kdn.flygon.net/docs/img/poll-python-ide-editor.html" alt="新投票:你在 2020 年使用最多的 Python IDE / 编辑器是哪个?> > 来自新投票:你在 2020 年使用最多的 Python IDE / 编辑器是哪个?" loading="lazy"></p>
</blockquote>
<h3 id="更多相关话题-37">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/n31.html" target="_blank">KDnuggets 新闻,8 月 3 日:10 个最常用的 Tableau 函数 • 是…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n01.html" target="_blank">KDnuggets™ 新闻 22:n01, 1 月 5 日:3 种跟踪和可视化工具…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/07/used-chatgpt-every-day-5-months-hidden-gems-change-life.html" target="_blank">我使用 ChatGPT(每天)5 个月。这里有一些隐藏的宝石…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/05/finding-best-ide-software.html" target="_blank">寻找最佳 IDE 软件</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n13.html" target="_blank">KDnuggets 新闻,3 月 30 日:最受欢迎的编程入门…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/08/10-used-tableau-functions.html" target="_blank">10 个最常用的 Tableau 函数</a></p>
</li>
</ul>
<h1 id="kdnuggets-新闻-20n34-9-月-9-日顶级在线数据科学硕士学位现代数据科学技能8-个类别核心技能和热门技能">KDnuggets™ 新闻 20:n34, 9 月 9 日:顶级在线数据科学硕士学位;现代数据科学技能:8 个类别、核心技能和热门技能</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2020/n34.html" target="_blank"><code>www.kdnuggets.com/2020/n34.html</code></a></p>
</blockquote>
<p>特点 | 新闻 | 教程 | 观点 | 排行榜 | 招聘 | 提交博客 | 本周图片</p>
<p>本期 KDnuggets:顶级在线分析学、商业分析和数据科学硕士学位;现代数据科学技能:8 个类别、核心技能和热门技能;在 Tableau 中创建强大的动画可视化;PyCaret 2.1 有什么新变化?;决定学习哪些数据科学技能;评估你的机器学习模型的性能;还有更多!</p>
<p>特点</p>
<ul>
<li>
<p>**<img src="https://kdn.flygon.net/docs/img/best-online-masters-data-science-analytics-online.html" alt="金色博客顶级在线分析、商业分析、数据科学硕士 - 更新版**" loading="lazy"></p>
</li>
<li>
<p><strong>现代数据科学技能:8 个类别、核心技能和热门技能</strong></p>
</li>
<li>
<p><strong>在 Tableau 中创建强大的动画可视化</strong></p>
</li>
<li>
<p><strong>PyCaret 2.1 已经上线:有什么新变化?</strong></p>
</li>
<li>
<p><strong>如何决定学习哪些数据技能</strong></p>
</li>
<li>
<p>**<img src="https://kdn.flygon.net/docs/img/performance-machine-learning-model.html" alt="银色博客如何评估机器学习模型的性能**" loading="lazy"></p>
</li>
</ul>
<p>新闻</p>
<ul>
<li>
<p><strong>NIST $240K 挑战:每次一个像素拯救生命</strong></p>
</li>
<li>
<p><strong>通过法律自动化扩展数据合规策略</strong></p>
</li>
<li>
<p><strong>书籍章节:统计学的艺术:从数据中学习</strong></p>
</li>
<li>
<p><strong>什么是数据丰富化以及它是如何工作的</strong></p>
</li>
<li>
<p><strong>电子书:词汇、文本挖掘和 FAIR 数据:信息管理者扮演的战略角色</strong></p>
</li>
</ul>
<p>教程,概述</p>
<ul>
<li>
<p><strong>在 Python 中有效使用 JSON 的 4 个技巧</strong></p>
</li>
<li>
<p><strong>深度学习梦想:在一个模型中实现准确性和可解释性</strong></p>
</li>
<li>
<p><strong>数据科学家认为数据是他们的头号问题。这里是他们为何错的原因。</strong></p>
</li>
<li>
<p><strong>数据科学中的实验设计</strong></p>
</li>
<li>
<p><strong>你不知道的关于 Scikit-Learn 的 10 件事</strong></p>
</li>
<li>
<p><strong>计算机视觉配方:最佳实践和示例</strong></p>
</li>
<li>
<p><strong>解决线性回归应使用哪些方法?</strong></p>
</li>
<li>
<p><strong>展示在 Intel® Xeon®可扩展平台上优化 AI 工作负载的软件优化的好处</strong></p>
</li>
<li>
<p><strong>自然语言处理的语言学基础:来自语义学和语用学的 100 个要点</strong></p>
</li>
<li>
<p><strong>加速计算机视觉:来自亚马逊的免费课程</strong></p>
</li>
<li>
<p><strong>微软的 DoWhy 是一个很酷的因果推断框架</strong></p>
</li>
<li>
<p><strong>使用 DALEX 和 Neptune 进行可解释和可重复的机器学习模型开发</strong></p>
</li>
<li>
<p>**<img src="https://kdn.flygon.net/docs/img/tensorflow-model-regularization-techniques.html" alt="Gold Blog4 种提升你的 TensorFlow 模型的方法 - 你需要知道的关键正则化技术**" loading="lazy"></p>
</li>
<li>
<p><strong>在 Azure Databricks 上使用 Spark、Python 或 SQL</strong></p>
</li>
<li>
<p><strong>数据版本控制:这是否如你所想?</strong></p>
</li>
<li>
<p><strong>在联邦学习中破坏隐私</strong></p>
</li>
</ul>
<p>Opinions</p>
<ul>
<li>
<p><strong>成为成功的数据科学家需要什么?</strong></p>
</li>
<li>
<p><strong>9 个数据科学与分析职位趋势</strong></p>
</li>
<li>
<p><strong>最重要的数据科学项目</strong></p>
</li>
<li>
<p><strong>这是我作为数据科学家两年的收获</strong></p>
</li>
<li>
<p><strong>关于 AI 意识辩论的一个有趣理论</strong></p>
</li>
<li>
<p><strong>数据无处不在,它驱动我们所做的一切!</strong></p>
</li>
<li>
<p><strong>超越图灵测试</strong></p>
</li>
<li>
<p><strong>如何优化你的简历以获得数据科学家的职业</strong></p>
</li>
</ul>
<p>Top Stories, Tweets</p>
<ul>
<li>
<p><strong>头条新闻,8 月 31 日 - 9 月 6 日:顶级在线分析、商业分析、数据科学硕士 - 更新版</strong></p>
</li>
<li>
<p><strong>头条 KDnuggets 推文,8 月 26 日 - 9 月 01 日:现实中数据科学家的工作时间</strong></p>
</li>
<li>
<p><strong>头条新闻,8 月 24-30 日:如果我必须重新学习数据科学,我会怎么做?;4 种提升你的 TensorFlow 模型的方法 - 你需要知道的关键正则化技术</strong></p>
</li>
<li>
<p><strong>头条 KDnuggets 推文,8 月 19-25 日:#机器学习 - 处理缺失数据</strong></p>
</li>
</ul>
<p>Jobs</p>
<ul>
<li>
<p>查看我们最近的 AI、分析、数据科学、机器学习职位</p>
</li>
<li>
<p>你可以在 KDnuggets 招聘页面免费发布与 AI、大数据、数据科学或机器学习相关的行业或学术职位,详情请发邮件 - 见 kdnuggets.com/jobs</p>
</li>
</ul>
<p>本周图片</p>
<blockquote>
<p><img src="https://kdn.flygon.net/docs/img/modern-data-science-skills.html" alt="现代数据科学技能:8 大类别、核心技能及热门技能> > 来源于《现代数据科学技能:8 大类别、核心技能及热门技能》" loading="lazy"></p>
</blockquote>
<h3 id="更多相关内容-24">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/go-to-university-from-home-with-these-online-degrees" target="_blank">从家里通过这些在线学位上大学</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/05/data-masking-core-ensuring-gdpr-regulatory-compliance-strategies.html" target="_blank">数据掩码:确保 GDPR 及其他合规性的核心</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/07/pandas-onehot-encode-data.html" target="_blank">Pandas:如何进行独热编码</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/dive-into-the-future-with-kaggle-ai-report-2023-see-what-hot" target="_blank">与 Kaggle 的 2023 年 AI 报告一起深入未来 – 查看热门趋势</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n28.html" target="_blank">KDnuggets 新闻,7 月 13 日:数据科学中的线性代数;10 个现代…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n03.html" target="_blank">KDnuggets™新闻 22:n03,1 月 19 日:深入了解 13 个数据…</a></p>
</li>
</ul>
<h1 id="kdnuggets新闻-20n256-月-24-日你应该了解的-pytorch-基础知识提升数据科学技能的免费数学课程">KDnuggets™新闻 20:n25,6 月 24 日:你应该了解的 PyTorch 基础知识;提升数据科学技能的免费数学课程</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2020/n25.html" target="_blank"><code>www.kdnuggets.com/2020/n25.html</code></a></p>
</blockquote>
<p>特性 | 教程 | 观点 | 排行榜 | 职位 | 提交博客 | 本周图片</p>
<p>本周在 KDnuggets:学习 PyTorch 的基础知识;寻找数学课程以提升数据科学技能;阅读关于分类项目的温和逐步指南;了解机器学习和计算机视觉如何在作物疾病检测中应用;还有更多内容。</p>
<p>安息吧,Tom Fawcett。</p>
<p>特性</p>
<ul>
<li>
<p>**<img src="https://kdn.flygon.net/docs/img/fundamentals-pytorch.html" alt="银色博客你应该了解的 PyTorch 最重要基础知识**" loading="lazy"></p>
</li>
<li>
<p><strong>4 门免费的数学课程以提升你的数据科学技能</strong></p>
</li>
<li>
<p><strong>机器学习中的分类项目:温和的逐步指南</strong></p>
</li>
<li>
<p><strong>使用机器学习和计算机视觉进行作物疾病检测</strong></p>
</li>
<li>
<p><strong>纪念 Tom Fawcett</strong></p>
</li>
</ul>
<p>教程,概述</p>
<ul>
<li>
<p><strong>使用 TensorFlow 数据集和 TensorBoard 的 TensorFlow 建模管道</strong></p>
</li>
<li>
<p><strong>AI 中的偏见:入门指南</strong></p>
</li>
<li>
<p><strong>Dask 中的机器学习</strong></p>
</li>
<li>
<p><strong>如何处理数据集中的缺失值</strong></p>
</li>
<li>
<p><strong>基因组预测中的图形机器学习</strong></p>
</li>
<li>
<p><strong>什么是情感 AI,为什么你应该关心?</strong></p>
</li>
<li>
<p><strong>modelStudio 和互动解释模型分析的语法</strong></p>
</li>
<li>
<p><strong>使用 Tensorflow.js 实现计算机视觉应用的 6 个简单步骤</strong></p>
</li>
<li>
<p><strong>LightGBM:高效的梯度提升决策树</strong></p>
</li>
<li>
<p><strong>使用 AWS Sagemaker 逐步构建狗品种分类器</strong></p>
</li>
</ul>
<p>意见</p>
<ul>
<li><strong>不要点击这个(如何识别深度伪造和 AI 生成的文本)</strong></li>
</ul>
<p>头条新闻,推文</p>
<ul>
<li>
<p><strong>头条新闻,6 月 15-21 日:使用 Python 轻松实现语音转文本;Google Colab 深度学习完全指南</strong></p>
</li>
<li>
<p><strong>KDnuggets 顶级推文,6 月 10-16 日:#机器学习中的博弈论速成课程:经典与新思想</strong></p>
</li>
</ul>
<p>职位</p>
<ul>
<li>
<p>查看我们最近的 AI、分析、数据科学、机器学习职位</p>
</li>
<li>
<p>你可以在 KDnuggets 的职位页面上免费发布与 AI、大数据、数据科学或机器学习相关的行业或学术职位,详情请邮件咨询 - 见 kdnuggets.com/jobs</p>
</li>
</ul>
<p>本周图片</p>
<blockquote>
<p>
</code></pre>
<p>安装支持 Jupyter 调试协议的内核</p>
<pre><code class="language-py">RUN conda install xeus-python -c conda-forge
</code></pre>
<p><strong>注意:</strong>这里我们使用了 conda 包管理器,你也可以使用 pip,但不推荐同时使用两者,因为这可能会破坏环境。</p>
<p>最后,暴露端口并定义入口点</p>
<pre><code class="language-py">EXPOSE 8888
ENTRYPOINT [“jupyter”, “lab”,” — ip=0.0.0.0",” — allow-root”]
</code></pre>
<p>我们最终的 Dockerfile 应如下所示:</p>
<p>启用 Visual Debugger 的 JupyterLab Docker 化</p>
<h3 id="从上述-dockerfile-构建-docker-镜像">从上述 Dockerfile 构建 Docker 镜像。</h3>
<p>导航到包含上述 Dockerfile 的文件夹并运行以下命令。</p>
<pre><code class="language-py">docker build -t visualdebugger .
</code></pre>
<p>另外,你也可以从任何地方运行命令,只要提供 Dockerfile 的绝对路径。</p>
<p>镜像成功构建后,通过以下命令列出 Docker 镜像以进行验证</p>
<pre><code class="language-py">docker image ls
</code></pre>
<p>输出应如下所示:</p>
<p><img src="https://kdn.flygon.net/docs/img/4d9348c00df9a889ea45e8f5a9d13fed.png" alt="" loading="lazy"></p>
<p>现在在新容器中运行 Docker 镜像,如下所示:</p>
<pre><code class="language-py">docker container run -p 8888:8888 visualdebugger-jupyter
</code></pre>
<p>这里我们将主机端口(冒号前的第一个)8888 映射到容器中暴露的端口 8888。这是为了使主机能够与容器中 Jupiter 监听的端口通信。</p>
<p>一旦运行上述命令,你应该会看到如下输出(前提是端口没有被其他进程占用):</p>
<p><img src="https://kdn.flygon.net/docs/img/52ee4e3c29d5a884d81fa56bd5e5c92f.png" alt="" loading="lazy"></p>
<p>这意味着我们的 Docker 容器已启动并运行。你现在可以打开上面输出中指定的 URL,使用 Jupyter 和可视化调试器,而无需意识到它并没有运行在主机机器上。</p>
<p>你还可以通过以下命令查看可用容器列表:</p>
<pre><code class="language-py">docker container ls
</code></pre>
<p>上述命令应列出容器及其元数据,如下所示:</p>
<p><img src="https://kdn.flygon.net/docs/img/23094ef9780246a9158aed1a0794f675.png" alt="" loading="lazy"></p>
<p>一旦你打开上述输出中指定的 URL,你应该会看到 JupyterLab 运行在主机的 localhost 和端口 8888 上。</p>
<p><img src="https://kdn.flygon.net/docs/img/109e93190201264d560fd95d2bad0e59.png" alt="图" loading="lazy"></p>
<p>在容器中运行的 JupyterLab 带有可视化调试器</p>
<p>现在要尝试可视化调试器,请在启动器中选择显示为 <strong>xpython</strong> 的 Notebook 或 Console,而不是 Python。</p>
<p>我已将我们刚刚构建的 Docker 镜像发布到 <a href="https://hub.docker.com/repository/docker/beingmanish/visualdebugger-jupyter" target="_blank">docker hub</a>,以防你需要一个带有启用可视化调试的 Jupyter 准备好使用的环境。</p>
<p>你可以使用以下命令拉取 Docker 镜像并进行尝试。</p>
<pre><code class="language-py">docker pull beingmanish/visualdebugger-jupyter
</code></pre>
<p>如果你希望深入了解 Jupyter 的可视化调试架构,你可以参考<a href="https://blog.jupyter.org/a-visual-debugger-for-jupyter-914e61716559" target="_blank">这里</a>。</p>
<p>有建议或问题?请在评论中写下。</p>
<p><strong>参考资料:</strong> <a href="https://blog.jupyter.org/" target="_blank">Jupyter 博客</a></p>
<p><a href="https://github.com/jupyter" target="_blank">Jupyter@Github</a></p>
<p><strong>个人简介:<a href="https://www.linkedin.com/in/manish-kumar-tiwari/" target="_blank">Manish Tiwari</a></strong> 是一位对分享 AI 领域学习和经验充满热情的数据爱好者。</p>
<p><a href="https://towardsdatascience.com/dockerize-jupyter-with-official-visual-debugger-enabled-cbce1840b7f" target="_blank">原文</a>。经许可转载。</p>
<p><strong>相关内容:</strong></p>
<ul>
<li>
<p>深度学习的 4 个最佳 Jupyter Notebook 环境</p>
</li>
<li>
<p>5 个 Google Colaboratory 提示</p>
</li>
<li>
<p>GitHub Python 数据科学亮点:高级机器学习与 NLP、集成、命令行可视化和 Docker 简化</p>
</li>
</ul>
<h3 id="更多相关内容-25">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/06/essential-math-data-science-visual-introduction-singular-value-decomposition.html" target="_blank">数据科学的基本数学:奇异值分解的视觉介绍</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/02/building-visual-search-engine-part-1.html" target="_blank">构建视觉搜索引擎 - 第一部分:数据探索</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/03/visual-chatgpt-microsoft-combine-chatgpt-vfms.html" target="_blank">Visual ChatGPT: 微软将 ChatGPT 与 VFMs 结合</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/06/ai-large-language-visual-models.html" target="_blank">AI: 大型语言与视觉模型</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/02/building-visual-search-engine-part-2.html" target="_blank">构建视觉搜索引擎 - 第二部分:搜索引擎</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/cutting-implementation-time-integrating-jupyter-knime.html" target="_blank">通过集成 Jupyter 和 KNIME 缩短实现时间</a></p>
</li>
</ul>
<h1 id="14-个数据科学项目以提升你的技能">14 个数据科学项目以提升你的技能</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2020/12/14-data-science-projects-improve-skills.html" target="_blank"><code>www.kdnuggets.com/2020/12/14-data-science-projects-improve-skills.html</code></a></p>
</blockquote>
<p>评论</p>
<p><img src="https://kdn.flygon.net/docs/img/c0446a6b11324e1ea21f3bf5f9e26764.png" alt="" loading="lazy"></p>
<p><em>照片由 <a href="https://unsplash.com/@austindistel?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Austin Distel</a> 提供,拍摄于 <a href="https://unsplash.com/s/photos/projects?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Unsplash</a>。</em></p>
<hr>
<h2 id="我们的三大课程推荐-15">我们的三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织 IT 需求</p>
<hr>
<p>首先,我想对所有的护士、医生、超市职员、公共行政人员以及其他为服务社区而冒着生命危险的人们表示衷心的感谢。</p>
<p>让我们不要理所当然地对待这一切。利用这段隔离时间学习新技能、阅读书籍并提升自己。对于那些对数据、数据分析或数据科学感兴趣的人,我提供了一份包括十四个数据科学项目的清单,你可以在闲暇时间做这些项目!</p>
<p>有三种类型的项目:</p>
<ol>
<li>
<p>可视化项目</p>
</li>
<li>
<p>探索性数据分析(EDA)项目</p>
</li>
<li>
<p>预测建模</p>
</li>
</ol>
<h3 id="可视化项目">可视化项目</h3>
<p>也许最快完成的项目就是数据可视化!下面是三个有趣的数据集,你可以用来创建一些引人入胜的可视化作品,丰富你的作品集。</p>
<ul>
<li><strong>冠状病毒可视化</strong></li>
</ul>
<p>难度:简单</p>
<p>数据集链接 <a href="https://www.kaggle.com/sudalairajkumar/novel-corona-virus-2019-dataset" target="_blank">在这里</a>。</p>
<p>学习如何使用 Plotly 构建动态可视化,展示冠状病毒如何在全球范围内传播,类似于上面的示例!Plotly 是一个了不起的库,它使数据可视化变得动态、吸引人且简单。</p>
<p><em>如果你想学习如何构建类似于上面示例的可视化,请查看我的教程 <em><a href="https://towardsdatascience.com/visualizing-the-coronavirus-pandemic-with-choropleth-maps-7f30fccaecf5" target="_blank"><em>在这里</em></a></em>。</em></p>
<p><em>我的朋友 Jack 还写了一篇关于预测冠状病毒恢复的文章 <em><a href="https://www.obviously.ai/post/predicting-coronavirus-recovery-with-machine-learning" target="_blank"><em>在这里</em></a></em>!</em></p>
<ul>
<li><strong>澳大利亚野火可视化</strong></li>
</ul>
<p>难度:简单</p>
<p>数据集链接 <a href="https://www.kaggle.com/carlosparadis/fires-from-space-australia-and-new-zeland" target="_blank">在这里</a>。</p>
<p><img src="https://kdn.flygon.net/docs/img/966be4545b1c478a1f74203c3e218071.png" alt="" loading="lazy"></p>
<p><em>摘自 Vox。</em></p>
<p>2019–2020 年丛林火灾季节,也称为“黑色夏天”,包括从 2019 年 6 月开始的几次极端火灾。火灾烧毁了约 1860 万公顷的土地和超过 5900 栋建筑,<a href="https://en.wikipedia.org/wiki/2019%E2%80%9320_Australian_bushfire_season" target="_blank">根据维基百科</a>。</p>
<p>这将是一个有趣的项目!利用你的数据可视化技能,使用 Plotly 或 Matplotlib 展示火灾的规模和地理影响。</p>
<p><em>看看我的朋友 Jack 如何预测巴西的火灾模式</em><a href="https://www.obviously.ai/post/predicting-brazils-wildfire-patterns-in-2020" target="_blank"><em>在这里</em></a><em>!</em></p>
<ul>
<li><strong>地球表面温度可视化</strong></li>
</ul>
<p>难度:简单-中等</p>
<p>数据集链接 <a href="https://www.kaggle.com/berkeleyearth/climate-change-earth-surface-temperature-data/kernels" target="_blank">在这里</a>。</p>
<p><img src="https://kdn.flygon.net/docs/img/a04975fedd0a795fa64add890c91bb9c.png" alt="" loading="lazy"></p>
<p><em>照片来源于 <a href="https://unsplash.com/@william_bossen?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">William Bossen</a> ,来自 <a href="https://unsplash.com/s/photos/climate-change?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Unsplash</a>。</em></p>
<p>是否有气候变化否认者?创建一些数据可视化,展示地球表面温度随时间的变化。你可以通过创建折线图或另一个动画的地理分布图来实现!</p>
<p>额外任务:创建一个预测模型,显示地球温度在五十年后的预期值。</p>
<h3 id="探索性数据分析项目">探索性数据分析项目</h3>
<p>探索性数据分析(EDA),也称为数据探索,是数据分析过程中的一个步骤,其中使用多种技术来更好地理解所使用的数据集。</p>
<p><em>如果你想了解更多关于 EDA 的内容,可以查看我的指南</em><a href="https://towardsdatascience.com/an-extensive-guide-to-exploratory-data-analysis-ddd99a03199e" target="_blank"><em>在这里</em></a><em>!</em></p>
<ul>
<li><strong>纽约 Airbnb 数据探索</strong></li>
</ul>
<p>难度:中等</p>
<p>数据集链接 <a href="https://www.kaggle.com/dgomonov/new-york-city-airbnb-open-data" target="_blank">在这里</a>。</p>
<p><img src="https://kdn.flygon.net/docs/img/17c3fbb64348ff80b9c12213afb0afdd.png" alt="" loading="lazy"></p>
<p><em>照片来源于 <a href="https://unsplash.com/@ojnibl?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Oliver Niblett</a> ,来自 <a href="https://unsplash.com/?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Unsplash</a>。</em></p>
<p>自 2008 年以来,客人和主持人利用 Airbnb 扩展旅行可能性,并提供更多个性化的世界体验方式。该数据集包含有关 2019 年纽约列表及其地理信息、价格、评论数量等信息。</p>
<p>你可以尝试回答的一些问题如下:</p>
<ul>
<li>
<p>哪些主持人最忙碌,为什么?</p>
</li>
<li>
<p>哪些地区的流量比其他地区多,为什么?</p>
</li>
<li>
<p>是否存在价格、评论数量和某个列表被预订天数之间的关系?</p>
</li>
<li>
<p><strong>与员工流失和表现相关的最重要因素</strong></p>
</li>
</ul>
<p>难度:简单</p>
<p>数据集链接 <a href="https://www.kaggle.com/pavansubhasht/ibm-hr-analytics-attrition-dataset" target="_blank">在这里</a>。</p>
<p><img src="https://kdn.flygon.net/docs/img/e7da4d61880c012bc6784768229cc284.png" alt="" loading="lazy"></p>
<p><em>照片由 <a href="https://unsplash.com/@campaign_creators?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Campaign Creators</a> 提供,发布于 <a href="https://unsplash.com/s/photos/employees?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Unsplash</a>。</em></p>
<p>IBM 创建了一个合成数据集,你可以用来了解各种因素如何影响员工的流失率和满意度。变量包括教育程度、工作参与、绩效评级和工作生活平衡。</p>
<p>探索这个数据集,看看是否有显著的变量确实影响了员工满意度。进一步尝试将这些变量按重要性从高到低排序。</p>
<ul>
<li><strong>世界大学排名</strong></li>
</ul>
<p>难度:简单</p>
<p>数据集链接 <a href="https://www.kaggle.com/mylesoneill/world-university-rankings" target="_blank">这里</a>。</p>
<p><img src="https://kdn.flygon.net/docs/img/6c46b6bc2ee36ac7797897f3a3214dde.png" alt="" loading="lazy"></p>
<p><em>照片由 <a href="https://unsplash.com/@napr0tiv?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Vasily Koloda</a> 提供,发布于 <a href="https://unsplash.com/s/photos/university?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Unsplash</a>。</em></p>
<p>你认为你所在的国家是否拥有世界上最好的大学?最初,‘最佳’大学的标准是什么?该数据集包含了三项全球大学排名。利用这些数据,看看你是否能回答以下问题:</p>
<ul>
<li>
<p>哪些国家拥有顶尖大学?</p>
</li>
<li>
<p>确定世界排名的主要因素是什么?</p>
</li>
<li>
<p><strong>酒精与学校成功</strong></p>
</li>
</ul>
<p>难度:简单</p>
<p>数据集链接 <a href="https://www.kaggle.com/uciml/student-alcohol-consumption" target="_blank">这里</a>。</p>
<p><img src="https://kdn.flygon.net/docs/img/f4c17b77a1c26a176bb2b53a3ba585c2.png" alt="" loading="lazy"></p>
<p><em>照片由 <a href="https://unsplash.com/@shootervision?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Kevin Kelly</a> 提供,发布于 <a href="https://unsplash.com/s/photos/alcohol?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Unsplash</a>。</em></p>
<p>酒精是否影响学生的成绩?如果没有,那是什么影响的呢?这些数据来自中学数学和葡萄牙语课程学生的调查。数据包括酒精消费、家庭规模、课外活动参与等多个变量。</p>
<p>利用此工具,探索学校表现与各种因素之间的关系。作为额外挑战,试着根据其他变量预测学生的最终成绩!</p>
<ul>
<li><strong>宝可梦数据探索</strong></li>
</ul>
<p>难度:简单</p>
<p>数据集链接 <a href="https://www.kaggle.com/rounakbanik/pokemon" target="_blank">这里</a>。</p>
<p><img src="https://kdn.flygon.net/docs/img/1f5684071213547be51feb86ede67877.png" alt="" loading="lazy"></p>
<p><em>摘自 Pokemon.com。</em></p>
<p>对于所有的玩家,这里有一个数据集,包含了所有七代宝可梦的 802 种信息。你可以尝试回答以下几个问题!</p>
<ul>
<li>
<p>哪一代的宝可梦最强?哪一代的最弱?</p>
</li>
<li>
<p>哪种宝可梦类型最强?最弱?</p>
</li>
<li>
<p>是否可以建立一个分类器来识别传奇宝可梦?</p>
</li>
<li>
<p>物理特征与力量统计(攻击、防御、速度等)之间有任何相关性吗?</p>
</li>
<li>
<p><strong>探索寿命期望的因素</strong></p>
</li>
</ul>
<p>难度:简单</p>
<p>数据集链接 <a href="https://www.kaggle.com/kumarajarshi/life-expectancy-who" target="_blank">这里</a>。</p>
<p>世界卫生组织创建了一个有关各国健康状况的数据集,其中包括寿命期望、成人死亡率等统计数据。利用这个数据集,探索各种变量之间的关系。什么因素对寿命期望影响最大?</p>
<p>该数据集的创建目的是回答以下问题:</p>
<ol>
<li>
<p>最初选择的各种预测因素是否确实影响了寿命期望?实际影响寿命期望的预测变量是什么?</p>
</li>
<li>
<p>一个寿命期望值较低的国家(<65 岁)是否应该增加医疗支出以提高其平均寿命?</p>
</li>
<li>
<p>婴儿和成人死亡率如何影响寿命期望?</p>
</li>
<li>
<p>寿命期望与饮食习惯、生活方式、锻炼、吸烟、饮酒等有正相关还是负相关?</p>
</li>
<li>
<p>教育对人类寿命的影响是什么?</p>
</li>
<li>
<p>寿命期望与饮酒有正相关还是负相关?</p>
</li>
<li>
<p>人口密度高的国家是否倾向于拥有较低的寿命期望?</p>
</li>
<li>
<p>免疫覆盖率对寿命期望有何影响?</p>
</li>
</ol>
<p><em>查看我关于</em><a href="https://medium.com/swlh/predicting-life-expectancy-w-regression-b794ca457cd4" target="_blank"><em>使用回归预测寿命</em></a>* 的文章,获取灵感!*</p>
<h3 id="预测建模">预测建模</h3>
<ul>
<li><strong>能源消耗的时间序列预测</strong></li>
</ul>
<p>难度:中等-高级</p>
<p>数据集链接 <a href="https://www.kaggle.com/robikscube/hourly-energy-consumption" target="_blank">这里</a>。</p>
<p><img src="https://kdn.flygon.net/docs/img/9271679674e7033c6b96c90cc7578ee8.png" alt="" loading="lazy"></p>
<p><em>照片由 <a href="https://unsplash.com/@matthewhenry?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Matthew Henry</a> 提供,来源于 <a href="https://unsplash.com/s/photos/energy?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Unsplash</a>。</em></p>
<p>该数据集由 PJM 网站的电力消耗数据组成。PJM 是美国的一个区域传输组织。利用这个数据集,看看你是否能构建一个时间序列模型来预测能源消耗。此外,还可以看看是否能发现有关一天中小时、节假日能源使用和长期趋势的规律!</p>
<ul>
<li><strong>贷款预测预测</strong></li>
</ul>
<p>难度:简单</p>
<p>数据集链接 <a href="https://datahack.analyticsvidhya.com/contest/practice-problem-loan-prediction-iii/" target="_blank">这里</a>。</p>
<p><img src="https://kdn.flygon.net/docs/img/905b8826937be058c936dc45a7b060df.png" alt="" loading="lazy"></p>
<p><em>照片由 <a href="https://unsplash.com/@wildbook?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Dmitry Demidko</a> 提供,来源于 <a href="https://unsplash.com/s/photos/bank?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Unsplash</a>。</em></p>
<p>取自 Analytics Vidhya,该数据集包含 615 行和 13 列关于过去贷款是否被批准的数据。看看你是否能创建一个预测贷款是否会获得批准的模型。</p>
<ul>
<li><strong>二手车价格估算器</strong></li>
</ul>
<p>难度:中级</p>
<p>数据集链接 <a href="https://www.kaggle.com/austinreese/craigslist-carstrucks-data" target="_blank">这里</a>。</p>
<p><img src="https://kdn.flygon.net/docs/img/cf8e230cbdee8b0c7e996aca82d9586b.png" alt="" loading="lazy"></p>
<p><em>图片来源于 <a href="https://unsplash.com/@parkergibbsmccullough?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Parker Gibbs</a> ,发布于 <a href="https://unsplash.com/s/photos/used-car?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Unsplash</a>。</em></p>
<p>Craigslist 是全球最大的二手车销售平台。该数据集由从 Craigslist 抓取的数据组成,并每隔几个月更新一次。利用这个数据集,看看你能否创建一个预测汽车上市价格是否合理的数据集。</p>
<p><em>查看我预测二手车价格的模型 <em><a href="https://towardsdatascience.com/a-machine-learning-project-predicting-used-car-prices-efbc4d2a4998" target="_blank"><em>这里</em></a></em>!</em></p>
<ul>
<li><strong>检测信用卡欺诈</strong></li>
</ul>
<p>难度:中级-高级</p>
<p>数据集链接 <a href="https://www.kaggle.com/janiobachmann/credit-fraud-dealing-with-imbalanced-datasets" target="_blank">这里</a>。</p>
<p><img src="https://kdn.flygon.net/docs/img/1af787809257df113cbf5d5db4dfcb29.png" alt="" loading="lazy"></p>
<p><em>图片来源于 <a href="https://unsplash.com/@rupixen?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">rupixen.com</a> ,发布于 <a href="https://unsplash.com/s/photos/credit-card?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Unsplash</a>。</em></p>
<p>该数据集展示了两天内发生的交易,共有 284,807 笔交易,其中 492 笔为欺诈交易。该数据集高度不平衡,正类(欺诈)仅占所有交易的 0.172%。学习如何处理不平衡数据集,并构建信用卡欺诈检测模型。</p>
<ul>
<li><strong>皮肤癌图像检测</strong></li>
</ul>
<p>难度:高级</p>
<p>数据集链接 <a href="https://www.kaggle.com/kmader/skin-cancer-mnist-ham10000" target="_blank">这里</a>。</p>
<p><img src="https://kdn.flygon.net/docs/img/327bd63cfd869fa40df4b5be5c76d9b2.png" alt="" loading="lazy"></p>
<p><em>图片来源于 <a href="https://unsplash.com/@creativegangsters?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Allie Smith</a> ,发布于 <a href="https://unsplash.com/s/photos/cancer?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" target="_blank">Unsplash</a>。</em></p>
<p>使用超过 10,000 张图片,看看你是否能构建一个神经网络来检测皮肤癌。这无疑是最难的项目,要求对神经网络和图像识别有深入了解。<em>提示:如果遇到困难,可以参考其他用户创建的内核!</em></p>
<p><a href="https://towardsdatascience.com/14-data-science-projects-to-do-during-your-14-day-quarantine-8bd60d1e55e1" target="_blank">原文</a>。转载经许可。</p>
<p><strong>相关内容:</strong></p>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2020/11/acquire-most-wanted-data-science-skills.html" target="_blank">如何获得最受欢迎的数据科学技能</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2020/10/level-up-data-science-skills-8-months.html" target="_blank">我如何在 8 个月内提升我的数据科学技能</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2020/10/data-science-minimum-10-essential-skills.html" target="_blank">数据科学必备:开始进行数据科学所需了解的 10 个核心技能</a></p>
</li>
</ul>
<h3 id="更多相关内容-26">更多相关内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/01/humbling-improve-data-science-skills.html" target="_blank">为什么谦虚会提升你的数据科学技能</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/03/chatgpt-improve-data-science-skills.html" target="_blank">如何利用 ChatGPT 提升你的数据科学技能</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/04/top-data-science-projects-build-skills.html" target="_blank">提升技能的顶级数据科学项目</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/5-data-science-projects-learn-5-critical-data-science-skills.html" target="_blank">学习 5 种关键数据科学技能的 5 个数据科学项目</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/06/3-ways-understanding-bayes-theorem-improve-data-science.html" target="_blank">理解贝叶斯定理将如何提升你的数据科学能力</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/7-gpts-to-help-improve-your-data-science-workflow" target="_blank">7 个 GPT 帮助提升你的数据科学工作流程</a></p>
</li>
</ul>
<h1 id="数据科学家的-14-个必备-git-命令">数据科学家的 14 个必备 Git 命令</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2022/06/14-essential-git-commands-data-scientists.html" target="_blank"><code>www.kdnuggets.com/2022/06/14-essential-git-commands-data-scientists.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/bc1e96a6b7d20a1e9400824cd14e2479.png" alt="数据科学家的 14 个必备 Git 命令" loading="lazy"></p>
<p>图片由<a href="https://www.pexels.com/photo/man-love-people-woman-11035539/" target="_blank">RealToughCandy.com</a>提供</p>
<p>历史上,大多数数据科学家对软件开发实践和工具(如版本控制系统)不太了解。但这种情况正在改变,数据科学项目正在采纳软件工程的最佳实践,Git 已成为文件和数据版本控制的重要工具。现代数据团队利用它来协作处理代码库项目,并更快地解决冲突。</p>
<hr>
<h2 id="我们的前三大课程推荐-25">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织进行 IT 管理</p>
<hr>
<p>在这篇文章中,我们将学习 14 个必备的 Git 命令,这些命令将帮助你初始化项目、创建和合并分支、版本控制文件、与远程服务器同步以及监控变更。</p>
<blockquote>
<p><strong>注意:</strong> 请确保你已从<a href="https://git-scm.com/downloads" target="_blank">官方站点</a>正确安装 Git。</p>
</blockquote>
<h1 id="1-初始化">1. 初始化</h1>
<p>你可以通过输入以下命令在当前目录中初始化 Git 版本控制系统:</p>
<pre><code class="language-py">git init
</code></pre>
<p>或者你可以在特定目录中初始化 Git。</p>
<pre><code class="language-py">git init <directory>
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/134072b98208116d3c05193c0944db4b.png" alt="在特定目录中初始化 Git" loading="lazy"></p>
<h1 id="2-克隆">2. 克隆</h1>
<p><strong>clone</strong>命令将从远程服务器复制所有项目文件到本地计算机。它还会将远程名称添加为<code>origin</code>以便与远程服务器同步文件。</p>
<p>Git clone 需要 HTTPS 链接,安全连接需要 SSH 链接。</p>
<pre><code class="language-py">git clone <HTTPS/SSH>
</code></pre>
<h1 id="3-添加远程">3. 添加远程</h1>
<p>你可以通过添加远程名称和 HTTPS/SSH 地址来连接到一个或多个远程服务器。</p>
<pre><code class="language-py">git remote add <remote name> <HTTPS/SSH>
</code></pre>
<blockquote>
<p><strong>注意:</strong> 从 GitHub 或任何远程服务器克隆一个仓库会自动将远程添加为<code>origin</code>。</p>
</blockquote>
<h1 id="4-创建分支">4. 创建分支</h1>
<p>分支是处理新功能或调试代码的最佳方式。它允许你在不干扰<code>main</code>分支的情况下进行隔离工作。</p>
<p>使用<strong>checkout</strong>命令和<code>-b</code>标签及分支名称创建一个新分支。</p>
<pre><code class="language-py">git checkout -b <branch-name>
</code></pre>
<p>或使用<strong>switch</strong>与<code>-c</code>标签和分支名称</p>
<pre><code class="language-py">git switch -c <branch-name>
</code></pre>
<p>或者简单地使用<strong>branch</strong>命令</p>
<pre><code class="language-py">git branch <branch-name>
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/e833ec961b40fe368ba8d4715abfd220.png" alt="创建 Git 分支" loading="lazy"></p>
<h1 id="5-切换分支">5. 切换分支</h1>
<p>要将分支从当前分支切换到不同的分支,你可以使用<strong>checkout</strong>或<strong>switch</strong>命令,后跟分支名称。</p>
<pre><code class="language-py">git checkout <branch-name>
git switch <branch-name>
</code></pre>
<h1 id="6-拉取">6. 拉取</h1>
<p>要与远程服务器同步更改,我们需要首先通过使用<strong>pull</strong>命令从远程拉取更改到本地仓库。这在远程仓库中进行了更改时是必需的。</p>
<pre><code class="language-py">git pull
</code></pre>
<p>你可以添加远程名称后跟分支名称来拉取单个分支。</p>
<pre><code class="language-py">git pull <remote name> <branch>
</code></pre>
<p>默认情况下,pull 命令会获取更改并将它们与当前分支合并。要进行变基,你可以在远程名称和分支之前添加<code>--rebase</code>标志。</p>
<pre><code class="language-py">git pull --rebase origin master
</code></pre>
<h1 id="7-添加">7. 添加</h1>
<p>使用<strong>add</strong>命令将文件添加到暂存区。它需要文件名或文件名列表。</p>
<pre><code class="language-py">git add <file-name>
</code></pre>
<p>你还可以使用<code>.</code>或<code>-A</code>标志一次性添加所有文件。</p>
<pre><code class="language-py">git add .
</code></pre>
<h1 id="8-提交">8. 提交</h1>
<p>在将文件添加到暂存区后,你可以使用<strong>commit</strong>命令创建一个版本。</p>
<p>提交命令需要通过<code>-m</code>标志指定提交的标题。如果你做了多个更改并想列出它们,请通过另一个<code>-m</code>标志将它们添加到描述中。</p>
<pre><code class="language-py">git commit -m "Title" -m "Description"
</code></pre>
<p><img src="https://kdn.flygon.net/docs/img/d4b0dfc7e8867355a9925c38126285c6.png" alt="Git Commit" loading="lazy"></p>
<blockquote>
<p><strong>注意:</strong> 在提交更改之前,请确保你已经配置了<strong>用户名</strong>和<strong>电子邮件</strong>。</p>
</blockquote>
<pre><code class="language-py">git config --global user.name <username>
git config --global user.email <youremail@yourdomain.com>
</code></pre>
<h1 id="9-推送">9. 推送</h1>
<p>要将本地更改同步到远程服务器,请使用<strong>push</strong>命令。你可以简单地输入<code>git push</code>来将更改推送到远程仓库。</p>
<p>要将更改推送到特定的远程服务器和分支,请使用下面的命令。</p>
<pre><code class="language-py">git push <remote name> <branch-name>
</code></pre>
<h1 id="10-撤销提交">10. 撤销提交</h1>
<p>Git <strong>revert</strong>会将更改撤销到特定提交,并将其作为新提交添加,保持日志不变。要撤销更改,你需要提供特定提交的哈希值。</p>
<pre><code class="language-py">git revert <commit>
</code></pre>
<p>你也可以通过使用<strong>reset</strong>命令撤销更改。它会将更改重置回特定提交,并丢弃之后所做的所有提交。</p>
<pre><code class="language-py">git reset <commit>
</code></pre>
<blockquote>
<p><strong>注意:</strong> 使用 reset 命令是不推荐的,因为它会修改你的 git 日志历史记录。</p>
</blockquote>
<h1 id="11-合并">11. 合并</h1>
<p><strong>merge</strong>命令将简单地将特定分支的更改合并到当前分支。该命令需要一个分支名称。</p>
<pre><code class="language-py">git merge <branch>
</code></pre>
<p>当你在多个分支上工作并且希望将更改合并到主分支时,这个命令非常方便。</p>
<h1 id="12-日志">12. 日志</h1>
<p>要检查之前提交的完整历史记录,你可以使用<strong>log</strong>命令。</p>
<p>要显示最近的日志,你可以添加<code>-</code>后跟数字,它将显示有限数量的最近提交历史。</p>
<p>例如,将日志限制为 5 条:</p>
<pre><code class="language-py">git log -5
</code></pre>
<p>你还可以查看特定作者所做的提交。</p>
<pre><code class="language-py">git log --author=”<pattern>”
</code></pre>
<blockquote>
<p><strong>注意:</strong> git log 有多个标志可以过滤特定类型的提交。查看完整的<a href="https://www.git-scm.com/docs/git-log" target="_blank">文档</a>。</p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/65d38b967464f4a3e64922c1f6c7c1df.png" alt="Git log" loading="lazy"></p>
<h1 id="13-差异">13. 差异</h1>
<p>使用<strong>diff</strong>命令将显示未提交更改与当前提交之间的比较。</p>
<pre><code class="language-py">git diff
</code></pre>
<p>对于比较两个不同的提交,请使用:</p>
<pre><code class="language-py">git diff <commit1> <commit2>
</code></pre>
<p>对于比较两个分支,可以使用:</p>
<pre><code class="language-py">git diff <branch1> <branch2>
</code></pre>
<h1 id="14-状态">14. 状态</h1>
<p><strong>status</strong>命令显示工作目录的当前状态。它包括有关要提交的更改、未合并路径、未暂存的更改以及未跟踪文件的列表的信息。</p>
<pre><code class="language-py">git status
</code></pre>
<blockquote>
<p><strong>注意:</strong> 查看 <a href="https://www.datacamp.com/tutorial/github-and-git-tutorial-for-beginners" target="_blank">Github 和 Git 初学者教程</a> 以了解更多关于数据科学中的版本控制系统的内容。</p>
</blockquote>
<p><strong><a href="https://www.polywork.com/kingabzpro" target="_blank">Abid Ali Awan</a></strong> (<a href="https://twitter.com/1abidaliawan" target="_blank">@1abidaliawan</a>) 是一位认证的数据科学专家,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个人工智能产品,以帮助那些面临心理健康问题的学生。</p>
<h3 id="更多相关话题-39">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/07/16-essential-dvc-commands-data-science.html" target="_blank">数据科学的 16 个基本 DVC 命令</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/10/10-essential-sql-commands-data-science.html" target="_blank">数据科学的 10 个基本 SQL 命令</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/01/12-essential-commands-streamlit.html" target="_blank">Streamlit 的 12 个基本命令</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/n26.html" target="_blank">KDnuggets 新闻,6 月 29 日:数据科学的 20 个基本 Linux 命令…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/01/12-docker-commands-every-data-scientist-know.html" target="_blank">每个数据科学家都应该知道的 12 个 Docker 命令</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/06/20-basic-linux-commands-data-science-beginners.html" target="_blank">数据科学初学者的 20 个基本 Linux 命令</a></p>
</li>
</ul>
<h1 id="我如何在-14-年里将我的薪水提高了-14-倍成为数据分析科学专业人士">我如何在 14 年里将我的薪水提高了 14 倍,成为数据分析/科学专业人士</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2021/12/14x-salary-in-14-years-data-professional.html" target="_blank"><code>www.kdnuggets.com/2021/12/14x-salary-in-14-years-data-professional.html</code></a></p>
</blockquote>
<p>评论</p>
<p><strong>作者</strong> <a href="https://www.linkedin.com/in/liangwei/" target="_blank">Leon Wei</a><strong>,instamentor.com 创始人,前苹果公司机器学习高级经理</strong>。</p>
<p><img src="https://kdn.flygon.net/docs/img/b3466184dac31c50fd3cf4aaa5eb40c3.png" alt="" loading="lazy"></p>
<hr>
<h2 id="我们的三大课程推荐-16">我们的三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业轨道。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织进行 IT 服务</p>
<hr>
<p><strong>70k => $ 1 million(如果我能做到,你也可以做到)</strong></p>
<p>在 2021 年初,我离开了在苹果公司的最后一份工作,专注于 <a href="http://instamentor.com/" target="_blank">instamentor</a> 和 <a href="http://sqlpad.io/" target="_blank">sqlpad</a> 这两个在 COVID 期间启动的副项目。</p>
<p>但由于它们的巨大吸引力和增长,我需要全身心投入。我别无选择,只能离开我在苹果公司的舒适工作。</p>
<p>今天,我不谈论 instamentor 或 sqlpad,因为它们仍处于早期阶段,未来有大量时间可以深入研究。</p>
<p>相反,我想回顾一下我的职业生涯,并分享几个故事,讲述我如何在过去的<strong>14 年</strong>里将我的公司工作收入<strong>增加了 14 倍</strong>。</p>
<p>如果我能做到,你肯定也可以做到。</p>
<p><em>TLDR.</em></p>
<blockquote>
<p>我在 2007 年开始了我的第一份全职工作,年薪为<strong>$70k</strong>。14 年后,到了 2020 年,我的年收入增长了<strong>14 倍</strong>,超过了<strong>$1 million</strong>。</p>
</blockquote>
<h3 id="时间线">时间线</h3>
<p><strong>2004 年:</strong> 在从中国获得学士学位后,我来到美国学习高级数学。</p>
<p>我很幸运:威廉与玛丽学院的应用科学系慷慨地给我提供了全额奖学金(<em>我将永远感激,Go Tribe!</em>)和一份兼职研究助理的工作,月薪高达 $1500(年薪 $18k)。</p>
<p><strong>2006 年:</strong> 我的博士生导师决定加入另一所大学,开始一个全新的学术项目,由于这个项目全新,他们还没有博士生,所以我无法和他一起转移。</p>
<p>回顾起来,这可能是我研究生学习期间发生的最好的事情。</p>
<p>正如史蒂夫·乔布斯所说:“<em>你无法在前方连接点,只能在回顾时连接它们。所以你必须相信,这些点将在未来某种方式上连接起来。</em>”</p>
<p>这正是发生的事情。</p>
<p>我总觉得在有限的实验数据样本上工作动力不足(在我的研究领域,收集数据非常昂贵)。</p>
<p>然而,作为数据研究员,你几乎总是希望拥有更大的数据集:以开发更好的统计模型,了解更多样本,这通常会显著提高模型表现。</p>
<p>我起初感到很慌张,但很快意识到我有两个选择:要么找一个新的博士生导师完成我的博士学位(这肯定会让我的父母感到骄傲),要么退出博士项目,获得硕士学位并找一份工作。</p>
<p>我决定在 2006 年底退出博士项目,并开始找工作。</p>
<p>我很快就得到了几次面试机会。2006 年,美国经济非常火爆,工作机会很多,住房市场在过去几年里也一直在繁荣。今天听起来很熟悉,不是吗?</p>
<p>我最终接受了一份数据挖掘研究(即数据分析师)职位的工作邀请,并搬到了波士顿,年薪高达<strong>$70k</strong>。</p>
<p>我几乎天真地认为我不会花光所有这些钱,所以毫不犹豫地买了一辆全新的 SAAB 93 来替换我那辆 10 年的福特 Escort。</p>
<p>哦,我当看到第一张薪水单和扣税金额时真是震惊不已,结果花了我一年多才还清车贷(约$27k)。</p>
<p>不过,总的来说,这份工作比我以前的研究助理职位要好得多。我赚了将近 4 倍的钱,生活很美好。</p>
<p><strong>2008–2010</strong>年:我换了几份工作,搬到了西海岸(西雅图,WA)。我在当时世界上最大的在线广告网络公司 Specific Media 开始了新工作。</p>
<p>一年后,他们收购了 MySpace,几年后又被 Time Inc.收购了。</p>
<p><em>收入:70K => 93K(15%) => 100K(20%)</em></p>
<p><strong>2011</strong>年:我加入了亚马逊,起始基本工资为<strong>$110k</strong>。他们还给我提供了<strong>$70k</strong>的 RSU(4 年归属期),<strong>$35k</strong>的第一年签约奖金和<strong>$40k</strong>的第二年签约奖金,总年薪大约为<strong>$150K</strong>:比我上一份工作高出<strong>50%</strong>。</p>
<p><strong>2013</strong>年:离开亚马逊,加入了 Chegg,在其 IPO 前阶段,基本工资为<strong>$190k</strong>,股票期权价值数百万(根据招聘团队的说法)。</p>
<p>(我还搬到了硅谷,随后遇到了很多了不起的人。)</p>
<p>嘿,谁不想去 IPO,发财,然后再也不需要工作呢?</p>
<p>但结果发现 2013 年是 IPO 的糟糕年份。</p>
<p>那一年只有少数几家公司上市,几乎所有公司在股市上的表现都很差。</p>
<p><strong>2014</strong>年:我加入了苹果公司(我一直是苹果产品的粉丝),所以当苹果的招聘人员通过 LinkedIn 联系我时,我非常兴奋,并努力准备面试。</p>
<p>几周后,我幸运地通过了他们的面试(由于假期季节,总共花了超过 2 个月)。</p>
<p>尽管我不得不减少一点基本工资,但在 RSUs 和签约奖金方面得到了很好的补偿。</p>
<p>快进到 5 到 6 年后(我于 2016 年离开去创办了一个机器学习初创公司,并于 2017 年回到苹果公司),到 2020 年,我大约获得了 5,000 股苹果股票,以今天的价值(每股约$160),我的公司工作的总收入约为<strong>$1—$1.1 百万</strong>。</p>
<h3 id="总结-10">总结</h3>
<p>根据我的经验:我从公司工作中获得的最显著的薪资增长来自于苹果股票的价值升值,我也看到我的前亚马逊同事经历了同样的情况。</p>
<p>当我第一次加入亚马逊时,股票价格约为<strong>$120</strong>每股,所以在过去十年里,股票价值<strong>30 倍</strong>增长至<strong>~$3600</strong>。哇。</p>
<p>在我看来,获得半百万或七位数收入的最可靠方法之一是加入一家 FAANG 公司,并在那待满至少四年,以获得所有初始 RSU 的归属。</p>
<p>加入一家 IPO 前的公司非常有趣且超级激动人心,但 IPO 后你可能会或者可能不会在经济上非常成功(想想 2018 年加入 Uber,或 2019 年加入 WeWork)。</p>
<p>很多因素、时机以及投资的整体经济环境都会影响你在 IPO 后的股票期权。</p>
<p>我仍然不会忘记 Chegg 在纽约证券交易所上市那天的公司聚会。那真是美好的一天!</p>
<p><strong>几点说明:</strong></p>
<ol>
<li>
<p>通常你不会在一次归属中获得所有的 RSU。它通常会在接下来的四年内均匀分配,例如,你可能每六个月收到总 RSU 授予的 1/8。</p>
</li>
<li>
<p>一些公司,如亚马逊或 Snap 的归属计划,鼓励员工待得更久。他们在第一年开始时提供<strong>5%</strong>(称为一年悬崖),然后在第二年提供<strong>15%</strong>,接着在接下来的两年里每六个月提供<strong>20%</strong>。</p>
</li>
<li>
<p>当我在第一份工作的年薪为<strong>$70k</strong>时,我似乎是最幸福的。从作为研究生的<strong>$20k</strong>年薪跳到<strong>$70k</strong>,让我获得了很多经济自由和更多的选择:我可以买得起一台 Mac 笔记本,或者买一台电视,甚至是 PlayStation,这些在之前都是无法负担的,所以在找到第一份行业工作后,生活变得更轻松(经济上)。</p>
</li>
</ol>
<p><a href="https://instamentor.com/articles/how-i-14xed-my-salary-in-14-years-as-a-data-analytics-science-professional" target="_blank">原文</a>。经许可转载。</p>
<p><strong>个人简介:</strong> <a href="https://www.linkedin.com/in/liangwei/" target="_blank">Leon Wei</a> (<a href="https://twitter.com/DataLeonWei" target="_blank">@DataLeonWei</a>) 是 <a href="http://instamentor.com" target="_blank">instamentor.com</a> 的创始人。在此之前,他曾在苹果公司担任高级机器学习经理,建立并招聘了一支世界级的机器学习团队,包括数据科学家、软件工程师、数据工程师和产品经理。在加入苹果之前,Leon 曾是 Chegg 的数据科学负责人,也曾在亚马逊担任研究科学家,开发亚马逊的实时动态定价引擎。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/10/tripled-my-income-data-science-18-months.html" target="_blank">如何在 18 个月内通过数据科学将收入增加三倍</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/06/double-income-data-science-machine-learning.html" target="_blank">我如何通过数据科学和机器学习翻倍我的收入</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/10/data-scientist-data-engineer-salary.html" target="_blank">数据科学家与数据工程师的薪资对比</a></p>
</li>
</ul>
<h3 id="了解更多主题-3">了解更多主题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/30-years-of-data-science-a-review-from-a-data-science-practitioner" target="_blank">30 年的数据科学:来自数据科学从业者的回顾</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/03/become-data-science-professional-five-steps.html" target="_blank">五步成为数据科学专业人士</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/08/ace-data-scientist-professional-certificate.html" target="_blank">如何通过数据科学家专业证书考试</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer" target="_blank">成为专业数据工程师所需的唯一免费课程</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/metas-new-data-analyst-professional-certification-has-dropped" target="_blank">Meta 新的数据分析师专业认证已上线!</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/12/top-5-nlp-cheat-sheets-beginners-professional.html" target="_blank">初学者到专业人士的前五名自然语言处理备忘单</a></p>
</li>
</ul>
<h1 id="15-个数据科学家在-python-中常犯的错误以及如何修复它们">15 个数据科学家在 Python 中常犯的错误(以及如何修复它们)</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2021/03/15-common-mistakes-python.html" target="_blank"><code>www.kdnuggets.com/2021/03/15-common-mistakes-python.html</code></a></p>
</blockquote>
<p>评论</p>
<p><strong>由 <a href="https://www.linkedin.com/in/gcsendes/" target="_blank">Gerold Csendes</a>,EPAM Systems 的数据科学家</strong>。</p>
<p><img src="https://kdn.flygon.net/docs/img/ec752ba42e144fea772521e9af7c7416.png" alt="" loading="lazy"></p>
<p><em>照片由 <a href="https://unsplash.com/@goshua13?utm_source=medium&utm_medium=referral" target="_blank">Joshua Aragon</a> 提供,来源于 <a href="https://unsplash.com/?utm_source=medium&utm_medium=referral" target="_blank">Unsplash</a>。</em></p>
<p>在我的数据科学职业生涯中,我逐渐意识到,通过应用软件工程的最佳实践,你可以交付更高质量的项目。更高的质量可能意味着更少的 bug、更可靠的结果以及更高的编码生产力。本文并不打算详细介绍这些最佳实践。相反,它总结了我遇到(并且自己也犯过)的最常见错误,并提供了方法、想法和资源,以帮助你最好地解决这些问题。</p>
<p>当你阅读我的文章时,你可能会想:“好吧,当我独自工作时,我并不真的需要遵循这些建议,因为我了解我的代码。” 实际上,至少会有另一个人阅读你的代码:你的未来自己。你目前认为显而易见的东西,几个月后可能会变成完全的胡言乱语。让她的生活更轻松一点,避免以下错误吧。</p>
<h3 id="1-你并不是在一个孤立的环境中工作">1. 你并不是在一个孤立的环境中工作</h3>
<p>好吧,这可能不完全是一个编码问题,但我仍然认为孤立的环境对于我的代码来说是一个重要的特性。为什么你要考虑为每个项目使用一个专门的环境?你想让你的代码具有可重现性:在你未来的计算机上、在你同事的机器上,以及在生产环境中。曾经遇到过你的同事无法运行你的代码的问题吗?很可能是因为她没有与你相同的依赖项。(或者也许在运行了数百个单元格后,你忘记检查在使用清除的内核时 Notebook 是否会崩溃)。如果你不知道什么是依赖项管理,那么最好从 <a href="https://docs.conda.io/projects/conda/en/latest/user-guide/tasks/manage-environments.html" target="_blank">Anaconda 虚拟环境</a> 或 <a href="https://realpython.com/pipenv-guide/" target="_blank">Pipenv</a> 开始。我个人使用 Anaconda,这里有一个很好的 <a href="https://towardsdatascience.com/a-guide-to-conda-environments-bc6180fc533" target="_blank">教程</a>,你可以通过点击链接访问。如果你想深入了解,那么 Docker 是你的首选。</p>
<h3 id="2-过度使用-jupyter-notebook">2. (过度使用) Jupyter Notebook</h3>
<p>Notebook 在教育用途和完成一些快速且粗糙的工作时确实很有用,但它在作为一个良好的 IDE 时却表现不佳。一个好的 IDE 是你处理数据科学任务时的真正武器,并且可以大大提高你的生产力。很多聪明的人都在指出 Notebook 的不足之处。我认为 Joel Grus 的 <a href="https://www.youtube.com/watch?v=7jiPeIFXb6U" target="_blank">演讲</a> 是最好的,而且非常有趣。</p>
<p>别误解我的意思,笔记本对于实验是很好的,你可以轻松地向同事展示结果。然而,它们非常容易出错,当涉及到长期的、协作的和可部署的项目时,你最好寻找一个真正的 IDE,比如 VScode、Pycharm、Spyder 等。我确实偶尔使用笔记本,但我建立了一个心理模型:只有在项目不超过一天的情况下,我才会使用笔记本。</p>
<h3 id="3-你没有组织你的代码">3. 你没有组织你的代码</h3>
<p>数据科学家有一个习惯,就是将所有项目文件堆放在一个目录中。这是一种不好的做法。看看下面的图,想象一下你需要接手同事的一个项目。哪种项目结构会让你在几个小时内尝试弄清楚发生了什么后陷入生存危机?当然,左侧的结构是你的首选。 <a href="https://drivendata.github.io/cookiecutter-data-science/" target="_blank">Cookiecutter</a> 是一个促进数据科学标准化项目结构的出色倡议。确保查看一下。</p>
<p><img src="https://kdn.flygon.net/docs/img/71a013d2741c042d3691b309182aa879.png" alt="" loading="lazy"></p>
<p><em>良好与不良的项目结构 — 作者截图。</em></p>
<h3 id="4-绝对路径而非相对路径">4. 绝对路径而非相对路径</h3>
<p>是否曾遇到过代码中的评论“pls fix your path”?这样的评论暗示了糟糕的代码设计。修复这个问题包括两个步骤。1) 与你的同事(也许是上述建议的那个)分享项目结构 2) 将你的 IDE 根目录/工作目录设置为项目根目录,通常是项目中的最外层目录。后者有时可能不那么简单,但绝对值得付出努力,因为你的同事将能够在不修改代码的情况下运行它。</p>
<h3 id="5-魔法数字">5. 魔法数字</h3>
<p>魔法数字是代码中没有上下文的数字。使用魔法数字可能会导致很难追踪的错误。下面的要点清楚地显示了,通过简单地在乘法中使用未赋值的数字,你会失去为什么会发生这种情况的上下文,并且如果你后来需要更改它,会感到相当有压力。因此,建议在 Python 中使用大写的命名常量。你实际上不必使用大写,这只是一个约定,但区分“常量”和“普通”变量是个好主意。</p>
<h3 id="6-不处理警告">6. 不处理警告</h3>
<p>我们都经历过代码运行时生成奇怪的警告信息的情况。你很高兴你的代码终于运行了,并且得到了有意义的输出。那么为什么要处理这些警告呢?其实,警告本身不是错误,但它们引起对潜在错误或问题的关注。当你的代码运行成功但可能不是按预期的方式运行时,警告会出现。我遇到的最常见的警告是 Pandas 的 SettingWithCopyWarning 和 DeprecationWarning。DataSchool 以一种 <a href="https://www.youtube.com/watch?v=4R4WsDJ-KVc" target="_blank">简洁的方式</a> 解释了 SettingWithCopyWarning 是如何触发的。DeprecationWarning 通常指出 Pandas 已经弃用了某些功能,并且你的代码在使用较新版本时会出现问题。当然,还有其他几种警告类型,我的经验是,当以非设计的方式使用某些功能时,它们就会出现。理解函数的源代码总是有帮助的。通过这样做,你可以 99% 的时间摆脱这些警告。</p>
<h3 id="7-你没有使用类型注解">7. 你没有使用类型注解</h3>
<p>我必须承认,这是我最近才学到的一个实践,但我已经能看到它的好处。类型注解(或类型提示)是一种给变量指定类型的方法。你基本上是用提示来扩展你的代码,这些提示实际上是对你的代码的扩展,指明了变量/参数的类型。这使得你的代码更易于阅读,因为编码者的意图是明确的。为了演示这一点,我从 Daniel Starner 的 <a href="https://dev.to/dstarner/using-pythons-type-annotations-4cfe" target="_blank">dev.to</a> 上拿了一个例子。没有类型提示的情况下,<em>mystery_combine()</em> 可以接受整数和字符串作为输入,并输出整数或字符串。这对其他开发者可能会造成困惑。通过使用类型注解,你可以明确你的意图,让同事的工作变得更轻松。</p>
<p>此外,带有类型注解的代码可以静态(在不实际运行代码的情况下)检查错误。下面的截图显示了前两个参数没有很好地指定。静态检查你的代码是运行前进行预检查的一个好方法。</p>
<p><img src="https://kdn.flygon.net/docs/img/265435f278090cebd9ed4a563ab16e6e.png" alt="" loading="lazy"></p>
<p><em>作者截图。</em></p>
<h3 id="8-你没有使用足够的列表推导式">8. 你没有使用(足够的)列表推导式</h3>
<p>列表推导式是 Python 的一个非常强大的特性。许多 for 循环可以用更具可读性、更符合 Python 风格并且更快的列表推导式来替代。下面的代码示例旨在读取目录中的 CSV 文件。你可能会说,在这种情况下使用 for 循环并没有错,但试着只检查 CSV 文件(可能还有其他格式的文件如 JSON)。你会发现,当使用列表推导式时,添加这样的功能很容易维护。</p>
<h3 id="9-你的-pandas-代码不可读">9. 你的 pandas 代码不可读</h3>
<p>方法链是一项在 pandas 中很棒的功能,但如果你将所有内容表达在一行中,代码可能会变得难以阅读。有一个技巧可以让你将表达式拆分开来。如果你将表达式放入括号中,那么你可以为表达式的每个组件使用单独的一行。这样不是更清晰吗?</p>
<h3 id="10-你害怕使用日期">10. 你害怕使用日期</h3>
<p>日期在 Python 中可能令人畏惧。语法很奇怪,很难理解。我看到的一个常见错误是,人们将日期处理得像数字一样。你可以始终做一些变通处理和编写黑客代码,但这真的容易出错,难以阅读和维护。以下是一个示例,任务是列出两个日期之间的所有月份,格式为 %Y%m。如果你遵循 datetime 实现,你会发现代码变得更加可读和易于维护。就我而言,处理日期仍然需要大量的 Google 搜索,但我已经学会了即使第一次尝试没有找到解决方案,也不要感到畏惧。</p>
<h3 id="11-你没有使用好的变量名">11. 你没有使用好的变量名</h3>
<p>将你的数据框命名为 df 和 i、j、k 作为循环索引只是没有描述性,并且使你的代码可读性降低。为了保持变量名过短而努力只会让项目中的其他开发者感到困惑。不要害怕为变量使用较长的名称。没有什么阻止你使用更多的‘_’。确保查看 Will Koehrsen 关于此主题的精彩<a href="https://towardsdatascience.com/data-scientists-your-variable-names-are-awful-heres-how-to-fix-them-89053d2855be" target="_blank">文章</a>,以获得更多见解。</p>
<h3 id="12-你没有模块化你的代码">12. 你没有模块化你的代码</h3>
<p>模块化意味着将长而复杂的代码拆分成更简单的模块,这些模块执行更小、更具体的任务。不要仅仅为你的项目创建一个长脚本。在代码的顶部定义类或函数是一种不好的做法。这很难维护和阅读。相反,创建模块(包)并根据它们的功能对其进行结构化。你可以访问 realpython.org 的<a href="https://realpython.com/courses/python-modules-packages/" target="_blank">Python 模块和包</a>教程,以获取深入的介绍。</p>
<h3 id="13-你不遵循-pep-规范">13. 你不遵循 PEP 规范</h3>
<p>当我开始学习 Python 编程时,我最终写出了丑陋且难以阅读的代码,并开始制定自己的设计规则来使代码看起来更好。花了相当多的时间来制定这些规则,而且我经常打破这些规则。然后,我发现了<a href="https://www.python.org/dev/peps/" target="_blank">PEP</a>,这是 Python 的官方样式指南。我非常喜欢 PEP,因为它通过使你的代码外观标准化来简化协作。顺便说一句,我确实忽略了一些 PEP 规则,但我会说我在 90% 的代码中使用了它们。</p>
<p>任何好的 Python IDE 都可以通过 linter 扩展。下面的图片演示了 linter 在实践中的工作原理。它们指出代码质量问题,如果这对你来说仍然不清楚,你可以查看括号中指示的具体 PEP 索引。如果你想了解有哪些可用的 linter,那么一如既往,<a href="https://realpython.com/python-code-quality/#linters" target="_blank">realpython.com</a> 是一个关于 Python 的好资源。</p>
<p><img src="https://kdn.flygon.net/docs/img/b91396aada9f5194acc8e4673d24152b.png" alt="" loading="lazy"></p>
<p><em>由作者截屏。</em></p>
<h3 id="14-你不会使用编码助手">14. 你不会使用编码助手</h3>
<p>想在编码中获得大幅度的生产力提升吗?开始使用编码助手,它可以通过智能自动完成、打开文档和提供改进代码的建议来帮助你。我喜欢使用 pylance,它是微软开发的一个新工具,并且在 VScode 中可用。Kite 是另一个非常不错的替代工具,也可以在多个编辑器中使用。</p>
<p>查看作者的<a href="https://thumbs.gfycat.com/BaggyNiceLemur-mobile.mp4" target="_blank">这个视频</a>。</p>
<h3 id="15-你不会在代码中隐藏秘密">15. 你不会在代码中隐藏秘密</h3>
<p>将秘密(密码、密钥)推送到公开的 GitHub 仓库是一个广泛存在的安全隐患。如果你想了解这个问题的严重性,请查看这篇<a href="https://qz.com/674520/companies-are-sharing-their-secret-access-codes-on-github-and-they-may-not-even-know-it/" target="_blank">qz</a>文章。网络上有机器人在等待你犯这样的错误。就我个人而言,安全性是数据科学课程中几乎从未涉及的话题。所以,你需要自己填补这个空白。我建议你首先使用操作系统环境变量。这个<a href="https://dev.to/biplov/handling-passwords-and-secret-keys-using-environment-variables-2ei0" target="_blank">dev.to</a>文章可能是一个好的开始。</p>
<p><a href="https://towardsdatascience.com/15-common-coding-mistakes-data-scientist-make-in-python-and-how-to-fix-them-7760467498af" target="_blank">原文</a>。经许可转载。</p>
<p><strong>相关:</strong></p>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2020/10/software-engineering-best-practices-data-science.html" target="_blank">数据科学的软件工程技巧和最佳实践</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2020/06/software-engineering-fundamentals-data-scientists.html" target="_blank">数据科学家的软件工程基础</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2020/05/coding-habits-data-scientists.html" target="_blank">数据科学家的编码习惯</a></p>
</li>
</ul>
<hr>
<h2 id="我们的前三个课程推荐-28">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业生涯。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析能力</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你组织中的 IT</p>
<hr>
<h3 id="更多相关话题-40">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/11/10-common-data-quality-issues-fix.html" target="_blank">10 种最常见的数据质量问题及其解决方法</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/5-common-data-science-mistakes-and-how-to-avoid-them" target="_blank">5 个常见的数据科学错误及其避免方法</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/5-common-python-gotchas-and-how-to-avoid-them" target="_blank">5 个常见的 Python 陷阱(及其避免方法)</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/avoid-these-5-common-mistakes-every-novice-in-ai-makes" target="_blank">避免这 5 个每个 AI 新手都会犯的常见错误</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/06/mistakes-newbie-data-scientists-avoid.html" target="_blank">新手数据科学家应避免的错误</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/02/much-data-scientists-make-2022.html" target="_blank">2022 年数据科学家的收入有多少?</a></p>
</li>
</ul>
<h1 id="2021-年-15-本免费数据科学机器学习与统计学电子书">2021 年 15 本免费数据科学、机器学习与统计学电子书</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2020/12/15-free-data-science-machine-learning-statistics-ebooks-2021.html" target="_blank"><code>www.kdnuggets.com/2020/12/15-free-data-science-machine-learning-statistics-ebooks-2021.html</code></a></p>
</blockquote>
<p>评论</p>
<p>在 KDnuggets,我们在过去一年中为读者带来了一些免费的电子书。在其他突显这些材料的文章中,自从疫情爆发以来,我写了一系列文章,考虑到更多人可能会在家中度过更多时间,从而增加了阅读时间。当然,过去九个月的生活显然不是大家所期待的,但是对于那些能在空闲时光抽出一点时间的人,我们希望在这段困难时期我们分享的一些电子书可能会有所帮助。</p>
<p><img src="https://kdn.flygon.net/docs/img/59a136278b8c7cd5b087089382fcd08b.png" alt="图像" loading="lazy"></p>
<p><a href="http://www.jessicascottauthor.com/why-free-books-dont-sell-books/" target="_blank">图片来源</a></p>
<hr>
<h2 id="我们的前三大课程推荐-26">我们的前三大课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业轨道</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织的 IT 需求</p>
<hr>
<p>当我回顾那些我在 2020 年撰写过书评的书籍时,我决定通过将 15 本书汇总到一个地方来结束这一年。如果你最初错过了其中的一些或全部书籍,这是你赶上阅读的机会。</p>
<p>随着这一点,我们随机再次呈现 15 本顶级免费电子书,帮助你开启 2021 年,并附上了我原始书评中的书单。</p>
<p><strong><a href="https://acems.org.au/data-science-machine-learning-book-available-download" target="_blank">数据科学与机器学习:数学与统计方法</a></strong>,作者:D.P. Kroese, Z.I. Botev, T. Taimre & R. Vaisman</p>
<blockquote>
<p>《数据科学与机器学习:数学与统计方法》是一本以实践为导向的教材,重点在于使用 Python 进行数据科学和实现机器学习模型。它很好地解释了相关理论,并在需要时介绍了必要的数学知识,从而使得这本实用书的节奏非常好。</p>
</blockquote>
<p><strong><a href="https://www.tidytextmining.com/index.html" target="_blank">R 文本挖掘:简洁方法</a></strong>,作者:Julia Silge 和 David Robinson</p>
<blockquote>
<p>《R 的文本挖掘:一种整洁的方法》代码密集,似乎能很好地解释概念。重点在于实际应用,这与书名不谋而合,对 R 新手来说,似乎做得非常好。我没有跟着整本书的内容,但读了前两章,感觉得到了预期的内容。</p>
</blockquote>
<p><strong><a href="https://www.hsph.harvard.edu/miguel-hernan/causal-inference-book/" target="_blank">因果推断:如果</a></strong>,作者 Miguel Hernán 和 Jamie Robins</p>
<blockquote>
<p>因果推断是一个复杂而全面的主题,但这本书的作者尽力将他们认为最重要的基本方面压缩到约 300 页的文本中。由于很少有专门讲述这个主题的书籍,如果你有兴趣建立自己的概念基础,这本书可能是你的首选。</p>
</blockquote>
<p><strong><a href="https://statisticswithjulia.org/StatisticsWithJuliaDRAFT.pdf" target="_blank">使用 Julia 进行统计:数据科学、机器学习和人工智能的基础</a></strong>,作者 Yoni Nazarathy 和 Hayden Klok</p>
<blockquote>
<p>这本书在下一章将进入统计概念,从那时起,概念将层层递进,涉及更高级的主题,如统计推断、置信区间、假设检验、线性回归、机器学习等。</p>
<p>这是我一直在等待的资源,它将有效地教我如何使用 Julia 进行数据科学,就像我一直想学的那样。我希望你和我一样,对开始你的学习之旅感到兴奋。</p>
</blockquote>
<p><strong><a href="https://www.cs.cornell.edu/jeh/book%20no%20so;utions%20March%202019.pdf" target="_blank">数据科学基础</a></strong>,作者 Avrim Blum、John Hopcroft 和 Ravindran Kannan</p>
<blockquote>
<p>在许多当代书籍中,数据科学被简化为一系列编程工具,只要掌握这些工具,就能为你完成数据科学工作。似乎对与代码无关的基本概念和理论的强调较少。这本书是这种趋势的一个反例,它无疑会为你提供从事数据科学所需的理论知识,建立坚实的基础。</p>
</blockquote>
<p><strong><a href="https://www.cse.huji.ac.il/~shais/UnderstandingMachineLearning/index.html" target="_blank">理解机器学习:从理论到算法</a></strong>,作者 Shai Shalev-Shwartz 和 Shai Ben-David</p>
<blockquote>
<p>一旦可能的数学理论冲击消退,你会发现对从偏差-方差权衡到线性回归再到模型验证策略、模型提升、核方法、预测问题等主题的全面阐述。这种全面处理的好处在于,你的理解将超越仅仅掌握抽象直觉。</p>
</blockquote>
<p><strong><a href="https://www.nltk.org/book/" target="_blank">使用 Python 进行自然语言处理</a></strong>,作者 Steven Bird、Ewan Klein 和 Edward Loper</p>
<blockquote>
<p>这本书开篇较慢——描述了自然语言处理(NLP)、Python 如何用于执行一些 NLP 编程任务、如何访问自然语言内容进行处理——然后逐步转向更大的概念,无论是概念上(NLP)还是编程上(Python)。很快,它就会涉及到分类、文本分类、信息提取以及其他通常被认为是经典 NLP 的主题。在掌握了这本书的 NLP 基础知识后,你可以继续学习更现代和前沿的技术,例如通过一些斯坦福大学的免费课程。</p>
</blockquote>
<p><strong>《利用 fastai 和 PyTorch 进行深度学习:无需博士学位的 AI 应用》</strong>,作者:杰里米·霍华德和西尔万·古格</p>
<blockquote>
<p>这本书的特别之处在于它是“自上而下”教学的。我们通过实际示例来讲授几乎所有内容。在构建这些示例的过程中,我们会逐步深入,并展示如何不断改进你的项目。这意味着你将逐渐在实际背景中学习所需的所有理论基础,从而看到其重要性和工作原理。我们花了多年时间构建工具和教学方法,使以前复杂的主题变得非常简单。</p>
<p>—杰里米·霍华德</p>
</blockquote>
<p><strong><a href="https://www.py4e.com/book.php" target="_blank">人人都能学 Python</a></strong>,作者:查尔斯·R·塞弗朗斯</p>
<blockquote>
<p>书籍的 448 条评价,平均评分为 4.6 分(满分 5 分),应能告诉你许多人也发现《人人都能学 Python》非常有用。共识似乎是,这本书快速覆盖了概念,以易于理解的方式进行,并直接跳入相应的代码中。</p>
</blockquote>
<p><strong>《自动化机器学习:方法、系统、挑战》</strong>,编辑:弗兰克·胡特、拉斯·科特霍夫和华金·范斯科伦</p>
<blockquote>
<p>如果你对自动化机器学习在实践中的理解几乎为零,也不要担心。这本书首先提供了对该主题的扎实介绍,并明确列出了每章的期望内容,这在由独立章节组成的书中非常重要。在此之后,书的第一部分直接涉及当代 AutoML 的重要话题,并且要相信这一点,因为这本书是在 2019 年编写的。接下来的部分是对实现这些 AutoML 概念的六种工具的逐步讲解。最后一部分分析了在 2015 年至 2018 年间存在的 AutoML 挑战系列,那时对自动化机器学习方法的兴趣似乎激增。</p>
</blockquote>
<p><strong><a href="https://www.deeplearningbook.org/" target="_blank">深度学习</a></strong>,作者:伊恩·古德费洛、约书亚·本吉奥和亚伦·库尔维尔</p>
<blockquote>
<p>这是一本从底向上、理论重的深度学习专著。这不是一本充满代码和相应注释的书,也不是对神经网络的表面式、挥手式概述。这是对该领域的数学基础解释的深入讲解。</p>
</blockquote>
<p><strong><a href="https://d2l.ai/" target="_blank">深入深度学习</a></strong>,作者:阿斯顿·张、扎卡里·C·利普顿、穆·李和亚历山大·J·斯莫拉</p>
<blockquote>
<p>Dive into Deep Learning (D2K) 的独特之处在于我们将<em>实践学习</em>的理念发挥到了极致,整本书都是可运行的代码。我们试图将教科书(清晰度和数学)的最佳方面与动手教程(实践技能、参考代码、实现技巧和直觉)的最佳方面结合起来。每一章通过多种方式教授一个关键思想,将散文、数学和一个可以轻松抓取和修改的自包含实现交织在一起,以便为你的项目提供一个良好的开端。我们认为这种方法对教学深度学习至关重要,因为深度学习中的核心知识大多来自实验(而非基本原理)。</p>
<p>—Zachary Lipton</p>
</blockquote>
<p><strong><a href="https://mml-book.com/" target="_blank">机器学习数学</a></strong>,作者:Marc Peter Deisenroth, A Aldo Faisal 和 Cheng Soon Ong</p>
<blockquote>
<p>书的第一部分涵盖了纯数学概念,而没有涉及机器学习。第二部分则将注意力转向将这些新学到的数学技能应用于机器学习问题。根据你的需求,你可以采取自上而下或自下而上的方法来学习机器学习及其基础数学,或专注于其中的一部分。</p>
</blockquote>
<p><strong><a href="https://web.stanford.edu/~hastie/Papers/ESLII.pdf" target="_blank">统计学习要素</a></strong>,作者:Trevor Hastie, Robert Tibshirani 和 Jerome Friedman</p>
<blockquote>
<p>所有这些都是在说,作者们也是研究人员和讲师,他们在传达他们的专业知识时有自己的方法。他们的方法似乎遵循了一个逻辑有序的方式,来决定读者应该学习什么以及何时学习。然而,单独的章节也可以独立阅读,因此,如果你已经理解了书中前面的内容,直接阅读关于模型推断的章节也会效果很好。</p>
</blockquote>
<p><strong><a href="https://statlearning.com/ISLR%20Seventh%20Printing.pdf" target="_blank">统计学习导论:R 语言应用</a></strong>,作者:Gareth James, Daniela Witten, Trevor Hastie 和 Robert Tibshirani</p>
<blockquote>
<p>《统计学习导论:R 语言应用》可以被视为对《统计学习要素》这本经典著作中涉及的主题的较少进阶的处理,后者由一些相同的作者编写。这两个标题之间的另一个主要区别,除了材料的深度外,是《统计学习导论》在介绍这些主题时结合了编程语言的实际实现,在这种情况下是 R 语言。</p>
</blockquote>
<p><strong>相关</strong>:</p>
<ul>
<li>
<p>2020 年最佳免费数据科学电子书:更新版</p>
</li>
<li>
<p>5 本免费统计学书籍学习数据科学</p>
</li>
<li>
<p>每个人都应该阅读的 5 本免费机器学习和深度学习电子书</p>
</li>
</ul>
<h3 id="更多相关话题-41">更多相关话题</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/build-solid-data-team.html" target="_blank">建立一个坚实的数据团队</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/write-clean-python-code-pipes.html" target="_blank">使用管道编写干净的 Python 代码</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/mozart-best-etl-tools-2021.html" target="_blank">2021 年最佳 ETL 工具</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/springboard-top-resources-learn-data-science-statistics.html" target="_blank">学习数据科学的统计学最佳资源</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/stop-learning-data-science-find-purpose.html" target="_blank">停止学习数据科学以寻找目标,然后找到目标去…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2021/12/6-predictive-models-every-beginner-data-scientist-master.html" target="_blank">每个初学者数据科学家应该掌握的 6 个预测模型</a></p>
</li>
</ul>
<h1 id="15-本免费机器学习和深度学习书籍">15 本免费机器学习和深度学习书籍</h1>
<blockquote>
<p>原文:<a href="https://www.kdnuggets.com/2022/10/15-free-machine-learning-deep-learning-books.html" target="_blank"><code>www.kdnuggets.com/2022/10/15-free-machine-learning-deep-learning-books.html</code></a></p>
</blockquote>
<p><img src="https://kdn.flygon.net/docs/img/a6a9f5a9bf9ecf2d478f04f2c84c2273.png" alt="15 本免费机器学习和深度学习书籍" loading="lazy"></p>
<p>图片由编辑提供</p>
<p>如果你希望在机器学习领域发展职业或作为数据科学家希望转型进入机器学习领域,下面是一些免费的电子书列表,帮助你实现这一目标。</p>
<h1 id="理解机器学习从理论到算法">《理解机器学习:从理论到算法》</h1>
<hr>
<h2 id="我们的前三个课程推荐-29">我们的前三个课程推荐</h2>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 1. <a href="https://www.kdnuggets.com/google-cybersecurity" target="_blank">谷歌网络安全证书</a> - 快速进入网络安全职业轨道。</p>
<p><img src="https://kdn.flygon.net/docs/img/e225c49c3c91745821c8c0368bf04711.png" alt="" loading="lazy"> 2. <a href="https://www.kdnuggets.com/google-data-analytics" target="_blank">谷歌数据分析专业证书</a> - 提升你的数据分析技能</p>
<p><img src="https://kdn.flygon.net/docs/img/0244c01ba9267c002ef39d4907e0b8fb.png" alt="" loading="lazy"> 3. <a href="https://www.kdnuggets.com/google-itsupport" target="_blank">谷歌 IT 支持专业证书</a> - 支持你的组织在 IT 领域</p>
<hr>
<p>作者:Shai Shalev-Shwartz 和 Shai Ben-David</p>
<p>这本书分为四部分:第一部分:基础,第二部分:从理论到算法,第三部分:附加学习模型,第四部分:高级理论。如果你想查看内容,请点击<a href="https://www.cs.huji.ac.il/~shais/UnderstandingMachineLearning/toc.html" target="_blank">这里</a>。</p>
<p><a href="https://www.cs.huji.ac.il/~shais/UnderstandingMachineLearning/understanding-machine-learning-theory-algorithms.pdf" target="_blank">点击这里阅读</a>。</p>
<h1 id="思考统计程序员的概率与统计">《思考统计:程序员的概率与统计》</h1>
<p>作者:Allen B. Downey</p>
<p>如果你已经对 Python 有了基本了解,并且能够应用它,你可以进一步应用这些技能,更好地理解概率和统计的概念。这本书深入讲解,会将你的机器学习之旅提升到新的水平。</p>
<p><a href="https://greenteapress.com/thinkstats2/thinkstats2.pdf" target="_blank">点击这里阅读</a>。</p>
<h1 id="统计学习入门">《统计学习入门》</h1>
<p>作者:Gareth James、Daniela Witten、Trevor Hastie 和 Rob Tibshirani</p>
<p>统计学是机器学习的一个重要部分,因此了解得越多越好。如果你正在寻找一本帮助你掌握统计学的书籍——这本书深入讲解了深度学习、生存分析、多重检验等内容。</p>
<p><a href="https://hastie.su.domains/ISLR2/ISLRv2_website.pdf" target="_blank">点击这里阅读</a>。</p>
<h1 id="机器学习为人类">《机器学习为人类》</h1>
<p>作者:Vishal Maini 和 Samer Sabri</p>
<p>另一本适合初学者的好书。如果你对机器学习还不太熟悉,想要增加对其基础知识的了解——这是一本非常有价值的电子书。你将学习监督学习、无监督学习、神经网络和深度学习、强化学习以及最佳的机器学习资源。</p>
<p><a href="https://everythingcomputerscience.com/books/Machine%20Learning%20for%20Humans.pdf" target="_blank">点击这里阅读</a>。</p>
<h1 id="大数据挖掘">《大数据挖掘》</h1>
<p>作者:Jure Leskovec, Anand Rajaraman, 和 Jeffrey D. Ullman</p>
<p>我们有大量的数据可用,数据越多,数据集就越大。能够挖掘庞大的数据集,并提取有价值的见解以进一步用于决策过程是一项越来越受欢迎的技能。</p>
<p><a href="http://infolab.stanford.edu/~ullman/mmds/book.pdf" target="_blank">点击这里阅读</a>。</p>
<h1 id="机器学习工程">机器学习工程</h1>
<p>作者:Andriy Burkov</p>
<p>如果你正在寻找一份工作,尤其是作为机器学习工程师——这本书适合你。书中分为 9 章:简介、项目开始前、数据收集与准备、特征工程、监督模型训练(第一部分)、监督模型训练(第二部分)、模型评估、模型部署、模型服务、监控与维护,以及结论。这是对机器学习工程师日常工作的终极解读。</p>
<p><a href="http://www.mlebook.com/wiki/doku.php" target="_blank">点击这里阅读</a>。</p>
<h1 id="百页机器学习书">《百页机器学习书》</h1>
<p>作者:Andriy Burkov</p>
<p>Burkov 还有另一本机器学习书籍,但这本书首先讲解该领域的基础知识,然后深入探讨更高级的实践,如符号和定义、基础算法及深入材料、学习算法的结构、基本实践、神经网络和深度学习、问题与解决方案、高级实践。</p>
<p><a href="http://themlbook.com/wiki/doku.php" target="_blank">点击这里阅读</a>。</p>
<h1 id="机器学习数学">机器学习数学</h1>
<p>作者:Marc Peter Deisenroth, A. Aldo Faisal, Cheng Soon Ong</p>
<p>我们永远无法忘记数学在机器学习中的重要性。这是一个需要花费大量时间才能掌握的领域。在这本书中,你将学习线性代数、解析几何、矩阵分解、线性回归、主成分分析(PCA)的降维、密度估计以及支持向量机分类。</p>
<p><a href="https://mml-book.github.io/book/mml-book.pdf" target="_blank">点击这里阅读</a>。</p>
<h1 id="特征工程与选择预测模型的实用方法">特征工程与选择:预测模型的实用方法</h1>
<p>作者:Max Kuhn 和 Kjell Johnson</p>
<p>特征工程是机器学习模型的重要元素。本电子书指导你正确进行特征工程和预测建模的实践。涵盖的主题包括使用实例进行预测建模、性能测量、参数调整、模型优化、探索性可视化等。</p>
<p><a href="http://www.feat.engineering/index.html" target="_blank">点击这里阅读</a>。</p>
<h1 id="模式识别与机器学习">模式识别与机器学习</h1>
<p>作者:Christopher M Bishop</p>
<p>这本 758 页的电子书内容丰富!你将首先广泛介绍概率及其分布。接着,你将进入回归和分类的线性模型,然后进一步学习神经网络和其他主题,如核方法等。</p>
<p><a href="https://www.microsoft.com/en-us/research/uploads/prod/2006/01/Bishop-Pattern-Recognition-and-Machine-Learning-2006.pdf" target="_blank">点击这里阅读</a>。</p>
<h1 id="实用机器学习与-r">实用机器学习与 R</h1>
<p>作者:Bradley Boehmke 和 Brandon Greenwell</p>
<p>如果 R 是你选择的编程语言,并且你已经开始深入了解机器学习——这本书适合你。它涵盖了最常见的机器学习方法,如广义低秩模型、聚类算法、自编码器、正则化模型、随机森林、梯度提升机器、深度神经网络、堆叠/超级学习器等。</p>
<p><a href="https://bradleyboehmke.github.io/HOML/" target="_blank">点击这里阅读</a>。</p>
<h1 id="机器学习解释性简介">机器学习解释性简介</h1>
<p>作者:Patrick Hall 和 Navdeep Gill</p>
<p>作为一名机器学习工程师,你可能会遇到需要解释你的模型的时刻。高管通常没有技术背景,因此能够解释和阐述你的 AI 给这类人群是一项非常重要的技能,并且能让你走得更远。</p>
<p><a href="https://h2o.ai/content/dam/h2o/en/marketing/documents/2019/08/An-Introduction-to-Machine-Learning-Interpretability-Second-Edition.pdf" target="_blank">点击这里阅读</a>。</p>
<h1 id="使用-python-进行自然语言处理">使用 Python 进行自然语言处理</h1>
<p>作者:Steven Bird, Ewan Klein, 和 Edward Loper</p>
<p>如果你对自然语言处理感兴趣并且精通 Python——这本书适合你。你将学习:</p>
<ol>
<li>
<p>语言处理与 Python</p>
</li>
<li>
<p>访问文本语料库和词汇资源</p>
</li>
<li>
<p>处理原始文本</p>
</li>
<li>
<p>编写结构化程序</p>
</li>
<li>
<p>分类和标记单词</p>
</li>
<li>
<p>学习文本分类</p>
</li>
<li>
<p>从文本中提取信息</p>
</li>
<li>
<p>分析句子结构</p>
</li>
<li>
<p>构建基于特征的语法</p>
</li>
<li>
<p>分析句子的意义</p>
</li>
<li>
<p>管理语言数据</p>
</li>
<li>
<p>后记:面对语言挑战</p>
</li>
</ol>
<p><a href="https://www.nltk.org/book/" target="_blank">点击这里阅读</a>。</p>
<h1 id="python-机器学习项目">Python 机器学习项目</h1>
<p>作者:Brian Bocheron 和 Lisa Tagliaferri</p>
<p>你可能已经到了想创建机器学习项目来测试你的技能和建立一个作品集的阶段。项目是你在科技行业职业生涯中的一个重要元素,并且对帮助你找到工作至关重要。</p>
<p><a href="http://assets.digitalocean.com/books/python/machine-learning-projects-python.pdf" target="_blank">点击这里阅读</a>。</p>
<h1 id="机器学习面试书介绍">机器学习面试书介绍</h1>
<p>作者:Chip Huyen</p>
<p>如果你已经对机器学习有了良好的理解,并且准备开始申请工作——了解你将面临的面试问题类型是非常有用的。你将更好地理解不同的角色、公司和面试流程。</p>
<p><a href="https://huyenchip.com/ml-interviews-book/" target="_blank">点击这里阅读</a></p>
<h1 id="结论-20">结论</h1>
<p>希望这篇文章能帮助你收集免费的资源,以帮助你在机器学习方面建立知识并启动你的职业生涯。</p>
<p>关注下一批免费的机器学习和深度学习电子书!</p>
<p><strong><a href="https://www.linkedin.com/in/nisha-arya-ahmed/" target="_blank">Nisha Arya</a></strong> 是一名数据科学家和自由职业技术作家。她特别感兴趣于提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探索人工智能如何(或可以)促进人类寿命的不同方式。作为一名热衷学习者,她寻求拓宽技术知识和写作技能,同时帮助指导他人。</p>
<h3 id="相关主题更多内容-1">相关主题更多内容</h3>
<ul>
<li>
<p><a href="https://www.kdnuggets.com/2022/n43.html" target="_blank">KDnuggets 新闻,11 月 2 日:数据科学的现状…</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2022/11/15-free-machine-learning-deep-learning-books.html" target="_blank">15 本更多免费的机器学习和深度学习书籍</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2020/03/24-best-free-books-understand-machine-learning.html" target="_blank">理解机器学习的 24 本最佳(且免费)书籍</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/25-free-books-to-master-sql-python-data-science-machine-learning-and-natural-language-processing" target="_blank">掌握 SQL、Python、数据科学、机器学习和自然语言处理的 25 本免费书籍</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/5-free-books-to-master-machine-learning" target="_blank">掌握机器学习的 5 本免费书籍</a></p>
</li>
<li>
<p><a href="https://www.kdnuggets.com/2023/01/5-free-data-science-books-must-read-2023.html" target="_blank">2023 年必读的 5 本免费数据科学书籍</a></p>
</li>
</ul>

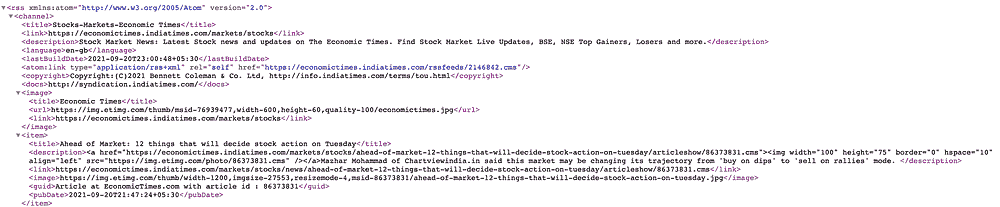


 浙公网安备 33010602011771号
浙公网安备 33010602011771号