KDNuggets-博客中文翻译-五-
KDNuggets 博客中文翻译(五)
原文:KDNuggets
立即提升你的数据科学技能的 5 个建议
原文:
www.kdnuggets.com/5-tips-to-step-up-your-data-science-game-right-away

作者提供的图片 | Midjourney & Canva
介绍
数据科学家在不断应对一个变化中的领域,以及其不断发展的技术和方法。这个行业的快速增长和动态特性促使从业人员需要不断学习和适应。由于这种持续增长,成为活跃且有效的从业者需要不断的个人发展。无论是新手还是经验丰富的数据科学家,总有更多的概念、工具和技术需要学习和掌握。
这也是我们今天在这里的原因。本文旨在提供实用建议,通过关注五个不同的能力领域,帮助你成为更好的数据科学家。无论你是刚刚起步,还是希望在多年从业后重新扎根,都可以参与进来,提升你的技能。
1. 掌握数学基础
理解所需数学的基础知识是处理数据的基本部分。线性代数、微积分和概率论是数据科学家进行建模和算法工作的基础。机器学习数学 这本书是一个很好的起点,Coursera 的 数据科学数学专攻 课程也是如此。3Brown1Blue 的 YouTube 视频 是这些主题的另一个极好的资源。将这些数学基础知识应用于实际项目和练习中将确保你的知识保持扎实。
2. 跟踪行业趋势
如果有人希望在这个既广泛又深入的领域中保持了解并长期保持就业,紧跟最新的工具、技术和方法是不可忽视的。从自动化机器学习和可解释性过程等技术创新,到大规模数据技术和最先进的机器学习算法,从“了解一下”到“必须了解”的领域在不断变化。这不是一个无关紧要的问题:个人和组织希望能够在适当的情况下融入最新的技术。KDnuggets(你已经在这里了)及我们的姊妹网站 Machine Learning Mastery 和 Statology 是关注这些话题的好去处。
但也有其他很棒的资源:像 Towards Data Science、DataCamp、MarkTechPost 这样受欢迎的网站,以及众多其他资源也值得你花时间关注。各种播客、网络研讨会和 YouTube 频道提供了替代途径,总有适合每个人的选择。在线和线下的社区及会议可以是建立网络和跟进最新趋势的好方法。
3. 发展强大的编程技能
这一点不能过分强调:精通 Python、R 和 SQL 中的一种或多种 —— 这些是该领域的关键编程语言 —— 是任何想成为有用数据科学家的绝对必要条件。掌握 Pandas 和 Matplotlib(Python)以及 dplyr 和 ggplot2(R)等库或包对于数据工作来说至关重要。学习编写 SQL 查询的最高效方法同样重要,因为 SQL 仍然是全球使用最广泛的语言之一,特别是在数据科学领域。当然,还有许多其他语言可能对数据工作有所帮助 —— Java、Rust、C++、Go、JavaScript、Ruby …… 列表还在继续。你可以从这些语言中选择适合自己的,但不要忽视上面提到的三大主要语言;忽略它们是很不值得冒这个风险的。
通过像 HackerRank 或 LeetCode 这样的平台,或通过 GitHub 贡献,可以提高自己的编程技能。参与小组项目需要理解 Git,这可以用于版本控制。简而言之,不要相信不需要编码的夸大宣传。如果你不能编码,就需要其他人来做,而由于许多数据科学家都会编码,你如何从中脱颖而出?作为基础,成为一个强大的编码者,然后再增加其他技能以使自己与众不同。
4. 使用真实数据集
对于任何想在这一领域超越学术界的人来说,处理最新的事实和数据是必不可少的。没有什么比主动解决数据问题更好的了。实现的方法包括在 Kaggle 上竞赛,承担独立的挑战项目,甚至寻找实习或志愿工作。通过准确地解决问题,包括恰当地应用算法、理解各种数据集并记录所有工作,能够建立一个 强大的作品集。
基于对 Iris 数据集进行重构的作品集项目和对坚固且现代的真实世界数据进行深入分析之间的差异如天壤之别。使用真实且有价值的数据。
5. 培养沟通和协作技能
为了将复杂的分析结果传达给非学术观众,强有力的沟通是成功的关键。通过引人入胜的数据故事、吸引眼球的可视化、引人注目的精心制作的演讲以及旨在预先回答问题和填补空白的辅助材料,能够有效传达信息。多个工具可助你讲述数据科学故事,包括 Tableau、Power BI,甚至是 PowerPoint 或 Google Slides。
除了这一鼓舞人心的展望,一位有效的数据科学家还需要运用积极倾听和预见性提问的技能,这对于传达你的领域权威感至关重要。这些相同的技能也有助于提高团队效能和项目产出。表达你的想法和发现,并与分析团队以及最终受众良好合作,是有效数据科学家的另一个关键要素,加强在这一方面的努力可以帮助你提升能力。
最终思考
本文旨在表达如何提升你在数据科学领域的各个方面。在这五个领域——全面的信息支持、了解行业发展动态、流利且有效的编码、实际操作真实数据、以及与他人协作的能力——我们寻找了帮助普通数据专业人士提升技能的方法。数据科学的学习和成长是持续不断的,因此确保你在这段旅程中全程参与。
Matthew Mayo (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 和 Statology 的主编以及 Machine Learning Mastery 的特约编辑,Matthew 致力于使复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、语言模型、机器学习算法和探索新兴的人工智能。他的使命是将知识普及到数据科学社区。Matthew 从 6 岁开始编程。
更多相关话题
编写干净 R 代码的 5 个技巧
原文:
www.kdnuggets.com/2021/08/5-tips-writing-clean-r-code.html
comments
由 Marcin Dubel,Appsilon

干净的 R 代码至关重要
多年的成功项目经验让我发现每个实施方案中都有一个共同的元素。一个干净、可读且简洁的代码库是有效协作的关键,并为客户提供了最高质量的价值。
代码审查是维护高质量代码流程的一个重要部分。它也是共享最佳实践和在团队成员之间分配知识的绝佳方式。在 Appsilon,我们将代码审查视为每个项目的必备环节。阅读更多关于我们如何组织工作的内容,查看 Olga 的博客文章,了解推荐给所有数据科学团队的最佳实践。
拥有一个完善的代码审查流程并不改变开发者编写良好、干净代码的责任!指出代码中的所有基本错误是痛苦的、耗时的,并且会分散审查员深入代码逻辑或提高代码有效性的注意力。
编写不良代码还可能伤害团队士气——代码审查员会感到沮丧,而代码创建者可能会因为大量评论而感到受伤。因此,在发送代码进行审查之前,开发者需要确保代码尽可能干净。同时,请注意,并不是总会有代码审查员可以提供帮助。有时候你需要独自处理项目。即使你现在认为代码没问题,也考虑在几个月后重新阅读一遍——你希望它足够清晰,以免以后浪费自己的时间。
在这篇文章中,我总结了在编程中需要避免的最常见错误,并概述了应该遵循的最佳实践。遵循这些提示可以加快代码审查的迭代过程,并在审查者眼中成为一名超级开发者!
避免带有注释的注释
向代码添加注释是开发者的一个关键技能。然而,更为关键且难以掌握的技能是知道何时不添加注释。编写好的注释更像是一门艺术而非科学。这需要大量的经验,你可以为此写整本书(例如,这里)。
你应该遵循几个简单的规则,以避免关于你注释的注释:
-
注释应向读者添加外部知识:如果它们在解释代码本身发生了什么,这是一个警示信号,说明代码不够清晰,需要重构。如果使用了某种黑客技术,则可能需要注释来解释发生了什么。注释所需的业务逻辑或例外是故意添加的。尝试考虑可能会让未来的读者感到惊讶的内容,并预先解决他们的困惑。
-
只写必要的注释!你的注释不应成为易于搜索的信息字典。一般来说,注释会分散注意力,没有代码本身解释逻辑好。例如,最近我看到代码中的注释是:
trimws(.) # 这个函数修剪前导/尾随空格——这是多余的。如果读者不知道trimws函数的作用,可以很容易查找。一个更稳健的注释可能会更有帮助,例如:trimws(.) # TODO(Marcin Dubel): 修剪空格在这里至关重要,因为数据库条目不一致;数据需要清理。 -
编写 R 语言函数时,即使你没有编写包,我也推荐使用{roxygen2}注释。这是一个组织关于函数目标、参数和输出知识的优秀工具。
-
仅用英语编写注释(以及所有代码部分)。使其对所有读者可理解可能会节省因使用母语特殊字符而出现的编码问题。
-
如果将来需要重构/修改某些代码,请用
# TODO注释标记。同时,添加一些信息以标识你作为此注释的作者(以便在需要详细信息时联系)以及简要解释为什么将以下代码标记为 TODO 而不是立即修改。 -
永远不要留下未注释的注释代码!保留一些部分供将来使用或暂时关闭是可以的,但始终标记此操作的原因。
请记住,注释将保留在代码中。如果有些事情你只想告诉审查者一次,请将注释添加到 Pull(Merge)请求中,而不是代码本身。
示例:我最近看到移除代码的一部分,附带注释如:“由于逻辑更改而移除。” 好的,这样知道了,但之后在代码中的这个注释显得奇怪且多余,因为读者不再看到被移除的代码。
字符串
与文本相关的常见问题是字符串连接的可读性。我遇到的一个问题是paste函数的过度使用。不要误解我的意思;当你的字符串很简单时,例如paste("我的名字是", my_name),它是一个很棒的函数,但对于更复杂的形式,阅读起来很困难:
paste("我的名字是", my_name, ",我住在", my_city, ",在", language, "中开发超过", years_of_coding)
更好的解决方案是使用sprintf函数或glue,例如
glue(“我的名字是{my_name},我住在{my_city},从事{language}开发已经有{years_of_coding}年了”)
没有那些逗号和引号不是更清楚吗?
当处理许多代码块时,将它们提取到单独的位置,例如,.yml 文件,会非常好。这使得代码和文本块更易于阅读和维护。
关于文本的最后一个提示:调试技术之一,通常在 Shiny 应用程序中使用,是添加print()语句。仔细检查代码中是否没有遗留的打印语句——这在代码审查时可能非常尴尬!
循环
循环是编程的基本构件之一,是非常强大的工具。然而,它们可能计算开销很大,因此需要谨慎使用。你应该遵循的经验法则是:总是仔细检查循环是否是一个好的选择。在data.frame中循环通常不是必要的:应该有一个{dplyr}函数来更有效地解决问题。
另一个常见的问题来源是使用对象的长度来循环元素,例如for(i in 1:length(x)) ...。但如果 x 的长度为零会怎样!是的,循环会对迭代器值 1 和 0 采取不同的方式。这可能不是你的计划。使用seq_along或seq_len函数要安全得多。
同时,记得使用apply系列函数进行循环。它们很棒(更不用说{purrr}解决方案了)!请注意,使用sapply可能会被审查者评论为不稳定——因为这个函数会自动选择输出的类型!所以有时它会是一个列表,有时会是一个向量。使用vapply更安全,因为程序员定义了预期的输出类。
代码共享
即使你是一个人工作,你也可能希望你的程序能在其他机器上正常运行。当你与团队共享代码时,这一点尤其重要!为此,切勿在代码中使用绝对路径,例如“/home/marcin/my_files/old_projects/september/project_name/file.txt”。它对其他人将不可访问。请注意,任何文件夹结构的违规都会导致代码崩溃。
由于你应该已经有一个用于所有编码工作的项目,你需要使用与特定项目相关的路径——在这种情况下,将是“./file.txt”。此外,我建议将所有路径作为变量保存在一个地方——这样重命名文件只需在代码中更改一次,而不是,例如,在六个不同的文件中更改二十次。
有时你的软件需要使用一些凭证或令牌,例如,访问数据库或私有库。你绝不应该将这些秘密提交到代码库中!即使团队中的条目是相同的。通常,好的做法是将这些值保存在.Renviron文件中作为环境变量,在启动时加载,并且该文件本身在仓库中被忽略。你可以在这里阅读更多关于它的内容。
良好的编程实践
最后,让我们关注如何改进你的代码。首先,你的代码应该易于理解且干净——即使你一个人工作,当你一段时间后回到代码时,它也会让你的生活更轻松!
使用具体的变量名,即使它们看起来较长——经验法则是你应该能仅通过读取名称来猜测内容,所以table_cases_per_country是可以的,但tbl1则不行。避免使用缩写。长度优于模糊。保持一致的对象命名风格(如 camelCase 或 snake_case),并在团队成员之间达成一致。
不要将逻辑值T缩写为TRUE和F缩写为FALSE——代码会工作,但T和F是常规对象,可以被覆盖,而TRUE和FALSE是特殊值。
不要使用等式来比较逻辑值,如if(my_logical == TRUE)。如果你可以与TRUE比较,这意味着你的值已经是逻辑值,因此if(my_logical)就足够了!如果你想双重检查该值是否确实是TRUE(而不是,例如,NA),可以使用isTRUE()函数。
确保你的逻辑语句是正确的。检查你是否理解 R 中单一和双重逻辑运算符之间的区别!
良好的间距对于可读性至关重要。确保规则在团队中是一致且达成一致的。这将使彼此的代码更易于遵循。最简单的解决方案是站在巨人的肩膀上,遵循tidyverse 风格指南。
然而,在审查过程中检查每一行的风格是相当低效的,因此确保在你的开发工作流程中引入linter和styler,正如Olga 的博客文章中所展示的那样。这可能会拯救你的生命!最近我们发现了一些遗留代码中的错误,这些错误本可以被 linter 自动识别:
sum_of_values <- first_element
+ second_element
这并没有返回作者所期望的元素之和。
说到变量名——这是编程中已知的最难的事情之一。因此,在不必要时应避免使用变量名。请注意,R 函数默认返回最后创建的元素,因此你可以轻松地替换它:
sum_elements <- function(first, second) {
my_redundant_variable_name <- sum(first, second)
return(my_redundant_variable_name)
}
用更简短(且简单的,你不需要考虑名称)的方式:
sum_elements <- function(first, second) {
sum(first, second)
}
另一方面,请在每次重复某些函数调用或计算时使用额外的变量!这将使计算更有效,并且未来更容易修改。记住保持代码DRY – 不重复自己。如果你复制粘贴一些代码,三思是否应该将其保存到变量中、在循环中完成,或移动到函数中。
结论
这样,你就有了五种编写清晰 R 代码并让你的代码审查者无话可说的策略。这五种方法将确保你编写出优质的代码,即使多年后也容易理解。祝编程愉快!
简介:Marcin Dubel 是 Appsilon 的工程师。
原始。经许可转载。
相关:
-
用于手写字母识别的支持向量机(R 语言)
-
顶级编程语言及其用途
-
如何成为数据科学家的指南(逐步方法)
我们的前三大课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
轻松进行数据科学的 5 种工具
原文:
www.kdnuggets.com/2021/01/5-tools-effortless-data-science.html
评论
图片由 Chevanon Photography 提供,来自 Pexels
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
在斯蒂芬·柯维的经典著作 高效能人士的七个习惯 中,第七个习惯是“磨快锯子”。这指的是提升我们的资产,以寻求在工作中的持续改进。正如亚伯拉罕·林肯所说,
给我八小时砍倒一棵树,我会花前六小时磨快锯子。
更好的工具来 构建、简化和拓展 我们的数据科学工作,将使我们成为更有效的思考者、决策者和从业者。
在这篇文章中,我们将探讨如何磨快我们的数据科学锯子——并调查未解之谜,即谁在给如此多的激励讲师发锯子。
这里有五种轻松进行数据科学的工具。
#1 — Cookiecutter
用例:通过这个预构建的文件结构设置来构建你的数据科学项目的仓库。
数据科学家应该有条理,以便通过可重复的项目获取见解。 DrivenData 的 Cookiecutter 帮助我们通过有组织的仓库结构共享和执行数据科学任务。要开始使用,只需在命令行运行 cookiecutter [github.com/drivendata/cookiecutter-data-science](https://github.com/drivendata/cookiecutter-data-science)。这将创建 Cookiecutter 文件结构。
初学者可以从 DrivenData 团队在构建最佳实践到这个仓库结构中的专业知识中受益。专家可以使用这个模板作为他们项目的灵活启动。

通过 DrivenData
最终,Cookiecutter 促进了逻辑上的标准化。这使得你、你的合作者和项目相关者更容易找到数据、笔记本、报告、可视化等。Cookiecutter 促进了可重复性和代码质量。使用 Cookiecutter 设置数据科学实验既快速又极其有用。
目录结构中提到的两个附加工具:
-
Sphinx — 文档生成器,将一组纯文本源文件转换为各种输出格式,自动生成交叉引用
-
Tox — virtualenv 管理和测试命令行工具,以确保包可以在不同的 Python 版本和解释器上正确安装;它还可以作为持续集成服务器的前端。
如何使用: 使用 cookiecutter [github.com/drivendata/cookiecutter-data-science](https://github.com/drivendata/cookiecutter-data-science) 开始你的下一个项目。
#2 — Deon
使用案例: 解决数据科学项目的伦理考虑并记录你的发现。
检查清单是一种有效的方式来限制盲点和减少错误。作为负责任的数据科学伦理检查清单,Deon 代表了任何项目的有希望的起点。团队应使用此工具评估从数据收集到机器学习模型部署的各种考虑因素。
从项目文件结构的根目录运行 deon -o ETHICS.md 将生成一个 Markdown 文件,你可以在其中记录对模型伦理考虑的审查。

通过 DrivenData
Deon 激发的细致讨论可以确保机器学习技术固有的风险不会对模型的对象或组织的声誉产生不利影响。阅读更多:
在将人工智能集成到组织的工作流程之前,考虑这些工具以防止机器…
如何使用: 通过运行 deon -o ETHICS.md 将检查清单 Markdown 文件添加到你的根文件夹中,然后安排与相关者的对话以填写检查清单。
#3 — PyCaret
使用案例: 只需几行代码,就能通过 PyCaret 库简化数据科学工作,提升你的潜力。
Pycaret 非常适合初学者或希望提高效率的资深编码员。这个库帮助你用更少的代码实现数据科学工作流的典型步骤。
如何使用: 利用 PyCaret 的功能进行预处理和建模 — 例如
from pycaret.regression import *
exp_name = setup(data = boston, target = 'medv', train_size = 0.7)
#4 — ktrain
用例: 一个低代码的 Keras 包装器,将机器学习最佳实践融入超参数和模型训练管道。
Arun Maiya,一位机器学习研究员和数据科学团队负责人,将 arXiv 上的最新进展整理成可以轻松部署于计算机视觉、自然语言处理和图基方法的功能。
使用方法: 简化最先进的机器学习模型的训练、检查和应用——例如。
model = txt.text_classifier ('bert', trn , preproc = preproc)
#5 — MLFlow
用例: 将你的实验跟踪从手动 Excel 日志迁移到这个自动化平台。
ML Flow实现了参数、代码版本、指标和输出文件的自动跟踪。MlflowClient 函数创建和管理实验、管道运行和模型版本。使用mlflow.log_artifact、.log_metric()和.log_param()记录工件(例如数据集)、指标和超参数。
你可以通过本地浏览器轻松查看所有实验的元数据和结果,使用mlflow ui命令。
使用方法: 配置 MLFlow…
**if** __name__ **==** "__main__":
*# Log a parameter (key-value pair)*
log_param("param1", randint(0, 100))
…然后使用mlflow run命令运行现有项目,该命令可以从本地目录或 GitHub URL 运行项目。
总结
好吧,我可能稍微有些夸张关于亚伯拉罕·林肯的简洁伐木工名言,但我希望你仍然喜欢这篇文章。拥有正确的工具确实能让任务变得容易得多。希望你现在已经具备了一些新的方法,将数据与战略成果连接起来。
如果你喜欢这篇文章,请关注我的Medium、LinkedIn、YouTube和Twitter账号,获取更多提升你数据科学技能的想法。
更多资源
通过这些技巧提升你的数据科学技能,以便更好地进行 EDA、目标分析、特征…
保持在数据科学领域领先的基础理念。
通过这份编码技巧清单,在数据科学和机器学习领域达到新高度。
机器学习模型选择与部署的 5 个关键要素
Python 是增长最快、最受喜爱的编程语言。通过这些数据科学技巧开始你的学习吧。
简介:Nicole Janeway Bills 是一名拥有商业和联邦咨询经验的数据科学家。她帮助组织利用他们的顶级资产:一个简单而强大的数据战略。注册获取她更多的文章。
原文。经许可转载。
相关内容:
-
每个数据科学家都应该知道的命令行基础
-
10 种被低估的 Python 技能
-
我从查看 200 种机器学习工具中学到了什么
更多相关内容
2024 年数据科学家工具箱中必备的 5 种工具
原文:
www.kdnuggets.com/5-tools-every-data-scientist-needs-in-their-toolbox-in-2024

图片来源于 DALL-E
随着数据世界的发展,数据科学的世界也在增长。跟上数据科学的步伐本身就是一份全职工作。市场不断扩展,工具也在不断发展和涌现,造成了混乱。然后你还要面对学习这些新工具的问题,了解它们的全部潜力,它们能替代什么,或者只是另一个附加工具。
我们的三大课程推荐
1. Google 网络安全证书 - 加速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
跟上这一切可能会很耗费精力。这就是为什么在你的数据科学家工具箱中拥有合适的工具对你出色完成工作至关重要。
一款好的工具改善你的工作方式。一款伟大的工具改善你的思维方式。
Python
如果你要为数据科学选择一种编程语言,它很可能是 Python。它是黄金标准,拥有最大的用户群体。许多数据科学工具都是用 Python 编写的,社区是最大、增长最快、最活跃的。你不把它纳入工具箱中实在是太傻了!
学习 Python 的课程:
数学和统计学
数学和统计学。这些数据科学的基本要素确保数据科学有意义!它们是机器学习算法的基石。它们帮助你理解问题,并使你能够用它们找到解决方案。从识别模式到从大型复杂数据集中输出期望结果,数据科学家可以利用数学和统计学提取洞察并可靠地解释结果。
学习数学和统计学的课程:
数据可视化工具
作为数据科学家,你应该为你的发现感到自豪,并让它们看起来漂亮!但也要记住,其他利益相关者可能技术水平不高,因此可视化对他们很重要。这是他们理解数据科学的方式。能够以各种方式可视化你的洞察力将帮助你更好地传达这些洞察,而不必多说。
你可以使用不同的库,例如 Matplotlib,或者使用可视化工具,如 Tableau——你只需找到适合你和你组织的工具即可。
学习数据可视化的课程:
SQL
结构化查询语言,简称 SQL,是一种用于管理关系数据库中数据的编程语言。作为数据科学家,你将管理大量数据库,而 SQL 是你浏览数据的关键。通过 SQL,你将能够处理存储在数据库中的结构化数据,轻松地提取、操作和分析数据。你可能主要想学习 Python 或 SQL,或者你想全面掌握,学习两者!
学习 SQL 的课程:
框架
随着数据科学、机器学习和人工智能在我们日常生活中变得越来越重要,确保从头到尾管道的准确性和有效性也很重要。框架提供了一系列灵活的软件组件,帮助开发人员加速从软件开发到生产部署的过程。
在框架方面,数据科学界有一系列流行的框架,例如 TensorFlow、PyTorch、Pandas、Keras 等。作为数据科学家,你必须学习所有这些框架,因为它们在不同的时间可能对你有帮助。
学习不同框架的课程:
总结
数据科学家的学习之旅是无止境的。市场上总会有新的工具和软件出现。然而,如果你的工具箱里有合适的工具,学习新技能将会轻松很多。
Nisha Arya是数据科学家、自由技术撰稿人,以及 KDnuggets 的编辑和社区经理。她特别感兴趣于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。Nisha 涵盖广泛的话题,并希望探索人工智能如何促进人类寿命的不同方式。作为一个热衷学习者,Nisha 希望拓宽她的技术知识和写作技能,同时帮助指导他人。
主题更多信息
自动化数据清理过程的五种工具
原文:
www.kdnuggets.com/5-tools-for-automating-data-cleaning-processes

图片来源于 freepik
脏数据可能导致不准确的分析和错误的决策。手动清理数据通常耗时且枯燥。几个工具可以自动化数据清理和准备。这些工具可以节省宝贵的时间和精力。本文探讨了一些工具,帮助你有效地清理数据。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
什么是数据清理?
数据清理是数据准备的第一步。它找出并修正错误,如缺失值、重复项或不一致的格式。任务包括去除重复项、填补空白和标准化格式。目的是提高数据的质量和可靠性。清洁的数据确保更好的分析和决策。例如,零售公司利用清洁的销售数据来决定库存量。这有助于避免产品库存过多或过少。
数据清理工具的功能
数据清理工具执行多个功能以提高数据质量:
-
错误修正:检测并修正数据中的错误,如印刷错误。
-
处理缺失数据:处理缺失的数据点,如插补(替换缺失值)或删除。
-
数据去重:识别并删除重复记录,以保持数据的准确性。
-
标准化:确保不同条目之间的数据格式一致,以便于分析的一致性。
-
标准化:将数值数据缩放到标准范围,以消除可能影响分析的变异。
-
数据验证:通过验证规则检查数据的准确性和完整性。
-
数据分析:提供汇总统计和可视化,以了解数据集的结构和质量。
数据清理工具前五名
1. OpenRefine
OpenRefine 是一个数据清理工具,帮助用户清理和组织混乱的数据。它是免费的开源工具,支持多种数据类型。用户可以轻松地浏览大型数据集,去除重复项并纠正错误。OpenRefine 可以将数据转换为不同格式。它适合初学者和专家,提高数据质量并节省时间。然而,对于复杂的转换,它需要技术技能。界面对新用户来说可能会有些复杂。与某些数据库和系统的集成将有限。
2. Trifacta Wrangler
Trifacta Wrangler 是一个数据准备工具。它帮助用户清理和组织数据。该工具支持不同类型的数据。它使用机器学习来建议改善数据的方法。这使得数据更易于用于分析。Trifacta Wrangler 对初学者和专家都很有用。它节省时间并减少数据准备中的错误。对于小型企业来说,它可能比较昂贵。它有一定的学习曲线。它可能无法高效处理大型数据集。与其他软件的集成可能有限。用户在处理复杂任务时需要技术支持。
3. Talend Open Studio
Talend Open Studio 是一个开源的数据集成工具。该工具提供了一个图形界面,用于设计数据工作流。这使得清理和转换数据变得简单。Talend 与多个数据源和系统集成良好。它强大且适用于复杂的数据处理任务。然而,对于新用户来说,它有一定的学习曲线。它还需要大量的系统内存和处理能力。
4. Pandas
Pandas 是一个流行的开源数据处理库,用于 Python。它提供了强大的功能来清理和转换数据。这些功能可以处理缺失值并去除重复项。Pandas 广泛用于数据分析,并与其他 Python 库集成良好。它非常适合通过脚本自动化数据清理。用户需要一定的编程知识才能有效使用它。一个缺点是其在处理大型数据集时的性能限制。
5. DataCleaner
DataCleaner 是一个免费的开源数据质量分析工具。它帮助分析、清理和监控数据质量。该工具提供了去重、标准化和识别数据质量问题的功能。DataCleaner 与多个数据源集成,并具有用户友好的界面。它适合技术和非技术用户。高级功能可能需要技术知识。与 Pandas 类似,它在扩展性方面有限。
总结
总之,这些免费的工具可以提升数据清理和准备工作。它们通过自动化数据清理节省了时间和精力。使用这些工具可以确保你的数据是高质量的,并且已准备好进行分析。今天就开始使用这些工具来简化数据管理吧。通过更清洁的数据改善你的决策过程。
Jayita Gulati 是一位机器学习爱好者和技术作家,她因热爱构建机器学习模型而充满激情。她拥有利物浦大学计算机科学硕士学位。
相关话题
5 种工具帮助构建你的 LLM 应用

Image generated with DALLE-3
在高级语言模型应用的时代,开发人员和数据科学家不断寻求高效的工具来构建、部署和管理他们的项目。随着像 GPT-4 这样的巨大语言模型(LLMs)的流行,越来越多的人希望在自己的应用程序中利用这些强大的模型。然而,没有合适的工具,使用 LLMs 可能会很复杂。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
这就是为什么我整理了这份包含五种重要工具的清单,它们可以显著提升 LLM 驱动的应用程序的开发和部署。不论你是刚开始还是经验丰富的 ML 工程师,这些工具都将帮助你提高生产力,构建更高质量的 LLM 项目。
1. Hugging Face
Hugging Face 不仅仅是一个 AI 平台;它是一个全面的生态系统,提供模型、数据集和演示的托管。它支持各种框架,允许用户训练、微调、评估以及生成多种形式的内容,如图像、文本和音频。丰富的模型选择、社区资源和开发者友好的 API 的结合,使 Hugging Face 成为许多 AI 从业者和 ML 工程师的首选平台。
学习如何使用 Hugging Face AutoTrain 微调 Mistral AI 7B LLM 并将模型推送到 Hugging Face Hub。
2. LangChain
LangChain 是一个使用可组合性方法构建 LLM 应用程序的工具。它被广泛用于通过将不同的上下文源与语言模型集成来开发具有上下文感知的应用程序。此外,它可以使用语言模型根据提供的上下文推理关于操作或响应。LangChain AI 团队最近推出了 LangSmith,这是一种新的工具,提供了一个统一的开发平台,以提高 LLM 应用程序生产的速度和效率。
如果你是 AI 开发的新手,可以查看 LangChain 的速查表以了解 Python API 和其他功能。
3. Qdrant
Qdrant是一个基于 Rust 的向量相似性搜索引擎和数据库,提供具有简单 API 的生产就绪服务。它特别适用于扩展过滤支持,使其成为使用神经网络或基于语义匹配的应用程序的理想选择。Qdrant 在高负载下的速度和可靠性使其成为将嵌入或神经网络编码器转化为匹配、搜索、推荐等综合应用的首选。你还可以尝试包括免费层在内的全托管 Qdrant Cloud 服务,方便使用。
阅读 2024 年你必须尝试的 5 个最佳向量数据库以了解 Qdrant 的其他替代方案。
4. MLflow
MLflow现在支持 LLMs,提供实验跟踪、评估和部署解决方案。它通过引入如 MLflow Deployments Server for LLMs、LLM Evaluation 和 Prompt Engineering UI 等功能,简化了 LLM 能力的集成。这些工具有助于导航复杂的 LLM 领域,比较基础模型、提供商和提示,以找到最适合你项目的选项。
查看 5 门免费课程以掌握 MLOps 的列表。
5. vLLM
vLLM是一个高吞吐量和内存高效的 LLM 推理与服务引擎。以其最先进的服务吞吐量和高效的注意力键和值内存管理而闻名,vLLM 提供了连续批处理、优化的 CUDA 内核以及对 NVIDIA CUDA 和 AMD ROCm 的支持等功能。其灵活性和易用性,包括与流行的 Hugging Face 模型和各种解码算法的集成,使其成为 LLM 推理和服务的宝贵工具。
结论
这五种工具中的每一种都带来了独特的优势,无论是在托管、上下文感知、搜索能力、部署还是推理效率方面。通过利用这些工具,开发人员和数据科学家可以显著简化工作流程,提升 LLM 应用的质量。
获取灵感并构建使用生成 AI 模型和开源工具的 5 个项目。
Abid Ali Awan (@1abidaliawan)是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为遭遇心理疾病困扰的学生构建 AI 产品。
更多相关话题
5 种数据科学替代职业路径
原文:
www.kdnuggets.com/5-top-data-science-alternative-career-paths

图片由编辑提供
数据科学仍然是年度最佳职业,尤其是在生成式 AI 的热潮中。然而,数据科学职位的需求往往远低于申请人数;显著的是,许多雇主仍然更倾向于招聘高级数据科学家而非初级数据科学家。这就是为什么许多学习数据科学的学生很难找到工作的原因。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
但是,这并不意味着你所学的知识会白费。对于了解数据科学的人来说,仍然有很多替代职业路径。无论是初学者还是专业人士,都有各种工作可以实现你的数据科学技能。
那么,这些替代职业路径是什么呢?以下是你应该考虑的五种不同的工作。
1. 机器学习工程师
从数据科学中可以分支出的第一个替代职业是机器学习工程师。人们有时会把这两个职业混淆为相同,但它们是不同的。
机器学习工程师更关注机器学习部署到生产中的技术方面,比如结构如何设计或生产如何扩展。另一方面,数据科学家则专注于从数据中提取洞察,并提供解决方案以解决业务问题。
这两者都共享数据分析和机器学习的基础,但不同之处使这些职业路径有所区分。如果你觉得机器学习工程师职位适合你,你应该专注于学习更多关于软件工程实践和 MLOps 的知识,以便转行。
文章 如何成为机器学习工程师 by Nisha Arya 也可以帮助你开启这条职业道路。
2. 数据工程师
下一个职位是数据工程师。在当前数据驱动的时代,数据工程师已成为一个重要职位,负责提供高质量的稳定数据流。在公司中,数据工程师会支持许多数据科学家的工作。
数据工程师的工作集中于后端基础设施,以支持任何数据任务,并维护数据管理和存储的架构。数据工程师还专注于根据需求构建数据管道,包括数据的收集、转换和交付。
数据工程师和数据科学家都处理数据,但数据工程师更侧重于数据基础设施。这意味着你必须掌握包括 SQL、数据库管理和大数据技术在内的附加技能。
想了解更多关于数据工程师职业的信息,请阅读 Bala Priya C 的《免费数据工程入门课程》。
3. 商业智能
商业智能(BI)是那些仍然喜欢从数据中获得洞察,但更感兴趣于分析历史数据以指导业务的人的一个替代职业路径。对于任何企业来说,这都是一个重要的职位,因为公司需要从数据中了解其当前状况。
BI 更侧重于描述性分析,业务领导者和利益相关者使用数据洞察来制定可行的举措。这些洞察将基于当前和历史数据,形式为 KPI 和业务指标,以便企业能够做出明智的决策。为了促进分析,BI 使用工具创建业务仪表板和报告。这使得 BI 与数据科学家不同,因为后者的工作重点是使用高级统计分析提供未来预测。
许多 BI 职位要求具备如基础统计学、SQL 以及 Power BI 等数据可视化工具的技能。这些都是数据科学家需要学习的技能,因此 BI 是那些喜欢分析数据的人的一个合适的替代职业路径。
如果你想提升自己在 BI 职位上的技能,Nahla Davies 的《大数据分析:为什么它对商业智能如此关键?》文章将给你提供优势。
4. 数据产品经理
如果你想转到一个技术要求较少但仍与数据科学相关的职位,数据产品经理可能非常适合你。这是一个更偏重于制定数据驱动的产品或服务路线图的职位。
数据产品经理的工作更侧重于理解当前市场趋势,并指导数据产品开发以满足客户需求。该职位还应了解如何将产品或服务定位为公司资产。同时,数据产品经理还应具备与技术人员沟通的技术知识,并管理产品开发的策略。
通常,数据产品经理应具备商业理解、数据技术理解和客户体验设计等技能。如果数据产品经理希望在此职位上取得成功,这些技能是必要的。你可以阅读这篇文章以了解更多关于数据产品经理的信息。
5. 数据分析师
你应该考虑的最后一个职业路径是数据分析师。数据分析师通常处理原始数据,以提供业务所需的特定问题的答案。这与 BI 的工作形成对比,尽管它们有重叠的技能,但 BI 通常使用工具创建仪表板和报告,以持续跟踪 KPI 和业务指标。相比之下,数据分析师通常以项目为基础工作。
数据分析师通常在每个部门工作,提供详细的临时分析以完成特定项目,并执行统计分析以从数据中获得洞察。数据分析师可以使用 SQL、编程语言(Python/R)和数据可视化工具,这些技能都是数据科学所学到的。
如果这是一个替代职业路径,你可以参加 Bala Priya C.讲解的免费数据分析师入门训练营
结论
如果数据科学的道路不适合你,仍然有许多其他职业选择。你不需要浪费你已经学到的技能,这里有五个你应该考虑的数据科学替代职业路径:
-
机器学习工程师
-
数据工程师
-
商业智能
-
数据产品经理
-
数据分析师
希望这对你有帮助!在这里列出的社区分享你的想法,并在下面添加你的评论。
Cornellius Yudha Wijaya****是一位数据科学助理经理和数据撰写员。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 在各种 AI 和机器学习主题上撰写文章。
相关话题
2024 年你可以参加的 5 个顶级机器学习课程
原文:
www.kdnuggets.com/5-top-machine-learning-courses-you-can-take-in-2024

作者提供的图片
我们都知道寻找合适的课程可能是件麻烦事。KDnuggets 团队齐心协力为你准备了这篇博客,以便你不必自己去做这项工作——我们已经为你做好了!
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
世界发展迅速,变化极快。2024 年技术的应用展示了它如何改善我们的工作流程、医疗行业、金融部门等。你可能正在考虑或者已经想过要成为这个社区的一部分。
如果你希望进入机器学习行业,并准备好采取下一步措施以获得资格,请继续阅读。
机器学习专业课程
链接:机器学习专业课程
级别:初级
持续时间:每周 10 小时,共 2 个月
由 AI 先驱 Andrew Ng 提供的三门课程程序,旨在帮助课程学员掌握基本的 AI 概念,并开发实用的机器学习 (ML) 技能,例如构建和训练机器学习模型。
你将学习如何使用 NumPy 和 scikit-learn 构建机器学习模型,构建和训练用于预测和二分类任务的监督模型。你还将学习如何使用 TensorFlow 构建和训练神经网络以进行多类别分类,并构建和使用决策树及树集成方法。
应用这些机器学习开发的最佳实践,使用无监督学习技术进行无监督学习,包括聚类和异常检测,然后构建基于协同过滤的方法和基于内容的深度学习方法的推荐系统,并构建深度强化学习模型。
IBM 机器学习专业证书
链接:IBM 机器学习专业证书
级别:中级
持续时间:3 个月,每周 10 小时
IBM 的在线六门课程教育计划为课程学员提供实用的机器学习技能,例如监督学习、无监督学习、神经网络和深度学习。完成这六门课程后,你将获得 IBM 和 Coursera 颁发的专业证书。
在本课程中,你将学习如何掌握机器学习专家在日常工作中使用的最新实用技能和知识,学习如何通过在 Python 中创建推荐系统来比较和对比不同的机器学习算法,并获得 KNN、PCA 以及非负矩阵分解协同过滤的实际知识。你还将通过训练神经网络和构建回归与分类模型来预测课程评分。
Google 专业机器学习工程师认证
级别:初级
时长:大约 2 小时
使用 Google Cloud 设计、构建和制作机器学习模型。在这门课程中,你将处理大型复杂数据集,并创建可重复使用的代码。你还将考虑在机器学习模型开发过程中负责任的 AI 和公平性,并与其他职位密切合作,以确保基于 ML 的应用的长期成功。
为了获得认证,你必须参加并通过一个由 50-60 道选择题组成的两小时考试,内容涉及机器学习问题的框架、机器学习解决方案的架构和机器学习模型的开发。
机器学习专项课程
链接:机器学习专项课程
级别:中级
时长:2 个月,每周 10 小时
由华盛顿大学提供的机器学习专项课程,这是一个四门课程的在线教育项目,涵盖了机器学习的主要领域,包括预测、分类、聚类和信息检索。通过该课程,你还将分析大型复杂数据集,创建可以随着时间推移而适应和改进的系统,并构建能够从数据中进行预测的智能应用。
完成课程后,你将获得一份可分享的证书,可以在简历上展示,以向潜在雇主展示你的知识和技能。
端到端机器学习
链接:端到端机器学习
级别:中级
时长:4 小时
如果你对机器学习模型的全过程感兴趣,从开始到结束 - 不妨查看由 DataCamps 提供的这门课程。
通过这门全面的课程,深入学习如何设计、训练和部署端到端模型。通过引人入胜的实际例子和动手练习,你将学习解决复杂的数据问题并构建强大的机器学习模型。到课程结束时,你将掌握创建、监控和维护高性能模型所需的技能,以提供可操作的见解。
总结
以大学费用的一小部分成本提升技能,这些顶级机器学习课程可以让你以更低的费用获得教育和提升 - 你只需要确保选择适合你的课程!
Nisha Arya 是一位数据科学家、自由技术作家,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及数据科学的理论知识。Nisha 涵盖了广泛的话题,并希望探索人工智能在延长人类寿命方面的不同方式。作为一个热衷于学习的人,Nisha 致力于扩展她的技术知识和写作技能,同时帮助指导他人。
了解更多相关话题
5 个棘手的 SQL 查询解决方案
原文:
www.kdnuggets.com/2020/11/5-tricky-sql-queries-solved.html
Sql 向量由 freepik 创建 - www.freepik.com
SQL(结构化查询语言)是数据科学家工具箱中的一个非常重要的工具。掌握 SQL 不仅在面试中至关重要,而且通过能够解决复杂查询的良好理解,会让我们在竞争中脱颖而出。
在本文中,我将讨论我找到的 5 个棘手问题及其解决方法。
注意 — 每个查询可以用不同的方式编写。在查看我的解决方案之前,尝试思考一下方法。你也可以在回复部分建议不同的方法。
查询 1
我们给定了一个包含两列的表,名称和职业。我们需要查询所有名称后面紧跟着职业列中的第一个字母,并用括号括起来。
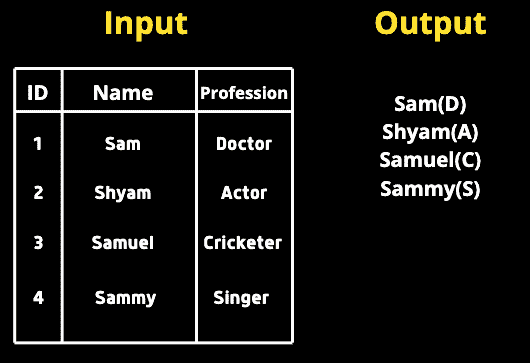
我的解决方案
**SELECT**
**CONCAT**(Name, ’(‘, **SUBSTR**(Profession, 1, 1), ’)’)
**FROM** table;
由于我们需要组合名称和职业,可以使用 CONCAT。我们还需要在括号中只包含一个字母。因此,我们将使用 SUBSTR 并传入列名、起始索引、结束索引。由于我们只需要第一个字母,我们将传入 1,1(起始索引包含,结束索引不包含)
查询 2
Tina 被要求计算她创建的 EMPLOYEES 表中所有员工的平均薪资,但结果显示的平均值非常低,发现键盘上的零键无法工作。她希望我们帮助找出计算错误的平均值与实际平均值之间的差异。
我们必须编写一个查询来找出错误(实际 AVG — 计算 AVG)。
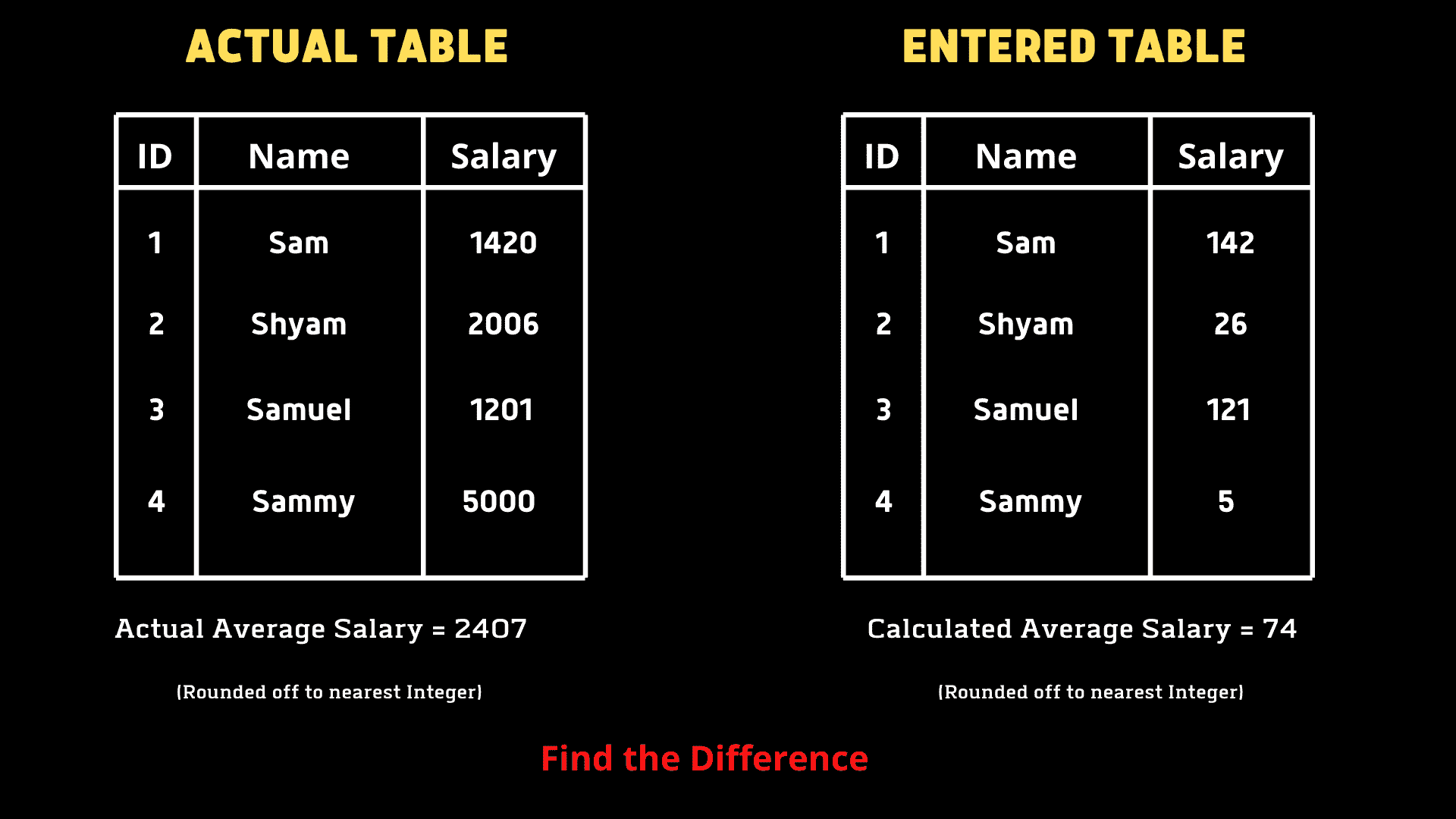
我的解决方案
**SELECT**
**AVG**(Salary) - **AVG**(**REPLACE**(Salary, 0, ’’))
**FROM** table;
需要注意的是,我们只有一个表,其中包含实际薪资值。为了创建错误场景,我们使用 REPLACE 来替换 0。我们将传入列名、要替换的值和替换值。然后,我们使用聚合函数 AVG 来找出平均值的差异。
查询 3
我们给定了一个表格,它是一个 二叉搜索树,包含两列 节点 和 父节点。我们必须编写一个查询,根据节点值的升序返回节点类型。有 3 种类型。
-
根节点 — 如果该节点是根节点
-
叶子节点 — 如果该节点是叶子节点
-
内部节点 — 如果该节点既不是根节点也不是叶子节点。
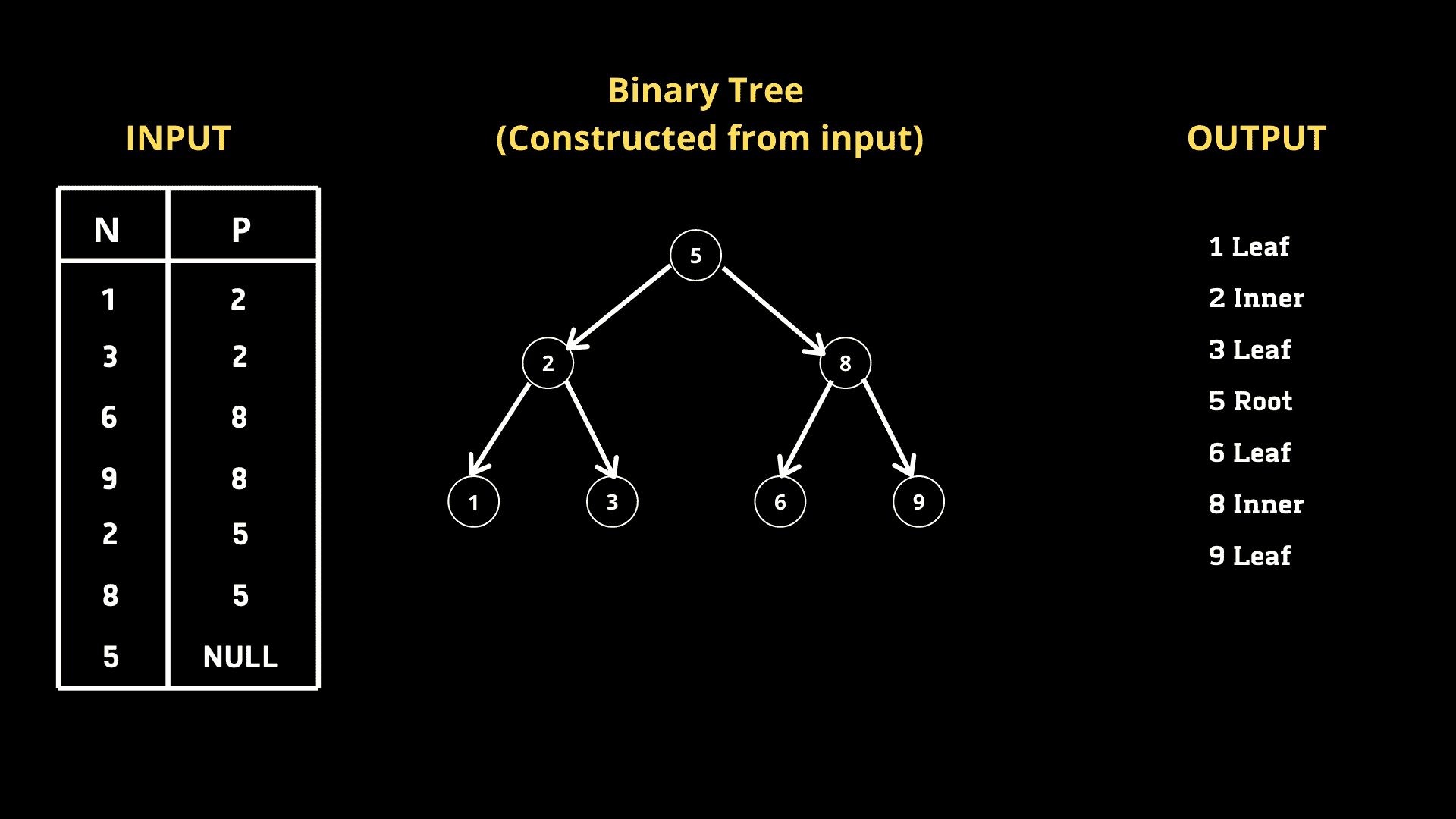
我的解决方案
经过初步分析,我们可以得出结论,如果给定节点 N 的相应 P 值为 NULL,则它是根节点。如果给定节点 N 存在于 P 列中,则它不是内部节点。基于这一想法,让我们编写一个查询。
**SELECT CASE**
**WHEN** P **IS NULL** **THEN** **CONCAT**(N, ' Root')
**WHEN** N **IN** **(SELECT DISTINCT** P from BST) **THEN** **CONCAT**(N, ' Inner')
**ELSE** **CONCAT**(N, ' Leaf')
**END**
**FROM** BST
**ORDER BY** N asc;
我们可以使用CASE,它作为一个开关函数。正如我提到的,如果 P 对于给定的节点 N 为空,则 N 是根节点。因此,我们使用CONCAT来组合节点值和标签。同样,如果一个给定的节点 N 在列 P 中,它就是一个内部节点。为了获得列 P 中的所有节点,我们编写了一个子查询,返回列 P 中的所有不同节点。由于我们被要求按节点值的升序排序输出,我们使用了ORDER BY子句。
查询 4
我们给定了一个交易表,包含transaction_id、user_id、transaction_date、product_id 和 quantity。我们需要查询那些在多个日期购买产品的用户的数量(注意,一个用户可以在同一天购买多个产品)。

我的解决方案
为了解决这个查询,我们不能直接计算用户 ID 的出现次数,如果出现次数多于一个则返回该用户 ID,因为一个用户在单一天内可能有多个交易。因此,如果一个用户 ID 与多个不同的日期相关联,意味着他在多个日期购买了产品。按照相同的方法,我编写了一个查询。(内部查询)
**SELECT COUNT**(user_id)
**FROM**
(
**SELECT** user_id
**FROM** orders
**GROUP BY** user_id
**HAVING COUNT**(**DISTINCT DATE**(date)) > 1
) t1
由于问题询问的是用户 ID 的数量而不是用户 ID 本身,因此我们在外部查询中使用COUNT。
查询 5
我们给定了一个订阅表,其中包含每个用户的订阅开始和结束日期。我们需要编写一个查询,根据日期与其他用户的重叠情况返回每个用户的 true/false。例如,如果用户 1 的订阅期与其他用户重叠,查询必须返回True给用户 1。
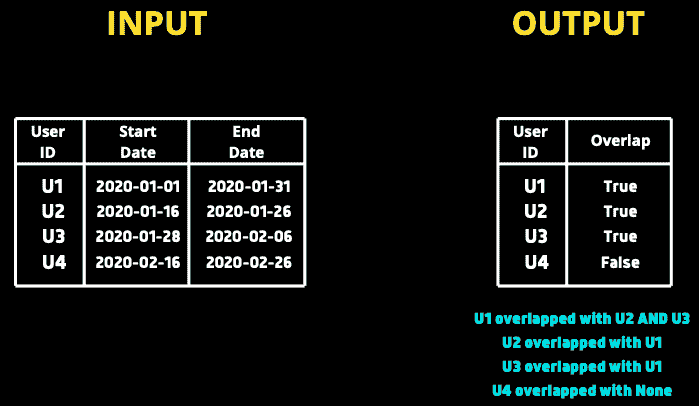
我的解决方案
初步分析后,我们了解到我们必须将每个订阅与其他所有订阅进行比较。让我们将userA的开始和结束日期分别记作**startA**和**endA**,同样地,对于userB,分别记作**startB**和**endB****。
如果**startA**≤**endB**和**endA**≥**startB**,那么我们可以说这两个日期范围重叠。让我们先比较 U1 和 U3。
startA = 2020–01–01
endA = 2020–01–31
startB = 2020–01–16
endB = 2020–01–26
在这里我们可以看到**startA**(2020–01–01)小于**endB**(2020–01–26),同样,endA**(2020–01–31)大于**startB**(2020–01–16),因此可以得出日期重叠的结论。类似地,如果你比较 U1 和 U4,上述条件不成立,将返回 false。
我们还必须确保一个用户不会与自己的订阅进行比较。我们还希望对自身执行左连接,以匹配满足条件的每个其他用户。现在我们将创建两个副本 s1 和 s2。
**SELECT** *
**FROM** subscriptions **AS** s1
**LEFT** **JOIN** subscriptions **AS** s2
**ON** s1.user_id != s2.user_id
AND s1.start_date <= s2.end_date
AND s1.end_date >= s2.start_date
鉴于条件连接,s2 中的一个 user_id 应该存在于 s1 中的每一个 user_id 上,只要存在日期重叠的情况。
输出

我们可以看到,每个用户在日期重叠的情况下存在另一个用户。对于用户 1,有 2 行显示他与 2 个用户匹配。对于用户 4,相应的 id 为 null,表示他与其他用户没有匹配。
现在总结一下,我们可以按 s1.user_id 字段分组,并检查 s2.user_id IS NOT NULL 的情况下是否存在任何值为 true。
最终查询
**SELECT**
s1.user_id
, (**CASE** **WHEN** s2.user_id **IS** NOT NULL **THEN** 1 **ELSE** 0 **END**) **AS** overlap
**FROM** subscriptions **AS** s1
**LEFT** **JOIN** subscriptions **AS** s2
**ON** s1.user_id != s2.user_id
AND s1.start_date <= s2.end_date
AND s1.end_date >= s2.start_date
**GROUP** **BY** s1.user_id
我们使用了CASE语句来根据给定用户的 s2.user_id 值标记 1 和 0。最终输出如下 -

在结束之前,我想推荐一本我非常喜欢并且觉得非常有用的 SQL 书籍。
SQL 食谱:数据库开发者的查询解决方案和技术 (Cookbooks (O’Reilly))
结论
掌握 SQL 需要大量的练习。在这篇文章中,我选择了 5 个棘手的问题并解释了解决方法。SQL 的特点是每个查询可以用多种不同的方式编写。请随时分享你的方法。我希望你今天学到了新东西!
如果你想联系我,请在LinkedIn上与我连接。
原文。经授权转载。
Saiteja Kura 诚恳、友好、雄心勃勃,对网页开发、数据科学和自然语言处理感兴趣。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关话题
5 种 DALL-E 3 使用案例

编辑者提供的图片
对于那些不知道的人,DALL-E 是一个最先进的 AI 模型,能够使用文本描述生成图像。它已经引起了轰动,人们在不同方面获益,这些在以前被认为是不可能的。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
对于那些还没有机会尝试 OpenAI 的 DALL-E 3 的人,您可能不确定可以用它做些什么。
在这篇博客中,我将介绍 DALL-E 3 的 5 种不同使用案例,并探讨 DALL-E 如何重塑不同的行业和工作流程。
您不需要成为 AI 爱好者才能从这个博客中获益,也许您只是想了解什么是 DALL-E 3,以及您可以用它做些什么。
在我们深入讨论之前,让我们快速了解一下 DALL-E。
什么是 DALL-E?
DALL-E,由 OpenAI 创建,是一个深度学习模型,能够根据文本描述创建视觉效果。这是通过计算机视觉和自然语言处理的结合实现的。
该模型经过多种数据集的训练,例如照片和书面描述,使模型能够检测对象和模式,从而能够生成不同风格的图像。
现在您了解了背景故事,让我们学习一下使用案例。
logo 设计
当你想到一个可以为你创建图像和视频的工具时,你会考虑它能为你做什么或在其他方面节省成本。这引起了很多组织的关注,因为 DALL-E 3 生成的图像都是您的!这意味着您无需获得 OpenAI 的许可即可重新打印、销售或进行商品化。
话说回来,您可以使用 DALL-E 3 创建一个 logo 来启动您的业务。例如:

如果您对 logo 的外观不满意,您可以随时要求 DALL-E 3 根据您的文本描述进行改进。例如,您可以要求 DALL-E 3 将圆形改为水滴/油滴,以更好地代表品牌。甚至可以完全改变外观以适应您的需求。
营销和广告
标志设计是视觉生成的一个方面,但这并不限制你创作各种类型的视觉内容。你可以创建适用于社交媒体帖子、网站的图像和视频。你可以轻松生成这些视觉内容,而不需要投入大量个人时间或聘请别人来为你完成。
我们来看一个创建数据科学训练营传单的例子:

AI 生成的艺术
曾经有过艺术眼光吗?还是想创造艺术却不知道从哪里开始?需要一点帮助,因为你的创意电池耗尽了?DALL-E 可以帮忙!
它不仅可以为你生成艺术,还可以帮助你指导自己创作艺术。许多人创建了 Instagram 账户,分享他们的 AI 生成艺术,并且做得非常好。其他艺术家也在请求 DALL-E 帮助他们完成初步草图,以便他们可以进一步发展。有些人希望模仿像梵高这样的艺术家,DALL-E 也在帮助他们。
这不仅为创意工作者提供了一个预制的画布,还节省了他们在产品原型上的大量时间和金钱。创意工作者现在可以探索新的想法,并从过去艺术家的风格和主题中受益。
我们来看一个例子:

书籍和漫画
你可以在几秒钟内用 DALL-E 创建整本漫画。惊人吧!你可以选择漫画的主题,一下子就有了自己的漫画。我们来试试吧:

但这还不是全部。你还可以使用 DALL-E 为你的书籍创建封面!无需为书籍封面支付高额费用,而且你可以将其调整到你想要的样子。让我们尝试为上面的漫画创建一个书籍封面。

教育材料
这篇是为老师们准备的。创建视觉材料以保持学生的参与感真是令人疲惫。有些老师甚至不包括视觉材料,这会让某些学生的学习过程变得更困难。
使用 DALL-E,你可以通过视觉辅助材料增强你的学习资料。例如,如果你正在进行生物学课程,并且重点讲解不同类型的肺部疾病,你可以使用 DALL-E 生成详细的图像,展示一个重度吸烟者的肺部如何随着时间的推移而恶化。
让我们输入这些内容,看看会出现什么:
酷吧?
总结
这些不是 DALL-E 的唯一应用场景,但我希望它已经给你一个良好的概念,关于你可以实现的目标、它如何改善你的工作流程以及整体日常。如果你使用 DALL-E 做了一些酷炫的事情,我们很想知道——请在下面留言!
尼莎·阿雅 是一位数据科学家、自由技术作家,同时也是 KDnuggets 的编辑和社区经理。她特别感兴趣于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。尼莎涵盖了广泛的主题,并希望探讨人工智能如何有助于人类寿命的延续。作为一个热衷学习者,尼莎希望拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关主题
每个懒惰的全栈数据科学家都应该使用的 5 种最有用的机器学习工具
原文:
www.kdnuggets.com/2020/11/5-useful-machine-learning-tools.html
评论
由 Ian Xiao,数据 | 机器学习 | 市场营销。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
照片由 Creatv Eight 提供,发布在 Unsplash 上。
构建优秀的机器学习应用程序就像制作米其林风格的菜肴。一个组织良好且管理得当的厨房至关重要,但选择的选项太多。在这篇文章中,我突出了在交付专业项目时发现有用的工具,并分享了一些想法和替代方案。像所有工具讨论一样,清单并不详尽。我尝试专注于最有用和最简单的工具。
免责声明: 本文未获得任何认证或赞助。我将数据科学和机器学习交替使用。
“我如何构建好的机器学习应用程序?”
这个问题在与学校的有抱负的数据科学家、寻求转行的专业人士以及团队经理的聊天中多次出现,并以不同的形式出现。
交付专业数据科学项目涉及许多方面。像许多人一样,我喜欢使用厨房烹饪的类比:有食材(数据)、食谱(设计)、烹饪过程(你的独特方法),最后是实际的厨房(工具)。
因此,本文走访了我的厨房。它突出了设计、开发和部署全栈机器学习应用程序的最有用工具——这些解决方案与系统集成或在生产环境中服务于用户。
令人眼花缭乱的可能性
我们正处于一个黄金时代。如果你在谷歌上搜索“机器学习工具”或询问顾问,你可能会得到类似这样的结果:

数据与人工智能格局 2019,图片来源。
目前有(太多)工具;可能的组合是无限的。这可能会令人困惑和不知所措。所以,让我帮助你缩小范围。也就是说,没有完美的设置。一切都取决于你的需求和限制。所以根据需要选择和修改。
我的列表优先考虑以下(不按顺序):
-
免费
-
容易学习和设置
-
未来证明(采纳与工具成熟度)
-
工程优于研究
-
在初创公司或大型企业中,适用于大小项目
-
完成任务即可
警告:我 99%的时间使用 Python。所以这些工具与 Python 原生兼容或是用 Python 构建的。我没有测试过其他编程语言,如 R 或 Java。
1. 冰箱:数据库
一个免费的开源关系数据库管理系统(RDBMS),强调扩展性和技术标准的符合性。它设计用于处理各种工作负载,从单台机器到数据仓库或有多个并发用户的网络服务。
图片来源。
替代方案:MySQL*, SAS, IBM DB2, Oracle, MongoDB, Cloudera, GCP, AWS, Azure, *PaperSpace
2. 操作台:部署管道工具
管道工具对于开发的速度和质量至关重要。我们应该能够在最小的手动处理下快速迭代。这里有一个有效的设置。查看我的12 小时 ML 挑战文章以了解更多细节。每个懒惰的数据科学家应该在项目早期尝试这个方法。
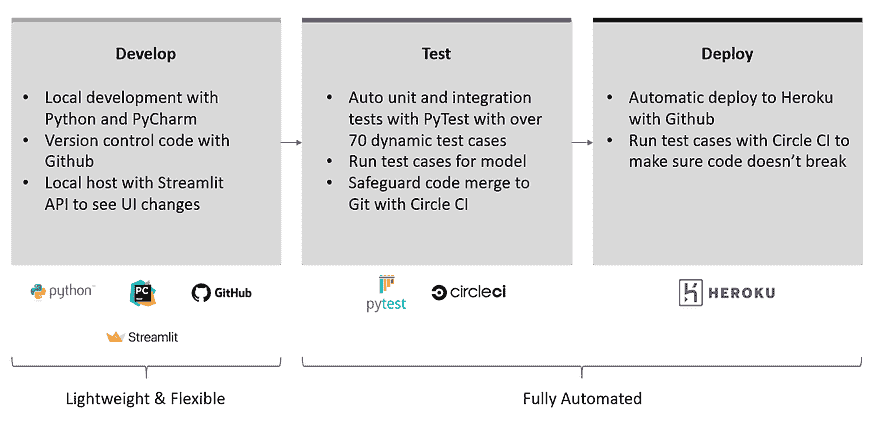
作者的工作,12 小时 ML 挑战。
它提供了 Git 的分布式版本控制和源代码管理(SCM)功能,以及自己的特性。它提供访问控制和若干协作功能,如错误跟踪、功能请求、任务管理和每个项目的维基。
PyCharm 社区版
一种集成开发环境(IDE),用于计算机编程,特别是针对 Python 语言。由捷克公司 JetBrains 开发。它提供代码分析、图形调试器、集成单元测试器、与版本控制系统(VCS)的集成,并支持 Django 的 Web 开发以及使用 Anaconda 进行的数据科学。
框架使得编写小型测试变得简单,同时也能支持复杂的功能测试,适用于应用程序和库。它节省了大量的手动测试时间。如果你每次更改代码时都需要测试某些内容,可以使用 Pytest 进行自动化测试。
备选方案:Unittest*
CircleCI 是一个持续集成和部署工具。它在你提交到 Github 时使用远程 Docker 创建自动化测试工作流。CircleCI 拒绝任何未通过 PyTest 设置的测试用例的提交。这确保了代码质量,尤其是在你与更大的团队合作时。
备选方案:Jenkins*, Travis CI, Github Action
Heroku (仅在需要网络托管时使用)
一种平台即服务(PaaS),使开发人员能够完全在云中构建、运行和操作应用程序。你可以与 CircleCI 和 Github 集成以实现自动部署。
备选方案:Google App Engine*, AWS Elastic Compute Cloud, 其他
Streamlit (仅在需要交互式用户界面时使用)
Streamlit 是一个开源应用框架,专为机器学习和数据科学团队设计。近年来,它已成为我最喜欢的工具之一。查看我如何使用它以及本节中的其他工具创建一个 电影 和 模拟 应用程序。
3. iPad:探索工具
Streamlit (再一次)
忘记 Jupyter Notebook 吧。没错,就是这样。
Jupyter 曾经 是我探索数据、进行分析以及试验不同数据和建模过程的首选工具。但我不记得有多少次:
-
我花了很多时间调试(并且揪心),但最终意识到我忘记从顶部运行代码;Streamlit 修复了这个问题。
-
我必须等待一段时间让数据管道重新运行,即使是小的代码更改;Streamlit Caching 修复了这个问题。
-
我不得不重写或转换 Jupyter 的代码到可执行文件——以及花费在重新测试上的时间;Streamlit 提供了一个捷径。
这很令人沮丧。因此,我使用 Streamlit 进行早期探索并提供最终的前端——一举两得。以下是我的典型屏幕设置。左侧是 PyCharm IDE,右侧是结果可视化。试试看吧。
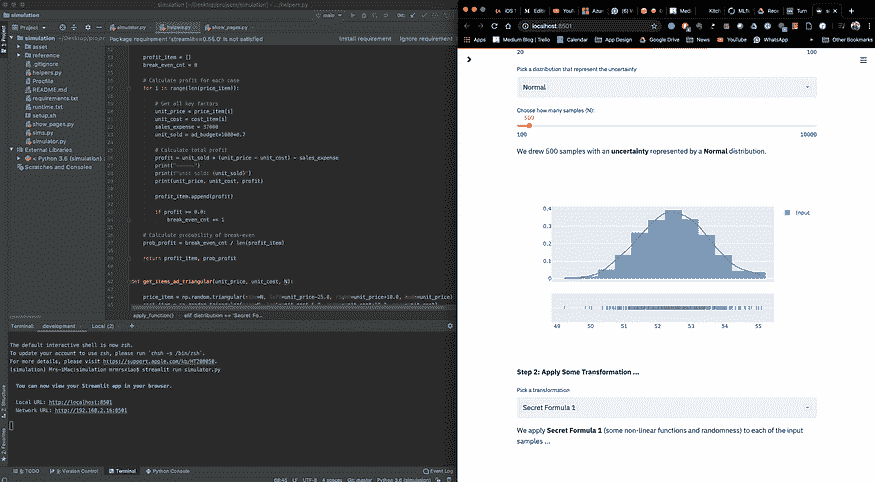
IDE(左侧)+ Streamlit 实时更新(右侧),作者的工作来自 被遗忘的算法
替代方案:Jupyter Notebook,Spyder from Anaconda,Microsoft Excel*(真的)
4. 刀具:ML 框架
就像使用真正的刀具一样,你应该根据食物和你想切割的方式选择合适的刀具。有通用刀和专业刀。
请谨慎。 使用专业的寿司刀切骨头将花费很长时间,尽管寿司刀更闪亮。选择合适的工具完成工作。
Scikit-Learn(常见 ML 使用案例)
用于在 Python 中进行一般机器学习的首选框架。不多说了。
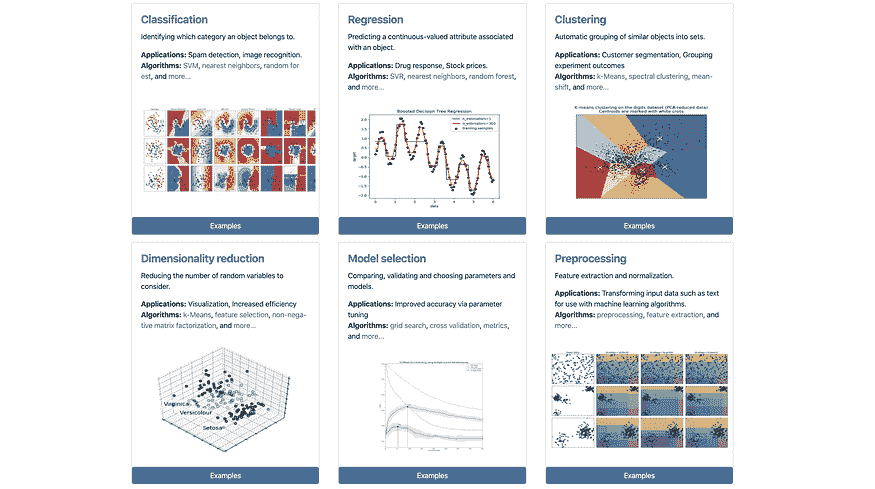
Scikit-Learn 的使用案例,来源。
替代方案:没有。
PyTorch(深度学习使用案例)
基于 Torch 库的开源机器学习库。鉴于深度学习的重点,它主要用于计算机视觉和自然语言处理等应用。它主要由 Facebook 的 AI 研究实验室(FAIR)开发。最近,许多知名 AI 研究机构,如 Open AI,正在将 PyTorch 作为他们的标准工具。
替代方案:Tensorflow,Keras,Fast.ai*
Open AI Gym(强化学习使用案例)
一个用于开发和比较强化学习算法的工具包。它提供 API 和可视化环境。这是一个社区正在构建工具的活跃领域。尚未有许多打包良好的工具。
替代方案:许多小项目,但没有多少维护得像 Gym 那样好。
5. 炉子:实验管理
一个免费的工具,允许数据科学家用几个代码片段设置实验,并将结果展示到基于 web 的仪表板上。

Atlas 过程,来源。
免责声明:我曾在 Dessa 工作,该公司创建了 Altas。
替代方案:ML Flow,SageMaker,Comet,Weights & Biases,Data Robot,Domino*
另一种视角
正如我提到的,没有完美的设置。这一切都取决于你的需求和限制。这是另一个可用工具及其如何协同工作的视角。
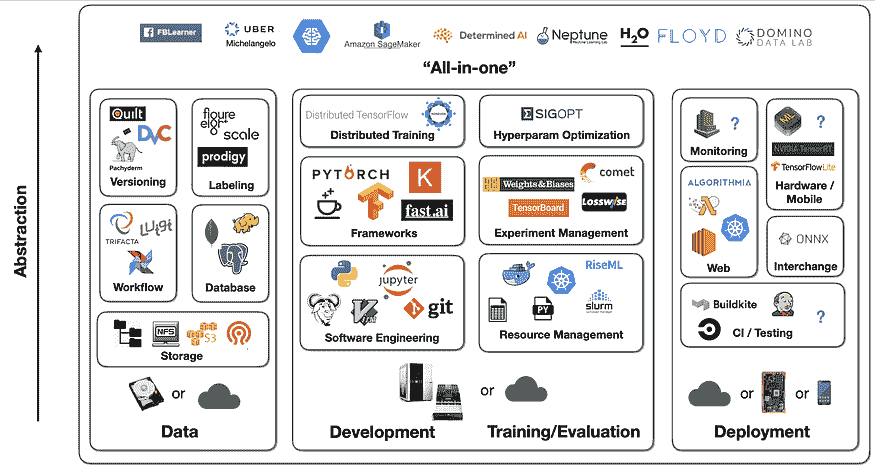
来自 Sergey Karayev 在 全栈深度学习 的演讲,2019 年。
原始文章。经允许转载。
相关:
更多相关话题
2023 年 AI 对 STEM 教育的五大影响
原文:
www.kdnuggets.com/2023/04/5-ways-ai-impacting-stem-education-2023.html

图片由编辑提供
STEM 教育是全国学生和教育工作者的重点。科学、技术、教育和数学是当前和未来需要技术工人的重要领域。随着技术进步和世界变得更加复杂,STEM 对学生的成功变得更加重要。
人工智能(AI)是一项塑造世界几乎每个方面的重要创新,教育也不例外。随着 AI 变得越来越普及,人们面临许多潜在挑战,但教育的好处是不可否认的。
AI 拥有几乎无限的可能性。STEM 教育工作者可以通过多种方式来提升科学和技术学习,适用于所有年龄段的学生,从日常教学到超越课堂的体验。
了解更多关于 AI 在 2023 年及以后对 STEM 教育影响的方式。
1. 个性化辅导
每个人的学习速度不同,学生有各种学习风格。例如,视觉学习者不会对阅读/写作学习者相同的方法做出反应。这意味着不是每个人都在同一页上,有些人可能会被落在后面。
AI 使教育工作者能够接受自适应学习——为每个学生定制的学习体验。人工智能程序可以收集和分析每个学生的数据,以创建个性化的课程。孩子们可以按自己的节奏学习,必要时获得额外的长除法练习或物理问题解决。
个性化辅导影响学生的成功率——接受辅导的孩子在大多数学科,包括 STEM 领域,相较于未接受辅导的同龄人表现更佳。AI 辅导将这种效果提升到一个新的层次——不再是“一刀切”的学习方式,避免了让某些孩子落后或被遗忘。
2. 更大的创造力
自适应学习的另一个好处是能够促进更多的创造性思维和解决问题的能力。传统的学习程序较为僵化,几乎没有空间让学生探索和尝试新想法。
AI 软件反应迅速,能够适应变化并建议新的路径。进入职场的 STEM 学生将面临更大的挑战,需要智能解决方案。早期获得创造性解决问题的经验将提升他们未来成功的可能性。
3. 包容性和访问
人工智能处于可访问技术的前沿。例如,虚拟现实(VR)使 STEM 教育和其他类型的学习对于非传统学生变得更加可及。那些可能无法亲自上课或有学习障碍的孩子,可以通过人工智能参与学习项目。
4. 更准确的评估
人为错误是不可避免的。准备或评分考试和标准化评估的教育工作者可能会犯错,这可能影响学生的教育。然而,人工智能程序在实际应用中的准确率很高。
这意味着所有教育阶段的 STEM 学生将会得到及时且准确的反馈。人工智能和人类教师提供的即时、有意义的反馈帮助学生回到正轨。更高的准确性也使教师能够 pinpoint 需要额外关注的学生或学术领域。
5. 对未来的准备
人工智能是技术的未来。然而,目前存在人工智能教育差距——对高度智能软件的需求很高,但能够胜任的工人数目难以跟上。这意味着学生准备一个以人工智能为导向的 STEM 职业比以往任何时候都更加重要。
学生获得经验的时间越早越好。教育中的人工智能程序使各个年龄段的学生能够熟悉这项技术,与之共同成长,并成为该领域的下一代领导者。
人工智能在 STEM 教育中的角色
人工智能和其他前沿技术在教育的未来中发挥着重要作用,尤其对于那些将开发未来程序的 STEM 学生来说。尽早在学习生涯中拥抱人工智能对于确保学术和职业成功至关重要。
April Miller 是ReHack杂志的消费技术主管编辑。她有创建优质内容的记录,这些内容推动了我所工作的出版物的流量。
更多相关信息
使用 AI 进行供应链管理的 5 种方法
原文:
www.kdnuggets.com/2022/02/5-ways-ai-supply-chain-management.html

使用人工智能优化我们的供应链
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT 部门
近年来,供应链管理变得越来越复杂。物理流动变得更加互联,而市场波动增加了对敏捷性和适应性的要求。
这在 COVID-19 大流行之后变得更加严重,全球对资源的需求增加,同时还需要应对各种不断变化的疫情防控措施。这就是为什么使用 AI 帮助优化供应链管理在各行各业中变得越来越普遍的原因。早期采用者在面对供应链管理行业中不可避免的人工智能未来时,更加有韧性和准备。

使用 AI 管理运输,图片来源
供应链管理是一个连接运输、生产、采购、市场营销、销售等的网络。公司可以利用供应链管理来制定集成计划,以平衡活动之间的权衡,从而优化收益。没有帮助,管理这些供应链可能会成为一项巨大的任务。
使用 AI 进行供应链管理是许多公司开始转变的一种方式,以应对全球和本地供应链日益增加的复杂性。在这篇博客文章中,我们探讨了 AI 的使用方式,哪些公司正在最佳利用它,并且还识别了人们当前使用人工智能来更好地掌握供应链管理的 5 种方法。
AI 如何在供应链过程中发挥作用?
通过利用公司运营产生的大量数据,组织能够使用 AI 驱动的解决方案和数据科学家团队来改造供应链操作:实施工厂自动化;提高质量控制,预测需求;预测性维护;等等!

汽车装配线,图片来源
供应链部门作为其所附属操作的大脑的一部分进行工作。供应链管理的角色变得如此重要,以至于在组织不断壮大的过程中,它们现在成为了一个主要的独立行业。
供应链问题并不是因为缺乏尝试,相反,它们通常是由于在疫情期间整个工业体系被需求压垮。供应链近年来更多地与最大化公司的价值和绩效相关联,而不是关注组织各部门之间的需求供应。
这一行业已从关注将产品运送给客户的物流转向关注在需求异常的特定行业中增长供应。公司们正越来越依赖人工智能解决方案来实现这一目标,以便在这些动荡时期中蓬勃发展。
基于人工智能的解决方案更容易获得,帮助企业实现更高级别的供应链管理绩效。
成功使用人工智能供应链管理的公司能够将物流成本降低 15%、库存减少 35%、服务水平降低 65%,与未适应和使用人工智能进行供应链管理的竞争对手相比。
哪些公司在供应链管理中使用人工智能?
人工智能在供应链和物流行业中迅速获得了人气。供应链和物流行业的领导者越来越明显地认识到,人工智能完全能够处理运行本地和全球物流网络中的复杂性。

装配线上的人工智能,图片来源
人工智能正在通过更高效地跟踪操作、改善供应链管理和生产力、补充商业计划,甚至与在线客户互动来改变行业。
像 IBM 和谷歌这样的主要公司充分利用人工智能进行供应链管理是自然的,但那些不以使用先进人工智能程序而闻名的公司也开始关注这一点。
例如,甲骨文正在利用人工智能创建自我更新和自我管理的数据库供其客户使用。Coupa是另一家利用人工智能进行供应链改善和管理的公司。Coupa 围绕帮助企业使用人工智能和其他深度学习程序管理供应链创建了整个业务结构。
从卡车司机的组织方式到产品的订购和调度,物流行业在供应链的各个阶段几乎完全采用了人工智能。随着每一次新成功,越来越多的企业开始使用人工智能来优化其商业模式。
5 种人工智能在供应链管理中的应用方式

利用人工智能组织卡车配送,图片来源
根据多项研究,人工智能可以为供应链和物流操作提供无与伦比的价值。如前所述,全球各地的公司开始倾向于使用人工智能来改进和管理供应链。
无论是通过使用人工智能来降低成本、消除操作冗余和风险、减轻不必要的风险、改善供应链预测、加快和提高产品交付效率,还是重新振兴客户服务策略,人工智能在供应链管理中变得至关重要。
具体而言,人工智能在创建需求预测模型、提高端到端透明度、整合商业计划、生成动态业务优化模型以及大幅改善物理流动自动化方面正产生巨大影响。
1. 需求预测模型
我们供应链的主要目的之一是维持最佳库存水平,以避免库存不足或库存过剩的灾难。平衡库存和仓库管理是实现最佳供应链的关键。
当人工智能用于创建需求预测模型时,它们能够对未来需求进行相当准确的估计,并与当前库存进行对比。

需求预测模型,图片来源
例如,人工智能程序可以用来预测产品在销售渠道中的衰退和生命周期结束(EOL)。该程序随后可以为预计将突破市场的新产品创建模型,以替代任何即将达到 EOL 的产品。
使用人工智能进行需求预测帮助许多公司最大化产品在市场中的生命周期。
2. 端到端透明度
当前全球供应链的预测情况复杂至极。制造商比以往任何时候都更加需要对整个供应链有全面的可视化了解。
制造商需要一目了然地了解其产品如何组装、生产量多少以及发货量多少。
认知人工智能驱动的自动化程序被用于提供数据可视化,这些可视化可以揭示供应链问题的原因和影响,减少或消除瓶颈问题,并识别改进和推动供应链的机会。
数据在地图上可视化,图片来源
供应链管理中的人工智能不仅利用历史数据,还通过获取和理解供应链多个层次上的实时数据来完成所有这些工作。
3. 集成业务规划
供应链经理在完全优化供应链方面面临困难,因为他们无法实时查看,检测扩展产品组合中的差异,理解消费者需求趋势的变化,或跟上工厂停工和运输问题等意外事件的最新情况。
这些都是复杂的过程,通常在到达供应链经理之前需要经过多个层次的沟通。
然而,AI 解决方案可以与这些系统集成,并使商业计划在多个公司和生产阶段之间进行整合。
当这些商业计划和供应链协调一致时,每位供应链经理都能更好地掌握他们的产品分配。
4. 动态规划优化
就像 AI 能够跨多个公司整合商业计划一样,AI 程序还被用来生成认知预测和建议,以进一步改进和优化供应链规划过程。
这可以节省公司通过复杂的手动商业模型进行规划的大量时间,并减少这一过程中的错误。

AI 集成的供应链软件放大供应链中的关键因素,从概念到交付产品进一步优化过程。这通过帮助制造商确定各种情景在时间、成本和收入方面的潜在后果,提高了供应链的性能。
5. 物理流自动化
在供应链预测和规划阶段的优化中,人工智能可以确保物料单和采购订单数据结构化并正确归档,从而在实时中创建更准确的预测。
这使得数据驱动的现场操作员能够根据当前和预测的消费者需求维持最佳水平。AI 在供应链中的集成使得识别和管理这些最佳水平成为可能。
有些人工智能程序利用计算机视觉和物理传感器来监控和修改供应链过程。这可以实时保持准确和更新的库存表格。
更进一步,一些人工智能甚至可以自动感知供应链中的需求,并进行适当的订单,以保持最佳水平,无需现场操作员或供应链经理在下订单前进行实际的库存盘点。例如,监控商店货架上的产品,并交叉参考剩余的产品库存和当前的需求,以便在需求高且库存几乎耗尽时主动重新订购库存。

所有这些数据以及组织的整体运营结构在管理供应链方面都是无价的,因为企业越来越多地尝试自动化物料和产品流动。
寻找有关人工智能或供应链管理的更多信息?
在当今世界,利用人工智能更好地管理供应链已经开始得到实践,并且正迅速成为各个行业的标准。随着其变得越来越普及,各国可能会推动全球供应链实践的标准化,以简化流程,使资源和产品跨境流动更加顺畅。
Kevin Vu 负责 Exxact Corp 博客,并与许多才华横溢的作者合作,他们撰写有关深度学习不同方面的内容。
更多相关话题
5 种将 AI 应用于小数据集的方法
原文:
www.kdnuggets.com/2022/02/5-ways-apply-ai-small-data-sets.html

技术照片由 rawpixel.com 创建 - www.freepik.com
人工智能和数据科学协同工作,以改善数据收集、分类、分析和解释。然而,我们只听说过使用 AI 理解大数据集。这是因为小数据集通常容易被人理解,应用 AI 来分析和解释它们并不必要。
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
如今,许多企业和制造商将 AI 集成到生产线中,逐渐造成数据稀缺。与大型公司不同,许多小型公司由于风险、时间和预算限制,无法收集大量训练数据。这导致了对小数据集的 AI 解决方案的忽视或错误应用。
由于大多数公司不知道如何正确地利用AI 在小数据集上的应用,它们盲目地将其应用于基于以往文件的未来预测。不幸的是,这会导致错误和风险决策。
因此,学习正确的方法将 AI 应用于小数据集并避免任何误解是至关重要的。
AI 在小数据集上的 5 种正确应用方法
将 AI 算法应用于小数据集可以获得无人工错误和虚假结果的结果,但前提是正确应用。你还可以节省时间和资源,通常用于手动解释小数据。
以下是将 AI 应用于小数据集的一些方法:
1. 少样本学习
少样本学习模型向 AI 引入少量训练数据,以作为新数据集解释的参考。这是一种常用的计算机视觉方法,因为它不需要许多示例进行识别。
例如,财务分析系统并不需要大量库存就能有效运作。因此,你可以根据系统的容量输入一个利润和损失表模板,而不是让 AI 系统承载大量信息。
与其他 AI 系统不同的是,如果你在这个模板中输入更多信息,它将导致虚假的结果。
当你在 AI 系统中上传样本数据时,它会从训练数据集中学习模式,以便对未来的小数据集进行解释。少量学习模型的吸引力在于,你不需要一个庞大的训练数据集来训练 AI,使其在低成本和低努力下可运行。
2. 知识图谱
知识图谱模型通过从一个大的原始数据集中筛选创建二级数据集。它用于存储事件、对象、实际情况以及理论或抽象概念的互联描述和特征。
除了作为数据存储,该模型还同时对特定数据集中的语义进行编码。
知识图谱模型的主要功能是组织和结构化数据集中的重要点,以整合从各种来源收集的信息。知识图谱被标注以关联特定含义。图谱中有两个主要组件 - 节点和边。节点是两个或更多的项,而边表示它们之间的连接和关系。
你可以使用知识图谱来存储信息,通过多个算法整合数据并操控数据,以突出新信息。此外,它们在组织小数据集方面非常有用,使数据高度可解释和可重用。
3. 迁移学习
公司避免在小数据集上应用 AI,因为他们对结果不确定。对于大数据集产生有效结果的方法在小数据集上往往适得其反,产生虚假的结果。然而,迁移学习方法可以在数据集大小不同的情况下产生类似且可靠的结果。
迁移学习使用一个 AI 模型作为起点,但通过一个新的 AI 模型获得结果。简而言之,它是将知识从一个模型转移到另一个模型的过程。
该模型主要用于计算机视觉领域和自然语言处理。原因在于这些任务需要大量的数据和计算能力。因此,使用迁移学习可以减少额外的时间和精力。
为了在小数据上应用迁移学习模型,新数据集必须与原始训练数据集相似。在应用过程中,移除神经网络的末端,并添加一个类似于新数据集类别的全连接层。在此之后,随机化全连接层的权重,同时冻结先前网络的权重。现在,根据新的全连接和操作层更新并训练 AI 网络。
4. 自监督学习
自监督学习或 SSL 模型从可用或训练数据集中获取监督信号。然后,它利用已有数据来预测未观察到或隐藏的数据。
SSL 模型主要用于执行回归分析和分类任务。然而,它在计算机视觉、视频处理和机器人控制领域标记未标记数据方面也很有帮助。该模型迅速解决了数据标记挑战,因为它独立构建并监督完整的过程。这样,公司节省了创建和应用不同 AI 模型的额外成本和时间。
使用 SSL 模型具有高度的适应性,因为它能够生成可靠的结果,无论数据集的大小如何,证明了模型的可扩展性。SSL 对于长期提高 AI 能力也非常有用,因为它支持升级。此外,它消除了对样本案例的需求,因为 AI 系统会独立演变。
5. 合成数据
这是一种人工生成的数据,由在真实数据集上训练过的 AI 算法创建。顾名思义,这些数据是人工创建的,不基于实际事件。合成数据的预测能力与原始数据的预测相匹配。它可以替代初始数据预测,因为它不使用伪装和修改。
合成数据在可用数据集中存在空白且无法通过积累数据填补的情况下使用效果最佳。此外,与其他 AI 学习和测试模型相比,它成本低廉,不会侵犯客户隐私。因此,合成数据迅速在多个领域占据主导地位,到 2024 年底,60% 的 AI 分析项目将会是合成生成的。
合成数据越来越受到关注,因为公司可以创建满足现有数据中不存在的特定条件的数据。因此,如果公司由于隐私限制无法访问数据集或产品无法进行测试,它们仍然可以利用 AI 算法创建合成数据以获得可靠的结果。
总结
人工智能正在快速发展并接管以简化每一个复杂任务。然而,大多数人不知道他们可以应用人工智能算法。例如,它非常适合组织和分析大数据,同时在较小的数据集上也相当有效。但为了获得正确的结果,你必须使用准确的人工智能方法和模型。使用本文中列出的人工智能模型,因为它们适用于在小数据集上创建正确的结果。
Nahla Davies 是一名软件开发者和技术作家。在全职从事技术写作之前,她曾担任过许多引人注目的职位,包括在一家《Inc. 5000》体验式品牌公司担任首席程序员,该公司客户包括三星、时代华纳、Netflix 和索尼。
更多相关主题
5 种将伦理应用于人工智能的方法
评论
作者 Marek Rogala,Appsilon 首席技术官
在 上一篇文章 中,我表达了我有机会在 ML in PL 会议上发表演讲的快乐。我有机会退后一步,反思一下我们作为数据科学从业者和机器学习模型构建者所做工作的伦理。这是一个重要的话题,却没有得到应有的关注。
我们构建的算法会影响生活。
我对这个话题进行了大量研究,在此过程中,我发现了一些对我印象深刻的故事。这里有六个基于真实生活的教训,我认为作为从事机器学习的人员,无论你是研究员、工程师还是决策者,我们都应该记住。
该是展示你卡片的时候了

现在是时候举一个更积极的例子了,这是我们在日常工作中可以遵循的做法。OpenAI 最终发布了完整的 GPT-2 模型 用于文本生成。OpenAI 注意到该模型功能强大,可能会被用于非常不良的方式(从个人测试来看,我可以确认它通常非常逼真)。因此,他们在 2 月份发布了一个限制版本,并启动了一个过程。他们邀请研究人员对模型进行实验,要求人们构建检测系统,以查看检测某些内容是否由机器人生成的方法的准确性。他们还聘请了社会科学家,因为作为工程师我们应该知道自己的局限性,无法理解我们发布的模型的所有影响。但我们可以与那些理解这些的人合作。
他们使用的工具之一是我们在日常工作中都可以使用的——模型卡片。这是 谷歌的几位员工建议的。模型卡片以标准化的方式展示了预期用途和误用情况。它显示了数据是如何收集的,以便研究人员可以进行实验并发现过程中的一些错误。卡片还可以包含警告和建议。无论你是向公众发布还是仅限内部使用,我认为完成一张“M-card”是很有用的。我认为 OpenAI 做得很好。这就引出了第 6 课。
第 6 课:评估风险。沟通预期用途。
前进。我上周在推特上看到了这个消息。一些研究人员展示了一种模型,这种模型将使用面部识别来支付伦敦地铁的入口费用。
面部识别可以让你的通勤变得轻松很多 pic.twitter.com/B3SISYq0Zb
— Mashable (@mashable) 2019 年 11 月 9 日
- 我震惊于他们根本没有提到任何风险,例如执法滥用、隐私问题、监控、移民权利、偏见以及威权国家的滥用。影响巨大。所以,第 7 课:获得媒体关注对一个酷炫的模型很容易,但我们不应该像布里斯托尔的那些研究人员那样。如果一个视频以这种方式被展示,我们应该确保风险被指出。
第 7 课:媒体报道很容易获得。确保风险被传达。
 这是我想给你展示的另一个正面例子——这是Evan Estola 的讲座,他是Meetup的首席机器学习工程师。他做了一个有用的讲座,名为“当推荐系统变坏时”,讨论了他们做出的一些决策。他提醒我们 Goodhart 定律:
这是我想给你展示的另一个正面例子——这是Evan Estola 的讲座,他是Meetup的首席机器学习工程师。他做了一个有用的讲座,名为“当推荐系统变坏时”,讨论了他们做出的一些决策。他提醒我们 Goodhart 定律:
“当一个衡量标准变成目标时,它就不再是一个好的衡量标准。”
“我们有道德义务不要教会我们的机器有偏见,”他补充道。例如,在美国,科技岗位中男性多于女性。那么 Meetup 推荐模型是否应该因为技术聚会主要由男性参加而劝阻女性参加?当然不应该。但是如果模型没有特别设计,模型可能会从数据中轻易推断出女性对技术活动不感兴趣,然后反过来维持性别刻板印象。所以第 8 课……
第 8 课:记住,一个指标始终是我们关心的事物的代理。
那么政府监管的问题呢?以下是对我来说最震惊的例子。也许你们中的一些人知道去年在缅甸发生了种族灭绝。数千名罗兴亚人在军队、警察和其他多数族群成员的手中丧生。Facebook 今年终于承认,他们没有做足够的工作——这个平台成为了人们传播暴力和暴力内容的途径。所以,基本上多数族群的人传播了对少数族群罗兴亚人的仇恨。他们信仰不同的宗教,这只会加剧暴力。

情况最糟糕的部分是,Facebook 高管早在 2013 年就已被警告。五年后,暴力爆发。在 2015 年,第一次警告后,Facebook 只有四名讲缅甸语的承包商审查内容——显然不够。他们只是没有足够重视。
瑞秋·托马斯 比较了 Facebook 在两个国家的反应。一个是针对缅甸,Facebook 宣称他们为缅甸语添加了“数十个”内容审查员。在同一年,他们在德国雇用了 1,500 名内容审查员。为什么会这样?因为德国威胁 Facebook(及其他公司)如果不遵守仇恨言论法,将处以 5000 万美元的罚款。这是一个法规如何发挥作用的例子,因为它使那些主要关注利润的管理者认真对待风险。
这是一个关于法规的个人例子。我有两个小孩,所以我对儿童座椅变得非常熟悉。过去,很多人声称汽车不能受到监管。安全问题被归咎于驾驶员。稍微快进一下,现在的计算结果是,相比于面向前方的座椅,儿童在面向后方的座椅中安全性提高了五倍。各国的法规不同。在瑞典,他们的法规基本上支持使用面向后方的座椅。因此,从 1992 年到 2013 年,仅有 15 名儿童在交通事故中死亡。相比之下,在没有这样的法规的波兰,每年有 70 到 150 名儿童在交通事故中死亡**。
监管最终会到来 AI。问题是它是否会明智还是愚蠢。技术人员通常反对监管,因为监管往往设计和实施不佳。但我认为这是因为我们需要使其明智。我们最终会有关于 AI 的监管,但尚不确定其质量和何时发生。
第 9 课:法规是我们的盟友,而不是敌人。倡导明智的法规。
最后的例子。在 Appsilon 我们投入了相当多的时间进行“AI for Good”倡议。因此,我们与非政府组织合作,利用 AI 模型研究气候变化、保护野生动物等,这非常好,我很高兴看到其他公司也在这样做。但我们应该意识到一种叫做技术主义的现象。
有一本书,作者是 Kentaro Toyama,书名为 “极客异端”。Toyama 先生是微软的工程师,他被派往印度通过技术帮助社会变革和改善人们的生活。他发现,人们在尝试用技术解决问题时,往往把西方视角应用于一切,结果犯了很多错误。他展示了许多通过技术解决问题的高期望是如何失败的例子。
我们应该与领域专家密切合作,首先解决简单问题,以合适的深度,以便在领域专家和工程师之间建立共同的理解。工程师需要了解问题的根源,而领域专家需要了解技术能够做什么。只有这样,真正有用的想法才能出现。
第 10 课:在 AI for Good 中,与领域专家紧密合作,并警惕技术主义。

我们所构建的算法影响着生活。通过互联网和社交媒体,它们可以字面上塑造你的思维。它们影响医疗、就业和法庭案件。考虑到不到百分之一的人口会编码,想象一下其中有多小的一部分真正理解人工智能。所以我们肩负着塑造社会未来的重大且令人兴奋的责任,以确保它光明。

你了解其他人不知道的问题。你对我们社会的形态负有责任。
你有自己的“经验教训”吗?请在下面的评论中添加。
感谢阅读!在 Twitter 上关注我 @marekog。
关注 Appsilon 数据科学的社交媒体
个人简介:Marek Rogala 是 Appsilon 的首席技术官。
原文。经许可转载。
相关:
-
床下的灰尘:机器学习者对我们社会未来的责任
-
5 个数据科学家应该避免的统计陷阱
-
设计伦理算法
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关话题
5 种使用 ChatGPT 代码解释器进行数据科学的方式
原文:
www.kdnuggets.com/2023/08/5-ways-chatgpt-code-interpreter-data-science.html

图片来源:作者
通过代码解释器集成,ChatGPT 现在可以在沙盒环境中编写和执行 Python 代码,从而提供更准确和精确的答案。这使得它能够通过代码执行而非仅仅文本预测来进行复杂计算、生成可视化等。用户可以上传数据文件供代码处理,并收到像输出文件这样的结果。一般而言,代码解释器功能减少了大语言模型中常见的错误,并显著扩展了 ChatGPT 从数据可视化到生成动画的能力。
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
在这篇博客中,我们将探讨五种使用 ChatGPT 代码解释器来处理数据科学任务和项目的简单方法,并附有示例。
1. 数据分析
ChatGPT 在 Python 数据分析方面具有显著能力。凭借其新的代码解释器集成,它现在可以执行 Python 代码并返回结果。它甚至可以生成带有动画的交互式可视化。
提供一个 CSV 文件,ChatGPT 将生成数据可视化和总结统计,甚至处理数据。只需一个自然的提示来描述你所需的分析。
ChatGPT 自然语言理解与运行 Python 代码的能力相结合,为非技术经理解锁了快速和自动化的数据分析。
图片来源 Soner Yıldırım
2. 数据清理
数据清理可能是数据科学家最繁琐的任务之一。手动清理 CSV 文件或编写自定义 Python 脚本非常耗时。然而,ChatGPT 的新功能简化了这一过程。它与代码解释器的集成使得通过简单的对话提示实现自动化数据清理成为可能。
例如,提供 ChatGPT 一个 CSV 文件,并要求它分析数据质量。ChatGPT 会检查数据框,识别如缺失值等问题,并提出解决方案。现在,助手可以彻底调查数百列数据。ChatGPT 甚至会生成自定义 Python 函数来实现推荐的数据清理步骤。

图片来自 DataCamp
数学
ChatGPT 已扩展了理解技术文档(如研究论文)的能力。只需提供 PDF 或方程式的图像,其集成的 OCR 将提取并理解数学内容。
例如,上传一篇解释新机器学习技术的论文。要求 ChatGPT 求解关键方程,并逐步演示推导过程。Code Interpreter 可以解析图像文件和 PDF 中的复杂公式,进行计算,并用简单语言解释方程的含义。
图片来自 DatHero
转换文件
使用这一创新功能让你的数据栩栩如生。只需上传一个包含欧洲灯塔位置的 CSV 文件。Code Interpreter 会自动生成一个动画地图,每个灯塔在黑暗的背景下闪烁如星星。
可能性还不止于此。轻松将你的 CSV 文件转换为 Excel 表格以进行进一步分析。或者上传图像文件,Code Interpreter 将其转化为独特的 GIF 动画。
图片来自 Ethan Mollick
图示
ChatGPT 提供以文本形式的有用回答。使用 Code Interpreter 可以将信息以可视化形式呈现。例如,生成 Venn 图在寻找多个主题之间的共同点时特别有用。
在多个主题之间难以找到共同点?轻松创建一个 Venn 图以突出交集。计划新的系统架构?Code Interpreter 将其呈现为专业的工作流程图。教授复杂概念?通过定制的图示吸引学生,展示关键点。
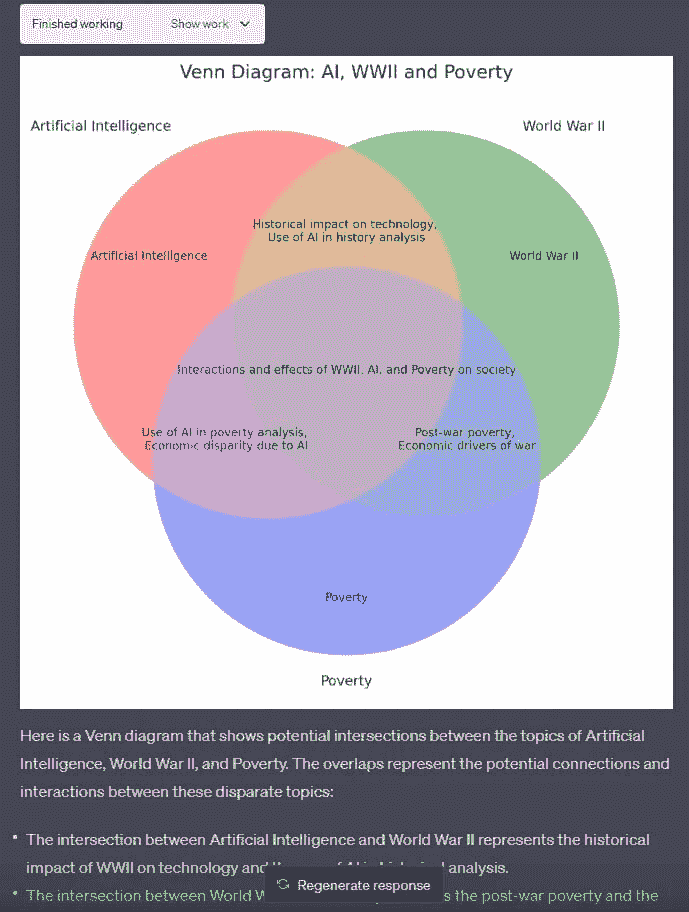
图片来自 DatHero
结论
ChatGPT 正日益成为所有数据相关问题的首选平台。通过简单的提示,用户可以生成数据分析报告,解决复杂的问题、数学方程式,转换文件,并创建维恩图。ChatGPT 的自然语言能力和执行 Python 代码的能力使其可供任何人执行技术性和复杂的任务。
资源
-
使用 ChatGPT 代码解释器的前 10 种方法 | 作者:DatHero | 2023 年 7 月 | Medium
-
ChatGPT 代码解释器:它如何节省了我数小时的工作 | 作者:Soner Yıldırım | 2023 年 7 月 | Towards Data Science
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,他喜欢构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些遭受心理疾病困扰的学生。
相关主题
通过数据科学翻倍收入的 5 种方法
原文:
www.kdnuggets.com/2022/05/5-ways-double-income-data-science.html

图片由 Alexander Mils 提供,来源于 Unsplash
传统的 9 到 5 工作并不是唯一的收入来源。目前对数据技能的需求非常高,如果你能从大量数据中提取价值,你可以在传统全职工作之外接很多高薪任务。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
我已经在这个领域自由职业超过一年了,并且有机会与来自世界各地的人在不同的领域合作。
从事自由职业的数据科学工作最棒的地方就是可以在家以自己的节奏工作。我可以挑选自己喜欢做的任务,拒绝那些我觉得无趣的工作。我还发现,由于需要与来自不同背景的人交流并传达我的发现,我的沟通技巧得到了显著提高。
在这篇文章中,我将列出 5 种不同的方式,你可以利用你的数据技能来生成额外收入。我还会提供一些见解,帮助你在其他自由职业者中脱颖而出,并持续获得高薪项目。
生成额外收入的任务
1. 构建机器学习模型
许多小型组织和初创公司没有数据科学团队。这些公司倾向于通过将数据科学工作外包给合同外聘人员来节省成本。
这意味着你不仅会与这些公司在一次性基础上合作构建模型,还需要持续监控性能,并在需要时用新数据更新算法。
这种合作方式为你提供了优势,因为公司会在较长时间内需要你的服务。
2. 数据收集
许多组织依赖第三方数据进行竞争对手情报分析、建立定价模型、进行情感分析,并在市场中保持领先地位。
像这样的自由职业任务需要你使用 APIs 来收集数据。我曾经帮助客户通过 API 收集 Twitter 数据,该客户需要过去 5 年的社交情绪数据来生成股市预测。
根据数据收集任务的复杂程度,你可能还需要爬取网页以从网站提取信息。我过去曾为几家公司抓取过定价、评论和产品数据。在某些情况下,将这些数据存储在 Excel 表格中就足够了。其他客户则希望我创建并定期更新一个包含所有抓取信息的数据库。
网页抓取是一个非常有用的技能,因为许多组织没有内部数据,几乎完全依赖于公开的数据源来收集信息。如果你对抓取不熟悉并希望学习,我建议从这个 DataCamp 课程开始,它会带你了解如何使用 Python 和 BeautifulSoup 进行数据收集。
3. 市场研究
市场研究是一个涉及评估公司目标受众以收集潜在客户信息的领域。
过去,大多数市场研究都是由营销专业人士完成的,他们会进行调查、访谈,并创建客户焦点小组。
然而,这些方法也有其缺点。调查可能会根据发送对象的性质提供有偏差的结果,它们并不总是能够真实反映整体人群。此外,由于时间限制,潜在消费者有时会错误回答调查,特别是当存在完成奖励时。
此外,一些形式的市场研究需要你处理大量从在线来源收集的外部数据。虽然营销专家可能擅长解读这些数据,但他们可能由于缺乏数据素养而没有分析数据所需的技能。
以上因素导致了市场研究员角色的转变。如今,公司在寻找具备数据分析技能和营销领域知识的人才。
我过去曾与几家公司合作进行市场研究任务。我的工作通常始于收集公开数据、清理数据和存储数据。接着,我会对这些数据进行分析,并尝试运用一些营销领域知识来解读。最后,我会提出整体市场洞察和相关建议,并交给公司的产品或营销团队以便采取行动。
如果你是一个希望扩展技能并获得市场研究或营销分析领域知识的数据科学家,这里是我建议你参加的课程。
4. 数据科学内容
我过去参与过许多形式的数据科学内容创建,包括博客文章、教程、白皮书和观点文章。
这个领域对能够将高度技术性材料浓缩并使其易于理解的人需求巨大。
像 Medium、Analytics Vidhya 和 KDNuggets 这样的平台是建立在线存在并获得写作报酬的绝佳途径。
我大约在两年前发现了 Medium 并开始在该平台上写文章。我发现自那时以来,我的讲故事技巧以及数据科学和写作技巧都有了显著提高。
此外,随着我在平台上获得更多读者,我也收到了多个雇主希望雇佣自由职业数据科学作家的工作邀请。
如果你想了解更多关于如何开始为数据科学写作的信息,我强烈建议阅读我之前创建的这个指南。
5. 数据科学讲师
数据科学和分析技能如今需求非常高。而且不仅仅是数据科学的 aspirants 在尝试学习这门学科;即使是组织中的非技术性高管也在努力处理定量数据,并愿意参加相关培训课程。
成为该领域的讲师并不需要精通数据科学的每个方面。例如,如果你对机器学习建模不熟悉,但对 SQL 有广泛了解,你可以选择教授一个面向行业新手的初级 SQL 课程。
如何获得高薪的数据科学职位
现在你已经对作为数据科学家可以从事的任务类型有所了解,你可能心中有一个迫切的问题:
“我究竟如何找到这些工作?”
我曾多次尝试通过 Fiverr 和 Upwork 等平台赚取副收入,但这些平台的竞争实在太激烈。我愿意接的每个项目,至少有五个人愿意以更低的价格竞标。
我将注意力从自由职业网站转移,开始在 LinkedIn 上向广泛的人群展示我的作品。我还注册了 Medium 等平台,撰写了描述我过去所做项目的文章。
随着更多读者开始注意到我的作品,工作请求也开始源源不断地涌入。
例如,我曾创建一个客户细分模型,并在 Medium 上写了一篇教程。我没想到会有很多人阅读它。然而,第二天,一位雇主通过 LinkedIn 联系我,询问我是否有空为他的公司做一个细分项目。至今已有一年多了,我仍与这位雇主在许多不同的项目上合作。
我相信,建立社交存在并与他人分享你的作品对进入自由职业至关重要,尤其是在数据科学这样竞争激烈的领域。
一旦你为多个客户工作并建立了强大的作品集,向你的客户请求积极反馈和高评分。这将帮助你在这些平台上更容易被注意到,你可以获得未来的工作机会,即使不需要投标。
Natassha Selvaraj 是一位自学成才的数据科学家,对写作充满热情。你可以在 LinkedIn 上与她联系。
更多相关内容
扩展数据科学知识的 5 种方法
原文:
www.kdnuggets.com/2022/04/5-ways-expand-knowledge-data-science-beyond-online-courses.html

图片来源于 Gabriella Marino,来自 Unsplash
关键要点
-
在当今的信息技术现代世界中,学习数据科学的在线资源是无限的。
-
大多数数据科学资源仅提供表面知识。
-
要在在线课程之外扩展你的知识,你必须付出额外的努力,以深入掌握核心数据科学概念。
我们的前 3 个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业道路
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你的组织 IT
学习数据科学的在线资源是无限的。这些资源可以在 YouTube、KDnuggets、Medium 等平台上找到,或者在提供大规模开放在线课程的数据科学平台上找到,如下所示:
-
edx:
www.edx.org/ -
Coursera:
www.coursera.org/ -
DataCamp:
www.datacamp.com/ -
Udemy:
www.udemy.com/ -
Udacity:
www.udacity.com/ -
Lynda:
www.lynda.com/
虽然使用这些资源作为学习数据科学基础知识的起点是有益的,但要扩展知识至基础知识之外,还需要更多的努力。
扩展知识的其他方法
数据科学教材
教材是很好的教学工具,适合那些希望深入学习在线课程内容以外的高级学习者。对我个人来说,有一本教材给我留下了深刻的印象(在进行数据科学项目时我仍然把这本书作为主要参考书),这本书是:“Machine Learning with PyTorch and Scikit-Learn”,作者 Sebastian Raschka。 这本书提供了数据科学和机器学习的绝佳入门,包含代码。该书的 GitHub 仓库可以通过点击以下链接访问:github.com/rasbt/machine-learning-book

这本书是针对初学者的最佳数据科学书籍之一。作者以非常易于理解的方式讲解了数据科学和机器学习的基本概念。此外,还包括了代码,你可以实际使用提供的代码进行练习并构建自己的模型。我个人发现这本书在我的数据科学学习旅程中非常有用。我会推荐这本书给任何数据科学志愿者。你只需要具备基础的线性代数和编程技能即可理解这本书。还有许多其他优秀的数据科学教材,如 Wes McKinney 的“Python for Data Analysis”、Kuhn & Johnson 的“Applied Predictive Modeling”和 Ian H. Witten, Eibe Frank & Mark A. Hall 的“Data Mining: Practical Machine Learning Tools and Techniques”。
真实世界的数据科学问题
虽然数据科学的在线课程提供了一些基础知识,但你可以通过将新获得的知识应用到数据科学项目中来提升自己的技能。当你挑战自己将知识应用于真实的数据科学项目时,它将帮助你深入理解核心的数据科学概念。Kaggle 的数据科学竞赛为具有高级知识的个人提供了很好的挑战项目。
与数据科学专业人士建立网络
根据我的个人经验,通过与其他数据科学志愿者组队,参与每周的群体讨论,我学到了很多关于数据科学和机器学习的知识。与其他数据科学志愿者和专业人士建立网络;在 GitHub 上分享你的代码;在 LinkedIn、Kaggle 或 Medium 等平台展示你的技能。这将帮助你在短时间内学到很多新概念和工具。你还会接触到新的方法,以及前沿的算法和技术。建立网络也能提升你的沟通能力和团队合作技能。
通过写博客分享你的数据科学知识
学习的最佳方式是通过教学。当你教别人时,你会被迫理解核心概念,你的目标是以易于理解的方式向学生或公众解释这些核心概念。写博客是提升和扩展你数据科学知识的绝佳方式。当我尝试学习新事物时,我总是挑战自己写一篇关于这个主题的博客。这是一种证明自己理解了概念的方式。数据科学领域有很多博客平台,如 Medium、KDnuggets 等。你还可以通过博客赚取收入,这对于补充收入非常好。
实习或兼职工作
实习将为你提供将数据科学知识应用于实际环境的机会。这将帮助你增加数据科学方面的知识。实习还提供了发展重要软技能的机会,例如沟通能力和团队合作能力。
总的来说,互联网上有无数的在线资源可以学习数据科学。大多数数据科学资源仅提供表层知识。为了将知识拓展到在线课程之外,需要额外的努力。这将使你深入了解核心数据科学概念。
本杰明·O·塔约 是一位物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的所有者。此前,本杰明曾在中奥克拉荷马大学、大峡谷大学和匹兹堡州立大学教授工程学和物理学。
更多相关内容
筛选 Python 列表的 5 种方法
原文:
www.kdnuggets.com/2022/11/5-ways-filtering-python-lists.html

图片作者
在这个简短的教程中,你将学习 5 种简单的列表筛选方法。它不仅限于数据工作者,甚至网页开发人员和软件工程师也每天使用它。简而言之,筛选列表是每个 Python 程序员在开始时应该学习的基本功能。
1. 使用 for 循环
通过使用 for 循环和 if-else 语句,我们将迭代列表并选择符合特定条件的元素。在我们的例子中,我们将筛选出大于或等于 100 的利润。
使用这种方法,我们创建了一个新列表,并将筛选出的值添加到新列表中。这是一种简单但效率不高的列表筛选方式。
profits = [200, 400, 90, 50, 20, 150]
filtered_profits = []
for p in profits:
if p >= 100:
filtered_profits.append(p)
print(filtered_profits)
[200, 400, 150]
2. 列表推导式
列表推导式是对列表使用 for 循环和 if-else 条件的一种聪明方法。你可以将方法一转换为一行代码。这种方法很简洁。
在我们的例子中,我们对所有列表元素进行循环,并选择大于或等于 150 的分数。
编写起来很简单,你甚至可以添加多个 if-else 条件而没有问题。
通过阅读 Python 中何时使用列表推导式 来学习列表推导式的代码示例。
scores = [200, 105, 18, 80, 150, 140]
filtered_scores = [s for s in scores if s >= 150]
print(filtered_scores)
[200, 150]
3. 模式匹配
要筛选字符串列表,我们将使用 re.match()。它需要字符串模式和字符串。
在我们的例子中,我们使用列表推导式通过提供正则表达式模式 “N.*” 给 re.match() 来筛选出以 “N” 开头的名称。
你可以通过访问 regex101 来学习、构建和测试正则表达式模式。
import re
students = ["Abid", "Natasha", "Nick", "Matthew"]
# regex pattern
pattern = "N.*"
# Match the above pattern using list comprehension
filtered_students = [x for x in students if re.match(pattern, x)]
print(filtered_students)
['Natasha', 'Nick']
4. 使用 filter() 方法
filter() 是一个内置的 Python 函数,用于筛选列表项。它需要一个筛选函数和列表 filter(fn, list)。
在我们的例子中,我们将创建一个 filter_height 函数。它在高度小于 150 时返回 True,否则返回 False。
之后,我们将使用 filter() 函数将 filter_height 函数应用于列表,然后返回一个筛选后的元素迭代器。你可以使用循环提取所有元素,也可以使用 list(<iter>) 函数将其转换为列表。
def filter_height(height):
if (height < 150):
return True
else:
return False
heights = [140, 180, 165, 162, 145]
filtered_heights = filter(filter_height, heights)
print(list(filtered_heights))
[140, 145]
5. 使用 Lambda 函数
你可以通过使用 Lambda 函数将方法四(filter() 方法)转换为一行代码。
与其单独创建一个 filter_age 函数,不如在 filter() 函数中使用 Lambda 编写条件。
在我们的例子中,我们筛选出年龄大于 50 的项,并将筛选后的迭代器转换为列表。
通过阅读 Python Lambda 教程,了解更多关于 Lambda 函数的信息。
ages = [20, 33, 44, 66, 78, 92]
filtered_ages = filter(lambda a: a > 50, ages)
print(list(filtered_ages))
[66, 78, 92]
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些挣扎于心理健康问题的学生开发一个 AI 产品。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
更多相关主题
强化学习入门的 5 种方法
原文:
www.kdnuggets.com/2017/09/5-ways-get-started-reinforcement-learning.html

艺术作品由 Robert Aguilera
机器学习算法,特别是神经网络,被认为是引发新一轮人工智能“革命”的原因。在本文中,我将介绍强化学习的概念,但技术细节有限,以便具有不同背景的读者能够理解该技术的本质、能力和局限性。
在文章末尾,我将提供 链接 到一些 资源 ,用于实施强化学习。
什么是强化学习?
广义上讲,数据驱动的算法可以分为三种类型:监督学习、无监督学习和强化学习。
前两种方法通常用于执行图像分类、检测等任务。虽然它们的准确性很高,但这些任务与我们期望的“智能”存在的任务有所不同。
这就是强化学习的作用所在。其概念非常简单,就像我们的进化过程一样:环境奖励代理正确的行为,并惩罚其错误的行为。主要的挑战是开发出学习数百万种可能行为的能力。
Q 学习与深度 Q 学习
Q 学习是一种广泛使用的强化学习算法。在不涉及详细数学的情况下,某个行动的质量由代理所在的状态决定。代理通常执行能获得最大奖励的行动。详细的数学内容可以在这里找到。
在这个算法中,代理根据环境给予的奖励量来学习每个行动(行动也称为策略)的质量(Q 值)。每个环境状态的值以及 Q 值通常存储在表格中。随着代理与环境的交互,Q 值会从随机值更新为实际有助于最大化奖励的值。
深度 Q 学习
使用 Q 学习和表格的问题在于其扩展性较差。如果状态数量过多,表格将无法存储在内存中。这时可以应用深度 Q 学习。深度学习基本上是一种通用的逼近机器,它可以理解并生成抽象表示。深度学习可以用来逼近 Q 值,也可以通过梯度下降轻松学习最优 Q 值。
趣味事实:
谷歌对深度 Q 学习的一些元素拥有专利:US20150100530
探索与利用
代理通常会记住一条路径而不会尝试探索其他路径。一般来说,我们希望代理不仅能利用好的路径,还能有时探索新的路径以执行操作。因此,一个名为ε的超参数用于控制探索新路径与利用旧路径的平衡。
经验重放
在训练神经网络时,数据不平衡发挥着非常重要的作用。如果模型是在代理与环境交互时进行训练的,就会存在不平衡。最新的操作显然比旧的操作有更多的影响。
因此,所有状态及相关数据都存储在内存中,神经网络可以随机挑选一批交互并进行学习(这使得它与监督学习非常相似)。
训练框架
这就是深度 Q 学习的整个框架。注意到γ。这表示折扣奖励。它是一个超参数,用于控制未来奖励的权重。符号´ 表示下一个。例如,s´ 表示下一个状态。
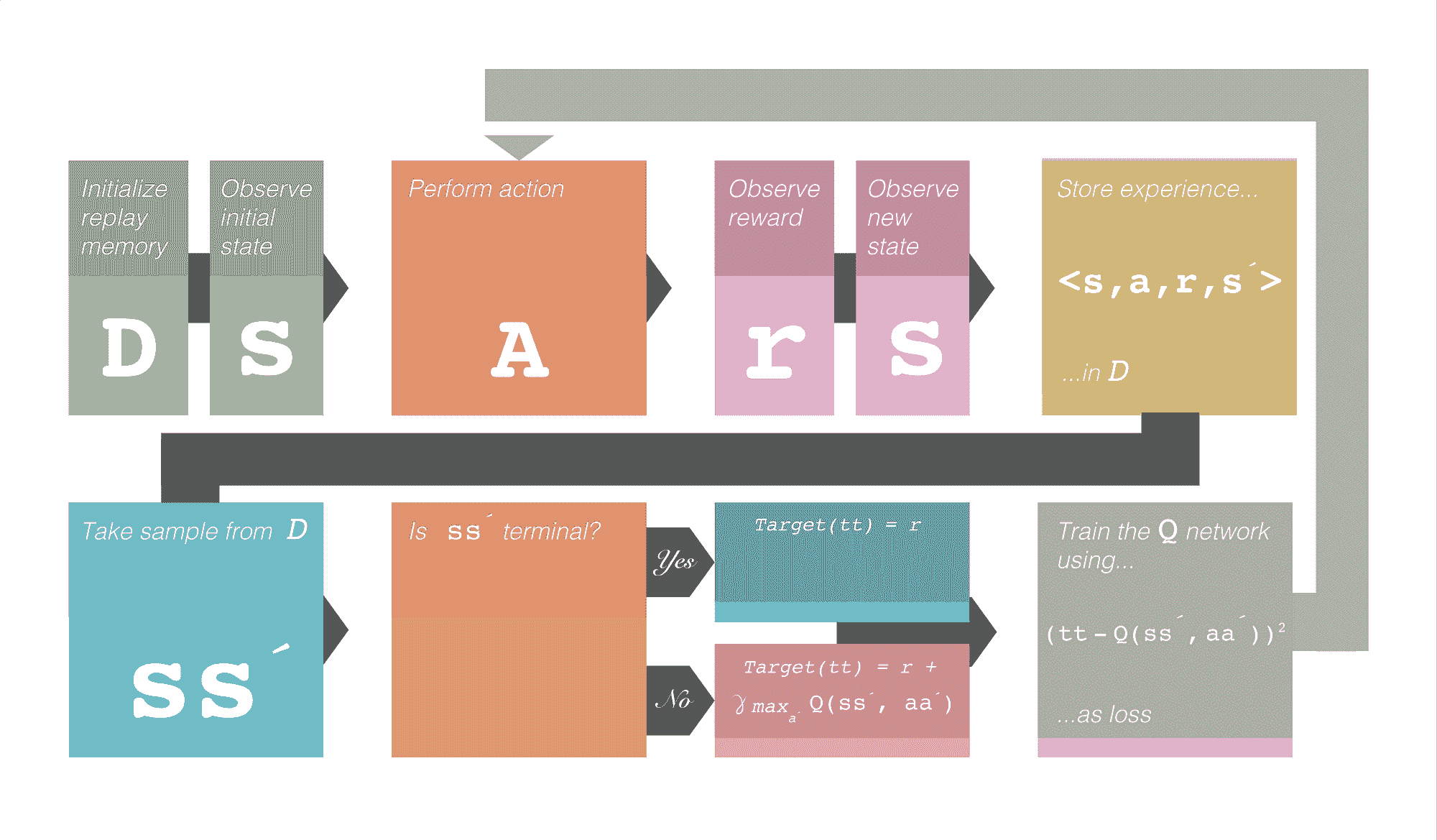
图 1.0 深度 Q 学习训练框架。致谢:Robert Aguilera
扩展强化学习
强化学习在许多方面表现良好(如 AlphaGo),但在反馈稀疏的地方经常失败。代理不会探索在长期内实际有益的行为。有时,探索一些行动是为了其自身的目的(内在动机),而不是直接解决问题。
这样做允许代理执行复杂的动作,并基本上允许代理‘规划’事务。层次化学习 允许这种抽象学习。
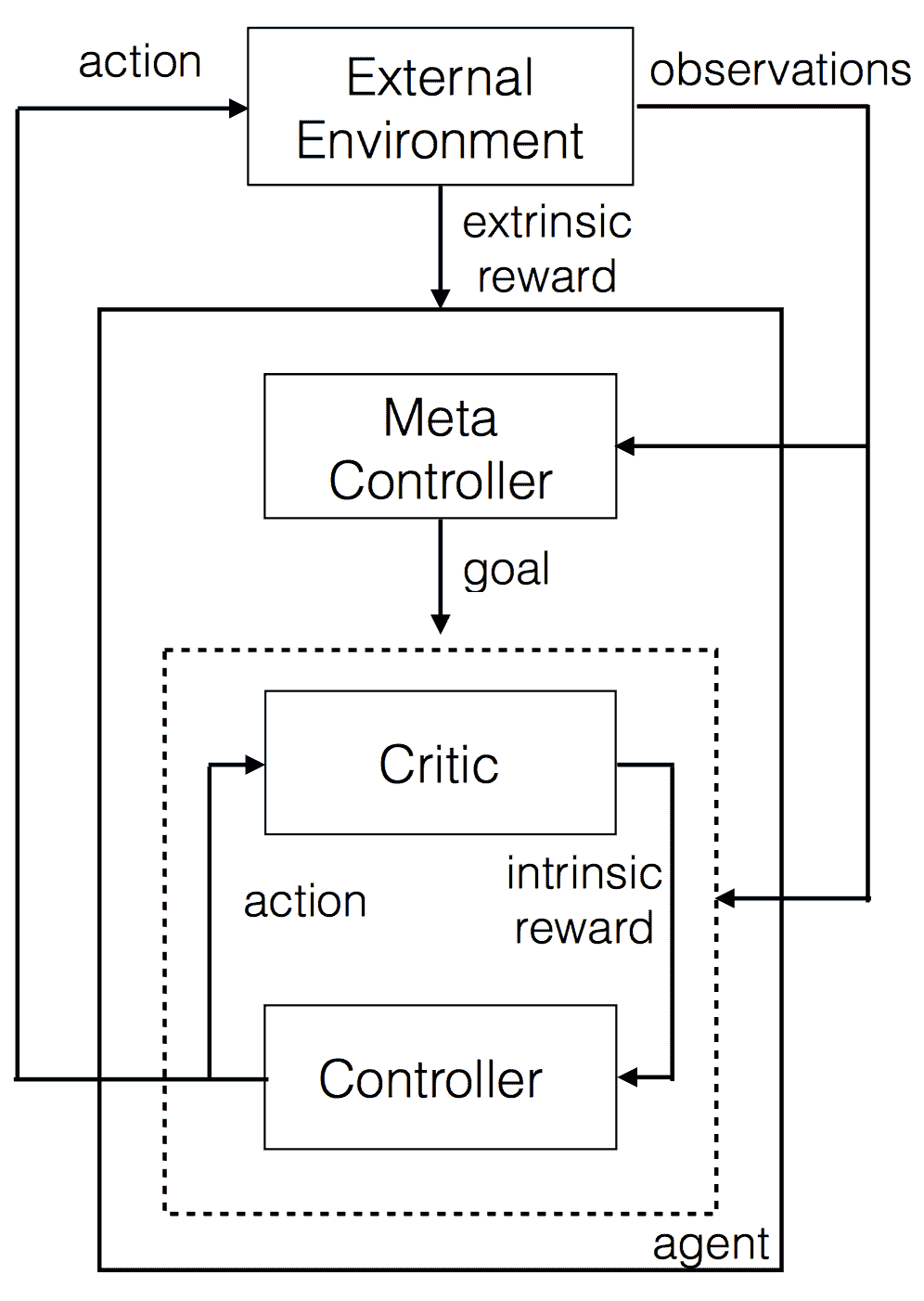
图 2.0 层次化深度 Q 学习
在这种设置中,有两个 Q 网络。它们分别表示为控制器和元控制器。元控制器查看原始状态并计算要跟随的‘目标’。控制器接受状态和目标,并输出解决目标的策略。评论者检查目标是否已达到,并给予控制器一些奖励。控制器在回合结束或目标达到时停止。然后,元控制器选择一个新目标,这个过程会重复进行。
‘目标’是最终帮助代理获得最终奖励的东西。这更好,因为可以在层次结构中进行 Q 学习。
强化学习的入门资源
这个列表对那些希望开始强化学习的人将会有所帮助:
-
深度 Q 学习基础。对理解强化学习的数学和过程非常有帮助。
-
层次学习论文,适合那些想详细了解层次学习的人。
-
层次学习论文解释 来自作者的视频。
-
深度 RL:概述 我认为这是强化学习的手册。它涵盖了理解当前研究水平所需的几乎所有方面。它深入探讨了数学内容,但也提供了高层次的概述。
-
使用单个 python 脚本实现深度 Q 学习。 也许是最简单的深度 Q 学习实现。这非常易读,是一个很好的起点。
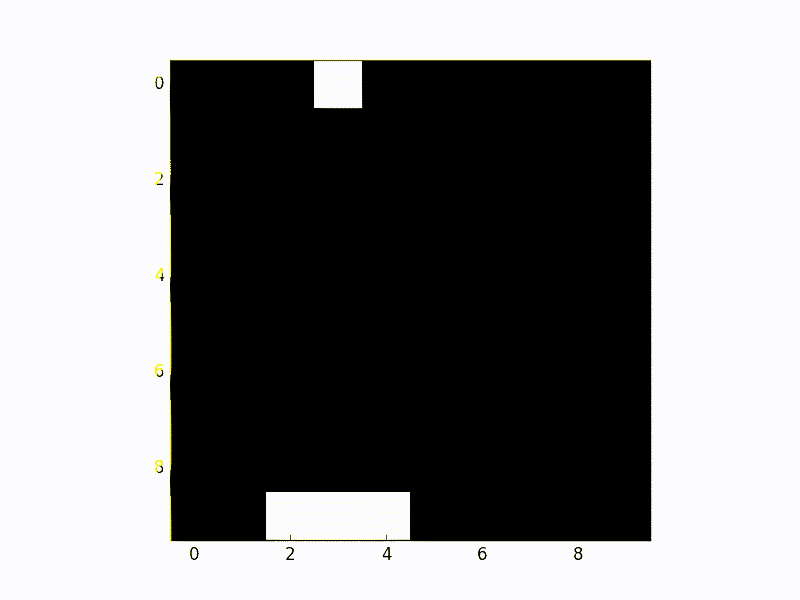
图 3.0 深度 Q 学习实际操作。 Python 脚本在第 5 点的输出
行动召唤
如果你有评论或问题,请随时在下方回复这篇文章。
特别感谢 罗伯特·阿吉莱拉 制作了艺术作品和流程图。
原文。经许可转载。
相关内容:
-
从自主学习到智能学习:强化学习基础
-
从零到一的深度学习:5 个令人惊叹的演示和代码,适合初学者
-
强化学习的下一个挑战
我们的 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
相关主题
处理数据不足的 5 种方法
原文:
www.kdnuggets.com/2019/06/5-ways-lack-data-machine-learning.html

图片由编辑提供
在我进行的许多项目中,公司尽管拥有出色的 AI 商业想法,但在意识到他们没有足够的数据时,往往会逐渐感到沮丧……然而,解决方案是存在的!本文的目的是简要介绍其中一些(我实践中证明有效的)解决方案,而不是列出所有现有的解决方案。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT
数据稀缺的问题非常重要,因为数据是任何 AI 项目的核心。数据集的大小往往是 ML 项目表现不佳的原因。
大多数情况下,数据相关问题是优秀 AI 项目无法完成的主要原因。在一些项目中,你会得出结论,认为没有相关数据或者收集过程太困难且耗时。
监督机器学习模型已成功用于应对各种业务挑战。然而,这些模型对数据的需求很高,其性能在很大程度上依赖于可用的训练数据的大小。在许多情况下,很难创建足够大的训练数据集。
另一个我可以提到的问题是,项目分析师往往低估了处理常见业务问题所需的数据量。我记得自己曾经在收集大型训练数据集时遇到过困难。在为大公司工作时,收集数据更是复杂。
我需要多少数据?
好吧,您大约需要模型自由度数量的 10 倍的示例。模型越复杂,越容易出现过拟合,但可以通过验证来避免。然而,根据使用情况,可以使用更少的数据。
过拟合: 指的是一个模型对训练数据建模得过于精准。当一个模型学习了训练数据中的细节和噪声到影响模型在新数据上表现的程度时,就会发生过拟合。
处理缺失值的问题也值得讨论。特别是如果数据中缺失值的数量足够多(超过 5%)。
再次强调,处理缺失值将取决于某些“成功”标准。此外,这些标准因数据集和不同应用(如识别、分割、预测和分类,即使是相同的数据集)而异。
重要的是要理解,没有完美的方法来处理缺失数据。
存在不同的解决方案,但这取决于问题的类型——时间序列分析、机器学习、回归等。
当涉及预测技术时,仅在缺失值不是完全随机观测时使用它们,并且用于填补这些缺失值的变量与缺失值有某种关系,否则可能会产生不准确的估计。
通常,可以使用不同的机器学习算法来确定缺失值。这通过将缺失的特征转化为标签,并使用没有缺失值的列来预测缺失值的列来实现。
根据我的经验,如果你决定构建一个 AI 驱动的解决方案,你将面临数据不足或缺失数据的问题,但幸运的是,有办法将这个劣势转化为优势。
数据不足?
如上所述,无法精确估计 AI 项目所需的数据最小量。显然,你的项目性质将显著影响你所需的数据量。例如,文本、图像和视频通常需要更多的数据。然而,为了做出准确的估计,还需要考虑许多其他因素。
-
预测的类别数量
你的模型期望的输出是什么?基本上,类别或数量越少越好。
-
模型性能 如果你计划将产品投入生产,你需要更多的数据。一个小数据集可能足够用于概念验证,但在生产中,你需要更多的数据。
通常,小数据集需要具有低复杂度的模型(或高偏差)以避免过拟合模型到数据上。
非技术解决方案
在探索技术解决方案之前,让我们分析一下我们可以做些什么来增强你的数据集。这可能听起来很明显,但在开始 AI 之前,请尽量通过开发外部和内部工具来获取尽可能多的数据。如果你知道机器学习算法预计要执行的任务,那么你可以提前创建数据收集机制。
尝试在组织内建立真实的数据文化。
为了启动机器学习执行,你可以依赖开源数据。有很多机器学习数据可用,一些公司愿意将其免费提供。
如果你需要外部数据来进行项目,与其他组织建立合作关系以获取相关数据可能会很有益。建立合作关系显然会花费一些时间,但获得的专有数据将为任何竞争对手建立自然障碍。
构建一个有用的应用程序,将其免费提供,并利用数据。
我在之前的项目中使用的另一种方法是向客户免费提供对云应用程序的访问权限。进入应用程序的数据可以用于构建机器学习模型。我的前一个客户为医院构建了一个应用程序,并将其免费提供。我们因此收集了大量数据,并成功创建了一个独特的数据集用于我们的机器学习解决方案。确实有助于向客户或投资者展示你已经构建了自己的独特数据集。
小数据集
根据我的经验,一些常见的方法可以帮助从小数据集中构建预测模型:

一般来说,机器学习算法越简单,它从小数据集中学习得越好。从机器学习的角度看,小数据需要具有低复杂性(或高偏差)的模型,以避免过拟合数据。我注意到朴素贝叶斯算法是最简单的分类器之一,因此在相对较小的数据集上学习得非常好。
朴素贝叶斯方法:* 一组基于应用贝叶斯定理并假设特征对条件独立性的监督学习算法。*
你还可以依赖其他线性模型和决策树。确实,它们在小数据集上也能表现相对良好。基本上,简单模型能比复杂模型(神经网络)更好地从小数据集中学习,因为它们本质上尝试学习的内容更少。
对于非常小的数据集,贝叶斯方法通常是最优秀的,尽管结果可能对先验选择敏感。我认为朴素贝叶斯分类器和岭回归是最佳的预测模型。
对于小数据集,你需要具有少量参数(低复杂性)和/或强先验的模型。你也可以将“先验”解释为你对数据行为的假设。

根据你的业务问题的具体性质和数据集的大小,确实存在许多其他解决方案。
迁移学习
定义:* 利用现有相关数据或模型来构建机器学习模型的框架。*
迁移学习利用从已学习任务中获得的知识来提升相关任务的性能,通常可以减少所需的训练数据量。
迁移学习技术非常有用,因为它们允许模型利用从另一个数据集或现有机器学习模型中学到的知识,对新领域或任务(即目标领域)进行预测。
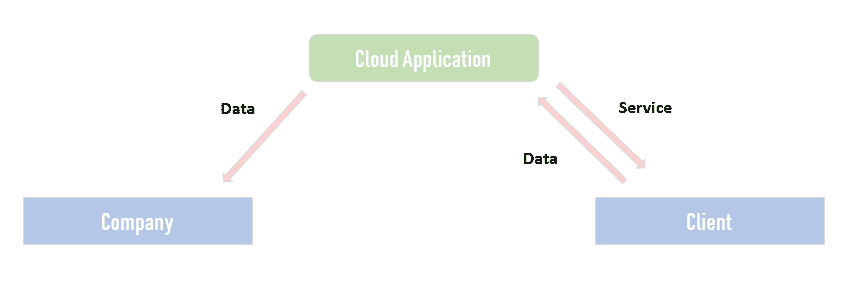
当你没有足够的目标训练数据,而源领域和目标领域有一些相似但并不完全相同时,迁移学习技术应该被考虑。
天真地聚合模型或不同数据集并不总是有效!如果现有数据集与目标数据非常不同,那么新学习者可能会受到现有数据或模型的负面影响。
迁移学习在你有其他数据集可以用来推断知识时效果很好,但如果你根本没有数据会发生什么呢?这就是数据生成可以发挥作用的地方。当没有数据可用或需要创建比通过聚合获得更多的数据时,就需要使用数据生成。
在这种情况下,存在的小量数据被修改以创建数据的变体来训练模型。例如,可以通过裁剪和缩小一张汽车图片来生成许多汽车的图片。
不幸的是,缺乏高质量标记数据也是数据科学团队面临的最大挑战之一,但通过使用迁移学习和数据生成等技术,可以克服数据稀缺的问题。
迁移学习的另一个常见应用是训练跨客户数据集的模型,以克服冷启动问题。我注意到 SaaS 公司在将新客户接入其机器学习产品时经常会遇到这个问题。确实,在新客户收集到足够的数据以实现良好的模型性能之前(这可能需要几个月),很难提供价值。
数据增强
数据增强意味着增加数据点的数量。在我最新的项目中,我们使用数据增强技术来增加数据集中图像的数量。对于传统的行/列格式数据来说,这意味着增加行数或对象数。
我们别无选择,只能依赖数据增强,原因有二:时间和准确性。每个数据收集过程都涉及成本。这些成本可能是金钱、人力、计算资源,当然还有过程中的时间消耗。

因此,我们不得不增强现有数据,以增加输入到机器学习分类器中的数据量,并补偿进一步数据收集所涉及的成本。
有很多方法可以增强数据。
在我们的案例中,你可以旋转原始图像,改变光照条件,或以不同方式裁剪图像,因此可以为一张图像生成不同的子样本。这样,你可以减少对分类器的过拟合。
然而,如果你使用过采样方法如 SMOTE 来生成人工数据,那么很可能会引入过拟合。
过拟合: 过拟合模型是指趋势线反映了训练数据中的错误,而不是准确预测未见数据的模型。
这是在开发 AI 解决方案时必须考虑的因素。

合成数据
合成数据指的是具有与其“真实”对应物相同的模式和统计属性的虚假数据。基本上,它看起来非常真实,以至于几乎无法判断它不是。
那么,合成数据的意义是什么?如果我们已经有真实数据,这点为什么重要?
我见过合成数据的应用,尤其是在我们处理私密数据(如银行、医疗等)时,这使得在某些情况下使用合成数据成为一种更安全的开发方法。
当真实数据不足时,或者针对特定模式的真实数据不足时,通常使用合成数据。其在训练和测试数据集中的使用大致相同。
合成少数类过采样技术(SMOTE)和修改版 SMOTE 是两种生成合成数据的技术。简单来说,SMOTE 将少数类数据点连接起来,创建位于任何两个最近数据点之间直线上的新数据点。
算法计算特征空间中两个数据点之间的距离,将这个距离乘以一个介于 0 和 1 之间的随机数,并将新数据点放置在用于距离计算的其中一个数据点的新距离上。
为了生成合成数据,你必须使用训练集来定义模型,这需要验证,然后通过改变感兴趣的参数,可以通过模拟生成合成数据。领域/数据类型很重要,因为它影响整个过程的复杂性。
在我看来,问自己是否拥有足够的数据会揭示出你可能从未发现的不一致性。它有助于突出你认为完美的业务流程中的问题,并使你理解在组织内创建成功数据策略的关键所在。
Alexandre Gonfalonieri 是一位驻扎在巴塞尔的 AI 顾问和作家。他写作关于脑机接口、M2M 经济和新的 AI 商业模式。他曾在哈佛商业评论和 ABC 新闻中出现。
原文。转载需经许可。
更多相关话题
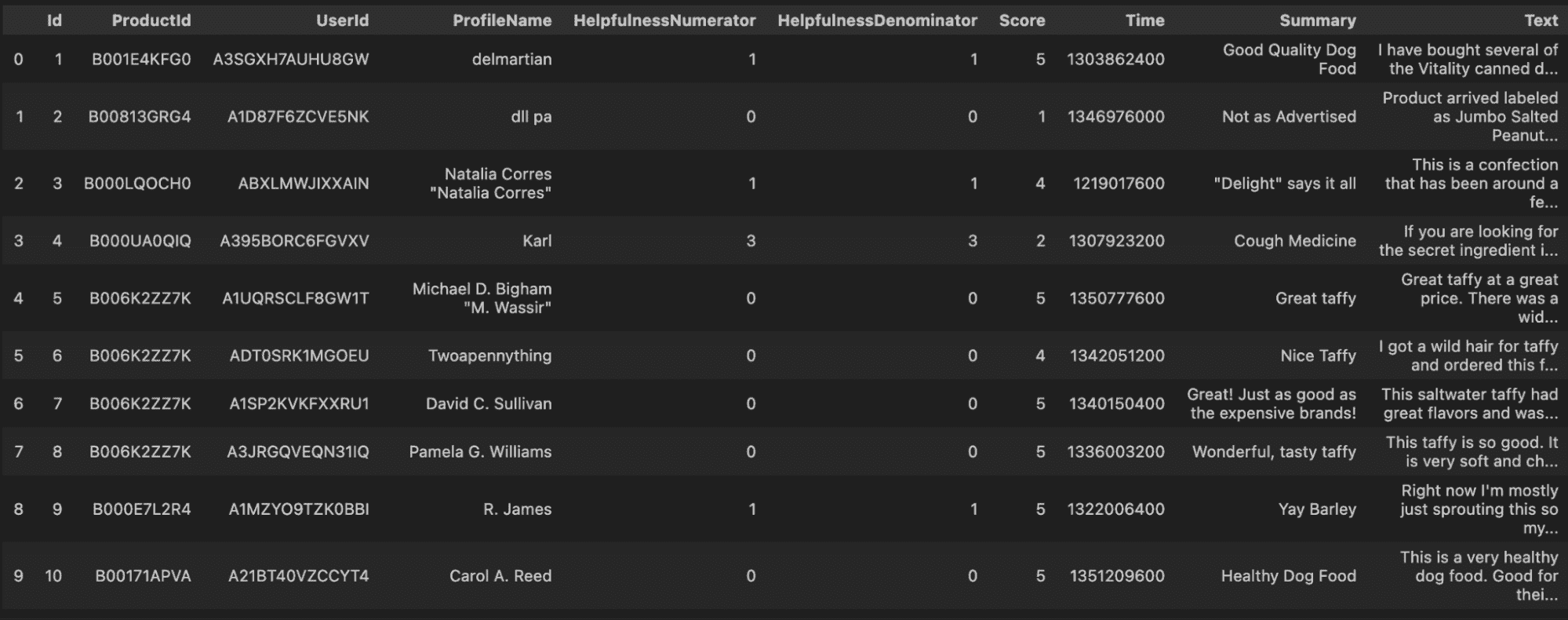
将非结构化数据转换为结构化见解的 5 种方法
原文:
www.kdnuggets.com/5-ways-of-converting-unstructured-data-into-structured-insights-with-llms
图片来源:作者
在今天的世界中,我们不断生成信息,但其中许多以非结构化的格式出现。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
这包括社交媒体上的大量内容,以及存储在组织网络中的无数 PDF 和 Word 文档。
从这些非结构化来源(无论是文本文件、网页还是社交媒体更新)获取见解和价值,是一个相当大的挑战。
然而,大型语言模型(LLMs)如 GPT 或 LlaMa 的出现彻底革新了我们处理非结构化数据的方式。
这些复杂的模型作为强大的工具,将非结构化数据转化为结构化的有价值信息,有效挖掘我们数字化环境中的隐藏宝藏。
让我们看看使用 GPT 提取非结构化数据见解的 4 种不同方法 👇🏻
为我们的挑战做准备
在本教程中,我们将使用 OpenAI 的 API。如果你还没有一个工作账户,请查看这个 如何获取你的 OpenAI API 账户的教程。
想象一下我们正在运营一个电子商务平台(在此案例中是亚马逊😉),我们需要处理用户对我们产品留下的数百万条评论。
为了展示 LLMs 处理这类数据所代表的机会,我正在使用一个 包含亚马逊评论的 Kaggle 数据集。
原始数据集
理解挑战
结构化数据指的是格式一致且重复的数据类型。经典示例包括银行交易、航空公司预订、零售销售和电话通话记录。
这些数据通常来自事务处理过程。
这种数据由于其统一格式,非常适合存储和管理在传统的数据库管理系统中。
另一方面,文本通常被归类为非结构化数据。历史上,在文本消歧义技术发展之前,由于其不够严格的结构,将文本纳入标准数据库管理系统是具有挑战性的。
这就引出了以下问题……
文本真的完全没有结构吗,还是它具有一种不立即显现的潜在结构?
文本本质上具有结构,但这种复杂性与计算机可以识别的传统结构格式不一致。计算机能够解释简单、直接的结构,但语言由于其复杂的语法超出了其理解范围。
这就引出了一个最终的问题:
如果计算机处理非结构化数据效率低下,那么是否有可能将这些非结构化数据转换为更易处理的结构化格式?
手动转换为结构化数据是耗时的,并且具有很高的人为错误风险。它通常是各种格式的单词、句子和段落的混合,这使得机器很难理解其含义并将其结构化。
这正是 LLMs 发挥关键作用的地方。如果我们想以某种方式处理或分析数据,包括数据分析、信息检索和知识管理,将非结构化数据转换为结构化格式是至关重要的。
像 GPT-3 或 GPT-4 这样的大型语言模型(LLMs)提供了强大的能力来从非结构化数据中提取见解。
我们的主要工具将是 OpenAI API 和创建我们自己的提示语来定义我们需要什么。以下是四种方法,您可以利用这些模型从非结构化数据中获取结构化见解:
1. 文本摘要
LLMs 可以高效地总结大量文本,例如报告、文章或长篇文档。这对于快速理解大量数据集中的关键点和主题尤其有用。
在我们的情况下,得到一个初步的评价摘要远比获得整个评价更好。因此,GPT 可以在几秒钟内处理它。
我们唯一的——也是最重要的任务——就是制定一个好的提示语。
在这种情况下,我可以告诉 GPT:
Summarize the following review: \"{review}\" with a 3 words sentence.
那么让我们通过几行代码来实践一下吧。
由作者编写的代码
我们将得到如下结果……
由作者提供的图片
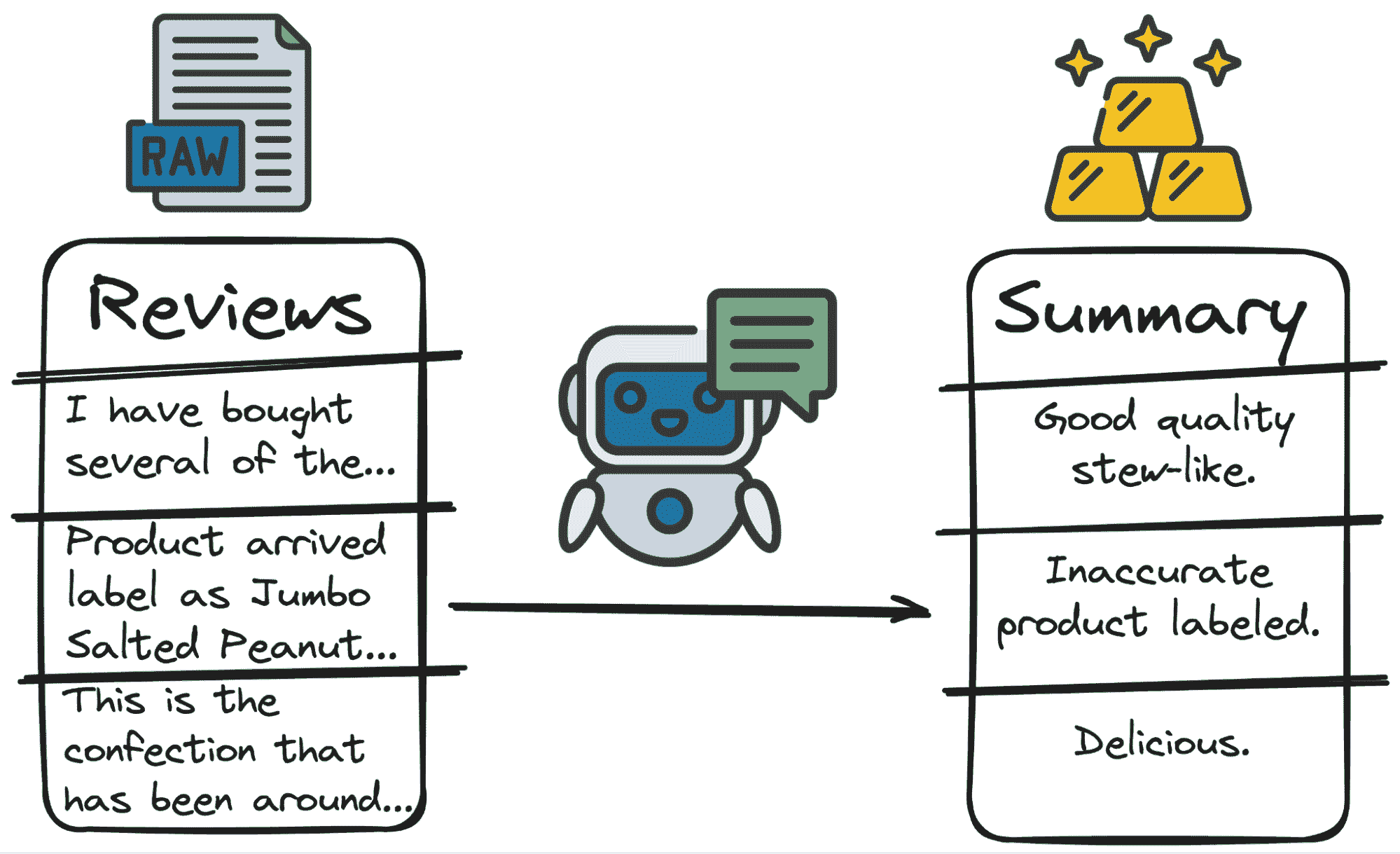
2. 情感分析
这些模型可以用于情感分析,确定文本数据的语气和情感,例如客户评价、社交媒体帖子或反馈调查。
最简单但最常用的分类方式是极性。
-
积极评价或人们为何对产品感到满意。
-
消极评价或他们为何感到不满。
-
中立态度或人们对产品的不感兴趣。
通过分析这些情感,企业可以评估公众意见、客户满意度和市场趋势。因此,与其让人来为每个评论做决定,不如让我们的朋友 GPT 为我们进行分类。
所以,再次强调,主要代码将包括一个提示和对 API 的简单调用。
让我们将其付诸实践。
作者代码
我们将获得如下结果:
作者图片
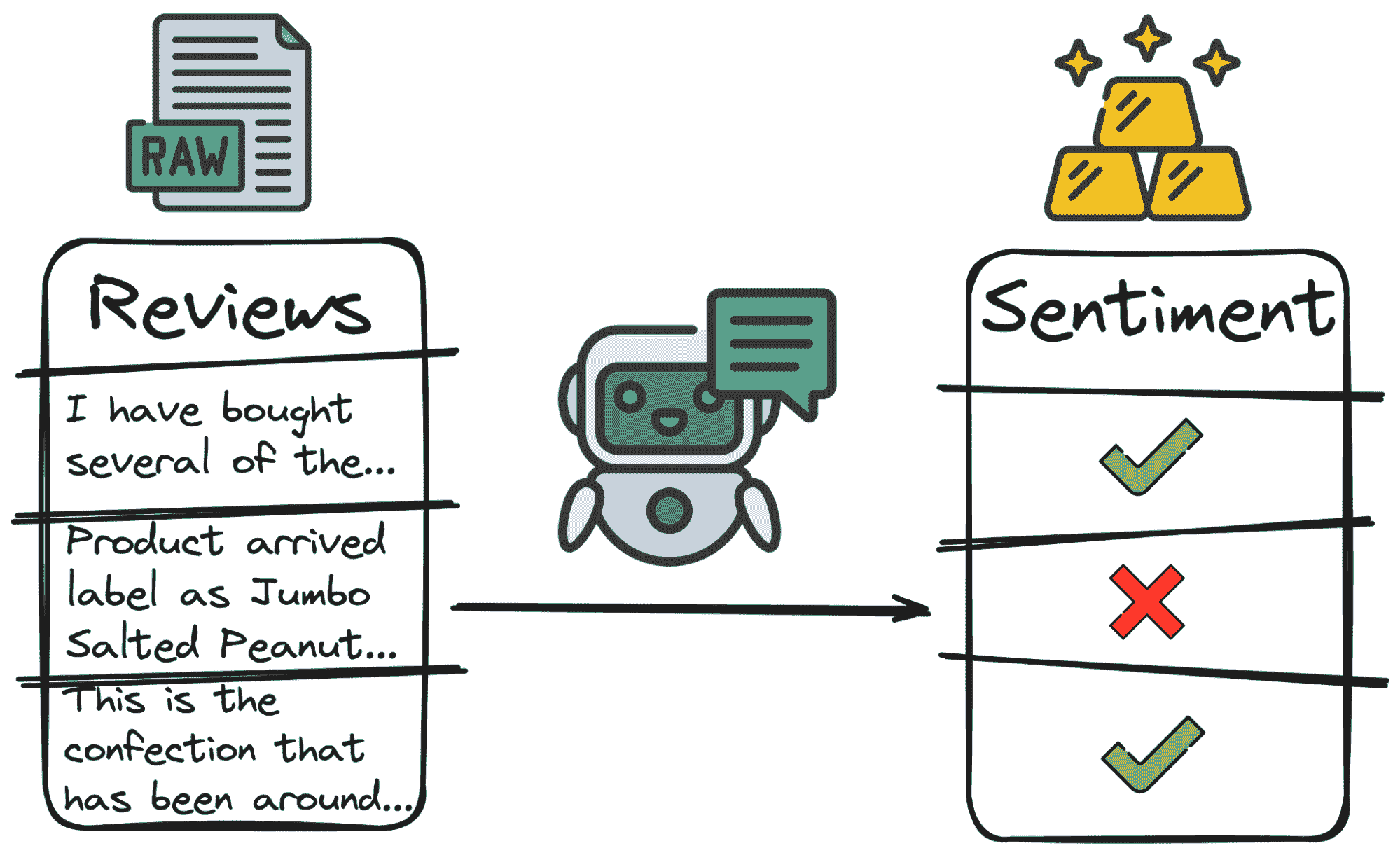
3. 主题分析
LLMs 可以识别和分类大型数据集中的主题或话题。这在定性数据分析中特别有用,在这种情况下,你可能需要筛选大量文本以理解常见的主题、趋势或模式。
在分析评论时,了解评论的主要目的可能会很有用。一些用户会抱怨某些问题(服务、质量、成本等),一些用户会评价他们对产品的体验(无论好坏),还有一些用户会提出问题。
再次手动完成这些工作将需要很多小时。但有了我们的朋友 GPT,只需几行代码:
作者代码
作者图片
4. 关键词提取
LLMs 可以用来提取关键词。这意味着,检测我们要求的任何元素。
比如说,我们想了解附带的评论中的产品是否是用户讨论的产品。为此,我们需要检测用户正在评论的是什么产品。
再次……我们可以让我们的 GPT 模型找出用户讨论的主要产品。
那么,让我们把这些应用到实践中吧!
作者代码
作者图片
主要结论
总之,大型语言模型(LLMs)在将非结构化数据转化为结构化洞察方面的变革力量不可低估。通过利用这些模型,我们可以从我们数字世界中流动的庞大非结构化数据中提取有意义的信息。
讨论的四种方法——文本总结、情感分析、主题分析和关键词提取——展示了大型语言模型(LLMs)在处理各种数据挑战中的多功能性和高效性。
这些能力使组织能够更深入地了解客户反馈、市场趋势和操作效率。
Josep Ferrer 是一位来自巴塞罗那的分析工程师。他毕业于物理工程专业,目前在应用于人类移动性的领域从事数据科学工作。他还是一名兼职内容创作者,专注于数据科学和技术。Josep 撰写有关 AI 的所有内容,涵盖了这一领域的持续爆炸性应用。
更多相关内容
免费访问 GPT-4o 的 5 种方法

由 ChatGPT 生成的图像
GPT-4o 是 OpenAI 推出的最新顶级 AI 模型。它是一个多模态 AI 模型,意味着它将文本、音频和视觉整合到一个模型中,提供更快的响应时间、改进的推理能力以及更好的非英语语言表现。与 GPT-4 Turbo 相比,它便宜 50%,速度快两倍。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
在本博客中,我们将学习 5 种免费访问 GPT-4o 模型的方法,体验多模态能力,并提高推理能力。
注意: 本博客中提到的平台提供对模型的有限访问,即每天可以提问 5-10 个问题。虽然免费,但有一定限制。
1. Poe
Poe 是我最喜欢的聊天机器人应用程序。它总是提供对最新模型的免费访问。你可以访问开源和闭源的 AI 模型。Poe 是迄今为止最慷慨的平台,提供对最新付费 AI 模型的免费访问。
要访问 GPT-4o 模型:
-
创建一个新的聊天。
-
点击文本输入框上方的“更多”按钮。
-
搜索“GPT-4o”并选择模型。
-
开始提问吧。
每天,你可以使用此模型提问 10 个问题。
2. Vercel AI 游乐场
Vercel AI 游乐场 是另一个受欢迎的平台,它提供对开源和闭源模型的免费访问。它还允许你同时组合多个模型。它速度快,并允许你切换模型。
使用 Vercel AI 游乐场最吸引人的部分是它没有限制。你可以无限次提问,而不会达到每日配额限制。
你可以通过创建一个新的聊天框,点击左上角的模型,然后向下滚动选择 GPT-4o 模型。就是这么简单。
阅读 2024 年值得尝试的 5 个免费 AI 游乐场 博客,了解其他 AI 游乐场。
3. You.com
You.com是一个 AI 搜索引擎,将 GPT-4o 等 AI 模型的力量与网络搜索结合,以提供最新和最相关的答案。
You.com提供了对所有顶级大语言模型的访问,如 GPT-4-turbo、Claude 3 Opus、Gemini 1.5 Pro、Llama 3、Command R+等。你只需点击“更多”按钮,然后选择“GPT-4o”模型即可。
4. ChatGPT
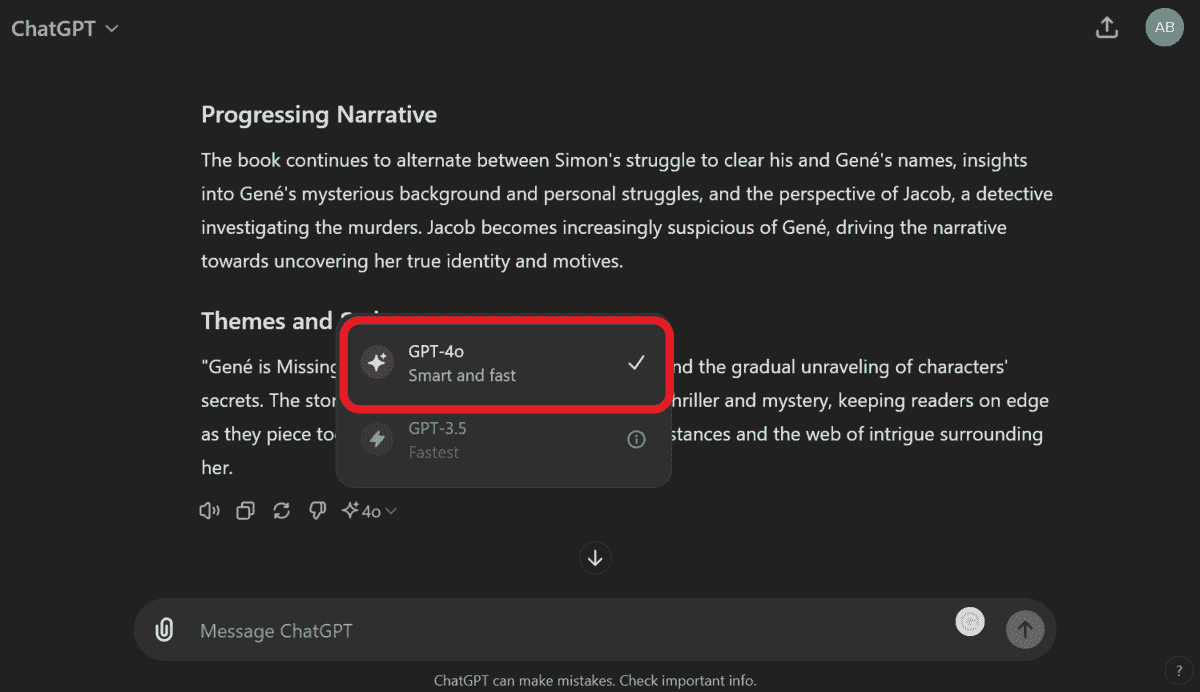
ChatGPT宣布随着 GPT-4o 的发布,它将为所有用户提供 GPT-4o 模型和高级工具的访问权限。作为免费用户,你可以使用 GPT-4o 模型几次,然后它将自动切换到 GPT-3.5-turbo 模型。
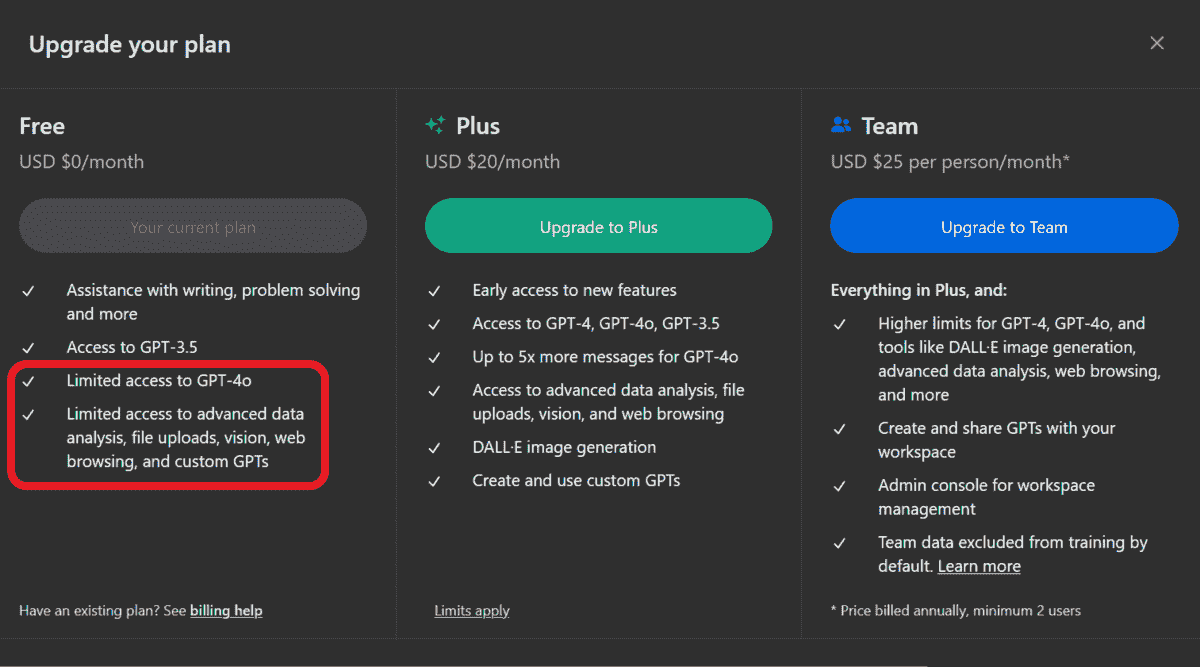
访问 GPT-4o 的最佳方式是上传文件或图像,并对其提出问题。它无法使用 GPT-3.5 来理解图像数据,因此这可能是始终使用 GPT-4o 的一个作弊码。
5. LMSYS Direct Chat
LMSYS Direct Chat是一个 AI 沙盒,允许你使用各种开源和闭源模型。要访问特定模型,请转到 Direct Chat 标签,点击模型下拉按钮,然后选择“gpt-4o-2024-05-13”模型。
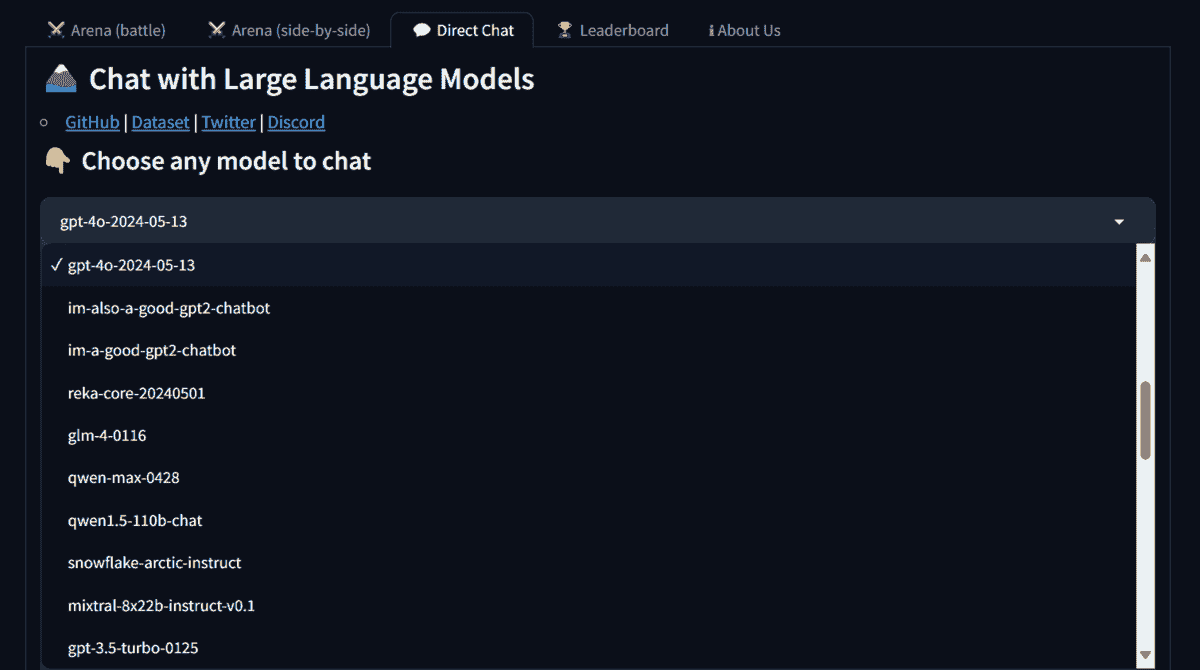
访问该模型是有限的,有时你可能需要争取使用机会。因此,这就是为什么我把它排在第 5 位,因为模型的可用性是不确定的。
结论
你也可以尝试由开源社区创建的OpenGPT 4o应用,它提供与 GPT-4o 模型类似的功能。它提供聊天机器人、带摄像头的实时聊天、语音聊天、图像生成和视频生成。它是一个超级应用。
在这篇博客中,我们学习了 5 种简单的方法来免费使用 GPT-4o 模型。并非所有 AI 模型在每个任务上都同样准确,因此选择像 GPT-4o 这样的顶级模型通常是最安全的选择。
Abid Ali Awan (@1abidaliawan)是一位认证数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些面临心理健康问题的学生。
更多相关内容
在你的笔记本电脑上使用 LLMs 的 5 种方法

图片由作者提供
在线访问 ChatGPT 非常简单——你只需一个互联网连接和一个好的浏览器。然而,这样做可能会妨碍你的隐私和数据。OpenAI 会存储你的提示响应和其他元数据以重新训练模型。虽然这对一些人来说可能不是问题,但注重隐私的人可能更愿意在本地使用这些模型,而没有任何外部跟踪。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业领域。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
在这篇文章中,我们将探讨五种在本地使用大语言模型(LLMs)的方法。大部分软件兼容所有主要操作系统,并可以轻松下载和安装以供立即使用。通过在你的笔记本电脑上使用 LLMs,你可以自由选择自己的模型。你只需从 HuggingFace 中心下载模型并开始使用。此外,你可以授权这些应用访问你的项目文件夹并生成上下文相关的响应。
1. GPT4All
GPT4All是一个前沿的开源软件,使用户能够轻松下载和安装最先进的开源模型。
只需从网站上下载 GPT4ALL 并在系统上安装。接下来,从面板中选择适合你需求的模型并开始使用。如果你安装了 CUDA(Nvidia GPU),GPT4ALL 将自动开始使用你的 GPU 以每秒最多生成 30 个 token 的快速响应。
你可以提供对包含重要文档和代码的多个文件夹的访问权限,GPT4ALL 将使用检索增强生成(Retrieval-Augmented Generation)生成响应。GPT4ALL 用户友好、快速,并且在 AI 社区中很受欢迎。
阅读有关 GPT4ALL 的博客,了解更多功能和用例:终极开源大语言模型生态系统。
2. LM Studio
LM Studio 是一个新软件,相较于 GPT4ALL 提供了多个优势。用户界面非常出色,你可以通过几次点击安装 Hugging Face Hub 中的任何模型。此外,它提供 GPU 卸载和 GPT4ALL 中没有的其他选项。然而,LM Studio 是封闭源代码的,无法通过读取项目文件生成上下文相关的响应。
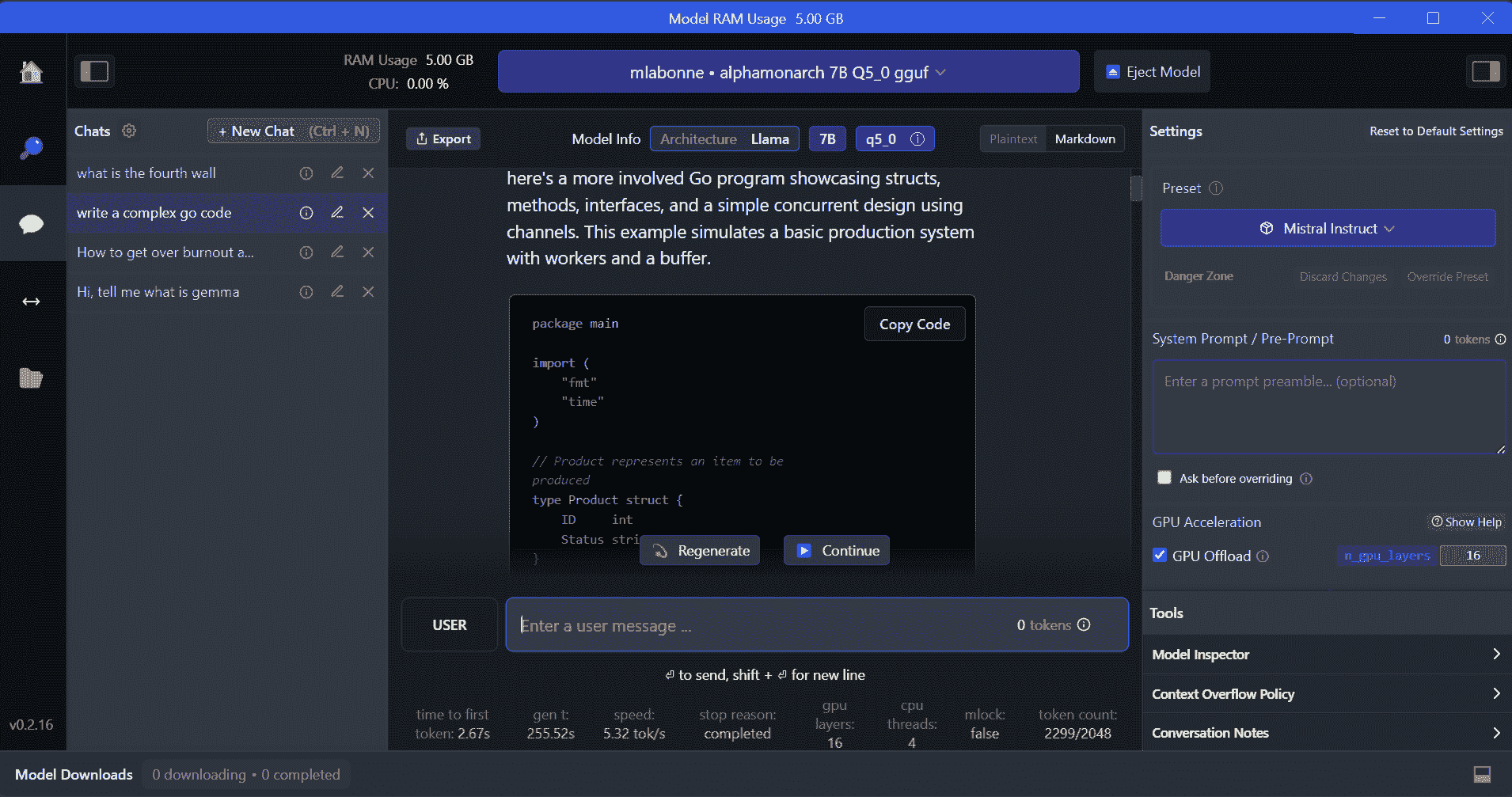
LM Studio 提供对数千个开源 LLM 的访问,使你能够启动一个本地推理服务器,其行为类似于 OpenAI 的 API。你可以通过互动用户界面和多个选项修改 LLM 的响应。
此外,请阅读 Run an LLM Locally with LM Studio 以了解更多有关 LM Studio 及其关键功能的信息。
3. Ollama
Ollama 是一个命令行界面 (CLI) 工具,能够快速操作大型语言模型,如 Llama 2、Mistral 和 Gemma。如果你是黑客或开发人员,这个 CLI 工具是一个极好的选择。你可以下载并安装软件,并使用 the llama run llama2 命令开始使用 LLaMA 2 模型。你可以在 GitHub 仓库中找到其他模型命令。

它还允许你启动一个本地 HTTP 服务器,并与其他应用程序集成。例如,你可以通过提供本地服务器地址来使用 Code GPT VSCode 扩展,开始将其用作 AI 编程助手。
使用这些 Top 5 AI Coding Assistants 改善你的编码和数据工作流程。
4. LLaMA.cpp
LLaMA.cpp 是一个提供 CLI 和图形用户界面 (GUI) 的工具。它允许你在本地无障碍地使用任何开源 LLM。该工具高度可定制,并能快速响应任何查询,因为它完全用纯 C/C++ 编写。
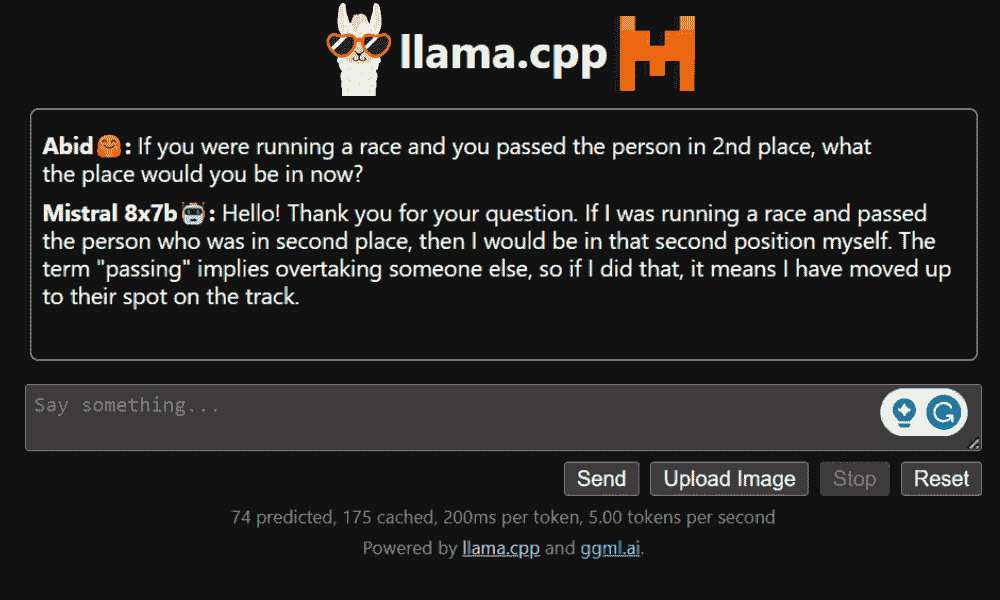
LLaMA.cpp 支持所有类型的操作系统、CPU 和 GPU。你还可以使用多模态模型,如 LLaVA、BakLLaVA、Obsidian 和 ShareGPT4V。
了解如何 Run Mixtral 8x7b On Google Colab For Free 使用 LLaMA.cpp 和 Google GPUs。
5. NVIDIA Chat with RTX
要使用 NVIDIA Chat with RTX,你需要在笔记本电脑上下载并安装 Windows 11 应用程序。该应用程序兼容于具有 30 系列或 40 系列 RTX NVIDIA 显卡、至少 8GB 内存和 50GB 可用存储空间的笔记本电脑。此外,你的笔记本电脑应至少具有 16GB 内存,以便顺畅运行 Chat with RTX。
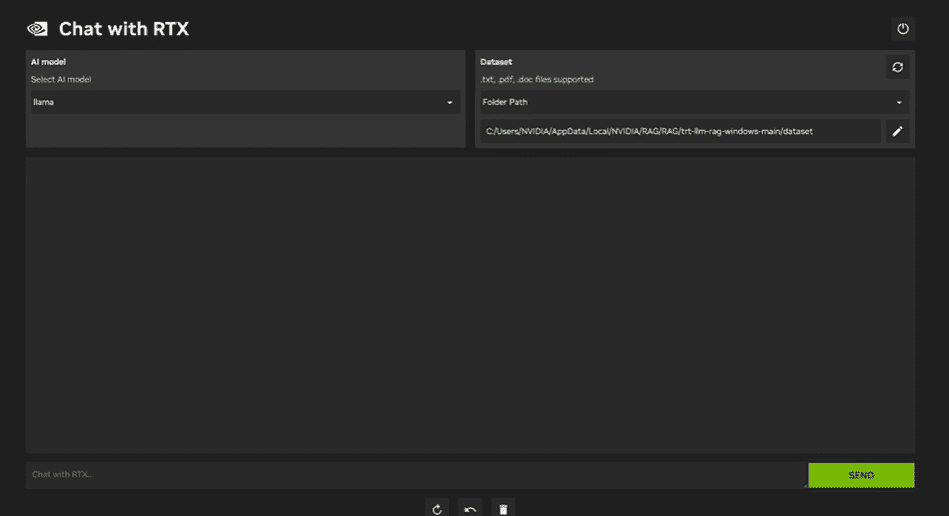
使用 Chat with RTX,你可以在笔记本电脑上本地运行 LLaMA 和 Mistral 模型。这是一个快速高效的应用程序,甚至可以从你提供的文档或 YouTube 视频中学习。然而,需要注意的是,Chat with RTX 依赖于 TensorRTX-LLM,该技术仅支持 30 系列或更新的 GPU。
结论
如果你想在确保数据安全和隐私的同时利用最新的 LLMs,可以使用 GPT4All、LM Studio、Ollama、LLaMA.cpp 或 NVIDIA Chat with RTX 等工具。每种工具都有其独特的优势,无论是易于使用的界面、命令行访问,还是对多模态模型的支持。通过正确的设置,你可以拥有一个强大的 AI 助手,生成定制化的上下文感知响应。
我建议从 GPT4All 和 LM Studio 开始,因为它们涵盖了大部分基本需求。之后,你可以尝试 Ollama 和 LLaMA.cpp,最后尝试 Chat with RTX。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,帮助那些面临心理健康问题的学生。
更多相关话题
你可以使用 ChatGPT 视觉进行数据分析的 5 种方法
原文:
www.kdnuggets.com/5-ways-you-can-use-chatgpt-vision-for-data-analysis
图片来源:作者
数据分析是做出数据驱动决策的关键部分,无论是在商业、研究还是日常生活中。它涉及从数据中提取见解和模式,以便深入理解潜在的信息。随着 ChatGPT 新视觉功能的引入,数据分析取得了重大进展。ChatGPT 视觉允许用户解读图像、方程式、图表和曲线图,为从视觉数据中提取见解开辟了广泛的可能性。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 部门
在本文中,我们将探讨 ChatGPT 视觉可以用于数据分析任务的 5 种关键方法。
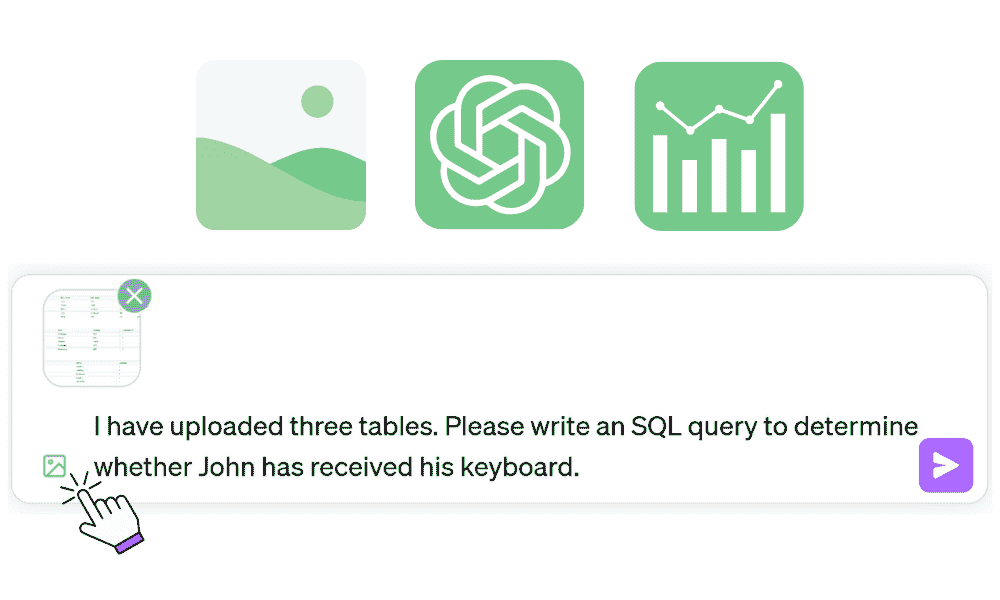
1. SQL 表
现在,你可以简单地截图数据集,并要求 ChatGPT 为你编写 SQL 查询。
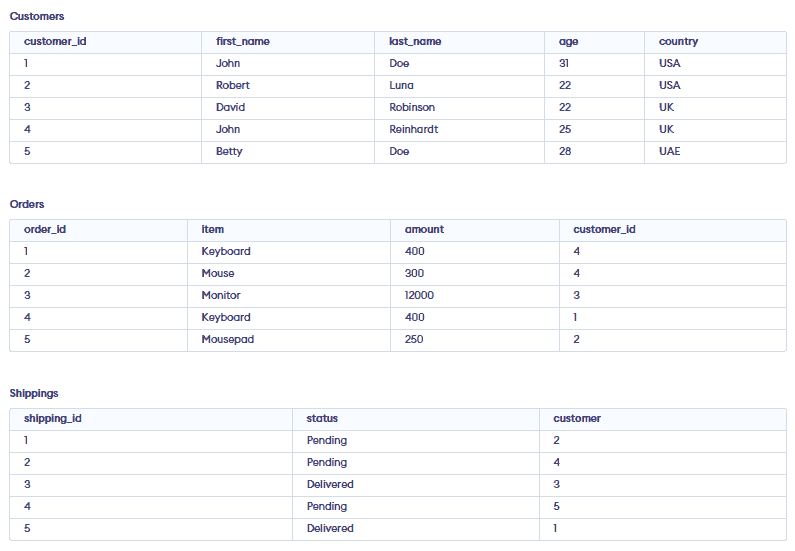
演示数据库来自 programiz.com
提示:
I have uploaded three tables. Please write an SQL query to determine whether John has received his keyboard.
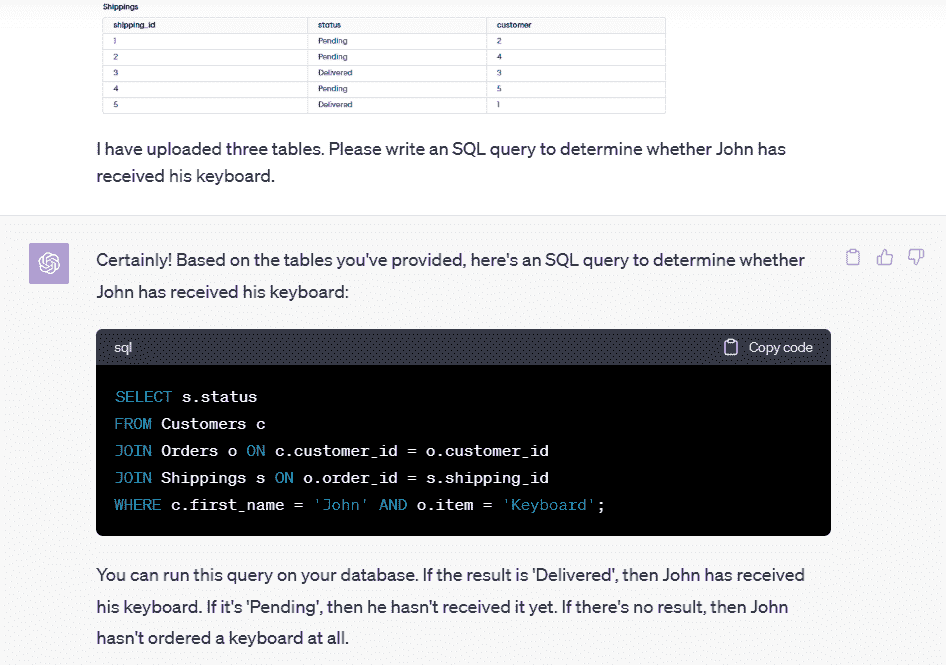
正如我们所见,SQL 查询运行得非常完美,我也得到了我的答案(待处理)。
SELECT s.status
FROM Customers c
JOIN Orders o ON c.customer_id = o.customer_id
JOIN Shippings s ON o.order_id = s.shipping_id
WHERE c.first_name = 'John' AND o.item = 'Keyboard';
结果:

ChatGPT 视觉功能使非技术经理能够对多个关系表和复杂问题进行查询。
2. 图表分析
使用 ChatGPT 视觉进行图表分析是理解每个图表所传达的信息的最佳方式。
在我们的案例中,我们提供了来自 COVID19 期间数字学习演变 笔记本的多张数据分析图像,并要求 ChatGPT 为我们编写详细报告。
提示:


作为数据科学家,制作一个合适的数据分析报告通常需要整整一天的时间。然而,借助 ChatGPT,我们能够在一分钟内完成报告。它能够识别出我在初步分析中遗漏的隐藏模式。再次证明,ChatGPT Vision 是一个宝贵而可靠的助手。
3. 仪表板
接下来,我们将提供超级样本超级商店仪表板的更复杂图像,以帮助理解每个组件及其含义。
提示:
Can you please explain each dashboard section in detail?
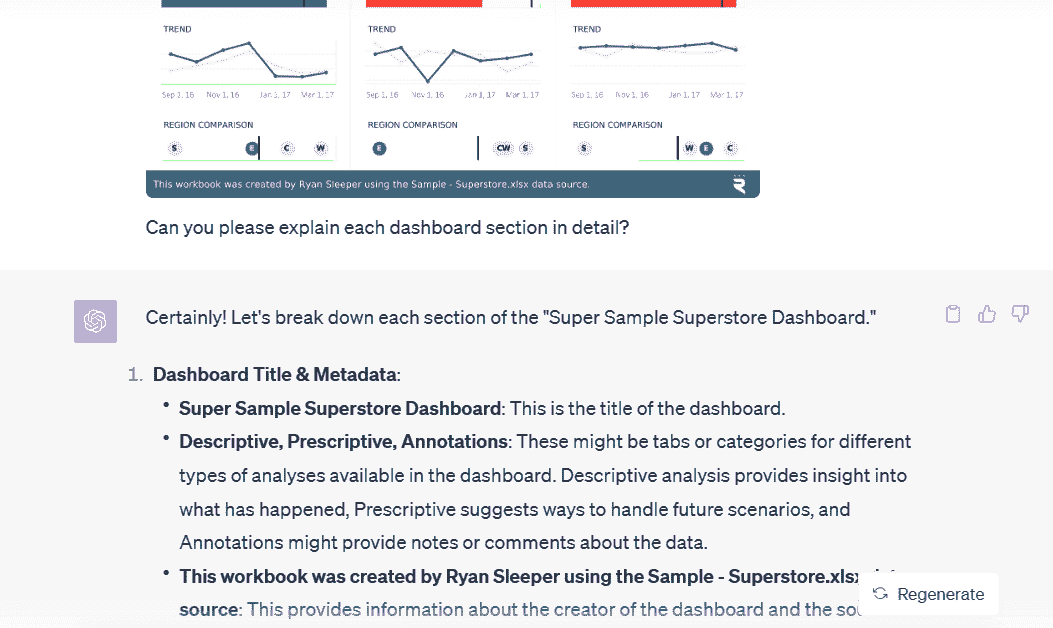
ChatGPT 通过一个简单的提示提供了详细的仪表板解释。此外,它解释了仪表板上的数字和图表,如 KPI、趋势和区域比较。
4. 评估
我经常在评估结果和理解结果时遇到困难。例如,当我尝试确定 KMeans 算法的最佳聚类数时,使用俄罗斯酒类促销数据集。所以,我会提供一个肘部图给 ChatGPT Vision,并让它为我选择一个数字,而不是检查多个聚类。
提示:
I have uploaded the elbow plot to figure out the optimal number of clusters for the KMeans algorithm. Please pick the number for me.

你还可以利用这个新功能来更好地理解机器学习结果。例如,理解移动价格分类模型的分类报告。
提示:
I have uploaded the classification report of Mobile Price Classification. Can you please explain the result?
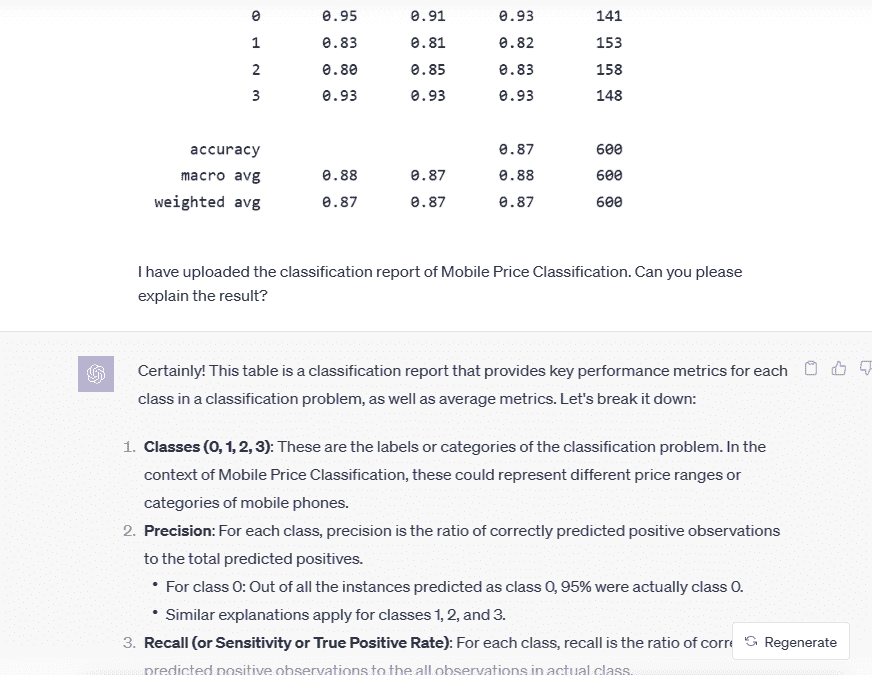
利用这些结果,我可以轻松向我的非技术经理和利益相关者解释我们的初步结果。这使我的生活变得简单。
5. 方程式
ChatGPT Vision 的最佳用法是用来理解研究论文、网站、视频和博客上的各种数学方程式。你可以直接截图方程式,并要求 ChatGPT 用简单的词汇为你解释。例如,我们要求它解释奇异值分解的方程式。
提示:
Can you explain the singular value decomposition using the uploaded image of equations

另一个例子是,我们将要求 ChatGPT 将基于人类偏好的微调语言模型研究论文中的奖励函数转换为 Latex。
提示:
Can you convert the reward function equation into latex?

如你所见,生成的 Latex 代码效果完美。
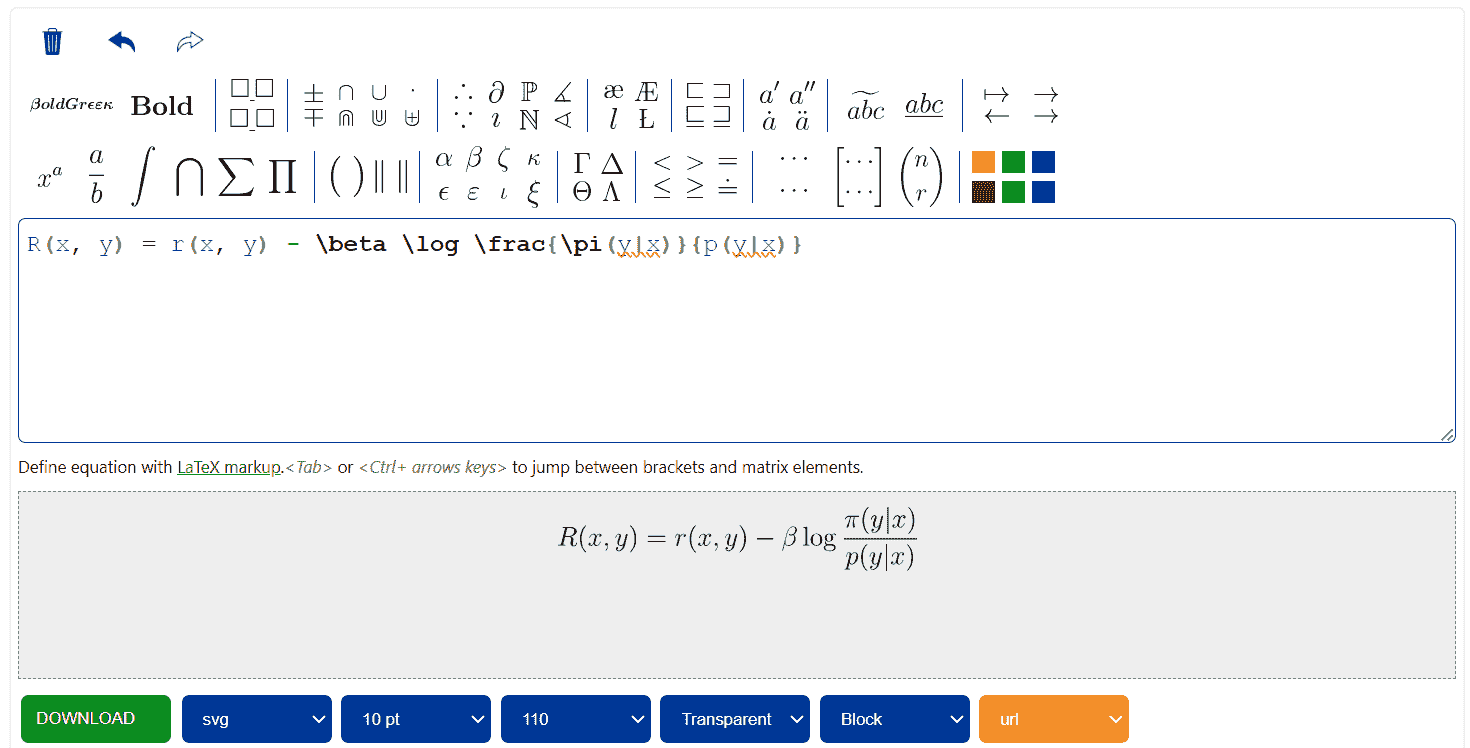
来自 Codecogs 的截图
最后的想法
凭借其视觉解释技能,ChatGPT 已成为数据科学家、分析师、研究人员甚至非技术专业人员在数据处理中的宝贵助手。它消除了手动分析的需求,并加快了从数据到洞察的过程。随着能力的不断提升,ChatGPT Vision 承诺将彻底改变我们处理和理解数据的方式。
Abid Ali Awan (@1abidaliawan) 是一位认证数据科学专业人员,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个帮助面临心理健康问题的学生的 AI 产品。
更多相关主题
50 家公司引领人工智能革命,详细信息
原文:
www.kdnuggets.com/2017/03/50-companies-leading-ai-revolution-detailed.html
我们详细列出了根据 CBInsights 的人工智能前 50 家公司。这份列表是 KDnuggets 最近的最受欢迎的推文,但推文只有图片,没有公司名称或详细信息。这里我们按类别和每组中高到低的股权融资顺序列出了公司概况(例如,总部位置和总股权融资额),信息基于crunchbase.com(截至 2017 年 3 月 8 日)。

我们的前三大课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业道路。
2. Google Data Analytics Professional Certificate - 提升您的数据分析技能
3. Google IT Support Professional Certificate - 支持您的组织在 IT 领域
初创公司的主要国家是:美国 39 个,中国 3 个,以色列 3 个,英国 3 个,法国 1 个,台湾 1 个。
对于美国,主要州是加利福尼亚州 23 个,马萨诸塞州 6 个,纽约州 4 个。
这里是按领域划分的总融资情况,显示出融资最多的领域是广告销售与客户关系管理、核心人工智能以及商业智能与分析。
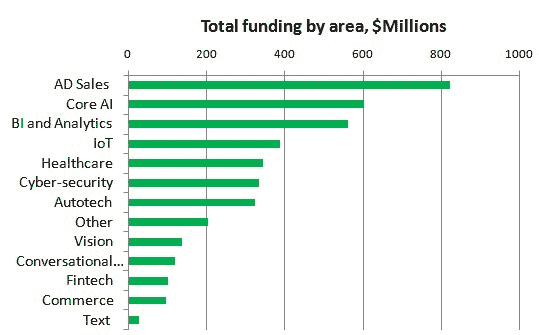
广告销售、客户关系管理($8.24 亿)
-
InsideSales.com(普罗沃,UT),融资$2.512 亿,提供基于预测和处方自学习引擎的销售加速平台。
-
Persado(纽约,NY),融资$6600 万,提供认知内容平台,生成激发行动的精准词汇、短语和图像组合。
-
APPIER(台北,台湾),融资$4900 万,向全球广告商提供下一代跨屏幕营销解决方案。
-
DrawBridge(圣马特奥,CA),融资$4600 万,是最大的独立跨设备身份识别公司,能够让品牌与消费者进行无缝对话。
Autotech($3.24 亿)
-
Zoox(门洛帕克,CA),融资$2.9 亿,是一家开创自主移动服务的机器人公司。
-
Nauto, Inc.(帕洛阿尔托,CA),融资$1490 万,是一家人工智能驱动的自动驾驶技术公司。
-
nuTonomy(马萨诸塞州剑桥)$19.6M,是一家专注于开发自驾车和自主移动机器人软件的公司。
商业智能和分析($562M)
-
Dataminr(纽约州纽约)$183.44M,开发模块化桌面和 API 产品,提供定制信号创建、数据集集成以及回测服务。
-
Trifacta(加利福尼亚州旧金山)$76.3M,是一家开发数据分析、管理和操作平台的生产力软件公司。
-
Paxata(加利福尼亚州红木城)$60.99M,是首个为分析师打造的自适应数据准备™平台,用于将原始数据转换为可用于分析的准备数据。
-
DataRobot(马萨诸塞州波士顿)$57.42M,提供预测分析平台,以快速构建和部署预测模型,无论是在云端还是企业内部。
-
Context Relevant(华盛顿州西雅图)$44.3M,是一家大数据分析公司。
-
Tamr(马萨诸塞州剑桥)$41.2M,使数据源连接和数据丰富变得快速、经济高效、可扩展,并且可供整个企业访问。
-
CrowdFlower Inc(加利福尼亚州旧金山)$38M,是数据科学团队必不可少的人工干预平台。
-
RapidMiner(马萨诸塞州波士顿)$36M,是一个数据科学平台,使组织能够轻松准备数据、创建模型和实现预测分析。
-
Logz.io(以色列特拉维夫)$23.9M,是一个企业级 ELK 服务,提供警报、无限扩展性和预测性故障检测。
电子商务($97M)
- BloomReach(加利福尼亚州山景城)$97M,开发一个云营销平台,分析大数据,帮助客户通过搜索引擎展示相关内容。
对话式 AI/机器人($121M)
-
Mobvoi Inc.(中国北京)$71.62M,是一家移动语音搜索公司。
-
x.ai(纽约州纽约)$34.3M,是一个 AI 驱动的个人助手,支持用户安排会议等。
-
MindMeld(加利福尼亚州旧金山)$15.4M,是一个先进的 AI 平台,为新一代智能对话界面提供支持。
核心 AI($604M)
-
Sentient Technologies(旧金山,加利福尼亚州)$135.78M,创建了全球最大、最强大的智能系统,彻底改变了企业处理复杂问题的方式。
-
Voyager Labs(以色列)$100M,开发了能够实时分析来自多个来源的全球数十亿数据点的核心技术。
-
Ayasdi(门洛帕克,加利福尼亚州)$106.35M,提供一个机器智能平台,帮助组织从大数据中获得变革性优势。
-
Digital Reasoning(富兰克林,田纳西州)$73.96M,是企业认知计算的领导者。
-
Vicarious(旧金山,加利福尼亚州)$72M,开发了递归皮层网络™,一种视觉感知系统,能够解读照片和视频的内容。
-
Affectva(沃尔瑟姆,马萨诸塞州)$33.72M,Affectiva Emotion AI 使人类与技术的互动更加人性化。
-
H20.ai(山景城,加利福尼亚州)$33.6M,提供快速可扩展的机器学习 API,以实现更智能的应用程序。
-
CognitiveScale(奥斯汀,德克萨斯州)$25M,提供企业级认知云软件。
-
Numenta(红木城,加利福尼亚州)$24M,引领机器智能的新纪元。
网络安全($335)
-
Cylance(尔湾,加利福尼亚州)$177M,是全球网络安全产品和服务的提供者,解决全球最复杂的安全问题。
-
Darktrace(伦敦,英国)$104.5M,提供企业级免疫系统技术用于网络安全。
-
Sift science(旧金山,加利福尼亚州)$53.6M,提供大规模机器学习技术服务,帮助电子商务企业检测和防范欺诈。
金融科技($102M)
-
Kensho(剑桥,马萨诸塞州)$67M,将自然语言搜索、图形用户界面和安全的云计算结合起来,创造了一类新型的分析工具。
-
Alphasense(旧金山,加利福尼亚州)$35M,是一个智能搜索引擎,提供复杂的语义分析,为您提供前所未有的信息优势。
医疗保健($344)
-
iCarbonX(深圳,中国)$199.48M,是一个用于健康数据的人工智能平台公司。
-
Benevolent.AI(伦敦,英国)$100M,利用人工智能的力量提升和加速全球科学发现。
-
Babylon health(伦敦,英国)$25M,通过移动电话提供高质量医疗服务。
-
Zebra medical vision(谢法因,哈梅尔卡兹,以色列)$20M,致力于创建全球最大的医学影像洞察平台。
物联网($388M)
-
Anki(旧金山,加州)$157.5M,是一家致力于将人工智能和机器人技术带入我们日常生活的娱乐机器人公司。
-
Ubtech(深圳,中国)$120M,是一家智能类人机器人制造商。
-
Rokid(杭州,浙江,中国)$50M,利用人工智能开发智能家居设备。
-
Sight Machine(旧金山,加州)$44.15M,是制造业分析领域的领导者。
-
Verdigris tech.(莫菲特菲尔德,加州)$16.1M,是一个基于 SaaS 的平台,开发人工智能以优化能源消耗。
文本分析/生成($29.4M)
- Narrative science(芝加哥,伊利诺伊)$29.4M,是企业级高级自然语言生成领域的领导者,能够大规模生成数据驱动的叙事。
Vision($139M)
-
Captricity(奥克兰,加州)$51.9M,是一个基于云的服务,将纸上的信息迅速有效地转换为数字数据。
-
Clarifai(纽约,纽约)$40M,为客户提供先进的图像识别系统,以检测近重复和视觉搜索。
-
Orbital Insight, Inc.(山景城,加州)$28.7M,构建了一个宏观观察系统,寻找在不断扩展的卫星图像供应中找到真相和透明度。
-
Chronocam(巴黎,法国)$18.35M,为自动导航和连接物体提供生物启发的计算机视觉解决方案。
其他($205M)
-
Zymergen(埃默里维尔,加州)$174.1M,是一家解锁生物学力量的科技公司。
-
Blue river tech(桑尼维尔,加州)$30.4M,利用计算机视觉和机器人技术为农业行业构建智能解决方案。
更多相关信息
2020 年每位数据科学家必读的 50 本免费书籍
原文:
www.kdnuggets.com/2020/03/50-must-read-free-books-every-data-scientist-2020.html
评论
作者:Reashikaa Verma,ParallelDots
数据科学是一个跨学科领域,包含统计学、机器学习、贝叶斯等领域的方法和技术。它们都旨在从数据中生成特定的洞见。本文列出了一些优秀的数据科学书籍,涵盖了数据科学领域的广泛主题。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
1. 数据分析风格的元素

本书概述了数据科学。数据科学是一个非常大的伞形术语,这本书适合任何第一次接触该领域的人。阅读它可以理解数据科学是什么、一些常见任务和算法,以及一些一般性建议和技巧。
2. 数据科学基础
《数据科学基础》是对数据科学基础领域的论述,如线性代数、LDA、马尔可夫链、机器学习基础和统计学。该书的理想读者是希望提高其数学和理论掌握水平的初学者数据科学家。
3. 大规模数据集挖掘
基于斯坦福课程 CS246 和 CS35A,该书帮助用户学习如何在大数据集上进行数据挖掘。数据科学家常常需要在非常大的数据集上执行简单的数值任务(可以通过编写小程序来完成)。《MMDS》正是为此而作。此外,还有像降维和推荐系统这样的主题,帮助你了解线性代数和度量距离在现实世界中的应用。这是所有数据科学家必须阅读的书籍。
4. Python 数据科学手册

《Python 数据科学手册》教授了在 Python 中应用各种数据科学概念的知识。这本书可能是学习 Python 数据科学的最佳书籍(唯一的等效书籍是 Wes McKinney 的《Python 数据分析》),这本书在 Github 上也是免费的。所以你可以在不花费任何金钱的情况下学习。
5. 实践中的机器学习与大数据

6. 统计思维

《统计思维》教授读者统计学的基础,即读者将应用统计概念和分布于现实世界的数据集,并试图通过数学特征了解更多数据。如果你想用 Python 学习统计学,这本书可能是最佳的入门书籍之一。
7. 贝叶斯思维

贝叶斯统计与常规统计的工作方式有所不同。由于不确定性和将分布拟合到现实世界数据集的概念,使得贝叶斯方法更适合学习实际的数据集。道尼教授极其酷炫的“通过用 Python 编程学习”风格使这本书成为了那些刚开始接触贝叶斯方法者的美好读物。
8. 线性动态系统导论
本书讲解了在现实世界系统中应用的线性代数。这些应用涉及电路、信号处理、通信和控制系统。可以通过 这里 查阅博伊德教授前几年的课程笔记。
9. 凸优化

凸优化是许多机器学习(几乎所有深度学习算法)算法在后台使用的技术,以达到最佳参数集。
10. 元启发式算法基础

元启发式算法是一种快速学习的概率性方法,用于完成那些需要编写程序以暴力搜索的任务。对于可能较小的数据集,暴力搜索方法的实现需要的努力较少,但随着数据量的增加,它们会迅速耗尽。这本书可能是介绍元启发式方法(如遗传算法、爬山算法、共同进化和(基础)强化学习)的最佳入门书籍。
11. Python 机器学习:数据科学、机器学习和人工智能中的主要发展和技术趋势
对数据科学中的 Python 工具的一个很好的概述。对于希望进入数据科学领域的高级 Python 开发者,或是从 R 转向 Python 的数据科学人士,这是一份非常好的文档。总体来说,如果你想了解 Python 在数据科学中能做什么,你应该阅读这篇文章。
12. 应用数据科学

Langmore 和 Krasner 的《应用数据科学》是一部非常实用的书籍,旨在教授数据科学。从使用 Git、基础 Python 教学开始,书中继续建立各种在数据科学领域中频繁使用的算法的基础。
13. 强盗算法书籍
随着数据的不断积累,决策不再仅仅依赖直觉,而是依赖收集到的数据。从电子商务网站上购买按钮的正确颜色到药物测试和金融投资组合决策,强盗算法无处不在。这是一本非常好的书,可以让你熟悉“强盗算法”!
14. 注释算法
一本教你用 Python 编写多种数值算法的书。如果你想了解数学程序是如何实现的,或者希望通过有趣的问题陈述来学习 Python,这本书是一个很好的资源。
15. 计算机时代的统计推断

这是 Efron 和传奇人物 Hastie 的一本书,探讨了如何利用现代计算能力进行统计推断(包括频率学派和贝叶斯学派),而不是大多数其他书籍所采用的笔纸方法。这是任何有意在现实生活中使用统计学的读者(无论是初学者还是有经验的)必须阅读的书籍。
16. 因果推断书籍
“相关性不等于因果性”是数据科学家常用的一个短语。但如何分辨这两者呢?这本书通过描述因果推断技术为数据科学家提供了答案。阅读这本书需要有良好的概率基础,不适合完全的初学者。
17. 计算最优传输
最优传输是将一个分布集分配到另一个分布集的数学。这可能是数据科学中为数不多的获得多个菲尔兹奖(数学最高荣誉)的领域之一。数学概念被广泛应用于许多机器学习和深度学习算法中,用作距离度量和分配问题求解。
18. 代数、拓扑学、微分计算和计算机科学与机器学习的优化理论
这本书旨在教授计算机科学和机器学习所需的各种数学领域。相当数学化,是那些希望从数学重的领域进入数据科学的人的好资源。
19. 数据挖掘与分析

数据挖掘,正如你可能在之前提到的更著名的 MMDS 书中看到的,是在大型数据集上有效进行计算的一种方法。这些计算可以通过蛮力方法完成,可能在小数据集上效果很好,但在大型数据集上可能需要很长时间运行。一本很好的数据挖掘入门和参考书。
20. 计算与推理思维
探讨了数据科学的各个方面,包括 Python 编程、因果关系、表格、可视化和基本统计。来自 UC Berkeley 的基础课程,是初学者的好资源。
21. 数据科学的数学基础

正如书名所示,本书给出了数据科学概念如凸优化和维度约简的数学理论及其解释。如果你喜欢数学或特别想了解这些概念背后的数学,这本书值得推荐。
22. 智能人的信息论
信息论是数据科学中的四大数学理论之一,其他三种是线性代数、凸优化和统计学。这是一个很好的教程来理解该理论。好在这个教程适合初学者。
23. 应用线性代数导论 – VMLS 书籍

我最喜欢的线性代数书籍之一。在我列出的许多书中,它适合初学者,并且有很强的应用感,让读者不会在大量数学概念中迷失。
24. 线性代数 – 赫弗伦

很多人认为这是继吉尔伯特·斯特朗的线性代数书之后最好的初学者线性代数资源。应用性也很强,(SAGE 中的编程练习,本质上是 Python),但更适合初学者而非从业者。
25. 线性代数 – 作为抽象数学的介绍
这本书让我想起了我大学时的线性代数书(那本书受到了许多学习工程的学生的喜爱)。当数学过多而应用稍少时,我会有些迷失,但很多人会享受这些书的优雅。
26. 线性代数与优化基础
这本书将线性代数与优化算法结合起来。再次说明,适合喜欢这种风格的数学导向书籍。
27. 线性代数讲义 – Lerner
我觉得这本书非常好,它就像展示了多个已解决的问题来帮助你学习。不像早期的书籍那样严谨,更注重通过展示来学习。对那些长时间未接触线性代数的人来说,是一个很好的复习资料。
28. 随机线性代数讲义
并不是每个人都需要阅读这本书,因为它涉及概率算法来解决线性代数问题。如果你处理大型矩阵和向量,这些简单算法可能无法奏效。
29. 通过外积学习线性代数
一种不同的看待线性代数的方式。如果你觉得线性代数很有趣,应该尝试用这种新方式来可视化问题。
30. 线性代数 – Cherney 等
另一本免费的大学级线性代数书籍。适合初学者。如果你想练习,它还附有作业题。
31. 深度学习所需的矩阵微积分
正如其名,这个教程帮助你理解深度学习所需的矩阵微积分。
32. 优化:导论
在工程领域的问题中,优化参数是必需的。虽然凸优化在许多深度学习算法中使用,了解线性规划、单纯形等其他算法可以拓宽视野。
33. Scipy 讲义

如果你打算从事数据科学工作,你需要学习科学计算的 Python 堆栈。可能这是学习 Numpy、Scipy、Scikit-Learn、Scikit-Image 和所有你需要的库的最佳常见教程。
34. Pandas 综合教程
这个巨大的教程由 Pandas 开发团队制作,用于学习和理解这个库。如果你在数据科学领域工作,Pandas 是必须学习的库,没有逃避的余地。
35. Python 中的卡尔曼和贝叶斯滤波器
卡尔曼滤波器和其他贝叶斯滤波器在处理带有时间噪声的数据时非常有用,这些数据可以拟合到某个具有待推导参数的模型中。这些模型的双重功能是推导参数以及建模噪声。尽管最常见的例子是位置数据,但类似的滤波器也能很好地用于预测。(也可以在 Github找到)
36. 数据科学的统计推断

我们在此之前已经看过多本统计推断的书籍,但这本书特别针对数据科学家编写。如果你是一名数据科学家,想快速掌握统计推断,这就是你的书。
37. 机器学习数学

一本详细讲解数学的书,以帮助理解大多数机器学习算法。适合初学者。
38. 理论的可视化
一本通过使用互动可视化使学习概率变得简单的书。
39. 统计学基础
一本介绍统计学学习的书。没有学过统计学的初学者应该从这里开始。
40. 开放统计
一本结合书籍和视频讲座的资源,介绍统计学。
41. 从基础视角看高级数据分析
一本介绍数据科学不同概念的书。这包括因果模型、回归模型、因子模型等。示例程序使用 R 语言。
42. 快速数据、智能且可扩展
解释如何优化数据库以进行快速查询的书。讲述了现实世界中的各种可能模型。
43. 多臂赌博机简介
多臂赌博机是一种在不确定性下逐步做出决策的算法。这本书是关于多臂赌博机的入门著作。
44. 量化经济学讲座
关于定量经济学的讲座,以及用你喜欢的编程语言:Python 或 Julia 的代码。
45. 使用 Julia 的统计学
统计学家学习 Julia 或(较少见的情况)Julia 程序员学习统计学?试试这本书。
46. 信息论、推断与学习算法
信息论和推断通常被分别处理,但已故的 MacKay 教授的书尝试同时处理这两个主题。
47. 决策制定和风险管理的科学改进
一本关于概率决策制定的非技术性教程。
48. 三十三个小品:线性代数的数学和算法应用
这实际上不是一本线性代数的书,而是几种线性代数的有趣应用汇编成的书。
49. 遗传算法教程
遗传算法是所有数据科学家在某个时候都需要使用的工具。这个教程帮助初学者理解遗传算法是如何工作的。
50. 使用 Julia 进行运筹学计算
如果你在处理排队或其他运筹学问题,Julia 可能是你会非常喜欢的编程语言。程序像 Python 一样易于阅读,运行速度极快。
如果你是一名有志成为数据科学家的新手,并且认为自己具备从事该领域工作的能力,请将你的简历发送给我们,以获得成为ParallelDots数据科学团队成员的机会。
原始版本。经许可转载。
相关:
-
机器学习和数据科学的 10 本免费必读书籍
-
机器学习和数据科学的另外 10 本免费必读书籍
-
机器学习和数据科学的另外 10 本免费必读书籍
更多相关话题
50+ 有用的机器学习与预测 API,2018 年版
原文:
www.kdnuggets.com/2018/05/50-useful-machine-learning-prediction-apis-2018-edition.html
 评论
评论
API 是一组用于构建软件应用的例程、协议和工具。对于 KDnuggets 的第三版文章,我们移除了过时的 API,并用新元素进行了更新。所有 API 都被分类到新兴应用组中:
-
人脸与图像识别。
-
文本分析、自然语言处理、情感分析。
-
语言翻译。
-
机器学习与预测。

在每个应用组中,列表按字母顺序排列。API 概述基于截至 2018 年 4 月 16 日其 URL 上的信息。查看这些 API 的应用情况!如果我们遗漏了一些受欢迎的活跃 API,请在下面的评论中提出建议。
人脸与图像识别
-
Animetrics 面部识别: 可用于检测图片中的人脸,并与已知面孔集进行匹配。该 API 还可以在可搜索的画廊中添加或移除对象,以及为对象添加或移除面孔。
-
Betaface: 人脸识别和检测的网络服务。功能包括多面孔检测、面孔裁剪、123 个面部点检测(22 个基本,101 个高级)、面孔验证、识别、大型数据库中的相似性搜索。
-
Eyedea 识别: 专注于高端计算机视觉解决方案,主要用于物体检测和物体识别软件。提供眼睛、面部、车辆、版权和车牌检测的识别服务。该 API 的主要价值在于即时理解对象、用户和行为。
-
Face++: 人脸识别和检测服务,提供检测、识别和分析功能以供应用使用。用户可以调用程序进行训练、检测面孔、识别面孔、分组面孔、操控人员、创建面部集、创建组,并获取信息。
-
FaceMark: 一款能够在正面面部照片上检测 68 个点,在侧面面部照片上检测 35 个点的 API。
-
FaceRect: 一款强大且完全免费的面部检测 API。该 API 可检测单张照片上的面孔(正面和侧面)或多个面孔,为每个检测到的面孔生成 JSON 输出。此外,FaceRect 还可以为每个检测到的面孔找出面部特征(眼睛、鼻子和嘴巴)。
-
Google Cloud Vision API: 由像TensorFlow这样的平台支持,能够让模型学习和预测图像内容。它帮助你快速且大规模地找到你最喜欢的图像,并获得丰富的注释。它将图像分类为成千上万的类别(例如,“船”,“狮子”,“埃菲尔铁塔”),检测面部及其情感,并识别多种语言中的印刷文字。
-
IBM Watson Visual Recognition: 理解图像的内容 - 视觉概念标记图像,找到人脸,估计年龄和性别,并在集合中找到相似图像。你还可以通过创建自己的自定义概念来训练服务。
-
Imagga: 提供自动为图像分配标签的 API,使你的图像可被查找。它基于图像识别平台即服务。
-
Microsoft Cognitive Service - Computer Vision: 基于云的 API 可以根据输入和用户选择以不同方式分析视觉内容。例如,根据内容标记图像;对图像进行分类;检测人脸并返回其坐标;识别特定领域的内容;生成内容描述;识别图像中的文本;标记成人内容。
-
ParallelDots Visual Analytics APIs 提供独特的服务,帮助你自动标记图像、过滤不适当内容、找出照片的传播评分或识别肖像图像中的情感。
-
Skybiometry Face Detection and Recognition: 提供面部检测和识别服务。新版 API 包括区分深色眼镜和透明眼镜的功能。
文本分析、自然语言处理、情感分析
-
Bitext: 提供市场上最准确的语义服务,包括实体提取 & 短语提取、情感分析、文本分类、词形还原、词性标注、语言识别以及其他聊天机器人增强服务 ,支持 50 多种语言。
-
Diffbot Analyze: 为开发者提供工具,可以识别、分析和提取任何网页的主要内容和部分。
-
免费自然语言处理服务: 是一项免费的服务,包括情感分析、内容提取和语言检测。这是在 mashape.com 上一个受欢迎的数据 API,大型云 API 市场。
-
谷歌云自然语言 API: 分析文本的结构和含义,包括情感分析、实体识别和文本注释。
-
Watson 自然语言理解: 分析文本以提取内容中的元数据,如概念、实体、关键词、类别、关系和语义角色。
-
MeaningCloud 文本分类: 该 API 执行预分类任务,如:提取文本、分词、去除停用词和词形还原。
-
微软认知服务 - 文本分析: 从文本中检测情感、关键短语、主题和语言。与此 API 同属一组的其他 API(语言认知服务)包括 必应拼写检查; 语言理解; 语言分析; 网络语言模型。
-
nlpTools: 一种简单的 JSON 通过 HTTP RESTful 网络服务用于自然语言处理。它解码在线新闻媒体以进行情感分析和文本分类。
-
Geneea: 可以对提供的原始文本、从给定 URL 提取的文本或直接提供的文档进行分析(自然语言处理)。
-
ParallelDots 文本分析 API 提供方便且多样的自然语言理解(NLU)算法,支持十四种不同语言,以发现任何文档的情感或情绪,找出其中的主要实体或从中移除脏话。ParallelDots 自定义分类器还允许你在自己的类别上构建文本分类器,而无需任何训练数据。
-
汤森路透 Open Calais™: 使用自然语言处理、机器学习和其他方法,Calais 对你的文档进行分类和链接到实体(如人、地点、组织等)、事实(如“x”人工作于“y”公司)和事件(如“z”人于“x”日期被任命为“y”公司主席)。
-
Yactraq Speech2Topics,一个将音频视觉内容通过语音识别和自然语言处理转换为主题元数据的云服务。
语言翻译
-
Google Cloud Translation:可以在数千种语言对之间动态翻译文本。该 API 允许网站和程序通过编程方式与翻译服务集成。
-
Google Cloud SPEECH-TO-TEXT:使开发者能够通过应用强大的神经网络模型将音频转换为文本,使用起来简便。该 API 支持 120 种语言及其变体,以支持你的全球用户群。
-
IBM Watson Language Translator:将文本从一种语言翻译成另一种语言。该服务提供多种特定领域的模型,可以根据你的专有术语和语言进行自定义。例如,可以用客户自己的语言进行沟通。
-
MotaWord:一个快速的人力翻译平台。它提供超过 70 种语言的翻译。该 API 还允许开发者获取每个翻译的报价,提交翻译项目及相关文档和风格指南,跟踪翻译项目的进度,并实时获取活动反馈。
-
WritePath Translation:API 允许开发者访问和集成 WritePath 的功能到其他应用程序中。此 API 可以执行的操作包括:检索字数、提交文档进行翻译,以及检索翻译后的文档和文本。
-
Houndify:通过一个独立的平台将语音和对话智能集成到你的产品中,该平台始终在学习。
-
IBM Watson Conversation:构建理解自然语言的聊天机器人,并将其部署到消息平台和网站上的任何设备上。与此 API 同组的其他语言认知服务 API 包括对话;自然语言分类器;个性洞察;文档转换;和情感分析器。
-
IBM Watson Speech:包括语音转文本和文本转语音(例如,用于转录呼叫中心的通话或创建语音控制的应用程序)。
机器学习与预测
-
Amazon Machine Learning: 用于在数据中发现模式。该 API 的示例应用包括欺诈检测、需求预测、目标营销和点击预测。
-
BigML: 提供云托管机器学习和数据分析服务。用户可以设置数据源并创建模型,通过标准 HTTP 使用基本的监督和非监督机器学习任务进行预测。
-
Google Cloud Prediction: 提供一个 RESTful API 来构建机器学习模型。这些工具可以帮助分析数据,为应用程序添加各种功能,例如客户情感分析、垃圾邮件检测、推荐系统等。
-
co: 提供电商网站的产品推荐引擎。Guesswork 使用语义规则引擎准确预测客户意图,该引擎运行在 Google Prediction API 之上。
-
Hu:toma: 帮助全球开发者通过提供免费访问一个专有平台来构建和盈利深度学习聊天机器人,平台提供了创建和分享对话 AI 的工具和渠道。
-
IBM Watson Retrieve and Rank: 开发者可以将数据加载到服务中,使用已知的相关结果来训练机器学习模型(Rank)。服务输出包括相关文档和元数据列表。例如,联系中心的客服人员也可以快速找到答案,以提高平均通话处理时间。
-
indico: 提供文本分析(例如情感分析、推特互动、情绪)和图像分析(例如面部情绪、面部定位)。indico API 免费使用,无需训练数据。
-
Microsoft Azure 认知服务 API: 替代了基于预测分析提供解决方案的 Azure 机器学习推荐服务。它为客户提供个性化的产品推荐,并提高销售。新版本具有批处理支持、更好的 API Explorer、更清洁的 API 界面、更一致的注册/计费体验等新功能。
-
Microsoft Azure 异常检测 API: 检测时间序列数据中的异常,这些数据的数值在时间上均匀分布。例如,在计算机内存使用监控中,向上的趋势可能引起兴趣,因为它可能表明内存泄漏。
-
微软认知服务 - 问答生成器: 将信息提炼成对话形式,易于导航。其他同组的 API(知识认知服务)包括 学术知识、实体链接、知识探索 和 推荐系统。
-
微软认知服务 - 说话人识别: 赋予您的应用识别说话人的能力。其他同组的 API(语音认知服务)包括 Bing Speech(将语音转换为文本并再转换回语音,并理解其意图)和 自定义识别。
-
MLJAR: 提供原型设计、开发和部署模式识别算法的服务。
-
NuPIC: 是一个用 Python / C++ 编写的开源项目,实现了 Numenta 的皮层学习算法,由 NuPIC 社区维护。该 API 允许开发者使用原始算法,将多个区域(包括层级)串联起来,并利用其他平台功能。
-
PredicSis: 针对大数据的强大洞察力,通过预测分析改善市场表现。
-
PredictionIO: 是一个开源机器学习服务器,建立在 Apache Spark、HBase 和 Spray 之上,采用 Apache 2.0 许可证发布。示例 API 方法包括创建和管理用户及用户记录、检索项目和内容,以及基于用户创建和管理推荐。
-
RxNLP - 句子和短文本聚类: 文本挖掘和自然语言处理服务。他们的一个 API,即句子聚类 API,可以将句子(如来自多个新闻文章的句子)或短文本(如 Twitter 或 Facebook 状态更新的帖子)分组为逻辑组。
-
Recombee: 提供使用数据挖掘、查询语言和机器学习算法(例如协同过滤和基于内容的推荐)的服务,通过 RESTful API 实现。
其他 API 集合: Mashape 博客 & RapidAPI 机器学习集合
我们是否遗漏了你最喜欢的 API?我们会不断更新列表!
相关:
-
高级 API 是否让机器学习变得简单?
-
50+有用的机器学习与预测 API,更新版
-
区块链与 API
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 需求
了解更多相关话题
50+ 数据科学和机器学习备忘单
www.kdnuggets.com/2015/07/good-data-science-machine-learning-cheat-sheets.html
评论
Python、R、Numpy、Scipy、Pandas 备忘单
数据科学领域中有成千上万的包和数百个函数!一个有志的数据爱好者无需了解所有内容。这里列出了一些最重要的内容,并在几页中进行了概括。
精通数据科学需要了解统计学、数学、编程知识,尤其是 R、Python 和 SQL,然后将这些知识组合起来,通过业务理解和直觉——来推动决策。
这里按类别列出了备忘单:
Python 的备忘单:
Python 是初学者的热门选择,同时也足够强大,支持一些世界上最受欢迎的产品和应用。它的设计使编程体验几乎像用英语写作一样自然。Python 基础或 Python 调试器备忘单适合初学者,涵盖了入门所需的重要语法。社区提供的库如 numpy、scipy、scikit 和 pandas 被广泛依赖,NumPy/SciPy/Pandas 备忘单提供了快速复习。
R 的备忘单:
R 的生态系统扩展得如此迅速,以至于需要大量参考。R 参考卡在几页中覆盖了大部分 R 领域。Rstudio 也发布了一系列备忘单,以便 R 社区使用。数据可视化与 ggplot2 似乎是一个受欢迎的工具,因为它在创建结果图表时非常有帮助。
MySQL & SQL 备忘单:
对于数据科学家来说,SQL 的基础知识与其他任何语言一样重要。PIG 和 Hive 查询语言都与 SQL——原始的结构化查询语言密切相关。SQL 备忘单提供了一个 5 分钟的快速指南,帮助你学习 SQL,然后你可以进一步探索 Hive 和 MySQL!
Spark 备忘单:
Apache Spark 是一个大规模数据处理的引擎。对于某些应用程序,例如迭代机器学习,Spark 的速度可以比 Hadoop(使用 MapReduce)快 100 倍。Apache Spark 备忘单解释了它在大数据生态系统中的位置,讲解了基本 Spark 应用程序的设置和创建,并解释了常用的操作和动作。
Hadoop 和 Hive 的备忘单:
Hadoop 作为一种非传统工具出现,通过提供一个开源软件框架来解决被认为无法解决的大量数据的并行处理问题。探索 Hadoop 备忘单,以了解在命令行中使用 Hadoop 时的有用命令。SQL 和 Hive 函数的结合也是值得查看的内容。
机器学习的备忘单:
我们经常会花时间思考哪个算法是最好的?然后回到大部头的书籍中查找参考!这些备忘单提供了关于数据的性质和你要解决的问题的想法,然后建议你尝试某种算法。
-
预测分析模式
Django 的备忘单:
Django 是一个免费的开源 web 应用框架,用 Python 编写。如果你是 Django 的新手,可以查看这些备忘单,快速理解基本概念,并深入学习每一个。
分享更多,学习更多!我们是否遗漏了什么?在下面的评论中添加你最喜欢的备忘单吧!
相关:
-
数据科学备忘单指南
-
最受欢迎的前 20 个 R 包
-
大数据与 Hadoop 中最具影响力的 150 人
更多相关话题
=SQL=
SQL 与 CSV

作者提供的图片
您可以在 CSV 文件上运行 SQL 查询:
-
通过在 SQL 在线 IDE 上导入 CSV 文件。
-
通过将 CSV 文件直接导入数据库。
-
通过使用 Python、R 或 Julia 包直接在 CSV 文件上运行 SQL。
-
通过使用 DuckDB,该工具在大型 CSV 文件上运行快速分析查询表现最佳。
-
通过使用 CLI 工具。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT
在这篇文章中,我们将回顾最流行的 CSV 文件处理 CLI 工具,并学习如何轻松地在 CSV 文件上运行 SQL 查询。
csvkit
csvkit 包含多个命令行转换和处理工具。它是表格文件格式的霸主。
-
您可以将 Excel 转换为 CSV,将 JSON 转换为 CSV,将 CSV 转换为 JSON 文件。
-
通过打印列名、查看列的子集、重新排序列、查找匹配单元格的行和生成汇总统计信息来分析数据。
-
在 CSV 文件上运行 SQL 查询。
-
将数据导入 PostgreSQL 数据库,并将数据从 PostgreSQL 提取到 CSV 文件中。
我们将重点关注运行 SQL 查询并显示和保存结果。
安装
您可以使用 PIP 安装 csvkit。
pip install csvkit
安装后,通过在 Shell 中输入以下命令或在线阅读 文档 来查看文档。
csvsql -h
语法
要运行 SQL,您需要使用 --query 参数,然后在引号中编写查询。对于较长的 SQL 查询,您可以使用换行符,因为它在 PowerShell/Bash 中效果很好。
csvsql --query "WRITE SQL QUERY HERE" data.csv
注意: 文件名必须与查询中的表名相同。
使用 csvkit 进行 SQL 查询与 CSV
在本节中,我们将使用修改版的 美国前 50 大快餐连锁店 数据集,运行 SQL 查询并打印和保存结果。
简单查询
首先,我们将运行一个简单的查询来测试命令是否有效。
csvsql --query "SELECT * FROM usa_ff LIMIT 2" usa_ff.csv
输出:
结果显示了四列和美国快餐连锁店的前两条记录。
Chains,Sales,Franchised Stores,Company Stores
Arby's,4462.0,2293.0,1116.0
Baskin-Robbins,686.0,2317.0,0.0
复杂查询
让我们尝试运行一个复杂的 SQL 查询,以筛选出销售额大于或等于 40 亿美元的前 5 大快餐连锁店。
csvsql --query "
SELECT Chains AS 'Food Chains', Sales
FROM usa_ff
WHERE Sales >= 4000
ORDER BY Sales DESC
LIMIT 5" usa_ff.csv
输出:
Food Chains,Sales
McDonald's,45960.0
Starbucks,24300.0
Chick-fil-A,16700.0
Taco Bell,12600.0
Wendy's,11111.0
使用 csvlook 的结果
我们将把“|”结果传递给csvlook命令,并将结果转换为表格形式。
csvsql --query "
SELECT Chains AS 'Food Chains', Sales
FROM usa_ff
WHERE Sales >= 4000
ORDER BY Sales DESC
LIMIT 5" usa_ff.csv | csvlook
输出:
这改善了 SQL 查询的输出。
| Food Chains | Sales |
| ----------- | ------ |
| McDonald's | 45,960 |
| Starbucks | 24,300 |
| Chick-fil-A | 16,700 |
| Taco Bell | 12,600 |
| Wendy's | 11,111 |
保存结果
我们将使用重定向“>”将 SQL 查询结果保存为 CSV 文件。你可以提供一个文件名或带有完整地址的文件名。
csvsql --query "
SELECT Chains AS 'Food Chains', Sales
FROM usa_ff
WHERE Sales >= 4000
ORDER BY Sales DESC
LIMIT 5" usa_ff.csv > filtered_usa_ff.csv
结果:
正如我们所看到的,文件已成功保存在当前目录中。
作者提供的图片 | 使用 SQL 过滤的 CSV 文件
结论
拥有一个方便的命令行工具可以帮助你自动化任务和数据管道。你甚至可以使用免费的在线 SQL 工具开始数据分析项目。
我建议你使用Deepnote在几秒钟内对 CSV 文件运行 SQL 查询。它在后台使用 DuckDB。
如果你对在 Jupyter Notebook、Deepnote、DuckDB 和 csvkit 中使用 SQL 有疑问,请告诉我。我会尽力帮助你。
Abid Ali Awan (@1abidaliawan)是一位认证数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些面临心理健康问题的学生开发一个 AI 产品。
更多相关内容
KDnuggets™ 新闻 21:n45, 12 月 1 日:数据科学面试中最常见的 SQL 错误;为什么机器学习工程师正在取代数据科学家
特点 | 产品 | 教程 | 观点 | 榜单 | 职位 | 提交博客 | 本周图片
本期内容:数据科学面试中最常见的 SQL 错误;为什么机器学习工程师正在取代数据科学家;在新的 KDnuggets 投票中投票:你有多少百分比的机器学习模型已经部署?
在出版和编辑 KDnuggets 28 年后,我将退休并将 KDnuggets 交给 Matthew Mayo,他将成为新的主编。这是 我与 KDnuggets 的故事,包含了我在这段精彩旅程中学到的有用经验。 - Gregory Piatetsky
KDnuggets 顶级博客奖励计划 每月向顶级博客作者支付报酬。接受转载,但原创投稿的转载率为三倍。阅读我们的 指南 并将你的博客首先提交到 KDnuggets!
特点
-
**
,作者 Nate Rosidi
-
为什么机器学习工程师正在取代数据科学家,作者 Arthur Mello
-
KDnuggets: 个人历史与经验之谈,作者 Gregory Piatetsky
-
新投票:你有多少百分比的机器学习模型已经部署?,作者 Eric Siegel
-
如何使用 Neo4J 和 Transformers 构建知识图谱,作者 Walid Amamou
-
PyCaret 2.3.5 来了!了解新内容,作者 Moez Ali
-
数据科学家:如何推销你的项目和自己,作者 Ilro Lee
 ,作者 Nate Rosidi
,作者 Nate Rosidi产品,服务
-
将负责任的 AI 付诸实践
参加 12 月 7 日的数字活动**](/2021/11/microsoft-responsible-ai-practice-attend-digital-event.html),由 Microsoft 主办
-
你能在线成为数据科学家吗?,作者 365 Data Science
-
电子书:101 种利用第三方数据做出更明智决策的方法,作者 Roidna
-
AI 与 BI 相遇:现代 BI 平台需要具备的关键能力,作者 Zoho Analytics
教程,概述
-
情感分析 API 与自定义文本分类:选择哪个?,作者:Jérémie Lambert
-
众包中的聚类:方法论和应用,作者:Daniil Likhobaba
-
使用 Microsoft Synapse ML 构建大规模可扩展的机器学习管道,作者:Jesus Rodriguez
-
使用 KNIME 进行情感分析,作者:Thiel & Rudnitckaia
-
生成 Python 的电子表格:Mito JupyterLab 扩展,作者:Roman Orac
-
现代企业的前 4 大数据集成工具,作者:Ammar Ali
-
关于差分隐私的常见误解,作者:Lipika Ramaswamy
-
关于 Python 序列的 5 个高级技巧,作者:Michael Berk
-
设备端深度学习:PyTorch Mobile 和 TensorFlow Lite,作者:Dhruv Matani
-
Dask DataFrame 与 Pandas 的区别,作者:Hugo Shi
-
数据科学与机器学习编程的 3 个区别,作者:Nahla Davies
-
分布式学习与联邦学习算法的区别,作者:Aishwarya Srinivasan
-
使用 AWS 云上的 ML 构建无服务器新闻数据管道,作者:Maria Zentsov
-
使用 Faker 在 Python 中生成合成数据,作者:Matthew Mayo
-
内部推荐:推荐系统如何推荐,作者:Sciforce
-
使用 OCR 和 Google Books API 获取书籍元数据和封面,作者:Cadili & Rudnitckaia
意见
-
漫画:感恩节的数据科学,作者:Gregory Piatetsky
-
数据科学家与数据分析师有什么区别?,作者:Nisha Arya Ahmed
-
通过 MLOps 加速 AI,作者:Yochay Ettun
-
获得第一份数据科学家工作的 5 个技巧,作者:Renato Boemer
-
停止将 AI 偏见归咎于人类,作者:Ahmer Inam
-
自然语言处理的未来方向,作者:Paul Barba
热点新闻,推文
-
头条新闻,11 月 22-28 日:数据科学面试中最常见的 SQL 错误,由 KDnuggets 提供
-
头条新闻,11 月 15-21 日:19 个适合初学者的数据科学项目创意,由 KDnuggets 提供
职位
-
查看我们最近的 AI、分析、数据科学、机器学习职位
-
你可以在 KDnuggets 职位页面免费发布与 AI、大数据、数据科学或机器学习相关的行业或学术职位,详情请参见 kdnuggets.com/jobs
本周图片

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
相关主题
KDnuggets™ 新闻 21:n36,9 月 22 日:机器与深度学习大全开放书;本地 Python 中的简单 SQL
功能 | 产品 | 教程 | 意见 | 精选 | 职位 | 提交博客 | 本周图片
本周在 KDnuggets:机器与深度学习大全开放书;本地 Python 中的简单 SQL;自动化机器学习简介;如何在没有 STEM 学位的情况下成为数据科学家;数据工程师与数据科学家的真正区别是什么?;以及更多内容。
我们的新 KDnuggets 顶级博客奖励计划 将支付顶级博客的作者 – 查看详情。接受转载,但我们更喜欢原创投稿,奖励是转载的三倍。
功能
-
**
,作者:Ori Cohen
-
本地 Python 中的简单 SQL,作者:Matthew Mayo
-
自动化机器学习简介,作者:Kevin Vu
-
如何在没有 STEM 学位的情况下成为数据科学家,作者:Terence Shin
-
数据工程师与数据科学家的真正区别是什么?,作者:Springboard
 ,作者:Ori Cohen
,作者:Ori Cohen产品、服务
-
如何高效标记时间序列 – 并提升你的 AI,作者:Visplore
-
DATAcated 展会,10 月 5 日,直播,
探索新的 AI / 数据科学技术**](/2021/09/datacated-expo-oct-5.html),作者:DATAcated
-
免费虚拟活动:多伦多大数据与 AI,作者:Corp Agency
教程,概述
-
如何发现你机器学习模型中的弱点,作者:Michael Berk
-
5 个必须尝试的超棒 Python 数据可视化库,作者:Roja Achary
-
数据科学中的悖论,作者:Pier Paolo Ippolito
-
介绍 TensorFlow 相似性,作者:Matthew Mayo
-
在触碰数据集之前,务必询问这 10 个问题,作者:Sandeep Uttamchandani
-
如何获得 Python PCAP 认证:路线图、资源、成功技巧,基于我的经验,作者:Mehul Singh
-
与 Github Actions、Iterative.ai、Label Studio 和 NBDEV 的 MLOps 冒险,作者:Soellinger & Kunz
-
数据工程技术 2021,作者:Tech Ninja
-
如果你会写函数,你就可以使用 Dask,作者:Hugo Shi
-
15 个必须知道的 Python 字符串方法,作者:Soner Yıldırım
意见
- 两年自学数据科学给我带来的启示,作者:Vishnu U
头条新闻
-
头条新闻,9 月 13-19 日: 没有数据工程技能的数据科学家将面临严峻的现实; 机器与深度学习大全开放书,作者:KDnuggets
-
KDnuggets 顶级博客奖励 2021 年 8 月,作者:Gregory Piatetsky
职位
-
查看我们最近的 AI、分析、数据科学、机器学习职位
-
你可以在 KDnuggets 招聘页面免费发布与 AI、大数据、数据科学或机器学习相关的行业或学术职位,电子邮件 - 详情见 kdnuggets.com/jobs
本周图片

我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关内容
Pandas 与 SQL:数据科学家何时应使用每种工具
评论

我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
这两种工具对数据科学家以及类似职位的人(如数据分析和商业智能)都非常重要。也就是说,数据科学家应该在什么时候使用 pandas 而不是 SQL,反之亦然?在某些情况下,你可以仅使用 SQL,而在其他情况下,pandas 的使用会更方便,特别是对专注于 Jupyter Notebook 环境中的研究的数据科学家。接下来,我将讨论你应该在什么时候使用 SQL,什么时候使用 pandas。请记住,这两种工具有其特定的使用场景,但在许多情况下,它们的功能是重叠的,这也是我将要比较的内容。
Pandas

照片由 Kalen Kemp 拍摄,来源于 Unsplash。
Pandas 是一个开源的数据分析工具,使用 Python 编程语言。当你已经有了主要数据集,通常是从 SQL 查询中获得时,pandas 的优势开始显现。这一主要区别可能意味着这两个工具是分开的。然而,你也可以在各自的工具中执行多个相同的功能。例如,你可以在 pandas 中从现有列创建新特征,这可能比在 SQL 中更简单、更快捷。
需要注意的是,我并不是在比较 pandas 和 SQL 各自无法完成的任务。我将选择那些在数据科学工作中更高效或更适用的工具——这是基于我的个人经验的观点。
在以下情况下,使用 pandas 比使用 SQL 更有利,同时也具备 SQL 的相同功能:
- 从现有特征创建计算字段
在整合更复杂的 SQL 查询时,你通常也会整合子查询,以便从不同的列中分离值。在 pandas 中,你可以更简单地分离特征,如下所示:
df["new_column"] = df["first_column"]/df["second_column"]
上面的代码演示了如何将两列分别相除,并将这些值分配给新列。在这种情况下,你是在整个数据集或数据框上执行特征创建。你可以在数据科学的特征探索和特征工程过程中使用这个功能。
- 按分组
还涉及到子查询,在 SQL 中,按分组可能变得相当复杂,需要大量代码,这些代码可能会让人视觉上感到不堪重负。在 pandas 中,你只需一行代码即可完成分组。我并不是指简单的表选择查询末尾的‘group by’,而是涉及多个子查询的情况。
df.groupby(by="first_column").mean()
这个结果会返回数据框中每一列的first_column的均值。还有很多其他使用这个分组函数的方法,这些方法在 pandas 文档中有很好的说明。
- 检查数据类型
在 SQL 中,你通常需要进行类型转换,但有时看到 pandas 以垂直格式呈现数据类型会更清晰,而不是在 SQL 中滚动查看水平输出。你可以预期某些 数据类型的返回值为 int64、float64、datetime64[ns] 和 object。
df.dtypes
尽管这些都是 pandas 和 SQL 中相对简单的功能,但在 SQL 中,它们特别棘手,有时在 pandas 数据框中实现起来会简单得多。现在,让我们看看 SQL 擅长的部分。
SQL
照片由 Caspar Camille Rubin 提供,来源于 Unsplash。
SQL 可能是使用最多的编程语言,涉及到各种不同职位。例如,数据工程师、Tableau 开发者或产品经理都可能使用 SQL。话虽如此,数据科学家往往频繁使用 SQL。需要注意的是,有几种不同版本的 SQL,通常它们具有相似的功能,只是格式略有不同。
以下是 SQL 比 pandas 更有优势的情况——同时具有与 pandas 相同的功能:
- WHERE 子句
这个 SQL 子句使用频繁,也可以在 pandas 中执行。然而,在 pandas 中,它稍微更困难或不太直观。例如,你需要编写冗余的代码,而在 SQL 中,你只需要WHERE。
SELECT id
FROM table
WHERE id > 100
在 pandas 中,它可能是这样的:
df[df["id"] > 100]["id"]
是的,两者都简单,但 SQL 更具直观性。
- 连接
Pandas 有几种连接方法,这可能会有些让人不知所措,而在 SQL 中,你可以像下面这样执行简单的连接:INNER、LEFT、RIGHT。
SELECT
one.column_A,
two.column_B
FROM first_table one
INNER JOIN second_table two ON two.id = one.id
在这段代码中,连接比在 pandas 中更易于阅读,因为在 pandas 中你必须合并数据框,尤其是当你合并多个数据框时,这在 pandas 中可能会变得相当复杂。SQL 可以在同一查询中执行多次连接,无论是 INNER 等等。
所有这些示例,无论是 SQL 还是 pandas,都可以在数据科学过程的探索性数据分析部分中使用,以及在特征工程和查询模型结果(一旦存储在数据库中)时使用。
摘要
pandas 与 SQL 的比较更多是个人偏好。话虽如此,你可能会有不同的看法。然而,我希望它仍能揭示 pandas 和 SQL 之间的差异,以及在这两种工具中使用略有不同的编码技术和完全不同的语言执行相同操作的能力。
总而言之,我们比较了使用 pandas 相较于 SQL 以及反之对几个共享功能的好处:
-
从现有特征创建计算字段
-
分组(grouping by)
-
检查数据类型
-
WHERE 子句
-
连接(JOINS)
原始。经许可转载。
相关:
更多相关主题
KDnuggets™ 新闻 19:n38, 10 月 9 日:最后一份 SQL 数据分析指南;数据科学技能的 4 个象限和 7 个病毒数据可视化步骤
特点 | 教程 | 意见 | 精选 | 新闻 | 课程 | 会议 | 招聘 | 本周图片
阅读全面的 SQL 数据分析指南;学习如何为数据选择合适的聚类算法;了解如何利用数据科学技能调查的数据创建病毒数据可视化;注册任何一个 10 个免费顶级自然语言处理课程;还有更多内容。
特点
-
**
-
数据科学技能的 4 个象限与创建病毒数据可视化的 7 个原则
-
为你的数据集选择正确的聚类算法
-
10 个免费顶级自然语言处理课程
-
培训机器学习工程师
-
倒计时 - 2 周后预测分析世界伦敦

教程,概述
-
人工神经网络简介
-
了解你的数据:第二部分
-
OpenAI 尝试训练 AI 代理玩捉迷藏,但他们却对所学的内容感到震惊
-
神经架构搜索研究指南
-
5 个基本 AI 原则
-
重塑想象力:DeepMind 构建了自发回放过去经历的神经网络
-
机器学习数据准备 101:为何重要以及如何进行
-
多任务学习 - ERNIE 2.0:最先进的 NLP 架构直观解释
意见
-
为什么“为什么方式”是恢复 AI 信任的正确途径
-
克服深度学习的难点
顶级故事,推文
-
九月顶级故事:我未能成为数据科学家,因此我寻求了关于谁能够成为的数据
-
热门新闻,9 月 30 日 - 10 月 6 日:你所需要的最后一本 SQL 数据分析指南;了解你的数据:第一部分
-
KDnuggets 推特精华,9 月 25 日 - 10 月 1 日:使用 spaCy 进行自然语言处理:介绍
新闻
- 我们生活中的数学视频合集来自 SIAM
课程,教育
- 工业问题解决的统计思维:一门免费的在线课程
会议
-
倒计时 - 预测分析世界伦敦还有 2 周
-
2019 ODSC West 6 位必看深度学习专家 - 20%折扣周五结束
职位
-
查看我们最近的 AI、分析、数据科学、机器学习职位
-
你可以在 KDnuggets 职位页面上发布与 AI、大数据、数据科学或机器学习相关的行业或学术职位的免费简短信息,邮件 - 详情见 kdnuggets.com/jobs
本周图片

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
更多相关话题
6 个需要密切关注的 AI 和机器学习领域
原文:
www.kdnuggets.com/2017/01/6-areas-ai-machine-learning.html
评论
由 Nathan Benaich 提供,投资于未来技术。

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
提炼出一个普遍接受的人工智能(AI)定义已成为近期重新讨论的话题。有些人将 AI 重新品牌化为“认知计算”或“机器智能”,而另一些人错误地将 AI 与“机器学习”混为一谈。这部分是因为 AI 不是一种技术。事实上,它是一个广泛的领域,由许多学科组成,从机器人技术到机器学习。大多数人认为,AI 的最终目标是构建能够执行任务和认知功能的机器,而这些任务和功能通常仅限于人类智能的范围。为了实现这一目标,机器必须能够自动学习这些能力,而不是将每项能力逐步编程。
在过去 10 年中,AI 领域取得了令人惊叹的进展,从自动驾驶汽车到语音识别和合成。背景下,AI 已成为越来越多公司和家庭讨论的话题,他们开始将 AI 视为不再是 20 年后的技术,而是正在影响他们生活的事物。的确,主流媒体几乎每天都报道 AI,科技巨头们也一个个阐明了他们的重要长期 AI 战略。尽管一些投资者和现有者渴望了解如何在这个新世界中获取价值,大多数人仍在摸索这意味着什么。与此同时,政府正在处理自动化对社会的影响(参见奥巴马的 告别演讲)。
鉴于 AI 将影响整个经济体,参与这些对话的各方代表了意图、理解水平和构建或使用 AI 系统的经验程度的全面分布。因此,关于 AI 的讨论——包括从中得出的问题、结论和建议——必须以数据和现实为基础,而非推测。从已发布的研究结果或技术新闻公告、投机性评论和思想实验中对结果进行大胆的外推是极其容易(有时也令人兴奋)的。
下面是六个在影响数字产品和服务未来方面特别值得关注的 AI 领域。我将描述它们是什么,为什么重要,它们的应用现状,并列出(绝非详尽)正在研究这些技术的公司和研究人员。
![人工智能]() 1. 强化学习 (RL)
1. 强化学习 (RL)
 1. 强化学习 (RL)
1. 强化学习 (RL)RL 是一种通过试错学习新任务的范式,灵感来自于人类学习新任务的方式。在典型的 RL 设置中,代理被任务化为观察其在数字环境中的当前状态,并采取最大化长期奖励的行动。代理从环境中收到每个行动的反馈,以便知道该行动是促进还是阻碍了它的进展。因此,RL 代理必须平衡对环境的探索,以找到获得奖励的最佳策略,同时利用其已发现的最佳策略来实现预期目标。这种方法在 Google DeepMind 关于Atari 游戏和围棋的研究中变得流行。在现实世界中,RL 的一个例子是优化 Google 数据中心的能效。在这里,RL 系统实现了40%的减少。在可以模拟的环境(例如视频游戏)中使用 RL 代理的一个重要固有优势是可以以极低的成本生成大量训练数据。这与通常需要昂贵且难以从现实世界中获取的训练数据的监督深度学习任务形成了鲜明对比。
-
应用:多个代理在共享模型的环境实例中学习或通过在同一环境中互动和学习,学习在像迷宫这样的 3D 环境中导航或城市街道以实现自主驾驶,逆向强化学习通过学习任务目标(例如学习驾驶)来重现观察到的行为,或者赋予非玩家视频游戏角色类似人类的行为。
-
主要研究人员:Pieter Abbeel(OpenAI),David Silver,Nando de Freitas,Raia Hadsell,Marc Bellemare(Google DeepMind),Carl Rasmussen(剑桥),Rich Sutton(阿尔伯塔),John Shawe-Taylor(UCL)及其他。
-
公司:Google DeepMind,Prowler.io,Osaro,MicroPSI,Maluuba/Microsoft,NVIDIA,Mobileye。
2. 生成模型
与用于分类或回归任务的判别模型相比,生成模型学习训练示例的概率分布。通过从这个高维分布中采样,生成模型输出的新示例与训练数据相似。例如,一个在真实面孔图像上训练的生成模型可以输出类似面孔的新合成图像。有关这些模型如何工作的更多细节,请参见 Ian Goodfellow 的精彩 NIPS 2016 教程。他介绍的架构,生成对抗网络(GANs),在研究界特别受关注,因为它们提供了一条通向无监督学习的路径。使用 GANs 时,有两个神经网络:一个生成器,以随机噪声作为输入,负责合成内容(例如图像),以及一个判别器,已学会真实图像的样子,负责识别生成器创建的图像是真实的还是伪造的。对抗训练可以被视为一种游戏,生成器必须迭代地学习如何从噪声中创建图像,以便判别器无法再区分生成的图像和真实图像。该框架正被扩展到许多数据模式和任务中。
-
应用:模拟时间序列的可能未来(例如,用于强化学习中的任务规划);图像超分辨率;从2D 图像恢复 3D 结构;从小型标记数据集中泛化;一个输入可以产生多个正确输出的任务(例如,预测视频中的下一帧);在对话接口中创建自然语言(例如,聊天机器人);密码学;在标签不全时的半监督学习;艺术风格迁移;合成音乐和声音;图像修复。
-
公司:Twitter Cortex,Adobe,Apple,Prisma,Jukedeck,Creative.ai,Gluru,Mapillary*,Unbabel。
-
主要研究人员:Ian Goodfellow(OpenAI),Yann LeCun 和 Soumith Chintala(Facebook AI Research),Shakir Mohamed 和 Aäron van den Oord(Google DeepMind),Alyosha Efros(伯克利)及其他研究人员。
![machine_learning]() 3. 具有记忆的网络
3. 具有记忆的网络
 3. 具有记忆的网络
3. 具有记忆的网络为了使 AI 系统能够像我们一样在多样化的现实环境中进行泛化,它们必须能够持续学习新任务并记住如何将所有任务执行到未来。然而,传统的神经网络通常无法在不遗忘的情况下进行这种顺序任务学习。这种缺陷被称为灾难性遗忘。它发生的原因是,当网络在之后被训练以解决任务 B 时,解决任务 A 所需的重要权重发生了变化。
然而,确实有几种强大的架构可以赋予神经网络不同程度的记忆。这些架构包括 长短期记忆 网络(一种递归神经网络变体),它能够处理和预测时间序列;DeepMind 的 可微神经计算机,它结合了神经网络和记忆系统,以便从复杂的数据结构中自主学习和导航;弹性权重巩固 算法,根据权重对先前任务的重要性来减缓特定权重的学习;以及渐进式神经网络,它学习任务特定模型之间的横向连接,从之前学习的网络中提取有用的特征以用于新任务。
-
应用:能够泛化到新环境的学习代理;机器人臂控制任务;自动驾驶车辆;时间序列预测(例如金融市场、视频、物联网);自然语言理解和下一个词预测。
-
公司:Google DeepMind,NNaisense(?),SwiftKey/Microsoft Research,Facebook AI Research。
-
主要研究人员:Alex Graves,Raia Hadsell,Koray Kavukcuoglu(Google DeepMind),Jürgen Schmidhuber(IDSIA),Geoffrey Hinton(Google Brain/Toronto),James Weston,Sumit Chopra,Antoine Bordes(FAIR)。
4. 从较少的数据中学习并构建更小的模型
深度学习模型以需要大量训练数据才能达到最先进的性能而著称。例如,ImageNet 大规模视觉识别挑战赛中,团队挑战其图像识别模型,包含 120 万张手动标记的训练图像,分为 1000 个物体类别。如果没有大规模的训练数据,深度学习模型将无法收敛到其最佳设置,也无法在语音识别或机器翻译等复杂任务中表现良好。这种数据需求在使用单一神经网络端到端解决问题时尤为突出;即,接受原始音频录音作为输入并输出语音的文本转录。这与使用多个网络每个提供中间表示(例如,原始语音音频输入→音素→单词→文本转录输出;或从相机直接映射到转向命令的原始像素)形成对比。如果我们希望人工智能系统解决那些训练数据特别具有挑战性、成本高昂、敏感或耗时的任务,那么开发能够从较少示例(即一-shot 或零-shot 学习)中学习最佳解决方案的模型是重要的。在小数据集上训练时,面临的挑战包括过拟合、处理异常值的困难、训练和测试数据分布之间的差异。另一种方法是通过转移知识来改善新任务的学习,这些知识是机器学习模型从先前任务中获得的,这些过程统称为迁移学习。
一个相关的问题是使用类似数量或显著更少的参数构建具有最先进性能的更小深度学习架构。优势包括更高效的分布式训练,因为数据需要在服务器之间传输,减少将新模型从云端导出到边缘设备的带宽,并提高在内存有限的硬件上部署的可行性。
-
应用:通过学习模仿深度网络的表现来训练浅层网络,这些深度网络最初是在大量标记数据上训练的;具有更少参数但性能等同于深度模型的架构(例如,SqueezeNet);机器翻译。
-
公司:Geometric Intelligence/Uber、DeepScale.ai、微软研究院、Curious AI Company、谷歌、Bloomsbury AI。
-
主要研究人员:Zoubin Ghahramani(剑桥)、Yoshua Bengio(蒙特利尔)、Josh Tenenbaum(麻省理工学院)、Brendan Lake(纽约大学)、Oriol Vinyals(谷歌 DeepMind)、Sebastian Riedel(伦敦大学学院)。
5. 用于训练和推理的硬件
AI 进步的一个主要催化剂是将图形处理单元(GPU)重新用于训练大型神经网络模型。与以顺序方式计算的中央处理单元(CPU)不同,GPU 提供了一个大规模并行架构,可以同时处理多个任务。鉴于神经网络必须处理大量(通常是高维)数据,在 GPU 上训练比在 CPU 上要快得多。这就是为什么自从 AlexNet 2012 年发布以来,GPU 实质上成为了淘金热中的铲子——第一个在 GPU 上实现的神经网络。NVIDIA 继续领先于 Intel、Qualcomm、AMD 和最近的 Google。
然而,GPU 并不是专门为训练或推断而设计的;它们是为了渲染视频游戏图形而创建的。GPU 拥有高计算精度,但这并不总是必要,并且存在内存带宽和数据吞吐量问题。这为新兴初创企业和大型公司如 Google 内部的新项目提供了机会,以专门为高维机器学习应用设计和生产硅片。新芯片设计承诺的改进包括更大的内存带宽、在图形而非向量(GPU)或标量(CPU)上进行计算、更高的计算密度、每瓦特效率和性能。这令人兴奋,因为 AI 系统为其所有者和用户提供了明显的加速回报:更快、更高效的模型训练 → 更好的用户体验 → 用户更多地与产品互动 → 生成更大的数据集 → 通过优化提高模型性能。因此,那些能够更快训练和部署计算及能源高效 AI 模型的人将占据显著优势。
-
应用: 更快的模型训练(尤其是在图形上);预测时的能源和数据效率;边缘(IoT 设备)上运行 AI 系统;始终监听的 IoT 设备;云基础设施即服务;自动驾驶汽车、无人机和机器人。
-
公司: Graphcore,Cerebras、Isocline Engineering、Google(TPU)、NVIDIA(DGX-1)、Nervana Systems(Intel)、Movidius(Intel)、Scortex
-
主要研究人员: ?
6. 仿真环境
如前所述,为 AI 系统生成训练数据通常具有挑战性。此外,AI 必须能够在多种情况下进行泛化,才能在现实世界中对我们有用。因此,开发能够模拟现实世界物理和行为的数字环境将为我们提供测试平台,以衡量和训练 AI 的通用智能。这些环境向 AI 展示原始像素,然后 AI 采取行动以实现设定(或学习)的目标。在这些模拟环境中进行训练可以帮助我们理解 AI 系统如何学习,如何改进它们,还可以为我们提供可以潜在转移到现实世界应用的模型。
-
应用:学习驾驶;制造业;工业设计;游戏开发;智能城市。
-
公司:Improbable、Unity 3D、微软(Minecraft)、谷歌 DeepMind/暴雪、OpenAI、Comma.ai、虚幻引擎、亚马逊 Lumberyard
-
研究员:安德烈亚·维达尔迪(牛津)
原创帖子。经许可转载。
简介:内森·贝奈奇 投资于科技公司@PlayfairCapital。涉及数据、机器智能、用户体验。前癌症研究员、摄影师、永恒的美食爱好者。
相关:
-
通过 AI/持续学习实现物联网的持续改进
-
强化学习与物联网
-
增强版聊天机器人:推动聊天机器人的 10 项关键机器学习能力
了解更多
6 个人工智能神话破解:分辨事实与虚构
原文:
www.kdnuggets.com/6-artificial-intelligence-myths-debunked-separating-fact-from-fiction

图片由编辑提供
人工智能无疑是我们时代的流行词。它的受欢迎程度,尤其是生成式人工智能应用如 ChatGPT 的出现,使其成为技术讨论的焦点。
每个人都在谈论生成式人工智能应用如 ChatGPT 的影响,以及利用其能力是否公平。
然而,在这场完美风暴中,关于人工智能或 AI 的众多神话和误解突然涌现。
我敢打赌你可能已经听过这些了!
让我们深入探讨这些神话,揭开它们,并了解人工智能的真正本质。
1. 人工智能是智能的
与普遍的看法相反,人工智能根本不具备智能。现在大多数人确实认为人工智能模型具有智能。这可能是由于“人工智能”这个名称中包含了“智能”一词。
那么,智能意味着什么呢?
智能是生物体特有的特质,定义为获取和应用知识和技能的能力。这意味着智能使生物体能够与其环境互动,从而学习如何生存。
另一方面,人工智能是一种机器模拟,旨在模仿这种自然智能的某些方面。我们与之互动的大多数人工智能应用,尤其是在商业和在线平台上,依赖于机器学习。
由 Dall-E 生成的图像
这些是经过专门训练的人工智能系统,使用大量数据来处理特定任务。它们在指定的任务中表现出色,无论是玩游戏、翻译语言还是识别图像。
然而,超出其范围的任务,它们通常是相当无用的…… 拥有跨任务类人智能的人工智能概念被称为通用人工智能,而我们距离实现这一里程碑还很遥远。
2. 更大总是更好
科技巨头之间的竞争往往围绕着炫耀他们的人工智能模型的规模。
Llama 的 2 个开源大型语言模型(LLM)推出时,以强大的 700 亿特征版本让我们感到惊讶,而谷歌的 Palma 拥有 5400 亿特征,OpenAI 最新推出的 ChatGPT4 以 1.8 万亿特征大放异彩。
然而,LLM 的特征数量并不一定意味着更好的性能。
数据的质量和训练方法通常是模型性能和准确性的更关键因素。这已经通过斯坦福的 Alpaca 实验得到证明,在这个实验中,一个简单的 70 亿特征的 Llama 基础 LLM 能与配备 1760 亿特征的 ChatGPT 3.5 相匹敌。
所以这是一个明确的“否”!
更大并不总是更好。优化 LLMs 的规模及其对应的性能将使这些模型的使用在本地得到普及,并使我们能够将其集成到日常设备中。
3. AI 的透明度和问责制
一个常见的误解是,AI 是一个神秘的黑箱,缺乏任何透明度。实际上,虽然 AI 系统可以很复杂且仍然相当不透明,但正在进行显著的努力以提高其透明度和问责制。
监管机构正在推动伦理和负责任的 AI 使用。重要的举措如斯坦福 AI 透明度报告和欧洲 AI 法案旨在促使公司提升 AI 透明度,并为政府制定这一新兴领域的法规提供依据。
透明 AI 已成为 AI 社区的一个焦点讨论点,涵盖了各种问题,如允许个人确定 AI 模型经过彻底测试的过程以及理解 AI 决策背后的理由。
这就是为什么全球的数据专业人士已经在致力于使 AI 模型更透明的方法。
因此,虽然这可能部分正确,但并不像普遍认为的那么严重!
4. AI 的绝对正确性
许多人认为 AI 系统是完美无误的,这远非事实。像任何系统一样,AI 的表现取决于其训练数据的质量,而这些数据通常,甚至总是,由人类创建或策划的。
如果这些数据包含偏见,AI 系统将无意中 perpetuate(延续)这些偏见。
麻省理工学院团队对广泛使用的预训练语言模型的分析揭示了在将性别与某些职业和情感相关联时的明显偏见。例如,像空乘人员或秘书这样的角色主要与女性特质相关,而律师和法官则与男性特质相关。情感方面也观察到了类似的行为。
其他被检测到的偏见涉及种族问题。随着大型语言模型(LLMs)进入医疗系统,人们担心它们可能会延续有害的种族医学实践,反映出训练数据中固有的偏见。
人类干预对于监督和纠正这些缺陷至关重要,以确保人工智能的可靠性。关键在于使用具有代表性且无偏的数据,并进行算法审计以对抗这些偏见。
5. 人工智能与就业市场
最广泛的恐惧之一是人工智能将导致大规模失业。
然而,历史表明,虽然技术可能使某些工作岗位变得过时,但同时也孕育了新的行业和机会。

图片来自 LinkedIn
例如,世界经济论坛预测,虽然人工智能可能在 2025 年取代 8500 万个工作岗位,但将创造 9700 万个新岗位。
6. 人工智能接管
最终且最具反乌托邦色彩的一个。流行文化中的电影,如《黑客帝国》和《终结者》,描绘了人工智能可能奴役人类的悲惨景象。
尽管像埃隆·马斯克和斯蒂芬·霍金这样的有影响力人物表达了担忧,但当前的人工智能状态远未达到这种反乌托邦的形象。
当今的人工智能模型,如 ChatGPT,旨在协助特定任务,不具备科幻故事中描绘的能力或动机。
所以现在……我们仍然安全!
主要结论
总之,随着人工智能不断发展并融入我们的日常生活,分辨事实与虚构至关重要。
只有在清楚理解的基础上,我们才能充分发挥其潜力,并负责任地解决其挑战。
神话可能会遮蔽判断并阻碍进步。
凭借对人工智能实际范围的知识和清晰理解,我们可以继续前进,确保技术服务于人类的最佳利益。
Josep Ferrer**** 是来自巴塞罗那的分析工程师。他拥有物理工程学位,目前从事应用于人类流动的数据科学工作。他是一个兼职内容创作者,专注于数据科学和技术。Josep 涵盖了人工智能的所有方面,涉及这一领域的持续爆炸性发展。
了解更多相关话题
6 本每个数据科学家都应随时备齐的书籍
原文:
www.kdnuggets.com/2017/10/6-books-every-data-scientist-should-keep-nearby.html

机器学习和数据科学是一组复杂且相互关联的概念。为了跟上,你需要准备花时间进行研究和更新知识。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你在 IT 组织中的工作
即使是天天在行业中工作,也有可能与当前趋势脱节。
保持联系的最佳方式是继续更新你的知识,同时保持经验。这是帮助你在行业中成功的完美风暴或技能组合。
虽然互联网上有很多资源,但我们将特别查看一些最好的印刷材料。
1. 机器学习渴望, 作者 Andrew Ng
这不是秘密:现代数据、大数据和数据科学流程的发展生成了准确的机器学习系统。虽然它们不一定是同义的,但它们是相关的,因此如果你在数据行业工作,更新对机器学习的理解和知识是个好主意。
从这个出色的资源中你可以学到的一些见解包括你应该多频繁地收集训练数据、如何使用端到端深度学习以及如何促进与你创建的系统共享数据和统计信息。
机器学习渴望| 免费
2. Hadoop: The Definitive Guide, 作者 Tom White
Apache Hadoop 是用于处理和管理大量数据的主要框架。任何从事编程或数据科学的人都会对这个平台非常熟悉,因为它是必需的。事实上,这是开发可扩展系统的最有效方法之一。
正好,Hadoop 专家和 Apache 软件基金会成员 Tom White 写了这本权威指南,因此它充满了见解和有用的资源。更重要的是,它将带你完成与 Hadoop 集群一起工作的整个过程和设置。
Apache Spark 是另一个你可能想要花时间学习的重要平台。
Hadoop: 权威指南 | $40+
3. 预测分析,由埃里克·西格尔著
名为预测分析:预测谁会点击、购买、撒谎或死亡的力量的这本书详细解释了如何将大多数形式的数据和信息转化为可操作的预测或洞见。关键在于帮助专业人士更好地了解他们的受众。你将学习如何识别他们购买的产品和服务、他们访问的地点、他们喜欢的内容等等。
数据科学家的工作是查看原始、未筛选的数据,并识别可用的趋势和模式。这本书不仅帮助你做到这一点,还提出了必要的预测算法,以改善未来的操作和流程。可以把它视为预测分析的圣经。
预测分析:预测谁会点击、购买、撒谎或死亡的力量 | $16+
4. 用数据讲故事,由科尔·努斯鲍默·克纳夫利克著
用数据讲故事:商业专业人士的数据可视化指南 是行业内任何人的重要读物,即使是那些可能与企业或商业世界没有直接联系的人也应阅读。为什么?
简而言之,这本书涉及到大规模数据的组织和提取。这意味着要去除多余和不清晰的数据,改进数据收集过程,并提出相关的、实用的数据可视化方案。
这是学习你应如何处理所有有用数据的权威指南,以及如何去做。许多见解适用于一般技术领域,即使对那些不在这个行业中的人也会有帮助。
用数据讲故事 | $20+
5. 拐点, 由斯科特·斯塔夫斯基著
同样题为云计算、移动性、应用程序和数据的融合将如何塑造商业未来的这本指南,对于理解当前数据分析和云计算行业的发展是必不可少的。
特别值得注意的是斯塔夫斯基直接关注原始数据存储和挖掘系统,它们如何部署以及它们在现实世界中的应用。
不仅仅是理论指南,它揭示了实际的工作系统,并描述了如何将它们调整以适应你的商业或企业。
重要的是,你从这本书中得到的明确理解是如何在你的组织内部署这些工具和平台。
拐点:云计算、移动性、应用程序和数据的融合将如何塑造商业未来| $40+
6. 统计学习导论:R 语言应用, 由加雷斯·詹姆斯等人著
统计学习及相关方法在数据科学工作中是必不可少的。这本教科书旨在帮助任何人,从本科生到博士生,都能理解这些概念。
当然,它还提供了丰富的 R 实验室和实践活动,包含详细的解释和演示。其理念是,你可以在进行数据科学实践时,特别是在教育阶段,直接利用这些资源。
此外,它是一个很好的资源,可以随时查看并经常回顾。其概念和信息对日常应用非常实用。
应用 R 的统计学习简介 | 免费
简介: 凯拉·马修斯 在《The Week》、《The Data Center Journal》和《VentureBeat》等出版物上讨论技术和大数据,并且已经撰写了超过五年。要阅读凯拉的更多帖子,订阅她的博客 Productivity Bytes。
相关:
-
进入机器学习职业前需阅读的 5 本电子书
-
Python 突然超级受欢迎的 6 个原因
-
4 个被机器学习和机器人技术改变的行业
更多相关主题
每位数据科学家都应阅读的 6 本开放数据书籍
原文:
www.kdnuggets.com/2019/02/6-books-open-data-every-data-scientist-read.html
评论
数据科学家预计在未来几年内将 保持高需求。无论你现在是否从事这个领域或希望尽快进入它,很明显,在这里茁壮成长需要不断学习。全球数据分析基础设施在扩大其覆盖面和实用性方面取得了显著进展——但这也进一步强调了开放性和问责制的必要性。
这些书籍中的一些涉及理解开放数据这一不断变化领域所需的硬技能,而另一些则探讨了数字连接世界的伦理影响。每一本书对各地的数据科学家来说都是有益且启发性的阅读。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作

1. "开放数据结构:入门" — Pat Morin
Pat Morin 的 开放数据结构:入门,由 CreateSpace 独立出版,是初学者开始探索开放数据的绝佳选择。该书探讨了如何在各种上下文中分析数据结构,包括序列、优先级队列、图、栈以及有序和无序字典。
如果这些听起来像希腊语,对你来说没关系。这毕竟是一个介绍——而且书中确保包含了每个主要组件的 Java 源代码。读者应会发现这是一种易于接触、实用且数学重点突出的方式,让你逐步了解这个复杂但引人入胜的话题。它旨在面向所有自学者以及本科生。
2. "开放数据的全球影响" — Stefaan Verhulst 和 Andrew Young
全球化是一个充满争议和复杂的概念,但没有人质疑我们数据变得多么流动和全球化。对于任何想要了解全球化与开放数据分析交汇点的现代观点的人来说,向思想领袖寻求帮助是明智的。来自纽约大学 GovLab 的作者 Verhulst 和 Young 编写了一本 O’Reilly 指南,这本书将吸引数据科学家、政策制定者、小企业主和隐私活动家。
这本书中的案例研究对于数据科学界尤其具有吸引力。一个数据开放、可共享并真正有用的未来,是技术专家与公共和私人实体携手合作以解决共同挑战、制定新标准和 API,并利用数据科学更好地理解天气和气候,甚至规划和预测公共健康危机的未来。
3. 《为人民的数据:如何让我们的后隐私经济为你服务》——Andreas Weigend
Andreas Weigend 的《为人民的数据》,现已在 Hachette Book Group 购得,是注重隐私的数据科学家必读的书籍。曾经,公民对其数字生活如何被监控、挖掘以获取盈利洞察甚至卖给不明第三方一无所知的时代已经过去。我们依赖的各种连接设备不仅仅是我们上网浏览习惯的延续——这些设备实际上构成了一个全球监控网络。人们是否将这个网络用于促进社会目标,取决于负责建设它的人的意图。
这就意味着数据科学家。Weigend 本人曾为企业、金融和医疗机构甚至教育界提供咨询。他认为大数据和数据科学是积极变革的工具,但我们尚未建立一个共同的框架来调和大企业的需求与在线隐私权利。这本书提出了“让数据为我们服务”的方法。而“我们”意味着“所有人”。
4. 《数据革命:大数据、开放数据、数据基础设施及其后果》——Rob Kitchin
这本书探讨了全球数据环境如何迅速变化和自我重塑,却始终没有忽视大数据与开放数据之间的区别。Rob Kitchin 的《数据革命》尽管标题如此,却揭示了围绕数据基础设施和分析的许多炒作和夸张——并通过回顾众多组成部分如何汇聚在一起,支持了关于现代数据环境的论点。
此处探讨的“革命”涉及企业、监管机构、地方和国家政府、游说者、记者等各方的数据多样性、广度和可获取性。该书提供了对现代开放数据趋势的“后果主义”解读,使其成为那些想了解在前所未有的数据传输和分析规模下的公民、伦理和政治影响的科学家的重要资源。
5. "开放数据现在:热 startups、智能投资、精明营销和快速创新的秘密" — 乔尔·古林
作者乔尔·古林将多年多样的经验运用于开放数据现在一书中。古林曾与非营利组织、记者、政府机构合作,并担任《消费者报告》的执行副总裁,他将开放数据视为帮助各种组织启动新项目和产品、理解数据如何促进创新以及更好地与受众建立联系的工具。
数据科学家不仅需要多种具体技能,还需要了解这些技能如何应用于数据驱动的决策,如投资、创业、研发、社区组织、与公众接触等。这本书非常适合决策者和数据科学家,因为它考虑了“大局”,并提供了在合作、伦理和有意义的方式中进行数据分析的可靠策略。
6. "运输数据科学:带有计算机练习的自学指南" — 查尔斯·福克斯
难以夸大大数据在未来智能城市和汽车技术中将发挥的重要作用。远程办公的兴起、用电动发动机替代燃烧发动机的紧迫性以及将自动驾驶引入商用和个人车辆的挑战意味着未来的城市规划将与今天大相径庭。
运输数据科学,由 Springer International 出版,展望了未来并强调了数据科学家在实现这一目标中的重要作用。此书深入探讨了研究人员和交通技术专家如何利用数据库和数学模型更好地理解全球交通问题,并提出切实可行、可扩展且包容的解决方案。
我们希望你喜欢这六本对当前和未来数据科学家至关重要的书籍的介绍。如果我们遗漏了你最喜欢的书籍,请在下方评论并告知我们!
简介: 凯拉·马修斯 在《The Week》、《数据中心期刊》和《VentureBeat》等出版物上讨论技术和大数据,并且从事写作已有五年以上。要阅读更多凯拉的文章,订阅她的博客 Productivity Bytes。
原创。经许可转载。
相关:
-
每个数据科学新手在 2019 年应该设定的 6 个目标
-
数据科学如何改善高等教育
-
在 2 年内提升你的数据科学技能的 8 种方法
更多相关话题
-
[2023 年 5 本免费的自然语言处理书籍]https://www.kdnuggets.com/2023/06/5-free-books-natural-language-processing-read-2023.html)
成为数据科学“独角兽”的六个商业概念
原文:
www.kdnuggets.com/2017/03/6-business-concepts-data-science-unicorn.html
评论
 在中世纪,独角兽是一个稀有的神秘生物,具有强大的力量。在今天的世界里,类似的神秘生物就是数据科学独角兽,能够同样精通技术、数据科学和业务。这种专业人士是任何数据科学团队中最宝贵的资源。许多数据专业人士在前两个领域——技术和数据科学上是专家,但缺乏业务/领域技能。
在中世纪,独角兽是一个稀有的神秘生物,具有强大的力量。在今天的世界里,类似的神秘生物就是数据科学独角兽,能够同样精通技术、数据科学和业务。这种专业人士是任何数据科学团队中最宝贵的资源。许多数据专业人士在前两个领域——技术和数据科学上是专家,但缺乏业务/领域技能。
数据科学项目不仅仅是关于 ETL 和构建模型,更在于理解业务及其战略问题,提出正确的问题,并利用技术和数据科学来解决这些问题。对业务及其问题的理解不清可能会使数据科学/分析项目以及整个业务战略陷入困境。典型的分析团队包括业务/数据分析师(他们了解业务,定义业务问题,并从业务角度解释数据科学结果)、数据科学家(数据科学专家)和数据工程师(技术专家,开发者,测试者和管理员)。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
尽管这三种专家在同一个团队中,但在整合他们的专业知识后,可能存在正确理解问题或解释结果的差距。因此,理想的角色是了解所有三个领域的人,帮助团队更好地理解业务及其问题,寻找创新解决方案,并以正确的方式解释结果,为业务创造价值。这个博客概述了数据科学的商业方面,特别适合那些希望提升分析职业生涯并成为“独角兽”的技术和数据科学专业人士。
要理解当今以数据/分析驱动的业务,以下概念非常重要:
-
战略规划
-
企业绩效管理(EPM)
-
商业智能与分析
-
关键绩效指标
-
管理报告
-
战略决策
-
战略规划是组织定义其战略或方向的过程,并决定如何分配资源以追求这一战略。它也可能扩展到指导战略实施的控制机制。”– Wikipedia
视频:
- “企业绩效管理(EPM)是一种与商业智能(BI)相关的业务规划,涉及评估和管理企业绩效,以实现绩效目标、提高效率或优化业务流程。”– Technopedia。
视频:
视频:
- “关键绩效指标(KPIs)帮助我们衡量公司、业务单元、项目或个人相对于其战略目标和目的的表现。设计良好的 KPIs 提供了至关重要的导航工具,让我们清晰了解当前的绩效水平。” – www.ap-institute.com
视频:
- 管理信息报告,是“一种沟通方法,允许业务经理向受众传达思想和概念,了解市场趋势,并确保高效的业务运作。” – reference.com
由于管理报告帮助业务高管做出明智决策,因此有效且视觉化地呈现组织信息变得非常重要。在今天的 IT 支持企业中,BI 仪表板和报告工具是非常受欢迎的管理报告方式。 商业管理报告示例
6. “战略决策是由高级管理层做出的长期复杂决策。这些决策将影响整个公司的方向。一个例子可能是成为该领域的市场领导者。
战术决策是由中层管理者做出的中期、较少复杂的决策。它们是战略决策的后续,旨在实现任何战略决策中所述的目标。例如,为了成为市场领导者,公司可能需要推出新产品/服务或开设新分支机构。
操作决策是由初级管理者做出的日常简单例行决策。这可能涉及到定期订购供应品或创建员工角色” – bbc.co.uk
了解更多关于 商业决策
视频:
以下是 Bernard Marr 的影片列表——一位著名的大数据、分析和企业绩效的作者、演讲者和顾问,解释了关于商业、大数据和分析的更多细节:
完全理解商业方面的知识需要多年甚至十年的时间;对于独角兽公司而言,重要的是了解商业领域的基础知识,并将这些知识与技术和数据科学技能结合起来,以理解和解决现实世界中的商业问题。有关商业分析特定领域的在线课程有很多,例如。
最佳建议是选择你感兴趣的业务领域或当前数据科学项目的业务领域,并开始你的数据科学世界的独角兽之旅。祝好运。
相关:
-
数据科学的幻觉
-
数据科学技能与商业问题
-
访谈:Kenneth Viciana,Equifax 关于数据湖及其他洞察文化策略
更多相关话题
6 个对数据科学家有利的商业趋势
原文:
www.kdnuggets.com/2021/05/6-business-trends-data-scientists.html
评论
各行业的公司领导越来越关注可能影响利润的商业趋势。他们往往会参与更多需要数据科学家专业知识的活动。以下是六个让数据科学家更加抢手的趋势。

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
1. 数据质量管理
数据质量管理结合了专业知识和专门工具,以不断提高公司信息的准确性和可靠性。其目的是开发和实施一套流程,以提升企业未来的数据质量并消除当前存在错误的信息。
一项 2021 年的调查显示,2200 多名商业智能专业人士选择数据质量管理作为年度最重要的趋势。研究还表明,该主题在前几年也曾获得过第一的位置。
数据科学家可以帮助商业领袖采纳这一趋势。取得进展需要了解公司目前如何使用数据以及存在的弱点。一旦数据专业人士掌握了这些见解,他们可以帮助公司领导最大限度地利用现有的信息并监控其质量。
2. 数据故事讲述
当商业领袖投资于数据故事讲述时,他们将数据和叙事融合在一起,把复杂的统计数据拆解成易于管理的格式,以便他们的受众理解。例如,在公司年报中添加条形图,使得利益相关者更容易理解和欣赏数据,同时看到数据的背景。
数据故事讲述并不总是直接为客户带来好处。一项研究显示,56%的营销人员为他们的团队成员创建数据可视化。而 52%的受访者则为销售人员制作这些资源。
在使用数据故事讲述时,营销人员可能会提供持续的反馈。然而,他们仍然可能需要数据科学家来帮助获取、清理和组织信息。
数据科学家还具备展示材料不误导人们的欢迎专业知识。仅仅以视觉上吸引人的方式呈现内容是不够的。观众还必须正确解读数据,即使他们只是简短地查看它。
3. 数据驱动的定制
向人们展示针对大众的内容已不再有效。他们希望更多的个性化——即使是在看到在线产品广告时。在一项 2020 年的研究中,31%的人对那些向他们分发个性化广告的品牌表现出更高的忠诚度。同样,30%的受访者表示,他们更有可能因个性化广告而购买某物。
尽管许多消费者喜欢更多的个性化,但一些人不希望品牌了解他们过多的信息。然而,一个有效的方式是展示公司如何使用数据及其需求的透明度,以帮助人们感到更加舒适。
此外,数据科学家可以确保公司领导遵循最佳实践,并在收集、存储和使用信息时遵守所有适用的法规。由于加州已经有了数据隐私法,而州立法者考虑在其他地方引入类似法律,商业代表必须了解他们的义务。
4. 实时数据
实时数据在收集后立即发送进行分析,而不是存储起来,等待几天、几周甚至几个月后再进行检查。如果公司领导从事的行业中,延迟决策可能会导致过多的不满客户或利润损失,他们特别希望收到及时的信息。
在沃尔玛的测试店中,智能摄像头和实时分析监控库存水平和购买模式。然后,零售助理会收到补充货架的警报,以便在货架空置之前进行补充。
实时数据在制造业中也至关重要,尤其是因为意外停机的成本极其高昂。许多品牌使用预测分析工具来获取机器性能和可能需要解决的问题的实时数据。数据科学家可以帮助公司领导确定利用实时数据实现业务目标的最佳方法。
5. 电子邮件自动化
一些市场营销分析师认为电子邮件自动化是与客户互动的最佳方式之一。这涉及在某些行动发生时向人们发送内容。例如,一旦一个人注册了电子邮件列表,他们可能会自动收到一条包含特别优惠的欢迎信息。
数据科学家拥有深入挖掘信息集合并确认公司领导者如何通过自动化电子邮件实现业务改进的必要专业知识。
也许统计数据显示,一家电子商务公司的购物车放弃率很高。如果是这样,自动发送电子邮件提醒购物者他们没有完成购买可能会促成交易的完成。
商业领袖还可以依赖数据科学家找到显示哪些电子邮件技巧最有效的统计数据。例如,一个人在邮件主题行中包含他们的名字更可能打开邮件吗?在主题行中注明特定的折扣百分比对客户的购买兴趣有何影响?
6. 数据作为核心业务功能
许多公司领导者不再将数据视为可选的业务部分。他们意识到持续获得准确的信息将有助于决策,并增强业务。数据科学家可以评估公司如何更依赖数据并扩展这些努力的最佳方式。
Gartner 的分析师提到数据作为核心业务功能被列入公司 2021 年的数据和分析趋势前十名名单中。他们澄清了,数据驱动的活动曾经是主要业务操作的辅助部分,通常由一个独立的团队处理。但这种情况正在发生变化,数据正成为企业的基础元素。
然而,他们警告说,商业领袖往往被数据淹没而错过相关的机会。Gartner 的专家建议涉及首席数据官来设定目标和策略。他们表示,这样做可能会导致业务价值的持续增长,增长倍数为 2.6 倍。
数据科学家至关重要
数据可以帮助各行业的商业领袖发现他们本来无法获得的洞察。然而,解读这些信息并不总是简单的。数据科学家拥有帮助公司决策者利用手头信息并以此取得成功的知识和技能。
Bio: Devin Partida 是一位大数据和技术作家,同时也是ReHack.com的主编。
相关内容:
-
使用数据科学预测和防止现实世界问题
-
如何成为数据科学家
-
如何成功成为自由职业数据科学家
更多相关话题
6 个令人惊叹的 ChatGPT 扩展,用于任何地方
原文:
www.kdnuggets.com/2023/04/6-chatgpt-mindblowing-extensions-anywhere.html

由 Dall-E 生成的图像。AI 驱动的图像生成器
今天,我想揭开 ChatGPT 的神秘面纱——这是一个令人着迷的新 AI 应用,最近发布并引起了很多关注。它是由 OpenAI 开发的 AI 聊天机器人,专注于对话,其主要目标是使 AI 系统的互动更加自然——它真的无所不知!
不过,今天我想讨论如何增强我们与这个全新工具的互动方式。
互联网已经充斥着由这个新发布的服务驱动的新工具和扩展,这些工具可以使我们的日常任务变得更轻松——并且提高我们的最终输出。
这就是为什么我在这里总结了 6 个工具,可以让 ChatGPT 成为你的日常助手,甚至超越这个功能!
#1. 在任何地方使用 ChatGPT — Google Chrome 扩展
你想要轻松地在任何地方使用 ChatGPT 吗?今天是你的幸运日,有一个很棒的 Chrome 扩展** 你可以用来写推文、检查电子邮件、找出代码漏洞……**字面上的任何你能想象的事情!
#2. 将 ChatGPT 与搜索引擎结合
如果你更愿意将 ChatGPT 集成到你平常使用的搜索引擎中,以便你可以直接获得答案而无需使用其自身界面,你也可以做到!
你只需为 Chrome 和 Firefox 添加这个扩展,就能在 Google 搜索中直接获取 ChatGPT 的回应。
如果你更愿意访问一个预集成的搜索引擎,你可以查看 这个搜索引擎,它将 OpenAI ChatGPT 和 Bing 结合在一起,直接回答你的问题。
#3. 使用语音命令与 ChatGPT
你是 Alexa 或 Siri 的粉丝吗?那我敢打赌你通常喜欢大声说出你的问题和需求。已经有一个扩展可以让你直接通过 Chrome 与 ChatGPT 对话。你可以在下面的视频中查看它的工作原理。
#4. 在 Telegram 和 WhatsApp 中集成 ChatGPT
你可以按照这些 GitHub 说明在 Telegram 中创建一个由 ChatGPT 驱动的机器人,并与它对话——或者我应该说是他或她????

Telegram 机器人的截图由 ChatGPTTelegramBot 提供。
你更喜欢 WhatsApp 吗?好消息!!你也可以在 WhatsApp 中集成 ChatGPT。你可以关注这个 GitHub 来实现。
#5. 在 Google Docs 或 Microsoft Word 中集成 ChatGPT
你可以在 Google Docs 和 Microsoft Word 中集成 ChatGPT,以便在你喜欢的文本编辑器中使用它的所有功能,使用以下 GitHub。
ChatGPT 集成在 Google 文档中的截图。图片由 CesarHuret 提供。
#6. 保存你在 ChatGPT 中生成的所有内容
你是否与 ChatGPT 有过深入且有趣的对话,并希望将它们保存起来以供重读——或者也许是写一本包含所有知识的书?
然后你可以使用 以下扩展 将所有对话保存为 PDF、PNG 或 HTML 链接,适用于 Chrome、Edge 或 Firefox。
图片由 liady 提供。
#7. 附加功能 — Twitter ChatGPT 账户.
Twitter 上充斥着允许你在提及它们时向 ChatGPT 提问的机器人,而不是直接在 openAI 网页上提问。
一些示例包括:
mobile.twitter.com/chatwithgpt
twitter.com/ChatGPTBot/with_replies
希望你觉得这些 ChatGPT 扩展有用! 😃
Josep Ferrer 是来自巴塞罗那的分析工程师。他拥有物理工程学位,目前在应用于人类流动性的数据科学领域工作。他还是一名兼职内容创作者,专注于数据科学和技术。
原文。经许可转载。
更多相关主题
6 个 ChatGPT 提示,提升工作生产力
原文:
www.kdnuggets.com/6-chatgpt-prompts-to-enhance-your-productivity-at-work

图片来源:Freepik
时间是我们在当前职业环境中最宝贵但却有限的资源之一。找到提高个人生产力的解决方案,在任务和待办事项不断涌入的情况下,已经成为一个优先事项。人工智能工具,特别是 ChatGPT,最近在许多组织中获得了重要地位,成为实现这一目标的宝贵资产。这篇文章列出了六种情况,其中 ChatGPT 可以帮助你在各种工作相关场景中提升生产力。只需制定准确有效的提示,就能引导 ChatGPT生成满足你需求的正确回应。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
注意: 以下六个示例中的提示响应是使用 ChatGPT 免费在线版本 3.5 生成的。
1. 一个美好的开始:规划与优先排序
开始一天时面对一大堆待办事项,不知道从何开始?通过让 ChatGPT 帮助你整理和优先排序你的日程,可以很快解决这个问题。以下是一个示例提示和生成的回应:
提示:
"ChatGPT,帮助我根据以下任务创建一个今天的待办事项列表:完成季度报告,回应客户邮件,为团队会议做准备,并审查项目提案。季度报告截止时间是今天结束前,团队会议在下午 2 点,昨天有大约 15 封客户邮件待处理。项目提案是下周战略会议的内容。"
回应:
"当然!这是今天的优先任务列表:
*完成季度报告(高优先级,截止时间为今天结束前)
截止日期:今天
理由:这是时间敏感的任务,需要立即处理,以确保按时提交。*
*为团队会议做准备(高优先级,会议在下午 2 点)
截止日期:今天下午 2 点
理由:为会议做准备至关重要,因为它直接影响你在会议中的表现和贡献。*
*回应客户邮件(中等优先级,确保所有问题得到解答)
截止日期:今天结束前,但在处理更高优先级任务后开始
原因:回复客户电子邮件对维护良好的客户关系很重要,但可以安排在更紧急的任务之后进行。*
*审查项目提案(优先级低,可以在下午如果时间允许的话完成)
截止日期:下周的战略会议
原因:虽然这些提案很重要,但不紧急,可以在更紧迫的任务完成后再审阅。"
2. 高效的电子邮件管理和回复技巧
以下示例提示展示了如何高效处理未读电子邮件的过载(特别是在您从假期归来后的第一天!),通过获得帮助来撰写回复,特别是对于那些可能需要仔细思考的挑战性案例:
提示:
“ChatGPT,我应该如何回应询问订单状态并对延迟感到非常不满的客户?”
回复:
"*亲爱的[客户的名字],
我对处理您的订单延迟表示真诚的歉意。我理解这对您来说可能很令人沮丧。您的订单目前正在加快处理,我们预计将在[具体日期]之前发货。感谢您的耐心和理解。如果您有任何其他问题或疑虑,请随时联系我。
*此致,
[你的名字]*"
3 - 在会议上掌握高管演示的关键要点和行动项目
您的直线经理要求您创建两张幻灯片,总结高管会议的要点和行动项目,而整个对话记录已经被记录下来。那么为什么不请求 ChatGPT 的帮助,以提升您的演示技巧并留下深刻印象呢?
提示:
“ChatGPT,总结一下我们上次高管会议的要点和行动项目。”
附件:
[Meeting_Minutes_2024_06_23.docx]
备注: 如上所示,这种情况下的提示通常会与详细的会议资料一起提供,例如会议记录或录音记录,这些资料可以作为文本文件附加,或如果文本不长,也可以粘贴为提示的一部分。
回复:
"上次高管会议的要点:
- 回顾第二季度财务业绩:超出目标 10%
- 讨论产品发布的新营销策略
- 评估了正在进行的并购谈判的进展
行动项目:
- 财务团队需在周五之前准备好第二季度业绩的详细报告。
- 营销团队需在下周一之前制定并呈现新的活动策略。
- 法务团队需完成并购协议条款并安排下周的跟进会议。"
4. 更好地理解复杂信息
想象一下,你必须向组织中的非技术部门讲解一个高度技术性的概念或技术,以获得提交财务支持申请的批准。像这样的简单提示可能在将复杂的概念转化为易于理解的见解方面非常有效。
提示:
"ChatGPT,你能用简单的术语解释区块链的概念吗?"
回应:
"当然!区块链是一种数字账本,记录了许多计算机上的交易,以确保数据无法被事后更改。它就像一串区块,每个区块包含一系列交易。这项技术安全且透明,使其非常适合用于加密货币交易和供应链管理。"
5. 将头脑风暴的想法转化为创意内容
团队头脑风暴会议是促进新想法和倡议的流行且有趣的方式。在收集了团队提供的所有想法后,使用此提示将你凌乱的“便签”转化为连贯的内容。
提示:
"ChatGPT,这是一个关于远程工作好处的头脑风暴想法列表。你能帮我将这些转化为一个组织良好且吸引人的博客帖子吗?
- 工作时间的灵活性
- 无需通勤
- 更好的工作与生活平衡
- 更高的生产力
- 雇主和员工的成本节省
- 访问全球人才库
- 减少环境影响
- 增加工作满意度"
回应:
"标题:远程工作的好处:为何越来越多的公司正在采纳它"
介绍:
远程工作变得越来越受欢迎,为员工和雇主提供了诸多优势。这一转变正在改变传统的工作场所,带来显著的好处。
主要观点:
1 -工作时间的灵活性:
远程工作最吸引人的好处之一是其提供的灵活性。员工可以制定适合个人生活的工作时间表,从而对日常工作有更大的自主权和控制权。
(...)
8 - 增加工作满意度:
远程工作相关的灵活性和自主性有助于提高工作满意度和员工士气,降低离职率,并培养更忠诚的员工队伍。
结论:
远程工作的好处很明显,随着越来越多的公司采用这种模式,工作的未来变得更加灵活和高效。拥抱远程工作可以带来更快乐、更高效和更环保的员工。"
注意: 为了简洁起见,上述回答部分内容已被省略。在完整的回应中,所有八个支持远程工作的头脑风暴要点将类似地详细阐述。
6. 打磨你的写作
最后,ChatGPT 可以作为一种有用的工具,以精准的方式完善你的写作,提高其清晰度和吸引力,或简单地进行语法和词汇检查。
提示:
*"ChatGPT,你能帮我编辑和润色这段文字,以提高其清晰度和简洁性吗?
'在当今快节奏的商业环境中,具备迅速做出明智决策的能力至关重要。AI 工具的实施可以通过提供实时数据分析和立即可用的见解来极大增强这一能力。'"*
回应:
""在当今快节奏的商业环境中,能够迅速做出明智的决策至关重要。实施 AI 工具可以通过提供实时数据分析和可操作的见解来增强这一能力。"
伊万·帕洛马雷斯·卡拉斯科萨 是 AI、机器学习、深度学习及大型语言模型领域的领军人物、作家、演讲者和顾问。他培训和指导他人在实际应用中利用 AI。
更多相关主题
数据科学中的六个常见错误及如何避免
原文:
www.kdnuggets.com/2020/09/6-common-data-science-mistakes.html
评论

照片由 chuttersnap 在 Unsplash 提供。
介绍
在数据科学或机器学习中,我们使用数据进行描述性分析,以从数据中得出有意义的结论,或者我们可以将数据用于预测目的,建立可以对未见数据进行预测的模型。任何模型的可靠性取决于数据科学家的专业水平。构建一个机器学习模型是一回事,确保模型最优且质量最高是另一回事。本文将讨论六个常见错误,这些错误可能会对机器学习模型的质量或预测能力产生不利影响,并包含几个案例研究。
数据科学中的六个常见错误
在本节中,我们讨论六个常见错误,这些错误可能严重影响数据科学模型的质量。包含了几个实际应用的链接。
- 我们经常假设我们的数据集质量良好且可靠
数据是任何数据科学和机器学习任务的关键。数据有不同的形式,如数值数据、分类数据、文本数据、图像数据、语音数据和视频数据。模型的预测能力取决于用于构建模型的数据质量。因此,在执行任何数据科学任务如探索性数据分析或构建模型之前,检查数据的来源和可靠性是极其重要的,因为即使是看似完美的数据集也可能包含错误。有几个因素可能会降低数据的质量:
-
错误数据
-
缺失数据
-
数据中的离群值
-
数据冗余
-
数据不平衡
-
数据缺乏变异性
-
动态数据
-
数据规模
欲了解更多信息,请参阅以下文章:数据总是不完美的。
根据我个人在工业数据科学项目中的经验,我的团队花了 3 个月的时间与系统工程师、电气工程师、机械工程师、现场工程师和技术员合作,才理解现有的数据集以及如何利用这些数据提出正确的问题。确保数据无误且质量高将有助于提高模型的准确性和可靠性。
- 不要专注于使用整个数据集
有时作为一个数据科学初学者,当你需要处理一个数据科学项目时,你可能会被诱惑使用提供的整个数据集。然而,如上所述,数据集可能存在若干缺陷,如异常值、缺失值和冗余特征。如果你的数据集中存在缺陷的数据部分非常小,你可以简单地从数据集中删除这些不完美的数据子集。然而,如果不适当数据的比例显著,则可以使用数据插补技术来近似缺失数据。
在实施机器学习算法之前,有必要只选择训练数据集中相关的特征。将数据集转化为只选择训练所需的相关特征的过程称为降维。特征选择和降维很重要,主要有三个原因:
a) 防止过拟合:一个具有过多特征的高维数据集有时可能导致过拟合(模型捕捉到真实和随机效应)。
b) 简洁性:一个特征过多的过于复杂的模型可能难以解释,特别是当特征之间相关时。
c) 计算效率:在低维数据集上训练的模型计算效率高(算法执行所需的计算时间更少)。
有关降维技术的更多信息,请参阅以下文章:
使用降维技术去除特征之间的不必要相关性可能有助于提高你的机器学习模型的质量和预测能力。
- 在使用数据进行模型构建之前对数据进行缩放
缩放你的特征将有助于提高模型的质量和预测能力。例如,假设你希望建立一个模型来预测目标变量信用度,基于预测变量如收入和信用评分。由于信用评分的范围从 0 到 850,而年收入的范围可能从 25,000 美元到 500,000 美元,如果不对特征进行缩放,模型将会偏向于收入特征。这意味着与收入参数相关的权重因子将非常小,这将导致预测模型仅仅基于收入参数来预测信用度。
为了将特征缩放到相同的尺度,我们可以选择对特征进行标准化或归一化。通常情况下,我们假设数据呈正态分布,并默认使用标准化,但这并非总是如此。在决定使用标准化还是归一化之前,重要的是先查看特征的统计分布。如果特征趋向于均匀分布,则可以使用归一化(MinMaxScaler)。如果特征大致呈高斯分布,则可以使用标准化(StandardScaler)。再次注意,无论你使用归一化还是标准化,这些方法都是近似的,并且会对模型的总体误差产生影响。
- 调整模型中的超参数
在模型中使用错误的超参数值可能导致模型非最优且质量较低。重要的是你需要对所有超参数进行训练,以确定性能最佳的模型。模型的预测能力如何依赖于超参数的一个很好的示例可以在下面的图中找到(来源:差劲与优秀的回归分析)。
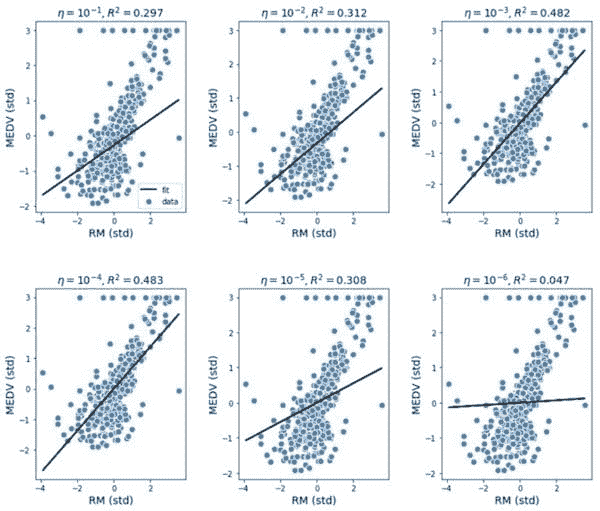
图 1。使用不同学习率参数进行回归分析。来源:差劲与优秀的回归分析,发布于 Towards AI,2019 年 2 月,由 Benjamin O. Tayo 编写。
请记住,使用默认超参数并不总能得到最佳模型。有关超参数的更多信息,请参见本文:机器学习中的模型参数和超参数 — 有什么区别。
- 比较不同算法
在选择最终模型之前,比较几个不同算法的预测能力是很重要的。例如,如果你正在构建一个分类模型,你可以尝试以下算法:
-
逻辑回归分类器
-
支持向量机(SVM)
-
决策树分类器
-
K-最近邻分类器
-
朴素贝叶斯分类器
如果你正在构建一个线性回归模型,你可以比较以下算法:
-
线性回归
-
K-邻近回归(KNR)
-
支持向量回归(SVR)
有关比较不同算法的更多信息,请参阅以下文章:
- 量化模型中的随机误差和不确定性
每个机器学习模型都有固有的随机误差。这种误差源于数据集的固有随机特性;源于在模型构建过程中数据集被划分为训练集和测试集的随机方式;或者源于目标列的随机化(用于检测过拟合的方法)。始终量化随机误差对模型预测能力的影响是非常重要的。这将有助于提高模型的可靠性和质量。有关随机误差量化的更多信息,请参见以下文章:机器学习中的随机误差量化。
总结
总结来说,我们讨论了六个常见的错误,这些错误可能影响机器学习模型的质量或预测能力。始终确保你的模型是最佳的且质量最高是非常有用的。避免上述讨论的错误可以帮助数据科学爱好者构建可靠和值得信赖的模型。
相关:
更多相关话题
我最近发现的 6 个酷炫的 Python 库
原文:
www.kdnuggets.com/2021/09/6-cool-python-libraries-recently.html
评论
作者 Dhilip Subramanian,数据科学家和 AI 爱好者

我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你在 IT 方面的组织
Python 是机器学习的核心组成部分,库使我们的生活更简单。最近,我在进行 ML 项目时发现了 6 个很棒的库。它们帮助我节省了大量时间,我将在这篇博客中讨论它们。
1. clean-text
一个真正不可思议的库,clean-text 应该是你处理抓取或社交媒体数据时的首选。最酷的地方在于,它不需要任何长的复杂代码或正则表达式来清理我们的数据。让我们看看一些示例:
安装
!pip install cleantext
示例
#Importing the clean text library
from cleantext import clean# Sample texttext = """ Zürich, largest city of Switzerland and capital of the canton of 633Zürich. Located in an Al\u017eupine. ([`google.com`](https://google.com/)). Currency is not ₹"""# Cleaning the "text" with clean textclean(text,
fix_unicode=True,
to_ascii=True,
lower=True,
no_urls=True,
no_numbers=True,
no_digits=True,
no_currency_symbols=True,
no_punct=True,
replace_with_punct=" ",
replace_with_url="",
replace_with_number="",
replace_with_digit=" ",
replace_with_currency_symbol="Rupees")
输出

从上面可以看到,它包含了“Zurich”中的 Unicode(字母‘u’已编码)、ASCII 字符(在 Al\u017eupine.)、货币符号(卢比)、HTML 链接和标点符号。
你只需要在 clean 函数中提及所需的 ASCII、Unicode、URLs、数字、货币和标点符号。或者,它们可以在上述函数中用 replace 参数替换。例如,我将卢比符号更改为 Rupees。
完全没有必要使用正则表达式或长代码。这个库非常方便,尤其是当你需要清理抓取或社交媒体数据的文本时。根据你的需求,你也可以单独传递参数,而不是将它们全部组合在一起。
欲了解更多详细信息,请查看这个GitHub 仓库。
2. drawdata
Drawdata 是我发现的另一个酷炫的 Python 库。你有多少次遇到需要向团队解释 ML 概念的情况?这肯定很常见,因为数据科学完全是团队合作的事。这个库可以帮助你在 Jupyter Notebook 中绘制数据集。
个人来说,当我向我的团队解释 ML 概念时,我非常喜欢使用这个库。对创建这个库的开发者致以敬意!
Drawdata 仅适用于具有四个类别的分类问题。
安装
!pip install drawdata
示例
# Importing the drawdata
from drawdata import draw_scatterdraw_scatter()
输出

图片来源:作者
执行 draw_Scatter() 后,上述绘图窗口将打开。显然,有四个类别,即 A、B、C 和 D。你可以点击任何类别并绘制你想要的点。每个类别在绘图中代表不同的颜色。你还可以选择将数据下载为 CSV 或 JSON 文件。此外,数据可以复制到剪贴板,并从以下代码中读取。
#Reading the clipboardimport pandas as pd
df = pd.read_clipboard(sep=",")
df
这个库的一个局限性是它只提供两个数据点和四个类别。但除此之外,它绝对值得尝试。有关更多细节,请查看这个GitHub 链接。
3. Autoviz
我永远不会忘记我使用 matplotlib 进行探索性数据分析的时光。有很多简单的可视化库。然而,我最近发现了 Autoviz,它可以用一行代码自动可视化任何数据集。
安装
!pip install autoviz
示例
我在这个示例中使用了 IRIS 数据集。
# Importing Autoviz class from the autoviz library
from autoviz.AutoViz_Class import AutoViz_Class#Initialize the Autoviz class in a object called df
df = AutoViz_Class()# Using Iris Dataset and passing to the default parametersfilename = "Iris.csv"
sep = ","graph = df.AutoViz(
filename,
sep=",",
depVar="",
dfte=None,
header=0,
verbose=0,
lowess=False,
chart_format="svg",
max_rows_analyzed=150000,
max_cols_analyzed=30,
)
上述参数是默认的。有关更多信息,请查看这里。
输出
图片来源:作者
我们可以通过一行代码查看所有的可视化并完成我们的 EDA。虽然有很多自动可视化库,但我真的很喜欢这个。
4. Mito
大家都喜欢 Excel,对吧?这是初步探索数据集最简单的方法之一。我几个月前遇到了 Mito,但直到最近才尝试,它真的让我爱不释手!
这是一个带有图形用户界面的 Jupyter-lab 扩展 Python 库,添加了电子表格功能。你可以加载你的 CSV 数据,并将数据集作为电子表格进行编辑,它会自动生成 Pandas 代码。非常酷。
Mito 确实值得写一整篇博客。然而,今天我不会详细介绍。相反,我会给你一个简单的任务演示。有关更多详细信息,请查看这里。
安装
**#First install mitoinstaller in the command prompt** pip install mitoinstaller**# Then, run the installer in the command prompt**
python -m mitoinstaller install**# Then, launch Jupyter lab or jupyter notebook from the command prompt** python -m jupyter lab
有关安装的更多信息,请查看这里。
**# Importing mitosheet and ruuning this in Jupyter lab**import mitosheet
mitosheet.sheet()
执行上述代码后,mitosheet 将在 jupyter lab 中打开。我使用的是 IRIS 数据集。首先,我创建了两列新数据。一列是平均萼片长度,另一列是总萼片宽度。其次,我更改了平均萼片长度的列名。最后,我为平均萼片长度列创建了一个直方图。
按照上述步骤操作后,代码会自动生成。
输出
图片来源:作者
以下代码是为上述步骤生成的:
from mitosheet import * # Import necessary functions from Mito
register_analysis('UUID-119387c0-fc9b-4b04-9053-802c0d428285') # Let Mito know which analysis is being run# Imported C:\Users\Dhilip\Downloads\archive (29)\Iris.csv
import pandas as pd
Iris_csv = pd.read_csv('C:\Users\Dhilip\Downloads\archive (29)\Iris.csv')# Added column G to Iris_csv
Iris_csv.insert(6, 'G', 0)# Set G in Iris_csv to =AVG(SepalLengthCm)
Iris_csv['G'] = AVG(Iris_csv['SepalLengthCm'])# Renamed G to Avg_Sepal in Iris_csv
Iris_csv.rename(columns={"G": "Avg_Sepal"}, inplace=True)
5. Gramformer
另一个令人印象深刻的库,Gramformer 基于生成模型,帮助我们纠正句子的语法。这个库有三个模型,分别是检测器、高亮器和纠正器。检测器识别文本是否有不正确的语法。高亮器标记出有问题的词性,而纠正器则修复错误。Gramformer 完全开源,并处于早期阶段,但它不适合处理长段落,因为它只在句子级别工作,并且已经训练了 64 长度的句子。
目前,纠正器和高亮器模型正在工作。我们来看一些示例。
安装
!pip3 install -U git+https://github.com/PrithivirajDamodaran/Gramformer.git
实例化 Gramformer
gf = Gramformer(models = 1, use_gpu = False) # 1=corrector, 2=detector (presently model 1 is working, 2 has not implemented)

示例
#Giving sample text for correction under gf.correctgf.correct(""" New Zealand is island countrys in southwestern Paciific Ocaen. Country population was 5 million """)
输出
作者提供的图片
从以上输出中,我们可以看到它纠正了语法甚至拼写错误。这是一个非常了不起的库,功能也很好。我还没有尝试高亮器,你可以尝试一下,并查看 GitHub 文档以了解更多细节。
6. Styleformer
我对 Gramformer 的积极体验促使我寻找更多独特的库。这就是我发现 Styleformer 的原因,它是另一个极具吸引力的 Python 库。Gramformer 和 Styleformer 都由 Prithiviraj Damodaran 创建,并且都基于生成模型。向创作者致以敬意,感谢开源。
Styleformer 帮助将休闲句子转换为正式句子,将正式句子转换为休闲句子,将主动句转换为被动句,将被动句转换为主动句。
来看看一些示例
安装
!pip install git+https://github.com/PrithivirajDamodaran/Styleformer.git
实例化 Styleformer
sf = Styleformer(style = 0)# style = [0=Casual to Formal, 1=Formal to Casual, 2=Active to Passive, 3=Passive to Active etc..]
示例
# Converting casual to formal sf.transfer("I gotta go")
# Formal to casual
sf = Styleformer(style = 1) # 1 -> Formal to casual# Converting formal to casual
sf.transfer("Please leave this place")

# Active to Passive
sf = Styleformer(style = 2) # 2-> Active to Passive# Converting active to passive
sf.transfer("We are going to watch a movie tonight.")
# passive to active
sf = Styleformer(style = 2) # 2-> Active to Passive# Converting passive to active
sf.transfer("Tenants are protected by leases")
查看上述输出,它的转换非常准确。我在一次分析中使用了这个库,将休闲语言转换为正式语言,特别是用于社交媒体帖子。有关更多详细信息,请查看 GitHub。
你可能对一些之前提到的库比较熟悉,但像 Gramformer 和 Styleformer 这样的库则是新兴的玩家。它们被极度低估,毫无疑问值得被了解,因为它们节省了我大量时间,并且我在 NLP 项目中大量使用了它们。
感谢阅读。如果你有任何补充意见,请随时留下评论!
你可能还喜欢我之前的文章 五个酷炫的 Python 数据科学库
个人简介: Dhilip Subramanian 是一名机械工程师,已获得分析硕士学位。他拥有 9 年的经验,专注于与数据相关的多个领域,包括 IT、营销、银行、电力和制造业。他对自然语言处理和机器学习充满热情。他是SAS 社区的贡献者,并喜欢在 Medium 平台上撰写有关数据科学的各种技术文章。
原文。经许可转载。
相关内容:
-
五个有趣的 Python 库用于数据科学
-
Python 中的简单语音转文本
-
学习数据科学和机器学习:第一步
相关阅读
6 个数据科学证书,让你的职业生涯更进一步
原文:
www.kdnuggets.com/2021/02/6-data-science-certificates.html
评论

由 Lewis Keegan 在 Unsplash 提供的照片。
我们的前三推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
由于数据科学领域的吸引力以及高收入的前景,越来越多的人决定加入这个领域。有些人可能来自技术背景,而另一些人则因好奇而加入;无论你决定加入该领域的原因是什么,你的首要目标可能是拥有一个强大而扎实的作品集,以帮助你获得理想的工作。
那么,如何提升你的作品集的吸引力?
尽管进入数据科学领域并不一定需要任何学位或证书,但有时拥有一些证书可以帮助你在申请工作时脱颖而出。
优秀的数据科学作品集的关键在于收集展示你技能、证明你知识并展示你构建稳固数据科学项目能力的项目。这是一个优秀作品集的核心,但你也可以添加一些证书来证明你投入了时间、精力和金钱来提升技能,成为更合格的数据科学家。
幸运的是,并非所有证书都要求你去考试中心。事实上,大多数受欢迎的数据科学证书可以在舒适的家中获得。
本文向你展示了 6 个极具吸引力的证书,这些证书能提高你获得实习或理想工作的机会。
Microsoft 认证:Azure 数据科学家助理
微软是技术和软件领域的领先企业之一;他们提供一个证书,旨在评估你进行实验、训练机器学习模型、优化模型性能并使用 Azure 机器学习工作区进行部署的能力。
要获得该证书,你需要通过一场考试,你可以通过两种方式之一为这场考试做准备。微软提供免费的在线材料供你自学以备考。如果你更喜欢有老师指导,他们还提供了一个收费选项,可以让 Azure 机器学习讲师对你进行辅导。
这次考试的费用大约为$165。费用因你所在的国家/地区而异。
IBM 数据科学专业证书
该证书由 IBM 颁发,并在一个系列课程结束时提供,该课程系列将带你从一个完全的数据科学初学者成长为一个在线的、按自己节奏的专业数据科学家。
IBM 数据科学专业证书在Coursera和edX上均可获得。在任何一个平台上,你都需要完成一系列涵盖数据科学核心知识的课程,以获得证书和 IBM 徽章。
要获得 Coursera 的证书,你需要每月支付$39 的费用,因此你完成系列课程的时间越早,你需要支付的费用就越少。另一方面,edX 要求支付$793 的费用以获得完整的课程体验,无论你需要多久才能完成它。
Google 专业数据工程师认证
Google 的专业数据工程师认证旨在考核你作为数据工程师所需的技能。数据工程师可以做出数据驱动的决策,构建可靠的模型,并对其进行训练、测试和优化。
你可以通过直接在 Google 证书的官方网站申请来获得该证书,或者你可以参加Coursera上的课程系列和证书。这些课程将教授你有关机器学习和 AI 基础知识的所有内容,以及如何构建高效的数据管道和分析。
要访问 Coursera 上的课程系列,你需要拥有 Coursera Plus 或支付每月$49 的费用,直到你完成系列课程并获得证书。
Cloudera 认证专业数据工程师(CCP Data Engineer)
Cloudera 针对开源开发者,提供CCP 数据工程师证书,让开发者测试他们在 Cloudera CDH 环境中高效收集、处理和分析数据的能力。
要通过这次考试,你将被提供 5-10 个数据科学问题,每个问题都有自己的大数据集和 CDH 集群。你的任务是为这些问题找到高精度的解决方案并正确实施。
要参加这次考试,你需要在考试中至少得分 70%。考试时间为 4 小时,费用为$400。你可以在任何地方在线参加这次考试。
SAS 认证 AI 与机器学习专业人员
与我们讨论过的证书不同,SAS AI & 机器学习专业证书是通过通过三场测试三个不同技能集的考试来获得的。你需要通过的三场考试包括:
-
机器学习考试将测试你构建、训练、测试性能和优化监督式机器学习模型的技能。
-
预测和优化测试。在此测试中,将测试你处理、可视化数据、构建数据管道和解决优化问题的能力。
-
自然语言处理和计算机视觉测试。
SAS 提供免费的 30 天备考资料,帮助你准备并通过这三场考试。
TensorFlow 开发者证书
TensorFlow 是广泛使用的机器学习、人工智能和深度学习应用程序包之一。TensorFlow 开发者证书授予开发者,以展示他们使用 TensorFlow 开发机器学习和深度学习解决方案的能力。
你可以通过完成DeepLearning.AI TensorFlow 开发者专业证书的 Coursera 课程系列来为这个证书做好准备。一旦获得此证书,你的名字和照片将被添加到Google Developers网页上。
TensorFlow 开发者证书有效期为 3 年。之后,你需要重新参加考试,以保持你的技能水平与 TensorFlow 包的最新更新同步。
收获
如果你问任何数据科学家他们是否需要学位或证书来获得他们的工作,大多数人会告诉你,他们是从非技术背景进入数据科学的,只有一个好奇的心态,想要更多地学习。
尽管你可以通过自学数据科学的核心概念和构建实际项目或可以轻松应用于实际数据的项目来成为数据科学家并获得好工作,但有时拥有一个证书可以帮助你的简历脱颖而出,吸引招聘人员的注意。
由于数据科学是目前流行的领域之一,你会发现网上有大量关于如何成为“优秀数据科学家”或“如何获得梦想的数据科学职位”的教程和指南,更不用说可以获得的证书和免费课程。我曾经也被数据科学领域的信息淹没,但我总是欣赏那些简单、直接的文章,它们直接切入要点,不拖延话题。
原文。经许可转载。
相关:
更多相关主题
2022 年值得工作的 6 家数据科学初创公司
原文:
www.kdnuggets.com/2022/02/6-data-science-startups-work-2022.html

Mika Baumeister 的照片,来源于 Unsplash
数据科学推动了未来。它帮助我们创造创新产品,为客户提供更好的服务,做出智能决策,并为所有利益相关者提供价值。难怪数据科学已经成为核心业务职能!
研究表明,到 2025 年,大数据市场的全球收入将达到$68.09 billion,这也是为什么我们看到许多围绕这一行业发展的初创公司。
我们的三大课程推荐
1. Google 网络安全证书 - 加速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
数据科学是少数几个期望员工随着工作进步而不断发展的领域之一。因此,随着数据科学家职业生涯的进展和技术的进步,存在着持续的学习曲线。
近年来,初创公司数量有所上升,其中包括数据科学、人工智能和机器学习模型。如果你想测试自己的技能,以下是 2022 年你应该考虑工作的六家顶尖初创公司。
数据科学领域的 6 家顶尖初创公司
研究表明,到 2025 年,全球组织将生成180 zettabytes的数据。这意味着许多新兴小型企业使用数据科学可以成为一个很好的工作场所,特别是对于刚进入这一领域的人来说。
在初创公司工作可以帮助你提升技能,并且你可以期望随着组织的成长而成长。以下是六家利用数据科学的顶尖初创公司,对于刚刚开始职业生涯的人来说,它们可能是一个绝佳的工作场所。
Avora
Avora 总部位于伦敦,组织致力于增强分析。公司提供一个简化方式进行深入分析的平台。通过隐藏数据分析的复杂性,使非技术用户能够创建报告。此外,借助机器学习模型,该平台将数据准备时间缩短了 80%。
此外,它帮助业务经理做出明智的决策并提高生产力。该平台可以服务于各种行业,包括供应链和金融服务、零售、广告及娱乐。希望提升技能并与公司一起学习的数据科学家可以将 Avora 视为一个很好的工作选择。
Cognino AI
当我们谈论人工智能与数据科学的结合时,Cognino AI 名列其中。尽管是一家初创公司,Cognino 在数据科学和 AI 领域取得了显著进展,创建了一种以研究为主导的 AI,具有深厚的自学习可解释 AI 专业知识。该解决方案使组织能够加快数据准备过程并获得有意义的洞察。他们有数据科学家培训 AI 以准备大型数据集来帮助客户。在 Cognino 工作可以帮助你磨练技能,并在 AI 主导的领域中朝着伟大的目标努力。
Databand
Databand 于 2018 年由 Joshua Benamram、Evgeny Shulman 和 Victor Shafran 创立。该组织在特拉维夫运营,为客户提供一个用于敏捷机器学习开发的软件平台。该平台使组织能够获得数据的全局视图,完成工作流管道,并管理资源消耗。
Databand 还可以原生适配你的现代数据栈,并可集成到如 Apache Airflow、Kubernetes、Spark 及其他云提供商的机器学习工具中。希望了解各种工具及其集成方式的数据科学家可以在 Databand 获得很好的学习体验。
Exceed.ai
Exceed.ai 通过其 AI 驱动的销售平台迅速崛起,允许组织与潜在客户进行沟通,帮助营销和销售团队改善潜在客户的参与度和资格审核工作。
利用自然语言和人工智能,该公司提供了一种通过聊天和电子邮件与潜在客户沟通的方式,从而释放资源并自动化重复任务。对人工智能有强烈兴趣和自然语言处理的数据科学家可以从 Exceed.ai 学到很多,这使其成为一个很棒的工作场所。
Indico
全球组织在准备非结构化数据和获得有意义的洞察时面临挑战,因为缺乏框架。Indico 推出了一个人工智能平台,帮助客户组织非结构化内容并自动化后台任务。Indico 因自动化手动流程和基于文档的工作流程而声名鹊起。
该平台使用户能够训练机器学习模型,并消除对传统规则基础技术的需求。它使大规模非结构化数据集的组织能够简单易用地采用人工智能和机器学习模型。任何对数据科学和创建机器学习模型感兴趣的人都会在 Indico 学到很多东西。
Algorithmia
Algorithmia 被认为是机器学习操作领域最优秀的初创公司之一,它帮助组织以企业级治理和安全性生产机器学习模型。
Algorithmia 提供机器学习部署、灵活的工具,并利用现有的软件开发生命周期和持续集成/持续交付实践。该组织已拥有超过 100,000 名工程师使用他们的解决方案,客户包括政府情报机构、财富 500 强公司甚至联合国。
Algorithmia 是数据科学业务的终极圣杯,它能帮助你提升技能,并推动你的职业发展。
总结
数据科学在过去几年中经历了爆炸性增长。因此,数据科学家正在寻找能够帮助他们磨练技能并与不断变化的行业同步发展的组织。一些初创公司围绕数据科学展开,已在这一领域取得了快速进展。寻找良好工作场所的数据科学家可以选择上述提到的初创公司作为职业发展的强大跳板。
Nahla Davies是一位软件开发者和技术写作专家。在全职投入技术写作之前,她还担任过 Inc. 5,000 排名的体验品牌组织的首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼等。
了解更多此话题
你需要的 6 种数据科学技术来构建你的供应链管道
原文:
www.kdnuggets.com/2022/01/6-data-science-technologies-need-build-supply-chain-pipeline.html
供应链管道是将不同过程组合在一起,以生产和分发产品和服务给客户的系统。供应链中包含了各种各样的活动。下图展示了供应链管道的鸟瞰图:
作者提供的图像
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
全球各地的公司正在不断努力提高供应链管道的效率,以通过提供价值来满足客户。这可以通过数据科学来实现,通过数据驱动的判断和决策。根据这篇文章,员工每年在电话和电子邮件上花费超过 1 亿小时,将数据在贸易伙伴之间来回移动,给英国公司造成近 20 亿美元的费用。这些浪费的时间可以通过使用技术自动化沟通来减少。以下是构建全面顺畅供应链管道所需的一些数据科学技术。
1. 大数据
要能够做出数据驱动的决策,你需要数据。这些数据可以是结构化的、非结构化的或半结构化的,无论是机器生成还是人工生成的。但这些数据从哪里来呢?它可以是来自气象站、船只和集装箱的传感器数据。
为了构建一个大数据解决方案以获得有价值的洞察,请考虑以下四个领域:
-
体量: 生成的数据量,例如 100 PB/年,500 TB/月
-
多样性: 生成的数据类型,例如文本、图像
-
速度: 需要处理和存储的数据频率,例如 1000 张图像/分钟 或 4000 吉字节/分钟
-
真实性: 生成数据的质量。
一旦你涵盖了这四个领域,你可以使用基于云的解决方案来处理、存储和分析数据。例如,Amazon Simple Storage Service(Amazon S3)可以存储可扩展、安全且高效的数据。之后,你可以将这些数据源接入其他服务,如 Amazon QuickSight,以创建互动式商业智能仪表盘。还有其他云服务提供商和服务提供类似的产品。公司可以根据现有技术选择服务提供商,这将帮助他们实现更容易的集成。
2. 机器学习
你可以利用大数据并在其基础上增加层次,创建有价值的洞察,这些洞察可以转化为行动。通过使用机器学习和人工智能,你可以通过展示相关产品来提高客户满意度。另一方面,你可以使用预测算法来预测客户需求。此外,预测数据可以帮助自动化仓库操作,以提高库存周转率。
通过这种方式,公司可以与其他企业竞争,并迅速将新产品推向市场。最后,供应链经理可以根据这些预测和预测计划并采取行动,做出关键决策,以促进业务增长。
3. 物联网(IoT)
通常称为物联网(IoT)的互联网技术,通过提供对操作的更多控制来帮助公司提高可见性。当你使用物联网传感器标记物品时,可以做出实时决策。例如,企业可以跟踪和监控船只,并根据交通情况重新路线,以实现可靠和更快的运输,从而减少运输延误。此外,公司可以通过监控冷藏运输容器的温度数据来避免因技术故障而损失资金。
物联网(IoT)可以为供应链管道增加可靠性。公司可以轻松跟踪丢失或错放的容器,以更快地处理争议。企业可以通过实时更新他们所购买的产品来增加对客户的价值。
4. 云计算
云计算允许企业部署其供应链管道软件,如客户关系管理(CRM)。云计算的好处是无穷无尽的。它们可以根据流量进行扩展。此外,根据服务水平协议(SLA),应用程序将有保证的正常运行时间(高可用性)。像 AWS 这样的云平台使其服务可靠、安全且具有成本效益。此外,按需付费模式帮助企业节省开支。
不仅是面向客户的应用,企业还可以部署其他应用来跟踪和监控库存系统。此外,BI 仪表盘可以提高公司的可见性。
5. 类似 JavaScript 的语言
上述应用程序可以根据需要强大,但需要一个前端才能使用。这个交互式用户界面可以使用 JavaScript 构建。前端数据验证可以帮助确保数据的真实性。
现在,有许多工具可以使用 JavaScript 更快地构建应用程序,例如 Webpack、Babel 和 NPM,等。Webpack 允许将 JavaScript 应用程序进行打包。Babel 用于将 JSX 转换为纯 JavaScript。NPM 注册库包含了许多构建企业级应用程序的库。
企业可以与其他第三方供应商集成,以提供诸如身份验证(auth0)、短信(twilio)、分析(powerbi)、消息传递(intercom)、文档(confluence)等服务。
6. 类似 React 的框架
React 是一个开源的 JavaScript 库,用于构建可组合的用户界面,它提供了构建企业级应用程序的最先进功能。诸如可重用组件、虚拟 DOM、JSX 等功能使得 React 成为一个优秀的 JavaScript 库。React 的懒加载功能可以动态加载组件,从而提高应用程序的性能。由于 React 是从 CDN 提供的,因此服务成本较低。此外,还有数以千计的 NPM 模块可以用于更快地构建应用程序。它提供了开箱即用的库,如 compromise。它可以用于进行自然语言处理。此外,企业还可以使用 React Native 创建跨平台的移动应用程序。
如果您的企业有多个软件团队在开发应用程序,他们可以使用模块联邦构建微前端,而不是构建一个单体应用程序。这将提供完全的自由来独立设计和构建,而不会破坏整个应用程序。例如,N 个微前端可以提供跟踪、分析、身份验证、报告等服务。
随着技术的进步,SCPs 已经采用了一些尖端技术,以优化和增强几乎每个人都依赖的管道。这些曾经新颖的六种技术,现在已成为供应链管道的关键部分。供应链经理应当关注这些数据科学技术,并尽早开始整合它们。这将帮助企业建立一个高效且具有成本效益的供应链管道,提高客户满意度。
Zulie Rane 是一位自由撰稿人和编码爱好者。
了解更多相关话题
使用 Tensorflow.js 实现计算机视觉应用的 6 个简单步骤
原文:
www.kdnuggets.com/2020/06/6-easy-steps-implement-computer-vision-application-tensorflow-js.html
评论
由 Bala Venkatesh,数据科学家

我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织中的 IT 工作
介绍
现在,很多人正在实现计算机视觉应用。你认为学习和实现它很困难吗?我的回答是否定的,因为现在有很多库可以实现如此强大的计算机视觉应用。最近你是否观看了 TensorFlow 峰会 2020?今年 TensorFlow 团队为我们宣布了许多酷炫的东西。现在我们将看到如何使用 Tensorflow.js 模型实现计算机视觉应用!!
TensorFlow.js 是什么?
TensorFlow.js 是一个用于机器学习应用的开源库,支持在 JavaScript 中开发 ML 模型,并直接在浏览器或 Node.js 中使用 ML。
Tensorflow.js 模型是什么?
Tensorflow.js 模型是预训练模型,这意味着你无需准备/收集数据来训练模型。这些模型托管在 NPM 和 unpkg 上,因此可以立即在任何项目中使用。
在这篇博客中,我们将介绍 Tensorflow.js 中的一个模型,即 MediaPipe Facemesh 模型。该模型专为移动设备上的前置摄像头设计,适用于面部在视野中占据相对较大画布比例的情况。
Facemesh 模型演示
我使用了 facemesh 模型来根据我的面部运动移动视频帧。请看下面的演示。我将告诉你实现下面的计算机视觉应用涉及的步骤。

演示
演示
步骤 1:- 这些是实现计算机视觉应用的三个重要独立脚本标签代码。
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-core"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-converter"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/facemesh"></script>
TensorFlow.js 核心,用于神经网络和数值计算的灵活低级 API。
TensorFlow.js 转换器,将 TensorFlow SavedModel 导入 TensorFlow.js 的工具。
facemesh 包在图像中找到面部边界和标志点。
步骤 2:- 在正文内容中包含视频 HTML 标签,以通过网络摄像头读取面部。
<video width=640 height=480 autoplay muted id=”camera”></video>
步骤 3:- 使用 canvas 标签通过脚本(通常是 JavaScript)动态绘制图形。
<canvas width=640 height=480 id=”augmented_canvas”></canvas>
步骤 4:- 包含一个视频标签,在 canvas 标签上播放视频帧,根据面部运动移动视频帧。
<video autoplay loop id=”movie” style=”visibility: hidden”>
<source src=”TensorFlowjs.mp4" type=”video/mp4"></source>
</video>
步骤 5:- 加载面部模型并估算面部,以找到图像中的面部边界和标志点。
//load camera stream
const frame = document.getElementById("camera");//load movie stream
const movie = document.getElementById("movie");
movie.play();//prepare canvas
const canvas = document.getElementById("augmented_canvas");
const draw = canvas.getContext("2d");const result = await model.estimateFaces(frame, false);
步骤 6:- 使用以下代码在检测到的面部上绘制视频帧。
//copy camera stream to canvas
draw.drawImage(frame, 0, 0, 640, 480);//check if face is detected
if(result.length > 0)
{
for (let i = 0; i < result.length; i++) {
const start = result[i].topLeft;
const end = result[i].bottomRight;
const size = [end[0] — start[0], end[1] — start[1]]; //Render a rectangle over each detected face.
draw.drawImage(movie, start[0], start[1], size[0], size[1]);
}
}
结论
就这样,我们按照上述六个步骤实现了一个计算机视觉应用。你可以在这里获取完整的源代码。
大家都说如果你想成为数据科学家,你应该熟悉 Python 或 R 编程语言,但现在我们可以使用 JavaScript 实现一个机器学习应用。

来源: miro.medium.com/max/1400/1*F-1fq9TNjDnAYPAXnZP4Ww.png
个人简介: Bala Venkatesh 是一名数据科学家。他热衷于从根本上理解技术,并分享想法和代码。
原文. 经许可转载。
相关:
-
利用 AI 对抗冠状病毒:通过深度学习和计算机视觉改进检测
-
利用机器学习和计算机视觉进行作物疾病检测
-
构建一个使用 TensorFlow 和 Streamlit 生成逼真面孔的应用
更多相关话题
每个有志数据科学家在 2019 年应设定的 6 个目标
原文:
www.kdnuggets.com/2018/11/6-goals-every-wannabe-data-scientist-2019.html
评论

许多已经在技术领域工作的人意识到,他们想要开始新的路径,最终成为数据科学家。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
这个目标本身是值得的,但人们也必须设定 2019 年的目标,以帮助自己更接近这个更广泛的目标。
1. 成为相关组织的会员
与其他对数据科学感兴趣的人建立联系,让人们了解现有的教育选项,理解数据科学行业中最突出的工具,并获得曾经也是数据科学初学者的人的鼓励。
运筹学与管理科学学会(INFORMS)是 最大国际组织之一,拥有成千上万的成员。虽然该组织有线下活动,但也有仅限会员的在线论坛。
然而,抱负的数据显示科学家也可以在他们的社区中探索本地选项。MeetUp.com 在全球提供各种会议,并 拥有超过 5,000 个与数据科学相关的活动。
2. 熟悉新兴趋势并将其应用于职业目标
数据科学是一个快速发展的行业,能够最好地跟上变化的专业人士通常是那些有意识地努力做到这一点的人。物联网、开源工具和预测分析是 2019 年可能会突出的 趋势。
寻求成为数据科学家的人不仅要了解趋势和最新消息,还需深入探讨如何将这些趋势应用到自己的职业目标中。
例如,一个人可以探索新的开源数据科学软件,并尽快开始使用,以熟悉其工作原理。或者,参加有关预测分析基础的在线课程,了解为什么这一领域的分支对招聘数据科学家的公司如此重要。
3. 设定具体目标以推进数据科学项目
许多数据科学家或希望进入该领域的人都有自学的阶段。这意味着即使人们尚未接受正式的数据科学培训,他们也可能会独立启动数据科学项目,受到好奇心和提升技能的愿望驱动。
希望从事数据科学职业的人应该尝试一种特定的目标设定系统,这种系统由 Google、Amazon 和其他知名公司用于他们的数据科学项目。它涉及制定目标和关键成果,即 OKRs。
目标与项目的目标相关,而关键成果则表明个人如何实现该目标。此外,OKRs 的成功标志是个人达成了70%的关键成果。
个人可以通过选择与数据科学项目最相关的指标来应用 OKRs。该指标定义了目标,关键成果深入探讨了个人必须经历的过程,以使项目取得成功。最好是每个关键成果都有一个相关的日期。
4. 考虑获得高级数据科学学位
如果一个人希望在未来的数据科学岗位中提高收入潜力,可以通过获得高级数据科学学位来实现。许多学校提供数据科学方向的工商管理硕士(MBA)学位。
了解更多关于它们的信息并做出短名单的一种方法是每个工作日晚上探索至少一所学校的课程。采取这种方法可以每月获得大约 20 所学校的详细信息,并且能够在不急于做决定的情况下获得知识。
MBA 毕业生的平均薪资因所选择的方向和工作经验年限等因素而异。由于数据科学技能需求极高,数据科学 MBA 方向有可能使求职者在众多候选人中脱颖而出。
最近编制的统计数据显示,美国存在数据科学短缺。拥有高级学位可以使人更好地填补这一空缺,并有可能获得高于平均水平的薪资。
5. 提高数据讲述能力
在数据集中找到有意义的信息是数据科学家的必要技能之一,但他们还必须成为优秀的数据讲故事者。否则,业务决策者将无法理解从数据中得出的特定结论为何有价值。如果观众认为见解不够引人注目,他们将不会进行更改。
在 2019 年,人们可以尝试将他们的数据科学结果传达给没有数据科学背景的朋友。他们可以请这些人提供改进建议。
6. 学习一些新的编程语言
数据科学家在工作中使用各种编程语言。2019 年学习新的编程语言是为了获得未来职业中必需的知识,是一种积极的举措。
如果希望从事数据科学工作的人尚未掌握任何编程语言,2019 年是扩展知识的最佳时机。Python 是一个快速增长和流行的编程语言,在数据科学领域中被广泛依赖。它还有易于理解的语法,使其成为一个优秀的第一编程语言。
R 和 SQL 是数据科学中另两个常用的语言,值得进一步研究。但在提高编程语言能力的过程中,人们必须记住,与其对许多其他语言仅有最低限度的了解,不如对一两种编程语言掌握得特别好。
拥有正确的心态至关重要
除了这些目标外,人们在经历挫折时保持自我激励也至关重要。
培养对数据科学工作的奉献精神可能使未来的数据科学家成为他们工作所在公司的更大资产。
简历:凯拉·马修斯在《The Week》、《The Data Center Journal》和《VentureBeat》等出版物上讨论技术和大数据,已有五年以上的写作经验。要阅读凯拉更多的文章,请订阅她的博客 Productivity Bytes。
相关内容:
-
数据科学如何改善高等教育
-
在 2 年内提升数据科学技能的 8 种方法
-
女性在数据科学社区中的参与增长
更多相关主题
数据科学家薪资最高的 6 家公司
原文:
www.kdnuggets.com/2022/05/6-highest-paying-companies-data-scientists.html

数据科学是一个蓬勃发展的行业。如果你拥有相关技能和兴趣,就有机会获得高薪。数据科学家的薪资水平即使与技术社区的其他人相比也很高。由于数据科学领域不断发展和变化,它被广泛认为是技术行业中最紧缺的技能。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
数据科学是一个很棒的行业,如果你想赚很多钱,这里是一个很好的选择。近年来,对数据科学家的需求只增不减,这意味着相对于其他技术行业及其他行业的薪资也可能上涨。美国的数据科学家平均年薪为\(117K](https://www.glassdoor.ie/Salaries/us-data-scientist-salary-SRCH_IL.0,2_IN1_KO3,17.htm?clickSource=searchBtn),而软件工程师的平均年薪为[\),而软件工程师的平均年薪为$108K。如果你想从软件开发转向数据科学,只需在一些领域提升技能即可。
这些是数据科学领域薪资最高的六家公司。我查看了绝对薪资,但我还会告诉你在选择数据科学工作时需要考虑的其他因素。
数据科学家薪资最高公司的总结
1. Airbnb
这家公司颠覆了酒店行业,对数据情有独钟。它被认为是全球最数据驱动的公司之一。Airbnb 专注于“建立复杂的数据基础设施,以便公司中的每个人都能访问信息。”虽然 Airbnb 赋予每位员工深入数据的权力,但你确实需要许多优秀的数据科学家来培训他们周围的人。他们的数据科学家还建立了 惊人的内部数据工具,其中一些他们慷慨地开放为开源。
显然,Airbnb 重视其数据,因为他们将数据视为在大规模上了解客户声音的一种方式。这就是为什么 Airbnb 排名第一,因为平均数据科学家的薪资是 \(188K](https://www.glassdoor.ie/Salary/Airbnb-Data-Scientist-US-Salaries-EJI_IE391850.0,6_KO7,21_IL.22,24_IN1.htm)。在 Airbnb 的顶级数据科学家可以赚取高达 [\)。在 Airbnb 的顶级数据科学家可以赚取高达 $286K。
2. Meta
Meta 期望其数据科学家找到 执行产品想法 的全球化方法,并找到理解用户行为的方式。Meta 的平台拥有超过 36 亿月活跃用户,这意味着有大量关于用户与 UI 交互、用户对广告或内容的反应以及用户之间互动的数据。
Meta 的数据科学家有机会挖掘策略,以根据从用户数据中得出的见解来改变 UI 以改善用户体验,或调整内容算法。Meta 的平均数据科学家薪资为 \(158K](https://www.glassdoor.ie/Salary/Meta-Data-Scientist-US-Salaries-EJI_IE40772.0,4_KO5,19_IL.20,22_IN1.htm),但顶级收入者的薪资高达 [\),但顶级收入者的薪资高达 $294K。
3. Apple
Apple 拥有广泛的产品,从操作系统软件到硬件设计。Apple 的数据科学家可能会使用机器学习模型来提高 Siri 的准确性,或分析 Apple Pages 以及其他 本地 Apple 应用 的性能。Apple 的产品涵盖操作系统如 iOS 和 Mac OS、支付系统 (Apple Pay)、云计算服务 (iCloud)、数字市场如 Apple Music 和 App Store,以及娱乐平台如 Apple TV 和 Podcasts。
所有这些知名产品为数据科学家创造了大量机会。安全性特别是苹果公司的一个重要焦点,因此你可能会在苹果公司作为数据科学家从事欺诈预防的预测建模工作。
苹果公司一直是且目前仍是世界上最有价值的公司,他们让这种财富展现出来。苹果公司平均支付给数据科学家的年薪为\(158K](https://www.glassdoor.ie/Salary/Apple-Data-Scientist-US-Salaries-EJI_IE1138.0,5_KO6,20_IL.21,23_IN1.htm),但最高可达[\),但最高可达$220K。
4. 思科系统
思科系统已将其产品系列扩展到数据科学工具市场。他们销售思科数据智能平台(CDIP),这是一种“将大数据、人工智能/计算农场和存储层整合在一起以作为一个整体工作,同时能够独立扩展以解决现代数据中心的 IT 问题的架构。”
一如既往,为了为数据科学家开发产品,你需要数据科学家来完成工作。思科寻找那些将数据清洗和预处理视为必要工作的数据科学家。在思科系统,平均数据科学家的年薪为\(157K](https://www.glassdoor.ie/Salary/Cisco-Systems-Data-Scientist-US-Salaries-EJI_IE1425.0,13_KO14,28_IL.29,31_IN1.htm),而收入最高的数据科学家的年薪可达[\),而收入最高的数据科学家的年薪可达$206K。
5. Oracle
Oracle 专注于帮助他们的客户“以新的方式查看数据,发现洞察,解锁无限可能。” Oracle 拥有一整套产品,其中许多与云工程服务和数据库管理系统相关。
Oracle 在数据领域已经存在了相当长时间,他们扩展了他们的数据解决方案仓库,包括作为数据科学云平台的产品。这些工具帮助数据科学家轻松访问数据、自动配置数据并生成可视化图表,并且支持 Pandas、Numpy、Plotly 和其他常见的开源数据科学工具。
Oracle 平均支付给他们的数据科学家的年薪为\(154K](https://www.glassdoor.ie/Salary/Oracle-Data-Scientist-US-Salaries-EJI_IE1737.0,6_KO7,21_IL.22,24_IN1.htm),而 Oracle 的顶级数据科学家的年薪达到[\),而 Oracle 的顶级数据科学家的年薪达到$187K。
6. Google
谷歌拥有近 40 亿的月活跃用户,而 YouTube 则有超过 19 亿的月活跃用户。谷歌依赖其数据科学家来解读他们通过谷歌搜索、谷歌地图、Gmail、YouTube 以及安卓操作系统等生成的大量数据。
在谷歌的一个数据科学家可能会利用自然语言处理(NLP),这是机器学习的一个领域,以更好地理解用户的搜索词,从而对最相关的搜索结果进行排序。或者,你也可能深入挖掘来自谷歌地图的地理位置数据,以提高驾驶方向的准确性。
谷歌的数据科学家的平均工资为\(150K](https://www.glassdoor.ie/Salary/Google-Data-Scientist-US-Salaries-EJI_IE9079.0,6_KO7,21_IL.22,24_IN1.htm)。然而,谷歌的薪资范围比大多数公司更大,因为谷歌的顶级数据科学家的收入为[\)。然而,谷歌的薪资范围比大多数公司更大,因为谷歌的顶级数据科学家的收入为$297K。
如何提升

如果你已经获得了数据科学家的职位,并且有兴趣在这些高薪公司找到工作,你需要专注于学习新的数据科学技能并提升一些现有的技能。
为了提升,你应该改善你的利益相关者管理技能,理解他们的目标、关切和困惑。你应该主动解答他们的问题,并提供建议的解决方案。
在清理和预处理数据方面,你应该具备全面的能力。无论数据是否是多语言的、未标记的,还是来自不同格式的来源,这些都无关紧要。你应该能够从别人认为无法解开的混乱中提取出可操作的洞察。
一位收入较高的数据科学家可能还会领导机器学习管道在生产环境中的部署和维护。为了做到这一点,你需要掌握数据科学的开发运维(dev-ops)。
对于那些在职业生涯中已经取得高级成就(获得上述最高薪水)的人员来说,一个重要的方面是指导他人。如果你拥有知识和经验,你应该寻找将这些智慧传授给周围人的方法。这样,你将最大化你的影响力,提高每个人的生产力和表现。
数据科学家的薪酬不仅仅是钱的问题
还有很多大公司平均支付的数据科学家薪资在$115K 到$150K 之间。其中包括 Uber(\(146K](https://www.glassdoor.ie/Salary/Uber-Data-Scientist-US-Salaries-EJI_IE575263.0,4_KO5,19_IL.20,22_IN1.htm))、IBM([\))、IBM(\(138K](https://www.glassdoor.ie/Salary/IBM-Data-Scientist-US-Salaries-EJI_IE354.0,3_KO4,18_IL.19,21_IN1.htm))、Amazon([\))、Amazon(\(138K](https://www.glassdoor.ie/Salary/Amazon-Data-Scientist-US-Salaries-EJI_IE6036.0,6_KO7,21_IL.22,24_IN1.htm))、Microsoft([\))、Microsoft(\(137K](https://www.glassdoor.ie/Salary/Microsoft-Data-Scientist-US-Salaries-EJI_IE1651.0,9_KO10,24_IL.25,27_IN1.htm))、Capital One([\))、Capital One(\(133K](https://www.glassdoor.ie/Salary/Capital-One-Data-Scientist-US-Salaries-EJI_IE3736.0,11_KO12,26_IL.27,29_IN1.htm))、Intel([\))、Intel(\(130K](https://www.glassdoor.ie/Salary/Intel-Corporation-Data-Scientist-US-Salaries-EJI_IE1519.0,17_KO18,32_IL.33,35_IN1.htm))、Quora([\))、Quora(\(127K](https://www.glassdoor.ie/Salary/Quora-Inc-Data-Scientist-US-Salaries-EJI_IE646885.0,9_KO10,24_IL.25,27_IN1.htm))、Walmart([\))、Walmart(\(120K](https://www.glassdoor.ie/Salary/Walmart-Data-Scientist-US-Salaries-EJI_IE715.0,7_KO8,22_IL.23,25_IN1.htm))、ServiceNow([\))、ServiceNow(\(119K](https://www.glassdoor.ie/Salary/ServiceNow-Data-Scientist-US-Salaries-EJI_IE403326.0,10_KO11,25_IL.26,28_IN1.htm))和 Wayfair([\))和 Wayfair($114K)。但还有其他因素需要考虑。
另请查看这个“最佳数据科学公司”的列表,旨在超越通常和预期的范围。这里有一些优秀的、可能被低估的选择,可以作为数据科学家的工作机会。
地点和生活成本
许多这些公司总部位于美国西海岸。一些公司在美国其他地方也有办事处,但那些非常关注硅谷的公司,需警惕生活成本极高。在比较薪资时,一定要考虑到你需要生活的地方及其生活成本。
例如,西雅图的生活成本约为旧金山的 83%。如果你收到的西雅图公司的报价超过了旧金山公司薪资报价的 83%,那么即使你接受的工作薪资在绝对值上较低,你也可能能够负担更高的生活标准或存更多的钱。
福利和津贴
除了薪资外,比较工作报价时还需考虑额外的补偿和福利。公司经常将股票作为薪酬包的一部分。此外,许多大科技公司还提供福利,如免费健身房会员、干洗、食物、儿童保育、全面健康保险,甚至学费或学生贷款援助。
从小公司收集薪酬数据是困难的。然而,小公司可能支付的薪资和这些科技巨头一样多甚至更多。根据你所在的城市、州或国家,雇主可能会被法律要求披露薪资。
你的个人兴趣
随着疫情期间数字化的增加和大数据的不断增长,公司拥有大量数据,他们需要数据科学家将这些数据整理成关键的可操作见解以引导公司。这是一项重大责任,任何拥有数据的公司都希望充分利用它。所有这些因素,加上数据科学家的短缺,促成了极具吸引力的薪酬包。
确保你了解自己的价值。如果你有足够的技能获得一个数据科学家的职位邀请,你绝对可以获得多个。抓住机会谈判薪资,选择那些能将你的数据科学技能应用于你最感兴趣的问题的职位。
我们还推荐这篇文章“数据科学家赚多少钱?”,它可以帮助你了解数据科学领域的薪资以及各种因素如何影响薪资。
内特·罗西迪 是一名数据科学家,专注于产品策略。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过来自顶级公司的真实面试问题为面试做准备。你可以通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
相关主题更多信息
用 Python 在 Facebook 数据上可以做的 6 件有趣的事
原文:
www.kdnuggets.com/2017/06/6-interesting-things-facebook-python.html
作者:Nour Galaby,数据爱好者。
在这篇文章中,我将分享如何使用 Facebook Graph API 结合 Python 和 pandas 进行分析的经验。

Facebook 拥有大量可供探索的数据,你可以利用这些数据做很多事情,比如:分析 Facebook 页面或群组,利用这些数据进行社交网络分析 (SNA),进行数字营销的数据分析,甚至为自己的个人项目收集和保存数据。你可以用这些数据做很多事情;一切取决于你。
在这些视频中,我将展示如何进行一些基础操作,例如:
-
从 Facebook 下载数据
-
从 json 转换到更方便的数据结构,以便我们能够处理
-
处理日期变量和 Graph API 中的其他数据
课程-01:介绍与理解 Graph API - Facebook 数据分析与 Python
在这段视频中,我将介绍 GRAPH API,我将使用 GRAPH API Explorer 并展示一些示例请求。
课程-02:下载与保存 Facebook 数据 - Facebook 数据分析与 Python
在这段视频中,我将展示如何下载并保存 Facebook 页面或 Facebook 群组中的所有数据,同时注意一些要点
课程-03:设置与清理数据 - Facebook 数据分析与 Python
在第三节课中,我将使用笔记本来清理和审计我从 Facebook 获得的数据,并使其准备好进行分析
课程-04:评论最多的帖子 - Facebook 数据分析与 Python
在第 4 课中,我将向你展示一种简单的方法来获取最受评论的帖子
课程-05:点赞最多的帖子及额外内容 - Facebook 数据分析与 Python
在第 05 课中发生了一些有趣的事情,因为我发现了一些被删除的帖子,并通过 API 获得了一些信息
课程-06:统计词频 - Facebook 数据分析与 Python
在这段视频中,我将展示如何计算一个组或页面中所有帖子的词频。
你也可以对评论使用相同的函数
课程-07:按关键词分组帖子 - Facebook 数据分析与 Python
在这段视频中,我将分组包含“免费”关键词的帖子,并统计这些帖子中包含该关键词的数量与不包含的数量。
分组是非常有用的,我们将在未来的视频中使用更多变量来进行分组
课程-08:按日期分组 - Facebook 数据分析与 Python
在这个视频中,我们将深入探讨“创建时间”变量,以按年、月或星期几对帖子进行分组。
这可以用来发现发布模式等。
有问题或建议吗?随时与我联系。
简介: Nour Galaby 是一位对数据科学和机器学习充满热情的数据科学爱好者。
相关:
-
初学者 Pandas 推文分析指南
-
数据科学的红利——财务数据分析的温和介绍
-
你可以用 Python 在 Facebook 数据上做的 6 件有趣的事情
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
了解更多相关内容
在数据科学领域的 6 个月中学到的 6 个教训
原文:
www.kdnuggets.com/2020/10/6-lessons-6-months-data-scientist.html
评论

照片由 Artem Beliaikin 提供,来源于 Unsplash。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
自从我六个月前从顾问转变为数据科学家以来,我的工作满意度比我想象的要高。为了庆祝我在这个引人入胜的领域的第一个半年,这里是我在过程中收集到的六个教训。
#1 — 阅读 arXiv 论文
你可能知道,查看 arXiv 是个好主意。那里充满了卓越的想法和最前沿的进展。
不过,我对这个平台上所获得的可操作性建议感到非常惊喜。例如,我可能没有访问到16 个 TPU 和$7k 来从头训练 BERT,但谷歌大脑团队推荐的超参数设置是一个很好的开始微调的起点(见附录 A.3)。
希望你喜欢的新包会在 arXiv 上有一篇启发性的读物,为其文档增添色彩。例如,我通过阅读关于 ktrain 的极易读且非常有用的文档学会了如何部署 BERT,该库基于 Keras,提供了一个简化的机器学习接口,适用于文本、图像和图形应用。
#2 — 收听播客以获得极佳的情境意识
播客虽然不能提高你的编码技能,但能提升你对机器学习领域的最新进展、流行包和工具、未解答的问题、新的解决旧问题的方法、以及职业中普遍存在的心理不安等方面的理解。
我日常收听的播客帮助我保持了对数据科学快速发展的参与感和更新感。
目前我最喜欢的播客是:2020 年提升数据科学学习的资源
最近,我特别兴奋地了解到自然语言处理的进展,关注最新的 GPU 发展和云计算,并质疑人工神经网络与神经生物学之间的潜在共生关系。
#3 — 阅读 GitHub 问题
根据我在这片抱怨的海洋中搜寻智慧巨鱼的经验,以下是三个潜在的收获:
-
我经常从别人使用和/或误用包的方式中得到灵感。
-
了解包在什么情况下容易崩溃也是有用的,这样可以培养你对自己工作中潜在失败点的感知。
-
在你设置环境并进行模型选择的预工作阶段,你最好考虑开发者和社区的响应性,然后再将开源工具添加到你的管道中。
#4 — 理解算法与硬件的关系
我在过去六个月里做了很多自然语言处理,所以让我们再谈谈 BERT。
在 2018 年 10 月,BERT问世并震撼了世界。就像超人在一次跃过高楼后那样(很疯狂地想象超人最初被引入时不能飞!)
BERT 代表了机器学习在处理文本任务能力上的一步飞跃。其最先进的结果基于其变换器架构在Google 的 TPU 计算芯片上运行的并行性。

第一次在 GPU 上训练的感觉。通过GIPHY。
理解 TPU 和基于 GPU 的机器学习的含义对提升你作为数据科学家的能力很重要。这也是提高你对machine learning 软件与其运行的硬件物理限制之间不可分割的关系的直觉的关键一步。
随着摩尔定律在 2010 年左右逐渐失效,需要越来越有创意的方法来克服数据科学领域的局限,继续向真正智能系统的目标迈进。
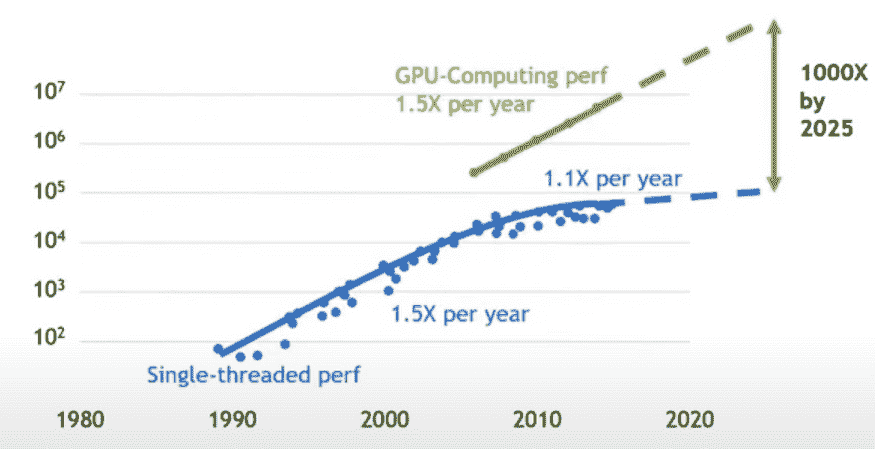
来自Nvidia 演示的图表,显示了每平方毫米的晶体管数量按年变化。这突显了 2010 年左右晶体管数量的停滞和基于 GPU 的计算的兴起。
我对ML 模型-计算硬件共同设计的兴起持乐观态度,对sparsity and pruning的依赖增加,甚至是“无专用硬件”机器学习也充满期待,这些都可能打破当前以 GPU 为中心的主导地位。
#5 — 从社会科学中学习
我们的年轻领域可以从 2010 年代中期社会科学中的可重复性危机中学到很多(在某种程度上,这一危机仍在继续):

“p-value hacking” 对于数据科学家。 Randall Monroe 的 xkcd 漫画。
2011 年,一项学术众包合作旨在复制 100 个已发表的实验和相关的心理学研究。结果失败了——只有 36%的重复实验报告了统计显著的结果,而原始实验的统计显著性为 97%。
心理学的可重复性危机揭示了将“科学”与不稳定的方法论结合的危险和责任。
数据科学需要可测试、可重复的方法来解决问题。为了消除 p-hacking,数据科学家需要设定对数据中预测特征的调查限制,以及评估指标时测试的数量限制。
有许多工具可以帮助进行实验管理。我有使用ML Flow的经验,这篇优秀的文章由Ian Xiao撰写,还提到了其他六种工具,以及关于机器学习工作流其他四个领域的建议。
我们还可以从数据科学领域近年来的许多失误和算法不当行为中汲取经验教训。
例如,有关方面无需再找其他地方,就可以看到社会工程推荐引擎、歧视性的信用算法和加深现状的刑事司法系统。我写过一些关于这些社会弊病以及如何通过有效的人本设计来避免它们的文章。
好消息是,有许多聪明且积极的从业者正在努力解决这些挑战,并防止未来公众信任的破裂。查看 Google’s PAIR、 Columbia’s FairTest 和 IBM’s Explainability 360。与社会科学研究人员的合作可以取得丰硕的成果,例如这个关于 算法审计歧视的项目。
当然,我们还可以从社会科学中学到许多其他东西,例如如何做一个有效的演讲。
学习社会科学对于理解人类对数据推断的直觉何时可能出错至关重要。人类在某些情况下非常擅长从数据中得出结论。我们推理的破坏方式是高度系统化和可预测的。
我们对这一人类心理学方面的理解大部分来自于丹尼尔·卡尼曼的优秀著作Thinking Fast and Slow。这本书应该成为任何对决策科学感兴趣的人的必读书。
卡尼曼研究中的一个与你的工作可能立即相关的元素是他对锚定效应的处理,锚定效应是“当人们考虑一个未知量的特定值时发生的现象。”
在传达建模结果(即表示准确性、精确度、召回率、f-1 等的数字)时,数据科学家需要特别注意管理期望。提供一种手动调整的程度是有用的,例如“我们仍在不断破解这个问题,这些指标可能会有所变化”到“这是最终产品,这就是我们期望我们的 ML 解决方案在实际环境中的表现”。
如果你要展示中间结果,卡尼曼建议为每个指标提供一个值范围,而不是具体的数字。例如,“f-1 分数,代表本表中其他指标(精确度和召回率)的调和均值,大致在 80–85% 之间。这表明还有改进的空间。”这种“手动调整”的沟通策略降低了观众在锚定你所分享的具体值的风险,而是能得到关于结果的方向性正确的信息。
#6 — 将数据与业务结果连接起来
在开始工作之前,确保你所解决的问题是值得解决的。
你的组织并没有付钱让你构建一个 90%准确的模型,写报告,在 Jupyter Notebook 中瞎折腾,甚至让你启发自己和他人了解 图数据库的准魔法属性。
你的任务是将数据与业务结果连接起来。
原文。已获许可转载。
个人简介: 妮可·贾纳威·比尔斯 是一名机器学习工程师,拥有商业咨询经验,精通 Python、SQL 和 Tableau,同时在自然语言处理(NLP)、云计算、统计测试、定价分析和 ETL 过程方面具有业务经验。妮可专注于将数据与业务结果相连接,并不断发展个人技术技能。
相关:
相关话题更多内容
2018 年最有用的 6 个机器学习项目
原文:
www.kdnuggets.com/2019/01/6-most-useful-machine-learning-projects-2018.html
评论
过去一年对于人工智能和机器学习来说是辉煌的一年。许多新的高影响力的机器学习应用被发现并公开,特别是在医疗保健、金融、语音识别、增强现实以及更复杂的 3D 和视频应用中。
我们已经看到更多的应用驱动型研究推动了进展,而不是理论研究。尽管这可能有其缺点,但目前它产生了一些巨大的积极影响,生成了可以迅速转化为业务和客户价值的新研发。这一趋势在许多机器学习开源工作中得到了强烈反映。
让我们来看看过去一年中最具实际用途的 6 个机器学习项目。这些项目发布了代码和数据集,使个人开发者和小团队能够学习并立即创造价值。它们可能不是最具理论突破性的作品,但它们是适用和实用的。
Fast.ai
Fast.ai 库旨在简化使用现代最佳实践训练快速准确的神经网络。它抽象化了实现深度神经网络时可能遇到的所有细节工作。使用起来非常简单,并且以实践者构建应用的思维方式进行设计。最初为 Fast.ai 课程的学生创建,该库基于易于使用的 Pytorch 库,以干净简洁的方式编写。他们的 文档 也非常出色。

Detectron
Detectron 是 Facebook AI 的物体检测和实例分割研究平台,编写在 Caffe2 上。它包含各种物体检测算法的实现,包括:
-
Mask R-CNN:使用 Faster R-CNN 结构进行物体检测和实例分割
-
RetinaNet:一种基于特征金字塔的网络,具有独特的 Focal Loss 用于处理困难示例。
-
Faster R-CNN:最常见的物体检测网络结构
所有网络都可以使用几种可选的分类骨干网之一:
-
Feature Pyramid Networks(与 ResNet/ResNeXt)
更进一步,这些都配备了在 COCO 数据集上预训练的模型,因此你可以直接使用它们!它们都已经使用标准评估指标在 Detectron 模型库中进行了测试。
Detectron
FastText
另一个来自 Facebook 研究的fastText库旨在文本表示和分类。它提供了 150 多种语言的预训练词向量。这些词向量可以用于许多任务,包括文本分类、摘要和翻译。

AutoKeras
Auto-Keras 是一个用于自动化机器学习(AutoML)的开源软件库。它由DATA Lab在德州 A&M 大学和社区贡献者开发。AutoML 的终极目标是为数据科学或机器学习背景有限的领域专家提供易于访问的深度学习工具。Auto-Keras 提供了自动搜索最佳架构和超参数的功能。

Dopamine
多巴胺是由谷歌创建的一个用于快速原型开发强化学习算法的研究框架。它旨在灵活且易于使用,实现标准的 RL 算法、指标和基准。
根据 Dopamine 的文档,他们的设计原则是:
-
简单实验:帮助新用户进行基准实验
-
灵活开发:促进新用户生成新的创新想法
-
紧凑可靠:提供一些较旧和更流行的算法的实现
-
可重复性:确保结果是可重复的

vid2vid
vid2vid 项目是 Nvidia 最先进的视频到视频合成算法的公开 Pytorch 实现。视频到视频合成的目标是学习一个映射函数,将输入源视频(例如,语义分割掩膜序列)映射到一个精准描绘源视频内容的输出逼真视频。
这个库的优点在于其选项:它提供了几种不同的 vid2vid 应用,包括自动驾驶/城市场景、面部和人体姿势。它还附带了包括数据集加载、任务评估、训练功能和多 GPU 支持等广泛的说明和功能!

将分割图转换为真实图像
荣誉提名
-
ChatterBot: 用于会话对话引擎和创建聊天机器人机器学习
-
Kubeflow: Kubernetes 上的机器学习工具包
-
imgaug: 深度学习中的图像增强
-
imbalanced-learn: 专门针对不平衡数据集的 scikit-learn 下的 Python 包
-
mlflow: 开源平台,用于管理机器学习生命周期,包括实验、可重复性和部署。
-
AirSim: 微软 AI 与研究部门开发的基于 Unreal Engine / Unity 的自动驾驶模拟器
喜欢学习吗?
在twitter上关注我,了解最新最棒的 AI、科技和科学动态!
简历: George Seif 是认证的极客和 AI / 机器学习工程师。
原文。转载自原作者授权。
相关:
-
2018 年数据科学、深度学习、机器学习中的顶级 Python 库
-
5 个快速简便的 Python 数据可视化及代码
-
数据科学家需要知道的 5 种聚类算法
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT 管理
更多相关话题
每位初学者数据科学家应掌握的 6 种预测模型
原文:
www.kdnuggets.com/2021/12/6-predictive-models-every-beginner-data-scientist-master.html
作者 Ivo Bernardo,数据科学家

图片由 @barnimages 提供 — unsplash.com
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
当你沉浸于机器学习和人工智能的炒作漩涡中时,似乎只有先进的技术才能解决你在构建预测模型时遇到的所有问题。但当你真正动手编写代码时,你会发现事实是非常不同的。作为数据科学家,你面临的许多问题是通过组合几种模型来解决的,而其中大多数模型已经存在了很久。
即使你使用更高级的模型解决问题,学习基础知识也会让你在大多数讨论中占得先机。特别是,了解更简单模型的优缺点将帮助你引导数据科学项目取得成功。事实是:高级模型能够做两件事——放大或修正它们所基于的简单模型的一些缺陷。
话虽如此,让我们跳入数据科学的世界,了解你在成为数据科学家时应该学习和掌握的 6 种模型。
线性回归
这是最古老的模型之一(例如,弗朗西斯·高尔顿在 19 世纪使用了“回归”一词),至今仍然是用数据表示线性关系的最有效方法之一。
学习线性回归是全球经济计量学课程的基本内容——学习这个线性模型将使你对解决回归问题(机器学习中最常见的问题之一)有一个良好的直觉,并且了解如何利用数学构建简单的线来预测现象。
学习线性回归还有其他好处——特别是当你学习了两种可以实现最佳性能的方法时:
此外,我们可以通过简单的二维图来实际可视化线性回归,这使得该模型成为理解算法的一个非常好的起点。
学习相关资源:
逻辑回归
尽管名为回归,逻辑回归仍然是你开始掌握分类问题的最佳模型。
学习逻辑回归有几个好处,即:
-
初步了解分类和多分类问题(机器学习任务中的一个重要部分)。
-
理解函数变换,例如 sigmoid 函数所做的变换。
-
理解梯度下降的其他函数的使用及其对优化函数的中立性。
-
初步了解对数损失函数。
学习逻辑回归后你应期待了解什么?你将能够理解分类问题背后的机制,以及如何利用机器学习来区分类别。此类问题的一些示例:
-
了解交易是否欺诈。
-
了解客户是否会流失。
-
根据贷款违约的概率对其进行分类。
就像线性回归一样,逻辑回归也是一种线性算法 —— 学习了这两者后,你将了解到线性算法的主要限制,以及它们如何无法表示许多现实世界的复杂性。
学习相关资源:
决策树
第一个非线性算法应该学习的是决策树。决策树是一个基于 if-else 规则的相当简单且可解释的算法,它将帮助你深入了解非线性算法及其优缺点。
决策树是所有树模型的基石——通过学习它们,你也将准备好学习其他技术,如 XGBoost 或 LightGBM(更多信息见下文)。
有趣的是,决策树既适用于回归问题,也适用于分类问题,两者之间的差异很小——选择影响结果的最佳变量的原理大致相同,你只是切换用于评估的标准——在这种情况下是误差度量。
尽管你有回归的超参数概念(如正则化参数),但在决策树中它们至关重要,能够区分一个好的模型和一个绝对无用的模型。超参数在你的机器学习之旅中将是至关重要的,决策树是测试它们的绝佳机会。
关于决策树的一些资源:
随机森林
由于对超参数的敏感性和相对简单的假设,决策树在结果上比较有限。当你学习它们时,你会明白它们非常容易过拟合,创建出不能对未来进行泛化的模型。
随机森林的概念非常简单——如果决策树是独裁制,随机森林就是民主制。它们帮助在不同的决策树之间实现多样性,从而增强你的算法的鲁棒性——就像决策树一样,你可以配置大量的超参数来提升这个袋装模型的性能。什么是袋装? 这是机器学习中一个非常重要的概念,它为不同的模型带来稳定性——你只需使用平均值或投票机制,将不同模型的结果转化为一种单一的方法。
在实践中,随机森林训练固定数量的决策树,并(通常)对所有这些模型的结果进行平均——就像决策树一样,我们有分类和回归随机森林。如果你听说过“集体智慧”这一概念,那么袋装模型就是将这一概念应用于机器学习模型训练中。
学习随机森林算法的一些资源:
XGBoost/LightGBM
基于决策树的其他算法,如 XGBoost 或 LightGBM,使其更加稳定。这些模型是提升算法,它们通过之前弱学习者所犯的错误来找到更稳健且更具泛化能力的模式。
关于机器学习模型的这一思路在Michael Kearns 关于弱学习者和假设检验的论文后获得了关注,展示了提升模型可能是解决模型偏差/方差权衡的一个优秀方案。此外,这些模型也是Kaggle 竞赛中的一些热门选择。
XGBoost 和 LightGBM 是两种著名的 Boosting 算法实现。学习它们的一些资源:
-
Pranjal Khandelwal的关于 XGBoost 与 LightGBM 的文章
人工神经网络
最终,当前预测模型的圣杯——人工神经网络(ANNs)。
人工神经网络目前是发现数据中非线性模式和建立独立变量与因变量之间复杂关系的最佳模型之一。通过学习它们,你将接触到激活函数、反向传播和神经网络层的概念——这些概念将为你学习深度学习模型提供良好的基础。
此外,神经网络在其架构上有许多不同的变体——学习最基本的神经网络将为跳到其他类型的模型(如循环神经网络(主要用于自然语言处理)和卷积神经网络(主要用于计算机视觉))打下基础。
学习它们的一些额外资源:
就这样!这些模型应该能为你在数据科学和机器学习方面提供一个良好的开端。通过学习它们,你将为学习更高级的模型做好准备,并且轻松掌握这些模型背后的数学原理。
好的一点是,更高级的内容通常基于我在这里展示的 6 个模型,因此了解它们的基本数学和机制永远不会有害,即使是在你需要用到“重型武器”的项目中。
你觉得有什么遗漏的吗?在下面的评论中写下来,我很想听听你的意见。
我已经在Udemy 课程 上设置了一个学习大多数这些模型的课程——这个课程适合初学者,我希望你能来参加。***
个人简介:Ivo Bernardo 是 DareData Engineering 的合伙人兼数据科学家,以及 Udemy 的畅销课程讲师和教师。
原文。经许可转载。
更多相关话题
LangChain 尝试评估的 6 个 LLM 问题
原文:
www.kdnuggets.com/6-problems-of-llms-that-langchain-is-trying-to-assess
图片由作者提供
我们的前三个课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
在不断发展的技术领域,大型语言模型(LLMs)的兴起堪称一场革命。像 ChatGPT 和 Google BARD 这样的工具位于前沿,展示了数字互动和应用开发的可能艺术。
ChatGPT 等模型的成功激发了公司对这些先进语言模型的兴趣激增。
然而,LLMs 的真正力量不仅仅在于它们的单独能力。
当 LLMs 与额外的计算资源和知识库集成时,它们的潜力得到了放大,创造出不仅智能且语言能力强大的应用程序,还丰富地依赖数据和处理能力。
而这种集成正是 LangChain 尝试评估的内容。
Langchain 是一个创新的框架,旨在释放 LLMs 的全部能力,实现与其他系统和资源的顺畅共生。它是一个赋予数据专业人员构建既智能又具上下文意识的应用程序的工具,利用今天广阔的信息和计算资源。
它不仅仅是一个工具,它是一个变革性的力量,正在重塑技术格局。
这引出了以下问题:
LangChain 将如何重新定义 LLMs 能够实现的边界?
跟随我,让我们一起探索所有内容。
什么是 LangChain?
LangChain 是一个围绕 LLMs 构建的开源框架。它为开发人员提供了一整套工具、组件和接口,简化了 LLM 驱动应用程序的架构。
然而,它不仅仅是另一个工具。
与 LLMs 一起工作有时感觉像是试图将方形 peg 放入圆形孔中。
有一些常见的问题,我敢打赌你们大多数人已经亲身经历过:
-
如何标准化提示结构。
-
如何确保 LLM 的输出可以被其他模块或库使用。
-
如何轻松切换不同的 LLM 模型。
-
如何在需要时保持某种记忆记录。
-
如何处理数据。
所有这些问题引出了以下问题:
如何开发一个复杂的应用程序,同时确保 LLM 模型按预期行为。
提示充满了重复的结构和文本,响应像幼儿的游乐场一样无结构,而这些模型的记忆?我们可以说,远远不如大象。
所以……我们如何与它们合作?
尝试使用 AI 和 LLM 开发复杂应用程序可能是一个完全的头痛问题。
这就是 LangChain 作为问题解决者的角色。
从本质上讲,LangChain 由几个巧妙的组件组成,这些组件允许你轻松地将 LLM 集成到任何开发中。
LangChain 因其能够通过赋予强大的大型语言模型记忆和上下文来增强其能力而激发了热情。这一附加功能使得模拟“推理”过程成为可能,从而能够更精确地处理更复杂的任务。
对于开发人员来说,LangChain 的吸引力在于其创新的方法来创建用户界面。用户无需依赖传统的拖放或编码方法,而是可以直接表达他们的需求,界面则根据这些请求进行构建。
这是一个旨在为软件开发人员和数据工程师提供超级动力的框架,能够无缝地将 LLM 集成到他们的应用程序和数据工作流程中。
这就引出了以下问题……
LangChain 如何尝试解决所有这些问题?
了解当前 LLM 存在 6 个主要问题后,我们现在可以看看 LangChain 如何尝试评估这些问题。
图片由作者提供
1. 提示现在过于复杂
让我们回顾一下,提示的概念在过去几个月里是如何迅速发展的。
一切始于一个简单的字符串,描述了一个容易执行的任务:
Hey ChatGPT, can you please explain to me how to plot a scatter chart in Python?
然而,随着时间的推移,人们意识到这过于简单。我们没有为 LLM 提供足够的上下文来理解其主要任务。
今天,我们需要告诉任何 LLM 的不仅仅是描述要完成的主要任务。我们必须描述 AI 的高级行为、写作风格,并包括确保答案准确的指令。还有其他任何细节,以便为我们的模型提供更具上下文的指令。
所以今天,我们不再使用最初的提示,而是提交更类似于:
Hey ChatGPT, imagine you are a data scientist. You are good at analyzing data and visualizing it using Python.
Can you please explain to me how to generate a scatter chart using the Seaborn library in Python
对吧?
然而,正如你们大多数人已经意识到的,我可以请求不同的任务,但仍保持 LLM 的相同行为。这意味着提示的大部分内容可以保持不变。
这就是为什么我们应该能够只写一次这一部分,然后将其添加到任何需要的提示中。
LangChain 通过提供提示模板来解决重复文本问题。
这些模板将你任务所需的具体细节(如准确要求散点图)与通常的文本(如描述模型的高层次行为)混合在一起。
所以我们最终的提示模板将是:
Hey ChatGPT, imagine you are a data scientist. You are good at analyzing data and visualizing it using Python.
Can you please explain to me how to generate a <type of="" chart=""> using the <python library=""> library in Python?</python></type>
有两个主要的输入变量:
-
图表类型
-
python 库
2. 响应本质上是无结构的
我们人类很容易解读文本,这就是为什么当与像 ChatGPT 这样的 AI 驱动聊天机器人对话时,我们可以轻松处理纯文本。
然而,当将这些相同的 AI 算法用于应用或程序时,这些回答应该以特定格式提供,比如 CSV 或 JSON 文件。
再次,我们可以尝试制作复杂的提示,要求特定的结构化输出。但我们不能百分之百确定这个输出会以对我们有用的结构生成。
这就是 LangChain 的输出解析器发挥作用的地方。
这个类允许我们解析任何 LLM 响应并生成一个结构化的变量,便于使用。忘记要求 ChatGPT 用 JSON 回答你,LangChain 现在允许你解析输出并生成自己的 JSON。
3. LLM 没有记忆——但某些应用可能需要记忆。
现在想象一下你正在和一个公司的问答聊天机器人对话。你发送了详细的需求描述,聊天机器人回答正确,但经过第二次迭代……一切都消失了!
这几乎就是通过 API 调用任何 LLM 时发生的情况。当使用 GPT 或其他用户界面的聊天机器人时,AI 模型会在我们转到下一轮时立即忘记对话的任何部分。
它们没有任何或几乎没有内存。
这可能导致令人困惑或错误的答案。
正如你们大多数人已经猜到的那样,LangChain 再次准备好来帮助我们。
LangChain 提供了一个名为 memory 的类。它允许我们保持模型的上下文感知,无论是保持整个聊天历史还是仅仅是一个总结,以免产生错误回复。
4. 为什么选择一个单一的 LLM,当你可以拥有它们所有?
我们都知道 OpenAI 的 GPT 模型仍然处于 LLM 的范畴。然而……还有许多其他选择,比如 Meta 的 Llama、Claude 或 Hugging Face Hub 的开源模型。
如果你只为一个公司的语言模型设计程序,你就会被困在他们的工具和规则中。
直接使用单一模型的原生 API 会使你完全依赖于它们。
想象一下,如果你用 GPT 构建了应用程序的 AI 功能,但后来发现你需要加入一个使用 Meta 的 Llama 更好评估的功能。
你将被迫从头开始……这一点一点都不好。
LangChain 提供了一个名为 LLM 类的工具。可以将其视为一个特殊工具,使得从一个语言模型切换到另一个语言模型,或在你的应用中同时使用多个模型变得容易。
这就是为什么直接使用 LangChain 开发可以让你同时考虑多个模型。
5. 向 LLM 传递数据是棘手的
像 GPT-4 这样的语言模型通过大量的文本进行训练。这就是为什么它们本质上处理文本。然而,当涉及到处理数据时,它们通常会遇到困难。
为什么?你可能会问。
可以区分两个主要问题:
-
在处理数据时,我们首先需要了解如何存储这些数据,以及如何有效选择我们想要展示给模型的数据。LangChain 通过使用称为索引的工具来解决这个问题。这些索引允许你从不同的地方如数据库或电子表格中引入数据,并将其设置好,以便逐步发送给人工智能。
-
另一方面,我们需要决定如何将数据放入你提供给模型的提示中。最简单的方法是将所有数据直接放入提示中,但也有更聪明的方法可以做到这一点。
在第二种情况下,LangChain 具有一些特殊工具,这些工具使用不同的方法将数据提供给人工智能。无论是使用直接的 Prompt stuffing,将整个数据集直接放入提示中,还是使用更先进的选项,如 Map-reduce、Refine 或 Map-rerank,LangChain 简化了我们将数据传递给任何 LLM 的方式。
6. 标准化开发接口
将 LLM 融入更大的系统或工作流程总是很棘手。例如,你可能需要从数据库中获取一些信息,将其提供给人工智能,然后在系统的其他部分使用人工智能的回答。
LangChain 对于这些类型的设置具有特殊功能。
-
链接就像是将不同步骤以简单、直线的方式联系在一起的字符串。
-
代理变得更聪明,可以根据人工智能的反馈做出下一步的选择。
LangChain 通过提供标准化的接口简化了这一过程,简化了开发流程,使集成和链式调用 LLM 和其他工具变得更容易,从而提升了整体开发体验。
结论
从本质上讲,LangChain 提供了一系列工具和功能,使得通过解决提示编写、响应结构化和模型集成的复杂性,开发与 LLM 相关的应用变得更加容易。
LangChain 不仅仅是一个框架,它在数据工程和 LLM 的世界中是一个颠覆性的变革者。
它是人工智能复杂且经常混乱的世界与数据应用中所需的结构化、系统化方法之间的桥梁。
当我们结束这次探索时,有一点是明确的:
LangChain 不仅在塑造 LLM 的未来,它还在塑造技术本身的未来。
Josep Ferrer 是一位来自巴塞罗那的分析工程师。他毕业于物理工程专业,目前在应用于人类移动性的领域从事数据科学工作。他还是一位兼职内容创作者,专注于数据科学和技术。Josep 撰写有关人工智能的所有内容,涵盖了该领域持续爆炸的应用。
更多相关内容
每个数据科学家应该了解的 6 个 Python 机器学习工具
原文:
www.kdnuggets.com/2022/05/6-python-machine-learning-tools-every-data-scientist-know.html

由 svstudioart 创建的后端矢量 - www.freepik.com
机器学习正在快速发展,是软件开发行业的关键焦点。人工智能与机器学习的融合已经改变了游戏规则。越来越多的企业正专注于广泛的研究和实施这一领域。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT
机器学习提供了巨大的优势。它可以迅速识别模式和趋势,自动化的概念通过机器学习变成现实。来自各个领域和行业的企业正快速采用机器学习,以现代化他们的用户界面、安全性和人工智能需求。
对于机器学习,Python 被认为是最佳编程语言。它是一个用户友好的编程语言,并且有多种简单的方法来加载数据。许多工具使得 Python 机器学习对数据科学家变得简单。让我们来看一下每个数据科学家应该使用的六个必备工具。
1. TensorFlow
TensorFlow 是一个先进的 Python 框架,用于执行深度机器学习算法。它由 Google Brain Team 开发,是一个第二代开源系统。
TensorFlow 的独特之处和开发者的青睐在于它不仅可以为计算机创建机器学习模型,还可以为智能手机创建模型。“TensorFlow Serving”提供高性能服务器的机器学习模型。
它允许无缝分配数据到各种 GPU 和 CPU 核心。TensorFlow 可以与多种编程语言一起使用,如 C++、Python 和 Java。它使用张量,即包含 n 维数据及其线性操作的存储。
TensorFlow 处理深度和神经网络、文本、语音和图像识别,这些是所有企业的主要关注点。它能够轻松处理偏微分方程。每两到三个月就会有新的更新,这可能会让用户觉得烦恼,因为需要下载并与当前系统绑定。
2. Keras
Keras 是由 Google 工程师 François Chollet 为项目 ONEIROS(开放式神经电子智能机器人操作系统)开发的。TensorFlow 是一个强大的 DL 和 ML 工具,但它没有用户友好的界面。
Keras 工具将自己定义为为人类而非机器开发的 API。它是一个用户友好的 API,非常适合初学者。它用于创建神经网络,并在 TensorFlow 主库中得到支持。Keras 建立在 TensorFlow 之上,使初学者能够高效利用许多好处。它还对加快文本和图像处理有帮助。
ML 和 DL 编程提供了便捷的模型构建和训练方式,神经层有助于目标 ML、批量归一化、池化层和神经网络中的丢弃。
Keras 非常适合那些希望快速开始 ML 工作的初学者。他们拥有一个大型的专注社区,并有一个 Slack 频道。在使用 Keras 时,获得支持非常容易。
3. PyTorch
它是一个基于 Torch 的开源 ML 库,由 Facebook AI 研究实验室于 2016 年创建。
我们可以将 PyTorch 视为 TensorFlow 的竞争对手,因为它能够与不同的编程语言配合使用,并作为一个对 ML 有价值的工具和 DL 学习工具。它像许多 ML 库一样是开源的;像 TensorFlow 一样,PyTorch 也使用张量。此外,它还支持 Python 和 C++ 编程语言。
然而,由于 PyTorch 相对较新,还有很多改进的空间。好消息是它拥有强大的支持社区。它更友好于 Python,并支持 GPU 和 CPU。PyTorch 是一个易于调试的工具,具有简单的代码、强大的 API、更好的优化以及计算图支持的优势。
它在处理深度学习方面享有很好的声誉,因为它在训练和构建神经网络方面运作高效。此外,它能够处理用于视觉和语言相关案例的大规模数据。所有 SaaS 提供商,包括医疗软件提供商,都可以利用这些 ML 工具为他们的业务创建网络助手。
4. Scikit-Learn
这个流行的 Python ML 库可以轻松与 ML 编程库集成。它专注于多个数据建模概念,包括聚类、回归和分类。这个库可以在 Matplotlib、Numpy 和 Scipy 上找到。
Sickit-Learn 基于“数据建模”这一元素,与许多机器学习工具不同,优先考虑数据建模和数据可视化。它是一个开源商业库。与 Keras 类似,它也具有用户友好的界面,并且可以轻松与 Panda 和 Numpy 等其他库集成。
预测、拟合和转换的简单命令可以通过简单的用户界面帮助调整、评估、数据处理和模型接口。由于界面,它在市场上作为标准库广泛使用,用于表格数据的机器学习。
5. Theano
Theano 是一个非常受欢迎的 Python 机器学习库,它允许用户优化和评估强大的数学表达式。Theano 能够处理大型科学方程,并支持 GPU,以便在进行重计算时性能更佳。无论操作多么复杂,Theano 都能迅速而高效地完成。它还可以与 NumPy 集成。
Theano 拥有一个额外的快速 GPU,在进行实验和测试时帮助加快计算速度。它不会妥协机器学习算法的质量和效率。在计算梯度时,Theano 非常智能,可以自动生成符号图。越来越多的 移动设备安全 开发者正在采用机器学习算法来保护用户数据的安全。
6. Pandas
Pandas 是另一个 Python 的开源数据分析库。它专注于数据分析和数据处理。对于希望轻松处理结构化的多维数据和时间序列数据的机器学习程序员来说,Pandas 是他们所需的机器学习库。
Pandas 提供了许多用于数据处理的功能,其中包括
-
数据过滤
-
数据对齐
-
处理数据
-
数据透视
-
数据重塑
-
数据集的合并
-
数据集的合并
与 Numpy 相比,Pandas 运行速度更快,它是少数能够独立处理 DateTime 的库之一,无需依赖外部库。这个工具涉及机器学习和数据分析的所有关键方面。
结论
数据科学家需要能够简化工作的软件——他们的大脑中已经有复杂的方程和复杂的算法!每个数据科学家在使用 Python 开发机器学习算法时都有具体的需求和优先级。
有许多 Python 库 可用于机器学习算法。每种库都有不同的优缺点。开发者可以根据自己的需求选择合适的工具。
深度学习和机器学习变得越来越容易理解,机器学习工具使编程任务更易管理、更高效、更及时。
Nahla Davies 是一位软件开发人员和技术作家。在全职从事技术写作之前,她曾担任过很多引人注目的职位,其中包括在一家《Inc. 5000》公司担任首席程序员,该公司的客户包括三星、时代华纳、Netflix 和索尼。
相关主题
Python 突然变得非常受欢迎的 6 个原因
原文:
www.kdnuggets.com/2017/07/6-reasons-python-suddenly-super-popular.html
评论
你可能知道也可能不知道,Python 编程语言并不是年轻的。虽然它没有一些其他语言那么古老,但它存在的时间比大多数人认为的要长。它首次发布于 1991 年,尽管这些年来发生了很大变化,但它仍然用于当时的相同用途。
实际上,这只是它近年来变得如此受欢迎的原因之一——它是一种基于生产的语言,旨在用于企业和一流项目,并且拥有丰富的历史。它几乎可以用于任何事情,这也是它被认为如此多功能的原因。你可以通过 Python 构建 Raspberry Pi 应用程序、桌面程序的脚本以及配置服务器,但这不仅限于这些任务。
使用 Python,确实没有限制。

Python 有什么特别之处?
Python 是一种通用语言——有时被称为实用语言——设计上简洁易读。它不是复杂的语言这一点非常重要。设计者更少关注传统语法,使其更易于使用,即使对于非程序员或开发者也是如此。
而且,由于它被认为真正通用并用于满足各种开发需求,这是一种 为程序员提供大量选择的语言。如果他们开始使用 Python 从事某项工作或职业,他们可以轻松转到另一个行业,即使这是一个不相关的领域。这种语言用于系统操作、网页开发、服务器和管理工具、部署、科学建模等。
但令人惊讶的是,许多开发者并没有将 Python 作为主要语言。因为它使用和学习起来非常简单,他们选择将其作为第二或第三语言。这也许是它在开发者中如此受欢迎的另一个原因。
此外,恰好全球最大的科技公司之一——谷歌——将这种语言用于他们的多个应用程序。他们甚至有一个 专门的 Python 开发者门户,提供免费的课程,包括练习、讲座视频等。
此外,Django 框架在网页开发中的使用增加以及 PHP 人气的下降也促成了 Python 的成功,但最终,这是一个完美的风暴——恰到好处的开发者和官方支持,以及需求。
以下是 Python 最近几年变得非常受欢迎的一些不那么明显的原因:
1. Python 拥有一个健康、活跃且支持性强的社区
由于显而易见的原因,缺乏文档和开发者支持的编程语言表现总是不佳。Python 不存在这些问题。它已经存在了相当长的时间,因此有大量的文档、指南、教程等等。此外,开发者社区非常活跃。这意味着每当有人需要帮助或支持时,他们都能及时获得帮助。
这个活跃的社区帮助确保所有技能水平的开发者——从初学者到专家——始终可以找到支持。而且,正如任何有经验的程序员或开发者所知道的那样,当你在紧张的开发时遇到问题时,支持可能是决定你成功与否的关键。
2. Python 拥有一些优秀的企业赞助商
编程语言有企业赞助商是非常有帮助的。C# 有微软,Java 曾有 Sun,而 PHP 被 Facebook 使用。谷歌在 2006 年大量采用了 Python,自那以后他们已经在许多平台和应用中使用它。
为什么这很重要?因为如果像谷歌这样的公司希望他们的团队——以及未来的开发者——与他们的系统和应用程序一起工作,他们需要提供资源。在谷歌的案例中,他们创建了大量关于使用 Python 的指南和教程。
这有助于提供不断增长的文档和支持工具列表,并在开发世界中为语言提供免费的广告。
3. Python 拥有大数据
在企业界使用大数据和云计算解决方案也帮助 Python 成功腾飞。它是数据科学中最受欢迎的语言之一,仅次于 R。它也被用于机器学习和人工智能系统以及各种现代技术。
当然,Python 易于分析和组织成可用数据,这也有所帮助。
4. Python 拥有令人惊叹的库
当你在处理更大的项目时,库可以帮助你节省时间并缩短初始开发周期。Python 拥有丰富的库选择,从用于科学计算的 NumPy 和 SciPy 到用于 Web 开发的 Django。
甚至还有一些专注于特定领域的库,比如用于机器学习应用的 scikit-learn 和用于自然语言处理的 nltk。
此外,像 Encoding.com 这样的巨大云媒体服务允许与 C 语言家族语言兼容。换句话说,有一些类似库的工具提供跨平台支持,这是一大优势。
5. Python 可靠且高效
问问任何一个 Python 开发者——或者任何使用过这种语言的人——他们都会同意 Python 既快速又可靠且高效。你可以在几乎任何环境中使用和部署 Python 应用程序,无论你使用什么平台,几乎不会有性能损失。
再次强调,由于其多功能性,这也意味着你可以跨多个领域工作,包括但不限于——网页开发、桌面应用程序、移动应用程序、硬件等。
你不受限于单一平台或领域,它在任何地方都能提供相同的体验。
6. Python 是易于访问的
对于新手和初学者来说,Python 极其容易学习和使用。实际上,它是最容易接触的编程语言之一。部分原因在于其简化的语法,强调自然语言。但也因为你可以更快地编写和执行 Python 代码。
无论如何,它都是初学者的绝佳语言,因此很多年轻开发者都从这里起步。更重要的是,经验丰富的开发者也不会被遗弃,因为仍有大量工作待做。
简介: 凯拉·马修斯 讨论技术和大数据,曾在《The Week》、《数据中心杂志》和《VentureBeat》等出版物上发表文章,拥有超过五年的写作经验。要阅读凯拉的更多帖子,订阅她的博客《生产力字节》。
相关:
-
2017 年数据科学的前 15 大 Python 库
-
用 Python 掌握数据准备的 7 个步骤
-
数据分析入门 Python
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 部门
更多相关话题
6 个适合有志数据科学家的副业
原文:
www.kdnuggets.com/2021/05/6-side-hustles-data-scientist.html
评论
作者:Ahmad Bin Shafiq,机器学习学生。

图片由 Sharon McCutcheon 提供,来源于 Unsplash。
数据科学无疑是目前最受欢迎的领域。难怪拥有高超技能的数据科学家在全球范围内都能获得丰厚的薪酬。
现在,你可能是一个对现有工作感到舒适的数据科学家,也可能是一个希望进入数据科学领域的有志者。不管怎样,我接下来要建议的点子都将帮助你提升技能,作为数据科学家赚取不错的副收入,最重要的是,成为自己的老板。
1. 撰写文章

图片由 Dan Counsell 提供,来源于 Unsplash。
如果你对数据科学有基础知识,并且写作能力不错,你可以通过撰写文章赚取丰厚的收入。Medium 是初学者开始写作的最佳平台。此外,还有一些网站支付作者原创博客的稿费。你可以为这些网站写作,或者甚至可以开设自己的博客(这不仅有助于你的经济状况,还会提升你的简历)。在自己的博客中,你可以撰写有关 AI/ML/DL/DS 的博客。一旦你的博客达到一定的访问量/流量阈值,你可以申请盈利。如果你的盈利功能开启,你将因每次博客浏览而获得收入。
2. 参加 Kaggle 竞赛
在 Kaggle 上有很多关于数据科学的竞赛。通过参加这些竞赛,你不仅可以学习新知识、提升技能,如果赢得竞赛,Kaggle 还会为获胜者提供现金奖励。此外,如果你有一个优秀的 Kaggle 个人资料,这肯定会引起招聘人员的广泛关注,有助于你找到工作!
3. 做自由职业工作

图片由 imtips.co 提供。
自由职业是最流行的在家赚钱方式。尤其是在 2020–21 年,一切都被封锁,人们都待在家中。因此,你可以在像 Fiverr、Upwork、freelancer 等网站上开始从事数据科学相关的自由职业工作。随着你完成越来越多的项目,你的个人资料将变得更加有价值,订单也会增加。
欲了解更多关于如何开始自由职业生涯的信息,请参阅以下文章:
4. 教学

照片由 NeONBRAND 提供,发布于 Unsplash。
有一句俗语:
学习某事的最佳方式是教授它
为了成为一名熟练的数据科学家,你的所有概念都应当清晰明确。因此,按照上述建议,你可以在大学担任助理教授教授数据科学,或在家里或其他地方开办一个数据科学学院。从初级水平开始,并在过程中进行调整。通过教学,你不仅可以赚取合理的收入,还能回馈程序员社区。
5. 开设 YouTube 频道

照片由 Sara Kurfeß 提供,发布于 Unsplash。
制作与自己专业领域相关的教育视频是另一种很好的收入方式。YouTube 对内容创作者提供了丰厚的回报。制作教育视频还能帮助你建立个人品牌并创建自己的影响力网络。在 YouTube 上,你可以上传任何内容,只要不违反内容政策。
6. 工作或实习

照片由 Ant Rozetsky 提供,发布于 Unsplash。
最近的研究显示:
这在 STEM 领域尤其如此——例如数据科学——因为实习能够极大地改变游戏规则。这是因为一些数据科学技能只有在实践环境中才能得到巩固。
在实习期间,你可以从专业团队中学习,建立强大的网络,并获得实际而有意义的经验。此外,实习也有助于你的经济状况,并且为未来打开了许多大门。
结论
在这篇文章中,我讨论了作为数据科学家我使用过或看到别人使用的 6 种额外收入方法。这些方法在难度、风险水平和可能赚取的金额上有所不同,但它们都有可能帮助你提升技能并赚取 $$$。
相关:
了解更多主题
6 个远程工作数据科学家的软技能
原文:
www.kdnuggets.com/2022/05/6-soft-skills-data-scientists-working-remotely.html
关键要点
-
随着远程工作成为常态,沟通技能在数据科学中至关重要。
-
作为数据科学家,你可能拥有出色的技术技能,但如果不能有效沟通,你将无法在虚拟会议中清晰地传达你的想法。
-
因此,在今天的虚拟世界中,将强大的技术技能与沟通能力结合起来尤为重要。
疫情带来了公司业务运营方式的前所未有的变化。许多公司现在允许员工远程工作。无论你是经验丰富的数据科学家还是仍在尝试进入这一领域的数据科学候选人,都必须在硬技能之外培养远程工作的关键软技能。加强沟通技能(包括写作、口语和积极倾听)至关重要。
本文探讨了在今天的虚拟世界中所需的 6 种基本软技能。
1. 口语技能
在虚拟会议中清晰表达你的想法是一项出色的技能,这将使你脱颖而出。一般来说,工业数据科学项目的范围和复杂性都非常广泛,并且非常多学科,涉及不同领域的专家。强大的口语能力将使你能够向团队成员清晰地传达你的想法。如果不能清晰表达,你将无法很好地作为团队成员发挥作用。如果你是一个仍在寻求进入数据科学领域的数据科学候选人,那么良好的口语技能将帮助你在 Zoom 面试过程中清晰地表达你的想法。展示技术能力和沟通技巧的能力将使你在无法清晰表达自己想法的候选人中脱颖而出。
2. 写作技能
写作技能在数据科学中发挥着至关重要的作用。假设你的团队已经成功完成了一个项目。现在是时候准备项目报告了。良好的写作技能将帮助你以清晰简洁的方式呈现项目结果。你希望利用这个机会充分证明项目结果的重要性,并表明如果实施,将能够改善业务的开展方式。你想要说服高管和经理,解释你如何得出解决方案的过程,方式要避免过于技术化。随着远程工作的普及,电子邮件使用量大幅增加。良好的写作技能对于撰写发送给商业高管或团队其他成员的电子邮件非常有帮助。你要确保写出专业且无错误的高质量电子邮件。作为数据科学的有志之士,写作技能将帮助你在面试过程后撰写出色的跟进邮件。
3. 听力技能
听力技能和口语及写作技能同样重要。在与团队成员进行虚拟 Zoom 会议时,仔细倾听非常必要。如果可能的话,记下会议中讨论的关键点。即使你是首席数据科学家,也不要主导会议发言。你必须认真听取团队成员的意见,因为他们经常提供有价值的解决问题的想法。作为数据科学的有志之士,你在面试过程中要认真听取,以确保你理解公司及你角色的所有细节。这将帮助你确定公司是否适合你。
4. 阅读技能
良好的阅读技能将帮助你跟上组织中的业务运作。作为终身学习者,良好的阅读技能还将帮助你了解领域内的新发展。一些帮助你保持更新的博客平台包括 Medium、LinkedIn、GitHub、KDnuggets 和 Kaggle。
5. 专业形象
展现专业形象不仅在求职和面试过程中重要——这也是职业生涯中应持续保持的习惯。你的着装反映了你对工作的看法以及他人如何看待你和你的公司。良好的商务着装将确保你始终展现出适当的形象。穿着休闲服如睡衣参加重要商务会议不是一个好主意。此外,如果参加 Zoom 会议,请确保你在一个安静且干扰有限的区域。你的 Zoom 背景如何?使用一个不会分散他人注意力的背景确实很有帮助。
6. 职业道德技能
作为数据科学家或在任何其他角色中远程工作需要很强的自律。要对自己保持道德和真实。留出时间来完成工作。确保每天投入足够的时间。找到一个没有干扰的工作环境。
总结一下,我们讨论了作为数据科学家远程工作所需的 6 项关键软技能。作为数据科学家,你可能拥有出色的技术技能,但如果不能有效沟通,就无法在虚拟会议中清晰表达你的想法。因此,将强大的技术技能与沟通能力结合起来尤其重要,特别是在今天这个虚拟世界中。
本杰明·O·塔约 是物理学家、数据科学教育者和作家,也是 DataScienceHub 的创始人。此前,本杰明曾在中欧大学、大峡谷大学和匹兹堡州立大学教授工程学和物理学。
更多相关话题
启动数据科学职业的六步计划
原文:
www.kdnuggets.com/2018/12/6-step-plan-starting-data-science-career.html
评论

当人们希望启动数据科学职业但尚未迈出第一步时,他们处于一种可以理解的令人畏惧且充满不确定性的情境中。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
然而,当他们遵循有助于进入该领域的明确流程时,成功变得更容易可视化和实现。以下是六个入门步骤:
1. 与业内人士交谈
尽管阅读数据科学专业人士撰写的文章或观看这些人接受采访的 YouTube 视频很有价值,但如果有抱负的数据科学家能够与目前在该领域工作的人进行面对面交谈则更为理想。
一些公司通过数据科学导师计划提供收入分成模式,这使得那些希望成为数据科学家的人员可以接受来自经验丰富的专业人士的指导。然后,如果学员在一定时间内获得数据科学职位,他们会用第一年工资的一小部分回报导师。
然而,也可以采取不那么正式的方法。人们可以参加他们所在地区的数据科学会议,并报名参加研讨会或与专家进行亲密的问答环节。还有机会通过留言板和 Skype 对话获取见解。
与了解行业并愿意分享经验的人交谈至关重要。这可以帮助未来的数据科学家确认这个职业路径是否适合他们,或者突出为什么另一个工作选择更合适。
2. 了解专业领域
与一些人的想法相反,数据科学家有很多专业方向可以选择。例如,那些在俄亥俄州立大学攻读数据分析专业的人可以从商业分析到生物医学信息学等五个专业方向中进行选择。
在学术界之外,人们需要考虑如何提升自己的技能,以增加在某些数据科学角色中工作的机会。那些特别注重解决问题的人可能会意识到,他们应该专注于与运营相关的数据分析,这涉及挖掘信息以确定如何帮助公司表现更好。
喜欢通过数据寻找趋势的人可以专注于统计分析。采取这种方法,他们将能够帮助雇主发现那些最终推动商业决策的模式。
当人们处于数据科学职业的早期阶段时,了解数据科学专业方向是至关重要的。他们所获得的知识可能帮助他们发现那些原本隐藏的热情。
3. 作为有目的的浏览者审视就业市场
现在评估就业市场可能显得为时已早,尤其是如果找到工作的目标可能还需要几年时间。然而,了解通常雇佣数据科学家的公司以及候选人应具备的技能是有价值的。
此外,了解某些城市或地区是否有高于平均水平的数据科学职位发布数量也很有用。这样,当人们继续规划职业时,他们可以衡量是否需要迁移以获得他们想要的工作。
不推荐的替代方法是等到找工作的时候再进行这种研究。那时,人们可能会发现,尽管他们努力达到了目标,但仍然缺乏必要的技能,或者虽然附近的数据科学工作不多,却没有准备好迁移。
4. 启动一个独立的数据科学项目
人们没有必要等到接受正式教育后才开始参与数据科学项目。存在一些在线资源,可以让data science learners start projects 即使他们还是初学者。他们可以先浏览那些免费提供的数据集,然后利用这些数据集作为起点,激发他们想要回答的问题。
如果数据科学爱好者不想设计独立项目,那也没关系。在线上有预制项目和教程 提供问题供人们解决。这些机会让个人在没有投资昂贵工具或培训的情况下开始获得实践经验。
5. 考虑参加数据科学训练营
许多想要成为数据科学家的人在做出这个决定时已经从事其他职业。因此,开始数据科学职业可能需要学习如何在准备另一份工作的同时平衡现有工作的职责。
在这种情况下,报名参加数据科学训练营可能是一个理想的解决方案。有些训练营仅为一周,而其他的则持续几个月。还有机会报名参加完全在线的训练营。
6. 寻找数据科学实习机会
当他们达到这个步骤时,准备从事数据科学职业的人应该通过独立的数据科学项目获得实际经验,并且可能已经选择了正式培训。
现在是他们尝试获得数据科学实习机会的绝佳时机。许多人将实习视为通向未来工作的途径,确实,如果他们给雇主留下深刻印象,实习也可以实现这一目标。
然而,任何朝着数据科学职业发展的人都必须意识到,即使实习生未直接获得工作机会,大多数实习仍然是有价值的。
根据实习的时间长度和公司需求,实习生可能会参与构建数据可视化和创建报告等任务。这些任务有时可能会让人感到不知所措,但这些经历会为他们的未来做好准备。
没有一种路径适合所有人
这些步骤应为他们提供所需的动力,以便采取果敢的行动,迈向最终的数据科学职业。
然而,必须注意的是,尽管这份清单提供了建议的基础组成部分,但每个人都是不同的。人们可能不会按照这个顺序前进,也可能不会完成所有步骤。这没关系,只要他们保持目标的清晰即可。
个人简介: Kayla Matthews 在《The Week》、《The Data Center Journal》和《VentureBeat》等出版物上讨论技术和大数据,并且已经写作超过五年。要阅读 Kayla 的更多文章,订阅她的博客 Productivity Bytes。
相关:
-
在 2 年内提升数据科学技能的 8 种方法
-
每个数据科学家都应该随手备着的 6 本书
-
每个有志数据科学家在 2019 年应设立的 6 个目标
更多相关话题
从零开始编写任何机器学习算法的 6 步:感知机案例研究
原文:
www.kdnuggets.com/2018/09/6-steps-write-machine-learning-algorithm.html
评论
由 John Sullivan 提供, DataOptimal
从零开始编写算法是一个值得的经历,能够带给你那种“啊哈!”的时刻,让你最终明白算法的内部运作。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
我是说,即使你之前用scikit-learn实现过该算法,从零开始编写也会很容易吗?绝对不是。
有些算法比其他算法更复杂,因此从简单的算法开始,例如单层感知机。
我将带你通过一个从零开始编写算法的 6 步流程,以感知机为案例研究。这种方法论可以很容易地转化为其他机器学习算法。
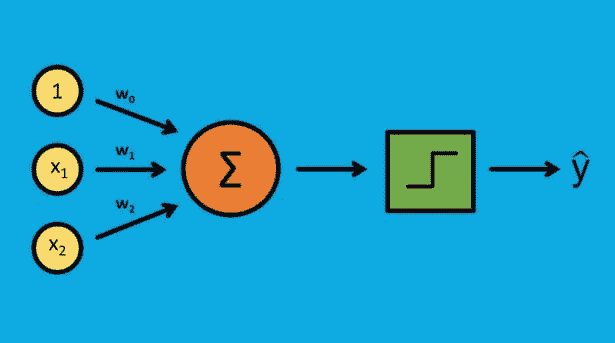
- 对算法有基本理解
这回到了我最初说的。如果你不理解基础知识,就不要从零开始尝试一个算法。至少,你应该能够回答以下问题:
-
那是什么呢?
-
它通常用于什么?
-
我什么时候不能使用它?
对于感知机,我们先回答这些问题:
-
单层感知机是最基本的神经网络。它通常用于二分类问题(1 或 0,“是”或“否”)。
-
它是一个线性分类器,因此只能在存在线性决策边界时使用。一些简单的应用可能是情感分析(积极或消极反馈)或贷款违约预测(“将违约”,“不会违约”)。对于这两种情况,决策边界都需要是线性的。
-
如果决策边界是非线性的,你确实不能使用感知机。对于这些问题,你需要使用其他方法。
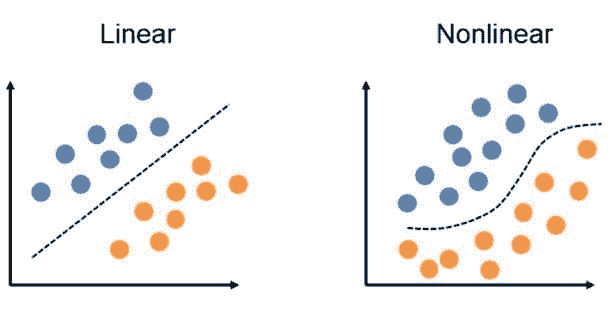
- 寻找一些不同的学习资源
在你对模型有了基本了解后,是时候开始进行研究了。我建议使用多种资源。有些人通过教科书学习效果更好,有些人则通过
视频效果更佳。我个人喜欢跳转使用各种类型的资源。对于数学细节,教科书做得很好,但对于更多实际示例,我更喜欢博客和 YouTube 视频。
关于感知器,这里有一些很好的资源:
-
教科书:
-
统计学习的元素,第 4.5.1 节
-
理解机器学习:从理论到算法,第 21.4 节
-
-
博客:
-
Jason Brownlee 在他的机器学习精通博客上的文章,如何从头开始在 Python 中实现感知器算法
-
Sebastian Raschka 的博客文章,单层神经网络和梯度下降
-
-
视频:

- 将算法分解成块
现在我们已经收集了资料,是时候开始学习了。先拿些纸和铅笔。与其整章阅读或阅读博客,不如先浏览章节标题及其他重要信息。记下要点,尝试概述算法。
在查看了这些资源之后,我将感知器算法分解成了以下几个部分:
-
初始化权重
-
将权重乘以输入并加总
-
将结果与阈值进行比较以计算输出(1 或 0)
-
更新权重
-
重复
将算法分解成块使学习更容易。基本上,我已经用伪代码概述了算法,现在可以回过头来填充详细信息。这是我对第二步的笔记的图片,即权重和输入的点积:
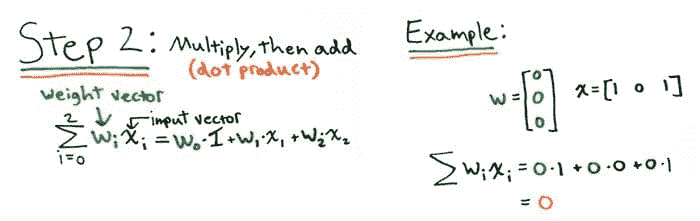
- 从简单示例开始
在我整理完算法笔记后,是时候开始在代码中实现它了。在处理复杂问题之前,我喜欢从简单示例开始。对于感知器, NAND 门 是一个完美的简单数据集。如果两个输入都为真(1),则输出为假(0),否则输出为真。这是数据集的一个示例:
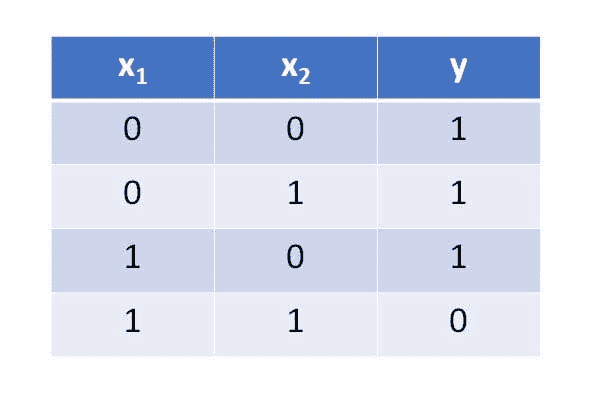
现在我有了一个简单的数据集,我将开始实现我在第 3 步中概述的算法。将算法分块编写并测试是个好习惯,而不是尝试一次性完成。这使得在刚开始时更容易调试。当然,最后你可以回去整理一下,让它看起来更漂亮。
这是我在第 3 步中概述的算法中点积部分的 Python 代码示例:
- 与可信实现进行验证
现在我们已经编写了代码并在一个小数据集上进行了测试,是时候将其扩展到 更大的数据集了。为了确保我们的代码在这个更复杂的数据集上正常工作,最好对其进行可信的实现测试。对于 Perceptron,我们可以使用 sci-kit learn 的实现。

为了测试 我的代码,我将查看权重。如果我正确实现了算法,我的权重应该与 sci-kit learn Perceptron 的权重一致。
起初,我没有得到相同的权重,这是因为我必须调整 scikit-learn Perceptron 中的默认设置。我每次没有实现一个新的随机状态,只是一个固定的种子,因此我必须关闭这个设置。对于洗牌也是如此,我也需要关闭它。为了匹配我的学习率,我将 eta0 改为 0.1。最后,我关闭了 fit_intercept 选项。我在特征数据集中包含了一列全为 1 的虚拟列,因此我已经自动拟合了截距(也称为偏置项)。
这引出了另一个重要的点。当你对模型的现有实现进行验证时,你需要非常关注模型的输入。你绝不能盲目使用一个模型,总是要质疑你的假设,以及每个输入的确切含义。
- 撰写你的过程
这一过程中的最后一步可能是最重要的。你刚刚完成了所有的学习工作,做了笔记,从头编写了算法,并将其与可信的实现进行了比较。不要让所有这些好工作白费!撰写过程文档很重要,原因有两个:
-
你将获得更深刻的理解,因为你正在教别人你刚刚学到的知识。
-
你可以将其展示给潜在的雇主。展示你能够实现一个机器学习库中的算法是一回事,但如果你能够从头开始自己实现它,那就更令人印象深刻了。
展示你工作的一个好方法是使用 GitHub Pages 作品集。
结论
从零开始编写算法可以是非常有成就感的经历。这是深入理解模型的绝佳方式,同时还能构建一个令人印象深刻的项目组合。
记得慢慢来,从简单的事情开始。最重要的是,确保记录和分享你的工作。
简介:约翰·沙利文是数据科学学习博客 DataOptimal 的创始人。你可以在 Twitter 上关注他 @DataOptimal。
相关内容:
更多相关内容
雇主不希望你知道的 6 件关于数据科学的事
原文:
www.kdnuggets.com/2020/12/6-things-data-science-employers.html
评论

照片由 Kristina Flour 提供,来源于 Unsplash。
我们的三大课程推荐
1. 谷歌网络安全证书 - 加速你的网络安全职业发展。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
我想揭示一下作为数据科学家的阴暗面。这篇文章并不是为了打击你,但和其他任何工作一样,数据科学作为职业也有它的不足之处。我认为重要的是你要了解这些事情,这样当你在生活中遇到它们时,不会像我一样被击得措手不及!
根据你的个性和兴趣,你可能不会觉得这些事情有多糟,这是一件好事!那么,话虽如此,这里是雇主不希望你知道的 6 件关于数据科学的事。
1. 一个模糊的术语,比如“数据科学”,意味着模糊的职责。
你阅读关于数据科学的材料越多,就越会意识到数据科学的广度。事实上,它广泛到有专门讨论各种数据科学职位的文章(数据科学家、数据分析师、决策科学家、研究科学家、应用科学家、数据工程师、数据专家……你明白了)。
此外,由于数据科学是一个多学科领域,“数据科学”这一术语涵盖了各种各样的技能,这些技能很可能超出了你一生中能够精通的范围。
因此在你数据科学的旅程中一定要记住这些事情……
-
保持开放的心态,不要过于专注于数据科学的光鲜部分。例如,如果你发现自己在查询表格或从事数据架构工作,而不是进行机器学习模型的工作,不要气馁。任何与数据相关的技能都是宝贵的技能,并且很可能在未来会派上用场!
-
与第一点类似,数据科学没有固定的路径。因此,抓住你遇到的任何机会,从每个机会中尽可能多地学习。你获得的经验越多,未来你可以选择的机会也就越多。
-
作为最后的总括性陈述,尽量不要在你足够有经验和知识之前对你想做的事情设定过于严格的期望。乞丐不能挑肥揸瘦!
总结: 在你的数据科学旅程中保持开放的心态。它不仅仅是关于建模的。
2. 你很可能会比你想象的更频繁地使用 SQL。
当我刚开始我的职业生涯时,我总是认为 SQL 是只有数据分析师才会使用的技能。由于我最初有这种心态,我从未真正欣赏我在 SQL 上发展的知识。
这不是你应该思考 SQL 的方式!
如果你从事与数据相关的工作,无论是否为数据科学职位,SQL 永远不会离开你。
作为数据科学家,如果你想构建机器学习模型,你需要数据,这意味着你要么需要查询数据,要么需要在数据尚不存在时构建数据管道。了解 SQL 是至关重要的,以确保你的数据是稳健和可扩展的。
总结: SQL 永远是你最好的朋友,所以确保你花时间掌握它。
3. 现实世界中的数据比你想象的要混乱得多。
如果你曾经在 Kaggle 上处理过数据,现实世界完全不同。在 Kaggle 上,数据通常是干净的,每个表都有描述,每一列和特征名称都比较直观。
现实世界并非如此。你不仅可能不会有我上面列出的任何问题,而且你可能一开始就没有可靠的数据。
我写了一篇文章,标题为 我必须处理的 10 个非常混乱的数据例子,但这里给出几个例子:
-
处理不同拼写的类别,例如,美国、USA、US、美利坚合众国。
-
处理逻辑被破坏的数据。例如,如果有一条记录显示某用户在未重新安装的情况下两次卸载了同一个应用……真是让人感到困惑。
-
处理不一致的数据。例如,一张表可能告诉我我们的月收入是 50,000 美元,但另一张类似的信息表可能显示我们的月收入是 50,105 美元。
总结: 你大部分时间将花在清理数据上。你很可能无法直接跳到建模阶段。
4. 很大一部分时间用于理解当前的业务问题。
不论你愿意与否,数据科学家实际上就是一个业务分析师。为什么?因为你需要对你所从事的领域和当前的业务问题有全面的理解。没有这些,你将错过关键的关系、假设和变量,这可能是 65%准确模型与 95%准确模型之间的差别。
例如,如果你是市场部门的数据科学家,你必须完全了解每种营销渠道,包括它的目的、在营销漏斗中的位置、通常吸引的用户类型,以及用于评估该渠道的指标。
举个例子,贸易展会通常比附属营销(CAC 更高)要贵。然而,来自贸易展会的客户的LTV 也更高。如果你只构建了一个关注 CAC 的模型,你可能会提供不完整的信息,导致不再通过贸易展会进行营销。
简而言之: 在开始任何模型构建之前,应该花费大量时间了解你所工作的业务问题和领域。
5. 你不需要了解每一个工具,但了解的越多,效果越好。
我之前说过,专注于少数几个工具并把它们做得非常好是更好的。我依然坚持这一观点,但悲哀的现实是,你的雇主很可能会期望你在工作中不断发展和学习更多工具。
你应该很好地掌握你的基本工具。这包括 Python、SQL 和 Git,以及几个 Python 库,如 Pandas、NumPy、scipy、scikit-learn 等等。
不过,如果你的雇主要求你尽快学习新工具,比如 Airflow、Hadoop、Spark、TensorFlow、Kubernetes 等等,不要感到惊讶。
此外,如果你在职业生涯中更换雇主,你很可能需要学习一套新的工具,因为每家公司都有自己期望的技术栈,所以在选择新雇主时要注意这一点。
简而言之: 学习永无止境。如果你不喜欢这个声音,数据科学可能不适合你。
6. 沟通技巧是你最好的朋友。
这个点主要是针对那些认为成为数据科学家就是可以整天待在房间里建模的人。不管雇主怎么说,即便他们说你可以 24/7 在家工作或作为一个团队的一员工作,你仍然需要与其他利益相关者进行合作和沟通。
即使你是一个团队中的唯一成员,你也将不得不与高层管理人员沟通你正在做的工作以及它所带来的实际业务影响。你还可能需要与其他团队和业务分析师合作,建立我们之前提到的领域知识。
简而言之: 数据科学需要比你想象的更多的沟通,而这在成为成功的数据科学家方面至关重要。
原文。已获得许可重新发布。
相关:
更多相关主题
关于数据管理和其在计算机视觉中的重要性的 6 个事项
原文:
www.kdnuggets.com/2022/05/6-things-need-know-data-management-matters-computer-vision.html

照片由 Nana Smirnova 提供,来自 Unsplash
向工业 4.0 迈进以及数字化自动化的加速普及正对各行业的组织施加压力。企业利用数据的能力正逐渐成为竞争优势的关键来源——这一原则在构建和维护计算机视觉应用时尤为重要。视觉自动化模型由捕捉我们物理世界数字化表现的图像和视频驱动。在大多数企业中,媒体通过多个传感器边缘设备进行捕捉,并存在于孤立的源系统中,这使得在构建旨在自动化视觉检查的计算机视觉系统时,跨环境集成媒体成为一个核心挑战,需要解决。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力。
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作。
在模型架构(即构建神经网络的代码)越来越商品化和稳定的世界中,媒体变得更加重要。这意味着有更多被行业信任的模型类型,现在关注点减少在调整这些模型的代码以优化性能,而更多地放在使用必要的数据训练行业标准模型,以最佳服务你的应用。在数据驱动的计算机视觉模型开发中,组织必须不断用新的真实数据训练模型,以防止领域和数据漂移。因此,无论是大型还是小型计算机视觉供应商,都必须确保组织能够以编程方式持续大规模整合媒体。接下来,我们将探讨在评估计算机视觉数据管理解决方案时,我们认为至关重要的几个领域。
预构建的数据连接器
要管理数据,首先必须将所有数据集中到一个地方。你今天的数据可能分布在各种商业云环境、本地系统和边缘设备上。你需要的是一种简化连接所有硬件和软件的方法。预构建的连接可以使这些过程在几次点击之间完成,而不是几行代码。最好还有一个代码编辑器(Python SDK),以便在需要时构建自定义连接。总之,你不想每次需要集成新的媒体源时都去敲 IT 部门的门,这对每个人来说都很麻烦!
数据组织
将来自不同来源的数据整合在一起可能是一项复杂的工作。为了快速找到所需的数据,组织结构如文件夹、桶或数据集将帮助你整理媒体。你可能会根据捕获日期来组织数据,或者你可能希望将由单一生产线捕获的所有数据放在同一个文件夹中。选择权在你,只要确保保持一致即可。
数据可视化
现在你的所有数据都集中在一个地方,但如何快速筛选这些数据以找到感兴趣的媒体呢?这就需要一个使浏览大规模媒体变得简单的可视化工具。这可能是你认为理所当然的事情,但看到页面上快速刷新并动态出现的缩略图,或者能够快速浏览不需要漫长加载时间的图片轮播,都是今天组织在尝试使用像 Google Cloud Platform 这样的商业消费应用来存储大规模媒体时面临的问题。简而言之,你需要采用一个具有灵活且可扩展的后端的解决方案,该解决方案专为大数据构建,并让你以最小的加载时间快速浏览你的媒体。请记住,将所有这些数据集中在一个地方对你的计算机视觉模型的成功至关重要。
数据可搜索性
那张图片到底在什么文件夹里?在处理数百万个媒体文件时,你不希望被这个问题困住。一个像 Google 那样的简单搜索栏将帮助你通过名称快速搜索并找到感兴趣的媒体。一些计算机视觉平台还允许你使用一种强大的工具——“视觉搜索”,它会自动检测图像的内容并让你基于此进行搜索,使媒体更易发现。记住,维持大规模媒体的快速搜索性能是一个独特的问题,需要一个能够随数据集规模增加而扩展的系统。
元数据管理和过滤器
说到大数据集中的媒体发现,我们来说说元数据的好处。元数据让你保存“关于数据的数据”,例如这张图片是 10 月 4 日由 Antigua 工厂的 Linespex 相机拍摄的,比仅仅图片的文件名提供了更多关于媒体的信息。而且,一些数据管理平台允许你基于元数据创建过滤器,让你更细致地找到感兴趣的媒体。
数据溯源
这个文件来源于哪里?完整的数据溯源将帮助你轻松回答这个问题,让你了解你的媒体来源,而无需猜测或追踪源系统。数据溯源意味着你将知道哪些媒体来自哪个系统,以及该系统向平台发送新媒体的频率。大多数组织会利用这些信息根据运营需求选择新的训练数据。例如,如果检测生产线 7 上的缺陷的模型表现下降,我们首先尝试获取一些来自监控该生产线的相机的新媒体。
将计算机视觉模型从研发转移到生产的关键在于更好地管理企业媒体。这对公司至关重要,以便利用数据获得竞争优势。为成功做好准备意味着在选择计算机视觉合作伙伴时,你需要认真对待数据管理。
穆尔塔扎·霍穆斯 是数据和 AI 领域经验丰富的市场推广领导者。他从 Palantir 等大型组织的成功初创到上市转型中积累了经验,最近还在系列 A 计算机视觉初创公司 CrowdAI 担任产品营销负责人。他本质上是一个建设者,非常专注于与业务里程碑和日常执行对齐的深思熟虑的战略。他坚信 Drucker 的话:“文化吃掉战略”以及“如果没有写下来,它就不存在。” 他在数字化转型、云迁移、AI、系统集成、决策数据、分析、计算机视觉、网络安全和 SaaS 市场方面拥有技术专长。
了解更多关于这个话题
机器学习培训数据策略的6 个提示
原文:
www.kdnuggets.com/2019/09/6-tips-training-data-strategy-machine-learning.html
评论
作者:Wilson Pang,Appen 首席技术官。
人工智能(AI)和机器学习(ML)这些术语现在使用频繁。AI 指的是机器模仿人类认知的概念。ML 是用于创建 AI 的一种方法。如果 AI 是计算机能够根据指令执行一系列任务,那么 ML 就是机器能够自行摄取、解析和学习数据,从而在完成任务时变得更加准确或精确。
从事汽车、金融、政府、医疗、零售和科技等行业的高管可能已经对 ML 和 AI 有基本了解。然而,并非每个人都擅长制定培训数据策略,这是实现高回报机器学习投资的必要第一步。
AI 系统通过示例进行学习,示例越多、质量越高,它们的学习效果就越好。数据不足或质量低劣可能导致系统不可靠、得出错误结论、做出糟糕决策、无法处理现实世界的变化,并引入或延续偏见等问题。劣质数据也很昂贵。IBM 估计 美国的劣质数据每年使国家经济损失约 3.1 万亿美元。
如果没有明确的数据收集和结构化策略,你可能会面临项目延迟、无法适当扩展以及竞争对手超越你的风险。以下是建立成功培训数据策略的六个提示。
1: 为培训数据制定预算
启动新的机器学习项目时,首先要定义你要实现的目标。这将告诉你需要什么类型的数据以及需要多少个“培训项目”——已分类的数据点——来训练你的系统。
例如,对于计算机视觉或模式识别项目,培训项目可能是由人工标注者标记的图像数据,以识别图像中的内容(树木、停车标志、人物、汽车等)。此外,根据你所构建的解决方案类型,你的模型可能需要不断重新训练或更新。你的解决方案可能需要季度、每月甚至每周更新。
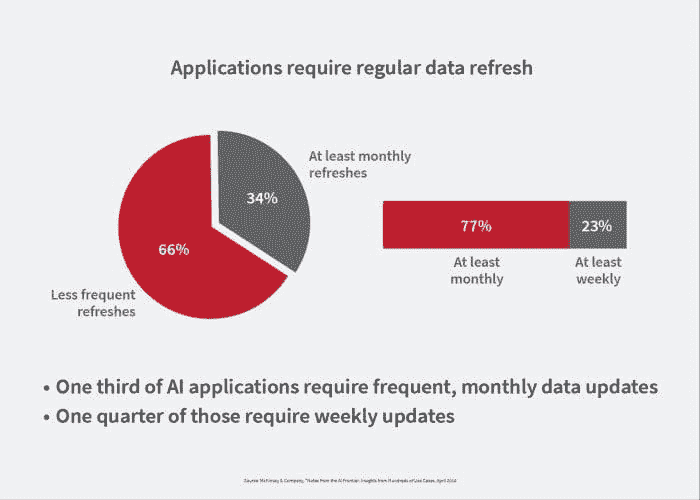
一旦培训项目和更新频率确定后,你就可以评估数据来源的选项,并计算预算。
重要的是要清楚地了解启动、维护和发展这个计划所需的时间和金钱投入——以及你的业务——以便解决方案能够保持相关性和对客户有用。启动机器学习项目是一项长期投资。获得良好的回报需要长期战略。
2: 获取合适的数据
你所需的数据类型取决于你所构建的解决方案类型。一些数据来源选项包括现实世界使用数据、调查数据、公共数据集和合成数据。例如,一个能够理解口头指令的语音识别解决方案必须在高质量的语音数据(现实世界数据)上进行训练,并且这些数据已被转录为文本。一个搜索解决方案需要人类评审员注释的文本数据,以告诉它哪些结果最相关。
在机器学习中最常见的数据类型包括图像、视频、语音、音频和文本。在用于机器学习之前,训练数据项必须被注释或标记,以识别它们的内容。注释告诉模型如何处理每一条数据。例如,如果虚拟家庭助手的数据项是录音中有人说“再订购一些双 A 电池”,注释可能会告诉系统在听到“order”时开始向特定的在线零售商下单,在听到“double-A batteries”时搜索“AA batteries”。
3: 确保数据质量
根据任务的不同,数据注释可能是相对简单的活动——但它也是重复的、耗时的,并且很难始终如一地做好。它需要人类的参与。
风险很高,因为如果你用不准确的数据来训练模型,模型可能会做出错误的判断。例如,如果你用标记错误为街道的人行道图像来训练自动驾驶汽车的计算机视觉系统,结果可能会非常糟糕。确实,“劣质数据质量是机器学习广泛、盈利使用的头号敌人。”
当我们谈论质量时,我们指的是这些标签的准确性和一致性。准确性是指标签接近真实情况的程度。一致性是指多个训练项上的注释彼此一致的程度。
4: 了解并减轻数据偏差
强调数据质量有助于公司在其人工智能项目中减轻偏差,这些偏差可能在你的人工智能解决方案进入市场之前是隐藏的。此时,偏差可能很难修复。
偏差通常来源于项目团队或训练数据中的盲点或无意识的偏好,从项目一开始就存在。人工智能中的偏差可能表现为对不同性别、口音或种族的不均衡语音或面部识别性能。随着人工智能在我们文化中的普及,现在是解决内在偏差的时机。
为了在项目级别避免偏见,要积极地将多样性融入定义目标、路线图、指标和算法的团队中。虽然雇佣一个多样化的数据团队说起来容易,但做起来却难,风险也很高。如果你的团队内部构成与潜在客户的外部构成不符,那么最终产品可能只适合或吸引一部分人,从而错过大众市场机会,甚至更糟:偏见可能导致现实中的歧视。
5: 在必要时,实施数据安全保护措施
并不是所有的数据项目都使用个人可识别信息(PII)或敏感数据。对于那些确实利用这类信息的解决方案,数据安全比以往任何时候都更为重要,特别是当你处理客户的 PII、金融或政府记录,或用户生成内容时。政府法规越来越多地规定了公司如何处理客户信息。
保护这些机密数据可以保护你及你的客户的信息。对你的实践保持透明和道德,并遵守服务条款,可以给你带来竞争优势。不这样做会使你面临丑闻和品牌负面影响的风险。
6: 选择合适的技术
你的训练数据越复杂或细致,结果就越好。大多数组织需要大量的高质量训练数据,且需要快速大规模地获取。为此,他们必须构建一个数据管道,以提供足够的量,并以刷新模型所需的速度运行。这就是为什么选择合适的数据注释技术至关重要。
你选择的工具必须能够处理与你的计划相关的适当数据类型,允许灵活的标注工作流程设计,管理个别标注员的质量和吞吐量,并提供机器学习辅助的数据标注,以增强人工标注员的表现。
制定策略使 AI 成功
最近一项来自 IHS Markit 的研究显示,87%的组织正在采用至少一种形式的变革性技术,如 AI,但只有 26%认为有合适的商业模式来充分捕捉这些技术的价值。
制定一个坚实的训练数据策略是捕捉 AI 价值的第一步。这包括设定预算、确定数据来源、确保质量,并构建安全措施。一个清晰的数据策略也有助于提供大多数机器学习模型所需的稳定数据管道。仅有的训练数据策略不能保证 AI 成功,但它可以帮助确保公司更好地利用 AI 提供的好处。
个人简介: Wilson Pang 是一位工程和数据科学技术领导者,精通大数据、数据科学、分布式系统工程、搜索科学、互联网营销和网络应用。Wilson 的热情是通过数据科学和工程创新与聪明的人才一起推动业务发展。
相关:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
更多相关主题
企业如何从机器学习中受益的 6 种方式
原文:
www.kdnuggets.com/2022/08/6-ways-businesses-benefit-machine-learning.html

图片由 Clay Banks 提供,来源于 Unsplash
越来越多的公司转向数据科学,利用技术来提升运营程序,原因如下:
-
一切都围绕数据的富余
-
通过机器学习实现自动推理
-
人工智能的发明
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织 IT
许多技术可以帮助组织充分利用其原始数据,而机器学习就是其中之一。数据挖掘和机器学习方法可以在几乎不需要编程的情况下,用于发现大量数据中的新模式和行为。
机器学习的不断演变和递归特性帮助公司跟上不断变化的商业和客户需求。目前所有主要的云服务提供商都提供机器学习平台,使得将机器学习创建或集成到现有工作流程中变得更加容易。
各行各业的组织都在实施机器学习(ML)技术,使其成为现代商业的支柱。
将机器学习融入业务的过程因缺乏如何开始使用它及其潜在好处的知识而受到阻碍。当我们展示实例并以教学方式描述技术时,或许可以解答我们收到的其他问题。
然而,首先,如何开始将其融入组织更为复杂,因为这需要你踏上实地并接触创新技术。机器学习将会持续存在,我们相信它将像手机一样改变社会。
本文旨在解释机器学习,它如何在业务运营中得到应用以及它可能带来的好处。
机器学习概述
我们必须首先对机器学习有一个基本的了解,以评估其潜在的优势。顾名思义,机器学习涉及从大量数据集中提取有用信息。
例如,考虑一个跟踪客户在网站上活动和购买的在线零售业务。这只是信息。机器学习在评估和提取这些数据中隐藏的模式、统计数据、事实和故事方面扮演着至关重要的角色。
机器学习中的算法在不断变化。随着算法获取更多数据,机器学习算法能够更好地分析和做出预测。机器学习算法的灵活性使其区别于更传统的数据分析和解释方法。
使用机器学习,企业能够:
-
更快适应不断变化的市场条件。
-
提升公司绩效
-
了解您的客户和业务需求。
机器学习的使用正在迅速扩展到经济的所有领域,包括农业、医学研究、股票市场和交通监控等应用。例如,农业可以利用机器学习来预测天气模式和确定作物轮作。
企业通过将机器学习和人工智能结合,可能获得额外的好处。像 Azure Machine Learning 和 Amazon SageMaker 这样的云计算服务使用户能够利用机器学习的灵活性和适应性来满足业务需求。
机器学习在商业中的应用案例
要了解机器学习在商业中的应用,您必须知道大多数机器学习技术的工作原理。主要有四个分支,即:
关联
从一个类别(X)购买食品的客户更可能购买另一个类别(Y)的食品。因此,我们可以向购买了类别 X 的客户推荐类别 Y,因为他们有 50% 的机会对其感兴趣。算法基于两个动作统计上关联的频率来计算可能性。
分类
为了使机器学习系统能够提供预测,它们必须首先在一些已经收集的数据上训练一个模型。客户的情感可以被分类为正面、负面或中立。利用我们对客户的了解,我们可以建立一个规则,告诉我们他们是否属于这四个类别中的一个。然后,算法将基于客户的过去经历来判断新客户是否对我们的服务感到满意。如果需要更多信息,请查看我们专门的数据分类帖子。
监督学习和无监督学习
无监督学习和监督学习在机器学习中都有使用。其含义可以总结如下。
在有监督学习中,使用已经标记或标注正确答案的数据来训练模型。算法可以被教导以分类和预测数据。
公司可以通过点击一个按钮解决现实世界的问题,比如从你的电子邮件中筛选垃圾邮件。顾名思义,无监督学习会自主评估和分组未标记的数据,在此过程中揭示新知识。这些算法被设计用来独立发现隐藏的模式或数据簇。
无监督学习算法可能解决比有监督学习系统更复杂的问题。它比较和分析数据的能力使其成为探索性数据研究的绝佳选择。公司可以利用无监督学习创新性地探索数据,使其比人工观察更快地识别模式。
顾名思义,这种学习类型依赖于从经验中收集或生成数据。基于以往的经验,它有助于优化性能需求并解决各种现实世界的计算难题。与训练有素的算法不同,无监督学习揭示了数据中之前未知的模式,并帮助识别有价值的分类特征。
当前可用的数据可以用于对客户进行分类,而尚未揭示的信息可以在无监督学习过程中使用。
强化学习
计算机学习模型通过将其置于类似游戏的环境中进行训练,以作出决策。计算机通过试错来解决问题。为了使计算机执行程序员指定的操作,它会收到正面和负面的反馈。为了最大化奖励,计算机必须进行一系列随机尝试,然后再做决定。最有效的方法是使用强化学习。
机器学习的前 6 大商业利益
1. 实时聊天代理
对话界面,例如聊天机器人,是自动化的早期例子之一,因为它们通过允许用户提问并接收回答来实现人机互动。在聊天机器人早期,机器人根据预定义的规则进行特定行为的编程。
聊天机器人在预测和响应用户需求方面变得越来越出色,并且表现得更像人类。随着人工智能的机器学习和自然语言处理(NLP)的加入,聊天机器人有潜力变得更加互动和高效。机器学习算法支持像 Siri、Google Assistant 和 Amazon Alexa 这样的数字助手,这项技术可能会被用于替代传统的聊天机器人,在新的客户服务和互动平台中发挥作用。
聊天机器人是工作场所中最受欢迎的机器学习应用之一。以下是一些获得好评的聊天机器人示例:
-
IBM 宣称其 Watson Assistant 是一种“快速、简单的解决方案”机器,该机器旨在确定何时需要进一步的信息以及何时应将请求升级到人工处理。
-
使用音乐流媒体服务的 Facebook Messenger 机器人来听音乐、搜索音乐和分享音乐。
-
通过聊天平台或电话提供骑手的车牌号和车型,以便他们能够找到自己的交通工具。
2. 促进准确的医疗预测和诊断
在医疗行业,机器学习(ML)使得识别高风险患者、诊断、开处方以及预测再入院成为可能。这些发现主要基于匿名化的患者记录和症状数据。通过避免不必要的药物,可以加快患者的康复。机器学习使医疗行业能够改善患者健康。
3. 简化数据录入中的时间密集型文档
计算机可以执行自动化数据录入工作,从而释放人力资源以专注于更高价值的工作。数据录入自动化带来了几个挑战,其中最重要的是数据重复和准确性。预测建模和机器学习方法可以显著改善这一问题。
4. 金融规则和模型更为准确
此外,机器学习在金融行业也产生了重大影响。投资组合管理和算法交易是机器学习在金融领域中最受欢迎的两种应用。
贷款承保是另一个应用领域。安永的《承保的未来》研究指出,机器学习可以通过持续的数据评估发现和分析异常和细微之处。通过这种方式,金融模型和法规可以更为准确。
5. 市场研究和客户细分
公司可以利用机器学习软件提供的预测库存规划和消费者细分能力,帮助制定价格,并在适当的时间将合适的产品和服务送到正确的地方。UST Global 的首席架构师 Adnan Masood,以及人工智能和机器学习专家,解释了零售商如何利用机器学习根据季节性因素、该地区的人口统计数据和其他数据点预测哪些商品在其位置上最畅销。
机器学习应用可以分析客户的购买习惯,使零售商能够更好地服务客户,通过在商店中储备更有可能被这些客户购买的产品(例如相似年龄、收入或教育水平的客户所购买的产品)。
6. 欺诈检测
在识别欺诈方面,机器学习是一种强大的工具,因为它能够识别模式并快速发现异常。金融公司在这一领域已经利用机器学习多年。
具体过程是这样的:机器学习可以学习单个客户的正常行为,例如他们使用信用卡的时间和地点。机器学习可以利用这些数据和其他数据集,通过在毫秒内分析数据,快速区分符合预期规范的交易和可能的欺诈交易。
机器学习可以用于检测各种业务中的欺诈行为,包括:
-
货币服务的提供
-
旅行
-
游戏
-
零售
结论
自动化和人工智能(AI)正在成为企业日常运营中越来越重要的工具,而机器学习是其中最广泛使用的技术之一。
要成功经营企业,你必须根据事实做出决策。如果你不跟上像“机器学习”这样的行业术语,你可能会错过一些新兴的分析工具,这些工具可能会帮助你做出更好的决策。
机器学习是人工智能(AI)领域的一个子集。机器学习技术帮助企业充分利用这些重要的变化,从而理解他们的数据。
尽管安装机器学习(ML)可能耗时且昂贵,人工智能开发公司愿意接受这一挑战,因为它相对于任何其他分析工具提供了自然且显著的优势。
Rajalekshmy KR 是一名 SEO 内容专家,供职于NeoITO,这是一家位于美国的可靠网站开发公司。她总是寻求来自技术创始人、产品负责人和商业策略师的反馈,以撰写对她的读者有价值的内容。
了解更多相关话题
6 个 YouTube 频道学习 AI

图片由编辑提供
学习新技能或新领域可能令人望而却步,特别是当费用很高时。这就是为什么 KDnuggets 在这里帮助你。与其不断陷入寻找合适课程的兔子洞,不如查看我们整理的 YouTube 频道列表,这些频道可以启动你的学习之旅,而且无需任何费用。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
想要有趣且互动——我们有适合的 YouTube 频道。想要高度教育性并提供课程——我们也有。想免费成为 AI 专家?
查看这些 YouTube 频道:
Matt Wolfe
目前有 214 个视频,Matt Wolfe 是一位科技狂热者,他所做的就是谈论科技。如果你想了解 AI,了解该领域的最新动态,注意哪些问题以及 AI 的未来——请查看 Matt Wolfe 的 YouTube 频道。他的视频将讨论 AI 领域的新闻,同时也会评测工具和产品——为你节省了大量的工作。了解 ChatGPT、AI 音乐、生成艺术以及更多无代码和未来主义概念的教程。
AI 解释
链接: AI 解释 YouTube 频道
另一个简化复杂 AI 过程、产品和机制的 YouTube 频道,适合普通人。无论你是 AI 世界的初学者还是完全有经验的科技爱好者——这个频道都适合你。你可以坐下来观看对新 AI 产品的终极评测,以及这些新产品和服务对未来的意义。
两分钟论文
链接: 两分钟论文 YouTube 频道
想要学习 AI 但由于过于忙碌而没时间?请查看“两分钟论文” YouTube 频道,该频道基于论文深入讲解最新的 AI 和机器学习研究项目——每个视频仅需 2 分钟。拥有超过 150 万的订阅者,Two Minute Papers 让你以有趣和互动的方式了解 AI 研究论文。
DeepLearning.AI
链接: DeepLearning.AI YouTube 频道
DeepLearning.AI 平台由 Andrew Ng 于 2017 年创立,已经成为最快增长和最受欢迎的 AI 学习平台之一。该平台旨在通过创建高质量的 AI 课程和培养紧密的社区来满足世界级 AI 教育的需求。
AI 优势
曾经想过如何将 AI 工具和服务融入你的日常生活或加以利用吗?现在,你可以通过 AI Advantage YouTube 频道来学习如何利用 AI 在商业环境中获得竞争优势,以及如何使你的任务对你更有生产力。
MattVidPro AI
如果你想学习 AI,以便跟上时代的步伐而不落后,我强烈推荐 MattVidPro AI YouTube 频道。这个频道将为你提供有关所有 AI 技术的深入覆盖,尤其是最新技术及其能力。他还提供了实用指南,告诉你如何使用这些 AI 工具——这样你就不必自己摸索了。
Siraj Raval
也许你想看看这些 AI 工具有趣的一面。现在,你可以通过 Siraj Raval 的 YouTube 频道来实现,他将 AI 的教育内容与娱乐结合起来。他让学习 AI 及其概念变得有趣和互动。发现你可以用 AI 工具如 ChatGPT 创造的有趣而引人入胜的东西。
总结一下
学习不必总是高度技术化和通过流程来进行。通过互动视频、带有观点的文章和教程来学习也是了解你感兴趣领域的一种好方式,同时保持对 AI 领域最新动态的了解。
如果你知道其他优秀的 YouTube 频道能为我们的读者带来帮助,请在评论中留言!
Nisha Arya 是一名数据科学家、自由技术作家,同时也是 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及数据科学的理论知识。Nisha 涵盖了广泛的主题,并希望探索人工智能如何有助于人类生命的持久性。作为一个积极学习者,Nisha 希望扩展她的技术知识和写作技能,同时帮助指导他人。
更多相关内容
7 个 AI 组合项目以提升简历
原文:
www.kdnuggets.com/7-ai-portfolio-projects-to-boost-the-resume

作者提供的图片
我真正相信,为了在人工智能领域找到工作,你需要拥有一个强大的作品集。这意味着你需要向招聘人员展示你能够构建解决现实问题的 AI 模型和应用程序。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
在这篇博客中,我们将回顾 7 个 AI 组合项目,这些项目将提升你的简历。这些项目附带教程、源代码和其他辅助材料,帮助你构建合适的 AI 应用程序。
1. 在 5 分钟内构建和部署你的机器学习应用程序
项目链接: 在 5 分钟内使用 Hugging Face 和 Gradio 构建 AI 聊天机器人
项目截图
在这个项目中,你将构建一个聊天机器人应用程序,并将其部署到 Hugging Face 空间。这是一个面向初学者的 AI 项目,只需了解少量的语言模型和 Python 知识即可。首先,你将学习 Gradio Python 库的各种组件来构建聊天机器人应用程序,然后你将使用 Hugging Face 生态系统加载模型并进行部署。
就这么简单。
2. 使用 DuckDB 构建 AI 项目:SQL 查询引擎
项目链接: DuckDB 教程:构建 AI 项目
项目截图
在这个项目中,你将学习如何使用 DuckDB 作为 RAG 应用程序的向量数据库,以及如何使用 LlamaIndex 框架作为 SQL 查询引擎。查询将接受自然语言输入,将其转换为 SQL,并以自然语言显示结果。这是一个简单直观的初学者项目,但在深入构建 AI 应用程序之前,你需要学习一些 DuckDB Python API 和 LlamaIndex 框架的基础知识。
3. 使用 LangChain 和 Cohere API 构建多步骤 AI 代理
项目链接: Cohere Command R+: 完整的逐步教程
项目中的截图
相比于 OpenAI API,Cohere API 在开发 AI 应用方面功能更强大。在这个项目中,我们将探索 Cohere API 的各种功能,并学习如何使用 LangChain 生态系统和 Command R+ 模型创建一个多步骤的 AI 代理。这个 AI 应用将接收用户的查询,使用 Tavily API 搜索网络,生成 Python 代码,使用 Python REPL 执行代码,然后返回用户请求的可视化结果。这是一个中级项目,适合具有基本知识并有兴趣使用 LangChain 框架构建高级 AI 应用的个人。
4. 微调 Llama 3 并本地使用
项目链接: 微调 Llama 3 并本地使用:逐步指南 | DataCamp
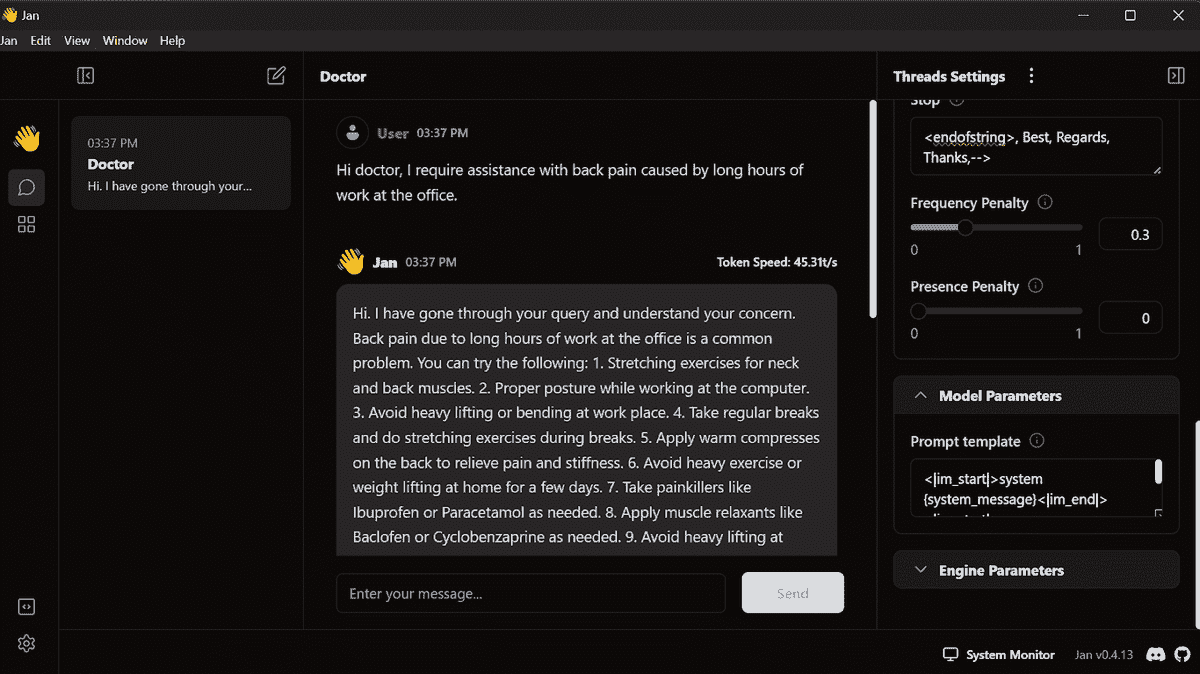
项目中的图片
一个受欢迎的 DataCamp 项目,将帮助你使用免费资源微调任何模型,并将模型转换为 Llama.cpp 格式,以便在没有互联网的情况下本地使用在你的笔记本电脑上。你将首先学习在医疗数据集上微调 Llama-3 模型,然后将适配器与基础模型合并,并将完整模型推送到 Hugging Face Hub。之后,将模型文件转换为 Llama.cpp GGUF 格式,对 GGUF 模型进行量化,并将文件推送到 Hugging Face Hub。最后,使用 Jan 应用在本地使用微调后的模型。
5. 多语言自动语音识别
模型仓库: kingabzpro/wav2vec2-large-xls-r-300m-Urdu
代码仓库: kingabzpro/Urdu-ASR-SOTA
教程链接: 使用 🤗 Transformers 微调 XLSR-Wav2Vec2 以进行低资源 ASR
截图来自 kingabzpro/wav2vec2-large-xls-r-300m-Urdu
我最受欢迎的项目!每个月下载量接近五十万次。我在一个乌尔都语数据集上使用 Transformer 库对 Wave2Vec2 Large 模型进行了微调。在此之后,我通过集成语言模型提高了生成输出的结果。
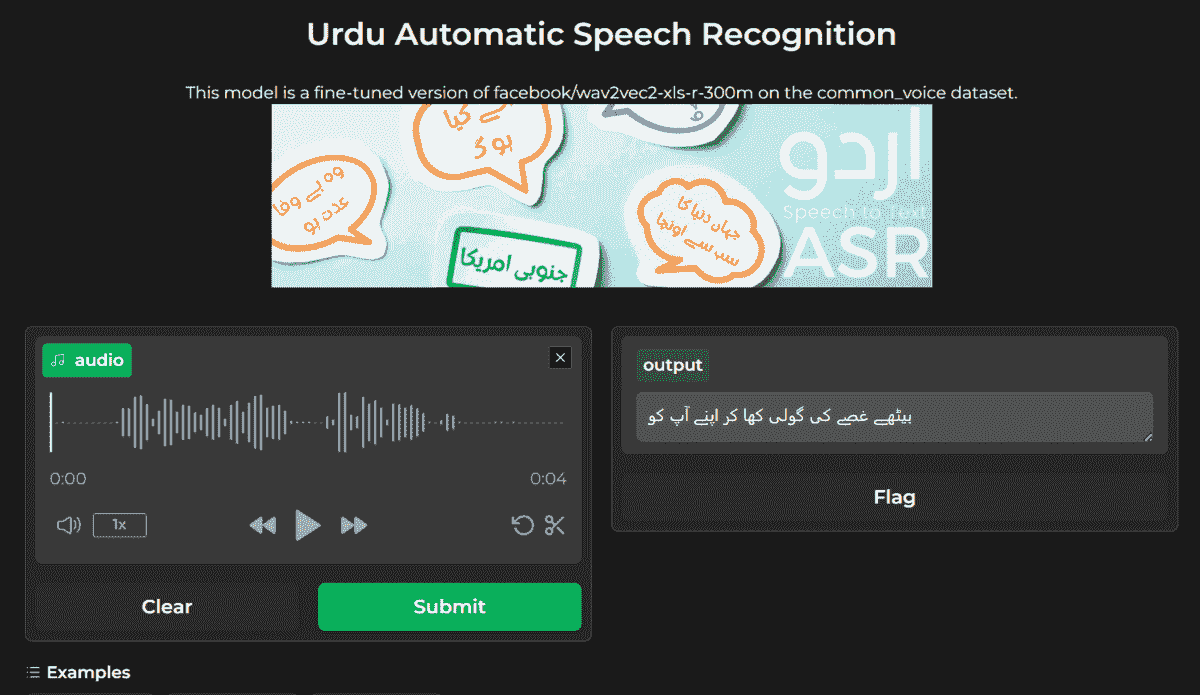
截图来自 Urdu ASR SOTA - a Hugging Face Space by kingabzpro
在这个项目中,你将微调一个语音识别模型,并将其与语言模型集成以提高性能。之后,你将使用 Gradio 构建一个 AI 应用程序并将其部署到 Hugging Face 服务器上。微调是一项具有挑战性的任务,需要学习基础知识、清理音频和文本数据集,并优化模型训练。
6. 构建机器学习操作的 CI/CD 工作流
项目链接: 面向初学者的 CI/CD 机器学习指南 | DataCamp
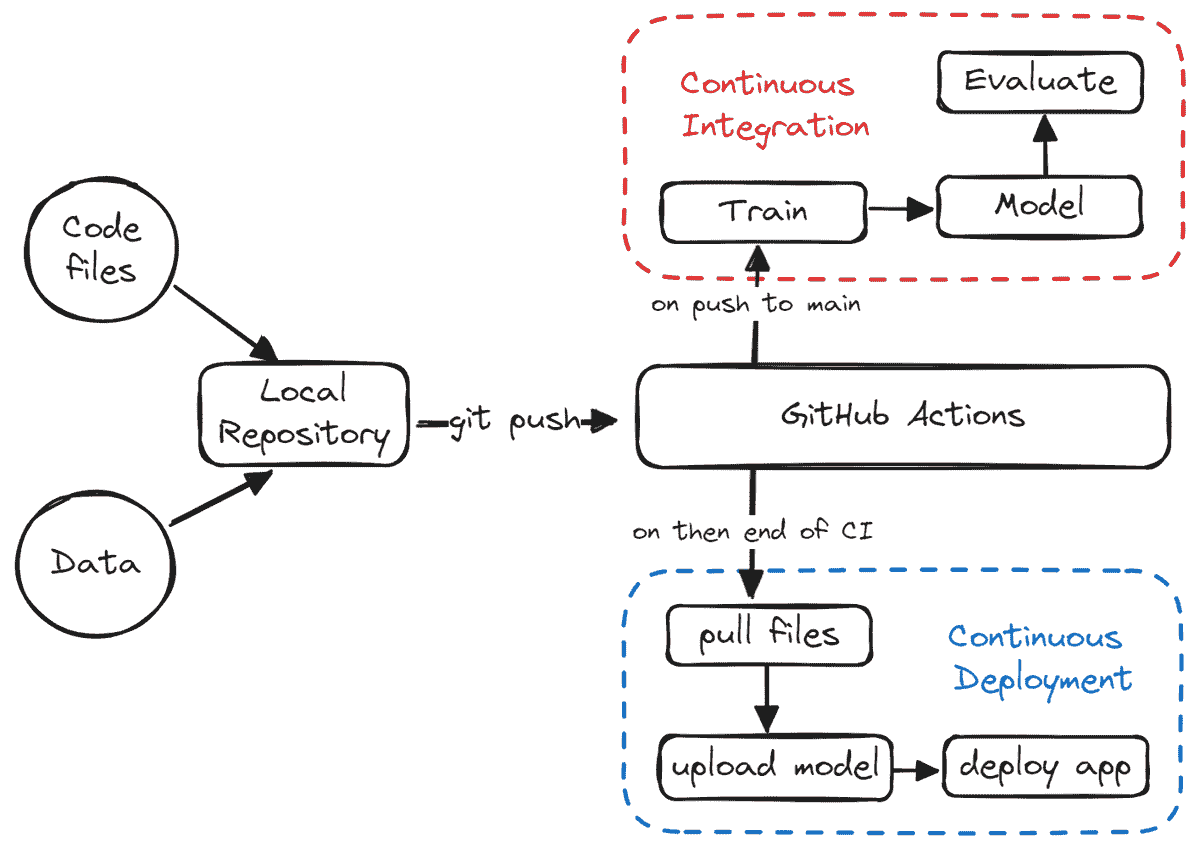
项目中的图片
另一个流行的 GitHub 项目。它涉及构建 CI/CD 管道或机器学习操作。在这个项目中,你将学习机器学习项目模板以及如何自动化模型训练、评估和部署的过程。你将了解 MakeFile、GitHub Actions、Gradio、Hugging Face、GitHub 密钥、CML 操作和各种 Git 操作。
最终,你将构建端到端的机器学习管道,当新数据被推送或代码被更新时,这些管道将自动运行。它将利用新数据重新训练模型,生成模型评估,提取训练好的模型,并将其部署到服务器上。这是一个完全自动化的系统,在每一步都会生成日志。
7. 使用 DreamBooth 和 LoRA 微调 Stable Diffusion XL
项目链接: 使用 DreamBooth 和 LoRA 微调 Stable Diffusion XL | DataCamp

项目中的图片
我们已经学习了如何微调大型语言模型,但现在我们将使用个人照片微调一个生成式 AI 模型。微调 Stable Diffusion XL 只需几张图片,因此你可以获得如上所示的最佳结果。
在这个项目中,你将首先了解 Stable Diffusion XL,然后使用 Hugging Face AutoTrain Advance、DreamBooth 和 LoRA 在新数据集上微调它。你可以使用 Kaggle 免费 GPU 或 Google Colab。该项目附带了一个指南,帮助你完成每一步。
结论
博客中提到的所有项目都是由我构建的。我确保包括了指南、源代码和其他支持材料。
完成这些项目将为你提供宝贵的经验,并帮助你建立一个强大的作品集,从而增加获得理想工作的机会。我强烈建议大家在 GitHub 和 Medium 上记录他们的项目,然后在社交媒体上分享以吸引更多关注。继续工作,持续构建;这些经历也可以作为实际经验添加到你的简历中。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理健康问题的学生打造一款 AI 产品。
更多相关话题
7 个人工智能应用案例正在改变实时体育制作和分发
原文:
www.kdnuggets.com/2020/01/7-ai-use-cases-transforming-live-sports-production-distribution.html
评论
由 Adrish Bera, Prime Focus Technologies 提供
今天,先进的人工智能(AI)和机器学习(ML)解决方案能够识别特定的游戏对象、结构、球员、事件和动作。这有助于近乎实时的内容发现,并帮助体育制作人员即使在比赛进行时也能自动创建体育高光包。体育迷总是希望找到新的方式来与体育互动,使他们更接近实时动作。现代 AI 和 ML 技术提供了一些真正沉浸式的体验,满足了球迷的需求。
以下是 7 个强大的 AI 驱动应用案例,适用于线性电视和 OTT 应用,正在改变实时体育制作的格局:
1. 体育档案的编目、发现和搜索以辅助讲故事
利用 AI 驱动的自动内容识别,比赛内容按段标记。这使得实时比赛以及整个体育档案可以由游戏制作人员搜索每一个可能的动作和戏剧性事件。
2. 自动高光包创建
一旦内容被自动和全面标记,机器可以根据预定义和自动学习的规则剪辑高光包。
3. 互动电视体验
广播公司可以为机顶盒提供商或有线运营商提供动态比赛内容、引人入胜的故事和高光片段。这些片段可以叠加在实时内容上,作为额外内容,通过遥控设备的“主动电视”按钮进行访问。

图 1:关键事件、视频点播高光包(例如 5 次击球、击球手的里程碑等)可以通过“主动电视”按钮进行通知。
4. OTT 应用的视频通知
用户在比赛的关键事件发生(如板球的 4 分、6 分、击球、足球的进球)后会自动收到通知。他们可以通过单击播放这些视频。
5. OTT 应用上的视频评分卡
AI 生成的视频片段可以添加到评分卡或评论文本流中。这使得枯燥的文本评分卡和评论变得生动有趣。
图 2:OTT 应用的视频通知和视频评分卡
6. 沉浸式 OTT 体验
利用 AI 引擎提取的游戏数据可以叠加在视频上,提供类似“亚马逊 X-Ray”的体验。用户可以更详细地探索游戏的不同方面,而无需妥协实时观看体验。
7. OTT 应用的个性化播放列表和搜索
用户可以在比赛进行时享受自动策划的精彩片段包或播放列表。他们可以使用自由文本搜索功能查找比赛事件,也可以生成自己的个性化播放列表。

图 3:比赛的自动生成精彩片段包可以作为覆盖层显示在 OTT 视频播放器上。用户可以即时查看镜头细节或搜索比赛中的任何事件。
用例的交付方式
为了交付上述强大的体验,我们需要能够全面、准确且快速地识别和标记体育事件。标签越细致,下游用例越丰富。如今,体育制作人试图通过部署一支实时观看比赛并每分钟猛烈标记关键属性的操作员队伍来实现这一目标。然后,还有许多编辑人员会搜索这些标签并组装精彩片段。这种操作不可扩展,因此观众最终只能看到有限种类的精彩片段,有时甚至在实际动作发生数小时后才能看到。
人工智能和机器学习极大地改变了局面——通过提供所需的准确性、多样性、速度和规模。人工智能可以快速检测动作,并在几秒钟内创建一套详尽的精彩片段,以从数百个不同的角度观看比赛。
体育中的机器学习
机器学习基于这样一个前提:机器需要大量的训练数据来构建分类算法。一旦算法建立,它就可以使用新的数据集(测试数据)来预测结果。根据这一逻辑,如果我们给机器大量某项运动的录像,它应该开始理解该运动的动作。然而,现实情况却大相径庭,因为每项运动都复杂且独特。即使是没有经验的成年人,如果仅仅让他/她看成千上万小时的比赛录像,也无法解读像板球这样的比赛。
因此,我们需要将基本的游戏逻辑和规则进行编码,并在一个专注的上下文中应用机器学习,以便机器模仿人类的认知。让我们以板球为例来更好地理解这一点。在观看板球比赛时,我们通过比赛内容中的不同元素来解读和欣赏比赛。这些元素包括:1)我们对比赛动作的知识,如投球、接球、裁判信号等;2)屏幕上的图形告诉我们得分亮点和比赛的当前状态;3)来自体育场的声音,如球击中球棒的声音、掌声、呼吁等;4)专家评论。

图 4:人工智能模拟人类识别以辨别比赛
为了帮助机器像人类一样理解比赛,我们需要基于这些多样化的输入建立一个模型。通常,我们会部署不同类型的神经网络以及计算机视觉技术,以解读上述四个元素的各个方面。多种分类和认知引擎被同时使用,以“辨别”比赛的不同视角。
为了训练这些引擎,我们需要筛选数百小时的比赛录像,注释不同的帧、物体、动作等,并生成机器学习的训练数据。然后,这些认知引擎会结合游戏逻辑和对体育制作的理解,将比赛逐段分类。例如,对于板球,我们部署了超过 11 个这样的引擎,以提取每个球的 25+属性,包括击球手、非击球手、投球手、得分、击球类型、四分、六分、重播、观众兴奋程度、庆祝、出局、投球类型、球的概况等。
搜索与发现
为了使单场比赛的档案或录像可以被检索,AI 生成的元数据应该成为使用像 Elastic Search 这样的高级语义搜索引擎的搜索索引的一部分。帮助提供更精确搜索结果的技术包括自然语言处理(NLP)、关键实体识别、词干提取、同义词、模糊逻辑和重复项移除。
精彩片段制作
一旦 AI 引擎彻底分类了比赛,下一个挑战是创建即时的精彩片段包,捕捉比赛的关键事件和戏剧性。对于观众而言,兴奋程度通常在比赛的高潮时达到顶点。例如,在足球比赛中,这可能是在进球或错失进球的时候。视觉线索如裁判/裁判员的信号或屏幕上的文字覆盖也表示关键事件。精彩片段制作引擎可以利用这些高潮和属性来创建一个简单的精彩片段包。
但制作引人入胜的精彩片段涉及更多内容。例如,一个好的板球比赛精彩集锦不仅仅是四分、六分和出局的组合。人类编辑巧妙地剪辑出一个捕捉悬念、幽默、戏剧性的包,并讲述一个引人入胜的故事。如果一个击球手在出局前被击中了几次,编辑会展示所有三球——而不仅仅是最后一球。其他元素如比赛剪辑、赛前仪式、球员入场、掷币等也需要学习并包含在精彩片段中。
AI 生成的精彩片段是使用从过去的比赛精彩片段制作中构建的可学习业务规则创建的。这些规则需要随着时间的推移不断改进,因为引擎会学习什么效果更好,什么效果不好。这些规则基于每场比赛段落的全面属性/标签。类似于人类编辑,机器也可以引入基于 AI 的音频平滑、两个片段之间的场景过渡、流畅的评论剪辑等,从而使人类编辑只需付出最少的努力进行质量检查(QC)和修整。
技术和物流挑战
没有两项运动是相同的。鉴于每项运动的复杂性,制作人员不能使用 Google、微软和 IBM Watson 等第三方视频识别引擎来标记内容、发现有意义的片段或创建精彩片段。需要建立和训练定制模型,以有效标记体育内容。此外,还需要为特定运动建立特定模型 - 包括游戏逻辑、专家方法和历史学习。这是一个繁琐的过程,但任何试图创建通用运动模型的尝试都可能失败。
每项运动的制作方式也各不相同。例如,在足球中,向球门移动的镜头通过不同的相机角度组合展示长镜头和特写镜头。对于板球或棒球,镜头尽量将球保持在画面的中央,而击球手正在击球。我们需要用这些细微差别和制作技术的特定知识来训练我们的引擎。
如今,制作人员需要迅速将精彩片段发布到 Facebook、Twitter 和 YouTube 等平台,因此他们需要快速进行游戏标记和精彩片段生成。具备本地和云托管能力的 AI 引擎可以帮助实现所需的速度。
人工智能下的体育制作未来已经到来
如今,观众期望以更加亲密和个性化的方式参与游戏。应用和采用 AI/ML 是实现这些期望的唯一途径。没有捷径。必须部署特定运动的 AI 主导的定制模型,并经过数月的微调以达到预期结果。像所有其他领域一样,AI 最终将帮助自动化日常任务,使人力资源可以将精力集中在更具创造性的追求上。
简介: Adrish Bera 是 Prime Focus Technologies (PFT) 的 SVP - 在线视频平台、人工智能和机器学习 - 通过 AI 和 ML 为媒体和娱乐行业建立尖端的视频认知能力,以实现规模化的自动化和效率。在 PFT 之前,Adrish 是 Apptarix 的首席执行官及共同创始人,Apptarix 是社交 OTT 平台 TeleTango 的创始公司。Adrish 是一位拥有 20 年移动软件和电信行业经验的资深人士,涵盖了从端到端的产品管理、产品开发和软件工程。他也是一位技术博主,对技术营销、智能手机、新兴市场、社交媒体和数字广告有广泛兴趣。
相关内容:
-
能源和公用事业中前 10 名数据科学应用案例
-
市场营销中前 8 名数据科学应用案例
-
使用时间序列编码发现棒球历史上最有趣的赛季
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
更多相关主题
7 款 AI 驱动的工具,以提升数据科学家的生产力
原文:
www.kdnuggets.com/2023/02/7-aipowered-tools-enhance-productivity-data-scientists.html

图片由作者提供
本文将讨论 7 款 AI 驱动的工具,这些工具可以帮助你提高作为数据科学家的生产力。这些工具可以帮助你自动化数据清理和特征选择、模型调整等任务,这些任务直接或间接地提高了你的工作效率、准确性和效果,同时也有助于做出更好的决策。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 工作
其中许多工具具有用户友好的界面,非常简单易用。同时,有些工具允许数据科学家与其他成员共享和协作项目,这有助于提高团队的生产力。
1. DataRobot
DataRobot 是一个基于网页的平台,帮助你自动化构建、部署和维护机器学习模型。它支持许多功能和技术,如深度学习、集成学习和时间序列分析。它使用先进的算法和技术,帮助快速而准确地构建模型,同时还提供维护和监控已部署模型的功能。

图片由DataRobot提供
它还允许数据科学家与他人共享和协作项目,使团队在复杂项目上的协作变得更容易。
2. H20.ai
H20.ai 是一个开源平台,提供了专业的数据科学工具。它的主要特点是自动化机器学习(AutoML),该功能自动化了构建和调整机器学习模型的过程。它还包括如梯度提升、随机森林等算法。
作为一个开源平台,数据科学家可以根据自己的需求自定义源代码,以便将其集成到现有系统中。

图片由H20.ai提供
它使用一个版本控制系统来跟踪所有的更改和代码修改。H2O.ai 还可以在云端和边缘设备上运行,并支持一个大型且活跃的用户和开发者社区,这些人贡献于该平台。
3. BigPanda
BigPanda 用于自动化 IT 操作中的事件管理和异常检测。简单来说,异常检测是识别数据集中显著偏离预期行为的模式、事件或观察结果。它用于识别可能指示问题的异常或不正常的数据点。
它使用各种 AI 和 ML 技术来分析日志数据并识别潜在问题。它可以自动解决事件,减少手动干预的需求。

图片来源:BigPanda
BigPanda 可以实时监控系统,有助于快速识别和解决问题。此外,它可以帮助识别事件的根本原因,使解决问题变得更加容易,并防止问题再次发生。
4. HuggingFace
HuggingFace 用于自然语言处理 (NLP),提供预训练模型,允许数据科学家快速实现 NLP 任务。它执行许多功能,如文本分类、命名实体识别、问答和语言翻译。它还提供了在特定任务和数据集上微调预训练模型的能力,从而提高性能。
其预训练模型在各种基准测试中达到了最先进的性能,因为它们在大量数据上进行了训练。这可以节省数据科学家的时间和资源,让他们能够快速构建模型,而不必从头开始训练。

图片来源:Hugging Face
该平台还允许数据科学家对特定任务和数据集上的预训练模型进行微调,从而提高模型的性能。这可以通过简单的 API 完成,即使是那些 NLP 经验有限的人也能轻松使用。
5. CatBoost
CatBoost 库用于梯度提升任务,并专门设计用于处理分类数据。它在许多数据集上实现了最先进的性能,并支持通过并行 GPU 计算加速模型训练过程。

图片来源:CatBoost
CatBoost 对过拟合和数据噪声的稳定性和鲁棒性最好,这可以提高模型的泛化能力。它使用一种称为“有序提升”的算法,迭代填补缺失值后再进行预测。
CatBoost 提供了特征重要性,这可以帮助数据科学家理解每个特征对模型预测的贡献。
6. Optuna
Optuna 也是一个开源库,主要用于超参数调整和优化。这帮助数据科学家找到机器学习模型的最佳参数。它使用了一种称为“贝叶斯优化”的技术,可以自动搜索给定模型的最佳超参数。

图片由 Optuna 提供
其另一个主要特性是可以轻松与各种机器学习框架和库,如 TensorFlow、PyTorch 和 scikit-learn 集成。它还可以同时优化多个目标,从而在性能和其他指标之间取得良好的平衡。
7. AssemblyAI
这是一个提供预训练模型的平台,旨在方便开发者将这些模型集成到现有的应用程序或服务中。
它还提供了各种 API,如语音转文本或自然语言处理。语音转文本 API 用于从音频或视频文件中获取文本,具有高准确性。此外,自然语言 API 可以帮助处理情感分析、图像实体识别、文本摘要等任务。
图片由 AssemblyAI 提供
结束语
训练一个机器学习模型包括数据收集和准备、探索性数据分析、特征工程、模型选择和训练、模型评估,最后是模型部署。要完成所有这些任务,你需要了解各种工具和命令。这七种工具可以帮助你以最小的努力训练和部署你的模型。
总结一下,希望你喜欢这篇文章并觉得它有用。如果你有任何建议或反馈,请通过 LinkedIn 联系我。
Aryan Garg 是一名电气工程学的 B.Tech.学生,目前在本科最后一年。他的兴趣在于网页开发和机器学习。他已经追求了这个兴趣,并渴望在这些方向上继续工作。
更多相关主题
7 个初学者友好的项目,帮助你开始使用 ChatGPT
原文:
www.kdnuggets.com/2023/08/7-beginnerfriendly-projects-get-started-chatgpt.html
作者提供的图像
在技术以空前速度发展的时代,人工智能?——还是朋友们称之为 AI 🤓,作为最具变革性的力量之一脱颖而出。
从自动化日常任务到预测复杂模式,AI 正在重塑行业并重新定义可能性。
随着我们站在这场 AI 革命的前沿,理解其潜力并将其融入我们的日常工作流中是至关重要的。
然而……我知道开始使用这些新技术可能会令人感到不知所措。
所以,如果你在考虑如何开始使用 AI,特别是像 ChatGPT 这样的模型……
今天我带来了一套 7 个项目,以从零开始学习如何处理这些项目。
让我们一起探索这些项目吧! 👇🏻
1. 使用 OpenAI API 生成语言翻译器
LLMs 展示了广泛的应用场景。而最有用的——也是最容易应用的——正是它将任何语言翻译成另一种语言的能力。
在教程使用 OpenAI ChatGPT 构建多语言翻译工具 API 中,由Kaushal Trivedi指导读者使用 OpenAI 的 gpt-3.5-turbo 模型通过 API 创建 AI 驱动的翻译应用程序。
教程的截图。
过程包括以下步骤:
-
设置 OpenAI API 凭证。
-
使用 Python 和 OpenAI API 定义翻译功能。
-
测试功能。
-
使用 Python 的 Tkinter 库创建用户界面。
-
测试用户界面。
关键的课程是 GPT-3.5 Chat API 在构建强大的 AI 工具中的潜力。在这个案例中,用于创建一个翻译工具。
2. 使用 ChatGPT 构建一个用于你业务的情感分析 AI 系统
LLM 的另一个常见应用是处理大量文本。想象一下你经营一家电商,每天收到成千上万的评论?——你可以利用 AI 驱动的工具来处理这些评论。
这正是 Courtlin Holt-Nguyen 在他的教程 Sentiment Analysis with ChatGPT, OpenAI, and Python?—?Use ChatGPT to build a sentiment analysis AI system for your business. 中展示的内容。他在 Google Colab 上完成了整个教程,并试图强调 ChatGPT 在处理各种 NLP 任务中的多功能性、结构化数据在有效分析中的重要性,以及 ChatGPT 理解和解释其回应的能力。
教程截图。
关键步骤如下:
-
描述要使用的数据集。你可以使用他的数据集,也可以选择你喜欢的其他数据集。
-
介绍了 OpenAI API。
-
在 Google Colab 中安装所需库,并开始使用 ChatGPT OpenAI API 进行情感分析。
-
GPT 模型处理评论的具体应用。
ChatGPT 强大的 AI 能力可以用于全面的情感分析、摘要生成以及从客户评论中提取可操作的见解。
3. LangChain 和 OpenAI 的基本使用
上个月我写了一篇易于理解的 LangChain 基础介绍文章,标题为 Transforming AI with LangChain: A Text Data Game Changer,这是一个旨在最大限度发挥大型语言模型在文本数据处理潜力的 Python 库。

教程截图
LangChain 处理大文本数据的多功能性及其提供结构化输出的能力使其成为处理大型语言模型并创建实际工具的最常用 Python 库之一。
本教程解释了该库的两个简单用例,这些用例可以应用于多种应用程序中。
- 摘要:
-
短文本摘要:使用 LangChain 和 ChatGPT 来总结短文本。
-
长文本摘要:通过将长文本分割成较小的块并总结每个块来处理较长的文本。
- 提取:
-
提取特定词汇:在文本中识别特定词汇。
-
使用 LangChain 的响应模式:将大型语言模型的输出结构化为 Python 对象。
LangChain 提供了一个强大的框架用于文本摘要和提取,简化了自然语言处理应用程序的过程。
4. 使用 LangChain 和 ChatGPT 自动化 PDF 交互
在前一篇教程的基础上,还有一篇更高级的文章,讲解如何导入 PDF 并使用 OpenAI 的 GPT 模型与其交互。

教程截图。
Lucas Soares 在他的教程 使用 LangChain 和 ChatGPT 自动化 PDF 互动 中向我们展示了如何利用 ChatGPT 和 LangChain 框架与 PDF 互动。这个过程分为三个主要步骤:
-
加载文档。
-
生成嵌入和向量化内容。
-
查询 PDF 中的特定信息。
这种方法允许用户直接向 PDF 提问,从而简化信息检索。你可以选择阅读他的文章或 观看他的 YouTube 频道。 根据你的喜好来选择!
关键的教训是 AI 在简化与传统静态文档的互动中的潜力,使数据访问变得更加动态和直观。
5. 使用 ChatGPT 构建简历解析器
Reo Ogusu 带来了一个易于跟随的项目,通过使用 OpenAI API 和 LangChain 来完成一个简历解析器。在教程 使用 GPT 将非结构化文档转换为标准化格式:构建简历解析器 中,他演示了如何使用 GPT 将非结构化文档,特别是简历,转换为标准化的 YAML 格式。
教程截图
主要步骤如下:
-
使用 PyPDF2 库从 PDF 中提取文本。
-
利用 LangChain 这个由社区驱动的框架来简化语言模型驱动应用程序的开发。
-
定义一个 YAML 模板来构建简历数据。
-
使用 LangChain 调用 OpenAI API 指示 GPT 按照 YAML 模板格式化数据。
GPT 证明了它在将非结构化数据转换为结构化格式方面的强大功能,提供了各种数据转换应用的潜力。
6. 使用 OpenAI API 生成一个简单的聊天机器人
要生成一个简单的聊天机器人,我们可以遵循 Avra 的教程 如何使用 ChatGPT API 和 Python 中的对话记忆构建聊天机器人,他在其中解释了如何使用 ChatGPT API 和 GPT-3.5-Turbo 模型构建聊天机器人实现。
它集成了 LangChain AI 的 ConversationChain 记忆模块,并具备 Streamlit 前端。
教程截图。
文章强调了对话记忆在聊天机器人的重要性,指出传统的无状态聊天机器人缺乏记忆过去互动的能力。
通过融入记忆,聊天机器人可以提供更无缝和自然的对话体验,类似于人类互动。
关键要点是上下文保留在增强聊天机器人与人类沟通中的重要性。
7. 一个完整的数据科学项目与 ChatGPT
作为最终项目,我带来一个非常有趣的数据科学教程,直接使用 ChatGPT 界面。
Abid Ali Awan 通过他的教程 使用 ChatGPT 进行数据科学项目的指南 教我们如何将 ChatGPT 集成到数据科学项目的各个阶段。它展示了 ChatGPT 在数据科学领域的强大功能。
从项目规划和探索性数据分析到特征工程、模型选择和部署,ChatGPT 可以协助每一个步骤。
最终产品是什么?
一个完全功能的贷款审批分类网页应用!

教程截图。
教程涵盖:
-
项目规划: 与 ChatGPT 互动以概述项目。
-
探索性数据分析 (EDA): 利用 Python 进行数据可视化和理解。
-
特征工程: 通过创建新特征来增强数据。
-
预处理: 清理数据、处理类别不平衡以及特征缩放。
-
模型选择: 训练各种模型并评估其性能。
-
超参数调优: 优化所选择的模型。
-
网页应用创建: 设计一个基于 Gradio 的贷款数据分类器网页应用。
-
部署: 在 Hugging Face Spaces 上发布应用。
教程强调了 ChatGPT 在自动化和增强各种数据科学任务中的强大作用,特别是在项目规划和代码生成方面。
关键要点是 AI 工具如 ChatGPT 与人类专业知识之间的协同作用,两者相辅相成,以实现最佳结果。
总结思考
上述项目集只是 ChatGPT 潜力的冰山一角。
开源社区正在积极开发新工具和改进现有工具,以帮助你创造你能想到的一切。LangChain 只是众多例子之一。
这就是为什么无论你是 ChatGPT 的初学者还是高级专家,都要记住在 AI 的世界里,唯一的限制就是你的想象力!
那么,为什么还要等待?
深入探索,进行实验,让生成式 AI 模型的世界为你打开无限可能的大门!
Josep Ferrer 是来自巴塞罗那的分析工程师。他毕业于物理工程专业,目前在应用于人类移动性的 数据科学领域工作。他还是一名兼职内容创作者,专注于数据科学和技术。你可以通过 LinkedIn、Twitter 或 Medium 联系他。
更多相关话题
7 个最佳云数据库平台

云计算为应用开发和托管开辟了新天地。在云服务成为主流之前,开发者必须维护自己昂贵的服务器。现在,像 AWS 和 Azure 这样的云平台提供了无需高硬件成本的轻松数据库托管。云数据库提供了云的灵活性和便利,同时提供标准的数据库功能。它们可以是关系型的、NoSQL 的,或其他任何数据库模型,通过 API 或网页界面访问。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
在这篇评论文章中,我们将深入探讨专业人士用来构建强大应用程序的前 7 大云数据库。这些领先的云数据库平台使开发者能够高效地存储和管理云中的数据。我们将考察每个平台的关键特性、优缺点,以便你可以确定哪一个最适合你的应用开发需求。
Azure SQL 数据库 是微软 Azure SQL 系列中的一个完全托管的关系型云数据库。它提供了一种专为云设计的数据库即服务解决方案,结合了多模型数据库的灵活性以及自动化管理、扩展和安全性。Azure SQL 数据库始终保持最新,由微软处理所有更新、备份和供应。这使开发者能够专注于构建应用程序,而无需担心数据库管理的负担。
🔑 Azure SQL 数据库关键点
-
无服务器计算和超大规模存储解决方案既灵活又响应迅速。
-
一个完全托管的数据库引擎,自动化更新、供应和备份
-
它具有内置 AI 和高可用性,以确保持续的高性能和耐用性
✅ 优点
-
友好的界面用于创建数据模型
-
简单的计费系统
-
完全托管且安全的 SQL 数据库
-
从本地到云存储的无缝迁移
❌ 缺点
-
工作和任务管理器的工作方式不同
-
数据库大小有限
-
需要更高效的数据库错误通知和日志系统。
-
没有适当的自动化实现的情况下,扩展和收缩成本很高。

亚马逊 Redshift 是一个完全托管的、宠物字节级别的基于云的数据仓库解决方案,旨在帮助组织高效地存储、管理和分析大量数据。基于 PostgreSQL 开源数据库系统构建,Redshift 使用列存储技术和大规模并行处理来提供对大数据量的快速查询性能。其分布式架构允许弹性扩展存储和处理能力,以适应不断增长的数据量。它与其他 AWS 服务的紧密集成也使得从 S3、EMR、DynamoDB 等无缝加载数据成为可能。最终结果是一个高性能、成本效益高且灵活的云数据仓库解决方案,适用于大规模数据分析。
🔑 亚马逊 Redshift 关键点
-
使用列式数据库。
-
其架构基于大规模并行处理。
-
包括机器学习以提高性能。
-
它具有容错性。
✅ 优势
-
简单的设置、部署和管理。
-
详细的文档使学习变得简单。
-
与存储在 S3 中的数据无缝集成。
-
简化的 ETL 设置。
❌ 缺点
-
SQL 中对 JSON 的支持有限。
-
缺少数组类型列,且会自动转换为字符串。
-
日志功能几乎不存在。

亚马逊 DynamoDB 是一个快速、灵活且可靠的 NoSQL 数据库服务,帮助开发人员构建可扩展的无服务器应用程序。它支持键值和文档数据模型,并且能够处理每天大量请求。DynamoDB 会自动水平扩展,确保可用性、持久性和故障容错,而用户无需额外操作。为互联网规模的应用程序设计,DynamoDB 提供无限扩展性和一致性能,最高可达 99.999% 的可用性。
🔑 亚马逊 DynamoDB 关键点
-
能够处理每天超过 10 万亿次请求。
-
支持 ACID 事务。
-
多区域和多主数据库。
-
NoSQL 数据库。
✅ 优势
-
操作快速简便。
-
处理动态且不断变化的数据。
-
索引数据可以快速检索。
-
即使处理大规模应用程序时也表现优异。
❌ 缺点
-
如果资源没有被正确监控,费用可能会很大。
-
不支持在不同区域备份。
-
对于需要创建多个环境的项目,成本可能会很高。
Google BigQuery 是一个强大的、完全托管的基于云的数据仓库,帮助企业分析和管理海量数据集。凭借其无服务器架构,BigQuery 实现了闪电般快速的 SQL 查询和数据分析,在几秒钟内处理数百万行数据。你可以将数据存储在 Google Cloud Storage 或 BigQuery 自身的存储中,并且它与 Data Flow 和 Data Studio 等其他 GCP 产品无缝集成,使其成为数据分析任务的首选。
🔑 Google BigQuery 关键点
-
它可以扩展到 PB 级别,非常具有可扩展性
-
它提供快速的处理速度,使你能够实时分析数据
-
提供按需和固定费用订阅模式
✅ 优点
-
自动优化查询以快速检索数据
-
客户支持出色
-
数据探索和可视化功能非常有用
-
它具有大量的原生集成
❌ 缺点
-
使用 Excel 上传数据库可能会耗时且容易出错
-
连接到其他云基础设施如 AWS 可能会很困难
-
如果不熟悉界面,可能会很难使用
MongoDB Atlas 是一个基于云的完全托管 MongoDB 服务,允许开发人员通过几个点击快速设置、操作和扩展 MongoDB 部署。由构建 MongoDB 数据库的工程师开发,Atlas 提供了流行的文档型 NoSQL 数据库的所有功能和能力,而无需进行本地部署所需的操作重担。Atlas 通过自动化繁琐的管理任务,如基础设施配置、数据库设置、安全加固、备份等,简化了 MongoDB 云操作。
🔑 MongoDB Atlas 关键点
-
它是一个面向文档的数据库
-
分片功能允许轻松的水平扩展
-
MongoDB Atlas 的数据库触发器非常强大,可以在特定事件发生时执行代码
-
对时间序列数据非常有用
✅ 优点
-
可以根据需要轻松调整服务规模
-
提供免费和试用计划,用于评估或测试,非常慷慨
-
上传到 MongoDB Atlas 的任何数据库信息都会备份
-
JSON 文档可以从任何地方访问
❌ 缺点
-
无法直接下载存储在 MongoDB Atlas 集群中的所有信息
-
缺乏更细粒度的计费
-
不支持跨表连接
Snowflake 是一个强大的自我管理数据平台,专为云设计。与传统解决方案不同,Snowflake 将新的 SQL 查询引擎与创新的云原生架构结合起来,为数据存储、处理和分析提供了更快、更易用和高度灵活的解决方案。作为真正的自我管理服务,Snowflake 负责硬件和软件管理、升级和维护,让用户可以专注于从数据中获取洞察。
🔑 Snowflake 关键点
-
提供查询和表优化
-
提供安全的数据共享和零复制克隆
-
Snowflake 支持半结构化数据
✅ 优点
-
Snowflake 可以从各种云平台(如 AWS、Azure 和 GCP)摄取数据
-
你可以以多种格式存储数据,包括结构化和非结构化
-
计算机是动态的,这意味着你可以根据成本和性能选择计算机
-
它非常适合管理不同的数据仓库
❌ 缺点
-
数据可视化可以改进
-
文档可能难以理解
-
Snowflake 缺乏 CI/CD 集成功能
Databricks SQL (DB SQL) 是一个强大的无服务器数据仓库,允许你在大规模上运行所有 SQL 和 BI 应用程序,其价格/性能比传统解决方案高达 12 倍。它提供了统一的治理模型、开放的格式和 API,并支持你选择的工具,确保没有锁定。DB SQL 支持的丰富工具生态系统,如 Fivetran、dbt、Power BI 和 Tableau,使你可以原地摄取、转换和查询所有数据。这使每位分析师能够更快地访问最新数据进行实时分析,并实现从 BI 到 ML 的无缝过渡,释放数据的全部潜力。
🔑 Databricks SQL 关键点
-
集中治理
-
作为基础的开放和可靠的数据湖
-
与生态系统的无缝集成
-
现代分析
-
轻松摄取、转换和编排数据
✅ 优点
-
数据科学与数据工程团队之间的协作得到增强
-
Spark 作业执行引擎高度优化
-
最近新增了用于构建可视化仪表板的分析功能
-
原生集成受管的 MLflow 服务
-
数据科学代码可以用 SQL、R、Python、Pyspark 或 Scala 编写
❌ 缺点
-
远程运行 MLflow 任务复杂,需要简化
-
所有可运行的代码必须保存在笔记本中,这些笔记本并不适合生产环境
-
会话有时会自动重置
-
Git 连接可能不可靠
云数据库彻底改变了企业存储、管理和利用数据的方式。正如我们所探讨的那样,领先的平台如 Azure SQL 数据库、Amazon Redshift、DynamoDB、Google BigQuery、MongoDB Atlas、Snowflake 和 Databricks SQL 都为应用开发和数据分析提供了独特的优势。
选择合适的云数据库时,关键因素包括可扩展性需求、管理便利性、集成性、性能、安全性和成本。最优的平台应与您的基础设施和工作负载需求相匹配。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,他热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为那些在精神健康方面遇到困难的学生开发 AI 产品。
更多相关内容
7 种最佳机器学习库解析
原文:
www.kdnuggets.com/2023/01/7-best-libraries-machine-learning-explained.html

图片由 rawpixel.com 提供,来源于 Freepik
主要要点
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
-
机器学习库是构建和部署机器学习模型的重要工具
-
它们提供了一系列功能和算法,可用于训练和测试模型,并基于数据进行预测和决策。
-
有许多不同的机器学习库可供选择,每个库都有其自身的优势和能力,因此选择适合你项目的库非常重要。
-
机器学习库是机器学习生态系统的重要组成部分,全球的开发者和数据科学家广泛使用它们。
介绍
机器学习的概念可以追溯到 1950 年代,当时早期的人工智能(AI)系统和用于从数据中训练模型的算法开始出现。然而,第一批现代机器学习库,即提供用于实现和训练机器学习模型的工具和框架的库,直到 1980 年代和 1990 年代才出现。
最早的机器学习库之一是 1980 年代在卡内基梅隆大学开发的Statlib 库。该库提供了用于统计分析和机器学习的工具,包括对决策树和神经网络的支持。
其他早期的机器学习库包括 1990 年代在新西兰怀卡托大学开发的Weka 库,以及 1990 年代末在台湾大学开发的 LIBSVM 库。这些库提供了用于各种机器学习任务的工具,包括分类、回归和聚类。
随着时间的推移,机器学习领域不断发展壮大,如今有许多机器学习库可供选择,每个库都有其独特的功能和特点。
机器学习是一个快速发展的领域,具有在各个行业的众多应用。机器学习中常用的工具之一是库。在本文中,我们将解释什么是机器学习库以及如何使用它们。
在编程中,库是一个预先编写的代码集合,可以在程序中用于执行特定任务或任务集。库通常作为一种方式提供,供程序员重用已经编写和测试过的代码,而无需每次都从头编写所有代码。
机器学习库是提供构建和实施机器学习模型的工具和函数的软件库。它们是机器学习生态系统的重要组成部分,因为它们提供了一系列功能,使开发人员和数据科学家能够轻松构建、训练和部署机器学习模型。
有许多机器学习库可用,每个库都有自己独特的功能和能力。一些最受欢迎的机器学习库包括 NumPy、Matplotlib、Pandas、Scikit-Learn、TensorFlow、PyTorch 和 Keras。
NumPy
NumPy 是一个用于科学计算的 Python 库,在机器学习领域被广泛使用。它提供了一个高性能的多维数组对象,以及用于操作这些数组的工具。在机器学习中,NumPy 通常用于存储和操作作为机器学习模型输入的大量数据,并对这些数据进行数学运算,以便为机器学习算法的使用做准备。NumPy 可以按如下方式在 Python 中导入:
import numpy as np
Matplotlib
Matplotlib 是一个全面的库,用于在 Python 中创建静态、动画和交互式可视化。Matplotlib 可以按如下方式导入:
import matplotlib.pyplot as plt
pandas
Pandas 是一个快速、强大、灵活且易于使用的开源数据分析和操作工具,基于 Python 编程语言构建。Pandas 可以按如下方式导入:
import pandas as pd
Scikit-learn
Scikit-learn 是一个用于 Python 的机器学习库。它被设计为易于使用,并提供了一系列构建和训练机器学习模型的工具。Scikit-learn 重点关注监督学习,并提供分类、回归和聚类的各种算法。它还具有特征选择、降维和模型评估的工具。由于其简单直观的界面和丰富的文档,scikit-learn 是初学者和专家的热门选择。以下是一些 Scikit-learn 的示例:
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
TensorFlow
TensorFlow 是一个由 Google 开发的机器学习库。它广泛用于构建、训练和部署机器学习模型,尤其侧重于深度学习。TensorFlow 提供了一整套构建和训练神经网络的工具,包括对卷积神经网络(CNN)和长短期记忆(LSTM)网络的支持。它还具有灵活高效的执行模型,使开发者能够构建可以在各种硬件上运行的模型,包括 CPU、GPU 和 TPU。可以通过以下方式在 Python 中导入 TensorFlow:
import tensorflow as tf
PyTorch
PyTorch 是一个由 Facebook 开发的 Python 机器学习库。它设计用于快速灵活的原型开发,特别侧重于深度学习。PyTorch 具有动态执行模型,允许开发者在训练过程中轻松修改模型。它还支持 GPU 加速,非常适合训练大型和复杂的模型。PyTorch 拥有一个不断增长的社区,并被广泛用于研究和生产机器学习应用。可以通过以下方式导入 PyTorch:
import torch
Keras
Keras 是一个构建在 TensorFlow 之上的高级机器学习库。它旨在简化深度学习模型的构建和训练。Keras 提供了一系列层和模型,可用于构建神经网络和其他机器学习模型。
import tensorflow as tf
from tensorflow import keras
除了这些库,还有许多其他机器学习库可用,包括 Theano、MXNet 和 Scipy。这些库各自具有独特的功能和能力,选择适合你项目的库将取决于你的具体需求和要求。
案例研究
使用 Python 库实现多元回归机器学习模型,用于预测邮轮的船员数量。

图片来源:Unsplash
在此案例研究中,使用了多元回归模型来构建一个机器学习模型,用于根据特征如 ['Tonnage', 'passengers', 'length', 'cabins'] 预测邮轮的船员数量。此案例研究中使用了以下库:
-
NumPy
-
Matplotlib
-
Pandas
-
Scikit-learn
本项目的数据集和代码可以从这里下载:
github.com/bot13956/ML_Model_for_Predicting_Ships_Crew_Size
总之,机器学习库是构建和部署机器学习模型的重要工具。它们提供了一系列功能和算法,可用于训练和测试模型,以及根据数据进行预测和决策。现有许多不同的机器学习库,每种库都有其独特的优势和能力,因此选择适合你项目的库非常重要。机器学习库是机器学习生态系统的核心部分,被全球的开发者和数据科学家广泛使用。
本杰明·O·泰约 是一位物理学家、数据科学教育者和作家,也是 DataScienceHub 的所有者。之前,本杰明曾在中央俄克拉荷马大学、大峡谷大学和匹兹堡州立大学教授工程学和物理学。
更多相关话题
7 个最佳 SQL 练习平台
原文:
www.kdnuggets.com/2023/01/7-best-platforms-practice-sql.html

图片由作者提供
你是否在数据科学面试中被 SQL 问题难住过?如果是这样,你并不孤单。
所有数据岗位——数据分析师、数据科学家、数据工程师(插入你的理想角色)——都要求具备 SQL 熟练度。虽然 SQL 是一种直观且易学的语言,但破解 SQL 面试从来不容易。这是因为,成功通过 SQL 面试需要的不仅仅是熟悉语法。
那么如何破解这个面试?是否有秘密钥匙?其实,刻意练习是掌握 SQL 的关键。在本指南中,我们将讨论一些练习平台,你可以利用这些平台来提升你的 SQL 技能。
让我们深入探讨吧!
1. HackerRank
从软件工程到数据分析,HackerRank 是一个练习编码面试问题的最佳平台之一。HackerRank 的 SQL 练习套件有数百个问题供你练习。
你可以按难度级别(简单、中等、困难)筛选问题。或者,根据你的舒适度,可以选择练习基础、中级和高级 SQL 主题的问题。此外,你还可以按主题筛选练习题,例如选择查询、连接和聚合。
练习后,你还可以参加 HackerRank 的技能认证测试 来测试你的 SQL 技能。这些测试是有时间限制的评估,要求你在限定时间内解决 SQL 问题。目前,有以下 SQL 评估:
你可以通过在平台上注册一个免费账户来访问整个练习题和评估的集合。
2. SQLPad
SQLPad 提供以下广泛领域的练习题:
-
单表操作如简单的 SELECT 查询、使用 WHERE 子句和 GROUPBY
-
多表操作如 JOIN 和 UNION
-
窗口函数
对于上述每个类别,都有不同难度级别的问题。它们还提供按行业分类的 SQL 编码问题,如金融科技、教育和电子商务。通过免费账户,你可以访问部分问题。
3. StrataScratch
StrataScratch,另一个流行的 SQL 面试练习平台,拥有大量的 SQL 面试问题。除了按主题和难度级别筛选外,你还可以通过问题列表筛选出公司特定的 SQL 面试问题。
他们的编码工作空间支持 PostgreSQL、MySQL 和 Microsoft SQL Server(测试版)。如果 Python 是你首选的编程语言,你可以使用 pandas 来解决这些问题。
在免费版中,你可以访问最多 50 个带有解答的问题,并尝试超过 500 个 SQL 问题。
4. DataLemur
DataLemur 收录了在 LinkedIn、Tesla、Microsoft 和 Walmart 等科技公司面试中出现过的 SQL 面试问题。
该平台有超过 40 个关于条件聚合、字符串和窗口函数以及累积和的 SQL 面试问题。
5. LeetCode
如果你是 Leetcode 用户,你也可以在上面练习 SQL。LeetCode 上的 SQL 问题集合 相当丰富,涵盖了不同的难度级别和主题。你还可以通过标签筛选问题:这些标签对应公司的名称。不过,使用免费账户只能访问部分问题。
6. Mode
如果你在寻找一个可以在学习的同时进行实践的 SQL 学习平台,那么 Mode 可能是一个很好的选择。Mode SQL 教程 具有最全面且结构精巧的课程。
Mode SQL 教程分为以下几个部分:
-
基础 SQL
-
中级 SQL 涵盖了连接、联合和聚合函数
-
高级 SQL 涵盖了 SQL 子查询、字符串函数、窗口函数和数据透视等主题
每节课都有若干练习题,你可以在 Mode SQL 编辑器中解决这些问题。
7. SQLZoo
SQLZoo 是另一个 SQL 学习和实践平台。在 SQLZoo 上,你可以访问简短的课程来学习 SQL:从基本的 SELECT 语句到更高级的概念,如窗口函数。每节课中嵌入了短小的练习题。为了测试你的 SQL 技能,还有一个专门的评估部分,其中包含更复杂的 SQL 问题。
结论
希望你觉得这个 SQL 练习平台的列表对你有帮助。如果你刚刚开始,可以尝试一个或多个这些平台来找到合适的选项。
选择合适的平台还需要考虑你已经掌握的知识量和你练习的时间。如果你正在积极面试,建议加倍关注面试问题,并刷新一些棘手的概念,比如窗口函数、子查询和公共表表达式。这里有一份 SQL 备忘单可以供你快速参考。继续编码!
Bala Priya 是一位技术写作专家,喜欢创作长篇内容。她的兴趣领域包括数学、编程和数据科学。她通过撰写教程、操作指南等方式与开发者社区分享她的学习成果。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
更多相关话题
7 个最佳平台来实践 Python

作者提供的图片
Python 是一种适合初学者的编程语言。你可以在几个小时内学习 Python 的语法和其他基础知识,开始编写简单的程序。但如果你正在为面试做准备——无论是软件工程还是数据科学的任何角色——并且希望使用 Python,你需要了解远远超出基础的内容。
要在编码面试中取得成功,你应该专注于用 Python 解决问题。我们汇编了一份平台清单,你可以在这些平台上通过解决广泛主题的编码挑战来学习和实践 Python——无论你是初学者还是有经验的程序员。
那么让我们开始吧!
1. 实践 Python
如果你是刚开始学习 Python 的初学者,你会发现Practice Python非常有用。该平台提供了一个包含大量 Python 练习的集合,针对的是学习 Python 基础的初学者。
这些练习涵盖了从基础语法到内置数据结构、f-Strings 和错误处理等各种主题。
此外,练习按难度级别分类,使学习者可以根据自己的节奏进步。你还可以在解决问题之后查找解决方案,以查看是否有更好的方法。
链接: Practice Python
2. Edabit
Edabit 是一个提供多种编程挑战的平台,包括 Python。它提供了一个游戏化的学习 Python 的方法。
挑战的难度从初学者到高级不等,涵盖算法、数据结构和通用问题解决技术的各种主题。Edabit 提供了教程和挑战来帮助你分别学习和实践 Python。
链接: Edabit
3. CodeWars
Codewars 是一个社区驱动的平台,提供针对多种编程语言(包括 Python)的编码挑战或 "kata"。挑战按难度级别排名,并分为不同的 "kyu" 等级。
在 Codewars 上,你可以解决各种主题的挑战。以下是一些例子:
-
数据结构
-
算法
-
设计模式
-
动态编程和记忆化
-
函数式编程
链接: Codewars
4. Exercism
Exercism 是一个学习和实践任何编程语言的优秀平台。它为大约 69 种编程语言提供专门的课程。你可以加入 Python 路线并完成概念模块和练习(总共 17 个概念模块和 140 个练习)。
Python 路线中的主题包括:
-
基本数据类型
-
字符串及其方法
-
列表、元组、字典和集合
-
解包和多重赋值
-
课程
-
生成器
Exercism 作为一个平台的另一个独特特点是个人辅导,你可以选择由经验丰富的程序员辅导并从他们那里学习。
链接: Exercism
5. PYnative
PYnative 是一个专为 Python 学习者量身定制的平台,提供各种练习、测验和教程。
教程涵盖以下主题:
-
Python 基础
-
文件处理
-
日期和时间
-
面向对象编程
-
随机数据生成
-
正则表达式
-
处理 JSON
-
数据库操作
除了 Python 练习,PYnative 还提供 pandas 的教程和练习——如果你想学习使用 pandas 进行数据分析,这非常有帮助。
链接: PYnative
6. Leetcode
LeetCode 是一个流行的平台,用于准备技术面试和提高编码技能。它提供了大量的编码问题,包括算法挑战和顶级科技公司面试问题。
如果你正在准备编码面试,Leetcode 是一个必要的伴侣。你可以解决一些问题集:
-
顶级面试 150
-
LeetCode 75
问题按难度等级和主题分类,因此你可以专注于特定的兴趣领域。此外,你还可以在 LeetCode 上练习 基本 pandas。
链接: LeetCode
7. HackerRank
HackerRank 和 Leetcode 类似,是一个为多种编程语言提供编码挑战和竞赛的平台。它还提供面试准备工具包和由公司赞助的编码竞赛,用于招聘目的。
HackerRank 上的 Python 挑战涵盖了各种主题:从数据类型和操作符到 Python 标准库中的模块。你还可以使用 Python 作为你偏好的编程语言来练习数据结构和算法,以备编码面试之用。
链接: HackerRank
总结
希望你发现这些 Python 实践平台的汇总对你有帮助。如果你在寻找课程,以下资源可能会对你有帮助:
如果你正在准备数据科学面试,也可以阅读 7 个最佳 SQL 实践平台。
Bala Priya C**** 是来自印度的开发者和技术写作者。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过编写教程、操作指南、观点文章等,学习和与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编程教程。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 需求
更多相关主题
7 个最佳机器学习实验追踪工具
原文:
www.kdnuggets.com/2023/02/7-best-tools-machine-learning-experiment-tracking.html
作者提供的图片
5 年前,数据科学家和机器学习工程师通常将机器学习 (ML) 实验数据存储在电子表格、纸张或 Markdown 文件中。这些日子已经一去不复返了。如今,我们拥有高效、用户友好的实验跟踪平台。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
除了轻量级实验跟踪外,这些平台还提供数据和模型版本控制、交互式仪表板、超参数优化、模型注册、机器学习管道,甚至模型服务。
在这篇文章中,我们将介绍 7 个用户友好、API 轻量级且具备交互式仪表板的顶级机器学习实验跟踪工具,以便查看和管理实验。
1. MLflow Tracking
MLflow Tracking 是开源库 MLflow 的一部分。该 API 用于记录实验、指标、参数、输出文件和代码版本。MLflow 跟踪还提供了基于 Web 的界面,让你可以可视化结果,并与参数和指标进行交互。
作者提供的图片
你可以使用 Python、R、Java 和 REST API 记录查询和实验。MLflow 还提供了与流行的机器学习框架(如 Scikit-learn、Keras、PyTorch、XGBoost 和 Spark)的集成。
2. DVC
数据版本控制 · DVC 是一个基于 Git 的开源工具,用于数据和模型版本控制、机器学习管道和机器学习实验跟踪。通过 Studio · DVC,你可以在提供 UI 的 Web 应用程序上记录实验,实现实时实验跟踪、可视化和协作。

图片来源于 DVC
DVC 是一个终极工具,它自动化你的工作流程,存储和版本控制你的数据和模型,提供机器学习的 CI/CD,并简化你的机器学习模型部署。你可以使用 Python API、CLI、VSCode 插件和 Studio 访问和存储实验。
3. ClearML
ClearML 实验 跟踪并自动化与 ML 操作相关的所有事务。你可以用它记录和分享实验,版本化工件,并创建 ML 流水线。
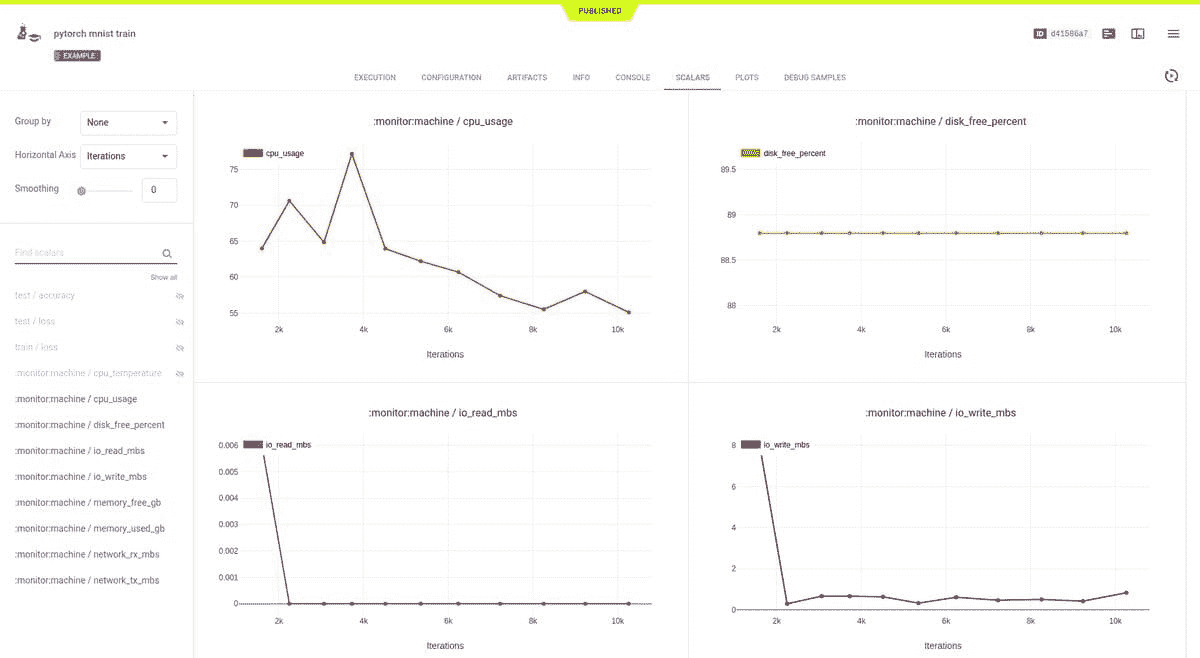
图片来源于 ClearML
你可以可视化结果、比较、重现和管理各种实验。ClearML 实验与流行的 ML 库如 PyTorch、TensorFlow 和 XGBoost 集成。你可以获得一个免费的基础版本,涵盖了 MLOps 的所有核心流程。
4. DAGsHub
DAGsHub Logger 允许你使用 Python API 记录指标、超参数和输出。该平台还支持通过 MLflow 记录实验,这对于跟踪实时模型性能非常有用。
作者提供的图像
DagsHub 为你提供代码、数据和模型版本控制、实验跟踪、ML 流水线可视化、模型服务、模型监控和团队协作。它是一个完整的数据科学和机器学习项目工具。
5. TensorBoard
TensorBoard 是我使用的第一个实验记录器。它简单且与 TensorFlow 包无缝集成。通过添加几行代码,你可以跟踪和可视化指标,如准确度、损失和 F1 分数。
图片来源于文档 | TensorBoard
你可以通过 TensorBoard UI 可视化模型图、投影嵌入、查看图像、文本和音频数据,并管理你的实验。它是一个简单、快速而强大的工具。缺点是它仅与 TensorFlow 框架兼容。
6. Comet ML
Comet ML 实验跟踪 是一个免费的 ML 实验跟踪工具,服务于社区。你可以使用简单的 Python、Java 和 R API 管理实验,这些 API 适用于所有流行的机器学习框架,如 Keras、LightGBM、Transformers 和 Pytorch。
图片来源于 Comet ML
你可以在网页应用上记录实验并查看、比较和管理它们。网页用户界面包含项目、报告、代码、工件、模型和团队协作。此外,你还可以修改可视化,甚至使用 Python 可视化库创建自己的图表。
7. Weights & Biases
Weights & Biases 是一个以社区为中心的平台,用于跟踪实验、工件、交互式数据可视化、模型优化、模型注册和工作流程自动化。只需几行代码,你就可以开始跟踪、比较和可视化 ML 模型。
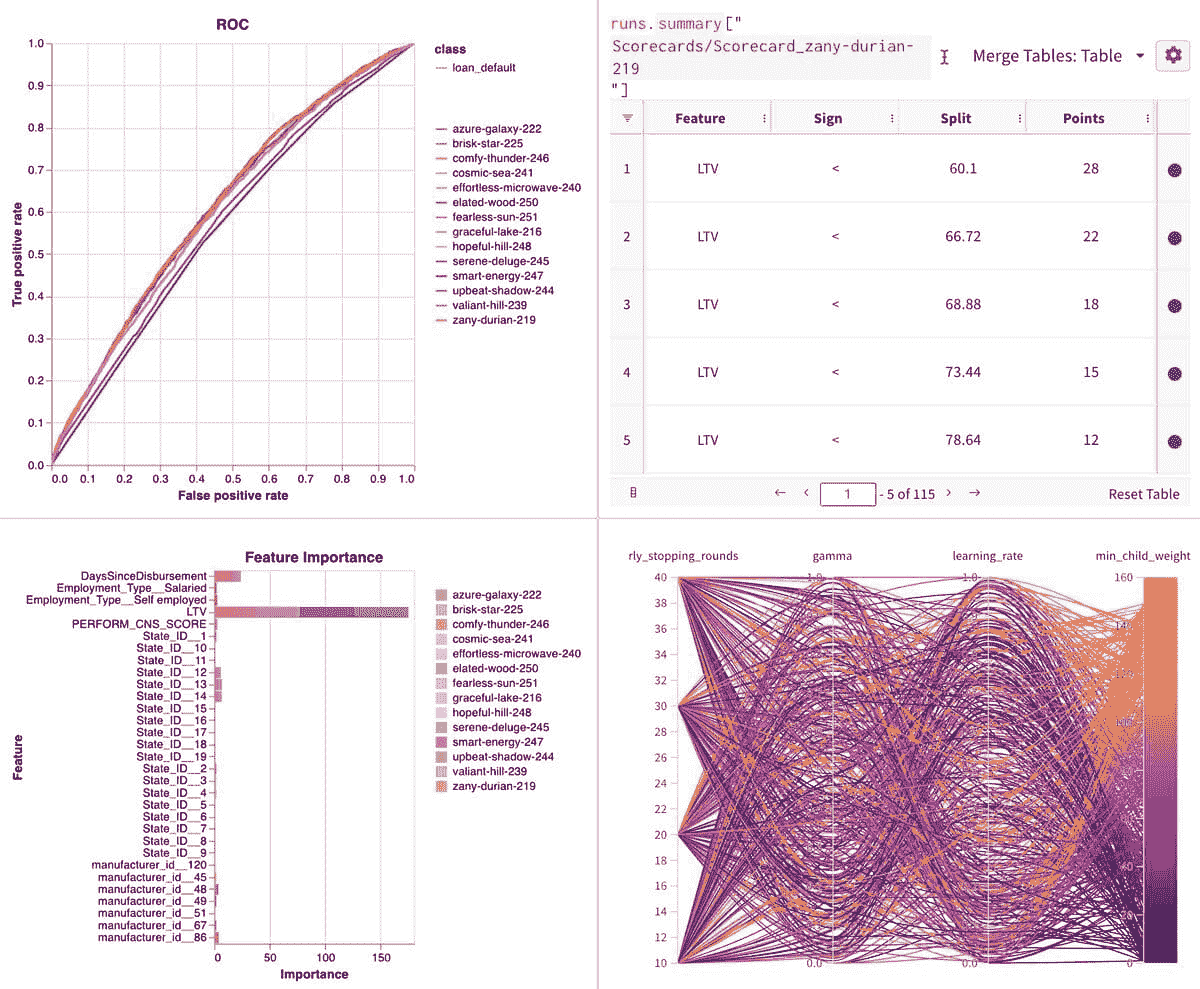
图片来自 Weights & Biases
除了指标、参数和输出,你还可以监控 CPU 和 GPU 的利用率,实时调试性能,存储和版本控制高达 100 GB 的数据集,并分享你的报告。
结论
这些平台都很棒。它们各有优缺点。你可以使用它们展示你的投资组合、协作项目、跟踪实验,并简化流程以减少人工干预。
让我为你简化一下。
-
MLflow: 开源、免费使用,并且提供了所有基本的 MLOps 功能。
-
DVC: 适用于已经使用 DVC 进行数据和模型版本管理,并希望使用同一工具进行机器学习管道和实验跟踪的人群。
-
CLearML: 端到端可扩展的 MLOps 平台。
-
DAGsHub: 适用于团队协作、机器学习项目和实验跟踪。它也是一个端到端的机器学习平台。
-
TensorBoard: 如果你是 TensorFlow 的粉丝或长期用户,为了简便起见,使用它来跟踪实验。
-
Comet ML: 这是一种简单且互动的机器学习模型跟踪方式。
-
Weights & Biases: 以社区为中心,简单,推荐用于机器学习投资组合。
我希望你喜欢我的工作。如果你有任何问题或想给我关于 MLOps 工具的建议,请在评论中告诉我。我知道这个领域充满了机器学习跟踪工具,每个机器学习平台现在都提供了轻量级实验记录功能。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些在心理健康方面挣扎的学生。
更多相关内容
掌握数据科学和机器学习数学基础的 7 本书
原文:
www.kdnuggets.com/2018/04/7-books-mathematical-foundations-data-science.html
评论
大多数人学习数据科学时侧重于编程。然而,要真正精通数据科学(和机器学习),你不能忽视数据科学背后的数学基础。在这篇文章中,我展示了七本我在学习数据科学数学基础时喜欢的书籍。‘喜欢’可能不是最合适的词,因为这项工作很艰难!
那么,为什么你应该努力学习数据科学的数学基础呢?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
以下是一些激励我的原因:
AI 正在迅速变化。Geoffrey Hinton 已经认为我们应该重新思考反向传播。理解数学将帮助你更好地理解 AI 的演变。它将帮助你区别于那些从表面层次接触 AI 的人。这也将帮助你更好地看到 AI 的知识产权(IP)潜力。最后,理解数据科学背后的数学也可能使你获得更高端的 AI 和数据科学职位。
我有两个额外的动机来研究这些书籍。
-
首先,作为我在牛津大学教授物联网数据科学课程的一部分,以及我个人在 AI 应用方面的教学,我包括了基于数学的方法。
-
其次,我正在写一本书,旨在从数学角度简化 AI,以适合 14 至 18 岁的学生。要理解数据科学和 AI 的数学基础,你需要了解四个方面,即线性代数、概率论、多变量微积分和优化。大多数这些内容在高中(至少部分)会教授。因此,我试图将高中数学与 AI 和数据科学联系起来,重点是数学建模。欢迎对这种方法提出评论。

所以,这是带有我评论的书单:
1. 统计学习理论的本质
作者:弗拉基米尔·瓦普尼克
你不能创建一个关于数学书籍的列表而不包括伟大的俄罗斯数学家!所以,我列表中的第一个是统计学习理论的本质,作者是弗拉基米尔·瓦普尼克。在这个列表中的所有书籍中,瓦普尼克的书是最难找到的。我有一本较旧的印度版。弗拉基米尔·瓦普尼克是 SVM 的创造者。他的维基百科页面提供了更多关于他工作的内容。
作者:理查德·O·杜达
像瓦普尼克博士的书一样,杜达的书也是另一个时代的经典。首次出版于 1973 年,25 年后(2000 年)更新一次,之后没有再更新!但仍然是一个重要的资源。这本书采用了模式识别的方法,提供了广泛的算法覆盖。
3. 机器学习:算法视角(第二版)(Chapman & Hall/Crc 机器学习与模式识别)
作者:斯蒂芬·马斯兰
斯蒂芬·马斯兰的书现在已经是第二版了。马斯兰是我早期读过的书之一(我只有第一版)。两版都非常好。我相信第二版有更多的 Python 代码。和前两本书一样,这本书也对算法给予了很大关注。
作者:特雷弗·哈斯提,罗伯特·蒂布希拉尼,杰罗姆·弗里德曼
Hastie 是另一本经典之作。我拥有的版本印刷得很好,颜色丰富。这是另一本参考书。
作者:克里斯托弗·M·比 ishop
克里斯托弗·M·比 ishop 的《模式识别与机器学习(信息科学与统计)》也是一本深入且表现良好的参考书。
作者:彼得·弗拉奇
我喜欢彼得·弗拉赫(Peter Flach)的书,尽管一些亚马逊评论称其内容冗长,并指出缺乏代码。我尤其喜欢弗拉赫对算法的分组(逻辑模型、线性模型、概率模型)以及对主题的整体处理。
最后,我最推荐的书:
7. 深度学习
作者:古德费洛(Goodfellow)、本吉奥(Bengio)和考维尔(Corville)
如果有一本书你应该从头到尾读,那就是这本。这本书详细且现代,涵盖了你能想到的一切。
再推荐两本值得一读的书
-
《机器学习入门(第二版)(机器学习与模式识别)》作者:西蒙·罗杰斯(Simon Rogers)、马克·吉罗拉米(Mark Girolami) 这是我得到的第一本书(第一版)。我不建议初学者阅读,但它仍然是一本很好的书(特别是第二版)。
-
Kevin Murphy 的《机器学习:概率视角》 评价很高——但我个人还没有读过(因此未在列表中)。
如果你能推荐我遗漏的书,请告诉我。
总结评论:
-
除了可能的古德费洛-本吉奥的书,我不建议从头到尾阅读这些书。我更喜欢按需按主题阅读这些书,即作为参考书。我还喜欢不同作者的例子,比如杜达(Duda)的鱼分类;- 哈斯蒂(Hastie)的广告数据销售电视和广播;弗拉赫(Flach)用海洋动物的例子解释假设空间等等。
-
我发现这些书教会了我一种谦逊感,即我们知道的非常有限,而这个领域则非常广阔复杂。
-
这些书是永恒的。弗拉基米尔·瓦普尼克(Vladimir Vapnik)现在 81 岁了。杜达(Duda)的书首次出版于 1973 年。我预计 50 年后,业内仍会继续阅读这些书,就像经历了时间考验的老朋友。这是一个令人安慰的想法。它展示了基于数学的方法的持久性。
相关:
更多相关内容
7 个数据分析面试问题及答案
原文:
www.kdnuggets.com/2022/09/7-data-analytics-interview-questions-answers.html

图片由作者提供
数据分析面试分为多个部分,如非技术性、技术性和 SQL。招聘经理将评估你对统计工具和概念的了解。此外,你还会被问到情境问题,要求你解释如何准备分析报告、清理数据或进行图表解读。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
在这篇博客中,我们将探讨在数据分析面试中常见的七个具有挑战性的问题。
非技术性问题
1. 你如何向非技术观众解释技术概念?
在这个问题中,面试官正在评估你的沟通、演讲和人际交往技能。能够向管理者或客户解释技术概念是一项重要技能。
除了均值、相关性或数据分布等技术术语外,你还需要了解更多关于数据及其特征的知识。尝试连接对业务有意义的点。你需要确保理解业务和受众,以便用通俗的语言解释概念。
2. 定义这个产品成功的前三个指标是什么?你会如何选择?
为了回答这个问题,你需要了解行业、业务和产品的领域知识。你可以请面试官讲述公司的战略和愿景,这有助于你形成答案。
对于社交媒体产品,三个指标可以是每日活跃用户数、前两周内添加好友的用户数量和每周的帖子数量。这些指标基于公司的愿景和产品策略。因此,在面试前最好先研究一下公司。
技术性问题
3. 什么是描述性分析、预测性分析和规范性分析?
描述性分析提供对过去的洞察,以回答类似“营销活动与去年相比表现如何”的问题
预测性分析是利用洞察力来预测未来事件或预测增长。
规范性分析用于建议各种行动方案,以防止灾难或改进产品。
4. 数据分析项目涉及哪些步骤?
这个问题完全取决于你。一般来说,数据分析项目包括理解问题陈述、收集数据、清理数据、探索、分析和可视化数据,最后为非技术观众解释结果。你还可以根据具体问题提到工具、技术和额外步骤。
5. 如何处理数据集中的缺失值?
处理缺失数据的方法有很多。最常用的方法是删除缺失值的行,如果数据集较大且平衡的话。
除此之外,你还可以:
-
删除缺失值的列
-
用常数填充。
-
平均值和中位数填补。你将用列的平均值或中位数替换缺失值。
-
使用多元回归分析来估算缺失值
-
考虑多个列,用平均模拟值和随机误差替换缺失值。
SQL 问题
6. 创建一个 SQL 查询,从 employee_details 中检索重复记录,忽略主键和 EmpId。
解决方案很简单。你将选择所需的列并计算(Count())。之后,按唯一标识进行分组,例如员工姓名、经理 ID、入职日期和城市。然后使用HAVING来筛选重复项。如果Count()值大于 1,则为重复记录。
你可以将相同的策略应用于任何表。确保按多个唯一 ID 列(例如姓名和地址)对表进行分组。
解决方案:
SELECT fullname,
managerID,
joining_date,
city,
COUNT(*)
FROM employee_details
GROUP BY fullname,
managerID,
joining_date,
city
HAVING COUNT(*) > 1;
7. 编写一个 SQL 查询,以查找在其演示文稿中插入了 1000 到 2000 张图像的用户数量
表: event_log
| user_id | event_date_time |
|---|---|
| 1255 | 1535308433 |
| 4566 | 1535308444 |
| 9566 | 1535308476 |
| … | … |
解决方案简单但棘手。首先,你需要计算每个用户的图像数量,然后计算图像数量在 1000 到 2000 之间的用户数量。
内部查询将计算event_date_time并按user_id分组,以找到每个用户的唯一用户 ID 和每个用户的图像数量。之后,创建外部查询,筛选出图像数量在 1000 到 2000 之间的用户,并计算他们的数量。
解决方案:
SELECT COUNT(*)
FROM (
SELECT user_id,
COUNT(event_date_time) AS image_per_user
FROM event_log
GROUP BY user_id AS image_per_user
WHERE image_per_user < 2000
AND image_per_user > 1000;
参考
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些面临心理健康问题的学生。
更多相关话题

获取免费的电子书《伟大的自然语言处理入门》和《数据科学备忘单全集》,以及有关数据科学、机器学习、人工智能和分析的领先新闻直达你的邮箱。
订阅即表示你接受 KDnuggets 的 隐私政策
最新帖子
|
精选帖子
|
© 2024 Guiding Tech Media | 关于我们 | 联系我们 | 广告 | 隐私政策 | 服务条款
由 Abid Ali Awan 于 2022 年 9 月 12 日发布
2021 年七个数据安全最佳实践
原文:
www.kdnuggets.com/2021/06/7-data-security-best-practices-2021.html
评论
Pixabay 提供的照片来自 Pexels
数据安全是任何公司面临的日益严重的问题,因为网络犯罪持续繁荣。由于数据科学家的整个工作都围绕着潜在的敏感数据,他们面临的压力比大多数人都大。如果你遭遇数据泄露,除了可能的财务和声誉损失外,你还可能无法履行工作职责。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 为你的组织提供 IT 支持
IBM 估计,数据泄露的平均成本为 386 万美元。根据事件的严重程度,它还可能影响你的声誉,甚至你的工作。考虑到这一点,以下是今年需要采纳的七个数据安全最佳实践。
1. 仅使用所需的内容
保护数据的最佳方法之一是最小化你存储的内容。虽然收集尽可能多的数据很有诱惑力,特别是在训练机器学习模型时,但这会使你更容易受到攻击。你只能失去你拥有的东西,所以检查你的数据库,删除任何不必要的内容。
这一原则的一部分是保持手头数据的最新记录。如果你发现不再需要某些信息,请从数据库中清除它。保留遗留数据对你没有帮助,只会意味着你有更多的损失风险。
2. 掩码敏感数据
“仅使用所需的内容”原则同样适用于你存储的数据类型。许多数据科学操作不需要特定于用户的信息,所以如果你不需要,就不要存储。如果必须使用诸如个人身份标识符等敏感数据,你应该对其进行掩码处理。
掩码敏感数据的最常见方法之一是使用替换密码。令牌化,用虚拟数据替换真实值是另一个选项,通常更安全,因为它将加密值放在单独的数据库中。无论你使用哪种方法,确保首先清除所有不必要的敏感信息。
3. 小心合作
数据科学通常是一个协作过程,您应考虑如何与合作者沟通。虽然电子邮件可能方便,但默认情况下并不加密,因此不适合用于共享数据或数据库访问凭证。有许多专门用于敏感文件共享的服务,因此它们是更好的选择。
无论与谁合作,都应尽量保持信任的最低限度。人们只能访问对其工作至关重要的信息。如果可能,您甚至可以考虑在共享信息前对其进行模糊处理,以减轻潜在泄露的影响。
4. 尽可能多地加密
当您分享数据时,应加密数据。数据存储在数据库中时也应加密。尽管加密不能解决所有安全问题,但它是增加保护层的低成本方法。
许多最佳数据加密工具今天也不会显著拖慢您的处理速度。查看您的选项,找到能在所有场景中加密静态和动态数据的工具。虽然这不会完全阻止数据泄露,但可以减轻其成本。
5. 不仅仅保护数据库
记住,安全不仅仅适用于您存储数据的位置。数据库应该是您最关注的区域,但它们不应该是您唯一关心的地方。备份、连接的应用程序和分析服务器都可能成为数据的后门,因此它们也需要保护。
任何触及您数据的程序、驱动器或文件都应确保安全。在此过程中,当数据连接较少时,工作会更容易。减少对数据库的访问权能使工作更轻松,并提供更多保护。
6. 小心第三方云供应商
如果您使用像 AWS 这样的第三方云服务,务必不要对安全感到自满。不幸的是,许多用户会如此,最近的一项研究显示82% 的公司给予这些供应商高度权限。第三方云服务本身并不危险,但您需要将安全放在首位。
检查您的权限,确保只给予供应商和其他应用程序最低限度的权限。使用强密码,包括多因素认证,并定期更换这些密码。如果您不知道该怎么办,许多这些供应商提供安全最佳实践供您参考。
7. 建立明确的治理政策
最后,你应该为你的整个团队建立一个清晰而具体的治理政策。拥有一份关于应该做什么和不应该做什么的书面文件,将有助于确保安全的用户行为。如果有人犯了危害安全的错误,你可以参考政策来查看哪里出了问题。
你的治理政策应该明确每个人在安全方面的角色。你可以设立轮班制度来监控和记录进出数据。你也可以给每个人分配一个固定角色。无论你做什么,都要具体明确,并确保每个人都理解。
数据科学安全必须改进
数据科学在当今商业中扮演着越来越核心的角色。随着这一趋势的持续,你的工作也成为了网络犯罪分子的更有价值的目标。数据科学团队必须在这些日益增长的威胁面前拥抱安全。
从这些最佳实践开始,然后寻找其他更小的领域来提高安全性。当你的数据安全时,你可以自信地工作,并给潜在客户留下深刻印象。
个人简介:德文·帕尔蒂达是一位大数据和技术作家,同时也是ReHack.com的主编。
相关:
-
自动化如何改善数据科学家的角色
-
数据科学家开发了一种更快的减少污染和减少温室气体排放的方法
-
数据专业人士如何为简历增加更多变化
了解更多相关话题
数据分析师与数据科学家之间的 7 个区别
原文:
www.kdnuggets.com/2021/09/7-differences-between-data-analyst-data-scientist.html
评论
作者:Zulie Rane,自由撰稿人和编码爱好者
剧透:差距是$30k。

成为数据分析师与数据科学家有什么好处?数据分析师与数据科学家的主要区别是什么?它们是同一工作吗?哪个职位,数据分析师还是数据科学家,薪资更高?你到底是怎么进行数据科学的呢?
自从《哈佛商业评论》称数据科学家是十年来最性感的工作以来,大多数人都听说过这个职位。数据分析师没有受到这样的称赞。
(如果你是或想成为数据分析师,我依然认为这是一个很性感的工作。)
数据分析师和数据科学家的主要区别在于他们如何处理数据。数据分析师做的就是名字所暗示的——她查看数据,尝试预测趋势,制作可视化,并传达结果。换句话说,数据分析师分析数据。
数据科学家的职位描述可能更难确定,因为你不能像分析数据那样直接“科学化”数据。然而,我们可以安全地说,数据科学家负责设计和构建新的数据模型。他们创建原型、算法和预测模型。
不过,在数据分析师与数据科学家的韦恩图中有很多重叠之处!例如,数据分析师和数据科学家都花费大量时间将数据整理成适合分析或研究的状态。
这还不仅仅是这些,所以你很幸运。这篇文章将详细探讨数据分析师与数据科学家之间的细微差别,旨在帮助你决定哪个更适合你。我将介绍典型背景、从事这些领域的工作感受、所需的技能和工具,以及最终如何选择最适合你的工作。
让我们深入了解一下吧。

1. 数据分析师与数据科学家:职位描述

首先,我们来高层次地描述一下数据科学家职位与数据分析师职位之间的区别。我通过谷歌搜索数据科学家职位描述和数据分析师职位描述,发现这些区别大致符合你对这些标题的预期。
数据科学家的职位描述通常包括机器学习、算法和自动化。大多数数据科学家的职位描述还包括使用可视化工具和统计技术来识别数据中的模式。
与此同时,数据分析师的职位描述通常是进行分析并从数据中开发可视化。主要责任是与公司内部其他团队沟通,以从数据中获取见解。如果你细心观察,你会发现这听起来非常像数据科学家职位描述的后半部分。
两种职位描述都涉及统计分析和将结果传达给利益相关者;数据科学家与数据分析师的区别仅在于,数据科学家多了一些创建发现这些见解的方法的工作。
2. 数据分析师与数据科学家:日常工作
让我们来比较一下数据分析师和数据科学家的任务、工具和工作流程。
数据科学家的典型一天通常包括会议、项目报告、检查电子邮件和创建模型。Gartner 的全球机器学习团队负责人 Andriy Burkov,表示他还帮助团队成员改进当前模型和训练示例,以解决模型中的问题。这还涉及大量的数据清理工作。
值得记住的是,数据科学专业宣言本身指出,“数据科学是解决问题,而不是模型或算法”,所以在讨论数据分析师的日常工作时,请记住这一点。
与数据科学家相比,数据分析师的日常工作非常相似。与数据科学一样,数据分析师的一个重要责任是沟通结果。这意味着数据分析师的大部分时间都用于开会、发送电子邮件、与其他团队检查情况以及审查当前项目状态。主要任务是收集、清理和研究数据以帮助解决问题。
数据分析师与数据科学家的日常工作之间的关键区别在于,数据科学家被期望创建和维护模型。除此之外,日常工作非常相似。
3. 数据分析师与数据科学家:薪资和职业前景
这是一个有趣的部分!数据分析师与数据科学家的预期薪资和职业前景如何?

对于这两个领域都有好消息。确实,报告显示,数据分析师职位预计从 2018 年到 2028 年增长 20%,这显然快于平均水平。这归因于不同领域对更好市场研究的需求。数据分析师可以在 IT、医疗保健、金融和保险行业找到工作。数据分析师在美国的平均薪资为$70,000。数据分析师的最高薪资潜力在北卡罗来纳州,实际上是每年$85,000。
我找不到关于数据科学的相同报告,因此我们不能做到直接比较。然而,正如非常明确的那样,数据科学工作的增长前景与数据分析师的工作增长同样有前途。IBM 预测 2020 年对数据科学家的需求将激增 28%;劳动统计局认为数据科学是增长最快的前 20 个职业之一,并预计未来 10 年增长 31%。
根据美国劳动统计局的数据,能够创建模型的工作薪资提升约为$30,000。数据科学家的平均薪资超过$100,000。查看我们关于数据科学家薪资多少的文章,了解数据科学的薪资以及这些薪资如何受到各种因素的影响。
数据科学和数据分析师的职位比所有其他职位多开放五天。竞争不激烈,公司对各种数据分析和科学需求很大。
4. 数据分析师与数据科学家:所需背景和教育
这两个选项都很棒,也许你开始对哪一个更适合你有了想法。本节将讨论你需要获得每个领域工作的要求和教育。
值得注意的是,这并不是数据分析师与数据科学家之间的非此即彼的选择。许多数据分析师希望在职业生涯后期成为数据科学家。不要把数据科学家视为入门级工作——很多人开始时从数据分析做起以获得行业经验,然后在掌握技能后转向数据科学。
从数据科学开始。例如,要 成为 Google 的数据科学家,你需要几个具体的条件:统计学、计算机科学或其他科学的硕士学位;相关工作经验;至少掌握一种统计语言,如 R 或 Python;以及熟练掌握数据库语言如 SQL。
数据分析师的职业轨迹 要求并没有那么高。你可能会受益于拥有数学、统计学、物理学或其他定量领域的学士学位,但这不是硬性要求。你也不 需要 精通任何语言,只需有学习的愿望。(当然,掌握语言总是有帮助的。)能够创建引人注目的数据可视化也很有用。如果你没有这些技能,可以学习掌握。
5. 数据分析师与数据科学家:技能

要成为数据分析师而不是数据科学家,你需要稍微不同的技能。然而,正如你可能从这篇文章的要点中了解到的那样,二者之间有相当大的重叠。
成为数据分析师,你需要对商业充满热情、具备沟通结果的能力和敏锐的问题解决直觉。你应该能够汇总和清理数据,进行统计分析,识别趋势并展示它们。
与数据科学相比,以 Google 为例,关于 公司在数据科学家身上看重的因素,成为数据科学家所需的技能包括跨学科沟通、大局观能量以及商业敏感度和客户导向。大多数公司会有类似的要求。你还应该能够建立预测未来趋势的模型。
换句话说,你需要能够与人交谈,需要了解的不仅是你的部门,还包括整个业务,需要知道你在销售什么以及如何销售。
在面试中,你将被考察这些技能。你可以练习 数据科学/数据分析师技能 ,以更好地了解具体公司所需的技能。
6. 数据分析师与数据科学家:下一步是什么?
展望未来五年。你获得了数据分析师职位——接下来会发生什么?对于许多数据分析师而言,典型的职业路径是晋升到中级或高级数据分析师职位,也许会专注于公司的数据战略中的某个特定领域。正如我之前提到的,许多数据分析师最终会成为数据科学家。
更远一点,许多数据分析师可能会成为数据分析顾问。他们的工作和普通数据分析师相同,只不过是为多个客户服务,而不是单一公司。
数据分析师有很多选择。你在数据分析职业道路上发展起来的技能对广泛的工作都很有用。
对于数据科学家来说,相比数据分析师,需要更长的时间。你至少需要两个学位,可能还需要三个。到你成为数据科学家时,大多数人对自己的选择相当确定。然而,还有成长的空间。你可以走管理路径或个人贡献者路径。在个人贡献者路径中,你将深化和强化在数据科学某个特定领域的技能,成为一个小领域的专家。作为数据科学家走管理路径时,你则会退后一步进行扩展。你将管理团队,扩展数据战略,并更全面地与数据组织合作。
这些路径不一定是线性的。它们会重叠、分叉,然后再汇聚。也没有任何年份的要求。你可以做三年数据分析师,然后在第二年成为数据科学家;你可以在数据科学家的职位上待 20 年而没有任何进展。很大程度上取决于你在过程中获得的技能。
7. 数据分析师与数据科学家:哪一个更好?
显然,没有明确的答案。如果你没有硕士学位,也许现在成为数据分析师是最佳选择。如果你已经拥有计算机科学博士学位,你可以跳过数据分析师阶段,直接进入数据科学领域。
主要区别在于,作为数据科学家,你将构建模型,并且你可能在数据领域有更多的教育背景,这也带来了更高的薪资。除此之外,数据分析师和数据科学家之间没有太大区别。两者都涉及到数据清洗、数据分析、数据展示以及影响业务方向。
如果这听起来像是你的兴趣,那么无论是数据分析师还是数据科学家,这两个职位对你都很适合。你只需要知道自己的技能水平和教育要求,以便明确目标。
简介:Zulie Rane 是一名自由撰稿人和编程爱好者。
原文。转载经许可。
相关内容:
-
数据科学家与机器学习工程师的区别
-
2021 年招聘数据科学家的顶尖行业
-
避免的 5 个数据科学职业错误
更多相关主题
2024 年你必须尝试的 7 个端到端 MLOps 平台
原文:
www.kdnuggets.com/7-end-to-end-mlops-platforms-you-must-try-in-2024
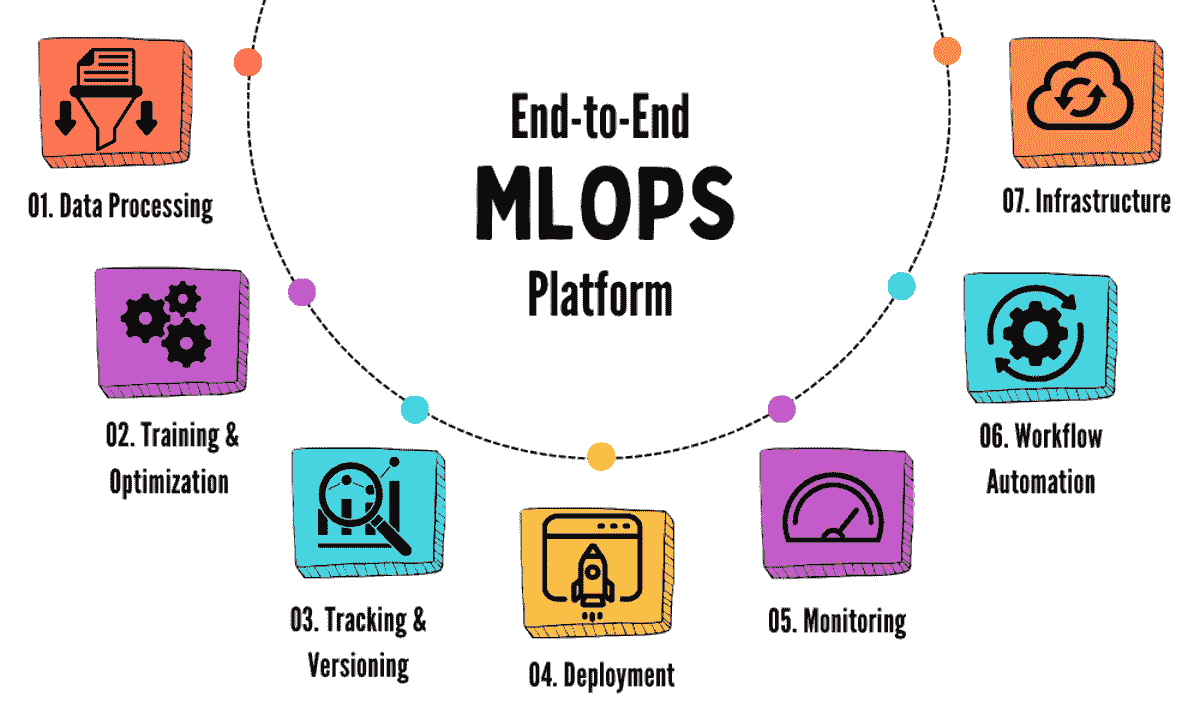
作者图片
你是否曾经觉得 MLOps 工具过于繁杂?无论是实验跟踪、数据和模型版本控制、工作流协调、特征存储、模型测试、部署和服务、监控、运行时引擎、LLM 框架,还是其他,每个工具类别都有多个选项,这使得希望找到简单解决方案、一个能轻松完成几乎所有 MLOps 任务的统一工具的管理者和工程师感到困惑。这时,端到端的 MLOps 平台便派上了用场。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
在这篇博客文章中,我们将评审个人和企业项目的最佳端到端 MLOps 平台。这些平台将使你能够创建一个自动化的机器学习工作流,能够训练、跟踪、部署和监控生产中的模型。此外,它们还提供与各种你可能已经在使用的工具和服务的集成,使得过渡到这些平台变得更容易。
1. AWS SageMaker
亚马逊 SageMaker 是一个相当受欢迎的端到端机器学习生命周期云解决方案。你可以跟踪、训练、评估,然后将模型部署到生产中。此外,你还可以监控和维护模型以保持质量,优化计算资源以节省成本,并使用 CI/CD 管道完全自动化你的 MLOps 工作流。
如果你已经在 AWS(亚马逊网络服务)云上,你将不会在机器学习项目中遇到问题。你还可以将 ML 管道与其他 Amazon Cloud 提供的服务和工具集成。
类似于 AWS Sagemaker,你还可以尝试 Vertex AI 和 Azure ML。它们都提供类似的功能和工具,用于构建端到端 MLOPs 管道并与云服务集成。
2. Hugging Face
我是 Hugging Face 平台及其团队的忠实粉丝,他们致力于为机器学习和大型语言模型构建开源工具。该平台现在已经成为端到端解决方案,提供多个 GPU 功能的企业解决方案。我强烈推荐给那些刚接触云计算的人。
Hugging Face 提供工具和服务,帮助你构建、训练、微调、评估和部署机器学习模型,使用统一的系统。它还允许你免费保存和版本化模型和数据集。你可以将其保持为私有或公开分享,并参与开源开发。
Hugging Face 还提供构建和部署网页应用程序及机器学习演示的解决方案。这是向他人展示你模型的卓越之处的最佳方式。
3. Iguazio MLOps Platform
Iguazio MLOps Platform 是你 MLOps 生命周期的全能解决方案。你可以构建一个完全自动化的机器学习管道,用于数据收集、训练、追踪、部署和监控。它本质上简单,所以你可以专注于构建和训练出色的模型,而不用担心部署和操作。
Iguazio 允许你从各种数据源中摄取数据,提供集成的功能商店,并拥有用于管理和监控模型及实时生产的仪表板。此外,它支持自动追踪、数据版本控制、CI/CD、持续模型性能监控和模型漂移缓解。
4. DagsHub
DagsHub 是我最喜欢的平台。我用它来构建和展示我的作品集项目。它类似于 GitHub,但专为数据科学家和机器学习工程师设计。
DagsHub 提供代码和数据版本控制、实验追踪、模式注册、模型训练和部署的持续集成和部署(CI/CD)、模型服务等工具。它是一个开放平台,意味着任何人都可以构建、贡献和学习项目。
DagsHub 的最佳功能包括:
-
自动数据标注。
-
模型服务。
-
ML 管道可视化。
-
对 Jupyter 笔记本、代码、数据集和图像进行差异比较和评论。
唯一缺少的就是一个专门用于模型推理的计算实例。
5. Weights & Biases
Weights & Biases 起初是一个实验性的追踪平台,但已发展成一个端到端的机器学习平台。现在,它提供实验可视化、超参数优化、模型注册、工作流自动化、工作流管理、监控以及无代码的机器学习应用开发。此外,它还提供 LLMOps 解决方案,例如探索和调试 LLM 应用程序以及 GenAI 应用评估。
Weights & Biases 提供云和私有托管。你可以在本地托管服务器或使用托管服务生存。个人使用免费,但团队和企业解决方案需要付费。你还可以使用开源核心库在本地机器上运行,享受隐私和控制。
6. Modelbit
Modelbit 是一个新兴但功能齐全的 MLOps 平台。它提供了一种简单的方法来训练、部署、监控和管理模型。你可以通过 Python 代码或 git push 命令来部署训练好的模型。
Modelbit 适用于 Jupyter Notebook 爱好者和软件工程师。除了训练和部署,Modelbit 允许我们使用你首选的云服务或他们专用的基础设施在自动扩展计算环境中运行模型。它是真正的 MLOps 平台,让你可以记录、监控并对生产中的模型发出警报。此外,它还配备了模型注册、自动重训练、模型测试、CI/CD 和工作流版本管理功能。
7. TrueFoundry
TrueFoundry 是构建和部署机器学习应用的最快且最具成本效益的方法。它可以在任何云上安装并进行本地使用。TrueFoundry 还提供多种云管理、自动扩展、模型监控、版本控制和 CI/CD 功能。
在 Jupyter Notebook 环境中训练模型,跟踪实验,使用模型注册保存模型和元数据,并通过一键部署。
TrueFoundry 还支持 LLMs,你可以轻松地微调开源 LLMs 并使用优化的基础设施进行部署。此外,它还集成了开源模型训练工具、模型服务和存储平台、版本控制、docker 注册中心等功能。
最后的想法
我之前提到的所有平台都是企业级解决方案。一些提供有限的免费选项,而另一些则附带开源组件。然而,最终你将需要转向托管服务,以享受功能齐全的平台。
如果这篇博客文章变得受欢迎,我将向你介绍一些免费的、开源的 MLOps 工具,这些工具能提供更大的数据和资源控制权。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专家,热衷于构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些与心理疾病作斗争的学生。
更多相关主题
数据工程的 7 个重要备忘单
原文:
www.kdnuggets.com/2022/12/7-essential-cheat-sheets-data-engineering.html
图片由作者提供
1. GCP 数据工程备忘单
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 部门
使用 GCP 的数据工程是一个完整的数据生命周期备忘单,适用于希望复习数据工程生态系统和工具的经验丰富的人员。

图片来自备忘单
在此备忘单中,你将学习:
-
数据工程的基本概念
-
Hadoop 生态系统
-
谷歌计算平台
-
身份访问管理
-
关键概念
-
计算选择
-
Stackdriver
-
存储、大表、BigQuery 和 Cloud SQL
-
DataStore、DataProc 和 DataFlow
-
Pub/Sub
2. PySpark 备忘单
PySpark 备忘单 包含处理 Python 中 DataFrames 的实用命令及示例。备忘单涵盖了从初始化 SparkSession 到运行查询和保存数据的 Apache Spark DataFrames 的基本操作。

图片来自备忘单
在此备忘单中,你将学习:
-
初始化 SparkSession
-
在 Python 中创建 DataFrames
-
过滤
-
复制值
-
运行 Spark 查询
-
程序化运行查询
-
修改列
-
处理缺失值
-
重新分区
-
GroupBy 和排序
-
检查数据、保存输出并停止会话。
3. dbt 命令备忘单
dbt(数据构建工具)命令 备忘单提供了多种命令的简单示例,你可以用来转换数据。dbt 是一个转换工具,它不执行加载或提取。

图片来自备忘单
在此备忘单中,您将学习:
-
dbt 介绍
-
dbt 通用命令
-
基于模型名称运行
-
基于文件夹名称运行
-
基于文件夹名称运行
-
dbt 命令中的多个模型输入
-
特殊命令
4. Apache Kafka 备忘单
Apache Kafka 是一个基于命令的备忘单,涵盖了分布式数据流的基本命令。
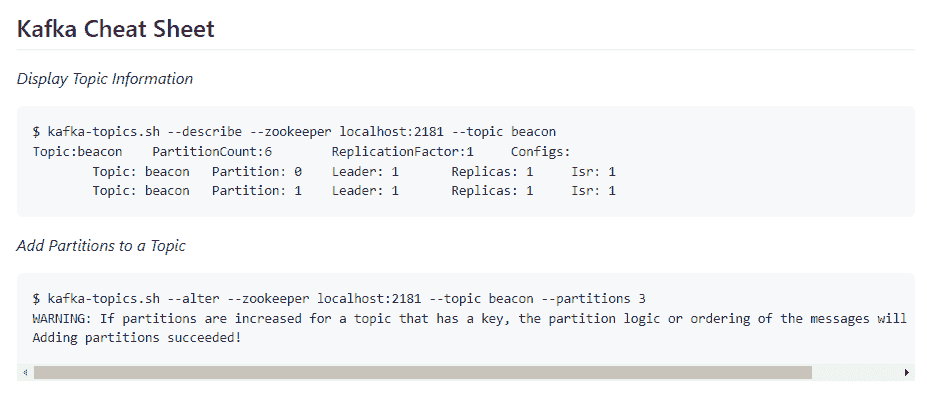
图片来自 备忘单
在此备忘单中,您将学习:
-
显示主题信息
-
更改主题保留期
-
列出现有主题
-
清除一个主题
-
删除一个主题
-
主题中最早的偏移量
-
主题中最新的偏移量
-
消费消息
-
获取主题的消费者偏移量
-
Kafka 消费者组
-
Kafkacat
-
Zookeeper
5. Google BigQuery 备忘单
Google BigQuery 是一个基于命令的备忘单,详细解释了 BigQuery 的每个功能。BigQuery 是一个完全托管的数据仓库,具有地理空间分析、BI 工具和机器学习等高级功能。

图片来自 备忘单
在此备忘单中,您将学习:
-
使用 DDL 初始化 BigQuery 资源
-
更改模式
-
更改表格
-
更改视图
-
更改物化视图
-
BigQuery 数据类型
-
数值类型
-
添加和编辑 BigQuery 数据
-
常见查询
6. Airflow 命令备忘单
Airflow 是一个基于命令的备忘单,涵盖了创建、调度和监控工作流的基本命令。Apache Airflow 是行业中广泛使用的数据管道工具。它提供了可扩展性、可扩展性和动态管道生成。
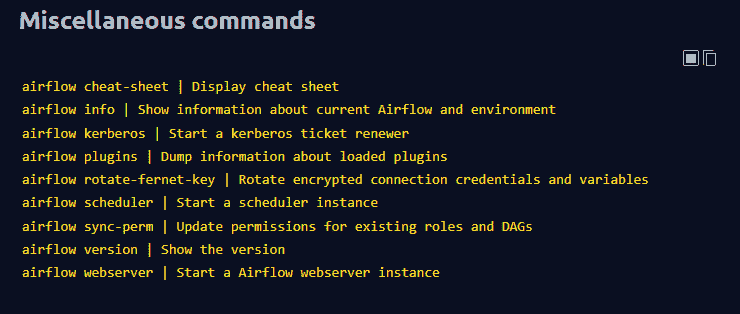
图片来自 备忘单
在此备忘单中,您将学习:
-
各种命令
-
Celery 组件
-
视图配置
-
管理连接
-
管理 DAG
-
数据库操作
-
帮助运行 KubernetesExecutor 的工具
-
管理池
-
显示提供者
-
管理角色、任务、用户和变量
7. Docker 备忘单
Docker 备忘单 涵盖了构建、运行和管理 Docker 镜像的基本功能。Docker 提供了操作系统级别的虚拟化,以便将软件打包为称为容器的形式。它用于可重复性和资源管理。
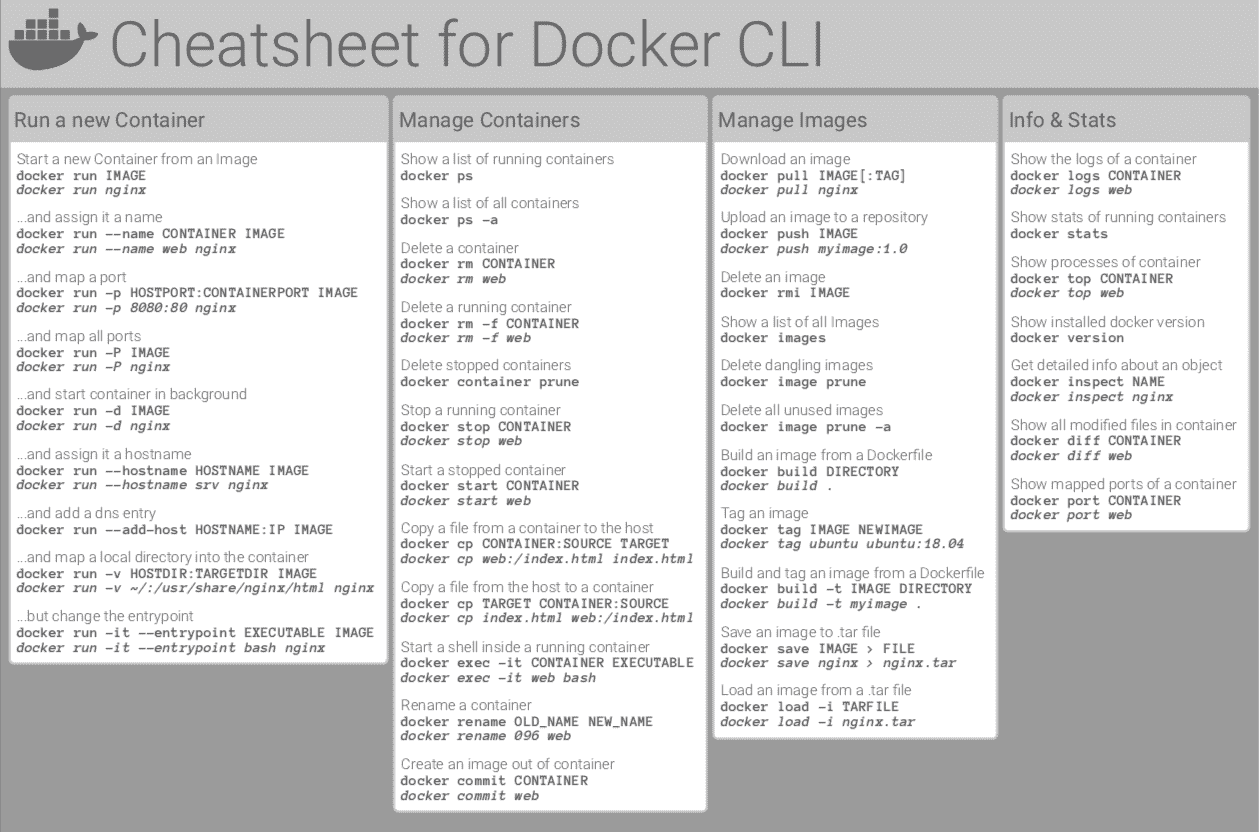
图片来自 备忘单
在这份备忘单中,你将学习:
-
运行新容器
-
管理容器
-
信息和统计
-
管理构建、配置、镜像和服务
结论
数据工程每日执行数据摄取、数据仓储、分析工程、工作流管理、批处理和流处理。为了完成所有这些任务,你需要了解相关工具和命令。这 7 份备忘单将帮助你复习各种工具、命令和概念。此外,它将帮助你在数据工程技术面试阶段以最小的努力取得成功。
希望你喜欢这些备忘单。别忘了在 Twitter 和 LinkedIn 上关注我,我会在这些平台上发布有趣的数据科学博客。
Abid Ali Awan(@1abidaliawan)是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一款 AI 产品,帮助那些在心理健康方面挣扎的学生。
更多相关主题
7 个重要的数据质量检查与 Pandas
原文:
www.kdnuggets.com/7-essential-data-quality-checks-with-pandas

图片由作者提供
作为数据专业人士,你可能熟悉数据质量差的成本。对于所有数据项目——无论大小——你都应该执行必要的数据质量检查。
我们的前三推荐课程
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的信息技术
数据质量评估有专门的库和框架。但是,如果你是初学者,你可以使用 pandas 运行简单但重要的数据质量检查。本教程将教你如何做。
我们将使用 加州住房数据集 作为本教程的示例。
加州住房数据集概述
我们将使用来自 Scikit-learn 的 数据集模块 的加州住房数据集。该数据集包含超过 20,000 条记录,涵盖八个数值特征和一个目标中位数房价。
让我们将数据集读取到 pandas 数据框 df 中:
from sklearn.datasets import fetch_california_housing
import pandas as pd
# Fetch the California housing dataset
data = fetch_california_housing()
# Convert the dataset to a Pandas DataFrame
df = pd.DataFrame(data.data, columns=data.feature_names)
# Add target column
df['MedHouseVal'] = data.target
要获取数据集的详细描述,请运行 data.DESCR,如下所示:
print(data.DESCR)
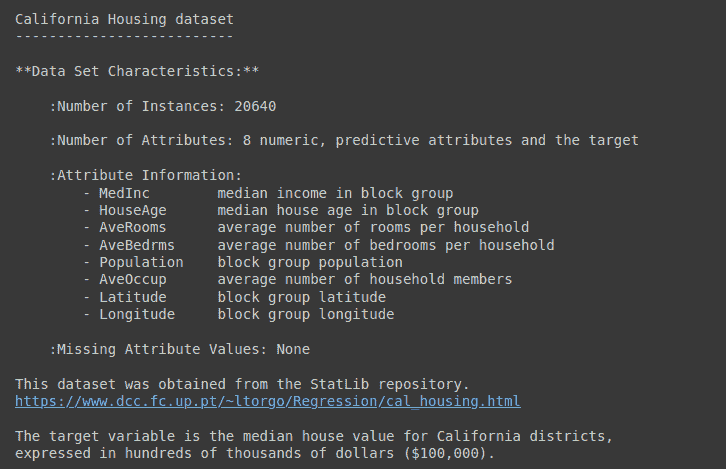
data.DESCR 的输出
让我们获取数据集的一些基本信息:
df.info()
这里是输出:
Output >>>
<class>RangeIndex: 20640 entries, 0 to 20639
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 MedInc 20640 non-null float64
1 HouseAge 20640 non-null float64
2 AveRooms 20640 non-null float64
3 AveBedrms 20640 non-null float64
4 Population 20640 non-null float64
5 AveOccup 20640 non-null float64
6 Latitude 20640 non-null float64
7 Longitude 20640 non-null float64
8 MedHouseVal 20640 non-null float64
dtypes: float64(9)
memory usage: 1.4 MB</class>
由于我们有数值特征,让我们还使用 describe() 方法获取摘要统计:
df.describe()
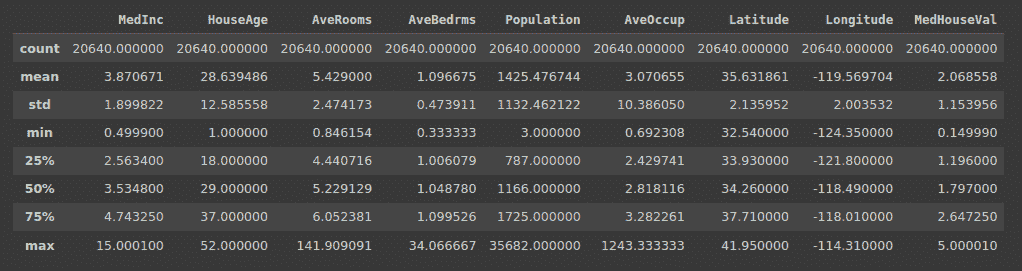
df.describe() 的输出
1. 检查缺失值
现实世界的数据集通常会有缺失值。为了分析数据和建立模型,你需要处理这些缺失值。
为了确保数据质量,你应该检查缺失值的比例是否在特定的容忍范围内。然后,你可以使用适当的插补策略来填补缺失值。
因此,第一步是检查数据集中所有特征的缺失值。
这段代码检查数据框 df 中每一列的缺失值:
# Check for missing values in the DataFrame
missing_values = df.isnull().sum()
print("Missing Values:")
print(missing_values)
结果是一个 pandas 系列,显示了每一列的缺失值计数:
Output >>>
Missing Values:
MedInc 0
HouseAge 0
AveRooms 0
AveBedrms 0
Population 0
AveOccup 0
Latitude 0
Longitude 0
MedHouseVal 0
dtype: int64
如所见,此数据集中没有缺失值。
2. 识别重复记录
数据集中的重复记录可能会扭曲分析结果。因此,你应该根据需要检查并删除重复记录。
这是用于识别和返回 df 中重复行的代码。如果存在任何重复行,它们将包含在结果中:
# Check for duplicate rows in the DataFrame
duplicate_rows = df[df.duplicated()]
print("Duplicate Rows:")
print(duplicate_rows)
结果是一个空的 DataFrame。这意味着数据集中没有重复记录:
Output >>>
Duplicate Rows:
Empty DataFrame
Columns: [MedInc, HouseAge, AveRooms, AveBedrms, Population, AveOccup, Latitude, Longitude, MedHouseVal]
Index: []
3. 检查数据类型
在分析数据集时,你通常需要转换或缩放一个或多个特征。为了避免在执行这些操作时出现意外错误,重要的是检查所有列是否都是预期的数据类型。
这段代码检查 DataFrame df 中每一列的数据类型:
# Check data types of each column in the DataFrame
data_types = df.dtypes
print("Data Types:")
print(data_types)
在这里,所有数值特征都是 float 数据类型,如预期:
Output >>>
Data Types:
MedInc float64
HouseAge float64
AveRooms float64
AveBedrms float64
Population float64
AveOccup float64
Latitude float64
Longitude float64
MedHouseVal float64
dtype: object
4. 检查异常值
异常值是数据集中与其他点显著不同的数据点。如果你还记得,我们在 DataFrame 上运行了 describe() 方法。
根据四分位数值和最大值,你可以识别出某些特征包含异常值。具体来说,这些特征:
-
MedInc
-
AveRooms
-
AveBedrms
-
人口
处理异常值的一种方法是使用 四分位距,即第 75 百分位数与第 25 百分位数之间的差异。如果 Q1 是第 25 百分位数,Q3 是第 75 百分位数,则四分位距为:Q3 - Q1。
然后我们使用四分位数和 IQR 来定义区间 [Q1 - 1.5 * IQR, Q3 + 1.5 * IQR]。所有超出此范围的点都是异常值。
columns_to_check = ['MedInc', 'AveRooms', 'AveBedrms', 'Population']
# Function to find records with outliers
def find_outliers_pandas(data, column):
Q1 = data[column].quantile(0.25)
Q3 = data[column].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = data[(data[column] < lower_bound) | (data[column] > upper_bound)]
return outliers
# Find records with outliers for each specified column
outliers_dict = {}
for column in columns_to_check:
outliers_dict[column] = find_outliers_pandas(df, column)
# Print the records with outliers for each column
for column, outliers in outliers_dict.items():
print(f"Outliers in '{column}':")
print(outliers)
print("\n")
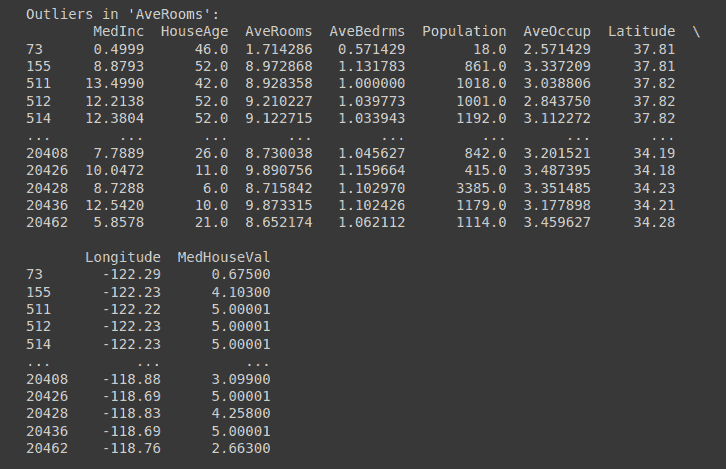
'AveRooms' 列中的异常值 | 异常值检查的截断输出
5. 验证数值范围
对于数值特征,一个重要的检查是验证范围。这确保了特征的所有观测值都在预期范围内。
这段代码验证了 'MedInc' 值是否在预期范围内,并识别出不符合此标准的数据点:
# Check numerical value range for the 'MedInc' column
valid_range = (0, 16)
value_range_check = df[~df['MedInc'].between(*valid_range)]
print("Value Range Check (MedInc):")
print(value_range_check)
你可以尝试其他你选择的数值特征。但我们看到 'MedInc' 列中的所有值都在预期范围内:
Output >>>
Value Range Check (MedInc):
Empty DataFrame
Columns: [MedInc, HouseAge, AveRooms, AveBedrms, Population, AveOccup, Latitude, Longitude, MedHouseVal]
Index: []
6. 检查跨列依赖性
大多数数据集包含相关特征。因此,基于列(或特征)之间逻辑相关关系的检查很重要。
尽管特征——单独来看——可能在预期范围内,但它们之间的关系可能不一致。
这是我们数据集的一个示例。在有效记录中,‘AveRooms’ 应通常大于或等于 ‘AveBedRms’。
# AveRooms should not be smaller than AveBedrooms
invalid_data = df[df['AveRooms'] < df['AveBedrms']]
print("Invalid Records (AveRooms < AveBedrms):")
print(invalid_data)
在我们处理的加州住房数据集中,我们看到没有这些无效记录:
Output >>>
Invalid Records (AveRooms < AveBedrms):
Empty DataFrame
Columns: [MedInc, HouseAge, AveRooms, AveBedrms, Population, AveOccup, Latitude, Longitude, MedHouseVal]
Index: []
7. 检查不一致的数据输入
不一致的数据输入是大多数数据集中常见的数据质量问题。示例包括:
-
datetime 列中的格式不一致
-
分类变量值的不一致记录
-
以不同单位记录的读数
在我们的数据集中,我们已经验证了列的数据类型并识别出了异常值。但你也可以进行不一致数据录入的检查。
让我们来一个简单的例子,检查所有日期条目是否具有一致的格式。
在这里,我们使用正则表达式与 pandas 的 apply() 函数结合,以检查所有日期条目是否符合 YYYY-MM-DD 格式:
import pandas as pd
import re
data = {'Date': ['2023-10-29', '2023-11-15', '23-10-2023', '2023/10/29', '2023-10-30']}
df = pd.DataFrame(data)
# Define the expected date format
date_format_pattern = r'^\d{4}-\d{2}-\d{2}$' # YYYY-MM-DD format
# Function to check if a date value matches the expected format
def check_date_format(date_str, date_format_pattern):
return re.match(date_format_pattern, date_str) is not None
# Apply the format check to the 'Date' column
date_format_check = df['Date'].apply(lambda x: check_date_format(x, date_format_pattern))
# Identify and retrieve entries that do not follow the expected format
non_adherent_dates = df[~date_format_check]
if not non_adherent_dates.empty:
print("Entries that do not follow the expected format:")
print(non_adherent_dates)
else:
print("All dates are in the expected format.")
这将返回不符合预期格式的条目:
Output >>>
Entries that do not follow the expected format:
Date
2 23-10-2023
3 2023/10/29
总结
在本教程中,我们讨论了 pandas 的常见数据质量检查。
当你在进行较小的数据分析项目时,这些使用 pandas 的数据质量检查是一个很好的起点。根据问题和数据集,你可以加入额外的检查。
如果你有兴趣学习数据分析,查看指南 7 步掌握 Pandas 和 Python 数据整理。
Bala Priya C** 是来自印度的开发者和技术作者。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过撰写教程、操作指南、观点文章等与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关主题
成为机器学习工程师的 7 个免费 Google 课程
原文:
www.kdnuggets.com/7-free-google-courses-to-become-a-machine-learning-engineer

图片来源:作者
作为机器学习工程师,你可以构建有效的机器学习解决方案来应对现实世界的挑战。听起来很激动人心,对吧?那么,如何成为一名机器学习工程师,你应该学习什么?
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
这份来自 Google 的免费课程合集将帮助你从机器学习新手成长为能够理解和框架现实世界问题的熟练 ML 工程师,这些问题可以用机器学习来解决。这些课程还将帮助你学习先进的机器学习技术,以及设计、测试和调试机器学习管道。
让我们开始吧。
1. 机器学习简介
如果你是机器学习新手,可以考虑从这个适合初学者的机器学习简介课程开始。
在这门课程中,你将学习:
-
机器学习的类型
-
监督学习的关键概念
-
机器学习与传统问题解决方法的不同之处
链接:机器学习简介
2. 机器学习速成课程
机器学习速成课程是一个使用 TensorFlow 框架的实践入门课程。你将学习机器学习算法是如何工作的以及如何在 TensorFlow 中实现它们。
这门课程分为以下几个部分:
-
机器学习概念
-
机器学习工程
-
现实世界中的机器学习
链接:机器学习速成课程
3. 机器学习问题框架
面对一个现实世界的问题,你如何使用机器学习框架来解决它?首先,你怎么确定机器学习是否必要来解决这个特定问题?
这就是机器学习问题框架课程变得相关的地方。在这门课程中,你将学习如何:
-
决定机器学习是否是解决你所面临问题的好方法
-
框架机器学习问题
-
选择合适的机器学习模型
-
为模型定义成功指标
链接: 机器学习问题框架介绍
4. 数据准备与特征工程
机器学习远不止是将原始数据投入并训练机器学习算法。你必须花时间了解你的数据,并专注于特征工程以识别最相关和重要的特征,处理并根据需要进行转换。
数据准备与特征工程课程将教你以下内容:
-
数据质量和数据大小的影响
-
机器学习工作流中的数据收集与转换
-
收集原始数据并从中构建可用的数据集
-
处理不平衡数据
-
处理数值和类别数据
链接: 数据准备与特征工程
5. 测试与调试
调试和测试机器学习系统比测试传统软件系统更加复杂且不同。
测试与调试机器学习模型的课程将教你以下内容:
-
调试机器学习模型
-
实施测试以帮助调试
-
优化机器学习模型
-
监控模型指标
链接: 测试与调试
6. 聚类
聚类是最广泛使用的无监督学习算法之一。在聚类课程中的动手介绍中,你将学习以下内容:
-
机器学习中的聚类
-
准备数据
-
定义相似性
-
K 均值聚类
-
评估聚类算法的结果
链接: 聚类
7. 推荐系统
从亚马逊和其他在线购物网站的推荐到 Netflix 上的系列推荐,推荐系统在我们的日常生活中非常相关。
推荐系统课程将教你推荐系统的组成部分以及如何构建你自己的应用程序。以下是你将学习的内容概述:
-
推荐系统的组成部分
-
嵌入
-
TensorFlow 实现的推荐算法
链接: 推荐系统
总结
我希望你发现这些免费课程的总结有帮助。这些课程大多旨在为你提供足够的实践机会,并帮助你构建自己的项目。
因此,尝试构建你自己的项目,以应用你在课程中所学到的知识。这将有助于你巩固理解,并建立你的项目组合。祝学习和编码愉快!
Bala Priya C**** 是来自印度的开发者和技术写作者。她喜欢在数学、编程、数据科学和内容创作的交集处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正在通过撰写教程、指南、观点文章等来学习并与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关主题
7 门免费哈佛大学课程提升你的技能
原文:
www.kdnuggets.com/7-free-harvard-university-courses-to-advance-your-skills

图片来源:编辑
你是否计划在 2024 年提升技能?也许你想了解更多计算机科学的知识,看看科技界的热议话题。也许学习最受欢迎的编程语言 Python?或者转向更具特定性的领域,比如游戏或网络安全。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 需求
在这篇博客中,我将介绍 X 门免费的哈佛大学课程,帮助你开启科技职业生涯!
计算机科学导论
这是一个免费的 12 周课程,如果每周投入 6 到 18 小时,您可以完成该课程,课程将介绍计算机科学的智力事业和编程艺术。这个入门课程将教会你如何戴上算法的帽子并高效解决问题。
你将学习算法、数据结构、软件工程和网页开发,以及编程语言如 C、Python、SQL 和 JavaScript。
使用 Python 进行人工智能导论
这是一个免费的 7 周课程,如果每周投入 10 到 30 小时,可以完成该课程,课程深入探讨现代人工智能的概念和算法。你将学习人工智能的不同元素,如图搜索算法、概率论、贝叶斯网络、机器学习、强化学习、神经网络和自然语言处理。
通过动手项目和对人工智能理论的理解,你将能够将这些理论融入到你自己的 Python 程序中。
数据科学:机器学习
链接:数据科学:机器学习
一个免费的 8 周课程,如果你每周投入 2-4 小时,可以完成,在这个课程中你将通过构建一个电影推荐系统来学习流行的机器学习算法、主成分分析和正则化。在这个课程中,你将学习训练数据、数据中的预测关系、如何训练算法、过拟合以及避免过拟合的技巧。
在 8 周内学习机器学习的基础知识——或者更少的时间!
数据科学:生产力工具
链接: 数据科学:生产力工具
一个免费的 8 周课程,如果你每周投入 1-2 小时,可以完成,将指导你如何使用生产力工具来组织和愉快地完成数据分析项目。数据分析项目包含许多部分,因此了解这些工具对于保持项目的掌控和避免挑战至关重要。
学习如何使用 Unix/Linux 等工具来管理文件和目录,以及使用版本控制系统如 git 来跟踪你的脚本和报告中的变化。
使用 Python 和 JavaScript 进行网络编程
链接: 使用 Python 和 JavaScript 进行网络编程
一个免费的 12 周课程,如果你每周投入 6-9 小时,可以完成,从CS50结束的地方继续。如果你想进入技术行业,但更感兴趣于网络应用的设计和实现——这个入门课程适合你。你将学习网络编程的不同方面,如数据库设计、安全性和用户体验。
通过这些知识,你将进入实际项目,测试你的知识,编写和使用 API,并创建互动用户界面。
游戏开发入门
链接: CS50 游戏开发入门
对游戏更感兴趣?不妨看看这个免费的 12 周课程,如果你每周投入 6-9 小时,可以完成,深入学习 2D 和 3D 互动游戏的开发,如《超级马里奥兄弟》,《口袋妖怪》等。你将学习 2D 和 3D 图形、动画、声音以及碰撞检测,使用流行的框架以及像 Lua 和 C#这样的编程语言。
编程自己的游戏,重温童年时光,并在过程中学习新技能!
网络安全入门
链接: CS50 网络安全入门
这个免费的 5 周课程,如果你每周投入 2-6 小时,可以完成,提供了针对技术和非技术观众的网络安全入门介绍。在这个课程中,你将学习如何保护自己的数据、设备和系统免受当今威胁,并能够识别和评估未来的威胁。这个课程对每个人都至关重要,因为这些措施在家里和工作中都适用。
这些作业灵感来源于现实世界事件,提供了高层次和低层次威胁的多种示例。
总结
7 门与哈佛大学合作的免费课程,帮助你开启技术职业生涯。这些课程涵盖广泛,无论你想从何处起步或最终目标是什么,它们都将为你提供开始伟大事业所需的技能,让你不再回头!
尼莎·阿利亚是一位数据科学家、自由技术作家,同时也是 KDnuggets 的编辑和社区经理。她特别感兴趣于提供数据科学职业建议、教程以及围绕数据科学的理论知识。尼莎涵盖了广泛的话题,并希望探索人工智能如何促进人类寿命的延续。作为一个热衷学习者,尼莎寻求拓宽她的技术知识和写作技能,同时帮助他人指导。
更多相关内容
7 个免费 Kaggle 微课程
原文:
www.kdnuggets.com/7-free-kaggle-micro-courses-for-data-science-beginners

编辑器提供的图像
你是否还记得那个你报名但从未完成的数据科学课程?嗯,你并不孤单。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
大多数数据科学初学者会报名一个或多个课程:免费或付费。但由于数据科学课程通常涵盖广泛的主题——从编程到数据分析、可视化等等——需要几周时间才能完成。即使它们起步强劲,大多数学习者在前几个模块后开始感到不知所措,进展缓慢。进入 Kaggle(微)课程。
如果你发现长时间课程难以完成,Kaggle 的微课程 是一个不错的替代选择。它们是学习数据科学技能的绝佳资源——Python、pandas、机器学习等——而不会感到不堪重负。这些课程设计得仅需几个小时即可完成,并包括教程和实践环节。现在让我们来看看一些适合初学者的课程及其内容。
1. Python
Python 是数据科学中最广泛使用的语言之一。除了帮助你在数据职业中,Python 还对你想要进入软件工程领域时非常有帮助。Kaggle 上的 Python 课程将帮助你学习以下内容:
-
Python 基础(语法和变量)
-
函数
-
布尔值和条件语句
-
列表、循环和列表推导式
-
字符串和字典
-
使用外部库
如果你觉得在深入学习 Python 之前需要一个更简单的编程介绍,你可以查看编程入门课程。
因为随后的 Pandas 和数据可视化课程需要你对本课程内容感到熟悉,所以如果你是编程新手,应该不要跳过 Python 课程。
链接: 学习 Python
2. Pandas
一旦你熟悉了基础 Python,你可以 学习 pandas,这是一个强大的数据分析和处理库。
通过一系列简短的课程和动手编码练习,pandas将帮助你学习在 pandas 数据框上执行以下操作:
-
创建、读取和写入
-
索引、选择和分配
-
重命名和合并
-
汇总函数和映射
-
分组和排序
-
数据类型和缺失值
链接:学习 Pandas
3. 数据可视化
现在你知道如何使用 Python 和 pandas 分析数据,是时候通过学习如何可视化数据来进一步提升技能了。
数据可视化课程涵盖了使用 Python 库 Seaborn 创建有用图表和图形的基础知识。该课程包括以下内容:
-
折线图
-
条形图和热图
-
散点图
-
直方图和密度图
-
选择图表类型
你还需要完成一个最终项目,以应用你所学到的知识。
链接:学习数据可视化
4. SQL 入门
SQL 是你可以学习的单一最重要的数据科学技能。要了解为什么 SQL 对数据科学如此重要,请阅读 KDnuggets 撰稿人 Nate Rosidi 的 "为什么 SQL 是数据科学必学语言"。
SQL 入门课程将教你如何使用 BigQuery Python 客户端查询数据集,并涵盖 SQL 基础知识、过滤和编写可读的 SQL 查询:
-
开始学习 SQL 和 BigQuery
-
选择、从和哪里
-
分组、筛选和计数
-
排序
-
作为和与
-
数据连接
链接:学习 SQL 入门
5. 高级 SQL
现在你已经掌握了 SQL 基础,可以参加 高级 SQL课程,以进一步提升你的 SQL 技能。此课程基于 SQL 入门课程,并涵盖了以下关于从多个表中结合数据和执行更复杂操作的主题:
-
连接和并集
-
分析函数
-
嵌套和重复数据
-
编写高效查询
链接:学习高级 SQL
6. 机器学习入门
如果你已经完成了上述课程,你应该能够舒适地进行 Python 和 SQL 编程及数据分析。你现在已经准备好开始学习机器学习。
机器学习入门课程包括:
-
机器学习模型的工作原理
-
基本数据探索
-
模型验证
-
欠拟合和过拟合
-
随机森林
你也可以提交到一个适合初学者的 Kaggle 比赛中。
链接: 学习机器学习简介
7. 中级机器学习
中级机器学习课程在机器学习简介课程的基础上进行,教你如何处理缺失值、分类变量,并避免在训练机器学习模型时出现数据泄漏的棘手问题。
涵盖的主题包括:
-
缺失值
-
分类变量
-
机器学习管道
-
交叉验证
-
XGBoost
-
数据泄漏
链接: 中级机器学习
总结
希望你觉得这次课程总结对你有帮助。
如前所述,这些课程都是免费的。学习一个基础的数据科学技能只需几小时。因此,你可以通过一个个微课程来开始你的数据科学之旅。祝学习愉快!
Bala Priya C是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正在通过撰写教程、使用指南、观点文章等来学习和与开发者社区分享她的知识。Bala 还制作了引人入胜的资源概述和编码教程。
更多相关内容
7 个免费平台,帮助构建强大的数据科学作品集
原文:
www.kdnuggets.com/2022/10/7-free-platforms-building-strong-data-science-portfolio.html

作者图片
在学习所需技能或获得数据科学学位之后,最重要的是要展示自己。即使是初学者,也强烈建议在 GitHub 和 Kaggle 上创建一个个人资料。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 事务
我们将在这篇博客中讨论的免费平台将帮助你获得招聘人员的邀请,并开启一个全新的职业机会世界。
我在这些平台上非常活跃,这使我成为了更好的数据科学家和内容创作者。除了显而易见的职业优势,它还帮助我建立了个人品牌和专业网络。
“通过构建强大的数据科学作品集,使我更容易找到工作。”
在详细讨论之前,我希望你在 GitHub、Kaggle、LinkedIn、Medium、DagsHub、Deepnote 和 DataCamp 上创建一个简单的账户。随着时间的推移,你将学会所有七个平台的重要性。
1. GitHub
在 GitHub 上创建一个作品集与撰写简历一样重要。招聘人员或招聘经理会要求你的个人资料链接,以便通过查看最近的项目来准备面试问题。
作者资料 | GitHub
如上所示,我已经在 README.md 文件中填写了我的介绍、愿景、兴趣和目标。我还链接了我的其他个人资料和最近的成就。如果你向下滚动,你会看到我最受欢迎的项目和贡献信息。
我通过 GitHub 收到了来自 CEO、招聘人员、初创公司创始人、学生和研究人员的接触。他们中的大多数人想了解更多关于我的项目以及如何将其应用于特定数据的情况。
2. Kaggle
Kaggle 是数据科学家和机器学习工程师的超级平台。它也被数百万寻求学习、查找数据集和讨论特定问题的学生使用。
“如果你不是 Kaggler,你就错过了数据科学社区所提供的一切。”
作者简介 | Kaggle
就像 GitHub 一样,你可以在个人简介部分填充成就和个人简介。此外,大家可以看到公开共享的笔记本、数据集、竞赛和讨论。
该平台通过 Kaggle 进阶系统推动数据专业人员追求卓越,并在技艺上不断进步。如果你获得足够的点赞,你可以赢得铜牌、银牌和金牌。这些奖牌将帮助你从贡献者晋升为大师。
“我通过参加竞赛并争取进入前 10 名,学到了大部分机器学习的知识。”
3. LinkedIn
LinkedIn是一个专业的社交网络网站,每个人都应该用来创建一个作品集。它是寻找工作、建立联系和打造个人品牌的绝佳平台。

作者简介 | LinkedIn
无论你处于哪个专业水平,维护你的 LinkedIn 个人资料都是找到理想工作的最佳机会。你还可以通过关注其他数据科学家、开源项目和内容创作者来学习一些新东西。
确保你已添加专业经验、成就、证书和个人简介。设计你的个人主页,使人们通过电子邮件或直接消息联系你变得简单。分享你关心的帖子,讨论最新趋势,以增加你的粉丝。如果你有才华,很快你就会收到各种人的邀请。
在 LinkedIn 上,我收到工作邀请、开源贡献请求、项目合作机会和数据科学产品测试的任务。
4. Medium
让你的工作自己发声。
为你的项目或你所学的内容撰写Medium博客可以提升你的在线影响力。你不仅是在推广你的项目,还在向初学者和专业人士传授新思想。
“回馈社区。”

作者简介 | Medium
我强烈建议你就某个主题、项目或工具撰写技术博客。这将提升你的沟通和技术能力。如果你是新手且粉丝较少,你可以通过将博客提交到 Towards Data Science 和 Towards AI 来扩大你的影响力。
撰写博客让我变得有名。它支付我的账单,并为我带来更好的机会。许多公司高管基于我的写作向我提出了工作邀请。
“即使你是初学者,也不要停止写作,写关于 Python 或简单的数学问题。”
5. DagsHub
DagsHub 是一个功能丰富的平台,让你可以与社区分享你的项目。这个项目不仅仅是一个 GitHub 仓库。它包括 DVC 存储、Git 和 MLflow 实验跟踪、Label Studio 集成、数据管道、自动化和报告。
“你可以免费体验完整的数据科学生态系统。”
作者资料 | DAGsHub
就像 GitHub 一样,你可以展示你的项目、数据集和实验。你需要添加个人简介和资料链接,让你的项目代言自己。
我使用 DagsHub 已经快 2 年了,我喜欢所有的功能。在此之前,我有不同的数据集存储、实验跟踪解决方案和自动化工具。将一切整合到一个平台上帮助了我作为数据科学家和内容创作者。
通过阅读 文档 了解更多关于 DagsHub 的功能。
6. Deepnote
另一个功能丰富的平台,你可以用作作品集构建器。 Deepnote 允许你在个人资料页面发布云 Jupyter 笔记本。这类似于写博客,但发布的页面包括代码和交互式输出。
“只需点击一下,你就可以复制笔记本并重现结果。”
作者资料 | Deepnote
我使用 Deepnote 处理所有数据重新加载的问题。我进行产品的 beta 测试,编写教程,运行 API 测试,连接数据库,甚至用于非技术任务。
我使用 Deepnote 已经 2 年了,我喜欢每一个功能。它帮助我作为内容创作者成长,因为我可以在 Jupyter 笔记本上工作,并仅用一次点击就发布我的作品。
查看 文档 以了解更多关于 Deepnote 的功能。
7. DataCamp
DataCamp 最近改进了个人资料页面。他们引入了传记、社交链接、认证、工作区出版物、数据技能概览、学习进度、工作经验和教育部分。你可以称之为一个互动简历。
作者资料 | DataCamp
DataCamp 的个人资料是教育生态系统的一部分。你学习技能、完成职业路线、参加评估测试并获得认证,这些都展示在你的个人资料上。
他们还引入了一个名为 Jobs 的新部分,你可以使用你的个人资料申请工作。
“从学习新技能到找到工作变得轻而易举。”
DataCamp 不断发展其学习平台,使全球任何人都能轻松找到工作。他们推出了免费的数据集、云 Jupyter Notebook 和学习资源。
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些饱受心理疾病困扰的学生打造一个人工智能产品。
更多相关话题
7 个数据工程师在 Google BigQuery 中需要注意的“陷阱”
原文:
www.kdnuggets.com/2019/03/7-gotchas-data-engineers-google-bigquery.html
评论

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 部门
如今,无论你看向哪里,IT 组织都在寻求通过云计算来解决数据存储、传输和分析的挑战……这也有很好的理由!来自 Amazon、Google、Microsoft 等的云服务彻底改变了我们对数据的思考方式,无论是从 IT 还是最终用户的角度来看。它们大大减少了企业数据中心的功能,这通常不是组织的核心能力。它们使数据、分析和处理能力变得民主化。它们打破了我们对数据仓储和分析成本的思考方式。云计算拥有所有这些特性以及更多,因此很多组织急于将大数据操作转移到云端也就不足为奇了。成本节约、性能提升和简化操作都是很好的,但当你真正开始工作时会发生什么呢?很可能你的数据工程师对你组织决定使用的任何云技术都很陌生。本文详细介绍了我作为数据工程师第一次接触 Google BigQuery (GBQ) 的经验。
我已经做了多年的数据工程师,并且在职业生涯中使用过大多数类型的 RDBMS 和 SQL。最近的一个项目中,我和我的同事将一个现有的 SQL Server 数据库重新设计为 GBQ,这激发了我撰写本文,作为对初次接触 GBQ 的数据工程师的资源。以下是一些可能需要适应的内容,以及我发现的缓解策略:
-
区分大小写 - 与大多数 RDBMS 不同,BigQuery 对大小写敏感,不仅在字符串比较中如此,在对象名称中也一样。对于字符串比较,在两边(或一边对比字面量)使用 UPPER 函数可以消除大小写敏感的影响。 有趣的是,虽然在 FROM 子句中引用对象名称时是区分大小写的,但列名称则不区分大小写。
-
完全限定的对象名称 - 在 FROM 子句中引用的所有对象名称必须完全限定到数据集级别,如果这些对象不在当前计费项目中,则必须到项目级别。不仅如此,整个完全限定的名称必须用反向单引号(通常与波浪键共享)括起来。你绝对会在某个时刻花费几分钟沮丧地尝试找出查询错误的原因,直到你意识到这些引号中的一个与其他的看起来不一样。
-
标准 SQL 与遗留 SQL - BigQuery 有两种 SQL 版本,不知何故。标准 SQL 非常类似于 ANSI SQL,这是你应该使用的。然而,经典的 BigQuery Web UI(由于某些我将很快提到的原因,我偏爱它)默认使用遗留 SQL。可以选择使用标准 SQL,也可以使用名为 BigQuery Mate 的 Chrome 扩展程序来跳过这一步。
-
没有存储过程或函数 - 这是一个大问题,真的没有简单的解决办法。Google 提供了进行 ETL 和数据转换准备的工具,但它们没有编码自己过程的灵活性。可以创建函数,但它们是临时的,只在单个会话中存在,这使得它们作为编程工具非常有限。
-
经典 UI 与新 UI - 经典 UI(看起来像 Gmail 的那个)有一个大优势,那就是它允许你添加一个你没有明确命名访问权限的项目到对象浏览器。出于某种原因,新 UI 没有这个功能。然而,它默认使用标准 SQL,这可以为你节省一些麻烦。两者都不错,但都不完美。
-
没有查询计划估算 - 你不得不怀疑运行 Google 云服务部门的那些人是否曾在前世当过医生。还有哪个行业会在没有先解释成本的情况下提供服务?这本质上就是 Google 在做的事情,尽管这种方式不那么掠夺性。简单来说,没有办法在实际运行复杂查询之前确定其是否高效。一旦运行查询,执行计划实际上非常有用且可操作。
-
有限的 DDL 能力 - 一旦表存在,就几乎没有能力去修改它。你不能移除列或更改数据类型。你不能重命名字段或表。几乎任何表或视图的修改操作都涉及“CREATE TABLE AS SELECT”类型的操作,这意味着你技术上会得到一个“新”的表或视图。
我想读到这份列表时,可能会觉得我对 BigQuery 有些贬低。这完全不是事实。这些大多数只是新 GBQ 开发人员会遇到并克服的烦恼。实际上,还有很多值得喜欢的地方。在我第一次 GBQ 项目中,我遇到了一些令人愉快的惊喜:
-
自动对象过期 - 这是为那些总是让 25 个临时表在数据库角落里积灰的懒惰 DBA 准备的。在 GBQ 中,你可以(而且应该)创建一个数据集并指定一个短暂的对象生命周期。这样,你可以拥有一个自动清理的沙盒环境,不必担心额外的存储费用,因为你不再需要的数据会被自动清理。
-
查询历史 - GBQ 会记录你运行的所有查询,当然是为了计费目的,但它也会将这些查询以易于搜索的列表形式展示给你。如果你丢失了某段代码,这会非常方便,这种情况即使对最优秀的人来说也会发生。
-
缓存查询结果 - 谷歌对存储数据和检索数据通常会收费。如果你像我一样,可能会在开发过程中定期运行相同的查询。GBQ 默认会缓存这些结果,你的项目将不会被收费。如果需要,你可以在 Web UI 选项中关闭此功能。
-
自动补全 - 大多数查询工具,如 TOAD 或 SQL Management Studio,会以不同程度的成功来自动补全表和列名称。我发现 GBQ Web UI 的自动补全功能非常好用。
-
基于 GUI 的表创建 - 有时你只需要创建一个快速的小表来存储参数或类似的东西。GBQ Web UI 允许没有 SQL 技能的用户创建表并添加各种数据类型的列。
总的来说,GBQ 需要一点时间适应,并且仍然有一两个明显的功能缺陷,主要与无法创建存储过程或函数有关。然而,云数据存储和分析的潜在好处远远超过了这些考虑因素。我每天都在学习新的快捷方式和技巧,随着我克服各种小挑战,我能看到前方光明的“云端”未来。
个人简介:Josh Levy 是 aspirent 分析实践部门的经理。他在商业智能领域从事了 20 多年的工作,担任过各种职位和行业。欲了解更多信息,请访问 www.aspirent.com。
相关内容:
-
BigQuery 与 Redshift:定价策略
-
旅行大数据工程炒作列车时你应该知道的事
-
构建有效数据科学团队
更多相关话题
提升数据科学工作流程的 7 个 GPT
原文:
www.kdnuggets.com/7-gpts-to-help-improve-your-data-science-workflow

图片由编辑提供
ChatGPT 已经成为改变世界运作方式的 OpenAI 产品。许多读者已经在使用它们,或者至少在测试它们。它帮助我们的方式,让我觉得我们可能无法回到过去的工作方式。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 需求
OpenAI 提供的一项创新是 GPT 商店,用户可以在其中开发自己的自定义 GPT 模型并与公众分享。超过 300 万个 ChatGPT 自定义 GPT 模型对外开放。的确,其中一些可能对提升数据科学家的活动有所帮助。
本文将讨论来自 GPT 商店的 7 个 GPT,它们可能会改善你的数据科学工作流程。这些 GPT 是什么?让我们深入了解。
顺便提一下,我会使用Kaggle 上的电信流失数据集作为 GPTs 使用的示例数据集。
1. ChatGPT 提供的数据分析师
让我们从 ChatGPT 团队为我们创建的数据分析师开始。这是一个专门训练用于分析我们的数据并按需可视化的自定义 GPT。通过上传文件,如 CSV 文件,并提供所需的提示,数据分析师 GPT 可以自动完成工作。
例如,我会要求数据分析师根据我提供的数据集进行流失相关性分析。
数据分析师执行相关性分析(图片由作者提供)
你可以向数据分析师 GPT 请求进一步分析。如果需要,你也可以使用 GPT 提供完整代码自行执行。
2. 由 Maryam Eskandari 撰写的机器学习
我们将讨论的下一个 GPT 是机器学习 GPT。这个自定义 GPT 被设计为机器学习和数据科学活动的助手。它的实用性包括讨论、学习和开发适合我们数据项目的算法。
作为一个例子,我请求机器学习 GPT 从我们的示例数据集中执行模型开发以预测流失。以下是结果。

机器学习执行模型实验(图像由作者提供)
这个 GPT 可以提供模型之间的出色比较。如果我们继续,可以让模型迭代更多模型,进行超参数调优,并让 GPT 提供每个行动的理由。
3. 机器学习工程师由 Hustle Playground 提供
与之前的条目类似,机器学习工程师 GPT 为用户提供了一个助手来开发机器学习模型。你可以输入你的数据集,并要求 GPT 给出必要步骤和完整代码。
机器学习工程师的不同之处在于,他们的 GPT 指定了用于自动化复杂任务的模型设计,特别是在模型部署方面。这个 GPT 适合讨论你如何构建模型以及如何在生产中部署模型。
4. AutoExpert (Dev) 由 llmimagineers.com 提供
说到模型结构,GPT 也适合帮助我们构建机器学习模型的代码。我发现的一个最佳编码助手是AutoExpert。它是一个旨在作为你可靠的对编程助手的 GPT。
这个 GPT 具备额外的代码生成能力、访问最新 API 的在线功能,以及保存会话状态的自定义命令,你可以在需要时用于后续会话。
使用这个 GPT,可以帮助你生成任何你在数据科学活动中需要的复杂代码。它还为你提供代码结构和脚本,帮助你更好地执行这些代码。
5. ScholarGPT 由 awesomegpts.ai 提供
让我们从技术编码部分转向理论部分。正如我们所知,数据科学工作是关于持续学习的,特别是在新颖的用例中。随着数据科学研究的不断增长,有时很难找到适合我们用例的完美研究。这时,ScholarGPT 就派上用场了。
这个 GPT 将帮助你找到适用于我们用例的最新研究论文。从简单的提示中,它会给我们提供与我们想要解决的问题相关的最新论文选择。
例如,下面的文本是 ScholarGPT 的结果,我上传了我们的数据集,并要求它提供与预测流失相关的研究论文。
标题:“决策透明度:可解释人工智能(XAI)在客户流失分析中的作用”
-
作者:C ÖZKURT
-
年份:2024
-
摘要:本研究侧重于使用机器学习预测流失客户,并解释其背后的原因,具体分析了电信行业的客户流失情况。
-
链接:阅读论文?source?。
ScholarGPT 提供了更多研究论文供你选择,因此你可以选择适用于你用例的论文。
6. 由 whimsical.com 提供的 Whimsical 图表
下一个我们要讨论的 GPT 是 Whimsical Diagram。对于许多数据科学活动来说,这不仅仅是研究和模型开发。我们经常需要可视化我们的工作流程并提供工作如何进行的解释。这正是 Whimsical Diagrams GPT 能够帮助你的地方。
这个 GPT 旨在用流程图、思维导图和序列图解释和可视化概念。提供提示和数据源可以帮助我们提供有助于工作的可视化效果。
例如,我要求模型从 Churn 数据集中提供一个建议图表,它建议通过特征来可视化流失情况。下面是图像结果。
特征流失(由 Whimsical Diagram GPT 生成的图像)
你可以与 GPT 进一步讨论,找到适合你数据科学工作的完美图表工作流程。
7. 由 canva.com 提供的 Canva
最后一个是 Canva GPT,它可以帮助我们更好地展示我们的结果。众所周知,Canva 是一个设计服务平台,帮助设计从徽标到个人照片、横幅和演示文稿等各种内容。通过 Canva GPT,他们可以帮助我们为我们的分析找到最佳设计。
数据科学的核心是将结果传达给他人,因此拥有有效的结果并以观众能够理解的方式展示是至关重要的。通过 Canva GPT,我们可以请求建议哪种设计最合适。例如,我要求模型提供一个适合展示流失统计数据的设计。

流失统计设计选择(Canva GPT)
GPT 会给出设计选项,我们可以选择喜欢的设计或提供额外提示以获得其他设计。
结论
这篇文章讨论了 GPTs Store 中的七个自定义 GPT,这些 GPT 可以改进我们的数据科学工作流程,它们是:
-
由 ChatGPT 提供的数据分析师
-
由 Maryam Eskandari 提供的机器学习
-
由 Hustle Playground 提供的机器学习工程师
-
AutoExpert (开发) 由 llmimagineers.com 提供
-
ScholarGPT 由 awesomegpts.ai 提供
-
由 whimsical.com 提供的 Whimsical 图表
-
由 canva.com 提供的 Canva
希望这对你有帮助!你是否有任何建议的 GPT 应该出现在此列表中?也请在评论中告诉我们。
Cornellius Yudha Wijaya 是数据科学助理经理和数据撰写员。他在印尼安联全职工作,同时通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 撰写了各种 AI 和机器学习的主题。
更多相关主题
数据科学家的七个高薪副业
原文:
www.kdnuggets.com/7-high-paying-side-hustles-for-data-scientists

图片由作者提供
近年来,经济形势发生了剧变。由于高通货膨胀和对衰退的担忧,许多专业人士的个人财务变得更加紧张。如果你在数据科学或相关领域工作,你可能在寻找补充收入的方法。好消息是,对数据技能的需求仍然很高,并且有很多机会赚取额外的收入。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
在本文中,我们将探讨七种适合数据科学家和其他技术专业人士的有利可图的副业。无论你想通过咨询提供数据专业知识、创建在线课程、进行自由分析工作,还是探索其他创业想法,你都可以利用副业和被动收入的灵活性。
1. 教学
教学仍然是数据科学领域的高薪职业。你可以创建一个在线课程,并通过 YouTube、DataCamp、Udemy、Skillshare、LinkedIn Learning 和 365 Data Science 等平台获得报酬。或者,你可以成为大学的客座讲师,教授数据科学课程。对于那些对持续教学感兴趣的人,你可以创建自己的学院或训练营,以培养有志成为数据专业人士的人。
图片来源于DataCamp 上的教学
通过在线或面对面的结构化课程和项目分享你的知识,你可以通过教学副业赚取丰厚收入。随着数据技能的需求仍然很高,学生们将热切希望向经验丰富的专业人士学习。教学使你能够设定自己的时间表,并接触到全球渴望获得实际数据科学专业知识的学习者。
2. 自由职业
自由职业是数据科学专业人士获得多样经验并为其专业知识获取报酬的绝佳方式。作为自由职业者,你是自己的老板,设定项目的时间表和条款。这种控制和灵活性可能非常有益。有许多平台可以找到自由职业机会,包括 Upwork、Fiverr、Toptal 和 LinkedIn。

图片来自 Toptal
你可以在这些网站和你的专业网络上展示你的项目和能力以吸引客户。随着你建立个人品牌和作品集,人们将开始联系你提供自由职业机会。自由职业使你能够扩展技能并与不同公司和行业合作。
3. 技术写作
在 Medium 和 Substack 等平台上进行技术写作可以为你带来额外收入。你可以选择数据科学中的特定细分领域进行定期写作。随着你建立受众和粉丝,你可以通过每篇文章的浏览量支付以及订阅者的定期收入来实现盈利。许多技术写作者仅通过在这些网站上的内容创作就赚取了六位数的收入。你也可以寻找需要文档、教程、博客和其他材料的公司合同技术写作工作。
图片来自 Medium
对高质量技术写作的需求很强烈,而你对数据科学的内部知识可以为你提供优势。定期在你选择的子领域内写作,并推广你的文章以逐步获得付费订阅者。通过选择合适的细分领域并定期发布,技术写作可以成为稳定的额外收入来源。
4. 咨询
你可以为本地公司提供咨询,以帮助改善他们的分析能力、工具、数据基础设施和建模。或者提供远程咨询服务给全国及全球的公司。
作为顾问,你利用你的经验审视当前的商业挑战,并提供战略性建议以改善数据实践。你可以提供短期咨询服务来诊断问题并制定改进计划,或者作为长期顾问参与更长时间的项目以监督实施。

图片来自 Guidepoint
对专家数据科学指导的需求使咨询变得极具盈利性,小时费率往往超过标准工资。你可以通过推广你在某些领域的专业能力,在多个行业领域进行咨询。随着时间的推移,咨询让你接触到各种商业问题,同时扩展你的专业知识。
5. 参与竞争
虽然这不是稳定的收入来源,但参与数据科学竞赛可以是一个有利可图的副业。像 Kaggle 这样的平台有奖池从 60,000 美元到 500,000 美元甚至更多。即使每年赢得或获得高排名几次,也能达到或超过你常规的年薪。
图片来自 Kaggle
虽然成功无法保证,但掌握正确的技能可以通过解决实际的机器学习挑战赢得数千美元。关键在于了解各个平台,并不断参与与你的专业知识相符的竞赛。虽然竞赛奖金不应替代稳定收入,但对于那些对数据科学能力有信心的人来说,竞赛提供了从才华中获利的机会。
6. 职业咨询
具有至少 5 年行业经验的数据专业人士可以将职业咨询服务作为高薪副业。你可以按小时收费,为应届毕业生或希望转行进入数据角色的人提供指导。像 Skilled 这样的平台允许你为模拟面试、简历审查和一般职业建议收费。

图片来自 Skilled
你还可以找到私人客户,提供个性化辅导以进入该领域。在付费的课程中,你将提供关于数据科学招聘和面试过程的内幕技巧。你将推荐课程、项目和其他成为强大候选人的步骤。你对招聘实践和资格的实际理解非常宝贵。辅导工作也很有成就感,因为你直接帮助人们推进他们的职业生涯。
7. 合作
在项目中合作可以为数据专业人士带来高薪机会。你可能会收到合作商业项目、初创企业或开源项目的邀请。虽然一些合作是不付费的,但许多合作是有报酬的,尤其是当你将其视为合同工作时。当因你的专业知识被带到团队中时,谈判公平的薪酬以报酬你的时间和贡献,即使你相信这个项目也是如此。还有像 Omdena 这样的平台提供付费的协作数据科学项目供你参与。
图片来自 Github
在 GitHub 上贡献开源项目也可以为数据专业人士带来丰厚的机会。许多流行的开源数据工具有企业赞助商,他们从贡献者社区中招聘。通过持续贡献优质的代码和文档,你可以引起注意并被聘用。你的开源工作作为你能力的证明。
除了潜在的就业机会,活跃的 GitHub 贡献者可以通过 GitHub Sponsors 直接获得资助。受欢迎的代码库可以吸引依赖该项目的用户提供财政支持。即使没有直接的资助,你的开源声誉也可以带来合同和咨询机会。
结论
尽管经济不确定性存在,对数据技能的需求依然强劲,数据专业人士在高薪副业方面具有优势。无论你是想做咨询、开设在线课程、做自由职业分析项目、撰写技术内容,还是参加数据科学竞赛,都有很多方式可以从你的专业知识中获利。
通过副业的灵活性和回报潜力,数据科学家和技术专业人士即使在企业薪资停滞的情况下也能在财务上蓬勃发展。与其局限于传统就业,不如接受那些可以让你将技能变现的创业想法。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,他热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一款 AI 产品,帮助那些面临心理健康问题的学生。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,他热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一款 AI 产品,帮助那些面临心理健康问题的学生。
更多相关话题
7 个你不能错过的机器学习算法
原文:
www.kdnuggets.com/7-machine-learning-algorithms-you-cant-miss

图片由编辑提供
数据科学是一个不断发展且多样化的领域,你作为数据科学家的工作可以涵盖许多任务和目标。学习不同场景下哪种算法效果最佳,将帮助你满足这些不同的需求。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
成为每种机器学习模型的专家几乎是不可能的,但你应该了解最常见的模型。以下是每位数据科学家应该了解的七种基本机器学习算法。
监督学习
许多公司倾向于使用监督学习模型,因为它们在现实世界应用中准确且直接。虽然无监督学习在增长,但监督学习技术作为数据科学家的入门是一个很好的起点。
1. 线性回归
线性回归是基于连续变量的最基本的预测模型。它假设两个变量之间存在线性关系,并利用这种关系根据给定的输入绘制结果。
在合适的数据集下,这些模型易于训练和实施且相对可靠。然而,现实世界中的关系通常不是线性的,因此在许多业务应用中相关性有限。它也无法很好地处理异常值,因此不适合大规模、多样化的数据集。
2. 逻辑回归
你应该了解的一个相似但不同的机器学习算法是逻辑回归。尽管名字与线性回归相似,它是一个分类算法,而不是估计算法。线性回归预测连续值,而逻辑回归预测数据落入给定类别的概率。
逻辑回归在预测客户流失、天气预报和产品成功率方面很常见。与线性回归类似,它易于实现和训练,但容易过拟合,并且在处理复杂关系时表现不佳。
3. 决策树
决策树是你可以用于分类和回归的基本模型。它们将数据分割成同质组,并将其进一步划分为更小的类别。
由于决策树的工作方式类似于流程图,它们非常适合复杂的决策制定或异常检测。尽管它们相对简单,但训练可能需要时间。
4. 朴素贝叶斯
朴素贝叶斯是另一种简单而有效的分类算法。这些模型基于贝叶斯定理进行操作,该定理确定条件概率——基于过去类似事件的结果概率。
这些模型在基于文本和图像的分类中很受欢迎。尽管它们可能对实际的预测分析过于简单,但它们在这些应用中表现优异,并且能够很好地处理大数据集。
5. 随机森林
正如你从名字中可能猜到的那样,随机森林由多个决策树组成。对每棵树进行随机数据训练并对结果进行分组,使这些模型能够产生更可靠的结果。
随机森林比决策树更能抵抗过拟合,并且在实际应用中更为准确。然而,这种可靠性也有代价,因为它们可能比较慢,并且需要更多的计算资源。
无监督学习
数据科学家还应了解基本的无监督学习模型。这些是这一较少见但仍重要类别中最受欢迎的一些模型。
6. K-means 聚类
K-means 聚类是最受欢迎的无监督机器学习算法之一。这些模型通过根据相似性将数据分组来对数据进行分类。
K-means 聚类非常适合客户细分。这使得它对希望优化营销或加速入职的企业具有价值,从而在过程中降低成本和客户流失率。它对异常检测也很有用。然而,在将数据输入这些算法之前,必须对数据进行标准化。
7. 奇异值分解
奇异值分解(SVD)模型通过将复杂数据集分解为更易理解的部分,并去除冗余信息,来简化数据集。
图像压缩和噪声去除是 SVD 的一些最流行的应用。考虑到文件大小不断增长,这些用例将随着时间的推移变得越来越有价值。然而,构建和应用这些模型可能会耗时且复杂。
了解这些机器学习算法
这七种机器学习算法并不是你作为数据科学家可能会使用的全部。然而,它们是一些最基本的模型类型。理解这些将有助于你启动数据科学职业生涯,并使理解其他建立在这些基础上的更复杂算法变得更容易。
April Miller**** 是 ReHack 杂志的消费技术主编。她在创建高质量内容方面有着丰富的经验,这些内容能够吸引流量到她所工作的出版物。
更多相关话题
7 个机器学习组合项目以提升简历
原文:
www.kdnuggets.com/2022/09/7-machine-learning-portfolio-projects-boost-resume.html
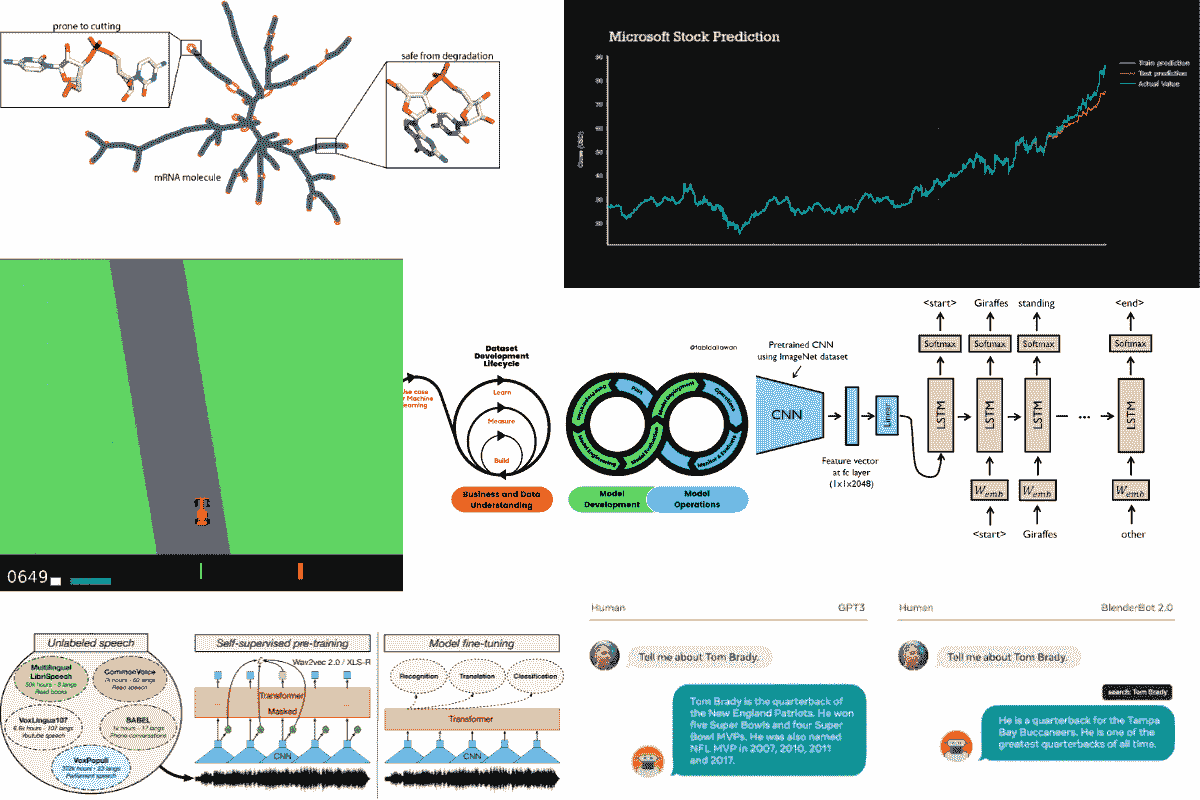
作者提供的图片
对机器学习工程师职位的需求很高,但招聘过程很难突破。公司希望聘用有经验处理各种机器学习问题的专业人士。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在的组织的 IT 工作
对于新手或应届毕业生来说,展示技能和经验的方式很少。他们可以选择实习、参与开源项目、在非政府组织项目中做志愿者,或进行组合项目。
在这篇文章中,我们将重点介绍能够提升你简历的机器学习组合项目,并在招聘过程中帮助你。单独进行项目也能让你在解决问题方面更有能力。
使用深度学习模型进行 mRNA 降解
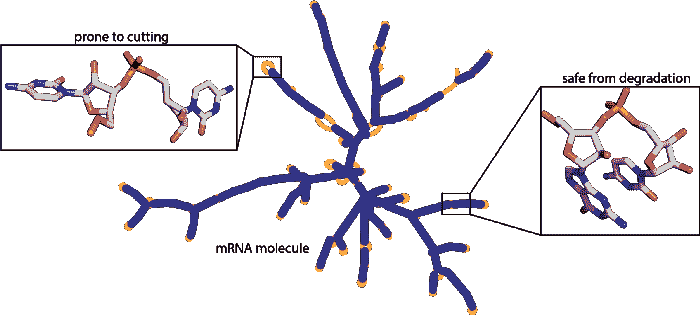
图片来自 OpenVaccine Kaggle
mRNA 降解项目是一个复杂的回归问题。这个项目的挑战在于预测降解率,这可以帮助科学家设计更稳定的疫苗。
这个项目已经进行 2 年了,但你将会学到很多关于使用复杂的 3D 数据处理和深度学习 GRU 模型解决回归问题的知识。此外,我们还将预测 5 个目标:反应性、deg_Mg_pH10、deg_Mg_50C、deg_pH10、deg_50C。
自动图像描述
图片来自 AnalyticsVidhya
自动图像描述 是你简历中必备的项目。你将了解计算机视觉、CNN 预训练模型以及用于自然语言处理的 LSTM。
最终,你将在 Streamlit 或 Gradio 上构建应用程序以展示你的结果。图像标题生成器将生成简单的文本来描述图像。
你可以在线找到多个类似项目,甚至可以创建自己的深度学习架构来预测不同语言的字幕。
作品集项目的主要目的是解决一个独特的问题。可以是相同的模型架构但使用不同的数据集。处理各种数据类型将提高你的招聘机会。
使用深度学习进行股票价格预测
图片由Soham Nandi提供
使用深度学习进行预测是一个流行的项目想法,你将学习时间序列数据分析、数据处理、预处理和时间序列问题的神经网络等许多内容。
时间序列预测并不简单。你需要理解季节性、假期、趋势和日常波动。大多数时候,你甚至不需要神经网络,简单的线性回归就能提供最佳表现的模型。但在风险较高的股市中,即使是一百分之一的差异也可能为公司带来数百万美元的利润。
自动驾驶汽车项目

Gif 由xtma提供
在你的简历上有一个强化学习项目可以在招聘过程中为你带来优势。招聘人员会认为你擅长解决问题,并且渴望拓展自己的界限,学习复杂的机器学习任务。
在自动驾驶汽车项目中,你将训练 OpenAI Gym 环境中的 Proximal Policy Optimization (PPO)模型(CarRacing-v0)。
在开始项目之前,你需要学习强化学习的基础知识,因为它与其他机器学习任务有很大不同。在项目中,你将尝试各种模型和方法,以提高代理性能。
对话式 AI 机器人

图片来自LamaAl聊天机器人
对话式 AI是一个有趣的项目。你将学习 Hugging Face Transformers、Facebook Blender Bot、处理对话数据以及创建聊天机器人界面(API 或 Web 应用)。
由于 Hugging Face 上提供了大量的数据集和预训练模型库,你基本上可以在新的数据集上微调模型。这可以是《瑞克与莫提》的对话、你喜欢的电影角色,或者你喜爱的任何名人。
除此之外,你可以根据特定的使用案例改进聊天机器人。在医疗应用的情况下,聊天机器人需要具备技术知识并理解患者的情感。
自动语音识别
作者提供的图片 | Hugging Face
自动语音识别是我最喜欢的项目。我学到了有关变换器、处理音频数据和提升模型性能的所有知识。我花了 2 个月时间理解基础知识,又花了 2 个月时间创建了一个可以在 Wave2Vec2 模型之上的架构。
你可以通过使用 n-grams 和文本预处理来提升 Wav2Vec2 模型的性能。我甚至预处理了音频数据以改善音质。
有趣的是,你可以在任何语言上微调 Wav2Vec2 模型。
NY 出租车行程:端到端机器学习项目

作者提供的图片
端到端机器学习项目经验是必须的。没有它,你被录用的机会相当渺茫。
你将学到:
-
数据分析
-
数据处理
-
建模、构建和训练
-
实验追踪
-
编排和机器学习管道
-
模型部署
-
云计算
-
模型监控
-
MLOps 最佳实践
这个项目的主要目的不是构建最好的模型或学习新的深度学习架构。主要目标是熟悉行业标准和构建、部署、监控机器学习应用的技术。你将学习很多有关开发运维的知识,并了解如何创建一个完全自动化的系统。
结论
在做了几个项目之后,我强烈建议你在 GitHub 或任何代码共享网站上创建一个个人资料,以便分享你的项目发现和文档。
从事项目的主要目的是提高你被录用的机会。展示项目并在潜在招聘人员面前展示自己是一种技能。
所以,在完成一个项目后,开始在社交媒体上推广它,使用 Gradio 或 Streamlit 创建一个有趣的网络应用,并写一篇引人入胜的博客。不要担心别人会说什么。继续做项目并不断分享。我相信很快会有多个招聘人员联系你。
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个人工智能产品,帮助那些在心理健康方面挣扎的学生。
更多相关话题
2024 年你必须知道的 7 个现代 SQL 数据库
原文:
www.kdnuggets.com/7-modern-sql-database-you-must-know-in-2024

图片由 ChatGPT 生成
高效存储、管理和分析大量信息的能力对任何组织来说都至关重要。随着数据量和复杂性的不断增长,传统数据库往往无法满足现代需求。这就是下一代数据库发挥作用的地方——它们旨在快速、安全和具有成本效益,提供处理大规模和多样化数据问题的创新解决方案。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
在这篇博客中,我们将学习七个在 2024 年引起关注的现代 SQL 数据库。这些数据库提供强大的性能和可扩展性,并配备了 AI 集成功能等先进特性。
1. Dolt
Dolt 是一个开源的版本控制数据库,它结合了 Git 的强大功能和关系型数据库的功能。使用 Dolt,你可以像处理 Git 仓库一样进行数据库的分叉、克隆、分支、合并、推送和拉取。
Dolt 与 MySQL 兼容,允许你运行 SQL 查询并使用命令行界面管理数据。这个版本控制的数据库非常适合需要跟踪更改和维护数据完整性的协作环境。
就像 GitHub 一样,DoltHub 是一个人们可以分享数据库的平台。你可以像 GitHub 一样免费访问公共数据库。
2. MongoDB
MongoDB 是一个因其灵活性和可扩展性而广受欢迎的 NoSQL 数据库。它使用面向文档的数据模型,允许存储半结构化数据。凭借其灵活的数据模型和丰富的工具及服务生态系统,MongoDB 成为开发者和企业的最爱。它处理大量非结构化数据的能力使其成为现代应用程序的理想选择。
MongoDB 可以在不同的环境中使用,包括 MongoDB Atlas(一个完全托管的云服务)、MongoDB Enterprise(一个基于订阅的自主管理版本)和 MongoDB Community(一个免费使用的自主管理版本)。
3. Redis
Redis 是一个快速的内存数据库,用作缓存、向量搜索、消息代理和 NoSQL 数据库,可以无缝地融入任何技术栈。Redis 以其高性能和低延迟而闻名,广泛用于实时应用,如缓存、会话管理和实时分析。它对各种数据结构(如字符串、哈希、列表、集合等)的支持使其成为开发人员的强大工具。
4. MindsDB
MindsDB 是一个通过机器学习能力增强 SQL 数据库的平台。它允许你直接在数据库中使用熟悉的 SQL 语法来构建、微调和部署机器学习模型。MindsDB 可以与众多数据源(包括数据库、向量存储和应用程序)以及流行的 AI/ML 框架(用于 AutoML 和 LLMs)集成。
想象一下将 Transformers、LangChain、向量数据库、OpenAI API、SQL 和 NoSQL 数据库以及代理整合在一起,并且可以使用 SQL 语法进行访问。这对于数据工程师和分析师来说是一个梦想。
5. Clickhouse
ClickHouse 是一个开源的列式数据库管理系统,旨在用于在线分析处理(OLAP)。它以处理大量数据时的高性能和高效性而著称。ClickHouse 特别适合实时分析和大数据应用,提供快速的查询性能和可扩展性。
除了速度极快外,ClickHouse 还对开发人员友好,因为复杂的数据分析可以使用简单的 SQL 完成。此外,它具有成本效益,压缩比降低了存储需求并加快了性能。
6. Elasticsearch
Elasticsearch 是一个基于 Apache Lucene 构建的分布式 RESTful 搜索和分析引擎。它安全地存储数据,以实现闪电般的搜索速度、精确的相关性调优和快速扩展的强大分析。Elasticsearch 通常与 ELK 堆栈(Elasticsearch、Logstash、Kibana)一起使用,进行日志和事件数据分析,使其成为监控和可观察性解决方案的热门选择。使用 Elasticsearch,你可以轻松应对大规模的数据挑战,确保你的搜索和分析能力与数据一起增长。
7. Snowflake
Snowflake 是一个基于云的数据仓储解决方案,提供了独特的架构来处理各种数据工作负载。它将存储和计算分开,使资源可以独立扩展。Snowflake 支持结构化和半结构化数据,提供强大的数据共享和协作功能。它与各种云平台的无缝集成使其成为现代数据仓储需求的首选。
最后的思考
选择最佳的数据库系统对于组织如何处理、分析数据并获取有用信息非常重要。通过了解这些现代 SQL 数据库的优势和特性,你可以做出符合具体需求的明智决策。使用这些技术不仅能提升你的数据工程操作,还能为你的组织未来的增长和成功奠定基础。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,他热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些与心理健康问题作斗争的学生。
更多相关内容
七个最推荐的学习数据科学技能
原文:
www.kdnuggets.com/2021/02/7-most-recommended-skills-data-scientist.html
comments

我想分享七个最推荐的数据科学技能,这些技能来源于与世界上一些最大数据领袖的数十次互动和讨论,包括 Google 的数据与分析主管、NVIDIA 的工程高级总监以及 Wealthsimple 的数据科学和工程副总裁。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
虽然这篇文章可能更多是个人见解,我觉得它分享了一个有价值的视角。我特别不提及从抓取的职位发布中获取的数据,因为根据我的经验,职位描述和实际工作内容之间似乎存在相当大的脱节。
你可能会注意到七个技能中没有涉及机器学习或深度学习,这并不是错误。目前,对于在建模前和建模后的阶段使用的技能需求远高于对机器学习和深度学习技能的需求。因此,七个最推荐的技能实际上与数据分析师、软件工程师和数据工程师的技能有重叠。
话虽如此,让我们深入探讨一下2021 年最推荐学习的七个数据科学技能:
1) SQL
SQL 是全球数据领域的通用语言。无论你是数据科学家、数据工程师还是数据分析师,你都需要知道 SQL。
SQL 用于从数据库中提取数据、处理数据和创建数据管道——本质上,它在数据生命周期中的几乎每个前期分析/前期建模阶段都很重要。
培养强大的 SQL 技能将使你能够将分析、可视化和建模提升到新的水平,因为你将能够以高级方式提取和处理数据。此外,编写高效和可扩展的查询对于处理数据量达到 PB 级别的公司来说越来越重要。
以下是一些我最喜欢的学习 SQL 资源:
2) 数据可视化与讲述
如果你认为创建数据可视化和讲述只适用于数据分析师的角色,那就再想一想。
数据可视化简单地指以视觉形式呈现的数据——它可以是图表的形式,也可以以非常规方式呈现。
数据讲述将数据可视化提升到一个新水平——数据讲述指的是你如何传达你的见解。可以把它想象成一本图画书。一本好的图画书有好的视觉效果,但它还需要一个引人入胜且强有力的叙述来连接这些视觉效果。
发展你的数据可视化和讲述技能是至关重要的,因为你总是在推销你的想法和模型,作为一个数据科学家。这在与技术不太熟练的人沟通时尤其重要。
以下是我学习数据可视化与讲述的一些最爱资源:
3) Python
根据我的互动,Python 似乎是学习的首选编程语言,而不是 R。这并不意味着使用 R 就不能成为数据科学家,只是说明你将使用与大多数人不同的语言。
学习 Python 语法很简单,但你应该能够编写高效的脚本并利用 Python 提供的广泛库和包。Python 编程是构建应用程序的基础,如数据处理、构建机器学习模型、编写 DAG 文件等。
以下是我学习 Python 的一些最爱资源:
4) Pandas
可以说,在 Python 中最重要的库是 Pandas,这是一个用于数据处理和分析的包。作为数据科学家,你将经常使用这个包,无论是清理数据、探索数据还是处理数据。
Pandas 已成为一个非常流行的包,不仅因为它的功能,还因为 DataFrames 已成为机器学习模型的标准数据结构。
以下是我学习 Pandas 的一些最爱资源:
5) Git/版本控制
Git 是技术社区中主要的版本控制系统。
如果这还不清楚,可以考虑这个例子。在高中或大学时,如果你曾经写过论文,你可能会在写作过程中保存不同版本的论文。例如:
????最终论文
└????Essay_v1
└????Essay_v2
└????Essay_final
└????Essay_finalfinal
└????Essay_OFFICIALFINAL
开玩笑归开玩笑,Git 是一个功能相似的工具,只不过它是一个分布式系统。这意味着文件(或仓库)既存储在本地也存储在中央服务器上。
Git 非常重要,原因有几个,其中包括:
-
这允许你恢复到旧版本的代码
-
这允许你与其他数据科学家和程序员并行工作
-
这允许你使用与其他人相同的代码库,即使你在完全不同的项目上工作
以下是我最喜欢的一些学习 Git 的资源:
6) Docker
Docker 是一个容器化平台,允许你部署和运行诸如机器学习模型的应用程序。
数据科学家不仅要知道如何构建模型,还要知道如何部署模型,这变得越来越重要。实际上,很多职位招聘现在要求具备模型部署的一些经验。
模型部署如此重要的原因在于,模型在与其关联的流程/产品实际集成之前不会带来业务价值。
以下是我最喜欢的一些学习 Docker 的资源:
7) Airflow
Airflow 是一个工作流管理工具,允许你自动化…嗯,工作流。更具体地说,Airflow 允许你为数据管道和机器学习管道创建自动化工作流。
Airflow 强大之处在于它允许你将可能用于进一步分析或建模的表格投入生产,它也是一个可以用来部署机器学习模型的工具。
以下是我最喜欢的一些学习 Airflow 的资源:
原文。已获授权转载。
相关:
更多相关主题
数据科学简历中的 7 个必备要素
原文:
www.kdnuggets.com/2021/04/7-must-haves-data-science-cv.html
评论
由 Elad Cohen,Riskified 数据科学与研究副总裁。

我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
图片由 Riskified 提供(经许可使用)。
管理 Riskified 的数据科学部门需要大量的招聘工作——我们在不到一年半的时间里增长了两倍多。作为多个职位的招聘经理,我也会阅读很多简历。招聘人员 在 7.4 秒内筛选简历,经过多年的招聘经验,我的平均时间也很快,但还不到那种极端的程度。在这篇博客中,我将介绍帮助我筛选简历的个人启发式方法(‘窍门’)。虽然我不能保证其他人使用相同的启发式方法,不同的职位对每个要点的重要性也会有所不同,但注意这些要点可以帮助你征服简历筛选阶段。此外,这些启发式方法可能看起来不公平或可能忽视合格的候选人。我同意那些不投资于简历的有才华的机器学习从业者可能会被这个筛选拒绝,但考虑到时间,这还是最佳的权衡。请记住,竞争激烈的职位可能会吸引一百份或更多的简历。如果你想要一个高效的过程,简历筛选必须快速。
这里是用来快速筛选你的数据科学简历的 7 个启发式方法:
1. 具有数据科学家的工作经验
我将快速浏览你的简历,查看你之前的职位,并确认哪些职位被标记为“数据科学家”。还有一些相邻的术语(具体取决于我招聘的角色),例如“机器学习工程师”、“研究科学家”或“算法工程师”。我不包括“数据分析师”在这个类别中,因为日常工作通常与数据科学家不同,而且数据分析师的职位称谓范围非常广泛。
如果你在目前的工作中从事数据科学工作,并且有其他创造性的职位描述,最好还是将你的职称更改为数据科学家。这对那些实际上是数据科学家的数据分析师尤其适用。请记住,即使简历中包含了你参与过的项目的描述(包括机器学习),如果职称不是数据科学家,会增加不必要的模糊性。
此外,如果你曾经参加过数据科学训练营或全日制硕士课程,这可能会被视为你数据科学经验的开始(除非你之前在类似角色工作过,这将在后续阶段引发问题)。
2. 以业务为导向的成就
理想情况下,我希望了解你所做的工作(技术方面)以及业务结果如何。缺乏能够用业务术语交流的技术精湛的数据科学家(了解业务术语的数据科学家)。如果你能分享你的工作对业务 KPI 的影响,这在我看来是一个很大的优点。例如,说明你的模型在 AUC 上的改进是可以的,但如果能说明由于模型改进导致的转化率提升,这意味着你“明白了”——最终业务影响才是最重要的。比较以下两个描述相同工作的替代方案(技术与业务):
-
银行贷款违约率模型——将模型的精准率-召回率 AUC 从 0.94 提高到 0.96。
-
银行贷款违约率模型——使业务单位的年收入增加了 3%(每年 50 万美元),同时保持违约率不变。
3. 教育背景
你的正式教育背景是什么,专业是什么?是否来自知名机构?对于较新的毕业生,我还会关注他们的 GPA 以及是否获得过任何卓越奖项或荣誉,例如是否进入了校长名单或院长名单。由于数据科学是一个广泛开放的领域,没有任何标准化测试或必要的知识要求,人们可以通过各种方式进入这个领域。在我上一篇博客中,我写到了进入数据科学领域的 3 条主要路径,根据你的教育背景和时间安排,我会判断你可能采取了哪一种路径。因此,时间帮助理解你的故事——你是如何以及何时转入数据科学领域的。如果你没有正式的数据科学教育背景也没关系,但你需要展示在该领域的工作记录和/或类似领域的高级学位。
4. 布局和视觉吸引力
我见过一些漂亮的简历(我也保存了一些供个人灵感使用),但我也收到过没有任何格式的文本文件(.txt)。制作简历可能是件痛苦的事,如果你选择了数据科学作为你的追求,你很可能不喜欢在空闲时间制作美观的设计。在不走极端的情况下,你确实希望找到一个合适的模板,使你能够在有限的空间内传达所有信息。明智地利用空间——将页面拆分并突出显示不属于按时间顺序排列的工作/教育经验的特定部分是有用的。这可以包括你熟悉的技术栈、自我项目列表、Github 或博客的链接等。几个简单的图标也有助于强调部分标题。
许多候选人在每种语言/工具旁边使用 1–5 星或条形图。我个人对这种方法不是很喜欢,原因有几个:
-
这极其主观——你的‘5 星’是否等同于别人的‘2 星’?
-
他们将语言与工具混合,最糟糕的是,还与软技能混合——说你在领导力方面‘4.5 星’没有帮助。作为一个坚定的growth mentality的信仰者,声称在某项技能(尤其是难以量化和掌握的软技能)上达到极致,感觉非常自负。
我还见过这种方法的进一步滥用,将主观测量转化为饼图(30% python,10% team-player 等)。虽然这可能本来是为了以创意的方式脱颖而出,但它展示了对不同图表概念的基本理解的缺乏。
这里有两个我发现视觉上令人愉悦的简历示例,细节已模糊处理以保持匿名。

感谢 Eva Mishor(经许可使用)。
数据科学家的视觉上令人愉悦的简历,细节已模糊处理。请注意两个示例中使用的垂直分割,以区分经验、技能、成就和出版物。在这两种情况下,简短的总结段落有助于描述他们的背景和愿望。经所有者许可使用。
5. 机器学习多样性
我寻找的两种多样性:
-
算法类型——结构化/经典 ML 与深度学习。一些候选人只使用过深度学习,包括在可以更好地使用基于树的模型的结构化数据上。虽然成为深度学习专家本身没有问题,但限制你的工具集可能会限制你的解决方案。正如马斯洛所说:“如果你唯一的工具是锤子,你倾向于把每个问题都看作钉子。”在Riskified,我们处理的是结构化的、以领域驱动的、特征工程的数据,这些数据最好用各种形式的提升树来处理。拥有整个简历都指向深度学习的候选人是个问题。
-
机器学习领域——这通常涉及到需要大量专业知识的两个领域——计算机视觉与自然语言处理。此领域的专家需求量大,在许多情况下,他们的整个职业生涯将专注于这些领域。虽然这对于寻找该领域的工作人员至关重要,但对于更一般的数据科学角色来说通常不适合。因此,如果你大部分经验都在自然语言处理领域,而你正在申请该领域以外的职位,尽量强调你在结构化数据方面的职位/项目,以展示你的多样性。
6. 技术栈
这通常可以分为编程语言、特定包(如 scikit learn、pandas、dplyr 等)、云服务及其服务(如 AWS、Azure、GCP)或其他工具。一些候选人将这与他们熟悉的算法或架构(如 RNN、XGBoost、K-NN)混淆。就个人而言,我更希望这围绕技术和工具展开;当提到具体算法时,我会想知道候选人的理论机器学习知识是否仅限于那些特定的算法。
在这里,我关注的是技术栈的相关性——这些技术栈是否来自最近几年(这是候选人动手能力和学习新技能的积极信号),技术栈的广度(是否仅限于特定工具,或是否对多种工具都很熟悉),以及与我们的技术栈的契合程度(我们需要教他们多少东西)。
7. 项目
是否有你在 GitHub 上可以分享的工作?任何 Kaggle 比赛或副项目都非常有帮助,并且可以查看简洁的代码、预处理类型、特征工程、探索性数据分析、算法选择以及需要解决的其他问题。添加你 GitHub 和 Kaggle 账户的链接,供面试官深入了解你的代码。如果你的经验不多,很可能会被问到一个或多个这些项目。在我进行的一些面试中,候选人对项目记忆不多,我们无法讨论他们做出选择的原因。确保你复习一下你做过的工作,或将其从简历中删除。同样,确保你展示了你最好的作品,并且你在其中投入了足够的时间和精力。拥有 2-3 个高质量的项目比 8-10 个中等(或更低)质量的项目更好。
总结
如果你正在寻找新的数据科学职位,请花些时间阅读本文中的要点。如果你无法勾选所有这些要点也没关系,但能做到的越多越好。希望这些建议能帮助你从众人中脱颖而出,并顺利通过简历筛选。
祝你好运,求职顺利!
原文。经许可转载。
相关信息:
更多相关主题
7 个编程面试必知的 Python 技巧
原文:
www.kdnuggets.com/2023/03/7-mustknow-python-tips-coding-interviews.html

图片由作者提供
几乎所有的数据科学职位面试都包括多达两轮的编程测试,以考察候选人的问题解决能力。因此,即使你有令人印象深刻的项目组合,你仍需通过初始编程面试轮次才能进一步晋级。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
选择像 Python 这样的语言来应对编程面试,可以非常有帮助,因为它比 C++ 和 Java 等语言更容易学习和使用。在本指南中,我们将介绍有用的 Python 面试技巧。
我们将讨论反转和排序数组、自定义数组排序、列表和字典推导式、解包可迭代对象等内容。让我们深入了解吧!
1. 原地反转数组
在任何编程面试中,你都会遇到关于数组的问题。在 Python 中,列表提供了与数组相同的功能。你可以进行如下操作:
-
在常数时间内查找特定索引处的元素。
-
在列表末尾添加元素,并在常数时间内从列表末尾移除项目。
-
在 O(n) 时间内在特定索引处插入元素。
当你需要在原地反转列表而不创建新列表时,可以调用 reverse() 方法。在这里,我们初始化 nums 列表并调用 reverse() 方法。
nums = [90,23,19,45,33,54]
nums.reverse()
print(nums)
我们看到原始列表已被反转:
Output >> [54, 33, 45, 19, 23, 90]
2. 排序数组并自定义排序
另一个常见的数组操作是排序。当你需要在原地排序列表时,可以调用列表对象的 sort() 方法。
在这里,nums 也是一个数字列表,调用 sort() 方法会在原地按升序对 nums 进行排序:
nums = [23,67,12,78,94,113,47]
nums.sort()
print(nums)
Output >> [12, 23, 47, 67, 78, 94, 113]
如图所示,sort() 方法默认按升序对列表进行排序。
要按降序排序列表,可以在 sort() 方法调用中将 reverse 设置为 True:
nums.sort(reverse=True)
print(nums)
Output >> [113, 94, 78, 67, 47, 23, 12]
注意:对于字符串列表(如 ["plums","cherries","grapes"]),默认排序为字母顺序。将 reverse = True 设置为反向字母顺序排序字符串列表。
使用 Lambda 自定义排序
有时候,你需要的排序方式不仅仅是简单的升序或降序。你可以通过将key参数设置为一个可调用对象来自定义sort()方法。
作为一个示例,让我们根据除以 7 的余数对nums列表进行排序。
nums.sort(key=lambda num:num%7)
print(nums)
Output >> [113, 78, 23, 94, 67, 47, 12]
为了检查输出是否正确,让我们创建一个余数列表rem_list:
rem_list = [num%7 for num in nums]
print(rem_list)
Output >> [1, 1, 2, 3, 4, 5, 5]
我们看到rem_list中 1 和 5 出现了两次。让我们解析一下这意味着什么:
-
13 和 78 在除以 7 时都留下一个余数。但 13 在排序列表中排在 78 之前,因为在原始
nums列表中它也排在 78 之前。 -
同样,47%7 和 12%7 的结果都是 5。47 在排序列表中排在 12 之前,因为在原始列表中它也排在 12 之前。
-
因此,
sort()方法执行稳定排序,即在原始列表中,如果两个或更多元素在给定排序标准下相等,它们的顺序会被保留。在此情况下,标准是num%7。
你还可以自定义字符串列表的排序。在这里,我们根据'p'的出现次数对str_list进行排序:
str_list = ["puppet","trumpet","carpet","reset"]
str_list.sort(key=lambda x:x.count('p'))
print(str_list)
Output >> ['reset', 'trumpet', 'carpet', 'puppet']
3. 列表和字典推导式
推导式是 Python 的一项强大功能,允许你编写更具惯用性的代码。它们允许你从现有的可迭代对象创建新的可迭代对象,通常是一种简洁的替代方案来代替 for 循环。
列表推导示例
假设我们有nums列表。我们现在想要获取nums中所有能被 3 整除的数字列表。为此,我们可以使用形式为[output for item in iterable if condition]的列表推导表达式。
在这里,我们根据条件num%3==0过滤nums列表,以获得div_by_3列表:
nums = [15,12,90,27,10,34,26,77]
div_by_3 = [num for num in nums if num%3==0]
print(div_by_3)
Output >> [15, 12, 90, 27]
字典推导示例
字典推导式在你需要从现有的可迭代对象创建新的字典时非常有用,而不是使用 for 循环。
这些表达式通常是这样的形式:{key:value for key in some_iterable}。这意味着我们可以在遍历过程中访问键并创建值(从键开始)!
假设我们想创建一个包含 1 到 10 的数字作为键以及这些数字的平方作为值的 Python 字典。我们可以使用字典推导式来做到这一点:
squares_dict = {i:i**2 for i in range(1,11)}
print(squares_dict)
我们看到我们有了数字和这些数字的平方作为键值对:
Output >>
{1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81, 10: 100}
这是另一个例子。从strings列表中,我们构建了str_len字典,其中键是字符串,值是这些字符串的长度:
strings = ["hello","coding","blue","work"]
str_len = {string:len(string) for string in strings}
print(str_len)
Output >> {'hello': 5, 'coding': 6, 'blue': 4, 'work': 4}
4. 解包可迭代对象
在 Python 中,你可以将可迭代对象解包到一个或多个变量中,具体取决于你想如何使用它们。这在你只需要使用元素的一个子集进行进一步处理时特别有用。
让我们创建一个列表list1:
list1 = [i*2 for i in range(4)]
print(list1)
Output >> [0, 2, 4, 6]
如果我们想使用list1中的所有四个元素,我们可以简单地将它们分配给四个不同的变量,如下所示:
num1, num2, num3, num4 = list1
print(num1)
Output >> 0
print(num2)
Output >> 2
print(num3)
Output >> 4
print(num4)
Output >> 6
如果你想将列表中的前几个元素存储在一个变量中,比如num1,将其余元素(子列表)存储在另一个变量中,比如num2,你可以在变量名前使用*,这样它会捕捉list1中的剩余元素:
num1, *num2 = list1
print(num1)
Output >> 0
print(num2)
Output >> [2, 4, 6]
同样,如果你想要列表中的第一个和最后一个元素,你可以像下面这样解包。元素 2 和 4 被包含在变量num2中:
num1, *num2, num3 = list1
print(num1)
Output >> 0
print(num2)
Output >> [2, 4]
print(num3)
Output >> 6
5. 用分隔符连接字符串列表
假设你有一个字符串列表,任务是用分隔符将它们连接成一个字符串。
你可以使用join()字符串方法,像这样:separator.join(list)将使用分隔符连接列表中的元素。
这里有几个例子。考虑下面的fruits列表:
fruits = ["apples","grapes","berries","oranges","melons"]
要使用 -- 作为分隔符来连接fruits列表中的字符串,请指定'--'作为分隔符字符串:
print('--'.join(fruits))
Output >> 'apples--grapes--berries--oranges--melons'
要在没有任何空白的情况下连接字符串,请使用空字符串作为分隔符:
print(''.join(fruits))
Output >> 'applesgrapesberriesorangesmelons'
要使用一个空格来连接字符串,请指定' '作为分隔符:
print(' '.join(fruits))
Output >> 'apples grapes berries oranges melons'
6. 使用 enumerate() 循环
让我们使用之前的fruits列表:
fruits = ["apples","grapes","berries","oranges","melons"]
你可以使用range函数和列表索引来同时获取项目和索引:
然而,使用enumerate()函数会更方便。你可以使用enumerate()函数同时循环访问索引和索引处的项目:
for idx,fruit in enumerate(fruits):
print(f"At index {idx}: {fruit}")
我们看到我们得到了索引 0 到 4,以及那些索引的元素:
Output >>
At index 0: apples
At index 1: grapes
At index 2: berries
At index 3: oranges
At index 4: melons
默认情况下,索引从零开始。有时你可能希望从非零索引开始。要做到这一点,你可以在enumerate()函数调用中将起始索引指定为第二个位置参数:
for idx,fruit in enumerate(fruits,1):
print(f"At index {idx}: {fruit}")
现在索引从 1 开始,而不是从零开始:
Output >>
At index 1: apples
At index 2: grapes
At index 3: berries
At index 4: oranges
At index 5: melons
因为enumerate()允许你循环遍历可迭代对象,所以你可以在列表和字典推导式中使用它。
例如,你可以使用enumerate()函数在字典推导式中将索引和项目作为键和值存储在字典中:
idx_dict = {idx:fruit for idx,fruit in enumerate(fruits)}
print(idx_dict)
Output >> {0: 'apples', 1: 'grapes', 2: 'berries', 3: 'oranges', 4: 'melons'}
7. 有用的数学函数
Python 内置的 math 模块提供了对常见数学操作的开箱即用支持。以下是一些有用的函数:
math.ceil() 和 math.floor()
你通常需要将数字四舍五入到最接近的整数;内置 math 模块中的floor()和ceil()函数可以帮助你做到这一点:
-
floor()函数将给定数字向下舍入到小于或等于给定数字的最大整数。 -
ceil()函数将给定数字四舍五入到大于或等于给定数字的最小整数。
这里是一个示例:
图片来源:作者
因为 3 是大于 2.47 的最小整数,所以ceil(2.47)的结果是 3:
import math
num1 = 2.47
print(math.ceil(num1))
Output >> 3
因为 3 是小于 3.97 的最大整数,所以floor(3.97)的结果也是 3:
num2 = 3.97
print(math.floor(num2))
Output >> 3
math.sqrt() 和列表推导式
要获取一个数字的平方根,你可以使用来自数学模块的sqrt()函数。你可以将它与列表推导式结合使用,以扩展功能。
在这里,我们在列表推导式表达式中使用sqrt()函数来生成平方根
sqrt_nums = [math.sqrt(num) for num in range(1,11)]
print(sqrt_nums)
Output >> [1.0, 1.4142135623730951, 1.7320508075688772, 2.0, 2.23606797749979, 2.449489742783178, 2.6457513110645907, 2.8284271247461903, 3.0, 3.1622776601683795]
为了获得更易读的输出,让我们使用内置的round()函数将数字四舍五入到小数点后两位:
sqrt_nums = [round(math.sqrt(num),2) for num in range(1,11)]
print(sqrt_nums)
Output >> [1.0, 1.41, 1.73, 2.0, 2.24, 2.45, 2.65, 2.83, 3.0, 3.16]
总结
到此为止!希望你找到了一些有用的技巧来丰富你的 Python 工具箱。
如果你想学习和练习 Python,并且有兴趣将 ChatGPT 集成到你的学习工作流程中,请查看这个关于如何使用 ChatGPT 作为 Python 编程助手的指南。
Bala Priya C 是一位技术作家,喜欢创作长篇内容。她的兴趣领域包括数学、编程和数据科学。她通过编写教程、操作指南等,分享她的学习经验与开发者社区。
更多相关主题
7 个 Pandas 绘图函数用于快速数据可视化
原文:
www.kdnuggets.com/7-pandas-plotting-functions-for-quick-data-visualization

使用 Segmind SSD-1B 模型生成的图像
当你使用 pandas 分析数据时,你会使用 pandas 函数来过滤和转换列、连接来自多个数据框的数据等。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
但生成图表——以可视化数据框中的数据——通常会比仅仅查看数字更有帮助。
Pandas 提供了几种绘图函数,您可以用来快速而轻松地进行数据可视化。我们将在本教程中介绍它们。
🔗 链接到 Google Colab 笔记本(如果你想要一起编码)。
创建 Pandas 数据框
让我们创建一个用于分析的示例数据框。我们将创建一个名为 df_employees 的数据框,包含员工记录。
我们将使用 Faker 和 NumPy 的 random module 来填充数据框,生成 200 条记录。
注意:如果你的开发环境中没有安装 Faker,你可以通过 pip 安装它:pip install Faker。
运行以下代码段以创建并填充 df_employees 记录:
import pandas as pd
from faker import Faker
import numpy as np
# Instantiate Faker object
fake = Faker()
Faker.seed(27)
# Create a DataFrame for employees
num_employees = 200
departments = ['Engineering', 'Finance', 'HR', 'Marketing', 'Sales', 'IT']
years_with_company = np.random.randint(1, 10, size=num_employees)
salary = 40000 + 2000 * years_with_company * np.random.randn()
employee_data = {
'EmployeeID': np.arange(1, num_employees + 1),
'FirstName': [fake.first_name() for _ in range(num_employees)],
'LastName': [fake.last_name() for _ in range(num_employees)],
'Age': np.random.randint(22, 60, size=num_employees),
'Department': [fake.random_element(departments) for _ in range(num_employees)],
'Salary': np.round(salary),
'YearsWithCompany': years_with_company
}
df_employees = pd.DataFrame(employee_data)
# Display the head of the DataFrame
df_employees.head(10)
我们设置了种子以确保结果可重复。因此,每次运行此代码时,您将获得相同的记录。
这是数据框的前几条记录:
df_employees.head(10) 的输出
1. 散点图
散点图通常用于理解数据集中任意两个变量之间的关系。
对于 df_employees 数据框,让我们创建一个散点图以可视化员工的年龄与薪资之间的关系。这将帮助我们了解员工的年龄与薪资之间是否存在任何相关性。
要创建散点图,我们可以使用 plot.scatter(),如下所示:
# Scatter Plot: Age vs Salary
df_employees.plot.scatter(x='Age', y='Salary', title='Scatter Plot: Age vs Salary', xlabel='Age', ylabel='Salary', grid=True)
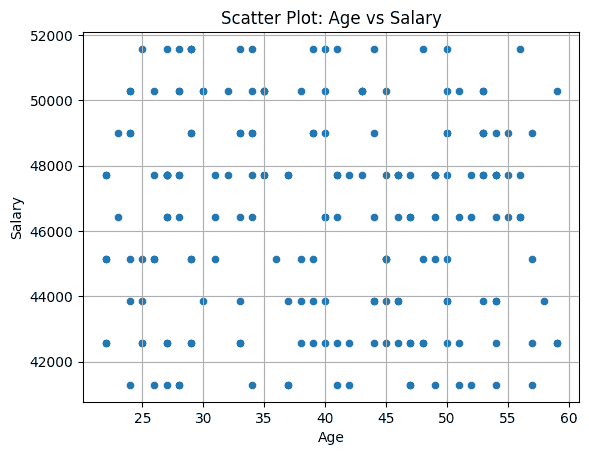
对于这个示例数据框,我们没有看到员工年龄与薪资之间的相关性。
2. 折线图
折线图适用于识别连续变量上的趋势和模式,这通常是时间或类似的尺度。
在创建df_employees数据框时,我们定义了员工在公司工作年数与其薪资之间的线性关系。让我们查看显示平均薪资随年限变化的折线图。
我们找到按公司年限分组的平均薪资,然后使用plot.line()创建折线图:
# Line Plot: Average Salary Trend Over Years of Experience
average_salary_by_experience = df_employees.groupby('YearsWithCompany')['Salary'].mean()
df_employees['AverageSalaryByExperience'] = df_employees['YearsWithCompany'].map(average_salary_by_experience)
df_employees.plot.line(x='YearsWithCompany', y='AverageSalaryByExperience', marker='o', linestyle='-', title='Average Salary Trend Over Years of Experience', xlabel='Years With Company', ylabel='Average Salary', legend=False, grid=True)
由于我们选择使用员工在公司工作的年数与薪资之间的线性关系来填充薪资字段,因此我们看到折线图反映了这一点。
3. 直方图
你可以使用直方图来可视化连续变量的分布——通过将值划分为区间或箱,并显示每个箱中的数据点数量。
让我们使用plot.hist()来理解员工年龄的分布,如下所示:
# Histogram: Distribution of Ages
df_employees['Age'].plot.hist(title='Age Distribution', bins=15)
4. 箱线图
箱线图有助于理解变量的分布、其范围以及识别异常值。
让我们创建一个箱线图,以比较不同部门的薪资分布——为组织内的薪资分布提供一个高层次的比较。
箱线图还将帮助识别薪资范围以及每个部门的中位薪资和潜在的异常值等有用信息。
在这里,我们使用按‘部门’分组的‘薪资’列的boxplot:
# Box Plot: Salary distribution by Department
df_employees.boxplot(column='Salary', by='Department', grid=True, vert=False)
从箱线图中,我们可以看到某些部门的薪资分布范围比其他部门更广。
5. 条形图
当你想了解变量的分布以发生频率来衡量时,你可以使用条形图。
现在让我们使用plot.bar()创建条形图,以可视化员工数量:
# Bar Plot: Department-wise employee count
df_employees['Department'].value_counts().plot.bar(title='Employee Count by Department')
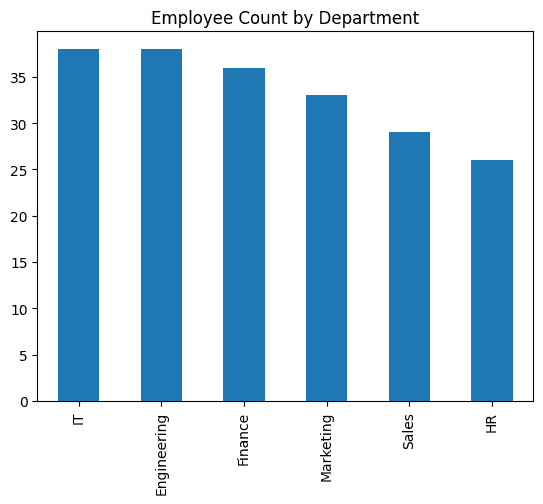
6. 面积图
面积图通常用于可视化变量在连续或分类轴上的累计分布。
对于员工数据框,我们可以绘制不同年龄组的累计薪资分布。为了将员工按年龄组分箱,我们使用pd.cut()。
然后我们计算薪资的累计和,将薪资按‘年龄组’分组。为了获得面积图,我们使用plot.area():
# Area Plot: Cumulative Salary Distribution Over Age Groups
df_employees['AgeGroup'] = pd.cut(df_employees['Age'], bins=[20, 30, 40, 50, 60], labels=['20-29', '30-39', '40-49', '50-59'])
cumulative_salary_by_age_group = df_employees.groupby('AgeGroup')['Salary'].cumsum()
df_employees['CumulativeSalaryByAgeGroup'] = cumulative_salary_by_age_group
df_employees.plot.area(x='AgeGroup', y='CumulativeSalaryByAgeGroup', title='Cumulative Salary Distribution Over Age Groups', xlabel='Age Group', ylabel='Cumulative Salary', legend=False, grid=True)
7. 饼图
饼图在你想要可视化每个类别在整体中所占比例时非常有用。
对于我们的示例,创建一个饼图来显示组织中各部门工资的分布是有意义的。
我们计算按部门分组的员工总薪资,然后使用 plot.pie() 绘制饼图:
# Pie Chart: Department-wise Salary distribution
df_employees.groupby('Department')['Salary'].sum().plot.pie(title='Department-wise Salary Distribution', autopct='%1.1f%%')
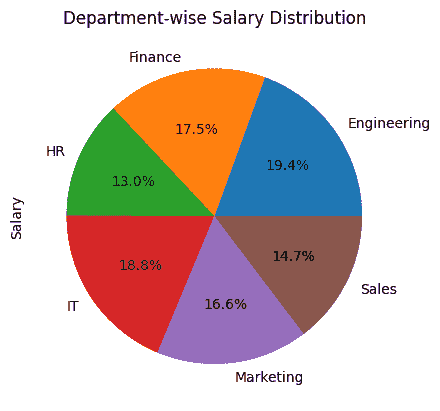
总结
希望你找到了一些在 pandas 中有用的绘图函数。
是的,你可以使用 matplotlib 和 seaborn 生成更漂亮的图表。但对于快速数据可视化,这些函数非常实用。
你经常使用哪些其他 pandas 绘图函数?请在评论中告诉我们。
Bala Priya C**** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和咖啡!目前,她正在通过撰写教程、使用指南、意见文章等与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关主题
获取高薪数据科学职位的 7 个平台
原文:
www.kdnuggets.com/7-platforms-for-getting-high-paying-data-science-jobs
图片来源于作者
如果你是刚毕业或最近被解雇的人,那么这篇博客文章适合你。这 7 个平台提供了一些高薪的数据科学职位。你只需创建一个个人资料并添加你的成就,就可以获得全职、兼职、合同或临时工作。我知道,我们正处于不确定的时期,找到理想的工作变得越来越困难,但你必须从某个地方开始。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
在这篇博客中,我们将讨论能够帮助你找到高薪数据科学职位的前 7 个平台。无论你是想进入这个领域还是提升职业生涯,这些网站将求职者与招聘数据科学家的顶级公司联系起来。随着对数据技能需求的不断增长,这些平台为你提供了远程、自由职业和传统的数据科学机会。
1. LinkedIn
我非常喜欢LinkedIn。这是数据科学家寻找高薪职位和获得技能认可的最佳平台之一。在 LinkedIn 上,你可以搜索数千个在各个行业的领先公司中的数据科学职位。LinkedIn 使用强大的算法来推荐与您的个人资料、技能和兴趣匹配的职位。
图片来源于 LinkedIn Jobs
你可以轻松申请职位并直接联系招聘人员。LinkedIn 还允许你扩展你的职业网络,并与数据科学领域的领导者建立联系。通过用关键技能、项目和推荐来完善你的个人资料,招聘人员可以快速将你识别为顶级数据科学候选人。该平台还通过精选内容使你能够轻松跟上最新的数据科学趋势和最佳实践。
2. Wellfound
Wellfound (前身为 AngelList Talent)是数据科学家寻找初创公司和顶级科技公司高薪远程职位的绝佳平台。通过在 Wellfound 上创建个人资料,你可以访问并申请快速增长的初创公司中的数据科学职位。
图片来自 Wellfound
该平台响应速度很快——你通常可以在申请后的几天内收到招聘经理的回复。Wellfound 使你能够轻松找到你相信并希望将数据技能贡献给的初创公司。它已被证明是初创公司领域中数据科学工作机会的极佳来源。
我在寻找初创公司职位时使用 Wellfound 的体验非常积极。该平台将你的个人资料和数据科学专业知识与最令人兴奋的年轻公司中的相关职位进行匹配。
3. Toptal
我与Toptal的经历非常棒——这是一个高薪自由职业和合同数据科学职位的极佳来源。Toptal 维护着全球顶尖 3%的数据专业人士网络,因此当你通过他们工作时会感觉自己是一名精英人才。你可以被聘为自由数据科学家、数据工程师、机器学习工程师等职位。
图片来自 Toptal
项目的报酬率非常高。Toptal 的客户是顶级公司、初创公司和组织,因此工作既具有挑战性又有回报。成为 Toptal 排名中的一部分对你作为数据科学专业人士的自尊和自我形象也是一种极大的提升。你需要通过严格的筛选过程来展示你的技能,这使得被接受时会感到非常成就感。
4. Upwork
Upwork是一个优秀的自由职业平台,适合数据科学家找到高薪且灵活的工作。与 Fiverr 类似,Upwork 将你与寻找项目基础工作、小时计费工作、长期合同甚至潜在全职工作的客户联系起来。
图片来自 Upwork
关键是要突出自己,并在 Upwork 上完善你的作品集。确保强调你具体的数据科学能力、你有经验的工具以及过去项目中的成就。
经常查看 Upwork 上的新数据科学职位招聘信息,找到与你的能力匹配的职位。在申请时,强调你如何为潜在客户提供价值。
5. Kolabtree
Kolabtree 是一个专门为科学家和行业专家提供的自由职业平台。虽然建立声誉需要时间,但 Kolabtree 可以成为高薪数据科学职位的来源。我花了大约 2 小时全面完善我的个人资料,包括所有学术和职业资历、成就以及专业领域。这立刻引起了潜在客户的注意。
来自 Kolabtree 的图片
Kolabtree 上的许多项目都有固定价格,但根据你的能力和经验可以协商费率。在开始时,由于我在平台上建立自己的声誉,我获得了一些报酬较低的数据项目。但通过坚持使用 Kolabtree 并成功完成多个项目,我开始接到更高薪合同的邀请。该平台响应迅速——客户可以直接联系你,寻求与你技能匹配的潜在项目。
6. Indeed
Indeed 是一个领先的求职平台,特别是在北美以外,能够提供高薪的本地数据科学职位。通过创建个人资料并有选择地申请,Indeed 将你与所在地区的数千个数据科学机会连接起来。重要的是不要随意申请——仔细审查并仅申请那些与你的能力强匹配的职位。
来自 Indeed 的图片
Indeed 以拥有许多入门级和初级数据科学职位而闻名,但凭借适当的经验,你也可以找到更高级和资深的职位。对于生活在南亚或其他北美以外市场的人,Indeed 往往是本地求职的首选平台。确保定期查看 Indeed,以获取你所在城市或国家的新高薪数据科学职位。
7. 亚马逊职位
像亚马逊这样的主要科技公司提供的高薪数据科学职位,并不总是在 LinkedIn 和 Indeed 等网站上公开列出。要获取这些独家职位,你应该查看 Amazon.jobs 和其他科技公司职位板块。这些内部网站展示了全球各地办公室的数百个数据科学职位。
来自 Amazon Jobs 的图片
大多数顶尖科技公司的数据职位仅在其内部职业网站上找到。亚马逊不断在 Alexa、AWS、零售、运营等部门招聘数据科学家。这些职位在各个层级上薪酬都非常优厚。如果你想在领先的科技品牌中找到具有强大薪酬和福利的数据科学职位,请关注 Amazon.jobs。
结论
获得高薪数据科学职位可以改变你的职业生涯。尽管顶级职位的竞争激烈,但利用在线平台可以让你接触到令人难以置信的机会。这 7 个高薪平台让你可以与寻找你专业数据技能的雇主和客户进行连接。无论是寻找全职工作还是高薪的自由职业工作,都可以在这些平台上提升你的存在感。
制作引人注目的个人资料,突出你的数据科学资质、专业知识和成就。申请时要有选择性,并展示你的能力如何增加价值。
并且要不断尝试。你最终会找到一份工作。在等待工作机会的同时,继续学习新技能并从事投资组合项目。
查看我的最新博客以了解更多:
-
最后一年数据科学学生的 5 个投资组合项目
-
如何通过数据科学家职业证书考试
-
转行数据科学职业时我犯的 5 个错误
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,他喜欢构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理健康问题的学生开发人工智能产品。
更多相关主题
7 个使用生成性 AI 构建的项目
原文:
www.kdnuggets.com/2023/08/7-projects-built-generative-ai.html
作者插图 | 来源: Flaticon
要进入数据科学职业市场,认为学位足够获得工作是一个错误。主要建议之一是构建一个强大的个人项目作品集,这可以在从人群中脱颖而出并给招聘人员留下深刻印象方面发挥重要作用。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
随着生成性 AI 工具的出现,如 ChatGPT,标准项目(如物体检测和推荐系统)已经不足以吸引公司的注意。最近几个月,公司正在为能够构建生成性 AI 解决方案的人开设职位。
因此,我们将探索 7 个使用大型语言模型解决任务的项目想法:
-
创建一个个人作品集网站
-
个性化语音助手
-
构建你自己的 AI 翻译器
-
分析研究论文
-
创建代码文档
-
自动化 Powerpoint 演示文稿
-
评论情感分析
1. 创建一个个人作品集网站
有很多教程解释如何构建数据科学作品集网站,但从零开始没有 HTML 和 CSS 知识可能会让人感到很有压力。我亲自尝试过,当你达成目标时,会感到很大的满足,但找到合适的资源并将所学应用到实践中花了一周时间。
现在,随着大型语言模型的兴起,你不再需要费力气了。你只需有一个好的想法,向 ChatGPT 提问,它将返回你网站的代码。你可以从这样的提示开始:
I decided to build a static website. Can you generate HTML code for building the website? Moreover, I need to have three pages: a page with my name and a short presentation, a page with my data science projects and a page with my work experience. In addition to these pages, I want a vertical navigation menu at the left to move from a page to the other.
与其他应用程序一样,你需要明确你想要生成的作品集网站。
项目链接: 使用 ChatGPT 构建数据科学作品集网站
2. 个性化语音助手
在我的个人生活中,我使用 Google Assistant 请求播放不同类型的音乐。例如,“Google,我想听摇滚音乐”,它会立即从 YouTube 音乐中播放一首随机歌曲。比起手动输入歌曲标题,这确实更快捷,而且它收集你的数据越多,就越能学习你的偏好。将这作为个人项目岂不更酷?这个项目可以通过使用 GPT-3 来回答问题和 Whisper API 来转录音频来轻松完成。
项目链接:使用 GPT 和 Whisper 的个性化语音助手
3. 构建你自己的 AI 翻译器
你是否厌倦了将文本复制并粘贴到 Google 翻译中?我个人也尝试过使用 Google Chrome 扩展程序来翻译网页上的文本,但当我必须阅读英文 PDF 文件时,仍然会遇到困难。一个可能的替代方案是构建你自己的 AI 应用程序。每天都有新的强大大型语言模型以其令人惊叹的结果让我们惊讶。我们为什么不利用这些模型呢?
这个应用程序可以使用 Hugging Face 创建,该平台提供了许多专门用于语言翻译的模型。例如,你可以选择这个模型,它专注于从英语到意大利语的翻译。在选择了翻译模型后,你可以通过使用 Streamlit 构建一个应用程序来实现这个想法。
项目链接:构建你自己的 AI 翻译器
4. 分析研究论文
在我的研究奖学金期间,我学会了如何快速高效地阅读论文。但仅仅阅读一篇至少 30 页的论文是非常耗时的,而且在每天发布大量论文的情况下,很难跟上研究的进展。为了提高研究生产力,提取学术论文中的相关信息不是更好吗?以下是三种可能对你数据科学领域职业有帮助的用例。
论文问答
从文档中生成问题和答案是非常有价值的应用之一。大多数教程使用 Chat-GPT 来创建自动问答会话,但这并不是唯一的解决方案。你也可以使用 LangChain 和 HuggingFace 的 Sentence Transformers 创建你个人化的机器人。步骤如下:
-
使用 PyPDFLoader 加载 PDF 文档
-
从文本中提取块
-
使用 Sentence Transformer 库提取嵌入
-
构建回答问题的机器人
项目链接:
总结论文
另一个常见的用例是总结论文。像之前一样,这个任务可以通过生成 AI 工具自动化。可以使用 GPT-3、LangChain 和 Streamlit 构建一个可爱的 web 应用程序。
项目链接: 总结论文
查询多篇论文
如果我们同时总结多篇论文,能够根据问题过滤查询这些摘要会很好。不是很酷吗?利用 LangChain 和 OpenAPI-API 可以非常简单地实现这一点。
项目链接: 查询多篇论文
5. 创建代码文档
在我最后一次作为数据科学家的工作中,我注意到每天记录代码的重要性。如果你单独工作,你可能不在意。但当你和团队合作时,没有代码文档就很难管理任务。特别是当一个团队成员离开公司,而他/她是唯一理解自己代码的人时,这种情况可能会发生。即使文档非常有用,它也是一项非常无聊且耗时的任务。感谢大型语言模型的兴起,我们可以再次通过 Chat-GPT 创建 Python Docstring 避免这项艰巨的工作。
项目链接: 创建代码文档
6. 自动化 PowerPoint 演示文稿
如果你是数据科学家,你肯定遇到过需要为客户准备 PowerPoint 幻灯片的情况。这是另一项耗时的工作,可以借助生成 AI 实现自动化。你可以让 Bing Chat 生成 VBA 代码来创建 PowerPoint 幻灯片,通过明确说明每张幻灯片的背景和信息来实现。
项目链接: 自动化 PowerPoint 演示文稿
7. 评论情感分析
在工业界,产品评论的情感分析可以帮助公司了解客户是否喜欢产品,从而改进服务并保持市场竞争力。这是一个经典的数据科学项目,涉及多个步骤:文本预处理、词嵌入和机器学习模型应用。
第一步是最费力的任务,需要对你分析的语言有很好的理解。这个问题可以通过使用 Chat-GPT 快速处理。除了这种分析外,还可以从每条评论中生成优缺点列表、创建改进产品的建议列表等。
项目链接:评论情感分析
最后的想法
就这样!这些是七个生成式 AI 项目,它们可以帮助你提升简历并提高工作效率。我建议你在做这些项目时尽量享受乐趣。受到灵感的驱动,一切皆有可能。如果你有一个想法,尝试将其付诸实践,瞧,你会对最终成果感到满意。感谢阅读。祝你有美好的一天!
尤金尼亚·安内洛 目前是意大利帕多瓦大学信息工程系的研究员。她的研究项目专注于将持续学习与异常检测相结合。
更多相关话题
每个数据工程师都应该知道的 7 个 Python 库
原文:
www.kdnuggets.com/7-python-libraries-every-data-engineer-should-know

图片由作者提供
作为数据工程师,你需要掌握的工具和框架列表可能会让人望而却步。但至少,你应该精通 SQL、Python 和 Bash 脚本。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
除了熟悉核心的 Python 特性和内置模块外,你还应该能够熟练使用 Python 库来完成你作为数据工程师经常要做的任务。在这里,我们将探讨一些这样的库,帮助你完成以下任务:
-
使用 API
-
网络爬取
-
连接数据库
-
工作流编排
-
批处理和流处理
让我们开始吧。
1. Requests
作为数据工程师,你经常需要使用 API 来提取数据。Requests 是一个 Python 库,可以让你从 Python 脚本中发出 HTTP 请求。使用 Requests,你可以从 RESTful API 获取数据,抓取网页,向服务器端点发送数据,等等。
这里是为什么 Requests 在数据专业人士和开发者中如此受欢迎的原因:
-
Requests 提供了一个简单直观的 API,用于发出 HTTP 请求,支持 GET、POST、PUT 和 DELETE 等各种 HTTP 方法。
-
它处理诸如身份验证、cookies 和会话等功能。
-
它还支持 SSL 验证、超时和连接池等功能,以实现与 web 服务器的稳健高效的通信。
要开始使用 Requests,请查看 快速入门 页面和官方文档中的 高级用法 指南。
2. BeautifulSoup
作为数据专业人士(无论是数据科学家还是数据工程师),你应该能够通过编程方式爬取网页以收集数据。BeautifulSoup 是最广泛使用的 Python 库之一,可用于解析和浏览 HTML 和 XML 文档。
让我们列出 BeautifulSoup 的一些特性,这些特性使它成为网络爬取任务的绝佳选择:
-
BeautifulSoup 提供了一个简单的 API 来解析 HTML 文档。你可以根据标签、属性和内容进行搜索、过滤和提取数据。
-
它支持各种解析器,包括 lxml 和 html5lib——为不同的使用场景提供性能和兼容性选项。
从导航解析树到仅解析文档的一部分,docs 提供了使用 BeautifulSoup 时可能需要执行的所有任务的详细指南。
一旦你对 BeautifulSoup 熟悉后,你也可以探索 Scrapy 进行网页抓取。对于大多数网页抓取任务,你通常会将 Requests 与 BeautifulSoup 或 Scrapy 一起使用。
3. Pandas
作为数据工程师,你将定期处理数据操作和转换任务。Pandas 是一个流行的 Python 库,用于数据操作和分析。它提供了数据结构和一套必要的功能,用于高效地清理、转换和分析数据。
这就是为什么 pandas 在数据专业人员中受欢迎的原因:
-
它支持读取和写入多种格式的数据,如 CSV、Excel、SQL 数据库等。
-
如前所述,pandas 还提供了用于过滤、分组、合并和重塑数据的函数。
Derek Banas 在 YouTube 上的 Pandas Tutorial: Pandas Full Course 是一个全面的教程,可以帮助你熟悉 pandas。你还可以查看 7 Steps to Mastering Data Wrangling with Python and Pandas ,了解如何掌握 pandas 的数据操作技巧。
一旦你对 pandas 熟悉后,根据需要扩展数据处理任务,你可以探索 Dask。Dask 是一个灵活的并行计算库,在 Python 中,支持在集群上进行并行计算。
4. SQLAlchemy
在作为数据工程师的工作日中,与数据库打交道是最常见的任务之一。SQLAlchemy 是一个 SQL 工具包和一个 Python 的对象关系映射(ORM)库,使得与数据库的操作变得简单。
SQLAlchemy 的一些关键功能包括:
-
一个强大的 ORM 层,允许将数据库模型定义为 Python 类,属性映射到数据库列。
-
允许从 Python 中编写和运行 SQL 查询。
-
支持多种数据库后端,包括 PostgreSQL、MySQL 和 SQLite——在不同数据库间提供一致的 API。
你可以查看 SQLAlchemy 文档中的详细参考指南,了解 ORM 和 连接和模式管理 等功能。
如果你主要使用 PostgreSQL 数据库,你可能想学习使用 Psycopg2,这是 Python 的 Postgres 适配器。Psycopg2 提供了一个低级接口,以便直接从 Python 代码中处理 PostgreSQL 数据库。
5. Airflow
数据工程师经常处理工作流编排和自动化任务。使用 Apache Airflow,你可以创建、调度和监控工作流。因此,你可以用它来协调批处理作业、编排 ETL 工作流或管理任务之间的依赖关系等。
让我们回顾一下 Airflow 的一些功能:
-
使用 Airflow,你可以将工作流定义为 DAGs,调度任务,管理依赖关系,并监控工作流执行。
-
它提供了一组用于与各种系统和服务(包括数据库、云平台和数据处理框架)交互的操作符。
-
它非常可扩展,因此你可以根据需要定义自定义操作符和钩子。
Marc Lamberti 的教程和课程是开始学习 Airflow 的极好资源。虽然 Airflow 被广泛使用,但也有一些替代品,如 Prefect 和 Mage,你也可以进行探索。要了解更多关于 Airflow 的编排替代品的信息,请阅读 5 Airflow Alternatives for Data Orchestration。
6. PySpark
作为数据工程师,你需要处理需要分布式计算能力的大数据处理任务。PySpark 是 Apache Spark 的 Python API,Apache Spark 是一个用于处理大规模数据的分布式计算框架。
PySpark 的一些功能如下:
-
它提供了用于批处理、机器学习和图形处理等的 API。
-
它提供了像 DataFrame 和 Dataset 这样的高级抽象,用于处理结构化数据,以及 RDDs 进行更低级别的数据操作。
PySpark 教程 在 freeCodeCamp 的社区 YouTube 频道是开始学习 PySpark 的一个好资源。
7. Kafka-Python
Kafka 是一个流行的分布式流平台,而 Kafka-Python 是一个用于从 Python 与 Kafka 交互的库。因此,当你需要处理实时数据处理和消息系统时,可以使用 Kafka-Python。
Kafka-Python 的一些功能如下:
-
提供了高级的生产者和消费者 API 用于发布和消费 Kafka 主题中的消息。
-
支持诸如消息批处理、压缩和分区等功能。
你可能不会在所有项目中都使用 Kafka。但如果你想了解更多,docs 页面有有用的使用示例。
总结
到此为止!我们已经涵盖了一些最常用的 Python 库用于数据工程。如果你想探索数据工程,可以尝试构建端到端的数据工程项目,看看这些库实际是如何工作的。
这里有几个资源可以帮助你入门:
-
数据工程初学者指南
-
初学者免费数据工程课程
祝学习愉快!
Bala Priya C**** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正致力于通过编写教程、操作指南、观点文章等方式学习和分享知识。Bala 还创建了引人入胜的资源概述和编程教程。
相关主题
适合初学者的 7 个 Python 项目
原文:
www.kdnuggets.com/2022/11/7-python-projects-beginners.html
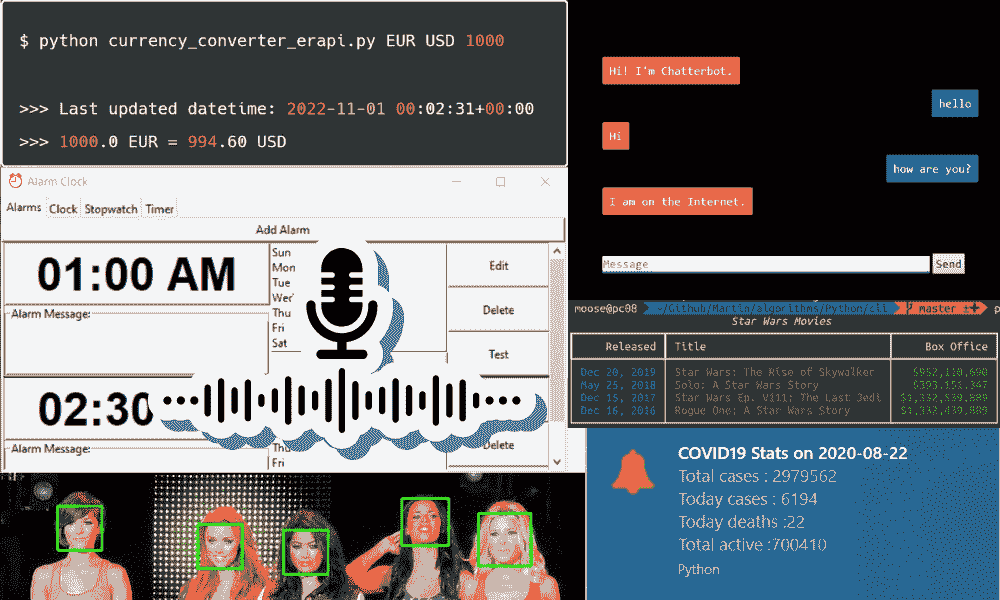
作者提供的图片
在学习了 Python 语言的基础后,你会想开始构建一些令人惊叹的东西。这 7 个 Python 项目将帮助你学习各种 Python 包和软件开发,并有助于你的职业组合和简历。
我们将学习的 Python 项目都很适合初学者,它们在提供各种类型应用的体验方面独特。你将使用 Tkinter 构建 GUI、通知、访问 API 和编写 Python 脚本、个人助理、聊天机器人、命令行工具和人脸识别。
桌面通知器
桌面通知器应用简单却独特。你将使用请求来访问网页 API,并每 4 小时通过 plyer 显示桌面通知。这是一个有趣的项目,你可以显示 Covid 统计数据、股票市场位置、RSS 提要等。桌面通知的应用限于你的想象力。

图片来自 桌面通知器
Tkinter 闹钟
闹钟 项目将帮助你掌握 GUI 工具 Tkinter、pygame 模块和 SQLite 数据库。你将构建一个用户界面,在其中可以设置闹钟,显示时钟、秒表和计时器。该项目将在每一个层面上测试你的 Python 技能。你还将学习基本的 SQL 脚本,如果你想被顶级公司雇用,这总是一个加分项。
图片来自 闹钟
货币转换器
货币转换器有点复杂,但对于初学者来说推荐。你将深入研究网页抓取和访问各种货币交易的网页 API。
首先,你将使用请求访问 API,用 Beautiful Soup 清理数据,并利用 Python 函数创建一个显示日期和时间以及货币兑换率的系统。教程中还提到了各种易于使用的货币兑换 API。

作者提供的图片
语音助手
语音助手是一个简单的项目,但如果你展示给朋友或同事,他们会感到兴奋。你将编写几行代码来将语音转换为文本,然后使用各种 Python 库和if-else语句来创建一个个人助手。
使用 Chatterbot 的聊天机器人
使用 Chatterbot 的聊天机器人是一个很棒的项目,可以在简历上展示。它在现实世界中有多个应用。我们将使用 Flash 创建 Web 应用程序,使用 ChatterBot 训练我们的机器人以进行简单的回复。它简单而令人兴奋,你可以通过研究基于规则和自我学习的方法来使其接近完美。
来自 项目 的图片
命令行应用程序
命令行应用程序教程将帮助你创建具有用户界面和图形的命令行工具。这不是一个完整的项目,但这就是诀窍,你将使用教程中提到的所有工具和示例来创建你的项目。
你可以查看 构建和发布命令行应用程序教程以获得灵感。这有点高级,你将学习提取数据、创建 CLI 和将包推送到 PyPI 的各个部分。
来自 项目 的图片
人脸识别
人脸识别将帮助你熟悉 OpenCV-2。你不会使用任何机器学习或深度学习模型来创建简单的人脸识别应用程序。只需 25 行代码,你就可以创建一个 Python 脚本,接受一张图片,并返回带有绿色边框的多张人脸图像。
来自 教程 的图片
总结
通过项目学习是建立编程技能的最佳方式。你将学会修复错误、启动和完成项目、学习各种 Python 包,一些公司将其视为专业经验。
接下来呢?你将开始在 GitHub 上寻找开源项目并进行贡献。你也可以寻找公司实习以获得实际经验,或启动一个可以解决实际问题的大项目。
例如,你可以构建辅助写作的 Web 应用程序,创建一个播放合成生成音乐的 Spotify 应用程序,以及一个面向希望节省客户支持成本的公司的 Chatbot API。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些在心理健康方面挣扎的学生。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关内容
你不该成为数据科学家的 7 个理由
原文:
www.kdnuggets.com/7-reasons-why-you-shouldnt-become-a-data-scientist

图片由编辑提供
你是一个有志成为数据科学家的人吗?如果是的话,你很可能见过或听说过许多成功转行到数据科学领域的人。你也希望有一天能够转行。
作为数据科学家,有几件事是令人兴奋的。你可以:
-
建立可以跨领域转移的硬技能和软技能
-
用数据讲述故事
-
用数据回答业务问题
-
为业务问题建立有影响力的解决方案
还有更多。尽管这一切听起来很激动人心,但成为数据科学家同样充满挑战,甚至更具挑战性。那么,这些挑战有哪些呢?
让我们深入探讨一下。
1. 你喜欢在孤立环境中工作
当你专注于编码和技术技能时,你可能会习惯独自工作。但作为一名数据科学家,你应该优先考虑合作与沟通。因为数据科学不仅仅是孤立地处理数据和分析数字。
你需要与其他专业人员合作——不仅是同一团队的,还经常是多个团队之间的合作。因此,你与不同团队和利益相关者合作的能力与技术技能一样重要。
此外,你还需要能够将你的发现和洞见传达给非技术利益相关者,包括商业领导者。
Nisha Arya Ahmed,一位数据科学家和技术作家,分享道:
“在数据科学团队中,你将与其他数据科学专业人员合作,共同处理每一个任务,了解他们的职责以及如何协同工作。这很重要,因为你不想重复已经完成的工作,浪费更多的时间和资源。此外,数据专业人员并不是你唯一需要合作的对象,你还将成为一个跨职能团队的一部分,包括产品、市场营销和其他利益相关者。”
– Nisha Arya Ahmed,数据科学家和技术作家
2. 你希望真正“完成”项目
如果你是一个喜欢完成项目并将其交付生产的人,你可能不会觉得数据科学是一个有回报的职业。
尽管你以一系列目标开始一个项目——这些目标会经过反复优化和改进——但你通常需要根据组织的业务目标变化来调整项目范围。也许,利益相关者看到了一个新的有前景的方向。
因此,你必须有效地重新优先排序并修改项目范围。在最坏的情况下,必要时放弃你的项目。
此外,在早期阶段的初创公司,你通常需要身兼数职。因此,你的工作不仅仅是构建模型。即使你成功地将机器学习模型部署到生产环境中,你还需要监控模型的性能,关注漂移情况,并根据需要进行回退和再训练。
Abid Ali Awan,KDnuggets 的作家、编辑和数据科学家,分享道:
“如果你在一家公司工作,你可能经常需要在多个团队之间切换,同时处理不同的项目。然而,你所参与的大多数项目可能甚至没有进入生产阶段。
由于公司的优先事项可能会改变,或者项目的影响可能没有那么显著。不断在团队和项目之间切换可能会让人感到疲惫,你可能会对自己正在贡献什么感到茫然。”
– Abid Ali Awan,KDnuggets 的作家、编辑和数据科学家
所以,进行数据科学项目的过程并不是一个线性的开始到结束的过程,你完成一个项目后就转到下一个项目。
3. 你对角色模糊感到沮丧
在两个不同组织中,数据科学家的日常工作可能完全不同。数据科学家、机器学习工程师和 MLOps 工程师的角色往往有很多重叠的功能。
假设你是一位非常有兴趣构建预测模型的数据科学家。你在一个你感兴趣的组织中获得了数据科学家的角色。
然而,如果你发现自己整天都在处理电子表格中的数据和制作报告,或者用 SQL 从数据库中提取数据,不要感到惊讶。你可能会认为使用 SQL 处理数据并寻找业务问题的答案更适合数据分析师的角色。
而在其他情况下,你可能负责构建和部署模型到生产环境中,监控模型漂移,并根据需要重新训练模型。在这种情况下,你既是数据科学家,又兼任 MLOps 工程师的角色。
让我们听听 Abid 对数据职业角色流动性的看法:
“我总是对被称为‘数据科学家’感到困惑。这到底意味着什么?我是数据分析师、商业智能工程师、机器学习工程师、MLOps 工程师,还是上述所有角色?如果你在一家小公司或初创公司工作,你的角色在公司内部是流动的。然而,大型组织可能会对角色有更明确的区分。但这并不能保证角色完全明确。你可能是数据科学家,但你做的很多工作可能是创建与商业目标对齐的分析报告。”
– Abid Ali Awan,KDnuggets 的作家、编辑和数据科学家
4. 你不关心业务目标
作为数据科学家,你应该将努力方向集中在对业务有重大影响的项目上,而不是追求那些技术上有趣但相关性较低的项目。为此,理解业务目标是关键,原因如下:
-
理解业务目标可以让你根据组织需求的变化调整和重新排序你的项目。
-
数据科学项目的成功通常通过其对业务的影响来衡量。因此,对业务目标的良好理解提供了一个明确的框架,用于评估项目的成功,将技术方面与实际的业务结果相联系。
Matthew Mayo,KDnuggets 的总编辑及数据科学家,分享了对业务成果漠不关心的代价:
“作为数据科学家,如果你对业务目标漠不关心,那你就像是在追逐激光指示器的猫——你会发现自己过于活跃却没有明确的方向,可能达不到多少有价值的成果。理解业务目标并能够将其从业务语言转换为数据语言是至关重要的技能,否则你可能会投入时间去构建最复杂却无关紧要的模型。有效的决策树每天都比最先进的失败模型更有价值!”
– Matthew Mayo,KDnuggets 总编辑及数据科学家
关于这一点,Nisha 这样说道:
“无论你做什么,都需要有一个理由。这就是你的意图,它在行动之前存在。当涉及到数据世界时,理解业务和挑战至关重要。没有这一点,你在过程中只会感到困惑。在数据科学项目中的每一步,你都需要参考推动项目的目标。”
– Nisha Arya Ahmed,数据科学家和技术作家
数据科学因此不仅仅是处理数字和建立复杂模型。它更多的是利用数据推动业务成功。
如果对业务目标没有透彻的理解,你的项目可能会偏离其原本要解决的业务问题——从而降低它们的价值和影响力。
5. 你不喜欢“无聊”的工作
构建模型是令人兴奋的。然而,通往这一点的道路可能并不那么有趣。
你可以预期会花费大量时间:
-
收集数据
-
确定使用的最相关的数据子集
-
清洗数据以使其适合分析
现在,这项工作可能不是特别令人兴奋。通常,你甚至不需要构建机器学习模型。一旦数据存储在数据库中,你可以使用 SQL 来回答问题。在这种情况下,你甚至不需要构建机器学习模型。
关于重要的工作往往不有趣,Abid 这样分享他的观点:
“重复做同样的事情可能会很乏味。你可能经常被分配清理数据的任务,这可能非常困难,特别是当处理多样化的数据集时。此外,数据验证和编写单元测试等任务可能没有那么令人兴奋,但它们是必要的。”
– Abid Ali Awan,作家、编辑及 KDnuggets 数据科学家
因此,你必须享受处理数据的过程——包括好的一面、坏的一面和丑陋的一面——才能拥有成功的数据科学职业生涯。因为数据科学完全是从数据中获取价值。而这通常不是构建最华丽的模型。
6. 你希望在某个时候停止学习
作为数据科学家,你(可能)永远无法达到你可以说“我已经学完所有东西”的地步。你需要学习什么以及学习多少取决于你正在做的工作。
这可能是一个相对简单的任务,比如学习并使用一个新的框架。或者是更繁琐的任务,例如将现有代码库迁移到如 Rust 这样的语言,以增强安全性和性能。除了技术能力外,你还应该能够根据需要快速学习和掌握框架、工具和编程语言。
此外,如果需要,你应该愿意更多地了解领域和业务。你在数据科学职业生涯中很可能不会一直在一个领域工作。例如,你可能一开始在医疗保健领域担任数据科学家,然后转到金融科技、物流等领域。
在研究生期间,我有机会参与医疗保健中的机器学习——一个疾病预后项目。我在高中之后从未读过生物学。因此,前几周都是在探索特定生物医学信号的技术细节——它们的属性、特征等。这些是我能够继续进行记录预处理之前非常重要的。
Kanwal Mehreen,一位技术作家与我们分享了她的经验:
“你知道当你终于学会一项新技能,想着‘啊,这就是了,我很棒’的感觉吗?在数据科学中,这一刻永远不会真正到来。这个领域不断发展,新的技术、工具和方法不断出现。所以,如果你是那种希望达到某个点之后学习可以退居二线的人,那么数据科学职业可能不是最佳选择。
此外,数据科学是统计学、编程、机器学习和领域知识的完美结合。如果探索从医疗保健到金融再到营销的不同领域的想法不能让你兴奋,你可能会在职业生涯中感到迷茫。”
– Kanwal Mehreen,技术作家
所以作为数据科学家,你绝不应该回避持续学习和技能提升。
7. 你不喜欢挑战
我们已经概述了成为数据科学家的几个挑战,包括:
-
超越编程和模型构建的技术技能
-
理解领域和商业目标
-
持续学习和提升技能以保持相关性
-
主动而不担心从字面上完成项目
-
准备好重新优先排序、回退和进行变更
-
做那些无聊但必要的工作
就像任何其他技术角色一样,困难的部分不是找到数据科学家的工作。是建立一个成功的数据科学职业。
马修·梅奥恰如其分地总结了作为数据科学家应如何迎接这些挑战:
“寻找一个轻松的职业,在你开始工作时就可以停止学习,不必担心最新的工具、技巧和技术?那么,忘掉数据科学吧!期待一个安静的数据专业生涯就像期待在季风中用鸡尾酒伞和乐观态度漫步一样。
这个领域是一个不断上升的技术难题和非技术谜团的过山车:有一天你在深入研究算法,接下来你却要向一个认为回归是退回到孩子般行为状态的人解释你的发现。但兴奋就在这些挑战中,它让我们的咖啡因依赖的大脑保持活跃。
如果你对挑战过敏,你可能会在编织中找到更多的安慰。但如果你还没有回避与数据洪流的对抗,数据科学可能正是你的那杯... 咖啡。”
– 马修·梅奥,KDnuggets 主编和数据科学家
听听坎瓦尔的想法:
“让我们面对这个事实:数据科学并不总是一帆风顺。数据并不总是以整洁有序的形式出现。你的数据可能看起来像经历了风暴,可能是不完整、不一致甚至不准确的。清理和预处理这些数据以确保其对分析的相关性可能是一个挑战。
在跨学科领域工作时,你可能需要与非技术利益相关者互动。向他们解释技术概念及其如何与他们的目标对齐可能非常具有挑战性。
因此,如果你是那种喜欢明确、直截了当的职业道路的人,数据科学职业可能对你来说充满了障碍。”
– 坎瓦尔·梅赫林,技术写作员
总结
所以,数据科学不仅仅是数学和模型;它是从数据到决策的过程。在这个过程中,你应该始终愿意学习和提升技能,理解业务目标和市场动态,以及更多。
如果你在寻找一个充满挑战、你愿意以韧性应对的职业,数据科学确实是一个不错的职业选择。祝你探索愉快!
感谢马修、阿比德、妮莎和坎瓦尔分享他们对数据科学职业多个方面的见解,并使这篇文章更加有趣和愉快!
Bala Priya C 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交集处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在学习并通过撰写教程、操作指南、观点文章等与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关主题
7 个原因你在获得数据科学职位时感到困难
原文:
www.kdnuggets.com/7-reasons-why-youre-struggling-to-land-a-data-science-job

编辑提供的图片
对于申请数据科学职位却没有得到公司回复感到厌倦了吗?也许你已经成功获得了一些面试机会,但未能将其转化为工作邀请?好吧,你并不孤单。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
现在的就业市场竞争异常激烈。所以,虽然困难,但这并不意味着你不够优秀。也就是说,退一步看看如何以及哪里可以改进既重要又有帮助。这正是本指南将帮助你的地方。
我们将讨论为什么像你这样的有志数据专业人士会在筛选中挣扎的常见原因,以及你如何提高获得面试机会并得到那个你想要的工作的机会!
1. 你的编码技能生疏了
这是一个残酷的事实。让我们面对它吧。
假设你已经申请了许多你感兴趣的公司中的数据科学职位,并被筛选出了面试。
恭喜你!你正在走在正确的轨道上。下一个目标是将面试机会转化为工作邀请。而第一步是破解那个编码面试。
你将首先经历一轮计时编码面试——测试你的问题解决技能——然后是一个 SQL 编码轮次。
但编码面试很难破解——即使对于经验丰富的专业人士也是如此。但通过持续练习和间隔重复,你可以成功破解这些面试。
定期在 Leetcode 和 Hackerrank 等平台上练习编码面试问题。
如果你在寻找资源,可以查看:
-
5 本免费书籍帮助你掌握 Python
-
7 个最佳 SQL 练习平台
一旦你通过了编码面试,专注并为技术面试做准备。复习你的机器学习基础知识。还要回顾你的项目,以便你可以自信地解释它们的影响。
2. 你的简历不突出
的确,招聘人员只会花几秒钟时间审阅你的简历,然后决定是进入下一阶段还是被拒绝。

作者提供的图片
因此,你应该认真编写你的简历。确保根据职位要求定制你的简历。
以下是一些简历建议:
-
包含相关的经验和教育部分。
-
按时间倒序列出经验和教育背景。
-
用项目符号总结经验—量化影响并添加简洁的解释。
-
包含相关的项目部分。用简洁的项目符号解释项目内容。同时包括项目的链接。
-
添加一个相关的技能部分,按类别分组,如编程语言、工具和框架等。
我还建议使用简单的单列布局,这比复杂和花哨的布局更容易解析。
3. 你的个人资料要么过于具体,要么过于通用
当你申请职位时,你的简历和 LinkedIn 个人资料应保持一致,没有任何冲突的细节。同时,它们也应与角色所要求的经验和技能相符。
不过,有几个注意事项你应该避免。
你的个人资料过于具体
假设你对医学成像和计算机视觉感兴趣。因此,几乎所有你的项目都集中在计算机视觉领域。这样的个人资料可能非常适合计算机视觉工程师或计算机视觉研究员的角色。
但是如果你申请的是一家金融科技公司的数据科学家职位呢?显然,你并没有脱颖而出。
你的个人资料过于通用
如果你是一名有着强大 SQL 技能和构建机器学习模型经验的潜在数据科学家,你也可以申请数据分析师和机器学习工程师的职位。
但你不希望让你的简历/候选人档案看起来像是你想同时成为数据分析师、机器学习工程师和数据科学家。
如果你对所有这些角色感兴趣,请为每个角色准备单独的简历。
重要的是找到一个甜美的中间点,使你能够展示你的专业技能,并作为一个拥有广泛技能集的潜在候选人脱颖而出,符合职位的要求。
4. 你的项目不够有趣
你的项目帮助你获得比其他候选人更强的竞争优势。所以请明智地选择它们。

作者提供的图片
一些有抱负的数据专业人士在简历和作品集中展示了一些他们不应该展示的项目。是的,有些初学者项目对学习有帮助,但你应该避免在作品集中展示它们。
以下是一些建议:
-
泰坦尼克号生存预测
-
MNIST 手写数字识别
-
使用鸢尾花数据集进行分类
-
酒类数据集上的项目
仅举几例。这些项目过于通用和基础,无法帮助你获得面试(更不用说工作机会)。
那么有什么有趣的项目—特别是如果你是一个希望进入这一领域的初学者?
以下是一些初学者级别的项目,它们将帮助你展示你的技能,并成为一个更强的候选人:
-
客户细分
-
贷款违约预测
-
市场篮子分析
-
客户流失预测
使用真实世界的数据集来构建你的项目。这样你可以展示许多重要的技能:数据收集、数据清理和探索性数据分析,以及模型构建。
还包括受你兴趣启发的项目。正如我在之前的 pandas 指南中建议的那样,尝试将你感兴趣的和爱好的数据转化为有趣的项目,以帮助你在面试官面前留下深刻的印象。
5. 你的学位成了障碍
另一个常见的障碍是你的教育背景。如果你主修的是社会学、心理学等领域,那么进入数据科学领域可能会特别困难。
尽管你的技能——硬技能和软技能——最终很重要,但你应当记住,你正在与那些拥有相关领域本科或高级学位的人竞争。
那么你能做些什么呢?
寻找不断提升自己的方式。记住,一旦你获得了第一份数据角色,你可以利用你的经验继续前进。
寻找在公司内部参与相关项目的机会。如果你的公司有一个专门的数据团队,尝试接受一个小的副项目。
6. 你可能没有在公开场合学习
在公开场合学习是非常重要的,特别是当你试图获得第一份工作时(老实说,即使之后也是如此)。
我在 2020 年底开始在网上写作。从那时起,我的大多数机会都是通过我在网上发布的教程和技术深度分析获得的。
那么你如何以及从哪里开始?利用 LinkedIn 和 Twitter (X) 等社交媒体平台与社区分享你的工作:
-
做了一个项目? 与你的网络分享。请求反馈。改进。
-
写了一个数据科学教程? 与你的网络分享。
-
学到了新东西? 还是要分享出来。
-
遇到了一个错误,最终解决了? 是的,这值得分享。
你在笔记本电脑上编码的内容将停留在你的笔记本电脑上。所以要准备好展示你所做的和学到的东西。
建立一个强大的作品集和在线形象在求职过程中非常有帮助。因为你永远不知道哪个项目或文章会引起未来雇主的兴趣。
7. 你可能需要更主动
由于目前就业市场的竞争非常激烈,你需要超越仅仅申请工作的阶段,开始变得更加主动。

图片由作者提供
这里有一些简单的步骤可以帮助你做出改变:
-
列出你感兴趣的公司。
-
检查相关职位空缺。
-
向招聘人员发送你的简历和作品集,解释为什么你适合这个职位。
-
与其他专业人士建立联系。即使在拥有稳定全职工作时,也要养成网络联系的习惯。
加入在线数据科学社区也会非常有帮助!
总结
以上就是总结。以下是我们讨论内容的简要回顾:
-
为编码面试做准备。在 Leetcode 和 Hackerrank 等平台上练习。
-
根据职位要求调整你的个人资料,但要保持一致。
-
努力完善你的简历和项目作品集。
-
开始公开学习。分享你构建和学习的内容。
-
积极与其他专业人士建立联系。
祝你求职顺利。希望你能尽快找到数据科学职位。你还有什么其他建议吗?请在评论中告诉我们。
Bala Priya C**** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她通过编写教程、操作指南、评论文章等与开发者社区分享自己的知识。Bala 还创建了引人入胜的资源概述和编码教程。
相关主题
7 种 SMOTE 变体用于过采样
原文:
www.kdnuggets.com/2023/01/7-smote-variations-oversampling.html
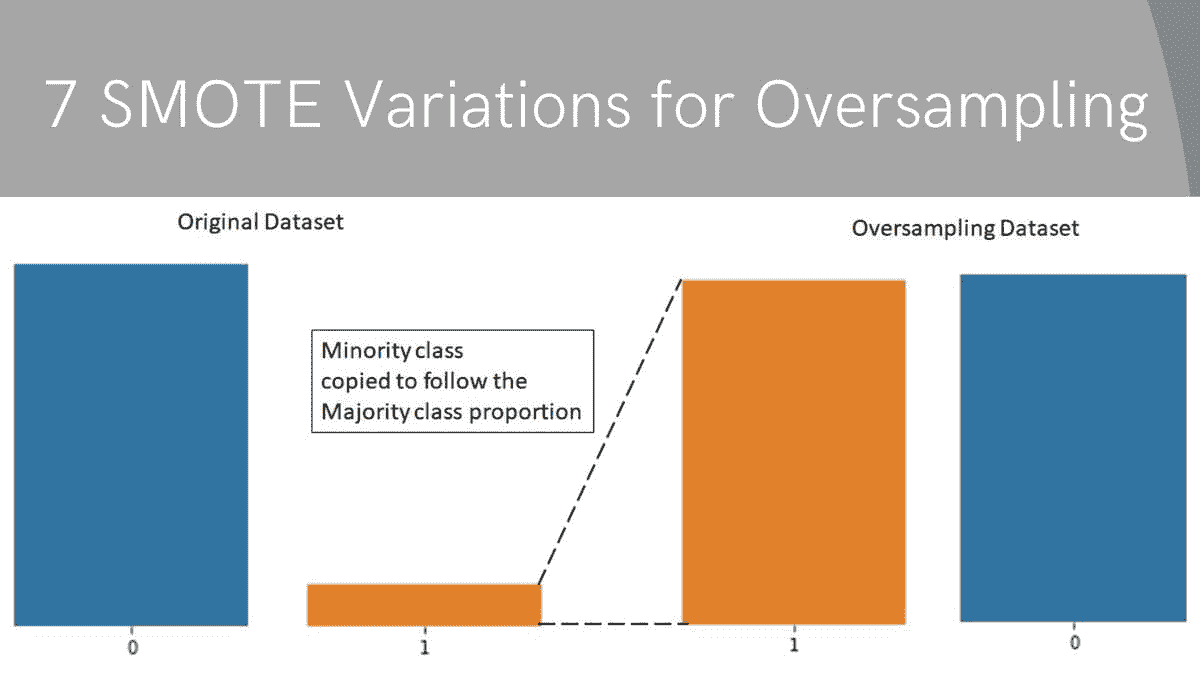
作者提供的图片
不平衡数据集是数据科学中的一个问题。这个问题发生是因为不平衡通常会导致建模性能问题。为了缓解不平衡问题,我们可以使用过采样方法。过采样是对少数类数据进行重采样以平衡数据。
我们的 Top 3 课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
过采样有许多方法,其中之一是使用 SMOTE1。让我们深入了解多种 SMOTE 实现,以进一步了解过采样技术。
SMOTE 变体
在继续之前,我们将使用来自 Kaggle2 的流失数据集来表示不平衡数据集。数据集的目标是“exited”变量,我们将观察 SMOTE 如何根据少数类目标进行过采样。
import pandas as pd
df = pd.read_csv('churn.csv')
df['Exited'].value_counts().plot(kind = 'bar', color = ['blue', 'red'])
我们可以看到流失数据集面临不平衡问题。让我们尝试使用 SMOTE 对数据进行过采样。
1. SMOTE
SMOTE 通常用于通过生成人工或合成数据来过采样连续数据以解决机器学习问题。我们使用连续数据是因为开发样本的模型只接受连续数据 1。
在我们的示例中,我们将使用数据集中的两个连续变量:“EstimatedSalary”和“Age”。让我们看看这两个变量与数据目标的分布情况。
import seaborn as sns
sns.scatterplot(data =df, x ='EstimatedSalary', y = 'Age', hue = 'Exited')
我们可以看到少数类大多分布在图的中间部分。让我们尝试用 SMOTE 进行过采样,看看差异如何形成。为了便于 SMOTE 过采样,我们将使用 imblearn Python 包。
pip install imblearn
使用 imblearn,我们将对流失数据进行过采样。
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state = 42)
X, y = smote.fit_resample(df[['EstimatedSalary', 'Age']], df['Exited'])
df_smote = pd.DataFrame(X, columns = ['EstimatedSalary', 'Age'])
df_smote['Exited'] = y
Imblearn 包基于 scikit-learn API,使用起来很方便。在上述示例中,我们已经使用 SMOTE 对数据集进行了过采样。让我们看看“Exited”变量的分布。
df_smote['Exited'].value_counts().plot(kind = 'bar', color = ['blue', 'red'])
从上述输出中可以看出,目标变量现在具有类似的比例。让我们看看连续变量在新的 SMOTE 过采样数据中的分布情况。
import matplotlib.pyplot as plt
sns.scatterplot(data = df_smote, x ='EstimatedSalary', y = 'Age', hue = 'Exited')
plt.title('SMOTE')
上面的图显示了少数类数据现在比我们过采样前的分布更广泛了。如果我们更详细地查看输出,可以看到少数类数据的分布仍然接近核心,并且比之前扩展得更广。这是因为样本是基于邻居模型的,该模型根据最近邻估算样本。
2. SMOTE-NC
SMOTE-NC 是针对分类数据的 SMOTE。如上所述,SMOTE 只适用于连续数据。
为什么我们不直接将分类变量编码为连续变量呢?
问题在于 SMOTE 基于最近邻创建样本。如果你对分类数据进行编码,比如‘HasCrCard’变量,它包含类 0 和 1,样本结果可能是 0.8 或 0.34 等。
从数据的角度来看,这没有意义。这就是为什么我们可以使用 SMOTE-NC 来确保分类数据的过采样是合理的。
让我们用示例数据试试。对于这个特定的样本,我们会使用变量‘HasCrCard’和‘Age’。首先,我想展示初始的‘HasCrCard’变量分布。
pd.crosstab(df['HasCrCard'], df['Exited'])
然后让我们看看使用 SMOTE-NC 进行过采样后的差异。
from imblearn.over_sampling import SMOTENC
smotenc = SMOTENC([1],random_state = 42)
X_os_nc, y_os_nc = smotenc.fit_resample(df[['Age', 'HasCrCard']], df['Exited'])
注意上面的代码中,分类变量的位置是基于 DataFrame 中变量的位置。
让我们看看‘HasCrCard’在过采样后的分布。
pd.crosstab(X_os_nc['HasCrCard'], y_os_nc)

可以看到,数据的过采样几乎保持了相同的比例。你可以尝试用其他分类变量看看 SMOTE-NC 的效果。
3. Borderline-SMOTE
Borderline-SMOTE 是一种基于分类器边界的 SMOTE。Borderline-SMOTE 会对接近分类器边界的数据进行过采样。这是因为接近边界的样本更容易被误分类,因此更重要需要进行过采样。
Borderline-SMOTE 有两种类型:Borderline-SMOTE1 和 Borderline-SMOTE2。它们的区别在于,Borderline-SMOTE1 会对接近边界的两个类都进行过采样,而 Borderline-SMOTE2 只会对少数类进行过采样。
我们来尝试一下使用 Borderline-SMOTE 与一个数据集示例。
from imblearn.over_sampling import BorderlineSMOTE
bsmote = BorderlineSMOTE(random_state = 42, kind = 'borderline-1')
X_bd, y_bd = bsmote.fit_resample(df[['EstimatedSalary', 'Age']], df['Exited'])
df_bd = pd.DataFrame(X_bd, columns = ['EstimatedSalary', 'Age'])
df_bd['Exited'] = y_bd
让我们看看在启动 Borderline-SMOTE 后,数据的分布情况。
sns.scatterplot(data = df_bd, x ='EstimatedSalary', y = 'Age', hue = 'Exited')
plt.title('Borderline-SMOTE')
如果我们查看上述结果,输出与 SMOTE 输出类似,但 Borderline-SMOTE 的过采样结果稍微接近于边界。
4. SMOTE-Tomek
SMOTE-Tomek 使用了 SMOTE 和欠采样 Tomek 链接的组合。Tomek 链接是一种清理数据的方法,用于去除与少数类重叠的多数类。
让我们尝试对样本数据集应用 SMOTE-TOMEK。
from imblearn.combine import SMOTETomek
s_tomek = SMOTETomek(random_state = 42)
X_st, y_st = s_tomek.fit_resample(df[['EstimatedSalary', 'Age']], df['Exited'])
df_st = pd.DataFrame(X_st, columns = ['EstimatedSalary', 'Age'])
df_st['Exited'] = y_st
让我们看看使用 SMOTE-Tomek 后的目标变量结果。
df_st['Exited'].value_counts().plot(kind = 'bar', color = ['blue', 'red'])
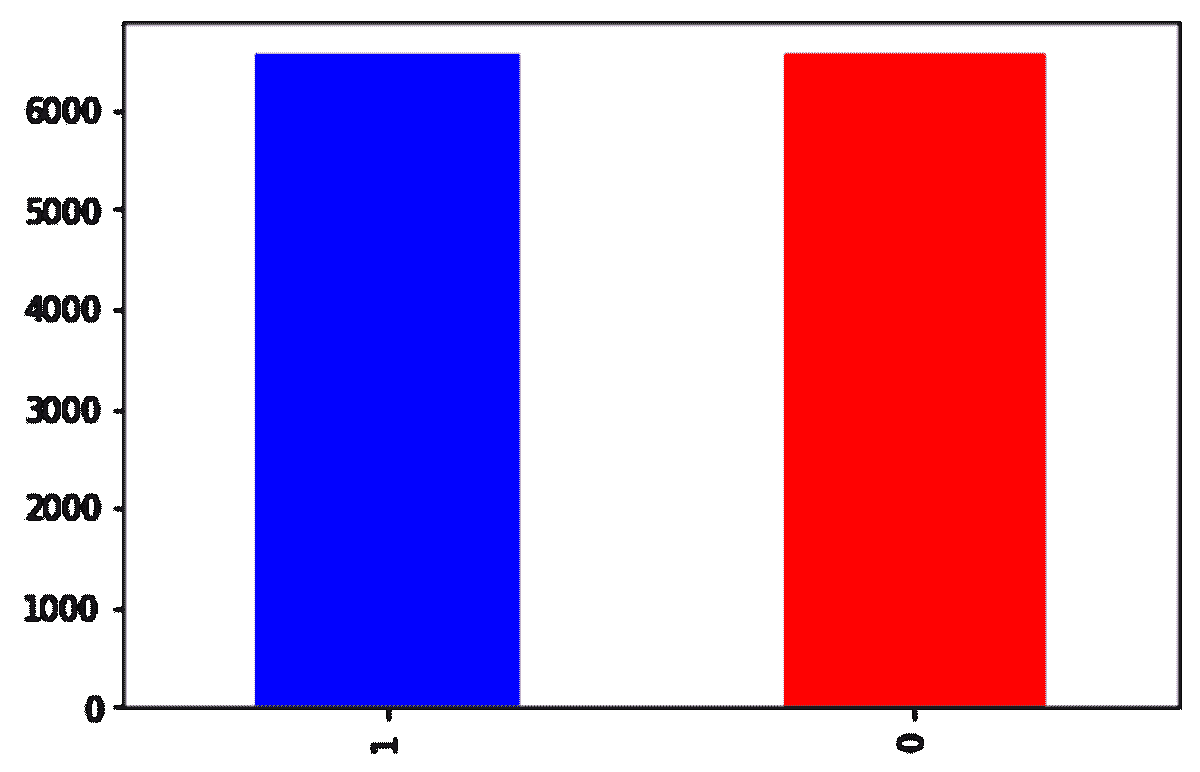
'Exited' 类别 0 的数量现在约为 6000,相比之下,原始数据集接近 8000。这是因为 SMOTE-Tomek 在进行过采样少数类的同时,对类别 0 进行了欠采样。
让我们看看在使用 SMOTE-Tomek 进行过采样后的数据分布。
sns.scatterplot(data = df_st, x ='EstimatedSalary', y = 'Age', hue = 'Exited')
plt.title('SMOTE-Tomek')
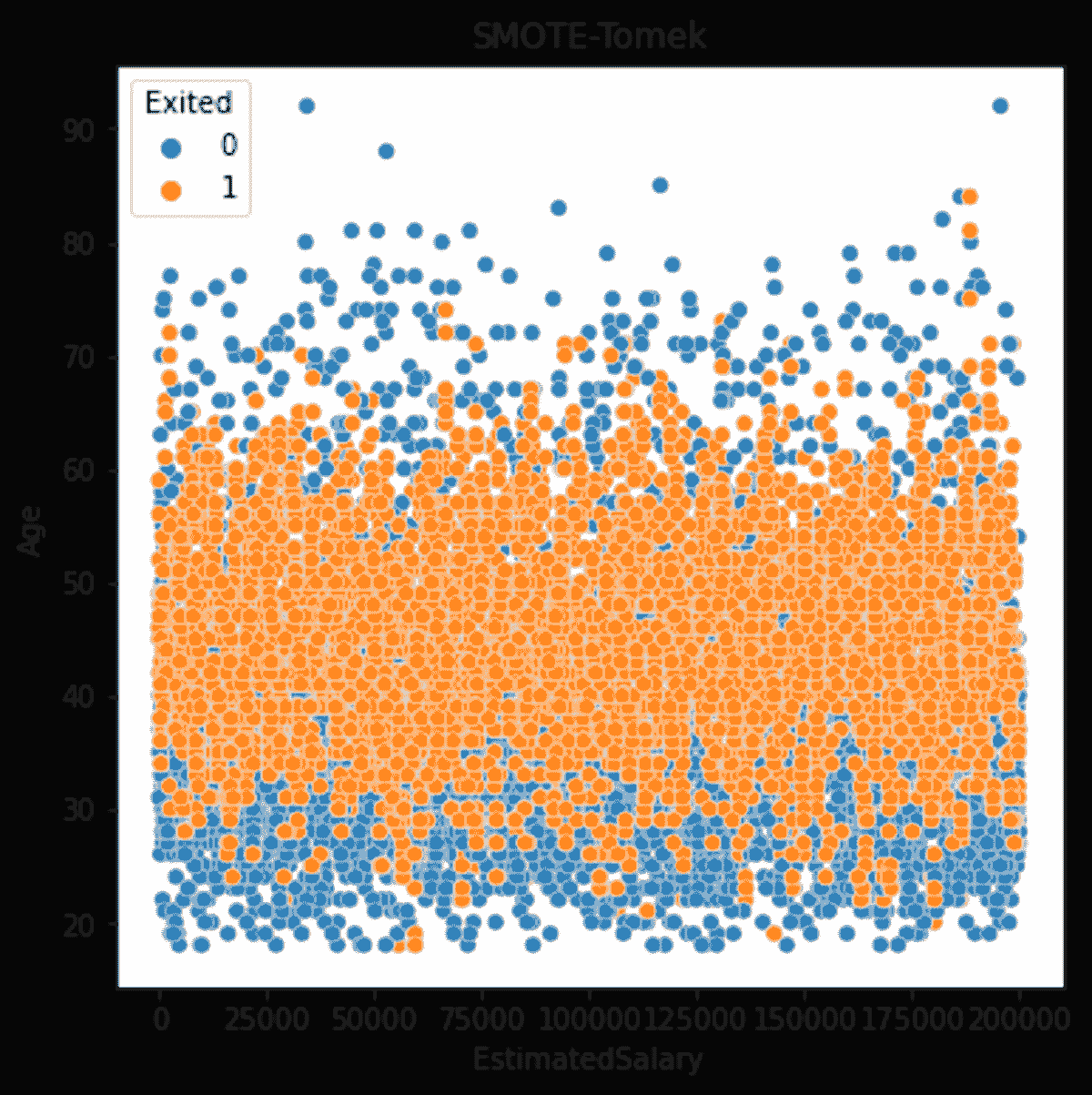
结果分布仍然类似于之前。但如果我们深入了解,距离数据越远,过采样的少数类样本越少。
5. SMOTE-ENN
类似于 SMOTE-Tomek,SMOTE-ENN(编辑最近邻)结合了过采样和欠采样。SMOTE 进行了过采样,而 ENN 进行了欠采样。
编辑最近邻是一种在原始和样本结果数据集中移除多数类样本的方法,当最近邻少数类样本将其错误分类时。它会移除接近边界的多数类样本,这些样本被错误分类了。
让我们尝试使用 SMOTE-ENN 与示例数据集。
from imblearn.combine import SMOTEENN
s_enn = SMOTEENN(random_state=42)
X_se, y_se = s_enn.fit_resample(df[['EstimatedSalary', 'Age']], df['Exited'])
df_se = pd.DataFrame(X_se, columns = ['EstimatedSalary', 'Age'])
df_se['Exited'] = y_se
让我们看看 SMOTE-ENN 的结果。首先,我们会查看目标变量。
df_se['Exited'].value_counts().plot(kind = 'bar', color = ['blue', 'red'])
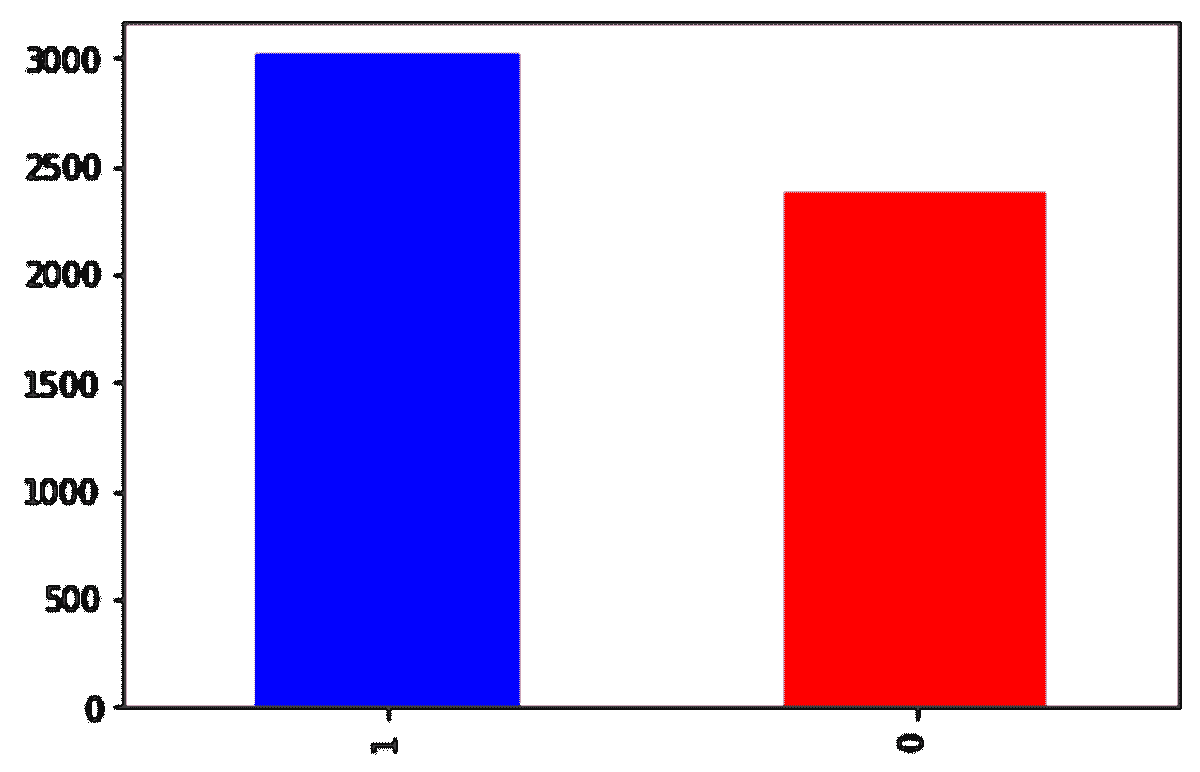
与 SMOTE-Tomek 相比,SMOTE-ENN 的欠采样过程严格得多。从上面的结果来看,超过一半的原始'Exited' 类别 0 被欠采样,仅少数类有所略微增加。
让我们看看应用 SMOTE-ENN 后的数据分布。
sns.scatterplot(data = df_se, x ='EstimatedSalary', y = 'Age', hue = 'Exited')
plt.title('SMOTE-ENN')
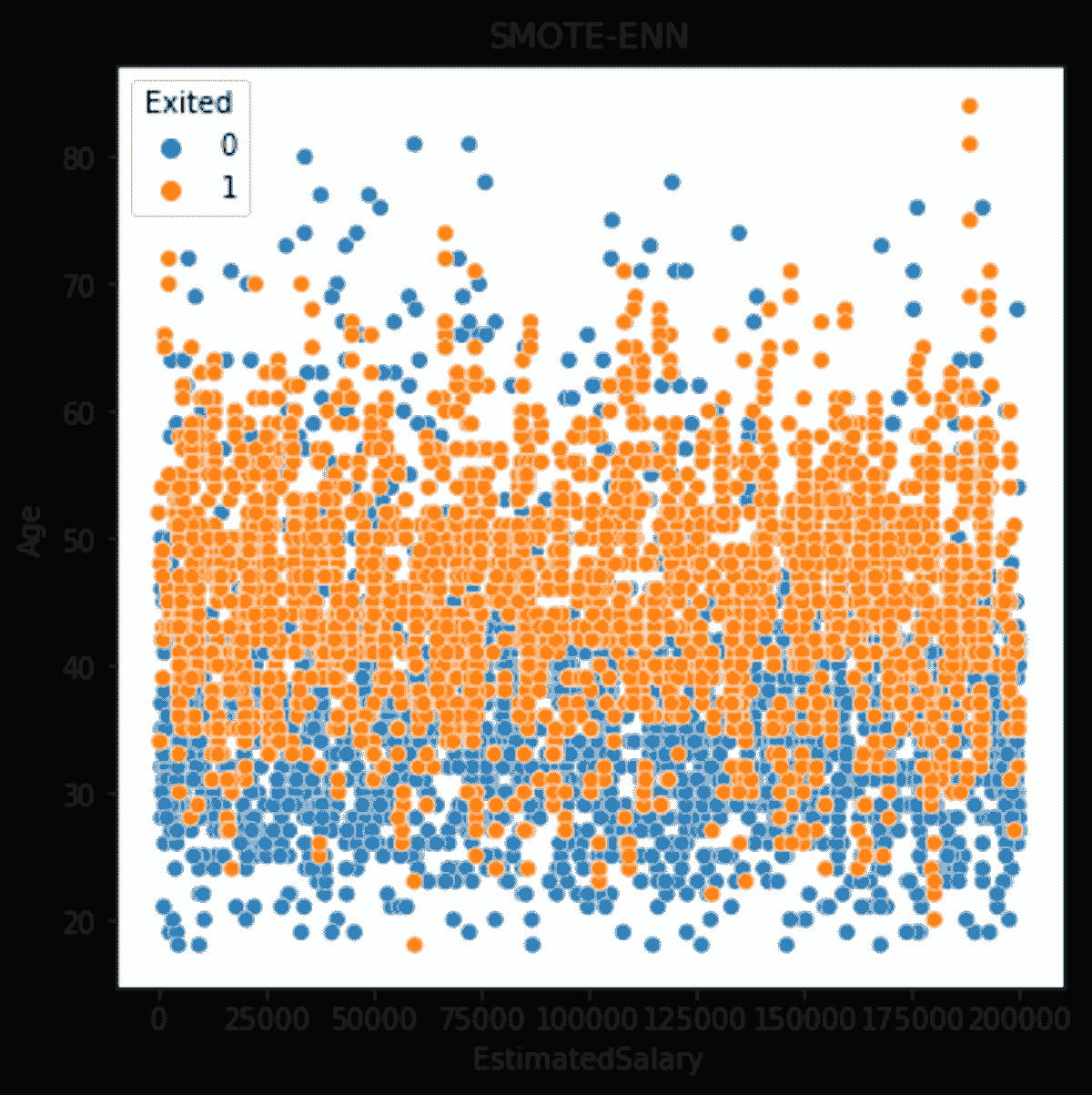
类别之间的数据分布比之前大得多。然而,我们需要记住,结果数据的数量较少。
6. SMOTE-CUT
SMOTE-CUT 或 SMOTE-聚类欠采样技术结合了过采样、聚类和欠采样。
SMOTE-CUT 实现了使用 SMOTE 进行过采样,聚类原始数据和结果,并从簇中移除多数类样本。
SMOTE-CUT 聚类基于 EM(期望最大化)算法,该算法为每个数据分配属于各个簇的概率。聚类结果会引导算法进行过采样或欠采样,从而使数据集分布变得平衡。
让我们尝试使用数据集示例。对于这个例子,我们将使用 crucio Python 包。
pip install crucio
使用 crucio 包,我们通过以下代码对数据集进行过采样。
from crucio import SCUT
df_sample = df[['EstimatedSalary', 'Age', 'Exited']].copy()
scut = SCUT()
df_scut= scut.balance(df_sample, 'Exited')
让我们看看目标数据分布。
df_scut['Exited'].value_counts().plot(kind = 'bar', color = ['blue', 'red'])
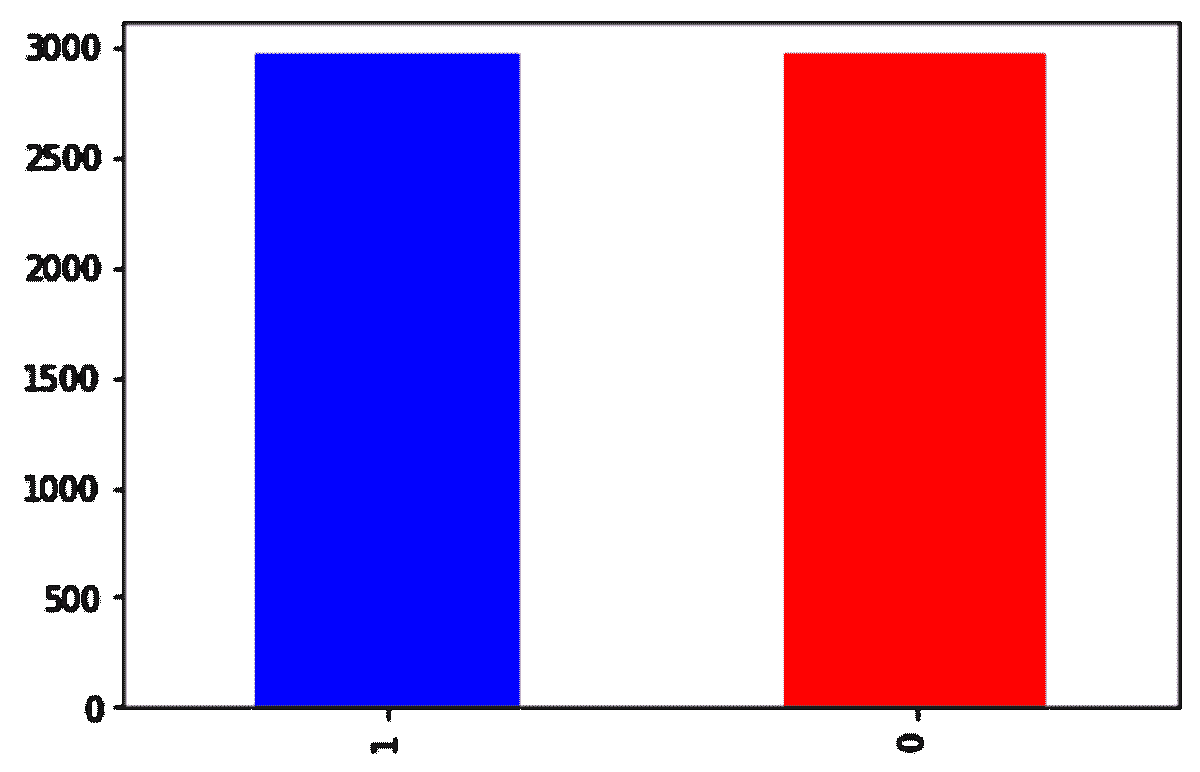
尽管欠采样过程相当严格,'Exited' 类别的分布仍然相等。许多'Exited' 类别 0 的样本由于欠采样而被移除。
让我们看看实施 SMOTE-CUT 后的数据分布。
sns.scatterplot(data = df_scut, x ='EstimatedSalary', y = 'Age', hue = 'Exited')
plt.title('SMOTE-CUT')
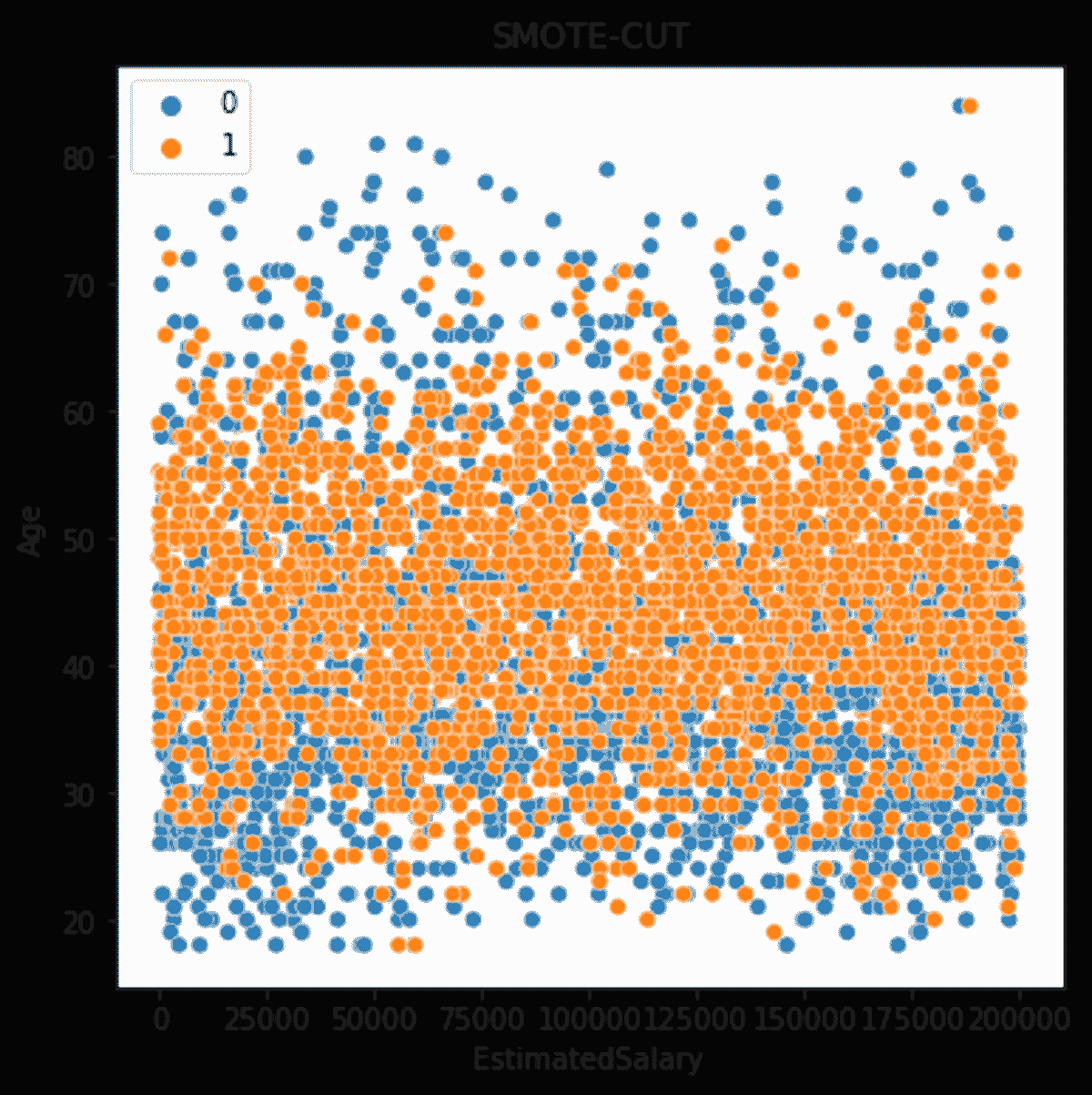
数据分布更分散,但仍然少于 SMOTE-ENN。
7. ADASYN
ADASYN 或自适应合成采样是一种 SMOTE,它试图根据数据密度对少数数据进行过采样。ADASYN 会为每个少数样本分配一个加权分布,并优先对更难学习的少数样本进行过采样 7。
让我们尝试用示例数据集进行 ADASYN。
from crucio import ADASYN
df_sample = df[['EstimatedSalary', 'Age', 'Exited']].copy()
ada = ADASYN()
df_ada= ada.balance(df_sample, 'Exited')
让我们看看目标分布结果。
df_ada['Exited'].value_counts().plot(kind = 'bar', color = ['blue', 'red'])
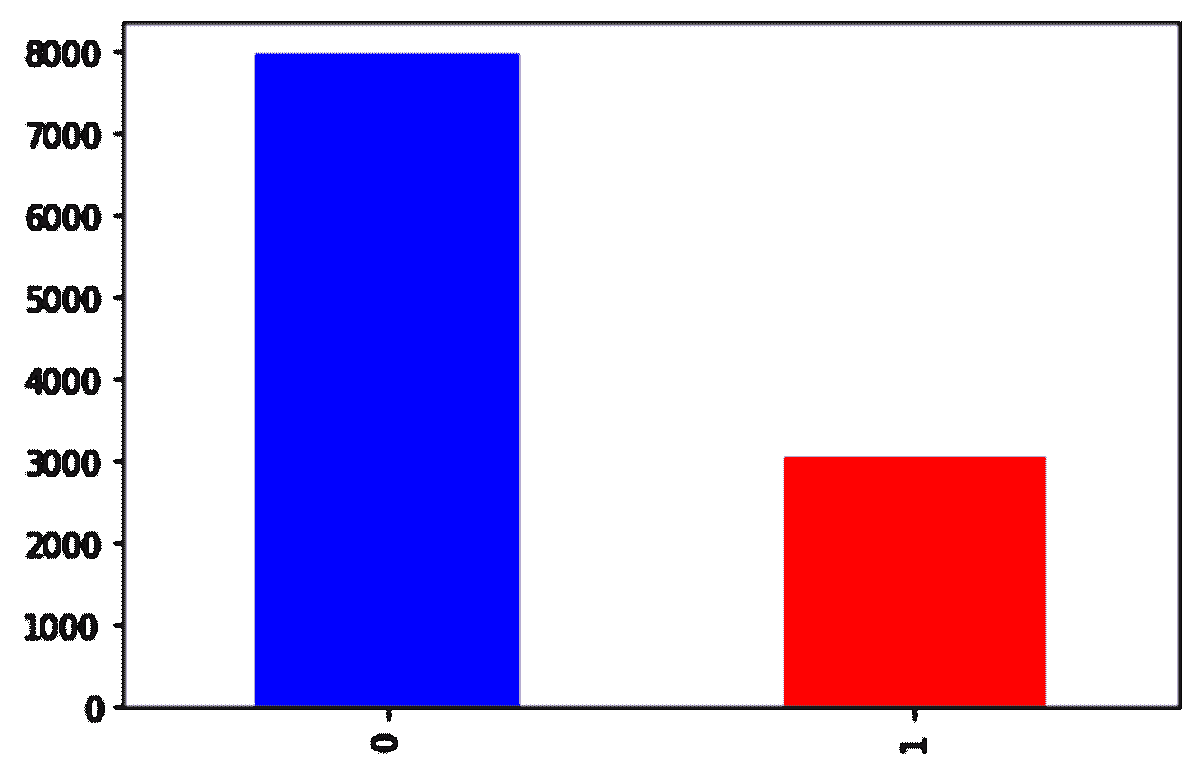
由于 ADASYN 会关注那些更难学习或密度较低的数据,因此其过采样结果低于其他方法。
让我们看看数据的分布情况。
sns.scatterplot(data = df_ada, x ='EstimatedSalary', y = 'Age', hue = 'Exited')
plt.title('ADASYN')
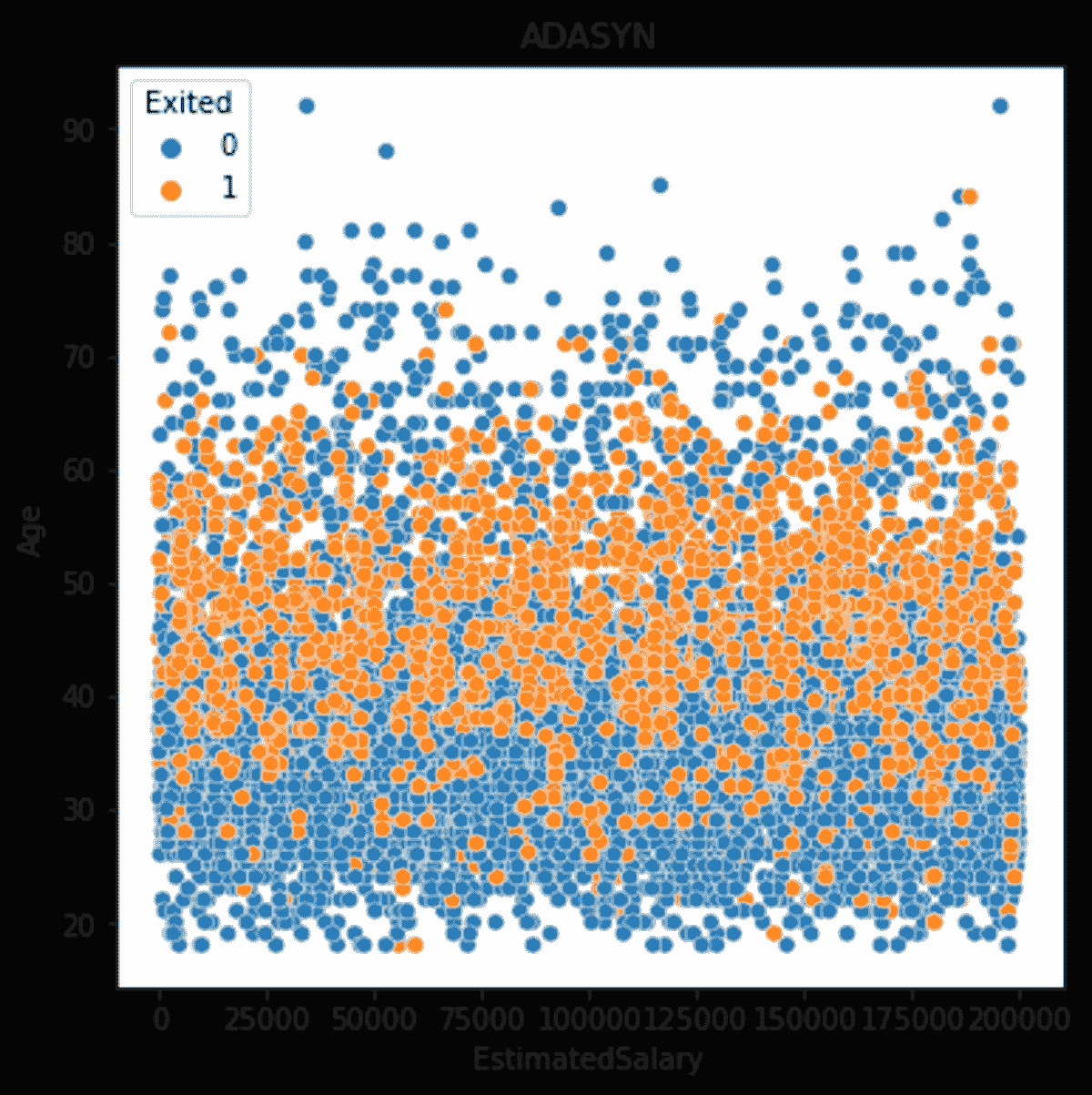
从上面的图像中可以看出,数据的分布更接近核心,但也接近低密度的少数数据。
结论
数据不平衡是数据领域中的一个问题。缓解不平衡问题的一种方法是通过 SMOTE 对数据集进行过采样。随着研究的发展,已经创建了许多我们可以使用的 SMOTE 方法。
在这篇文章中,我们将探讨 7 种不同的 SMOTE 技术,包括
-
SMOTE
-
SMOTE-NC
-
边界线-SMOTE
-
SMOTE-TOMEK
-
SMOTE-ENN
-
SMOTE-CUT
-
ADASYN
参考文献
-
SMOTE: 合成少数类过采样技术 - Arxiv.org
-
客户流失建模数据集来自 Kaggle,许可证为 CC0: 公开领域。
-
边界线-SMOTE: 不平衡数据集学习中的一种新过采样方法 - Semanticscholar.org
-
平衡自动标注关键词的训练数据:一个案例研究 - inf.ufrgs.br
-
改进慢性心力衰竭不良结果的风险识别:使用 SMOTE+ENN 和机器学习 - dovepress.com
-
使用 Crucio SMOTE 和聚类欠采样技术处理不平衡数据集 - sigmoid.ai
-
ADASYN: 自适应合成采样方法用于不平衡学习 - ResearchGate
Cornellius Yudha Wijaya是一名数据科学助理经理和数据撰稿人。在全职工作于印尼安联保险期间,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
更多相关话题
数据科学中你应该了解的 7 个 SQL 概念
原文:
www.kdnuggets.com/2022/11/7-sql-concepts-needed-data-science.html

编辑提供的图片
介绍
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
随着世界向数字化发展,大多数公司现在都是数据驱动的。他们收集的大量数据存储在数据库中。这些数据的管理、分析和处理通过数据库管理系统(DBMS)完成。由于这种转变,数据科学成为了一个极具前景的领域,提供了无数的就业机会。数据科学家需要从数据库中提取数据,这就是 SQL 发挥作用的地方。你一定听说过掌握数据科学领域的顶级技能,而 SQL 就是其中之一。现在,问题是:作为一个优秀的数据科学家,我真的需要精通 SQL 吗?
答案是否定的,但掌握 SQL 的基本知识是必要的,因为它已成为许多数据库系统的标准。这篇文章旨在提及你必须了解的 SQL 关键要素,并获得数据科学从业者的推荐。
数据科学中 SQL 的需求
SQL 代表结构化查询语言,旨在管理关系数据库。让我们首先理解 SQL 在数据科学中的需求。是什么使它独特,并成为数据科学中最受追捧的技能之一?以下是一些帮助你理解其重要性的要点:
-
广泛使用: 尽管 SQL 约有 40 年的历史,但它仍用于大多数关系数据库系统中,并且已成为实验数据的标准工具。
-
简化数据理解: SQL 在浏览数据库内容时非常方便。它使你能够有效地理解数据的特性。
-
易于学习: 这是初学者的完美起点,语法类似于简单的英语,你只需几行代码即可提取有价值的见解。
-
支持大数据处理: SQL 使你能够以有组织的方式管理大量数据,使其成为数据科学应用的理想选择。
-
与其他编程语言和应用程序的兼容性:将 SQL 与 Python、C++、R 等语言集成非常方便。它还支持商业智能和数据可视化工具,如 Power BI 和 Tableau,使开发过程变得稍微容易一些。
七个 SQL 概念
1) 基本命令的理解
基本命令的知识构建了终身学习的基础。否则,你将只是记忆事实,而不了解它们如何相互关联。一些常用的 SQL 命令如下:
-
SELECT & FROM:从提到的表中检索数据的属性。
-
SELECT DISTINCT:它消除重复的行,只显示唯一的记录。
-
WHERE:它过滤记录,只显示满足给定条件的记录。
-
AND, OR, NOT:当条件不为真时不执行查询。而 AND 和 OR 用于应用多个条件。
-
ORDER BY:它将数据按升序或降序排序
-
GROUP BY:它将相同的数据分组。
-
HAVING:通过 GROUP BY 聚合的数据可以在这里进一步筛选。
-
聚合函数:聚合函数如 COUNT()、MAX()、MIN()、AVG() 和 SUM() 用于对给定数据进行操作。
让我们以 Employee 表为例进行应用,
| ID | Name | Department | Salary ($) | Gender |
|---|---|---|---|---|
| 1 | Julia | Admin | 20000 | F |
| 2 | Jasmine | Admin | 15000 | F |
| 3 | John | IT | 20000 | M |
| 4 | Mark | Admin | 17000 | M |
现在,我们想要获取在 Admin 部门工作的女性的平均薪资。
SELECT Department,
AVG(Salary)
FROM Employees
WHERE Gender="F"
GROUP BY Department
HAVING Department = "Admin";
输出:
Admin | 17500.0
2) Case When
这是 SQL 中一个非常强大和灵活的语句,用于编写复杂的条件语句。它提供了 IF.THEN.ELSE 语句的功能。我们来看看它的语法,
CASE expression
WHEN value_1 THEN result_1
WHEN value_2 THEN result_2
...
WHEN value_n THEN result_n
ELSE result
END
它按顺序执行语句,并在条件变为真时立即返回值。如果没有满足条件,则执行 ELSE 块,如果没有 ELSE 块,则返回 NULL。
假设我们有一个学生数据库,我们想根据他们的分数进行评分,则可以使用以下 SQL 语句:
SELECT student_name,
marks,
CASE
WHEN marks >= 85 THEN 'A'
WHEN marks >= 75
AND marks < 85 THEN 'B+'
WHEN marks >= 65
AND marks < 75 THEN 'B'
WHEN marks >= 55
AND marks < 65 THEN 'C'
WHEN marks >= 45
AND marks < 55 THEN 'D'
ELSE 'F'
END AS grading
FROM Students;
3) 子查询
作为数据科学家,对子查询的了解至关重要,因为他们需要处理不同的表,并且一个查询的结果可能会被再次使用,以进一步限制主查询中的数据。这也被称为嵌套查询或内查询。子查询必须用括号括起来,并且在主查询之前执行。如果返回多于一行,则称为多行子查询,必须与多行操作符一起使用。
假设保险公司引入了一项新政策,取消了年龄超过 80 岁的人的保险。这可以通过如下的子查询来完成:
DELETE
FROM INSURANCE_CUSTOMERS
WHERE AGE IN
(SELECT AGE
FROM INSURANCE_CUSTOMERS
WHERE AGE > 80 );
内部子查询选择所有年龄超过 80 岁的客户,然后在这一组上执行删除操作。
4) 连接
SQL 连接用于根据表之间的逻辑关系组合多个表中的行。以下列出了 4 种 SQL 连接类型:
- 内连接:内连接仅显示两个表中满足给定条件的行。在集合术语中,它可以被视为交集。
![7 SQL Concepts You Should Know For Data Science]()
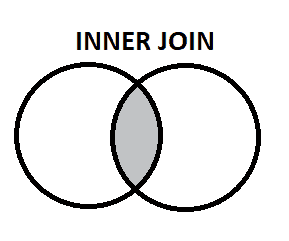
SELECT Student.Name
FROM Student
INNER JOIN Sports ON Student.ID = Sports.ID;
它返回那些已注册参加体育活动的学生。注意:体育 ID 与学生的注册 ID 相同。
- 左连接:它返回 LEFT 表中的所有记录,而右表中仅显示匹配的记录。
![7 SQL Concepts You Should Know For Data Science]()
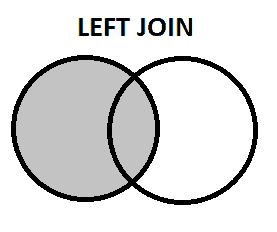
SELECT Student.Name
FROM Student
LEFT JOIN Sports ON Student.ID = Sports.ID;
- 右连接:它与左连接的作用正好相反。
![7 SQL Concepts You Should Know For Data Science]()
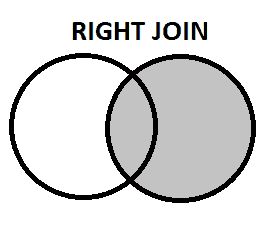
SELECT Student.Name
FROM Student
RIGHT JOIN Sports ON Student.ID = Sports.ID;
- 全外连接:它包含了两个表中的所有行,如果没有对应的匹配项,则显示为 NULL 值。
![7 SQL Concepts You Should Know For Data Science]()
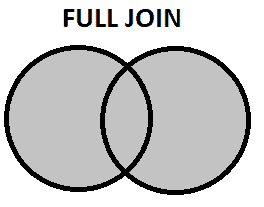
SELECT Student.Name
FROM Student
FULL JOIN Sports ON Student.ID = Sports.ID;
5) 存储过程
存储过程允许我们在数据库中存储多个 SQL 语句以便后续使用。它支持重用,并且在调用时还可以接受参数值。它提高了性能,并且修改起来更加容易。
CREATE PROCEDURE SelectStudents @Major nvarchar(30),
@Grade char(1) AS
SELECT *
FROM Students
WHERE Major = @Major
AND Grade = @Grade GO;
EXEC SelectStudents @Major = 'Data Science',
@Grade = 'A';
这个过程允许我们根据学生的成绩提取不同专业的学生。例如,我们试图提取所有在数据科学专业中获得 A 等级的学生。请注意,CREATE PROCEDURE 类似于函数声明,需要通过 EXEC 调用以进行执行。
6) 字符串格式化
我们都知道,原始数据需要清洗,以提高整体生产力,从而做出更高质量的决策。在这个背景下,字符串格式化发挥了重要作用,它涉及到操作字符串以去除无关的内容。SQL 提供了广泛的字符串函数来转换和处理字符串。其中最常用的 5 个如下:
- CONCAT: 用于将两个或更多字符串连接在一起。
SELECT CONCAT(Name, ' has a major of ', Major)
FROM Students
WHERE student_Id = 37;
- SUBSTR: 它返回字符串的一部分,并在参数中接收起始位置和要返回的子字符串的长度。
SELECT student_name,admission_date,
SUBSTR(admission_date, 4, 2) AS day
FROM Students
日期列将会从 admission_date 中单独提取出来。
- TRIM: trim 的主要功能是去除字符串开头、结尾或两者的字符(如果指定的话)。你必须指定开头、结尾或两者,然后是要移除的字符,再跟上要移除的字符串。
SELECT age,
TRIM(trailing ' years' FROM age)
FROM Students
它将把“26 years”改为“26”。
- INSERT: 它允许我们在指定的位置插入字符串到给定字符串中。你需要指定新子字符串的位置和长度。请注意,这个新字符串将覆盖之前的文本。
SELECT INSERT("OldWebsite.com", 1, 9, "NewWebsite");
将更新到 NewWebsite.come。
- COALESCE: 它可以用来用用户定义的值替换空值,这在数据科学中经常需要。
SELECT COALESCE (NULL, NULL, 10, 'John’')
这将返回 10。
7) 窗口函数
窗口函数类似于聚合函数,但它不会在计算后使行合并成一行。相反,行保持其独立的身份。它们分为三个主要类别:
- 聚合函数: 它展示了来自数值列的汇总值,如 AVG()、COUNT()、MAX()、MIN()、SUM() 等。
SELECT name,
AVG(salary) over (PARTITION BY department)
FROM Employees;
它展示了来自员工表的不同部门的平均工资。
- 值函数: 每个分区使用值窗口函数分配一些值。一些常用的值函数包括 LAG()、LEAD()、FIRST_VALUE()、LAST_VALUE() 和 NTH_VALUE()。
SELECT
bank_branch, month, income,
LAG(income,1) OVER (
PARTITION BY bank_branch
ORDER BY month
) income_next_month
FROM Bank;
我们比较了银行不同分支机构本月与上月的收入。
- 排名函数: 它们用于根据某些预定义的排序给行分配排名。ROW_NUMBER()、RANK()、DENSE_RANK()、PERCENT_RANK()、NTILE() 是其中的一些。
SELECT
product_name, price,
RANK () OVER (
ORDER BY list DESC
) price_hightolow
FROM Products;
产品按价格使用 RANK() 进行排名。
结论
我希望你喜欢阅读这篇文章,它为你提供了作为数据科学家需要了解多少 SQL 的全面理解。如果你想深入探讨这些概念,这里有一些资源:
Kanwal Mehreen 是一位有抱负的软件开发者,对数据科学和人工智能在医学中的应用充满兴趣。Kanwal 被选为 2022 年亚太地区的 Google Generation Scholar。Kanwal 喜欢通过撰写有关热门话题的文章来分享技术知识,并且热衷于提高女性在科技行业中的代表性。
更多相关话题
7 个步骤打造获奖的数据科学简历
原文:
www.kdnuggets.com/2020/01/7-steps-job-winning-data-science-resume.html
评论
由 Aditya Sharma,Hiration 联合创始人
根据 LinkedIn 2017 年美国新兴职位报告,数据科学家职位在新兴职位的前 20 名中排名第二,增长率为 6.5 倍(2012-2017)。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
鉴于全球各行各业对数据科学家的前所未有的需求,你可能会认为获得数据科学职位轻而易举。
但你在这方面严重误解了。
获得数据科学认证或参加 Kaggle 比赛并不足以确保你在这个行业找到工作。你可能已经培养了该领域的技能,但如果你未能在纸面上展示这些素质,那么即使你非常熟练也没有意义。
这就是为什么你的数据科学简历很重要。
在本文中,我们将讨论一些可以采取的实际步骤,以制作一份出色的数据科学简历并获得理想的工作。
不再赘述,让我们开始吧。
你的名字应该放在首位。不是‘简历’或‘履历’。
如果你的简历因为忘记在顶部写上你的名字而在一大堆文件中丢失了,这样的简历还有什么用呢?
尽管听起来令人惊讶,但我们确实经常遇到这样的情况,这也是我们在讨论数据科学简历的细节之前,决定提前说明的原因。
通常做法是确保你的名字位于顶部。不需要在顶部写上‘简历’或‘履历’,因为文档的性质已经很明显。
超越你的基本联系信息
你知道简历中需要包含哪些基本联系信息,对吧?为了重述,它们是你的:
-
手机号码:仅提及一个即可。
-
电子邮件地址:选择一个与当前/以前雇主无关的专业电子邮件地址。
-
位置:你可以提及你目前的位置。如果你正在搬迁,跳过简历中的这些细节,而在求职信中提及即可。
但这还不是全部。
作为一名数据科学家,你正在推动一场变革。除了这些基本信息外,随意添加你的作品集或其他公共细节,如 LinkedIn、GitHub、Kaggle 等。
只有在这样做会对你的简历增值的情况下才做。如果你链接的是一个空的 LinkedIn 个人资料或几个月前最后更新过的 GitHub 账户,那是没有意义的。如果 GitHub、Kaggle 或其他公共平台上有显著的成就,可以在简历的单独部分提及这些成就。
然而,这样做只有在你的工作经验部分缺乏数据科学相关内容时才有意义。如果你的工作经验本身已经证明了你的技能,你就不需要额外强调这些成就来验证它们。
但是,如果你正在过渡到数据科学,正确展示这些成就将对你进入那份梦寐以求的短名单发挥重要作用。
你的个人简介标题可能会决定你的机会。
首先,了解一下,并不是很多人在简历上有个人简介标题。所以,添加这样的标题将有助于让你在竞争中脱颖而出。
但在继续之前,什么是个人简介(或职位)标题呢?
这无非是你名字下方的一个标识符,传达你的职业身份。招聘人员不应该需要扫描你的工作经验来判断你是否适合他们。你添加职位标题是为了让他们的工作更轻松。
这里有一个快速的建议,告诉你如何根据你的职业阶段制定个人简介标题:
你有数据科学的认证但没有相关的工作经验。
比如说,你获得了数据科学认证作为任何在线课程的一部分,但你还没有工作经验。
你可以在简历上简单地写“认证数据科学专业人士”作为你的个人简介标题。
这样做可以立即传达即使你还没有专业经验,你也拥有相关的认证。
你有相关的工作经验。
假设你曾担任数据科学工程师或数据科学家。在这种情况下,只需在你名字下方提及你当前的职称即可。
假设你现在是数据分析师,而你的目标职位是数据工程师。不要试图欺骗招聘人员,把“数据工程师”写成你的职位名称。坚持事实是获得你想要的唯一可持续的方法。
你正在从相关(或不相关)领域过渡到数据科学。
如果你正在过渡到数据科学,提及你当前或最近担任的职务。如果你在过渡,你需要让招聘人员相信你对数据科学是认真的,即使你没有相关的工作经验。
如果你有任何认证来帮助你的情况,我们已经在第一点中涵盖了。如果没有,你可以在相关部分提及你的项目或竞赛。在这种情况下,职位标题可以变成类似“<当前职位> & 数据科学爱好者”。
在你的总结中少谈数据科学,更多地谈论“影响”
总结应该是一个简短的 3-4 行陈述,描述你能为下一个组织带来的影响。在这里不要过多涉及你的数据科学技能——这正是简历其他部分的内容。总之,仅仅提及你通过特定技能能带来的价值。
不要详细描述你熟悉的技术、算法和库。提及你能带来的商业影响:明智的决策、改进的流程、领导力支持等。
将你的技能分为“关键技能”和“技术技能”
作为数据科学家,请将你的核心技能与技术技能分开。这有助于你更有效地概述和传达你的技能。
以下快照展示了理想的数据科学简历中该部分的样子:

数据科学简历中的关键技能和技术技能部分
将你的技术技能按相关子标题分组,使招聘人员更容易快速阅读重要内容并跳过其余部分。
在专业经验部分量化你的成就
招聘人员最喜欢的就是实际展示你能带给组织的成果。公司不在乎你是否具备正确的技能——如果你无法展示使用这些技能所取得的成果,你可能连这些技能都不算具备。
从中学到什么?尽可能量化你的成就。
此外,
-
使用一行式要点展示你的主要成就,使用以行动为导向的成就陈述。
-
将类似的要点分组在独特的子标题或类别下。因此,与其在工作经验中写 10+点,不如将它们分成 4-5 点一组。
-
用一个动词开头每个要点。
-
使用绩效数据量化你的成就。如果你没有确切的数字,甚至一个大致的数字也可以。
同样,如果你详细描述你的项目/竞赛,请提供关于你贡献、参与者数量等的近似数据。以下是你数据科学简历中专业编排的工作经验部分的快照:

数据科学简历中的专业经验部分
说明你的认证、会议和出版物
认证的重要性是数据科学简历中的一个关键元素,因为它传达了你在不断变化的环境中的最新技能。
同时,在简历中列出你参加的会议和发表的学术论文也有助于留下良好印象。
关键要点
总结:
-
在简历标题中写上你的全名。
-
除了基本联系方式外,还要包含你的 GitHub/LinkedIn/Kaggle 详情。
-
如果你是一位有经验的专业人士,请正确地将你最新的职位名称作为个人资料标题。如果你还没有相关的工作经验,可以将个人资料标题简单地标记为“认证数据科学专业人士”。
-
你的简历总结应专注于你能够带来的影响,而不是充满行话。
-
将你的技能分为关键技能和技术技能,后者包含语言、库、工具等相关子标题。
-
使用行动动词和绩效数据列出你的专业经历部分。
-
确保你的简历在相关部分中列出你的认证、出版物和参加的会议。
就是这些!还有更多关于你数据科学简历的疑问吗?在下方留言!
附注:如果你想深入了解我们讨论的细节,或者想查看一个完整的数据科学简历样本,请查阅这份详尽的指南 关于数据科学简历。
简介:Aditya Sharma 正在致力于帮助全球专业人士获得梦想工作。他对 Hiration — 一个由 AI 驱动的简历生成器和帮助求职者在严酷的就业市场中找到方向的平台 — 充满热情,他是联合创始人及非正式的首席问题解决官(Chief Problem-solving Officer)。
相关:
-
我没有被聘用为数据科学家。所以我寻求了关于谁在聘用的数据。
-
数据科学家最受欢迎的技术技能
-
完整的数据科学 LinkedIn 个人资料指南
更多相关话题
Python 基础机器学习的 7 个步骤——2019 版
原文:
www.kdnuggets.com/2019/01/7-steps-mastering-basic-machine-learning-python.html
评论
对于那些对 Python 机器学习速成课程感兴趣的人来说,那里有大量免费材料可供使用。
不久前,我写了掌握 Python 机器学习的 7 个步骤和掌握 Python 机器学习的 7 个附加步骤,这两篇文章试图将一些优质的材料汇总和组织成一个速成课程。然而,这些文章已经有几年时间了,随着新的一年的到来,我认为是时候重新审视这个概念,并为掌握 Python 机器学习制定一条新的学习路径。
这一次,我们将把路径分成 3 篇文章,每篇文章分别覆盖基础、中级和高级主题。然而,我们需要相对看待这些术语,不要期望在完成(最终的)高级文章后成为研究级机器学习工程师。学习路径面向那些对编程、计算机科学概念和/或机器学习有一定理解的人,他们希望能够使用流行 Python 库的机器学习算法实现来构建自己的机器学习模型。
第一篇文章将从零开始,引导读者设置环境、理解 Python,并尝试各种算法以应对不同的场景。我们将利用现有的教程、视频和各种作者的作品,因此任何包含在此的内容的感谢应该仅向他们致以。
与其对每个主题步骤(比如 聚类)提供大量资源,我尝试选择一两个优质教程,并附上一个简明视频,初步介绍给定主题的基础理论、数学或直觉。
如果这些步骤大多针对机器学习算法,不必担心,因为在过程中你还会遇到其他重要概念,如数据预处理、损失度量、数据可视化等等。
所以,拿起一杯你喜欢的饮料,准备好迎接系列的第一篇文章,开始通过这 7 个步骤掌握基础的 Python 机器学习。
第一步:掌握 Python 基础
我寻找了一些更新的材料,以补充我在之前的版本中指出的内容,这不仅是为了变化,也为了跟上最新的 Python 版本。
这个 GitHub 库由 Jerry Pussinen 创建,包含了“用于教学/学习 Python 3 的 Jupyter 笔记本”,似乎提供了对 Python 的一个不错概述,那些有编程基础或有动力的人可以在几个小时内完成。你需要安装 Python 3.5+以及 Jupyter 笔记本。
由于在进展过程中你会需要使用到多个流行的 Python 科学库,我建议使用 Anaconda 发行版,你可以在这里下载(选择最新的 Python 3.X 版本,而不是 Python 2.X),而不是单独安装各个组件。只需启动安装程序,安装完成后你将拥有 Python、Jupyter 笔记本以及前进所需的一切。
第 2 步:理解 Python 科学计算环境
所以,你已经安装并准备好使用 Python 和科学计算栈了。但为什么?
在深入探讨之前,了解科学计算栈是什么,它最突出的和重要的组件有哪些,以及它们在机器学习环境中如何使用是一个好主意。
这篇来自 Dataquest 的文章,恰当地标题为Jupyter 笔记本入门:教程,深入探讨了我们为何使用 Jupyter 笔记本,并介绍了一些你在这条路上会遇到的最重要的 Python 库,即 Pandas、Numpy 和 Matplotlib。
本教程不涉及 Scikit-learn,这是 Python 生态系统中实际机器学习过程的主要引擎之一,其中包含了数十种算法的实现,供你在自己的项目中使用。然而,来自 Scikit-learn 维护者的介绍性文章Scikit-learn 机器学习简介将帮助你在 5 分钟内了解其基础知识。
作为留给读者的练习,我建议找到并熟悉 Pandas、Numpy、Matplotlib 和 Scikit-learn 的文档内容,并将链接作为参考保存。无论如何,确保你对这 4 个工具的基础知识感到熟悉,因为它们在基础 Python 机器学习中被广泛使用。
第 3 步:分类
分类是监督学习的主要方法之一,它是对具有类别标签的数据进行预测的方式。分类涉及找到描述数据类别的模型,然后可以用来对未知数据的实例进行分类。训练数据与测试数据的概念对于分类至关重要。用于模型构建的流行分类算法以及展示分类器模型的方式包括(但不限于)决策树、逻辑回归、支持向量机和神经网络。
首先,观看麻省理工学院教授约翰·古塔格关于分类的讲座。
然后查看以下教程,每个教程都涵盖了一个基础的机器学习分类算法(多么激动人心,你的第一个机器学习算法!)。
苏珊·李在用 Python 构建逻辑回归,从头到尾中提供了关于实现最基本分类器——逻辑回归的详细概述。
完成苏珊的教程后,继续阅读拉塞尔·布朗的简明教程 用 Python 创建和可视化决策树。
作为额外内容,由于我们还在学习如何使用 Jupyter Notebook,请查看达夫尼·西迪罗普洛的用 Jupyter 小部件进行决策树的交互式可视化,以了解使用 Jupyter Notebook 进行模型可视化和调整的一些好处。
第 4 步:回归
回归与分类类似,都是另一种主流的监督学习形式,对预测分析很有用。它们的不同之处在于分类用于预测具有不同有限类别的数据,而回归用于预测连续的数值数据。作为一种监督学习形式,训练/测试数据在回归中也是一个重要概念。
首先,观看卡内基梅隆大学教授汤姆·米切尔关于回归的讲座。
然后查看并跟随 Adi Bronshtein 的教程,标题为 Python 中的简单线性回归和多重线性回归。
第 5 步:聚类
聚类用于分析不包含预先标记的类别的数据。数据实例通过最大化类内相似性和最小化不同类别之间的相似性来进行分组。这意味着聚类算法会识别并分组非常相似的实例,而不是将彼此之间相似度较低的实例进行分组。由于聚类不需要预先标记类别,因此它是一种无监督学习形式。
首先,观看 MIT 的 John Guttag 的讲座。
k-means 聚类可能是最著名的聚类算法,但并不是唯一的。存在不同的聚类方案,包括层次聚类、模糊聚类和密度聚类,还有不同的质心式聚类方法(k-means 所属的家族)。要了解更多,阅读 Jake Huneycutt 的 Python 中聚类算法简介。然后阅读 Michael J. Garbade 的 理解机器学习中的 k-means 聚类 并亲自实现 k-means。
然后查看 Gabriel Pierobon 的 DBSCAN 聚类处理 k-means 无法处理的数据形状(在 Python 中),以实现基于密度的聚类模型。
第 6 步:更多分类
现在我们已经采样过了,让我们切换回分类,查看更复杂的算法。
观看 CMU 的 Maria Florina Balcan 讨论支持向量机(SVM)的讲座视频。
阅读 Aakash Tandel 的 支持向量机——简要概述,这是对 SVM 的高级处理。接着阅读 Georgios Drakos 的 支持向量机与逻辑回归的比较。
最后,通过阅读 Jake VanderPlas 的深入了解:支持向量机,这是一段他强烈推荐的Python 数据科学手册中的摘录,来完善你对支持向量机的理解。
第 7 步:集成方法
最后,让我们了解一下集成方法。
首先,观看 Vrije University 的 Peter Bloem 讲授的视频课程。
然后阅读这两个主要是解释性文章:
最后,跟随这些教程尝试一下集成方法。
-
Python 集成方法简介,作者 Sebastian Flennerhag
-
CatBoost vs. Light GBM vs. XGBoost,作者 Alvira Swalin
-
在 Python 中使用 XGBoost,作者 Manish Pathak
希望你已经从这 7 个步骤中受益,掌握了基本的机器学习(Python)。下次加入我们时,我们将深入探讨一些更高级的话题。
相关内容:
-
掌握机器学习的 7 个步骤(Python)
-
掌握机器学习的 7 个额外步骤(Python)
-
掌握数据准备的 7 个步骤(Python)
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
更多相关主题
掌握数据清理和预处理技术的 7 个步骤
原文:
www.kdnuggets.com/2023/08/7-steps-mastering-data-cleaning-preprocessing-techniques.html
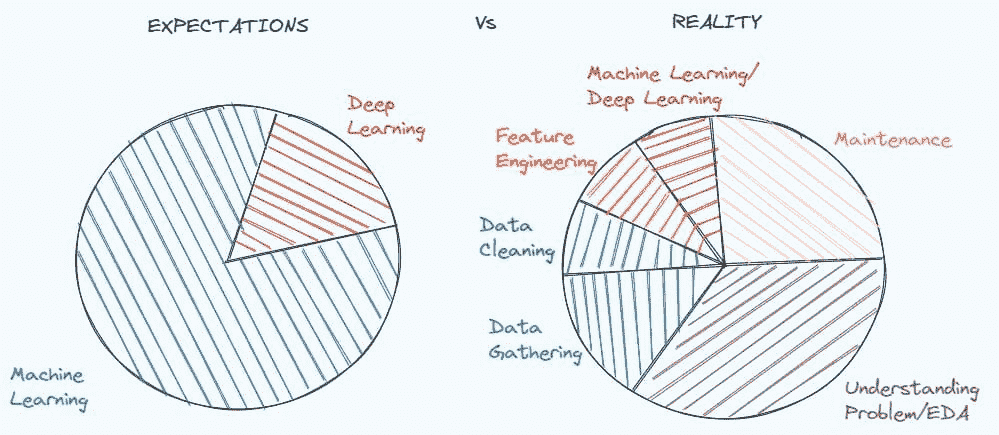
插图作者。灵感来源于 Dr. Angshuman Ghosh 的 MEME
掌握数据清理和预处理技术对解决许多数据科学项目至关重要。一个简单的演示可以在 meme 中找到,该 meme 展示了学生在进入数据科学领域之前对工作的期望与数据科学家的实际工作的对比。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
我们往往会在没有具体经验之前对职位进行理想化,但现实总是与我们真正的期待不同。当处理实际问题时,数据没有文档,并且数据集非常脏乱。首先,你必须深入挖掘问题,理解你缺少了什么线索以及可以提取哪些信息。
在理解问题后,你需要为你的机器学习模型准备数据集,因为数据在初始状态下从来是不够的。在这篇文章中,我将展示七个步骤,这些步骤可以帮助你进行数据集的预处理和清理。
第一步:探索性数据分析
数据科学项目的第一步是探索性分析,这有助于理解问题并在下一步做出决策。这一步往往被跳过,但这是最糟糕的错误,因为你之后会花费很多时间去找出模型为何出现错误或未达到预期的原因。
根据我作为数据科学家的经验,我将探索性分析分为三个部分:
-
检查数据集的结构、统计信息、缺失值、重复值以及分类变量的唯一值
-
了解变量的含义和分布
-
研究变量之间的关系
为了分析数据集的组织方式,可以使用以下 Pandas 方法:
df.head()
df.info()
df.isnull().sum()
df.duplicated().sum()
df.describe([x*0.1 for x in range(10)])
for c in list(df):
print(df[c].value_counts())
在试图理解变量时,将分析分为两个部分:数值特征和分类特征是有用的。首先,我们可以关注那些可以通过直方图和箱线图可视化的数值特征。之后,轮到分类变量。如果这是一个二分类问题,最好先查看类别是否平衡。接下来,我们可以集中关注其余的分类变量,使用条形图进行分析。最后,我们可以检查每对数值变量之间的相关性。其他有用的数据可视化方法可以是散点图和箱线图,用于观察数值变量和分类变量之间的关系。
步骤 2:处理缺失值
在第一步中,我们已经检查了每个变量是否存在缺失值。如果存在缺失值,我们需要了解如何处理这些问题。最简单的方法是删除包含 NaN 值的变量或行,但我们最好避免这样做,因为我们可能会丢失有助于机器学习模型解决问题的有用信息。
如果我们处理的是数值变量,有几种方法可以填补这些空值。最常用的方法是用该特征的均值/中位数来填补缺失值:
df['age'].fillna(df['age'].mean())
df['age'].fillna(df['age'].median())
另一种方法是用按组插补的方法来替代空值:
df['price'].fillna(df.group('type_building')['price'].transform('mean'),
inplace=True)
如果数值特征和分类特征之间存在强关系,这可能是一个更好的选择。
同样,我们可以根据该变量的众数来填补分类特征的缺失值:
df['type_building'].fillna(df['type_building'].mode()[0])
步骤 3:处理重复项和异常值
如果数据集中存在重复项,最好删除重复的行:
df = df.drop_duplicates()
决定如何处理重复项比较简单,但处理异常值可能会具有挑战性。你需要问自己“是否删除异常值?”。
如果你确定异常值只提供噪声信息,则应该删除异常值。例如,数据集中包含两个人的年龄为 200 年,而年龄范围在 0 到 90 之间。在这种情况下,最好删除这两个数据点。
df = df[df.Age<=90]
不幸的是,大多数时候,删除异常值可能会导致丢失重要的信息。最有效的方法是对数值特征应用对数变换。
我在最近的经验中发现的另一种技术是剪辑方法。在这种技术中,你选择上界和下界,这可以是第 0.1 百分位数和第 0.9 百分位数。低于下界的特征值将被替换为下界值,而高于上界的变量值将被替换为上界值。
for c in columns_with_outliers:
transform= 'clipped_'+ c
lower_limit = df[c].quantile(0.10)
upper_limit = df[c].quantile(0.90)
df[transform] = df[c].clip(lower_limit, upper_limit, axis = 0)
步骤 4:对分类特征进行编码
下一阶段是将分类特征转换为数值特征。实际上,机器学习模型只能处理数字,不能处理字符串。
在进一步讨论之前,你应该区分两种类别变量:非序数变量和序数变量。
非序数变量的例子包括性别、婚姻状况、工作类型。因此,如果变量没有遵循顺序,则为非序数变量,与序数特征不同。序数变量的一个例子可以是教育水平,如“童年”、“小学”、“中学”和“大学”,以及收入水平,如“低”、“中”等“高”。
当我们处理非序数变量时,One-Hot 编码是最常用的技术,用于将这些变量转换为数值型。
在这种方法中,我们为每个类别特征的水平创建一个新的二进制变量。当水平名称与变量值相同时,该二进制变量的值为 1,否则为 0。
from sklearn.preprocessing import OneHotEncoder
data_to_encode = df[cols_to_encode]
encoder = OneHotEncoder(dtype='int')
encoded_data = encoder.fit_transform(data_to_encode)
dummy_variables = encoder.get_feature_names_out(cols_to_encode)
encoded_df = pd.DataFrame(encoded_data.toarray(), columns=encoder.get_feature_names_out(cols_to_encode))
final_df = pd.concat([df.drop(cols_to_encode, axis=1), encoded_df], axis=1)
当变量是序数时,最常用的技术是序数编码,它将类别变量的唯一值转换为遵循顺序的整数。例如,收入的水平“低”、“中”和“高”将分别编码为 0、1 和 2。
from sklearn.preprocessing import OrdinalEncoder
data_to_encode = df[cols_to_encode]
encoder = OrdinalEncoder(dtype='int')
encoded_data = encoder.fit_transform(data_to_encode)
encoded_df = pd.DataFrame(encoded_data.toarray(), columns=["Income"])
final_df = pd.concat([df.drop(cols_to_encode, axis=1), encoded_df], axis=1)
如果你想进一步探索其他可能的编码技术,可以查看这里,以了解替代方案。
第五步:将数据集拆分为训练集和测试集
现在是时候将数据集划分为三个固定的子集:最常见的选择是将 60%用于训练,20%用于验证,20%用于测试。随着数据量的增长,训练集的比例增加,而验证集和测试集的比例减少。
拥有三个子集很重要,因为训练集用于训练模型,而验证集和测试集可以用来了解模型在新数据上的表现。
要拆分数据集,我们可以使用 scikit-learn 的 train_test_split:
from sklearn.model_selection import train_test_split
X = final_df.drop(['y'],axis=1)
y = final_df['y']
train_idx, test_idx,_,_ = train_test_split(X.index,y,test_size=0.2,random_state=123)
train_idx, val_idx,_,_ = train_test_split(train_idx,y_train,test_size=0.2,random_state=123)
df_train = final_df[final_df.index.isin(train_idx)]
df_test = final_df[final_df.index.isin(test_idx)]
df_val = final_df[final_df.index.isin(val_idx)]
如果我们处理的是分类问题且类别不平衡,最好设置分层参数,以确保训练集、验证集和测试集中类别的比例相同。
train_idx, test_idx,y_train,_ = train_test_split(X.index,y,test_size=0.2,stratify=y,random_state=123)
train_idx, val_idx,_,_ = train_test_split(train_idx,y_train,test_size=0.2,stratify=y_train,random_state=123)
这种分层交叉验证还帮助确保三个子集中的目标变量百分比相同,从而提供更准确的模型性能。
第六步:特征缩放
一些机器学习模型,如线性回归、逻辑回归、KNN、支持向量机和神经网络,需要特征缩放。特征缩放只是帮助变量处于相同范围内,并不改变分布。
最流行的三种特征缩放技术是归一化、标准化和鲁棒缩放。
归一化,也称为最小-最大缩放,将变量的值映射到 0 和 1 之间。这是通过从特征值中减去特征的最小值,然后除以该特征的最大值和最小值之间的差值来实现的。
from sklearn.preprocessing import MinMaxScaler
sc=MinMaxScaler()
df_train[numeric_features]=sc.fit_transform(df_train[numeric_features])
df_test[numeric_features]=sc.transform(df_test[numeric_features])
df_val[numeric_features]=sc.transform(df_val[numeric_features])
另一种常见方法是标准化,它将列的值重新缩放以符合标准正态分布的特性,即均值为 0,方差为 1。
from sklearn.preprocessing import StandardScaler
sc=StandardScaler()
df_train[numeric_features]=sc.fit_transform(df_train[numeric_features])
df_test[numeric_features]=sc.transform(df_test[numeric_features])
df_val[numeric_features]=sc.transform(df_val[numeric_features])
如果特征包含无法移除的离群值,建议使用鲁棒缩放方法,该方法根据鲁棒统计量(中位数、第一四分位数和第三四分位数)对特征值进行缩放。缩放值通过从原始值中减去中位数,然后除以四分位距(即特征的第 75 和第 25 四分位数之间的差异)来获得。
from sklearn.preprocessing import RobustScaler
sc=RobustScaler()
df_train[numeric_features]=sc.fit_transform(df_train[numeric_features])
df_test[numeric_features]=sc.transform(df_test[numeric_features])
df_val[numeric_features]=sc.transform(df_val[numeric_features])
通常,最好基于训练集计算统计数据,然后用这些统计数据来缩放训练、验证和测试集上的值。这是因为我们假设只有训练数据,然后希望在新数据上测试我们的模型,新数据应具有与训练集相似的分布。
第 7 步:处理不平衡数据
这一步骤仅在我们处理分类问题并发现类别不平衡时才包含。
如果类别之间存在细微差异,例如类别 1 包含 40% 的观察数据,类别 2 包含剩余的 60%,我们无需应用过采样或欠采样技术来改变某一类别的样本数量。我们只需避免关注准确率,因为准确率只有在数据集平衡时才是一个良好的衡量指标,我们应该只关注评估指标,如精确度、召回率和F1 分数。
但有可能正类的数据点比例非常低(0.2),与负类(0.8)相比。机器学习可能在样本较少的类别上表现不佳,从而导致无法解决任务。
为了克服这个问题,有两种可能性:对多数类进行欠采样和对少数类进行过采样。欠采样通过随机移除一些数据点来减少样本数量,而过采样通过从较少出现的类别中随机添加数据点来增加少数类的观察数量。imblearn 可以用少量代码实现数据集平衡:
# undersampling
from imblearn.over_sampling import RandomUnderSampler,RandomOverSampler
undersample = RandomUnderSampler(sampling_strategy='majority')
X_train, y_train = undersample.fit_resample(df_train.drop(['y'],axis=1),df_train['y'])
# oversampling
oversample = RandomOverSampler(sampling_strategy='minority')
X_train, y_train = oversample.fit_resample(df_train.drop(['y'],axis=1),df_train['y'])
然而,有时删除或重复一些观察可能在提高模型性能方面效果不佳。更好的方法是创建新的人工数据点在少数类中。为解决此问题,提出了一种技术 SMOTE,它以生成在代表性较少的类别中的合成记录而闻名。像 KNN 一样,其思路是基于特定距离 t 确定属于少数类的观察的 k 个最近邻。然后在这些 k 个最近邻之间的随机位置生成新点。这个过程将持续创建新点,直到数据集完全平衡。
from imblearn.over_sampling import SMOTE
resampler = SMOTE(random_state=123)
X_train, y_train = resampler.fit_resample(df_train.drop(['y'],axis=1),df_train['y'])
我应该强调,这些方法应仅应用于重新采样训练集。我们希望我们的机器模型以稳健的方式学习,然后,我们可以将其应用于对新数据进行预测。
最终想法
我希望你发现这个全面的教程对你有帮助。开始我们的第一个数据科学项目时,如果不掌握所有这些技巧,可能会很困难。你可以在 这里 找到我的所有代码。
当然,还有其他方法我在文章中没有涵盖,但我更愿意专注于最受欢迎和知名的方法。你还有其他建议吗?如果有有见地的建议,请在评论中留言。
有用的资源:
尤金尼亚·安内洛 目前是意大利帕多瓦大学信息工程系的研究员。她的研究项目集中在持续学习与异常检测的结合上。
更多相关主题
7 步掌握 Python 数据准备
原文:
www.kdnuggets.com/2017/06/7-steps-mastering-data-preparation-python.html/2
第 4 步:处理异常值
这不是关于制定处理数据中异常值策略的教程;在建模时,有时包括异常值是合适的,有时则不合适(无论有人怎样告诉你)。这取决于情况,没人能对你的情况是否属于 A 列或 B 列做出笼统的断言。
你能找到异常值吗?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
一些关于处理异常值的讨论:
-
异常值:删除还是保留,The Analysis Factor
-
从数据中去除异常值可以吗?,Stack Exchange
异常值可能是由于数据收集不当,也可能是真正的异常数据。这是两种不同的情况,必须以不同的方式处理,因此没有“一刀切”的建议,类似于处理缺失值。以上来自 Analysis Factor 文章的一个特别有价值的见解如下:
一个选项是尝试变换。平方根和对数变换都能拉拢高值。如果异常值是因变量,这可以使假设工作得更好;如果异常值是自变量,这可以减少单个点的影响。
我们将决定是否在数据集中保留异常值留给你。然而,如果你的模型确实需要以某种方式处理异常值,这里有一些讨论方法:
-
处理异常值的 3 种方法,作者:Alberto Quesada
-
使用标准差去除 Python 中的异常值,作者:Punit Jajodia
-
使用百分位数在 Pandas DataFrame 中去除异常值,Stack Overflow
第 5 步:处理不平衡数据
那么,如果你的数据集在其他方面都很强大——没有缺失值和异常值——但由 2 个类别组成:一个包含 95%的实例,另一个仅包含 5%?或者更糟——99.8%对 0.2%?
如果是这样,那么你的数据集是不平衡的,至少在类别方面是这样。这可能会带来问题,我相信这些问题不需要指出。但也无需急于抛弃数据;当然有处理这种情况的策略。
请注意,虽然这可能不真正是数据准备任务,但这种数据集特征会在数据准备阶段早期显现出来(EDA 的重要性),并且这种数据的有效性可以在这一准备阶段初步评估。
首先,看看 Tom Fawcett 对如何处理的讨论:
- 从不平衡类中学习,作者 Tom Fawcett
接下来,看看关于处理类别不平衡的技术的讨论:
- 处理不平衡数据的 7 种技术,作者 Ye Wu & Rick Radewagen

识别和处理不平衡是很重要的。
对于为什么我们可能会遇到不平衡数据的一个很好的解释,以及为什么在某些领域中我们可能比其他领域更频繁地遇到这种情况(来自上述链接的《处理不平衡数据的 7 种技术》):
这些领域使用的数据通常包含不到 1%的稀有但“有趣”的事件(例如,信用卡欺诈者,用户点击广告或损坏的服务器扫描其网络)。然而,大多数机器学习算法在处理不平衡数据集时效果不好。以下七种技术可以帮助你训练分类器以检测异常类别。
第 6 步:数据变换
维基百科将 数据变换 定义为:
在统计学中,数据变换是将确定性的数学函数应用于数据集中的每一个点 —— 即,每个数据点 zi 被替换为变换后的值 y[i] = f(z[i]),其中 f 是一个函数。通常应用变换是为了使数据更符合要应用的统计推断程序的假设,或改善图表的可解释性或外观。
数据变换是数据准备中最重要的方面之一,并且比大多数其他方面更需要技巧。当数据中出现缺失值时,它们通常很容易被发现,并可以通过上述常见方法(至少从表面上看)处理,或者通过在领域中获得的深入见解使用更复杂的措施。然而,何时需要数据变换——更不用说所需的变换类型——往往不那么容易识别。
存在大量的转换;与其尝试概括何时以及为什么转换有用,不如看几个具体的转换,以便更好地掌握它们。
Scikit-learn 文档中的这一概述提供了对一些最重要的预处理转换的理由,即标准化、归一化和二值化(还有一些其他的转换):
- 数据预处理,Scikit-learn 文档

独热编码转换的示例结果。
独热编码“将分类特征转换为更适合分类和回归算法的格式”(取自下文的第一个链接)。参见对独热转换的讨论以及使用 Pandas 的方法:
-
什么是独热编码,它在数据科学中什么时候使用?,Håkon Hapnes Strand 在 Quora 的回答
-
如何在 Python 中进行独热编码?,Stack Overflow
对数分布转换在“你假设一个非线性模型形式,但可以转换为线性模型”的情况下可能会很有用(取自下文)。稍微阅读一下这种被低估的转换类型:
- 什么时候(以及为什么)应该对分布(数据)取对数?,Stack Exchange
如上所述,取决于数据和需求,可以进行多种转换。我希望未来能更详细地探讨数据转换,并在那时进行更深入的讨论。
请注意,整个讨论完全有意跳过了特征选择的提及,原因是:它在这篇更广泛的讨论中值得比简单几句话更多的关注。即将发布的特征选择专门指南将在完成后链接到这里。
第 7 步:最后润色与前进
好的,你的数据是“干净”的。就我们而言,这意味着你此时拥有一个有效且可用的 Pandas DataFrame。但你该如何处理它呢?
如果你想直接将数据输入到机器学习算法中以尝试构建模型,你可能需要将数据以更合适的表示形式准备。在 Python 生态系统中,这通常是 numpy ndarray(或矩阵)。你可以查看以下内容,以获取一些初步的想法(从基础的角度):
- 将 Pandas DataFrame 转换为数组并评估多元线性回归模型,Stack Overflow
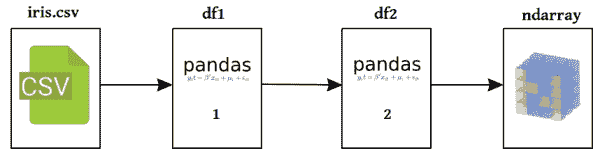
非常简单的数据准备过程。
一旦你在 Python 中获得了适合机器学习的干净数据,为什么不看看以下这对文章呢,它们旨在涵盖你现在已经准备好的领域:
-
掌握 Python 机器学习的 7 个步骤,作者 Matthew Mayo
-
掌握 Python 机器学习的 7 个额外步骤,作者 Matthew Mayo
如果你不想马上进入建模阶段怎么办?或者,即使你想进入建模阶段,但你希望将数据输出到更适合你情况的存储形式呢?以下是有关 Pandas DataFrame 存储的一些信息:
-
将 Pandas DataFrame 写入 MySQL,Stack Overflow
-
快速使用 Pandas 处理 HDF5,作者 Giuseppe Vettigli
不要忘记,在继续之前,还有一些数据集特定和相关的注意事项,包括(特别是?)将数据集拆分为训练集和测试集,这是所有机器学习任务都适用的过程:
-
Numpy: 如何将数据集(数组)拆分/分区为训练集和测试集,例如用于交叉验证?,Stack Overflow
-
有没有 Python 函数可以将数据拆分为训练集、交叉验证集和测试集?,Quora 上 Harizo Rajaona 的回答
作为纯粹的惩罚,以下是一些关于数据准备的额外见解:
-
在 Python 中整理数据,作者 Jean-Nicholas Hould
-
数据科学实践:Kaggle 指南 第三部分 – 清理数据,作者 Brett Romero
-
从零开始的 Python 机器学习工作流 第一部分:数据准备,作者 Matthew Mayo
相关内容:
-
理解 NoSQL 数据库的 7 个步骤
-
掌握数据科学 SQL 的 7 个步骤
-
理解深度学习的 7 个步骤
更多相关内容
使用敏捷方法掌握数据科学项目管理的 7 个步骤
原文:
www.kdnuggets.com/2023/07/7-steps-mastering-data-science-project-management-agile.html

图片来源:作者
什么是敏捷?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织中的 IT
敏捷方法论是在 2001 年初,当 17 人聚在一起讨论软件开发的未来时发现的。它基于 4 个核心价值观和 12 条原则。
它在快节奏、不断变化的科技行业中非常受欢迎,这很好地反映了它的特点。作为一种完美的数据科学项目管理方法,它允许团队成员在项目增长的过程中不断审查项目要求,来回调整,并进行更多的沟通。该模型随着用户导向的结果而发展,节省了时间、金钱和精力。
在数据科学生命周期的不同阶段做出关于更改的决定,比在项目完成后再做决定要好。让我们谈谈你可以采取的 2 个步骤,以启动你的敏捷数据科学项目管理。
Scrum
一种敏捷方法的例子是Scrum。Scrum 方法使用一个框架,通过一系列的价值观、原则和实践来帮助团队创建结构。
例如,使用 Scrum,数据科学项目可以将其较大的项目拆分为一系列较小的项目。这些迷你项目将被称为 sprint,并包括 sprint 计划,以定义目标、要求、责任等。
为什么这有益?因为它帮助团队的不同成员对自己的任务负责,以完成一个 sprint。已完成的 sprints 在业务的最终目标中扮演重要角色,例如推出新产品。
员工通过能够发现解决挑战的方案来专注于为最终用户提供价值,这些挑战可能会在 sprints 中遇到。
Scrum 工具包括:
看板
Kanban 是敏捷方法的另一个示例。它是一个源自日本库存管理系统的流行框架。Kanban 向员工展示当前和待办任务的可视状态。每个任务,也称为 Kanban 卡片,都显示在 Kanban 状态板上,代表其完成的生命周期。
例如,你可以设置生命周期列,如进行中的工作、已开发、已测试、已完成等。这可以帮助数据科学家更早地识别瓶颈,并减少进行中的任务量。
Kanban 被认为是数据科学领域非常流行的框架,许多数据爱好者采用这种方法。它是一个轻量级的过程,具有可视化的特性,以改善工作流程并轻松识别挑战。这是一种易于实施的方法,数据科学家对于“你的下一个任务是什么?”的反应很好,而不是“你在下一个冲刺中有哪些任务?”。
Kanban 的工具包括:
先走后跑
敏捷方法的第一个初始步骤是计划。计划,计划,再计划!我无法强调这一点的重要性,这就是为什么重要的是学会先走后跑。拥有像 Monday 或 Jira 这样的工具很好,但如果不进行计划,你将无济于事。
召开讨论会议,以确保你和你的员工都在同一页面上,每个人都理解需要做什么,并且每个人心中都有相同的计划,这是至关重要的。缺乏规划可能导致错过截止日期、缺乏动力和员工生产力下降,以及项目不可行。
一旦每个人都在同一平台上,你就可以继续进行下一步。
作为团队设计
下一阶段是设计你的项目,这基于你与员工的讨论。你团队在规划讨论中涵盖的所有方面将帮助你设计一个有效的解决方案来解决当前任务。
在这个阶段,沟通是你最大的工具。你团队的其他成员可能有不同的工作方式或任务划分方法。因此,作为团队成员,你有责任设计一个满足所有人需求的解决方案,基于他们的工作方法、可用性等。
在这个阶段,你可以分配谁负责项目的哪个方面。这会给员工一种重要感,从而提高他们的生产力。一旦员工被赋予了任务的一部分的所有权,他们有责任确保该部分任务顺利进行,按时完成,一切按照计划进行。
发展你的解决方案
这就是你讨论、规划和设计显现的地方。你可能认为在这个阶段你不需要再与团队成员沟通,可以直接开始工作。这是不对的。这个阶段沟通尤为重要。每周站会很重要,它帮助所有员工保持信息同步,并相互交流。
在你为当前任务开发解决方案的过程中,你将遇到挑战或瓶颈,这些可能会让人感到非常压倒,并改变你的时间表以及其他人完成任务的能力。沟通每一个成功和失败的步骤对保持所有成员的了解很重要,也让其他人能够给予你帮助。
测试,测试,测试
如果你正在分析数据、创建算法或为业务生产新产品,你将需要对其进行测试。然后再测试一次,甚至要多测试几次。
确保你在数据科学项目中尽可能准确没有任何坏处。不仅团队成员投入了时间和精力在这个解决方案上,如果它准确并解决了问题,那就更好了。
最后你想做的事情就是反复回去,因为你的结果没有像第一次那样准确。
部署
数据科学项目中最自豪的时刻之一。与团队成员沟通,将最新的增量投入生产,在它可供实际用户使用之前。
数据科学家需要将自己置于一种情境中,仿佛接下来要将解决方案交给客户一样。对整个数据科学项目及其高低起伏进行审查、文档记录、修正和讨论是很重要的。
因为说实话,类似的项目将会出现,与其从头开始,不如利用你以前项目的文档作为你下一个项目的垫脚石。正是这些审查和文档将在讨论/规划下一个数据科学项目的第一步中被使用。
总结
确保你拥有成功进行敏捷数据科学项目管理所需的正确工具是一回事。但能够从每个阶段中获得最大收益则更为重要。沟通很重要,你现在已经知道这一点了,因为我提到了无数次。但为了获得回报,你必须努力工作,这需要大量的沟通。
Nisha Arya 是一名数据科学家、自由技术作家和 KDnuggets 的社区经理。她特别感兴趣于提供数据科学职业建议或教程及理论知识。她还希望探索人工智能如何有益于人类寿命的不同方式。作为一名热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助引导他人。
更多相关内容
掌握 Python 中的中级机器学习的 7 个步骤 — 2019 年版
原文:
www.kdnuggets.com/2019/06/7-steps-mastering-intermediate-machine-learning-python.html
评论
你对使用 Python 学习更多关于机器学习的内容感兴趣吗?
我最近写了掌握基础机器学习的 7 个步骤(2019 年版),这是对我之前写的一对文章的更新尝试(掌握机器学习的 7 个步骤和掌握机器学习的 7 个额外步骤),这对文章现在已经有些过时了。是时候在“基础”文章的基础上添加一套步骤,用于学习 Python 中的“中级”机器学习了。
我们谈论的“中级”是相对而言的,因此不要期望在阅读完这篇文章后成为研究级别的机器学习工程师。学习路径旨在那些对编程、计算机科学概念和/或机器学习有一定理解的人,他们希望能够使用流行的 Python 库实现机器学习算法,以构建自己的机器学习模型。

这篇文章以及之前的文章,将利用现有的教程、视频和各种专家的工作,因此任何包含的感谢应当致敬于他们。
相较于为每个主题步骤(例如降维)提供大量资源,我尝试选择一两个高质量的教程,并附上一段初步描述相关理论、数学或直觉的可及视频(如适用)。
这些步骤涉及机器学习算法、特征选择与工程的重要性、模型训练、迁移学习等。
所以,拿上一杯饮料,坐下来阅读该系列的第二部分,并开始通过这 7 个步骤掌握 Python 中的中级机器学习。
1. 入门
这可能不言而喻,但你的第一步应该是回顾该系列中的上一篇文章,掌握基础机器学习的 7 个步骤(2019 年版)。
保持谷歌的机器学习词汇表随手可用,或在之前快速查看一下,也许是个好主意。
每个以下 Python 库的官方文档中的快速入门指南也是很好的参考,这些库用于处理机器学习和其他数据分析任务:
现在,进入有趣的部分。
2. 特征选择
特征是来自输入数据集的变量,可用于帮助进行预测。然而,并非所有特征都是平等的,有时需要使用原始特征来构造新的特征,这些新特征可能在预测中更有用。
阅读 Raheel Shaikh 的Python 机器学习中的特征选择技术,了解特征选择技术的方法,以及它们在 Python 中的应用。
接下来,阅读Beware Default Random Forest Importances,作者为 Terence Parr、Kerem Turgutlu、Christopher Csiszar 和 Jeremy Howard,这篇文章深入探讨了“[t]scikit-learn 的随机森林特征重要性和 R 的默认随机森林特征重要性策略存在偏差”的原因。随机森林是一种常见的特征选择方法,基于其重要性进行预测,这篇文章提供了为什么盲目使用任何特定方法并不是一个好主意的见解。
最后,查看这篇文章,逐步特征选择:Python 中的实际示例,该文章展示了逐步特征选择的实现,这是一个有纪律的统计方法。
3. 特征工程
有时,所有原始特征或其中的一些子集可以直接用于预测。其他时候,可以从现有特征中构造新的特征,以促进更好的预测。
以一个简单的日期为例。这个日期本身可能对预测没有用。然而,知道这个日期是工作日还是周末,或者是否是法定假日,可能会非常有帮助。利用这个原始日期来创建一个新的、更有用的特征是特征工程的一个简单例子。
首先,阅读Google 机器学习速成课程中的特征工程文章,以获取该主题的概述。
接着阅读 Will Koehrsen 的特征工程:推动机器学习的力量,获取更多关于此主题的信息,将 Python 引入其中。
最后,阅读Python 中的自动特征工程,这也是 Will Koehrsen 的作品,介绍了如何自动化和外包特征工程到算法中。
4. 进一步的分类
接下来,让我们转向一些分类算法。本系列的第一部分讨论了逻辑回归、决策树和支持向量机。这次我们将关注另一对常用且经过时间考验的技术:k-最近邻和朴素贝叶斯。
首先,观看这段来自 StatQuest 的短视频,了解什么是 k-最近邻(k-NN),以及它的分类方法。
然后阅读 Sam Grassi 的文章在 Python 中构建和改进 K-最近邻算法,首先使用 Scikit-learn 的 k-NN 实现进行分类,然后在 Python 中从头实现 k-NN 以进行比较。
在了解了 k-NN 之后,我们将注意力转向朴素贝叶斯。观看这段来自 StatQuest 的视频,以建立对该算法的直觉。
接下来是实际操作。通过马丁·穆勒的朴素贝叶斯分类与 Sklearn教程,学习如何使用 Scikit-learn 的实现来构建分类器。
5. 模型训练与选择
继续进行模型训练和选择。
这里有两个主要点。首先,没有经过训练的模型,我们无法进行预测。其次,在多个模型中,我们需要选择“最佳”模型。
我们将首先查看训练、测试和验证集的概念。阅读 Tarang Shah 的文章关于机器学习中的训练、验证和测试集,介绍了这些概念。
然后观看这段来自 StatQuest 的视频,了解相关的交叉验证概念。
以上概念对模型训练至关重要。但当我们有多个模型时,如何选择它们之间的最佳模型呢?
首先,这段来自 StatQuest 的视频解释了混淆矩阵是什么,它如何帮助总结机器学习分类器的结果。
更深入地了解这个主题,请观看另一部关于模型敏感性和特异性的 StatQuest 视频。
之后,阅读有关机器学习分类指标的内容,并了解如何在 Python 中使用 Scikit-learn 实际实现这些指标。Andrew Long 的这篇文章每个人的数据科学性能指标介绍了这些指标,因此从这里开始。
然后,继续阅读 Andrew Long 的另一篇文章在 Python 中使用 Scikit-Learn 理解数据科学分类指标,了解分类指标如何在 Python 中实现。
最后,通过阅读 Alvira Swalin 的选择正确的评估机器学习模型的指标 – 第一部分和选择正确的评估机器学习模型的指标 – 第二部分,了解如何在这些资源中选择评估指标的过程。
6. 维度减少
什么是维度减少?既然你问了,可以看看斯坦福大学的 Jure Leskovec 解释这个问题的视频。
最常用的维度减少形式之一是主成分分析(PCA),这是一种将可能相关的变量数据集转换为线性无关变量的变换;这些线性无关变量被称为主成分。观看这个来自 StatQuest 的视频,更详细地了解 PCA。
现在看看 Zichen Wang 的这篇文章用 numpy 解释 PCA 和 SVD,演示了如何在 Python 中使用 Numpy 从头实现 PCA——以及奇异值分解(SVD),另一种流行的维度减少技术。
最后,Jake VanderPlas 的书《Python 数据科学手册》中的深入分析:主成分分析章节详细讲解了如何使用 Scikit-learn 实现 PCA。
7. 迁移学习
迁移学习是将模型用于与其最初训练任务不同的任务。当然,迁移学习远比这简单的一句话解释要复杂得多,但它传达了基本概念。
观看这个来自 Kaggle 的视频,更好地描述了迁移学习是什么以及它可以做什么。
然后阅读塞巴斯蒂安·鲁德(Sebastian Ruder)对迁移学习概念的概述,迁移学习 - 机器学习的下一个前沿。这篇文章已有几年历史,尽管迁移学习发展迅速,但所涵盖的概念今天仍然有效。
为了看到迁移学习的价值,我们来看一下如何使用 Keras 深度学习库创建的神经网络进行图像分类(这是其最大的成就之一)。如果您不熟悉 Keras,可以查看这份快速入门指南,Keras 深度学习简介,由吉尔伯特·坦纳(Gilbert Tanner)编写。
现在通过乔治·赛义夫(George Seif)编写的教程,将迁移学习应用于实际使用,使用 Keras 进行图像分类的迁移学习。这应该足以展示迁移学习的强大功能,不仅在图像分类中,而且在自然语言处理任务及其他领域也同样有效。
希望这些掌握中级机器学习的 7 个步骤对你有所帮助。请加入我们下一期,我们将讨论一些更高级的主题。
相关:
-
掌握基础机器学习的 7 个步骤 — 2019 版
-
掌握数据科学 SQL 的 7 个步骤 — 2019 版
-
掌握数据准备的 7 个步骤
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT 工作
更多相关内容
2022 年掌握 Python 机器学习的 7 个步骤
原文:
www.kdnuggets.com/2022/02/7-steps-mastering-machine-learning-python.html

图片由编辑提供
引言
我们的 3 大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
你是否正在尝试从零开始自学机器学习,但不知道从哪里开始?或者你可能已经参加了一两门在线课程,但在学习过程中遇到阻碍,不知道如何继续。
两年前我也处于类似的境地。我在大学花费了超过$25K,但仍然经验不足,未为就业市场做好准备。
我经过了大量的反复试验才制定出机器学习路线图。我观看了在线课程、YouTube 视频,并下载了无数电子书。我在线获得的知识超越了我在大学学到的所有知识。而且最棒的是——它的成本仅是大学费用的一小部分!
在这篇文章中,我将尝试将我多年来使用的所有资源浓缩成 7 个步骤,你可以按照这些步骤自学机器学习。
步骤 1:学习机器学习编程
在深入机器学习之前,你需要具备一定的编程知识。大多数数据科学家使用 Python 或 R 来构建机器学习模型。
我从 Python 开始,因为它是一种通用编程语言,需求量高于 R。
Python 技能也可以转移到不同领域,因此,如果将来你想扩展到网页开发或数据分析等领域,转换会更容易。
2022 年完整 Python 训练营课程由 Jose Portilla 主讲,如果你是编程新手,这是一个很好的 Python 入门课程。该课程在 Udemy 上提供,他们经常有促销活动,可以将课程价格降到$10. 购买之前等促销活动是个不错的主意。
参加这门课程的另一个好处是它完全通过 Jupyter Notebook 进行教学。这是数据科学家最常用的 Python IDE,Jose 会让你熟悉这个界面,这样你就不需要花时间自己去学习了。
如果你希望寻找免费的课程替代选项,以下是我的建议:
-
Jupyter Notebook 教程:简介、设置和操作指南 — 这门课程将帮助你熟悉 Jupyter 的界面。
-
学习 Python:初学者完整课程 [教程] — 这门课程将带你了解 Python 编程的基础知识,如变量、数据类型、函数、条件语句和循环。它使用 Pycharm IDE 教学,但你也可以使用 Jupyter Notebook 代替。
-
Python for Everybody — 这是一本可以免费下载的电子书。这本书与其他在线 Python 教程不同,它通过解决数据问题来介绍编程概念,使其成为数据科学有志者的理想读物。
一旦你掌握了 Python 基础,就开始将这些概念应用于解决问题。尽管完成了三年的计算机科学本科学位,但我从未真正学会编程,因为我从未将所学概念应用于实际问题。
因此,我对如何编程有了理论上的理解,但缺乏将问题分解并编写解决方案的能力。
一个帮助我提高解决问题能力的工具是 HackerRank。HackerRank 是一个提供各种编程挑战的平台,难度级别各异。每天尝试解决至少 2-3 道 HackerRank 问题。从最简单的开始,然后逐渐提高难度。
如果你在解决问题时遇到困难,可以随时参考其他人的解决方案,以了解他们是如何解决的。然后,尝试用自己的代码复制他们的思路。
随着你不断进行这些练习题,你将开始对自己的编码能力充满信心。
然后你可以进入下一步——学习如何在 Python 中处理数据。
步骤 2:Python 中的数据收集和预处理
现在你已经知道如何用 Python 编程了,你可以开始学习数据收集和预处理。
我发现大多数数据科学行业的初学者有一个共性,那就是他们直接跳入掌握机器学习的阶段。他们没有过多关注数据收集或分析,这本身就是一项独立的技能。
因此,当被要求执行如寻找第三方数据或为机器学习建模准备数据等任务时,他们在工作中常常会遇到困难。
这里有一些我推荐的课程来完成上述任务。我还会提供一些免费的替代选项,你可以选择去学习。
-
数据收集 — 许多公司需要外部数据收集来支持他们的数据科学工作流程。你可以使用 API 来收集这些数据,或者根据你被分配的任务类型从零开始创建网页抓取器。由 365datascience 提供的 网页抓取和 API 基础 课程将教你如何在 Python 中收集网页数据。如果你想要一个免费的替代方案,那么我建议你跟着 Python API 教程进行编码,然后是 Dataquest 上的 Python 网页抓取 教程。
-
数据预处理 — 你收集的数据可能会以许多不同的格式出现。你需要能够将这些数据转换成机器学习模型可以接受的格式。这通常是通过使用一个叫做 Pandas 的 Python 库来完成的,在开始学习 ML 建模之前,掌握这个库是个好主意。你可以从 365datascience 提供的这个 使用 Pandas 进行数据预处理 课程开始。如果你想要一个替代课程,你可以观看一个免费的 YouTube 视频,Python 数据预处理简介。
第 3 步:在 Python 中进行数据分析
接下来,开始学习使用 Python 进行数据分析是一个好主意。数据分析是识别大量数据中的模式并发现有价值的见解的过程。
在创建任何机器学习模型之前,你需要了解你所处理的数据。探究数据集中不同变量之间的关系。一个变量可以告诉你关于另一个变量什么信息?你能基于在数据集中发现的见解提供推荐吗?
我建议你参加由 Jose Portilla 主讲的《Python 数据分析与可视化学习》课程,以提高你在这一领域的技能。
在 Python 中,有四个主要用于数据分析的库:Pandas、Numpy、Matplotlib 和 Seaborn。Jose 的课程将教你使用所有这些库进行数据分析。这个课程的最佳部分是他包括了与现实世界中的例子类似的示例项目。
如果你在寻找免费的替代方案,你可以参加 FreeCodeCamp 的 使用 Python 进行数据分析 课程,或者下载 使用 Python 进行探索性数据分析 电子书。
图片来自 Scikit-learn 文档
第四步:使用 Python 进行机器学习
最后,你可以开始学习机器学习了!我总是建议采用自上而下的方法来学习机器学习。
与其学习理论和机器学习模型的深入工作,不如首先采用实现优先的方法。
首先学习如何使用 Python 包来构建预测模型。在真实世界的数据集上运行模型并观察结果。一旦你对机器学习在实践中的表现有了了解,就可以深入研究每个算法的工作原理。
Python for Data Science and Machine Learning是一个很好的课程,你可以通过它学习在 Python 中实现机器学习模型。同样,这也是由 Jose Portilla 讲授的,是我曾经参加过的最好的入门机器学习课程之一。
Jose 将带你通过整个机器学习工作流程。你将学习如何使用名为 Scikit-Learn 的库在 Python 中构建、训练和评估机器学习模型。
Jose 会让你逐渐熟悉机器学习概念,而不会深入到令人不知所措的细节中,这使得它成为你入门的一个很好的课程。
FreeCodeCamp 的Machine Learning with Scikit-Learn课程是一个很好的免费替代选择。如果你喜欢阅读,你可以下载一本免费的电子书,标题为Building Machine Learning Systems with Python。这是一本简短的动手教材,将提供大量实际例子,而不会过多涉及每个算法的工作原理。
第五步:深入学习机器学习算法
一旦你对不同的模型及其实现方式有了了解,就可以开始学习这些模型背后的底层算法。
我建议你参考两个资源:
- 统计学习—edX:本课程将提供对不同机器学习算法如何工作的深入理解。该课程对复杂数学公式的依赖较少,如果你没有数学背景,这使得课程更易于跟随。
本课程涵盖了监督学习和非监督学习的技术,如线性回归、逻辑回归、线性判别分析、K 均值聚类和层次聚类。讲师还介绍了交叉验证和正则化等概念,以避免模型过拟合——这些在处理真实世界数据集时非常有用。
本课程中的一些实用讲座是用 R 语言讲授的,你可以随意跳过这些部分,因为课程的主要价值在于其理论材料。
这门课程基于由其讲师编写的书籍《统计学习导论》。这也是一个包含 R 语言代码示例的资源。然而,我找到了一本将所有代码示例翻译为 Python 的GitHub 库,这样你可以阅读书籍并跟随 Python 示例进行编程。
以上所有资源都可以免费获取。虽然 edX 课程需要付费,但你可以申请财政援助以免除课程费用。你还可以免费下载上述提到的电子书。
- Krish Naik 的机器学习播放列表——YouTube:Krish Naik 是一位数据科学家,他在 YouTube 上创建了机器学习教程,可以免费访问。
在这个播放列表中,他有视频带领学习者了解不同机器学习模型背后的数学直觉。他解释了线性和逻辑回归的基础算法、诸如袋装和提升的概念,以及 K 均值和层次聚类等无监督学习技术。
与统计学习课程类似,他没有用复杂的数学符号来解释这些内容。相反,他用简单的英语解释每个算法的工作原理,以便不同背景的学习者容易理解。

图片来源:geralt 在 Pixabay
第 6 步:深度学习
到目前为止,以上所有资源都专注于传统的机器学习算法,或称为“浅层学习算法”。现在你可以开始学习另一类机器学习算法——深度学习。
深度学习算法能够在几乎不需要特征工程的情况下识别数据中的表示。深度学习算法能够直接从数据中识别表示并推导特征。因此,深度学习通常用于处理没有显式特征的数据,例如图像、语音和文本数据。
我建议的两个开始深度学习的资源是:
-
Andrew Ng 的深度学习专业课程——Coursera:这是学习深度学习最受欢迎的在线资源之一。Andrew Ng 将教你如何构建和训练神经网络,并将深度学习技术应用于图像和文本数据。Coursera 在你报名课程时会收取月费,完成课程后会提供证书。然而,你可以选择旁听该课程,免费获得所有课程材料。
-
《Python 深度学习》 — 这是我最喜欢的深度学习资源。这本教材将带你深入理解深度学习模型的理论和实现。作者假设读者没有数学背景,因此所有概念都用简单的英语解释。我更喜欢这本书而不是 Andrew Ng 的深度学习课程,因为它提供了更多的现实世界例子和 Python 代码。我能够将所学应用于现实项目,相比之下 Andrew Ng 的课程则更理论化。
第 7 步:项目
最后一步:构建项目!
上面提供了大量的资料。如果你不将其应用于现实项目,你会忘记所学的内容。你可以记住概念、获得认证,参加尽可能多的考试。但只有当你开始动手构建项目时,你才真正学到了东西。
这里有一篇文章,汇总了其他数据科学家创建的机器学习项目,并提供了源代码供参考。你可以跟随这些项目的代码进行一些小的修改,然后再从零开始做自己的项目。
这里还有一些资源可以帮助你入门:
自学机器学习可能耗时且令人不知所措。然而,这也是一段非常有价值的旅程。每当你学习一个新概念或解决一个你认为不可能的问题时,你距离掌握机器学习的目标就更近一步。
Natassha Selvaraj 是一位自学成才的数据科学家,对写作充满热情。你可以在LinkedIn上与她联系。
更多相关主题
精通数据科学中的 Python 的 7 个步骤
原文:
www.kdnuggets.com/2022/06/7-steps-mastering-python-data-science.html

图片来源:编辑提供的图片
尽管获得了计算机科学学位,我毕业后仍然不知道如何编码。我在大学时修的编程课程非常理论化,我无法将学到的概念应用于解决实际问题。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
我想从事数据科学和分析的职业,但缺乏获得相关工作的编程技能。
即使跟随了无数编程 YouTube 视频进行编码,我发现自己仍然无法独立完成整个项目。我根本不知道从哪里开始,解决问题时没有编码教程的帮助,我感到很挣扎。
在经历了看似无尽的 Python 学习失败后,我最终向几位在该领域有经验的程序员和数据科学家寻求建议。
我根据他们给我的建议制定了一个 Python 学习路线图,并严格遵循。在花了大约每天 7-8 小时编程三个月后,我在 Python 方面变得足够熟练,顺利获得了我的第一个数据科学实习。
在这篇文章中,我将把我用来学习 Python 的所有资源浓缩成 7 个步骤。为了确保这个路线图对每个人都能获取,我还将提供每个资源的免费替代方案。
第一步:学习基础知识
如果你是一个完全没有编程知识的初学者,首先要学习 Python 的基础知识。这包括以下概念:
-
变量
-
运算符
-
条件语句
-
控制流
-
数据结构
-
方法
-
函数
这些基础概念是每种编码语言的支柱,你必须掌握它们以建立坚实的编程基础。
为了学习 Python 编程基础,我推荐在 Udemy 上参加 2022 完整 Python 训练营。Jose Portilla 是一位专业的数据科学和编程培训师,是我学到的最优秀的讲师之一。
编程曾经是一个令我感到畏惧的学科,有时甚至让我感到不知所措,但 Jose 的教学风格让我觉得这门学科很有趣。他的课程从简单的讲解和练习开始,复杂度逐渐增加,进度也很容易跟上。
如果你想要一个免费的课程替代方案,可以跟随 FreeCodeCamp’s 在 YouTube 上的 4 小时 Python 教程来学习语言基础。补充观看 W3School’s Python 学习路径,其中包含了 FreeCodeCamp 教程中没有涉及的如读写文件等主题。
第 2 步:练习编码挑战
单靠在线课程不足以学习编程。
当我第一次尝试学习编程时,我犯了一个错误,就是不断参加在线课程。我花了很多小时跟着教程进行编码,但在尝试编写自己的程序时完全迷失了方向。
这种情况被称为 教程陷阱。许多程序员不断地参加在线课程,却无法将学到的概念付诸实践。因此,他们无法解决真实世界的编程挑战,也无法在没有教程帮助的情况下编写代码。
教程陷阱是一个可怕的境地,因此我建议只参加一到两个编程在线课程。你不需要更多的课程来学习编码基础。
在掌握了编程基础之后,开始将你的知识付诸实践。
HackerRank 是一个编码挑战平台,提供各种语言的编程问题。你可以用 Python 来解决这些挑战。从最简单的问题开始,逐步提升到更复杂的问题。
当我第一次开始在 HackerRank 上解决编码挑战问题时,即使是最简单的问题也需要我花费几个小时才能完成。随着我不断练习和复习其他程序员的解决方案,我开始变得越来越擅长,并能够更快地解决更难的问题。
这里是 HackerRank 提供的那种问题的一个例子 (这些挑战随着你不断解决它们而变得越来越困难):
HackerRank 也常被公司用来在面试过程中评估候选人,因此在该平台上练习编码挑战将使你更容易通过技术数据科学面试。
第 3 步:Python 数据分析
一旦你在像 HackerRank 这样的网站上解决编码问题,你将对 Python 编程有一个相当强的掌握。
接下来,你需要学习如何利用这些编程技能来处理和分析大量数据。Python 拥有丰富的库,可用于数据处理和分析,例如 Pandas、Matplotlib 和 Seaborn。
如果你想学习用于数据分析的 Python,你可以参加 Jose Portilla 的 Python 数据分析与可视化 课程。
另一种选择是 Datacamp 提供的《Python 探索性数据分析》课程。这个课程的第一个模块可以免费学习,因此你可以在购买之前先试用一下。
如果你想要一个完全免费的课程,可以查看 FreeCodeCamp 的 Python 数据分析 4 小时 YouTube 教程。
第 4 步:用于机器学习的 Python
作为数据科学家,你必须了解如何使用像 Scikit-Learn 这样的 Python 包来构建和解释预测算法的性能。
《Python 机器学习基础》是 Datacamp 提供的一门优秀课程,你可以通过它学习在 Python 中实现 ML 模型。
本程序将指导你如何使用 Scikit-Learn 库构建、训练和评估监督学习和无监督学习的 ML 算法。此外,你还将学习关于线性分类器,如支持向量机及其内部工作原理的知识。
最后,本课程将教你如何使用 Keras 框架在 Python 中实现深度学习算法。
如果你想要一个免费的替代课程,我建议跟随 Krish Naik 的 Python 机器学习 播放列表进行编码。这个播放列表包含了上述 Datacamp 课程中涉及的所有概念,尽管顺序和教学风格可能略有不同。
第 5 步:用于数据收集的 Python
许多公司依赖公开的外部数据来构建机器学习项目。作为数据科学家,你可能需要从在线来源收集数据,例如政府报告、社会情绪和评论。
要实现这一点,你需要能够从网页上自动提取大量数据——无论是通过 API 还是网页抓取。Python 提供了内置库,如 BeautifulSoup,可以帮助你轻松地收集和解析外部数据。
如果你想学习如何构建自动化网页抓取工具,Datacamp 的 Python 网页抓取 课程是一个很好的起点。这个课程的免费替代方案是 FreeCodeCamp 的 使用 BeautifulSoup 的网页抓取 教程。
你还可以跟随我不久前创建的 这个 网页抓取教程进行编码。
第 6 步:项目
完成上述所有步骤后,你应该对 Python 编程有足够的掌握,能够开始创建自己的项目。
构建一个端到端的项目是提升你编程技能的最佳方式之一。如果你没有技术学位,项目将让招聘经理对你的编程能力充满信心。
许多没有技术背景的数据科学 aspirants 通过展示他们的项目成功转行进入该领域。
建立展示多种技能的项目是非常重要的。
数据科学家的角色通常涉及使用编程工具来收集数据、进行探索性分析和可视化,以及构建预测模型。
确保创建各种项目,以展示你在所有这些领域的能力,这将帮助你在只具备一两个领域技能的候选人中脱颖而出。
如果你想用 Python 构建数据科学项目但不确定从哪里开始,可以阅读这篇文章,获取可以让你的简历脱颖而出的项目创意。
第七步:建立一个引人注目的作品集
现在你已经学会了 Python 并创建了展示你技能的项目,你可以建立一个作品集来集中展示你所有的工作。
我建议建立一个作品集网站并在线托管。这样,人们可以通过一个链接看到你所有的工作。
当我申请我的第一个数据科学实习时,我只是给招聘经理发了一个指向我作品集网站的链接。尽管那个网站当时还不完整,只展示了三个项目,但它足够打动了他,让我获得了面试机会——甚至没有询问我的学位、成绩或技术背景。
我使用 GitHub 页面创建了我的作品集,你可以阅读我如何做到这一点的这里.
如果你想要一个更简单的无代码替代方案,你可以使用 Wix 或 WordPress 等网站构建器来建立你的作品集网站。
记住,实践成就完美。
学习编码可能会令人不知所措,这是许多数据科学 aspirants 在尝试进入该领域时遇到的障碍。然而,经验丰富的程序员和新手程序员之间只有一个区别,那就是实践。随着你不断构建项目和尝试编程挑战,你的编码技能将不断提高。
Natassha Selvaraj 是一位自学成才的数据科学家,热爱写作。你可以通过LinkedIn与她联系。
更多相关内容
掌握 SQL 数据科学的 7 个步骤 — 2019 年版
原文:
www.kdnuggets.com/2019/05/7-steps-mastering-sql-data-science-2019-edition.html
评论
什么是结构化查询语言(SQL),为什么它对数据管理如此重要?
一段时间前,我写了 掌握 SQL 数据科学的 7 个步骤,这篇文章试图将一些现有的优质免费材料汇总成一个简短但有用的速成课程。然而,包含的材料现在已经过时,许多链接也不再有效,这也是合情合理的,因为原文已经存在几年了。由于近期有人要求更新版本,我认为现在是重新审视这个概念并制定一个新的学习路径来掌握 SQL 数据科学的好时机。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
这一次,我们的目标是再次制定通往 SQL 精通的路径。然而,我们要相对看待“精通”一词,不要期望在学习材料完成后就能达到数据库专家的水平。学习路径旨在帮助那些对数据库、编程、计算机科学概念和/或数据管理有一定理解的人,能够使用 SQL 来管理和查询自己的数据,并扩展到更大的系统中。

与每个主题步骤(如视图和连接)拥有大量资源不同,我尝试选择一两个优质的阅读资源,以及一个覆盖特定主题的可访问视频。
所以,拿起你喜欢的饮料,放松一下,让我们在这 7 个步骤中开始掌握 SQL 数据科学。
步骤 1:关系型数据库基础
我们从文章开始时提出的问题开始:什么是结构化查询语言(SQL),为什么它对数据管理如此重要?
很简单,SQL 是用于管理和查询关系型数据库管理系统(RDBMS)中的数据的语言。
SQL 和 RDBMS(关系数据库管理系统)的术语如此交织,以至于它们经常被混淆,有时是初学者的误解,但通常只是出于方便,SQL 这个术语被用来区分关系系统和非关系数据库系统,后者通常被统称为 "NoSQL"。然而,SQL 技能在非 RDBMS 系统上也并非浪费;所有顶级数据处理框架都在其架构上实现了一些 SQL。
首先,让我们观看和听取 Carnegie Mellon University 的 Andy Pavlo 教授讨论数据库、数据库系统、关系模型、关系代数及相关概念。这是一个很好的起点。
第二步:SQL 概述
现在我们都熟悉了关系范式,我们将重点转向 SQL。
我们将以以下方式接触 SQL 的初步内容。首先观看下面的视频,标题为“SQL - 简要回顾”,由 Charles Germany 制作,快速了解 SQL 的起源以及通过几个简短的示例了解语法。与视频下方的资源和示例一样,不必担心完全理解语法,只需了解 SQL 在做什么、可以用于什么以及它的样子。
接下来,看看这两个简短的教程:SQL 基础查询(来自 Data Carpentry)如其标题所示进行讲解,而 SQL 命令列表(来自 Codecademy)则提供了 SQL 命令及用法的更广泛概述。特别是第二个资源,未来可能会成为一个便捷的参考。其中一些命令在后续步骤中会更详细地讲解,因此,不必担心一开始就理解所有内容。同时,这些初步的示例非常直观,有助于你的理解。
最后,为了准备下一步,启动一个 SQL 环境。你可能不想输入每一个遇到的 SQL 语句,但运行一个 SQL 解释器是很有意义的。我建议在本地安装 SQLite;它是一个简单但功能强大的 SQL 安装程序。
第三步:选择、插入、更新
虽然 SQL 可以用于执行各种数据管理任务,但使用 SELECT 查询数据库、使用 INSERT 插入记录以及使用 UPDATE 更新现有记录是一些最常用的命令,是实际使用 SQL 的好起点。
阅读并完成以下初步练习,所有这些都由 SQL Course 提供。
本教程,来自Arachnoid的MySQL 教程 1:概述、表、查询,涵盖了 SQL 基础知识以及初学者到中级查询,并对我们迄今所见的内容进行了全面复习,甚至更多。它从 MySQL 的角度呈现,但其中的内容并不局限于该平台的 SQL 实现。
第 4 步:创建、删除、删除
我们的第二组命令包括用于创建和删除表以及删除记录的命令。通过理解这一不断增长的命令集合,许多可以称之为常规数据管理和查询的操作突然变得可实现(当然需要实践)。
通过SQL 课程再次尝试以下教程。
第 5 步:视图和连接
进入一些稍微高级的 SQL 主题。
首先,我们来看视图,它可以被看作是由查询结果填充的虚拟表,在包括应用开发、数据安全和简化数据共享等多个不同场景中都很有用。观看这段来自 Socratica 的视频以获得见解。
连接有不同的类型,而在学习 SQL 时,理清它们可能是更复杂的主题之一。这实际上更能证明 SQL 的易用性,而不是学习连接的实际难度。通过这段 Socratica 视频获得对连接的更好理解。
查看来自Code Project的SQL 连接的可视化表示。
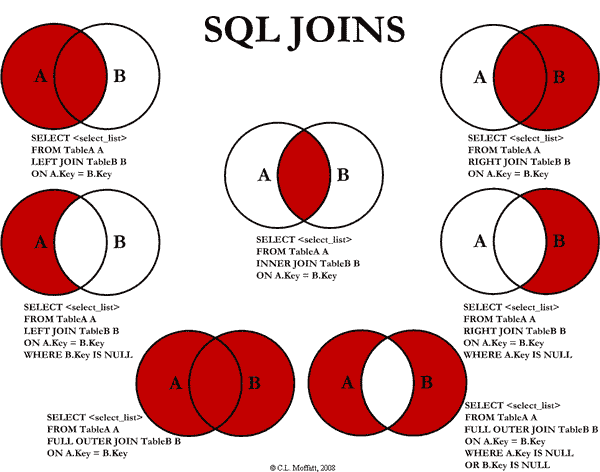
本教程,来自Arachnoid的MySQL 教程 2:视图和连接,涵盖了视图和连接。它也从 MySQL 的角度呈现,但其中的内容并不局限于该平台的 SQL 实现。
第 6 步:高级 SQL
高级 SQL 可能意味着很多不同的东西,因此我们将缩小范围。
首先观看来自卡内基梅隆大学的 Andy Pavlo 教授的讲座,他讨论了聚合、独特聚合、分组、筛选、字符串操作、日期和时间操作、嵌套查询、表表达式等内容。
在了解了 SQL 的这些方面后,将注意力转向存储过程这一重要概念,并查看来自MySQL Tutorial的MySQL 存储过程教程。
第 7 步:查询优化
一旦你知道如何编写查询,你将希望学习如何优化它们,以便在结果和运行时间上都达到最佳。这在大数据库上的复杂查询中尤其重要。
观看卡内基梅隆大学的安迪·帕夫洛教授讲解这个主题的视频讲座。
然后查看来自初学者 SQL 教程的SQL 调优或 SQL 优化 教程。
希望到目前为止,你已经学到了足够的 SQL,能够将自己视为数据科学领域的“专家”。但不要止步于此;在线上还有很多免费的优质资源,可以用来在这基础上进一步提升。你永远无法学够 SQL,正如许多其他技能一样,实践是强化的关键。
相关:
-
用 Python 掌握基础机器学习的 7 个步骤 — 2019 版
-
SQL 案例研究:帮助初创公司 CEO 管理数据
-
SQL 还是非 SQL:这是一个问题!
更多相关内容
掌握数据科学所需的 SQL 的 7 个步骤
原文:
www.kdnuggets.com/2022/04/7-steps-mastering-sql-data-science.html

为什么你应该学习 SQL 来成为一名数据科学家?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
掌握 SQL 是申请大多数数据科学职位的前提。事实上,根据这篇 2021 年的分析,SQL 是数据岗位上需求最旺盛的技术技能,其次是 Python 和机器学习。
然而,数据科学课程和训练营并不强调教学生处理大量数据。大多数数据科学学习材料的重点是预测建模,完成这些程序的候选人往往没有查询和操作数据库的能力。
当我开始我的第一次数据科学实习时,我很兴奋地期待在第一天就开始构建机器学习算法。然而,我被分配的任务与我预期的完全不同。我必须从数据库中查询数据,清理数据,并进行分析以回答一个业务问题。
在公司工作的第一周后,我意识到许多组织中的业务用例根本不需要预测建模来解决。通常,一个简单的 SQL 查询就足以根据利益相关者的需求来筛选和汇总数据。
起初,我不能像我的同事一样迅速完成这些任务,因为我对 SQL 不熟悉,因此花了更多时间在数据提取和预处理上。幸运的是,由于这只是一次实习,期望值并不高,我能够随着时间的推移提高我的查询技能。
我能给有志于数据科学的人的最大建议就是学习 SQL。这是大多数数据科学学习提供者常常忽视的一项技能,但它的重要性不亚于机器学习建模。
即使是那些需要你构建复杂预测算法的任务,掌握 SQL 也是必须的。大多数组织中的数据管道以关系数据库的形式存储,你需要从这些数据库中提取数据并进行预处理,才能开始构建机器学习模型。
如果你缺乏 SQL 知识,即使你在机器学习方面非常专业,你也会在数据准备和分析上花费比预期更多的时间。
在这篇文章中,我将带你了解掌握 SQL 所需的 7 个步骤,以适用于任何数据科学或分析角色。
如何学习数据科学的 SQL
第 1 步:SQL 基础
作为一名数据科学家,你将从数据库中读取数据并进行分析以适应你的使用场景。通常,你不需要创建或操作现有的数据库 — 公司有专门的团队来完成这些任务。
如果你完全没有 SQL 知识,先从这个教程开始,了解什么是 RDBMS。
然后,观看 Lucidchart 的这个YouTube 视频,学习如何创建和读取 ER 图。ER 图是一种结构化图表,用于可视化数据库中的表以及它们之间的关系。作为数据科学家,当从不同的表中提取数据时,你通常需要参考 ER 图以理解表之间的互动关系。
之后,你可以立即开始学习如何在 SQL 中查询数据。我强烈推荐你按照 W3Schools 的这些教程来学习以下命令 — SELECT、IN、WHERE、BETWEEN、AND、OR、NOT、LIKE。
这些是一些最简单的 SQL 命令,用于查询和筛选数据库表。一旦你熟悉了这些命令,就可以开始学习CASE语句。它们与任何编程语言中的 if-else 命令非常相似。
第 2 步:聚合
SQL 聚合函数用于对多个表值执行计算并返回单一结果。SQL 有 5 个聚合函数 — SUM、COUNT、AVG、MIN、MAX。
第 3 步:分组和排序
接下来,了解GROUPBY和ORDERBY命令。这些命令在你需要以不同的分组查看数据或按特定顺序排序行时特别有用。
学习HAVING子句也是很有用的,因为它在上述命令中经常使用。
第 4 步:连接
上述所有查询只能用于从单个表中提取数据。如果你想要结合多个表中的数据,你需要学习 JOIN 命令。
这里是 SQL 连接的可视化表示:
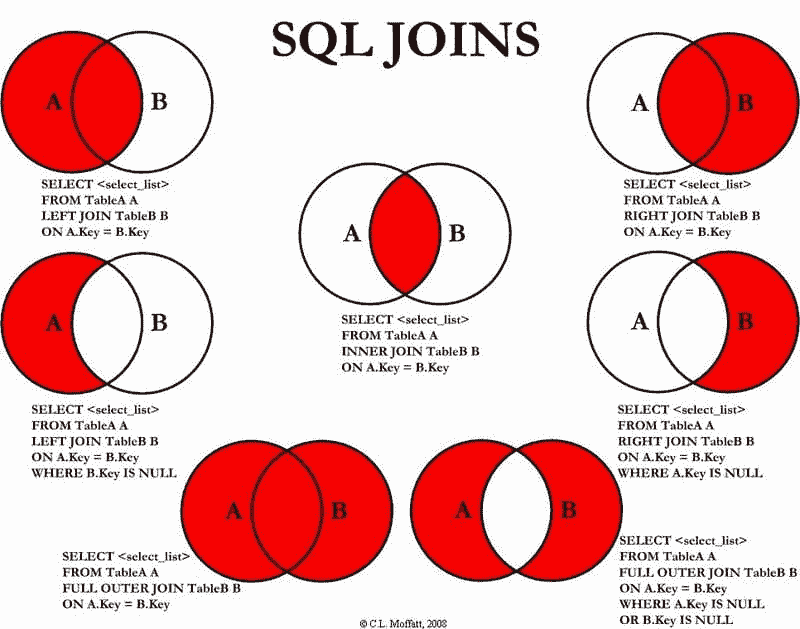
图片来源:CodeProject
Edureka 在 YouTube 上发布了一个名为 SQL Joins Tutorial For Beginners 的免费视频,你可以跟随它进行学习。你也可以选择在 这个 W3Schools 关于不同连接的教程中进行编程练习。完成后,学习 SQL UNION 运算符也是很有用的。
步骤 5:子查询
子查询也称为 SQL 中的嵌套查询,用于当你想要的结果需要多个查询时。在嵌套查询中,内层命令的结果用作主查询的输入。
这开始可能看起来有些混乱,但一旦你习惯了,它实际上是一个相当直观的概念。
如果你想学习如何在 SQL 中使用子查询,可以阅读 这篇 W3Resources 的文章。
步骤 6:用 SQL 解决业务问题
作为数据科学家,你为组织带来的价值在于你使用数据解决业务问题的能力。当利益相关者给出用例时,你需要能够将这一需求转化为技术分析。
例如,你的经理要求提供一个客户列表,以根据他们的在线浏览行为来确定不同的行业目标。作为数据科学家,你需要将这个任务拆分为以下步骤:
-
查看这些客户访问的网站,并根据他们的网站访问情况按行业进行分类。这可以通过 SQL 中的一些基本筛选和分组来完成。
-
然后,你可以查看网站访问的最近性和频率,以识别这些行业中潜力大的客户。这可能需要一些额外的数据预处理、筛选以及可能的排名。
-
最后,你可以将按行业分组的筛选后输出数据交给你的经理。如果你想丰富这些客户类别,你甚至可以在这些数据基础上构建一个聚类算法,以识别高潜力的个人。
上面的例子很简单,但它捕捉了数据科学家在面对业务问题陈述时的思维过程。这是一种随着时间和实践而发展的技能。
Udemy 有一门 SQL Business Intelligence 课程,旨在帮助学生使用 SQL 支持更好的决策。该课程的第一部分涵盖了 SQL 的基础知识(连接、运算符、子查询、聚合等),第二部分则重点讲解将所学知识应用于解决业务问题。
步骤 7:窗口函数
窗口函数是一个稍微高级的 SQL 话题。它们使用户能够对结果集的分区执行计算。要学习 SQL 窗口函数,请观看这个 YouTube 视频。
练习,练习,再练习
学习以上列出的所有概念将帮助你建立 SQL 编程的坚实基础。然而,要解决实际用例,你需要大量练习。
HackerRank 和 PGExercises 是两个可以帮助你实现这一点的平台。它们提供了一系列从初学者到高级的 SQL 问题,解决这些问题将使你对语言有更深入的理解。
像 HackerRank 这样的站点通常被招聘经理用来评估候选人在不同编程语言上的能力,解决它们的 SQL 问题将增加你在数据科学面试中脱颖而出的机会。
Natassha Selvaraj 是一位自学成才的数据科学家,热衷于写作。你可以通过LinkedIn与她联系。
更多相关话题
7 步骤获得你的第一个数据科学工作
原文:
www.kdnuggets.com/7-steps-to-landing-your-first-data-science-job
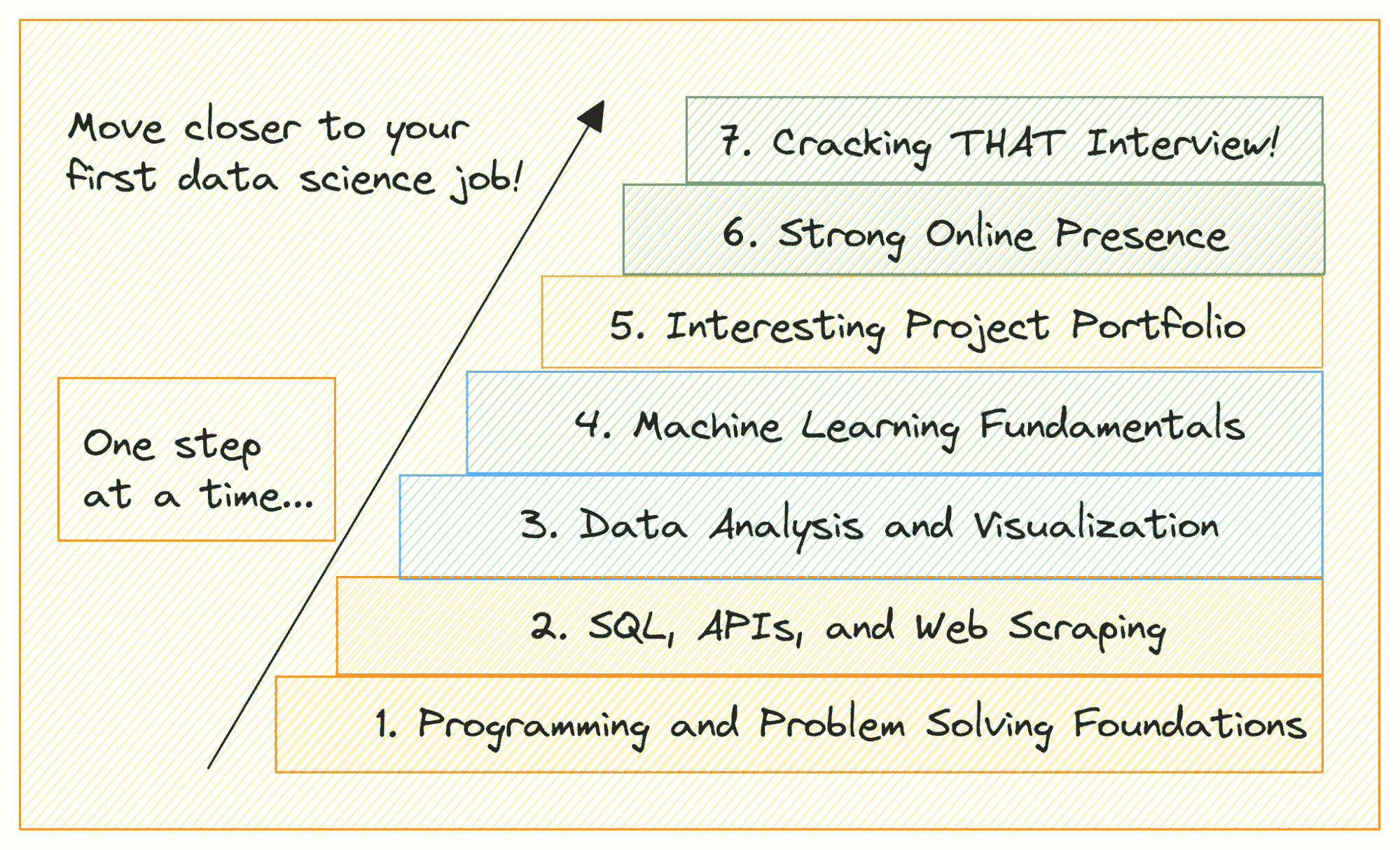
作者提供的图像
你是否希望转行到数据科学领域?如果是的话,你可能已经报名参加了在线课程、训练营等。也许你还收藏了一份自学数据科学的路线图,计划逐步学习。那么,这份指南将如何帮助你呢?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT 部门
如果你决定追求数据科学职业,你必须为之努力。别无他法。此外,获得数据科学职位远不止于学习数据科学概念。即使在学习过程中,你需要掌握的概念、工具、技术和库也可能让人不堪重负。
本文并非点击诱饵,因此不会夸大其词地承诺在 X 天内帮助你获得数据科学工作。相反,我们提供了一个全面的数据科学求职流程,包括:
-
学习数据科学概念
-
通过项目展示你的技术专长
-
自我营销作为专业人士
-
战略性准备面试
我们希望这份指南对你有所帮助!
1. 学习编程和问题解决基础
要进入数据科学领域,你首先应该打下坚实的编程和问题解决基础。我建议你将 Python 作为第一门编程语言来学习。
通过简洁易懂的语法和许多优秀的学习资源,你可以在几个小时内掌握 Python。之后,你可以花几周时间专注于以下编程基础知识:
-
内置数据结构
-
循环
-
函数
-
类和对象
-
函数式编程基础
-
Pythonic 特性:推导式和生成器
如果你想快速入门 Python,请参加 这门 Python 讲座,这是哈佛 CS50 课程的一部分。更多深入学习,请查看 哈佛的 Python 入门课程。
为了练习,你可以通过上面的 Python 课程中的项目,并且在Hackerrank上解决一些问题。
此外,在这个阶段,你应该能够在命令行工作。了解如何创建和使用Python 虚拟环境也是很有帮助的。
2. 学习 SQL、API 和网页抓取
无论你申请的是哪个数据角色,学习和掌握 SQL 都是非常重要的。你可以从以下主题开始:
-
基本 SQL 查询
-
条件过滤
-
连接操作
-
子查询
-
SQL 字符串函数
与 Python 一样,SQL 也需要专门的练习,有几个有用的 SQL 练习平台。如果你喜欢通过教程学习,可以查看Mode Analytics 的 SQL 教程。
现在你已经掌握了 Python 的基础,可以在此基础上学习使用 Python 进行网页抓取。作为一名数据专业人士,你应该能够熟练进行数据收集。具体来说,就是以编程方式抓取网页数据并解析来自 API 的 JSON 响应。
在熟悉了基本的 HTTP 方法之后,你可以通过学习以下内容来提升你的 Python 技能:
-
使用Requests 库进行 HTTP 请求
-
使用 BeautifulSoup Python 库进行网页抓取;学习 Scrapy 也会很有帮助
-
使用内置的json 模块解析 API 的 JSON 响应
此时,你可以尝试编写一个简单的网页抓取项目。保持简单且相关,以便你有兴趣。例如,你可以抓取你在 Amazon 上的购物数据,以便之后进行分析。这只是一个示例;你可以做一个你感兴趣的项目。
3. 学习数据分析和可视化
在你的数据科学学习旅程中,此时你应该对 Python 和 SQL 都感到自如。掌握了这些基础技能后,你可以继续分析和可视化数据,以便更好地理解数据:
-
对于使用 Python 进行数据分析,你可以学习使用 pandas 库。如果你寻找 pandas 的逐步学习指南,可以查看掌握数据清洗的 7 个步骤。
-
对于数据可视化,你可以学习如何使用 matplotlib 和 seaborn 库。
这个免费的Python 数据分析认证课程来自 freeCodeCamp,涵盖了你需要了解的所有基本 Python 数据科学库。你还将编写一些简单的项目代码。
在这里,你再次有机会构建一个项目:尝试使用网络抓取收集数据;使用 pandas 进行分析;学习像Streamlit这样的库来创建一个交互式仪表板以展示你分析的结果。
4. 探索机器学习
通过编程和数据分析,你可以构建有趣的项目。但学习机器学习基础知识也是很有帮助的。
即使你没有时间更详细地了解算法的工作原理,也要关注:
-
了解算法的高级概述以及
-
使用 scikit-learn 构建模型
这个scikit-learn 速成课程将帮助你迅速掌握使用 scikit-learn 构建机器学习模型的方法。一旦你学会了如何使用 scikit-learn 构建基线模型,你还应该关注以下内容,以帮助你构建更好的模型:
-
数据预处理
-
特征工程
-
超参数调优
现在再次是构建项目的时候了。你可以从简单的贷款违约预测项目开始,逐渐过渡到员工离职预测、市场篮子分析等。
5. 建立项目作品集
在之前的步骤中,我们确实谈到了构建项目以巩固学习。然而,大多数有抱负的数据专业人士往往更关注学习,而忽视了建立有趣项目作品集的这一步——应用部分。
无论你学到了多少(和知道多少),如果没有展示你能力的项目,是无法说服招聘人员你的专业技能的。
由于创建一个简单的页面来展示项目需要大量的前端编码,大多数学习者不会建立作品集。你可能使用 GitHub 存储库—带有详细的 README 文件—来跟踪项目代码的变化。然而,为了构建一个展示你项目的数据科学作品集,你可以查看其他免费的平台,例如 Kaggle 和 DataSciencePortfol.io。
根据你希望进入的数据科学领域选择你的项目:医疗保健、金融科技、供应链等等。这样你可以展示你的兴趣和能力。或者,你可以尝试构建几个项目来找出你感兴趣的领域。
6. 建立强大的在线存在
在线被发现并展示你的经验对求职过程有帮助,尤其是在你职业生涯的早期阶段。这就是为什么建立强大的在线存在是我们的下一步。
为此,最佳路径是建立你自己的个人网站,包括:
-
一个信息丰富的“关于”页面和联系信息
-
一个展示你撰写的文章和教程的博客
-
一个包含你参与项目详细信息的项目页面
拥有个人网站总是更受欢迎。但至少你应该在求职过程中拥有 LinkedIn 个人资料和 Twitter(现在称为 X)账户。
在 Twitter 上,添加相关的标题,并积极参与技术和职业建议的讨论。在 LinkedIn 上,确保你的个人资料尽可能完整和准确:
-
更新你的标题以反映你的专业技能
-
填写经验和教育部分
-
在“项目”部分,添加你的项目并附上简短描述。同时链接到这些项目
-
将你发表的文章添加到你的个人资料中
在这些平台上主动进行网络交流。同时定期分享你的学习进展。如果你不想现在就开始写自己的博客,可以尝试在社交媒体上写作,以提高你的写作技巧。
你可以在 LinkedIn 上发布关于你刚学到的数据科学概念或你正在进行的项目的帖子或文章。或者在推特上分享你正在学习的内容、你在过程中犯的错误以及你从中学到的东西。
注意,这一步骤并不是完全独立于构建你的项目组合的。在提升技术技能和构建项目(是的,你的项目组合)之外,你还需要建立你的在线存在感。这样,招聘人员才能找到你,并在寻找候选人时向你提供相关机会。
7. 战略性准备;破解面试
要破解数据科学面试,你需要在测试你解决问题技能的编码环节以及核心技术面试中都表现出色,在技术面试中你应该能够展示你对数据科学的理解。
我建议你至少参加一个关于数据结构和算法的入门课程,然后在Hackerrank和Leetcode上解决问题。如果时间紧迫,你可以解决Blind 75问题集。这个问题集包含了数组、动态规划、字符串、图等所有主要概念的问题。
在所有数据科学面试中,你至少会有一个 SQL 环节。你也可以在 Hackerrank 和 Leetcode 上练习 SQL。此外,你还可以在StrataScratch和DataLemur等平台上解决以前问过的面试问题。
一旦你破解了这些编码面试并进入下一轮,你应该能够展示你在数据科学方面的熟练程度。你应该对你的项目有详细了解。在解释你所做的项目时,你还应该能够解释:
-
你试图解决的业务问题
-
你为什么以这种方式处理问题
-
这种方法的好处和原因
不仅从算法和概念的角度准备,还要从理解业务目标和解决业务问题的角度准备。
总结
这就是全部内容了。在本指南中,我们讨论了获得第一个数据科学职位的不同步骤。
我们还讨论了将自己作为专业人士和潜在候选人的重要性,以及学习数据科学概念。在涉及学习数据科学概念的步骤中,我们还查看了有用的资源。
祝你在数据科学的旅程中好运!
Bala Priya C是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过编写教程、使用指南、意见文章等,学习并分享她的知识给开发者社区。Bala 还创建了引人入胜的资源概述和编码教程。
了解更多相关话题
数据讲述的 7 个步骤
原文:
www.kdnuggets.com/7-steps-to-master-the-art-of-data-storytelling

作者提供的图片 | Midjourney & Freepik
如果数据可以被转化为信息丰富的视觉表现形式,那为什么不利用数据来阐述和传达一个故事呢?本教程强调了数据讲述的重要性,并通过七个步骤解释了如何成为一名熟练的数据讲述者。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 部门
数据讲述是有效利用数据讲述一个历史的艺术和过程,该过程向预期受众传达信息和见解。它是一种有价值的工具,用于传达数据分析结果,使数据驱动的见解对更广泛的受众更具可及性,或以更吸引人的方式传播数据。
没有唯一的方式来进行数据讲述,但以下步骤构成了一种方法,如果按顺序进行,将最大化成功讲述关于数据的有洞察力、吸引人且令人信服的故事的机会。
作者提供的图片
第一步:定义你想讲述的故事
这一步为一个引人入胜的数据故事奠定了基础。从确定通过数据传达的关键消息开始。识别你希望受众掌握的主要见解,并指明通向这些见解的明确方向。
假设你正在分析一个时尚零售公司的销售数据。你故事的意图可能是展示季节性趋势并突出高峰期。这个清晰的定义将帮助你提取出不同季节对销售的影响,并据此制定营销策略。
第二步:了解你的受众
了解你的受众是谁,他们的背景、兴趣和听取你意见的动机是什么,对于打造一个量身定制的引人入胜的数据故事至关重要。
例如,对于时尚零售销售故事,你的受众可能包括公司的高层管理人员和营销部门,他们需要有关销售的见解,以优化促销活动和库存管理。这一档案分析帮助你确定合适的可操作见解,并调整围绕数据使用的语言,使其对决策者具有相关性和可访问性。
第 3 步:收集适当的数据
确保你准确全面地收集故事所需的数据,捕捉所有必要的细节,以符合其目标并支持你的叙述。收集的数据应当是相关的、可靠的,并且足够支持你的核心信息。
收集过去四年的销售数据,并按季节、产品类别和地点分类,这有助于发现有洞察力的销售模式,从而支持你的叙述。
第 4 步:理解数据
分析收集到的数据以揭示趋势,例如假期销售高峰或夏季开始时泳装销售的激增。识别异常现象,如意外的销售下降,并比较各年度的月销售数据。这个分析过程对于突出关键洞察至关重要,例如找出推出某些促销活动的最佳时机。
第 5 步:构建你的叙述
你的分析是否揭示了关于季节性销售趋势的有趣事实?那么,是时候围绕这些事实构建一个扎实的叙述了。这是一个关键步骤,你需要认真考虑以下几点来构建一个引人入胜且信息丰富的故事:
-
介绍背景,强调数据背后的重要事实,例如描述理解销售波动的重要性。
-
突出描述涉及的关键元素或参与者,例如畅销产品和商店。
-
描述发现的挑战,例如销售数据的不一致或意外的销售下降,并提出解决方案,如在关键时期开展有针对性的活动。
第 6 步:可视化你的数据
没有视觉支持的数据故事是不完整的。确定合适的图表类型来可视化数据中的事实或属性:折线图用于展示随时间变化的销售趋势,柱状图用于比较不同产品类别的销售,或者热力图用于指出销售最好的地点。
视觉效果是数据故事的灵魂:使复杂的数据变得易于理解,并通过帮助观众把握关键信息来对其产生积极影响。
第 7 步:向观众传达故事
最后,是时候通过一份全面的报告和一个包含第 6 步制作的可视化内容的互动仪表板向你的观众展示你的数据故事了。
记得在这里回到第 2 步(了解你的观众),使用清晰、简洁的语言,调整你的展示以满足他们的需求,并强调可操作的洞察。
在时尚零售的场景中,你可能会想通过概述利用高峰销售期的策略和应对意外销售下降的措施来结束。这将使你的观众在离开时感到有能力根据你刚刚传达的见解来提升他们的营销和销售策略。
总结
通过实施这七个步骤来打造引人入胜的数据故事,你将能够将原始数据转化为有洞察力的故事,推动参与度,赋能你的观众做出明智的决策,并最终实现成功的结果。
伊万·帕洛马雷斯·卡拉索萨 是人工智能、机器学习、深度学习和大语言模型领域的领导者、作家、演讲者和顾问。他训练和指导他人将人工智能应用于现实世界。
更多相关内容
掌握数据清理的 7 个步骤,使用 Python 和 Pandas
原文:
www.kdnuggets.com/7-steps-to-mastering-data-cleaning-with-python-and-pandas

图片由作者提供
Pandas 是最广泛使用的 Python 数据分析和操作库。但从源头读取的数据通常需要一系列的数据清理步骤——在你能够分析数据以获得洞察、回答业务问题或构建机器学习模型之前。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
本指南将数据清理过程拆解为 7 个实际步骤。我们将创建一个示例数据集并逐步完成数据清理。
让我们开始吧!
创建一个示例 DataFrame
在开始实际的数据清理步骤之前,让我们创建一个包含员工记录的 pandas 数据框。我们将使用 Faker 进行合成数据生成。因此,请先安装它:
!pip install Faker
如果你愿意,可以跟随相同的示例,也可以使用你选择的数据集。这里是生成 1000 条记录的代码:
import pandas as pd
from faker import Faker
import random
# Initialize Faker to generate synthetic data
fake = Faker()
# Set seed for reproducibility
Faker.seed(42)
# Generate synthetic data
data = []
for _ in range(1000):
data.append({
'Name': fake.name(),
'Age': random.randint(18, 70),
'Email': fake.email(),
'Phone': fake.phone_number(),
'Address': fake.address(),
'Salary': random.randint(20000, 150000),
'Join_Date': fake.date_this_decade(),
'Employment_Status': random.choice(['Full-Time', 'Part-Time', 'Contract']),
'Department': random.choice(['IT', 'Engineering','Finance', 'HR', 'Marketing'])
})
让我们稍微调整一下这个数据框,以引入缺失值、重复记录、异常值等:
# Let's tweak the records a bit!
# Introduce missing values
for i in random.sample(range(len(data)), 50):
data[i]['Email'] = None
# Introduce duplicate records
data.extend(random.sample(data, 100))
# Introduce outliers
for i in random.sample(range(len(data)), 20):
data[i]['Salary'] = random.randint(200000, 500000)
现在让我们创建一个包含这些记录的数据框:
# Create dataframe
df = pd.DataFrame(data)
请注意,我们设置的是 Faker 的种子,而不是随机模块。因此,你生成的记录会有一些随机性。
第一步:理解数据
第 0 步始终是理解你要解决的业务问题/问题。一旦你知道这一点,你就可以开始处理你已读入 pandas 数据框的数据。
但在你对数据集进行任何有意义的操作之前,首先获取数据集的总体概述是很重要的。这包括获取不同字段的一些基本信息和记录的总数,检查数据框的头部等。
这里我们对数据框运行info()方法:
df.info()
Output >>>
<class>RangeIndex: 1100 entries, 0 to 1099
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Name 1100 non-null object
1 Age 1100 non-null int64
2 Email 1047 non-null object
3 Phone 1100 non-null object
4 Address 1100 non-null object
5 Salary 1100 non-null int64
6 Join_Date 1100 non-null object
7 Employment_Status 1100 non-null object
8 Department 1100 non-null object
dtypes: int64(2), object(7)
memory usage: 77.5+ KB</class>
检查数据框的头部:
df.head()
df.head()的输出
第二步:处理重复项
重复记录是一个常见问题,会影响分析结果。因此,我们应该识别并删除所有重复记录,以便我们只处理唯一的数据记录。
下面是如何在数据框中查找所有重复项,然后删除所有重复项的方法:
# Check for duplicate rows
duplicates = df.duplicated().sum()
print("Number of duplicate rows:", duplicates)
# Removing duplicate rows
df.drop_duplicates(inplace=True)
Output >>>
Number of duplicate rows: 100
第 3 步:处理缺失数据
缺失数据是许多数据科学项目中的常见数据质量问题。如果你快速查看上一步的info()方法的结果,你应该会看到非空对象的数量在所有字段中并不相同,并且在电子邮件列中有缺失值。我们仍然会得到准确的计数。
要获取每列缺失值的数量,你可以运行:
# Check for missing values
missing_values = df.isna().sum()
print("Missing Values:")
print(missing_values)
Output >>>
Missing Values:
Name 0
Age 0
Email 50
Phone 0
Address 0
Salary 0
Join_Date 0
Employment_Status 0
Department 0
dtype: int64
如果一个或多个数值列中有缺失值,我们可以应用合适的填补技术。但由于'Email'字段缺失,我们暂时将缺失的电子邮件设置为占位符电子邮件,如下所示:
# Handling missing values by filling with a placeholder
df['Email'].fillna('unknown@example.com', inplace=True)
第 4 步:数据转换
当你处理数据集时,可能会有一个或多个字段没有预期的数据类型。在我们的示例数据框中,'Join_Date'字段必须被转换成有效的日期时间对象:
# Convert 'Join_Date' to datetime
df['Join_Date'] = pd.to_datetime(df['Join_Date'])
print("Join_Date after conversion:")
print(df['Join_Date'].head())
Output >>>
Join_Date after conversion:
0 2023-07-12
1 2020-12-31
2 2024-05-09
3 2021-01-19
4 2023-10-04
Name: Join_Date, dtype: datetime64[ns]
由于我们有加入日期,实际上拥有一个Years_Employed列会更有帮助,如下所示:
# Creating a new feature 'Years_Employed' based on 'Join_Date'
df['Years_Employed'] = pd.Timestamp.now().year - df['Join_Date'].dt.year
print("New feature 'Years_Employed':")
print(df[['Join_Date', 'Years_Employed']].head())
Output >>>
New feature 'Years_Employed':
Join_Date Years_Employed
0 2023-07-12 1
1 2020-12-31 4
2 2024-05-09 0
3 2021-01-19 3
4 2023-10-04 1
第 5 步:清理文本数据
字符串字段中经常会遇到格式不一致或类似的问题。清理文本可以像应用大小写转换一样简单,也可以像编写复杂的正则表达式以使字符串符合要求格式一样困难。
在我们拥有的示例数据框中,我们看到'地址'列包含许多‘\n’字符,这些字符影响了可读性。所以让我们将它们替换为空格,如下所示:
# Clean address strings
df['Address'] = df['Address'].str.replace('\n', ' ', regex=False)
print("Address after text cleaning:")
print(df['Address'].head())
Output >>>
Address after text cleaning:
0 79402 Peterson Drives Apt. 511 Davisstad, PA 35172
1 55341 Amanda Gardens Apt. 764 Lake Mark, WI 07832
2 710 Eric Estate Carlsonfurt, MS 78605
3 809 Burns Creek Natashaport, IA 08093
4 8713 Caleb Brooks Apt. 930 Lake Crystalbury, CA...
Name: Address, dtype: object
第 6 步:处理异常值
如果你向上滚动,你会看到我们将'薪水'列中的一些值设置得极高。这些异常值也应被识别和适当处理,以免影响分析结果。
你通常需要考虑什么使数据点成为异常值(如果是错误的数据输入,还是它们实际上是有效值而不是异常值)。然后你可以选择处理它们:删除异常值记录或获取包含异常值的行的子集并单独分析。
让我们使用 z-score 找到那些比均值偏离三倍标准差以上的薪资值:
# Detecting outliers using z-score
z_scores = (df['Salary'] - df['Salary'].mean()) / df['Salary'].std()
outliers = df[abs(z_scores) > 3]
print("Outliers based on Salary:")
print(outliers[['Name', 'Salary']].head())
Output >>>
Outliers based on Salary:
Name Salary
16 Michael Powell 414854
131 Holly Jimenez 258727
240 Daniel Williams 371500
328 Walter Bishop 332554
352 Ashley Munoz 278539
第 7 步:合并数据
在大多数项目中,你拥有的数据可能不是你想用于分析的数据。你必须找到最相关的字段并从其他数据框中合并数据,以获得更多有用的数据用于分析。
作为一个快速练习,创建另一个相关的数据框,并在一个公共列上与现有数据框合并,使合并具有意义。pandas 中的合并与 SQL 中的连接非常相似,因此我建议你将其作为练习尝试!
总结
这就是本教程的全部内容!我们创建了一个包含记录的示例数据框,并逐步完成了各种数据清理步骤。以下是步骤概述:理解数据、处理重复数据、缺失值、数据转换、清理文本数据、处理异常值和合并数据。
如果你想了解关于 pandas 数据整理的所有内容,可以查看 掌握 Pandas 和 Python 数据整理的 7 个步骤。
Bala Priya C 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正致力于学习并通过编写教程、操作指南、观点文章等与开发者社区分享她的知识。Bala 还制作引人入胜的资源概述和编程教程。
更多相关主题
掌握数据工程的 7 个步骤

作者提供的图片
数据工程指的是创建和维护结构和系统的过程,这些结构和系统收集、存储和转换数据,使其以易于数据科学家、分析师和业务相关人员分析和使用的格式存在。本路线图将指导你掌握各种概念和工具,使你能够有效地构建和执行不同类型的数据管道。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
1. 容器化和基础设施即代码
容器化允许开发人员将他们的应用程序和依赖项打包成轻量级的、可移植的容器,这些容器可以在不同的环境中一致地运行。另一方面,基础设施即代码是通过代码管理和配置基础设施的实践,使开发人员能够定义、版本化和自动化云基础设施。
在第一步中,你将了解 SQL 语法、Docker 容器和 Postgres 数据库的基本知识。你将学习如何在本地使用 Docker 启动数据库服务器,以及如何在 Docker 中创建数据管道。此外,你将了解 Google Cloud Provider (GCP)和 Terraform。Terraform 对于你在云端部署工具、数据库和框架特别有用。
2. 工作流编排
工作流编排管理和自动化数据流经不同处理阶段的过程,如数据摄取、清理、转换和分析。这是一种更高效、更可靠和可扩展的工作方式。
在第二步中,你将学习关于数据编排工具的信息,例如 Airflow、Mage 或 Prefect。它们都是开源的,具有观察、管理、部署和执行数据管道的多个重要功能。你将学习如何使用 Docker 设置 Prefect,并利用 Postgres、Google Cloud Storage (GCS)和 BigQuery APIs 构建 ETL 管道。
查看 5 种 Airflow 替代方案,选择适合你的工具。
3. 数据仓储
数据仓库是从各种来源收集、存储和管理大量数据的过程,将其集中在一个存储库中,从而使分析和提取有价值的见解变得更容易。
在第三步中,你将学习有关 Postgres(本地)或 BigQuery(云端)数据仓库的所有内容。你将学习分区和聚类的概念,并深入了解 BigQuery 的最佳实践。BigQuery 还提供机器学习集成功能,你可以在大数据上训练模型、调整超参数、预处理特征,并进行模型部署。这就像是机器学习的 SQL。
4. 数据分析工程师
分析工程是一个专注于为商业智能和数据科学团队设计、开发和维护数据模型及分析管道的专业领域。
在第四步中,你将学习如何使用 dbt(数据构建工具)构建分析管道,使用现有的数据仓库,如 BigQuery 或 PostgreSQL。你将理解 ETL 与 ELT 等关键概念以及数据建模。你还将学习 dbt 的高级功能,如增量模型、标签、钩子和快照。
最终,你将学习使用 Google Data Studio 和 Metabase 等可视化工具来创建交互式仪表板和数据分析报告。
5. 批处理
批处理是一种数据工程技术,涉及将大量数据按批次(每分钟、每小时甚至每天)处理,而不是实时或近实时地处理数据。
在你学习旅程的第五步中,你将接触到使用 Apache Spark 进行批处理。你将学习如何在各种操作系统上安装它,使用 Spark SQL 和 DataFrames,准备数据,执行 SQL 操作,并了解 Spark 的内部机制。在这一步的最后,你还将学习如何在云端启动 Spark 实例并将其与数据仓库 BigQuery 集成。
6. 流处理
流处理指的是实时或近实时地收集、处理和分析数据。与传统的批处理不同,后者是在定时间隔内收集和处理数据,流处理允许对最新信息进行持续分析。
在第六步中,你将学习如何使用 Apache Kafka 进行数据流处理。从基础开始,然后深入了解与 Confluent Cloud 的集成以及涉及生产者和消费者的实际应用。此外,你还需要了解流连接、测试、窗口处理以及 Kafka ksqldb 和 Connect 的使用。
如果你希望探索用于各种数据工程过程的不同工具,可以参考 2024 年必备的 14 种数据工程工具。
7. 项目:构建一个端到端的数据管道
在最后一步,你将运用之前学到的所有概念和工具,创建一个全面的端到端数据工程项目。这将涉及构建数据处理管道,将数据存储在数据湖中,创建将处理后的数据从数据湖转移到数据仓库的管道,在数据仓库中转换数据,并为仪表盘做准备。最后,你将构建一个可视化呈现数据的仪表盘。
最后的思考
本指南中提到的所有步骤都可以在 数据工程 ZoomCamp 中找到。此 ZoomCamp 包含多个模块,每个模块都包括教程、视频、问题和项目,以帮助你学习和构建数据管道。
在这个数据工程路线图中,我们学习了学习、构建和执行数据管道以进行数据处理、分析和建模的各种步骤。我们还了解了云应用程序和工具以及本地工具。你可以选择在本地构建所有内容,也可以使用云以方便操作。我建议使用云,因为大多数公司倾向于此,并希望你在如 GCP 等云平台上获得经验。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一款帮助心理疾病学生的人工智能产品。
更多相关话题
7 步骤掌握 pandas 和 Python 的数据整理
原文:
www.kdnuggets.com/7-steps-to-mastering-data-wrangling-with-pandas-and-python

使用 DALLE 3 生成的图像
你是一个有志成为数据分析师的人吗?如果是的话,学习使用 pandas 进行数据整理是你工具箱中必备的技能。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织中的 IT
几乎所有的数据科学课程和训练营都在其课程中涵盖 pandas。尽管 pandas 易于学习,但其习惯用法和掌握常用函数及方法调用仍需要练习。
本指南将学习 pandas 分解为 7 个简单的步骤,从你可能已经熟悉的内容开始,逐步探索 pandas 的强大功能。从先决条件,到各种数据整理任务,再到构建仪表板,这是一个全面的学习路径。
步骤 1:Python 和 SQL 基础
如果你希望进入数据分析或数据科学领域,你首先需要掌握一些基本的编程技能。我们建议从 Python 或 R 开始,但本指南将重点关注 Python。
学习 Python 和网页抓取
要刷新你的 Python 技能,你可以使用以下资源之一:
Python 易于学习和构建。你可以专注于以下主题:
-
Python 基础:熟悉 Python 语法、数据类型、控制结构、内置数据结构和基本的面向对象编程 (OOP) 概念。
-
网页抓取基础:学习网页抓取的基本知识,包括 HTML 结构、HTTP 请求和解析 HTML 内容。熟悉用于网页抓取任务的库,如 BeautifulSoup 和 requests。
-
连接数据库:学习如何使用 SQLAlchemy 或 psycopg2 等库将 Python 连接到数据库系统。了解如何从 Python 执行 SQL 查询并从数据库中检索数据。
虽然不是强制性的,但使用 Jupyter Notebooks 进行 Python 和网络抓取练习可以提供一个互动的学习和实验环境。
学习 SQL
SQL 是数据分析的必备工具;那么学习 SQL 如何帮助你学习 pandas 呢?
一旦您了解编写 SQL 查询的逻辑,将这些概念转移到 pandas 数据框上进行类似操作是非常简单的。
学习 SQL(结构化查询语言)的基础知识,包括如何创建、修改和查询关系数据库。了解 SQL 命令,如 SELECT、INSERT、UPDATE、DELETE 和 JOIN。
要学习和刷新您的 SQL 技能,您可以使用以下资源:
通过掌握本步骤中概述的技能,您将拥有坚实的 Python 编程、SQL 查询和网络抓取基础。这些技能作为更高级的数据科学和分析技术的基石。
第 2 步:从各种来源加载数据
首先,设置您的工作环境。安装 pandas(及其所需的依赖项,如 NumPy)。遵循最佳实践,例如使用虚拟环境来管理项目级安装。
如前所述,pandas 是一个强大的 Python 数据分析库。然而,在开始使用 pandas 之前,您应该熟悉基本的数据结构:pandas DataFrame 和 series。
为了分析数据,您首先需要将数据从其源加载到 pandas 数据框中。学习如何从各种来源(如 CSV 文件、Excel 电子表格、关系数据库等)摄取数据是很重要的。以下是概述:
-
从 CSV 文件中读取数据:学习如何使用
pd.read_csv()函数从逗号分隔值(CSV)文件中读取数据并将其加载到 DataFrame 中。了解您可以使用的参数,以自定义导入过程,例如指定文件路径、分隔符、编码等。 -
从 Excel 文件中导入数据:探索
pd.read_excel()函数,它允许您从 Microsoft Excel 文件(.xlsx)中导入数据,并将其存储在 DataFrame 中。了解如何处理多个工作表并自定义导入过程。 -
从 JSON 文件中加载数据:学习使用
pd.read_json()函数从 JSON(JavaScript 对象表示法)文件中导入数据并创建 DataFrame。了解如何处理不同的 JSON 格式和嵌套数据。 -
从 Parquet 文件中读取数据:了解
pd.read_parquet()函数,它允许您从 Parquet 文件(一种列式存储文件格式)中导入数据。学习 Parquet 文件如何在大数据处理和分析中提供优势。 -
从关系数据库表中导入数据:了解
pd.read_sql()函数,它允许你从关系数据库查询数据并将其加载到数据框中。了解如何建立数据库连接、执行 SQL 查询,并直接将数据提取到 pandas 中。
我们现在已经学习了如何将数据集加载到 pandas 数据框中。那么接下来呢?
第 3 步:选择行和列,筛选数据框
接下来,你应该学习如何从 pandas 数据框中选择特定的行和列,以及如何根据特定标准筛选数据。学习这些技巧对于数据处理和从数据集中提取相关信息至关重要。
索引和切片数据框
理解如何根据标签或整数位置选择特定的行和列。你应该学习如何使用.loc[]、.iloc[]和布尔索引来切片和索引数据框。
-
.loc[]:此方法用于基于标签的索引,允许你通过标签选择行和列。 -
.iloc[]:此方法用于基于整数索引,使你能够通过整数位置选择行和列。 -
布尔索引:这种技术涉及使用布尔表达式根据特定条件筛选数据。
按名称选择列是常见的操作。因此,学习如何使用列名访问和检索特定列。练习使用单列选择和一次选择多列。
筛选数据框
在筛选数据框时,你应该熟悉以下内容:
-
根据条件筛选:理解如何使用布尔表达式根据特定条件筛选数据。学习使用比较运算符(>、<、==等)创建过滤器,以提取满足特定标准的行。
-
组合过滤器:学习如何使用逻辑运算符如'&'(和)、'|'(或)和'~'(非)组合多个过滤器。这将使你能够创建更复杂的筛选条件。
-
使用 isin():学习使用
isin()方法根据值是否在指定列表中进行数据筛选。这对提取某列值匹配任何提供项的行非常有用。
通过学习本步骤中概述的概念,你将能够有效地从 pandas 数据框中选择和筛选数据,从而提取出最相关的信息。
关于资源的快速说明
对于第 3 到第 6 步,你可以使用以下资源进行学习和实践:
第 4 步:探索和清理数据集
到目前为止,你已经知道如何将数据加载到 pandas 数据框中,选择列和过滤数据框。在这一步,你将学习如何使用 pandas 探索和清理数据集。
探索数据帮助你理解其结构、识别潜在问题,并在进一步分析之前获得洞察。清理数据包括处理缺失值、处理重复项以及确保数据一致性。
-
数据检查:学习如何使用
head()、tail()、info()、describe()和shape属性来概述数据集。这些方法提供有关前几行/最后几行、数据类型、摘要统计信息和数据框维度的信息。 -
处理缺失数据:了解处理数据集中的缺失值的重要性。学习如何使用
isna()和isnull()方法识别缺失数据,并使用dropna()、fillna()或插补方法处理这些缺失值。 -
处理重复项:学习如何使用
duplicated()和drop_duplicates()方法检测和删除重复行。重复项可能会扭曲分析结果,应加以处理以确保数据准确性。 -
清理字符串列:学习使用
.str访问器和字符串方法执行字符串清理任务,如去除空格、提取和替换子字符串、拆分和连接字符串等。 -
数据类型转换:了解如何使用
astype()等方法转换数据类型。将数据转换为适当的类型可以确保数据准确表示并优化内存使用。
此外,你可以通过简单的可视化来探索数据集,并执行数据质量检查。
数据探索和数据质量检查
使用 可视化和统计分析 来获得数据洞察。学习如何使用 pandas 和其他库如 Matplotlib 或 Seaborn 创建基本图表,以可视化数据中的分布、关系和模式。
执行 数据质量检查 以确保数据完整性。这可能涉及验证值是否在预期范围内、识别异常值或检查相关列的一致性。
你现在知道如何探索和清理数据集,从而获得更准确和可靠的分析结果。适当的数据探索和清理对于任何数据科学项目都至关重要,因为它们为成功的数据分析和建模奠定了基础。
第 5 步:转换、分组和聚合
到现在为止,你已经能够使用 pandas DataFrames 并执行基本操作,如选择行和列、过滤和处理缺失数据。
你通常会想要 根据不同标准总结数据。为此,你应该学习如何执行数据转换、使用 GroupBy 功能以及对数据集应用各种聚合方法。可以进一步分解为以下内容:
-
数据转换:学习如何使用添加或重命名列、删除不必要的列以及在不同格式或单位之间转换数据等技术来修改数据。
-
应用函数:理解如何使用
apply()方法将自定义函数应用于数据框,从而以更灵活和定制的方式转换数据。 -
数据重塑:探索其他数据框方法,如
melt()和stack(),这些方法允许你重塑数据,使其适合特定的分析需求。 -
GroupBy 功能:
groupby()方法允许你根据特定的列值对数据进行分组。这使你可以在每个组的基础上执行聚合和数据分析。 -
聚合函数:了解常见的聚合函数,如总和、均值、计数、最小值和最大值。这些函数与
groupby()一起使用,用于汇总数据并计算每个组的描述统计。
本步骤中概述的技术将帮助你有效地转换、分组和聚合数据。
第 6 步:连接和透视表
接下来,你可以通过学习如何使用 pandas 执行数据连接和创建透视表来提升技能。连接 允许你根据共同的列合并来自多个数据框的信息,而 透视表 帮助你以表格格式汇总和分析数据。以下是你应该了解的内容:
-
合并数据框:了解不同类型的连接,如内连接、外连接、左连接和右连接。学习如何使用
merge()函数根据共享列合并数据框。 -
连接:学习如何使用
concat()函数纵向或横向连接数据框。当你需要合并结构相似的数据框时,这非常有用。 -
索引操作:理解如何设置、重置和重命名数据框中的索引。正确的索引操作对于有效地执行连接和创建透视表至关重要。
-
创建透视表:
pivot_table()方法允许你将数据转换为汇总和交叉表格式。学习如何指定所需的聚合函数,并根据特定的列值对数据进行分组。
可选地,你可以探索如何创建多级透视表,通过多列作为索引级别来分析数据。通过足够的练习,你将知道如何使用连接将多个数据框的数据结合起来,并创建信息丰富的透视表。
第 7 步:构建数据仪表板
现在你已经掌握了 pandas 数据整理的基础知识,是时候通过构建数据仪表板来检验你的技能了。
构建交互式仪表板将帮助你提升数据分析和可视化技能。为此步骤,你需要熟悉 Python 中的数据可视化。数据可视化 - Kaggle Learn 是一个全面的入门介绍。
当你在数据领域寻找机会时,你需要拥有一系列项目作品集——而且你需要超越 Jupyter notebooks 中的数据分析。是的,你可以学习并使用 Tableau。但你可以在 Python 基础上进行扩展,使用 Python 库 Streamlit 来构建仪表板。
Streamlit 帮助你构建交互式仪表板——无需担心编写数百行 HTML 和 CSS 代码。
如果你在寻找灵感或学习 Streamlit 的资源,你可以查看这个免费的课程:使用 Python 和 Streamlit 构建 12 个数据科学应用,包括股票价格、体育和生物信息学数据的项目。选择一个真实世界的数据集,分析它,并构建一个数据仪表板,以展示你的分析结果。
下一步
在具备扎实的 Python、SQL 和 pandas 基础之后,你可以开始申请并面试数据分析师职位。
我们已经包括了构建数据仪表板的内容:从数据收集到仪表板和洞察。因此,确保建立一个项目作品集。在此过程中,超越常规,包含那些你真正喜欢的项目。如果你喜欢阅读或音乐(大多数人都是这样),试着分析你的 Goodreads 和 Spotify 数据,构建一个仪表板,并加以改进。继续努力!
Bala Priya C**** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正致力于学习并通过编写教程、操作指南、评论文章等方式与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编程教程。
更多相关话题
掌握探索性数据分析的 7 个步骤
原文:
www.kdnuggets.com/7-steps-to-mastering-exploratory-data-analysis
作者提供的图片
探索性数据分析(或 EDA)是数据分析过程中的核心阶段,强调对数据集内部细节和特征的彻底调查。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
它的主要目的是揭示潜在模式,理解数据集的结构,并识别变量之间的任何潜在异常或关系。
通过执行 EDA,数据专业人员检查数据的质量。因此,它确保进一步的分析基于准确和有洞察力的信息,从而减少后续阶段出现错误的可能性。
所以,让我们一起尝试理解如何进行良好的 EDA,为我们的下一个数据科学项目做好准备。
EDA 的重要性
我非常确定你已经听过这个短语:
垃圾进,垃圾出
输入数据质量始终是任何成功数据项目中最重要的因素。
不幸的是,大多数数据一开始都是杂乱的。通过探索性数据分析的过程,几乎可以用的数据集可以转变为完全可用的数据集。
需要澄清的是,这并不是一个用于净化任何数据集的魔法解决方案。尽管如此,许多 EDA 策略在解决数据集中的常见问题时是有效的。
所以……让我们根据 Ayodele Oluleye 在他的《使用 Python 烹饪书进行探索性数据分析》一书中学习最基本的步骤。
步骤 1:数据收集
任何数据项目的第一步是获得数据本身。这一步骤就是从各种来源收集数据以进行后续分析。
2. 概要统计
在数据分析中,处理表格数据是很常见的。在分析这种数据时,通常需要快速洞察数据的模式和分布。
这些初步洞察为进一步探索和深入分析提供了基础,被称为概要统计。
这些方法提供了数据集分布和模式的简要概述,通过均值、中位数、众数、方差、标准差、范围、百分位数和四分位数等指标来概括。
作者图片
3. 数据准备以进行探索性数据分析
在开始探索之前,数据通常需要为进一步分析做好准备。数据准备涉及使用 Python 的 pandas 库对数据进行转换、聚合或清理,以适应分析的需求。
这一步骤针对数据的结构,可能包括分组、附加、合并、排序、分类和处理重复项。
在 Python 中,使用 pandas 库的各种模块可以方便地完成这一任务。
表格数据的准备过程并没有遵循通用的方法;而是由数据的具体特征决定,包括其行、列、数据类型和包含的值。
4. 数据可视化
可视化是探索性数据分析的核心组件,使数据集中的复杂关系和趋势易于理解。
使用合适的图表可以帮助我们识别大型数据集中的趋势,发现隐藏的模式或异常值。Python 提供了不同的数据可视化库,包括 Matplotlib 和 Seaborn 等。
作者图片
5. 变量分析:
变量分析可以是单变量、双变量或多变量。每种分析方法提供了对数据集中变量之间分布和相关性的见解。技术的使用根据分析的变量数量而有所不同:
单变量
单变量分析的主要关注点是检查数据集中每个变量本身。在这一分析过程中,我们可以揭示如中位数、众数、最大值、范围和异常值等见解。
这种类型的分析适用于分类变量和数值变量。
双变量
双变量分析旨在揭示两个选定变量之间的见解,并专注于理解这两个变量之间的分布和关系。
当我们同时分析两个变量时,这种类型的分析可能会更复杂。它可以包括三种不同的变量对:数值-数值、数值-分类和分类-分类。
多变量
大数据集的一个常见挑战是同时分析多个变量。尽管单变量和双变量分析方法提供了有价值的见解,但通常不足以分析包含多个变量(通常超过五个)的数据集。
管理高维数据的问题,通常被称为维度灾难,已经被充分记录。大量变量可能带来好处,因为它允许提取更多的见解。与此同时,这种优势也可能对我们不利,因为可用于同时分析或可视化多个变量的技术有限。
6. 时间序列数据分析
这一步骤重点在于检查在规律时间间隔内收集的数据点。时间序列数据适用于随时间变化的数据。这基本上意味着我们的数据集由一组在规律时间间隔内记录的数据点组成。
当我们分析时间序列数据时,我们通常可以发现随时间重复的模式或趋势,并呈现出时间上的季节性。时间序列数据的关键组成部分包括趋势、季节变动、周期变动和不规则变动或噪声。
7. 处理异常值和缺失值
异常值和缺失值如果没有得到妥善处理,会扭曲分析结果。这就是为什么我们应始终考虑一个阶段来处理它们。
确定、移除或替换这些数据点对维持数据集分析的完整性至关重要。因此,在开始分析数据之前,处理这些问题是非常重要的。
-
异常值是与其他数据点显著偏离的点。它们通常呈现出异常高或低的值。
-
缺失值是指缺少与特定变量或观察相关的数据点。
处理缺失值和异常值的一个关键初步步骤是了解它们为何存在于数据集中。这种理解通常指导了选择最适合的处理方法。需要考虑的其他因素包括数据的特征以及将要进行的具体分析。
结论
EDA 不仅提升了数据集的清晰度,还使数据专业人士能够通过提供管理具有众多变量的数据集的策略来应对维度灾难。
通过这些细致的步骤,使用 Python 进行的探索性数据分析(EDA)为分析师提供了提取有意义洞察所需的工具,为所有后续的数据分析工作奠定了坚实的基础。
Josep Ferrer**** 是一位来自巴塞罗那的分析工程师。他毕业于物理工程专业,目前在应用于人类移动的数据科学领域工作。他还是一名兼职内容创作者,专注于数据科学和技术。Josep 涵盖了人工智能领域的最新发展。
更多信息
掌握大型语言模型微调的 7 个步骤
原文:
www.kdnuggets.com/7-steps-to-mastering-large-language-model-fine-tuning
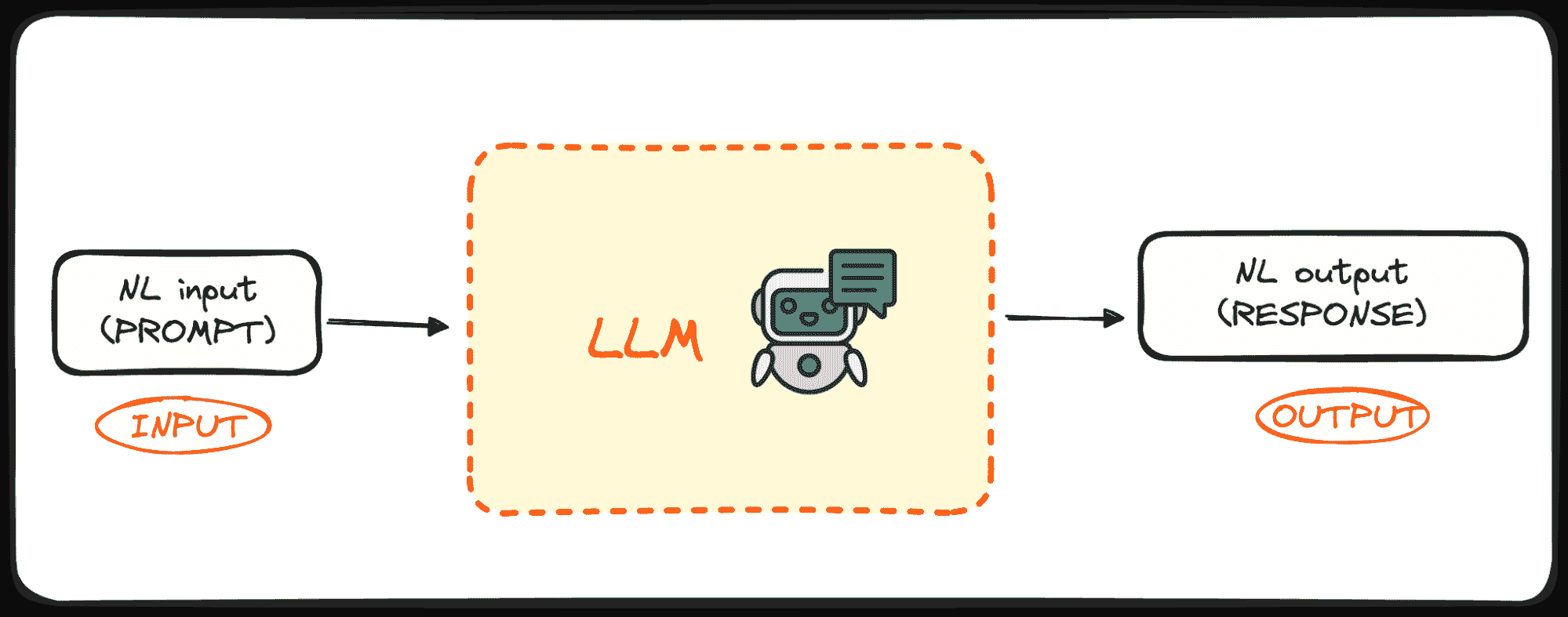
作者提供的图像
在过去一年半中,自然语言处理(NLP)的格局发生了显著演变,这主要得益于大型语言模型(LLMs)如 OpenAI 的 GPT 系列的崛起。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
这些强大的模型已经彻底改变了我们处理自然语言任务的方法,提供了前所未有的翻译、情感分析和自动文本生成能力。它们理解和生成类似人类的文本的能力开辟了曾经被认为无法实现的可能性。
然而,尽管它们具有令人印象深刻的能力,训练这些模型的过程仍然充满挑战,如所需的大量时间和财务投资。
这引出了微调 LLMs 的关键作用。
通过微调这些预训练的模型以更好地适应特定应用或领域,我们可以显著提升它们在特定任务上的表现。这一步骤不仅提升了它们的质量,还扩展了它们在广泛领域中的实用性。
本指南旨在将这个过程分解为 7 个简单的步骤,以便将任何 LLM 微调到特定任务。
理解预训练的大型语言模型
LLMs 是机器学习算法的一个专门类别,旨在根据前面的词语提供的上下文预测序列中的下一个词。这些模型建立在变换器架构上,这是一项机器学习技术的突破,首次在谷歌的你所需要的只是注意力文章中解释。
像 GPT(生成预训练变换器)这样的模型是预训练语言模型的例子,这些模型已经接触到了大量的文本数据。这种广泛的训练使它们能够捕捉语言使用的基本规则,包括词语如何组合成连贯的句子。

作者提供的图像
这些模型的一个关键优势在于它们不仅能理解自然语言,还能根据给定的输入生成接近人类写作风格的文本。
那么这有什么好处呢?
这些模型已经通过 API 向大众开放。
什么是微调,为什么它很重要?
微调是选择一个预训练模型,并通过在特定领域数据集上进一步训练来改进它的过程。
大多数大型语言模型具有非常好的自然语言处理能力和通用知识表现,但在特定任务导向的问题上表现较差。微调过程提供了一种方法,以提高模型在特定问题上的性能,同时降低计算开支,无需从头构建模型。
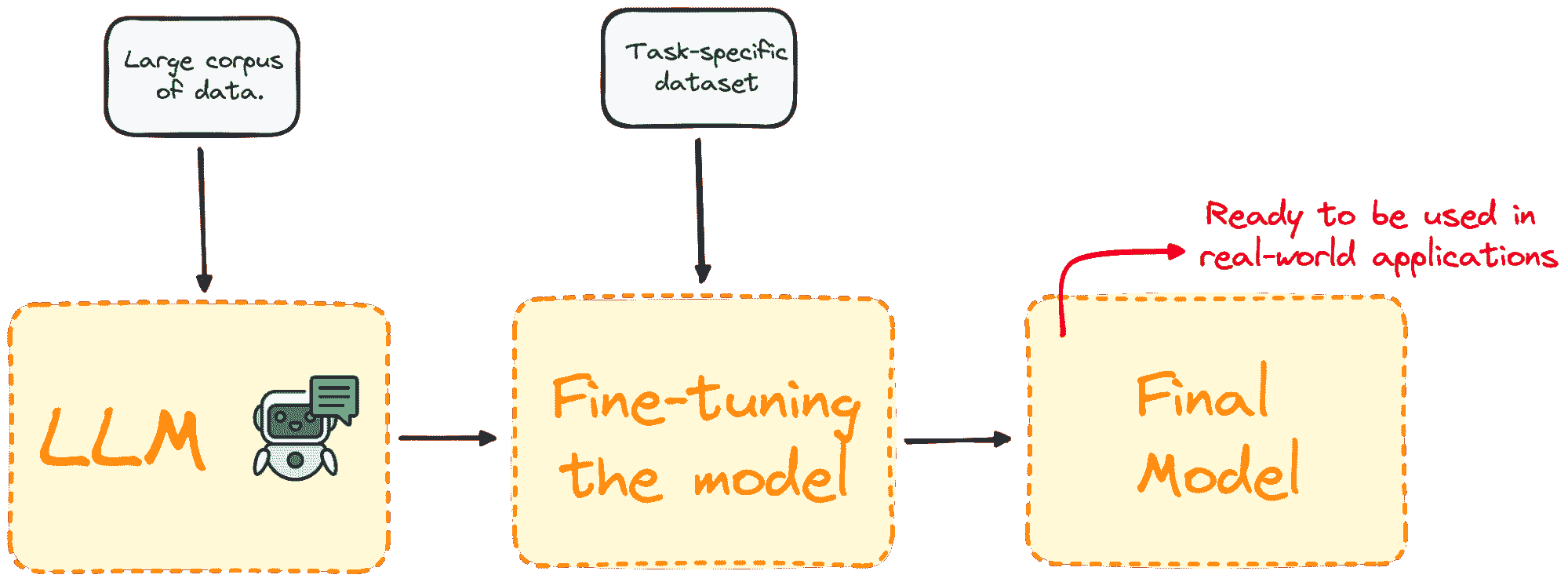
作者提供的图片
简而言之,微调使模型在特定任务上的表现更好,从而使其在实际应用中更有效、更具适应性。这个过程对于改进现有模型以适应特定任务或领域至关重要。
微调 LLM 的逐步指南
让我们通过在仅仅 7 个步骤中微调一个实际模型来说明这个概念。
第一步:明确我们的具体目标
想象一下,我们想要推断任何文本的情感,并决定尝试使用 GPT-2 来完成这个任务。
我敢肯定,毫无惊讶,我们很快会发现它在这方面的表现相当糟糕。然后,一个自然的问题是:
我们能做些什么来提高它的性能?
当然,答案是我们可以!
通过利用微调,对 Hugging Face Hub 上的预训练 GPT-2 模型进行训练,使用一个包含推文及其相应情感的数据集,从而提高性能。
我们的最终目标是拥有一个能够准确推断文本情感的模型。
第二步:选择一个预训练模型和一个数据集
第二步是选择一个作为基础模型的模型。在我们的案例中,我们已经选择了模型:GPT-2。因此,我们将对其进行一些简单的微调。
Hugging Face 数据集中心的截图。选择 OpenAI 的 GPT2 模型。
始终记住选择一个适合你任务的模型。
第三步:加载要使用的数据
现在我们已经有了模型和主要任务,我们需要一些数据来进行操作。
但不用担心,Hugging Face 已经安排好了所有内容!
这就是它们的数据集库发挥作用的地方。
在这个例子中,我们将利用 Hugging Face 数据集库导入一个包含推文及其相应情感(积极、中性或消极)标签的数据集。
from datasets import load_dataset
dataset = load_dataset("mteb/tweet_sentiment_extraction")
df = pd.DataFrame(dataset['train'])
数据大致如下:

要使用的数据集。
第四步:分词器
现在我们已经拥有了模型和要微调的数据集。所以下一步自然是加载一个标记器。由于 LLMs 以令牌(而非单词!!)为单位工作,我们需要一个标记器来将数据发送到模型中。
我们可以利用 map 方法轻松地对整个数据集进行标记化。
from transformers import GPT2Tokenizer
# Loading the dataset to train our model
dataset = load_dataset("mteb/tweet_sentiment_extraction")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
附加内容: 为了提高我们的处理性能,生成了两个较小的子集:
-
训练集: 用于微调我们的模型。
-
测试集: 用于评估它。
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
第 5 步:初始化我们的基础模型
一旦我们拥有要使用的数据集,我们加载我们的模型并指定预期的标签数量。通过 Tweet 的情感数据集,你可以知道有三种可能的标签:
-
0 或 消极
-
1 或 中性
-
2 或 积极
from transformers import GPT2ForSequenceClassification
model = GPT2ForSequenceClassification.from_pretrained("gpt2", num_labels=3)
第 6 步:评估方法
Transformers 库提供了一个名为“Trainer”的类,用于优化我们模型的训练和评估。因此,在实际训练开始之前,我们需要定义一个函数来评估微调后的模型。
import evaluate
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
第 7 步:使用 Trainer 方法进行微调
最终步骤是微调模型。为此,我们设置训练参数以及评估策略,并执行 Trainer 对象。
要执行 Trainer 对象,我们只需使用 train()命令。
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="test_trainer",
#evaluation_strategy="epoch",
per_device_train_batch_size=1, # Reduce batch size here
per_device_eval_batch_size=1, # Optionally, reduce for evaluation as well
gradient_accumulation_steps=4
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
一旦我们的模型被微调,我们使用测试集来评估其性能。Trainer 对象已经包含了一个优化的 evaluate()方法。
import evaluate
trainer.evaluate()
这是对任何 LLM 进行微调的基本过程。
同样,请记住,微调 LLM 的过程计算要求非常高,因此你的本地计算机可能没有足够的性能来执行它。
主要结论
今天,针对特定任务对预训练的大型语言模型(如 GPT)进行微调对于提升 LLMs 在特定领域的表现至关重要。这使我们能够利用它们的自然语言能力,同时提高其效率和定制化的潜力,使得这一过程变得可及且具有成本效益。
按照这 7 个简单步骤——从选择合适的模型和数据集到训练和评估微调后的模型——我们可以在特定领域实现更优的模型性能。
对于那些想查看完整代码的人,可以在我的 大型语言模型 GitHub 仓库 中找到。
Josep Ferrer**** 是一位来自巴塞罗那的分析工程师。他毕业于物理工程专业,目前在应用于人类移动性的领域从事数据科学工作。他还是一位兼职内容创作者,专注于数据科学和技术。Josep 撰写有关人工智能的内容,涵盖该领域持续爆炸的应用。
更多相关内容
掌握大型语言模型(LLMs)的 7 个步骤
原文:
www.kdnuggets.com/7-steps-to-mastering-large-language-models-llms
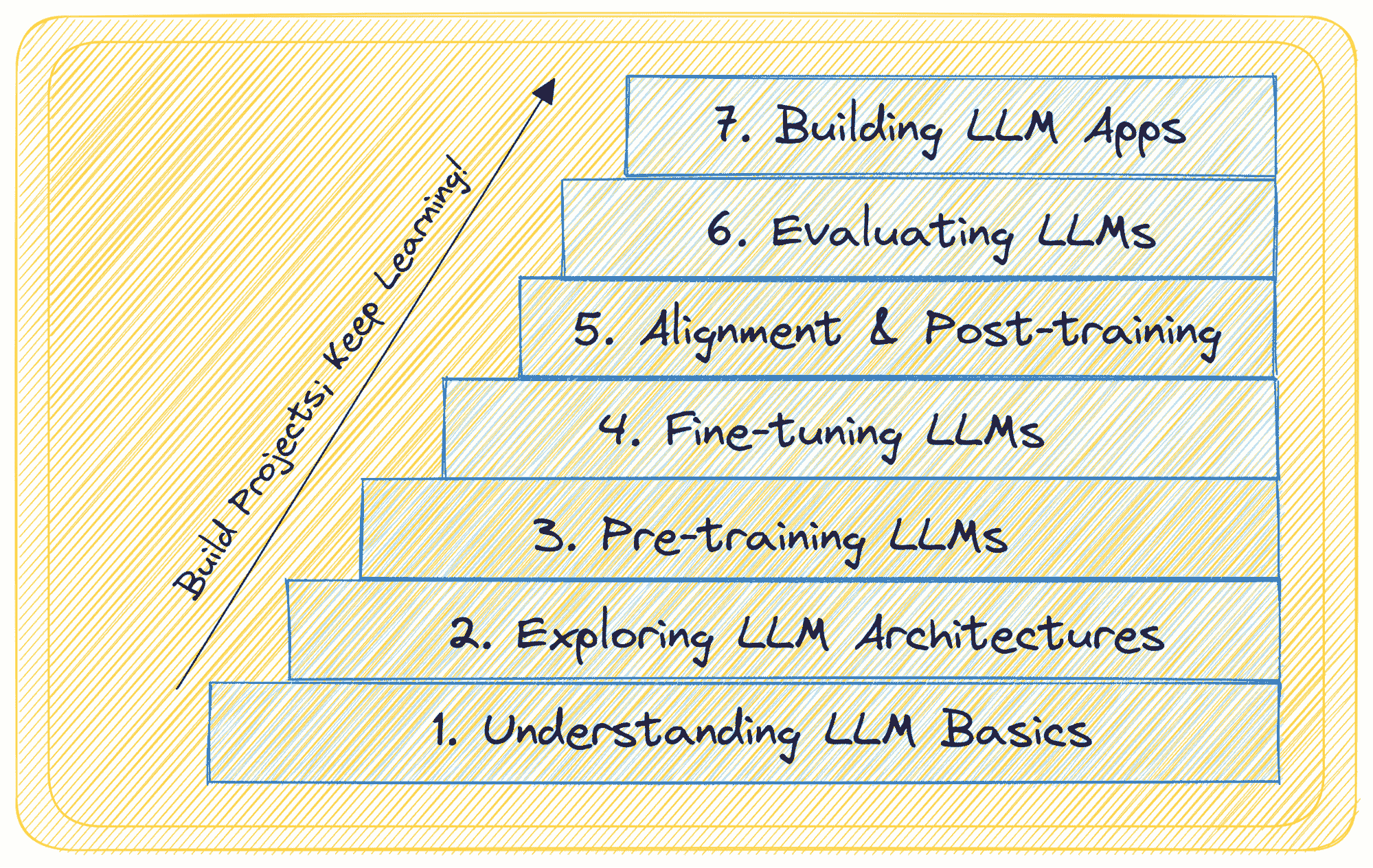
图片来源:作者
GPT-4、Llama、Falcon 等——大型语言模型(LLMs)——真的是当下的热门话题。如果你正在阅读这些内容,你很可能已经通过聊天界面或 API 使用过一个或多个这些大型语言模型。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
如果你曾经好奇 LLMs 到底是什么,它们如何工作,以及你可以用它们构建什么,这份指南将是你所需要的。不论你是对大型语言模型感兴趣的数据专业人士,还是对它们感到好奇的普通人,这都是一份全面的 LLM 领域指南。
从 LLMs 是什么到如何构建和部署应用程序,我们将分解成 7 个简单的步骤,帮助你全面了解大型语言模型,内容包括:
-
你应该知道的事项
-
概念概览
-
学习资源
让我们开始吧!
第一步:理解 LLM 基础知识
如果你是大型语言模型的新手,首先了解 LLMs 的高层次概况以及它们为何如此强大是有帮助的。从尝试回答这些问题开始:
-
LLMs 究竟是什么?
-
为什么它们如此受欢迎?
-
LLMs 与其他深度学习模型有什么不同?
-
常见的 LLM 使用案例有哪些?(你可能已经熟悉这些;仍然是一个列出它们的好练习)
你能回答所有这些问题吗?好吧,让我们一起做吧!
什么是 LLMs?
大型语言模型(Large Language Models,简称 LLMs)是深度学习模型的一个子集,经过大规模文本数据的训练。它们非常庞大——拥有数百亿个参数——并且在各种自然语言任务上表现极为出色。
它们为什么这么受欢迎?
LLMs 具备理解和生成连贯、上下文相关且语法准确的文本的能力。它们的受欢迎和广泛应用的原因包括:
-
在各种语言任务上表现卓越
-
预训练 LLMs 的可访问性和可用性,使 AI 驱动的自然语言理解和生成得以民主化
那么 LLMs 与其他深度学习模型有何不同?
由于其规模和架构,包括自注意力机制,LLMs 与其他深度学习模型不同。关键差异包括:
-
变换器架构,它彻底改变了自然语言处理并支撑了 LLMs (在我们的指南中即将介绍)
-
捕捉长距离依赖的能力,能够更好地理解上下文
-
能够处理各种语言任务,从文本生成到翻译、总结和问答
LLMs 的常见应用案例有哪些?
LLMs 在语言任务中得到了应用,包括:
-
自然语言理解:LLMs 在情感分析、命名实体识别和问答等任务中表现出色。
-
文本生成:它们可以为聊天机器人和其他内容生成任务生成类人文本。(如果你曾使用过 ChatGPT 或其替代品,这完全不会让你感到惊讶)
-
机器翻译:LLMs 显著提高了机器翻译的质量。
-
内容总结:LLMs 可以生成长篇文档的简明总结。你是否尝试过总结 YouTube 视频的文字记录?
现在你对 LLMs 及其能力有了初步了解,以下是一些资源,如果你有兴趣进一步探索:
步骤 2:探索 LLM 架构
既然你已经了解了什么是 LLMs,让我们继续学习支撑这些强大 LLMs 的变换器架构。所以,在 LLM 的学习过程中,这一步中变换器需要你所有的注意力 (没有任何双关意思)
原始变换器架构,在论文"Attention Is All You Need"中介绍,彻底改变了自然语言处理:
-
关键特性:自注意力层、多头注意力、前馈神经网络、编码器-解码器架构。
-
应用案例:变换器是著名的语言模型(LLMs),如 BERT 和 GPT 的基础。
原始变换器架构使用编码器-解码器架构;但也存在仅编码器和仅解码器的变体。这里是这些架构的全面概述,包括它们的特性、著名 LLMs 和应用案例:
| 架构 | 关键特性 | 著名 LLMs | 应用案例 |
|---|---|---|---|
| 仅编码器 | 捕捉双向上下文;适用于自然语言理解 |
-
BERT
-
同样基于 BERT 架构的 RoBERTa,XLNet
|
-
文本分类
-
问答系统
|
| 仅解码器 | 单向语言模型;自回归生成 |
|---|
-
GPT
-
PaLM
|
-
文本生成(各种内容创建任务)
-
文本补全
|
| 编码器-解码器 | 输入文本到目标文本;任何文本到文本的任务 |
|---|
-
T5
-
BART
|
-
总结
-
翻译
-
问答系统
-
文档分类
|
以下是学习变换器的绝佳资源:
第 3 步:预训练 LLMs
既然你已经熟悉了大型语言模型(LLMs)和变换器架构的基础知识,你可以继续学习 LLMs 的预训练。预训练为 LLMs 奠定基础,通过让它们接触大量的文本数据,使它们能够理解语言的各个方面和细微差别。
这里是你应该了解的概念概览:
-
LLMs 预训练的目标:让 LLMs 接触大量文本语料,以学习语言模式、语法和上下文。了解具体的预训练任务,如掩蔽语言建模和下一句预测。
-
LLMs 预训练的文本语料:LLMs 在大量多样化的文本语料上进行训练,包括网页文章、书籍和其他来源。这些是大规模数据集——包含数十亿到万亿的文本标记。常见的数据集包括 C4、BookCorpus、Pile、OpenWebText 等。
-
训练过程:理解预训练的技术细节,包括优化算法、批量大小和训练轮次。了解挑战,如减轻数据中的偏差。
如果你有兴趣进一步学习,请参考 CS324: 大型语言模型中的LLM 训练模块。
这些预训练的 LLMs 作为微调特定任务的起点。是的,微调 LLMs 是我们的下一步!
第 4 步:微调 LLMs
在对 LLMs 进行大规模文本语料的预训练后,下一步是对其进行特定自然语言处理任务的微调。微调可以让你使预训练模型适应执行特定任务,如情感分析、问答或翻译,以更高的准确性和效率完成任务。
为什么要微调 LLMs
微调是必要的,原因有几个:
-
预训练的 LLMs 已经获得了通用的语言理解,但需要微调才能在特定任务上表现良好。微调帮助模型学习目标任务的细微差别。
-
微调相比从头训练模型显著减少了所需的数据和计算量。因为它利用了预训练模型的理解,所以微调数据集可以比预训练数据集小得多。
如何微调 LLMs
现在让我们深入了解微调 LLMs 的方法:
-
选择预训练 LLM: 选择与任务匹配的预训练 LLM。例如,如果你在处理问答任务,选择一个有助于自然语言理解的预训练模型。
-
数据准备:为 LLM 执行的特定任务准备数据集。确保数据集包含标记的示例,并格式正确。
-
微调:在选择了基础 LLM 并准备好数据集之后,接下来就是真正的微调模型。但怎么做呢?
有没有参数高效的技术? 请记住,LLM 有数十亿个参数。权重矩阵非常庞大!
如果你无法访问权重怎么办?
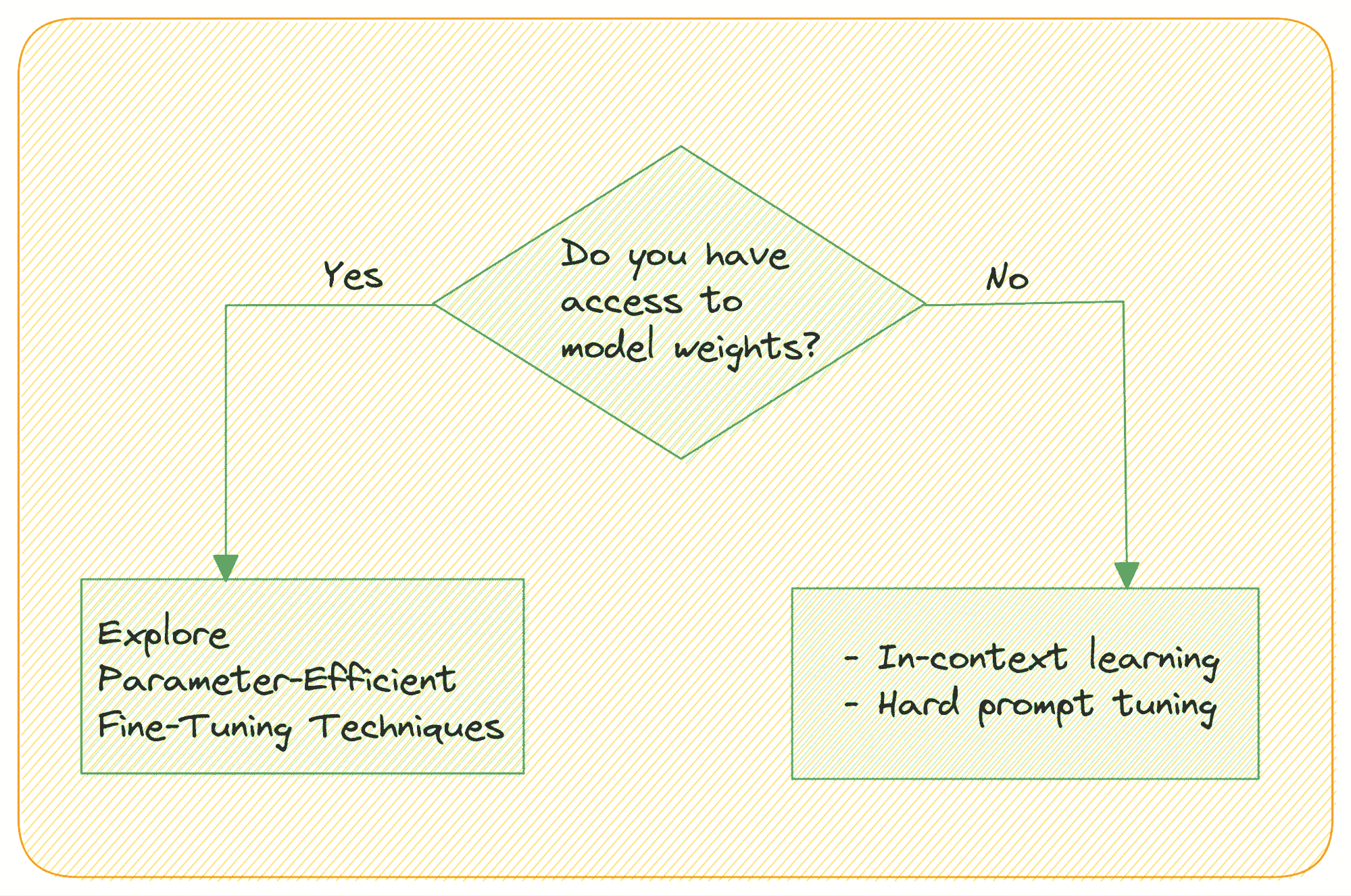
图片由作者提供
当你无法访问模型的权重并通过 API 访问模型时,如何微调 LLM?大型语言模型具备上下文学习的能力——无需明确的微调步骤。你可以通过提供输入和任务的示例输出来利用它们从类比中学习。
提示调优——修改提示以获取更有帮助的输出——可以是:硬提示调优或(软)提示调优。
硬提示调优涉及直接修改提示中的输入令牌,因此不会更新模型的权重。
软提示调优将输入嵌入与一个可学习的张量拼接在一起。一个相关的想法是前缀调优,在每个 Transformer 块中使用可学习的张量,而不仅仅是输入嵌入。
如前所述,大型语言模型具有数十亿个参数。因此,微调所有层中的权重是一项资源密集型任务。最近,参数高效微调技术(PEFT)如 LoRA 和 QLoRA 变得流行。使用 QLoRA,你可以在单个消费级 GPU 上微调 4 位量化的 LLM,而不会降低性能。
这些技术引入了一小组可学习的参数——适配器——而不是整个权重矩阵。以下是一些有用的资源,以了解更多关于微调 LLMs 的内容:
第 5 步:LLMs 中的对齐和后训练
大型语言模型可能会生成有害、偏见或与用户实际期望不符的内容。对齐是指将 LLM 的行为与人类偏好和伦理原则对齐的过程。其目的是减少模型行为相关的风险,包括偏见、争议性回应和有害内容生成。
你可以探索以下技术:
-
从人类反馈中强化学习(RLHF)
-
对比后训练
RLHF 使用人类偏好注释来优化 LLM 输出,并根据这些注释拟合奖励模型。对比后训练旨在利用对比技术自动构建偏好对。
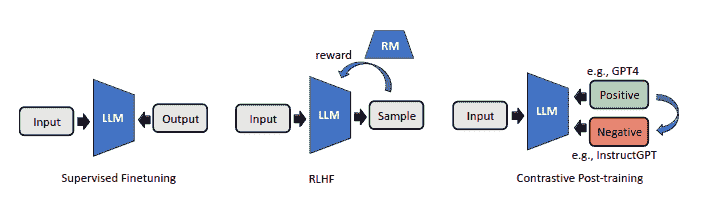
LLM 中的对齐技术 | 图片来源
欲了解更多信息,请查看以下资源:
第 6 步:LLM 中的评估与持续学习
一旦你为特定任务微调了 LLM,评估其性能并考虑持续学习和适应的策略至关重要。此步骤确保你的 LLM 保持有效并与时俱进。
LLM 的评估
评估性能以衡量其有效性并识别改进领域。以下是 LLM 评估的关键方面:
-
任务特定指标:为你的任务选择合适的指标。例如,在文本分类中,你可以使用传统的评估指标,如准确率、精确率、召回率或 F1 分数。对于语言生成任务,常用的指标有困惑度和 BLEU 分数。
-
人类评估:让专家或众包标注员在现实场景中评估生成内容或模型的响应质量。
-
偏见与公平性:评估 LLM 的偏见和公平性问题,特别是在将其应用于现实世界时。分析模型在不同人口群体中的表现,并解决任何差异。
-
鲁棒性与对抗测试:通过对 LLM 进行对抗攻击或挑战性输入来测试其鲁棒性。这有助于发现漏洞并增强模型安全性。
持续学习与适应
为了保持 LLM 与新数据和任务的同步,考虑以下策略:
-
数据增强:持续扩充数据存储,以避免因缺乏最新信息而导致的性能下降。
-
重新训练:定期用新数据重新训练 LLM,并对其进行针对不断变化任务的微调。对最新数据的微调有助于模型保持最新状态。
-
主动学习:实施主动学习技术以识别模型不确定或可能出错的实例。收集这些实例的注释以完善模型。
LLM 的另一个常见问题是幻觉。确保探索像检索增强这样的技术来减轻幻觉。
这里有一些有用的资源:
第 7 步:构建和部署 LLM 应用
在为特定任务开发和微调 LLM 后,开始构建和部署利用 LLM 能力的应用程序。实质上,利用 LLM 构建有用的现实世界解决方案。
图片由作者提供
构建 LLM 应用程序
以下是一些考虑事项:
-
任务特定的应用开发:开发针对特定用例的应用程序。这可能涉及创建基于网页的界面、移动应用、聊天机器人或集成到现有软件系统中。
-
用户体验(UX)设计:关注以用户为中心的设计,确保你的 LLM 应用程序直观且易于使用。
-
API 集成:如果你的 LLM 作为语言模型后台,创建 RESTful API 或 GraphQL 端点,以便其他软件组件能够无缝地与模型互动。
-
可扩展性和性能:设计应用程序以处理不同级别的流量和需求。优化性能和可扩展性,以确保流畅的用户体验。
部署 LLM 应用程序
你已经开发了你的 LLM 应用程序,并准备将其部署到生产环境中。以下是你应该考虑的事项:
-
云部署:考虑将 LLM 应用程序部署到 AWS、Google Cloud 或 Azure 等云平台,以实现可扩展性和便于管理。
-
容器化:使用 Docker 和 Kubernetes 等容器化技术打包应用程序,并确保在不同环境中的一致部署。
-
监控:实施监控以跟踪已部署的 LLM 应用程序的性能,并实时检测和解决问题。
合规性和法规
数据隐私和伦理考虑是潜在的:
-
数据隐私:在处理用户数据和个人身份信息(PII)时,确保遵守数据隐私法规。
-
伦理考虑:在部署 LLM 应用程序时遵循伦理指南,以减轻潜在的偏见、虚假信息或有害内容生成。
你还可以使用像 LlamaIndex 和 LangChain 这样的框架来帮助你构建端到端的 LLM 应用程序。以下是一些有用的资源:
总结
我们通过定义大型语言模型是什么、为什么它们受到欢迎开始讨论,逐渐深入技术方面。我们总结了构建和部署 LLM 应用程序的讨论,这需要仔细规划、以用户为中心的设计、强大的基础设施,同时优先考虑数据隐私和伦理。
正如你可能已经意识到的,跟进该领域的最新进展并不断构建项目是重要的。如果你有一些自然语言处理的经验,本指南将在此基础上进行深入探讨。即使没有经验,也不用担心。我们的 7 个步骤掌握自然语言处理指南将帮助你。祝学习愉快!
Bala Priya C**** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉点工作。她的兴趣和专业领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过编写教程、如何做指南、观点文章等,学习并与开发者社区分享她的知识。Bala 还制作引人入胜的资源概述和编码教程。
更多相关话题
掌握数据科学数学的 7 个步骤
原文:
www.kdnuggets.com/7-steps-to-mastering-math-for-data-science

作者提供的图片 | 创建于 Canva
由于有大量免费的高质量资源,学习数据科学变得更加容易。因此,如果你有兴趣,你可以免费自学数据科学——学习和实践。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
学习编程语言和其他工具及库可能很简单。但你也需要学习数据科学的数学基础。如果你没有数学或计算机科学的背景,这可能会相当令人生畏。但这仍然是可以做到的。
有一个指导来帮助你学习数据科学的数学可以使事情变得更简单。这就是为什么我们编写了这个指南来帮助你学习数据科学的数学。让我们开始吧。
第一步:复习代数基础
从你已经知道的东西开始总是很容易。因此,从复习代数基础开始(你应该已经通过学校的数学课程熟悉这些内容)。
你可以复习如何解方程组、解未知数以及绘制函数。
重点关注
-
线性方程和不等式:学习如何解带有一个或多个变量的方程,并解释解的意义。
-
函数和图形:了解不同类型的函数以及如何绘制它们。
-
多项式:使用多项式函数,这些函数在各种回归模型中用于拟合数据点。
-
矩阵和向量:这些在对数据集进行操作时非常关键,尤其是在高维数据中。你可以在关注线性代数时学到更多。
资源
第二步:学习微积分基础
微积分是数据科学中的另一个重要数学工具。它对于理解数据随时间变化、建模连续数据以及优化算法至关重要。
你应该学习如何对一个或多个变量的函数进行微分。积分在学习概率和随机变量时会派上用场——用于计算曲线下的面积——代表累计分布函数或概率密度。
关注的重点
-
极限和连续性:理解极限和连续性的概念,以及它们如何用于理解函数在输入接近某些值时的行为。
-
微分:学习如何计算和解释导数,导数表示变化率。
-
多变量微积分:扩展你的知识到多个变量的函数,这对于理解涉及多个输入的复杂模型至关重要。
-
积分:理解积分过程及其用于计算曲线下面积的方法。
资源
第三步:熟悉线性代数
线性代数对于数据科学中的许多算法至关重要,包括用于降维(如 PCA)、数据变换等的算法。
它提供了处理具有多维数据集的数学框架,并帮助高效存储和操作高维空间中的数据。
关注的重点
-
向量和向量空间:学习如何处理向量,这对高维数据表示至关重要。理解向量空间对于数据变换和机器学习算法是必要的。
-
矩阵运算:掌握矩阵乘法、逆矩阵和行列式等操作,这些都是许多机器学习模型的基础,尤其是在处理数据变换和多变量分析时。
-
线性变换:理解线性变换如何用于将数据从一个空间映射到另一个空间。
-
特征值和特征向量:理解方阵的特征分解及其重要性,特别是在那些减少数据维度或提取特征的算法中。
资源
第四步:学习离散数学
如果你想自学计算机科学和数据科学,应该参加一个(短期)离散数学课程。
这在图论、密码学和组合优化等领域尤为重要。离散数学帮助你理解并解决数据库、计算机算法和网络分析中的问题。
关注的重点
-
集合论:学习集合的基本知识,包括并集、交集和差集等操作。集合论对于理解逻辑、函数和数据库及算法中的关系是必不可少的。
-
组合学:学习计数、排列和组合的技巧。这对概率和算法分析很有帮助。
-
图论:了解图(网络)的属性以及它们如何用于建模实体之间的关系。
-
布尔代数:探索布尔逻辑的基本知识,这对于设计和理解算法尤其是在决策过程中的基础是非常重要的。
资源
第 5 步:学习概率与统计
概率与统计可以让你根据数据做出明智的决策,建模不确定性和检验假设。这些都是数据科学中预测建模、风险评估和数据解释的基础工具。
从构建概率模型到理解数据分布,对这些概念的深入掌握都是必不可少的。
重点关注
-
概率论:了解概率的基本知识,包括条件概率、贝叶斯定理和独立性。
-
随机变量与概率分布:了解不同类型的随机变量(离散和连续)的行为,以及如何使用概率分布(如正态分布、二项分布和泊松分布)对其建模。
-
描述性统计与推断统计:掌握总结数据(均值、中位数、众数、方差)和基于样本数据对总体进行推断的技术。
-
假设检验:学习如何执行和解释假设检验,这些检验用于通过评估证据对抗零假设来做出数据驱动的决策。
资源
第 6 步:探索优化技术
在处理机器学习算法和统计模型时,你会遇到优化问题。无论是寻找模型的最佳参数还是最小化误差率,理解优化技术可以提高模型的性能和效率。在进行优化时,你会发现需要掌握微积分和线性代数。
重点关注
-
线性规划:学习如何在约束条件下优化线性函数。
-
梯度下降:学习这一基本优化算法,它用于在机器学习和深度学习模型中最小化损失函数。
-
凸优化:理解凸函数的性质,以及如何将某些优化问题表述为简化问题。
-
有约束与无约束优化:学习有约束和无约束优化问题的区别,以及如何使用适当的算法解决这些问题。
资源
第 7 步:拥抱及时学习
我们已经讲解了数据科学中你需要了解的不同数学主题。但你也可能意识到,事先掌握每一个数学概念是不可能的。一旦你获得了一些基础知识,你可以根据需要及时学习其他概念。
面对特定问题时,识别解决它所需的数学技术——无论是统计方法、优化算法还是矩阵变换——并随时学习这些概念。
总结
就这样结束了!
我希望你发现这份关于数据科学数学学习的指南对你有所帮助。如前所述,你需要了解的所有内容列表似乎很长。但你可以在进行项目时随时学习所需的数学知识。
学习愉快!
Bala Priya C**** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉点工作。她的兴趣和专长包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过编写教程、操作指南、意见文章等,与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关话题
掌握 MLOPs 的 7 个步骤

作者提供的图片
如今,许多公司希望将 AI 纳入其工作流程,特别是通过微调大型语言模型并将其投入生产。由于这种需求,MLOps 工程变得越来越重要。公司不仅仅寻找数据科学家或机器学习工程师,而是希望找到能够自动化和简化在云中训练、评估、版本控制、部署和监控模型过程的人员。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
在本初学者指南中,我们将专注于掌握 MLOps 工程的七个关键步骤,包括设置环境、实验追踪和版本控制、编排、持续集成/持续交付(CI/CD)、模型服务和部署以及模型监控。在最后一步中,我们将使用各种 MLOps 工具构建一个完全自动化的端到端机器学习管道。
1. 本地和云环境设置
为了训练和评估机器学习模型,你首先需要设置本地和云环境。这涉及到使用 Docker 对机器学习管道、模型和框架进行容器化。之后,你将学习使用 Kubernetes 自动化部署、扩展和管理这些容器化应用程序。
在第一步结束时,你将熟悉你选择的云平台(例如 AWS、Google Cloud 或 Azure),并学习如何使用 Terraform 实现基础设施即代码,以自动化设置你的云基础设施。
注意: 你需要对 Docker、Git 有基本了解,并熟悉命令行工具。然而,如果你有软件工程背景,你可能可以跳过这一部分。
2. 实验追踪、版本控制和模型管理
你将学习如何使用 MLflow 跟踪机器学习实验,使用 DVC 进行模型和数据版本控制,以及使用 Git 进行代码版本控制。MLflow 可以用于记录参数、输出文件、模型管理和服务。
这些实践对于维护一个文档齐全、可审计且可扩展的 ML 工作流程至关重要,最终有助于 ML 项目的成功和效率。
查看 7 款最佳机器学习实验跟踪工具,选择适合你工作流程的工具。
3. 编排和机器学习管道
在第三步中,你将学习如何使用像Apache Airflow或Prefect这样的编排工具来自动化和调度机器学习工作流程。工作流程包括数据预处理、模型训练、评估等,确保从数据到部署的管道无缝且高效。
这些工具使得机器学习流程中的每个步骤都可以在不同项目中模块化和重用,从而节省时间并减少错误。
了解 5 款数据编排的 Airflow 替代方案,这些方案用户友好且具备现代功能。同时,查看 使用 Prefect 进行机器学习工作流程教程,构建并执行你的第一个机器学习管道。
4. 机器学习的 CI/CD
将持续集成和持续部署(CI/CD)实践融入你的机器学习工作流程中。像Jenkins、GitLab CI和GitHub Actions这样的工具可以自动化机器学习模型的测试和部署,确保变更能够高效且安全地推出。你将学习将数据、模型和代码的自动化测试纳入其中,以便早期发现问题并维持高质量标准。
通过遵循 机器学习的 CI/CD 初学者指南,了解如何使用 GitHub Actions 来自动化模型训练、评估、版本控制和部署。
5. 模型服务和部署
模型服务是有效利用机器学习模型在生产环境中的关键方面。通过使用如BentoML、Kubeflow、Ray Serve或TFServing等模型服务框架,你可以高效地将模型作为微服务进行部署,使其在多个应用程序和服务中可访问和可扩展。这些框架提供了一种无缝的方式来本地测试模型推断,并提供功能以安全高效地在生产环境中部署模型。
了解 7 款顶级模型部署和服务工具,这些工具被顶级公司用于简化和自动化模型部署过程。
6. 模型监控
在第六步中,你将学习如何实现监控,以跟踪模型的性能并检测数据随时间的变化。你可以使用像Evidently、Fiddler这样的工具,甚至编写自定义代码进行实时监控和警报。通过使用监控框架,你可以构建一个完全自动化的机器学习管道,其中模型性能的任何显著下降都会触发 CI/CD 管道。这将导致在最新数据集上重新训练模型,并最终将最新模型部署到生产环境中。
如果你想了解构建、维护和执行端到端 ML 工作流所使用的重要工具,你应该查看2024 年需要了解的 25 大 MLOps 工具列表。
7. 项目
在本课程的最终步骤中,你将有机会利用迄今为止学到的所有内容构建一个端到端的机器学习项目。该项目将包括以下步骤:
-
选择一个你感兴趣的数据集。
-
在选定的数据集上训练模型并跟踪实验。
-
创建一个模型训练管道,并使用 GitHub Actions 自动化它。
-
将模型部署到批处理、Web 服务或流式服务中。
-
监控模型的性能,并遵循最佳实践。
收藏此页面:掌握 MLOps 的 10 个 GitHub 仓库。利用它来了解有关 MLOps 的最新工具、指南、教程、项目和免费课程。
结论
你可以注册一个 MLOps 工程师课程,该课程详细涵盖了所有七个步骤,帮助你获得必要的经验,来训练、跟踪、部署和监控生产中的机器学习模型。
在本指南中,我们了解了成为一名专业 MLOps 工程师所需的七个必要步骤。我们了解了工程师在云中自动化和简化训练、评估、版本控制、部署和监控模型过程所需的工具、概念和流程。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为面临心理疾病困扰的学生构建一个 AI 产品。
更多相关内容
掌握自然语言处理的 7 个步骤
原文:
www.kdnuggets.com/7-steps-to-mastering-natural-language-processing
作者提供的图片
现在是进入自然语言处理(NLP)最激动人心的时刻。你是否有一些构建机器学习模型的经验,并且对探索自然语言处理感兴趣?也许你已经使用了如 ChaGPT 这样的 LLM 驱动的应用程序,并且意识到它们的实用性,并希望深入研究自然语言处理?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 在 IT 领域支持你的组织
好吧,你可能还有其他理由。不过既然你已经在这里,这里有一个关于 NLP 的 7 步指南。在每一步中,我们提供:
-
你应该学习和理解的概念概述
-
一些学习资源
-
你可以构建的项目
让我们开始吧。
第一步:Python 和机器学习
第一步,你应该在 Python 编程上打下坚实的基础。此外,熟练掌握 NumPy 和 Pandas 这样的库用于数据处理也是必要的。在深入 NLP 之前,了解机器学习模型的基础知识,包括常用的监督学习和无监督学习算法。
熟悉如 scikit-learn 这样的库,它们使得实现机器学习算法变得更加容易。
总结一下,你需要知道以下内容:
-
Python 编程
-
熟练掌握类似 NumPy 和 Pandas 这样的库
-
机器学习基础(从数据预处理和探索到评估和选择)
-
熟悉监督学习和无监督学习两种范式
-
类似 Scikit-Learn 这样的 Python 机器学习库
查看这个 freeCodeCamp 提供的 Scikit-Learn 入门课程。
这是一些你可以进行的项目:
-
房价预测
-
贷款违约预测
-
用于客户细分的聚类
第二步:深度学习基础
在你掌握机器学习并对模型构建和评估感到舒适之后,你可以继续学习深度学习。
从理解神经网络、其结构以及如何处理数据开始。了解激活函数、损失函数和优化器,这些都是训练神经网络所必需的。
理解反向传播的概念,它促进了神经网络的学习,以及梯度下降作为优化技术。熟悉深度学习框架如 TensorFlow 和 PyTorch 以便于实际应用。
总结来说,你应该了解:
-
神经网络及其架构
-
激活函数、损失函数和优化器
-
反向传播和梯度下降
-
TensorFlow 和 PyTorch 等框架
以下资源将对学习 PyTorch 和 TensorFlow 的基础知识非常有帮助:
你可以通过以下项目来应用所学知识:
-
手写数字识别
-
CIFAR-10 或类似数据集上的图像分类
第 3 步:NLP 基础和重要语言学概念
首先了解 NLP 是什么及其广泛应用,从情感分析到机器翻译、问答系统等。
理解语言学概念,如分词,这涉及将文本分解为更小的单位(标记)。了解词干提取和词形还原,这些技术将单词还原为其根形式。
还需探索词性标注和命名实体识别等任务。
总结来说,你应该理解:
-
NLP 及其应用介绍
-
分词、词干提取和词形还原
-
词性标注和命名实体识别
-
基本语言学概念,如句法、语义和依存句法分析
CS 224n 的依存句法分析讲座提供了你所需语言学概念的良好概述。免费的书籍用 Python 进行自然语言处理(NLTK)也是一个很好的参考资源。
尝试构建一个命名实体识别(NER)应用程序,选择一个用例(如解析简历和其他文档)。
第 4 步:传统自然语言处理技术
在深度学习革命化 NLP 之前,传统技术奠定了基础。你应该理解词袋模型(BoW)和 TF-IDF 表示,这些方法将文本数据转换为机器学习模型所需的数值形式。
学习 N-grams,它们捕捉单词的上下文及其在文本分类中的应用。接着,探索情感分析和文本摘要技术。此外,理解隐马尔可夫模型(HMMs)用于词性标注等任务,矩阵分解及其他算法如潜在狄利克雷分配(LDA)用于主题建模。
因此,你应该熟悉:
-
词袋模型(BoW)和 TF-IDF 表示
-
N-grams 和文本分类
-
情感分析、主题建模和文本摘要
-
隐马尔可夫模型(HMMs)用于词性标注
这里有一个学习资源:完整的 Python 自然语言处理教程。
以及几个项目想法:
-
垃圾邮件分类器
-
在新闻源或类似数据集上的主题建模
第五步:深度学习用于自然语言处理
目前,你已经熟悉了 NLP 和深度学习的基础知识。现在,将你的深度学习知识应用于 NLP 任务。从词嵌入开始,例如 Word2Vec 和 GloVe,它们将单词表示为密集向量并捕捉语义关系。
然后深入学习序列模型,例如递归神经网络(RNNs),用于处理顺序数据。理解长短期记忆(LSTM)和门控递归单元(GRU),它们以捕捉文本数据中的长期依赖关系而著称。探索序列到序列模型用于诸如机器翻译等任务。
总结:
-
RNNs
-
LSTM 和 GRUs
-
序列到序列模型
CS 224n:深度学习自然语言处理 是一个优秀的资源。
一些项目想法:
-
语言翻译应用
-
在自定义语料库上的问答
第六步:使用 Transformers 进行自然语言处理
Transformers的出现彻底改变了 NLP 领域。了解注意力机制,这是 Transformers 的一个关键组成部分,使模型能够专注于输入的相关部分。了解 Transformer 架构及其各种应用。
你应该理解:
-
注意力机制及其重要性
-
Transformer 架构简介
-
Transformers 的应用
-
利用预训练语言模型;对预训练模型进行微调以适应特定的自然语言处理任务
学习 NLP 与 Transformers 最全面的资源是HuggingFace 团队的 Transformers 课程。
你可以构建的有趣项目包括:
-
客户聊天机器人/虚拟助手
-
文本情感检测
第七步:构建项目、继续学习并保持最新
在像自然语言处理这样的快速发展领域(或任何领域),你只能不断学习并通过更具挑战性的项目进行探索。
实践项目是必不可少的,因为它们提供了实际经验,并加深对概念的理解。此外,通过博客、研究论文和在线社区保持与自然语言处理研究社区的互动,将帮助你跟上 NLP 的最新进展。
OpenAI 的 ChatGPT 在 2022 年底上市,GPT-4 于 2023 年初发布。同时(我们已经看到并且仍在看到)有大量开源大型语言模型的发布、LLM 驱动的编码助手、新颖且资源高效的微调技术等。
如果你希望提升你的 LLM 技能,这里有一份由两部分组成的有用资源汇编:
-
大型语言模型的顶级免费课程
-
更多关于大型语言模型的免费课程
你还可以探索像 Langchain 和 LlamaIndex 这样的框架,以构建有用且有趣的 LLM 驱动的应用程序。
总结
希望你觉得这份掌握自然语言处理的指南对你有帮助。这里回顾了七个步骤:
-
第一步:Python 和机器学习基础
-
第二步:深度学习基础
-
第三步:自然语言处理基础和重要语言学概念
-
第四步:传统自然语言处理技术
-
第五步:自然语言处理的深度学习
-
第六步:使用变换器进行自然语言处理
-
第七步:构建项目,持续学习,并保持更新!
如果你在寻找教程、项目演练等,查看 KDnuggets 上的 自然语言处理资源合集。
Bala Priya C 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正在通过撰写教程、操作指南、观点文章等方式,学习并与开发者社区分享她的知识。
相关阅读
在本地 CPU 上运行小型语言模型的 7 个步骤
原文:
www.kdnuggets.com/7-steps-to-running-a-small-language-model-on-a-local-cpu
图像由 Freepik 提供
第 1 步:介绍
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织在 IT 方面
语言模型已经彻底改变了自然语言处理领域。虽然像 GPT-3 这样的巨大模型常常成为新闻头条,但小型语言模型同样具有优势,适用于各种应用。在本文中,我们将详细探讨小型语言模型的重要性及其使用场景,并逐步讲解所有实施步骤。
小型语言模型是其大型对应模型的紧凑版本。它们提供了几个优点。以下是一些优点:
-
效率: 与大型模型相比,小型模型需要的计算能力较少,使它们适合资源有限的环境。
-
速度: 它们可以更快地进行计算,例如更快地生成基于给定输入的文本,使它们非常适合实时应用程序,这些应用程序可能会有高频次的日常流量。
-
定制: 您可以根据领域特定任务的需求对小型模型进行微调。
-
隐私: 小型模型可以在没有外部服务器的情况下使用,从而确保数据隐私和完整性。
作者提供的图像
小型语言模型的多个使用场景包括聊天机器人、内容生成、情感分析、问答等。
第 2 步:设置环境
在我们深入探讨小型语言模型的工作原理之前,您需要设置您的环境,包括安装必要的库和依赖项。选择合适的框架和库来在本地 CPU 上构建语言模型变得至关重要。常见的选择包括基于 Python 的库,如 TensorFlow 和 PyTorch。这些框架提供了许多用于机器学习和深度学习应用的预构建工具和资源。
安装所需库
在此步骤中,我们将安装 "llama-cpp-python" 和 ctransformers 库,以便向你介绍小型语言模型。你必须打开终端并运行以下命令来安装它。在运行以下命令时,请确保你的系统上已安装 Python 和 pip。
pip install llama-cpp-python
pip install ctransformers -q
输出:
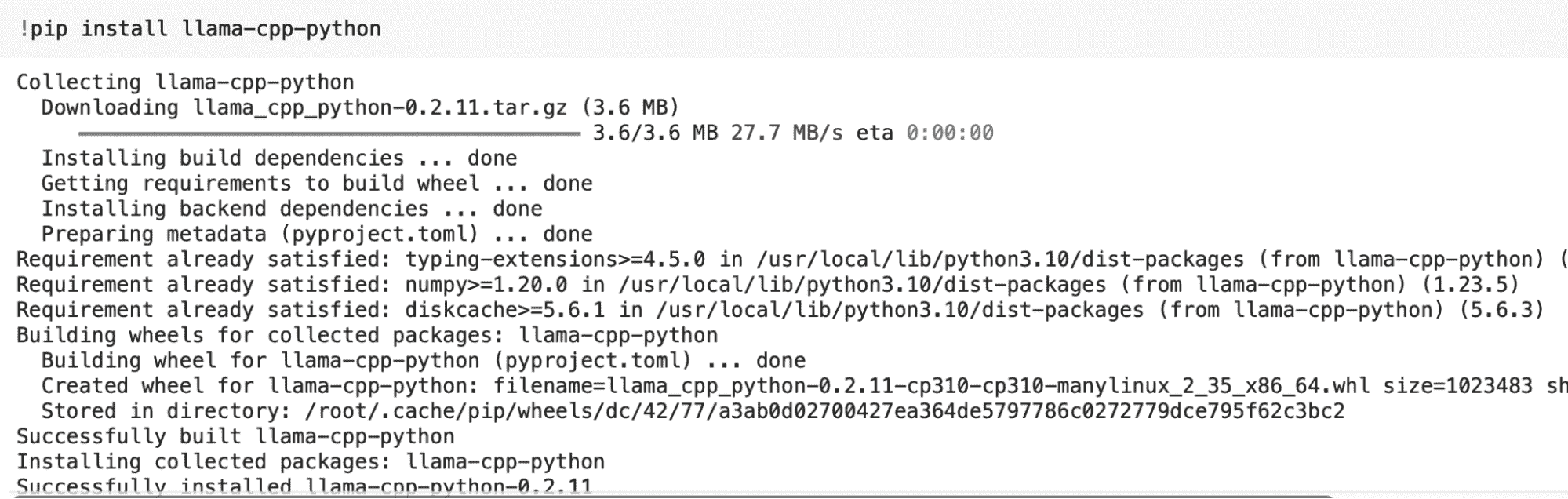

第三步:获取预训练的小型语言模型
现在我们的环境已经准备好,我们可以获取一个用于本地使用的预训练小型语言模型。对于小型语言模型,我们可以考虑像 LSTM 或 GRU 这样较简单的架构,这些架构在计算上比像 transformers 这样更复杂的模型要轻量。你还可以使用预训练的词嵌入来提高模型的性能,同时减少训练时间。但为了快速工作,我们将从网络上下载一个预训练模型。
下载预训练模型
你可以在像 Hugging Face (huggingface.co/models) 这样的平台上找到预训练的小型语言模型。这里是一个快速浏览网站的指南,你可以轻松观察到提供的模型序列,并通过登录应用程序下载这些开源模型。
你可以通过这个链接轻松下载所需的模型,并将其保存到本地目录以备后续使用。
from ctransformers import AutoModelForCausalLM
第四步:加载语言模型
在上一步中,我们已经确定了来自 Hugging Face 的预训练模型。现在,我们可以通过将其加载到我们的环境中来使用这个模型。我们在下面的代码中从 ctransformers 库中导入了 AutoModelForCausalLM 类。这个类可以用于加载和使用因果语言建模的模型。
图片来自 Medium
# Load the pretrained model
llm = AutoModelForCausalLM.from_pretrained('TheBloke/Llama-2-7B-Chat-GGML', model_file = 'llama-2-7b-chat.ggmlv3.q4_K_S.bin' )
输出:

第五步:模型配置
小型语言模型可以根据你的具体需求进行微调。如果你需要在实际应用中使用这些模型,主要需要记住的是效率和可扩展性。因此,为了使小型语言模型在性能上优于大型语言模型,你可以调整上下文大小和批处理(将数据划分为较小的批次以加快计算速度),这也有助于解决可扩展性问题。
修改上下文大小
上下文大小决定了模型考虑多少文本。根据你的需求,你可以选择上下文大小的值。在这个示例中,我们将此超参数的值设置为 128 个标记。
model.set_context_size(128)
提高效率的批处理
通过引入批处理技术,可以同时处理多个数据片段,这可以并行处理查询,并帮助扩展应用程序以支持大量用户。但在决定批量大小时,必须仔细检查系统的能力。否则,系统可能因负载过重而出现问题。
model.set_batch_size(16)
第 6 步:生成文本
到目前为止,我们已经完成了模型的创建、调优和保存。现在,我们可以根据我们的使用情况快速测试模型,并检查它是否提供了我们期望的输出。因此,让我们输入一些查询并基于我们加载和配置的模型生成文本。
for word in llm('Explain something about Kdnuggets', stream = True):
print(word, end='')
输出:

第 7 步:优化和故障排除
为了获得适当的结果以满足大多数输入查询,您可以考虑以下事项。
-
微调: 如果您的应用程序需要高性能,即查询的输出需要在显著更短的时间内解决,那么您需要在特定的数据集上对模型进行微调,即您正在训练模型的语料库。
-
缓存: 通过使用缓存技术,您可以将基于用户的常用数据存储在内存中,以便当用户再次请求这些数据时,可以轻松提供,而不是从磁盘中重新提取,这样会花费相对更多的时间,从而有助于加快未来请求的处理速度。
-
常见问题: 如果在创建、加载和配置模型时遇到问题,您可以参考文档和用户社区的故障排除提示。
总结
在本文中,我们讨论了如何通过遵循文章中概述的七个简单步骤,在本地 CPU 上创建和部署小型语言模型。这种经济高效的方法为各种语言处理或计算机视觉应用打开了大门,并为更高级的项目提供了一个踏脚石。但在进行项目时,您需要记住以下事项以克服任何问题:
-
在训练过程中定期保存检查点,以确保您可以在中断时继续训练或恢复您的模型。
-
优化您的代码和数据管道,以提高内存使用效率,特别是在使用本地 CPU 时。
-
如果您将来需要扩展模型,考虑使用 GPU 加速或基于云的资源。
总之,小型语言模型为各种语言处理任务提供了多功能且高效的解决方案。通过正确的设置和优化,您可以有效地利用它们的强大功能。
Aryan Garg**** 是一名电气工程学的 B.Tech.学生,目前正在本科的最后一年。他的兴趣领域包括网页开发和机器学习。他已经追求了这一兴趣,并渴望在这些方向上做更多的工作。
了解更多相关话题
7 个你需要掌握的超级备忘单以应对机器学习面试
原文:
www.kdnuggets.com/2022/12/7-super-cheat-sheets-need-ace-machine-learning-interview.html

图片由作者提供
在这篇文章中,你将学习机器学习和深度学习的算法和框架。此外,你还将学习如何处理数据、选择指标以及提高模型性能的小窍门。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
最后也是最重要的备忘单是关于机器学习面试问题及答案,并附有视觉示例。
机器学习算法备忘单
机器学习算法 备忘单涵盖了算法的描述、应用、优缺点。它是你进入监督和无监督机器学习模型世界的门户,在这里你将学习到线性模型和基于树的模型、聚类以及关联分析。
图片来源于 备忘单
备忘单包含:
-
线性回归
-
逻辑回归
-
岭回归
-
Lasso 回归
-
决策树
-
随机森林
-
梯度提升回归
-
XGBoost
-
LightGBM 回归器
-
K-Means
-
层次聚类
-
高斯混合模型
-
Apriori 算法
Scikit-learn 机器学习备忘单
Scikit-learn 机器学习备忘单 包含了 Scikit-learn 的数据加载、数据拆分、监督和无监督模型、预测、模型评估和模型调优的 API。
你将学习数据处理、特征工程、应用各种模型以及使用 Grid Search 改善模型性能。

图片来源于 备忘单
备忘单包含:
-
数据加载
-
训练和测试数据
-
数据预处理
-
监督学习模型
-
无监督学习模型
-
模型拟合
-
预测
-
评估
-
交叉验证
-
模型调优
机器学习技巧和窍门备忘单
机器学习技巧和窍门 备忘单主要涉及模型指标、模型选择和评估。这是一份由斯坦福大学提供的网络备忘单,您可以了解分类和回归、交叉验证和正则化,以及偏差与方差的权衡。
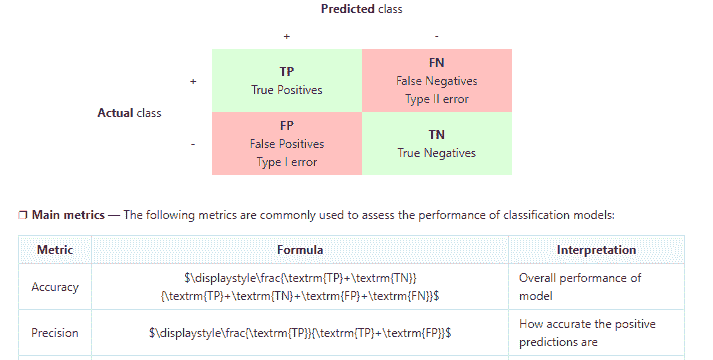
来自 备忘单 的图片
备忘单包括:
-
分类指标
-
回归指标
-
模型选择
-
诊断
深度学习超级 VIP 备忘单
深度学习超级 VIP 备忘单解释了深度学习的各种组件,通过图表和数学讲解。您将学习卷积神经网络、递归神经网络、深度学习技巧和窍门,深入了解计算机视觉和自然语言处理模型。
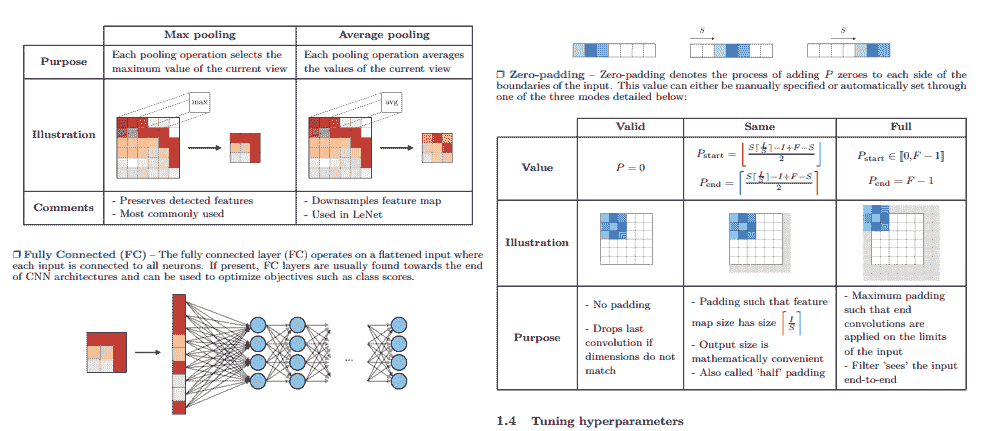
来自 备忘单 的图片
备忘单包括:
-
神经网络层的类型
-
筛选超参数
-
调整超参数
-
常用激活函数
-
对象检测
-
处理长期依赖关系
-
学习词向量表示
-
比较词汇
-
语言模型
-
机器翻译
-
注意力
-
数据处理
-
训练神经网络
-
参数调整
-
正则化
Keras 中的神经网络备忘单
在 Keras:Python 中的神经网络 备忘单中,您将学习如何处理和准备神经网络模型的数据。此外,您将学习如何构建模型架构、编译、训练、调优以及执行模型评估。
这份备忘单是快速复习 Keras 命令和学习新知识的好方法。

来自 备忘单 的图片
备忘单包括:
-
加载数据
-
预处理
-
模型架构
-
预测
-
检查模型
-
编译模型
-
模型训练
-
模型评估
-
保存和重新加载模型
-
模型微调
使用 Pytorch 的深度学习备忘单
PyTorch 官方备考清单包括处理数据和构建深度学习模型的命令和 API。它是一个为有经验的 PyTorch 用户提供的简明 API。

图片来源于备考清单
备考清单包括:
-
导入: 神经网络 API、Torchscript 和 JIT、ONNX、Vision 以及分布式训练。
-
张量: 创建、维度、代数以及 GPU 使用。
-
深度学习: 损失函数、激活函数、优化器和学习率调度。
-
数据工具: 数据集、数据加载器和数据采样器。
机器学习面试备考清单
在机器学习面试备考清单中,作者通过图形化表示解释了机器学习面试中最常见的问题。该备考清单将帮助你通过了解各种机器学习算法、问题、权衡、数据处理和模型调优来在面试中取得成功。

图片来源于备考清单
面试备考清单包括:
-
偏差与方差
-
数据不平衡
-
贝叶斯定理
-
降维
-
回归
-
正则化
-
卷积神经网络
-
著名的深度神经网络
-
集成学习
-
自编码器和变分自编码器
结论
除了备考清单,你还可以阅读书籍、参加编码评估测试,甚至与同事进行模拟面试,以提高通过面试阶段的几率。
我强烈推荐你阅读征服数据科学面试 这本书,并参加LeetCode 75的数据科学和机器学习面试学习计划。
如果你喜欢我的工作,请在社交媒体上分享,或者如果你对职业有任何疑问,可以通过LinkedIn联系我。
Abid Ali Awan (@1abidaliawan) 是一名认证数据科学专业人士,他热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为那些面临心理健康问题的学生开发一个人工智能产品。
更多相关话题
处理不平衡数据的 7 种技术
原文:
www.kdnuggets.com/2017/06/7-techniques-handle-imbalanced-data.html
作者:Ye Wu & Rick Radewagen
介绍
像银行欺诈检测、市场实时竞标或网络入侵检测等领域的数据集有什么共同之处?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
这些领域使用的数据通常少于 1% 是稀有但“有趣”的事件(例如,欺诈者使用信用卡、用户点击广告或受损服务器扫描其网络)。然而,大多数机器学习算法在处理不平衡数据集时效果并不好。以下七种技术可以帮助你训练一个分类器来检测异常类别。
1. 使用正确的评估指标
使用不平衡数据生成模型时应用不适当的评估指标可能会很危险。假设我们的训练数据如上图所示。如果使用准确率来衡量模型的好坏,一个将所有测试样本分类为“0”的模型将具有优秀的准确率(99.8%),但显然,这个模型对我们没有任何有价值的信息。
在这种情况下,还可以应用其他替代评估指标,如:
-
精确率/特异性:选择的实例中有多少是相关的。
-
召回率/敏感性:选择了多少相关实例。
-
F1 分数:精确率和召回率的调和均值。
-
MCC:观察到的二分类和预测二分类之间的相关系数。
-
AUC:真实正例率和假正例率之间的关系。
2. 重新采样训练集
除了使用不同的评估标准外,还可以尝试获取不同的数据集。从不平衡数据集中制作平衡数据集的两种方法是欠采样和过采样。
2.1. 欠采样
欠采样通过减少大量类别的大小来平衡数据集。当数据量足够时使用这种方法。通过保留稀有类别中的所有样本,并随机选择大量类别中的相同数量样本,可以获得一个平衡的新数据集以进行进一步建模。
2.2. 过采样
相反,当数据量不足时使用过采样。它试图通过增加稀有样本的大小来平衡数据集。不是去除丰裕样本,而是通过使用例如重复、自助法或 SMOTE(合成少数类过采样技术)[1]生成新的稀有样本。
请注意,没有一种重采样方法比另一种方法绝对优越。这两种方法的应用取决于其适用的用例和数据集本身。过采样和欠采样的组合通常也会成功。
3. 以正确的方式使用 K 折交叉验证
值得注意的是,使用过采样方法时,交叉验证应正确应用,以解决不平衡问题。
请记住,过采样会取出观察到的稀有样本,并应用自助法生成基于分布函数的新随机数据。如果在过采样后应用交叉验证,那么我们实际上是在将模型过拟合到特定的人工自助结果。这就是为什么交叉验证应始终在数据过采样之前进行,就像特征选择应实施一样。只有通过重复重采样数据,才能将随机性引入数据集,确保不会出现过拟合问题。
4. 集成不同的重采样数据集
成功地推广模型的最简单方法是使用更多数据。问题在于,开箱即用的分类器,如逻辑回归或随机森林,往往通过丢弃稀有类来进行泛化。一个简单的最佳实践是构建 n 个模型,这些模型使用稀有类的所有样本和 n 个不同的丰裕类样本。假设你要集成 10 个模型,你会保留例如稀有类的 1,000 个案例,并随机抽取 10,000 个丰裕类案例。然后你只需将这 10,000 个案例分成 10 个块,并训练 10 个不同的模型。
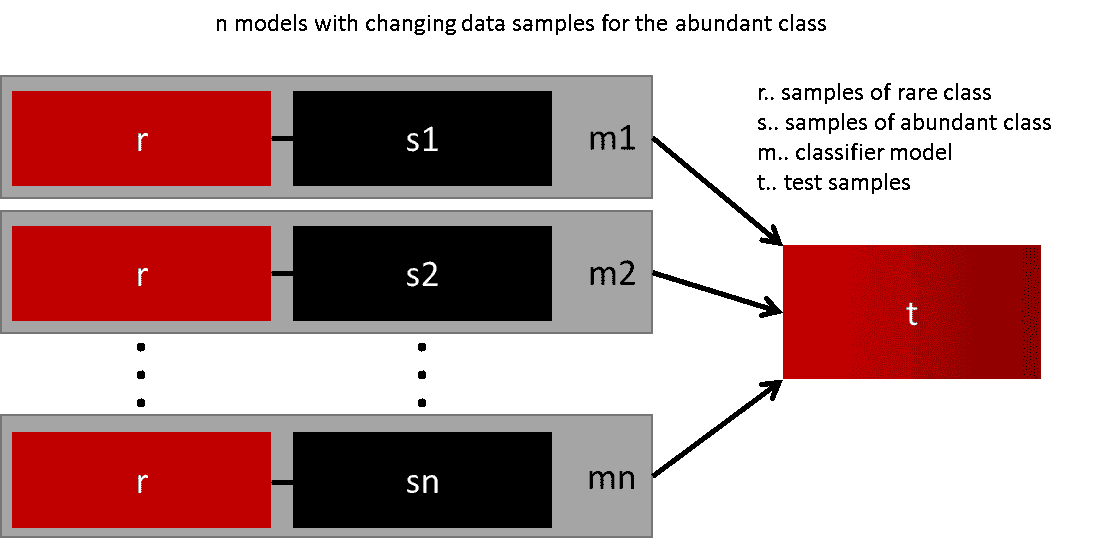
这种方法很简单,如果你有大量数据,它在水平扩展上也非常好,因为你可以在不同的集群节点上训练和运行模型。集成模型通常也能更好地进行泛化,这使得这种方法易于处理。
5. 使用不同的比例重采样
之前的方法可以通过调整稀有类和丰裕类之间的比例来进行微调。最佳比例严重依赖于数据和所使用的模型。但不是所有模型都以相同的比例进行集成,值得尝试集成不同的比例。因此,如果训练 10 个模型,可能会有一个模型的比例是 1:1(稀有:丰裕),另一个是 1:3,甚至是 2:1。根据所用模型,这可以影响一个类获得的权重。
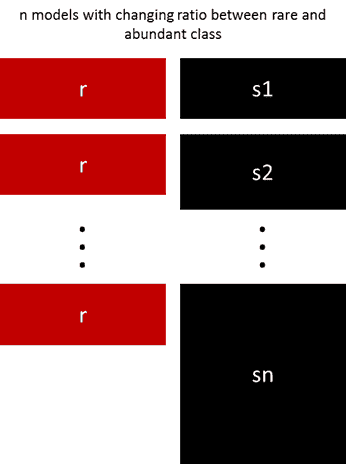
6. 对丰裕类进行聚类
Sergey 在 Quora 上提出了一种优雅的方法[2]。他建议将丰富类划分为 r 组,其中 r 为 r 中的案例数,而不是依赖随机样本来覆盖训练样本的多样性。对于每个组,仅保留 medoid(簇的中心)。然后仅用稀有类和 medoids 来训练模型。
7. 设计你的模型
之前的方法都集中于数据,并将模型作为固定组件。但实际上,如果模型适用于不平衡数据,则无需重新抽样数据。著名的 XGBoost 已经是一个很好的起点,如果类别没有过于偏斜,因为它内部会处理所训练的袋子不平衡的问题。但即使如此,数据确实会被重新抽样,只是这个过程是秘密进行的。
通过设计一个对稀有类别错误分类给予更高惩罚的成本函数,可以设计出许多自然倾向于稀有类别的模型。例如,调整 SVM,以相同的比例惩罚稀有类别的错误分类,这个比例是该类别的不足比例。
最后的备注
这不是处理不平衡数据的独家技术列表,而是处理不平衡数据的起点。没有一种最适合所有问题的方法或模型,强烈建议尝试不同的技术和模型,以评估哪个效果最好。尝试创造性地结合不同的方法。还需要注意的是,在许多领域(例如欺诈检测、实时竞标)中,不平衡类别发生时,“市场规则”是不断变化的。因此,检查过去的数据是否可能已变得过时。
[1] arxiv.org/pdf/1106.1813.pdf
Ye Wu 是 FARFETCH 的高级数据分析师。她具有会计背景,并在市场营销和销售预测方面有实际经验。
Rick Radewagen 是 Sled 的共同创建者,同时也是一位有计算机科学背景的有抱负的数据科学家。
更多相关主题
你可能不知道的 7 种低代码工具应用
原文:
www.kdnuggets.com/2022/09/7-things-didnt-know-could-low-code-tool.html
今天我想打破一些神话。我想揭示一个低代码工具只能解决简单问题的误解。特别是,我想带你参观使用开源低代码工具进行数据科学开发的应用,例如 KNIME Analytics Platform 和它的商业对应产品 KNIME Server。例如,你知道使用 KNIME 软件可以连接到传感器板并将数据传输到仓库吗?或者你可以用深度学习模型创作音乐?或者你可以用 GANs 制作深度伪造图像?或者进行网页抓取?或者连接到云端的数据仓库?或者将应用程序部署为 REST 服务?或者构建仪表板?所有这些都可以通过低代码,甚至是非常低代码来实现。
让我们开始这次 tour。
1. 从传感器板获取传感器数据
我想展示的第一个低代码解决方案是一个物联网应用,具体来说,是一个将数据从传感器板传输到数据仓库的 web 服务。通常,物联网问题涉及传感器连接、数据存储设置以及可选的时间序列分析来预测未来。我们也挑战自己解决了一个物联网问题,并建立了一个完全依赖 KNIME 软件的温度预测解决方案。具体来说,该项目的目标是了解第二天会有多热,即一个温度预测解决方案。
气象站由两个主要部分组成:数据收集部分和数据预测部分。
数据收集:
-
一个传感器板
-
一个用于数据存储的数据仓库
-
一个 REST 服务,将数据从传感器板传输到数据存储
数据预测:
-
一个经过训练的 sARIMA 模型,用于预测下一小时的温度
-
一个用于清理和处理获取的数据,并训练 sARIMA 模型的应用
-
一个仪表板应用,用于使用 sARIMA 模型预测下一小时的温度,以及预测第二天的最低和最高温度。
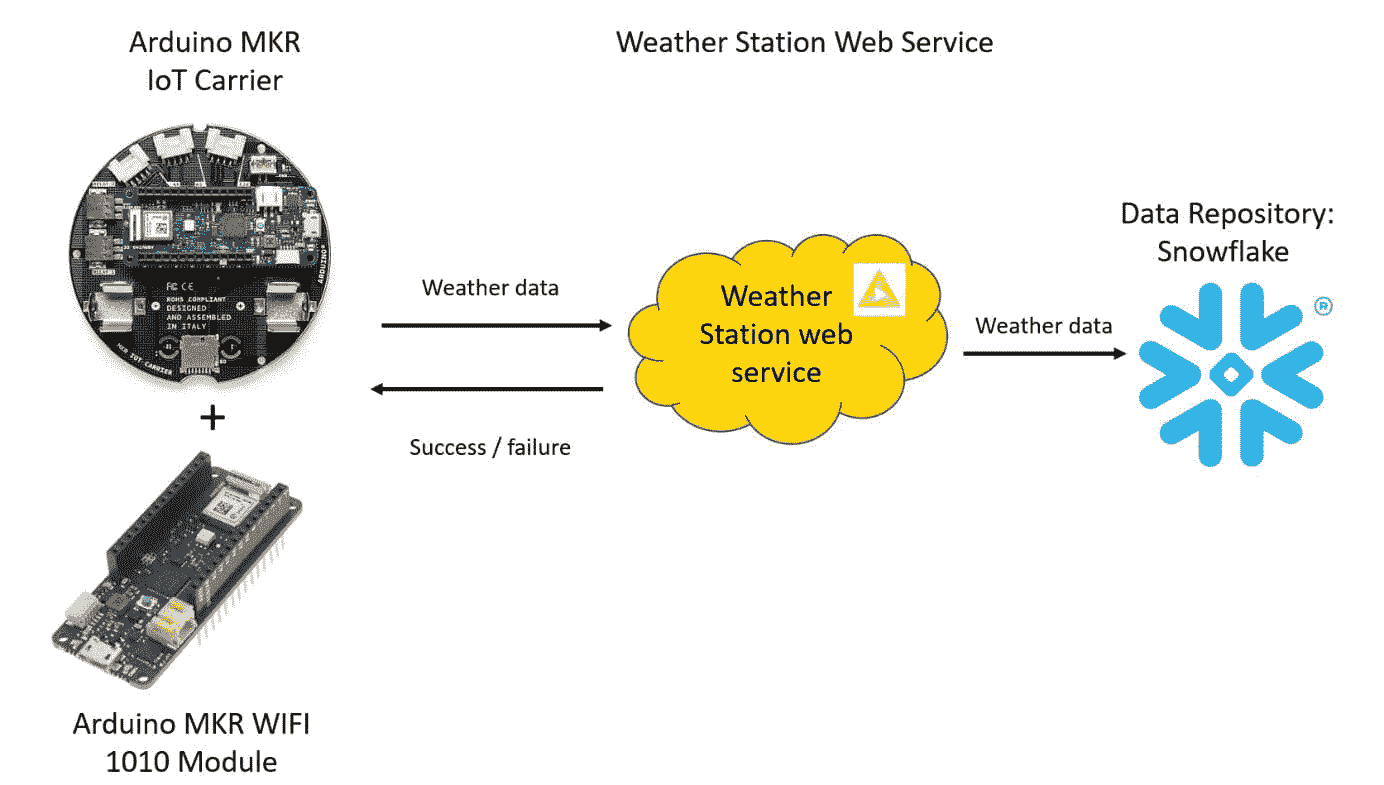
图 1. 负责收集物联网传感器数据的 web 服务是用 KNIME 软件实现的。
每当有新的样本可用时,传感器板会触发数据收集的 REST 服务。REST 服务的唯一任务是验证请求数据的完整性,并将其存储到数据仓库中。
你可以在 KNIME Hub 文件夹 “KNIME Weather Station” 中找到所有用于构建这个气象站的应用程序,更多细节可以参考 KNIME 博客中的这篇文章 “Temperature Forecast from IoT sensor data”。
2. 通过 iPhone 截图导入书籍元数据
类似于从传感器板传输数据的问题,还有从手机传输图像的问题。在这个第二个应用程序中,我们构建了一个书籍库存应用程序。在这里,一个 web 服务从 iPhone 接收一本书的照片,提取书籍元数据和封面,并通过 KNIME Server 将所有信息保存到最终的存储库中。
-
一个原生的定制移动应用通过 iPhone 相机捕捉书籍版权页的图像,将其转换为 base64 编码,并以请求对象的形式发送到 KNIME Server 上的 web 服务。这个 iPhone 应用的代码是按照 Apple 提供的规格实现的。
-
该 web 服务接受图像,通过 OCR 提取 ISBN 识别码,通过 Google Books 检索书籍元数据和封面图像,并最终将信息存储到数据存储库中(例如 SQLite 数据库)。
执行传输的 web 服务是使用 KNIME Analytics Platform 实现的,实际上非常简单,如图 1 所示。制作这个 web 服务只用了一行 Python 代码,具体在 “Decode base64 image” 元节点中。这行代码嵌入在 Python 脚本节点中,并引用了 Python 中的 base64.decodebytes() 函数。
你可以从 KNIME Hub 免费下载工作流。
图 2. 一个无代码的 RESTful API,从 iPhone 应用中导入截图,从 ISBN 识别码中提取书籍元数据和封面图像,并将其存储在数据库中。
3. 将应用程序部署为 REST 服务
说到 REST 服务,你能想象使用 KNIME 创建 REST 服务有多简单吗?图 3 展示了一个示例。你只需要一个容器输入节点来接受请求中的数据,一个容器输出节点来提供响应的数据,以及中间的所有必要操作。实际上,每个移到 KNIME 服务器上的 KNIME 工作流都会自动作为 REST 服务生产化。因此,你所需要的只是两个用于数据输入和输出的容器节点。
图 3. 包含容器节点以设置请求和响应数据结构的 KNIME 工作流,可部署为 REST 服务
通过 KNIME 工作流组装 REST 服务的过程在这篇文章 “探索 REST 能力以实现 RESTful 工作流” 中进行了说明。作为 REST 服务在 KNIME 服务器上执行 KNIME 工作流的过程在这篇文章 “KNIME REST 服务器 API” 中进行了说明。
4. 构建仪表盘
不是所有的应用程序都作为 REST 服务投入生产。有些应用程序作为 web 应用程序部署,具有美观的仪表盘在网页浏览器上运行。使用 KNIME Analytics Platform 构建更复杂或简单的仪表盘也是可能的(而且很容易)。
Widget 和数据可视化节点提供视图项。将这些节点组装成一个组件,会生成一个复合视图,结合和关联组件内所有视图项的图形节点。图 4. 显示了由一个非常简单但强大的组件生成的仪表盘示例。正如你所见,一些条形图和表格视图节点生成了一个复杂的仪表盘,包含连接和交互的表格及条形图。
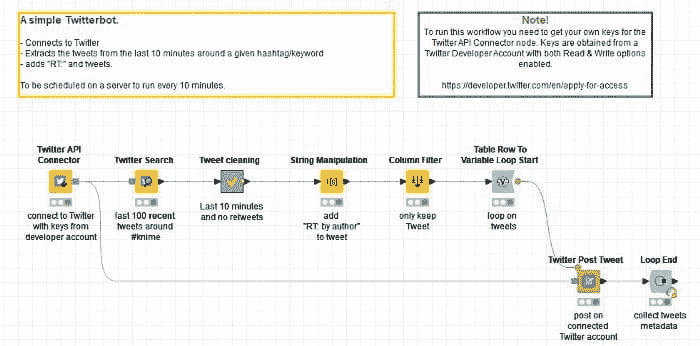
图 4. 负责创建仪表盘(右侧)的组件内容(左侧)。
该应用的参考文章是 “使用非常简单的组件创建仪表盘”,刊登在 Medium 杂志“高级数据科学的低代码”。相应的工作流也可在KNIME Hub上找到。
5. 使用深度学习模型创建音乐
够了工程类型的任务!下一个问题是:像 KNIME Analytics Platform 这样的低代码工具能否实现先进的数据科学应用?让我们开始另一个探索。
KNIME Analytics Platform 提供了广泛的机器学习算法:从聚类到决策树,从随机森林到 XGBoost,从梯度提升树到回归,以及从神经网络到深度学习。使用基于 Keras 库的KNIME 深度学习扩展,可以将实现不同神经层的不同节点组合在一起,创建不同类型的神经架构。
在图 5 中,棕色节点实现了神经层。神经架构相当复杂,包括三个输入层和三个输出层并行,因为音乐由三组向量序列表示:音符、时值和偏移量。该网络在舒伯特音乐数据上进行了训练,以生成音乐。尽管构建复杂,该网络的构建、训练和部署都无需编写一行代码。在“AI 演奏钢琴”中聆听该网络生成的音乐样本。
这个项目的详细信息在文章“我的 AI 为我弹钢琴”中报告,刊登在“低代码高级数据科学”期刊上。
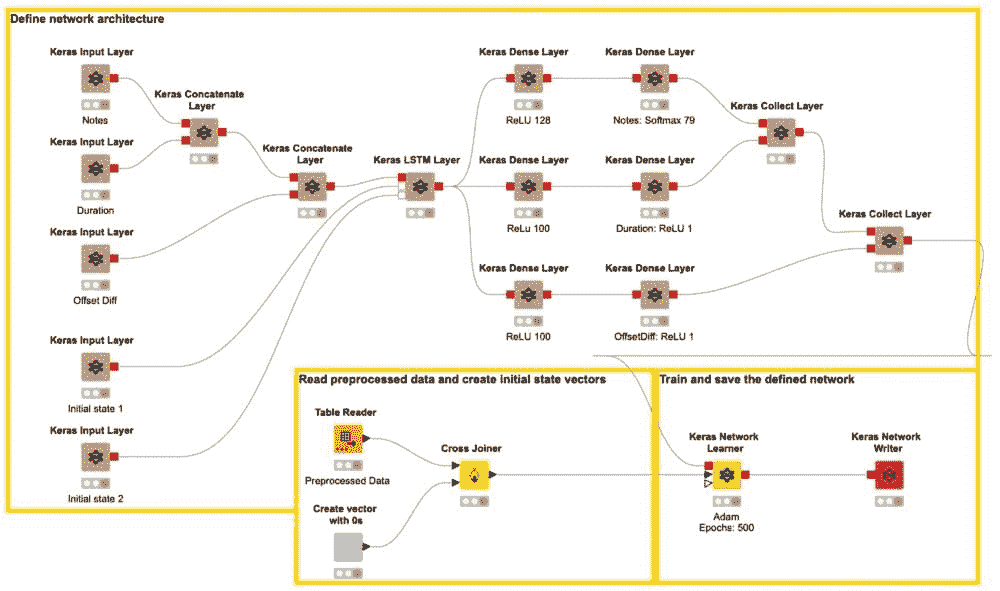
图 5. 这个深度学习网络包含一层 LSTM 单元,经过训练以生成舒伯特风格的音乐。
这个 AI 音乐生成项目实际上是对之前 AI 说唱歌曲(以及莎士比亚文本)生成项目的扩展。相关的文章“使用深度学习像莎士比亚一样写作”也可以在同一 Medium 杂志中找到。
6. 使用 GANs 创建假图像
另一个有趣的应用是生成对抗网络(GANs)在图像生成中的应用,在我们的案例中是生成面孔。
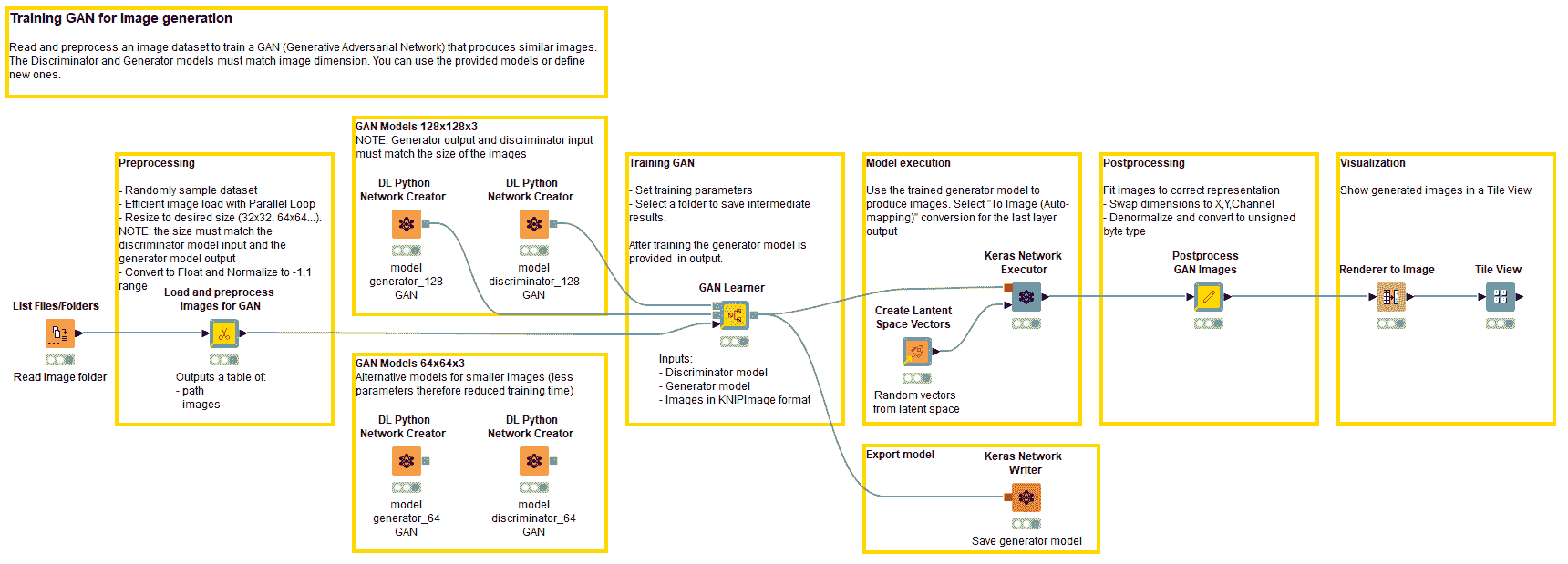
图 6. 这个工作流程实现了一个 GAN,并在面孔数据集上进行了训练。
由于 KNIME 深度学习扩展目前尚未提供生成器和判别器层,因此在这里采用了 Python-KNIME 混合方法。所需的几行 Python 代码被打包在一个 KNIME 组件节点中,名为 DL Python Creator。不同参数的 DL Python Creator 组件实例分别实现了 GAN 的生成器和判别器部分(图 6)。一旦打包在组件中,所需的 Python 代码可以像处理其他 KNIME 节点一样处理,无需读取或更改底层代码。
使用了一个流行的 Github 面孔数据集 来训练该网络。请注意,该数据集包含大量高分辨率彩色图像,因此训练该网络的计算量相当大。深度学习包的 GPU 加速使得在合理的时间内训练网络成为可能。
然后使用该网络生成假面孔,您可以在图 7 中查看结果。
关于此应用的更多细节可见于 Medium Journal “Low Code for Advanced data science” 上的文章 如何用 KNIME Analytics Platform 创建 GAN。
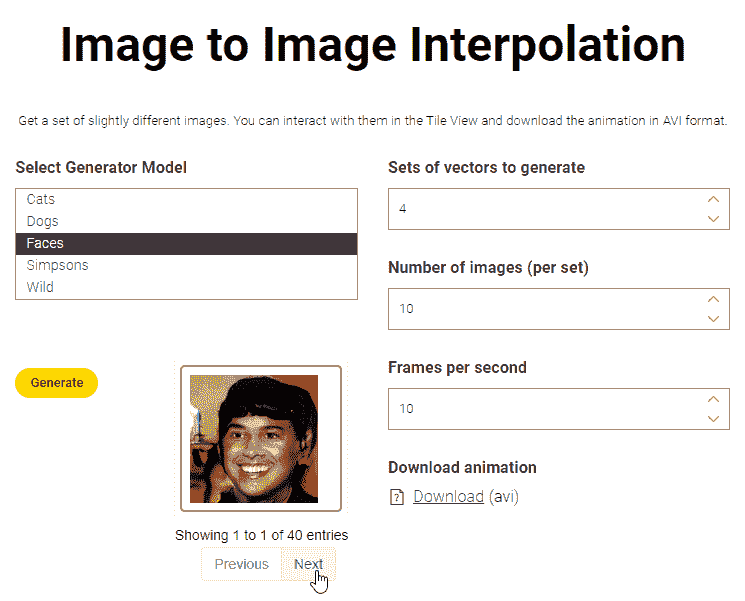
图 7. 由我们训练的 GAN 生成的一些虚假面孔。
7. 构建一个推特机器人
我想在我的列表中插入的最后一个应用是推特机器人。也就是说,一个应用程序(机器人)访问推特,提取所有包含给定标签的推文,然后转发这些推文。实现这个推特机器人的工作流相当简单(图 8)。它访问一个推特账户,执行对选定标签的搜索,进行一些清理,如删除转发的推文,然后重新发布所有剩余的推文。
该应用程序在期刊“Low Code for Advanced data science”中的文章 “确认你是机器人” 中有所描述。
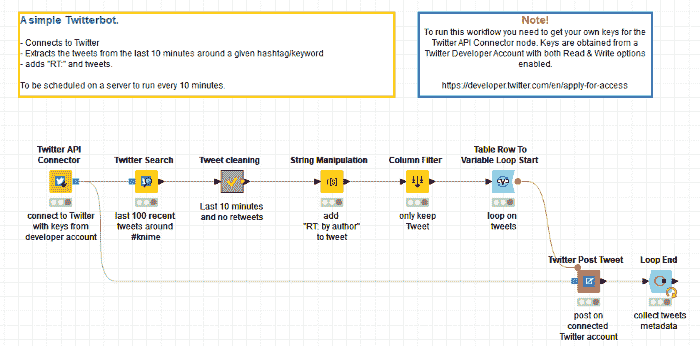
图 8. 实现推特机器人的工作流。
结论
这些简单的工作流只是低代码世界中某些任务变得如此轻松的一个例子,相较于编码世界。实际上,连接节点——所有连接节点——必须实现所有所需操作以访问选定的数据源。这使得连接操作变得像拖放一样简单,并将所需的权限、驱动程序和配置的所有复杂性隐藏在用户的视线之外。
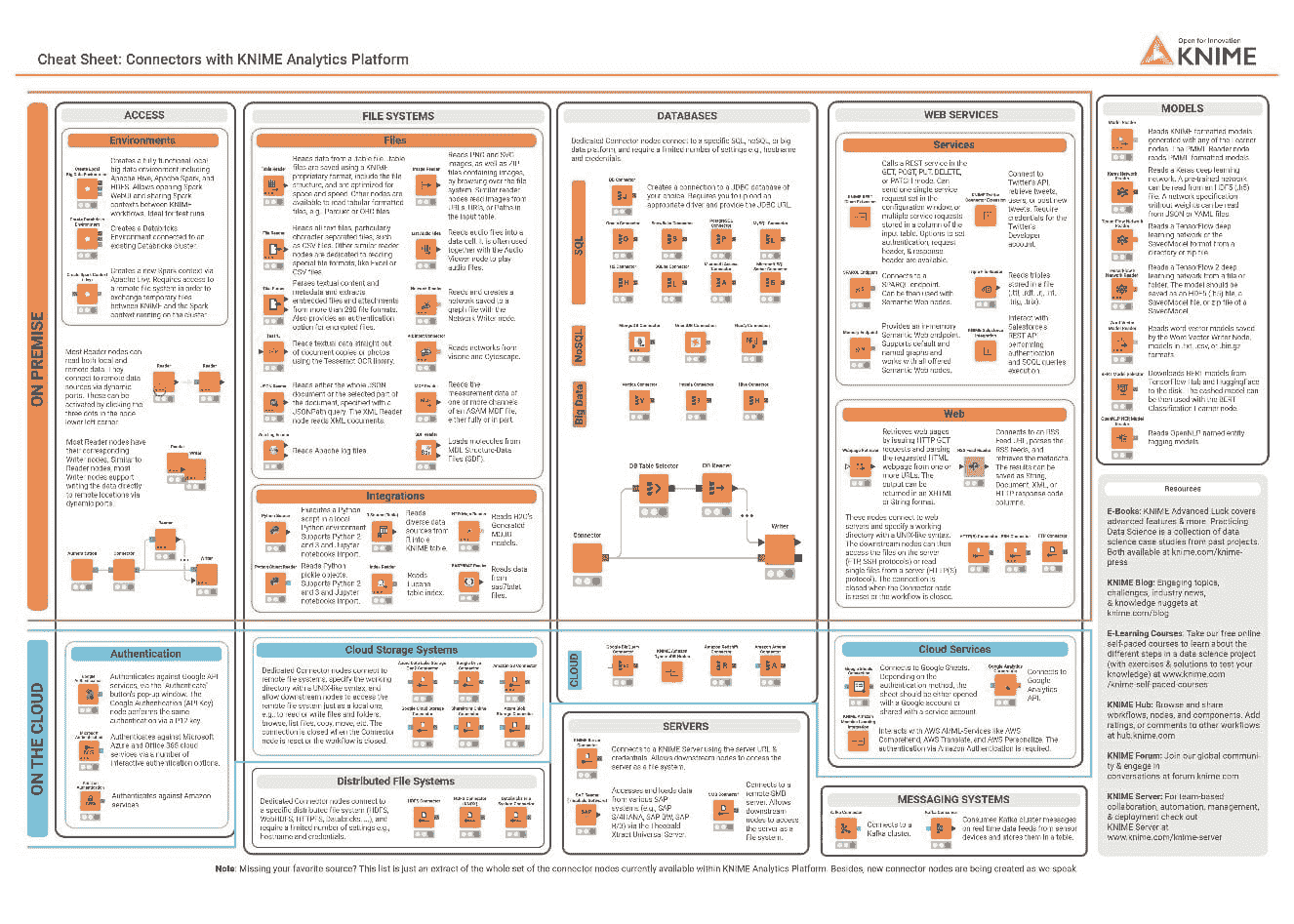
图 9. KNIME 连接器备忘单。
KNIME Analytics Platform,例如,包含了大量这样的高级连接节点,以访问各种数据源,如 SQL 和 noSQL 数据库、REST 服务、云存储、大数据平台、Spark、Kafka、各种文件、MS Office 文档、Google 文档等等。通过 KNIME 连接器可以访问的大部分数据源见图 9。此备忘单可以从 KNIME 网站的页面 “KNIME Connector Cheatsheet.pdf” 免费下载。
Rosaria Silipo不仅在数据挖掘、机器学习、报告和数据仓库方面是一位专家,还成为了 KNIME 数据挖掘引擎的公认专家,她已出版了三本相关书籍:《KNIME 初学者的好运》、《KNIME Cookbook》 和 《KNIME Booklet for SAS Users》。Rosaria 曾在整个欧洲为许多公司担任自由数据分析师。她还曾在 Viseca(苏黎世)领导 SAS 开发团队,在 Spoken Translation(加州伯克利)用 C#实现语音转文字和文字转语音接口,并在 Nuance Communications(加州门洛帕克)开发了多种语言的语音识别引擎。Rosaria 于 1996 年在意大利佛罗伦萨大学获得生物医学工程博士学位。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关主题
学生在数据科学简历中遗漏的 7 件事
原文:
www.kdnuggets.com/7-things-students-are-missing-in-a-data-science-resume

作者提供的图片
回顾我作为学生的日子,我现在意识到我的数据科学简历中缺少了一些关键要素。这些不足可能导致我被多种职位拒绝。我不仅无法向潜在团队展示自己作为有价值的资产的能力,还难以展示解决数据科学问题的能力。然而,随着时间的推移,我逐渐进步,并与多个团队合作,找出我遗漏的内容以及如果重新开始,我该如何做得更好。
在这篇博客中,我将分享学生们在数据科学简历中常常忽略的 7 件事,这些遗漏可能会导致招聘经理不联系他们面试。
1. 简单且易读的简历
使简历复杂化,如使用技术术语、过多的信息或非常规格式,可能会导致其立即被拒绝。你的简历应该易于阅读和理解,即使是对数据科学不太熟悉的人也能明白。使用简洁、专业的布局,配有明确的标题、项目符号和标准字体。避免使用密集的文本块。记住,目标是尽可能快速有效地向招聘经理传达你的技能和经历。
2. 可量化的成就
当你在经历部分列出你以前的工作经历或项目时,建议专注于量化的成就,而不是仅仅列出你的职责。
例如,不要只是写“开发了机器学习模型”,你可以写成“开发了一个提高销售额 15%的机器学习模型。”这将展示你工作的实际影响,并展示你推动结果的能力。
3. 数据科学特定技能
在列出你的技术技能时,至关重要的是要突出与数据科学直接相关的技能。避免包括与数据科学无关的技能,如平面设计或视频编辑。保持技能列表简洁,并写明你在每项技能上的经验年限。
确保提及编程语言,如 Python 或 R,数据可视化工具,如 Tableau 或 Power BI,以及数据分析工具,如 SQL 或 pandas。此外,值得提及你使用过流行的机器学习库,如 PyTorch 或 scikit-learn 的经验。
4. 软技能和团队合作
数据科学不仅仅依赖于技术能力。合作和沟通技能同样重要。包括你作为团队成员工作的经历,尤其是在多学科环境中或将复杂数据洞察传达给非技术利益相关者的经历,可以展示你的软技能。
5. 真实世界经验
雇主重视数据科学领域的实践经验。如果你完成了数据科学的实习、项目或研究,一定要在简历中突出这些经历。包括你参与的项目、使用的工具和技术以及取得的成果。
学生们常常低估展示相关项目的重要性。无论是课堂作业、顶点项目还是你为乐趣而制作的东西,都要包括展示你在数据分析、编程、机器学习和问题解决方面技能的项目。务必描述项目目标、你的角色、使用的工具和技术,以及成果。GitHub 仓库或项目网站的链接也可以增加可信度。
6. 适应能力和解决问题的技能
数据科学领域不断发展,雇主正在寻找能够适应新挑战和技术的候选人。
作为数据科学家,你可能会发现自己在几个月内从数据分析师跳到机器学习工程师。你的公司甚至可能要求你在生产环境中部署机器学习模型并学习如何管理它们。
数据科学家的角色是流动的,你需要在心理上为角色变化做好准备。你可以通过突出任何需要快速学习新工具或技术的经历,或成功解决复杂问题的经历,来展示你的适应能力和解决问题的能力。
7. 专业作品集的链接
创建一个在线作品集并在简历中分享是非常重要的。这将使招聘经理能够快速查看你的过去项目及你用于解决特定数据问题的工具。你可以查看创建数据科学作品集的顶级免费平台:7 个免费平台构建强大的数据科学作品集
未能包含指向你的 GitHub 仓库或展示你项目的个人网站的链接是一个错失的机会。
最终思考
提交简历时,需要根据职位要求进行修改。查找工作所需的技能,并尝试在简历中包含这些技能,以增加获得面试机会的可能性。除了简历,网络和 LinkedIn 在寻找工作和自由项目方面也非常有帮助。持续维护你的 LinkedIn 个人资料并定期发布内容,可以大大提高你的职业存在感。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一款人工智能产品,帮助那些在精神健康方面挣扎的学生。
更多相关主题
数据科学项目管理的 7 个技巧
原文:
www.kdnuggets.com/2023/03/7-tips-data-science-project-management.html

图片由 freepik 提供
项目管理是数据科学中的一个重要方面。良好的项目管理技能将有助于提高你的效率和生产力。本文将讨论一些管理数据科学项目的技巧。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
1. 提出正确的问题
提出正确的问题是数据科学项目中最重要的步骤之一。你需要确定你希望从数据中获得什么见解。在某些情况下,你甚至需要在数据收集过程之前就提出正确的问题。
2. 收集数据
你有可供分析的数据吗?如果数据已经存在,你可以进入下一步。如果数据不可用,你可能需要找出如何收集数据,例如通过调查,或购买已经存在的数据。如果你需要自己收集数据,需要注意以下几点:所需数据的数量、数据收集所需时间以及数据收集的成本。你还需要确保数据能够代表整体人群。不论你的数据来自何处,确保所收集的数据质量良好,因为不良数据会产生低质量且不可靠的预测模型。
3. 清理和处理数据
任何收集的数据都会存在缺陷,如缺失数据或数据可能以错误格式输入到问卷中。原始数据需要进行清理和预处理,以使其适合进一步分析。
4. 决定哪个模型是适合的
你需要决定适合该项目的模型。你是对描述性数据科学感兴趣,如数据可视化,还是使用数据进行预测分析?对于预测分析,你可以使用线性回归(用于连续目标变量)或分类(用于离散目标变量)。如果数据没有目标变量,你可以使用聚类算法进行模式识别建模。
5. 构建、评估和测试模型
对于机器学习模型,如线性回归、分类或聚类,你需要构建、测试和评估你的模型。这将涉及将数据分为训练集和测试集。然后你需要确定适合的评估指标,如均方误差、R2 得分、平均绝对误差、整体准确度、敏感性、特异性、混淆矩阵、交叉验证得分等。
6. 决定是否需要团队
你是在独自完成项目还是与合作者一起进行?大规模项目可能需要团队。如果与团队合作,确保根据成员的经验和专长分配角色。确保团队成员之间有有效的沟通,这将有助于提高生产力。
7. 撰写项目报告以总结你的发现
项目完成后,撰写项目报告以总结你的分析结果。重要的是以一种不太技术性的方式总结你的结果。
结论
总结一下,我们讨论了在管理数据科学项目时需要牢记的重要提示。谨慎的准备、规划和执行将帮助你高效、及时地完成数据科学项目。
本杰明·O·泰约 是一位物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的创始人。之前,本杰明曾在中奥克拉荷马大学、大峡谷大学和匹兹堡州立大学教授工程学和物理学。
更多相关话题


 浙公网安备 33010602011771号
浙公网安备 33010602011771号