KDNuggets-博客中文翻译-四-
KDNuggets 博客中文翻译(四)
原文:KDNuggets
5 本免费数据科学书籍
作者插图
当你进入数据科学领域时,你会发现各种资源触手可及,比如 Udemy 课程、YouTube 视频和文章。但是,你需要给自己一个明确的学习结构,以避免感到不知所措和失去动力。
我们的前三个课程推荐
 1. Google 网络安全证书 - 快速进入网络安全职业。
1. Google 网络安全证书 - 快速进入网络安全职业。
 2. Google 数据分析专业证书 - 提升你的数据分析技能
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
本文将探讨五本涵盖数据科学旅程中应学习的基本概念的书籍。这些书籍各自帮助学习:
-
Python
-
统计
-
线性代数
-
机器学习
-
深度学习
《Python 极速之旅》
书籍链接: Python 极速之旅
如果你有兴趣开始学习 Python 而不想花费太多时间,这本书可能非常适合你。它对 Python 的基本概念进行了非常简短的概述。除了这本 100 页的书之外,还有一个包含练习的 GitHub 代码库。
特别是,你可以快速学习 Python 的主要数据类型:整数、浮点数、字符串、布尔值、列表、元组、字典和集合。在书的最后,有一个对 Python 库的简要概述,包括 NumPy、Pandas、Matplotlib、Scipy。
它涵盖了以下内容:
-
基本语法
-
变量
-
运算符
-
主要数据类型
-
For Loop
-
While 循环
-
函数
-
If-elif-else
-
Python 库的快速概览
Think Stats: 为程序员准备的概率与统计
书籍链接: Think Stats: Probability and Statistics
在没有将所学内容付诸实践的情况下,很难获得良好的概率和统计知识。这本书的美妙之处在于它专注于一些基本概念,不仅展示理论,还有用 Python 编写的实际练习。
这本书涵盖了:
-
概要统计
-
数据分布
-
概率分布
-
贝叶斯定理
-
中心极限定理
-
假设检验
-
估计
适用于应用机器学习的线性代数入门
书籍链接: 应用机器学习的线性代数入门
当你在大学学习线性代数时,大多数时候教授会讲解所有的理论而没有任何实际应用。因此,你最终参加考试,并在完成后忘记所有概念,因为在你的头脑中这些太抽象了。
幸运的是,我找到了一本出色的书,它为你介绍了线性代数的基础知识,这些知识在学习机器学习模型时会遇到。每个理论概念后面都有一个使用 NumPy 编写的实际例子,NumPy 是一个知名的科学计算 Python 库。
主要涵盖的主题包括:
-
向量
-
矩阵
-
投影
-
行列式
-
特征值和特征向量
-
奇异值分解
机器学习与 Python 简介
图书链接:Introduction to Machine Learning with Python
在学习 Python、统计学和线性代数后,是时候深入了解机器学习模型,以解决实际问题。这本书适合刚入门的人,并使用 scikit-learn 进行机器学习应用。
主要解释的机器学习模型包括:
-
线性回归
-
朴素贝叶斯
-
决策树
-
决策树集成
-
支持向量机
-
主成分分析
-
t-SNE
-
K 均值聚类
-
DBSCAN
深度学习与 Python
图书链接:Deep Learning with Python
这本第五本也是最后一本书是为那些已经具备 Python 编程知识的人设计的,不需要先前的机器学习经验。这本书的作者是Francois Chollet,他是谷歌的工程师和 AI 研究员,以创建 Keras 而闻名,Keras 是 2015 年发布的深度学习库。这些是最重要的概念:
-
神经网络
-
卷积神经网络
-
循环神经网络
-
LSTM
-
生成对抗网络
最终思考
这些建议对于希望进入数据科学领域的初学者都很有帮助。此外,它们对那些意识到自己在某些概念上知识不足并需要加强理解的数据科学家和研究人员也很有用。希望你喜欢这份书单。你知道其他关于数据科学的有用书籍吗?如果有值得一提的建议,请在评论中分享。
Eugenia Anello目前是意大利帕多瓦大学信息工程系的研究员。她的研究项目专注于结合异常检测的持续学习。
更多相关主题
5 本免费书籍掌握机器学习
原文:
www.kdnuggets.com/5-free-books-to-master-machine-learning

图片生成于 DALL-E 3
在今天的高科技世界中,机器学习非常重要。你可能已经参加了一些在线课程,但它们往往忽略了细节。如果你真的想深入探究并掌握机器学习,书籍是最佳选择。我知道面对如此多的选择可能会感到不知所措。但别担心,我们会为你提供帮助。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
我精心挑选了五本在我自己的机器学习旅程中产生重大影响的书籍。这些书籍将帮助你在 2023 年更好地理解机器学习。
所以,如果你准备好将你的知识提升到一个新的水平,深入探索这一迷人领域,继续阅读。
1. 绝对初学者的机器学习
作者: 奥利弗·西奥博德
链接: 绝对初学者的机器学习

书籍封面
你听说过机器学习这个词,想要深入了解这个激动人心的领域,但不知道从哪里开始。那么这本书是适合你的!
这本书非常适合那些对这个领域新手且没有任何编程经验的人。它以通俗易懂的语言编写,不需要任何先前的编程经验。书中提供了机器学习的高层次介绍、可下载的代码练习和视频演示。还有什么比这更好的呢?
涵盖的主题:
-
什么是机器学习?
-
机器学习类别
-
机器学习工具箱
-
数据清洗
-
设置你的数据
-
回归分析
-
聚类
-
偏差与方差
-
人工神经网络
-
决策树
-
集成建模
-
在 Python 中构建模型
-
模型优化
2. 机器学习的数学
作者: 马克·彼得·德森罗斯
链接: 机器学习数学

书籍封面
既然你已经了解了一些基本概念,现在是时候为复杂的机器学习主题打下基础了。你现在应该做什么?机器学习的数学就是你所需要的!
这是一本自包含的教科书,介绍了理解机器学习所需的基本数学工具。该书以最少的先决条件呈现数学概念,并利用这些概念推导出四种核心机器学习方法:线性回归、主成分分析、高斯混合模型和支持向量机。
本书的作者 Marc Peter Deisenroth 是伦敦大学学院的 DeepMind 人工智能主席,并因其在机器学习领域的研究获得了多个奖项。
涉及主题:
-
线性代数
-
解析几何
-
矩阵分解
-
向量微积分
-
概率与分布
-
连续优化
-
当模型遇到数据
-
线性回归
-
主成分分析的维度缩减
-
使用高斯混合模型的密度估计
-
使用支持向量机的分类
3. 《黑客的机器学习》
作者: Drew Conway 和 John Myles White
链接: 黑客的机器学习

书籍封面
你至今一直在学习理论,现在你真的想开始深入的机器学习编码。那就不用担心了。如果你对编程和编码有天赋,这本书就是为你量身定制的。
本书结合了实际案例研究,展示了机器学习算法的现实相关性。这些示例,包括一个关于构建 Twitter 关注者推荐系统的示例,帮助将抽象概念与具体应用联系起来。这本书最适合喜欢实际案例研究的程序员。
涉及主题:
-
数据探索
-
分类: 垃圾邮件过滤
-
排序: 优先收件箱
-
回归: 预测页面浏览量
-
正则化: 文本回归
-
优化: 破解代码
-
PCA: 构建市场指数
-
MDS: 视觉探索美国参议员相似性
-
kNN: 推荐系统
-
分析社交图谱
-
模型比较
4. 《使用 Scikit-Learn、Keras 和 TensorFlow 的动手机器学习》
作者: Geron Aurelien
链接: 使用 Scikit-Learn、Keras 和 TensorFlow 的动手机器学习

书籍封面
这本书是一本实用的机器学习指南,重点在于构建端到端的系统。书中涵盖了线性回归、决策树、集成方法、神经网络、深度学习等广泛主题。
本书的最新版本包含了来自前沿版本的机器学习和深度学习库(如 TensorFlow 和 Scikit-Learn)的代码。
涵盖的主题:
-
性能测量选择
-
测试集创建
-
使用梯度下降进行线性回归
-
岭回归、套索回归和弹性网回归
-
用于分类的 SVM
-
决策树与基尼不纯度
-
集成学习方法
-
主成分分析(PCA)
-
使用 K-Means 和 DBSCAN 进行聚类
-
使用 Keras 的人工神经网络
-
深度神经网络训练
-
使用 TensorFlow 的自定义模型
-
使用 TensorFlow 的数据加载和预处理
-
深度学习中的 CNN、RNN 和 GAN
5. 接近(几乎)任何机器学习问题
作者:Abhishek Thakur

书籍封面
想把你的机器学习技能提升到一个新水平吗?这本书是你通向应用机器学习精彩世界的通行证。虽然它没有让你陷入复杂的算法,但它全是关于如何和什么来解决现实世界中的问题。若你渴望弥合理论与实践之间的差距,这本书肯定会成为你的指南!
涵盖的主题:
-
监督学习与非监督学习
-
交叉验证技术
-
评估指标
-
结构化机器学习项目
-
处理分类变量
-
特征工程
-
特征选择
-
超参数优化
-
图像和文本分类、集成和可重复代码
结论
在这篇文章中,我们向你介绍了 2023 年学习机器学习的五本最佳书籍。这些书涵盖了从机器学习基础到更高级的深度学习主题,内容都写得很好,即使是初学者也容易跟随。
如果你认真对待机器学习,我建议你阅读这五本书。然而,如果你只能读一两本,我推荐 Oliver Theobald 的《绝对初学者的机器学习》 和 Aurélien Géron 的《动手机器学习:使用 Scikit-Learn、Keras 和 TensorFlow》。
我们很想知道哪些书在你的机器学习旅程中发挥了关键作用。欢迎在评论区分享你的推荐。
Kanwal Mehreen**** Kanwal 是一名机器学习工程师和技术作家,对数据科学和人工智能与医学的交叉领域充满了深厚的热情。她共同撰写了电子书《利用 ChatGPT 最大化生产力》。作为 2022 年 APAC 的 Google Generation Scholar,她倡导多样性和学术卓越。她还被认定为 Teradata 技术多样性学者、Mitacs Globalink 研究学者和哈佛 WeCode 学者。Kanwal 是变革的坚定倡导者,她创立了 FEMCodes 以支持 STEM 领域的女性。
更多相关主题
5 本免费 SQL 书籍

图片由Freepik提供
SQL,或结构化查询语言,是许多公司标准的数据库操作语言。目前,每个数据相关的职位都期望了解 SQL 语言,因为我们的工作涉及提取这些存储的数据以进行进一步分析。这就是为什么无论我们的专业水平如何,都应该提升我们的 SQL 知识。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
本文将讨论五本免费书籍,这些书籍可以提升你的 SQL 水平。我们将涵盖从初级到高级的各种需求。
这些书籍是什么?让我们深入了解一下。
SQL 专业笔记
GoalKicker.com提供的《SQL 专业笔记》是一本超过 150 页的免费 SQL 书籍,涵盖了 SQL 的主要使用场景。在每一章中,你将学习到语法的简要说明、示例用法以及使用语法时的技巧。
这本书可以成为你学习和刷新基础知识的首选,因为它适合任何专业水平。这本书主要涵盖以下概念:
-
SQL 基础知识
-
数据操作
-
数据库和表管理
-
函数和表达式
-
数据清理和维护
-
处理特殊数据类型
你可以在以下页面获取这本书:SQL 专业笔记。
学习 SQL
这是另一本适合任何初学者和高级用户的免费书籍,旨在提升你的 SQL 技能。该书由 Stack Overflow 的贡献者编写,旨在解答你大部分的 SQL 问题。
这本书提供了 64 章,超过 200 页。每章包含简单的解释和易于跟随的用法示例。总体而言,这本书的内容如下:
-
SQL 基础知识
-
数据库设计
-
高级查询技术
-
管理和错误处理
-
理解 SQL 的元数据
-
SQL 的信息检索
你可以在以下页面获取这本书:SQL 学习。
SQL 简介
Bobby Iliev 的入门书籍是一本开源书籍,旨在教会初学者使用 SQL。它为每一章提供了清晰的解释,并提供了跟随示例所需的教程和前提条件。这本书使用了 MySQL,所以如果你想进一步了解这种语言,它也是不错的选择。
书籍内容包括:
-
MySQL 基础
-
数据操作
-
使用 JOINS 和子查询的高级查询
-
使用 MySQL 特定功能
-
最佳实践和编写干净代码
你可以在以下页面获取该书:SQL 入门。
必备 SQL
必备 SQL 是 必备编程 书籍的一部分,是 2017 年停止更新的 Stack Overflow 文档的延续。电子书对每个主题提供了简单的解释,并提供了一个示例操作场地,你可以在其中进行调整。这是一本适合初学者和高级用户的优秀电子书。
电子书包含以下内容:
-
SQL 基础知识
-
数据检索和操作
-
优化和高级查询
-
数据库设计和管理
-
最佳实践和维护
你可以在这里访问电子书:必备 SQL。
SQL 索引和调优
SQL 索引和调优是由 Markus Winand 开发的电子书,专注于索引 SQL 活动。这本电子书更适合高级用户,但从长远来看将有助于我们的工作。
电子书内容包括:
-
索引基础
-
索引结构
-
索引性能问题
-
索引管理最佳实践
-
高级索引技术和考虑事项
结论
SQL 是数据专业人员必备的重要技能,因为它将成为我们日常工作的一个部分。为了提高你的 SQL 知识,我们可以利用一些免费的 SQL 书籍,这些书籍在本文中有讨论。这些书籍增强了你的 SQL 基础,并提供了实际案例中的示例。
Cornellius Yudha Wijaya**** 是一名数据科学助理经理和数据撰写员。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作分享 Python 和数据技巧。Cornellius 在各种 AI 和机器学习主题上都有所撰写。
更多相关内容
5 本免费书籍掌握数据科学中的统计学
原文:
www.kdnuggets.com/5-free-books-to-master-statistics-for-data-science

编辑图片
要学习数据科学,你还需要扎实的数学基础。统计学是数据科学中必不可少的数学技能之一。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织中的 IT
然而,学习统计学可能会让人感到畏惧,尤其是如果你来自非数学或计算机科学领域。为了帮助你入门,我们整理了一份免费书籍清单,使数据科学中的统计学变得易于获取。
大多数这些书籍采用了实践导向的方法来讲解统计学概念,这是作为数据科学家有效使用统计学所需的。让我们来详细了解这些统计书籍。
1. 入门统计学
入门统计学 这本书是一本易于理解的统计学入门书,涵盖了大学里通常教授的一个学期的入门统计学课程内容。
本书在 OpenStax 上可免费访问,由一组贡献专家作者撰写,采用了应用优先的统计学方法,而非理论优先,并且在每个主题的练习中包含了例子。
这本书将帮助你学习以下内容:
-
采样与数据
-
描述性统计
-
概率和随机变量主题
-
正态分布
-
中央极限定理
-
置信区间
-
假设检验
-
卡方分布
-
线性回归和相关性
-
F 分布和单因素方差分析
链接: 入门统计学 2e
2. 现代统计学导论
现代统计学导论 是 OpenIntro 项目的免费在线教科书,由 Mine Çetinkaya-Rundel 和 Johanna Hardin 撰写。
如果你想学习有效数据分析的统计学基础,那么这本书适合你。此书的内容如下:
-
数据介绍
-
探索性数据分析
-
回归建模
-
推断基础
-
统计推断
-
推断建模
链接: 现代统计学导论
3. 《思考统计学》
思考统计学 作者 Allen B. Downey 将帮助你使用 Python 学习和实践统计学概念。
这样你可以运用你的 Python 技能学习统计学和概率概念,以有效处理数据。通过阅读这本书,你将编写简短的 Python 程序并使用真实数据集来加深对统计学概念的理解。
涵盖的主题如下:
-
探索性数据分析
-
分布
-
概率质量函数
-
累积分布函数
-
建模分布
-
概率密度函数
-
变量之间的关系
-
估计
-
假设检验
-
线性最小二乘法
-
回归
-
生存分析
-
分析方法
链接: 思考统计学 2e
4. 计算与推断思维
计算与推断思维:数据科学基础 由 Ani Adhikari、John DeNero 和 David Wagner 合著,将帮助你学习数据科学的统计学基础。
本书作为 UC Berkeley 提供的 Data 8: 数据科学基础 课程的配套书籍开发。书中涵盖的主题包括:
-
数据科学导论
-
Python 编程
-
数据类型、序列和表格
-
可视化
-
函数和表格
-
随机性
-
抽样和经验分布
-
假设检验
-
估计
-
回归
-
分类
链接: 计算与推断思维:数据科学基础
5. 概率编程与黑客的贝叶斯方法
概率编程与黑客的贝叶斯方法 或《黑客的贝叶斯方法》是一本关于贝叶斯统计方法的热门书籍。
“黑客的贝叶斯方法”:介绍贝叶斯方法 + 概率编程,以计算/理解优先、数学次之的视角。全用纯 Python 😉 - 来源
你将熟悉概率理论和贝叶斯推断,同时使用 PyMC 包。这本书的内容如下:
-
贝叶斯方法导论
-
PyMC 库
-
马尔可夫链蒙特卡洛
-
大数法则
-
损失函数
-
先验
链接: 概率编程与黑客的贝叶斯方法
总结
希望你觉得这些免费统计学书籍的汇总对你有帮助。理论和实践的结合应该能帮助你提升数据科学技能,并在处理大型真实数据集时做出更明智的决策。
如果你喜欢通过免费课程学习或希望通过课程来补充阅读,请查看 5 个免费课程掌握数据科学统计学。
Bala Priya C** 是来自印度的开发人员和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过撰写教程、使用指南、观点文章等,学习并与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。**
更多相关内容
5 个免费证书助你获得首个开发者职位
原文:
www.kdnuggets.com/5-free-certifications-to-land-your-first-developer-job

作者提供的图片
技能比任何证书都更有价值。那么为什么获得认证仍然有帮助呢?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT
如果你有计算机科学或相关领域的学位,那么在开始寻找软件开发角色时,可能不需要认证。但是现在,我们知道的许多人都在寻求转向软件角色——从非技术或技术相关角色。认证在这里可以发挥作用。
通过学习特定的轨道——一个认证或课程——可以帮助你确定自己的兴趣,并使学习针对目标角色的核心技能变得更容易。此外,还有一些高质量的认证,具有精心设计的课程,涵盖了数十小时的编码练习和项目。因此,如果你想成为开发人员,以下证书将帮助你学习你需要掌握的最相关和最基本的技能!
1. 响应式网页设计 – freeCodeCamp
如果你是软件开发的新手,响应式网页设计认证是一个很好的起点。完成这个认证将帮助你学习 HTML、CSS、CSS 网格和 Flexbox。
从基本的 HTML 标签到 CSS 动画和变换,整个认证的结构是一系列的小项目。因此,你将通过实际应用这些概念来构建项目,从而学习这些概念。
除了一系列的小项目外,还有五个项目必须完成才能获得证书。一旦你对 HTML 和 CSS 感到熟悉,你可以继续学习 JavaScript。
链接: 响应式网页设计认证
2. JavaScript 数据结构与算法 – freeCodeCamp
如果你想进入前端开发领域,学习 JavaScript 并熟练掌握前端库是至关重要的。既然你已经学会了 HTML 和 CSS,那么学习 JavaScript 编程是很好的选择。
-
freeCodeCamp 的JavaScript 算法和数据结构认证将帮助你通过 JavaScript 学习编程基础、正则表达式、数据结构和算法。
-
你还将学习面向对象编程(OOP)和函数式编程范式。像响应式网页设计认证一样,这也要求你完成若干 JavaScript 编码挑战和五个项目,以获得证书。
3. 前端开发库 – freeCodeCamp
-
当你熟悉 HTML、CSS 和 JavaScript 后,你应该学习如何使用流行的 JavaScript 前端库,如 React 和 Redux。freeCodeCamp 的前端开发库认证将帮助你学习所有必需的知识。
-
通过详细的课程安排,这个认证将帮助你学习以下内容:
-
Bootstrap
-
jQuery
-
SASS
-
React
-
Redux
- 在掌握了所有 HTML 和 CSS 基础、JavaScript 以及 JavaScript 库后,你应该能够为你的开发者作品集构建有趣的项目。
链接: 前端开发库认证
4. CS50 的计算机科学导论 – 哈佛
-
CS50 的计算机科学导论由哈佛大学的 David J. Malan 教授及其团队教授,是一门非常受欢迎的计算机科学入门课程。如果你是编程新手,这门课程将帮助你学习计算机科学和编程基础、计算思维、数据结构等。
-
在为期 11 周的课程中,这个课程将帮助你掌握计算机科学和编程基础。你将学习低级编程语言如 C,然后转向 Python。你还将学习 SQL 基础,以查询数据库。此外,你还将学习 HTML、CSS 和 JavaScript。
-
这个课程包含需要解决的问题集和一个最终项目,以应用你所学到的知识。课程中探讨的主题范围也应帮助你了解下一步想要追求的方向,比如专注于网页编程、数据分析等。
链接: CS50 的计算机科学导论
5. CS50 的 Python 和 JavaScript 网页编程
CS50 的 Python 和 JavaScript 网页编程专注于使用 Python、JavaScript 和 SQL 开发网页应用程序,同时使用 React 和 Django 等框架。你还将学习如何设计 API 和 UI、使用云服务等。
与所有 CS50 课程一样,你将在课程中完成多个项目。CS50 网络编程课程有九周的课程内容,包括以下内容:
-
HTML, CSS
-
Git
-
Python
-
SQL、模型和迁移
-
JavaScript
-
用户界面
-
测试,CI/CD
-
可扩展性和安全性
链接: CS50 的 Python 和 JavaScript 网络编程
总结
我希望你觉得这些免费认证有帮助。这些认证的最佳部分在于,它们强调通过编码挑战、问题集和项目主动应用所学内容,而不是被动地消耗内容。
运用这些课程学到的技能,你应该能够构建一个令人印象深刻的项目组合,并为技术面试做好充分准备。祝学习愉快,编程顺利!
Bala Priya C** 是来自印度的开发者和技术写作者。她喜欢在数学、编程、数据科学和内容创作的交叉点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正通过编写教程、操作指南、观点文章等,与开发者社区分享她的知识。Bala 还创建引人入胜的资源概述和编码教程。**
更多相关内容
5 个免费竞赛,适合有志的数据科学家
原文:
www.kdnuggets.com/5-free-competitions-for-aspiring-data-scientists
 图片由编辑 | Midjourney & Canva
图片由编辑 | Midjourney & Canva
数据科学就像艺术,因为解决问题的方法有很多种。这就是为什么数据科学竞赛存在的原因,以获得破解数据科学问题的最佳方法。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
我见过一些有志的数据科学家因为数据科学竞赛而开启职业生涯。这些竞赛展示了参与者能够解决问题并且具有创造力。此外,竞赛还允许你进行网络交流并向同行学习。
数据科学竞赛是提高我们技能的有趣方式,同时使我们在其他有志之士中具有竞争优势。在本文中,我将解释你现在可以参加的五个免费数据科学竞赛。
你感兴趣吗?让我们开始吧。
Kaggle 竞赛
Kaggle 是一个专为数据科学家设计的在线平台和社区。它提供了许多功能,包括公开数据集共享用于分析和数据项目、免费的教程学习以及一个 竞赛平台。
竞赛平台是数据科学竞赛最受欢迎的地方之一,因为许多现实世界的公司在这里举办竞赛。此外,无论你的经验水平如何,这里都有许多竞赛供有志之士参加。
一些竞赛有时间限制,但许多竞赛总是可以参加。所有这些竞赛都是免费的,许多竞赛甚至还有奖金。然而,那里的竞争可能非常激烈,因为许多才华横溢的专业人士也会参加这些竞赛。不过,如果你想开始你的数据科学竞赛经历,这里是一个不错的地方。
DataHack 由 Analytic Vidhya 主办
你可以参加的下一个免费竞赛是 DataHack。这是由 Analytics Vidhya 主办的数据科学竞赛平台,Analytics Vidhya 是一个在线平台和数据科学社区。它提供了许多文章、教程、职位平台和竞赛。
DataHack 是一个数据科学竞赛平台,允许参与者解决现实世界中的问题并争夺奖品。你不需要有数据科学经验就可以参加竞赛,而且是免费的。此外,许多竞赛对公众开放,没有奖品,因为它们旨在用于学习。
总体而言,该平台非常适合那些希望体验与全球其他人竞争的感觉,同时仍能与社区互动的人。通过观察他人如何应对竞赛,你可以学到很多东西。
MachineHack 的 AI Hackathons
MachineHack 是一个为数据科学和机器学习爱好者提供的在线平台。它主要提供竞赛和黑客马拉松,以提高用户的技能和积累经验。排行榜是公开的,这使得它成为通过竞赛建立声誉的绝佳平台。
AI Hackathon 是 MachineHack 提供竞赛的地方。你可以加入各种竞赛,无需支付任何费用,同时争夺第一名。有些竞赛可能提供奖金,而许多则用于练习你的技能。
竞赛吸引了许多有才华的个人,因此你可以尝试与他们竞争,提高你的数据科学能力。同时,你可以建立一个项目组合,并与该领域的其他专业人士建立联系。
AI Crowd
AI Crowd 旨在作为一个研究平台,但它是通过提供数据科学竞赛来推动研究的。该平台的原则是开放科学和可重复的研究,这可能会带来现实问题的创造性解决方案。
与前一个平台类似,这个平台提供了许多有奖金的竞赛。然而,竞赛的种类并不多,因为许多竞赛是为了研究目的而设计的。尽管如此,该平台上的竞赛大多足够高级,可以作为竞赛者的学习经历。
DrivenData
DrivenData 与 AI Crowd 相似,它是一个基于现实世界问题的数据科学竞赛平台。它为用户提供了解决具有实际影响问题的机会。
竞赛的例子包括预测疾病传播或管理水资源,这使它们非常适合学习并带来实际改变。该平台是提升数据科学技能和积累现实经验的绝佳方式。你甚至可以在过程中赢得一些奖金。
结论
竞赛是提高数据科学技能并与同行建立联系的绝佳方式。如果你在竞赛中表现出色,可能会赢得一些奖品。在本文中,我们讨论了 5 个适合有志数据科学家的免费竞赛:
-
Kaggle 竞赛
-
Analytic Vidhya 的 DataHack
-
MachineHack 的 AI Hackathons
-
AI Crowd
-
DrivenData
希望这对你有所帮助。
Cornellius Yudha Wijaya 是一名数据科学助理经理和数据编写员。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 在各种人工智能和机器学习主题上撰写文章。
更多相关内容
5 个免费的 ChatGPT 课程

你可能听说过很多关于 ChatGPT 的事情,使用过它,也听说过人们用它做的各种疯狂的事情。你可能会想,这些人是如何学会使用 ChatGPT 的,我该从哪里学习?
不用再寻找了。本文将介绍 5 个免费课程,帮助你提升 ChatGPT 技能,并充分利用它!所以我们开始吧
1. ChatGPT 入门
链接: ChatGPT 入门
如果你在玩弄 ChatGPT,但不清楚它的全部潜力 - 这个 DataCamp 的 ChatGPT 入门课程可能适合你。无需任何先前知识,因此你可以开始了解 ChatGPT 的能力和局限性,以及如何在日常生活中利用它。
许多人在提示 ChatGPT 时遇到困难,本课程的前半部分将讲解提示 ChatGPT 以生成高质量相关内容的最佳实践。然后,你将学习如何通过了解文本摘要和代码解释等不同用例,将 ChatGPT 转化为业务价值。
2. ChatGPT 初学者指南:适用于每个人的终极用例
很多人想知道如何利用 ChatGPT 将业务提升到新的水平。ChatGPT 已经简化了许多员工的生活,但仍有些人不清楚这些功能是如何实现的。
该课程将介绍如何通过从商业和个人的角度审视 ChatGPT 的能力来大幅提升当前业务。你将了解到如何利用 ChatGPT 为你完成工作,从而赚取更多利润并最大化成本效益。
3. ChatGPT 的提示工程
链接: ChatGPT 的提示工程
由计算机科学副教授 Dr. Jules White 设计的课程,旨在向学生介绍如何为大规模语言模型(LLMs)编写有效提示的模式和方法。该课程对任何人开放,只需要基础的计算机知识,例如使用浏览器和访问 ChatGPT。
你将从理解基本提示开始,逐渐建立起编写更复杂提示的能力,帮助你解决各种任务。ChatGPT 具有许多用途,例如担任辅导员、制定餐计划、为软件应用编写代码等。能够理解如何提示 ChatGPT 将使你成为这些生成型 AI 工具的专家用户,拥有强大的提示工程技能,适用于任何用例。
4. ChatGPT 提示工程师课程
链接: ChatGPT 提示工程师课程
由 DeepLearning.AI 和 OpenAI 提供的 1 小时短期课程,适合所有人——初学者和高级人员。讲师是 Isa Fulford(OpenAI)和 Andrew Ng(DeepLearning.AI),课程仅限时间免费。
在这个短期课程中,你将学习如何使用大型语言模型(LLMs)构建新的高效应用程序,了解提示工程的最佳实践,并展示如何将 LLM API 用于各种任务。
例如,你将学习如何总结用户评价,确定情感,识别主题,改善语法等。在课程中,你将学习如何创建一个独特的聊天机器人,并编写强有力的提示。这些都有助于为开发人员提供如何最有效使用 LLMs 的知识。
无论你有什么样的编程经验,这门课程在 LLMs 如雨后春笋般涌现的世界中都至关重要。
5. 使用 ChatGPT API 构建系统
另一个由 DeepLearning.AI 和 OpenAI 提供的短期课程,你将深入了解 ChatGPT API 以及如何使用这些 API 通过链式调用 LLMs 来自动化复杂的工作流程。讲师是 Isa Fulford 和 Andrew Ng,课程仅限时间免费。
这是一个适合初学者的课程,你需要具备基础的 Python 知识来完成课程。该课程也适合中级或高级的机器学习工程师,他们希望了解关于 LLMs 的前沿提示工程技能。
你将学习如何构建与之前提示相关的提示链,创建与完成和新提示交互的系统,以及从课程中学到的知识制作一个客户服务聊天机器人。
总结
完成上述所有免费课程后,你将能够熟练理解 ChatGPT,学习如何在不同的应用场景中使用它,定制符合你需求的提示,并利用 ChatGPT API 创建聊天机器人等。
如果你知道其他免费的 ChatGPT 课程,请在下方评论中分享,以便其他人学习!
Nisha Arya 是一位数据科学家、自由技术作家以及 KDnuggets 的社区经理。她特别关注于提供数据科学职业建议或教程以及数据科学的理论知识。她还希望探索人工智能如何或将如何促进人类寿命的延续。她是一位热衷学习的者,寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关主题
5 个免费课程帮助你入门人工智能
原文:
www.kdnuggets.com/2017/02/5-free-courses-getting-started-artificial-intelligence.html
对人工智能感兴趣?不知道从哪里或如何开始学习?
没有任何东西可以替代严格的正规教育,但由于各种原因,这并非对每个人都是一个选项。然而,深入了解人工智能及其众多交叉和相关领域与应用领域并不需要博士学位。刚开始可能会让人感到不安,但不要灰心;查看这个激励和启发的帖子,作者在一年内从对机器学习的初步了解,到积极有效地在工作中应用这些技术。
寻找来自网络上自由提供的材料的研究生级人工智能课程?随着越来越多的高等教育机构决定通过网络让课程材料对非学生开放,几乎任何地方的任何人都可以突然体验到伪大学课程。查看以下所有适合初学者的免费课程材料,其中一些也涵盖了特定应用概念和材料。
一些教授及其分享的材料在塑造世界顶尖 AI 研究人员和从业者的思想方面发挥了重要作用。你完全可以从这些相同的材料和教学中受益。
这可能被视为现存的首屈一指、开创性的、面向在线的开放访问大学级人工智能课程。
并非所有内容对非加州大学伯克利分校的学生开放(作业和自动评分),但绝大多数材料都是公开的。这些材料完整且组织良好,包括以下内容:
-
2014 年春季的课程样本时间表
-
讲义和视频的完整集
-
电子作业提交接口
-
课件
-
Pacman 项目规格
-
伯克利 CS188 课程的源文件和过去的考试 PDF
-
申请 edX 托管的自动评分器的表单(用于作业和项目等)
-
联系信息

虽然提到作业不公开,但一系列逐步进行的 Pacman 项目是公开的,涵盖了搜索、强化学习、分类等方面。
由 Dan Klein 和 Pieter Abbeel 教授主讲,讲座、视频、考试及其他材料可追溯到 2014 年;然而,你在这门课程中学到的内容绝不会过时。我自己几年前就学习了这部分课程材料,你可以在这里获得对基础 AI 主题的充分概述,包括理论和实践。
斯坦福大学在其网站上对这门课程这样描述:
这门课程讲什么? 网络搜索、语音识别、人脸识别、机器翻译、自动驾驶和自动排程有什么共同之处?这些都是复杂的现实世界问题,而人工智能(AI)的目标是用严格的数学工具来解决这些问题。在这门课程中,你将学习驱动这些应用的基础原理,并练习实现一些这些系统。

从一些领域内最受推崇的文本(Russell & Norvig;Koller & Friedman;Hastie, Tibshirani & Friedman;Sutton & Barto)中汲取灵感,这些材料包括笔记、幻灯片、作业、考试和项目(包括解决方案)。你会发现与上述伯克利课程有重叠,但这里开放的作业种类可能更丰富,其中包括如下项目:
-
情感分类
-
二十一点
-
吃豆人
-
排程
-
汽车跟踪
-
语言与逻辑
很容易认为,这前两门课程材料的某种组合会提供一个实质性的人工智能入门教育。此外,考虑到斯坦福课程中至少有一些文本是(合法地)在线免费提供的,几乎可以实现沉浸式体验。
3. 强化学习
这是 David Silver 在伦敦大学学院的著名强化学习课程。材料简明扼要,包括讲座视频和对应的幻灯片,内容丰富。
这不是一门入门 AI 课程,与前两门课程不同,它专注于最令人兴奋和活跃研究的领域之一。由 Google DeepMind 的专家构建的这门课程非常值得花时间学习。
由 Sergey Levine、John Schulman 和 Chelsea Finn 教授的这门课程是对强化学习的另一种探讨。课程目前正在进行中,新的讲座会实时直播,并且课程结束后也可以观看。
课程材料包括前述的视频、幻灯片、教程和作业。计划安排了嘉宾讲座,其中包括 OpenAI 的 Igor Mordatch 和 Google Brain Team 的 Mohammad Norouzi(以及其他伯克利的明星教授)。作业使用了如 TensorFlow 和 OpenAI Gym 等标准框架。
再次提一下,这门课程仍在进行中,所以你需要跟随课程的进度,因为下周的讲座材料尚不可用 😃
这门课程自上线以来在网上引起了广泛关注,这是由 Lex Fridman 主讲的 MIT 自动驾驶汽车课程。与之前的课程一样,这门课程也在进行中。

随着深度学习从研究转向实际应用,看到这些专注于深度学习的应用课程在世界各地的知名大学中涌现出非常有趣。此外,随着Udacity 的自动驾驶汽车纳米学位的最近宣布,将这两种热门技术结合到课程材料中是顺理成章的。这不是隐晦的批评:这些技术是非常互补的,代表了事实上的技术必要的结合。
回到课程,它包含了视频讲座以及大量相关材料,从经过验证的 Python 和深度学习入门教程到历史性自动驾驶车辆信息。
课程依赖于 DeepTesla 和 DeepTraffic 模拟器,并计划在学期末安排一些嘉宾讲座。有趣的是,公众(非 MIT 学生)甚至可以在网站上注册账户。
相关:
-
进入机器学习职业之前需要阅读的 5 本电子书
-
1 月你不能忽视的 5 个机器学习项目
-
自动化机器学习的现状
更多相关内容
掌握微积分的 5 门免费课程
原文:
www.kdnuggets.com/2022/10/5-free-courses-master-calculus.html
如果你希望理解机器学习算法是如何工作的,数学是不可避免的。线性代数、统计学、概率论和微积分是学习算法内部原理的四个关键子领域。本文列出了学习微积分的课程,但让我们首先了解为什么需要学习微积分。
为什么你需要学习微积分?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 部门
你需要了解微积分才能计算导数,例如,调整神经网络反向传播中的神经元权重。实质上,你需要微积分来理解一组输入与输出变量之间的关联。这种多属性的研究被称为多元微积分,应用于计算函数的最小值和最大值、导数、成本函数等。

来源:图像由 Freepik 上的 storyset 提供
学习微积分的前提条件
现在我们了解了为什么微积分是理解机器学习算法如何工作的一个重要前提条件,让我们来学习你需要掌握哪些技能来学习微积分。
你应该对代数、几何和三角学有一个合理的理解,以掌握微积分。此外,我强烈推荐阅读这篇由可汗学院撰写的优秀文章,该文章强调了在开始微积分课程之前所需的关键技能。
学习微积分的五门免费课程列表
1. 可汗学院的微积分 1
可汗学院的视频和讲解使得学习任何新的数学概念变得非常简单,即使是新手也能轻松理解,并且通常被高度推荐。微积分课程涵盖了极限、连续性、积分、导数等基本和高级主题,如链式法则、二阶导数等。
2. 由 Jon Krohn 讲授的《机器学习的微积分》
这是一个由 Jon Krohn 制作的56 个视频播放列表。它涵盖了微积分的基础,如偏导数、增量法、幂法则等。Jon 还创建了一个类似的线性代数课程,作为理解当代机器学习和数据科学技术的基础概念。
3. 机器学习数学:多变量微积分– 伦敦帝国学院
本课程是 Coursera 平台上“机器学习数学专修”系列的一部分。这是一个自定进度的课程,具有灵活的截止日期,非常适合在职专业人士。完成课程总共需要 18 小时,由伦敦帝国学院提供。
根据课程列表页面,它帮助学习者建立对以下概念的理解:
-
多变量微积分用于构建许多常见的机器学习技术
-
函数的梯度
-
构建对函数的近似
-
神经网络在训练神经网络中的作用
-
微积分在线性回归模型中的应用
你也可以在这里观看这个在线专修的播放列表。
4. 悉尼大学的微积分导论
这是一个中级课程,总共需要 59 小时,分五周完成。课程由副教授 David Easdown 授课,由悉尼大学提供。课程解释了基础概念,如预备微积分、切线、极限等。课程在 Coursera 上提供,完成后可获得可分享的证书。
5. MIT 的 18.01x 单变量微积分
这是 MIT 提供的一个高级课程,旨在掌握微积分的概念,并学习如何计算导数和积分。课程的关键收获在于,它不仅解释了几何解释,还通过实际应用帮助学习这些数学概念。
引用课程网页,学习者将理解
-
解释函数的导数和积分的各种方法,以及如何计算这些量
-
如何使用函数的线性和二次近似来简化计算并洞察系统行为
-
导数和积分的应用,例如优化生产成本或计算建筑梁上的应力
-
参数化曲线和极坐标的微积分
-
如何通过一系列简单函数来近似复杂函数
该项目是由三门课程组成——微分、积分和坐标系统,以及无穷级数。每门课程需要每周投入 6-10 小时,课程总时长约为 13-15 周。
额外推荐
一个额外的提示是来自 Jason Brownlee 的七天微积分迷你课程。他是一位 AI/ML 专家,擅长将理论和数学密集的机器学习概念以实际和代码导向的形式进行讲解。
他的迷你课程涵盖了机器学习中常用的微积分概念,并包括 python 练习。课程为期七天,期望学习者具备机器学习模型、python 和线性代数的基础知识。该课程涵盖的关键概念包括微分、积分、向量函数的梯度、反向传播、优化等。
在每节课结束时,课程建议你完成一个类似于上节课所教内容的作业,并在课程结束时分享结果。
总结
为了帮助你成为一名熟悉机器学习算法内部运作的数据科学家,本文分享了五个免费课程来掌握微积分概念。希望你能在数据科学之旅中找到这些课程列表有用。
Vidhi Chugh 是一位获奖的 AI/ML 创新领袖和 AI 伦理学家。她在数据科学、产品和研究的交汇处工作,以提供商业价值和洞察力。她是数据驱动科学的倡导者,也是数据治理领域的领先专家,致力于建立可信赖的 AI 解决方案。
更多相关主题
5 门免费课程掌握线性代数
原文:
www.kdnuggets.com/2022/10/5-free-courses-master-linear-algebra.html
介绍
我们的前三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您组织的 IT 工作
数据科学是一个流行词,很多爱好者希望学习其基础知识,以在这一领域中获得丰厚的职业前景。线性代数是学习数据转换技术(如预处理、降维等)的重要概念之一。

来源: 图片由 rawpixel.com 提供于 Freepik
如何选择合适的课程?
有很多课程可以选择,但选择适合您需求的正确课程是很困难的。决定正确课程的多个因素包括:
-
您手头上有多少时间?例如,如果您已经了解了这些概念但需要复习,那么您可以选择一门课程来快速浏览关键主题。
-
您是否在寻找高级话题并希望深入了解该学科?
-
有些学习者喜欢播放列表风格的视频,而其他人则喜欢通过解决练习题来巩固对概念的理解
-
您是否愿意为课程付费,还是选择从免费的课程列表中学习?如果您像我一样相信教育应该对所有人开放,那么有一个好消息。最近,免费课程的数量有所增加,这有助于您迅速提升技能,并使您成为一名自学成才的数据科学家。
这篇文章的确切意图就是通过列出五门免费课程来帮助您轻松找到学习数据科学线性代数基础的资源。
为什么需要学习线性代数?
在我直接列出课程之前,让我先解释一些常见的问题——我们为什么需要学习线性代数?它与数据科学和机器学习概念有什么关系?
机器学习算法通常需要了解标量、向量和矩阵,以计算损失函数、特征值、协方差矩阵等。此外,线性代数在神经网络、正则化技术、推荐系统、奇异值分解(SVD)、主成分分析(PCA)等领域也被广泛使用。
免费掌握线性代数的五门课程:
现在我们了解了掌握线性代数概念的重要性,接下来让我们找出五门免费课程,以掌握这些概念:
1) 3Blue1Brown 的线性代数精髓
这是一个包含 16 个视频的播放列表,包括交叉乘积、点积、特征向量、特征值等概念。3Blue1Brown 是一个 YouTube 频道,专注于通过独特的可视化技术以易于理解的方式教授数学概念。尽管它不算作正式的课程,但由于其独特的数学发明和可视化主题,该频道已被推荐在我们的列表中。
2) Khan Academy 的线性代数
这是一门很好的课程,用于学习线性代数的基本知识,如向量积、线性变换、求行列式等。如果你希望快速复习基础知识,可以参考这个链接。
3) AI 应用课程中的线性代数
这是一个短课程,包含一个 10 个视频的播放列表,重点讲解为什么你需要学习线性代数以应用于机器学习。该课程是一个入门课程,可以在 90 分钟内很好地理解线性代数的概念。
Khan Academy 和 3Blue1Brown 的视频容易理解,能够帮助你作为初学者快速上手。一旦你从这些资源中学会了基本概念,你就可以开始学习下面推荐的更深入、更全面的课程内容。
4) 德克萨斯大学奥斯汀分校在 EDX 上的线性代数 - 从基础到前沿
该课程由罗伯特·范·德·盖恩教授讲授,包括短视频和可视化内容,之后是练习和编程作业。
该课程持续 15 周,需要每周 6-10 小时的学习时间。最棒的是它是自学课程,可以根据学习者的便利完成。
课程提供两种格式——验证(付费)和审计(免费)轨道。如果你希望获得完成证书并有权访问评分作业和考试,则需要选择验证,即付费轨道。你可以在这里查看每个轨道的更多详细信息。
5) 伦敦帝国学院在 Coursera 上的机器学习数学:线性代数
这个课程是“机器学习数学专业化”系列的一部分,并且评分很高(4.7/5)。这门课程的独特之处在于,它不仅解释了理论概念,还通过 Python 代码帮助学习者理解和实现这些想法。
对于没有足够 Python 背景的学习者,这门课程也适合入门,因为它通过短小的代码块和重点概念进行指导。课程持续四周,需要 19 小时完成。
摘要
这篇文章列出了五个流行的课程来掌握线性代数。最棒的是,所有列出的课程都是免费的,并且按从初级到更高级的概念进行排名。虽然机器学习社区不断质疑是否有必要学习线性代数以入门机器学习,我还是强烈推荐采用更灵活的方法,持续迭代并参考这些课程,以规划你的机器学习算法之旅。
Vidhi Chugh 是一位获奖的 AI/ML 创新领导者和 AI 伦理学家。她在数据科学、产品和研究的交汇处工作,旨在提供业务价值和洞察力。她倡导以数据为中心的科学,并在数据治理方面是领先专家,致力于构建值得信赖的 AI 解决方案。
更多相关主题
5 免费的 AI 和 ChatGPT 课程,从 0 到 100
原文:
www.kdnuggets.com/5-free-courses-on-ai-and-chatgpt-to-take-you-from-0-100

图片来源:DALLE 3
生活在这个时代真是太棒了。而现在学习 AI 元素,比如生成式 AI,特别是 ChatGPT,再好不过了!很多人对这个领域感兴趣,但有些人需要更多的知识来达到目标。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在的组织的 IT 工作
本博客提供了来自哈佛、IBM、DeepLearning.AI 等可信机构的免费课程列表。
让我们开始吧。
Python 人工智能简介(哈佛)
这是一个为期 7 周的自学课程,学习如何在 Python 中使用机器学习来进行人工智能研究。在这门课程中,你将学习现代人工智能的不同概念和算法。你将深入探讨实际应用案例,如手写识别和机器翻译。
你不仅会学习到相关知识,还有机会参与实际项目,这将使你能够将理论知识应用于机器学习和人工智能的不同方面,并将其融入到自己的 Python 程序中。
到课程结束时,你将对机器学习中使用的库和人工智能的原理有深刻的了解,以便你可以构建自己的智能系统。
人工智能基础知识(IBM)
AI 无处不在,每个人都在谈论它。如果你对它了解不多——这门课程就是为你准备的。在这门课程中,你将掌握人工智能的基础知识,并理解其应用及机器学习、深度学习和神经网络等关键概念。
你还将深入探讨与 AI 相关的伦理问题,这是目前非常热门的话题。通过这门课程,你还将获得有关如何开始 AI 新职业的专家建议。
数据与 AI 基础(Linux)
链接: Linux Foundation - 数据与 AI 基础
Linux 是一种操作系统,通过他们提供的课程,你将学习人工智能的基础知识,以及 Linux Foundation AI & Data 项目生态系统的概述。这是一个为期 10 周的课程,采用自我节奏学习,适合任何对人工智能感兴趣的人,无论其职业背景和技术知识水平如何。
该课程将为你提供进入 Linux Foundation AI & Data 生态系统的机会,这与开源工具相关,帮助你继续发展新的数据和人工智能技能。如前所述,这个课程对来自金融、制造等各种行业的任何人都有帮助。
通过这个课程,你将能够了解人工智能技术领域中可用的不同职业选择。
微调大型语言模型(DeepLearning.AI)
链接: 深度学习 - 微调大型语言模型
你们中的一些人可能已经对人工智能和大型语言模型(LLMs)有了较好的了解,并可能希望完善技能或学习新知识。这个与 DeepLearning.AI 合作的课程将通过一个快速的 1 小时课程讲解微调 LLM 的基础知识。
你将了解微调与提示工程的不同之处,以及何时使用这两者,同时获得使用真实数据集的实践经验,并学习如何将这些工具和技术应用到自己的项目中。
如果你对 Python 语言已经比较熟悉,并且对深度学习框架如 PyTorch 和微调的应用有较好的理解,那么这个课程适合你。
人工智能项目
链接: 人工智能项目
在科技领域,有很多很棒的资源供你学习和发展新技能。然而,重要的是要记住,你必须在实际场景中应用这些技能——以项目的形式。
这个课程旨在帮助学习者将人工智能的解决方案和模型应用于实际问题。你将学习人工神经网络(ANNs)、时间序列预测、聊天机器人等内容。
总结
这个博客针对的是人工智能领域的新手,但不限于初学者。如果你想提升现有技能或适应现有技能,这些免费课程可以帮助你快速入门,而无需花费一分钱!
Nisha Arya是一位数据科学家、自由技术写作人,以及 KDnuggets 的编辑和社区经理。她特别感兴趣于提供数据科学职业建议或教程,并围绕数据科学的理论知识展开讨论。Nisha 涉及广泛的主题,并希望探索人工智能如何有益于人类生命的长寿。作为一个热衷学习者,Nisha 寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关内容
2024 年微软提供的 5 门免费 AI 课程
原文:
www.kdnuggets.com/5-free-courses-on-ai-with-microsoft-for-2024

图片来源:编辑
新的一年开始了。你想实现你的目标。想要探索新领域?想要职业转型?这可能会让人感到畏惧。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力。
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理。
你不知道从哪里开始,也不确定哪个课程最适合你实现职业目标。你不确定该走哪条路。这一切可能让人感到过于压倒。
本博客旨在提供帮助。
如果你考虑职业转型,特别是与 AI 相关的方向,你来对地方了。微软提供了一些非常棒的免费资源,帮助你达到目标。
在支付课程费用或回到大学之前,尽可能多地吸收免费的内容将是你最好的起步方式。免费资源可以帮助你判断这是否是你真正想做的事情。
AI 初学者
链接:AI 初学者
微软提供了一个为期 12 周、24 节课的课程,帮助你了解人工智能的世界。
在 12 周内,你将学习到 AI 的简介与历史、符号 AI、神经网络简介、计算机视觉、自然语言处理以及其他 AI 技术。
使用 Azure OpenAI 服务
你可能在 2023 年听到了很多关于 OpenAI 的消息。现在是时候深入了解了!
随着大型语言模型(LLMs)越来越受欢迎,一些人可能对学习它们更感兴趣。提示工程和生成式 AI 正是科技界关注的焦点,你也可以通过这个课程深入了解。
从学习提示工程开始,然后深入了解负责任的生成式 AI 基础知识。通过使用 GitHub Copilot 和 Azure OpenAI 将所学知识付诸实践。
如果你想继续学习 Azure OpenAI,你可以提升你的生成式 AI 技能!
自定义机器学习模型
链接:自定义机器学习模型
现在你对 AI 和 Azure AI 服务有了一个很好的概述,接下来你可能会想要深入了解更底层的内容——机器学习模型。这时你将理解 AI 背后的真正美丽。
另一个学习路径将帮助你发现构建和运行你自己数据模型的工具。提升你的机器学习模型本身就是一种技能。
你将学习如何创建计算机视觉解决方案、处理和翻译文本、从表单中提取数据、自动化机器学习模型选择,并部署和使用模型。
使用 Azure AI 构建应用
想要进一步了解 Azure 吗?让我们通过包含文章、YouTube 视频和实际模块内容的学习资料来深入探讨。
这个课程将帮助你了解使用 Azure AI 服务构建 AI 驱动应用的工具。如果生成性 AI 是你的兴趣所在,你可以使用 Azure OpenAI 服务开发解决方案,还可以在 Microsoft Copilot Studio 中探索聊天机器人和其他 AI 模型。
在日常工作中使用 AI
链接:在日常工作中使用 AI
这样你将有机会了解 AI 及其基本原理,然后通过构建自定义机器学习模型和应用程序将其付诸实践。你可能会想,‘AI 如何融入我的日常生活?’。
这个课程正是讲解这些内容。虽然这些内容推荐给开发者,但这可能是你想要的路径。
通过 GitHub Copilot 简化你的工作,首先学习 AI 与 GitHub Copilot 的配合方式。
总结
就这样,你离实现 2024 年的目标又近了一步,享受一些很棒的免费资源。请在评论区告诉我们你对内容的喜爱之处!
Nisha Arya是一名数据科学家、自由技术写作员,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程及理论知识。Nisha 涉及广泛的话题,希望探索人工智能如何有利于人类寿命的不同方式。作为一名热衷学习者,Nisha 致力于拓展她的技术知识和写作技能,同时帮助他人。
更多相关话题
5 个免费课程助你进入数据分析领域
原文:
www.kdnuggets.com/5-free-courses-to-break-into-data-analytics

图像由 DALLE-3 生成
如果你想转行进入数据领域,学习数据分析非常有帮助。这就是为什么我们整理了这份免费数据分析课程的列表,帮助你启动你的学习之旅!
我们的 3 个顶级课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
即使你是一个对数据领域充满热情的绝对初学者,你也会发现这些课程非常有用。因为它们针对的是有志于成为数据专业人士的人,并且不需要先前的编程经验。
让我们开始吧。
1. Google 数据分析专业证书
Google 数据分析专业证书 是 Coursera 上最受欢迎的专业化之一,全球近 200 万学习者参与其中。这个认证项目旨在让你迅速掌握数据分析的基础知识,以帮助你在不到 6 个月的时间内获得入门级的数据分析职位。它也不需要任何先前的经验。
该专业化包括 8 门课程,帮助你学习使用 SQL、电子表格、Tableau 和 R 编程进行数据分析的基础知识。Google 数据分析证书项目包括以下课程:
-
基础知识:数据,数据,无处不在
-
提出问题以做出数据驱动的决策
-
为探索准备数据
-
将数据从脏数据处理为干净数据
-
分析数据以回答问题
-
通过可视化艺术分享数据
-
使用 R 编程进行数据分析
-
Google 数据分析总结项目:完成一个案例研究
注意:如果你有兴趣获得 Google 数据分析专业化证书,你需要拥有 Coursera Plus 订阅。如果你无法支付证书费用,你可以考虑申请经济援助。不过,你可以免费审计课程并访问课程材料。
2. 针对 Excel 用户的 Python 数据分析
谷歌数据分析专业证书应该让你对数据分析领域有了良好的掌握,并掌握了一些基本工具,如电子表格、SQL、R 和 Tableau。
既然你已经熟练使用电子表格,你可以学习用于数据分析的 Python。Python 不仅比 R 更容易学习,而且应用范围更广。
Excel 用户的数据分析与 Python 课程由 freeCodeCamp 提供,是一门免费课程,用于学习 Python 数据分析的基础。它从教你如何设置 Python 开发环境和使用 Jupyter notebooks 开始。
本课程包括以下三个模块:
-
模块 1: Hello world(涵盖 Python 基础)
-
模块 2: Pandas 简介
-
模块 3: Pandas 中的透视表简介
这门课程应该帮助你打下用 Python 分析数据的基础,然后可以根据需要进行扩展。
3. freeCodeCamp 的 Python 数据分析
链接: Python 数据分析认证
既然你已经掌握了 Python 数据分析的基础,现在是时候进一步学习了。Python 数据分析,这是 freeCodeCamp 提供的免费认证课程,将教你 Python 数据分析库的所有内容,同时还会进行简单项目的实践。
你将学习使用 Python 库 NumPy、pandas、matplotlib 和 Seaborn:
-
Jupyter notebooks 基础
-
NumPy
-
Pandas
-
数据清洗
-
数据可视化
-
从各种来源读取数据
-
解析 HTML
你将在这个认证中构建的项目包括:
-
均值-方差-标准差计算器
-
人口数据分析器
-
医疗数据可视化工具
-
页面浏览时间序列可视化工具
-
海平面预测器
这个认证完全免费。在完成课程后,你需要完成所有项目才能领取证书。
4. 谷歌高级数据分析专业证书
链接: 谷歌高级数据分析专业证书
谷歌高级数据分析专业证书将帮助你深入了解 Python 数据分析,同时学习统计学概念和构建机器学习模型。本专业还提供了一个结业项目的机会,以应用你所学的知识。
本专业的课程如下:
-
数据科学基础
-
开始使用 Python
-
超越数字: 将数据转化为洞察
-
统计学的力量
-
回归分析: 简化复杂的数据关系
-
机器学习的基础知识
-
谷歌高级数据分析结业项目
注意:与 Google 数据分析专业证书一样,你可以免费旁听 Google 高级数据分析专项。
5. IBM 数据分析师专业证书
IBM 数据分析师专业证书是 IBM 在 Coursera 上提供的另一个全面的数据分析专项,它将帮助你学习所有基础知识和必备工具,以启动你的数据分析职业生涯。
该认证也适合初学者,因此你无需具备编程和数据分析的先前经验。通过一系列课程和顶点项目,该专项将帮助你在以下方面提高熟练度:
-
Python 和 SQL 基础
-
Excel 和 Tableau
-
使用 API 和网络服务
-
Python 数据科学库
推荐的时间框架大约为 4 个月,每周学习约 10 小时。以下是该数据分析师专业证书的课程:
-
数据分析导论
-
数据分析基础知识
-
使用 Excel 和 Cognos 进行数据可视化和仪表盘
-
Python 在数据科学、AI 和开发中的应用
-
数据科学的 Python 项目
-
数据库和 SQL 在 Python 中的数据科学
-
使用 Python 进行数据可视化
-
IBM 数据分析师顶点项目
注意:与其他 Coursera 专项课程一样,你可以免费旁听此课程。
总结
希望你觉得这份数据分析课程列表对你有帮助。如果你打算很快转向数据分析领域,祝你学习顺利。
如果你在寻找数据岗位市场的技巧,请阅读 你在找数据科学工作时遇到的 7 个困难原因。
Bala Priya C**** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过撰写教程、使用指南、观点文章等与开发者社区分享她的知识。Bala 还创建了有趣的资源概述和编码教程。
更多相关内容
掌握数据工程的 5 门免费课程
原文:
www.kdnuggets.com/5-free-courses-to-master-data-engineering

数据领域正处于激动人心的时刻,数据工程师在其中发挥着重要作用。通过准备和管理数据基础设施,数据工程师提供了数据收集、存储、处理和分析所需的工具。这就是为什么数据工程师在数据驱动的公司中扮演着重要角色。
我们的 Top 3 课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升您的数据分析水平
3. Google IT 支持专业证书 - 支持您的组织进行 IT 工作
在这样一个重要的角色下,公司愿意支付相当高的薪资来聘请数据工程师解决数据基础设施问题。那么,我们如何才能掌握数据工程的艺术呢?这里有五门免费的课程可以帮助您提升职业生涯。
IBM:面向所有人的数据工程基础
让我们从 IBM 在 edX 上的精彩数据工程课程 开始。这门课程旨在向初学者介绍数据工程基础,为更高级的应用场景做好准备。
我喜欢这门课程,因为它为我提供了数据工程的基础,即使我是一名数据科学家。我相信这门课程将为初学者提供掌握数据工程师所需的技能。
通过这门课程,您将学习到的核心概念包括:
-
数据工程师概念
-
工作流管理
-
关系型数据库
-
数据湖
-
数据存储
-
IBM 云计算
这些课程也可以自定进度学习,因此您可以在分配的时间内学习而不会感到受限。
Google 数据工程师学习路径
在了解了 IBM 之后,您还应该查看 Google 提供的内容。在他们的 Cloud Skill Boost 中,有一个 数据工程师学习路径,可以通过 Google 云平台提升您的数据工程师技能。
在学习路径中,您将通过 13 门为初学者和专业人士设计的课程学习各种数据工程技能。在这些课程中,您将了解以下技能:
-
Google 云计算
-
数据管道
-
数据仓库
-
数据湖
-
数据存储
-
无服务器数据处理
和之前的课程一样,这门课程也是自学进度的,你可以按照自己的节奏完成。随着未来云计算的发展,这门课程将为你在未来的雇主面前提供优势。
Meta 数据库工程师专业证书
让我们继续介绍由另一家知名公司 Meta 提供的免费数据工程课程。Meta 数据库工程师专业证书课程将重点提升数据工程师的技能,即数据库。
数据工程师负责整个数据流;这一流的一个重要部分是拥有一个强大的数据库。如果没有可靠的数据库,整个数据生态系统将会崩溃。这就是为什么 Meta 为任何愿意在数据库领域开辟自己道路的人提供这门课程。
在这门课程中,你将学习以下技能:
-
数据库基础
-
数据库结构
-
数据库客户端
-
版本控制
-
高级 MySQL
通过 9 门课程和灵活的时间安排,你可以轻松提升自己的技能。
UC San Diego 大数据专业化
专业课程对你的数据工程师职业至关重要,因为它可以让你脱颖而出。免费的课程UC San Diego 大数据专业化将为你在大数据领域奠定基础。
在数据工程领域,大数据是一个复杂的问题,需要特定的方法。数据工程师需要能够设计数据流,使公司能够处理和利用大数据,而这正是这门课程的核心内容。在这门课程中,你将学习:
-
大数据基础
-
大数据管理
-
大数据集成与处理
-
图形分析与大数据
该系列有 6 门课程,时间安排灵活。估计如果每周学习 10 小时,你可以在 3 个月内完成课程。
数据工程 Zoomcamp
数据工程 Zoomcamp是由Ankush Khanna、Victoria Perez Mola和Alexey Grigorev为初学者开设的免费课程,由社区提供支持。
这些课程将从领域专家那里为你提供完整的数据工程视角,并为你准备好工作。通过 9 周的学习,你将掌握以下技能:
-
数据工程师基础
-
数据工作流和编排
-
数据仓库
-
数据管道
-
分析工程
这门课程有两种学习方式:自学进度和学习小组课程。学习小组注册有其开放时间表,因此请持续关注他们的页面。
结论
为了做出数据驱动的决策,公司需要支持这一过程的数据基础设施。数据工程师承担着提供复杂数据工作流的任务。要掌握数据工程技能,我们可以通过本文讨论的五门课程进行学习。借助著名讲师提供的结构化课程,这些课程将帮助你了解一切,获得数据工程师职位。
Cornellius Yudha Wijaya**** 是一位数据科学助理经理和数据撰稿人。他在全职工作于印尼安联的同时,热衷于通过社交媒体和写作平台分享 Python 和数据技巧。Cornellius 在各种 AI 和机器学习主题上撰写文章。
更多相关主题
5 门免费课程掌握数据科学
作者图片
你是一个有志于成为数据专业人士并想要启动数据科学职业吗?如果是的话,你可能在考虑各种选择:在线课程、训练营、硕士学位等。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织中的 IT
但如果你有足够的动力,有几个高质量的免费资源可以帮助你达到目标。在这里,我们编制了五门免费课程的列表,可以帮助你学习并掌握数据科学。
从编程基础到构建和部署数据科学应用,这些课程将教会你成功转型所需的一切。
让我们直接深入!
1. Python for Everybody
Python for Everybody,由密歇根大学的查尔斯·塞弗伦斯教授讲授,是学习 Python 的绝佳课程。它从零开始教授 Python 编程——涵盖了处理数据时所需了解的一切。
你还可以结合使用 Python for Everybody 书籍 与课程。课程涵盖以下广泛主题:
-
使用 Python 编程基础
-
Python 数据结构
-
条件执行、循环和迭代
-
函数
-
正则表达式
-
网络服务和联网程序
-
数据可视化
课程链接: Python for Everybody
2. 使用 Python 进行数据分析
现在你已经掌握了 Python 基础,是时候使用 Python 分析数据了。Jovian 提供的 Python 数据分析(在 freeCodeCamp 的 YouTube 频道上)是一个免费课程,它将帮助你学习使用数据科学库,包含多个练习和课程项目。
这门课程从 Python 编程基础开始(这对你来说应该是一个复习),逐渐介绍 Python 数据分析库。最后以一个关于探索性数据分析的课程项目结束。
以下是课程大纲概述:
-
Python 基础
-
使用 NumPy 进行数值计算
-
使用 pandas 分析表格数据
-
使用 Matplotlib 和 Seaborn 进行可视化
-
课程项目:探索性数据分析
课程链接:Python 数据分析
3. 数据库和 SQL
数据科学中的数据库介绍概述了数据专业人员必备的数据库技能。
从设计数据库到编写高效的 SQL 查询及更多,数据库和 SQL 是你数据职业生涯中必备的技能。这个数据库和 SQL课程来自 freeCodeCamp,将教你以下内容:
-
数据库基础
-
SQL 基础
-
CRUD 操作
-
函数、连接和并集
-
嵌套查询
-
设计数据库模式
课程链接:数据库和 SQL
4. 推断统计学简介
除了高中数学——微积分、概率和线性代数,你还需要在统计学方面有坚实的基础,才能在数据科学领域取得卓越成绩。
推断统计学简介来自 Udacity 的免费课程库,将教你以下概念——同时包含编码练习以测试你的技能:
-
估计
-
假设检验
-
t 检验
-
方差分析
-
卡方检验
-
相关性
-
回归分析
课程链接:推断统计学简介
5. 机器学习 Zoomcamp
目前列出的课程应当帮助你掌握 Python 基础、数据分析和统计学基础。
现在是时候开始构建和部署机器学习模型了。机器学习 Zoomcamp由 DataTalks.Club 提供,是学习机器学习基础的绝佳课程,通过以代码为主的方式进行。它还涵盖了包括模型部署和深度学习在内的广泛主题。
课程大纲包括以下内容:
-
回归分析
-
分类
-
评估机器学习模型
-
部署机器学习模型
-
决策树和集成学习
-
神经网络和深度学习
-
Kubernetes 和 TensorFlow Serving
课程链接:机器学习 Zoomcamp
总结
我希望你发现这些推荐课程有帮助。大多数课程要求你进行编码、构建、拆解和学习。因此,你将拥有一个良好的基础。
即使你在学习这些课程时,也要在旁边构建你的作品集。你的目标应该是构建一些有趣的项目,以展示你的优势和技能。如果你需要一些灵感来开始,可以查看 3 个数据科学项目保证让你获得工作。祝学习愉快!
Bala Priya C** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她致力于通过撰写教程、操作指南、观点文章等,学习并与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编程教程。**
更多相关内容
5 门免费课程,掌握生成式人工智能

你是否希望深入探索生成式人工智能的激动人心的世界?
我们的前三推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
正如你所知道的,生成式人工智能目前正处于最前沿,并自 ChatGPT 推出以来已经掀起了整个世界的风暴。技能需求量很高,但由于这一领域尚处于起步阶段且不断变化,紧跟最新进展对这一新兴领域尤为重要。
无论你是人工智能广泛领域的初学者还是希望提升现有技能,都有许多免费的课程可以帮助你掌握这项前沿技术。以下是五门可以启动或提升你在生成式人工智能领域旅程的课程。
1. 生成式人工智能初学者课程
这门来自微软的综合性 12 课时课程教授构建生成式人工智能应用的基础知识。每节课包括一个视频介绍、书面材料、包含代码示例的 Jupyter Notebook、挑战任务和额外资源。你将学习诸如理解生成式人工智能和大型语言模型、提示工程、构建各种应用以及为 AI 应用设计用户体验等主题。
课程链接:生成式人工智能初学者课程
2. 生成式人工智能基础
这门 Databricks 课程通过四个视频提供生成式人工智能的基础知识,包括大型语言模型(LLMs)。它涵盖了生成式人工智能的各个方面,如应用、成功策略以及潜在的风险和挑战。在完成课程并通过知识测试后,你可以获得一个徽章,以便在 LinkedIn 个人资料或简历中分享。
课程链接:生成式人工智能基础
3. 生成式人工智能学习路径简介
由 Google Cloud Skills Boost 提供的这门入门级微学习课程概述了生成式 AI 概念,探讨了大型语言模型、负责任的 AI 原则以及 Google 工具,用于开发自己的生成式 AI 应用。课程包括生成式 AI 简介、大型语言模型简介、负责任的 AI 简介、生成式 AI 基础和负责任的 AI:使用 Google Cloud 应用 AI 原则。完成课程后可获得徽章。
课程链接:生成式 AI 学习路径简介
4. 与大型语言模型一起学习生成式 AI
这门 AWS 课程提供了对生成式 AI 的全面理解,重点讲解了基于 LLM 的 AI 生命周期、变换器架构、模型优化以及实际部署方法。该课程旨在为具有基础 LLM 知识的开发者提供关于有效训练和部署这些模型的最佳实践。先前的 Python 经验和基本的机器学习概念是先决条件,使得这是一门中级课程。
课程链接:与大型语言模型一起学习生成式 AI
5. 适用于每个人的生成式 AI
由 Deeplearning.AI 提供,并由 AI 专家 Andrew Ng 教授的《适用于每个人的生成式 AI》课程,专注于理解和应用生成式 AI 于各种背景中。课程涵盖了生成式 AI 的基本原理、功能和局限性,并包括在提示工程和高级 AI 应用中的实际练习。参与者将探索现实世界的应用,参与生成式 AI 项目,了解其对商业和社会的影响。旨在为学习者提供有关 AI 项目生命周期、潜在机会以及生成式 AI 技术相关风险的知识。
课程链接:适用于每个人的生成式 AI
总结
这些课程为任何对学习和掌握生成式 AI 感兴趣的人提供了一系列很好的起点。它们提供了实践见解、基础知识和开发及部署 AI 应用的实践经验。随着你的进步,记得通过项目实践和构建展示你技能与创意的作品集来应用你新获得的知识,这一领域正迅速发展。
祝学习顺利!
Matthew Mayo (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 和 Statology 的总编辑,以及 Machine Learning Mastery 的特约编辑,Matthew 旨在使复杂的数据科学概念变得易于理解。他的职业兴趣包括自然语言处理、语言模型、机器学习算法以及探索新兴 AI。他致力于在数据科学社区中普及知识。Matthew 从 6 岁起便开始编程。
更多相关话题
5 个免费课程,掌握机器学习
原文:
www.kdnuggets.com/5-free-courses-to-master-machine-learning

图片由 DALLE-3 生成
机器学习在数据领域变得越来越受欢迎。但通常有一种观念认为,要成为机器学习工程师,你需要拥有高级学位。然而,这并不完全正确。因为技能和经验始终优于学位。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
如果你正在阅读这篇文章,你可能是数据领域的新手,并希望作为机器学习工程师起步。也许你已经作为数据分析师或 BI 分析师在数据领域工作,并希望转向机器学习角色。
无论你的职业目标是什么,我们已精心策划了一份完全免费的机器学习课程列表,以帮助你在机器学习方面获得熟练度。我们包括了帮助你理解理论和构建机器学习模型的课程。
开始吧!
1. 适合所有人的机器学习
如果你在寻找一个易于访问的机器学习课程,适合所有人的机器学习是适合你的。
由 Kylie Ying 教授,本课程采取代码优先的方法,在 Google Colab 中构建简单有趣的机器学习模型。启动自己的笔记本并在学习足够理论的同时构建模型是一种很好的熟悉机器学习的方法。
该课程使机器学习概念变得易于理解,并涵盖以下主题:
-
机器学习简介
-
K-最近邻
-
朴素贝叶斯
-
逻辑回归
-
线性回归
-
K 均值聚类
-
主成分分析(PCA)
课程链接:适合所有人的机器学习
2. Kaggle 机器学习课程
Kaggle 是参与现实世界数据挑战、建立数据科学作品集以及磨练模型构建技能的绝佳平台。此外,Kaggle 团队还有一系列微型课程来让你快速掌握机器学习的基础知识。
你可以查看以下(微型)课程。每个课程通常需要几个小时来完成并完成练习:
-
机器学习简介
-
中级机器学习
-
特征工程
机器学习简介 课程涵盖以下主题:
-
机器学习模型如何工作
-
数据探索
-
模型验证
-
欠拟合和过拟合
-
随机森林
在中级机器学习课程中,你将学习:
-
处理缺失值
-
处理分类变量
-
机器学习管道
-
交叉验证
-
XGBoost
-
数据泄漏
特征工程 课程涵盖:
-
互信息
-
创建特征
-
K 均值聚类
-
主成分分析
-
目标编码
建议按上述顺序学习课程,以便在从一个课程转到下一个课程时,你已具备必要的前提知识。
课程链接:
3. 使用 Scikit-Learn 的 Python 机器学习
使用 Scikit-Learn 的 Python 机器学习 在 FUN MOOC 平台上是由 scikit-learn 核心团队开发的免费自学课程。
它涵盖了广泛的主题,帮助你学习使用 scikit-learn 构建机器学习模型。每个模块包含视频教程和配套的 Jupyter 笔记本。你需要对 Python 编程和 Python 数据科学库有一定的熟悉度,以充分利用课程。
课程内容包括:
-
预测建模管道
-
评估模型性能
-
超参数调优
-
选择最佳模型
-
线性模型
-
决策树模型
-
模型集成
课程链接:使用 Scikit-Learn 的 Python 机器学习
4. 机器学习速成课程
机器学习速成课程来自 Google,是另一个学习机器学习的好资源。从模型构建的基础到特征工程等,本课程将教你如何使用 TensorFlow 框架构建机器学习模型。
该课程分为三个主要部分,大部分课程内容在机器学习概念部分:
-
机器学习概念
-
机器学习工程
-
现实世界中的机器学习系统
上这门课程,你需要对高中数学、Python 编程和命令行有一定的了解。
机器学习概念部分包括:
-
机器学习基础
-
TensorFlow 介绍
-
特征工程
-
逻辑回归
-
正则化
-
神经网络
机器学习工程部分涵盖:
-
静态 vs 动态训练
-
静态 vs 动态推断
-
数据依赖
-
公平性
而《现实世界中的机器学习系统》是一组案例研究,用于理解现实世界中如何进行机器学习。
课程链接: 机器学习速成课程
5. CS229: 机器学习
到目前为止,我们已经看到了一些课程,它们在专注于构建模型的同时,给你提供了理论概念的初步了解。
虽然这是一开始的好选择,但你将需要更详细地了解机器学习算法的工作原理。这对破解技术面试、职业发展和进入机器学习研究非常重要。
CS229: 机器学习 由斯坦福大学提供,是最受欢迎且强烈推荐的机器学习课程之一。本课程将提供与一个学期的大学课程相同的技术深度。
你可以在线访问讲座和讲座笔记。本课程涵盖以下广泛主题:
-
监督学习
-
无监督学习
-
深度学习
-
泛化和正则化
-
强化学习和控制
课程链接: CS229: 机器学习
总结
希望你找到有用的资源来帮助你在机器学习之旅中!这些课程将帮助你获得理论概念和实际模型构建的良好平衡。
如果你已经熟悉机器学习且时间有限,我建议查看《使用 scikit-learn 的 Python 机器学习》以深入了解 scikit-learn,并参考 CS229 以获取基本的理论基础。祝学习愉快!
Bala Priya C**** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和咖啡!目前,她正在通过撰写教程、操作指南、意见文章等,与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关话题
5 门免费课程掌握数据科学数学
原文:
www.kdnuggets.com/5-free-courses-to-master-math-for-data-science
图片由storyset on Freepik提供
在学习数据科学时,建立良好的数学基础将使你的学习之旅更轻松且更有效。即使你已经获得了你的第一个数据职位,学习数据科学的数学基础也只会进一步提升你的技能。
我们的三大推荐课程
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
从探索性数据分析到构建机器学习模型,拥有良好的数学基础,如线性代数和统计学,将使你更好地理解为什么你做什么。所以即使你是初学者,这个课程列表也将帮助你学习:
-
基础数学技能
-
微积分
-
线性代数
-
概率和统计
-
优化
听起来有趣,是吗?让我们开始吧!
1. 数据科学数学技能 – 杜克大学
数据科学课程要求你在数学方面有一定的基础。具体来说,大多数课程假设你对高中代数和微积分感到舒适。如果还没有,也不用担心。
数据科学数学技能课程,由杜克大学在 Coursera 上提供,将帮助你在尽可能短的时间内掌握数学基础。课程内容包括:
-
问题解决
-
函数和图形
-
微积分简介
-
概率简介
建议你在开始其他深入探讨特定数学主题的课程之前,先学习这门课程。
链接: 数据科学数学技能 – 杜克大学在 Coursera 上的课程
2. 微积分 – 3Blue1Brown
当我们谈论数据科学中的数学时,微积分绝对是你应该熟悉的内容。但大多数学习者发现高中微积分令人畏惧(我也经历过!)。然而,这部分是因为我们学习的方式——主要关注概念、少量说明性示例和大量练习题。
但如果有有用的可视化帮助你从直觉到方程,专注于为什么,你会更好地理解和学习微积分。
微积分课程由 3Blue1Brown 的 Grant Sanderson 讲授,正是我们所有人需要的!通过一系列带有超级有用的可视化的课程——尽可能从几何到公式——这门课程将帮助你学习以下内容以及更多:
-
极限和导数
-
幂法则、链式法则、积法则
-
隐式微分
-
高阶导数
-
泰勒级数
-
积分
线性代数 – 3Blue1Brown
作为数据科学家,你所处理的数据集本质上是维度为 num_samples x num_features 的矩阵。因此,你可以将每个数据点视为特征空间中的一个向量。所以理解矩阵的工作原理、矩阵的常见操作、矩阵分解技术都是重要的。
如果你喜欢了 3Blue1Brown 的微积分课程,那么你可能同样会喜欢 Grant Sanderson 的线性代数课程,甚至可能更加喜欢。线性代数课程将帮助你学习以下内容:
-
向量和向量空间的基础
-
线性组合、跨度和基
-
线性变换和矩阵
-
矩阵乘法
-
3D 线性变换
-
行列式
-
逆矩阵、列空间和零空间
-
点积和叉积
-
特征值和特征向量
-
抽象向量空间
概率与统计 – Khan Academy
统计学和概率是你数据科学工具箱中极好的技能。但这些技能绝不是易于掌握的。然而,掌握基础并在其上构建相对较容易。
统计与概率课程来自 Khan Academy,将帮助你学习开始更有效地处理数据所需的概率和统计知识。以下是涵盖的主题概述:
-
分类和定量数据分析
-
数据分布建模
-
概率
-
计数、排列和组合
-
随机变量
-
抽样分布
-
置信区间
-
假设检验
-
卡方检验
-
方差分析(ANOVA)
如果你对深入研究统计感兴趣,也可以查看 5 个免费课程掌握数据科学中的统计。
链接: 统计与概率 - 可汗学院
5. 机器学习中的优化 - ML Mastery
如果你曾经训练过机器学习模型,你会知道算法学习模型参数的最佳值。在后台,它运行优化算法以找到最佳值。
机器学习优化速成课程来自 Machine Learning Mastery,是一个全面的资源,用于学习机器学习中的优化。
该课程采用代码优先的方法,使用 Python。因此,在了解优化的重要性后,你将编写 Python 代码来查看流行的优化算法的实际效果。以下是涵盖的主题概述:
-
优化的必要性
-
网格搜索
-
SciPy 中的优化算法
-
BFGS 算法
-
爬山算法
-
模拟退火
-
梯度下降
链接: 机器学习优化速成课程 - MachineLearningMastery.com
总结
我希望你发现这些资源有帮助。由于这些课程大多数是针对初学者的,你应该能够掌握所有基本的数学知识,而不会感到不堪重负。
如果你在寻找学习 Python 用于数据科学的课程,可以阅读 5 个免费课程,掌握数据科学中的 Python。
祝学习愉快!
Bala Priya C**** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过编写教程、指南、评论文章等来学习和分享知识。Bala 还创建了引人入胜的资源概述和编程教程。
相关主题
5 个免费课程掌握 MLOps
图片由Microsoft Bing生成
介绍
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
在数据驱动决策的今天,仅仅创建机器学习(ML)模型是不够的。组织需要的不仅仅是构建模型——他们需要成功地部署、管理并持续改进这些模型在现实世界中的表现。想象一下:你构建了一个超级智能的系统来预测天气模式,但除非你确保它每天都在工作,并且随着新数据变得更聪明,否则它就像是一个在棚子里积灰的强大工具。这就是 MLOps 的作用。
如果你对将你的 MLOps 技能提升到下一个水平感到好奇,并想知道如何将你出色的模型转化为现实世界的解决方案,这篇文章将是你的指南。我将向你介绍五个免费课程,这些课程将 MLOps 分解为易于理解的部分。无论你是刚起步还是已经是机器学习的专家,这里都有适合你的课程。
MLOps 的 Python 基础

MLOps 的 Python 基础课程
这个课程将教你在 MLOps 角色中成功所需的基本 Python 技能。它涵盖了 Python 编程语言的基础知识,包括数据类型、函数、模块和测试技术。它还涉及如何有效地处理数据集和其他数据科学任务,使用 Pandas 和 NumPy。在这个课程中,通过一系列动手练习,你将获得在 MLOps 工作流程中使用 Python 的实践经验。课程结束时,你将掌握编写 Python 脚本来自动化常见 MLOps 任务的必要技能。
这个课程非常适合那些希望进入 MLOps 领域的人或那些希望提升 Python 技能的经验丰富的 MLOps 专业人员。
涵盖的主题:
-
数据探索
-
分类:垃圾邮件过滤
-
排名:优先收件箱
-
回归:预测页面浏览量
-
正则化:文本回归
-
优化:破解代码
-
PCA: 构建市场指数
-
MDS: 视觉探索美国参议员相似性
-
kNN: 推荐系统
-
分析社交图谱
-
模型比较
MLOps 入门
链接: MLOps 入门

MLOps 入门课程
既然你已经复习了 Python,现在是时候深入了解一些实质性的内容了!这门课程《MLOps 入门》是 Udemy 上的一门免费教程,教你如何提供一个端到端的机器学习开发过程,以设计、构建和管理 AI 模型生命周期。
这门课程由 Prem Naraindas(一位经验丰富的 MLOps 从业者)讲授,并包括多个动手练习。到课程结束时,你将对 MLOps 的基础有一个良好的理解,并能够将其应用到你的工作中。
涵盖主题:
-
MLOps 概述
-
MLOps 工具和平台
-
创建管道
-
自动化模型训练、评估、实验
-
部署和监控
-
服务
-
扩展
-
MLOps 最佳实践
生产环境下的机器学习工程(MLOps)专业化

生产环境下的机器学习工程专业化
如果你准备从理论知识转向实际的机器学习编码,你需要参加 Coursera 上的《生产环境下的机器学习工程(MLOps)专业化》课程。这门由 deeplearning.ai 提供的综合性专业化课程,专为那些有 Tensorflow 经验并对实践应用和动手编码经验充满热情的程序员设计。此课程非常适合那些掌握 Python 和 TensorFlow 并希望直接进入 MLOps 领域的人!
最棒的是,这门课程由 Andrew Ng(谷歌的领先 AI 推广者)、Lawrence Moroney 和 Robert Crowe(来自谷歌)讲授。
涵盖主题:
-
生产就绪的机器学习系统
-
数据管道和模型管理技术
-
概念漂移
-
模型训练
-
基于云的 MLOps 工具
-
模型监控
-
模型优化
-
Tensorflow 生产(TFX)
MLOps | 机器学习操作专业化
链接: 机器学习操作专业化

机器学习操作专业化
这个全面的课程系列是为那些有编程知识并对学习 MLOps 感兴趣的个人设计的。课程将教你如何使用 Python 和 Rust 进行 MLOps 任务,使用 GitHub Copilot 提高生产力,并利用 Amazon SageMaker、Azure ML 和 MLflow 等平台。你还将学习如何使用 Hugging Face 微调大型语言模型(LLMs),并理解 ONNX 格式下可持续高效的二进制嵌入模型的部署。课程还将为你在 MLOps 领域的各种职业道路做好准备,如数据科学、机器学习工程、云 ML 解决方案架构和人工智能(AI)产品管理。
这个全面的课程系列非常适合特别是那些有编程知识的个人,例如软件开发人员、数据科学家和研究人员。
涵盖的主题:
-
微软 Azure
-
大数据
-
数据分析
-
Python 编程
-
Github
-
机器学习
-
云计算
-
数据管理
-
DevOps
-
亚马逊网络服务(Amazon AWS)
-
Rust 编程
-
MLOps
Made With ML MLOps 课程

Made With ML MLOps 课程
Goku Mohandas 开发了一个卓越且公开访问的端到端机器学习系统课程。Made with ML 是最受欢迎的 GitHub 存储库之一,已有超过 30,000 人注册此课程。
Made with ML 课程涵盖了机器学习的基础知识以及模型部署、测试和生产监控的复杂性。Goku 的课程解释了引入概念的基本思想,提供了实用的基于项目的作业,并为学生提供了一些在 MLOps 角色中成功所需的软件工程最佳实践。
涵盖的主题:
-
机器学习基础
-
端到端系统开发
-
部署策略
-
测试方法
-
模型监控
-
概念背后的直觉
-
实践项目作业
-
软件工程最佳实践
结论
MLOps 是一个迅速发展的领域,对技能娴熟的专业人员有着很高的需求。通过掌握 MLOps,你可以开启新的职业机会,并在世界上产生真正的影响。借助这五个免费课程,你可以迈出成为 MLOps 专家的第一步。那么你还在等什么呢?立即注册并开始学习吧!
如果你是机器学习和 MLOps 的初学者,你可能想看看我们的文章掌握机器学习的 5 本免费书籍。但如果你想直接深入 MLOps,只打算选择一两门课程,我建议你参加Andrew Ng 的机器学习工程生产(MLOps)专业化和Made with MLOps课程。
我们很想知道,哪些课程在你的机器学习旅程中发挥了关键作用。欢迎在下面的评论中分享你的想法!
Kanwal Mehreen**** Kanwal 是一位机器学习工程师和技术作家,对数据科学以及人工智能与医学的交汇处充满深厚的热情。她共同撰写了电子书《利用 ChatGPT 最大化生产力》。作为 2022 年 APAC 的 Google Generation Scholar,她倡导多样性和学术卓越。她还被认定为 Teradata 多样性技术学者、Mitacs Globalink 研究学者和哈佛 WeCode 学者。Kanwal 还是变革的热心倡导者,她创立了 FEMCodes 以赋能女性进入 STEM 领域。
相关话题
5 门免费课程,掌握自然语言处理
原文:
www.kdnuggets.com/5-free-courses-to-master-natural-language-processing

作者图片
自从知名的大型语言模型(LLMs)如 ChatGPT 推出以来,许多人对语言的使用产生了兴趣。我们正在看到这些 LLMs 对我们日常生活的巨大影响,有些人希望转向这一蓬勃发展的领域。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
然而,当你考虑转行时,首先想到的是如何迈入新领域。这些步骤有时可能非常昂贵。你可能需要回到大学,或报名参加认证课程等。
想要提升职业发展和技能提升却不考虑成本是很困难的。话虽如此,对于那些正在关注自然语言处理(NLP),想了解更多,或希望将职业发展方向转向此领域的人,这篇博客适合你。
数据科学基础专门化
链接:数据科学基础专门化
级别:初学者
时长:1 个月,每周 10 小时
如果你是数据科学领域的新手,或者需要对该领域的基础知识进行补充,请查看由加州大学欧文分校提供的这一初学者专门化课程。
在本课程中,你将获得数据科学基础的概述,深入了解关键的数据科学技能、技术和概念。课程开始于基础概念,如分析分类、跨行业数据挖掘标准流程和数据诊断,然后继续比较数据科学与经典统计技术。课程还概述了数据科学中最常用的技术,包括数据分析、统计建模、数据工程、大数据的数据处理、数据挖掘算法、数据质量、修复和一致性操作。
Python 中的自然语言处理入门
级别:中级
时长:4 小时
如果你需要掌握自然语言处理的基础知识,可以查看 DataCamp 提供的 Python 入门自然语言处理课程。
在这门课程中,你将学习自然语言处理的基础知识,例如如何识别和分离单词、如何提取文本中的主题,以及如何构建自己的假新闻分类器。你还将学习如何使用基本的库,如 NLTK,以及利用深度学习解决常见自然语言处理问题的库。这门课程将为你在 Python 学习中继续处理和解析文本打下基础。
无编程构建 AI 驱动的聊天机器人
级别:初级
时长:约 12 小时
如果你对聊天机器人中的自然语言处理更感兴趣,这门由 IBM 提供的初级课程将讲解聊天机器人的好处及其在客户支持等任务中的有用性。你将学习如何使用 Watson Assistant 创建一个有用的聊天机器人,而无需编写任何代码,同时指定行为和语气,以提升聊天机器人并使其用户友好。开发、测试并部署一个聊天机器人到 WordPress 网站并进行互动。
这门单独的课程是两个专业课程的一部分:IBM AI Developer Professional Certificate和AI Foundations for Everyone Specialization。如果你对更深入的课程感兴趣,可以查看这些课程。
自然语言处理专业课程
链接:自然语言处理专业课程
级别:中级
时长:每周 10 小时,持续 3 个月
如果你对自然语言处理有基本了解并准备提升技能,可以查看 DeepLearning.AI 提供的中级专业课程。
在这门课程中,你将使用逻辑回归、朴素贝叶斯和词向量来实现情感分析、完成类比和翻译单词。你还将使用动态编程、隐马尔可夫模型和词嵌入来实现自动更正、自动完成和识别单词的词性标记。课程还包括使用递归神经网络、LSTMs、GRUs 和 Siamese 网络进行情感分析、文本生成和命名实体识别,以及使用编码器-解码器、因果和自注意力进行机器翻译完整句子、文本摘要、构建聊天机器人和问答系统。
Google Cloud 上的自然语言处理
级别:高级
时长:约 13 小时
如果你准备提升到下一个层次,可以查看 Google 提供的自然语言处理课程。该课程介绍了解决 Google Cloud 上自然语言处理问题的产品和解决方案。此外,它探索了使用 Vertex AI 和 TensorFlow 开发自然语言处理项目的过程、技术和工具。
你还将认识到 Google Cloud 上的 NLP 产品和解决方案,使用 Vertex AI 的 AutoML 创建端到端的 NLP 工作流。学习如何使用 TensorFlow 构建不同的 NLP 模型,包括 DNN、RNN、LSTM 和 GRU。识别高级 NLP 模型,如编码器-解码器、注意力机制、变换器和 BERT,并理解迁移学习,应用预训练模型来解决 NLP 问题。
这门课程是Google Cloud 上的高级机器学习专项课程的一部分。
总结
在这篇博客中,我希望能够带你探索如果你对 NLP 行业感兴趣,可以选择的不同课程。如果你知道任何值得推荐的课程,请在评论中告诉我!
Nisha Arya 是一名数据科学家、自由职业技术作家,同时担任 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程,并围绕数据科学的理论知识进行讲解。Nisha 涵盖了广泛的主题,并希望探索人工智能如何促进人类生命的长寿。作为一个渴望学习者,Nisha 寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关主题
5 个免费课程掌握数据科学中的 Python
原文:
www.kdnuggets.com/5-free-courses-to-master-python-for-data-science

作者提供的图片
学习 Python 对于想要转行数据职业的人来说非常有帮助。但有很多需要学习的内容:从 Python 编程基础到数据分析、机器学习以及破解编码面试。那么你如何找到最佳的学习资源呢?
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
为了帮助你,我们编制了一份课程清单,帮助你掌握 Python 在数据科学中的应用。无论你是初学者还是经验丰富的专业人士,希望刷新你的 Python 技能,这些课程都适合你。推荐的课程将帮助你学习以下内容:
-
Python 基础
-
Python 数据科学库
-
使用 Python 进行数据分析和机器学习
-
使用 Python 进行数据结构和算法
让我们开始吧。
1. 初学者的 Python
Mosh 的初学者 Python课程将帮助你熟悉 Python 编程的绝对基础。
在大约一个小时内,你可以掌握以下基础知识:
-
变量
-
接收输入
-
类型转换
-
字符串
-
运算符及运算符优先级
-
if 语句
-
while 和 for 循环
-
列表和元组
链接:初学者的 Python
2. 中级 Python 编程
现在你掌握了基础知识,你可以参加这个中级 Python 编程课程。该课程从讨论各种 Python 内置数据结构开始,并继续讲解语言的更高级特性。
本课程涵盖的主题包括:
-
Python 的内置数据结构
-
集合
-
itertools
-
Lambda 函数
-
异常和错误
-
日志记录
-
处理 JSON
-
随机数生成
-
装饰器
-
生成器
-
多线程和多进程
-
函数参数
-
浅拷贝与深拷贝
-
上下文管理器
链接:中级 Python 编程
3. 使用 Python 进行数据分析
一旦你对 Python 有了良好的掌握,你可以继续学习各种 Python 数据科学库。
Python 数据分析 认证将帮助你学习所有必要的 Python 数据科学库:
-
NumPy
-
Pandas
-
Matplotlib
-
Seaborn
你还将构建一些数据分析项目。你应完成这些项目以获得 Python 数据分析认证。
链接: Python 数据分析认证
4. 使用 Python 和 Scikit-Learn 的机器学习
你现在应该能够熟练使用 Python 编程并操作 Python 数据科学库。现在你可以开始探索机器学习。
使用 Python 和 Scikit-Learn 的机器学习 将帮助你了解机器学习算法的理论(如何工作)和使用 scikit-learn 实现这些算法。该课程还将教你如何规划和实施机器学习项目,并构建和部署机器学习应用。
这是所涉及主题的概述:
-
线性回归和梯度下降
-
用于分类的逻辑回归
-
决策树和随机森林
-
如何接近机器学习项目
-
使用 XGBoost 的梯度提升机
-
从零开始的机器学习项目
-
以课堂形式部署机器学习项目
链接: 使用 Python 和 Scikit-Learn 的机器学习
5. Python 中的数据结构和算法
在数据科学面试过程中,你应该首先破解编码面试,才能进入下一个阶段。为了破解它们,并使你的编码练习更有效,你应首先在数据结构和算法方面打下坚实的基础。
Python 中的数据结构和算法 是一个免费课程,将帮助你学习基本的数据结构和算法,重点是 Python。
只需遵循数据结构和算法课程,你将学习到以下内容
-
二分查找、链表和复杂度
-
二叉搜索树、遍历和递归
-
哈希表和 Python 字典
-
排序算法、分治法
-
递归和动态编程
-
图算法
-
Python 面试问题、技巧和建议
链接: Python 中的数据结构和算法
总结
希望你觉得这些课程有帮助。我们整理了一份全面的课程列表,将帮助你在 Python 数据科学方面变得熟练。
如果你还记得,我们的课程从 Python 编程的基础开始,到使用 Python 进行数据分析和机器学习。我们还包括了一门课程,帮助你学习数据结构和算法的基础,以备编码面试之需。祝学习愉快,编码顺利!
Bala Priya C是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和咖啡!目前,她正致力于通过撰写教程、操作指南、观点文章等方式学习和分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关话题
5 个免费课程,掌握数据科学中的 SQL
原文:
www.kdnuggets.com/5-free-courses-to-master-sql-for-data-science

编辑器提供的图片
SQL 是所有数据专业人员必备的技能。然而,掌握 SQL 是一个持续的过程。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
在这里,我们汇编了一份五个非常有用且免费的 SQL 课程列表,帮助你学习并精通 SQL。这些课程涵盖了数据科学所需的所有 SQL:从基础关系数据库和 SQL 到 NoSQL 数据库等。
无论你是 SQL 新手还是想要提升 SQL 技能,这些课程都将帮助你提升水平。让我们来看看这些课程吧!
1. SQL 教程 – 初学者完整数据库课程
这门课程向你介绍 SQL 和数据库管理系统的基础知识。你将学习:
-
CRUD 操作
-
模式设计
-
聚合
-
嵌套查询
-
连接和联合
-
函数和触发器
-
实体关系图
2. Mode SQL 教程
链接:Mode SQL 教程
Mode 的 SQL 教程 是最全面的课程之一,帮助你学习如何使用 SQL 查询关系数据库表并回答业务问题。
这门课程的结构是由 4 个模块组成的:
-
基础 SQL
-
中级 SQL
-
高级 SQL
-
SQL 分析培训
在基础 SQL 模块中,你将学习和实践:
-
SELECT、LIMIT 和 WHERE 子句
-
比较和逻辑运算符
-
LIKE、IN 和 BETWEEN 运算符
-
IS NULL
-
AND、OR、NOT 运算符
-
ORDER BY
在中级 SQL 部分,你将学习:
-
聚合函数
-
按组和 HAVING
-
DISTINCT
-
不同类型的连接
在高级 SQL 模块中,你将学习以下内容:
-
数据类型:日期和字符串
-
数据处理
-
SQL 字符串函数和窗口函数
-
子查询
-
性能调优
然后你将在 SQL 分析培训模块中处理真实世界的案例研究。
3. 数据科学的 SQL 基础
Coursera 上的数据科学 SQL 基础专业课程将教授你在数据科学职业中几乎所有需要的 SQL 知识。
该专业课程中的课程如下:
-
数据科学中的 SQL
-
使用 SQL 进行数据整理分析和 AB 测试
-
使用 Spark SQL 的分布式计算
-
数据科学 SQL 顶点项目
注意: 这个专业课程在 Coursera 上提供,所以你可以免费试听。不过,如果你需要获得认证证书,你应该拥有 Coursera Plus 订阅。如果你无法支付证书费用,你也可以申请经济援助。
4. SQL 与 NoSQL
链接: NoSQL 与 SQL – 你应该使用哪种类型的数据库?
作为数据科学家,你必须同时使用关系型和 NoSQL 数据库。在深入了解 NoSQL 数据库之前,理解 SQL 和 NoSQL 数据库的特点以及它们的使用场景是很有帮助的。
在这个关于 SQL 与 NoSQL 数据库 的简短课程中,你将探索以下内容:
-
关系型和 NoSQL 数据库的特点
-
NoSQL 数据库的需求
-
每种数据库类型的优缺点
-
何时使用 RDBMS 与 NoSQL 数据库
5. NoSQL 数据库教程 – 初学者完整课程
在这个关于 NoSQL 数据库的简短课程中,你将探索不同类型的 NoSQL 数据库,并且还会进行项目实践。你将学习到:
-
为什么你应该使用 NoSQL 数据库
-
表格数据库
-
文档数据库
-
图形数据库
-
键值数据库
-
多模型类型
总结
希望你发现这份 SQL 课程汇编对数据科学有帮助。你可以免费参加所有这些课程。如果你已经对 SQL 有一定了解,你可以选择仅学习数据科学中的 SQL 专业课程。
Bala Priya C**** 是来自印度的开发者和技术写作者。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过编写教程、操作指南、观点文章等,学习和分享她的知识给开发者社区。Bala 还创建了引人入胜的资源概述和编码教程。
主题更多信息
5 门免费课程助你掌握数据科学统计学
原文:
www.kdnuggets.com/5-free-courses-to-master-statistics-for-data-science

图片由 pch.vector 在 Freepik 提供
如果你想成为一名熟练的数据科学家,你应该知道如何理解和分析数据。统计学在这方面非常重要。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
然而,学习统计学可能会感觉困难,尤其是对于没有数学或计算机科学背景的人。但不用担心,我们整理了一份统计课程列表——从入门统计到稍微高级的概念——你可以免费参加这些课程。
你不必完成所有这些课程才能在数据科学领域掌握统计学。因此,请随意查看你特别感兴趣的课程。开始吧!
注意:你可以在 Coursera 上免费旁听以下所有课程。
1. 统计学导论
统计学导论课程来自斯坦福大学,是一门很好的统计学入门课程。该课程旨在教授理解和分析数据所需的所有统计思维概念。
这是课程内容的概述:
-
数据探索的引言和描述性统计
-
数据生成和抽样
-
概率
-
正态近似和二项分布
-
抽样分布和中心极限定理
-
回归分析
-
置信区间
-
显著性检验
-
重新抽样
-
分类数据分析
-
单因素方差分析(ANOVA)
-
多重比较
链接: 统计学导论
2. 基础统计学
基础统计学课程来自阿姆斯特丹大学,这也是一个适合初学者的统计课程。该课程要求你对 R 编程有所了解,并涵盖以下主题:
-
数据探索
-
相关性和回归分析
-
概率和概率分布
-
抽样分布
-
置信区间和显著性测试
链接: 基础统计学
3. 数据科学中的统计学与 Python
数据科学中的统计学与 Python由 IBM 提供,作为数据科学基础与 Python 和 SQL 专业化的一部分。
这门课程将教你如何使用 Python 进行统计测试并解释统计分析的结果。课程内容如下:
-
Python 基础
-
介绍和描述统计学
-
数据可视化
-
概率分布介绍
-
假设检验
-
回归分析
4. 统计学的力量
统计学的力量由 Google 提供,作为他们 Google 高级数据分析专业证书的一部分。
从总结数据集到进行假设检验以及使用概率分布进行数据建模,这门课程还侧重于使用 Python 进行统计分析。课程内容包括:
-
统计学导论
-
概率
-
采样
-
置信区间
-
假设检验导论
链接: 统计学的力量
5. 使用 Python 进行统计学
使用 Python 的统计学专业化由密歇根大学提供,教授如何使用 Python 进行数据可视化、统计推断和建模。它还强调将你需要回答的业务问题与相关的数据分析方法相连接的重要性。
这是一个包含三门课程的专业化项目,涵盖了所需的理论知识以及 Python 编程作业,帮助你应用所学的所有内容。该专业化项目的课程如下:
-
使用 Python 理解和可视化数据
-
使用 Python 进行推断统计分析
-
使用 Python 拟合统计模型
总结
就这些了。我们介绍了五门可以免费学习统计学并提升数据科学技能的课程。
因为这些课程大多数侧重于使用 Python 编程和运行统计测试,而不仅仅是学习理论概念,我相信你会发现有很多机会来应用你所学到的知识。祝学习愉快,继续编码!
Bala Priya C** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过撰写教程、操作指南、观点文章等,学习并与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。**
更多相关主题
2023 年必须阅读的 5 本免费数据科学书籍
原文:
www.kdnuggets.com/2023/01/5-free-data-science-books-must-read-2023.html

图片由作者提供
如果你和我一样是一个书迷,你应该开始关注那些免费的数据科学书籍。这些书将教你 Python 编程、数据科学的艺术、机器学习,并介绍新的工具和框架。此外,一些书籍像网站一样构建,以便你可以探索、搜索和互动。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
1. 正确学习 Python
《正确学习 Python》 是一本适合初学者的书,专门为那些想学习 Python 但不知道从何开始的人准备。你可以下载这本书或使用网页界面在线阅读。每一章都有一个 YouTube 教程,详细解释语法和功能。

书封面
你可以阅读书籍,观看教程,甚至在免费的在线 IDE Replit 上练习代码。它涵盖了你开始数据科学职业生涯所需的所有基础知识。
本书涵盖:
-
Python 设置和基础
-
变量、表达式和语句
-
创建第一个 Python 程序
-
函数
-
条件语句
-
复杂函数。
-
迭代
-
字符串
-
元组
-
事件处理,异常
-
列表,字典,模块,文件
-
算法,类,对象,面向对象编程,继承
-
PyGame,递归,队列
-
链表,栈,树
2. 数据科学的艺术
Roger D. Peng 等人的《数据科学的艺术》 将数据分析表现为理解问题、探索数据、进行正式建模、解释结果和沟通发现的艺术。
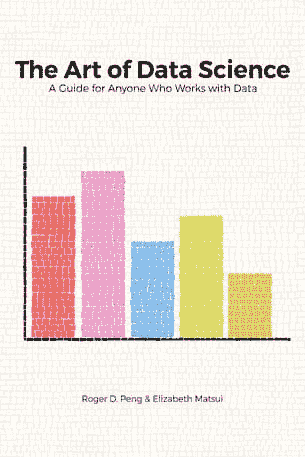
书封面
这本书不仅关注统计和编码,还教你批判性思维。你将学习如何细化问题,进行探索性数据分析,应用线性回归或随机森林,并解释结果以提供可操作的见解。
本书涵盖:
-
分析的周期
-
陈述和细化问题
-
探索性数据分析
-
使用模型探索数据
-
推理:入门
-
形式化建模
-
推理与预测:对建模策略的影响
-
解释你的结果
-
沟通
3. 命令行中的数据科学
命令行中的数据科学是我最喜欢的书籍,我在 KDnuggets 博客上写了详细的评价。你可以选择从 Amazon 购买这本书,也可以免费阅读在线版本。在线版本具有互动性,并带有有趣的功能。

书籍封面
本书通过示例介绍了执行各种数据科学任务所需的基本命令行工具。你可以在终端中完成数据清洗、数据分析和可视化,以及训练机器学习模型。
书中涵盖:
-
获取数据
-
创建命令行工具
-
数据清洗
-
使用 Make 进行项目管理
-
探索数据
-
并行管道
-
数据建模
-
多语言数据科学
4. 使用 Scikit-Learn、Keras 和 TensorFlow 的动手机器学习
使用 Scikit-Learn、Keras 和 TensorFlow 的动手机器学习将从头开始教你所有关于机器学习的知识。你将学习如何使用 Scikit-Learn、Keras 和 TensorFlow 构建基础到深度学习模型。你将学习分类、RNNs、CNNs、NLP、GANs 和强化学习模型。

书籍封面
在阅读本书之前,你需要了解本书假设你已经掌握了 Python 及 NumPy、pandas、matplotlib 等库的基础知识。
书中涵盖:
-
从头到尾的机器学习项目
-
分类
-
训练模型
-
支持向量机
-
决策树
-
集成学习
-
降维
-
RNNs 和 CNNs
-
自然语言处理
-
GANs
-
强化学习
-
规模化训练和部署模型
5. 实用深度学习(面向程序员)
实用深度学习(面向程序员)是一本纸质书、一本基于网页的书籍,以及一门介绍如何使用 fastai 和 PyTorch 进行深度学习的课程。这是我最喜欢的课程和书籍。你将学习所有关于神经网络的知识,而无需深入数学或编程。这门课程适合任何了解 Python 基础的人。

书籍封面
书中涵盖:
-
从模型到生产
-
数据伦理
-
训练数字分类器
-
图像分类
-
其他计算机视觉问题
-
训练最先进的模型
-
协同过滤深入探讨
-
表格建模深入分析
-
NLP 深入分析:RNNs
-
使用 fastai 的中级 API 进行数据清洗
-
从头开始的语言模型
-
卷积神经网络
-
ResNets
-
应用架构深入分析
-
训练过程
-
从基础开始的神经网络
-
使用 CAM 进行 CNN 解释
-
从头开始的 fastai 学习者
结论
这五本书都非常棒,我强烈推荐给任何对数据科学职业感到怀疑的初学者。此外,这些书还附有实用指南、代码示例和视觉辅助,以简单的方式解释复杂的术语。
希望你喜欢我的列表。如果你有任何推荐,请在评论中提到,我会尝试将它们添加到下一个列表中。
Abid Ali Awan(@1abidaliawan)是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些正在与心理健康问题作斗争的学生开发一个 AI 产品。
更多相关内容
进入机器学习职业之前需要阅读的 5 本电子书
原文:
www.kdnuggets.com/2016/10/5-free-ebooks-machine-learning-career.html
请注意,尽管网上有许多免费的机器学习电子书,包括许多非常著名的书籍,但我选择跳过这些“常规书籍”,寻求更少为人知晓的、更具小众特色的选项。
对机器学习职业感兴趣?不知道从哪里开始?那么,总有这里,一个关于在 Python 生态系统中追求机器学习的教程集合。如果你想了解更多,你可以查看这里,获取 MOOCs 和在线讲座的概述,来自自由提供的大学讲座。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
当然,没有什么可以替代严格的正式教育,但假设因为某些原因这种教育不在计划之中。并非所有机器学习职位都需要博士学位;这真的取决于你想在机器学习的哪个领域中定位自己。看看这篇激励人心的文章,作者在一年内从对机器学习的几乎没有了解到在工作中积极有效地运用技术。
想在入门级研究生机器学习课程和在线教程中获得平衡吗?正如几百年来一样,书籍是一个很好的选择。😃 当然,如今我们可以即时访问免费的数字书籍,这使得这一选择非常有吸引力。请查看以下免费的电子书,这些书籍都适合初学者阅读,同时涵盖了各种不同的概念和材料。
1. 机器学习简介
斯坦福大学的 Nils J. Nilsson 在 1990 年代中期整理了这些笔记。在你对学习 90 年代的内容感到不屑之前,请记住,基础就是基础,无论它是在何时写成的。
当然,自从编写本书以来,机器学习领域已经取得了许多重要进展,正如 Nilsson 本人所说,但这些笔记以直接而集中的方式涵盖了许多仍被认为是相关的基础材料。书中没有涉及过去几十年的进展,作者们常常在介绍性文本中侧面提及这些内容。然而,书中包含了大量关于统计学习、学习理论、分类及各种算法的信息,引人入胜。在不到 200 页的篇幅下,可以相当迅速地阅读完毕。
这本关于机器学习的书籍由 Shai Shalev-Shwartz 和 Shai Ben-David 编写。与之前的书籍相比,这本书较新、篇幅较长且更为高级,但也是一个合乎逻辑的下一步。它将深入探讨更多的算法、其描述,并提供实践方面的桥梁。对理论的关注应该对新手明确其重要性,以真正理解驱动机器学习算法的内容。高级理论部分涵盖了一些可能超出新手范围或兴趣的概念,但也可以选择查看。
3. 贝叶斯推理与机器学习
这本关于贝叶斯机器学习的入门书籍是我所知道的最知名的书籍之一,并且恰好有一个免费的在线版本可供获取。明尼苏达大学的 Arindam Banerjee 在 Amazon 评价 中这样评价:
这本书广泛涵盖了概率机器学习,包括离散图模型、马尔可夫决策过程、潜变量模型、高斯过程、随机和确定性推理等。该材料非常适合高级本科生或图形模型或概率机器学习的入门研究生课程。全书使用了大量的图表和示例,并且附带了一个广泛的软件工具箱...
应注意,所提到的工具箱是用 MATLAB 实现的,而 MATLAB 已不再是默认的机器学习实现语言,至少通常情况下不是。然而,这个工具箱并不是这本书唯一的优点。
这为那些对概率机器学习感兴趣的人提供了一个很好的起点。
4. 深度学习
这是 Goodfellow、Bengio 和 Courville 即将出版的深度学习书籍,官方网页上有一个免费的最终草稿版本。
以下两个摘录来自该书的官方网站,一个提供了内容概述,另一个让几乎所有有兴趣阅读这本书的人放心:
《深度学习》教科书旨在帮助学生和从业者进入机器学习领域,尤其是深度学习。该书的在线版本现已完成,将继续在线免费提供。印刷版将很快上市。
其中一个目标受众是学习机器学习的大学生(本科生或研究生),包括那些刚开始从事深度学习和人工智能研究的学生。另一个目标受众是没有机器学习或统计背景的软件工程师,但希望快速掌握相关知识并开始在其产品或平台中使用深度学习。
要找到一个更好的资源来全面学习深度学习,你将面临很大的困难。
5. 强化学习:导论
萨顿和巴托的权威经典正在进行改版。这是第二版草稿的链接,目前正在进展中(并且在此期间免费提供)。
强化学习现在是一个极具研究兴趣的领域,原因很充分。鉴于其在 AlphaGo 中的成功、高度关注、在自动驾驶汽车及类似系统中的潜力以及与深度学习的结合,很难相信强化学习(毫无疑问将在任何形式的“通用人工智能”(或类似事物)中发挥重要作用)会消失。实际上,这些都是为什么这本书的第二版正在进行的原因。
你可以感受到这本书在强化学习领域的重要性,因为它被简单地称为“萨顿和巴托”。这篇亚马逊评论由 David Tan 撰写,很好地总结了这本书(并消除了关于“是否太复杂难以理解”的疑虑):
这本书以示例和对强化学习的直观介绍和定义开始。接下来的 3 章讨论了强化学习的 3 种基本方法:动态规划、蒙特卡罗方法和时序差分方法。后续章节在这些方法基础上进行扩展,涵盖整个解决方案和算法范围。
这本书对普通计算机学生来说非常易读。可能唯一难度较大的章节是第八章,它涉及一些神经网络概念。
请记住,上述内容针对的是第一版;它也适用于第二版。
祝你在从免费的电子书中学习更多关于机器学习的过程中顺利。查看下面的相关链接,获取更多相关的电子书资源。
相关:
-
数据爱好者必备的 10 本重要书籍
-
进入数据科学或大数据职业前需要阅读的 5 本电子书
-
60+ 本关于大数据、数据科学、数据挖掘、机器学习、Python、R 等的免费书籍
更多主题
5 个免费的 Google 课程助你成为软件工程师
原文:
www.kdnuggets.com/5-free-google-courses-to-become-a-software-engineer

图片来源:作者
进入科技领域的时机从未如此激动人心。对于熟练的软件工程师的需求不断增长。那么,即使你是自学成才,没有计算机科学学位,你如何获得软件工程师职位呢?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
为了帮助你实现目标,我们整理了这份来自 Google 的免费课程和指南列表。这些资源将帮助你学习以下内容:
-
编程基础
-
使用 Python 编程
-
数据结构和算法
-
软件工程原则
还有更多内容。这样你可以免费学习所需的一切,以获得软件工程师职位。
1. 编程基础
如果你没有编程经验,可以从编程基础课程开始。
在这个课程中,你将学习基本的编程概念,如:
-
变量和操作符
-
控制流
-
字符串和数组
这将提供编程的高层次概述,以便你可以通过参加其他课程在这些基础上进一步学习。
链接:编程基础
2. Python
要进入软件工程领域,你需要至少熟练掌握一种编程语言。Python 容易学习,你可以直接开始做项目。此外,Python 在编程面试中非常实用。
Google's Python 课程将帮助你通过讲座视频、文本材料和编程练习来学习 Python 编程。以下是你将学到的内容概述:
-
Python 基础
-
列表和字符串
-
排序
-
字典和文件
-
正则表达式
-
实用工具(来自 Python 标准库)
链接:Python
3. 数据结构和算法
一旦你学会了如何编程,理解数据结构和算法的工作原理对于解决问题是基本的。这对于编程面试也非常重要。
数据结构与算法合集将帮助你学习和实践以下内容:
-
哈希表
-
链表
-
树
-
字典树
-
栈和队列
-
堆
-
图
-
运行时分析
-
搜索和排序
-
递归和动态编程
链接: 数据结构与算法
4. 面试准备
我们迄今审阅的资源将帮助你学习编程、数据结构和算法。从根本上说,这些都是你应了解的内容,以应对编码和技术面试。
但是如何策略性地准备技术面试呢?这就是面试准备指南派上用场的地方。
指南中的资源将帮助你了解如何:
-
为编码面试做准备
-
技术面试中的沟通
-
练习编码面试问题和模拟面试
链接: 面试准备
5. 软件工程原则
作为软件工程师,你应该编写干净且文档齐全的代码,易于理解和维护。因此,你也应该熟悉编写可维护和清晰代码的原则。
软件工程原则课程涵盖以下主题:
-
测试和调试
-
使用开源工具
-
设计和文档
链接: 软件工程原则
总结
所以如果你想启动你的软件工程师职业生涯,我希望你能在学习过程中发现这些课程的帮助。正如你可能猜到的,这些课程是免费的,但需要你付出勤奋的努力、兴趣和练习来破解面试并获得软件工程师职位。所以继续努力!
如果你特别寻找帮助你进行编码面试准备的资源,可以查看 5 门免费大学课程以攻克编码面试。
Bala Priya C是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过编写教程、指南、评论文章等来学习和分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关内容
5 个免费托管平台用于机器学习应用
原文:
www.kdnuggets.com/2022/05/5-free-hosting-platform-machine-learning-applications.html

作者提供的图片
在完成机器学习项目后,是时候展示你的模型表现如何了。你可以创建前端应用程序或使用 REST API。随着 Streamlit、Gradio 和 FAST API 的引入,创建前端应用程序变得轻松自如。这些 Web 框架只需几行代码即可创建交互式用户界面。与公众分享你的工作有助于你建立强大的数据科学作品集。它也帮助非技术人员理解你的项目。因此,在构建 Web 应用程序后,是时候将应用程序部署到云服务器上了。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
在这篇博客中,我们将了解五个最佳免费的机器学习演示托管平台。我将分享我在每个平台上的经验,并解释它们为何独特。
1. Hugging Face Spaces
Spaces 已成为机器学习社区的新亮点。我使用这个平台来部署几乎所有的机器学习演示。它通过 Git 提供了简单的部署选项,并为环境和 Python 包相关的问题提供了友好的解决方案。Spaces 允许你部署 Streamlit、Gradio 和基于 HTML 的 Web 应用程序。它速度快且可靠,服务器运行时间长。你甚至不需要上传模型或数据。它与 Hugging Face 数据集和模型的集成无缝。此外,Gradio 允许我们使用回调保存和更新标记数据集,这是一个非常令人兴奋的功能。
Spaces 是社区主导的机器学习演示共享平台。你可以找到计算机视觉、音频、自然语言处理、表格数据甚至简单仪表板的 Web 应用程序。你可以将你的应用程序保持私密或与公众分享。这个平台的最佳部分是,它为你提供了许多功能而不收取任何费用。Hugging Face 确实在让机器学习变得更加民主化。
Gradio 应用在 Spaces 上: 实时乌尔都语 ASR
2. Streamlit Cloud
Streamlit Cloud 允许你免费部署一个私人和无限制的公共 Streamlit 应用。该平台提供了一键部署选项,支持 GitHub 集成。简而言之,你将代码推送到 GitHub 仓库,Streamlit 云会自动检测更改并重建服务器。此外,你可以享受与数据源的安全集成、身份验证、Streamlit 项目的协作,以及最多 1 GB 的存储空间。
我喜欢 Streamlit Cloud,因为它完全是为 Streamlit 开源 Web 框架量身定制的。每个新版本,平台在速度、正常运行时间和可访问性方面都在不断改进。它对初学者友好,提供了无忧的部署体验。
Cloud 上的 Streamlit 应用: Traingenerator
3. Heroku
Heroku 是一个用于部署各种 Web 应用程序的云平台。你可以从小做起,然后随着时间的推移扩展项目。Heroku 支持最流行的编程语言、数据库和 Web 框架。此外,你可以找到大量的集成用于日志记录、电子邮件通知、测试、仪表盘、图像处理和 DevOps。
我第一次使用托管服务是 Heroku,我发现修改和部署更改到服务器相当容易。你可以使用 GitHub 集成、Heroku CLI 和 Git 远程部署你的应用。我由于存储限制停止使用它,但我仍然认为它是数据应用程序的顶级托管平台之一。易于使用和多个集成使其成为我前三个首选的 Web 开发平台。
深度学习 Streamlit 应用在 Heroku 上: dagshub-pc-app.herokuapp.com
教程: 将 Streamlit WebApp 部署到 Heroku 使用 DAGsHub
4. Deta
Deta 最适合微服务。你可以免费部署 REST API 或 Node.JS 应用,提供免费的存储和数据库。Deta 提供了其风格的 SQL 数据库和大容量存储服务。除此之外,你还可以安排运行、自定义域名,并添加 API 密钥。
在我第一次使用 Deta 时,我完全被 Deta CLI 和服务器提供的简洁性和强大功能所吸引。我甚至写了一篇博客: 部署你的第一个机器学习 API。我花了 5 分钟理解文档、安装 CLI 并部署我的机器学习应用。如果你想创建自己的机器学习微服务并启动自己的公司,那么 Deta 是最好的起点。
FastAPI ML 应用在 Deta 上: fastapimlproject.deta.dev/docs
5. Replit
Replit是一个云集成开发环境(IDE),为各种项目提供免费计算、存储和托管服务。它是一个由社区驱动的平台,人们(主要是学生)在这里分享与游戏、网页设计、微服务构建,甚至创建新框架相关的项目。
它如何帮助我们构建机器学习应用程序?在每个项目中,你可以运行一个临时服务器,并使用公共 URL 托管你的应用程序。例如,创建一个 FastAPI 机器学习应用程序,当你按下运行按钮时,它会自动启动一个带有 URL 的 Web 服务器,你可以分享这个 URL。你可以使用 ping 技巧保持服务器在线,或者购买 Pro 版本。
目前,我在运行四个强化学习机器人、三个 NLP 聊天机器人和一个 FastAPI 项目。你可以在一个地方创建和部署应用程序,而无需担心依赖关系或开发问题。这是我尝试新事物和测试 API 的首选平台。如果你是编程初学者,想进入机器学习的世界,那么从 Replit 开始吧。
Replit 上的应用程序: DailoGPT-RickBot
Abid Ali Awan(@1abidaliawan)是一位认证数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一款 AI 产品,帮助那些在精神健康方面挣扎的学生。
相关话题
5 本免费的 Julia 数据科学书籍
原文:
www.kdnuggets.com/2023/06/5-free-julia-books-data-science.html

作者提供的图片
你可能经常听到关于 Julia 以及它为何是数据科学未来的讨论,但你不知道从何开始。我有一个完美的解决方案。你可以通过查看关于 Julia 编程语言的精彩免费书籍列表来为软件工程和数据科学相关任务做好准备。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 部门
你将学习有关 Julia 数据框架、数据可视化、机器学习以及创建和运行网络服务的库。此外,你还将学习面向对象编程、元编程和并行计算。
1. 《Think Julia》
《Think Julia: How to Think Like a Computer Scientist》由 Ben Lauwens 和 Allen B. Downey 编写,是一本适合所有想学习 Julia 的读者的书,从初学者到经验丰富的程序员皆可。

图书封面
本书从 Julia 的介绍开始,解释了它是什么、如何工作以及为什么与其他编程语言不同。作者随后简要回顾了 Julia 的历史,并讨论了它当前的发展和未来潜力。
本书通过简单的示例来说明每个概念,并在每章末尾提供练习题以巩固学习。
本书还涵盖了更高级的主题,包括数组、矩阵、字符串和输入/输出。此外,它还涉及面向对象编程、元编程和并行计算。
2. 《Julia 作为第二语言》
《Julia 作为第二语言》由 Erik Engheim 编写,是一本适合已经熟悉其他编程语言的程序员的入门指南,帮助他们将 Julia 学习为第二语言。
本书从 Julia 及其历史的介绍开始,接着讨论了它的特性、优点和独特的卖点。它将 Julia 与其他流行编程语言,如 Python、MATLAB 和 R 进行了比较。

书籍封面
书中还涵盖了面向对象编程、函数式编程和高级主题,如数组、矩阵、字符串以及输入/输出。作者还涉及了元编程、并行计算以及如何使用外部库和包。
3. 使用 Julia 进行统计分析
使用 Julia 进行统计分析 由 Hayden Klok 和 Yoni Nazarathy 编写,是一本关于使用 Julia 编程语言进行统计分析的全面指南。适合任何希望学习如何使用 Julia 进行统计分析和建模的人。

书籍封面
书中涵盖了基本语法,接着介绍了统计学基础,包括概率论、描述性统计、统计推断、统计方法和模型,包括线性回归、逻辑回归、聚类和时间序列分析。
书中还涵盖了如何处理外部数据源,包括 CSV 文件和数据库,以及如何使用 Julia 的绘图库可视化数据。
你将学习统计分析中的可重复性以及如何组织和记录代码和数据。
4. Julia 数据科学
Julia 数据科学 由 Storopoli、Huijzer 和 Alonso 编写,是一本开源且开放访问的书籍,介绍了如何使用 Julia 编程进行数据科学相关任务。
书中首先解释了什么是数据科学和软件工程,然后解释了为什么你应该花时间学习那些在招聘信息中从未提到的语言。

书籍封面
书本开始介绍 Julia 语法、数据结构、文件系统和标准库。然后,转到数据分析和建模所需的重要主题,使用数据框和数据可视化库。
这本书写得很好,易于理解,为初学者或有经验的数据科学家提供了数据分析和建模库的全面介绍。
5. Julia 数据分析
Julia 数据分析 由 Bogumi? Kami?ski 编写,是一本实用指南,适合经验丰富的数据分析师、程序员以及希望学习如何使用 Julia 进行有效数据分析和报告的初学者。

书籍封面
这本书分为两个部分。
第一部分是关于 Julia 编程的基础,你将学习语法、循环和数据结构。接着,你将学习在创建可扩展项目时 Julia 语言中重要的元素。
第二部分涉及数据分析的工具箱。在这一部分,你将学习如何使用数据框处理数据,清洗、操作和转换数据以进行分析,并创建一个用于分享数据分析结果的网页服务。
Abid Ali Awan (@1abidaliawan) 是一位认证数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些在心理健康方面挣扎的学生打造一款人工智能产品。
更多相关主题
5 门免费 MIT 数学课程,助你学习数据科学
原文:
www.kdnuggets.com/5-free-mit-courses-to-learn-math-for-data-science

图片由作者提供
作为数据专业人士,你可能知道数学对数据科学至关重要。数学是数据科学的基础:从理解数据点如何在向量空间中表示到优化算法寻找模型的最佳参数等等。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
掌握数学基础知识有助于你在面试中表现出色,并深入理解你实现的算法。我们在这里整理了麻省理工学院(MIT)提供的关于以下数学主题的免费课程:
-
线性代数
-
微积分
-
统计学
-
概率
你可以在麻省理工学院开放课程平台上学习这些课程。充分利用这些课程,提高你的数据科学技能!
1. 线性代数
除了熟悉高中数学外,线性代数是数据科学中最重要的数学主题。由 Gilbert Strang 教授讲授的超受欢迎的线性代数课程是你可以选修的最佳数学课程之一。对于此课程及后续课程,请完成习题集并尝试考试以测试你的理解。
课程分为以下三个主要模块:
-
方程组 Ax = b 和四个矩阵子空间
-
最小二乘法、行列式和特征值
-
正定矩阵及其应用
链接: 线性代数
2. 单变量与多变量微积分
对微积分有良好的理解对掌握数据科学概念至关重要。你应该熟练掌握单变量和多变量微积分的计算、导数、偏导数、链式法则等。以下是关于单变量和多变量微积分的两个课程。
微积分 I:单变量微积分课程涵盖:
-
微分
-
积分
-
坐标系统与无穷级数
一旦你对单变量微积分感到熟练,可以继续学习多变量微积分课程,该课程涵盖:
-
向量和矩阵
-
偏导数
-
平面上的双重积分和线积分
-
3D 空间中的三重积分和曲面积分
课程链接:
3. 概率系统分析与应用概率
概率是数据科学中另一个重要的数学主题,良好的概率基础对掌握数学建模、统计分析和推断至关重要。
概率系统分析与应用概率课程是一个很好的资源,涵盖以下主题:
-
概率模型和公理
-
条件概率和贝叶斯规则
-
独立性
-
计数
-
离散与连续随机变量
-
连续贝叶斯规则
链接: 概率系统分析与应用概率
4. 应用统计学
要在数据科学中获得精通,你需要对统计学有坚实的基础。应用统计学课程涵盖了许多在数据科学中相关的应用统计概念。
下面是所涵盖的主题列表:
-
参数推断
-
最大似然估计
-
矩
-
假设检验
-
拟合优度
-
回归分析
-
贝叶斯统计
-
主成分分析
-
广义线性模型
如果你对深入探讨统计学感兴趣,可以查看5 Free Courses to Master Statistics for Data Science。
链接: 应用统计学
5. 机器学习及其他领域的矩阵微积分
你应该已经通过单变量和多变量微积分课程对优化有一定了解。但在机器学习中,你可能会遇到需要矩阵微积分和任意向量空间微积分的大规模优化问题。
机器学习及其他领域的矩阵微积分将帮助你在你所学的线性代数和微积分课程的基础上进一步深入。这可能是这个列表中最高级的课程。但如果你打算进行数据科学的研究生课程或想探索机器学习和研究,它将非常有帮助。
以下是该课程所涵盖的一些主题:
-
作为线性算子的导数;在任意向量空间上的线性近似
-
以矩阵作为输入或输出的函数的导数
-
矩阵分解的导数
-
多维链式法则
-
正向和反向模式的手动与自动微分
你还可以探索许多其他的近似和优化算法。
总结
如果你想掌握数据科学中的数学,这些课程列表应该足以让你学习所有你需要的内容——无论是进入机器学习研究还是获得数据科学的高级学位。
如果你还在寻找更多的课程来学习数据科学中的数学,可以阅读5 门免费课程掌握数据科学中的数学。
Bala Priya C**** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过编写教程、操作指南、观点文章等方式学习和分享知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关内容
五门免费在线课程,学习数据工程基础
原文:
www.kdnuggets.com/5-free-online-courses-to-learn-data-engineering-fundamentals

作者提供的图片 | Canva
如果你打算成为数据工程师,所需学习的工具和技能可能会让人感到不知所措。数据工程职位的描述要求很多,这使得很多人选择回避。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
然而,只要你掌握了基础知识,就不需要过于担心所有要求。学习数据工程的基础可以帮助你顺利开展数据工程师的职业生涯。
在这篇博客中,我将介绍五门免费在线课程,帮助你学习数据工程的基础知识。
面向所有人的数据工程
链接: 面向所有人的数据工程
正如标题所述,无论你是刚开始还是已经完成了一半——这门由 DataCamp 提供的课程适合所有对数据工程感兴趣的人。这是一门无代码的数据工程入门课程,你将学习所有有关数据工程师的知识。
你将学习数据工程师如何奠定基础,以及这如何帮助数据科学家完成他们的任务。理解数据工程师和数据科学家的区别非常重要。从数据存储到数据处理技术,这将帮助你学习如何开发数据管道,以及如何在数据工程项目中使用并行计算和云计算。
数据工程初学者课程
链接: 数据工程初学者课程
也许你不喜欢按照书面的课程大纲学习,想要感觉像在课堂环境中。这门由 freeCodeCamp 提供的 3 小时数据工程初学者课程可以满足你的需求。
在这门面向初学者的课程中,你将学习数据工程的基本要素。你将了解数据库、Docker 和分析工程,探索像使用 Airflow 构建数据管道这样的高级主题,并参与使用 Spark 进行批处理和使用 Kafka 进行流数据处理。课程的最后一个部分是一个全面的项目,考验你创建完整端到端管道的技能。
ASUx: 数据工程
链接:ASUx: 数据工程
在 5 周内,每周 1-9 小时,你将获得由亚利桑那州立大学提供的数据工程入门知识。在本课程中,你将通过互动视频来帮助你理解分析概念和软件。
该课程专注于数据工程中的数据库操作以及如何使用 SQL 与数据库进行交互。从学习数据库结构和如何从多个表中连接数据开始,你将能够建立坚实的数据工程基础知识,之后可以利用 SQL 创建报告并编写数据处理脚本。
Python 和 Pandas 数据工程
精通 Python 和 Pandas 对你的数据工程职业生涯至关重要。作为非常流行的编程语言和库,掌握这些技能将提升你的数据工程之旅。
在不到 4 周的时间里,你将学习如何设置开发环境、操作数据并高效解决实际问题。你还将学习核心的 Python 语法和数据结构、用于数据操作的 pandas DataFrame 以及用于大数据的 Pandas 替代品。
IBM 数据工程职业证书
链接:IBM 数据工程职业证书
假设你是那种从头到尾、从初学者到专家都致力于完成课程的人,那么这个课程可能适合你。由 IBM 提供的这个数据工程课程是一个包含 16 个系列的职业证书,如果每周投入 10 小时,可以在 6 个月内完成。
在本课程中,你将学习数据工程师在日常工作中使用的最新实用技能和知识。然后,你将深入创建、设计和管理关系型数据库,并将数据库管理(DBA)概念应用于如 MySQL、PostgreSQL 和 IBM Db2 的 RDBMS。随着时间的推移,你将通过使用 MongoDB、Cassandra、Cloudant、Hadoop、Apache Spark、Spark SQL、Spark ML 和 Spark Streaming 发展对 NoSQL 和大数据的实际知识。
到课程结束时,你将能够使用 Bash、Airflow 和 Kafka 实现 ETL 和数据管道;设计、填充和部署数据仓库;以及创建 BI 报告和互动仪表板。
总结
在这个博客中,我旨在带你从小块课程到完整认证的过程中学习数据工程的基础知识。每个人的学习水平不同,我们的学习方式也各不相同。选择适合你的课程对学习数据工程的基础知识非常重要。
尼莎·阿雅 是一名数据科学家、自由撰稿人,同时担任 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。尼莎涵盖了广泛的话题,并希望探索人工智能如何有助于延长人类寿命。作为一个热衷学习者,尼莎寻求拓宽她的技术知识和写作技能,同时帮助他人指导。
更多相关话题
5 门免费在线课程,学习数据科学基础
原文:
www.kdnuggets.com/5-free-online-courses-to-learn-data-science-fundamentals

作者提供的图片
很多技术专家和课程销售商会告诉你,你可以在短短两周或两个月内成为一名准备好的数据科学家。然而,他们往往隐藏了很多事实。虽然在短时间内成为专业数据科学家是可能的,但这通常假设你已经具备了数据科学基础知识,如统计学、概率论、SQL 和用于数据管理和分析的 Python,以及各种数据处理和分析技术。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
在开始数据科学之旅之前,我强烈建议你花时间学习这些基础知识。我在这篇博客中分享的课程来自顶尖大学和 IBM,提供高质量的教育,帮助你建立坚实的基础。
1. 数据库入门与 SQL - 哈佛大学
数据库入门与 SQL 是任何希望了解数据存储和处理核心的人的绝佳起点。该课程涵盖了 SQL 的基础知识,SQL 是用于与数据库沟通的语言。通过动手项目和现实世界的例子,你将学习如何查询数据库、设计模式、查询优化等。
链接: CS50 的 SQL 数据库入门 (harvard.edu)
2. Python 数据科学入门 - 哈佛大学
Python 数据科学课程非常适合那些希望使用 Python 这个数据科学和机器学习中最受欢迎的编程语言来深入数据科学的人。该课程涵盖数据处理、可视化、分析和建模,使用的库包括 pandas、matplotlib 和 scikit-learn。课程结束时,你将能够进行复杂的数据分析并构建预测模型。
3. 使用 R 进行统计学习 – 斯坦福大学
统计学习与 R 课程是对数据科学和机器学习中使用的关键概念和技术的全面介绍。本课程涵盖统计方法、线性回归、分类、重采样方法、基于树的方法、聚类、深度学习等。它为那些具备基础统计学和线性代数知识的人设计。课程材料包括讲座视频和练习。
链接: 统计学习 | 斯坦福在线
4. 数据科学数学主题 – 麻省理工学院
数据科学数学主题课程深入探讨了数据科学的数学基础。该课程专为那些对研究用于从数据中提取信息的算法理论方面有浓厚兴趣的人而设计。课程内容包括主成分分析、流形学习和扩散图谱、谱聚类、群体测试、随机图上的聚类等。
链接: 数据科学数学主题 | 数学 | 麻省理工学院开放课程
5. 数据分析入门 - IBM
数据分析入门课程,提供于 Coursera,提供了对数据分析的实用介绍。本课程涵盖数据分析过程,从数据清理和准备到可视化和解释。你将通过视频教程、书面内容、测验和最终作业来学习基础概念。
结论
如果你对数据科学职业感到困惑或不知从何开始,我建议从免费数据科学基础课程开始。这些课程简短且涵盖 Python、SQL、统计学和各种数据分析技术的基础知识。完成这些课程后,我强烈建议报名参加付费训练营,以成为一名专业的数据科学家。训练营将为你提供实际经验,并为现代职场做好准备。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为患有心理疾病的学生开发 AI 产品。
关于这个话题更多
构建强大数据科学作品集的 5 个免费平台
原文:
www.kdnuggets.com/5-free-platforms-for-building-a-strong-data-science-portfolio
作者提供的图片
在数据驱动的世界中,拥有一个强大的数据科学作品集对于获得理想工作或作为自由职业者获得客户至关重要。你的作品集可以展示你的技能、经验和项目工作给潜在的雇主或客户。虽然有付费平台用于创建作品集,但你可以利用免费平台来构建一个令人印象深刻的作品集,而无需花费一分钱。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织 IT
作为一个对数据科学充满热情并帮助他人进入这一领域的人,我总是鼓励新数据科学家花时间建立一个稳健的作品集。一个好的作品集通常包括你参与过的数据科学项目的链接、每个项目的描述、你的教育背景、相关工作经验以及一些基本的个人信息。这让雇主或客户能够全面了解你的能力。
特别是项目描述可以让招聘人员和客户快速评估你在数据整理、分析、建模等方面的技术技能。通过提供这种现实世界的经验展示,你可以使自己在其他候选人中脱颖而出。在本文中,我将分享你可以用来建立和展示数据科学作品集的前五个免费平台。
1. Kaggle
Kaggle 是一个顶尖的数据科学和机器学习平台。它在寻求提升知识、发现数据集以及讨论具体问题的学生中非常受欢迎。此外,它还是展示你技能并吸引招聘经理注意的绝佳平台。要实现这一点,你只需参与竞赛、发布你的笔记本/项目,并参与社区讨论。
Kaggle 进阶系统鼓励数据专业人士追求卓越并提升他们的技能。通过获得点赞,用户可以获得铜牌、银牌和金牌,从而使他们能够从贡献者晋升到大师级别。
Kaggle 作品集
2. DagsHub
对于那些希望以简洁、用户友好的方式展示工作的数据科学家来说,DagsHub 是一个必试的平台,也是 GitHub 的更酷的兄弟。DagsHub 允许你在一个专为机器学习从业者和学生设计的集中平台上完成几乎所有与数据科学和机器学习模型构建相关的操作。
使用 DagsHub,你可以轻松托管你的数据科学项目,包括代码、数据、模型、可视化、实验和文档。它还使部署你的机器学习模型变得无缝。
DagsHub 作品集
3. LinkedIn
虽然 LinkedIn 可能被认为是一个通用的职业社交平台,但它也可以作为数据科学家展示他们的项目、技能和成就的绝佳方式。鉴于 LinkedIn 的庞大用户基础和职业焦点,它为提升你的数据科学个人资料以便与潜在雇主或客户建立联系提供了很好的机会。
在 LinkedIn 上,你可以分享你的数据科学写作链接,比如展示你的分析能力的技术博客文章。你还可以发布你完成的数据科学项目的摘要,无论是学术的、职业的还是个人的。展示数据科学或机器学习的认证是另一个表明你技术能力的方式。
该平台还允许你与其他数据专业人士建立联系,关注你感兴趣的公司,并加入相关小组。通过积极参与 LinkedIn,你可以提高被发现从事数据角色或工作的机会。本质上,它使潜在的联系和雇主能够基于你最近的数据科学工作和成就轻松找到你。
LinkedIn 作品集
4. Medium
Medium 提供了一个理想的博客平台,供数据科学家通过撰写有关他们的项目和研究的文章来展示他们的工作和技能。凭借其简单的发布格式和广泛的读者群体,Medium 是创建数据科学内容作品集的绝佳方式,展示你的分析能力和沟通技巧。
在 Medium 上,你可以发布详细的文章,全面讲解一个数据科学项目从开始到完成的过程。解释你是如何处理问题、处理和探索数据、开发和评估模型以及解释结果的。你还可以撰写有关你在特定数据科学技术和工具方面的专长的文章。
此外,你可以撰写关于最新数据科学研究和新闻的博客,以展示你对该领域的知识。撰写关于新算法、突破性模型、伦理问题和行业趋势的文章表明你跟上了最新进展。
Medium 作品集
5. DataSciencePortfol.io
对于那些寻求简单方法来组建在线作品集的数据科学家来说,datascienceportfol.io 是一个用户友好且专注的平台,用于展示你的工作。专门为数据科学社区设计,datascienceportfol.io 使你能够在几分钟内创建一个精致、专业的数据科学作品集。
借助直观的界面,你可以轻松突出显示你在 datascienceportfol.io 页面上的教育背景、工作经历、技能、项目等。你可以提供有关数据科学项目的描述,解释其目的、使用的技术和结果。还可以包含指向 GitHub 仓库或实时演示的链接,以提供你动手能力的证据。
数据科学作品集 作品集
结论
通过我作为数据科学家的亲身经历,我深刻体会到拥有一个强大作品集来展示你的技能并从众人中脱颖而出的重要性。一个精心构建的数据科学作品集让你可以向潜在雇主或客户展示你的最佳作品。
我强烈推荐花时间利用现在可用的优秀免费平台来构建你的作品集。精心挑选你的最佳项目,撰写有吸引力的描述,并在接受新挑战时保持你的作品集更新。将你的作品集视为你数据科学成就的不断演变的展示。
不要等到你急需工作时才开始考虑你的作品集。尽早开始开发它,并在你的职业生涯中不断提升。利用像 Kaggle、DagsHub、LinkedIn、Medium 和 DataSciencePortfol.io 这样的平台来创建一个强大且可共享的作品集。
一个强大的作品集展示了你作为数据科学家的独特身份。它提供了你能为寻找分析和机器学习技能的组织带来的实际价值的证据。通过投资你的作品集来投资自己。当激动人心的数据科学机会来敲门时,你会为你的付出感到欣慰!
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,他热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为有心理健康问题的学生开发一款 AI 产品。
更多相关主题
5 个适合数据科学初学者的免费 Python 课程
原文:
www.kdnuggets.com/5-free-python-courses-for-data-science-beginners

图片由作者提供
如果你正在阅读这篇文章,你可能希望学习数据科学并尽快找到你的第一个数据角色。那么你该如何开始学习数据科学呢?
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你组织的 IT
在复习完基本的数学技能后,你可以开始学习 SQL 或者像 Python 或 R 这样的编程语言。如果你学习 R,你可以进行数据和统计分析。但 Python 比 R 更加多才多艺且更易于学习。
这里有一份适合初学者的 Python 编程课程列表,这些课程将帮助你学习基础知识并开始构建项目。让我们开始吧!
1. Python for Beginners – freeCodeCamp
初学者的 Python 课程是 freeCodeCamp 的 YouTube 频道上的一门完整的 Python 入门课程。该课程超过 4.5 小时,通过编写两个简单的游戏:石头剪子布和 Blackjack,让你掌握 Python 基础知识并快速上手。
课程开始时会探讨像数据类型、变量和运算符等基础知识。然后覆盖控制流、内置函数和数据结构。课程还探讨了高级概念,如装饰器、面向对象编程和函数式编程。
该课程不要求具备 Python 的任何编程经验。但它涵盖了足够的内容,帮助你感到自信,开始构建自己的项目。
链接: Python for Beginners – Full Course [Programming Tutorial]
2. Python – Kaggle
如果你喜欢通过简短的文本课程进行学习,并在过程中运行代码片段,那么 Python 课程适合你。
除了 Python 的语法和变量基础之外,该课程还涵盖了以下主题:
-
函数
-
布尔值和条件语句
-
列表
-
循环和列表推导
-
字符串和字典
-
使用外部库
3. Python 教程(含迷你项目)– freeCodeCamp
在第一门课程中,Python 初学者,你将完成两个简单的游戏项目。 初学者 Python 教程(附迷你项目) 是一个包含 23 章的免费视频课程,每章专注于一个不同的主题。
在课程中,你还将参与几个迷你项目。课程从基础知识如数据类型和内置数据结构开始。但它还涵盖了以下主题:
-
函数
-
递归
-
作用域和闭包
-
命令行参数
-
Lambda 函数和高阶函数
-
面向对象编程
-
错误和异常
-
文件操作
-
虚拟环境
4. Python 教程 – W3Schools
Python 教程在 W3Schools 上提供了简短的课程内容和快速练习题及示例,你可以在浏览器中运行这些示例。
W3Schools 的 Python 教程涵盖了以下主题:
-
控制流
-
内置数据结构
-
类和对象
-
继承多态
-
处理日期、JSON 和正则表达式
除了 Python 基础知识,Python 教程还包括有关 Python 数据科学库的课程:NumPy、pandas 和 matplotlib。
链接: Python 教程
5. Python 的面向对象编程
从目前所学的课程中,你应该已经对 Python 中的面向对象编程(OOP)有所了解,现在是时候进一步学习了。 Python 的面向对象编程 在 freeCodeCamp 的 YouTube 频道上免费提供,是一门全面的课程,旨在学习 OOP 基础知识。
这门课程涵盖了以下内容:
-
开始学习类
-
构造函数
-
类方法与静态方法
-
继承
-
获取器和设置器
-
OOP 原则
总结
如果你是一个希望学习 Python 的数据科学初学者,我希望你发现这个课程列表对你有帮助。即使在学习 Python 的过程中,也要确保在旁边做一些有趣的项目,以便你能够应用所学的知识并构建你的项目作品集。
祝学习愉快,编码顺利!
Bala Priya C**** 是来自印度的开发人员和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和咖啡!目前,她正在通过编写教程、操作指南、观点文章等,学习并与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关主题
开始学习自然语言处理的深度学习的 5 个免费资源
原文:
www.kdnuggets.com/2017/07/5-free-resources-getting-started-deep-learning-nlp.html
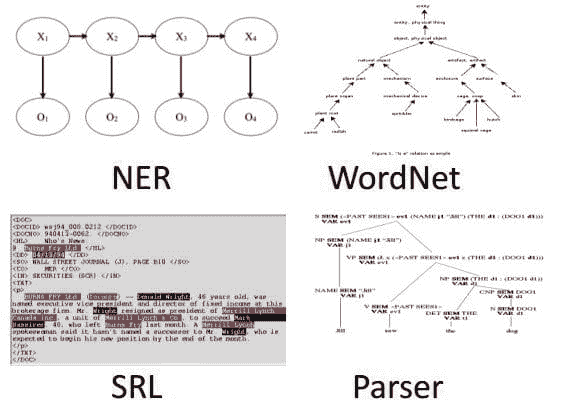
来源于 Richard Socher 的幻灯片,见下文。
对将深度学习应用于自然语言处理(NLP)感兴趣?不知道从哪里或如何开始学习?
这是为初学者准备的 5 个资源的集合,这些资源应当能让你对可能性和 NLP 与深度学习交集的最新进展有一些了解。它也应该能提供一些下一步的建议。希望这些资源对你有所帮助。
这是斯坦福大学和 MetaMind 的 Richard Socher 的一套幻灯片,最初在里斯本的机器学习暑期学校上展示。你会发现这是对 NLP 和深度学习,以及深度学习在 NLP 中的应用的一个扎实入门。期待没有魔法。
此外,从Socher学习也是一个不错的主意。
这是 Marc Moreno Lopez 和 Jugal Kalita 的一篇综述论文。摘要如下:
卷积神经网络(CNNs)通常与计算机视觉相关联。CNNs 在图像分类方面取得了重大突破,并且是大多数计算机视觉系统的核心。最近,CNNs 也被应用于自然语言处理问题,并取得了一些有趣的结果。在这篇论文中,我们将尝试解释 CNNs 的基础知识、不同的变体及其在自然语言处理中的应用。
这比下面的论文更为简洁,且在五分之一的篇幅中做得很不错。
这是 Yoav Goldberg 的全面概述。摘要如下:
本教程从自然语言处理研究的角度调查神经网络模型,试图让自然语言研究人员了解神经技术。教程涵盖了自然语言任务的输入编码、前馈网络、卷积网络、递归网络和递归网络,以及自动梯度计算的计算图抽象。
作为额外的收获,你可能还想阅读 Yoav 最近的一系列简短博客文章,这些文章讨论了同一主题,不过从不同的角度来看:
无论你在上述内容中的立场如何(即使你有一个“立场”),这句话都是绝对的金句:
我反对的是“深度学习社区”进入(包括自然语言处理在内)他们仅有非常肤浅理解的领域,并在没有花时间了解问题领域的情况下做出广泛且毫无根据的声明。

来自斯坦福的 CS224n:深度学习中的自然语言处理课程。
这是一个最受欢迎和最受尊敬的自然语言处理课程,由 Chris Manning 和 Richard Socher 教授。课程网站上说:
这门课程全面介绍了应用于自然语言处理的前沿深度学习研究。在模型方面,我们将涵盖词向量表示、基于窗口的神经网络、递归神经网络、长短期记忆模型、递归神经网络、卷积神经网络以及一些涉及记忆组件的最新模型。
如果你有兴趣直接跳转到讲座视频,请点击这里。
另一个来自顶尖大学的优秀课程资源,这门课程由牛津大学的 Phil Blunsom 教授。课程网站上说:
这是一个高级的自然语言处理课程。自动处理自然语言输入并产生语言输出是人工通用智能的一个关键组成部分。人类沟通中固有的模糊性和噪音使得传统的符号 AI 技术在表示和分析语言数据方面无效。最近,基于神经网络的统计技术在自然语言处理方面取得了一些显著的成功,导致了这一领域的商业和学术兴趣的大幅增长。
你可以直接访问这个链接查看课程材料的 Github 仓库。
相关资源:
-
5 个免费资源帮助你入门自动驾驶车辆
-
5 个免费课程帮助你入门人工智能
-
进入机器学习职业之前必读的 5 本电子书
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT 工作
更多相关内容
5 个免费的资源,帮助你入门自动驾驶车辆
原文:
www.kdnuggets.com/2017/07/5-free-resources-getting-started-self-driving-vehicles.html
来自《计算机视觉在自主车辆中的应用:问题、数据集和最新进展》,见下文。
对自动驾驶车辆感兴趣?不知道从哪里或如何开始学习?
正式的相关教育资源稀缺,因此有兴趣学习的人必须以黑客的心态进行。我收集了一份短名单,包括 5 个免费的资源,帮助新手找到自己的方向。希望这些对一些人有用。
1. 自动驾驶汽车中使用的机器学习算法
这篇 KDnuggets 文章将让你初步了解自主驾驶车辆算法的世界,提供对这条道路的入门见解,言外之意。
机器学习应用包括通过来自不同外部和内部传感器的数据融合来评估驾驶员状况或驾驶场景分类。我们考察了用于自动驾驶汽车的不同算法。
由 Joel Janai、Fatma Güney、Aseem Behl 和 Andreas Geiger 总结的当前自主车辆计算机视觉的状态。从摘要:
近年来,人工智能相关领域,如计算机视觉、机器学习和自主车辆,取得了惊人的进展。然而,随着任何快速发展的领域,保持最新或作为初学者进入该领域变得越来越困难。虽然已经撰写了几篇特定主题的调查论文,但至今没有关于自主车辆计算机视觉中问题、数据集和方法的一般调查。这篇论文试图通过提供该主题的最新调查来缩小这一差距。我们的调查包括历史上最相关的文献以及几个特定主题的最新进展,包括识别、重建、运动估计、跟踪、场景理解和端到端学习。
一篇详细而全面的概述,可能是任何希望快速入门该领域的最佳起点,集中在一个地方。
3. 自动驾驶汽车的深度学习
这是 MIT 6.S094 的课程网站。
这门课程通过构建自动驾驶汽车的实际主题介绍深度学习的实践。它对初学者开放,并设计为适合那些对机器学习新手,但也可以为希望了解深度学习方法及其应用的高级研究人员提供实用概述。
通过讲座幻灯片、视频和嘉宾讲座,这对于任何对深度神经网络应用于自动驾驶汽车感兴趣的人来说,都是一个很好的资源。
这是 Harrison Kinsley(又名 sentdex)的一系列持续视频,描述如下:
这个项目的目的是使用 Python 玩《侠盗猎车手 5》。GTA V 中有很多事情可以做,但我们的首要目标是创建一个自动驾驶汽车(在这种情况下是滑板车)。
来自 Harrison Kinsley 的 Python 玩《侠盗猎车手 V》视频系列。
该系列目前已超过 17 个视频,分成易于消化的部分。查看这里的附带代码:探索使用 Python 玩《侠盗猎车手 5》。此外,Harrison 还有许多其他视频教程系列,涵盖从 Python 基础到使用 Python 进行财务分析、实践机器学习等,可能也会引起读者的兴趣。
自动驾驶汽车代表了现代历史上最重要的进展之一。它们的影响将超越技术、超越交通、超越城市规划,改变我们日常生活的方式,这些方式我们尚未想象。
参与此项目的学生将掌握将塑造未来的技术。
除了 Udacity 的市场营销之外,这可能是目前在自动驾驶车辆领域中可以获得的最全面、最集中的正规培训/教育。我之所以说可能,是因为我没有第一手经验,但我也没有看到其他可能竞争者。目前课程资料可以免费访问,而报名纳米学位证书则需要一些费用。
这里是一个学生的 第一学期回顾,帮助填补这个空白。如果你想了解你将在这样的课程集合中学到什么,可以在这里找到另一位学生的 课程笔记和代码。以下是直接来自 Udacity 的一些 额外自动驾驶汽车资源。
相关:
-
开始人工智能的 5 个免费课程
-
进入机器学习职业前要读的 5 本电子书
-
机器学习和数据科学必读的 10 本免费书籍
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 在 IT 领域支持你的组织
更多相关内容
5 个免费资源来掌握你的数据科学求职
原文:
www.kdnuggets.com/5-free-resources-to-master-your-data-science-job-search

图片作者
求职确实很艰难,这一点毫无疑问。发送简历、重新撰写求职信、申请和等待回复(或者干脆被“幽灵化”)之间的漫长等待——这都不是一件有趣的事。
好消息是,现在比以前容易多了。你不再需要亲自邮寄或递送信件;你可以通过几次点击完成很多申请。有许多专业的招聘网站、面试准备工具和其他资源,使得找到、申请并真正获得你梦想中的数据科学工作更有可能。
让我们来谈谈手头上最好的免费资源,以便获得那份数据科学工作。
Kaggle – 真实世界技能
如果你没有足够的技能来支撑你的资历,那么无论你的简历多么光鲜也没用。获得数据科学技能的最佳方式之一是通过自己的项目。
有时获取数据科学项目的创意可能会有点棘手,这时 Kaggle就派上用场了。Kaggle 提供了大量的数据集、机器学习竞赛,并包含了不同的解决方案和处理各种项目的方法。
这是一个极好的资源,因为它允许你在实际场景中应用数据科学技能,获得反馈,并从他人的解决方案中学习。不仅如此,如果你真的赢得了 Kaggle 竞赛,这可以成为对任何雇主的一种炫耀。大多数数据科学家都知道 Kaggle,能够解决这些问题会让他们印象深刻。
简而言之,Kaggle 提供的最有价值的资产是现实世界的数据和问题。它提供了对行业级问题的宝贵曝光机会——以及被顶级公司注意的机会。
StrataScratch – 面试准备
作为StrataScratch的创始人,我可能会稍微有些偏见,但我创建这个公司是因为我发现了一个真正的问题:准备数据科学面试很困难。因此,我开始收集来自尽可能多公司的面试问题,并按难度、问题类型和公司进行分类。结果是一个包含一千多个真实面试问题——包括编码和非编码问题——的数据库,此外还有解决方案,如果你真的陷入困境的话。
根据我的数据科学工作面试经验,这不仅仅是关于拥有技能,还要能够保持冷静,思考他们抛给你的任何问题。正如你可以想象的那样,如果你之前见过面试问题——或其某些变体——那么做到这一点会容易得多。
在数据科学求职的每个阶段,练习面试问题也是一个好主意,而不仅仅是在你有面试安排的时候。现实生活中的面试问题练习让你了解数据科学公司感兴趣解决的问题,以及你应该专注于学习或提升的技能。
edX 和 Coursera(审计模式)– 获得知识
有趣的事实是,虽然edX和Coursera提供的 数据科学课程价格非常昂贵,但你可以通过审计这些课程免费获得所有相同的知识。这意味着你不会获得完成课程的证书,这确实可能很有价值,但你可以免费获得世界级的课程、教程和指南。
来源:www.edx.org/verified-certificate
只需找到你感兴趣的信息课程,并以审计模式注册即可。你可以利用这个来弥补简历上的薄弱点,学习项目所需的技能,或只是探索你热衷的主题。
KDNuggets 和 Towards Data Science – 阅读数据科学博客
你正在阅读 KDNuggets,所以你应该已经知道这是一个获得数据科学工作的有用资源。然而,KDNuggets 不仅提供博客文章。它还有数据集(同样对项目有用)、实时和虚拟活动(非常适合网络交流)、编程备忘单以及精心挑选的工具推荐。
我还推荐Towards Data Science,因为这是另一个充满教程、指南、操作方法、个人故事和经验的博客。虽然一些故事需要付费,但许多故事是免费的。你可以轻松浏览 TDS 主页,寻找那些作者名字旁边没有小星星的免费故事。
简而言之,获得数据科学工作的一种最佳方式是向其他数据科学家学习。他们中的许多人很慷慨地在线发布免费的内容供你阅读和享受。
Wellfound – 招聘网站
不确定从哪里开始你的数据科学求职搜索?经典的选择如 LinkedIn 和 Indeed 在数量上确实占优势,但我喜欢Wellfound来寻找数据科学职位,因为它提供了精心挑选的方面。
Wellfound 相对于其他招聘网站有一些优势。首先,筛选选项非常强大。你可以轻松找到基于投资轮次、薪资、股权、市场、公司规模等的职位。
其次,这主要是初创公司。如果你曾经尝试过却未能获得 FAANG 职位,可能是时候将目光转向不同的领域。初创公司对数据科学人才需求旺盛,如果你能拓宽视野,考虑稍微不那么传统的雇主,你可能会更幸运。
第三,它只是稍微更新和新鲜一些,因此我认为这是更好的求职体验。功能包括告知你谁投资了公司,招聘人员最近审查申请者的时间,以及从 Glassdoor 中获取关于领导力和生活/工作平衡评分的统计信息。
最后的想法
求职从来都不轻松,感觉今年的情况更糟,尤其是公司不再回应,要求你经过多轮面试却最后表示职位已内部填补,或者直接发布虚假职位以在潜在投资者面前显得更好。也许你甚至遇到过虚假职位发布。
希望这个免费的资源列表能让你的生活稍微轻松一点。通过这五个免费的工具,你将更好地准备找到并获得理想的数据科学职位。
内特·罗西迪是一名数据科学家和产品策略专家。他还是一名兼职教授,教授分析课程,并且是 StrataScratch 的创始人,这是一个帮助数据科学家准备面试的平台,提供来自顶级公司的真实面试问题。内特会撰写职业市场的最新趋势,提供面试建议,分享数据科学项目,并涵盖所有 SQL 内容。
更多相关话题
5 个针对数据科学初学者的免费 SQL 课程
原文:
www.kdnuggets.com/5-free-sql-courses-for-data-science-beginners

图片来源:作者
如果你有兴趣转行做数据相关的工作,你可能知道有效使用数据来回答业务问题是大多数数据职业的核心——无论你使用什么工具。通过建立正确的技能组合,你可以获得数据分析师的职位,并逐步探索数据科学家、BI 分析师等其他角色。那么你应该从哪里开始呢?
你应该学习像 Python 或 R 这样的编程语言吗?还是应该直接学习像 Tableau 这样的 BI 工具?还是 SQL?
嗯,SQL 就是你需要掌握的工具——无疑是从数据分析师到数据科学家和数据工程师等多个数据职业中最重要的技能。这就是为什么我们整理了这份适合初学者的课程列表,以便在几小时内学习 SQL 基础。
1. SQL 入门:查询和管理数据
SQL 入门:查询和管理数据是你可以在 Khan Academy 上免费学习的课程。你将学习如何在关系数据库表中查询和操作数据。
这个课程包含几个小的课程单元,后面跟着挑战题,考验你的理解。课程分为以下几个部分:
-
SQL 基础部分涵盖了创建表和插入数据、查询数据和聚合等基础知识。
-
更高级的 SQL 查询部分涵盖了逻辑运算符、IN 和 LIKE 运算符以及 HAVING。
-
SQL 中的关系查询部分专注于使用不同类型的连接来利用多个表中的数据回答问题。
-
使用 SQL 修改数据库部分教你如何使用 SQL 修改表模式。
2. SQL 和数据库基础
如果你喜欢通过讲师指导的视频教程学习,那么SQL 教程 - 初学者的完整数据库课程是一个很好的 SQL 入门课程。
在大约 4.5 小时内,你将学习数据库设计的基础知识以及如何使用 SQL 查询数据库。你将使用 MySQL,这是一种广泛使用的关系数据库管理系统 (RDBMS)。
首先,你将探索数据库架构设计和使用 SQL 执行 CRUD 操作。然后,你将学习聚合、嵌套查询、连接、联合、函数和触发器。
3. SQL 入门
Kaggle 上的 Intro to SQL 课程也是一个不错的选择,如果你更喜欢以文本为基础的教程并辅以练习的话。
在这个入门 SQL 课程中,你将学习如何使用 BigQuery Python 客户端查询数据集。涵盖的主题包括:
-
SQL 基础
-
过滤
-
聚合
-
联接
-
编写可读的 SQL 查询
链接:Intro to SQL
4. SQL Tutorial – W3Schools
SQL Tutorial 由 W3Schools 提供,是另一个很好的初学者友好的资源,用于学习 SQL 命令和函数的基础知识。该教程分为多个小巧的课程,每一节都专注于特定的命令或函数。所以你将学习这些命令是什么,它们如何工作,并附有示例。
你可以在在线编辑器中解决这些示例—无需在本地环境中安装任何东西。这个教程涵盖了 SQL 的基础知识以及各种逻辑运算符、窗口函数等。此外,这还涵盖了修改数据库表、约束等内容。
这个教程不仅是一个学习资源,还是一个简明的参考资料。如果你想快速查找某个函数的语法和示例用法,这个 SQL 教程是你可能想要收藏的参考。
链接:SQL Tutorial
5. SQLZoo
SQLZoo 是另一个适合初学者的平台,用于学习和练习 SQL。从基本的 SELECT 语句到像窗口函数这样的高级概念,SQLZoo 提供了小巧的课程和每个概念的快速练习。
涵盖的主题包括:
-
SELECT 语句
-
聚合函数
-
JOIN 的类型
-
理解 NULL
-
窗口函数
你还可以完成一组评估问题,其中包含稍微难一些的 SQL 问题,你可以用来测试自己。
链接:SQLZoo
总结
我希望你发现这份免费 SQL 课程的汇总很有用。这些课程旨在帮助你在几小时内掌握 SQL 基础。
如果你在寻找更广泛的课程的免费学习资源,这里有几个汇总你可能会觉得有帮助:
-
5 门免费课程掌握 SQL 数据科学
-
5 门免费大学课程学习数据库和 SQL
这些课程也需要你付出更多的努力,通常需要几周时间来完成。所以继续学习和练习吧!
Bala Priya C是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉领域工作。她的兴趣和专长包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正致力于通过撰写教程、操作指南、观点文章等,与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关内容
5 个免费斯坦福 AI 课程

图像由 ideogram.ai 生成
我们正处在一个人工智能已经被应用于许多业务并带来大量价值的时代。由于这些好处,有许多公司在寻找能够提供这些价值的 AI 专家。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
你想成为这些 AI 专家之一吗?好吧,你现在就可以做到这一点。免费!
许多顶尖大学提供开放课程,例如斯坦福大学。
那么,斯坦福大学的这些 AI 免费课程是什么呢?让我们深入了解一下。
StanfordOnline: 使用 Python 进行统计学习
要开始现代人工智能,你应该理解统计方法和 Python 编程。
统计学将非常重要,因为这些概念在许多 AI 基础工具中被使用,并且它是理解 AI 机制的重要领域。有效地,统计知识将引导你构建更好的 AI。
另一方面,Python 是用于构建现代 AI 工具的编程语言。因此,学习它们也很重要。
斯坦福大学的 Python 统计学习课程将教你基本的统计方法和监督学习,同时继续使用 Python。你会熟悉统计建模的工作原理,并且这将帮助你理解下一个课程。
斯坦福大学还提供了免费书籍材料来配合此课程,你可以在他们的网站上访问这些材料。
CS229:机器学习
机器学习可能被视为人工智能的一个子集,但现代 AI 工具需要扎实的机器学习基础。要开发一个出色的 AI,我们需要机器学习知识,因为它让我们能够驱动 AI 的发展方向并增强输出效果。
你可以在斯坦福大学的 CS229 机器学习课程中学习许多机器学习基础知识。这些包括:
-
监督学习
-
无监督学习
-
学习理论
-
强化学习
-
自适应理论
-
机器学习应用
这门课程将巩固你的机器学习基础,并进而巩固人工智能基础。
人工智能入门
让我们通过斯坦福大学的人工智能入门课程学习人工智能的基础知识。这门课程可以开启你的 AI 学习之旅,因为你所需的所有基础知识都在这一门课程中。
通过 22 节课和 9 个练习考试,你将学习到多个概念,包括:
-
概率
-
机器学习
-
博弈论
-
计算机视觉
-
机器人技术
-
自然语言处理
这些课程将让你有信心深入探索人工智能。
CS221:人工智能:原理与技术
下一门课程是对 AI 的更深入学习,因为我们将在CS221:人工智能:原理与技术中探索比基础更广泛的内容。
这门课程将为你提供多种人工智能技术,用于实现你需要了解的各种 AI 系统,包括:
-
搜索
-
马尔可夫决策过程
-
游戏玩法
-
约束满足
-
图模型
-
逻辑
这是一个相当高级的课程,因此你可能希望在学习此课程之前刷新一下斯坦福推荐的许多基础课程。
AI 觉醒:对经济和社会的影响
最后,我们需要了解 AI 对成为顶级 AI 专家的影响。我们可能理解了技术方面,但知道如何利用 AI 产生影响则将我们与其他人才区分开来。
AI 觉醒:对经济和社会的影响斯坦福大学的课程将为技术人员提供不同的视角。与其学习如何开发它们,该课程将更多地涉及影响和风险。
这是一门可以在一天内完成的短期课程,但对 AI 专家来说非常重要。
结论
这来自斯坦福大学的课程将帮助你了解 AI,并为成为专家做好准备。
如果你对数据科学更感兴趣,可以阅读5 门免费斯坦福大学数据科学课程。
Cornellius Yudha Wijaya****是一位数据科学助理经理和数据撰稿人。在全职工作于安联印尼的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 撰写了多种 AI 和机器学习主题的文章。
相关主题
5 门免费斯坦福大学数据科学课程
原文:
www.kdnuggets.com/5-free-stanford-university-courses-to-learn-data-science

作者提供的图片
学习数据科学从未如此便捷。如果你有动力,你可以通过世界各地顶级大学提供的课程免费自学数据科学。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
我们整理了这份来自斯坦福大学的免费课程列表,以帮助你掌握所有必需的数据科学技能:
-
编程基础
-
数据库和 SQL
-
机器学习
-
处理大型数据集
所以今天就开始学习,以实现你的学习目标并开启你的数据职业生涯。现在让我们深入了解这些课程。
1. 编程方法论
要开始数据科学,建立如 Python 等编程语言的基础很重要。编程方法论课程从零基础教你 Python 编程,不需要任何编程经验。
在这门课程中,你将学习使用 Python 解决问题,同时熟悉语言的特点。你将从基础知识开始,例如变量和控制流,然后学习内置数据结构,如列表和字典。
在此过程中,你还将学习如何处理图像,探索 Python 中的面向对象编程和内存管理。
链接: 编程方法论
2. 数据库
对数据库和 SQL 有深入理解对任何数据职业都至关重要。你可以在 edX 上参加由 Jennifer Widom 教授主讲的流行数据库课程,课程分为五个自学模块。
备注: 你可以免费旁听课程并访问所有课程内容。
如果你是数据库新手,请先学习涵盖关系数据库基础的第一门课程,然后再学习更高级的课程。通过学习这些课程系列,你将掌握:
-
关系数据库和 SQL
-
查询性能
-
事务和并发控制
-
数据库约束、触发器、视图
-
OLAP 立方体,星型模式
-
数据库建模
-
处理半结构化数据如 JSON 和 XML
课程链接:
3. 机器学习
作为数据科学家,你应该能够使用 Python 和 SQL 分析数据并回答业务问题。但有时你还需要构建预测模型。这就是学习机器学习的帮助所在。
机器学习 或 CS229: 机器学习 斯坦福大学的课程之一,是最受欢迎和高度推荐的机器学习课程之一。你将学习到一个学期大学课程中通常涵盖的所有内容。此课程包括以下主题:
-
监督学习
-
无监督学习
-
深度学习
-
泛化和正则化
-
强化学习和控制
链接: 机器学习
4. 用 Python 进行统计学习
《Python 统计学习导论》(或 ISL with Python)是流行的 ISLR 统计学习书籍的 Python 版。
用 Python 进行统计学习 课程涵盖了 ISL with Python 书籍的所有内容。因此,你将学习到数据科学和统计建模的基本工具。以下是此课程涵盖的一些重要主题概述:
-
线性回归
-
分类
-
重采样
-
线性模型选择
-
基于树的方法
-
无监督学习
-
深度学习
链接: 用 Python 进行统计学习
5. 挖掘大规模数据集
挖掘大规模数据集 是一个专注于数据挖掘和机器学习算法,用于处理和分析大规模数据集的课程。
为了充分利用此课程,你应该对编程感到自如,最好是 Java 或 Python。你还应熟悉数学:概率和线性代数。如果你是初学者,考虑在参加此课程之前完成之前提到的课程。
该课程涵盖的一些主题包括:
-
高维空间中的最近邻搜索
-
局部敏感哈希(LSH)
-
降维
-
大规模监督机器学习
-
聚类
-
推荐系统
你可以使用 Mining Massive Datasets 这本书作为本课程的补充。该书也可以在网上免费获取。
总结
这份来自斯坦福大学的免费课程汇编应该能帮助你学习几乎所有你需要的内容,如果你想探索数据科学的话。
如果你正在寻找免费学习 Python 和数据科学的大学课程,以下是几篇你可能会觉得有用的文章:
-
5 门免费大学 Python 课程
-
5 门免费大学数据科学课程
快乐学习!
Bala Priya C** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和咖啡!目前,她正在通过撰写教程、操作指南、观点文章等方式学习并与开发者社区分享她的知识。Bala 还制作引人入胜的资源概述和编码教程。**
更多相关主题
Jupyter Notebook 上的数据科学项目的 5 个免费模板
原文:
www.kdnuggets.com/5-free-templates-for-data-science-projects-on-jupyter-notebook

图片由作者使用 DALL·E 3 生成
对于许多专业的数据科学家来说,Jupyter Notebook 已成为他们的主要工作环境。即使对我来说,它也是我进行任何数据科学实验和工作流时的首选地方。
我们的三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
作为数据科学家的工作环境,Jupyter Notebook 是一个独特的 IDE,因为代码可以在每个单元格中独立执行。同时,作者可以解释每个单元格。这种区别使得笔记本可以被其他人重用,并成为项目模板。
在本文中,我们将讨论五个用于在 Jupyter Notebook 上构建数据科学项目的免费模板。那么,这些 Jupyter Notebook 模板是什么呢?让我们深入了解一下。
1. Python 数据科学项目的 Cookiecutter 模板
我们讨论的第一个模板不一定是我们可以直接填写的完整代码项目。我们将讨论的模板不仅仅是 Jupyter Notebook,还有支持 Jupyter Notebook 的完整项目。我们会涉及到 AWS 的 Python 数据科学项目。
这个模板创建了一个完整的数据科学项目结构,准备好用于你的实际项目。使用 Cookiecutter CLI,你可以生成数据科学项目的目录结构,类似于下面的结构。
|-- bin/
|-- notebooks # A directory to place all notebooks files.
| |-- *.ipynb
| `-- my_nb_path.py # Imported by *.ipynb to treat src/ as PYTHONPATH
|-- requirements/
|-- src
| |-- my_custom_module # Your custom module
| |-- my_nb_color.py # Imported by *.ipynb to colorize their outputs
| `-- source_dir # Additional codes such as SageMaker source dir
|-- tests/ # Unit tests
|-- MANIFEST.in # Required by setup.py (if module name specified)
|-- setup.py # To pip install your Python module (if module name specified)
# These sample configuration files are auto-generated too:
|-- .editorconfig # Sample editor config (for IDE / editor that supports this)
|-- .gitattributes # Sample .gitattributes
|-- .gitleaks.toml # Sample Gitleaks config (if pre_commit is advanced)
|-- .gitignore # Sample .gitignore
|-- .pre-commit-config.yaml # Sample precommit hooks
|-- LICENSE # Boilperplate (auto-generated)
|-- README.md # Template for you to customize
|-- pyproject.toml # Sample configurations for Python toolchains
`-- tox.ini # Sample configurations for Python toolchains
如果你对模板如何应用于实际项目感兴趣,可以查看上面的这个 强化学习能源存储用例。
2. Coen Meintjes 的数据科学笔记本模板
接下来我们要讨论的 Jupyter 笔记本模板是Coen Meintjes 的模板。这是一个从数据探索到模型评估的基本 Jupyter 笔记本合集。它不是一个针对特定项目的模板;实际上,它主要由基本代码组成,没有更多内容。但我会说它是好的。为什么呢?
这是一个基础模板,每个人都可以用来进行各种项目,仅需进行少量调整。你可以使用这个 Jupyter 笔记本模板来开发任何项目创意。此外,这里的模板深入解释了笔记本中的许多过程,因此任何初学者或专业人士都可以从中受益。
3. Yusuf Cinarci 的数据科学项目
让我们来看一个更具项目针对性的模板,Yusuf Cinarci 的《数据科学项目 Jupyter 笔记本模板》。在这些模板中,你可以用它们来开发简单的项目,适用于你的投资组合或任何商业需求。
你可以从许多项目模板中进行选择。从简单的 Python 工资数据探索,到假新闻检测和电影推荐系统的开发,选择众多。这些笔记本非常适合那些希望轻松启动项目的你。
我喜欢 Yusuf Cinarci 模板合集的地方在于,它们并不过于复杂,因此初学者在学习数据科学时可以直接开始他们的项目。然而,许多项目都是针对初学者的,如果你在寻找数据科学项目,可能会发现它们的项目比较少。
4. Sukman Singh 的数据科学项目
如果你需要一个更复杂的项目 Jupyter 笔记本模板,那么Sukman Singh 的《数据科学项目 Jupyter 笔记本模板》可能适合你。它非常适合那些希望轻松开发预测模型但需要创意灵感的人。
该模板合集包含许多数据科学项目模板,包括客户流失预测、贷款审批预测和索赔欺诈项目。这些是标准的商业项目,你可以用来丰富你的数据项目组合。
该项目可能看起来单一,但你也可以扩展它。它是一个你可以用来开发项目的模板,并使用你认为适合商业问题的其他数据集。
5. Jupyter Naas 的精彩笔记本
最后,我们将讨论Jupyter Naas 的精彩笔记本。精彩笔记本是 Jupyter Naas 推出的一个项目,旨在创建最大规模的生产就绪 Jupyter 笔记本模板目录。从中你可以选择丰富的免费 Jupyter 笔记本模板。
该项目包含许多具有特定使用案例的专业 Jupyter Notebook 模板。从人工智能开发到分析商业漏斗,再到 YouTube 视频下载,有很多模板可供选择。
许多模板要求你理解如何作为数据科学家工作,因此学习如何将 Python 作为数据科学家的工具将帮助你使用这些模板。一旦你明白你的需求,这些模板集合将帮助你的工作。
结论
Jupyter Notebook 是许多专业数据科学家使用的环境,因为许多数据科学突破都发生在这个平台上。它的一个优点是易于分享,并且可以成为许多人使用的模板。
在这篇文章中,我们讨论了五个可以提升数据科学活动的免费 Jupyter Notebook 模板。这些模板包括:
-
用于 Python 数据科学项目的 Cookiecutter 模板
-
Coen Meintjes 提供的数据科学笔记本模板
-
Yusuf Cinarci 的数据科学项目
-
Sukman Singh 的数据科学项目
-
Jupyter Naas 提供的精彩笔记本
Cornellius Yudha Wijaya**** 是一名数据科学助理经理和数据撰写者。他在全职工作于 Allianz Indonesia 的同时,喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 涉及各种人工智能和机器学习主题的撰写工作。
相关话题
5 个免费工具,用于检测 ChatGPT、GPT3 和 GPT2
原文:
www.kdnuggets.com/2023/02/5-free-tools-detecting-chatgpt-gpt3-gpt2.html

作者提供的图片
在 ChatGPT 推出后,潘多拉的盒子被打开了。我们现在观察到工作方式的技术转变。人们正在使用 ChatGPT 创建网站、应用程序,甚至撰写小说。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
随着 AI 生成工具的热度和推出,我们看到恶意行为者的增加。如果你关注最新新闻,你一定听说过 ChatGPT 已经通过了沃顿 MBA 考试。ChatGPT 已通过的考试列表从医学到法律学位 - 列表:ChatGPT 迄今已通过的考试。
除了考试,学生还使用它来提交作业,作家提交生成内容,研究人员只需输入提示即可生成高质量论文。
为了应对生成内容的滥用,我向你介绍 5 个免费的 AI 内容检测工具。你可以使用它们来检查内容的有效性并提高你的 SEO 排名。
1. GPT-ZERO
GPTZero 是由普林斯顿大学的高年级生爱德华·田设计的,用于检测 ChatGPT 生成的写作。创造者发现这项技术被学生用来作弊,因此提出了这个保护措施。

图片来自 GPTZero
这个基于网络的应用程序相当简单。你可以粘贴文本或加载 pdf、docx 和 txt 文件。只需点击一次“获取结果”按钮,你就能找到摘要、平均困惑度和突发性评分。此外,它还会突出显示可能由 AI 撰写的文本。

图片来自 GPTZero
注意: 如果内容完全由 AI 撰写,你将不会看到突出显示的文本。
你还可以试用 Streamlit 演示 应用程序。
2. OpenAI GPT2 输出检测器
OpenAI GPT2 输出检测器 是由 OpenAI 开发,并托管在 HuggingFace 上供用户自由检查内容有效性。它可以检测由 ChatGPT、GPT3 和 GPT2 生成的文本。该应用程序使用基于 Transformers 的 GPT-2 输出检测器 模型。

来自 OpenAI GPT2 输出检测器的图像
要检查内容有效性,只需复制并粘贴文本,它将自动显示真实/虚假的百分比。
我使用了几天,认为它在检测各种 AI 文本生成方面相当准确。
3. Hello-SimpleAI ChatGPT 检测器
Hello-SimpleAI ChatGPT 检测器 包含三种版本来检测由 ChatGPT 生成的文本。
-
QA 版本:需要同时提供问题和答案,以检查是否由 ChatGPT 生成。在后台,它使用基于 PLM 的分类器。
-
单文本版本:需要较长文本来检测由 ChatGPT 生成的文本,使用基于 PLM 的分类器。
-
语言学版本:根据语言特征检测 ChatGPT。

来自 Hello-SimpleAI 的图像
在我看来,最准确的是语言学版本。你需要提供文本并点击预测按钮来查看结果。该应用程序将展示来自两个不同模型 GLTR 和 PPL 的结果。你可以在 chatgpt-comparison-detection 项目 上了解更多信息。
4. Contentatscale AI 内容检测器
Contentatscale AI 内容检测器 是我经常用于质量评估的工具。它快速、简单且准确。AI 内容检测器允许用户通过粘贴文本来获取人工内容分数。

来自 Contentatscale 的图像
注意: 为了获得准确的结果,请尝试粘贴一小段文本(150-200 字)。
5. Writers AI 内容检测器
Writers AI 内容检测器 类似于 Contentatscale。它需要页面的 URL 或文本来计算“人工生成内容”分数。它快速且相当准确。
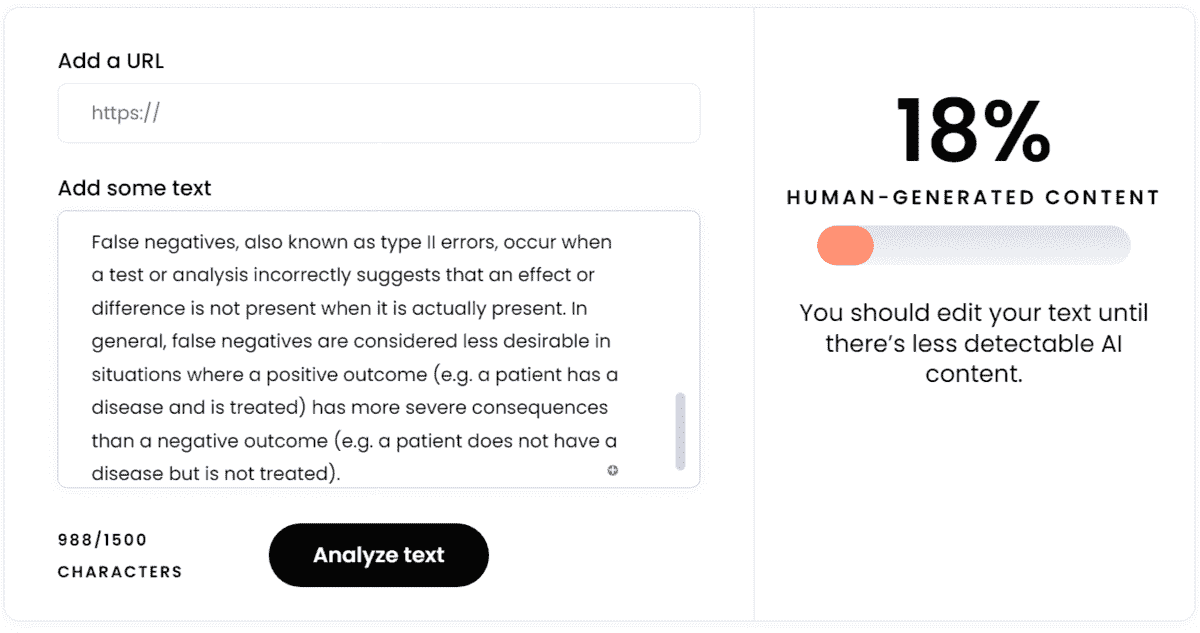
来自 Writers AI 内容检测器的图像
注意: 你有 1500 个字符的限制,因此请尽量粘贴小段文本以生成分数。
结论
随着 AI 生成工具的兴起,我们也看到了 AI 检测工具的崛起。在目前阶段,它们在检测代码片段和混合文本(人类 + AI)方面不够准确,但未来你会看到许多公司采用检测工具来提高质量和生产力。
在这篇文章中,我们了解了检测 AI 生成文本的 5 个最佳工具。这些工具快速、可靠且简单。你只需粘贴文本即可获得结果。
如果你对学习更多关于 AI、机器学习、MLOps 和数据科学感兴趣,请关注我的社交媒体。谢谢。
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为挣扎于心理疾病的学生开发 AI 产品。
更多相关主题
5 个免费大学数据分析课程
原文:
www.kdnuggets.com/5-free-university-courses-on-data-analytics

作者图片
在某个地方,有人正在谈论想要进入科技领域。如果是成为一名软件工程师,或者他们对数据科学感兴趣。当这些人开始他们的数据科学旅程时,特别是,有各种在线课程、培训营和学位可供选择。这可能非常困难,所以我来这里帮助你减轻负担。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
所以,让我们直接进入主题……
哈佛大学的《Python 数据科学导论》
课程链接:Python 数据科学导论
哈佛大学是一所著名的私立常春藤研究型大学。为了满足当前市场对技术专业人员日益增长的需求,他们理解为感兴趣或新生提供免费的材料以启动他们在科技领域的旅程的重要性。
上述课程旨在为数据分析新手提供帮助。目前,Python 是数据科学中最受欢迎的编程语言,因此它总是一个很好的起点。该课程包括每周承诺 3-4 小时的学习,其中你将了解:
-
学习回归模型
-
利用流行的库,如 sklearn、Pandas、matplotlib 和 numPy
-
机器学习概念,如过拟合、评估不确定性和权衡取舍
-
机器学习模型的基础理解
-
机器学习(ML)和人工智能(AI)的基本概念理解
如果你在寻找其他课程,哈佛大学还提供:
统计思维与数据分析 - MIT
链接:统计思维与数据分析
MIT 也是另一所领先的学习机构。在 2001 年,他们推出了一个名为开放课程网的平台。这是另一所理解提供免费教育材料需求的学习机构,帮助人们了解新市场及其新职业潜力。
统计思维和数据分析的实施是一个非常重要的概念。有些人说统计学有用但不是必需的,你不需要了解所有细节,但在我的数据科学家经历中,我理解了统计学的重要性以及它如何能改进和加快我的职业发展。
在本课程中,你需要每周参加 2 节,每节 1.5 小时的课程,你将学习到:
-
概率
-
讨论抽样技术
-
数据总结
-
常见的抽样分布
-
统计推断和假设检验
-
回归
-
非参数推断
MIT 提供的其他数据分析课程:
数据分析入门 - IBM
链接:数据分析入门
国际商业机器公司不是大学,但它的课程受到广泛认可,为新人提供了合适的学习材料以开启新的旅程。已有 397,828 人注册该课程,并以 8 种语言授课,这门数据分析入门课程为人们提供了顺利进入数据世界的途径。
该课程灵活,需要你投入大约 10 小时学习:
-
数据分析是什么以及关键步骤
-
不同类型的数据结构、文件格式和数据来源
-
描述数据分析过程,包括数据收集、整理、挖掘和可视化
-
区分不同的数据角色
挖掘海量数据集 - 斯坦福大学
课程链接:挖掘海量数据集
另一个提供优秀学习材料的领先大学是斯坦福大学。如果你认真考虑从事数据分析工作,了解科技领域的更受欢迎和快速发展的领域,如机器学习和人工智能,也是非常有益的。自然,许多数据分析师会转向机器学习模型的工作,然后找到自己的细分领域,如自然语言处理。
机器学习领域的一部分是处理大量数据集。这门课程为期 7 周,你将学习以下内容:
-
MapReduce
-
提取模型的算法
-
大型数据集中的信息
如果你对机器学习、人工智能和深度学习感兴趣,以下课程可能会引起你的兴趣:
人工智能简介 - 伯克利
链接: 人工智能简介
如果你已经掌握了数据分析的知识,并准备开始人工智能的职业或学习旅程,那么伯克利大学的人工智能入门课程非常适合你。
课程持续 8 周,在提供的链接中,你将获得不同格式的讲座主题、阅读笔记和作业。课程从智能计算机系统设计的基本概念和技术开始,深入探讨统计和决策理论建模范式。
总结一下
这 5 个免费的数据分析课程将带你踏上数据世界的旅程。你将从学习基础知识开始,逐渐深入到数据分析师/科学家的技术领域。
Nisha Arya是一名数据科学家、自由技术作家以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。Nisha 涵盖了广泛的话题,并希望探索人工智能在延续人类生命方面的不同方式。作为一个热衷的学习者,Nisha 寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
相关话题
5 个免费大学课程,助你成功通过编程面试
原文:
www.kdnuggets.com/5-free-university-courses-to-ace-coding-interviews

使用 Segmind SSD-1B 模型生成的图像
鉴于当前技术职位市场的竞争激烈,你应该不断提升技能和提高技术水平。对于数据和软件工程领域的任何角色,面试过程通常从一轮或两轮编程面试开始。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
虽然项目和技术专长会帮助你在面试的后期阶段,但编程面试往往很难通过——尤其是当你有一段时间没有练习时。而且,扎实的数据结构和算法基础是必要的。
即使你没有计算机科学学位,参加大学级别的编程、数据结构和算法课程也会帮助你为编程面试做准备。因为学习基础知识之后,再经过几周的刻意练习,是通过编程面试所必需的。
我们整理了一些免费的大学课程,帮助你学习数据结构和算法。让我们来看看这些课程吧。
1. 使用 Python 的编程、数据结构和算法 – CMI
使用 Python 的编程、数据结构和算法 由 Chennai Mathematical Institute 的 Madhavan Mukund 教授讲授,是学习 Python 中的数据结构和算法的优秀入门课程。
在准备编程面试时,你通常需要理解高级概念。你可能会发现一些大学课程难以跟上。因此,如果你以前没有学习过数据结构和算法的课程,那么这是一个很好的入门课程。
我在本科阶段修了这门课程,觉得非常有用。我强烈推荐在进行其他课程之前先学习这门课程。
这门课程包含大约 8 周的内容。以下是课程涵盖的内容概述:
-
编程介绍
-
Python 基础
-
搜索算法
-
排序算法
-
Python 中的内置数据结构
-
异常处理、文件 I/O 和字符串处理
-
回溯算法
-
数据结构,如栈、队列和堆
-
类、对象和用户定义的数据类型
-
动态规划
2. 算法工具箱 – 加州大学圣地亚哥分校
算法工具箱 由加州大学圣地亚哥分校提供,是学习解决问题技术基础的绝佳课程,这将帮助你应对编码面试。
你将学习首先编写一个有效的暴力解法,逐步过渡到更优的解法,同时学习像动态规划这样的技术。你可以在 Coursera 上免费旁听这门课程,并使用你熟悉的编程语言。
这门课程应该需要你几周的时间来完成。如果你有兴趣,你还可以旁听整个 数据结构与算法专业课程,以获得更完整的学习路径。
课程内容包括:
-
编程挑战
-
搜索与排序算法
-
贪心算法
-
分治算法
-
动态规划
课程链接:算法工具箱
3. 算法导论 – 麻省理工学院
算法导论 是麻省理工学院最受欢迎的高推荐算法课程之一。
如果你有一些编程经验,并且已经熟悉数据结构和算法的基础知识,那么这门课程将帮助你提升水平,并学习常见的数据结构算法和算法范式的基础知识。
你可以在课程网站上免费访问课程资料:讲义、问题集和解答。以下是课程内容概述:
-
算法的计算复杂度
-
搜索与排序
-
图算法
-
动态规划
课程链接:算法导论
4. 算法:设计与分析,第一部分 – 斯坦福大学
由蒂姆·罗夫加登教授在斯坦福大学教授的,算法设计与分析课程(这一部分和下一部分)将帮助你努力提升算法思维和解决问题的能力。
如果你在面试准备期间有时间,我建议你参加这门课程和下一门课程。在深入学习这门算法课程之前,有一个或多个之前课程的坚实基础将非常有帮助。
在这门设计与分析算法课程的第一部分,你将学习:
-
大 O 符号
-
搜索与排序
-
分治算法
-
随机算法
-
数据结构,如哈希表和布隆过滤器
-
图上的算法
课程链接:算法:设计与分析,第一部分
5. 算法:设计与分析,第二部分 – 斯坦福大学
在这个算法设计与分析课程的第二部分中,你将学习到更多高级概念,包括:
-
贪心算法
-
动态编程
-
NP 完备性
-
启发式分析
-
局部搜索
你可以在 YouTube 上观看讲座,或者在 edX 上免费旁听这些课程。这些课程也可以作为 Coursera 上的五门课程专门化课程提供。所以如果你更喜欢这个版本,你可以在 Coursera 上免费旁听这个算法专门化课程。
课程链接: 算法:设计与分析,第二部分
总结
希望你找到了一些有用的资源来帮助你准备编码面试。
然而,在你开始准备编码面试之前,你应该刷新编程概念,专注于熟悉特定语言的功能。这将帮助你选择合适的内置数据结构,以设计出空间和运行时复杂度最优的算法。
祝你面试顺利,成功获得梦想职位!如果你在寻找一些关于如何获得数据科学职位的实用建议,可以查看 7 个你为何难以获得数据科学职位的原因。
Bala Priya C****是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过编写教程、操作指南、观点文章等来学习和与开发者社区分享她的知识。Bala 还制作了引人入胜的资源概述和编程教程。
更多相关内容
5 个免费大学课程学习数据科学编程
原文:
www.kdnuggets.com/5-free-university-courses-to-learn-coding-for-data-science

图片作者
我花了大约 30,000 美元攻读了一个为期 3 年的计算机科学学位,以成为数据科学家。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
这曾是一个昂贵且耗时的过程。
毕业后,我意识到其实可以在线学习所有必要的技能。顶级大学如哈佛、斯坦福和麻省理工学院已经发布了许多课程供任何人学习。
最棒的部分是什么?
这些课程完全免费。
由于互联网的存在,你现在可以在家中免费获得常春藤联盟的教育。
如果我可以重新开始,这里有 5 个我会选择的免费大学课程,用于学习数据科学编程。
注意:Python 和 R 是数据科学中使用最广泛的编程语言,因此该列表中的大多数课程都集中于其中一个或这两种语言。
1. 哈佛大学 — CS50 计算机科学导论
哈佛的 CS50课程是大学提供的最受欢迎的入门级编程课程之一。
该课程带你了解计算机科学的基础,包括理论概念和实际应用。你将接触到多种编程语言,如 Python、C 和 SQL。
将此课程视为一个迷你计算机科学学位,打包成 24 小时的 YouTube 内容。相比之下,CS50 涵盖了我在大学学习了三个学期的内容。
在 CS50 中,你将学到:
-
编程基础
-
数据结构与算法
-
使用 HTML 和 CSS 进行网页设计
-
软件工程概念
-
内存管理
-
数据库管理
如果你想成为数据科学家,必须具备坚实的编程和计算机科学基础。你将经常被期望从数据库中提取数据,部署生产中的机器学习模型,并构建可扩展的模型管道。
像 CS50 这样的课程为你提供了前往学习旅程下一阶段所需的技术基础。
课程链接: 哈佛 CS50
2. 麻省理工学院——计算机科学与编程导论
MITx 的计算机科学与编程导论 是另一门旨在为你提供计算机科学和编程基础技能的入门课程。
然而,与 CS50 不同的是,这门课程主要用 Python 进行教学,并且着重于计算思维和问题解决。
此外,麻省理工学院的计算机科学入门课程更加侧重于数据科学及 Python 的实际应用,因此对于那些只想学习数据科学编程的学生来说,是一个很好的选择。
完成麻省理工学院的计算机科学入门课程后,你将对以下概念有一定了解:
-
Python 编程:语法、数据类型、函数
-
计算思维:问题解决、算法设计
-
数据结构:列表、元组、字典、集合
-
算法复杂度:大 O 符号
-
面向对象编程:类、对象、继承、多态
-
软件工程原则:调试、软件测试、异常处理
-
计算机科学中的数学:统计与概率、线性回归、数据建模
-
计算模型:仿真原理与技术
-
数据科学基础:数据可视化与分析
你可以在 edX 上免费旁听这门课程。
课程链接: MITx——计算机科学导论
3. 麻省理工学院——算法导论
完成了像 CS50 这样的基础计算机科学课程后,你可以选择 MIT 的算法导论 学习路径。
该项目将教你算法和数据结构的设计、分析和实现。
作为数据科学家,你常常需要实现能够在数据集规模增大时保持性能的解决方案。你还需要处理可能计算成本较高的大型数据集。
这门课程将教你优化数据处理任务,并根据可用的计算资源做出明智的决策,选择合适的算法。
你将在《算法导论》中学到以下内容:
-
算法分析
-
数据结构
-
排序算法
-
图算法
-
算法技术
-
哈希
-
计算复杂度
你可以在 MIT OpenCourseWare 上找到《算法导论》的所有讲座视频。
课程链接: MIT——算法导论
4. 密歇根大学——面向每个人的 Python
人人学 Python 是一个入门级编程专业课程,专注于教授 Python。
这是一个包含 5 门课程的学习路径,涵盖了 Python 基础、数据结构、API 使用和使用 Python 访问数据库。
与之前列出的课程不同,人人学 Python 主要是实践性的。这个专业化课程专注于实际应用,而不是理论概念。
这使得它非常适合那些想要立即投入实际项目实施的人。
在完成这个 5 门课程的专业化之后,你将熟悉以下一些概念:
-
Python 变量
-
函数和循环
-
数据结构
-
API 和访问网络数据
-
使用 Python 操作数据库
-
使用 Python 进行数据可视化
你可以在 Coursera 上免费旁听这门课程。
课程链接: 人人学 Python
5. 约翰霍普金斯大学 — R 编程
你可能注意到到目前为止,每门课程都专注于 Python 编程。
那是因为我有点儿 Python 爱好者的情结。
我发现这种语言多功能且用户友好,并且 Python 的知识可以转移到数据科学以外的广泛领域。
然而,学习 R 在数据科学中也有一些好处。R 编程是专门为统计分析设计的,而且 R 中有许多专门用于参数调整和优化的包,而这些在 Python 中是没有的。
如果你对深入的统计分析、学术研究和高级数据可视化感兴趣,你应该考虑学习 R。如果你想学习 R,约翰霍普金斯大学的 R 编程专业化是一个很好的起点。
在这个专业化课程中,你将学到以下内容:
-
数据类型和函数
-
控制流
-
在 R 中阅读、清理和处理数据
-
探索性数据分析
-
数据模拟和分析
你可以在 Coursera 上免费旁听这门课程。
课程链接: R 编程专业化
数据科学编程学习:下一步
一旦你完成了本文中列出的一个或多个课程,你将拥有大量新的编程知识。
但旅程并不会就此结束。
如果你的最终目标是建立一个数据科学职业生涯,这里有一些你应该考虑的潜在下一步:
1. 练习你的编程技能
我建议访问像HackerRank和Leetcode这样的编程挑战网站来练习你的编程技能。
由于编程是一种通过逐步挑战来发展技能的过程,我建议从这些平台上标记为“简单”的问题开始,例如加法或乘法两个数字。
随着你的编程技能提升,你可以开始增加难度并解决更复杂的问题。
当我刚开始进入数据科学领域时,我每天做 HackerRank 问题,大约两个月后发现我的编程技能有了显著提高。
2. 创建个人项目
一旦你花了几个月时间解决 HackerRank 挑战,你会发现自己已经准备好处理端到端的项目了。
你可以从创建一个简单的 Python 计算器应用开始,然后逐步进阶到更具挑战性的项目,比如数据可视化仪表板。
如果你还不知道从哪里开始,查看这个Python 项目创意列表以获得灵感。
3. 建立一个作品集网站
在你学会编码并完成一些个人项目后,你可以将你的作品展示在一个集中式的作品集网站上。
当潜在雇主寻找程序员或数据科学家时,他们可以在一个地方查看你的所有工作(技能、认证和项目)。
如果你想自己构建一个作品集网站,我已经创建了一个完整的视频教程,讲解如何用 ChatGPT 免费构建数据科学作品集网站。
你可以查看教程,以获取创建视觉上吸引人的作品集网站的逐步指南。
 
 
Natassha Selvaraj是一位自学的数据科学家,热衷于写作。Natassha 写关于所有数据科学相关的内容,是所有数据话题的真正大师。你可以在LinkedIn上与她联系,或查看她的YouTube 频道。
更多相关主题
5 门免费大学计算机科学课程
原文:
www.kdnuggets.com/5-free-university-courses-to-learn-computer-science

图片来源:Freepik
如果你想在技术领域建立职业生涯,学习计算机科学基础是你实现职业转换的第一步。这是一些顶级大学计算机科学课程的汇编,将帮助你学习以下内容:
-
计算机科学基础
-
使用 Python 编程
-
数据结构与算法
-
软件工程的基本工具
我们的前 3 推荐课程
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 部门
我们来看看这些课程列表。
1. 计算机科学 101 – 斯坦福大学
链接: 计算机科学 101
如果你在寻找一个适合初学者的计算机科学导论,计算机科学 101 课程来自斯坦福大学。
在这个课程中,你将学习到以下内容及更多:
-
计算机能做什么(以及不能做什么)
-
计算机硬件的工作原理
-
软件如何工作
-
循环与逻辑
-
抽象、逻辑和错误
-
互联网如何工作
-
计算机安全
2. 计算机科学逻辑导论 – 利兹大学
链接: 计算机科学逻辑导论
理解逻辑是解决问题、算法设计等的基础。计算机科学逻辑导论 课程来自利兹大学,将帮助你掌握:
-
命题逻辑和
-
逻辑建模
这个课程只需几小时完成,但教你逻辑基础,通常是传统计算机科学课程的一部分。
3. CS50:计算机科学导论 – 哈佛大学
CS50 的计算机科学导论 由哈佛大学的 David J Malan 教授及其团队教授。这门课程在全球有志于成为开发者的人中非常受欢迎。
在此过程中,你将学习以下内容,并通过积极参与项目来巩固学习:
-
编程概念
-
算法思维和问题解决
-
算法中的数据结构
-
Python
-
SQL
-
HTML、CSS 和 JavaScript
4. 使用 Python 的计算机科学和编程导论 – MIT
使用 Python 的计算机科学和编程导论 由 MIT 提供,将介绍计算机科学和编程基础知识,使用 Python 编程语言。
因此,你将学会计算思维,并编写 Python 程序来解决问题。以下是你将学到的内容概述:
-
计算概念
-
Python
-
测试和调试
-
算法复杂度
-
数据结构
5. 计算机科学教育的缺失学期 – MIT
链接:计算机科学教育的缺失学期
目前我们列出的课程将帮助你学习 Python 编程、数据结构和计算机科学的基础知识。然而,这些课程并没有涵盖软件工程师经常使用的工具,如 bash 脚本和其他命令行工具。
这就是计算机科学教育的缺失学期——来自 MIT 的免费课程——的用武之地,它将帮助你学习这些内容以及更多内容。以下是本课程将教授的内容概述:
-
Shell 工具和脚本
-
Vim 编辑器
-
数据处理
-
命令行环境
-
使用 Git 进行版本控制
-
调试和分析
-
元编程
-
安全和加密
总结
这就是总结。这些课程列表的编制旨在帮助你接触广泛的主题。如果你计划通过自学来掌握计算机科学并获得技术工作的职位,这些课程将特别有帮助。
祝学习愉快,编程顺利!
Bala Priya C**** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点工作。她的兴趣和专业领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正致力于通过编写教程、使用指南、评论文章等与开发者社区分享她的知识。Bala 还制作了引人入胜的资源概述和编程教程。
更多相关内容
免费大学课程来学习数据科学
原文:
www.kdnuggets.com/5-free-university-courses-to-learn-data-science

使用 Segmind SSD-1B 模型生成的图像
技术数据专业人员仍然需求旺盛。因此,现在是进入数据科学领域的好时机。但是,如何以及从哪里开始呢?
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
你应该报名参加训练营、专业证书和研究生课程来学习数据科学吗?是的,这些都是很好的选择。然而,你可以免费学习数据科学,并成功转行。
为了帮助你入门,我们汇编了一份免费的高质量大学课程列表,这些课程将帮助你从零开始学习数据科学。因为这些课程有结构化的课程设置,你不必担心学习什么和学习顺序,只需专注于学习和提升自己。
开始吧!
1. 使用 Python 的数据科学入门 – 哈佛大学
如果你需要在学习数据科学之前复习 Python 编程,可以查看 CS50 的 Python 编程入门 课程,该课程在哈佛大学教授。
在学习了 Python 的编程基础后,你可以查看这个 使用 Python 的数据科学入门 课程,同样来自哈佛大学。
在本课程中,你将学习以下内容:
-
编程基础
-
使用 Python 进行编码、统计和数据叙事
-
Python 数据科学库,如 NumPy、pandas、matplotlib 和 scikit-learn
-
构建和评估机器学习模型
-
机器学习的应用
课程链接:使用 Python 的数据科学入门
2. 计算思维与数据科学入门 – MIT
MIT 的计算思维与数据科学入门 是另一个很好的课程来学习数据科学基础。这个课程将帮助你熟悉数据科学和基本统计概念。
这是本课程内容的概述:
-
优化问题
-
随机思维
-
随机游走
-
蒙特卡洛模拟
-
置信区间
-
理解实验数据
-
聚类
-
分类
课程链接:计算思维与数据科学导论
3. 统计学习 – 斯坦福大学
统计学习是斯坦福大学的另一个受欢迎的课程,用于学习不同的机器学习算法如何工作。
本课程中的编程练习使用的是 R。不过你也可以使用 Python 来完成这些练习。我还建议你使用统计学习导论(Python 版)(也是免费的)作为本课程的辅助教材。
本课程涵盖以下主题:
-
线性回归
-
分类
-
重采样方法
-
模型选择
-
正则化
-
基于树的方法
-
支持向量机
-
无监督学习,这门课程涵盖的一些主题
课程链接:统计学习
4. 数据科学中的数学主题 – MIT
即使你已经熟悉使用 Python 和 scikit-learn 等 Python 库构建机器学习模型,你也应该了解一些数学概念。
学习数学概念将对你进入机器学习研究有所帮助,并在技术面试中给予你优势。这些学习对你获得技术面试的优势是重要的。
MIT 的数据科学中的数学主题课程将教授你与数据科学相关的某些数学主题。具体而言,高级降维和聚类概念。
以下是你将学习的一些主题:
-
主成分分析
-
光谱聚类
-
压缩感知
-
近似算法
课程链接:数据科学中的数学主题
5. 数据科学:机器学习 – 哈佛大学
从我们到目前为止看到的一个或多个课程中,你应该对以下内容感到熟悉:
-
Python 数据科学库
-
机器学习算法的工作原理
哈佛大学的数据科学:机器学习课程将帮助你复习机器学习基础知识,并将其应用于构建推荐系统。
因此,本课程教给你:
-
机器学习基础
-
交叉验证
-
流行的机器学习算法
-
正则化技术
-
构建推荐系统
课程链接:数据科学:机器学习
总结
现在你有一份来自哈佛、麻省理工学院和斯坦福等精英大学的高质量数据科学课程清单。
从 Python 数据科学库到机器学习算法的内部工作原理,你可以再查看这些课程之一,找到最适合你的课程。祝学习愉快!
Bala Priya C**** 是来自印度的开发人员和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过撰写教程、指南、观点文章等,学习并与开发者社区分享她的知识。Bala 还创建引人入胜的资源概述和编程教程。
更多相关内容
5 免费大学课程学习数据库和 SQL
原文:
www.kdnuggets.com/5-free-university-courses-to-learn-databases-and-sql

图片由编辑提供
作为数据专业人员,你应该学习并持续提高数据库和 SQL 技能。原因如下。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
用 SQL 查询数据库以回答一组业务问题可能对某些项目来说已经足够。然而,要构建稳健的系统和应用,你应该熟悉数据库内部结构、数据模型、数据库设计等。
虽然你可以自行学习和实践 SQL,但学习数据库概念可能通过结构化课程会更容易。为了简化这个过程,我们精心整理了来自全球一些顶尖大学的免费数据库和 SQL 课程列表。
1. 数据库简介 - 康奈尔
康奈尔大学 Trummer 教授教授的《数据库简介》课程涵盖几个重要主题:从 SQL 基础到 NoSQL 和 NewSQL 系统。以下是主题概览:
-
SQL
-
存储和索引
-
关系数据处理
-
事务处理
-
数据库设计
-
分布式数据处理
-
超越关系数据
课程链接:数据库系统 - 康奈尔大学课程(SQL、NoSQL、大规模数据分析) 和 课程第二部分。
2. 数据库和 SQL 简介 - 哈佛
SQL 数据库简介 或哈佛大学教授的 CS50 SQL 是一个很好的资源,可以让你对 SQL 和关系数据库基础知识感到舒适。
该课程包括七周的课程内容,涵盖关系数据库的工作,包含以下模块:
-
查询
-
关联
-
设计
-
编写
-
视图
-
优化
-
扩展
课程链接:CS50 的 SQL 数据库简介
3. 数据库课程系列 - 斯坦福
斯坦福大学的 Jennifer Widom 教授的数据库课程现在可以在 edX 上以五个自学课程的形式进行,你可以免费旁听。
如果你是数据库新手,建议先学习基础关系数据库课程,然后再学习更高级的课程。让我们来看看这些单独的课程及其内容。
数据库:关系数据库与 SQL涵盖了 SQL 和关系模型。建议你先学习这门课程,然后再继续本系列的其他课程。
数据库:SQL 高级主题涵盖:
-
查询性能
-
事务和并发控制
-
数据库约束
-
数据库触发器
-
创建和更新数据库视图
数据库:OLAP 和递归涵盖以下主题:
-
OLAP 立方体
-
星型模式
-
OLAP 特性
-
带递归关系的 SQL 查询
数据库:建模与理论将教你:
-
关系代数
-
正规化形式
-
递归关系
-
UML
最终课程数据库:半结构化数据涵盖了 JSON 和 XML 的处理。还涉及了 XPath 和 XSLT 的基础知识。
课程链接:
4. 数据库系统入门 - CMU
如果你想深入了解数据库内部,卡内基梅隆大学的数据库系统入门和高级数据库系统是很好的资源。
数据库系统入门课程涵盖以下广泛主题:
-
关系模型和代数
-
数据库存储与压缩
-
数据库内存和磁盘 I/O 管理
-
哈希表和 B+树等数据结构
-
索引并发控制
-
查询执行
-
查询规划与优化
-
排序、聚合和连接算法
-
数据库日志记录
-
分布式数据库系统
课程链接:数据库系统入门
5. 高级数据库系统 - CMU
如果你有兴趣专注于数据库工程、数据工程或相关领域,了解现代 OLAP 数据库的内部结构将非常有帮助。高级数据库系统课程正是涉及这一点。
本课程深入探讨数据库内部结构:从构成 OLAP 系统的组件到现代分析数据仓库如 Google BigQuery 和 Snowflake 的内部,本课程涵盖了广泛的话题,包括:
-
现代 OLAP 数据库
-
存储模型和数据布局
-
查询执行和调度
-
向量化执行
-
高级算法
-
Google BigQuery、Amazon RedShift、Databricks、Snowflake 等数据库内部
课程链接: 高级数据库系统
总结
当你开始职业生涯时,你在大学修读的数据库系统课程通常会证明是最有帮助的!但即使你不能上大学获得计算机科学学位,这些课程也应该教会你几乎所有你想了解的数据库知识。
无论你是希望学习 SQL 和足够的关系数据库设计,还是想深入了解数据库内部结构,这些课程都能满足你的需求。祝学习愉快!
Bala Priya C**** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过编写教程、操作指南、观点文章等方式学习并分享她的知识。Bala 还创建了有趣的资源概述和编码教程。
更多相关主题
5 个免费大学课程来学习机器学习
原文:
www.kdnuggets.com/5-free-university-courses-to-learn-machine-learning

图片由作者提供
如果你对数据职业感兴趣,熟悉机器学习是很重要的。通过数据分析,你可以分析相关的历史数据来回答业务问题。但通过机器学习,你可以更进一步,构建可以基于现有数据预测未来趋势的模型。
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
为帮助你入门机器学习,我们整理了一些来自 MIT、哈佛、斯坦福和 UMich 等大学的免费课程列表。我建议你浏览这些课程的内容,以了解它们所涵盖的内容。然后根据你感兴趣的学习内容,你可以选择一个或多个课程进行学习。
让我们开始吧!
1. 机器学习导论 – MIT
MIT 的 机器学习导论 课程深入涵盖了多个机器学习主题。你可以在 MIT 开放学习图书馆免费访问包括练习和实践实验室在内的课程内容。
从机器学习基础到卷积神经网络和推荐系统,这里列出了一些该课程所涵盖的主题:
-
线性分类器
-
感知机
-
边际最大化
-
回归
-
神经网络
-
卷积神经网络
-
状态机和马尔可夫决策过程
-
强化学习
-
推荐系统
-
决策树和最近邻
链接: 机器学习导论
2. 数据科学:机器学习 – 哈佛
数据科学:机器学习 是另一门课程,你将通过实际应用如电影推荐系统来学习机器学习基础。
该课程涵盖以下主题:
-
机器学习基础
-
交叉验证和过拟合
-
机器学习算法
-
推荐系统
-
正则化
链接: 数据科学:机器学习
3. 应用机器学习与 Python – 密歇根大学
应用机器学习与 Python由密歇根大学在 Coursera 上提供。你可以免费注册 Coursera 并免费访问课程内容(审计模式)。
这是一个全面的课程,重点关注流行的机器学习算法及其 scikit-learn 实现。你将使用 scikit-learn 进行简单的编程练习和项目。以下是本课程涵盖的主题:
-
机器学习与 scikit-learn 简介
-
线性回归
-
线性分类器
-
决策树
-
模型评估与选择
-
朴素贝叶斯、随机森林、梯度提升
-
神经网络
-
无监督学习
这个课程是密歇根大学在 Coursera 上提供的应用数据科学与 Python专业的一部分。
链接: 应用机器学习与 Python
4. 机器学习 – 斯坦福大学
作为数据科学家,你还应该能舒适地构建预测模型。因此,了解机器学习算法的工作原理并能够用 Python 实现它们将非常有帮助。
CS229: 机器学习在斯坦福大学是推荐的 ML 课程之一。这个课程让你探索不同的学习范式:监督学习、无监督学习和强化学习。此外,你还会学习如正则化等技术,以防止过拟合并构建泛化良好的模型。
这里是所涵盖主题的概述:
-
监督学习
-
无监督学习
-
深度学习
-
泛化与正则化
-
强化学习与控制
链接: 机器学习
5. 使用 Python 的统计学习 – 斯坦福大学
使用 Python 的统计学习课程涵盖了ISL 与 Python一书的所有内容。通过完成课程并使用该书作为参考,你将学习数据科学和统计建模的基本工具。
这里列出了本课程涵盖的关键领域:
-
线性回归
-
分类
-
重采样
-
线性模型选择
-
基于树的方法
-
无监督学习
-
深度学习
链接: 使用 Python 的统计学习
总结
我希望你觉得这个来自顶尖大学的免费机器学习课程列表有用。无论你是想成为机器学习工程师还是希望探索机器学习研究,这些课程都会帮助你打下基础。
这里有几个相关的资源你可能会觉得有用:
祝学习愉快!
Bala Priya C**** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过撰写教程、操作指南、观点文章等方式学习并与开发者社区分享知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关话题
5 个免费大学课程学习 Python
原文:
www.kdnuggets.com/5-free-university-courses-to-learn-python

图片由作者提供
如果你想在数据科学或软件工程领域开展职业生涯,Python 是一个很好的入门语言。那么从哪里开始呢?
我们的三大推荐课程
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
为了帮助你决定,我们编制了一个 Python 编程课程的列表——这些课程在世界上一些顶级大学教授。你可以免费参加这些课程,并在舒适的家中学习编程。
大多数这些课程假设你没有编程经验,并教授编程和计算机科学的基础知识。因此,即使你从未编程过,也可以通过学习 Python 迈出第一步——转行或职业转型。
让我们开始吧!
1. Python 编程入门 - 哈佛大学
CS50’s Introduction to Programming with Python 或 CS50 Python 是一个针对希望学习 Python 的初学者友好的课程——即使他们没有编程经验。
你可以在课程网站上访问讲座、讲座笔记和习题集。在为期十周的课程中,本课程将把你从一个完全的初学者培养成能够流利地用 Python 编写应用程序的人。
课程涵盖以下内容:
-
函数和变量
-
条件语句
-
循环
-
异常处理
-
库
-
单元测试
-
文件 I/O
-
正则表达式
-
面向对象编程
-
Python 最佳实践
课程链接:CS50’s Introduction to Programming with Python
2. Python for Everybody - 密歇根大学
Python for Everybody 是一个强烈推荐的 Python 课程。课程由密歇根大学的 Charles Severance 博士讲授。
如果你想快速了解 Python 的特性,并开始处理不同类型的数据和应用程序,如 Web 抓取和数据库处理,这门课程适合你。
这里是你将学到的内容概述:
-
Python 基础
-
Python 数据结构
-
文件 I/O 操作
-
正则表达式
-
网络编程
-
面向对象编程简介
-
使用 Python 的 Web 服务
-
在 Python 中使用数据库
-
数据可视化
课程链接: Python for Everybody
3. 计算机科学与 Python 编程导论 - MIT
计算机科学与 Python 编程导论来自 MIT,教授使用 Python 的计算机科学基础。该课程不要求有编程和计算机科学的先验知识。
该课程旨在向即使是非计算机科学专业的学生介绍计算和编程的基本原理。在十二节讲座中,你将学习编程的原则和 Python 的基础知识。
以下是这门课程涵盖的一些主题:
-
计算基础
-
分支和迭代
-
字符串操作、近似、二分法等
-
分解、抽象和函数
-
元组、列表及相关概念
-
递归和字典
-
测试和调试
-
面向对象编程
-
程序效率
-
搜索和排序
课程链接: 计算机科学与 Python 编程导论
4. 编程方法论 - 斯坦福
CS106A: 编程方法论课程在斯坦福大学开设,是另一门学习 Python 编程基础的全面课程。该课程也不要求有 Python 编程的先前经验,旨在教导初学者如何用 Python 编程。
如果你有兴趣学习如何用 Python 解决问题,这门课程适合你。课程中有大量的作业,通过这些作业你将能将所学的知识应用于实践。
该课程涵盖以下主题:
-
变量和控制流
-
列表和图像
-
列表的列表和字符串
-
文件读取
-
嵌套结构
-
字典和绘图
-
排序
-
面向对象编程
-
内存管理
课程链接: 编程方法论
5. Python 计算原理 - CMU
卡内基梅隆大学(CMU)通过其开放学习计划提供了一个免费的Python 计算原理课程。该课程向你介绍了 Python 以及计算的基本原理。
你将学习诸如迭代和递归等主题。此外,你还将学习核心计算机科学主题,如元胞自动机、加密和计算的限制。
这里是所涵盖主题的概述:
-
Python 编程
-
迭代过程
-
递归思维
-
数据和指令的二进制表示
-
元胞自动机
-
加密方法
-
可计算性的限制
课程链接:Python 计算入门
总结
我希望你找到了一些有用的资源来学习 Python。你不必修完所有这些课程才能熟练掌握 Python 编程。
你们中的一些人可能希望学习语言的特性,并将其用于如网页抓取、数据库操作等任务。而另一些人可能对解决问题和用 Python 编写算法的头脑风暴方法感兴趣。
根据你的学习目标,你可以选择一个或多个你认为最适合你的课程。祝学习愉快!
Bala Priya C** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专业领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她致力于学习并通过撰写教程、操作指南、观点文章等与开发者社区分享知识。Bala 还制作引人入胜的资源概述和编码教程。**
更多相关内容
5 个 Google Colaboratory 小贴士
原文:
www.kdnuggets.com/2020/03/5-google-colaboratory-tips.html
评论
作为一个用于学习和实践的计算平台,特别是用于机器学习和数据科学,Google Colab 几乎无与伦比。无需设置、易于使用、稳定的笔记本环境——与从多个设备无缝访问云端的功能相结合——在许多非关键情况下,这种速度、可靠性和可配置性的适度降低是值得的。对我来说,笔记本、工作站和 Chromebook 之间无忧的便携共享访问对于学习和测试至关重要,Colab 在这方面做得非常好,且极为简便。
我们之前介绍了以下 Google Colab 小贴士与技巧:
3 个重要的 Google Colaboratory 小贴士与技巧
-
使用免费 GPU 运行时
-
安装库
-
上传和使用数据文件
3 个更多的 Google Colab 环境管理小贴士
-
下载文件到本地计算机
-
访问你的 Google Drive 文件系统
-
使用存储在 Google Drive 中的自定义库和模块
现在,这里有 5 个额外的技巧和窍门,帮助你充分利用 Colab 冒险。
1. 使用张量处理单元 (TPU) 运行时
你已经知道可以免费使用 Colab 的 GPU 运行时。但是你知道还可以使用 张量处理单元 (TPU) 吗?
什么是 TPU?
云 TPU 是定制设计的机器学习 ASIC,支持 Google 产品,如 Translate、Photos、Search、Assistant 和 Gmail。
在处理单元的层级中,从低到高,依次是 CPU → GPU → TPU。这些由 Google 设计的 ASIC 仅用于一个目的,即一个目的:
云 TPU 资源加速线性代数计算的性能,这在机器学习应用中被广泛使用。TPU 最小化训练大型复杂神经网络模型时的时间与准确性。以前在其他硬件平台上需要几周时间训练的模型,现在在 TPU 上可以在几小时内收敛。
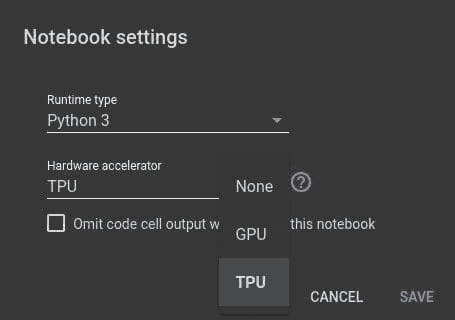
要测试 TPU,并查看它们如何影响你的张量处理代码的执行速度,请选择 Runtime → Change Runtime Type,然后从 Accelerator type 下拉菜单中选择 TPU。你需要重新启动笔记本的运行时环境,但选择即时提示中的 "Yes" 将会为你完成这项操作。
2. 使用文件资源管理器 GUI
你可以使用内联代码来上传文件到和从本地驱动器下载文件到 Colab。然而,Colab 编辑器左侧的文件浏览器 GUI 也可以通过点击完成相同操作。你还可以使用这个菜单来挂载你的 Google Drive,以便无缝访问其中的所有文件。
下面的图片展示了点击位置以启用菜单的可见性,上传和挂载驱动器的选项都可以在其中看到。
3. 在 Colab 中打开 Jupyter 笔记本
如果你想在 Colab 内打开现有的 Colab 笔记本,说明无需解释。但如果你想打开一个存储在你电脑上或互联网上其他地方的 Jupyter 笔记本呢?实际上,这也很简单。
点击文件 → 打开笔记本,将打开与启动 Colab 时相同的笔记本选择窗口。然而,如果你通常不太注意顶部的功能区,你可能会错过从 GitHub repo 打开笔记本或从本地驱动器上传的选项。以下是GitHub 标签的样子:
填入 repo 和路径(或使用搜索功能),然后就可以开始了。上传 标签更容易使用:只需点击即可。
4. 直接在计算机上处理文件
你是否有数据文件、训练参数权重、自定义库或其他文件要使用,但不想手动上传到 Colab?你是否更愿意在本地处理这些文件?
Google Drive 同步可以在这里派上用场。每个操作系统的过程不同,但基本的想法是设置你的 Google Drive 账户和本地计算机之间的同步,选择你要与 Google Drive 同步的本地文件夹,然后直接在这些文件夹中工作,文件更改后会立即同步到 Google Drive。
对于 Chrome OS,这种设置和配置尤其简单,特别是对于那些至少在该环境中工作的我们。
5. 训练完成时的电子邮件提醒
这是一个通过Rohit Midha提供的实用技巧。这不仅仅是一个 Colab 或机器学习或数据科学的提示,但对我们来说仍然很有用。
如果你在 Colab 上运行了一个长时间的训练任务,为什么要费心监控它呢,当你可以在训练完成后直接给自己发送一封邮件?这段代码再次感谢 Rohit Midha,可以放在你的训练循环之后,训练完成后会向你发送一条消息。你可能会设想一些更有创意的方式来配置失败任务、完成任务等类型的邮件,或者在机器学习管道的不同点设置检查点邮件。
这段代码片段使用了 smtplib 库,该库默认包含在你的 Colab 环境中。只需填写电子邮件地址和密码(例如,两个都使用相同的,以便发送邮件给自己),以及消息内容,就可以开始使用了。
py` import smtplib server = smtplib.SMTP('smtp.gmail.com', 587) server.starttls() server.login("sender_gmail_here@gmail.com", "your_password_here") msg = "your message to email goes here" server.sendmail("sender_gmail_here@gmail.com", "receiver_gmail_here@gmail.com", msg) server.quit() ```py ````
还有 5 个额外的 Google Colab 提示和技巧。下一次我们将深入探讨如何有效使用 Google Colab 中的代码片段,以及它们如何自动化环境设置和配置,并简化其他常见和重复的代码任务。
相关:
-
3 个更多 Google Colab 环境管理技巧
-
3 个必备的 Google Colaboratory 提示和技巧
-
如何优化你的 Jupyter Notebook
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 支持
更多相关话题
数据科学家应该知道的 5 种图算法
原文:
www.kdnuggets.com/2019/09/5-graph-algorithms-data-scientists-know.html
评论
作为数据科学家,我们对 Pandas、SQL 或任何其他关系型数据库都已经相当熟悉。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 工作
我们习惯于将用户按行显示,属性作为列。但现实世界真的这样吗?
在一个连通的世界中,用户不能被视为独立的实体。他们之间存在某些关系,我们有时希望在构建机器学习模型时包括这些关系。
现在,在关系型数据库中,我们无法在不同的行(用户)之间使用这样的关系,而在图数据库中,这相当简单。
在这篇文章中,我将讨论一些你应该了解的重要图算法以及如何使用 Python 实现它们。
此外,这里有一个 由加州大学圣地亚哥分校提供的 Coursera 上的图分析课程,我强烈推荐学习图论基础。
1. 连通分量
一个包含 3 个连通分量的图
我们都知道聚类是如何工作的?
你可以把连通分量看作是一种硬聚类算法,它在相关/连接的数据中找到簇/岛屿。
举个具体的例子:假设你有关于全球各个城市间道路的数据。你需要找出所有大洲以及这些大洲包含哪些城市。
你将如何实现这一点?来想一想吧。
我们用来实现这一点的连通分量算法基于 BFS/DFS 的特殊情况。我在这里不会详细讨论它的工作原理,但我们将看到如何使用 Networkx 运行代码。
应用
从零售角度看:假设我们有很多客户使用很多账户。我们可以使用连通组件算法的一种方式是找出数据集中不同的家庭。
我们可以根据相同的信用卡使用、相同的地址或相同的手机号码等,假设在 CustomerID 之间有边(道路)。一旦有了这些连接,我们可以在其上运行连通组件算法,以创建独立的簇,然后可以为每个簇分配一个家庭 ID。
我们可以利用这些家庭 ID 提供基于家庭需求的个性化推荐。我们还可以使用这些家庭 ID 通过基于家庭创建分组特征来推动分类算法。
从金融角度看:另一个用例是使用这些家庭 ID 捕捉欺诈行为。如果一个账户过去曾发生过欺诈,那么与之连接的账户也很可能会受到欺诈的影响。
可能性只受限于你的想象力。
代码
我们将使用Networkx模块在 Python 中创建和分析我们的图。
让我们从一个示例图开始,该图用于我们的目的。包含城市及其之间的距离信息。
图带有一些随机距离
我们首先开始创建一个包含边及其距离的列表,这些距离将作为边的权重添加:
edgelist = [['Mannheim', 'Frankfurt', 85], ['Mannheim', 'Karlsruhe', 80], ['Erfurt', 'Wurzburg', 186], ['Munchen', 'Numberg', 167], ['Munchen', 'Augsburg', 84], ['Munchen', 'Kassel', 502], ['Numberg', 'Stuttgart', 183], ['Numberg', 'Wurzburg', 103], ['Numberg', 'Munchen', 167], ['Stuttgart', 'Numberg', 183], ['Augsburg', 'Munchen', 84], ['Augsburg', 'Karlsruhe', 250], ['Kassel', 'Munchen', 502], ['Kassel', 'Frankfurt', 173], ['Frankfurt', 'Mannheim', 85], ['Frankfurt', 'Wurzburg', 217], ['Frankfurt', 'Kassel', 173], ['Wurzburg', 'Numberg', 103], ['Wurzburg', 'Erfurt', 186], ['Wurzburg', 'Frankfurt', 217], ['Karlsruhe', 'Mannheim', 80], ['Karlsruhe', 'Augsburg', 250],["Mumbai", "Delhi",400],["Delhi", "Kolkata",500],["Kolkata", "Bangalore",600],["TX", "NY",1200],["ALB", "NY",800]]
让我们使用Networkx创建一个图:
g = nx.Graph()
for edge in edgelist:
g.add_edge(edge[0],edge[1], weight = edge[2])
现在我们想要找出图中的不同大陆及其城市。
我们现在可以使用连通组件算法来实现:
for i, x in enumerate(nx.connected_components(g)):
print("cc"+str(i)+":",x)
------------------------------------------------------------
cc0: {'Frankfurt', 'Kassel', 'Munchen', 'Numberg', 'Erfurt', 'Stuttgart', 'Karlsruhe', 'Wurzburg', 'Mannheim', 'Augsburg'}
cc1: {'Kolkata', 'Bangalore', 'Mumbai', 'Delhi'}
cc2: {'ALB', 'NY', 'TX'}
如你所见,我们能够在数据中找到不同的组件。仅使用边和顶点就能实现。这种算法可以在不同的数据上运行,以满足我之前提出的任何用例。
2. 最短路径

继续以上示例,我们得到一个包含德国城市及其间距离的图。
你想找出如何从法兰克福(起始节点)到慕尼黑,以覆盖最短距离。
我们用来解决这个问题的算法叫做Dijkstra。用 Dijkstra 的话来说:
从鹿特丹到格罗宁根的最短路径是什么?一般来说,从给定城市到给定城市的最短路径。这是最短路径算法,我在大约二十分钟内设计了这个算法。一天早晨,我和我的年轻未婚妻在阿姆斯特丹购物,累了,我们坐在咖啡馆的露台上喝咖啡,我在想是否能做到这一点,然后我设计了最短路径算法。正如我所说,这是一个二十分钟的发明。实际上,它是在 1959 年发布的,比设计时晚了三年。这个出版物仍然可以阅读,实际上,相当不错。它之所以这么好,其中一个原因是我没有使用铅笔和纸进行设计。我后来了解到,无铅笔和纸的设计方式的一个优点是,你几乎被迫避免所有可避免的复杂性。最终,这个算法成为了我声誉的一个基石,令我感到非常惊讶。
— 埃德斯格·迪克斯特拉,在与菲利普·L·弗拉纳的访谈中,《ACM 通讯》,2001[3]
应用
-
Dijkstra 算法的变体在 Google Maps 中被广泛使用,以寻找最短路线。
-
你在沃尔玛商店里。你有不同的过道以及所有过道之间的距离。你想为顾客提供从过道 A 到过道 D 的最短路径。
- 你已经看到 LinkedIn 如何显示一级连接、二级连接。幕后发生了什么?

代码
print(nx.shortest_path(g, 'Stuttgart','Frankfurt',weight='weight'))
print(nx.shortest_path_length(g, 'Stuttgart','Frankfurt',weight='weight'))
--------------------------------------------------------
['Stuttgart', 'Numberg', 'Wurzburg', 'Frankfurt']
503
你也可以使用以下方法找到所有对之间的最短路径:
for x in nx.all_pairs_dijkstra_path(g,weight='weight'):
print(x)
--------------------------------------------------------
('Mannheim', {'Mannheim': ['Mannheim'], 'Frankfurt': ['Mannheim', 'Frankfurt'], 'Karlsruhe': ['Mannheim', 'Karlsruhe'], 'Augsburg': ['Mannheim', 'Karlsruhe', 'Augsburg'], 'Kassel': ['Mannheim', 'Frankfurt', 'Kassel'], 'Wurzburg': ['Mannheim', 'Frankfurt', 'Wurzburg'], 'Munchen': ['Mannheim', 'Karlsruhe', 'Augsburg', 'Munchen'], 'Erfurt': ['Mannheim', 'Frankfurt', 'Wurzburg', 'Erfurt'], 'Numberg': ['Mannheim', 'Frankfurt', 'Wurzburg', 'Numberg'], 'Stuttgart': ['Mannheim', 'Frankfurt', 'Wurzburg', 'Numberg', 'Stuttgart']})('Frankfurt', {'Frankfurt': ['Frankfurt'], 'Mannheim': ['Frankfurt', 'Mannheim'], 'Kassel': ['Frankfurt', 'Kassel'], 'Wurzburg': ['Frankfurt', 'Wurzburg'], 'Karlsruhe': ['Frankfurt', 'Mannheim', 'Karlsruhe'], 'Augsburg': ['Frankfurt', 'Mannheim', 'Karlsruhe', 'Augsburg'], 'Munchen': ['Frankfurt', 'Wurzburg', 'Numberg', 'Munchen'], 'Erfurt': ['Frankfurt', 'Wurzburg', 'Erfurt'], 'Numberg': ['Frankfurt', 'Wurzburg', 'Numberg'], 'Stuttgart': ['Frankfurt', 'Wurzburg', 'Numberg', 'Stuttgart']})....
3. 最小生成树

现在我们遇到了另一个问题。我们为一家铺设水管或互联网光纤的公司工作。我们需要使用最少量的电线/管道连接图中的所有城市。我们该如何做到这一点?
一个无向图及其右侧的最小生成树。
应用
-
最小生成树在网络设计中有直接应用,包括计算机网络、通信网络、交通网络、供水网络和电力网(这些网络最初就是为了这些目的发明的)。
-
MST 用于近似旅行商问题
-
聚类——首先构建最小生成树,然后使用簇间距离和簇内距离确定一个阈值,以断开最小生成树中的一些边。
-
图像分割——它用于图像分割,其中我们首先在一个图上构建最小生成树(MST),图中的像素是节点,像素之间的距离基于某些相似度度量(如颜色、强度等)。
代码
# nx.minimum_spanning_tree(g) returns a instance of type graph
nx.draw_networkx(nx.minimum_spanning_tree(g))
我们图的最小生成树。
如你所见,上面是我们要铺设的线路。
4. PageRank
这是长期以来驱动谷歌的页面排序算法。它根据传入和传出链接的数量和质量为页面分配分数。
应用
PageRank 可以用于任何需要估计网络中节点重要性的地方。
-
它已经被用来通过引用找到最具影响力的论文。
-
已被谷歌用于排名页面
-
它可以用于排名推文——用户和推文作为节点。如果用户 A 关注用户 B,则在用户之间创建连接;如果用户发布/转发一条推文,则在用户和推文之间创建连接。
-
推荐引擎
代码
对于这个练习,我们将使用 Facebook 数据。我们有一个 Facebook 用户之间的边/链接文件。我们首先使用以下代码创建 FB 图:
# reading the datasetfb = nx.read_edgelist('../input/facebook-combined.txt', create_using = nx.Graph(), nodetype = int)
它的外观如下:
pos = nx.spring_layout(fb)import warnings
warnings.filterwarnings('ignore')plt.style.use('fivethirtyeight')
plt.rcParams['figure.figsize'] = (20, 15)
plt.axis('off')
nx.draw_networkx(fb, pos, with_labels = False, node_size = 35)
plt.show()
FB 用户图
现在我们想要找出具有高影响力的用户。
直观地,PageRank 算法会给那些拥有大量朋友且这些朋友又有很多 FB 朋友的用户更高的分数。
pageranks = nx.pagerank(fb)
print(pageranks)
------------------------------------------------------
{0: 0.006289602618466542,
1: 0.00023590202311540972,
2: 0.00020310565091694562,
3: 0.00022552359869430617,
4: 0.00023849264701222462,
........}
我们可以使用排序后的 PageRank 或最具影响力的用户:
import operator
sorted_pagerank = sorted(pagerank.items(), key=operator.itemgetter(1),reverse = True)
print(sorted_pagerank)
------------------------------------------------------
[(3437, 0.007614586844749603), (107, 0.006936420955866114), (1684, 0.0063671621383068295), (0, 0.006289602618466542), (1912, 0.0038769716008844974), (348, 0.0023480969727805783), (686, 0.0022193592598000193), (3980, 0.002170323579009993), (414, 0.0018002990470702262), (698, 0.0013171153138368807), (483, 0.0012974283300616082), (3830, 0.0011844348977671688), (376, 0.0009014073664792464), (2047, 0.000841029154597401), (56, 0.0008039024292749443), (25, 0.000800412660519768), (828, 0.0007886905420662135), (322, 0.0007867992190291396),......]
上面的 ID 是最具影响力的用户。
我们可以看到最具影响力用户的子图:
first_degree_connected_nodes = list(fb.neighbors(3437))
second_degree_connected_nodes = []
for x in first_degree_connected_nodes:
second_degree_connected_nodes+=list(fb.neighbors(x))
second_degree_connected_nodes.remove(3437)
second_degree_connected_nodes = list(set(second_degree_connected_nodes))subgraph_3437 = nx.subgraph(fb,first_degree_connected_nodes+second_degree_connected_nodes)pos = nx.spring_layout(subgraph_3437)node_color = ['yellow' if v == 3437 else 'red' for v in subgraph_3437]
node_size = [1000 if v == 3437 else 35 for v in subgraph_3437]
plt.style.use('fivethirtyeight')
plt.rcParams['figure.figsize'] = (20, 15)
plt.axis('off')nx.draw_networkx(subgraph_3437, pos, with_labels = False, node_color=node_color,node_size=node_size )
plt.show()

我们最具影响力的用户(黄色)
5. 中心性度量
有很多中心性度量可以作为机器学习模型的特征。我将讨论其中两个。你可以在这里查看其他度量。
中介中心性: 不仅仅是拥有最多朋友的用户很重要,连接一个地理位置到另一个地理位置的用户也很重要,因为这让用户可以看到来自不同地理位置的内容。中介中心性量化了一个特定节点在两个其他节点之间的最短路径中出现的次数。
度中心性: 这是节点的连接数量。
应用
中心性度量可以作为任何机器学习模型的特征。
代码
这里是用于找到子图中介中心性的代码。
pos = nx.spring_layout(subgraph_3437)
betweennessCentrality = nx.betweenness_centrality(subgraph_3437,normalized=True, endpoints=True)node_size = [v * 10000 for v in betweennessCentrality.values()]
plt.figure(figsize=(20,20))
nx.draw_networkx(subgraph_3437, pos=pos, with_labels=False,
node_size=node_size )
plt.axis('off')

你可以在这里看到按其中介中心性值大小显示的节点。它们可以被认为是信息传递者。打破任何一个具有高中介中心性的节点将会把图分割成许多部分。
结论
在这篇文章中,我谈到了改变我们生活方式的一些最具影响力的图算法。
随着大量社交数据的出现,网络分析可以在改善我们的模型和创造价值方面发挥很大作用。
甚至对世界有更多的了解。
有很多图算法,但这些是我最喜欢的。如果你喜欢的话,可以更详细地了解这些算法。在这篇文章中,我只是想介绍这一领域的基本知识。
如果你觉得我遗漏了你最喜欢的算法,请在评论中告诉我。
这里是包含完整代码的 Kaggle Kernel。
如果你想深入了解图算法,这里有一个由 UCSanDiego 提供的大数据图分析课程,我强烈推荐学习图论基础。
感谢阅读。我将来还会写更多适合初学者的文章。关注我在 Medium 或订阅我的 博客 以获取相关信息。像往常一样,我欢迎反馈和建设性的批评,可以通过 Twitter 联系我 @mlwhiz。
个人简介: Rahul Agarwal 是沃尔玛实验室的数据科学家。
原文。经许可转载。
相关:
-
10 个适合有抱负的数据科学家的 Python 资源
-
用 100 行代码编写随机森林*
-
用世界填充 GRAKN.AI 知识图谱
更多相关内容
解决 5 个复杂 SQL 问题:棘手的查询解析

编辑器提供的图片
我们许多人都体验过将计算集中在云数据仓库中带来的速度和效率的核心优势。虽然这确实如此,但我们也意识到,就像任何事情一样,这种价值也伴随着自己的缺点。
这种方法的主要缺点之一是你必须学习和执行不同语言的查询,特别是 SQL。虽然编写 SQL 比建立一个运行 python 的辅助基础设施(在你的笔记本电脑或办公室服务器上)更快、更便宜,但它带来了许多复杂性,具体取决于数据分析师希望从云数据仓库中提取什么信息。转向云数据仓库增加了复杂 SQL 相较于 python 的实用性。经历了这一过程后,我决定记录那些在 SQL 中最难学和执行的具体转换,并提供缓解这些痛苦所需的实际 SQL。
为了帮助你的工作流程,你会注意到我在转换执行前后提供了数据结构示例,这样你可以跟随并验证你的工作。我还提供了进行这 5 个最难转换所需的实际 SQL。你需要新的 SQL 来执行多个项目的转换,因为你的数据会变化。我们提供了每个转换的动态 SQL 链接,以便你可以根据需要继续捕获分析所需的 SQL!
日期脊
术语“日期脊”来源不明确,但即使是不知道这个术语的人,也可能对它的概念很熟悉。
想象一下你正在分析每日销售数据,它看起来像这样:
| sales_date | product | sales |
|---|---|---|
| 2022-04-14 | A | 46 |
| 2022-04-14 | B | 409 |
| 2022-04-15 | A | 17 |
| 2022-04-15 | B | 480 |
| 2022-04-18 | A | 65 |
| 2022-04-19 | A | 45 |
| 2022-04-19 | B | 411 |
16 号和 17 号没有销售,因此这些行完全缺失。如果我们尝试计算平均每日销售额或构建时间序列预测模型,这种格式将是一个主要问题。我们需要做的是插入缺失日期的行。
这是基本概念:
-
生成或选择唯一日期
-
生成或选择唯一产品
-
交叉连接(笛卡尔积)1 和 2 的所有组合
-
外连接 #3 到你的原始数据
最终结果将如下所示:
| sales_date | product | sales |
|---|---|---|
| 2022-04-14 | A | 46 |
| 2022-04-14 | B | 409 |
| 2022-04-15 | A | 17 |
| 2022-04-15 | B | 480 |
| 2022-04-16 | A | 0 |
| 2022-04-16 | B | 0 |
| 2022-04-17 | A | 0 |
| 2022-04-17 | B | 0 |
| 2022-04-18 | A | 65 |
| 2022-04-18 | B | 0 |
| 2022-04-19 | A | 45 |
| 2022-04-19 | B | 411 |
Pivot / Unpivot
有时候,在进行分析时,你可能需要重新构建表格。例如,我们可能有一个学生、科目和成绩的列表,但我们想将科目拆分到每一列。我们都知道并喜欢 Excel 的数据透视表。但你是否尝试过在 SQL 中实现它?不仅每个数据库在如何支持 PIVOT 方面有令人烦恼的差异,而且语法也不直观,容易忘记。
之前:
| 学生 | 科目 | 成绩 |
|---|---|---|
| Jared | 数学 | 61 |
| Jared | 地理 | 94 |
| Jared | 体育 | 98 |
| Patrick | 数学 | 99 |
| Patrick | 地理 | 93 |
| Patrick | 体育 | 4 |
结果:
| Student | Mathematics | Geography | Phys Ed |
|---|---|---|---|
| Jared | 61 | 94 | 98 |
| Patrick | 99 | 93 | 4 |
一热编码
这个方法不一定困难,但确实耗时。大多数数据科学家不考虑在 SQL 中做一热编码。虽然语法很简单,他们宁愿将数据从数据仓库中转移出来,也不愿意写 26 行的 CASE 语句。我们不怪他们!
然而,我们建议利用你的数据仓库及其处理能力。这里是一个使用 STATE 作为列进行一热编码的示例。
之前:
| Babyname | State | Qty |
|---|---|---|
| Alice | AL | 156 |
| Alice | AK | 146 |
| Alice | PA | 654 |
| … | … | … |
| Zelda | NY | 417 |
| Zelda | AL | 261 |
| Zelda | CO | 321 |
结果:
| Babyname | State | State_AL | State_AK | … | State_CO | Qty |
|---|---|---|---|---|---|---|
| Alice | AL | 1 | 0 | … | 0 | 156 |
| Alice | AK | 0 | 1 | … | 0 | 146 |
| Alice | PA | 0 | 0 | … | 0 | 654 |
| … | … | … | … | |||
| Zelda | NY | 0 | 0 | … | 0 | 417 |
| Zelda | AL | 1 | 0 | … | 0 | 261 |
| Zelda | CO | 0 | 0 | … | 1 | 321 |
市场篮分析
在进行市场篮分析或挖掘关联规则时,第一步通常是将数据格式化以将每笔交易汇总为一个记录。这对你的笔记本电脑来说可能是一个挑战,但你的数据仓库旨在高效地处理这些数据。
典型交易数据:
| 销售订单号 | 客户密钥 | 英文产品名称 | 列表价格 | 重量 | 订单日期 |
|---|---|---|---|---|---|
| SO51247 | 11249 | Mountain-200 黑色 | 2294.99 | 23.77 | 1/1/2013 |
| SO51247 | 11249 | 水瓶 - 30 oz. | 4.99 | 1/1/2013 | |
| SO51247 | 11249 | Mountain 水瓶架 | 9.99 | 1/1/2013 | |
| SO51246 | 25625 | Sport-100 头盔 | 34.99 | 12/31/2012 | |
| SO51246 | 25625 | 水瓶 - 30 oz. | 4.99 | 12/31/2012 | |
| SO51246 | 25625 | Road 水瓶架 | 8.99 | 12/31/2012 | |
| SO51246 | 25625 | Touring-1000 蓝色 | 2384.07 | 25.42 | 12/31/2012 |
结果:
| NUMTRANSACTIONS | ENGLISHPRODUCTNAME_LISTAGG |
|---|---|
| 207 | 山地瓶架,水瓶 - 30 盎司 |
| 200 | 山地轮胎内胎,修补工具包/8 片补丁 |
| 142 | LL 公路轮胎,修补工具包/8 片补丁 |
| 137 | 修补工具包/8 片补丁,公路轮胎内胎 |
| 135 | 修补工具包/8 片补丁,旅行轮胎内胎 |
| 132 | HL 山地轮胎,山地轮胎内胎,修补工具包/8 片补丁 |
时间序列聚合
时间序列聚合不仅被数据科学家使用,也被用于分析。它们难以处理的原因在于窗口函数要求数据格式正确。
例如,如果你想计算过去 14 天的平均销售金额,窗口函数要求你将所有销售数据分解为每天一行。不幸的是,任何处理过销售数据的人都知道,销售数据通常是以交易级别存储的。这就是时间序列聚合派上用场的地方。你可以在不重新格式化整个数据集的情况下创建聚合的历史指标。如果我们想一次添加多个指标,这也很有用:
-
过去 14 天的平均销售
-
过去 6 个月的最大购买
-
过去 90 天的不同产品类型数量
如果你想使用窗口函数,每个指标都需要独立构建,并经过多个步骤。
更好的处理方式是使用公共表表达式(CTEs)来定义每个历史窗口,并进行预聚合。
例如:
| 交易 ID | 客户 ID | 产品类型 | 购买金额 | 交易日期 |
|---|---|---|---|---|
| 65432 | 101 | 杂货 | 101.14 | 2022-03-01 |
| 65493 | 101 | 杂货 | 98.45 | 2022-04-30 |
| 65494 | 101 | 汽车 | 239.98 | 2022-05-01 |
| 66789 | 101 | 杂货 | 86.55 | 2022-05-22 |
| 66981 | 101 | 药品 | 14 | 2022-06-15 |
| 67145 | 101 | 杂货 | 93.12 | 2022-06-22 |
结果:
| 交易 ID | 客户 ID | 产品类型 | 购买金额 | 交易日期 | 过去 14 天的平均销售 | 过去 6 个月的最大购买 | 过去 90 天不同产品类型的计数 |
|---|---|---|---|---|---|---|---|
| 65432 | 101 | 杂货 | 101.14 | 2022-03-01 | 101.14 | 101.14 | 1 |
| 65493 | 101 | 杂货 | 98.45 | 2022-04-30 | 98.45 | 101.14 | 2 |
| 65494 | 101 | 汽车 | 239.98 | 2022-05-01 | 169.21 | 239.98 | 2 |
| 66789 | 101 | 杂货 | 86.55 | 2022-05-22 | 86.55 | 239.98 | 2 |
| 66981 | 101 | 药品 | 14 | 2022-06-15 | 14 | 239.98 | 3 |
| 67145 | 101 | 杂货 | 93.12 | 2022-06-22 | 53.56 | 239.98 | 3 |
结论
我希望这篇文章能够帮助揭示数据从业者在现代数据堆栈操作过程中会遇到的各种问题。SQL 在查询云仓库时是把双刃剑。虽然将计算集中在云数据仓库中可以提高速度,但有时也需要一些额外的 SQL 技能。我希望这篇文章能够回答一些问题,并提供解决这些问题所需的语法和背景知识。
Josh Berry (@Twitter)领导 Rasgo 的客户数据科学工作,自 2008 年以来一直从事数据和分析工作。Josh 曾在 Comcast 工作了 10 年,在那里他建立了数据科学团队,并且是内部开发的 Comcast 特征商店的关键负责人之一——这是市场上首批推出的特征商店之一。离开 Comcast 后,Josh 在 DataRobot 继续担任客户数据科学团队的重要领导。业余时间,Josh 会对如棒球、F1 赛车、房地产市场预测等有趣的话题进行复杂分析。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织的 IT
了解更多相关话题
5 个数据科学的隐藏宝石 Python 库
原文:
www.kdnuggets.com/5-hidden-gem-python-libraries-for-data-science

图片由编辑 | Ideogram
数据科学已经发展到几乎依赖 Python 生态系统以提高工作效率的地步。这就是为什么如此多的 Python 库被开发出来以适应数据科学任务。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
然而,许多优秀的库可能因受 Pandas、Scikit-learn、Seaborn 等流行库的掩盖而陷入默默无闻的境地。事实上,许多隐藏的宝石在某些情况下比流行库表现更好。
本文将深入探讨 5 个这样的数据科学隐藏宝石 Python 库,这些库可以帮助你的工作。
1. Cleanlab
数据科学的核心在于数据。如果你拥有质量差的数据,你的分析和模型也会差。甚至有一句话:“垃圾进,垃圾出。”这就是为什么我们需要妥善管理数据质量。Cleanlab 是一个可以帮助你提升数据质量的库。
Cleanlab 自动清理我们的数据集,并识别目标标签中的问题。该库在发现数据集中的问题并处理错误以提高模型性能方面表现良好。如果你有数据质量问题,不要犹豫,去看看 Cleanlab 库。
2. H3 Uber
地理数据可能是最令人兴奋的数据科学项目之一,但处理起来却是最困难的之一。保持数据的一致性以获得精确的空间数据具有挑战性,因为分段通常是不规则的,并且随着时间的推移而变化。
Uber 的开源 H3 库可以帮助促进地理数据的使用。H3 库使用六边形网格系统,将数据划分为六边形单元和结构,以获得一致的位置数据。这些数据可以用于任何精确的基于位置的分析,并改善地理应用。
3. IceCream
不,这不是甜点。Python 库 IceCream 是一种甜蜜的工具,可以通过改善调试过程来丰富你的数据科学工作。一般来说,大部分编程活动发生在后台,我们看不到发生了什么,包括数据结构和处理。
IceCream 将简单的打印函数转变为一个调试机器,可以生成更好的信息。该库可以做很多事情,例如输出同时打印函数或变量名称及其值,并突出显示输出语法。打印数据结构也变得很美观,消除了混乱。此外,它还可以检查程序的整体执行情况。
4. Fairlearn
数据科学项目对企业有用,但我们还必须记住,许多我们使用的数据集与人类有诸多关联。我们建立的模型系统需要尽可能地避免偏见,消除任何可能歧视某些社会群体的可能性。虽然在模型创建过程中进行偏见评估可能不是你的首要直觉,但它应始终存在。这正是 Fairlearn 可以帮助你的地方。
Fairlearn是一个 Python 库,帮助减少我们机器学习系统中的不公平问题。该库包含公平性指标和算法。公平性指标评估哪些群体受到了模型的负面影响以及整体公平性。同时,算法提供了减少偏差和不公平的缓解技术。
5. Scikit-posthocs
数据科学涉及大量的统计分析,尤其是比较数据集和组。人们可能认为数据科学完全依赖于机器学习建模,但简单的统计分析也能解决许多项目问题。一项常见的分析是组间假设检验,例如 ANOVA。
后验分析是在初步的方差分析(ANOVA)或类似分析中发现显著性之后进行的。Scikit-posthocs是一个 Python 库,便于在我们的工作流程中进行后验分析。它提供了所有你可以使用的工具来执行参数检验和非参数检验,API 类似于 Scikit-learn。如果你想验证你的测试结果,可以尝试使用这个库。
结论
在本文中,我们探讨了 5 个你可能不太熟悉的 Python 数据科学库。尝试使用这些隐藏的宝石,可能会为你的分析库增添新兵器。
Cornellius Yudha Wijaya 是数据科学助理经理和数据撰稿人。尽管全职在 Allianz Indonesia 工作,他仍喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 涉猎广泛的 AI 和机器学习主题。
了解更多相关内容
今年值得学习的 5 种高薪语言
原文:
www.kdnuggets.com/2023/07/5-highestpaid-languages-learn-year.html
图片来源:作者
今年的 Stack Overflow 开发者调查 带来了惊喜——一年间发生了很多变化。你可能会认为 JavaScript 或 Python 会排名靠前,但排名是基于需求而非受欢迎程度。公司愿意为小众语言支付更多费用,今天我们将了解所有这些语言。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域的职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 在 IT 领域支持你的组织
1. Zig
中等年薪: $103,611
Zig 是一种编程语言,专注于帮助开发者构建可靠、高效和可重用的软件。
Zig 旨在创建强健的软件,其特点是:
-
在所有情况下,包括边缘情况,都能良好运行。
-
通过最优地使用系统资源高效运行。
-
可以在不同的环境中重用。
-
代码随着时间的推移保持可维护性。代码清晰,因此后续修复问题也很容易。
Zig 在高层抽象与低层控制之间取得了平衡,以实现最佳性能。
演示
创建一个 hello.zig 文件并编写 hello world 代码。
const std = @import("std");
pub fn main() !void {
const stdout = std.io.getStdOut().writer();
try stdout.print("Hello, {s}!\n", .{"world"});
}
在终端中运行它。
$ zig build-exe hello.zig
$ ./hello
Hello, world!
阅读 文档 以了解更多关于 Zig 语法和函数的信息。
2. Erlang
中等年薪: $99,492
Erlang 是一种非常适合构建大型分布式系统的编程语言,这些系统需要高可扩展性、高可用性和快速性能。Erlang 最初由 Ericsson 在 1980 年代中期为构建电信系统而设计。
Erlang 是在电信、银行、电子商务和即时消息等领域构建任务关键型、软实时系统的热门选择,这些领域对高可用性、可扩展性和响应能力有着严格要求。Erlang 的运行时系统提供了对语言依赖的并发、分布和容错功能的内建支持。
演示
% hello world program
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite("Hello, world!\n").
输出:
Hello, world!
在 tutorialspoint.com 上学习基础的 Erlang 语法。
3. F#
中等年薪: $99,311
F# 是一种通用的跨平台编程语言,旨在实现功能性、互操作性和性能。其主要目标是帮助开发人员编写:
-
简洁的代码:默认关注于编写清晰、简洁且自文档化的代码。
-
稳健的代码:使用强大的类型提供程序和先进的类型系统来在编译时捕捉错误。
-
高性能代码:F# 代码在底层编译为高效的 .NET IL 或 JavaScript。
F# 运行在 .NET 框架上,并提供与其他 .NET 语言如 C# 的无缝互操作,同时还允许通过 JavaScript 编译来面向网页和移动端。
关键特性:
-
简约的语法使代码更易读。
-
变量默认是不可变的,减少了错误,使代码更易于推理。
-
编译器为大多数变量推断类型,从而减少了样板代码。
-
在函数之间传递数据可以减少中间变量。
-
异步工作流使得编写可扩展的异步代码变得自然。
-
强大的模式匹配功能,支持对联合、元组、数组、字符串等的操作。
-
支持继承、接口实现和封装。
-
了解更多功能,请访问 F# 文档 - 入门、教程、参考。
演示
使用终端运行以下命令以创建你的应用程序:
dotnet new console -lang F# -o MyApp -f net7.0
导航到新目录
cd MyApp
编辑 Program.fs 文件。
printfn "Hello World"
使用终端运行以下命令以运行应用程序:
dotnet run
4. Ruby
中位年薪: $98,522
Ruby 是一种开源的动态编程语言,优先考虑生产力和简单性。它由松本行弘(Yukihiro "Matz" Matsumoto)在 1990 年代中期创建,并因其在网页开发、脚本编写和通用编程中的流行而广受欢迎。
Ruby 的优雅语法易于阅读和编写,其面向对象的特性提供了灵活性。它是一种解释型语言,这意味着代码可以直接执行而无需编译,从而加快了开发速度。Ruby 拥有一个庞大且活跃的开发者社区,他们为其开发做出了贡献,形成了一个丰富的库和工具生态系统。
演示
创建一个 hello.rb 文件并添加代码。
puts "Hello, world!"
使用以下命令在终端运行 Ruby 文件:
ruby hello.rb
输出:
Hello, world!Hello, world!
5. Clojure
中位年薪: $96,381
Clojure 是一种编程语言,它结合了脚本语言的易用性和交互性与编译语言的效率和健壮性。它特别擅长处理多线程编程,并且可以轻松访问 Java 框架。Clojure 是 Lisp 的一种方言,主要是一种函数式编程语言。当需要可变状态时,它提供了软件事务内存系统和响应式代理系统。
演示
使用终端中的 clj 命令启动 Clojure REPL,然后粘贴下面的代码以查看输出。
(defn sum [numbers]
(reduce + numbers))
(println (sum [1 2 3 4 5]))
输出:
15
nil
结论
总之,Stack Overflow 开发者调查显示,对小众编程语言的需求在上升,这体现在它们的高薪水平上。尽管 JavaScript 和 Python 依然流行,但公司愿意在专注于不那么主流语言的开发者上投入更多。因此,值得考虑扩展你的技能,学习今年的五种最高薪资编程语言,包括 Zig、Erlang、F#、Clojure 和 Ruby。
此外,你可能想要探索在 2022 年到 2023 年之间薪资有所上升的四种顶级编程语言。

图片来源于Stack Overflow 开发者调查 2023
Abid Ali Awan (@1abidaliawan)是一位认证的数据科学专家,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一款帮助精神疾病学生的 AI 产品。
更多相关内容
数据共享平台的 5 个关键组成部分
原文:
www.kdnuggets.com/2022/05/5-key-components-data-sharing-platform.html
越来越多的公司专注于寻找连接新的、宝贵的数据源的方法,以增强其分析能力,丰富其模型,或为其业务部门提供更多洞察。
由于对新数据源的需求增加,公司也开始以不同的方式看待其内部数据。那些拥有有价值数据集的组织开始探索让他们可以在业务四面墙之外共享和货币化数据的机会。
数据共享的格局是什么样的?
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT
数据共享受到了很多关注。部分原因是因为数据货币化正在成为一个大问题,公司需要找到一种机制来将数据展示给愿意购买的人。更普遍地说,公司对来自非传统来源的数据非常渴望,这些数据可以用来增强模型,揭示隐藏的趋势,并(是的)发现“alpha”。这种需求引起了对数据发现平台和市场的广泛关注。Venturebeat 特别将数据共享作为其2021 年机器学习、人工智能和数据生态的一部分,并重点介绍了该领域的一些关键发展:
Google 于 2021 年 5 月推出了Analytics Hub作为一个结合数据集和共享数据、仪表板和机器学习模型的平台。Google 还推出了Datashare,这是一个针对金融服务并基于 Analytics Hub 开发的工具。
Databricks 在 Google 发布的同一天宣布了Delta Sharing。Delta Sharing 是一种用于跨组织安全数据共享的开源协议。
2021 年 6 月,Snowflake 开放了其数据市场的广泛访问权限,并配备了安全的数据共享功能。
我工作的公司 ThinkData 最初是在开放数据领域起步的,因此一直将数据共享作为我们技术的基石。最近,我们利用数据虚拟化来帮助我们合作的组织安全地共享数据(你可以在这里阅读更多相关内容)。
企业需求的变化
分享数据时需要考虑一些问题。你选择谁使用你的数据以及用途的过程是一个组织应该深思熟虑的战略问题。但除了关于谁将使用你的数据以及为什么使用的规则外,分享数据还有一些更具技术性而非法律性质的后勤问题。
无论是数据的输入还是输出,公共还是私有,核心流程的一部分还是实验的一小部分,你如何连接到数据上往往和为什么要连接一样重要。对于希望从数据中获得更多收益的现代公司来说,选择部署数据目录不应意味着你必须迁移数据。一个让你组织、发现、共享和变现数据的平台的好处不能以将你的数据库迁移到公共云为代价。
发现和使用新数据的价值很明显,但组织应该如何分享和接收数据的过程却不那么清晰。
闪存驱动器是行不通的,那么一个好的共享解决方案应该是什么样的呢?
什么是所有者定义的访问权限?
通常,当组织想要分享他们拥有的数据时,他们必须对数据集进行切割和处理,以去除敏感信息或创建面向客户的数据集副本。除了构建客户友好版本的数据集的开销外,从数据治理的角度来看,这也是一种不良做法。
制作和分发数据集的副本每次都会创建一种新的数据处理错误方式,并且可能导致不一致、错误和安全问题。如果你想将数据集分享给十个不同的人用于十种不同的用途,每次你这样做都会重复工作并增加风险。
一个好的数据共享解决方案允许数据所有者在数据集上创建行级和列级权限,创建一个主文件的定制视图,确保所有的数据共享仍然汇总到一个真实的来源。
一致且可配置的元数据
大多数数据集并不是为消费者设计的。如果数据是作为核心业务过程的副产品生成的,它可能特别适用于某个特定的使用场景,这可能不会被希望使用数据的最终用户所共享。
元数据是让我们有效理解和使用数据的关键。无论是描述性(告诉我们谁创建了数据以及我们应该如何解读)还是管理性(声明谁拥有数据以及如何使用),附加和维护高质量的元数据是确保任何人都能理解如何使用他们所访问的数据的最有效方式。
在 ThinkData 平台中构建自定义元数据模板。这些模板可以添加到任何引入数据目录的数据集中。
数据应该如何安全共享?
这应该是不言而喻的,但你可能会惊讶于仍然有很多组织在不同楼层之间通过电子邮件发送电子表格。如果你分享的是开放数据,你可能不必担心数据安全,但如果数据即使只是略微敏感(更不用说有价值),你将需要确保有办法追踪数据的去向。
确保数据通过具有足够数据保护措施的服务进行传递是很重要的,并且确保传递过程可靠稳定将增加信任。
这涵盖了内部共享,但组织之间,甚至部门之间的数据共享怎么办?
从历史上看,如果你将数据提供给另一个业务部门,这就像是将数据从一个黑箱传输到另一个黑箱。但如果你是一个对数据使用有严格限制的组织,你需要知道哪些用户在未来访问数据集。一个好的数据共享平台不仅应让你控制数据流动,还应提供有关用户如何连接数据及其时间的洞察。
支持本地和公共云
大多数现代数据共享计划专门为公共云设计,这不仅限制了谁可以利用它们,还增加了提供商和消费者的开支,因为他们使用更多的存储来访问所有共享给他们的数据。
现实是,任何处于数据驱动转型阶段的现代化公司都需要在尽可能少扰动其标准操作程序的情况下,建立系统和基础设施。许多共享解决方案和传统数据目录的问题之一是,迁移到公共云的主要步骤不可行。对于具有关键任务或敏感数据以及事务性工作负载的组织来说,数据中心的细粒度控制将始终是必要的。
即使对于那些希望将业务迁移到公共云的组织来说,法律和实际操作方面的各种考量也会使这一过程停滞不前,尤其是在他们尝试现代化的过程中。一个跨国金融机构无法花几个月时间将数据物理迁移到云端。
无论你的数据库状态如何,你仍然应该能够安全地提供对数据的访问,而无需将其迁移到公共云或创建不必要的副本。
发现新数据的机制
数据市场的兴起表明,大多数组织强烈需要利用一种解决方案,帮助他们找到并连接到存在于其业务四壁之外的数据。
然而,数据市场通常失败的地方在于,它们提供的是购物体验,而不是消费模型。数据市场历来是一个让用户能够找到数据的地方,但不是一个可以让他们连接到数据的机制,这有点像让某人购物但不给他们试穿任何衣物的感觉。
从这一需求中,出现了一个新的数据共享模型,Snowflake 在去年推出了 Snowflake 数据市场,作为一个用户可以双向共享数据到彼此账户的地方,引起了轰动。
这种模型在公共云中效果良好,在那里创建一个新云区域中的数据集相对容易,但它有点笨重(在每个云区域中重新创建数据会给过程带来相当大的开销),如果不小心,还可能产生计算和存储的高额费用。
ThinkData 平台允许任何组织在各种数据源中一致地获取数据,并以标准化的方式直接交付。 ThinkData 市场 是一个展示可用公共数据的商店,也是数据提供者与数据买家连接的中心枢纽。
ThinkData 平台提供了一系列的消费模型。通过按需数据产品化,你可以轻松地将公共数据资产配置成理想的格式和模式。通过数据虚拟化,你可以确保即时的数据共享,而不引发数据仓库和安全问题。ThinkData 市场提供了一个数据消费模型,使数据需求旺盛的组织不仅能够发现各种数据,还能快速有效地开始使用新的数据来源。
引入低迁移数据共享
需要的是一种方式,让组织能够在不需要先移动数据的情况下进行数据共享。
数据虚拟化提供了一个解决方案,它允许用户在不移动或复制数据的情况下,将外部仓库的数据与其他来源的数据一起查看。
| 公共云数据共享模型 | 私有云数据共享模型 |
|---|
|
-
跨多个仓库的数据冗余
-
新工具、培训和时间的开销
-
繁琐的操作复杂性
|
-
数据的唯一真实来源
-
在现有基础设施上启用共享
-
简单且低维护的数据访问
|
ThinkData 平台使组织能够实现数据虚拟化,这些组织希望对数据应用治理、元数据管理和数据共享,而无需将数据从其存放的位置移出。通过直接从数据仓库中获取数据并通过平台 UI 提供,我们让用户在无需大规模迁移的操作障碍(和成本)的情况下,获得数据目录的所有好处。
如果你对数据共享感兴趣,观看我们的网络研讨会,看看在团队和个人之间分发数据有多么简单。我们的平台超越了数据目录所提供的传统发现和治理。通过添加数据共享和报告,ThinkData 平台解锁了以前不可能实现的协作和货币化机会。
路易斯·温恩-琼斯 是 ThinkData Works 的产品总监,他在帮助构建行业领先的数据目录,以帮助组织通过连接、丰富和分发数据资产来解锁数据的价值,并在安全且可配置的环境中操作。
更多相关内容
5 个关键数据科学趋势和分析趋势
原文:
www.kdnuggets.com/2022/08/5-key-data-science-trends-analytics-trends.html

图片由 Karolina Grabowska 提供,来源于 Pexels
数据科学和分析的发展速度比以往任何时候都快——许多预测表明这些领域不会很快减速。考虑到它们在当前商业环境中的整合,这很有道理。但这不仅仅是这样。这些领域目前是许多重要部门中的主要驱动力,包括那些以利润为主要动机的部门。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
在医疗保健到物流等广泛行业中,实施先进分析解决方案的空间很大。在许多方面,我们只是触及了可能性的表面,未来的走向令人兴奋。在此之前,让我们看看目前的一些关键趋势。
1. 欺诈——协助和对抗
数据科学在欺诈中扮演了重要角色——不幸的是,这个角色在欺诈的两边都有。一方面,我们有恶意行为者利用技术轻松伪造其他方的通信,包括生成假语音录音和视频。尽管大多数人关注的是这项技术在娱乐领域的影响,但金融等各种领域已经因这些趋势面临重大问题。视频作为身份验证的形式正迅速变得不可靠,企业一直在寻找不会引起隐私敏感用户担忧的替代方案。
另一方面,先进的分析系统正处于 打击诈骗者的前沿。许多经典诈骗几乎可以完全自动识别,从而减轻人工操作员的大部分工作,让他们专注于实际需要人工干预的案件。
2. 技术栈变得更加精简
起初,当数据科学还在积累势头时,该领域的技术前沿一片混乱。研究人员试图使用几乎所有的语言和技术栈来搞清楚什么有效,什么无效,新手很难在一个没有过时风险的方向上定位自己。现在,情况有所不同。像 R 和 Python 这样的几种语言已成为行业领导者,我们已经看到一些完整的技术栈在市场上稳定下来,并受到各级公司关注。
对那些有兴趣涉足该领域的人来说,这是一个很大的变化,因为它在学习阶段提供了更多的安全感和信心,这无疑是人们最需要这种支持的时候。
3. 技术入门门槛降低
数据分析曾经被视为仅限于那些能负担昂贵专家的公司。但现在情况不同了。先进的分析解决方案越来越多地以用户友好的方式打包,面向完全没有经验的人。总体来说,这并不是技术行业的新趋势。看看应用程序开发——几十年前,仅仅完成一些基础工作就需要昂贵且高素质的专家。今天,这些专家依然必不可少,但在定义更为明确的位置上。科学家们仍在推动编程范式的进一步发展。而其余的工作则由经验较少的人通过经过多年打磨的技术来完成,这些技术已足够普通人使用。
数据科学和分析领域也正在经历同样的情况。这种情况可能会在未来几年,甚至整个十年中持续下去。这对所有相关人员来说都是好消息——公司将更容易获取深入的分析,而专家将能够从事更具挑战性的项目,而不是不断被分配琐碎的工作。
4. 对合格专家的需求不断增长
这就引出了另一个重要点。随着这些变化的发生,劳动力市场已经开始以一些可预测的方式发生变化。虽然公司不再需要高级专家来处理其分析工作(至少在基础层面上是这样),但该领域最有资格的专业人士的需求却在稳步上升。这是因为资金雄厚的公司希望走在该领域新发展的前沿,这仍然需要巨大的投资和有能力的劳动力。
那些打算朝这个方向发展的人员确实有很大的潜力。而且没有迹象表明情况会在短期内发生变化。
5. 更多关注数据集的清理和维护
在过去的十年里,数据收集和存储的爆炸性增长使得未来分析成为可能。先进的数据分析的一个好处是,它对历史数据的处理效果同样良好,这促使一些市场上最大的公司出现了边际囤积的行为——那些可以负担得起存储所有这些信息所需的大型数据中心的公司。
但最近,新的趋势开始浮现。公司们开始意识到,许多他们为后续分析而积累的数据实际上可能会在当前状态下大部分无用。数据收集实践最初并不完全尽职和简化,这意味着许多公司现在拥有大量需要大量清理工作的数据集。不幸的是,这仍然在很大程度上需要手工操作——而这正是未来十年关注的重点。
一般来说,数据科学正朝着更加简化的方向发展,其中每个人在行业中都有一个特定的位置,项目的典型要求也可以提前知道。不过,这并不意味着对有能力的专家来说机会会减少——正好相反。现在是那些希望尽可能深入参与这一领域的最佳时机。
如果你有兴趣深入了解数据科学,Springboard 的数据科学职业发展课程可以为你提供对这一主题关键概念的深入理解,还提供了可以选择的专业方向,帮助你深化对某一领域的知识。如果你希望在数据科学领域更进一步,今天就考虑查看一下这个课程吧!
Riley Predum 在数据领域如产品和数据分析、数据科学以及数据/分析工程方面有着丰富的职业经验。他对写作和教学充满热情,喜欢向专注于学习和职业成长的在线社区贡献学习材料。Riley 在他的Medium 博客上编写编码教程。
更多相关内容
成为优秀数据科学家需要的 5 项关键技能
原文:
www.kdnuggets.com/2021/12/5-key-skills-needed-become-great-data-scientist.html
作者:Sharan Kumar Ravindran,高级经理(数据科学)
成为成功的数据科学家并不需要天赋。然而,成功的数据科学家需要一些技能。这些关键技能可以通过适当的培训和实践获得。本文将分享一些重要技能,为什么这些技能对数据科学家至关重要,以及如何获得这些技能。
批判性思维
数据科学家应培养批判性思维的习惯。这有助于更好地理解问题。除非问题被理解到最细粒度,否则解决方案无法做到最好。批判性思维有助于分析不同的选项,并帮助选择正确的选项。
在解决数据科学问题时,决策不总是简单的好或坏。很多选项位于好与坏之间的灰色区域。数据科学项目涉及许多决策,比如选择正确的属性集、方法论、算法、评估模型性能的指标等。这需要更多的分析和清晰的思维来选择正确的选项。

照片由 Diana Parkhouse 提供,来自 Unsplash
培养批判性思维的一个简单方法是像孩子一样保持好奇。尽可能多地提出问题,直到没有更多的问题。提问越多,我们了解得越多。理解问题越好,结果就会越好。
让我通过一个例子来演示批判性思维。我们以一家电信公司为例。我们想识别忠诚且高净值的客户。为了识别这一客户群体,我们需要从一系列问题开始,比如:
-
客户的不同档案类别是什么?
-
客户的平均年龄是多少?
-
客户的花费是多少?
-
客户互动的频率是多少?
-
客户是否按时支付账单?
-
是否有过迟付款或漏付款的情况?
-
客户的生命周期价值是多少?
这些有助于识别精英客户。这有助于组织确保这些客户获得最佳服务。
有一些技术可以帮助提高批判性思维能力。其中一种技术是第一性原理思维。这是一种帮助更好地理解问题的思维模型。以下是利用第一性原理解决数据科学问题的一个例子。
思维模型是帮助清晰思考和更好决策的绝妙工具。因此,采用思维模型有助于提高你的批判性思维能力。这里有一篇文章强调了在工作中采用思维模型的好处。
编码
编码技能对数据科学家来说就像眼睛对艺术家一样重要。数据科学家所做的任何事情都需要编码技能。从读取来自多个来源的数据、进行数据探索性分析、建立模型到评估模型。

AutoML 解决方案会发生什么?近年来,许多 AutoML 产品不断出现。许多人甚至认为不久之后将不再需要任何编码技能。让我们举个例子,
-
有 2 家公司,A 公司和 B 公司。
-
他们都在使用最受欢迎的 AutoML 产品。
-
他们能够使用 AutoML 解决多个数据科学问题。
-
现在其中一个公司想要主导市场。
-
能够在 AutoML 解决方案的基础上进一步发展的公司将有更好的机会。
毋庸置疑,AutoML 解决方案在未来将广泛应用。许多数据科学团队今天解决的标准问题将会被自动化。这并不意味着数据科学工作将结束或数据科学家不再需要编写代码。它将使数据科学团队能够专注于新问题。
如今捕获的数据量非常大。许多组织现在只使用了可用数据的一部分。通过 AutoML,重点将转向未开发的数据。
你对数据科学感兴趣,但觉得自己没有编码技能吗?这里有一篇文章可以帮助你学习数据科学的编码技巧。
数学
数学是数据科学家需要理解的另一个重要技能。虽然在学习数据科学时你可能对某些数学概念不了解,但如果不理解数学概念,将无法在数据科学领域取得卓越成绩。
由ThisisEngineering RAEng拍摄,来源于Unsplash
让我用一个简单的例子来演示数学概念在解决问题中的作用。我们选择客户流失分析作为例子。
-
我们将从理解不同客户群体的行为和特征开始。解决这一问题的一种方法是挑选不同的样本数据并寻找模式。这里所需的数学概念是统计学和概率论。
-
为了高效地进行数据分析,理解线性代数将非常有用。
-
假设我们想建立一个预测用户可能流失的模型。理解梯度下降的概念时,微积分知识将会有所帮助。如果你使用决策树,那么信息理论的知识将有助于理解构建树的逻辑。
-
如果你希望优化参数,那么运筹学和优化知识可能会有所帮助。
-
为了高效地实现模型评估,代数等数学概念会非常有帮助。
这还不是全部,没有数学的机器学习算法是不存在的。这并不意味着你需要成为数学家才能成为成功的数据科学家。所需的只是高中水平的数学知识。
如果你有兴趣学习数据科学中的数学,这里是最适合你的课程。
合作
数据科学家不能孤立工作。数据科学家应与多方合作,以确保项目的成功。即使在今天,许多数据科学项目也会失败。大多数失败的主要原因是团队之间缺乏理解和合作。

为了说明合作的重要性及跨团队工作的意义。我们考虑一个场景,其中数据科学团队与客户增长团队合作。目标是了解客户流失的原因。
你决定与几个不同的团队交谈,以下是他们的反馈。
增长团队— 客户流失主要是由于竞争对手提供的激进折扣。
市场营销团队— 产品团队发布的新功能可能会导致一些问题,从而使客户流失。
产品团队— 市场营销团队只关注引入大量新客户,而没有确立客户的价值或意图。
客户支持团队 — 许多客户报告了许多与支付相关的问题。这可能是导致客户流失的原因。
如果你没有与其他团队沟通,你可能仅仅依赖于增长团队提供的输入来开始解决问题。仅凭一个团队的输入是无法解决问题的。即使增长团队是主要赞助方,但仅仅依赖他们提供的输入也是不够的。为了获得全面的视角,你需要与不同的利益相关者交流。当你限制与你合作的人或团队时,那些人的偏见将会传递到你正在构建的解决方案中。
此外,在许多情况下,数据科学团队需要与数据工程和其他技术团队密切合作。如果没有良好的协作努力,就不会成功。
沟通和讲故事
-
项目投入的努力程度
-
部署在生产环境中的最终机器学习模型的准确性
-
从探索性分析中识别出的见解
如果解决方案没有很好地传达给利益相关者,那么这些解决方案都是无用的。数据科学中的问题和解决方案通常更加复杂。将其简化后再与业务沟通非常重要。讲故事的方法在沟通中非常有帮助。
让我举个例子,更简单地说明良好沟通的重要性。假设数据科学团队正在开发一个预测零售能源客户能耗的预测模型。数据科学团队需要说服业务和基础设施团队,解释拥有并运行至少 10 个不同模型以提高准确性的重要性。这意味着需要更高的计算能力和更多的时间来训练模型。
选项 A — 你讨论了将客户分组的聚类技术,因此你认为需要为每个组建立一个模型。
问题在于业务团队没有了解到实际上为每个组建立一个模型的好处。因此,如果成本较高,他们可能不会被说服。
选项 B — 你从客户的档案和特征开始。你展示客户的能耗模式。你向业务团队展示一些独特的模式,比如一些家庭在周末几乎不使用电力,可能是因为他们通常在不同的地方度过周末。同样,你展示其他独特的模式,从而解释一个模型无法适用于所有这些不同的客户,因此需要至少 10 个不同的模型,每个模型对应于 10 个不同的独特客户类别。
现在,业务部门理解拥有如此多不同模型的重要性。他们可以轻松地将增量效益与所需的基础设施成本进行比较,以评估选项。
数据科学团队的工作是清楚地向利益相关者传达想法。这不是一件容易的事情,因为大多数人对数据科学的了解有限。只有当业务从中获得价值时,数据科学项目才被视为成功。
改善组织内部协作的一个好方法是提供一个团队之间信息流畅的环境。
领导技能——值得拥有
最后但同样重要的是领导技能。大多数组织都有一个小型的数据科学团队,他们通常会处理不同的问题集。数据科学家经常会被拉入不同的会议和临时询问。数据科学家的工作是决定何时说“是”,何时说“否”。设定正确的优先级非常重要。
此外,数据科学家需要有清晰的思维过程,并且应该具备展望结果的能力。许多时候,业务团队会施加很大压力,要求快速完成分析。数据科学家的角色是管理期望,并提供高质量的结果。
保持联系
-
如果你喜欢这篇文章并对类似的文章感兴趣,在 Medium 上关注我。订阅 Medium以访问与职业、财务及更多内容相关的数千篇文章。
-
我在我的 YouTube 频道上教授和讨论各种数据科学话题。在这里订阅我的频道。
-
注册到我的电子邮件列表,获取更多数据科学技巧,并保持与我工作的联系
简介:Sharan Kumar Ravindran 是一位高级经理(数据科学),在 Medium 上是人工智能领域的顶级作者,并且是一位拥有超过 10 年经验的数据科学领袖。他撰写和讨论数据科学,旨在使其更易于理解。
原文。经许可转载。
相关:
-
我作为数据科学家的前六个月
-
停止学习数据科学以寻找目标,寻找目标以学习数据科学
-
数据科学家如何赢得 CFO 的关注(以及为什么你需要这样做)
更多相关话题
每个科技人士都应该注册的 5 个学习平台
原文:
www.kdnuggets.com/5-learning-platforms-that-every-techie-should-sign-up-to

图片来源: Peter Olexa
正如我们所知,科技行业的变化速度远超我们的想象。如果你已经是一名科技专业人士,你会知道学习是永无止境的。你必须跟上行业的步伐,总有新的事物不断涌现。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
如果你希望进入科技行业,许多现有的科技专业人士会给出的主要建议是你必须成为一个热衷学习的人,因为这将是你职业生涯的大部分工作。
说到这里,有些人可能不知道从哪里获取知识或持续学习。因此,我编写了这篇文章,为你提供不同的平台,以满足不同的需求。
Coursera
链接: Coursera
Coursera 是一个知名的学习平台,不仅限于技术课程和认证。他们服务于个人、企业、大学和政府。多年来,Coursera 变得越来越受欢迎,特别是在与许多知名大学如密歇根大学和普林斯顿大学合作方面。
他们提供广泛的课程,从数据科学、计算机科学到个人发展等。你可能有兴趣在提高公共演讲或领导技能的同时学习一种新的编程语言。Coursera 应有尽有!
如果你想成为数据科学家,可以查看 一份免费的数据科学学习路线图:适用于所有级别的 IBM,或者如果你对 SQL 感兴趣,可以查看 提升你的数据科学技能:你需要的关键 SQL 认证。
edX
链接: edX
另一个提供各种在线课程的平台是 edX。你可以参加课程,获得证书,甚至获得学位!
edX 平台上的兴趣领域是最新的,例如,如果你希望成为一名提示工程师,可以特别学习人工智能和 ChatGPT。或者,你可以深入了解金融行业并学习区块链。曾经,edX 提供的课程主要针对特定行业,但随着技术行业的发展,这些技能具有高度的可转移性,能够惠及任何人!
例如,如果你希望成为一名全面的数据专业人员,可以查看 提升技能的 7 个免费哈佛大学课程。
DataCamp
链接: DataCamp
DataCamp 是一个知名的学习平台,专门针对希望提升数据和人工智能技能的个人。该平台提供了一系列免费课程,你可以在免费计划下参加这些课程,或者通过每月不到 11 英镑的高级版访问他们的完整内容库!你还可以以团队的形式学习,并将学习平台应用到你的公司中!
他们有从初学者到专家的各种课程,确保数据专业人员具备跟上技术世界所需的所有技能和知识。你还可以受益于他们的网络研讨会、代码练习、博客、播客和真实项目!
如果你希望进入科技行业,可以查看 30 天内成为求职准备好的 4 个认证。
O’Reilly
链接: O’Reilly
O’Reilly 是一个知名的出版商,但这并不是他们唯一的提供服务。多年来,他们举办了许多技术会议、现场培训、互动学习、认证体验、视频等。
他们的在线学习和培训平台服务于那些喜欢通过书籍学习的人,也服务于那些更喜欢通过课堂学习的人。你可以作为个人学习,也可以通过你的企业、政府机构或高等教育机构作为团队学习。
除了课程、认证和互动学习,O’Reilly 还提供洞察报告,分析数据讨论当前在技术市场上发生的情况。
如果你希望通过 O’Reilly 学习,可以查看 通过 O’Reilly 学习生成式人工智能的书籍、课程和现场活动,或者如果你想获得免费的报告,可以查看 2024 年技术趋势:O’Reilly 免费报告中的人工智能突破与发展洞察。
Pluralsight
链接: Pluralsight
你可能没听说过这个平台,我来告诉你,你错过了!Pluralsight 致力于帮助个人和团队缩短周期时间。他们希望组织加快入职速度,并确保你的团队具备完成任务所需的技能!他们的目标是解决挑战和优先事项,使工作更加高效和有效。
该学习平台认为,技术团队只有在技能相关的情况下才能成功。该平台提供广泛的课程、评估和实验室,以确保个人在商业世界中具备技术流利性。
总结一下
作为技术专业人士,学习应该是你职业目标的一部分。如果不是,你将不幸地落后,并觉得自己在不断追赶行业的步伐。学习平台旨在消除这些挑战,使你能够保持最新,并在职业生涯中感到安全。
自我发展不应被视为成本,而是你如何提升职业生涯。
尼莎·阿雅 是一位数据科学家、自由技术作家,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及理论知识。尼莎涵盖了广泛的话题,并希望探索人工智能如何有助于人类寿命的不同方式。作为一个热衷学习者,尼莎寻求扩展她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
麦肯锡教给我的 5 个经验教训,让你成为更好的数据科学家
原文:
www.kdnuggets.com/2021/07/5-lessons-mckinsey-taught-better-data-scientist.html
评论
作者 Tessa Xie,数据科学家

由Dan Dimmock拍摄,发布在Unsplash
我们的前三个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业道路。
2. Google Data Analytics Professional Certificate - 提升你的数据分析能力
3. Google IT Support Professional Certificate - 支持你的组织的 IT 工作
数据科学是近年来最热门的领域之一,吸引了大量有才华的人才争夺顶级公司数据科学团队的职位。虽然有很多文章教你如何准备数据科学面试并“从其他面试者中脱颖而出”,但求职之旅显然不仅仅是获得聘用。获得工作邀请只是第一步;然而,很少有人讨论如何在你通过面试并加入公司后,在其他被录用的数据科学家中脱颖而出。
在我于麦肯锡工作的这些年里,我有幸与麦肯锡及我服务的顶级公司中的无数聪明的数据科学家共事,并观察到那些获得合作伙伴和客户高度评价的顶尖数据科学家所具备的共同特质。也许对你们中的一些人来说,最优秀的数据科学家并不一定是那些构建最炫酷模型或编写最高效代码的人(当然,他们必须具备相当高的技术技能才能被聘用),而是那些在分析能力之上还拥有一些重要“软技能”的人。本文总结了我在麦肯锡期间的经验和观察,归纳为 5 条经验教训,帮助你成为更优秀的数据科学家。
作为一个喜爱精确的数据人士,我想指出,尽管“数据科学家”这一职称如今涵盖了行业中广泛的工作,但在本文中,我主要关注的是对业务决策有影响的数据科学家的技巧(而不是那些在更多研究导向的“核心数据科学”角色中的人)。
课程 1. 自上而下的沟通是关键
自上而下的沟通,或称金字塔原则,是由麦肯锡合伙人芭芭拉·敏托提出并普及的,许多人认为这是在商业(甚至个人生活)中最有效的沟通结构。尽管对于一些像战略顾问这样的职业来说,这是第二天性,但很多数据科学家在这方面却会陷入困境。这个想法很简单:当你尝试传达一个观点/论点时,如果你从关键信息开始,然后是几个主要论点来支持这个关键信息;如果需要,每个论点可以跟随支持数据,这样对观众来说最有效、最容易理解。
采用自上而下的沟通有以下几个优势:
-
关键要点在前:如果你在电子邮件/备忘录的开头看到TLDR或在研究论文的开头看到执行摘要,你会理解这点的重要性。将关键信息放在前面,可以确保即使观众没有抓住所有细节,他们也能大致了解内容。
-
演示/沟通可以轻松地针对不同的听众进行调整:你可以准备一套沟通材料,保持“关键信息”的水平,针对高层管理人员的主要论点,并根据需要扩展细节以满足对细节有兴趣的同行和其他分析型听众。
对于那些大部分时间都在进行深入分析的数据科学家来说,这种沟通结构可能不自然且可能违反直觉。太频繁地看到数据科学家以深入细节开始演示或沟通,导致观众迷失而未能传达关键信息。
如何实践:一个简单的实践方法是在会议前根据这种结构记录下你的想法,以便在沟通分析的关键发现时保持方向。同时,频繁地退后一步问自己你实际要解决的问题是什么,这应该是你传达的关键信息。
作者提供的图片
课程 2. 成为“翻译者”
如果你查看麦肯锡建议的 公司数据组织蓝图,它强调了一个名为“翻译者”的角色的重要性,该角色被认为是业务和数据团队之间沟通的桥梁,将分析洞察转化为业务可操作的内容(我认为这个角色部分来源于我上面提到的挫折)。我相信作为数据科学家,你已经被要求“像给五岁小孩讲解一样解释”或者“用简单的英语解释”。那些脱颖而出的数据科学家正是能做到这一点的人——充当自己的翻译者;如果被要求,他们可以向没有分析背景或时间阅读白皮书的首席执行官很好地解释他们的机器学习模型,并始终将分析结果与业务影响联系起来。这些数据科学家因以下原因而受到重视:
-
从非分析型人员那里获取“翻译者”是很困难的:麦肯锡确实尝试过培训一组战略顾问,成为不同分析研究的“翻译者”;但在我看来,从未成功。原因很简单:为了准确解释复杂分析的关键要点和准确反映警告,你需要具备分析思维和深刻理解,这些是通过几周的分析训练营无法获得的。例如,如果你不知道肘部法则,你如何解释你为 K 均值选择的簇数?如果你不知道 SSE 是什么,你如何解释肘部法则?作为数据科学家,你花时间教授这门大多不成功的速成课程,可能更好地用于打造自己的沟通风格,并自己进行翻译。
-
如果数据科学家可以解释自己的分析,可以避免精确度丧失:我相信大多数人玩过“电话”游戏或其变体。信息传递时间越长,保持其精确度就越困难。现在想象你的分析工作经历同样的过程;如果你依赖他人来解释/翻译你的工作,信息到达最终用户时可能与现实相差甚远。
如何练习:与朋友(最好是没有任何分析背景的朋友)练习,通过向他们解释你的模型/分析(当然不透露任何敏感信息)。这也是发现你方法中的知识差距的好方法;正如“大解释者”理查德·费曼所相信的,如果你无法简单地解释某事,很大程度上是因为你自己没有很好地理解它。
第 3 课:以解决方案为驱动是第一规则
这不仅限于数据人才;对公司中任何职能/角色的人来说都是至关重要的。能够识别问题并提出关注点当然非常有价值,但更受欢迎的是提出潜在解决方案的能力。如果房间里没有一个以解决方案为导向的人,讨论往往会陷入循环,过于执着于问题而不是尝试找出前进的路径。
在大多数顶级咨询公司中,以解决方案为导向是第一条规则,我认为这种方法也应该转移到科技界。作为数据科学家,你可能经常遇到由于缺乏分析背景而出现荒谬的数据要求的令人沮丧的情况。我见过无数的数据科学家不知道如何处理这些情况,因而在利益相关者管理中失败,因为他们总是消极拒绝。与其直接否定,不如以解决方案为导向,利用你对数据和分析工具的更好理解,帮助他们重新定义要求并限定范围。
注重解决方案并不意味着你不能对任何事物说“不”或总是必须有完美的解决方案;而是意味着你应该在每次说“不”的同时,总要跟上一句“但如果…会怎么样呢?”。
如何实践:当你遇到问题时,花一点时间考虑潜在的解决方案,然后再向你的团队或经理提出。运用你的创造力解决问题,不要害怕提出新的解决方案。还可以跳出你的工作领域,了解更多关于业务和其他团队的工作。了解全局通常有助于你将点连起来,并带你找到创造性的解决方案。
第 4 课:在商业环境中,解释性优于精确性
没有人真正想要预测客户流失,每个人都在试图理解客户流失。
现在,当每家公司都在构建模型来预测客户流失时,很难退一步问自己为什么我们最初想要预测客户流失。公司希望预测流失,以便找到可行的解决方案来防止它。所以,如果你的模型告诉 CEO“网站访问次数的立方根是指示客户流失的重要特征之一”,那他能用这些信息做什么?可能什么也做不了……
作为数据科学家,就像许多你们一样,我过去只关注准确性作为建模时的成功指标。但我逐渐意识到,通过添加无法解释的特征和微调超参数将准确性从 96%提高到 98%,对业务来说没有意义,如果你不能将其与业务影响联系起来(当然,这只适用于面向业务的数据科学家,在某些机器学习领域,这种增加可能意义重大)。
如果模型是黑箱子,那么从 C 级高管那里获得可信度也很困难。模型归根结底是用来指导商业决策的工具,所以它的价值在很大程度上基于其实用性和可解释性,这一点不应感到意外。
如何实践:在构建模型或进行分析时始终保持对商业影响的关注。在构建模型时,避免随意将互动特征丢给模型并希望其中一个会有效;相反,在开始构建模型之前,对特征工程阶段要非常用心。记录下模型/分析得出的商业建议,也将帮助你重新评估构建模型时所做的设计选择。
第 5 课:确保有一个假设,但不要固守于一个假设

作者提供的图片
对于大多数分析,从特征探索到探索性数据分析(EDA),有假设作为起点是重要的。没有假设,你将没有方向来切分和处理数据进行 EDA 或测试哪些特征。没有假设,进行 AB 测试也没有意义(这就是它被称为假设检验的原因)。但我经常看到数据科学家在没有明确假设的情况下深入分析阶段,然后迷失在复杂的情况中。更常见的是,数据科学家将假设构建过程完全留给不了解数据的团队成员,后来发现没有足够的数据来测试这些假设。在我看来,最佳方法是数据科学家从一开始就参与这些假设头脑风暴会议,并利用假设来指导和优先考虑后续分析。
虽然假设非常重要,但它们应该作为起点,而不是终点。我多次见过许多数据科学家(或与数据科学家合作的人)坚持一个假设,即使有相反的发现。这种对初始假设的“忠诚”会导致数据窥探和调整数据以适应某种叙事。如果你对“辛普森悖论”熟悉,你会理解数据讲述“错误故事”的力量。好的数据科学家应该能够保持数据完整性,并将叙事调整为符合数据,而不是相反。
如何实践: 重要的是建立业务理解和洞察力,以便提出好的假设。保持对假设的关注,以指导你在数据探索过程中,但要开放心态,承认数据可能与最初的“有根据的猜测”不同。良好的商业感觉也将帮助你在过程中调整最初的理论,并根据数据调整叙述。
在涉及业务角色时,人们往往认为才能可以分为两类:分析型和战略型,好像这两种能力处于光谱的两端。我告诉你一个秘密,最好的分析型人才也是那些理解战略/业务方面,并知道如何与业务利益相关者沟通的人,而最好的战略角色人才则对分析和数据有一定的理解。
简介:Tessa Xie 目前是一名 AV 行业的数据科学家,曾任麦肯锡数据科学家;热爱旅行、潜水和绘画。
原文。经授权转载。
相关:
-
作为数据科学初学者你应该避免的 10 个错误
-
数据科学家将在 10 年内消失
-
数据科学在 10 年内不会消失,你的技能可能会
更多相关话题
面向 NLP 从业者的 5 门语言学课程
原文:
www.kdnuggets.com/2022/11/5-linguistics-courses-nlp-practitioners.html
照片由 Charl Folscher 提供,来源于 Unsplash
大多数 NLP 从业者,尤其是 KDnuggets 的读者,我认为,他们是通过 计算 路径进入自然语言处理的(请记住,计算语言学 是我们所称的 NLP 的另一种说法)。也就是说,这些从业者将拥有坚实的技术基础。这与从 语言学 路径进入 NLP 的受过训练的语言学家形成了直接对比。技能差异应该是相对明显的。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
根据你选择的路径,你一开始所具备的专业知识将会有所不同。虽然语言学背景的人需要努力学习所需的计算技能,但来自计算背景的人则需要弥补他们的语言学知识。
这 5 门课程旨在帮助自然语言处理(NLP)从业者或有志之士弥补他们缺乏的语言学知识。
1. 人类语言的奇迹:语言学导论
来自莱顿大学和梅尔滕斯研究所(通过 Coursera)
这门课程的目标是为你提供语言学的快速入门。它声称如果你打算进一步学习语言学、研究相关学科,或者希望提升你的分析技能,这门课程将特别有用。
《人类语言的奇迹》将带你深入多面的语言研究,这让人类自历史开始便感到惊叹。你将与全球许多其他语言的使用者以及像诺姆·乔姆斯基和阿黛尔·戈尔德堡等著名语言学家一起,学习理解和分析你的母语如何与许多其他语言既相似又不同。你将学习语言学的基本概念,了解一些大语言和小语言的关键特征,并深入了解语言学家的工作。
基本上,如果你想了解语言是如何运作的,以及语言如何用于理解人类思维,《人类语言的奇迹》是适合你的课程。
2. 应用语言学
来自莱斯特大学
莱斯特大学的应用语言学课程采用了明显少一些理论化的方法,与之前的课程不同,重点在于如何在现实世界中运用语言学学科的技能。
这个在线课程将介绍实际的、现实世界的应用,包括语言教学、语言评估和法医语言学。从减少性别偏见到简化法律文本,应用语言学对有效沟通至关重要。通过一系列案例研究,并在我们的应用语言学学位课程中,借助专家的帮助,你将学习到让你从全新视角看待语言使用的技术和研究方法。
该课程的目标人群是对语言学或语言教学感兴趣的人,以及那些可能考虑攻读研究生语言学学位的人。
3. 比较印欧语言学导论
来自莱顿大学(通过 Coursera)
印欧语系是一个庞大的家族,包括一些世界上最著名的语言。
增强你对印欧语言的知识,了解它们如何随时间变化以及如何重构古代语言。每种语言都属于一个语言家族;这是一个彼此基因相关的语言群体。印欧语系是英语所属的语言家族名称,还有许多子家族,如日耳曼语和罗曼语。
该课程将考察这一语言树的许多分支的结构和起源,展示语言比较,并讨论语言重构,帮助你拼凑 原始印欧语言。
4. 语料库语言学:方法、分析、解释
来自兰卡斯特大学(通过 Future Learn)
这门来自莱斯特大学的课程在实际应用上比之前的课程更具针对性。该课程旨在从研究的角度介绍语料库语言学的方法论。
在八周的时间里,你将建立必要的技能,以收集和分析大规模数字文本集合(语料库)。
你将接触到多个主题,展示如何在话语分析、社会语言学、语言学习和教学等领域使用语料库。
这是唯一一个公开的研究语料库构建课程,内容看起来非常有趣。
5. 社会语言学入门:口音、态度与身份
来自约克大学
该课程专注于人们如何与语言互动。
这门课程适合任何对社会语言学感兴趣的人。内容包括:对英国口音的态度;社会语言学家如何测量口音和态度;口音与身份之间的关系;口音在现实世界中的重要性
这是另一门高度专业化的课程,带有社会语言学的倾向。课程内容涵盖了口音、对口音的态度以及这些如何帮助形成身份,这是对语言学世界的一种新视角。
Matthew Mayo (@mattmayo13) 是数据科学家及 KDnuggets 的主编,KDnuggets 是重要的数据科学和机器学习在线资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系到。
相关主题
5 种机器学习模型在 5 分钟内解释
原文:
www.kdnuggets.com/5-machine-learning-models-explained-in-5-minutes

图片由作者提供
机器学习是一种计算机算法,帮助机器在不需要明确编程的情况下进行学习。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
今天,我们在导航系统、电影流媒体平台和电子商务应用中都能看到机器学习的应用。
实际上,从你早上醒来到晚上睡觉,你可能已经与数十个机器学习模型互动而未曾意识到。
预计机器学习行业将在 2024 年至 2030 年间增长超过 36%。
鉴于几乎每个大型组织都在积极投资于人工智能,你只会从提升机器学习技能中受益。
无论你是数据科学爱好者、开发者,还是想提升该领域知识的普通人,以下是 5 种你应该了解的常用机器学习模型:
1. 线性回归
线性回归是最受欢迎的机器学习模型,用于执行定量任务。
该算法用于使用一个或多个自变量(X)预测连续结果(y)。
例如,如果你被要求根据房屋大小预测房价,你会使用线性回归。
在这种情况下,房屋大小是你的自变量 X,用于预测房价,房价是因变量。
这是通过拟合一个线性方程来建模 X 与 y 之间的关系,表示为 y=mX+c。
这里是一个表示线性回归的图示,用于建模房价与房屋大小之间的关系:
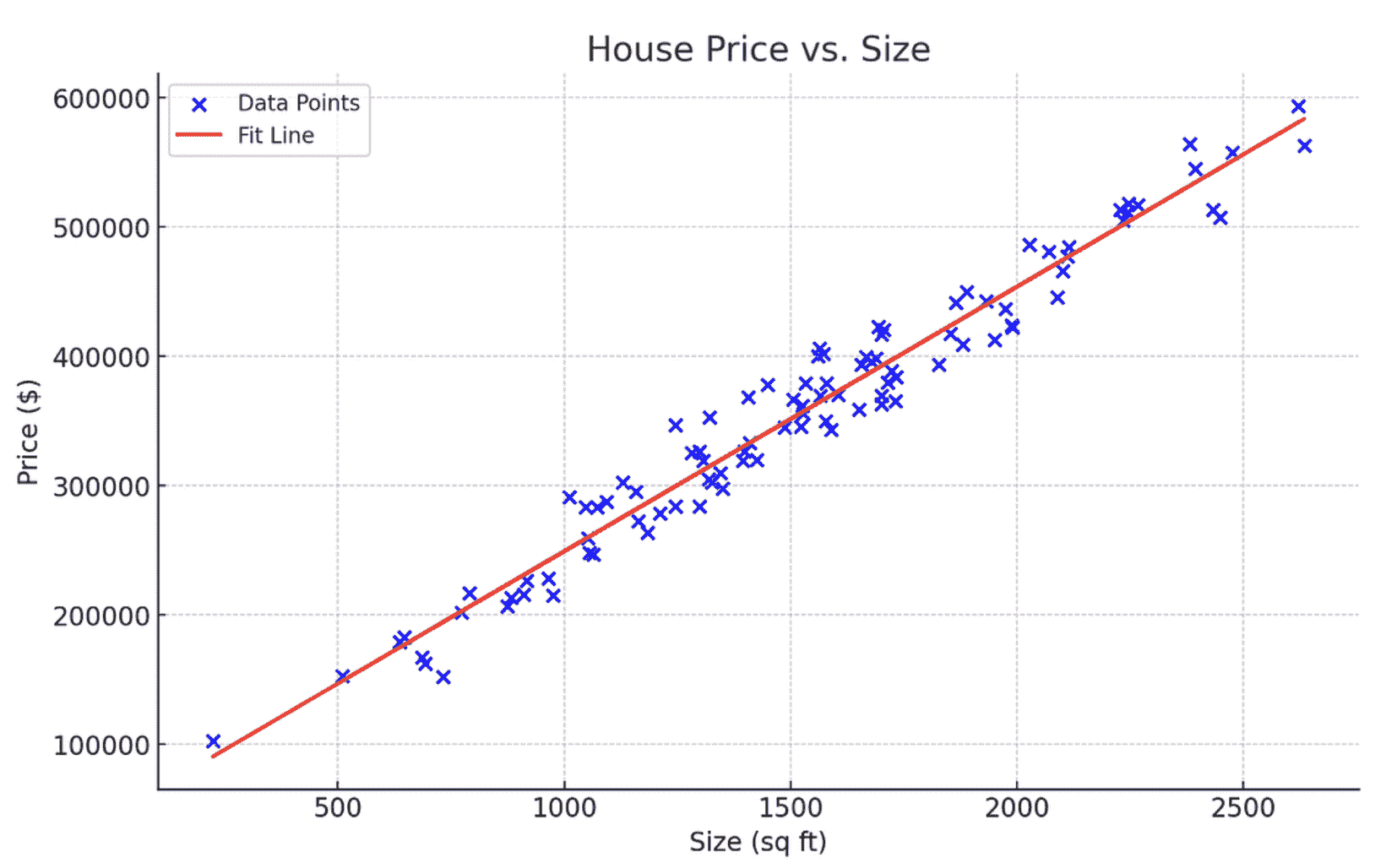
图片由作者提供
学习资源
要了解更多关于线性回归的直觉以及它如何在数学上运作,我推荐观看Krish Naik 的 YouTube 教程。
2. 逻辑回归
逻辑回归是一种分类模型,用于预测给定一个或多个自变量的离散结果。
例如,给定一个句子中的负面关键词数量,可以使用逻辑回归预测给定消息是否应该被分类为合法或垃圾邮件。
这里是展示逻辑回归如何工作的图表:
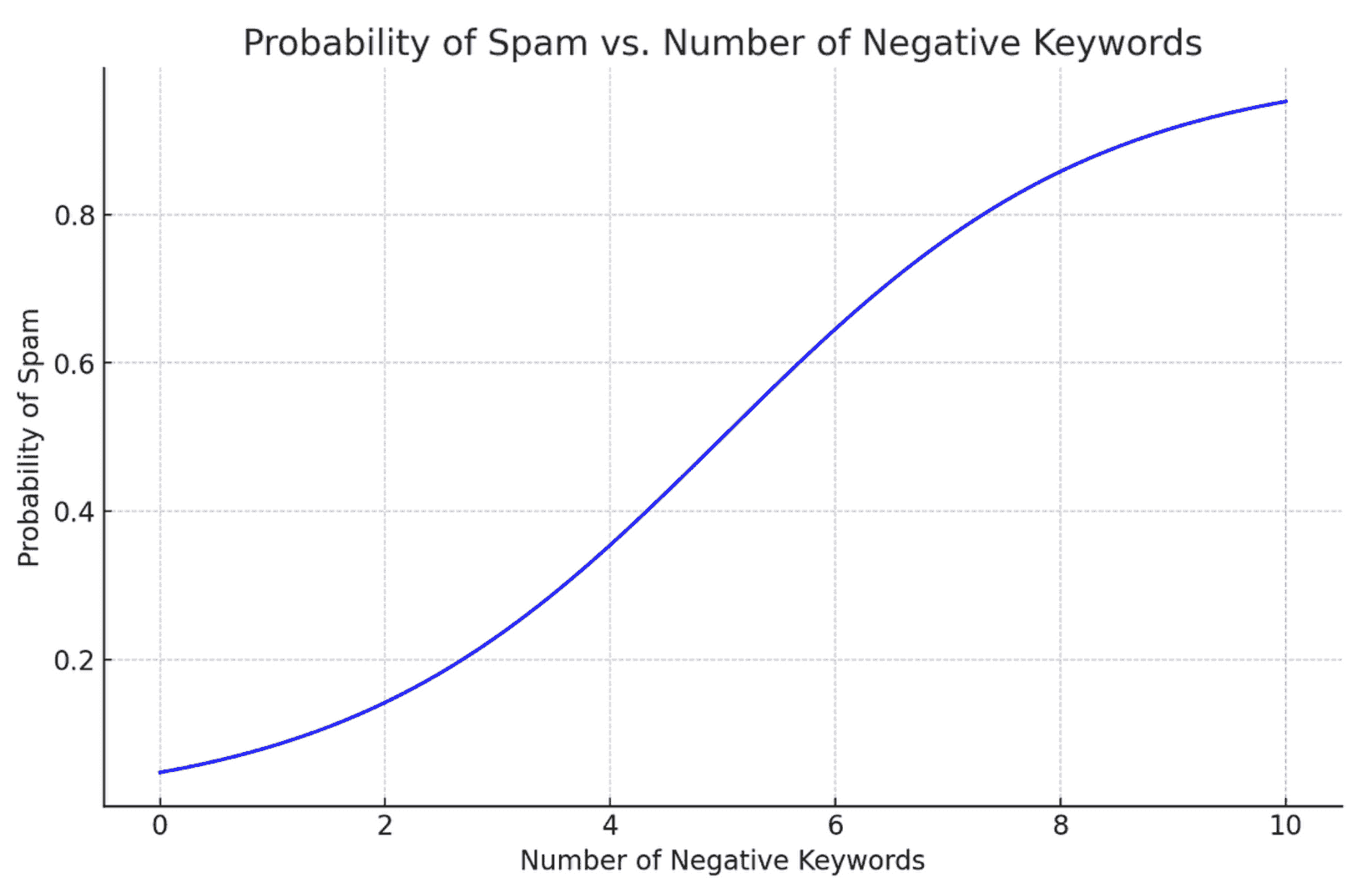
作者提供的图片
注意,与表示直线的线性回归不同,逻辑回归被建模为 S 形曲线。
正如上面的曲线所示,负面关键词的数量增加时,消息被分类为垃圾邮件的概率也增加。
此曲线的 x 轴表示负面关键词的数量,y 轴显示邮件被标记为垃圾邮件的概率。
通常,在逻辑回归中,0.5 或更高的概率表示正面结果——在这种情况下,这意味着消息是垃圾邮件。
相反,低于 0.5 的概率表示负面结果,意味着消息不是垃圾邮件。
学习资源
如果你想了解更多关于逻辑回归的内容,StatQuest 的逻辑回归教程是一个很好的起点。
3. 决策树
决策树是一种流行的机器学习模型,用于分类和回归任务。
它们通过根据数据集的特征将其分解,创建树状结构来建模这些数据。
简而言之,决策树允许我们根据特定参数持续拆分数据,直到做出最终决策。
这里是一个简单决策树的示例,用于确定一个人在某一天是否应该吃冰淇淋:
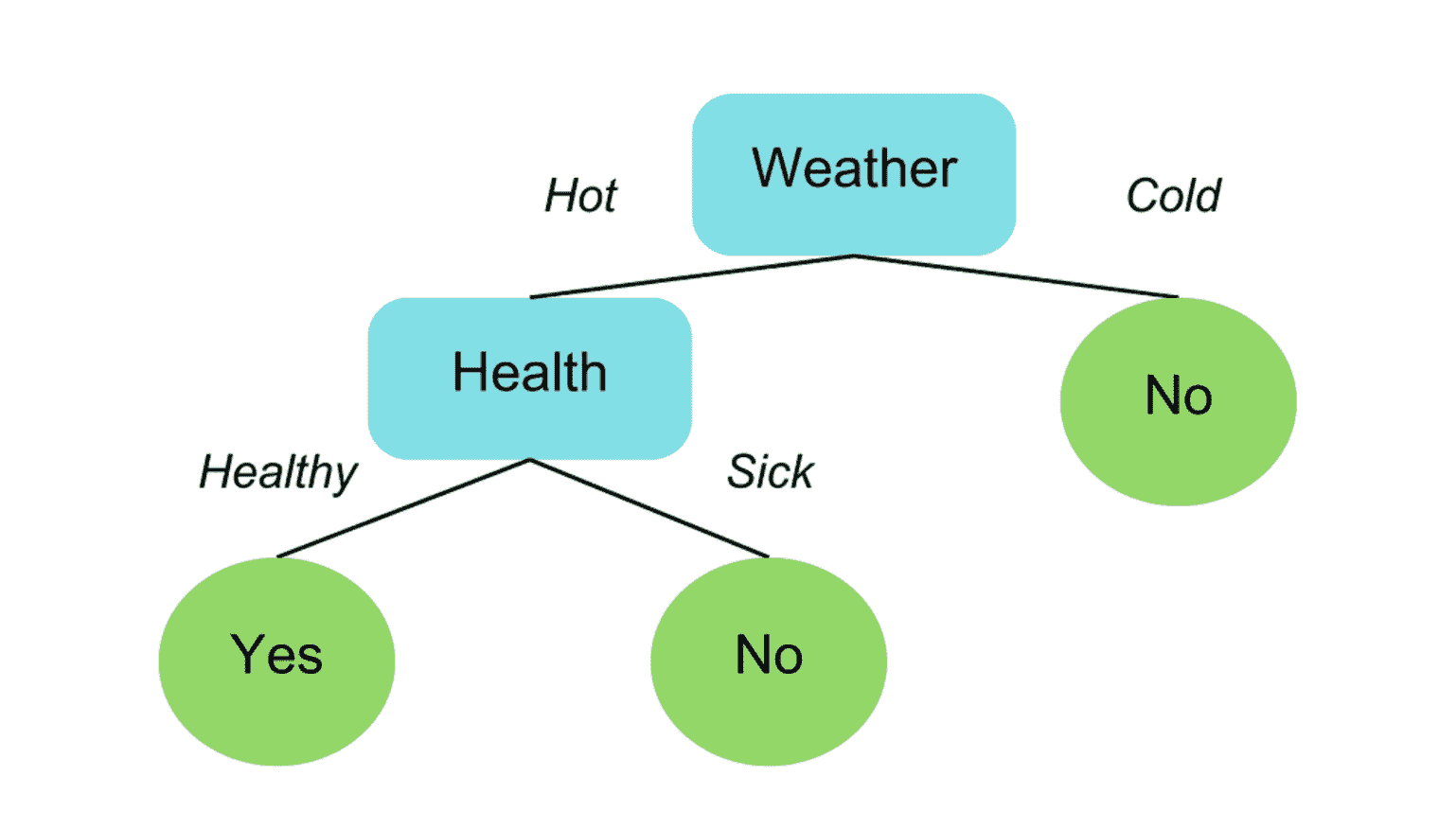
作者提供的图片
-
树从天气开始,识别是否适合吃冰淇淋。
-
如果天气温暖,则进入下一个节点,即健康。如果不是,决策为“不”,不再进行拆分。
-
在下一个节点,如果这个人健康,他们可以吃冰淇淋。否则,他们应该避免这样做。
注意决策树中每个节点的数据如何拆分,将分类过程分解为简单、易管理的问题。
你可以为回归任务绘制类似的决策树,且过程中的直觉将保持不变。
学习资源
要了解更多关于决策树的内容,我建议观看StatsQuest 的视频教程。
4. 随机森林
随机森林模型结合了多个决策树的预测,并返回一个单一的输出。
直观上,这种模型应优于单一决策树,因为它利用了多个预测模型的能力。
这借助一种称为袋装法或自助聚合的技术来完成。
以下是袋装法的工作原理:
一种叫做自助法的统计技术用于多次有放回地抽样数据集。
然后,在每个样本数据集上训练一个决策树。所有树的输出最终合并以生成一个单一的预测。
对于回归问题,最终输出是通过对每个决策树做出的预测进行平均来生成的。对于分类问题,则是做出多数类预测。
学习资源
你可以观看 Krish Naik 关于随机森林的教程以深入了解模型背后的理论和直觉。
5. K-Means 聚类
到目前为止,我们讨论的所有机器学习模型都属于一种叫做监督学习的方法。
监督学习是一种利用标记数据集来训练算法以预测结果的技术。
相比之下,非监督学习是一种不处理标记数据的技术。它识别数据中的模式,而无需训练以确定特定的结果。
K-Means 聚类是一种非监督学习模型,基本上处理未标记的数据并将每个数据点分配到一个簇中。
观察属于与均值最近的簇。
这里是 K-Means 聚类模型的可视化表示:
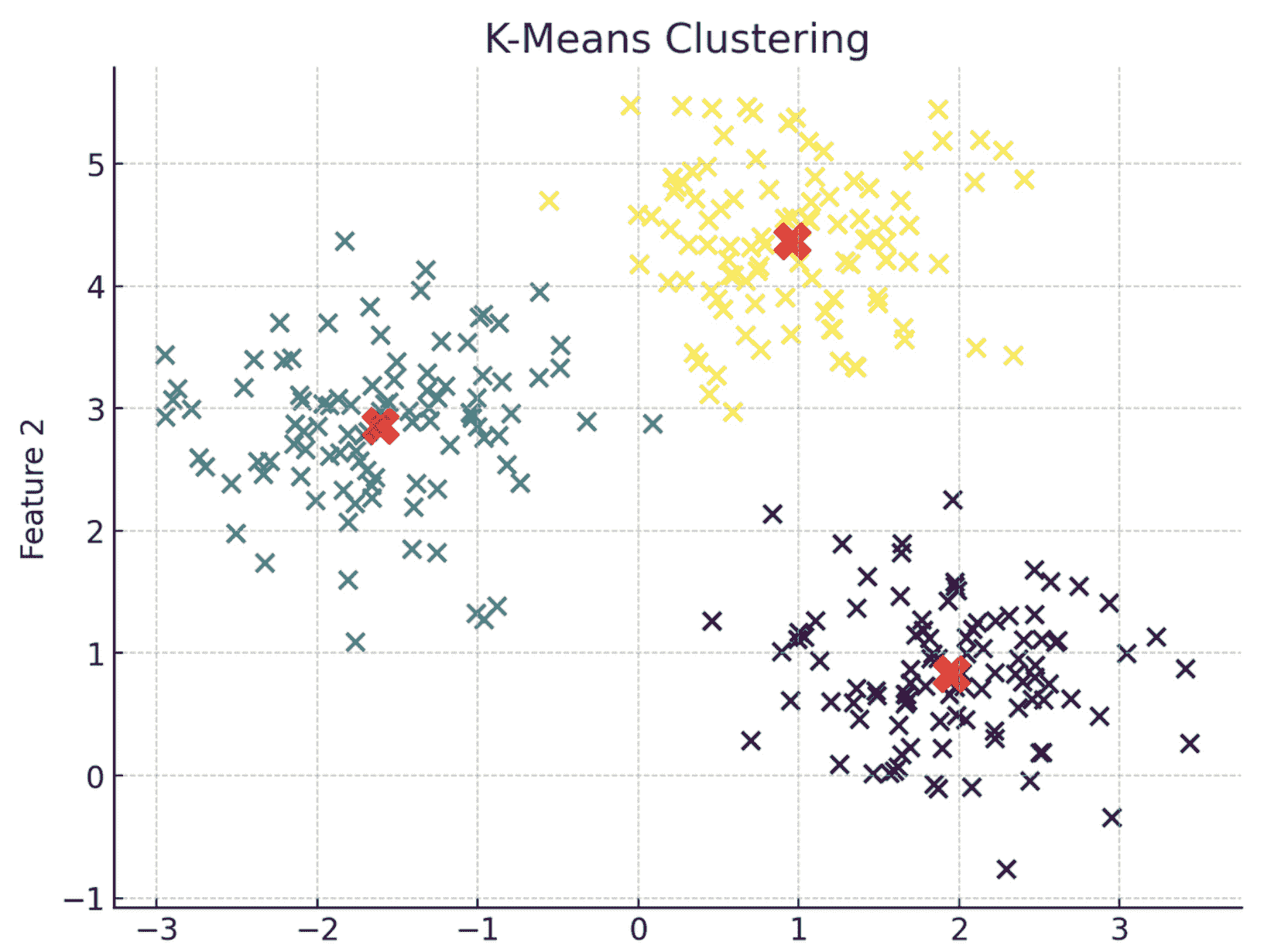
作者提供的图片
注意算法如何将每个数据点分组为三个不同的簇,每个簇由不同的颜色表示。这些簇是根据它们与中心点的接近程度进行分组的,中心点由一个红色的 X 标记表示。
简单来说,Cluster 1 中的所有数据点都具有相似的特征,这就是它们被归为一组的原因。相同的原则也适用于 Cluster 2 和 Cluster 3。
在构建 K-Means 聚类模型时,你必须明确指定你想生成的簇数量。
这可以通过一种叫做肘部法的方法实现,该方法只是将模型在不同簇值下的错误分数绘制在折线图上。然后,你选择曲线的拐点,或称为“肘部”,作为最佳的簇数量。
这里是肘部法的可视化表示:
作者提供的图片
注意到此曲线上的拐点在 3 簇标记处,这意味着该算法的最佳簇数量是 3。
学习资源
如果你想了解更多关于该主题的信息,StatQuest 提供了一个
8 分钟视频清晰地解释了 K-Means 聚类的工作原理。
下一步
本文解释的机器学习算法在行业应用中非常常见,例如预测、垃圾邮件检测、贷款审批和客户细分。
如果你能坚持到这里,恭喜你!你现在已经对最广泛使用的预测算法有了扎实的掌握,并迈出了进入机器学习领域的第一步。
但旅程并未结束。
为了巩固你对机器学习模型的理解,并能够将它们应用于实际应用,我建议学习一种编程语言,如 Python 或 R。
Freecodecamp 的 初学者 Python 课程
课程是一个很好的起点。如果你在编程学习过程中遇到困难,我有一个 YouTube 视频 解释了如何从零开始学习编程。
一旦你学会了编程,你将能够使用像 Scikit-Learn 和 Keras 这样的库在实践中实现这些模型。
为了提高你的数据科学和机器学习技能,我建议你利用像 ChatGPT 这样的生成式 AI 模型为自己制定一个量身定制的学习路径。这里有一个更详细的路线图,帮助你开始利用 ChatGPT 学习数据科学。
Natassha Selvaraj 是一位自学成才的数据科学家,热衷于写作。Natassha 涉及所有数据科学相关的话题,是数据领域的真正大师。你可以通过 LinkedIn 与她联系,或者查看她的 YouTube 频道。
更多相关内容
5 篇关于面部识别的机器学习论文
原文:
www.kdnuggets.com/2020/05/5-machine-learning-papers-face-recognition.html
评论

面部识别,或称面部识别,是计算机视觉领域最大的研究领域之一。我们现在可以使用面部识别来解锁手机、在安检门验证身份,以及在一些国家进行购买。由于其使众多过程更高效的能力,许多公司投资于面部识别技术的研究与开发。本文将重点介绍一些相关研究,并介绍五篇关于面部识别的机器学习论文。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织在 IT 方面
面部识别领域的基础机器学习论文
1. 一个大规模多模态面部反欺骗的数据集与基准
随着面部识别技术在现实世界中的应用越来越广泛,它变得越来越重要。从智能手机解锁到面部验证支付方式,面部识别可以在许多方面提高安全性和监控。然而,这项技术也带来了若干风险。众多面部欺骗方法可能被用来欺骗这些系统。因此,面部反欺骗技术对防止安全漏洞至关重要。
为了支持面部反欺骗研究,本文的作者引入了一个名为 CASIASURF 的多模态面部反欺骗数据集。截至本文撰写时,这是最大的公开面部反欺骗数据集。具体而言,该数据集包括 21,000 段视频,拍摄自 1,000 名受试者,涵盖 RGB、深度和红外模态。除了数据集之外,作者还提出了一个新颖的多模态融合模型,作为面部反欺骗的基准。
发布 / 最后更新 – 2019 年 4 月 1 日
作者与贡献者 – Shifeng Zhang(NLPR, CASIA, UCAS, 中国),Xiaobo Wang(JD AI Research),Ajian Liu(MUST, 澳门,中国),Chenxu Zhao(JD AI Research),Jun Wan(NLPR, CASIA, UCAS, 中国),Sergio Escalera(巴塞罗那大学),Hailin Shi(JD AI Research),Zezheng Wang(JD Finance),Stan Z. Li(NLPR, CASIA, UCAS, 中国)。
2. FaceNet:一个统一的面部识别与聚类嵌入
在本文中,作者介绍了一种名为 FaceNet 的人脸识别系统。该系统使用深度卷积神经网络来优化嵌入,而不是使用中间瓶颈层。作者指出,这种方法最重要的方面是系统的端到端学习。
团队在 CPU 集群上对卷积神经网络进行了 1,000 到 2,000 小时的训练。然后,他们在四个数据集上评估了他们的方法。值得注意的是,FaceNet 在著名的 Labeled Faces in the Wild (LFW) 数据集上达到了 99.63% 的准确率,在 Youtube Faces Database 上达到了 95.12% 的准确率。
发布时间/最后更新 – 2015 年 6 月 17 日
作者和贡献者 – Florian Schroff、Dmitry Kalenichenko 和 James Philbin,来自 Google Inc.
3. 概率性人脸嵌入
在撰写本文时,用于人脸识别的当前嵌入方法能够在受控环境中实现高性能。这些方法通过拍摄人脸图像并将关于该人脸的数据存储在潜在语义空间中来工作。然而,在完全不受控的环境中测试时,当前方法的表现不能那么好。这是由于图像中缺少或模糊的面部特征。例如,在监控视频中的人脸识别就是这样一个案例,视频质量可能较低。
为了帮助解决这个问题,本文的作者提出了概率性人脸嵌入(PFEs)。作者提出了一种将现有确定性嵌入转换为 PFEs 的方法。最重要的是,作者指出这种方法有效地提高了人脸识别模型的性能。
发布时间/最后更新 – 2019 年 8 月 7 日
作者和贡献者 – Yichun Shi 和 Anil K. Jain,来自密歇根州立大学。
4. 人脸识别的难题在于噪声
在这项研究中,来自 SenseTime Research、加利福尼亚大学圣地亚哥分校和南洋理工大学的研究人员研究了噪声在大规模人脸图像数据集中的影响。许多大数据集由于其规模和成本效益的性质,容易受到标签噪声的影响。通过这篇论文,作者旨在提供有关标签噪声来源及其对人脸识别模型的影响的知识。此外,他们还计划构建并发布一个名为 IMDb-Face 的干净人脸识别数据集。
研究的两个主要目标是发现噪声对最终性能的影响,并确定标注人脸身份的最佳策略。为此,团队手动清理了两个流行的开放人脸图像数据集 MegaFace 和 MS-Celeb-1M。他们的实验显示,使用其清理后的 MegaFace 数据集的 32% 和清理后的 MS-Celeb-1M 数据集的 20% 训练的模型,性能与在原始未清理数据集上训练的模型相似。
发布日期 / 最后更新 – 2018 年 7 月 31 日
作者和贡献者 – Fei Wang(SenseTime)、Liren Chen(加州大学圣地亚哥分校)、Cheng Li(SenseTime)、Shiyao Huang(SenseTime)、Yanjie Chen(SenseTime)、Chen Qian(SenseTime)和 Chen Change Loy(南洋理工大学)。
5. VGGFace2: 一个用于识别姿势和年龄变化面孔的数据集
许多研究已经对面部识别的深度卷积神经网络进行了研究。反过来,也创建了许多大规模的面部图像数据集来训练这些模型。然而,本文的作者指出,之前发布的数据集在面部姿势和年龄变化方面的数据并不多。
在本文中,牛津大学的研究人员介绍了 VGGFace2 数据集。该数据集包含了具有广泛年龄、种族、光照和姿势变化的图像。总的来说,该数据集包含 331 万张图像和 9131 个对象。
发布日期 / 最后更新 – 2018 年 5 月 13 日
作者和贡献者 – 牛群曹、李申、魏迪·谢、Omkar M. Parkhi 和安德鲁·齐瑟曼,来自牛津大学视觉几何组。
希望上述关于面部识别的机器学习论文能帮助你加深对该领域工作的理解。
每年都有新的面部识别研究。为了跟上最新的机器学习论文和其他人工智能新闻,请 订阅我们的新闻通讯。有关面部识别的更多阅读,请参阅下面的相关资源。
个人简介:Limarc Ambalina 是一位驻东京的作家,专注于人工智能、技术和流行文化。他为包括 Hacker Noon、Japan Today 和 Towards Data Science 在内的多个出版物撰写过文章。
原文。经授权转载。
相关:
-
每个数据科学家都应阅读的 5 篇 CNN 论文
-
2020 年 3 月 10 篇必读的机器学习文章
-
2018 版 50+个有用的机器学习与预测 API
更多相关内容
2024 年值得阅读的 5 篇机器学习论文
原文:
www.kdnuggets.com/5-machine-learning-papers-to-read-in-2024

使用 DALL-E 3 生成的图像
机器学习是人工智能的一个子集,它通过提供效率和预测性洞察来为企业带来价值。它是任何企业的宝贵工具。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织进行 IT 工作
我们知道去年充满了机器学习的突破,今年也不例外。需要学习的内容实在太多了。
在如此多的学习内容中,我挑选了 2024 年几篇值得阅读的论文,以提升您的知识。
这些论文是什么?让我们深入了解一下。
HyperFast:表格数据的即时分类
HyperFast 是由Bonet et al. (2024)研究开发的一个元训练超网络模型。它旨在提供一个能够在一次前向传递中即时分类表格数据的分类模型。
作者表示,HyperFast 可以生成一个任务特定的神经网络,用于未见数据集的分类预测,且无需训练模型。这种方法可以显著减少计算需求和部署机器学习模型所需的时间。
HyperFast 框架展示了输入数据通过标准化和降维处理,然后经过一系列超网络生成网络层的权重,这些权重包括基于最近邻的分类偏差。
总的来说,结果显示 HyperFast 表现出色。它比许多经典方法更快,无需微调。论文总结道,HyperFast 可能成为一种可以应用于许多实际案例的新方法。
EasyRL4Rec:一个用户友好的基于强化学习的推荐系统代码库
接下来的论文讨论的是由Yu et al. (2024)提出的新库 EasyRL4Rec。这篇论文的重点是一个旨在开发和测试基于强化学习(RL)的推荐系统(RSs)的用户友好型代码库,名为 EasyRL4Rec。
该库提供了一个具有四个核心模块(环境、策略、状态跟踪器和收集器)的模块化结构,每个模块处理强化学习过程的不同阶段。
整体结构表明,它围绕强化学习工作流的核心模块进行操作,包括用于模拟用户交互的环境(Envs)、用于收集交互数据的收集器、用于创建状态表示的状态跟踪器以及用于决策的策略模块。它还包括一个用于管理数据集的数据层和一个包含训练评估器的执行器层,用于监督 RL 代理的学习和性能评估。
作者总结道,EasyRL4Rec 包含一个用户友好的框架,可以解决推荐系统中 RL 的实际挑战。
标签传播用于视觉语言模型的零-shot 分类
Stojnic et al. (2024) 的论文介绍了一种名为 ZLaP 的技术,即 Zero-shot Classification with Label Propagation。它是通过利用测地距离进行分类的视觉语言模型零-shot 分类的增强方法。
众所周知,像 GPT-4V 或 LLaVa 这样的视觉模型具备零-shot 学习能力,可以在没有标注图像的情况下进行分类。然而,这些模型仍然可以进一步增强,这也是研究小组开发 ZLaP 技术的原因。
ZLaP 的核心思想是利用图结构数据集中的标签传播,该数据集包括图像和文本节点。ZLaP 在此图中计算测地距离以进行分类。该方法还设计用于处理文本和图像的双重模态。
在性能方面,ZLaP 显示了在零-shot 学习中持续超越其他最先进方法的结果,通过在 14 个不同数据集实验中利用转导和归纳推理方法。
总的来说,该技术显著提高了多个数据集上的分类准确性,这表明 ZLaP 技术在视觉语言模型中的前景广阔。
不留任何上下文:使用 Infini-attention 的高效无限上下文 Transformer
我们将讨论的第四篇论文由 Munkhdalai et al. (2024) 发表。该论文介绍了一种名为 Infini-attention 的方法,以在有限计算能力下处理无限长输入,来扩展基于 Transformer 的大型语言模型(LLMs)。
Infini-attention 机制将压缩内存系统集成到传统的注意力框架中。将传统的因果注意力模型与压缩内存结合,可以存储和更新历史上下文,并通过在 Transformer 网络内聚合长期和局部信息来高效处理扩展序列。
总体而言,该技术在处理长上下文语言建模任务方面表现优越,例如从长序列中检索密码和书籍总结,相较于当前可用模型。
该技术可能提供许多未来的应用途径,尤其是对需要处理大量文本数据的应用。
AutoCodeRover: 自主程序改进
我们将讨论的最后一篇论文由 Zhang et al. (2024) 撰写。该论文的主要关注点是名为 AutoCodeRover 的工具,它利用能够执行复杂代码搜索的大型语言模型(LLMs)来自动解决 GitHub 问题,主要是错误和功能请求。通过使用 LLM 解析和理解 GitHub 上的问题,AutoCodeRover 可以比传统的基于文件的方法更有效地导航和操作代码结构以解决问题。
AutoCodeRover 的工作有两个主要阶段:上下文检索阶段和补丁生成目标。它通过分析结果来检查是否已收集到足够的信息以识别代码中的错误部分,并尝试生成补丁来修复问题。
论文表明,AutoCodeRover 相较于之前的方法提升了性能。例如,它解决了 SWE-bench-lite 数据集中 22-23% 的问题,平均每个问题的解决时间少于 12 分钟。这是一个改进,因为通常解决这些问题需要两天时间。
总体而言,论文显示出前景,因为 AutoCodeRover 能显著减少程序维护和改进任务所需的人工努力。
结论
2024 年有许多机器学习论文可读,以下是我推荐的论文:
-
HyperFast: 表格数据的即时分类
-
EasyRL4Rec: 面向基于强化学习的推荐系统的用户友好型代码库
-
使用视觉-语言模型进行零样本分类的标签传播
-
留住上下文:具有 Infini-attention 的高效无限上下文变换器
-
AutoCodeRover: 自主程序改进
希望这些对你有帮助!
Cornellius Yudha Wijaya**** 是数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 撰写了多种 AI 和机器学习主题的文章。
更多相关主题
5 个你不应忽视的机器学习项目
原文:
www.kdnuggets.com/2018/02/5-machine-learning-projects-overlook-feb-2018.html
 评论
评论
在暂别之后,本月的“忽视...”帖子将卷土重来,继续温和地引入一些强大的鲜为人知的 机器学习项目。
查看下面的 5 个项目,获得一些潜在的新机器学习点子。
1. skift: scikit-learn 的 Python fastText 封装器
什么是 skift?
skift 包含几个与 fastText Python 包兼容的 scikit-learn 封装器,以适应这些用例。
什么是 fastText?
fastText 是一个高效学习词表示和句子分类的库。
fastText 仅适用于文本数据,这意味着它将只使用数据集中的一列,而这个数据集可能包含许多不同类型的特征列。因此,一个常见的用例是让 fastText 分类器使用单列作为输入,忽略其他列。当 fastText 被用作堆叠分类器中的多个分类器之一时,其他分类器使用非文本特征时,这一点尤其如此。
理解 fastText 是拼图中的重要一环,但一旦掌握了这一理解,skift 可以帮助你轻松实现 fastText,并将其与其他 Scikit-learn 功能集成。
>>> from skift import FirstColFtClassifier
>>> df = pandas.DataFrame([['woof', 0], ['meow', 1]], columns=['txt', 'lbl'])
>>> sk_clf = FirstColFtClassifier(lr=0.3, epoch=10)
>>> sk_clf.fit(df[['txt']], df['lbl'])
>>> sk_clf.predict([['woof']])
[0]

对于 PHP 没有体面的机器学习替代方案感到厌倦了吗?你是一个受虐狂(如果你在用 PHP,这个问题答案已经显而易见)?那么,这个项目可能正适合你!
PHP 中机器学习的新方法。一库包含算法、交叉验证、神经网络、预处理、特征提取等功能。
虽然我是在开玩笑,但我已经远离 PHP 世界,不知道这是否能满足某些特定的紧迫需求;5K+ 的星标表明它可能确实有这个作用!除此之外,我总是对不同编程语言环境中的机器学习生态系统如何展开感兴趣。也许你也一样,或者更重要的是,你可能真的需要一个初看起来对 PHP 用户来说是一个坚实的库。

虽然这从技术上讲不是一个独立项目,但我认为它足够重要,值得在这里突出显示。
你可以通过在 keras.wrappers.scikit_learn.py 找到的包装器,将 Sequential Keras 模型(仅单输入)作为 Scikit-Learn 工作流的一部分使用。
类似于了解 skift(如上文)的底层项目最重要,理解使用 Keras 实现神经网络的部分是这个难题的关键,Keras 本身是一个高级 API。能够将 Keras 与额外的 Scikit-learn 功能集成,并使用熟悉的 API 和方法,就是这些包装器所实现的功能。可以在官方 Keras Github repository 上找到 API。
如果你已经在使用 Keras,这对你来说可能并不陌生。如果你还没有,知道这个集成是可能的可能足以让你看看。

梯度提升依然非常流行。或者至少某种程度上流行。最近进入梯度提升树领域的是 CatBoost。
CatBoost 的主要优势:
- 相较于其他 GBDT 库,质量更优。
- 同类最佳的推断速度。
- 支持数值和分类特征。
- 对训练的快速 GPU 和多 GPU(在一个节点上)支持。
- 包含数据可视化工具。
CatBoost 提供 Python、R 和命令行界面版本。查看 这里的教程,以及完整的 文档。

PyMC3 是一个用于贝叶斯统计建模和概率机器学习的 Python 包,专注于高级 Markov 链蒙特卡罗和变分拟合算法。它的灵活性和可扩展性使其适用于大量问题。
PyMC3 基于 Theano 提供:
- 计算优化和动态 C 编译
- Numpy 广播和高级索引
- 线性代数运算符
- 简单的可扩展性
……还有更多。你可以查看 入门指南 和 API 快速入门指南。
相关:
-
5 个你无法再忽视的机器学习项目
-
5 个你无法再忽视的机器学习项目
-
5 个你无法再忽视的机器学习项目 – 第六集
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
更多相关话题
不容错过的 5 个机器学习项目,2018 年 6 月
原文:
www.kdnuggets.com/2018/06/5-machine-learning-projects-overlook-jun-2018.html
评论
我们回来了。又一次。“Overlook...” 的帖子已经沉寂了几个月,但不用担心,这里有另一篇文章。我们继续着这个谦逊的任务,将强大的、不太为人知的机器学习项目展示给更多的眼睛。
这次外出活动完全由 Python 项目组成,这并非故意设计,而是无疑受到了我自身偏见的影响。虽然之前的版本包含了各种语言的项目(R、Go、C++、Scala、Java 等),我保证不久将推出一个全 R 版本,并在评估这些项目时会请外部协助(我承认对 R 生态系统的了解不深)。
这里有 5 个精心挑选的项目,可以提供一些潜在的新机器学习想法。
1. 实时损失图
不要盲目训练深度学习模型!要有耐心,查看你训练的每个周期!
在 Jupyter Notebook 中的 Keras、PyTorch 和其他框架的实时训练损失图。这是 Piotr Migdał 等人发布的一个开源 Python 包。
与 Keras 一起使用时,实时损失图是一个简单的回调函数。
from livelossplot import PlotLossesKeras
model.fit(X_train, Y_train,
epochs=10,
validation_data=(X_test, Y_test),
callbacks=[PlotLossesKeras()],
verbose=0)
2. Parfit
我们下一个项目来自 Jason Carpenter,他是旧金山大学数据科学硕士候选人,同时也是 Manifold 的机器学习工程实习生。
一个用于并行拟合和灵活评分 sklearn 机器学习模型的包,带有可视化例程。
导入后,你可以自由使用 bestFit() 或其他函数。
一个代码示例:
from parfit import bestFit # Necessary if you wish to use bestFit
# Necessary if you wish to run each step sequentially
from parfit.fit import *
from parfit.score import *
from parfit.plot import *
from parfit.crossval import *
grid = {
'min_samples_leaf': [1, 5, 10, 15, 20, 25],
'max_features': ['sqrt', 'log2', 0.5, 0.6, 0.7],
'n_estimators': [60],
'n_jobs': [-1],
'random_state': [42]
}
paramGrid = ParameterGrid(grid)
best_model, best_score, all_models, all_scores = bestFit(RandomForestClassifier(), paramGrid,
X_train, y_train, X_val, y_val, # nfolds=5 [optional, instead of validation set]
metric=roc_auc_score, greater_is_better=True,
scoreLabel='AUC')
print(best_model, best_score)
3. Yellowbrick
Yellowbrick 是“用于机器学习模型选择的视觉分析和诊断工具。” 更详细地说:
Yellowbrick 是一套被称为“可视化工具”的视觉诊断工具,它扩展了 scikit-learn API,以允许人工引导模型选择过程。简而言之,Yellowbrick 将 scikit-learn 与 matplotlib 结合在一起,延续了 scikit-learn 文档的最佳传统,但用于生成模型的可视化!

查看 Github 仓库中的示例,以及 文档以获取更多信息。
4. textgenrnn
textgenrnn 为文本生成任务带来了额外的抽象层,旨在让你“轻松训练自己规模和复杂度的文本生成神经网络,只需几行代码即可在任何文本数据集上进行训练。”
该项目基于 Keras 构建,具有以下精选功能:
- 一种现代的神经网络架构,利用新的技术,如注意力加权和跳跃嵌入,以加速训练并提高模型质量。
- 能够在字符级别或词级别上训练和生成文本。
- 能够配置 RNN 大小、RNN 层数以及是否使用双向 RNN。
- 能够在任何通用的输入文本文件上进行训练,包括大型文件。
- 能够在 GPU 上训练模型,然后使用 CPU 生成文本。
- 能够利用强大的 CuDNN 实现的 RNN,在 GPU 上训练时显著加速训练时间,相比于典型的 LSTM 实现。
textgenrnn 非常容易启动和运行:
from textgenrnn import textgenrnn
textgen = textgenrnn()
textgen.train_from_file('hacker-news-2000.txt', num_epochs=1)
textgen.generate()

你可以在上述链接的 Github 仓库中找到更多信息和示例。
5. Magnitude
Magnitude 是“一个快速、简单的向量嵌入实用库”。
这是一个功能丰富的 Python 包和向量存储文件格式,用于以快速、高效和简单的方式在机器学习模型中利用向量嵌入,由 Plasticity 开发。它主要旨在成为 Gensim 的一个更简单/更快速的替代品,但也可以作为一个通用的键-向量存储,用于 NLP 之外的领域。
该仓库提供了各种流行嵌入模型的链接,这些模型已经以 .magnitude 格式准备好使用,还包括将其他词嵌入文件转换为相同格式的说明。
如何导入?
from pymagnitude import *
vectors = Magnitude("/path/to/vectors.magnitude")
一针见血。
Github 仓库里充满了更多信息,包括使用这个简化的预训练词嵌入库所需了解的一切。
相关:
-
5 个你不应忽视的机器学习项目,2018 年 2 月
-
5 个你再也不能忽视的机器学习项目
-
5 个你再也不能忽视的机器学习项目(续)
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
更多相关主题
2023 年每位机器学习工程师应该掌握的 5 项机器学习技能
原文:
www.kdnuggets.com/2023/03/5-machine-learning-skills-every-machine-learning-engineer-know-2023.html

图片来源 olia danilevich
2022 年,越来越多的人开始接受人工智能。最引人注目的是,文本生成图像模型(AI 艺术)变得极其流行。搜索引擎被像 ChatGPT 这样的复杂聊天机器人所取代。随着像 PaLM + RLHF 这样的开源替代品的出现,人工智能和机器学习将变得对新手开发人员更加可及。然而,成为真正的机器学习工程师需要的不仅仅是脚本编写或编码技能。它目前是全球最需求量大的技术职位之一。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在的组织的 IT 需求
因此,越来越多的人开始将其视为潜在的职业道路。然而,随着机器学习和人工智能的迅速发展,即使是最有经验的机器学习工程师也很难跟上最新的实践。那么,2023 年你需要具备哪些技能才能成为机器学习工程师或提升为一名机器学习工程师呢?本指南将回答这些问题。
什么是机器学习工程师?
那么,机器学习工程师与软件开发人员或工程师之间的区别是什么呢?归根结底,其实没有区别。机器学习工程师 是软件开发人员的下一次进化。
他们是高度专业的程序员,专注于编写促进软件和机器自动化的算法。从根本上说,如果你对编程充满热情或已经是软件开发人员,你已经在成为机器学习工程师的路上。但有哪些好处呢?为什么不继续做传统的软件或网页开发人员呢?
晋升为机器学习工程师可以帮助你丰富工作 portfolio,并且开启你更多的就业机会,让你积极参与人工智能和共生网络的发展。这是一个非常有成就感的职业。你也不必走就业的路线,你仍然可以以自由职业者的身份与个人客户合作。但是,哪些技能能带你到达下一个水平呢?
1. 深度学习
深度学习是机器学习的一个子集,因其能够分析和解释大量数据而变得至关重要。它利用受到人脑结构启发的人工神经网络,旨在检测数据中的模式并从中学习,以做出准确的预测。
深度学习的一个主要应用是计算机视觉,它用于分析和分类图像和视频。例如,它可以用于识别面孔、识别图像中的物体以及检测医学图像中的异常。
深度学习还用于自然语言处理,以分析和解释人类语言。这包括情感分析、机器翻译和语言建模等任务。此外,深度学习还用于语音识别,以转录口语和识别语音模式。
作为一名机器学习工程师,深入理解深度学习并熟练使用深度学习工具和库如TensorFlow、Keras和PyTorch是非常重要的。
2. 自然语言处理
自然语言处理(NLP)是人工智能的一个子领域,专注于计算机和人类语言之间的互动。NLP 的目标是使机器能够理解、解释和生成包括书面文本和口语在内的人类语言。它涉及开发可以分析语言数据并从中提取意义的算法和模型。
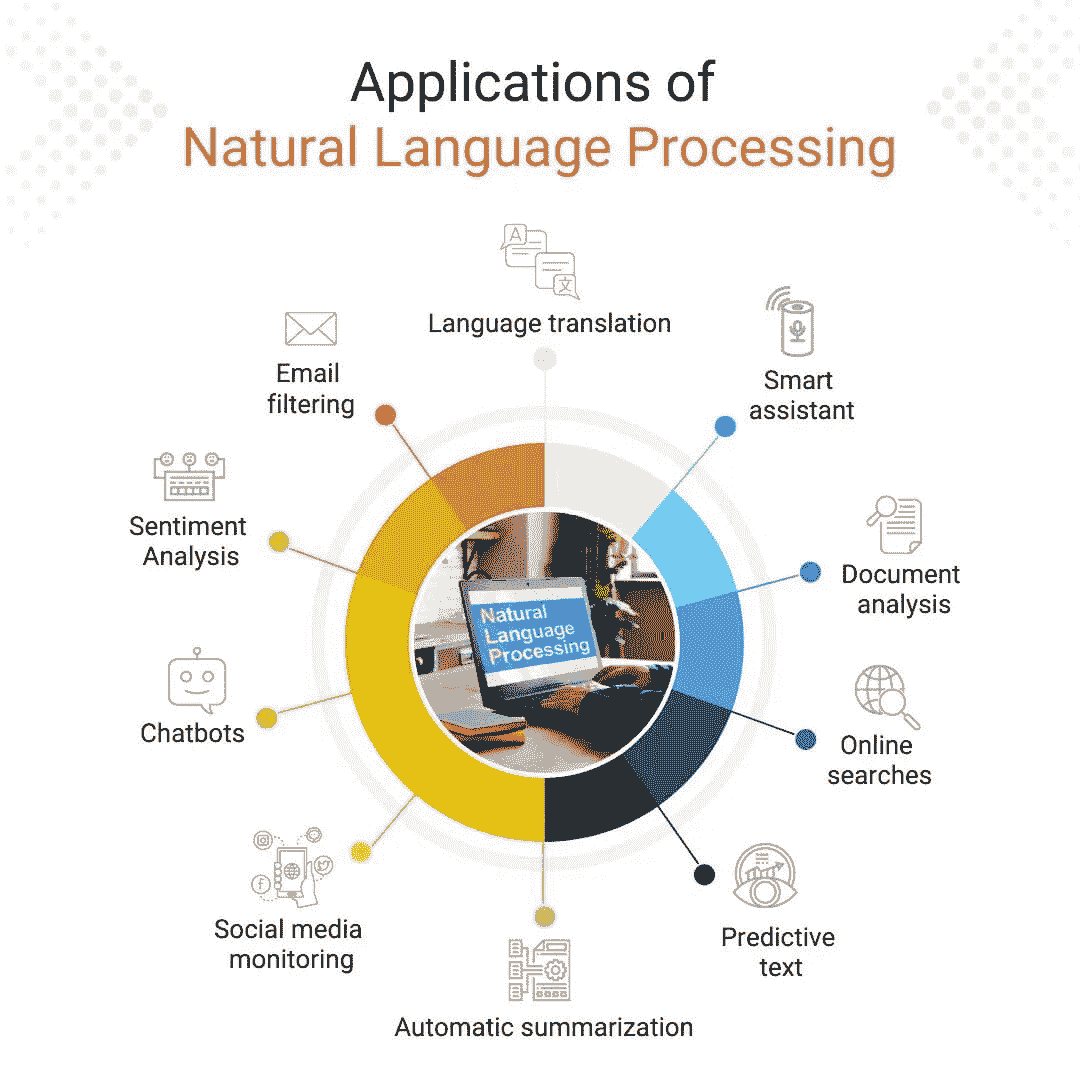
来自datasciencedojo的图像
自然语言处理在机器学习中很重要,因为它使机器能够以自然的方式与人类交流。这一点尤其重要,因为越来越多需要人机互动的应用正在开发。如果没有 NLP,这些互动将仅限于简单的命令或响应,这将显著降低它们的有用性和潜在影响。
3. 统计分析
统计分析是收集、分析和解释数据的过程 以获取洞察 并做出明智的决策。统计分析是机器学习中的一个关键技能,因为它为许多机器学习算法提供了数学基础。统计分析用于识别数据中的模式、检验假设和做出预测。
在统计分析中使用的一些关键工具和库包括 R、Python、SAS 和 SPSS。了解这些工具和语言对于提高统计分析的能力至关重要。
4. 数据准备
数据准备 是这个过程 收集、清理和组织数据,以便在训练机器学习模型之前使用。这是机器学习流程中的一个关键步骤,因为用于训练模型的数据质量显著影响预测的准确性。数据质量差会导致不正确或不可靠的预测,而高质量的数据有助于创建更准确的模型。
数据准备涉及的数据处理任务包括数据清理、数据转换、特征工程和数据整合。
在数据准备中使用的一些关键工具和库包括 Python 中的 pandas、NumPy 和 scikit-learn,以及 R 中的 dplyr 和 tidyr。了解这些工具和库,以及像 Python 和 R 这样的编程语言,对于提高数据准备能力是非常重要的。

图片来自 Pexels
此外,了解统计概念,如概率和假设检验,以及数据库系统和 SQL 的知识也很重要。
5. 编程
编程是机器学习工程师的一个重要技能,因为它是创建和训练机器学习模型的主要工具。Python、R 和 Java 等编程语言在机器学习中被广泛使用,因为它们易于使用,并且有许多机器学习库和框架。
获得编程技能的最佳方式之一是 通过实践和从事机器学习项目。这提供了将编程概念应用于实际问题的动手经验。参与机器学习项目还提供了向其他开发人员学习和与他们合作的机会。
作为机器工程师,你应该学习的一些关键编程概念包括数据结构、算法、面向对象编程以及软件开发原则,如版本控制、调试和测试。
附加提示
成为一名机器学习工程师是一个多方面的职业,需要相当多的时间和精力。因此,你必须务实地学习和分配时间。这本身就是一种技能。然而,有一些技能你不应浪费太多时间去磨练。
例如,有些来源可能会告诉你,成为一名有效的机器学习工程师绝对需要掌握应用数学。这是不准确的。现代应用机器学习涉及的数学很少。然而,掌握这些技能仍然是非常有价值的。它可以教会你如何系统地和逻辑地解决问题。然而,难度较大的应用数学通常是多余的。
此外,你也不应该浪费时间磨练你的建模技能。许多机器学习建模已被民主化。因此,你所需的许多模型都是可用且自动化的。然而,你必须能够识别出最适合特定问题的模型。归根结底,建模是一个已解决的问题,它是机器学习工程师工作中最简单的部分之一。
获得认证
如果你计划寻求机器学习工程师的职位,你必须确保你获得了适当的认证。大多数公司要求拥有计算机科学或相关领域(如应用数学和物理学)的学士学位。
几乎具有讽刺意味的是,许多招聘人员使用自动化和机器学习来识别最佳候选人。如果你的目标是找到工作,你必须争取尽可能多的面试机会。
这些招聘工具关注的标准之一是认证。在某些情况下,认证的来源甚至无关紧要。只要你在简历上有认证即可。认证应该与上述指南中的技能相关联。因此,你应该拥有所有编程语言的专业认证,机器学习的应用统计学认证,如何使用机器学习库的认证等。
建立公共代码库
当你等待关于求职申请的回复时,你应该考虑开设一个公共 GitHub 仓库,里面包含你自己个人的机器学习项目。这个仓库应该得到妥善维护,并且定期更新。你也可以在简历中包含它,让潜在的雇主看到你的工作样本。
结论
与大多数技术职位一样,机器学习工程师必须愿意终身学习。你必须跟上最新框架、技术和实践。耐心、韧性以及开放的学习态度是作为机器学习工程师需要磨练的好技能。这是辛苦的工作,需要时间,但这个过程是充实的。优秀的软件开发人员和机器学习工程师很少会长时间处于失业状态。上述指南探讨了 2023 年每个机器学习工程师应该掌握的 5 项机器学习技能。将其收藏起来,随时回顾,当你感到迷茫并希望提升自己时。
Nahla Davies 是一名软件开发人员和技术作家。在全职从事技术写作之前,她还曾担任 Inc. 5,000 名企业品牌组织的首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼。
更多相关话题
我希望在数据科学职业生涯中避免的 5 个错误
原文:
www.kdnuggets.com/2021/07/5-mistakes-data-science-career.html
评论
由 Tessa Xie,Cruise 高级数据科学家。

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT
照片来源于 bruce mars ,发布于 Unsplash。
当我第一次从金融转到数据科学时,我感觉自己站在了世界的顶端——我得到了理想领域的工作,职业轨迹已定,我只需低头努力工作,会有什么问题呢?实际上,有一些事情……在接下来的一年中,作为数据科学家,我犯了几个错误,我很高兴自己早早发现了这些错误。这样,我有时间反思并调整方向,避免了为时已晚。过了一段时间,我意识到这些错误相当普遍。事实上,我观察到很多数据科学家仍在犯这些错误,而未意识到这些错误可能会长期伤害他们的数据职业生涯。
如果我的5 Lessons McKinsey Taught Me That Will Make You a Better Data Scientist是我从最优秀的身上学到的,那么这篇文章中的教训是我通过艰难的方式学到的,我希望能帮助你避免犯同样的错误。
错误 1:将自己视为脚下的士兵而非思想合作伙伴
从小到大,我们总是根据我们遵循规则和指令的能力来评估,特别是在学校里。如果你按照教材和模拟考试进行练习并努力工作,你就会成为顶尖学生。许多人似乎把这种“步兵”心态带入工作环境。在我看来,这正是阻碍许多数据科学家最大化影响力并从同事中脱颖而出的心态。我观察到很多数据科学家,尤其是初级的,认为他们对决策过程没有贡献,宁愿退到背景中,消极地执行为他们做出的决策。这开启了一个恶性循环——你对这些讨论的贡献越少,利益相关者就越不可能让你参与未来的会议,你将获得的贡献机会也会越少。
让我举一个在模型开发中步兵和思想伙伴之间区别的具体例子。在数据收集和特征头脑风暴会议中,我以前会消极地记录利益相关者的建议,以便后来可以“完美”地实施它们。当有人提议一个我知道我们没有数据的特征时,我会因为假设他们更资深、一定知道我忽视的东西而不说任何话。但猜猜怎么着,他们并不知道。后来,我会遇到这样的问题:我们头脑风暴的 50%特征需要额外的数据收集,这将使我们的项目截止日期面临风险。结果,我常常发现自己处于最后的坏消息传播者的位置。现在为了成为思想伙伴,我会在对话中早早介入,并利用我作为离数据最近的人的独特位置。这种方式让我可以早早管理利益相关者的期望,并提出建议以帮助团队前进。
如何避免这一点:
-
确保在你可以从数据角度贡献的会议中不要保留意见:利益相关者对指标的定义是否足够测量他们想要的东西?是否有数据可用来测量这组指标?如果没有,我们能否找到我们拥有数据的替代方案?
-
冒名顶替综合症确实存在,尤其是在初级数据科学家中。确保你意识到这一点,无论何时你怀疑是否应该说出“别人可能已经想到”的话或问一个“愚蠢的澄清问题”,你都应该这样做。
-
保持对其他人工作内容的好奇心。有很多情况下,我发现通过注意到其他人可能因为对公司数据理解不足而忽视的空白,我可以增加价值。
错误 2:把自己限制在数据科学的特定领域
我是想成为数据工程师还是数据科学家?我想处理市场营销和销售数据,还是做地理空间分析?你可能注意到,我在本文中一直使用“DS”这一术语,作为许多数据相关职业路径(例如数据工程师、数据科学家、数据分析师等)的通用称谓。这是因为在数据世界中,这些职称的界限变得模糊不清,尤其是在较小的公司里。我观察到许多数据科学家仅将自己视为构建模型的科学家,而不关注任何业务方面,或数据工程师只关注数据管道而不想了解公司中的建模情况。
最优秀的数据人才是那些能够扮演多种角色的人,或者至少能够理解其他数据角色的工作流程。这在你想要进入一个早期阶段或成长阶段的初创公司时尤其重要,因为在这些公司中,职能可能还不够专业化,你需要灵活应对,承担各种数据相关的职责。即使你在一个明确定义的工作岗位上,随着经验的积累,你可能会发现自己对转向不同类型的数据角色感兴趣。如果你没有将自己和你的技能局限于一个特定角色的狭窄领域,这种转变会更容易。
如何避免:
-
再次,关注其他数据角色正在做的项目。定期安排与同事的会议,讨论有趣的项目,或者让不同的数据团队定期分享他们的工作/项目。
-
如果你无法在工作中接触到其他数据角色,尝试在闲暇时间保持或练习你未使用的数据技能。例如,如果你是数据分析师,并且有一段时间没有接触建模,考虑通过参加像 Kaggle 比赛这样的外部项目来练习这些技能。
错误 3:未跟上领域的发展
自满会致命
每个士兵都知道这一点,每个 DS 也应当知道。对自己的数据技能感到自满,并不花时间学习新技能是一个常见的错误。在数据领域,这种情况比在其他领域更危险,因为数据科学是一个相对较新的领域,仍在经历急剧的变化和发展。不断有新的算法、新的工具,甚至新的编程语言被引入。
如果你不想成为那个在 2021 年仍然只会使用 STATA 的数据科学家(他确实存在,我曾与他合作过),那么你需要跟上该领域的发展。
不要成为这样的人 (GIF 由 GIPHY 提供)。
如何避免:
-
报名参加在线课程,学习新概念和算法,或者复习你已经知道但在工作中久未使用的内容。学习能力是一项所有人都应该不断练习的技能,而终身学习可能是你能给予自己最好的礼物。
-
订阅 DS 新闻通讯或关注 Medium 上的 DS 博主/出版物,并养成跟踪 DS “新闻”的习惯。
错误 4:过度发挥你的分析能力
如果你只有一把锤子,一切看起来都像钉子。不要成为那个试图对所有事物都使用机器学习的 DS。当我第一次进入数据科学领域时,我对在学校学到的所有新模型感到非常兴奋,迫不及待地想在现实世界的问题上尝试它们。但现实世界与学术研究不同,80/20 法则始终在发挥作用。
在我之前关于“麦肯锡教我的 5 个教训”的文章中,我提到商业影响和可解释性有时比模型的额外几个百分点准确率更为重要。有时,也许一个基于假设的 Excel 模型比多层神经网络更有意义。在这些情况下,不要过度发挥你的分析能力,使你的方法变得过于复杂。相反,发挥你的商业能力,成为一个同时具备商业洞察的 DS。
如何避免:
-
在你的工具库中拥有全面的分析技能/工具,从简单的 Excel 到先进的机器学习建模技能,这样你才能在不同情况下评估哪个工具最合适,而不是在刀枪不入的情况下带上枪。
-
在深入分析之前,了解业务需求。有时利益相关者会因为 ML 是一个流行概念而请求一个 ML 模型,他们对 ML 模型能做什么有不切实际的期望。作为 DS,你的工作是管理这些期望,并帮助他们找到更好、更简单的方法来实现他们的目标。记住?成为一个思想伙伴,而不是一个步兵。
错误 5:认为建立数据文化是其他人的工作
在我的文章“构建伟大数据文化的 6 个关键步骤”中,我写到,如果公司没有良好的数据文化,数据科学家的生活可能会变得糟糕而低效。事实上,我听到很多数据科学家抱怨那些应该由利益相关者自助处理的不必要的临时数据请求(例如,在 Looker 中将聚合从每月改为每日,实际上只需两次点击)。不要认为改变这种文化是别人的工作。如果你想看到改变,就去做。毕竟,谁比数据科学家更适合建立数据文化并教育利益相关者呢?帮助建立公司的数据文化将使你和你的利益相关者在未来的工作中轻松很多。
如何避免这些问题:
-
让自己负责对非分析型利益相关者进行培训,并开发自助资源。
-
确保你开始实践你所宣扬的内容,将查询链接到幻灯片,将真实数据源链接到文档,并开始记录你的代码和数据库。你无法一夜之间建立数据文化,所以这确实需要耐心。
我想指出的是,在职业生涯中犯错是可以的。最重要的是从这些错误中学习,并在未来避免它们。更好的是,将这些错误记录下来,帮助他人避免相同的错误。
原文。经许可转载。
简介:Tessa Xie是一位经验丰富的高级分析顾问,擅长数据科学、SQL、R、Python、消费者研究和经济研究,拥有强大的工程背景,硕士学位专注于金融工程,毕业于 MIT。
相关内容:
更多相关话题
切换到数据科学职业时我犯的 5 个错误
原文:
www.kdnuggets.com/2023/07/5-mistakes-made-switching-data-science-career.html

作者提供的图片
我从技术管理转行到数据科学,因为我对之前职业的分析方面感兴趣。在过去,将物联网(IoT)融入业务并利用各种分析技术来收集和分析数据受到高度重视。我开始学习编程、统计学和多个数据术语,以追求数据科学。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT 维护
在这篇博客中,我将分享五个让我浪费了时间和精力的错误。此外,我将提供避免在未来犯这些错误的建议解决方案。
1. 随意参加课程
我试图通过观看 YouTube 或 Coursera 上的随机免费课程来学习数据科学,但这只让我感到更加困惑。尽管我认为我理解了所学内容,但我仍然无法独立解决问题。
三个月后,我意识到我需要一种更有结构的方法。这就是为什么我决定参加 DataCamp 的职业发展课程。该程序包括理解数据科学基础所需的所有课程。职业发展课程还包括指导项目、互动练习和评估测试,这些都帮助我在分析能力上建立了更多的信心。
解决方案: 可以考虑报名参加一个付费职业发展课程,该课程提供涵盖基础和高级概念的各种互动课程。许多知名教育平台提供这种选项。
2. 我对数学和统计学不够重视
你必须理解模型背后的数学基础,以维护你的职业声誉。我在求职面试、会议和创建文档时因这一点感到尴尬。我清晰地记得一次面试中,一位专家问我关于梯度下降方程的问题,而我无法给出答案。那时我意识到我需要重新审视和加强对统计基础的理解。
解决方案: 建议参加统计学和概率论课程,了解机器学习模型在数学上的工作原理。
3. 未记录我的工作
尽管我参与了多个项目和 Kaggle 比赛,但我未能记录我的进展和成就。我花了一年时间才意识到记录项目和历程的重要性,这可以帮助我获得更好的职位机会并建立更强的作品集。回顾过去,我应该从一开始就通过 LinkedIn 和 Medium 分享我的历程。这样可以让我结识新的人脉,扩大影响力,增强职业作品集,并促进合作。
解决方案: 为了展示你的项目,最好在 GitHub 上分享项目元素和代码。你也可以在 Medium 上撰写博客文章,并在 LinkedIn 数据科学小组中分享。这将帮助你获得更多曝光。
4. 我申请了错误的职位
过去,我申请了所有的数据科学、数据分析或商业智能职位,却没有研究公司所需的内容。我认为自己可以轻松过渡到数据科学领域。然而,我低估了这一领域所需的广泛知识和技能。要成功,关键是保持谦虚,认识到自己的知识空白,并致力于持续学习。
在这个行业中取得成功,重要的是熟悉标准实践并获得相关技能。如果你缺乏经验,可以考虑寻找实习机会或参与声誉良好的开源项目。
解决方案: 完成基础课程后,专注于建立一个强大的数据科学作品集。花时间研究职位期望和要求,持续学习新工具和技能,以增强你的简历。避免立即申请工作,而是努力充分了解潜在雇主对候选人的期望。
5. 参与过多的比赛
在发现一些关于机器学习的技巧后,我开始参加 Kaggle 的比赛。我变得上瘾,甚至在没有事先了解话题的情况下加入竞赛。我说服自己在向他人学习新技术,但实际上,我只是浪费了时间。
作为通过比赛学习机器学习的倡导者,我必须警告新手,赢得比赛是困难的。虽然我曾接近并经常进入前 1%,但这并没有对我的职业生涯产生显著价值。相反,我应该专注于实际项目,或通过实习或工作获得经验。
解决方案: 不要自欺欺人。始终保持目标在心中。与其通过参与过多的比赛而分散精力,不如考虑专注于一个复杂的开源项目,撰写 Medium 文章,建立你的作品集,并参与社区活动。
最后的想法
我犯过许多错误,这些错误让我对自己和自己的处境有了更多的了解。支撑我度过困难时期的唯一东西就是奉献精神和明确的目标。虽然可能比其他人花费更多时间,但我不会放弃。
如果你感到沮丧,并且认为眼前的任务太困难,我建议你探索适合你的其他选择。不要让任何人打击你。继续尝试,你最终会找到一个适合你的系统,帮助你实现梦想工作。此外,从一开始就利用 Kaggle、GitHub、DagsHub 和 Deepnote 等平台来构建你的数据科学作品集是至关重要的。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些在精神健康方面挣扎的学生打造一款 AI 产品。
更多相关主题
5 门谷歌 MLOps 课程,提升你的机器学习工作流程
原文:
www.kdnuggets.com/5-mlops-courses-from-google-to-level-up-your-ml-workflow

图片来源:作者
我们的三大推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
MLOps 对于任何生产中的机器学习系统的成功都是必不可少的。因此,组织对熟练的 MLOps 工程师的需求并不令人惊讶。但 MLOps 工程师到底做什么呢?
MLOps 工程师的角色是灵活的,并且因组织而异。然而,考虑到 MLOps 工程师比数据科学家更具端到端的特性,这种想法既有说服力又简单明了。也就是说,他们的工作超越了机器学习模型的构建,还包括模型构建、部署和监控等角色。
本文汇编了谷歌的 MLOps 课程。这将帮助你学习生产环境中机器学习系统的基础知识,重点关注谷歌的 Vertex AI 平台。
让我们开始吧!
1. 生产机器学习系统
要理解和欣赏 MLOps,首先需要了解机器学习系统在生产中的运作方式。生产机器学习系统课程将帮助你了解生产环境中机器学习系统的实施,重点关注:
-
静态、动态和持续训练
-
静态和动态推理
-
批处理和在线处理
这是本课程中的一些关键模块:
-
架构生产机器学习系统
-
设计适应性强的机器学习系统
-
设计高性能的机器学习系统
-
构建混合机器学习系统
链接: 生产机器学习系统
2. 机器学习运维 (MLOps):入门
机器学习运维 (MLOps):入门课程是对机器学习运维的介绍。在这里你将学习如何在生产环境中部署、测试、监控和评估机器学习系统。
你将了解 MLOps 的工具和最佳实践,并学习谷歌的 Vertex AI 平台。本课程的模块如下:
-
采用机器学习操作
-
Vertex AI 和 Vertex AI 上的 MLOps
3. 使用 Vertex AI 的机器学习操作 (MLOps):管理特性
使用 Vertex AI 的机器学习操作 (MLOps):管理特性 课程将帮助你进一步了解在 Google Cloud 平台上进行 MLOps,重点是 Vertex AI 特性库。
因此,你将熟悉在 Google Cloud 上部署、监控和操作机器学习系统。它将介绍 Vertex AI 特性库及其关键功能。
链接: 使用 Vertex AI 的机器学习操作 (MLOps):管理特性
4. Google Cloud 上的机器学习管道
本课程 Google Cloud 上的机器学习管道 是一门深入的课程,专注于在 Google Cloud Platform 上构建和编排机器学习管道。本课程包含多个模块,涵盖以下关键主题:
-
使用 TensorFlow Extend (TFX) 构建和编排机器学习管道,这是 Google 的生产机器学习平台
-
机器学习的 CI/CD
-
自动化机器学习管道
-
使用 Cloud Composer 编排持续培训管道
5. 在 Vertex AI 上构建和部署机器学习解决方案
在 在 Vertex AI 上构建和部署机器学习解决方案 课程中,你将处理实际用例以训练和部署机器学习解决方案。
在本课程中,你将深入学习以下企业机器学习用例:
-
零售客户生命周期价值预测
-
移动游戏流失预测
-
视觉汽车零件缺陷识别
-
微调 BERT 以进行评论情感分类
在这个过程中,你还将学习如何利用 AutoML。
链接: 在 Vertex AI 上构建和部署机器学习解决方案
总结
我希望通过这些课程及其实验室,你能对使用 Vertex AI 构建和部署机器学习解决方案有一个良好的掌握。
如果你正在寻找一个全面的训练营来学习 MLOps,你可以查看 DataTalks.Club 的 MLOps Zoomcamp。你可以在 成为专业 MLOps 工程师所需的唯一免费课程 中了解更多关于这个训练营的信息。
Bala Priya C**** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程以及喝咖啡!目前,她正在通过撰写教程、操作指南、观点文章等方式学习并与开发者社区分享知识。Bala 还创建了引人入胜的资源概述和编码教程。
了解更多相关主题
处理不平衡数据集的 5 种最有用的技术
原文:
www.kdnuggets.com/2020/01/5-most-useful-techniques-handle-imbalanced-datasets.html
评论
你是否曾遇到过这样的问题,即在数据集中正类样本非常少,模型无法学习?
在这种情况下,你只需预测多数类就能获得相当高的准确率,但你未能捕捉到少数类,而这往往是创建模型的初衷。
这种数据集是一种相当常见的现象,称为不平衡数据集。
不平衡数据集是分类问题中的一个特殊情况,其中类别分布在各个类别之间不均匀。通常,它们由两个类别组成:多数(负类)和少数(正类)。
不平衡数据集可以在各种领域的不同用例中找到:
-
金融:欺诈检测数据集中通常欺诈率为 ~1–2%
-
广告投放:点击预测数据集的点击率也不高。
-
交通/航空:飞机故障是否会发生?
-
医学:患者是否患有癌症?
-
内容审查:帖子是否包含不适内容?
那么我们如何解决这些问题呢?
这篇文章讲解了你可以用来处理不平衡数据集的各种技术。
1. 随机下采样和上采样
一种广泛采用且可能最直接的方法来处理高度不平衡的数据集称为重采样。它包括从多数类中删除样本(下采样)和/或从少数类中添加更多样本(上采样)。
首先,我们创建一些示例不平衡数据。
from sklearn.datasets import make_classificationX, y = make_classification(
n_classes=2, class_sep=1.5, weights=[0.9, 0.1],
n_informative=3, n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=1,
n_samples=100, random_state=10
)X = pd.DataFrame(X)
X['target'] = y
我们现在可以使用以下方法进行随机上采样和下采样:
num_0 = len(X[X['target']==0])
num_1 = len(X[X['target']==1])
print(num_0,num_1)# random undersampleundersampled_data = pd.concat([ X[X['target']==0].sample(num_1) , X[X['target']==1] ])
print(len(undersampled_data))# random oversampleoversampled_data = pd.concat([ X[X['target']==0] , X[X['target']==1].sample(num_0, replace=True) ])
print(len(oversampled_data))------------------------------------------------------------
OUTPUT:
90 10
20
180
2. 使用 imbalanced-learn 进行下采样和上采样
imbalanced-learn(imblearn) 是一个用于解决不平衡数据集问题的 Python 包。
它提供了多种下采样和上采样的方法。
a. 使用 Tomek 链接进行下采样:
其中一种方法称为 Tomek 链接。Tomek 链接是相邻的相反类别样本对。
在此算法中,我们最终会移除 Tomek 链接中的多数类元素,这为分类器提供了更好的决策边界。
from imblearn.under_sampling import TomekLinkstl = TomekLinks(return_indices=True, ratio='majority')X_tl, y_tl, id_tl = tl.fit_sample(X, y)
b. 使用 SMOTE 进行上采样:
在 SMOTE(合成少数类过采样技术)中,我们在已有样本的附近合成少数类元素。
from imblearn.over_sampling import SMOTEsmote = SMOTE(ratio='minority')X_sm, y_sm = smote.fit_sample(X, y)
在[imblearn](https://github.com/scikit-learn-contrib/imbalanced-learn#id3)包中,有多种其他方法用于欠采样(Cluster Centroids, NearMiss 等)和过采样(ADASYN 和 bSMOTE),你可以查看。
3. 模型中的类别权重

大多数机器学习模型提供了一个名为class_weights的参数。例如,在随机森林分类器中使用class_weights,我们可以通过字典为少数类指定更高的权重。
from sklearn.linear_model import LogisticRegression*clf =* LogisticRegression(*class_weight={0:1,1:10}*)
但后台究竟发生了什么?
在逻辑回归中,我们使用二元交叉熵计算每个样本的损失:
Loss = −*y*log(*p)* − (1−*y*)log(1−*p*)
在这种特定形式下,我们对正类和负类赋予了相等的权重。当我们将 class_weight 设置为class_weight = {0:1,1:20}时,后台的分类器尝试最小化:
NewLoss = −20**y*log(*p)* − *1**(1−*y*)log(1−*p*)
那么这里究竟发生了什么?
-
如果我们的模型给出的概率是 0.3,而我们错误分类了一个正例,那么 NewLoss 的值是-20log(0.3) = 10.45。
-
如果我们的模型给出的概率是 0.7,而我们错误分类了一个负例,那么 NewLoss 的值是-log(0.3) = 0.52。
这意味着当我们的模型错误分类一个正例少数样本时,我们会惩罚模型约二十倍。
我们如何计算类别权重?
没有一种方法可以做到这一点,这应该被构建为针对你特定问题的超参数搜索问题。
但如果你想使用 y 变量的分布来获取类别权重,你可以使用sklearn中的以下实用工具。
from sklearn.utils.class_weight import compute_class_weightclass_weights = compute_class_weight('balanced', np.unique(y), y)
4. 更改你的评估指标

选择正确的评估指标在处理不平衡数据集时非常重要。通常情况下,在这种情况下,我希望使用 F1 分数作为我的评估指标。
F1 分数是介于 0 和 1 之间的一个数字,是精度和召回率的调和均值。
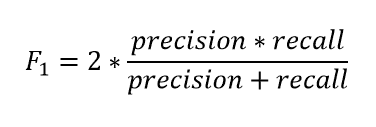
那么这有什么帮助呢?
让我们从一个二分类预测问题开始。我们正在预测小行星是否会撞击地球。
因此,我们创建了一个对整个训练集预测“否”的模型。
准确率(通常是最常用的评估指标)是多少?
它超过 99%,所以根据准确率,这个模型相当好,但实际上毫无价值。
那么,F1 分数是多少?
我们在这里的精度是 0。我们正类的召回率是多少?它是零。因此,F1 分数也是 0。
因此,我们得知一个准确率为 99%的分类器在我们的案例中毫无价值。这样它解决了我们的问题。
精度-召回权衡
简单来说,F1 分数在分类器的精准度和召回率之间保持了一种平衡。如果你的精准度低,F1 分数也低;如果召回率低,F1 分数也低。
如果你是一个警察检查员,你想确保你抓到的人是罪犯(精准度),同时你还希望抓到尽可能多的罪犯(召回率)。F1 分数管理了这种权衡。
如何使用?
你可以使用以下公式计算二元预测问题的 F1 分数:
from sklearn.metrics import f1_score
y_true = [0, 1, 1, 0, 1, 1]
y_pred = [0, 0, 1, 0, 0, 1]
*f1_score(y_true, y_pred)*
这是我用来获得最佳阈值以最大化二元预测 F1 分数的一个函数。下面的函数会遍历可能的阈值以找到最佳 F1 分数。
# y_pred is an array of predictions
def bestThresshold(y_true,y_pred):
best_thresh = None
best_score = 0
for thresh in np.arange(0.1, 0.501, 0.01):
score = f1_score(y_true, np.array(y_pred)>thresh)
if score > best_score:
best_thresh = thresh
best_score = score
return best_score , best_thresh
5. 杂项

尝试新的事物和探索新的领域
根据你的使用案例和你要解决的问题,可能会有其他各种方法有效:
a) 收集更多数据
如果可能的话,这是一件你应该尝试的事情。获取更多数据和更多的正例将帮助你的模型获得对多数类和少数类的更广泛的视角。
b) 将问题视为异常检测
你可能想把你的分类问题当作异常检测问题来处理。
异常检测 是识别那些与大多数数据显著不同的稀有项、事件或观察的过程,这些差异会引起怀疑。
你可以使用隔离森林或自编码器进行异常检测。
c) 基于模型的方法
一些模型特别适合处理不平衡数据集。
例如,在提升模型中,我们在每次树迭代中对被错误分类的案例给予更多的权重。
结论
在处理不平衡数据集时,没有一种通用的解决方案。你需要根据你的问题尝试多种方法。
在这篇文章中,我谈到了每当遇到这种问题时,我脑海中浮现的常见问题。
建议是尝试上述所有方法,并看看哪种方法最适合你的使用案例。
如果你想要了解更多关于不平衡数据集及其带来的问题,可以查看这个由 Andrew Ng 提供的优秀课程。这是让我入门的课程。请务必查看一下。
感谢阅读。我未来也会写更多适合初学者的文章。关注我的 Medium 或订阅我的 博客以获取相关信息。如往常一样,我欢迎反馈和建设性的批评,可以通过 Twitter @mlwhiz 联系我。
另外,一个小声明——这篇文章中可能包含一些关联链接,分享知识从来不是坏主意。
简介: Rahul Agarwal 是 WalmartLabs 的高级统计分析师。关注他的 Twitter @mlwhiz。
原文。已获得许可转载。
相关:
-
使用 5 种机器学习算法分类稀有事件
-
每个数据科学家必须知道的 5 种分类评估指标
-
每个数据科学家需要知道的 5 种采样算法
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
更多相关内容
5 个必须了解的 R 数据分析包
原文:
www.kdnuggets.com/5-must-know-r-packages-for-data-analysis

图片来源 | Ideogram
R 是一种功能强大且多用途的编程语言,广泛用于数据分析和统计。该编程语言的一个主要优势是其强大的包生态系统。这些包增强了基础 R 的功能,使得执行各种分析任务变得更简单。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
以下是五个必须了解的 R 数据分析包。
1. dplyr
Dplyr 是 tidyverse 套件中的一部分,旨在有效的数据处理。它提供了直观的功能,使数据处理变得更简单。这些功能包括 filter 用于从数据集中选择满足特定条件的行,mutate 用于创建新列,arrange 用于排序数据,以及 summarize 用于生成汇总统计。
dplyr 的一个关键特点是管道操作符 (%>%)。这允许你将数据分析中的多个步骤链接成一个连续的流程。例如,你可以先过滤数据集,然后将结果通过管道传递给 mutate 函数以创建新列,再通过管道传递给 arrange 以排序最终结果,这一切都可以在一行代码中完成。dplyr 也与下文讨论的其他包如 ggplot2 和 tidyr 兼容良好,使其成为任何数据分析项目中一个关键的包。
2. ggplot2
ggplot2 包 也是 tidyverse 套件的一部分。它允许你使用最少的代码生成各种图表,包括散点图、条形图和折线图。每个图表都是分层开发的,你首先设置坐标轴,然后叠加你想要包含的点或线,再添加标签、图例和其他元素。这允许创建非常复杂但高度自定义的可视化。
ggplot2 的一个好处是这种分层方法可以创建独特的可视化。例如,你可以从箱线图开始,然后在其上叠加散点图。ggplot2 包还与其他 tidyverse 包集成得非常好,使其成为任何工作流程中的可靠组成部分。
3. tidyr
tidyr 包 再次是 tidyverse 集合的一部分。它的目的是用于数据清理和组织,将数据从混乱的原始格式转换为整洁的版本。主要功能包括 gather 将宽数据转换为长格式,spread 将长数据转换为宽格式,以及 unite 将多个列合并为一个。虽然它是一个简单的包,但在处理复杂数据集或合并多个数据源时是不可或缺的。
4. lubridate
处理日期和时间变量可能非常棘手,因为格式多样且时区复杂。lubridate 包 通过提供一组专门为处理日期和时间变量构建的函数来简化这些复杂性。其核心特征是日期和时间格式函数,如 ymd 和 mdy_hms,这些函数可以自动识别常见的日期时间格式并将其转换为 R 能够直接操作的日期对象。
函数如 year 或 minute 也允许你提取日期时间对象的特定组件。你可以使用这些函数快速创建一个只包含变量年份的新列,或者计算两个日期之间的年份差。这些包对于处理事件、时间序列数据或包含出生日期的人口统计数据的人至关重要。
5. shiny
shiny 包 是一个强大的框架,用于在 R 中直接构建交互式可视化和网页应用程序。你可以创建动态数据仪表板和可视化,而无需了解网页开发语言(如 HTML 或 JavaScript)。用 shiny 构建的应用程序将包括用户界面部分(定义视觉布局和外观)和服务器部分(定义如何处理和更新数据以响应用户交互)。
Shiny 由反应式编程驱动,因此当用户与之交互时,视觉化内容会自动更新。例如,你可以创建一个散点图,根据用户输入过滤数据。Shiny 与其他 R 包(如 ggplot2 和 dplyr)集成良好,以增强分析和可视化效果。
摘要
这些 R 包是任何数据分析师的必备工具,提供了高效的数据操作、可视化和分析方法。掌握这些包将显著提升你的分析能力和生产力。
Mehrnaz Siavoshi 拥有数据分析硕士学位,是一名全职生物统计学家,专注于医疗保健中的复杂机器学习开发和统计分析。她拥有人工智能方面的经验,并在人民大学教授生物统计学和机器学习课程。
更多相关信息
5 篇必读的数据科学论文(以及如何使用它们)
原文:
www.kdnuggets.com/2020/10/5-must-read-data-science-papers.html
评论

照片由 Rabie Madaci 在 Unsplash 提供。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你所在组织的 IT
数据科学可能是一个年轻的领域,但这并不意味着你不会面临对某些话题的认知期望。本文涵盖了几项最重要的最新发展和有影响力的思想文章。
这些论文涵盖的主题从 数据科学工作流的协调 到 更快的神经网络突破 再到 重新思考我们用统计学解决问题的基本方法。对于每篇论文,我提供了如何将这些想法应用到你自己工作的建议。
#1 — 机器学习系统中的隐性技术债务
Google Research 团队提供了 关于设置数据科学工作流时要避免的反模式的明确说明。这篇论文借用了软件工程中的技术债务隐喻,并将其应用于数据科学。

通过 DataBricks。
正如下一篇论文更详细探讨的那样,构建机器学习产品是软件工程的一个高度专业化的子集,因此从这一学科中汲取的许多经验也适用于数据科学。
如何使用:遵循专家的 实用技巧 来简化开发和生产过程。
#2 — 软件 2.0
Andrej Karpathy 的这篇经典文章阐述了机器学习模型是 基于数据的代码的软件应用程序 这一范式。
如果数据科学是软件,那么我们到底在建设什么?Ben Bengafort 在一篇有影响力的博客文章中探讨了这个问题,标题为 《数据产品的时代》。

数据产品代表了机器学习项目的操作化阶段。照片由 Noémi Macavei-Katócz 拍摄,来源于 Unsplash。
如何使用:进一步阅读关于数据产品如何融入 模型选择过程的内容。
#3 — BERT:深度双向转换器的预训练用于语言理解
在这篇论文中,Google Research 团队提出了一种自然语言处理(NLP)模型,这代表了我们在文本分析能力上的一次跃迁。
尽管关于 BERT 为何如此有效有 一些争议,但这提醒我们,机器学习领域可能已经发现了一些成功的方法,而并未完全理解其工作原理。正如自然界中的情况,人工神经网络充满了神秘感。
在这段有趣的片段中,Nordstrom 的数据科学总监解释了人工神经网络如何从自然界中汲取灵感。
如何使用:
-
BERT 论文非常易读,并包含了一些建议的默认超参数设置作为宝贵的起点(见附录 A.3)。
-
无论你是否对 NLP 新手,都可以查看 Jay Alammar 的 《首次使用 BERT 的视觉指南》 来获得对 BERT 能力的生动插图。
-
另外,查看 ktrain,这是一个基于 Keras(进而基于 TensorFlow)的包,它允许你轻松地在工作中实现 BERT。Arun Maiya 开发了这个强大的库,以加快 NLP、图像识别和基于图的方法的洞察速度。
#4 — 彩票票据假设:寻找稀疏的、可训练的神经网络
尽管 NLP 模型越来越大(例如 GPT-3 有 1750 亿参数),但也有一种正交的努力在寻找更小、更快、更高效的神经网络。这些网络承诺更快的运行时间、更低的训练成本和更少的计算资源需求。
在这篇开创性的论文中,机器学习天才 Jonathan Frankle 和 Michael Carbin 概述了一种剪枝方法,以发现能够达到与原始的显著更大神经网络相当性能的稀疏子网络。
彩票票据指的是具有初始权重的连接,使得它们特别有效。这个发现提供了许多在存储、运行时间和计算性能上的优势——并且在 ICLR 2019 上获得了最佳论文奖。进一步的研究基于这一技术,证明了其适用性和将其应用于原本稀疏的网络。
如何使用:
-
在将神经网络投入生产之前,请考虑剪枝。剪枝网络权重可以将参数数量减少 90%以上,同时仍能实现与原始网络相同的性能水平。
-
此外,查看这个Data Exchange 播客的剧集,Ben Lorica 与Neural Magic的创始人讨论了该初创公司如何利用剪枝和量化等技术,并提供了一个使得实现稀疏性的 UI 更加简单的解决方案。
阅读更多:
- 看看这篇有趣的侧边栏来自“彩票票据”作者之一,讨论了机器学习社区在评估好主意时存在的缺陷。
#5 — 摆脱零假设统计检验的束缚 (p < .05)
经典假设检验方法导致过度确定性,并产生通过统计方法已识别原因的错误观念。 (阅读更多)
假设检验早于计算机的使用。鉴于这种方法所面临的挑战(例如,即使是统计学家也发现解释 p 值几乎是不可能的),也许是时候考虑一些替代方案,例如稍微精确的结果测试(SPOT)。

“显著”通过xkcd。
如何使用:
- 查看这篇博文,“统计假设检验的终结”,一位沮丧的统计学家阐述了传统方法的一些挑战,并解释了使用置信区间的替代方案。
原文。经许可转载。
简介: 妮可·詹维·比尔斯 是一位拥有商业和联邦咨询经验的机器学习工程师。妮可精通 Python、SQL 和 Tableau,具有自然语言处理(NLP)、云计算、统计测试、定价分析和 ETL 流程的业务经验,旨在利用这些背景将数据与业务成果连接起来,并继续发展技术技能。
相关:
了解更多相关话题
5 个你可能不知道的 Pandas 绘图函数
原文:
www.kdnuggets.com/2023/02/5-pandas-plotting-functions-might-know.html

图片由rawpixel.com提供,Freepik上的图片。
Pandas 是一个著名的数据处理包,许多人使用它。它之所以著名,是因为它直观且易于使用。此外,Pandas 得到了社区的广泛支持,以增强该包。
我们的前三个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业生涯。
2. Google Data Analytics Professional Certificate - 提升您的数据分析技能
3. Google IT Support Professional Certificate - 在 IT 领域支持您的组织
然而,只有少数人知道 Pandas 也有绘图函数。Pandas 的一些绘图函数非常特别,并且为您的数据分析提供了洞察力。这些函数是什么?让我们一起探索。
对于我们的示例,我们将使用商业上可用的Titanic Data from Kaggle。
Bootstrap 图
Bootstrap 图是 Pandas 中的一个绘图函数,通过使用自助法函数(数据采样带替换)来估计统计不确定性。当测量数据统计(均值、中位数、范围)并进行区间估计时,这是一个快速的绘图函数。
让我们尝试使用这个函数与数据样本。
import pandas as pd
df = pd.read_csv('train.csv')
pd.plotting.bootstrap_plot(df['Fare'], size = 150, samples = 1000)
该图将根据样本参数的大小重新采样数据。
均值的分布估计接近 30 到 40,中位数接近 12 到 15。通过这个图,我们可以尝试估计实际的人口统计数据。由于采样是随机的,您的结果可能与我的不同。
Scatter Matrix 图
Scatter Matrix 图是 Pandas 中的一个绘图函数,用于从所有可用的数值数据中创建散点图。让我们尝试这个函数,了解散点矩阵。
pd.plotting.scatter_matrix(df)
如上图所示,散点矩阵函数自动检测数据框中的所有数值列,并为每个组合创建散点矩阵。该函数为相同列创建直方图以测量数据分布。
Radviz 图
Radviz 图是一种将 N 维数据可视化为 2D 图的图表。通常,具有超过 3 个维度的数据很难可视化,但我们可以使用 Radviz 图做到这一点。让我们用数据示例来尝试一下。
pd.plotting.radviz(df[['SibSp', 'Parch', 'Pclass', 'Age', 'Fare','Survived']], 'Survived', color =['blue', 'red'])
在上述函数中,我们仅使用了带有目标的数值数据来划分数据。
结果如上图所示。然而,我们如何解释上述图表?对于每个变量,它将被均匀地表示为一个圆圈。每个变量中的数据点将根据其值被绘制在圆圈内。高度相关的变量将在圆圈中更靠近,而低相关的变量则会较远。
Andrew 曲线图
Andrew 曲线绘图是一种可视化多变量数据的方法,以潜在地识别数据中的聚类。它也可以用于识别数据中是否存在任何分离。让我们用数据示例来尝试一下。
Andrew 曲线在数据标准化到 0 到 1 之间时效果最佳,因此我们在应用函数之前会预处理数据。
from sklearn.preprocessing import MinMaxScaler
df = df.drop(['PassengerId', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis =1)
scaler = MinMaxScaler()
df_scaled = scaler.fit_transform(df.drop('Survived', axis =1))
df_scaled = pd.DataFrame(df_scaled, columns = df.drop('Survived', axis =1).columns)
df_scaled['Survived'] = df['Survived']
pd.plotting.andrews_curves(df_scaled, 'Survived', color =['blue', 'red'])
从上面的图像中,我们可以看到“生存”类别可能具有不同的聚类。
延迟图
延迟图是一个特定的时间序列数据图,用于检查时间序列数据是否与自身相关以及是否随机。延迟图通过将时间数据与其延迟数据进行绘图来工作。例如,延迟 1 的 T1 数据将是 T1 与 T1+1(或 T2)数据的绘图。让我们尝试这些函数以更好地理解。
我们将为这个示例创建样本时间序列数据。
np.random.seed(34)
x = np.cumsum(np.random.normal(loc=1, scale=5, size=100))
s = pd.Series(x)
s.plot()
我们可以看到我们的时间序列数据显示出递增模式。让我们看看使用延迟图时它的表现。
pd.plotting.lag_plot(s, lag=1)
当我们使用延迟 1 的延迟图时,我们可以看到数据表现出线性模式。这意味着数据在 1 天差异上存在自相关。让我们看看使用按月的情况是否存在相关性。
pd.plotting.lag_plot(s, lag=30)
现在数据变得稍微随机一些,尽管仍然存在线性模式。
结论
Pandas 是一个数据处理包,还提供了各种独特的绘图函数。在这篇文章中,我们讨论了 5 种不同的 Pandas 绘图函数:
-
自助绘图
-
散点矩阵图
-
Radviz 图
-
Andrew 曲线图
-
延迟图
Cornellius Yudha Wijaya 是数据科学助理经理和数据撰写员。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
更多相关主题
每个机器学习爱好者都应该关注的 5 个播客
原文:
www.kdnuggets.com/5-podcasts-every-machine-learning-enthusiast-should-follow

图片来源:编辑
机器学习是一个巨大的领域,改变了世界,我敢打赌它会继续增长。如果你关注当前的趋势,你会发现人工智能和机器学习已经慢慢但确实地融入了人们的日常生活,不仅仅是创造商业竞争优势的工具,而是为人们的生活提供真正的价值。
我们的三大课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业的快车道。
2. Google Data Analytics Professional Certificate - 提升你的数据分析能力
3. Google IT Support Professional Certificate - 支持你组织的 IT 需求
随着机器学习的普及,越来越多的人尝试进入这一领域。然而,很难找到一个能够引导这些热衷者进入机器学习领域的声音。
幸运的是,许多播客专门讨论机器学习及其相关职业。这些播客都是什么?让我们来了解一下。
1. 本周机器学习与人工智能
由 Sam Charrington 主持的热门播客《本周机器学习与人工智能》自 2016 年开始运行,已经发布了数百期节目。它是最久经考验的机器学习播客之一,并且仍在持续进行。每周该播客都会发布一期新节目,邀请各种机器学习和人工智能专家讨论该领域的最新话题。
播客话题讨论通常围绕机器学习的最新突破,例如新的算法或方法论。但它也可以扩展到相关的任何内容,例如应用、商业用途和伦理考量。
讨论的话题可能对爱好者来说比较先进,但它可能为你未来的职业提供洞察和灵感。你将获得在教科书或论文中找不到的见解,确保你与最新发现保持同步。
2. 机器学习播客
机器学习播客由 Tobias Macey 主持,是一个自 2022 年开始运行的机器学习专注播客,每月为听众制作一期节目。这个播客邀请了各种机器学习领域的嘉宾讨论机器学习中的重要话题以及幕后发生的事情。
话题可以是最新的算法、技术、工具、公司或任何与机器学习相关的内容。重要的是每集一小时的节目都希望听众能从机器学习中获得价值,并将其带到商业中。
这是一个适合那些想了解商业中发生什么以及机器学习在公司中为何重要的爱好者的好播客。如果你想在机器学习领域获得优势,不要错过这些播客。
3. 实用 AI
实用 AI播客由 Chris Benson 和 Daniel Whitenack 主持,是你机器学习收听列表中的一个极好补充。自 2018 年以来,该播客每周提供一期节目,以便让听众更容易理解机器学习和人工智能。
许多话题涵盖了实用的方法和高级的机器学习,使得听众能够在行业外工作。然而,它主要集中在当前流行的主题上,如 LLM,因此可能无法涵盖机器学习行业中发生的所有事情。
这个播客非常适合那些想要理解高级内容并跟上世界动态的爱好者。
4. 超级数据科学播客
超级数据科学播客由 Jon Krohn 主持,并不一定只集中于机器学习,因为该话题涵盖了整个数据科学领域。然而,许多集讨论了适合初学者的机器学习介绍及相关领域,以更好地教会听众该领域的知识。
该播客自 2016 年开始运行,至今每周制作一期专注于数据科学领域的节目。对于机器学习爱好者来说,有超过 100 集节目供你收听和学习,因此你不必担心很快就会用尽所有节目。
5. 机器学习街谈
机器学习街谈播客由 Tim Scarfe 主持,是一个顶尖播客,较为轻松地讨论了许多最近的机器学习和人工智能话题。有时,节目会深入讨论该领域,但有时也会是主持人与嘉宾之间的辩论。
这个播客的推广比其他播客更轻松,因此非常适合那些因技术术语而害怕进入该领域的爱好者。你可以听上数百集,尽管更新不固定,长度可能在 1 小时到 3 小时甚至更长之间变化。
结论
这些是推荐给机器学习爱好者的五个播客。播客将为你带来专家对机器学习的全新视角,并提供关于如何在该领域导航的见解。如果你有更多的播客推荐,请在评论中分享。
Cornellius Yudha Wijaya****是一位数据科学助理经理和数据撰写员。在全职工作于印尼安联期间,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 涉及各种 AI 和机器学习主题的写作。
更多相关主题
5 个数据科学最终年学生的作品集项目
原文:
www.kdnuggets.com/5-portfolio-projects-for-final-year-data-science-students

图片作者提供
构建数据科学项目的作品集是初学者进入该领域的重要一步。随着动手实践变得越来越重要,拥有展示你技能的多样化作品集可以帮助你脱颖而出。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
除了展示技术能力,项目还允许你突出你的问题解决技能和分析思维。招聘人员通常寻找能够利用数据提供战略业务洞察并构建数据驱动解决方案以应对现实问题的候选人。执行良好的项目可以让你脱颖而出,成为能为组织增值的人。
在这篇博客中,我们将探索从数据分析到机器学习的简单作品集项目。你将发现如何清理和处理数据,然后使用各种分析技术向非技术利益相关者传达洞察。
1. 从头到尾的数据科学项目与 ChatGPT
在 从头到尾的数据科学项目与 ChatGPT 项目中,你将使用 ChatGPT 进行项目规划、数据分析、数据预处理、模型选择、超参数调整、开发 web 应用程序以及在 Spaces 上部署它。
现在,任何知识有限的人都可以使用 ChatGPT 理解数据并构建机器学习应用程序。这个项目将展示你可以使用最新的 AI 技术来产生快速而有效的结果。
图片来自项目
2. 新加坡节约的回收能源
对于新加坡回收能源节省项目,你将使用回收统计数据来确定 2003 年至 2020 年间从五种不同废物类型(塑料、纸张、玻璃、铁金属和非铁金属)中节省的年度能源量。具体来说,你将加载和组织数据集,合并不同的 CSV 文件,并进行探索性数据分析。这个项目将挑战你的分析和数据处理能力。
项目图片
3. 股票市场分析
股票市场分析 项目使用现实世界的金融数据来展示时间序列分析技能。清洗数据后,使用 Matplotlib 和 Seaborn 进行探索性分析和可视化,以分析风险指标和股票之间的关系。
长短期记忆(LSTM)模型在时间序列数据上进行训练,以预测未来价格。通过涵盖数据收集、清洗、可视化和建模,这个项目突显了在核心数据分析和机器学习工作流程中的熟练程度。
项目图片
4. 分析和预测消费者参与
在分析和预测消费者参与项目中,你将使用来自 Kaggle 的互联网新闻和消费者参与数据集来预测最受欢迎的文章及其受欢迎程度分数。你将分析数据以寻找模式,如相关性、分布、均值和时间序列分析。你将使用文本回归和文本分类模型来预测参与分数和基于标题的热门文章。
在这个项目中,你将学习如何处理文本数据,使用 Python 库进行文本分析,将文本转换为向量,并构建 LGBM 分类器模型。
项目图片
5. COVID19 期间数字学习的演变
在COVID19 期间数字学习的演变项目中,我们将使用数据分析工具来找出数字学习的趋势以及它对改善社区的有效性。我们将比较各地区和各州在人口统计、互联网接入、学习产品接入和财务等因素上的差异。最后,我们将总结报告并指出需要更多关注的领域,以使美国所有学生都能获得教育。
你将学习使用所有主要的数据分析和可视化工具。这也是一个指南,适合那些希望在展示中生成引人注目的可视化效果的人。
项目中的图像
结论
构建数据科学项目作品集可以帮助初学者向潜在雇主展示他们的技术技能和解决问题的能力。通过展示在数据收集、清理、分析、建模和可视化方面的能力,这些项目可以突出个人在数据科学工作流中的熟练程度。
在这篇博客中,我们回顾了五个针对最终年数据科学学生的作品集项目。它涵盖了数据处理、操控、可视化和建模基础。要探索更多项目,请查看数据科学项目完整合集 – 第一部分和第二部分。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为那些在精神健康上挣扎的学生开发 AI 产品。
主题更多内容
2022 年 5 个实用的数据科学项目,帮助你解决实际业务问题
原文:
www.kdnuggets.com/2021/12/5-practical-data-science-projects.html
评论

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 事务
“告别无用的副项目。”
自从我开始写文章以来已经快两年了——这相当于写了 175 篇文章!我之前的一些文章的一个缺点是,我建议了一些有趣的数据科学项目,但不够实际。
成为数据科学家的最简单方法之一是展示你已经完成了类似的项目,并且这些项目与职位描述相符。因此,我想与您分享一些我在职业生涯中亲自完成的实用数据科学项目,这些项目将增强你的经验和作品集。
1. 客户倾向建模
什么?
倾向模型是预测某人会做某事的模型。举几个例子:
-
网站访问者注册账户的可能性。
-
注册用户支付和订阅的可能性。
-
用户推荐其他用户的可能性。
倾向建模不仅涉及“谁”和“什么”——还涉及“何时”(何时应该针对你所识别的用户)和“如何”(如何向目标用户传达信息?)。
为什么?
倾向建模使你可以更明智地分配资源,从而提高效率,同时获得更好的结果。举个例子:与其发送一个用户点击的概率为 0%-100%的电子邮件广告,不如通过倾向建模,针对那些有 50%以上点击概率的用户。减少邮件数量,增加转化率!
如何:
下面是两个代码演示,展示了如何构建基本的倾向模型:
这里有两个数据集,你可以用来构建一个倾向模型。请注意每个数据集中提供的特征类型:
2. 指标预测
什么?
指标预测是自解释的——它指的是对给定指标(如收入或总用户数)在短期内进行预测。
具体来说,预测涉及使用历史数据作为输入来生成预测输出。即使输出本身并不完全准确,预测也可以用来衡量特定指标的总体趋势。
为什么?
预测基本上就像是窥视未来。通过(以一定的信心水平)预测未来会发生什么,你可以更加主动地做出更明智的决策。结果是,你将有更多时间做出决定,并最终降低失败的可能性。
如何:
第一个资源提供了几种时间序列模型的总结:
第二个资源提供了使用 Prophet 创建时间序列模型的逐步指南,Prophet 是 Facebook 专为时间序列建模开发的 Python 库:
3. 推荐系统
什么?
推荐系统是旨在向用户建议最相关信息的算法,无论是亚马逊上的类似产品,Netflix 上的类似电视节目,还是 Spotify 上的类似歌曲。
推荐系统主要有两种类型:协同过滤和基于内容的过滤。
-
基于内容的推荐系统根据之前选择的项目特征推荐特定项目。例如,如果我之前看了很多动作片,它会将其他动作片排名更高。
-
协同过滤则是根据类似用户的反应来筛选用户可能喜欢的项目。例如,如果我喜欢歌曲 A,而其他人喜欢歌曲 A 以及歌曲 C,那么我会被推荐歌曲 C。
为什么?
推荐系统是最广泛使用且最实用的数据科学应用之一。不仅如此,它在数据产品中的投资回报率也最高之一。据估计,亚马逊在 2019 年由于其推荐系统销售额增加了 29%。 同样,Netflix 宣称其推荐系统在 2016 年价值高达 10 亿美元!
但是什么让它如此有利可图?正如我之前提到的,关键在于一个词:相关性。通过向用户提供更多相关的产品、节目或歌曲,你最终会增加他们购买更多产品和/或保持更长时间的可能性。
如何:
资源和数据集
4. 深度分析
什么?
深度分析只是对特定问题或主题的深入分析。它们可以是探索性的,以发现新信息和见解,也可以是调查性的,以了解问题的原因。
这不是一个广泛讨论的技能,部分原因是它需要经验,但这并不意味着你不能提高它!像其他任何技能一样,这只是一个练习的问题。
为什么?
深度分析对于任何数据相关的专业人士来说都是必不可少的。能够找出为什么某些东西不起作用,或者能够找到灵丹妙药,是区别优秀与一般的关键。
资源和数据集
以下是一些你可以自己尝试的深度分析任务:
5. 客户细分
什么?
客户细分是将客户基础划分为几个细分市场的实践。
最常见的细分类型是按人口统计进行,但还有许多其他类型的细分,包括地理、心理、需求和价值细分。
为什么?
细分对企业有几个重要的价值:
-
它使你能够进行更有针对性的营销,并向每个细分市场传达更个性化的信息。年轻的青少年和多个孩子的父母看重的东西大相径庭。
-
当资源有限时,它允许你优先考虑特定的细分市场,尤其是那些更具盈利性的细分市场。
-
细分市场还可以作为其他应用的基础,如追加销售和交叉销售。
如何:
数据集
原文。已获得许可转载。
相关:
-
19 个适合初学者的数据科学项目创意
-
数据科学家:如何推销你的项目和自己
-
计算机视觉中的 10 个 AI 项目创意
相关主题
5 个每个数据科学家应该知道的概率分布
原文:
www.kdnuggets.com/2019/07/5-probability-distributions-every-data-scientist-should-know.html
评论
概率分布就像是 3D 眼镜。它们使得有技能的数据科学家能够识别出在完全随机变量中存在的模式。
从某种程度上说,大多数其他数据科学或机器学习技能都基于对数据概率分布的某些假设。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
这使得概率知识成为你作为统计学家构建工具包的基础之一。如果你正在了解 如何成为数据科学家 的第一步。
不再啰嗦,让我们直接切入正题。
什么是概率分布?
在概率论和统计学中,随机变量 是一个 取随机值 的事物,例如“我看到的下一个人的身高”或“我下一碗拉面中的厨师头发数量”。
给定一个随机变量 X,我们希望有一种方式来描述它取的值。更进一步,我们希望能够表征 该变量取某一特定值 x 的 可能性。
例如,如果 X 是“我女朋友有多少只猫”,那么这个数字有可能是 1。可以说,这个值甚至有可能是 5 或 10。
然而,没有办法(因此也没有概率)一个人会有负数只猫。
因此,我们希望有一种明确的数学方式来表达变量 X 可以取的每一个可能值 x,以及事件 (X= x) 的可能性。
为了做到这一点,我们定义一个函数 P,使得 P(X = x) 是变量 X 具有值 x 的概率。
我们也可以请求 P(X < x) 或 P(X > x),用于区间而不是离散值。这将变得更加相关。
P 是变量的 密度函数,它描述了该变量的 分布。
随着时间的推移,科学家们逐渐认识到,许多自然现象和现实生活中的事物往往行为类似,变量共享某种分布,或者拥有相同的密度函数(或在其中改变几个常数的类似函数)。
有趣的是,为了使P成为实际的密度函数,需要满足一些条件。
-
P(X =x)** <= 1** 对于任何值x。没有什么比确定更确定的了。
-
P(X =x)** >= 0** 对于任何值x。某件事可以是不可能的,但不可能比这更不可能。
-
最后一条:P(X=x) 对于所有可能值x的总和 *是 1。
最后一条意味着“X 取任何值的概率,必须加起来等于 1,因为我们知道它会取某个值”。
离散与连续随机变量分布
最后,随机变量可以被认为属于两个组:离散和连续随机变量。
离散随机变量
离散变量有一组离散的可能值,每个值都有一个非零的概率。
例如,当掷硬币时,如果我们说
X = “如果硬币是正面则为 1,如果是反面则为 0”
然后P(X = 1) = P(X = 0) = 0.5。
但要注意,离散集不必是有限的。
几何分布用于建模某个事件在概率p 经过k** 次重试后发生的机会**。
它具有以下密度公式。

其中k可以取任何具有正概率的非负值。
注意所有可能值的概率的总和仍然加起来等于 1。
连续随机变量
如果你说
X = “从我头上随机拔取的头发的长度(以毫米为单位,不进行四舍五入)”
X可以取哪些可能值?我们可能都同意负值在这里没有意义。
但是如果你说它正好是 1 毫米,而不是 1.1853759…或者类似的数字,我要么会怀疑你的测量技能,要么会怀疑你的测量误差报告。
连续随机变量可以在给定的(连续)区间内取任何值。
因此,如果我们给它所有可能的值分配非零概率,它们的总和将不会加起来等于 1。
为了解决这个问题,如果X是连续的,我们将P(X=x) = 0 对于所有k,而是给X在某个区间内取值分配一个非零的机会。
要表示 X 在a和b之间的概率,我们说 P(a < X < b)。
你需要通过对X的密度函数从a到b进行积分来获得P(a < X < b),而不是仅仅替换密度函数中的值。
哇,你已经完成了整个理论部分!这是你的奖励。

奖励小狗。来源:Pixabay。
现在你知道什么是概率分布了,我们来学习一些最常见的概率分布吧!
伯努利概率分布
伯努利分布的随机变量是最简单的分布之一。
它表示一个二元事件:“这发生了”与“这没发生”,并以p作为其唯一参数,代表事件发生的概率。
一个参数为p的伯努利分布的随机变量B将具有以下密度函数:
P(B = 1) = p, P(B = 0) = (1-p)
这里B=1表示事件发生,B=0表示事件未发生。
注意这两个概率之和为 1,因此B的其他值是不可能的。
均匀概率分布
有两种均匀随机变量:离散型和连续型。
离散均匀分布将取(有限)的一组值 S,并为每个值分配1/n的概率,其中n是S中的元素数量。
这样,如果我的变量Y在{1,2,3}中均匀分布,那么每个值出现的概率为 33%。
骰子是一个非常典型的离散均匀随机变量例子,其中你的典型骰子有值集{1,2,3,4,5,6}。
连续均匀分布仅取两个值 a 和 b 作为参数,并对它们之间的区间中的每个值分配相同的密度。
这意味着 Y 在一个区间内取值(从c到d)的概率是与其大小成比例的,相对于整个区间(b-a)的大小。
因此,如果Y在a和b之间均匀分布,那么

这样,如果Y是 1 和 2 之间的均匀随机变量,
P(1 < X < 2) = 1 和 P(1 < X < 1.5) = 0.5
Python 的random包中的random方法对 0 和 1 之间的均匀分布连续变量进行采样。
有趣的是,任何其他分布都可以通过均匀随机值生成器和一些微积分进行采样。
正态概率分布
正态分布。来源:维基百科
正态分布变量在自然界中如此常见,实际上是标准。这也正是其名字的来源。
如果你把所有同事聚在一起,测量他们的身高,或称量他们的体重并绘制直方图,结果很可能会接近正态分布。
我实际上在展示探索性数据分析的示例时看到了这种效果。
还可以证明,如果你取一个样本的任何随机变量并计算这些测量的平均值,然后多次重复这个过程,这个平均值也将有一个正态分布。这个事实非常重要,所以它被称为统计学基本定理。
正态分布的变量:
-
是对称的,围绕一个均值(通常称为μ)中心对称。
-
可以取实数空间中的所有值,但只有 5%的时间会偏离标准差的两倍。
-
无处不在。
如果你测量的任何经验数据是对称的,假设它是正态分布通常也能奏效。
例如,掷K颗骰子并加总结果将近似于正态分布。
对数正态概率分布
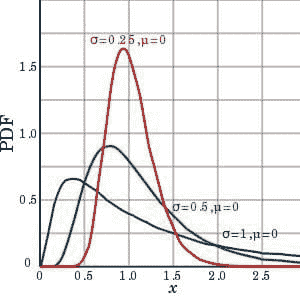
对数正态分布。来源:维基百科
对数正态分布是正态分布的一个较小、出现频率较低的姐妹。
如果一个变量X被称为对数正态分布,则意味着变量Y = log(X)遵循正态分布。
当在直方图中绘制时,对数正态概率分布是不对称的,如果其标准差更大则更加明显。
我认为对数正态分布值得一提,因为大多数基于金钱的变量都表现得如此。
如果你查看任何与金钱相关的变量的概率分布,比如
-
某家银行最新一次转账的金额。
-
华尔街最新交易的交易量。
-
一组公司在某一季度的季度收益。
它们通常不会有正态概率分布,但会更接近于对数正态随机变量。
(其他数据科学家:如果你能想到在工作中遇到的任何其他经验对数正态变量,请在评论中补充!尤其是金融以外的领域)。
指数概率分布
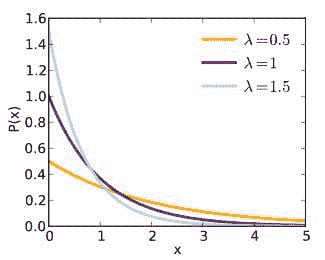
指数分布。来源:维基百科
指数概率分布也无处不在。
它们与一个叫做泊松过程的概率概念密切相关。
直接引用维基百科,泊松过程是“一个事件不断独立发生且以恒定平均速率发生的过程”。
这意味着,如果:
-
你有很多事件正在发生。
-
它们以某种速率发生(这个速率不会随时间变化)。
-
仅仅因为一个事件发生了,另一个事件发生的概率不会改变。
那么你就有一个泊松过程。
一些例子可能是服务器上的请求、超市中的交易,或是在某个湖泊中捕鱼的鸟类。
想象一个频率率为λ的泊松过程(假设事件每秒发生一次)。
指数随机变量用于建模事件发生后,下一次事件发生所需的时间。
有趣的是,在泊松过程中事件可以在任何时间间隔内发生 0 到无限次(概率逐渐减少)。
这意味着无论你等待多久,都有非零的事件不会发生的可能性。这也意味着它可能在很短的时间间隔内发生很多次。
在课堂上,我们曾经开玩笑说公交车到达是泊松过程。我认为,当你向某些人发送 WhatsApp 消息时,响应时间也符合这个标准。
然而,λ参数调节事件的频率。
它将使期望时间实际发生事件的时间围绕某个值。
这意味着,如果我们知道一辆出租车每 15 分钟经过我们这条街道,虽然理论上我们可以永远等待,但极有可能我们不会等待超过 30 分钟。
指数概率分布在数据科学中的应用
这里是一个指数分布随机变量的密度函数:

假设你有一个变量的样本,想要查看它是否可以用指数分布变量建模。
最优的λ参数可以很容易地估计为你采样值的平均值的倒数。
指数变量非常适合建模那些非常少见但巨大的(并且破坏均值的)离群值的概率分布。
这是因为它们可以取任何非负值,但更集中在较小的值上,随着值的增长,频率下降。
在一个特别离群值多的样本中,你可能想将λ估计为中位数而不是平均数,因为中位数对离群值更鲁棒。这方面的效果可能会有所不同,所以要谨慎对待。
结论
总结来说,作为数据科学家,我认为学习基础知识对我们很重要。
概率和统计可能不如深度学习或无监督机器学习那样引人注目,但它们是数据科学的基石,特别是机器学习。
在我的经验中,给机器学习模型提供特征而不知道它们遵循哪种分布,通常是一个糟糕的选择。
记住指数分布和正态分布的普遍性及其较小的对应分布——对数正态分布,也是很好的。
了解它们的属性、用途和表现对训练机器学习模型具有颠覆性。在进行任何数据分析时,通常也要将它们牢记在心。
你发现本文的任何部分有用吗?这些都是你已经知道的内容吗?你学到了什么新东西吗?在评论中告诉我吧!
如果有任何不清楚的地方、你不同意的观点,或者有任何明显错误的内容,请在 Twitter、 Medium 或 dev.to 联系我。不用担心,我不会咬人的。
个人简介: Luciano Strika 是布宜诺斯艾利斯大学的计算机科学学生,同时也是 MercadoLibre 的数据科学家。他还在 www.datastuff.tech 上撰写关于机器学习和数据的文章。
原文。经许可转载。
相关内容:
-
数据科学基础:幂律和分布
-
Python 中的基础统计学:概率
-
概率质量和密度函数
更多相关话题
5 个保持数据科学家技能更新的项目创意
原文:
www.kdnuggets.com/2022/07/5-project-ideas-stay-uptodate-data-scientist.html

我相信实践。实践是知识和思想的应用。我不相信的一种观点是,理论与实践之间的道路是一条单向高速公路。换句话说,它告诉我们实践仅仅是理论原则的应用。但实践远不止如此;它也是新理论的诞生地,推动了新理论的发展。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
阅读文章或研究论文、参加会议或聚会以跟上最新技术,并获得更好的理论基础是值得赞赏的。我强烈推荐这样做!但无论你获取了什么更新,作为数据科学家的工作仍然会归结为几个基本技能:数据收集、分析和可视化。
而且你需要使用它们!如果你缺乏机会,你必须自己创造机会。最全面的方法是构思一个数据科学项目,并从头到尾完成它。
在这样的项目中,你会使用 API 来获取实际数据。通过数据清洗和分析,你将获得洞见,并可以将其呈现在一些漂亮的可视化图表中。最后,你可以将其发布在 reddit 上,获得反馈,并可能考虑这些反馈以改进你的项目。
理想情况下,项目也应该有趣,而不仅仅是枯燥的技能打磨方式。
1. 前 10 首歌曲的歌词词数变化
项目的构思是通过Spotify API获取 Spotify 上前 10 首最受欢迎歌曲的数据。然后,可以将 Spotify 的元数据与来自Genius API或其他歌词网站的歌词进行关联。
歌词中“词”的定义由你决定。例如,你可以计算总词数或仅计算唯一词数。你是否包括像‘na na na’或‘la la la’这样的合唱部分?
通过分析这些数据,你可以展示历史发展并预测未来的趋势。你可以包括其他一些参数,如歌曲长度或前奏长度。尤其是前奏,研究 如俄亥俄州立大学的研究 显示了歌曲前奏长度随着时间的推移大幅减少,这将特别有趣。
你可以从 这个项目 中获取一些方法和可视化的灵感。
2. 投资出租物业

如果你考虑在全国范围内投资物业以便出租,分析哪些因素影响租金价格,从而影响业务的盈利性和潜力将是非常有用的。
数据可以通过一些 租赁 API 获取。决定投资何处何时的重要因素可能包括地点、物业大小、建造日期、设施、租金价格趋势等。
方法的灵感可以来自这个很棒的 Airbnb 数据科学项目。
3. 识别虚假新闻
在这里,你可以使用 Facebook、Twitter 或 reddit API 来获取你将使用的数据。根据你拥有的数据,你可以分析社交媒体上的帖子,并将虚假新闻与非虚假新闻区分开来。你的方法可以更为一般化,但你也可以关注某个特定的主题。例如,选择一个主题,如 COVID-19 疫情、美国总统选举或乌克兰战争。你可以分析虚假新闻的地理分布、传播虚假新闻的人的人口统计特征,或最容易受虚假新闻影响的主题。
也许你可以尝试训练一个识别虚假新闻的模型。你可以从 Kai Shu、Depak Deepak Mahudeswaran 和 Huan Liu 的工作 中找到一些方法的灵感。其他有用的资源包括 Data Flair 项目 或 这个,你可以用 R 完成,也可以用 Python 重新创建。
4. 邮票上的人物类型
如果你有兴趣在邮票上引入更多关于职业、种族或性别代表性的平等,这个项目可能适合你。这个想法是使用维基百科 API获取邮票上的人物名单,例如在美国。你也可以为其他国家甚至全世界做类似的分析。也许还可以比较各国的数据,看看它们之间的比较情况。一个想法是将这些数据与不平等数据连接起来。看看邮票上的代表性不平等如何与国家的经济不平等相关联会很有趣。
有一个项目分析了各国货币上庆祝的人员类型。我认为你可以从中获取一些关于项目方法和可视化的好点子。
5. 预测书籍销售

亚马逊 API是这个项目的一个很好的工具。通过它,你可以获得有关书籍销售的数据。例如,你可以分析不同类型、出版社、作者、页数、价格、评论数、评分等方面的销售情况。
一旦获取数据并分析,你可以预测你的书籍必须满足的参数,以成为畅销书。如果你需要关于如何处理和可视化这个项目的点子,可以查看在 ResearchGate 上发布的这份 20 页的工作。
6. 创建你自己的项目
当然,你不应该仅限于这五个项目。我强烈建议你提出自己的数据分析项目创意。当你想到一个项目时,考虑以下几点:
-
目标: 项目的目标应该是利用现代数据科学创建一些用户喜欢的东西。
-
使其有趣且用户友好: 这通常意味着构建一个互动模型并进行可视化。
-
创意: 一个好的项目灵感和可视化来源是数据之美 subreddit。
-
复制与创新: 尝试复制你在其中找到的创意,或用它们来提出你自己对项目的改编。
将帮助你作为数据科学家保持最新的项目因素是:
-
使用 API 收集数据
-
使用一些可视化库来创建图形
-
将你的工作发布到 subreddit 上以获得反馈
总结
我相信这些项目中的任何一个都会挑战你运用现有的知识,并尝试一些全新的事物。在选择项目时,关键是它能够带来实际的成果,并且你在过程中也能享受乐趣。这就是为什么我尝试选择涉及我们生活各个方面的项目。
这些项目的共同点在于它们使你运用所有基本的数据科学技术和技能。使用这些项目是保持这些技能的最佳方式。
- 如果你能利用这些项目想出一些更好、更有趣的点子,那就更好了。想象力也是一个重要但常被忽视的数据科学技能。但请确保这些项目能挑战你其他的数据科学技能。
内特·罗西迪 是一名数据科学家,专注于产品战略。他还是一名兼职教授,教授分析课程,并且是 StrataScratch、一个帮助数据科学家准备面试的平台的创始人。你可以通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
更多相关内容
5 个 Python 数据科学最佳实践
原文:
www.kdnuggets.com/5-python-best-practices-for-data-science

图片由作者提供
扎实的 Python 和 SQL 技能对许多数据专业人员都至关重要。作为数据专业人员,你可能对 Python 编程非常熟悉——以至于编写 Python 代码感觉相当自然。但在进行数据科学项目时,你是否遵循了最佳实践呢?
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
尽管学习 Python 并用它构建数据科学应用很简单,但写出难以维护的代码可能更容易。为了帮助你编写更好的代码,本教程探讨了一些 Python 编码最佳实践,这些实践有助于依赖管理和维护性,例如:
-
在本地进行数据科学项目时,设置专用的虚拟环境
-
通过类型提示提高可维护性
-
使用 Pydantic 进行数据建模和验证
-
代码分析
-
尽可能使用矢量化操作
所以让我们开始编码吧!
1. 为每个项目使用虚拟环境
虚拟环境确保项目依赖被隔离,防止不同项目之间的冲突。在数据科学中,项目通常涉及不同的库和版本集合,虚拟环境对于维护可重复性和有效管理依赖特别有用。
此外,虚拟环境还使合作者能够更轻松地设置相同的项目环境,而无需担心依赖冲突。
你可以使用像 Poetry 这样的工具来创建和管理虚拟环境。使用 Poetry 有很多好处,但如果你只需要为你的项目创建虚拟环境,你也可以使用 内置的 venv 模块。
如果你使用的是 Linux 机器(或 Mac),你可以这样创建和激活虚拟环境:
# Create a virtual environment for the project
python -m venv my_project_env
# Activate the virtual environment
source my_project_env/bin/activate
如果你是 Windows 用户,你可以 查看文档 了解如何激活虚拟环境。因此,为每个项目使用虚拟环境有助于保持依赖的隔离和一致性。
2. 添加类型提示以提高可维护性
由于 Python 是动态类型语言,你不需要为你创建的变量指定数据类型。然而,你可以添加类型提示——指明期望的数据类型——以使你的代码更易维护。
让我们以一个计算数据集中数值特征均值的函数为例,并进行适当的类型注释:
from typing import List
def calculate_mean(feature: List[float]) -> float:
# Calculate mean of the feature
mean_value = sum(feature) / len(feature)
return mean_value
在这里,类型提示让用户知道calcuate_mean函数接受一个浮点数列表并返回一个浮点值。
记住,Python 在运行时不会强制类型。但你可以使用 mypy 或类似工具来对无效类型引发错误。
3. 使用 Pydantic 建模你的数据
之前我们讨论了添加类型提示以使代码更易维护。这对于 Python 函数非常有效。但是在处理来自外部来源的数据时,通常通过定义具有预期数据类型的类和字段来建模数据会更有帮助。
你可以使用 Python 内置的数据类,但没有开箱即用的数据验证支持。使用 Pydantic,你可以建模你的数据,还可以利用其内置的数据验证功能。要使用 Pydantic,你可以通过 pip 安装它及其邮件验证器:
$ pip install pydantic[email-validator]
这里是一个使用 Pydantic 建模客户数据的示例。你可以创建一个继承自BaseModel的模型类,并定义各种字段和属性:
from pydantic import BaseModel, EmailStr
class Customer(BaseModel):
customer_id: int
name: str
email: EmailStr
phone: str
address: str
# Sample data
customer_data = {
'customer_id': 1,
'name': 'John Doe',
'email': 'john.doe@example.com',
'phone': '123-456-7890',
'address': '123 Main St, City, Country'
}
# Create a customer object
customer = Customer(**customer_data)
print(customer)
你可以通过添加验证来进一步检查字段是否都具有有效值。如果你需要关于使用 Pydantic——定义模型和验证数据的教程——请阅读 Pydantic 教程:Python 数据验证简化。
4. 进行代码性能分析以识别性能瓶颈
性能分析对于优化应用程序性能是非常有帮助的。在数据科学项目中,你可以根据具体情况分析内存使用和执行时间。
假设你正在进行一个机器学习项目,其中预处理大数据集是训练模型之前的关键步骤。让我们对一个应用常见预处理步骤(如标准化)的函数进行性能分析:
import numpy as np
import cProfile
def preprocess_data(data):
# Perform preprocessing steps: scaling and normalization
scaled_data = (data - np.mean(data)) / np.std(data)
return scaled_data
# Generate sample data
data = np.random.rand(10000000)
# Profile preprocessing function
cProfile.run('preprocess_data(data)')
当你运行脚本时,你应该会看到类似的输出:
在这个例子中,我们正在对preprocess_data()函数进行性能分析,该函数用于预处理样本数据。性能分析通常有助于识别潜在的瓶颈——指导优化以提高性能。以下是一些关于 Python 性能分析的教程,你可能会觉得有用:
5. 使用 NumPy 的向量化操作
对于任何数据处理任务,你总是可以从头编写 Python 实现。但是,当处理大量数字数组时,你可能不想这样做。对于大多数常见操作——这些操作可以表述为对向量的操作——你可以使用 NumPy 更高效地执行它们。
让我们以以下逐元素相乘的例子为例:
import numpy as np
import timeit
# Set seed for reproducibility
np.random.seed(42)
# Array with 1 million random integers
array1 = np.random.randint(1, 10, size=1000000)
array2 = np.random.randint(1, 10, size=1000000)
这里是 Python 仅实现和 NumPy 实现:
# NumPy vectorized implementation for element-wise multiplication
def elementwise_multiply_numpy(array1, array2):
return array1 * array2
# Sample operation using Python to perform element-wise multiplication
def elementwise_multiply_python(array1, array2):
result = []
for x, y in zip(array1, array2):
result.append(x * y)
return result
让我们使用timeit模块中的timeit函数来测量上述实现的执行时间:
# Measure execution time for NumPy implementation
numpy_execution_time = timeit.timeit(lambda: elementwise_multiply_numpy(array1, array2), number=10) / 10
numpy_execution_time = round(numpy_execution_time, 6)
# Measure execution time for Python implementation
python_execution_time = timeit.timeit(lambda: elementwise_multiply_python(array1, array2), number=10) / 10
python_execution_time = round(python_execution_time, 6)
# Compare execution times
print("NumPy Execution Time:", numpy_execution_time, "seconds")
print("Python Execution Time:", python_execution_time, "seconds")
我们看到 NumPy 实现的速度快了约 100 倍:
Output >>>
NumPy Execution Time: 0.00251 seconds
Python Execution Time: 0.216055 seconds
总结
在本教程中,我们探讨了几种数据科学的 Python 编码最佳实践。希望你觉得这些实践对你有帮助。
如果你对学习用于数据科学的 Python 感兴趣,请查看5 个免费课程掌握 Python 数据科学。祝学习愉快!
Bala Priya C** 是一位来自印度的开发人员和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正在通过编写教程、操作指南、评论文章等与开发者社区分享她的知识。Bala 还制作了引人入胜的资源概述和编码教程。**
更多相关话题
5 个 Python 面试问题与答案
原文:
www.kdnuggets.com/2022/09/5-python-interview-questions-answers.html
图片来源:ThisIsEngineering
想象你坐在笔记本电脑前,听取招聘经理的指示并阅读编码问题陈述。如果你没有为定时编码面试做好准备,你将会犯错误。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT 方面的需求
因此,在参加面试之前,复习最常见的问题总是好的。这将为你准备好棘手、条件性和高级的编码问题。
Q1: 奇数还是偶数?确定一下!
确定“n”个连续数字的和是偶数、奇数还是任意。
示例:
-
odd_or_even(3) 应返回“Either”。总和可以是偶数或奇数。
-
odd_or_even(2) 应返回“Odd”。连续数字的和包含一个奇数和一个偶数,因此总和将始终是奇数。
-
odd_or_even(4) 应返回“Even”。连续数字的和包含两个偶数和两个奇数,因此总和将始终是偶数。
解决方案:
-
如果将“n”除以 2 后余数为 1,则返回“Either”。
-
如果第一个条件失败,请转到第二个条件。
-
首先,将数字除以 2,然后再除以 2 以检查是否返回余数。如果余数为 1,则返回“Odd”,否则返回“Even”
def odd_or_even(n):
if n % 2 == 1:
return "Either"
elif (n / 2) % 2 == 1:
return "Odd"
else:
return "Even"
为了在第一次尝试中通过此问题,您需要多次阅读描述。答案已经在示例中给出。
这并不是唯一的解决方案。你可以在 Codewars 平台上找到各种解决方案。你甚至可以提出自己独特的解决方案以获得更多积分。
Q2: 元组和列表有什么区别?
元组和列表都用于存储和收集数据。
列表使用方括号 [1,2,3,..] 声明,而元组使用圆括号 (1,2,3,...) 声明。
列表是可变的,主要用于数据插入和删除。它还具有多个内置函数。
元组是不可变的。与列表相比,它的迭代速度较快,占用的内存较少。它主要用于快速访问元素。
Q3: 什么是 Lambda 函数?为什么使用它们?
Lambda 函数通常称为匿名函数。它们没有名称。
当表达式适合一行时,它可以作为常规函数的替代。Lambda 函数非常简单且轻量。它们提高了代码质量。
要创建一个简单的函数,将 20 添加到输入参数中,我们将编写 lambda 并提供两个组件:参数和表达式。
lambda arguments : expression
参数是“a”,表达式是“a+20”。可以通过提供输入给“x”变量来激活函数。
就这么简单!
x = lambda a : a + 20
print(x(10))
>>> 30
我们还可以向函数提供多个输入参数。在我们的例子中,它将 2 和 5 相乘以输出 10。
x = lambda a, b : a * b
print(x(2, 5))
>>> 10
Q4:最大 69 数字
你得到一个正整数“num”。它仅由 6 和 9 数字组成。
通过更改一个数字(6 或 9)来返回最大数字。
示例:
-
输入:num = 9669,输出:9969
-
输入:num = 9996,输出:9999
-
输入:num = 9999,输出:9999
解决方案:
为了得到最大数字,我们必须始终将 6 改为 9,并且应该是第一个数字(6)。
假设我们有 num = 9669
-
更改第一个数字将得到 6669。
-
更改第二个数字将得到 9969。
-
更改第三个数字将得到 9699。
-
更改第四个数字将得到 9666。
9969 是最高的数字。
我们只需要创建一个简单的函数,在开始时将一个 6 转换为 9。
为此,我们将数字转换为字符串,并使用.replace函数将“6”替换为“9”。第三个参数是“count”为 1。它只会替换一个数字。替换后,我们将字符串转换为整数。
def maximum69Number(num):
return int(str(num).replace('6','9',1))
num = 966696696
maximum69Number(num)
>>> 996696696
Q5:谁先获胜?
微软编码面试中的问题:
“艾米和布拉德轮流掷一个公平的六面骰子。谁先掷到“6”谁就赢。艾米先掷。艾米获胜的概率是多少?”
在我们进入解决方案部分之前,我希望你再读一遍问题。这是一个模拟问题,我们将找到艾米获胜的概率。
艾米总是先掷骰子,如果她第一次掷到 6 就赢了。否则,布拉德掷骰子,如果他掷到 6 就赢了。如果没有,则轮到艾米,直到其中一人获胜。
这个问题完全是关于迭代和逻辑的。
-
将 A_count 和 B_count 初始化为零。我们将使用它们来计算概率。
-
之后,我们将对“size”进行模拟。在我们的例子中,它是 1000。
-
利用 Numpy 的 random randint 函数,我们将生成一个从 1 到 6 的数字。randint 函数需要低(包含)和高(不包含)数字。你甚至可以使用 random 库代替 Numpy。
-
如果随机数是 6,则 A_count(艾米)加一,否则布拉德再掷一次。
-
如果 B_role 掷到 6,则 B_count(布拉德)加一。否则,转到艾米。
-
这个循环将运行一千次,我们将收集艾米和布兰德的胜利来计算概率。
-
为了计算艾米获胜的概率,我们将把艾米掷出 6 的次数除以艾米和布拉德的总获胜次数。
import numpy as np
def win_probability(size):
A_count = 0
B_count = 0
for i in range(size):
A_role = np.random.randint(1,7)
if A_role == 6:
A_count+=1
else:
B_role = np.random.randint(1,7)
if B_role == 6:
B_count+=1
return A_count/(A_count+B_count)
为了确保结果的可重复性,我们将使用 Numpy 的种子。
np.random.seed(125)
win_probability(1000)
>>> 0.5746031746031746
正如我们所见,艾米由于先开始,较布拉德更占优势。她在 1000 次迭代中的胜率为 57.5%。
参考资料
-
奇数还是偶数?来确定一下吧!| Codewars
-
元组和列表有什么区别? | Codecademy
-
什么是 lambda 函数?它们为什么会被使用?| Codecademy
-
最大 69 数字 | LeetCode
-
谁先赢得比赛?| Leihua Ye, PhD
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些在心理健康方面挣扎的学生构建一个 AI 产品。
进一步了解此主题
5 个用于地理空间数据分析的 Python 包
原文:
www.kdnuggets.com/2023/08/5-python-packages-geospatial-data-analysis.html
介绍
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
地理空间数据分析在城市规划、环境研究、农业和交通运输等行业至关重要。不断增长的需求导致了 Python 包的使用增加,用于各种地理数据分析需求,例如分析气候模式、调查城市发展或追踪疾病传播等。评估和选择具有快速处理、修改和可视化能力的正确工具,对于有效分析和可视化地理空间数据至关重要。
理解地理空间数据
首先理解什么是地理空间数据是很重要的。地理空间数据是具有地理或地理组件的数据,代表地球表面上对象、特征或事件的位置和属性。它描述了物理宇宙中各种项目的空间连接、分布和属性。地理空间数据主要有两种类型:
-
光栅数据:适用于没有固定边界的连续信息,以网格单元的形式表示,其中值指示观察到的特征。通常在固定间隔进行监测,并通过插值创建连续的表面。
-
矢量数据:使用点、线和多边形来表示空间属性,包括兴趣点、交通网络、行政边界和土地区块,通常用于具有精确位置或硬约束的离散数据。
地理空间数据可以存储在各种格式中,例如:
-
ESRI Shapefile
-
GeoJSON
-
Erdas Imagine 图像文件格式(EIF)
-
GeoTIFF, Geopackage(GPKG)
-
GeoJSON, 光检测
-
范围(LiDAR)等许多其他类型。
地理空间数据涵盖多种类型,如卫星图像、海拔模型、点云、土地使用分类和基于文本的信息,为跨行业的空间分析和决策提供了宝贵的见解。像微软、谷歌、Esri 和亚马逊网络服务这样的主要公司利用地理空间数据获得有价值的见解。让我们来探讨五个用于地理空间数据分析的顶级 Python 包。这些包支持数据的读取/写入、处理、可视化、地理编码和地理索引,适合初学者和经验丰富的用户。发现这些包如何有效地进行探索、可视化和从地理空间数据中提取见解。让我们开始吧!
1. Geopandas
适合: 矢量数据
Geopandas 是一个广泛使用的 Python 库,用于处理矢量地理空间数据,在 Pandas DataFrames 中提供直观的地理数据处理。它支持 Shapefiles 和 GeoJSON 等格式,并提供如合并、分组和空间连接等空间操作。Geopandas 与 Pandas、NumPy 和 Matplotlib 等流行库无缝集成。它可以处理大型数据集,但这可能会带来挑战。Geopandas 包通常用于空间数据分析任务,包括空间连接、查询和像缓冲区和交集分析等地理空间操作。Geopandas 需要不同的包,如 Shapely 处理几何操作,Fiona 访问文件,matplotlib 用于绘图。
例如,Geopandas 可以用于探索房地产数据,以识别城市中最昂贵的社区,或分析人口数据以可视化不同社区的增长和迁移模式。
我们可以使用 pip 安装该包:
pip install geopandas
使用 GeoPandas 绘图
让我们查看下面显示的内置地图:
import geopandas
# Check available maps
geopandas.datasets.available
我们将使用 Geopandas 加载一个世界地图数据集,提取美国的 shapefile,并用以下代码在图表上绘制它:
# Selecting a particular map
geopandas.datasets.get_path('naturalearth_lowres')
# Open the selected map - GeoDataFrame
world = geopandas.read_file(geopandas.datasets.get_path('naturalearth_lowres'))
# Create a subset of the GeoDataFrame
usa = world[world.name == "United States of America"]
# Plot the subset
usa.plot();
上述代码打印了子集数据框的地图:
2. Folium
适合: 点云
Folium 是一个用于创建带有标记、弹出窗口、等值线图和其他地理空间可视化的 Python 库。它与 Leaflet JavaScript 库集成,并允许将地图导出为 HTML。它可以与 Geopandas 和 Cartopy 结合使用,并通过 Map Tiles 处理大型数据集。Folium 在简单性、美观性和与其他地理空间库的集成方面表现出色。然而,对于高级地理空间分析和处理,Folium 可能有其局限性。
例如,Folium 可以在供应链和物流中用于可视化分销网络、优化路线和监控货物位置。
我们可以使用以下命令安装 Folium:
pip install folium
使用 Folium 绘图
让我们用以下代码行打印一个以 [0, 0] 为中心的样本交互式地图,并在同一位置放置一个标记:
import folium
# Generate a Folium map with center coordinates (0, 0)
map = folium.Map(location=[0, 0], zoom_start=2)
# Locate the coordinates 0, 0
folium.Marker([0, 0]).add_to(map)
# Display the map
map
这个地图可以通过添加标记、图层或根据特定地理空间数据进行样式调整来进一步自定义。
3. ipyleaflet
适用于: 点云,互动
ipyleaflet 包使在 Python 中创建交互式地图变得简单,特别是在 Jupyter notebooks 中,允许用户生成和共享具有各种底图、标记和其他地理空间操作的交互式地图。ipyleaflet 基于 leaflet JavaScript 库,支持 GeoJSON 和 WMS 图层、CSS 和 JavaScript 样式以及地理空间计算。虽然 ipyleaflet 在交互式小部件方面表现出色,但由于其对 JavaScript 的依赖,可能不适合纯 Python 项目。
例如,ipyleaflet 可以应用于环境监测,以可视化传感器数据、监测空气质量,并实时评估环境变化。
要安装 ipyleaflet,我们使用 pip 命令:
pip install ipyleaflet
使用 ipyleaflet 绘图
让我们使用以下代码创建一个交互式地图,在坐标 (40.7128, -74.0060) 放置一个标记,表示纽约市的一个兴趣点:
from ipyleaflet import Map, Marker
# Create the map
m = Map(center=(40.7128, -74.0060), zoom=12)
# Add the market
marker = Marker(location=(40.7128, -74.0060))
m.add_layer(marker)
以下是代码的输出:
4. Rasterio
适用于: 光栅数据
Rasterio 是一个功能强大的 Python 库,用于处理地理空间光栅数据,提供高效的性能和广泛的操作,如裁剪、重新投影和重采样。它支持多种光栅格式,并与其他地理空间库集成良好,尽管它在处理矢量数据和复杂分析任务时存在局限性。然而,Rasterio 是 Python 中高效的光栅数据操作和处理的必备工具。
例如,rasterio 可用于读取和写入卫星图像、进行地形分析、从数字高程模型中提取数据以及进行遥感分析等任务。
!pip install rasterio
rasterio.open() 函数打开文件,read() 方法将图像读取为 numpy 数组。最后,使用 Matplotlib 的 plt.imshow() 函数来显示图像,plt.show() 显示输出中的图表。
使用 rasterio 绘图
import rasterio
from rasterio.plot import show
我们使用 rasterio 库从 kaggle 数据集‘气候数据的高分辨率 GeoTIFF 图像’中的 'sample.tif' 文件打开并可视化一个光栅图像,显示红色通道(图像中的颜色通道之一)作为一个子图,并使用 Reds 颜色图谱,而原始图像(包含多个颜色通道)作为另一个子图,使用 viridis 颜色图谱。其他颜色通道,如绿色和蓝色,也可以使用这种方法进行可视化。
src = rasterio.open('/content/sample.tif')
plt.figure(figsize=(15,10))
fig, (axr, axg) = plt.subplots(1,2, figsize=(15,7))
show((src, 1), ax=axr, cmap='Reds', title='red channel')
show((src), ax=axg, cmap='viridis', title='original image')
plt.show()
原始 GeoTIFF 图像(右)来源:kaggle.com
在地理空间分析中分析特定的颜色通道如红色、蓝色和绿色,目的是关注或提取与这些颜色组件相关的特定属性、特征或特性的信息。例如,可能包括遥感中的植被健康、植被指数或水体等。
5. Geoplot
适用于: 矢量数据,交互式
Geoplot 是一个用户友好的 Python 库,用于快速创建视觉上吸引人的地理空间可视化,包括分层地图和散点图。它与流行的数据处理库如 Pandas 无缝集成,并支持多种地图投影。然而,Geoplot 在交互式地图支持方面有局限性,且与专门的地理空间库相比,图表类型的范围较小。尽管如此,它仍然在快速地理空间数据可视化和洞察空间模式方面具有价值。
!pip install geoplot
使用 geoplot 绘图
我们将使用 Geoplot 绘制分层地图可视化,从世界 shapefile 中选择亚洲国家,基于“pop_est”属性分配颜色强度,并使用“icefire”颜色映射绘制地图,图例的大小为 10 x 5。
import geoplot
#Plotting population for Asia
asia = world.query("continent == 'Asia'")
geoplot.choropleth(asia, hue = "pop_est", cmap = "icefire",legend=True, figsize = (10, 5));
例如,geoplot 包可以创建人口密度的分层地图,绘制犯罪事件的空间模式,展示环境因素的分布,并基于地理数据分析疾病的传播。
结论
总之,地理空间 Python 包有助于有效地分析基于位置的信息。每个讨论过的包都有其优点和缺点,但它们结合在一起可以形成一个强大的 Python 工具套件,用于处理地理空间数据。因此,对于初学者或经验丰富的 GIS 专业人士,这些包在分析、可视化和处理地理空间数据方面都非常有价值。
你可以在我的 GitHub 仓库 这里 找到本文的代码。
如果你觉得这篇文章有启发,欢迎在 LinkedIn 和 Twitter 上与我联系。记得关注我在 Kaggle 的页面,那里你可以访问我的机器学习和深度学习项目、笔记本以及引人注目的数据可视化作品。
Devashree Madhugiri 拥有德国信息技术硕士学位,并具有数据科学背景。她喜欢从事各种机器学习和深度学习项目。她通过在多个技术平台上撰写与数据可视化、机器学习、计算机视觉相关的技术文章来分享她在 AI 方面的知识。她目前是 Kaggle Notebooks Master,闲暇时间喜欢解数独谜题。
更多相关话题
5 个用于数据科学投资组合的 Python 项目
原文:
www.kdnuggets.com/2022/12/5-python-projects-data-science-portfolio.html
作者提供的图片
在掌握 Python 和数据科学基础知识后,是时候将你的技能付诸实践并获得经验。这些项目将帮助你培养解决问题的习惯。此外,它还将提供新的工具和概念,让你理解端到端的项目生命周期。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织 IT
在这五个项目中,我们将学习:
-
抓取实时雅虎股票价格
-
对 Instagram 帖子覆盖率进行数据分析
-
开发预测航班价格的网络应用
-
执行时间序列分析和预测
-
为低资源语言构建深度学习 ASR 模型
1. 从雅虎财经抓取股票价格
项目图片
学习使用各种 Python 库抓取和清理雅虎的金融数据。你将理解 HTML 的各种组件以及如何利用这些信息提取网站的特定组件。此外,你将编写函数以解析原始数据,选择一些股票,并将数据导出为 JSON 文件。
网络抓取是数据分析师、BI 工程师和数据科学家工作中最基本的部分。你需要理解各种 Python 工具,以创建抓取脚本或网络爬虫,从各种网站获取持续流动的实时数据。
项目链接: 如何使用 Python 从雅虎财经抓取股票价格
2. Instagram 达到分析项目
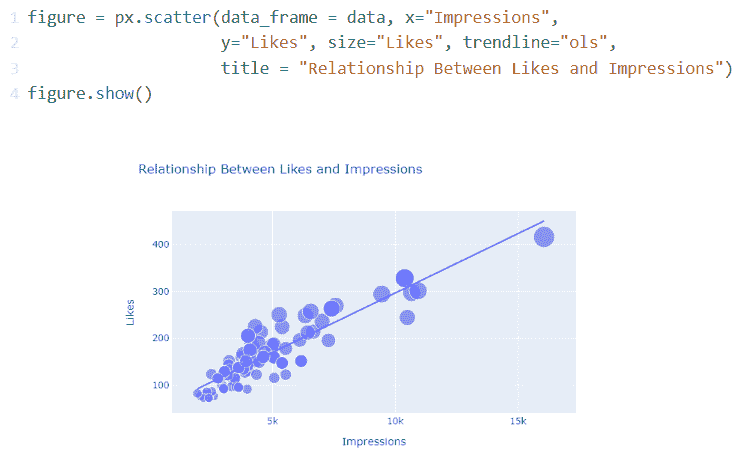
项目图片
分析项目并不是关于创建花哨的可视化。它是关于理解数据并以通俗的语言解释数据。数据科学家需要清理数据,进行统计分析,添加数据可视化图表,用非技术语言向利益相关者解释可视化,并进行预测分析。
在这个项目中,你将分析 Instagram 数据集,使用各种可视化图表来解释模式和趋势,并最终创建一个简单的机器学习模型来预测 Instagram 帖子的覆盖率。
项目链接: 使用 Python 的 Instagram 覆盖分析
3. 使用 Flask 应用程序的航班价格预测
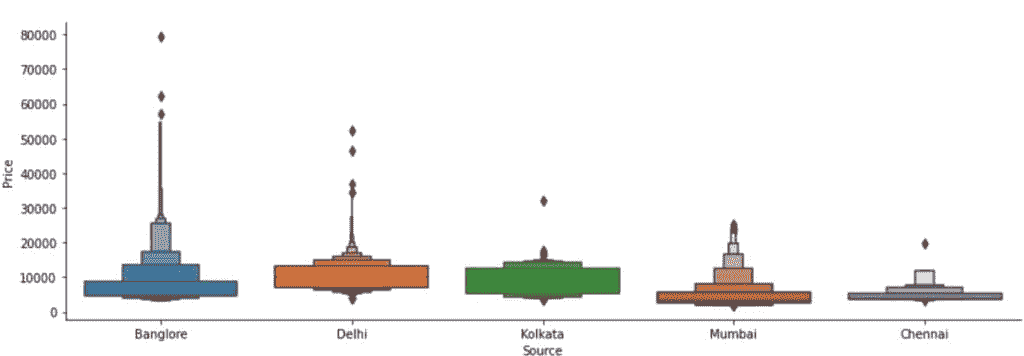
项目中的图像
在这个项目中,你将清理数据,进行探索性数据分析,可视化数据以理解票价趋势,训练和评估模型,并使用 Flask 构建模型推断。
如果你是初学者,这是你想要的完美起点。你将了解如何处理数据并部署你的机器学习解决方案。
项目链接: 使用 Flask 应用程序的航班价格预测
4. 时间序列分析与预测端到端项目
项目中的图像
金融市场对时间序列分析和预测的需求巨大。公司正在开发方法来理解模式和趋势,以避免灾难,并为利益相关者赚取更多利润。
在这个项目中,你将分析数据,然后可视化趋势,以制定更好的预测策略。之后,你将训练和评估 ARIMA 模型,并使用预测结果比较过去和未来的趋势。
这个项目深入探讨了时间序列分析,我强烈推荐给所有的毕业年学生。
项目链接: 基于 Python 的时间序列分析与预测的端到端项目
5. 自动语音识别项目
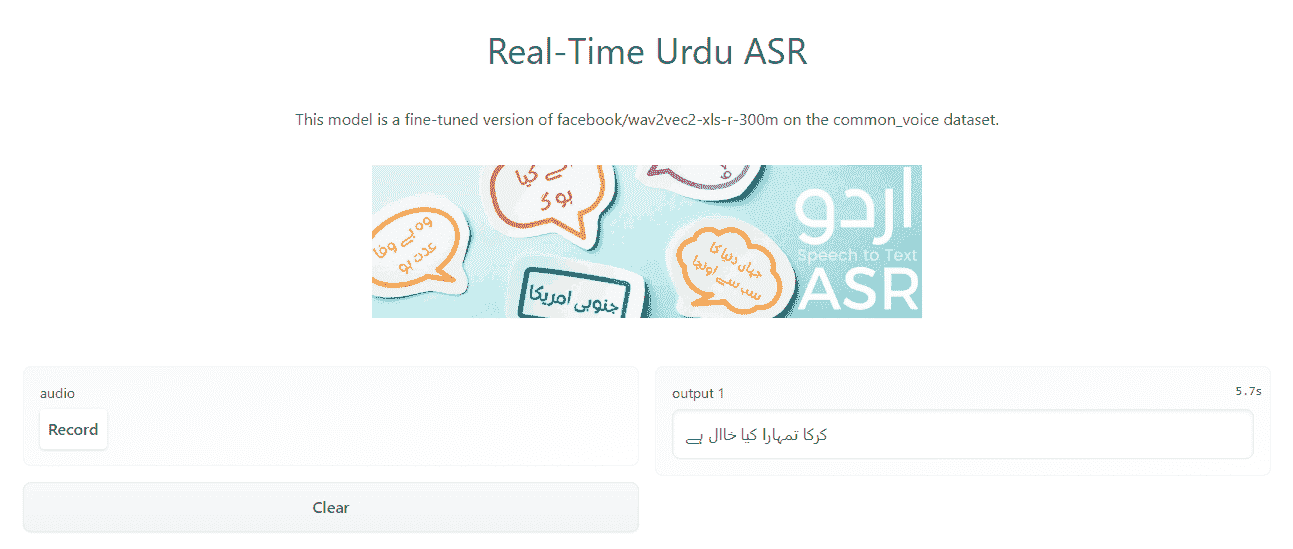
作者提供的图像 | 实时乌尔都语 ASR
这是一个对任何人来说都稍具挑战性的项目。我花了两个月时间理解处理音频数据及其处理,以创建自动语音识别模型。
在这个项目中,你将学习处理和处理音频及文本数据。之后,你将使用 HuggingFace transformers 来构建和改进多语言语音识别模型。此外,你还将学习清理音频和文本数据,并使用 n-gram 语言模型来改善 WER 性能指标。
项目链接: 使用 Facebook wav2vec2-xls-r-300m 的自动语音识别
结论
通过项目学习是必要的。它帮助你了解项目生命周期,并为职业生涯做好准备。除了独立项目,我强烈建议你参与开源项目,以获得更多工业实践和工具的经验。
希望你喜欢我提到的所有项目,如果你需要数据科学和机器学习职业方面的帮助,请告诉我。
在 Twitter 和 LinkedIn 上关注我,我会发布有关数据科学和机器学习的精彩博客。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为饱受心理疾病困扰的学生打造一个 AI 产品。
了解更多相关话题
提升数据效率和速度的 5 个 Python 小技巧
原文:
www.kdnuggets.com/5-python-tips-for-data-efficiency-and-speed

图片由作者提供
编写高效的 Python 代码 对于优化性能和资源使用非常重要,无论你是在进行数据科学项目、构建 web 应用程序,还是在进行其他编程任务。
我们的 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
利用 Python 强大的功能和最佳实践,你可以减少计算时间,提高应用程序的响应速度和可维护性。
在本教程中,我们将探讨五个重要的技巧,通过每个例子的编码来帮助你编写更高效的 Python 代码。让我们开始吧。
1. 使用列表推导式代替循环
你可以使用列表推导式从现有列表和其他可迭代对象(如字符串和元组)中创建列表。它们通常比普通循环在列表操作中更简洁和更快。
假设我们有一个用户信息的数据集,我们想提取那些分数大于 85 的用户的姓名。
使用循环
首先,让我们使用 for 循环和 if 语句来完成这个任务:
data = [{'name': 'Alice', 'age': 25, 'score': 90},
{'name': 'Bob', 'age': 30, 'score': 85},
{'name': 'Charlie', 'age': 22, 'score': 95}]
# Using a loop
result = []
for row in data:
if row['score'] > 85:
result.append(row['name'])
print(result)
你应该得到以下输出:
Output >>> ['Alice', 'Charlie']
使用列表推导式
现在,让我们使用列表推导式重新编写。你可以使用通用语法 [output for input in iterable if condition] 来实现:
data = [{'name': 'Alice', 'age': 25, 'score': 90},
{'name': 'Bob', 'age': 30, 'score': 85},
{'name': 'Charlie', 'age': 22, 'score': 95}]
# Using a list comprehension
result = [row['name'] for row in data if row['score'] > 85]
print(result)
这应该会给你相同的输出:
Output >>> ['Alice', 'Charlie']
如所见,列表推导式版本更简洁,更易于维护。你可以尝试其他示例并 对你的代码进行性能分析 使用 timeit 比较循环和列表推导式的执行时间。
因此,列表推导式让你编写更具可读性和高效的 Python 代码,特别是在转换列表和过滤操作时。但要小心不要过度使用它们。阅读 为什么你不应该过度使用 Python 中的列表推导式 来了解过度使用它们可能会变成一种过度的好事。
2. 使用生成器进行高效的数据处理
你可以在 Python 中使用生成器来迭代大型数据集和序列,而无需一开始就将它们全部存储在内存中。这在内存效率重要的应用程序中特别有用。
与常规 Python 函数使用 return 关键字返回整个序列不同,生成器函数返回一个生成器对象。你可以对其进行循环,以按需逐个获取单独的项。
假设我们有一个大型 CSV 文件,其中包含用户数据,我们想逐行处理每一行——一次处理一行——而不是一次将整个文件加载到内存中。
这是生成器函数的示例:
import csv
from typing import Generator, Dict
def read_large_csv_with_generator(file_path: str) -> Generator[Dict[str, str], None, None]:
with open(file_path, 'r') as file:
reader = csv.DictReader(file)
for row in reader:
yield row
# Path to a sample CSV file
file_path = 'large_data.csv'
for row in read_large_csv_with_generator(file_path):
print(row)
注意:请记得在上述代码片段中将‘large_data.csv’替换为你文件的路径。
如你所见,在处理流数据或数据集大小超出可用内存时,使用生成器尤其有用。
要详细了解生成器,请阅读 开始使用 Python 生成器。
3. 缓存昂贵的函数调用
缓存可以通过存储昂贵函数调用的结果并在函数再次调用相同输入时重用这些结果,从而显著提高性能。
假设你正在从头开始编写 k-means 聚类算法并希望缓存计算出的欧几里得距离。以下是如何使用 @cache 装饰器缓存函数调用:
from functools import cache
from typing import Tuple
import numpy as np
@cache
def euclidean_distance(pt1: Tuple[float, float], pt2: Tuple[float, float]) -> float:
return np.sqrt((pt1[0] - pt2[0]) ** 2 + (pt1[1] - pt2[1]) ** 2)
def assign_clusters(data: np.ndarray, centroids: np.ndarray) -> np.ndarray:
clusters = np.zeros(data.shape[0])
for i, point in enumerate(data):
distances = [euclidean_distance(tuple(point), tuple(centroid)) for centroid in centroids]
clusters[i] = np.argmin(distances)
return clusters
让我们来看以下示例函数调用:
data = np.array([[1.0, 2.0], [2.0, 3.0], [3.0, 4.0], [8.0, 9.0], [9.0, 10.0]])
centroids = np.array([[2.0, 3.0], [8.0, 9.0]])
print(assign_clusters(data, centroids))
其输出为:
Outputs >>> [0\. 0\. 0\. 1\. 1.]
要了解更多信息,请阅读 如何通过缓存加速 Python 代码。
4. 使用上下文管理器进行资源处理
在 Python 中,上下文管理器 确保资源——如文件、数据库连接和子进程——在使用后得到适当管理。
假设你需要查询数据库并希望在使用后确保连接被正确关闭:
import sqlite3
def query_db(db_path):
with sqlite3.connect(db_path) as conn:
cursor = conn.cursor()
cursor.execute(query)
for row in cursor.fetchall():
yield row
你现在可以尝试对数据库运行查询:
query = "SELECT * FROM users"
for row in query_database('people.db', query):
print(row)
要了解更多关于上下文管理器的使用,请阅读 Python 上下文管理器的 3 种有趣用途。
5. 使用 NumPy 向量化操作
NumPy 允许你对数组执行逐元素操作——如对向量的操作——而无需显式循环。这通常比循环要快得多,因为 NumPy 在底层使用 C。
假设我们有两个大型数组,分别表示来自两个不同测试的分数,我们想为每个学生计算平均分。让我们使用循环来完成这个任务:
import numpy as np
# Sample data
scores_test1 = np.random.randint(0, 100, size=1000000)
scores_test2 = np.random.randint(0, 100, size=1000000)
# Using a loop
average_scores_loop = []
for i in range(len(scores_test1)):
average_scores_loop.append((scores_test1[i] + scores_test2[i]) / 2)
print(average_scores_loop[:10])
下面是如何使用 NumPy 的向量化操作重写它们的示例:
# Using NumPy vectorized operations
average_scores_vectorized = (scores_test1 + scores_test2) / 2
print(average_scores_vectorized[:10])
循环与向量化操作
让我们使用 timeit 测量循环和 NumPy 版本的执行时间:
setup = """
import numpy as np
scores_test1 = np.random.randint(0, 100, size=1000000)
scores_test2 = np.random.randint(0, 100, size=1000000)
"""
loop_code = """
average_scores_loop = []
for i in range(len(scores_test1)):
average_scores_loop.append((scores_test1[i] + scores_test2[i]) / 2)
"""
vectorized_code = """
average_scores_vectorized = (scores_test1 + scores_test2) / 2
"""
loop_time = timeit.timeit(stmt=loop_code, setup=setup, number=10)
vectorized_time = timeit.timeit(stmt=vectorized_code, setup=setup, number=10)
print(f"Loop time: {loop_time:.6f} seconds")
print(f"Vectorized time: {vectorized_time:.6f} seconds")
如所见,使用 Numpy 的向量化操作比循环版本要快得多:
Output >>>
Loop time: 4.212010 seconds
Vectorized time: 0.047994 seconds
总结
本教程到此为止!
我们回顾了以下技巧——使用列表推导代替循环、利用生成器进行高效处理、缓存昂贵的函数调用、使用上下文管理器管理资源以及利用 NumPy 进行向量化操作——这些都能帮助优化代码性能。
如果你在寻找针对数据科学项目的技巧,请阅读 5 个 Python 数据科学最佳实践。
Bala Priya C**** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过编写教程、操作指南、意见文章等方式,学习并与开发者社区分享她的知识。Bala 还制作了引人入胜的资源概述和编码教程。
相关话题
使用代码进行的 5 种快速简便的数据可视化
原文:
www.kdnuggets.com/2018/07/5-quick-easy-data-visualizations-python-code.html
评论
数据可视化是数据科学家工作的重要组成部分。在项目的早期阶段,你通常会进行探索性数据分析(EDA),以获得对数据的一些见解。创建可视化图表有助于让事物更加清晰和易于理解,特别是在处理较大、高维数据集时。在项目结束时,能够以清晰、简洁和有说服力的方式展示最终结果是很重要的,以便你的观众(通常是非技术客户)能够理解。
Matplotlib 是一个流行的 Python 库,可以轻松创建数据可视化。然而,每次启动新项目时,设置数据、参数、图形和绘图可能会变得相当麻烦和繁琐。在这篇博客文章中,我们将介绍 6 种数据可视化方法,并用 Python 的 Matplotlib 为它们编写一些快速简便的函数。同时,这里有一个很棒的图表,可以帮助你选择适合的可视化方式!
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 需求
用于选择适当数据可视化技术的图表
散点图
散点图非常适合展示两个变量之间的关系,因为你可以直接看到数据的原始分布。通过对不同数据组进行颜色编码,你还可以查看这些数据组之间的关系,如下图所示。想要可视化三个变量之间的关系?没问题!只需使用另一个参数,如点的大小,将第三个变量编码进去,如下图所示。
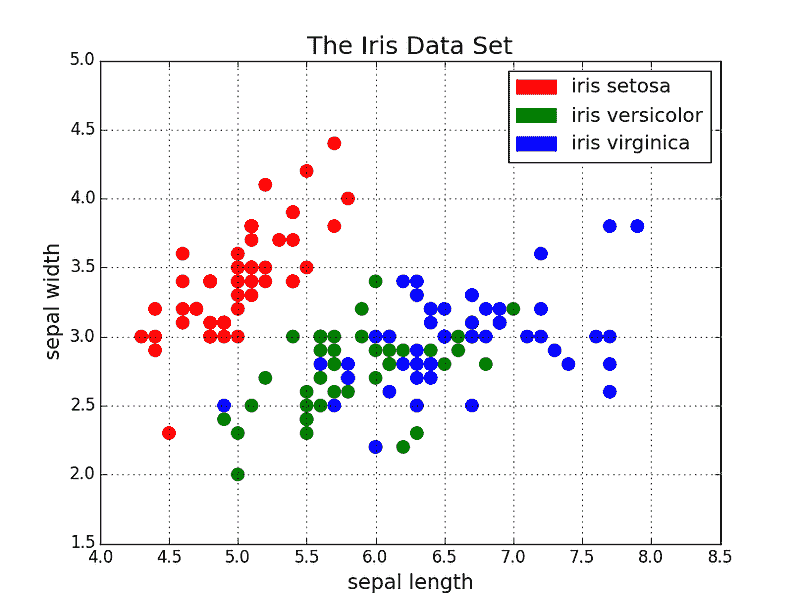
带有颜色分组的散点图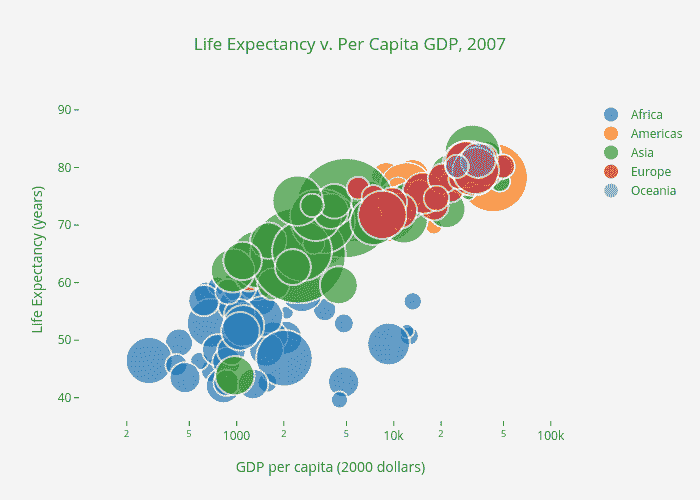
带有颜色分组和尺寸编码的散点图,用于表示国家的大小
现在是代码部分。我们首先导入 Matplotlib 的 pyplot,别名为“plt”。要创建新的图形,我们调用plt.subplots()。我们将 x 轴和 y 轴数据传递给函数,然后传递给ax.scatter()来绘制散点图。我们还可以设置点的大小、颜色和透明度。甚至可以将 y 轴设置为对数尺度。然后为图形设置标题和轴标签。这是一个易于使用的函数,从头到尾创建散点图!
折线图
当你可以清楚地看到一个变量随着另一个变量的变化而变化很大,即它们具有较高的协方差时,折线图最为适用。我们来看看下面的图示。我们可以清楚地看到所有专业的百分比随时间的变化量很大。用散点图绘制这些数据会非常混乱且杂乱无章,使得很难真正理解和看到发生了什么。折线图在这种情况下非常适合,因为它们基本上为我们提供了两个变量(百分比和时间)协方差的快速总结。同样,我们也可以使用颜色编码进行分组。
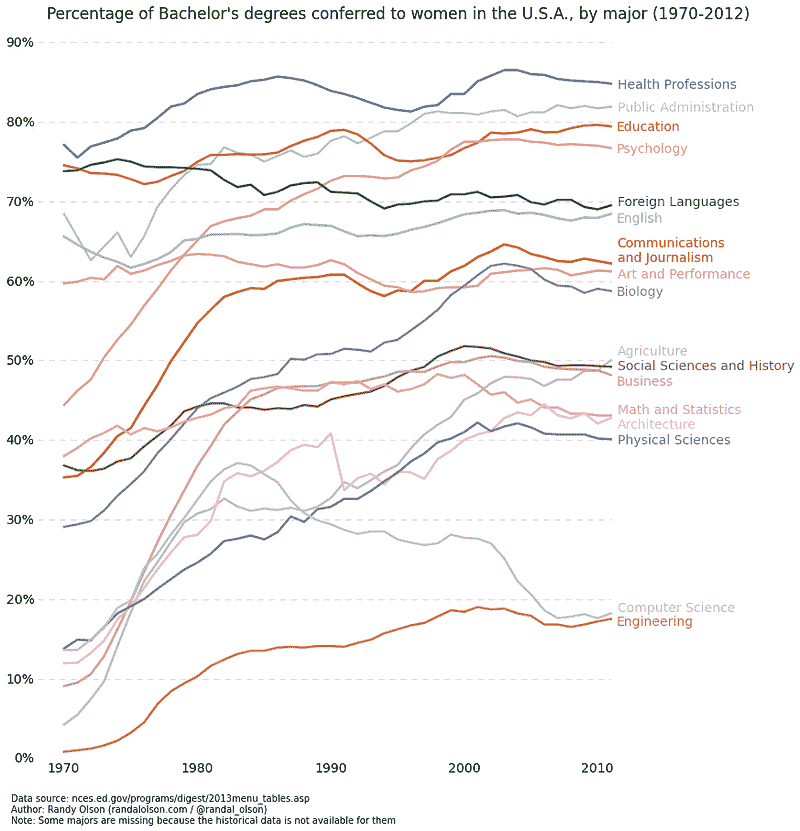
示例折线图
这里是折线图的代码。它与上面的散点图非常相似,只是变量有一些小的变化。
直方图
直方图对于查看(或真正发现)数据点的分布非常有用。查看下面的直方图,我们绘制了频率与智商的直方图。我们可以清楚地看到中心的集中情况以及中位数。我们还可以看到它遵循高斯分布。使用条形图(例如,而不是散点图)确实可以清晰地可视化每个箱子的频率之间的相对差异。使用箱子(离散化)真的帮助我们看到“大局”,而如果我们使用所有数据点而没有离散箱子,可能会有很多噪音在可视化中,使得很难看到实际情况。
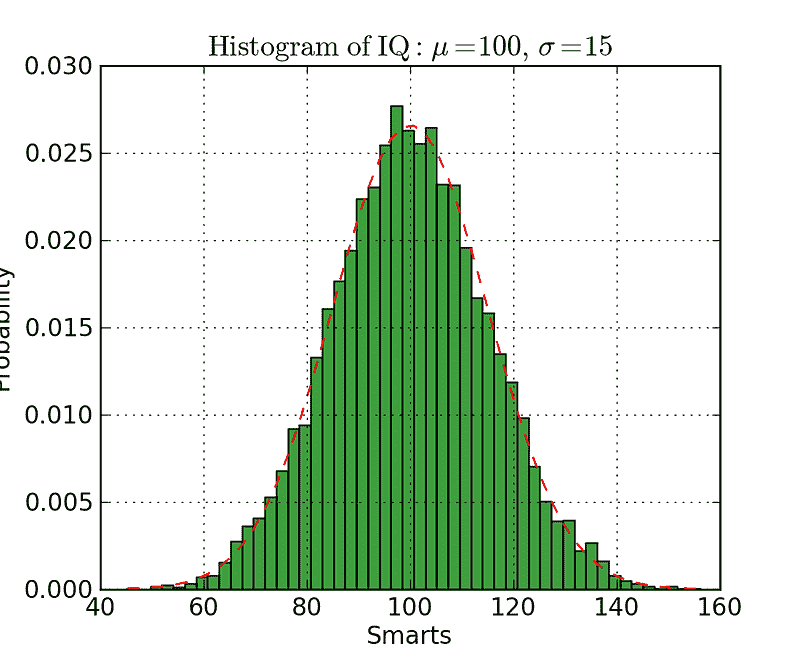
直方图示例
Matplotlib 中的直方图代码如下。需要注意两个参数。首先,n_bins参数控制我们希望为直方图设置多少个离散的箱子。更多的箱子将提供更精细的信息,但也可能引入噪音并使我们偏离大局;另一方面,较少的箱子则能给我们一个更“宏观的视角”,并提供事件的整体图像,而没有细节。其次,cumulative参数是一个布尔值,允许我们选择直方图是否为累积的。这基本上是在选择概率密度函数(PDF)或累积分布函数(CDF)。
想象一下我们要比较数据中两个变量的分布。可能有人会认为你需要制作两个单独的直方图并将它们并排放置以进行比较。但是,实际上有一个更好的方法:我们可以将直方图叠加,并改变透明度。查看下图。均匀分布的透明度设置为 0.5,以便我们可以看到其背后的内容。这使我们能够在同一图上直接查看两个分布。
叠加直方图
为叠加直方图设置代码有几个步骤。首先,我们设置水平范围以适应两个变量分布。根据这个范围和所需的箱数,我们可以计算每个箱的宽度。最后,我们将两个直方图绘制在同一图上,其中一个稍微更透明。
条形图
当你试图可视化分类数据且分类较少(可能<10)时,条形图最为有效。如果分类过多,则条形图会在图中显得非常杂乱且难以理解。条形图对于分类数据很有用,因为你可以很容易地根据条形的大小(即幅度)看到分类之间的差异;分类也很容易分割和颜色编码。我们将要查看三种不同类型的条形图:普通、分组和堆积。查看下方的代码。
正常的条形图在下图的第一个图中。在barplot()函数中,x_data表示 x 轴上的刻度线,y_data表示 y 轴上的条形高度。误差条是在每个条形中心绘制的额外线条,用于显示标准差。
分组条形图允许我们比较多个分类变量。查看下图中的第二个条形图。我们比较的第一个变量是分数如何按组(G1、G2、... 等)变化。我们还通过颜色编码比较性别本身。查看代码,y_data_list变量现在实际上是一个列表的列表,每个子列表代表一个不同的组。然后我们遍历每个组,对于每个组,我们为 x 轴上的每个刻度绘制条形;每个组也有颜色编码。
堆积条形图非常适合可视化不同变量的分类组成。在下面的堆积条形图中,我们比较了从一天到另一天的服务器负载。通过颜色编码的堆积条形图,我们可以轻松地看到和理解哪些服务器在每一天工作最多,以及这些负载如何与其他服务器在所有天数上的负载进行比较。其代码遵循与分组条形图相同的风格。我们遍历每个组,只是这一次我们将新条形绘制在旧条形上方,而不是旁边。
普通条形图
堆积条形图
箱型图
我们之前看过直方图,它们对于可视化变量的分布非常有用。但如果我们需要更多的信息呢?也许我们想更清楚地看到标准差?也许中位数与均值差异很大,从而出现许多异常值?如果有偏斜,且许多值集中在一侧呢?
这就是箱型图的用武之地。箱型图为我们提供了上述所有信息。箱子的底部和顶部始终是第一个和第三个四分位数(即数据的 25% 和 75%),箱子内部的带子始终是第二个 四分位数(即 中位数)。须状线(即带有末端条的虚线)从箱子延伸以显示数据的范围。
由于箱型图是为每个组/变量绘制的,所以设置起来非常简单。x_data 是一个包含组/变量的列表。Matplotlib 函数 boxplot() 为 y_data 的每一列或 y_data 中的每个向量绘制箱型图;因此,x_data 中的每个值对应于 y_data 中的一列/向量。我们需要设置的只是图表的美学。
箱型图示例
结论
这里是使用 Matplotlib 制作的 5 个快速且简单的数据可视化。将内容抽象成函数总能使你的代码更易读、更易用!希望你喜欢这篇文章并学到了新的有用的知识。如果是这样,请随意点赞。
干杯!
简介:George Seif 是一位认证极客及人工智能/机器学习工程师。
原始。已获得许可转载。
相关:
-
数据科学家需要了解的 5 种聚类算法
-
你应该了解的 7 种 R 中的简单数据可视化
-
我们最喜欢的 5 个免费可视化工具
更多相关主题
5 种稀有的数据科学技能,能够帮助你获得就业机会
原文:
www.kdnuggets.com/5-rare-data-science-skills-that-can-help-you-get-employed

图片由作者提供
如果你知道如何创建机器学习决策树,恭喜你,你已经具备了与 ChatGPT 及成千上万其他数据科学家相当的编码专业水平,而这些数据科学家也在竞争你想要的职位。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT。
最近,招聘经理们发现一个有趣的趋势,那就是单纯的编码能力已经不再足够了。要获得聘用,你需要超越对编程语言、框架和如何在 StackOverflow 上搜索的了解。你需要更深入的概念理解,以及对当今数据科学领域的把握——包括那些你认为只有公司 CEO 才需要关注的事项,如数据治理和伦理。
你应该知道许多技术性和非技术性的数据科学技能,但如果你在找工作时遇到困难,这些较为少见的数据科学技能可能是帮助你迈入就业门槛的关键。
1. 模型可视化
以前,数据科学家通常在孤立的环境中工作,在黑暗的地下室里生产模型。这些模型会生成预测或洞察;这些内容会传递给高层管理人员,他们会在没有理解模型的情况下采取行动。(我稍微夸张了一点,但差别不会很大。)
今天,领导层在理解数据科学家的产品方面扮演着更加积极的角色。这意味着,作为数据科学家,你需要能够解释模型的工作原理、它们的运作方式以及它们如何得出特定的预测。
尽管你可以向你的老板展示运行你模型的实际代码,但通过可视化展示模型的工作原理要更有用(也就是说,更具备就业价值)。例如,假设你开发了一个预测电信公司客户流失的机器学习模型。与其展示代码的截图,你可以使用流程图或决策树图来直观地解释模型如何对客户进行分段,并识别出有流失风险的客户。这使得模型的逻辑变得透明,更易于理解。
理解如何可视化代码是一个罕见的技能,但绝对值得培养。虽然目前还没有相关课程,但我建议你尝试使用像 Miro 这样的免费工具来创建文档化决策树的流程图。更好的是,试着向非数据科学家朋友或家人解释你的代码。解释得越简单越好。
2. 特征工程

作者提供的图像
许多数据科学家倾向于更多地关注模型算法,而忽视输入数据的细微差别。特征工程是选择、修改和创建特征(输入变量)的过程,以提高机器学习模型的性能。
例如,如果你正在开发一个房地产价格预测模型,你可能会从基本特征开始,比如平方英尺、卧室数量和位置。然而,通过特征工程,你可以创建更细化的特征。你可能会计算到最近公共交通站的距离,或创建一个表示物业年龄的特征。你甚至可以结合现有特征来创建新的特征,例如基于犯罪率、学校评分和便利设施接近度的“位置吸引力评分”。
这是一个罕见的技能,因为它不仅需要技术知识,还需要深入的领域知识和创造力。你需要真正理解你的数据和手头的问题,然后创造性地转化数据,使其对建模更有用。
特征工程通常作为 Coursera、edX 或 Udacity 等平台上更广泛的机器学习课程的一部分进行讲解。但我发现最好的学习方式是通过实践经验。在真实世界的数据上工作,并尝试不同的特征工程策略。
3. 理解数据治理
这里有一个假设性的问题:假设你是一家医疗保健公司的数据科学家。你被委托开发一个预测模型来识别某种疾病的高风险患者。你可能面临的最大挑战是什么?
如果你回答了“处理 ETL 管道”,那你错了。你最大的挑战可能是确保你的模型不仅有效,而且符合合规、伦理和可持续性要求。这包括确保你为模型收集的任何数据都符合像 HIPAA 和 GDPR 这样的法规,这取决于你的所在地区。你需要知道何时使用这些数据是合法的,如何对其进行匿名处理,需要从患者那里获得哪些同意,以及如何获得这些同意。
你还需要能够记录数据来源、转换过程和模型决策,以便非专家能够审计模型。这种可追溯性不仅对法规合规至关重要,也对未来模型的审计和改进至关重要。
学习数据治理的地方:虽然内容很复杂,但一个很好的资源是全球数据管理社区。
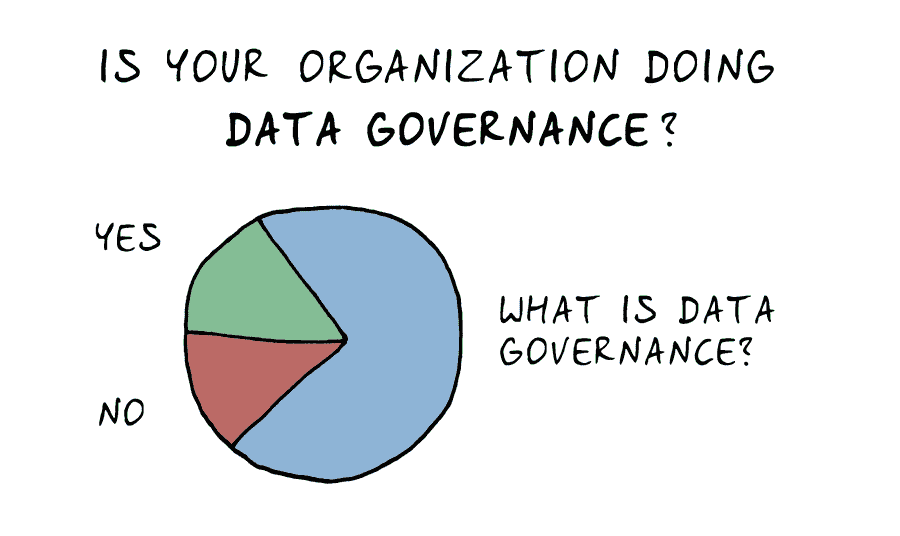
图片来源于dataedo
4. 伦理
“我知道数据科学基本上涉及统计学、模型创建、趋势发现,但如果你问我,我无法想到任何真正的伦理困境,我认为数据科学只是揭示真实的事实,”Reddit 用户 Carlos_tec17 错误地说道。
除了法律合规之外,还需要考虑伦理方面。你需要确保你创建的任何模型不会无意中引入可能导致对某些群体不平等待遇的偏见。
我喜欢用亚马逊旧招聘模型来说明伦理问题的重要性。如果你不熟悉这个案例,亚马逊的数据科学家们试图通过创建一个能够基于简历挑选潜在雇员的模型来加快招聘流程。问题在于,他们用的是现有的简历数据,这些数据中男性占据主导地位。他们的新模型对男性雇员有偏见。这是极其不道德的。
我们已经远离了数据科学的“快速行动,破坏一切”阶段。现在,作为一名数据科学家,你需要知道你的决策会对人们产生真正的影响。无知不再是借口;你需要充分了解模型可能带来的所有后果,并理解它做出这些决策的原因。
UMichigan 提供了一门关于“数据科学伦理”的课程。我还喜欢这本书,它展示了伦理如何以及为何在数据科学等“基于数字”的科学中出现。
5. 市场营销
一个秘密的生活窍门是,你越了解如何推销自己,找工作的难度就会越小。所谓“推销”,我指的是“知道如何让事情变得吸引人”。有了市场营销的能力,你将更擅长制作能推销自己技能的简历。你将更擅长吸引面试官。而在数据科学领域,你将更擅长解释为什么你的模型及其结果很重要。
记住,无论你的模型有多好,如果你无法说服其他人它是必要的,那也没有意义。例如,假设你开发了一个可以预测制造工厂设备故障的模型。从理论上讲,你的模型可以为公司节省数百万的计划外停机时间。但如果你无法向高管传达这一点,你的模型将会在电脑上闲置。
利用市场营销技巧,你可以通过有说服力的展示证明你模型的使用价值和必要性,突出财务利益、生产力提升的潜力,以及采用你模型的长期优势。
这在数据科学领域是一项非常罕见的技能,因为大多数数据科学家本质上是数字型的人。大多数有志成为数据科学家的人真的相信,只需尽力而为、默默工作就是一种成功的就业策略。不幸的是,雇佣你的不是计算机,而是人类。在今天的就业市场上,能够推销自己、自己的技能和产品是一个真正的优势。
要学习如何推销自己,我推荐一些初学者的免费课程,如 Coursera 提供的《数字世界中的营销》。我特别喜欢其中关于“在数字世界中提供持久的产品创意”的部分。虽然目前没有针对数据科学的专门市场营销课程,但我喜欢这篇博客文章,它介绍了如何将自己作为数据科学家进行市场推广。
结束语
外面的环境很艰难。尽管根据劳动统计局的数据,数据科学家就业的预计增长 仍然存在,但许多初级数据科学的求职者发现很难找到工作,正如 这些 Reddit 帖子 所示。ChatGPT 的竞争以及裁员的阴影也在盘旋。
要在就业市场中竞争并脱颖而出,你必须超越单纯的技术能力。数据治理、伦理、模型可视化、特征工程和营销技能使你成为一个更具深度、全面且引人注目的候选人。
Nate Rosidi 是一名数据科学家,专注于产品战略。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过来自顶级公司的真实面试问题来准备面试。Nate 撰写关于职业市场最新趋势的文章,提供面试建议,分享数据科学项目,并涵盖所有 SQL 内容。
更多相关内容
为什么你应该在数据科学项目中使用交叉验证的 5 个理由
原文:
www.kdnuggets.com/2018/10/5-reasons-cross-validation-data-science-projects.html
评论
由 Dima Shulga,HiredScore 数据科学家

交叉验证是数据科学家工具箱中的一个重要工具。它使我们能够更好地利用我们的数据。在我给你介绍使用交叉验证的五个理由之前,我想简单讲解一下交叉验证是什么,并展示一些常见的策略。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
当我们使用数据构建机器学习模型时,我们通常会将数据拆分为训练集和验证/测试集。训练集用于训练模型,而验证/测试集用于验证模型在从未见过的数据上的表现。经典的方法是进行简单的 80%-20%拆分,有时也会用 70%-30%或 90%-10%。在交叉验证中,我们会进行多次拆分。我们可以进行 3 次、5 次、10 次或任何 K 次拆分。这些拆分称为折叠(Folds),我们可以使用多种策略来创建这些折叠。
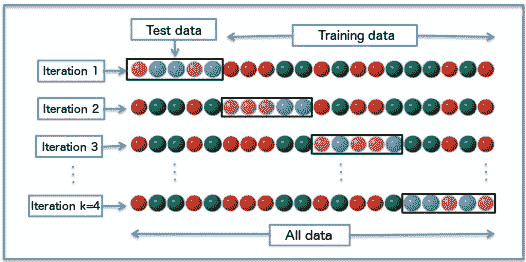
k 折交叉验证的图示,k=4。
简单 K 折交叉验证 — 我们将数据拆分为 K 个部分,以 K=3 作为玩具示例。如果我们有 3000 个实例的数据集,我们将其拆分为三个部分,部分 1、部分 2 和部分 3。然后我们构建三个不同的模型,每个模型在两个部分上训练,并在第三个部分上测试。我们的第一个模型在部分 1 和 2 上训练,并在部分 3 上测试。我们的第二个模型在部分 1 和 3 上训练,并在部分 2 上测试,以此类推。
留一法 — 这是最极端的交叉验证方式。对于数据集中的每个实例,我们使用所有其他实例构建一个模型,然后在选定的实例上进行测试。
分层交叉验证 — 当我们将数据拆分为折叠时,我们希望确保每个折叠都能很好地代表整个数据。最基本的例子是,我们希望每个折叠中的不同类别的比例相同。大多数时候,通过随机拆分就能实现,但有时在复杂的数据集中,我们必须强制每个折叠中有正确的分布。
以下是我建议你使用交叉验证的五个理由:
1. 使用你所有的数据

当我们拥有的数据非常少时,将其分割为训练集和测试集可能会导致测试集非常小。例如,如果我们只有 100 个样本,简单的 80-20 划分会得到 20 个测试样本。这是不够的。我们几乎只能因为运气而在这个集合上获得任何性能。当我们遇到多类问题时,情况更糟。如果我们有 10 个类别,只有 20 个样本,那么平均每个类别只有 2 个样本。仅在 2 个样本上测试是无法得出任何实际结论的。
如果在这种情况下使用交叉验证,我们会构建 K 个不同的模型,从而能够对所有数据进行预测。对于每个实例,我们通过一个没有见过这个示例的模型来做出预测,因此我们在测试集上获得了 100 个样本。对于多类问题,我们平均每个类别得到 10 个样本,这比仅有的 2 个样本要好得多。在评估我们的学习算法之后(见下文第 #2 点),我们现在可以在所有数据上训练模型,因为如果我们的 5 个模型在使用不同训练集时具有相似的性能,我们假设在所有数据上训练会得到类似的性能。
通过进行交叉验证,我们能够将所有 100 个样本同时用于训练和测试,同时在从未见过的样本上评估我们的学习算法。
2. 获取更多的指标

如第 #1 点所述,当我们使用学习算法创建五个不同的模型并在五个不同的测试集上进行测试时,我们可以对算法的性能更有信心。当我们在测试集上进行单次评估时,我们只会得到一个结果。这个结果可能是由于运气或某种原因造成的偏差测试集。通过训练五个(或十个)不同的模型,我们可以更好地了解情况。例如,我们训练了五个模型,并以准确率作为衡量标准。我们可能会遇到几种不同的情况。最佳情况是我们的准确率在所有折叠中都相似,比如 92.0、91.5、92.0、92.5 和 91.8。这意味着我们的算法(和数据)是一致的,我们可以确信在所有数据集上训练并部署到生产中将会得到类似的性能。
但是,我们可能会遇到稍微不同的情况,比如 92.0、44.0、91.5、92.5 和 91.8。这些结果看起来很奇怪。看起来我们的一个折叠来自不同的分布,我们必须回去确认我们的数据是否如我们所想。
我们可能面临的最糟糕的情况是结果有很大的差异,比如 80、44、99、60 和 87。这里看起来我们的算法或数据(或两者)都不一致,可能是我们的算法无法学习,或者数据非常复杂。
通过使用交叉验证,我们能够获得更多的指标,并对我们的算法和数据得出重要结论。
3. 使用模型堆叠

有时我们希望(或必须)构建一个模型管道来解决问题。例如,考虑神经网络。我们可以创建多个层。每一层可以使用前一层的输出,并学习数据的新表示,因此最终能够产生良好的预测。我们能够训练这些不同的层,因为我们使用了反向传播算法。每一层计算其误差并将其传递给前一层。
当我们做类似的事情但不使用神经网络时,我们不能以相同的方式进行训练,因为并不总是有一个明确的“误差”(或导数)可以传递回去。
例如,我们可能创建一个随机森林模型来为我们做预测,然后我们希望进行线性回归,依赖于之前的预测并产生一些实际的数字。
这里的关键部分是我们的第二个模型必须学习第一个模型的预测。最好的解决方案是为每个模型使用两个不同的数据集。我们在数据集 A 上训练随机森林。然后我们使用数据集 B 来进行预测。接着我们使用数据集 B 的预测来训练我们的第二个模型(逻辑回归),最后我们使用数据集 C 来评估我们的完整解决方案。我们使用第一个模型进行预测,将其传递给我们的第二个模型,然后与真实值进行比较。
当我们拥有有限的数据(在大多数情况下),我们实际上无法做到这一点。此外,我们不能在相同的数据集上训练两个模型,因为这样,第二个模型会在第一个模型已经看到的预测上进行学习。这些预测可能会过拟合,或者至少在不同的数据集上效果更好。这意味着我们的第二个算法并不是在其将被测试的内容上进行训练的。这可能会在最终评估中导致不同的效果,这将很难理解。
通过使用交叉验证,我们可以以之前描述的相同方式对数据集进行预测,从而使第二个模型的输入将是真实的预测,而这些数据是第一个模型之前从未见过的。
4. 处理依赖/分组数据

当我们对数据进行随机训练-测试拆分时,我们假设我们的样本是独立的。这意味着知道/看到某个实例不会帮助我们理解其他实例。然而,这并不总是如此。
以语音识别系统为例。我们的数据可能包括不同的发言者说不同的词。以这个数据集为例,其中有 3 个发言者和 1500 个录音(每个发言者 500 个)。如果我们进行随机拆分,我们的训练集和测试集将会包含相同发言者说的相同词!这当然会提升我们的算法性能,但一旦在新发言者上测试,我们的结果将会大幅下滑。
正确的方法是将发言者分开,即使用 2 个发言者进行训练,使用第三个发言者进行测试。然而,这样我们只能在一个发言者上测试我们的算法,这还不够。我们需要了解我们的算法在不同发言者上的表现。
我们可以在发言者层面上使用交叉验证。我们将训练 3 个模型,每次使用一个发言者进行测试,其他两个进行训练。这样我们可以更好地评估我们的算法(如上所述),最终在所有发言者上构建我们的模型。
5. 参数微调

这是进行交叉验证最常见和明显的原因之一。大多数学习算法需要进行一些参数调整。这可能是梯度提升分类器中的树木数量,神经网络中的隐藏层大小或激活函数,支持向量机中的核类型等等。我们希望找到适合我们问题的最佳参数。我们通过尝试不同的值并选择最佳值来实现。方法有很多,可以是手动搜索、网格搜索或更复杂的优化。然而,在所有这些情况下,我们不能仅在训练测试集上进行,也不能在测试集上进行。我们必须使用第三组数据,即验证集。
通过将我们的数据拆分成三组而不是两组,我们将处理之前讨论过的所有相同问题,尤其是在数据量不多的情况下。通过交叉验证,我们能够使用单一数据集完成所有这些步骤。
结论
交叉验证是一个非常强大的工具。它帮助我们更好地利用数据,并提供有关算法性能的更多信息。在复杂的机器学习模型中,有时很容易没有足够注意,并在管道的不同步骤中使用相同的数据。这可能导致大多数情况下的良好但不真实的性能,或者在其他情况下引入奇怪的副作用。我们必须确保对我们的模型充满信心。交叉验证帮助我们应对数据科学项目中的非平凡挑战。
如果你想了解更多关于数据科学管道中可能出现的不同陷阱,欢迎阅读我关于如何在数据科学中撒谎的文章。
如果你想阅读一些其他的做事理由,欢迎阅读我的文章 5 个理由为什么“逻辑回归”应该是你成为数据科学家时首先学习的内容
个人简介:迪玛·舒尔加 是 HiredScore 的数据科学家。
原文。经授权转载。
相关:
-
通过交叉验证构建可靠的机器学习模型
-
5 个理由为什么逻辑回归应该是你成为数据科学家时首先学习的内容
-
如何在数据科学中撒谎
更多相关内容
逻辑回归应成为你成为数据科学家时学习的第一件事的 5 个理由
原文:
www.kdnuggets.com/2018/05/5-reasons-logistic-regression-first-data-scientist.html
评论
作者:Dima Shulga,HiredScore 数据科学家

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT 部门
几年前我开始涉足数据科学领域。当时我是一名软件工程师,首先在网上学习(在开始攻读硕士学位之前)。我记得,当我搜索在线资源时,只看到了学习算法的名称——线性回归、支持向量机、决策树、随机森林、神经网络等等。很难理解应该从哪里开始。今天我知道,成为数据科学家最重要的事情是学习管道,即获取和处理数据、理解数据、构建模型、评估结果(包括模型和数据处理阶段的结果)以及部署。因此,作为这篇文章的TL;DR:首先学习逻辑回归,以便熟悉管道,而不会被复杂的算法所困扰。
你可以在这篇文章中了解更多关于我从软件工程转向数据科学的经验。
所以,这里是我认为我们应该首先学习逻辑回归成为数据科学家的 5 个理由。这仅仅是我的观点,当然,对其他人来说,可能以不同的方式做事情会更容易。
因为学习算法只是管道的一部分
正如我在开头所说,数据科学工作不仅仅是模型构建。它包括这些步骤:
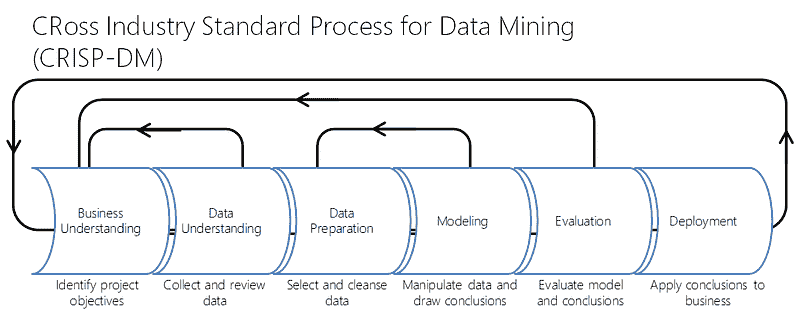
你可以看到“建模”是这个重复过程的一部分。在构建数据产品时,最好先构建完整的管道,保持尽可能简单,了解你到底想要实现什么,如何衡量自己以及你的基准是什么。之后,你可以进行复杂的机器学习,并且能够知道自己是否在进步。
顺便提一下,逻辑回归(或任何机器学习算法)不仅可以用于“建模”部分,还可以用于“数据理解”和“数据准备”,插补就是一个例子。
因为你将更好地理解机器学习
我认为,当人们阅读这篇文章标题时,首先会问自己为什么使用“逻辑回归”而不是“线性回归”。而事实是,这并不重要。仅仅这个问题就引出了两种类型的监督学习算法——分类(逻辑回归)和回归(线性回归)。当你用逻辑回归或线性回归构建你的工作流程时,你会在保持简单的同时熟悉大多数机器学习的概念。诸如监督学习与非监督学习、分类与回归、线性与非线性问题等概念。此外,你还会对如何准备数据、可能遇到的挑战(如插补和特征选择)、如何评估你的模型、是否使用“准确率”、“精确率-召回率”、“ROC AUC”?还是“均方误差”和“皮尔逊相关系数”?等有个大致了解。这些概念是数据科学过程中的重要部分。一旦你熟悉了这些概念,你将能够用更复杂的模型替换你的简单模型。
因为“逻辑回归”有时已经足够
逻辑回归是一个非常强大的算法,即使面对非常复杂的问题,它也能发挥良好的作用。以 MNIST 为例,仅使用逻辑回归就可以达到 95%的准确率,这虽然不是一个惊人的结果,但足以确保你的工作流程有效。实际上,只要特征表示得当,它可以发挥出色的表现。在处理非线性问题时,我们有时会尝试以可以用线性方式解释的方式来表示原始数据。以下是这个想法的一个小示例:我们希望对以下数据执行一个简单的分类任务:
X1 x2 | Y
==================
-2 0 1
2 0 1
-1 0 0
1 0 0
如果我们绘制这些数据,我们将能够看到没有一条直线可以将其分开:
plt.scatter([-2, 2], [0, 0 ], c='b')
plt.scatter([-1, 1], [0, 0 ], c='r')
在这种情况下,如果我们不对数据进行处理,逻辑回归将不会对我们有帮助,但如果我们去掉x2特征,改用x1²,效果就会是这样:
X1 x1² | Y
==================
-2 4 1
2 4 1
-1 1 0
1 1 0
现在,有了一条简单的直线可以分开数据。当然,这个玩具示例与现实生活相差甚远,在现实中,很难确定如何准确地改变数据以使线性分类器有效,但是,如果你在特征工程和特征选择上投入一些时间,你的逻辑回归可能会表现得非常出色。
因为它是统计学中的一个重要工具
线性回归不仅对预测很有用,一旦你有了一个拟合的线性回归模型,你可以了解依赖变量和自变量之间的关系,或者用“机器学习”语言来说,你可以了解特征与目标值之间的关系。考虑一个简单的例子,我们有关于房价的数据,我们有一堆特征和实际价格。我们拟合一个线性回归模型并得到不错的结果。我们可以查看模型为每个特征学习到的实际权重,如果这些权重显著,我们可以说某些特征比其他特征更重要。此外,我们可以说房屋大小,例如,对房价变化的贡献为 50%,每增加 1 平方米将使房价增加 1 万元。线性回归是从数据中学习关系的强大工具,统计学家经常使用它。
因为这是学习神经网络的一个很好的起点
对我来说,学习逻辑回归首先帮助了我在开始学习神经网络时很多。你可以把网络中的每个神经元看作是一个逻辑回归,它有输入、权重、偏置,你对这些做点积,然后应用一些非线性函数。此外,神经网络的最终层通常是一个简单的线性模型。看一下这个非常基础的神经网络:
让我们更详细地看看“输出层”,你可以看到这其实是一个简单的线性(或逻辑)回归,我们有输入(隐藏层 2),有权重,我们做点积,然后添加一个非线性函数(取决于任务)。一个很好的方式来理解神经网络是将其分为两部分:表示部分和分类/回归部分:
第一部分(左侧)试图学习一个好的数据表示,这将帮助第二部分(右侧)执行线性分类/回归。你可以在这个很棒的文章中阅读更多关于这个想法的内容。
结论
如果你想成为数据科学家,有很多知识需要掌握,乍一看,学习算法似乎是最重要的部分。现实情况是,学习算法在大多数情况下非常复杂,需要大量时间和精力来理解,但只是数据科学流程中的一小部分。
个人简介: 迪玛·舒尔加 是 HiredScore 的数据科学家。
原文。经许可转载。
相关内容:
-
机器学习新手的十大算法之旅
-
初学者的 10 大机器学习算法
-
逻辑回归:简明技术概述
相关主题
5 个理由说明机器学习应用需要更好的 Lambda 架构
原文:
www.kdnuggets.com/2016/05/5-reasons-machine-learning-applications-lambda-architecture.html
评论
作者 Monte Zweben,Splice Machine首席执行官。
Lambda 架构在机器学习和数据科学应用中随处可见。Lambda 架构能够实现对实时数据的持续处理,而不会受到传统 ETL 延迟的困扰,这种延迟困扰着传统的操作型(OLTP)和分析型(OLAP)实现。在传统架构中,OLTP 数据库经过性能优化的规范化处理,然后大量 ETL 管道将这些数据反规范化,通常转换为 OLAP 引擎上的星型模式。这一过程通常需要至少一天时间。Lambda 架构绕过了这种延迟。在其最纯粹的形式中,Lambda 架构将数据分为两条路径:批处理层和速度层。批处理层聚合原始数据并训练模型。批处理层的结果随后转移到服务层,以供应用展示。速度层允许应用访问“错过”上一个批处理窗口的最新数据。
那么公司如何实施这一架构呢?对于批处理层,他们通常使用 Hadoop 上的批分析处理引擎,如 MapReduce、Hive 或 Spark。对于服务层,他们使用表现良好的 NoSQL/键值引擎,如 ElephantDB 和 Voldemort。对于速度层,他们需要支持快速读取和写入的数据存储,如 Cassandra 或 HBase。在这一架构的前端,通常会有一个排队系统,如 Kafka,以及一个流处理系统,如 Storm、Spark 或 Flink,用于将连续数据分割成块进行处理。
企业使用我称之为企业级“胶带”的方法来维持这一架构。这是一个痛苦的过程,虽然能够完成工作,但代价巨大。以下是我们需要更好 Lambda 架构的五个理由:
-
简化操作复杂性——基于版本保持这些系统同步并调优性能是非常昂贵的。这需要对过多的技术有专门的知识。
-
消除对专门编码技能的需求——开发人员必须能够编写相当低级的代码来处理基本操作,如连接、聚合、排序和分组,更不用说应用分析了。他们还需要编写批处理程序来清理和过滤单个记录。
-
提供对标准工具的访问 – 99% 的数据科学家知道 SQL 并使用 BI 可视化工具。为什么我们要放弃这些强大的工具,现在它们不再面临第一代数据库的性能和灵活性问题?
-
最小化存储 – Lambda 通常需要在多个引擎中重复存储数据。
-
支持集成应用程序 – 现代应用程序的逻辑与分析逻辑并不分离。这些工作负载需要交融。你希望能够在业务应用中实时使用操作原始数据,用它来执行特征工程和训练模型,并能够同时进行可视化。这需要传统数据库的 ACID 属性、NoSQL 的摄取能力和 Hadoop/Spark 引擎的可扩展能力。
那么,什么是更好的解决方案呢?我们称之为 Lambda-R (ƛ-R) 关系型 Lambda。使用新的可扩展 RDBMS 系统,你现在可以以更简单的架构获得 Lambda 的所有好处。
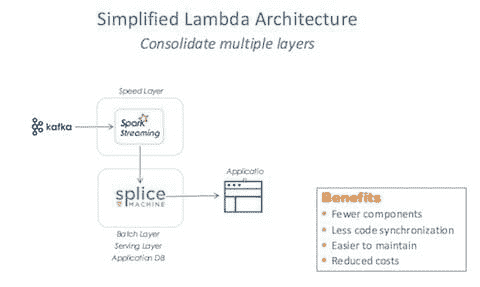
这就是机器学习应用如何使用 ƛ-R:
-
批量文件摄取 – 原始数据文件的导入直接插入到分片表中,并与数据原子性更新的索引并行,以实现快速访问。
-
实时流摄取 – 存储过程使用标准 SQL 和自动分片连续摄取流数据。
-
数据清理 – 使用标准 SQL、约束和触发器,高效地清理小子集数据以及整个数据集,无需大批处理或文件爆炸。
-
特征工程和广泛的 ETL – 执行复杂的聚合、连接、排序和分组,使用高效的 SQL 自动并行化和优化,无需在应用程序级别编写代码。
-
模型训练 – 存储过程直接对数据执行分析,例如,使用内置函数如 ResultSetToRDD,将 SQL 结果处理为 Spark RDDs,或直接在数据库结果集上执行 R 和 Python 库。
-
应用逻辑 – ACID 语义使架构能够在没有额外移动部件的情况下支持并发的 CRUD 应用程序。
-
模型执行 – 存储过程和用户定义的函数封装模型。
-
报告和数据可视化 – 使用 Tableau、Domo、MicroStrategy 和其他 ODBC/JDBC 工具进行开箱即用。
能做到这一点的一个可扩展 RDBMS 是 Splice Machine。Splice Machine 是一个双引擎 RDBMS,建立在 Hadoop 和 Spark 之上。
Splice Machine RDBMS 提供:
-
ANSI SQL – Splice Machine 提供 ANSI SQL-99 覆盖,包括完整的 DDL 和 DML。
-
ACID 事务 – Splice Machine 提供完全的 ACID 事务,并具有快照隔离语义,可以处理非常小的操作查询和大规模的分析查询。
-
原地更新 – Splice Machine 中的更新从单行到数百万行的单次事务都能扩展。
-
二级索引 – Splice Machine 支持数据的真实二级索引,包括唯一和非唯一形式
-
参考完整性 – 参考完整性,如主键和外键约束,可以在不需要底层应用程序行为的情况下强制执行
-
联接 – Splice Machine 支持使用广播、合并、合并排序、批量嵌套循环和嵌套循环等算法的内连接、外连接、交叉连接和自然连接
-
资源隔离 基于查询计划的估算,成本优化器选择数据流引擎 – OLTP 运行在 HBase 上,OLAP 运行在 Spark 上
总结来说,通过集中在 ƛ-R 架构上,团队可以非常快速地构建 ML 应用程序,用标准的运营人员维护这些应用程序,并能够将 ML 紧密集成到应用程序中,而无需广泛使用“企业胶带”。
相关:
-
访谈:Antonio Magnaghi,TicketMaster 论通过 Lambda 架构统一异构分析
-
Bill Moreau,美国奥委会关于通过分析赋能世界顶级运动员
-
Hobson Lane,SHARP 实验室关于如何通过分析展示“你看不到的所有光”
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关内容
5 个你需要合成数据的理由
原文:
www.kdnuggets.com/2023/02/5-reasons-need-synthetic-data.html

从 Kubric 生成的合成数据
要训练机器学习模型,你需要数据。数据科学任务通常不是 Kaggle 竞赛那种拥有大型整理过的数据集的情况,这些数据集都是预标记好的。有时你必须收集、整理和清洗自己的数据。这个在现实世界中收集和标记数据的过程可能是费时的、繁琐的、昂贵的、不准确的,有时甚至是危险的。此外,在这个过程中,你最终获得的数据可能在质量、多样性(例如,类别不平衡)和数量上不一定符合你的期望。以下是处理真实数据时常见的问题:
-
真实数据收集和标记不可扩展
-
手动标记真实数据有时可能是不可能的
-
真实数据存在隐私和安全问题
-
真实数据不可编程
-
仅通过真实数据训练的模型表现不够好(例如,开发速度慢)
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
幸运的是,像这些问题可以通过合成数据来解决。你可能会想知道,什么是合成数据? 合成数据可以定义为通过模拟现实世界过程的算法生成的人工数据,从其他道路使用者的行为到光线与表面交互的行为。这篇文章讨论了现实世界数据的局限性,以及合成数据如何帮助克服这些问题并提高模型性能。
真实数据收集和标记不可扩展
对于小型数据集,通常可以收集和手动标注数据;然而,许多复杂的机器学习任务需要大量数据来训练。例如,为自动驾驶汽车应用训练的模型需要从附加在汽车或无人机上的传感器收集大量数据。这个数据收集过程很慢,可能需要几个月甚至几年。原始数据收集后,还必须由人类手动注释,这也是昂贵且耗时的。此外,返回的标注数据可能不一定对训练数据有益,因为它可能不包含解决模型当前知识缺口的示例。
标注这些数据通常涉及人类在传感器数据上手工绘制标签。这是非常昂贵的,因为高薪的机器学习团队通常花费大量时间确保标签的正确性,并将错误反馈给标注员。合成数据的一大优势是你可以生成任意多的完美标注数据。你需要的只是生成高质量合成数据的方法。
生成合成数据的开源软件: Kubric (多对象视频,包含分割掩码、深度图和光流) 和 SDV (表格数据、关系数据和时间序列数据)。
一些(众多的)销售产品或构建平台来生成合成数据的公司包括 Gretel.ai (合成数据集,确保真实数据的隐私)、 NVIDIA (全视界) 和 Parallel Domain (自动驾驶)。更多信息, 请参见 2022 年合成数据公司名单。
手动标注真实数据有时是不可能的

图片来自 Parallel Domain
有些数据人类无法完全解读和标注。以下是一些合成数据是唯一选择的使用案例:
-
从单张图像准确估计深度和光流
-
利用雷达数据进行自驾应用,这些数据对人眼不可见
-
生成深度伪造技术以测试人脸识别系统
真实数据存在隐私和安全问题
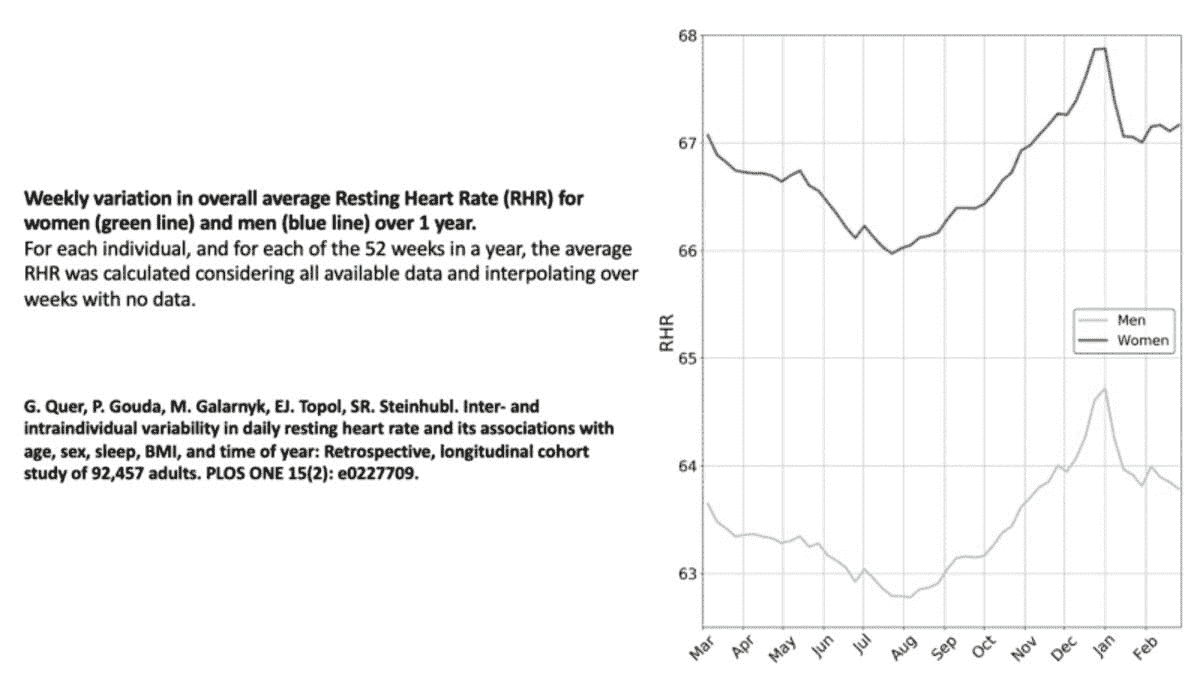
图片由 Michael Galarnyk 提供
合成数据对于那些难以获得真实数据的领域非常有用。这包括一些类型的车祸数据和大多数受隐私限制的健康数据(例如,电子健康记录)。近年来,医疗研究人员对利用 ECG 和 PPG 信号预测房颤(不规则心律)产生了兴趣。开发一种心律失常检测器不仅具有挑战性,因为这些信号的标注繁琐且成本高,而且还受到隐私限制。这也是模拟这些信号的研究存在的一个原因。
重要的是要强调,收集真实数据不仅需要时间和精力,而且实际上可能是危险的。像自动驾驶汽车这样的机器人应用程序的核心问题之一是,它们是机器学习的物理应用。你不能在现实世界中部署一个不安全的模型,因为缺乏相关数据而发生碰撞。使用合成数据来增强数据集可以帮助模型避免这些问题。
以下是一些使用合成数据提高应用安全性的公司: 丰田, Waymo,和 Cruise。
真实数据不可编程

图片来自 Parallel Domain
合成图像展示了一个被学校巴士遮挡的骑自行车的孩子在加州风格的郊区环境中从巴士后面出现并横穿街道。
自动驾驶应用程序通常处理相对“不常见”(与正常驾驶条件相比)的事件,如夜间行人或骑自行车的人在道路中间行驶。模型通常需要数十万甚至数百万个例子来学习一个场景。一个主要的问题是,收集到的真实世界数据可能在质量、多样性(例如,类别不平衡、天气条件、地点)和数量上不符合要求。另一个问题是,对于自动驾驶汽车和机器人,你并不总是知道你需要什么数据,这与具有固定数据集和固定基准的传统机器学习任务不同。虽然一些数据增强技术可以系统或随机地改变图像是有帮助的,但这些技术也可能引入自身的问题。
这就是合成数据派上用场的地方。合成数据生成 API 允许你工程化数据集。这些 API 可以为你节省大量费用,因为在现实世界中建造机器人和收集数据非常昂贵。尝试生成数据并利用合成数据集生成来搞清楚工程原理要好得多,也更快速。
以下是一些突显可编程合成数据如何帮助模型学习的示例: 防止欺诈交易(美国运通), 更好的骑行者检测(Parallel Domain),以及 手术分析与评审(Hutom.io)。
仅依赖真实数据训练的模型表现不够理想
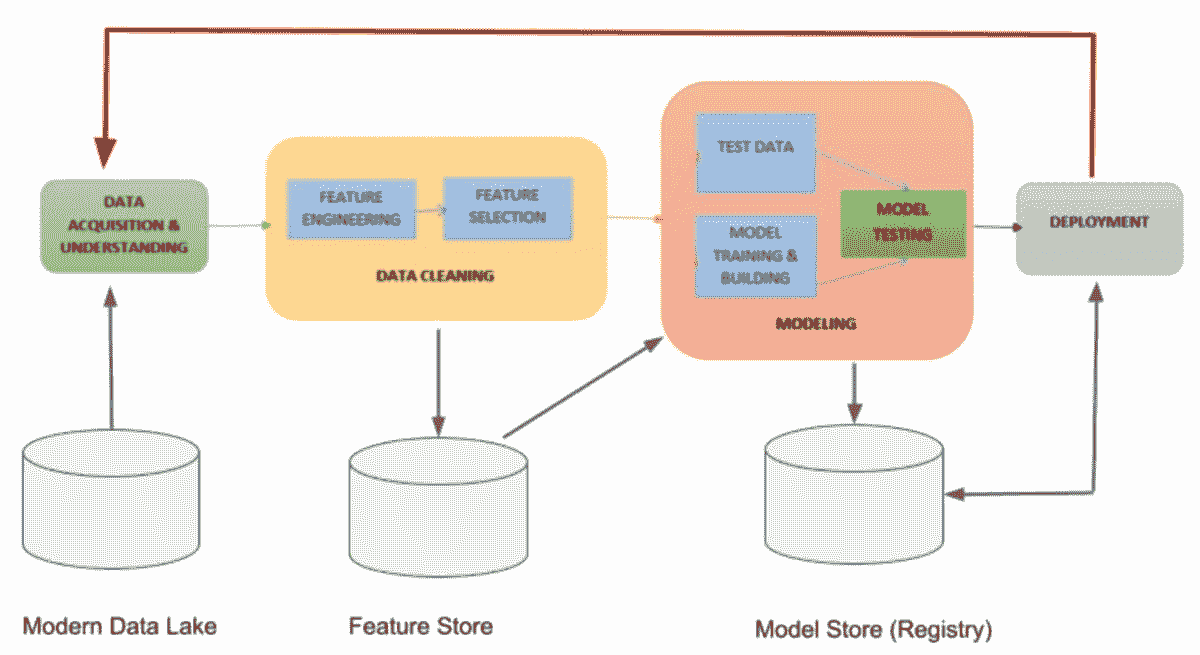
模型开发周期的阶段 | 图片来自 Jules S. Damji
在行业中,有很多因素影响机器学习项目在开发和生产中的可行性/性能(例如,数据获取、注释、模型训练、扩展、部署、监控、模型重新训练和开发速度)。最近,18 名机器学习工程师参加了一项访谈研究,旨在了解各组织和应用(如自动驾驶、计算机硬件、零售、广告、推荐系统等)中的常见 MLOps 实践和挑战。研究得出的结论之一是开发速度的重要性,这可以大致定义为快速原型设计和迭代想法的能力。
影响开发速度的一个因素是需要数据来进行初始模型训练和评估 以及由于数据漂移、概念漂移或训练-服务偏差造成的模型性能下降,需要频繁重新训练模型。
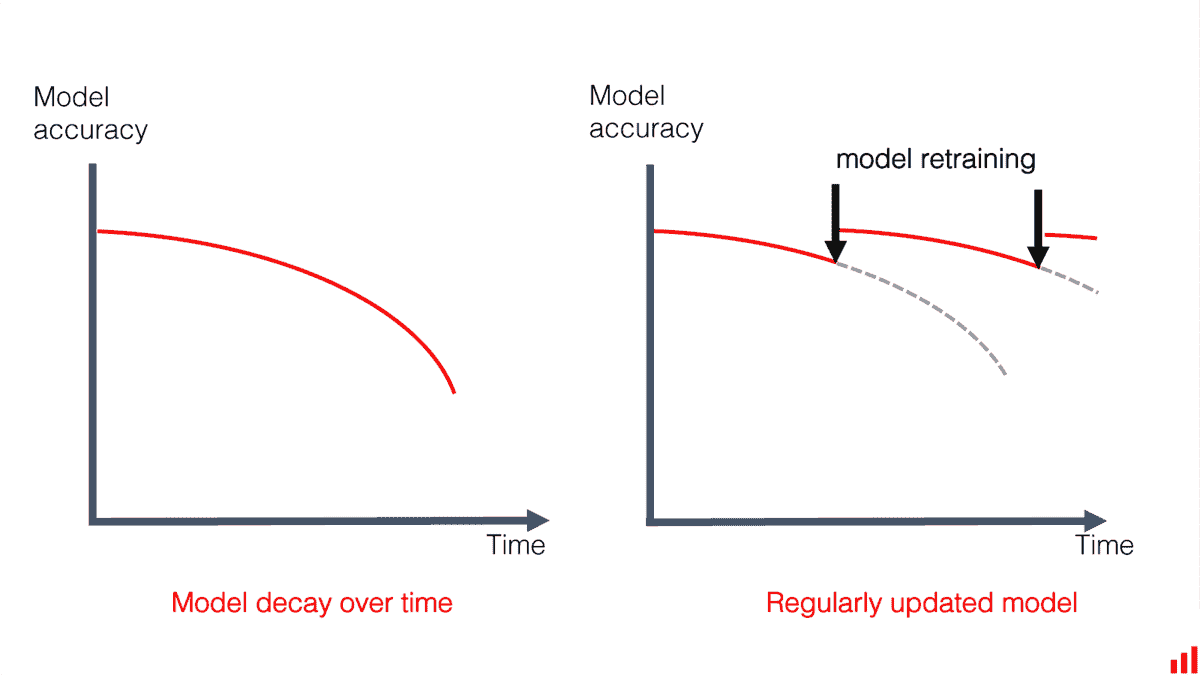
图片来自 Evidently AI
研究还报告说,这种需求导致一些组织设置团队来频繁标记实时数据。这既昂贵又耗时,还限制了组织频繁重新训练模型的能力。
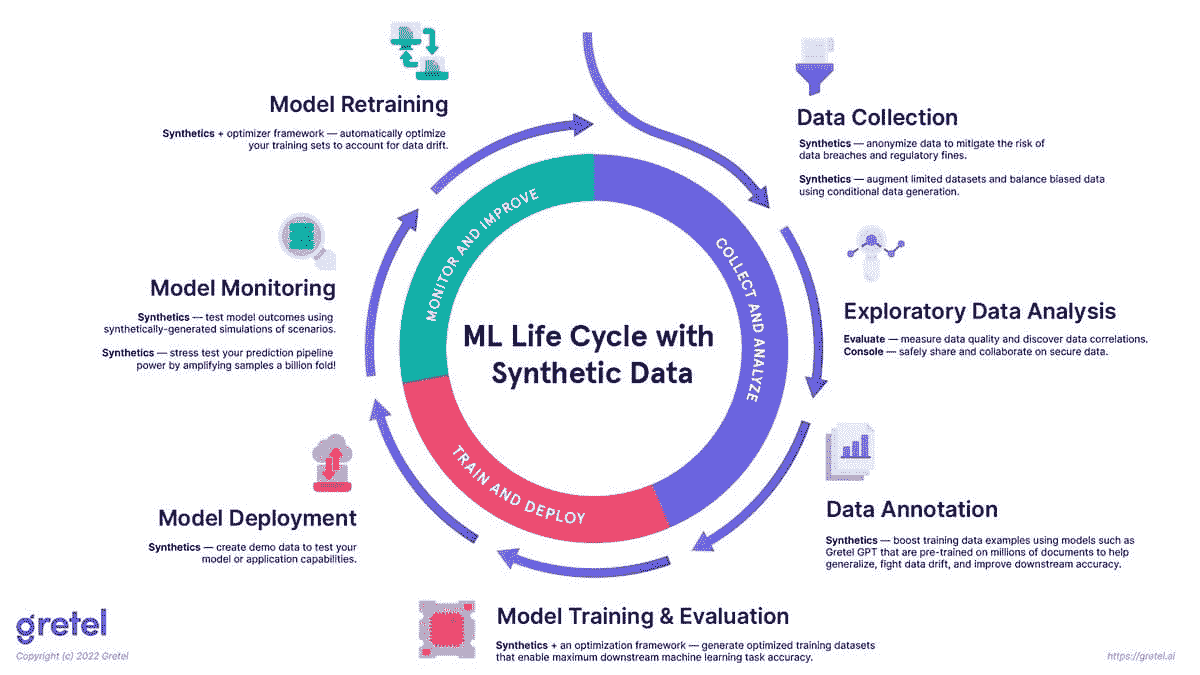
图片来自 Gretel.ai
注意,这个图示并没有涵盖合成数据如何用于 推荐系统中的 MLOps 测试。
合成数据有潜力在机器学习生命周期中(如上图所示)与真实数据一起使用,以帮助组织保持模型的长期性能。
结论
合成数据生成在机器学习工作流中变得越来越普遍。事实上,Gartner预测到 2030 年,合成数据将比真实数据用于训练机器学习模型的频率要高得多。如果你对这篇文章有任何问题或想法,欢迎在评论区或通过Twitter与我联系。
Michael Galarnyk 是一名数据科学专家,在 Parallel Domain 从事合成数据工作。
更多相关话题
5 个资源来激发你下一个数据科学项目的灵感
原文:
www.kdnuggets.com/2018/09/5-resources-inspire-data-science-project.html
评论
由 Conor Dewey,弗吉尼亚理工大学

我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
开始
我们接触到的关于数据科学职业的建议似乎无穷无尽,但有一个话题没有得到足够的关注:副项目。副项目因许多原因而非常棒,但我喜欢Julie Zhuo在下面简单的维恩图中对它的描述。
副项目作为一种在比工作或学校环境更少目标驱动的环境中应用数据科学的方式。它们提供了一个玩转数据的机会,同时学习实际技能。
除了非常有趣且是学习新技能的好方法之外,副项目还可以提高你在求职时的机会。招聘人员和经理喜欢看到项目,这表明你对数据的兴趣超越了课堂和工作。
问题
你是否曾经想开始一个新项目,却不知道做什么?首先,你花几个小时来头脑风暴。然后是几天。没过多久,几周过去了,却没有推出任何新东西。
自我驱动的项目在所有领域都非常普遍,数据科学也不例外。拥有宏大的抱负很容易,但执行起来却更加困难。我发现数据科学项目中最难的部分是开始和决定走哪条路。
在这篇文章中,我的意图是提供一些有用的技巧和资源, 让你在下一个数据科学项目中获得突破。
注意事项
在我们深入了解以下资源之前,有几个快速提示值得注意,那就是你的目标和兴趣。
你的目标
数据科学是一个极其多样化的领域,这意味着几乎不可能将所有概念和工具都挤入一个单一的项目中。你需要选择和决定你想进一步发展的技能。一些相关的示例包括:
-
机器学习和建模
-
探索性数据分析
-
指标和实验
-
数据可视化和沟通
-
数据挖掘和清理
请注意,虽然很难将每个概念都融入到一个项目中,但你可以将其中一些概念结合起来。例如,你可以抓取数据进行探索性数据分析,然后以有趣的方式进行可视化。
基本上,如果你想成为更高效的机器学习工程师,做一个数据可视化项目可能无法实现这个目标。你的项目应该反映你的目标。这样,即使它没有大放异彩或揭示任何突破性的见解,你仍然会收获胜利和一堆实际应用的知识。
你的兴趣
正如我们之前提到的,副项目应该是令人愉快的。无论我们意识到与否,我们每天都会问自己成百上千个问题。尝试在今天剩下的时间里更多地关注这些问题。你会对发生的事情感到惊讶。你可能会发现自己对某些事物比想象中更有创意和兴趣。
现在将这应用到你的下一个数据科学项目中。你是否对如何classify your morning runs感到好奇?想知道特朗普什么时候和如何发推特吗?对体育史上的最伟大的“一曲成名”感兴趣吗?
可能性真的无限。让你的兴趣、好奇心和目标驱动你的下一个项目。一旦你确认了这些目标,我们就可以获得灵感了。
灵感
我们容易认为自己是孤军奋战,但实际上情况很少是这样。如果你足够努力地寻找,总会有其他人有相似的兴趣和目标。这种效果对创意产生极具威力。
“没有什么是原创的。从任何激发灵感或燃料你想象力的地方偷取。” — 吉姆·贾木许
找到你喜欢或钦佩的项目,然后加入你自己的独特创意。将这些项目作为起点,生成新的、原创的独立作品。以下是一些我最喜欢的灵感来源:
我可以花几个小时仅仅浏览这个数据可视化的子版块。你会对人们想到的所有独特的想法和问题感兴趣。还有一个每月挑战的活动,选择一个数据集,用户的任务是以最有效的方式进行可视化。按最佳排序获取即时满足感。
如果不提及在线数据科学的标志性代表,那将是我的失职。有效利用 Kaggle 获得灵感有几种方法。首先,你可以查看 热门数据集 并思考如何利用这些信息。如果你对机器学习和具体示例更感兴趣,kernels 功能 随着时间的推移变得越来越好。
视觉论文确实是一种新兴的新闻形式。布丁(The Pudding)体现了这一运动的独特之处。团队使用原创数据集、原始研究和互动性来探索大量有趣的话题。
经典但至今仍然有效。我是说, Nate Silver 是那个传奇人物。这个数据驱动的博客涉及从政治到体育到文化的所有话题。更不用说,他们刚刚重新设计了改进的数据导出页面 data export。
最后,我必须向 TDS 团队 致敬,他们将这一群聪明且热衷于实现目标并帮助他人在数据科学中成长的人们汇聚在一起。浏览近期的故事,你会在任何一天发现一些有趣的项目创意。
总结
侧项目不仅在我的发展过程中帮助了我很多,而且通常也非常有趣。最近,关于数据科学作品集的精彩内容越来越多。如果你感兴趣,我强烈推荐查看以下链接:
做任何事情最难的部分就是开始。我希望以上的建议和资源能帮助你完成并发布下一个数据科学项目。我会留意的。
个人简介: Conor Dewey (Medium) 是一位数据科学家和作家,目前在弗吉尼亚理工大学学习。
原始。已获许可转载。
相关:
-
2018 年将助你找到工作的 5 个数据科学项目
-
GitHub Python 数据科学聚焦:AutoML、NLP、可视化、ML 工作流
-
数据科学预测未来
了解更多此主题的信息
良好的数据科学项目文档的 5 条规则
原文:
www.kdnuggets.com/2022/12/5-rules-good-data-science-project-documentation.html

图片由编辑提供
所以你完成了项目,得到了优秀的数据,处理了它,清洗了它,训练了你的模型,将其应用于数据,并获得了极好的结果。就这样。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
实际上并非如此。
通常,软件是为了他人使用而开发的,因此一旦程序员或数据科学家完成了项目,他们将需要完成大多数人都不喜欢的任务…
记录代码。
在软件工程中,一般来说,编写文档是指主要开发者编写一个脚本,详细解释代码的功能、目标及实现方式。程序员讨厌写文档的主要原因是,作为程序员,你更愿意编写代码而不是解释它。
不仅如此,为了使文档质量良好,它需要简单易懂,即使不是专业程序员也能理解。正如我们所知 — 也许不是所有人 — 程序员擅长编写代码,但不擅长解释其理论。
1. 一个好的描述
在文档的开头,必须有一个简短而精炼的描述。这个描述应该只有几句话,并清楚地解释项目的功能及其实现方式。
你已经在之前的工作中使用了一些开源项目,因此这里有一些知名数据科学项目的优秀描述。
Pandas: “pandas 是一个快速、强大、灵活且易于使用的开源数据分析和处理工具,建立在 Python 编程语言之上。” — Pandas 文档
Matplotlib: “Matplotlib 是一个用于创建静态、动画和交互式可视化的全面库。Matplotlib 使简单的事情变得简单,使困难的事情变得可能。” — Matplotlib 文档
Bokeh:“Bokeh 是一个用于现代网络浏览器的互动可视化库。它提供了优雅、简洁的多功能图形构建,并在大型或流数据集上提供高性能的互动。Bokeh 可以帮助任何希望快速轻松地制作互动图表、仪表板和数据应用程序的人。” — Bokeh 文档。
2. 清晰简明的安装指南
当你开发一个项目时,你通常会将其托管在远程服务器上供人们使用。他们可能需要从 GitHub 克隆它、使用 pip 安装,或者从官方网站下载。
对于经验丰富的程序员来说,这可能显得很简单;毕竟,他们在职业生涯中安装了许多库。然而,如果一个新程序员试图使用你的项目呢?他们可能需要一些帮助。
在描述了你的项目及其功能之后,接下来应有一个“快速入门”部分。该部分的主要目标是为用户提供安装项目和运行一个小示例以证明其安装正确的简单步骤。
此外,它通常包含该项目依赖的其他库或模块,以便正常运行。
3. 教程
此时,用户已经知道项目的功能以及如何安装它。现在,是时候深入探讨并开始使用它了。好的文档通常会包含关于项目不同用例的教程以及如何利用项目的内部函数完成这些用例。
许多教程并不等同于优秀的文档;重要的是质量而非数量。然而,一些项目有少量教程突出项目的用法,明确说明如何扩展到其他情况。这意味着用户只需阅读 2 或 3 个教程即可理解项目代码的内部工作原理。
最常用的教程格式是几行解释后跟一些代码、更多描述等。
4. 详细的 API 参考
这一部分通常会在你听到或阅读“文档”这个词时浮现。这部分是你对项目中的所有函数、公共变量和类进行说明的地方,简要解释其功能、属性和返回值。
简短的解释通常是两到三句话,直接解释函数/类的目的,展示其类型、常见属性的类型及其返回值,形式为函数头。这个头部通常包括一个嵌入链接,指向源代码中的函数/类定义(无论它托管在哪里)。
5. 架构解释
到目前为止,你的文档已经解释了项目的核心内部工作原理、主要功能和一些用例。文档的最后一部分应解释为什么你的项目按这种方式工作。
并非所有代码都包含这一部分;毕竟,它不像我们讨论的其他部分那么重要。然而,这一部分可能对于将项目开源是必要的。在这种情况下,这一部分可以指导贡献者如何在不影响核心功能的情况下向代码中添加新功能。
收获
如今,编写强健的代码已不再是唯一要求;为了证明你的能力和你对项目及领域的熟悉程度,你需要提供撰写良好的文档,突出说明你的代码如何工作以及如何使用。
产生优质文档取决于许多因素;在这篇文章中,我们探讨了 5 个部分,如果包含这些部分,将为你的文档增加价值,并使其尽可能有用。
你可能认为“良好的文档”这个术语非常模糊,并且因人而异。例如,我可能会认为某些文档很好且有用,而你可能认为正好相反。如果我们不能设定严格的规则来定义什么是好的文档,我们如何决定文档是否好?
简单的答案就是反馈。大多数现代文档通常包含一个“请给我们反馈”的部分。用户可以联系程序员,报告文档中的遗漏或不准确的信息,以便使其更加完善和有用。
Sara Metwalli 是庆应义塾大学的博士候选人,研究测试和调试量子电路的方法。我是 IBM 的研究实习生和 Qiskit 倡导者,致力于构建一个更加量子化的未来。我还是 Medium、Built-in、She Can Code 和 KDN 上的文章作者,撰写关于编程、数据科学和技术主题的文章。我也是 Woman Who Code Python 国际章的负责人,火车爱好者、旅行者和摄影爱好者。
更多相关主题
5 Simple Steps 系列:掌握 Python、SQL、Scikit-learn、PyTorch 和 Google Cloud
原文:
www.kdnuggets.com/5-simple-steps-series-master-python-sql-scikit-learn-pytorch-google-cloud
对数据科学和机器学习世界不太熟悉?欢迎来到你的终极指南和起点,无论你是想进入这一行业、学习新知识,还是提升现有技能。Back to Basics: Getting Started in 5 Steps 系列是你所需要的一切,旨在将复杂的概念转化为简单明了的知识。
作为 KDnuggets 在数据科学、机器学习和人工智能领域 30 年历程的一部分,团队齐心协力为你策划了一系列文章,供你尽可能多地吸收知识。
我们的前三个课程推荐
1. Google 网络安全证书 - 加速你的网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT 事务
开始新的事物时,总是很难入门。KDnuggets 团队通过我们的 Back to Basics: Getting Started in 5 Steps 系列,帮你减轻这个负担,该系列包括:
-
Python 数据结构
-
SQL
-
Scikit-learn
-
PyTorch
-
Google Cloud Platform
所以让我们直接进入主题……
Python 数据结构的 5 个步骤
本教程涵盖了 Python 的基础数据结构——列表、元组、字典和集合。了解它们的特性、使用场景和实际示例,所有这些都在 5 个步骤中完成。
在学习编程时,不管你使用哪种编程语言,你会发现有几个主要主题可以对大部分你接触到的内容进行分类。
其中一些,按理解的基本顺序排列,包括语法(语言的词汇);命令(将词汇组合成有用的方式);流程控制(如何引导命令执行的顺序);算法(我们为解决特定问题所采取的步骤……这个词怎么变得如此令人困惑?);最后,数据结构(我们在算法执行过程中用于数据操作的虚拟存储库(这些算法又是一系列步骤))。
学习 5 个步骤:开始 Python 数据结构的 5 个步骤
SQL in 5 Steps
本全面的 SQL 教程涵盖了从设置 SQL 环境到掌握如连接和子查询等高级概念,以及优化查询性能的所有内容。通过逐步示例,这个指南非常适合想要提升数据管理技能的初学者。
在关系型数据库中管理和操作数据时,结构化查询语言(SQL)是最重要的名称。SQL 是一个主要的领域特定语言,它是数据库管理的基石,并提供了一种标准化的方式与数据库进行交互。
随着数据成为决策和创新的驱动力,SQL 仍然是一个关键技术,数据分析师、开发人员和数据科学家必须给予高度关注。
学习这 5 个步骤:5 步快速入门 SQL
Scikit-learn 5 步
本教程提供了 Scikit-learn 机器学习的全面实践指南。读者将学习包括数据预处理、模型训练与评估、超参数调优和编译集成模型以提升性能的关键概念和技术。
在学习如何使用Scikit-learn时,我们必须具备对机器学习基本概念的理解,因为 Scikit-learn 只是实现机器学习原理和相关任务的实用工具。机器学习是人工智能的一个子集,使计算机能够通过经验进行学习和改进,而无需明确编程。算法利用训练数据通过揭示模式和洞察进行预测或决策。
学习这 5 个步骤:5 步快速入门 Scikit-learn
PyTorch 5 步
本教程提供了使用 PyTorch 及其高级封装库 PyTorch Lightning 的深入介绍。文章涵盖了从安装到高级主题的必要步骤,提供了构建和训练神经网络的实践方法,并强调了使用 Lightning 的好处。
PyTorch是一个基于 Python 的流行开源机器学习框架,经过优化以支持 GPU 加速计算。最初由 Meta AI 于 2016 年开发,现在成为 Linux 基金会的一部分,PyTorch 迅速成为深度学习研究和应用中最广泛使用的框架之一。
与其他框架如 TensorFlow 不同,PyTorch 使用动态计算图,允许更大的灵活性和调试能力。
学习这 5 个步骤:5 步快速入门 PyTorch
Google Cloud Platform 5 步
探索 Google Cloud Platform 在数据科学和机器学习中的基本要素,从账户设置到模型部署,包含实际项目示例。
本文旨在提供一个关于如何开始使用Google Cloud Platform(GCP)进行数据科学和机器学习的逐步概述。我们将介绍 GCP 及其在分析方面的关键功能,演示账户设置,探索BigQuery和Cloud Storage等基本服务,构建一个示例数据项目,并使用 GCP 进行机器学习。
无论你是 GCP 的新手还是寻找快速复习的方式,请继续阅读以学习基础知识,并迅速上手 Google Cloud。
学习这 5 个步骤:5 步开始使用 Google Cloud Platform
结束语
这个《回到基础:5 步开始使用》系列将使你了解数据科学中使用的基础工具。你将熟悉 Python、SQL、使用 Scikit-learn 和 PyTorch 进行机器学习的基础知识,同时也将涉足 Google Cloud Platform。
数据掌握之路并未止步于此,它是一个持续的旅程,需要你不断学习新技能和工具以提高熟练度。
关注 KDnuggets,获取更多见解、高级指南,并享受一个和你一样对数据科学充满热情的社区的支持。
Nisha Arya 是一名数据科学家、自由撰稿人以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及与数据科学相关的理论知识。Nisha 涉及广泛的话题,并希望探索人工智能如何有助于人类寿命的延续。作为一个热衷的学习者,Nisha 致力于拓宽她的技术知识和写作技能,同时帮助他人。
更多相关话题
使用 Python 自动化数据清理的 5 个简单步骤
原文:
www.kdnuggets.com/5-simple-steps-to-automate-data-cleaning-with-python
作者提供的图像
数据科学家普遍认为,数据清理占据了我们大量的工作时间。然而,这也是最不令人兴奋的部分之一。因此,这就引出了一个非常自然的问题:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
是否有办法自动化这个过程?
自动化任何过程总是说起来容易做起来难,因为执行步骤大多依赖于具体项目和目标。但总有办法至少自动化其中的一部分。
本文旨在生成一个管道,包含一些步骤以确保我们的数据干净且准备好使用。
数据清理过程
在生成管道之前,我们需要了解哪些部分的过程可以自动化。
由于我们希望构建一个几乎可以用于任何数据科学项目的过程,因此我们需要首先确定哪些步骤是反复执行的。
因此,在处理新的数据集时,我们通常会问以下问题:
-
数据以什么格式存在?
-
数据是否包含重复项?
-
数据是否包含缺失值?
-
数据包含哪些数据类型?
-
数据是否包含异常值?
这 5 个问题可以轻松地转换为 5 个代码块来处理每一个问题:
1. 数据格式
数据可以有不同的格式,例如 JSON、CSV,甚至 XML。每种格式都需要自己特定的数据解析器。例如,pandas 提供 read_csv 处理 CSV 文件,以及 read_json 处理 JSON 文件。
通过识别格式,你可以选择合适的工具来开始清理过程。
我们可以使用 os 库中的 path.plaintext 函数轻松识别我们处理的文件格式。因此,我们可以创建一个函数,首先确定文件扩展名,然后直接应用于相应的解析器。
2. 重复数据
数据的某些行往往包含与其他行完全相同的值,即我们所说的重复数据。重复数据可能会扭曲结果,导致分析不准确,这一点非常不好。
这就是为什么我们总是需要确保没有重复项的原因。
Pandas 提供了 drop_duplicated() 方法来处理重复数据,该方法可以删除数据框中的所有重复行。
我们可以创建一个简单的函数,利用此方法来删除所有重复值。如有必要,我们添加一个列输入变量,使函数能够根据特定的列名列表删除重复项。
3. 缺失值
在处理数据时,缺失数据是一个常见问题。根据数据的性质,我们可以简单地删除包含缺失值的观察数据,或者使用前向填充、后向填充、或用列的均值或中位数填充这些空缺。
Pandas 提供了 .fillna() 和 .dropna() 方法来有效处理这些缺失值。
处理缺失值的选择取决于:
-
缺失值的类型
-
缺失值相对于我们拥有的总记录数的比例。
处理缺失值是一个相当复杂的任务——通常也是最重要的任务之一!——你可以在以下文章中了解更多。
对于我们的管道,我们将首先检查所有包含空值的行的总数。如果只有 5% 或更少的行受影响,我们将删除这些记录。如果更多行存在缺失值,我们将逐列检查,然后采取以下措施:
-
填充该值的中位数。
-
生成警告以便进一步调查。
在这种情况下,我们通过混合人工验证过程来评估缺失值。正如你所知,评估缺失值是一个不能被忽视的重要任务。
在处理常规数据类型时,我们可以直接使用 pandas 的 .astype() 函数来转换列,因此你可以实际修改代码以生成常规对话。
否则,通常假设在处理新数据时转换会顺利进行是过于冒险的。
5. 处理异常值
异常值可以显著影响数据分析的结果。处理异常值的技术包括设定阈值、限制值或使用统计方法如 Z 分数。
为了确定数据集中是否存在异常值,我们使用一个常见的规则,将超出以下范围的记录视为异常值。[Q1 — 1.5 * IQR , Q3 + 1.5 * IQR]
其中 IQR 代表四分位距,Q1 和 Q3 分别是第一四分位数和第三四分位数。下面你可以看到所有之前的概念在箱线图中的展示。
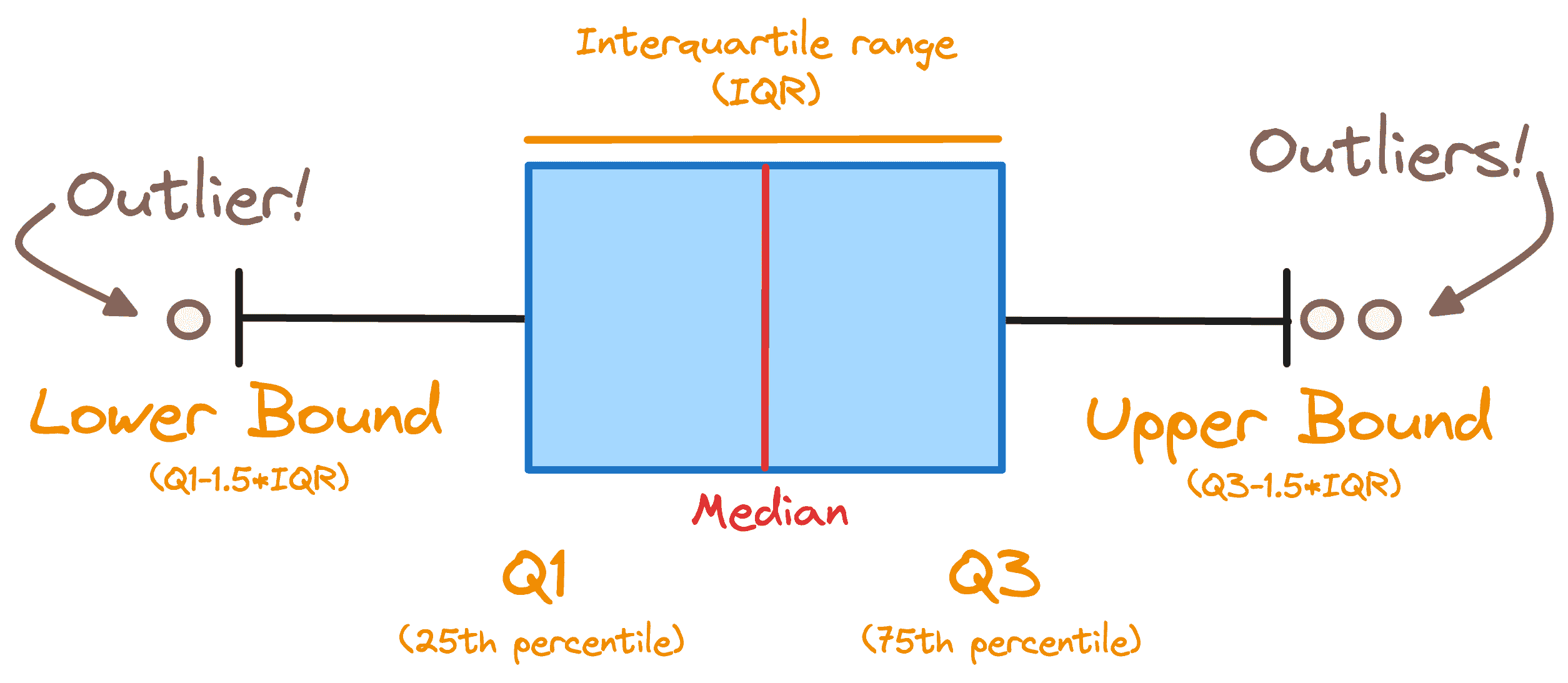
图片来源:作者
为了检测异常值的存在,我们可以轻松定义一个函数,检查哪些列中的值超出了先前的范围,并生成警告。
最终思考
数据清理是任何数据项目中至关重要的一部分,但它通常也是最枯燥和浪费时间的阶段。这就是为什么本文将全面的方法提炼为一个实用的 5 步流程,以 Python 实现数据清理自动化。
这个流程不仅仅是实现代码。它整合了深思熟虑的决策标准,指导用户处理不同的数据场景。
这种将自动化与人工监督相结合的方法确保了效率和准确性,使其成为数据科学家优化工作流程的强大解决方案。
你可以在以下的 GitHub 仓库查看我完整的代码。
Josep Ferrer**** 是一位来自巴塞罗那的分析工程师。他毕业于物理工程专业,目前在应用于人类移动的数据科学领域工作。他还是一位兼职内容创作者,专注于数据科学和技术。Josep 关注人工智能的所有事物,涵盖了该领域正在爆炸式增长的应用。
更多相关内容
5 个 Apache Spark 数据科学最佳实践
原文:
www.kdnuggets.com/2020/08/5-spark-best-practices-data-science.html
评论
由Zion Badash提供,Wix.com 的数据科学家

图片由chuttersnap提供,来自Unsplash
我们的前三个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业轨道。
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你的组织在 IT 领域
为什么转向 Spark?
尽管我们都在talk about Big Data,但通常在你的职业生涯中需要一些时间才能遇到它。对我来说,在Wix.com这个过程比我想象的要快,拥有超过 1.6 亿用户会生成大量数据——这也带来了扩展我们数据处理的需求。
虽然还有其他选项(例如,Dask),但我们决定选择 Spark,主要有两个原因——(1)它是目前的技术前沿,并广泛用于大数据。(2)我们已有了需要的 Spark 基础设施。
如何为熟悉 pandas 的人编写 PySpark
你可能对 pandas 很熟悉,当我说熟悉时,我的意思是非常流利,你的母语 😃
接下来讲座的标题一语道破——Data Wrangling with PySpark for Data Scientists Who Know Pandas,这是一个很棒的讲座。
现在正是指出,仅仅把语法弄对可能是个好的开始,但要成功完成 PySpark 项目,你需要更多的知识,你需要了解 Spark 是如何工作的。
让 Spark 正常工作是很困难的,但当它工作时——它表现非常好!
Spark 概述
我这里只会讲到一部分,但我建议访问以下文章,阅读 MapReduce 解释,以获得更全面的解释——The Hitchhikers guide to handle Big Data using Spark。
我们在这里要理解的概念是水平扩展。
垂直扩展更容易。如果我们有一个运行良好的 pandas 代码,但数据变得太大,我们可以考虑迁移到具有更多内存的更强大机器上,希望它能处理。这意味着我们仍然有一台机器处理所有数据——我们进行了垂直扩展。
如果我们决定使用 MapReduce,将数据拆分成块,并让不同的机器处理每个块——我们就是在进行水平扩展。
5 个 Spark 最佳实践
这些是帮助我将运行时间减少 10 倍并扩展项目的 5 个 Spark 最佳实践。
1 - 从小做起 —— 采样数据
如果我们想让大数据发挥作用,首先要使用小块数据来确认我们在正确的方向上。在我的项目中,我对 10% 的数据进行了采样,并确保管道正常工作,这使我能够在 Spark UI 中使用 SQL 部分,并观察整个流程中的数字增长,同时不会等待太长时间。
根据我的经验,如果你在小样本上达到了所需的运行时间,通常可以比较容易地进行扩展。
2 - 理解基础知识 —— 任务、分区、核心
这可能是使用 Spark 时最重要的事情:
1 个分区对应 1 个任务,运行在 1 个核心上
你必须始终注意分区的数量——跟踪每个阶段的任务数量,并将其与 Spark 连接中的核心数量匹配。以下是一些提示和经验法则来帮助你做到这一点(所有这些都需要用你的情况进行测试):
-
任务与核心的比例应为每个核心 2–4 个任务。
-
每个分区的大小应为 200MB–400MB,这取决于每个工作节点的内存,按需进行调整。
3 - 调试 Spark
Spark 使用延迟计算,这意味着它在执行计算指令图之前会等待操作的调用。操作的例子有 show(), count(),...
这使得很难理解代码中哪里有错误或需要优化的地方。我发现有用的一种实践是通过使用 df.cache() 将代码分成几个部分,然后使用 df.count() 强制 Spark 计算每个部分的 df。
现在,使用 Spark UI 你可以查看每个部分的计算并发现问题。需要注意的是,如果没有使用我们在(1)中提到的采样,这种做法可能会导致非常长的运行时间,这将很难调试。
4 - 查找和解决倾斜
让我们从定义数据倾斜开始。正如我们提到的,我们的数据被分成多个分区,并且在转换过程中每个分区的大小可能会发生变化。这可能导致分区之间的大小差异很大,这意味着我们的数据存在倾斜。
查找倾斜可以通过查看 Spark UI 中的阶段详细信息,并寻找最大值和中位数之间的显著差异来完成:

大的方差(中位数=3 秒,最大值=7.5 分钟)可能暗示数据中的倾斜
这意味着我们有一些任务显著比其他任务慢。
为什么这不好——这可能导致其他阶段等待这些少量任务,而让核心空闲等待而无所事事。
如果你知道倾斜的来源,最好直接解决并更改分区。如果不知道 / 没有直接解决的选项,可以尝试以下方法:
调整任务和核心之间的比例
如我们所提到的,通过让任务数量多于核心数量,我们希望在较长任务运行时,其他核心能继续忙于其他任务。虽然这是真的,但前面提到的比例(2-4:1)无法真正解决任务持续时间之间的巨大差异。我们可以尝试将比例提高到 10:1 看看是否有效,但这种方法可能还有其他缺点。
对数据进行 Salting
Salting 是使用随机键重新分区数据,以使新的分区平衡。以下是 PySpark 的代码示例(使用 groupby,这通常是导致倾斜的罪魁祸首):
5 - Spark 中迭代代码的问题
这是一个真正棘手的问题。正如我们提到的,Spark 使用延迟计算,因此在运行代码时——它只是构建了一个计算图,一个 DAG。但当你有一个迭代过程时,这种方法可能非常有问题,因为 DAG 重新打开先前的迭代并变得非常大,我是说非常非常大。这可能对驱动程序来说太大,无法保存在内存中。这个问题很难定位,因为应用程序被卡住了,但它在 Spark UI 中显示为没有作业运行(这是真的)很长时间——直到驱动程序最终崩溃。
目前这是 Spark 的一个固有问题,我使用的解决方法是每 5-6 次迭代使用 df.checkpoint() / df.localCheckpoint()(通过实验找到你的数字)。之所以有效,是因为 checkpoint() 打破了血统和 DAG(不同于 cache()),保存结果并从新的检查点开始。缺点是,如果发生了不好的情况,你没有完整的 DAG 来重新创建 df。
总结
正如我之前说的,学习如何让 Spark 发挥魔力需要时间,但这 5 个实践确实推动了我的项目,并在我的代码中洒上了一些 Spark 魔力。
总之,这是我在开始项目时寻找的(但未找到)的文章——希望你正好找到了。
参考文献
-
Spark: 权威指南 — 第十八章关于监控和调试的内容非常精彩。
简介: Zion Badash 是 Wix.com 的预测团队数据科学家。他的兴趣包括机器学习、时间序列、Spark 以及相关领域的一切。
原文。经授权转载。
相关:
-
使用 Apache Spark 和 PySpark 的好处及示例
-
Apache Spark 集群在 Docker 上
-
Dataproc 上的 Apache Spark 与 Google BigQuery
了解更多相关话题
5 个 SQL 数据可视化工具
原文:
www.kdnuggets.com/2023/02/5-sql-visualization-tools-data-engineers.html
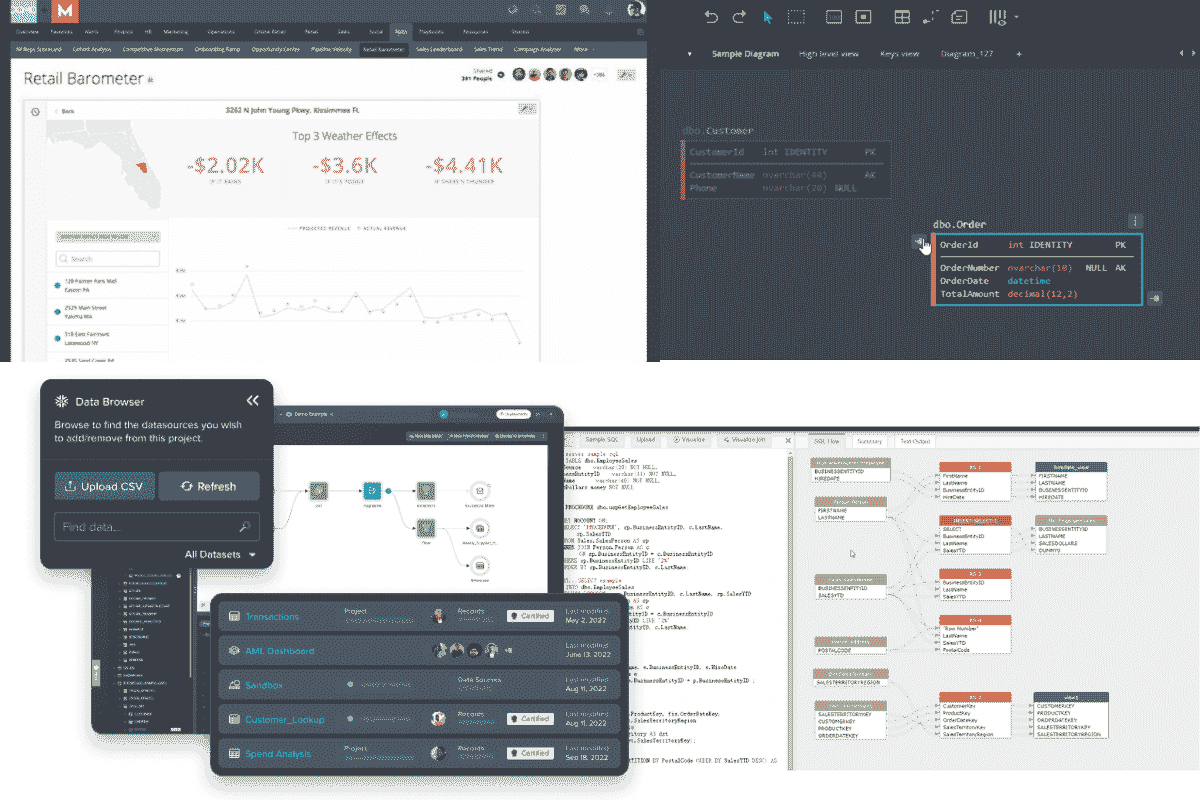
图片由编辑提供
毫无疑问,人类单独无法从今天所有的数据资产中获得最佳价值。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 部门
不过,快速声明一下,技术本身是无法做到的。
这是一种共生关系——技术在一方面帮助人们;而人们则将技术引导到一个设定的、以价值为导向的目标。
我们可以用当前引起热议的生成性 AI 工具之一——Chat GPT,作为一个好的用例。
Sequoia 的分析 显示,随着像 Chat GPT 这样的系统接收更多用户数据,模型正在学习和调整。
可以这样说,“我们增强了系统,而系统也增强了我们”…虽然有些简单却很深刻。
本文将讨论一个增强概念——SQL 可视化,它在增强现代数据工程师中的作用,以及五种 SQL 可视化工具的分类。
人工增强的崛起
Gartner 对 2022 年及以后的价值方程预测了人类和决策的增强。
这一趋势强调了在 2022 年及以后,可组合的人机增强解决方案将成为进步的 AI 中心系统的基础技术。
您可以在 这里 深入阅读完整报告。
2023 年初,我们看到更多面向数据分析师/工程师的公民数据科学工具和增强技术。
那么这些与 SQL 可视化有什么关系呢?
我们将在下一部分深入探讨这一点。
那么,什么是 SQL?
要理解 SQL 可视化,我们需要回顾其后缀 SQL。
SQL,或称为 S-e-q-u-e-l,是一种有 43 年历史的查询语言,因其在数据库技术中的广泛应用而闻名。
Stack Overflow 的 调查 统计显示,超过 50% 的开发者使用 SQL。
可以说,SQL 是有效的。
所以...
为什么需要 SQL 可视化?
SQL 可视化正在通过图形化、视觉组件简化 SQL 处理的采用。
在多云、混合云和云数据仓库部署与过渡的时代,企业对 SQL 可视化工具的需求日益增加,以帮助优化数据堆栈和流程。这部分由于以下原因:
新的复杂性
随着组织通过利用新技术渠道和数据源来优化数据流程,新挑战和复杂性不断出现。
短周期迭代的需求
数据消费者现在比以往任何时候都更期望数据集周围的相关、实时背景。
分析师角色也期望能够快速整合数据,并采用快速失败的方法,而不依赖 IT。
克服非民主化的数据准备
利益相关者希望获得更多权限,以便在没有深厚技术知识的情况下进行临时分析和自助分析。
数据工程师的稀缺性
截至 2022 年,数据主控领域的领先品牌 Tamr,强调了对数据工程师的需求激增及相应的资源稀缺。
以数据工程资源为中心的战略公司可能会遇到缺陷。
SQL 可视化工具的类别和示例
我喜欢将各种 SQL 可视化工具分为四个类别,即:
SQL 流可视化工具
SQL 流/谱系工具提供对 SQL 语法的深入分析,并生成视觉直观的谱系结果。
类似于 JSON crack - 用于视觉探索 JSON 格式的 API 输出,SQLflow由 Gudusoft 提供,是一个自动化的 SQL 谱系可视化工具。

图片由 Gudusoft 的 SQLFlow 提供
SQL 模式可视化工具
这些 SQL 工具集允许你在协作和互动环境中在线可视化数据库设计。SqlDBM 就是这样一个工具的优秀例子。
SqlDBM 是一个开发平台,使公司能够在不编写代码的情况下构建在线数据库。因此,开发人员可以更多地专注于数据库模型,而不是语法。
图片由 SqlDBM 提供
SQL 查询可视化工具
这些 SQL 可视化工具主要用于数据处理、转换和建模活动。
这一领域中知名的工具是Datameer。
Datameer是一个一体化解决方案,用于探索、准备、可视化和编目 Snowflake 的见解。Datameer 使数据工程师和分析师能够通过简洁的 SQL 代码或无代码界面直接修改 Snowflake 中的数据。
来自 Datameer 的图片
SQL 仪表板工具
我们的典型数据生命周期从基础 SQL 查询开始,经过 ? 模型,? 仪表板。然而,像 SQL 仪表板软件这样的工具正在打破这一范式——通过大幅缩短临时分析和原型设计的洞察时间。
一个很好的例子就是 Domo。
Domo 是一款可视化软件,它直接连接到数据所在的位置,实时提供重要指标数据,以便快速分析。
来自 Domo 的图片
最后的想法
这就是我为数据工程师/分析师角色精心挑选的 SQL 可视化工具的列表的结尾……希望你觉得这些内容对你有帮助。
如果你是使用云分析堆栈的数据分析师或工程师,我强烈建议你尝试这些工具中的任何一个。
关于推荐,我经常使用 Datameer 进行低代码转型,以及 SqlDBM 在我的雪花环境中进行简单的数据库建模。因此,我可以证实它们对“数据工程师和分析师角色”的增强效果。
如果你有任何其他类别的推荐,请在评论中提及;期待听到你的想法。
Ndz Anthony 是一位高级 BI 分析师和讲师。他喜欢通过与商业智能和企业分析相关的写作进行教育。
更多相关话题
数据科学家应该了解的 5 个统计悖论
原文:
www.kdnuggets.com/2023/02/5-statistical-paradoxes-data-scientists-know.html

图片由作者提供
简介
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
作为数据科学家,我们依赖统计分析来从数据中挖掘不同变量之间关系的信息,以回答问题,这将帮助企业和个人做出正确决策。然而,一些统计现象可能会违反直觉,可能导致分析中的悖论和偏差,这将破坏我们的分析。
我将向你解释的这些悖论易于理解,不包括复杂的公式。
在本文中,我们将探讨数据科学家应了解的 5 个统计悖论:准确性悖论、假阳性悖论、赌徒谬论、辛普森悖论和伯克森悖论。
这些悖论中的每一个都可能是导致你分析结果不可靠的潜在原因。

图片由作者提供
我们将讨论这些悖论的定义和现实生活中的例子,以说明这些悖论如何在现实数据分析中发生。理解这些悖论将帮助你消除可能影响可靠统计分析的障碍。
那么,事不宜迟,让我们深入探讨准确性悖论的世界。
准确性悖论
图片由作者提供
准确性显示出在分类时准确性不是一个好的评价指标。
假设你正在分析一个包含 1000 个患者指标的数据集。你想检测一种罕见的疾病,这种疾病最终会在 5%的人群中显现。所以总体上,你必须在 1000 人中找到 50 个人。
即使你总是说这些人没有疾病,你的准确率也会是 95%。而你的模型在这个群体中不能捕捉到一个生病的人。(0/50)
数字数据集
让我们通过一个著名的数字数据集的例子来解释这一点。
该数据集包含从 0 到 9 的手写数字。
图片由作者提供
这是一个简单的多标签分类任务,但也可以被解读为图像识别,因为数字是以图像的形式呈现的。
现在我们将加载这些数据集,并重新塑造数据集以应用机器学习模型。我跳过了这些部分的解释,因为你可能也对这些部分很熟悉。如果不熟悉,可以尝试搜索数字数据集或 MNIST 数据集。MNIST 数据集也包含相同类型的数据,但形状比这个更大。
好的,我们继续。
现在我们尝试预测数字是否为 6。为此,我们将定义一个预测不是 6 的分类器。让我们查看这个分类器的交叉验证分数。
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.base import BaseEstimator
import numpy as np
digits = datasets.load_digits()
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
x_train, x_test, y_train, y_test = train_test_split(
data, digits.target, test_size=0.5, shuffle=False
)
y_train_6 = y_train == 6
from sklearn.base import BaseEstimator
class DumbClassifier(BaseEstimator):
def fit(self, X, y=None):
pass
def predict(self, X):
return np.zeros((len(X), 1), dtype=bool)
dumb_clf = DumbClassifier()
cross_val_score(dumb_clf, x_train, y_train_6, cv=3, scoring="accuracy")
结果将如下所示。
这意味着什么?这意味着即使你创建一个从不估计 6 的估计器并将其放入你的模型中,准确率也可能超过 90%。为什么?因为我们的数据集中存在其他 9 个数字。所以如果你说这个数字不是 6,你会有 9/10 的准确率。
这表明选择评估指标非常重要。如果你想评估分类任务,准确率不是一个好的选择。你应该选择精确度或召回率。
那些是什么?它们出现在假阳性悖论中,所以请继续阅读。
假阳性悖论
图片由作者提供
现在,假阳性悖论是一种统计现象,当我们测试稀有事件或条件的存在时,可能会出现这种现象。
它也被称为“基本率谬误”或“基本率忽视”。
这个悖论意味着在测试稀有事件时,假阳性结果会多于正结果。
让我们看一个数据科学的例子。
欺诈检测

图片由作者提供
想象一下你正在开发一个机器学习模型来检测欺诈性信用卡交易。你使用的数据集包括大量正常(非欺诈性)交易和少量欺诈交易。然而,当你在现实世界中部署模型时,你发现它产生了大量的假阳性。
经过进一步调查,你会发现现实世界中欺诈交易的发生率远低于训练数据集中的发生率。
假设 1/10,000 的交易是欺诈的,并且假设测试也有 5%的假阳性率。
TP = 1/10,000
FP = 10,000(100-40)/1000,05 = 499,95 / 9,999
那么当发现一个欺诈交易时,它真的有可能是欺诈交易吗?
P = 1/500,95 =0,001996
结果接近 0.2%。这意味着当事件被标记为欺诈时,实际为欺诈事件的概率仅为 0.2%。
这就是假阳性悖论。
下面是如何在 Python 代码中实现它。
import pandas as pd
import numpy as np
# Number of normal transactions
normal_count = 9999
# Number of fraudulent transactions
true_positive = 1
# Number of normal transactions flagged as fraudulent by the model
false_positives = 499.95
# Number of fraudulent transactions flagged as normal by the model
false_negatives = 0
# Calculate precision
precision = (true_positive) / true_positive + false_positives
print(f"Precision: {precision:.2f}")
# Calculate recall
recall = (fraud_count) / fraud_count + false_negatives
print(f"Recall: {recall:.2f}")
# Calculate accuracy
accuracy = (
normal_count - false_positives + fraud_count - false_negatives
) / (normal_count + fraud_count)
print(f"Accuracy: {accuracy:.2f}")
你可以看到,召回率非常高,但精确度却很低。
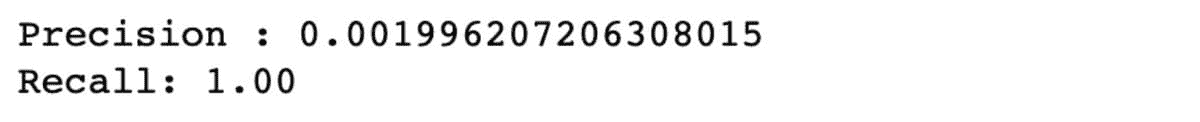
要理解为什么系统会这样做,让我解释一下精确度/召回率和精确度/召回率权衡。
召回率(真正率)也称为敏感度。你应该首先找到正面案例,并计算其中真正例的比例。
召回率 = TP / (TP + FP)
精确度是正向预测的准确率。
精确度 = TP / (TP + FN)
假设你希望有一个分类器来进行情感分析,并预测评论是正面的还是负面的。你可能希望有一个召回率高的分类器(它能够正确识别大量的正面或负面评论)。然而,为了获得更高的召回率,你应该能接受较低的精确度(错误分类正面评论),因为删除负面评论比偶尔删除一些正面评论更为重要。
另一方面,如果你想构建一个垃圾邮件分类器,你可能希望有一个精确度高的分类器。它能准确识别高比例的垃圾邮件,但偶尔会漏掉一些垃圾邮件,因为保持重要邮件更为重要。
现在,在我们的案例中,为了找到欺诈交易,你牺牲了许多非欺诈的错误。然而,如果你这样做,你也必须采取预防措施,例如在银行系统中。当他们检测到欺诈交易时,他们开始进行进一步调查,以确保绝对准确。
通常,当进行超过预设限额的交易时,他们会向你的手机或电子邮件发送消息以进行进一步确认等。
如果你允许你的模型有假阴性,那么你的召回率将会很低。然而,如果你允许你的模型有假阳性,你的精确度将会低。
作为数据科学家,你应该调整你的模型或添加一个步骤进行进一步调查,因为可能会有很多假阳性。
赌徒谬误

图片由作者提供
赌徒谬误,也称为蒙特卡洛谬误,是一种错误的信念,即如果某事件发生的频率高于其正常概率,它将在随后的试验中更频繁地发生。
让我们来看一个数据科学领域的例子。
客户流失

图片由作者提供
设想一下,你正在构建一个机器学习模型来预测客户是否会流失,基于他们的历史行为。
现在,你已经收集了许多不同类型的数据,包括与服务互动的客户数量、客户成为客户的时间长度、客户提出的投诉数量等等。
在这一点上,你可能会觉得长期使用服务的客户流失的可能性较小,因为他们在过去对服务表现出了承诺。
然而,这仍然是一个赌徒谬误的例子,因为客户流失的概率不受他们成为客户的时间长度的影响。
流失概率是由多种因素决定的,包括服务质量、客户对服务的满意度等。
因此,如果你构建一个机器学习模型,请特别注意不要创建包含客户时间长度的列,并试图用它来解释模型。此时,你应该意识到这可能会因为赌徒谬误而毁坏你的模型。
现在,这只是一个概念性的例子。让我们通过一个硬币抛掷的例子来解释这一点。
首先让我们看看硬币抛掷概率的变化。你可能会觉得如果硬币多次出现正面,未来出现正面的可能性会减少。这实际上是赌徒谬误的一个很好的例子。
正如你所见,在开始时,可能性有所波动。然而,当翻转次数增加时,得到正面的概率将趋于 0.5。
import random
import matplotlib.pyplot as plt
# Set up the plot
plt.xlabel("Flip Number")
plt.ylabel("Probability of Heads")
# Initialize variables
num_flips = 1000
num_heads = 0
probabilities = []
# Simulate the coin flips
for i in range(num_flips):
if (
random.random() > 0.5
): # random() generates a random float between 0 and 1
num_heads += 1
probability = num_heads / (i + 1) # Calculate the probability of heads
probabilities.append(probability) # Record the probability
# Plot the results
plt.plot(probabilities)
plt.show()
现在,让我们看看输出结果。
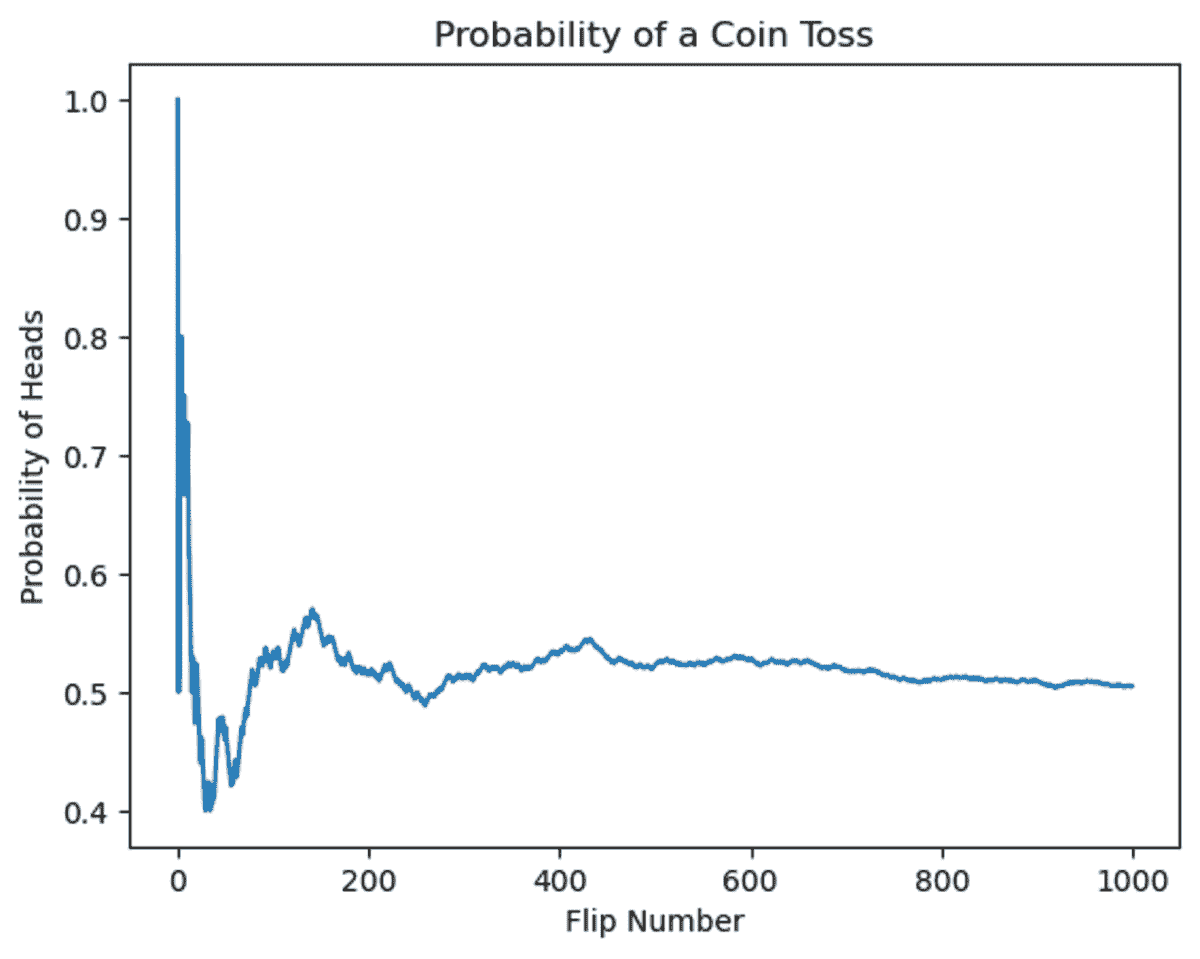
作者提供的图片
显然,概率会随时间波动,但最终它会趋向于 0.5。
这个例子展示了赌徒谬误,因为之前翻转的结果不会影响任何一次翻转中得到正面的概率。概率始终保持在 50%,无论过去发生了什么。
辛普森悖论

图片由Roland Steinmann提供,来源于Pixabay
这个悖论发生在当数据被汇总时,两变量之间的关系似乎发生了变化。
现在,为了解释这个悖论,我们来使用 seaborn 中的内置数据集 tips。
提示

作者提供的图片
为了解释辛普森悖论,我们将使用 tips 数据集计算女性和男性在午餐时间和整体的平均小费。tips 数据集包含客户在餐馆给出的提示数据,如总小费、性别、日期、时间等。
小费数据集是顾客在餐馆给小费的数据集合。它包括小费金额、顾客性别、星期几和一天中的时间等信息。该数据集可用于分析顾客的小费行为并识别数据中的趋势。
import seaborn as sns
# Load the tips dataset
tips = sns.load_dataset("tips")
# Calculate the tip percentage for men and women at lunch
men_lunch_tip_pct = (
tips[(tips["sex"] == "Male") & (tips["time"] == "Lunch")]["tip"].mean()
/ tips[(tips["sex"] == "Male") & (tips["time"] == "Lunch")][
"total_bill"
].mean()
)
women_lunch_tip_pct = (
tips[(tips["sex"] == "Female") & (tips["time"] == "Lunch")]["tip"].mean()
/ tips[(tips["sex"] == "Female") & (tips["time"] == "Lunch")][
"total_bill"
].mean()
)
# Calculate the overall tip percentage for men and women
men_tip_pct = (
tips[tips["sex"] == "Male"]["tip"].mean()
/ tips[tips["sex"] == "Male"]["total_bill"].mean()
)
women_tip_pct = (
tips[tips["sex"] == "Female"]["tip"].mean()
/ tips[tips["sex"] == "Female"]["total_bill"].mean()
)
# Create a data frame with the average tip percentages
data = {
"Lunch": [men_lunch_tip_pct, women_lunch_tip_pct],
"Overall": [men_tip_pct, women_tip_pct],
}
index = ["Men", "Women"]
df = pd.DataFrame(data, index=index)
df
好的,这就是我们的数据框。
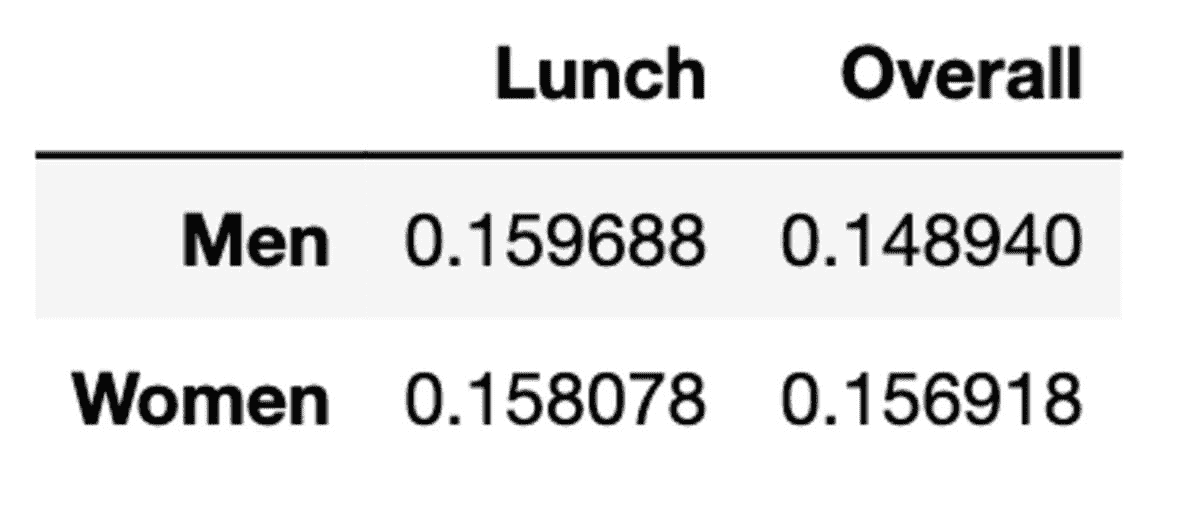
如我们所见,午餐时男性和女性的平均小费更高。然而,当数据汇总时,均值发生了变化。
让我们看一下柱状图,以查看变化。
import matplotlib.pyplot as plt
# Set the group labels
labels = ["Lunch", "Overall"]
# Set the bar heights
men_heights = [men_lunch_tip_pct, men_tip_pct]
women_heights = [women_lunch_tip_pct, women_tip_pct]
# Create a figure with two subplots
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 5))
# Create the bar plot
ax1.bar(labels, men_heights, width=0.5, label="Men")
ax1.bar(labels, women_heights, width=0.3, label="Women")
ax1.set_title("Average Tip Percentage by Gender (Bar Plot)")
ax1.set_xlabel("Group")
ax1.set_ylabel("Average Tip Percentage")
ax1.legend()
# Create the line plot
ax2.plot(labels, men_heights, label="Men")
ax2.plot(labels, women_heights, label="Women")
ax2.set_title("Average Tip Percentage by Gender (Line Plot)")
ax2.set_xlabel("Group")
ax2.set_ylabel("Average Tip Percentage")
ax2.legend()
# Show the plot
plt.show()
这是输出结果。
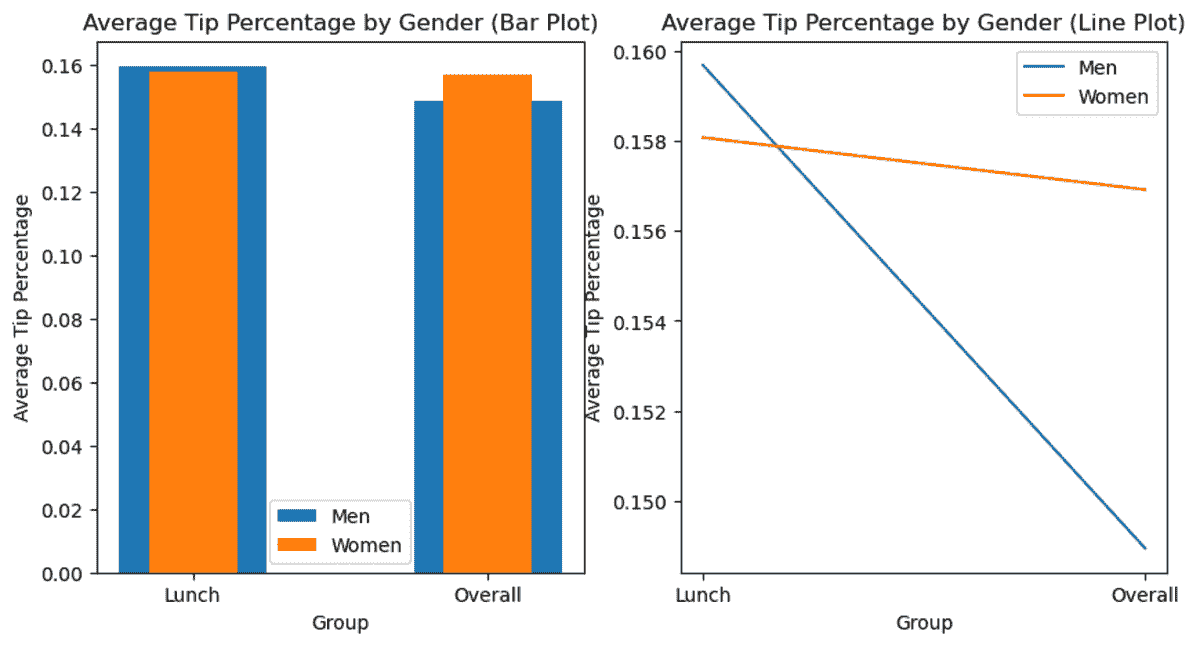
图片来源:作者
现在,如你所见,数据汇总后平均值发生了变化。突然间,你会看到总体上女性的小费比男性更多。
有什么陷阱?
在观察子集版本的趋势并从中提取意义时,要小心不要忘记检查这一趋势是否仍然适用于整个数据集。因为如你所见,特殊情况下可能并非如此。这可能导致数据科学家做出误判,从而做出糟糕的(商业)决策。
伯克森悖论
伯克森悖论是一种统计悖论,当两个变量在数据中相互关联时,但当数据被子集化或分组时,这种相关性没有被观察到或发生了变化。
简单来说,伯克森悖论是指在数据的不同子组中,相关性看起来有所不同。
现在,让我们通过分析 Iris 数据集来深入了解。
Iris 数据集

图片来源:作者
Iris 数据集是机器学习和统计学中常用的数据集。它包含了不同鸢尾花观测的数据,包括花瓣和萼片的长度和宽度以及观察到的花卉种类。
在这里,我们将绘制两个图表,显示萼片长度和宽度之间的关系。但在第二个图表中,我们将物种过滤为 Setosa。
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import linregress
# Load the iris data set
df = sns.load_dataset("iris")
# Subset the data to only include setosa species
df_s = df[df["species"] == "setosa"]
# Create a figure with two subplots
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 5))
# Plot the relationship between sepal length and width.
slope, intercept, r_value, p_value, std_err = linregress(
df["sepal_length"], df["sepal_width"]
)
ax1.scatter(df["sepal_length"], df["sepal_width"])
ax1.plot(
df["sepal_length"],
intercept + slope * df["sepal_length"],
"r",
label="fitted line",
)
ax1.set_xlabel("Sepal Length")
ax1.set_ylabel("Sepal Width")
ax1.set_title("Sepal Length and Width")
ax1.legend([f"R² = {r_value:.3f}"])
# Plot the relationship between setosa sepal length and width for setosa.
slope, intercept, r_value, p_value, std_err = linregress(
df_s["sepal_length"], df_s["sepal_width"]
)
ax2.scatter(df_s["sepal_length"], df_s["sepal_width"])
ax2.plot(
df_s["sepal_length"],
intercept + slope * df_s["sepal_length"],
"r",
label="fitted line",
)
ax2.set_xlabel("Setosa Sepal Length")
ax2.set_ylabel("Setosa Sepal Width")
ax2.set_title("Setosa Sepal Length and Width ")
ax2.legend([f"R² = {r_value:.3f}"])
# Show the plot
plt.show()
你可以看到萼片长度与 Setosa 物种之间的变化。实际上,它显示了与其他物种不同的相关性。
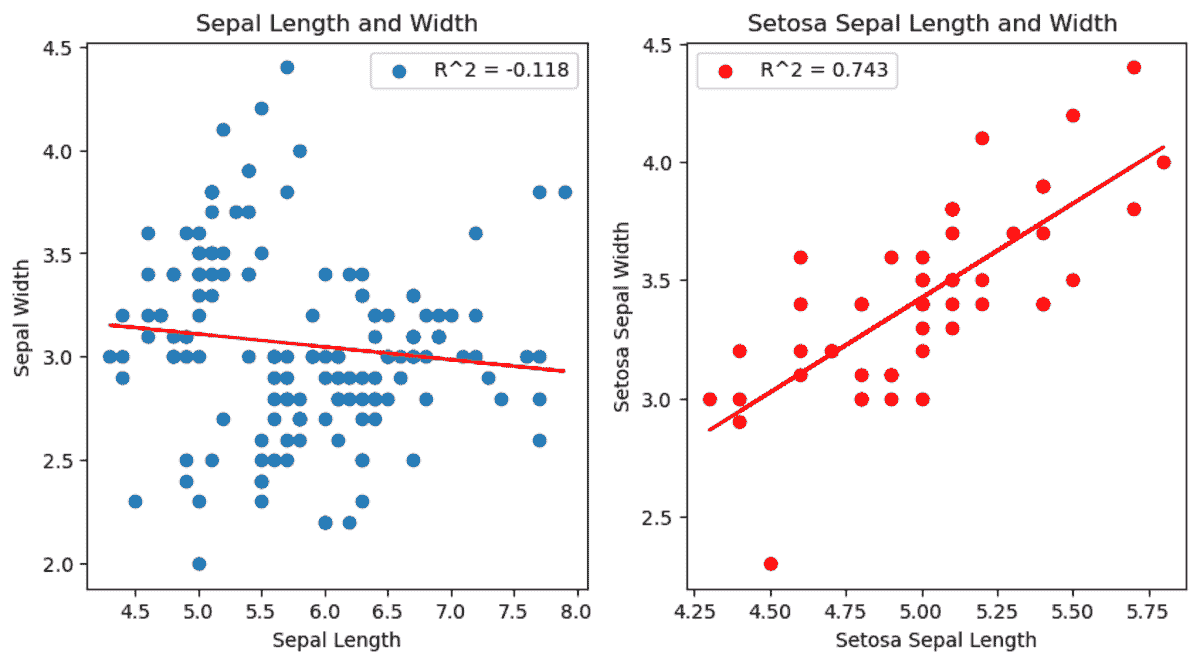
图片来源:作者
此外,你可以在第一个图中看到 Setosa 的不同相关性。
在第二个图表中,你可以看到萼片宽度和萼片长度之间的相关性发生了变化。当分析所有数据集时,显示了萼片长度增加时,萼片宽度减少。然而,如果我们开始分析选择 Setosa 物种的数据,相关性现在为正,并且显示萼片宽度增加时,萼片长度也增加。
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import linregress
# Load the tips data set
df = sns.load_dataset("iris")
# Subset the data to only include setosa species
df_s = df[df["species"] == "setosa"]
# Create a figure with two subplots
fig, ax1 = plt.subplots(figsize=(5, 5))
# Plot the relationship between sepal length and width.
slope, intercept, r_value_1, p_value, std_err = linregress(
df["sepal_length"], df["sepal_width"]
)
ax1.scatter(df["sepal_length"], df["sepal_width"], color="blue")
ax1.plot(
df["sepal_length"],
intercept + slope * df["sepal_length"],
"b",
label="fitted line",
)
# Plot the relationship between setosa sepal length and width for setosa.
slope, intercept, r_value_2, p_value, std_err = linregress(
df_s["sepal_length"], df_s["sepal_width"]
)
ax1.scatter(df_s["sepal_length"], df_s["sepal_width"], color="red")
ax1.plot(
df_s["sepal_length"],
intercept + slope * df_s["sepal_length"],
"r",
label="fitted line",
)
ax1.set_xlabel("Sepal Length")
ax1.set_ylabel("Sepal Width")
ax1.set_title("Sepal Length and Width")
ax1.legend([f"R = {r_value_1:.3f}"])
这里是图表。
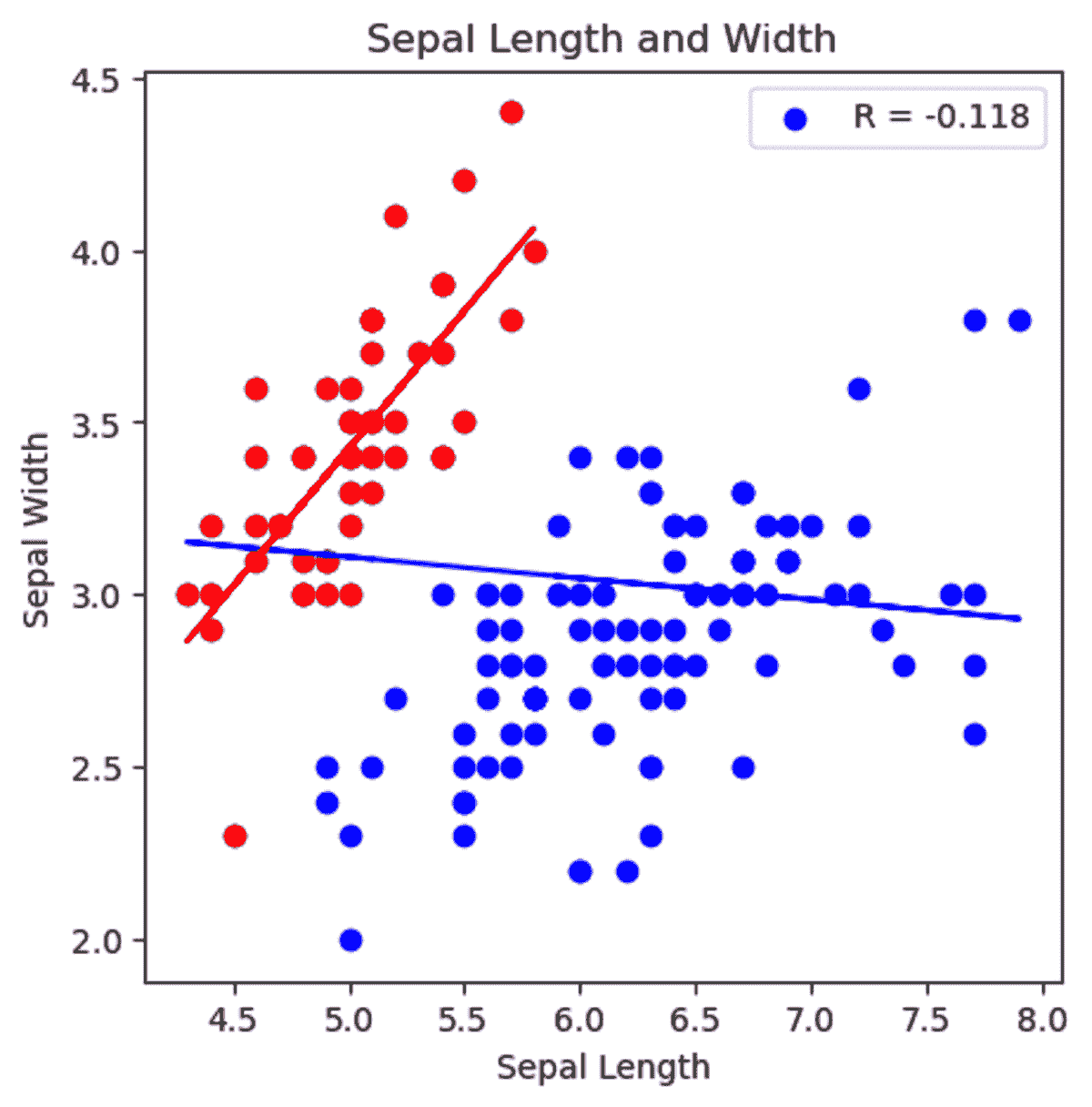
图片来源:作者
你可以看到,从分析 setosa 开始并将其花萼宽度和长度的相关性进行概括,可能会导致你根据分析得出错误的结论。
结论
在这篇文章中,我们探讨了数据科学家应当了解的五个统计学悖论,以便进行准确的分析。假设你发现数据集中存在某种趋势,表明花萼长度增加时,花萼宽度也增加。然而,当你查看整个数据集时,情况实际上完全相反。
或者你可能通过查看准确度来评估你的分类模型。你会发现,即使是完全无操作的模型也能实现超过 90% 的准确率。如果你试图通过准确度来评估模型并进行分析,考虑一下你可能会犯多少错误。
通过理解这些悖论,我们可以采取措施避免常见的陷阱,并提高统计分析的可靠性。用健康的怀疑态度来对待数据分析,避免分析中的潜在悖论和局限性也是很重要的。
总之,这些悖论对于数据科学家在高水平分析时非常重要,因为意识到这些悖论可以提高分析的准确性和可靠性。我们还推荐这份 “统计学备忘单”,它可以帮助你理解统计学和概率的重要术语和方程,并帮助你准备下一次数据科学面试。
感谢阅读!
Nate Rosidi 是一位数据科学家,专注于产品策略。他还是一名兼职教授,教授分析学,并且是 StrataScratch,一个帮助数据科学家准备面试的平台,提供来自顶级公司的真实面试问题。可以通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
相关主题
下一步数据科学问题的 5 步蓝图
原文:
www.kdnuggets.com/5-step-blueprint-to-your-next-data-science-problem

图片由 fanjianhua 提供,来源于 Freepik
公司在处理数据时面临的主要挑战之一是实施连贯的数据战略。我们都知道问题不在于数据不足,我们知道我们有很多数据。问题在于我们如何将数据转化为可操作的见解。
然而,有时候可用的数据过多,这使得做出明确决策变得更加困难。奇怪的是,数据过多竟然成了一个问题,对吧?这就是为什么公司必须理解如何应对新的数据科学问题。
让我们深入了解如何做到这一点。
制定完美的问题陈述
在深入讨论之前,我们必须做的第一件事是定义问题。你需要准确地定义要解决的问题。这可以通过确保问题在你组织的限制范围内是明确、简洁和可衡量的来完成。
你不希望过于模糊,因为这会带来额外的问题,但也不希望过于复杂化。两者都会使数据科学家难以转化为机器代码。
这里有一些提示:
-
问题实际上是一个需要进一步分析的问题
-
问题的解决方案有很高的概率产生积极影响
-
有足够的可用数据
-
利益相关者参与应用数据科学来解决问题
选择你的方向
现在你需要决定你的方法,是走这条路还是那条路?只有在你对问题有全面了解并且已将其定义得非常清晰时,才能回答这个问题。
有多种算法可以用于不同的情况,例如:
-
分类算法:用于将数据分类到预定义的类别中。
-
回归算法:适用于预测数值结果,如销售预测。
-
聚类算法:非常适合根据相似性将数据分组,如客户细分。
-
降维:有助于简化复杂的数据结构。
-
强化学习:适用于决策会导致后续结果的场景,如游戏或股票交易。
数据质量的追求
正如你所想,对于一个数据科学项目,你需要数据。明确了问题并根据它选择了合适的方法后,你需要去收集数据以支持你的分析。
数据来源很重要,因为你需要确保从相关来源收集数据,并且所有收集的数据需要在日志中组织,记录收集日期、来源名称和其他有用的元数据。
记住一点。仅仅因为你收集了数据,并不意味着它已经准备好进行分析。作为数据科学家,你将花时间清理数据,并将其整理成适合分析的格式。
深入分析深度
所以你已经收集了数据,清理得一尘不染,现在我们准备进入数据分析阶段。
分析数据的第一阶段是探索性数据分析。在这个阶段,你需要理解数据的性质,能够识别不同的模式、关联和可能的异常值。在这一阶段,你希望彻底了解数据,以避免后续出现令人震惊的意外。
一旦完成这些,分析数据的第二阶段的简单方法是尝试所有基本的机器学习方法,因为你将处理较少的参数。你还可以使用各种开源数据科学库来分析数据,例如 scikit-learn。
解读数据故事
整个过程的关键在于解释。在这一阶段,你将开始看到隧道尽头的光芒,感觉离问题的解决更近了。
你可能会发现你的模型运行良好,但结果与实际问题不符。解决方案是添加更多数据并重新尝试,直到你对结果感到满意。
迭代改进是数据科学的重要部分,它帮助确保数据科学家不会放弃并从头开始,而是继续改进他们已经构建的内容。
结论
我们生活在一个数据饱和的环境中,公司不断吸引数据。数据被用来获得竞争优势,并继续基于数据决策过程进行创新。
在改进和提升组织时,数据科学的道路并非易事,但组织们正在看到投资的好处。
Nisha Arya 是一位数据科学家、自由技术作家以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。Nisha 涵盖了广泛的主题,并希望探索人工智能如何有利于人类寿命的延续。作为一名热衷学习者,Nisha 希望扩展她的技术知识和写作技能,同时帮助指导他人。
更多相关内容
使用 d6tflow 构建可扩展深度学习管道的 5 步指南
原文:
www.kdnuggets.com/2019/09/5-step-guide-scalable-deep-learning-pipelines-d6tflow.html
评论
作者 Norman Niemer,首席数据科学家 & Samuel Showalter,技术顾问
介绍:为什么要这样做?
构建深度学习模型通常涉及复杂的数据管道,以及大量的试错过程、调整模型架构和参数,这些参数的性能需要进行比较。通常很难跟踪所有实验,这往往会导致困惑,最糟糕的情况则是得出错误结论。
在 4 个原因说明为什么你的机器学习代码很糟糕 中,我们探讨了如何将机器学习代码组织为 DAG 工作流以解决这个问题。在本指南中,我们将通过一个实际案例研究,将现有的 pytorch 脚本转换为使用 d6tflow 的可扩展深度学习管道。起点是 Facebook 的 pytorch 深度推荐模型,我们将经过将代码迁移到可扩展深度学习管道的 5 个步骤。下面的步骤以部分伪代码形式编写以说明概念,完整代码也可用,详见文章末尾的说明。
开始吧!
步骤 1:规划你的 DAG
为了规划你的工作并帮助他人理解你的管道如何整合在一起,你需要首先考虑数据流、任务之间的依赖关系和任务参数。这有助于你将工作流组织成逻辑组件。你可能会想绘制一个类似这样的图示
以下是 FB DLRM 的 pytorch 模型训练 DAG。它展示了训练任务TaskModelTrain及其所有依赖项,以及这些依赖项之间的关系。如果你编写的是函数式代码,很难看到你的工作流如何像这样整合在一起。
task = TaskModelTrain()
print(d6tflow.preview(task, clip_params=True))
##
## └─--[TaskModelTrain-{'data_generation': 'random'}[more] ([94mPENDING[0m)]
## |--[TaskBuildNetwork-{'data_generation': 'random'}[more] ([94mPENDING[0m)]
## | └─--[TaskGetTrainDataset-{'data_generation': 'random'}[more] ([94mPENDING[0m)]
## |--[TaskGetTrainDataset-{'data_generation': 'random'}[more] ([94mPENDING[0m)]
## └─--[TaskGetTestDataset-{'data_generation': 'random'}[more] ([94mPENDING[0m)]
## None
步骤 2:编写任务而不是函数
数据科学代码通常以函数的形式组织,这会导致很多问题,具体见 4 个原因说明为什么你的机器学习代码很糟糕。相反,你应该编写 d6tflow 任务。这样做的好处包括:
-
将任务链入 DAG,以便所需的依赖项自动运行
-
轻松从依赖项中加载任务输入数据
-
轻松保存任务输出,如预处理数据和训练模型。这样你就不会意外地重新运行长时间运行的训练任务
-
参数化任务,以便可以智能地管理(见下一步)
-
将输出保存到 d6tpipe,以将数据与代码分开并轻松共享数据,参见 数据科学家的十大编码错误
下面是将功能代码转换为 d6tflow 任务后的 FB DLRM 代码的前后对比。
典型的 pytorch 功能代码扩展性差:
# ***BEFORE***
# see dlrm_s_pytorch.py
def train_model():
data = loadData()
dlrm = DLRM_Net([...])
model = dlrm.train(data)
torch.save({model},'model.pickle')
if __name__ == "__main__":
parser.add_argument("--load-model")
if load_model:
model = torch.load('model.pickle')
else:
model = train_model()
使用可扩展的 d6tflow 任务编写的相同逻辑:
# ***AFTER***
# see flow_tasks.py
class TaskModelTrain(d6tflow.tasks.TaskPickle):
def requires(self): # define dependencies
return {'data': TaskPrepareData(), 'model': TaskBuildNetwork()}
def run(self):
data = self.input()['data'].load() # easily load input data
dlrm = self.input()['model'].load()
model = dlrm.train(data)
self.save(model) # easily save trained model as pickle
if __name__ == "__main__":
if TaskModelTrain().complete(): # load ouput if task was run
model = TaskModelTrain().output().load()
第 3 步:参数化任务
为了提高模型性能,你将尝试不同的模型、参数和预处理设置。为了跟踪这些,你可以将参数添加到任务中。这样你可以:
-
跟踪哪些模型使用了哪些参数进行训练
-
智能地重新运行任务以应对参数变化
-
帮助他人理解工作流中引入参数的位置
下面设置了 FB DLRM 模型训练任务及其参数。请注意,你不再需要手动指定保存训练模型和数据的位置。
# ***BEFORE***
# dlrm_s_pytorch.py
if __name__ == "__main__":
# define model parameters
parser.add_argument("--learning-rate", type=float, default=0.01)
parser.add_argument("--nepochs", type=int, default=1)
# manually specify filename
parser.add_argument("--save-model", type=str, default="")
model = train_model()
torch.save(model, args.save_model)
# ***AFTER***
# see flow_tasks.py
class TaskModelTrain(d6tflow.tasks.TaskPickle):
# define model parameters
learning_rate = luigi.FloatParameter(default = 0.01)
num_epochs = luigi.IntParameter(default = 1)
# filename is determined automatically
def run(self):
data = self.input()['data'].load()
dlrm = self.input()['model'].load()
# use learning_rate param
optimizer = torch.optim.SGD(dlrm.parameters(), lr=self.learning_rate)
# use num_epochs param
while k < self.num_epochs:
optimizer.step()
model = optimizer.get_model()
self.save(model) # automatically save model, seperately for each parameter config
比较训练模型
现在你可以使用该参数轻松比较不同模型的输出。确保在加载任务输出之前运行带有该参数的工作流(参见第 #4 步)。
model1 = TaskModelTrain().output().load() # use default num_epochs=1
print_accuracy(model1)
model2 = TaskModelTrain(num_epochs=10).output().load()
print_accuracy(model2)
继承参数
通常,你需要让参数通过工作流向下级传递。如果你编写功能代码,你必须在每个函数中重复参数。使用 d6tflow,你可以继承参数,这样终端任务可以根据需要将参数传递给上游任务。
在 FB DLRM 工作流中,TaskModelTrain 从 TaskGetTrainDataset 继承参数。这样你可以运行 TaskModelTrain(mini_batch_size=2),它会将参数传递给上游任务,即 TaskGetTrainDataset 和所有依赖于它的其他任务。在实际代码中,请注意使用了 self.clone(TaskName) 和 @d6tflow.clone_parent。
class TaskGetTrainDataset(d6tflow.tasks.TaskPickle):
mini_batch_size = luigi.FloatParameter(default = 1)
# [...]
@d6tflow.inherit(TaskGetTrainDataset)
class TaskModelTrain(d6tflow.tasks.TaskPickle):
# no need to repeat parameters
pass
第 4 步:运行 DAG 以处理数据和训练模型
要启动数据处理和模型训练,你需要运行 DAG。你只需运行终端任务,它会自动运行所有依赖项。在实际运行 DAG 之前,你可以预览将要运行的内容。如果你对代码或数据进行了任何更改,这尤其有用,因为它只会运行已更改的任务,而不是完整的工作流。
task = TaskModelTrain() # or task = TaskModelTrain(num_epochs=10)
d6tflow.preview(task)
d6tflow.run(task)
第 5 步:评估模型性能
现在工作流已经运行完毕,所有任务都已完成,你可以加载预测结果和其他模型输出进行比较和可视化。因为任务知道每个输出保存的位置,你可以直接从任务中加载输出,而不必记住文件路径或变量名。这也使你的代码更具可读性。
model1 = TaskModelTrain().output().load()
print_accuracy(model1)
比较模型
你可以轻松比较不同模型和不同参数的输出。
model1 = TaskModelTrain().output().load() # use default num_epochs=1
print_accuracy(model1)
model2 = TaskModelTrain(num_epochs=10).output().load()
print_accuracy(model2)
不断迭代
当您迭代、更改参数、代码和数据时,您将需要重新运行任务。d6tflow 智能地判断哪些任务需要重新运行,这使得迭代变得非常高效。如果您更改了参数,您无需做任何操作,它会自动知道需要运行什么。如果您更改了代码或数据,您需要使用 .invalidate() 将任务标记为未完成,d6tflow 会处理其余的部分。
在 FB DLRM 工作流中,例如,您更改了训练数据或对训练预处理进行了更改。
TaskGetTrainDataset().invalidate()
# or
d6tflow.run(task, forced=TaskGetTrainDataset())
完整源代码
所有代码都提供在 github.com/d6tdev/dlrm。它与 github.com/facebook/dlrm 相同,只是添加了 d6tflow 文件:
-
flow_run.py: 运行 flow => 运行此文件
-
flow_task.py: 任务代码
-
flow_viz.py: 显示模型输出
-
flow_cfg.py: 默认参数
-
dlrm_d6t_pytorch.py: 为 d6tflow 采用的 dlrm_data_pytorch.py
亲自尝试!
对于您的下一个项目
在本指南中,我们展示了如何构建可扩展的深度学习工作流。我们使用了现有的代码库,并展示了如何将线性深度学习代码转换为 d6tflow DAG 以及这样做的好处。
对于新项目,您可以从 github.com/d6t/d6tflow-template 开始一个可扩展的项目模板。结构非常相似:
-
run.py: 运行工作流
-
task.py: 任务代码
-
cfg.py: 管理参数
Norman Niemer 是一家大型资产管理公司的首席数据科学家,他提供数据驱动的投资洞察。他拥有哥伦比亚大学的金融工程硕士学位和卡斯商学院(伦敦)的银行与金融学士学位。
Samuel Showalter 是一名技术顾问。他是近期毕业生,对数据科学、软件开发以及这些领域对个人和职业生活的价值充满热情。他曾在多个不同的角色中工作,但所有这些角色都专注于数据管理和分析。
原文。已获授权转载。
相关:
-
数据科学家犯的 10 个编码错误
-
4 个原因说明你的机器学习代码可能不好
-
数据管道、Luigi、Airflow:您需要知道的一切
我们的 Top 3 课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT 工作
相关主题
用 5 步骤开始学习 Python 数据结构
原文:
www.kdnuggets.com/5-steps-getting-started-python-data-structures
Python 数据结构简介
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织的 IT
当谈到学习如何编程时,无论你使用什么特定的编程语言,你会发现你所接触的大部分内容都可以归类为你新选择的学科中的几个主要主题。其中的一些,按理解的顺序排列,大致有:语法(语言的词汇);命令(将词汇组合成有用的方式);流程控制(我们如何引导命令执行的顺序);算法(我们解决特定问题所采取的步骤……这个词为什么变得如此令人困惑?);最后是数据结构(我们在算法执行期间用于数据操作的虚拟存储库(再次……一系列步骤))。
实质上,如果你想通过将一系列命令拼凑成算法的步骤来实现问题的解决方案,那么数据最终会被处理,数据结构就会变得至关重要。这些数据结构提供了一种有效组织和存储数据的方法,对创建快速、模块化的代码至关重要,这些代码能够执行有用的功能并良好地扩展。Python,这种特定的编程语言,拥有一系列内置的数据结构。
本教程将重点介绍这四种基础的 Python 数据结构:
-
列表 - 有序、可变,允许重复元素。用于存储数据序列。
-
元组 - 有序、不可变,允许重复元素。将它们视为不可变的列表。
-
字典 - 无序、可变,通过键值对映射。用于以键值格式存储数据。
-
集合 - 无序、可变,包含唯一元素。用于成员测试和消除重复。
除了基本的数据结构,Python 还提供了更高级的结构,如堆、队列和链表,这些都可以进一步提升你的编码能力。这些高级结构在基础结构的基础上构建,支持更复杂的数据处理,并且常用于特定场景。但是,你并不受限于这些结构;你可以利用所有现有的结构作为基础,来实现自己的结构。然而,对列表、元组、字典和集合的理解仍然至关重要,因为这些是更高级数据结构的基础。
本指南旨在提供对这些核心结构的清晰和简明的理解。随着你开始 Python 之旅,以下章节将引导你掌握基本概念和实际应用。从创建和操作列表到利用集合的独特功能,本教程将为你提供在编码中脱颖而出的技能。
步骤 1:在 Python 中使用列表
什么是 Python 中的列表?
Python 中的列表是有序的、可变的数据类型,可以存储各种对象,允许重复元素。列表通过使用方括号 [ ] 定义,元素之间用逗号分隔。
例如:
fibs = [0, 1, 1, 2, 3, 5, 8, 13, 21]
列表在组织和存储数据序列方面极其有用。
创建列表
列表可以包含不同的数据类型,如字符串、整数、布尔值等。例如:
mixed_list = [42, "Hello World!", False, 3.14159]
操作列表
列表中的元素可以被访问、添加、修改和删除。例如:
# Access 2nd element (indexing begins at '0')
print(mixed_list[1])
# Append element
mixed_list.append("This is new")
# Change element
mixed_list[0] = 5
# Remove last element
mixed_list.pop(0)
有用的列表方法
一些用于列表的实用内置方法包括:
-
sort()- 就地排序列表 -
append()- 将元素添加到列表末尾 -
insert()- 在索引处插入元素 -
pop()- 移除索引处的元素 -
remove()- 移除值的第一个出现 -
reverse()- 就地反转列表
实战示例:列表
# Create shopping cart as a list
cart = ["apples", "oranges", "grapes"]
# Sort the list
cart.sort()
# Add new item
cart.append("blueberries")
# Remove first item
cart.pop(0)
print(cart)
输出:
['grapes', 'oranges', 'blueberries']
步骤 2:理解 Python 中的元组
什么是元组?
元组是 Python 中另一种序列数据类型,与列表类似。然而,与列表不同的是,元组是不可变的,这意味着其元素一旦创建就无法更改。它们通过用圆括号 ( ) 括起来来定义。
# Defining a tuple
my_tuple = (1, 2, 3, 4)
何时使用元组
元组通常用于不应修改的项集合。元组比列表更快,这使得它们非常适合只读操作。一些常见的使用场景包括:
-
存储常量或配置数据
-
函数返回值包含多个组件
-
字典键,因为它们是可哈希的
访问元组元素
访问元组中的元素与访问列表元素的方式类似。索引和切片的工作方式相同。
# Accessing elements
first_element = my_tuple[0]
sliced_tuple = my_tuple[1:3]
对元组的操作
由于元组是不可变的,许多列表操作如append()或remove()不适用。然而,你仍然可以执行一些操作:
- 连接: 使用
+运算符组合元组。
concatenated_tuple = my_tuple + (5, 6)
- 重复: 使用
*运算符重复元组。
repeated_tuple = my_tuple * 2
- 成员资格: 使用
in关键字检查元素是否存在于元组中。
exists = 1 in my_tuple
元组方法
元组相较于列表由于其不可变特性,内置方法较少。一些有用的方法包括:
count(): 统计特定元素的出现次数。
count_of_ones = my_tuple.count(1)
index(): 查找值第一次出现的索引。
index_of_first_one = my_tuple.index(1)
元组打包和解包
元组打包和解包是 Python 中的便捷特性:
- 打包: 将多个值分配给一个元组。
packed_tuple = 1, 2, 3
- 解包: 将元组元素分配给多个变量。
a, b, c = packed_tuple
不可变但不是严格的
虽然元组本身是不可变的,但它们可以包含像列表这样的可变元素。
# Tuple with mutable list
complex_tuple = (1, 2, [3, 4])
请注意,虽然你不能改变元组本身,但可以修改其中的可变元素。
步骤 3:掌握 Python 中的字典
Python 中的字典是什么?
Python 中的字典是一个无序的、可变的数据类型,用于存储唯一键到值的映射。字典用大括号{ }表示,并由用逗号分隔的键值对组成。
例如:
student = {"name": "Michael", "age": 22, "city": "Chicago"}
字典对于以结构化方式存储数据并通过键访问值非常有用。
创建字典
字典的键必须是不可变对象,如字符串、数字或元组。字典的值可以是任何对象。
student = {"name": "Susan", "age": 23}
prices = {"milk": 4.99, "bread": 2.89}
操作字典
元素可以通过键进行访问、添加、更改和移除。
# Access value by key
print(student["name"])
# Add new key-value
student["major"] = "computer science"
# Change value
student["age"] = 25
# Remove key-value
del student["city"]
有用的字典方法
一些有用的内置方法包括:
-
keys()- 返回键的列表 -
values()- 返回值的列表 -
items()- 返回(key, value)元组 -
get()- 返回键的值,避免 KeyError -
pop()- 移除键并返回值 -
update()- 添加多个键值对
使用字典的实际示例
scores = {"Francis": 95, "John": 88, "Daniel": 82}
# Add new score
scores["Zoey"] = 97
# Remove John's score
scores.pop("John")
# Get Daniel's score
print(scores.get("Daniel"))
# Print all student names
print(scores.keys())
步骤 4:探索 Python 中的集合
Python 中的集合是什么?
Python 中的集合是一个无序的、可变的唯一不可变对象的集合。集合用大括号{ }表示,但与字典不同,没有键值对。
例如:
numbers = {1, 2, 3, 4}
集合对成员测试、消除重复项和数学操作非常有用。
创建集合
可以通过将列表传递给set()构造函数来创建集合:
my_list = [1, 2, 3, 3, 4]
my_set = set(my_list) # {1, 2, 3, 4}
集合可以包含混合数据类型,如字符串、布尔值等。
操作集合
元素可以从集合中添加和移除。
numbers.add(5)
numbers.remove(1)
有用的集合操作
一些有用的集合操作包括:
-
union()- 返回两个集合的并集 -
intersection()- 返回集合的交集 -
difference()- 返回集合之间的差集 -
symmetric_difference()- 返回对称差集
使用集合的实际示例
A = {1, 2, 3, 4}
B = {2, 3, 5, 6}
# Union - combines sets
print(A | B)
# Intersection
print(A & B)
# Difference
print(A - B)
# Symmetric difference
print(A ^ B)
步骤 5:比较列表、字典和集合
特性比较
以下是对我们在本教程中提到的四种 Python 数据结构的简明比较。
| 结构 | 有序 | 可变 | 允许重复元素 | 用途 |
|---|---|---|---|---|
| 列表 | 是 | 是 | 是 | 存储序列 |
| 元组 | 是 | 否 | 是 | 存储不可变序列 |
| 字典 | 否 | 是 | 键:否 值:是 | 存储键值对 |
| 集合 | 否 | 是 | 否 | 消除重复项,成员测试 |
何时使用每种数据结构
将此视为在特定情况下选择数据结构的软性指南。
-
使用列表来处理有序的、基于序列的数据。适合堆栈/队列。
-
使用元组来表示有序的、不可变的序列。当你需要一个不应更改的固定元素集合时,元组非常有用。
-
使用字典来存储键值数据。适合存储相关属性。
-
使用集合来存储唯一元素和进行数学操作。
使用所有四种数据结构的实际示例
让我们看看这些结构如何在一个比单行代码更复杂的示例中协同工作。
# Make a list of person names
names = ["John", "Mary", "Bob", "Mary", "Sarah"]
# Make a tuple of additional information (e.g., email)
additional_info = ("john@example.com", "mary@example.com", "bob@example.com", "mary@example.com", "sarah@example.com")
# Make set to remove duplicates
unique_names = set(names)
# Make dictionary of name-age pairs
persons = {}
for name in unique_names:
persons[name] = random.randint(20,40)
print(persons)
输出:
{'John': 34, 'Bob': 29, 'Sarah': 25, 'Mary': 21}
这个例子利用列表来表示有序序列,利用元组来存储附加的不可变信息,利用集合来去除重复项,利用字典来存储键值对。
向前推进
在这个全面的教程中,我们深入探讨了 Python 中的基础数据结构,包括列表、元组、字典和集合。这些结构是 Python 编程的基石,提供了数据存储、处理和操作的框架。理解这些结构对于编写高效且可扩展的代码至关重要。从使用列表操作序列,到用字典组织数据,再到利用集合确保唯一性,这些基本工具在数据处理上提供了巨大的灵活性。
正如我们通过代码示例所见,这些数据结构可以以各种方式组合使用来解决复杂问题。通过利用这些数据结构,你可以开启数据分析、机器学习及其他领域的广泛可能性。不要犹豫,查阅官方的Python 数据结构文档以获得更多见解。
编程愉快!
马修·梅约 (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 的主编,马修旨在使复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、机器学习算法和探索新兴的人工智能。他致力于使数据科学社区的知识普及化。马修从 6 岁起便开始编程。
关于这个话题的更多内容
使用 PyTorch 的 5 步入门指南
PyTorch 和 PyTorch Lightning 简介
PyTorch 是一个流行的基于 Python 的开源机器学习框架,并优化了 GPU 加速计算。最初由 Meta AI 在 2016 年开发,现在是 Linux 基金会的一部分,PyTorch 很快成为深度学习研究和应用中使用最广泛的框架之一。
与一些其他框架(如 TensorFlow)不同,PyTorch 使用动态计算图,这允许更大的灵活性和调试能力。PyTorch 的关键好处包括:
-
简单直观的 Python API,用于构建神经网络
-
广泛支持 GPU/TPU 加速
-
内置自动微分支持
-
分布式训练能力
-
与其他 Python 库(如 NumPy)的互操作性
PyTorch Lightning 是一个建立在 PyTorch 之上的轻量级封装,进一步简化了研究人员的工作流程和模型开发过程。使用 Lightning,数据科学家可以更多地专注于设计模型,而不是重复的代码。Lightning 的主要优点包括:
-
提供组织 PyTorch 代码的结构
-
处理训练循环的样板代码
-
通过超参数调优加速研究实验
-
简化模型的扩展和部署
通过将 PyTorch 的强大功能和灵活性与 Lightning 的高级 API 相结合,开发人员可以快速构建可扩展的深度学习系统,并加快迭代速度。
第 1 步:安装和设置
要开始使用 PyTorch 和 Lightning,您首先需要安装一些先决条件:
-
Python 3.6 或更高版本
-
Pip 包管理器
-
推荐使用 NVidia GPU 进行加速操作(仅 CPU 设置可能会更慢)
安装 Python 和 PyTorch
建议使用 Anaconda 设置用于数据科学和深度学习工作的 Python 环境。请按照以下步骤操作:
-
从 这里 下载并安装适用于您操作系统的 Anaconda
-
创建一个 Conda 环境(或使用其他 Python 环境管理器):
conda create -n pytorch python=3.8 -
激活环境:
conda activate pytorch -
安装 PyTorch:
conda install pytorch torchvision torchaudio -c pytorch
通过在 Python 中运行一个快速测试来验证 PyTorch 是否正确安装:
import torch
x = torch.rand(3, 3)
print(x)
这将打印出一个随机的 3x3 张量,确认 PyTorch 正常工作。
安装 PyTorch Lightning
安装了 PyTorch 后,我们现在可以使用 pip 安装 Lightning:
pip install lightning
让我们确认 Lightning 是否正确设置:
import lightning
print(lightning.__version__)
这应该会打印出版本号,如 0.6.0。
现在我们准备开始构建深度学习模型了。
第 2 步:使用 PyTorch 构建模型
PyTorch 使用张量,类似于 NumPy 数组,作为其核心数据结构。张量可以由 GPU 操作,并支持自动微分以构建神经网络。
让我们定义一个用于图像分类的简单神经网络:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
这定义了一个具有两个卷积层和三个全连接层的卷积神经网络,用于分类 10 个类别。forward() 方法定义了数据如何通过网络传递。
我们现在可以使用 Lightning 在样本数据上训练这个模型。
第 3 步:使用 Lightning 训练模型
Lightning 提供了一个 LightningModule 类来封装 PyTorch 模型代码和训练循环样板代码。让我们转换我们的模型:
import lightning as pl
class LitModel(pl.LightningModule):
def __init__(self):
super().__init__()
self.model = Net()
def forward(self, x):
return self.model(x)
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self.forward(x)
loss = F.cross_entropy(y_hat, y)
return loss
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=0.02)
model = LitModel()
training_step() 定义了前向传递和损失计算。我们配置了一个学习率为 0.02 的 Adam 优化器。
现在我们可以轻松地训练这个模型:
trainer = pl.Trainer()
trainer.fit(model, train_dataloader, val_dataloader)
Trainer 处理时期循环、验证、日志记录自动化。我们可以在测试数据上评估模型(更多关于数据模块的信息):
result = trainer.test(model, test_dataloader)
print(result)
作为对比,这里是纯 PyTorch 中的网络和训练循环代码:
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader
# Assume Net class and train_dataloader, val_dataloader, test_dataloader are defined
class Net(torch.nn.Module):
# Define your network architecture here
pass
# Initialize model and optimizer
model = Net()
optimizer = torch.optim.Adam(model.parameters(), lr=0.02)
# Training Loop
for epoch in range(10): # Number of epochs
for batch_idx, (x, y) in enumerate(train_dataloader):
optimizer.zero_grad()
y_hat = model(x)
loss = F.cross_entropy(y_hat, y)
loss.backward()
optimizer.step()
# Validation Loop
model.eval()
with torch.no_grad():
for x, y in val_dataloader:
y_hat = model(x)
# Testing Loop and Evaluate
model.eval()
test_loss = 0
with torch.no_grad():
for x, y in test_dataloader:
y_hat = model(x)
test_loss += F.cross_entropy(y_hat, y, reduction='sum').item()
test_loss /= len(test_dataloader.dataset)
print(f"Test loss: {test_loss}")
Lightning 使得 PyTorch 模型开发变得非常快速和直观。
第 4 步:高级主题
Lightning 提供了许多内置功能,用于超参数调优、防止过拟合和模型管理。
超参数调优
我们可以使用 Lightning 的 tuner模块来优化超参数,例如学习率:
tuner = pl.Tuner(trainer)
tuner.fit(model, train_dataloader)
print(tuner.results)
这在超参数空间上执行贝叶斯搜索。
处理过拟合
像 dropout 层和早停等策略可以减少过拟合:
model = LitModel()
model.add_module('dropout', nn.Dropout(0.2)) # Regularization
trainer = pl.Trainer(early_stop_callback=True) # Early stopping
模型保存和加载
Lightning 使得保存和重新加载模型变得简单:
# Save
trainer.save_checkpoint("model.ckpt")
# Load
model = LitModel.load_from_checkpoint(checkpoint_path="model.ckpt")
这保留了完整的模型状态和超参数。
第 5 步:比较 PyTorch 和 PyTorch Lightning
PyTorch 和 PyTorch Lightning 都是强大的深度学习库,但它们服务于不同的目的并提供独特的功能。虽然 PyTorch 提供了设计和实现深度学习模型的基础构件,但 PyTorch Lightning 旨在简化模型训练的重复部分,从而加速开发过程。
关键区别
这是 PyTorch 和 PyTorch Lightning 之间关键差异的总结:
| 特征 | PyTorch | PyTorch Lightning |
|---|---|---|
| 训练循环 | 手动编写 | 自动化 |
| 样板代码 | 需要 | 最小 |
| 超参数调优 | 手动设置 | 内置支持 |
| 分布式训练 | 可用但需要手动设置 | 自动化 |
| 代码组织 | 无特定结构 | 鼓励模块化设计 |
| 模型保存和加载 | 需要自定义实现 | 使用检查点简化 |
| 调试 | 高级但手动 | 使用内置日志更容易 |
| GPU/TPU 支持 | 可用 | 更容易设置 |
灵活性与便利性
PyTorch 以其灵活性而闻名,特别是动态计算图,这对于研究和实验非常出色。然而,这种灵活性通常需要编写更多的模板代码,特别是对于训练循环、分布式训练和超参数调优。另一方面,PyTorch Lightning 抽象化了这些模板代码,同时在需要时仍然允许完全自定义和访问低级 PyTorch API。
开发速度
如果你从零开始一个项目或进行复杂的实验,PyTorch Lightning 可以节省你大量的时间。LightningModule 类简化了训练过程,自动化日志记录,甚至简化了分布式训练。这使你可以更多地专注于模型架构,而不是模型训练和验证中的重复工作。
判决结果
总结来说,PyTorch 提供了更细粒度的控制,适合需要这种详细级别的研究人员。然而,PyTorch Lightning 的设计旨在使研究到生产的周期更顺畅、更快速,同时不剥夺 PyTorch 提供的力量和灵活性。你选择 PyTorch 还是 PyTorch Lightning 将取决于你的具体需求,但好消息是你可以轻松地在两者之间切换,甚至在项目的不同部分同时使用它们。
展望未来
在本文中,我们涵盖了使用 PyTorch 和 PyTorch Lightning 进行深度学习的基础知识:
-
PyTorch 提供了一个强大而灵活的框架,用于构建神经网络
-
PyTorch Lightning 简化了训练和模型开发工作流程
-
关键功能如超参数优化和模型管理加速了深度学习研究
有了这些基础,你可以开始构建和训练高级模型,如 CNN、RNN、GAN 等。活跃的开源社区还提供了 Lightning 支持和 Bolt 等组件及优化库。
祝深度学习愉快!
马修·梅奥 (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 的主编,马修的目标是让复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、机器学习算法以及探索新兴的人工智能。他致力于在数据科学社区中普及知识。马修从 6 岁起就开始编程。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
相关话题
使用 Scikit-learn 的 5 个步骤入门

Scikit-learn 简介
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 部门
学习如何使用 Scikit-learn 时,我们必须显然了解机器学习的基本概念,因为 Scikit-learn 只是实现机器学习原理和相关任务的实用工具。机器学习是人工智能的一个子集,它使计算机能够从经验中学习和改进,而无需明确编程。算法使用训练数据通过发现模式和洞察来做出预测或决策。机器学习有三种主要类型:
-
监督学习 - 模型在标记数据上进行训练,学习将输入映射到输出
-
无监督学习 - 模型在未标记的数据中发现隐藏的模式和分组
-
强化学习 - 模型通过与环境互动进行学习,接受奖励和惩罚以鼓励最佳行为
正如你无疑知道的,机器学习驱动了现代社会的许多方面,生成了大量数据。随着数据可用性持续增长,机器学习的重要性也在提升。
Scikit-learn 是一个流行的开源 Python 机器学习库。其广泛使用的一些关键原因包括:
-
简单高效的数据分析和建模工具
-
对 Python 程序员友好,注重清晰性
-
基于 NumPy、SciPy 和 matplotlib,便于集成
-
用于分类、回归、聚类、降维等任务的广泛算法
本教程旨在提供一个逐步介绍如何使用 Scikit-learn(主要针对常见的监督学习任务),重点是通过大量实践示例入门。
步骤 1:使用 Scikit-learn 入门
安装和设置
为了安装和使用 Scikit-learn,你的系统必须有一个正常运行的 Python 安装。我们在这里不会涵盖这个内容,但会假设你此时已有一个正常运行的安装。
Scikit-learn 可以使用 pip,Python 的包管理器进行安装:
pip install scikit-learn
这也将安装所有必需的依赖项,如 NumPy 和 SciPy。安装完成后,可以在你的 Python 脚本中如下导入 Scikit-learn:
import sklearn
测试你的安装
安装完成后,你可以启动 Python 解释器并运行上述的导入命令。
Python 3.10.11 (main, May 2 2023, 00:28:57) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import sklearn
只要你没有看到任何错误信息,你现在就可以开始使用 Scikit-learn 了!
加载示例数据集
Scikit-learn 提供了多种示例数据集,我们可以用于测试和实验:
from sklearn import datasets
iris = datasets.load_iris()
digits = datasets.load_digits()
数字数据集包含手写数字的图像及其标签。我们可以利用这些示例数据集来熟悉 Scikit-learn,然后再转向实际数据。
第 2 步:数据预处理
数据预处理的重要性
实际数据往往是不完整、不一致的,并且包含错误。数据预处理将原始数据转换为可用于机器学习的格式,是一个重要的步骤,可以影响后续模型的性能。
许多新手往往忽视了数据预处理,而是直接进入模型训练。然而,无论所用算法多么复杂,低质量的数据输入都会导致低质量的模型输出。像正确处理缺失数据、检测和移除异常值、特征编码和特征缩放这样的步骤,有助于提高模型的准确性。
数据预处理占据了机器学习项目中大量的时间和精力。老电脑科学格言“垃圾进,垃圾出”在这里非常适用。高质量的数据输入是高性能机器学习的前提。数据预处理步骤将原始数据转换为精炼的训练集,使机器学习算法能够有效地发现预测模式和洞察。
总之,数据预处理是任何机器学习工作流中不可或缺的一步,应给予充分关注和认真对待。
加载和理解数据
让我们使用 Scikit-learn 加载一个示例数据集进行演示:
from sklearn.datasets import load_iris
iris_data = load_iris()
我们可以探索特征和目标值:
print(iris_data.data[0]) # Feature values for first sample
print(iris_data.target[0]) # Target value for first sample
在继续之前,我们应当了解特征和目标的含义。
数据清洗
实际数据经常包含缺失、损坏或异常值。Scikit-learn 提供了处理这些问题的工具:
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean')
imputed_data = imputer.fit_transform(iris_data.data)
插补器用均值替代缺失值,这是一种常见的——但不是唯一的——策略。这只是数据清洗的一种方法。
特征缩放
像支持向量机(SVM)和神经网络这样的算法对输入特征的尺度非常敏感。不一致的特征尺度可能导致这些算法对尺度较大的特征赋予过多的权重,从而影响模型的性能。因此,在训练这些算法之前,规范化或标准化特征以将其调整到类似的尺度是至关重要的。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaled_data = scaler.fit_transform(iris_data.data)
StandardScaler 将特征标准化为均值 0 和方差 1。还提供了其他缩放器。
数据可视化
我们还可以使用 matplotlib 对数据进行可视化,以获得更多见解:
import matplotlib.pyplot as plt
plt.scatter(iris_data.data[:, 0], iris_data.data[:, 1], c=iris_data.target)
plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
plt.show()
数据可视化在机器学习工作流中发挥着多个关键功能。它可以让你发现数据中的潜在模式和趋势,识别可能影响模型性能的异常值,并更深入地理解变量之间的关系。通过提前可视化数据,你可以在特征选择和模型训练阶段做出更明智的决策。
步骤 3:模型选择与训练
Scikit-learn 算法概述
Scikit-learn 提供了多种有监督和无监督的算法:
-
分类:逻辑回归、SVM、朴素贝叶斯、决策树、随机森林
-
回归:线性回归、SVR、决策树、随机森林
-
聚类:k-均值、DBSCAN、凝聚聚类
以及其他许多。
选择算法
选择最合适的机器学习算法对于构建高质量模型至关重要。最佳算法取决于多个关键因素:
-
可用的训练数据的大小和类型。是小数据集还是大数据集?包含什么样的特征——图像、文本、数字?
-
可用的计算资源。算法在计算复杂性上有所不同。简单的线性模型训练速度比深度神经网络快。
-
我们想解决的具体问题是什么?我们是在进行分类、回归、聚类,还是更复杂的任务?
-
是否有任何特殊要求,比如对可解释性的需求。线性模型比黑箱方法更具可解释性。
-
期望的准确度/性能。有些算法在某些任务上的表现优于其他算法。
对于我们这个特定的分类鸢尾花问题,像逻辑回归或支持向量机这样的分类算法最为合适。这些算法可以根据提供的特征测量有效地对花朵进行分类。其他简单的算法可能无法提供足够的准确性。同时,像深度神经网络这样的复杂方法对于这个相对简单的数据集来说过于复杂。
随着我们不断训练模型,始终选择最适合我们当前问题的算法至关重要,基于上述考虑因素。可靠地选择合适的算法将确保我们开发出高质量的机器学习系统。
训练一个简单模型
让我们训练一个逻辑回归模型:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(scaled_data, iris_data.target)
就这些!模型已训练好,准备好进行评估和使用。
训练一个更复杂的模型
虽然像逻辑回归这样的简单线性模型通常可以提供不错的性能,但对于更复杂的数据集,我们可能需要利用更先进的算法。例如,集成方法结合了多个模型,使用诸如袋装(bagging)和提升(boosting)等技术,以提高整体预测准确性。举例来说,我们可以训练一个随机森林分类器,它汇聚了许多决策树:
from sklearn.ensemble import RandomForestClassifier
rf_model = RandomForestClassifier(n_estimators=100)
rf_model.fit(scaled_data, iris_data.target)
随机森林可以捕捉特征之间的非线性关系和复杂交互,从而比任何单一的决策树产生更准确的预测。我们还可以使用像 SVM、梯度提升树和神经网络这样的算法,以在具有挑战的数据集上获得进一步的性能提升。关键是要尝试不同的算法,超越简单的线性模型,以发挥它们的优势。
然而,请注意,无论是使用简单算法还是更复杂的算法进行模型训练,Scikit-learn 的语法都允许使用相同的方法,从而显著减少学习曲线。事实上,几乎所有使用该库的任务都可以通过 fit/transform/predict 模式来表达。
第 4 步:模型评估
评估的重要性
评估机器学习模型的性能是最终部署到生产环境之前一个绝对关键的步骤。全面评估模型建立了系统在部署后能够可靠运行的基本信任。同时,这也能识别需要改进的潜在领域,以提高模型的预测准确性和泛化能力。一个模型可能在其训练数据上表现得非常准确,但在实际数据上却可能表现不佳。这突显了在持出的测试集和新数据上测试模型的重要性,而不仅仅是训练数据。
我们必须模拟模型在部署后的表现。严格评估模型还提供了对可能的过拟合情况的见解,即模型记住了训练数据中的模式,但未能学习到对样本外预测有用的可泛化关系。检测到过拟合会促使采取适当的对策,如正则化和交叉验证。评估还允许比较多个候选模型,以选择表现最佳的选项。那些没有比简单基准模型提供足够提升的模型可能需要重新设计或完全替换。
总结来说,全面评估机器学习模型对于确保其可靠性和增加价值是不可或缺的。这不仅仅是一个可选的分析任务,而是模型开发工作流中一个 integral 的部分,能够部署真正有效的系统。因此,机器学习从业者应在考虑部署之前,投入大量精力在相关性能指标上正确评估他们的模型。
训练/测试拆分
我们将数据拆分以评估模型在新数据上的表现:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(scaled_data, iris_data.target)
按惯例,X 代表特征,y 代表目标变量。请注意,y_test 和 iris_data.target 是指代相同数据的不同方式。
评估指标
对于分类任务,关键指标包括:
-
准确率:正确预测的总体比例
-
精确率:实际为正的预测中正预测的比例
-
召回率:实际为正的预测中正预测的比例
可以通过 Scikit-learn 的分类报告来计算这些指标:
from sklearn.metrics import classification_report
print(classification_report(y_test, model.predict(X_test)))
这让我们对模型性能有了深入了解。
步骤 5:提升性能
超参数调整
超参数是模型配置设置。调整它们可以提高性能:
from sklearn.model_selection import GridSearchCV
params = {'C': [0.1, 1, 10]}
grid_search = GridSearchCV(model, params, cv=5)
grid_search.fit(scaled_data, iris_data.target)
这在不同的正则化强度下进行网格搜索,以优化模型的准确性。
交叉验证
交叉验证提供了更可靠的超参数评估:
from sklearn.model_selection import cross_val_score
cross_val_scores = cross_val_score(model, scaled_data, iris_data.target, cv=5)
它将数据划分为 5 个折叠,并在每个折叠上评估性能。
集成方法
结合多个模型可以提升性能。为了演示这一点,让我们首先训练一个随机森林模型:
from sklearn.ensemble import RandomForestClassifier
random_forest = RandomForestClassifier(n_estimators=100)
random_forest.fit(scaled_data, iris_data.target)
现在我们可以继续创建一个使用逻辑回归和随机森林模型的集成模型:
from sklearn.ensemble import VotingClassifier
voting_clf = VotingClassifier(estimators=[('lr', model), ('rf', random_forest)])
voting_clf.fit(scaled_data, iris_data.target)
这个集成模型结合了我们之前训练的逻辑回归模型(称为 lr)和新定义的随机森林模型(称为 rf)。
模型堆叠与融合
更高级的集成技术如堆叠和融合构建一个元模型来组合多个基础模型。在单独训练基础模型之后,元模型学习如何最好地组合它们以获得最佳性能。这比简单的平均或投票集成提供了更多的灵活性。元学习者可以学习哪些模型在不同的数据段上表现最佳。使用多样化基础模型的堆叠和融合集成通常在许多机器学习任务中取得了最先进的结果。
# Train base models
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
rf = RandomForestClassifier()
svc = SVC()
rf.fit(X_train, y_train)
svc.fit(X_train, y_train)
# Make predictions to train meta-model
rf_predictions = rf.predict(X_test)
svc_predictions = svc.predict(X_test)
# Create dataset for meta-model
blender = np.vstack((rf_predictions, svc_predictions)).T
blender_target = y_test
# Fit meta-model on predictions
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier()
gb.fit(blender, blender_target)
# Make final predictions
final_predictions = gb.predict(blender)
这将分别训练一个随机森林和一个支持向量机(SVM)模型,然后在它们的预测结果上训练一个梯度提升树以产生最终输出。关键步骤是从基础模型生成测试集上的预测,然后使用这些预测作为输入特征来训练元模型。
继续前进
Scikit-learn 提供了一个广泛的 Python 机器学习工具包。在本教程中,我们介绍了使用 Scikit-learn 的完整机器学习工作流程——从安装库和理解其功能,到加载数据、训练模型、评估模型性能、调整超参数和编译集成模型。由于其设计良好的 API、算法的广度和与 PyData 堆栈的集成,Scikit-learn 已成为非常受欢迎的库。Sklearn 使用户能够快速高效地构建模型并生成预测,而不会陷入实现细节中。凭借这一坚实的基础,你现在可以使用 Scikit-learn 将机器学习实际应用于现实世界问题。下一步是识别适合使用机器学习技术的问题,并利用本教程中的技能提取价值。
当然,关于 Scikit-learn 以及机器学习的知识总是有更多的内容可以学习。该库实现了前沿算法,如神经网络、流形学习和深度学习,通过其估计器 API 提供支持。你可以通过研究这些方法的理论工作来不断提升你的能力。Scikit-learn 还与其他 Python 库如 Pandas 集成,以增加数据处理能力。此外,像 SageMaker 这样的产品提供了一个用于大规模操作 Scikit-learn 模型的生产平台。
本教程只是一个起点——Scikit-learn 是一个多功能工具包,将继续满足你在面对更高级挑战时的建模需求。关键是通过实践和完善你的技能来不断进步。对整个建模生命周期的实践经验是最好的老师。通过勤奋和创造力,Scikit-learn 提供了从各种数据中解锁深刻洞察的工具。
Matthew Mayo (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 的主编,Matthew 旨在使复杂的数据科学概念变得易于理解。他的职业兴趣包括自然语言处理、机器学习算法以及探索新兴的 AI。他致力于在数据科学社区中普及知识。Matthew 从 6 岁起就开始编程。
相关话题
SQL 入门五步骤

结构化查询语言简介
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
在关系型数据库中管理和操作数据时,结构化查询语言(SQL)是最重要的工具。SQL 是一个主要的领域特定语言,它是数据库管理的基石,并提供了一种与数据库交互的标准化方式。随着数据驱动决策和创新的力量,SQL 仍然是一个至关重要的技术,需要数据分析师、开发人员和数据科学家给予高度关注。
SQL 最初由 IBM 于 1970 年代开发,并在 1980 年代末由 ANSI 和 ISO 标准化。各种类型的组织——从小型企业到大学,再到大型公司——都依赖于如 MySQL、SQL Server 和 PostgreSQL 等 SQL 数据库来处理大规模数据。随着数据驱动行业的扩展,SQL 的重要性不断增长。其普遍应用使其成为各种专业人士在数据领域及其他领域的关键技能。
SQL 允许用户执行各种数据相关任务,包括:
-
查询数据
-
插入新记录
-
更新现有记录
-
删除记录
-
创建和修改表
本教程将提供 SQL 的逐步讲解,重点是通过大量的实操示例开始学习。
第一步:设置你的 SQL 环境
选择 SQL 数据库管理系统(DBMS)
在深入 SQL 查询之前,你需要选择一个适合你项目需求的数据库管理系统(DBMS)。DBMS 是你 SQL 活动的支柱,提供不同的功能、性能优化和定价模型。你对 DBMS 的选择会显著影响你与数据的互动方式。
-
MySQL:开源,广泛采用,被 Facebook 和 Google 使用。适用于从小项目到企业级应用的各种应用。
-
PostgreSQL:开源,功能强大,被 Apple 使用。以其性能和标准遵从性而闻名。
-
SQL Server Express:微软的入门级选项。适用于具有有限扩展需求的小型到中型应用程序。
-
SQLite:轻量级、无服务器、自包含。非常适合移动应用和小型项目。
MySQL 安装指南
为了本教程的目的,我们将重点介绍 MySQL,因为它的使用广泛且功能全面。安装 MySQL 是一个简单的过程:
-
访问 MySQL 的网站 并下载适合你操作系统的安装程序。
-
运行安装程序,按照屏幕上的指示操作。
-
在设置过程中,你会被要求创建一个 root 帐户。请确保记住或安全存储 root 密码。
-
安装完成后,你可以通过打开终端并输入
mysql -u root -p来访问 MySQL shell。系统会提示你输入 root 密码。 -
成功登录后,你将看到 MySQL 提示符,表示你的 MySQL 服务器正在运行。
设置 SQL IDE
集成开发环境 (IDE) 可以显著提升你的 SQL 编程体验,提供如自动补全、语法高亮和数据库可视化等功能。虽然运行 SQL 查询不一定需要 IDE,但对于更复杂的任务和大型项目,IDE 是强烈推荐的。
-
DBeaver:开源,并支持广泛的 DBMS,包括 MySQL、PostgreSQL、SQLite 和 SQL Server。
-
MySQL Workbench:由 Oracle 开发,这是 MySQL 的官方 IDE,提供了专门为 MySQL 量身定制的全面工具。
下载并安装你选择的 IDE 后,你需要将其连接到你的 MySQL 服务器。这通常涉及指定服务器的 IP 地址(如果服务器在你的机器上则为 localhost)、端口号(通常 MySQL 的端口号为 3306)以及授权数据库用户的凭据。
测试你的设置
让我们确保一切正常工作。你可以通过运行一个简单的 SQL 查询来显示所有现有的数据库来做到这一点:
SHOW DATABASES;
如果这个查询返回一个数据库列表,并且没有错误,那么恭喜你!你的 SQL 环境已经成功设置好,你可以开始 SQL 编程了。
步骤 2:基本 SQL 语法和命令
创建数据库和表
在添加或操作数据之前,你首先需要一个数据库和至少一个表。创建数据库和表的方法如下:
CREATE DATABASE sql_tutorial;
USE sql_tutorial;
CREATE TABLE customers (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50),
email VARCHAR(50)
);
操作数据
现在你已经准备好进行数据操作。让我们看看基本的 CRUD 操作:
-
插入:
INSERT INTO customers (name, email) VALUES ('John Doe', 'john@email.com'); -
查询:
SELECT * FROM customers; -
更新:
UPDATE customers SET email = 'john@newemail.com' WHERE id = 1; -
删除:
DELETE FROM customers WHERE id = 1;
过滤和排序
SQL 中的过滤涉及使用条件选择性地检索表中的行,通常使用 WHERE 子句。SQL 中的排序将检索到的数据按特定顺序排列,通常使用 ORDER BY 子句。SQL 中的分页将结果集划分为更小的块,每页显示有限数量的行。
-
过滤:
SELECT * FROM customers WHERE name = 'John Doe'; -
排序:
SELECT * FROM customers ORDER BY name ASC; -
分页:
SELECT * FROM customers LIMIT 10 OFFSET 20;
数据类型与约束
理解数据类型和约束对于定义表的结构至关重要。数据类型指定列可以包含的数据种类,如整数、文本或日期。约束强制实施限制以确保数据的完整性。
-
整数类型: INT、SMALLINT、TINYINT 等。用于存储整数。
-
十进制类型: FLOAT、DOUBLE、DECIMAL。适合存储带小数的数字。
-
字符类型: CHAR、VARCHAR、TEXT。用于文本数据。
-
日期和时间: DATE、TIME、DATETIME、TIMESTAMP。用于存储日期和时间信息。
CREATE TABLE employees (
id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
birth_date DATE,
email VARCHAR(50) UNIQUE,
salary FLOAT CHECK (salary > 0)
);
在上述示例中,NOT NULL 约束确保列不能有 NULL 值。UNIQUE 约束保证列中的所有值都是唯一的。CHECK 约束验证工资必须大于零。
第 3 步:更高级的 SQL 概念
表连接
连接用于基于相关列将两张或多张表的行组合在一起。当你想检索分布在多个表中的数据时,它们是必不可少的。理解连接对复杂的 SQL 查询至关重要。
-
INNER JOIN:
SELECT * FROM orders JOIN customers ON orders.customer_id = customers.id; -
LEFT JOIN:
SELECT * FROM orders LEFT JOIN customers ON orders.customer_id = customers.id; -
RIGHT JOIN:
SELECT * FROM orders RIGHT JOIN customers ON orders.customer_id = customers.id;
连接可能很复杂,但在需要从多个表中提取数据时,它们非常强大。让我们通过详细的示例来深入了解不同类型的连接如何工作。
考虑两个表:员工 和 部门。
-- Employees Table
CREATE TABLE Employees (
id INT PRIMARY KEY,
name VARCHAR(50),
department_id INT
);
INSERT INTO Employees (id, name, department_id) VALUES
(1, 'Winifred', 1),
(2, 'Francisco', 2),
(3, 'Englebert', NULL);
-- Departments Table
CREATE TABLE Departments (
id INT PRIMARY KEY,
name VARCHAR(50)
);
INSERT INTO Departments (id, name) VALUES
(1, 'R&D'),
(2, 'Engineering'),
(3, 'Sales');
让我们探索不同类型的连接:
-- INNER JOIN
-- Returns records that have matching values in both tables
SELECT E.name, D.name
FROM Employees E
INNER JOIN Departments D ON E.department_id = D.id;
-- LEFT JOIN (or LEFT OUTER JOIN)
-- Returns all records from the left table,
-- and the matched records from the right table
SELECT E.name, D.name
FROM Employees E
LEFT JOIN Departments D ON E.department_id = D.id;
-- RIGHT JOIN (or RIGHT OUTER JOIN)
-- Returns all records from the right table
-- and the matched records from the left table
SELECT E.name, D.name
FROM Employees E
RIGHT JOIN Departments D ON E.department_id = D.id;
在上述示例中,INNER JOIN 只返回两个表中都有匹配的行。LEFT JOIN 返回左表中的所有行,以及右表中匹配的行,如果没有匹配,则填充 NULL。RIGHT JOIN 则相反,返回右表中的所有行,以及左表中匹配的行。
分组与聚合
聚合函数对一组值进行计算,并返回单个值。聚合通常与 GROUP BY 子句一起使用,将数据分组并对每个组进行计算。
-
计数:
SELECT customer_id, COUNT(id) AS total_orders FROM orders GROUP BY customer_id; -
求和:
SELECT customer_id, SUM(order_amount) AS total_spent FROM orders GROUP BY customer_id; -
筛选组:
SELECT customer_id, SUM(order_amount) AS total_spent FROM orders GROUP BY customer_id HAVING total_spent > 100;
子查询和嵌套查询
子查询允许你在查询中执行查询,为主查询提供一种方法,以便根据条件进一步限制检索到的数据。
SELECT *
FROM customers
WHERE id IN (
SELECT customer_id
FROM orders
WHERE orderdate > '2023-01-01'
);
事务
事务是作为一个工作单元执行的一系列 SQL 操作。它们对维护数据库操作的完整性非常重要,特别是在多用户系统中。事务遵循 ACID 原则:原子性、一致性、隔离性和持久性。
BEGIN;
UPDATE accounts SET balance = balance - 500 WHERE id = 1;
UPDATE accounts SET balance = balance + 500 WHERE id = 2;
COMMIT;
在上面的示例中,两个 UPDATE 语句都被包含在一个事务中。要么两者都成功执行,要么出现错误时两者都不执行,从而确保数据的完整性。
第 4 步:优化和性能调优
理解查询性能
查询性能对维持一个响应快速的数据库系统至关重要。一个低效的查询可能导致延迟,影响整体用户体验。以下是一些关键概念:
-
执行计划: 这些计划提供了查询将如何执行的路线图,允许分析和优化。
-
瓶颈: 识别查询中缓慢的部分可以指导优化工作。像 SQL Server Profiler 这样的工具可以帮助进行这项工作。
索引策略
索引是提高数据检索速度的数据结构。在大型数据库中至关重要。它们的工作原理如下:
-
单列索引: 单列上的索引,通常用于 WHERE 子句;
CREATE INDEX idx_name ON customers (name); -
复合索引: 多列上的索引,用于根据多个字段过滤的查询;
CREATE INDEX idx_name_age ON customers (name, age); -
了解何时索引: 索引提高读取速度,但可能会降低插入和更新的速度。需要仔细考虑以平衡这些因素。
优化连接和子查询
连接和子查询可能会占用大量资源。优化策略包括:
-
使用索引: 在连接字段上应用索引可以提高连接性能。
-
减少复杂性: 尽量减少连接的表和选择的行数。
SELECT customers.name, COUNT(orders.id) AS total_orders
FROM customers
JOIN orders ON customers.id = orders.customer_id
GROUP BY customers.name
HAVING orders > 2;
数据库规范化和反规范化
数据库设计在性能中扮演着重要角色:
-
规范化: 通过将数据组织到相关表中减少冗余。这可以使查询变得更复杂,但确保数据一致性。
-
反规范化: 合并表以提高读取性能,但可能会导致潜在的不一致性。用于读取速度优先的场景。
监控和分析工具
利用工具监控性能,确保数据库平稳运行:
-
MySQL 性能模式: 提供有关查询执行和性能的见解。
-
SQL Server Profiler: 允许跟踪和捕捉 SQL Server 事件,帮助分析性能。
编写高效 SQL 的最佳实践
遵循最佳实践使 SQL 代码更具可维护性和效率:
-
*避免使用 SELECT : 仅选择所需的列以减少负载。
-
最小化通配符: 在 LIKE 查询中谨慎使用通配符。
-
使用 EXISTS 而不是 COUNT: 检查存在时,EXISTS 更有效。
SELECT id, name
FROM customers
WHERE EXISTS (
SELECT 1
FROM orders
WHERE customer_id = customers.id
);
数据库维护
定期维护确保最佳性能:
-
更新统计信息: 帮助数据库引擎做出优化决策。
-
重建索引: 随着时间推移,索引会变得碎片化。定期重建可以提高性能。
-
备份: 定期备份对数据完整性和恢复至关重要。
第 5 步:性能和安全最佳实践
性能最佳实践
优化 SQL 查询和数据库的性能对于维持响应和高效的系统至关重要。以下是一些性能最佳实践:
-
明智地使用索引: 索引加速数据检索,但可能会降低数据修改操作(如插入、更新和删除)的速度。
-
限制结果: 使用
LIMIT子句仅检索所需的数据。 -
优化连接: 始终在索引或主键列上连接表。
-
分析查询计划: 理解查询执行计划可以帮助你优化查询。
安全最佳实践
在处理数据库时,安全至关重要,因为它们通常包含敏感信息。以下是增强 SQL 安全性的最佳实践:
-
数据加密: 存储敏感数据前始终进行加密。
-
用户权限: 只授予用户完成任务所需的最小权限。
-
防止 SQL 注入: 使用参数化查询防护 SQL 注入攻击。
-
定期审计: 进行定期安全审计以识别漏洞。
结合性能和安全
在性能和安全之间找到正确的平衡通常具有挑战性但却是必要的。例如,虽然索引可以加速数据检索,但也可能使敏感数据更易获取。因此,始终考虑性能优化策略的安全影响。
示例:安全高效的查询
-- Using a parameterized query to both optimize
-- performance and prevent SQL injection
PREPARE secureQuery FROM 'SELECT * FROM users WHERE age > ? AND age < ?';
SET @min_age = 18, @max_age = 35;
EXECUTE secureQuery USING @min_age, @max_age;
这个示例使用了参数化查询,不仅可以防止 SQL 注入,还允许 MySQL 缓存查询,提高性能。
前进的方向
本入门指南涵盖了 SQL 的基本概念和流行的实际应用。从启动到掌握复杂查询,这本指南应该已经为你提供了通过详细示例和实际方法来驾驭数据管理的技能。随着数据继续塑造我们的世界,掌握 SQL 为各种领域打开了大门,包括数据分析、机器学习和软件开发。
随着你的进步,可以考虑通过额外资源扩展你的 SQL 技能。像 w3schools SQL 教程 和 SQLBolt 的 SQL 练习 提供了额外的学习材料和练习。此外,HackerRank 的 SQL 问题 提供了目标导向的查询练习。无论你是在构建复杂的数据分析平台,还是开发下一代网络应用程序,SQL 都是你必定会经常使用的技能。记住,掌握 SQL 的过程是一条漫长的道路,这条道路因持续的实践和学习而更加丰富。
Matthew Mayo (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 的主编,Matthew 致力于使复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、机器学习算法以及探索新兴的人工智能。他的使命是让数据科学社区中的知识变得更具普及性。Matthew 从 6 岁起就开始编程。
更多相关主题
5 步骤开始使用 Google Cloud Platform

Google Cloud Platform 介绍
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
本文旨在提供一个逐步的概述,帮助你开始使用 Google Cloud Platform (GCP) 进行数据科学和机器学习。我们将概述 GCP 及其分析功能,介绍帐户设置,探索 BigQuery 和 Cloud Storage 等重要服务,构建一个示例数据项目,并使用 GCP 进行机器学习。无论你是 GCP 新手还是寻找快速复习的机会,继续阅读以了解基础知识,并迅速上手 Google Cloud。
什么是 GCP?
Google Cloud Platform 提供了一系列云计算服务,帮助你在 Google 的基础设施上构建和运行应用程序。对于计算能力,有 Compute Engine 让你创建虚拟机。如果你需要运行容器,Kubernetes 可以完成任务。BigQuery 处理你的数据仓储和分析需求。通过 Cloud ML,你可以通过 API 获取预训练的机器学习模型,用于视觉、翻译等功能。总的来说,GCP 的目标是提供你所需的基础构件,以便你专注于创建出色的应用程序,而不必担心底层基础设施。
GCP 对数据科学的好处
GCP 为数据分析和机器学习提供了几个好处:
-
可扩展的计算资源,能够处理大数据工作负载
-
托管服务如 BigQuery 用于大规模数据处理
-
高级机器学习能力如 Cloud AutoML 和 AI 平台
-
集成的分析工具和服务
GCP 如何与 AWS 和 Azure 比较
与亚马逊网络服务和微软 Azure 相比,GCP 在大数据、分析和机器学习方面具有优势,并且提供如 BigQuery 和 Dataflow 这样的托管服务用于数据处理。AI 平台使训练和部署机器学习模型变得简单。总体而言,GCP 价格具有竞争力,是数据驱动应用程序的首选。
| 特性 | Google Cloud Platform (GCP) | 亚马逊网络服务 (AWS) | 微软 Azure |
|---|---|---|---|
| 定价* | 具有持续使用折扣的竞争性定价 | 带有预留实例折扣的每小时定价 | 带有预留实例折扣的每分钟定价 |
| 数据仓库 | BigQuery | Redshift | Synapse Analytics |
| 机器学习 | Cloud AutoML、AI Platform | SageMaker | Azure Machine Learning |
| 计算服务 | 计算引擎、Kubernetes 引擎 | EC2、ECS、EKS | 虚拟机、AKS |
| 无服务器服务 | Cloud Functions、App Engine | Lambda、Fargate | Functions、Logic Apps |
请注意,为了我们的目的,定价模型已经简化。AWS 和 Azure 也提供类似于 GCP 的持续使用或承诺使用折扣;定价结构复杂,可能会根据多种因素有显著变化,因此建议读者进一步了解以确定实际成本。
在此表中,我们根据定价、数据仓库、机器学习、计算服务和无服务器服务等各种功能比较了 Google Cloud Platform、Amazon Web Services 和 Microsoft Azure。这些云平台各自拥有独特的服务和定价模式,满足不同的业务和技术需求。
步骤 1:设置您的 GCP 账户
创建 Google Cloud 账户
要使用 GCP,请首先注册一个 Google Cloud 账户。前往 主页 并点击“免费开始”。按照提示使用您的 Google 或 Gmail 凭据创建账户。
创建账单账户
接下来,您需要设置账单账户和付款方式。这允许您在免费层之外使用付费服务。请在控制台中导航到“账单”部分,并按照提示添加您的账单信息。
理解 GCP 定价
GCP 提供了为期 12 个月的慷慨免费层,并附带 $300 信用额度。这允许免费使用 Compute Engine、BigQuery 等关键产品。请查看定价计算器和文档以估算总成本。
安装 Google Cloud SDK
在本地机器上安装 Cloud SDK,以通过命令行管理项目/资源。从 Cloud SDK 指南页面 下载并按照安装指南进行操作。
最后,请务必查看并随时参考 开始使用 Google Cloud 文档。
步骤 2:GCP 数据科学服务
Google Cloud Platform (GCP) 提供了大量服务,旨在满足各种数据科学需求。在这里,我们将深入探讨一些关键服务,如 BigQuery、Cloud Storage 和 Cloud Dataflow,揭示它们的功能和潜在用途。
BigQuery
BigQuery 是 GCP 完全托管、低成本的分析数据库。凭借其无服务器模型,BigQuery 通过利用 Google 基础设施的处理能力,能够对追加式表进行超快速 SQL 查询。它不仅仅是一个运行查询的工具,而是一个强大、大规模的数据仓库解决方案,能够处理 PB 级的数据。无服务器的方法消除了对数据库管理员的需求,使其成为希望降低运营开销的企业的一个有吸引力的选择。
示例:深入研究公共出生数据集,以获取有关美国出生的洞察。
SELECT * FROM `bigquery-public-data.samples.natality`
LIMIT 10
云存储
Cloud Storage 提供了强大、安全和可扩展的对象存储。它是企业的一个优秀解决方案,因为它允许以高度的可用性和可靠性存储和检索大量数据。Cloud Storage 中的数据被组织到存储桶中,存储桶作为数据的独立容器,可以单独管理和配置。Cloud Storage 支持标准、近线、冷线和归档存储类,允许优化价格和访问要求。
示例:使用 gsutil CLI 将示例 CSV 文件上传到 Cloud Storage 存储桶。
gsutil cp sample.csv gs://my-bucket
Cloud Dataflow
Cloud Dataflow 是一个完全托管的服务,用于流处理和批处理数据。它在实时或接近实时的分析中表现出色,并支持提取、转换和加载 (ETL) 任务以及实时分析和人工智能 (AI) 用例。Cloud Dataflow 旨在以可靠、容错的方式处理大量数据的复杂性。它与 BigQuery 等其他 GCP 服务无缝集成,进行分析,与 Cloud Storage 集成进行数据暂存和临时结果,使其成为构建端到端数据处理管道的基石。
步骤 3:构建你的第一个数据项目
开始数据项目需要系统化的方法以确保准确和有洞察力的结果。在这一步,我们将通过创建一个 Google Cloud Platform (GCP) 项目,启用必要的 API,并为数据的摄取、分析和可视化设置基础,使用 BigQuery 和 Data Studio。对于我们的项目,让我们深入分析历史天气数据以识别气候趋势。
设置项目并启用 API
通过在 GCP 上创建一个新项目来开始你的旅程。导航到 Cloud Console,点击项目下拉菜单并选择“新建项目”。命名为“天气分析”,并按照设置向导完成操作。一旦你的项目准备好,前往 API 和服务仪表板,启用 BigQuery、Cloud Storage 和 Data Studio 等必需的 API。
将数据集加载到 BigQuery 中
对于我们的天气分析,我们需要一个丰富的数据集。NOAA 提供了大量的历史天气数据。下载部分数据后,前往 BigQuery 控制台。在这里,创建一个名为weather_data的新数据集。点击“创建表”,上传你的数据文件,并按照提示配置模式。
Table Name: historical_weather
Schema: Date:DATE, Temperature:FLOAT, Precipitation:FLOAT, WindSpeed:FLOAT
在 BigQuery 中查询数据并进行分析
拥有数据后,是时候发掘洞察了。BigQuery 的 SQL 界面使运行查询变得轻而易举。例如,要找出多年的平均温度:
SELECT EXTRACT(YEAR FROM Date) as Year, AVG(Temperature) as AvgTemperature
FROM `weather_data.historical_weather`
GROUP BY Year
ORDER BY Year ASC;
这个查询提供了每年的平均温度细分,这对我们的气候趋势分析至关重要。
使用 Data Studio 可视化洞察
数据的可视化展示通常揭示了原始数字中看不到的模式。将你的 BigQuery 数据集连接到 Data Studio,创建一个新报告,并开始构建可视化。展示多年温度趋势的折线图是一个不错的开始。Data Studio 的直观界面使拖放和自定义可视化变得简单易行。
使用“共享”按钮与团队分享你的发现,使利益相关者能够轻松访问和互动你的分析结果。
通过完成这一步骤,你已经设置了一个 GCP 项目,获取了真实世界的数据集,执行了 SQL 查询以分析数据,并可视化了你的发现以便更好地理解和分享。这种动手实践不仅有助于理解 GCP 的机制,还能从数据中获得可操作的洞察。
第 4 步:GCP 上的机器学习
利用机器学习 (ML) 可以显著增强你的数据分析,提供更深入的洞察和预测。在这一步中,我们将扩展我们的“天气分析”项目,利用 GCP 的 ML 服务基于历史数据预测未来的温度。GCP 提供了两种主要的 ML 服务:适合 ML 新手的 Cloud AutoML 和适合经验丰富的从业者的 AI 平台。
Cloud AutoML 和 AI 平台概述
-
Cloud AutoML:这是一个完全托管的 ML 服务,简化了定制模型的训练过程,代码量很少。非常适合没有深厚机器学习背景的人士。
-
AI 平台:这是一个用于构建、训练和部署 ML 模型的托管平台。它支持流行的框架,如 TensorFlow、scikit-learn 和 XGBoost,非常适合具有 ML 经验的人士。
使用 AI 平台的实际操作示例
在继续我们的天气分析项目时,我们的目标是使用历史数据预测未来的温度。首先,准备训练数据是一个关键步骤。将数据预处理成适合 ML 的格式,通常是 CSV,并将其分成训练集和测试集。确保数据清洁,并选择相关特征以进行准确的模型训练。准备好后,将数据集上传到 Cloud Storage 桶中,创建类似gs://weather_analysis_data/training/和gs://weather_analysis_data/testing/的结构化目录。
训练模型是下一个重要步骤。导航到 GCP 的 AI Platform 并创建一个新模型。选择预构建的回归模型,因为我们正在预测一个连续目标——温度。将模型指向 Cloud Storage 中的训练数据,并设置训练所需的参数。GCP 将自动处理训练过程、调优和评估,简化模型构建过程。
在成功训练后,将训练好的模型部署到 AI Platform。部署模型可以方便地与其他 GCP 服务和外部应用程序集成,使模型能够进行预测。确保设置适当的版本控制和访问控制,以便安全有序地管理模型。
现在模型已经部署,是时候测试其预测结果了。通过 GCP Console 或 SDK 发送查询请求,测试模型的预测结果。例如,输入某一天的历史天气参数,观察预测的温度,这将给出模型准确性和表现的初步了解。
使用 Cloud AutoML 进行实际操作
对于更简单的机器学习方法,Cloud AutoML 提供了一个用户友好的界面来训练模型。首先确保数据格式正确并已分割,然后将其上传到 Cloud Storage。这一步与 AI Platform 中的数据准备类似,但更适合那些机器学习经验较少的用户。
接下来,导航到 GCP 上的 AutoML Tables,创建一个新数据集,并从 Cloud Storage 导入数据。这一设置非常直观,配置要求最低,使数据准备工作变得轻松。
在 AutoML 中训练模型是直接的。选择训练数据,指定目标列(Temperature),并启动训练过程。AutoML Tables 将自动处理特征工程、模型调优和评估,这样就能减轻你的负担,让你专注于理解模型的输出。
一旦模型训练完成,将其部署到 Cloud AutoML 中,并使用提供的界面或通过 GCP SDK 发送查询请求来测试其预测准确性。这一步将模型投入实际使用,允许你对新数据进行预测。
最后,评估模型的表现。检查模型的评估指标、混淆矩阵和特征重要性,以更好地了解其性能。这些见解至关重要,因为它们可以告知是否需要进一步的调优、特征工程或收集更多数据以提高模型的准确性。
通过深入了解 AI Platform 和 Cloud AutoML,你可以获得在 GCP 上应用机器学习的实际理解,为你的天气分析项目增添预测能力。通过这些实际操作示例,机器学习融入数据项目的路径被揭示,奠定了更高级探索的坚实基础。
步骤 5:将模型部署到生产环境
一旦您的机器学习模型训练满意,下一步就是将其部署到生产环境。这种部署允许您的模型开始接收实际数据并返回预测。在这一阶段,我们将探讨 GCP 上的各种部署选项,以确保您的模型能够高效且安全地提供服务。
通过无服务器服务提供预测
可以利用 GCP 上的无服务器服务,如 Cloud Functions 或 Cloud Run 来部署训练好的模型并提供实时预测。这些服务抽象了基础设施管理任务,使您可以专注于编写和部署代码。由于其自动扩展功能,它们非常适合间歇性或低容量的预测请求。
例如,通过 Cloud Functions 部署您的温度预测模型涉及将模型打包成一个函数,然后将其部署到云端。部署后,Cloud Functions 会根据需要自动扩展或缩减实例数量,以处理请求的速率。
创建预测服务
对于高容量或对延迟敏感的预测,将训练好的模型打包到 Docker 容器中并部署到 Google Kubernetes Engine (GKE) 是一种更合适的方法。这种设置允许可扩展的预测服务,满足潜在的大量请求。
通过将您的模型封装在容器中,您创建了一个可移植且一致的环境,确保无论容器部署在哪里,它都能以相同的方式运行。一旦您的容器准备好后,将其部署到 GKE,GKE 提供了一个托管的 Kubernetes 服务,可以高效地协调您的容器化应用。
最佳实践
将模型部署到生产环境还涉及遵循最佳实践,以确保模型的平稳运行和持续准确性。
-
监控生产环境中的模型:密切关注模型随时间的表现。监控可以帮助检测模型漂移等问题,即当模型的预测随着基础数据分布的变化而变得不那么准确时。
-
定期在新数据上重新训练模型:随着新数据的出现,重新训练您的模型以确保它们继续做出准确的预测。
-
为模型迭代实施 A/B 测试:在完全替换生产环境中的现有模型之前,使用 A/B 测试将新模型的性能与旧模型进行比较。
-
处理故障场景和回滚:做好故障准备,并制定回滚计划,以便在必要时恢复到先前的模型版本。
成本优化
成本优化对于在性能和费用之间保持平衡至关重要。
-
使用预 emptible VMs 和自动扩展:为了管理成本,利用预 emptible VMs,它们的成本远低于常规 VMs。结合自动扩展,可以确保在需要时拥有必要的资源,而不会过度配置。
-
比较无服务器与容器化部署:评估无服务器和容器化部署之间的成本差异,以确定最具成本效益的方法。
-
根据模型资源需求选择合适的机器类型:选择与模型资源需求相匹配的机器类型,以避免对低使用率资源的过度花费。
安全考虑
保护你的部署至关重要,以保护你的模型及其处理的数据。
-
了解 IAM、认证和加密最佳实践:熟悉身份和访问管理(IAM),并实施适当的认证和加密,以保护对模型和数据的访问。
-
生产模型和数据的安全访问:确保只有授权的个人和服务可以访问生产中的模型和数据。
-
防止未经授权访问预测端点:实施强有力的访问控制,防止未经授权访问预测端点,保护模型免受潜在滥用。
将模型部署到 GCP 的生产环境涉及技术和操作方面的考量。通过遵循最佳实践、优化成本和确保安全,你为成功的机器学习部署奠定了坚实的基础,使你的模型在实际应用中能够提供价值。
继续前进
在这本全面指南中,我们遍历了启动 Google Cloud Platform (GCP) 机器学习和数据科学之旅的要点。从设置 GCP 账户到在生产环境中部署模型,每一步都是创建强大数据驱动应用程序的基石。以下是继续在 GCP 上探索和学习的下一步。
-
GCP 免费层:利用 GCP 免费层进一步探索和实验云服务。免费层提供对核心 GCP 产品的访问,是无需额外费用的动手体验的绝佳方式。
-
高级 GCP 服务:深入了解更高级的 GCP 服务,如 Pub/Sub 实时消息传递、Dataflow 流处理和批处理,或 Kubernetes Engine 容器编排。了解这些服务将拓宽你在 GCP 上管理复杂数据项目的知识和技能。
-
社区和文档:GCP 社区是丰富的知识源,官方文档也很全面。参与论坛、参加 GCP 聚会,探索教程以继续学习。
-
认证:考虑获取 Google Cloud 认证,如专业数据工程师或专业机器学习工程师,以验证你的技能并提升职业前景。
-
参与项目合作:与同事合作项目或参与利用 GCP 的开源项目。实际的合作提供了不同的视角,并提升你的解决问题的技能。
技术领域,尤其是云计算和机器学习,持续不断地发展。保持对最新进展的关注、参与社区活动并从事实际项目是不断提升技能的绝佳方式。此外,反思已完成的项目,从遇到的挑战中学习,并将这些经验应用于未来的工作中。每个项目都是一个学习机会,而持续改进是你在 GCP 上数据科学和机器学习之旅成功的关键。
通过遵循本指南,你为在 Google Cloud Platform 上的冒险奠定了坚实的基础。未来的道路充满了学习、探索和大量的机会,让你的数据项目产生重大影响。
马修·梅奥 (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 的总编辑,马修旨在让复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、机器学习算法以及探索新兴的人工智能。他的使命是将数据科学社区的知识普及化。马修从 6 岁起就开始编程。
更多相关主题
2024 年免费学习人工智能的 5 个步骤

图片来源:作者
为什么你应该在 2024 年学习人工智能?
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT 需求
对人工智能专业人才的需求在接下来的几年里将呈指数级增长。
随着公司开始将人工智能模型整合到工作流程中,新的角色将会出现,如人工智能工程师、人工智能顾问和提示工程师。
这些职业薪资高,年薪在\(136,000](https://www.coursera.org/articles/ai-engineer-salary)到[\)到$375,000之间。
由于这个领域刚刚开始获得广泛关注,现在是进入职场、掌握人工智能技能的最佳时机。
然而,人工智能领域有太多东西需要学习。
行业内几乎每天都有新的发展,跟上这些变化并以如此快的速度学习新技术似乎是不可能的。
幸运的是,你不需要这样做。
进入人工智能领域并不需要了解每一种新技术。
你只需要了解几个基础概念,然后可以在此基础上开发适用于任何场景的人工智能解决方案。
在这篇文章中,我将给你提供一个由免费在线课程组成的5 步人工智能路线图。
这个框架将教你基础的人工智能技能——你将学习人工智能模型的理论,如何实现它们,以及如何使用 LLMs 开发人工智能驱动的产品。
最棒的部分是什么呢?
你将从一些世界顶级机构,如哈佛、谷歌、亚马逊和DeepLearning.AI那里免费学习这些技能。
让我们开始吧!
第一步:学习 Python
目前市场上有几十种低代码人工智能工具,可以让你在没有任何编程知识的情况下开发人工智能应用。
不过,如果你对入门人工智能非常认真,我仍然建议学习至少一种编程语言。如果你是初学者,我建议从 Python 开始。
原因如下:
-
多功能性和控制:无代码工具通常会限制你能够构建的应用类型。使用这些工具,你只能依赖付费平台内提供的功能。
你还不了解你所构建的模型背后的运作方式,这可能导致透明度和控制方面的问题。
-
广泛的库:Python 拥有大量专为 AI 和机器学习设计的库。
它还允许与数据库、网页应用程序和数据处理管道集成,从而使你能够构建一个端到端的 AI 解决方案,而不受任何限制。
-
就业能力:编程知识无疑能带来更多的职业机会,让你可以轻松过渡到数据科学、分析甚至网页开发等领域。
免费课程
要学习 Python,我推荐你参加 Freecodecamp 的初学者 Python 课程。
这是一个 4 小时的教程,将教你 Python 编程的基础知识,如数据类型、控制流程、运算符和函数。
步骤 2:通过哈佛的免费课程学习 AI
在完成 Python 课程后,你应该对该语言的基础知识有一定了解。
当然,要成为一个优秀的程序员,单靠在线课程是不够的。你需要实践并构建自己的项目。
如果你想学习如何提升你的编程技能,从初学者成长为能够实际构建酷炫项目的人,可以观看我的 YouTube 编程学习视频。
在获得一定的编程熟练度后,你可以开始学习如何在 Python 中构建 AI 应用。
这个阶段你需要学习两件事:
-
理论:AI 模型是如何工作的?这些算法背后的基本技术是什么?
-
实际应用:如何利用这些模型构建对最终用户有价值的 AI 应用?
免费课程
上述概念在 哈佛的 Python AI 入门课程中教授。
你将学习用于开发 AI 解决方案的技术背后的理论,如图搜索算法、分类、优化和强化学习。
然后,课程将教你如何在 Python 中实现这些概念。在课程结束时,你将构建用于玩井字棋、扫雷和尼姆等游戏的 AI 应用。
哈佛 CS50 的 Python 人工智能课程可以在 YouTube 和 edX 上找到,在这些平台上可以免费试听。
步骤 3:学习 Git 和 GitHub
完成上述课程后,你将能够使用各种数据集在 Python 中实现 AI 模型。
在这个阶段,学习 Git 和 GitHub 对于有效管理模型的代码并与更广泛的 AI 社区合作至关重要。
Git 是一种版本控制系统,允许多个人同时在一个项目上工作而不互相干扰,而 GitHub 是一个流行的托管服务,让你可以管理 Git 仓库。
简而言之,通过 GitHub,你可以轻松克隆他人的 AI 项目并对其进行修改,这对于初学者来说是提高知识的好方法。
你还可以轻松跟踪你对 AI 模型所做的任何更改,与其他程序员在开源项目上合作,甚至向潜在雇主展示你的作品。
免费课程
要学习 Git 和 GitHub,你可以参加 Freecodecamp 提供的一个小时速成课程。
步骤 4:掌握大型语言模型
自从 2022 年 11 月 ChatGPT 发布以来,大型语言模型(LLMs)一直处于 AI 革命的前沿。
这些模型与传统 AI 模型的不同之处在于:
-
规模和参数:LLMs 在来自互联网的大型数据集上进行训练,拥有万亿级参数。这使它们能够理解人类语言的复杂性,并理解类似人类的文本。
-
泛化能力:虽然传统 AI 模型在特定任务中表现出色,但生成式 AI 模型可以在广泛的领域内执行任务。
-
上下文理解:LLMs 使用上下文嵌入,这意味着它们在生成响应之前会考虑一个词出现的整个上下文。这种细致的理解使得这些模型在生成响应时表现良好。
大型语言模型的上述特性使它们能够执行各种任务,从编程到任务自动化和数据分析。
公司越来越倾向于将 LLMs 集成到他们的工作流程中以提高效率,因此了解这些算法的工作原理对你来说至关重要。
免费课程
这里有 2 个免费课程可以帮助你深入了解大型语言模型:
-
这个课程提供了一个初学者友好的大型语言模型介绍,仅需 30 分钟。你将了解 LLMs 是什么,它们如何训练,以及它们在各个领域的应用。
-
DeepLearning.AI 和 AWS 的生成式 AI 与 LLMs:
在这个课程中,你将从在 Amazon 工作的行业专家那里学习有关 LLMs 的知识。你可以免费旁听这个课程,但如果你想获得认证,则需要支付 $50。该课程的主题包括生成式 AI 生命周期、LLMs 背后的 Transformer 架构,以及语言模型的训练和部署。
步骤 5:微调大型语言模型
在学习了大型语言模型的基础知识及其工作原理之后,我推荐深入探讨如微调这些模型和提升其能力等主题。
微调是将现有的语言模型(LLM)适应特定数据集或任务的过程,这是一个能产生大量商业价值的用例。
公司通常会拥有专有的数据集,可能希望基于这些数据集构建最终产品,如客户聊天机器人或内部员工支持工具。他们通常会为此招聘人工智能工程师。
免费课程
要了解更多关于大型语言模型的微调,你可以参加 DeepLearning.AI 提供的这个免费课程。
如何在 2024 年免费学习人工智能——下一步
完成本文中概述的 5 个步骤后,你将获得大量关于人工智能的新知识。
这些技能将为机器学习、人工智能工程和人工智能咨询的工作铺平道路。
然而,旅程并没有结束。
在线课程是获得基础知识的好方法。然而,为了提高找到工作的机会,我推荐你做以下三件事:
1. 项目
项目将帮助你应用你所学的技能,通过自定义数据集获得实际经验。
它们还可以帮助你脱颖而出并获得该领域的工作,尤其是当你没有工作经验时。
如果你不知道从哪里开始,这篇文章为你提供了一系列独特的、适合初学者的人工智能项目创意。如果你对数据科学和分析相关的项目感兴趣,你可以观看我关于该主题的视频。
2. 紧跟人工智能趋势
人工智能行业正在比以往任何时候都更快地发展。
新技术和模型不断发布,保持对这些技术的更新将使你在行业专业人士中脱颖而出。
KDNuggets 和 Towards AI 是两个将复杂的人工智能话题转化为易于理解的出版物。
如果你想了解更多关于人工智能、编程和数据科学的内容,我还有一个 YouTube 频道,为初学者提供这些主题的技巧和教程。
此外,我推荐浏览 Papers with Code 平台。这是一个免费的资源,可以让你阅读学术论文及其相应的代码。
Papers with Code 让你通过在一个平台上阅读论文的摘要、方法论、数据集和代码,快速了解人工智能领域的前沿研究。
3. 加入社区
最后,你应该考虑加入一个社区,以深化你在人工智能方面的知识和技能。
寻找志同道合的人进行合作是学习新事物的最佳方式,并且会为你在这个领域打开大量机会。
我建议你加入你所在地区的 AI 网络活动,以建立与该领域其他人的联系。
你还可以在 GitHub 上贡献开源项目,这将帮助你建立一个 AI 开发者的专业网络。
这些联系可以显著提高你获得工作、合作机会和导师指导的机会。
Natassha Selvaraj 是一位自学成才的数据科学家,热衷于写作。Natassha 撰写与数据科学相关的所有内容,是数据话题的真正大师。你可以通过LinkedIn与她联系,或者查看她的YouTube 频道。
更多相关内容
掌握数据科学的 5 大超级备忘单
原文:
www.kdnuggets.com/5-super-cheat-sheets-to-master-data-science

作者提供的图片
数据科学是一个广阔的领域,结合了统计学、机器学习和数据分析的元素。为了导航这个复杂的领域,拥有一套实用的备忘单可以极大地帮助你。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
这些备忘单还可以作为准备技术面试、复习关键概念和为初学者提供数据科学职业概述的宝贵资源。
以下是每个数据科学专业人员和爱好者都应该拥有的五个超级备忘单:
1. 数据科学超级备忘单
链接: 数据科学备忘单/data-science-cheatsheet.pdf

这份 9 页的综合参考资料涵盖了概率、统计学、统计学习、机器学习、大数据框架和 SQL 的基础知识。适合对统计学和线性代数有基本了解的人,是进入数据科学领域的绝佳起点。
2. 斯坦福大学概率和统计备忘单
这份备忘单是概率和统计学关键概念的简明总结。它包括随机样本、估计量、中心极限定理、置信区间、假设检验、回归分析、相关系数等主题。它非常适合理解数据科学中至关重要的基础统计概念。
3. 数据科学备忘单 2.0

这份备忘单是数据科学知识的精华版本,涵盖了基于 MIT 机器学习课程 6.867 和 15.072 的一个学期的入门级机器学习内容。它包括线性回归、逻辑回归、决策树、支持向量机、K 最近邻等主题。这份备忘单是考试复习、面试准备和快速回顾关键机器学习概念的宝贵资源。
4. 超级机器学习备忘单
链接: afshinea/stanford-cs-229-machine-learning
这份备忘单总结了斯坦福大学 CS 229 机器学习课程中的关键概念。它包括相关主题(概率和统计、代数和微积分)的复习,以及每个机器学习领域的详细备忘单,最后汇总了重要概念。对于任何希望深入了解机器学习的人来说,这是一个必备的资源。它旨在为专家提供一个基础概念的快速参考。
5. 超级深度学习备忘单
链接: afshinea/stanford-cs-230-deep-learning
如果你对深度学习感兴趣,斯坦福大学的 CS 230 课程提供了一系列出色的资料,涵盖了关于卷积神经网络和递归神经网络的所有知识点,并提供了训练深度学习模型的技巧。这个资源对于专注于数据科学中深度学习方面的任何人来说都是无价的,而且是免费的。
结论
这些备忘单提供了一种简明有效的方式来复习和巩固你在数据科学各个学科的理解。从统计学基础到机器学习和深度学习的复杂性,这些资源对学生、专业人士和爱好者都非常宝贵。经常参考它们,以巩固基础概念或更新最新方法。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一款 AI 产品,帮助那些挣扎于心理健康问题的学生。
更多相关内容
5 个你不能错过的超级有用的 SQL 备忘单!
原文:
www.kdnuggets.com/5-super-helpful-sql-cheat-sheets-you-cant-miss

图片来源:Freepik
作为数据专业人员,你将会经常使用 SQL。即使你知道 SQL,拥有一个快速参考工具来查找某些语法和用例也是有帮助的。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
这里有五个非常有用的 SQL 备忘单/参考资料,涵盖以下主题:
-
SQL 基础
-
使用 SQL 进行数据准备
-
SQL 连接
-
SQL 窗口函数
-
SQL 面试问题
那么我们开始吧!
1. SQL 基础
你可以在几个小时内学习 SQL 基础。你只需要熟悉语法,然后练习解决几个问题以应用你刚刚学到的概念。如果你需要复习过滤操作符、连接类型、分组和聚合函数等主题,可以参考 LearnSQL 提供的 SQL 基础 备忘单。
涵盖的主题包括:
-
查询单个表
-
过滤输出
-
查询多个表
-
聚合和分组
-
子查询
-
集合操作
2. 数据准备与 SQL
对于任何数据科学项目来说,数据准备都是非常重要的。Stan Pugsley 为 KDnuggets 提供的《数据准备与 SQL》 备忘单将帮助你回顾关键的数据准备技巧。
你可以回顾如何使用 SQL 执行以下数据准备任务:
-
配置数据集
-
验证属性
-
标准化属性
-
创建属性
-
派生属性
-
合并数据集
-
拆分数据集
链接: 数据准备与 SQL 备忘单 – KDnuggets
3. SQL 连接
SQL 中的连接在你需要使用来自多个数据库表的信息来回答问题时非常常见。但如果你是初学者,连接可能看起来比较困难,直到你练习得足够多。
DataCamp 的SQL 连接备忘单是一个快速参考,涵盖了以下连接类型:
-
内连接
-
自连接
-
左连接
-
完全连接
-
交叉连接
以及 SQL 中的以下集合理论运算符:
-
联合
-
全连接
-
交集
-
差集
4. SQL 窗口函数
如果你已经学会了 SQL 的基础知识,你应该能熟练使用聚合函数。在列上应用聚合函数可以将行集合缩减为特定的值,如平均值、最小值和最大值。
类似于聚合函数,窗口函数也允许你计算列中值的数量,但结果不会缩减为单一值,而是返回一组行。例如,移动平均、累计和等。
如果你在准备面试,窗口函数也极为重要。DataCamp 的SQL 窗口函数备忘单将帮助你快速回顾 SQL 窗口函数。它首先涵盖以下内容:
-
窗口函数的语法
-
ORDER BY 和 PARTITION BY 子句
-
窗口框架范围
备忘单还涵盖了以下窗口函数类别:
-
排名窗口函数
-
值窗口函数
-
聚合窗口函数
-
LEAD 和 LAG
5. SQL 面试问题
这不是一个备忘单,而是一个有用的参考,用于常见的面试问题。它旨在快速回顾你的基础概念理解。
这份来自 Edureka 的SQL 面试问题合集包含了许多关于数据库基础的问题,如关系、模式、约束等。如果你有一些关系数据库的工作经验,你应该对这些问题非常熟悉。
此外,你还需要了解以下主题:
-
归一化
-
OLAP 与 OLTP 系统
-
数据库索引类型
-
查询优化
-
数据库触发器
-
子查询
-
存储过程
-
针对 SQL Server 和 PostgreSQL 的特定问题
链接: 前 115 个 SQL 面试问题 – Edureka
总结
无论你是在工作中使用 SQL、学习 SQL,还是在下次面试前需要快速复习,我相信这些备忘单会帮助你回顾所需内容。
但要精通 SQL,实践与学习同样重要。事实上,实践应该是学习过程的一部分。所以,如果你正在寻找好的 SQL 实践平台,可以查看汇总的 7 个最佳 SQL 实践平台。
Bala Priya C**** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交集处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过撰写教程、操作指南、观点文章等,学习并与开发者社区分享她的知识。Bala 还制作了引人入胜的资源概述和编程教程。
更多相关内容
5 项支持技能,助你获得数据科学职位
原文:
www.kdnuggets.com/2021/02/5-supporting-skills-data-science-job.html
评论

当你开始追求数据科学职位时,一些需要掌握的技能会很明显。你知道你需要具备编码、分析和数学经验,但你也应该培养一些软技能。虽然这些技能在你想到数据科学时可能不会立刻浮现,但它们将在你的职业生涯中发挥关键作用。
数据科学职位仍然需求旺盛,但新职位的数量在下降,虽然下降速度比其他职业要慢。该领域的盈利能力也会吸引更多的申请者,因此竞争在上升。如果你想在申请者中脱颖而出,以下是一些你应该发展的辅助技能。
1. 批判性思维
许多职位会寻找具备强大批判性思维技能的申请者,特别是在数据科学领域。你应该能够从多个角度看待问题,了解如何处理它并分析你的结果。这个过程是许多数据科学应用的基础,即使它并非行业所独有。
作为数据科学家,你需要知道如何正确地提出问题,而不仅仅是回答问题。你必须从多个角度分析一个问题,以找到问题的根源。在解决问题后,你应该反思这个过程,并理解它为何如此发展。
要培养批判性思维技能,利用空闲时间参与各种解决问题的项目。尝试从多个角度进行分析,并展示多种解决方法。培养这样一个项目组合可以向潜在雇主展示你在批判性思维方面的能力。
2. 沟通能力
你可能不会把数据科学当作一个沟通密集的领域,但事实远非如此。虽然分析可能是你工作的核心,但你必须沟通你的结果。数据科学涉及大量的协作和报告,因此你需要知道如何有效地进行沟通。
研究表明,沟通不畅使大型公司每年平均损失$62.4 百万。如果你不能向同事和管理层解释你的问题或想法,他们将无法看到你技术能力的全部。误沟通可能导致流程未优化、缺陷和损失。
幸运的是,发展和展示沟通技能相对简单。你在工作和个人生活中,寻找团队项目。你在团队中工作的越多,你的沟通能力就会越强,并且你将拥有相关的证据。
3. 知识好奇心
一个好的数据科学家会寻找问题的解决方案,但一个伟大的数据科学家会寻找需要修复的事物。数据科学是一个潜在的颠覆性领域,因此你应该能够跳出传统框架进行思考。知识好奇心驱动数据科学家发现隐蔽的问题并创造性地解决它们。
雇主希望看到一个有强烈学习欲望的数据科学家。这种心态有助于找到解决方案,并可能推动公司扩展。好奇心驱动增长,因此任何企业都会乐意找到一个知识好奇的候选人。
为了培养知识好奇心,开始提问吧。追求独立项目,在每一个步骤中询问为什么和如何。随着时间的推移,你将积累一个充满独特问题解决方法和好奇心的作品集。
4. 适应能力
虽然科学看似严谨,但作为数据科学家,你必须具备适应能力。适应能力在几乎所有技术工种中都是令人向往的,因为员工经常在工作中获得新技能,以满足多样化的需求。你能够更好地应对新挑战,你就会成为更有价值的员工。
数据科学影响着今天商业的许多方面,因此你必须适应各种情况。作为一个技术导向的领域,数据科学也在不断发展。新的技术和方法不断出现,你需要能够适应这些变化。
你可以通过故意将自己置于陌生的情况来培养适应能力。开始一些你不太熟悉或不了解的领域的项目。在你当前的工作或学校中,志愿参与新的项目或过程。你将学习在这个过程中如何发展。
5. 时间管理
作为数据科学家,你应该具备可靠的时间管理技能。这个领域可能会很有挑战性,在今天快节奏的工作环境中,很容易感到不堪重负。如果你能够有效管理时间,你会更高效地工作,并避免倦怠。
一项研究发现,65% 的美国工人报告称工作压力造成了困难,其中 10%的人表示问题非常严重。时间管理技能可以帮助你减少这种压力。因此,你会感觉更好,工作也会有所改善。
你可以在当前职位或学业中开始应用时间管理技巧。测试不同的策略,比如设置定时器和优先处理重要任务,并找到最适合你的方法或组合。然后你可以向潜在的雇主解释你如何有效地管理时间。
成为最优秀的数据科学候选人
在你努力获得数据科学所需的经验和技术技能时,请记住这些辅助技能。如果你能培养这些能力,你将成为更有价值的候选人。即使你已经在相关领域工作,也可以开始应用这些技能,以最大化你的潜力。
个人简介:Devin Partida 是一位大数据和技术作家,同时也是ReHack.com的主编。
相关:
-
如何获得数据科学家的职位
-
7 个最推荐的技能,助你成为数据科学家
-
本文介绍了数据专业人士可以通过七种方式增加简历的多样性。
更多相关话题
你可以用 R 做的 5 件令人惊讶的事

编辑器提供的图片
R 已经改变了我们处理数据的方式。从数据可视化和分析到机器学习和人工智能,R 在数据科学的众多领域产生了深远的影响。因此,许多数据科学家、分析师和学术专业人士都在使用功能强大的 R 编程语言。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
R 是TIOBE 指数的长期成员,该指数衡量不同编程语言的流行程度,R 被各类专业背景的人士使用。本文将深入探讨 R 的不同用途,并展示你学习这个编程语言后可以做些什么。
1. 创建和定制仪表板和数据可视化
没有数据可视化,几乎无法理解你的数据。数据可视化将你收集和分析的数据转化为易于消化的视觉内容,如图像和图表。这些视觉效果帮助数据科学家和分析师识别数据中难以察觉的趋势。
数据可视化是分析大型数据集时不可或缺的工具,而 R 的 ggplot2 包是其中最优秀的数据可视化工具之一。这个包允许用户绘制几乎任何想要的数据图表,掌握 ggplot2 是充分发挥 R 潜力的一个重要步骤。
你还可以考虑将 ggplot2 包提供的语法与 Plotly 或 Shiny 等工具结合使用。这将使你能够定制数据可视化和仪表板,并使其更具交互性。如果你有一个前端开发人员合作,你可以利用他们的技能使你的视觉效果更具吸引力和易于阅读。同时,也可以考虑探索与 ggplot2、Plotly 和 Shiny 相关的数据可视化课程。
2. 更高级的探索性数据分析
大多数数据科学项目要求在开始其他工作之前进行探索性数据分析。探索性数据分析包括你用来描述数据集的相同步骤。确定不同类型的数据、找到缺失的信息,以及识别值的分布和数据点之间的相关性通常都属于探索性数据分析的范畴。
在使用和掌握 R 时,了解你的数据集包含什么通过探索性数据分析是获取新数据后必不可少的。R 提供了一个名为 "tidyverse" 的套件,包括 tidyr 和 dplyr,允许用户探索、操作和计算数据集。tidyverse 套件具有简单易用的语法,使用户能够快速获得他们想要的答案。
如果你对使用 R 的 tidyverse 套件来探索、操作和计算数据集感兴趣,探索那些深入讲解如何使用 dplyr 和 tidyr 操作数据的课程是个好主意。
3. 执行更具科学严谨性的数据分析
如果你打算学习和掌握 R 编程语言,你需要一种确保你的数据分析具有科学严谨性的方法。统计正是你确保数据分析中存在科学严谨性的关键,而 R 是你可以利用多个统计工具的语言。
在所有可用的编程语言中,R 可能拥有最多专注于统计的工具。R 的工具套件允许你执行各种统计功能。无论你需要获得描述性统计,如标准差和均值,创建映射逻辑回归和线性回归的模型,还是进行 A/B 测试,R 的统计能力确实非常广泛。
想要利用 R 提供的统计能力吗?建议你探索一些介绍统计学、线性回归和逻辑回归以及 A/B 测试的课程。
4. 利用机器学习做出更准确的预测
机器学习无疑是数据科学社区中最广泛讨论的话题之一,也很容易理解原因。机器学习允许数据科学家和分析师自动化地获取重要见解、识别数据模式和开发高精度的预测模型。而且最棒的是?你无需使用明确定义的编程指令即可利用机器学习的强大能力。
在使用 R 编程语言的背景下,机器学习使数据科学家和分析师能够进行准确且广泛的预测。机器学习的核心是通过数据的力量来进行预测的艺术。与统计学一样,R 为用户提供了大量工具,使他们能够运行自己选择的多种机器学习模型。
5. 使用 R Markdown 文档来自动化报告
R Markdown 包在经常生成自动化演示和报告的专业人士中非常受欢迎。为什么会这样?主要是因为 R Markdown 能在文档渲染时运行 R 编写的代码。
Markdown 的扩展,R Markdown 是一种标记语言,它轻量且易于使用。虽然 Markdown 允许用户向文档中添加标题和列表等内容,但 R Markdown 更进一步,处理 R 编程语言。
如果你想知道这为什么重要,请记住,一旦你完成数据分析,你将希望能够报告你的发现。R Markdown 正是你需要的包,用于将你的发现组织成易于理解的报告。它为用户提供了一种易于使用的语法,让他们可以以多种格式创建报告,无论是书面文档、演示文稿还是书籍。
值得注意的是,借助 R Markdown,用户可以在文档中填入与他们进行的复杂计算相关的信息。例如,你可以在由 R Markdown 生成的报告中包括你进行的问卷调查的结果,这些结果考虑了许多受访者的反馈。通过 R Markdown,你可以生成一个包含真实数据的文档,而且既干净又具有视觉吸引力。
结论
R 编程语言在数据科学的几乎每个方面都有专长,它彻底改变了数据科学家和分析师处理数据的方式。一旦掌握了 R,它提供了许多潜在的用途,我们希望我们介绍的五种令人惊讶的 R 使用方式能激励你开始你的学习之旅!
Nahla Davies 是一名软件开发人员和技术作家。在将全部精力投入技术写作之前,她曾担任许多有趣的职位,包括作为一家 Inc. 5,000 实验性品牌机构的首席程序员,该机构的客户包括三星、时代华纳、Netflix 和索尼。
更多相关话题
使用 Python 自动化的 5 个任务

作者照片
你自动化,我自动化,我们都自动化。我们自动化我们的财务、待办事项和社交生活。那么,为什么在自动化我们的职业生活时仍然有这么多抵触呢?我当了十多年的软件工程师,并且一直是自动化的倡导者。我亲眼见证了自动化的好处,并帮助公司采用了它。在这篇博客文章中,我将分享 10 个你可以用 Python 自动化的小任务。
介绍
无论你是在编写软件、编写业务逻辑,还是仅仅在做笔记,自动化都是你的朋友。软件界长期以来一直在与竞争对手进行“人工智能军备竞赛”。即便是 Google 也在开发自主机器人。作为开发者,我们如何竞争?通过专注于自己的优势。我们可以通过将用于产品开发的相同技术应用到软件开发中来做到这一点。我们可以将先进的技术应用于问题解决,然后自动化收集用于这些解决方案的信息。我个人发现,我解决的问题越深入,我就越容易成为解决方案的高手,并且专注于我觉得最有趣的部分。
使用 Python 自动化的 5 个任务
这绝不是一个全面的列表,也不会对每个任务提供相同的细节。但它应该为你提供一个坚实的起点。如果你对自动化不太熟悉,我建议你查看机器人学院的档案以了解更多信息。
#1. 阅读(将任何文件转化为有声书)
你可以使用下面的脚本将 Mac 上的任何文件转化为有声书,并在后台收听。
首先,安装以下依赖项。
pip install mac-say
然后创建一个你将用于执行此任务的 Python 文件。
import sys
import mac_say
mac_say.say(["-f", sys.argv[1], "-v", "Alex"])
然后在命令行中指向你选择的文件,尽情享受
python audiobook.py fileofyourchoice.txt
#2. 快速天气报告
查看天气通常是一件很快的事情,但通过点击一个按钮来完成它可能会带来一些满足感。
这也只需要一个依赖项。
pip install requests
安装后,只需创建一个文件并使用下面的脚本运行。
import sys
import requests
resp = requests.get(f'[https://wttr.in/{sys.argv[1].replace(](https://wttr.in/%7Bsys.argv[1].replace()" ", "+")}')
print(resp.text)
然后,你准备好每天运行或安排以下任务。
python weather.py "Your City"
#3. 货币转换
这项任务稍微简单一些,我们只需按如下方式安装库。
pip install --user currencyconverter
这个安装应该将currency_converter放到我们的$PATH中,因此要执行转换,只需像示例执行那样写下以下内容。
currency_converter 1 USD --to EUR
#4. 自动整理你的下载文件夹
在这个示例中,我们将只监听 PDF、图片、音频和视频,但这可以扩展得相当多,并且应该足够让你开始。我对此稍微过于投入了。
import sys
import os
import time
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
folder_to_monitor = sys.argv[1]
file_folder_mapping = {
".png": "images",
".jpg": "images",
".jpeg": "images",
".gif": "images",
".pdf": "pdfs",
".mp4": "videos",
".mp3": "audio",
".zip": "bundles",
}
class DownloadedFileHandler(FileSystemEventHandler):
def on_created(self, event):
if any(event.src_path.endswith(x) for x in file_folder_mapping):
parent = os.path.join(
os.path.dirname(os.path.abspath(event.src_path)),
file_folder_mapping.get(f".{event.src_path.split('.')[-1]}"),
)
if not os.path.exists(parent):
os.makedirs(parent)
os.rename(
event.src_path, os.path.join(parent, os.path.basename(event.src_path))
)
event_handler = DownloadedFileHandler()
observer = Observer()
observer.schedule(event_handler, folder_to_monitor, recursive=True)
print("Monitoring started")
observer.start()
try:
while True:
time.sleep(10)
except KeyboardInterrupt:
observer.stop()
observer.join()
一旦你创建了这个文件,你所需要做的就是运行它,并指向你的下载目录以开始监控它。
python downloads-watchdog.py "/your/downloads/folder"
#5. 早晨设置脚本
早晨通常你想要做很少的事情,直到咖啡因发挥作用。这个脚本会通过打开你每早通常需要打开的所有浏览器标签页来提前启动你的早晨。保存一个包含你选择的网址的脚本文件,如下面的示例所示。
python -m webbrowser -t "https://www.google.com"
python -m webbrowser -t "https://www.dylanroy.com"
python -m webbrowser -t "https://www.usesql.com"
结论
Python 是一个强大的工具,但你学习和实践得越多,你会变得越高效和生产力更强。我很高兴与大家分享一些有趣或有用的自动化任务,希望你们觉得它们有用。如果你有任何问题,请随时询问。
资源
迪伦·罗伊 目前与道琼斯公司合作,利用尖端技术和创业精神提供创新产品。经常利用大数据和云技术持续为客户创造价值。他在爱荷华州立大学工程学院获得计算机工程学士学位。点击这里订阅更多内容(dylanroy.com)
原文。已获许可转载。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
更多相关话题
你需要了解的数据科学的 5 件事。
原文:
www.kdnuggets.com/2018/02/5-things-about-data-science.html
我经常被问到有关数据科学的问题,因此这里是我对一些常见问题的回答,以及关于数据科学和数据科学家的 5 件有用的事宜。
1. 商业智能、业务分析、数据科学、数据分析、数据挖掘、预测分析——它们之间的区别是什么?
商业智能 或 BI 主要关注数据分析和报告,但不包括预测建模,因此 BI 可以被视为数据科学的一个子集。
其他术语:业务分析,数据分析,数据挖掘,预测分析 本质上与数据科学相同。
数据科学 关注于分析数据并从中提取有用的知识。建立预测模型通常是数据科学家最重要的活动。
然而,由于“数据科学”这个术语相对较新,该名称尚未被广泛接受,其他名称常用于同一领域。
数据科学可以通过 数据科学过程 理解,其中包括业务理解、数据理解、数据准备、建模、评估和部署,如 CRISP-DM 框架所描述:
 图 1:CRISP-DM - 数据科学过程。
图 1:CRISP-DM - 数据科学过程。
许多大学最近创建了商业分析、数据分析或数据科学学位。商业分析,如其名称所示,更注重商业技能和方法,而“数据科学”和“数据分析”则更注重数据工程方面。
在科学界,这个领域最受欢迎的名称随着时间的推移发生了变化。
-
数据挖掘:首次出现在 1970 年代,约在 2002 年达到顶峰,但今天仍在使用。
-
KDD(知识发现与数据挖掘):在 1990 年代使用,KDD 会议开始后使用,但现在仅在研究界使用。
-
预测分析:出现在 2000 年代,由 预测分析世界 推广,但尚未为大众所熟知。
-
数据科学,2012 年至今,受到了“数据科学家”职位流行的推动。
这个 Google Trends 图表显示了 2004 年至 2017 年间与数据科学相关的 5 个术语的相对流行度变化。
图 2:2004-2017 年间数据挖掘、数据科学、数据分析、业务分析、预测分析的 Google 趋势。
2. 数据科学与机器学习:有什么区别?
数据科学和机器学习可以被视为亲密的“亲戚”。
它们的共同点在于使用监督学习方法——从历史数据中学习。
然而,数据科学还涉及数据可视化以及以人们易于理解的形式呈现结果。数据科学更加注重数据准备和数据工程。
机器学习的主要关注点是学习算法——例如,它不涉及数据可视化。机器学习不仅研究从历史数据中学习,还包括实时学习。机器学习的重要组成部分是为在环境中行动并从其行为中学习的智能体设计算法。这被称为强化学习(RL)。要了解更多关于 RL 的历史和现状,请参见我与强化学习之父 Rich Sutton 的访谈。
RL 是 AlphaGo Zero 和 AlphaZero 最近成功的关键部分。
Q3. 数据科学家是个好工作吗?
是的!数据科学家被 Glassdoor 评选为美国最佳职位已经连续 3 年——请参见
-
数据科学家 - 连续 3 年被评为美国最佳职位
-
数据科学家 - 2017 年被评为美国最佳职位
-
数据科学家 - 2016 年被评为美国最佳职位

最近的 LinkedIn 经济图谱报告也为这一领域带来了好消息。机器学习工程师和数据科学家在 2017 年是美国的顶级新兴职位,机器学习工程师的职位在 5 年内增长了 9.8 倍,数据科学家的职位增长了 6.5 倍。
4. 我可以在哪里学习数据科学?
数据科学教育是 KDnuggets 上最受欢迎的话题之一,有一个专门的部分用于介绍这一主题。
学习数据科学及相关主题有很多选择。
我们最近进行了一系列关于最佳分析与数据科学硕士课程的调查,还考察了学费和课程排名。请参见
-
最佳在线数据科学与分析硕士课程
-
美国/加拿大最佳数据科学与分析硕士课程
-
最佳数据科学与分析硕士课程 - 欧洲版
-
最佳数据科学与分析硕士课程 - 亚洲和澳大利亚版
以下是第一篇文章中排名前列的项目概览图:
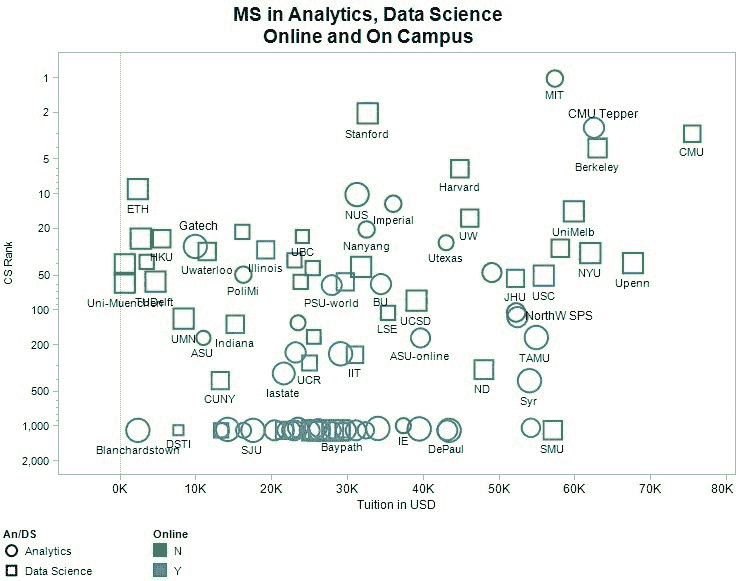 分析、数据科学 - 在线与校园课程,来自这篇帖子
分析、数据科学 - 在线与校园课程,来自这篇帖子
符号颜色为在线课程的蓝色,校园课程的绿色;形状为分析硕士的圆形;数据科学硕士的方形。
我们注意到排名与学费之间几乎没有相关性。大多数高排名的大学不提供在线学位。伯克利和 CMU 是例外。
我们调查的 MS 学位中略多于一半被称为“数据科学”——其中大部分是技术导向的,而略少于一半被称为“分析”——大多是商业导向的。
还有许多选择
-
分析、 大数据、数据科学、机器学习的证书与认证
-
数据科学在线课程和课程。
-
分析、大数据和数据科学的训练营
另见 KDnuggets 关于数据科学课程和教育的相关帖子
-
标签:在线教育(201)
-
标签:数据科学教育(167)
-
标签:理学硕士(64)
-
标签:数据科学硕士(40)
-
标签:分析硕士(27)
-
标签:商业分析硕士(25)
5. 数据科学家使用哪些算法和方法?
尽管深度学习似乎每天都在推动最先进的技术,并且像 XGBoost 这样的先进方法赢得了许多 Kaggle 比赛,但大多数数据科学工作涉及的是更基础的算法和方法。
KDnuggets 最近的调查
你在过去 12 个月中为实际应用使用了哪些数据科学/机器学习方法和工具?
排名前十的结果如下:

2017 年 KDnuggets 调查中使用的前 10 大数据科学、机器学习方法
大约 20%的受访者使用了深度学习。
我们的调查还发现了哪些方法与行业联系最紧密:
-
提升建模(连续第二年)
-
异常/偏差检测
-
梯度提升机
最“学术”的方法是与深度学习相关的高级主题:
-
生成对抗网络(GAN)
-
强化学习
-
循环神经网络(RNN)
-
卷积网络
在 Kaggle 2017 调查中,数据科学与机器学习现状的工作中最常用的数据科学方法包括:
-
逻辑回归,63.5%
-
决策树,49.9%
-
随机森林,46.3%
-
神经网络,37.6%
-
贝叶斯技术,30.6%
要了解更多关于最重要算法的内容,请查看我们关于算法的最受欢迎的文章。
-
初学者的十大机器学习算法
-
数据科学家需要掌握的 10 种统计技术
-
逻辑回归:简明技术概述
-
2118 年将使用哪些机器学习算法?
-
机器学习算法:为你的问题选择哪个
-
随机森林(r)解析
-
XGBoost:Kaggle 上的顶级机器学习方法解析
-
机器学习算法:简明技术概述 - 第一部分
-
自驾车中使用的机器学习算法
-
保持简单!如何理解梯度下降算法
-
机器学习工程师需要了解的 10 种算法
以及 KDnuggets 标签文章
-
算法 (116)
-
解析 (37)
更多相关话题
在急于开始数据科学之前要知道的 5 件事
原文:
www.kdnuggets.com/2018/03/5-things-before-rushing-data-science.html
评论
以下是我希望一年前决定开始数据科学之旅时能知道的 5 件重要事情:
1. 高中数学对于数据科学至关重要。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
矩阵计算、导数、特征值、集合论、函数、向量、线性变换等,对于理解统计方法和编程背后的理论至关重要。因此,在开始下一个 MOOC 或机器学习书籍之前,重新复习所有这些概念是至关重要的。大多数学校要求学生掌握这些方法才能毕业,但幸运的是,刷新或获得这些知识不会占用你太多时间。
有很多资源可以开始,但对我有效的是《漫画线性代数指南》,这本书非常简单、图文并茂,并且在深入更复杂的内容之前提供了很好的基础。
图 1:3x3 矩阵的逆矩阵
我的建议是安排几周时间来复习这些概念,并使用Feynman 技巧以便能够用简单的术语解释每一个主题。
2. 尽管有很多有用的互联网资源,书籍仍然是学习的最佳工具之一。
人们在尝试进入像数据科学这样的领域时面临的一个问题是信息过载,这个术语用来描述拥有太多资源时的影响。有数以百计的 MOOC、在线课程、专业化、视频等等,但对我们最宝贵的资源“时间”来说,最好的利用方式是选择一本书,从基础开始学习新概念,然后用其他书籍填补知识空白。
学习数据科学应该被视作一种积木游戏。

图 2:乐高积木
我相信这个类比对于学习大多数东西来说是最好的,但在我们的数据科学旅程中尤为有用:
-
首先,你需要选择你想要构建的玩具模型。
-
打开所有塑料袋,把不同的部件铺在平面上,这样你可以看到所有不同的部分。
-
了解每个部分的使用方法。学习它们的特征:维度、颜色、重量、形状。
-
开始构建小块,直到你掌握了所有的用途。
-
最后,当你按照说明手册完成了想要的模型后,把所有部件拆开,开始实验。
数据科学的每个领域中的所有技术都应该如此。学习所有的积木是什么,学习如何使用它们,然后当你想创建更复杂的东西时,寻找你没有的缺失部分。
3. 计算技能至关重要,不仅仅是对于数据科学,也对于未来的世界。
直到我开始学习数据科学硕士课程,我才意识到一个通过所有博客文章、书籍和新闻已经被低声传达了一段时间的信息:
“计算机代码占据了我们今天生活的 80%以上。”
代码存在于我们的智能手机、网站、汽车、电视、健康系统、公共交通、商品制造等领域。

图 3:编程语言词云
几乎每个行业的工作/职业都直接受到某些程序的影响,这些程序能实现信息的输入、转换和打印。学习编程以及代码的工作原理不仅仅是为了制作软件、应用程序或创建一个伟大的网站。学习编程将使你有优势去理解技术如何影响我们的生活。与其责怪计算机程序“无法工作”,你现在会系统地思考并理解问题可能出在哪里。谁知道呢,也许你会从用户的角度提出改进技术的更好想法。
4. 你的批判性和分析能力非常重要。
我是犯罪和问题解决类电视节目的大粉丝。例如,《蝎子》(Scorpion)讲述了一群天才利用技术和数学技能解决各种问题的故事。这类节目最突出的特点,除了所有的动作、笑话和英雄场景外,就是角色们用来解决各种问题的“批判性思维”。这是大多数数据科学资源中没有提到的一点。找到正确的角度来解决问题将帮助你确定不仅要使用哪些工具,还会有时带你找到最有效的解决方案。
5. 每个人都喜欢 TED 演讲,每个人都分享关于领导者的精彩演讲。然而,你必须准备好展示你的发现。
有许多可视化包(seaborn、ggplot、matplotlib)和软件(tableau、excel)可以帮助创建精美的图表。因此,要避免因选择过多而感到困惑。最重要的是信息的传递方式。有时候,最简单的工具会产生清晰、相关的结果。
相关:
更多相关内容
你在 PyCaret 中做错的 5 件事
原文:
www.kdnuggets.com/2020/11/5-things-doing-wrong-pycaret.html
评论
由 Moez Ali,PyCaret 的创始人及作者

我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
PyCaret
PyCaret 是一个开源的低代码机器学习库,能够自动化机器学习工作流程。它是一个端到端的机器学习和模型管理工具,加速机器学习实验周期,提高生产力。
与其他开源机器学习库相比,PyCaret 是一个低代码的替代库,可以用几行代码替代数百行代码。这使得实验变得指数级地快速和高效。
官方网站: www.pycaret.org
文档: pycaret.readthedocs.io/en/latest/
Git: www.github.com/pycaret/pycaret
???? compare_models 比你想象的要做得更多
当我们在 2020 年 4 月发布 PyCaret 1.0 版本时,compare_models 函数会比较库中的所有模型,并返回平均交叉验证性能指标。基于此,你可以使用create_model来训练表现最佳的模型,并获取可以用于预测的训练模型输出。
这个行为在版本 2.0 中有所改变。compare_models 现在返回基于n_select参数的最佳模型,该参数默认设置为 1,这意味着它会返回最佳模型(默认情况下)。
compare_models(n_select = 1)
通过将默认的n_select参数更改为 3,你可以获得前 3 个模型的列表。例如:
compare_models(n_select = 3)
返回的对象是训练好的模型,你实际上不需要再次调用create_model来训练它们。你可以使用这些模型来生成诊断图或进行预测,例如:
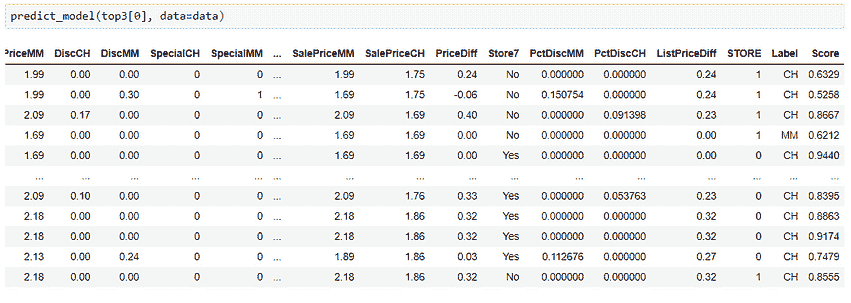
predict_model函数
???? 你认为你只能使用 scikit-learn 模型
我们收到很多请求,要求在模型库中包括非scikit-learn模型。许多人没有意识到,你不仅限于默认模型。create_model函数除了接受模型库中模型的 ID 外,还接受未训练的模型对象。只要你的对象与scikit-learn fit/predict API 兼容,它就会正常工作。例如,在这里我们通过简单地导入未训练的 NGBClassifier,训练并评估了来自ngboost库的NGBClassifier:
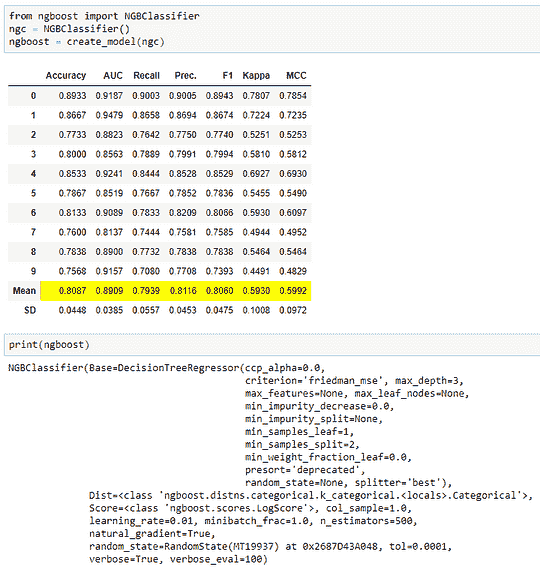
使用外部模型的 create_model
你也可以将未训练的模型传递给compare_models的include参数,它将正常工作。
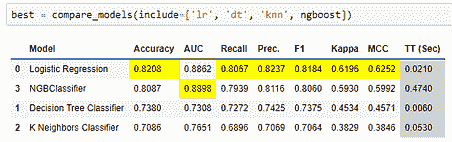
使用未训练对象的 compare_models
请注意,包括的参数包括模型库中三个未训练的模型的 ID,即逻辑回归、决策树和 K 邻近,以及 ngboost 库中的一个未训练对象。此外,请注意索引表示在 include 参数中输入的模型的位置。
???? 你不了解 pull()函数
PyCaret 中的所有训练函数(create_model、tune_model、ensemble_model 等)显示一个分数网格,但不返回分数网格。因此,你无法将分数网格存储在像 pandas.DataFrame 这样的对象中。然而,有一个叫做pull的函数可以实现。例如:
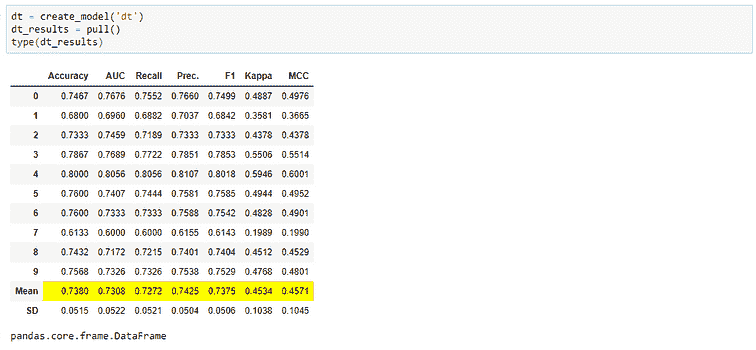
使用 create_model 的 pull 函数
这也适用于使用predict_model函数的 holdout 分数网格。
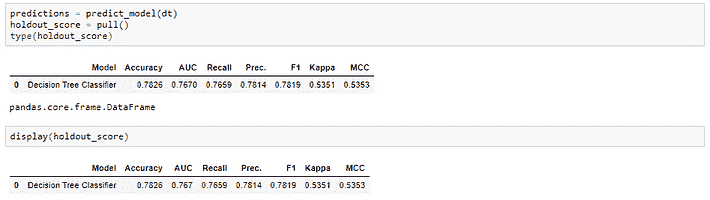
使用predict_model函数拉取
现在你可以将指标作为 pandas.DataFrame 访问,你可以做很多事情。例如,你可以创建一个循环来训练不同参数的模型,并用这段简单的代码创建比较表:
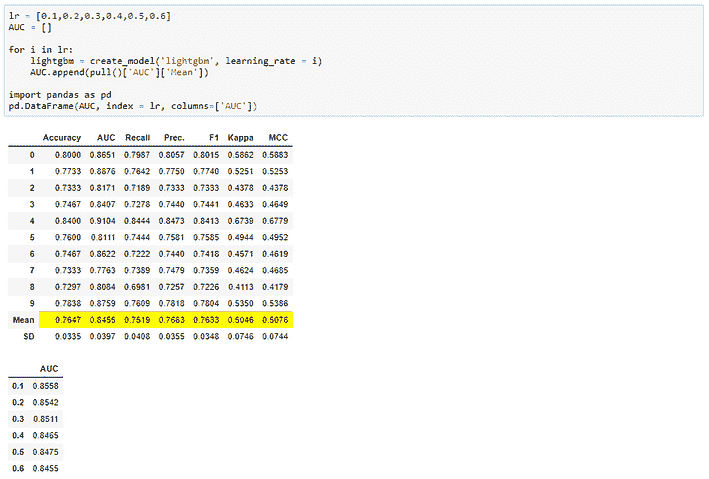
create_model 和 pull 函数
???? 你认为 PyCaret 是一个黑箱,但它不是。
另一个常见的误解是所有的预处理操作都在后台进行,用户无法访问。因此,你无法审计运行setup函数时发生了什么。这是不对的。
PyCaret 中有两个函数get_config和set_config,它们允许你访问和更改后台的所有内容,从你的训练集到模型的随机状态。你可以通过调用help(get_config)来查看可以访问哪些变量:
help(get_config)
你可以通过在get_config函数内部调用变量来访问它。例如,要访问X_train转化后的数据集,你可以这样写:
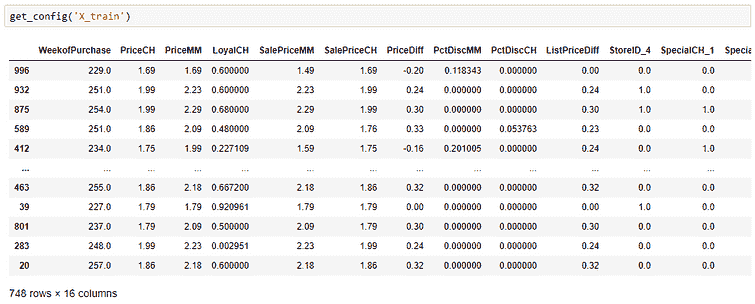
get_config(‘X_train’)
你可以使用set_config函数来更改环境变量。根据你目前对pull、get_config和set_config函数的了解,你可以创建一些非常复杂的工作流。例如,你可以对保留集进行N 次重采样,以评估平均性能指标,而不是依赖于一个保留集:
import numpy as npXtest = get_config('X_test')
ytest = get_config('y_test')AUC = []for i in np.random.randint(0,1000,size=10):
Xtest_sampled = Xtest.sample(n = 100, random_state = i)
ytest_sampled = ytest[Xtest_sampled.index]
set_config('X_test', Xtest_sampled)
set_config('y_test', ytest_sampled)
predict_model(dt);
AUC.append(pull()['AUC'][0])>>> print(AUC)**[Output]:** [0.8182, 0.7483, 0.7812, 0.7887, 0.7799, 0.7967, 0.7812, 0.7209, 0.7958, 0.7404]>>> print(np.array(AUC).mean())**[Output]: 0.77513**
你还没有记录你的实验
如果你没有记录你的实验,现在就应该开始记录。无论你是否打算使用 MLFlow 后台服务器,你都应该记录所有的实验。当你进行任何实验时,你会生成大量的元数据,这些数据很难手动追踪。
PyCaret 的日志记录功能在你使用get_logs函数时会生成一个漂亮、轻量、易于理解的 Excel 电子表格。例如:
**# loading dataset**
from pycaret.datasets import get_data
data = get_data('juice')**# initializing setup**
from pycaret.classification import *s = setup(data, target = 'Purchase', silent = True, log_experiment = True, experiment_name = 'juice1')**# compare baseline models**
best = compare_models()**# generate logs**
get_logs()
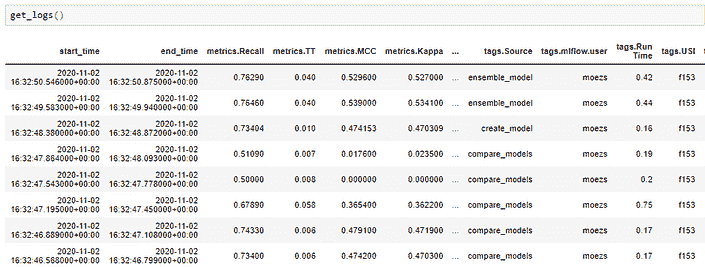
get_logs()
在这个非常简短的实验中,我们生成了 3000 多个元数据点(指标、超参数、运行时间等)。想象一下你将如何手动跟踪这些数据点?也许,这在实际操作中是不可能的。幸运的是,PyCaret 提供了一种简单的方法来实现。只需在setup函数中将log_experiment设置为 True 即可。
使用 Python 中的轻量级工作流自动化库,你可以实现无限的可能性。如果你觉得这些内容有用,请不要忘记在我们的GitHub 仓库上给我们⭐️。
想了解更多关于 PyCaret 的内容,请关注我们的LinkedIn和Youtube。
要了解更多关于 PyCaret 2.2 的更新,请查看发行说明或阅读此公告。
重要链接
想了解某个特定模块吗?
点击下面的链接查看文档和示例。
简介: Moez Ali 是一名数据科学家,也是 PyCaret 的创始人和作者。
原文。经许可转载。
相关内容:
-
你对 PyCaret 不了解的 5 件事
-
使用 Docker 容器将机器学习管道部署到云端
-
GitHub 是你所需的最佳 AutoML 工具
了解更多相关内容
使我作为数据科学家的工作更轻松的 5 件事
原文:
www.kdnuggets.com/2021/08/5-things-job-data-scientist-easier.html
评论
由Shree Vandana,数据科学家

图片由Boitumelo Phetla提供,来源于Unsplash
1. 使用 Pandas 处理时间序列数据
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业之路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
如果你处理时间序列数据,你可能花费了大量时间来处理缺失记录或通过 SQL 查询或编写自定义函数在特定时间粒度下聚合数据。Pandas 有一个非常高效的重采样函数,通过将 DataFrame 索引设置为时间戳列,你可以按特定频率处理数据。
我将使用房间占用数据集来举例说明这个函数。你可以在这里找到数据集。这个数据集记录了每分钟的观察数据。
import pandas as pd
data = pd.read_csv('occupancy_data/datatest.txt').reset_index(drop = True)
data.head(5)
首先,我展示一个简单的聚合方法,用于在每小时级别获取指标。
data.index = pd.to_datetime(data['date'])
pd.DataFrame(data.resample('H').agg({'Temperature':'mean',
'Humidity':'mean',
'Light':'last',
'CO2':'last',
'HumidityRatio' : 'mean',
'Occupancy' : 'mean'})).head(5)
尽管这个数据集并不稀疏,但在现实世界中,我们常常遇到缺失记录的数据。处理这些记录非常重要,因为你可能需要将缺失的记录填充为 0,或者使用前一个或下一个时间步长进行插补。下面,我删除了 15 小时的记录,展示了如何使用 14 小时的时间戳来填补缺失的值:
data = pd.read_csv('occupancy_data/datatest.txt').reset_index(drop = True)data_missing_records = data[~(pd.to_datetime(data.date).dt.hour == 15)].reset_index(drop = True)data_missing_records.index = pd.to_datetime(data_missing_records['date'])data_missing_records.resample('H', base = 1).agg({'Temperature':'mean',
'Humidity':'mean',
'Light':'last',
'CO2':'last',
'HumidityRatio' : 'mean',
'Occupancy' : 'mean'}).fillna(method = 'ffill').head(5)
2. 通过 Plotly Express 进行快速可视化
从分析到模型训练再到模型报告,通常需要可视化。特别是在时间序列图中,我发现自己花费了很多时间尝试自定义 matplotlib 中 x 轴刻度的大小和角度。在切换到使用 Plotly Express 后,我将使图表看起来更清晰的时间减少了大约 70%。如果我想在我的可视化中实现特定的细节,我仍然可以使用 Plotly Graph Objects。此外,Plotly 通过 Express 提供了很多简单的选项,例如在图表中设置组颜色,这样可以产生更强大的可视化效果。
import plotly.express as px
data['Temp_Bands'] = np.round(data['Temperature'])
fig = px.line(data, x = 'date',
y = 'HumidityRatio',
color = 'Temp_Bands',
title = 'Humidity Ratio across dates as a function of
Temperature Bands',
labels = {'date' : 'Time Stamp',
'HumidityRatio' : 'Humidity Ratio',
'Temp_Bands' : 'Temperature Band'})
fig.show()
使用上述提到的占用数据集,我用 Plotly Express 创建了颜色分组的折线图。我们可以看到仅用两个函数就能轻松创建这些图表。
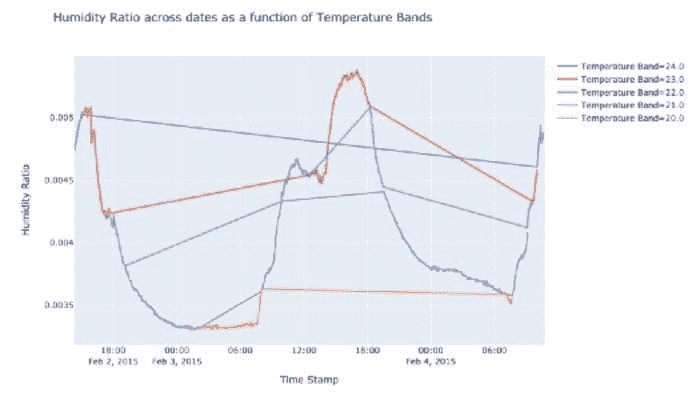
3. 通过 Swifter 加速 pandas apply()
我有时遇到处理 pandas 列时的长时间等待,即使在一个大实例的笔记本上运行代码也是如此。相反,只需添加一个简单的单词就可以加快 pandas DataFrame 中的 apply 功能。只需导入 swifter 库即可。
def custom(num1, num2):
if num1 > num2:
if num1 < 0:
return "Greater Negative"
else:
return "Greater Positive"
elif num2 > num1:
if num2 < 0:
return "Less Negative"
else:
return "Less Positive"
else:
return "Rare Equal"import swifter
import pandas as pd
import numpy as npdata_sample = pd.DataFrame(np.random.randint(-10000, 10000, size = (50000000, 2)), columns = list('XY'))
我创建了一个 5000 万行的数据框,并比较了通过 swifter 的 apply() 和原生 apply() 处理它所需的时间。我还创建了一个具有简单 if else 条件的虚拟函数,以测试这两种方法。
%%timeresults_arr = data_sample.apply(lambda x : custom(x['X'], x['Y']), axis = 1)
%%timeresults_arr = data_sample.swifter.apply(lambda x : custom(x['X'], x['Y']), axis = 1)

我们将处理时间从 7 分钟 53 秒减少了 64.4%,到 2 分钟 38 秒。
4. Python 中的多线程
在减少时间复杂度的话题上,我经常需要处理多个粒度的数据集。使用 Python 中的多线程可以通过利用多个工作线程来节省时间。
我展示了使用相同的 5000 万行数据框的多线程效果,除了这次我添加了一个分类变量,这是从一组元音中随机选择的值。
import pandas as pd
import numpy as np
import randomstring = 'AEIOU'data_sample = pd.DataFrame(np.random.randint(-10000, 10000, size = (50000000, 2)), columns = list('XY'))
data_sample['random_char'] = random.choices(string, k = data_sample.shape[0])
unique_char = data_sample['random_char'].unique()
我使用了一个 for 循环与来自 concurrent.futures 的 Process Pool 执行器,展示了我们可以实现的运行时减少。
%%timearr = []for i in range(len(data_sample)):
num1 = data_sample.X.iloc[i]
num2 = data_sample.Y.iloc[i]
if num1 > num2:
if num1 < 0:
arr.append("Greater Negative")
else:
arr.append("Greater Positive")
elif num2 > num1:
if num2 < 0:
arr.append("Less Negative")
else:
arr.append("Less Positive")
else:
arr.append("Rare Equal")

def custom_multiprocessing(i):
sample = data_sample[data_sample['random_char'] == \
unique_char[i]]
arr = []
for j in range(len(sample)):
if num1 > num2:
if num1 < 0:
arr.append("Greater Negative")
else:
arr.append("Greater Positive")
elif num2 > num1:
if num2 < 0:
arr.append("Less Negative")
else:
arr.append("Less Positive")
else:
arr.append("Rare Equal")
sample['values'] = arr
return sample
我创建了一个函数,允许我单独处理每个元音分组:
%%time
import concurrentdef main():
aggregated = pd.DataFrame()
with concurrent.futures.ProcessPoolExecutor(max_workers = 5) as executor:
results = executor.map(custom_multiprocessing, range(len(unique_char)))if __name__ == '__main__':
main()

我们看到 CPU 时间减少了 99.3%。不过,必须记住谨慎使用这些方法,因为它们不会序列化输出,因此通过分组使用它们可以很好地利用这一能力。
5. MASE 作为指标
随着时间序列预测中机器学习和深度学习方法的兴起,使用的指标不仅仅基于预测值和实际值之间的距离。预测模型的指标还应考虑时间趋势中的错误,以评估模型的表现,而不仅仅是瞬时误差估计。引入均值绝对尺度误差! 该指标考虑了如果我们使用随机游走方法,即最后一个时间戳的值将是下一个时间戳的预测值时,我们会得到的误差。它将模型的误差与天真预测的误差进行比较。
def MASE(y_train, y_test, pred):
naive_error = np.sum(np.abs(np.diff(y_train)))/(len(y_train)-1)
model_error = np.mean(np.abs(y_test - pred))return model_error/naive_error
如果 MASE > 1,则模型的表现不如随机游走。MASE 越接近 0,预测模型的效果越好。
在这篇文章中,我们介绍了一些我经常使用的技巧,以便作为数据科学家让自己的工作更轻松。评论分享你的一些技巧吧!我很想了解其他数据科学家在工作中使用的技巧。
这也是我的第一篇 Medium 文章,我感觉像是在对着虚空发言,如果你有任何反馈,请随时批评和联系我 😃
感谢 Anne Bonner。
个人简介:Shree Vandana 是亚马逊的数据科学家,拥有罗切斯特大学的数据科学硕士学位,对数据和机器学习充满热情!
原文。经许可转载。
相关:
-
如何为你的数据科学问题选择初始模型
-
ROC 曲线解释
-
如何查询你的 Pandas 数据框
相关话题
选择下一个数据科学工作的 5 个注意事项
原文:
www.kdnuggets.com/2022/01/5-things-keep-mind-selecting-next-job.html

图片来源:Jac Alexandru 在 Unsplash,(2020)
介绍
在考虑你的第一份数据科学工作或下一个数据科学职位时,你会想问自己什么是重要的。对我来说,我在数据科学领域有过几个职位,这些问题在选择下一个工作时是我认为最关键的。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT
你的团队里有 MLOps 工程师吗?
学习数据科学通常包括掌握机器学习算法,但有一个巨大的部分在学术界常被忽视,那就是这些算法的操作。这可能是因为有许多不同的方法来部署模型,而很多选项可能包括成本高昂的、已经集成到你业务中的特定平台。由于这种变异性,学校或课程可能选择不在教学大纲中包含操作部分,这是可以理解的。
话虽如此,你很可能需要问清楚这项工作是否会由你作为数据科学家负责,还是会有专门的 MLOps 工程师(或机器学习工程师等)。当然,也有一些人能够同时处理这两个部分,并且希望精通模型创建和部署的两个过程,但仅专注于算法的数据科学家也是可以的。与未来或当前的经理明确这一点尤为重要。
你会与 SQL/数据/业务分析师合作吗?
与上述考虑类似,你会想知道你的团队中是否有精通 SQL 的人员。一些数据科学职位对 SQL 的要求较少,而其他职位几乎每天都需要使用 SQL。在面试中,你需要明确你将需要使用多少 SQL,以及是否是唯一负责的人。
有时,可能会有其他人,如数据分析师、业务分析师或数据工程师,他们是 SQL 方面的专家。然而,在某些数据科学职位中,你将需要在建模过程之前和之后查询数据。
你是否需要一次只做一个项目?
一次只做一个项目在进入专业数据科学家角色之前听起来可能是个简单的任务,但它很快可能变成一个全职项目。
你可以期望在任何特定项目中进行以下一些步骤:
-
定义业务问题
-
获取数据
-
查询数据
-
特征工程(不仅仅是排名现有特征,还要提出在概念上合理的新特征)
-
模型比较/误差/准确性分析
-
AB/测试模型
-
模型部署
-
以上所有内容都可能涉及与其他人合作,例如产品经理、执行人员、软件工程师、数据工程师、AB 测试员、业务分析师、数据分析师等。
你是唯一一个在项目上工作的数据科学家吗?
在数据科学领域,有些职位的项目仅由一个人完成,而其他角色中,有几个人在同一个模型上工作。人们的工作进度不同,有的日子生产力高,有的低,并且每天与他人一起工作可能会有不同的体验。
最终你要决定自己喜欢什么,同时也要了解进入角色之前的期望。
项目完成的通常时间线是什么?
算法/模型创建的测试出奇的快。真正花费大部分时间的是在开发模型和将其集成到业务中之前和之后的部分。
时间线对于任何项目都可能波动,就像上述其他考虑因素一样,这关乎期望——获取有用结果所需的工作量。
总结
总的来说,重要的是要记住,当你面试数据科学角色(或任何角色)时,你应该同样面试他们,这些问题或考虑因素就是你可以提出和讨论的内容。此外,即使在当前角色中,你仍然可以提出一些这些问题。
总结一下,选择下一个数据科学工作时需要记住以下五件事:
-
你团队中有 MLOps 工程师吗?
-
你会与 SQL/数据/业务分析师合作吗?
-
你是否需要一次只做一个项目?
-
你是唯一一个在项目上工作的数据科学家吗?
-
项目完成的通常时间线是什么?
感谢阅读,请随时通过 LinkedIn 或 Medium 联系我。
马修·普热比拉 (Medium) 是位于德克萨斯州 Favor Delivery 的高级数据科学家。他拥有南美 Methodist 大学的数据科学硕士学位。他喜欢撰写关于数据科学领域的流行话题和教程,从新算法到数据科学家日常工作的建议。Matt 喜欢强调数据科学的商业方面,而不仅仅是技术方面。欢迎通过他的 LinkedIn 联系 Matt。
更多相关话题
5 件你需要知道的关于机器学习的事
原文:
www.kdnuggets.com/2018/03/5-things-know-about-machine-learning.html
评论
在任何快速发展的领域总有新的东西可以学习,机器学习也不例外。这篇文章将指出 5 件你可能不知道的、可能不曾意识到的,或曾经知道但现在已忘记的关于机器学习的事。
请注意,这篇文章的标题不是“最重要的 5 件事...”或“关于机器学习的前 5 件事...”;它只是“5 件事”。这不是权威或详尽的,而是 5 件可能有用的事情的集合。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织的 IT 工作
1. 数据准备占机器学习的 80%,所以...
数据准备在机器学习任务中确实占用了不成比例的时间。或者说,看起来占用了不成比例的时间。
在这些讨论中,除了执行数据准备的具体细节和其重要性原因外,常常缺乏的是为什么你应该关心数据准备。我指的不仅仅是为了获得合规的数据,而更像是哲学上的讨论,为什么你应该接受数据准备。活在数据准备中,与数据准备融为一体。
在CRISP-DM 模型中的数据准备。
我能想到的一些最佳机器学习建议是,因为你最终注定会花费大量时间准备数据以迎接大场面,所以决心成为最优秀的数据准备专业人士是一个相当不错的目标。由于这不仅耗时且对后续步骤(垃圾进,垃圾出)极为重要,拥有一个出色的数据准备者的声誉也不会是世界上最糟糕的事情。
所以,是的,虽然数据准备可能需要花费一些时间来执行和掌握,但这其实并不是一件坏事。这一必要性带来的机会,不仅可以在你的角色中脱颖而出,还有认识到你在工作中很优秀的内在价值。
若要获取更多关于数据准备的实用见解,可以从以下几个地方开始:
-
掌握 Python 数据准备的 7 个步骤
-
从零开始的 Python 机器学习工作流 第一部分:数据准备
2. 性能基准的价值
所以你使用特定算法对一些数据进行了建模,花时间调整了超参数,进行了特征工程和/或选择,并且你很高兴地发现训练准确率达到了 75%。你为自己的辛勤工作感到自豪。
但你在将结果与什么进行比较呢?如果没有基准 -- 一个简单的合理检查包括将估计器与简单的经验法则进行比较 -- 那么你实际上是在将那辛苦的工作与 空无 进行比较。合理的假设是,没有可以比较的东西,几乎任何准确度都可以被认为值得拍背。
随机猜测不是基准的最佳策略;相反,存在用于确定基准准确度的公认方法。例如,Scikit-learn 提供了一系列基准分类器,位于其 [DummyClassifier](http://scikit-learn.org/stable/modules/model_evaluation.html#dummy-estimators) 类中:
stratified通过尊重训练集类别分布来生成随机预测。most_frequent总是预测训练集中最频繁的标签。prior总是预测最大化类别先验的类别(例如,pymost_frequent`) and ``predict_proba返回类别先验。uniform生成均匀随机的预测。constant总是预测由用户提供的常量标签。
基准不仅仅适用于分类器;例如,存在用于基准回归任务的统计方法。
在进行探索性数据分析和数据准备及预处理之后,建立基准是机器学习工作流中的逻辑下一步。
3. 验证:超越训练和测试
当我们构建机器学习模型时,我们使用 训练数据 进行训练。当我们测试结果模型时,我们使用 测试数据。那么验证在哪里呢?
Rachel Thomas 在 fast.ai 最近写了一篇关于 如何及为何创建良好验证集 的深入文章。在其中,她介绍了这三种数据类型:
- 训练集用于训练给定模型
- 验证集用于在模型之间进行选择(例如,随机森林还是神经网络更适合你的问题?你想要一个有 40 棵树还是 50 棵树的随机森林?)
- 测试集告诉你你的表现如何。如果你尝试了很多不同的模型,你可能会偶然间得到一个在验证集上表现良好的模型,而有一个测试集有助于确保这不是偶然的。
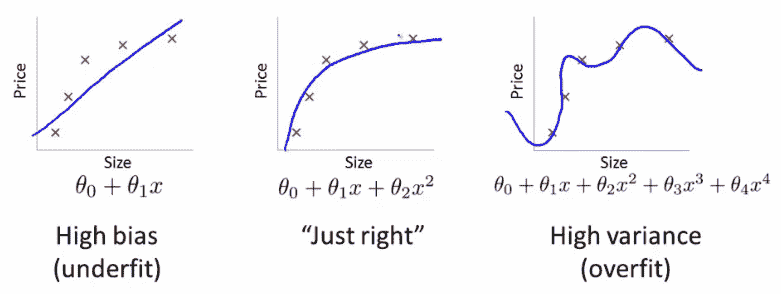
来源:斯坦福大学 Andrew Ng 的机器学习课程
那么,将数据随机拆分为测试集、训练集和验证集总是一个好主意吗?事实证明,不一定。Rachel 在时间序列数据的背景下讨论了这一点:
Kaggle 目前有一个竞赛,旨在预测厄瓜多尔连锁超市的销售情况。Kaggle 的“训练数据”涵盖了 2013 年 1 月 1 日至 2017 年 8 月 15 日,而测试数据的时间跨度为 2017 年 8 月 16 日至 2017 年 8 月 31 日。一个好的方法是将 2017 年 8 月 1 日至 8 月 15 日作为你的验证集,将所有早期的数据作为训练集。
其余部分的内容将数据集拆分与 Kaggle 竞赛数据相关联,这些是实用的信息,同时也涉及交叉验证的讨论,这部分我留给你自己去探索。
其他时候,数据的随机拆分也会有用;这取决于你获取数据时的状态(数据是否已经被拆分为训练集/测试集?),以及数据的类型(见上面的时间序列摘录)。
对于随机拆分可行的情况,Scikit-learn 可能没有 train_validate_test_split 方法,但你可以利用标准 Python 库来创建你自己的方法,例如这里提到的。
4. 集成方法不仅仅是树的集合
对于机器学习新手来说,算法选择可能是一个挑战。通常在构建分类器时,尤其是对于初学者,采用的方法会考虑单个算法的单个实例。
然而,在特定场景中,将分类器串联或分组在一起,利用投票、加权和组合的技术,以追求最准确的分类器可能会更有用。集成学习器就是以各种方式提供这种功能的分类器。
随机森林是一个非常突出的集成学习器的例子,它在单一预测模型中使用了大量的决策树。随机森林已经成功地应用于许多问题,并因此受到赞誉。但它们并不是唯一存在的集成方法,还有许多其他方法也值得一看。
Bagging 的操作原理很简单:构建多个模型,观察这些模型的结果,然后选择多数结果。我最近在车的后轴组件上遇到了问题:我对经销商的诊断不太信服,于是把车送到了另外 2 家车库,这两家车库都认为问题与经销商所说的不同。瞧。Bagging 在实际应用中。随机森林基于修改过的 bagging 技术。
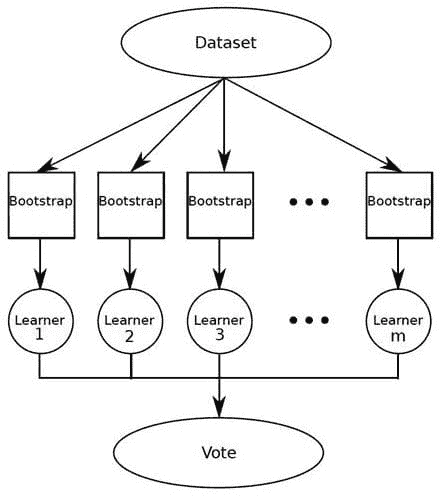
Bagging,或自助聚合。
Boosting 与 bagging 类似,但有一个概念上的修改。与给模型分配相等的权重不同,boosting 为分类器分配不同的权重,并根据加权投票得出最终结果。
再次考虑我的汽车问题,或许我曾经去过某个特定的车库多次,并且稍微更信任他们的诊断。此外,假设我对与经销商的先前互动不太满意,并且对他们的见解不太信任。我分配的权重将会反映这种情况。
Stacking 与之前的两种技术略有不同,因为它训练多个单一分类器,而不是相同学习器的不同版本。虽然 bagging 和 boosting 使用使用同一种分类算法(例如决策树)的多个模型,stacking 则使用不同的分类算法(可能是决策树、逻辑回归、人工神经网络或其他组合)来构建模型。
随后,训练一个组合算法来利用其他算法的预测做出最终预测。这个组合器可以是任何集成技术,但逻辑回归通常被发现是一种有效且简单的组合算法。除了分类,堆叠也可以应用于无监督学习任务,如密度估计。
了解更多细节,请阅读这篇关于集成学习者的介绍。你可以在这篇非常详尽的教程中阅读更多关于在 Python 中实现集成学习的内容。
5. Google Colab?
最后,让我们来看一些更实用的内容。Jupyter Notebook 已经成为一个事实上的数据科学开发工具,大多数人都在本地或通过其他需要大量配置的方法(如 Docker 容器或虚拟机)运行 Notebook。Google 的 Colaboratory 是一个可以直接在你的 Google Drive 中运行 Jupyter 风格和兼容的 Notebook 的项目,无需配置。
Colaboratory 预配置了许多流行的 Python 库,并且可以在 Notebook 中安装更多库,这得益于支持的包管理。例如,TensorFlow 已包含在内,但 Keras 尚未包含,然而通过 pip 安装 Keras 只需几秒钟。
在可能是最好的消息中,如果你正在使用神经网络,你可以免费使用 GPU 硬件加速进行训练,每次最长可达 12 小时。这并不是一剂灵丹妙药,但它是一个额外的好处,也是实现 GPU 访问民主化的良好开端。
阅读 3 个必备的 Google Colaboratory 提示与技巧 了解如何充分利用 Colaboratory 的云端笔记本。
相关:
-
数据科学你需要知道的 5 件事
-
掌握 Python 机器学习的 7 个步骤
-
你可能不知道的 4 个机器学习和人工智能的应用
相关主题
构建 LLM 应用时需要了解的 5 个事项
原文:
www.kdnuggets.com/2023/08/5-things-need-know-building-llm-applications.html
基于 LLM 的应用程序无疑可以为多个问题提供宝贵的解决方案。然而,了解和积极应对诸如幻觉、提示上下文、可靠性、提示工程和安全性等挑战,将在发挥 LLM 的真正潜力的同时,确保最佳性能和用户满意度。在本文中,我们将深入探讨这些构建 LLM 应用程序时开发人员和从业者需要了解的五个关键考虑因素。

图片由Nadine Shaabana拍摄,来源于Unsplash
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT 方面的工作
1. 幻觉

图片由Ehimetalor Akhere Unuabona拍摄,来源于Unsplash
使用 LLM 时需要注意的主要方面之一是幻觉。在 LLM 的上下文中,幻觉指的是生成虚假的、不正确的、无意义的信息。LLM 非常有创造力,可以用于和调整到不同的领域,但仍然存在一个非常关键的未解决问题,那就是它们的幻觉。由于 LLM 不是搜索引擎或数据库,因此这些错误是不可避免的。
为了克服这个问题,可以通过提供足够的细节和限制条件来控制生成,以限制模型产生幻觉的自由。
2. 选择合适的上下文
如前所述,解决幻觉问题的一种方法是为输入提示提供适当的上下文,以限制 LLM 的幻觉自由。然而,另一方面,LLM 对可以使用的单词数量有限。解决这个问题的一种可能方法是使用索引,将数据转换为向量并存储在数据库中,并在运行时搜索适当的内容。索引通常有效,但实现起来较为复杂。
3. 可靠性和一致性
如果你基于大语言模型(LLM)构建应用程序,你将面临一个问题,那就是可靠性和一致性。LLM 并不可靠,也不一致,无法确保每次模型输出都是正确的或符合预期的。你可以构建一个应用程序的演示并多次运行它,但当你正式发布应用程序时,你会发现输出可能不一致,这会给用户和客户带来很多问题。
4. 提示工程不是未来
与计算机沟通的最佳方式是通过编程语言或机器语言,而不是自然语言。我们需要明确的指令,以便计算机理解我们的要求。LLM 的问题在于,如果你用相同的提示要求 LLM 做一件特定的事情十次,你可能会得到十个不同的输出。
5. 提示注入安全问题 A
当构建基于 LLM 的应用程序时,你将面临的另一个问题是提示注入。在这种情况下,用户会强迫 LLM 给出某个不符合预期的输出。例如,如果你创建了一个生成 YouTube 视频脚本的应用程序,用户可以指示 LLM 忘记一切并编写一个故事。
总结
构建 LLM 应用程序非常有趣,可以解决多个问题并自动化许多任务。然而,它也带来了一些在构建基于 LLM 的应用程序时需要处理的问题。从幻觉开始,到选择正确的提示上下文以克服幻觉和输出的可靠性和一致性,再到提示注入的安全问题。
参考文献
尤瑟夫·拉法特 是一位计算机视觉研究员和数据科学家。他的研究重点是开发用于医疗保健应用的实时计算机视觉算法。他还在营销、金融和医疗保健领域担任了超过 3 年的数据科学家。
相关主题
关于 PyCaret 的 5 件你不知道的事
评论
作者:Moez Ali,PyCaret 创始人及作者

来自 PyCaret 的作者
PyCaret
PyCaret 是一个开源的 Python 机器学习库,用于在低代码环境中训练和部署监督和无监督机器学习模型。它以易用性和高效性著称。
与其他开源机器学习库相比,PyCaret 是一个低代码库,可以用少量的代码替代数百行代码。
如果你以前没有使用过 PyCaret 或想了解更多,可以从这里开始。
“在与许多每天使用 PyCaret 的数据科学家交谈后,我筛选出了 5 个较少为人知但非常强大的 PyCaret 特性。”
— Moez Ali
你可以在无监督实验中调整“n 参数”。
在无监督机器学习中,“n 参数”即聚类实验中的簇数、异常检测中的离群点比例以及主题建模中的主题数量,是至关重要的。
当实验的最终目标是使用无监督实验的结果来预测结果(分类或回归)时,pycaret.clustering 模块、pycaret.anomaly 模块和pycaret.nlp模块中的 tune_model() 函数会非常有用。
为了理解这一点,让我们使用“Kiva”数据集来看一个例子。
这是一个微型银行贷款数据集,每一行代表一个借款人及其相关信息。‘en’列捕获每个借款人的贷款申请文本,‘status’列表示借款人是否违约(违约 = 1,未违约 = 0)。
你可以使用tune_model函数在pycaret.nlp中优化num_topics参数,基于监督实验的目标变量(即预测所需的最佳主题数量以提高最终目标变量的预测)。你可以通过estimator参数定义训练模型(在这种情况下为‘xgboost’)。该函数返回一个训练好的主题模型和一个显示每次迭代的监督指标的可视化图。
tuned_lda = tune_model(model='lda', supervised_target='status', estimator='xgboost')
通过增加“n_iter”可以改善超参数调整的结果。
pycaret.classification模块和pycaret.regression模块中的tune_model函数使用随机网格搜索而非预定义网格搜索进行超参数调优。这里默认的迭代次数设置为 10。
tune_model的结果不一定会优于使用create_model创建的基础模型的结果。由于网格搜索是随机的,你可以增加n_iter参数来提高性能。参见下面的示例:
#tune with default n_iter i.e. 10
tuned_dt1 = tune_model('dt')
#tune with n_iter = 50
tuned_dt2 = tune_model('dt', n_iter = 50)
????你可以以编程方式定义数据类型
当你初始化setup函数时,你将被要求通过用户输入确认数据类型。当你作为工作流的一部分运行脚本或将其作为远程内核(例如 Kaggle Notebooks)执行时,这种情况下需要以编程方式提供数据类型,而不是通过用户输入框。
参见下面使用 “insurance” 数据集的示例。

# import regression module
from pycaret.regression import *
# init setup
reg1 = setup(data, target = 'charges', silent=True,
categorical_features=['sex', 'smoker', 'region', 'children'],
numeric_features=['age', 'bmi'])
silent 参数设置为 True 以避免输入,categorical_features 参数以字符串形式接收分类列的名称,numeric_features 参数以字符串形式接收数值列的名称。
????你可以忽略某些列进行模型构建
在许多情况下,你的数据集中有些特征你不一定想要删除,但希望在训练机器学习模型时忽略它们。一个好的例子是聚类问题,在创建集群时你想要忽略某些特征,但后来你需要这些列来分析集群标签。在这种情况下,你可以在setup中使用ignore_features参数来忽略这些特征。
在下面的示例中,我们将进行一个聚类实验,并希望忽略‘Country Name’和‘Indicator Name’。
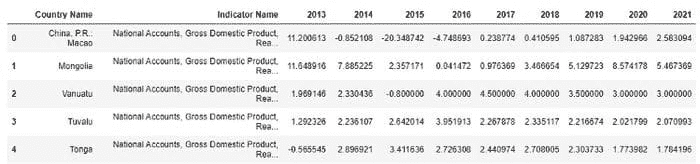
from pycaret.clustering import *
clu1 = setup(data, ignore_features = ['Country Name', 'Indicator Name'])
????你可以在二分类中优化概率阈值%
在分类问题中,假阳性的成本几乎从来不与假阴性的成本相同。因此,如果你正在优化一个商业问题的解决方案,其中类型 1和类型 2错误的影响不同,你可以通过分别定义真正例、真负例、假阳性和假阴性的成本来优化分类器的概率阈值,以优化自定义损失函数。默认情况下,所有分类器的阈值为 0.5。
参见下面使用 “credit” 数据集的示例。
# Importing dataset
from pycaret.datasets import get_data
credit = get_data('credit')
# Importing module and initializing setup
from pycaret.classification import *
clf1 = setup(data = credit, target = 'default')
# create a model
xgboost = create_model('xgboost')
# optimize threshold for trained model
optimize_threshold(xgboost, true_negative = 1500, false_negative = -5000)
然后您可以将 0.2 作为 probability_threshold 参数传递到 predict_model 函数中,以使用 0.2 作为分类正类的阈值。请参见下面的示例:
predict_model(xgboost, probability_threshold=0.2)
PyCaret 2.0.0 即将推出!
我们收到了数据科学社区的热烈支持和反馈。我们正在积极改进 PyCaret 并为下一个版本做准备。PyCaret 2.0.0 将更大更好。如果您想分享反馈并进一步帮助我们改进,可以在网站上 填写此表单 或在我们的 GitHub 或 LinkedIn 页面留下评论。
关注我们的 LinkedIn 并订阅我们的 YouTube 频道,以了解更多关于 PyCaret 的信息。
想了解特定模块吗?
自第一次发布 1.0.0 版本以来,PyCaret 提供了以下模块供使用。点击下面的链接查看 Python 中的文档和工作示例。
另见:
PyCaret 入门教程在 Notebook 中:
想贡献吗?
PyCaret 是一个开源项目。欢迎大家贡献。如果您想贡献,请随时处理 开放问题。接受带有单元测试的 dev-1.0.1 分支的拉取请求。
如果你喜欢 PyCaret,请在我们的 GitHub repo 上给我们 ⭐️。
Medium: medium.com/@moez_62905/
LinkedIn: www.linkedin.com/in/profile-moez/
Twitter: twitter.com/moezpycaretorg1
个人简介: Moez Ali 是数据科学家,同时也是 PyCaret 的创始人和作者。
原文。经许可转载。
相关:
-
宣布 PyCaret 1.0.0
-
在 Power BI 中使用 PyCaret 进行机器学习
-
在 AWS Fargate 上部署机器学习管道
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织的 IT
更多相关话题
关于强化学习的 5 个重要事项
原文:
www.kdnuggets.com/2018/03/5-things-reinforcement-learning.html
评论
强化学习是当前最热门的研究主题之一,它的受欢迎程度日益增长。让我们来看一下关于强化学习的 5 个有用的知识点。
- 什么是强化学习?它如何与其他机器学习技术相关?
强化学习(RL)是一种机器学习技术,使代理能够通过试错法在互动环境中学习,利用其自身行动和经验的反馈。
尽管监督学习和强化学习都使用输入和输出之间的映射,但不同于监督学习中代理收到的是执行任务的正确动作集合,强化学习使用奖励和惩罚作为正面和负面行为的信号。
与无监督学习相比,强化学习在目标上有所不同。无监督学习的目标是找到数据点之间的相似性和差异性,而强化学习的目标是找到一个合适的动作模型,以最大化代理的总累计奖励。下图表示了强化学习模型中的基本思想和元素。
图 1
- 如何制定基本的强化学习问题?
描述 RL 问题元素的一些关键术语包括:
环境:代理操作的物理世界
状态:代理的当前情况
奖励:来自环境的反馈
策略:将代理的状态映射到动作的方法
价值:代理在特定状态下采取某个动作所获得的未来奖励
强化学习问题可以通过游戏来最好地解释。以《吃豆人》游戏为例,代理(吃豆人)的目标是吃掉网格中的食物,同时避开幽灵。网格世界是代理的互动环境。吃豆人吃到食物会获得奖励,被幽灵杀死(输掉游戏)则会受到惩罚。状态是吃豆人在网格世界中的位置,总累计奖励是吃豆人赢得游戏。
为了建立一个最佳策略,代理面临在探索新状态的同时最大化奖励的困境。这被称为探索与利用的权衡。
马尔可夫决策过程(MDPs)是描述强化学习环境的数学框架,几乎所有的 RL 问题都可以用 MDP 进行形式化。一个 MDP 由一组有限的环境状态 S、一组在每个状态下的可能动作 A(s)、一个实值奖励函数 R(s)和一个转移模型 P(s’,s | a)组成。然而,现实世界的环境往往缺乏关于环境动态的先验知识。在这种情况下,无模型的 RL 方法非常有用。
Q 学习是一种常用的无模型方法,可用于构建自我对弈的 PacMan 代理。它围绕更新 Q 值的概念展开,这些 Q 值表示在状态s下执行动作a的价值。价值更新规则是 Q 学习算法的核心。

图 2: 强化学习更新规则

图 3: PacMan
这是一个视频,展示了一个深度强化学习的 PacMan 代理
- 一些最常用的强化学习算法有哪些?
Q 学习和 SARSA(状态-动作-奖励-状态-动作)是两种常用的无模型 RL 算法。它们在探索策略上有所不同,而在利用策略上则相似。Q 学习是一种离策略方法,其中代理基于从另一策略中派生的动作 a来学习价值,而 SARSA 是一种在策略方法,其中代理基于当前策略中派生的当前动作a*来学习价值。这两种方法简单易实现,但缺乏通用性,因为它们无法估计未见过状态的值。
这可以通过更先进的算法来克服,例如使用神经网络来估计 Q 值的深度 Q 网络(DQN)。但 DQN 只能处理离散的低维动作空间。DDPG(深度确定性策略梯度)是一种无模型、离策略、演员-评论家算法,通过在高维连续动作空间中学习策略来解决这个问题。
图 4: 强化学习的演员-评论家架构
- 强化学习的实际应用有哪些?
由于强化学习(RL)需要大量数据,因此它最适用于那些模拟数据随手可得的领域,如游戏和机器人技术。
-
强化学习在构建用于玩计算机游戏的人工智能方面被广泛使用。AlphaGo Zero是第一个击败围棋世界冠军的计算机程序。其他包括 ATARI 游戏、双陆棋等。
-
在机器人技术和工业自动化中,强化学习用于使机器人创建一个高效的自适应控制系统,该系统通过自身的经验和行为进行学习。DeepMind 的工作在异步策略更新的机器人操作中的深度强化学习是一个很好的例子。
-
观看这个有趣的演示视频。
-
强化学习的其他应用包括文本摘要引擎、对话代理(文本、语音),这些代理能够从用户互动中学习并随着时间的推移不断改进,医疗保健中的最佳治疗政策学习,以及基于强化学习的在线股票交易代理。
- 我如何开始强化学习?
要理解强化学习的基本概念,
-
强化学习导论,这是强化学习之父理查德·萨顿和他的博士生导师安德鲁·巴托合著的一本书。该书的在线草稿可以在这里找到
incompleteideas.net/book/the-book-2nd.html -
教学材料由大卫·西尔弗提供,包括视频讲座,是入门强化学习的绝佳课程。
-
这是彼得·阿贝尔和约翰·舒尔曼(Open AI/伯克利人工智能研究实验室)提供的另一个技术教程。
-
要开始构建和测试强化学习代理,
-
这个博客由安德烈·卡帕西撰写,讲述了如何通过策略梯度从原始像素中训练一个神经网络 ATARI Pong 代理,它将帮助你用仅 130 行 Python 代码启动你的第一个深度强化学习代理。
-
DeepMind Lab 是一个开源的类似 3D 游戏的平台,专为基于代理的人工智能研究创建,具有丰富的模拟环境。
-
Project Malmo 是另一个人工智能实验平台,用于支持人工智能的基础研究。
-
OpenAI gym 是一个用于构建和比较强化学习算法的工具包。
简历:Shweta Bhatt 是一位在私营和公共部门有经验的人工智能研究员,热衷于从数据中提取知识以解决具有挑战性的问题。她喜欢用数据讲故事,现居伦敦。
相关:
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 维护
更多相关话题
接受数据科学家职位前需要审查的 5 件事
原文:
www.kdnuggets.com/2019/05/5-things-review-before-accepting-data-scientist-job-offer.html
评论

如果你正在阅读这篇文章,你可能已经收到了至少一个数据科学职位的录用通知。祝贺你!这本身就是一种成就,特别是考虑到数据科学职位市场的竞争激烈。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
但在你过于兴奋并签署确认你新职位的文件之前,有些事情需要先检查。以下是其中的五个:
1. 薪资
根据 PayScale,数据科学家的平均薪资为$92,949。对于入门级职位,这一数字降至$88,973。希望你在开始求职之前,已经研究过与自己经验相当的数据科学家的薪资。如果没有,现在是时候获取这些数据,并看看它们与工作报价的对比情况。
考虑生活成本等因素,尤其是当工作要求你搬到一个新地方时。此外,评估你是否需要忍受长时间的通勤来每天上班。是否有公共交通线路可用?回答这些问题可以帮助你确定所提供的薪水是否能让你过上舒适的生活。
当你处于谈判阶段时,公司可能会问,“这个工作对你来说值多少钱?”即使这看起来是一个随意的问题,它也可能是为了看看你是否会接受一个较低的数字。
2. 其他福利
薪资无疑是关键,但在考虑数据科学公司为员工提供的条件时,你也应该采取全局的视角。Label Insight 是一家利用数据科学提升食品标签透明度的公司。它还为团队成员提供了优秀的福利,包括无限的假期、宠物友好的工作环境和配备齐全的厨房,以及更多常规福利,如补贴健康保险。
考虑一下哪些因素会使数据科学公司成为理想的工作场所,并评估提供该职位的公司是否符合这些偏好。也许你希望每周能有一天在家工作,或者希望公司能经常为员工支付参加数据科学会议和课程的费用。
如果公司没有提供你希望的大部分或至少几个福利,这不一定是拒绝报价的理由,但可能会成为谈判的事项。例如,公司可能没有为所有员工制定远程工作政策,但也许你的角色比大多数人更适合独立工作。
3. 你是否是随意雇佣员工
宾夕法尼亚州是一个随意雇佣州,与弗吉尼亚州、德克萨斯州和其他 11 个州一样。这意味着,如果你住在这些州之一,合同标识为随意雇佣员工,你的雇主可以因任何理由或没有理由解雇你。如果看到合同中有可能随时终止的条款,请仔细考虑是否接受该工作。
有些公司决定投资数据科学主要是为了跟上竞争对手。但它们通常没有具体计划说明如何使用数据科学或数据如何帮助解决具体问题。
在这种情况下,想象一下如果你认为合同至少会持续三年,但随意雇佣条款允许雇主终止你,而他们确实这样做了,因为他们的数据科学期望没有实现,这种困扰会有多大。这可能是由于资源不足,而非你个人的失败。但随意雇佣条款仍可能导致你失去工作。
4. 工作职责
工作内容可能已经在你之前的很多讨论中出现过。但你仍然应该仔细查看工作邀请,确保一切如你所预期。在查看职位细节时,你可能会注意到一些红旗。例如,合同可能写着你将是公司唯一涉及数据科学的人。
或者,也许人力资源代表提到公司希望启动高级分析程序,但合同上却写着你是该项目的团队负责人,只需指导另外两个人。在这种情况下,任务可能过于庞大,你应寻找其他工作机会。
理想的工作应该挑战你,但不会让你觉得自己不断追求不可能的期望。即使你在数据科学班级中名列前茅或有多年经验,如果现有资源与工作要求不符,你也难以获得成功。
5. 工作时间
工作合同中还应说明此职位每周涉及的小时数。此外,还要检查合同以了解如果加班会发生什么情况。
在美国,联邦法律规定,如果你是符合领取加班费的员工,你将获得基本工资加 50%——通常称为时间和一半。然而,并非所有工人都能获得加班费。作为数据科学自由职业者或每小时收入超过某一额度可能意味着你无法获得加班费。
你的数据科学角色可能会要求你偶尔在平常工作时间之外工作,例如完成一个有紧迫截止日期的项目。但如果你没有加班费,考虑到你可能会因为为了薪资而过度工作,进而对这份看似理想的工作产生反感。
谨慎会带来结果
在收到工作邀请后,几乎立刻接受是很有诱惑的。但最好的做法是要求时间审视,并评估上述因素以及其他对你重要的因素。这样展示的谨慎帮助你判断这份工作是否适合你。
简介:Kayla Matthews 在《The Week》、《The Data Center Journal》和《VentureBeat》等出版物上讨论技术和大数据,已有五年以上的写作经验。要阅读更多 Kayla 的文章,订阅她的博客 Productivity Bytes。
原创。已获授权转载。
相关:
-
如何识别一个好的数据科学家职位与不好的职位
-
数据科学家的日常生活
-
如何自行 DIY 数据科学教育
更多相关主题
区分数据科学家与其他职业的五大特点
原文:
www.kdnuggets.com/2021/11/5-things-set-data-scientist-apart-other-professions.html

由 pressfoto 提供的照片,来源于 www.freepik.com
我最近写了一篇文章,标题为 数据科学家、数据工程师及其他数据职业解析,在文章中我尽力简明扼要地定义和区分了五种流行的数据相关职业。每种职业在文章中都进行了非常高水平的单句总结,数据科学家则被描述如下:
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业领域
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
数据科学家主要关注数据、从数据中提取的见解以及数据能够讲述的故事。
除了我为每个职业写的额外几段文字外,我试图找出一个统一的区别特征,这五个特征可以整合成一个流程图,或许能帮助有志于数据行业的人确定哪个职业最适合他们。
我收到一些读者的反馈,明显表明我过于强调预测分析作为数据科学家职业的定义特征,这可能让人觉得数据科学家比其他职业更多地从事预测分析,而其他数据专业人员则完全不涉及这方面的工作。
这种建设性的批评自然让我思考:究竟是什么使数据科学家与其他数据专业人士有所区别?数据科学家使用了许多技术技能、特定的技术语言、系统和工具。此外,数据科学家以及其他各种职业的专业人员也运用了许多软技能来提升职业表现。那么,成功的数据科学家有哪些固有特征,是数据科学家与生俱来的,还是可以在进入这一职业后培养的?
以下是我提出的五个方面,当它们综合在一起时,有助于使数据科学家与其他职业区分开来。
让我们先说明一点,所有的数据科学家角色都是不同的,但它们都有一些共同的联系点,希望这些观点能够帮助你连接这些联系点。
1. 预测分析思维
我因为对这个特点的关注而受到了一些批评。然而,我会进一步强调,预测分析思维是数据科学家的主要定义特征之一,可能比其他任何特征都更重要。它是唯一的定义特征吗?当然不是。它是否应该在流程图中用于区分数据科学家与其他职业?回过头来看,可能不应该。
数据科学家进行预测分析吗?绝对是。非数据科学家也会吗?当然。然而,如果我把数据科学家放在预测分析的跷跷板一端,把<插入其他数据专业人员>放在另一端,我预计数据科学家会始终落地。
但这不仅仅是预测分析在特定情况中的应用;这是一种思维方式。而且这不仅仅是分析型思维(减去预测),而是一种始终考虑如何利用我们已经知道的来发现我们尚未知晓的事物的思维方式。这表明预测是方程式的一个重要组成部分。
数据科学家不仅仅考虑预测,从我的观点来看,始终以这种思维方式工作是这个角色的定义特征之一,而许多其他职业,无论是否与数据相关,都不具备这种特征。那些具备这种特征的其他职业,可能会将其列在职业价值的较低位置。
2. 好奇心
显然,仅仅利用我们所知道的来发现我们不知道的还不够。数据科学家必须具备其他角色不一定需要的好奇心(请注意,我没有说其他角色绝对没有这种好奇心)。好奇心几乎是预测分析思维的另一面:预测分析思维在寻找X与Y的关系,而好奇心则是在确定Y是什么。
-
“我们如何增加销售?”
-
“为什么某些月份的流失率高于其他月份?”
-
“为什么这需要像那样做?”
-
“如果我们对 Y 做 X,会发生什么?”
-
“X 是如何融入这里发生的事情中的?”
-
“我们尝试过...吗?”
-
诸如此类...
要成为一名有用的数据科学家,必须具备自然的好奇心,事情就是这样。如果你是那种早上醒来后整天都不会考虑宇宙奇观的人——无论从哪个层面——那么数据科学可能不适合你。
在失败之前,好奇心为猫的长期成功职业生涯做出了贡献。
3. 系统思维
这里有一段严肃的哲学观点:世界是一个复杂的地方。一切以某种方式相互连接,远超显而易见的层面,导致现实世界的复杂性层层叠加。复杂系统与其他复杂系统互动,从而产生它们自身的额外复杂系统,宇宙如此运作。这种复杂性游戏不仅仅是认识大局:这个大局如何融入更大的背景,等等。
但这不仅仅是哲学层面的。数据科学家认识到这个现实世界的无限复杂网络。他们对相关的互动,无论是显性还是隐性,都非常感兴趣,因为他们在解决问题的过程中要了解尽可能多的相关信息。他们寻找情况依赖的已知已知、已知未知和未知未知,理解任何给定的变化都可能在其他地方产生意想不到的后果。
数据科学家的工作是尽可能多地了解他们相关系统的情况,并利用他们的好奇心和预测分析思维来考虑这些系统操作和交互的尽可能多的方面,以确保即使在调整时也能平稳运行。如果你不能理解为什么没有一个人能够完全解释经济如何运作,那么数据科学可能不适合你。
4. 创造力
现在我们到了必需的“跳出框框思考”特质。难道我们不鼓励每个人在某种程度上这样做吗?当然是的。但我在这里的意思有所不同。
记住,数据科学家并不是在真空中工作;我们与各种不同角色合作,并在我们的工作中遇到各种不同的领域专家。这些领域专家对他们特定领域有特定的看法,即使在跳出框框思考时也是如此。作为数据科学家,凭借一套独特的技能和一种特定的思维方式——我在这里尽力描述的——你可以从领域专家所在的框框之外来解决问题。你可以成为用新视角看待问题的新鲜眼光——当然,前提是你对问题有足够的理解。你的创造力将帮助你想出新的想法和视角。
这并不是要贬低领域专家;实际上,恰恰相反。我们数据科学家是他们的支持,通过带来一套经过训练的技能,我们(希望)能够在支持角色中带来新的视角,从而帮助领域专家在他们的领域中出类拔萃。这种新视角将由数据科学家的创造性思维驱动,这种创造力与好奇心相结合,将导致能够提出问题并追寻答案。
当然,我们需要技术、统计和其他技能来跟进这些问题,但如果我们没有创造力来想到有趣和非显而易见的方式来调查并最终提供答案,这些技能也将毫无用处。这就是为什么数据科学家必须天生具有创造力。
5. 讲故事的敏感性
每个人都需要能够有效地与他人沟通,无论他们的社会地位如何。数据科学家也不例外。
但即便如此,数据科学家在向其他利益相关者解释他们的工作时,往往还需要进行一些辅助,因为这些利益相关者可能并未 — 也可能无意 — 完全融入统计分析的电影宇宙™。数据科学家必须能够将某人从 A 点讲解到 B 点,即使这个人对这两个点到底是什么知之甚少。直言不讳地说,讲故事就是能够将数据和你的分析过程编织成一个现实的叙述:我们是如何从这个到那个的。
这不仅仅是陈述事实;数据科学家必须看到利益相关者在方程中的位置,并使叙述旅程相关——也许通过有用的视觉图像或其他道具来帮助完成所谓的交易。
这种讲故事方式不同于虚构故事;它更像是“华丽的解释”,或者是针对听众提供直观的解释。你不会给五岁的孩子讲斯蒂芬·金的故事入睡,就像你不会给从事研发的人讲解供应链指标的枯燥、冗长的叙述一样。要注意你的受众。
这种讲故事方式也不是说服性质的;它是解释性的。我们不是数据政治家,我们是数据科学家。科学家为了使他人屈从于自己的意愿而歪曲统计数据,永远不会有好结果。那种事留给当选官员去做吧。
我希望这有助于描绘出我认为成功的数据科学家应具备的重要特征。我祝愿你在职业生涯中一切顺利。
Matthew Mayo (@mattmayo13) 是数据科学家和 KDnuggets 的主编,KDnuggets 是一个重要的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。你可以通过 editor1 at kdnuggets[dot]com 联系他。
进一步阅读此主题
5 个获得第一份数据科学家工作的技巧
原文:
www.kdnuggets.com/2021/11/5-tips-first-data-scientist-job.html
评论
由 Renato Boemer 提供,Renato Boemer

由 Sam Dan Truong 拍摄,来源于 Unsplash
所以,你已经学习了一段时间的数据科学,并且现在期待迈出下一步:获得你的第一份数据科学家的工作。然而,如果这不是你第一次找工作,那么这可能是你第一次申请与之前职业无关的角色。那么,为什么不从他人的错误中学习呢?
在我关于 转行数据科学 的帖子中,我开始于 DataQuest 的在线学习。然后,在今年早些时候,我做出了职业生涯中的最佳决定之一:我报名参加了 Le Wagon 训练营——我还写了一篇 帖子 讲述了这件事。虽然训练营本质上是密集的,但任何职业转变中最困难的部分是获得你的“第一份工作”。
最近,我加入了一家名为 Nextdoor 的公司,担任位于英国伦敦的数据科学家。但找到第一份数据科学家工作的过程绝非易事。我申请了超过五十个职位,进行了几次面试,其中一些是纯技术面试或包括现场编码。在这个过程中,我学到了很多东西,并希望分享五个可能帮助你找到第一份数据科学家工作的技巧:
1- 自我意识
这看似显而易见,但不幸的是,很难识别你不知道的东西。更糟糕的是,你可能认为你知道,但其实并不了解。让我举个例子:在训练营期间,我使用 Scikit-learn 的逻辑回归创建了几个机器学习模型。我几乎是直观地调整惩罚参数,特别是在 l1 和 l2 之间,它们分别指代 Lasso 和 Ridge。到目前为止一切顺利。
在我的第一次面试中,我决定抛出一些概念来展示知识,但结果适得其反。当我试图解释这些概念的区别时,我意识到自己知道如何应用它们,但并不理解背后的概念(更不用说数学了)。不用说,我没有获得那份工作。我的建议是深入研究几个项目,直到你能逐行理解自己的代码。尝试向其他同事解释、在模拟面试中说明你选择每个模型、参数的原因。你会发现许多可以在面试前填补的知识空白。这样,你也会听起来很流利,使用正确的术语,并在解释你的工作时感到自信。
2- 向他人学习
如果你认真对待在头几个月内获得数据科学家的工作,那么你应该向那些有丰富经验的人学习。教师和助教是绝佳的信息来源,因此每天都要与他们交谈。询问有关招聘流程、面试以及如何与招聘人员交流以了解更多关于公司和职位的信息。
此外,我和另外两个训练营的校友创建了一个 Slack 频道。在这个频道中,我们分享我们的简历、求职信、面试和测试的反馈。我们讨论面试问题和答案,并且我们总是分享我们的代码和笔记本以互相帮助。不要害怕分享你的工作,而是学会合作。毕竟,你有相同的目标:尽快成为数据科学家。

图片来源: JESHOOTS.COM 在 Unsplash
3- 学习动机超过编码技能
对任何招聘人员来说,你没有“商业经验”作为数据科学家应该是一个惊讶的事情。仅仅通过查看你的简历,任何人都可以看出你正在寻求你的第一份工作。也就是说,不要试图将自己推销为一位专家数据科学家(通过 Kaggle 项目),在这个阶段这不是你最宝贵的技能。
在我收到 Nextdoor 的录取通知后,人力资源经理给了我每一次面试的反馈。这可以总结为一个“优点”和一个“缺点”:我渴望学习,但没有编码经验。我了解到招聘经理们寻找的是那些渴望学习新事物并跟上行业发展的人员。
因此,展示你是一个好奇的人,你喜欢学习数据相关话题的过程,并且你每天都在练习编码。展示你对数据、计算机科学、统计学领域的热情。你的动力和对持续学习的承诺将(并且应该)超过你当前的编码技能。
4- 知道你想要什么
了解你想要什么而没有经历过它是有些抽象的。你怎么知道你想成为数据科学家,而不是机器学习工程师、数据工程师或数据分析师?起初,这些职位看起来都很相似,也许你会接受其中任何一个作为你的第一份工作。嗯,这就是我最初的想法,而这是一个错误。
求职阶段的关键区别在于面试的准备。如果你知道你想要一个数据科学家职位,确保你确切知道数据科学家做什么。在研究过程中,一些细微差别将开始显现。例如,数据科学家往往不使用由数据分析师使用的 Tableau,或由数据工程师使用的 Docker。你不需要掌握广泛的数据科学知识,而是可以提高你在新工作中需要的知识深度。一些示例包括 Pandas、Numpy、Scikit-learn 的线性和逻辑回归、matplotlib 和 seaborn。如果你掌握了这些,我相信你很快就会找到数据科学家职位。
**5- 学会接受拒绝
我不能过于强调这一点:请学会接受招聘人员、招聘经理和公司的拒绝。在寻求你第一个数据科学家职位的过程中,你会充满动力,什么也不能阻挡你。
然而,随着时间的推移,拒绝不断涌入你的收件箱,你的动力水平不可避免地会下降。数据科学家职位有很多,同时候选人数量也在增加。此外,招聘过程很慢,但从候选人的角度来看更慢。我在新工作后收到拒绝邮件。这是正常的,接受拒绝。
保持动力的一个方法是与一群正在经历相同过程的朋友分享。正如我之前所说,创建一个与其他校友的 Slack 频道,分享你的挫折。我相信他们也正在经历相同的事情。这很重要,因为你会发现你并不是编程不行,只是时间、坚持和努力的问题。
永不放弃!
想要获取 Medium 文章的完整访问权限并支持我的工作?每月仅需 5 美元。请使用下面的链接订阅:
通过我的推荐链接加入 Medium — Renato Boemer
以下是一些你可能感兴趣的文章:
提升生产力:使用 Python 和 Pandas 进行数据清理
简介:Renato Boemer 是一位以影响力为导向的数据科学专业人士,拥有创新和营销背景,使他能够将统计学、编程和商业洞察力相结合。
原文。转载已获许可。
相关:
-
数据科学家职业路径从新手到第一份工作
-
数据科学家:如何推销你的项目和你自己
-
数据科学家的虚拟演讲技巧
相关话题更多内容
5 个有效数据可视化的技巧
原文:
www.kdnuggets.com/5-tips-for-effective-data-visualization

图片来源:编辑 | Midjourney
你是否曾想过如何将数据转化为清晰且有意义的见解?数据可视化正是实现这一目标的工具。它们将复杂的信息转化为简单的视觉图表,使每个人都能快速理解。本文将探讨五个技巧,帮助你创建强大的数据可视化图表。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
1. 了解你的受众
了解你的受众是有效数据可视化的关键。根据他们的需求和期望调整你的视觉图表。根据观众的背景、角色和兴趣来识别他们。例如,投资者关注财务指标,而管理者则优先考虑运营效率。根据你的受众调整细节层次。专家可能需要深入的数据分析,而决策者则更喜欢用于战略决策的清晰总结。考虑受众的首选格式。有些人喜欢互动仪表盘,其他人则偏好静态信息图或详细报告。例如,营销团队可能会更喜欢互动仪表盘来跟踪实时的广告活动绩效指标。与此同时,公关团队可能发现静态信息图对于直观展示媒体覆盖率非常有用。确保每个人都能访问数据。考虑语言能力和视觉障碍等因素。
2. 选择合适的视觉图表
不同类型的视觉图表各有其优点。选择适合的图表对于每个目的来说都非常重要。
使用折线图来显示随时间变化的趋势。在提供的示例中,折线图用于绘制多年来的销售趋势。
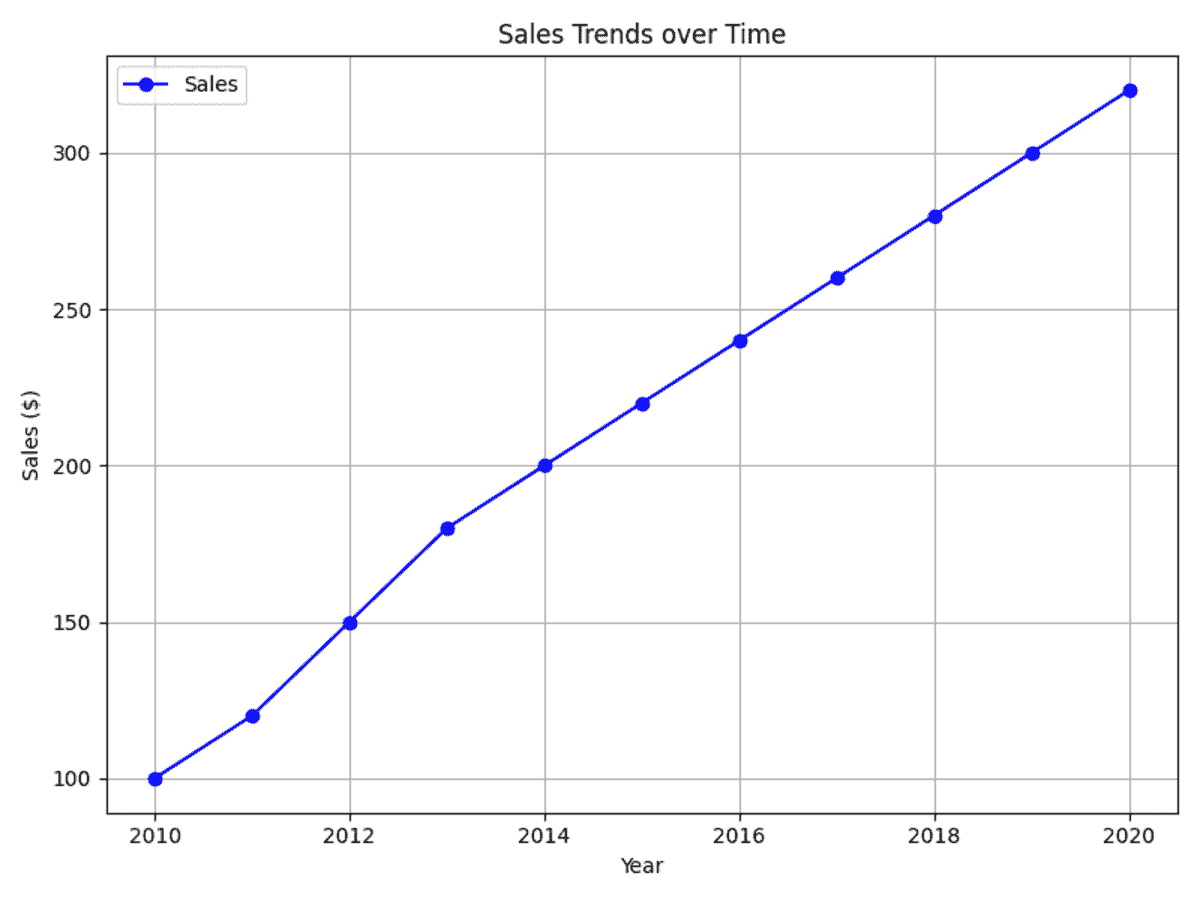
当比较不同组中的类别时,选择柱状图。例如,柱状图可以比较五种不同产品类别的销售表现。
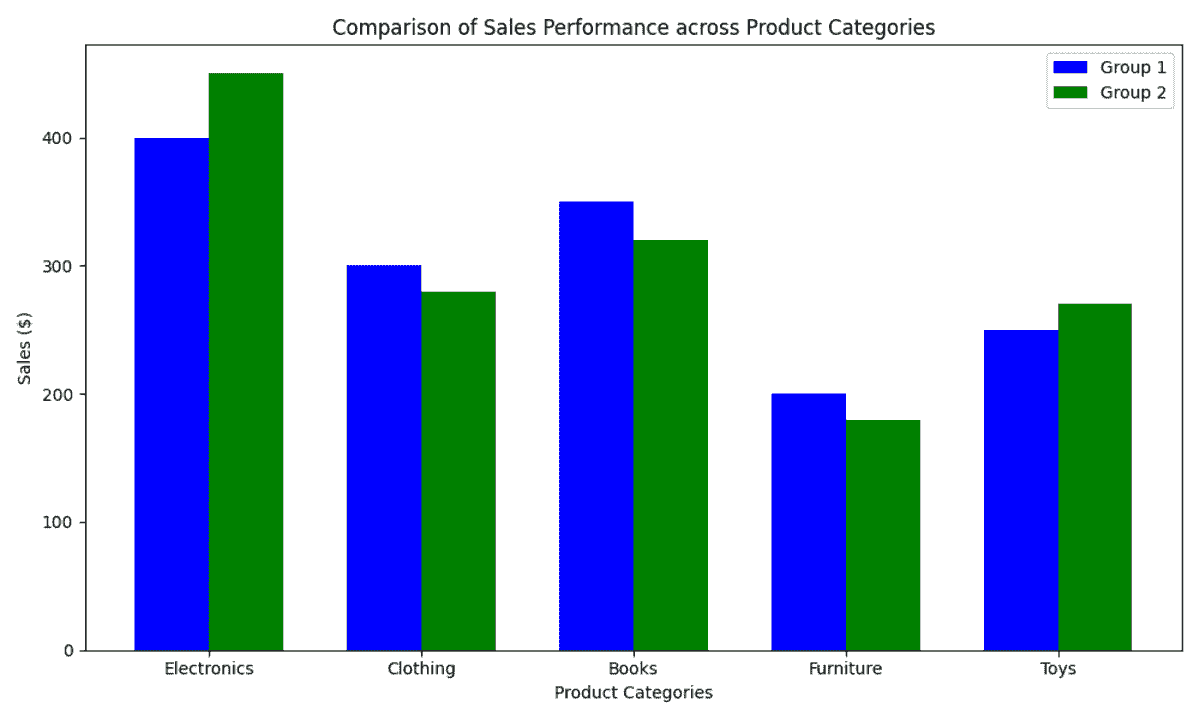
避免使用饼图来清晰地表示数据。饼图难以准确阅读和比较。切片之间的小差异难以辨别。如果类别过多,饼图会显得杂乱。下面的饼图展示了不同类别的销售比例。由于类别众多且每个类别的销售差异小,因此很难解读饼图。
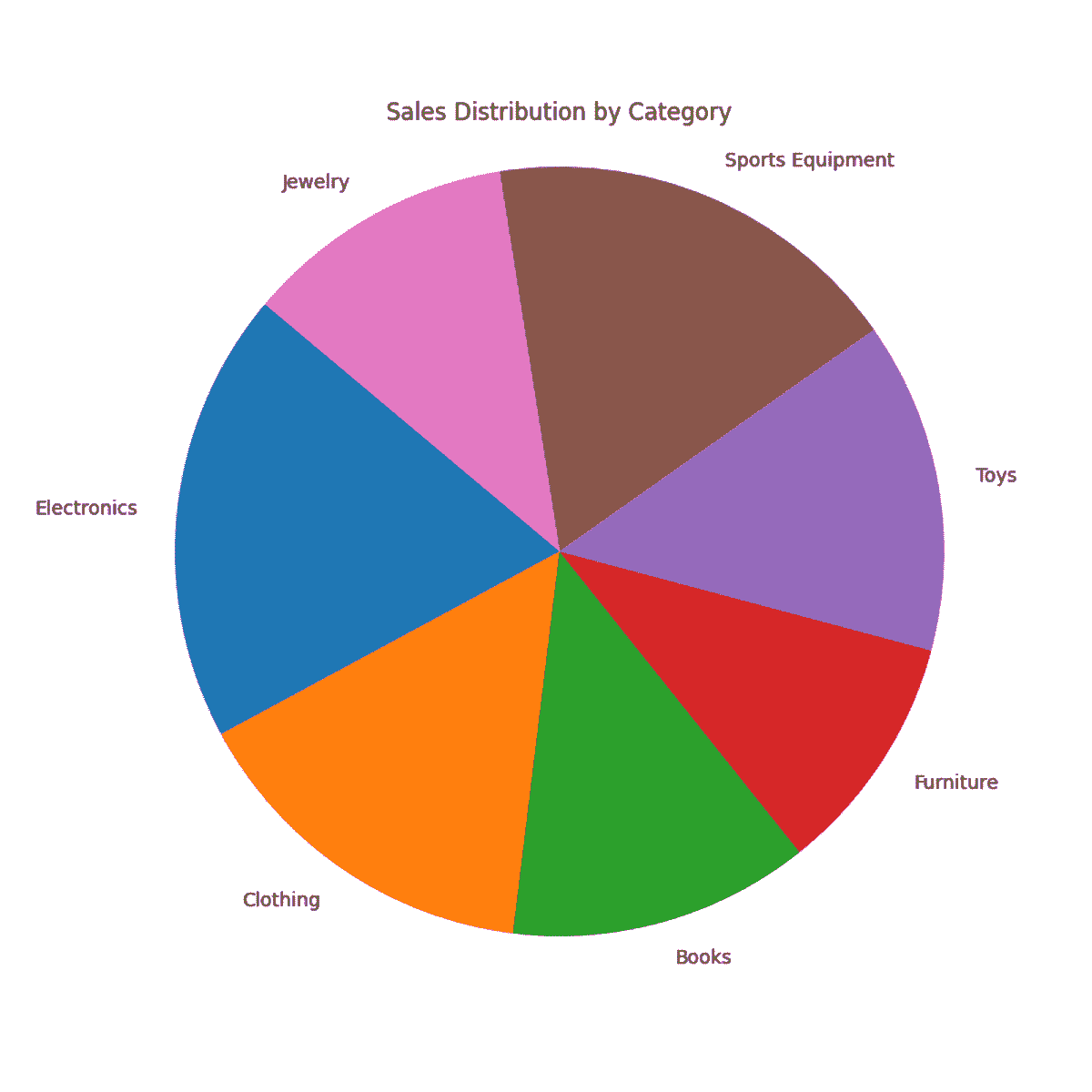
3. 避免误导性的可视化
误导性的可视化可能会扭曲事实,导致数据的误解。使用准确的刻度来真实地表示数据。避免使用截断的坐标轴或不一致的刻度,这些都会扭曲数据点之间的差异。标注可视化中的所有元素:坐标轴、数据点和类别。不明确或缺失的标签可能会让观众感到困惑。所有数据点和坐标轴中应使用一致的单位,以避免混淆。三维效果可能会扭曲数据的感知。除非第三维度提供了有意义的信息,否则应使用二维表示。注意形状(如圆形或方形)表示数量时的准确性。确保它们的大小或面积与它们所表示的数值相符。在创建可视化之前验证数据的准确性。数据收集或处理中的错误可能会导致误导性的表现。
4. 保持简洁
在创建数据可视化时,简洁是提升清晰度和有效性的关键。清晰且直接的视觉效果帮助观众快速准确地理解信息,而不会有不必要的干扰或困惑。使用简洁的标签来明确描述可视化中的每个元素。避免使用可能会让非专家困惑的技术术语。选择易于阅读的字体。确保文字足够大,方便在屏幕或打印件上阅读。专注于传达信息的核心元素。策略性地使用空白以保持视觉平衡,避免过度拥挤。确保一致使用颜色方案,以增强而不是分散对数据的关注。
5. 讲述故事
讲故事始于围绕数据本身构建叙述。确定数据分析旨在解决的具体问题。使用图表或图形来说明变量之间的模式。解释发现以发现有意义的见解。总结分析中最重要的发现。
想象一个零售连锁店正在分析其门店的客户购买行为。他们想知道哪些产品最受欢迎以及顾客为什么偏爱某些商品。图表和图形展示了多个地点的各种产品类别的销售数据。这些数据显示了过去一年客户偏好和购买模式的趋势。研究结果揭示了畅销产品以及客户偏好的地区差异。
总结
总之,使用这些技巧来创建清晰且有影响力的数据可视化。现在就应用它们,以改善理解并利用数据做出更好的决策。
Jayita Gulati 是一位对构建机器学习模型充满热情的机器学习爱好者和技术作家。她拥有利物浦大学计算机科学硕士学位。
更多相关话题
开始使用语言模型的 5 个技巧
原文:
www.kdnuggets.com/5-tips-for-getting-started-with-language-models

语言模型(LMs)无疑革新了自然语言处理(NLP)和人工智能(AI)领域,推动了对文本理解和生成的重大进展。对于那些希望进入这一迷人领域并且不确定从何开始的人,这份清单涵盖了结合理论基础与实践操作的五个关键技巧,帮助你在开发和利用语言模型方面打下坚实的基础。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
1. 理解语言模型背后的基础概念
在深入了解语言模型的实际应用之前,每位该领域的初学者都应熟悉一些关键概念,以帮助他们更好地理解这些复杂模型的所有细节。以下是一些不容错过的概念:
-
自然语言处理基础:理解文本处理的关键过程,例如分词和词干提取。
-
概率与统计基础,特别是将统计分布应用于语言建模。
-
机器学习与深度学习:理解这两个嵌套的人工智能领域的基本概念至关重要,原因之一是语言模型架构主要基于高复杂度的深度神经网络。
-
嵌入:用于文本的数值表示,便于其计算处理。
-
Transformer 架构:这种强大的架构结合了深度神经网络堆叠、嵌入处理和创新的注意机制,是今天几乎所有最先进的语言模型的基础。
2. 熟悉相关工具和库
现在是深入了解语言模型(LM)的实际应用的时候了!每个 LM 开发者都应该熟悉一些工具和库,它们提供了广泛的功能,极大地简化了构建、测试和利用 LM 的过程。这些功能包括加载预训练模型——即已经在大数据集上训练过以解决语言理解或生成任务的 LM,并在你的数据上进行微调,使其专注于解决更具体的问题。Hugging Face Transformers 库,以及对 PyTorch 和 Tensorflow 深度学习库的了解,是学习的完美组合。
3. 深入研究语言任务的优质数据集
理解 LM 能解决的语言任务范围涉及理解每个任务所需的数据类型。除了其 Transformers 库,Hugging Face 还托管一个 数据集中心,其中包含了大量用于文本分类、问答、翻译等任务的数据集。探索这个及其他公共数据中心,如 Papers with Code,以识别、分析和利用高质量的语言任务数据集。
4. 从简单开始:训练你的第一个语言模型
从简单的任务如情感分析开始,利用你在 Hugging Face、Tensorflow 和 PyTorch 上学到的实际技能来训练你的第一个语言模型(LM)。你不需要一开始就处理像完整的(编码器-解码器)变换器架构这样的复杂任务,而是应该从一个简单且更易管理的神经网络架构入手:因为此时最重要的是巩固所学的基本概念,并在逐步过渡到更复杂的架构(如用于文本分类的仅编码器变换器)时建立实际的信心。
5. 利用预训练的 LM 处理各种语言任务
在某些情况下,你可能不需要训练和构建自己的 LM,预训练模型可能就能完成工作,从而节省时间和资源,同时为你的预期目标取得不错的结果。回到 Hugging Face,尝试各种模型以执行和评估预测,学习如何在你的数据上对其进行微调,以提高解决特定任务的性能。
Iván Palomares Carrascosa 是人工智能、机器学习、深度学习和大型语言模型领域的领军人物、作家、演讲者和顾问。他训练和指导他人如何在现实世界中利用人工智能。
更多相关主题
提升 SQL 查询性能的 5 个技巧
原文:
www.kdnuggets.com/5-tips-for-improving-sql-query-performance

作者提供的图像
强大的数据库和 SQL 技能对所有数据角色都很重要。在实际工作中,你会查询超大数据库表——通常有几千甚至几百万行。这就是为什么 SQL 查询的性能成为决定应用程序整体性能的一个重要因素。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
未优化的查询通常会导致响应时间变慢、服务器负载增加以及用户体验不佳。因此,理解和应用 SQL 查询优化技术至关重要。
本教程介绍了优化 SQL 查询的实用技巧。让我们开始吧。
在开始之前:获取一个示例数据库表
在编写任何数据库的 SQL 查询时,可以使用以下技巧。但如果你希望使用示例数据库表来运行这些查询,可以使用这个 Python 脚本。
它连接到一个 SQLite 数据库:employees.db,创建了一个employees表,并填充了 10000 条记录。如前所述,你总是可以创建你自己的示例。
1. 不要使用 SELECT *; 应选择特定列
初学者使用**SELECT ***来检索表中的所有列是很常见的。如果你只需要少数几列,这可能会低效——这几乎总是如此。
使用**SELECT ***可能会导致数据处理过多,特别是如果表有很多列或你在处理大型数据集时。
替代方法如下:
SELECT * FROM employees;
这样做:
SELECT employee_id, first_name, last_name FROM employees;
只读取必要的列可以使查询更加易读和易于维护。
2. 避免使用 SELECT DISTINCT; 使用 GROUP BY 代替
SELECT DISTINCT 可能代价高昂,因为它需要对结果进行排序和过滤以移除重复项。最好通过设计上的唯一性来确保查询的数据是唯一的——使用主键或唯一约束。
替代方法如下:
SELECT DISTINCT department FROM employees;
以下带有 GROUP BY 子句的查询要有帮助得多:
SELECT department FROM employees GROUP BY department;
GROUP BY 可以更高效,特别是使用适当的索引时(我们稍后会讨论索引)。所以在编写查询时,确保你理解数据——不同的字段——在数据模型层面。
3. 限制查询结果
通常你会查询包含数千行的大表,但你不总是需要(也无法)处理所有行。使用 LIMIT 子句(或其等效功能)有助于减少返回的行数,从而加快查询性能。
你可以将结果限制为 15 条记录:
SELECT employee_id, first_name, last_name FROM employees LIMIT 15;
使用 LIMIT 子句减少结果集的大小,减少处理和传输的数据量。这也对应用程序中的分页结果很有用。
4. 使用索引以加快检索速度
索引可以显著提高查询性能,通过使数据库比扫描整个表更快地找到行。它们对于经常在 WHERE、JOIN 和 ORDER BY 子句中使用的列特别有用。
这是一个在‘department’列上创建的示例索引:
CREATE INDEX idx_employee_department ON employees(department);
你现在可以运行涉及‘department’列的过滤查询,并比较执行时间。你应该能够看到使用索引后结果速度大幅提高。要了解更多关于创建索引和性能改进的信息,请访问 如何使用索引加速 SQL 查询 [Python 版]。
如前所述,索引提高了对索引列的过滤查询的效率。但创建过多的索引可能会适得其反。这引出了下一个提示!
5. 谨慎使用索引
虽然索引提高了读取性能,但它们可能会降低写入性能——INSERT、UPDATE 和 DELETE 查询——因为每次修改表时,索引必须更新。根据你经常运行的查询类型,平衡索引的数量和类型是很重要的。
作为通用规则:
-
仅索引经常查询的列。
-
避免对低基数(唯一值较少)的列进行过度索引。
-
定期检查索引,根据需要更新和删除它们。
总之,创建索引以加快对经常查询但很少更新的列的检索。这确保了索引的好处超过其维护成本。
总结
优化 SQL 查询涉及理解查询的具体需求和数据的结构。
通过避免使用 SELECT *,小心使用 SELECT DISTINCT,限制查询结果,创建适当的索引,并注意索引的权衡,你可以显著提高数据库操作的性能和效率。
祝你查询愉快!
Bala Priya C**** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正致力于通过撰写教程、操作指南、观点文章等方式学习并与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编程教程。
相关主题
管理数据科学团队的 5 个技巧

数据科学在商业中的重要性日益增加,特别是随着技术突破。每个公司都视数据为商业优势,并愿意投资数据科学家的人力资源。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织在 IT 方面
随着企业将数据科学家视为资产,团队必须证明他们能正确完成工作。然而,个体贡献者只有在工作时间内有明确方向时才能恢复。这就是为什么领导者有责任管理和组织团队以成功完成工作。
我将在本文中根据我的经验和他人的经验分享管理数据科学团队的技巧。那么,让我们深入探讨吧。
1. 创建一个协作和包容的环境
在任何商业团队中,成员都由来自不同背景的个人组成。除了文化差异,还有技能差异,因此创造一个接纳任何文化的环境,同时推动成员以协作方式共同工作是很重要的。
通过在团队会议中定期分享知识、使用同行评审过程或进行跨职能项目(涉及具有不同技能和经验的多个成员),可以实现这一点。重要的是消除团队内部的任何分裂和歧视。
创建一个协作和包容的环境后,团队将从更好的问题解决和工作过程中的更多创造力中受益。
2. 始终设定明确的目标和期望
数据科学项目通常是持续的和开放的。如果没有方向,团队成员将难以知道该做什么以及何时交付工作,从而导致灾难性的结果。
与团队建立关于数据科学项目与业务目标的目标和期望,可以帮助成员集中精力,更好地工作。尝试制定可衡量和可实现的目标,并设置适当的时间线,以便我们可以了解团队的表现。
3. 投资于成员技能发展
作为个人,我们知道我们总是希望成长。这对于我们的团队成员也同样适用,他们希望提升自己的技能。这在数据科学领域尤为重要,因为这个领域发展迅速,人们需要跟上步伐,以便不断为公司带来价值。
通过允许团队成员提升技能,我们可以保持团队技能的最新,并维持相较于竞争对手的竞争优势。尝试为团队分配时间学习新技能和工具,同时鼓励他们参加研讨会或讲座。你还可以投资于团队的认证培训,或开展从资深到初级的导师计划。
投资于技能发展是至关重要的,如果我们想要保留顶尖表现的成员,因为这表明公司和领导者关心他们。
4. 允许实验和失败
我发现许多初级数据科学家无法发挥他们的最佳潜力,因为他们太害怕失败或无法达到业务期望。虽然数据科学家是被聘用来解决业务问题的,但通常需要经过多次迭代才能取得成功。因此,如果我们允许团队在工作中进行实验并从失败中学习,这对团队来说更为直观。
数据科学家通过实验工作,我们从所有发生的失败中学习。通过营造一个允许成员尝试新方法的环境,我们鼓励他们在工作中变得更加创造性和负责。庆祝任何形式的成长,因为这最终将有利于公司。
5. 管理工作与生活平衡
数据科学项目可能复杂,可能会影响工作与生活平衡。然而,与团队成员达成适合的健康工作安排对于维持生产力,同时避免团队成员的倦怠是很重要的。
尊重团队成员的个人时间,并鼓励他们休息。让他们享受生活是很重要的。也要以身作则,保持工作与生活平衡。
数据科学团队成员常常工作过度,因此确保他们拥有良好的工作与生活平衡是很重要的。
结论
数据科学团队是一个独特的业务单元,拥有自己独特的色彩。作为管理者,我们需要管理好我们的团队。以下是一些管理团队的建议,包括:
-
创建一个合作和包容的环境
-
总是设定明确的目标和期望
-
投资于成员技能发展
-
允许实验和失败
-
管理工作与生活平衡
希望这能有所帮助!
Cornellius Yudha Wijaya 是数据科学助理经理和数据编写者。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和撰写媒体分享 Python 和数据技巧。Cornellius 涉猎各种 AI 和机器学习主题。
更多相关内容
5 个优化机器学习算法的提示
原文:
www.kdnuggets.com/5-tips-for-optimizing-machine-learning-algorithms

图片来源:编辑
机器学习(ML)算法是构建智能模型的关键,这些模型通过从数据中学习来解决特定任务,即进行预测、分类、检测异常等。优化机器学习模型涉及调整数据和算法,以构建更准确和高效的模型,提高其在新情况或意外情况中的表现。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
以下列表总结了优化机器学习算法性能的五个关键提示,特别是优化所构建的机器学习模型的准确性或预测能力。我们来看一下。
1. 准备和选择正确的数据
在训练机器学习模型之前,预处理用于训练的数据是非常重要的:清理数据、去除异常值、处理缺失值,并在需要时对数值变量进行缩放。这些步骤通常有助于提高数据质量,而高质量的数据通常与高质量的机器学习模型密切相关。
此外,并非数据中的所有特征都可能与所构建的模型相关。特征选择技术有助于识别最相关的属性,这些属性将影响模型结果。仅使用这些相关特征可能有助于减少模型的复杂性,并改善其性能。
2. 超参数调优
与在训练过程中学习的机器学习模型参数不同,超参数是我们在训练模型之前选择的设置,就像控制面板上的按钮或齿轮,可以手动调整。通过找到最大化模型在测试数据上性能的配置来适当地调整超参数可以显著影响模型性能:尝试不同的组合以找到最佳设置。
3. 交叉验证
实施交叉验证是一种聪明的方法,可以在实际部署后提高机器学习模型的稳健性和对新见数据的泛化能力。交叉验证将数据分成多个子集或折叠,并在这些折叠上使用不同的训练/测试组合,以测试模型在不同情况下的表现,从而获得对其性能的更可靠的了解。它还减少了过拟合的风险,过拟合是机器学习中的常见问题,其中你的模型“记住”了训练数据而不是从中学习,因此当遇到即使稍微不同于其记忆实例的新数据时,它难以泛化。
4. 正则化技术
继续讨论过拟合问题,有时是因为构建了过于复杂的机器学习模型。决策树模型是这一现象容易察觉的明显例子:一个深度数十层的过度生长的决策树可能比一个深度较小的简单树更容易出现过拟合。
正则化是一种非常常见的策略,用于克服过拟合问题,从而使你的机器学习模型对任何真实数据更具泛化能力。它通过调整训练过程中用于学习错误的损失函数来适应训练算法,从而鼓励“更简单的路径”朝向最终的训练模型,同时惩罚“更复杂的路径”。
5. 集成方法
团结就是力量:这一历史格言是集成技术背后的原则,集成技术通过策略如自助法、提升法或堆叠法将多个机器学习模型结合在一起,能够显著提升解决方案的性能,相较于单一模型。随机森林和 XGBoost 是常见的集成技术,与许多预测问题中的深度学习模型表现相当。通过利用个体模型的优势,集成方法可以成为构建更准确且稳健预测系统的关键。
结论
优化机器学习算法可能是构建准确且高效模型的最重要步骤。通过关注数据准备、超参数调优、交叉验证、正则化和集成方法,数据科学家可以显著提升模型的性能和泛化能力。尝试这些技术,不仅能提高预测能力,还能帮助创建更为稳健的解决方案,以应对现实世界的挑战。
伊万·帕洛马雷斯·卡拉斯科萨 是人工智能、机器学习、深度学习和大型语言模型领域的领导者、作家、演讲者和顾问。他培训和指导他人如何在现实世界中利用人工智能。
更多相关内容
使用正则表达式进行数据清洗的 5 个技巧
原文:
www.kdnuggets.com/5-tips-for-using-regular-expressions-in-data-cleaning

作者提供的图片 | 使用 Canva 创建
如果你是 Linux 或 Mac 用户,你可能已经在命令行中使用过 grep 来通过匹配模式搜索文件。正则表达式(regex)允许你基于模式搜索、匹配和操作文本。这使得它们成为处理文本和清洗数据的强大工具。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
对于 Python 中的正则表达式匹配操作,你可以使用内置的 re 模块。在本教程中,我们将探讨如何使用正则表达式来清洗数据。我们将讨论如何去除不需要的字符、提取特定模式、查找和替换文本等。
1. 去除不需要的字符
在继续之前,我们先导入内置的 re 模块:
import re
字符串字段(几乎)总是需要广泛清洗才能进行分析。不需要的字符——通常源于不同的格式——会使你的数据难以分析。正则表达式可以帮助你高效地去除这些字符。
你可以使用 sub() 函数从 re 模块中替换或删除模式或特殊字符的所有出现。假设你有包含破折号和括号的电话号码字符串。你可以像下面这样去除它们:
text = "Contact info: (123)-456-7890 and 987-654-3210."
cleaned_text = re.sub(r'[()-]', '', text)
print(cleaned_text)
在这里,re.sub(pattern, replacement, string) 将字符串中所有模式的出现替换为替换内容。我们使用 r'[()-]' 模式来匹配任何出现的 (, ), 或 -,得到如下输出:
Output >>> Contact info: 1234567890 or 9876543210
2. 提取特定模式
从文本字段中提取电子邮件地址、网址或电话号码是常见任务,因为这些都是相关的信息。为了提取所有特定的感兴趣模式,你可以使用 findall() 函数。
你可以像这样从文本中提取电子邮件地址:
text = "Please reach out to us at support@example.org or help@example.org."
emails = re.findall(r'\b[\w.-]+?@\w+?\.\w+?\b', text)
print(emails)
re.findall(pattern, string) 函数找到并返回(作为列表)字符串中所有模式的出现。我们使用模式 r'\b[\w.-]+?@\w+?.\w+?\b' 来匹配所有电子邮件地址:
Output >>> ['support@example.com', 'help@example.org']
3. 替换模式
我们已经使用sub()函数去除不必要的特殊字符。但你也可以用另一种模式替换原有模式,以便字段适合更一致的分析。
这是一个移除不必要空格的示例:
text = "Using regular expressions."
cleaned_text = re.sub(r'\s+', ' ', text)
print(cleaned_text)
r'\s+'模式匹配一个或多个空白字符。替换字符串是一个单一的空格,得到的输出是:
Output >>> Using regular expressions.
4. 验证数据格式
验证数据格式可以确保数据的一致性和正确性。正则表达式可以验证如电子邮件、电话号码和日期等格式。
这是你如何使用match()函数来验证电子邮件地址:
email = "test@example.com"
if re.match(r'^\b[\w.-]+?@\w+?\.\w+?\b$', email):
print("Valid email")
else:
print("Invalid email")
在这个例子中,电子邮件字符串是有效的:
Output >>> Valid email
5. 按模式分割字符串
有时你可能想根据模式或特定分隔符的出现将一个字符串拆分成多个字符串。你可以使用split()函数来实现。
我们来把text字符串分割成句子:
text = "This is sentence one. And this is sentence two! Is this sentence three?"
sentences = re.split(r'[.!?]', text)
print(sentences)
在这里,re.split(pattern, string) 在模式的所有出现处分割字符串。我们使用r'[.!?]'模式来匹配句号、感叹号或问号:
Output >>> ['This is sentence one', ' And this is sentence two', ' Is this sentence three', '']
使用正则表达式清理 Pandas 数据框
将正则表达式与 pandas 结合使用,可以高效地清理数据框。
要从名称中去除非字母字符并在数据框中验证电子邮件地址:
import pandas as pd
data = {
'names': ['Alice123', 'Bob!@#', 'Charlie$$$'],
'emails': ['alice@example.com', 'bob_at_example.com', 'charlie@example.com']
}
df = pd.DataFrame(data)
# Remove non-alphabetic characters from names
df['names'] = df['names'].str.replace(r'[^a-zA-Z]', '', regex=True)
# Validate email addresses
df['valid_email'] = df['emails'].apply(lambda x: bool(re.match(r'^\b[\w.-]+?@\w+?\.\w+?\b$', x)))
print(df)
在上述代码片段中:
-
df['names'].str.replace(pattern, replacement, regex=True)替换序列中模式的出现。 -
lambda x: bool(re.match(pattern, x)):这个 lambda 函数应用正则表达式匹配并将结果转换为布尔值。
输出结果如下:
names emails valid_email
0 Alice alice@example.com True
1 Bob bob_at_example.com False
2 Charlie charlie@example.com True
总结
我希望你觉得这个教程有用。让我们回顾一下我们学到的内容:
-
使用
re.sub去除不必要的字符,如电话号码中的破折号和括号。 -
使用
re.findall从文本中提取特定模式。 -
使用
re.sub替换模式,例如将多个空格转换为一个空格。 -
使用
re.match验证数据格式,以确保数据符合特定格式,如验证电子邮件地址。 -
要根据模式分割字符串,应用
re.split。
实际操作中,你将结合正则表达式和 pandas 来高效清理数据框中的文本字段。注释你的正则表达式以解释其目的也是一种良好的实践,能够提高可读性和可维护性。要了解更多关于使用 pandas 进行数据清理的内容,请阅读 掌握 Python 和 Pandas 数据清理的 7 个步骤。
Bala Priya C**** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过编写教程、操作指南、观点文章等方式向开发者社区学习和分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关主题
提高 Python 函数质量的 5 个技巧
原文:
www.kdnuggets.com/5-tips-for-writing-better-python-functions

图片来自作者
我们在 Python 中编写函数时,都会写函数。但我们是否总是编写优质函数呢?好吧,让我们来找出答案。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织的 IT
Python 中的函数让你编写模块化代码。当你在多个地方需要执行一个任务时,你可以将该任务的逻辑封装到一个 Python 函数中。然后,每次需要执行该特定任务时,你可以调用这个函数。虽然开始使用 Python 函数看起来很简单,但编写可维护且高性能的函数并非那么直接。
这就是为什么我们将探讨一些实践,帮助你编写更干净、更易维护的 Python 函数。让我们开始吧……
1. 编写只做一件事的函数
在 Python 中编写函数时,通常会有把所有相关任务放入一个函数中的诱惑。虽然这可以帮助你快速编写代码,但它只会让你的代码在不久的将来变得难以维护。这不仅使理解函数的作用变得更加困难,还会导致其他问题,比如参数过多(稍后会详细介绍!)。
作为一种良好的实践,你应该始终尝试让你的函数只做一件事——一个任务——并且做到最好。但有时,对于一个任务,你可能需要通过一系列子任务来完成。那么你怎么决定函数是否以及如何重构呢?
根据函数试图做什么和任务的复杂程度,你可以解决子任务之间的关注点分离。然后确定一个合适的层次来将函数重构成多个函数——每个函数专注于一个特定的子任务。
重构函数 | 图片来自作者
这是一个示例。看看函数 analyze_and_report_sales:
# fn. to analyze sales data, calculate sales metrics, and write it to a file
def analyze_and_report_sales(data, report_filename):
total_sales = sum(item['price'] * item['quantity'] for item in data)
average_sales = total_sales / len(data)
with open(report_filename, 'w') as report_file:
report_file.write(f"Total Sales: {total_sales}\n")
report_file.write(f"Average Sales: {average_sales}\n")
return total_sales, average_sales
很容易看出,它可以重构成两个函数:一个计算销售指标,另一个将销售指标写入文件,如下所示:
# refactored into two funcs: one to calculate metrics and another to write sales report
def calculate_sales_metrics(data):
total_sales = sum(item['price'] * item['quantity'] for item in data)
average_sales = total_sales / len(data)
return total_sales, average_sales
def write_sales_report(report_filename, total_sales, average_sales):
with open(report_filename, 'w') as report_file:
report_file.write(f"Total Sales: {total_sales}\n")
report_file.write(f"Average Sales: {average_sales}\n")
现在更容易分别调试销售指标计算和文件操作中的任何问题。下面是一个示例函数调用:
data = [{'price': 100, 'quantity': 2}, {'price': 200, 'quantity': 1}]
total_sales, average_sales = calculate_sales_metrics(data)
write_sales_report('sales_report.txt', total_sales, average_sales)
你应该能在工作目录中看到包含销售指标的‘sales_report.txt’文件。这是一个简单的示例来开始,但在处理更复杂的函数时尤其有用。
2. 添加类型提示以改善可维护性
Python 是一种动态类型语言。所以你不需要为创建的变量声明类型。但你可以添加类型提示来指定变量的预期数据类型。当你定义函数时,可以添加参数和返回值的预期数据类型。
因为 Python 在运行时不强制类型,所以添加类型提示在运行时没有效果。但使用类型提示仍然有好处,特别是在可维护性方面:
-
向 Python 函数添加类型提示作为内联文档,能够更好地了解函数的功能以及它处理和返回的值。
-
当你给函数添加类型提示时,可以配置你的 IDE 以利用这些类型提示。如果你尝试传递不正确类型的参数,或实现返回值类型不匹配的函数,IDE 会给出有用的警告。这样可以提前最小化错误。
-
你可以选择使用像 mypy 这样的静态类型检查器,以便及早捕捉错误,而不是让类型不匹配引入难以调试的微妙错误。
这是一个处理订单详细信息的函数:
# fn. to process orders
def process_orders(orders):
total_quantity = sum(order['quantity'] for order in orders)
total_value = sum(order['quantity'] * order['price'] for order in orders)
return {
'total_quantity': total_quantity,
'total_value': total_value
}
现在让我们像这样给函数添加类型提示:
# modified with type hints
from typing import List, Dict
def process_orders(orders: List[Dict[str, float | int]]) -> Dict[str, float | int]:
total_quantity = sum(order['quantity'] for order in orders)
total_value = sum(order['quantity'] * order['price'] for order in orders)
return {
'total_quantity': total_quantity,
'total_value': total_value
}
使用修改后的版本,你可以知道函数接受一个字典列表。字典的键应为字符串,值可以是整数或浮点值。函数还返回一个字典。让我们看一个示例函数调用:
# Sample data
orders = [
{'price': 100.0, 'quantity': 2},
{'price': 50.0, 'quantity': 5},
{'price': 150.0, 'quantity': 1}
]
# Sample function call
result = process_orders(orders)
print(result)
这是输出结果:
{'total_quantity': 8, 'total_value': 600.0}
在这个例子中,类型提示帮助我们更好地了解函数的工作原理。今后,我们将为我们编写的所有更好的 Python 函数添加类型提示。
3. 只接受实际需要的参数
如果你是初学者或刚刚开始你的第一个开发角色,在定义函数签名时考虑不同的参数非常重要。函数签名中引入额外的参数,而这些参数函数实际上并未处理,是很常见的。
确保函数只接受实际必要的参数,使函数调用更简洁、易于维护。相关的,函数签名中参数过多也会使维护变得困难。那么如何定义易于维护的函数,并使用正确数量的参数呢?
如果你发现自己在编写函数签名时参数数量不断增加,第一步是从签名中删除所有未使用的参数。如果即使在这一步之后参数仍然过多,请回到提示 #1:将任务分解为多个子任务,并将函数重构为多个较小的函数。这将有助于控制参数数量。
保持 num_params 受控 | 作者提供的图片
现在是一个简单的示例。这里计算学生成绩的函数定义包含一个从未使用的 instructor 参数:
# takes in an arg that's never used!
def process_student_grades(student_id, grades, course_name, instructor'):
average_grade = sum(grades) / len(grades)
return f"Student {student_id} achieved an average grade of {average_grade:.2f} in {course_name}."
你可以这样重写函数,去掉 instructor 参数:
# better version!
def process_student_grades(student_id: int, grades: list, course_name: str) -> str:
average_grade = sum(grades) / len(grades)
return f"Student {student_id} achieved an average grade of {average_grade:.2f} in {course_name}."
# Usage
student_id = 12345
grades = [85, 90, 75, 88, 92]
course_name = "Mathematics"
result = process_student_grades(student_id, grades, course_name)
print(result)
这是函数调用的输出:
Student 12345 achieved an average grade of 86.00 in Mathematics.
4. 强制关键字仅参数以最小化错误
实际上,大多数 Python 函数接受多个参数。你可以将参数作为位置参数、关键字参数或两者的混合传递给 Python 函数。阅读 Python 函数参数:权威指南 以快速了解函数参数。
一些参数自然是位置参数。但有时仅包含位置参数的函数调用可能会令人困惑。当函数接受多个相同数据类型的参数时,尤其如此,有些是必需的,有些是可选的。
如果你记得,使用位置参数时,参数按照它们在函数调用中出现的相同顺序传递到函数签名中的参数。因此,参数顺序的变化可能会引入微妙的错误和类型错误。
将可选参数设置为仅限关键字通常很有帮助。这也使添加可选参数变得更容易——而不会破坏现有的调用。
这是一个示例。process_payment 函数接受一个可选的 description 字符串:
# example fn. for processing transaction
def process_payment(transaction_id: int, amount: float, currency: str, description: str = None):
print(f"Processing transaction {transaction_id}...")
print(f"Amount: {amount} {currency}")
if description:
print(f"Description: {description}")
假设你想将可选的 description 改为仅限关键字的参数。以下是你可以做到的方式:
# enforce keyword-only arguments to minimize errors
# make the optional `description` arg keyword-only
def process_payment(transaction_id: int, amount: float, currency: str, *, description: str = None):
print(f"Processing transaction {transaction_id}:")
print(f"Amount: {amount} {currency}")
if description:
print(f"Description: {description}")
让我们来一个示例函数调用:
process_payment(1234, 100.0, 'USD', description='Payment for services')
这输出:
Processing transaction 1234...
Amount: 100.0 USD
Description: Payment for services
现在尝试将所有参数作为位置参数传递:
# throws error as we try to pass in more positional args than allowed!
process_payment(5678, 150.0, 'EUR', 'Invoice payment')
你将得到如示所示的错误:
Traceback (most recent call last):
File "/home/balapriya/better-fns/tip4.py", line 9, in <module>process_payment(1234, 150.0, 'EUR', 'Invoice payment')
TypeError: process_payment() takes 3 positional arguments but 4 were given</module>
5. 不要从函数返回列表;改用生成器
编写生成序列(例如数值列表)的 Python 函数很常见。但尽可能地,你应该避免从 Python 函数返回列表。你可以将它们重写为生成器函数。生成器使用惰性求值,因此它们按需生成序列元素,而不是事先计算所有值。阅读 Python 生成器入门 了解生成器在 Python 中的工作原理。
例如,考虑以下生成斐波那契序列直到某个上限的函数:
# returns a list of Fibonacci numbers
def generate_fibonacci_numbers_list(limit):
fibonacci_numbers = [0, 1]
while fibonacci_numbers[-1] + fibonacci_numbers[-2] <= limit:
fibonacci_numbers.append(fibonacci_numbers[-1] + fibonacci_numbers[-2])
return fibonacci_numbers
这是一个递归实现,计算开销较大,填充列表并返回似乎比必要的要冗长。以下是使用生成器的改进版函数:
# use generators instead
from typing import Generator
def generate_fibonacci_numbers(limit: int) -> Generator[int, None, None]:
a, b = 0, 1
while a <= limit:
yield a
a, b = b, a + b
在这种情况下,函数返回一个生成器对象,你可以遍历它来获取序列的元素:
limit = 100
fibonacci_numbers_generator = generate_fibonacci_numbers(limit)
for num in fibonacci_numbers_generator:
print(num)
这是输出结果:
0
1
1
2
3
5
8
13
21
34
55
89
如你所见,使用生成器在处理大输入量时可以更加高效。此外,你可以将多个生成器链式连接,从而创建高效的数据处理管道。
总结
就这样。你可以在GitHub上找到所有的代码。以下是我们讨论的不同技巧的回顾:
-
编写只做一件事的函数。
-
添加类型提示以提高可维护性
-
仅接受实际需要的参数
-
强制使用仅关键字参数以减少错误
-
不要从函数返回列表;使用生成器代替。
希望你觉得这些技巧有帮助!如果你还没尝试过,写 Python 函数时可以尝试这些实践。祝编程愉快!
Bala Priya C** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专业领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在学习并通过撰写教程、操作指南、观点文章等与开发者社区分享她的知识。Bala 还创作引人入胜的资源概述和编码教程。**
相关主题


 浙公网安备 33010602011771号
浙公网安备 33010602011771号