
KDNuggets-博客中文翻译-十一-
KDNuggets 博客中文翻译(十一)
原文:KDNuggets
使用 BERT 进行长文本文档分类
原文:
www.kdnuggets.com/2022/02/classifying-long-text-documents-bert.html
由 Sinequa 提供
我们想要实现什么目标?
我们想将文本分类到预定义的类别中,这是 NLP 中非常常见的任务。多年来,简单文档的经典方法是使用TF-IDF生成特征,并将其与逻辑回归结合。以前我们在 Sinequa 用来进行文本分类时依赖于这一套方案,剧透一下,使用这里介绍的模型,我们将非常嘈杂和长文档数据集的基线从 5%提高到了 30%。这种旧方法有两个主要问题:特征稀疏性,我们通过压缩技术解决了这一问题,以及词匹配问题,我们通过利用 Sinequa 强大的语言学能力(主要通过我们自家开发的分词器)来克服。
后来,语言模型的潘多拉盒子被打开了(这些模型在海量语料库上进行无监督预训练,并在下游监督任务中进行微调),TF-IDF 基础的技术不再是最先进的。这些语言模型可能是word2vec与 LSTM 或 CNN、ELMo,以及最重要的 Transformer(2017 年:arxiv.org/pdf/1706.03762.pdf)。
BERT是一个基于 Transformer 的语言模型,近年来获得了大量关注,因为它远远超越了所有 NLP 基线,并成为构建我们文本分类的自然选择。
那么挑战是什么呢?
基于 Transformer 的语言模型如 BERT 在理解语义上下文方面表现出色(这是词袋方法所无法做到的),因为它们专门为此目的而设计。如引言中所述,BERT 在所有 NLP 基线测试中表现优异,但正如我们在科学界所说的,“没有免费的午餐”。像 BERT 这样的模型提供的广泛语义理解带来了一个大问题:它无法处理非常长的文本序列。基本上,这个限制是 512 个标记(标记是文本中的一个词或子词),这大致相当于两到三段维基百科内容,而我们显然不希望仅仅考虑如此小的文本子部分进行分类。
为了说明这一点,考虑将全面的产品评论分类为正面或负面评论的任务。前几句话或段落可能只包含产品的描述,可能需要进一步阅读评论才能理解评论者是否真正喜欢这个产品。如果我们的模型不能涵盖全部内容,可能无法做出正确的预测。因此,我们的模型的一个要求是捕捉文档的上下文,同时正确管理文档开头和结尾之间的长期依赖关系。
从技术上讲,核心限制是内存占用,它随着标记数量的增加而按平方增长,同时使用的预训练模型具有由 Google 等公司确定的固定大小。这是预期中的情况,因为每个标记都“注意” [https://arxiv.org/pdf/1706.03762.pdf] 到每个其他标记,因此需要一个 [N x N] 的注意力矩阵,其中 [N] 是标记的数量。例如,BERT 接受最多 512 个标记,这很难称为长文本。超过 512 个标记很快就会达到甚至现代 GPU 的极限。
在生产环境中使用 Transformers 另一个出现的问题是由于模型的大小(BERT base 具有 110M 参数)以及平方成本导致推理非常缓慢。因此,我们的目标不仅是找到一个在训练过程中适合内存的架构,还要找到一个在推理过程中也能合理快速响应的架构。
我们在这里面临的最后一个挑战是基于各种特征类型构建一个模型:当然包括长文本,还包括附加的文本元数据(如标题、摘要等)和类别(如位置、作者等)。
那么,如何处理非常长的文档呢?
主要的想法是将文档拆分成更短的序列,并将这些序列输入到 BERT 模型中。我们为每个序列获得 CLS 嵌入并合并这些嵌入。合并有几种可能性,我们尝试了:
-
卷积神经网络(CNN)
-
长短期记忆网络(LSTM)
-
Transformers(用来聚合 Transformers,没错 😃)
我们在不同标准文本分类语料库上的实验表明,使用额外的 Transformer 层来合并生成的嵌入效果最佳,而不会引入大量计算成本。
想要正式描述,对吧?
我们考虑一个具有 L 标签的文本分类任务。对于一个文档 D,其由 WordPiece 分词 提供的标记可以表示为 X =( x₁, …, xₙ),其中 N 为 D 中标记的总数。设 K 为最大序列长度(对于 BERT 为 512)。设 I 为 D 中 K 个标记或更少的序列数,它由 I=⌊ N/K ⌋ 给出。
请注意,如果文档中的最后一个序列的大小小于 K,它将用 0 填充,直到 Kᵗʰ 索引。如果 sⁱ 其中 i ∈ {1, .., I} 是 D 中第 i 个具有 K 元素的序列,我们有:
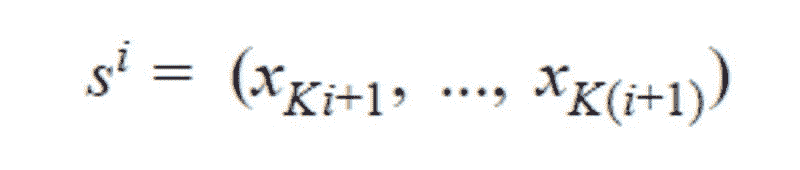
我们可以注意到
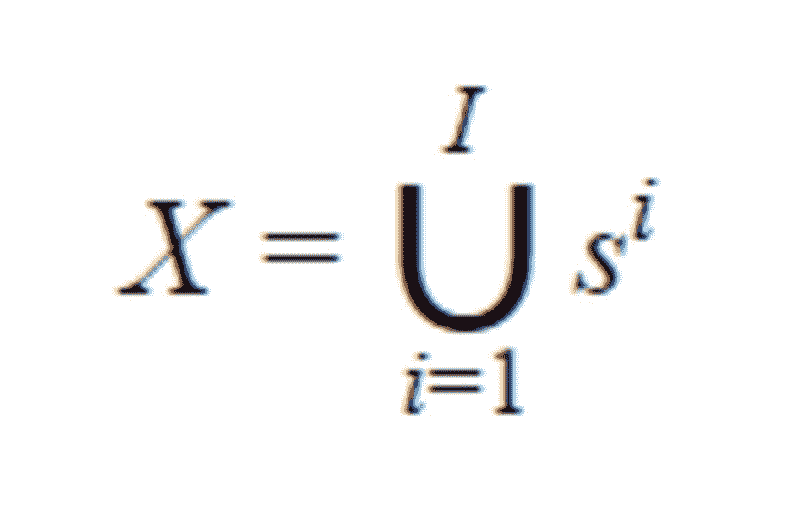
BERT 返回 CLS 嵌入以及每个 token 的嵌入。
让我们定义 BERT 为文档的第 i 个序列返回的每个 token 的嵌入,如下所示:
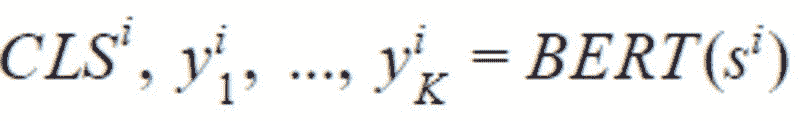
其中 CLS 是插入到每个输入 BERT 的文本序列前的特殊 token 的嵌入,通常被认为是总结整个序列的嵌入。
为了结合这些序列,我们只使用 CLSᵢ,不使用 y。我们使用 t 个变换器 T₁, …,Tₜ 来获得最终向量,以便输入到网络的最后一个全连接层:
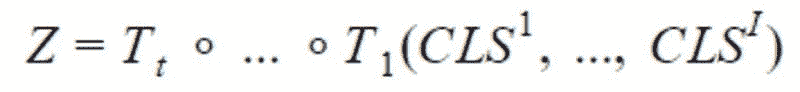
其中 ∘ 是函数复合操作。
给定最后一个全连接层的权重 W ∈ ℝᴸˣᴴ,其中 H 是变换器的隐藏大小,偏置 b ∈ ℝᴸ
概率 P ∈ ℝᴸ 由以下公式给出:
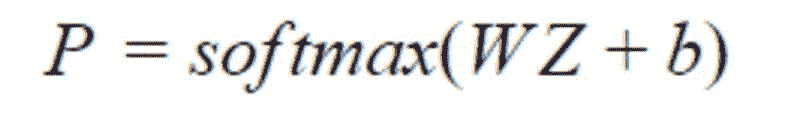
最后,对向量 P 应用 argmax 返回预测的标签。有关上述架构的总结,您可以查看图 1。
上述架构使我们能够利用 BERT 进行文本分类任务,绕过变换器的最大序列长度限制,同时保持对多个序列的上下文。让我们看看如何将其与其他类型的特征结合。
如何处理元数据?
文档通常不仅仅包含其内容,还可能有我们分为两个组的元数据:文本元数据和分类元数据。
文本元数据
文本元数据是指短文本,它(在分词后)具有相对较少的 token 数量。这是为了能够完全适配到我们的语言模型中。此类元数据的典型示例包括标题或摘要。
给定一个具有 M 个元数据注释的文档。让
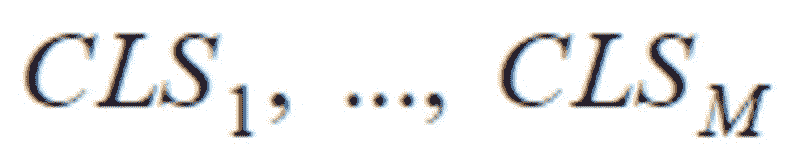
是 BERT 为每个元数据生成的 CLS 嵌入。使用与上述相同的技术来获取概率向量,如下所示:
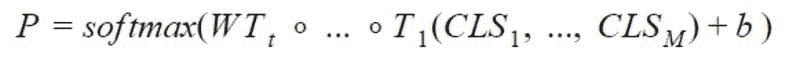
分类元数据
分类元数据可以是表示类别的数值或文本值。数值可以是页数,而文本值可以是出版商名称或地理位置。
处理此类特征的一种常见方法是实现 宽和深架构。我们的实验表明,这个网络的深度部分产生的结果已经足够好,而宽度部分是不必要的。
我们使用 one-hot 编码将分类元数据编码为一个单一的跨类别向量。然后,将该编码传递到嵌入层,该层学习每个不同类别的向量表示。最后一步是对结果嵌入矩阵应用池化层。
我们考虑了最大池化、平均池化和最小池化,并发现使用平均池化对我们的测试语料库效果最好。
完整的架构是怎样的?
希望你坚持到现在,下面的图示将有助于进一步澄清问题。
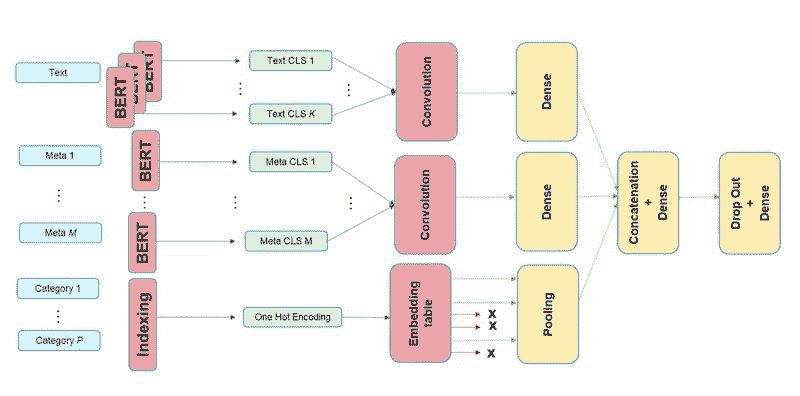
图 1
有三个子模型,一个用于文本,另一个用于文本元数据,最后一个用于分类元数据。三个子模型的输出仅仅是串联成一个单一的向量,然后通过一个 dropout 层,最后进入一个具有 softmax 激活的最后密集层进行分类。
你可能已经注意到,在架构中描绘了多个 BERT 实例,这不仅用于文本输入,还用于文本元数据。由于 BERT 需要训练许多参数,我们决定不为每个子模型包含一个单独的 BERT 模型,而是共享一个模型的权重。共享权重确实减少了模型使用的 RAM(使得可以使用更大的批量大小进行训练,从而在某种程度上加速训练),但它并不会改变推理时间,因为无论权重是否共享,BERT 执行的次数依然是一样的。
推理时间怎么样?
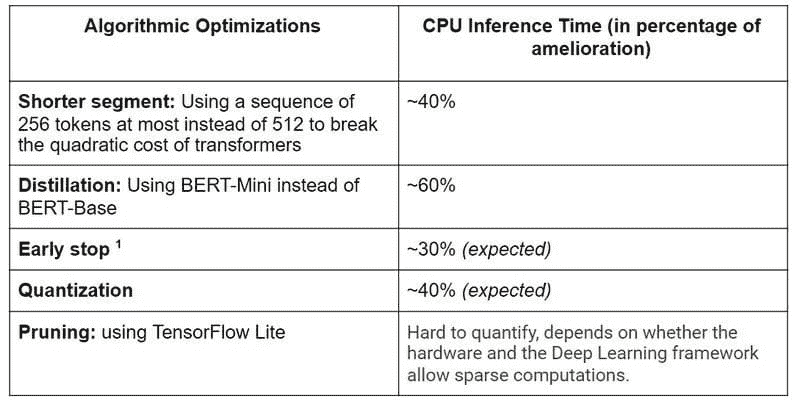
到现在,你一定已经猜到包含如此多的 BERT 模型调用并不是免费的。确实,运行这样的模型推理计算代价昂贵。然而,有几个技巧可以提高推理时间。以下内容我们将重点讨论 CPU 推理,因为这在生产环境中非常重要。
对于进行的实验,有几点说明:
-
我们考虑了一个仅包含文本特征的简化模型。
-
我们将每个文档使用的 tokens 限制为 25,600 个,这大致相当于 130,000 个字符(如果文档包含英文文本)。
-
我们用具有上述最大长度的文档进行实验。实际上,文档的大小各不相同,由于我们在模型中使用了动态大小的张量,因此短文档的推理时间显著更快。作为一个经验法则,使用一个长度是原文档一半的文档,推理时间会减少 50%。

参考文献
还有什么可以做的?
线性 Transformer
构建一种类似于 Transformer 的架构,但没有时间和内存的二次复杂度,目前是一个非常活跃的研究领域。一旦预训练模型发布,有几个候选者绝对值得尝试:
-
Linformer [
arxiv.org/pdf/2006.04768.pdf] -
BigBird [
arxiv.org/pdf/2007.14062.pdf] -
改革者 [
arxiv.org/pdf/2001.04451.pdf](仅 O(N log(N)) 复杂度) -
Performers [
arxiv.org/pdf/2009.14794.pdf] -
等等…
对非常有前景的 Longformer 模型进行的初步测试未能成功执行。我们尝试使用 Hugging Face 的 TensorFlow 实现来训练 LongFormer 模型。然而,似乎该实现尚未进行内存优化,因为即使在具有 48 GB 内存的大型 GPU 上也无法训练。
推理时间是任何需要在生产中运行的 ML 项目的基石,因此我们计划在未来使用这种“线性 Transformer”,除此之外还会进行剪枝和量化。
我们完成了吗?
是的,感谢你坚持到最后。如果你对我们的模型有任何问题或评论,请随时留言。我们非常乐意听取你的意见。
原文。经许可转载。
我们的前三个课程推荐
 1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
 2. 谷歌数据分析专业证书 - 提升你的数据分析能力
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
更多相关主题
使用 Pandas 管道函数进行更清晰的数据分析
原文:
www.kdnuggets.com/2021/01/cleaner-data-analysis-pandas-pipes.html
comments
我们的前三个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业道路。
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持组织的 IT 工作
Pandas 是一个广泛使用的数据分析和处理库,提供了众多功能和方法,以实现强大且高效的数据分析过程。
在典型的数据分析或清理过程中,我们可能会执行许多操作。随着操作数量的增加,代码开始变得杂乱且难以维护。
克服此问题的一种方法是使用 Pandas 的管道函数。管道函数的作用是允许以链式方式组合多个操作。
在本文中,我们将通过示例了解如何使用管道函数来生成更清晰、更易维护的代码。
我们首先将在单独的步骤中对样本数据框进行数据清理和处理。之后,我们将使用管道函数将这些步骤合并。
首先导入库并创建数据框。
import numpy as np
import pandas as pd
marketing = pd.read_csv("/content/DirectMarketing.csv")
marketing.head()
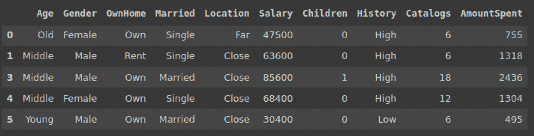
(图片由作者提供)
数据集包含有关营销活动的信息。可在 Kaggle 上 这里 获取。
我想做的第一个操作是删除缺失值很多的列。
thresh = len(marketing) * 0.6
marketing.dropna(axis=1, thresh=thresh, inplace=True)
上面的代码删除了缺失值占 40% 或更多的列。我们传递给 dropna 函数的 thresh 参数值表示所需的最小非缺失值数量。
我还想删除一些异常值。在工资列中,我希望保留在第 5 百分位数和第 95 百分位数之间的值。
low = np.quantile(marketing.Salary, 0.05)
high = np.quantile(marketing.Salary, 0.95)
marketing = marketing[marketing.Salary.between(low, high)]
我们通过使用 numpy 的 quantile 函数找到所需范围的下限和上限。这些值随后用于过滤数据框。
需要注意的是,检测异常值的方法有很多种。实际上,我们使用的方法有些表面化。还有更现实的替代方案。然而,这里重点是管道函数。因此,你可以实现最适合你任务的操作。
数据框包含许多分类变量。如果类别的数量相对于总数值比较少,最好使用类别数据类型而不是对象。这可以根据数据大小节省大量内存。
以下代码将遍历对象数据类型的列。如果类别的数量少于总值的 5%,则该列的数据类型将更改为类别。
cols = marketing.select_dtypes(include='object').columns
for col in cols:
ratio = len(marketing[col].value_counts()) / len(marketing)
if ratio < 0.05:
marketing[col] = marketing[col].astype('category')
我们完成了三步数据清洗和处理。根据任务的不同,步骤的数量可能更多。
让我们创建一个管道来完成所有这些任务。
管道函数接受函数作为输入。这些函数需要以数据框作为输入,并返回一个数据框。因此,我们需要为每个任务定义函数。
def drop_missing(df):
thresh = len(df) * 0.6
df.dropna(axis=1, thresh=thresh, inplace=True)
return df
def remove_outliers(df, column_name):
low = np.quantile(df[column_name], 0.05)
high = np.quantile(df[column_name], 0.95)
return df[df[column_name].between(low, high, inclusive=True)]
def to_category(df):
cols = df.select_dtypes(include='object').columns
for col in cols:
ratio = len(df[col].value_counts()) / len(df)
if ratio < 0.05:
df[col] = df[col].astype('category')
return df
你可能会争辩说,如果我们需要定义函数,那有什么意义?这似乎并没有简化工作流程。对于一个特定的任务你是对的,但我们需要从更广泛的角度思考。考虑你多次进行相同的操作。在这种情况下,创建一个管道可以使过程更简单,并提供更清晰的代码。
我们提到过管道函数接受一个函数作为输入。如果我们传递给管道函数的函数有任何参数,我们可以将这些参数与函数一起传递给管道函数。这使得管道函数更加高效。
例如,remove_outliers 函数接受一个列名作为参数。该函数会去除该列中的异常值。
我们现在可以创建我们的管道。
marketing_cleaned = (marketing.
pipe(drop_missing).
pipe(remove_outliers, 'Salary').
pipe(to_category))
它看起来整洁而干净。我们可以根据需要添加任意多的步骤。唯一的标准是管道中的函数应该接受一个数据框作为参数并返回一个数据框。就像使用 remove_outliers 函数一样,我们可以将函数的参数作为参数传递给管道函数。这种灵活性使管道更加有用。
一个重要的事情是,管道函数会修改原始数据框。如果可能,我们应该避免更改原始数据集。
为了克服这个问题,我们可以在管道中使用原始数据框的副本。此外,我们可以在管道的开始阶段添加一个步骤,以创建数据框的副本。
def copy_df(df):
return df.copy()
marketing_cleaned = (marketing.
pipe(copy_df).
pipe(drop_missing).
pipe(remove_outliers, 'Salary').
pipe(to_category))
我们的管道现在完成了。让我们比较原始数据框和清洗后的数据框,以确认它正在正常工作。
marketing.shape
(1000,10)
marketing.dtypes
Age object
Gender object
OwnHome object
Married object
Location object
Salary int64
Children int64
History object
Catalogs int64
AmountSpent int64
marketing_cleaned.dtypes
(900,10)
marketing_cleaned.dtypes
Age category
Gender category
OwnHome category
Married category
Location category
Salary int64
Children int64
History category
Catalogs int64
AmountSpent int64
管道如预期般工作。
结论
管道提供了更清晰、更易于维护的数据分析语法。另一个优点是它们自动化了数据清洗和处理的步骤。
如果你反复进行相同的操作,你应该考虑创建一个管道。
感谢阅读。如果你有任何反馈,请告诉我。
个人简介: Soner Yıldırım 是一位数据科学爱好者。查看他的作品集。
原文。经授权转载。
相关内容:
-
数据清理:任何数据科学项目成功的秘密成分
-
SQL 数据清理与整理
-
在 Python 中合并 Pandas 数据框
更多相关内容
在 Pandas 中清理和预处理文本数据以用于 NLP 任务
原文:
www.kdnuggets.com/cleaning-and-preprocessing-text-data-in-pandas-for-nlp-tasks

图片由作者提供
清理和预处理数据通常是构建由数据驱动的 AI 和机器学习解决方案中最令人畏惧但又至关重要的阶段,而文本数据也不例外。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
本教程破冰地解决了为 NLP 任务(如语言模型(LMs)可以解决的任务)准备文本数据的挑战。通过将你的文本数据封装在 pandas DataFrames 中,以下步骤将帮助你准备文本数据,以便被 NLP 模型和算法处理。
将数据加载到 Pandas DataFrame 中
为了保持本教程简单明了并专注于理解必要的文本清理和预处理步骤,让我们考虑一个包含四个单属性文本数据实例的小样本,这些实例将被移动到一个 pandas DataFrame 实例中。从现在起,我们将在这个 DataFrame 对象上应用每个预处理步骤。
import pandas as pd
data = {'text': ["I love cooking!", "Baking is fun", None, "Japanese cuisine is great!"]}
df = pd.DataFrame(data)
print(df)
输出:
text
0 I love cooking!
1 Baking is fun
2 None
3 Japanese cuisine is great!
处理缺失值
你注意到示例数据实例中的'None'值了吗?这被称为缺失值。缺失值由于各种原因通常会被收集,往往是偶然的。关键点是:你需要处理这些值。最简单的方法是检测并删除包含缺失值的实例,如下代码所示:
df.dropna(subset=['text'], inplace=True)
print(df)
输出:
text
0 I love cooking!
1 Baking is fun
3 Japanese cuisine is great!
规范化文本以保持一致
规范化文本意味着标准化或统一那些在不同实例中可能以不同格式出现的元素,例如日期格式、全名或大小写敏感性。规范化文本的最简单方法是将所有文本转换为小写,如下所示。
df['text'] = df['text'].str.lower()
print(df)
输出:
text
0 i love cooking!
1 baking is fun
3 japanese cuisine is great!
去除噪音
噪音是指不必要或意外收集的数据,如果处理不当,可能会妨碍后续的建模或预测过程。在我们的示例中,我们假设像“!”这样的标点符号在后续的 NLP 任务中是不需要的,因此我们通过使用正则表达式检测文本中的标点符号来进行噪音去除。Python 的're'包用于基于正则表达式匹配进行文本操作。
import re
df['text'] = df['text'].apply(lambda x: re.sub(r'[^\w\s]', '', x))
print(df)
输出:
text
0 i love cooking
1 baking is fun
3 japanese cuisine is great
对文本进行分词
分词可以说是进行 NLP 和语言模型使用前最重要的文本预处理步骤之一 - 以及将文本编码为数字表示 - 它包括将每个文本输入拆分成一系列片段或标记。在最简单的情况下,标记通常与单词相关,但在复合词等某些情况下,一个单词可能会导致多个标记。某些标点符号(如果它们之前没有被作为噪音去除)有时也会被识别为独立的标记。
这段代码将我们三个文本条目中的每一个分割成单独的单词(标记),并将其添加为 DataFrame 中的新列,然后显示更新后的数据结构及其两列。应用的简化分词方法被称为简单的空格分词:它仅使用空格作为检测和分隔标记的标准。
df['tokens'] = df['text'].str.split()
print(df)
输出:
text tokens
0 i love cooking [i, love, cooking]
1 baking is fun [baking, is, fun]
3 japanese cuisine is great [japanese, cuisine, is, great]
移除停用词
一旦文本被分词,我们会过滤掉不必要的标记。这通常是停用词的情况,比如冠词“a/an, the”或连词,这些词对文本没有实际语义贡献,应被移除以便后续有效处理。这个过程依赖于语言:下面的代码使用 NLTK 库下载英语停用词字典,并从标记向量中过滤掉它们。
import nltk
nltk.download('stopwords')
stop_words = set(stopwords.words('english'))
df['tokens'] = df['tokens'].apply(lambda x: [word for word in x if word not in stop_words])
print(df['tokens'])
输出:
0 [love, cooking]
1 [baking, fun]
3 [japanese, cuisine, great]
词干提取和词形还原
快完成了!词干提取和词形还原是可能根据具体任务使用的附加文本预处理步骤。词干提取将每个标记(单词)还原为其基础或根形式,而词形还原则进一步将其还原为词形或基础词典形式,取决于上下文,例如“best” -> “good”。为了简化起见,我们在这个示例中将只应用词干提取,使用 NLTK 库中实现的 PorterStemmer,借助 wordnet 数据集的词根关联。得到的词干词保存在 DataFrame 中的新列中。
from nltk.stem import PorterStemmer
nltk.download('wordnet')
stemmer = PorterStemmer()
df['stemmed'] = df['tokens'].apply(lambda x: [stemmer.stem(word) for word in x])
print(df[['tokens','stemmed']])
输出:
tokens stemmed
0 [love, cooking] [love, cook]
1 [baking, fun] [bake, fun]
3 [japanese, cuisine, great] [japanes, cuisin, great]
将文本转换为数字表示
最后但同样重要的是,计算机算法包括 AI/ML 模型并不理解人类语言,而是数字,因此我们需要将我们的词向量映射到数字表示中,通常称为嵌入向量,或简称为嵌入。下面的示例将“tokens”列中的分词文本转换为 TF-IDF 向量化方法(这是经典 NLP 的黄金时代中最受欢迎的方法之一)来将文本转换为数字表示。
from sklearn.feature_extraction.text import TfidfVectorizer
df['text'] = df['tokens'].apply(lambda x: ' '.join(x))
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(df['text'])
print(X.toarray())
输出:
[[0\. 0.70710678 0\. 0\. 0\. 0\. 0.70710678]
[0.70710678 0\. 0\. 0.70710678 0\. 0\. 0\. ]
[0\. 0\. 0.57735027 0\. 0.57735027 0.57735027 0\. ]]
就这样!尽管对我们来说可能显得难以理解,这种我们预处理文本的数字表示就是智能系统,包括 NLP 模型,能够理解并且在挑战性语言任务如文本情感分类、总结或甚至翻译成另一种语言时表现得异常出色的内容。
下一步是将这些数字表示输入到我们的 NLP 模型中,让它施展魔法。
伊万·帕洛马雷斯·卡拉斯科萨 是一位在人工智能、机器学习、深度学习和大型语言模型方面的领导者、作家、演讲者和顾问。他培训和指导他人在实际应用中利用人工智能。
更多相关内容
澄清“提升”相关问题
原文:
www.kdnuggets.com/2019/06/clearing-air-around-boosting.html
 评论
评论
作者 Puneet Grover, 帮助机器学习。

注意: 尽管这篇文章稍微偏重数学,但你仍然可以通过阅读前两节,即 介绍 和 历史,理解提升和梯度提升的核心工作。之后的部分是对不同梯度提升算法论文的解释。
这是我 Concepts 类别中的一篇文章,可以在我的 GitHub 仓库 这里 找到。
目录
-
介绍
-
历史(袋装、随机森林、提升和梯度提升)
-
AdaBoost
-
XGBoost
-
LightGBM
-
CatBoost
-
进一步阅读
-
参考文献
注意: 本文配有在我 GitHub 仓库中的Jupyter Notebook:[ClearingAirAroundBoosting]
1) 介绍
提升 是一种集成元算法,主要用于减少监督学习中的偏差和方差。
如今,提升算法是获得各种问题和情境下最先进结果的最常用算法之一。它已成为解决任何机器学习问题或竞赛的首选方法。现在,
-
这种提升算法的巨大成功背后的原因是什么?
-
它是如何产生的?
-
我们可以期待未来发生什么?
我将通过这篇文章尝试回答所有这些问题以及更多问题。
2) 历史 ^
照片来源 Andrik Langfield 在 Unsplash
提升基于 Kearns 和 Valiant(1988, 1989)提出的问题:“一组 弱学习器 能否创建一个 强学习器?”
罗伯特·沙皮雷在 1990 年论文中对凯恩斯和瓦利安特提出的问题的肯定回答在机器学习和统计学中产生了重大影响,最显著的是导致了 Boosting 的发展。
在 Bagging 方法中,还有一些其他集成方法在同一时期出现,可以说它们是现代梯度提升算法的子集,它们包括:
- Bagging(Bootstrap Aggregating):(即自助采样 + 聚合)
Bagging 是一种集成元算法,有助于提高稳定性和准确性。它还帮助减少方差,从而减少过拟合。
在 bagging 中,如果我们有 N 个数据点,并且我们想要生成‘m’个模型,那么我们将从数据中取出一些数据的分数[通常是(1–1/e)≈63.2%],从数据中重复‘m’次并重复一些行,使其长度等于 N 个数据点(尽管其中一些是冗余的)。现在,我们将在这些‘m’个数据集上训练‘m’个模型,然后得到‘m’组预测。然后我们将这些预测进行汇总以获得最终预测。
它可以与神经网络、分类和回归树以及线性回归中的子集选择一起使用。
- 随机森林:
随机森林(或随机决策森林)方法是一种集成学习方法,通过构建大量决策树来操作。它有助于减少在决策树模型(具有较高深度值)中常见的过拟合。
随机森林结合了“bagging”思想和特征的随机选择,以构建一个决策树集合来对抗方差。与 bagging 一样,我们为决策树创建自助采样训练集,但现在在树生成过程中每次进行分裂时,我们只选择总特征数的一部分[通常为√n 或 log2(n)]。
这些方法,自助采样和子集选择,使树之间更不相关,有助于更多地减少方差,因此以更具概括性的方法减少过拟合。
- Boosting:
以上方法使用了互斥模型的平均以减少方差。Boosting略有不同。Boosting 是一种序列集成方法。对于总数为‘n’的树,我们以序列方式添加树的预测(即我们添加第二棵树来提高第一棵树的性能,或者说尝试纠正第一棵树的错误,依此类推)。所以我们所做的是,从目标值中减去第一模型的预测值乘以常数(0<λ≤1),然后将这些值作为目标值来拟合第二模型,依此类推。我们可以将其视为:新模型尝试纠正之前模型/之前模型的错误。Boosting 可以通过一个公式来概括:
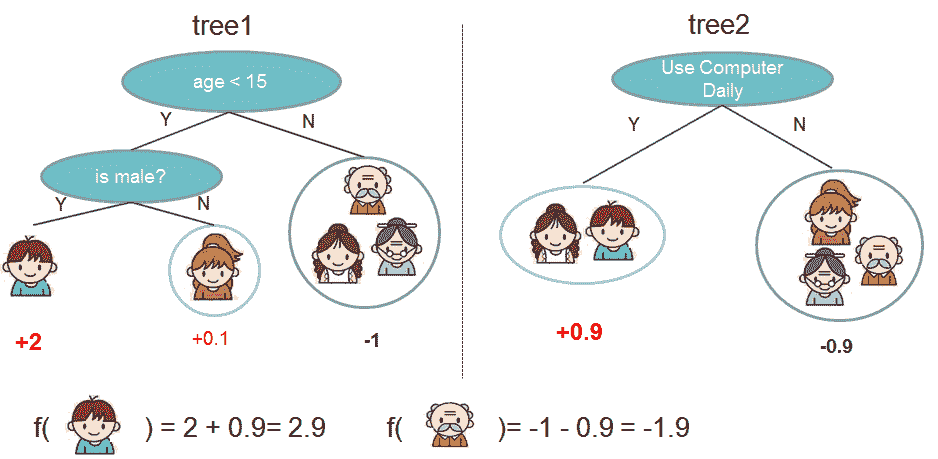
示例:预测某人是否会喜欢计算机游戏。[来源:XGBoost 文档]
即最终预测是所有模型预测的总和,每个预测乘以一个小常数(0<λ≤1)。这是一种观察提升算法的另一种方式。
实际上,我们尝试从每个学习器(这些都是弱学习器)中学习少量关于目标的信息,这些学习器试图改进先前的模型,然后将它们汇总以获得最终预测(这是可能的,因为我们只拟合先前模型的残差)。因此,每个顺序学习器试图预测:
(初始预测) — (λ * 前述学习器所有预测的总和)
每个树预测器也可以根据其表现具有不同的 λ 值。
- 梯度提升:
在梯度提升中,我们使用一个损失函数,在每次拟合周期中进行评估(就像在深度学习中一样)。Jerome H. Friedman 首次提出的论文集中于最终函数的加性扩展,类似于我们上面看到的内容。
我们首先预测一个目标值(例如,γ),这是一个给出最小误差的常数(即第一次预测是 F0 = γ)。之后我们计算数据集中每个点相对于我们之前输出的梯度。因此,我们计算误差函数相对于之前模型所有输出总和的梯度,在平方误差的情况下是:
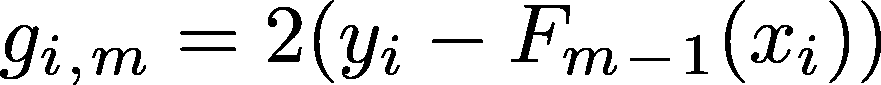
相对于该数据点所有值之和的梯度(即第 i 个梯度)
这样我们就得到了相对于之前模型所有输出的梯度。
我们为什么要这样计算梯度?
在神经网络中,计算所有参数(即所有神经节点)梯度是很直接的,因为神经网络在所有层中只是线性(或某个梯度容易计算的函数)组合,因此通过反向传播(相对于所有参数)计算梯度并更新它们更为容易。但是在决策树中,我们无法计算输出相对于任何参数(如深度、叶子数量、分裂点等)的梯度,因为这并不直接(实际上是抽象的)。
- Friedman 使用每个输出的误差梯度(误差函数)并将模型拟合到这些梯度。
这如何有助于获得更好的模型?
每个输出的梯度表示我们应该朝哪个方向移动以及移动多少,以获得该特定数据点/行的更好结果,将树拟合问题转化为优化问题。我们可以使用任何可微分且可以针对我们当前任务进行定制的损失函数,这在普通提升方法中是不可能的。例如,我们可以使用 MSE 进行回归任务,用 Log Loss 进行分类任务。
这里梯度如何用于获得更好的结果?
与提升算法不同,在提升算法中,我们在第i次迭代时学习了一部分输出(目标),而第(i+1)棵树会尝试预测剩余的部分,即我们对残差进行拟合;而在梯度提升中,我们计算相对于所有数据点/行的梯度,这告诉我们要前进的方向(负梯度)以及前进的幅度(可以看作是梯度的绝对值),并在这些梯度上拟合一棵树。
这些梯度基于我们的损失函数(选择以比其他方法更好地优化问题),反映了我们希望对预测进行的变化。例如,在凸损失函数中,我们会随着残差的增加而得到梯度的指数增加的倍数,而残差是线性增加的。因此,收敛时间更好。这取决于损失函数和优化方法。
这为数据点的梯度区域提供了类似的更新,因为它们将有相似的梯度。现在我们将找到该区域的最佳值,这将为该区域提供最小的误差。(即树拟合)
在这之后,我们将这些预测添加到之前的预测中,以获得本阶段的最终预测。
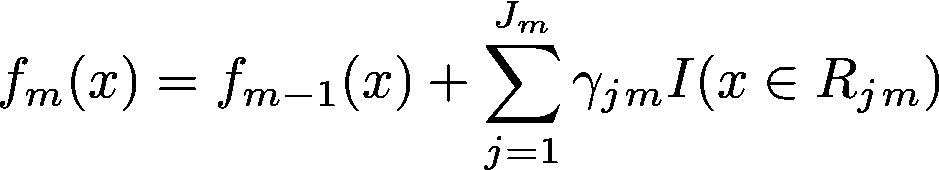
其中 γjm 是第 j 区域第 m 棵树的预测值,Jm 是第 m 棵树的区域数量。因此,为该区域添加 γ 乘以身份,若数据点在当前区域,则为 1。
这为每个数据点/行提供了新的预测。
正常提升和梯度提升的基本区别在于,在正常提升中,我们将下一模型拟合到残差上,而在梯度提升中,我们将下一模型拟合到残差的梯度上。嗯……梯度提升实际上使用损失函数,因此我们将下一模型拟合到该损失函数的梯度(其中通过使用之前的预测找到梯度)。
注意开始
进一步可能的改进:
目前的梯度提升库远不止这些,例如:
-
树的约束(例如
max_depth,或num_leaves等) -
缩减(即
learning_rate) -
随机采样(行采样,列采样)[在树和叶子级别]
-
惩罚学习(L1 回归,L2 回归等)[这需要修改的损失函数,正常提升无法实现]
-
以及更多……
这些方法(其中一些)在一种称为 随机梯度提升的提升算法中实现。
注意结束
3) AdaBoost

照片由 Mehrshad Rajabi 提供,来自 Unsplash
这是第一个在机器学习领域留下巨大印记的提升算法。它由 Freund 和 Schapire(1997)开发,这里是相关论文。
除了顺序地添加模型的预测(即提升)外,它还为每个预测添加权重。它最初是为分类问题设计的,其中它增加了所有错误分类样本的权重,并减少了所有正确分类样本的权重(虽然也可以应用于回归)。因此,下一个模型将更多地关注权重较大的样本,而较少关注权重较小的样本。
他们还使用一个常数来缩小每棵树的预测值,这个常数的值是在拟合过程中计算得出的,并且取决于拟合后的误差。误差越大,该树的常数值就越小。这使得预测更准确,因为我们从不够准确的模型中学习较少,从更准确的学习器中学习更多。
它最初用于两类分类,并选择输出为{-1, +1},其中:
-
它以每个数据点的权重相等= 1/N(其中,N:数据点数量)开始,
-
然后,它使用初始权重(最初相同)拟合第一个分类模型 h_0(x)到训练数据上,
-
然后计算总误差,并基于此更新所有数据点的权重(即增加错误分类的权重,减少正确分类的权重)。总误差在计算该特定树的缩小常数时也变得有用(即我们计算常数α,对于大误差较小,对于小误差较大,并用于缩小和权重计算)。
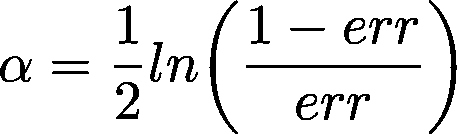
- 最终,当前轮次的预测结果会在与α相乘后加到之前的预测结果上。由于最初是分类为+1 或-1,因此最终预测结果取最后一轮的预测符号:
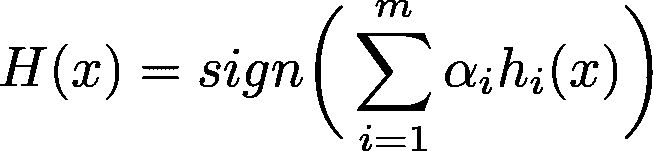
其中 α_i 是第 i 个常数(前一位置),h_i 是第 i 个模型预测值
(AdaBoost 不是基于梯度的)
4) XGBoost

照片由 Viktor Theo 提供,来源于 Unsplash
XGBoost 试图在先前的梯度提升算法基础上进行改进,以提供更好、更快和更具通用性的结果。
它在梯度提升的基础上进行了一些不同的和新的改进,例如:
- a) 正则化学习目标:
与许多其他目标函数实现类似,这里建议向损失函数中添加一个额外的函数来惩罚模型的复杂性(如 LASSO、Ridge 等),称为正则化项。这有助于模型避免过拟合数据。
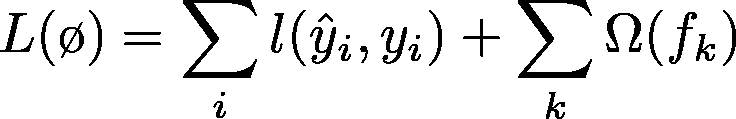
一些损失函数 + (一些正则化函数以控制模型的复杂性)
现在,对于具有加法性质的梯度提升,我们可以将第‘t’次预测写作 F_t(x) = F_t-1(x) + y_hat_t(x),即此轮预测加上所有先前预测的总和。损失函数:
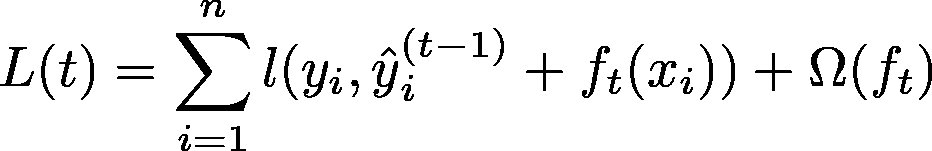
经过泰勒级数近似后,可以写成:
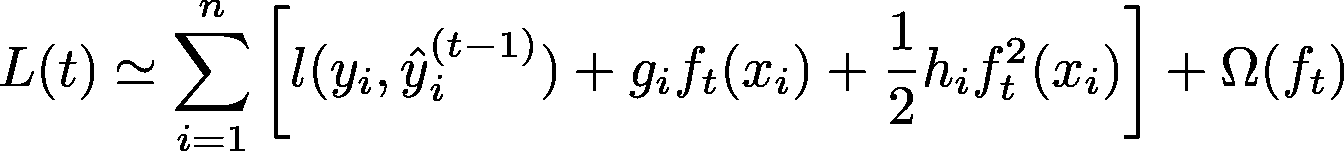
其中 g_i 和 h_i 是损失函数的梯度和 Hessian,即损失函数的一阶和二阶导数
为什么到二阶?
仅使用一阶梯度的梯度提升算法面临收敛问题(只有在步长较小的情况下才可能收敛)。而且它对损失函数的近似效果相当好,加上我们不希望增加计算量。
然后通过将损失函数的梯度设置为零,从而找到损失函数的最优值,并通过损失函数找到用于分裂的函数。(即,分裂后损失的变化函数)
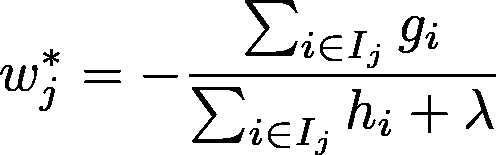
通过将上述公式的导数设置为零来发现。[最优变化值]
- b) 收缩和列子采样:
它还为每棵树增加了收缩,以减少单棵树的影响,并对列进行子采样,以对抗过拟合并减少方差,如历史部分所讨论的。
- c) 不同的分裂查找算法:
梯度提升算法遍历所有可能的分裂,以找到该级别的最佳分裂。然而,如果我们的数据非常庞大,这可能是一个昂贵的瓶颈,因此许多算法使用某种近似或其他技巧来寻找一个特别好的分裂,而不是最佳分裂。因此,XGBoost 查看特定特征的分布,并选择一些百分位数(或分位数)作为分裂点。
注意:
为了近似分裂的查找,这些方法也被使用,而不是百分位数方法:
- 通过构造梯度统计的近似直方图。2) 通过使用其他变体的分箱策略。
它建议选择一个值,称之为 q,现在从[0, 100]的分位数范围中,几乎每个 q 分位值都被选为分裂的候选点。将会大约有 100/q 个候选点。
它还添加了稀疏感知分裂查找,这在稀疏的 BigData 数组中可能很有帮助。
- d) 为了提高速度和空间效率:
它建议将数据划分为块,内存中的块。每个块中的数据以压缩列(CSC)格式存储,其中每列按相应的特征值存储。因此,在块中对列进行线性搜索足以获取该列的所有分裂点。
块格式使得在线性时间内找到所有拆分变得容易,但当需要获取这些点的梯度统计时,它变成了非连续的梯度统计提取(因为梯度仍然以之前的格式存在,其中块值指向它们的梯度),这可能导致缓存缺失。为了解决这个问题,他们制定了缓存感知算法用于梯度累积。在这种算法中,每个线程都会获得一个内部缓冲区。这个缓冲区用于以小批量的方式获取梯度并进行累积,而不是按顺序从这里获取一些梯度,再从那里获取一些梯度。
找到最佳块大小也是一个问题,它可以帮助最佳利用并行性并最大程度地减少缓存缺失。
它还提出了一个叫做块分片的方案。它在多个磁盘上交替写入数据(如果你有这些磁盘的话)。所以,当它想读取一些数据时,这种设置可以帮助同时读取多个块。例如,如果你有 4 个磁盘,这四个磁盘可以在一个单位时间内读取 4 个块,实现 4 倍的速度提升。
5) LightGBM

照片由 Severin D. 提供,来自 Unsplash
这篇论文提出了两种技术来加速整体的 Boosting 过程。
对于第一个,它提出了一种方法,在这种方法中,他们不必为特定模型使用所有数据点,而不会损失太多的信息增益。它被称为基于梯度的单侧采样(GOSS)。在这种方法中,他们计算损失函数的梯度,然后按绝对值排序。它还有一个证明,证明梯度值较大的值对信息增益的贡献更大,因此它建议忽略许多梯度较低的数据点。
因此,为特定模型选择一部分顶部梯度和从其余部分中选择不同的部分(从剩余梯度中随机选择),对随机梯度集施加较低的权重,因为它们的梯度值较低,不应对当前模型贡献太多。

获取损失的梯度,排序,取顶部梯度集和其余的随机梯度,减少随机梯度的权重,然后将此模型添加到之前模型的集合中。
需要注意的一点是,LightGBM 使用基于直方图的算法,将连续特征值分成离散的箱子。这加速了训练并减少了内存使用。
此外,他们使用了一种不同的决策树,它优化叶节点而不是普通决策树的深度(即,它枚举所有可能的叶子节点,并选择错误最少的一个)。
对于第二种方法,它提出了一种将许多特征组合成一个新特征的方法,从而在减少数据维度的同时不会丢失太多信息。这种方法称为独占特征捆绑(EFB)。它表示,在高维数据的世界中,存在许多相互排斥的列。为什么?因为高维数据有许多高度稀疏的列,可能有许多列在同一时间内没有取任何值(即,通常只有其中一个取非零值,即相互排斥)。因此,他们建议将这些特征捆绑成一个,没有冲突超过某个预设值(即,它们在许多点上在相同数据点没有非零值,即它们并非完全相互排斥,但在某种程度上是相互排斥)。为了区分来自不同特征的每个值,它建议对来自不同特征的值添加不同的常数,这样来自一个特征的值会落在一个特定的范围内,而来自其他特征的值则不在该范围内。例如,假设我们有三个特征要组合,所有特征的范围是 0-100。因此,我们将对第二个特征加 100,对第三个特征加 200,以获得三个特征的三个范围,分别为 0, 100)、[100, 200) 和 [200, 300)。在基于树的模型中,这种做法是可以接受的,因为它不会影响通过分裂获得的信息增益。

本文着重于提升算法面临的一个问题,即泄漏,目标泄漏。在提升中,多个模型在训练示例上进行拟合依赖于目标值(用于计算残差)。这会导致测试集中目标值的偏移,即预测偏移。因此,它提出了一种绕过这个问题的方法。
此外,它还提出了一种将类别特征转换为目标统计量(TS)的方法(如果处理不当可能会导致目标泄漏如果做错了)。
提出了一个叫做有序提升的算法,帮助防止目标泄漏,以及一个处理分类特征的算法。虽然两者都使用了某种叫做排序原则的方法。
首先,为了将分类特征转换为目标统计(TS)。如果你了解均值编码或目标编码的分类特征,特别是 K 折均值编码,这将很容易理解,因为这只是稍作调整。他们为了避免目标泄漏但仍能进行目标编码,是从数据集中获取第 i 个元素的(i-1)个元素,以获得该元素的特征值(即,如果第 i 个元素上方有 7 个相同类别的元素,则他们取这些值的目标均值来获得第 i 个元素的特征值)。
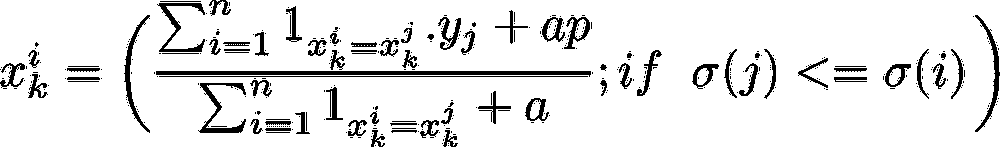
如果 i,j 属于同一类别,则平均目标值仅在该元素在本次迭代的随机排列中位于第 i 个元素之上时才计算(如声明中的条件)。‘a’和‘p’是防止等式下溢的参数。
其次,为了使算法预测偏移稳健,它提出了一个称为有序提升的算法。在每次迭代中,它独立地抽取一个新的数据集 D_t,并通过将当前模型应用于此数据集来获取未偏移的残差(因为这是一个不同的数据集),然后拟合一个新模型。实际上,他们将新数据点添加到之前的数据点中,从而为当前迭代中新添加的数据点提供至少未偏移的残差。
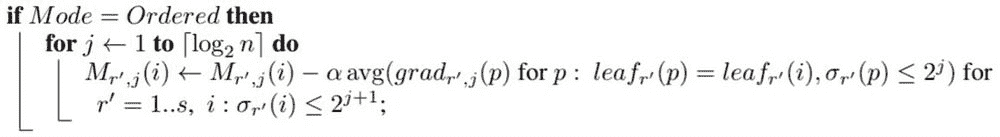
对于 i=1..n,从随机排列 r中计算 avg(如果它属于同一叶子节点的梯度),仅在排列 r中该叶子节点位于 2^(j+1) th 点之上时计算。[通过添加新预测更新模型]
使用此算法,我们可以为'n'个示例制作’n’个模型。但由于时间考虑,我们只制作 log_2(n)个模型。因此,第一个模型拟合 2 个示例,第二个模型拟合 4 个,以此类推。
CatBoost 也使用一种不同的决策树,称为盲树。在这种树中,相同的分裂标准用于树的整个层级。这种树是平衡的,且不容易过拟合。
在盲树中,每个叶子索引可以编码为长度等于树深度的二进制向量。这个事实在 CatBoost 模型评估器中被广泛使用:它首先将所有浮点特征和所有独热编码特征二值化,然后使用这些二进制特征来计算模型预测。这有助于以非常快的速度进行预测。
7) 进一步阅读
-
Trevor Hastie; Robert Tibshirani; Jerome Friedman (2009). 统计学习的元素:数据挖掘、推断与预测(第 2 版)。纽约:Springer。 (ISBN 978–0–387–84858–7)
-
所有参考文献
8) 参考文献
-
Trevor Hastie; Robert Tibshirani; Jerome Friedman (2009). 统计学习的要素: 数据挖掘、推断与预测(第 2 版)。纽约: Springer. (ISBN 978–0–387–84858–7)
-
论文 — 提升简介 — Yoav Freund, Robert E. Schapire(1999) — AdaBoost
-
论文 — CatBoost: 无偏提升与分类特征 — Prokhorenkova, Gusev 等 — v5 (2019)
-
YouTube — CatBoost — 新一代梯度提升 — 安娜·维罗妮卡·多罗戈什
-
渐进式介绍梯度提升算法 — MachineLearningMastery
原文. 经允许转载。
资源:
相关:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 方面的工作
了解更多相关信息
关闭源代码与开源图像注释
原文:
www.kdnuggets.com/closed-source-vs-open-source-image-annotation

计算机是否可以被训练来识别猫的可爱程度?那你会想做些什么呢?是否在猫的图片上难以集中注意力?你是否是那些希望为了方便而想要改变的技术爱好者之一?你还记得当你想让计算机相信停车标志不是让行标志时,试图说服计算机这一点的情景吗?这不再是技术爱好者们的担忧。为了让你在注释和标记过程中保持参与和娱乐,有大量的开源工具可以选择。图像注释工具的使用在像素化混乱的世界中崭露头角。通过使用注释工具,可以快速而高效地识别图像。因此,机器将能够像人类一样理解世界,计算机程序也将能够做出更好的决策。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
我们所生活的数字世界迅速发展,这为图像注释工具的准确性、公正性和快速性提出了要求。从自动驾驶汽车、医疗、增强现实、农业和机器人,到电子商务——对人工智能的依赖正在增加。因此,对可靠且高效的图像注释资源的需求也在迅速增长。在这篇文章中,我们将比较开源和闭源图像注释,并引用实际例子得出一个积极的结论。
准确的图像注释
作为 AI 模型的训练数据,图像注释既费时又繁琐,但值得付出努力,因为它是算法成功的关键。每张图像必须经过注释,以便机器能够正确读取(没有错误或偏见)。为了开发高质量的无错误 AI 模型,图像注释过程必须具有准确性和精确性。因此,我们获得的结果可以说是公正、准确且精确的。
优势:开源图像注释工具的强大功能
毋庸置疑,由于价格实惠、易于访问和定制功能,开源图像标注正在获得越来越多的关注。由于大多数开源工具正在不断改进,这吸引了用户获取免费的附加功能。
缺点:开源图像标注的挑战
尽管最初免费或较便宜的工具可能会很吸引人。开源工具可能只是那些关注可扩展性、创新和持续发展的人的临时试用工具。此外,并不是所有的开源工具都足够强大以产生高质量的输出。标注和标记每张图像或视频的准确性越高,如果你真的试图通过 AI 改造传统实践,你将会受益更多。
准确标注图像:工具和技术
无论是通过开源工具还是闭源工具。图像标注对于提高机器学习算法的能力至关重要,以确保它们能准确识别和解释视觉数据。当图像按标准进行标注时,AI 模型能够正常运行,并识别图像中呈现的对象、区域和特征。
一些开源标注工具的例子
LabelImg 是一个常用的图像标注工具,允许用户在对象周围绘制边界框并添加标签。它是使用 Python 和 Qt 库实现的。这里是一个仓库 - github.com/tzutalin/labelImg
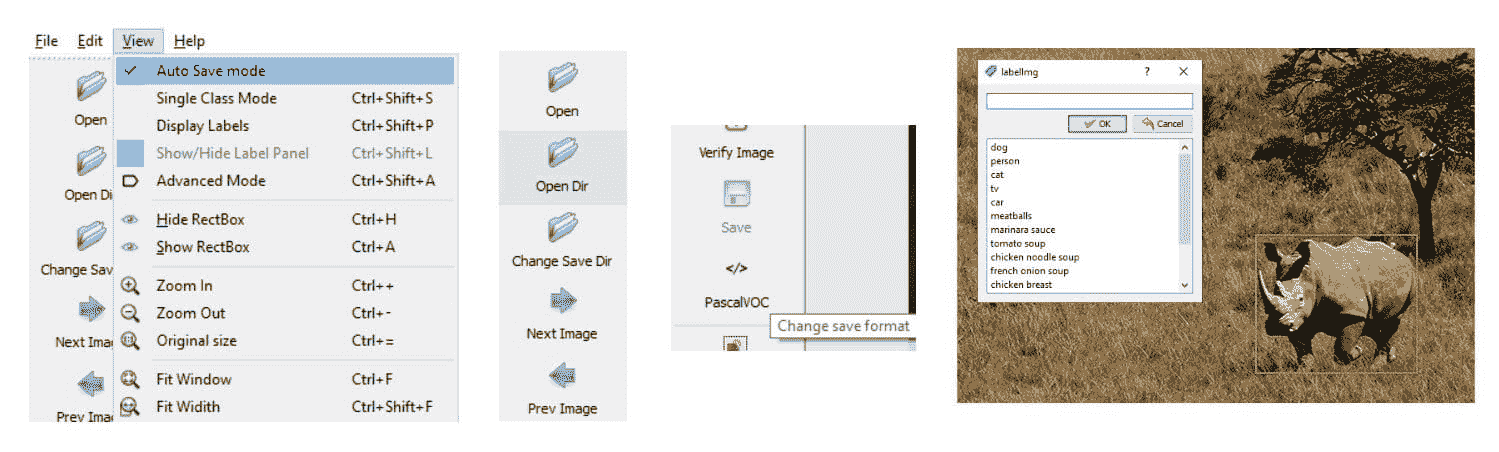
一旦你安装了 LabelImg 并准备好一组待标注的图像,你可以使用下面提到的 python 脚本为每张图像打开 LabelImg。标注后的图像将以 XML 文件的形式保存。
## https://github.com/tzutalin/labelImg
import os
import subprocess
image_dir = "/path/to/your/image/directory"
# List all image files in the directory
image_files = [f for f in os.listdir(image_dir) if f.endswith(".jpg") or f.endswith(".png")]
# Path to LabelImg executable
labelimg_executable = "/path/to/labelImg.py"
# Loop through the image files and open LabelImg for annotation
for image_file in image_files:
image_path = os.path.join(image_dir, image_file)
subprocess.call([labelimg_executable, image_path])
COCO Annotator 是一个专为 COCO 格式图像标注设计的基于网页的工具。它以支持多种类型的标注而闻名,如边界框、多边形和关键点。这个标注工具使用 JavaScript 和 Django 构建。

VGG 图像标注工具(VIA)是由牛津大学视觉几何组开发的图像标注工具。它允许用户自由标注不同类型的对象,包括点、线和区域。VIA 提供的界面对标注图像来说非常用户友好且直观。
一些闭源标注工具的例子
Labelbox 是一个平台,允许用户对图像进行标注,任务包括物体检测、图像分割和分类。这个工具提供了众多协作功能,可以高效地与机器学习框架集成。
Supervisely - 该工具支持图像注释,并提供数据版本控制和模型部署等功能。
图像注释工具的应用及案例

图像注释工具用于各个行业中的图像注释。使用图像注释工具,如行人、车辆和交通标志,自动驾驶汽车能够安全导航并做出明智的决策。此外,自动驾驶汽车能够安全行驶并做出明智的决策。因此,在医疗成像中,图像注释帮助医疗专业人员进行无误的诊断。基于这些信息,患者可以获得有效的治疗。除了对产品进行分类和提高搜索功能外,电子商务平台还利用图像注释来改善客户的整体购物体验,提升他们的体验。以下提到的例子展示了图像注释工具在不同领域的多样性和重要性。
现实生活中的图像注释
让我们通过检查一些现实生活中的例子来了解图像注释工具的实际应用:
1. 自动驾驶车辆
为了使自动驾驶车辆能够无故障地感知和导航环境,必须使用可靠的图像注释工具。这些上述工具通过检测行人、车辆和交通标志,帮助自动驾驶车辆做出明智的决策。因此,确保每次乘车的乘客安全。
2. 医学成像
说到医疗行业,放射科医生正在享受人工智能解决方案的优势。临床医生利用人工智能获取有用的医学数据,帮助他们更准确地阅读和分析 X 光片、CT 扫描和/或磁共振图像。通过更好的数据和对患者疾病的可见性,医生能够以更好的关怀和谨慎来治疗患者。
3. 视觉搜索在电子商务中的作用
在电子商务行业中,图像注释的使用非常广泛。产品按功能、颜色、风格和视觉搜索等多个参数进行分类,以便使客户的购物旅程更加轻松、愉快和便捷。
4. 增强现实(AR)
图像注释在增强现实(AR)应用中用于将虚拟对象和信息根据现实世界环境正确放置。从对象的深度、尺度和方向开始,一切都被注释,以提供给用户一个真实而沉浸的 AR 体验。
5. 机器人技术与自动化
机器人专业人士可以借助图像标注工具来操控物体。当机器人被标注上相关属性时,它们能够有效地感知和与环境互动。
最后的思考
尽管开源图像标注工具的受欢迎程度确实在上升,但它们也带来了许多缺点。使用开源图像标注工具很难扩展大型项目并确保高质量的标注图像。因此,选择闭源工具将是一个明智的选择。
如果你是一个技术爱好者,你可能会想了解更多关于提示工程在人工智能中的影响。
Mirza Arique Alam 是一位充满激情的人工智能与机器学习作者和出版作者。他在人工智能与技术的交汇处创作引人入胜且信息丰富的内容,旨在激励和教育世界,展示人工智能的无限潜力。目前,他与 Cogito 和 Anolytics 合作。
更多相关话题
缩小人类理解与机器学习之间的差距:可解释人工智能作为解决方案

图片由 Bing 图像创作者提供
介绍
你是否曾打开你最喜欢的购物应用程序,看到的第一件事是推荐一个你甚至不知道需要的产品,但由于及时的推荐你最终购买了它?或者你是否打开你常用的音乐应用程序,看到一个被遗忘的宝藏由你最喜欢的艺术家推荐在最上面,作为“你可能喜欢”的内容感到高兴?无论是知道还是不知道,我们今天都遇到由人工智能(AI)生成的决策、行动或体验。虽然这些体验中的一些是相当无害的(比如精准的音乐推荐),但有些可能会引起一些不安(“这个应用怎么知道我一直在考虑进行减肥计划?”)。当涉及到关于自己和亲人的隐私问题时,这种不安会升级为担忧和不信任。然而,了解如何或为什么会推荐某些内容,可以帮助缓解一些这种不安。
这就是可解释人工智能(Explainable AI,简称 XAI)的作用所在。随着人工智能系统变得越来越普及,理解这些系统如何做出决策的需求也在增长。本文将探讨 XAI,讨论可解释 AI 模型中的挑战,介绍使这些模型更具可解释性的进展,并为公司和个人提供在产品中实施 XAI 的指导,以促进用户对人工智能的信任。
什么是可解释人工智能?
可解释人工智能(XAI)是指 AI 系统能够提供其决策或行动的解释的能力。XAI 填补了 AI 系统决策与最终用户理解为什么做出该决策之间的重要差距。在人工智能出现之前,系统通常是基于规则的(例如,如果客户购买裤子,则推荐皮带;或者如果某人打开“智能电视”,则在固定的三个选项之间循环推荐#1)。这些经历提供了一种可预测的感觉。然而,随着人工智能的普及,倒推为什么会显示某些内容或某些决策是如何由产品做出的并不简单。可解释人工智能可以在这些情况下提供帮助。
可解释的 AI(XAI)允许用户理解 AI 系统做出某个决策的原因以及决策所依据的因素。例如,当你打开音乐应用时,你可能会看到一个名为“因为你喜欢泰勒·斯威夫特”的部件,接着是类似泰勒·斯威夫特歌曲的流行音乐推荐。或者你可能打开一个购物应用,看到“基于你最近的购物历史的推荐”,接着是婴儿产品推荐,因为你在最近几天购买了一些婴儿玩具和衣物。
XAI 在 AI 做出高风险决策的领域尤为重要。例如,算法交易和其他金融建议、医疗保健、自动驾驶汽车等。能够提供决策解释有助于用户理解决策理由,识别因训练数据引入的模型偏见,纠正决策错误,并帮助建立人类与 AI 之间的信任。此外,随着日益增加的监管指南和法律要求,XAI 的重要性只会不断增长。
XAI 的挑战
如果 XAI 能够向用户提供透明度,那为什么不使所有 AI 模型都具备可解释性呢?有几个挑战阻碍了这一目标的实现。
高级 AI 模型如深度神经网络在输入和输出之间有多个隐藏层。每一层接受来自前一层的输入,对其进行计算,然后将结果传递给下一层。层与层之间的复杂交互使得跟踪决策过程以使其可解释变得困难。这就是为什么这些模型通常被称为黑箱的原因。
这些模型还处理高维数据,如图像、音频、文本等。解释每一个特征的影响以确定哪个特征对决策的贡献最大是具有挑战性的。简化这些模型以提高可解释性会导致性能下降。例如,更简单且“易于理解”的模型如决策树可能会牺牲预测性能。因此,为了可预测性而在性能和准确性之间进行权衡也是不可接受的。
XAI 的进展
随着对 XAI 的需求日益增长以继续建立人类对 AI 的信任,近年来在这一领域取得了一些进展。例如,一些模型如决策树或线性模型使可解释性相当明显。还有一些符号或基于规则的 AI 模型专注于信息和知识的明确表示。这些模型通常需要人为定义规则并向模型提供领域信息。随着这一领域的积极发展,也出现了结合深度学习与可解释性的混合模型,最大限度地减少了性能上的牺牲。
实施 XAI 的产品指南
赋予用户更多理解 AI 模型决策原因的能力,有助于促进对模型的信任和透明度。这可以导致人机之间改进的、互利的合作,其中 AI 模型帮助人类做出透明的决策,而人类则帮助调整 AI 模型以消除偏差、不准确和错误。
以下是公司和个人可以在其产品中实施 XAI 的一些方式:
-
选择可解释的模型 – 在可解释的 AI 模型能满足需求且表现良好的情况下,应优先选择这些模型。例如,在医疗保健领域,像决策树这样的简单模型可以帮助医生理解 AI 模型推荐某种诊断的原因,这有助于建立医生与 AI 模型之间的信任。应使用提高可解释性的特征工程技术,如独热编码或特征缩放。
-
使用事后解释 – 使用像特征重要性和注意力机制这样的技术生成事后解释。例如,LIME(局部可解释模型无关解释)是一种解释模型预测的技术。它生成特征重要性分数,以突出每个特征对模型决策的贡献。例如,如果你最终“喜欢”某个播放列表推荐,LIME 方法会尝试添加和移除播放列表中的某些歌曲,并预测你喜欢该播放列表的可能性,从而得出播放列表中歌曲的艺术家在你喜欢或不喜欢该播放列表中扮演了重要角色。
-
与用户的沟通 – 可以使用像 LIME 或 SHAP(SHapley Additive exPlanations)这样的技术,提供关于具体局部决策或预测的有用解释,而不必解释模型的所有复杂性。还可以利用激活图或注意力图等视觉提示,突出输入与模型生成的输出之间的相关性。像 Chat GPT 这样的新技术可以用来简化复杂的解释,以用户可以理解的简单语言表达。最后,给予用户一定的控制权,以便他们与模型互动,这有助于建立信任。例如,用户可以尝试以不同的方式调整输入,以查看输出的变化。
-
持续监测 – 公司应实施机制来监控模型的性能,并在检测到偏差或漂移时自动发出警报。应定期更新和微调模型,并进行审计和评估,以确保模型符合监管法律并满足伦理标准。最后,即使很少,也应有人参与提供反馈和必要的修正。
结论
总结来说,随着人工智能的不断发展,构建可解释的人工智能(XAI)变得至关重要,以维持用户对人工智能的信任。通过采用上述指导方针,公司和个人可以构建更透明、易于理解和简单的人工智能。公司越多地采用 XAI,用户与人工智能系统之间的沟通就会越好,用户也会越有信心让人工智能改善他们的生活。
Ashlesha Kadam 领导着亚马逊音乐的全球产品团队,为来自 45 多个国家的数百万客户在 Alexa 和亚马逊音乐应用(网页、iOS、Android)上打造音乐体验。她还是女性科技领域的热情倡导者,担任 Grace Hopper Celebration(全球最大的女性科技会议,参会者超过 3 万人,来自 115 个国家)的计算机与人类交互(HCI)分会的联合主席。在空闲时间,Ashlesha 喜欢阅读小说、听商业科技播客(当前最爱 - Acquired),在美丽的太平洋西北地区徒步旅行,以及和丈夫、儿子及 5 岁的金毛猎犬共度时光。
我们的前三推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
更多相关主题
云计算、数据科学和 ML 趋势 2020–2022:巨头之战
原文:
www.kdnuggets.com/2021/01/cloud-computing-data-science-ml-trends-2020-2022-battle-giants.html
评论
由 George Vyshnya,SBC 联合创始人/CTO

每次你看到一个巨头时,你必须知道那个巨头可能在其他地方只是个侏儒! ― Mehmet Murat ildan
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
介绍
我将致力于一系列文章,分享 Kaggle “2020 年数据科学和机器学习现状”调查中收集的数据见解 (www.kaggle.com/c/kaggle-survey-2020)。
调查涵盖了很多不同的话题,每一个话题都值得单独讨论各自的趋势。
备注:
-
Kaggle (www.kaggle.com) 是一个由全球各地的数据科学家和机器学习者组成的社区,成员技能和背景各异。社区拥有约 300 万活跃成员。虽然从社会学角度来看,它并不完全代表全球数据科学和 ML 专业人士的总体情况,但它仍然构成了该领域从业者和专业人士的重要部分。因此,调查结果确实可以对数据科学和 AI/ML 行业在未来几年可能的发展方向进行有价值的预测。
-
你可以查看仓库
github.com/gvyshnya/state-of-data-science-and-ml-2020以了解本文讨论的每个见解是如何发现的。
巨头之战
在这篇文章中,我们将探讨参与调查的数据科学和 ML 专业人士对云计算平台和产品的受欢迎程度。特别是,它将涵盖
-
云平台使用情况
-
云计算产品使用情况
-
云 ML 产品使用情况
-
大数据平台
-
BI 工具(主要是基于云的工具)
本章的叙述线将经常附带关于市场上前三大云服务提供商的好消息和机会
-
亚马逊 Web 服务 (AWS)
-
Google Cloud Platform (GCP)
-
Microsoft Azure Cloud (MS Azure)
注意:
- 调查组织者将非专业人士定义为学生、失业者以及从未在云中花费过任何钱的回应者。其他所有人被视为专业人士
云服务提供商的使用
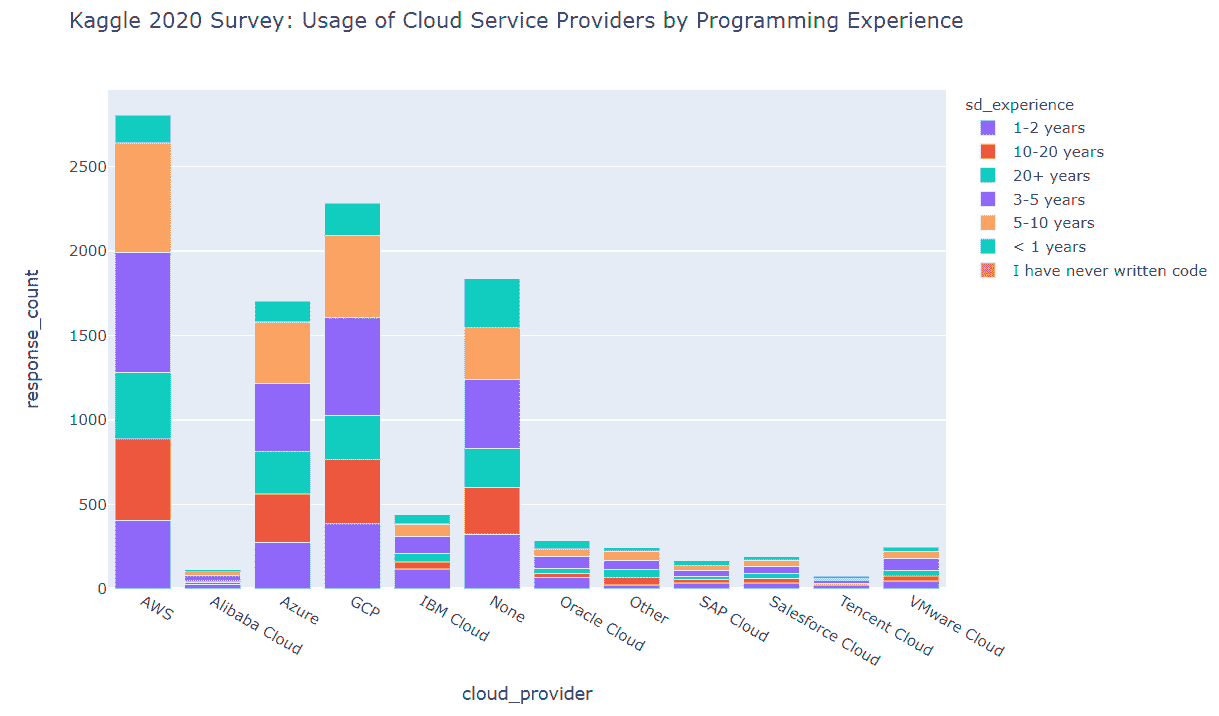
我们发现 Kaggle 调查的回应者中前三名的云服务提供商是
-
AWS
-
GCP
-
MS Azure
其余的云服务提供商目前似乎在与上述前三名提供商的竞争中失去了竞争优势。
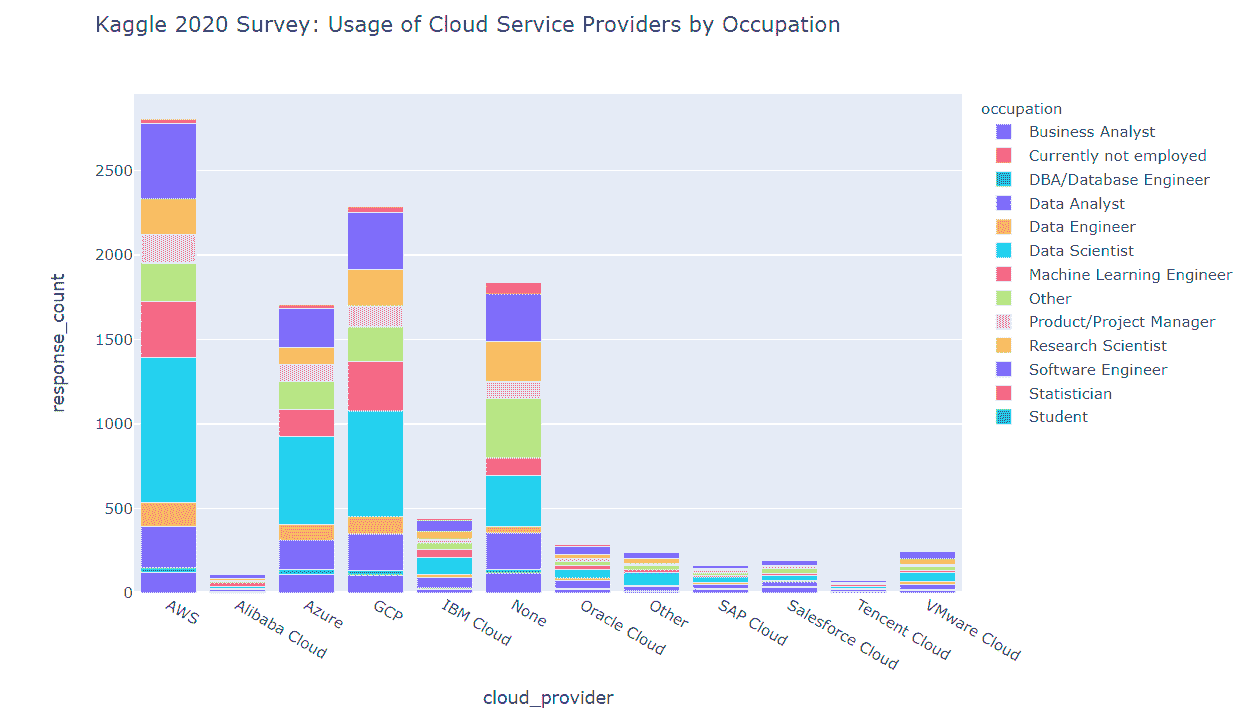
同时,值得注意的是,“无”类别略微超过了 MS Azure 条形图的大小,这意味着市场可能尚未被云服务提供商的产品饱和。
我们还看到具有 3–5 年和 5–10 年编程经验的专业人士是前三大云服务提供商中最大的用户群体。具有 10 年以上经验的高级专业人士在前三大平台的云服务用户中占比相对较少(根据市场营销优先级,特别的行动来教育这些高级专业人士可能有助于更好地推广云服务)。
正如我们所看到的,前三大云服务提供商的用户大多数符合以下角色
-
数据科学家
-
软件工程师
第三名职位由以下人员担任
-
机器学习工程师(AWS,GCP)
-
数据分析师(MS Azure)
正如之前所述,“其他”职业组本身范围过大,未来的调查中可能值得将其拆分为更细化的类别。我们看到,“其他”组在每个云服务平台用户中占据了相当大的比例(尽管在任何平台的前三名列表中都未出现)。
就用户职业和编程经验而言,前三大云服务提供商共享以下相同的趋势
-
数据科学家中具有 3–5 年和 5–10 年编程经验的用户是调查回应者中 AWS 的主要用户群体
-
在软件工程师、机器学习工程师和数据分析师组中,具有 3–5 年和 5–10 年经验的专业人士占主导地位
-
在研究科学家、数据工程师、DBA、统计学家和其他组中,具有 10 年以上经验的专业人士占据了最大的用户比例
-
在产品/项目管理组中,具有 5 年以上经验的专业人士占据了最大的用户比例
-
在商业分析师组中,我们看到具有 1–2 年经验的用户占据主导地位
就组织环境而言,最能使用云服务的数据科学和机器学习专业人士可以在以下领域找到
-
员工人数为 0–49 的组织中,拥有 1–2 名专门从事数据科学工作的员工
-
员工人数超过 10000 的组织中,拥有 20 名以上专门从事数据科学工作的员工
因此我们可以得出结论,AWS、GCP 和 MS Azure 在相同类型的组织/用户中进行激烈竞争。
云计算产品的使用
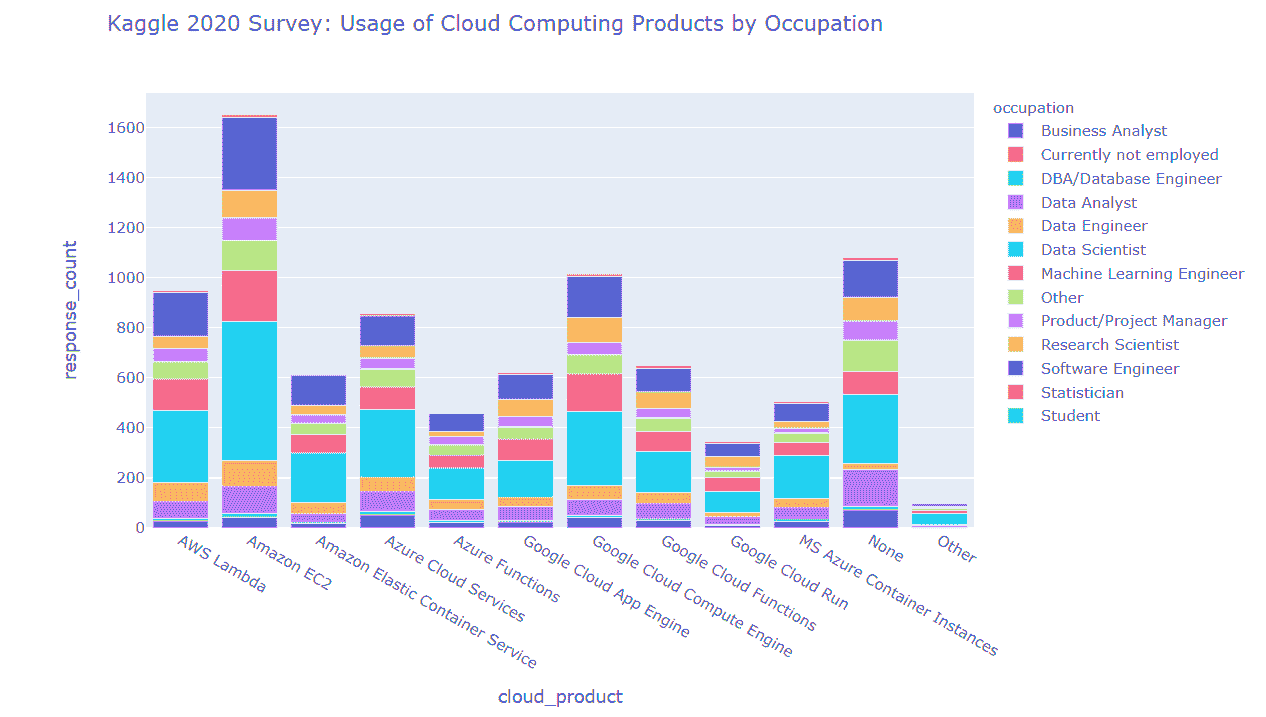
我们发现
-
在云计算引擎领域,Amazon EC2 比 Google(Google Cloud Computing Engine)和 MS Azure(Azure Cloud Services)的竞争对手更受欢迎
-
在云函数领域,AWS Lambda 比 Google(Google Cloud Functions)和 MS Azure(Azure Functions)的竞争对手更受欢迎
-
在云容器运行器领域,Amazon Elastic Container Service 比 Google(Google Cloud Run)和 MS Azure(MS Azure Container Instances)的竞争对手更受欢迎
-
Google 在云计算引擎和云函数领域位居第二,在云容器运行器领域位居第三
-
有大量回应为“无”,这很可能表明整个云计算应用市场尚未饱和
在用户角色方面,所有上述云计算产品的用户都担任以下角色(从上到下)
-
数据科学家
-
软件工程师
-
机器学习工程师
-
数据分析师
编程经验对云计算产品使用的影响
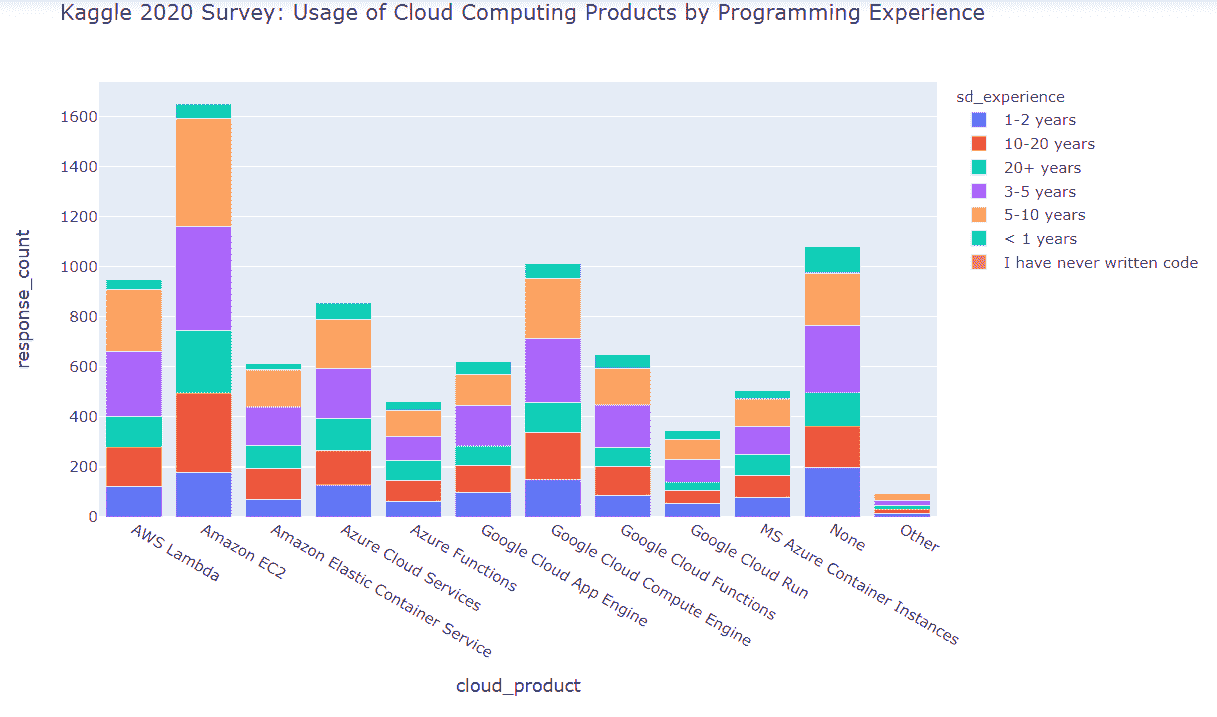
除了上述见解外,我们还看到,云计算产品用户的顶尖数量按编程经验划分为以下几个群体
-
5–10 年的经验
-
3–5 年的经验
-
10–20 年的经验
初级和超级资深(20 年以上编程经验)的覆盖程度似乎较低。
云机器学习产品使用情况
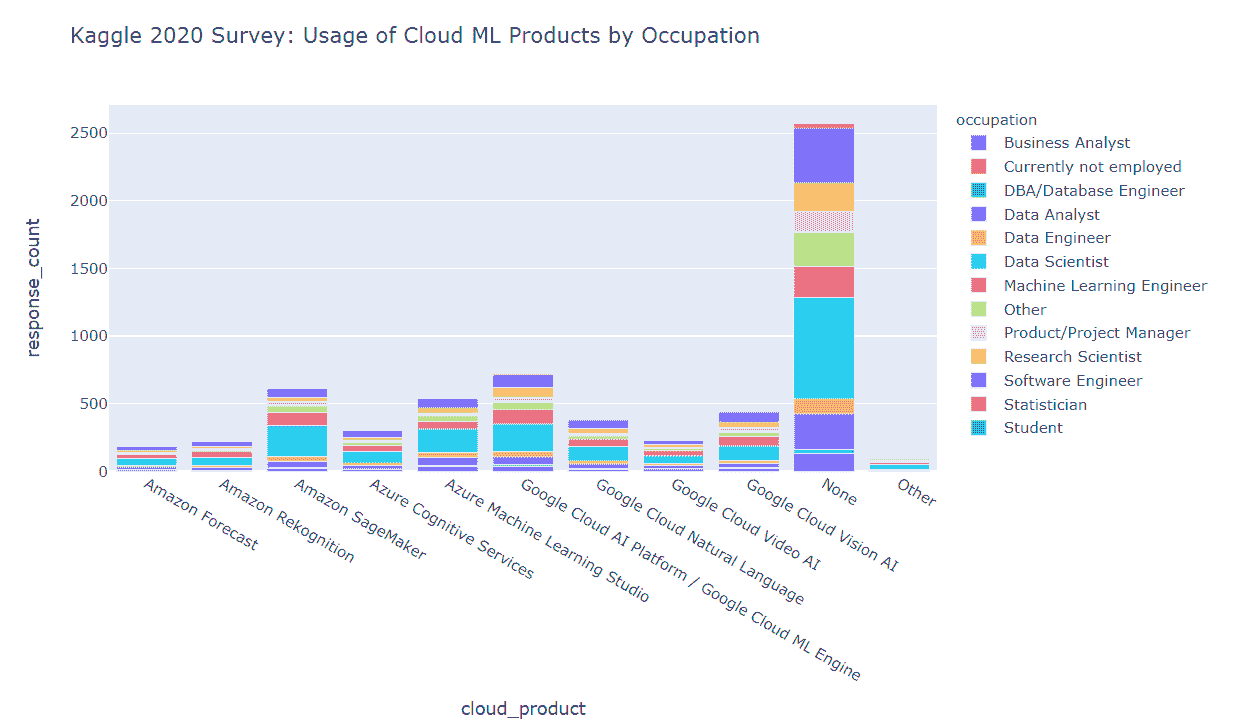
我们发现
-
Google Cloud AI Platform / Google Cloud ML Engine 在机器学习云产品使用方面的“提名”领先
-
第二和第三名分别是 Amazon SageMaker 和 Azure Machine Learning Studio
-
数据科学家是云机器学习产品的主要用户(针对每个调查的产品)
-
有一大部分回应者表示他们根本不使用云机器学习产品——这表明市场尚未饱和,还有很好的增长潜力,但需要解决市场推广和最终用户障碍
编程经验对云机器学习产品使用的影响
除了上述见解外,我们还可以看到云机器学习产品主要被具有以下编程经验的回应者使用
-
3–5 年
-
5–10 年
按组织规模和数据科学能力分类的云机器学习产品使用情况
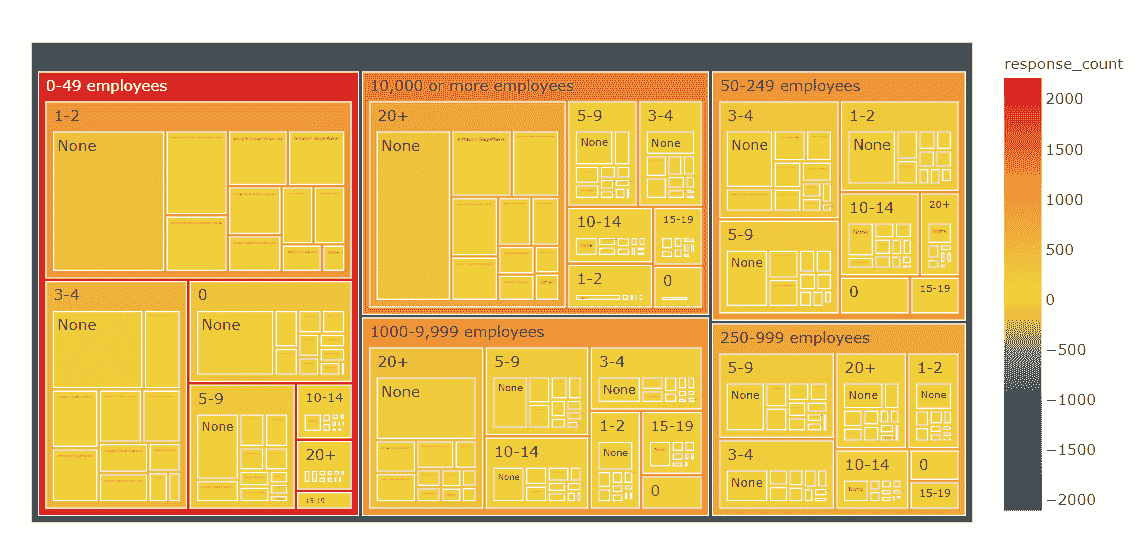
我们发现,在每个规模类别的大多数组织目前都不使用任何云机器学习产品。
对于那些使用它们的少数人来说,有以下有趣的见解
-
在小型组织(0–49 名员工)中,Google Cloud AI Platform / Google Cloud ML Engine 占据主导地位
-
在中型组织(50–249 名员工)中,Google Cloud AI Platform / Google Cloud ML Engine 和 Amazon SageMaker 不分上下
-
对于较大规模的公司(250+名员工),数据科学团队的规模通常与首选的云 ML 产品相关(较小的团队更倾向于使用 Google Cloud AI Platform / Google Cloud ML Engine,而拥有 20+人的数据科学团队则更倾向于使用 Amazon SageMaker)。
按职业分类的大数据产品使用情况
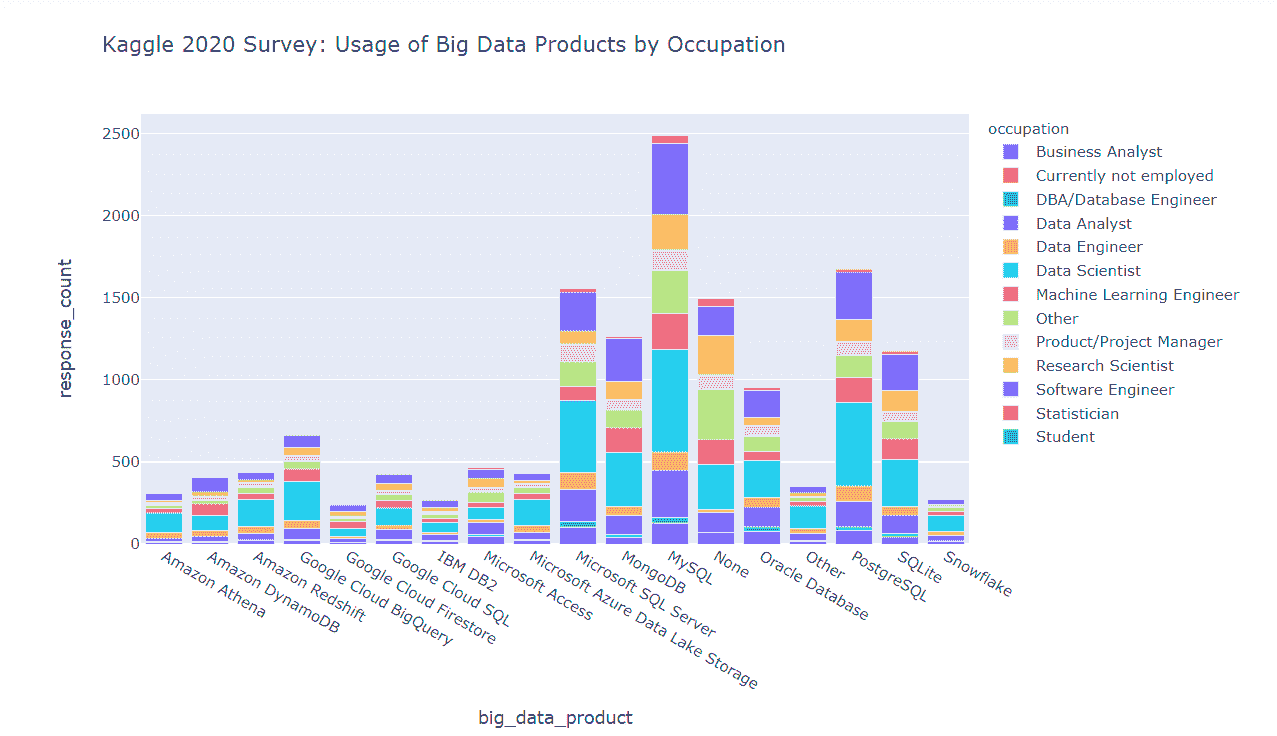
我们发现
-
总体前 3 名列表由三个关系型 DBMS 平台(MySQL、PostgreSQL、MS SQL Server)组成。
-
MongoDB 作为一种非关系型数据库平台,在列表中排名第 4。
-
列表中的其他关系型 DBMS 平台(Oracle、IBM DB2、SQLite)在 MongoDB 之后。
-
在真正基于云的大数据产品领域,Google BigQuery 超越了其 Amazon 和 MS Azure 竞争对手(Amazon Redshift、Amazon Athena、Amazon DynamoDB 和 Microsoft Azure Data Lake Storage)。
-
Google Cloud SQL 实例的受欢迎程度仍低于 MySQL 和 PostgreSQL 的“原生”关系型数据库实例。
-
MS Access 在业内仍在使用。
-
数据科学家是本列表中每种产品的主要用户。
按用户职业和编程经验分类的大数据产品使用模式
我们发现
-
MySQL 和 PostgreSQL 是各职业中最受欢迎的数据库管理平台。
-
MongoDB 在软件工程师中非常受欢迎(尽管不如 MySQL 和 PostgreSQL 受欢迎)。
按组织规模和数据科学能力分类的大数据产品使用模式
我们发现
-
除了超大型组织外,几乎所有组织都主要使用 MySQL、PostgreSQL 和 MongoDB 来满足其数据管理需求。
-
超大型组织(10000+名员工)更倾向于使用 MySQL、MS SQL Server、Oracle 和 PostgreSQL。
BI 工具的使用情况
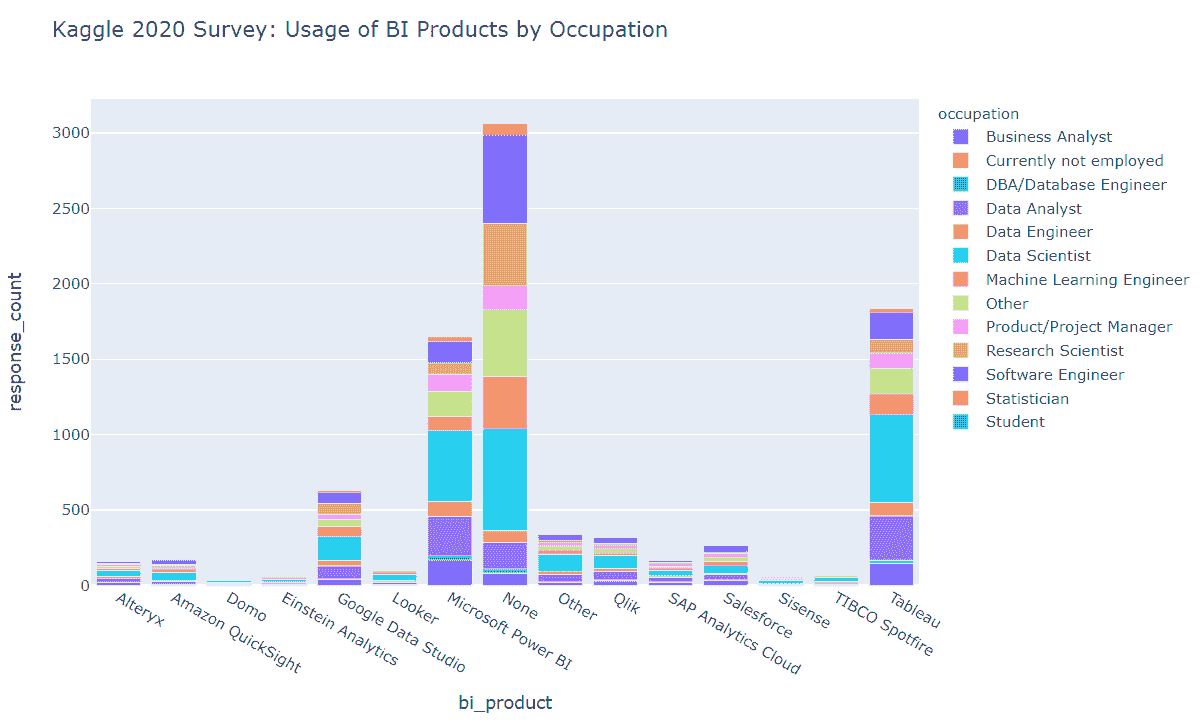
我们发现
-
Tableau 和 MS Power BI 显著超越其他竞争对手。
-
Google Data Studio 成为上述领先 BI 产品的挑战者,排名第三。
-
数据科学家、数据分析师、研究科学家和机器学习工程师是 BI 工具的最频繁用户。
-
大量调查回应者表示他们根本不使用 BI 工具。
全球范围内的 AWS 专业用户
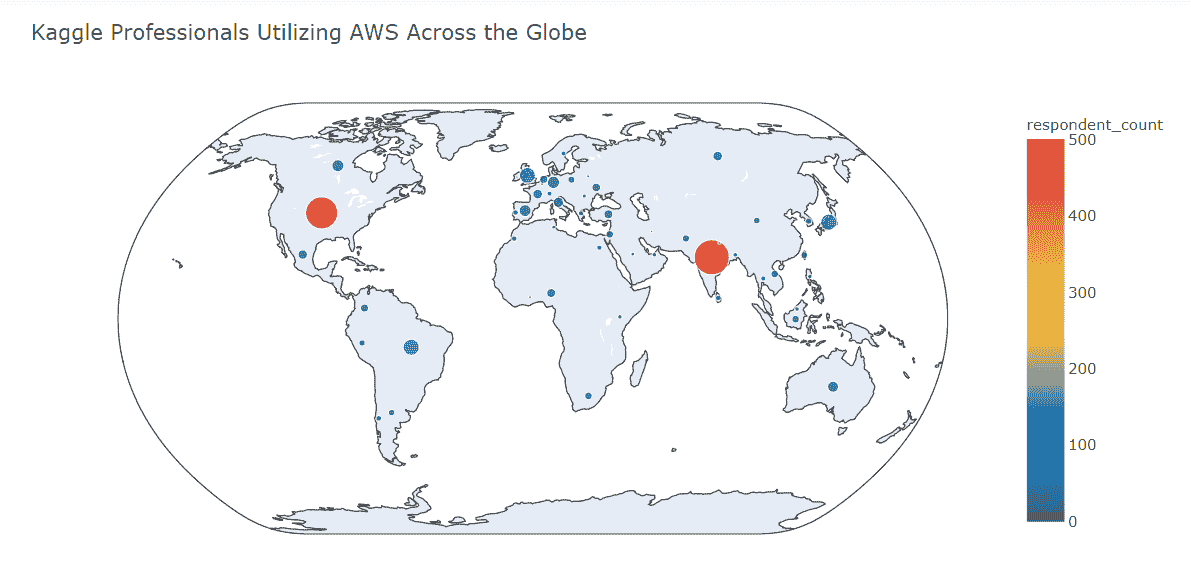
我们发现
-
AWS 在印度和美国的调查回应者中最受欢迎。
-
巴西、日本和英国在使用 AWS 的这些国家中排名第 2 层级。
全球范围内的 GCP 专业用户
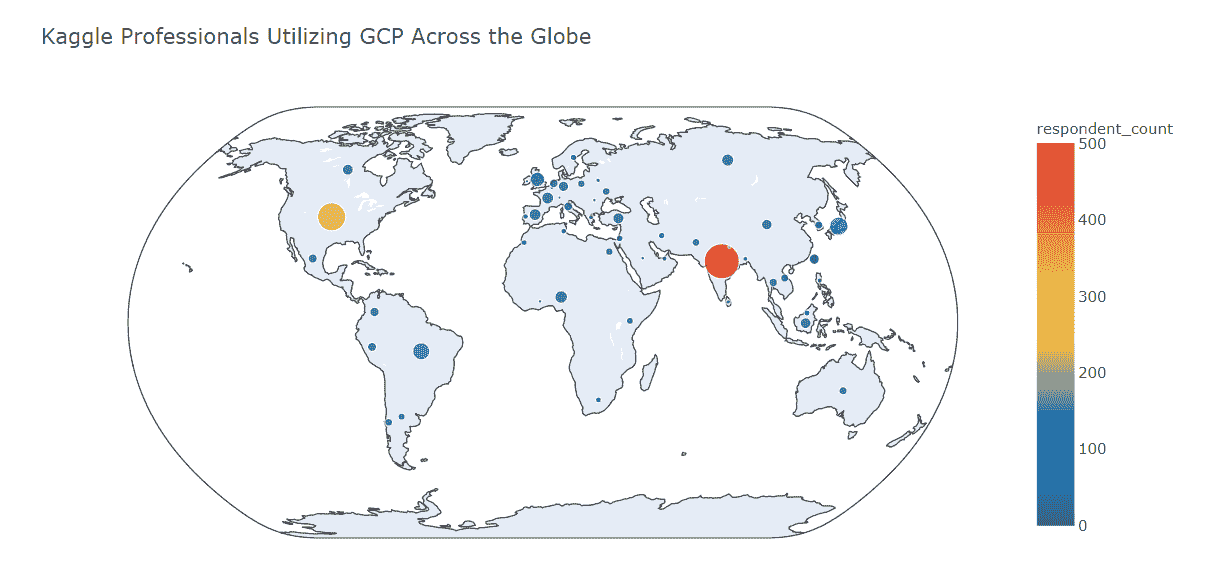
我们发现
-
印度是 GCP 使用最广泛的国家。
-
美国排名第二,但远低于印度(与 AWS 不同,印度和美国的排名相对接近)。
-
日本和巴西在使用 AWS 的这些国家中排名第 2 层级。
-
在英国、加拿大和澳大利亚,GCP 的受欢迎程度低于 AWS。
-
GCP 在土耳其、印度尼西亚和俄罗斯的表现优于 AWS
全球 MS Azure 专业用户
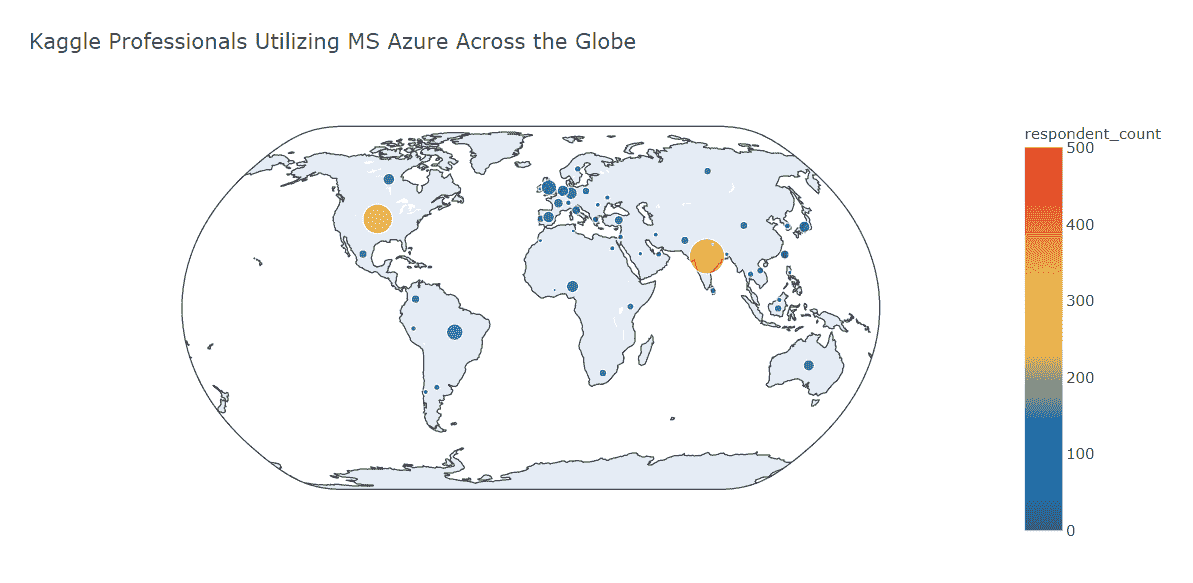
我们发现
-
MS Azure 用户数量最多的国家是印度(尽管在这里 MS Azure 远远落后于 AWS 和 GCP)
-
美国在排名中位居第二,MS Azure 用户数量与美国的 GCP 用户数量相当
-
在 MS Azure 用户数量方面,巴西属于第二梯队
-
在大多数国家(美国除外),MS Azure 用户数量少于 GCP 和 AWS 用户数量
摘要
在这篇文章中,我们回顾了数据科学和机器学习行业专业人士使用云计算平台、产品和工具的现状。这些不仅仅是他们在 2020 年底的偏好。这些都是最有可能决定 2021–2022 年趋势的基石。
未来几年在数据科学和机器学习行业,云计算巨头们在争夺头脑、资源和预算的战斗中将至关重要。尽管 AWS 的位置仍然看起来比其他顶级竞争对手更强,但 GCP 带来的挑战可能成为未来市场重塑的复杂部分。同时,MS Azure 似乎在北美保持着强势地位(虽然在其他大陆的渗透机会相对较少,尤其是与 AWS 和 GCP 相比)。
然而,我们进入了全球动荡的时代。2021 年,星辰之年的年份,可能会在我们生活的各个方面给我们带来意想不到的惊喜。
备注: 你可以查看这个库 github.com/gvyshnya/state-of-data-science-and-ml-2020 来查看上述每一项洞见是如何被发现的。
简介: 乔治·维什尼亚 是 SBC 的联合创始人兼首席技术官,帮助首席执行官和首席技术官通过实施智能 AI、BI 和 Web 解决方案来增加收入。
原文。已获转载许可。
相关:
-
2021 年人工智能(AI)趋势前五名
-
2020 年数据科学和机器学习现状:3 项关键发现
-
2020 年必须掌握的 5 项数据科学技能
更多相关内容
云计算如何提升数据科学工作流程
原文:
www.kdnuggets.com/2023/08/cloud-computing-enhances-data-science-workflows.html

图片来源:Rakicevic Nenad
如果数据是世界上最宝贵的资源,那么数据科学就是其最具影响力的过程。随着更多组织意识到需要数据科学以保持竞争优势,这一实践在各行各业变得越来越重要。这种快速增长在很大程度上是有益的,但也可能带来一些挑战。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
数据量和处理需求正在以比传统工作流程更快的速度飙升。数据科学团队需要更好的方式来管理这些不断增加的需求,而云计算提供了一个理想的解决方案。以下是五个原因。
1. 降低成本
云计算的成本效率是其最大的优势之一。实施和维护本地服务器可能非常昂贵,需要大量的初期投资和持续的劳动及 IT 成本。在云上存储和处理数据可以消除许多这些开支。
在云模型中,你不需要购买或维护自己的设备。考虑到现代数据科学可能需要的处理能力,这可以带来巨大的节省。你也只需为你使用的资源付费,因此任何随着增长而产生的成本都反映了实际的数据量增长,没有多余的费用。
2. 简化工作流程
云还可以简化数据科学工作流程。软件即服务(SaaS)解决方案让你能够获得可能无法负担的计算速度和容量。因此,你可以进行更复杂的计算,减少处理延迟。
云系统还将曾经分开的数据库和工作负载整合在一起。这种整合消除了在应用程序之间切换的浪费时间,并减少了数据输入和传输错误的风险。错误的数据可能显著阻碍操作效率,因此这种可靠性进一步提高了生产力。
3. 提升安全性
尽管对云计算安全性的担忧依然存在,云计算实际上有几个安全优势。绝大多数云安全漏洞来自人为错误,而非云本身的技术缺陷。然而,SaaS 模型可以让高安全性变得更加可及。
云服务提供商通常拥有数据科学家可能无法负担或在内部实施的高级安全功能。这可能包括自动监控、自动合规和广泛的加密备份。在云中,网络分段也更容易,这使得零信任和类似的安全架构变得更易于实现。
4. 扩展数据容量
使用云计算还可以让你存储和处理比本地解决方案更多的数据。数据科学应用通常在信息更多时效果最佳,但在内部系统上管理大量数据会迅速变得昂贵和低效。
全球数据量预计将在 2025 年超过 180 泽字节。这可以让数据科学变得比以往更可靠,但前提是你拥有支持这种规模存储和分析的能力。云计算使得在本地实施这一级别的存储和分析成为可能,而成本将会过高。
5. 改善可扩展性
类似地,云计算比传统的数据科学工作流程更具扩展性。以传统方式扩展能力意味着购买和设置额外的服务器,这既昂贵又可能打乱当前的工作流程。使用云计算,你只需支付更高的费用来获得更多的容量,并能立即获得。
考虑到数字数据当前的增长速度,快速的扩展性至关重要。然而,如果你需要缩减运营规模,在云中进行缩减仍然比传统方式更具成本效益。随着容量的减少,你的费用也会减少,确保缩减不会导致浪费未使用的硬件。
现代数据科学需要云计算
当今的数据科学工作流程必须快速、可靠、安全,并能处理大量工作负荷。随着这些需求的增加,传统的本地设置迅速变得不足。
云计算提供了数据科学团队所需的可负担性、效率、安全性、容量和扩展性。利用这一机会将帮助你最大化数据科学应用的回报。
April Miller 是 ReHack 杂志的消费技术主编。她拥有创作优质内容并吸引流量的记录。
更多相关话题
云机器学习透视:2021 年的惊喜,2022 年的预测
原文:
www.kdnuggets.com/2021/12/cloud-ml-perspective-surprises-2021-projections-2022.html
由George Vyshnya,SBC 的联合创始人/首席技术官

~ 生活就是一系列的适应性测试。— 威廉·约瑟夫·多诺万
引言
在我 2021 年 1 月发表在 KDnuggets 上的文章中,我对 2021 年的云计算和云机器学习行业做出了以下预测
-
未来几年对于云计算巨头在数据科学和机器学习行业争夺思想、资源和预算将至关重要。虽然 AWS 的位置依然比其他主要竞争对手更强,但来自 GCP 的挑战可能是未来市场重塑的复杂部分。同时,MS Azure 似乎在北美保持着强势地位(而在与 AWS 和 GCP 相比中,进入其他大陆的机会较小)。
-
然而,我们进入了全球动荡的时代。2021 年,星辰之年,可能会在我们生活的各个方面带来意想不到的惊喜
我必须承认这两个预测都得到了实现。
巨头之战中,AWS、GCP 和 MS Azure 在争夺市场份额和收入的竞争中持续进行,各大巨头在全球范围内定位其产品时都有其强项和弱点。
至于惊喜,它确实发生了。在云机器学习行业中,我们观察到了 2021 年几个难以预测的现象
***- Google ***在最近将其单独的云机器学习产品整合到统一产品平台(Google Cloud Vertex AI)后,市场份额下降了
***- Databricks ***跃升为云机器学习市场的前三大产品,取代了 Google 的竞争产品
让我们回顾 2021 年的云机器学习市场(偶尔也回顾 2020 年的实际情况)。本文接下来的部分将揭示行业洞察。
注意:在挖掘洞察时,使用了 Kaggle 对‘2020 年数据科学和机器学习现状’的调查数据(www.kaggle.com/c/kaggle-survey-2020)以及对‘2021 年数据科学和机器学习现状’的调查数据(www.kaggle.com/c/kaggle-survey-2021)。
Databricks 突破壁垒及 2021 年其他云机器学习趋势

我们可以发现许多关于 2021 年云机器学习行业的吸引人事实和趋势。它们如下
-
Google 在 2021 年将其所有云机器学习产品整合到新的统一平台(即 Google Cloud Vertex AI)中的举措,并未带来 Google 在企业(商业)云机器学习市场的市场份额增长。
-
此外,Big Three Cloud Giants 中的主要 Cloud ML 竞争者——Amazon SageMaker 和 Azure ML Studio——在其市场地位上有所提升,并且到 2021 年成为了市场的最终领导者(Amazon SageMaker 排名第一,略微领先于 Azure ML Studio)。
-
我们可以看到 Databricks 在 2021 年的 Cloud ML 产品排名中位居第三(高于 Google Cloud Vertex AI,略低于 Amazon SageMaker 和 Azure ML Studio)。
-
其他 Cloud ML 竞争产品(DataRobot、Dataiku、Alteryx、Rapidminer)远远落后于 Databricks 和 Google Cloud Vertex AI。
-
Amazon SageMaker 在 Cloud ML 市场中连续两年(2020–2021)保持领先地位。
-
尽管如此,大量受访者表示他们在日常活动中根本不使用 Cloud ML(需要注意的是,‘None’在 2020 年和 2021 年可能有不同的含义,因为 2020 年和 2021 年调查中提供的 Cloud ML 产品列表差异很大)。
-
Databricks 在 2021 年对 Google 的统一 AI 平台发起了强有力的进攻(因此,Google 最近决定投资 Databricks 可能是 Databricks 市场份额在 2021 年显著增长的触发因素)。
-
Cloud ML 行业领头羊——Amazon SageMaker 和 Azure ML Studio——在 2021 年底保持了相对强势的地位,相比于 Databricks 和 Google Cloud Vertex AI。
-
印度和美国是 Kaggle 2021 调查问卷中 Cloud ML 产品用户最多的前两大国家。
-
Amazon SageMaker 在印度和美国都占据了领先地位。
-
Azure Machine Learning Studio 在印度排名第二。
-
Databricks 在美国排名第二,并且在 2022 年在英国和欧盟国家也有良好的增长潜力。
-
ML 支出最多的公司更倾向于使用 Amazon SageMaker 和 Databricks,而 Azure ML Studio 在这种排名中位列第三(Google Cloud Vertex AI 则远远落后)。
-
Google Cloud Vertex AI 在中等和小规模 ML 支出公司的地位更好(这可能是一个未来将这些公司转化为高支付客户的机会);它有可能在 2022 年在北美和欧盟以外的多个地点探索增长机会。
现在我们来详细了解一下上述洞察背后的数据驱动故事。
注意:如果你对详细复现我的发现感兴趣,欢迎查看 Github 仓库中的相关 Jupyter 笔记本(github.com/gvyshnya/kaggle-2021-survey)。
按职业和编程经验划分的 Cloud ML 产品使用情况(2020–2021)
让我们回顾一下 2021 年调查中提到的 Cloud ML 产品是如何被调查参与者使用的(根据他们的职业和编程经验进行分类)。
2021 年按职业分类的情况如下:
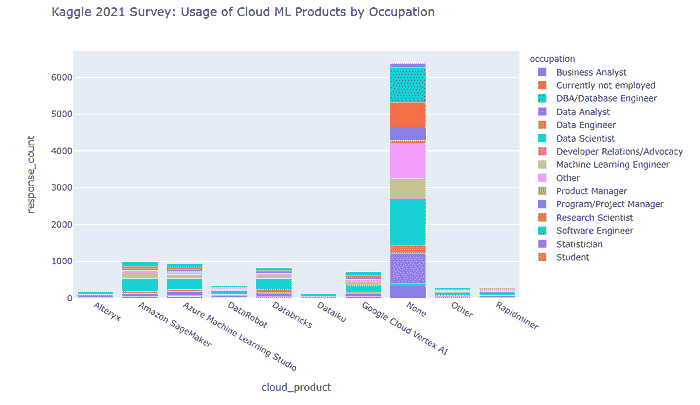
关于主要 Cloud ML 产品用户的编程经验,情况如下所示。
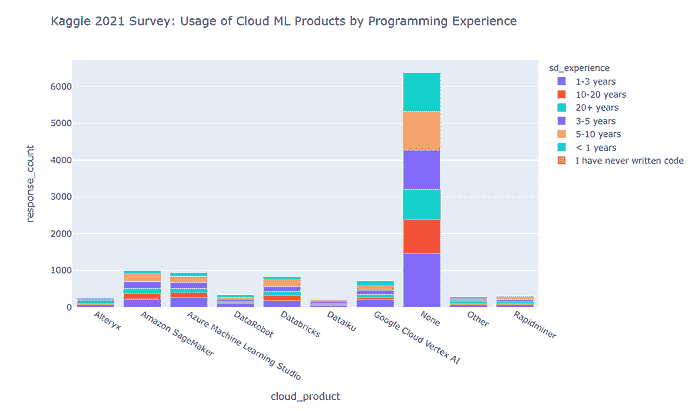
从上面的图表中可以明显看出,
-
大部分受访者在日常活动中不使用任何 Cloud ML 产品。
-
在少数使用这些工具的受访者中,数据科学家占主导地位。
-
Amazon SageMaker 和 Azure ML Studio 在使用人数方面领先。
-
来自 Google 的竞争产品(即 Google Cloud Vertex AI)落后于领导者,同时也落后于今年调查中出现的挑战者产品(即 Databricks)。
-
其他挑战者产品(DataRobot、Dataiku、Alteryx、Rapidminer)远远落后于领导者。
-
此外,Cloud ML 产品的使用最多的是具有 1–3 年和 10–20 年编程经验的专业人士。
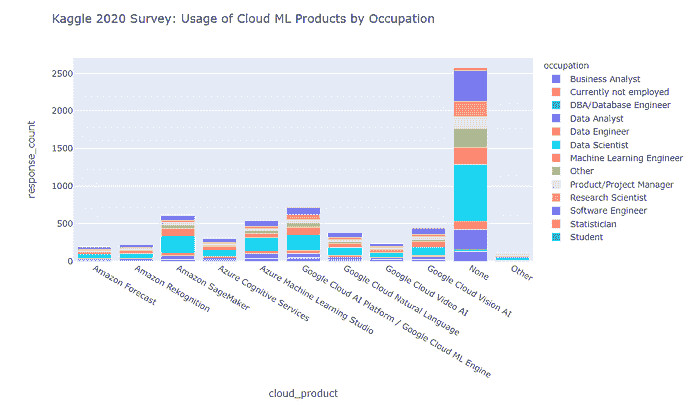
现在,让我们回顾一下 2020 年调查中提到的 Cloud ML 产品如何被参与者使用(按职业和编程经验分类)。
截至 2020 年的按职业分类如下所示。
2020 年按编程经验分布的 Cloud ML 产品用户如下所示。
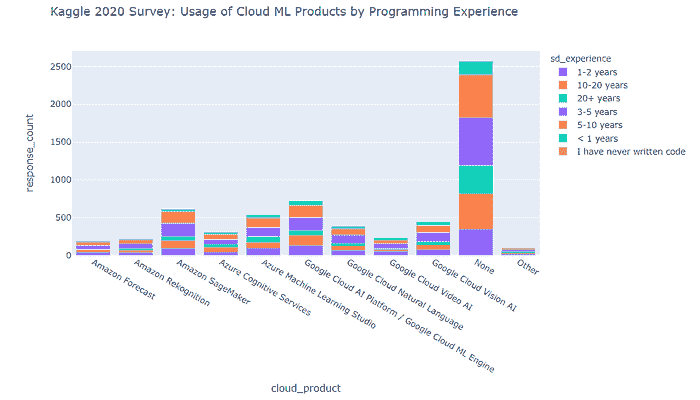
我们可以看到,
-
Google Cloud AI Platform / Google Cloud ML Engine 在 2020 年领先了机器学习云产品的使用“提名”。
-
第二和第三名分别是 Amazon SageMaker 和 Azure Machine Learning Studio。
-
数据科学家是云机器学习产品的主要用户(针对每个调查的产品)。
-
有一大部分受访者表示他们完全不使用云机器学习产品——这表明市场尚未饱和,仍有良好的增长潜力,但需要解决市场营销和终端用户的障碍。
-
此外,截至 2020 年,我们看到具有 3–5 年和 5–10 年编程经验的专业人士使用云机器学习产品最多。
如果我们分别汇总 2020 年和 2021 年的观察结果,我们会看到,
-
Google 在 2021 年将所有 Cloud ML 产品整合到新的统一平台(即 Google Cloud Vertex AI)上的举措,并未导致 Google 在企业(商业)Cloud ML 市场中的市场份额增长。
-
此外,三大云巨头中的主要 Cloud ML 竞争者——Amazon SageMaker 和 Azure ML Studio——改善了他们的市场位置,并成为截至 2021 年的最终市场领导者(其中 Amazon SageMaker 排名第一,略微领先于 Azure ML Studio)。
-
Azure Cognitive Services 在 2021 年被排除在调查之外,因此很难估算其在 Kagglers 中的市场位置相较于 2020 年的变化。
-
很难估算挑战者云机器学习产品(DataRobot、Databricks、Dataiku、Alteryx、Rapidminer)在 2021 年与 2020 年的市场地位变化,因为这些产品在 2020 年的调查中未被列出。
-
然而,我们可以看到,到 2021 年,Databricks 在云机器学习产品排名中位居第三(高于 Google Cloud Vertex AI,略低于 Amazon SageMaker 和 Azure ML Studio)。
-
其他云机器学习挑战者产品(DataRobot、Dataiku、Alteryx、Rapidminer)远低于 Databricks 和 Google Cloud Vertex AI。
-
尽管如此,大多数受访者表示他们在日常活动中根本不使用云机器学习(Cloud ML)(需要注意的是,2020 年和 2021 年的“无”可能有很大不同,因为 2020 年和 2021 年调查选项中云机器学习产品列表有着显著差异)。
如果我们尝试结合上述观察与 Databricks 在 2021 年 2 月至 8 月间取得的主要业务发展、融资和宣传进展(详见附录),我们可以说
-
Databricks 在 2021 年对 Google 的统一 AI 平台进行了强力进攻(因此 Google 最近决定投资 Databricks 可能是 Databricks 市场份额在 2021 年良好增长的触发因素)。
-
云机器学习行业领头羊——Amazon SageMaker 和 Azure ML Studio——在 2021 年底保持了相对于 Databricks 和 Google Cloud Vertex AI 的强势地位。
按组织规模和行业划分的云机器学习工具使用情况(2021 年)
关于各种规模组织中云机器学习的使用情况(截至 2021 年),我们观察到以下情况
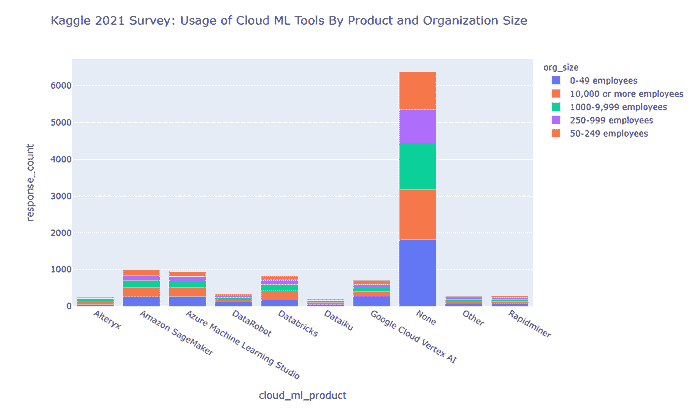
很明显
-
到 2021 年,各行业中许多组织不使用云机器学习产品。
-
计算机/技术行业的公司最常使用云机器学习,学术/教育行业排在第二位,会计/金融行业排在第三位。
-
对于每种正在审查的云机器学习产品,大多数用户都来自计算机/技术行业。
-
对于 Azure Machine Learning Studio 和 Google Cloud Vertex AI,第二受欢迎的行业是学术/教育。
-
对于 Amazon SageMaker 和 Databricks,第二受欢迎的行业是会计/金融。
关于 2021 年按行业划分的云机器学习用户,其情况如下
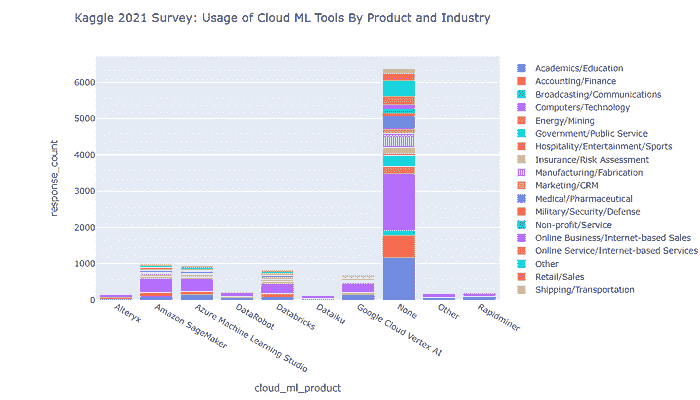
我们发现
-
到 2021 年,各行业中许多组织不使用云机器学习产品。
-
Google Cloud Vertex AI 和 DataRobot 在最小规模(0–49 名员工)的组织中最受欢迎。
-
Azure Machine Learning Studio 和 Amazon SageMaker 在最小(0–49 名员工)和最大(10k+名员工)规模的组织中同样受欢迎。
-
Databricks 在大型组织(分别为 10k+和 1000–9999 名员工)中更受欢迎。
云机器学习和组织内机器学习支出
2021 年的情况如下图所示
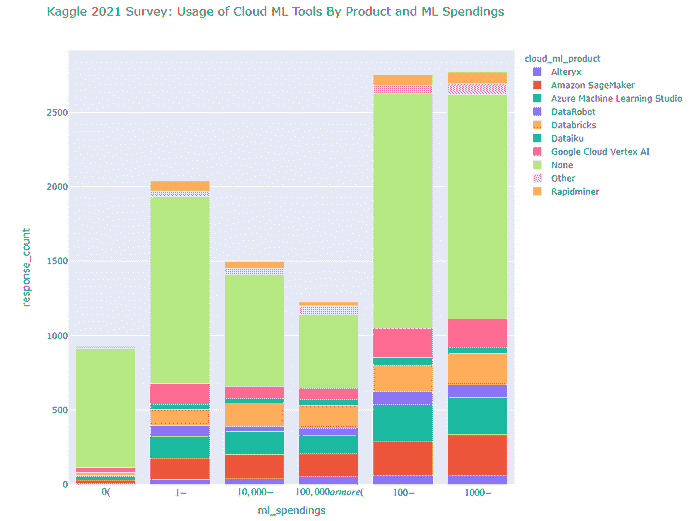
正如我们所见,2021 年的行业趋势如下
-
机器学习支出最多的公司更倾向于使用 Amazon SageMaker 和 Databricks
-
Azure ML Studio 在这种排名中位列第三
-
Google Cloud Vertex AI 在机器学习支出较多的组织中远远落后于上述三位领导者
-
Google Cloud Vertex AI 在中小型机器学习支出的公司中的表现更佳(这可能是将这些公司转化为 2022 年付费客户的机会)
-
其他云机器学习产品远远落后
如果我们回顾 2020 年,可以看到下面的图景
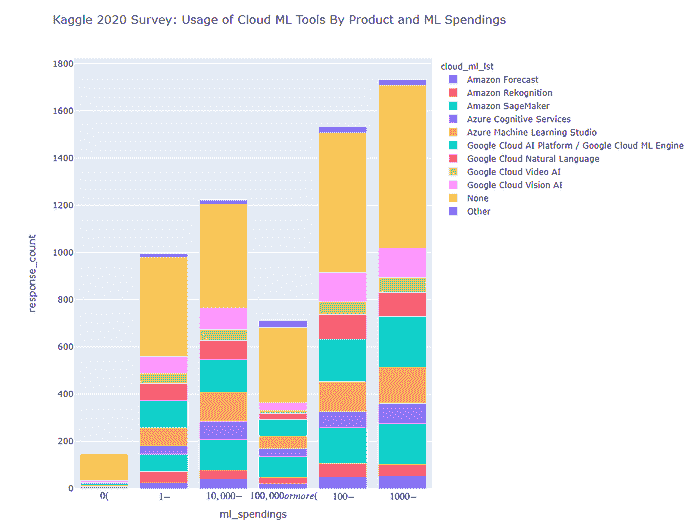
显然
-
截至 2020 年,Amazon SageMaker 在每一个机器学习支出类别中显然都处于领先地位(2021 年也是如此)。
-
截至 2020 年,Azure ML Studio 和当时的一个 Google Cloud ML 产品(Google Cloud AI Platform/Google Cloud ML Engine)几乎平分秋色,位居第二,仅次于 Amazon SageMaker。
云机器学习地理分布(2021)
让我们看看参与 Kaggle 2021 调查的领先云机器学习产品用户的地理分布。
首先,需要指出的是印度和美国是拥有最多机器学习工程师的国家。
话虽如此,让我们看看每个领先的云机器学习产品的地理洞察。
Amazon SageMaker
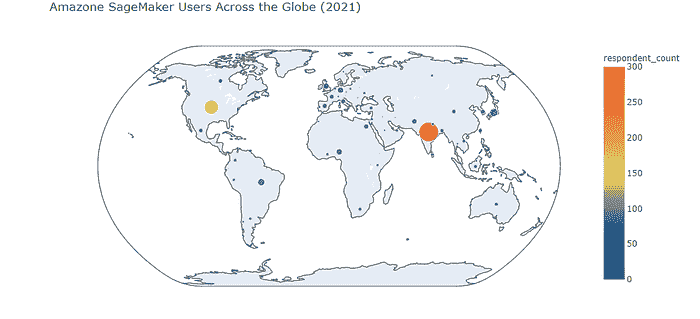
正如我们所见,Amazon SageMaker 用户的地理分布表明
-
印度排名第一(看起来 Azure SageMaker 在这个国家也是最受欢迎的云机器学习产品)
-
美国排名第二
-
其他国家远远落后于印度和美国
-
日本在 Amazon SageMaker 用户基础中排名第三(在 Kaggle 2021 调查的受访者中)
-
我们可以看到该产品在巴西、英国、欧盟国家和尼日利亚的适度受欢迎程度
Azure Machine Learning Studio
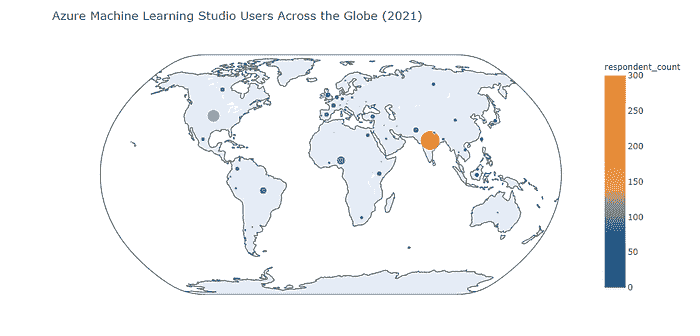
正如我们所见,Azure Machine Learning Studio 用户的地理分布表明
-
印度是产品用户的主要地区(其在印度的受欢迎程度仅略低于 Amazon SageMaker 的受欢迎程度)
-
美国排名第二(不过,Azure Machine Learning Studio 在受欢迎程度上远低于 Amazon SageMaker)
-
其他国家远远落后于印度和美国
-
尼日利亚在 Amazon SageMaker 用户基础中排名第三(在 Kaggle 2021 调查的受访者中)
-
我们可以看到该产品在巴西、英国、欧盟国家、巴基斯坦和肯尼亚的适度受欢迎程度
Google Cloud Vertex AI
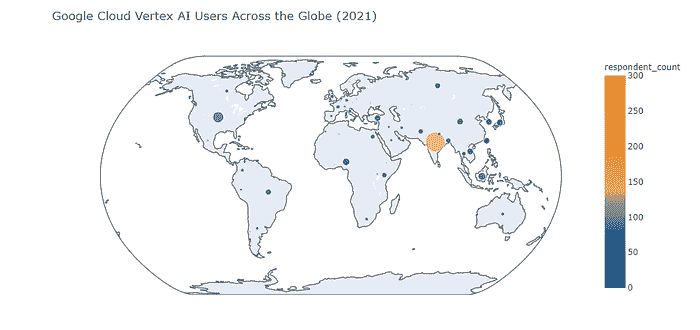
正如我们所见,Google Cloud Vertex AI 用户的地理分布表明
-
印度是产品用户的主要地区(尽管其在印度的受欢迎程度远低于 Amazon SageMaker 和 Azure Machine Learning Studio 的受欢迎程度)
-
美国排名第二(不过,与印度一样,它在美国的受欢迎程度远低于 Amazon SageMaker 和 Azure Machine Learning Studio 的受欢迎程度)。
-
其他国家远远落后于印度和美国。
-
令人惊讶的是,印度尼西亚在 Google Cloud Vertex AI 的热门地点排名中位列第三。
-
全球有一系列国家在产品使用调查受访者数量上接近印度尼西亚(尼日利亚、台湾、中国、日本、韩国、土耳其)——这些地区可能是 Google Cloud Vertex AI 销售和收入增长的潜在机会。
-
加拿大、英国和欧盟国家对 Google Cloud Vertex AI 的兴趣非常低(这可以通过某些国家和行业政策来解释,这些政策在欧盟和英国偏向 MS Azure 和 Amazon AWS)。
Databricks
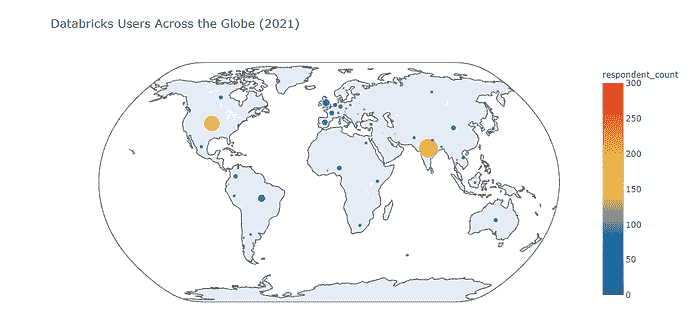
正如我们所见,Databricks 用户的地理分布表明
-
印度是 2021 年调查受访者中 Databricks 用户最多的国家(Databricks 在印度的表现优于 Google Cloud Vertex AI,而在 Amazon SageMaker 和 Azure Machine Learning AI 方面则逊色)。
-
美国在全球产品用户数量方面排名第二(Databricks 实际上在美国排名第二,仅次于 Amazon SageMaker,超越了 Azure Machine Learning 和 Google Cloud Vertex AI)。
-
其他国家远远落后于印度和美国。
-
巴西在全球“Databricks 排名”中位列第三(不过,英国和欧盟国家与其差距不大)。
2022 年的前景是什么?

上述趋势将无疑塑造 2022 年行业的未来。从我在数据驱动的钻研中收集的洞察来看,我可以预测
-
作为 2020-2021 年的行业领导者,Amazon SageMaker 将在 2022 年继续保持全球领先地位。
-
Databricks 作为云 ML 产品在 2022 年的进一步扩展可能会受到持续讨论的影响,即在 Spark 上进行 ML 是否是一个好主意(虽然 Spark ML 库在 BigData 规模数据集上非常强大,但 Spark 和 Databricks 的某些 API 缺陷仍然存在一些批评空间)。
-
尽管有提到的 Spark ML 争论,Databricks 很可能进一步提升其在美国和中国的领先地位,并在 2022 年在英国和欧盟国家也有良好的增长潜力。
-
Azure ML Studio 的产品在“Databricks 攻势”下相当受保护,因为 Azure Cloud 平台曾经将 Databricks 视为仅仅是 BigData 工程工具(Azure Databricks 服务已经在这一角色运行了几年)。
-
Google Cloud Vertex AI 可能会探索在 2022 年北美和欧盟以外的多个地点增长的机会,瞄准那里的中型和快速增长的公司。
-
在 2022 年,Google Cloud ML 生态系统的变革者可能是 BigQuery ML 的广泛推广;由于它可以成为 Databricks 的大数据规模机器学习解决方案的真正替代品,它可能会在即将到来的一年中改变云计算机器学习工具的格局。
方法论与参考文献
本文基于 Kaggle 的《2020 年数据科学与机器学习现状》(www.kaggle.com/c/kaggle-survey-2020)和《2021 年数据科学与机器学习现状》(www.kaggle.com/c/kaggle-survey-2021)调查数据中的见解。
Kaggle (www.kaggle.com) 是一个全球性的社区,由来自世界各地、具有不同技能和背景的数据科学家和机器学习者组成。这个社区拥有超过 300 万的活跃成员。尽管从社会学的角度来看,它并不能严格代表全球数据科学和机器学习专业人士的整体人口,但它仍然占据了该领域的一个重要比例。因此,这项调查的结果可以真正预测数据科学和 AI/ML 行业在未来几年可能的发展方向。
我的 Kaggle 2020 调查和 Kaggle 2021 调查的全面 EDA 风格笔记本如下所示:
-
www.kaggle.com/gvyshnya/kaggle-2020-survey-associated-insights -
www.kaggle.com/gvyshnya/kaggle-2021-ml-and-ds-survey-comprehensive-eda
收集本文描述的见解的数据驱动工具的源代码可以在 GitHub 的github.com/gvyshnya/kaggle-2021-survey仓库中找到。
我的文章《云计算、数据科学与机器学习趋势 2020–2022:巨头之战》已于 2021 年 1 月由 KDNuggets 发布,详见 /2021/01/cloud-computing-data-science-ml-trends-2020-2022-battle-giants.html。
你还可以在《2021 年 AI 现状报告》中找到许多有趣的见解(www.stateof.ai/)。
附录:Databricks 的历史
自 2015 年推出基于 Apache Spark 的数据平台以来,Databricks 已发展成为一个一站式的数据(非)结构化存储、自动化 ETL、协作数据科学笔记本、使用 SQL 的商业智能和基于开源 MLflow 的全栈机器学习的平台。有趣的是,所有三大主要云供应商——亚马逊、谷歌和微软——都在 2021 年 2 月投资了 Databricks。
Databricks 的总部位于旧金山。它在加拿大、英国、荷兰、新加坡、澳大利亚、德国、法国、日本、中国和印度也有业务。
由于该公司截至 2021 年 2 月已获得三大云计算巨头(亚马逊、微软和谷歌)的投资,并且截至 2021 年 8 月的估值超过竞争对手,成为行业中的强劲竞争者。从这个角度来看,Databricks 的产品/服务具有潜在的
-
部分蚕食其他大数据、云机器学习和 AutoML 产品,来自三大云计算提供商(AWS、微软 Azure、谷歌云平台)
-
在云机器学习和企业 AutoML 领域(如 H20.ai、DataRobot 等)与竞争产品形成强劲竞争
下图展示了公司的企业历史关键点

个人简介:George Vyshnya 是 SBC 的联合创始人/首席技术官,帮助首席执行官和首席技术官通过实施智能 AI、BI 和 Web 解决方案来增长收入。
原文。经许可转载。
相关内容:
-
2020-2022 年云计算、数据科学和机器学习趋势:巨头之战
-
人工智能、分析、机器学习、数据科学、深度学习研究在 2021 年的主要发展及 2022 年的关键趋势
-
2021 年主要发展及 2022 年人工智能、数据科学、机器学习技术的关键趋势
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
更多相关信息
云存储的采用是企业当前的紧迫需求
原文:
www.kdnuggets.com/2022/02/cloud-storage-adoption-need-hour-business.html
社交媒体、物联网设备和传感器的激增导致数据爆炸性增长。虽然更多的数据总是受欢迎的,但它带来了自身的一系列挑战,特别是在数据管理方面。数据如果没有得到有效管理,就等于没有数据。
根据 IDC 的研究,组织预计数据(主要是非结构化数据)每年增长 30-40%。所以,如果一家企业今天处理和管理约 10PB 的数据,假设明年它将管理 14PB 的数据。现在,这种数据的指数级增长问题在于,它迫使企业迅速扩展和适应。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 需求
扩展本地数据中心意味着需要通过投资硬件来承担巨大的成本,然后处理维护问题。而且,这一切不能随时完成。
在这种情况下,似乎只有一个解决方案——云存储。难怪云存储市场正在蓬勃发展。IDC 预计到 2025 年,全球 87%的总存储将存储在云端。
市场上的大牌如 Netflix、ETSY 和通用电气已经纷纷上车,小型和中型企业的转变只是时间问题。
那么,云存储提供了什么是本地数据中心所没有的?从表面上看,你可能会说是便利性,因为它让你的数据随时随地可用。但这种快速的转变是否合理?实际上,云存储还有更多的东西值得深入了解。
云存储市场
预计云存储市场将从 2020 年的 501 亿美元增长到 2025 年的 1373 亿美元,年复合增长率为 22%。市场上有几个主要参与者,如 Amazon Web Services、Google 和 Microsoft 等。
这些顶级云服务提供商提供三种类型的云存储解决方案:对象存储、块存储和文件存储。对象存储非常适合处理非结构化数据,如图像和视频。对象存储与其他存储方式的区别在于使用了元数据。一些常见的对象存储示例包括 Amazon S3、Google Cloud 和 Azure Blob 存储。
文件存储以文件和文件夹的层次结构呈现非结构化数据。虽然它不像对象存储那样灵活,但它在市场上也越来越受欢迎。
块存储更适合结构化数据。它提供了高吞吐量和低延迟的数据访问。
每种存储类型都适用于不同的用例,因此在迁移到云端之前,组织必须分析自己的需求。
云计算能提供什么?
由于向云存储的急剧转变,云计算必须向企业提供有价值的提议。让我们探讨一下为何无论规模大小的企业都应该考虑迁移到云端。
1. 成本效益
迁移到云端意味着您不再需要投资昂贵的硬件、软件和人力资源来维护本地数据中心。一些公司由于迁移过程复杂和成本高而犹豫不决。然而,随着组织学习适应,云计算的成本会降低。一个易于使用的云数据集成工具也可以帮助使过程无缝并降低成本。
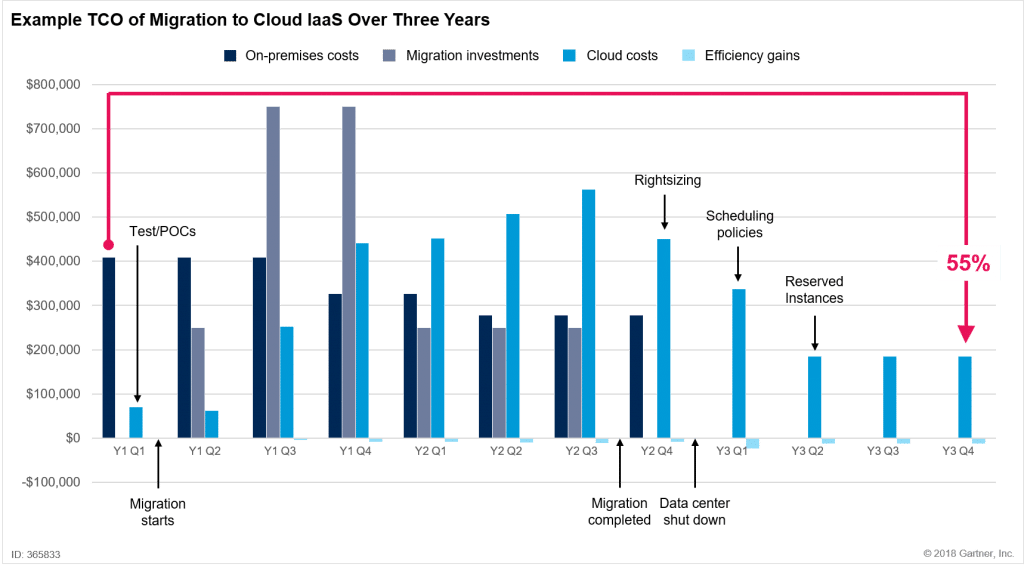
上面的图表来自 Gartner,展示了云计算和迁移的初始成本,但一旦云迁移完成,云计算的成本比本地数据中心低 55%。
此外,云存储选项的最佳部分是它提供了成本效益高的存储层,因此您可以根据数据的使用情况管理存储成本。例如,Azure Blob 存储具有三种访问层级:热存储、冷存储和归档存储。热存储的访问成本低,但存储成本高,非常适合当前数据。相反,归档层的存储成本低但访问成本高,更适合历史数据。
2. 可扩展性
使用传统的本地数据中心时,您必须请专家增加额外的硬件并提升服务器的容量。这不仅会导致成本增加,还会造成停机时间,这是如今的公司无法承受的。
当数据存储有限时,它会影响整个组织快速增长和创新的能力。工程师变得更多地参与数据基础设施的维护,而不是关注实际问题,同时响应市场变化也需要时间。
今天的公司变得更加灵活,云计算是支持他们速度的现代解决方案。借助云计算,您可以通过简单的几次点击来增加或减少资源,并仅为实际使用的部分付费。
3. 安全性
在这个黑客变得越来越臭名昭著的时代,安全问题已成为组织面临的重大问题。数据中心容易受到黑客攻击,我们并非夸大其词。2014 年,Target(塔吉特)遭受攻击,4000 万张借记卡和信用卡信息被盗。2015 年,JP Morgan Chase(摩根大通)也发生了类似的黑客事件。这是其中之一最大的黑客事件,8000 万个账户遭到泄露。黑客利用了加密软件中的漏洞,获取了金融机构的信息。
云计算并非无懈可击。然而,它设计得足以抵御大多数黑客攻击甚至自然灾害。然而,当选择云计算与本地部署时,云计算始终是更好的选择,因为运行数据中心不是组织的核心竞争力或主要业务。因此,他们更适合使用像 Amazon 这样的公司提供的专业服务。
是时候做出转变了
云计算是现代企业的解决方案。它安全、成本效益高,并且减轻了你的负担,使你可以专注于核心业务。迁移过程可能最初看起来令人畏惧,但从长远来看,云计算绝对比本地数据中心更有价值。
附加资源
全球云存储市场(2020 年至 2025 年)- 容器化的兴起带来了机遇
Jeveria Rahim 是 Astera Software 的内容策略师。作为一名市场营销专家,技术爱好者和内心的作家,Javeria Rahim 喜欢与世界分享她的观点。她对让生活变得更轻松的云数据集成技术充满热情。
更多相关话题
众包中的聚类:方法论与应用
原文:
www.kdnuggets.com/2021/11/clustering-crowdsourcing-methodology-applications.html
评论
作者:Daniil Likhobaba,Toloka 的分析师。
聚类是将一组对象分组的任务,使得同一组(称为簇)中的对象彼此之间比与其他组中的对象更相似。在大多数情况下,聚类需要知道对象之间的距离,这通常以距离矩阵的形式呈现。然而,距离的函数通常是未知的,或者聚类规则无法定义。因此,描述标记指令中的过程并利用众包来进行数据聚类更为合理。遗憾的是,目前没有现成的管道用于此目的,而大多数相关论文都限于理论。我们希望能找到一种更实际的解决方案。这就是我们最终得到的结果。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 部门
配对对象标记
起初,我们重现了 Larsen 等人(WWW'20) 的一个简单算法,其中所有标记的数据被分为两个簇。为此,我们需要对这两个对象子集进行两次比较,然后使用专门的算法汇总数据。尽管如此,两个簇任务相当少见。此外,进行包含所有对象的配对子集比较是非常昂贵的。最后,该算法提供了一个单一集合及其补集,从技术上讲,这不算真正的聚类。但我们必须从某处开始。
数据来自 Leipzig 语料库集合 – 各 360 个英语和德语单词。
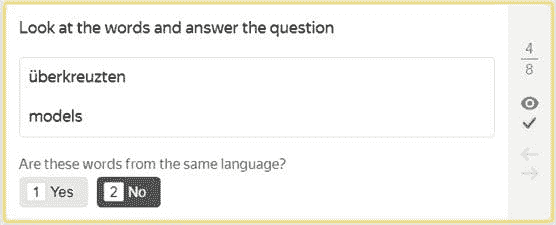
众包执行者必须指示显示的两个词是否属于同一种语言。结果令人惊讶地好:每种语言组中 98% 的词汇被正确识别。这是一个令人鼓舞的第一步。但由于我们希望找到更高效的解决方案,我们继续寻找可行的替代方案。

多次比较
在Gomes et al. 论文NIPS'11)中,作者建议了一种可以处理任意数量图像聚类的方法。其工作原理如下:我们从一个包含图像和颜色调色板的页面开始。执行者选择一种颜色并用它标记相似的图像。然后,执行者选择另一种颜色,根据另一个共享特征将另一组图像分组。如此重复,直到所有图像都被上色标记。
任务是随机创建的。主要参数是每张图像显示的平均页面数量。这个数字必须为每种情况选择,或者根据数据集大小来定义。标记数据与文章中提供的概率模型进行汇总,然后算法随后生成聚类。值得注意的是,这种方法不需要已知的对象之间的距离。
按风格对鞋子进行聚类
为了测试上述方法,我们从SIGMOD/PODS'20 Toloka 教程中获取了一个包含 100 张穿着衣物的图像的数据集。为了跳过机器学习已经训练过的内容,我们要求众包参与者根据风格对物体进行分组,而不考虑颜色。这样做的逻辑是,大多数人能够区分不同的时尚风格,即使我们无法总是用语言描述任何特定风格的定义特征。指令包含了一些特征和细节,帮助参与者,例如高跟鞋。

最终,我们得到了七个易于识别的鞋子聚类。其中包括男鞋、女靴、运动鞋和其他四种。我们很高兴看到女鞋和女凉鞋形成了两个独立的聚类。每个聚类的样本图像如下所示。

可以浏览所有子集,亲眼看到聚类的整齐程度,即使是肉眼也能观察到。这种方法对我们证明了有效,但我们决定进一步探讨。
按风格对鞋子进行聚类
现在,我们想在更大数据集上测试这种方法。我们从Feidegger数据集中取了 2,000 张连衣裙的图片,并再次决定按风格对它们进行聚类。然而,与鞋子不同,连衣裙通常包含更多特征,这就是为什么我们需要为完成这项任务的群众表演者制定一套准确但简洁的指示。
主要困难在于我们无法向表演者描述所有可能性和特殊情况,因为我们实际上不知道这个数据集的结构。我们向Crowd Solutions Architect (CSA)团队的Toloka同事寻求帮助。他们帮助我们配置了质量控制,创建了一个带有培训计划的实践池,并撰写了适当的指示。结果,任务对表演者变得明确,这反过来提高了标注质量。
这些指示没有包含任何最坏情况或所有分组标准。我们建议表演者专注于确定连衣裙的风格、细节层次(例如,领口的大小但不是其形状),并识别具有总体相似或不同外观的连衣裙的图片。我们想解释可以使用什么逻辑来比较连衣裙,概述基本的聚类方法,但不列出任何具体特征供表演者在实际标注过程中记忆和依赖。
培训过程中难度逐步增加,从两个连衣裙的比较开始,最终增加到八件连衣裙。关键规则在通往最终考试的过程中进行了讲解,最终考试由多张具有明显差异的图片组成。


之后,俄语被添加为界面语言,并为随后的任务设置了每页最多八张图片。这是为了简化任务,将每页的平均处理时间缩短到 40 秒。

在任务过程中,有一个方面特别引人关注——负责预期图像数量的页面参数。该参数与数据集大小的关系被确定,这告诉我们成功聚合所需的对象比较数量。我们最终得到了 12 个易于解释的簇:其中包括蓬松的无袖连衣裙、长袖连衣裙、针织连衣裙等等。下图展示了我们获得的每个簇中的一些对象。

收获
通过这些努力,我们确认了通过众包进行聚类确实是可能的,并且效果非常好。我们获得的质量达到了预期,并且我们制定了一个可复制的流程。此外,我们找到了一种让说明对参与者更清晰的方法,并为任务创建了合适的界面。关键是,这一切都在没有我们最初采用的配对比较的情况下完成。标记时间不长,成本也比预期的便宜。
我们目前正在通过Chang 等(NIPS '11)的众包评价方法评估结果标记的质量。他们建议使用入侵者,即在聚类中添加一个故意不正确的对象,并要求参与者找到它。参与者越频繁地选择这个明显错误的对象而不是聚类中的其他对象,我们认为质量越高。
我们认为,使用众包进行聚类可能在电子商务、搜索结果排名以及在任何领域调查未知数据集结构时会很有用。
相关:
更多相关话题
使用 scikit-learn 进行聚类:无监督学习教程
原文:
www.kdnuggets.com/2023/05/clustering-scikitlearn-tutorial-unsupervised-learning.html

图片由作者提供
聚类是一种流行的无监督机器学习技术,这意味着它用于目标变量或结果变量未提供的数据集。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
在无监督学习中,算法的任务是识别数据中的模式和关系,而无需任何预先存在的知识或指导。
聚类的作用是什么?它将相似的数据点分组,使我们能够发现数据中的隐藏模式和关系。
在本文中,我们将探索可用的不同聚类算法及其各自的应用场景,以及用于评估聚类结果质量的重要评价指标。
我们还将演示如何使用流行的 Python 库 scikit-learn 同时开发多个聚类算法。
最后,我们将突出一些最著名的实际应用案例,讨论所使用的算法和评价指标。
但首先,让我们熟悉一下聚类算法。
聚类算法是什么?
以下是聚类算法的概述及简短定义。
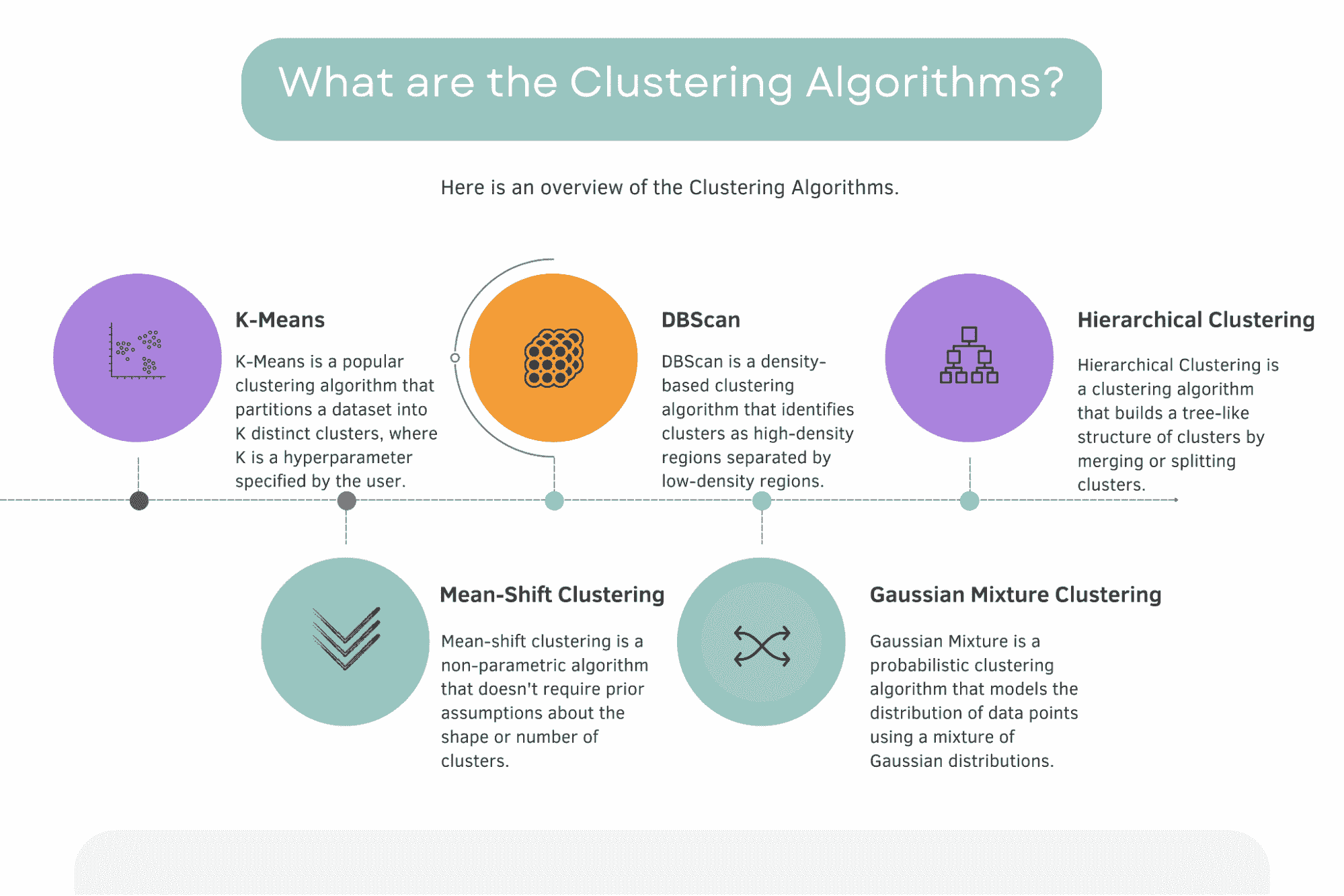
图片由作者提供
根据 scikit-learn 官方文档,现有 11 种不同的聚类算法:K-Means、Affinity propagation、Mean Shift、Special Clustering、Hierarchical Clustering、Agglomerative Clustering、DBScan、Optics、Gaussian Mixture、Birch、Bisecting K-Means。
在这里你可以找到官方文档。
本节将探讨五种最著名和最重要的聚类算法。它们是 K-Means、Mean-Shift、DBScan、高斯混合模型和层次聚类。
在深入探讨之前,我们来看一下下面的图表。它展示了这五种算法在六个不同结构的数据集上的表现。
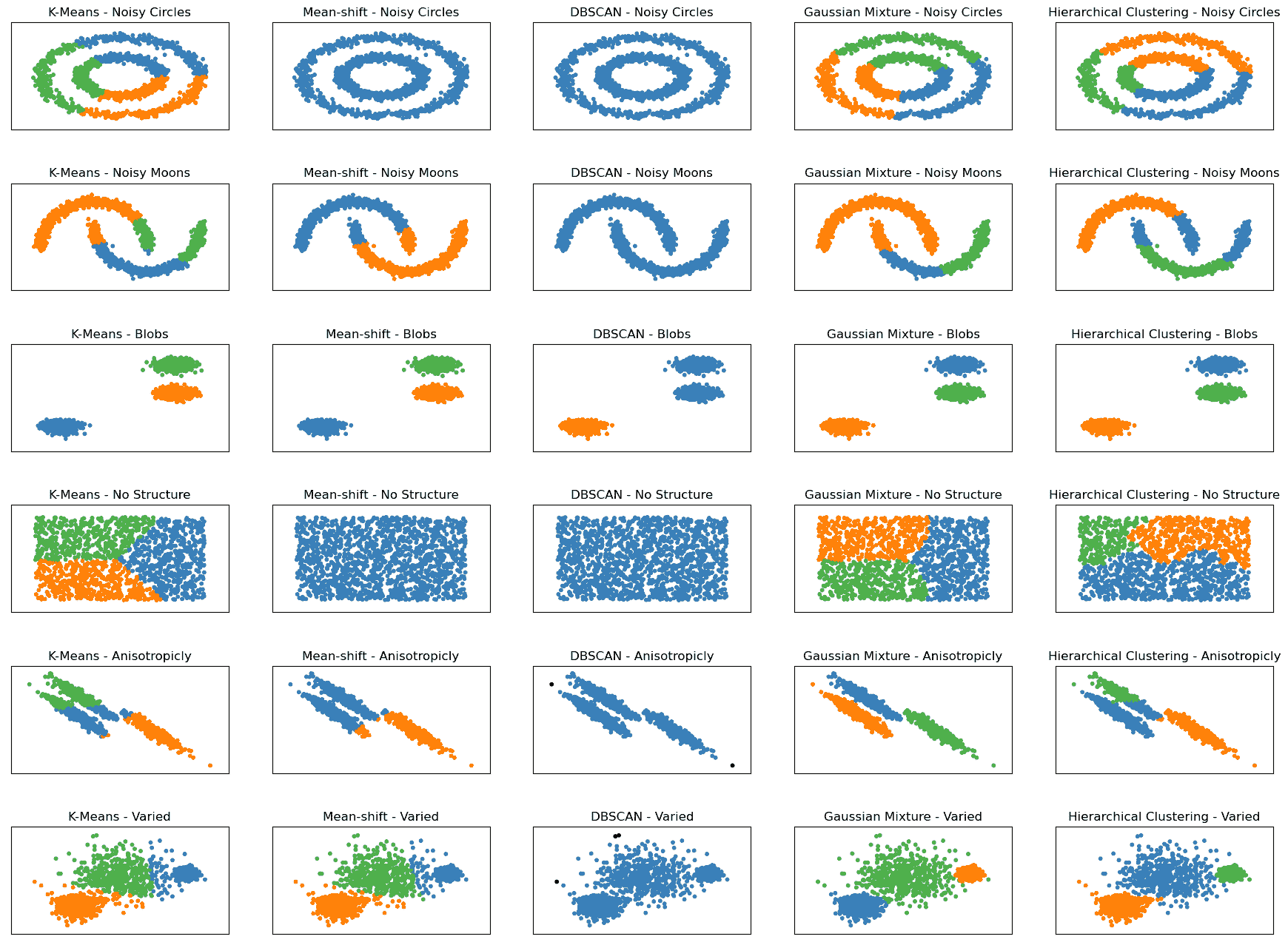
聚类算法 - 作者提供的图片
在 scikit-learn 文档 中,您将找到类似的图形,这些图形启发了上面的图片。我将其限制在五种最著名的聚类算法上,并在算法名称旁边添加了数据集的结构,例如 K-Means - 噪声月牙或 K-Means 变化。
显示了六种不同的数据集,全部由 scikit-learn 生成:
-
噪声圆形: 该数据集由一个大圆和一个不完全居中的小圆组成。数据中还加入了随机的高斯噪声。
-
噪声月牙: 该数据集由两个交错的半月形状组成,这些形状不是线性可分的。数据中还加入了随机的高斯噪声。
-
斑点: 该数据集由随机生成的斑点组成,这些斑点在大小和形状上相对均匀。数据集包含三个斑点。
-
无结构: 该数据集由随机生成的数据点组成,没有固有的结构或聚类模式。
-
各向异性分布: 该数据集由随机生成的各向异性分布的数据点组成。这些数据点通过特定的变换矩阵生成,以使它们沿某些轴延长。
-
变化: 该数据集由具有不同方差的随机生成的斑点组成。数据集包含三个斑点,每个斑点具有不同的标准差。
查看这些图形以及每种算法在这些图形上的表现,将帮助我们比较算法在每个数据集上的性能。如果您的数据与这些图形中的结构相似,这可能会对您的数据项目有所帮助。
现在让我们深入了解这五种算法,从 K-Means 算法开始。
K-Means
K-Means 2D | 作者提供的图片
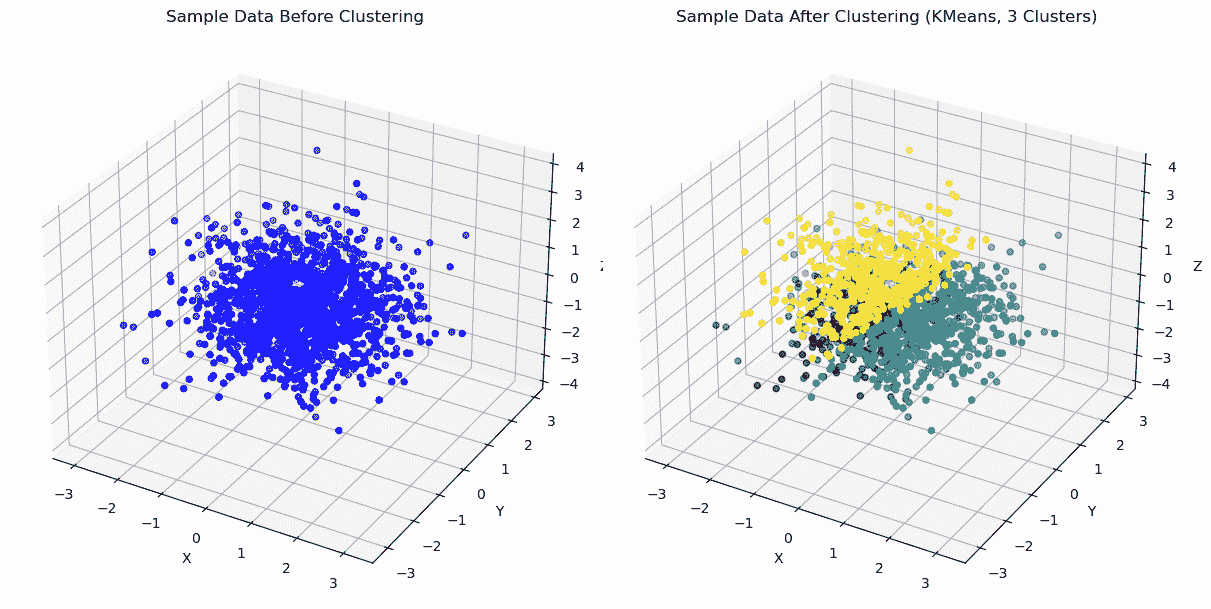
K Means 3D | 作者提供的图片
K-Means 是一种流行的聚类算法,它将数据集划分为 K 个不同的聚类,其中 K 是用户指定的超参数。
该算法通过将每个数据点分配到最近的聚类中心,并根据该聚类中所有数据点的平均值重新计算中心点来工作。
该过程持续进行,直到中心点不再移动或达到指定的最大迭代次数。
它还被应用于各种实际场景,如电子商务中的客户细分、医疗保健中的疾病聚类以及计算机视觉中的图像压缩。
要了解 K-Means 或其他算法的实际应用,请继续阅读。我们将在后续部分讨论这些内容。
DBScan
DBScan | 图片由作者提供
DBScan(基于密度的空间聚类与噪声)是一种基于密度的聚类算法,通过将高密度区域与低密度区域分隔开来识别簇。
算法根据密度阈值和最小点数将彼此接近的点分组在一起。
DBScan 常用于异常检测、空间聚类和图像分割,目标是识别数据中的不同簇,同时处理噪声或异常数据点。
层次聚类
层次聚类 | 图片由作者提供
层次聚类是一种通过合并或分裂簇来构建树状结构的聚类算法。
根据采用的方法,算法可以是聚合型(自下而上)或分裂型(如上图所示)。
层次聚类已在各种实际应用中使用,如社交网络分析、图像分割和生态研究,其目标是识别簇与子簇之间的有意义关系。
Mean-Shift 聚类
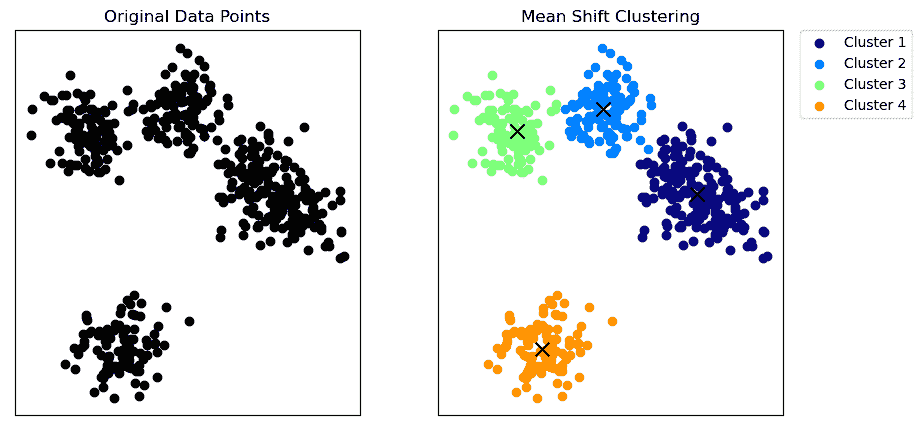
Mean-Shift 聚类 | 图片由作者提供
Mean-shift 聚类是一种非参数算法,不需要对簇的形状或数量进行先验假设。
该算法通过将每个数据点向局部均值(上图中的 x)移动直到收敛来工作,其中核密度函数估计局部均值。
Mean-shift 算法将簇识别为特征空间中的高密度区域。
Mean-shift 聚类已在实际应用中使用,例如图像分割、视频监控中的物体跟踪以及 网络入侵检测中的异常检测,其目标是识别数据中的不同区域或模式。
高斯混合聚类
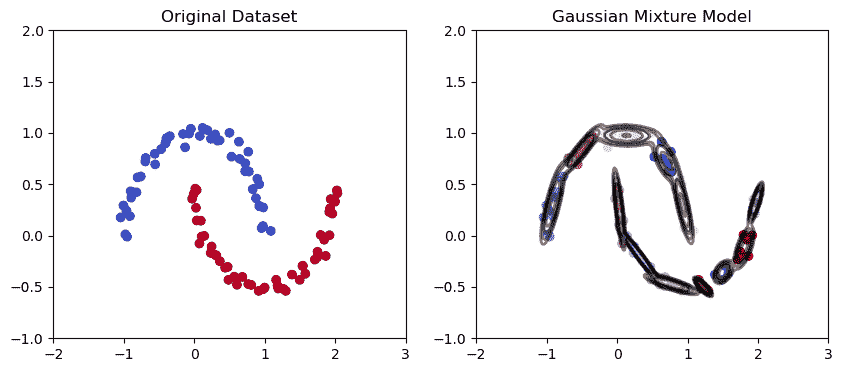
高斯混合模型在月牙形数据集中的应用 | 图片由作者提供 
K Means 聚类模型在月牙形数据集中的应用 | 图片由作者提供
高斯混合模型是一种概率聚类算法,通过高斯分布的混合来建模数据点的分布。该算法将一组高斯分布拟合到数据上,其中每个高斯分布对应一个独立的簇。
高斯混合模型已在各种实际应用中使用,如语音识别、基因表达分析和面部识别,其目标是对数据的潜在分布进行建模,并根据拟合的高斯分布识别聚类。
从上图可以看出,高斯混合模型在捕捉椭圆形数据点的趋势和绘制椭圆形聚类方面具有更好的能力。
总体而言,每种聚类算法都有其独特的优缺点。算法的选择取决于具体问题和数据集的特征。
理解每种算法的细微差别及其使用场景对于实现准确和有意义的结果至关重要。
聚类评估指标
应用算法后,你需要评估其性能,以查看是否有改进的空间,或在算法性能不符合标准时更改算法。为此,你应该使用评估指标。
这里是最流行的一些概述。
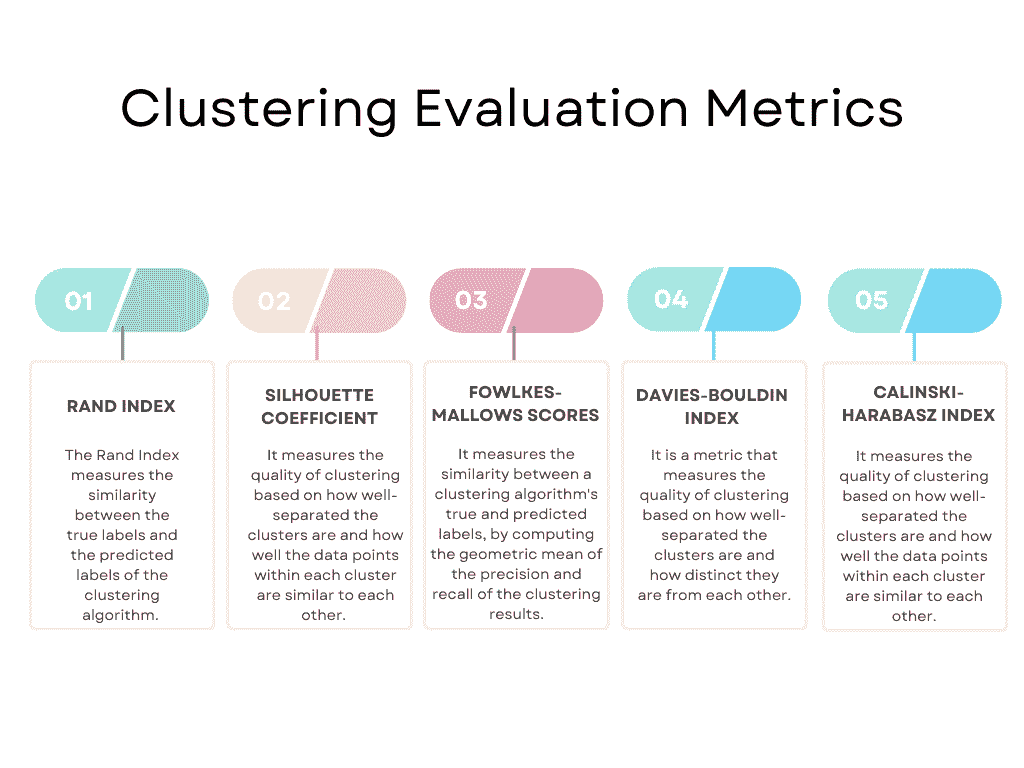
图片来源:作者
当然,这些并不是全部。你可以在 scikit-learn 上获取完整的列表。它列出了以下评估指标:Rand 指数、基于互信息的分数、轮廓系数、Fowlkes-Mallows 分数、同质性、完整性、V 计量、Calinski-Harabasz 指数、Davies-Bouldin 指数、混淆矩阵、配对混淆矩阵。
这里你可以查看官方文档。
我们将坚持使用流行的算法,并从 Rand 指数开始。
Rand 指数
Rand 指数评估真实聚类标签与预测聚类标签之间的相似性。
该指数的范围从 0 到 1,其中 1 表示真实标签和预测标签之间的完美匹配。
Rand 指数通常用于图像分割、文本聚类和文档聚类等领域,其中数据的真实标签是已知的。
轮廓系数
轮廓系数基于聚类的分离程度和每个聚类内部数据点的相似度来衡量聚类的质量。
该系数的范围从 -1 到 1,其中 1 表示聚类分离良好且紧凑,-1 表示聚类不正确。
轮廓系数通常用于市场细分、客户画像和产品推荐,其目标是基于客户行为和偏好识别有意义的聚类。
Fowlkes-Mallows 分数
Fowlkes-Mallows 指数以两位研究人员的名字命名,Edward Fowlkes 和 S.G. Mallows,他们在 1983 年提出了这一指标。
该指数衡量聚类算法的真实标签与预测标签之间的相似性。
该分数的范围从 0 到 1,其中 1 表示真实标签和预测标签之间的完美匹配。
Fowlkes-Mallows 分数通常用于图像分割、文本聚类和文档聚类,其中数据的真实标签是已知的。
Davies-Bouldin 指数
Davies-Bouldin 指数以两位研究人员 David L. Davies 和 Donald W. Bouldin 的名字命名,他们在 1979 年提出了这一指标。
该指数的范围从 0 到无穷大,较低的值表示更好的聚类质量。
它对于识别数据中的最佳簇数量和检测簇重叠或彼此过于相似的情况非常有用。然而,该指数假设簇是球形的且具有相似的密度,这在现实世界的数据集中可能并不总是成立。
Davies-Bouldin 指数通常用于市场细分、客户画像和产品推荐,其目标是基于客户行为和偏好识别有意义的簇。
Calinski-Harabasz 指数
Calinski-Harabasz 指数以 T. Calinski 和 J. Harabasz 的名字命名,他们在 1974 年提出了这一指标。
Calinski-Harabasz 指数根据簇之间的分离程度和每个簇内的数据点相似度来衡量聚类质量。
该指数的范围从 0 到无穷大,较高的值表示更好的聚类效果。
Calinski-Harabasz 指数通常用于市场细分、客户画像和产品推荐,其目标是基于客户行为和偏好识别有意义的簇。
比较评价指标

图片作者
对于 Rand 指数、轮廓系数和 Fowlkes-Mallows 分数,较高的值表示更好的聚类性能。
最佳得分是 1。
对于 Davies-Bouldin 指数,较低的值表示更好的聚类性能。
最佳得分是 0。
对于 Calinski-Harabasz 指数,最高得分表示更好的性能。
最佳得分是 ∞。(无穷大。)
理论上,Calinski-Harabasz (CH) 指数的最佳得分应该是无穷大,因为这表明簇间离散度远高于簇内离散度。然而,在实践中实现无穷大的 CH 指数值是不现实的。
最佳得分没有固定的上限,因为它依赖于具体的数据和聚类情况。
别忘了:没有哪个算法或脚本是完美的。如果你在这些评价指标中达到了最佳得分,你的模型很可能存在过拟合。
如何在 scikit-learn 中一次性开发多个聚类算法?
这里的目的是对 Iris 数据集应用多个聚类算法,并使用不同的评价指标计算其性能。
在这里我们将使用 IRIS 数据集。
你可以在 这里 找到这个数据集。
鸢尾花数据集是一个著名的多类分类数据集,包含 150 个鸢尾花样本,每个样本具有四个特征(萼片和花瓣的长度和宽度)。

图片来源 R 语言机器学习入门
数据集中有三个类别,代表三种不同类型的鸢尾花。
数据集通常用于机器学习和模式识别任务,特别是用于测试和比较不同的分类算法。它由英国统计学家和生物学家 Ronald Fisher 于 1936 年引入。
这里我们将编写代码,导入加载数据集所需的库,实施五种聚类算法(DBSCAN、K-Means、层次聚类、高斯混合模型和均值漂移),并使用五个指标评估它们的性能。
为此,我们将把评估指标和算法添加到字典中,并用两个 for 循环相互应用它们。
但我们这里有一个例外。rand_score 和 fowlkes_mallows_score 函数将聚类结果与真实标签进行比较,因此我们将添加if-else 块来提供这些结果。
然后我们将把这些结果添加到数据框中,以进行进一步分析。
这是代码。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cluster import (
DBSCAN,
KMeans,
AgglomerativeClustering,
MeanShift,
)
from sklearn.mixture import GaussianMixture
from sklearn.metrics import (
silhouette_score,
calinski_harabasz_score,
davies_bouldin_score,
rand_score,
fowlkes_mallows_score,
)
# Load the Iris dataset
iris = load_iris()
X = iris.data
y = iris.target
# Implement clustering algorithms
dbscan = DBSCAN(eps=0.5, min_samples=5)
kmeans = KMeans(n_clusters=3, random_state=42)
agglo = AgglomerativeClustering(n_clusters=3)
gmm = GaussianMixture(n_components=3, covariance_type="full")
ms = MeanShift()
# Evaluate clustering algorithms with three evaluation metrics
labels = {
"DBSCAN": dbscan.fit_predict(X),
"K-Means": kmeans.fit_predict(X),
"Hierarchical": agglo.fit_predict(X),
"Gaussian Mixture": gmm.fit_predict(X),
"Mean Shift": ms.fit_predict(X),
}
metrics = {
"Silhouette Score": silhouette_score,
"Calinski Harabasz Score": calinski_harabasz_score,
"Davies Bouldin Score": davies_bouldin_score,
"Rand Score": rand_score,
"Fowlkes-Mallows Score": fowlkes_mallows_score,
}
for name, label in labels.items():
for metric_name, metric_func in metrics.items():
if metric_name in ["Rand Score", "Fowlkes-Mallows Score"]:
score = metric_func(y, label)
else:
score = metric_func(X, label)
pred_df = pred_df.append(
{"Algorithm": name, "Metric": metric_name, "Score": score},
ignore_index=True,
)
# Display the DataFrame
pred_df.head(10)
这是输出结果。
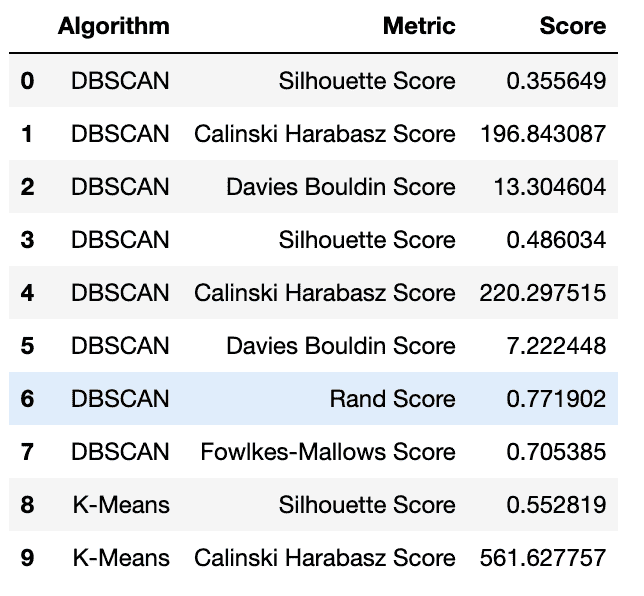
预测数据框 | 图片由作者提供
现在,让我们制作一个可视化图表,以更好地查看结果。这里的目的是创建聚类算法评估指标的可视化图。
以下代码将数据透视为算法作为列,指标作为行,然后为每个指标生成条形图。这允许对不同评估指标的聚类算法性能进行轻松比较。
这是代码。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Pivot the data to have algorithms as columns and metrics as rows
pivoted_df = pred_df.pivot(
index="Metric", columns="Algorithm", values="Score"
)
# Define the three metrics to plot
metrics = [
"Silhouette Score",
"Calinski Harabasz Score",
"Davies Bouldin Score",
]
# Define a colormap to use for each algorithm
cmap = plt.get_cmap("Set3")
# Plot a bar chart for each metric
fig, axs = plt.subplots(nrows=1, ncols=3, figsize=(15, 5))
# Add a main title to the figure
fig.suptitle("Comparing Evaluation Metrics", fontsize=16, fontweight="bold")
for i, metric in enumerate(metrics):
ax = pivoted_df.loc[metric].plot(kind="bar", ax=axs[i], rot=45)
ax.set_xticklabels(ax.get_xticklabels(), ha="right")
ax.set_ylabel(metric)
ax.set_title(metric, fontstyle="italic")
# Iterate through the algorithm names and set the color for each bar
for j, alg in enumerate(pivoted_df.columns):
ax.get_children()[j].set_color(cmap(j))
plt.show()
这是输出结果。
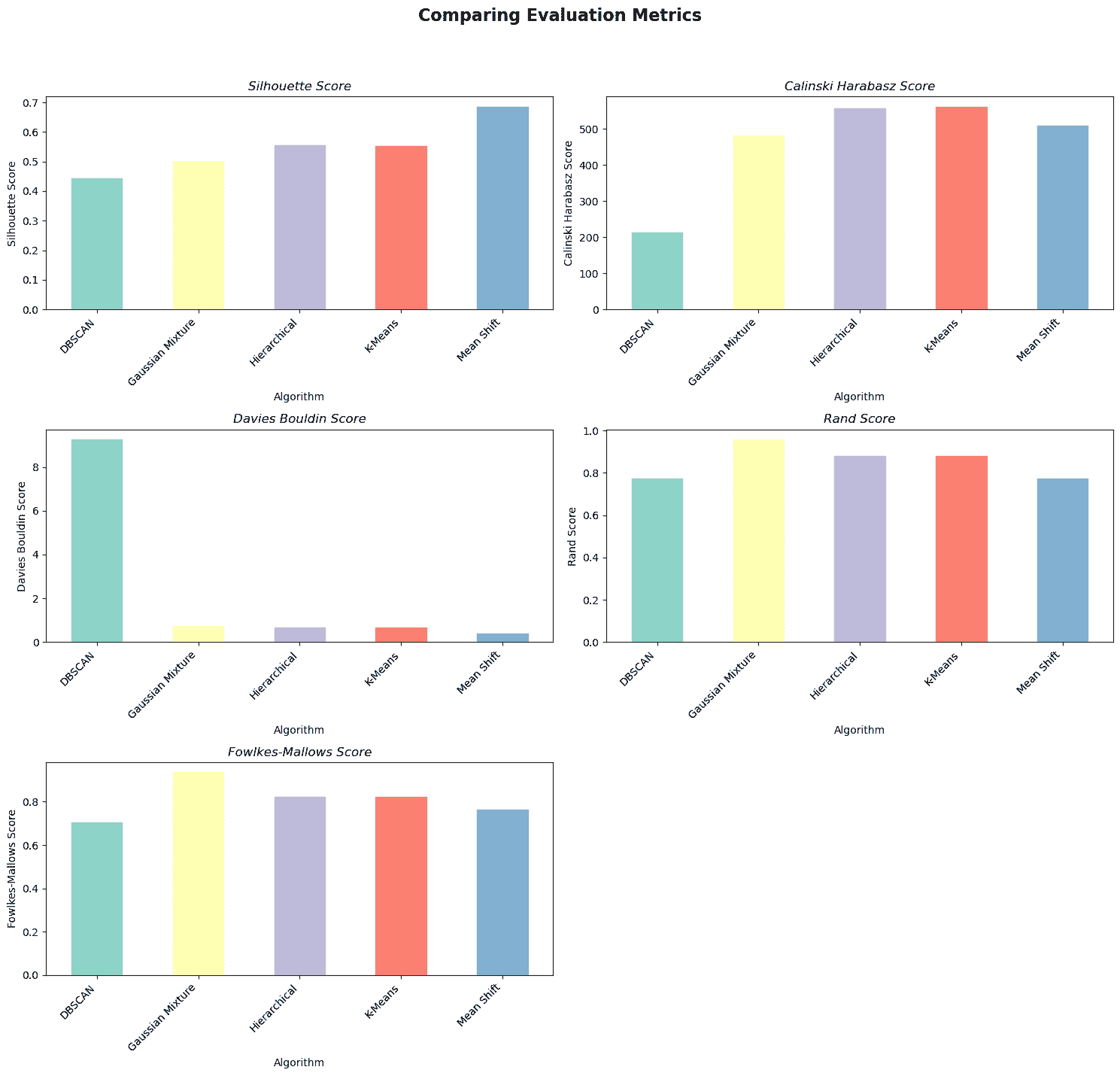
图片由作者提供
总结来说,均值漂移算法根据轮廓系数和戴维斯-鲍尔丁分数表现最佳。
K-Means 算法在 Calinski Harabasz 分数上表现最佳,而 GMM 算法在 Rand 分数和 Fowlkes-Mallows 分数上表现最佳。
聚类算法之间没有明显的赢家,因为每种算法在不同的指标上表现良好。
最佳算法的选择取决于具体需求以及在聚类问题中对每个评估指标的重要性分配。
聚类的实际应用
现在,让我们看看我们算法和评估指标的实际例子,以进一步掌握逻辑。
这里是我们将详细讨论的例子的概述。
作者提供的图像
超市连锁个性化

作者提供的图像
实际例子:一家超市连锁希望为其客户创建个性化的营销活动。他们使用 K-Means 聚类根据客户的购买习惯、人口统计数据和店铺访问频率来细分客户。这些细分帮助公司量身定制营销信息,以更好地吸引和服务客户。
算法: K-Means 聚类
K-Means 被选择是因为它是一个简单、高效且广泛使用的聚类算法,适用于大数据集。它可以快速识别模式并根据输入特征创建明确的客户细分。
评估指标: Silhouette Score
Silhouette Score 用于评估客户细分的质量,通过测量每个数据点在其分配的聚类内的适配度,与其他聚类进行比较。这有助于确保聚类是紧凑且分离良好的,这对于创建有效的个性化营销活动至关重要。
欺诈交易

作者提供的图像
实际例子:一家信用卡公司希望检测欺诈交易。他们使用 DBSCAN 根据交易金额、时间和地点等因素对交易进行聚类。那些不符合任何聚类的异常交易会被标记为潜在欺诈,进行进一步调查。
算法: DBSCAN
DBSCAN 被选择是因为它是一个基于密度的聚类算法,能够识别形状和大小各异的聚类,并检测不属于任何聚类的噪声点。这使它适合检测异常模式或离群点,如潜在的欺诈交易。
评估指标: Silhouette Score
选择 Silhouette Score 作为评估指标是因为它有助于评估 DBSCAN 的有效性,通过将正常交易与表示欺诈的潜在离群点分开。
更高的 Silhouette Score 表示常规交易的聚类之间分隔良好,噪声点(离群点)也被有效分离。这种分离使得识别和标记显著偏离正常模式的可疑交易变得更容易。
癌症基因组学关系
作者提供的图像
现实生活中的例子:研究癌症基因组学的研究人员希望理解不同类型癌细胞之间的关系。他们使用层次聚类根据基因表达模式对细胞进行分组。得到的簇帮助他们识别癌症类型之间的共性和差异,并开发针对性的治疗方法。
算法:凝聚层次聚类
选择凝聚层次聚类是因为它创建了一个树状结构(树状图),这使研究人员能够以多层次的粒度可视化和解释癌细胞之间的关系。这种方法可以揭示嵌套的子群体,并帮助研究人员理解基于基因表达模式的癌症类型的层次组织。
评估指标:Calinski-Harabasz 指数
选择 Calinski-Harabasz 指数是因为它测量了簇间离散度与簇内离散度的比率。对于癌症基因组学,它帮助研究人员评估基于基因表达模式的癌细胞分组的质量,判断组间是否明显且分隔良好。
自主驾驶汽车
作者提供的图像
现实生活中的例子:一家自动驾驶汽车公司希望提高汽车识别周围物体的能力。他们使用均值漂移聚类将汽车摄像头捕捉的图像根据颜色和纹理分割成不同的区域,这帮助汽车识别和跟踪行人及其他车辆等物体。
算法:均值漂移聚类
选择均值漂移聚类是因为它是一种非参数的基于密度的算法,可以自动适应数据的底层结构和规模。
这使得它特别适合于图像分割任务,其中簇或区域的数量可能事先未知,并且区域的形状可能复杂且不规则。
评估指标:Fowlkes-Mallows 评分(FMS)
选择 Fowlkes-Mallows 评分是因为它测量了两个聚类之间的相似性,通常将算法的输出与真实的聚类进行比较。
在自动驾驶汽车的背景下,FMS 可以用于评估均值漂移聚类算法在分割图像方面的效果,相较于人工标注的分割结果。
新闻推荐

作者提供的图像
实际案例:一个在线新闻平台希望将文章分组,以改善对用户的内容推荐。他们使用 Gaussian Mixture Models 根据从文本中提取的特征(如词频和术语共现)对文章进行聚类。通过识别不同的主题,该平台可以推荐与用户兴趣更相关的文章。
算法:Gaussian Mixture Model (GMM) 聚类
选择 Gaussian Mixture Models 是因为它们是一种概率生成方法,可以建模复杂的重叠簇。这对文本数据特别有用,因为文章可能属于多个主题或具有共享特征。GMM 可以捕捉这些细微差别,并提供软聚类,为每篇文章分配属于每个主题的概率。
评估指标:Silhouette Coefficient
选择 Silhouette Coefficient 是因为它衡量了簇的紧密性和分离度,有助于评估主题分配的质量。
更高的 Silhouette Coefficient 表明一个主题内的文章彼此更相似,并且与其他主题明显不同,这对准确的内容推荐至关重要。
如果你想了解更多关于无监督算法的信息,你可以在这里获取更多资料:“Unsupervised Learning Algorithms”。还可以查看“Supervised vs Unsupervised Learning”,这两种方法是机器学习领域我们应该了解的。
结论
总之,聚类是一种重要的无监督学习技术,用于在没有预先了解类标签的情况下发现数据中的相似性或模式。
我们讨论了不同的聚类算法,包括 K-Means、Mean Shift、DBScan、Gaussian Mixture 和 Hierarchical Clustering,以及它们的应用场景和实际应用。
此外,我们还探索了各种评估指标,包括 Silhouette Coefficient、Calinski-Harabasz Index 和 Davies-Bouldin Index,这些指标帮助我们评估聚类结果的质量。
我们还学习了如何使用 scikit-learn 同时开发多个聚类算法,并使用我们已发现的指标对其进行评估。
最后,我们讨论了一些利用聚类算法解决实际问题的热门应用。
如果你还有问题,这里有一篇文章解释了Clustering and its algorithms。
聚类有广泛的应用,从市场营销中的客户细分到计算机视觉中的图像识别,它是发现数据中隐藏模式和洞察的重要工具。
内特·罗西迪 是一名数据科学家和产品策略专家。他还是一名兼任教授,教授分析学,并且是StrataScratch,一个帮助数据科学家准备顶级公司面试问题的平台的创始人。可以通过Twitter: StrataScratch或LinkedIn与他联系。
更多相关主题
聚类释放:理解 K-Means 聚类
原文:
www.kdnuggets.com/2023/07/clustering-unleashed-understanding-kmeans-clustering.html

图片来源:作者
在分析数据时,我们的目标是发现隐藏的模式并提取有意义的洞察。让我们进入基于 ML 的新类别,即无监督学习,其中一个强大的算法用于解决聚类任务的是 K-Means 聚类算法,它彻底改变了数据理解的方式。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
K-Means 已成为机器学习和数据挖掘应用中的一种有用算法。在这篇文章中,我们将深入探讨 K-Means 的工作原理、使用 Python 实现,以及探索其原则、应用等。所以,让我们开始这段旅程,揭示隐藏的模式并利用 K-Means 聚类算法的潜力。
什么是 K-Means 算法?
K-Means 算法用于解决属于无监督学习类别的聚类问题。借助这个算法,我们可以将观察数据分组到 K 个簇中。
图 1 K-Means 算法工作原理 | 图片来自 Towards Data Science
这个算法内部使用向量量化,通过这种方式,我们可以将数据集中的每个观察值分配到距离最小的簇中,这是聚类算法的原型。这个聚类算法在数据挖掘和机器学习中常用于根据相似性度量将数据分区成 K 个簇。因此,在这个算法中,我们需要最小化观察值与其对应质心之间的平方和距离,这最终会产生明显且同质的簇。
K-Means 聚类的应用
以下是这个算法的一些标准应用。K-Means 算法在工业应用中常用于解决与聚类相关的问题。
-
客户细分: K-means 聚类可以根据客户的兴趣对不同客户进行细分。它可以应用于银行、电信、电子商务、体育、广告、销售等。
-
文档聚类: 在这种技术中,我们将把一组文档中相似的文档归为一类,从而在相同的簇中得到相似的文档。
-
推荐引擎: 有时,K-means 聚类可用于创建推荐系统。例如,你想向朋友推荐歌曲。你可以查看那个人喜欢的歌曲,然后使用聚类来找到类似的歌曲,并推荐最相似的那些。
还有许多更多应用,我相信你已经想到了一些,可能会在本文下方的评论区分享。
使用 Python 实现 K-Means 聚类
在本节中,我们将开始在一个数据集上使用 Python 实现 K-Means 算法,这在数据科学项目中主要使用。
1. 导入必要的库和依赖项
首先,让我们导入实现 K-means 算法所需的 Python 库,包括 NumPy、Pandas、Seaborn、Marplotlib 等。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
2. 加载和分析数据集
在此步骤中,我们将通过将数据存储在 Pandas 数据框中来加载学生数据集。要下载数据集,请参考这里的链接。
问题的完整管道如下所示:

图 2 项目管道 | 图片来源:作者
df = pd.read_csv('student_clustering.csv')
print("The shape of data is",df.shape)
df.head()
3. 数据集的散点图
现在进入建模步骤,我们需要可视化数据,因此我们使用 matplotlib 绘制散点图,以检查聚类算法如何工作并创建不同的簇。
# Scatter plot of the dataset
import matplotlib.pyplot as plt
plt.scatter(df['cgpa'],df['iq'])
输出:
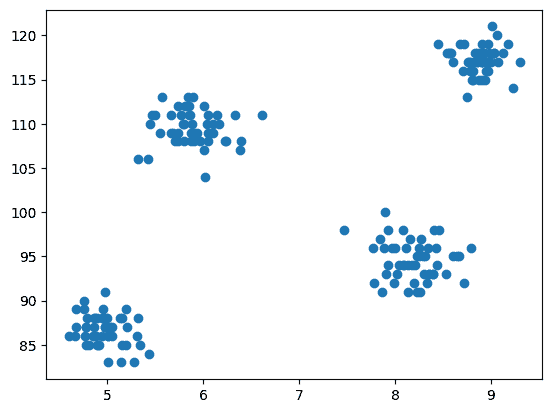
图 3 散点图 | 图片来源:作者
4. 从 Scikit-learn 的 Cluster 类中导入 K-Means
现在,由于我们需要实现 K-Means 聚类,我们首先导入 cluster 类,然后我们将 KMeans 作为该类的模块。
from sklearn.cluster import KMeans
5. 使用肘部法找到 K 的最优值
在此步骤中,我们将找到 K 的最优值,这是实现算法时的一个超参数。K 值表示我们必须为数据集创建多少个簇。直观地找到这个值是不可能的,因此,为了找到最优值,我们将创建 WCSS(簇内平方和)和不同 K 值之间的图,并选择给我们最小 WCSS 值的 K。
# create an empty list for store residuals
wcss = []
for i in range(1,11):
# create an object of K-Means class
km = KMeans(n_clusters=i)
# pass the dataframe to fit the algorithm
km.fit_predict(df)
# append inertia value to wcss list
wcss.append(km.inertia_)
现在,让我们绘制肘部图以找到 K 的最优值。
# Plot of WCSS vs. K to check the optimal value of K
plt.plot(range(1,11),wcss)
输出:
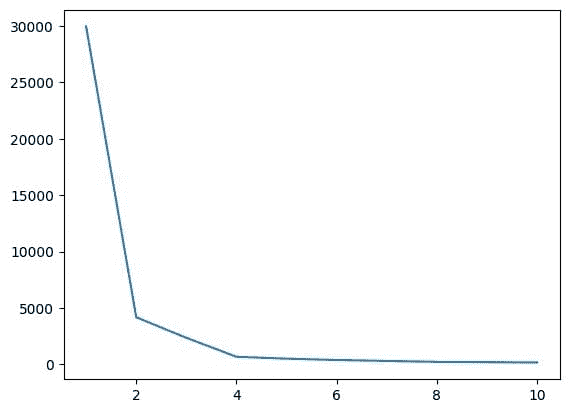
图 4 肘部图 | 图片来源:作者
从上述肘部图中,我们可以看到在 K=4 时,WCSS 的值有一个下降,这意味着如果我们将最佳值设置为 4,那么聚类将提供良好的性能。
6. 使用最佳 K 值拟合 K-Means 算法
我们已经完成了 K 的最佳值的寻找。现在,让我们进行建模,我们将创建一个 X 数组,存储所有特征的完整数据集。在这里无需分离目标和特征向量,因为这是一个无监督问题。之后,我们将创建一个 KMeans 类的对象,并用选定的 K 值对数据集进行拟合。最后,我们打印 y_means,它表示不同聚类的均值。
X = df.iloc[:,:].values # complete data is used for model building
km = KMeans(n_clusters=4)
y_means = km.fit_predict(X)
y_means
7. 检查每个类别的聚类分配
让我们检查数据集中哪些点属于哪个聚类。
X[y_means == 3,1]
到目前为止,我们为中心初始化使用了 K-Means++ 策略,现在,让我们改为使用随机中心初始化,而不是 K-Means++,并通过相同的过程比较结果。
km_new = KMeans(n_clusters=4, init='random')
y_means_new = km_new.fit_predict(X)
y_means_new
检查有多少值匹配。
sum(y_means == y_means_new)
8. 聚类的可视化
为了可视化每个聚类,我们在坐标轴上绘制它们,并通过不同的颜色来区分,这样我们可以很容易地看到形成的 4 个聚类。
plt.scatter(X[y_means == 0,0],X[y_means == 0,1],color='blue')
plt.scatter(X[y_means == 1,0],X[y_means == 1,1],color='red')
plt.scatter(X[y_means == 2,0],X[y_means == 2,1],color='green')
plt.scatter(X[y_means == 3,0],X[y_means == 3,1],color='yellow')
输出:
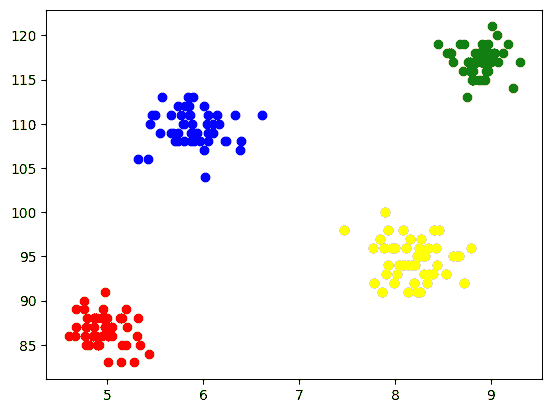
图 5 聚类形成的可视化 | 作者提供的图像
9. K-Means 在三维数据上的应用
由于之前的数据集有 2 列,我们面临的是二维问题。现在,我们将使用相同的一组步骤处理三维问题,并尝试分析代码在 n 维数据上的可重复性。
# Create a synthetic dataset from sklearn
from sklearn.datasets import make_blobs # make synthetic dataset
centroids = [(-5,-5,5),(5,5,-5),(3.5,-2.5,4),(-2.5,2.5,-4)]
cluster_std = [1,1,1,1]
X,y = make_blobs(n_samples=200,cluster_std=cluster_std,centers=centroids,n_features=3,random_state=1)
# Scatter plot of the dataset
import plotly.express as px
fig = px.scatter_3d(x=X[:,0], y=X[:,1], z=X[:,2])
fig.show()
输出:
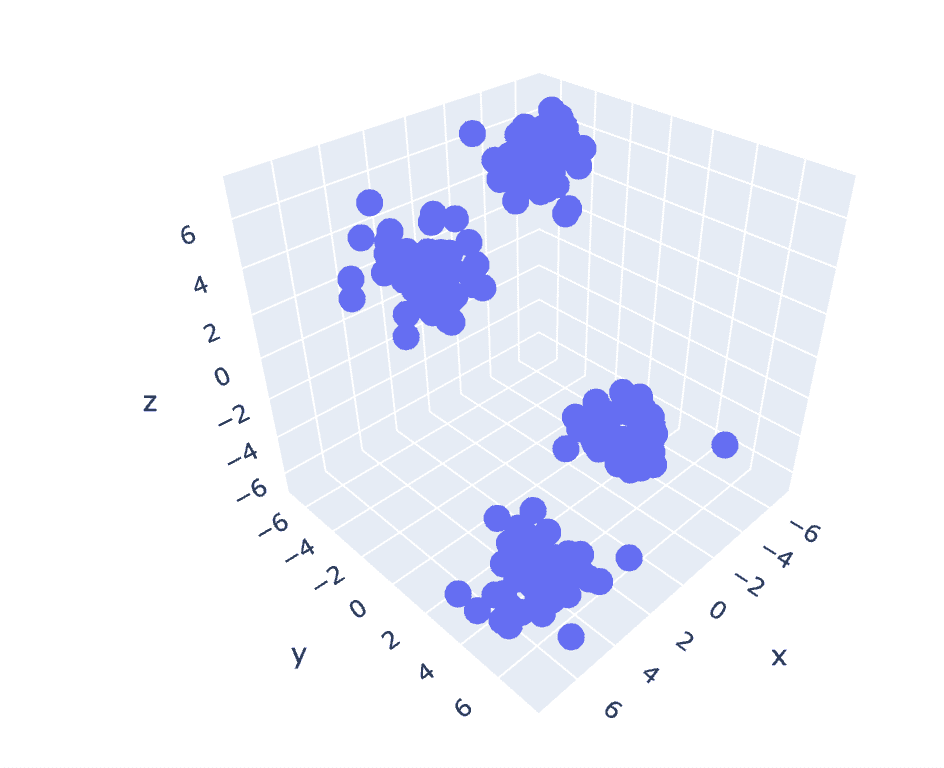
图 6 三维数据集的散点图 | 作者提供的图像
wcss = []
for i in range(1,21):
km = KMeans(n_clusters=i)
km.fit_predict(X)
wcss.append(km.inertia_)
plt.plot(range(1,21),wcss)
输出:
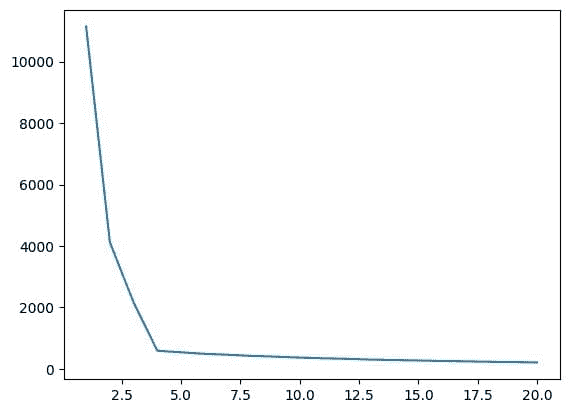
图 7 肘部图 | 作者提供的图像
# Fit the K-Means algorithm with the optimal value of K
km = KMeans(n_clusters=4)
y_pred = km.fit_predict(X)
# Analyse the different clusters formed
df = pd.DataFrame()
df['col1'] = X[:,0]
df['col2'] = X[:,1]
df['col3'] = X[:,2]
df['label'] = y_pred
fig = px.scatter_3d(df,x='col1', y='col2', z='col3',color='label')
fig.show()
输出:
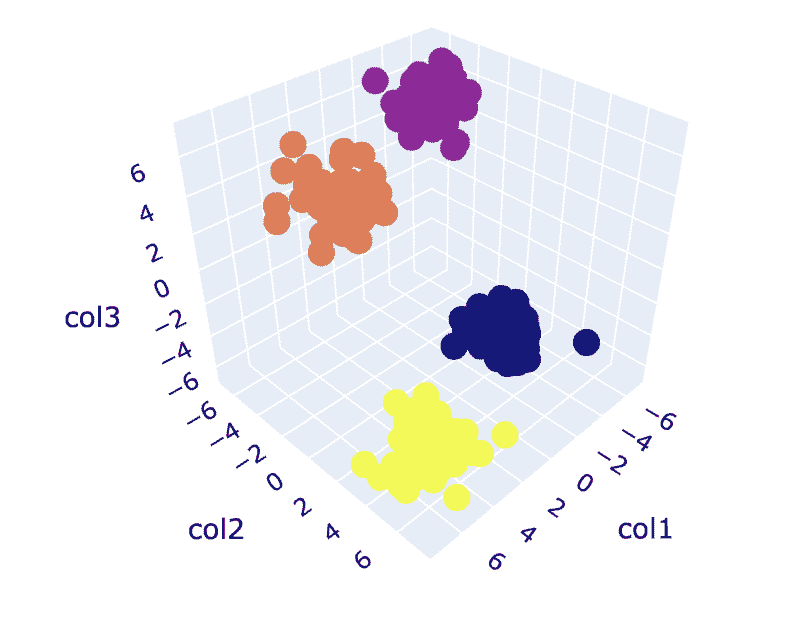
图 8. 聚类可视化 | 作者提供的图像
您可以在这里找到完整的代码 - Colab Notebook
总结
这完成了我们的讨论。我们讨论了 K-Means 的工作原理、实现和应用。总之,实施聚类任务是一种广泛使用的无监督学习算法,提供了一种简单而直观的方法来对数据集的观察值进行分组。该算法的主要优点在于,利用所选的相似性度量将观察值分成多个集合,同时借助实施该算法的用户。
然而,根据第一步质心的选择,我们的算法表现不同,可能收敛到局部或全局最优解。因此,选择要实施的聚类数、数据预处理、处理异常值等,对于获得良好的结果至关重要。但是,如果我们深入了解这个算法的局限性之外,K-Means 是一种有助于探索性数据分析和各种领域模式识别的有用技术。
Aryan Garg 是一名电气工程学士学位学生,目前在本科最后一年。他对网页开发和机器学习领域感兴趣,并且追求了这一兴趣,渴望在这些方向上进一步工作。
更多关于这个话题
如何在机器学习模型中使用持续学习,6 月 19 日网络研讨会
原文:
www.kdnuggets.com/2019/05/cnvrg-io-continual-learning-ml-models.html
赞助帖子。
学术界和实践者都认为,持续学习(CL)是迈向人工智能的基本步骤。CL 是指模型从数据流中持续学习的能力。在实践中,这意味着支持模型在生产环境中随着新数据的到来,自主学习和适应。CL 的理念是模拟人类在其生命周期中不断获取、微调和转移知识和技能的能力。生产中的模型 CL 将提高准确性,并使 AI 更接近真实的人类智能。
加入数据科学专家、cnvrg.io 首席执行官 Yochay Ettun,他将讨论生产中的持续学习。本次网络研讨会将探讨持续学习,并帮助你将持续学习应用到你的生产模型中,使用如 Tensorflow、Kubernetes 和 cnvrg.io 等工具。本次面向专业数据科学家的网络研讨会将介绍如何在生产中监控模型,以及如何设置自动适应的机器学习。
关键要点包括:
-
理解持续学习
-
通过 CL 优化准确性
-
如何使用 TensorFlow 应用 CL
-
如何实现自动适应的机器学习
-
适应数据分布的变化
-
应对异常值
-
生产中的再训练
-
适应新任务
-
将机器学习管道部署到生产中
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
更多相关主题
数据科学家的编码习惯
原文:
www.kdnuggets.com/2020/05/coding-habits-data-scientists.html
评论
作者:David Tan,ThoughtWorks。
最初发布于 ThoughtWorks Insights。经许可转载。
作为一个 ML 从业者,你会知道代码很快就会失控。一个出色的 ML 模型很容易变成一个难以理解的大块代码。因此,修改代码变得痛苦且容易出错,同时 ML 从业者在演进其 ML 解决方案时变得越来越困难。
本文分享了一些识别增加代码复杂性的坏习惯的技巧,以及有助于我们分解复杂性的习惯。它现在也是一个视频系列,涵盖了以下主题:
-
如何重构 Jupyter notebook
-
针对你的 ML 代码库的自动化测试
-
如何使用 IDE 提高生产力
-
在 17 分钟内入门 Docker
如果你尝试过机器学习或数据科学,你会知道代码可以迅速变得混乱。
通常,训练 ML 模型的代码是用 Jupyter notebooks 编写的,里面充满了(i)副作用(例如打印语句、格式化的数据框、数据可视化)和(ii)没有任何抽象、模块化和自动化测试的粘合代码。虽然这对于旨在教授机器学习过程的笔记本可能没问题,但在实际项目中,这会变成一个难以维护的混乱。缺乏良好的编码习惯使得代码难以理解,因此,修改代码变得痛苦且容易出错。这使得数据科学家和开发人员在演进其 ML 解决方案时变得越来越困难。
在本文中,我们将分享识别增加代码复杂性的不良习惯的技巧,以及有助于我们分解复杂性的习惯。
复杂性的贡献因素是什么?
管理软件复杂性的最重要技巧之一是设计系统,使开发人员在任何给定时间只需要面对总体复杂性的一小部分。 - John Ousterhout
要处理复杂性,我们必须首先了解它的样子。当某物是由相互关联的部分组成时,它就是复杂的。每当我们以添加另一个活动部分的方式编写代码时,我们就增加了复杂性,并且需要在脑海中记住更多的内容。
虽然我们不能——也不应尝试——逃避问题的本质复杂性,但我们经常通过不良实践如:
-
没有抽象。 当我们在单个 Python 笔记本或脚本中编写所有代码而没有将其抽象成函数或类时,我们迫使读者阅读大量代码行并弄清楚“如何”来了解代码的功能。
-
长函数做多个事情。 这迫使我们在处理函数的一部分时必须在脑海中保持所有中间数据转换。
-
没有单元测试。 当我们重构时,确保没有破坏任何东西的唯一方法是重新启动内核并运行整个笔记本。即使我们只想处理其中的一小部分,我们也被迫承担整个代码库的复杂性。
复杂性是不可避免的,但可以进行分隔。在我们的家庭中,当我们没有主动组织和理顺物品的放置位置、原因和方式时,杂乱就会积累,本应简单的任务(例如,找钥匙)变得不必要地耗时和令人沮丧。我们的代码库也是如此。新代码不断被添加用于数据清理、特征工程、错误修复、处理新数据等。除非我们严格维护我们的代码库并不断重构(而且没有单元测试我们无法重构),否则混乱和复杂性是不可避免的。
在本文的其余部分,我们将分享一些增加复杂性的常见不良习惯和帮助管理复杂性的更好习惯:
-
保持代码简洁
-
使用函数来抽象复杂性
-
尽快将代码从 Jupyter 笔记本中提取出来
-
应用测试驱动开发
-
进行小而频繁的提交
减少复杂性的习惯
保持代码简洁
不洁净的代码通过使代码难以理解和修改来增加复杂性。因此,修改代码以响应业务需求变得越来越困难,有时甚至是不可能的。
一种糟糕的编码习惯(或称为“代码异味”)是死代码。死代码是已经执行但其结果从未在其他计算中使用的代码。死代码是开发人员在编写代码时不得不记住的另一件无关紧要的事。例如,对比这两个代码示例:
# bad example
df = get_data()
print(df)
# do_other_stuff()
# do_some_more_stuff()
df.head()
print(df.columns)
# do_so_much_stuff()
model = train_model(df)
# good example
df = get_data()
model = train_model(df)
关于清洁代码的实践已经在 几种语言中广泛书写,包括 Python。我们已经调整了这些“清洁代码”原则,你可以在这个 clean-code-ml 仓库中找到它们:
-
设计 (代码示例)
- 不要暴露你的内部实现(保持实现细节隐藏)
-
可有可无的 (代码示例)
-
删除死代码
-
避免使用打印语句(即使是像 head()、df.describe()、df.plot() 这样的夸张打印语句)
-
-
变量(代码示例)
- 变量名应该揭示意图
-
函数(代码示例)
-
使用函数来保持代码的“DRY” (不要重复自己)
-
函数应该做一件事
-
使用函数来抽象复杂性
函数通过抽象复杂的实现细节并用更简单的表示——它的名称——来简化我们的代码。
想象你在一家餐厅,你得到了一份菜单。这个菜单不是告诉你菜品的名称,而是详细列出了每道菜的食谱。例如,其中一道菜是:
第 1 步。在一个大锅中,加热油。加入胡萝卜、洋葱和芹菜;搅拌至洋葱变软。加入香草和大蒜,再煮几分钟。
第 2 步。加入扁豆、番茄和水。将汤煮沸后转小火炖煮 30 分钟。加入菠菜并煮至菠菜变软。最后,用醋、盐和胡椒调味。
如果菜单隐藏了菜谱中的所有步骤(即实现细节),而只给出了菜品的名称(一个接口,即菜品的抽象),对我们来说会更容易(答案是:那是扁豆汤)。
为了说明这一点,这里是来自 Kaggle Titanic 比赛的一个笔记本中的代码示例,重构前后对比。
# bad example
pd.qcut(df['Fare'], q=4, retbins=True)[1] # returns array([0., 7.8958, 14.4542, 31.275, 512.3292])
df.loc[ df['Fare'] <= 7.90, 'Fare'] = 0 df.loc[(df['Fare'] > 7.90) & (df['Fare'] <= 14.454), 'Fare'] = 1 df.loc[(df['Fare'] > 14.454) & (df['Fare'] <= 31), 'Fare'] = 2 df.loc[ df['Fare'] > 31, 'Fare'] = 3
df['Fare'] = df['Fare'].astype(int)
df['FareBand'] = df['Fare']
# good example (after refactoring into functions)
df['FareBand'] = categorize_column(df['Fare'], num_bins=4)
通过将复杂性抽象为函数,我们得到了什么?
-
可读性。我们只需阅读接口(即
categorize_column())即可了解其功能。我们不必阅读每一行代码或在互联网上搜索我们不理解的内容(例如pd.qcut)。如果我还是不理解这个函数的功能,我可以查看它的单元测试或定义。 -
因为现在它是一个函数,我们可以很容易地为其编写单元测试。如果我们不小心更改了它的行为,单元测试会失败,并在毫秒内给我们反馈。
-
为任何列(例如“Age”或“Income”)重复相同的转换,我们只需要一行(而不是七行)代码。
当我们重构为函数时,我们的整个笔记本可以简化并变得更优雅:
# 糟糕的例子
# good example
df = impute_nans(df, categorical_columns=['Embarked'],
Continuous_columns =['Fare', 'Age'])
df = add_derived_title(df)
df = encode_title(df)
df = add_is_alone_column(df)
df = add_categorical_columns(df)
X, y = split_features_and_labels(df)
# an even better example. Notice how this reads like a story
prepare_data = compose(impute_nans,
add_derived_title,
encode_title,
add_is_alone_column,
add_categorical_columns,
split_features_and_labels)
X, y = prepare_data(df)
我们的心理负担现在大大减少了。我们不再被迫处理大量的实现细节来理解整个流程。相反,抽象(即函数)抽象了复杂性,告诉我们它们的功能,免去了我们在弄清楚它们如何实现时所需的心理努力。
尽快将代码从 Jupyter 笔记本中剥离出来
在室内设计中,有一个概念(“平面表面法则”)指出“家或办公室中的任何平面表面都倾向于积累杂物。” Jupyter 笔记本是机器学习世界的平面表面。

当然,Jupyter 笔记本非常适合快速原型开发。但这也是我们倾向于放入许多东西的地方——粘合代码、打印语句、被夸大的打印语句(df.describe() 或 df.plot())、未使用的导入语句,甚至堆栈跟踪。尽管我们尽了最大努力,但只要笔记本存在,混乱往往会积累。
笔记本很有用,因为它们给我们快速反馈,这通常是我们在面对新数据集和新问题时所需要的。然而,笔记本变得越长,获取我们更改是否有效的反馈就越困难。
相反,如果我们将代码提取到函数和 Python 模块中,并且有单元测试,测试运行器会在几秒钟内对我们的更改进行反馈,即使有数百个函数也是如此。

图 1: 代码越多,笔记本就越难快速反馈我们是否一切正常。
因此,我们的目标是尽早将代码从笔记本中迁移到 Python 模块和包中。这样,它们可以在单元测试和领域边界的安全范围内。这将通过提供逻辑组织代码和测试的结构来帮助管理复杂性,并使我们更容易发展我们的机器学习解决方案。
那么,我们如何将代码从 Jupyter 笔记本中移出呢?
假设你已经在 Jupyter 笔记本中有了代码,你可以遵循这个过程:

图 2: 如何重构 Jupyter 笔记本。
这个过程每一步的详细信息(例如,如何以监视模式运行测试)可以在 clean-code-ml 仓库中找到。
应用测试驱动开发
到目前为止,我们已经讨论了在代码已经写在笔记本之后编写测试。这种推荐并不是理想的,但总比没有单元测试要好得多。
有一个误解认为我们不能将测试驱动开发(TDD)应用于机器学习项目。对我们来说,这显然是不正确的。在任何机器学习项目中,大部分代码涉及数据转换(例如数据清洗、特征工程),而小部分代码才是实际的机器学习。这样的数据转换可以写成纯函数,对于相同的输入返回相同的输出,因此我们可以应用 TDD 并获得其好处。例如,TDD 可以帮助我们将大型复杂的数据转换拆解为可以逐个处理的小问题。
至于测试代码的实际机器学习部分是否按预期工作,我们可以编写功能测试以验证模型的指标(如准确性、精确度等)是否高于我们预期的阈值。换句话说,这些测试验证模型是否按照我们的预期运行(因此得名功能测试)。以下是一个示例:
import unittest
from sklearn.metrics import precision_score, recall_score
from src.train import prepare_data_and_train_model
class TestModelMetrics(unittest.TestCase):
def test_model_precision_score_should_be_above_threshold(self):
model, X_test, Y_test = prepare_data_and_train_model()
Y_pred = model.predict(X_test)
precision = precision_score(Y_test, Y_pred)
self.assertGreaterEqual(precision, 0.7)
进行小而频繁的提交
当我们不进行小而频繁的提交时,我们会增加心理负担。当我们在处理当前问题时,早期的更改仍显示为未提交,这在视觉上和潜意识中都造成了干扰,使我们更难以专注于当前问题。
例如,请看下面的第一张和第二张图片。你能找出我们正在处理哪个函数吗?哪张图片让你更容易理解?


当我们进行小而频繁的提交时,我们会获得以下好处:
-
减少视觉干扰和认知负担。
-
如果代码已经被提交,我们不必担心意外地破坏工作中的代码。
-
除了红-绿-重构方法,我们还可以使用红-红-红-回退方法。如果我们不小心破坏了什么,我们可以轻松回退到最新提交,然后重试。这可以避免我们在解决关键问题时,浪费时间撤销意外创建的问题。
那么,提交的大小要小到什么程度才算足够小呢?当存在一组逻辑相关的更改并且测试通过时,尝试进行提交。一种技巧是留意提交信息中的“and”一词,例如,“添加探索性数据分析并将句子拆分为标记并重构模型训练代码。”这三项更改可以拆分成三次逻辑提交。在这种情况下,你可以使用git add --patch将代码分批暂存以便提交。
结论
“我不是一个伟大的程序员;我只是一个有着良好习惯的好程序员。” - Kent Beck,极限编程和 xUnit 测试框架的先驱
这些习惯帮助我们管理机器学习和数据科学项目中的复杂性。我们希望这些习惯也能帮助你在数据项目中变得更加灵活和高效。
简介: David在 ThoughtWorks 工作了 2 年,在决定转行做软件工程之前,他在政府部门从事非技术性工作。在过去两年中,他参与了多个机器学习的副项目,包括股票市场价格预测、欺诈保护以及啤酒数量图像识别。他还是 ThoughtWorks JumpStart!计划的培训师。David 对敏捷软件开发和知识共享充满热情。在空闲时间,他喜欢和家人一起度过时光,作为一个新晋爸爸。
相关:
我们的前三推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
更多相关内容
用 100 行代码编写随机森林®*
评论
由 STATWORX 提供
动机
现有的机器学习算法种类繁多。要掌握所有算法的细节几乎是不可能的;然而,许多算法源自最成熟的算法,例如普通最小二乘法、梯度提升、支持向量机、基于树的算法和神经网络。在 STATWORX 我们每天讨论算法,以评估它们在特定项目中的好处。无论如何,理解这些核心算法是文献中大多数机器学习算法的关键。
为什么要从头开始编写?
虽然我喜欢阅读机器学习研究论文,但数学有时难以理解。这就是为什么我喜欢自己用 R 实现算法。当然,这意味着深入挖掘数学和算法。然而,你可以直接挑战你对算法的理解。
在我上一篇博客中,我用 150 行 R 代码介绍了两种机器学习算法。你可以在我们的 博客 上找到关于用代码实现 梯度提升机 和 回归树 的其他博客帖子,或者在我的 GitHub 上的 readme 中找到。这篇博客文章介绍了随机森林,这可能是最著名的机器学习算法。你可能注意到了标题中的星号(*)。这些通常暗示着有些问题。就像在电视广告中看到手机计划的价格,而在阅读小字时你发现它仅适用于你成功攀登了珠穆朗玛峰,并且你的游艇上有三只长颈鹿。此外,是的,你的怀疑是合理的;不幸的是,100 行代码仅适用于如果我们不添加回归树算法的代码,而回归树算法对随机森林来说是至关重要的。因此,如果你不熟悉回归树算法,我强烈建议阅读关于 回归树 的博客。
用简单和可访问的代码理解机器学习
在这个系列中,我们尝试生成非常通用的代码,即它不会产生最先进的性能。它的设计旨在非常通用且易于阅读。
毋庸置疑,有大量出色的文章理论上解释了随机森林,并配有实际操作示例。但这不是这篇博客文章的目的。如果你对包含所有必要理论的实际教程感兴趣,我强烈推荐这个 教程。这篇博客文章的目的是通过编写简单的 R 代码来建立算法的理论。除了回归树的基础知识外,你需要知道的唯一事情是我们的目标:我们希望用一组实值特征(X)来估计我们的实值目标(y)。
使用特征重要性减少维度
幸运的是,我们在这个教程中不需要覆盖太多的数学,因为那部分已经在回归树 教程中涵盖了。然而,有一个部分,我在代码中加入了,因为自上一个 博客文章以来发生了变化。回归树,因此随机森林,相对于标准的 OLS 回归,可以忽略不重要的特征。这是基于树的算法的一个重要优势,也是我们基本算法中应该涵盖的内容。你可以在新的 reg_tree_imp.R 脚本中找到这一改进,位于 GitHub。我们使用这个函数来在森林中生长树木。
在我们跳入随机森林代码之前,我想简要介绍一下如何计算回归树中的特征重要性。当然,有许多方法可以计算特征重要性,但以下方法相当直观和直接。
评估分割的好坏
回归树通过选择最小化某个标准的特征来分割数据,例如我们预测的平方误差。当然,有些特征可能永远不会被选择用于分割,这使得计算它们的重要性变得非常简单。然而,如何计算已选择特征的重要性呢?一个初步的方法可能是计算每个特征的分割次数,并以所有分割的总数进行相对化。这个度量简单而直观,但它不能量化分割的影响力,这可以通过一个简单但更复杂的度量来实现。这个度量是加权拟合优度。我们从定义每个节点的拟合优度开始。例如,均方误差,定义为:

该指标描述了我们在用预测器(当前节点的平均值 \bar(y)_{node})估计目标 y_i 时所犯的平均平方误差。现在我们可以通过选择特征来分裂数据来测量改进,并比较父节点的拟合优度与其子节点的表现。本质上,这与我们为当前节点评估最佳分裂特征时所执行的步骤基本相同。
权重分裂的影响
树顶的分裂具有更大的影响,因为在树的这一阶段,更多的数据到达了这些节点。这就是为什么在考虑到到达该节点的观测数量时,更早的分裂显得更为重要。

这个权重描述了当前节点中的观测数量,相对于总观测数量。结合以上结果,我们可以推导出单个节点中特征 p 的加权改进:
通过在回归树中分裂数据来量化改进
![Improvement^{[p]}_{node} = w_{node}MSE_{node} - (w_{left}MSE_{left} + w_{right}MSE_{right})](../Images/2018c97a3834cc3069d6c190f0194edb.png)
这种加权改进在每个被分裂的节点中计算,针对相应的分裂特征 p。为了更好地解释这种改进,我们将树中每个特征的改进总和,并通过树中的整体改进进行归一化。
量化回归树中特征的重要性
![Importance^{[p]} = \frac{\sum_{k=1}^{p} Improvement{[k]}}{\sum_{i=1}{n_{node}} Improvement^{[i]}}](../Images/e7110ee9243f520f45e655f6c4072946.png)
这是回归树算法中使用的最终特征重要性度量。同样,您可以在回归树的代码中按照这些步骤进行。我已经将所有参与特征重要性计算的变量、函数和列名标记为imp_*或IMP_*,这应该会使其更易于跟踪。
随机森林算法
好了,回归树和重要性讲得差不多了——在这篇博客文章中,我们关心的是随机森林。随机森林的目标是结合多个回归树或决策树。这种单一结果的组合被称为集成技术。这个技术的理念非常简单但却非常强大。
构建回归树乐团
在一个交响乐团中,不同组的乐器组合成一个合奏,这创造了更强大且多样的和声。本质上,机器学习中的情况也相同,因为我们在随机森林中生成的每一个回归树都有机会从不同的角度探索数据。我们的回归树乐团因此对数据有不同的视角,这使得组合比单一回归树更强大和多样。
随机森林的简单性
如果你不熟悉这个算法的机制,你可能会觉得代码变得非常复杂且难以跟随。对我来说,这个算法令人惊讶的地方在于它的简单性和有效性。编码部分并不像你想象的那么具有挑战性。就像在其他博客文章中,我们首先查看整个代码,然后逐步分析。
一窥算法
#' reg_rf
#' Fits a random forest with a continuous scaled features and target
#' variable (regression)
#'
#' @param formula an object of class formula
#' @param n_trees an integer specifying the number of trees to sprout
#' @param feature_frac an numeric value defined between [0,1]
#' specifies the percentage of total features to be used in
#' each regression tree
#' @param data a data.frame or matrix
#'
#' @importFrom plyr raply
#' @return
#' @export
#'
#' @examples # Complete runthrough see: www.github.com/andrebleier/cheapml
reg_rf <- function(formula, n_trees, feature_frac, data) {
# source the regression tree function
source("algorithms/reg_tree_imp.R")
# load plyr
require(plyr)
# define function to sprout a single tree
sprout_tree <- function(formula, feature_frac, data) {
# extract features
features <- all.vars(formula)[-1]
# extract target
target <- all.vars(formula)[1]
# bag the data
# - randomly sample the data with replacement (duplicate are possible)
train <-
data[sample(1:nrow(data), size = nrow(data), replace = TRUE)]
# randomly sample features
# - only fit the regression tree with feature_frac * 100 % of the features
features_sample <- sample(features,
size = ceiling(length(features) * feature_frac),
replace = FALSE)
# create new formula
formula_new <-
as.formula(paste0(target, " ~ ", paste0(features_sample,
collapse = " + ")))
# fit the regression tree
tree <- reg_tree_imp(formula = formula_new,
data = train,
minsize = ceiling(nrow(train) * 0.1))
# save the fit and the importance
return(list(tree$fit, tree$importance))
}
# apply the rf_tree function n_trees times with plyr::raply
# - track the progress with a progress bar
trees <- plyr::raply(
n_trees,
sprout_tree(
formula = formula,
feature_frac = feature_frac,
data = data
),
.progress = "text"
)
# extract fit
fits <- do.call("cbind", trees[, 1])
# calculate the final fit as a mean of all regression trees
rf_fit <- apply(fits, MARGIN = 1, mean)
# extract the feature importance
imp_full <- do.call("rbind", trees[, 2])
# build the mean feature importance between all trees
imp <- aggregate(IMPORTANCE ~ FEATURES, FUN = mean, imp_full)
# build the ratio for interpretation purposes
imp$IMPORTANCE <- imp$IMPORTANCE / sum(imp$IMPORTANCE)
# export
return(list(fit = rf_fit,
importance = imp[order(imp$IMPORTANCE, decreasing = TRUE), ]))
}
正如你可能已经注意到的,我们的算法大致可以分为两个部分。首先是一个函数 sprout_tree(),然后是一些调用这个函数并处理其输出的代码行。现在让我们逐块分析所有的代码。
# source the regression tree function
source("algorithms/reg_tree_imp.R")
# load plyr
require(plyr)
# define function to sprout a single tree
sprout_tree <- function(formula, feature_frac, data) {
# extract features
features <- all.vars(formula)[-1]
# extract target
target <- all.vars(formula)[1]
# bag the data
# - randomly sample the data with replacement (duplicate are possible)
train <-
data[sample(1:nrow(data), size = nrow(data), replace = TRUE)]
# randomly sample features
# - only fit the regression tree with feature_frac * 100 % of the features
features_sample <- sample(features,
size = ceiling(length(features) * feature_frac),
replace = FALSE)
# create new formula
formula_new <-
as.formula(paste0(target, " ~ ", paste0(features_sample,
collapse = " + ")))
# fit the regression tree
tree <- reg_tree_imp(formula = formula_new,
data = train,
minsize = ceiling(nrow(train) * 0.1))
# save the fit and the importance
return(list(tree$fit, tree$importance))
}
在森林中生成一个单一回归树
代码的第一部分是 sprout_tree() 函数,它只是回归树函数 reg_tree_imp() 的一个封装,我们将其作为代码的第一个动作来调用。然后我们从公式对象中提取我们的目标和特征。
通过数据的袋装创建不同的角度
之后,我们对数据进行袋装,这意味着我们随机抽取数据,并且有可能重复。还记得我说过每棵树将从不同的角度查看我们的数据吗?好吧,这就是我们创建这些角度的部分。随机抽样与替代仅仅是对我们观察结果生成权重的另一种说法。这意味着在某棵树的数据集中,一个特定的观察值可能会被重复 10 次。然而,下一棵树可能完全丢失这个观察值。此外,还有另一种在我们的树中创建不同角度的方法:特征抽样。
解决森林中树之间的共线性问题
从我们的完整特征集 X 中,我们随机抽取 feature_frac * 100 百分比来减少维度。通过特征抽样,我们可以 a) 更快地计算和 b) 从假设上较弱的特征捕捉数据的角度,因为我们降低了 feature_frac 的值。假设,我们的特征之间存在一定程度的多重共线性。如果我们在每棵树中使用所有特征,回归树可能只会选择某个特定的特征。
然而,特征的改进较少可能会带来对模型有价值的新信息,但却未获得机会。这可以通过将参数feature_frac降低来实现。如果分析的目标是特征选择,例如特征重要性,你可能希望将该参数设置为 80%-100%,因为这样你会得到更明确的选择。好吧,函数的其余部分是拟合回归树,并导出拟合值以及重要性。
培育森林
在接下来的代码块中,我们开始使用plyr::raply()函数n_trees次来应用sprout_tree()函数。该函数重复应用具有相同参数的函数调用,并将结果合并为列表。请记住,我们无需更改sprout_tree()函数中的任何内容,因为每次调用函数时角度都是随机生成的。
# apply the rf_tree function n_trees times with plyr::raply
# - track the progress with a progress bar
trees <- plyr::raply(
n_trees,
sprout_tree(
formula = formula,
feature_frac = feature_frac,
data = data
),
.progress = "text"
)
# extract fit
fits <- do.call("cbind", trees[, 1])
# calculate the final fit as a mean of all regression trees
rf_fit <- apply(fits, MARGIN = 1, mean)
# extract the feature importance
imp_full <- do.call("rbind", trees[, 2])
# build the mean feature importance between all trees
imp <- aggregate(IMPORTANCE ~ FEATURES, FUN = mean, imp_full)
# build the ratio for interpretation purposes
imp$IMPORTANCE <- imp$IMPORTANCE / sum(imp$IMPORTANCE)
# export
return(list(fit = rf_fit,
importance = imp[order(imp$IMPORTANCE, decreasing = TRUE), ]))
之后,我们将单个回归树的拟合结果合并到一个数据框中。通过计算行均值,我们得到了森林中每棵回归树的平均拟合值。我们的最后一步是计算集成模型的特征重要性。这是所有树中某一特征的平均特征重要性,经过所有变量总体均值的归一化。
应用算法
让我们应用这个函数,看看拟合是否确实比单一回归树更好。此外,我们还可以检查特征的重要性。我在GitHub上创建了一个小例子,你可以查看。首先,我们用Xy包模拟数据。在这个模拟中,使用了五个线性变量来创建我们的目标y。为了增加一点难度,我们还添加了五个在模拟中创建的不相关变量。现在的挑战是,算法是否会使用任何不相关特征,或者算法能否完美识别重要特征。我们的公式是:
eq <- y ~ LIN_1 + LIN_2 + LIN_3 + LIN_4 + LIN_5 + NOISE_1 + NOISE_2 + NOISE_3 + NOISE_4 + NOISE_5
森林的力量
随机森林和回归树都没有选择任何不必要的特征。然而,回归树仅由两个最重要的变量进行分裂。相反,随机森林选择了所有五个相关特征。
这并不意味着回归树无法找到正确的答案。这取决于树的最小观测量(minsize)。如果我们降低最小尺寸,回归树肯定会最终找到所有重要特征。然而,随机森林在相同的最小尺寸下找到了所有五个关键特征。
学习优势与劣势
当然,这只是一个例子。我强烈建议你自己动手操作函数和示例,因为只有这样你才能真正感受算法的优劣。随意克隆 GitHub 仓库并尝试示例。模拟总是不错的,因为你会得到明确的答案;然而,将算法应用于熟悉的现实世界数据也可能对你有益。
简介: STATWORX 是一家位于法兰克福、苏黎世和维也纳的数据科学、统计学、机器学习和人工智能咨询公司。
原文。经许可转载。
RANDOM FORESTS 和 RANDOMFORESTS 是 Minitab, LLC 的注册商标。
相关:
-
机器学习和数据科学的决策树指南
-
解释随机森林(带 Python 实现)
-
随机森林直观解释
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
训练机器学习模型时应避免的 6 个错误
原文:
www.kdnuggets.com/2021/04/cogitotech-6-mistakes-avoid-training-machine-learning.html
赞助帖子。
开发 AI 或 ML 模型并非易事。它需要丰富的知识和技能以及丰富的经验,才能使模型在多种场景下成功运行。
此外,你需要高质量的计算机视觉训练数据,特别是用于训练你的视觉感知 AI 模型。AI 开发中最关键的阶段是获取和收集训练数据,并在训练模型时使用这些数据。
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你在 IT 领域的组织
在训练模型时的任何错误不仅会使模型表现不准确,还可能在做出关键业务决策时造成灾难,特别是在医疗或自动驾驶汽车等领域。
在训练 AI 模型时,进行多阶段活动以最佳方式利用训练数据,以便结果令人满意。因此,了解这 6 个常见错误,以确保你的 AI 模型成功。
#1 使用未经验证和非结构化的数据
使用未经验证和非结构化的数据是机器学习工程师在 AI 开发中最常见的错误之一。未经验证的数据可能存在重复、冲突数据、缺乏分类、数据冲突、错误及其他数据问题,这些问题可能在训练过程中造成异常。
因此,在使用数据进行机器学习训练之前,仔细检查你的原始数据集,去除不需要或无关的数据,帮助你的 AI 模型更准确地工作。
#2 使用已使用过的数据测试你的模型
应避免重复使用已经用于测试模型的数据。因此,应避免此类错误。例如,如果某人已经学到了某些知识并将其应用于自己的工作领域;在另一个工作领域使用相同的学习内容可能会导致推理时存在偏见和重复。
同样,在机器学习中,AI 可以通过大量数据集进行学习,以准确预测答案。将相同的训练数据用于模型或基于 AI 的应用程序可能会使模型存在偏见,并产生来自其先前学习的结果。因此,在测试你的 AI 模型的能力时,使用之前未用于机器学习训练的新数据集非常重要。
#3 使用不足的训练数据集
为了使你的 AI 模型成功,你需要使用正确的训练数据,以便它可以以最高的准确度进行预测。缺乏足够的训练数据是模型失败的主要原因之一。
然而,根据 AI 模型或行业的类型,训练数据的需求领域有所不同。对于深度学习,你需要更多的定量和定性数据集,以确保它可以高精度地工作。
#4 确保你的 AI 模型不带偏见
不可能开发出在各种场景下都能提供百分之百准确结果的 AI 模型。就像人类一样,机器也可能由于年龄、性别、取向、收入水平等各种因素而存在偏见,这些因素可能会以某种方式影响结果。因此,你需要通过统计分析来最小化这种偏差,找出每个个人因素如何影响数据和 AI 训练数据的过程。
#5 依赖 AI 模型独立学习
尽管你需要专家来训练你的 AI 模型,并使用大量的训练数据集。但如果 AI 在使用重复的机器学习过程,这一点在训练此类模型时需要考虑。
作为一名机器学习工程师,你需要确保你的 AI 模型以正确的策略进行学习。为确保这一点,你必须定期检查 AI 训练过程及其结果,以获得最佳结果。
然而,在开发机器学习 AI 时,你需要不断问自己一些重要问题,例如:你的数据来源是否可信?你的 AI 是否覆盖了广泛的人群,是否还有其他因素影响结果?
#6 未使用正确标记的数据集
要在通过机器学习开发 AI 模型时取得成功,你需要一个明确的策略。这不仅有助于你获得最佳结果,还能使机器学习模型在最终用户中更加可靠。
上述提到的要点是你在训练模型时需要牢记的关键点。然而,以最高精度准确训练数据对于使 AI 成功并在各种场景中达到最佳准确性至关重要。如果你的数据标签不准确,会影响模型的性能。
如果你的机器学习模型是以计算机视觉为导向的,要获得正确的训练数据,图像注释 是创建此类数据集的精确技术。获取正确的标签数据是 AI 公司在训练模型时面临的另一个挑战。但许多公司提供机器学习和 AI 的数据标注服务。
更多相关话题
分布式和可扩展机器学习 [网络研讨会]
原文:
www.kdnuggets.com/2021/02/coiled-distributed-machine-learning.html
赞助帖子。
Mike McCarty 和 Gil Forsyth 在 Capital One 机器学习中心工作,他们正在构建与 Dask 和 RAPIDS 扩展的内部 PyData 库。此次网络研讨会中,他们将与 Hugo Bowne-Anderson 和 Matthew Rocklin 一起讨论他们在 Python 中扩展数据科学和机器学习的历程。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织的 IT
在 2020 年,Capital One 完成了向云的过渡,抛弃了数据中心,现在他们使用 Dask 在云中扩展数据科学和机器学习。我们将快速了解这一过程,并深入探讨一些关键细节,如如何在 AWS 上部署 Dask 和 RAPIDS,扩展 XGBoost 工作流的细节,以及 Capital One 如何利用 scikit-learn API 通过自定义估计器进行扩展。
我们还会探讨一些文化方面的内容,例如 Capital One 如何构建内部社区,掌握使用这些开源工具的最佳实践,以及企业公司为什么今天需要参与这些社区。
参加后,你将了解:
-
Dask 在 Capital One 的成长及他们面临的一些挑战。
-
如何(以及为何)扩展 XGBoost 训练
-
如何利用 scikit-learn API 构建自己的可扩展估计器
-
机构参与其使用的开源项目的重要性
请于 2 月 23 日(星期二)美国东部时间下午 5:00,通过在这里注册,深入探索 Dask 及可扩展 Python 的精彩世界,了解 Capital One 的应用!
时间:2021 年 2 月 23 日,太平洋时间下午 2 点,东部时间下午 5 点
立即注册
更多相关话题
使用 Prefect 和 Coiled 进行工作流编排
原文:
www.kdnuggets.com/2021/06/coiled-workflow-orchestration-prefect.html
赞助帖子。

时间:2021 年 6 月 30 日,上午 9 点 PDT,下午 12 点 EDT,17:00 BST。
Prefect 创始人兼首席执行官 Jeremiah Lowin 将与 Prefect 的开源社区工程师 Kevin Kho 一起讨论公司更新,并演示一个新发布的功能,称为 KV Store。
Prefect 是一个开源的工作流编排工具,旨在处理现代数据堆栈。Prefect 建立在 Dask 之上,允许工作流的并行执行。Coiled 帮助数据科学家使用 Python 解决复杂问题,扩展到云端以获得计算能力、便利性和速度——所有这些都针对团队和企业的需求进行调整。这意味着 Coiled 和 Prefect 之间有很强的协同效应。在本次演示中,我们还将展示如何启动一个 Coiled 集群,以在运行时执行 Prefect 作业。Coiled 集群将为 Prefect 中动态映射的任务提供并行性。
参加后,您将了解到:
-
如何创建一个简单的 Prefect Flow
-
如何使用新的 Prefect 功能 KV store
-
如何将 Coiled 和 Prefect 一起使用
-
更多关于 Prefect 作为公司的知识
我们期待您的光临!
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT
更多相关主题
ColabCode:从 Google Colab 部署机器学习模型
原文:
www.kdnuggets.com/2021/07/colabcode-deploying-machine-learning-models-google-colab.html
评论
作者 Kaustubh Gupta,Python 开发者

照片由 Niclas Illg 提供,来源于 Unsplash
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
Google colab 是最方便的在线 Python 和数据科学爱好者的 IDE。它于 2017 年对公众发布,最初是 Google 研究团队用来协作进行不同 AI 项目的内部项目。自那时起,它因其易于使用的界面、类似 Jupyter notebooks 的特性以及对 GPU 的支持而获得了极大的关注。
大多数流行的机器学习库,如 numpy、pandas、seaborn、matplotlib、sklearn、TensorFlow,都在这个云环境中预装,因此你不需要任何显式的先决条件。你也可以安装任何你选择的 Python 包来运行你的代码。在这篇文章中,我将向你解释如何使用 FastAPI 和 ngrok 将你的机器学习模型作为 API 部署。
什么是 FastAPI?
这是一个高性能的 Python Web 框架,用于构建 API。传统上,大多数开发者选择 flask 作为构建 API 的首选,但由于一些限制,如数据验证、认证、异步等,FastAPI 获得了很高的普及度。FastAPI 提供了自动文档生成、认证、通过 pydantic 模型进行数据验证等功能。要详细了解这两个框架之间的重大差异,可以查看我在 Analytics Vidya 上的文章:
本文作为数据科学博客马拉松的一部分发表。介绍 在完成模型构建后……
FastAPI 帮助设置生产就绪的服务器,但如果你想在将其部署到实际的云平台(如 Heroku)之前与团队分享,这时 ngrok 就会派上用场,通过隧道化你的本地主机并将其公开到互联网。现在,任何人都可以通过提供的链接访问你的 API 端点,但如果所有这些都可以在 Google Colab 上完成呢?解决方案就是 ColabCode!
什么是 ColabCode?
它是一个 Python 包,可以让你直接从 Colab 笔记本启动代码服务器,而无需在系统上进行任何本地设置。它可以用来启动 VS Code 环境、Jupyter Lab 服务器,或将 FastAPI 服务器隧道到网络中,所有这些都在 Colab 笔记本中完成。这对那些在云中训练模型并希望以 API 形式与世界分享发现的热衷编码者来说是一个极大的优势。我们将讨论 ColabCode 的所有功能,直到本文的最后。
为 ColabCode 准备 FastAPI 代码
我将用于本文的任务声明是一个决策树分类器,用于对两种音乐类型进行分类:Hip-Hop 或 Rock。我已经完成了数据集的清理,它可以在我的 GitHub 仓库 中找到。现在,我已经将数据集导入到笔记本中,并训练了一个决策树模型,没有进行任何预处理或 EDA,因为本文更多的是关于部署。因此,这个模型可能会返回一些错误的结果!
模型创建代码
1. 现在,如果你熟悉 FastAPI 架构,我们将需要一个数据类来处理输入。这个数据类允许 FastAPI 验证发送到模型的输入,如果输入错误,它会简单地抛出错误而不将其传递给模型。
2. 创建数据类非常简单,只需要接受参数和数据类型。为了进一步自定义,你还可以添加一个自定义示例以快速测试结果。这个类的代码是:
数据类代码
3. 现在,我们需要创建一个端点,所有请求都将在此端点提供服务。FastAPI 中的端点创建与 Flask 非常相似,只需端点函数接收数据类进行验证。
FastAPI 代码
如果你希望探索一些有趣的项目,可以查看我的 GitHub 个人资料:
???? 我目前正在探索 Python 及其所有功能。 ???? 我目前正在学习如何工作…
ColabCode
我们的 FastAPI 已经准备好,现在唯一需要做的就是通过 Colab 环境运行它。首先,导入这个包并初始化服务器:
from colabcode import ColabCodeserver = ColabCode(port=10000, code=False)
端口号可以自选,代码参数应设置为 false。现在,服务器已准备好接收 FastAPI 对象,通过 ngrok 的帮助,本地主机被隧道化并通过唯一的 URL 公开到公众。
server.run_app(app=app)
就这样!你将获得一个 ngrok URL,可以与社区、团队或任何人分享。该链接将在你终止单元格进程后立即过期,如果你不终止,Google Colab 会在一段时间后终止它。下面展示了这个过程的示例 GIF:
作者提供的 GIF
在这里,点击链接后,我导航到了 FastAPI 自动生成的 /docs 端点,在这里我们可以测试结果。如果你想运行并尝试这个东西,整个笔记本代码都在这里。只需打开这个笔记本并运行所有单元格。
作者提供的代码
其他功能
ColabCode 不仅限于在 Colab 上运行 FastAPI 代码,它还可以提供 VS Code 服务器和 Jupyter Lab 服务器!它可以帮助用户在基于云的服务中获得熟悉的环境。即使资源非常有限的用户也能从这些服务中受益。这与新推出的 GitHub Codespaces 非常相似,后者在网页上提供 VS Code 环境。要通过 ColabCodes 运行 VS Code 服务器,请执行以下操作:
from colabcode import ColabCode
ColabCode()
你将看到一个 ngrok URL 提示,加载完成后,你将会看到类似于以下的 VS Code 运行在你的网页浏览器中:
作者提供的图片
同样,如果你想打开 Jupyter Lab 服务器,将 lab 参数设置为 true,将 code 参数设置为 false。
from colabcode import ColabCode
ColabCode(code=False, lab=True)
你将获得一个 URL 和一个用于服务器身份验证的令牌。输入令牌并点击登录,将会看到类似于以下的屏幕:
作者提供的图片
结论
在这篇文章中,我解释了 ColabCode 的功能,并简要介绍了 FastAPI。目前,Abhishek Thakur(该包的创建者)发布了 v0.2.0。如果你希望贡献,可以查看这个包的GitHub 仓库。
说到这里,这篇文章就结束了,希望你能有所收获,我会通过其他文章再次出现在你的信息流中!
我其他受欢迎的文章:
探索 ExplainerDashBoard,开发互动仪表板的最简单方法
这是我如何重建我的 Python 项目:数据科学、网络开发与 Android 应用
JavaScript 等效的 Python 脚本
使用 Python 和基础前端的 Docker 化 GitHub Action。
简介: Kaustubh Gupta 是一位对数据科学和机器学习感兴趣的 Python 开发人员,曾参与多个数据相关项目,关注机器学习的实际应用。
原始。经许可转载。
相关:
-
如何通过 API 创建和部署简单的情感分析应用
-
多语言 CLIP 与 Huggingface + PyTorch Lightning
-
何时重新训练机器学习模型?运行这 5 个检查以决定时间表
更多相关话题
数据协作失败的原因(以及 4 种解决方案)
原文:
www.kdnuggets.com/2023/01/collaboration-fails-around-data-4-tips-fixing.html

图片来源于 Freepik 上的 creativeart
数据团队越来越像软件工程团队一样工作,采用工程和开发工具来管理工作。这些工具包括版本控制系统如 Github、敏捷实践如 Kanban 和 Scrum,以及每日站会、冲刺承诺和冲刺演示等仪式。市场上已经出现了针对数据建模、测试和集成的定制解决方案(如 dbt),支持软件工程思维。这些解决方案使大型、分布式的数据团队能够发挥最佳水平。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
但在数据团队与业务其他部门之间的协作方面,仍然有很大的创新空间。
即使是最具前瞻性的数据驱动型组织,仍然依赖标准的协作工具和实践(例如 Slack、电子邮件或定期会议)来管理数据团队与业务利益相关者之间的沟通。毕竟,为什么不呢?数据团队及其工作流程难道不应该与组织中的其他职能类似吗?这种论点和行为在互动相对通用的情况下有效。但在团队动态更加复杂(且数据在每个重要对话和决策中更为核心)的情况下,依赖通用解决方案是不够的。
随着数据在业务运营中的重要性增加,数据团队成员通常需要担任多个角色。在某些情况下,他们需要像产品经理一样,理解业务用户的需求,以便改进数据平台。在其他情况下,他们需要以支持角色处理临时请求。在又一些情况下,他们需要引导新用户,并帮助他们使用可用的数据资产。
在这些情况下,通用协作工具和传统的工作管理方法很快会失效。产品团队和支持团队拥有专门设计的工具来管理他们的工作。数据团队是否也需要一个解决方案来最佳地管理利益相关者请求?或者管理他们的支持文档,或培训最终用户的工具?最优秀的数据团队常常在这个工作环节中挣扎,并最终采用为其他团队(在此情况下为产品和支持团队)构建的解决方案。
由于大多数数据工作和互动都是内部的,团队很难找到与业务利益相关者合作的正确方式,而不产生混乱或遇到尴尬的情况。
减少信息不对称
如果你深入探讨数据团队与其他团队之间的协作问题,你必定会发现构建者和数据资产使用者之间的信息不对称。一方面,你有对底层数据有深刻了解的数据构建者,他们知道如何操作和分析数据,并在更大的数据资产体系中对其进行上下文化。另一方面,你有数据消费者,他们通常是对业务本身具有丰富知识的领域专家,这对于提供更广泛的背景、理解数据以及发展数据平台至关重要。
以简为例。她刚刚加入了一家财富 500 强公司担任销售经理,负责管理一个分布在东南部的 15 人的销售团队。在新工作的第二天,她收到了一封同事转发的电子邮件,里面包含了多个链接到各种资源:一个包含管道信息的电子表格、Salesforce 中的各种报告,以及公司 BI 解决方案中有关个人表现的几个仪表板。在看了一会儿数据后,她意识到自己根本不知道自己在看什么,以及这些数据的含义。她给销售运营经理发了一条求助信息,销售运营经理将数据团队的合作伙伴也拉进来,数据分析师阅读了邮件,叹了口气,然后花了一个小时写了回复。他们在 JIRA 面板上创建了一个“重新评估文档”的票据。
这些数据协作问题的根本原因是构建者和消费者之间的信息不对称,这使得每个人都感到沮丧和不满。
不幸的是,最常受到这些动态影响的是初级员工或中层管理人员,因为他们通常在组织中权力较小,对数据决策的理解背景也最少。没有深入培训,这些员工容易受到信息不对称导致的沟通问题的影响。他们也容易受到“吱吱作响的轮子症候群”的影响,即执行人员和高级领导的声音自然最容易被数据团队听到(因此他们的请求和需求被优先考虑)。
4 个提升协作的主动技巧
为了从对数据工具和团队的大量投资中获得更好的投资回报,我们需要从根本上解决这些信息不对称问题。达到零信息不对称可能是一个理想目标,但数据团队应不断通过实践、合作伙伴关系和工具来缩小这一差距。这样可以消除摩擦,增加透明度和信任,并让每个人从公司的数据产品中获得更多收益。
以下是 4 个主动技巧,适用于希望减少信息不对称并在组织中实现更好协作的数据领导者:
-
将组织和团队结构与业务需求对齐。这不仅包括报告模型,还包括数据团队的角色和职能。我们已经开始看到更多类似“数据产品经理”或“数据敏捷教练”的职位招聘。这些新职能将帮助数据团队管理协作挑战,这些挑战最终通常与人员和流程有关,而不是潜在的技术问题。
-
考虑投资于矩阵模型,在这种模型中,你的团队成员——或者在某些情况下是整个小组——将与特定的业务部门对齐。这将使长期的数据计划与即时的业务需求对齐,促进知识共享,以及分析师与他们日常支持的人员之间建立更紧密、合作的关系。
-
从小处着手,并随着进展积累成功。 初次印象的力量 不可被低估。数据团队的初步印象对其工作的接纳度至关重要,因此要考虑与关键团队成员建立良好的前期关系。通过与组织中 1-2 个关键支持者建立稳固的关系来建立自己的声誉,然后从那里扩展。
-
注意哪些协作工具 可以贯穿于数据计划和数据产品的生命周期。例如,考虑如何为以下每个类别调动人员、流程和系统。通常,某些类别有效的工具在其他类别中会失败。
-
数据团队内的合作
-
与团队之外其他员工的通用合作
-
临时问题或新功能请求
-
对数据产品的持续支持
-
规划新的数据项目或数据产品
-
根据业务的价值演变你的数据产品
-
结论
创新的数据团队已经开始迁移到软件工程最佳实践中,这一趋势可能在未来几年继续。 当你考虑投资数据基础设施以支持未来增长时,考虑支持业务伙伴合作的工具。
尼古拉斯·弗洛伊德 是一位经验丰富的 SaaS 行业高管,拥有十多年领导专注于产品驱动增长的初创公司的经验。作为 Workstream.io 的创始人兼首席执行官,Nick 领导一家种子阶段的技术初创公司,帮助数据团队管理关键数据资产。在创办 Workstream 之前,Nick 曾担任 BetterCloud 的运营副总裁,这是一家提供领先 SaaS 运营管理解决方案的独立软件供应商。此前,Nick 在特斯拉担任高级财务职位,同时在哈佛大学获得 MBA 学位。
更多相关主题
如何收集客户情感分析的数据
原文:
www.kdnuggets.com/2022/12/collect-data-customer-sentiment-analysis.html

编辑提供的图像
客户情感分析是利用机器学习(ML)从客户在评论、论坛、调查等中提供的反馈中发现客户对品牌的意图和看法的过程。对客户体验数据的情感分析为企业提供了对购买决策动机、基于时间线或事件变化的品牌情感模式的深刻洞察,以及有助于产品和服务改进的市场差距分析。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你在 IT 方面的组织
目录:
-
什么是客户情感分析?
-
你如何收集客户情感分析的数据?
-
如何从客户反馈中得出情感评分
-
结论
情感分析细致地检查客户反馈数据,以识别特定的情感或情绪。大致上,这些情感是积极的、消极的或中性的。但在这些参数内,基于机器学习任务如自然语言处理(NLP)和语义分析的情感分析模型可以发现词语的语义和句法方面,从而帮助发现不同类型的消极情感。
例如,它可以根据表示不同负面情绪的词汇,如焦虑、失望、遗憾、愤怒等,提供不同的情感评分。积极的微观情感也同样如此。
这种细致的情感挖掘结合基于方面的品牌体验分析至关重要。例如,当你了解基于价格、便利性、购买容易程度、客户服务等方面的情感时,你可以获得可依赖的行动洞察,以便在质量控制和产品改进方面做出正确决策。
你如何收集客户情感分析的数据?
获取有针对性和深刻品牌情感情报的重要部分是拥有可靠的客户反馈数据。以下是你可以收集这些数据的五种基本方法。
1. 社交媒体评论和视频
社交媒体监听是你获取关于品牌的当前客户反馈的方式之一,包括你的产品以及服务。一个能够处理和评估社交媒体评论以及视频内容的情感分析模型,是利用这一数据来源的最佳选择。
借助这样的工具,你可以从以文本为主的社交媒体网站(如 Twitter)到以视频为主的网站(如 TikTok 或 Instagram)中获取客户情感分析数据。这给你带来了极大的优势,因为并不是所有社交媒体平台在客户选择上都是一刀切的。客户选择。
例如,虽然客户主要使用 Twitter 直接与品牌互动,但 Facebook 用户通常会留下详细的关于他们与企业相关的评论。这种明显的差异是由于业务性质、年龄、地理位置、数字使用等因素造成的。
以下示例展示了客户在两个不同社交媒体渠道上留下评论的情况。
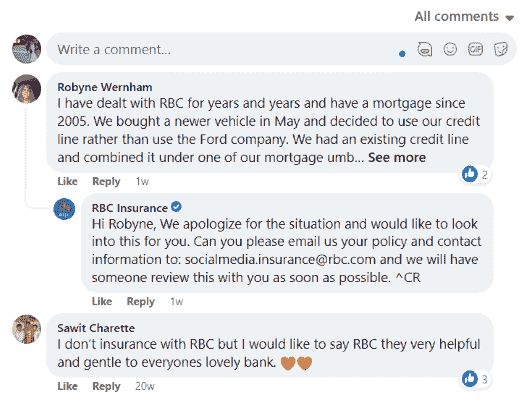
社交媒体情感分析的另一个巨大优势是,你还可以找到符合要求的社交媒体意见领袖,他们可以成为你数字营销策略中的绝佳补充。意见领袖的成本仅为雇用公关公司或名人代言的一半。
此外,人们信任产品评论和他们可以相关的意见领袖的推荐。这无论是你是寻找专业造型建议的实习生,还是寻找青少年手机最佳选择的四个孩子的父亲,这都是事实。这就是数据科学和机器学习如何帮助找到适合业务的 TikTok 意见领袖。
2. 超越定量调查,如 NPS、CES 或 CSAT
客户反馈指标,如净推荐值(NPS)、客户努力值(CES)或星级评分,可以一眼看出人们是否对你的业务满意。但这并不会真正提供任何实际的业务洞察。
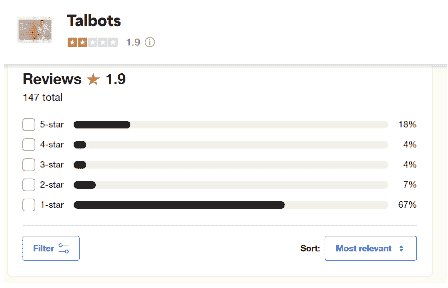
要获取真实的客户情感洞察,你需要超越定量指标。为此,你需要分析评论和开放式调查回应,这些回应没有固定的回答。这允许客户写下自由流动的评论,从而为你提供关于你业务的某些方面的洞察,甚至是你未曾意识到的。
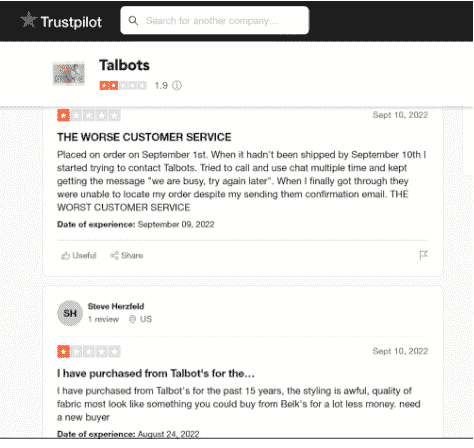
在上述示例中,我们可以看到客户对企业给予了 1 星评价。但在阅读评论后,我们意识到负面情绪背后的原因完全不同。
一位客户对公司的在线客服感到不满,而另一位则提到,尽管他们是长期客户,但由于质量下降和新的定价,他们可能不再购买他们的产品。
这些是可操作的洞察,企业可以准确知道在哪些方面需要改进以维持客户满意度和忠诚度。超越单纯的数字指标可以获得这些洞察。
3. 分析客户论坛和网站上的评论
另一个获取多样化客户反馈数据的优秀方法是筛选产品评论网站如 GoogleMyBusiness 和论坛如 Reddit。重要的是,从不同的数据来源获得的洞察更具价值,因为不同平台吸引的受众类型各异。
例如,Reddit 通常被那些对某个主题或产品更有热情的客户使用,因为这个论坛允许他们进行详细的讨论。而 Amazon 评论或 Google 评论则主要被那些希望在商家催促下或因为经历了好的或坏的体验而留下评论的普通客户使用。
这些 基于机器学习的技术洞察 从 Florida 的 Disney World 评论中提取的客户评论展示了这一点。
4. 非传统来源的客户声音(VoC)数据
非传统来源的客户反馈数据,如 聊天机器人历史记录、客户邮件、客户支持记录等,都是获取客户体验洞察的绝佳来源。这些来源的一个优势是这些数据已经存在于你的客户关系管理(CRM)工具中。
当你能够收集和分析这些数据时,你将能够发现许多潜在问题,即使是精心规划的客户调查或社交媒体监测也可能无法突出这些问题。
5. 分析新闻和播客
包含文章、新闻视频和播客的新闻数据可以为品牌绩效和认知提供详细的见解。新闻来源的市场反馈可以帮助企业进行有效的公关(PR)活动,以管理品牌声誉。
它还可以通过行业趋势来帮助进行竞争对手分析,这些趋势是情感分析模型从新闻文章或视频中的品牌体验数据中提取的,同时帮助他们了解消费者行为。
如何从客户反馈中推导情感分数?
为了说明情感是如何提取和计算分数的,让我们以新闻来源作为客户反馈的重要来源,看看机器学习模型如何分析这些数据。
1. 收集数据
为了获得最准确的结果,我们必须使用所有公开的新闻来源。这包括来自电视台、在线杂志和其他出版物、广播、播客、视频等的新闻。
这可以通过两种方式完成。我们可以直接通过像 Google 新闻 API、ESPN 头条 API、BBC 新闻 API等直播新闻 API 上传数据。或者,我们可以手动将数据上传到我们使用的机器学习模型中,通过下载 .csv 文件中的评论和文章。
2. 使用机器学习任务处理数据
现在模型处理数据,并识别不同的格式 - 文本、视频或音频。在文本的情况下,过程相对简单。模型提取所有文本,包括表情符号和标签。在播客、广播和视频的情况下,则需要通过语音转文本软件进行音频转录。这些数据也会被发送到文本分析流程中。
一旦进入处理流程,自然语言处理(NLP)、命名实体识别(NER)、语义分类等技术会确保从数据中提取和归纳出关键方面、主题和话题,以便进行情感分析。
3. 分析情感
现在文本已经被分离,每个主题、方面和实体都进行情感分析,计算情感分数。这可以通过三种方法中的任何一种完成 - 词数统计方法、句子长度方法和正负面词汇的比例。
让我们以这个句子为例。“体育场的观众评论说座位很好。然而,票价确实显得有些昂贵,因为没有季票可供购买,而且许多人在票务柜台甚至遇到了粗鲁的工作人员,根据《每日先驱报》的报道。”
假设在经过分词、文本规范化(去除非文本数据)、词干提取(寻找词根)和停用词移除(去除冗余词)后,我们获得了负面和正面情感的以下分数。
正面 - 好 - 1(+ 0.07)
负面 - 昂贵(- 0.5),粗鲁(- 0.7) - 2
现在让我们使用前三种方法计算情感分数。
词数统计方法
这是计算情感分数最简单的方法。在此方法中,我们从正面出现的次数中减去负面出现的次数(1 - 2 = -1)。
因此,上述示例的情感分数为 -1。
句子长度方法
积极词汇的数量从消极词汇中减去。结果再除以文本中的总词数。由于得出的分数可能非常小,并且有很多小数位,因此通常将其乘以一个数字。这是为了使得分数更大,从而更容易理解和比较。在我们的例子中,得分将是。
1-2/42 = -0.0238095
**### 负面-正面词汇计数比例
积极词汇的总数除以消极词汇的总数,然后结果加上 1。这比其他方法更为平衡,尤其是在大量数据的情况下。
1/ 2+1 = 0.33333
4. 洞察可视化
一旦数据被分析出情感,洞察将呈现在可视化仪表板上,让你了解从所有数据中获得的智慧。你可以看到基于时间线的情感分析,以及基于事件的分析,如产品发布、股市波动、新闻发布、公司声明、新定价等。
这些基于方面的洞察在你规划营销和增长策略时,可以提供极大的价值。
结论
在营销活动中,AI 和数据科学具有巨大的重要性,尤其是在不断创新和市场动态不断变化的时代。由直接从客户反馈数据中获取的客户情感分析,可以为你提供确保持续增长的可持续营销策略所需的一切杠杆。
马丁·奥斯特罗夫斯基 是 Repustate 的创始人兼首席执行官。他对 AI、机器学习和自然语言处理充满热情。他制定了 Repustate 全球文本分析 API、情感分析、深度搜索和命名实体识别解决方案的战略、路线图和功能定义。
更多相关话题
学习数据科学、数据工程、机器学习、MLOps 和 LLMOps 的免费课程集合

图片来源于作者
数据已成为当今快速发展的数字环境中企业、政府和个人的重要资产。随着数据科学、机器学习和人工智能的兴起,现在是深入这些领域的最佳时机。在本博客中,我们将向你介绍一系列免费课程,这些课程可以帮助你学习和掌握数据科学、数据工程、机器学习、MLOps 和 LLMOps 的各个方面。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 部门
这些课程在 GitHub 上免费提供,并且在社区成员中获得了极大的欢迎。这些学习路径的最佳之处在于它完全是自我驱动和社区基础的,允许你以自己的节奏学习,并与志同道合的对数据充满热情的人建立联系。
数据科学
数据科学本科项目 包含了理论、数学、算法、统计学、数据科学工具、数据库和机器学习等方面的核心课程。该项目旨在涵盖所有必要和可选的课程,帮助学习者掌握数据科学,并为职业生涯做好准备。

数据科学课程是为那些自我激励并希望在生活中取得重大成就的个人设计的。它提供了一个全面的数据科学本科项目,提供了来自世界上最负盛名的大学的课程。
数据工程
如果你想成为一名专业的数据工程师,DataTalksClub 正在提供一个 6 周的训练营,你现在可以报名参加。训练营包含多个模块和课程,将教你各种技能。课程结束时,你将能够使用 GCP、Docker、Postgres、Terraform、Mage、BigQuery、Spark 和 Kafka。

数据工程训练营旨在挑战和提升你的技能,同时通过各种项目为你提供实际经验。
机器学习
查看 10 个 GitHub 仓库来掌握机器学习 获取一系列资源,从初学者友好的教程到高级生产用机器学习工具。

这 10 个仓库包含:
-
微软的 12 周 ML-For-Beginners 课程
-
Clatech、斯坦福大学和麻省理工学院的 ML 课程、教程和讲座链接。
-
机器学习数学
-
深度学习电子书。
-
机器学习训练营。
-
机器学习教程列表。
-
极好的机器学习工具列表。
-
机器学习面试列表。
-
机器学习备忘单。
-
MLOps 工具列表。
MLOps
DataTalks.Club 的 MLOps 训练营 专注于生产化机器学习服务的实际方面。该课程专为数据科学家、机器学习工程师、软件工程师和数据工程师设计,旨在教授如何将机器学习模型部署到生产环境中。

训练营包括多个模块,结合了视频讲座、实际练习、家庭作业和进一步的阅读材料,以加深对概念的理解和应用。课程旨在为学生提供扎实的 MLOps 基础,使他们能够在实际场景中有效管理和部署机器学习模型。
LLMOps
大型语言模型(LLM)课程是一个全面的课程,将教你 LLM 的基本知识,训练和微调你自己的 LLM,并将其部署到生产环境中。每个核心部分涵盖一系列主题,支持通过免费在线 YouTube 教程、指南和资源进行学习。
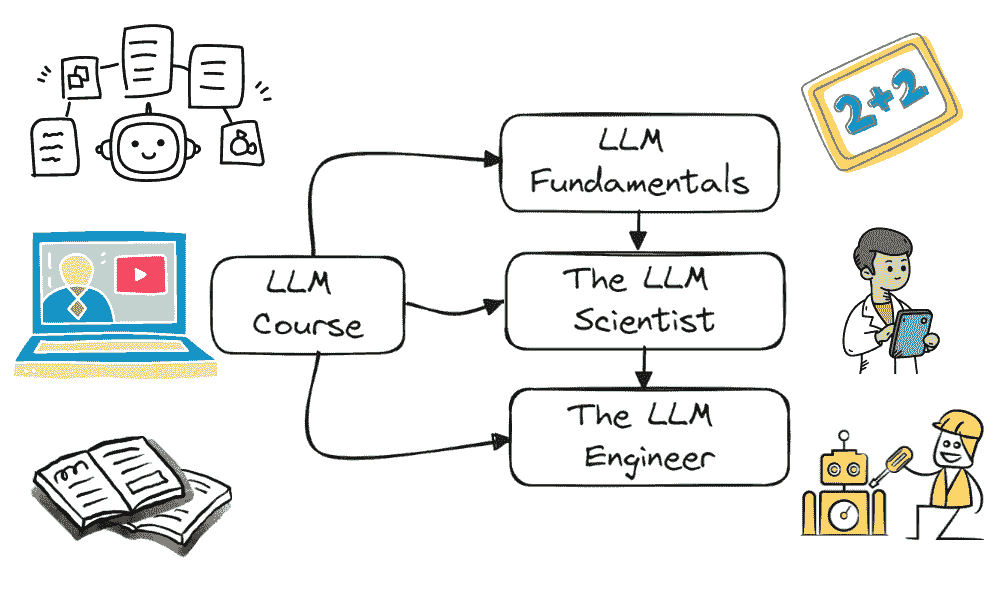
LLM 课程提供了结构化的学习方法。它提供了一系列资源,包括教程、视频、笔记本和文章,所有这些都可以在一个便捷的 GitHub 仓库中找到。
结论
这系列免费的课程为那些希望开始数据科学、数据工程、机器学习、MLOps 和 LLMOps 职业生涯的人提供了丰富的资源。课程涵盖了理论、工具、示例和实际应用,这些自学进度的职业轨迹无论是对初学者还是资深专业人士都有着宝贵的价值。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些面临心理健康问题的学生开发一个 AI 产品。
更多相关主题
掌握 SQL、Python、数据清理、数据处理和探索性数据分析的指南合集

作者提供的图片
数据在推动信息决策和实现人工智能应用中起着至关重要的作用。因此,各行各业对技能娴熟的数据专业人士的需求不断增长。如果你是数据科学的新手,这个全面的指南合集旨在帮助你发展从大量数据中提取见解所需的基本技能。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
掌握 SQL 的 7 个步骤以支持数据科学
链接: 掌握 SQL 的 7 个步骤以支持数据科学

这是一个逐步掌握 SQL 的方法,涵盖了 SQL 命令的基础知识、聚合、分组、排序、连接、子查询和窗口函数。
该指南还强调了使用 SQL 解决现实世界商业问题的意义,通过将需求转化为技术分析。为了进行实践和准备数据科学面试,建议通过像 HackerRank 和 PGExercises 这样的在线平台练习 SQL。
掌握 Python 的 7 个步骤以支持数据科学
链接: 掌握 Python 的 7 个步骤以支持数据科学

本指南提供了一个逐步的路线图,用于学习 Python 编程和发展从事数据科学和分析所需的技能。它从通过在线课程和编码挑战学习 Python 基础开始,然后涵盖了数据分析、机器学习和网页抓取的 Python 库。
职业指南强调通过项目实践编程的重要性,并建立在线作品集以展示你的技能。它还提供了每个步骤的免费和付费资源推荐。
掌握数据清洗和预处理技术的 7 个步骤
链接: 掌握数据清洗和预处理技术的 7 个步骤
这是一个逐步指南,帮助掌握数据清洗和预处理技术,这是任何数据科学项目的重要部分。指南涵盖了各种主题,包括探索性数据分析、处理缺失值、处理重复项和异常值、编码分类特征、将数据分为训练集和测试集、特征缩放以及解决分类问题中的不平衡数据。
你将学习理解问题陈述和数据的重要性,并通过使用 Pandas 和 scikit-learn 等 Python 库的示例代码进行各种预处理任务。
掌握 Pandas 和 Python 数据处理的 7 个步骤
链接: 掌握 Pandas 和 Python 数据清洗的 7 个步骤

这是一个全面的学习路径,用于掌握 Pandas 数据处理。指南涵盖了学习 Python 基础、SQL 和网络抓取等先决条件,然后是从各种来源加载数据、选择和过滤数据框、探索和清理数据集、执行转换和聚合、连接数据框和创建数据透视表的步骤。最后,它建议使用 Streamlit 构建一个互动数据仪表板,以展示数据分析技能并创建项目作品集,这对寻求工作机会的未来数据分析师至关重要。
掌握探索性数据分析的 7 个步骤
链接: 掌握探索性数据分析的 7 个步骤
该指南概述了使用 Python 进行有效探索性数据分析(EDA)的 7 个关键步骤。这些步骤包括数据收集、生成统计摘要、通过清理和转换准备数据、可视化数据以识别模式和异常值、对变量进行单变量、双变量和多变量分析、分析时间序列数据以及处理缺失值和异常值。EDA 是数据分析中的一个关键阶段,使专业人士能够了解数据质量、结构和关系,确保在随后的阶段中进行准确且有洞察力的分析。
结论
要开始你的数据科学之旅,建议从掌握 SQL 开始。这将使你能够高效地处理数据库。一旦你熟悉了 SQL,就可以深入学习 Python 编程,Python 拥有强大的数据分析库。学习诸如数据清洗等基本技术非常重要,因为它将帮助你维护高质量的数据集。
然后,通过使用 pandas 来掌握数据处理的技能,以重塑和准备你的数据。最重要的是,掌握探索性数据分析,以全面了解数据集并揭示洞察。
在遵循这些指导方针之后,下一步是进行项目实践并积累经验。你可以从一个简单的项目开始,然后逐步过渡到更复杂的项目。在 Medium 上撰写相关内容,并学习最新的技术来提升你的技能。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,他喜欢构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络开发一款 AI 产品,帮助那些遭受心理健康困扰的学生。
更多相关主题
我在数据科学中学到的东西
原文:
www.kdnuggets.com/2019/07/collection-things-learned-data-science.html
评论
由 Saeed Hajebi,沃达丰大数据与人工智能主管

-
数据总是很混乱。如果你认为你的数据很干净,也许你还没有深入查看;如果你认为你的数据很混乱,那它可能更混乱。
-
没有人关心你是怎么做的;只要正确地做就可以了。
-
人们不会关心你知道多少,直到他们知道你关心他们及他们的业务有多少。
-
数据 > 大数据。在 2-3 年内,没人会再谈论大数据。
-
交付价值 > 算法、工具和技术。
-
交付价值 > 精美图表。
-
交付价值 > 行话。
-
SQL > 任何语言(Python、R,甚至英语)。
-
精通数字、Excel 和 PowerPoint(是的,还有演示技巧)总是有回报的;Tableau 是一个很大的加分项。
-
下载一些代码和数据并运行它们并不会让你成为数据科学家。同样,参加数据科学课程也是如此。
-
参加 Kaggle 竞赛并不会让你成为数据科学家,但它可以帮助你从他人那里学习。
-
获得 Kaggle 竞赛的胜利并不一定能让你成为一个优秀的数据科学家。
-
现实世界的经验>任何东西。
-
ETL 总是需要的——擅长它并学习一个好的工具(Talend 是一个不错的选择)。此外,还要学习 ETL 的脚本语言。
-
深度学习很酷,但如果在不需要的时候不使用它,它仍然很酷,在 99% 的情况下你不需要它。
-
算法是商品,你的数据不是。
-
创意是商品,执行则不是。
-
深度学习的专长很快会成为商品;问题解决技能则不会。
-
合适的统计知识>学习一个新的工具或库。
-
学习并使用你业务的语言;否则,人们会把你看作一个不懂任何东西的书呆子。
-
在许多情况下,一个简单的业务规则(SQL 中的 if else 或 CASE WHEN)就能完成工作。
-
线性模型和决策树很好,深入学习并经常使用它们。
-
如果你需要良好的表现却没有足够的时间,使用 GBM,但要正确使用它。
-
学习并使用模型可解释性技术——shap 是一个不错的选择。
-
Python 和 R 都很好。停止争论,学习并使用两者。
-
在传达你的模型结果时,不要使用 AUC、Kappa、R² 等;业务用户不理解这些,也不在乎。改用 lift 和 gains。
-
AUC 与准确率不同。不要用 AUC 混淆你的客户。AUC 只是“随机选择的正样本获得比随机选择的负样本更高分数的概率”。例如:如果你的应用场景是流失预测,而你的 AUC 是 0.8,那么随机选择的流失者获得比随机选择的非流失者更高分数的概率是 80%。对客户来说并不太有趣,对吧?客户可能会认为,如果你给他们 1000 个高流失风险的客户,800 个会是真正的流失者;但这与现实相去甚远,尤其是在高度不平衡的问题中。
-
在预测建模的应用场景中,如果人类表现不佳(或者贝叶斯误差率较高),例如,预测用户流失或点击预测等,人为的高准确率或 AUC(>0.9)可能是数据泄漏的迹象。
-
如果模型性能提升对业务没有重大影响,不要花费过多时间;“足够好”就是足够的。将大部分时间用来更好地理解你的领域、业务问题、数据以及如何通过分析增加价值。不论你的模型有多准确,它们很可能不会按照预期的方式使用。例如:你花一个月时间将模型的 AUC 从 0.8 提高到 0.82,但你的市场团队总是需要更多的潜在客户,因此你最终使用了你不满意的结果部分。你发送了 1000 个高潜力客户的名单,他们需要 5000 个。我见过数据科学家花了超过 3 个月的时间将 AUC 提高 0.0001,但他们的模型根本没有被使用。现实世界不是 Kaggle 竞赛。考虑业务需求。
-
当你没有好的表格数据,并且问题对人类而言容易(专家可以在 2 秒内给出正确答案)但对计算机而言困难时,深度学习是合适的;例如,图像分类、自然语言处理、计算机视觉等。如果你有结构化(表格)数据,或者通过特征工程可以从原始数据中创建出有意义的表格数据,并且问题对人类并不容易(例如,人类行为预测如流失预测、下一个点击预测等),并且你需要最佳的预测能力,经过微调的梯度提升树(GBM、XGBoost、CatBoost、LightGBM)可能是最好的选择。在这种情况下,不要在深度学习上浪费时间和金钱。
-
如果机器学习确实是你的应用场景所需的(请参见#21),那么在大多数情况下(也许超过 90%),二分类是最佳选择;即,问题已经是二分类问题或者可以简化为二分类问题。在约 5%的情况下,回归是合适的。因此,在约 95%的情况下,你将处理监督学习。对于剩下的 5%,如果可能的话,尝试将问题重新框定为监督学习问题。尽量避免无监督学习,因为结果并不总是有用——存在随机性、需要做出任意选择等。
-
对于每个使用案例请求,“从结果开始思考”。换句话说,考虑整个“数据到价值”过程,端到端。在跳到模型训练之前,向你的客户提出这些问题:
-
要解决的业务问题是什么?定义、假设、指标等是什么?
-
需要影响/改进的决策是什么?
-
谁是客户?
-
用户是谁?
-
谁是业务赞助者?
-
从分析中增加价值的一般机会是什么(例如,成本节省、收入提升等)?
-
使用案例的年度货币价值是多少?
-
他们今天是如何进行流程或做出决策的?
-
选择标准是什么(例如,这是一个涉及所有客户还是特定客户群的问题)?
-
预期的交付物是什么?深入分析和见解、数据驱动的决策、预测模型、数据产品、仪表板等?
-
成功标准或 KPI 是什么(成功或改进的衡量标准是什么)?
-
数据将来自哪里?
-
我们是否有权使用这些数据?
-
如何确保数据质量?记住,垃圾进,垃圾出。这对目标变量尤为重要。
-
应该开发哪些 ETL 过程?
-
结果将如何使用?例如:更好的定位和减少联系次数、节省费用、额外收入、识别新线索等。
-
结果影响了哪些组织单位?(考虑 RACI 模型:负责、问责、咨询、告知。)
-
假设模型已经准备好,是否存在潜在的部署/利用限制?
-
利用模型/结果需要哪些能力?
-
会影响到哪些流程和系统?
-
一切准备好以利用模型/结果了吗?如果没有,还缺少什么?
-
是否存在模型/结果利用的潜在障碍?如果有,解决这些障碍的计划是什么?
-
谁将确保基础设施支持端到端的客户体验?
-
解决方案的运行频率是多少(实时、每日、每周、每月等)?
-
谁将维护、支持和服务解决方案?
-
-
不要用大量的信息、图表、数字、流行词汇和废话轰炸你的客户。保持简洁明了(KISS)。如果所需的结果是深入分析,尽量将自己限制在 3 个可操作的见解。我强烈建议进一步提升,并提供有见地的行动建议。请注意,这两者之间有很大的区别;前者只是一些见解/想法,而后者则涉及行动/执行(请参见第 17 条——想法是商品,执行不是。)。不过,请始终与运营和业务人员咨询,以了解你的行动建议的有效性和影响。
-
从简单开始,迅速交付解决方案,然后再添加功能并增强你的解决方案。这就是软件工程中所说的最小可行产品(MVP)。交付一个没有任何机器学习但在第一天/周/月中在很大程度上满足客户需求的有效解决方案并无害——这取决于请求和环境的复杂性。如果需要,你可以在之后添加机器学习来使其更智能——请参见#21。
-
预测很简单,但创造业务影响很困难。让我们用一个具体的例子来解释这一点;然而,这个想法是可以普遍适用的。我以客户保留为例。业务问题是我们想要增加客户在公司停留和消费的生命周期。我们可以从这个用例中定义出许多分析问题。为了简单起见,我只关注流失率。我们需要首先预测哪些客户可能会流失,然后定义一些保留活动以使他们留在公司并继续消费。虽然流失预测是一个具有挑战性的分析问题,但它是整个客户保留业务问题中最简单的部分。你建立了一个 AUC 为 0.85 的优秀模型,这非常好。你的模型在前 10%中创造了 60%的提升,因此你可以在前 10%的高风险客户中识别出 60%的真实流失者。你建议你的营销团队用营销活动来针对前 10%。一个月后,你会发现流失率增加了!是的,预测很简单,保留很困难。你可能已经唤醒了“沉睡的狗”。你可能需要使用更先进的技术,如响应建模和提升建模来识别可说服者(更多内容将在未来的帖子中讨论)。此外,你需要与营销团队合作,深入了解业务背景、客户需求等。记住:预测很简单,创造业务影响很困难。
-
数据科学(和/或 AI)可能大部分时间都是无聊的——如果你只喜欢机器学习的部分。人们可能认为我们 AI 专家会坐在一个空旷的房间里,享受美丽的视野,思考人类的未来。然而,现实却大相径庭。我们必须应对不切实际的期望、不明确的需求、脏乱和分散的数据,以及不断改变问题和请求的客户,并期望昨天得到答案。我们都听说过数据科学家 80%的时间都花在数据清理上。这可能仅适用于技术部分。在完整的背景中(详见#32),技术方面的时间不会超过项目时间的 50%。根据我的经验,模型训练和调整不会超过项目时间的 2-3%。所以,如果这是你唯一喜欢的部分,你可能需要考虑换工作。更好的选择是尝试享受工作的每一个方面。
-
什么时候使用机器学习?第 21 点认为“在很多情况下,一个简单的业务规则(在 SQL 中使用 if else 或 CASE WHEN)就可以完成工作”。所以,问题是什么时候使用机器学习,什么时候使用业务规则?答案在于传统编程和机器学习之间的区别。在传统编程中,我们有“数据”和“逻辑”(作为逻辑编码的领域知识)作为系统的输入,而输出是“标记数据”(或一个动作或一个决策)。你的输出质量是输入数据和编码逻辑的质量及复杂性的函数,这通常由领域专家定义。然而,在机器学习中,我们有“数据”和“标记数据”作为输入,而逻辑(由算法识别的数据中的模式)是系统的输出,称为“模型”。因此,如果你有良好的历史数据和标记输出,你可以从机器学习中获益。否则,业务规则将是更好的起点,可以收集“数据”和“标记数据”。在收集到足够的“标记数据”后,你可以使用机器学习来识别更复杂的模式,实现更好的预测性能。
-
为了更好的业务表现,牺牲模型的表现。第 28 和第 29 点已经讨论了数据泄露和模型表现。这里的重点略有不同。在预测建模和机器学习中,当我们进行特征工程和特征选择时,我们必须考虑很多问题。其中最棘手的问题之一是:虽然包含一个特征可能会改善模型表现(即使没有造成数据泄露),但它可能会降低模型的业务影响。例如,假设我们正在建模 XXX 产品的交叉销售用例。拥有像“收到的 XXX 营销活动数量”这样的特征很可能会提高模型表现,但它会优先考虑那些已经收到活动的客户,这并不是业务所希望的。为了更好的业务表现,牺牲模型的表现(AUC,再次强调!)是更明智的选择,而不是反过来。
-
每天学习——成为一个学习机器。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能。
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作。
简历:Saeed Hajebi 是沃达丰大数据与人工智能部门的负责人。
原文。经授权转载。
相关:
-
加速 Python 数据分析的 10 个简单技巧
-
调试神经网络的检查清单
-
Kaggle 上的优秀特征构建技巧和窍门
更多主题内容
关于 Python 中的集合

图片由编辑提供
Python 拥有一个名为 collections 的模块,其中包含不同类型的容器。容器是一个 Python 对象,它包含不同的对象,并实现了一种检索这些对象和对它们进行迭代的方法。
在本教程中,我们将深入探讨由 collections 模块实现的不同类型的容器。
-
Counters
-
OrderedDict
-
DefaultDict
-
ChainMap
-
NamedTuple
-
DeQue
Counters
Counter 是 dict 的子类,用于在无序字典中保持可迭代对象中元素的计数,其中键表示元素,值表示该元素在可迭代对象中的计数
为了初始化一个计数器对象,我们使用 counter() 函数,它可以以以下方式调用
from collections import Counter
1) 使用项的序列
counter = Counter(['D','C','C','E','E','E','A','A','X'])
print(counter)
输出:
Counter({'D': 1, 'C': 2, 'E': 3, 'A': 2, 'X': 1})
2) 使用字典
counter = Counter({'X':3,'Y':2,'Z':1})
print(counter)
输出:
Counter({'X': 3, 'Y': 2, 'Z': 1})
3) 使用关键字参数
counter = Counter(X=3,Y=2,Z=1)
print(counter)
输出:
Counter({'X': 3, 'Y': 2, 'Z': 1})
OrderedDict
OrderedDict 是 dict 的子类,但不同于普通字典,它们记住键插入的顺序
from collections import OrderedDict
orderdict = OrderedDict()
orderdict["x"] = 2
orderdict["y"] = 3
orderdict["z"] = 4
print(orderdict)
输出:
OrderedDict([('x', 2), ('y', 3), ('z', 4)])
1) 当在现有有序字典中插入新项目时,新项目会附加在字典的末尾,从而保持字典的顺序
orderdict["v"] = 5
print(orderdict)
输出:
OrderedDict([('x', 2), ('y', 3), ('z', 4), ('v', 5)])
2) 当从现有有序字典中删除一个项目并重新插入相同的项目时,该特定项目会被插入到字典的末尾
del orderdict["x"]
print(orderdict)
输出:
OrderedDict([('y', 3), ('z', 4), ('v', 5)])
orderdict["x"] = 2
print(orderdict)
输出:
OrderedDict([('y', 3), ('z', 4), ('v', 5), ('x', 2)])
3) 当重新分配或更新 OrderedDict 对象中现有键值对的值时,键的位置保持不变,但键的值会更新
orderdict.update(z = "four")
print(orderdict)
输出:
OrderedDict([('y', 3), ('z', 'four'), ('v', 5), ('x', 2)]
DefaultDict
DefaultDict 是 dict 的子类,为从未存在的键提供默认值,从而避免抛出 keyError
from collections import defaultdict
1) 使用 list 作为 defaultdict
dftdict = defaultdict(list)
for i in range(3):
dftdict[i].append(i)
print(dftdict)
输出:
defaultdict(list, {0: [0], 1: [1], 2: [2]})
2) 使用 int 作为 defaultdict
intdict = defaultdict(int)
X = [1,2,3,4,5,1,1,3,4,5]
for i in X:
#The default value is 0 so there is no need to enter the key first
intdict[i] += 1
print(intdict)
输出:
defaultdict(int, {1: 3, 2: 1, 3: 2, 4: 2, 5: 2})
ChainMap
ChainMap 用于将多个字典合并成一个单元,因此返回字典列表
from collections import ChainMap
x1 = {'a': 0, 'b': 1}
x2 = {'c':2,'d':3}
x3 = {'e':4,'f':5}
chainmap = ChainMap(x1,x2,x3)
print(chainmap)
输出:
ChainMap({'a': 0, 'b': 1}, {'c': 2, 'd': 3}, {'e': 4, 'f': 5})
1) 使用键名访问值
print(chainmap['a'])
输出:
0
2) 访问值
print(chainmap.values())
输出:
ValuesView(ChainMap({'a': 0, 'b': 1}, {'c': 2, 'd': 3}, {'e': 4, 'f': 5}))
3) 访问键
print(chainmap.keys())
输出:
KeysView(ChainMap({'a': 0, 'b': 1}, {'c': 2, 'd': 3}, {'e': 4, 'f': 5}))
4) 插入新字典
通过使用 new_child() 方法,新字典被插入到 ChainMap 的开头
chainmap1 = chainmap.new_child({'g':6,'h':7})
print(chainmap1)
输出:
ChainMap({'g': 6, 'h': 7}, {'a': 0, 'b': 1}, {'c': 2, 'd': 3}, {'e': 4, 'f': 5})
NamedTuple
NamedTuple 是一个具有每个位置名称的元组对象
from collections import namedtuple
1) 声明 namedtuple
band = namedtuple('Country',['name','capital','famousband'])
2) 向 namedtuple 中插入值
val = band("south korea","Seoul","BTS")
print(val)
输出:
Country(name='south korea', capital='Seoul', famousband='BTS')
3) 使用索引访问值
print(val[0])
输出:
'south korea'
4) 使用名称访问值
print(val.name)
输出:
'south korea'
Deque
deque 是一个列表,用于在容器的两侧实现 append 和 pop 操作
from collections import deque
1) 声明 deque
queue = deque([4,5,6])
print(queue)
输出:
deque([4, 5, 6])
2) 使用 append 在 deque 的右侧插入元素,即 deque 的末尾
queue.append(7)
print(queue)
输出:
deque([4, 5, 6, 7])
3) 使用 append 在 deque 的左侧插入元素,即 deque 的开始位置
queue.appendleft(3)
print(queue)
输出:
deque([3, 4, 5, 6, 7])
4) 使用 pop 从 deque 的右侧删除元素,即 deque 的末尾
queue.pop()
print(queue)
输出:
deque([3, 4, 5, 6])
5) 使用 popleft 从 deque 的左侧删除元素,即 deque 的开头
queue.popleft()
print(queue)
输出:
deque([4, 5, 6])
Priya Sengar (Medium, Github) 是一名来自旧金山大学的数据科学家。Priya 热衷于解决数据问题并将其转化为解决方案。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业领域。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关内容
将数据管理与数据讲述结合起来以创造价值
原文:
www.kdnuggets.com/combining-data-management-and-data-storytelling-to-generate-value
最近,我专注于数据讲述及其在有效传达数据分析结果以创造价值方面的重要性。然而,我的技术背景非常接近数据管理及其问题,这促使我思考数据管理需要满足哪些条件,以确保你能够迅速构建以数据为驱动的故事。我得出一个常常被视为理所当然的结论,但始终值得牢记。你不能仅仅依靠数据来构建数据驱动的故事。数据管理系统还必须考虑至少两个方面。你想知道是哪两个方面吗?让我们在本文中尝试找出答案。
我们将在本文中涵盖的内容:
-
数据介绍
-
数据管理系统
-
数据讲述
-
数据管理与数据讲述
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织在 IT 领域
1. 数据介绍
我们不断谈论、使用和生成数据。但你是否想过什么是数据以及数据有哪些类型?让我们试着定义一下。
数据是原始事实、数字或符号,可以处理以生成有意义的信息。数据有不同类型:
-
结构化数据是按照固定模式组织的数据,如 SQL 或 CSV。这种数据的主要优点是易于得出见解。主要缺点是模式依赖限制了扩展性。数据库就是这种数据的一个例子。
-
半结构化数据是部分组织但没有固定模式的数据,如 JSON XML。优点是它们比结构化数据更灵活。主要缺点是元级结构可能包含非结构化数据。示例包括带有标签的推文等注释文本。
-
非结构化数据,如音频、视频和文本,未被注释。其主要优点是它们是非结构化的,因此存储起来较为容易,并且具有很好的扩展性。然而,它们管理起来却具有挑战性。例如,很难提取其含义。纯文本和数字照片就是非结构化数据的例子。
为了组织数据并应对其不断增长的体量,妥善管理数据至关重要。
2. 数据管理
数据管理是摄取、处理、安全存储组织数据的实践,这些数据随后用于战略决策,以改善业务成果 [1]。数据管理系统主要有三种:
-
数据仓库
-
数据湖
-
数据湖仓
2.1 数据仓库
数据仓库只能处理结构化数据,经过提取、转换和加载(ETL)过程后。一旦加工,数据可以用于报告、仪表板或挖掘。下图总结了数据仓库的结构。
图 1:数据仓库的架构
数据仓库的主要问题是:
-
可扩展性 - 它们不可扩展
-
非结构化数据 - 他们不管理非结构化数据
-
实时数据 - 它们不管理实时数据。
2.2 数据湖
数据湖可以摄取原始数据。与数据仓库不同,数据湖管理并提供处理结构化、半结构化和非结构化数据的方法。摄取原始数据允许数据湖在原始存储系统中摄取历史数据和实时数据。
数据湖增加了元数据和治理层,如下图所示,使数据可以被上层(报告、仪表板和数据挖掘)消费。下图显示了数据湖的架构。
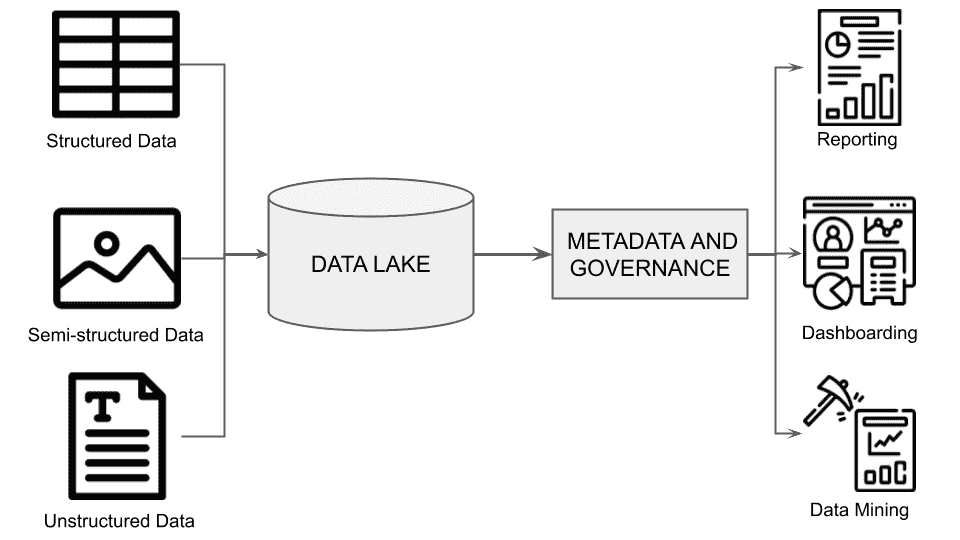
图 2:数据湖的架构
数据湖的主要优势在于可以快速摄取任何类型的数据,因为它不需要任何初步处理。数据湖的主要缺点是,由于它摄取原始数据,因此不支持数据仓库的语义和事务系统。
2.3 数据湖仓
随着时间的推移,数据湖的概念演变为数据湖仓,即一个增强的数据湖,支持其顶部的事务。在实际应用中,数据湖仓根据数据仓库的语义修改数据湖中的现有数据,如下图所示。
图 3:数据湖仓的架构
数据湖仓从操作源中摄取数据,如结构化、半结构化和非结构化数据。它将数据提供给分析应用程序,如报告、仪表板、工作区和应用程序。数据湖仓包括以下主要组件:
-
数据湖,包括表格式、文件格式和文件存储
-
数据科学和机器学习层
-
查询引擎
-
元数据管理层
-
数据治理层。
2.4 数据管理系统架构的概述
下图概述了数据管理系统的架构。
图 4. 数据管理系统的一般架构
一个数据管理系统(数据仓库、数据湖、数据湖屋,或其他)接收数据作为输入,并生成输出(报告、仪表盘、工作空间、应用程序等)。输入由人生成,输出再次被人利用。因此,我们可以说,我们有输入中的人和输出中的人。数据管理系统是从人到人的。
输入中的人包括生成数据的人员,如佩戴传感器的人、回答调查的人、撰写评论的人、有关人员的统计数据等。输出中的人可以属于以下三类之一:
-
普通公众,其目标是学习某些东西或获得娱乐
-
专业人士,他们是希望理解数据的技术人员
-
决策者,即做出决策的人员。
在这篇文章中,我们将重点关注高管,因为他们生成价值。
那么价值是什么呢?《剑桥词典》对价值有不同的定义[2]。
-
能够获得的金钱数量
-
对某人而言事物的重要性或价值
-
价值:人们拥有的信念,特别是关于什么是对的和错的,什么是生活中最重要的,这些信念控制着他们的行为。
如果我们接受价值作为金钱数量的定义,决策者可以为他们工作的公司生成价值,并间接为公司内的人员以及使用公司服务或产品的人员生成价值。如果我们接受价值作为事物重要性的定义,那么价值对生成数据的人员以及其他外部人员至关重要,如下图所示。
图 5:生成价值的过程
在这种情况下,正确有效地将数据传达给决策者变得至关重要,以生成价值。因此,整个数据管道应该设计成将数据传达给最终观众(决策者),以便生成价值。
3. 数据讲故事
有三种传达数据的方式:
-
数据报告包括数据描述,涵盖数据探索和分析阶段的所有细节。
-
数据展示仅选择相关数据,并以有组织和结构化的方式呈现给最终观众。
-
数据讲故事在数据上构建一个故事。
让我们专注于数据讲故事。数据讲故事是通过故事向观众传达数据分析过程的结果。根据你的观众,你将选择一个合适的
-
语言和语气:传达的词汇(语言)和通过这些词汇表达的情感(语气)
-
背景:根据观众的文化敏感性,为故事添加的细节水平
数据讲故事必须考虑数据及其相关信息(背景)。数据背景指的是围绕数据集的背景信息和相关细节。在数据管道中,这些数据背景作为元数据存储[3]。元数据应提供以下问题的答案:
-
谁收集了数据
-
数据内容
-
数据何时被收集
-
数据从何处收集
-
数据为何被收集
-
数据如何被收集
3.1 元数据的重要性
让我们从数据讲故事的角度重新审视数据管理管道,它包括数据和元数据(背景)
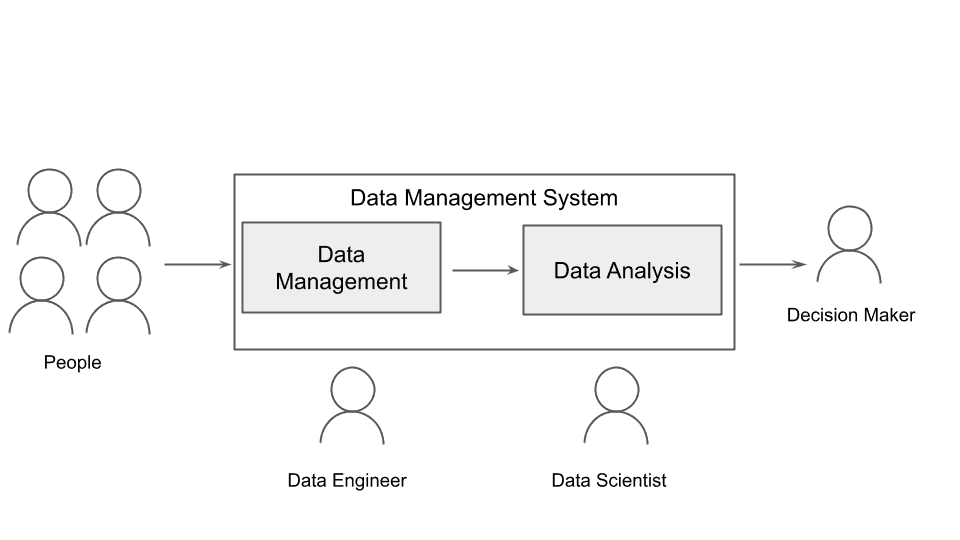
图 6:从数据讲故事的角度看数据管理管道
数据管理系统包括两个要素:数据管理,主要角色是数据工程师;数据分析,主要角色是数据科学家。
数据工程师应关注不仅仅是数据,还要关注元数据,这有助于数据科学家围绕数据构建背景。元数据管理系统有两种类型:
-
被动元数据管理,它将元数据聚合并存储在静态数据目录中(例如,Apache Hive)
-
主动元数据管理,它提供动态和实时的元数据(例如,Apache Atlas)
数据科学家应构建数据驱动的故事。
4. 数据管理和数据讲故事
结合数据管理和数据讲故事意味着:
-
考虑最终从数据中获益的人。数据管理系统从人到人。
-
考虑元数据,它帮助构建最强大的故事。
如果我们从期望结果的角度看待整个数据管道,我们会发现每一步背后人员的重要性。只有当我们关注数据背后的人员时,我们才能从数据中创造价值。
总结
恭喜!你刚刚学会了如何从数据讲故事的角度看待数据管理。除了数据之外,你应该考虑两个方面:
-
数据背后的人员
-
元数据,它为你的数据提供背景。
而且,最重要的是,永远不要忘记人员!数据讲故事帮助你了解数据背后的故事!
参考文献
[1] IBM. 什么是数据管理?
[2] 剑桥词典. 价值.
[3] Peter Crocker. 提升数据背景的指南:谁,什么,何时,哪里,为什么,以及如何
外部资源
Angelica Lo Duca**** (Medium) (@alod83) 是意大利比萨国家研究委员会(IIT-CNR)信息学与电信研究所的研究员。她是比萨大学数字人文学科硕士课程“数据新闻学”的教授。她的研究兴趣包括数据科学、数据分析、文本分析、开放数据、网络应用、数据工程和数据新闻学,应用于社会、旅游和文化遗产领域。她是《Comet for Data Science》一书的作者,该书由 Packt Ltd. 出版;即将出版的《Data Storytelling in Python Altair and Generative AI》一书的作者,该书由 Manning 出版;以及即将出版的《Learning and Operating Presto》一书的合著者,该书由 O'Reilly Media 出版。Angelica 还是一位热衷的技术作家。
了解更多相关话题
结合不同方法创建高级时间序列预测
原文:
www.kdnuggets.com/2016/11/combining-different-methods-create-advanced-time-series-prediction.html
评论
Taras Firman, 数据科学家于 ELEKS
现在,企业需要能够预测需求和趋势,以便应对突发的市场变化和经济波动。这正是由数据科学驱动的预测工具发挥作用的地方,使组织能够成功处理战略和产能规划。智能预测技术可以用来降低潜在风险,并协助做出明智的决策。我们的一个客户,一家来自中东的企业,需要预测接下来十二周的市场需求。他们需要一个市场预测,以帮助他们设定短期目标,例如生产策略,并协助进行产能规划和价格控制。因此,我们想出了一个创建定制时间序列模型的想法,能够应对这一挑战。在本文中,我们将探讨建模过程以及我们在过程中必须克服的陷阱。
有许多构建时间序列预测的方法……没有一种适合我们
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 工作
随着基于机器学习的强大预测方法的出现,未来预测变得更加准确。一般来说,预测技术可以分为两类:定性预测和定量预测。定性预测在没有数据可用时应用,仅基于专家判断。定量预测则基于时间序列建模。这种模型使用历史数据,尤其在预测发生在一段时间内的某些事件时特别有效,例如价格、销售数字、生产量等。
现有的时间序列预测模型包括主要用于建模时间序列数据但不直接处理季节性的ARIMA 模型;VAR 模型,Holt-Winters季节性方法,TAR 模型及其他。不幸的是,这些算法可能无法提供所需的预测准确度,因为它们可能涉及不完整、不一致或含有错误的原始数据。由于质量决策仅基于高质量的数据,因此进行预处理以准备进一步处理的输入信息是至关重要的。
为什么结合模型是一个解决方案
显然,单一的预测技术无法在所有情况下都有效。每种方法都有其特定的应用场景,可以根据许多因素(历史数据的可用周期、需要观察的时间段、预算规模、期望的准确度水平)和所需的输出进行应用。因此,我们面临着一个问题:使用哪种方法/方法组合来获得期望的结果?由于不同的方法各有独特的优缺点,我们决定将多种方法结合起来,使它们协同工作。这样,我们就能够建立一个能够提供可靠预测的时间序列模型,以确保数据可靠性和节省时间/成本。这就是我们如何做到的。
建模过程;让我们深入了解细节
需求数据依赖于各种因素,这些因素可能会影响预测结果,例如价格和商品类型、地理位置、国家经济状况、制造技术等。为了使我们的时间序列模型能为客户提供高准确度的预测,我们使用了插值方法来处理缺失值,以确保输入数据的可靠性。
在使用 Python 2.7 进行时间序列分析时,我们分析了从 2010 年到 2015 年的过去数据,以准确计算需求并预测未来的行为。
图 1. 2010-2015 时间段的需求数据
初看起来,似乎没有恒定的需求值,因为方差上下波动,使得预测几乎不可能。然而,有一种方法可以帮助解决这个问题。
我们使用了分解方法来分别提取趋势(时间段内的系列增长或减少)、季节性(系列在每周、每月等周期内的波动)和残差(落在预期数据范围之外的数据点)。通过这三个组成部分,我们建立了加性模型:
其中 yt 是数据,Tt 是趋势周期分量,St 是季节分量,Rt 是残差分量,所有这些都在时间段 t 上定义。
描述系列各种组件的一个重要的第一步是平滑,尽管它并没有真正提供一个现成的模型。一开始,我们估计了趋势(行为)组件。像移动平均、指数平滑、Chow 的自适应控制、Winter 的线性和季节性指数平滑方法都没有提供我们期望的趋势估计准确性。最可靠的结果是使用霍德里克-普雷斯科特滤波器技术获得的。
图 2. 估计的趋势
然后,我们从现有数据中定义了季节性。这个组件可能随时间变化,因此我们应用了一种强大的时间序列分解工具——Loess 方法。这种方法可以处理任何类型的季节性,变化率可以由用户控制。
图 3. 多季节性
我们获得了一个多季节性组件,其高低方差造成了大幅波动。
在应用了弹性网回归和傅里叶变换之后,我们基于获得的结果建立了趋势预测。趋势的近似可以从以下公式中找到,
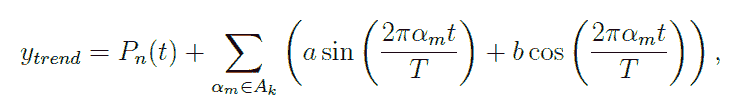
其中 Pn(t) 是一个多项式,Ak 是一组索引,包括前 k 个幅度最大的索引。
然后,我们使用离散傅里叶变换(DFT)计算了傅里叶系数。
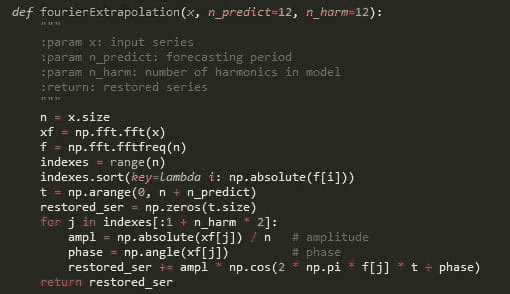
图 4. DFT 在 Python 中的代码示例
模型中用作外部回归量的傅里叶项的效果如下所示。
图 5. 傅里叶项的可视化效果
我们使用加法模型建立了趋势预测。
图 6. 趋势预测
当模型中去除趋势和季节分量后,我们可以从剩余部分获得残差(观察值与基于其他观察值的预测值之间的差异),以验证和拟合我们的数学模型。
图 7. 获得的残差
你可能会注意到存在一些负值,这表明在那段时间里发生了异常情况。我们旨在找出导致这种行为的情况,因此我们提出了一个主意,利用一个简单的日历来汇总异常值,并发现负值与如斋月、开斋节等公共假期紧密相关。在收集和总结所有数据后,我们应用了基于先前数据点的输入特征的机器学习方法和时间序列预测的机器学习策略。
经过几次使用机器学习模型进行的训练,我们建立了一个关于残差的预测,如下所示。
图 8. 残差预测
结果,我们得到了一个最终的预测模型,使得一个特定城市的平均绝对百分比误差(MAPE)降低到 6%,整个国家的一般误差为 10%。
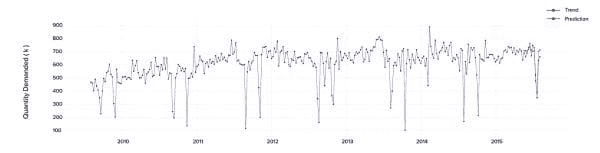
图 9. 原始比例下的预测
24 倍更快的预测?是的,这完全可能。
在构建我们的模型时,我们不仅尝试使用可用的信息,还试图发现可能影响结果的因素。这种方法帮助我们开发了一个比现有模型生成更准确预测结果的模型。例如,训练开发出的模型以对 300 个不同城市进行预测,我们只需约 15 分钟,而其他方法则需要约 6 小时。
此外,实际需求与预测需求之间的偏差仅为 6%,这使得解决供需不匹配的可能性增加。现在,客户可以更快、更轻松地规划产能,最小化未来风险,并优化库存。
接下来是什么?
好吧,结果相当有希望。而且我们可以在这个模型的改进上走得更远,以便它也能提供准确的长期预测。目前,长期预测的误差程度仍然较高。这听起来像是个挑战?那就敬请期待吧!一些新的实验正在进行中!
简介: Taras Firman 是 ELEKS 的数据科学家,从事统计分析、优化、预测等严肃工作。Taras 受过数学教育并以此为职业,通过研究生课程不断发展自己的专业技能,同时教授运筹学和数据分析。此外,他从不忽视任何有趣的数据科学或机器学习新闻,并且有很多要贡献的内容,也决定开始写博客。当他完成数学和数据科学工作后,Taras 还喜欢足球和音乐。
相关:
-
从时间序列数据中获得更好的洞察力:周期图
-
周期性大数据流中的简单异常检测方法
-
伟大的算法教程汇总
更多相关内容
简化 Pandas DataFrame 的合并
原文:
www.kdnuggets.com/2022/09/combining-pandas-dataframes-made-simple.html
介绍
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT
在许多现实场景中,我们的数据为了管理和简便被放置在不同的文件中。我们常常需要将它们合并为一个更大的 DataFrame 进行分析。Pandas 包通过提供各种合并 DataFrame 的方法,如 concat 和 merge,来帮助我们。此外,它还提供了用于比较的工具。
我们将通过示例来理解这两种方法的工作原理。对于本教程,我们假设你对 Python 和 Pandas 有基本了解。
连接 DataFrame
如果两个 DataFrame 的格式相同,我们选择 .concat() 方法。它将一个 DataFrame 的列或行附加到另一个 DataFrame 上。.concat() 负责在指定轴上执行连接操作。在我们深入了解其细节之前,先快速看一下函数语法及其参数。
pd.concat(objs, axis=0, join="outer",ignore_index=False, keys=None,
levels=None, names=None, verify_integrity=False, copy=True, )
虽然有很多内容,但我们将重点关注主要参数:
-
objs: 要连接的 DataFrame 对象或 Series 列表
-
axis: axis = 0 告诉 pandas 将第二个 DataFrame 堆叠在第一个 DataFrame 下方(按行连接),而 axis = 1 告诉 pandas 将第二个 DataFrame 堆叠在第一个 DataFrame 右侧(按列连接)。默认情况下,axis = 0。
-
join: 默认情况下,join=outer,outer 用于并集,inner 用于交集
-
ignore_index: 在连接过程中将忽略索引轴,默认情况下保持为 False,因为它们在连接中受到尊重。然而,如果索引轴没有有意义的信息,那么忽略它们是有用的。
-
verify_integrity: 它检查新连接轴中的重复项,但默认情况下保持为 False,因为相对于实际的连接操作,它可能非常昂贵。
示例
import pandas as pd
# First Dict with two 2 and 4 columns
data_one = {'A' : ['A1','A2','A3','A4'] , 'B' : ['B1','B2','B3','B4']}
# Second Dict with two 2 and 4 columns
data_two = {'C' : ['C1','C2','C3','C4'] , 'D' : ['D1','D2','D3', 'D4']}
# Converting to DataFrames
df_one=pd.DataFrame(data_one)
df_two=pd.DataFrame(data_two)

场景 1:按列连接
假设列 A、B、C 和 D 代表不同的功能,但索引号指的是相同的 ID,那么将 C 和 D 行合并到 df_one 的右侧更有意义。让我们来做一下,
# Joining the columns
new_df = pd.concat([df_one,df_two],axis=1)
场景 2:按行拼接
如果我们继续上述假设并按行拼接它们,那么结果 DataFrame 将会有很多 NaN 值缺失数据。原因很简单,假设在 df_two 中的索引 = 0,我们不能直接将其放置在列 A 和 B 下,因为我们认为它们是两个不同的函数,而值不存在。因此,pandas 会自动创建一个包含 A、B、C 和 D 的完整行,并在各自的列中填充缺失值。
# Joining the rows
new_df1 = pd.concat([df_one,df_two],axis=0)
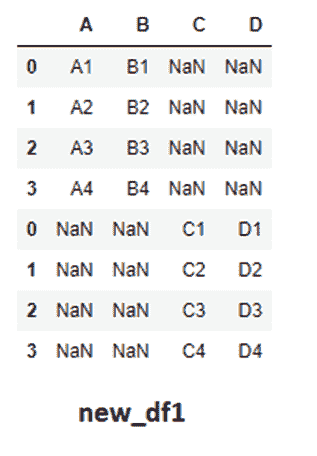
请注意,我们的最终结果中有重复的索引。这是因为默认情况下 ignore_index 设置为 False,它保留了 DataFrames 的原始索引。这在我们的情况下可能不实用,所以我们将设置 ignore_index = True。
# Joining the rows
new_df2 = pd.concat([df_one,df_two],axis=0 , ignore_index= True)
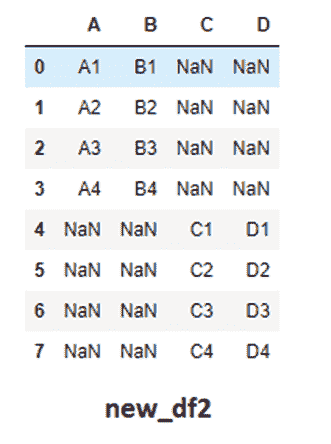
如果两个 DataFrame 中的列表示相同的内容,只是名称不同,那么我们可以在拼接之前重命名这些列。
# Joining the rows
df_two.columns = df_one.columns
new_df3 = pd.concat([df_one,df_two],axis=0 , ignore_index= True)

合并 DataFrames
合并或连接 DataFrames 与拼接不同。拼接仅仅是将一个 DataFrame 堆叠在另一个 DataFrame 上,沿着所需的轴。而连接就像 SQL 中的连接一样。我们可以基于一个唯一的列合并 DataFrames。这些方法具有高性能,并表现得显著更好。当一个 DataFrame 是包含额外数据的“查找表”,我们想要将其连接到另一个 DataFrame 时,这非常有用。让我们看看它的语法和参数:
pd.merge( left, right, how="inner", on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True, suffixes=("_x", "_y"),
copy=True, indicator=False, validate=None)
让我们看看它的主要参数及其用途:
-
left: DataFrame 对象
-
right: DataFrame 对象
-
how: 连接类型,即 inner、outer、left、right 等。默认情况下 how = “inner”
-
on: 在两个 DataFrame 中都存在的列,并且构成连接操作的基础。
-
left_on: 如果您使用 right_index 作为连接的列,则必须指定将用作键的列。
-
right_on: 左侧的反向操作
-
left_index: 如果设置为 True,则使用左侧 DataFrame 的行标签(索引)作为连接键。
-
right_index: 左侧索引的反向操作
-
sort: 按连接键的字典顺序对结果 DataFrame 进行排序,但不推荐这样做,因为这会显著影响性能。
-
suffixes: 如果我们有重叠的列,可以为它们指定后缀以区分它们。默认情况下,它设置为 ('_x', '_y')。
示例
以体育和图书馆数据框为例,假设两个 DataFrame 中的 “name” 列是唯一的,并可以用作主键。
import pandas as pd
# First DataFrame
sports= pd.DataFrame({'sports_id':[1,2,3,4],'name':['Alex','David','James','Sara']})
# Second DataFrame
library= pd.DataFrame({'library_id':[1,2,3,4],'name':['David','James','Peter','Harry']})
情景 1: 内连接和外连接
对于这两者,你在 .merge() 方法中放置数据框的顺序并不重要,因为最终结果仍然是相同的。如果我们将两个 DataFrame 视为两个集合,则内连接指的是它们的交集,而外连接指的是它们的并集。
inner_join = pd.merge(sports,library,how="inner",on="name")
outer_join= pd.merge(library,sports,how="outer",on="name")

情景 2: 左连接和右连接
在这里,我们放置 DataFrames 的顺序是重要的。例如,在左连接中,位于左侧位置的 DataFrame 对象的所有条目将显示出来,并且其匹配的条目来自右侧 DataFrame 对象。右连接则完全相反。让我们通过一个示例来理解这个概念,
left_join = pd.merge(sports,library,how="left",on="name")
right_join= pd.merge(library,sports,how="right",on="name")
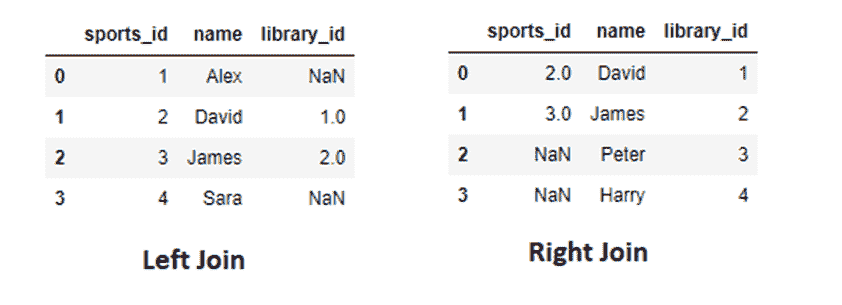
情景 3: 使用索引进行连接
首先,让我们通过使用 set_index() 方法将“name”列修改为索引。
sports = sports.set_index("name")
现在我们将应用内连接操作,并将 left_index= True 设置为如果我们将体育作为左侧数据框。
index_join = pd.merge(sports,library,how="inner",left_index = True , right_on="name")
注意,它显示了与我们之前对内连接所做的结果相同。
情景 4: 后缀属性
让我们对原始数据框做一个小修改,将 sports_id 和 login_id 改为 id。现在虽然名称相同,但我们指的是不同的 id。Pandas 足够聪明,能够识别它,并自动添加后缀。稍后我们将看到如何自定义这些后缀。
# First DataFrame
sports= pd.DataFrame({'id':[1,2,3,4],'name':['Alex','David','James','Sara']})
# Second DataFrame
library= pd.DataFrame({'id':[1,2,3,4],'name':['David','James','Peter','Harry']})
inner_join = pd.merge(sports,library,how="inner",on="name")

这里,id_x 指代左侧数据框,而 id_y 指代右侧数据框。虽然它完成了工作,但为了提高可读性和代码的简洁性,我们通过使用 suffixes 属性来自定义这些后缀。
suffix_ = pd.merge(sports,library,how="inner",on="name", suffixes=('_sport','_lib'))
结论
本文旨在简化在 Pandas 中合并行的概念。当你从大型 .csv 文件中提取数据时,建议在执行合并操作之前先分析数据的类型和格式。Pandas 在这方面也有一些优秀的方法。如果遇到问题,你应该参考 Pandas 的官方文档。最后但同样重要的是,一切都需要通过实践来掌握,因此在自己的时间里尝试不同的 DataFrames,以便更好地理解。
Kanwal Mehreen 是一位有抱负的软件开发人员,她相信持续的努力和承诺。她是一位雄心勃勃的程序员,对数据科学和机器学习领域充满浓厚兴趣。
更多相关主题
Comet.ml —— 机器学习实验管理
原文:
www.kdnuggets.com/2018/04/comet-ml-machine-learning-experiment-management.html
赞助帖子。
由 Gideon Mendels,数据科学家兼 CEO,Comet.ml
在过去十年里,机器学习已经从学术界显著转向了工业界。大量数据集、计算资源和重大投资的结合使研究人员能够在大多数机器学习基准测试中推动最先进的结果。
然而,我们缺乏管理机器学习团队和流程的基本工具。
在过去的一年里,我们与来自各种公司和研究机构的 200 多位数据科学家进行了简短的访谈。我们询问了他们的流程和团队动态。虽然我们正在努力发布一篇全面的分析帖子,但有一个特别的数据点引起了我们的注意:
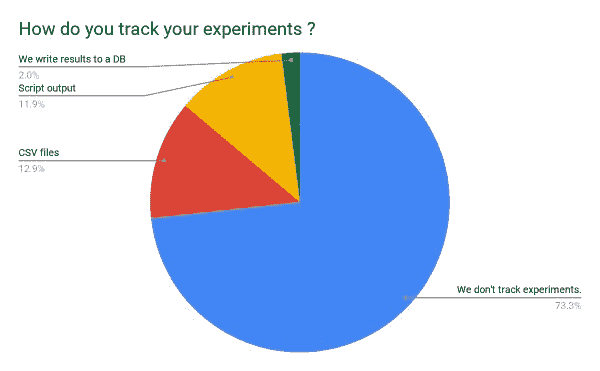
大多数数据科学家不会跟踪他们的前期工作。机构和个人数据科学家都面临着失去实验结果的风险。
如果公司没有跟踪其结果,它如何保留其机构知识?
根本问题不是最佳实践或缺乏纪律,而是当前工具的状态。GIT 和其他代码版本控制系统是为软件设计的,而非机器学习。它们不旨在跟踪数据集、结果和其他工件。
当涉及到分享实验、维护知识以及发布可重复工作的时,无论是在公共领域还是公司内部,我们还未能找到最佳实践。
这篇文章介绍了 comet.ml —— 一个强调协作和知识共享的机器学习实验跟踪平台。它允许你保持当前工作流程,并从任何机器上报告你的结果 —— 无论是你的笔记本电脑还是 GPU 集群。
你的宝贵训练数据也将安全保存,永远不会离开你的机器。
它是如何工作的?
要使用 Comet.ml,只需在你的 Python 脚本中添加几行代码(R 支持即将推出!)。
例如,考虑下面这段简短的 Keras 代码:

每次执行此脚本时,以下内容将自动(但以可配置的方式)报告到你的私人仪表板:
-
超参数:命令行参数和模型定义中的所有内容将自动报告。可以轻松添加额外的超参数。
-
指标:来自 ML 库代码的实时图表,展示了你模型的收敛情况。额外的指标可以轻松自定义。
-
代码(可选): 你的源代码的快照(单个脚本或 Github 仓库差异),将结果和代码关联在一起。
-
标准输出/错误: 无需通过 SSH 远程访问机器即可显示的异常或输出。
-
模型结构: 你模型的序列化版本。
-
依赖项: 所有 Python 依赖项及其版本。
-
数据集哈希: 与数据集关联的哈希值,本地计算以避免基础数据更改的情况。
协作
Comet.ml 上的项目可以与你的整个团队、单个同事或全世界公开分享。通过提供上面收集的信息的可见性,我们希望使可重复性更容易。合作者还可以对你的工作发表评论和提问。
实验文档
你可以为每个实验或单个项目添加丰富的文档(Markup/Latex)。
比较和分析
你可以比较实验,并将实验信息提取到本地 Pandas 数据框中。这对于查看超参数的重要性和相关性可能很有用。
Github 集成
我们的大多数用户在大型软件导向的组织中工作。通过 Comet.ml,你可以轻松创建一个 GitHub 拉取请求,将表现最佳的模型提交到任何 git 分支。
接下来是什么?
我们正在开发的新功能将于未来几周内发布:
-
超参数分析 - 提供不同超参数之间的重要性和相关性的测量,包括高级可视化。
-
绘图生成器 - 创建自定义图表和图形以可视化度量、结果、混淆矩阵,甚至神经网络激活图。
-
生产监控 - 提供模型漂移、训练数据和推理数据分布之间的差异等测量。
Comet.ml 对于公共项目和学术用途完全免费。如果你想在提交之前先试用私有项目,我们还提供 30 天的试用期。我们希望 Comet.ml 能对你的团队有所帮助,并期待你的反馈。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
更多相关主题
为什么软件工程流程和工具不适用于机器学习
原文:
www.kdnuggets.com/2019/12/comet-software-engineering-machine-learning.html
赞助帖子。
“人工智能是新的电力。”至少,这就是Andrew Ng在今年的Amazon re:MARS大会上所提出的观点。在他的主题演讲中,Ng 讨论了人工智能(AI)的快速增长——它不断渗透到各个行业;每天头条中对 AI 突破、技术或恐惧的持续关注;来自寻求现代化的既有企业(例如:Sony)以及从风险投资者在 AI 领域创始人潮流中进入市场的大量投资。
“人工智能是下一个重大变革,”Ng 坚持说,我们正在见证这一变革的展开。
尽管人工智能可能是新的电力(作为Comet的数据科学家,我不需要太多说服),但这一领域要实现其潜力仍面临重大挑战。在这篇博客文章中,我将讨论为什么数据科学家和团队不能依赖软件工程团队过去 20 年用于机器学习 (ML)的工具和流程。
依赖软件工程的工具和流程是合理的——数据科学和软件工程都是以代码为主要工具的学科。然而,数据科学团队正在做的与软件工程团队正在做的有着根本的不同。检查这两个学科之间的核心差异,有助于明确我们应该如何构建工具和流程以进行人工智能。
在 Comet,我们相信,采用专为人工智能设计的工具和流程将帮助从业者解锁并实现 Ng 所说的那种革命性转变。
不同学科,不同流程
软件工程是一个学科,其目标是广泛地设计和实现计算机可以执行以完成定义功能的程序。假设软件程序的输入在预期(或受限)范围内,其行为是可知的。在 2015 年 ICML 的一个talk中,Leon Bottou 很好地阐述了这一点:在软件工程中,算法或程序可以被证明是正确的,意味着在给定特定输入假设的情况下,某些属性在算法或程序终止时将是正确的。

来源:Futurice
可证明的程序正确性已经塑造了我们在软件工程中使用的工具和流程。考虑一下从可证明正确性中衍生出的一个相关特性:如果一个程序对某些输入值是可证明正确的,那么程序中包含的子程序对于这些输入值也同样是可证明正确的。这就是为什么像敏捷这样的工程流程在软件团队中通常是成功和高效的。将这些项目拆解为子任务是有效的。大多数瀑布模型和scrum实现也包括了子任务的划分。

我们看到许多数据科学团队使用与这些软件方法完全相同或大致相似的工作流程。不幸的是,这些方法效果并不好。原因是什么?软件工程的可证明正确性并没有扩展到人工智能和机器学习中。在(监督)机器学习中,对于我们建立的模型,唯一的保证是,如果训练集是某个分布的iid(独立同分布)样本,那么来自同一分布的另一个 iid 样本上的性能将会接近训练集上的性能。由于不确定性是机器学习的固有特性,子任务划分可能导致不可预见的下游影响。
为什么不确定性是机器学习的固有特性?
部分答案在于这样一个事实:那些既对我们有趣又适合机器学习解决方案(例如自动驾驶汽车、物体识别、图像标注和生成语言模型等)的难题,并没有明确可重复的数学或程序规范。作为规范的替代,机器学习系统通过输入大量数据来检测模式并生成预测。换句话说,机器学习的目的是创建一个统计代理,它可以作为这些任务之一的规范。我们希望我们收集的数据是现实世界分布的一个代表性子样本,但实际上我们无法确切知道这个条件被满足的程度。最后,我们使用的算法和模型架构是复杂的,足够复杂到我们无法总是将它们拆解成子模型以准确理解发生了什么。
从这个描述中,机器学习系统的可知性障碍应该是显而易见的。机器学习所适用的问题类型固有地缺乏明确的数学规范。在没有规范的情况下,我们使用的统计代理是积累大量我们希望是独立同分布且具有代表性的环境数据。我们用来从这些收集的数据中提取模式的模型足够复杂,以至于我们无法可靠地拆解它们并准确理解它们的工作原理。Comet 的同事 Dhruv Nair 写了一系列关于机器学习不确定性的三部分系列文章(这是第一部分的链接),如果你想深入探讨这个话题。
然后,考虑一下类似于在机器学习项目上使用的敏捷方法的影响。我们不可能希望将机器学习任务拆解成子任务,作为某个更大冲刺的一部分来处理,然后像乐高一样拼凑成一个整体产品、平台或功能,因为我们无法可靠地预测子模型或模型本身的功能。

来源:Youtube
Ng 在 re:MARS 上也讨论了这个话题。他透露了他的团队如何采用专为 ML 设计的工作流系统:1 天冲刺,结构如下:
-
每天构建模型并编写代码
-
设置训练并进行过夜实验
-
早晨分析结果,然后…
-
重复
Ng 的 1 天冲刺方法反映了理解和设计从事机器学习的团队的一个关键点:它本质上是实验性科学。由于所构建的系统缺乏明确的规范,因为数据收集是一门不完美的科学,并且机器学习模型极其复杂,实验是必要的。与其围绕多周冲刺来组织团队流程,不如快速测试多种不同的架构、特征工程选择和优化方法,直到出现一个大致的有效和无效的图景。1 天冲刺使团队能够快速移动,短时间内测试许多假设,并开始在建模任务上建立直觉和知识。
机器学习工具:实验管理
假设你采用 Andrew Ng 的 1 天冲刺方法或类似的东西(你应该这样做)。你正在设置新的超参数,调整特征选择,并每晚运行实验。你使用什么工具来跟踪这些决策以进行每次模型训练?你如何比较实验以查看不同配置的效果?你如何与同事共享实验?你的经理或同事能否可靠地重现你昨天进行的实验?
除了过程之外,你所使用的机器学习工具也很重要。在 Comet,我们的使命是通过提供一个能够为你完成这些工作的工具,帮助公司从机器学习中提取商业价值。我们与许多数据科学团队交流时发现,他们仍然依赖于 git、电子邮件以及(信不信由你)电子表格来记录每次实验的所有成果。

Comet: 20 多个实验的超参数空间可视化
考虑一个建模任务,其中你需要跟踪 20 个超参数、10 个指标、数十种架构和特征工程技术,同时快速迭代,每天运行数十个模型。手动跟踪所有这些成果可能变得极为繁琐。构建一个好的机器学习模型有时就像用 50 个旋钮调节收音机一样。如果你不记录所有尝试过的配置,找到建模空间中的信号的组合复杂度可能会变得非常繁琐。

Comet: 单次实验的实时指标跟踪和仪表板
我们在构建 Comet 时考虑了这些需求(以及当我们在谷歌、IBM 以及哥伦比亚大学和耶鲁大学的研究团队中从事数据科学和机器学习工作时的需求)。每次训练模型时,都应该有某种工具来捕捉你实验的所有成果,并将它们保存在某个中央账本中,以便你可以查看、比较和筛选你(或你的团队)的所有工作。Comet 的设计就是为了提供这一功能给机器学习从业者。
衡量工作流程效率是一个 notoriously difficult的任务,但我们的用户平均报告称,通过使用 Comet 节省了20-30%的时间(注意:Comet 对个人和研究人员免费—你可以在这里注册)。这还不包括从对超参数空间的可视化理解、实时指标跟踪、团队协作和实验比较等方面获得的独特见解和知识。这些知识不仅节省时间,而且更重要的是,使得构建更好的模型成为可能。
展望未来
忽视有关机器学习工具和过程的问题是很有诱惑力的。在一个负责自动驾驶汽车、语音助手、人脸识别以及许多其他突破性技术的领域中,人们可能会被允许直接投入到构建这些工具的工作中,而不考虑如何最好地构建它们。
如果你相信软件工程技术栈对 AI 的应用足够好,你不会被彻底证明对错。毕竟,这是一个充满不确定性的领域。但或许最好像数据科学家看待建模任务一样来考虑这个问题:可能未来的概率分布是什么?什么更可能或不太可能?一个如此强大且充满潜力的领域,是否会继续依赖为不同学科构建的工具和流程,还是会有新的工具出现,以充分赋能从业者?
如果你对这些机器学习工具感兴趣或有任何问题,欢迎通过niko@comet.ml联系我。
额外阅读
关于机器学习与软件工程差异的博客:
-
KDnuggets 关于机器学习与软件工程的博客
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的捷径。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 部门
了解更多相关主题
每位数据科学家都应该了解的命令行基础
原文:
www.kdnuggets.com/2019/08/command-line-basics-every-data-scientist.html
评论
作者:Rebecca Vickery,数据科学家
照片由 Almos Bechtold 拍摄,来源于 Unsplash
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
如果你是数据科学家或正在学习数据科学,并且希望从使用 jupyter notebooks 转向编写生产就绪的代码,那么你很可能需要在某些任务中使用命令行。我发现生产数据科学工具和过程的文档通常假设你已经了解这些基础知识。然而,如果你没有计算机科学背景,你可能不知道如何在终端完成一些较简单的任务。
我想写这篇简短的指南,介绍使用命令行执行简单任务的基本知识。了解这些基础知识无疑会使你的工作流程更加高效,并在处理生产系统时提供帮助。
文件和目录导航
当你打开终端时,通常会看到这样的界面。

~符号是你主目录的简写,这意味着你当前在这个目录中。如果你输入命令pwd,它会显示你当前的工作目录,在我们的例子中看起来像这样/Users/myname。
如果你想创建一个新的目录,可以输入mkdir test,这将创建一个名为 test 的新目录。你现在可以使用cd命令进入这个目录。
你也可以通过输入..来导航目录,这会让你返回到上一级目录。在我们的情况下,我们将返回到主目录。
文件和目录操作
接下来,让我们在测试目录中创建一个新的 Python 文件。要创建文件,你可以输入这个命令touch test.py。这将创建一个空白的 Python 文件。ls命令会将目录的内容打印到终端,因此我们可以使用它来检查文件是否已创建。
我们将使用一个名为nano的程序来编辑文件。要打开文件,只需输入nano test.py,然后将打开一个新标签页,如下所示。
在这个例子中,我们将进行一个小的修改,因此我们将输入print('this is a test')。要保存文件,你可以使用快捷键Ctrl+O,要退出程序,使用Ctrl+X。
现在我们已经编辑了文件,我们可以使用这个命令python test.py来运行它。简单的 Python 代码被执行,‘this is a test’会显示在终端上。

移动和删除
让我们快速创建一个新的目录mkdir new,以探索如何移动文件。你可能会想用三种主要的方法来做到这一点。
在下面的命令中,./new前面的.是父目录(test)的简写。
-
复制并移动文件,以保留当前目录中的原始文件
cp test.py ./new -
移动文件而不复制
mv test.py ./new -
复制文件并在新位置重命名文件
cp test.py ./new/test_new.py
最后,要删除文件,我们可以使用rm test.py。要删除一个空目录,你可以使用rmdir new。要删除包含一些文件的目录,使用rm -rf new。
本文涵盖了数据科学家可能需要完成的一些最基本的命令行任务。如果你想探索一些更高级的命令行工具,我已经写了另一篇指南在这里。
感谢阅读!
个人简介: Rebecca Vickery 正在通过自学数据科学。Holiday Extras 的数据科学家。alGo 的联合创始人。
原文。经许可转载。
相关:
-
数据科学中的五款命令行工具
-
数据科学家必备的前 12 款命令行工具
-
命令行中的数据科学:探索数据
更多相关内容
数据科学家的命令行技巧
原文:
www.kdnuggets.com/2018/06/command-line-tricks-data-scientists.html
评论
作者 Kade Killary,数据科学家与工程师

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT
对于许多数据科学家来说,数据处理开始和结束于 Pandas 或 Tidyverse。理论上,这种观念没有错。毕竟,这些工具存在的初衷就是如此。然而,这些选项对于像分隔符转换这样简单的任务来说,往往会显得过于复杂。
每个开发者,尤其是数据科学家,都应该把掌握命令行作为目标。学习你终端的来龙去脉无疑会让你更高效。除此之外,命令行还为计算机科学提供了极好的历史课程。例如,awk——一种基于数据的脚本语言。Awk 最早出现在 1977 年,得到了 布赖恩·柯宁汉 的帮助,他是传奇的 K&R 书籍 中的 K。直到今天,近 50 年后,awk 依然相关,每年都有 新书 继续出版!因此,可以放心地认为,对命令行技巧的投资不会很快贬值。
我们将涵盖的内容
-
ICONV
-
HEAD
-
TR
-
WC
-
SPLIT
-
SORT & UNIQ
-
CUT
-
PASTE
-
JOIN
-
GREP
-
SED
-
AWK
ICONV
文件编码可能很棘手。现在大多数文件都是 UTF-8 编码的。要了解 UTF-8 背后的部分魔力,可以查看这个 精彩视频。尽管如此,有时我们会收到不是这种格式的文件。这可能会导致一些奇怪的尝试去更换编码方案。在这里,iconv 是救星。Iconv 是一个简单的程序,可以将一种编码的文本转换为另一种编码的文本。
# Converting -f (from) latin1 (ISO-8859-1)
# -t (to) standard UTF_8
iconv -f ISO-8859-1 -t UTF-8 < input.txt > output.txt
有用的选项:
-
iconv -l列出所有已知编码 -
iconv -c静默丢弃无法转换的字符
HEAD
如果你是频繁使用 Pandas 的用户,那么head将是熟悉的。通常在处理新数据时,我们首先想要了解数据的内容。这导致我们启动 Pandas,读取数据,然后调用df.head()——可以说是相当费劲。head在没有任何标志的情况下,会打印出文件的前 10 行。head的真正力量在于测试清理操作。例如,如果我们想将文件的分隔符从逗号更改为管道字符。一个快速的测试方法是:head mydata.csv | sed 's/,/|/g'。
# Prints out first 10 lines
head filename.csv
# Print first 3 lines
head -n 3 filename.csv
有用的选项:
-
head -n打印特定行数 -
head -c打印特定字节数
TR
tr类似于翻译。这个强大的工具在基本文件清理中是一个主力军。一个理想的用例是用于在文件中交换分隔符。
# Converting a tab delimited file into commas
cat tab_delimited.txt | tr "\\t" "," comma_delimited.csv
tr的另一个特性是所有内置的[:class:]变量。这些包括:
[:alnum:] all letters and digits
[:alpha:] all letters
[:blank:] all horizontal whitespace
[:cntrl:] all control characters
[:digit:] all digits
[:graph:] all printable characters, not including space
[:lower:] all lower case letters
[:print:] all printable characters, including space
[:punct:] all punctuation characters
[:space:] all horizontal or vertical whitespace
[:upper:] all upper case letters
[:xdigit:] all hexadecimal digits
你可以将各种这些选项链在一起,组成强大的程序。以下是一个基本的单词计数程序,你可以用来检查你的 README 文件是否过度使用。
cat README.md | tr "[:punct:][:space:]" "\n" | tr "[:upper:]" "[:lower:]" | grep . | sort | uniq -c | sort -nr
另一个使用基本正则表达式的示例:
# Converting all upper case letters to lower case
cat filename.csv | tr '[A-Z]' '[a-z]'
有用的选项:
-
tr -d删除字符 -
tr -s压缩字符 -
\b退格键 -
\f换页符 -
\v垂直制表符 -
\NNN具有八进制值 NNN 的字符
WC
单词计数。其值主要由-l标志派生,该标志会给出行数。
# Will return number of lines in CSV
wc -l gigantic_comma.csv
这个工具很方便用来确认各种命令的输出。因此,如果我们将文件中的分隔符转换,然后运行wc -l,我们可以期望总行数保持不变。如果不一致,那么我们知道出现了问题。
有用的选项:
-
wc -c打印字节计数 -
wc -m打印字符计数 -
wc -L打印最长行的长度 -
wc -w打印单词计数
SPLIT
文件大小可以有很大差异。根据任务的不同,拆分文件可能会有好处——因此使用split。split的基本语法是:
# We will split our CSV into new_filename every 500 line
split -l 500 filename.csv new_filename_
# filename.csv
# ls output
# new_filename_aaa
# new_filename_aab
# new_filename_aac
两个怪癖是命名约定和缺乏文件扩展名。后缀约定可以通过-d标志设置为数字。要添加文件扩展名,你需要运行以下find命令。它会通过追加.csv来更改当前目录下所有文件的名称,因此要小心。
find . -type f -exec mv '{}' '{}'.csv \;
# ls output
# filename.csv.csv
# new_filename_aaa.csv
# new_filename_aab.csv
# new_filename_aac.csv
有用的选项:
-
split -b按特定字节大小拆分 -
split -a生成长度为 N 的后缀 -
split -x使用十六进制后缀进行拆分
SORT & UNIQ
前面的命令很直观:它们执行的正是它们所描述的功能。这两个命令配合使用效果最佳(即唯一词汇计数)。这是因为uniq只作用于相邻的重复行。因此,原因在于在将输出通过管道传输之前需要sort。一个有趣的说明是,sort -u将实现与典型的sort file.txt | uniq模式相同的结果。
sort对数据科学家有一个非常有用的功能:根据特定列对整个 CSV 文件进行排序。
# Sorting a CSV file by the second column alphabetically
sort -t, -k2 filename.csv
# Numerically
sort -t, -k2n filename.csv
# Reverse order
sort -t, -k2nr filename.csv
这里的 -t 选项用于指定逗号作为分隔符。更常见的是假定使用空格或制表符。此外,-k 标志用于指定键。
有用的选项:
-
sort -f忽略大小写。 -
sort -r反向排序。 -
sort -R打乱顺序。 -
uniq -c计算出现次数。 -
uniq -d仅打印重复的行。
CUT
Cut 用于删除列。例如,如果我们只想要第一列和第三列。
cut -d, -f 1,3 filename.csv
选择除第一列之外的所有列。
cut -d, -f 2- filename.csv
结合其他命令,cut 作为一个过滤器。
# Print first 10 lines of column 1 and 3, where "some_string_value" is present
head filename.csv | grep "some_string_value" | cut -d, -f 1,3
找出第二列中的唯一值数量。
cat filename.csv | cut -d, -f 2 | sort | uniq | wc -l
# Count occurences of unique values, limiting to first 10 results
cat filename.csv | cut -d, -f 2 | sort | uniq -c | head
PASTE
Paste 是一个具有有趣功能的小众命令。如果你有两个需要合并的文件,并且它们已经排序,paste 能满足你的需求。
# names.txt
adam
john
zach
# jobs.txt
lawyer
youtuber
developer
# Join the two into a CSV
paste -d ',' names.txt jobs.txt > person_data.txt
# Output
adam,lawyer
john,youtuber
zach,developer
对于更类似 SQL 的变体,请参见下面的内容。
JOIN
Join 是一种简单的、类 SQL 的操作。最大区别在于 join 会返回所有列,匹配只能在一个字段上进行。默认情况下,join 会尝试使用第一列作为匹配键。要获得不同的结果,需要使用以下语法:
# Join the first file (-1) by the second column
# and the second file (-2) by the first
join -t, -1 2 -2 1 first_file.txt second_file.txt
标准的 join 是内连接。然而,通过 -a 标志也可以进行外连接。另一个值得注意的特点是 -e 标志,可以在找到缺失字段时替换一个值。
# Outer join, replace blanks with NULL in columns 1 and 2
# -o which fields to substitute - 0 is key, 1.1 is first column, etc...
join -t, -1 2 -a 1 -a2 -e ' NULL' -o '0,1.1,2.2' first_file.txt second_file.txt
不是最用户友好的命令,但在紧急情况下,采取紧急措施。
有用的选项:
-
join -a打印无法配对的行。 -
join -e替换缺失的输入字段。 -
join -j等同于-1 FIELD -2 FIELD。
GREP
全局搜索正则表达式并打印,或 grep;可能是最知名的命令,也是有充分理由的。Grep 功能强大,特别是在大型代码库中查找内容时。在数据科学领域,它作为其他命令的精炼机制。虽然它的标准用法也很有价值。
# Recursively search and list all files in directory containing 'word'
grep -lr 'word' .
# List number of files containing word
grep -lr 'word' . | wc -l
计算包含词语/模式的总行数。
grep -c 'some_value' filename.csv
# Same thing, but in all files in current directory by file name
grep -c 'some_value' *
使用或操作符 \| 为多个值执行 grep。
grep "first_value\|second_value" filename.csv
有用的选项:
-
alias grep="grep --color=auto"使 grep 显示彩色。 -
grep -E使用扩展正则表达式。 -
grep -w仅匹配完整单词。 -
grep -l打印包含匹配项的文件名。 -
grep -v反向匹配。
大招
Sed 和 Awk 是本文中最强大的两个命令。为了简洁,我不会详细讨论它们。相反,我将介绍各种证明其强大能力的命令。如果你想了解更多,有一本书专门讲解这些内容。
SED
从本质上讲,sed 是一个逐行操作的流编辑器。它擅长于替换,但也可以用于全面的重构。
最基本的 sed 命令是 s/old/new/g。这表示搜索旧值,将所有出现的旧值替换为新值。如果没有 /g,我们的命令将在行中第一次出现后终止。
要快速体验这种强大功能,我们来看看一个例子。在这个场景中,你会得到以下文件:
balance,name
$1,000,john
$2,000,jack
我们首先可能要做的是移除美元符号。-i标志表示就地修改。''表示零长度的文件扩展名,从而覆盖我们的初始文件。理想情况下,你应当逐一测试这些命令,然后输出到新文件。
sed -i '' 's/\$//g' data.txt
# balance,name
# 1,000,john
# 2,000,jack
接下来是我们balance列值中的逗号。
sed -i '' 's/\([0-9]\),\([0-9]\)/\1\2/g' data.txt
# balance,name
# 1000,john
# 2000,jack
最后,Jack 决定有一天辞职了。所以,再见,我的朋友。
sed -i '' '/jack/d' data.txt
# balance,name
# 1000,john
如你所见,sed确实非常强大,但乐趣并不止于此。
AWK
最后的最好。Awk 不仅仅是一个简单的命令:它是一种全面的语言。在本文涵盖的一切中,awk无疑是最酷的。如果你感到印象深刻,还有很多很棒的资源 - 见这里、这里和这里。
awk的常见用例包括:
-
文本处理
-
格式化文本报告
-
执行算术操作
-
执行字符串操作
Awk 可以在最初形态上与grep并驾齐驱。
awk '/word/' filename.csv
或者通过一些魔法结合grep和cut。这里,awk打印第三和第四列,以制表符分隔,针对所有包含我们word的行。-F,只是将分隔符改为逗号。
awk -F, '/word/ { print $3 "\t" $4 }' filename.csv
Awk 内置了许多有用的变量。例如,NF - 字段数 - 和NR - 记录数。要获取文件中的第 53 条记录:
awk -F, 'NR == 53' filename.csv
一个额外的功能是基于一个或多个值进行筛选。下面的第一个例子,将打印记录的行号和列,对于第一列等于string的记录。
awk -F, ' $1 == "string" { print NR, $0 } ' filename.csv
# Filter based off of numerical value in second column
awk -F, ' $2 == 1000 { print NR, $0 } ' filename.csv
多个数值表达式:
# Print line number and columns where column three greater
# than 2005 and column five less than one thousand
awk -F, ' $3 >= 2005 && $5 <= 1000 { print NR, $0 } ' filename.csv
求第三列的和:
awk -F, '{ x+=$3 } END { print x }' filename.csv
对于第一列等于“something”的值,第三列的总和。
awk -F, '$1 == "something" { x+=$3 } END { print x }' filename.csv
获取文件的尺寸:
awk -F, 'END { print NF, NR }' filename.csv
# Prettier version
awk -F, 'BEGIN { print "COLUMNS", "ROWS" }; END { print NF, NR }' filename.csv
打印出现两次的行:
awk -F, '++seen[$0] == 2' filename.csv
移除重复行:
# Consecutive lines
awk 'a !~ $0; {a=$0}']
# Nonconsecutive lines
awk '! a[$0]++' filename.csv
# More efficient
awk '!($0 in a) {a[$0];print}
使用内置函数gsub()替换多个值。
awk '{gsub(/scarlet|ruby|puce/, "red"); print}'
这个awk命令会合并多个 CSV 文件,忽略头部,然后在末尾追加。
awk 'FNR==1 && NR!=1{next;}{print}' *.csv > final_file.csv
需要缩小一个庞大的文件?嗯,awk可以在sed的帮助下处理。具体来说,这条命令会根据行数将一个大文件拆分成多个小文件。这条单行命令也会添加一个扩展名。
sed '1d;$d' filename.csv | awk 'NR%NUMBER_OF_LINES==1{x="filename-"++i".csv";}{print > x}'
# Example: splitting big_data.csv into data_(n).csv every 100,000 lines
sed '1d;$d' big_data.csv | awk 'NR%100000==1{x="data_"++i".csv";}{print > x}'
结束
命令行具有无尽的力量。本文所涵盖的命令足以让你迅速从新手成长为高手。除了这些,还有许多实用工具可供考虑,以应对日常数据操作。Csvkit、xsv 和 q 是值得注意的三个。如果你希望进一步深入探讨命令行数据科学,那么不妨看看 这本书。这本书也可以在线 免费阅读!
更多内容请见我的博客!
链接
简介:Kade Killary 是 XMedia 的数据科学家和工程师。
原文。经许可转载。
相关:
-
数据科学家的 12 大必备命令行工具
-
命令行中的数据科学:探索数据
-
使用 Python 掌握数据准备的 7 个步骤
更多相关主题
不要成为商品化的数据科学家
原文:
www.kdnuggets.com/2022/10/commoditized-data-scientist.html

保持独特并脱颖而出(照片由 Ricardo Gomez Angel 提供,来自 Unsplash)
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
商品是用于商业的基本商品,可以与其他同类商品互换。商品通常作为生产其他商品或服务的输入。 [...] 给定商品的质量可能略有不同,但在生产者之间基本一致。
数据科学家的商品化
粮食是商品。牛肉是商品。天然气、石油和黄金也是商品。
作为数据科学家,你不应该成为商品。
数据科学家都一样吗?所有相同形状的钉子都能适应任何组织可能需要填补的孔吗?他们只是可互换的普通人员吗?
当然不是。数据科学家在各种环境中执行不同的任务,并使用不同的技术和非技术技能来满足其角色的要求。
至少,这应该是这样。然而,似乎越来越多的数据科学家将数据科学领域视为需要完成的技能列表,实际上这导致了大量类似技能的个人争夺雇主的注意。
✔️ 基本的 Python 编程技能
✔️ Python 科学计算生态系统的概述
✔️ 对神经网络的基本理解及import tensorflow as tf
✔️ 自然语言处理基础及导入 HuggingFace Transformers
✔️ 计算机视觉基础的工作知识
✔️ SQL,或者至少如何SELECT * FROM Customers WHERE Country='Canada';
✔️ 了解 MLOps 是什么,无论你是否曾经使用过它
很好,现在你拥有了和其他人一样的技能组合。
这不是让你脱颖而出的方法,更重要的是,这也不是你完成工作的方式。如果情况确实如此,每个组织需要的数据科学家都相同,他们会直接选择下一个候选人,而不考虑某个个体的技能。
不要误解:我们都需要建立一个坚实的基础,在此基础上发展自己独特的数据科学技能。但即使你对上述技能有中级到专家级的理解——这本身已经非常令人印象深刻——你在纸面上也无法与他人区别开来。
你已经掌握了基础知识,完成了所有步骤。是时候在此基础上进行进一步发展了。
负责招聘数据科学家的组织和个人往往不知道他们在寻找什么……但他们在寻找某种东西!是时候让数据科学家脱颖而出了,这将需要运用“s”字:专业化。
成为濒危物种
我猜测你从事数据科学是因为你有好奇心,是个逻辑思维者,并且想要解决有趣的问题。这些特征并不意味着你应该获得与其他人相同的技能和专长!数据科学家的天生特质在大声地呼唤“个体性”,而成为数据科学家的通用路径和所获取的技能则在低语“顺应性”。
为了确保你的长期就业能力,你需要在众人中脱颖而出,你需要区分自己,而做到这一点意味着你需要彰显你的个性。数据科学家的一般化时代已经结束,甚至从未真正存在过。
提升技能。专注。专业化。这些是数据科学领域长久发展的关键。
独角兽并不存在。相反,目标是成为一种濒危物种。
没错,就是濒危物种。如果你拥有周围人没有的技能,包括技术技能和非技术技能,你就是一种濒危物种。在动物王国,这可能对物种的长期生存不利,但作为一个可雇佣的数据科学家,这肯定是有利的。
那么,你如何成为一种濒危物种呢?发展一套专业技能,无论是技术的还是非技术的,或两者兼具。
技术技能
如今有这么多的技术技能可以加入你的技能库,列出任何一种似乎都显得不必要。但为了证明这不必是你认为的那样困难,我将列出几种。
首先,我们需要从小众技能的角度来考虑技术技能。你已经(假设)在广泛和浅显的层面上覆盖了数据科学技能领域;现在是时候从深度和狭窄度的双重视角来考虑了。
我能想到两种基本方法来获取“小众”技术技能。
新奇而耀眼
在掌握最新技术所需的技能时,你需要平衡过早和过晚,这可能是一场刺激的高空行走表演。没有人会寻找刚刚发布的新工具的专家,但一旦每个人都在使用它,你的技能就不再让你成为那种濒临灭绝的物种。
一个建议是寻找最近开发的尚未流行但显示出真正潜力的开源工具。早期参与并做出一些贡献将是一个很好的方式,让你在这些工具中脱颖而出,特别是当它们进入主流时。
经过验证(但未主流)
这是一个慢烧过程。这个工具已经存在了一段时间,但尚未取得应有的成功。我认为 JAX 就是一个很好的例子。JAX 已经存在了几年,它的层次低于其他类似工具,因此有一群寻求这种优势的人,它的受欢迎程度持续增长。在这里添加一些专业知识会让你从 TensorFlow 或 PyTorch 人群中脱颖而出,尤其是如果你对所有这些工具都很熟悉。
看到的不是不懂其他东西,而是懂得和其他东西。
非技术技能
我认为在非技术技能方面,区分的两种方法非常明显,我们将在下面讨论这些方法。
沟通
沟通在数据科学中至关重要。这点没有什么新鲜事。然而,沟通实际包含的内容在不断变化。你能想象在 3 年前,“在同步在线会议环境中与多个同事有效沟通思想”的技能有多么稀缺吗?
也许为了使自己与众不同,你可以想出自己的一种品牌推广方法:花时间开发用于传达项目结果的工件,以及围绕这些工件构建的故事。这是对新数据科学家始终强调的内容,但常常是闪亮的新工具或技术优先。作为团队中被其他人视为有效向其他利益相关者推销团队成果和愿景的人,并没有什么错。
领域专业知识
这是显而易见的。想把你的机器学习技能带到金融行业吗?你最好了解金融行业!
这超越了行业领域;有太多人从技术角度攻击自然语言处理,却没有对语言学有扎实的理解,这一点显而易见。如果你有兴趣在 NLP 领域脱颖而出?去阅读一些语言学的书籍。计算机视觉也是如此:如果你不知道色调、插值、高斯噪声等,通过学习来脱颖而出。这只会帮助你融入你想要融入的领域。
总结
让我们忘记所有数据科学家需要了解 X、Y 和 Z 的想法。技能的字母表中还有许多其他字母,所以学习一下 E、J,甚至是一些 M 吧。
并且始终...

作者提供的图像
马修·梅奥 (@mattmayo13) 是一位数据科学家和 KDnuggets 的主编,KDnuggets 是开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。马修拥有计算机科学硕士学位和数据挖掘研究生文凭。他的联系方式是 editor1 at kdnuggets[dot]com。
更多相关话题
常见的数据问题(及解决方案)
原文:
www.kdnuggets.com/2022/02/common-data-problems-solutions.html

Shubham Dhage 通过 Unsplash
数据科学家数量的激增纯粹是由于大量数据能够为我们提供解决现实问题的方案。然而,当涉及到数据科学时,理论与现实之间的差距并不总是一致。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
作为数据科学家,接收大量有问题的数据并进行数据清洗、模型设计和模型执行是非常正常的。这些问题纯粹是由于用于回答问题的数据的复杂性和范围。数据中的问题可能包括特征数量、错误、特性等。
在处理数据问题时,确保问题被正确和高效地处理是至关重要的。
让我们来看看一些常见的数据问题及其解决方案。
数据不足
数据科学家的主要组成部分是数据;这是他们头衔的一部分。没有数据,数据科学的进展会受到限制,这对于一个现在高度依赖数据的世界来说是一个问题。
如果数据不足,这将成为一个问题,因为数据是训练算法的重要元素。如果数据有限,可能导致不准确和低效的输出,这会耗费公司大量的时间和资源。然而,有解决方案可以生成更多数据来训练你的模型。
1. 随机生成
如果你知道你要找的值,有可能随机生成这些值。
一种方法是伪随机生成,这通过伪随机数生成器(PRNG)来实现。这是一种生成看似随机但仍可重复的数据的算法。可重复性是指使用与原始研究相同的数据和代码获得一致结果的能力。
你还可以使用输入分析来了解数据的分布,然后根据数据分布模仿或复制值。
2. 数据增强
数据增强是一种显著增加用于训练模型的数据多样性的策略,而无需收集新数据。例如;裁剪、填充和水平翻转等技术在训练大型神经网络时被大量使用。
然而,你需要记住假设和正在解决的任务,以确保你生成的输入是有效的。
3. 避免过拟合
在处理较小的数据集时,过拟合的可能性会自动增加。提醒一下:过拟合是指当一个函数过于紧密地对准一组有限的数据点时发生的建模错误。
为了避免过拟合,你可以使用特征选择、正则化或交叉验证等技术。
数据过多
数据不足的问题与数据过多的问题一样存在。数据更多并不保证你的模型会产生准确的输出。
计算能力、所需时间和整体输出等因素。你可能会发现使用较少的数据可以让你的模型更高效、更快速地运行。在处理大量数据时,有些事情你可以考虑。
1. p 值
根据维基百科,p 值是:
“是在零假设正确的前提下,获得至少与实际观察结果一样极端的测试结果的概率。”
通俗来说,p 值是你样本数据结果发生偶然的概率,因此低 p 值是好的。任何小于 0.5%的 p 值在统计上是显著的,允许我们拒绝零假设。p 值依赖于被测试数据的大小:样本越大,p 值越小。如果样本量很大,就更有可能找到显著的关系(如果存在的话)。随着样本量的增加,随机误差的影响被减少。
如果你的 p 值因数据过多而过高,你可以从数据中抽取多个样本来训练你的模型,并生成更好的 p 值。
2. 计算能力
计算能力是计算机以速度和准确性执行某项任务的能力。当用大数据集训练模型时,这可能变得非常困难,因为你需要大量的计算能力和内存来处理数据。这需要太多时间,而且整体过程效率不高。一种解决方案是:
分层抽样
分层抽样是一种将数据划分为较小子组(称为层)的技术。在分层随机抽样或分层中,这些层是根据独特的属性或特征(如收入或年龄组)在普查数据中形成的。
多少数据算是合适的数量?
难以确定什么是“好”的数据量,因为没有固定的规则。这完全取决于数据的类型、问题的复杂性以及其他因素,如成本。然而,下面是一个你可以在决定有效样本大小时考虑的解决方案:
- 样本 - 从数据中提取子样本,确保每个变量的某个百分比被涵盖。一个例子就是我们上面讨论的分层抽样。
不过,这一切最终取决于你试图解决的机器学习问题。例如:
-
图像分类问题 - 这需要数万张图像,以创建一个具有准确输出的分类器。
-
情感分析问题 - 由于单词和短语的数量,这也需要数千个示例文本。N-gram 模型通过计算语料库文本中出现的单词序列的频率来建立,然后估计概率。
-
回归问题 - 许多研究人员建议你应该有 10 倍于特征数量的观察值。例如,如果我们有三个独立变量,那么最好有至少 30 个样本。
目前仍无固定规则
有一个粗略的指南来自研究人员和其他从事模型创建的数据显示者,但这些并非刻板规则或黄金法则。
根据不同变量之间的相关性,你可能需要更多的数据,但也可能只需要较少的数据。在工作流程的前几个阶段,你应该问自己这些问题:
- 我期望的时间框架是什么?
如果你试图预测未来 5 年的情况,仅有 1 年的数据是不够高效的。你需要至少 5 年的数据,并确保数据中没有大量缺失,以产生准确的结果。
- 我的数据粒度是什么?
如果我需要一年的数据,那我的数据是否符合这个要求?我的数据是以天、周还是月为单位?一年的数据可以是 365 个数据点(天)、52 个数据点(周)或 12 个数据点(个月)。所有这些都是有效的,关键在于你的实际问题和需求。
尼莎·阿里亚 是一名数据科学家和自由职业技术作家。她特别感兴趣于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何有助于人类寿命的不同方式。作为一个积极的学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
最常见的数据科学面试问题及答案
原文:
www.kdnuggets.com/2021/08/common-data-science-interview-questions-answers.html
评论

成为数据科学家被认为是一种令人羡慕的职业。早在 2012 年,《哈佛商业评论》称数据科学家是 21 世纪最性感的工作,行业角色的增长趋势似乎证实了这一说法。为了确认这一“性感”是否仍在持续,Glassdoor 的数据表明,数据科学家在 2021 年是美国第二最佳职业。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
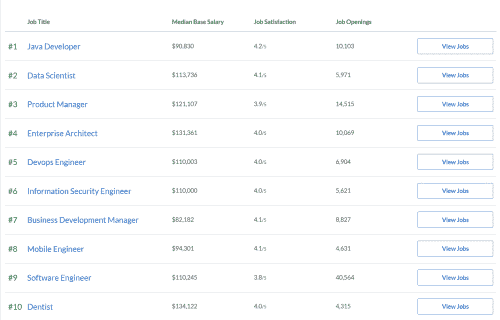
来源:Glassdoor。
要获得如此高端的职位,你必须经过严格的面试。数据科学的问题可以非常广泛和复杂。考虑到数据科学家通常涉及多个领域,这种情况是可以预见的。为了帮助你准备数据科学的面试,我审查了所有相关的问题,并将它们分为不同的类别。以下是我的分类方法。
分析的描述和方法论
我从各种招聘网站和公司评价平台如 Glassdoor、Indeed、Reddit 和 Blind App 收集了数据。更准确地说,过去四年收集了 903 个问题。
这些问题被分成预定的类别。这些类别是根据专家对面试经历描述的分析结果而得出的。
这些类别包括:
-
编程
-
建模
-
算法
-
统计
-
概率
-
产品
-
商业案例
-
系统设计
-
技术
你应该期待什么类型的面试问题?
该图表显示了根据收集的数据,每个类别的问题类型。
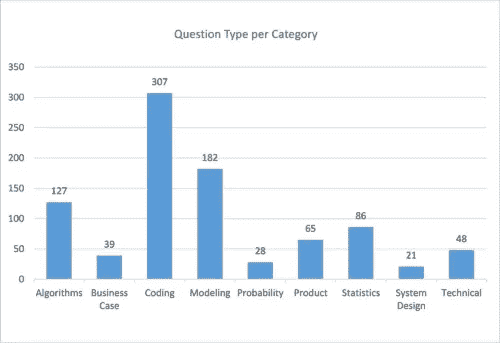
转换为百分比后,图表如下所示:
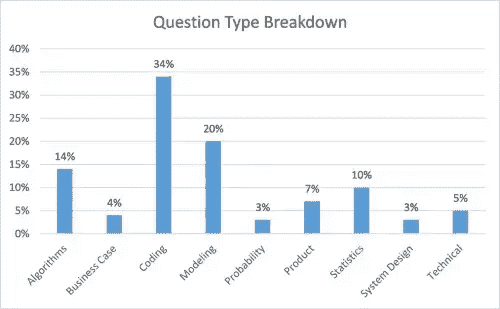
如你所见,编程和建模问题占据了主导地位。超过一半的问题来自这两个领域。考虑到这一点,也不奇怪。编程和建模可能是数据科学家最重要的两个技能。编程类型的问题很普遍,占所有问题的三分之一以上。其他问题类型,如算法和统计,也相当重要;24%的问题来自这两个类别。其他类别的代表性则较少。考虑到数据科学家的角色性质,我认为这是合理的。
现在,我想引导你了解每个问题类别,并展示一些被问到的问题示例。
数据科学面试中最常考察的概念
编程
正如你所见,编程问题是数据科学中最重要的话题。这类问题通常需要通过代码对数据进行某种形式的操作,以识别洞察力。这些问题旨在测试编码能力、解决问题的技巧和创造力。你通常会在计算机或白板上完成这些任务。
编程面试问题示例
一个来自微软的示例是这样的:
问题:“计算新用户和现有用户的比例。输出月份、新用户比例和现有用户比例。新用户定义为在当前月份开始使用服务的用户。现有用户是指在当前月份开始使用服务并且在之前任何月份也使用过服务的用户。假设所有日期都来自 2020 年。”
你将使用fact_events表,样本数据如下:
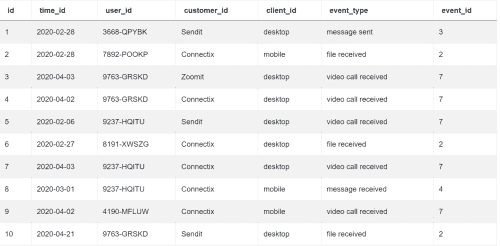
为了获得所需的输出,你应该编写以下代码:
with all_users as (
SELECT date_part('month', time_id) AS month,
count(DISTINCT user_id) as all_users
FROM fact_events
GROUP BY month),
new_users as (
SELECT date_part('month', new_user_start_date) AS month,
count(DISTINCT user_id) as new_users
FROM
(SELECT user_id,
min(time_id) as new_user_start_date
FROM fact_events
GROUP BY user_id) sq
GROUP BY month
)
SELECT
au.month,
new_users / all_users::decimal as share_new_users,
1- (new_users / all_users::decimal) as share_existing_users
FROM all_users au
JOIN new_users nu ON nu.month = au.month
编写 SQL 代码是编程中最常考察的概念。这也不奇怪,因为 SQL 是数据科学中使用最广泛的工具。你几乎无法避免的一个概念就是连接(joins)。所以请确保你了解不同连接的区别以及如何使用它们来获得所需的结果。
此外,你可以预期经常使用 GROUP BY 子句对数据进行分组。其他常被询问的概念包括使用 WHERE 和/或 HAVING 子句过滤数据。你还会被要求选择不同的数据。此外,确保你了解聚合函数,如 SUM()、AVG()、COUNT()、MIN()、MAX()。
一些概念出现的频率不高,但值得提及并为这些问题做好准备。例如,公用表表达式(CTEs)就是一个这样的主题。另一个是 CASE()子句。此外,别忘了复习一下字符串数据类型和日期的处理方法。
建模
在我们的研究数据中,建模是第二大类别,占所有问题的 20%。这些问题旨在测试你构建统计模型和实现机器学习模型的知识。
建模面试问题示例
回归是面试中最常见的技术数据科学概念。考虑到统计建模的性质,这也就不足为奇了。
一个来自 Galvanise 的示例是如下的:
问题:“回归中的正则化是什么?”
下面是你可以回答这个问题的方式:
回答:“正则化是一种特殊的回归类型,其中系数估计值被约束(或正则化)为零。通过这样做,可以减少模型的方差,同时降低采样误差。正则化用于避免或减少过拟合。过拟合发生在模型过于完美地学习训练数据,从而影响模型在新数据上的表现。为了避免过拟合,通常使用 Ridge 或 Lasso 正则化。”
一些经常测试的概念包括其他回归分析概念,如逻辑回归、贝叶斯逻辑回归和朴素贝叶斯分类器。你也可能会被问到随机森林,以及测试和评估模型。
算法
算法相关的问题都是需要通过编程语言解决数学问题的问题。这些问题涉及逐步过程,通常需要调整或计算以得出答案。这些问题测试了问题解决和数据处理的基础知识,这些知识可以应用于工作中的复杂问题。
算法面试问题示例
在算法方面,最常测试的技术概念是用编程语言解决数学或语法问题。
问题:“给定两个非空链表,表示两个非负整数。数字以逆序存储,每个节点包含一个数字。将两个数字相加,并将和作为链表返回。”
数据示例可能如下所示:
来源:Leetcode。
回答:用 Java 编写的代码应该是:
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
ListNode dummyHead = new ListNode(0);
ListNode p = l1, q = l2, curr = dummyHead;
int carry = 0;
while (p != null || q != null) {
int x = (p != null) ? p.val : 0;
int y = (q != null) ? q.val : 0;
int sum = carry + x + y;
carry = sum / 10;
curr.next = new ListNode(sum % 10);
curr = curr.next;
if (p != null) p = p.next;
if (q != null) q = q.next;
}
if (carry > 0) {
curr.next = new ListNode(carry);
}
return dummyHead.next;
}
其他类型问题经常测试的常见概念包括数组、动态规划、字符串、贪心算法、深度优先搜索、树、哈希表和二分搜索。
统计
统计面试问题是测试统计理论及其相关原则的知识的问题。这些问题旨在考察你对数据科学基础理论原则的熟悉程度。理解分析所依据的理论和数学背景非常重要。回答好这些问题,每位面试官都会对你刮目相看。
统计面试题例子
最常提到的技术概念是抽样和分布。对于数据科学家来说,这是数据科学家每天实施的最常用的统计原则之一。
例如,IBM 的面试题问道:
问题:“一个非高斯分布的数据类型的例子是什么?”
要回答这个问题,你可以先定义高斯分布。然后可以给出非高斯分布的例子。像这样:
答案:“高斯分布是一个分布,其中在检查从均值的标准差时,可以找到一定已知百分比的数据,也称为正态分布。非高斯分布的一些例子可以是指数分布或二项分布。”
准备面试时,确保你还涵盖以下主题:方差和标准差、协方差和相关性、p 值、均值和中位数、假设检验和贝叶斯统计。这些都是数据科学家需要掌握的概念,所以在面试中也要有所准备。
概率
这些问题只需要对概率概念的理论知识。面试官提出这些问题是为了深入了解你对概率方法和用途的知识,以完成通常在工作场所进行的复杂数据研究。
概率面试题例子
很有可能,你得到的问题是计算从一组骰子/卡片中抽到某张卡片/数字的概率。这似乎是我们研究中大多数公司最常问的问题,因为许多公司都提出过这些问题。
这样一个来自 Facebook 的概率问题的例子:
问题:“在一副 52 张牌的牌堆中,分别抽取两张牌得到一对的概率是多少?”
这里是你可以回答的方式:
答案:“你抽的第一张卡片可以是任意一张,所以它不会影响结果,除了在牌堆中少了一张卡片。抽出第一张卡片后,剩下的牌堆中有三张卡片可以组成一对。所以,与第一张卡片匹配成对的几率是 51 张剩余卡片中的 3 张。也就是说,这个事件发生的概率是 3/51 或 5.89%。”
由于这是一个只涉及概率的“专业”问题,没有其他概念被提问。唯一的区别是问题的想象力。然而,基本上,你总是需要计算某个事件的概率并展示你的思考过程。
产品
产品面试问题将要求你通过数据评估产品/服务的表现。这些问题测试你在任何环境中适应和使用数据科学原则的知识,就像日常工作一样。
产品面试问题示例
这一类别中最突出的技术概念是从数据科学家的角度识别公司的产品并提出改进建议。产品方面测试的技术概念差异大,可以通过产品问题的性质和回答这些问题所需的更高创造性来解释。
一个来自 Facebook 的产品问题示例 是:
问题: “你最喜欢的 Facebook 产品是什么?你会如何改进它?”
回答: 由于问题的性质,我们将让你自己回答这个问题。
测试的常见概念很大程度上依赖于面试公司的具体情况。只要你熟悉公司的业务和他们的产品(理想情况下,你也是他们的用户),你就会没问题。
业务案例
这一类别包括案例研究和与业务相关的通用问题,这些问题将测试数据科学技能。了解如何回答这些问题的意义可能是巨大的,因为一些面试官希望候选人在被聘用之前能知道如何将数据科学原则应用于解决公司特定问题。
业务案例问题示例
由于问题类型的性质,我无法确定一个突出的技术概念。由于这里分类的大多数问题都是案例研究,它们在某种程度上都是独特的。
不过,以下是一个来自 Uber 的业务案例问题示例:
问题: “有一组人从两个相近的城市乘坐了 Uber,比如 Menlo Park 和 Palo Alto,你可以收集的任何数据都可以被考虑。你会收集什么数据,以便确定乘客的出发城市?”
回答: “要确定城市,我们需要访问位置/地理数据。收集的数据可以是 GPS 坐标、经度/纬度和邮政编码。”
系统设计
系统设计问题是所有与设计技术系统相关的问题。提出这些问题是为了分析候选人在解决问题、创建和设计系统以帮助客户/客户的过程中。对于数据科学家来说,了解系统设计非常重要;即使你的角色不是设计系统,你也很可能在已建立的系统中扮演角色,需要知道它是如何工作的,以便完成你的工作。
系统设计面试问题示例
这些问题涵盖了不同的主题和任务。但最突出的是构建数据库。数据科学家每天都大量处理数据库,因此询问这个问题以了解你是否能从零开始构建一个数据库是有意义的。
这是一个 来自 Audible 的问题示例,在我们的研究中揭示:
问题:“你能详细说明一下你将如何构建推荐系统吗?”
答案:由于回答这个问题有各种不同的方法,我们将留给你自己想出构建一个的方法。
再次强调,为了回答这些问题,了解公司的业务至关重要。考虑一下公司最可能需要的数据库,并在面试前稍微展开你的方法。
技术
技术问题是所有询问各种数据科学技术概念解释的问题。技术问题是理论性的,需要了解你将在公司使用的技术。由于其性质,它们可能看起来与编码问题相似。了解你所做事情的理论是非常重要的,因此技术问题在面试中经常被提问。
技术面试问题示例
最常被考察的领域是 Python 和 SQL 的理论知识。不足为奇,因为这两种语言在数据科学中占据主导地位,R 语言则补充了 Python。
一个 来自 Walmart 的实际技术问题示例 是:
问题:“Python 中的数据结构有哪些?”
答案:“数据结构用于存储数据。Python 中有四种数据结构:列表、字典、元组和集合。这些是内置的数据结构。列表用于创建可以包含不同类型数据的列表。字典基本上是一组键;它们用于存储带有键的值,并使用相同的键获取数据。元组与列表相同。不同之处在于在元组中数据不能更改。集合包含无序的元素且没有重复。除了内置的数据结构,还有用户定义的数据结构。”
这些是包含所有无法干净地归入其他类别的问题的类别。因此,没有特定的概念出现得更多或更少。
结论
本数据科学面试指南旨在支持理解数据科学面试中提出的问题类型的研究。面试问题的数据来自于四年期间几十家公司并进行了分析。这些问题被分类为九种不同的问题类型(算法、商业案例、编码、建模、概率、产品、统计、系统设计和技术问题)。
在分析过程中,我讨论了每种问题类型类别中一些最常见的技术概念。例如,最常被问及的统计问题涉及采样和分布。每个问题类别都有一个实际问题的示例。
本文旨在为你提供重要的面试准备指南或简单地了解更多关于数据科学的知识。希望我能帮助你在数据科学面试过程中更加自信。祝你面试顺利!
原文。经许可转载。
相关内容:
更多相关话题
关于机器学习的常见误解
原文:
www.kdnuggets.com/2021/11/common-misconception-about-machine-learning.html
评论

作者图像 | 元素来自 freepik。
目前关于机器学习(ML)有很多炒作,许多初学者因错误的理由而成为这种炒作的受害者。你的教授会解释,如果你想要进步,获得博士学位是必要的,或者你的同学会告诉你如何获得更好的 GPU 和 IDE(集成开发环境)。当你开始从在线课程中学习时,你意识到你需要一个更大的数据集和对 Python 的熟练掌握。在学习了所需的技能后,当你申请工作时,你发现仅凭几个课程或认证是不够的。最后,在获得工作后,你意识到这是一项要求很高的工作,有时这些工作在初期的薪水并不高。
本文将帮助你克服这些失望,并准备好面对这些问题。我们将学习许多关于初学者进入机器学习领域所面临的现实问题。
有明确的实证证据表明,你不需要大量的数学,你不需要大量的数据,也不需要大量的昂贵的计算机。— Jeremy Howard (实用深度学习课程)
学习编程?
是的,编程是进入机器学习领域(特别是深度学习)所必需的。这并不意味着你要先花时间学习 Python、C++ 或 R,然后再开始学习机器学习。编程部分会在你学习基础知识时自然出现。你不需要记住语法或模型架构,你可以通过简单的 Google 搜索找到这些信息。就是这么简单。世界正朝着无代码机器学习和 AutoML 的方向发展。AutoML 是一个强大的工具,它会为你完成所有任务,并提供一个有效的机器学习模型。有时你只需要写两行代码,而不是两百行代码,就能获得类似的结果。
你需要数学或博士学位吗?
是的,你需要一些数学知识,但主要是为了进行研究和推动深度学习的边界。如果你打算训练模型并将其部署到生产环境中,那么你可能需要学习 MLOps,而不是数学。
你不需要数学来进行应用机器学习,但在进行任何研究和推动边界时,你需要学习高级统计学。— Jakub Žitný
你还需要了解模型架构的工作原理和各种矩阵函数。这些可以通过 8 小时的课程来教授,有时你甚至不需要了解所有可用的模型架构来解决问题。我是 Jeremy 的忠实粉丝,他在他的书 深度学习编程员的书:使用 Fastai 和 PyTorch 中解释了深度学习领域存在很多门槛。学术界会要求你学习高级微积分,了解所有数学模型,最终获得特定领域的博士学位才能成功。但你不需要这些。我见过很多没有学位而有商业背景的人现在在这些领域成为了专家。因此,请专注于基础知识,学习整个课程,并通过在作品集项目上工作来不断成长。
你需要一个庞大的数据集吗?
是的,但在少数情况下。现代深度学习模型现在能够用有限的样本产生高精度。即使是数据集的获取也变得更容易了,像 Kaggle 这样的平台提供了数以千计的开源数据集,可以下载并用于商业目的。我们还可以在 GitHub、DAGsHub、HuggingFace、Knoema 和 Google Dataset Search 上找到数据集,以训练我们的模型,并最终将其用于生产。
你需要学位或认证吗?
一些职位确实要求机器学习学位或 TensorFlow 证书,但如果你在 GitHub 和 Kaggle 上有强大的作品集,这些就变得次要了。很多开发者正在转向机器学习,他们没有专门的学位或证书,但有深度学习模型的经验并将其投入生产。如果你能向雇主证明你可以完成机器学习生命周期中的每个任务,那么你就是完美的候选人。总的来说,如果你有强大的机器学习作品集,就不必考虑获得证书或学位。要获得强大的 ML 作品集,请阅读:如何作为初学者构建强大的数据科学作品集 — KDnuggets。

使用 Google Cloud 上的 TensorFlow 进行机器学习 | Coursera
你需要昂贵的计算设备或 IDE 吗?
不,我有一台旧笔记本电脑,我可以借助 Kaggle 平台在云端 GPU 和 TPU 上训练这些大型模型。世界正从个人电脑转向云计算机。你可以从 Kaggle 和Google Colab获得免费的 CPU、GPU 和 TPU。还有其他平台也可以帮助你进行数据分析和创建完整的项目,如Deepnote、JetBrains Datalore和Paperspace。这些平台为你提供免费的工作空间来构建你的机器学习产品,并且附带协作工具。在我的日常工作中,我使用 Deepnote 来处理新的研究或项目,如果需要更好的 GPU 或 TPU,我会切换到 Kaggle 或 Colab。
你不需要购买昂贵的 IDE 或计算设备来构建你的产品。现在你可以使用这些免费的云工具。

2021 年数据科学前 5 大免费云 IDE | by Abid Ali Awan | Towards AI
职场的真实情况
在获得所需技能后,你开始在市场上寻找工作,但很快你会意识到公司要求更多。他们希望你了解数据工程、数据分析和 MLOps。在面试阶段,他们会询问你最近的项目和你在模型部署方面的工作经验。
即使学习了关键的必需技能,你也可能感到相当失望。这是因为大多数公司在寻找有经验的个人或具有多种技能的人。唯一能提高你机会的方法就是不断学习新技能,并且不断参与机器学习竞赛。这也会提升你的机器学习作品集,并最终让你脱颖而出。如果你刚开始,很难找到工作。继续提升自己,最终你会找到理想的工作。
机器学习工程师的生活
如我之前提到的,这需要擅长多种技能:显然,包括成为一名优秀的机器学习工程师所需的一切,比如好奇心、分析能力、算法知识、理解业务需求的能力以及有效沟通的需求。此外,你还需要擅长构建需要机器学习操作经验的软件解决方案。机器学习工程师的一天 | by Shanif Dhanani
除此之外,有时你必须执行诸如数据集标注这样的迭代任务。你可能不会得到高薪工作,但最终你会得到一个需要全职和专注的工作。如果你进入这个领域只是因为它提供高薪工作,那么你应该开始考虑其他选项。你在职业生涯中成功的唯一途径是对 AI 技术的热爱。
结论
最终,我总是建议你不断学习新技能,并开始参加 Kaggle 比赛。为了你的职业生涯,不断寻找新工作并为技术面试做准备。我只是想向你展示这个领域的现实情况。它并不美好,并不是每个人都能成功。只有通过努力工作和持续学习,你才能达到一个舒适的职位,获得高薪工作。
我们也讨论了机器学习不需要大量的数学、专业学位或博士学位。它不需要大量的计算能力或庞大的数据集。它只需要你的时间和努力。你可以找到令人惊叹的在线课程,学会一些技能后,将这些技能应用到你的作品集中。
相关:
更多相关内容
在进行机器学习和数据科学时常见的错误
原文:
www.kdnuggets.com/2018/12/common-mistakes-data-science.html
评论
由 Jekaterina Kokatjuhha,Zalando 公司的研究工程师撰写。
这是本系列的第二部分,第一部分请参见 - 如何从零开始构建数据科学项目。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
在抓取或获取数据之后,还有许多步骤需要完成在应用机器学习模型之前。
你需要可视化每个变量,以查看分布,找到异常值,并理解为何会有这些异常值。
你可以对某些特征中的缺失值做些什么?
将分类特征转换为数值特征的最佳方法是什么?
有许多类似的问题,但我会详细说明大多数初学者遇到错误的那些问题。
1. 可视化
首先,你应该可视化连续特征的分布,以便了解是否有许多异常值,分布情况如何,以及是否合理。
可视化的方式有很多,例如 箱线图、直方图、累计分布函数 和 小提琴图。然而,应该选择能提供关于数据最多信息的图表。
要查看分布(是否为 正态分布 或 双峰分布),直方图将是最有用的。虽然直方图是一个很好的起点,但箱线图在识别异常值的数量和查看中位数四分位数方面可能更优。
根据图表,最有趣的问题是:你是否看到了你预期的结果?回答这个问题将帮助你发现见解或找出数据中的错误。
为了获得灵感并了解哪种图表会带来最大价值,我经常参考 Python 的 seaborn 画廊。另一个很好的可视化和洞察发现的灵感来源是 Kaggle 上的 Kernels。这是我的 Kaggle Kernel,用于深入可视化 Titanic 数据集。
在租金的背景下,我绘制了每个连续特征的直方图,并预计租金(不含账单)和总面积的分布会有较长的右尾。
连续特征的直方图
箱线图帮助我查看了每个特征的异常值数量。实际上,大多数基于租金(不含账单)的异常公寓要么是面积超过 200m²的小商铺要么是租金非常低的学生宿舍。
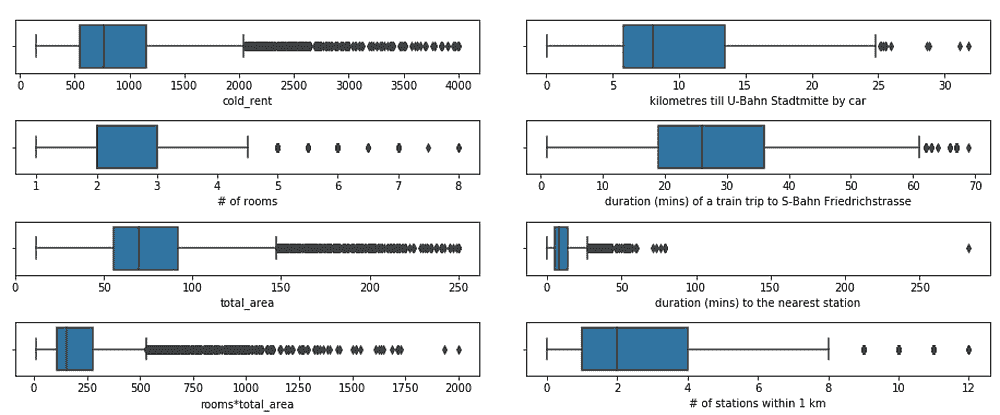
连续特征的箱线图
2. 我是否根据整个数据集来填补缺失值?
有时会因为各种原因出现缺失值。如果我们排除每个至少有一个缺失值的观测值,可能会导致数据集非常缩减。
有 许多填补方法 ,例如均值或中位数。如何进行填补是你自己的选择,但 要确保只在训练数据上计算填补统计,以避免 数据泄露。
在租赁数据中,我还提取了公寓的描述。每当质量、条件或公寓类型缺失时,我会从描述中填补这些信息,如果描述中包含这些信息的话。
3. 我如何转换分类变量?
一些算法根据实现方式,可能无法直接处理分类数据,因此需要以某种方式将其转换为数值型。
将分类变量转换为数值特征的方法有很多,例如 Label Encoder、One Hot Encoding、bin encoding 和哈希编码。然而,大多数人错误地使用 Label Encoding,而应该使用 One Hot Encoding。
假设在我们的租赁数据中,有一个公寓类型列,值为:[ground floor, loft, maisonette, loft, loft, ground floor]。LabelEncoder 可以将其转换为 [3,2,1,2,2,1],引入序次,这意味着 ground_floor > loft > maisonette。对于像决策树及其变种这样的算法,这种特征编码方式是可以接受的,但对回归和 SVM 应用可能意义不大。
在租金数据集中,条件 编码如下:
-
new:1
-
renovated:2
-
需要翻新: 3
和 质量 如下:
-
Luxus:1
-
好于正常: 2
-
正常: 3
-
简单: 4
-
未知: 5
4. 我需要对变量进行标准化吗?
标准化将所有连续变量缩放到相同的范围,这意味着如果一个变量的值从 1K 到 1M,而另一个变量的值从 0.1 到 1,标准化后它们将具有相同的范围。
L1 或 L2 正则化是减少过拟合的常见方法,可以在许多回归算法中使用。然而,在应用 L1 或 L2 之前进行特征标准化是很重要的。
租金以欧元为单位,因此拟合的系数会比价格以分为单位时的拟合系数大约大 100 倍。L1 和 L2 会对较大的系数施加更多惩罚,这意味着它会对较小尺度的特征施加更多惩罚。为了避免这种情况,特征应该在应用 L1 或 L2 之前进行标准化。
标准化的另一个原因是,如果你或你的算法使用梯度下降,梯度下降在特征缩放的情况下会收敛得更快。
5. 我需要对目标变量进行对数变换吗?
我花了一段时间才明白没有普遍的答案。
这取决于许多因素:
-
你是想要分数误差还是绝对误差
-
你使用的是哪种算法
-
残差图和指标变化告诉你什么
在回归中,首先关注残差图和指标。有时,对目标变量进行对数变换会得到更好的模型,模型的结果仍然容易理解。然而,还有其他的变换可能也值得关注,比如取平方根。
关于这个问题在 Stack Overflow 上有很多答案,我认为残差图和原始与对数目标变量的 RMSE解释得非常好。
对于租赁数据,我对价格进行了对数变换,因为残差图看起来好一点。
对数的残差图(左)和未变换数据(右)不包括账单变量的租金。右侧的图展示了“异方差性”——残差随着预测从小到大而变大。
其他一些重要内容
一些算法,如回归,会受到数据中的共线性的影响,因为系数变得非常不稳定(更多数学)。支持向量机(SVM) 可能会或可能不会受到共线性的影响,这取决于核函数的选择。
基于决策的算法不会受到多重共线性的影响,因为它们可以在不同的树中互换使用特征,而不会影响性能。然而,特征重要性的解释变得更困难,因为相关变量可能不会显得像实际那样重要。
机器学习
在你熟悉数据并清理了异常值之后,是时候掌握机器学习了。你可以使用许多算法进行这种监督式机器学习。
我想探索三种不同的算法,比较它们的特性,如性能差异和速度。这三种算法分别是不同实现的梯度提升树(XGBoost 和 LightGBM)、随机森林(FR,scikit-learn)和 3 层神经网络(NN,Tensorflow)。我选择了 RMSLE(均方根对数误差)作为过程优化的指标。我使用 RMSLE 是因为我对目标变量进行了对数转换。
XGBoost 和 LightGBM 表现相当,RF 稍差,而 NN 表现最差。
算法在测试集上的表现(RMSLE)。
基于决策树的算法非常擅长解释特征。例如,它们会生成特征重要性分数。
特征重要性:寻找租金价格的驱动因素
在拟合决策树模型后,你可以看到哪些特征对于价格预测最为宝贵。
特征重要性提供了一个分数,表示每个特征在模型中构建决策树时的贡献度。计算这个分数的一种方法是统计一个特征在所有树中被用于分割数据的次数。这个分数可以通过不同的方式来计算。
特征重要性可以揭示关于主要价格驱动因素的其他见解。
对于租金价格预测来说,总面积是价格最重要的驱动因素也不足为奇。有趣的是,一些通过外部 API 工程化的特征也在最重要的特征之列。
通过分割(上图)和增益(下图)计算的特征重要性
然而,如在《可解释的机器学习与 XGBoost》中提到的,根据归因选项,特征重要性可能会存在不一致。链接博客的作者和 SHAP NIPS 论文提出了一种新的特征重要性计算方法,该方法既准确又一致。它使用了shap Python 库。SHAP 值表示特征对模型输出变化的责任。
租赁价格数据分析的结果见下图。
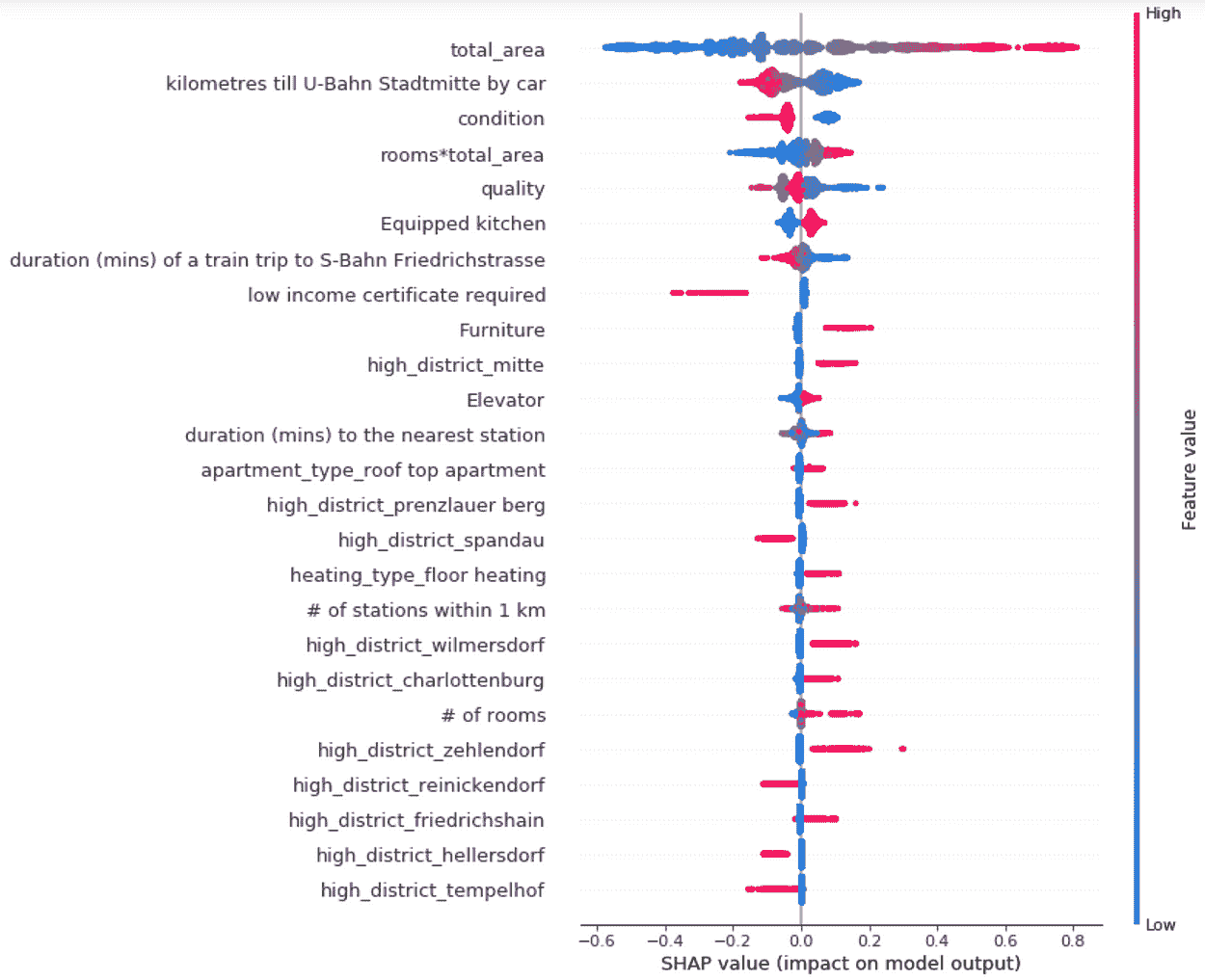
每个公寓在每一行上都有一个点。点的 x 位置表示该特征对模型预测的影响,点的颜色表示该特征对公寓的值
该图包含了大量有价值的信息(特征按均值排序(|Tree SHAP|))。小说明:数据来自 2018 年初;地区可能会有所变化,因此价格相关因素也可能会变化。
-
离市中心的距离(开车到 U-Bahn Stadtmitte 的公里数以及乘火车到 S-Bahn Friedrichstrasse 的时间)会提高预测的租赁公寓价格。
-
总面积是租赁价格最重要的驱动因素。
-
如果公寓所有者要求你提供低收入证明(德语中的 WBS),则预测价格较低。
-
在这些区域租赁公寓也会提高租金价格:Mitte, Prenzlauer Berg, Wilmersdorf, Charlottenburg, Zehlendorf 和 Friedrichshain。
-
价格较低的地区包括:Spandau, Tempelhof, Wedding 和 Reinickendorf
-
显然,公寓的状态越好——数值越低越好——质量越高——数值越低越好——有家具、内置厨房和电梯的公寓会更贵。
以下特征的影响很有趣:
-
到最近地铁站的时间
-
1 公里范围内的车站数量。
到最近地铁站的时间:
对于一些公寓,这一特征的高值表示价格较高。原因是这些公寓位于柏林市外的非常富裕的住宅区。
还可以看到,靠近地铁站有两种效果:对某些公寓,它会降低和提高价格。原因可能是距离地铁站非常近的公寓也会受到地下噪音或列车震动的影响,但另一方面,这些公寓与公共交通连接良好。然而,仍需深入研究这一特征,因为它仅显示了距离最近的地铁站的距离,而不是电车/公交车站。
1 公里范围内的车站数量:
对于距离公寓一公里以内的车站数量也是如此。一般来说,附近的地铁站越多,租金价格会越高。然而,它也有负面影响——更多的噪声。
集成平均
在尝试不同模型并比较性能之后,你可以将每个模型的结果进行组合并构建一个集成模型!
Bagging 是一种机器学习集成模型,它利用多个算法的预测来计算最终的聚合预测。它旨在防止过拟合并减少算法的方差。
使用集成模型的优点:红色模型在左下角的表现更好,而蓝色模型在右上角的表现更好。通过结合这两个模型的预测,可以提升整体性能。图取自 这里。
由于我已经有了上述算法的预测,我将所有四个模型以所有可能的方式进行组合,并根据验证集的 RMSLE 选择了七个最佳的单模型和集成模型。
然后计算了这七个模型在测试集上的 RMSLE。
算法的测试 RMSLE。
三种基于决策树的算法的集成效果最好,相较于每个单一模型。
你也可以产生一个加权集成模型,给予更好的单一模型更多的权重。其理由是,其他模型只有在它们一致同意一个替代方案时,才可能会推翻最好的模型。
实际上,人们永远不会知道一个平均的集成模型是否比单一模型更好,除非尝试一下。
堆叠模型
平均或加权的集成模型不是唯一的结合不同模型预测的方法。你也可以以非常不同的方式堆叠模型!
堆叠模型的理念是创建多个基础模型,并在基础模型的结果之上构建一个元模型,以产生最终预测。然而,训练元模型并不那么明显,因为它可能会偏向于最好的基础模型。关于如何正确进行堆叠的一个很好的解释可以在帖子 “堆叠模型以改进预测” 中找到。
对于租金价格的情况,堆叠模型并没有改善 RMSLE——它们甚至增加了指标。这可能有几个原因——要么是我编码有误 😉 要么就是堆叠引入了过多噪声。
如果你想探索更多关于集成和堆叠模型的文章,Kaggle 集成指南 解释了多种不同类型的集成,包括性能比较和如何让这些堆叠模型在 Kaggle 竞赛中名列前茅的参考资料。
最终思考
-
倾听你周围人的谈话,他们的抱怨可以作为解决重大问题的良好起点
-
通过提供交互式仪表板,让人们发现自己的见解
-
不要将自己限制在常见的特征工程(例如两个变量的乘积)中。尝试寻找额外的数据来源或解释
-
尝试集成模型和堆叠模型,这些方法可能提高性能
请提供您展示的数据的日期!
图表来源:
www.pinterest.de/minimalcouture/paris-apartments/
www.theodysseyonline.com/the-struggles-of-moving-into-your-first-apartment
www.fashionbeans.com/content/the-worlds-10-smallest-apartments-are-downright-shocking/
个人简介:耶卡特琳娜·科卡修哈 是 Zalando 的研究工程师,专注于可扩展的机器学习用于欺诈预测。
原文。经授权转载。
资源:
相关资料:
更多相关主题
数据科学面试中的最常见 SQL 错误
原文:
www.kdnuggets.com/2021/11/common-sql-mistakes-data-science-interviews.html
评论

这些错误涉及到在 数据科学编程面试问题 中经常出现的概念,这些概念可能会导致你的面试失败,因此了解如何避免它们以及如何纠正它们非常重要。
我们的三大课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业生涯。
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持组织的 IT 工作
错误 1: LIMIT 用于最大值/最小值
可能最常见的错误与在数据集中查找最高或最低值的记录有关。这听起来是一个简单的问题,但由于 SQL 的工作方式,我们通常不能简单地使用 MAX 或 MIN 函数。相反,我们需要设计另一种方法来输出相关的行。在这样做时,有一种常用的方法在逻辑上似乎是正确的,更糟糕的是,它经常产生预期的结果。问题在于这种解决方案没有考虑所有可能性,并跳过了一些重要的边缘情况。让我们看一个例子来理解这个错误。

链接: platform.stratascratch.com/coding/10353-workers-with-the-highest-salaries
这个问题来源于 DoorDash 数据科学家职位的实际面试。我们需要在员工和他们的职位数据集中找到薪资最高的职位名称。一个常见且可能是最简单的解决方案如下:
SELECT t.worker_title
FROM worker AS w
LEFT JOIN title AS t ON w.worker_id = t.worker_ref_id
ORDER BY w.salary DESC
LIMIT 1
我们需要合并两个表,因为列 worker_title 来自一个数据集,而列 'salary 来自另一个,但这不是我们应该关注的部分。其余的代码是一种相当直接的方式来返回具有最高值的行。我们选择要返回的列,按某个值降序排列表格,并仅通过使用 LIMIT 1 输出第一行。你能看到这个解决方案的问题吗?
在许多情况下,使用这种方法会产生预期的输出,但问题是它忽略了一个重要且常见的边界情况。也就是说,如果数据中存在并列怎么办?如果两行有相同的最高值怎么办?正如你在这个例子中看到的,这个解决方案被标记为不正确,因为实际上有两个职位的薪资相同,而且还是最高薪资。使用 LIMIT 语句要求我们知道多少行共享最高值,而在大多数情况下,我们不知道,因此这种方法是不正确的。
如何纠正这个解决方案?实际上,有多种方法可以以稳健的方式找到具有最大或最小值的行。一种方法是使用一个子查询,在其中找到感兴趣的值,然后在主查询中使用它作为过滤条件。在我们的例子中,我们可以保留前三行代码,但将 ORDER BY 和 LIMIT 语句替换为 WHERE 子句。在其中,我们要告诉引擎只留下那些“薪资”列等于整个数据集最高薪资的行。在 SQL 中,这看起来是这样的:
SELECT t.worker_title
FROM worker AS w
LEFT JOIN title AS t ON w.worker_id = t.worker_ref_id
WHERE w.salary IN
(SELECT max(salary)
FROM worker)
在 WHERE 子句中,有一个子查询只返回一个值——最高薪资。然后我们使用这个数字来过滤数据集,只输出薪资等于该数字的行。
另一种常见的方法是使用窗口函数 RANK() 添加一个新的列,以根据职位薪资进行排名。
SELECT t.worker_title,
RANK() OVER (
ORDER BY w.salary DESC) AS rnk
FROM worker AS w
LEFT JOIN title AS t ON w.worker_id = t.worker_ref_id
如你所见,RANK() 函数考虑了结果中的并列情况,因为在这里,两个职位的薪资相同,它们都被赋予了第一名。然后我们可以将这个排名用作内部查询,并添加主查询,只留下排名等于 1 的这些职位。
SELECT worker_title
FROM
(SELECT t.worker_title,
RANK() OVER (
ORDER BY w.salary DESC) AS rnk
FROM worker AS w
LEFT JOIN title AS t ON w.worker_id = t.worker_ref_id) a
WHERE rnk = 1
错误 2:Row_Number() 与 Rank() 与 Dense_Rank()
链接: platform.stratascratch.com/coding/10062-fans-vs-opposition
说到 RANK() 和窗口函数,常见的一个错误与它们有关。看看上面 Facebook 的 SQL 面试问题。这里 Facebook 说他们对员工进行了调查,以量化一些新编程语言的受欢迎程度。现在他们希望将最喜欢它的人与最讨厌它的人匹配。最大的粉丝与最大的反对者配对,第二大的粉丝与第二大的反对者配对,以此类推。
尽管这个面试问题很长且看起来很难,但解决方案并不特别复杂。我们可以简单地将数据集按受欢迎程度降序排序,然后再按升序排序,将这两张表放在一起,或者用技术术语说,合并它们。解决方案可能是这样的:
SELECT fans.employee_fan_id,
opposition.employee_opposition_id
FROM
(SELECT employee_id AS employee_fan_id,
RANK() OVER (
ORDER BY s.popularity DESC) AS position
FROM facebook_hack_survey s ) fans
INNER JOIN
(SELECT employee_id AS employee_opposition_id,
RANK() OVER (
ORDER BY s.popularity ASC) AS position
FROM facebook_hack_survey s ) opposition
ON fans.position = opposition.position
这个解决方案的关键部分是这个 ‘INNER JOIN’ 语句两边的两个子查询。它们返回相同的表,但排序方式相反。为了将这些表合并在一起并创建匹配,SQL 中最简单的方法是根据这些排序方式给员工分配连续的编号,并将这些编号匹配在一起。因此,最受欢迎的粉丝将得到编号 1,并与在 ‘opposition’ 表中也得到编号 1 的最大对手匹配。
但当我们运行这段代码时,出现了问题。从结果的顶部可以看到,员工 17 与员工 13 和 2 都配对了。更有甚者,相同的员工 13 和 2 也与员工 5 配对了。然后再次与员工 8 配对。显然有什么地方出错了。让我们修改 SELECT 子句以显示排名。
SELECT fans.employee_fan_id,
opposition.employee_opposition_id,
Fans.position AS position_fans,
Opposition.position AS position_opp
FROM
(SELECT employee_id AS employee_fan_id,
RANK() OVER (
ORDER BY s.popularity DESC) AS position
FROM facebook_hack_survey s ) fans
INNER JOIN
(SELECT employee_id AS employee_opposition_id,
RANK() OVER (
ORDER BY s.popularity ASC) AS position
FROM facebook_hack_survey s ) opposition
ON fans.position = opposition.position
这里发生了什么?似乎调查中有得分相同的员工。换句话说,数据中存在并列的情况。正如你可能还记得之前的错误,RANK() 函数会给所有具有相同值的行分配相同的分数。所以在这里,员工 17、5 和 8 都得到了相同的最高人气分数,而员工 13 和 2 则得到了相同的最低分数。这就是为什么这五个人在所有可能的组合中都被匹配在一起。但是,如果只有 13 和 2 共享了相同的最低分数,那么本应有一个排名为 3 的对手员工。然而,由于没有排名为 3 的粉丝,他们没有与任何人匹配。
如何解决这个问题?有些人可能会说,如果 RANK() 函数不起作用,我们可以尝试用 DENSE_RANK() 替换它。这两者的区别在于处理并列的方式。如果我们有四个值,其中前两个相同,那么 RANK() 会给它们分配排名 1、1、3 和 4。与此同时,DENSE_RANK() 会将它们排名为 1、1、2 和 3。但在这种情况下这是正确的解决方案吗?
SELECT fans.employee_fan_id,
opposition.employee_opposition_id,
fans.position as position_fans,
opposition.position as position_opp
FROM
(SELECT employee_id AS employee_fan_id,
DENSE_RANK() OVER (
ORDER BY s.popularity DESC) AS position
FROM facebook_hack_survey s ) fans
INNER JOIN
(SELECT employee_id AS employee_opposition_id,
DENSE_RANK() OVER (
ORDER BY s.popularity ASC) AS position
FROM facebook_hack_survey s ) opposition
ON fans.position = opposition.position
我们解决了员工 10 之前没有与任何人匹配的问题,但其他问题仍然存在。DENSE_RANK() 仍然对具有相同值的行给予相同的排名,因此仍然有一些员工与多于一个人配对。那么正确的解决方案是什么呢?有一个叫做 ROW_NUMBER() 的类似窗口函数。有人认为它“基础”是因为它只是计数行而不处理并列值。但这正是使这个函数在这种情况下完美的特性。
SELECT fans.employee_fan_id,
opposition.employee_opposition_id,
fans.position as position_fans,
opposition.position as position_opp
FROM
(SELECT employee_id AS employee_fan_id,
ROW_NUMBER() OVER (
ORDER BY s.popularity DESC) AS position
FROM facebook_hack_survey s ) fans
INNER JOIN
(SELECT employee_id AS employee_opposition_id,
ROW_NUMBER() OVER (
ORDER BY s.popularity ASC) AS position
FROM facebook_hack_survey s ) opposition
ON fans.position = opposition.position
现在所有员工都被赋予了唯一的排名,因此可以在不重复和不遗漏任何人的情况下进行配对。虽然在数据科学面试中,粉丝与对手配对的问题并不是最常见的,但基于这个例子,我们想展示一下理解 RANK()、DENSE_RANK() 和 ROW_NUMBER() 之间的区别有多么重要——它们都是非常相似的 窗口函数。
错误 3:引号中的别名

在这个例子中,我们给一些子查询和列命名,如‘fans’和‘opposition’。这些是所谓的别名,在 SQL 中非常流行,但也是一些常见错误的来源。让我们换个简单的例子来看一下这些错误。

链接: platform.stratascratch.com/coding/2061-users-with-many-searches?python=
在这个最近的数据科学面试问题中,Facebook 要求根据某些搜索数据库计算 2021 年 8 月进行过超过五次搜索的用户数量。解决方案如下:
SELECT count(user_id) AS result
FROM
(SELECT user_id,
count(search_id) AS "AugustSearches"
FROM fb_searches
WHERE date::date BETWEEN '2021-08-01' AND '2021-08-31'
GROUP BY user_id) a
WHERE AugustSearches > 5
在内部查询中,我们统计了每个用户在所需时间框架内的搜索次数,然后在外部查询中,我们只考虑进行过超过五次搜索的用户,并对他们进行计数。但是,当我们尝试运行时,出现了错误。它说‘列 "augustsearches" 不存在’。这怎么可能呢?毕竟,我们在内部查询中将别名赋予了‘AugustSearches’,所以我们应该可以在外部查询的 WHERE 子句中使用它,对吗?是的,但不幸的是,我们在分配别名时犯了一个错误。你能看出来吗?修复它的最简单方法是去掉别名中的引号:
SELECT count(user_id) AS result
FROM
(SELECT user_id,
count(search_id) AS AugustSearches
FROM fb_searches
WHERE date::date BETWEEN '2021-08-01' AND '2021-08-31'
GROUP BY user_id) a
WHERE AugustSearches > 5
这是一个常见错误,因为我们在 SQL 中使用引号来书写字符串,而别名感觉像是字符串。但实际上,这个问题起因于其他地方,涉及到大写字母。为了节省内存,SQL 总是将列名转换为小写字母。所以即使我们写‘WHERE AugustSearches’,SQL 也会将其解释为‘WHERE augustsearches’。但当我们在引号中定义别名时,SQL 保留所有的大写字母,但当我们将别名与不带引号的别名进行比较时,会导致问题。理论上,我们可以始终使用带引号的别名:
SELECT count(user_id) AS result
FROM
(SELECT user_id,
count(search_id) AS "AugustSearches"
FROM fb_searches
WHERE date::date BETWEEN '2021-08-01' AND '2021-08-31'
GROUP BY user_id) a
WHERE “AugustSearches” > 5
这段代码会运行,但计算时间会更长,消耗更多内存,并可能造成一些混淆。我们需要记住每次使用别名时都要加上引号。因此这里的教训是不使用别名,并且只使用小写字母作为别名。
SELECT count(user_id) AS result
FROM
(SELECT user_id,
count(search_id) AS august_searches
FROM fb_searches
WHERE date::date BETWEEN '2021-08-01' AND '2021-08-31'
GROUP BY user_id) a
WHERE august_searches > 5
错误 4:别名的不一致性
链接: platform.stratascratch.com/coding/10353-workers-with-the-highest-salaries
另一个常见的问题是别名使用的不一致。这不是一个重大错误,只要不同表中没有相同的列名,它不会造成主要问题。但这是一个可以决定你的数据科学面试成功与否的细节。让我们回到开始的问题,即关于最高收入职位的那个。这是另一个可能的正确解决方案:
SELECT t.worker_title
FROM worker w
LEFT JOIN title t ON w.worker_id = t.worker_ref_id
WHERE salary =
(SELECT MAX(salary)
FROM worker w
LEFT JOIN title t ON w.worker_id = t.worker_ref_id)
ORDER BY worker_title ASC
你能看到别名的问题吗?首先,我们为两个表定义了别名。在这种情况下,是字母 ‘w’ 和 ‘t’。然后我们说 ‘t.worker_title’,但为什么在 WHERE 子句中 ‘salary’ 没有任何别名?为什么 ‘worker_title’ 列在 ORDER BY 子句中突然没有别名?再看看子查询:我们为表指定了别名,但在选择这个查询中的唯一列时没有使用它们。另一个问题是内外查询中使用了相同的别名,但由于在这种情况下它们总是用于相同的表,我们可以忽略。保持一致地使用别名,这个解决方案会显得更加干净和清晰。
SELECT t.worker_title
FROM worker w
LEFT JOIN title t ON w.worker_id = t.worker_ref_id
WHERE w.salary =
(SELECT MAX(w.salary)
FROM worker w
LEFT JOIN title t ON w.worker_id = t.worker_ref_id)
ORDER BY t.worker_title ASC
错误 5: 不必要的 JOIN
但我们还没有完全解决问题。这个解决方案还有一个错误。是的,它仍然有效并产生预期结果,但我们不能说它是高效的。你能看到为什么吗?看看内层查询。在其中,我们只选择了一列,salary。这个列来自于一个名为‘worker’的表。现在我们已经修复了别名,这一点尤为清晰。但如果是这种情况,那我们为什么在内层查询中合并这两个表呢?这并不必要,并且使得解决方案的效率降低。毕竟,每次 JOIN 操作都需要一些计算时间,如果表很大,这个时间可能会很可观。我们知道,当问题涉及多个表时,逻辑上的第一步是将它们合并在一起。但正如这个例子所示,我们应该仅在必要时才这样做。
SELECT t.worker_title
FROM worker w
LEFT JOIN title t ON w.worker_id = t.worker_ref_id
WHERE w.salary =
(SELECT MAX(w.salary)
FROM worker w
ORDER BY t.worker_title ASC
错误 6: 在包含 NULL 值的列上进行 JOIN
链接: platform.stratascratch.com/coding/9627-3-bed-minimum
让我们再展示一个常见的错误,同样与 JOIN 语句有关。看看这个问题,Airbnb 要求找出每个至少有三个床的邻里中的平均床数。虽然存在更简单的解决方案,但一种有效的方法是将原始表与自身合并,但以汇总的方式,这样我们就已经得到每个邻里的床数,前提是床数至少为三个。我们可以通过子查询或像这个解决方案中的 JOIN 语句来实现:
SELECT anb.neighbourhood,
avg(anb.beds) AS avg_n_beds
FROM airbnb_search_details AS anb
RIGHT JOIN
(SELECT neighbourhood,
sum(beds)
FROM airbnb_search_details
GROUP BY 1
HAVING sum(beds)>=3) AS fil_anb
ON anb.neighbourhood = fil_anb.neighbourhood
GROUP BY 1
ORDER BY avg_n_beds DESC
当我们运行这段代码时,乍一看还不错,但顶部的这个空白是什么?当我们将输出与预期结果进行比较时,发现我们的代码不正确。那么发生了什么?让我们仅运行内层查询以寻找线索。
SELECT neighbourhood,
sum(beds)
FROM airbnb_search_details
GROUP BY 1
HAVING sum(beds)>=3
你能看到这一行吗?结果显示有 33 张床没有分配到任何邻里。相反,邻里的值为‘NULL’。为什么这会造成问题?因为在我们的主要查询中,我们在邻里列上对两个表进行了 JOIN - 这两个列都包含 NULL 值。而在 SQL 中,如果我们在 NULL 值之间使用操作符‘=’,引擎将无法正确匹配它们。
如何解决这个问题?如果我们确实需要基于包含 NULL 值的列合并两个表,我们需要明确告诉引擎如何处理它们。因此,我们可以像之前一样开始,写下‘anb.neighbourhood = fil_anb.neighbourhood’,然后继续添加第二种情况:如果 anb.neighbourhood 中的值为 NULL,则 fil_anb.neighbourhood 中的值也应为‘NULL’。在代码中,它看起来像这样:
SELECT anb.neighbourhood,
avg(anb.beds) AS avg_n_beds
FROM airbnb_search_details AS anb
RIGHT JOIN
(SELECT neighbourhood,
sum(beds)
FROM airbnb_search_details
GROUP BY 1
HAVING sum(beds)>=3) AS fil_anb
ON (anb.neighbourhood= fil_anb.neighbourhood) or (anb.neighbourhood is NULL
and fil_anb.neighbourhood is NULL)
GROUP BY 1
ORDER BY avg_n_beds DESC
结论
这些就是我们为你准备的所有示例。我们展示了不同的编码错误,有的更严重,有的较轻,但都同样重要,特别是在面试环境中。在那里,不仅是解决方案是否有效,还有它的书写方式以及你作为候选人是否注重细节。如果你记住这些最常见的错误,并在未来尽量避免它们,这将提高你在data science interview中成功的机会!
原文。已获许可转载。
相关:
更多相关话题
合成数据社区的出现及其必要性
原文:
www.kdnuggets.com/2022/04/community-synthetic-data-need.html
OpenSynthetics 社区
合成数据是一项有前景的技术,目前正处于早期采用阶段。为了过渡到主流采用,研究社区需要一个可以了解、讨论最新创新和进行实验的地方。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 需求
我很高兴地宣布 OpenSynthetics.com,这是一个用于计算机视觉和机器学习(ML)中创建和使用合成数据的开放社区。
合成数据是计算机生成的图像数据,用于模拟真实世界。在视觉领域,合成数据在创建更强大和更具伦理的 AI 模型方面展现了潜力。通过创建一个集中的数据集、论文、代码和资源的中心,我们旨在将业界和学术界的研究人员汇聚在一起,以推动最先进的合成数据发展。
为什么是现在?
下一代计算机视觉将由合成数据驱动。近年来,合成数据作为一种颠覆性的训练 AI 模型的新范式已经出现。通过视觉效果(VFX)、神经渲染和生成 AI 技术,研究人员展示了快速构建大量逼真、多样化且完全标注的数据集的能力,同时降低了成本。这将使自主驾驶、机器人、无人机、增强现实/虚拟现实/元宇宙、生成媒体等领域的模型更加强大,并扩展到从消费者到医疗等各种应用。
目前的计算机视觉模型需要大量人工标注的数据来帮助摄像头识别它们所看到的内容。这既费时又费力,成本高昂,并且有显著的缺陷。人类很难解释关键数据属性,如物体的 3D 位置或其与环境的互动。
此外,无法捕捉足够多样和均衡的数据集通常会导致偏见,这在以人为本的系统中具有重要的伦理影响。此外,监管审查的增加和消费者隐私问题使得收集和利用人像变得复杂。
使用合成数据的方法,每个场景中的每个像素的信息都被明确地定义。以前无法获得的 3D 地标、深度、材料属性、表面法线、子分割等的像素级标签现在都可以获得。此外,这些数据和标签可以根据需要提供,使得 ML 从业者能够比以往任何时候都快几个数量级地进行实验和迭代。合成数据还通过减少偏见、保护隐私和民主化数据访问来解决关键的伦理问题。
时机正好,需求也已出现。我们正处于合成数据的一个拐点:
-
关于深度学习的第一本合成数据书籍 (link) 于 2021 年发布;
-
Gartner 预测,未来几年合成数据的体量将是实际数据的 10 倍;
-
《MIT 技术评论》指出 (link) 合成数据被评为 2022 年十大突破性技术之一。
随着越来越多的研究人员对合成数据产生兴趣,OpenSynthetics 将作为一个强大的参考,帮助教育更广泛的社区。
为什么要贡献和参与?
合成数据代表了训练计算机视觉模型的范式转变,但它也是构建更通用智能的关键技术。未来,研究人员将越来越多地利用这些数字世界来构建能够深刻理解并互动和操控周围世界的 AI 模型。
OpenSynthetics 将汇集学术界和工业界的研究人员和从业者,建立一个开放且合作的社区,推动该领域的发展。我们相信,合成数据将驱动下一代计算机视觉的发展,我们可以共同帮助催化创新。通过在该网站上贡献和参与,社区将积极建立知识库,以帮助提高对这一新兴技术的理解并推动其采用。我们希望您能加入我们,共同创建一个蓬勃发展的 OpenSynthetics 社区。
Yashar Behzadi 博士 是 Synthesis AI 的首席执行官兼创始人。他是一位经验丰富的企业家,在 AI、医疗技术和物联网市场中建立了变革性的企业。
更多相关话题
LangChain 与 LlamaIndex 的比较分析
原文:
www.kdnuggets.com/comparative-analysis-of-langchain-and-llamaindex
图片由编辑提供 | Midjourney
最近,人工智能(AI)和大型语言模型(LLM)的领域迅速发展,达到了新的高度。举几个例子,LangChain 和 LlamaIndex 已成为主要参与者。每个工具都有其独特的功能和优势。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您在 IT 领域的组织
本文比较了这两种引人入胜的技术之间的较量,比较了它们的功能、优势和实际应用。如果您是 AI 开发人员或爱好者,这一分析将帮助您了解哪种工具可能适合您的需求。
LangChain
LangChain 是一个全面的框架,旨在构建由 LLM 驱动的应用程序。其主要目标是简化和增强 LLM 应用程序的整个生命周期,使开发者更容易创建、优化和部署 AI 驱动的解决方案。LangChain 通过提供工具和组件来实现这一目标,从而简化了开发、生产化和部署过程。
LangChain 提供的工具
LangChain 的工具包括模型输入/输出、检索、链、记忆和代理。所有这些工具将在下面详细解释:
模型输入/输出: LangChain 功能的核心在于模块模型输入/输出(Input/Output),这是利用 LLM 潜力的关键组成部分。该功能为开发者提供了一个标准化且用户友好的接口,用于与 LLM 进行交互,简化了创建 LLM 驱动的应用程序的过程,以应对现实世界的挑战。
检索: 在许多 LLM 应用中,必须纳入超出模型原始训练范围的个性化数据。这是通过检索增强生成(RAG)实现的,该过程涉及提取外部数据并在生成过程中提供给 LLM。
Chains: 虽然独立的 LLM 适用于简单任务,但复杂应用需要将 LLM 进行链式协作或与其他关键组件结合。LangChain 提供了两个主要框架来进行这一迷人的过程:传统的 Chain 接口和现代的 LangChain 表达语言 (LCEL)。虽然 LCEL 在新应用中的链式组合中占据主导地位,LangChain 也提供了宝贵的预构建 Chains,确保这两个框架的无缝共存。
Memory:在 LangChain 中,Memory 指的是存储和回忆过去的互动。LangChain 提供了多种工具,将 Memory 集成到你的系统中,满足简单和复杂的需求。此 Memory 可以无缝地融入链条中,使它们能够读取和写入存储的数据。保存在 Memory 中的信息指导 LangChain Chains,通过借鉴过去的互动来提升响应。
Agents:Agents 是动态实体,利用 LLM 的推理能力实时决定行动顺序。与传统链条中预定义的序列不同,Agents 使用语言模型的智能动态决定下一步及其顺序,使其在协调复杂任务时非常适应和强大。
此图显示了 LangChain 框架的架构 | 来源:Langchain 文档
LangChain 生态系统包括以下内容:
-
LangSmith: 这帮助你追踪和评估你的语言模型应用程序和智能代理,助你从原型阶段过渡到生产阶段。
-
LangGraph: 是一个强大的工具,用于构建具有状态的多参与者应用程序。它建立在 LangChain 原语之上(并且旨在与之配合使用)。
-
LangServe: 使用此工具,你可以将 LangChain 可执行模块和链条部署为 REST API。
LlamaIndex
LlamaIndex 是一个复杂的框架,旨在优化 LLM 驱动应用程序的开发和部署。它提供了一种结构化的方法来将 LLM 集成到应用软件中,通过独特的架构设计提升其功能和性能。
曾被称为 GPT Index 的 LlamaIndex 作为一个专门的数据框架出现,旨在提升和强化 LLM 的功能。它专注于摄取、结构化和检索私有或特定领域的数据,提供了一个简化的界面,用于在庞大的文本数据集中索引和访问相关信息。
LlamaIndex 提供的工具
LlamaIndex 提供的一些工具包括数据连接器、引擎、数据代理和应用集成。所有这些工具在下面有详细解释:
数据连接器:数据连接器在数据集成中发挥着关键作用,简化了将数据源链接到数据仓库的复杂过程。它们消除了手动数据提取、转换和加载(ETL)的需求,这些操作可能繁琐且容易出错。这些连接器通过直接从原始来源和格式摄取数据来简化过程,从而节省了数据转换的时间。此外,数据连接器自动提升数据质量,通过加密保障数据安全,通过缓存提升性能,并减少了数据集成解决方案所需的维护。
引擎:LlamaIndex 引擎实现了数据与 LLMs 之间的无缝协作。它们提供了一个灵活的框架,将 LLMs 连接到各种数据源,简化了对现实世界信息的访问。这些引擎具备直观的搜索系统,能够理解自然语言查询,方便数据互动。它们还会组织数据以便更快访问,丰富 LLM 应用程序的附加信息,并帮助选择适合特定任务的 LLM。LlamaIndex 引擎在创建各种 LLM 驱动的应用程序时至关重要,弥合了数据与 LLMs 之间的差距,以应对现实世界的挑战。
数据代理:数据代理是 LlamaIndex 内部智能的、由 LLM 驱动的知识工作者,擅长管理你的数据。它们能够智能地导航未结构化、半结构化和结构化的数据源,并以有序的方式与外部服务 API 互动,处理“读取”和“写入”操作。这种多功能性使得它们在自动化数据相关任务中不可或缺。与仅限于从静态来源读取数据的查询引擎不同,数据代理可以动态地摄取和修改来自各种工具的数据,使其对不断变化的数据环境具有高度适应性。
应用集成:LlamaIndex 在构建 LLM 驱动的应用程序方面表现卓越,通过与其他工具和服务的广泛集成发挥其全部潜力。这些集成简化了与各种数据源、观察工具和应用框架的连接,推动了更强大和多样化的 LLM 驱动应用程序的开发。
实现比较
这两种技术在构建应用程序时可能会有相似之处。以聊天机器人为例。以下是如何使用 LangChain 构建本地聊天机器人的方法:
from langchain.schema import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
openai_api_base="http://localhost:5000",
openai_api_key="SK******",
max_tokens=1600,
Temperature=0.2
request_timeout=600,
)
chat_history = [
SystemMessage(content="You are a copywriter."),
HumanMessage(content="What is the meaning of Large language Evals?"),
]
print(llm(chat_history))
这是如何使用 LlamaIndex 构建本地聊天机器人的方法:
from llama_index.llms import ChatMessage, OpenAILike
llm = OpenAILike(
api_base="http://localhost:5000",
api_key=”******”,
is_chat_model=True,
context_window=32768,
timeout=600,
)
chat_history = [
ChatMessage(role="system", content="You are a copywriter."),
ChatMessage(role="user", content="What is the meaning of Large language Evals?"),
]
output = llm.chat(chat_history)
print(output)
主要区别
虽然 LangChain 和 LlamaIndex 在构建强健和适应性强的 LLM 驱动应用程序方面可能表现出某些相似性并互相补充,但它们之间存在相当大的不同。以下是两个平台的显著区别:
| 标准 | LangChain | LlamaIndex |
|---|---|---|
| 框架类型 | 开发和部署框架。 | 增强 LLM 能力的数据框架。 |
| 核心功能 | 提供 LLM 应用的构建块。 | 专注于数据的摄取、结构化和访问。 |
| 模块化 | 高度模块化,具有各种独立的软件包。 | 模块化设计以提高数据管理效率。 |
| 性能 | 针对构建和部署复杂应用进行了优化。 | 在基于文本的搜索和数据检索方面表现出色。 |
| 开发 | 使用开源组件和模板。 | 提供集成私有/特定领域数据的工具 |
| 生产化 | LangSmith 用于监控、调试和优化。 | 强调高质量的响应和精确的查询。 |
| 部署 | LangServe 将链转化为 API。 | 未提及具体部署工具。 |
| 集成 | 通过 langchain-community 支持第三方集成。 | 与 LLM 集成以增强数据处理能力。 |
| 现实世界应用 | 适用于跨行业复杂的 LLM 应用。 | 适合文档管理和精确的信息检索。 |
| 优势 | 多功能,支持多种集成,社区强大。 | 精确回应,数据处理高效,工具强大。 |
最终思考
根据具体需求和项目目标,任何由 LLM 驱动的应用都可以从使用 LangChain 或 LlamaIndex 中受益。LangChain 以其灵活性和先进的定制选项而闻名,非常适合上下文感知的应用。
LlamaIndex 在快速数据检索和生成简洁回应方面表现出色,非常适合知识驱动的应用,如聊天机器人、虚拟助手、基于内容的推荐系统和问答系统。结合 LangChain 和 LlamaIndex 的优势,可以帮助你构建高度复杂的 LLM 驱动应用。
资源
Shittu Olumide是一名软件工程师和技术作家,热衷于利用前沿技术创造引人入胜的叙述,具有敏锐的细节洞察力和简化复杂概念的能力。你还可以在Twitter上找到 Shittu。
更多相关主题
比较聚类技术:简明技术概述
原文:
www.kdnuggets.com/2016/09/comparing-clustering-techniques-concise-technical-overview.html
聚类用于分析未标记类别的数据。数据实例被分组在一起,使用最大化类内相似度和最小化不同类别之间相似度的概念。这意味着聚类算法识别并分组非常相似的实例,而不是那些彼此相似度较低的未分组实例。由于聚类不需要预先标记类别,它是一种无监督学习。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
- k *-均值聚类可能是最著名的聚类算法示例。然而,它并不是唯一的。完全不同的方案存在,如层次聚类、模糊聚类和密度聚类,还有不同的质心风格聚类方法,例如使用中位数(而不是均值),或确保质心是簇成员(请继续阅读以了解更多背景)。
以下是* k *-均值聚类算法的简要技术概述,以及基于高斯分布的期望最大化(EM)聚类方法。这两种方法都试图最大化类内相似度和最小化类间相似度,但采用了不同的方法来实现。
k-均值聚类
- k -均值是一种简单但通常有效的聚类方法。 k *个点被随机选择作为簇中心或质心,所有训练实例被绘制并添加到最近的簇中。在所有实例被添加到簇中后,代表每个簇实例均值的质心会重新计算,这些重新计算的质心将成为各自簇的新中心。
此时,所有的簇成员资格被重置,所有训练集中的实例被重新绘制并-添加到其最近的、可能重新中心化的簇中。这个迭代过程会持续进行,直到质心或其成员资格没有变化,簇被认为是稳定的。

图 1: k-均值聚类算法。
收敛是在重新计算的中心点与上一次迭代的中心点匹配,或在某个预设的范围内时实现的。在k-均值算法中,距离度量通常是欧几里得的,对于形式为(x, y)的 2 个点,可以表示为:
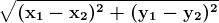
技术上特别要注意的是,特别是在并行计算时代,k-均值中的迭代聚类本质上是串行的;然而,迭代中的距离计算不必是串行的。因此,对于大规模数据集,距离计算是k-均值聚类算法中值得并行化的目标。
期望最大化
概率聚类旨在在给定数据集的情况下确定最可能的聚类集。EM 是一种概率聚类算法,因此涉及确定实例属于特定聚类的概率。EM “接近统计模型中参数的最大似然或最大后验估计”(Han, Kamber & Pei)。EM 过程以一组参数开始,迭代直到在 k 个聚类的情况下最大化聚类。
正如其名称所示,EM 包括两个不同的步骤:期望和最大化。期望步骤(E 步骤)根据参数将特定对象分配到聚类中。这也可以称为聚类概率计算步骤,聚类概率是“期望的”类别值。最大化步骤(M 步骤)计算分布参数,最大化期望的似然。
参数估计方程表达了每个聚类的概率是已知的,而不是聚类本身。聚类的均值计算为
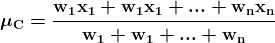
聚类的标准差由以下公式确定
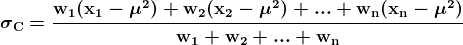
其中 w[i] 是实例 i 属于聚类 C 的概率,而 x[i] 是数据集中的所有实例。
当给定一个新的实例进行聚类时,其聚类成员概率被计算并与每个聚类进行比较。该实例成为具有最高成员概率的聚类的成员。这些步骤会重复进行,直到聚类间的变化低于预定的阈值。实际上,迭代应继续进行,直到对数似然增加微不足道,并且对数似然在前几次迭代期间通常会急剧增加,并迅速收敛到这个微不足道的点。
需要注意的是,EM 也可以用于模糊聚类,而不是概率聚类。
虽然* k *均值和期望最大化采用了不同的方法,但它们都是聚类技术。这种差异应该是对广泛存在的各种聚类技术之间差异的良好提示,这些技术在今天仍在使用。
相关:
-
MDL 聚类:无监督属性排序、离散化和聚类
-
期望最大化(EM)算法教程
-
支持向量机:简明技术概述
更多相关内容
使用 Python 和 SciPy 比较距离测量
原文:
www.kdnuggets.com/2017/08/comparing-distance-measurements-python-scipy.html

聚类或聚类分析用于分析不包含预先标记类别的数据。数据实例通过最大化类内相似性和最小化不同类别之间的相似性来进行分组。这意味着聚类算法识别并分组非常相似的实例,而不是那些彼此相似度较低的未分组实例。由于聚类不需要预先标记类别,它是一种无监督学习的形式。
聚类分析的核心是测量不同数据点维度之间的距离。例如,在考虑 k-means 聚类时,需要测量:a) 各个数据点维度与所有聚类中心维度之间的距离,b) 聚类中心维度与所有聚类成员数据点维度之间的距离。
虽然 k-means,作为最简单且最显著的聚类算法,通常使用欧几里得距离作为相似性距离测量,但设计创新或变体聚类算法,其中包括使用不同的距离测量方法并非难事。换句话说,使用不同的聚类相关距离测量技术是相对容易实现的。然而,实际这样做的原因则需要对领域和数据有深入的了解。
我们将跳过追求特定距离测量的“为什么”的讨论,而是快速介绍五种有效的测量数据点之间距离的方法。我们还将使用 Python 和 SciPy 库进行简单的演示和比较。有关 SciPy spatial.distance模块中可用的距离测量,请点击这里。
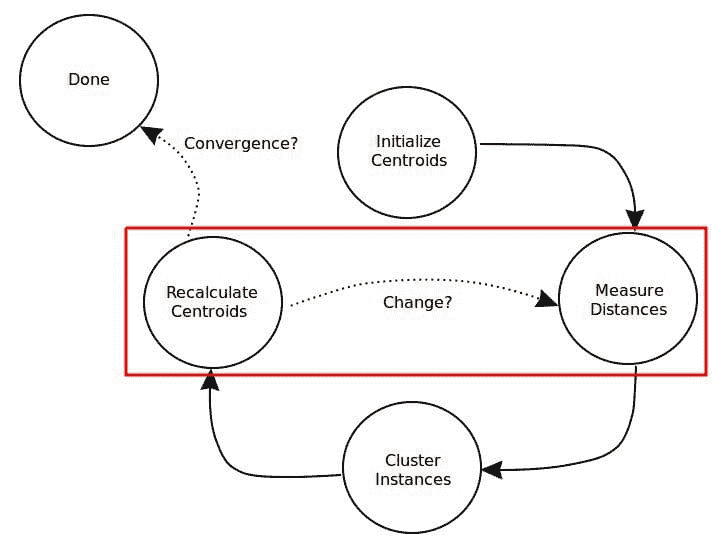
图 1:距离测量在聚类中扮演着重要角色。
对 k-means 聚类算法过程的简单概述,并指出了与距离相关的步骤。
欧几里得距离
我们不妨从永恒的欧几里得空间距离测量冠军开始。欧几里得距离是"'欧几里得空间中两点之间的“普通”直线距离"。
作为提醒,给定两个形式为(x, y)的点,欧几里得距离可以表示为:
曼哈顿距离
曼哈顿——也称为城市街区和出租车——距离定义为“两个点之间的距离是它们的笛卡尔坐标绝对差的总和。”
图 2: 曼哈顿几何以蓝色(楼梯)可视化,欧几里得以绿色(直线)(来源:维基百科)。
切比雪夫
切比雪夫——也称为棋盘——距离最好定义为一种距离度量“其中两个向量之间的距离是它们在任何坐标维度上的差异的最大值。”
图 3: 使用棋盘可视化切比雪夫(来源:维基百科)。
堪培拉
堪培拉距离是曼哈顿距离的加权版本,“曾被用作比较排名列表的度量和计算机安全中的入侵检测。”
堪培拉距离可以表示为

其中 p 和 q 是向量

余弦
余弦相似度 定义为:
...在内积空间中度量两个非零向量之间相似度的度量,它衡量它们之间角度的余弦。0°的余弦值为 1,对于其他角度则小于 1。因此,它是对方向的判断而非大小:具有相同方向的两个向量的余弦相似度为 1,90°的两个向量的相似度为 0,而两个相反的向量的相似度为-1,与它们的大小无关。余弦相似度特别用于正空间,其中结果 neatly 限定在 [0,1]。
余弦相似度常用于聚类中评估凝聚力,而不是确定簇的成员资格。
Python 和 SciPy 比较
为了明确我们在做什么,首先创建两个向量——每个向量有 10 维——然后使用 5 种测量技术对这些向量之间的距离进行逐元素比较,这些技术在 SciPy 函数中实现,每个函数接受一对一维向量作为参数。其次,创建一对 100 维的向量,并进行相同的距离测量和报告。
py` 10 维向量 ------------------------ [ 3.77539984 0.17095249 5.0676076 7.80039483 9.51290778 7.94013829 6.32300886 7.54311972 3.40075028 4.92240096] [ 7.13095162 1.59745192 1.22637349 3.4916574 7.30864499 2.22205897 4.42982693 1.99973618 9.44411503 9.97186125] 10 维向量的距离测量 ------------------------------------------------- 欧几里得距离为 13.435128482 曼哈顿距离为 39.3837553638 切比雪夫距离为 6.04336474839 堪培拉距离为 4.36638963773 余弦距离为 0.247317394393 100 维向量的距离测量 -------------------------------------------------- 欧几里得距离为 42.6017789666 曼哈顿距离为 359.435547878 切比雪夫距离为 9.06282495069 堪培拉距离为 40.8173353649 余弦距离为 0.269329456631 ```py ````
从这些测量结果中,我们可以迅速发现两个重要的结论:
-
报告的距离(显然)在距离测量技术之间差异很大
-
一些测量技术在(至少在这个实验中)更容易受到维度增加的影响(而相反,有些技术的影响要小得多)
尽管从这个简单的概述和展示中无法得出重大结论,但这些结果应该将 Hastie、Tibshirani 和 Friedman 的《统计学习元素》的这段摘录放在合适的背景下考虑:
适当的差异度量在聚类的成功中比聚类算法的选择更为重要。这个问题的这一方面……取决于领域特定知识,并且不太适合通用研究。
同样重要的是要注意,距离的关键概念在聚类分析中,并不是测量值的确切数值,而是这些测量值如何用于对数据点进行分组。例如,如果你将每个测量值乘以 100,数值会有所不同,但最终的聚类结果仍然保持不变。
在考虑“聚类”时,很多人往往只会将数据集直接投入到 k-means 算法中,使用默认设置。希望这篇简短的文章能为聚类算法及其组成部分的潜在复杂性和影响提供一些见解。
相关:
-
比较聚类技术:简明技术概述
-
聚类关键术语解释
-
从头开始的 Python 机器学习工作流程第二部分:k-means 聚类
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 部门
更多相关话题
比较线性回归和逻辑回归
原文:
www.kdnuggets.com/2022/11/comparing-linear-logistic-regression.html
数据科学面试的深度有所不同。有些面试会深入探讨候选人对高级模型或复杂微调的知识。而许多面试则在入门级别进行,测试候选人的基本知识。在本文中,我们将看到一个可以在这种面试中讨论的问题。尽管这个问题非常简单,但讨论涉及到许多有趣的机器学习基础方面。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
问题:线性回归和逻辑回归有什么区别?
实际上,两者之间有许多相似之处,从它们的名字发音相似开始。它们都使用直线作为模型函数。它们的图形也非常相似。
图片由作者提供
尽管存在这些相似之处,但它们在方法和应用上却大相径庭。我们现在将重点突出这些差异。为了比较,我们将使用以下通常在讨论任何机器学习模型时考虑的要点:
-
假设或模型家族
-
输入和输出
-
损失函数
-
优化技术
-
应用
我们现在将对线性回归(LinReg)和逻辑回归(LogReg)在每一点上进行比较。让我们从应用开始,以便将讨论引导到正确的轨道上。
应用

图片由 Rajashree Rajadhyax 提供
线性回归用于根据其他数量估计一个数量。例如,想象一下你作为学生,在暑假期间经营一个柠檬水摊。你想预测明天会卖出多少杯柠檬水,以便你可以购买足够的柠檬和糖。通过你在售卖柠檬水方面的长期经验,你已经发现销量与当天的最高温度有很强的关系。因此,你想利用预测的最高温度来预测柠檬水的销售。这是一个经典的 LinReg 应用,通常在 ML 文献中称为预测。
LinReg 也用于找出特定输入如何影响输出。在柠檬水摊的例子中,假设你有两个输入——最高温度和是否是节假日。你想找出哪一个对销售的影响更大——最高温度还是节假日。LinReg 将在识别这一点时发挥作用。
LogReg 主要用于分类。分类是将输入归入多个可能类别之一的行为。分类对于人类智能如此重要,以至于可以说“智能大多是分类”。一个好的分类例子是临床诊断。考虑一位可靠的家庭医生。一个女士走进来,抱怨不停地咳嗽。医生进行各种检查以决定多种可能的病症。某些可能的病症相对无害,如喉咙感染。但有些则很严重,例如结核病甚至肺癌。根据各种因素,医生决定她所患的病症,并开始适当的治疗。这就是分类的实际应用。
我们必须记住,估计和分类都是猜测任务,而不是计算任务。这类任务没有准确或正确的答案。猜测任务是机器学习系统擅长的领域。
模型家族
机器学习系统通过检测模式来解决猜测问题。它们从给定的数据中检测模式,然后利用这些模式执行任务,如估计或分类。在自然现象中发现的一个重要模式是关系模式。在这种模式下,一个量与另一个量相关。这种关系在大多数情况下可以用数学函数来近似。
从给定的数据中识别数学函数被称为“学习”或“训练”。学习有两个步骤:
-
函数的“类型”(例如线性、指数、多项式)由人工选择。
-
学习算法从给定的数据中学习参数(如直线的斜率和截距)。
所以当我们说机器学习系统从数据中学习时,这只是部分正确。选择函数类型的第一步是手动的,并且是模型设计的一部分。函数的类型也称为“假设”或“模型家族”。
在 LinReg 和 LogReg 中,模型家族都是线性函数。正如你所知道的,一条线有两个参数——斜率和截距。但这仅在函数只有一个输入时才成立。对于大多数实际问题,输入不止一个。这些情况的模型函数称为线性函数,而不是线。线性函数有更多的参数需要学习。如果模型有 n 个输入,线性函数有 n+1 个参数。如前所述,这些参数是从给定的数据中学习的。为了本文的目的,我们将继续假设函数是具有两个参数的简单直线。LogReg 的模型函数稍微复杂一点。直线存在,但它与另一个函数组合在一起。我们稍后会看到这一点。
输入和输出
如上所述,LinReg 和 LogReg 都从给定的数据中学习线性函数的参数,这些数据被称为训练数据。训练数据包含了什么?
训练数据是通过记录一些实际世界现象(RWP)来准备的。例如,最高气温与柠檬水销售之间的关系就是一个 RWP。我们看不到潜在的关系。我们只能看到每天的温度值和销售情况。在记录观察时,我们将一些量指定为 RWP 的输入,其他量指定为输出。在柠檬水的例子中,我们称最高气温为输入,柠檬水的销售为输出。

作者提供的图片
我们的训练数据包含输入和输出的对。在这个示例中,数据将包括每日最高气温和售出的柠檬水数量。这将是 LinReg 的输入和输出。
LogReg 执行的任务是分类,因此它的输出应该是一个类别。假设有两个类别,称为 0 和 1。模型的输出也应该是 0 或 1。
然而,这种指定输出的方法不是很合适。请看下面的图:
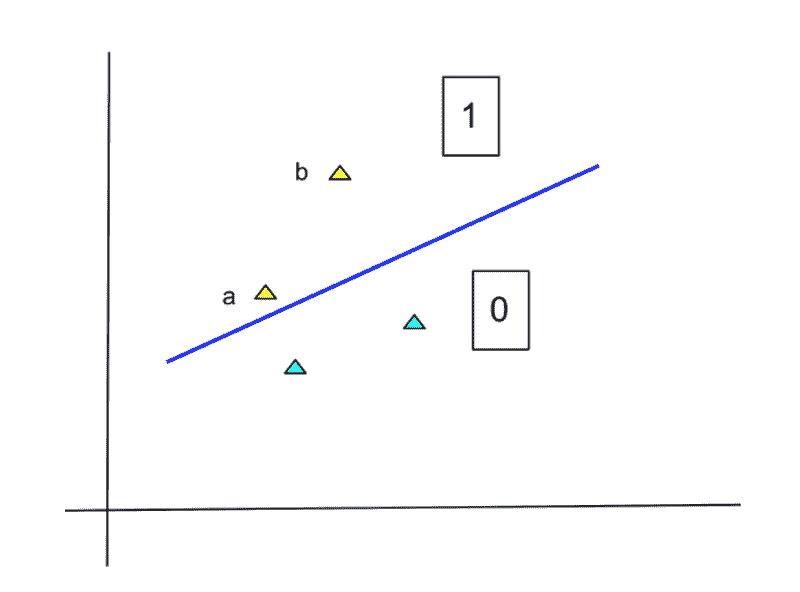
作者提供的图片
黄色点属于类别 1,浅蓝色点属于类别 0。那条线是我们的模型函数,它将这两个类别分开。根据这个分隔线,黄色点(a 和 b)都属于类别 1。然而,点 b 的隶属度比点 a 更确定。如果模型只是输出 0 和 1,那么这一事实就会丢失。
为了纠正这种情况,LogReg 模型会产生每个点属于某个类别的概率。在上述示例中,点‘a’属于类别 1 的概率较低,而点‘b’的概率较高。由于概率是 0 到 1 之间的数值,LogReg 的输出也是如此。
现在请看下面的图:
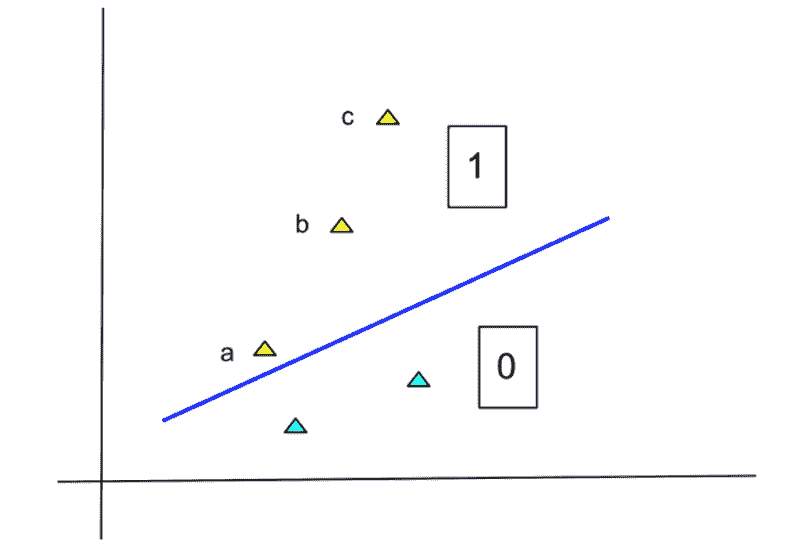
作者提供的图片
这个图与之前的相同,只是添加了点 c。这个点也属于类别 1,并且实际上比点 b 更加确定。然而,将点的概率按其与直线的距离成比例地增加是错误的。直观上,一旦你离直线一定距离,我们对这些点的类别就或多或少有了确定性。我们不需要进一步增加概率。这符合概率的性质,其最大值为 1。
为了使 LogReg 模型能够产生这样的输出,线性函数必须连接到另一个函数。这个第二个函数叫做 sigmoid,其方程为:
图片由作者提供
因此,LogReg 模型看起来像:
图片由作者提供
Sigmoid 函数也称为‘逻辑斯蒂’函数,这也是‘逻辑回归’这个名字的由来。
如果有超过两个类别,LogReg 的输出是一个向量。输出向量的元素是输入属于特定类别的概率。例如,如果临床诊断模型的第一个元素值为 0.8,这意味着模型认为患者有 80% 的可能性患有感冒。
损失函数
我们看到 LinReg 和 LogReg 都从训练数据中学习线性函数的参数。那么它们是如何学习这些参数的呢?
它们使用一种叫做‘优化’的方法。优化通过生成许多可能的解决方案来解决给定的问题。在我们的例子中,可能的解决方案是 (斜率, 截距) 的集合。我们使用性能度量来评估这些解决方案中的每一个。最终选择在这一度量下表现最好的解决方案。
在机器学习模型的学习中,性能度量有时被称为‘损失’,而帮助我们计算损失的函数被称为‘损失函数’。我们可以将其表示为:
Loss = Loss_Function (Parameters_being_evaluated)
‘损失’和‘损失函数’这两个术语有负面含义,这意味着较低的损失值表示更好的解决方案。换句话说,学习是一个优化过程,旨在找到产生最小损失的参数。
我们现在来看一下优化 LinReg 和 LogReg 时常用的损失函数。注意,实际操作中使用了许多不同的损失函数,因此我们可以讨论那些最常见的。
对于 LinReg 参数的优化,最常见的损失函数称为平方和误差 (SSE)。这个函数接受以下输入:
- 所有训练数据点。对于每个点,我们指定:
a) 输入,例如最大数据温度,
b) 输出,例如出售的柠檬水杯数
- 带参数的线性方程
然后函数使用以下公式计算损失:
SSE Loss = Sum_for_all_points(
Square_of(
output_of_linear_equation_for_the_inputs — actual_output_from_the_data point
))
LogReg 的优化度量以非常不同的方式定义。在 SSE 函数中,我们问以下问题:
If we use this line for fitting the training data, how much error will it make?
在设计 LogReg 优化度量时,我们问:
If this line is the separator, how likely is it that we will get the distribution of classes that is seen in the training data?
该度量的输出因此是一个似然性。度量函数的数学形式使用对数,因此得名对数似然性(LL)。在讨论输出时,我们看到 LogReg 函数涉及指数项(e ‘提升到’ z 的项),对数有助于有效处理这些指数项。
你应该直观地理解优化应当最大化 LL。这样考虑:我们想找到使训练数据最可能的线。然而在实际中,我们更倾向于使用可以最小化的度量,因此我们只是取 LL 的负值。我们因此得到了负对数似然性(NLL)损失函数,尽管我认为称之为损失函数并不完全正确。
因此,我们有两个损失函数:LinReg 的 SSE 和 LogReg 的 NLL。请注意,这些损失函数有许多名称,你应当熟悉这些术语。
总结
尽管线性回归和逻辑回归看起来非常相似,但实际上它们有很大不同。LinReg 用于估计/预测,而 LogReg 用于分类。确实它们都使用线性函数作为基础,但 LogReg 进一步添加了逻辑函数。它们在消耗训练数据和生成模型输出的方式上有所不同。两者也使用了非常不同的损失函数。
进一步的细节可以深入探讨。为什么选择 SSE?如何计算似然性?我们没有在这里深入优化方法以避免更多的数学内容。然而,你必须记住,LogReg 的优化通常需要迭代梯度下降方法,而 LinReg 通常可以使用快速的封闭形式解法。我们可以在另一篇文章中讨论这些和更多的点。
Devesh Rajadhyax 已在人工智能领域工作了八年。他创立了 Cere Labs 公司,致力于 AI 的各个方面。Cere Labs 创建了一个名为 Cerescope 的 AI 平台,基于深度学习、机器学习和认知计算。该平台已经被用于金融服务、医疗保健、零售、制造等领域的解决方案建设。
原文。转载授权。
更多相关主题
比较机器学习模型:统计学意义与实际意义
评论
由 Dina Jankovic,Hubdoc

左边还是右边?虽然已经投入了大量工作来构建和调整机器学习模型,但一个自然的问题是——我们到底如何比较我们构建的模型?如果我们面临模型 A 和模型 B 的选择,哪个模型是赢家,为什么?是否可以将这些模型结合起来以实现最佳性能?
一种非常浅显的方法是比较测试集上的总体准确率,比如,模型 A 的准确率是 94%,模型 B 的准确率是 95%,然后盲目地得出 B 赢了的结论。事实上,除了总体准确率之外,还有很多因素需要调查和考虑。
在这篇博客文章中,我想分享我最近在模型比较方面的发现。我喜欢使用简单的语言来解释统计学,所以这篇文章对于那些不太擅长统计学但希望多了解一点的人来说,是一篇很好的阅读材料。
1. “理解”数据
如果可能的话,最好提出一些可以立即告诉你实际情况的图表。在这个时候进行绘图似乎有些奇怪,但图表可以提供一些数字无法提供的见解。
在我的一个项目中,我的目标是比较两个机器学习模型在预测用户文档上的税务准确性时在同一测试集上的表现,因此我认为通过用户 ID 聚合数据并计算每个模型正确预测的税务比例是个好主意。
我拥有的数据集很大(100K+实例),所以我按地区划分分析,集中在较小的数据子集上——子集间的准确性可能会有所不同。这在处理极其庞大的数据集时通常是个好主意,因为一次性消化大量数据几乎是不可能的,更不用说得出可靠的结论了(样本量问题稍后再谈)。大数据集的一个巨大优势是,不仅有大量的信息可供利用,还可以放大数据并探索某一像素子集中的情况。
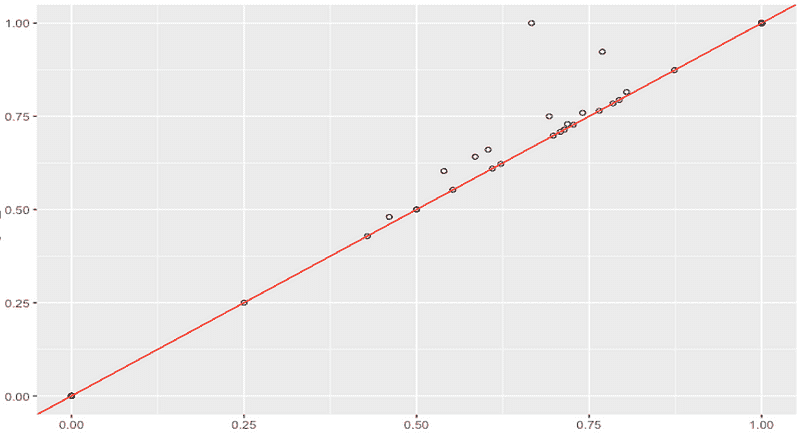
子集 1:模型 A vs. 模型 B 得分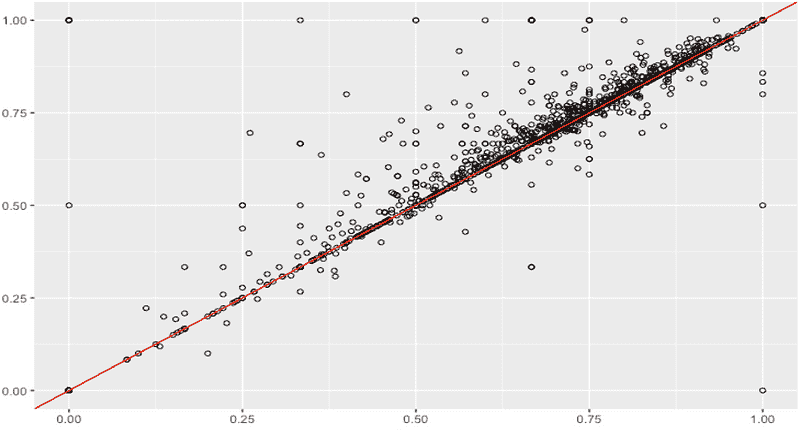
子集 2:模型 A vs. 模型 B 得分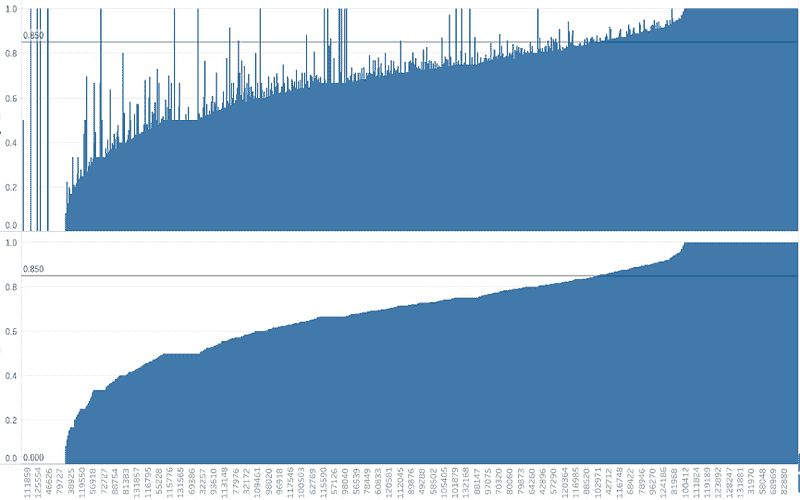
子集 2:模型 A 显然比 B 表现更好……看看那些 spikes!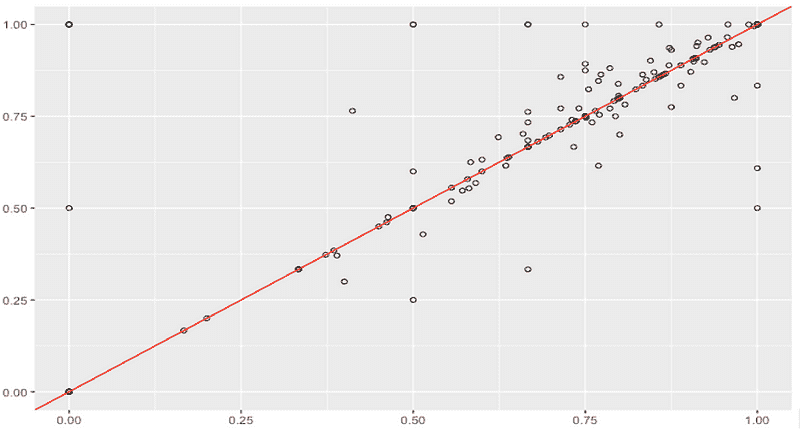
子集 3:模型 A 与模型 B 的评分在这一点上,我怀疑某些子集中一个模型表现更好,而在其他子集中的表现差不多。这比仅仅比较整体准确性要进步很多。但这种怀疑可以通过假设检验进一步调查。假设检验能比肉眼更好地发现差异——我们在测试集中的数据量有限,可能会想知道如果在不同的测试集上比较模型,准确性会如何变化。可惜的是,往往无法获得不同的测试集,因此了解一些统计学知识可能有助于调查模型准确性的性质。
2. 假设检验:让我们正确地做!
起初看起来很简单,你可能之前见过:
-
设定 H0 和 H1
-
提出一个检验统计量,并突然假设正态分布
-
不知怎么计算 p 值
-
如果 p < alpha = 0.05,则拒绝 H0,然后就完成了!
实际上,假设检验要复杂且敏感得多。可悲的是,人们使用它时往往不够谨慎,并且误解结果。让我们一步步来做!
步骤 1. 我们设定 H0:原假设 = 两个模型之间没有统计显著差异,H1:备择假设 = 两个模型的准确性之间有统计显著差异——由你决定:模型 A != B(双尾)或模型 A < 或 > 模型 B(单尾)
步骤 2. 我们设定一个检验统计量,以在观察到的数据中量化区分原假设和备择假设的行为。有很多选择,即使是最好的统计学家也可能对一些统计检验感到困惑——这完全没问题!需要考虑的假设和事实太多,一旦你了解了数据,就可以选择合适的。关键是理解假设检验的工作原理,而实际的检验统计量只是一个容易用软件计算的工具。
注意,应用任何统计检验前需要满足一系列假设。每种检验都有其所需假设;然而,大多数实际数据不会严格满足所有条件,因此可以适当放宽一些!但如果你的数据,例如,严重偏离正态分布怎么办?
统计检验分为两个大类:参数和非参数检验,我强烈建议你稍微了解一下这里。我会简短说明:这两者之间的主要区别在于参数检验要求对总体分布有某些假设,而非参数检验则更为稳健(没有参数,请!)。
在我的分析中,我最初想使用配对样本 t 检验,但我的数据显然不符合正态分布,因此我选择了Wilcoxon 符号秩检验(配对样本 t 检验的非参数等效检验)。你可以决定在分析中使用哪种检验统计量,但一定要确保假设条件得到满足。
我的数据不符合正态分布 😦 第 3 步。 现在讨论 p 值。p 值的概念有点抽象,我敢打赌很多人以前使用过 p 值,但让我们澄清一下 p 值到底是什么:p 值只是一个衡量反对 H0 证据的数字:反对 H0 的证据越强,p 值就越小。如果你的 p 值足够小,你就有足够的理由来拒绝 H0。
幸运的是,p 值可以很容易地在 R/Python 中找到,所以你不需要折磨自己手动计算,尽管我主要使用 Python,但我更喜欢在 R 中进行假设检验,因为 R 提供了更多选项。下面是一个代码片段。我们看到在子集 2 上,我们确实得到了一个较小的 p 值,但置信区间无用。
> wilcox.test(data1, data2, conf.int = TRUE, alternative="greater", paired=TRUE, conf.level = .95, exact = FALSE)
V = 1061.5, p-value = 0.008576
alternative hypothesis: true location shift is less than 0
95 percent confidence interval:
-Inf -0.008297017
sample estimates:
(pseudo)median
-0.02717335
第 4 步。 非常简单:如果 p 值 < 预设的 alpha(通常是 0.05),你可以拒绝 H0 以支持 H1。否则,证据不足以拒绝 H0,这并不意味着 H0 真实存在! 实际上,它可能仍然是错误的,只是根据数据没有足够的证据来拒绝它。如果 alpha 是 0.05 = 5%,这意味着在实际不存在差异的情况下,得出差异存在的结论的风险仅为 5%(即第一类错误)。你可能会问:为什么不能将 alpha 设置为 1% 而不是 5%?这是因为分析会变得更保守,因此更难以拒绝 H0(而我们的目标是拒绝它)。
最常用的 alpha 值是 5%、10% 和 1%,但你可以选择任何你喜欢的 alpha!这真的取决于你愿意承担的风险。
alpha 可以是 0%(即没有第一类错误的机会)吗?不行 😃 实际上,总是有可能会犯错,所以选择 0% 并没有意义。总是留有一些出错的余地比较好。
如果你想玩玩p-hacking,你可以提高你的 alpha 值并拒绝 H0,但你必须接受较低的置信水平(随着 alpha 的增加,置信水平降低——你不能同时拥有一切 😃)。
3. 事后分析:统计显著性与实际显著性
如果你得到了一个极其小的 p 值,那肯定意味着两个模型的准确性之间存在 统计显著 差异。之前我确实得到了一个小 p 值,从数学上讲,模型确实存在差异,但“显著”并不意味着“重要”。这个差异实际上意味着什么?这个小差异对业务问题有意义吗?
统计显著性 指的是观察到的样本均值差异由于抽样误差发生的可能性很小。给定足够大的样本,尽管总体差异看似微不足道,仍然可能找到统计显著性。另一方面,实际显著性 关注的是差异是否足够大以在实际意义上有价值。虽然统计显著性是严格定义的,但实际显著性更直观和主观。

到这个阶段,你可能已经意识到 p 值并不像你想的那样强大。还有更多需要探讨的内容。考虑一下 效应大小 也非常重要。效应大小衡量的是差异的大小——如果存在统计显著差异,我们可能会对其 大小 感兴趣。效应大小 强调的是差异的规模,而不是与样本大小混淆。
> abs(qnorm(p-value))/sqrt(n)
0.14
# the effect size is small
什么算是小、中、大效应大小?传统的界限是 0.1、0.3、0.5,但这真的取决于你的业务问题。
样本大小有什么问题? 如果你的样本太小,那么你的结果将不可靠,但这是显而易见的。如果你的样本大小太大呢?这看起来很棒——但在这种情况下,即使是极其微小的差异也可能通过假设检验被检测到。数据太多,即使是微小的偏差也可能被视为显著。这就是效应大小变得有用的原因。
还有更多需要做的——我们可以尝试找出检验的效能或最佳样本量。但现在这些就足够了。
如果假设检验做得对,它在模型比较中可能非常有用。设定 H0 和 H1,计算检验统计量和寻找 p 值是常规工作,但解读结果需要一些直觉、创造力和对业务问题的深入理解。记住,如果测试是基于一个非常大的测试集,发现的 统计显著性 可能没有太多 实际意义。不要盲目相信那些神奇的 p 值:深入数据并进行事后分析总是一个好主意! 😃
随时通过 电子邮件 或 LinkedIn 联系我,我随时乐意聊聊数据科学!
个人简介:Dina Jankovic 是位于加拿大多伦多的 Hubdoc 数据科学团队的数据分析师。她获得了贝尔格莱德大学的数学学士学位和渥太华大学的统计学硕士学位。她利用计算统计学和机器学习技术做出明智的商业决策,并更好地理解世界。
原文。经许可转载。
相关:
-
理解偏差-方差权衡:概述
-
如何计算两个分类器性能差异的统计显著性
-
统计建模:入门指南
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关内容
在 TensorFlow 中比较 MobileNet 模型
原文:
www.kdnuggets.com/2019/03/comparing-mobilenet-models-tensorflow.html
评论
由 Harshit Dwivedi 提供,Android 讲师

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 管理
近年来,神经网络和深度学习在 自然语言处理(NLP)和 计算机视觉 领域取得了巨大进展。
虽然许多 人脸、物体、地标、徽标和 文本识别 和检测技术已提供给联网设备,但我们相信 移动设备日益增长的计算能力 可以使这些技术随时随地交到用户手中,无论是否有互联网连接。
然而,针对设备和嵌入式应用的计算机视觉面临许多挑战——模型必须在资源受限的环境中快速运行并保持高准确率,同时利用有限的计算能力、功耗和空间。
TensorFlow 提供了各种预训练模型,例如拖放模型,以识别约 1,000 种默认对象。
与其他类似模型(如 Inception 模型数据集)相比,MobileNet 在延迟、大小和准确性方面表现更好。在输出性能方面,完整模型存在显著的延迟。
然而,当模型可以部署到移动设备上进行实时离线检测时,这种权衡是可以接受的。
让我们看一个如何使用 MobileNet 的示例。我们将编写一个简单的分类器来识别图片中的 Pikachu。以下是显示 Pikachu 图片和不含 Pikachu 图片的示例:

Pikachu
不是 Pikachu,假设在 Pokémon Go 中没有 Pikachu 可收集……
构建数据集
要构建我们自己的分类器,我们需要有包含 Pikachu 和不包含 Pikachu 的图片的数据集。
让我们从每个数据库的 1,000 张图片开始。你可以在这里获取这样的图片:
[CC 搜索
Creative Commons 许可证为作者、艺术家和教育工作者提供了一系列灵活的保护和自由。
接下来,让我们创建两个文件夹,命名为pikachu和no-pikachu,并将图片分别放入这些文件夹中。
另一个包含所有第一代 Pokémon 图片的实用数据集可以在这里找到:
[Pokemon 第一代
必须训练全部!
现在我们有了一个图片文件夹,结构如下:
/dataset/
/pikachu/[image1,..]
/no-pikachu/[image1,..]
重训练图片
现在我们可以开始标记我们的图片了。使用 TensorFlow,这项工作变得更容易。假设 TensorFlow 已经在训练机器上安装,下载以下重训练脚本:
curl https://github.com/tensorflow/hub/blob/master/examples/image_retraining/retrain.py
接下来,我们将使用此 Python 脚本重训练图片:
python retrain.py \
--image_dir ~/MLmobileapps/Chapter5/dataset/ \
--learning_rate=0.0001 \
--testing_percentage=20 \
--validation_percentage=20 \
--train_batch_size=32 \
--validation_batch_size=-1 \
--eval_step_interval=100 \
--how_many_training_steps=1000 \
--flip_left_right=True \
--random_scale=30 \
--random_brightness=30 \
--architecture mobilenet_1.0_224 \
--output_graph=output_graph.pb \
--output_labels=output_labels.txt
注:如果将
validation_batch_size设置为 -1,它将验证整个数据集。learning_rate= 0.0001 的效果很好。你可以调整并自己尝试。在
architecture标志中,我们选择使用哪个版本的 MobileNet,版本包括 1.0、0.75、0.50 和 0.25。后缀数字 224 代表图像分辨率。你也可以指定 224、192、160 或 128。
从 GraphDef 到 TFLite 的模型转换
TOCO 转换器用于将 TensorFlow GraphDef 文件或 SavedModel 转换为 TFLite FlatBuffer 或图形可视化。
(TOCO 代表TensorFlow Lite 优化转换器)
我们需要通过命令行参数传递数据。在转换模型时可以传递一些命令行参数:
--output_file OUTPUT_FILE
Filepath of the output tflite model.
--graph_def_file GRAPH_DEF_FILE
Filepath of input TensorFlow GraphDef.
--saved_model_dir
Filepath of directory containing the SavedModel.
--keras_model_file
Filepath of HDF5 file containing tf.Keras model.
--output_format {TFLITE,GRAPHVIZ_DOT}
Output file format.
--inference_type {FLOAT,QUANTIZED_UINT8}
Target data type in the output
--inference_input_type {FLOAT,QUANTIZED_UINT8}
Target data type of real-number input arrays.
--input_arrays INPUT_ARRAYS
Names of the input arrays, comma-separated.
--input_shapes INPUT_SHAPES
Shapes corresponding to --input_arrays, colon-separated.
--output_arrays OUTPUT_ARRAYS
Names of the output arrays, comma-separated.
我们现在可以使用 TOCO 工具将 TensorFlow 模型转换为TensorFlow Lite模型:
toco \
--graph_def_file=/tmp/output_graph.pb
--output_file=/tmp/retrained_model.tflite
--input_arrays=Mul
--output_arrays=final_result
--input_format=TENSORFLOW_GRAPHDEF
--output_format=TFLITE
--input_shape=1,${224},${224},3
--inference_type=FLOAT
--input_data_type=FLOAT
同样,我们可以在类似的应用中使用 MobileNet 模型;例如,在下一部分中,我们将讨论性别模型和情感模型。
性别模型
该模型使用IMDB WIKI 数据集,包含超过 50 万张名人面孔。它使用 MobileNet_V1_224_0.5 版本的 MobileNet。
公开数据集中有数千张图像的情况非常罕见。该数据集基于大量名人面部图像集合构建。两个常见的来源是 IMDb 和维基百科。通过脚本从这两个来源的资料中检索了超过 10 万名名人的详细信息。
然后通过去除噪声(无关内容)来组织数据。所有没有时间戳的图像被删除,假设只有单张照片的图像更可能显示正确的出生日期细节。最终,共有来自 IMDb 的 20,284 名名人的 460,723 张面孔和来自维基百科的 62,328 张面孔,总计 523,051 张。
情感模型
该模型基于超过 100 万张图像的 AffectNet 模型。它使用了 MobileNet_V2_224_1.4 版本的 MobileNet。
数据模型项目的链接可以在这里找到:
AffectNet - Mohammad H. Mahoor, PhD
当前测试集尚未发布。我们计划在不久的将来组织一个 AffectNet 挑战赛,敬请期待…
AffectNet 模型通过从互联网收集和标注超过 100 万张面部图像而建立。这些图像来自三个搜索引擎,使用了约 1250 个相关关键词,涵盖六种不同的语言。
在收集的图像中,一半的图像被手动标注了七种不同的面部表情(分类模型)以及情感的强度和唤醒度(维度模型)。
MobileNet 版本对比
在上述两种模型中,使用了不同版本的 MobileNet 模型。MobileNet V2 主要是 V1 的更新版本,使其在性能方面更加高效和强大。

注意:值越低越好
MACs 是multiply-accumulate operations,用于测量对单张 224×224 RGB 图像进行推断所需的计算次数。
从 MACs 的数量来看,V2 的速度应当几乎是 V1 的两倍。然而,这不仅仅关乎计算次数。在移动设备上,内存访问比计算要慢得多。V2 的参数数量只有 V1 的 80%,因此它比 V1 更优。
从结果来看,我们可以假设 V2 的速度几乎是 V1 模型的两倍。在内存访问受限的移动设备上,V2 的计算能力表现得非常好。
在准确性方面:

在这里,MobileNet V2 在性能上比 V1 稍好,虽然不一定显著。
结论
MobileNet 是一系列以移动为优先的计算机视觉模型,适用于TensorFlow,旨在有效地最大化准确性,同时考虑到设备或嵌入式应用的有限资源。
MobileNets 是小型、低延迟、低功耗的模型,参数化以满足各种使用情况的资源限制。它们可以用于分类、检测、嵌入和分割,类似于其他流行的大规模模型,如 Inception。
如果你想进一步探索和满足好奇心,可以在这里找到一堆预训练模型:
[tensorflow/models
使用 TensorFlow 构建的模型和示例。通过创建账户来为 tensorflow/models 开发贡献力量…
此外,这里有一篇博客文章概述了如何使用 MobileNets 和 TensorFlow Lite 构建一个真实的 Pokémon 分类器:
[在 Android 中使用 TensorFlow Lite 和 Firebase 的 ML Kit 构建“宝可梦图鉴”
感谢阅读!如果你喜欢这个故事,请点击 ???? 按钮并分享以帮助其他人找到它!欢迎在下面留下评论 ????。有反馈?我们可以在Twitter上联系。
如果你觉得这篇文章有趣,可以探索移动应用的机器学习项目。由 ML 专家 Karthikeyan MG 撰写,移动应用的机器学习项目* 介绍了 7 个实际的、真实世界的项目实施,这些项目将教你如何利用 TensorFlow Lite 和 Core ML 在跨平台移动操作系统上执行高效的机器学习。*
想要开始构建令人惊叹的 Android 应用程序吗?查看我在 Coding Blocks 上的课程:online.codingblocks.com/courses/android-app-training-online
准备好进入代码世界了吗?查看 Fritz 在 GitHub 上。你会找到流行的机器学习和深度学习模型的开源、适用于移动设备的实现,以及训练脚本、项目模板和用于构建自己的 ML 驱动的 iOS 和 Android 应用程序的工具。
加入我们在 Slack 上的讨论,以获得技术问题的帮助,分享你正在做的工作,或与我们讨论移动开发和机器学习。关注我们的 Twitter 和 LinkedIn 以获取移动机器学习世界的最新内容、新闻及更多信息。
感谢 Austin Kodra。
简介: Harshit Dwivedi 对许多事物有大致的了解。他是 Coding Blocks 的 Android 教师,Fritz 的 Heartbeat 贡献作者,公共演讲者,以及天体物理学爱好者。
原文。经授权转载。
相关:
-
如何在计算机视觉中做一切
-
数据科学家/数据分析师的 10 款最佳移动应用
-
人工智能和机器学习的最新进展 - 带代码的论文亮点
更多相关主题
比较自然语言处理技术:RNN、变换器、BERT
原文:
www.kdnuggets.com/comparing-natural-language-processing-techniques-rnns-transformers-bert

图片由 Freepik 提供
自然语言处理(NLP)是人工智能领域中的一个领域,旨在让机器具备理解文本数据的能力。NLP 研究已经存在了很长时间,但随着大数据和更高计算处理能力的引入,它最近才变得更加突出。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 工作
随着 NLP 领域的不断扩大,许多研究人员会尝试提高机器理解文本数据的能力。经过多次进展,许多技术在 NLP 领域中被提出和应用。
本文将比较 NLP 领域中处理文本数据的各种技术。本文将重点讨论 RNN、变换器和 BERT,因为它们是研究中经常使用的技术。让我们开始吧。
递归神经网络
递归神经网络(RNN)于 1980 年开发,但最近才在 NLP 领域获得关注。RNN 是神经网络家族中的一种特殊类型,用于处理序列数据或彼此之间不能独立的数据。序列数据的例子有时间序列、音频或文本句子数据,基本上是任何具有有意义顺序的数据。
RNN(递归神经网络)与普通的前馈神经网络不同,因为它们处理信息的方式不同。在普通的前馈神经网络中,信息是按层次进行处理的。然而,RNN 是通过对信息输入进行循环处理来考虑的。要理解这些差异,我们可以看看下面的图像。
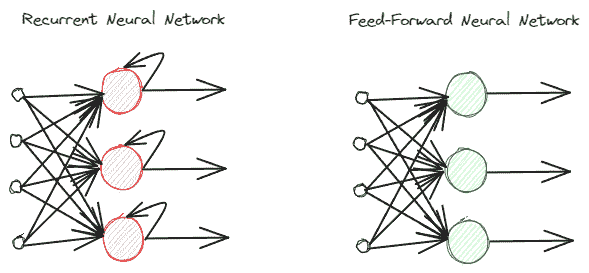
图片由作者提供
如您所见,RNN 模型在信息处理过程中实现了循环。RNN 在处理这些信息时会考虑当前和先前的数据输入。这就是为什么该模型适用于任何类型的序列数据。
如果我们以文本数据为例,假设我们有句子“I wake up at 7 AM”,并且将每个单词作为输入。在前馈神经网络中,当我们到达单词“up”时,模型可能已经忘记了单词“I”、“wake”和“up”。然而,RNN 会利用每个单词的输出并将其循环回来,以便模型不会遗忘。
在自然语言处理领域,RNN 常用于许多文本应用,例如文本分类和生成。它常用于词级应用,如词性标注、下一个词生成等。
深入分析文本数据中的 RNN,有许多不同类型的 RNN。例如,下面的图像展示了多对多类型。
图片由作者提供
从上面的图像可以看到,每一步的输出(RNN 中的时间步)是逐步处理的,每次迭代始终考虑先前的信息。
另一种在许多 NLP 应用中使用的 RNN 类型是编码器-解码器类型(序列到序列)。其结构如下面的图像所示。
图片由作者提供
这种结构引入了模型中使用的两个部分。第一个部分称为编码器,它接收数据序列并基于其创建一个新的表示。该表示将用于模型的第二部分,即解码器。通过这种结构,输入和输出的长度不一定需要相等。一个示例用例是语言翻译,输入和输出之间的长度通常不相同。
使用 RNN 处理自然语言数据有多种好处,包括:
-
RNN 可以处理没有长度限制的文本输入。
-
模型在所有时间步中共享相同的权重,这使得神经网络在每一步使用相同的参数。
-
由于记忆过去的输入,使得 RNN 适用于任何序列数据。
但是,也存在一些缺点:
-
RNN 容易受到梯度消失和梯度爆炸的影响。这是指梯度结果接近零值(消失),导致网络权重只更新很少,或者梯度结果非常显著(爆炸),使网络赋予不现实的巨大重要性。
-
由于模型的序列性质,训练时间较长。
-
短期记忆意味着模型在训练时间较长时开始遗忘。有一种名为LSTM的 RNN 扩展用于缓解此问题。
变换器
变换器是一个自然语言处理模型架构,旨在解决之前在 RNN 中遇到的序列到序列任务。如前所述,RNN 存在短期记忆问题。输入越长,模型遗忘信息的现象越明显。这是注意力机制可以帮助解决的问题所在。
注意力机制在Bahdanau et al. (2014)的论文中引入,用于解决长输入问题,特别是对于编码器-解码器类型的 RNN。我不会详细解释注意力机制。基本上,它是一个允许模型在进行输出预测时关注模型输入关键部分的层。例如,如果任务是翻译,那么“Clock”这个词在印尼语中与“Jam”会有很高的相关性。
变换器模型由Vaswani et al. (2017)引入。该架构受到编码器-解码器 RNN 的启发,并在设计时考虑了注意力机制,且不按顺序处理数据。整体变换器模型结构如下图所示。
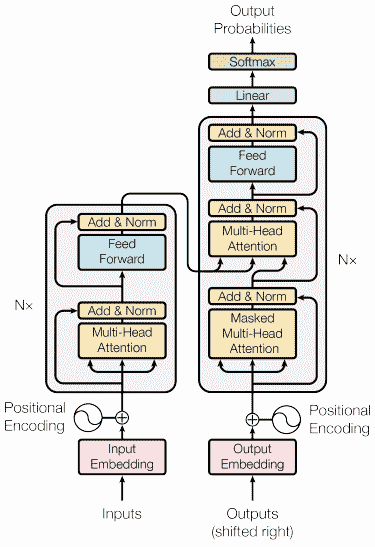
变换器架构 (Vaswani et al. 2017)
在上述结构中,变换器将数据向量序列编码为带有位置编码的词嵌入,同时使用解码将数据转换回原始形式。借助注意力机制,编码可以根据输入赋予不同的重要性。
与其他模型相比,变换器提供了一些优势,包括:
-
并行化过程提高了训练和推理速度。
-
能够处理更长的输入,这提供了对上下文的更好理解。
变换器模型仍然存在一些缺点:
-
高计算处理和需求。
-
注意力机制可能要求对文本进行拆分,因为它能处理的长度有限制。
-
如果拆分方式不正确,可能会丢失上下文。
BERT
BERT,即双向编码器表示变换器,是由Devlin et al. (2019)开发的模型,包含两个步骤(预训练和微调)来构建模型。比较而言,BERT 是一个变换器编码器堆叠(BERT Base 有 12 层,而 BERT Large 有 24 层)。
BERT 的整体模型开发可以在下图中看到。
BERT 整体流程(Devlin et al. (2019))
预训练任务同时启动模型的训练,完成后,模型可以针对各种下游任务(问答、分类等)进行微调。
BERT 的独特之处在于它是第一个在文本数据上进行预训练的无监督双向语言模型。BERT 之前在整个维基百科和书籍语料库上进行了预训练,包含了超过 30 亿个词。
BERT 被认为是双向的,因为它没有顺序读取数据输入(从左到右或反之),而是变换器编码器同时读取整个序列。
与顺序读取文本输入(从左到右或从右到左)的方向模型不同,变换器编码器同时读取整个词序列。这就是为什么该模型被认为是双向的,并且使模型能够理解输入数据的整体上下文。
为了实现双向,BERT 使用了两种技术:
-
掩码语言模型(MLM)——词掩码技术。该技术会掩盖输入词的 15%,并尝试根据未掩盖的词来预测被掩盖的词。
-
下一句预测(NSP)——BERT 尝试学习句子之间的关系。该模型将句子对作为数据输入,并尝试预测后续句子是否存在于原始文档中。
在 NLP 领域使用 BERT 有几个优点,包括:
-
BERT 易于用于预训练的各种 NLP 下游任务。
-
双向使 BERT 能够更好地理解文本上下文。
-
这是一个受到社区广泛支持的热门模型。
尽管如此,仍然存在一些缺点,包括:
-
对于一些下游任务微调,需要较高的计算能力和较长的训练时间。
-
BERT 模型可能会导致一个需要更大存储空间的大型模型。
-
对于复杂任务,BERT 的表现更好,因为在简单任务上的表现与使用更简单的模型并没有太大区别。
结论
自然语言处理(NLP)最近变得更加突出,许多研究集中在改进应用上。在本文中,我们讨论了三种常用的 NLP 技术:
-
RNN
-
变换器
-
BERT
每种技术都有其优缺点,但总体而言,我们可以看到模型在不断进化。
Cornellius Yudha Wijaya 是数据科学助理经理和数据撰稿人。在全职工作于安联印尼期间,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 撰写了各种人工智能和机器学习主题的文章。
更多相关内容
顶级 6 个 Python NLP 库的比较
原文:
www.kdnuggets.com/2018/07/comparison-top-6-python-nlp-libraries.html
comments
由 ActiveWizards 提供

自然语言处理(NLP)在今天变得非常流行,这在深度学习的发展背景下尤为显著。NLP 是一个人工智能领域,旨在从文本中理解和提取重要信息,并基于文本数据进一步训练。主要任务包括语音识别和生成、文本分析、情感分析、机器翻译等。
在过去几十年中,只有具有适当语言学教育的专家才能从事自然语言处理工作。除了数学和机器学习,他们还应该熟悉一些关键语言学概念。现在,我们可以直接使用已经编写好的 NLP 库。它们的主要目的是简化文本预处理。我们可以专注于构建机器学习模型和调整超参数。
有许多工具和库被设计用于解决 NLP 问题。今天,我们希望基于我们的经验概述并比较最受欢迎和最有用的自然语言处理库。你应该理解,我们查看的所有库的任务仅部分重叠。因此,有时直接比较它们是困难的。我们将绕过一些功能,仅比较那些可以直接比较的库。
总体概述
NLTK(自然语言工具包)用于如分词、词形还原、词干提取、解析、词性标注等任务。这个库几乎涵盖了所有 NLP 任务的工具。
Spacy 是 NLTK 的主要竞争对手。这两个库可以用于相同的任务。
Scikit-learn 提供了一个大型机器学习库。这里也提供了文本预处理的工具。
Gensim 是用于主题和向量空间建模、文档相似性的包。
Pattern 库的总体任务是作为网页挖掘模块。因此,它只将 NLP 作为附加任务支持。
Polyglot 是另一个用于 NLP 的 Python 包。它虽然不太流行,但也可以用于广泛的 NLP 任务。
为了使比较更生动,我们准备了一个表格,显示库的优缺点。
更新日期:2018 年 7 月
结论
在这篇文章中,我们比较了几种流行的自然语言处理库的功能。尽管大多数库提供了重叠任务的工具,但有些库对特定问题采用了独特的方法。显然,当前最受欢迎的 NLP 包是 NLTK 和 Spacy。它们是 NLP 领域的主要竞争者。在我们看来,它们之间的区别在于解决问题的方法的总体哲学。
NLTK 更加学术。你可以用它尝试不同的方法和算法,进行组合等。而 Spacy 则提供了针对每个问题的现成解决方案。你不必考虑哪个方法更好:Spacy 的作者已经解决了这个问题。此外,Spacy 的速度非常快(比 NLTK 快几倍)。一个缺点是 Spacy 支持的语言数量有限。不过,支持的语言数量在不断增加。因此,我们认为 Spacy 在大多数情况下是最佳选择,但如果你想尝试一些特别的东西,可以使用 NLTK。
尽管这两个库很受欢迎,但还有许多不同的选项,选择哪个 NLP 包取决于你需要解决的具体问题。因此,如果你知道其他有用的 NLP 库,请在评论区告知我们的读者。
ActiveWizards 是一个专注于数据项目(大数据、数据科学、机器学习、数据可视化)的数据科学家和工程师团队。核心专业领域包括数据科学(研究、机器学习算法、可视化和工程)、数据可视化(d3.js、Tableau 等)、大数据工程(Hadoop、Spark、Kafka、Cassandra、HBase、MongoDB 等),以及数据密集型 Web 应用开发(RESTful API、Flask、Django、Meteor)。
原文。经授权转载。
相关:
-
2017 年数据科学领域的 15 个 Python 库
-
2018 年数据科学领域的 15 个 Scala 库
-
金融领域数据科学的 7 大应用案例
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT
更多相关内容
数据库的完整收藏 – 第一部分
原文:
www.kdnuggets.com/2022/04/complete-collection-data-repositories-part-1.html

作者提供的图片
编辑注:有关本系列两个部分所包含的完整数据库范围,请参见 数据仓库的完整收藏 – 第二部分。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
找到适合您业务的数据可能需要大量时间。虽然有多个数据共享平台提供各种数据集,但它们不能为特定的研究领域提供数据集。因此,我创建了一个数据仓库列表,可以帮助您找到任何数据集,而无需在互联网上搜索。单个数据仓库包含了某一特定研究领域的多个数据集。
数据库的集合分为两部分,共 20 个类别,涵盖各种科学领域。下面列出的大多数数据来源是免费的,但也有一些不是。我花了超过两天的时间来收集这些高质量且易于下载的数据库。我使用了 duckduckgo.com 搜索大多数资源,但大部分数据库来自于 Awesome Public Datasets 和 KDnuggets。
在第一部分中我们将涵盖:
-
农业
-
音频
-
生物学
-
气候
-
计算机视觉
-
经济学
-
教育
-
能源
-
财务
-
政府
农业
在这一类别中,数据集大多与作物监测、遥感指数、谷物大小、地球化学、土壤和沉积物分析有关。数据集大多为表格形式,但你也可以找到用于作物监测和杂草检测的视觉数据。
音频
音频库内容丰富,可用于自动语音识别、文本转语音、歌曲分类、情感检测、翻译以及仇恨言论检测。这对任何初学者或中型公司来说,都是开发最先进解决方案的金矿。
生物学
生物学类别主要包括细胞、癌细胞、基因组类型、基因和蛋白质结构的图像。你可以用它们生成新型病毒株或开发救命药物。大多数数据集用于研究目的,可以直接轻松下载。
气候
气候数据存储库包含卫星图像、风速和温度的时间序列数据、全球天气和气候空间数据。你可以用它来预测天气、监测全球变暖的影响和检测自然灾害。
图片来源 Freepik
计算机视觉
计算机视觉需求极高。公司正在开发各种解决方案,以改善当前流程或创造新服务,如仓库管理、自动驾驶汽车、人脸检测、生成艺术和机器人。
经济学
世界经济数据包括贸易统计、人类发展指数、食品供应的地理空间数据和宏观经济数据。你可以利用这些数据分析当前的贸易逆差并预测各国的发展。
教育
在教育类别中,你可以找到学生评估、成绩单、大学表现、毕业率以及由个人学生、学校校长和家长填写的调查数据。
能源
能源类别包含全球电力消费、各建筑物的智能电表数据以及发电站的能源生产率。我们可以利用这些数据策划可再生能源的实施、节省电力成本,并满足全球能源消耗的高需求。

图片来源 rawpixel.com
金融
在这一部分,你可以找到关于债务、银行统计、GDP、汇率、消费者价格等的数据。金融是现代经济的支柱,为了创建一个稳定的经济体系,我们可以使用这些数据预测下一个金融危机、检测犯罪和预测股价。
政府
你可以找到任何国家、州或甚至县的政府数据。许多政府官员通过与公众分享数据来促进公平和包容性。最突出的数据集来自美国、印度、加拿大、新西兰和联合国。这些数据涵盖了从犯罪到食品安全的各种信息。
结论
在这篇博客中,我们涵盖了 10 个类别的数据仓库。我们还发现了数据集的类型及其使用案例。这些数据集是宝贵的金矿,你无法在 Kaggle 或任何普通网站上找到它们。大多数数据科学家要么在 Kaggle 上,要么在 Google 上搜索数据集,有时他们对所得到的数据感到满意。他们大部分时间都在清理和增强数据,而不是寻找更好的数据资源。这一切都将改变,因为我将利用我的数据仓库收藏来寻找我所需要的内容。
在第二部分,我们将探讨医疗保健、自然语言、神经科学、物理学、社交网络、体育、时间序列、交通、杂项和超级数据仓库。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个人工智能产品,以帮助那些挣扎于心理疾病的学生。
更多相关内容
数据仓库完整合集 – 第二部分
原文:
www.kdnuggets.com/2022/04/complete-collection-data-repositories-part-2.html

图片来源于作者
编辑注:有关此 2 部分系列中包含的所有数据仓库的完整范围,请参见数据仓库完整合集 – 第一部分。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 工作
在人工智能项目中,数据策划占用了大部分资源和时间。它是决定服务或产品成功的关键部分。为了减少寻找适合的数据集的努力,我创建了一个数据仓库集合。单个数据仓库包含一个特定研究领域的多个数据集,我向你展示的是高质量数据集的金矿。
下面列出的大多数数据源都是免费的,向公众开放。然而,也有一些不是。数据仓库的集合分为 2 部分,共包含 20 个基于不同科学领域的类别。第一部分包括农业、音频、生物学、气候、计算机视觉、经济学、教育、能源、金融和政府。
在第二部分中,我们将涵盖:
-
医疗保健
-
自然语言
-
神经科学
-
物理学
-
社交网络
-
体育
-
时间序列
-
交通运输
-
杂项
-
超级数据仓库
医疗保健
医疗保健类别包括患者和医院记录。你可以找到有关空气质量、病毒、疾病、死亡统计和疫苗接种进展的数据。政府和制药行业可以利用这些数据制定应对病毒爆发的策略或制定标准操作程序。
自然语言
自然语言包括用于机器翻译、情感分析和命名实体识别的文本数据。你可以使用大型多语言 NLP 语料库来训练变换器,并用其执行文本生成、总结、问答以及构建对话应用程序。
神经科学
神经科学包括从 FMRI 到各种 CT 扫描的大脑影像数据。脑活动数据可以用于检测神经系统疾病,并提出重塑大脑以治疗各种疾病的方法。FMRI 数据还可用于检测脑部肿瘤和异常。
物理
你拥有来自 CERN 的纳米颗粒数据和来自 Exoplanet 的宇宙探索数据。这个类别的数据有限,但你可以利用这些数据来理解纳米颗粒,并为解决能源问题提出解决方案,发现创造的宇宙钥匙。

图片来自 rawpixel.com
社交网络
社交网络数据通常来自 GitHub、Reddit 和其他社交媒体网站。你可以利用这些数据进行情感分析或在某个平台上创建不同群体的聚类。一些数据科学家正在使用 Reddit 和 Twitter 数据来训练聊天机器人,这些机器人会分析趋势并与其他用户互动。
体育
获取你最喜欢的运动的统计数据并预测获胜的团队。运动类别不仅仅是一个记分板。你可以获取有关球队历史、逐场记录、运动分析的视频数据以及实时比赛数据的元数据。
时间序列
现在你可以访问各种时间序列数据,如能源消耗、天气、地理异常、交通、体育、股票价格。简而言之,本收藏中提到的所有类别都有某种时间序列数据。你可以用它们来预测事件和检测异常或事件。
运输
从共享单车的 GPS 数据到实时监控航空交通。你可以访问各种交通数据,这些数据可以追溯到 20 年。公司利用这些数据来创建营销活动、优化燃料消耗、制定新路线,并观察消费者行为。
杂项
一些数据存储库难以分类,因此我创建了一个新类别来包含随机数据存储库。这些存储库包括数据转储、餐馆评分和网络安全数据集。

图片由 macrovector 提供
超级数据存储库
超级数据仓库是各个科学领域的数据银行。你可以通过在下面提到的任何平台上运行简单查询来发现许多相关数据集。我通常从 Kaggle 开始,然后转到 HuggingFace 找到适合我的数据集。有时我在寻找特定的数据集,这时其他平台如 Zenodo 和 data.hub 就很有用。
提示: 如果你正在寻找最前沿的机器学习数据集,可以查看 Papers With Code。
结论
没有数据的数据科学不过是一堆数学方程式而已。获取数据集或在网上找到开源数据可能是一项艰巨的任务,因此我们需要某种列表或备忘单来发现各种数据。数据仓库正在帮助研究人员、公司和非营利组织提出解决全球问题的方案。
在这篇博客中,我们了解了医疗保健、自然语言、神经科学、物理学、社交网络、体育、时间序列、交通运输、杂项和超级数据仓库。就像数据科学备忘单一样,你可以将这个合集收藏起来,每当你开始一个新的数据项目时,只需浏览一下列表,发现适合你的数据仓库。
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专家,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为正在挣扎于心理健康问题的学生开发一款 AI 产品。
更多相关主题
数据科学书籍完整合集 - 第一部分
原文:
www.kdnuggets.com/2022/05/complete-collection-data-science-books-part-1.html

作者图片
编辑备注:有关此两部分系列中包含的所有数据科学书籍的完整范围,请参见 数据科学书籍完整合集 - 第二部分。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
现代时代的书籍已经发生了彻底的变化。您可以在智能手机、桌面和平板电脑上阅读书籍,而不是纸上的文字。有些书籍是基于网站的,您可以在阅读时浏览章节、搜索术语,甚至播放视频教程。这些文档风格的书籍增强了阅读体验,使测试编码示例变得非常有趣。
在这个两部分系列中,我将分享所有数据科学子领域中的最佳书籍。您可以购买纸质书或简单地获取在线版本或下载 PDF/EPub/Kindle。有些书籍是基于网站的,可以免费访问。
在第一部分中,我们将回顾以下书籍:
-
编程
-
统计学
-
数据分析
-
商业智能
-
数据工程
-
网络抓取
-
数据应用
-
数据管理
-
大数据
-
云架构
编程
如果您是初学者,学习编程应该是您列表上的首位。在开始时,您会在 Python、R 和 Julia 之间进行选择,但我强烈建议您从 Python 开始。之后,学习 SQL 和 Scala 以推进您的职业生涯。
Python
R
Julia
SQL
Scala
统计学
统计学是现代数据科学和机器学习发展的基础。没有它,你无法理解算法或进行研究。与其学习所有内容,不如先学习基础知识,然后在实践中不断学习。

图片来源:Karolina Grabowska
数据分析
这些书中提到的一些工具使数据分析变得轻而易举。这不仅仅是编写代码生成数据可视化,而是通过图表和视觉表示来理解数据。
商业智能
商业智能工具是现代商业中最重要的部分。你将学习如何创建报告、跟踪绩效、开发仪表板、抓取数据和管理数据源。
-
商业智能、分析与数据科学:管理视角:Sharda, Ramesh, Delen, Dursun, Turban, Efraim: 9780134633282: 书籍 - 亚马逊
-
DAX 权威指南:适用于 Microsoft Power BI、SQL Server 分析服务和 Excel 的商业智能
数据工程
构建数据管道、规划数据管理策略、处理数据并为各种团队成员提供安全访问。数据工程师还致力于可扩展和灵活的存储系统。
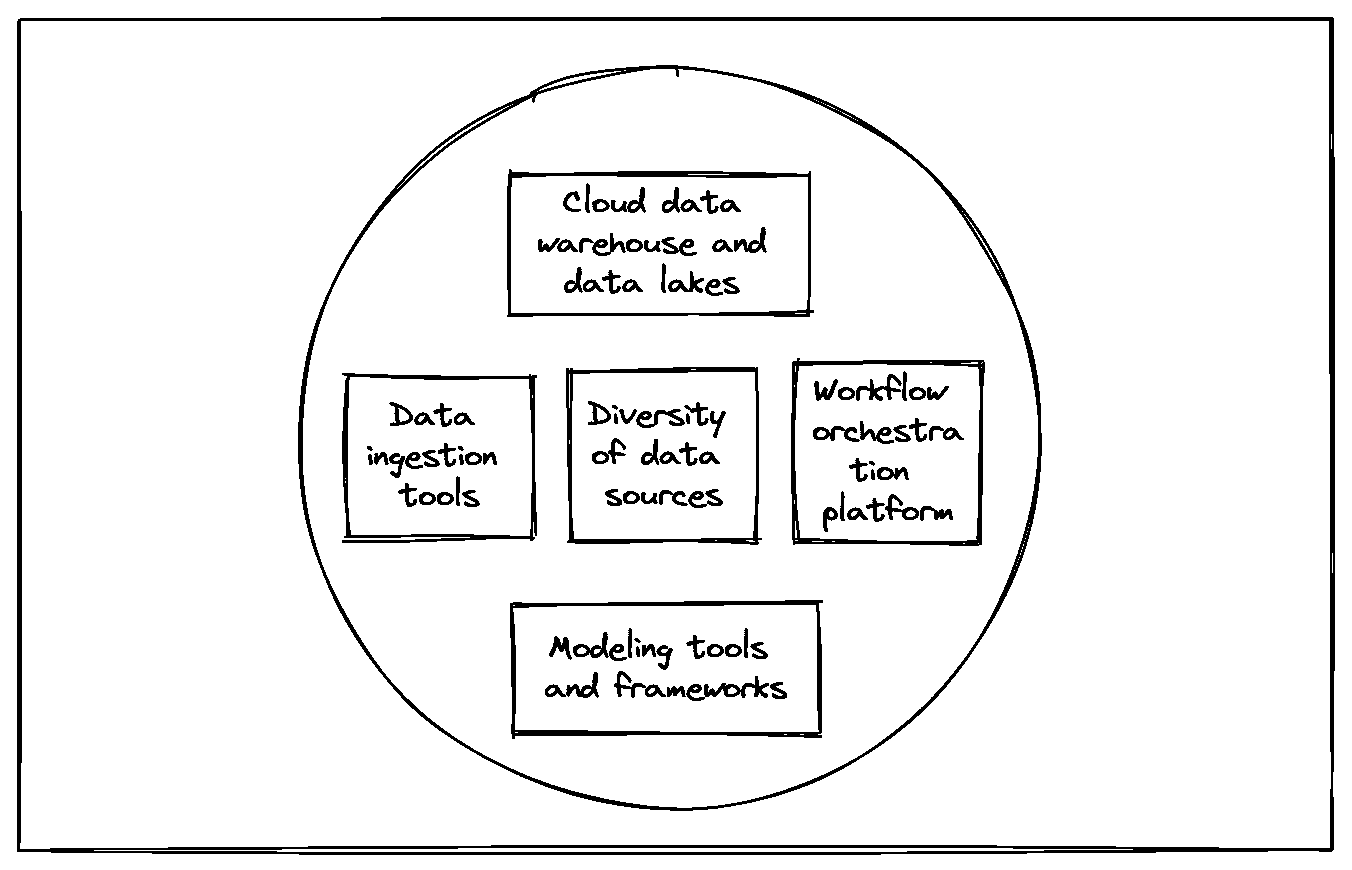
现代基础设施 | 图片来源:作者
网页抓取
网页抓取已经成为数据科学家和分析师工作的核心部分。即使在技术面试或测试中,你也必须展示一些使用 BeautifulSoup 和 Selenium 解析 HTML 数据的技能。它还使你能够创建完全自动化的系统。
数据应用
在创建机器学习模型或进行深入的数据分析后,是时候创建一个网络应用程序,以便可以与其他团队成员共享你的项目。你可以使用 FastAPI、Flask、Streamlit 和 Django 来创建 API 或网络应用程序。
数据管理
你的数据团队正在扩展,你正在随着时间的推移收集更多数据。是时候开始使用分布式数据库、数据仓库、数据湖和工具来管理你的数据了。这些工具将帮助你扩展当前的数据系统。
大数据
我们的传统数据库系统并不适合收集每日的 PB 级数据。这些书籍将帮助你学习可扩展的、易于理解的大数据系统方法,这些方法可以由一个小团队构建和运行。你还将了解 Hadoop、Storm 和 NoSQL 数据库等技术。
成熟的四个阶段 | 图片来自 企业大数据湖
云架构
尽管了解云架构并不是数据科学家的核心技能,但它在数据社区中越来越受欢迎。基于 AI 的公司希望机器学习、MLOps 和数据工程师了解 Kubernetes、Docker、API 集成、分布式计算、计算监控和混合云解决方案。
结语
数据科学书籍通过代码示例教你所有技术概念。你不仅仅是在阅读研究书籍,你在提升自己的技能。大多数书籍会鼓励你进行长时间的编码,以便通过调试问题更好地理解概念。
如果你和我一样,是数据科学爱好者,就会想不断学习。因此,在接下来的部分,我们将学习关于机器学习、深度学习、计算机视觉、自然语言处理(NLP)、MLOps、机器人技术、物联网(IoT)、AI 产品管理、高管数据科学以及数据科学超级书籍的最佳书单。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为有心理问题的学生构建一个 AI 产品。
更多相关内容
数据科学书籍完整合集 – 第二部分
原文:
www.kdnuggets.com/2022/05/complete-collection-data-science-books-part-2.html

图片来源于作者
编辑注:关于这一两部分系列中的数据科学书籍的完整范围,请参见数据科学书籍完整合集 – 第一部分。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
数据科学书籍在我的数据科学之旅中发挥了重要作用。Deep Learning for Coders with Fastai and PyTorch 让我从新的角度思考深度神经网络及我们如何处理几乎所有的机器学习问题。我爱上了 NLP 书籍及其附带的 GitHub 代码库、Jupyter 笔记本练习和易于探索的选项。Data Science at the Command Line 是一本现在可以在线访问(文档风格)的书籍,支持术语搜索、导航,并可以直接复制代码进行测试。它提供了免费的互动阅读体验。
在这两部分系列中,我将分享数据科学各子领域的最佳书籍。你可以购买纸质书籍,或仅仅获取在线版本,或下载 PDF/EPub/Kindle 版本。有些书籍基于网站,可以免费访问。
在第二部分中,我们将回顾以下书籍:
-
机器学习
-
深度学习
-
计算机视觉
-
自然语言处理
-
MLOps
-
机器人技术
-
物联网
-
AI 产品管理
-
数据科学高管版
-
数据科学超级书籍
机器学习
这是数据科学领域中最受欢迎的术语。大多数数据专业人士都需要执行某种机器学习任务,即使是开发一个简单的线性回归模型。这些书籍将教你最流行框架中的基础和高级概念,并附有代码示例。
深度学习
在简单的机器学习之后,我们将深入了解深度神经网络。这是机器学习的一个子领域,并且正在迅速改变世界。从计算机视觉到智能聊天机器人,你每天都在与它们互动。这些书籍将教你如何创建你的第一个深度学习模型,并介绍深度学习技术的子领域。
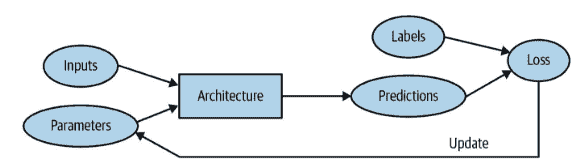
详细训练循环 | 深度学习实践:使用 Fastai 和 PyTorch
计算机视觉
计算机视觉需求量很大,借助深度学习,这个领域正在主导全球。你可以在仓库管理、机器人、自驾车、面部识别、生成艺术,甚至现代武器中找到它。
自然语言处理
学习如何创建机器翻译、自动语音识别、摘要生成器、文本和音频分类,以及对话机器人。自然语言处理是数据科学中的全新领域。你正在与音频、视觉和文本数据互动,以理解上下文和词汇。随着变换器的引入,这个领域在研究和开发上得到了真正的提升。我们现在正在训练具有 1760 亿个参数的模型 - bigscience。
变换器时间线 | 使用变换器的自然语言处理
MLOps
你将学习创建机器学习流水线,将应用部署到云端,维护多个数据库,并学习自动化所有流程。机器学习运维由开发运维驱动,工程师自动化流程、监控指标和管理多个系统。如果你想变得面向未来,投资时间和金钱学习 MLOps 是值得的。
机器人技术
虽然它不是数据科学的核心部分,但它已经是人工智能的一部分很长时间了。你可以学习如何在 Raspberry Pi 上使用 Python 训练和开发你的机器学习模型,或创建边缘应用。机器人技术是未来,如果你想保持相关性,我强烈建议你至少学习基础知识。
物联网
物联网无处不在。这些包括智能手机、智能手表、墙上的传感器,甚至是你的数字冰箱。我们被这些传感器包围,它们每小时都会收集和生成大量的数据。你将学习如何使用 Rust 构建服务器端应用,并将其与 Raspberry Pi 和云系统集成。你还将了解智能城市、物联网安全以及微控制器上的 TensorFlow Lite。

图片来源于 实用物联网黑客
AI 产品管理
你不能让任何一个 MBA 毕业生来管理数据团队。这个业务人员需要了解这些系统是如何工作的以及如何管理数据。AI 产品经理涉及数据的采购和处理,制定数据标注策略,理解业务问题和解决方案。要成为一个成功的 AI 经理,你需要同时具备商业理解和技术专长。
《高管数据科学》
针对那些负责根据投资回报率和增长潜力做决策的高级管理人员的非技术书籍。你将了解其他公司如何在管理数据项目方面取得进展,以及如何利用机器学习推动业务发展。
数据科学超级书籍
这些书籍涵盖了数据科学的各个方面,从统计学到高级机器学习算法。你将复习数据科学面试,了解如何管理数据,并学习所有入门基础知识。
一本书统治所有。
结束语
数据科学不仅仅是统计和编码。我们需要理解业务问题并提出最佳解决方案。并非所有问题都可以通过机器学习解决。我们还需要理解 MLOps 和其他集成系统如何对数据应用的成功至关重要。
在上一部分中,我们回顾了有关编程语言、统计学、数据工程、网页抓取、数据分析、商业智能、数据应用、数据管理、大数据和云架构的书籍。
“我强烈建议你将这两个页面添加到书签,这样你就不需要在网上搜索书籍,而是可以直接访问数据科学特定领域的最佳书籍。”
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理健康问题的学生开发 AI 产品。
更多相关话题
数据科学备忘单的完整集合 - 第一部分
原文:
www.kdnuggets.com/2022/02/complete-collection-data-science-cheat-sheets-part-1.html

图片来源:作者
编辑注释:有关此两部分系列中包含的备忘单的完整范围,请参阅数据科学备忘单的完整集合 - 第二部分。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
备忘单可以帮助我们复习统计学概念、编程语言语法、数据分析工具和机器学习框架。它也可以帮助你在技术面试和评估测试中表现出色。Jupyter Notebook是每个人都应该学习的必备备忘单。它包含了运行 Python 笔记本的快捷方式、技巧和函数。
我使用备忘单来准备技术面试,因为技术招聘人员希望评估主题领域的专业知识。寻找适合你的备忘单可能需要几个小时,因为大多数备忘单都不容易理解。这些博客分为两部分,包括易于跟随和总结的备忘单,以复习所有的数据科学概念。
两部分系列进一步分为子类别;SQL、网页抓取、统计学、数据分析、商业智能、大数据、数据结构与算法、机器学习、深度学习、自然语言处理、数据工程、网络框架和 VIP 备忘单。
第一篇博客包含六个子类别:
-
SQL
-
网页抓取
-
统计学、概率与数学
-
数据分析
-
商业智能
-
大数据
SQL
大多数技术面试和评估测试都包括某种类型的 SQL 问题,因此,最好使用 SQL 备忘单集合来准备面试。这些备忘单还将帮助你在创建和管理数据库方面做得更好。它还将帮助你理解复杂的 SQL 查询。

图片来源:freepik
网络抓取
网络抓取是数据科学的重要组成部分,它用于数据收集、市场研究和维护数据管道。Beautiful Soup 是一个流行的库,用于解析 HTML/Java 脚本并将其转换为人类可读的数据框。本节包含用于解析 Python 和 R 脚本的工具。
统计学、概率论与数学
人工智能、数据分析和现代研究依赖于统计学。统计学是现代社会的支柱,因此如果你想复习旧的概念或学习新的复杂思想,请查看一系列统计学作弊手册。

图片由 stories 提供
数据分析
数据分析用于制定业务决策、市场营销活动、科学研究和设计独特的数据产品。整个 IT 行业都依赖于它。此类别进一步分为三个子类别:Python、R 和 Julia。所有这些语言在数据科学家和数据分析师中都很受欢迎。
Python
该列表包含了用于数据摄取、处理和可视化的最常用 Python 包。Numpy 和 Pandas 是数据社区中进行科学计算和数据增强的最受欢迎工具。
R
R 在统计学家和数据分析专业人士中非常受欢迎。建议学习著名包如 Tidyverse 的语法和函数。Tidyverse 提供了一个完整的数据科学解决方案,从数据导入到创建视觉上引人入胜的数据报告。
Julia
Julia 是一种新兴的语言,我认为这是数据科学的未来。此列表包含 Julia 语法、数据整理和数据可视化的快速介绍。
商业智能
无代码应用程序在商业智能中正成为行业标准。这些应用程序可以帮助你创建数据分析报告、仪表板和沉浸式可视化。这些工具正在帮助企业做出数据驱动的决策。最受欢迎的工具包括 MS Excel、Power BI 和 Tableau。
图片来源 rawpixel.com
大数据
到 2025 年,预计全球每天将创造 463 亿 GB 的数据 - (weforum.org)。因此,主要的数据公司正在寻找数据工程师和数据科学家来处理大数据解决方案。这些备忘单可以为你介绍基本的大数据工具。
结论
在这篇博客中,我们涵盖了所有能够帮助你为数据分析、商业智能和数据科学面试做准备的备忘单。博客中包括了 SQL、网页抓取、统计学、数据分析、商业智能和大数据备忘单的合集。这些备忘单帮助我准备了求职面试,我希望它们也能对你有所帮助。明智的做法是将此页面收藏,以便每当你有技术面试时,可以立即开始准备,而不是在网上搜索备忘单。
在第二部分,我们将涵盖更多高级类别,如数据结构与算法、机器学习、深度学习、自然语言处理、数据工程、网络框架。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,他喜欢构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些挣扎于心理健康问题的学生开发 AI 产品。
更多相关主题
数据科学备忘单完整合集 – 第二部分
原文:
www.kdnuggets.com/2022/02/complete-collection-data-science-cheat-sheets-part-2.html

作者提供的图像
编辑注:有关本系列两个部分的完整备忘单范围,请参见 数据科学备忘单完整合集 - 第一部分。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
寻找适合你的备忘单可能需要一些时间,因为大多数备忘单并不容易理解。该博客包含易于跟随和总结的备忘单,以复习数据科学的高级概念。
该博客系列分为两部分,包含易于跟随和总结的备忘单,以复习所有的数据科学概念。这两部分系列进一步分为子类别 SQL、网页抓取、统计学、数据分析、商业智能、大数据、数据结构与算法、机器学习、深度学习、自然语言处理、数据工程、网络框架,以及一体化 VIP 备忘单。
第二篇博客包含七个子类别:
-
数据结构与算法
-
机器学习
-
深度学习
-
自然语言处理
-
数据工程
-
网络框架
-
VIP 备忘单
数据结构与算法
最常见的技术面试问题涉及数据结构和算法。如果你是软件工程师或数据科学家,你必须了解常见的数据结构操作、搜索和排序算法以及数据结构类型。这个列表旨在帮助你理解复杂的排序函数和算法。
机器学习
- 这是数据社区中最受欢迎的备忘单。每当我进行机器学习或深度学习的面试时,我会花几个小时复习所有机器学习和模型架构的关键概念。有时,招聘经理可能没有技术知识,因此他们也会使用备忘单进行准备。这个集合包括机器学习框架、算法和神经网络架构的备忘单。
深度学习
- 现代机器学习应用运行在深度神经网络上,每个与数据相关的工作都期望你具备一定的深度学习或先进人工智能技术的知识。深度学习模型推动了现代技术的发展,例如计算机视觉、自动语音识别、自然语言处理、医学研究和自动驾驶汽车。以下列表包含有关深度学习框架(Pytorch/Keras/Tensorflow)、模型架构、图神经网络和数据处理技术的信息。
自然语言处理
自然语言处理(NLP)用于处理和清理文本、音频和图像数据,以便我们提取有用的信息。NLP 应用广泛,包括语言翻译、转录、对话 AI、问答、生成技术、分类、命名实体识别等。该备忘单集合包含了关于最著名的 NLP 工具和算法的简明信息。
数据工程
数据工程师的职位要求包括精通 SQL、提取-转换-加载(ETL)操作、创建和管理数据库、自动化数据管道以及处理大数据。数据工程师职位需求旺盛,公司希望招聘最优秀的工程师来创建和管理完全自动化的数据管道。下面的列表包含了有关最受欢迎的数据工程工具(如 Apache Airflow 和 Kafka)的备忘单。

图片来源于 vectorjuice
网页框架
尽管这是可选的,但我曾经被招聘经理问到过我在端到端机器学习应用方面的经验。他们会询问你关于 Django、Flask 和 FastAPI 的经验,或者将模型部署到生产环境的经验。在技术面试前了解网页框架是一个好习惯。列表中包含 R-shiny、Plumber、Golem、Streamlit、FastAPI、Flask 和 Django 等网页框架。
VIP 备忘单
VIP 备忘单是数据科学的宝贵资源,其中包含关于数据科学及其核心主题的大量信息。这些备忘单包括有关数据类型、算法、自然语言处理、机器学习、数据分析和数据处理的基本信息。如果你正在准备一次普通的数据面试,我建议你下载任何 VIP 备忘单,并复习所有核心的数据科学和机器学习主题。
结论
如果你正在准备面试或演讲,使用这些备忘单来复习数据科学的核心概念。我们涵盖了数据结构与算法、机器学习、深度学习、自然语言处理、数据工程和网页框架。如果你想在下一次面试中表现出色,请收藏这个网页,以便随时回来准备技术面试。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理健康问题的学生构建 AI 产品。
更多相关主题
数据科学免费课程完整合集 – 第一部分
原文:
www.kdnuggets.com/2023/03/complete-collection-data-science-free-courses-part-1.html

图片来源:作者
编辑注: 要了解此两部分系列中包含的数据科学课程的完整范围,请参见 数据科学免费课程完整合集 - 第二部分。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
注意: 博客中提到的 Coursera 课程可以免费审计,这意味着你可以免费访问所有课程内容。
编程
编程是数据科学旅程中的重要部分。如果你会用 R、Python 或 Julia 编程,那么将算法转化为函数将会非常容易。此外,你将学到更好的技术来创建程序或数据报告。
我强烈推荐你先从 Python 开始,学习基础语法和高级功能。之后,你可以转向 R 以进行更好的统计分析,或转向 Julia 以获得更好的性能。
Python
-
Python 入门课程 | DataCamp
-
学习 Python - 初学者完整课程 | freeCodeCamp
-
人人学习 Python | 密歇根大学
R
-
R 编程入门 | DataCamp
-
R 编程教程 - 学习统计计算基础 | freeCodeCamp
-
R 编程与免费证书 | mygreatlearning
Julia
-
程序员的 Julia 入门 | Logan Kilpatrick
-
Julia 数据科学基础全课程(初学者) | Abhishek Agarwal
-
数据科学的 Julia | Julia Academy
网页抓取
网页抓取是数据和商业分析师工作的一个重要部分。它是一个家庭作业的一部分,招聘经理将要求从网站抓取数据并创建一个完全自动化的仪表板。
以下课程将教你如何使用 Beautiful Soup 抓取和清理 HTML 数据,并帮助你使用 Selenium 创建完全自动化的网页抓取机器人。
-
使用 Python 进行网页抓取 - Beautiful Soup 快速入门课程 | freeCodeCamp
-
使用 Python 进行网页抓取课程 | mygreatlearning
-
初学者的 Selenium 课程 - 网页抓取机器人、浏览器自动化、测试 | freeCodeCamp
统计学和概率
在编程之后,最重要的事情是统计学和概率的知识。你需要了解这些 AI / 机器学习模型是基于概率和统计算法的。要正确使用它们,你需要了解它们的工作原理以及如何为你的独特情况进行优化。
这些课程将教你统计学和概率的基础知识,并介绍统计分析、Z 分数和概率。
-
统计学与概率 | 可汗学院
-
统计学 - 数据科学基础的完整大学课程 | freeCodeCamp
-
数据科学:概率 | 哈佛大学
数据分析
数据科学家的核心工作是分析数据,这个过程分为多个部分。你从数据获取、数据清洗、数据处理、数据可视化、数据建模和报告开始。
这些课程将教你 SQL、数据处理和可视化、机器学习、统计技术和理解数据。
-
数据分析介绍:经理的指南 | 密歇根大学
-
数据分析速成课程:30 天自学 | freeCodeCamp
-
数据分析与可视化 | Udacity
SQL
每个数据科学家和分析师都必须知道如何运行 SQL 查询以及如何使用 SQL 进行简单的分析任务。为什么?大多数公司不使用 CSV 或 Excel 文件,他们有 SQL 数据库,SQL 查询可以让你快速轻松地从关系数据库中检索和操作数据。
以下课程将教你基本语法、SQL 连接、SQL 聚合、子查询和临时表、SQL 数据清洗和窗口函数。
-
SQL 数据分析 | Udacity
-
学习数据科学的 SQL 基础 | 加州大学戴维斯分校
-
MySQL 数据库 - 完整课程 | freeCodeCamp
商业智能
商业智能对于理解商业和客户行为、如何改善你的产品和服务以及保持领先于竞争对手非常重要。
你将学习 Power BI 和 Tableau,这些是最流行的商业智能软件,用于收集、分析和呈现商业数据,以帮助人们做出更好的决策。
-
Power BI 完整课程 | Edureka
-
数据科学的 Tableau | Simplilearn
-
业务智能的数据仓库 | 科罗拉多大学
结论
与昂贵的训练营和认证相比,免费课程可以帮助你节省金钱和时间。大多数课程是短期的,帮助你学习基础知识,如果你想学更多,可以选择认证课程。因此,与其参加训练营后发现自己不适合,不如先免费学习基础知识。
在第一部分,我们已经查看了编程、网页抓取、统计与概率、数据分析、SQL 和商业智能方面的顶级免费课程。
希望你喜欢我的列表,如果你有免费的课程建议,请在评论区写下。谢谢。
在下一部分,我们将涵盖:
-
机器学习
-
深度学习
-
计算机视觉
-
自然语言处理
-
数据工程
-
MLOps
这是该系列的第六版,请查看:
-
数据科学备忘单完整合集 – 第一部分 和 第二部分
-
数据仓库完整合集 – 第一部分 和 第二部分
-
数据科学书籍完整合集 – 第一部分 和 第二部分
-
数据科学面试完整合集 – 第一部分 和 第二部分
数据科学项目完整合集 – 第一部分 和 第二部分
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理问题的学生开发一款人工智能产品。
更多相关内容
数据科学免费课程完整合集 – 第二部分
原文:
www.kdnuggets.com/2023/03/complete-collection-data-science-free-courses-part-2.html
作者提供的图片
编辑注: 有关本系列两部分中包含的数据科学课程的完整范围,请参见 数据科学免费课程完整合集 - 第一部分。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
注意: 博客中提到的 Coursera 课程可以免费旁听,这意味着你可以访问所有课程内容,并在无需任何费用的情况下阅读和查看它。
机器学习
机器学习是现代技术的基石。几乎每一家大公司都在尝试利用它来最大化数据的价值。
通过这些免费课程,你将学习分类、回归、聚类和强化学习。此外,你还将了解特征工程、高级算法和优化技术。
-
人人都能学的机器学习 | freeCodeCamp
-
机器学习在线课程 | Udacity
-
大规模机器学习 | 多伦多大学
深度学习
深度学习推动了现代人工智能技术,如 ChatGPT。它们使用深度神经网络来处理数据并做出预测。
通过这些课程,你将学习高级机器学习算法、预处理技术、特征工程和神经网络架构。
你还将学习各种用于计算机视觉、自然语言处理、预测、自动语音识别、生成艺术和强化学习的算法。
-
实用深度学习课程 | fast.ai
-
从零到精通学习 PyTorch 进行深度学习 | learnpytorch
-
Keras 与 TensorFlow 课程 | freeCodeCamp
计算机视觉
DALLE.2 和 Stable Diffusion 2.0 是生成算法,它们结合了计算机视觉和自然语言处理技术,生成高质量的生成艺术。计算机视觉通常用于图像分类、生成、分割和物体检测。
你可以通过学习 OpeCV、Keras 和深度算法开始你的计算机视觉工程师之旅。
-
OpenCV 课程 | freeCodeCamp
-
学习计算机视觉 | Kaggle
-
使用 Python 的高级计算机视觉 | freeCodeCamp
自然语言处理(NLP)
我知道我们都对大型语言模型 ChatGPT 和 Bard AI 感到兴奋,为了开始成为 AI 工程师的旅程,你需要首先掌握基本的自然语言处理工具和技术。
你将学习有关 spaCy、分类、向量空间、概率模型、序列模型和注意力模型的内容。
-
使用 spaCy 和 Python 的自然语言处理 | freeCodeCamp
-
deeplearning.ai 的自然语言处理 | deeplearning.ai
-
使用深度学习的 NLP | 斯坦福大学
数据工程
我最喜欢的学科,也是每项技术的支柱是数据工程。如果没有它,我们将通过像 Excel 表格和 CSV 文件这样的无效方式共享数据。
通过这些课程,你将学习现代数据工具,用于收集、转换、加载、处理、查询和管理数据,以便数据消费者能够用于操作和决策。此外,你还将学习工作流编排、数据仓库、分析工程、批处理和流处理。
-
数据工程基础知识 | IBM
-
数据工程课程 | Intellipaat
-
数据工程 ZoomCamp | DataTalksClub
MLOps
机器学习操作(MLOps)是一组用于自动化、管理和监控机器学习生命周期的实践。MLOps 由 DevOps 的软件工程最佳实践驱动。
通过参加这些课程,你将学习简化开发、实验跟踪、测试、部署和维护机器学习模型的过程。此外,你还将自动化测试、数据和模型版本控制以及模型监控。
-
有效的 MLOps 与 W&B | wandb
-
机器学习工程(MLOps)专业化 | deeplearning.ai
-
MOps ZoomCamp | DataTalksClub
结论
第二部分中的一些课程确实是瑰宝。如果问我,它们比付费课程还要好。这些课程旨在让你为现代世界做好准备。你将学习最新的算法、技术、软件和技术。
我强烈推荐你参加 DataTalksClub 和 fast.ai 课程,开始你的机器学习和数据工程职业生涯。
在第二部分中,我们查看了关于机器学习、深度学习、计算机视觉、自然语言处理、数据工程和 MLOps 的顶级免费课程。
希望你喜欢我的列表,如果你有免费课程建议,请在评论区写下。谢谢。
在前一部分中,我们已经涵盖了:
-
编程
-
网络抓取
-
统计与概率
-
数据分析
-
SQL
-
商业智能
-
时间序列
这是该系列的第 6 版,查看:
-
数据科学备忘单完整合集 – 第一部分 和 第二部分
-
数据库完整合集 – 第一部分 和 第二部分
-
数据科学书籍完整合集 – 第一部分 和 第二部分
-
数据科学面试完整合集 – 第一部分 和 第二部分
数据科学项目完整合集 – 第一部分 和 第二部分
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为挣扎于心理疾病的学生构建一个 AI 产品。
更多相关话题
数据科学面试完整系列 – 第一部分
原文:
www.kdnuggets.com/2022/06/complete-collection-data-science-interviews-part-1.html

图片来源 | Canva Pro
编者按: 要查看本系列两部分中包含的所有资源,请参见 数据科学面试完整系列 – 第二部分。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
你是否遇到过面试官问你一个情境或技术问题时,你感到僵住了?只是因为你没有准备好。这种情况发生在许多人身上,包括我。我在技术面试中有时会感到僵住,招聘经理可能会把这当作我的弱点,在招聘过程的初期阶段拒绝我。
为了克服这个问题,我开始查看样本面试问题。假设面试与机器学习工程师有关,公司正在构建 NLP 解决方案。我会准备基础统计学、Python、深度学习和 NLP 面试问题。
这两部分的数据科学面试问题合集将帮助你为所有与数据相关的工作做准备。面试合集按照主题和数据领域进行分类。
目录
-
行为面试问题
-
情境面试问题
-
统计面试问题
-
Python 面试问题
-
R 面试问题
-
SQL 面试问题
-
数据分析面试问题
-
商业智能面试问题
行为面试问题
行为面试基于候选人与技能、能力和知识相关的经验。面试者将解释他过去是如何处理特定情况的。这些问题旨在评估候选人在日常任务中适应、沟通和解决问题的能力。
示例问题: “当你的日程被打断时,你会如何处理?”
-
21+ 行为面试问题 - novoresume.com
-
前 10 个行为面试问题及样本答案 - thebalancecareers.com
-
50 个顶级行为面试问题及候选人提问 - apollotechnical.com
情境面试问题
情境问题类似于行为问题。不同于经验,它关注于未来的假设场景。它用于评估你处理工作场所实际场景的能力。这些问题帮助招聘经理理解你的思维过程和在资源有限的情况下解决问题的能力。
样例问题: “你会如何处理一个你管理的员工,其工作成果不符合期望?”
-
20+顶级情境面试问题及答案 - zety.com
-
5 个情境面试问题 - Indeed.com
-
情境面试问题:定义 + 如何准备 - Coursera
统计面试问题
数据科学完全基于统计。在面试中,你需要解释某个算法如何工作或如何在相应业务中实施统计解决方案。最好熟悉所有基础术语和问题。
样例问题: “描述统计和推断统计之间的区别是什么?”
-
2022 年顶级 75 个统计面试问题及答案 - Intellipaat
-
2021 年 9 个有价值的统计面试问题及答案 - educba.com -
2022 年数据科学家的 50+统计面试问题及答案 - Towards Data Science
Python 面试问题
如果你提到 Python 是你进行分析和机器学习任务的主要语言,你必须了解所有最佳编码实践。面试问题涉及特性、数据类型、函数、创建单元测试、编写干净和生产就绪的代码,以及数据科学用例。
样例问题: “什么是 lambda 函数?”
-
2022 年 50 个顶级 Python 面试问题及答案 - hackr.io
-
2022 年 15 个最佳 Python 面试问题及答案 - codesubmit.io
-
顶级 Python 面试问题(2022) - InterviewBit
R 面试问题
R 是一种统计分析语言。面试问题涉及 R 相对于 Python 的优势、内存管理、变量、函数、循环和构建数据解决方案。确保你了解 R 的数据库及其使用案例。
示例问题: “描述 R 如何用于预测分析?”
-
2022 年排名前 50 的 R 面试问题及答案 - Edureka
-
27 个必备的 R 面试问题 - springboard.com
-
2022 年排名前 105 的 R 面试问题与答案 - Intellipaat
SQL 面试问题
SQL 是数据专业人员的母语。在深度学习工程师的面试中,我也被问到了 SQL。要训练一个大型模型,你需要学习从多个数据库中获取数据。SQL 也用于数据分析。在面试前,确保你了解语法及其功能。
示例问题: “描述 R 如何用于预测分析?”
-
2022 年排名前 115 的 SQL 面试问题及答案 - Edureka
-
SQL 面试问题及答案 - educba.com
-
SQL 面试问题:数据分析师指南 - Coursera
数据分析面试问题
对于数据分析问题,你需要为使用现代分析工具解决商业相关问题做好准备。你需要了解数据获取、数据清理、探索和分析,以及结果解释。确保你熟悉统计和分析工具,如 SQL、Python、R、Tableau 和电子表格。
示例问题: “你如何处理数据集中的异常值?”
-
2022 年排名前 60 的数据分析师面试问题及答案 - simplilearn.com
-
49 个数据分析面试问题 - Indeed.com
-
47 个数据分析师面试问题 - springboard.com
商业智能面试问题
商业智能(BI)在监控业务绩效以提供可操作的洞察方面发挥着至关重要的作用。作为 BI 分析师,你必须了解业务流程,监控关键绩效指标,能够使用 SQL 提取和清理数据,并使用 Tableau 或 PowerBI 创建仪表板和分析报告。你必须为案例研究或 BI 情境面试做好准备。
示例问题: “你将如何定义 OLTP(在线事务处理)?”
-
前 10 个商业智能面试问题及答案 - upGrad 博客
-
13 个商业智能分析师面试问题及答案 - techtarget.com
-
TOP 250+ 商业智能面试问题及答案 - Wisdom Jobs India
最后的想法
现在是暑期实习时间,大多数学生都在寻找顶级公司的实习机会。数据科学面试问题的合集将帮助你为各种情况和技术问题做好准备。
如果你在寻找一个信息的单一来源,我建议你阅读 Nick Singh 和 Kevin Huo 的 Ace the Data Science Interview 书籍。
在下一部分,我们将涵盖:
-
数据管理面试问题
-
数据工程面试问题
-
机器学习面试问题
-
深度学习面试问题
-
自然语言处理面试问题
-
MLOps 面试问题
-
云计算面试问题
-
人工智能经理面试问题
这是数据科学系列的第 4 版,查看:
-
数据科学备忘单完整合集 – 第一部分 和 第二部分
-
数据库完整合集 – 第一部分 和 第二部分
-
数据科学书籍完整合集 – 第一部分 和 第二部分
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理健康困扰的学生开发 AI 产品。
相关主题更多内容
数据科学面试完整合集 – 第二部分
原文:
www.kdnuggets.com/2022/06/complete-collection-data-science-interviews-part-2.html

图片来源 | Canva Pro
编辑注:有关此两部分系列中包含的完整存储库范围,请参阅 数据科学面试完整合集 – 第一部分。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
第二部分涉及与复杂算法、流程和工具相关的更高级问题。这些面试将为角色特定的工作做好准备。例如,MLOps 工程问题涉及机器学习算法、自动化、管道、实验监控和工业标准。
两部分的数据科学面试问题合集将帮助你为所有数据相关职位做准备。这些问题根据主题和数据领域分类。
目录
-
数据管理面试问题
-
数据工程面试问题
-
机器学习面试问题
-
深度学习面试问题
-
自然语言处理面试问题
-
MLOps 面试问题
-
云计算面试问题
-
AI 经理面试问题
数据管理面试问题
对于数据科学家来说,数据管理技能是核心点。你将被问及数据治理、软件分析和设计工具、试金石、SQL、Java 和大数据管理工具。数据经理的工作是制定并执行有效的数据管理政策。
示例问题: “为什么灾难恢复计划对所有使用数据系统的公司至关重要?”
-
数据经理面试问题 - indeed.com
-
28 个数据管理面试问题 - mockquestions.com
-
2022 年 20 个数据管理经理面试问题及答案 – projectpractical.com
数据工程面试问题
数据工程的问题完全围绕你的经验。大公司不会冒险招聘应届毕业生。要通过数据工程师面试,你必须了解流行的数据协调工具、SQL 和 No SQL 数据库、数据仓库、分析工程、批处理和流处理。
样本问题: “数据建模的设计模式有哪些?”
-
50 个数据工程师面试问题 - indeed.com
-
2022 年顶级 62 个数据工程师面试问题及答案 - guru99.com
-
14 个数据工程师面试问题及回答方式 - Coursera
机器学习面试问题
我知道机器学习在互联网上随处可见,但其技术面试却很难。大多数人甚至不知道基本术语。为了确保你顺利通过这阶段,我希望你关注机器学习算法和框架、数据管理、处理各种数据类型,以及创建在生产中表现良好的坚固模型。
经验丰富的机器学习工程师信息:“不要以为你知道一切。如果你掉以轻心,你会失败的。”
样本问题: “机器学习模型中的偏差和方差是什么?”
-
2022 年顶级 45 个机器学习面试问题回答 - Simplilearn
-
2022 年顶级 50 个机器学习面试问题 - javatpoint
-
51 个机器学习面试问题及答案 - Springboard
深度学习面试问题
在我看来,深度学习面试是最难的。我被要求优化一个在多个 Nvidia GPU 上的模型推理。除了深度学习算法,你还必须了解数据归一化、激活函数、dropout 和批归一化、先进的计算机视觉技术以及数据增强。
涉及的内容非常多,你必须做好准备。深度学习工程师年薪超过$160K - indeed.com,只有顶级专业人士才能获得这些职位。
样本问题: “你对迁移学习有什么理解?列举一些常用的迁移学习模型。”
-
2022 年顶级深度学习面试问题及答案 - Simplilearn
-
30 个深度学习面试问题及样本答案 - indeed.com
-
2022 年顶级 50 个深度学习面试问题 - javatpoint
自然语言处理(NLP)面试问题
在你参加面试之前,确保你有处理文本、音频和图像数据集的经验。此外,你将被问到关于词袋模型、TF-IDF、命名实体识别、正则表达式、先进的 NLP Python 库、变压器架构、深度学习框架和大型语言模型的问题。
由于 Huggingface 的影响,大多数公司会询问你有关在云端训练、验证和部署大型语言模型解决方案的问题。
示例问题: “在 NLP 的上下文中,解析是什么?”
-
2022 年 Top 30 NLP 面试问题及答案 - Intellipaat
-
10 个必备 NLP 面试问题及答案 - educba.com
-
2022 年 50+ NLP 面试问题及答案 - mygreatlearning.com
MLOps 面试问题
如果你没有 MLOps 经验,你将在面试阶段难以取得进展。这意味着你需要具备训练、验证和部署模型的经验。MLOps 问题与机器学习生命周期、实验跟踪、编排和 ML 管道、模型部署、生产环境中的模型监控以及软件开发最佳实践的理解相关。
示例问题: “解释数据漂移和概念漂移”
-
Top 30 MLOps 面试问题及答案 - MLStack.Cafe
-
Top MLOps 面试问题 - Tech Interview help
-
Top MLOps 面试问题及答案 - 360DigiTMG
云计算面试问题
处理云实例对数据科学家来说变得越来越必要。经验丰富的云工程师能够节省成本并提供最佳的存储和计算解决方案。你必须能够回答与主要云服务提供商(如 AWS、Azure 和 Google)相关的问题。这些问题围绕可扩展性、数据库管理、处理 API、节省成本的解决方案以及模型部署展开。
示例问题: “可扩展性和弹性有什么区别?”
-
2022 年 Top 37 云计算面试问题 - javatpoint
-
2022 年 Top 40 云计算面试问题及答案 - guru99.com
-
2022 年 Top 70+ 云计算面试问题及答案 - mygreatlearning.com
AI 经理面试问题
AI 经理是经验丰富的数据科学家或产品经理。要获得这个职位,你需要展示管理和数据科学技能。面试问题主要围绕数据获取、解决业务问题、理解数据、管理数据团队、机器学习生命周期以及指标和性能监控。
示例问题: “你使用什么技术指标来衡量分类模型的性能?”
-
AI 产品经理面试问题 - vitalflux.com
-
产品经理:机器学习面试问题 - DZone AI
-
12 个数据科学产品管理面试问题及解答 - productmanagerhq.com
最终思考
数据领域的专业职位需求很高。如果你具备经验,你可以顺利进入顶尖公司。为了帮助你通过技术面试的早期阶段,我整理了大量的数据科学面试问题清单。
那你还在等什么?
前一部分包括:
-
行为面试问题
-
情景面试问题
-
统计面试问题
-
Python 面试问题
-
R 面试问题
-
SQL 面试问题
-
数据分析面试问题
-
商业智能面试问题
这是数据科学系列的第 4 版,请查看:
-
数据科学备忘单完整合集 – 第一部分 和 第二部分
-
数据库完整合集 – 第一部分 和 第二部分
-
数据科学书籍完整合集 – 第一部分 和 第二部分
Abid Ali Awan (@1abidaliawan) 是一位认证数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理问题的学生构建一个 AI 产品。
更多相关内容
数据科学项目完整合集 - 第一部分
原文:
www.kdnuggets.com/2022/08/complete-collection-data-science-projects-part-1.html
图片由作者提供
编辑注: 有关本系列 2 部分中包含的所有仓库的完整范围,请参见 数据科学项目完整合集 - 第二部分。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
编程
如果你是数据科学新手,编程项目将帮助你熟悉语法、调试和学习新工具。Python、R 和 Julia 主要用于数据处理、数据分析、机器学习和研究项目。
Python
R
Julia
网页抓取
网页抓取是数据工程和数据科学的核心部分,你可以从多个网站收集新的数据,以构建数据集用于数据分析或机器学习任务。一般来说,它用于创建实时数据系统。
数据分析
该分析项目将教你数据清理、处理和可视化的新工具。你将学习如何理解数据并创建具有有价值见解的报告。
SQL
SQL 是创建、管理和流式处理数据库系统的最常用工具。在大多数情况下,你已经运行了一些 SQL 脚本进行分析任务,但将它们集成到你的项目中可能很难想象。这些项目将教你如何使用脚本创建数据库、存储和检索数据,以及如何将它们与其他工具集成。
商业智能
学习使用 BI 工具创建交互式仪表板和分析报告。你将学习如何将小模块结合起来创建仪表板以及它为业务带来的价值。
时间序列
学习理解、处理和可视化时间序列数据。你将学习创建异常检测系统、进行预测并可视化多个图表进行比较。时间序列是数据科学中的一个全新领域,因此将其中一个项目添加到你的作品集中将非常有价值。
结论
在完成几个课程后,你应该立即开始项目。进行项目会提高你对主题的理解,同时也会成为你简历上的一部分。做项目还能提高你的问题解决能力。你将在解决更复杂的问题时学到新的工具和概念。
在这篇博客中,我们学习了编程、网页抓取、数据分析、SQL、商业智能和时间序列项目。你可以通过源代码、教程或 ReadMe 中的初步描述来学习这些项目。关键是你需要复制这些结果。
在下一部分,我们将涵盖:
-
机器学习
-
深度学习
-
计算机视觉
-
自然语言处理
-
数据工程
-
MLOps
这是系列中的第 5 版,请查看:
-
数据科学备忘单完整合集 – 第一部分 和 第二部分
-
数据仓库完整合集 – 第一部分 和 第二部分
-
数据科学书籍完整合集 – 第一部分 和 第二部分
-
数据科学面试完整合集 – 第一部分 和 第二部分
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,帮助那些与心理疾病斗争的学生。
更多相关内容
数据科学项目完整合集 – 第二部分
原文:
www.kdnuggets.com/2022/08/complete-collection-data-science-projects-part-2.html

图片来源:作者
编辑注: 有关本系列两部分包含的所有库的完整范围,请参阅数据科学项目完整合集 – 第一部分。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
机器学习
机器学习是数据科学中的热门话题,你将学习分类、回归和聚类项目,以解决业务问题。这将帮助你理解表格数据集、数据处理、算法训练和模型验证。
深度学习
你将学习更高级的机器学习算法、神经网络和数据处理技术。深度学习是一个庞大的主题,要掌握它,你需要学习其在计算机视觉、自然语言处理、预测、自动语音识别、生成艺术和强化学习中的应用。
计算机视觉
在计算机视觉中,你将学习如何处理图像数据,并训练模型以执行各种计算机视觉任务,如图像分类、生成、分割和物体检测。
自然语言处理 (NLP)
你将通过图像、文本和音频来学习理解语言。由于大型语言模型和变换器的引入,自然语言处理在现实世界中得到了广泛应用。它被用于翻译、问答、文本摘要、文本分类、文本生成和对话 AI。
数据工程
设计、验证和部署数据科学项目的数据管道。你将学习有关数据工程过程的所有内容。你还将学习这些现代工具如何集成以提供无缝的数据流。它将介绍 ETL、数据建模、编排、分析和服务工具。
MLOps
这是机器学习的生产侧,工程师在这里测试、重新训练、验证和进行生产中的推理。你将学习有关 ml 管道工具、实验和工件跟踪、数据和模型的存储与版本控制、云计算、REST API 和 Web 应用程序的知识。你将学习创建一个端到端的机器学习系统。
结论
从事项目并复现结果将使你在解决问题方面更为出色,并且有助于你找到理想的工作。
我建议初学者和寻找工作的人可以开始一个个人项目或参与开源项目,以了解更多标准实践。
我们已经了解了机器学习、深度学习、计算机视觉、自然语言处理、数据工程和 MLOps。项目包括描述和代码来源。有些甚至有详细的教程来指导你完成整个项目。
在上一部分中,我们已经涵盖了:
-
编程
-
网络抓取
-
数据分析
-
SQL
-
商业智能
-
时间序列
这是该合集系列的第 5 版,请查看:
-
数据科学备忘单完整合集 – 第一部分 和 第二部分
-
数据仓库完整合集 – 第一部分 和 第二部分
-
数据科学书籍完整合集 – 第一部分 和 第二部分
-
数据科学面试完整合集 – 第一部分 和 第二部分
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些在心理健康上挣扎的学生。
更多相关主题
完整的数据工程学习路线图
原文:
www.kdnuggets.com/2022/11/complete-data-engineering-study-roadmap.html

作者提供的图片
完整的数据科学学习路线图 似乎很受欢迎,所以我觉得做一个版本是个好主意。在这篇文章中,我将介绍成为数据工程师所需的一切。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在的组织进行 IT 工作
1. 打造你的基础
成为数据工程师有许多复杂之处,有时可能会让人感到有些不知所措。但唯一能让你坚持下去的就是建立一个坚实的基础。
你的基础将包括熟练掌握一到两种编程语言、SQL 以及更多关于服务器的知识。
Python
如果你选择了 Python 作为编程语言,以下是一些推荐的课程:
-
100 天代码挑战:2022 年完整 Python 专业实战营 - Udemy
-
人人皆可编程(Python 入门) - Coursera(密歇根大学)
SQL
-
终极 MySQL 实战营:从 SQL 初学者到专家 - Udemy
-
完整的 SQL 精通课程 - CodeWithMosh
基础知识
使用 SQL、Python 和 PySpark 的数据工程基础 - Udemy
2. 数学和统计学
就像任何涉及数据分析和工程的职业一样,数学总是必需的。它将帮助你更好地理解日常任务,并更有效地运用你的技能。
这里有一些其他的资源来帮助你:
-
Josh Starmer 的统计学基础 - YouTube
-
机器学习的数学基础 - Udemy
-
数据科学与商业分析的统计学 - Udemy
2. 数据库管理系统
作为数据工程师,你将频繁使用数据库管理系统——它们帮助处理大型数据集。市面上有很多数据库管理系统,因此不必感到需要掌握所有系统。这取决于你工作的公司或你偏好的工具。
-
数据库管理原则 - YouTube
-
数据库管理系统(DBMS)与 SQL:2022 完整包 - Udemy
-
DBMS 简介 - 文章/文档
-
前 30 名最受欢迎的数据库管理软件 - 博客
如果你还想了解更多关于 SQL 和数据库的免费课程,可以查看这个:免费 SQL 和数据库课程
4. 数据仓储与数据管道
这一领域的重点是区分数据工程师和数据科学家的关键。两者都学习相同的基础知识并使用相同的编程语言、SQL 等。但数据仓储和数据管道是使数据工程师与众不同的因素——使他们成为优秀的数据工程师。
我推荐的数据仓库资源有:
-
数据仓库工具包 - PDF 书籍。这本书由建立数据仓库基础之一的 Ralph Kimball 所著。
-
数据仓储教程 - 文章
-
数据库与数据仓库与数据湖的比较 - YouTube
以下是学习数据管道的一些资源:
-
数据管道解释 - YouTube
-
ETL 与 ELT - 文章
-
用 Python 构建数据工程管道 - DataCamp
5. 云计算
最后但同样重要的是云计算。你不需要了解所有内容,但你应该对不同的服务提供商、他们的能力、局限性等有一个不错的了解。
你需要了解云计算的基础知识,如 IAAS、PAAS 和 SAAS,以及云计算的架构。
这里是一些关于云计算的资源:
6. 分析工程
分析工程也很重要。它包括:
-
ETL(提取、转换和加载)
-
创建数据模型(dbt 模型)
-
测试和文档编制
-
部署到云端和本地
-
使用分析应用(Google Data Studio 和 Metabase)可视化数据
你可以通过 DataTalksClub YouTube 播放列表 学习所有这些概念。
这里有一些额外的资源可以帮助你:
dbt 免费课程 - dbt
分析工程训练营 - Udemy
从零开始学习 DBT - Udemy
7. 项目
看起来这需要大量学习 - 的确如此。这就是为什么你在这些领域感到熟练至关重要,才能成为一名成功的数据工程师。你可以在学习过程中或之后完成这一阶段 - 由你决定。有些人喜欢在所有学习之后应用他们的知识和技能,有些人则喜欢在学习过程中应用,以测试自己。
所以下一阶段是应用你的代码并将你的技能付诸实践。你的项目清单应该旨在涵盖所有这些领域:
-
探索不同类型的数据格式
-
数据仓库
-
数据分析
-
数据源
-
大数据工具
数据工程项目的想法
在数据工程之外,你可以通过 LeetCode 挑战来练习你的编码技能,不过这可以应用于大多数技术职业。
8. 面试准备
你们一直在等待但又感到紧张的时刻 - 面试。要记住的内容很多,因此准备好自己是你能做的最好的事情。
这里有一些资源可以帮助你:
如果 Python 是你选择的编程语言,建议你熟悉一下Google Python 风格指南
不要忘记软技能:面试时询问员工的 73 个问题
进一步阅读
如果你想继续学习(这是很多人建议的),这里有一本书单是成为数据工程师的必备书籍。
如果你在寻找最终的数据工程课程,我推荐这个:Google Cloud 认证准备:云数据工程师专业证书
成为数据工程师的旅程不会轻松。你需要付出努力,但我向你保证,一旦你付出,就会得到回报。
尼莎·阿亚是一位数据科学家和自由职业技术作家。她特别感兴趣于提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探索人工智能在延长人类寿命方面的不同方式。作为一个热衷学习的人,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
完整的数据科学学习路线图
原文:
www.kdnuggets.com/2022/08/complete-data-science-study-roadmap.html

图片由作者提供
在这篇文章中,我将详细说明成为数据科学家的步骤。虽然这篇文章可能专为初学者准备,但现有的初级数据科学家可能会遗漏一些东西。我在这里帮助填补这些空白,让你在数据科学的旅程中不会感到冒名顶替或缺乏自信。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
我将带你走过这些步骤——这终究是一张路线图。
Python
Python 是目前最流行的编程语言之一,越来越多的人因其简单性而采用它。如果你打算进入数据科学但还没有选择编程语言——Python 总是一个好的开始。
以下是一些帮助你入门的课程:
-
100 天代码:2022 年完整的 Python 专业训练营 - Udemy
-
编程入门(Python 入门指南) - Coursera(密歇根大学)
数据科学和机器学习
一旦你理解了字母表和元音的工作原理,就可以开始构建句子。我将编程语言以及数据科学和机器学习领域视作如此。
一旦你掌握了编程语言 Python,你应该能够很好地利用这个技能,将其应用于数据科学和/或机器学习。
以下是一些帮助你达到目标的课程:
-
数据科学与机器学习 Python 训练营 - Udemy
-
数据科学课程 2022:完整的数据科学训练营 - Udemy
数学和统计学
由于对数据科学家、数据工程师、机器学习工程师等的需求很大,市场上有很多训练营。虽然它们都很棒,但其中一些忽视了数学和统计学在成为最佳数据科学家或机器学习工程师中的重要性。
数学和统计学非常重要,你需要彻底理解它们,以便将你的编码技能应用到实际世界中。虽然上述的数据科学和机器学习训练营课程会涉及数学和统计学,但这是你数据科学之旅中一个至关重要的元素,你需要搞清楚。
这里有一些其他资源可以帮助你:
-
Josh Starmer 的统计学基础 - YouTube
-
机器学习的数学基础 - Udemy
-
数据科学与商业分析的统计学 - Udemy
机器学习、深度学习与人工智能
如果你只是想成为一名数据科学家,这仍然很重要,你需要深入理解机器学习和深度学习的概念。人工智能涵盖了这三方面,并且它们之间有相似之处,因此了解和精通这些领域对你和你的职业生涯都有好处。
这里有一些课程可以进一步帮助你:
机器学习
-
CS229 机器学习 - Stanford
-
Andreas Mueller 的应用机器学习 - YouTube
-
Josh Starmer 的机器学习 - YouTube
深度学习
-
freeCodeCamp.org 的初学者深度学习速成课程 - YouTube
-
Krish Naik 的完整深度学习课程 - YouTube
-
Andrew Ng 的深度学习专项课程 - Coursera
-
深度学习 A-Z™:实践人工神经网络 - Udemy
人工智能
-
Microsoft Azure Cloud 的初学者人工智能课程 - GitHub。如果你想了解更多关于这个课程的信息,可以点击这个链接阅读我们首席编辑在 KDN 上撰写的博客。
-
人工智能 A-Z™:学习如何构建 AI - Udemy
项目
在学习阶段,通过实际问题应用你的技能总是很好且非常有用。如果你从事的是数据科学、机器学习、人工智能等领域,项目对你职业的发展至关重要。数据是新的黄金,你可以利用大量数据来解决问题、回答问题等。
以下是一些提供数据科学项目以及开放数据集网站的文章:
-
2022 年能让你获得工作的数据科学项目 由 Natassha Selvaraj 提供
-
Abid Ali Awan 的《数据科学项目完整合集》 – 第一部分 和 第二部分
简历
一旦你有了一些项目经验并且对编程感到自信,下一步就是申请工作。但在此之前,你需要一份简历。不仅仅是任何简历,而是一份好的简历,一份优秀的数据科学简历。
你正在进入一个新的领域,因此你将与不同类型的招聘人员或老板打交道。因此,拥有一份正确构建的简历将有助于你获得初次面试机会。
阅读这篇文章,了解你如何实现这一目标:
- 数据科学简历必备要素 由 Nisha Arya 提供
面试准备
每个人都害怕的部分,但也是每个人都在努力的部分——找到工作!这个行业的需求非常高,因此你不会缺少工作机会。然而,准备好并顺利通过面试才是难点。
记忆内容很多,当你在压力下被当场提问时,可能会很困难。然而,有数据科学备考课程、面试官常问的问题等,可以在这个阶段帮助你。
这里有一些资源:
-
Nisha Arya 的《数据科学面试指南》 – 第一部分:结构 和 第二部分:面试资源
-
250+数据科学面试问题由 Krish Naik 提供 - YouTube
-
21 份数据科学面试备考资料 由 Nate Rosidi 提供
-
数据科学职业指南面试准备 - Udemy
额外资源
-
免费大学数据科学资源
-
3 门免费的统计学课程用于数据科学
-
最值得关注的数据科学、机器学习和人工智能的 Instagram 账户
结论
我希望这个数据科学学习路线图能够激励你换个职业,或者最终迈出一步,开始学习数据科学。这些资源中的大多数要么因其优质内容而闻名,要么是畅销书,要么已被证明能帮助人们在数据科学旅程中取得进展。
祝一切顺利!
Nisha Arya 是一名数据科学家和自由技术写作人员。她特别感兴趣于提供数据科学职业建议或教程以及与数据科学相关的理论知识。她还希望探索人工智能如何能够或已经对人类寿命产生益处。作为一个热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关主题
完整的探索性数据分析与文本数据可视化:结合可视化和 NLP 生成见解
原文:
www.kdnuggets.com/2019/05/complete-exploratory-data-analysis-visualization-text-data.html
评论
作者 Susan Li,高级数据科学家
 照片来源:Pixabay
照片来源:Pixabay
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的 IT 组织
直观呈现文本文件的内容是文本挖掘领域中最重要的任务之一。作为数据科学家或NLP专家,我们不仅从不同的角度和细节层次探索文档的内容,还总结单个文档,展示词汇和主题,检测事件,并创建故事情节。
然而,在可视化非结构化(文本)数据和结构化数据之间存在一些差距。例如,许多文本可视化并未直接表示文本,而是表示语言模型的输出(词频、字符长度、词序列等)。
在这篇文章中,我们将使用女性服装电子商务评论数据集,并尽可能多地探索和可视化数据,使用Plotly 的 Python 图形库和Bokeh 可视化库。我们不仅将探索文本数据,还将可视化数值和分类特征。让我们开始吧!
数据
df = pd.read_csv('Womens Clothing E-Commerce Reviews.csv')
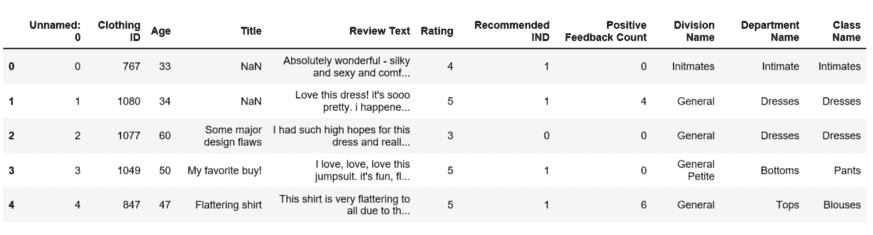 表 1
表 1
在对数据进行简要检查后,我们发现需要进行一系列的数据预处理工作。
-
移除“标题”特征。
-
移除“评论文本”缺失的行。
-
清理“评论文本”列。
-
使用TextBlob计算情感极性,其范围在[-1,1]之间,1 表示积极情感,-1 表示消极情感。
-
创建评论长度的新特征。
-
创建评论字数的新特征。
df.drop('Unnamed: 0', axis=1, inplace=True)
df.drop('Title', axis=1, inplace=True)
df = df[~df['Review Text'].isnull()]
def preprocess(ReviewText):
ReviewText = ReviewText.str.replace("(
)", "")
ReviewText = ReviewText.str.replace('().*()', '')
ReviewText = ReviewText.str.replace('(&)', '')
ReviewText = ReviewText.str.replace('(>)', '')
ReviewText = ReviewText.str.replace('(<)', '')
ReviewText = ReviewText.str.replace('(\xa0)', ' ')
return ReviewText
df['Review Text'] = preprocess(df['Review Text'])
df['polarity'] = df['Review Text'].map(lambda text: TextBlob(text).sentiment.polarity)
df['review_len'] = df['Review Text'].astype(str).apply(len)
df['word_count'] = df['Review Text'].apply(lambda x: len(str(x).split()))
text_preprocessing.py
为了预览情感极性分数是否有效,我们随机选择了 5 条情感极性分数最高的评论 (1):
print('5 random reviews with the highest positive sentiment polarity: \n')
cl = df.loc[df.polarity == 1, ['Review Text']].sample(5).values
for c in cl:
print(c[0])
 图 1
图 1
然后随机选择 5 条情感极性分数最中性的评论(零):
print('5 random reviews with the most neutral sentiment(zero) polarity: \n')
cl = df.loc[df.polarity == 0, ['Review Text']].sample(5).values
for c in cl:
print(c[0])
 图 2
图 2
只有 2 条评论的情感极性分数最为负面:
print('2 reviews with the most negative polarity: \n')
cl = df.loc[df.polarity == -0.97500000000000009, ['Review Text']].sample(2).values
for c in cl:
print(c[0])
 图 3
图 3
成功了!
使用 Plotly 进行单变量可视化
单变量或单维可视化是最简单的可视化类型,仅由对单一特征或属性的观察组成。单变量可视化包括直方图、条形图和折线图。
评论情感极性分数的分布
df['polarity'].iplot(
kind='hist',
bins=50,
xTitle='polarity',
linecolor='black',
yTitle='count',
title='Sentiment Polarity Distribution')
图 4
绝大多数的情感极性分数都大于零,这意味着大多数评论都相当积极。
评论评分的分布
df['Rating'].iplot(
kind='hist',
xTitle='rating',
linecolor='black',
yTitle='count',
title='Review Rating Distribution')
图 5
评分与极性分数一致,即大多数评分都很高,处于 4 或 5 的范围内。
评论者年龄的分布
df['Age'].iplot(
kind='hist',
bins=50,
xTitle='age',
linecolor='black',
yTitle='count',
title='Reviewers Age Distribution')
图 6
大多数评论者年龄在 30 到 40 岁之间。
评论文本长度的分布
df['review_len'].iplot(
kind='hist',
bins=100,
xTitle='review length',
linecolor='black',
yTitle='count',
title='Review Text Length Distribution')
图 7
评论字数的分布
df['word_count'].iplot(
kind='hist',
bins=100,
xTitle='word count',
linecolor='black',
yTitle='count',
title='Review Text Word Count Distribution')
图 8
有相当多人喜欢留下长评论。
对于类别特征,我们简单使用条形图来展示频率。
部门的分布
df.groupby('Division Name').count()['Clothing ID'].iplot(kind='bar', yTitle='Count', linecolor='black', opacity=0.8, title='Bar chart of Division Name', xTitle='Division Name')
图 9
General 部门的评论最多,而 Initmates 部门的评论最少。
部门的分布
df.groupby('Department Name').count()['Clothing ID'].sort_values(ascending=False).iplot(kind='bar', yTitle='Count', linecolor='black', opacity=0.8, title='Bar chart of Department Name', xTitle='Department Name')
图 10
说到部门,Tops 部门的评论最多,而 Trend 部门的评论最少。
类别的分布
df.groupby('Class Name').count()['Clothing ID'].sort_values(ascending=False).iplot(kind='bar', yTitle='Count', linecolor='black', opacity=0.8, title='Bar chart of Class Name', xTitle='Class Name')
图 11
现在我们来探索“评论文本”功能,在探索这个功能之前,我们需要提取 N-Gram 特征。N-grams 用于描述作为观察点的单词数量,例如 unigram 指单字,bigram 指二字短语,trigram 指三字短语。为此,我们使用 scikit-learn’s [CountVectorizer](https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html) 函数。
首先,比较去除停用词前后的单词分布将会很有趣。
去除停用词前的顶级单词分布
def get_top_n_words(corpus, n=None):
vec = CountVectorizer().fit(corpus)
bag_of_words = vec.transform(corpus)
sum_words = bag_of_words.sum(axis=0)
words_freq = [(word, sum_words[0, idx]) for word, idx in vec.vocabulary_.items()]
words_freq =sorted(words_freq, key = lambda x: x[1], reverse=True)
return words_freq[:n]
common_words = get_top_n_words(df['Review Text'], 20)
for word, freq in common_words:
print(word, freq)
df1 = pd.DataFrame(common_words, columns = ['ReviewText' , 'count'])
df1.groupby('ReviewText').sum()['count'].sort_values(ascending=False).iplot(
kind='bar', yTitle='Count', linecolor='black', title='Top 20 words in review before removing stop words')
top_unigram.py
图 12
去除停用词后的顶级单词分布
def get_top_n_words(corpus, n=None):
vec = CountVectorizer(stop_words = 'english').fit(corpus)
bag_of_words = vec.transform(corpus)
sum_words = bag_of_words.sum(axis=0)
words_freq = [(word, sum_words[0, idx]) for word, idx in vec.vocabulary_.items()]
words_freq =sorted(words_freq, key = lambda x: x[1], reverse=True)
return words_freq[:n]
common_words = get_top_n_words(df['Review Text'], 20)
for word, freq in common_words:
print(word, freq)
df2 = pd.DataFrame(common_words, columns = ['ReviewText' , 'count'])
df2.groupby('ReviewText').sum()['count'].sort_values(ascending=False).iplot(
kind='bar', yTitle='Count', linecolor='black', title='Top 20 words in review after removing stop words')
top_unigram_no_stopwords.py
图 13
其次,我们希望比较去除停用词前后的二元组。
去除停用词前的顶级二元组分布
def get_top_n_bigram(corpus, n=None):
vec = CountVectorizer(ngram_range=(2, 2)).fit(corpus)
bag_of_words = vec.transform(corpus)
sum_words = bag_of_words.sum(axis=0)
words_freq = [(word, sum_words[0, idx]) for word, idx in vec.vocabulary_.items()]
words_freq =sorted(words_freq, key = lambda x: x[1], reverse=True)
return words_freq[:n]
common_words = get_top_n_bigram(df['Review Text'], 20)
for word, freq in common_words:
print(word, freq)
df3 = pd.DataFrame(common_words, columns = ['ReviewText' , 'count'])
df3.groupby('ReviewText').sum()['count'].sort_values(ascending=False).iplot(
kind='bar', yTitle='Count', linecolor='black', title='Top 20 bigrams in review before removing stop words')
top_bigram.py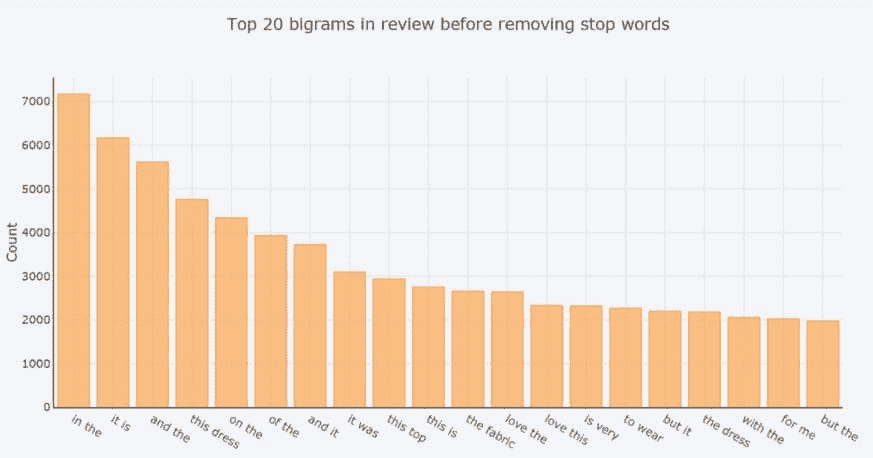 图 14
图 14
去除停用词后的顶级二元组分布
def get_top_n_bigram(corpus, n=None):
vec = CountVectorizer(ngram_range=(2, 2), stop_words='english').fit(corpus)
bag_of_words = vec.transform(corpus)
sum_words = bag_of_words.sum(axis=0)
words_freq = [(word, sum_words[0, idx]) for word, idx in vec.vocabulary_.items()]
words_freq =sorted(words_freq, key = lambda x: x[1], reverse=True)
return words_freq[:n]
common_words = get_top_n_bigram(df['Review Text'], 20)
for word, freq in common_words:
print(word, freq)
df4 = pd.DataFrame(common_words, columns = ['ReviewText' , 'count'])
df4.groupby('ReviewText').sum()['count'].sort_values(ascending=False).iplot(
kind='bar', yTitle='Count', linecolor='black', title='Top 20 bigrams in review after removing stop words')
top_bigram_no_stopwords.py
图 15
最后,我们比较去除停用词前后的三元组。
去除停用词前的顶级三元组分布
def get_top_n_trigram(corpus, n=None):
vec = CountVectorizer(ngram_range=(3, 3)).fit(corpus)
bag_of_words = vec.transform(corpus)
sum_words = bag_of_words.sum(axis=0)
words_freq = [(word, sum_words[0, idx]) for word, idx in vec.vocabulary_.items()]
words_freq =sorted(words_freq, key = lambda x: x[1], reverse=True)
return words_freq[:n]
common_words = get_top_n_trigram(df['Review Text'], 20)
for word, freq in common_words:
print(word, freq)
df5 = pd.DataFrame(common_words, columns = ['ReviewText' , 'count'])
df5.groupby('ReviewText').sum()['count'].sort_values(ascending=False).iplot(
kind='bar', yTitle='Count', linecolor='black', title='Top 20 trigrams in review before removing stop words')
top_trigram.py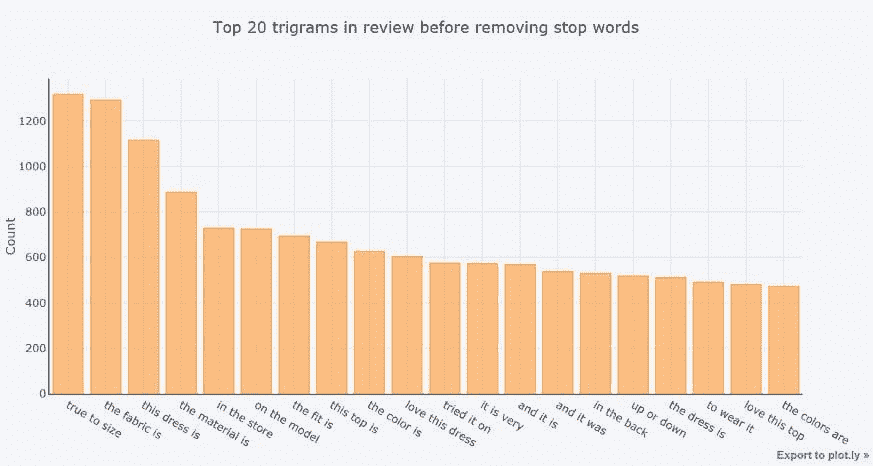 图 16
图 16
去除停用词后的顶级三元组分布
def get_top_n_trigram(corpus, n=None):
vec = CountVectorizer(ngram_range=(3, 3), stop_words='english').fit(corpus)
bag_of_words = vec.transform(corpus)
sum_words = bag_of_words.sum(axis=0)
words_freq = [(word, sum_words[0, idx]) for word, idx in vec.vocabulary_.items()]
words_freq =sorted(words_freq, key = lambda x: x[1], reverse=True)
return words_freq[:n]
common_words = get_top_n_trigram(df['Review Text'], 20)
for word, freq in common_words:
print(word, freq)
df6 = pd.DataFrame(common_words, columns = ['ReviewText' , 'count'])
df6.groupby('ReviewText').sum()['count'].sort_values(ascending=False).iplot(
kind='bar', yTitle='Count', linecolor='black', title='Top 20 trigrams in review after removing stop words')
top_trigram_no_stopwords.py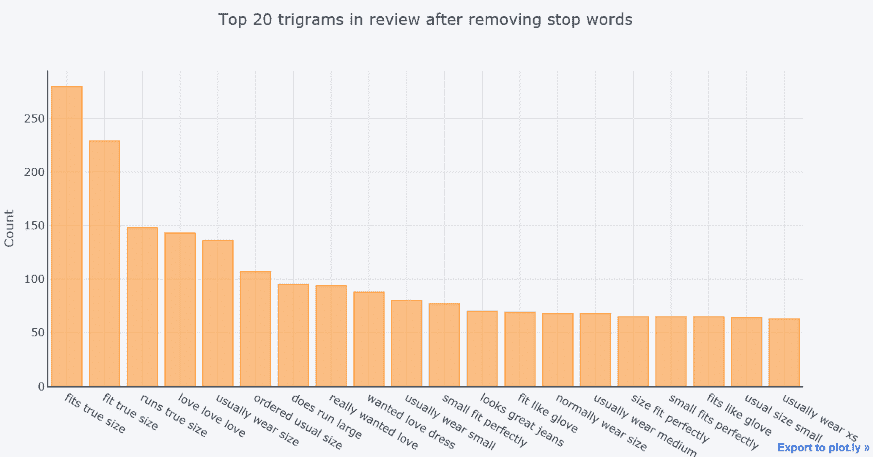 图 17
图 17
词性标注 (POS) 是一种将词语标注为不同词性的过程,例如名词、动词、形容词等。
我们使用一个简单的 TextBlob API 来深入探讨数据集中的“评论文本”功能的词性,并可视化这些标签。
评论语料库的顶级词性标注分布
blob = TextBlob(str(df['Review Text']))
pos_df = pd.DataFrame(blob.tags, columns = ['word' , 'pos'])
pos_df = pos_df.pos.value_counts()[:20]
pos_df.iplot(
kind='bar',
xTitle='POS',
yTitle='count',
title='Top 20 Part-of-speech tagging for review corpus')
POS.py
图 18
箱形图用于比较电子商务商店每个部门或分部的情感极性得分、评级、评论文本长度。
各部门对情感极性的分析
y0 = df.loc[df['Department Name'] == 'Tops']['polarity']
y1 = df.loc[df['Department Name'] == 'Dresses']['polarity']
y2 = df.loc[df['Department Name'] == 'Bottoms']['polarity']
y3 = df.loc[df['Department Name'] == 'Intimate']['polarity']
y4 = df.loc[df['Department Name'] == 'Jackets']['polarity']
y5 = df.loc[df['Department Name'] == 'Trend']['polarity']
trace0 = go.Box(
y=y0,
name = 'Tops',
marker = dict(
color = 'rgb(214, 12, 140)',
)
)
trace1 = go.Box(
y=y1,
name = 'Dresses',
marker = dict(
color = 'rgb(0, 128, 128)',
)
)
trace2 = go.Box(
y=y2,
name = 'Bottoms',
marker = dict(
color = 'rgb(10, 140, 208)',
)
)
trace3 = go.Box(
y=y3,
name = 'Intimate',
marker = dict(
color = 'rgb(12, 102, 14)',
)
)
trace4 = go.Box(
y=y4,
name = 'Jackets',
marker = dict(
color = 'rgb(10, 0, 100)',
)
)
trace5 = go.Box(
y=y5,
name = 'Trend',
marker = dict(
color = 'rgb(100, 0, 10)',
)
)
data = [trace0, trace1, trace2, trace3, trace4, trace5]
layout = go.Layout(
title = "Sentiment Polarity Boxplot of Department Name"
)
fig = go.Figure(data=data,layout=layout)
iplot(fig, filename = "Sentiment Polarity Boxplot of Department Name")
department_polarity.py
图 19
除了 Trend 部门外,所有六个部门的情感极性得分都很高,而 Tops 部门的情感极性得分最低。Trend 部门具有最低的中位极性得分。如果你还记得,Trend 部门的评论数量最少。这解释了为什么它的评分分布没有其他部门那么广泛。
各部门对评分的影响
y0 = df.loc[df['Department Name'] == 'Tops']['Rating']
y1 = df.loc[df['Department Name'] == 'Dresses']['Rating']
y2 = df.loc[df['Department Name'] == 'Bottoms']['Rating']
y3 = df.loc[df['Department Name'] == 'Intimate']['Rating']
y4 = df.loc[df['Department Name'] == 'Jackets']['Rating']
y5 = df.loc[df['Department Name'] == 'Trend']['Rating']
trace0 = go.Box(
y=y0,
name = 'Tops',
marker = dict(
color = 'rgb(214, 12, 140)',
)
)
trace1 = go.Box(
y=y1,
name = 'Dresses',
marker = dict(
color = 'rgb(0, 128, 128)',
)
)
trace2 = go.Box(
y=y2,
name = 'Bottoms',
marker = dict(
color = 'rgb(10, 140, 208)',
)
)
trace3 = go.Box(
y=y3,
name = 'Intimate',
marker = dict(
color = 'rgb(12, 102, 14)',
)
)
trace4 = go.Box(
y=y4,
name = 'Jackets',
marker = dict(
color = 'rgb(10, 0, 100)',
)
)
trace5 = go.Box(
y=y5,
name = 'Trend',
marker = dict(
color = 'rgb(100, 0, 10)',
)
)
data = [trace0, trace1, trace2, trace3, trace4, trace5]
layout = go.Layout(
title = "Rating Boxplot of Department Name"
)
fig = go.Figure(data=data,layout=layout)
iplot(fig, filename = "Rating Boxplot of Department Name")
rating_division.py
图 20
除了 Trend 部门,所有其他部门的中位评分均为 5。总体而言,评分较高,情感在该评论数据集中较为积极。
部门评论长度
y0 = df.loc[df['Department Name'] == 'Tops']['review_len']
y1 = df.loc[df['Department Name'] == 'Dresses']['review_len']
y2 = df.loc[df['Department Name'] == 'Bottoms']['review_len']
y3 = df.loc[df['Department Name'] == 'Intimate']['review_len']
y4 = df.loc[df['Department Name'] == 'Jackets']['review_len']
y5 = df.loc[df['Department Name'] == 'Trend']['review_len']
trace0 = go.Box(
y=y0,
name = 'Tops',
marker = dict(
color = 'rgb(214, 12, 140)',
)
)
trace1 = go.Box(
y=y1,
name = 'Dresses',
marker = dict(
color = 'rgb(0, 128, 128)',
)
)
trace2 = go.Box(
y=y2,
name = 'Bottoms',
marker = dict(
color = 'rgb(10, 140, 208)',
)
)
trace3 = go.Box(
y=y3,
name = 'Intimate',
marker = dict(
color = 'rgb(12, 102, 14)',
)
)
trace4 = go.Box(
y=y4,
name = 'Jackets',
marker = dict(
color = 'rgb(10, 0, 100)',
)
)
trace5 = go.Box(
y=y5,
name = 'Trend',
marker = dict(
color = 'rgb(100, 0, 10)',
)
)
data = [trace0, trace1, trace2, trace3, trace4, trace5]
layout = go.Layout(
title = "Review length Boxplot of Department Name"
)
fig = go.Figure(data=data,layout=layout)
iplot(fig, filename = "Review Length Boxplot of Department Name")
length_department.py
图 21
Tops 和 Intimate 部门的中位评论长度相对低于其他部门。
更多相关话题
完整免费 PyTorch 深度学习课程
原文:
www.kdnuggets.com/2022/10/complete-free-pytorch-course-deep-learning.html
来源于Learn PyTorch for Deep Learning: Zero to Mastery
就是它了。这是你一直在寻找的完整PyTorch机器学习和深度学习课程。内容全面。信息丰富。相关性强。而且完全免费。
课程PyTorch for Deep Learning & Machine Learning由机器学习专家Daniel Bourke制作。你可能知道 Daniel,因为他在过去几年里有着丰富的在线存在,他的博客和内容与机器学习有关。
下面是来自 Daniel 本人对课程的概述:
这个课程将教你用 PyTorch(一个用 Python 编写的机器学习框架)学习机器学习和深度学习的基础。
课程是基于视频的。不过,视频内容基于这本在线书籍的内容。
课程涵盖了你需要了解的一切,以便迅速掌握 PyTorch 和深度学习。当我说一切时,我真的意味着:这个视频课程长达 25 小时。没错,比一天还要长。字面意思上的。
课程分为以下章节。
1. PyTorch 基础
本章涵盖了入门主题,包括 PyTorch 介绍、深度学习、课程准备,以及深度学习的基本构建块——张量及其基本功能的介绍。
2. PyTorch 工作流程
本章介绍了 PyTorch,并介绍了它的工作流程。你将学习关于模型的知识,训练模型,评估模型,以及保存和加载模型。你还会在学习过程中编写代码,边做边学。
3. 神经网络分类
现在是时候进行分类了。课程涵盖了机器学习的基础知识:输入和输出、分类神经网络架构、将数据转换为张量、损失、优化器、评估等。
4. 计算机视觉
本章转向计算机视觉(CV),涵盖卷积神经网络(CNNs)、获取 CV 数据集、使用 PyTorch DataLoaders、训练 CNNs,以及在 GPU 上训练。
5. 自定义数据集
本章介绍了创建自己的数据集、相关的考虑因素、如何实际操作、将图像转换为张量、数据增强、在自定义数据上的基线模型等。
你可以在这里找到课程材料,包括代码和资源。
Daniel 编写的随附在线书籍,从零开始掌握 PyTorch 深度学习,可以在这里找到。
课程的唯一视频,所有 25 小时的内容,可以在下面或 YouTube 上找到。
如果你想学习 PyTorch 以及如何将其用于深度学习,这确实是一个很好的课程。Daniel 在这样一个广泛的课程中将如此多的信息包装在一起,做得非常出色,他应当因这门强大课程所付出的努力而受到称赞。
Matthew Mayo (@mattmayo13) 是一名数据科学家,也是 KDnuggets 的主编,KDnuggets 是开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
更多相关内容
构建基于 TensorFlow 和 Flask RESTful Python API 的 ConvNet HTTP 应用程序完全指南
原文:
www.kdnuggets.com/2018/05/complete-guide-convnet-tensorflow-flask-restful-python-api.html/2
评论
4. 训练 CNN
在构建 CNN 的计算图后,接下来是对其进行训练,使用之前准备好的训练数据。训练是按照以下代码进行的。代码首先准备数据集的路径,并将其准备为一个占位符。请注意,路径应更改为适合你的系统。然后调用之前讨论的函数。训练好的 CNN 的预测用于衡量网络的成本,这些成本将通过梯度下降优化器进行最小化。注意:一些张量有一个名称,这在测试 CNN 时有助于检索这些张量。
#Nnumber of classes in the dataset. Used to specify number of outputs in the last fully connected layer.
num_datatset_classes = 10
#Number of rows & columns in each input image. The image is expected to be rectangular Used to reshape the images and specify the input tensor shape.
im_dim = 32
#Number of channels in rach input image. Used to reshape the images and specify the input tensor shape.
num_channels = 3
#Directory at which the training binary files of the CIFAR10 dataset are saved.
patches_dir = "C:\\Users\\Dell\\Downloads\\Compressed\\cifar-10-python\\cifar-10-batches-py\\"
#Reading the CIFAR10 training binary files and returning the input data and output labels. Output labels are used to test the CNN prediction accuracy.
dataset_array, dataset_labels = get_dataset_images(dataset_path=patches_dir, im_dim=im_dim, num_channels=num_channels)
print("Size of data : ", dataset_array.shape)
"""
Input tensor to hold the data read above. It is the entry point of the computational graph.
The given name of 'data_tensor' is useful for retreiving it when restoring the trained model graph for testing.
"""
data_tensor = tensorflow.placeholder(tensorflow.float32, shape=[None, im_dim, im_dim, num_channels], name='data_tensor')
"""
Tensor to hold the outputs label.
The name "label_tensor" is used for accessing the tensor when tesing the saved trained model after being restored.
"""
label_tensor = tensorflow.placeholder(tensorflow.float32, shape=[None], name='label_tensor')
#The probability of dropping neurons in the dropout layer. It is given a name for accessing it later.
keep_prop = tensorflow.Variable(initial_value=0.5, name="keep_prop")
#Building the CNN architecure and returning the last layer which is the fully connected layer.
fc_result2 = create_CNN(input_data=data_tensor, num_classes=num_datatset_classes, keep_prop=keep_prop)
"""
Predicitions probabilities of the CNN for each training sample.
Each sample has a probability for each of the 10 classes in the dataset.
Such tensor is given a name for accessing it later.
"""
softmax_propabilities = tensorflow.nn.softmax(fc_result2, name="softmax_probs")
"""
Predicitions labels of the CNN for each training sample.
The input sample is classified as the class of the highest probability.
axis=1 indicates that maximum of values in the second axis is to be returned. This returns that maximum class probability fo each sample.
"""
softmax_predictions = tensorflow.argmax(softmax_propabilities, axis=1)
#Cross entropy of the CNN based on its calculated probabilities.
cross_entropy = tensorflow.nn.softmax_cross_entropy_with_logits(logits=tensorflow.reduce_max(input_tensor=softmax_propabilities, reduction_indices=[1]),
labels=label_tensor)
#Summarizing the cross entropy into a single value (cost) to be minimized by the learning algorithm.
cost = tensorflow.reduce_mean(cross_entropy)
#Minimizng the network cost using the Gradient Descent optimizer with a learning rate is 0.01.
error = tensorflow.train.GradientDescentOptimizer(learning_rate=.01).minimize(cost)
#Creating a new TensorFlow Session to process the computational graph.
sess = tensorflow.Session()
#Wiriting summary of the graph to visualize it using TensorBoard.
tensorflow.summary.FileWriter(logdir="./log/", graph=sess.graph)
#Initializing the variables of the graph.
sess.run(tensorflow.global_variables_initializer())
"""
Because it may be impossible to feed the complete data to the CNN on normal machines, it is recommended to split the data into a number of patches.
A percent of traning samples is used to create each path. Samples for each path can be randomly selected.
"""
num_patches = 5#Number of patches
for patch_num in numpy.arange(num_patches):
print("Patch : ", str(patch_num))
percent = 80 #percent of samples to be included in each path.
#Getting the input-output data of the current path.
shuffled_data, shuffled_labels = get_patch(data=dataset_array, labels=dataset_labels, percent=percent)
#Data required for cnn operation. 1)Input Images, 2)Output Labels, and 3)Dropout probability
cnn_feed_dict = {data_tensor: shuffled_data,
label_tensor: shuffled_labels,
keep_prop: 0.5}
"""
Training the CNN based on the current patch.
CNN error is used as input in the run to minimize it.
SoftMax predictions are returned to compute the classification accuracy.
"""
softmax_predictions_, _ = sess.run([softmax_predictions, error], feed_dict=cnn_feed_dict)
#Calculating number of correctly classified samples.
correct = numpy.array(numpy.where(softmax_predictions_ == shuffled_labels))
correct = correct.size
print("Correct predictions/", str(percent * 50000/100), ' : ', correct)
与其将整个训练数据喂给 CNN,不如将数据划分为若干补丁,并通过循环逐个补丁地输入网络。每个补丁包含训练数据的一个子集。使用 get_patch 函数返回这些补丁。该函数接受输入数据、标签以及要从数据中返回的样本百分比,然后根据输入的百分比返回数据的子集。
def get_patch(data, labels, percent=70):
"""
Returning patch to train the CNN.
:param data: Complete input data after being encoded and reshaped.
:param labels: Labels of the entire dataset.
:param percent: Percent of samples to get returned in each patch.
:return: Subset of the data (patch) to train the CNN model.
"""
#Using the percent of samples per patch to return the actual number of samples to get returned.
num_elements = numpy.uint32(percent*data.shape[0]/100)
shuffled_labels = labels#Temporary variable to hold the data after being shuffled.
numpy.random.shuffle(shuffled_labels)#Randomly reordering the labels.
"""
The previously specified percent of the data is returned starting from the beginning until meeting the required number of samples.
The labels indices are also used to return their corresponding input images samples.
"""
return data[shuffled_labels[:num_elements], :, :, :], shuffled_labels[:num_elements]
5. 保存训练好的 CNN 模型
在训练 CNN 后,模型会被保存以便在其他 Python 脚本中进行测试时重用。你还应该将模型保存路径更改为适合你系统的位置。
#Saving the model after being trained.
saver = tensorflow.train.Saver()
save_model_path = "C:\\model\\"
save_path = saver.save(sess=sess, save_path=save_model_path+"model.ckpt")
print("Model saved in : ", save_path)
6. 准备测试数据和恢复训练好的 CNN 模型
在测试训练好的模型之前,需要准备测试数据并恢复之前训练好的模型。测试数据的准备类似于训练数据的处理,只不过只需解码一个二进制文件。测试文件会根据修改后的 get_dataset_images 函数进行解码。该函数调用 unpickle_patch 函数,过程与处理训练数据时相同。
def get_dataset_images(test_path_path, im_dim=32, num_channels=3):
"""
Similar to the one used in training except that there is just a single testing binary file for testing the CIFAR10 trained models.
"""
print("Working on testing patch")
data_dict = unpickle_patch(test_path_path)
images_data = data_dict[b"data"]
dataset_array = numpy.reshape(images_data, newshape=(len(images_data), im_dim, im_dim, num_channels))
return dataset_array, data_dict[b"labels"]
7. 测试训练好的 CNN 模型。
准备好测试数据和恢复经过训练的模型后,我们可以根据以下代码开始测试模型。值得一提的是,我们的目标是仅返回输入样本的网络预测。这就是为什么 TF 会话运行时只返回预测结果。在训练 CNN 时,会话运行是为了最小化成本。在测试中,我们不再关心最小化成本。另一个有趣的点是,dropout 层的保持概率现在设置为 1\。这意味着不丢弃任何节点。这是因为我们在确定了丢弃哪些节点后,只使用预训练模型。现在我们只是使用模型之前的状态,而不再关心通过丢弃其他节点来进行修改。
#Dataset path containing the testing binary file to be decoded.
patches_dir = "C:\\Users\\Dell\\Downloads\\Compressed\\cifar-10-python\\cifar-10-batches-py\\"
dataset_array, dataset_labels = get_dataset_images(test_path_path=patches_dir + "test_batch", im_dim=32, num_channels=3)
print("Size of data : ", dataset_array.shape)
sess = tensorflow.Session()
#Restoring the previously saved trained model.
saved_model_path = 'C:\\Users\\Dell\\Desktop\\model\\'
saver = tensorflow.train.import_meta_graph(saved_model_path+'model.ckpt.meta')
saver.restore(sess=sess, save_path=saved_model_path+'model.ckpt')
#Initalizing the varaibales.
sess.run(tensorflow.global_variables_initializer())
graph = tensorflow.get_default_graph()
"""
Restoring previous created tensors in the training phase based on their given tensor names in the training phase.
Some of such tensors will be assigned the testing input data and their outcomes (data_tensor, label_tensor, and keep_prop).
Others are helpful in assessing the model prediction accuracy (softmax_propabilities and softmax_predictions).
"""
softmax_propabilities = graph.get_tensor_by_name(name="softmax_probs:0")
softmax_predictions = tensorflow.argmax(softmax_propabilities, axis=1)
data_tensor = graph.get_tensor_by_name(name="data_tensor:0")
label_tensor = graph.get_tensor_by_name(name="label_tensor:0")
keep_prop = graph.get_tensor_by_name(name="keep_prop:0")
#keep_prop is equal to 1 because there is no more interest to remove neurons in the testing phase.
feed_dict_testing = {data_tensor: dataset_array,
label_tensor: dataset_labels,
keep_prop: 1.0}
#Running the session to predict the outcomes of the testing samples.
softmax_propabilities_, softmax_predictions_ = sess.run([softmax_propabilities, softmax_predictions],
feed_dict=feed_dict_testing)
#Assessing the model accuracy by counting number of correctly classified samples.
correct = numpy.array(numpy.where(softmax_predictions_ == dataset_labels))
correct = correct.size
print("Correct predictions/10,000 : ", correct)
8. 构建 Flask Web 应用程序
训练 CNN 模型后,我们可以将其添加到 HTTP 服务器上,并允许用户在线使用它。用户将通过 HTTP 客户端上传图像。上传的图像将由 HTTP 服务器接收,或者更具体地说,由 Flask Web 应用程序接收。该应用程序将根据训练好的模型预测图像的类别标签,并最终将类别标签返回给 HTTP 客户端。这一讨论总结在图 5 中。
图 5
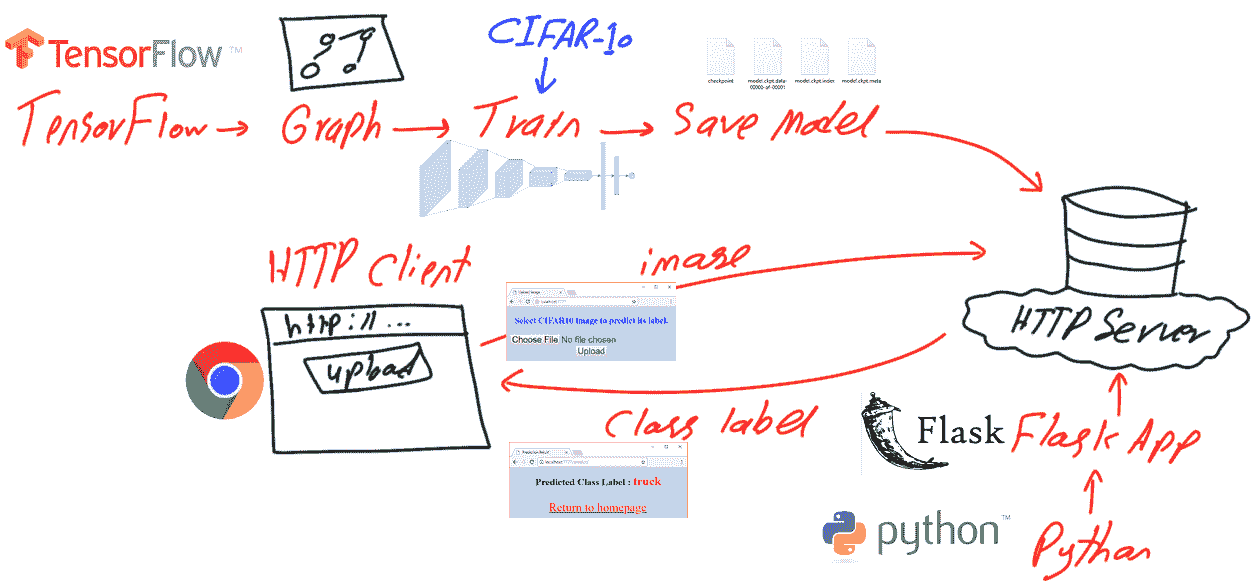
import flask
#Creating a new Flask Web application. It accepts the package name.
app = flask.Flask("CIFAR10_Flask_Web_App")
"""
To activate the Web server to receive requests, the application must run.
A good practice is to check whether the file is whether the file called from an external Python file or not.
If not, then it will run.
"""
if __name__ == "__main__":
"""
In this example, the app will run based on the following properties:
host: localhost
port: 7777
debug: flag set to True to return debugging information.
"""
app.run(host="localhost", port=7777, debug=True)
目前,服务器没有提供任何功能。服务器应该做的第一件事是允许用户上传图像。当用户访问应用程序的根 URL 时,应用程序不会执行任何操作。应用程序可以将用户重定向到一个 HTML 页面,用户可以在该页面上传图像。为此,应用程序有一个名为 redirect_upload 的函数,用于将用户重定向到一个上传图像的页面。让此函数在用户访问应用程序的根目录后执行的是通过以下代码创建的路由:
app.add_url_rule(rule="/", endpoint="homepage", view_func=redirect_upload)
这一行表示,如果用户访问应用程序的根目录(标记为"/"),则会调用视图函数(redirect_upload)。该函数除了渲染一个名为upload_image.html的 HTML 页面之外,不执行其他操作。该页面位于服务器的特殊templates目录下。templates 目录中的页面是通过调用 render_template 函数进行渲染的。请注意,有一个名为 endpoint 的属性,使得可以方便地多次重用相同的路由,而无需硬编码。
def redirect_upload():
"""
A viewer function that redirects the Web application from the root to a HTML page for uploading an image to get classified.
The HTML page is located under the /templates directory of the application.
:return: HTML page used for uploading an image. It is 'upload_image.html' in this exmaple.
"""
return flask.render_template(template_name_or_list="upload_image.html")
"""
Creating a route between the homepage URL (http://localhost:7777) to a viewer function that is called after getting to such URL.
Endpoint 'homepage' is used to make the route reusable without hard-coding it later.
"""
app.add_url_rule(rule="/", endpoint="homepage", view_func=redirect_upload)
渲染的 HTML 页面屏幕如图 6 所示。
图 6
这是该页面的 HTML 代码。它是一个简单的表单,允许用户上传图像文件。提交该表单时,将返回一个 POST HTTP 消息到 URL http://localhost:7777/upload/。
<!DOCTYPE html>
<html lang="en">
<head>
<link rel="stylesheet" type="text/css" href="{{url_for(endpoint='static', filename='project_styles.css')}}">
<meta charset="UTF-8">
<title>Upload Image</title>
</head>
<body>
<form enctype="multipart/form-data" method="post" action="http://localhost:7777/upload/">
<center>
<h3>Select CIFAR10 image to predict its label.</h3>
<input type="file" name="image_file" accept="image/*"><br>
<input type="submit" value="Upload">
</center>
</form>
</body>
</html>
从 HTML 表单返回到服务器后,将调用与form action属性中指定的 URL 关联的 viewer 函数,即 upload_image 函数。该函数获取用户选择的图像并将其保存到服务器。
def upload_image():
"""
Viewer function that is called in response to getting to the 'http://localhost:7777/upload' URL.
It uploads the selected image to the server.
:return: redirects the application to a new page for predicting the class of the image.
"""
#Global variable to hold the name of the image file for reuse later in prediction by the 'CNN_predict' viewer functions.
global secure_filename
if flask.request.method == "POST":#Checking of the HTTP method initiating the request is POST.
img_file = flask.request.files["image_file"]#Getting the file name to get uploaded.
secure_filename = werkzeug.secure_filename(img_file.filename)#Getting a secure file name. It is a good practice to use it.
img_path = os.path.join(app.root_path, secure_filename)#Preparing the full path under which the image will get saved.
img_file.save(img_path)#Saving the image in the specified path.
print("Image uploaded successfully.")
"""
After uploading the image file successfully, next is to predict the class label of it.
The application will fetch the URL that is tied to the HTML page responsible for prediction and redirects the browser to it.
The URL is fetched using the endpoint 'predict'.
"""
return flask.redirect(flask.url_for(endpoint="predict"))
return "Image upload failed."
"""
Creating a route between the URL (http://localhost:7777/upload) to a viewer function that is called after navigating to such URL.
Endpoint 'upload' is used to make the route reusable without hard-coding it later.
The set of HTTP method the viewer function is to respond to is added using the 'methods' argument.
In this case, the function will just respond to requests of method of type POST.
"""
app.add_url_rule(rule="/upload/", endpoint="upload", view_func=upload_image, methods=["POST"])
在成功将图像上传到服务器后,我们准备好读取图像并使用先前训练的 CNN 模型预测其类别标签。为此,upload_image 函数将应用程序重定向到负责预测图像类别标签的 viewer 函数。可以通过其 endpoint 达到该 viewer 函数,如这一行所指定:
return flask.redirect(flask.url_for(endpoint="predict"))
与 endpoint="predict" 相关的方法将被调用,即 CNN_predict 函数。该方法读取图像并检查其是否符合 CIFAR-10 数据集的尺寸,即 32x32x3。如果图像符合 CIFAR-10 数据集的规格,则将传递给负责进行预测的函数,如下行所示:
predicted_class = CIFAR10_CNN_Predict_Image.main(img)
负责预测图像类别标签的主要功能如下所示。它恢复了训练好的模型并运行一个会话,返回图像的预测类别。预测的类别会返回到 Flask Web 应用程序。
def CNN_predict():
"""
Reads the uploaded image file and predicts its label using the saved pre-trained CNN model.
:return: Either an error if the image is not for CIFAR10 dataset or redirects the browser to a new page to show the prediction result if no error occurred.
"""
"""
Setting the previously created 'secure_filename' to global.
This is because to be able invoke a global variable created in another function, it must be defined global in the caller function.
"""
global secure_filename
#Reading the image file from the path it was saved in previously.
img = scipy.misc.imread(os.path.join(app.root_path, secure_filename))
"""
Checking whether the image dimensions match the CIFAR10 specifications.
CIFAR10 images are RGB (i.e. they have 3 dimensions). It number of dimenions was not equal to 3, then a message will be returned.
"""
if(img.ndim) == 3:
"""
Checking if the number of rows and columns of the read image matched CIFAR10 (32 rows and 32 columns).
"""
if img.shape[0] == img.shape[1] and img.shape[0] == 32:
"""
Checking whether the last dimension of the image has just 3 channels (Red, Green, and Blue).
"""
if img.shape[-1] == 3:
"""
Passing all conditions above, the image is proved to be of CIFAR10.
This is why it is passed to the predictor.
"""
predicted_class = CIFAR10_CNN_Predict_Image.main(img)
"""
After predicting the class label of the input image, the prediction label is rendered on an HTML page.
The HTML page is fetched from the /templates directory. The HTML page accepts an input which is the predicted class.
"""
return flask.render_template(template_name_or_list="prediction_result.html", predicted_class=predicted_class)
else:
# If the image dimensions do not match the CIFAR10 specifications, then an HTML page is rendered to show the problem.
return flask.render_template(template_name_or_list="error.html", img_shape=img.shape)
else:
# If the image dimensions do not match the CIFAR10 specifications, then an HTML page is rendered to show the problem.
return flask.render_template(template_name_or_list="error.html", img_shape=img.shape)
return "An error occurred."#Returned if there is a different error other than wrong image dimensions.
"""
Creating a route between the URL (http://localhost:7777/predict) to a viewer function that is called after navigating to such URL.
Endpoint 'predict' is used to make the route reusable without hard-coding it later.
"""
app.add_url_rule(rule="/predict/", endpoint="predict", view_func=CNN_predict)
负责预测图像类别标签的主要功能如下所示。它恢复了训练好的模型并运行一个会话,返回图像的预测类别。预测的类别会返回到 Flask Web 应用程序。
def main(img):
"""
The 'main' method accepts an input image array of size 32x32x3 and returns its class label.
:param img:RGB image of size 32x32x3.
:return:Predicted class label.
"""
#Dataset path containing a binary file with the labels of classes. Useful to decode the prediction code into a significant textual label.
patches_dir = "C:\\cifar-10-python\\cifar-10-batches-py\\"
dataset_array = numpy.random.rand(1, 32, 32, 3)
dataset_array[0, :, :, :] = img
sess = tensorflow.Session()
#Restoring the previously saved trained model.
saved_model_path = 'C:\\model\\'
saver = tensorflow.train.import_meta_graph(saved_model_path+'model.ckpt.meta')
saver.restore(sess=sess, save_path=saved_model_path+'model.ckpt')
#Initalizing the varaibales.
sess.run(tensorflow.global_variables_initializer())
graph = tensorflow.get_default_graph()
"""
Restoring previous created tensors in the training phase based on their given tensor names in the training phase.
Some of such tensors will be assigned the testing input data and their outcomes (data_tensor, label_tensor, and keep_prop).
Others are helpful in assessing the model prediction accuracy (softmax_propabilities and softmax_predictions).
"""
softmax_propabilities = graph.get_tensor_by_name(name="softmax_probs:0")
softmax_predictions = tensorflow.argmax(softmax_propabilities, axis=1)
data_tensor = graph.get_tensor_by_name(name="data_tensor:0")
label_tensor = graph.get_tensor_by_name(name="label_tensor:0")
keep_prop = graph.get_tensor_by_name(name="keep_prop:0")
#keep_prop is equal to 1 because there is no more interest to remove neurons in the testing phase.
feed_dict_testing = {data_tensor: dataset_array,
keep_prop: 1.0}
#Running the session to predict the outcomes of the testing samples.
softmax_propabilities_, softmax_predictions_ = sess.run([softmax_propabilities, softmax_predictions],
feed_dict=feed_dict_testing)
label_names_dict = unpickle_patch(patches_dir + "batches.meta")
dataset_label_names = label_names_dict[b"label_names"]
return dataset_label_names[softmax_predictions_[0]].decode('utf-8')
图像返回的类别标签将根据 CNN_predict 函数在这一行的指示显示在名为prediction_result.html的新 HTML 页面上,如图 7 所示。
图 7
请注意,Flask 应用程序使用 Jinja2 模板引擎,允许 HTML 页面接受输入参数。此情况下传递的输入参数是 predicted_class=predicted_class。
return flask.render_template(template_name_or_list="prediction_result.html", predicted_class=predicted_class)
这样的页面的 HTML 代码如下。
<!DOCTYPE html>
<html lang="en">
<head>
<link rel="stylesheet" type="text/css" href="{{url_for(endpoint='static', filename='project_styles.css')}}">
<script type="text/javascript" src="{{url_for(endpoint='static', filename='result.js')}}"></script>
<meta charset="UTF-8">
<title>Prediction Result</title>
</head>
<body onload="show_alert('{{predicted_class}}')">
<center><h1>Predicted Class Label : <span>{{predicted_class}}</span></h1>
<br>
<a href="{{url_for(endpoint='homepage')}}"><span>Return to homepage</span>.</a>
</center>
</body>
</html>
这是一个模板,由图像的预测类别填充,该类别作为参数传递给 HTML 页面,如代码的这一部分所示:
<span>{{predicted_class}}</span>
有关 Flask RESTful API 的更多信息,请访问此教程 www.tutorialspoint.com/flask/index.htm。
完整的项目可以在 Github 上通过此链接获取: github.com/ahmedfgad/CIFAR10CNNFlask
简历: Ahmed Gad 于 2015 年 7 月获得埃及门努非亚大学计算机与信息学院(FCI)信息技术专业优秀荣誉学士学位。因在学院排名第一,他于 2015 年被推荐在埃及的一所学院担任助教,随后于 2016 年担任助教和研究员。他目前的研究兴趣包括深度学习、机器学习、人工智能、数字信号处理和计算机视觉。
原文。经许可转载。
相关:
-
使用 NumPy 从头构建卷积神经网络
-
从全连接网络逐步推导卷积神经网络
-
遗传算法优化入门
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT 工作
更多相关主题
决策树软件的完整指南
原文:
www.kdnuggets.com/2022/08/complete-guide-decision-tree-software.html

编辑器图片
什么是决策树?
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT 工作
决策树软件是一种以机器学习为主导的应用程序,帮助采取最佳行动并组织数据以形成最相关和最兼容的决策。从图示来看,决策树是一个类似树的框架,节点包含信息。
决策树将相关数据集分类并整理成有意义且易于解释的信息基础。此外,决策树还可以被训练以根据提交到框架的先前数据预测未来的行动。
决策树是如何工作的?
决策树模型用于将信息分类为有意义的顺序结果。
决策树由根节点组成——根节点是决策树的起始点。它进一步分为分支和内部节点。内部节点是查看者在得出结论之前分析的后续信息片段。
最终,决策树有多个叶节点。叶节点是终点,标志着在决策树中沿特定路径跟随时信息的结束。
内部节点描绘了条件,而叶节点则代表基于所选需求的最终决策。从根节点开始,用户或机器学习/人工智能模式建立所需的条件,最终到达提供最终决策的叶节点。
决策树用于什么?
决策树在各种行业中有着先进的应用场景:
#1 数据挖掘
决策树软件用于构建数据挖掘的分类和回归模型。数据分析师可以通过预测值或类别标签轻松地可视化数据集的结果。
#2 工程
不变尺度是一个分析函数,当尺度被乘以一个共同的因子时不会改变。决策树机器学习模型不受特征缩放的影响,因此被广泛用于分析与工程相关的数据集。
#3 医学科学
决策树赋能医学科学中的知识支持、有效和可靠的决策。根据收集的信息,医疗从业者可以通过决策树中的相关信息快速推导出相关结果。
#4 人工智能
人工智能驱动的动态决策树用于根据过去提供的数据预测未来的值。它帮助 AI 模式确定最佳的下一步行动,并避免不相关的结论。
#5 认知科学
一个决策树软件绑定并展示了认知类别、教育方法、学习目标和结果测量之间的关系。此外,决策树还帮助分析认知,以理解模式和偏见。
#6 客户服务
简单易用的客户服务决策树生成器提升了客户体验。客户服务人员可以通过下一步最佳行动方法迅速解决复杂的客户问题。根据客户反馈,决策树允许代理做出智能决策。此外,决策树还可以与聊天机器人集成,使自助服务渠道在解决问题时更加灵活和可靠。
使用决策树的优势是什么?
#1 改善决策制定
决策树帮助矿工、数据科学家和分析师仔细整理数据,以做出最佳决策。决策树模型可以根据每个数据的核心值进行训练,以进行复杂分析,配置数据集的顺序流。同样,对于较简单的问题,易于使用的交互式决策树根据下一步最佳行动原则提供逻辑流的信息。
#2 分类和回归分析
决策树软件在分类和回归分析中表现良好。决策树软件可以分析连续和离散数据集。它提供了数据集的多类分类。同样,决策树还解决了复杂的回归问题,以推动数据驱动的决策制定。
#3 易于理解和可视化
训练过的决策树基于最佳替代原则来得出终端数据类别。决策树模型易于理解和解释,因为任何分支的相应值都是逻辑上最佳的替代方案。此外,数据集的树状表示进一步帮助简化和直观化数据库。
#4 关系的快速分析
训练过的决策树模型通过快速映射数据点之间的关系来帮助数据探索。它识别出最重要的值,并能够迅速确定两个或更多数据值之间的关系性质。
#5 数据准备
决策树不需要对数据集进行繁重的数据准备。它直接处理数据库中的值,不受节点中任何缺失值的影响。同样,决策树模型不需要像规范化和创建虚拟变量这样的分析准备。
决策树解决了哪些挑战?
决策树解决了各种问题:
#1 信息杂乱
机器学习驱动的决策树通过关系整合大量数据值。由于决策树可以对连续和离散数据库进行分析,它们可以处理不同的数据集以组织数据并得出有意义的结果。
#2 定位相关数据
决策树软件解决了延迟到达预期结果的问题。由于值通过关系被整合到决策树中,用户可以通过下一步最佳行动的方法迅速达到期望的结果。
在下一步最佳行动方法中,用户可以根据条件回答节点问题,并迅速做出最佳决策。
#3 复杂分析
通常,分析模型和函数具有复杂的接口,需要进行解读和理解。相比之下,决策树则简单。树状框架可以很容易地解释,并且非技术人员也能进一步理解。
决策树和随机森林之间的关系是什么?
决策树和随机森林是两种流行的决策启用算法。如前所述,决策树是一个树状框架,具有顺序信息流。在这里,用户或机器学习/人工智能模式遵循节点中封装的条件的相关性。相反,随机森林结合了不相关的决策树。
随机森林在数据科学家需要从庞大而杂乱的数据中得出结果的领域更受欢迎。由于决策树遵循类似的思维过程,单一树给出的最终预测可能会受到偏见的影响。随机森林可以消除这种情况。
在这里,通过分析不同决策树给出的预测来做出决策。根据特定结果的出现频率来判断预测,最受欢迎的预测被选为结果。
读者还需要了解关于决策树和机器学习的什么?
决策树软件正在帮助数据科学家和分析师整合和学习各种数据。此外,机器学习驱动的决策帮助他们做出智能的数据驱动决策。有趣的是,决策树不仅限于分析。
除了复杂的基于研究的预测或分析,决策树在多个现代决策导向的实践中也有应用。许多基于机器学习的决策树 DIY 版本存在,帮助个人做出正确的决策。
从寻找 BFSI 领域的相关贷款计划到解决电信领域的互联网路由器相关问题,决策树正在强化可靠、相关且快速的决策方法。
未来,预计将出现更复杂的机器学习主导的决策树版本。
哈曼普里特·辛格·甘比尔 是 Knowmax 的客户成功专家,该公司提供企业知识库管理系统,用于客户服务。当他不在桌前时,他喜欢探索更多关于客户成功最佳实践的内容。
更多相关内容
完整指南:Python 中的生存分析,第一部分
原文:
www.kdnuggets.com/2020/07/complete-guide-survival-analysis-python-part1.html
评论
由Pratik Shukla,有志的机器学习工程师。

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力。
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求。
生存分析基础
生存分析是一组统计方法,用于找出某个事件发生所需的时间。生存分析用于研究时间直到某个事件(通常指死亡)发生。时间可以以年、月、周、天等为单位。事件可以是任何感兴趣的事物,如实际的死亡、出生、退休等。
如何分析持续的 COVID-19 疫情数据?
(1) 我们可以找出患者出现 COVID-19 症状的天数。
(2) 我们可以发现哪个年龄组的死亡率更高。
(3) 我们可以找出哪种治疗方法具有最高的生存概率。
(4) 我们可以发现一个人的性别是否对他们的生存时间有显著影响?
(5) 我们还可以找出患者的生存天数中位数。
我们将对肺癌患者进行深入分析。别担心,一旦你理解了其中的逻辑,你将能够在任何数据集上应用它。激动人心,不是吗?
生存分析在以下领域中使用:
-
针对患者生存时间的癌症研究。
-
社会学中的“事件历史分析”。
-
在工程学中用于“失效时间分析”。
-
直到产品故障的时间。
-
从保修索赔开始到索赔完成的时间。
-
直到过程达到关键水平的时间。
-
从初次销售联系到完成销售的时间。
-
从员工入职到终止或离职的时间。
-
从销售人员入职到他们第一次销售的时间。
在癌症研究中,典型的研究问题包括:
(1) 某些临床特征对患者生存的影响是什么?例如,高血糖人群和非高血糖人群之间有何差异?
(2) 个体在特定时间段(年、月、天)内幸存的概率是多少?例如,给定一组癌症患者,如果诊断癌症后的 300(随机数字)天已过去,那么该人在那时仍然存活的概率为 0.7(随机数字)。
(3) 不同患者组之间的生存是否存在差异?例如,假设有 2 组癌症患者,这 2 组接受了两种不同的治疗。现在我们的目标是找出这两组基于所接受治疗的生存时间是否存在显著差异。
目标
在癌症研究中,大多数生存分析使用以下方法。
(1) Kaplan-Meier 图 用于可视化生存曲线。
(2) Nelson-Aalen 图 用于可视化累积风险。
(3) Log-rank 检验 用于比较两个或多个组的生存曲线
(4) Cox 比例风险回归 用于找出不同变量如年龄、性别、体重对生存的影响。
基本概念
这里,我们首先定义生存分析的基本术语,包括:
-
生存时间和事件。
-
数据删失。
-
生存函数和风险函数。
癌症研究中的生存时间和事件类型
生存时间:指一个受试者存活或积极参与调查的时间。
事件主要有三种类型,包括:
(1) 复发:健康状况在暂时改善后的恶化。
(2) 进展:逐渐发展或向更高级状态过渡的过程。(健康状况的改善。)
(3) 死亡:某事物的毁灭或永久终结。
删失
如上所述,生存分析关注的是感兴趣事件的发生(例如,出生、死亡、退休)。但仍有可能因各种原因未观察到该事件。这些观察被称为删失观察。
删失可能以以下方式出现:
-
患者在研究期间尚未(还未)经历感兴趣的事件(在我们的案例中为死亡或复发)。
-
患者不再被跟踪。
-
如果患者搬到另一个城市,那么医院工作人员可能无法进行跟踪。
这种删失类型,被称为右删失,在生存分析中处理。
删失一般分为三种类型:右删失、左删失和区间删失。
右删失:指人的死亡。
左删失:由于某种原因无法观察到事件。这包括实验开始前发生的事件。(例如,从出生开始到孩子开始走路的天数。)
区间删失:当我们只有一些区间的数据时。
生存与风险函数
我们通常使用两个相关的概率来分析生存数据。
(1) 生存概率
(2) 风险概率
要计算生存概率,我们将使用生存函数 S(t),这就是 Kaplan-Meier 估计器。生存概率是指个体(例如患者)从时间起点(例如癌症诊断)到指定未来时间 t 存活的概率。例如,S(200) = 0.7 表示在癌症诊断后经过 200 天,患者的生存概率下降至 0.7。如果该人在实验结束时仍然活着,那么这些数据将被视为删失数据。
风险概率,用 h(t) 表示,是指在时间 t 观察下的个体(例如患者)在该时间发生事件(例如死亡)的概率。例如,如果 h(200) = 0.7,那么意味着在 t=200 天时该人死亡的概率是 0.7。
请注意,与关注事件未发生的生存函数不同,风险函数关注事件的发生。我认为我们可以清楚地看到,较高的生存概率和较低的风险概率对患者有利。
让我们继续进入有趣的编码部分吧!
你可以从这里下载数据集。
数据描述

Kaplan-Meier 估计器
Kaplan–Meier 估计器 是一种非参数统计方法,用于从生存数据中估计生存函数(个体存活的概率)。在医学研究中,它常用于测量患者在治疗后存活一段时间的比例。例如,计算某患者在被诊断为癌症或治疗开始后的存活时间(年、月、日)。该估计器以 Edward L. Kaplan 和 Paul Meier 的名字命名,他们各自向 美国统计学会杂志 提交了类似的稿件。
Kaplan-Meier 的公式如下:
在时间 ti,S(ti) 的概率计算为
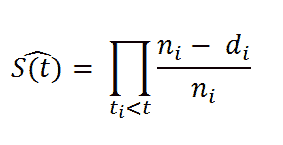
我们也可以将其写成
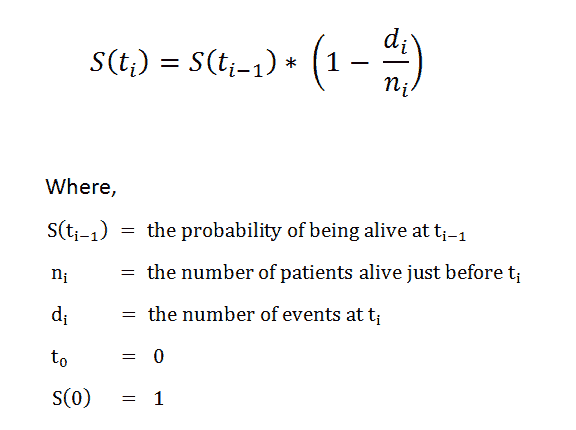
生存函数
例如,
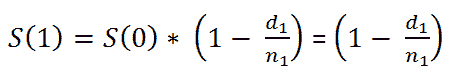
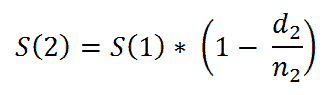
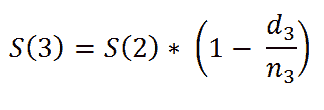
更一般地,我们可以说,
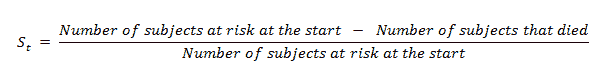
生存函数简化版。
例如,我们可以说,
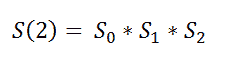
在下一篇文章中,我们将使用 Python 实现 Kaplan-Meier 估计器和 Nelson-Aalen 估计器。
最终结果
在这个三部分系列的最后,你将能够绘制这样的图表,从中我们可以推断患者的生存情况。坚持住!
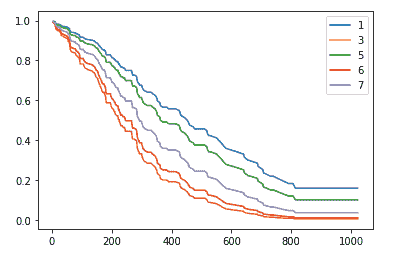
整个系列:
-
Python 中生存分析的完整指南,第一部分 这三部分系列涵盖了逐步解释和代码的回顾,展示了如何进行统计生存分析,以调查某些事件发生所需的时间,例如 COVID-19 大流行期间的患者生存时间、工程产品的故障时间,甚至是首次客户接触后的销售关闭时间。
-
Python 中生存分析的完整指南,第二部分 我们详细查看了 Kaplan-Meier 适配器理论和 Nelson-Aalen 适配器理论的实现示例,包含实例和共享代码。
-
Python 中生存分析的完整指南,第三部分 我们详细查看了基于不同组的 Kaplan-Meier 适配器、Log-Rank 检验和 Cox 回归的实现示例,包含实例和共享代码。
原创。经许可转载。
简介:Pratik Shukla是一位有抱负的机器学习工程师,喜欢将复杂理论以简单方式呈现。Pratik 在计算机科学领域完成了本科课程,并正在南加州大学攻读计算机科学硕士学位。 “瞄准月亮。即使错过了,你也会落在星星中。-- Les Brown”
相关:
更多主题
完整的机器学习学习路线图
原文:
www.kdnuggets.com/2022/12/complete-machine-learning-study-roadmap.html

图片来源于作者
机器学习领域比数据科学和数据工程更具针对性,后者自然包含了机器学习。那么你需要做什么才能成为这个领域的一部分呢?
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT
1. 前提条件
为了让你理解机器学习的概念及其所有内容 - 你需要彻底掌握基础知识。这包括背后的理论、概念、方法和算法 - 了解它们为何如此运作,以及它们如何作为机器学习的基石。这些前提条件涉及分析工作,帮助你在作为机器学习工程师的过程中:
-
标准差
-
线性代数
-
统计学
-
概率
这里有一些资源可以帮助你深入理解:
-
机器学习数学 - 书籍
-
Khan Academy 的线性代数 - YouTube
-
Khan Academy 的统计学与概率 - YouTube
-
机器学习的数学基础 - Udemy
2. 机器学习的阶段
机器学习由以下阶段组成:
1. 研究/收集数据
在这个阶段,你将从业务角度更好地了解手头的问题或任务。这将帮助你收集正确的数据以输入到模型中。数据的质量和数量将决定你的预测模型能否产生可信的输出。
2. 数据准备
数据准备需要大量时间,因为数据从来都不是我们需要的格式。这将包括去重、标准化、错误修正以及特征工程等进一步的准备工作。
3. 构建模型
根据手头的任务,你将选择正确的模型来帮助解决问题。这个路线图过程的下一阶段会涉及到你通常会遇到的不同机器学习算法。
4. 训练和测试你的模型
这个阶段是用你收集和准备的数据来测试你的模型。训练数据集将用于提高模型的预测能力。测试数据集是训练数据集的一个子集,提供了对最终模型的无偏评价。
5. 模型优化和评估
模型优化是一个迭代训练模型的过程,导致最大值和最小值函数评估。进一步的评估包括使用在训练阶段未使用的数据来测试模型,以查看模型在未见过的数据上的表现。
6. 实验跟踪
为了使你的模型表现得非常好,你将经历大量的调整。所有这些已调节的组件,从模型到指标,都需要跟踪,以保持项目的有序,并提供对模型历史的便捷访问。
7. 模型部署
这是机器学习过程的最后阶段。将你的机器学习模型投入生产,以便它可以用于基于数据做出业务决策。
如果你想对机器学习过程有更深入的理解,可以查看这些资源:
-
接近(几乎)任何机器学习问题 - 书籍
-
机器学习的 7 个步骤 - YouTube
-
接近机器学习过程的框架 - 博客
-
部署机器学习模型的意义是什么? - 博客
3. 机器学习算法
一旦你对基础数学有了良好的理解,你将能够迅速理解机器学习算法——因为这都是基于数学的。
作为一名机器学习工程师,你将始终使用算法——它们是指示计算机该做什么的指令。因此,你需要理解这些指令。
有 4 种不同类型的机器学习算法:
-
有监督学习
-
无监督学习
-
半监督学习
-
强化学习
你将频繁使用并且非常流行的机器学习算法类型是:
-
线性回归
-
逻辑回归
-
决策树
-
随机森林
-
支持向量机(SVMs)
-
朴素贝叶斯
-
KNN 分类
-
K-Means
-
人工神经网络(ANNs)
-
循环神经网络(RNNs)
阅读这篇文章:每种机器学习算法的解释不到 1 分钟。
如果你想要更深入的解释,可以阅读这个:流行的机器学习算法
这里还有一些其他资源供你查看:
-
Simplilearn 的机器学习算法 - YouTube
-
《理解机器学习:从理论到算法》 作者 Shai Shalev-Shwartz,?Shai Ben-David - 书籍
在这个阶段,了解机器学习算法的基础也很重要。这与手头的任务有关 - 这是分类任务吗?如果是,哪种算法最合适?这是监督学习还是无监督学习?通过这些,你将看到基础知识和机器学习算法之间的联系。
4. 库
作为一名机器学习工程师,你将花费大量时间来构建算法和应用。因此,你需要了解帮助构建这些的库。机器学习库是一系列创建来帮助开发机器学习应用的函数 - 通过它们的预打包函数。
这里列出了一些最知名和使用的库:
-
Pandas - 管理表格数据
-
NumPy - 科学计算
-
Matplotlib - 数据可视化
-
Scikit-Learn - 数据预处理和建模
-
SciPy - 科学计算
-
NLTK - 文本处理
-
TensorFlow - 深度学习
-
Keras - 深度学习
-
PyTorch - 深度学习
-
HuggingFace - 构建、训练和部署机器学习模型的工具
学习这些库的最佳方式是通过它们的用户指南和文档,上面都已经链接了。
5. 项目
所以你已经掌握了基础知识、机器学习算法和库,下一步是将所有这些知识和技能应用于实际案例。这不仅测试你的技能,还可以展示你在该领域的优点和缺点。它还帮助你丰富你的作品集,这将有助于你进入下一阶段!
我遇到了 Thecleverprogrammer,他有一个不同类型的机器学习项目列表,适合初学者和中级学习者。自己尝试解决挑战,然后反思他是如何处理手头的问题或任务的,这是很好的。
这里列出了一些适合初学者的机器学习项目
- 如果你准备好挑战一些更具难度的项目,可以看看这些:
通过这些项目,你不仅是在测试自己的技能,还在了解自己的优点和帮助定义你的弱点。这些项目不仅在这方面帮助你,还将帮助你建立作品集/简历 - 为面试做好准备!
6. 面试准备
有很多资源可以帮助你为面试做准备,包括书籍、PDF、在线课程和网络研讨会,你也可以通过与行业内的人交流获取有价值的信息。
以下是一些资源,帮助你为机器学习面试做准备:
-
赢得下一个机器学习面试 - 网络研讨会(免费)
-
机器学习面试准备 - Udacity(免费)
-
机器学习面试问题 + 小抄 - PDF(免费)
-
机器学习面试 - 书籍
-
掌握机器学习面试 - Educative
7. 进一步阅读
如果你在寻找一些额外的资源来帮助你在机器学习领域变得更加熟练。
-
15 本免费机器学习和深度学习书籍
-
15 本更多免费机器学习和深度学习书籍
尼莎·阿里亚 是一位数据科学家和自由技术写作者。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探索人工智能在延长人类寿命方面的不同方式。作为一名热衷学习者,她希望扩展自己的技术知识和写作技能,同时帮助指导他人。
更多相关主题
-
[KDnuggets 新闻,12 月 14 日:3 个免费的机器学习课程](https://www.kdnuggets.com/2022/n48.html)
-
[KDnuggets 新闻,8 月 31 日:完整的数据科学学习路线图](https://www.kdnuggets.com/2022/n35.html)
完整的 MLOps 学习路线图
原文:
www.kdnuggets.com/2022/12/complete-mlops-study-roadmap.html

图片由作者提供
所以下一版的学习路线图是 MLOps - 机器学习、DevOps 和数据工程的结合体。目标是以可靠和高效的方式部署和维护机器学习系统。那么,如何成为一名 MLOps 工程师呢?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
1. 基础
如果 MLOps 是机器学习、DevOps 和数据工程的结合体 - 你可以想象 MLOps 的基础也是这些子领域的基础。
那么基础是什么呢?
Python
如果你选择 Python 作为你的编程语言,以下是一些推荐的课程:
-
100 天代码:2022 完整 Python 高级训练营 - Udemy
-
人人编程(Python 入门) - Coursera(密歇根大学)
作为 MLOps 工程师,强烈建议使用脚本语言,因为你需要在高水平上自动化流程。Python、Go 和 Ruby 是你可以选择的流行脚本语言的例子。
SQL:
-
终极 MySQL 训练营:从 SQL 初学者到专家 - Udemy
-
完整 SQL 精通 - CodeWithMosh
数学:
-
机器学习数学 - 书
-
可汗学院的线性代数 - YouTube
-
??可汗学院的统计与概率 - YouTube
-
机器学习的数学基础 - Udemy
2. 机器学习算法和库
作为一名 MLOps 工程师,你的日常任务将围绕机器学习算法展开,因此理解你所使用的模型至关重要。你还需要了解相关的库和框架,以便在你的角色中取得成功。
机器学习算法资源:
-
理解机器学习:从理论到算法 由 Shai Shalev-Shwartz, Shai Ben-David - 书籍
-
1 分钟内解释机器学习算法 - 博客
-
流行的机器学习算法 - 博客
-
Simplilearn 的机器学习算法 - YouTube
机器学习库资源:
-
Pandas - 管理表格数据
-
NumPy - 科学计算
-
Matplotlib - 数据可视化
-
Scikit-Learn - 数据预处理和建模
-
SciPy - 科学计算
-
NLTK - 文本处理
-
TensorFlow - 深度学习
-
Keras - 深度学习
-
PyTorch - 深度学习
还有更多的库,但这些是你通常会使用的最受欢迎的库。
3. 数据库
从数据工程师的角度来看,数据库及其管理系统是 MLOps 工程师角色和职责中的重要元素。为了以可靠和高效的方式维护机器学习系统,你需要数据库来帮助你完成这一任务。
以下是一些资源:
-
数据库管理原则 - YouTube
-
免费 SQL 和数据库课程 - 博客
-
终极 MySQL 速成班:从 SQL 初学者到专家 - Udemy
-
完整 SQL 和数据库速成班:从零到精通 - Udemy
4. 模型部署
作为 MLOps 工程师,你需要学习如何部署你的模型。大型公司通常使用云平台来托管他们的应用程序,如 AWS、GCP 和 Microsoft Azure。因此,你很可能也会这样做,因此我强烈建议你对这些平台有良好的理解,因为作为 MLOps 工程师,你肯定会使用它们。
以下是一些资源来帮助你:
5. 实验跟踪
对于一些数据工作者来说,他们的最终目标是实现模型部署。然而,作为一名 MLOps 工程师,实验跟踪至关重要。实验跟踪允许我们管理所有实验及其组件,如参数、指标等。这使我们更容易组织每个实验的组件,重现过去的结果并记录所有内容。
作为一名 MLOps 工程师,你应该了解可以用来跟踪实验的不同工具。我将列出最受欢迎的几种:
6. 元数据管理
元数据是关于数据的数据,管理这种数据可以帮助你更好地理解、分组和排序数据以供其他用途。从模型中生成元数据可以用于训练参数、评估指标、测试管道输出等。
在工作流程生命周期中,糟糕的元数据管理可能导致信息冲突、对数据的不信任以及成本增加。
这里有一些资源可以帮助你更好地理解:
-
Data Management - Metadata Management - YouTube
-
Data Management Masterclass - Udemy
-
Prepare Data for Exploration - Coursera
7. 数据和管道版本管理
数据版本管理是对随着时间推移创建的不同版本的数据进行存储。数据随时间变化的原因有很多,例如数据科学家测试是否能够提高机器学习模型的效率或信息流动。数据版本管理的优势和必要性从商业角度来看,通过使消费者了解数据集是否有更新版本来提供帮助。
以下是用于数据版本管理的流行工具列表:
8. 模型监控
模型监控阶段在模型部署之后,是一个如其名所示的过程——监控模型。你需要注意模型退化、数据漂移等问题,以确保模型保持良好的性能水平。
这里有一些资源可以帮助你:
-
Continuous monitoring - MLOps guide
-
测试和监控机器学习模型部署 - Udemy
-
机器学习模型监控检查清单:7 个跟踪项 - 博客
-
IBM Watson OpenScale - 工具
9. 项目
你应该对成为 MLOps 专业人员所需的技能有良好的理解和深入的知识。一旦掌握了这些技能,下一步就是通过项目进行测试——这些项目随后可以作为你的作品集的一部分。
这里有一些项目想法:
-
Made With ML - MLOps 的所有方面
实践你的技能并完善它们是这里的主要目标!
10. 面试
现在我们已经准备好迎接面试了。在准备面试时,目标是准备、准备,然后放松!对于技术角色,有很多东西需要记住,有时紧张会导致你忘记一切。所以我总是建议人们保持冷静,享受这个阶段——享受你付出的所有努力,并证明解决这些挑战是轻而易举的!
这里有一些资源可以帮助你:
-
前 30 名 MLOps 面试问题 - 博客
-
打好你下一个机器学习面试 - 网络研讨会(免费)
-
MLOps 社区会议播放列表 - YouTube
-
机器学习面试准备 - Udacity(免费)
-
掌握机器学习面试 - Educative
总结
由于 MLOps 涉及机器学习、DevOps 和 IT——有许多资源可以帮助你成为最成功的 MLOps 工程师。查看这篇文章的其他版本,来帮助你:
-
完整的数据科学学习路线图
-
完整的机器学习学习路线图
-
完整的数据工程学习路线图
尼莎·阿雅 是一名数据科学家和自由职业技术写作人员。她特别关注提供数据科学职业建议或教程以及与数据科学相关的理论知识。她还希望探索人工智能如何/可以促进人类生命的持久性。她是一个热衷学习者,寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关主题
复杂逻辑以飞快速度:尝试使用 Julia 进行数据科学
原文:
www.kdnuggets.com/2020/05/complex-logic-breakneck-speed-julia-data-science.html
评论

注意:我正在建立一个包含 Julia 基础和数据科学示例的 Github 仓库。 点击这里查看。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
介绍
“像 Python 一样行走,像 C 一样运行” — 这是对 Julia 的描述,这是一种现代编程语言,专注于科学计算,并且拥有越来越多的追随者和开发者。
Julia 是一种通用编程语言,专门用于科学计算。它是一种灵活的动态类型语言,性能可与传统静态类型语言相媲美。
Julia 试图提供一个足够高效的环境,既适合原型设计,又适合工业级应用。它是一种多范式语言,包含函数式和面向对象编程组件,尽管大多数用户喜欢它的函数式编程方面。
该编程语言的起源可以追溯到 2009 年。首席开发者 Alan Edelman、Jeff Bezanson、Stefan Karpinski 和 Viral Shah 开始致力于创建一种可以用于更好、更快数值计算的语言。开发者们在 2012 年 2 月推出了商业版本。
为什么它对数据科学如此出色?
Julia 是数据科学和机器学习工作的优秀选择,因为它在快速数值计算方面也表现出色。其优势包括,
-
平滑的学习曲线,以及广泛的基础功能。尤其是,如果你已经熟悉像 Python 和 R 这样的流行数据科学语言,掌握 Julia 将轻松自如。
-
性能:Julia 最初是编译语言,而 Python 和 R 是解释型语言。这意味着 Julia 代码直接在处理器上执行作为可执行代码。
-
GPU 支持:这与性能直接相关。GPU 支持由一些包如
TensorFlow.jl和MXNet.jl透明地控制。 -
分布式和并行计算支持:Julia 通过多种拓扑结构透明地支持并行和分布式计算。同时,它也支持协程,例如 Go 编程语言中的协程,这些协程在多核架构上并行工作。对线程和同步的广泛支持主要旨在最大化性能并减少竞争条件的风险。
-
丰富的数据科学和可视化库:Julia 社区了解到它被设想为数据科学家和统计学家的首选语言。因此,专注于数据科学和分析的高性能库正在不断开发中。
-
与其他语言/框架的协作:Julia 与其他成熟的数据科学和机器学习语言及框架配合得非常好。使用
PyCall或RCall可以在 Julia 脚本中使用原生的 Python 或 R 代码。Plots包支持包括Matplotlib和Plotly在内的各种后端。流行的机器学习库如Scikit-learn或TensorFlow已经有 Julia 等效的实现或封装。
Julia 是数据科学和机器学习工作的绝佳选择,原因之一是它在快速数值计算方面表现出色。
一些与 Python 脚本的基准测试
关于“Julia 比 Python 更快吗?”的问题存在很多争议。
就像生活中的几乎所有事情一样,答案是:这要看情况。
官方的 Julia 语言门户有一些相关数据,尽管基准测试是针对除了 Python 之外的各种语言进行的。
实际上,这个问题几乎总是涉及 Julia 与某种优化/矢量化的 Python 代码(如 Numpy 函数使用的代码)的比较。否则,由于编译代码执行,原生 Julia 几乎总是比 Python 快,而 原生 Python 远慢于 Numpy 类型的执行。
Numpy 的速度确实非常快。它是一个超优化函数的库(许多函数已经预编译),专注于为 Python 用户(尤其是数据科学家和 ML 工程师)提供接近 C 的速度。简单的 Numpy 函数如 sum 或标准差 可以与等效的 Julia 实现相媲美或超越(尤其是对于大型输入数组)。
但是,为了充分利用 Numpy 函数,你必须从向量化代码的角度来思考。而且将复杂的逻辑写成向量化代码并不容易。
因此,与 Julia 的速度比较应在对数组进行某种处理时应用较复杂的逻辑时进行。
在这篇文章中,我们将展示几个这样的例子以说明这一点。
但是,为了充分利用 Numpy 函数,你必须从向量化代码的角度来思考。
Julia 的 for 循环比 Python 的 for 循环表现得更好
让我们计算一百万个随机整数的总和来测试一下。
Julia 代码如下。该函数耗时稍微超过 1 毫秒。
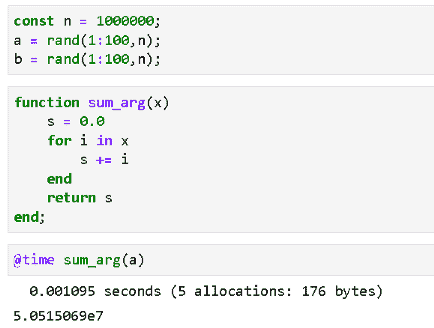
Python 代码如下。我们保持了代码的相同功能性质(Julia 是函数式语言),以保持比较公平且易于验证。for 循环耗时 超过 200 毫秒!
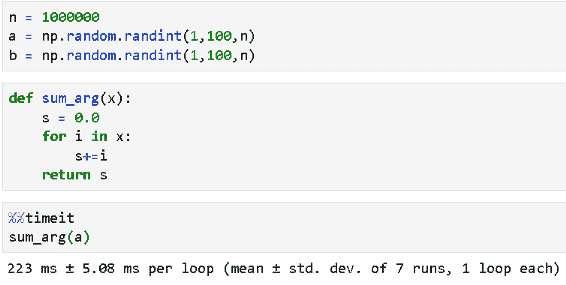
那么 Julia 数组与 Numpy 数组相比如何?
在上面的代码中,我们创建了一个数组变量。这是 Julia 中最有用的数据结构,因为它可以直接用于统计计算或线性代数操作,开箱即用。
不需要额外的库或其他东西。Julia 数组的速度比 Python 列表快几个数量级。
但 Numpy 数组很快,让我们基准测试一下相同的求和操作。
Julia 代码使用 sum() 函数对数组进行求和。它需要约 451 毫秒(比 for 循环方法快,但仅为一半时间)。

这是 Numpy 执行的结果,

哇! 353 毫秒,这比 Julia 的速度还要快,几乎比天真的 Python for 循环代码快 628 倍。
那么,最终判决是倾向于 Numpy 数组吗?
不要太快。那如果我们只想对数组中的奇数求和呢?
不需要额外的库。Julia 数组的速度比 Python 列表快几个数量级。
下面是逻辑
对于 Julia,代码的更改将非常直接。我们只需使用 for 循环,检查数组的一个元素是否能被 2 整除,如果不能(即奇数),则将其添加到累加和中。尽可能的细致!
所以,这运行了 接近 4 毫秒。确实比单纯的盲目求和(使用 for 循环)慢,但差别不大(for 循环的普通求和也大约 1.1 毫秒)。
现在,我们显然无法用 Python 的 for 循环与这种速度竞争!我们知道结果会如何,对吧?所以,我们必须使用 Numpy 向量化代码。
但是如何在 Numpy 数组中检查奇数并只对其求和呢?幸运的是,我们有 np.where() 方法。
这是 Python 代码。并不那么直接(除非你知道如何正确使用 np.where,对吧?

但看看速度吧。即使是使用 Numpy 方法的一行矢量化代码,平均也花费了16.7 毫秒。
Julia 的代码更简单,运行得更快!
另一个稍微复杂的操作
假设我们有三个数组(比如 W、X 和 B),其浮点数在 -2 到 2 之间随机分布,我们想计算一个特殊的量:两个数组的乘积加到第三个数组上,即 A.X+B,但只有当逐元素线性组合超过零时,这个量才会被加到最终和中。
这个逻辑对你来说熟悉吗?这是任何密集连接神经网络(甚至是单个感知器)的变体,其中权重、特征和偏置向量的线性组合必须超过某个阈值才能传播到下一层。
所以,这里是 Julia 的代码。再次,简单且高效。花费了 ~1.8 毫秒。注意,它使用了一个名为 muladd() 的特殊函数,该函数将两个数字相乘并加到第三个数字上。

我们使用类似的代码(使用 for 循环)尝试了 Python,结果如预期般糟糕!平均花费了超过一秒。
我们再次尝试发挥创意,使用 Numpy 矢量化代码,结果比 for 循环要好,但比 Julia 的情况差,约为 14.9 毫秒。

那么,它看起来如何?
此时,趋势变得清晰。对于需要在某些数学操作之前检查复杂逻辑的数值操作,Julia 击败 Python(即使是 Numpy),因为我们可以在 Julia 中用尽可能简单的代码编写逻辑,并将其遗忘。得益于即时编译器(JIT)和内部类型相关的优化(Julia 具有极其复杂的类型系统来使程序以正确的数据类型快速运行,并相应地优化代码和内存)。
使用原生 Python 数据结构和 for 循环编写相同的代码效率极低。即使是 Numpy 的矢量化代码,随着复杂性的增加,其速度也比 Julia 慢。
Numpy 在处理数组自带的简单方法(如 sum()、mean() 或 std())时非常出色,但与这些方法结合使用逻辑并不总是直观的,而且会显著降低操作速度。
在 Julia 中,不用费心思考如何矢量化你的代码。即使是看起来很笨的代码,使用普通的 for 循环和逐元素逻辑检查,也能运行得惊人快速!
对于需要在某些数学操作发生之前检查复杂逻辑的数值操作,Julia 绝对超过 Python(甚至 Numpy),因为我们可以用最简单的代码在 Julia 中编写逻辑,并且可以不用再考虑它。
摘要
在这篇文章中,我们展示了 Julia 和 Python 之间的数值计算对比基准——包括本地 Python 代码和优化的 Numpy 函数。
虽然在处理简单函数时,Numpy 的速度与 Julia 不相上下,但当计算问题中引入复杂逻辑时,Julia 的表现更胜一筹。Julia 代码本身很简单,无需过多考虑如何向量化函数。
随着数据科学和机器学习支持系统的不断发展,Julia 是未来几天最令人期待的新语言之一。这是一个初学数据科学者应该加入到他们工具库中的工具。
我正在构建一个包含 Julia 基础和数据科学示例的 Github 仓库。点击这里查看。
附加阅读
-
docs.julialang.org/en/v1/manual/performance-tips/#man-performance-tips-1 -
dev.to/epogrebnyak/julialang-and-surprises---what-im-learning-with-a-new-programming-language--21df
如果你有任何问题或想法,请通过 tirthajyoti[AT]gmail.com 联系作者。同时,你也可以查看作者的 GitHub** 代码库 **,了解机器学习和数据科学的代码、想法和资源。如果你像我一样,对 AI/机器学习/数据科学充满热情,请随时 在 LinkedIn 上添加我 或 在 Twitter 上关注我。
个人简介: Tirthajyoti Sarkar 是 ON Semiconductor 的高级首席工程师。
原文。转载已获许可。
相关信息:
-
《使用 Julia 的游击学习指南》
-
《掌握数据科学的全世界》
-
《介绍 Gen:MIT 的新语言,想成为可编程推理的 TensorFlow》
更多相关话题
卷积神经网络综合指南
原文:
www.kdnuggets.com/2023/06/comprehensive-guide-convolutional-neural-networks.html
人工智能 近年来在缩小人类与机器能力之间的差距方面取得了巨大进展。研究人员和爱好者们在该领域的多个方面进行工作,创造出令人惊叹的成果。诸如此类的一个领域是 计算机视觉。
该领域的目标是使机器能够像人类一样看待世界,以类似的方式感知它,甚至利用这些知识完成多种任务,如图像和视频识别、图像分析与分类、媒体再创作、推荐系统、自然语言处理 等。计算机视觉在 深度学习 的进步中得到了构建和完善,主要是通过一个特定的 算法——卷积神经网络。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT 工作
介绍
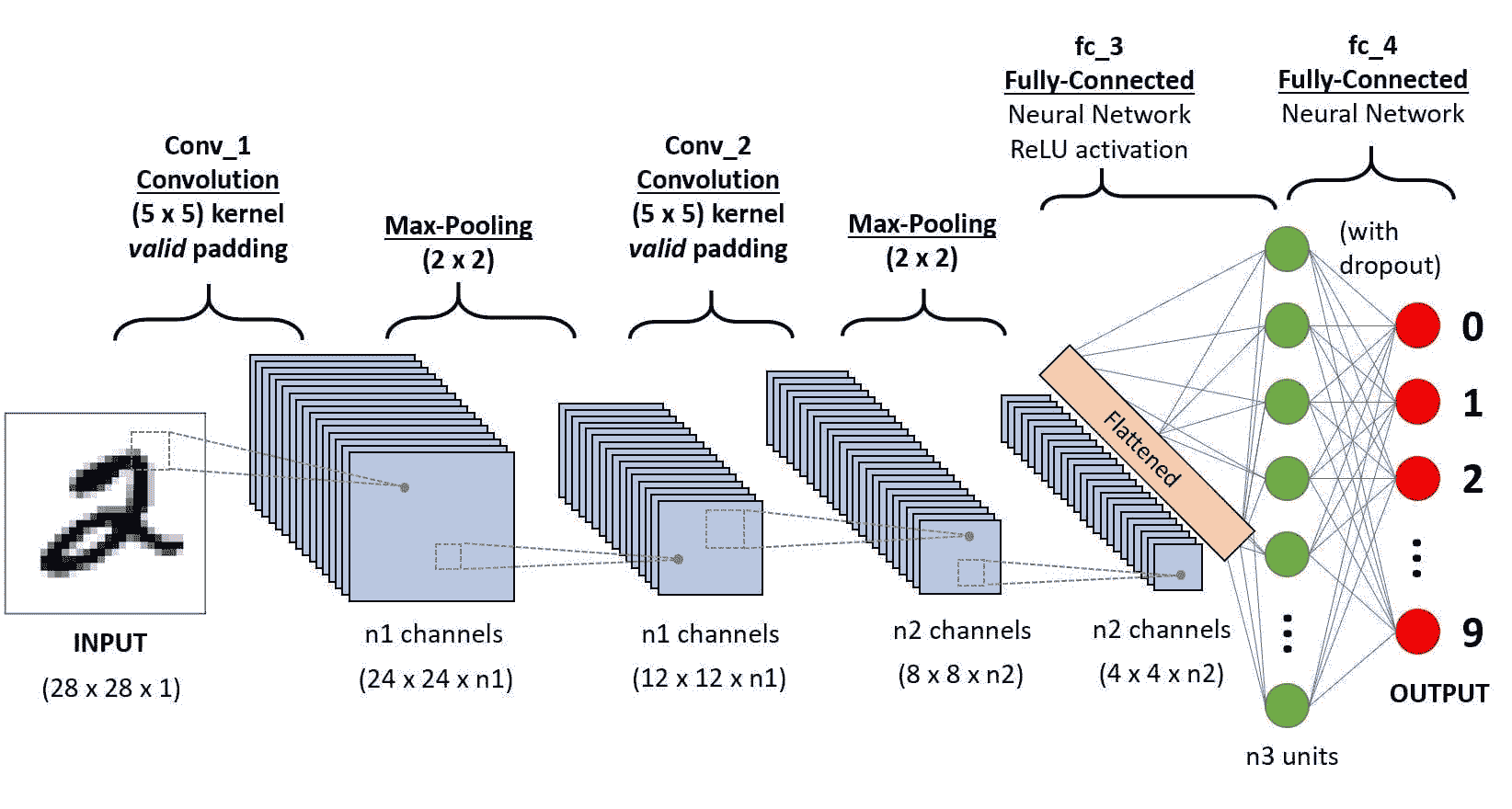
一个用于分类手写数字的 CNN 序列
卷积神经网络 (ConvNet/CNN) 是一种 深度学习 算法,它能够接受输入图像,对图像中的各个方面/对象赋予重要性(可学习的权重和偏置),并能够区分它们。与其他分类算法相比,ConvNet 所需的预处理要低得多。虽然在原始方法中过滤器是手工设计的,但经过足够的训练,ConvNets 有能力学习这些过滤器/特征。
ConvNet 的架构类似于人脑中神经元的连接模式,并且受到视觉皮层组织的启发。单个神经元仅对称称为感受野的视觉区域内的刺激作出反应。这些区域的集合重叠以覆盖整个视觉区域。
为什么选择 ConvNets 而不是前馈神经网络?
将一个 3x3 的图像矩阵展平为 9x1 的向量
图像无非就是像素值的矩阵,对吧?那么为什么不将图像展平(例如 3x3 的图像矩阵展平为 9x1 的向量)然后送入多层感知机进行分类呢?嗯,不完全是这样。
对于极其简单的二值图像,这种方法在执行类别预测时可能会显示出一个平均的精度得分,但对于具有像素依赖的复杂图像,准确率可能会很低或没有准确率。
ConvNet 能够通过应用相关滤波器成功捕捉图像中的空间和时间依赖性。由于参数数量的减少和权重的可重用性,该架构能够更好地拟合图像数据集。换句话说,网络可以被训练得更好地理解图像的复杂性。
输入图像
4x4x3 RGB 图像
在图中,我们有一张 RGB 图像,该图像已被分离成其三个颜色通道——红色、绿色和蓝色。图像存在于多种颜色空间中——灰度、RGB、HSV、CMYK 等。
你可以想象,当图像达到例如 8K (7680×4320)的尺寸时,计算量会变得多么庞大。ConvNet 的作用是将图像缩减成一种更易处理的形式,同时不丢失对获得良好预测至关重要的特征。当我们设计一种不仅擅长学习特征而且能够扩展到大规模数据集的架构时,这一点尤为重要。
卷积层——卷积核
用一个 3x3x1 的核对一个 5x5x1 的图像进行卷积以获得一个 3x3x1 的卷积特征
图像尺寸 = 5(高度)x 5(宽度)x 1(通道数,例如 RGB)
在上述演示中,绿色部分类似于我们的5x5x1 输入图像,I。卷积层第一部分中涉及的元素被称为卷积核/滤波器,K,用黄色表示。我们选择了K 作为一个 3x3x1 矩阵。
Kernel/Filter, K =
1 0 1
0 1 0
1 0 1
由于步幅长度 = 1(无步幅),卷积核移动 9 次,每次执行逐元素****乘法操作(哈达玛积),在卷积核悬停的图像区域K和P部分之间。
卷积核的移动
滤波器以一定的步幅值向右移动,直到遍历完整的宽度。接着,它跳回图像的开始(左侧),以相同的步幅值重复这个过程,直到整个图像被遍历。
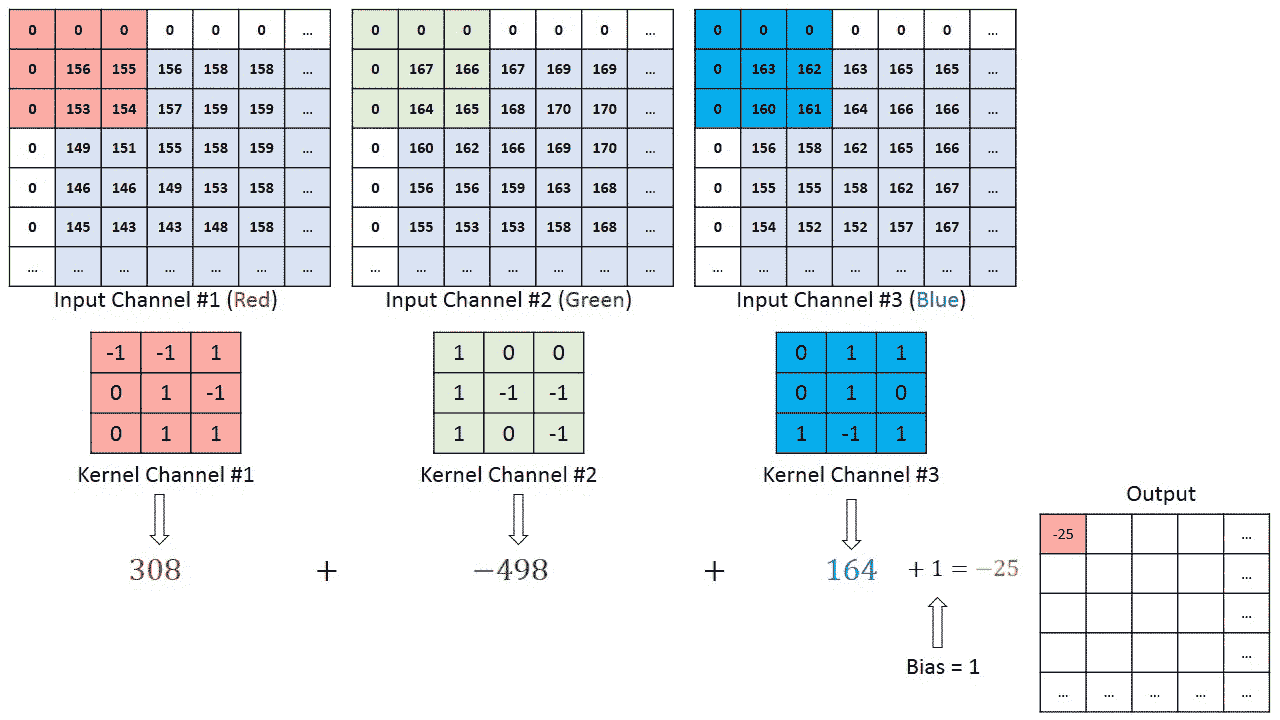
在一个 MxNx3 图像矩阵上进行的卷积操作,使用 3x3x3 卷积核。
对于具有多个通道(例如 RGB)的图像,卷积核的深度与输入图像相同。进行Kn与In堆叠([K1, I1]; [K2, I2]; [K3, I3])之间的矩阵乘法,并将所有结果与偏差相加,以给出一个压缩的一深度通道卷积特征输出。
步幅长度 = 2 的卷积操作
卷积操作的目标是提取高级特征,如边缘,从输入图像中。卷积网络不必仅限于一个卷积层。传统上,第一个卷积层负责捕捉低级特征,如边缘、颜色、梯度方向等。通过添加更多层,架构还适应高级特征,给我们一个对数据集中的图像有全面理解的网络,就像我们自己一样。
操作有两种结果——一种是卷积特征的维度相对于输入减少,另一种是维度增加或保持不变。这通过在前者情况下应用有效填充,或在后者情况下应用相同填充来实现。
当我们将 5x5x1 图像扩展到 6x6x1 图像,并对其应用 3x3x1 卷积核时,我们发现卷积矩阵的尺寸为 5x5x1。因此,称之为相同填充。
另一方面,如果我们在没有填充的情况下执行相同的操作,我们会得到一个尺寸为卷积核本身(3x3x1)的矩阵——有效填充。
以下仓库包含许多这样的 GIF,有助于更好地理解填充和步幅长度如何协同工作,以实现与我们需求相关的结果。
关于深度学习中的卷积算术的技术报告 - vdumoulin/conv_arithmetic
池化层
类似于卷积层,池化层负责减少卷积特征的空间大小。这样做是为了降低处理数据所需的计算能力,通过降维。此外,它对于提取主导特征非常有用,这些特征在旋转和位置上是不变的,从而保持了有效训练模型的过程。
池化有两种类型:最大池化和平均池化。最大池化返回内核覆盖的图像部分的最大值。另一方面,平均池化返回内核覆盖的图像部分的所有值的平均值。
最大池化还充当噪声抑制器。它完全丢弃噪声激活,并且在降维的同时也进行去噪处理。另一方面,平均池化仅作为噪声抑制机制执行降维。因此,我们可以说最大池化比平均池化效果要好得多。
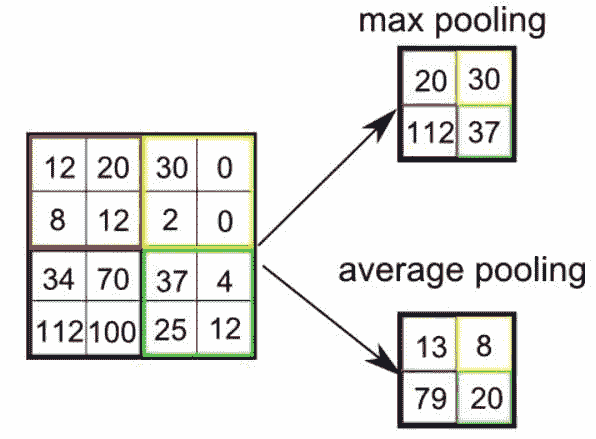
池化类型
卷积层和池化层共同构成卷积神经网络的第 i 层。根据图像中的复杂性,这些层的数量可能会增加,以进一步捕捉低级细节,但这也需要更多的计算能力。
经过上述过程后,我们成功地使模型理解了特征。接下来,我们将展平最终输出,并将其输入到一个普通的神经网络中进行分类。
分类 — 全连接层(FC 层)
添加一个全连接层通常是一种廉价的方法,用于学习卷积层输出表示的高级特征的非线性组合。全连接层在该空间中学习一个可能的非线性函数。
现在我们已经将输入图像转换为适合我们的多层感知机的形式,我们将把图像展平成列向量。展平后的输出被输入到前馈神经网络中,并在每次训练迭代中应用反向传播。经过多次训练周期,模型能够区分图像中的主导特征和某些低级特征,并使用Softmax 分类技术对其进行分类。
目前有各种 CNN 架构可供使用,它们在构建算法方面发挥了关键作用,并将在可预见的未来继续推动整体人工智能的发展。以下是其中一些架构:
-
LeNet
-
AlexNet
-
VGGNet
-
GoogLeNet
-
ResNet
-
ZFNet
Sumit Saha 是一位数据科学家和机器学习工程师,目前致力于构建以人工智能驱动的产品。他对人工智能在社会公益方面的应用充满热情,尤其是在医学和医疗保健领域。我有时也会进行一些技术博客写作。
原文。已获许可转载。
更多相关主题
集成学习全面指南 – 正是你需要知道的内容
原文:
www.kdnuggets.com/2021/05/comprehensive-guide-ensemble-learning.html
评论
集成学习技术已经证明在机器学习问题上能取得更好的表现。我们可以将这些技术用于回归和分类问题。
从这些集成技术中获得的最终预测结果是通过结合多个基础模型的结果得到的。平均值、投票和堆叠是一些将结果组合以获得最终预测的方法。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 为你的组织提供 IT 支持
在这篇文章中,我们将探讨如何使用集成学习来得出最佳的机器学习模型。
什么是集成学习?
集成学习是将多个机器学习模型组合在一个问题中的方法。这些模型被称为弱学习器。其直观的理解是,当你结合多个弱学习器时,它们可以变成强学习器。
每个弱学习器都在训练集上进行训练并提供预测。最终的预测结果是通过结合所有弱学习器的结果来计算的。
基本的集成学习技术
让我们花点时间来看看简单的集成学习技术。
最大投票
在分类中,每个模型的预测都是一票。在最大投票中,最终预测结果来自于票数最多的预测。
让我们看一个例子,假设你有三个分类器,其预测结果如下:
-
分类器 1 – 类 A
-
分类器 2 – 类 B
-
分类器 3 – 类 B
最终的预测结果是类 B,因为它获得了最多的票数。
平均值
在平均值方法中,最终输出是所有预测值的平均值。这适用于回归问题。例如,在 随机森林回归中,最终结果是来自各个决策树预测值的平均值。
让我们看一个例子,其中三个回归模型预测商品价格如下:
-
回归器 1 – 200
-
回归器 2 – 300
-
回归器 3 – 400
最终预测结果是 200、300 和 400 的平均值。
加权平均
在加权平均中,具有更高预测能力的基础模型更重要。在价格预测示例中,每个回归模型会被分配一个权重。
权重的总和应等于 1。假设回归模型的权重分别为 0.35、0.45 和 0.2。最终模型的预测可以如下计算:
0.35 * 200 + 0.45 * 300 + 0.2 * 400 = 285
高级集成学习技术
上述是一些简单的技术,现在让我们来看看集成学习的高级技术。
堆叠
堆叠是将各种估计器组合在一起以减少其偏差的过程。每个估计器的预测结果被堆叠在一起,并作为输入传递给最终估计器(通常称为元模型),以计算最终预测。最终估计器的训练通过交叉验证进行。
堆叠可以用于回归和分类问题。
堆叠可以被认为是以下步骤:
-
将数据分割为训练集和验证集,
-
将训练集划分为 K 折,例如 10 折,
-
在 9 折上训练一个基础模型(例如 SVM)并对第 10 折进行预测,
-
直到你对每一折有一个预测,
-
在整个训练集上拟合基础模型,
-
使用模型对测试集进行预测,
-
对其他基础模型(例如决策树)重复步骤 3 至 6,
-
使用测试集的预测作为新模型的特征——元模型,
-
使用元模型对测试集做最终预测。
对于回归问题,传递给元模型的值是数值型的。对于分类问题,它们是概率或类别标签。
混合
混合类似于堆叠,但使用训练集的留出集进行预测。因此,预测仅在留出集上进行。预测和留出集用于构建一个最终模型,该模型在测试集上进行预测。
你可以将混合视为一种堆叠,其中元模型在基础模型对留出的验证集进行的预测上进行训练。
你可以将混合过程视为:
-
将数据分割为测试集和验证集,
-
在验证集上拟合基础模型,
-
对验证集和测试集进行预测,
-
使用验证集及其预测结果来构建最终模型,
-
使用此模型进行最终预测。
混合的概念由 Netflix 奖竞赛推广。获胜团队使用了混合解决方案,在 Netflix 的电影推荐算法上实现了 10 倍的性能提升。
根据这个Kaggle 集成指南:
“混合”是 Netflix 获胜者引入的术语。它非常接近堆叠泛化,但更简单,且信息泄露的风险较小。一些研究人员将“堆叠集成”和“混合”互换使用。
使用混合时,不是为训练集创建折外预测,而是创建一个小的保留集,比如训练集的 10%。然后,堆叠模型仅在这个保留集上进行训练。”
混合与堆叠
混合比堆叠更简单,并且防止模型中的信息泄露。泛化器和堆叠器使用不同的数据集。然而,混合使用的数据较少,可能导致过拟合。
交叉验证在堆叠上比在混合上更可靠。与在混合中使用小的保留数据集相比,堆叠的交叉验证是在更多的折叠上计算的。
自助法
自助法采用随机样本数据,构建学习算法,并使用均值来找出自助法概率。这也称为自助聚合。自助法通过整合多个模型的结果来获得一个泛化的结果。
该方法包括:
-
从原始数据集中创建多个有替换的子集,
-
为每个子集构建一个基础模型,
-
所有模型并行运行,
-
将所有模型的预测结果结合起来以获得最终预测。
提升法
提升法是一种机器学习集成技术,通过将弱学习者转化为强学习者来减少偏差和方差。弱学习者以顺序方式应用于数据集。第一步是构建初始模型并将其拟合到训练集中。
然后拟合一个第二模型,该模型尝试修正第一个模型产生的错误。整个过程如下:
-
从原始数据中创建一个子集,
-
使用这些数据构建初始模型,
-
对整个数据集进行预测,
-
使用预测和实际值计算错误,
-
对不正确的预测赋予更多权重,
-
创建另一个模型,尝试修正上一个模型的错误,
-
使用新模型对整个数据集进行预测,
-
创建多个模型,每个模型旨在修正前一个模型产生的错误,
-
通过对所有模型的均值加权来获得最终模型。
集成学习的库
介绍完这些内容后,我们来谈谈你可以用来进行集成的库。广义上讲,有两个类别:
-
自助法算法,
-
提升算法。
自助法算法
自助法算法基于上述自助法技术。让我们看看其中的几个。
自助法元估计器
Scikit-learn 允许我们实现一个[BaggingClassifier](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.BaggingClassifier.html)和一个[BaggingRegressor](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.BaggingRegressor.html)。包袋元估计器在原始数据集的随机子集上拟合每个基础模型。然后通过汇总单个基础模型的预测来计算最终预测。汇总是通过投票或平均来完成的。这种方法通过在构建过程中引入随机化来减少估计器的方差。
包袋有几种变体:
-
将数据的随机子集作为样本的随机子集抽取被称为pasting。
-
当样本是有放回地抽取时,这种算法被称为包袋。
-
如果随机数据子集作为特征的随机子集被抽取,算法被称为随机子空间。
-
当你从样本和特征的子集创建基础估计器时,这被称为随机补丁。
让我们看看如何使用 Scikit-learn 创建一个包袋估计器。
这需要几个步骤:
-
导入
BaggingClassifier, -
导入一个基础估计器——一个决策树分类器,
-
创建一个
BaggingClassifier的实例。
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bagging = BaggingClassifier(base_estimator=DecisionTreeClassifier(),n_estimators=10, max_samples=0.5, max_features=0.5)
包袋分类器有几个参数:
-
基础估计器——这里是一个决策树分类器,
-
你想要在集成中使用的估计器数量,
-
使用
max_samples来定义从训练集中为每个基础估计器抽取的样本数量, -
max_features用于指定用于训练每个基础估计器的特征数量。
接下来,你可以在训练集上拟合这个分类器并对其进行评分。
bagging.fit(X_train, y_train)
bagging.score(X_test,y_test)
对于回归问题,过程将是相同的,唯一的区别是你将使用回归估计器。
from sklearn.ensemble import BaggingRegressor
bagging = BaggingRegressor(DecisionTreeRegressor())
bagging.fit(X_train, y_train)
model.score(X_test,y_test)
随机化树的森林
一个随机森林®是一个由随机决策树组成的集成。每棵决策树都是从数据集的不同样本中创建的。这些样本是有放回地抽取的。每棵树都会产生自己的预测。
在回归中,这些结果会被平均以得到最终结果。
在分类中,最终结果可以作为获得最多投票的类别。
平均和投票通过防止过拟合来提高模型的准确性。
在 Scikit-learn 中,随机化树的森林可以通过RandomForestClassifier和ExtraTreesClassifier来实现。类似的估计器也适用于回归问题。
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
clf = RandomForestClassifier(n_estimators=10, max_depth=None, min_samples_split=2, random_state=0)
clf.fit(X_train, y_train)
clf.score(X_test,y_test)
clf = ExtraTreesClassifier(n_estimators=10, max_depth=None, min_samples_split=2, random_state=0)
clf.fit(X_train, y_train)
clf.score(X_test,y_test)
提升算法
这些算法基于之前描述的提升框架。让我们来看一下其中几个。
AdaBoost
AdaBoost 通过拟合一系列弱学习器来工作。它在后续迭代中给予错误预测更多的权重,而给予正确预测较少的权重。这迫使算法关注那些更难预测的观测值。最终预测来自加权的多数投票或总和。
AdaBoost 可以用于回归和分类问题。让我们花点时间看看如何使用 Scikit-learn 将算法应用于分类问题。
我们使用 AdaBoostClassifier。n_estimators 决定了集成中的弱学习器数量。每个弱学习器对最终组合的贡献由 learning_rate 控制。
默认情况下,决策树被用作基估计器。为了获得更好的结果,可以调整决策树的参数。你还可以调整基估计器的数量。
from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(n_estimators=100)
model.fit(X_train, y_train)
model.score(X_test,y_test)
梯度树提升
梯度树提升还将一组弱学习器组合成一个强学习器。关于梯度提升树,有三项主要事项需要注意:
-
必须使用差分损失函数,
-
决策树被用作弱学习器,
-
它是一个加法模型,因此树是一个接一个地添加的。梯度下降被用来在添加后续树时最小化损失。
你可以使用 Scikit-learn 基于梯度树提升构建模型。
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=0)
model.fit(X_train, y_train)
model.score(X_test,y_test)
eXtreme Gradient Boosting
eXtreme Gradient Boosting,广泛称为XGoost,是一个顶级的梯度提升框架。它基于一组弱决策树。它可以在单台计算机上进行并行计算。
该算法使用回归树作为基学习器。它还内置了交叉验证。开发者喜欢它的准确性、效率和可行性。
import xgboost as xgb
params = {"objective":"binary:logistic",'colsample_bytree': 0.3,'learning_rate': 0.1,
'max_depth': 5, 'alpha': 10}
model = xgb.XGBClassifier(**params)
model.fit(X_train, y_train)
model.fit(X_train, y_train)
model.score(X_test,y_test)
LightGBM
LightGBM 是一种基于树学习的梯度提升算法。与使用按深度增长的其他基于树的算法不同,LightGBM 使用按叶子增长的树。叶子增长算法的收敛速度通常比基于深度的算法要快。
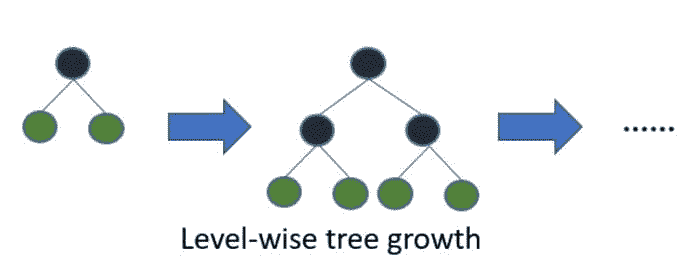
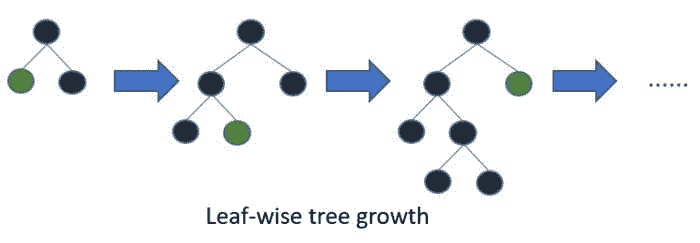
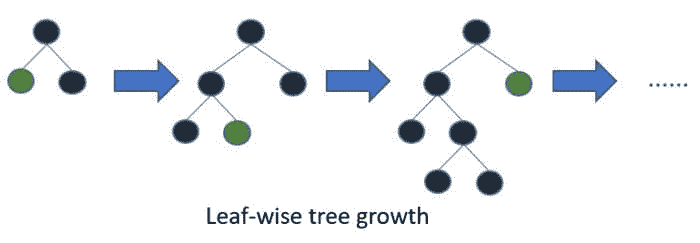
LightGBM 可以通过设置适当的目标来用于回归和分类问题。
下面是如何将 LightGBM 应用于二分类问题。
import lightgbm as lgb
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
params = {'boosting_type': 'gbdt',
'objective': 'binary',
'num_leaves': 40,
'learning_rate': 0.1,
'feature_fraction': 0.9
}
gbm = lgb.train(params,
lgb_train,
num_boost_round=200,
valid_sets=[lgb_train, lgb_eval],
valid_names=['train','valid'],
)
CatBoost
CatBoost 是一个由 Yandex 开发的深度梯度提升库。它使用遗忘决策树来生长平衡树。正如下面的图像所示,在每一层的左右分裂时使用相同的特征。
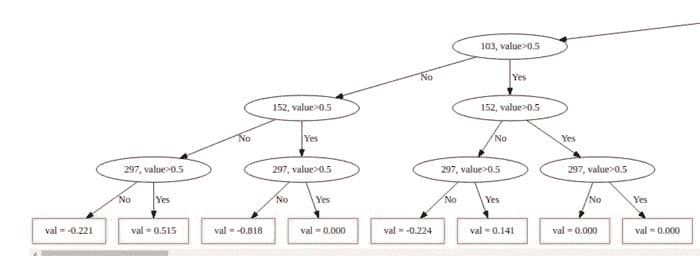
研究人员需要 Catboost 的原因如下:
-
具有本地处理分类特征的能力,
-
模型可以在多个 GPU 上进行训练,
-
它通过提供默认参数的优秀结果来减少参数调整时间,
-
模型可以导出到 Core ML 进行设备端推理(iOS),
-
它内部处理缺失值,
-
它可以用于回归和分类问题。
这是如何将 CatBoost 应用于分类问题的。
from catboost import CatBoostClassifier
cat = CatBoostClassifier()
cat.fit(X_train,y_train,verbose=False, plot=True
帮助你对基础模型进行堆叠的库
在堆叠时,单个模型的输出被堆叠,并使用最终估计器来计算最终预测。估计器在整个训练集上进行拟合。最终估计器在基础估计器的交叉验证预测上进行训练。
Scikit-learn 可以用于堆叠估计器。让我们来看看如何为分类问题堆叠估计器。
首先,你需要设置要使用的基础估计器。
estimators = [
('knn', KNeighborsClassifier()),
('rf', RandomForestClassifier(n_estimators=10, random_state=42)),
('svr', LinearSVC(random_state=42))
]
接下来,实例化堆叠分类器。其参数包括:
-
上面定义的估计器,
-
你希望使用的最终估计器。默认使用逻辑回归估计器,
-
cv交叉验证生成器。默认使用 5 折交叉验证, -
stack_method用于指定应用于每个估计器的方法。如果为auto,它将按顺序尝试predict_proba、decision_function或predict。
from sklearn.ensemble import StackingClassifier
clf = StackingClassifier(
estimators=estimators, final_estimator=LogisticRegression()
)
然后,你可以将数据拟合到训练集,并在测试集上进行评分。
clf.fit(X_train, y_train)
clf.score(X_test,y_test)
Scikit-learn 还允许你实现投票估计器。它使用基础估计器的多数投票或概率平均值来做出最终预测。
这可以使用 VotingClassifier 实现分类问题,用 VotingRegressor 实现回归问题。就像堆叠一样,你首先需要定义一组基础估计器。
让我们看看如何为分类问题实现它。VotingClassifier 让你选择投票类型:
-
soft表示将使用概率的平均值来计算最终结果, -
hard通知分类器使用预测的类别进行多数投票。
from sklearn.ensemble import VotingClassifier
voting = VotingClassifier(
estimators=estimators,
voting='soft')
投票回归器使用多个估计器,并将最终结果返回为预测值的平均值。
使用 Mlxtend 进行堆叠
你还可以使用 Mlxtend 的 [StackingCVClassifier](http://rasbt.github.io/mlxtend/user_guide/classifier/StackingCVClassifier/) 来进行堆叠。第一步是定义一个基础估算器列表,然后将这些估算器传递给分类器。
你还需要定义将用于聚合预测的最终模型。在这种情况下,就是逻辑回归模型。
knn = KNeighborsClassifier(n_neighbors=1)
rf = RandomForestClassifier(random_state=1)
gnb = GaussianNB()
lr = LogisticRegression()
estimators = [knn,gnb,rf,lr]
stack = StackingCVClassifier(classifiers = estimators,
shuffle = False,
use_probas = True,
cv = 5,
meta_classifier = LogisticRegression())
何时使用集成学习
当你想提高机器学习模型的性能时,可以采用集成学习技术。例如,提高分类模型的准确性或减少回归模型的平均绝对误差。集成学习还会导致模型更加稳定。
当你的模型在训练集上过拟合时,你还可以采用集成学习方法来创建更复杂的模型。集成中的模型将通过结合它们的预测来提高数据集上的性能。
集成学习最佳的应用时机
当基础模型不相关时,集成学习效果最佳。例如,你可以在不同的数据集或特征上训练不同的模型,如线性模型、决策树和神经网络。基础模型的相关性越低,效果越好。
使用不相关模型的思想在于每个模型可能解决了其他模型的弱点。它们还有不同的优点,当这些优点结合起来时,会形成一个表现良好的估算器。例如,单纯创建树基模型的集成可能不如将树型算法与其他类型算法结合效果更佳。
最后的思考
在本文中,我们探讨了如何使用集成学习来提高机器学习模型的性能。我们还介绍了可以用于集成的各种工具和技术。希望你的机器学习技能得到了提升。
祝集成学习愉快!
资源
简介:Derrick Mwiti 是一位对分享知识充满热情的数据科学家。他是数据科学社区的积极贡献者,参与了 Heartbeat、Towards Data Science、Datacamp、Neptune AI、KDnuggets 等多个博客。他的内容在互联网上已经被观看超过一百万次。Derrick 还是一名作者和在线讲师。他还与各种机构合作,实施数据科学解决方案并提升员工技能。你可以查看他的完整数据科学与机器学习 Python 课程。
原文。经许可转载。
相关:
-
XGBoost:它是什么,何时使用
-
梯度提升决策树 – 概念解释
-
最佳机器学习框架及 Scikit-learn 的扩展
更多相关主题
MLOps 综合指南

介绍
近年来,ML 模型显著增长,企业越来越依赖它们来自动化和优化操作。然而,管理 ML 模型可能会面临挑战,尤其是当模型变得更加复杂并需要更多资源进行训练和部署时。这导致了 MLOps 的出现,以标准化和简化 ML 工作流。MLOps 强调在 ML 工作流中需要持续集成和持续部署 (CI/CD),确保模型实时更新以反映数据或 ML 算法的变化。这种基础设施在准确性、可重复性和可靠性至关重要的领域,如医疗保健、金融和自动驾驶汽车中非常有价值。通过实施 MLOps,组织可以确保其 ML 模型持续更新和准确,从而推动创新、降低成本并提高效率。
什么是 MLOps?
MLOps 是一种结合 ML 和 DevOps 实践的方法论,旨在简化 ML 模型的开发、部署和维护。MLOps 与 DevOps 具有几个关键特征,包括:
-
CI/CD:MLOps 强调在 ML 工作流中需要持续的代码、数据和模型更新循环。这种方法要求尽可能多地进行自动化,以确保结果的一致性和可靠性。
-
自动化:与 DevOps 一样,MLOps 强调在 ML 生命周期中自动化的重要性。自动化 ML 工作流中的关键步骤,如数据处理、模型训练和部署,可以实现更高效、更可靠的工作流。
-
协作和透明性:MLOps 鼓励跨团队共享知识和专业技能的协作与透明文化。这有助于确保流程的流畅,因为交接期望将更加标准化。
-
基础设施即代码 (IaC):DevOps 和 MLOps 采用“基础设施即代码”的方法,其中基础设施被视为代码,并通过 版本控制系统 进行管理。这种方法使团队能够更高效且可重复地管理基础设施变更。
-
测试和监控:MLOps 和 DevOps 强调测试和监控的重要性,以确保结果的一致性和可靠性。在 MLOps 中,这涉及到对 ML 模型的准确性和性能进行长期的测试和监控。
-
灵活性和敏捷性:DevOps 和 MLOps 强调对不断变化的业务需求和要求做出灵活和敏捷的响应。这意味着能够迅速部署和迭代 ML 模型,以跟上不断发展的业务需求。
底线是,机器学习在行为上具有很大的变异性,因为模型本质上是一个用于生成预测的黑箱。虽然 DevOps 和 MLOps 共享许多相似之处,但 MLOps 需要更专业的工具和实践来应对数据驱动和计算密集型机器学习工作流所带来的独特挑战。机器学习工作流通常需要广泛的技术技能,这些技能超出了传统软件开发的范围,并且可能涉及专用的基础设施组件,如加速器、GPU 和集群,以管理训练和部署机器学习模型的计算需求。尽管如此,将 DevOps 的最佳实践应用于机器学习工作流将显著缩短项目时间,并为机器学习在生产中发挥作用提供所需的结构。
现代商业中 MLOps 的重要性和好处
机器学习已经彻底改变了企业分析数据、做出决策和优化操作的方式。它使组织能够创建强大的数据驱动模型,揭示模式、趋势和洞察,从而带来更为明智的决策和更有效的自动化。然而,有效地部署和管理机器学习模型可能是具有挑战性的,这正是 MLOps 介入的地方。MLOps 对现代企业变得越来越重要,因为它提供了一系列好处,包括:
-
更快的开发时间:MLOps 允许组织加速机器学习模型的开发生命周期,减少市场推出时间,并使企业能够迅速应对市场需求的变化。此外,MLOps 可以帮助自动化数据收集、模型训练和部署中的许多任务,从而释放资源,加快整体过程。
-
更好的模型性能:通过 MLOps,企业可以持续监控和改善其机器学习模型的性能。MLOps 促进了机器学习模型的自动化测试机制,这些机制能够检测与模型准确性、模型漂移和数据质量相关的问题。通过及早解决这些问题,组织可以提高机器学习模型的整体性能和准确性,从而带来更好的业务成果。
-
更可靠的部署:MLOps 允许企业在不同的生产环境中更可靠且一致地部署机器学习模型。通过自动化部署过程,MLOps 减少了部署错误和不同环境之间不一致的风险。
-
降低成本和提高效率:实施 MLOps 可以帮助组织降低成本并提高整体效率。通过自动化数据处理、模型训练和部署中的许多任务,组织可以减少对人工干预的需求,从而实现更高效且具有成本效益的工作流程。
总结来说,MLOps 对于希望利用 ML 的变革性力量来推动创新、保持竞争优势和改善业务成果的现代企业至关重要。通过加速开发时间、提升模型性能、提高部署可靠性和增强效率,MLOps 在释放 ML 的全部潜力方面发挥了关键作用。利用 MLOps 工具还将使团队成员能够专注于更重要的事务,企业也可以减少维持冗余工作流程的大型专门团队的开支。
MLOps 生命周期
无论是创建自己的 MLOps 基础设施还是从各种在线 MLOps 平台中选择,确保基础设施包含以下四个关键功能对成功至关重要。通过选择解决这些关键方面的 MLOps 工具,你将建立一个从数据科学家到部署工程师的持续循环,以便快速部署模型而不牺牲质量。
持续集成(CI)
持续集成(CI)涉及不断测试和验证对代码和数据所做的更改,以确保它们符合一组定义的标准。在 MLOps 中,CI 集成了新的数据和 ML 模型及其支持代码的更新。CI 帮助团队在开发过程中及早发现问题,使他们能够更有效地协作,并维持高质量的 ML 模型。MLOps 中 CI 实践的例子包括:
-
自动化的数据验证检查以确保数据的完整性和质量。
-
模型版本控制,用于跟踪模型架构和超参数的变化。
-
自动化的模型代码单元测试,以在代码合并到生产库之前发现问题。
持续部署(CD)
持续部署(CD)是将软件更新自动发布到生产环境,如 ML 模型或应用程序。在 MLOps 中,CD 关注确保 ML 模型的部署无缝、可靠和一致。CD 减少了部署过程中的错误风险,并使得根据业务需求变化更容易维护和更新 ML 模型。MLOps 中 CD 实践的例子包括:
-
自动化的 ML 流水线,配合持续部署工具如 Jenkins 或 CircleCI,整合和测试模型更新,然后将其部署到生产环境中。
-
使用 Docker 等技术对 ML 模型进行容器化,以实现一致的部署环境,减少潜在的部署问题。
-
实施滚动部署或蓝绿部署,以最小化停机时间,并允许轻松回滚有问题的更新。
持续培训(CT)
持续训练(CT)涉及在新数据变得可用或现有数据随着时间变化时更新机器学习模型。MLOps 的这一关键方面确保机器学习模型在考虑最新数据的同时保持准确性和有效性,防止模型漂移。定期用新数据训练模型有助于维持最佳性能,并实现更好的业务成果。MLOps 中 CT 实践的例子包括:
-
设置触发模型重新训练的政策(即准确度阈值),以保持最新的准确性。
-
使用主动学习策略来优先收集用于训练的有价值的新数据。
-
使用集成方法将多个在不同数据子集上训练的模型结合起来,从而实现持续的模型改进和对数据模式变化的适应。
持续监控(CM)
持续监控(CM)涉及不断分析生产环境中机器学习模型的性能,以识别潜在问题,验证模型是否符合定义标准,并维持整体模型的有效性。MLOps 从业者使用 CM 来检测如模型漂移或性能下降等问题,这些问题可能会危及预测的准确性和可靠性。通过定期监控模型的性能,组织可以主动解决任何问题,确保其机器学习模型保持有效并生成期望的结果。MLOps 中 CM 实践的例子包括:
-
追踪生产中模型的关键性能指标(KPIs),例如精确度、召回率或其他领域特定的指标。
-
实施模型性能监控仪表盘,以实时可视化模型健康状况。
-
应用异常检测技术来识别和处理概念漂移,确保模型能够适应数据模式的变化并维持其准确性。
MLOps 如何有利于机器学习生命周期?
管理和部署机器学习模型可能既耗时又具有挑战性,主要原因是机器学习工作流的复杂性、数据的可变性、需要进行迭代实验以及持续监控和更新已部署模型的需求。当机器学习生命周期未能与 MLOps 正确对接时,组织可能会面临诸如数据质量不一致导致结果不一致、由于手动流程成为瓶颈而导致部署缓慢以及难以迅速维护和更新模型以应对变化的业务条件等问题。MLOps 带来了效率、自动化和最佳实践,这些都促进了机器学习生命周期的每个阶段。
设想一个没有专门 MLOps 实践的数据科学团队正在开发一个销售预测的机器学习模型的场景。在这种情况下,团队可能会遇到以下挑战:
-
数据预处理和清洗任务耗时较长,原因是缺乏标准化的实践或自动化的数据验证工具。
-
由于模型架构、超参数和数据集版本控制不足,实验的可重复性和可追溯性面临困难。
-
手动和低效的部署过程会导致将模型发布到生产环境的延迟,并增加生产环境中出现错误的风险。
-
手动部署也可能增加在多个服务器上自动扩展部署的失败,影响冗余性和正常运行时间。
-
无法迅速调整部署模型以应对数据模式的变化,可能导致性能下降和模型漂移。
ML 生命周期中有五个阶段,这些阶段可以通过下述 MLOps 工具得到直接改进。
数据收集和预处理
ML 生命周期的第一阶段涉及数据的收集和预处理。通过在此阶段实施最佳实践,组织可以确保数据质量、一致性和可管理性。数据版本控制、自动化数据验证检查以及团队内的协作将带来更好的准确性和 ML 模型的有效性。示例包括:
-
数据版本控制以跟踪用于建模的数据集的变化。
-
自动化数据验证检查以维护数据质量和完整性。
-
团队内部的协作工具,用于有效地共享和管理数据源。
模型开发
MLOps 帮助团队在模型开发阶段遵循标准化实践,同时选择算法、特征和调整超参数。这减少了低效和重复工作,从而提高了模型的整体性能。实施版本控制、自动化实验跟踪和协作工具显著简化了 ML 生命周期的这一阶段。示例包括:
-
对模型架构和超参数实施版本控制。
-
建立中央中心以自动跟踪实验,从而减少重复实验,促进轻松的比较和讨论。
-
可视化工具和指标跟踪以促进协作,并在开发过程中监控模型的性能。
模型训练和验证
在训练和验证阶段,MLOps 确保组织使用可靠的过程来训练和评估其 ML 模型。通过利用自动化和训练中的最佳实践,组织可以有效优化模型的准确性。MLOps 实践包括交叉验证、训练管道管理和持续集成,以自动测试和验证模型更新。示例包括:
-
交叉验证技术以获得更好的模型评估。
-
管理训练管道和工作流程,以实现更高效和简化的过程。
-
持续集成工作流程,以自动测试和验证模型更新。
模型部署
第四阶段是将模型部署到生产环境中。此阶段的 MLOps 实践帮助组织更可靠和一致地部署模型,减少部署过程中出现错误和不一致的风险。容器化技术(如 Docker)和自动化部署管道等技术可以实现模型在生产环境中的无缝集成,支持回滚和监控功能。示例包括:
-
使用 Docker 进行容器化,以确保一致的部署环境。
-
自动化部署管道以处理模型发布,无需人工干预。
-
回滚和监控功能,用于快速识别和修复部署问题。
模型监控和维护
第五阶段涉及对生产中机器学习模型的持续监控和维护。在这一阶段应用 MLOps 原则使组织能够持续评估和调整模型。定期监控有助于检测模型漂移或性能下降等问题,这些问题可能会影响预测的准确性和可靠性。关键绩效指标、模型性能仪表盘和警报机制确保组织能够主动解决任何问题,并保持其机器学习模型的有效性。示例包括:
-
跟踪生产中模型性能的关键绩效指标。
-
用于实时可视化模型健康状况的模型性能仪表盘。
-
警报机制,用于通知团队模型性能的突然或渐进变化,从而实现快速干预和修复。
MLOps 工具和技术
采用合适的工具和技术对于成功实施 MLOps 实践和管理端到端的机器学习工作流至关重要。许多 MLOps 解决方案提供了多种功能,从数据管理和实验跟踪到模型部署和监控。一款宣传全面机器学习生命周期工作流的 MLOps 工具,你应该期望这些功能以某种方式实现:
-
端到端机器学习生命周期管理:所有这些工具都旨在支持机器学习生命周期的各个阶段,从数据预处理和模型训练到部署和监控。
-
实验跟踪和版本控制:这些工具提供了一些机制用于跟踪实验、模型版本和管道运行,实现可重复性并比较不同的方法。一些工具可能通过其他抽象方式展示可重复性,但仍具有某种形式的版本控制。
-
模型部署:虽然工具之间的具体细节有所不同,但它们都提供某种模型部署功能,帮助用户将模型迁移到生产环境,或提供快速部署端点以便测试请求模型推理的应用程序。
-
与流行的 ML 库和框架集成:这些工具兼容流行的 ML 库,如 TensorFlow、PyTorch 和 Scikit-learn,允许用户利用现有的 ML 工具和技能。然而,各个框架的支持程度在工具之间有所不同。
-
可扩展性:每个平台都提供扩展工作流程的方法,无论是水平扩展、垂直扩展还是两者兼具,使用户能够高效处理大数据集和训练更复杂的模型。
-
扩展性和定制化:这些工具提供了不同程度的扩展性和定制化,允许用户根据自己的特定需求调整平台,并根据需要将其与其他工具或服务集成。
-
协作与多用户支持:每个平台通常都支持团队成员之间的协作,使他们能够共享资源、代码、数据和实验结果,从而促进更有效的团队合作,并在整个机器学习生命周期中实现共同理解。
-
环境和依赖处理:这些工具大多包括处理一致且可重复环境的功能。这可能涉及使用容器(即 Docker)或虚拟环境(即 Conda)进行依赖管理,或提供预配置的设置,预安装流行的数据科学库和工具。
-
监控和警报:端到端 MLOps 工具也可能提供某种形式的性能监控、异常检测或警报功能。这有助于用户维护高性能模型,识别潜在问题,并确保其 ML 解决方案在生产中保持可靠和高效。
尽管这些工具在核心功能上有很大的重叠,但它们独特的实现、执行方法和关注领域使它们各具特色。换句话说,仅从纸面上比较 MLOps 工具可能很困难。这些工具提供了不同的工作流程体验。
在接下来的部分中,我们将展示一些显著的 MLOps 工具,这些工具旨在提供完整的端到端 MLOps 体验,并突显它们在处理和执行标准 MLOps 特性方面的差异。
MLFlow
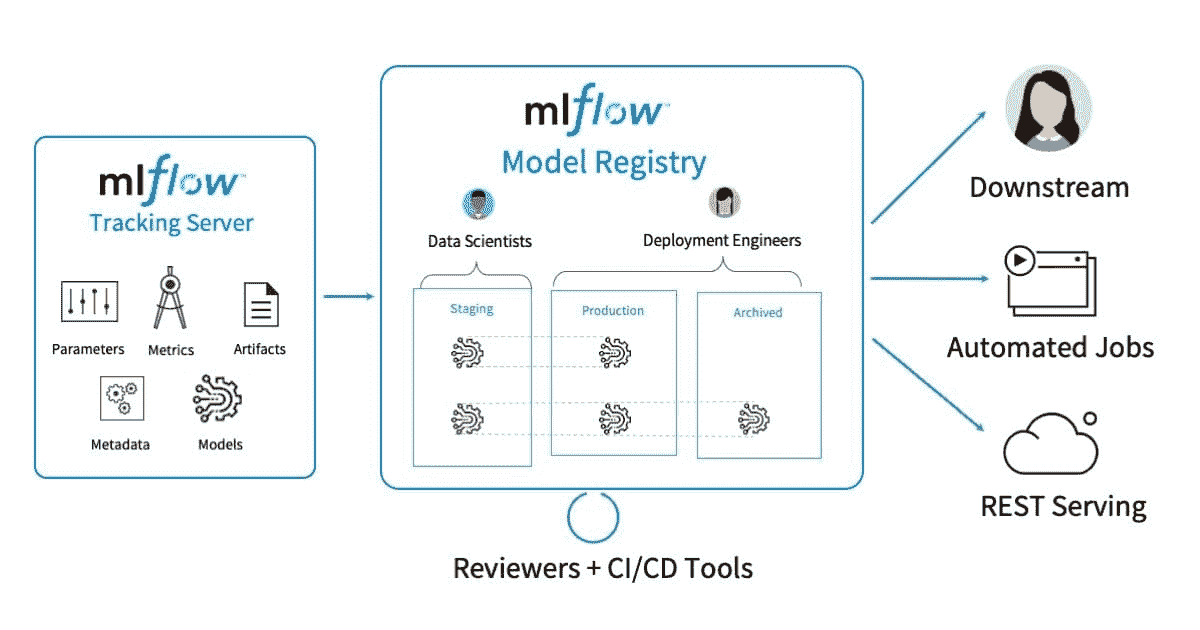
MLflow 具有独特的特性和特点,使其与其他 MLOps 工具有所区别,这使得它对具有特定需求或偏好的用户更具吸引力:
-
模块化:MLflow 的一个重要优势是其模块化架构。它由独立的组件(跟踪、项目、模型和注册表)组成,这些组件可以单独使用,也可以组合使用,使用户能够根据自己的具体需求调整平台,而无需强制使用所有组件。
-
语言无关性:MLflow 支持包括 Python、R 和 Java 在内的多种编程语言,使其对具有不同技能组合的用户都能接触。这主要有利于团队中那些偏好不同编程语言来处理 ML 工作负载的成员。
-
与流行库的集成:MLflow 设计用于与 TensorFlow、PyTorch 和 Scikit-learn 等流行 ML 库配合使用。这种兼容性允许用户将 MLflow 无缝集成到现有的工作流中,利用其管理功能,而无需采用全新的生态系统或更改当前工具。
-
活跃的开源社区:MLflow 拥有一个充满活力的开源社区,致力于其开发并保持平台与 MLOps 领域的新趋势和需求同步。这种活跃的社区支持确保了 MLflow 仍然是一个前沿且相关的 ML 生命周期管理解决方案。
尽管 MLflow 是一个功能多样且模块化的工具,用于管理 ML 生命周期的各个方面,但与其他 MLOps 平台相比,它有一些局限性。一个显著的不足是 MLflow 需要集成的、内置的管道编排和执行功能,例如 TFX 或 Kubeflow Pipelines 提供的功能。虽然 MLflow 可以使用其跟踪、项目和模型组件来构建和管理你的管道步骤,但用户可能需要依赖外部工具或自定义脚本来协调复杂的端到端工作流并自动化管道任务的执行。因此,寻求更简化、开箱即用的复杂管道编排支持的组织可能会发现 MLflow 的能力需要改进,并探索替代平台或集成解决方案以满足其管道管理需求。
Kubeflow
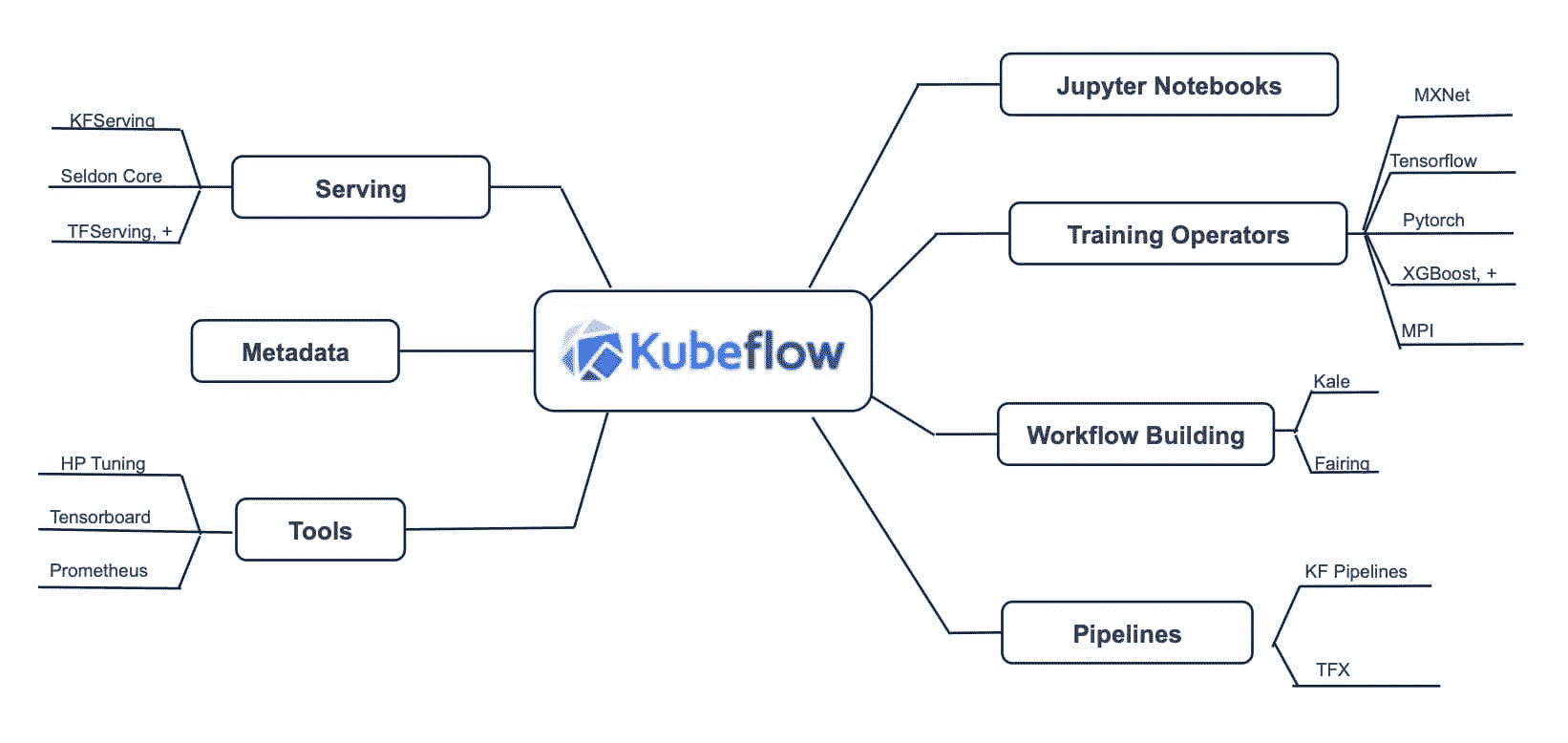
尽管 Kubeflow 是一个全面的 MLOps 平台,提供了一套适应 ML 生命周期各个方面的组件,但与其他 MLOps 工具相比,它也有一些局限性。Kubeflow 可能存在的一些不足之处包括:
-
更陡峭的学习曲线:Kubeflow 与 Kubernetes 的紧密耦合可能导致用户需要更多时间来熟悉 Kubernetes 的概念和工具。这可能增加了新用户上手的时间,也可能对没有 Kubernetes 经验的团队构成障碍。
-
有限的语言支持:Kubeflow 最初专注于 TensorFlow,尽管它扩展了对 PyTorch 和 MXNet 等其他 ML 框架的支持,但它仍然对 TensorFlow 生态系统有更大的偏向。与其他语言或框架合作的组织可能需要额外的努力来采用和集成 Kubeflow。
-
基础设施复杂性:Kubeflow 对 Kubernetes 的依赖可能会给没有现有 Kubernetes 环境的组织带来额外的基础设施管理复杂性。对于不需要 Kubernetes 全部功能的小型团队或项目而言,Kubeflow 的基础设施要求可能会被认为是一种不必要的负担。
-
对实验追踪关注较少:尽管 Kubeflow 通过其 Kubeflow Pipelines 组件提供实验追踪功能,但可能没有像 MLflow 或 Weights & Biases 那样广泛或用户友好,这些工具是其他专注于实时模型可观测性的端到端 MLOps 工具。那些对实验追踪和比较有较强需求的团队可能会发现 Kubeflow 在这一方面相比于具有更高级追踪功能的其他 MLOps 平台需要改进。
-
与非 Kubernetes 系统的集成:Kubeflow 的 Kubernetes 原生设计可能会限制它与其他非 Kubernetes 基础系统或专有基础设施的集成能力。相比之下,更灵活或无关基础设施的 MLOps 工具,如 MLflow,可能提供更多可访问的集成选项,能够与各种数据源和工具进行整合,无论底层基础设施如何。
Kubeflow 是一个 MLOps 平台,设计为 Kubernetes 的包装器,简化了 ML 工作负载的部署、扩展和管理,并将其转换为 Kubernetes 原生工作负载。这种与 Kubernetes 的密切关系提供了许多优点,如高效的复杂 ML 工作流编排。然而,对于缺乏 Kubernetes 专业知识的用户、使用各种语言或框架的用户,或使用非 Kubernetes 基础设施的组织而言,这可能会引入复杂性。总体而言,Kubeflow 的 Kubernetes 中心特性在部署和编排方面提供了显著的好处,组织在评估 Kubeflow 是否适合其 MLOps 需求时应考虑这些权衡和兼容性因素。
Saturn Cloud
Saturn Cloud 是一个 MLOps 平台,提供无忧扩展、基础设施、协作和 ML 模型的快速部署,专注于并行化和 GPU 加速。Saturn Cloud 的一些关键优势和强大功能包括:
-
资源加速关注:Saturn Cloud 强调为 ML 工作负载提供易于使用的 GPU 加速和灵活的资源管理。尽管其他工具也可能支持基于 GPU 的处理,但 Saturn Cloud 简化了这一过程,减少了数据科学家在使用加速时的基础设施管理负担。
-
Dask 和分布式计算:Saturn Cloud 与 Dask 紧密集成,Dask 是一个流行的 Python 并行和分布式计算库。这种集成允许用户轻松扩展其工作负载,利用多节点集群上的并行处理。
-
托管基础设施和预构建环境:Saturn Cloud 在提供托管基础设施和预构建环境方面更进一步,减轻了用户在基础设施设置和维护方面的负担。
-
简化的资源管理和共享:Saturn Cloud 通过允许用户定义所有权和访问资产权限,简化了资源如 Docker 镜像、机密和共享文件夹的共享。这些资产可以由个人用户、一个用户组(用户集合)或整个组织拥有。所有权决定了谁可以访问和使用共享资源。此外,用户可以轻松克隆完整的环境,让其他人能够在任何地方运行相同的代码。
-
基础设施即代码:Saturn Cloud 使用配方 JSON 格式,使用户能够通过以代码为中心的方法定义和管理资源。这促进了一致性、模块化和版本控制,简化了平台对基础设施组件的设置和管理。
Saturn Cloud 虽然为许多用例提供了有用的功能和特性,但与其他 MLOps 工具相比,可能存在一些局限性。以下是 Saturn Cloud 可能存在的一些局限性:
-
与非 Python 语言的集成:Saturn Cloud 主要面向 Python 生态系统,广泛支持流行的 Python 库和工具。然而,任何可以在 Linux 环境中运行的语言都可以在 Saturn Cloud 平台上运行。
-
开箱即用的实验跟踪:虽然 Saturn Cloud 确实支持实验记录和跟踪,但其在扩展性和基础设施方面的关注度高于实验跟踪能力。然而,那些希望在 MLOps 工作流的跟踪方面获得更多自定义和功能的用户会高兴地知道,Saturn Cloud 可以与包括但不限于 Comet、Weights & Biases、Verta 和 Neptune 在内的平台集成。
-
Kubernetes 原生编排:尽管 Saturn Cloud 通过 Dask 提供了可扩展性和托管基础设施,但它缺乏像 Kubeflow 提供的 Kubernetes 原生编排。那些深度投资于 Kubernetes 的组织可能更倾向于选择与 Kubernetes 深度集成的平台。
TensorFlow Extended (TFX)
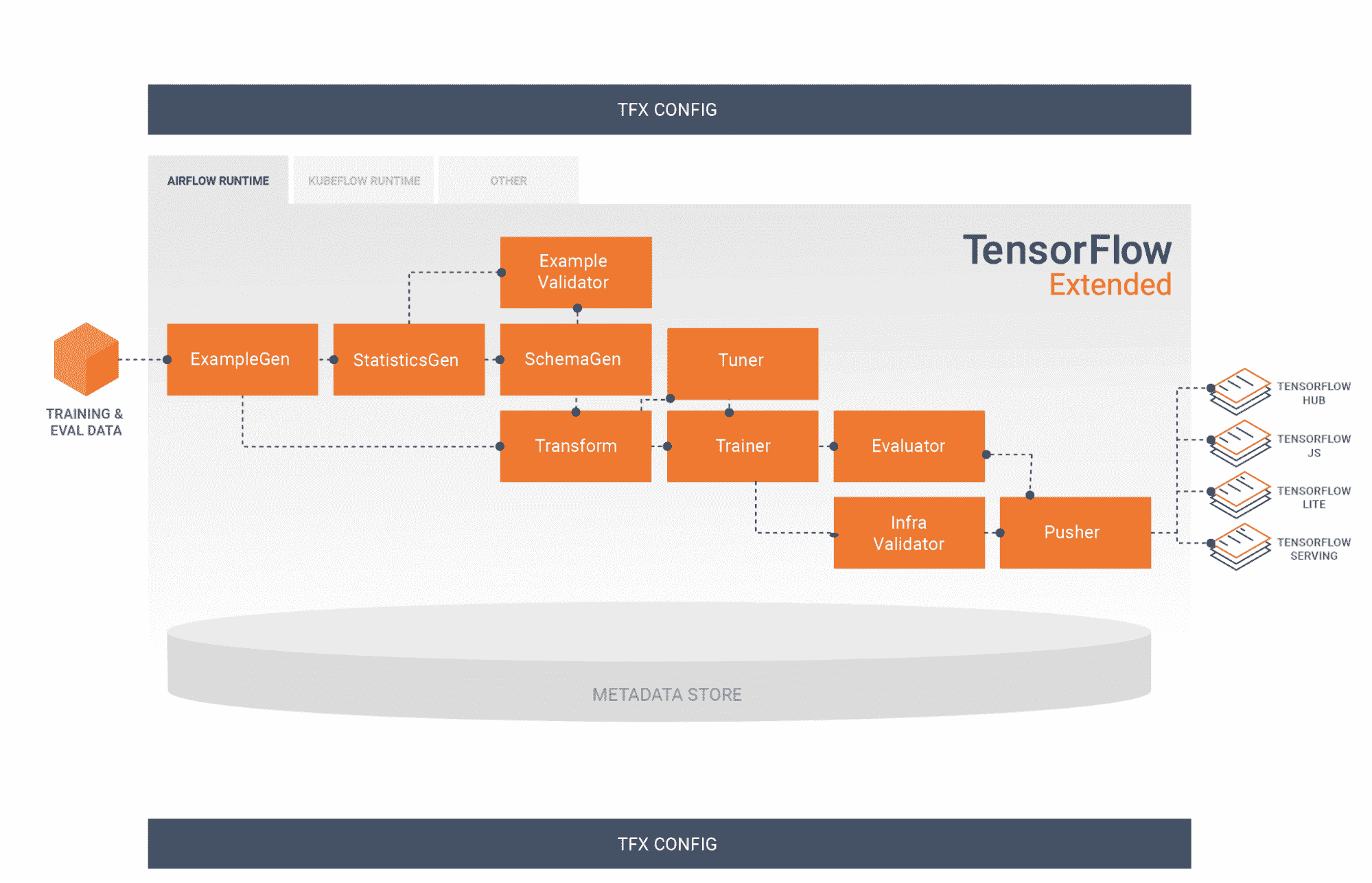
TensorFlow Extended (TFX) 是一个专为 TensorFlow 用户设计的端到端平台,提供了一个全面且紧密集成的解决方案,用于管理基于 TensorFlow 的机器学习工作流。TFX 在以下方面表现出色:
-
TensorFlow 集成:TFX 的最大优势是其与 TensorFlow 生态系统的无缝集成。它提供了一整套专为 TensorFlow 量身定制的组件,使已经投入 TensorFlow 的用户能够更轻松地构建、测试、部署和监控他们的机器学习模型,而无需切换到其他工具或框架。
-
生产就绪性:TFX 以生产环境为重点,强调稳健性、可扩展性以及支持关键任务 ML 工作负载的能力。它处理从数据验证和预处理到模型部署和监控的所有内容,确保模型在生产环境中准备就绪并能够在规模上提供可靠的性能。
-
端到端工作流:TFX 提供了广泛的组件来处理 ML 生命周期的各个阶段。支持数据摄取、转换、模型训练、验证和服务,TFX 使用户能够构建端到端的管道,确保其工作流的可重复性和一致性。
-
扩展性:TFX 的组件是可定制的,允许用户在需要时创建和集成自己的组件。这种扩展性使组织能够根据特定要求定制 TFX,整合他们喜欢的工具,或实现针对 ML 工作流中可能遇到的独特挑战的自定义解决方案。
但是,值得注意的是,TFX 对 TensorFlow 的主要关注可能对依赖其他 ML 框架或更喜欢语言无关解决方案的组织构成限制。尽管 TFX 为基于 TensorFlow 的工作负载提供了强大而全面的平台,但使用 PyTorch 或 Scikit-learn 等框架的用户可能需要考虑其他更适合其需求的 MLOps 工具。TFX 强大的 TensorFlow 集成、生产就绪性和可扩展组件使其成为对 TensorFlow 生态系统有深度投入的组织具有吸引力的 MLOps 平台。组织可以评估当前工具和框架的兼容性,并决定 TFX 的功能是否与他们在管理 ML 工作流中的特定用例和需求相匹配。
MetaFlow
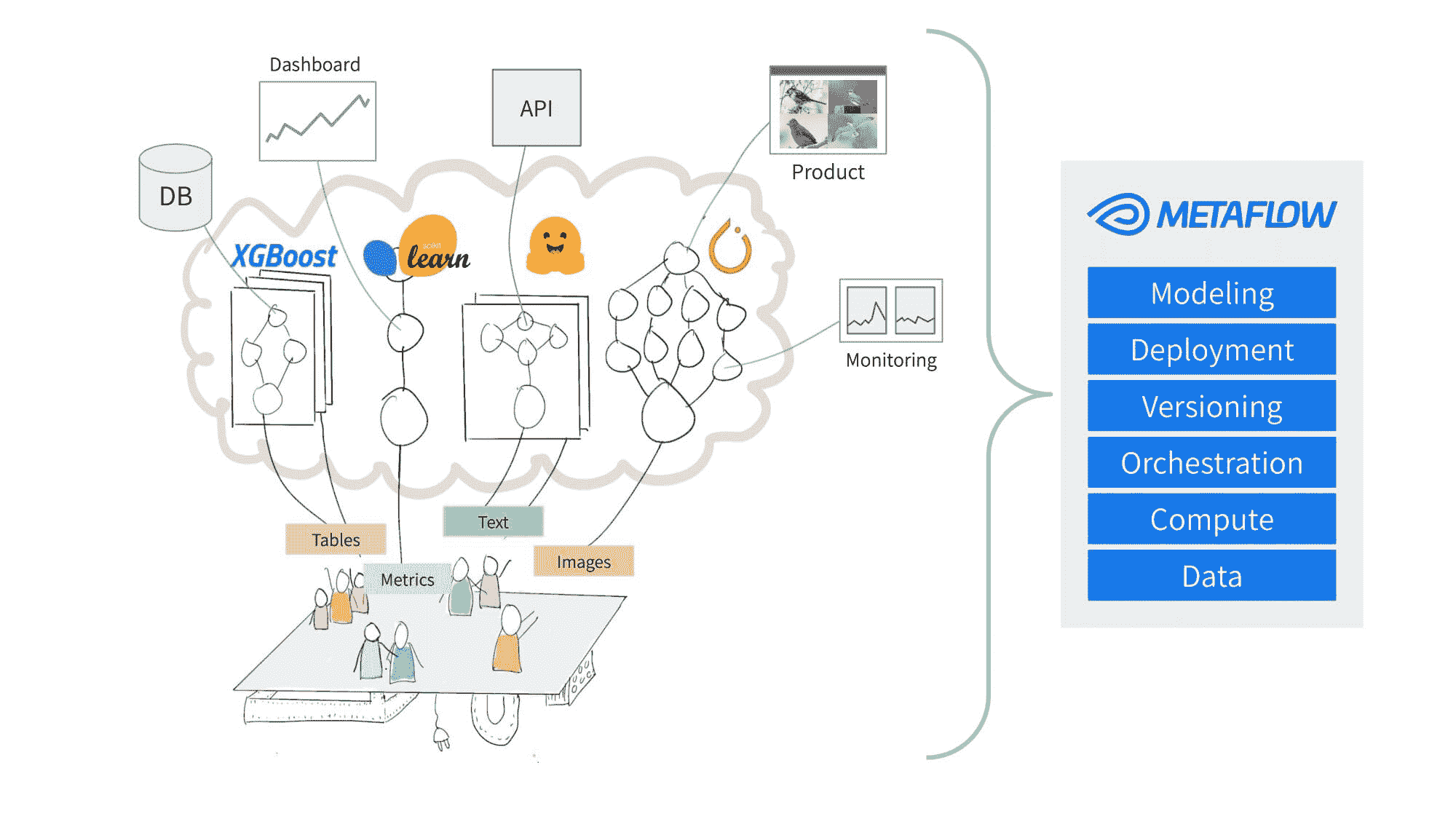
Metaflow 是 Netflix 开发的 MLOps 平台,旨在简化复杂的现实世界数据科学项目。Metaflow 在处理现实世界数据科学项目和简化复杂 ML 工作流方面表现出色。以下是 Metaflow 在一些领域中的优势:
-
工作流管理:Metaflow 的主要优势在于有效管理复杂的现实世界 ML 工作流。用户可以通过内置的版本控制、依赖管理以及基于 Python 的领域特定语言来设计、组织和执行复杂的处理和模型训练步骤。
-
可观察性:Metaflow 提供了在每个管道步骤后观察输入和输出的功能,使得跟踪数据在管道各个阶段变得简单。
-
可扩展性:Metaflow 能轻松将工作流从本地环境扩展到云端,并与 AWS 服务如 AWS Batch、S3 和 Step Functions 紧密集成。这使得用户能够轻松运行和部署他们的工作负载,而无需担心底层资源。
-
内置数据管理:Metaflow 提供了高效的数据管理和版本控制工具,通过自动跟踪工作流使用的数据集来实现。它确保不同管道运行之间的数据一致性,并允许用户访问历史数据和工件,从而有助于实验的可重复性和可靠性。
-
容错性和弹性:Metaflow 旨在处理现实世界机器学习项目中出现的挑战,如意外失败、资源限制和需求变化。它提供了自动错误处理、重试机制以及恢复失败或中断步骤的功能,确保在各种情况下工作流能够可靠高效地执行。
-
AWS 集成:由于 Netflix 开发了 Metaflow,它与 Amazon Web Services (AWS) 基础设施紧密集成。这使得已经投入使用 AWS 生态系统的用户能够在由 Metaflow 管理的机器学习工作负载中利用现有的 AWS 资源和服务。这种集成实现了对 AWS 资源的无缝数据存储、检索、处理和控制访问,进一步简化了机器学习工作流的管理。
尽管 Metaflow 有几个优点,但在与其他 MLOps 工具相比时,仍有某些领域可能存在不足之处:
-
有限的深度学习支持:Metaflow 最初的开发重点是典型的数据科学工作流和传统机器学习方法,而不是深度学习。这可能使得它对于主要使用深度学习框架(如 TensorFlow 或 PyTorch)的团队或项目不太适合。
-
实验跟踪:Metaflow 提供了一些实验跟踪功能。其对工作流管理和基础设施简单性的关注可能使得其跟踪功能不如专门的实验跟踪平台(如 MLflow 或 Weights & Biases)全面。
-
Kubernetes 原生编排:Metaflow 是一个多功能平台,可以部署在各种后端解决方案上,如AWS Batch 和容器编排系统。然而,它缺乏像 Kubeflow 那样的 Kubernetes 原生管道编排,这允许将整个机器学习管道作为 Kubernetes 资源运行。
-
语言支持:Metaflow 主要支持Python,这对大多数数据科学从业者有利,但对于在机器学习项目中使用其他编程语言(如 R 或 Java)的团队来说,可能会成为限制。
ZenML
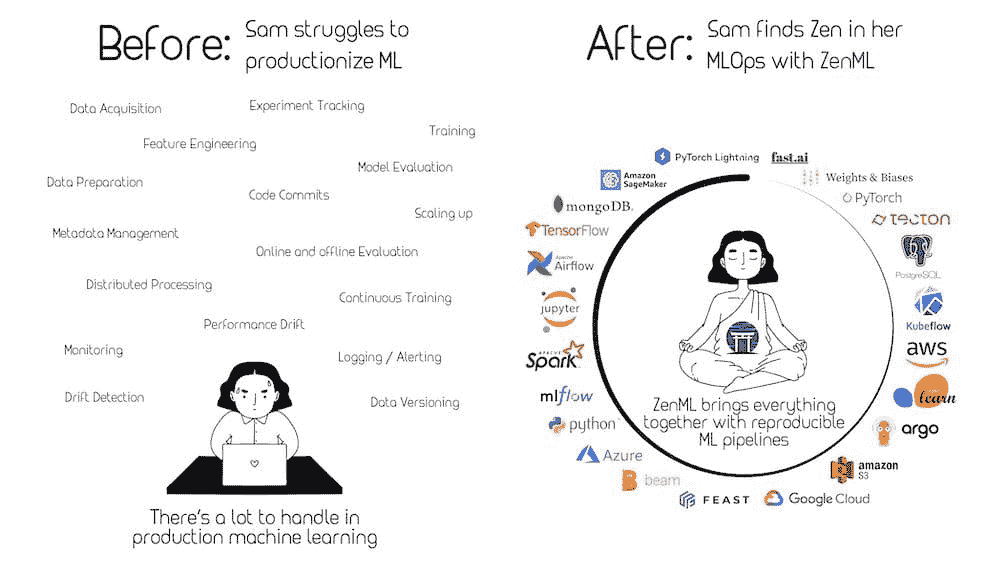
ZenML 是一个可扩展的开源 MLOps 框架,旨在使 ML 可重复、可维护和可扩展。ZenML 旨在成为一个高度可扩展和适应性的 MLOps 框架。它的主要价值主张在于,它允许你轻松集成和“粘合”各种机器学习组件、库和框架,以构建端到端的管道。ZenML 的模块化设计使数据科学家和工程师能够根据特定任务混合和匹配不同的 ML 框架和工具,减少了集成各种工具和框架的复杂性。
以下是 ZenML 出色的领域:
-
ML 管道抽象:ZenML 提供了一种干净、Pythonic 的方式来定义 ML 管道,使用简单的抽象,使创建和管理 ML 生命周期的不同阶段(如数据摄取、预处理、训练和评估)变得容易。
-
可重复性:ZenML 强调可重复性,确保管道组件通过精确的元数据系统进行版本控制和跟踪。这保证了 ML 实验可以一致地复制,防止与不稳定环境、数据或依赖项相关的问题。
-
后端协调器集成:ZenML 支持多种后端协调器,如 Apache Airflow、Kubeflow 等。这种灵活性使用户能够选择最适合他们需求和基础设施的后端,无论是在本地机器、Kubernetes 还是云环境中管理管道。
-
可扩展性:ZenML 提供了一个高度可扩展的架构,允许用户为不同的管道步骤编写自定义逻辑,并轻松与他们首选的工具或库集成。这使得组织能够根据其特定需求和工作流量身定制 ZenML。
-
数据集版本控制:ZenML 专注于高效的数据管理和版本控制,确保管道能够访问正确版本的数据和工件。这个内置的数据管理系统允许用户在不同的管道运行中保持数据一致性,并促进 ML 工作流的透明度。
-
与 ML 框架的高集成:ZenML 与流行的 ML 框架(包括 TensorFlow、PyTorch 和 Scikit-learn)提供了顺畅的集成。它能够与这些 ML 库协作,使从业者能够利用他们现有的技能和工具,同时利用 ZenML 的管道管理。
总结来说,ZenML 在提供干净的管道抽象、促进可重复性、支持各种后端协调器、提供可扩展性、维护高效的数据集版本控制以及与流行的 ML 库集成方面表现出色。它对这些方面的关注使 ZenML 特别适合那些希望提高 ML 工作流的可维护性、可重复性和可扩展性的组织,而不需要将过多的基础设施迁移到新工具上。
适合我的工具是什么?
在众多 MLOps 工具中,你如何确定哪个适合你和你的团队?在评估潜在的 MLOps 解决方案时,几个因素需要考虑。以下是在选择适合你组织特定需求和目标的 MLOps 工具时需要关注的一些关键方面:
-
组织规模和团队结构:考虑你的数据科学和工程团队的规模、专业水平以及他们需要协作的程度。较大的团队或更复杂的层级结构可能会从具有强大协作和沟通功能的工具中受益。
-
ML 模型的复杂性和多样性:评估你组织中使用的算法、模型架构和技术的范围。一些 MLOps 工具专门针对特定的框架或库,而其他工具则提供更广泛和多样化的支持。
-
自动化和可扩展性水平:确定你对数据预处理、模型训练、部署和监控等任务的自动化需求程度。同时,了解可扩展性在组织中的重要性,因为一些 MLOps 工具提供了更好的支持,用于扩展计算和处理大量数据。
-
集成和兼容性:考虑 MLOps 工具与现有技术栈、基础设施和工作流的兼容性。与当前系统的无缝集成将确保更顺利的采纳过程,并最小化对正在进行的项目的干扰。
-
定制性和可扩展性:评估你的 ML 工作流所需的定制性和可扩展性水平,因为一些工具提供了更灵活的 API 或插件架构,允许创建自定义组件以满足特定要求。
-
成本和许可:记住 MLOps 工具的定价结构和许可选项,确保它们符合组织的预算和资源限制。
-
安全性和合规性:评估 MLOps 工具在安全、数据隐私和合规要求方面的表现。这对在受监管行业运营或处理敏感数据的组织尤为重要。
-
支持和社区:考虑文档质量、社区支持和在需要时的专业协助可用性。活跃的社区和响应迅速的支持在解决挑战或寻求最佳实践时可能是非常有价值的。
通过仔细检查这些因素,并将其与组织的需求和目标对齐,你可以在选择最支持你的 ML 工作流并实现成功 MLOps 策略的工具时做出明智的决定。
MLOps 最佳实践
在 MLOps 中建立最佳实践对希望开发、部署和维护高质量机器学习模型并推动价值和积极影响业务结果的组织至关重要。通过实施以下实践,组织可以确保其机器学习项目高效、协作并易于维护,同时最小化因数据不一致、模型过时或开发缓慢和易出错等潜在问题带来的风险。
-
确保数据质量和一致性:建立健全的预处理管道,使用自动化数据验证检查工具,如 Great Expectations 或 TensorFlow 数据验证,并实施定义数据存储、访问和处理规则的数据治理政策。缺乏数据质量控制可能导致模型结果不准确或有偏差,从而导致决策不佳和潜在的业务损失。
-
数据和模型的版本控制:使用 Git 或 DVC 等版本控制系统跟踪对数据和模型所做的更改,改善协作并减少团队成员之间的混乱。例如,DVC 可以管理数据集和模型实验的不同版本,允许轻松切换、共享和重现。通过版本控制,团队可以管理多个迭代并重现过去的结果以进行分析。
-
协作与可重现的工作流程:通过实施明确的文档、代码审查流程、标准化的数据管理以及如 Jupyter Notebooks 和 Saturn Cloud 等协作工具和平台来鼓励协作。支持团队成员高效且有效地合作有助于加快高质量模型的开发。另一方面,忽视协作和可重现的工作流程会导致开发速度变慢、错误风险增加以及知识共享受阻。
-
自动化测试与验证:通过将自动化测试和验证技术(例如,使用 Pytest 的单元测试、集成测试)整合到机器学习流程中,采用严格的测试策略,利用 GitHub Actions 或 Jenkins 等持续集成工具定期测试模型功能。自动化测试有助于在部署之前识别和修复问题,确保生产中的模型性能高质量且可靠。跳过自动化测试会增加未发现问题的风险,影响模型性能,最终影响业务结果。
-
监控和警报系统:使用像 Amazon SageMaker Model Monitor、MLflow 或自定义解决方案等工具来跟踪关键性能指标,并设置警报以尽早发现潜在问题。例如,当检测到模型漂移或特定性能阈值被突破时,在 MLflow 中配置警报。不实施监控和警报系统会延迟诸如模型漂移或性能下降等问题的发现,从而导致基于过时或不准确的模型预测做出次优决策,负面影响整体业务表现。
通过遵循这些 MLOps 最佳实践,组织可以高效地开发、部署和维护机器学习模型,同时最大限度地减少潜在问题,提升模型效果和整体业务影响。
MLOps 和数据安全
数据安全在 MLOps 的成功实施中扮演着至关重要的角色。组织必须采取必要的预防措施,以确保他们的数据和模型在机器学习生命周期的每个阶段都保持安全和保护。确保数据安全的关键考虑因素包括:
-
模型鲁棒性:确保你的机器学习模型能够抵御对抗性攻击或在嘈杂或意外条件下可靠运行。例如,你可以采用对抗训练等技术,将对抗样本注入训练过程,以提高模型对恶意攻击的抵御能力。定期评估模型鲁棒性有助于防止潜在的利用,从而避免错误预测或系统故障。
-
数据隐私和合规性:为了保护敏感数据,组织必须遵守相关的数据隐私和合规性规定,如《通用数据保护条例》(GDPR)或《健康保险可移植性和问责法》(HIPAA)。这可能涉及实施强有力的data governance政策、对敏感信息进行匿名化,或利用数据掩码或伪名化等技术。
-
模型安全和完整性:确保机器学习模型的安全性和完整性有助于保护它们免受未经授权的访问、篡改或盗窃。组织可以实施措施,如对模型工件进行加密、安全存储和模型签名,以验证真实性,从而最小化外部方进行破坏或操控的风险。
-
安全部署和访问控制:在将 ML 模型部署到生产环境时,组织必须遵循快速部署的最佳实践。这包括识别和修复潜在漏洞,实施安全通信渠道(例如 HTTPS 或 TLS),并强制执行严格的访问控制机制,限制只有授权用户才能访问模型。组织可以通过基于角色的访问控制和像 OAuth 或 SAML 这样的认证协议来防止未经授权的访问,并保持模型的安全。
在 MLOps 周期中涉及安全团队,如红队,也可以显著提高整体系统安全性。红队可以模拟对模型和基础设施的对抗性攻击,帮助识别可能被忽视的漏洞和弱点。这种主动的安全方法使组织能够在问题成为威胁之前加以解决,确保遵守法规,并提升 ML 解决方案的整体可靠性和可信度。在 MLOps 周期中与专门的安全团队合作,培养强大的安全文化,这最终有助于 ML 项目的成功。
行业中的 MLOps
MLOps 已在各行各业成功实施,显著提升了效率、自动化水平和整体业务表现。以下是展示 MLOps 在不同领域潜力和有效性的实际案例:
医疗保健领域与 CareSource
CareSource 是美国最大的 Medicaid 提供商之一,专注于高风险妊娠的分诊,并与医疗提供者合作,主动提供救命的产科护理。然而,一些数据瓶颈需要解决。CareSource 的数据分散在不同的系统中,且并不总是最新的,这使得访问和分析变得困难。在模型训练时,数据格式不一致,导致清理和准备分析变得困难。
为解决这些挑战,CareSource 实施了一个 MLOps 框架,使用 Databricks Feature Store、MLflow 和 Hyperopt 来开发、调整和跟踪 ML 模型,以预测产科风险。他们随后使用 Stacks 帮助创建一个生产就绪的模板用于部署,并及时将预测结果发送给医疗合作伙伴。
加速的 ML 开发与生产就绪部署之间的过渡,使 CareSource 能够在为时已晚之前直接影响患者的健康和生命。例如,CareSource 及早识别高风险妊娠,从而改善了母亲和婴儿的结局。他们还通过防止不必要的住院减少了护理成本。
财务领域与 Moody’s Analytics
作为金融建模的领先者,穆迪分析面临着工具和基础设施访问受限、模型开发和交付中的摩擦以及分布式团队中的知识孤岛等挑战。他们为包括信用风险评估和财务报表分析在内的各种应用开发和使用 ML 模型。为了应对这些挑战,他们实施了 Domino 数据科学平台,以简化端到端工作流程并实现数据科学家的高效协作。
通过利用 Domino,穆迪分析加速了模型开发,将原本需要九个月的项目缩短至四个月,并显著提升了其模型监控能力。这一转型使公司能够高效地开发和交付定制化的高质量模型,以满足客户需求,如风险评估和财务分析。
娱乐与Netflix
Netflix 利用 Metaflow 来简化 ML 工作负载的开发、部署和管理,用于各种应用,如个性化内容推荐、优化流媒体体验、内容需求预测和情感分析以促进社交媒体互动。通过推动高效的 MLOps 实践并为其内部工作流量身定制以人为本的框架,Netflix 使数据科学家能够快速实验和迭代,从而实现更灵活和高效的数据科学实践。
根据前 Netflix 机器学习基础设施经理 Ville Tuulos 的说法,实施 Metaflow 将项目构思到部署的平均时间从四个月缩短至仅一周。这一加速工作流程突显了 MLOps 和专用 ML 基础设施的变革性影响,使 ML 团队能够更快、更高效地运作。通过将机器学习整合到业务的各个方面,Netflix 展示了 MLOps 实践在彻底改革行业和改善整体业务运营方面的价值和潜力,为快节奏的公司提供了显著优势。
MLOps 经验教训
正如我们在上述案例中所见,MLOps 的成功实施展示了有效的 MLOps 实践如何在业务的不同方面带来显著改善。得益于从实际经验中获得的教训,我们可以深入了解 MLOps 对组织的重要性。
-
标准化、统一的 API 以及简化 ML 生命周期的抽象。
-
将多个 ML 工具整合到一个统一的框架中,以简化流程并减少复杂性。
-
解决可重复性、版本控制和实验跟踪等关键问题,以提高效率和协作。
-
发展以人为本的框架,以满足数据科学家的具体需求,减少摩擦,促进快速实验和迭代。
-
监控生产中的模型并保持适当的反馈机制,以确保模型保持相关性、准确性和有效性。
Netflix 和其他实际的 MLOps 实施经验可以为那些希望提升自身机器学习能力的组织提供宝贵的见解。它们强调了制定周密策略和投资于稳健的 MLOps 实践的重要性,以开发、部署和维护高质量的机器学习模型,这些模型在扩展和适应不断变化的业务需求时能够带来价值。
MLOps 中的未来趋势和挑战
随着 MLOps 的不断发展和成熟,组织必须保持对新兴趋势和挑战的关注,这些趋势和挑战可能会在实施 MLOps 实践时出现。一些显著的趋势和潜在障碍包括:
-
边缘计算:边缘计算的兴起为组织提供了在边缘设备上部署机器学习模型的机会,从而实现更快的本地决策、减少延迟和降低带宽成本。在边缘计算环境中实施 MLOps 需要针对设备资源有限、安全性和连接限制的新策略来进行模型训练、部署和监控。
-
可解释的人工智能:随着人工智能系统在日常流程和决策中扮演越来越重要的角色,组织必须确保其机器学习模型是可解释的、透明的和无偏的。这需要整合模型解释、可视化工具和减轻偏见的技术。将可解释和负责任的人工智能原则融入 MLOps 实践有助于增加利益相关者的信任、遵守监管要求,并维护伦理标准。
-
复杂的监控和警报:随着机器学习模型的复杂性和规模的增加,组织可能需要更先进的监控和警报系统来维持足够的性能。异常检测、实时反馈和自适应警报阈值是一些能够帮助快速识别和诊断如模型漂移、性能退化或数据质量问题的技术。将这些先进的监控和警报技术集成到 MLOps 实践中,可以确保组织能够主动解决出现的问题,并保持其机器学习模型的高准确性和可靠性。
-
联邦学习:这种方法允许在分散的数据源上训练机器学习模型,同时维护数据隐私。组织可以通过实施 MLOps 实践进行分布式训练和多方协作,从而从联邦学习中受益,而不暴露敏感数据。
-
人机互动过程:对将人类专业知识融入许多机器学习应用的兴趣日益增长,特别是那些涉及主观决策或复杂背景的应用,这些背景无法完全编码。将人机互动过程整合到 MLOps 工作流中需要有效的协作工具和策略,以便无缝地结合人类和机器智能。
-
量子机器学习:量子计算是一个新兴领域,显示出解决复杂问题和加速特定机器学习过程的潜力。随着这一技术的成熟,MLOps 框架和工具可能需要进化,以适应基于量子的机器学习模型,并处理新的数据管理、训练和部署挑战。
-
鲁棒性与弹性:确保机器学习模型在面对对抗性情况(如噪声输入或恶意攻击)时的鲁棒性和弹性是一个日益关注的问题。组织需要在其 MLOps 实践中融入鲁棒机器学习策略和技术,以保证模型的安全性和稳定性。这可能涉及到 对抗训练、输入验证,或部署监控系统以识别并警报模型遇到意外输入或行为时。
结论
在今天的世界中,实施 MLOps 对于希望释放机器学习全部潜力、简化工作流程并在整个生命周期中保持高效模型的组织来说变得至关重要。本文探讨了 MLOps 实践和工具、各行业的使用案例、数据安全的重要性以及随着领域不断发展所面临的机遇和挑战。
总结一下,我们讨论了以下内容:
-
MLOps 生命周期的各个阶段。
-
可以部署到你选择的基础设施中的流行开源 MLOps 工具。
-
MLOps 实施的最佳实践。
-
不同工业领域的 MLOps 使用案例以及宝贵的 MLOps 经验教训。
-
未来趋势和挑战,例如边缘计算、可解释和负责任的人工智能,以及人机互动过程。
随着 MLOps 领域的不断演进,组织和从业者必须保持对最新实践、工具和研究的了解。强调持续学习和适应将使企业能够保持领先地位,完善其 MLOps 策略,并有效应对新兴趋势和挑战。
机器学习的动态性质和技术的快速发展意味着组织必须准备好随 MLOps 解决方案的迭代和演变。这涉及采用新技术和工具、在团队内培养协作学习文化、分享知识,并从更广泛的 MLOps 社区中获取见解。
采用 MLOps 最佳实践、保持对数据安全和伦理 AI 的高度关注,并在响应新兴趋势方面保持灵活的组织,将更有利于最大化其机器学习投资的价值。随着各行业企业利用机器学习,MLOps 在确保 AI 驱动解决方案的成功、负责任和可持续部署方面将变得越来越重要。通过采用强大且面向未来的 MLOps 策略,组织可以释放机器学习的真正潜力,并在各自领域推动变革。
Honson Tran 致力于技术的进步以造福人类。他是一个极具好奇心的人,热爱一切与技术相关的事物。从前端开发到人工智能和自动驾驶,他都充满热情。他的最终目标是尽可能多地学习,希望能参与全球关于人工智能未来的讨论。他拥有 10 年以上的 IT 经验,5 年的编程经验,并且始终充满活力,建议和实施新想法。他与我的工作永远相伴。他并不在乎成为墓地中最富有的人。对他来说,每晚入睡前能说自己为技术做出了新的贡献,这才是最重要的。
原文。经授权转载。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关主题
正态分布的综合指南
原文:
www.kdnuggets.com/2021/01/comprehensive-guide-normal-distribution.html
评论
照片由 Cameron Casey 提供,来源于 Pexels
数据分布是指数据的分布方式。在本文中,我们将讨论与正态分布相关的基本概念:
-
测量正态性的方式
-
将数据集转换为适应正态分布的方法
-
使用正态分布来表示自然发生的现象并提供统计洞察
概述
数据分布在统计学中非常重要,因为我们几乎总是在从一个总体中抽样,而这个总体的完整分布是未知的。样本的分布可能会限制我们可用的统计技术。
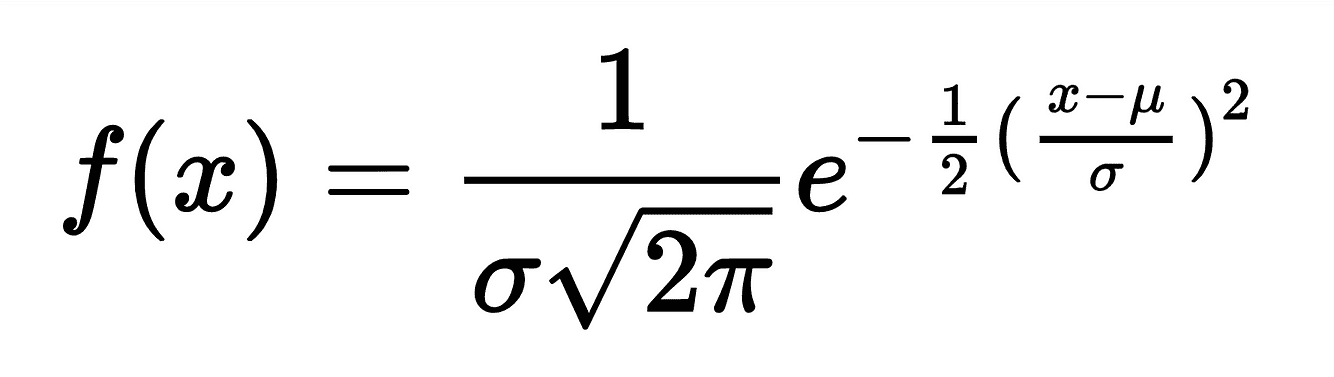
正态分布,其中 f(x) = 概率密度函数,σ = 标准差,μ = 均值
正态分布是一种常见的连续概率分布。当数据集符合正态分布时,可以利用许多方便的技术来探索数据:
-
了解每个标准差内的数据百分比
-
线性最小二乘回归
-
基于样本均值的推断(例如,t 检验)
在某些情况下,将偏斜的数据集转换为符合正态分布是有益的,从而解锁这一统计技术的使用。当你的数据几乎是正态分布的,只是有一些扭曲时,这尤其相关。稍后会详细讨论这个问题。
正态分布具有以下特征:
-
对称的钟形曲线
-
均值和中位数相等(在分布的中心)
-
≈68%的数据落在均值的 1 个标准差以内
-
≈95%的数据落在均值的 2 个标准差以内
-
≈99.7%的数据落在均值的 3 个标准差以内
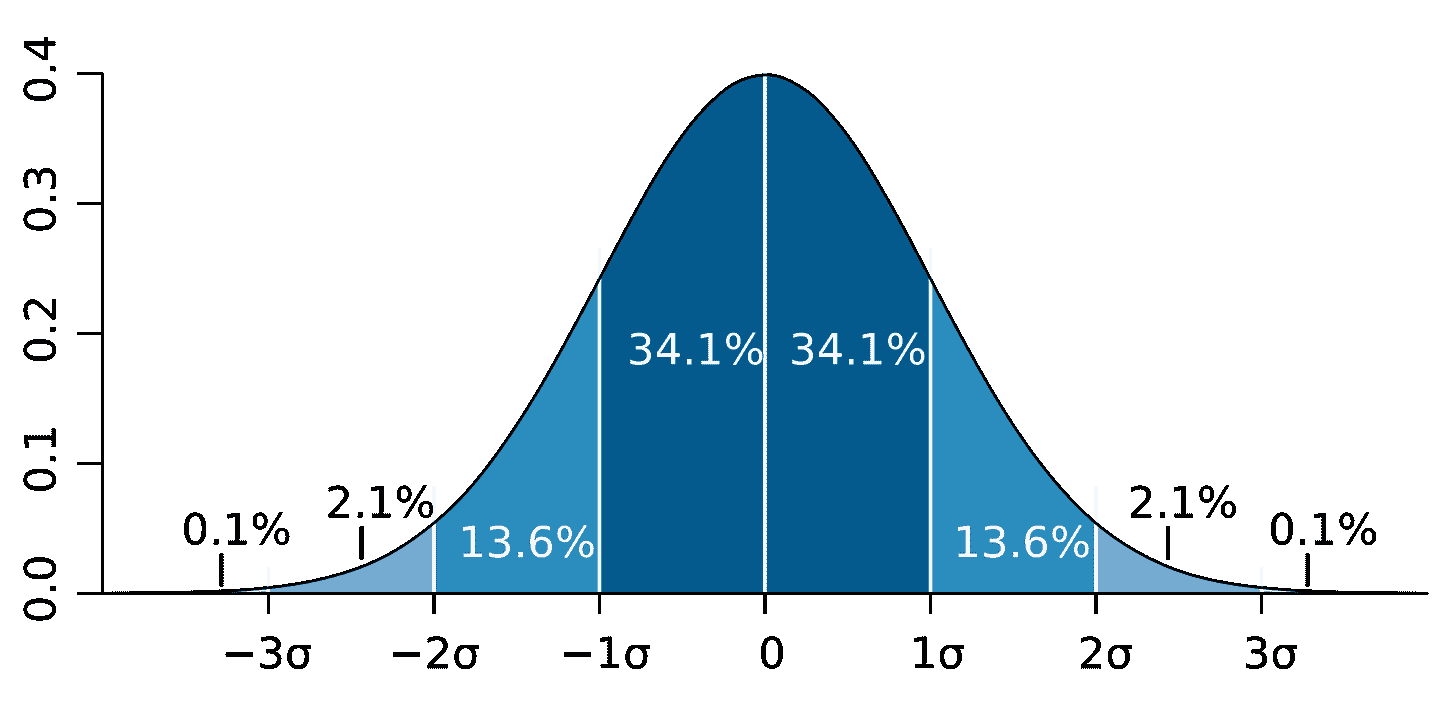
M.W. Toews 通过 维基百科
下面是一些你应该熟悉的与正态分布概述相关的术语:
-
正态分布:一种对称的概率分布,常用于表示实值随机变量;有时称为钟形曲线或高斯分布
-
标准差:衡量一组值的变异或离散程度;计算为方差的平方根
-
方差:每个数据点与均值的距离
如何使用正态分布
如果你的数据集不符合正态分布,以下是一些建议:
-
收集更多数据:小样本量或数据质量不足可能会扭曲你原本正常分布的数据集。正如数据科学中经常遇到的那样,解决方案可能是收集更多的数据。
-
减少方差来源:减少离群值可能会导致数据正态分布。
-
应用幂变换:对于偏斜的数据,你可以选择使用 Box-Cox 方法,它涉及对观察值进行平方根和对数变换。
在接下来的章节中,我们将探讨一些正态性的度量标准以及如何在数据科学项目中使用它们。
偏度
偏度是相对于均值的非对称度量。以下是一个左偏分布的图示。
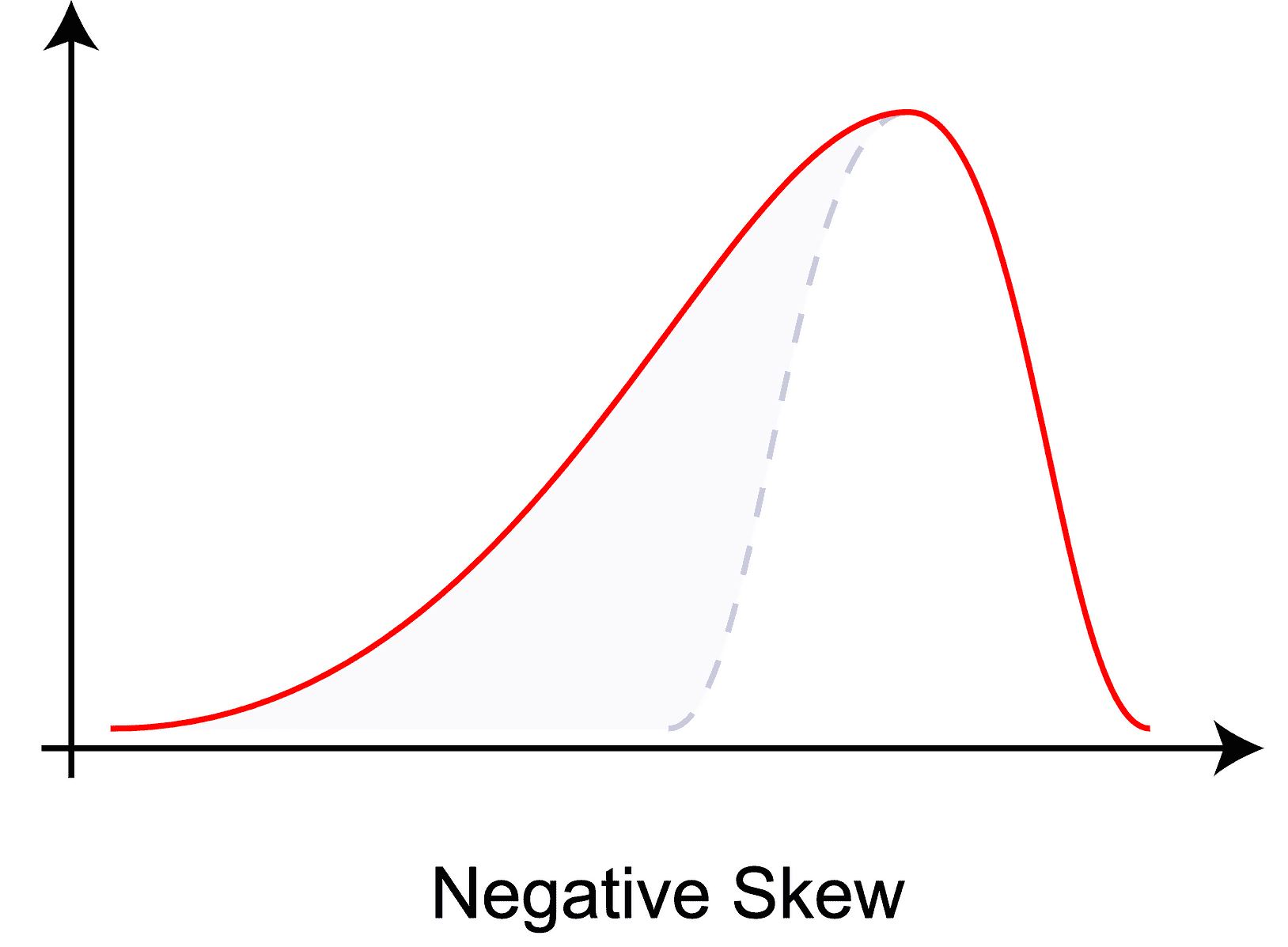
???? 我总是觉得这有点反直觉,所以这里值得特别注意。这个图形具有负偏度。这意味着分布的尾部在左侧更长。对我而言,这有点反直觉的是,大多数数据点都集中在右侧。不要被右偏度或正偏度所迷惑,它们会由这个图形的镜像图表示。
如何使用偏度
理解偏度很重要,因为它是模型性能的关键因素。要测量偏度,可以使用[skew](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.skew.html) 来自[scipy.stats](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.skew.html) 模块。

通过 SciPy
偏度度量可以提示我们模型性能在特征值上的潜在偏差。像上面第二个数组那样的正偏特征,将在较低值上提供更好的性能,因为我们在那个范围内提供了更多数据(与较高值离群点相对)。
峰度
源自希腊文kurtos,意为“弯曲”,峭度是衡量分布尾部厚度的一个指标。峭度通常相对于 0 来衡量,即正态分布的峭度值,使用Fisher’s definition来定义。正的峭度值表示尾部更“肥”(即更瘦的钟形曲线和更多的异常值)。
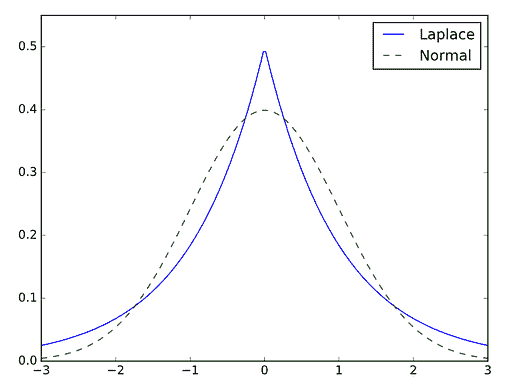
拉普拉斯分布的峭度> 0。通过John D. Cook Consulting。
如何使用峭度
理解峭度可以提供对数据集中异常值存在的洞察。要测量峭度,请使用[kurtosis](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.kurtosis.html)来自[scipy.stats](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.kurtosis.html)模块。

通过SciPy
负峭度值表示数据围绕均值更紧密地分布,异常值较少。
关于正态分布的一个警示
你可能听说过许多自然发生的数据集符合正态分布。这一说法已经被应用于从智商到人体身高的各种数据。
虽然正态分布确实是从自然观察中得出的,并且确实经常出现,但如果过于宽泛地应用这个假设,我们可能会面临过度简化的风险。
正态模型在极端情况通常不适用。它通常低估了罕见事件的概率。黑天鹅由纳西姆·尼古拉斯·塔勒布(Nassim Nicholas Taleb)提供了许多例子,说明罕见事件并不像正态分布预测的那样罕见。
在我之前的文章中,我对为什么身高呈正态分布进行了推测,也就是说,为什么它们的统计分布...
摘要
在这篇关于正态分布的简短文章中,我们涵盖了一些基本概念、如何测量以及如何使用它。要小心不要过度应用正态分布,否则你可能会低估异常值的可能性。希望这篇文章能为你提供对这一常见且极具实用性的统计概念的一些见解。
你可能会喜欢的更多文章
使用 sklearn 的聚类算法创建一个城市互动仪表板的逐步指南。
应对新常态的数据科学——来自一个 14 亿美元初创公司的经验教训
后疫情时代,机器学习对商业成功的作用越来越重要。
通过这份编码技巧列表,攀登数据科学和机器学习的新高度。
简介:Nicole Janeway Bills 是一位数据科学家,拥有商业和联邦咨询经验。她帮助组织利用他们最重要的资产:一个简单而稳健的数据策略。注册获取她的更多文章。
原始内容。经许可转载。
相关内容:
-
数据分布概述
-
数据科学的基础数学:泊松分布
-
正常(或近似正常)分布
我们的 3 个顶级课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织在 IT 领域
更多相关主题
最全面的 Kaggle 解决方案和创意列表
原文:
www.kdnuggets.com/2022/11/comprehensive-list-kaggle-solutions-ideas.html

编辑者提供的图片
被称为 Kaggle 的社区是机器学习和数据科学爱好者的首选平台,他们可以在这里与志同道合的用户合作。在这个平台上有很多事情可以做:除了合作,用户还可以搜索和发布数据集,使用集成 GPU 的笔记本电脑,也许最令人兴奋的是,用户可以参与与其他用户的比赛,以解决数据科学和机器学习挑战。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT
这些 Kaggle 竞赛 是平台如此受欢迎的一个重要原因;这些竞赛鼓励公司发布各种难以解决的数据科学任务,这些任务的奖品可以被初学者和专家争取。事实上,几乎任何人都可以参加 Kaggle 竞赛——从想深入了解 AI 的学生到在自己领域内的世界顶尖数据科学家,Kaggle 促进了合作的独特融合,并将其用户置于实时排行榜上。
多亏了一位绅士的努力,现在用户还有一个网站 catalogues and organizes solutions 用于组织 Kaggle 竞赛的解决方案。让我们快速深入了解 Kaggle,探索一下这个网站的概况,查看它收集的一些解决方案,并了解如何通过学习其他数据科学家解决 Kaggle 问题的方法来提高自己的实践能力。
Kaggle 简介
你可以把 Kaggle 想象成 AI 和数据科学爱好者的 AirBnB。这个平台是众包的,旨在吸引那些希望通过参与机器学习、数据科学和预测分析挑战来提高解决问题能力的数据科学家。其活跃成员来自 190 多个国家,Kaggle 每月从用户那里收到近 150,000 个提交。
正如我们提到的,Kaggle 的主要吸引力在于其竞争场景。该平台发布的挑战涉及从分析患者数据到预测癌症,再到情感分析的各种内容。这些挑战的共同点是,竞争者必须应用数据科学来获取解决方案。
在 Kaggle 上发布的挑战来自不同来源,其中一些仅为会员提供提升技能的机会,而另一些则由有实际问题的企业发布,需要立即解决。Kaggle 鼓励尽可能多的用户参与,通过提供奖金给竞赛获胜者或解决挑战并取得前 X 名的选手。奖品也可以是公司提供的产品或职位。
什么是 Kaggle 解决方案?
Kaggle 解决方案网站致力于收集几乎每一个顶级竞争者在之前 Kaggle 竞赛中设计的解决方案。每当新的竞赛结束时,网站都会更新,提供竞赛的标题和描述、重要细节(奖品类型、参与创建解决方案的团队成员数量、竞赛类型及其指标以及竞赛发生的年份)。
该网站由单个数据科学家和研究员Farid Rashidi制作。Rashidi 目前担任国家癌症研究所研究员,进行基于数据科学的癌症疫苗研究。Rashidi 曾就读于印第安纳大学,获得计算机科学博士学位,并创建了利用单细胞测序数据分析肿瘤异质性和进化的计算工具。
Kaggle 解决方案和创意示例
现在你对 Kaggle 解决方案有了一个快速的概述,让我们看看网站上发布的一些最近解决方案。
American Express - 违约预测
该竞赛由 American Express 发布,要求预测客户未来是否会违约支付。竞赛奖金高达 100,000 美元,并要求参赛者使用机器学习准确预测客户信用违约。American Express 特别要求参赛者使用工业级数据集来创建一个挑战现有生产模型的机器学习模型。
第一名的解决方案由一位名为“daishu”的用户发布,他是首次独自赢得 Kaggle 竞赛的获胜者。Daishu 使用了重型集成方法与 NN 和 LGB,并将其解决方案的代码发布在Github上。
Ubiquant 市场预测
另一场最近的比赛由中国量化对冲基金 Ubiquant Investment Co., Ltd 提供,奖金为$100,000。Ubiquant 要求参赛者创建一个模型来预测金融投资的回报率,并对其算法进行训练和测试,使用之前的真实世界价格数据。
理想情况下,获胜的解决方案将改善定量研究人员未来预测投资回报的方式。第一名解决方案已发布在 Kaggle,提供了总结和详细描述。
表格游戏系列 - 2022 年 8 月
最新的比赛是 Kaggle 的“Playground Series”系列的一部分,Kaggle 成员需改进一个虚构公司的主要产品。'Playground Series'比赛鼓励所有技能水平的成员对表格数据集进行建模。Kaggle 指出,这些比赛主要适合那些希望接受中级挑战的成员。排名靠前的解决方案由一名名为'Sawaimilert'的用户发布在 Kaggle 上。
参加 Kaggle 比赛的好处
参加 Kaggle 比赛最初可能会让人感到非常畏惧;你可能会觉得获胜的机会很渺茫,也不确定自己是否能学到有价值的东西来提升技能。此外,排名靠前的参赛者通常会利用相当复杂的集成方法来应对那些人工且显然不现实的数据集。
尽管如此,即使你对竞争有一些顾虑,参加至少几个 Kaggle 比赛还是值得的——对某个你尝试过的数据科学相关的事物有一个意见,比对从未参与过的事物有意见更有意义。
例如,你可能会发现一个专注于你感兴趣的新兴话题的比赛,这些话题在数据科学相关领域尚未出现。例如,像区块链这样的新兴话题可能会成为未来比赛的重点。考虑到 Kaggle 作为一个平台正因被 Google 收购而快速发展,这一点尤其可能。定期查看一些能引起你兴趣的新比赛可能会值得你的时间。
结论
我们鼓励你保持对 Kaggle 解决方案和顶级 Kaggle 竞争者开发的想法的最新了解。如果你想涉足数据科学的竞争领域,也可以考虑在正式参与 Kaggle 之前先参加其他非 Kaggle 相关的比赛。
Nahla Davies是一名软件开发人员和技术作家。在全职从事技术写作之前,她曾担任 Inc. 5000 经验品牌组织的首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼等。
更多相关主题
关于可信赖的图神经网络的综合调查:隐私、鲁棒性、公平性和可解释性
调查链接: arxiv.org/pdf/2204.08570.pdf
图结构数据在现实世界中广泛存在,如社交网络、交通网络、知识图谱和蛋白质互作网络。图神经网络(GNNs)通过汇聚邻域信息来更新表示,从而扩展了神经网络以处理图结构数据。GNNs 的消息传递机制在图建模中取得了巨大成功。例如,Pinterest 已经将 GNNs 应用于他们的图像推荐系统中。也有努力将 GNNs 应用于信用风险估计。然而,与其他深度学习模型类似,GNNs 也存在一些信任问题,引发了极大的关注:
-
隐私和鲁棒性在图神经网络(GNNs)中并不保证。GNNs 易受到隐私攻击,这些攻击窃取私人数据或对抗性攻击,这些攻击可以欺骗模型。例如,黑客可以利用 GNNs 的输出或节点嵌入来推断社交网络中的节点属性信息和好友信息。他们还可能通过注入恶意链接或节点来欺骗用于信用风险估计的 GNNs,从而导致个人、机构和社会的重大财务损失。
-
GNN 模型自身在公平性和可解释性方面存在问题。更具体地说,GNNs 被证明会放大数据中的偏差,从而导致对性别、种族和其他受保护敏感属性的歧视。由于模型的高度非线性,GNNs 的预测结果难以理解,这在很大程度上限制了 GNNs 的应用。
这些弱点严重阻碍了 GNNs 在现实世界应用中的采纳,特别是在金融和医疗等高风险场景中。因此,如何构建可信赖的 GNN 模型已成为一个重点话题。在我们最近的调查论文[6]中,我们从隐私、鲁棒性、公平性和可解释性等计算视角对现有可信赖的 GNNs 进行了全面回顾,并讨论了有前景的未来工作。在这篇博客中,我们简要介绍了调查中每个方面的结构和涵盖的主题。
图 1. 调查中隐私部分(第三部分)的结构。
隐私
如前所述,由于隐私攻击,用户的私人信息可能会从模型发布或提供的服务中泄露。然而,现有的调查主要关注于独立同分布(i.i.d)数据(如图像和文本)的隐私问题,而这些方法无法处理 GNNs 的图结构和信息传递机制。因此,我们概述了针对 GNNs 的隐私攻击以及隐私保护 GNNs 的方法。所涉及的主题如图 1 所示。我们首先制定了一个统一的框架来描述现有的图隐私攻击方法。然后,详细介绍了四种类型的隐私攻击,即成员推断攻击、重建攻击、属性推断攻击和模型提取攻击。至于隐私保护方法,我们将其分为三类,即差分隐私、联邦学习和对抗隐私保护。我们在图中列出了部分讨论的方法。有关更多方法和详细信息,请参阅调查论文中的第三部分。我们还包括了各个领域相关的数据集以及隐私保护 GNNs 的应用。我们发现,对图上的许多隐私攻击(如属性信息攻击和模型提取攻击)的防御方法研究较少。因此,防御各种隐私攻击是一个有前景的研究方向。还讨论了其他一些方向。详细信息请参见我们的调查。
图 2. 调查中鲁棒性部分(第四部分)的组织结构。
鲁棒性
鲁棒性是可信度的另一个重要方面。由于信息传递机制和图结构,GNNs 可能会受到图结构和节点属性上的对抗扰动的负面影响。例如,欺诈者可以创建多个有意选择高信用用户的交易,以逃避基于 GNN 的欺诈检测器。这表明有必要在安全关键领域(如医疗保健和金融系统)研究鲁棒的 GNNs。
关于图结构数据的鲁棒性已经有几个调查。因此,在我们的调查中,我们更多地关注于新兴方向中的方法,例如可扩展攻击、图后门攻击和最近的防御方法。具体而言,扰动采样和扰动候选减少是两个已被探索以提高现有攻击方法可扩展性的方向。此外,节点注入攻击,其注入一个节点的时间复杂度与图大小线性相关,是另一个有前景的方向。至于图后门攻击,我们详细介绍了少数现有工作。我们将现有的针对图对抗攻击的鲁棒 GNNs 进行分类,如图 2所示。带有自监督的防御是一个新方向,之前很少讨论。因此,我们详细介绍了这一方向的方法,如 SimP-GNN [1]。对于其他类别,我们添加了最新的方法,如 RS-GNN [2],该方法同时处理标签稀疏性和对抗扰动。我们还讨论了鲁棒 GNNs 的一些未来研究方向。更多细节可以在调查的第四部分中找到。
图 3. 我们调查中公平性部分(第五部分)的组织结构。
公平性
我们最近的研究[3]表明,与 MLP 相比,GNNs 的消息传递机制可能会放大偏差,这验证了研究专门针对图结构数据的公平算法的必要性。近年来,许多研究工作已经出现,旨在开发公平感知的 GNNs,以在不同任务中实现各种类型的公平性。因此,我们从多个方面全面回顾了图神经网络的公平性,这些方面在图 3 中展示。
首先,我们讨论了图结构数据中的潜在偏差,包括所有数据格式中普遍存在的偏差和由图拓扑造成的独特偏差。在公平性研究中,最重要的问题之一是如何以数学方式定义公平性。我们列出了文献中关于公平 GNNs 的广泛使用的公平性定义。除二分公平性外,大多数定义适用于 i.i.d 数据和图结构数据,二分公平性是专门为链路预测设计的。
我们将公平 GNNs 分为对抗性去偏差、公平性约束和其他类别。部分代表性的方法在图 3 中展示。对于对抗性去偏差和公平性约束,统一的框架和目标函数已经制定。接着,介绍了现有方法的详细实现和目标公平性。用于训练和评估公平 GNNs 的数据集需要包含用户的敏感属性,这可能很难获得。因此,我们列出了各种应用领域中用于公平感知 GNNs 的图数据集。
图 4。我们调查中解释性部分(第六部分)的组织结构。
解释性
由于复杂图结构的离散性和高度非线性,以及图神经网络(GNNs)中消息传递机制的使用,GNN 模型通常缺乏可解释性。开发可解释的 GNNs 是非常重要的。解释可以增强从业者对 GNN 的信任。此外,解释可以揭示捕获的知识,帮助我们评估潜在的偏差和对抗攻击。因此,许多工作已投入到可解释的 GNNs 中,我们提供了关于可解释 GNNs 的综合综述。解释性部分的总体组织结构如图 4 所示。我们首先讨论 GNNs 中的解释分类。然后,我们将可解释 GNNs 分为实例级后处理、模型级后处理和自解释方法。值得一提的是,自解释 GNNs 是一个新的方向,之前的综述未曾涉及。我们详细介绍了自解释 GNN 方法,如 SE-GNN [4] 和 ProtGNN [5]。对于其他方法组,我们进一步基于实现技术提供了更低级的分类。由于在实际图中获得真实解释非常困难,数据集和评估指标也是验证学习到的解释正确性的重大挑战。而解释性基准数据集可以成为未来研究 GNN 解释性的有前景的研究方向。更多细节可以在我们的调查论文中找到。
参考文献
[1] Jin, Wei, Tyler Derr, Yiqi Wang, Yao Ma, Zitao Liu, and Jiliang Tang. "节点相似性保留图卷积网络。" 见第 14 届 ACM 国际网页搜索与数据挖掘会议论文集,第 148-156 页。2021 年。
[2] Dai, Enyan, Wei Jin, Hui Liu, and Suhang Wang. "面向噪声图和稀疏标签的鲁棒图神经网络。" 第 15 届 ACM 国际网页搜索与数据挖掘会议论文集。2022 年。
[3] Dai, Enyan, and Suhang Wang. "说不对歧视:利用有限的敏感属性信息学习公平的图神经网络。" 第 14 届 ACM 国际网页搜索与数据挖掘会议论文集。2021 年。
[4] Dai, Enyan, and Suhang Wang. "面向自解释图神经网络。" 第 30 届 ACM 国际信息与知识管理会议论文集。2021 年。
[5] Zhang, Zaixi, Qi Liu, Hao Wang, Chengqiang Lu, and Cheekong Lee. "ProtGNN:面向自解释图神经网络。" arXiv 预印本 arXiv:2112.00911 (2021)。
[6] 戴恩言,赵天翔,朱怀生,徐俊杰,郭志萌,刘辉,唐继良,王苏航。 "关于可信赖图神经网络的全面调查:隐私、鲁棒性、公平性和可解释性。" arXiv 预印本 arXiv:2204.08570 (2022)。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持组织的 IT 工作
更多相关主题
农业中的计算机视觉
原文:
www.kdnuggets.com/2021/09/computer-vision-agriculture.html
评论

田间的深度学习:现代计算机视觉在农业中的应用
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
在当今快节奏的城市生活和压力重重的工作生活失衡中,尤其是在(希望是)疫情隔离措施的尾声,许多年轻人渴望更接近自然和家庭。面对重新出现的通勤问题以及回到办公室与混合或完全远程工作的拉锯战,许多年轻机器人宁愿放弃现状,回到乡村像他们的祖先一样从土地上谋生。他们还会带上激光器。
当然,我们不是在谈论那些在一年幸福的居家工作后被驱赶回办公室的疲惫的办公室职员,而是那些配备深度学习计算机视觉系统和精密驱动器的新型农业自动化机器人。这种新型自动化农业有望减少现代农业的投入和副作用,同时帮助农民应对从劳动力短缺到气候变化等各种挑战。
深度学习不仅仅用于投放广告或识别猫。相反,一些年轻的初创公司已经开始将计算机视觉的进步,通过越来越大的神经网络,应用于实际工作中的机器人。
对于大多数这些新兴企业来说,初始产品提供类似:去除那些讨厌的杂草(和讨厌的人力除草工)。每种机器人的选择武器可能大相径庭,从激光到除草剂施用器、机械干扰甚至火焰,但使这一切成为可能的计算机视觉进步都继承自现代机器学习和深度卷积网络。去除杂草可能是展示农业智能自动化的自然最小可行产品,但这不是唯一的选择。
其他项目正在从采摘细腻水果到全自动奢华温室等方面展开工作。
解决拖拉机视觉问题的合适方案:卷积神经网络
本文中描述的大多数农业机器人系统的关键组件是计算机视觉。基于过去十年中我们逐渐熟悉的深度学习框架和卷积神经网络,这些模型可以处理分类、定位,以及语义和实例分割。
深度学习的老手可以跳过下一部分,该部分将概述卷积神经网络的一些特性,使现代计算机视觉如此有效。
卷积神经网络(CNNs)由多个卷积层构建,卷积是一种操作,其中权重的滑动窗口与输入矩阵相乘,每个点乘积的总和就是卷积的输出。
卷积层在输入矩阵(如图像)上应用滑动窗口中的权重。图示来源于公共领域,source.
卷积的一个关键特性,也是使其成为视觉系统理想组件的原因,是输入位置的平移不变性(更准确地说是平移等变性)。由于滑动窗口(在神经网络中称为卷积核),无论西红柿出现在左中部还是右下角,该位置的卷积结果都是一样的。旋转不变性则是另一回事,卷积模型通常不具备这种特性。但对于从顶部俯视作物和杂草的拖拉机来说,这不太可能成为主要问题,因为有大量的训练数据和许多从上方观看的植物的径向对称性。
卷积神经网络作为视觉系统的另一个吸引人的方面是与动物视觉系统的紧密类比。在深度卷积网络中连续应用卷积核,使人联想到视网膜(以及视觉系统更远处)中一束束神经元,它们对按照特定模式出现的刺激作出共同反应。这些称为感受野,它们与卷积核在简单训练目标下学习到的边缘、点、圆圈以及更抽象的特征非常相似。
卷积具有一个宝贵的特性,即对图像中不同位置出现的物体具有鲁棒性;图像左上角的西红柿与右下角的西红柿会被同样识别。图示来源于公共领域,source.
谁在解决农业自动化问题?
目前有不少初创公司同时致力于通过深度学习增强农业自动化。对于许多公司来说,第一个产品类似于配备卷积神经网络视觉系统的自主除草拖拉机(或半自主拖拉机附件)。另一种流行的方法是将视觉引导自动化应用于大规模室内园艺,在极端情况下,这看起来像是一个与整个温室一样大的机器人。
我们将主要关注机器除草的案例,并在最后简要提及其他正在开发的应用。
半自主:牵引式设备
在人工操作农用设备与将 5 吨农业工业设备配备自主智能和 150 瓦激光器之间存在一个中间点,一些公司选择了这一初步路径。实际情况是在传统拖拉机上添加一个配备摄像头传感器、执行器和分析软件的附件,但仍然依赖人工驾驶员和监督员。
这是瑞士公司 Ecorobotix 的 Ara 挂载喷雾器的方法。Ara 利用计算机视觉引导除草剂、杀菌剂或杀虫剂的施用,目标是由机载摄像头捕捉到的植物,公司声称这可以减少 95%的 pesticide 输入。这也是 蓝河科技采取的方法,总部位于加利福尼亚,他们开发了 “See & Spray”技术。公司对“See & Spray”的声明是平均减少 77%的除草剂使用量。
针对杂草进行定点喷洒的主要激励之一是,相比于均匀喷洒整个田地(广播喷洒),杂草和其他植物会随着时间的发展对各种杀虫剂产生耐药性。这导致了对草甘膦(即“RoundUp”)等除草剂喷洒的耐受性增加,因为在每个季节受到强烈暴露的选择压力。
这有点像抗生素耐药性,新的抗生素使用后耐药性迅速出现。青霉素作为第一个现代抗生素的耐药性早在 1940 年就被注意到了,这一现象与其发展同步,且早于其在人体患者中的广泛使用。事实上,草甘膦耐药性在著名的“RoundUp Ready”转基因作物于 1990 年代推向市场之前就通过定向进化实验早已出现,因此杂草在增加选择压力下发展耐药性并不令人惊讶。
有针对性的喷洒相比于广泛喷洒的主要优势在于减少了对整个田地的选择性压力,并且伴随着与较低投入相关的成本下降。然而,这只是一个部分解决方案,如果可能的话,完全摆脱化学除草解决方案还有额外的好处。通常这可能意味着激进的机械耕作或需要额外(且缓慢)人工的手工除草,但下一节的初创公司正在开发一系列机器人替代方案。
全自主除草机器人

自主除草机器人,来源
本节中描述的解决方案将除草自动化向前推进了一步,从有针对性的除草到精确除草。这些自主农业机器人尺寸从几百磅到近 5 吨或更多不等!
每种解决方案在细节上有所不同,最明显的区别在于除草工具的选择,这些工具包括激光、机械破坏、除草剂,甚至电流。还有许多相似之处:大多数这些机器人使用深度学习计算机视觉解决方案来定位杂草,避开作物植物,通过物理执行器或光学定位来施加除草工具。
碳机器人 是一个引人注目的例子,展示了一家公司如何解决自主除草问题。这一点尤其体现在他们开发的强大除草平台上:这是一台重达近五吨的激光重型机械,它利用相机、GPS 和激光雷达传感器的组合在大田中作业。制造商声称,他们的机器人可以减少除草剂和人工的需求,降低成本,并且不会破坏土壤。在这些优势之上,这种机器人方法已获得在完全有机农场上使用的认证。
| 碳机器人的深度学习、激光使用、农场机器人
-
9,500 磅的自动化除草平台
-
12 个相机
-
由 NVIDIA 提供动力的机器学习视觉系统。
-
8 150W CO2 激光器
-
前后驱动相机
-
GPS 导航
-
激光雷达
-
有机
|
Small Robot Company 是一家在英国开发农业技术的初创公司,他们的机器人提供了一个轻便的田间监测和杂草管理解决方案。他们将机器人功能拆分成三个独立的实体:Tom,一个处理田间监测的移动传感器平台;Dick,一个配备强大电击的除草机器人;以及 Wilma,一套机器学习和分析工具,协调这一工作。第三个机器人 Harry 也在开发中。像本文中的其他机器人除草器一样,除草机器人 Dick 使用深度卷积网络来定位作物中的杂草。与其他机器人不同的是,它对杂草施加电流,燃烧不需要的植物的核心。
你会记住Ecorobotix的“亚拉”挂载喷雾器在拖车部分的描述。他们还开发了一个独立的机器人,Avo,用于完全自主操作。他们声称 Avo 与亚拉一样可以减少 95%的除草剂使用,并且节省 50%的成本。除了视觉系统,Avo 还使用 GPS、激光雷达和超声波进行导航和障碍物检测。与大型拖拉机相比,Avo 重 750 公斤,并承诺在操作过程中减少土壤压实。
一些开发了自动化农场服务的公司提供机器人拖拉机作为服务,而不是直接销售或租赁资本设备。采取这种方法的企业包括Farmwise,他们在加利福尼亚的部分地区试验了一台大型自动化除草拖拉机服务。
机器人温室、自动化搬运车和采摘机器人
另一个正在经历兴趣激增的“农业技术”类别是先进的温室自动化。这些温室使用包括视觉、土壤湿度、温度和湿度在内的多种感应方式,记录大量数据,并在需要采取行动时提醒操作员。追求这种自动化温室方法的公司包括Iron Ox和iUNU。其中,iUNU 似乎采取了一种更随意的方法,将自动化和分析添加到现有温室系统中,而 Iron Ox 的网站上展示了一台时尚的医疗白色机器,看起来就像是在医院或动画电影中出现的设备。
另一个应用领域是自动化搬运农产品和植物。Harvest Automation提供了 HV-100,这是一种中型机器人,对植物苗圃的作用类似于仓库机器人对分销中心的作用。Burro.ai提供了一种工作马自驾车,它与人力工人一起工作,将手工采摘的农产品从田间搬运到附近的加工中心。可以把同名的 Burro 机器人看作是一种重型手推车,具备全面的自驾能力,不同于某些提供该功能的汽车,这台机器确实可以在没有人驾驶的情况下运行。
承担自主运输采摘产品的负担是一个有用的功能,但实际的收获呢?Tevel和Abundant Robotics是两家早期公司,正在开发用于采摘水果的机器人。它们都首先关注果园的收获,但它们的方法大相径庭。Tevel 正在开发一群飞行无人机,通过果园的行间快速穿梭,使用前置夹具抓取水果,而 Abundant 则建造了一种看起来像巨大的机械毛毛虫的东西,它在行间滚动时吸取苹果。看起来它确实是一只非常饥饿的毛毛虫。然而,它们无疑有一个共同点,那就是使用深度卷积神经网络来驱动视觉系统,使其能够精准锁定目标。

自动化机器人采摘产品,来源
为什么计算机视觉农业创新?
大量早期阶段的初创公司可能让人相信,使用自主机器人进行除草和其他劳动密集型(但又精细)的农业任务是一个新想法。实际上,这更多的是一种缓慢的进展(随后是疯狂的冲刺),十多年前就有类似的项目在为农场制造自主机器人。早在 2007 年,“Hortibot”就因其发明者来自奥胡斯大学而获得了主流的,尽管不是特别有声望,新闻报道。Hortibot 是一种自动化拖拉机,主要用于针对性喷洒除草剂以控制杂草。
实际上,它的目标与本文描述的深度学习驱动的除草机器人非常相似。尽管 Hortibot 项目似乎已经没有太多进展(旧网站是奇怪的丹麦垃圾邮件混合体),但它至少是一个足够现实的前景,以至于在 2012 年《新科学家》的关于农业机器人的文章中再次被提及,这些主要是学术项目,不太可能推广到实际农业中。
像这样的机器人项目总是随着脆弱的实施与混乱的现实之间的碰撞而起伏不定,人们可能会被诱使认为这批热切的农场初创公司与过去的农业机器人项目没有什么不同。然而,正如凯文·邓拉普为《风险投资》撰写的那样,风险投资家在 2020 年对农业技术初创公司的投资比前一年多了 60%,几乎是 2010 年的 20 倍。时间会证明这些投资是否像它们投资的机器人一样聪明。
农场自动化的提升在过去二十年中形成了一种缓慢而稳步的趋势,而 SARS-CoV-2 疫情加速了这种技术的发展,就像它对许多其他趋势一样。与病毒相关的劳动和供应链中断可能会促使农民重新考虑那些可能曾经不确定、风险过高或其他原因使其不值得尝试的技术解决方案。
作者: Kevin Vu 负责管理 Exxact Corp 博客,并与许多撰写关于深度学习不同方面的才华横溢的作者合作。
原文。已获许可转载。
相关内容:
-
3 种数据采集、注释和增强工具
-
计算机视觉的开源数据集
-
用 5 行代码提取图像和视频中的对象
更多相关话题
计算机视觉初学者:第一部分
评论
作者 Jiwon Jeong,延世大学数据科学研究员和 DataCamp 项目讲师

计算机视觉是人工智能中最热门的话题之一。它在自动驾驶汽车、机器人以及各种照片修正应用程序中取得了巨大进展。物体检测的稳步进展每天都在进行。GANs 也是研究人员当前关注的焦点。视觉展示了技术的未来,我们甚至无法想象它的最终可能性。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 事务
那么,你想迈出计算机视觉的第一步并参与这场最新的潮流吗?欢迎,你来对地方了。通过这篇文章,我们将进行一系列关于图像处理和物体检测基础的教程。这是针对初学者的 OpenCV 教程的第一部分,系列的完整内容如下:
-
理解颜色模型和在图像上绘制图形
本系列的第一个故事将涉及安装 OpenCV,解释颜色模型和在图像上绘制图形。本教程的完整代码也可以在Github上找到。现在让我们开始吧。
OpenCV 简介
图像处理 是对图像执行某些操作以获得预期的处理效果。想想我们在开始新的数据分析时会做什么。我们进行数据预处理和特征工程。图像处理也是一样的。我们进行图像处理以操控图片,从中提取有用的信息。我们可以减少噪声,控制亮度和颜色对比度。要学习详细的图像处理基础知识,请访问 这个视频。
OpenCV 代表 开源计算机视觉 库,它由英特尔于 1999 年发明。它最初是用 C/C++ 编写的,因此你可能会看到更多的 C 语言教程而非 Python。不过,现在它在计算机视觉中也被广泛用于 Python。首先,我们需要为使用 OpenCV 设置一个合适的环境。安装过程如下所示,但你也可以在 这里找到详细说明。
pip install opencv-python==3.4.2
pip install opencv-contrib-python==3.3.1
安装完成后,尝试导入包以查看它是否正常工作。如果没有出现任何错误返回,那么你现在可以开始使用了!
import cv2
cv2.__version__
我们使用 OpenCV 的第一步是导入图像,可以按照如下步骤完成。
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline# Import the image
img = cv2.imread('burano.jpg')
plt.imshow(img)

你去过布拉诺吗?它是意大利最美丽的岛屿之一。如果你还没去过,下一次假期你一定要去看看。但如果你已经知道这个岛屿,你可能会注意到这张图片有些不同。它与我们通常看到的布拉诺的图片有些许差异。它应该比这张图更令人愉快!
这是因为 OpenCV 的默认颜色模式设置为 BGR 顺序,这与 Matplotlib 的顺序不同。因此,为了以 RGB 模式查看图像,我们需要将其从 BGR 转换为 RGB,方法如下。
# Convert the image into RGB
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img_rgb)

现在,这就是布拉诺!意大利的一个可爱岛屿!
不仅仅是 RGB
让我们多谈谈一下颜色模式。 颜色模型是一种使用原色创建全范围颜色的系统。这里有两种不同的颜色模型:加色模型和减色模型。加色模型使用光来表示计算机屏幕上的颜色,而减色模型使用墨水在纸上打印这些数字图像。前者的原色是红色、绿色和蓝色 (RGB),而后者的原色是青色、品红色、黄色和黑色 (CMYK)。我们在图像中看到的所有其他颜色都是通过组合或混合这些原色得到的。因此,当图像以 RGB 和 CMYK 模式表示时,可能会有些许不同。
 (来源)
(来源)
你可能对这两种模型已经比较熟悉。然而,在颜色模型的世界中,还有不止两种模型。其中,灰度、HSV 和 HLS 是你在计算机视觉中会经常看到的模型。
灰度图像很简单。它通过黑白的强度来表示图像和形态,这意味着它只有一个通道。要查看灰度图像,我们需要将颜色模式转换为灰色,就像我们之前处理 BGR 图像一样。
# Convert the image into gray scale
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
plt.imshow(img_gray, cmap = 'gray')

实际上,RGB 图像是通过叠加三个通道(R、G 和 B)组成的。因此,如果我们逐一展示每个通道,就可以理解颜色通道的结构。
# Plot the three channels of the image
fig, axs = plt.subplots(nrows = 1, ncols = 3, figsize = (20, 20))
for i in range(0, 3):
ax = axs[i]
ax.imshow(img_rgb[:, :, i], cmap = 'gray')
plt.show()

看一下上面的图像。这三张图展示了每个通道的组成。在 R 通道的图片中,高饱和度的红色部分看起来是白色的。这是为什么呢?这是因为红色部分的值接近 255。在灰度模式中,值越高,颜色越白。你也可以用 G 或 B 通道来检查并比较某些部分的差异。

HSV 和 HLS 采用了稍微不同的视角。如上图所示,它们有三维表示,并且更类似于人类的感知方式。HSV 代表色调、饱和度和明度。HSL 代表色调、饱和度和亮度。HSV 的中心轴是颜色的明度,而 HSL 的中心轴是光的量。沿着从中心轴的角度,有色调,即实际颜色。而从中心轴的距离属于饱和度。颜色模式的转换可以按如下方式进行。
# Transform the image into HSV and HLS models
img_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
img_hls = cv2.cvtColor(img, cv2.COLOR_BGR2HLS)# Plot the converted images
fig, (ax1, ax2) = plt.subplots(nrows = 1, ncols = 2, figsize = (20, 20))
ax1.imshow(img_hsv)
ax2.imshow(img_hls)
plt.show()

但为什么我们需要转换颜色?这些转换有什么用?一个可以回答这个问题的例子是车道检测。请看下面的图片。查看在不同颜色模式下车道是如何被检测到的。在计算机视觉任务中,我们进行多次颜色模式转换和掩模操作。如果你想了解更多关于图像处理在车道检测任务中的应用,请查看 这篇文章 ,作者是 nachiket tanksale。

现在我相信你明白了这个概念。图像处理就是‘数据预处理’。它是减少噪声和提取有用的模式,以便使分类和检测任务变得更加容易。因此,包括我们接下来要讨论的技术在内的所有这些技术,都是为了帮助模型更容易地检测模式。
在图像上绘图
让我们在图像上添加一些图形。现在,我们要去巴黎。你听说过爱的墙吗?那是一面用各种国际语言写着“我爱你”字样的墙。我们要做的是找到我们语言中的这些字词,并用矩形标记它们。由于我来自韩国,所以我会查找韩语中的“我爱你”。首先,我会复制原始图像,然后用cv2.rectangle()绘制一个矩形。我们需要给出左上角和右下角的坐标值。
# Copy the image
img_copy = img.copy()# Draw a rectangle
cv2.rectangle(img_copy, pt1 = (800, 470), pt2 = (980, 530),
color = (255, 0, 0), thickness = 5)
plt.imshow(img_copy)
很好!我觉得我找对了位置。我们再试一次。我可以从图像中看到一个韩语单词,所以这次我会画一个圆圈。使用cv2.circle(),我们需要指定圆心的位置和半径的长度。
# Draw a circle
cv2.circle(img_copy, center = (950, 50), radius = 50,
color = (0, 0, 255), thickness = 5)
plt.imshow(img_copy)

我们也可以在图像上添加文本数据。这次我们为何不写下这面墙的名字呢?使用cv2.putText(),我们可以指定文本的位置、字体样式和大小。
# Add text
cv2.putText(img_copy, text = "the Wall of Love",
org = (250, 250),
fontFace = cv2.FONT_HERSHEY_DUPLEX,
fontScale = 2,
color = (0, 255, 0),
thickness = 2,
lineType = cv2.LINE_AA)
plt.imshow(img_copy)

这真是一面“可爱的”墙,不是吗?试试自己找找看你语言中的“我爱你”吧! ????
超越图像
现在我们已经去了意大利和法国。你想去哪里呢?为什么不放一张地图并标记这些地方呢?我们将创建一个窗口,并通过直接在窗口上点击来绘制图形,而不是指定点。我们先试试绘制一个圆圈。我们首先创建一个函数,该函数将根据鼠标的位置和点击数据绘制一个圆圈。
# Step 1\. Define callback function
def draw_circle(event, x, y, flags, param):
if event == cv2.EVENT_LBUTTONDOWN:
cv2.circle(img, center = (x, y), radius = 5,
color = (87, 184, 237), thickness = -1)
elif event == cv2.EVENT_RBUTTONDOWN:
cv2.circle(img, center = (x, y), radius = 10,
color = (87, 184, 237), thickness = 1)
使用cv2.EVENT_LBUTTONDOWN或cv2.EVENT_RBUTTONDOWN,我们可以获取按下鼠标按钮时的位置数据。鼠标的位置将是(x, y),我们将绘制一个以该点为中心的圆圈。
# Step 2\. Call the window
img = cv2.imread('map.png')cv2.namedWindow(winname = 'my_drawing')
cv2.setMouseCallback('my_drawing', draw_circle)
我们将设置一张地图作为窗口的背景,并将窗口命名为my_drawing。窗口的名称可以是任何名称,但它应该保持一致,因为这就像是窗口的 ID。使用cv2.setMouseCallback(),我们将窗口和在第 1 步中创建的函数draw_circle连接起来。
# Step 3\. Execution
while True:
cv2.imshow('my_drawing',img)
if cv2.waitKey(10) & 0xFF == 27:
break
cv2.destroyAllWindows()
现在我们使用 while 循环来执行窗口。除非你在做无限循环,否则不要忘记设置中断。if 语句的条件是当我们按下键盘上的 ESC 时,关闭窗口。将这个文件保存并在你的终端中导入。如果你使用的是 jupyter lab,将代码放在一个单元格中并执行。现在,告诉我!你想去哪里?

让我们尝试绘制一个矩形。由于矩形需要两个点作为pt1和pt2在cv2.rectangle()中,我们需要额外的步骤将第一个点击点设置为pt1,最后一个点设置为pt2。我们将使用cv2.EVENT_MOUSEMOVE和cv2.EVENT_LBUTTONUP来检测鼠标的移动。
我们首先将drawing = False定义为默认值。当按下左键时,drawing变为真,我们将第一个位置设为pt1。如果绘制开启,它将当前点作为pt2并在移动鼠标时继续绘制矩形。就像重叠图形一样。当左键释放时,drawing变为假,并将鼠标的最后位置作为pt2的最终点。
# Initialization
drawing = False
ix = -1
iy = -1# create a drawing function
def draw_rectangle(event, x, y, flags, params):
global ix, iy, drawing
if event == cv2.EVENT_LBUTTONDOWN:
drawing = True
ix, iy = x, y
elif event == cv2.EVENT_MOUSEMOVE:
if drawing == True:
cv2.rectangle(img, pt1=(ix, iy), pt2=(x, y),
color = (87, 184, 237), thickness = -1)
elif event == cv2.EVENT_LBUTTONUP:
drawing = False
cv2.rectangle(img, pt1=(ix, iy), pt2=(x, y),
color = (87, 184, 237), thickness = -1)
在步骤 1 中,将draw_circle函数替换为draw_rectangle。请不要忘记在回调函数cv2.setMouseCallback()中也进行更改。因此,整个代码脚本如下。保存此脚本文件并在终端或 Jupyter Notebook 中运行。
接下来是什么?
你喜欢第一次使用 OpenCV 的体验吗?你还可以尝试其他函数,例如绘制直线或多边形。请随意查看文档,文档链接在这里。下次,我们将讨论更高级的技术,例如合并两张不同的图像、图像轮廓和对象检测。
有什么错误你希望纠正吗?请与我们分享你的见解。我随时乐于交谈,请随时在下面留言,分享你的想法。我还在LinkedIn上分享有趣和有用的资源,欢迎关注或联系我。我下次会带来另一个有趣的故事!
简介:Jiwon Jeong,是一名数据科学家,目前正在攻读工业工程硕士学位,并担任 DataCamp 的项目讲师。
原文。已获授权转载。
相关内容:
-
端到端机器学习:从图像制作视频
-
深度学习的预处理:从协方差矩阵到图像白化
-
使用 Numpy 和 OpenCV 进行基本图像数据分析 – 第一部分
更多相关话题
构建计算机视觉模型:方法和数据集
原文:
www.kdnuggets.com/2019/05/computer-vision-model-approaches-datasets.html
评论
由 Javier Couto,Tryolabs。
计算机视觉是机器学习中最热门的子领域之一,鉴于其广泛的应用和巨大的潜力。其目标是复制人类视觉的强大能力。但这如何通过算法实现呢?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
让我们深入了解最重要的数据集和方法。
现有数据集
计算机视觉算法并非魔法。它们需要数据才能工作,它们的效果仅能与输入的数据质量相匹配。以下是根据任务收集正确数据的不同来源:
其中一个最大且最著名的数据集是ImageNet,这是一个拥有 1400 万张图像的现成数据集,手动标注了使用WordNet 概念。在全球数据集中,100 万张图像包含边界框注释。

带有边界框的 ImageNet 图像。图片来源

带有对象属性注释的 ImageNet 图像。图片来源
另一个著名的数据集是Microsoft Common Objects in Context (COCO),包含 328,000 张图像,包括 91 种对象类型,这些类型对于 4 岁的孩子来说很容易识别,总共有 250 万个标注实例。

来自 COCO 数据集的标注图像示例。图片来源
尽管可用的数据集不是很多,但有几个适合不同任务的,例如 CelebFaces 属性数据集(CelebA,包含超过 20 万张名人图像的面部属性数据集);室内场景识别 数据集(15,620 张室内场景图像);和 植物图像分析 数据集(来自 11 个不同物种的 100 万张植物图像)。
一般策略
深度学习方法和技术 深刻地改变了计算机视觉以及人工智能的其他领域,以至于对于许多任务,其使用被认为是标准的。特别是,卷积神经网络(CNN)利用传统计算机视觉技术取得了超越现有技术水平的成果。
这四个步骤概述了使用 CNN 构建计算机视觉模型的一般方法:
-
创建一个由标注图像组成的数据集,或者使用现有的数据集。标注可以是图像类别(用于分类问题);一对对的边界框和类别(用于物体检测问题);或每个图像中感兴趣对象的逐像素分割(用于实例分割问题)。
-
从每张图像中提取与当前任务相关的特征。这是建模问题的关键点。例如,用于识别面孔的特征,与基于面部标准的特征显然不同于用于识别旅游景点或人体器官的特征。
-
基于提取的特征训练深度学习模型。训练意味着向机器学习模型输入许多图像,模型将根据这些特征学习如何解决手头的任务。
-
使用未在训练阶段使用的图像评估模型。通过这样做,可以测试训练模型的准确性。
这个策略非常基础,但能够很好地达到目的。这样的做法,被称为 监督式机器学习,需要一个涵盖模型需要学习的现象的数据集。
训练物体检测模型
维奥拉和琼斯方法
有许多方法可以解决物体检测挑战。多年来,流行的方法是保罗·维奥拉和迈克尔·琼斯在论文中提出的 鲁棒实时物体检测。
尽管可以训练以检测多种类别的对象,但这一方法最初是以面部检测为目标的。它速度快且简单,已被实现到傻瓜相机中,允许在实时面部检测中使用极少的处理能力。
该方法的核心特征是使用基于Haar 特征的大量二分类器进行训练。这些特征表示边缘和线条,在扫描图像时计算非常简单。

Haar 特征。图片来源
尽管相当基础,但在面部识别的具体情况下,这些特征可以捕捉到如鼻子、嘴巴或眉毛之间的距离等重要元素。这是一种监督方法,需要许多正例和负例的目标对象样本。
检测蒙娜丽莎的面部
基于 CNN 的方法
深度学习在机器学习领域带来了真正的变革,尤其是在计算机视觉领域,基于深度学习的方法现在在许多常见任务中处于最前沿。
在为实现目标检测而提出的不同深度学习方法中,R-CNN(具有 CNN 特征的区域)特别容易理解。该工作的作者提出了一个三阶段的过程:
-
使用区域提案方法提取可能的对象。
-
使用 CNN 识别每个区域的特征。
-
使用支持向量机(SVMs)对每个区域进行分类。

R-CNN 架构。图片来源
原作中选择的区域提案方法是选择性搜索,尽管 R-CNN 算法对于采用的具体区域提案方法没有偏好。第 3 步非常重要,因为它减少了对象候选数量,使得该方法计算开销较小。
这里提取的特征不如之前提到的 Haar 特征直观。总而言之,使用 CNN 从每个区域提案中提取一个 4096 维的特征向量。由于 CNN 的特性,输入必须始终具有相同的维度。这通常是 CNN 的一个弱点,各种方法以不同的方式解决这个问题。就 R-CNN 方法而言,训练好的 CNN 架构需要固定尺寸的 227 × 227 像素的输入。由于提议的区域大小与此不同,作者的方法简单地将图像扭曲以适应所需的尺寸。

与 CNN 所需输入维度匹配的扭曲图像示例。图片来源
尽管取得了优异的成果,但训练过程中遇到了一些障碍,最终该方法被其他方法超越。文章中详细回顾了一些这些内容,深度学习目标检测:终极指南。
本文摘自计算机视觉入门指南,作者为 Tryolabs,最初发布于这里。
简介:Javier Couto 是 Tryolabs 的自由职业机器学习顾问和数据科学家,专注于应用机器学习解决商业问题。
资源:
相关:
更多相关主题
计算机视觉食谱:最佳实践和示例
原文:
www.kdnuggets.com/2020/09/computer-vision-recipes-best-practices-examples.html
comments
最近我们聚焦了来自微软的类似资源,自然语言处理最佳实践与示例 仓库,今天我们为您带来了它的计算机视觉对应物。

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能。
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 需求。
计算机视觉最佳实践与示例 GitHub 仓库描述如下:
该仓库的目标是构建一个全面的工具和示例集,利用计算机视觉算法、神经网络架构以及操作化这些系统的最新进展。我们不从零开始创建实现,而是借鉴现有的最先进库,围绕加载图像数据、优化和评估模型及扩展到云端构建附加功能。此外,经过多年的工作经验,我们旨在回答常见问题,指出常见陷阱,并展示如何利用云进行训练和部署。
该仓库包含多个 Jupyter 笔记本,旨在突出“全面的工具和示例集”。仓库的 readme 进一步强调了其快速迭代的实际解决方案实施方法:
我们希望这些示例和工具能够显著缩短“上市时间”,通过从定义业务问题到解决方案开发的经验简化幅度。此外,示例笔记本将作为指南,展示在各种语言中工具的最佳实践和使用。
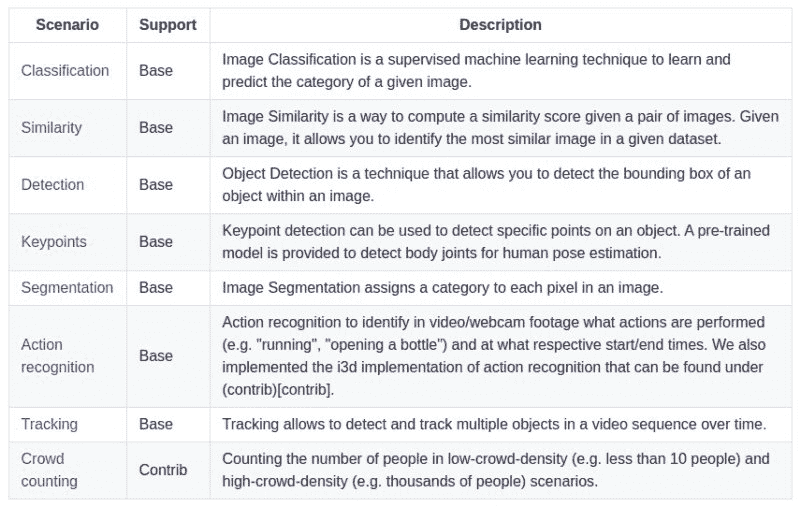
这些笔记本及其附带的实用函数被组织成常见的计算机视觉场景,如分类、分割和人群计数。点击这些场景中的任何一个都会带您到相应的食谱和最佳实践文件夹,下面展示了一个示例:

笔记本还依赖于utils_cv模块中的脚本“以简化开发和评估计算机视觉系统时使用的常见任务。” 请务必查看微软研究开发的实用工具,这些工具旨在节省时间并加快一些与计算机视觉相关的繁琐任务。
我不是计算机视觉专家,也没有像许多机器学习领域的其他人那样花费大量时间研究这个领域。因此,我发现像这样的资源非常宝贵。无论你是否处于类似的情况,还是作为全职计算机视觉工程师希望找到一个有用的代码集合来获取灵感和想法,我建议你查看微软的这个以最佳实践为导向的代码库。
相关:
-
自然语言处理食谱:最佳实践和示例
-
加速计算机视觉:亚马逊的免费课程
-
10 个免费的顶级机器学习课程
更多相关话题
-
计算机视觉的 5 个应用
-
KDnuggets 新闻 2022 年 3 月 9 日:在 5 分钟内构建一个机器学习 Web 应用
创建你自己的计算机视觉沙箱
评论
由 Waun Broderick,首席技术官,Gyroscopic 联合创始人

图片由 Lorenzo Herrera 提供,来源于 Unsplash
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
难度级别:初级( ★ ☆ ☆ ☆ ☆)
推荐前提:
-
熟悉 Python
-
CNN 的基础知识
开发成果:
-
一个网络爬虫
-
自动化数据增强工具
-
智能 CNN 吸收管道
-
CNN 模型训练师
我们将一起创建一个 CNN 沙箱,它可以收集图像、增强数据,并轻松改变架构,以便为各种项目快速而灵活地调整。
这个过程是为那些 CNN 构建经验很少的人编写的,因此会抽象掉高级细节,以便能够对一些基本组件有一个宏观的了解。同时,添加了一些非必要的步骤,以便可视化输出并提供过程的透明性。
这些步骤中的每一个都被编写为可以直接过渡到创建完全由你选择的模型,包含任何数量的分类;例如狗与猫、国家旗帜、热狗与非热狗。然而,准确性将大大取决于类别的数量和它们之间的相似性。
永久链接 关闭 GitHub 是一个有超过 4000 万开发者共同协作的地方,用于托管和审查代码,管理…
数据收集
在构建 CNN 的初期,你可能还没有数据集来开始工作,这没关系!在开发过程中,有一个广泛接受的原则是,如果是手动且单调的过程,我们通常可以将任务自动化!所以,代替不断滚动浏览图片,我们将通过构建一个子程序来开始我们的旅程。
不过请放心,我们并没有在原本不存在的地方创建嵌套问题,而是确保我们能够创建出可以在本次演练中以及未来项目中使用的小段落。

迷茫的男子在做心理数学
要开始这个过程,我们需要一个 Microsoft Azure API 密钥(应用程序编程接口密钥),它允许我们利用他们的服务能力,使这个过程更容易。通过访问Bing 图像搜索页面,你可以注册一个免费试用版,你将获得一个 API 密钥,允许你抓取图像。
下载以下 Python 脚本;
WaunBroderick/MSB_ImageScraper
你现在无法执行该操作。你在另一个标签页或窗口中登录。你在另一个标签页或…
打开你电脑上的bing_image_scraper.py文件,并用你的 API 密钥、所需的限制进行修改,然后保存。
# for results (maximum of 50 per request)
API_KEY = "{{API KEY}}"
MAX_RESULTS = 250
GROUP_SIZE = 50
在命令行/终端中调用文件,并传递输出目录和搜索词的参数。
python ./bing_image_scraper.py --query "{{TERM}}" --output {{DIR}}
重复这个过程,找到所有你希望为 CNN 模型准备的必要图像类别。接下来的代码将依赖于每个文件夹的名称为一个类别,并且所有图像都放在各自的文件夹中。
建议的照片目录结构
建议你尽力保持每个类别中的照片数量大致相同,以避免模型偏向某一个类别。
最好浏览一下抓取到的图像,并删除那些不符合搜索标准的图像。由于其缺乏严格的规范,网络图像抓取工具常常会获取与搜索主题不直接相关的图像,如果不加以监控,最终会变成‘垃圾进,垃圾出’。
男子在用吸尘器处理火焰
数据增强
你现在应该有一系列包含各自图像类别的目录。我们必须确保在构建模型时,数据集足够大,以便为模型提供足够的类别信息。数据样本的大小受许多因素的影响,如特征数量、分类器、图像特性等。然而,为了本教程的目的,我们将按你选择的倍数扩展数据集,而不深入讨论这个问题。
数据增强是可以在计算机视觉管道中使用的一步,它可以为否则同质的数据集添加一些噪声或变异,如:反射、旋转、模糊或扭曲。这一步不仅可以增加你的数据集,还能让你的 CNN 有机会从更多的数据变异中学习。
对于这一步,我们将使用 Keras 和 Tensorflow 库(请参阅 GitHub 页面以获取所有库的导入信息)。开始时创建一个操作列表并分配目录,我们将指示在完整列表上执行的操作可以在 这里 找到。
#A sereis of operations that were selected to apply to images to create a greater amount of image variation
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')#root directory for data augmentation
rootdir = '/xxx/data/'
然后,我们编写如何期望我们的程序遍历我们创建的文件结构的说明。
#Move through the designated root directory and traverse through the individual files inside
for subdir, dirs, files in os.walk(rootdir):
print("working in " +subdir)
#Iterate over only the compatible image files
for file in files:
if file.endswith(".jpg") or file.endswith(".jpeg") or file.endswith(".png"):
#Loading the image
img = load_img(subdir + "/" + file)
#The Numpy array responsible for shape adhearance
x = img_to_array(img)
x = x.reshape((1,) + x.shape) # the .flow() command below generates batches of randomly transformed images
# and saves the results to the `preview/` directory
i = 0
for batch in datagen.flow(x, batch_size=1,
save_to_dir= subdir + "/", save_prefix='DA', save_format='jpg'):
i += 1
#Set to desired iterations
if i > 3:
#Setting bound to break loop so to avoid indefinite run
break
运行脚本后,你的文件夹现在应该包含原始抓取的图像,以及具有你选择的不同变换的新图像。

相同的蜘蛛侠互相指向对方
我们可以使用此目录文件夹结构和功能来将类别拆分到这些文件夹中,并轻松地将相应的图像链接到这些标签。
#The number of class labels == total number of categories which == length of the folders in .dir
data=load_files(dataDir, load_content= False)
total_categories=len(data.category_names)# input image dimensions
img_rows, img_cols = 64, 64
dataDir= '{{INPUT YOUR TOP LEVEL IMAGE DIR}}'#The function responsible for connecting the image data with the categories created
def build_data(data):
X = []
y = []
#Operations to assign the categories to data structures
encoder = LabelBinarizer()
encoded_dict=dict()
hotcoded_label = encoder.fit_transform(data.category_names)
#Matching the category target names to the labels
for i in range(len(data.category_names)):
encoded_dict[data.category_names[i]]=hotcoded_label[i]
for country in os.listdir(dataDir):
label=encoded_dict[country]
#labeling the images
for each_flag in os.listdir(dataDir+'/'+country):
actual_path = os.path.join(dataDir,country,each_flag)
img_data = cv2.imread(actual_path)
img_data = cv2.resize(img_data, (img_rows, img_cols))
X.append(np.array(img_data))
y.append(label)
#Creating a test and training set split with space for declaed variables
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=36)
X_train = np.asarray(X_train)
X_test = np.asarray(X_test)
y_train = np.asarray(y_train)
y_test = np.asarray(y_test)#returns the training and testing set
return [X_train, X_test, y_train, y_test]
模型构建
然后,我们在其顺序池化和卷积层中创建 CNN 的架构。变量的大小过滤器、层结构、正则化器 或 核心层 也可以根据你的项目要求进行添加和修改。本项目使用了修改版的 VGG-16 网络架构作为基础,但可以更改为你选择或创建的任何架构。
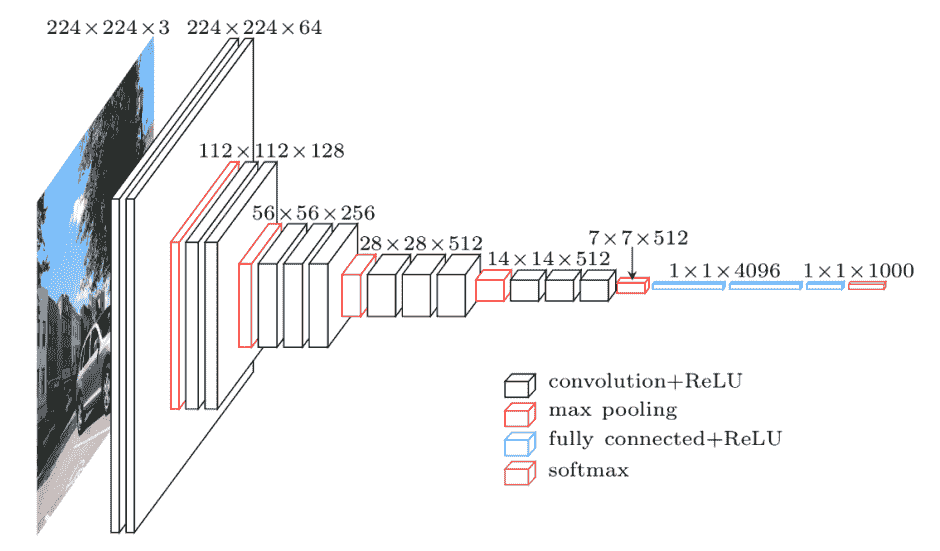
VGG-16 架构
#epochs = number of passes through entire training set
epochs = 100def create_model(input_shape,classes):
#Takes the specifications of the image inputted
img_input = Input(shape=input_shape)
#The following is an architecture structuring
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv1')(img_input)x = MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool')(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv1')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv1')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool')(x)
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block4_conv1')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool')(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block5_conv1')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block5_pool')(x)
x = Flatten(name='flatten')(x)
x = Dense(512, activation='relu', name='fc1')(x)
x = Dropout(0.2)(x)
x = Dense(256, activation='relu', name='fc2')(x)
x = Dropout(0.2)(x)
x = Dense(classes, activation='softmax', name='final_output')(x)model = Model(img_input, x, name='flag')
return model
然后我们将到目前为止构建的部分组合在一起,并将测试和训练集数据输入到 CNN 架构中。在这个示例中,使用了 Adams 自适应学习率算法 和 分类交叉熵 损失函数。在你自己的项目中,你应该考虑每一个选择。
def train_model(x_train, x_test, y_train, y_test):
input_shape=(img_rows,img_cols,3)
model=create_model(input_shape,total_countries)
adams=optimizers.Adam(lr=1e-4)
model.compile(loss=’categorical_crossentropy’,
optimizer= adams,
metrics=[‘accuracy’])
model.fit(x = x_train, y = y_train, epochs=epochs)
score = model.evaluate(x_test, y_test, verbose=1)
print(‘Test loss:’, score[0])
print(‘Test accuracy:’, score[1])
model.save(‘flagFinder.model’)
return model
恭喜!你已成功创建了第一个 CNN 模型和数据收集管道!
女人胜利地欢呼
以下是将构建的模型应用于新一组图像以测试其准确性的示例。还增加了一个额外的步骤,将结果打印到文本文件中以便于查看。
def flag_identify(positiveDir): #An array to keep the list of countries built from the data ingestion step
countries = [] #iterate through the ingestion stage names and append them to a list for ease of labeling
for i in range(len(datas.target_names)):
i += 1
countries.append(datas.target_names[i-1]) #Another data preperation step for image ingestion for prediction identification
def prepare(filepath):
IMG_SIZE = 64
img_array = cv2.imread(filepath)
new_array = cv2.resize(img_array, (IMG_SIZE, IMG_SIZE))
return new_array.reshape(-1, IMG_SIZE, IMG_SIZE, 3) #Load in the previously built model
model = tf.keras.models.load_model("flagFinder.model") #Traverses through the given directory containing test images
for filename in os.listdir(positiveDir):
#Accpets various photo formats that were processed previous
if filename.endswith(".jpg") or filename.endswith(".jpeg") or filename.endswith(".png"):
prediction = model.predict([prepare(positiveDir + filename)])
topCountry = int(np.argmax(prediction, axis=1))
secondCountry = int(np.argmax(prediction, axis=1)-1)
#Writes predictions to a set directory for ease of view
with open("/xxx/flags.txt", "a") as myfile:
#Generic sentence for output both the filename and the TOP PREDICTION (can be adjusted for other predictions)
myfile.write("A flag was found in photo: " + filename + ", It is most likely to from the Nation: " + countries[topCountry] +", or ," + countries[secondCountry] +"\n" )
现在你可以依次调用这些程序片段来促进管道的不同部分。在相关的 GitHub 示例中,还有一个额外的目标检测段,位于数据增强和 CNN 模型构建之间,以展示系统如何以模块化方式构建。
def build_flag_identifier():
x_train, x_test, y_train, y_test = build_data(datas)
train_model(x_train, x_test, y_train, y_test)def main():
build_flag_identifier()
flag_identify({{DIR}})if __name__ == "__main__":
main()
如果你将这个代码框架作为未来项目的起点,确保你研究整个过程中的技术决策变异性。尽管每一步都已简化,但每个算法和架构的权衡和决策将大大影响你的准确性和整体项目成功。CNN 不是一刀切的,应该根据每个项目和数据集的规格进行构建。
快乐编程!
简介:Waun Broderick 是 Gyroscopic 的首席技术官兼联合创始人。他是一位充满热情的应用程序开发者、海军战争官员和社区建设者。
原创。经许可转载。
相关:
-
如何将 RGB 图像转换为灰度图像
-
如何将图片转换为数字
-
谷歌开源 MobileNetV3:改进移动计算机视觉模型的新思路
更多相关内容
使用 Dask 和 PyTorch 进行大规模计算机视觉
原文:
www.kdnuggets.com/2020/11/computer-vision-scale-dask-pytorch.html
评论
由 Stephanie Kirmer,Saturn Cloud 的高级数据科学家提供
将深度学习策略应用于计算机视觉问题为数据科学家打开了无限可能。然而,要在大规模上使用这些技术创造商业价值,需要大量的计算资源——而这正是 Saturn Cloud 旨在解决的挑战!
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 在 IT 领域支持你的组织
在本教程中,你将看到使用流行的 Resnet50 深度学习模型在 Saturn Cloud 上的 NVIDIA GPU 集群进行图像分类推断的步骤。利用 Saturn Cloud 提供的资源,我们可以将任务运行速度提高 40 倍,相比非并行化方法更快!

今天我们将对狗的图像进行分类!
你将在这里学到的内容:
-
如何在 Saturn Cloud 上设置和管理 GPU 集群以进行深度学习推断任务
-
如何在 GPU 集群上使用 Pytorch 运行推断任务
-
如何使用批处理加速在 GPU 集群上进行 Pytorch 推断任务
设置
首先,我们需要确保我们的图像数据集可用,并且我们的 GPU 集群正在运行。
在我们的案例中,我们将数据存储在 S3 上,并使用s3fs库进行处理,如下所示。
如果你想使用相同的数据集,它是斯坦福狗数据集,可以在这里获取:vision.stanford.edu/aditya86/ImageNetDogs/
要设置我们的 Saturn GPU 集群,过程非常简单。
import dask_saturn
from dask_saturn import SaturnCluster
cluster = SaturnCluster(n_workers=4, scheduler_size='g4dnxlarge', worker_size='g4dn8xlarge')
client = Client(cluster)
client
[2020-10-15 18:52:56] INFO – dask-saturn | Cluster is ready
我们没有明确说明,但我们在集群节点上使用 32 个线程,总共 128 个线程。
提示:个别用户可能需要调整线程数量,如果文件非常大,可以减少线程数量——同时运行大量任务的线程可能会需要比你的工作节点一次性可用的内存更多。
这一步可能需要一些时间,因为我们请求的所有 AWS 实例都需要启动。调用client,它将监控启动过程,并在一切准备好时通知你!
GPU 能力
目前,我们可以确认我们的集群具有 GPU 能力,并确保我们已经正确设置了一切。
首先,检查 Jupyter 实例是否具有 GPU 能力。
torch.cuda.is_available()
True
太棒了——现在让我们检查一下我们的四个工作节点。
client.run(lambda: torch.cuda.is_available())
{‘tcp://10.0.24.217:45281’: True,
‘tcp://10.0.28.232:36099’: True,
‘tcp://10.0.3.136:40143’: True,
‘tcp://10.0.3.239:40585’: True}
在这里,我们将设置“设备”为始终使用 CUDA,以便我们可以使用这些 GPU。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
注意:如果你需要帮助来了解如何运行单张图像分类,我们的 GitHub 上有一个 扩展代码笔记本,可以为你提供这些指令以及剩下的内容。
推断
现在,我们准备开始进行一些分类!我们将使用一些自定义编写的函数来高效完成这项任务,并确保我们的工作能够充分利用 GPU 集群的并行化优势。
预处理
单图像处理
@dask.delayed
def preprocess(path, fs=__builtins__):
'''Ingest images directly from S3, apply transformations,
and extract the ground truth and image identifier. Accepts
a filepath. '''
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(250),
transforms.ToTensor()])
with fs.open(path, 'rb') as f:
img = Image.open(f).convert("RGB")
nvis = transform(img)
truth = re.search('dogs/Images/n[0-9]+-([^/]+)/n[0-9]+_[0-9]+.jpg', path).group(1)
name = re.search('dogs/Images/n[0-9]+-[a-zA-Z-_]+/(n[0-9]+_[0-9]+).jpg', path).group(1)
return [name, nvis, truth]
这个函数允许我们处理一张图像,但当然,我们有很多图像需要处理!我们将使用一些列表推导策略来创建我们的批次,并为推断做好准备。
首先,我们将从 S3 文件路径获取的图像列表分解成定义批次的块。
3fpath = 's3://dask-datasets/dogs/Images/*/*.jpg'
batch_breaks = [list(batch) for batch in toolz.partition_all(60, s3.glob(s3fpath))]
然后我们将每个文件处理成嵌套列表。接着我们会稍微重新格式化这个列表设置,这样我们就准备好了!
image_batches = [[preprocess(x, fs=s3) for x in y] for y in batch_breaks]
请注意,我们在所有这些操作中都使用了 Dask 的delayed装饰器——我们不希望它现在就实际运行,而是等待我们在 GPU 集群上并行处理时再运行!
格式化批次
这一步只是为了确保图像批次按模型所期望的方式组织好。
@dask.delayed
def reformat(batch):
flat_list = [item for item in batch]
tensors = [x[1] for x in flat_list]
names = [x[0] for x in flat_list]
labels = [x[2] for x in flat_list]
return [names, tensors, labels]
image_batches = [reformat(result) for result in image_batches]
运行模型
现在我们准备进行推断任务了!这将有几个步骤,所有这些步骤都包含在下面描述的函数中,但我们会逐一讲解,以确保一切清楚。
在这一点上,我们的工作单位是一次 60 张图像的批次,我们在上面的部分中创建了这些批次。它们都被整齐地安排在列表中,以便我们可以有效地处理它们。
我们需要对列表做的一件事是“堆叠”张量。我们本可以在处理早些时候做这件事,但由于我们在预处理中使用了 Dask 的delayed装饰器,我们的函数实际上直到处理后期才知道它们正在接收张量。因此,我们也将“堆叠”操作延迟到预处理之后的这个函数中。
@dask.delayed
def run_batch_to_s3(iteritem):
''' Accepts iterable result of preprocessing,
generates inferences and evaluates. '''
with s3.open('s3://dask-datasets/dogs/imagenet1000_clsidx_to_labels.txt') as f:
classes = [line.strip() for line in f.readlines()]
names, images, truelabels = iteritem
images = torch.stack(images)
...
现在我们已经将张量堆叠起来,以便可以将批次传递给模型。我们将使用相当简单的语法来检索我们的模型:
...
resnet = models.resnet50(pretrained=True)
resnet = resnet.to(device)
resnet.eval()
...
方便的是,我们加载了库 torchvision,其中包含了几个有用的预训练模型和数据集。这就是我们从中获取 Resnet50 的地方。调用 .to(device) 方法允许我们将模型对象传递给我们的工作者,使他们能够进行推理而无需回到客户端。
现在我们准备运行推理了!它在同一个函数中,以这种方式呈现:
...
images = images.to(device)
pred_batch = resnet(images)
...
我们将图像堆栈(即我们正在处理的批次)传递给工作者,然后运行推理,返回该批次的预测结果。
结果评估
然而,我们目前的预测和实际情况并不真正易读或可比,因此我们将使用接下来的函数来修正它们,得到可解释的结果。
def evaluate_pred_batch(batch, gtruth, classes):
''' Accepts batch of images, returns human readable predictions. '''
_, indices = torch.sort(batch, descending=True)
percentage = torch.nn.functional.softmax(batch, dim=1)[0] * 100
preds = []
labslist = []
for i in range(len(batch)):
pred = [(classes[idx], percentage[idx].item()) for idx in indices[i][:1]]
preds.append(pred)
labs = gtruth[i]
labslist.append(labs)
return(preds, labslist)
这将我们的模型结果和一些其他元素整合在一起,返回易读的预测和模型分配的概率。
preds, labslist = evaluate_pred_batch(pred_batch, truelabels, classes)
从这里开始,我们就快完成了!我们希望以整洁、易读的方式将结果传回 S3,因此其余的函数处理了这个过程。它将遍历每张图片,因为这些功能不支持批量处理。is_match 是我们自定义的函数之一,你可以在下面查看。
...
for j in range(0, len(images)):
predicted = preds[j]
groundtruth = labslist[j]
name = names[j]
match = is_match(groundtruth, predicted)
outcome = {'name': name, 'ground_truth': groundtruth, 'prediction': predicted, 'evaluation': match}
# Write each result to S3 directly
with s3.open(f"s3://dask-datasets/dogs/preds/{name}.pkl", "wb") as f:
pickle.dump(outcome, f)
...
将所有内容整合在一起
现在,我们不会手动拼接所有这些函数,而是将它们组装成一个单一的延迟函数,完成我们的工作。重要的是,我们可以将其映射到集群中所有的图像批次上!
def evaluate_pred_batch(batch, gtruth, classes):
''' Accepts batch of images, returns human readable predictions. '''
_, indices = torch.sort(batch, descending=True)
percentage = torch.nn.functional.softmax(batch, dim=1)[0] * 100
preds = []
labslist = []
for i in range(len(batch)):
pred = [(classes[idx], percentage[idx].item()) for idx in indices[i][:1]]
preds.append(pred)
labs = gtruth[i]
labslist.append(labs)
return(preds, labslist)
def is_match(la, ev):
''' Evaluate human readable prediction against ground truth.
(Used in both methods)'''
if re.search(la.replace('_', ' '), str(ev).replace('_', ' ')):
match = True
else:
match = False
return(match)
@dask.delayed
def run_batch_to_s3(iteritem):
''' Accepts iterable result of preprocessing,
generates inferences and evaluates. '''
with s3.open('s3://dask-datasets/dogs/imagenet1000_clsidx_to_labels.txt') as f:
classes = [line.strip() for line in f.readlines()]
names, images, truelabels = iteritem
images = torch.stack(images)
with torch.no_grad():
# Set up model
resnet = models.resnet50(pretrained=True)
resnet = resnet.to(device)
resnet.eval()
# run model on batch
images = images.to(device)
pred_batch = resnet(images)
#Evaluate batch
preds, labslist = evaluate_pred_batch(pred_batch, truelabels, classes)
#Organize prediction results
for j in range(0, len(images)):
predicted = preds[j]
groundtruth = labslist[j]
name = names[j]
match = is_match(groundtruth, predicted)
outcome = {'name': name, 'ground_truth': groundtruth, 'prediction': predicted, 'evaluation': match}
# Write each result to S3 directly
with s3.open(f"s3://dask-datasets/dogs/preds/{name}.pkl", "wb") as f:
pickle.dump(outcome, f)
return(names)
在集群上
我们已经完成了所有艰苦的工作,可以让我们的函数从这里开始。我们将使用 .map 方法高效地分配任务。
futures = client.map(run_batch_to_s3, image_batches)
futures_gathered = client.gather(futures)
futures_computed = client.compute(futures_gathered, sync=False)
使用 map 我们确保所有批次都会应用该函数。使用 gather,我们可以同时收集所有结果,而不是逐个收集。使用 compute(sync=False),我们返回所有的期货,准备在我们需要时进行计算。这可能看起来很费劲,但这些步骤是允许我们迭代未来所必需的。
现在我们实际运行任务,并且还设有一个简单的错误处理系统,以防我们的文件出现问题或其他意外情况。
import logging
results = []
errors = []
for fut in futures:
try:
result = fut.result()
except Exception as e:
errors.append(e)
logging.error(e)
else:
results.extend(result)
评估
我们当然希望从这个模型中得到高质量的结果!首先,我们可以查看一个单独的结果。
with s3.open('s3://dask-datasets/dogs/preds/n02086240_1082.pkl', 'rb') as data:
old_list = pickle.load(data)
old_list
{‘name’: ‘n02086240_1082’,
‘ground_truth’: ‘Shih-Tzu’,
‘prediction’: [(b”203: ‘West Highland white terrier’,”, 3.0289587812148966e-05)],
‘evaluation’: False}
虽然这里有一个错误的预测,但我们得到了预期的结果!为了进行更彻底的检查,我们会下载所有结果文件,然后查看有多少个 evaluation: True。
检查的狗照片数量:20580
正确分类的狗的数量:13806
正确分类的狗的百分比:67.085%
不完美,但总体上结果还是很不错的!
性能比较
因此,我们已经在大约 5 分钟内对超过 20,000 张图像进行了分类。这听起来不错,但还有什么替代方案呢?

| 技术 | 运行时间 |
|---|---|
| 无集群批处理 | 3 小时 21 分钟 13 秒 |
| GPU 集群与批处理 | 5 分钟 15 秒 |
添加 GPU 集群能带来巨大的不同!如果你想亲自体验这个效果,今天就注册获取 Saturn Cloud 的免费试用吧!
简历:Stephanie Kirmer 是 Saturn Cloud 的高级数据科学家。
原文。转载自原作者许可。
相关链接:
-
云计算中的数据科学与 Dask
-
深度学习、自然语言处理和计算机视觉的顶级 Python 库
-
如何获得最受欢迎的数据科学技能
更多相关内容
在深入了解 Transformer 之前应该了解的概念
原文:
www.kdnuggets.com/2023/01/concepts-know-getting-transformer.html
1. 输入嵌入
神经网络通过数字进行学习,因此每个单词都会被映射到向量中以表示特定的单词。嵌入层可以被认为是一个查找表,用于存储单词嵌入并通过索引检索它们。
具有相同含义的单词在欧氏距离/余弦相似度方面会很接近。例如,在下面的单词表示中,“Saturday”,“Sunday”和“Monday”与相同的概念相关,因此我们可以看到这些单词的结果是相似的。

2. 位置编码
确定单词的位置的原因,为什么我们需要确定单词的位置?因为,transformer 编码器没有像递归神经网络那样的递归,我们必须在输入嵌入中添加一些关于位置的信息。这是通过位置编码来完成的。论文的作者使用了以下函数来建模单词的位置。
我们将尝试解释位置编码。
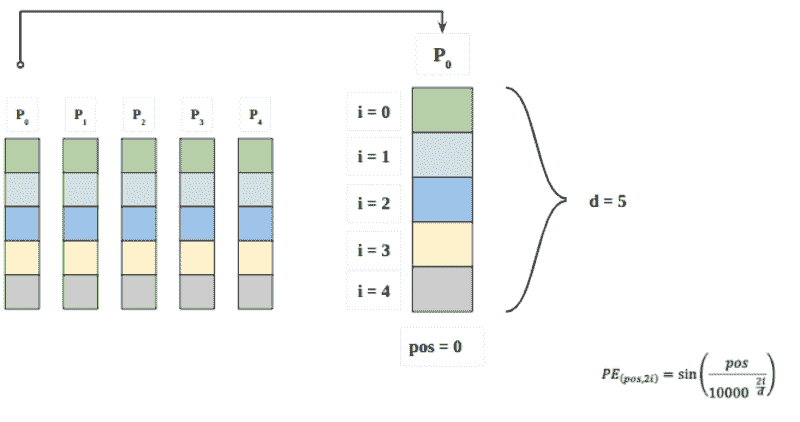
这里“pos”指的是序列中“单词”的位置。P0 指的是第一个单词的位置嵌入;“d”表示单词/标记嵌入的大小。在这个例子中,d=5。最后,“i”指的是嵌入的 5 个单独维度(即 0、1、2、3、4)。
如果上面的方程中的“i”发生变化,你将得到一系列频率不同的曲线。通过读取不同频率下的位置嵌入值,会在不同的嵌入维度中为 P0 和 P4 提供不同的值。
3. 缩放点积注意力
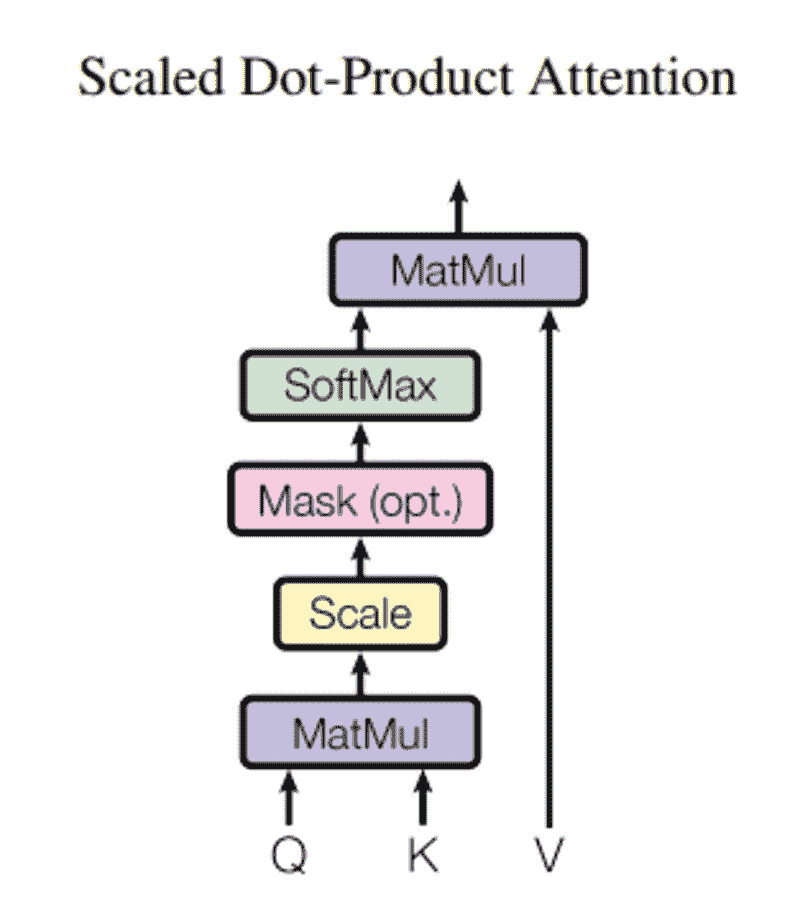
在这个查询 Q中,表示一个向量单词,键 K是句子中的所有其他单词,而值 V表示单词的向量。
注意力的目的是计算关键术语与查询术语相比的重要性,关键术语与相同的人/事物或概念相关。
在我们的例子中,V 等于 Q。
注意力机制给出了句子中单词的重要性。
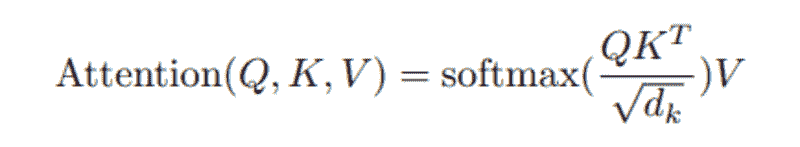
当我们计算查询和键之间的归一化点积时,我们得到一个张量,表示每个其他单词对查询的相对重要性。
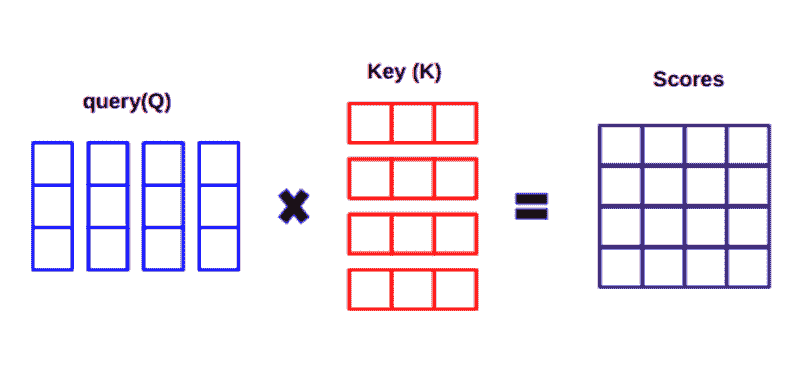
当计算 Q 和 K.T 之间的点积时,我们尝试估计向量(即查询和键之间的词)是如何对齐的,并为句子中的每个词返回一个权重。
然后,我们对 d_k 的平方结果进行归一化,softmax 函数对项进行正则化并将其重新缩放到 0 和 1 之间。
最后,我们将结果(即权重)乘以值(即所有词汇),以减少不相关词汇的重要性,并仅关注最重要的词汇。
4. 残差连接
多头注意力输出向量被添加到原始位置输入嵌入中。这被称为残差连接/跳跃连接。残差连接的输出经过层归一化。归一化后的残差输出经过逐点前馈网络进行进一步处理。
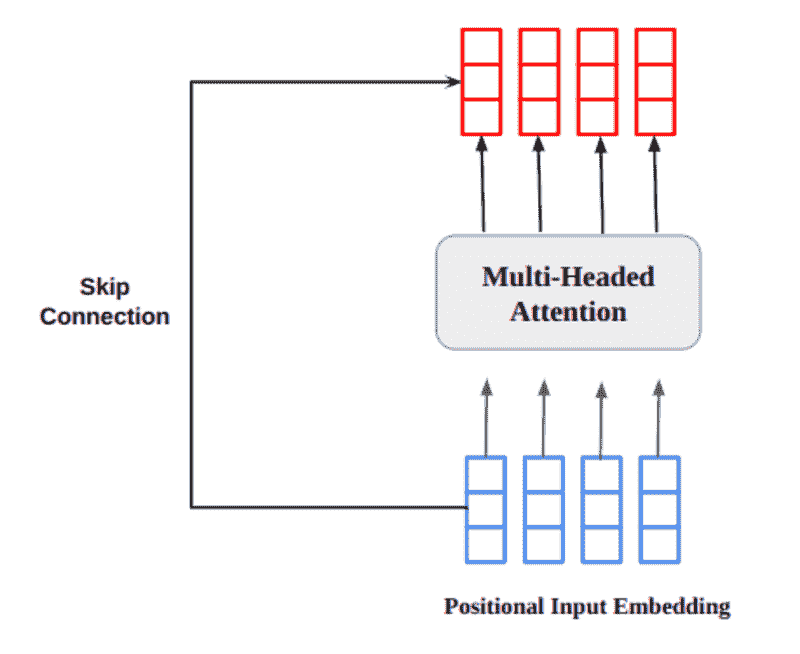
5. 掩码
掩码是一个与注意力分数大小相同的矩阵,填充了 0 和负无穷值。
使用掩码的原因是,一旦对掩码后的分数进行 softmax 操作,负无穷将变为零,从而使未来的词汇注意力分数为零。
这告诉模型对那些词不加关注。
6. softmax 函数
softmax 函数的目的是将真实数(正数和负数)转换为总和为 1 的正数。
Ravikumar Naduvin 正忙于使用 PyTorch 构建和理解 NLP 任务。
原文。经许可转载。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关主题
标准模型拟合方法的简明概述
原文:
www.kdnuggets.com/2016/05/concise-overview-model-fitting-methods.html/2
3) 随机梯度下降(SGD)
在梯度下降(GD)优化中,我们基于完整的训练集计算成本梯度,因此我们有时也称其为批量 GD。在数据集非常大的情况下,使用 GD 可能会非常昂贵,因为我们每次只对训练集进行一次迭代——因此,训练集越大,我们的算法更新权重的速度就越慢,直到收敛到全局成本最小值所需的时间也可能更长(注意,SSE 成本函数是凸的)。
在随机梯度下降(SGD;有时也称为迭代或在线 GD)中,我们不像上面 GD 中看到的那样累积权重更新:
相反,我们在每个训练样本后更新权重:
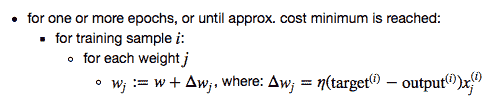
在这里,“随机”一词源于基于单个训练样本的梯度是“真实”成本梯度的“随机近似”。由于其随机性质,通向全局成本最小值的路径不像 GD 那样“直接”,而是可能在我们将成本面可视化为 2D 空间时“曲折”。然而,已经证明,如果成本函数是凸的(或伪凸的)[1],SGD 几乎可以肯定地收敛到全局成本最小值。此外,还有不同的技巧可以改进基于 GD 的学习,例如:
-
自适应学习率 η 选择一个减少常数d,该常数随时间缩小学习率:
![]()
-
通过将前一个梯度的一个因子添加到权重更新中以加速更新的动量学习:
![]()
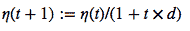

关于洗牌的说明
SGD 有几种不同的变体,这些变体可以在文献中看到。让我们看看三种最常见的变体:



在场景 A [3]中,我们仅在开始时对训练集进行一次洗牌;而在场景 B 中,我们在每个纪元后对训练集进行洗牌,以防止重复更新周期。在场景 A 和场景 B 中,每个训练样本仅在每个纪元中使用一次来更新模型权重。
在场景 C 中,我们从训练集中随机抽取训练样本并进行替换[2]。如果迭代次数t等于训练样本的数量,我们基于训练集的自助样本来学习模型。
4) 小批量梯度下降(MB-GD)
Mini-Batch 梯度下降(MB-GD)是批量 GD 和 SGD 之间的折中。在 MB-GD 中,我们基于较小的训练样本组更新模型;而不是从 1 个样本(SGD)或所有 n 个训练样本(GD)计算梯度,我们从 1 < k < n 个训练样本计算梯度(一个常见的 mini-batch 大小是 k=50)。
MB-GD 比 GD 收敛所需的迭代次数更少,因为我们更频繁地更新权重;然而,MB-GD 使我们可以利用矢量化操作,这通常带来比 SGD 更高的计算性能提升。
参考资料
[1] Bottou, Léon (1998). "在线算法与随机近似". 在线学习与神经网络. 剑桥大学出版社. ISBN 978-0-521-65263-6
[2] Bottou, Léon. "大规模机器学习与 SGD." COMPSTAT'2010 论文集. Physica-Verlag HD, 2010. 177-186.
[3] Bottou, Léon. "SGD 技巧." 神经网络:技巧的艺术. 斯普林格柏林海德堡, 2012. 421-436.
简介: Sebastian Raschka 是一位数据科学家和机器学习爱好者,对 Python 和开源有着极大的热情。《Python 机器学习》的作者。密歇根州立大学。
原文. 已获许可转载。
相关:
-
深度学习何时优于 SVM 或随机森林?
-
分类的发展作为学习机器
-
为什么从头实现机器学习算法?
我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关话题
使用混淆矩阵来量化错误的成本
原文:
www.kdnuggets.com/2018/10/confusion-matrices-quantify-cost-being-wrong.html
评论
统计学中有很多令人困惑且有时甚至违反直觉的概念。 我是说,来吧……即使解释零假设和替代假设之间的区别也可能是一场折磨。 我所想做的就是理解并量化我的分析模型出错的成本。
例如,假设我是一名视力不佳的牧羊人,难以区分狼和牧羊犬。这显然是一个不好的特质,因为错误的成本非常高:
-
有时我会把狼误认为是牧羊犬而不采取任何行动,这导致羊群的损失。 这一事件每次花费我$2,000,发生的概率是 10%。
-
另一方面,有时我会把牧羊犬误认为是狼,并意外地杀死牧羊犬,这导致羊群无人保护。 这一事件每次花费我$5,000,发生的概率是 5%。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT
好吧,我可能不是一个很好的牧羊人,但我确实是一个非常高明的牧羊人,并且我已经建立了一个神经网络应用来区分牧羊犬和狼。 经过大量的“狼检测”神经网络训练,我现在拥有一个可以以 95%准确率正确区分牧羊犬和狼的工具(见图 1)。
图 1: 来源: “为什么深度学习突然改变了你的生活” (http://fortune.com/ai-artificial-intelligence-deep-machine-learning/?xid=for_em_sh)
好吧,这似乎相当不错,但考虑到假阳性和假阴性的成本,95%的准确率是否足够好? 我是否应该投入更多的时间和精力来提高这个准确率,以确保我的模型是“有利可图的”;量化那 5%的不准确性,这使我的分析模型出错?
进入混淆矩阵(如果有哪个名字能准确描述某样东西,这个名字就是了)。
理解混淆矩阵
那么如何利用混淆矩阵量化错误的成本呢?也就是说,确定一个模型在例如 95%的准确率下是否在给定业务情况和错误成本的情况下是足够好的。
在讨论混淆矩阵时,会使用“真实条件”(“正面结果”)和“预测条件”(“负面结果”)这两个术语。这意味着你需要理解 I 型和 II 型错误的差异(以及最终与之相关的成本)。
-
I 型错误(或假阳性)是一种结果,表明给定条件存在时实际上并不存在。在我们的牧羊人示例中,这将是错误地将动物识别为狼,而实际上它是一只狗。
-
II 型错误(或假阴性)是一种结果,表明给定条件不存在时实际上是存在的。在我们的牧羊人示例中,这将是错误地将动物识别为狗,而实际上它是一只狼。
首先,让我们为测试条件“那只树林中的动物是狼吗?”建立混淆矩阵。正面条件是“动物是狼”,在这种情况下,我将采取适当的行动(可能不会尝试去抚摸它)。以下是我们用例的 2x2 混淆矩阵。
| 真实情况 |
|---|
| 预测条件 |
| 真实(狼) |
| 错误(狗) |
其中:
-
真实阳性(TP)是指真实情况是狼,模型准确地预测为狼。
-
真实阴性(TN)是指真实情况是狗,模型准确地预测为狗。
-
假阳性(FP)是一种 I 型错误,其中真实情况是狗,但模型不准确地预测为狼(这样我就可能误伤保护羊群的狗)。
-
假阴性(FN)是一种 II 型错误,其中真实情况是狼,但模型不准确地预测为狗(这样我就忽视了狼,狼就能在羊群盛宴上大快朵颐)。
一旦神经网络模型生成了覆盖上述四种情况的混淆矩阵,我们就可以计算适配度和有效性指标,如模型的精确度、灵敏度和特异性。
| 真实情况 |
|---|
| 预测条件 |
| 真实(狼) |
| 错误(狗) |
然后可以利用混淆矩阵创建适配度和模型准确度的以下指标。
-
精确度 = TP / (TP + FP)
-
召回率或灵敏度 = TP / (TP + FN)
-
特异性 = TN / (FP + TN)
-
准确率 = (TP + TN) / (TP + FP + TN + FN)
将混淆矩阵付诸实践
现在我们回到牧羊人的例子。我们想要确定模型错误的成本,或者神经网络提供的节省。我们需要确定模型提供的改进是否足够优于牧羊人自己已经做的工作。
在使用狼检测应用之前,我(作为牧羊人)有以下混淆矩阵,其中:
-
假阳性 10%的时间,他将狼误认为牧羊犬,未采取行动,狼造成$2,000 的损害。
-
假阴性 5%的时间,他将牧羊犬误认为狼,意外杀死牧羊犬,导致羊群无人保护,造成$5,000 的损失。
| 无狼检测应用 |
|---|
| 真实情况 |
| 预测情况 |
| 真实(狼) |
| 假(狗) |
根据之前的定义,不使用狼检测应用的相应指标为:
-
精确度 = 88%
-
召回率/敏感度 = 94%
-
特异性 = 50%
-
准确率 = 85%
现在使用狼检测应用,我们得到下面的混淆矩阵:
| 使用狼检测应用 |
|---|
| 真实情况 |
| 预测情况 |
| 真实(狼) | 真阳性 = 4,000 无成本
4000 / 5000 = 80% | 假阳性 = 200 每次成本 = $2,000
200 / 5000 = 4% |
| 假(狗) | 假阴性 = 50 每次成本 = $5,000
50 / 5000 = 1% | 真阴性 = 750 无成本
750 / 5000 = 15% |
使用狼检测应用的混淆矩阵指标为:
-
精确度 = 95%
-
召回率/敏感度 = 99%
-
特异性 = 79%
-
准确率 = 95%
将这些内容整合成一个表格:
| 无狼检测应用 | 有狼检测应用 | 改进 | % 改进 | |
|---|---|---|---|---|
| 精确度 | 88% | 95% | 7 分 | 8.0% |
| 召回率/敏感度 | 94% | 99% | 5 分 | 5.3% |
| 特异性 | 50% | 79% | 29 分 | 58.0% |
| 准确率 | 85% | 95% | 10 分 | 11.8% |
投资回报率则等于:
-
假阳性从 10%减少到 4%(每次减少$2,000)
-
假阴性从 5%减少到 1%(每次减少$5,000)
最终,每次预测的期望值(EvP)=
= ($2000 * 假阳性变化%) + ($5000 * 假阴性变化%)
= ($2000.06) + ($5000.04)
= 每晚平均节省$320
总结
并非所有的 I 型和 II 型错误都具有相同的价值。需要投入时间来理解 I 型和 II 型错误相对于特定情况的成本。真正的挑战是确定分析模型的性能改进是否“足够好”。混淆矩阵可以帮助我们做出这个判断。
如果有人仍然对 I 型和 II 型错误的概念感到困惑,希望下面的图像能帮助澄清差异。 呵呵

特别感谢我的高级数据科学家之一,Larry Berk,感谢他对本博客的指导。他对混淆矩阵的理解仍然远胜于我!
来源:
“混淆矩阵”来自维基百科(顺便提一下,我确实向维基百科做了一个捐款。他们是这些主题的宝贵信息来源)。
相关内容:
-
为构建你的数据科学团队制定一个成功的游戏计划
-
数据集成与数据工程之间有什么区别?
-
伟大的数据科学家不仅是跳出框框思考,他们还重新定义了框框
更多相关话题
混淆矩阵、精确度和召回率解释
原文:
www.kdnuggets.com/2022/11/confusion-matrix-precision-recall-explained.html
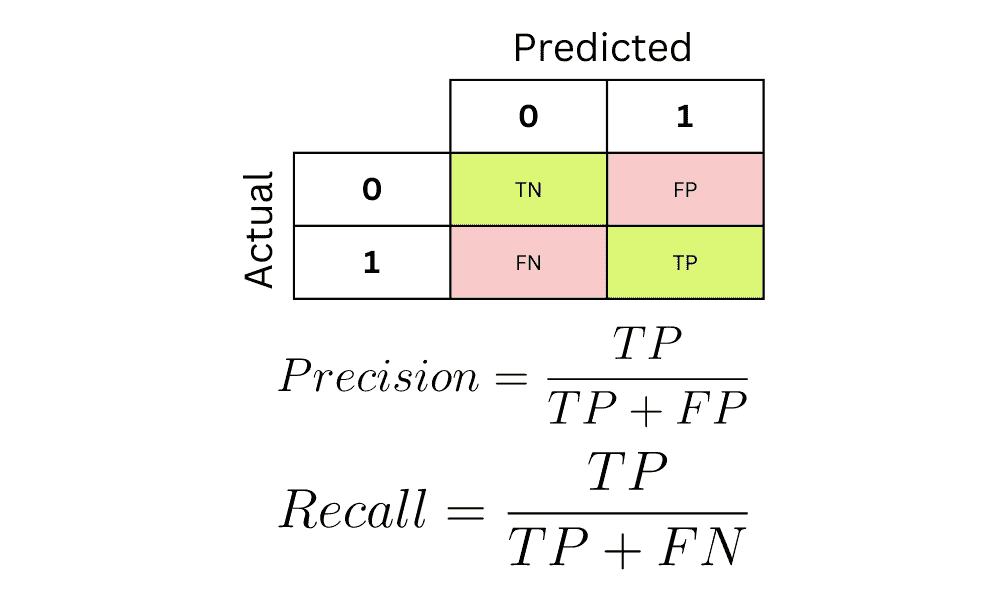
图片由编辑提供
混淆矩阵是用于总结分类模型性能的表格。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 部门
如果你不太熟悉,分类模型是用于解决具有分类结果的问题的机器学习算法,例如预测电子邮件是否为垃圾邮件。
准确率是评估分类模型最常用的指标。
然而,它并不总是最可靠的,这就是为什么数据科学家生成混淆矩阵并使用如精确度和召回率等指标的原因。
混淆矩阵是数据科学面试中最常测试的概念之一。招聘经理经常要求候选人解释混淆矩阵,或者提供一个用例并要求他们手动计算模型的精确度和召回率。
因此,彻底了解这些技术如何工作以及何时应使用这些技术来代替准确率是非常重要的。
在本文中,我们将涵盖以下概念,以巩固你对分类指标的理解:
-
分类准确率的局限性
-
什么是混淆矩阵,为什么要使用它?
-
如何读取混淆矩阵
-
什么是精确度和召回率,它们如何克服分类准确率的局限性?
-
如何在 Python 中生成混淆矩阵
分类准确率的局限性
让我们看一个简单的例子来理解分类准确率失败的地方:
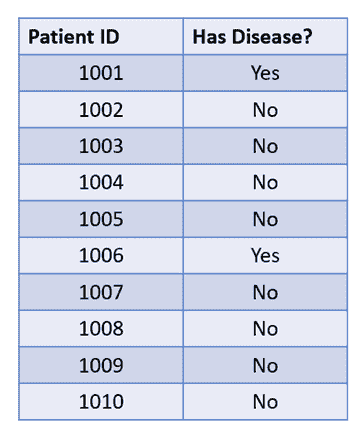
上表包含与 10 名患者相关的数据。10 名患者中有 8 名没有罕见疾病,而 2 名有。
这是一个不平衡分类问题的例子。
如果你的数据集具有不平衡的比例,即一个类别的过度代表和另一个类别的不足代表,那么数据集是不平衡的。
在这种情况下,即使你构建的分类模型总是预测多数类,准确率也会很高。
在这个例子中,如果模型总是预测患者没有疾病,它会在 10 次中有 8 次预测正确,准确度为 80%:
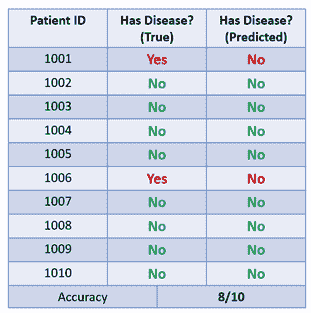
这是一个糟糕的模型,因为它总是预测多数类别,但其高准确度可能会欺骗我们,让我们认为模型表现良好。
由于准确度并不总是显示出完整的情况,我们可以使用混淆矩阵来告诉我们模型的实际表现如何。
什么是混淆矩阵?
混淆矩阵总结了分类器的性能,并使我们能够识别准确度无法告诉我们的细节。
为了更好地理解它是如何工作的,让我们基于上表构建一个混淆矩阵:
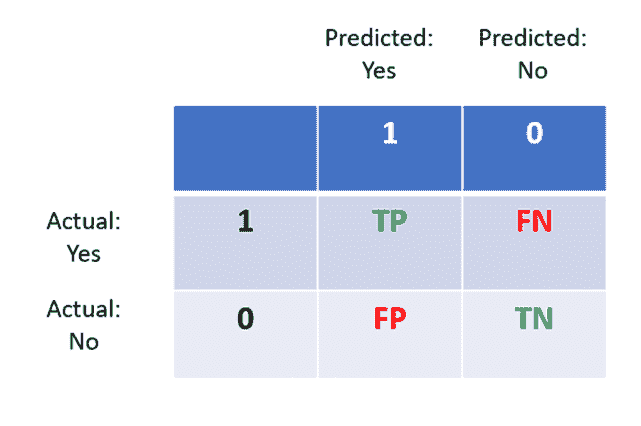
上面的图显示了混淆矩阵的结构。以下是如何解读它:
-
列表示实际值,行表示预测。
-
如果一个人实际上有疾病,而模型准确地预测出他们有疾病,那么这称为真正的 阳性。
-
如果一个人没有疾病而模型预测为“否”,那么这就是真正的 阴性。
-
真阳性和真阴性在混淆矩阵中形成对角线。我们可以用以下公式计算模型的准确度:
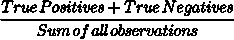
-
如果一个人有疾病(是)但模型预测为“否”,这就是假阴性。
-
最后,如果一个人没有疾病(否),但模型预测为“是”,那么这就是假阳性。
现在,让我们根据疾病预测数据填写混淆矩阵。
步骤 1:真阳性
请记住,这表示准确预测为有疾病的人数。由于模型对每位患者的预测都是“没有”,所以数据集中有0 个真阳性。
步骤 2:真阴性
有 8 名没有疾病的患者,模型成功识别了他们所有人。所以有8 个真阴性。
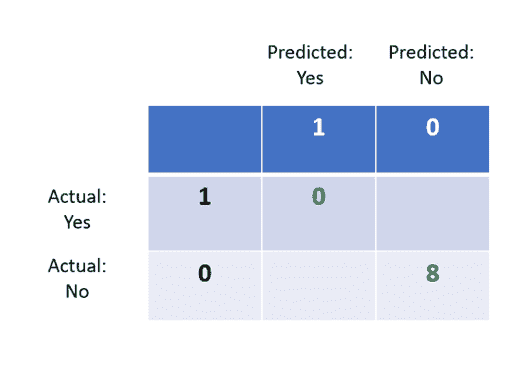
步骤 3:假阳性
这些人没有疾病,但模型预测为“是”。由于我们的模型从未预测“是”,所以有0 个假阳性。
步骤 4:假阴性
这些人确实有疾病,但模型预测为“没有”。数据集中有2 个假阴性。
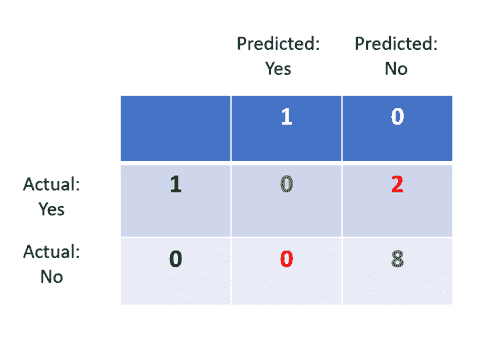
现在,虽然我们知道这个模型的准确度是 80%,但通过观察其混淆矩阵,我们可以看出模型存在一些问题。
混淆矩阵中“预测: 是”这一列全是零,这表明模型没有预测出任何一个人有疾病。
该模型仅预测了多数类“否”,表明其在疾病分类方面表现不佳,需要进一步改进。
精确度和召回率
现在你了解了混淆矩阵的工作原理,让我们深入探讨两个可以从中计算的指标。
精确度和召回率是数据科学家用来优化模型性能的两个流行分类指标。它们提供了准确率无法告诉我们的模型性能洞察。
精确度
精确度是一个指标,用于衡量正面预测的质量。在所有被预测有疾病的人中,有多少人实际上有这种疾病?
计算公式如下:
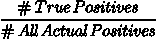
在这种情况下,我们只关注混淆矩阵的左侧。
真正阳性的数量是 0。
所有预测的正面包括真正阳性和虚假阳性的总和,也为 0。
因此,模型的精确度是 0/0+0 = 0。
召回率
召回率告诉我们模型识别真正阳性的能力。所有有疾病的患者中,有多少被正确识别?
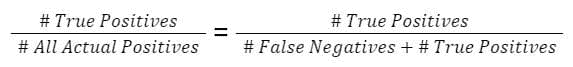
在这种情况下,真正阳性的数量是 0。虚假阴性的数量是 2。
因此,模型的召回率是 0/2+0 = 0。
请注意,这个例子中精确度和召回率都为零。这是因为模型没有真正阳性,使得分类器无用,因为它无法做出一个正确的正面预测。
什么是“好的”分类模型?
一个好的分类器应具备高准确率、精确度和召回率。
在某些用例中,数据科学家会根据场景优化其模型以提高精确度或召回率。
一种召回率高于精确度的模型通常会做出更多的正面预测。这种模型会带来更多的虚假阳性和较低的虚假阴性。
在疾病预测这类场景中,模型应始终优化召回率。与虚假阴性相比,虚假阳性在医疗行业中更为可接受。
另一方面,精确度较高的模型会有较少的虚假阳性和更多的虚假阴性。如果你要为在线商店构建一个机器人检测机器学习模型,你可能会希望优化较高的精确度,因为禁止合法用户访问网站将导致销售下降。
正确理解这一概念很重要,因为数据科学面试官经常会提出如上所述的使用案例,并询问候选人是否优化精确度还是召回率。
如何在 Python 中构建混淆矩阵
你可以运行以下代码行来使用 Python 中的 Scikit-Learn 构建混淆矩阵:
from sklearn.metrics import confusion_matrix
true = [1, 0, 0, 0, 0, 1, 0, 0, 0, 0]
predicted = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
print(confusion_matrix(true, predicted))
Natassha Selvaraj 是一位自学成才的数据科学家,热衷于写作。你可以在LinkedIn上与她联系。
主题更多信息
为什么你应该考虑成为数据工程师而不是数据科学家
原文:
www.kdnuggets.com/2021/04/consider-being-data-engineer-instead-data-scientist.html
评论

图片来源于 Ryan Harvey 在 Unsplash
我只想说,无论你选择数据科学还是数据工程,最终都应该取决于你的兴趣和激情所在。然而,如果你处于犹豫状态,不确定选择哪个,因为这两个领域都同样吸引你,那么继续阅读吧!
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
数据科学已经成为一个热门话题,但丛林中的新王者——数据工程师已经到来。在这篇文章中,我将与大家分享几个为什么你可能会考虑追求数据工程而非数据科学的理由。
请注意,这是一篇带有个人观点的文章,请自行斟酌。话虽如此,希望你喜欢!
1. 数据工程在根本上比数据科学更为重要。
我们都听过“垃圾进,垃圾出”的说法,但只有现在公司才开始真正理解这一点。机器学习和深度学习可以很强大,但仅在非常特殊的情况下才有效。除了需要大量数据和实际用途之外,公司还需要从底层开始满足数据需求层次。
图片由作者创建
就像我们在满足社交需求(即人际关系需求)之前需要满足生理需求(即食物和水),公司需要满足几个通常属于数据工程范畴的要求。注意数据科学,特别是机器学习和深度学习,通常是最后需要关注的事项。
简单来说,没有数据工程就不会有数据科学。数据工程是成功的数据驱动公司基础。
2. 数据工程师的需求正在大幅增长。
如我之前所说,公司正意识到对数据工程师的需求。因此,目前对数据工程师的需求正在增长,并且有证据证明这一点。
根据Interview Query 的数据科学面试报告,2019 年至 2020 年间,数据科学面试数量仅增长了 10%,而在同一时间段内,数据工程面试的数量增长了 40%!
此外,Mihail Eric 对 Y-Combinator 职位发布进行的分析发现,数据工程岗位的招聘数量比数据科学家岗位多出大约 70%。
你可能会想,“当然增长率更高,但从绝对数字来看怎么样?”
我冒昧地从 Indeed、Monster 和 SimplyHired 上抓取了所有数据科学家和数据工程师的职位发布,发现这两者的职位数量差不多!
总体而言,共有 16577 个数据科学家职位和 16262 个数据工程师职位。
作者创建的图片
3. 数据工程技能对数据科学家非常有用。
在更成熟的公司中,工作通常是分开的,以便数据科学家可以专注于数据科学工作,而数据工程师则专注于数据工程工作。
但这对大多数公司来说通常不是这样。 我会说,大多数公司实际上要求他们的数据科学家具备一定的数据工程技能。
很多数据科学家最终需要具备数据工程技能。
作为数据科学家,了解数据工程技能也是极其有益的,我举个例子:如果你是一个不懂 SQL 的业务分析师,每次想获取洞察时都需要请数据分析师查询信息,这会在你的工作流程中造成瓶颈。同样,如果你是一个没有数据工程师基本知识的数据科学家,你一定会遇到需要依赖别人来修复 ETL 管道或清理数据的情况,而不是自己动手。
4. 数据科学比数据工程更容易学习。
在我看来,作为数据工程师学习数据科学比作为数据科学家学习数据工程技能要容易得多。为什么?因为数据科学的资源明显更多,且已经有很多工具和库被建立以简化数据科学。
所以,如果你刚开始你的职业生涯,我个人认为花时间学习数据工程比学习数据科学更值得,因为你有更多的时间投入。当你开始全职工作,职业生涯进入几年后,你可能会发现你没有足够的能力或精力投入这么多时间来学习。因此,从这个角度看,我认为最好先学习更困难的领域。
5. 它涵盖了一个尚未开发的机会市场。
我不仅仅是在谈论工作机会,还包括通过新工具和方法创新和简化数据工程的机会。
当数据科学最初被大肆宣传时,人们发现学习数据科学存在几个障碍,比如数据建模和模型部署。后来,像 PyCaret 和 Gradio 这样的公司出现,解决了这些问题。
目前,我们正处于数据工程的初期阶段,我预见到有许多机会可以使数据工程变得更简单。
感谢阅读!
尽管这是一篇带有观点的文章,但我希望这能稍微解释一下你为什么可能希望成为数据工程师。我想重申的是,无论你选择数据科学还是数据工程,最终都应取决于你的兴趣和热情所在。像往常一样,祝你在你的努力中好运!
不确定接下来读什么?我为你挑选了一篇文章:
还有一个!
有志成为数据科学家的最大误解](https://towardsdatascience.com/want-to-be-a-data-scientist-dont-learn-machine-learning-28e418d9af2f)
特伦斯·申
-
如果你喜欢这篇文章,请在 Medium 上关注我,获取更多内容
-
对合作感兴趣?让我们在LinkedIn上联系
-
立即注册我的邮件列表点击这里!
原文。已获授权转载。
相关:
-
想成为数据科学家?不要从机器学习开始
-
7 个最推荐学习的技能,成为数据科学家
-
2021 年数据科学家最需掌握的技能
更多相关话题
你应该考虑 DataOps 职业吗?

图片来自 Bing Image Creator
DataOps 结合了数据科学与软件工程,创造了强大的技术知识、数据分析和过程优化的结合。随着自动化和机器学习机会的增加,DataOps 职业可以非常有回报,面临令人兴奋的挑战和成长潜力。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织中的 IT 工作
让我们深入了解进入这个充满活力的行业所需的条件——包括 DataOps 工程师的工作内容、职位福利以及所需技能——以便你可以决定这是否是你未来的正确选择!
什么是 DataOps?
DataOps(数据操作) 是一种将 DevOps 的敏捷性与数据分析能力相结合的方法论。旨在提高 IT 和数据相关团队之间的协作,通过优化构建和利用企业数据资产的端到端生命周期,使业务更加敏捷。
作为一种实践,DataOps 通过自动化和优化各种流程来简化数据管道过程,从数据采集到数据分析。这使得组织能够实时分析数据,并迅速响应不断变化的业务需求。
DataOps 与 DevOps
DataOps 和 DevOps 是两个不同的过程,但它们通过提供对软件开发操作的增强可见性和控制来协同工作,从而帮助更快、更高效地实现目标。
DataOps 与 DevOps 的区别在于关注点:前者关注如何快速通过给定系统移动数据——无论是实时流动大量非结构化数据还是管理组织系统中的现有资产——而后者关注如何在不牺牲服务质量或多个服务器/应用堆栈稳定性的情况下快速部署更改。
为什么 DataOps 是一个好的职业选择?
DataOps 提供了与前沿技术合作的绝佳机会,并且处于数据管理解决方案的最前沿。这个领域的专业人员需求量很大,随着越来越多的公司认识到有效数据管理的价值,这种需求只会增加。
DataOps 作为职业选择的主要吸引力集中在:
-
薪资
-
职业机会
-
工作多样性
薪资
根据 Talent.com,2023 年美国 DataOps 工程师的平均基本工资为每年 $130,350,入门级工资起薪为每年 $87,653。薪资根据地点、经验和目标公司而异,但越来越明显的是,对经验丰富的 DataOps 工程师的需求日益增加,从而推动了行业薪资的上涨。
职业机会
随着组织对 DataOps 的需求增加,职位机会也随之增长。这些职位包括传统的如数据工程师或分析师,也有新兴的角色如大数据开发人员和云架构师。这些职位根据你在编程、云计算和机器学习算法方面的经验水平,提供了良好的职业发展潜力。
通过持续研究、自学或正式教育课程在这些领域获得更复杂的技术知识,将帮助你在 DataOps 职业生涯中不断提升。
工作多样性
DataOps 工程师可以选择在许多令人兴奋的领域工作,面临有趣的挑战。随着人工智能(AI)的发展,大数据技术也在上升,这创造了更多与 DataOps 相关的职位机会,如图像识别或自然语言处理(NLP)项目。
网络物联网系统或保护无线网络周围的防火墙也提供了许多职位机会。其他相关角色则专注于利用现有数据集进行机器学习项目,如深度学习,或通过使用 R Studio 等工具提升前端视觉展示能力。
DataOps 职业的挑战是什么?
DataOps 职业道路并非心志薄弱者的选择,因为它面临一些严峻的挑战。以下是其中的一些:
-
技术熟练度:DataOps 需要在广泛的技术和技能集上具备技术熟练度,如软件工程、DevOps 实践、云计算架构、分析平台/应用等,这使得从业者必须保持对不同工具和技术的最新了解。
-
协作与跨职能沟通:考虑到涉及的团队数量(包括 IT 运维和商业智能/分析团队),有效的协作对于 DataOps 领域的成功至关重要。建立跨团队的关系并沟通期望是高效和专业地启动项目的关键。
-
适应性和灵活性:不仅行业变化迅速,数据趋势也在不断变化。这意味着,DataOps 专业人员在响应业务需求或技术需求变化时必须快速应对。他们还需要了解内部数据库结构和外部数据源(如 API)。
-
持续改进的心态:每个项目或变化都带来了改进的机会,无论是通过改进方法论还是工具实施。实践者必须具备创造性解决问题的能力,并对特定领域内的创新持开放态度。
成为 DataOps 成功的关键技能有哪些?
成功的 DataOps 所需的技能和特质适用于任何分析或以数据为中心的职业。以下是你应该培养的关键技能:
技术知识
理解全栈技术是理想的,但至少 DataOps 专业人员应深入了解他们将要使用的数据和系统。这包括对数据库、服务器操作系统以及 SQL、Python 或 MATLAB 等脚本语言的了解。
沟通技能
成为一名成功的 DataOps 工程师需要在团队内部和与客户及供应商沟通时都具备强大的沟通技巧。在解决问题或进行头脑风暴会议时,需要良好的人际交往技巧,以便与各部门的同事有效协作,探讨与项目相关的数据集的收集/处理/分析的高效方式。
关注细节
关注细节至关重要,因为即使是从外部来源收集原始数据、将信息输入数据库或编写脚本生成输出时做出的微小更改,也会显著影响整体结果。同时,能够解决错误和调试代码也是有益的。
项目管理专长
成为一名有效的 DataOps 工程师需要项目管理技能(如敏捷开发原则和 Scrum 框架方法)与技术专长的结合。因此,拥有规划、协调和管理数据相关项目的经验将是一个极大的资产。
DataOps 适合你吗?
在涉足 DataOps 职业之前,重要的是要问自己几个关键问题:
我的技术熟练程度如何?
DataOps 职位要求对 Python 或 SQL 等编程语言有深入了解,以及对机器学习算法等新兴技术有一定掌握。如果这些话题对你来说陌生,那么在追求这个领域的职业之前,可能需要先提高相关技能。
我是否对使用技术分析数据充满热情?
从本质上讲,DataOps 专注于高效利用资源和技术来有效管理需要快速处理的大量数据或数据集。这需要对不同类型系统如何相互作用有深入了解,并掌握最新的处理大规模数据的解决方案。你需要具备迎接这些挑战的热情。
我对 DevOps 过程有多熟悉?
在 DataOps 环境中的工作流开发过程中,你需要了解多个团队如何协同工作以实现共同目标,同时协调源代码管理实践、自动化管道、自动化测试框架和不同交付渠道的部署策略。能够弥合开发人员和运维团队之间的差距,对于在组织内构建有效的软件产品并通过持续的体验更新/产品发布快速吸引用户至关重要。
总结
如果你热爱数据分析和管理,那么 DataOps 领域可能适合你。这个领域专注于高效处理大量数据,为企业和组织提供服务,并且不断发展。这意味着总有新的工具和技术可以学习,使工作既具有挑战性又充满回报。而且,考虑到高薪和有吸引力的职业发展机会,DataOps 职业可能是一个令人兴奋和充实的选择。
马里乌什·米哈洛夫斯基 是 Spacelift 的社区经理,Spacelift 是一个灵活的基础设施即代码管理平台。他对自动化、DevOps 和开源解决方案充满热情。在闲暇时间,他喜欢汽车美容、游泳和阅读非小说书籍。
更多相关主题
使用 Docker 在 5 个简单步骤中容器化 Python 应用程序
原文:
www.kdnuggets.com/containerize-python-apps-with-docker-in-5-easy-steps
作者提供的图片
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
在使用 Python 构建应用程序时,你常常会遇到依赖冲突、版本不匹配等问题。使用 Docker,你可以将应用程序——连同所需的依赖、运行时和配置——打包成一个称为镜像的单一可移植工件。然后,你可以使用这个镜像启动一个运行应用程序的 Docker 容器。
无论是简单的 Python 应用程序还是数据科学应用程序,Docker 都使得管理依赖变得更加简单。这在数据科学项目中特别有用,因为你需要不同的库和这些库的特定版本以确保应用程序没有错误地运行。使用 Docker,你可以为所有应用程序创建隔离、一致和可重现的环境。
作为迈出这一步的第一步,让我们学习如何将 Python 应用程序容器化。
第 1 步:开始使用
首先,在你使用的平台上安装 Docker。你可以在 Windows、Linux 和 MacOs 上运行 Docker。以下是安装 Docker 后你可能需要做的几件事。
Docker 守护进程绑定到一个默认由root用户拥有的 Unix 套接字。因此,你只能使用sudo访问它。为了避免在所有 Docker 命令前加上sudo,可以创建一个docker组,并像这样将用户添加到该组:
$ sudo groupadd docker
$ sudo usermod -aG docker $USER
对于较新的 Docker 版本,BuildKit 是默认的构建工具。然而,如果你使用的是较旧版本的 Docker,当你运行docker build命令时,可能会收到弃用警告。这是因为旧版构建客户端将在未来的版本中被弃用。作为解决方法,你可以安装 buildx,这是一个 CLI 工具,用于使用 BuildKit 的功能。然后使用docker buildx build命令来使用 BuildKit 进行构建。
第 2 步:编写你的 Python 应用程序
接下来,编写一个 Python 应用程序,我们可以使用 Docker 对其进行容器化。在这里,我们将容器化一个简单的命令行待办事项列表应用程序。该应用程序的代码在 GitHub 上:todo.py 文件。
你可以将任何你选择的 Python 应用程序容器化,或者按照我们在这里使用的示例进行操作。如果你对逐步教程构建命令行 TO-DO 应用程序感兴趣,请阅读 用 Python 在 7 个简单步骤中构建命令行应用程序。
第 3 步:创建 Dockerfile
接下来,我们将创建一个 Dockerfile。把它看作是定义如何为应用程序构建 Docker 镜像的配方。在你的工作目录中创建一个名为 Dockerfile 的文件,内容如下:
# Use Python 3.11 as base image
FROM python:3.11-slim
# Set the working directory in the container
WORKDIR /app
# Copy the current directory contents into the container at /app
COPY . /app
# Command to run the Python script
CMD ["/bin/bash"]
在这里,我们使用 Python 3.11 作为基础镜像。然后我们使用 WORKDIR 命令设置所有后续指令的工作目录。接着,我们使用 COPY 命令将项目中的文件复制到容器的文件系统中。
因为我们要将一个命令行应用容器化,我们将要执行的命令指定为 “/bin/bash”。这样,当我们运行镜像并启动容器时,就会启动一个交互式的 bash shell。
第 4 步:构建 Docker 镜像
我们已经准备好 todo.py 文件和 Dockerfile。接下来,我们可以使用以下命令构建 Docker 镜像:
docker build -t todo-app .
使用构建命令中的 -t 选项,你可以同时指定一个名称和标签,如:docker build -t name:tag .
这个命令根据 Dockerfile 中的指令构建一个名为 todo-app 的 Docker 镜像。末尾的 . 指定了构建上下文为当前目录。
构建过程需要几分钟:
Sending build context to Docker daemon 4.096kB
Step 1/4 : FROM python:3.11-slim
3.11-slim: Pulling from library/python
13808c22b207: Pull complete
6c9a484475c1: Pull complete
b45f078996b5: Pull complete
16dd65a710d2: Pull complete
fc35a8622e8e: Pull complete
Digest: sha256:dad770592ab3582ab2dabcf0e18a863df9d86bd9d23efcfa614110ce49ac20e4
Status: Downloaded newer image for python:3.11-slim
---> c516402fec78
Step 2/4 : WORKDIR /app
---> Running in 27d02ba3a48d
Removing intermediate container 27d02ba3a48d
---> 7747abda0fc0
Step 3/4 : COPY . /app
---> fd5cb75a0529
Step 4/4 : CMD ["/bin/bash"]
---> Running in ef704c22cd3f
Removing intermediate container ef704c22cd3f
---> b41986b633e6
Successfully built b41986b633e6
Successfully tagged todo-app:latest
第 5 步:运行你的 Docker 容器
一旦镜像构建完成,你可以使用以下命令从构建好的镜像启动一个 Docker 容器:
docker run -it todo-app
-it 选项是 -i 和 -t 的组合:
-
-i选项用于交互式运行容器,并且即使没有附加,也保持 STDIN 开放。 -
-t选项分配一个伪 TTY。因此,它在容器内提供一个可以交互的终端界面。
现在,我们的 TO-DO 应用程序在 Docker 容器内运行,我们可以在命令行中与之交互:
root@9d85c09f01ec:/app# python3 todo.py
usage: todo.py [-h] [-a] [-l] [-r]
Command-line Todo List App
options:
-h, --help show this help message and exit
-a , --add Add a new task
-l, --list List all tasks
-r , --remove Remove a task by index
root@9d85c09f01ec:/app# python3 todo.py -a 'walk 2 miles'
root@9d85c09f01ec:/app# python3 todo.py -l
1\. walk 2 miles
总结
就这样!你已经成功地使用 Docker 容器化了一个命令行 Python 应用程序。在这个教程中,我们展示了如何使用 Docker 容器化一个简单的 Python 应用程序。
我们在 Python 中构建了这个应用程序,没有使用任何外部 Python 库。因此我们没有定义 requirements.txt 文件。requirements.txt 文件通常列出各种库及其版本,你可以使用简单的 pip install 命令安装它们。如果你对专注于数据科学的 Docker 教程感兴趣,请查看 数据科学家的 Docker 教程。
Bala Priya C**** 是来自印度的开发者和技术写作者。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过编写教程、指南、观点文章等来学习和分享她的知识,与开发者社区互动。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关内容
基于内容的推荐系统使用自然语言处理(NLP)
原文:
www.kdnuggets.com/2019/11/content-based-recommender-using-natural-language-processing-nlp.html
评论
作者 James Ng,数据科学,项目管理

Netflix 屏幕截图
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织的 IT
当我们在互联网上为产品和服务提供评分时,我们表达的所有偏好和共享的数据(无论是显式的还是隐式的),都被推荐系统用来生成推荐。最常见的例子包括亚马逊、谷歌和 Netflix。
推荐系统有两种类型:
-
协作 过滤器 — 基于用户评分和消费习惯将相似用户分组,然后向用户推荐产品/服务
-
基于内容 过滤器 — 根据产品/服务的属性进行推荐
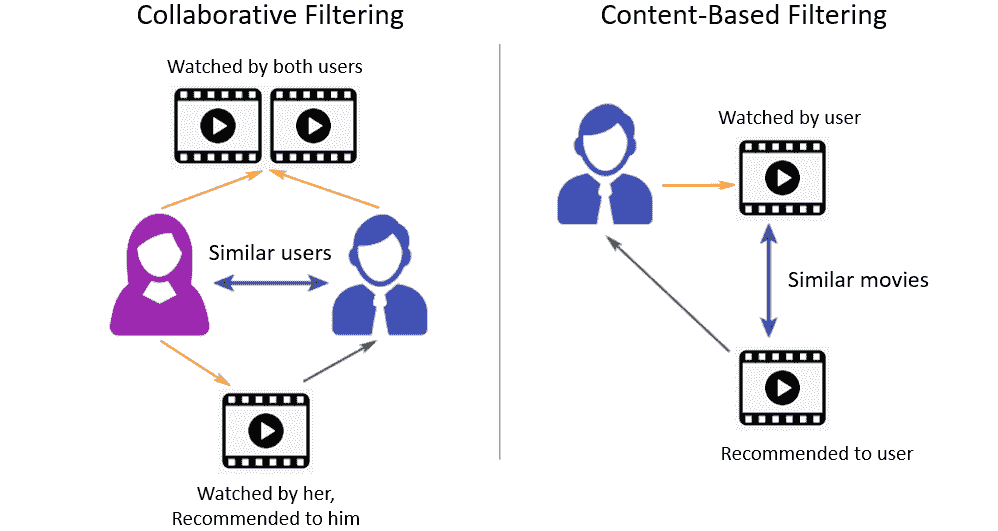
在这篇文章中,我结合了电影的属性如类型、情节、导演和主要演员,以计算其与另一部电影的余弦相似度。数据集是从 data.world 下载的 IMDB 前 250 部英语电影。
步骤 1:导入 Python 库和数据集,执行探索性数据分析(EDA)
确保已安装 快速自动关键词提取(RAKE)库(或通过 pip 安装 rake_nltk)。
from rake_nltk import Rake
import pandas as pd
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.feature_extraction.text import CountVectorizerdf = pd.read_csv('IMDB_Top250Engmovies2_OMDB_Detailed.csv')
df.head()
探索数据集后,发现有 250 部电影(行)和 38 个属性(列)。然而,只有 5 个属性是有用的:‘标题’,‘导演’,‘演员’,‘情节’,和‘类型’。以下是 10 位热门导演的列表。
df['Director'].value_counts()[0:10].plot('barh', figsize=[8,5], fontsize=15, color='navy').invert_yaxis()
250 部电影中最受欢迎的 10 位导演
步骤 2:数据预处理 删除停用词、标点符号、空白字符,并将所有词转换为小写字母
首先,需要使用自然语言处理(NLP)对数据进行预处理,以获得仅包含每部电影所有属性(以文字形式)的单列。之后,通过向量化将这些信息转换为数字,为每个词分配分数。随后可以计算余弦相似度。
我使用 Rake 函数从‘Plot’列中的整个句子中提取最相关的词。为此,我将该函数应用于‘Plot’列下的每一行,并将关键字列表分配给新列‘Key_words’。
df['Key_words'] = ''
r = Rake()for index, row in df.iterrows():
r.extract_keywords_from_text(row['Plot'])
key_words_dict_scores = r.get_word_degrees()
row['Key_words'] = list(key_words_dict_scores.keys())

Rake 函数用于提取关键字
演员和导演的名字被转换为唯一的身份值。这是通过将所有名字和姓氏合并为一个词来完成的,这样 Chris Evans 和 Chris Hemsworth 将显示为不同的(否则,它们将有 50%的相似度,因为它们都有‘Chris’)。每个词都需要转换为小写以避免重复。
df['Genre'] = df['Genre'].map(lambda x: x.split(','))
df['Actors'] = df['Actors'].map(lambda x: x.split(',')[:3])
df['Director'] = df['Director'].map(lambda x: x.split(','))for index, row in df.iterrows():
row['Genre'] = [x.lower().replace(' ','') for x in row['Genre']]
row['Actors'] = [x.lower().replace(' ','') for x in row['Actors']]
row['Director'] = [x.lower().replace(' ','') for x in row['Director']]

所有名字都被转换为唯一的身份值
步骤 3:通过结合列属性创建‘Bag_of_words’的词表示
数据预处理后,这 4 列‘Genre’,‘Director’,‘Actors’和‘Key_words’被合并成一列‘Bag_of_words’。最终的数据框只有 2 列。
df['Bag_of_words'] = ''
columns = ['Genre', 'Director', 'Actors', 'Key_words']for index, row in df.iterrows():
words = ''
for col in columns:
words += ' '.join(row[col]) + ' '
row['Bag_of_words'] = words
df = df[['Title','Bag_of_words']]
最终的词表示是新列‘Bag_of_words’
步骤 4:为‘Bag_of_words’创建向量表示,并创建相似度矩阵
推荐模型只能读取和比较一个向量(矩阵)与另一个向量,因此我们需要使用CountVectorizer将‘Bag_of_words’转换为向量表示,这是一种对‘Bag_of_words’列中每个词的频率进行计数的简单计数器。一旦得到包含所有词计数的矩阵,就可以应用 cosine_similarity 函数来比较电影之间的相似度。
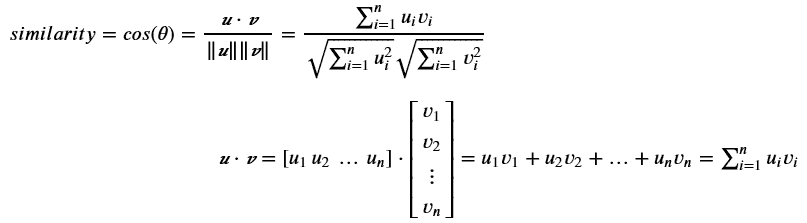
计算相似度矩阵中值的余弦相似度公式
count = CountVectorizer()
count_matrix = count.fit_transform(df['Bag_of_words'])cosine_sim = cosine_similarity(count_matrix, count_matrix)
print(cosine_sim)
相似度矩阵(250 行 x 250 列)
接下来是创建一个电影标题系列,以便系列索引可以匹配相似度矩阵的行和列索引。
indices = pd.Series(df['Title'])
步骤 5:运行并测试推荐模型
最后的步骤是创建一个函数,该函数以电影标题作为输入,并返回前 10 部相似电影。该函数将输入的电影标题与相似度矩阵的对应索引匹配,并按降序提取相似度值的行。通过提取前 11 个值并随后丢弃第一个索引(即输入电影本身),可以找到前 10 部相似电影。
def recommend(title, cosine_sim = cosine_sim):
recommended_movies = []
idx = indices[indices == title].index[0]
score_series = pd.Series(cosine_sim[idx]).sort_values(ascending = False)
top_10_indices = list(score_series.iloc[1:11].index)
for i in top_10_indices:
recommended_movies.append(list(df['Title'])[i])
return recommended_movies
现在我准备好测试模型了。让我们输入我最喜欢的电影“复仇者联盟”,看看推荐结果。
recommend('The Avengers')

与“复仇者联盟”相似的前 10 部电影
结论
模型推荐了非常相似的电影。根据我的“领域知识”,我可以看到一些相似性主要基于导演和情节。我已经看过大多数这些推荐电影,并期待观看那些少数未看过的电影。
带有内联注释的Python代码可在我的GitHub上找到,欢迎参考。
[JNYH/movie_recommender
使用自然语言处理(NLP)的内容推荐系统。构建基于内容的电影推荐器的指南……](https://github.com/JNYH/movie_recommender?source=post_page-----159d0925a649----------------------)
感谢阅读!
简介:James Ng 对从数据中发掘洞察有深入的兴趣,热衷于将实践数据科学、强大的业务领域知识和敏捷方法论结合起来,为企业和社会创造指数级的价值。热衷于提升数据流畅度,使数据易于理解,以便业务能够做出数据驱动的决策。
原文. 经许可转载。
相关:
-
YouTube 如何推荐你的下一个视频
-
在线聊天的主题提取与分类
-
文本编码:回顾
更多相关主题
背景、一致性和协作是数据科学成功的关键
原文:
www.kdnuggets.com/2022/01/context-consistency-collaboration-essential-data-science-success.html

到 2021 年底,人工智能(AI)和机器学习(ML)领域已不再是未来充满不确定性的初创领域。AI 和 ML 已成为对更广泛的数据科学领域产生巨大影响的领域,这一事实在今年更是显而易见。这点比以往任何时候都更真实。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 部门
随着 AI、ML 以及数据科学的持续扩展,能够影响数据科学团队成功的参数也在不断增加。要从 AI 和 ML 领域获得重要而深刻的见解,需要的数据科学团队规模远超过仅由一位数据科学家和一台笔记本电脑组成的团队。获取、清洗和准备分析所需的大量数据——这一过程消耗了数据科学家平均工作日的很大一部分——是任何一个人单独无法完成的。
现代数据科学项目围绕着数据准备、先前的数据科学项目以及可能的前进方式展开,这些信息必须与多个数据科学团队共享。因此,研究数据科学团队为何需要背景、一致性和安全的协作,以确保数据科学的成功至关重要。让我们快速审视这些要求,以便更好地理解未来数据科学成功的样貌。
第一部分:背景
我们对未来数据科学成功的审视始于背景:没有经过迭代的模型构建依赖于尝试与失败的实验的过程无法长久存在,除非有已记录、储存并提供给数据科学家的机构知识。然而,仍然有大量机构知识因为缺乏适当的文档和存储而经常丢失。
设想一个常见场景:一位初级或公民数据科学家被拉入一个项目以提高其技能,但由于缺乏背景知识,很快就会在同步与异步协作中遇到困难。这些临时团队成员需要了解更多关于他们正在互动的数据、过去解决问题的人以及以前的工作如何影响当前项目环境的背景信息。
适当记录项目以及数据模型和其工作流的必要性很容易分散数据科学团队的注意力,更不用说单独操作的人员了。领导者可以考虑雇佣自由开发者来投入时间,以维护和传播机构知识,从而提高现代数据科学项目的标准审查和反馈环节。这些环节以及软件系统、工作台和最佳实践可以简化更有效地捕捉项目相关背景的过程,改善未来初级和公民数据科学家的数据发现能力。
数据科学的成功需要知识的精简管理及其周围背景。如果没有它,新手、初级和公民数据科学家可能会在入职和对项目的有意义贡献上遇到困难,这反过来又会导致团队重建项目,而不是贡献于之前的工作。
第二部分:一致性
机器学习(ML)和人工智能(AI)领域在金融服务、健康与生命科学以及制造业方面带来了基础性的变化;不过,这些行业受到严格的监管环境的约束。这意味着在受监管的环境中进行的 AI 项目必须具有可重复性,并且有明确的审计痕迹。换句话说,涉及数据科学项目的 IT 和业务领导者需要确保数据一致性。
IT 和商业领袖可以期待可靠的一致性水平,也可以在进行 AI 促进的战略调整时享有更多信心。数据科学项目涉及大量的投资,因此数据科学家理应拥有一个可以保证重现性的基础设施从开始到结束。这种完全重现性转化为高管在决定数据科学项目是否足够重要以及是否与业务目标一致时所需的数据一致性。
这些高级管理人员应当预期,随着他们的科学团队扩展,确保旧项目结果一致性的所需培训集和硬件要求也会增加。因此,帮助管理环境的过程和系统对数据科学团队的扩展至关重要。例如,如果一个数据科学家使用笔记本电脑,而一个数据工程师在云虚拟机上运行不同版本的库,那么数据科学家可能会发现他们的数据模型在不同机器上产生不同的结果。关键是:高管应确保他们的数据协作者有一种一致的方式来共享完全相同的软件环境。
第三部分:协作
最后,我们来谈谈安全协作的重要性。随着企业不断将运营模式转移到居家办公模式,组织们意识到数据科学协作比面对面协作要困难得多。虽然一些核心的数据科学任务(如数据准备、研究和数据模型迭代)可以通过一个数据科学家来管理,但大多数商业高管错误地忽视了协作,从而阻碍了远程生产力。
那么,如何促进项目参与者之间的有效远程协调以及项目数据的安全性呢?答案在于可共享的工作文件和与数据科学项目相关的数据,这些数据使得远程信息传播更具可行性。随着项目相关数据传播变得更简单,信息共享也变得更容易,从而促进了远程数据协作。数据科学项目的参与者可以利用基于云的工具来增强其研究的安全性,但太多领导者犯了未能鼓励协作的错误,从而降低了生产力。
结论
近年来,数据科学领域的巨大进展前所未有,确实令人惊叹。数据科学的发展使全球公司能够解决以前几乎没有现成答案的问题,这些创新得益于人工智能和机器学习的进步。
然而,随着数据科学领域的不断成熟和发展,是时候让顶级高管和他们所监督的数据科学团队摆脱更为临时和被动的工作方式了。数据科学家可以利用生成背景、一致性和更大协作的资源,如软件工作台,这些对于数据科学的成功可能至关重要。最终,项目将对数据科学家、工程师、分析师和研究人员的要求减少,他们将能更好地加速该领域的持续和惊人成功。
Nahla Davies 是一名软件开发人员和技术作家。在全职从事技术写作之前,她曾管理——除了其他有趣的事情外——担任了一家《Inc. 5,000》体验品牌机构的首席程序员,该机构的客户包括三星、时代华纳、Netflix 和索尼。
更多相关内容
通过 AI 实现 IoT 的持续改进 / 持续学习
原文:
www.kdnuggets.com/2016/11/continuous-improvement-iot-ai-learning.html
评论
概要

在这篇文章中,我们讨论了如何在 IoT 系统中实施持续改进和持续学习。持续改进是一个众所周知的概念(例如来自 Kaizen 或 Six Sigma)。对于 IoT,我们建议实施持续改进时,必须实施持续学习。具体来说,这意味着我们在一个环境中训练一个模型,并将其部署到 IoT 生态系统中的多个点(设备级、工作流级和系统级)。模型可以在各个设备之间构建和部署,以在不同点捕捉学习。这些学习然后通过一个中央模型进行整合。新数据会持续监控,当数据模式发生变化时,模型会重新校准以适应最新的知识。因此,这个模型与企业 AI 相关联。我们将在即将推出的企业 AI 实施课程,2024 年 1 月开课中讨论这些想法。
IoT 数据分析——数据流动和分析应用
在我们讨论持续改进和持续学习的问题之前,我们首先讨论一个问题:你可以在 IoT 生态系统中的哪些点应用分析?
通常,传感器生成的数据是时间序列格式,并且通常带有地理标签。这意味着,IoT 的分析有两种形式:时间序列和空间分析。时间序列分析通常会导致像异常检测这样的洞察。因此,异常检测用来检测异常模式。在此基础上,通过查看历史趋势、流数据、结合多个事件的数据(传感器融合),我们可以获得新的洞察。
IoT 设备生成大量数据。通常,IoT 分析的目标是尽可能接近事件地分析数据,因为我们需要实时交互。因此,对于 IoT 分析,我们经常需要执行边缘处理——这是我在 IoT 边缘分析中讨论过的主题。
此外,你可以在多个 IoT 流中关联数据。通常,在流处理中,我们试图了解现在发生了什么(而不是过去发生了什么)。传感器数据可以结合起来推断事件(复杂事件处理)。最后,你可以在数据湖中应用这些模型。
因此,IoT 分析(IoT 的数据科学)可以应用于 IoT 生态系统中的多个地方:边缘、流、数据湖,以及像复杂事件处理这样的模式。
物联网分析:实施持续改进
物联网数据的流动和物联网分析的应用显示在图表的右侧。左侧则讲述了持续改进。持续改进并不是一个新概念。它是精益管理和六西格玛的一部分,通过反馈循环等技术实现。
在这里,我们提出,在物联网的实施层面,持续改进与持续学习相关联。 具体而言,
-
每个设备都有一个状态和一个‘智能’——构建和/或部署模型的能力。模型可以在设备之间构建和部署,以在不同点捕捉学习。
-
这些学习随后通过中央模型进行整合。
持续学习可以在物联网设备的三个层级上实施
-
设备级别分析主要关注设备的状态和报告其状态,监控条件如阈值。
-
工作流级别分析主要关注一个或多个物理设备上的链式过程状态。
-
系统级别分析主要关注历史趋势和推断新的分析。
在这个背景下,分析是一个模型(基于数据集训练的算法)。分析通常可以在系统级别开发。一旦开发完成,它可以部署到设备(操作级别)或与其他分析链接以创建一个工作流(可能跨多个设备)。分析可以在多个层级进行协调。
持续学习和持续改进的实施
通过不断学习的模型实施持续改进的想法虽然复杂但并非纯概念。在行业中有许多实际例子,最著名的是Predix(GE)和西门子(工业 4.0)。
我们还可以看到在各种地方,如Salesforce.com Einstein、Dell Edge 分析与 Statistica、IBM 的 PMML 实现、Databricks(Spark)的 PMML 支持、Python 中的 PMML 支持以及H2O.ai 的 POJO,这些模型在一个平台上创建并在其他平台上部署。我们还可以看到它在DevOps 作为持续改进模型方面的应用,即角色的模糊和开发与运营的整合,分析处于中心位置。这也符合我一直在谈论的一个模型,即企业的 AI 层。
结论
在物联网的实施层面上,我们提出持续改进与持续学习相结合。具体来说,
-
持续改进需要持续学习。
-
每个设备都有一个状态和一个“智能”,并且可能具有构建和/或部署模型的能力。
-
模型可以跨设备构建和部署,以捕捉各个点的学习。这些学习然后通过中央模型进行整合。
-
通过不断学习的模型来实现持续改进的理念复杂但并非纯粹概念性的。在行业中有许多实际的这种模型的例子。
我们将在即将开设的实施企业人工智能课程(从 2017 年 1 月开始)中讨论这些想法。
个人简介: Ajit Jaokar的工作涉及物联网、预测分析和移动性的研究、创业和学术。他目前的研究重点是将数据科学算法应用于物联网应用。这包括时间序列、传感器融合和深度学习(主要在 R/Apache Spark 中)。这一研究支撑了他在牛津大学(物联网数据科学)和 UPM(马德里)的“城市科学”项目的教学。Ajit 还是 UPM(马德里大学)新成立的未来城市 AI/深度学习实验室的主任。
相关:
-
工业 4.0 内幕:第四次工业革命的驱动力是什么?
-
KDnuggets 顶级博主:与 Ajit Jaokar 关于物联网和数据科学的访谈
-
物联网(IoT)的数据科学:与传统数据科学的十个区别
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 部门
更多相关话题
机器学习的持续训练 – 成功策略的框架
原文:
www.kdnuggets.com/2021/04/continuous-training-machine-learning.html
评论
由 Or Itzary 和 Liran Nahum,Superwise.ai 数据科学家。

照片由 Monika Pejkovska 提供,来源 Unsplash。
机器学习模型的构建基于假设,即生产中使用的数据将与我们训练模型时观察到的数据相似。虽然对于某些特定用例这可能是正确的,但大多数模型在数据动态变化的环境中工作,在这种环境中“概念漂移”很可能发生并对模型的准确性和可靠性产生不利影响。
为了解决这个问题,机器学习模型需要定期重新训练。正如谷歌在 “MLOps: Continuous delivery and automation pipelines in machine learning” 中所述:
“为了应对这些挑战并保持模型在生产中的准确性,你需要执行以下操作:积极监控生产中模型的质量 [...] 并频繁重新训练你的生产模型。”
这个概念被称为‘持续训练’(CT),是 MLOps 实践的一部分。持续训练旨在自动和持续地重新训练模型,以适应数据中可能发生的变化。
有不同的方法/方法论来执行持续再训练,每种方法都有其优缺点和成本。然而,与赤脚行走的鞋匠类似,我们--数据科学家--似乎过度使用再训练,有时是手动进行的,常常将其作为“默认”解决方案,而没有足够的生产驱动洞察。
每个机器学习用例都有其自身动态的数据环境,可能会导致概念漂移:从实时交易到欺诈检测,面对对手改变数据分布,或是推荐引擎面临大量新电影和新趋势。然而,无论用例如何,在设计持续训练策略时需要解决三个主要问题:
1 - 何时应重新训练模型? 由于目标是保持运行的模型在任何时候都高度相关且表现最佳,模型应该多久重新训练一次?
2 - 应使用什么数据? 选择适当数据集的常见假设是数据的相关性与其时效性相关,这引发了一系列问题:我们应该仅使用新数据还是添加到旧数据集?旧数据和新数据之间的良好平衡是什么?多新的数据算作新数据,或者说旧数据和新数据的分界线在哪里?
3 - 应该重新训练什么? 我们可以仅仅替换数据并用相同的超参数重新训练相同的模型吗?还是应该采取更具侵入性的方法,运行一个完整的流程来模拟我们的研究过程?
上述三个问题中的每一个都可以单独回答,并有助于确定每种情况的最佳策略。然而,在回答这些问题时,还有一些需要考虑的因素,我们在这里进行调查。对于每个问题,我们描述了对应不同自动化水平和机器学习过程成熟度的不同方法。
何时重新训练?
三种最常见的策略是周期性重新训练、基于性能的重新训练,或者基于数据变化的重新训练。
周期性重新训练
周期性重新训练时间表是最简单直接的方法。通常,它是基于时间的:每三个月重新训练一次模型——但也可以基于数量,即每 100K 个新标签进行一次重新训练。
周期性重新训练的优势同样直截了当:这是一个非常直观且易于管理的方法,因为很容易知道下一个重新训练的迭代什么时候发生,并且易于实施。
不过,这种方法通常被证明是不适合或效率低下的。 你多久重新训练一次模型?每天?每周?每三个月?每年一次?虽然我们希望频繁重新训练以保持模型更新,但在没有实际原因(即没有概念漂移)的情况下过于频繁地重新训练模型是成本高昂的。此外,即使重新训练是自动化的,它仍然需要重要的资源——包括计算资源和数据科学团队的资源,这些团队需要监督重新训练过程以及部署后新模型在生产中的表现。然而,长时间间隔的重新训练可能会错过持续重新训练的关键,无法适应数据的变化,更不用说在噪声数据上重新训练的风险了。
归根结底,如果周期性重新训练的频率与领域的动态性相一致,那是有意义的。否则,选择一个随机的时间/里程碑可能会让你面临风险,并使你拥有的模型的相关性低于其之前的版本。
基于性能的触发器
这几乎是一个常识性的说法,基于古老的工程格言:“如果没有坏,就不要修理。” 第二种最常见的确定何时重新训练的方法是利用基于性能的触发器,一旦检测到性能下降,就重新训练模型。
这种方法,比第一个方法更具经验性,假设你对生产中模型的性能有持续的监控视角。
仅依赖性能的主要限制是获取真实数据所需的时间——如果你能够获取的话。在用户转化预测的情况下,可能需要 30 或 60 天才能获得真实数据,或者在交易欺诈检测或 LTV 等情况中可能需要 6 个月或更长时间。如果你需要等待这么长时间才能获得全面反馈,这意味着你将会在业务已经受到影响之后才重新训练模型。
另一个需要回答的非琐碎问题是:什么被视为‘性能退化’? 你可能依赖于阈值的敏感性和校准的准确性,这可能导致你过于频繁或不够频繁地重新训练。
总体来说,使用基于性能的触发器适用于反馈快速且数据量大的用例,如实时竞价,在这种情况下,你可以尽可能接近预测时间来测量模型的性能,时间间隔短且置信度高(数据量大)。
由数据变化驱动
这种方法是最具动态性的,它自然地从领域的动态中触发重新训练。通过测量输入数据的变化,即模型使用的特征分布的变化,你可以检测到数据漂移,这表明你的模型可能已经过时,需要在新数据上进行重新训练。
对于没有快速反馈或无法实时评估模型在生产环境中性能的情况,这是一种替代基于性能的方法。此外,即使在有快速反馈的情况下,将这种方法结合使用也是一种良好的实践,因为它可能表明性能不佳,即使没有退化。理解数据变化以启动重新训练过程是非常有价值的,尤其是在动态环境中。
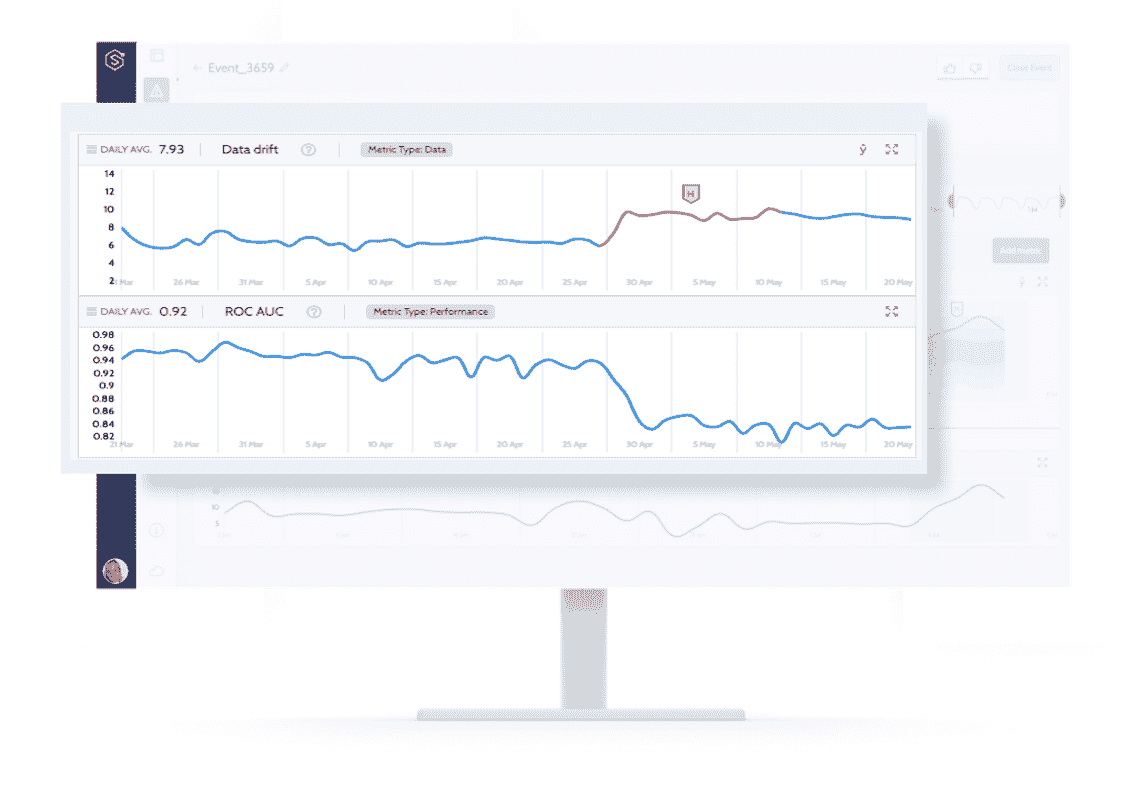
来自 superwise.ai 的截图。
上图由监控服务生成,展示了一个营销用例的数据漂移指标(上图)和性能 KPI(下图)。数据漂移图是一个时间轴,Y 轴显示了每一天的漂移水平(即该日的数据)相对于训练集。在这个营销用例中,新活动非常频繁地引入,业务扩展到新国家。显然,生产中的数据正在漂移,与模型训练时的数据变得越来越不相似。通过对模型在生产中的全面了解,重新训练迭代可以在业务观察到性能退化之前触发。
那么什么时候重新训练?这取决于一些关键因素,如反馈的可用性、数据的量以及对模型性能的可见性。总体而言,选择合适的重新训练时间没有“一刀切”的答案。相反,根据你的资源,目标应该尽可能以生产驱动为主。
应该使用什么数据?
虽然我们已经看到时机决定一切(即,什么时候重新训练我的模型?),现在让我们来看所有 MLOps 的核心:数据。在重新训练时,我如何选择要使用的正确数据?
固定窗口大小
最简单的方法是使用固定窗口大小作为训练集。例如,使用过去 X 个月的数据。显然,该方法的优势在于其简单性,非常直接。
缺点来源于选择合适窗口的挑战:如果窗口过宽,可能会错过新的趋势;如果窗口过窄,则会出现过拟合和噪声。窗口大小的选择还应考虑重新训练的频率:如果你只使用最近一个月的数据作为训练集,那么每三个月重新训练一次是没有意义的。
此外,所选的数据可能与在生产中流入的数据差异很大,因为它可能发生在变化点之后(在快速/突发变化的情况下),或者可能包含不规则事件(例如假期或特殊日子如选举日)、数据问题等。
总的来说,固定窗口方法,像其他所有“静态”方法一样,是一种简单的启发式方法,可能在某些情况下效果良好,但在变化率多样化且不规则事件(如假期或技术问题)常见的环境中,它将无法捕捉到环境的高度动态性。
动态窗口大小
动态窗口大小方法试图通过以更数据驱动的方式确定应包含多少历史数据,并将窗口大小视为可以优化的另一个超参数,从而解决一些预定义窗口大小的限制。
这种方法最适合于快速反馈的情况(例如实时竞价或食品配送预估)。可以将最相关的数据用作测试集,并在其上优化窗口大小,就像模型的其他超参数一样。在下面的案例中,通过取最近 3 周的数据来获得最佳性能,这就是本次迭代应选择的窗口。对于未来的迭代,可以根据与测试集的比较选择不同的窗口。
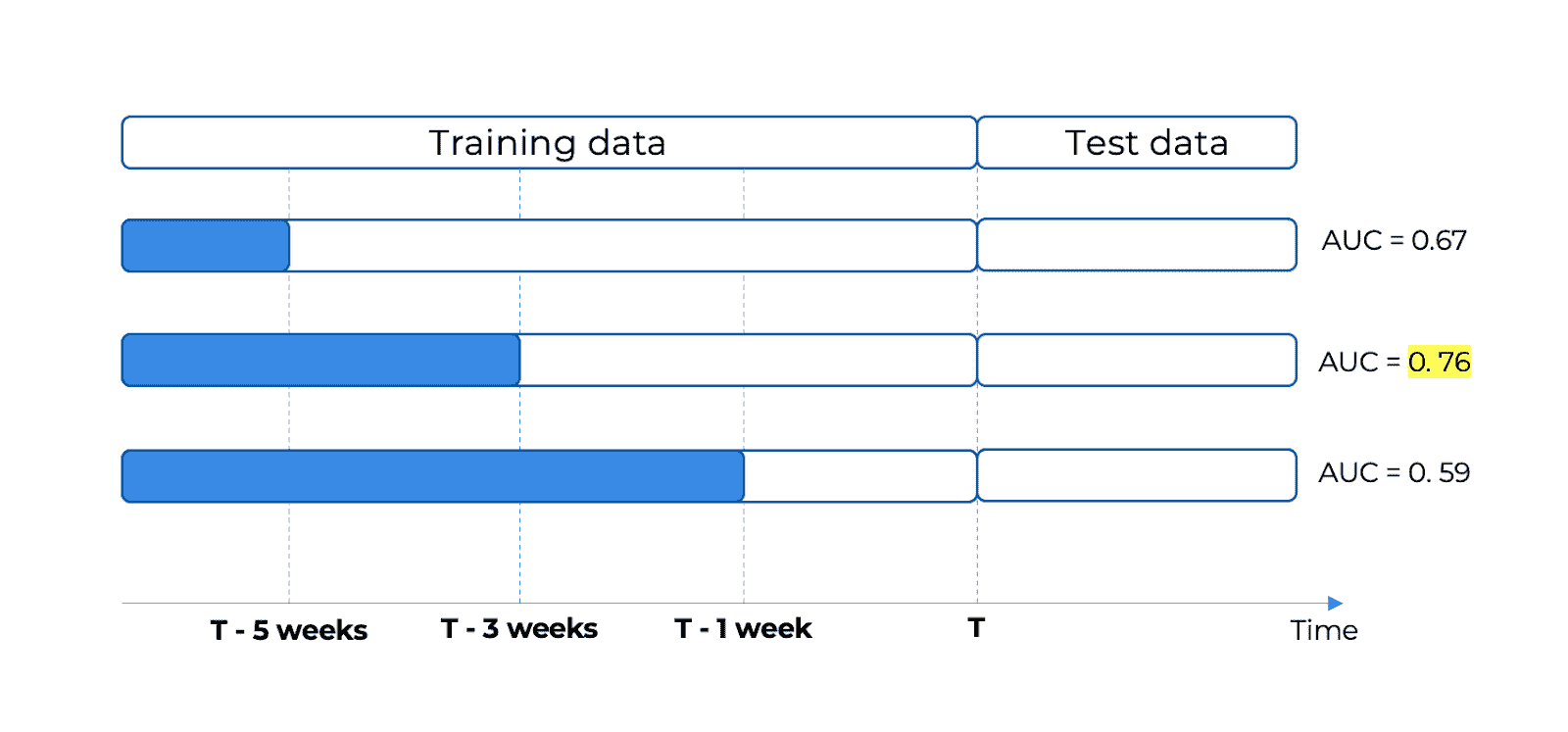
动态窗口大小方法的优势在于它更具数据驱动性,基于模型性能,这是最终标准,因此在高度时间敏感的环境中更为稳健。
缺点是它需要更复杂的训练流程(见下一个问题“训练什么”)来测试不同的窗口大小并选择最佳窗口,并且计算密集度更高。此外,像固定窗口大小一样,它假设最新的数据是最相关的,这并不总是正确的。
动态数据选择
选择数据以训练模型的第三种方法旨在实现任何重新训练策略的基本目标,也就是任何 ML 模型的基本假设:使用与生产数据相似的训练数据。换句话说,模型应该在尽可能与实际预测数据相似的数据上进行重新训练。这种方法复杂且需要对生产数据有很高的可见性。
要做到这一点,你需要对生产数据的演变进行透彻分析,以了解它是否以及如何随时间变化。 一种方法是计算每对日期之间的输入数据漂移,即某一天的数据与另一天天的数据有多不同,并生成一个热图,揭示数据随时间变化的模式,如下图所示。下面的热图是随时间变化的漂移评估的可视化,其中轴(列和行)是日期,每个点(矩阵中的单元格)表示两天之间的漂移水平,漂移越大,单元格越红。

Superwise 数据 DNA 视图。
上面,你可以看到由 superwise.ai 自动生成的这种分析结果,帮助发现与当前流数据尽可能相似的数据。从这个视图中可以轻松得出不同类型的见解:
1 - 十二月份的数据与其他时间的数据(前后)非常不同。这一见解使我们能够避免将整个时期视为一个整体,并在你想重新训练时排除这些天,因为这个月的数据不能代表你在生产中观察到的正常数据。
数据的季节性可以被可视化——这可能引发关于在工作日和周末使用不同模型的必要性的讨论。
还有一点非常强大的是:你实际上可以得到一个图像证明最新的数据不一定是最相关的。
简而言之,选择合适的数据来重新训练你的模型需要对生产数据行为有透彻的了解。虽然使用固定或动态窗口大小可能帮助你“勾选”选项,但这通常仍然是猜测,可能比高效更昂贵。
应该重新训练什么?
现在我们已经分析了何时重新训练以及使用什么数据,接下来解决第三个问题:应该重新训练什么?可以选择仅基于新数据重新训练(重新拟合)模型实例,包含一些或所有的数据准备步骤,或者采取更具侵入性的方法,运行一个模拟研究过程的完整管道。
重新训练的基本假设是,研究阶段训练的模型由于概念漂移将变得过时,因此需要重新训练。然而,在大多数情况下,模型实例只是研究阶段构建的更广泛管道的最后阶段,包括数据准备步骤。问题是:漂移的严重程度及其影响如何?或者在重新训练的背景下,模型管道的哪些部分应受到挑战?
在研究阶段,你会在模型管道步骤中尝试和评估许多元素,以优化模型。这些元素可以分为两个高层次的部分:数据准备和模型训练。数据准备部分负责准备数据(显然!)以供模型使用,包括特征工程、缩放、填补、降维等方法,模型训练部分负责选择最佳模型及其超参数。最后,你会得到一个顺序步骤的管道,这些步骤处理数据,准备数据以供模型使用,并使用模型预测目标结果。
仅用新相关数据对模型进行重新训练,即管道中的最后一步,是最简单和天真的方法,可能足以避免性能下降。然而,在某些情况下,这种仅模型的方法可能不够全面,应采取更全面的方法来进行重新训练的范围。扩展重新训练的范围可以从两个方面进行:
1 - 重新训练什么? 管道中的哪些部分应该使用新数据进行重新训练?
2 - 重新训练的层次: 你只是用新数据重新拟合模型(或其他步骤)吗?你会进行超参数优化吗?还是挑战模型本身的选择并测试其他模型类型?
另一种看法是,在重新训练过程中,你基本上是在尝试自动化并避免数据科学家在没有自动重新训练过程的情况下进行的模型优化研究的手动工作。因此,你需要决定你想在多大程度上模拟手动研究过程,如下图所示。
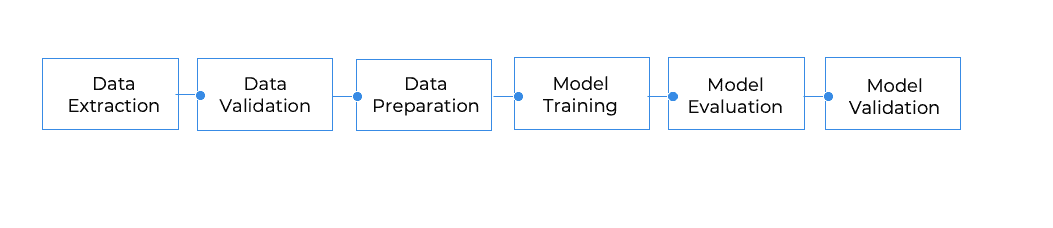
如《MLOps: Continuous delivery and automation pipelines in machine learning》中所述的模型研究阶段。
请注意,自动化流程的第一步更加复杂,随着这些实验周围自动化的增加,过程变得更加强健和灵活,以适应变化,但也增加了复杂性,因为需要考虑更多的终端情况和检查。
示例与结论
以一个简单的模型管道为例,这个管道是我们出色的数据科学团队为某些分类任务进行手动研究的结果:
你可以采取简单的方法,仅仅重新训练模型本身,让它学习一个新的树,或者你可以包括一些(或全部)数据准备步骤(例如,重新学习填补器中的均值或缩放器中的最小/最大值)。但除了选择要重新训练的步骤之外,你还需要决定到什么程度。例如,即使你选择仅重新训练模型,也可以在多个层次上进行。你可以仅仅重新训练模型本身,让它学习一个新的树,即 model.fit (new_X, new_y),或者你可以搜索和优化模型超参数(最大深度、最小叶子大小、最大叶子节点等),甚至挑战模型本身的选择,测试其他模型类型(例如,逻辑回归和随机森林)。数据准备步骤也可以(且应该)重新训练,以测试不同的缩放器或不同的填补方法,甚至测试不同的特征选择。
当选择更全面的方法并执行超参数优化/模型搜索时,你还可以使用旨在自动化构建和优化模型管道过程的 Auto-ML 框架,包括数据准备、模型搜索和超参数优化。它不必涉及复杂的元学习。它可以很简单:用户选择一系列模型和参数。有很多工具可用:AutoKeras,Auto SciKitLearn。然而,尽管 AutoML 非常吸引人,但它并不免除用户必须拥有一个强健的过程来跟踪、测量和监控模型在整个生命周期中的表现,特别是在生产环境中部署前后。
到头来,“翻转开关”和自动化你的流程必须伴随强健的流程,以确保你对数据和模型保持控制。
为了实现高效的持续培训,你应该能够以生产驱动的见解为主导。对于任何和每个用例,创建一个强健的机器学习基础设施严重依赖于对模型健康状况和生产中的数据健康状况的可见性和控制能力。这就是成为数据驱动的数据科学家的要求。
原文。经许可转载。
相关:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关话题
可视化 10 亿数据点:做对了 - 8 月 18 日网络研讨会
原文:
www.kdnuggets.com/2016/08/continuum-visualizing-1-billion-points-data.html
可视化是探索和传达数据见解的最佳方式。无论你处理的是地理空间数据、时间序列数据还是表格数据,互动图形都能让你团队中的每个人,从分析师到高管,都能理解数据中的模式。
但随着数据量增长到数百万甚至数十亿点,传统的可视化技术会出现问题。无论你是将数据加载到有限的内存中,还是将信号与噪声分离,当成千上万的数据点占据每一个像素,数据量变大时,可视化变得具有挑战性。
我们在这里提供帮助 - Continuum Analytics 的数据科学家和工程师们开发了一种新的大数据可视化方法,称为 datashading。请加入我们,于 8 月 18 日参加由 Continuum Analytics 首席技术官 Peter Wang 和解决方案架构师 Dr. Jim Bednar 主持的关于大数据可视化的网络研讨会。
在本次网络研讨会中,你将学习如何:
-
以正确的方式可视化大数据 - 以及为什么这么多人做错了
-
在 Jupyter Notebook 中互动式地可视化 30 亿数据点
-
使用不到 300 行 Python 创建实时互动的“大数据”仪表盘,无需 JavaScript
有问题吗? 点击这里 联系我们。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
相关主题
在 Python 中将字节转换为字符串:初学者教程
原文:
www.kdnuggets.com/convert-bytes-to-string-in-python-a-tutorial-for-beginners
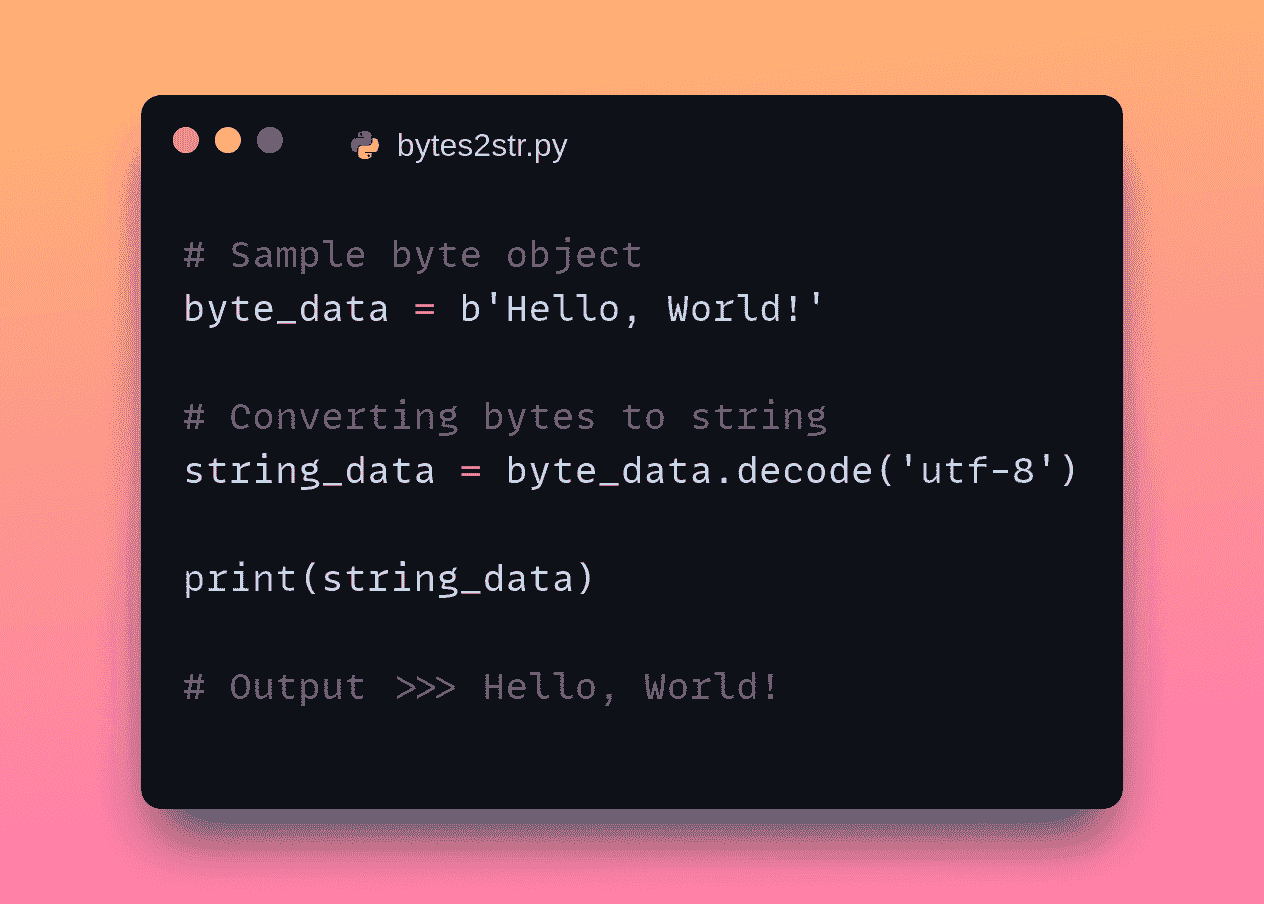
图片由作者提供
在 Python 中,字符串是不可变的字符序列,具有可读性,并通常编码为特定的字符编码,例如 UTF-8。字节表示原始的二进制数据。字节对象是不可变的,由字节数组(8 位值)组成。在 Python 3 中,字符串文字默认是 Unicode,而字节文字以 b 为前缀。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你在 IT 领域的组织
将字节转换为字符串是 Python 中的一个常见任务,特别是在处理来自网络操作、文件 I/O 或某些 API 响应的数据时。这是一个关于如何在 Python 中将字节转换为字符串的教程。
1. 使用 decode() 方法将字节转换为字符串
将字节转换为字符串的最简单方法是使用字节对象(或字节字符串)上的 decode() 方法。此方法需要指定所使用的字符编码。
注意:字符串没有关联的二进制编码,而字节没有关联的文本编码。要将字节转换为字符串,你可以在字节对象上使用
decode()方法。要将字符串转换为字节,你可以在字符串上使用encode()方法。在这两种情况下,都需要指定使用的编码。
示例 1:UTF-8 编码
这里我们使用 decode() 方法将 byte_data 转换为 UTF-8 编码的字符串:
# Sample byte object
byte_data = b'Hello, World!'
# Converting bytes to string
string_data = byte_data.decode('utf-8')
print(string_data)
你应该得到以下输出:
Output >>>
Hello, World!
你可以像这样验证转换前后的数据类型:
print(type(bytes_data))
print(type(string_data))
数据类型应该如预期那样:
Output >>>
<class 'bytes'>
<class 'str'>
示例 2:处理其他编码
有时,字节序列可能包含除 UTF-8 之外的编码。你可以通过在调用字节对象的 decode() 方法时指定相应的编码方案来处理这种情况。
下面是如何使用 UTF-16 编码解码字节字符串的方法:
# Sample byte object
byte_data_utf16 = b'\xff\xfeH\x00e\x00l\x00l\x00o\x00,\x00 \x00W\x00o\x00r\x00l\x00d\x00!\x00'
# Converting bytes to string
string_data_utf16 = byte_data_utf16.decode('utf-16')
print(string_data_utf16)
这是输出结果:
Output >>>
Hello, World!
使用 Chardet 检测编码
实际上,你可能并不总是知道所使用的编码方案。不匹配的编码可能导致错误或乱码。那么你该如何解决这个问题呢?
你可以使用chardet 库(使用 pip 安装 chardet: pip install chardet)来检测编码。然后在decode()方法调用中使用它。下面是一个示例:
import chardet
# Sample byte object with unknown encoding
byte_data_unknown = b'\xe4\xbd\xa0\xe5\xa5\xbd'
# Detecting the encoding
detected_encoding = chardet.detect(byte_data_unknown)
encoding = detected_encoding['encoding']
print(encoding)
# Converting bytes to string using detected encoding
string_data_unknown = byte_data_unknown.decode(encoding)
print(string_data_unknown)
你应该得到类似的输出:
Output >>>
你好
解码中的错误处理
你正在使用的bytes对象可能并不总是有效;它有时可能包含指定编码的无效序列。这将导致错误。
在这里,byte_data_invalid包含无效序列 \xff:
# Sample byte object with invalid sequence for UTF-8
byte_data_invalid = b'Hello, World!\xff'
# try converting bytes to string
string_data = byte_data_invalid.decode('utf-8')
print(string_data)
当你尝试解码时,会出现以下错误:
Traceback (most recent call last):
File "/home/balapriya/bytes2str/main.py", line 5, in <module>string_data = byte_data_invalid.decode('utf-8')
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 13: invalid start byte</module>
但是有几种方法可以处理这些错误。你可以在解码时忽略这些错误,也可以用占位符替换无效序列。
忽略错误
要在解码时忽略无效序列,你可以将errors设置为ignore,在decode()方法调用中:
# Sample byte object with invalid sequence for UTF-8
byte_data_invalid = b'Hello, World!\xff'
# Converting bytes to string while ignoring errors
string_data = byte_data_invalid.decode('utf-8', errors='ignore')
print(string_data)
你现在会得到以下没有错误的输出:
Output >>>
Hello, World!
替换错误
你也可以用占位符替换无效序列。为此,你可以将errors设置为replace,如下所示:
# Sample byte object with invalid sequence for UTF-8
byte_data_invalid = b'Hello, World!\xff'
# Converting bytes to string while replacing errors with a placeholder
string_data_replace = byte_data_invalid.decode('utf-8', errors='replace')
print(string_data_replace)
现在,无效序列(在末尾)被占位符替换:
Output >>>
Hello, World!�
2. 使用 str() 构造函数将字节转换为字符串
decode()方法是将字节转换为字符串的最常见方法。但你也可以使用str()构造函数从字节对象获取字符串。你可以将编码方案传递给str(),如下所示:
# Sample byte object
byte_data = b'Hello, World!'
# Converting bytes to string
string_data = str(byte_data,'utf-8')
print(string_data)
这输出:
Output >>>
Hello, World!
3. 使用 Codecs 模块将字节转换为字符串
在 Python 中将字节转换为字符串的另一种方法是使用内置的codecs模块中的decode()函数。该模块提供了编码和解码的便利函数。
你可以像下面这样调用decode()函数,传入字节对象和编码方案:
import codecs
# Sample byte object
byte_data = b'Hello, World!'
# Converting bytes to string
string_data = codecs.decode(byte_data,'utf-8')
print(string_data)
正如预期的,这也输出:
Output >>>
Hello, World!
总结
在本教程中,我们学习了如何在 Python 中将字节转换为字符串,同时优雅地处理不同的编码和潜在的错误。具体来说,我们学习了如何:
-
使用
decode()方法将字节转换为字符串,指定正确的编码。 -
使用
errors参数处理潜在的解码错误,选项包括ignore或replace。 -
使用
str()构造函数将有效的字节对象转换为字符串。 -
使用 Python 标准库中内置的
codecs模块的decode()函数将有效的字节对象转换为字符串。
编程愉快!
Bala Priya C** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她享受阅读、写作、编码和咖啡!目前,她正在通过编写教程、操作指南、观点文章等,学习并与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。**
更多相关话题
如何将图片转换为数字
评论
体验周围世界几乎无法用几句话来捕捉,从蚂蚁的细致步伐,到巴勃罗·毕加索和比阿特丽克斯·波特的作品,再到孤独而庄严的橡树。认为我们能将一切归结为零和一是荒谬的。尽管如此,我们确实做到了。事实上,我们的图像现在如此逼真,以至于我们费尽心思重新引入伪影,比如宝丽来相片的褪色颜色或胶卷上的划痕。
这可能对浪漫主义是一种打击,但对机器学习从业者来说却是极大的好运。将图像转换为数字使其可以进行计算。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 加速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT

颜色感知
颜色吸引我,因为它更多的是关于人类感知的生理学和心理学,而不是物理学。我们所有的标准都是由人类感知决定的。需要覆盖的范围、表示颜色所需的通道数量、必须指定颜色的分辨率,以及信息密度和存储需求,都取决于人类的视网膜和视觉皮层。
这也意味着,与所有人类事务一样,存在很大的变异性。存在一些缺陷,比如color blindness(我自己有deuteranomaly,一种红绿色盲的类型),也有一些具有非凡能力的人,比如tetrachromats,他们有四种颜色感受器,而不是三种,能够区分其他人无法识别的颜色。因此,请记住,我们对感知所做的所有陈述仅仅是概括,并且会存在个体差异。
尽管光子在所有频率上振动,我们有三种不同类型的颜色感知锥体,每种锥体都有其特征频率响应,对特定颜色有强烈的反应。这意味着,通过精心选择颜色和强度的三种光源的组合,可以使我们体验到自然界中我们能够看到的任何颜色。
制造颜色
在计算机屏幕中,这通常是通过红色、绿色和蓝色光源来完成的,通常是发光二极管(LED)。

实际上,计算机屏幕上的红色、绿色和蓝色 LED 无法表示我们能看到的所有颜色。为了制造彩色 LED,引入了一种化学物质,该物质在大致正确的颜色下发光。这些接近理想的红色、蓝色和绿色,但并不完美。因此,现实世界中你能看到的颜色范围(色域)与计算机屏幕上能看到的颜色之间存在一定的差距。
作为附带说明,激光能够产生更接近理想的颜色。市售的激光投影系统覆盖了更多的人类可见色域,激光微阵列用于计算机屏幕是当前的研究和开发课题。
将颜色转换为数字
屏幕上的每个像素都是一个由红色、绿色和蓝色光源组成的三元组,但当你从足够远的地方看这些像素时,它们太小以至于你的眼睛无法区分,它们看起来像是一小块单一的颜色。确定产生哪种颜色的一种方法是指定每个光源的强度水平。由于人类对颜色强度的可觉察差异 (JND)往往保持在百分之一左右,使用 256 个离散级别提供了足够精细的控制,使颜色渐变看起来很平滑。
256 个强度级别可以用 8 位或 1 字节表示。它也可以用两个十六进制数字表示,范围从 0x00(零亮度)到 0xff(最大亮度)。指定三种颜色的强度需要三倍的位数:6 个十六进制数字(24 位或 3 字节)。十六进制表示提供了一种简洁的方式来表示红-绿-蓝颜色。前两位数字显示红色级别,第二对数字对应绿色级别,第三对数字对应蓝色级别。以下是一些极端的示例。

有许多更有用的颜色十六进制代码。为了方便和代码的可读性,颜色也可以表示为十进制三元组,例如(255, 255, 255)表示白色,或(0, 255, 0)表示绿色。
从像素构建图像
为了重建整个图像,计算机使用可靠的技巧,即将图像切割成小块。为了生成高质量图像,需要将小块做得非常小,以至于人眼难以单独识别它们。
 图像来源:黛安·罗赫
图像来源:黛安·罗赫
每个像素的颜色可以用 6 位十六进制数字或 0 到 255 之间的三元组表示。在图像处理中,通常采用后者。为了方便,红色、绿色和蓝色的像素值被分离到各自的数组中。
将图像读取到 Python 代码中
读取图像到 Python 的一个可靠方法是使用Pillow,这是经典 Python 图像库或 PIL 的一个积极维护的分支,以及 Numpy。
import numpy as np
from PIL import Image
img = np.asarray(Image.open("image_filename.jpg"))
当读取彩色图像时,结果对象img是一个三维的 Numpy 数组。数据类型通常是numpy.uint8,这是表示 0 到 255 之间颜色级别的自然且高效的方法。我尚未确定这总是如此,因此在开始处理数据集中的图像之前,最好确认一下。
为了便于计算,我发现将图像值转换为 0 到 1 之间的浮点数最为方便。在 python3 中,最简单的方法是除以 255:img *= 1/255
记住图像在存储和传输时,可以用各种令人眼花缭乱的格式表示。这些解析是一个单独的工作。我们将依赖Image.open()和numpy.asarray()为我们完成所有这些转换。我仍然没找到绕过验证像素范围和数据类型的方法,但我会继续关注。
现在我们将所有图像信息以紧凑的数字集合形式存储。在我们的数组中,第 0 维表示像素行,从图像的顶部到底部。第 1 维表示从左到右的列。第 2 维表示红色、绿色和蓝色的颜色通道,按此顺序。
在这种格式中,你可以通过img[row, column, channel]获取所需的任何值。左上角像素的绿色值由img[0, 0, 1]给出。左下角像素的红色值是img[2, 0, 0]。你可以使用Numpy 的切片和索引工具。
不要被第 0 行在图像顶部的事实困扰。当你向上数行号时,你实际上是在向图像底部移动。这与我们的 (x, y) 坐标轴约定不符,但与我们二维数组的 [行, 列] 布局完全匹配。
还可以有一个第四个颜色通道表示像素的透明度,称为 alpha。它控制图像下方的内容透过的程度。如果像素范围是 0 到 1,那么 alpha 为 1 完全不透明,alpha 为 0 完全透明。如果不存在 alpha,则假定 alpha 完全不透明。
另一种特殊情况是灰度图像,其中每个像素的三个颜色通道具有相同的值。由于重复,为了节省空间,只存储一个颜色通道,其他的则隐含。二维数组也可以用于任何类型的单色图像。按定义,它们只有一个颜色通道。
让乐趣开始吧
现在我们可以将图像转换为浮点数组,我们可以真正大展身手。我们可以对像素值进行加法、乘法和重新排列。我们可以调整色调和亮度,裁剪和滤镜。我们可以去除错误的像素,甚至在神经网络的帮助下识别不同的狗种。所有这些都因为我们看到的东西现在变成了数字格式。
将图像转换为数字并不会亵渎它,反而是对它的一种致敬。这个过程需要小心和对媒介的深深尊重。它还需要大量的磁盘空间。一张 8 百万像素的彩色图像未压缩时占据 24 兆字节。他们说一图胜千言,但这一点他们错了。它的价值是百万倍的。
原文。经许可转载。
相关内容:
更多相关话题
将 Python 字典转换为 JSON:初学者教程
原文:
www.kdnuggets.com/convert-python-dict-to-json-a-tutorial-for-beginners
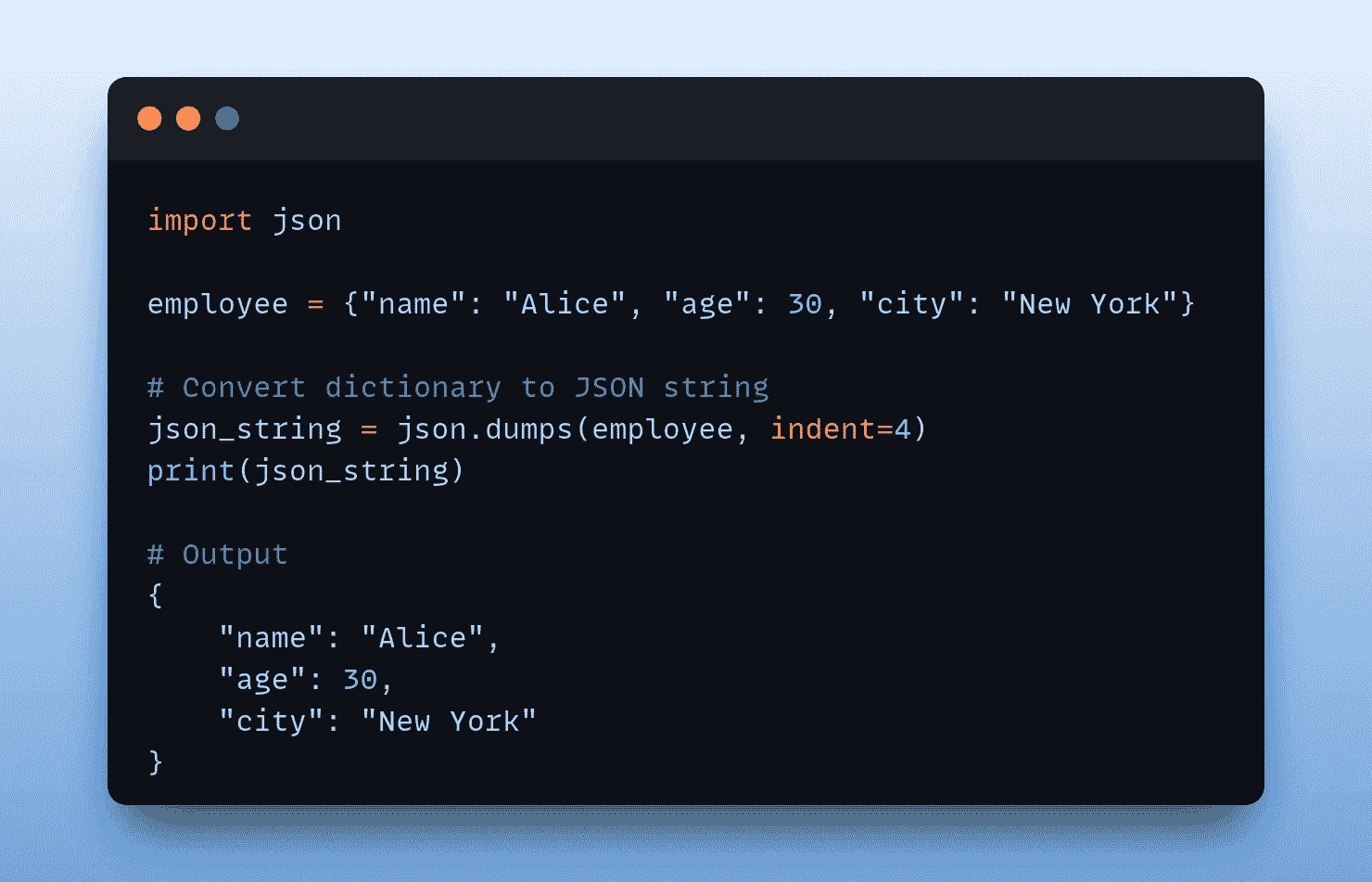
图片由作者提供
在用 Python 构建应用程序时,JSON 是你将经常使用的数据格式之一。如果你曾经处理过 API,你可能已经熟悉从 API 解析 JSON 响应。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT
如你所知,JSON 是一种基于文本的数据交换格式,它以键值对的形式存储数据,并且易于人类阅读。Python 字典也是以键值对的形式存储数据。这使得将 JSON 字符串加载到字典中进行处理以及将字典中的数据转储为 JSON 字符串变得直观。
在本教程中,我们将学习如何使用 内置的 json 模块将 Python 字典转换为 JSON。所以让我们开始编码吧!
将 Python 字典转换为 JSON 字符串
要将 Python 字典转换为 JSON 字符串,你可以使用 json 模块中的 dumps() 函数。dumps() 函数接受一个 Python 对象,并返回 JSON 字符串表示。然而,实际上你需要转换的不是单个字典,而是一个集合,例如字典列表。
那么我们来选择一个这样的例子。假设我们有 books,这是一个字典列表,每个字典包含一本书的信息。所以每本书的记录都是一个包含以下键的 Python 字典:title、author、publication_year 和 genre。
在调用 json.dumps() 时,我们设置了可选的 indent 参数——JSON 字符串中的缩进,这有助于提高可读性(是的,我们在进行 JSON 的漂亮打印 ??):
import json
books = [
{
"title": "The Great Gatsby",
"author": "F. Scott Fitzgerald",
"publication_year": 1925,
"genre": "Fiction"
},
{
"title": "To Kill a Mockingbird",
"author": "Harper Lee",
"publication_year": 1960,
"genre": "Fiction"
},
{
"title": "1984",
"author": "George Orwell",
"publication_year": 1949,
"genre": "Fiction"
}
]
# Convert dictionary to JSON string
json_string = json.dumps(books, indent=4)
print(json_string)
当你运行上述代码时,你应该会得到类似的输出:
**Output >>>**
[
{
"title": "The Great Gatsby",
"author": "F. Scott Fitzgerald",
"publication_year": 1925,
"genre": "Fiction"
},
{
"title": "To Kill a Mockingbird",
"author": "Harper Lee",
"publication_year": 1960,
"genre": "Fiction"
},
{
"title": "1984",
"author": "George Orwell",
"publication_year": 1949,
"genre": "Fiction"
}
]
将嵌套的 Python 字典转换为 JSON 字符串
接下来,让我们以一个嵌套的 Python 字典列表为例,并获取它的 JSON 表示。我们将通过添加一个 “reviews” 键来扩展 books 字典。这个键的值是一个字典列表,每个字典包含关于评论的信息,即 “user”、“rating” 和 “comment”。
所以我们将 books 字典修改如下:
import json
books = [
{
"title": "The Great Gatsby",
"author": "F. Scott Fitzgerald",
"publication_year": 1925,
"genre": "Fiction",
"reviews": [
{"user": "Alice", "rating": 4, "comment": "Captivating story"},
{"user": "Bob", "rating": 5, "comment": "Enjoyed it!"}
]
},
{
"title": "To Kill a Mockingbird",
"author": "Harper Lee",
"publication_year": 1960,
"genre": "Fiction",
"reviews": [
{"user": "Charlie", "rating": 5, "comment": "A great read!"},
{"user": "David", "rating": 4, "comment": "Engaging narrative"}
]
},
{
"title": "1984",
"author": "George Orwell",
"publication_year": 1949,
"genre": "Fiction",
"reviews": [
{"user": "Emma", "rating": 5, "comment": "Orwell pulls it off well!"},
{"user": "Frank", "rating": 4, "comment": "Dystopian masterpiece"}
]
}
]
# Convert dictionary to JSON string
json_string = json.dumps(books, indent=4)
print(json_string)
注意,我们使用了相同的缩进值 4,运行脚本得到如下输出:
**Output >>>**
[
{
"title": "The Great Gatsby",
"author": "F. Scott Fitzgerald",
"publication_year": 1925,
"genre": "Fiction",
"reviews": [
{
"user": "Alice",
"rating": 4,
"comment": "Captivating story"
},
{
"user": "Bob",
"rating": 5,
"comment": "Enjoyed it!"
}
]
},
{
"title": "To Kill a Mockingbird",
"author": "Harper Lee",
"publication_year": 1960,
"genre": "Fiction",
"reviews": [
{
"user": "Charlie",
"rating": 5,
"comment": "A great read!"
},
{
"user": "David",
"rating": 4,
"comment": "Engaging narrative"
}
]
},
{
"title": "1984",
"author": "George Orwell",
"publication_year": 1949,
"genre": "Fiction",
"reviews": [
{
"user": "Emma",
"rating": 5,
"comment": "Orwell pulls it off well!"
},
{
"user": "Frank",
"rating": 4,
"comment": "Dystopian masterpiece"
}
]
}
]
将 Python 字典转换为 JSON 时排序键
dumps 函数有几个可选参数。我们已经使用了其中一个可选参数 indent。另一个有用的参数是 sort_keys。当你需要在将 Python 字典转换为 JSON 时排序键时,这尤其有用。
因为 sort_keys 默认为 False,所以如果你需要在转换为 JSON 时排序键,可以将其设置为 True。
这是一个简单的 person 字典:
import json
person = {
"name": "John Doe",
"age": 30,
"email": "john@example.com",
"address": {
"city": "New York",
"zipcode": "10001",
"street": "123 Main Street"
}
}
# Convert dictionary to a JSON string with sorted keys
json_string = json.dumps(person, sort_keys=True, indent=4)
print(json_string)
如所示,键按字母顺序排序:
**Output >>>**
{
"address": {
"city": "New York",
"street": "123 Main Street",
"zipcode": "10001"
},
"age": 30,
"email": "john@example.com",
"name": "John Doe"
}
处理不可序列化的数据
在我们到目前为止编写的示例中,字典的键和值都是 JSON 可序列化的。具体来说,值都是字符串或整数。但情况可能并非总是如此。一些常见的不可序列化数据类型包括 datetime、Decimal 和 set。
不用担心。你可以通过为这些数据类型定义自定义序列化函数来处理不可序列化的数据类型。然后将 json.dumps() 的 default 参数设置为你定义的自定义函数。
这些自定义序列化函数应该将不可序列化的数据转换为 JSON 可序列化的格式(谁能猜到呢!)。
这是一个简单的 data 字典:
import json
from datetime import datetime
data = {
"event": "Meeting",
"date": datetime.now()
}
# Try converting dictionary to JSON
json_string = json.dumps(data, indent=2)
print(json_string)
我们像以前一样使用了 json.dumps(),所以我们会遇到以下 TypeError 异常:
Traceback (most recent call last):
File "/home/balapriya/djson/main.py", line 10, in <module>
json_string = json.dumps(data, indent=2)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.11/json/__init__.py", line 238, in dumps
**kw).encode(obj)
^^^^^^^^^^^
...
File "/usr/lib/python3.11/json/encoder.py", line 180, in default
raise TypeError(f'Object of type {o.__class__.__name__} '
TypeError: Object of type datetime is not JSON serializable</module>
错误的相关部分是:对象类型 datetime 不能被 JSON 序列化。好吧,现在我们做以下操作:
-
定义一个
serialize_datetime函数,将datetime对象转换为 ISO 8601 格式,使用isoformat()方法。 -
在调用
json.dumps()时,我们将default参数设置为serialize_datetime函数。
所以代码如下:
import json
from datetime import datetime
# Define a custom serialization function for datetime objects
def serialize_datetime(obj):
if isinstance(obj, datetime):
return obj.isoformat()
data = {
"event": "Meeting",
"date": datetime.now()
}
# Convert dictionary to JSON
# with custom serialization for datetime
json_string = json.dumps(data, default=serialize_datetime, indent=2)
print(json_string)
这里是输出结果:
**Output >>>**
{
"event": "Meeting",
"date": "2024-03-19T08:34:18.805971"
}
结论
就这样!
总结一下:我们讨论了将 Python 字典转换为 JSON,并根据需要使用 indent 和 sort_keys 参数。我们还学习了如何处理 JSON 序列化错误。
你可以在 GitHub 上找到代码示例。我会在另一个教程中见到大家。在那之前,继续编码吧!
Bala Priya C**** 是一位来自印度的开发者和技术作者。她喜欢在数学、编程、数据科学和内容创作的交汇点工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过编写教程、操作指南、观点文章等,学习并与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关内容
如何将 RGB 图像转换为灰度图像
原文:
www.kdnuggets.com/2019/12/convert-rgb-image-grayscale.html
有时需要将彩色图像转换为灰度图像。这一需求在加载火星表面拍摄的图像时出现,作为端到端机器学习课程 313,高级神经网络方法的一部分。我们处理了混合的彩色和灰度图像,需要将它们转换为统一的格式——全部为灰度图像。我们将使用 Python,结合 Pillow、Numpy 和 Matplotlib 包。
顺便提一下,本帖子中的所有有趣信息都来自维基百科上的灰度图。(如果你觉得有帮助,也许可以给他们捐一美元。)
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
读取彩色图像
该代码用于加载 jpeg 图像,供自编码器作为输入。这通过使用 Pillow 和 Numpy 实现:
from PIL import Image
import numpy as np
color_img = np.asarray(Image.open(img_filename)) / 255
这将图像读取并转换为 Numpy 数组。有关此过程的详细描述,请查看上一篇文章:如何将图片转换为数字。对于灰度图像,结果是一个二维数组,行数和列数等于图像的像素行数和列数。较低的数值表示较暗的阴影,较高的数值表示较亮的阴影。像素值的范围通常是 0 到 255。我们将其除以 255,以获得 0 到 1 的范围。
彩色图像表示为三维 Numpy 数组——由三个二维数组组成,分别对应红色、绿色和蓝色通道。每个数组像灰度数组一样,每个像素一个值,其范围相同。

图片来源:黛安·罗赫
简单易行:平均化通道
将彩色图像 3D 数组转换为灰度 2D 数组的直观方法是,对于每个像素,取红色、绿色和蓝色像素值的平均值以获得灰度值。这将每个颜色通道贡献的亮度或 亮度 合并成一个合理的灰色近似值。
img = numpy.mean(color_img, axis=2)
axis=2 参数告诉 numpy.mean() 对所有三个颜色通道进行平均。 (axis=0 会在像素行之间平均,axis=1 会在像素列之间平均。)

好吧,实际上……通道相关的亮度感知
在我们眼中,绿色看起来比蓝色亮大约十倍。通过许多精心设计的实验,心理学家已经弄清楚了我们如何感知红色、绿色和蓝色的亮度差异。他们为我们的通道平均提供了一套不同的权重,以获得总亮度。
结果明显不同,对我来说,更加准确。

好吧,实际上……Gamma 压缩
当亮度较低时,我们能够看到细微的差异,但在高亮度水平下,我们对这些差异的敏感度要低得多。为了避免在高亮度下浪费精力表示不可察觉的差异,颜色尺度被扭曲,使其在范围的低端集中更多值,而在高端则分布得更广。这就是 gamma 压缩。
在计算灰度亮度之前,为了撤销 gamma 压缩的效果,有必要应用逆操作,即 gamma 扩展:
Gamma 压缩的好处在于它消除了在平滑变化的暗色中出现的带状效果,比如黄昏时天空的照片。缺点是如果我们要做加法、减法或平均值等操作,我们必须先撤销压缩,将亮度恢复为线性表示。

在考虑 gamma 压缩后,图像的亮度得到增强,使其更接近原始图像的亮度。最终,我们得到高质量的灰度表示。
好吧,实际上……线性近似
相比于之前我们使用的加权平均,伽马解压和重新压缩的计算成本非常高。有时,速度比尽可能准确的亮度计算更为重要。对于这种情况,有一种线性近似方法:
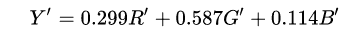
这可以让你得到一个更接近伽马压缩校正版本的结果,但不需要额外的计算时间。

正如你所看到的,结果一点也不好。它们往往稍显偏暗,尤其是在红色中间值范围,但在大多数实际方面可以说也非常好。
这种亮度计算方法在标准 ITU-R BT.601 Studio encoding parameters of digital television for standard 4:3 and wide screen 16:9 aspect ratios.中进行了规范,该标准在 1983 年获得了艾美奖。
我该使用哪个?
如果接近就足够好,或者你真的关心速度,可以使用伽马校正的线性近似。这是 MATLAB、 Pillow 和 OpenCV 使用的方法。它包含在我的 Lodgepole 图像和视频处理工具箱中:
import lodgepole.image_tools as lit
gray_img = lit.rgb2gray_approx(color_img)
但如果你确实追求最佳结果,可以花费在整个伽马解压 - 视觉亮度校正 - 伽马重新压缩流程上:
import lodgepole.image_tools as lit
gray_img = lit.rgb2gray(color_img)
如果阅读到这里你仍坚持将三个通道直接平均,我会对你做出评判。
现在去制作美丽的灰度图像吧!
原文。经允许转载。
布兰登·罗赫 是 LinkedIn 的高级机器学习工程师。布兰登的专长是创建算法和计算方法。你可以在 这里 找到他的工作实例。
更多相关主题
使用 tfidfvectorizer 将文本文档转换为 TF-IDF 矩阵
原文:
www.kdnuggets.com/2022/09/convert-text-documents-tfidf-matrix-tfidfvectorizer.html

图片来源于作者
TF-IDF 矩阵
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
词频-逆文档频率 (TFIDF) 是一个统计公式,用于根据单词的相关性将文本文档转换为向量。它基于词袋模型来创建一个包含文档中相关性较低和较高单词信息的矩阵。
TF-IDF 在自然语言处理任务、主题建模和机器学习任务中特别有用。它帮助算法利用单词的重要性来预测结果。
词频 (TF)
它是文档 (d) 中单词 (w) 出现次数与文档中总单词数的比率。通过这个简单的公式,我们测量的是一个单词在文档中的频率。
例如,如果句子有 6 个单词,其中包含两个“the”,这个单词的 TF 比率就是 (2/6)。
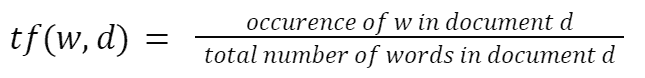
逆文档频率 (IDF)
IDF 计算单词在语料库 D 中的重要性。像“of, we, are”这样的高频词几乎没有意义。它通过将语料库中文档的总数除以包含该单词的文档数来计算。
词频-逆文档频率 (TFIDF)
TF-IDF 是词频和逆文档频率的乘积。它对语料库中稀有而文档中常见的单词给予更多重要性。
来自 Vaibhav Jayaswal 博客的 TF-IDF 矩阵示例:
语料库中有两个文档:文本 A 和文本 B。我们将使用它们来创建 TF-IDF 矩阵。
-
文本 A: 木星是最大的行星
-
文本 B: 火星是离太阳第四近的行星
下表显示了 A 和 B 的 TF 值、IDF 值以及 A 和 B 的 TFIDF 值。
| Words | TF ( A ) | TF ( B ) | IDF | TFIDF ( A ) | TFIDF ( B ) |
|---|---|---|---|---|---|
| jupiter | 1/5 | 0 | In (2/1)=0.69 | 0.138 | 0 |
| is | 1/5 | 1/8 | In (2/2)=0 | 0 | 0 |
| the | 1/5 | 2/8 | In (2/2)=0 | 0 | 0 |
| largest | 1/5 | 0 | In (2/1)=0.69 | 0.138 | 0 |
| planet | 1/5 | 1/8 | In (2/2)=0 | 0.138 | 0 |
| mars | 0 | 1/8 | In (2/1)=0.69 | 0 | 0.086 |
| fourth | 0 | 1/8 | In (2/1)=0.69 | 0 | 0.086 |
| from | 0 | 1/8 | In (2/1)=0.69 | 0 | 0.086 |
| sun | 0 | 1/8 | In (2/1)=0.69 | 0 | 0.086 |
TF-IDF 教程
在本教程中,我们将使用scikit-learn 中的 TfidfVectorizer将文本转换并查看 TF-IDF 矩阵。
在下面的代码中,我们有一个包含 4 个文档的小语料库。首先,我们将使用TfidfVectorizer()创建一个向量化对象,并将文本数据拟合和转换为向量。之后,我们将使用向量化器提取单词名称。
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'KDnuggets Collection of data science Projects',
'3 Free Statistics Courses for data science',
'Parallel Processing Large File in Python',
'15 Python Coding Interview Questions You Must Know For data science',
]
vectorizer = TfidfVectorizer()
*# TD-IDF Matrix*
X = vectorizer.fit_transform(corpus)
*# extracting feature names*
tfidf_tokens = vectorizer.get_feature_names_out()
我们现在将使用 TF-IDF 令牌和向量创建一个 pandas 数据框。
-
将向量转换为数组,并将其添加到数据参数中。
-
四个索引是手动创建的。
-
tfidf_tokens 名称已添加到列中。
import pandas as pd
result = pd.DataFrame(
data=X.toarray(),
index=["Doc1", "Doc2", "Doc3", "Doc4"],
columns=tfidf_tokens
)
result
pandas 数据框将列显示为单词,行显示为文档。
在下面的数据框中,每个单词都有一个基于 TF-IDF 公式的重要值。
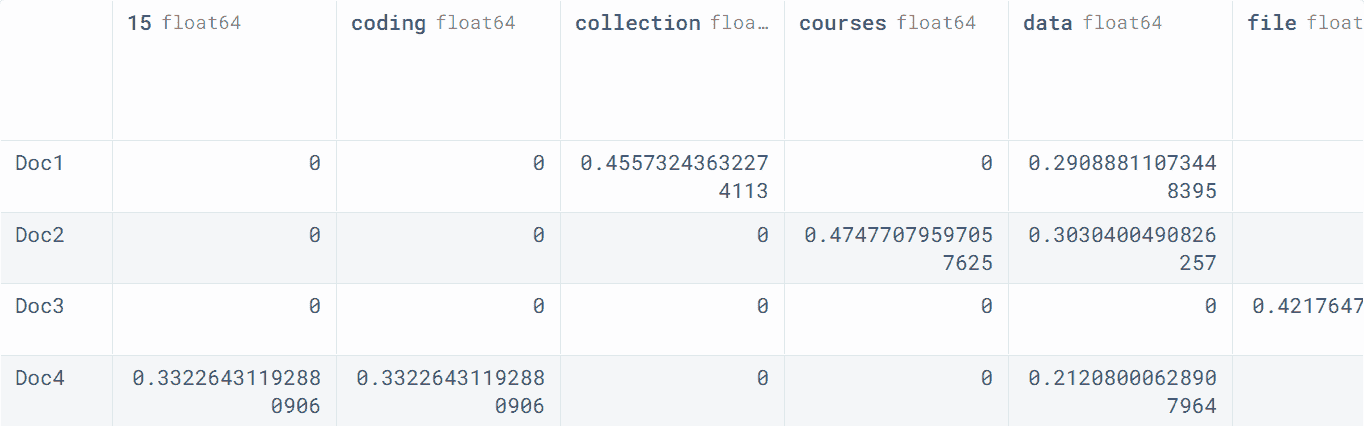
TF-IDF 用于文本分类
让我们更进一步,使用 TF-IDF 将文本转换为向量,然后用它来训练文本分类模型。为了训练模型,我们将使用Kaggle 上的 Spotify App Reviews数据。
我们将使用 read_csv 加载数据并查看前五行。
import pandas as pd
spotify = pd.read_csv("reviews.csv")
spotify.head()
我们只会使用Review和Rating列来训练模型。
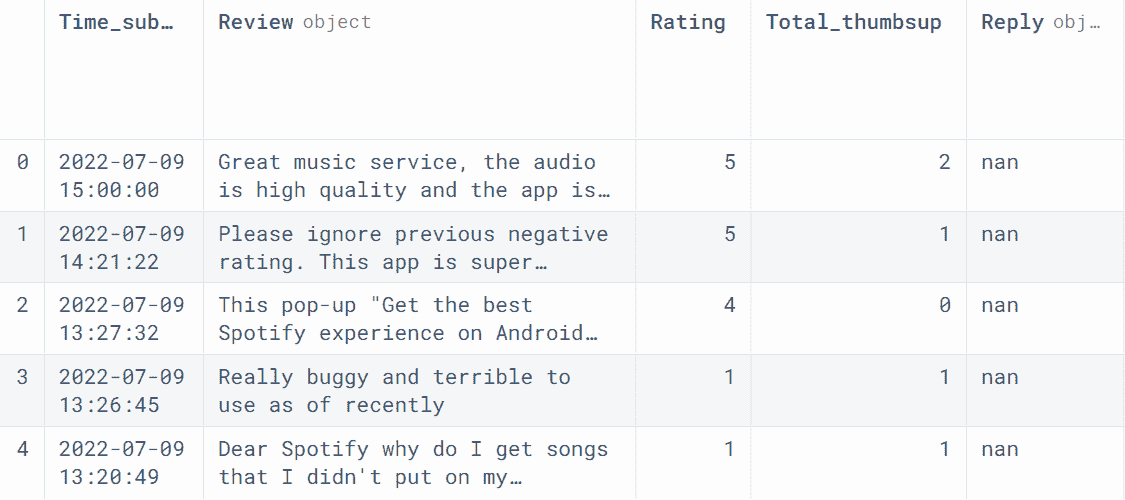
我们将把Review列转换为向量,并将Rating作为目标。之后,我们将拆分数据集用于训练和测试。
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
*# Transform features*
X = spotify.Review
X_tfidf = vectorizer.fit_transform(X)
*# create target*
y = spotify.Rating
*# split the dataset for training and testing*
X_train, X_test, y_train, y_test = train_test_split(
X_tfidf, y, test_size=0.33, random_state=42
)
我们不会深入探讨特征工程、文本处理或超参数优化。我们将选择一个简单的模型(SGDClassifier)并在 X_train 和 y_train 上训练它。
对于模型验证,我们将使用 X_test 预测值,并打印分类报告。
from sklearn.linear_model import SGDClassifier
from sklearn.metrics import classification_report
*# Training classifier model*
clf = SGDClassifier()
clf.fit(X_train, y_train)
*# model validation*
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
正如我们所观察到的,通过在默认配置上训练,我们得到了 0.69 的 F1 分数。我们可以通过交叉验证、超参数优化、文本清理和处理以及特征工程来提高模型性能。
precision recall f1-score support
1 0.57 0.90 0.69 5817
2 0.25 0.03 0.05 2274
3 0.28 0.06 0.10 2293
4 0.41 0.19 0.26 2556
5 0.73 0.91 0.81 7387
accuracy 0.62 20327
macro avg 0.45 0.42 0.38 20327
weighted avg 0.54 0.62 0.54 20327
“感谢您阅读本教程。希望我能帮助您理解 TF-IDF 的基础知识。如果您有任何进一步的问题,请在下面输入或通过 LinkedIn 联系我。”
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是通过图神经网络为那些面临心理健康问题的学生构建一个 AI 产品。
更多相关内容
将 JSON 转换为 Pandas DataFrames:正确解析
原文:
www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way
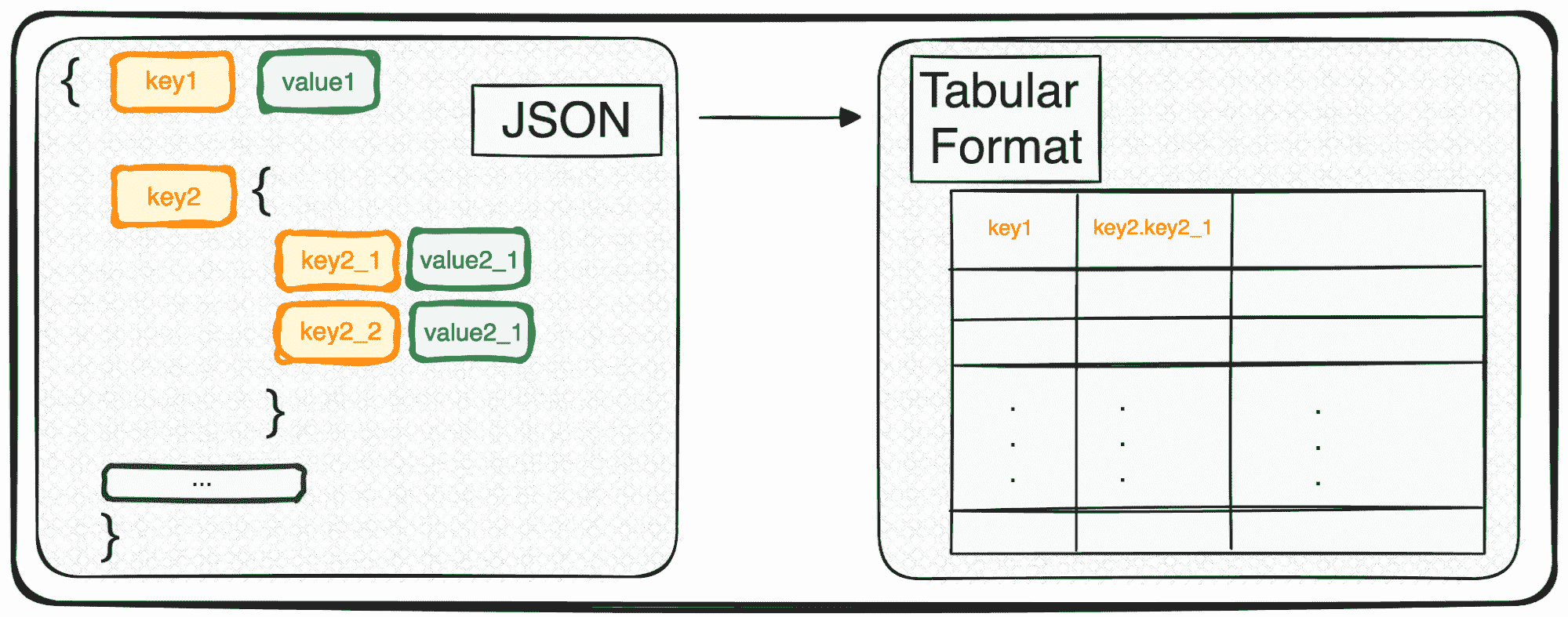
图片由作者提供
深入数据科学和机器学习的世界,你会遇到的基本技能之一就是数据读取的艺术。如果你已经有一些经验,你可能对 JSON(JavaScript 对象表示法)很熟悉,它是一种流行的数据存储和交换格式。
我们的前三名课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业生涯。
2. Google Data Analytics Professional Certificate - 提升您的数据分析技能
3. Google IT Support Professional Certificate - 支持您的组织的 IT
想象一下 NoSQL 数据库如 MongoDB 喜欢以 JSON 格式存储数据,或者 REST API 经常以相同的格式响应。
然而,虽然 JSON 非常适合存储和交换,但在原始形式下,它还不适合深入分析。这时我们需要将其转换成更适合分析的格式——表格格式。
所以,无论你是处理单个 JSON 对象还是一个令人愉快的 JSON 数组,从 Python 的角度来看,你实际上是在处理一个字典或一个字典列表。
一起探索这种转换如何展开,使我们的数据准备好进行分析 ????
今天我将解释一个神奇的命令,它能让我们在几秒钟内轻松地将任何 JSON 解析为表格格式。
这就是…… pd.json_normalize()
那么让我们看看不同类型的 JSON 是如何工作的。
1. 处理简单的 JSON 和 JSON 列表
我们可以处理的第一种类型的 JSON 是单级 JSON,具有少量的键和值。我们定义我们的第一个简单 JSON 如下:
代码由作者提供
所以让我们模拟一下处理这些 JSON 的需要。我们都知道,在 JSON 格式下做的事情不多。我们需要将这些 JSON 转换成一些可读且可修改的格式……这就意味着 Pandas DataFrames!
1.1 处理简单的 JSON 结构
首先,我们需要导入 pandas 库,然后可以使用命令 pd.json_normalize(),如下所示:
import pandas as pd
pd.json_normalize(json_string)
通过将此命令应用于单条记录的 JSON,我们得到最基本的表格。然而,当我们的数据稍微复杂一些并呈现 JSON 列表时,我们仍然可以使用相同的命令,且不会出现进一步的复杂情况,输出将对应于一个包含多个记录的表格。

作者提供的图像
简单吧?
下一个自然的问题是当一些值丢失时会发生什么。
1.2 处理空值
假设某些值没有被提供,例如,David 的收入记录丢失。当我们将 JSON 转换为简单的 pandas 数据框时,相应的值将显示为 NaN。

作者提供的图像
如果我只想获取一些字段怎么办?
1.3 仅选择感兴趣的列
如果我们只想将某些特定字段转换为表格 pandas DataFrame,则 json_normalize() 命令不允许我们选择要转换的字段。
因此,应对 JSON 进行小规模预处理,过滤出那些感兴趣的列。
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
所以,让我们深入研究一些更复杂的 JSON 结构。
2. 处理多级 JSON
在处理多级 JSON 时,我们会发现不同级别中存在嵌套的 JSON。程序与之前相同,但在这种情况下,我们可以选择想要转换的层级数量。默认情况下,命令总是扩展所有层级,并生成包含所有嵌套层级名称的列。
所以如果我们规范化以下 JSON。
作者提供的代码
我们将获得如下表格,其中在字段 skills 下有 3 列:
-
skills.python
-
skills.SQL
-
skills.GCP
并在字段 roles 下有 4 列
-
roles.项目经理
-
roles.数据工程师
-
roles.数据科学家
-
roles.数据分析师
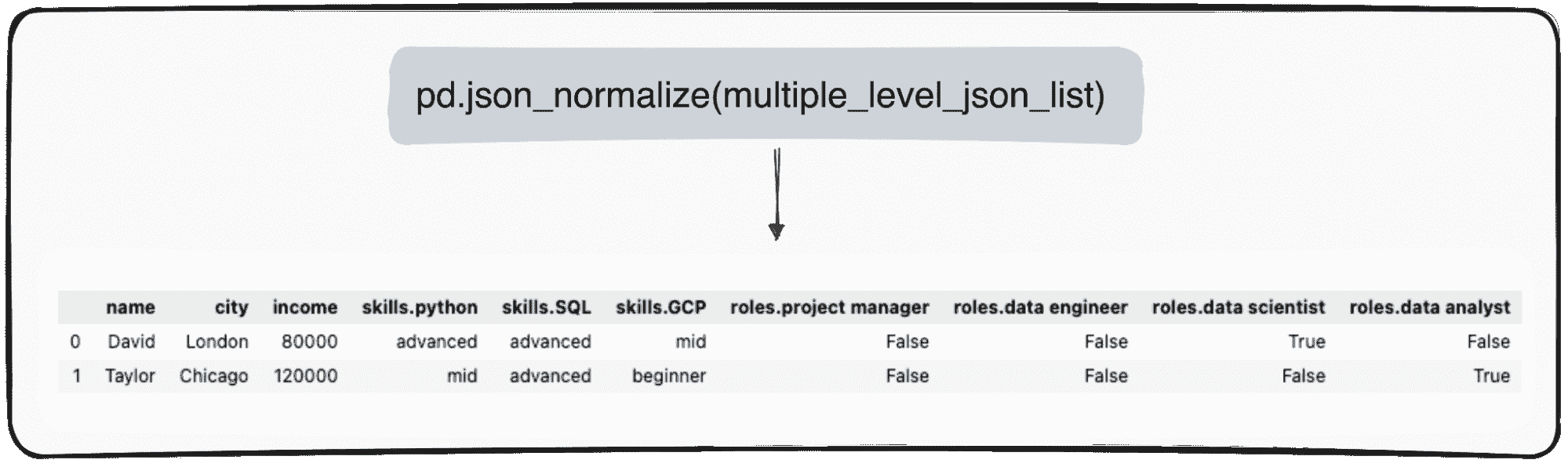
作者提供的图像
但是,假设我们只想转换顶层。我们可以通过将参数 max_level 设定为 0(我们想扩展的最大层级)来实现。
pd.json_normalize(mutliple_level_json_list, max_level = 0)
待处理的值将保留在 JSON 中,并存在于我们的 pandas DataFrame 中。

作者提供的图像
3. 处理嵌套列表 JSON
最后一种情况是 JSON 字段中包含嵌套列表。所以我们首先定义要使用的 JSON。
作者提供的代码
我们可以使用 Python 中的 Pandas 有效管理这些数据。pd.json_normalize() 函数在这种情况下特别有用。它可以将 JSON 数据(包括嵌套列表)展平为适合分析的结构化格式。当此函数应用于我们的 JSON 数据时,它会生成一个规范化的表格,其中将嵌套列表作为字段的一部分。
此外,Pandas 提供了进一步完善此过程的能力。通过利用 pd.json_normalize() 中的 record_path 参数,我们可以指定函数专门规范化嵌套列表。
这个操作会生成一个专门的表格,仅包含列表的内容。默认情况下,此过程只会展开列表中的元素。然而,为了丰富该表格的额外上下文,例如为每条记录保留相关的 ID,我们可以使用 meta 参数。

图片由作者提供
结论
总之,使用 Python 的 Pandas 库将 JSON 数据转换为 CSV 文件既简单又有效。
JSON 仍然是现代数据存储和交换中最常见的格式,特别是在 NoSQL 数据库和 REST API 中。然而,当处理原始格式的数据时,它也带来了一些重要的分析挑战。
Pandas 的 pd.json_normalize() 在处理此类格式并将数据转换为 pandas DataFrame 方面发挥了关键作用。
希望本指南对你有所帮助,下次处理 JSON 数据时,你可以更有效地进行操作。
你可以在以下 GitHub 仓库查看对应的 Jupyter Notebook。
Josep Ferrer** 是一位来自巴塞罗那的分析工程师。他拥有物理工程学位,目前在应用于人类流动的数据科学领域工作。他还是一名兼职内容创作者,专注于数据科学和技术。Josep 撰写有关 AI 的所有内容,涵盖了该领域的持续爆炸性应用。
更多相关主题


 浙公网安备 33010602011771号
浙公网安备 33010602011771号