KDNuggets-博客中文翻译-十五-
KDNuggets 博客中文翻译(十五)
原文:KDNuggets
揭示糟糕科学

图片由 LoganArt 在 Pixabay 提供
许多广泛接受的科学理论后来被证明是错误的,正如这篇简短的 文章 所展示的。这怎么会发生?
我们的前三大课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 在 IT 支持中为你的组织提供帮助
首先,科学仍在发展中,我们对许多基本现象的理解仍远未完成。另一个原因是,科学——至少在我们的星球上——是由人类进行的,而我们人类有许多缺陷。各种偏见、资金冲突、自我膨胀和纯粹的无能是一些可能破坏任何研究的非常人性化的因素。
科学家有时正确,但报道这些的记者却错误。很少有记者曾做过科学家,大多数人接受的科学培训与他们的读者或观众大致相同。然而,公平地说,许多科学家自己也在研究方法和统计学方面的课程有限,正如我在 统计错误即使科学家也会犯 中指出的那样。**
同行评审有时像是朋友评审,而且,一些研究在完全没有经过同行评审的情况下就登上了头版。很少有科学出版物的编辑和审稿人是统计学家——统计学家不多,他们有自己的工作。在“较软”的领域,标准可能甚至更不严格。
零假设显著性测试(NHST)多年来遭到统计学家的严厉批评。许多人会记得这来自于初级统计学课程。虽然表面上看似简单,NHST 被广泛误解和滥用。
《美国统计学家》已专门为此及相关主题刊出了一个开放获取的专刊。简而言之,一个重要的问题是,p值大于 0.05 的发现比统计显著的发现更不容易被接受发表,甚至不容易提交发表。这被称为出版偏倚或文件抽屉问题。
然而,“负面发现”与统计显著结果同样重要,而且许多潜在的重要研究结果显然从未公之于众。由于知识的积累是科学的本质,这是一个严重的问题,直到最近才开始引起许多统计学家长期以来认为应当重视的关注。统计显著性与决策显著性也不完全相同。
另一个原因是,小样本研究在许多领域中很常见。尽管一个庞大的样本并不自动意味着结果可以被信任,但当样本较小时,效应量的估计在研究之间变异性更大。相反,当样本量较大时, trivial 的效应量可能具有统计显著性,并且在某些情况下,获得广泛的宣传。
非实验性(观察性)研究在许多学科中普遍存在,并且在大数据时代似乎正经历繁荣。虽然随机实验并不总是可行或伦理的,但这并不意味着非实验性研究就足够。
我在倾向得分:它们是什么以及它们的作用和元分析与市场研究**中总结了一些这些问题。简而言之,非实验性研究中的效应量估计通常变异性更大——可靠性较低。再次回到出版偏倚...
每年在世界各地进行成千上万的研究,这意味着即使标准普遍较高,也会有大量的劣质科学。科学是艰难的。以下是需要注意的一些问题。
横断面数据与纵向数据。原因应当先于其效果,在观察性研究中,当数据仅涉及一个时间点时,通常无法确定这种排序。然而,当数据在多个时间点收集时,我们通常可以确认假设中的原因是否确实在其假设的效果之前出现。一般来说,纵向数据允许更广泛的分析,这可以帮助我们更好地理解变量之间的相互关系。
生态研究 通常存在问题,因为研究的单位是群体,因此不能对个体研究参与者做出推断。研究人员通常没有关于个体水平的暴露和疾病的数据。
非概率抽样。 推断统计学假设使用概率抽样。当数据来源于便利样本或其他非概率样本时,很难确定结果可以推广到哪个总体。
WEIRD参与者。 在一些领域,如流行病学和药理学,参与者可能甚至不是人类。例如,从老鼠到人类的推广需要许多假设。
线性无阈值模型 (LNT). 这是一种高度简化的剂量反应模型,受到了严厉的批评。在商业中,通常假设“剂量”(例如顾客体验的各个方面)与“反应”(例如对公司的总体满意度)之间存在线性(直线)关系。这通常是合理的,但并非总是如此,在毒理学等领域中,这种假设可能没有意义,因为已知非常小的剂量通常没有效果,并且超出某个水平后,毒性不再随剂量增加。
不适当的统计模型。 这可能很难检测,但可以说在任何学科中,统计使用不当并不少见。适当的统计模型也可能以不恰当的方式使用。
不充分的协变量控制。 这在观察性研究中尤为常见,其中可能重要的背景变量并未始终得到调整。在一些研究中,连续变量如年龄被分组为宽泛的类别,导致信息丢失。因此,声称该变量已经“控制”可能是有问题的。
遗漏变量。 重要变量可能未能提供,或者出于某种原因被排除在分析之外。许多研究因此受到批评。
未考虑其他解释。 多种原因可能导致相同的效果,而未考虑竞争解释会削弱研究的可信度。与遗漏变量类似,这可能是偶然的,也可能是故意的。
未对多重比较进行校正。 同一数据上的统计检验彼此并不独立。因此,如果在四种类型的患者中进行成对比较,在标准的 0.05 alpha 水平下需要进行六次检验,而这些比较的整体置信水平大约为 75%,而非 95%。
使用替代变量作为因变量。 通常,无法直接测量结果,研究人员必须依赖替代变量。医疗研究中的一个例子是使用测试结果来指示某种特定疾病的存在。虽然使用替代变量不一定是缺陷,但在一些研究中可能会出现问题。
未对测量误差进行调整。 在大多数研究中,变量是带有误差的。在某些情况下,如人格评估或能力测量,误差可能很大。一般来说,测量误差会削弱相关性,因此x 和 y 之间的关系可能比基于相关性或其他关联测量的结果更强。困扰调查的测量误差之一是回应风格,例如,当被调查者倾向于使用量表的高端而不管所评估的内容。
开采直到发现 似乎是一些研究人员的座右铭,这是被称为HARKing的一种特别危险的失职形式的表现。Stuff Happens对这个复杂的主题进行了更多阐述。
回归均值 是一种统计现象,可能使重复数据中的自然变异看起来像是真实的变化。当异常大的或异常小的测量值往往会被接近均值的测量值所跟随时,就会发生这种现象。这种现象可能使教育项目或疗法看起来有效,但实际上并非如此。
"影响人数百万。" 这样的标题可能掩盖了统计上为零的小效应。我们需要考虑这些令人惊恐的数字是基于何种基数计算得出的。
使用新的未经检验的方法论。 新的并不总是更好,经过验证的方法论通常比那些尚未经过独立研究人员和统计学家检验的创新方法更值得信赖。
与其他研究的冲突。 一个有争议的发现可能打破了现有的范式,但也可能表明方法论不当或统计使用不当。
资助冲突 可能会削弱研究的可信度,但对资助冲突的指控本身也可能以可疑的方式获得资助。
生态谬误、辛普森悖论 和 伯克森偏差 是其他需要注意的问题。
流行的名言“谎言、该死的谎言和统计数据”的起源不确定,尽管它被归因于马克·吐温、迪斯雷利以及其他几位。不过,不论其来源如何,它并不指现代统计学领域,当时统计学刚刚开始出现。很可能,它涉及的是官方数据,这也是统计学最初的含义。以下是一些用统计数据说谎的方法。
通过重复建立“真相” 是一种非常常见的策略,约瑟夫·戈培尔——一个著名的欺骗专家——明确推荐了这种方法。很少有人仔细审视主张,更少有人会记住同一个人或组织过去做出的错误预测。
稻草人论证和“反驳”是常见的,就像人身攻击一样,这些都特别有利于那些自己有事情要隐藏的人。
以例外概括和使稀有事件看似典型也是常用的策略。将可能的与可信的、可信的与事实混淆,是这一主题的一个变种。
还有挑选数据、模型和先前的研究。一种挑选数据的形式是仅选择支持自己观点的时间序列的一部分。“调整”数据虽然比直接伪造要逊色,但也是一种相关技术。巧妙的、尽管值得怀疑的数据或统计模型解释是另两种不道德的武器。
计算机模拟 有时被误称为实验,并且模拟数据微妙地被当作经验数据。现在,制造一个计算机模型来“证明”自己的理论比以往任何时候都容易。
社会本质上是等级化的,而人类倾向于二元思维,因此权威往往被引用,科学或政策问题的辩论常常呈现出好人对坏人的色彩。误传权威的真实观点也并不罕见。
我们还常常在频率、百分比和比例之间挣扎,这一点我们需要非常注意。例如,我们可能会读到如果政策制定者做了某事或不做某事,可能会影响到数百万人。然而,仔细阅读所引用的证据可能会揭示一个非常微弱的效应大小,其置信区间或可信区间可能与零重叠。将一个微小的比例乘以数亿或数十亿人会得出一个令人恐惧的数字。另外,请记住,“50% 增加”可能意味着从 0.001 到 0.0015。
我还没有提到数据可视化,它们很容易欺骗我们。许多人被误导相信随机意味着均匀,实际上,均匀分布的数据很可能并非随机。此外,还有我称之为打地鼠的现象,迅速列举一个又一个可疑的主张而不回应对任何一个主张的批评。
统计思维,在科学中至关重要,并非天生具备。没有人生来就是统计学家,教育课程中经常对统计学有所忽略。
总结来说,严谨的科学是具有挑战性的,任何研究都可以受到质疑。欺骗是人类本性的一部分,科学家、人类、记者和政策制定者都是如此。我们也是如此,必须小心,不要仅仅因为研究令人兴奋、让我们感到安慰或符合我们的信念就信任它。
凯文·格雷 是 Cannon Gray 的总裁,该公司是一家市场科学和分析咨询公司。他在尼尔森、坎塔尔、麦肯和 TIAA-CREF 拥有超过 30 年的市场研究经验。
更多相关话题
让决策树在现实世界中变得清晰
原文:
www.kdnuggets.com/demystifying-decision-trees-for-the-real-world

作者提供的图片
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
决策树将复杂的决策分解为简单、易于遵循的阶段,因此类似于人类大脑的功能。
在数据科学中,这些强大的工具被广泛应用于数据分析和决策指导。
在这篇文章中,我将介绍决策树的运作方式,提供现实世界的例子,并给出一些提升决策树效果的建议。
决策树的结构
从根本上说,决策树是简单明了的工具。它们将复杂的选项分解为更简单的顺序选择,从而反映了人类的决策过程。现在让我们深入探讨构成决策树的主要元素。
节点、分支和叶子
三个基本组件定义了一个决策树:叶子、分支和节点。每一个都是决策过程中的绝对关键。
-
节点:它们是决策点,通过这些点,树根据输入数据做出决定。在表示所有数据时,根节点是起始点。
-
分支:它们关联决策的结果并连接节点。每个分支对应一个潜在的结果或决策节点的值。
-
叶子:决策树的终点是叶子,有时称为叶节点。每个叶节点提供一个特定的结果或标签;它们反映最后的选择或分类。
概念示例
假设你在根据温度决定是否外出。“下雨吗?”根节点会问。如果是的话,你可能会找到一条指向“带伞”的分支。但这种情况不应该发生;另一条分支可以说“戴太阳镜”。
这些结构使得决策树易于解读和可视化,因此在各个领域都很受欢迎。
现实世界示例:贷款审批冒险
想象一下:你是格林戈茨银行的一名巫师,决定谁能获得贷款购买他们的新扫帚。
-
根节点:“他们的信用评分是否很神奇?”
-
如果是 → 分支到“批准,快得比你说魁地奇还快!”
-
如果否 → 分支到“检查他们的精灵金币储备。”
-
如果高 →,“批准,但要留意他们。”
-
如果低 → “拒绝,速度比 Nimbus 2000 还快。”
-
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import matplotlib.pyplot as plt
data = {
'Credit_Score': [700, 650, 600, 580, 720],
'Income': [50000, 45000, 40000, 38000, 52000],
'Approved': ['Yes', 'No', 'No', 'No', 'Yes']
}
df = pd.DataFrame(data)
X = df[['Credit_Score', 'Income']]
y = df['Approved']
clf = DecisionTreeClassifier()
clf = clf.fit(X, y)
plt.figure(figsize=(10, 8))
tree.plot_tree(clf, feature_names=['Credit_Score', 'Income'], class_names=['No', 'Yes'], filled=True)
plt.show()
这是输出结果。
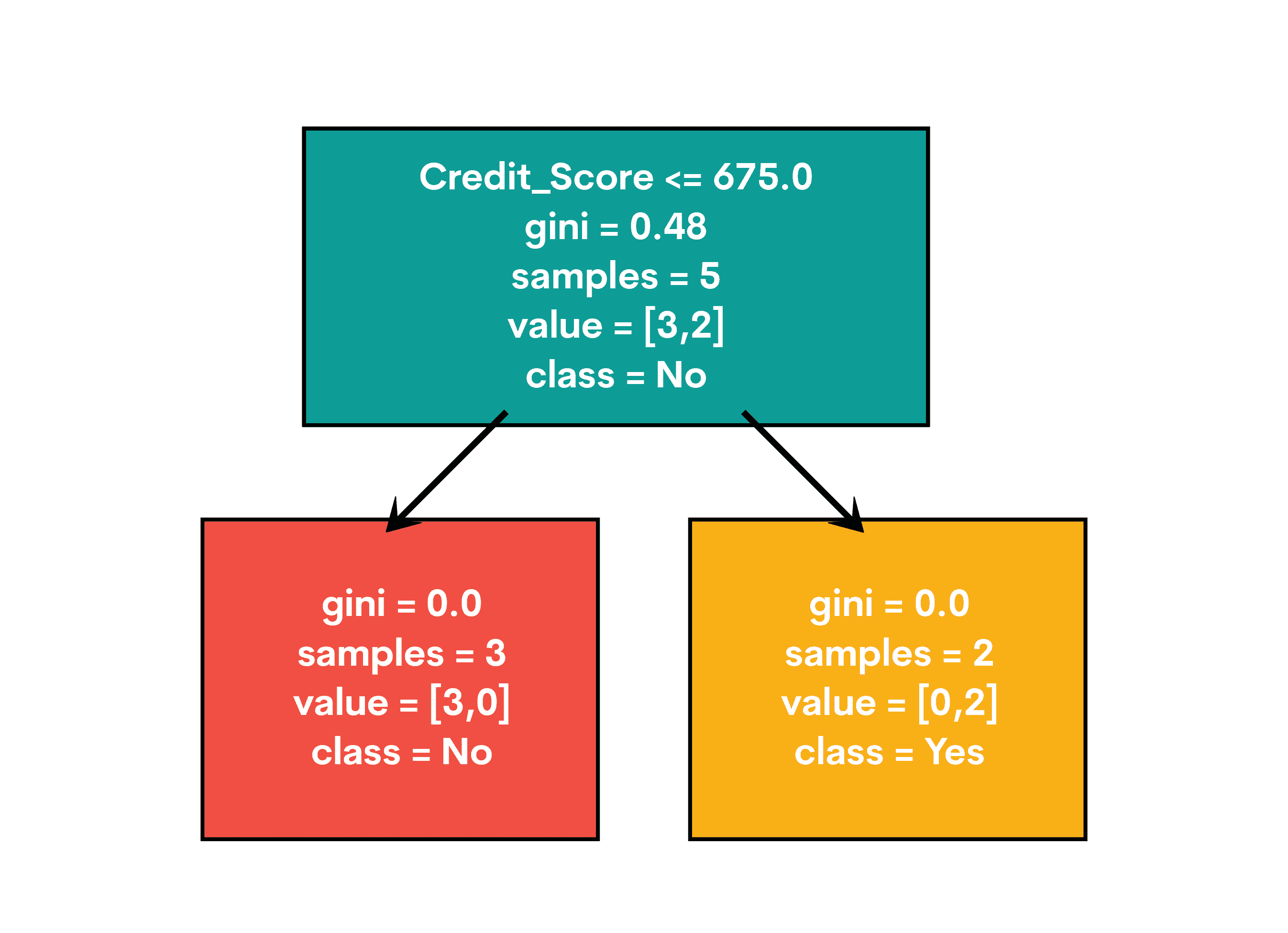 当你运行这个魔法时,你会看到一棵树出现!它就像贷款批准的掠夺者地图:
当你运行这个魔法时,你会看到一棵树出现!它就像贷款批准的掠夺者地图:
-
根节点在 Credit_Score 上进行划分
-
如果小于等于 675,我们向左前进
-
如果大于 675,我们向右行进
-
叶子节点显示我们的最终决定:“是”表示批准,“否”表示拒绝
太棒了!你刚刚创建了一个决策制定的水晶球!
思维挑战:如果你的生活是一个决策树,根节点问题会是什么?“今天早上喝咖啡了吗?”可能会引出一些有趣的分支!
决策树:在分支背后
决策树的功能类似于流程图或树状结构,通过一系列的决策点来工作。它们从将数据集划分为更小的部分开始,然后建立一个决策树来配合它。我们应该关注这些树如何处理数据划分和不同变量的方式。
划分标准:基尼不纯度和信息增益
选择最佳质量来划分数据是构建决策树的主要目标。可以通过信息增益和基尼不纯度提供的标准来确定这个过程。
-
基尼不纯度:想象一下你在玩猜测游戏。如果你随机选择一个标签,你会经常出错吗?这就是基尼不纯度所衡量的。基尼系数越低,我们的猜测越准确,树也就越快乐。
-
信息增益:你可以将其比作神秘故事中的“啊哈!”时刻。信息增益衡量提示(属性)在解决案件中所起的帮助程度。更大的“啊哈!”意味着更多的增益,这意味着树更加兴奋!
要预测客户是否会从你的数据集中购买某个产品,你可以从基本的人口统计信息开始,比如年龄、收入和购买历史。这个方法考虑了所有这些因素,并找出能够将买家和其他人区分开的因素。
处理连续数据和分类数据
我们的树探员可以调查所有类型的信息。
对于容易改变的特征,如年龄或收入,树设置了一个测速点。“30 岁以上的人,请走这边!”
对于分类数据,如性别或产品类型,这更像是一种排列。“智能手机在左边;笔记本电脑在右边!”
现实世界的冷案:客户购买预测器
为了更好地理解决策树的工作原理,我们来看看一个实际的例子:使用客户的年龄和收入来预测他们是否会购买产品。
为了预测人们会买什么,我们将创建一个简单的集合和决策树。
代码的描述
-
我们导入像 pandas 这样的库来处理数据,从 scikit-learn 导入 DecisionTreeClassifier 来构建树,使用 matplotlib 来展示结果。
-
创建数据集:使用年龄、收入和购买状态来制作一个样本数据集。
-
准备特征和目标:目标变量(购买)和特征(年龄、收入)已经设置好。
-
训练模型:利用这些信息设置和训练决策树分类器。
-
查看决策树:最后,我们绘制决策树,以便观察决策过程。
这是代码。
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import matplotlib.pyplot as plt
data = {
'Age': [25, 45, 35, 50, 23],
'Income': [50000, 100000, 75000, 120000, 60000],
'Purchased': ['No', 'Yes', 'No', 'Yes', 'No']
}
df = pd.DataFrame(data)
X = df[['Age', 'Income']]
y = df['Purchased']
clf = DecisionTreeClassifier()
clf = clf.fit(X, y)
plt.figure(figsize=(10, 8))
tree.plot_tree(clf, feature_names=['Age', 'Income'], class_names=['No', 'Yes'], filled=True)
plt.show()
这是输出结果。
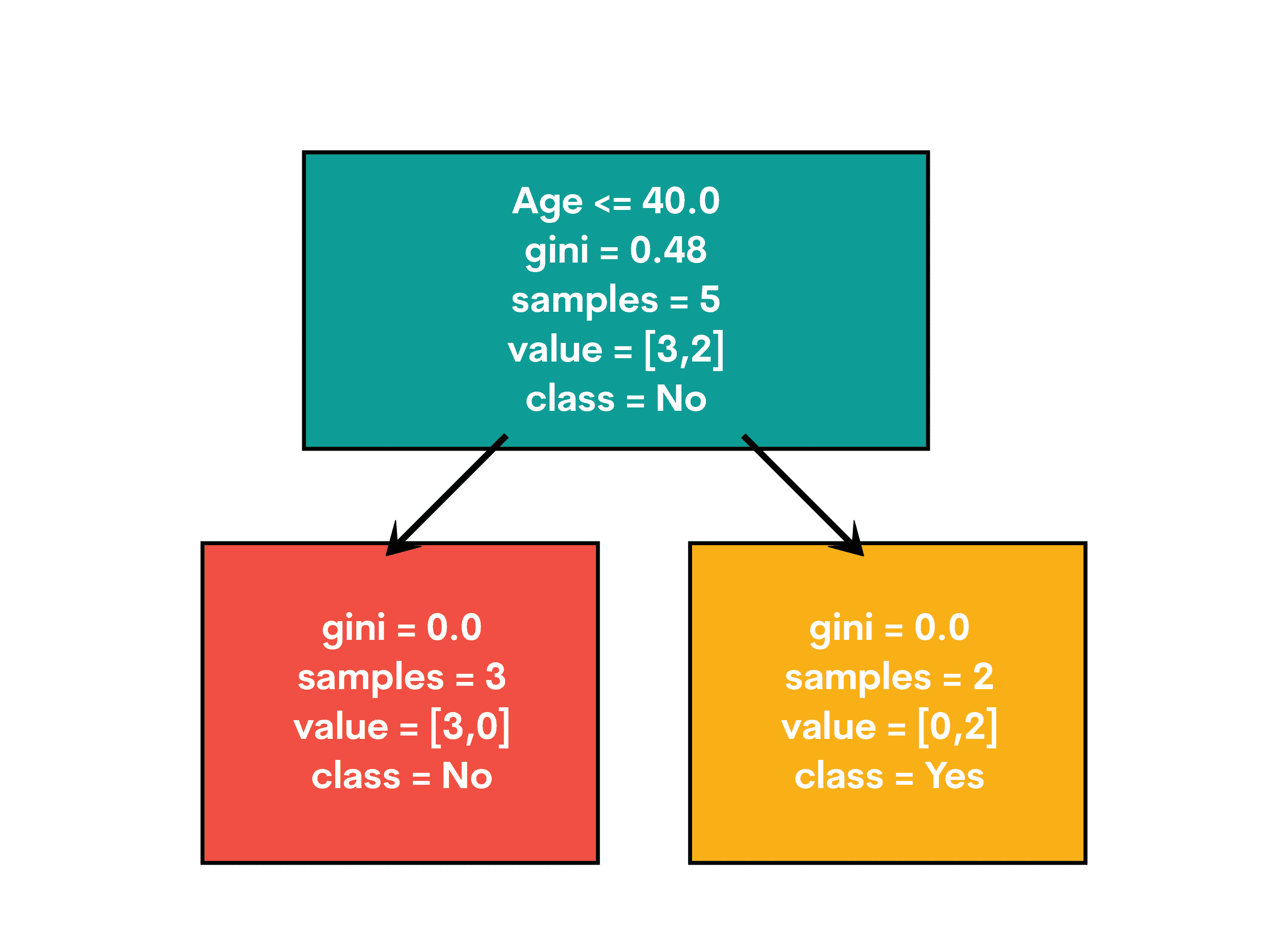
最终决策树将展示如何根据年龄和收入来划分树,以确定客户是否可能购买某个产品。每个节点是一个决策点,分支显示不同的结果。最终决策由叶节点展示。
现在,让我们来看看面试在现实世界中的应用吧!
现实世界应用
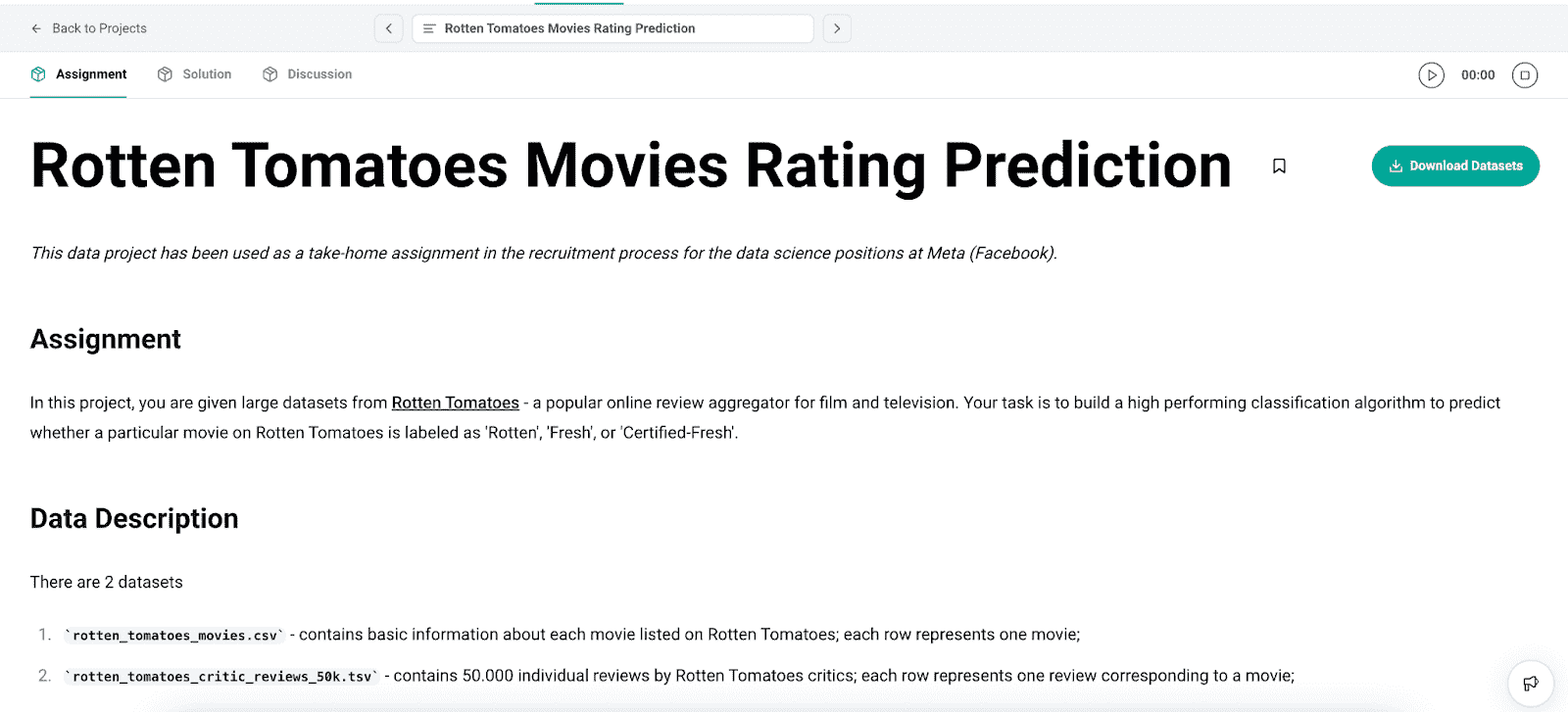
该项目被设计为 Meta(Facebook)数据科学职位的家庭作业,目标是构建一个分类算法,预测 Rotten Tomatoes 上的电影是否标记为“烂片”、“新鲜”或“认证新鲜”。
这是该项目的链接:platform.stratascratch.com/data-projects/rotten-tomatoes-movies-rating-prediction
现在,让我们将解决方案拆解为可编码的步骤。
逐步解决方案
-
数据准备:我们将根据 rotten_tomatoes_link 列合并两个数据集。这将为我们提供一个包含电影信息和评论的综合数据集。
-
特征选择与工程:我们将选择相关特征并执行必要的转换,包括将类别变量转换为数值变量、处理缺失值和标准化特征值。
-
模型训练:我们将对处理后的数据集训练决策树分类器,并使用交叉验证评估模型的稳定性。
-
评估:最后,我们将使用准确率、精确率、召回率和 F1 分数等指标来评估模型的性能。
这是代码。
import pandas as pd
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report
from sklearn.preprocessing import StandardScaler
movies_df = pd.read_csv('rotten_tomatoes_movies.csv')
reviews_df = pd.read_csv('rotten_tomatoes_critic_reviews_50k.csv')
merged_df = pd.merge(movies_df, reviews_df, on='rotten_tomatoes_link')
features = ['content_rating', 'genres', 'directors', 'runtime', 'tomatometer_rating', 'audience_rating']
target = 'tomatometer_status'
merged_df['content_rating'] = merged_df['content_rating'].astype('category').cat.codes
merged_df['genres'] = merged_df['genres'].astype('category').cat.codes
merged_df['directors'] = merged_df['directors'].astype('category').cat.codes
merged_df = merged_df.dropna(subset=features + [target])
X = merged_df[features]
y = merged_df[target].astype('category').cat.codes
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
clf = DecisionTreeClassifier(max_depth=10, min_samples_split=10, min_samples_leaf=5)
scores = cross_val_score(clf, X_train, y_train, cv=5)
print("Cross-validation scores:", scores)
print("Average cross-validation score:", scores.mean())
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
classification_report_output = classification_report(y_test, y_pred, target_names=['Rotten', 'Fresh', 'Certified-Fresh'])
print(classification_report_output)
这是输出结果。
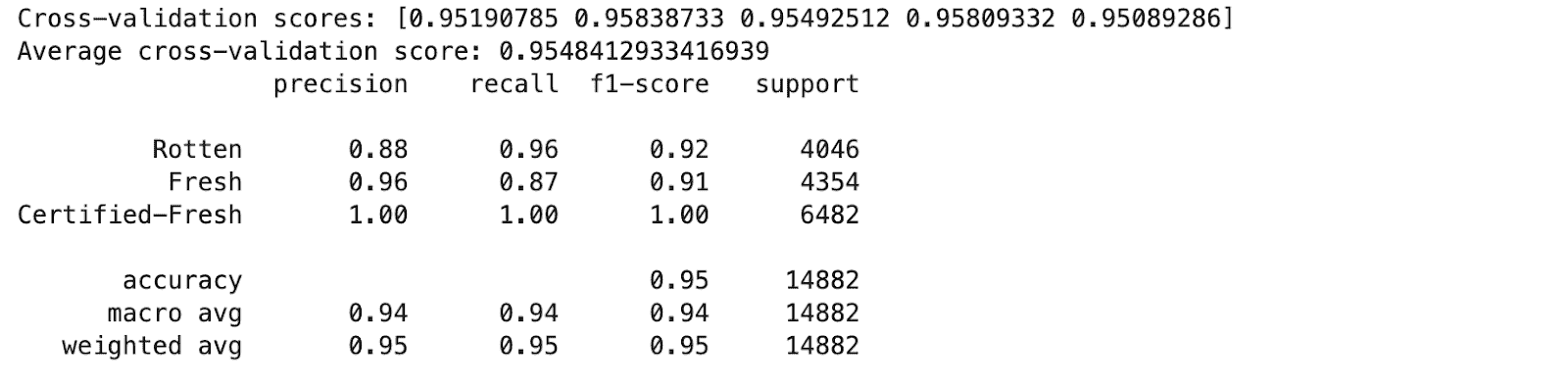
该模型在各类中显示出高准确率和 F1 分数,表明性能良好。让我们来看一下关键要点。
关键要点
-
特征选择对模型性能至关重要。内容评分、类型、导演、时长和评分被证明是有价值的预测因子。
-
决策树分类器有效捕捉了电影数据中的复杂关系。
-
交叉验证确保模型在不同数据子集上的可靠性。
-
在“认证新鲜”类别中表现出色的情况下,值得进一步调查可能的类别不平衡。
-
该模型在预测电影评分和提升如 Rotten Tomatoes 平台的用户体验方面显示出良好的前景。
提升决策树:将你的幼苗成长为参天大树
现在,你已经成长了第一棵决策树。令人印象深刻!但为何止步于此?让我们将这棵幼苗变成一棵森林巨人,让 Groot 也感到嫉妒。准备好增强你的树了吗?让我们深入了解吧!
剪枝技术
剪枝是一种通过去除对目标变量预测能力较小的部分来缩减决策树大小的方法。这有助于特别减少过拟合。
-
前剪枝:通常称为早期停止,这涉及立即停止树的生长。在训练之前,模型会被指定参数,包括最大深度(max_depth)、分裂节点所需的最小样本数(min_samples_split)和叶节点所需的最小样本数(min_samples_leaf)。这防止了树的过度复杂化。
-
后剪枝:这种方法将树生长到最大深度,然后移除那些贡献不大的节点。虽然计算成本比前剪枝更高,但后剪枝可能更有效。
集成方法
集成技术将多个模型结合以产生超过单一模型的性能。应用于决策树的两种主要集成技术是装袋法和提升法。
-
装袋法(Bootstrap Aggregating):该方法在数据的多个子集(通过有放回抽样生成)上训练多个决策树,然后对它们的预测结果取平均。一个常用的装袋技术是随机森林。它减少了方差并有助于防止过拟合。查看 "决策树与随机森林算法" 深入了解决策树算法及其扩展“随机森林算法”相关的一切。
-
提升:提升方法依次创建树,每棵树都试图修正下一棵树的错误。提升技术在算法中包括 AdaBoost 和梯度提升。这些算法通过强调难以预测的示例,有时能提供更精确的模型。
超参数调优
超参数调优是确定决策树模型的最佳超参数集合以提升其性能的过程。可以通过使用如网格搜索或随机搜索等方法,评估多个超参数组合以找出最佳配置。
结论
在本文中,我们讨论了决策树的结构、工作机制、实际应用以及提升决策树性能的方法。
练习决策树对于掌握其使用和理解其细微差别至关重要。处理实际数据项目也可以提供宝贵的经验,提升解决问题的技能。
内特·罗西迪 是一名数据科学家,专注于产品策略。他还是一位兼职教授,教授分析学,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过来自顶级公司的真实面试问题准备面试。内特撰写关于职业市场的最新趋势,提供面试建议,分享数据科学项目,并涵盖所有 SQL 相关内容。
更多相关主题
揭示机器学习

作者提供的图片
传统与变革:回顾与展望
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
传统上,计算机需要遵循一套明确的指令。例如,如果你想让计算机执行两个数字的加法,你必须逐步详细说明每一个步骤。然而,随着数据的复杂性增加,这种手动逐步指令的方法变得不够用了。
这就是机器学习作为游戏改变者出现的地方。我们希望计算机通过示例学习,就像我们通过经验学习一样。想象一下教一个孩子骑自行车,通过几次示范,然后让他摔倒、自己摸索和学习。这就是机器学习的理念。这项创新不仅改变了行业,还成为了现代世界中不可或缺的必要性。
学习基础知识
现在我们对“机器学习”这一术语有了基本了解,让我们熟悉一些基本术语:
数据
数据是机器学习的命脉。它指的是计算机用于学习的信息。这些信息可以是数字、图片或计算机可以理解的其他任何内容。进一步分为两个类别:
-
训练数据: 这些数据指的是我们用来教计算机的示例。
-
测试数据: 在学习后,我们使用一些新的、未见过的数据来测试计算机的表现,这些数据被称为测试数据。
标签和特征
想象一下,你在教一个孩子如何区分不同的动物。动物的名称(如狗、猫等)将是标签,而这些动物的特征(如腿的数量、毛发等)则是帮助你识别它们的特征。
模型
这是机器学习过程的结果。它是数据中模式和关系的数学表示。就像在探索新地方后绘制一张地图一样。
机器学习的类型
机器学习有四种主要类型:
监督式机器学习
它也被称为指导学习。我们向机器学习算法提供标签数据集,其中正确的输出已知。基于这些示例,它学习数据中的隐藏模式,并可以预测或正确分类新数据。监督学习中的常见类别包括:
-
分类: 将事物分类到不同的类别中,例如将图片分类为猫或狗,将电子邮件分类为垃圾邮件或非垃圾邮件等。
-
回归: 它涉及预测数值,例如房价、你的 GPA 或基于某些特征的销售数量。
无监督机器学习
这里计算机接收没有标签的数据,没有事先的提示,它会自行探索隐藏的模式。想象一下,你被交给了一盒拼图,没有图案,你的任务是将相似的拼图块分组,以形成完整的图片。聚类是最常见的无监督学习类型,其中相似的数据点被分组到一个组中。例如,我们可以使用聚类将相似的社交媒体帖子分组,用户可以关注他们感兴趣的子主题。
半监督机器学习
半监督学习包含标签数据集和未标签数据集的混合,其中标签数据集作为识别数据模式的指导点。例如,你给厨师提供了一份主要食材的清单,但没有提供完整的食谱。所以虽然他们没有食谱,但有一些可能帮助他们入门的提示。
强化学习
强化学习也称为通过实践学习。它与环境互动,并根据其行为获得奖励或惩罚。随着时间的推移,它学会了最大化奖励并表现良好。想象一下你在训练一只小狗,当它表现良好时你给予积极反馈(奖励),当它表现不佳时你不给予奖励。随着时间的推移,小狗学会了哪些行为会带来奖励,哪些不会。
高级机器学习过程
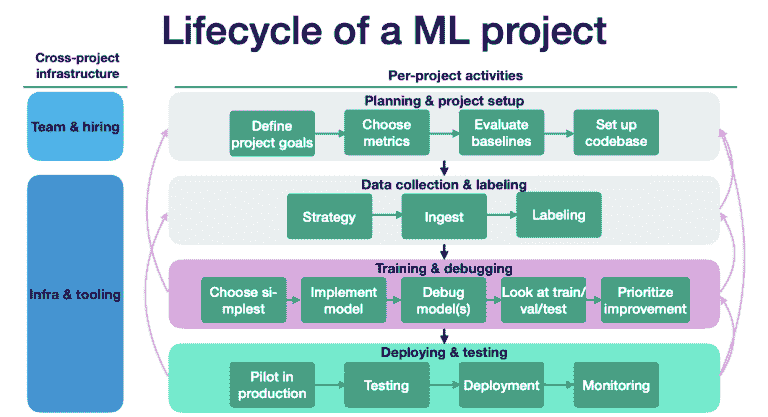
机器学习,就像烹饪艺术一样,拥有将原始、不同的元素转化为深刻见解的神奇能力。就像一位熟练的厨师巧妙地结合各种食材来制作美味的菜肴一样。以下是执行机器学习任务的 6 个基本步骤:
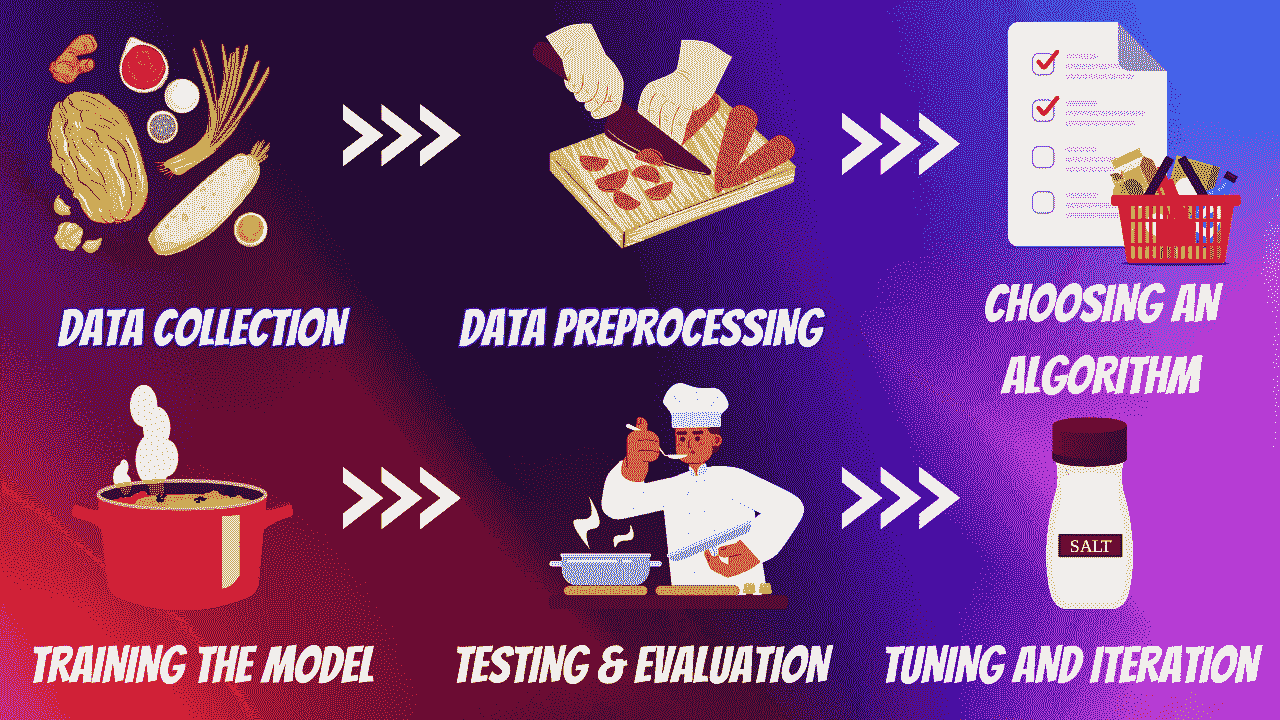
作者提供的图片
1. 数据收集
数据是一个重要的资源,其质量非常重要。多样化、更相关的数据会带来更好的结果。你可以把它想象成厨师从不同的市场收集各种食材。
2. 数据预处理
我们的大多数数据并不是以期望的形式存在的。就像在烹饪前洗净、切割和准备食材一样,数据预处理涉及清理和组织数据以供学习过程使用。一些常见的问题包括缺失数据、异常值、格式不正确等。
3. 选择算法
就像选择特定菜肴的食谱一样,你需要根据你要解决的问题选择算法。这一选择也可能会受到你拥有的数据类型的影响。
4. 训练模型
想象一下烹饪过程,我们等待味道融合。同样地,我们让模型从训练数据中学习。学习率是一个重要概念,它决定了模型在每次训练迭代中的步伐大小。如果一次加了太多盐或香料,菜肴可能会变得过于浓烈。相反,如果加得太少,味道可能无法完全发展。学习率找到逐渐增强味道的完美平衡。
5. 测试与评估
一旦学习过程结束,我们使用特殊的测试数据对其进行测试,就像在与他人分享之前品尝菜肴并检查其外观一样。常见的评估指标包括准确性、精确度、召回率和 F1 分数,具体取决于当前的问题。
6. 调优和迭代
就如同调整调料或配料来完善菜肴一样,你通过引入更多变量、选择不同的学习算法和调整参数或学习率来微调模型。
总结
在我们结束对机器学习基础的探索时,请记住这全在于赋予计算机在最小的人为干预下学习和做出决策。保持好奇,并留意我们的下一篇文章,我们将深入探讨各种机器学习算法。以下是一些适合初学者进一步探索的资源:
Kanwal Mehreen 是一位有志的软件开发者,对数据科学和人工智能在医学中的应用充满兴趣。Kanwal 被选为 2022 年 Google Generation Scholar APAC 区域奖学金获得者。Kanwal 喜欢通过撰写有关趋势话题的文章来分享技术知识,并热衷于改善女性在科技行业中的代表性。
主题相关
基于密度的空间聚类(DBSCAN)
原文:
www.kdnuggets.com/2017/10/density-based-spatial-clustering-applications-noise-dbscan.html
由 Abhijit Annaldas, Microsoft 提供。
DBSCAN 是一种不同类型的聚类算法,具有一些独特的优势。正如名称所示,该方法更加关注观测值的接近度和密度来形成簇。这与 K-Means 很不同,在 K-Means 中,观测值成为由最近的中心点表示的簇的一部分。DBSCAN 聚类可以识别离群值,即不会属于任何簇的观测值。由于 DBSCAN 聚类也能够识别簇的数量,因此在我们不知道数据中可能有多少个簇时,它在无监督学习中非常有用。
K-Means 聚类可能将松散相关的观测值聚集在一起。即使观测值在向量空间中相距甚远,每个观测值最终也会成为某个簇的一部分。由于簇依赖于簇元素的均值,每个数据点在形成簇的过程中发挥作用。数据点的微小变化 可能 会影响聚类结果。由于簇的形成方式,DBSCAN 大大减少了这个问题。
在 DBSCAN 中,聚类发生基于两个重要参数,即:
-
邻域 (n) - 点与(核心点 - 下面讨论)之间的截止距离,以使其被视为簇的一部分。通常称为 epsilon(缩写为 eps)。
-
最小点数 (m) - 形成簇所需的最小点数。通常称为 minPts。
DBSCAN 聚类完成后,会出现三种类型的点,即:
-
核心 - 这是一个点,该点自身距离 n 内至少有 m 个点。
-
边界 - 这是一个点,该点至少与一个核心点的距离为 n。
-
噪声 - 这是一个既不是核心点也不是边界点的点。它在距离 n 内的点少于 m 个。
DBSCAN 聚类可以总结为以下步骤...
-
对数据集中的每个点 P,识别距离 n 内的点 pts。
-
如果 pts >= m,将 P 标记为 核心 点
-
如果 pts < m 且核心点距离 n,将 P 标记为 边界 点
-
如果 pts < m,将 P 标记为 噪声 点
-
-
为了便于解释,假设 一个 核心 点及其距离 n 内的所有点 组成一个核心集。所有重叠的核心集被分组到一个簇中。就像多个单独的图被连接形成一个连通图的集合。

由于聚类完全依赖于参数 n 和 m(如上所述),正确选择这些值非常重要。虽然对该领域有较好的领域知识有助于选择这些参数的良好值,但也有一些方法可以在没有深厚领域专业知识的情况下相对准确地估算这些参数。
查看 DBSCAN 演示于 sklearn 示例 并尝试使用 sklearn.cluster.DBSCAN 在 sklearn 中实现。
个人简介:Abhijit Annaldas 是一名软件工程师和狂热学习者,他在机器学习领域获得了相当程度的知识和专业技能。他通过学习新事物和不懈练习,日益提高自己的专业能力,并且自 2012 年 6 月以来,在微软印度担任软件工程师,拥有丰富的经验,构建了多种企业级应用,涉及多种 Microsoft 和开源技术。
原文。经许可转载。
相关:
-
用 Python 和 SciPy 比较距离测量
-
必须知道:如何确定最有用的聚类数?
-
文本聚类:从非结构化数据中获取快速洞察
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关内容
功能数据中的密度核深度异常检测
原文:
www.kdnuggets.com/density-kernel-depth-for-outlier-detection-in-functional-data

图像由 DALLE-3 生成
介绍
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
在当今大数据集和复杂数据模式的时代,检测异常值或离群点的艺术与科学变得更加细致。尽管传统的异常检测技术能够有效处理标量或多变量数据,但功能数据——即由曲线、表面或任何连续体组成的数据——带来了独特的挑战。为了解决这一问题,已经开发出一种开创性的技术,即“密度核深度”(DKD)方法。
在这篇文章中,我们将深入探讨 DKD 的概念及其在功能数据异常检测中的影响,站在数据科学家的角度来看。
1. 理解功能数据
在深入探讨 DKD 的复杂性之前,了解功能数据的定义是至关重要的。与传统的标量数据点不同,功能数据由曲线或函数组成。可以把它想象成将整个曲线作为一个数据观察值。这类数据通常出现在时间上连续测量的情况,比如一天中的温度曲线或股市轨迹。
给定一个在域D上观察到的n条曲线的数据集,每条曲线可以表示为:
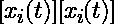
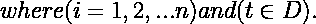
2. 功能数据中异常检测的挑战
对于标量数据,我们可能会计算均值和标准差,然后基于数据点距离均值的标准差数量来确定异常值。
对于功能数据,这种方法更为复杂,因为每个观察值都是一条曲线。
一种测量曲线中心性的办法是计算其相对于其他曲线的“深度”。例如,使用一种简单的深度度量:
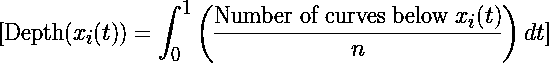
其中 n 是曲线的总数。
虽然上述内容是简化表示,但实际上,功能数据集可能包含数千条曲线,这使得视觉离群点检测具有挑战性。像深度度量这样的数学公式提供了一种更结构化的方法来评估每条曲线的中心性,并可能检测到离群点。
在实际场景中,需要更高级的方法,如密度核深度,以有效确定功能数据中的离群点。
3. DKD 的工作原理
DKD 通过将每条曲线在每个点的密度与该点上整个数据集的总体密度进行比较来工作。密度通过核方法进行估计,这些方法是非参数技术,允许在复杂的数据结构中估计密度。
对于每条曲线,DKD 在每个点上评估其“异常性”,并将这些值在整个领域上积分。结果是一个代表曲线深度的单一数字。较低的值表示潜在的离群点。
给定曲线 Xi?(t) 在点 t 的核密度估计定义为:
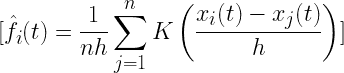
其中:
-
K (.) 是核函数,通常是高斯核。
-
h 是带宽参数。
核函数 K (.) 和带宽 h 的选择可以显著影响 DKD 值:
-
核函数:由于其平滑特性,高斯核常被使用。
-
带宽 ?:它决定了密度估计的平滑度。通常使用交叉验证方法来选择最佳的 h。
3. 密度核深度计算
曲线 Xi?(t) 在点 t 相对于整个数据集的深度计算为:
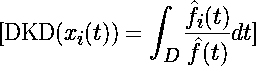
其中:
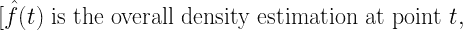
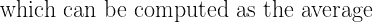
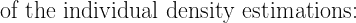
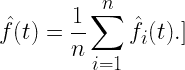
每条曲线得到的 DKD 值提供了其中心性的度量:
-
DKD 值较高的曲线更接近数据集的中心。
-
DKD 值较低的曲线是潜在的离群点。
4. 使用 DKD 进行功能数据分析的优势
灵活性:DKD 对数据的基础分布没有强假设,使其对各种功能数据结构都很通用。
可解释性:通过为每条曲线提供一个深度值,DKD 使理解哪些曲线是中心的,哪些是潜在的离群点变得直观。
效率:尽管复杂,DKD 在计算上是高效的,使其适用于大型功能数据集。
5. 实际应用
想象一个场景,其中数据科学家正在分析患者 24 小时内的心率曲线。传统的异常值检测可能会将偶尔的高心率读数标记为异常。然而,使用功能数据分析和 DKD,整个异常的心率曲线——可能指示心律失常——可以被检测到,提供对患者健康的更全面视角。
结论
随着数据复杂性的不断增长,用于分析这些数据的工具和技术必须同步演变。密度核深度提供了一种有前景的方法来应对功能数据的复杂格局,确保数据科学家能够自信地检测异常值并从中得出有意义的见解。虽然 DKD 只是数据科学家工具箱中的众多工具之一,但它在功能数据分析中的潜力是不可否认的,并且有望为未来更复杂的分析技术铺平道路。
Kulbir Singh**** 是分析和数据科学领域的杰出领袖,拥有超过二十年的信息技术经验。他的专业知识广泛,包括领导力、数据分析、机器学习、人工智能(AI)、创新解决方案设计和问题解决。目前,Kulbir 担任 Elevance Health 的健康信息经理。Kulbir 对人工智能(AI)的进步充满热情,创办了 AIboard.io,这是一个致力于创建以 AI 和医疗保健为中心的教育内容和课程的创新平台。
更多相关内容
如何在 Kubernetes 中部署 Flask API 并将其与其他微服务连接
原文:
www.kdnuggets.com/2021/02/deploy-flask-api-kubernetes-connect-micro-services.html
评论
作者:Rik Kraan, Vantage AI
Kubernetes 是一个强大的容器编排工具,它自动化了 容器 的部署和管理。如果你有一个简单的轻量级应用,由一个服务组成,不用考虑使用 Kubernetes。Kubernetes 的优势在于,当你的应用具有 微服务 架构并且多个组件协同工作时,它会显现出来。它是一个‘自动化部署、扩展和管理容器化应用的开源系统’,具有以下几个优势:
-
根据需求进行简单(自动)扩展
-
通过分配负载以使应用在部分故障时仍能正常运行,从而使应用具有容错能力
-
自动化健康检查和自我修复过程
-
处理微服务之间的通信,并将传入的流量均匀分配到所有资源上
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
初次使用 Kubernetes 可能会让人感到畏惧,但如果你掌握其主要概念,并在 官方网站 上进行一些练习,你可以相对轻松地入门。
在本博客中,我将:
-
提供 Kubernetes 主要概念的快速概述
-
演示如何启动自己的本地集群
-
在集群上部署 MySQL 数据库
-
设置一个作为 REST API 与数据库通信的 Flask 应用

网络。照片由 Alina Grubnyak 提供,来自 Unsplash
Kubernetes 基础
在这一部分,我将介绍 Kubernetes 的基础知识而不涉及过多细节;可以通过阅读官方文档深入了解。
一个 Kubernetes 集群由一个主节点和一个或多个工作节点组成。这种架构是 Kubernetes 的主要特征之一。如你所见,你的微服务分布在不同的节点上,以便在其中一个工作节点故障时保持健康。主节点负责管理集群,并通过 API 让你与集群进行通信。默认情况下,工作节点 配备了一些组件,包括预安装的软件,以便运行流行的容器服务如Docker 和 containerd。
部署你自己应用程序到 Kubernetes 集群上有三个主要概念是必不可少的:部署、Pods 和服务。
- 一个部署 是一组指令,提供给主节点,用于创建和更新你的应用程序。根据这些指令,主节点 将调度并在各个工作节点上运行你的应用程序。部署会持续由主节点监控。如果你的应用程序的某个实例出现故障(例如,如果工作节点出现故障),它将被自动替换为一个新实例。
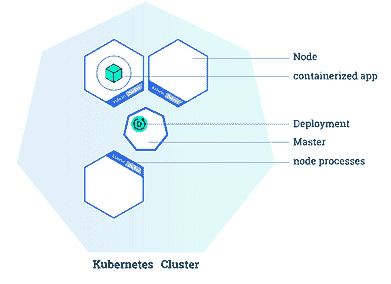
Kubernetes 集群与部署(来源:kubernetes.io/docs/tutorials/kubernetes-basics/deploy-app/deploy-intro/)
- 一个Pod 是 Kubernetes 平台中的原子单位。它代表一个或多个容器及这些容器共享的一些资源(共享存储、唯一的集群 IP 地址等)。如果你创建一个部署,该部署将创建带有容器的pods。每个pod 都绑定到一个工作节点。需要理解的是,一个工作节点可以拥有多个pods,如果当前的工作节点出现故障,这些pods 将会在另一个可用的工作节点上重新创建。
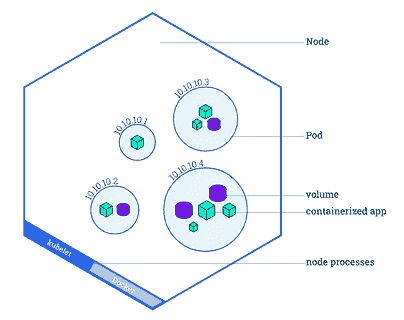
带有多个 pods 的工作节点概述(来源:kubernetes.io/docs/tutorials/kubernetes-basics/explore/explore-intro/)
- 一个service基本上定义了一组逻辑上的pods并定义了访问它们的策略。这是必要的,因为pods可能会停止并重启(例如,如果工作节点被删除或崩溃)。一个service在一组 pods 之间路由流量,并允许 pods 在不影响应用程序的情况下死亡和复制。在定义一个服务时,你可以指定服务的类型。默认情况下,Kubernetes 创建一个 ClusterIP 服务,这使得你的service只能从集群内部访问。你可能想将一些services(例如前端)暴露给外界。在这种情况下,你可以创建一个LoadBalancer服务,它创建一个外部负载均衡器并分配一个固定的外部 IP,使其可以从集群外部访问(例如在你的浏览器中)。
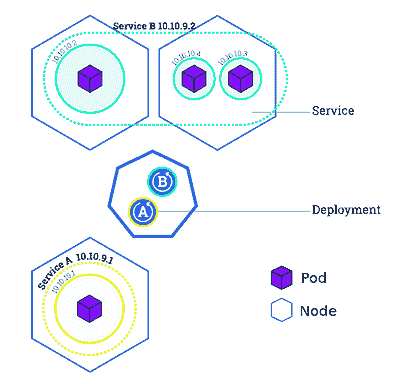
一个包含 3 个工作节点、若干个 pods 和两个将 pods 绑定在一起的服务(A & B)的集群(来源:kubernetes.io/docs/tutorials/kubernetes-basics/expose/expose-intro/)
开始使用自己的集群
如果你想让你的集群快速运行:本博客中的所有代码(以及一个说明性的 Readme)可以在此处找到。我们将构建的应用程序由两个微服务组成:
-
一个 MySQL 数据库
-
一个实现 API 以访问和执行数据库 CRUD(创建、读取、更新、删除)操作的 Flask 应用程序。
先决条件:请确保已安装
*kubectl*和*minikube*(https://kubernetes.io/docs/tasks/tools/)。并确保你的Docker CLI通过命令*eval $(minikube docker-env)*使用集群中的Docker daemon。不用担心:如果你重启终端,你将自动使用自己的Docker daemon。最后通过命令*minikube start*启动本地集群。
首先:在设置 MySQL 数据库时,我们需要考虑两件事。1) 要访问数据库,我们需要配置一些凭据;2) 我们需要一个持久卷,以防节点意外关闭时不会丢失所有数据。
创建密钥
Kubernetes 有自己处理敏感信息的方法,通过配置 Kubernetes Secrets。这可以通过一个简单的 YAML 文件完成。这些secrets可以通过指定环境变量(稍后我们将看到)被集群中的任何pod访问。Secrets应该指定为base64 编码字符串。因此,我们首先需要通过终端获取密码的编码版本:echo -n <super-secret-passwod> | base64。复制输出并将其嵌入到以下secrets.yml文件中的db_root_password字段中。metadata.name字段很重要,因为我们需要在后面的阶段中指定它,所以一定要记住它。
现在你可以通过终端将秘密添加到集群中:kubectl apply -f secrets.yml。然后通过kubectl get secrets检查是否成功。
持久卷
持久卷是一个生命周期独立于Pod的存储资源。这意味着如果pod崩溃,存储将继续存在。由于 Kubernetes 可以在任何时候重新启动pods,因此将数据库存储设置为persistent volume是一种良好的实践。persistent volume可以是本地文件系统上的目录,也可以是云提供商的存储服务(例如 AWS Elastic Block Storage 或 Azure Disk)。创建persistent volume时可以指定其类型。在本教程中,你将使用hostPath类型,这将在你的minikube节点上创建一个卷。然而,在生产环境中,确保使用其他类型(参见文档),因为使用hostPath类型时,如果删除 minikube 节点,数据将会丢失。
使应用程序使用persistent volume包括两个部分:
-
指定卷的实际存储类型、位置、大小和属性。
-
指定一个persistent volume claim,请求部署所需的特定大小和访问模式的持久卷。
创建一个persistent-volume.yml文件,并指定大小(在本例中为 2GB)、访问模式以及文件存储的路径。spec.persistentVolumeReclaimPolicy指定了如果persistent volume claim被删除时应该执行的操作。对于像MySQL数据库这样的有状态应用程序,你希望在删除声明时保留数据,以便手动检索或备份数据。默认的回收策略是继承自persistent volume的类型,因此在 yml 文件中始终指定它是一种良好的实践。
你可以通过kubectl apply -f persistent-volume.yml再次添加存储。然后通过kubectl describe pv mysql-pv-volume和kubectl describe pvc mysql-pv-claim查看你创建的资源的详细信息。由于你创建了一个主机路径类型的persistent volume,你可以通过登录到 minikube 节点minikube ssh并导航到指定路径(/mnt/data)来查找数据。
部署 MySQL 服务器
在我们的秘密和持久卷(声明)就位后,我们可以开始构建我们的应用程序。首先,我们将部署一个 MySQL 服务器。拉取最新的 mysql 镜像 docker pull mysql 并创建 mysql-deployment.yml 文件。关于这个文件,有几件事值得提及。我们指定仅启动一个 Pod(spec.replicas: 1)。该部署将管理所有带有标签 db 的 Pod,标签由 spec.selector.matchLabels.app: db 指定。template 字段及其所有子字段指定了 pod 的特征。它将运行 mysql 镜像,名称也为 mysql,并在 flaskapi-secrets secret 中查找 db_root_password 字段,将其值设置为 MYSQL_ROOT_PASSWORD 环境变量。此外,我们指定了一个容器暴露的端口,以及持久卷应该挂载的路径 spec.selector.template.spec.containers.volumeMounts.mountPath: /var/lib/mysql。在底部,我们还指定了一个名为 mysql 的 LoadBalancer 类型的服务,以便我们可以通过该服务访问我们的数据库。
现在你可以通过 kubectl apply -f mysql-deployment.yml 部署 MySQL 服务器。然后通过 kubectl get pods 查看 Pod 是否正在运行。
创建数据库和表格
在实现 API 之前,我们必须做的最后一件事是初始化 MySQL 服务器上的数据库和模式。我们可以使用多种方法来完成这项工作,但为了简单起见,让我们通过新创建的 service 访问 MySQL 服务器。由于运行 MySQL service 的 Pod 仅能从集群内部访问,你需要启动一个作为 mysql-client 的临时 Pod:
-
通过终端设置
mysql-client:kubectl run -it --rm --image=mysql --restart=Never mysql-client -- mysql --host mysql --password=<your_password>。填写你在 secrets.yml 文件中指定的(解码)密码。 -
创建数据库、表格和模式。你可以做任何你喜欢的事,但为了确保样本 Flask 应用程序能够正常工作,请按照以下步骤操作:
CREATE DATABASE flaskapi;
USE flaskapi;
CREATE TABLE users(user_id INT PRIMARY KEY AUTO_INCREMENT, user_name VARCHAR(255), user_email VARCHAR(255), user_password VARCHAR(255));
部署 API
最后是时候部署你的 REST API 了。以下示例展示了一个实现了只有两个端点的 Flask 应用程序的示例。一个用于检查 API 是否正常工作,另一个用于在我们的数据库中创建用户。在 GitHub 的 repo 中,你可以找到具有读取、更新和删除数据库条目的端点的 Python 文件。连接到数据库 API 的密码是从创建的 secrets 中检索的。其余的环境变量(例如 MYSQL_DATABASE_HOST)则从之前实现的 MySQL service 中检索(稍后我将解释如何确保 Flask 应用程序能够访问这些信息)。
要在 Kubernetes 集群中部署这个应用,你需要通过创建一个简单的 Dockerfile 来制作这个 Flask 应用的镜像。没有特别之处,准备你的容器,安装所需的软件包,复制文件夹内容并运行 Flask 应用。前往 GitHub 仓库 查找构建镜像所需的 Dockerfile 和 requirements.txt 文件。在你可以将 Flask 应用部署到 Kubernetes 集群之前,你首先需要构建镜像并将其命名为 flask-api,命令为 docker build . -t flask-api。
现在是定义 deployment 和 service 的时候了,目的是为了实现一个 RESTful API 的 Flask 应用。部署将启动 3 个 Pod(在 flaskapp-deployment.yml 的 spec.replicas: 3 字段中指定)。在每个这些 pods 中,将从你刚刚构建的 flask-api 镜像创建一个容器。为了确保 Kubernetes 使用本地构建的镜像(而不是从外部仓库如 Dockerhub 下载镜像),请确保将 imagePullPolicy 设置为 never。为了确保 Flask 应用可以与数据库通信,应该设置一些环境变量。db_root_password 是从你创建的 secrets 中获取的。每个启动的容器都继承包含所有正在运行的 services 信息的环境变量,包括 IP 和 port 地址。因此,你不必担心在 Flask 应用中指定 MySQL 数据库的 host 和 port。最后,你将定义一个 LoadBalancer 类型的 service,以便在三个 Pod 之间分配传入的流量。
向 API 发起请求
你现在可以使用我们的 API 并与数据库交互。最后一步是通过终端暴露 API service:minikube service flask-service。你现在会看到类似的内容

访问提供的 URL,你将看到 Hello World 消息,以确保你的 API 正常运行。现在你可以使用你喜欢的请求服务如 Postman 或 curl 在终端中与 API 交互。要创建一个用户,提供一个 json 文件,其中包含 name、email 和 pwd 字段。例如:curl -H "Content-Type: application/json" -d '{"name": "<user_name>", "email": "<user_email>", "pwd": "<user_password>"}' <flask-service_URL>/create。如果你也实现了 API 的其他方法(如在 GitHub 仓库 中定义),你现在可能可以通过以下命令查询数据库中的所有用户:curl <flask-service_URL>/users。
结论
在你的终端中使用 curl。要创建用户,提供一个包含 name、email 和 pwd 字段的json文件。例如:curl -H "Content-Type: application/json" -d '{"name": "<user_name>", "email": "<user_email>", "pwd": "<user_password>"}' <flask-service_URL>/create。如果你还实现了 API 的其他方法(如GitHub 仓库中定义的那样),你现在可以通过以下命令查询数据库中的所有用户:curl <flask-service_URL>/users。
在这个动手教程中,你将设置部署、服务和Pods,通过部署 Flask 应用实现一个 RESTful API,并将其与其他微服务(在此案例中是 MySQL 数据库)连接。你可以在本地持续运行,也可以在云等远程服务器上实现并投入生产。欢迎克隆仓库并根据需要调整 API,或者添加其他微服务。
如果你有任何额外的问题、意见或建议,随时与我联系!
简介: Rik Kraan 是一位医学博士,拥有放射学博士学位,目前在Vantage AI,一家位于荷兰的数据科学咨询公司担任数据科学家。可以通过 rik.kraan@vantage-ai.com 与他联系。
原文。经授权转载。
相关:
-
Kubernetes 与 Amazon ECS 对数据科学家的比较
-
使用 Python 和 Heroku 创建并部署你的第一个 Flask 应用
-
数据科学与 DevOps 的结合:Jupyter、Git 和 Kubernetes 下的 MLOps
更多相关主题
部署机器学习模型是什么意思?
原文:
www.kdnuggets.com/2020/02/deploy-machine-learning-model.html
评论
由 Luigi Patruno、数据科学家和 ML in Production 的创始人。
我最近向Twitter 社区询问了他们在机器学习方面最大的痛点,以及他们的团队在 2020 年的工作重点。最常提到的痛点之一是部署机器学习模型。更具体地说,“你如何以自动化、可重现和可审计的方式部署机器学习模型?”

好问题!
在教授机器学习时,很少讨论 ML 部署的话题。训练算法和神经网络架构往往是重点,因为这些是“核心”机器学习思想。我并不反对这一点,但我认为如果数据科学家不能部署模型,他将无法为业务增加多少价值。
如果你搜索有关如何部署模型的资源,你会发现很多关于编写 Flask API 的博客文章。虽然这些文章做得很好,但并非所有 ML 模型都需要部署在 Flask API 后面。实际上,有时这会适得其反。这些文章很少讨论部署模型时需要考虑的因素、可使用的各种工具以及其他重要概念。这些话题非常广泛,一篇博客文章无法全面覆盖。
这就是为什么我写了一个关于部署机器学习模型的多部分博客系列。该系列将讨论部署机器学习模型的意义、部署模型时需要考虑的因素、使用的软件开发策略以及需要利用的工具和框架。如果你希望在每篇文章发布时收到通知,请留下你的电子邮件地址!
在讨论任何工具之前,我们先问一个问题:部署模型是什么意思?
部署机器学习模型是什么意思?
在考虑使用什么工具来部署模型之前,你需要对部署的意义有一个清晰的理解。为了获得这种理解,将自己置身于软件工程师的角度是很有帮助的。软件工程师如何看待“部署”代码?将代码的部署概念转移到机器学习领域时会发生什么?将部署视为软件工程师而非数据科学家,将显著简化部署模型的含义。
为了理解部署 ML 模型的含义,让我们简要讨论一下 ML 项目的生命周期。假设一位产品经理 (PM) 发现了一些用户需求,并确定可以使用机器学习来解决这个问题。这将涉及创建一个新产品或通过机器学习功能增强现有产品,通常以监督学习模型的形式。
产品经理将与 ML 团队负责人会面,通过定义项目目标、选择指标和设置代码库来规划项目。如果存在适当的训练和验证数据,项目将交给数据科学家或 ML 工程师处理特征工程和模型选择的迭代过程。
此阶段的目标是构建一个预测性能水平达到或超过规划阶段设定目标的模型。在这些初始阶段,驱动这个项目的用户需求仍未得到满足。即使存在一个达到最低预测性能要求的模型,这些需求也不会得到满足。
只有当一个机器学习模型的洞察定期提供给其构建目标的用户时,这个模型才会开始为组织创造价值。将训练好的 ML 模型的预测提供给用户或其他系统的过程被称为部署。部署与特征工程、模型选择或模型评估等常规机器学习任务完全不同。
因此,部署在缺乏软件工程或 DevOps 背景的数据科学家和 ML 工程师中并不十分理解。但幸运的是,这些技能并不难学。通过实践,任何数据科学家都可以学习如何将模型部署到生产环境中。
你如何决定如何部署?
要决定如何部署一个模型,你需要了解最终用户应该如何与模型的预测进行互动。这最好通过几个示例来理解。我们将从一个非常简单的用例开始,逐步增加复杂性。
部署示例 1:部署潜在客户评分模型
假设一位数据科学家为一组精通 SQL 的技术分析师构建了一个潜在客户评分模型。这些分析师希望根据潜在客户转化为客户的可能性将新的潜在客户分组。
每天早晨,他们希望利用数据库中的数据来创建/更新他们在 BI 工具中维护的仪表盘。
由于分析师知道 SQL 并期望将模型评分存储在数据库中,“部署”潜在客户评分模型意味着为新的潜在客户生成每日评分,并将这些评分存储在分析师的数据库中。
部署的关键方面是
-
预测可以在一组新潜在客户上生成,
-
这些预测需要每天提供,并且
-
预测需要存储在数据库中。部署过程需要满足这三项约束条件,以便机器学习模型能为业务带来价值。
考虑一个稍微复杂一点的情况。
销售部门负责人了解了模型,并希望将模型的见解提供给他的账户执行者。自然地,也让我们感到遗憾的是,账户执行者不知道 SQL,因此在这种情况下,将预测存储在数据库中还不够。
产品经理决定,为了增加业务价值,必须在账户执行者使用的 CRM 工具中显示潜在客户评分。
之前示例中的部署方面 1 和 2(为一组潜在客户生成预测并每天生成一次)仍然有效,但方面 3 不再适用。部署涉及将分数从数据库流入 CRM 工具。这将涉及设置额外的 ETL 过程。

部署示例 2:部署推荐系统
对于我们的最终示例,假设我们考虑一下推荐系统——机器学习的一个流行应用,如何进行部署。假设我们在一家电子商务公司工作,该公司希望向用户展示购买产品的推荐。我们将考虑两种部署的变体。
场景 1:公司希望在用户登录到网站或移动应用程序后展示产品推荐。预测需要在任何时候都可以获取,这对我们的部署提出了延迟约束,影响我们是否能够在用户登录时即时生成预测,或是必须提前生成并缓存预测。部署必须使模型的预测对移动应用和网页应用都可用。因此,将我们的部署与这些应用程序分离是可取的。
场景 2:公司希望向现有客户的营销邮件中添加 5 条推荐。这些邮件每周发送给用户两次;一封邮件在周一下午发送,另一封在周五早上发送。在这种情况下,可以同时计算所有用户的推荐并进行缓存。与之前的场景相比,延迟要求要宽松得多。将这些推荐存储在数据库中就足够了。生成邮件的过程可以在数据库中查找用户的推荐,并将前 5 条推荐添加到个性化邮件中。
从这些示例中,我们可以看到,确定如何部署机器学习模型时需要考虑多个因素。这些因素包括:
-
预测应生成的频率
-
是否应该一次生成单个实例的预测,还是一批实例的预测
-
访问模型的应用程序数量
-
这些应用程序的延迟要求
结论
机器学习模型的自动化部署是 2020 年数据科学家和机器学习工程师面临的最大难题之一。由于模型只有在洞察定期提供给最终用户时才能为组织增值,因此机器学习从业者必须了解如何尽可能简单高效地部署他们的模型。确定如何部署模型的第一步是理解最终用户应如何与模型的预测进行互动。
原文。经授权转载。
简介:Luigi Patruno是一位数据科学家和机器学习顾问。他目前是 2U 的数据科学总监,领导一个负责构建机器学习模型和基础设施的数据科学团队。作为顾问,Luigi 帮助公司通过应用现代数据科学方法来生成战略业务和产品倡议的价值。他创办了MLinProduction.com以收集和分享将机器学习应用于实际操作的最佳实践,并且他还教授了统计学、数据分析和大数据工程的研究生课程。
相关:
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT 需求
更多相关内容
如何将机器学习/深度学习模型部署到网络
原文:
www.kdnuggets.com/2021/04/deploy-machine-learning-models-to-web.html
评论

如果你已经在机器学习领域工作了一段时间,你一定创建过一些机器学习或深度学习模型。你一定会想,人们会如何使用你的 Jupyter notebook?答案是他们不会。
我们的前三个课程推荐
1. Google 网络安全证书 - 加入网络安全职业的快车道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
人们无法使用你的 Jupyter notebooks,你需要将你的模型部署为 API 或完整的网络服务,或在移动设备、Raspberry PI 等上。
在本文中,你将学习如何将深度学习模型部署为 REST API,并添加一个表单以获取用户输入,并返回模型的预测结果。
我们将使用 FastAPI 创建 API 并免费部署到 Heroku 上。
第 1 步:安装
你需要安装必要的软件包。
1. FastAPI + Uvicorn
我们将使用 FastAPI 来处理 API,并使用 Uvicorn 服务器来运行和托管这个 API。
$ pip install fastapi uvicorn
2. Tensorflow 2
我们将在本教程中使用 Tensorflow 2,你可以使用你选择的框架。
$ pip install tensorflow==2.0.0
3. Heroku
你可以在 Ubuntu 上通过终端直接使用以下命令安装 Heroku,
$ sudo snap install --classic heroku
在 macOS 上,你可以通过以下方式安装,
$ brew tap heroku/brew && brew install heroku
对于 Windows,你可以从官方 网站 安装压缩文件。
4. Git
你还需要安装 git 并在 GitHub 上创建一个帐户,以便我们可以直接推送到 GitHub 并将主分支连接到我们的 Heroku,这样它就会自动部署。
你可以使用apt在 Debian 上安装 git。
$ sudo apt install git-all
要在 Windows 上安装,你可以直接从 这里下载。
要在 macOS 上安装,你可以安装 XCode 命令行工具并运行以下命令来激活它,
git --version
你也可以从 macOS 上的 git 官网 安装。
第 2 步:创建我们的深度学习模型
我们将创建一个简单的深度学习模型,该模型与情感分析相关。使用的数据集可以从 Kaggle下载,与 GOP 推文相关。
我们将创建这个模型、训练它并保存,以便我们可以在 API 中使用保存的模型,而不必每次 API 启动时都训练模型权重。我们将在文件 model.py 中创建这个模型。
import pandas as pd
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, LSTM, SpatialDropout1D
from sklearn.model_selection import train_test_split
import re
在这里,我们导入了重要的库,这些库将帮助我们创建模型和清理数据。我不会深入探讨深度学习模型或 Tensorflow 的工作原理。有关详细信息,你可以查看 KDnuggets 上的文章,对于情感分析模型的工作,请查看 CNVRG 上的文章。
我们将使用 Pandas 读取数据。
data = pd.read_csv('archive/Sentiment.csv')
# Keeping only the neccessary columns
data = data[['text','sentiment']]
我们将创建一个函数,使用正则表达式移除推文中的不需要的字符。
def preProcess_data(text):
text = text.lower()
new_text = re.sub('[^a-zA-z0-9\s]','',text)
new_text = re.sub('rt', '', new_text)
return new_text
data['text'] = data['text'].apply(preProcess_data)
我们将使用 Tensorflow 的分词器对数据集进行分词,并使用 Tensorflow 的 pad_sequences 对序列进行填充。
max_fatures = 2000
tokenizer = Tokenizer(num_words=max_fatures, split=' ')
tokenizer.fit_on_texts(data['text'].values)
X = tokenizer.texts_to_sequences(data['text'].values)
X = pad_sequences(X, 28)
Y = pd.get_dummies(data['sentiment']).values
现在我们将数据集拆分为训练集和测试集。
X_train, X_test, Y_train, Y_test = train_test_split(X,Y, test_size = 0.20)
现在是设计和创建深度学习模型的时候了。我们将简单地使用嵌入层和一些带有 dropout 的 LSTM 层。
embed_dim = 128
lstm_out = 196
model = Sequential()
model.add(Embedding(max_fatures, embed_dim,input_length = X.shape[1]))
model.add(SpatialDropout1D(0.4))
model.add(LSTM(lstm_out, dropout=0.3, recurrent_dropout=0.2, return_sequences=True))
model.add(LSTM(128,recurrent_dropout=0.2))
model.add(Dense(3,activation='softmax'))
model.compile(loss = 'categorical_crossentropy', optimizer='adam',metrics = ['accuracy'])
我们现在将拟合模型。
batch_size = 512
model.fit(X_train, Y_train, epochs = 10, batch_size=batch_size, validation_data=(X_test, Y_test))
现在深度学习模型已经训练完成,我们将保存模型,以便每次重新加载服务器时无需重新训练。我们只需使用训练好的模型。请注意,我没有进行太多超参数调优或模型改进,你可以自行进行以部署改进后的模型。
model.save('sentiment.h5')
在这里,我们已将模型保存为 'hdf5' 格式。你可以在 这篇文章 中了解更多关于模型保存和加载的信息。
第 3 步:使用 FAST API 创建 REST API
我们将使用 FAST API 创建一个 REST API。我们将创建一个名为 app.py 的新文件。我们将首先进行重要的导入。
import numpy as np
from fastapi import FastAPI, Form
import pandas as pd
from starlette.responses import HTMLResponse
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import tensorflow as tf
import re
在这里,我们从 FastAPI 库中导入了 FastAPI 和 Form,通过这些我们将为 API 创建一个输入表单和端点。我们还从 starlette.response 中导入了 HTMLResponse,这将帮助我们创建输入表单。
我们将首先创建一个输入表单,以便用户可以输入数据,即我们可以测试情感的测试字符串。
app = FastAPI()
@app.get('/predict', response_class=HTMLResponse)
def take_inp():
return '''
<form method="post">
<input maxlength="28" name="text" type="text" value="Text Emotion to be tested" />
<input type="submit" />'''
我们在第一行创建了 FastAPI 应用,并在 /predict 路由上使用了 get 方法,这将返回一个 HTML 响应,以便用户可以看到真实的 HTML 页面,并使用 post 方法在表单中输入数据。我们将利用这些数据进行预测。
你现在可以通过运行以下命令来启动你的应用程序。
uvicorn app:app --reload
这将使你的应用程序在 localhost 上运行。在 http://127.0.0.1:8000/predict 路由下,你可以看到输入表单。

现在让我们定义一些辅助函数,这些函数将用于预处理数据。
data = pd.read_csv('archive/Sentiment.csv')
tokenizer = Tokenizer(num_words=2000, split=' ')
tokenizer.fit_on_texts(data['text'].values)
def preProcess_data(text):
text = text.lower()
new_text = re.sub('[^a-zA-z0-9\s]','',text)
new_text = re.sub('rt', '', new_text)
return new_text
def my_pipeline(text):
text_new = preProcess_data(text)
X = tokenizer.texts_to_sequences(pd.Series(text_new).values)
X = pad_sequences(X, maxlen=28)
return X
这些函数本质上执行相同的工作,用于清理和预处理数据,这些函数已在我们的 model.py 文件中使用。
现在我们将在 "/predict" 路由上创建一个 POST 请求,以便可以将使用表单发布的数据传递到我们的模型中,并进行预测。
@app.post('/predict')
def predict(text:str = Form(...)):
clean_text = my_pipeline(text) #clean, and preprocess the text through pipeline
loaded_model = tf.keras.models.load_model('sentiment.h5') #load the saved model
predictions = loaded_model.predict(clean_text) #predict the text
sentiment = int(np.argmax(predictions)) #calculate the index of max sentiment
probability = max(predictions.tolist()[0]) #calulate the probability
if sentiment==0:
t_sentiment = 'negative' #set appropriate sentiment
elif sentiment==1:
t_sentiment = 'neutral'
elif sentiment==2:
t_sentiment='postive'
return { #return the dictionary for endpoint
"ACTUALL SENTENCE": text,
"PREDICTED SENTIMENT": t_sentiment,
"Probability": probability
}
现在代码有点多。让我们来拆解它。我们在 POST 请求上定义了一个路由 "/predict",表单中的数据将作为我们的输入。我们在函数参数中将其指定为Form(…)。我们将文本传递给 pipeline 函数,以便它可以返回清理和预处理后的数据,然后我们可以将其输入到加载的模型中并获取预测。我们可以使用 numpy 的argmax函数来获取最高预测的索引。我们可以使用 Python 的max函数来挑选最大概率。请注意,FastAPI 的端点必须返回一个字典或一个Pydantic 基础模型。
现在你可以通过以下方式运行你的应用程序:
$ uvicorn app:app --reload
在 "/predict" 路由上,你可以给模型提供输入。

模型将预测情感并返回结果。

我们还可以在主页上创建一个虚拟路由,即“/”,以确保它也能正常工作。
@app.get('/')
def basic_view():
return {"WELCOME": "GO TO /docs route, or /post or send post request to /predict "}
你可以在这里查看完整的代码:
FastAPI 上的文档路由
FastAPI 为每个应用程序提供了一个出色的“/docs”路由,你可以在这里测试你的 API 以及它的请求和路由。
在我们的 API 中,总共有 3 个路由:

我们可以通过点击它们来测试所有 3 个请求。我们将测试最重要的一个,即对预测路由的 POST 请求,它执行所有的计算。
点击“尝试一下”以传入所需的文本并获取其情感:
现在你可以在响应中检查结果:
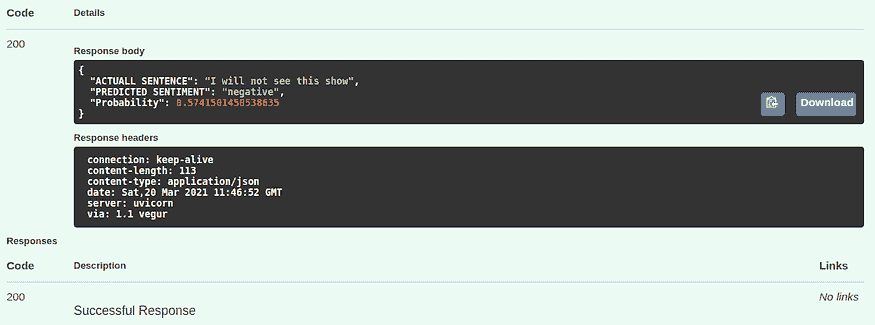
响应状态码 200 表示请求成功,你将得到一个有效的期望输出。
第 4 步:添加有助于部署的适当文件
要为你的应用程序在 Heroku 上定义 Python 版本,你需要在你的文件夹中添加一个runtime.txt文件。在该文件中,你可以定义你的 Python 版本。只需在其中写入合适的 Python 版本。注意这是一个敏感文件,所以确保以指定的正确格式写入,否则 Heroku 会报错。
python-3.6.13
要在 Heroku 上运行 uvicorn 服务器,你需要添加一个 Procfile。注意这个文件没有扩展名。只需创建一个名为“Procfile”的文件。在 Procfile 中添加以下命令。
web: uvicorn app:app --host=0.0.0.0 --port=${PORT:-5000}
请注意,你需要在 0.0.0.0 上运行服务器,并且端口应该是 5000。
另一个重要的文件是requirments.txt文件。将你项目所需的所有重要库添加到其中。
sklearn
fastapi
pandas
pydantic
tensorflow==2.0.0
uvicorn
h5py==2.10.0
python-multipart
你可以添加一个.gitignore文件来忽略你不需要的文件:
__pycache__
model.py
第 5 步:在 Github 上部署
下一步是在 GitHub 上部署这个 Web 应用程序。你需要在 GitHub 上创建一个新的仓库。然后打开命令行并将目录更改为项目目录。
你需要初始化仓库:
$ git init
然后添加所有文件:
$ git add -A
提交所有文件:
$ git commit -m "first commit"
将分支更改为 main:
$ git branch -M main
将文件夹连接到 GitHub 上的仓库:
$ git remote add origin https://github.com/username/reponame.git
推送仓库:
$ git push -u origin main
第 6 步:在 Heroku 上部署
你需要在 Heroku 仪表板上创建一个新的应用程序。
为你的应用程序选择一个合适的名称。
在部署部分,在部署方法中选择 GitHub。
在这里搜索你的仓库,并连接到它。

你可以选择自动部署,这样每次在 GitHub 上的部署分支有变更时,应用程序将自动部署。第一次需要手动部署应用程序。然后每次你在 GitHub 上更新部署分支时,它将会自动部署。
点击“部署分支”将启动部署过程,你可以通过点击“更多”来查看日志,这可以帮助你查看应用程序的日志,如果遇到错误,你可以看到。
一旦构建成功,你可以点击“打开应用程序”来检查你的应用程序。你可以访问你在应用程序中之前定义的所有路由,并进行测试。
查看部署历史
你可以通过检查 GitHub 上底部左侧的环境标签来查看应用程序的部署历史记录。
这也会显示所有的部署历史记录。
使用 Python Requests 访问你的 API
你可以访问你的 API,这意味着你可以在你的普通代码中使用这个 API 来执行情感分析任务。
import requests #install using pip if not already
url = 'https://sentiment-analysis-gopdebate.herokuapp.com/predict'
data = {'text':'Testing Sentiments'} #test is the function params
resp = requests.post(url, data=data) #post request
print(resp.content)

你将收到的输出就像在端点中看到的一样。
使用 Curl 访问你的 API
Curl 是一个命令行工具(你可以从这里下载),用于从命令行发起请求。我们可以使用以下命令发送请求。
$ curl -X 'POST' \
'https://sentiment-analysis-gopdebate.herokuapp.com/predict' \
-H 'accept: application/json' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d 'text=WORST%20SHOW%20EVER
在 -X 参数之后我们提到了请求的类型,即 POST 请求。然后 -H 显示我们的 API 使用的头部信息,分别是 application/JSON 和内容类型。接着我们需要使用 -d 参数提供数据并传递文本。要添加空格,请使用 %20。

你可以在我的 GitHub 仓库这里查看完整的代码。
学习成果
在这篇文章中,你学会了如何通过 Heroku 和 GitHub 将你的机器学习/深度学习模型部署为 REST API。你还学会了如何使用 Python requests 模块和 CURL 访问该 API。
相关:
更多相关主题
在 AWS Fargate 上部署机器学习管道
原文:
www.kdnuggets.com/2020/07/deploy-machine-learning-pipeline-aws-fargate.html
评论
由 Moez Ali,PyCaret 创始人兼作者

总结
在我们 上一篇文章 中,我们展示了如何在云中开发机器学习管道,使用 PyCaret 容器化,并通过 Google Kubernetes Engine 作为 Web 应用进行服务。如果你以前没有听说过 PyCaret,请阅读这个 公告 以了解更多。
在本教程中,我们将使用之前构建和部署的相同机器学习管道和 Flask 应用。这一次,我们将演示如何使用 AWS Fargate 将机器学习管道容器化并进行无服务器部署。
???? 本教程的学习目标
-
什么是容器?什么是 Docker?什么是 Kubernetes?
-
什么是 Amazon Elastic Container Service (ECS)?
-
什么是 AWS Fargate 和无服务器部署?
-
构建并推送 Docker 镜像到 Amazon Elastic Container Registry。
-
使用 AWS 管理的基础设施(即 AWS Fargate)创建并执行任务定义。
-
看到一个实际运行的 Web 应用,它使用训练好的机器学习管道实时预测新数据点。
本教程将涵盖从本地构建 Docker 镜像、将其上传到 Amazon Elastic Container Registry、创建集群,然后使用 AWS 管理的基础设施(即 AWS Fargate)定义和执行任务的整个工作流程。
在过去,我们已经涵盖了在其他云平台如 Azure 和 Google 上的部署。如果你对了解这些感兴趣,可以阅读以下故事:
???? 本教程所需工具箱
PyCaret
PyCaret 是一个开源的、低代码的 Python 机器学习库,用于训练和部署机器学习管道和模型到生产环境中。PyCaret 可以通过 pip 轻松安装。
pip install pycaret
Flask
Flask 是一个允许你构建 web 应用程序的框架。web 应用程序可以是商业网站、博客、电子商务系统,或是利用训练模型从实时提供的数据中生成预测的应用程序。如果你还没有安装 Flask,你可以使用 pip 来安装它。
Docker Toolbox for Windows 10 Home
Docker 是一个旨在通过使用容器简化应用程序创建、部署和运行的工具。容器用于将应用程序与其所有必要组件(如库和其他依赖项)打包,并作为一个整体进行分发。如果你以前没有使用过 Docker,本教程还涵盖了在Windows 10 Home上安装 Docker Toolbox(遗留版)。在前一教程中,我们讲解了如何在Windows 10 Pro 版上安装 Docker Desktop。
亚马逊网络服务(AWS)
亚马逊网络服务(AWS)是一个全面且广泛采用的云平台,由亚马逊提供。它在全球数据中心提供超过 175 种功能齐全的服务。如果你以前没有使用过 AWS,你可以注册一个免费账户。
✔️让我们开始吧……
什么是容器?
在我们开始使用 AWS Fargate 进行实现之前,先来了解一下什么是容器,以及我们为什么需要它?

www.freepik.com/free-photos-vectors/cargo-ship
你是否曾遇到过这样的情况:你的代码在你的电脑上运行良好,但当朋友尝试运行完全相同的代码时,它却无法运行?如果你的朋友重复完全相同的步骤,他或她应该会得到相同的结果,对吧?这个一词答案就是环境。你朋友的环境与你的不同。
环境包括什么?→ 包括编程语言(如 Python)以及构建和测试应用程序时使用的所有库和依赖项的确切版本。
如果我们能创建一个可以转移到其他机器的环境(例如:你朋友的电脑或像 Google Cloud Platform 这样的云服务提供商),我们就可以在任何地方重现结果。因此,容器 是一种软件类型,它打包了应用程序及其所有依赖项,使得应用程序能够在一个计算环境到另一个计算环境之间可靠运行。
什么是 Docker?
Docker 是一家公司,提供名为Docker的软件,允许用户构建、运行和管理容器。虽然 Docker 的容器是最常见的,但也有其他不那么知名的替代品,如LXD和LXC。

现在你在理论上理解了容器是什么以及 Docker 如何用于容器化应用程序,让我们设想一个场景,你需要在一组机器上运行多个容器,以支持一个企业级的机器学习应用程序,在白天和夜晚处理不同的工作负载。这在现实生活中相当常见,虽然听起来简单,但手动完成是非常繁重的工作。
你需要在正确的时间启动正确的容器,搞清楚它们如何互相通信,处理存储问题,应对失败的容器或硬件以及其他各种问题!
管理数百个甚至数千个容器以保持应用程序正常运行的整个过程被称为 容器编排。现在不要被技术细节困住。
此时,你必须认识到管理实际应用程序需要多个容器,并且管理所有基础设施以保持容器运行是繁琐、手动且具有管理负担的。
这将我们引向 Kubernetes。
什么是 Kubernetes?
Kubernetes 是一个由 Google 于 2014 年开发的开源系统,用于管理容器化应用程序。简单来说,Kubernetes 是一个用于在一群机器上运行和协调容器化应用程序的系统。

由 chuttersnap 在 Unsplash 拍摄的照片
虽然 Kubernetes 是由 Google 开发的开源系统,但几乎所有主要的云服务提供商都将 Kubernetes 作为托管服务提供。例如:亚马逊弹性 Kubernetes 服务 (EKS) 由亚马逊提供,Google Kubernetes 引擎 (GKE) 由 Google 提供,和 Azure Kubernetes 服务 (AKS) 由微软提供。
到目前为止,我们已经讨论和理解了:
✔️ 一个 容器
✔️ Docker
✔️ Kubernetes
在介绍 AWS Fargate 之前,还剩下一件事要讨论,那就是亚马逊自家的容器编排服务 Amazon Elastic Container Service (ECS)。
AWS 弹性容器服务 (ECS)
亚马逊弹性容器服务 (Amazon ECS) 是亚马逊自家研发的容器编排平台。ECS 的理念类似于 Kubernetes (它们都是编排服务)。
ECS 是 AWS 原生服务,这意味着它只能在 AWS 基础设施上使用。另一方面,EKS 基于 Kubernetes,这是一个开源项目,适用于运行在多云(AWS、GCP、Azure)甚至本地环境中的用户。
亚马逊还提供了一种基于 Kubernetes 的容器编排服务,称为 Amazon Elastic Kubernetes Service (Amazon EKS)。 尽管 ECS 和 EKS 的目的非常相似,即 编排容器化应用程序,但在定价、兼容性和安全性方面存在一些差异。没有最佳答案,解决方案的选择取决于使用案例。
无论你使用的是哪种容器编排服务(ECS 或 EKS),你可以通过两种方式来实现底层基础设施:
-
手动管理集群和底层基础设施,如虚拟机/服务器(也称为 AWS 中的 EC2 实例)。
-
无服务器 — 完全不需要管理任何东西。只需上传容器即可。← 这就是 AWS Fargate。
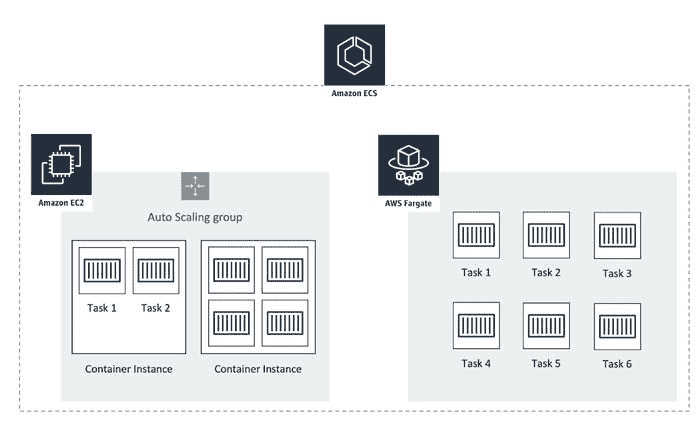
Amazon ECS 底层基础设施
AWS Fargate — 为容器提供无服务器计算
AWS Fargate 是一种无服务器计算引擎,支持与 Amazon Elastic Container Service (ECS) 和 Amazon Elastic Kubernetes Service (EKS) 一起使用。Fargate 使你能够专注于构建应用程序。Fargate 消除了配置和管理服务器的需要,允许你按应用程序指定和支付资源,并通过设计上的应用隔离来提高安全性。
Fargate 分配合适的计算资源,消除了选择实例和扩展集群容量的需要。你只为运行容器所需的资源付费,因此无需担心资源过度配置或额外服务器的费用。
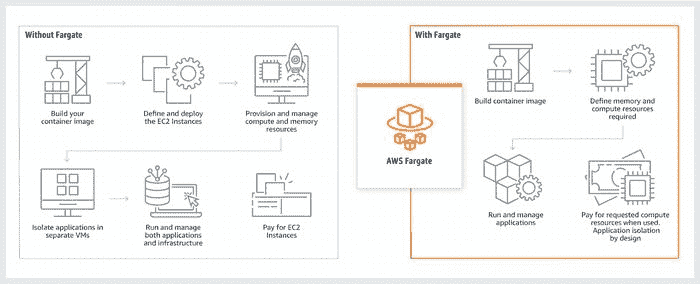
AWS Fargate 的工作原理 — aws.amazon.com/fargate/
哪种方法更好没有最优答案。选择无服务器还是手动管理 EC2 集群取决于具体的使用案例。一些可以帮助你做出选择的指针包括:
ECS EC2(手动方法)
-
你完全依赖于 AWS。
-
你有一个专门的运维团队来管理 AWS 资源。
-
你在 AWS 上已有现有的足迹,即你已经在管理 EC2 实例
AWS Fargate
-
你没有一个庞大的运维团队来管理 AWS 资源。
-
你不想承担操作责任或希望减少操作责任。
-
你的应用程序是无状态的 (无状态应用程序是指在一个会话中生成的客户端数据不会保存到下一次会话中使用的应用程序)。
设置业务背景
一家保险公司希望通过更好地预测住院时的患者费用来改善其现金流预测,使用的是人口统计数据和基本的患者健康风险指标。
(数据源)
目标
构建和部署一个 Web 应用程序,其中患者的群体和健康信息输入到一个基于 Web 的表单中,然后输出预测的费用金额。
任务
-
训练和开发用于部署的机器学习管道。
-
使用 Flask 框架构建 Web 应用程序。它将使用训练好的 ML 管道实时生成新数据点的预测。
-
将 Docker 镜像构建并推送到 Amazon Elastic Container Registry。
-
创建并执行一个任务,使用 AWS Fargate 无服务器基础设施部署应用程序。
由于我们已经在初始教程中涵盖了前两个任务,我们将快速回顾它们,然后关注上面列表中的剩余项目。如果你有兴趣了解更多关于使用 PyCaret 开发机器学习管道和使用 Flask 框架构建 Web 应用程序的内容,请阅读 本教程。
???? 开发机器学习管道
我们在 Python 中使用 PyCaret 训练和开发机器学习管道,该管道将作为我们 Web 应用程序的一部分。机器学习管道可以在集成开发环境(IDE)或 Notebook 中开发。我们使用了 Notebook 来运行以下代码:
当你在 PyCaret 中保存模型时,基于 **setup() **函数中定义的配置创建了整个转换管道。所有相互依赖关系都自动协调。查看存储在‘deployment_28042020’变量中的管道和模型:

使用 PyCaret 创建的机器学习管道
???? 构建 Web 应用程序
本教程不专注于构建 Flask 应用程序。这里只是为了完整性进行讨论。现在我们的机器学习管道已准备好,我们需要一个 Web 应用程序来连接到我们训练好的管道,以实时生成新数据点的预测。我们使用 Python 中的 Flask 框架创建了 Web 应用程序。此应用程序分为两个部分:
-
前端(使用 HTML 设计)
-
后端(使用 Flask 开发)
这就是我们的 Web 应用程序的样子:
本地机器上的 Web 应用程序
如果你到目前为止没有跟上进度,没关系。你可以从 GitHub 上简单地 fork 这个 仓库。这就是此时你的项目文件夹的样子:
使用 AWS Fargate 部署 ML 管道的 10 个步骤:
???? 步骤 1 — 安装 Docker Toolbox(适用于 Windows 10 家庭版)
为了在本地构建 Docker 镜像,你需要在计算机上安装 Docker。如果你使用的是 Windows 10 64 位:专业版、企业版或教育版(构建版本 15063 或更高),你可以从 DockerHub 下载 Docker Desktop。
然而,如果你使用的是 Windows 10 家庭版,你需要从 Docker 的 GitHub 页面 安装最后一版的旧版 Docker Toolbox(v19.03.1)。

github.com/docker/toolbox/releases
下载并运行 DockerToolbox-19.03.1.exe 文件。
检查安装是否成功的最简单方法是打开命令提示符并输入‘docker’。它应该打印出帮助菜单。
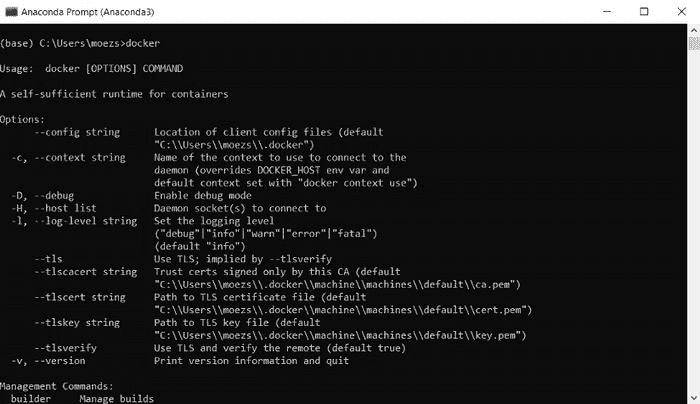
使用 Anaconda Prompt 检查 Docker
???? 步骤 2— 创建 Dockerfile
创建 Docker 镜像的第一步是在项目目录中创建一个 Dockerfile。Dockerfile 只是一个包含一组指令的文件。这个项目的 Dockerfile 如下:
Dockerfile 是区分大小写的,必须与其他项目文件一起放在项目文件夹中。Dockerfile 没有扩展名,可以使用任何文本编辑器创建。你可以从这个 GitHub 存储库 下载本项目中使用的 Dockerfile。
???? 步骤 3— 在 Elastic Container Registry (ECR) 中创建一个存储库
(a) 登录到你的 AWS 控制台并搜索 Elastic Container Registry:
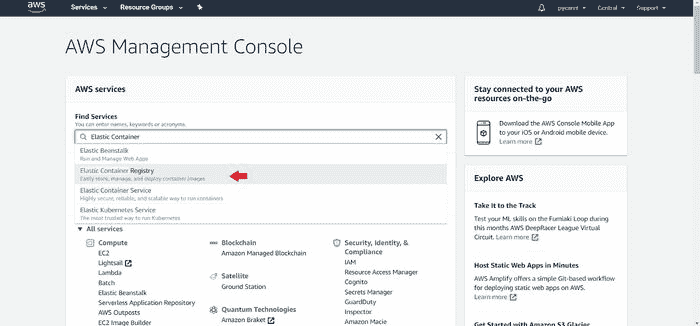
AWS 控制台
(b) 创建一个新的存储库:
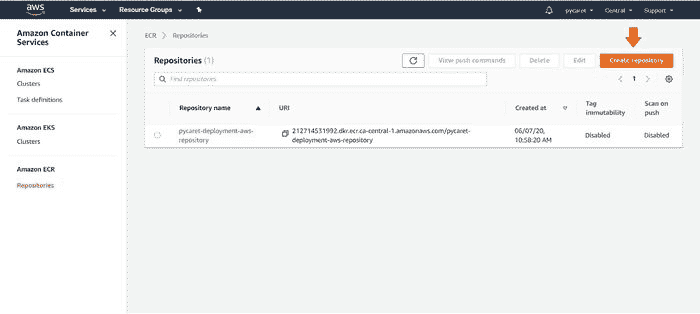
在 Amazon Elastic Container Registry 上创建新存储库
为了这个演示,我们创建了‘pycaret-deployment-aws-repository’。
(c) 点击“查看推送命令”:
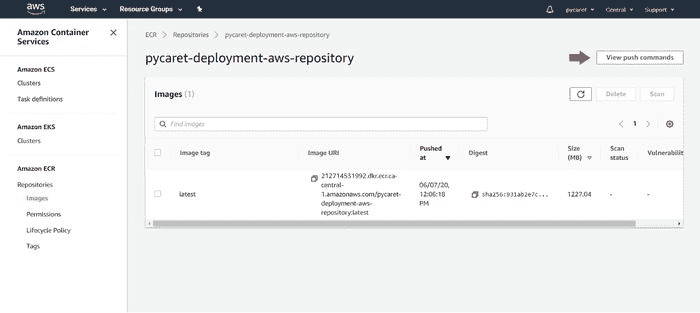
pycaret-deployment-aws-repository
(d) 复制推送命令:
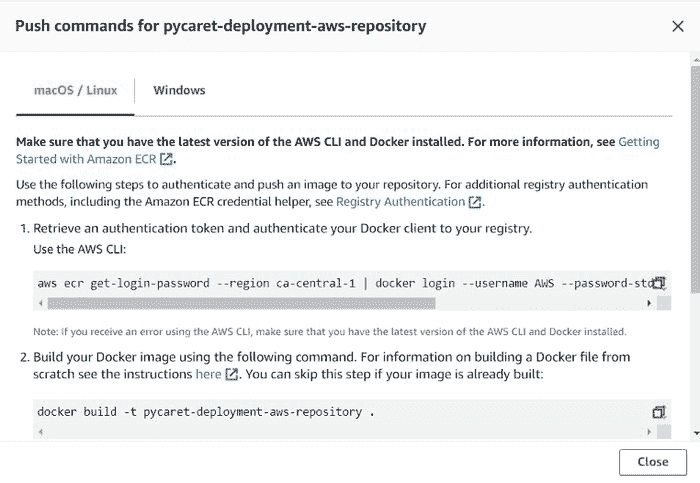
pycaret-deployment-aws-repository 的推送命令
???? 步骤 4— 执行推送命令
使用 Anaconda Prompt 导航到你的项目文件夹,并执行你在上一步中复制的命令。下面的代码仅用于演示,可能无法直接使用。要获得正确的执行代码,你必须从存储库中的“查看推送命令”获取一份代码。
在执行这些命令之前,你必须位于包含 Dockerfile 和其他代码的文件夹中。
**Command 1**
aws ecr get-login-password --region ca-central-1 | docker login --username AWS --password-stdin 212714531992.dkr.ecr.ca-central-1.amazonaws.com**Command 2**
docker build -t pycaret-deployment-aws-repository .**Command 3**
docker tag pycaret-deployment-aws-repository:latest 212714531992.dkr.ecr.ca-central-1.amazonaws.com/pycaret-deployment-aws-repository:latest**Command 4**
docker push 212714531992.dkr.ecr.ca-central-1.amazonaws.com/pycaret-deployment-aws-repository:latest
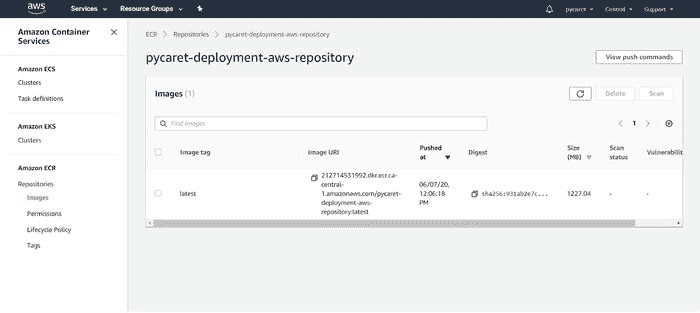
???? 步骤 5— 检查你上传的镜像
点击你创建的存储库,你将看到在上述步骤中上传的镜像的 URI。复制镜像 URI(在下面的步骤 7 中会用到)。
???? 步骤 6 — 创建和配置集群
(a) 点击左侧菜单中的“集群”:
创建集群 — 步骤 1
(b) 选择“仅网络”并点击下一步:
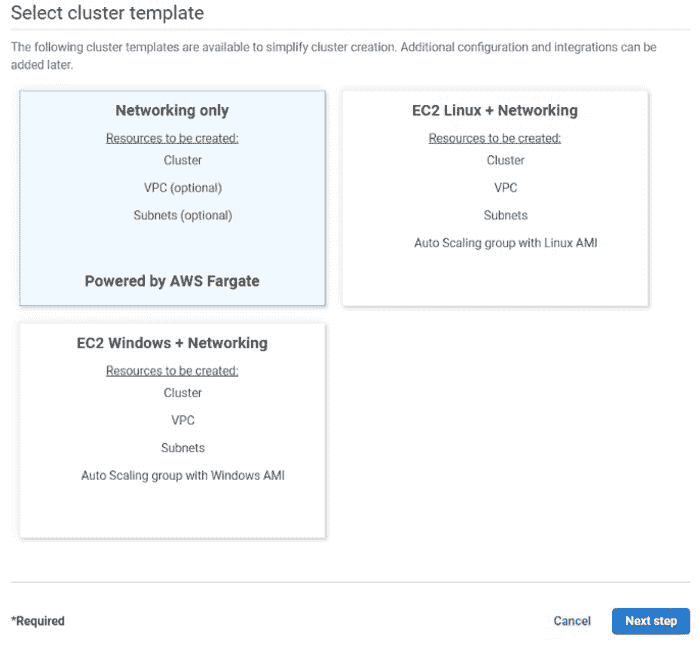
选择仅网络模板
(c) 配置集群(输入集群名称)并点击创建:
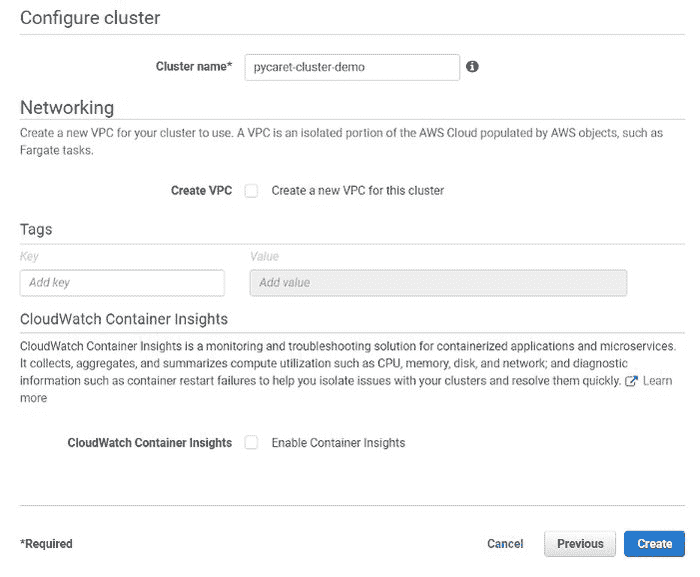
配置集群
(d) 集群创建完成:

集群已创建
???? 步骤 7— 创建一个新的任务定义
一个任务定义是运行 Amazon ECS 中的 Docker 容器所必需的。您可以在任务定义中指定的一些参数包括:每个容器使用的 Docker 镜像。每个任务或任务中每个容器使用的 CPU 和内存量。
(a) 点击“创建新任务定义”:
创建新任务定义
(b) 选择“FARGATE”作为启动类型:

选择启动类型兼容性
(c) 填写详细信息:
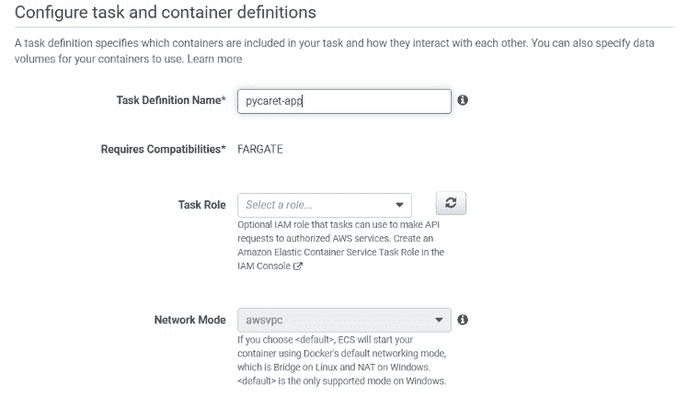
配置任务和容器定义(第一部分)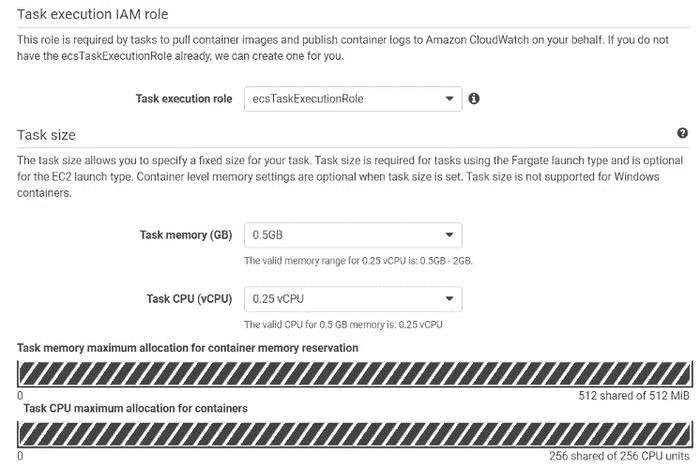
配置任务和容器定义(第二部分)
(d) 点击“添加容器”并填写详细信息:
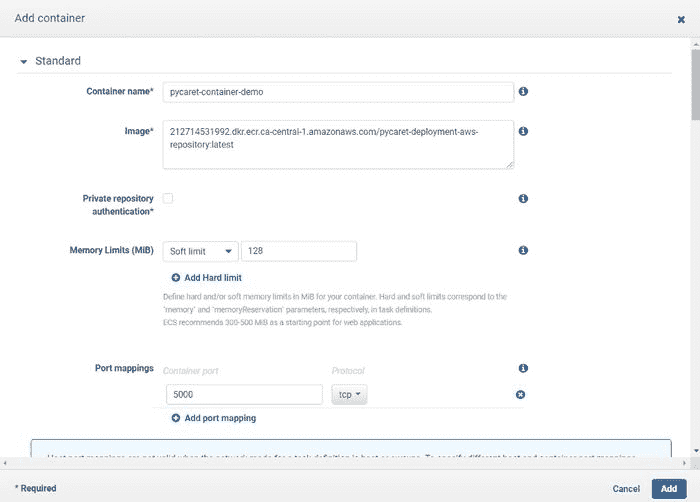
在任务定义中添加容器
(e) 点击右下角的“创建任务”。

???? 第 8 步 — 执行任务定义
在第 7 步中,我们创建了一个将启动容器的任务。现在我们将通过点击“运行任务”在操作下执行任务。
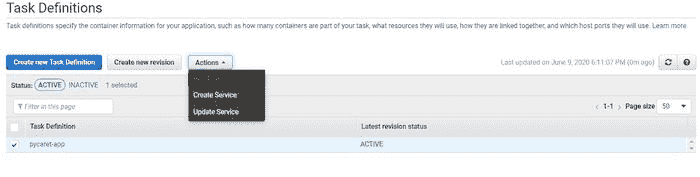
执行任务定义
(a) 点击“切换启动类型”将类型更改为 Fargate:
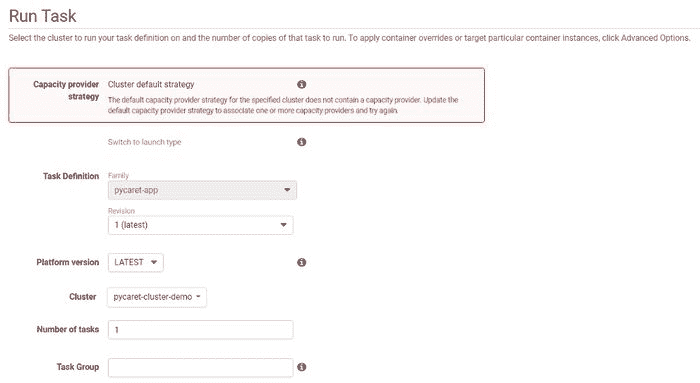
运行任务 — 第一部分
(b) 从下拉菜单中选择 VPC 和子网:
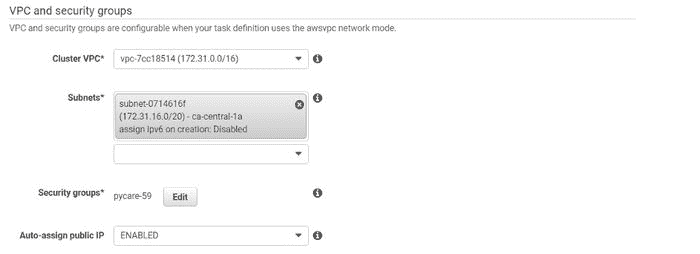
运行任务 — 第二部分
(c) 点击右下角的“运行任务”:
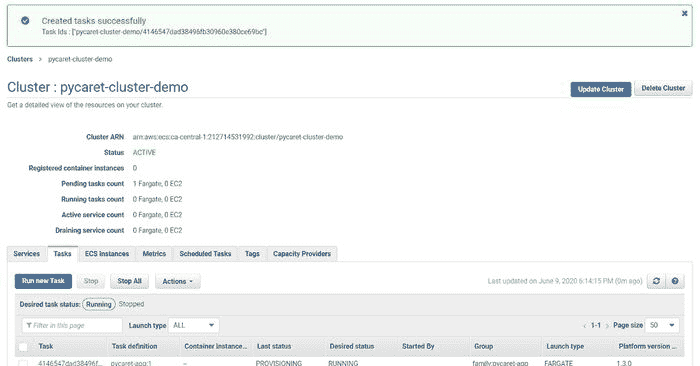
任务创建成功
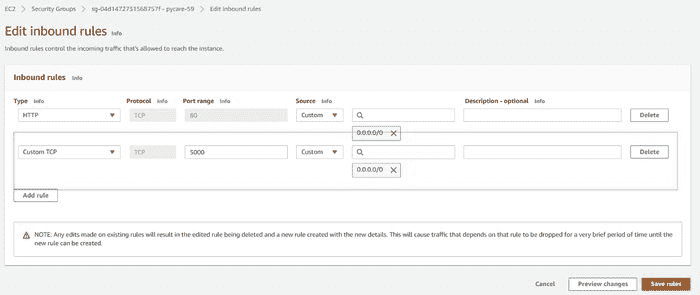
???? 第 9 步— 从网络设置中允许入站端口 5000
在我们可以在公共 IP 地址上查看应用运行之前的最后一步是通过创建新规则来允许端口 5000。为此,请按以下步骤操作:
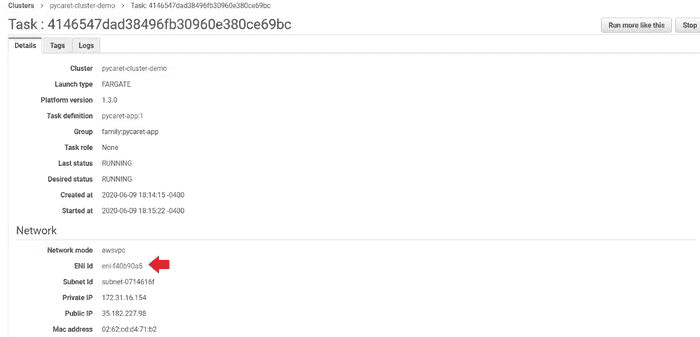
(a) 点击任务
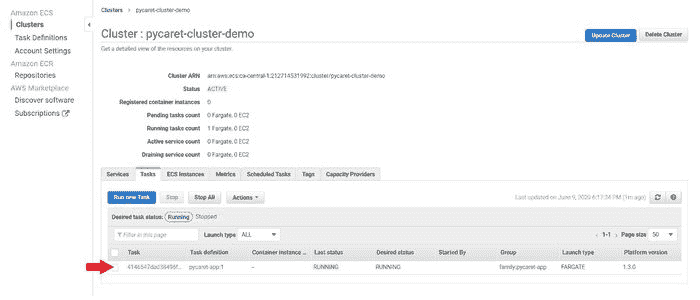
(b) 点击 ENI Id:
(c) 点击安全组
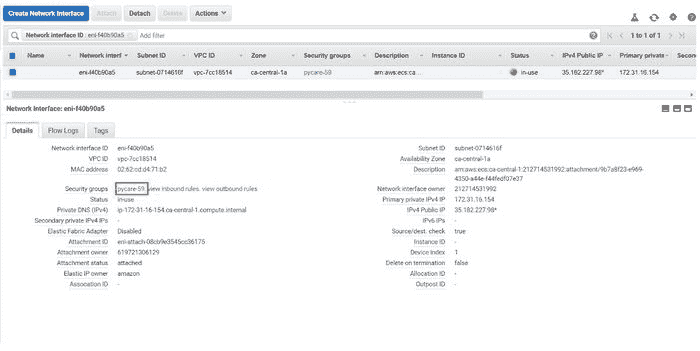
(d) 点击“编辑入站规则”
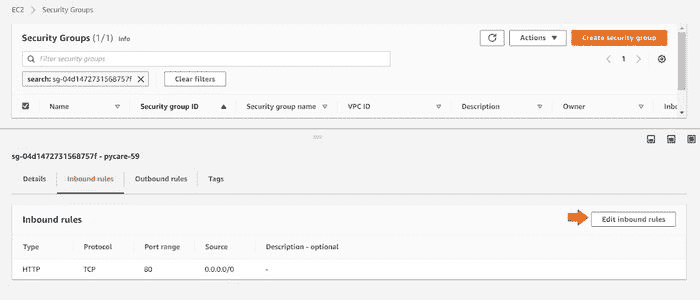
(e) 添加端口 5000 的自定义 TCP 规则
???? 第 10 步 — 查看应用运行情况
使用公共 IP 地址和端口 5000 访问应用程序。
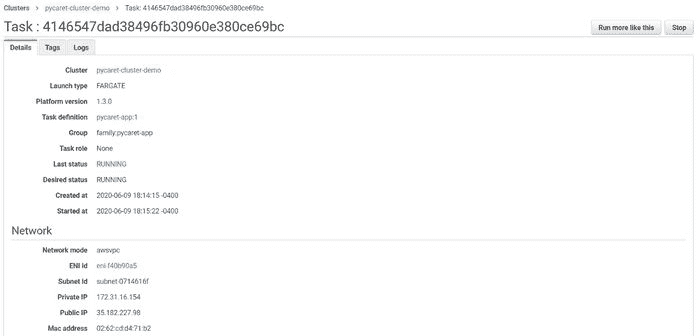
任务定义日志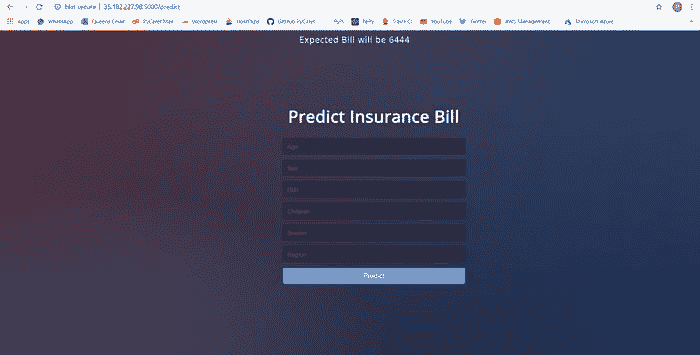
最终应用上传至35.182.227.98:5000
注意: 在这篇文章发布时,该应用将从公共地址中移除,以限制资源消耗。
PyCaret 2.0.0 即将来临!
我们收到了来自社区的热烈支持和反馈。我们正在积极改进 PyCaret,并为下一个版本做准备。PyCaret 2.0.0 将更大更好。如果你想分享你的反馈并帮助我们进一步改进,你可以在网站上 填写此表单 或在我们的 GitHub 或 LinkedIn 页面留言。
关注我们的 LinkedIn 和订阅我们的 YouTube 频道,以了解更多关于 PyCaret 的信息。
想了解特定模块吗?
从 1.0.0 版本首次发布开始,PyCaret 提供了以下模块供使用。点击下面的链接查看 Python 中的文档和工作示例。
另见:
PyCaret 入门教程在 Notebook 中:
你想要贡献吗?
PyCaret 是一个开源项目。欢迎大家贡献。如果你想贡献,请随时处理 开放问题。拉取请求将接受 dev-1.0.1 分支上的单元测试。
如果你喜欢 PyCaret,请在我们的 GitHub 仓库 上给我们 ⭐️。
Medium: medium.com/@moez_62905/
LinkedIn: www.linkedin.com/in/profile-moez/
推特: twitter.com/moezpycaretorg1
简介: Moez Ali 是一位数据科学家,也是 PyCaret 的创始人兼作者。
原文。已获许可转载。
相关:
-
使用 Docker 容器将机器学习管道部署到云
-
构建并部署你的第一个机器学习 web 应用
-
宣布 PyCaret 1.0.0
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关内容
使用 Docker 容器将机器学习管道部署到云端
原文:
www.kdnuggets.com/2020/06/deploy-machine-learning-pipeline-cloud-docker.html
评论
由 Moez Ali,PyCaret 的创始人和作者

回顾
在我们 上一篇文章中,我们展示了如何使用 PyCaret 和 Flask 框架在 Python 中开发机器学习管道并将其作为 web 应用进行部署。如果你以前没有听说过 PyCaret,请阅读此 公告 以了解更多。
在本教程中,我们将使用之前构建和部署的相同机器学习管道和 Flask 应用。这次我们将演示如何使用 微软 Azure Web 应用服务将机器学习管道作为 web 应用进行部署。
为了在 Microsoft Azure 上部署机器学习管道,我们需要在一个叫做“Docker”的软件中将我们的管道容器化。如果你不知道什么是容器化,没关系—本教程正是关于这个内容的。
???? 本教程的学习目标
-
什么是容器?什么是 Docker?我们为什么需要它?
-
在你的本地计算机上构建 Docker 文件并将其发布到 Azure 容器注册表 (ACR)。
-
使用我们上传到 ACR 的容器在 Azure 上部署一个 web 服务。
-
查看一个实际操作中的网络应用,使用训练好的机器学习管道对新的数据点进行实时预测。
在我们上一篇文章中,我们介绍了模型部署的基础知识及其必要性。如果你想了解更多关于模型部署的内容, 点击这里 阅读我们的上一篇文章。
本教程将涵盖从本地构建容器到将其推送到 Azure 容器注册表,再到将我们预训练的机器学习管道和 Flask 应用部署到 Azure Web 服务的整个工作流程。
工作流程:创建图像 → 本地构建容器 → 推送到 ACR → 在云端部署应用
???? 本教程的工具箱
PyCaret
PyCaret 是一个开源、低代码的 Python 机器学习库,用于训练和部署机器学习管道和模型到生产环境中。PyCaret 可以通过 pip 轻松安装。
pip install **pycaret**
Flask
Flask是一个允许你构建网络应用程序的框架。网络应用程序可以是商业网站、博客、电子商务系统,或者是一个使用训练过的模型实时生成预测的应用程序。如果你没有安装 Flask,可以使用 pip 进行安装。
Docker
Docker是一个旨在通过使用容器来简化创建、部署和运行应用程序的工具。容器用于将应用程序及其所有必要组件(例如库和其他依赖项)打包在一起,并将其作为一个整体进行传输。如果你以前没有使用过 Docker,本教程还涵盖了在 Windows 10 上安装 Docker 的过程。
Microsoft Azure
Microsoft Azure是一组用于在大规模全球网络上构建、管理和部署应用程序的云服务。其他常用于部署机器学习管道的云服务包括Amazon Web Services (AWS)、Google Cloud、IBM Cloud和Alibaba Cloud。我们将在未来的教程中涵盖它们中的大多数。
如果你以前没有使用过 Microsoft Azure,你可以在这里注册一个免费账户。当你第一次注册时,你会获得一个 30 天的免费信用额度。你可以通过按照本教程来利用这些信用额度构建你自己的网络应用程序。
什么是容器,为什么我们需要它?
你是否遇到过这样的问题:你的 Python 代码(或任何其他代码)在你的计算机上运行正常,但当你的朋友尝试运行完全相同的代码时,却无法运行?如果你的朋友重复完全相同的步骤,他们应该得到相同的结果,对吧?这个问题的答案是环境。你朋友的 Python 环境与你的不同。
环境包括什么?→ Python(或你使用过的任何其他语言)以及构建和测试应用程序所使用的所有库和依赖项及其确切版本。
如果我们能以某种方式创建一个可以转移到其他计算机(例如:你朋友的计算机或像 Microsoft Azure 这样的云服务提供商)的环境,我们就可以在任何地方重现结果。
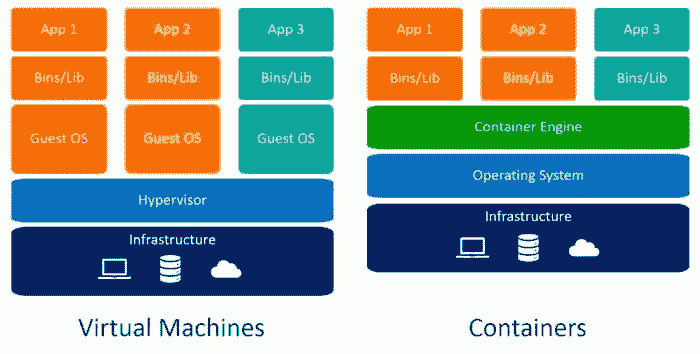
因此,容器是一种软件,它打包了一个应用程序及其所有依赖项,以便该应用程序在不同的计算环境中可靠地运行。
“当你想到容器时,就要想到容器。”
www.freepik.com/free-photos-vectors/cargo-ship
这是理解数据科学中容器的最直观的方式。它们就像船上的集装箱,其目标是将一个容器的内容与其他容器隔离,以免混淆。这正是数据科学中使用容器的目的。
现在我们理解了容器背后的隐喻,让我们看看创建应用隔离环境的其他选择。一个简单的替代方案是为每个应用程序使用一台独立的机器。
(1 台机器 = 1 个应用 = 无冲突 = 一切正常)
使用单独的机器是直接的,但它无法超越使用容器的好处,因为为每个应用程序维护多台机器是昂贵的,维护起来如同噩梦且难以扩展。简而言之,在许多实际场景中,这并不切实际。
创建隔离环境的另一个替代方案是虚拟机。在这里,容器更为可取,因为它们需要更少的资源,非常便携,并且启动速度更快。
虚拟机 vs. 容器
你能发现虚拟机和容器之间的区别吗?使用容器时,你不需要客操作系统。想象一下在虚拟机上运行 10 个应用程序。这将需要 10 个客操作系统,而使用容器时则无需这些操作系统。
我了解容器,但 Docker 是什么?
Docker 是一家提供软件(也称为 Docker)的公司,允许用户构建、运行和管理容器。虽然 Docker 的容器最为常见,但也有其他不那么著名的替代方案,如 LXD 和 LXC,它们提供容器解决方案。
在本教程中,我们将使用Docker Desktop for Windows创建一个容器,并将其发布到 Azure 容器注册表中。然后,我们将使用该容器部署一个 web 应用。

Docker 镜像 vs. Docker 容器
Docker 镜像和 Docker 容器有什么区别?这是最常被问到的问题,所以让我们马上澄清。虽然有许多技术定义,但直观的理解是将 Docker 镜像看作是创建容器的模具。镜像本质上是容器的快照。
如果你更倾向于稍微技术性的定义,那么可以这样理解:Docker 镜像在运行时会转变为容器,当它们在 Docker 引擎上运行时。
打破炒作:
到头来,Docker 只是一个包含几行指令的文件,保存在你的项目文件夹中,文件名为“Dockerfile”。
另一种看待 docker 文件的方法是,它们就像你在自己厨房里发明的食谱。当你与其他人分享这些食谱,并且他们按照完全相同的步骤操作时,他们也能制作出相同的菜肴。同样,你可以将你的 docker 文件分享给其他人,他们可以基于这个 docker 文件创建镜像并运行容器。
现在你已经了解了容器、docker 以及为什么我们应该使用它们,让我们快速设定业务背景。
设定业务背景
一家保险公司希望通过更好地预测患者费用来改善现金流预测,方法是使用在住院时的基本人口统计和患者健康风险指标。
(数据来源)
目标
构建和部署一个 Web 应用程序,在其中输入患者的基本信息和健康信息,然后输出预测的费用金额。
任务
-
训练并开发用于部署的机器学习管道。
-
使用 Flask 框架构建一个 Web 应用程序。它将使用训练好的 ML 管道实时生成新数据点的预测。
-
创建一个 docker 镜像和容器。
-
将容器发布到 Azure 容器注册表(ACR)。
-
通过发布到 ACR,将 Web 应用程序部署到容器中。一旦部署,它将公开可用,并可以通过 Web URL 访问。
由于我们在上一个教程中已经涵盖了前两个任务,我们将快速回顾这些任务,并重点关注上述列表中的剩余任务。如果你对使用 PyCaret 开发机器学习管道和使用 Flask 框架构建 Web 应用程序感兴趣,你可以阅读我们的 最后一个教程。
???? 开发机器学习管道
我们在 Python 中使用 PyCaret 进行机器学习管道的训练和开发,这将作为我们 Web 应用程序的一部分。机器学习管道可以在集成开发环境(IDE)或笔记本中开发。我们使用笔记本运行以下代码:
当你在 PyCaret 中保存模型时,基于在setup()函数中定义的配置会创建整个转换管道。所有的相互依赖关系会自动协调。查看存储在‘deployment_28042020’变量中的管道和模型:
使用 PyCaret 创建的机器学习管道
???? 构建 Web 应用程序
本教程不专注于构建 Flask 应用程序。这里只是为了完整性进行讨论。现在我们的机器学习管道已经准备好,我们需要一个可以连接到训练管道以实时生成新数据点预测的网页应用程序。我们使用 Python 中的 Flask 框架创建了这个网页应用程序。这个应用程序分为两个部分:
-
前端(使用 HTML 设计)
-
后端(使用 Flask 开发)
这就是我们的网页应用的样子:
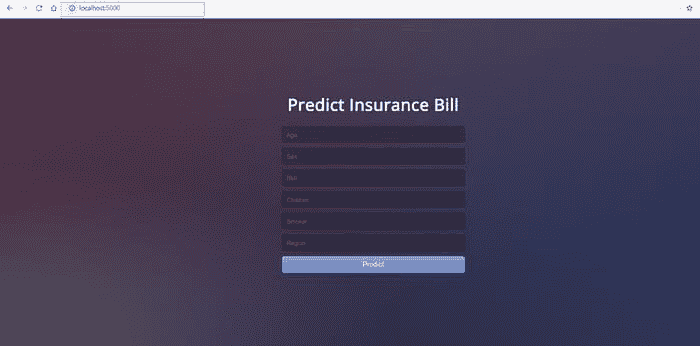
本地机器上打开的网页应用
如果你想查看这个网页应用的实际效果,请 点击这里 打开一个部署在 Heroku 上的网页应用(可能需要几分钟才能打开)。
如果你没有跟随操作,也没关系。你可以从 GitHub 上直接 fork 这个 代码库。如果你不知道如何 fork 一个 repo,请 阅读这个 官方 GitHub 教程。到这个时候,你的项目文件夹应该是这样的:
github.com/pycaret/deployment-heroku
现在我们有了一个完全功能的网页应用程序,我们可以开始使用 Docker 将应用程序容器化。
部署 ML 管道到 docker 容器的 10 个步骤:
???? 第 1 步 — 安装 Windows 版 Docker Desktop
你可以在 Mac 和 Windows 上使用 Docker Desktop。根据你的操作系统,你可以从 这个链接 下载 Docker Desktop。在本教程中,我们将使用 Windows 版本的 Docker Desktop。
hub.docker.com/editions/community/docker-ce-desktop-windows/
检查安装是否成功的最简单方法是打开命令提示符并输入‘docker’。它应该会打印出帮助菜单。
命令提示符
???? 第 2 步 — 安装 Kitematic
Kitematic 是一个直观的图形用户界面(GUI),用于在 Windows 或 Mac 上运行 Docker 容器。你可以从 Docker 的 GitHub 仓库 下载 Kitematic。
github.com/docker/kitematic/releases
下载后,只需将文件解压到所需位置。
???? 第 3 步 — 创建 Dockerfile
创建 Docker 镜像的第一步是创建一个 Dockerfile。Dockerfile 只是一个包含一组指令的文件。这个项目的 Dockerfile 长这样:
Dockerfile 区分大小写,必须与其他项目文件一起放在项目文件夹中。Dockerfile 没有扩展名,可以使用任何编辑器创建。我们使用了 Visual Studio Code 来创建它。
???? 第 4 步——创建 Azure 容器注册表
如果你没有 Microsoft Azure 账户或之前未使用过,可以 注册 免费注册。当你首次注册时,会获得 30 天的免费信用额度。你可以利用这笔信用额度在 Azure 上构建和部署 web 应用程序。注册后,请按照以下步骤操作:
-
登录到
portal.azure.com。 -
点击“创建资源”。
-
搜索“容器注册表”并点击“创建”。
-
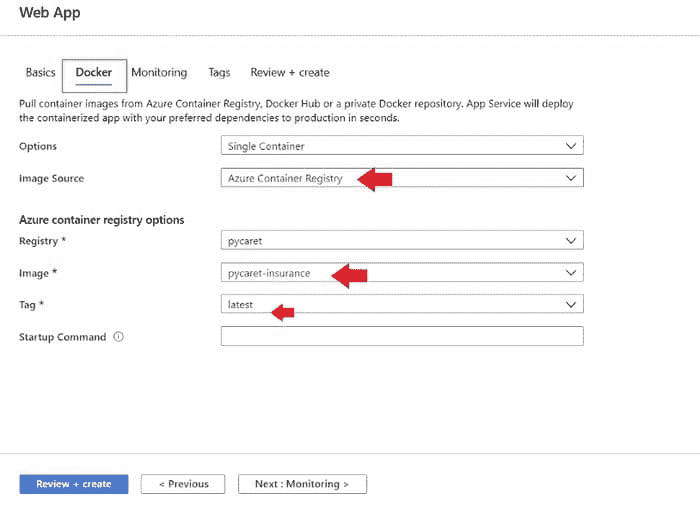
选择订阅、资源组和注册表名称(在我们的例子中:pycaret.azurecr.io 是我们的注册表名称)
portal.azure.com → 登录 → 创建资源 → 容器注册表
???? 第 5 步——构建 Docker 镜像
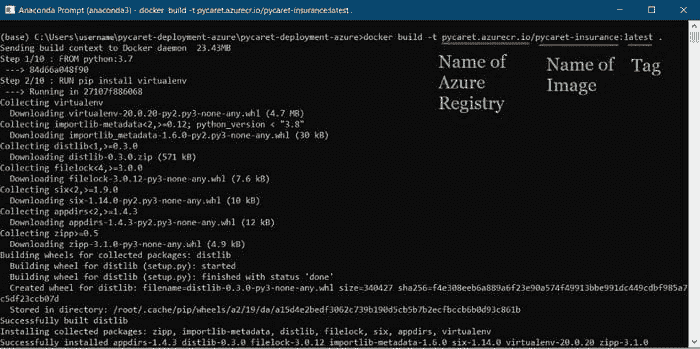
在 Azure 门户中创建注册表后,第一步是使用命令行构建一个 Docker 镜像。导航到项目文件夹并执行以下代码。
docker build -t pycaret.azurecr.io/pycaret-insurance:latest .

使用 Anaconda 提示符构建 Docker 镜像
-
pycaret.azurecr.io 是你在 Azure 门户上创建资源时得到的注册表名称。
-
pycaret-insurance 是镜像名称,latest 是标签。这个标签可以是你想要的任何名称。
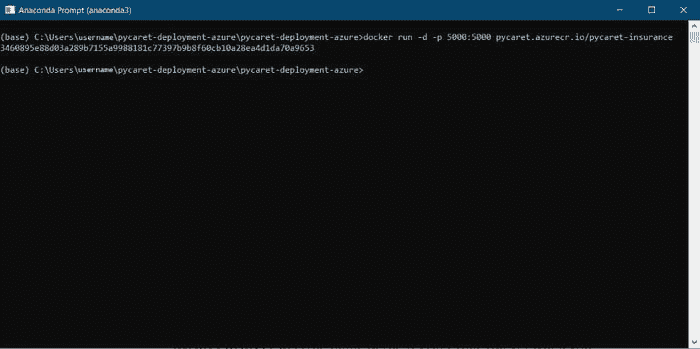
???? 第 6 步——从 Docker 镜像运行容器
现在图像已经创建,我们将在本地运行一个容器并测试应用程序,然后再将其推送到 Azure 容器注册表。要在本地运行容器,请执行以下代码:
docker run -d -p 5000:5000 pycaret.azurecr.io/pycaret-insurance
一旦此命令成功执行,它将返回创建的容器的 ID。
本地运行 Docker 容器
???? 第 7 步——在本地计算机上测试容器
打开 Kitematic,你应该能看到一个正在运行的应用程序。
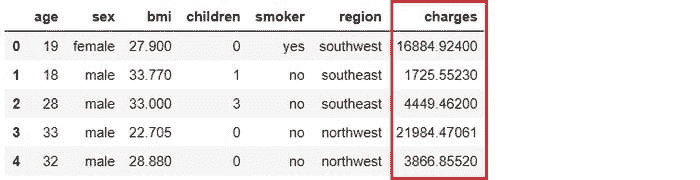
Kitematic — 一个用于在 Mac 和 Windows 操作系统上管理容器的图形用户界面
你可以通过在互联网浏览器中访问 localhost:5000 来查看应用程序的实际效果。它应该会打开一个 web 应用程序。

本地容器上运行的应用程序(localhost:5000)
完成后,请确保使用 Kitematic 停止应用程序,否则它会继续占用计算机上的资源。
???? 第 8 步——验证 Azure 凭据
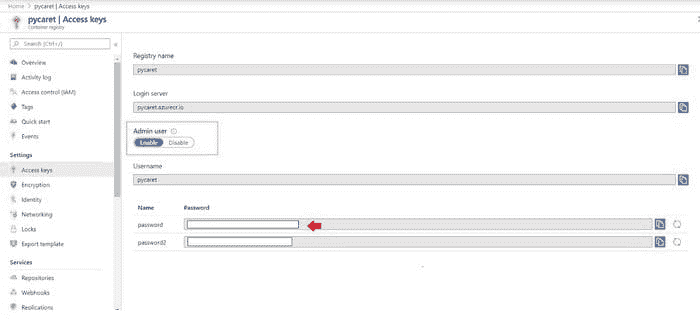
在将容器上传到 ACR 之前的最后一步是验证本地计算机上的 Azure 凭据。请在命令行中执行以下代码:
docker login pycaret.azurecr.io
系统会提示你输入用户名和密码。用户名是你的注册表名称(在此示例中,用户名为“pycaret”)。你可以在你创建的 Azure Container Registry 资源的访问密钥下找到你的密码。
portal.azure.com → Azure Container Registry → 访问密钥
???? 第 9 步——将容器推送到 Azure Container Registry
现在你已认证到 ACR,你可以通过执行以下代码将你创建的容器推送到 ACR:
docker push pycaret.azurecr.io/pycaret-insurance:latest
根据容器的大小,推送命令可能需要一些时间来将容器传输到云端。
???? 第 10 步——创建一个 Azure Web 应用并查看你的模型的实际效果
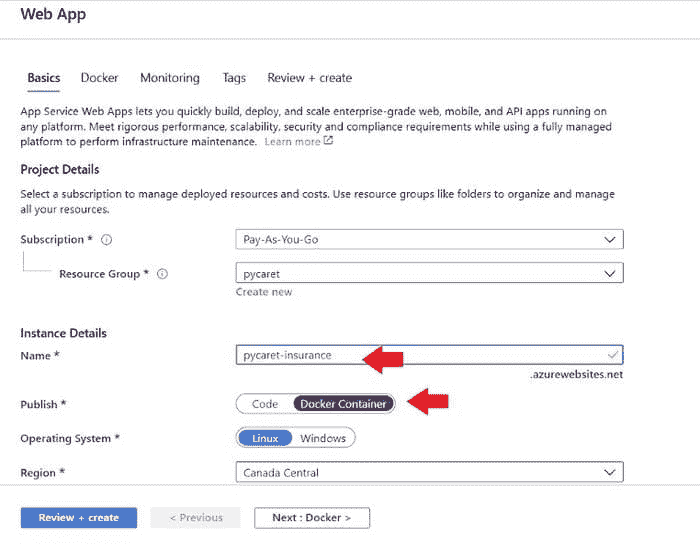
要在 Azure 上创建 Web 应用,请按照以下步骤操作:
-
登录
portal.azure.com。 -
点击创建资源。
-
搜索 Web 应用并点击创建。
-
将你在(步骤 9 中)推送的 ACR 镜像链接到你的应用。
portal.azure.com → Web 应用 → 创建 → 基本设置 
portal.azure.com → Web 应用 → 创建 → Docker
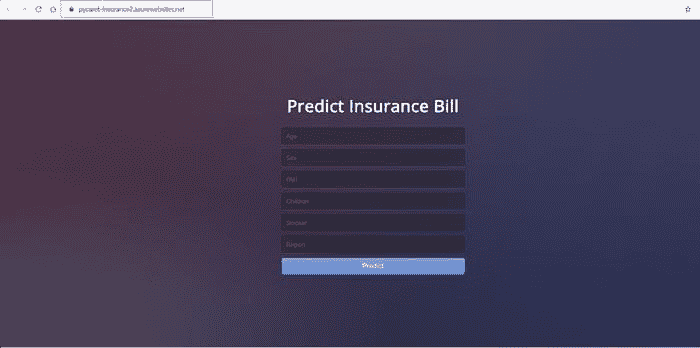
BOOM!! 现在应用已在 Azure Web Services 上运行。
https://pycaret-insurance2.azurewebsites.net
注意: 当本故事发布时,来自 pycaret-insurance2.azurewebsites.net 的应用将被移除以限制资源消耗。
GitHub 仓库链接用于 Heroku 部署。** (不使用 docker) **
下一个教程
在下一个关于部署机器学习管道的教程中,我们将深入探讨如何使用 Google Cloud 和 Microsoft Azure 的 Kubernetes 服务来部署机器学习管道。
关注我们的 LinkedIn 并订阅我们的 YouTube 频道,了解更多关于 PyCaret 的信息。
重要链接
PyCaret 1.0.1 即将到来!
我们收到了来自社区的巨大支持和反馈。我们正在积极改进 PyCaret,并准备我们的下一次发布。PyCaret 1.0.1 将会更大更好。如果你想分享你的反馈并帮助我们进一步改进,你可以在网站上填写这个表格或在我们的GitHub或LinkedIn页面留下评论。
想了解某个特定模块吗?
从 1.0.0 版本开始,PyCaret 提供了以下模块可供使用。点击下面的链接查看 Python 中的文档和工作示例。
另见:
PyCaret 入门教程在 Notebook 中:
你想要参与吗?
PyCaret 是一个开源项目,欢迎大家参与。如果你想参与,请随时处理开放问题。拉取请求必须包含 dev-1.0.1 分支上的单元测试。
如果你喜欢 PyCaret,请在我们的GitHub 仓库上给我们⭐️。
Medium : medium.com/@moez_62905/
LinkedIn : www.linkedin.com/in/profile-moez/
Twitter : twitter.com/moezpycaretorg1
简介: Moez Ali 是一名数据科学家,同时也是 PyCaret 的创始人和作者。
原文。经许可转载。
相关:
-
宣布 PyCaret 1.0.0
-
构建并部署你的第一个机器学习 Web 应用
-
使用 PyCaret 在 Power BI 中进行机器学习
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
更多相关话题
使用 Heroku 部署机器学习 Web 应用程序
原文:
www.kdnuggets.com/2022/04/deploy-machine-learning-web-app-heroku.html
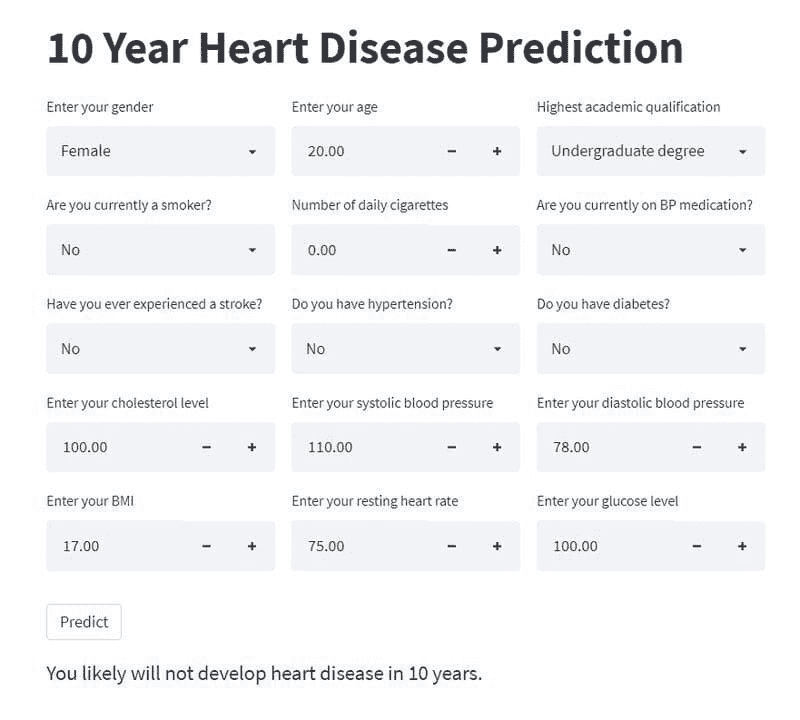
在之前的 博客文章 中,我展示了如何使用 Streamlit 库在 Python 中构建机器学习 Web 应用程序。最终产品看起来是这样的:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
这是一个允许用户输入有关健康和生活方式信息的应用程序,并返回一个输出,预测一个人在 10 年内患心脏病的可能性。
如果你想了解更多关于模型以及应用程序如何构建的信息,可以通过这个 教程 来学习。
否则,你可以简单地访问这个 Github 仓库 并克隆它。它包含了构建和部署 Web 应用程序所需的所有代码文件。
步骤 0:前置条件
要运行 Streamlit web 应用程序并将其部署到 Heroku,你需要安装一个非 GUI 的 Python 代码编辑器(Jupyter Notebook 不够用)。我目前使用的是 Visual Studio Code,但 PyCharm 和 Atom 也是不错的替代选择。
完成后,确保使用‘pip’命令安装这三个库—— Streamlit、Joblib 和 Pandas。
第一步:在本地运行应用程序
现在环境已准备好,尝试在本地运行应用程序以检查一切是否正常。
打开你的终端并输入以下代码行:
streamlit run streamlit_fhs.py
然后,打开浏览器并访问 localhost:8501。你应该会看到一个类似这样的 Web 应用程序:
第两步:创建必要的文件
我们的文件夹目前有三个文件:

为了成功将应用部署到 Heroku,我们需要创建另外三个文件:
1. requirements.txt
首先,创建一个文本文件并命名为 requirements.txt。然后,将以下内容粘贴到文件中:
pandas==1.3.2
gunicorn==19.9.0
streamlit==1.5.1
joblib==1.1.0
sklearn==0.22
2. Procfile
接下来,你需要创建一个 Procfile。它告诉 Heroku 你的应用程序位置以及如何启动它。
要创建 Procfile,只需打开终端并导航到你刚刚克隆的文件夹。输入以下命令:
echo web: gunicorn app:app >Procfile
3. setup.sh
最后,创建一个名为 setup.sh 的文件,内容如下:
mkdir -p ~/.streamlit/
echo "\ [server]\n\
headless = true\n\
port = $PORT\n\
enableCORS = false\n\
\n\" > ~/.streamlit/config.toml
第三步:设置 Heroku
现在,你需要 创建一个免费的 Heroku 账户。
完成后,下载 Heroku CLI 并运行可执行文件。
为了确保你已成功安装 Heroku,在终端中输入以下命令:
heroku --version
如果你收到“命令未找到”的错误,这意味着某些东西出错了,Heroku 在你的设备上未正确设置。否则,你的安装成功了,你可以进入下一步。
第四步:部署 Web 应用
再次打开终端并导航到你的应用程序所在的目录。
输入以下命令:
heroku create my_app
注意:你可以将“my_app”替换为你选择的任何名称。
然后,你需要初始化并将代码推送到 Git。为此,在终端中输入以下命令:
git init
git add .
git commit -m "first commit"
最后,运行这两个命令将你的代码部署到 Heroku:
heroku git:remote -a my_app
git push heroku master
注意:再次记得将 my_app 改为你的应用名称。
完成后,你会在终端上看到类似这样的输出:
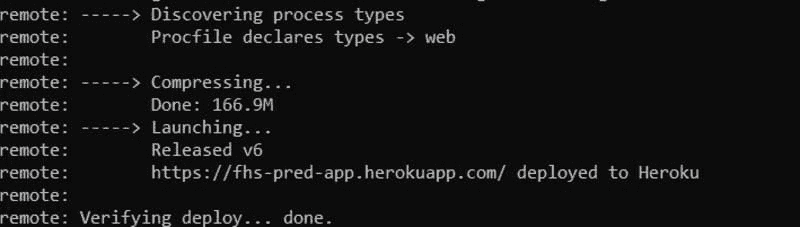
上面显示的链接是你的应用所在的位置,你现在可以在线访问它。以下是我的 Web 应用的 URL:fhs-pred-app.herokuapp.com/。
就这样!如果你正确执行了所有步骤,你现在已经部署了一个功能齐全的 Web 应用,你可以通过一个链接与其他人分享。
Natassha Selvaraj 是一位自学成才的数据科学家,热衷于写作。你可以在 LinkedIn 上与她联系。
了解更多相关内容
如何将 PyTorch Lightning 模型部署到生产环境中
原文:
www.kdnuggets.com/2020/11/deploy-pytorch-lightning-models-production.html
评论
由 Caleb Kaiser,Cortex Labs

来源: Pexels
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
从机器学习的角度来看,主要趋势之一是越来越多的项目专注于将软件工程原则应用于机器学习。例如,Cortex 重新创建了无服务器函数的部署体验,但用于推理管道。类似地,DVC 实现了现代版本控制和 CI/CD 管道,但用于机器学习。
PyTorch Lightning 有类似的理念,只是应用于训练。该框架提供了一个 PyTorch 的 Python 包装器,使数据科学家和工程师可以编写干净、可管理且高效的训练代码。
作为那些部分原因是因为厌倦了编写样板代码而建立了完整部署平台的人,我们非常喜欢 PyTorch Lightning。怀着这种精神,我整理了这份关于将 PyTorch Lightning 模型部署到生产环境中的指南。在过程中,我们将探讨几种将 PyTorch Lightning 模型导出以纳入推理管道的不同选项。
部署 PyTorch Lightning 模型进行推理的所有方式
有三种方法可以将 PyTorch Lightning 模型导出以供服务:
-
将模型保存为 PyTorch 检查点
-
将模型转换为 ONNX
-
将模型导出为 Torchscript
我们可以用 Cortex 服务这三种方式。
1. 直接打包和部署 PyTorch Lightning 模块
从最简单的方法开始,让我们在没有任何转换步骤的情况下部署一个 PyTorch Lightning 模型。
PyTorch Lightning Trainer,一个抽象样板训练代码的类(想想训练和验证步骤),具有一个内置的 save_checkpoint() 函数,可以将你的模型保存为 .ckpt 文件。要将模型保存为检查点,只需将以下代码添加到你的训练脚本中:

来源:作者
现在,在我们开始服务这个检查点之前,重要的是要注意,虽然我一直说“PyTorch Lightning 模型”,但 PyTorch Lightning 是 PyTorch 的一个封装——项目的 README 上明确写道“PyTorch Lightning 只是组织好的 PyTorch”。因此,导出的模型是一个普通的 PyTorch 模型,可以相应地提供服务。
有了保存的检查点,我们可以在 Cortex 中很容易地服务模型。如果你对 Cortex 不熟悉,可以 在这里快速了解,但 Cortex 的部署过程的简单概述是:
-
我们用 Python 为我们的模型编写一个预测 API
-
我们在 YAML 中定义我们的 API 基础设施和行为
-
我们使用 CLI 中的命令部署 API
我们的预测 API 将使用 Cortex 的 Python Predictor 类来定义一个 init() 函数来初始化 API 并加载模型,以及一个 predict() 函数来在查询时提供预测:
相当简单。我们从训练代码中重新利用一些代码,添加一点推理逻辑,仅此而已。需要注意的一点是,如果你将模型上传到 S3(推荐),你需要添加一些逻辑来访问它。
接下来,我们在 YAML 中配置我们的基础设施:
再次,简单。我们给 API 命名,告诉 Cortex 我们的预测 API 在哪里,并分配一些 CPU。
接下来,我们进行部署:
来源:作者
请注意,我们也可以将模型部署到由 Cortex 启动和管理的集群中:
来源:作者
所有部署中,Cortex 会将我们的 API 容器化,并将其公开为网络服务。在云部署中,Cortex 配置负载均衡、自动缩放、监控、更新以及许多其他基础设施功能。
就这样!现在我们有一个实时的 web API,根据请求从我们的模型中提供预测。
2. 导出为 ONNX 并通过 ONNX Runtime 提供服务
现在我们已经部署了一个普通的 PyTorch 检查点,让我们稍微复杂化一下。
PyTorch Lightning 最近增加了一个方便的抽象层,用于将模型导出为 ONNX(之前,你可以使用 PyTorch 内置的转换函数,但需要更多的样板代码)。要将你的模型导出为 ONNX,只需在你的训练脚本中添加这段代码:

来源:作者
请注意,你的输入样本应该模拟实际模型输入的形状。
一旦你导出了 ONNX 模型,你可以使用 Cortex 的 ONNX Predictor 来服务。代码基本相同,过程也完全一样。例如,这是一个 ONNX 预测 API:
基本上是一样的。唯一的区别是,我们不是直接初始化模型,而是通过 onnx_client 访问它,这是 Cortex 启动的一个 ONNX Runtime 容器,用于提供模型服务。
我们的 YAML 看起来也相当相似:
我在这里添加了一个监控标志,只是为了展示配置的简便性,虽然有一些 ONNX 特定的字段,但除此之外,它还是相同的 YAML。
最后,我们使用之前相同的 $ cortex deploy 命令进行部署,我们的 ONNX API 现已上线。
3. 使用 Torchscript 的 JIT 编译器序列化
对于最终部署,我们将 PyTorch Lightning 模型导出到 Torchscript 并使用 PyTorch 的 JIT 编译器进行服务。要导出模型,只需将以下内容添加到你的训练脚本中:

来源:作者
这个 Python API 与普通的 PyTorch 示例几乎一样:
YAML 保持不变,CLI 命令当然也一致。如果需要,我们实际上可以通过简单地用新的脚本替换旧的 predictor.py 脚本,然后重新运行 $ cortex deploy 来更新之前的 PyTorch API:
来源:作者
Cortex 在这里自动执行滚动更新,即启动一个新的 API 然后与旧的 API 交换,防止模型更新之间出现任何停机时间。
就是这样。现在你有一个完全操作的实时推理预测 API,能够从 Torchscript 模型中提供预测。
那么,你应该使用哪种方法呢?
这里显而易见的问题是哪个方法表现最好。事实是没有简单的答案,因为这取决于你的模型。
对于像 BERT 和 GPT-2 这样的 Transformer 模型,ONNX 可以提供惊人的优化(我们测得 在 CPU 上吞吐量提升了 40 倍)。对于其他模型,Torchscript 的表现可能优于普通 PyTorch —— 尽管这也有一些 caveats,因为并非所有模型都能顺利导出到 Torchscript。
幸运的是,使用任何选项进行部署都非常简单,你可以同时测试这三种方法,看看哪一种在你的特定 API 上表现最好。
个人简介:Caleb Kaiser (@KaiserFrose) 是 Cortex Labs 创始团队成员之一,他帮助维护 Cortex。
原文。经许可转载。
相关内容:
-
PyTorch 多 GPU 指标库及新 PyTorch Lightning 发布的更多内容
-
Pytorch Lightning vs PyTorch Ignite vs Fast.ai
-
训练 Lightning 快速神经网络的 9 个技巧
更多相关内容
将你的 PyTorch 模型部署到生产环境
原文:
www.kdnuggets.com/2019/03/deploy-pytorch-model-production.html
评论
由 Nicolás Metallo,Audatex
在上一篇关于训练 Choripan 分类器的文章中,我们讨论了如何使用 PyTorch 和 Google Colab 进行训练。接下来,我们将探讨如果你想将最近训练的模型作为 API 部署,可以采取哪些步骤。关于如何使用 Fast.ai 进行此操作的讨论正在进行中(更多),可能会持续到 PyTorch 发布其官方 1.0 版本。你可以在 Fast.ai 论坛、PyTorch 文档/论坛及其各自的 GitHub 仓库中找到更多信息。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
保存和加载模型
推荐你查看PyTorch 文档,它是一个很好的起点,简而言之,有两种序列化和恢复模型的方法。一种是仅加载权重,另一种是加载整个模型(包括权重)。你需要首先创建一个模型来定义其架构,否则你将得到一个只包含权重值的 OrderedDict。这两种选项都适用于推断和/或从以前的检查点恢复模型训练。
1. 使用 torch.save() 和 torch.load()
这种保存/加载过程使用了最直观的语法,涉及的代码最少。以这种方式保存模型会使用 Python 的 pickle 模块保存整个模块。这种方法的缺点是序列化数据绑定到模型保存时使用的特定类和确切目录结构。这是因为 pickle 不保存模型类本身,而是保存指向包含类的文件的路径,该路径在加载时使用。因此,当在其他项目或重构后使用时,代码可能会出现各种问题。
保存模型
torch.save(learner.model, PATH)
有时 pickle 无法序列化一些模型创建函数(例如在旧版本的 Fastai 中发现的 resnext_50_32x4d),因此你需要使用 dill。这是解决方法。
import dill as dill
torch.save(learner.model, PATH, pickle_module=dill)
你可以在这篇 文章 中阅读有关 pickle 限制的更多信息。一个常见的 PyTorch 约定是使用 .pt 或 .pth 文件扩展名保存模型。
加载模型
# Model class must be defined somewhere
model = torch.load(PATH)
model.eval()
2. 使用 state_dict
在 PyTorch 中,torch.nn.Module 模型的可学习参数(例如权重和偏差)包含在模型的 parameters 中(通过 model.parameters() 访问)。state_dict 只是一个 Python 字典对象,将每一层映射到其参数张量。注意,只有具有可学习参数的层(卷积层、线性层等)才会在模型的 state_dict 中有条目。
我们需要以与最初定义和创建模型时相同的方式重新初始化模型,并确保创建模型所需的变量、类、函数可用,无论是通过模块导入还是直接在同一个脚本/文件中。使用这种方法的一个潜在优势是,如果参数相同,你可以使用更新的脚本加载旧模型,它也是官方文档推荐的 方法。另一个需要记住的事情是 state_dict 接受的是字典对象,而不是保存对象的路径,因此你不能使用 model.load_state_dict(PATH) 来加载。
保存模型
torch.save(model.state_dict(), PATH)
加载模型
model = TheModelClass(*args, **kwargs) # Model class must be defined somewhere
model.load_state_dict(torch.load(PATH))
model.eval() # run if you only want to use it for inference
加载后运行 model.eval(),因为你通常会有 BatchNorm 和 Dropout 层,它们在构建时默认是训练模式。如果你想恢复模型训练,则不需要调用 model.eval()。
由于我们已经使用 Fastai 进行了训练,我们可以调用 [Learner.save](https://docs.fast.ai/basic_train.html#Learner.save) 和 [Learner.load](https://docs.fast.ai/basic_train.html#Learner.load) 来保存和加载模型(更多信息请参见 文档)。这会在后台运行 state_dict(),因此只会保存模型参数,而不是模型结构。这意味着你需要运行 create_cnn 方法来从给定的结构中获取一个预训练模型(与之前用于训练模型的结构相同,例如 models.resnet34),并且要为你的数据设置一个合适的自定义头。模型会保存在 path/model_dir 目录中,并且 .pth 扩展名会在这两个操作中自动添加。
使用 Flask 进行简单部署
在我们使用 Google Colab 提供的免费 GPU 训练完分类器后,我们准备在本地进行推理。我们可以在本地或云端进行推理,并且有许多不同的选项(AWS、Paperspace、Google Cloud 等)可供选择。由于我还有一些免费的 Amazon AWS 额度,我将使用一个预装了多个 ML 库的 Amazon AMI,并在 t2.medium 实例上托管。以下是一些在你的端运行 Docker 镜像的简单说明(在不进行 GPU 训练时应该差不多)。
即开即用的 Docker 镜像
Jupyter Docker Stacks 是一种快速启动 notebook 并使用最新库的绝佳方式。这些是即开即用的 Docker 镜像,包含 Jupyter 应用程序和交互式计算工具。在 官方文档 中了解更多关于它们的信息。我们将使用来自 此仓库 的 Jupyter Notebook 数据科学栈。
一旦你 安装 了 Docker,打开终端,cd 进入你的工作目录,然后运行
$ docker run --rm -p 8888:8888 -e JUPYTER_ENABLE_LAB=yes -v "$PWD":/home/jovyan/work jupyter/datascience-notebook:e5c5a7d3e52d
这将创建一个你可以登录的服务器,你可以在那里连接到 Jupyter notebook。你可以直接从那里运行一些命令,也可以通过获取 container id、在终端中输入 docker ps,然后运行 bash 或任何命令在 Docker 容器中执行。
$ docker exec -it {container-id} /bin/bash
安装 PyTorch 和 Fastai
根据你的机器配置,你可能希望在 GPU 或 CPU 上运行推理。在我们的例子中,我们将所有操作都在 CPU 上进行,因此你需要运行以下命令来安装最新的 PyTorch。
pip install torch_nightly -f https://download.pytorch.org/whl/nightly/cpu/torch_nightly.html
现在你可以通过 pip install fastai 安装 Fastai。
创建 Flask 应用程序
通过运行安装 Flask 库
pip install -U flask
我们将创建一个名为 flask_app 的文件夹和两个新的 Python 文件 server.py(包含加载模型权重和运行推理服务器的代码)以及 settings.py(设置一些基本参数,为未来提供更多灵活性)。以下是 flask_app/settings.py 可能的示例。然后我们将使用 from settings import * 导入到 server.py 中。
# add your custom labels
labels = ['Not Choripan', 'Choripan']
# set your data directory
data_dir = 'data'
# set the URL where you can download your model weights
MODEL_URL = 'https://s3.amazonaws.com/nicolas-dataset/stage1.pth' # example weights
# set some deployment settings
PORT = 8080
现在我们可以查看 flask_app/server.py。这第一部分将导入库和设置。
# flask_app/server.py
# import libraries
print('importing libraries...')
from flask import Flask, request, jsonify
import logging
import random
import time
from PIL import Image
import requests, os
from io import BytesIO
# import fastai stuff
from fastai import *
from fastai.vision import *
import fastai
# import settings
from settings import * # import
print('done!\nsetting up the directories and the model structure...')
为了运行我们的单图像推理预测,我们首先需要创建一个新的模型,遵循我们训练时使用的相同文件夹结构。这就是为什么我们将基于之前在 settings.py 中设置的标签创建一个新的空目录。
# set dir structure
def make_dirs(labels, data_dir):
root_dir = os.getcwd()
make_dirs = ['train', 'valid', 'test']
for n in make_dirs:
name = os.path.join(root_dir, data_dir, n)
for each in labels:
os.makedirs(os.path.join(name, each), exist_ok=True)
make_dirs(labels=labels, data_dir=data_dir) # comes from settings.py
path = Path(data_dir)
一旦 path 被定义,我们将创建一个新的 learn 模型并下载 Choripan 分类器 的预训练权重。
# download model weights if not already saved
path_to_model = os.path.join(data_dir, 'models', 'model.pth')
if not os.path.exists(path_to_model):
print('done!\nmodel weights were not found, downloading them...')
os.makedirs(os.path.join(data_dir, 'models'), exist_ok=True)
filename = Path(path_to_model)
r = requests.get(MODEL_URL)
filename.write_bytes(r.content)
print('done!\nloading up the saved model weights...')
fastai.defaults.device = torch.device('cpu') # run inference on cpu
empty_data = ImageDataBunch.single_from_classes(
path, labels, tfms=get_transforms(), size=224).normalize(imagenet_stats)
learn = create_cnn(empty_data, models.resnet34)
learn = learn.load('model')
网上已经有很多很棒的 教程 详细介绍了 Flask 的使用,因此我不会多讲 Flask 是如何工作的。我创建了一个 predict 函数,该函数接受作为输入的 URL,通过 learn.predict(img) 获得预测类别,然后返回一个 json。
print('done!\nlaunching the server...')
# set flask params
app = Flask(__name__)
@app.route("/")
def hello():
return "Image classification example\n"
@app.route('/predict', methods=['GET'])
def predict():
url = request.args['url']
app.logger.info("Classifying image %s" % (url),)
response = requests.get(url)
img = open_image(BytesIO(response.content))
t = time.time() # get execution time
pred_class, pred_idx, outputs = learn.predict(img)
dt = time.time() - t
app.logger.info("Execution time: %0.02f seconds" % (dt))
app.logger.info("Image %s classified as %s" % (url, pred_class))
return jsonify(pred_class)
if __name__ == '__main__':
app.run(host="0.0.0.0", debug=True, port=PORT)
一旦完成这些,我们可以进入终端,切换到 flask_app 目录,并运行 python server.py。我们应该会看到类似的内容。
* Serving Flask app "server" (lazy loading)
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: on
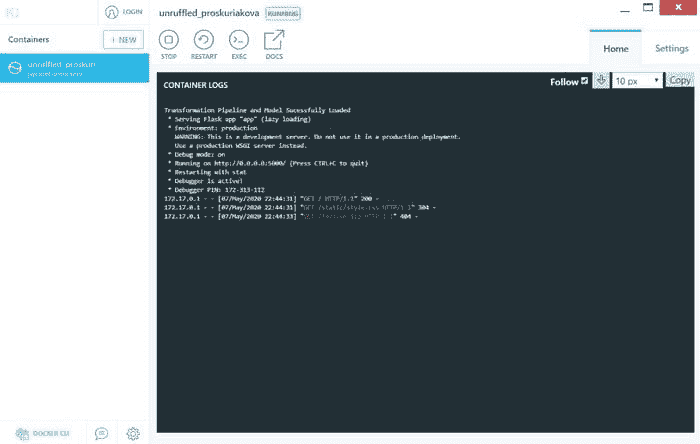
* Running on http://0.0.0.0:8080/ (Press CTRL+C to quit)
* Restarting with stat
importing libraries...
done!
setting up the directories and the model structure...
done!
loading up the saved model weights...
done!
launching the server...
* Debugger is active!
* Debugger PIN: 261-786-850
就这些! 现在我们可以从终端运行类似这样的命令(我正在运行一个 AWS 实例)。以这张图片为例。

$ curl http://ec2-100-24-34-242.compute-1.amazonaws.com:8080/predict?url=https://media.minutouno.com/adjuntos/150/imagenes/028/853/0028853430.jpg
"Choripan"
从服务器端来看,它的样子是这样的
[2018-11-13 16:49:32,245] INFO in server: Classifying image https://media.minutouno.com/adjuntos/150/imagenes/028/853/0028853430.jpg
[2018-11-13 16:49:33,836] INFO in server: Execution time: 1.35 seconds
[2018-11-13 16:49:33,858] INFO in server: Image https://media.minutouno.com/adjuntos/150/imagenes/028/853/0028853430.jpg classified as Choripan
不错! 你现在拥有了自己的“Choripan/Not Choripan” API。如果你想提升到下一个层次,请查看 Flask 文档中的这个教程 以部署到生产环境和/或 另一个教程,如果你想将 Flask 应用程序 Docker 化(你也可以使用 docker-compose)。
部署到生产环境的其他方法
1. 使用 Clipper 的图像分类示例
在 ClipperTutorials GitHub 上有一个很棒的 ipynb 文件,你可以跟随它了解一切的基本工作原理。他们提供了一个 Docker 镜像,或者你可以直接运行他们的 Amazon AMI。遗憾的是,这仅适用于 PyTorch 0.4.0,这使得将其转换为最新预览版本的 PyTorch 和 Fastai 训练的模型变得非常麻烦。不过,它与示例预训练模型配合得很好。
创建 ClipperConnection
要启动 Clipper,你必须首先创建一个 [ClipperConnection](http://docs.clipper.ai/en/develop/#clipper-connection) 对象,并指定你想要使用的 ContainerManager 类型。在这种情况下,你将使用 DockerContainerManager。
from clipper_admin import ClipperConnection, DockerContainerManager
clipper_conn = ClipperConnection(DockerContainerManager())
启动 Clipper
现在你已经拥有了一个 ClipperConnection 对象,你可以启动一个 Clipper 集群。
以下命令将启动 3 个 Docker 容器:
-
查询前端:查询前端容器监听传入的预测请求,并将其调度和路由到已部署的模型。
-
管理前端:管理前端容器管理和更新集群的内部配置状态,例如跟踪已部署的模型和已注册的应用程序端点。
-
一个 Redis 实例:Redis 用于持久存储 Clipper 的内部配置状态。默认情况下,Redis 在端口 6380 上启动,而不是标准 Redis 默认端口 6379,以避免与已经运行的 Redis 实例发生冲突。
clipper_conn.start_clipper()
clipper_addr = clipper_conn.get_query_addr()
查看 Clipper 启动的容器。
!docker ps --filter label=ai.clipper.container.label
创建应用程序
app_name = "squeezenet-classsifier"
default_output = "default"
clipper_conn.register_application(
name=app_name,
input_type="bytes",
default_output=default_output,
slo_micros=10000000)
当你列出已注册的应用程序时,你应该会看到新注册的 squeezenet-classifier 应用程序。
clipper_conn.get_all_apps()
加载一个示例预训练的 PyTorch 模型
from torchvision import models, transforms
model = models.squeezenet1_1(pretrained=True)
PyTorch 模型不能仅通过 pickle 序列化并加载。相反,它们必须使用 PyTorch 的原生序列化 API 保存。因此,你不能使用通用的 Python 模型部署工具来将模型部署到 Clipper。相反,你将使用 Clipper 的 PyTorch 部署工具进行部署。Docker 容器在启动时将从序列化的模型检查点中加载并重建模型。
预处理
# First we define the preproccessing on the images:
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
preprocess = transforms.Compose([
transforms.Scale(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize
])
# Then we download the labels:
labels = {int(key):value for (key, value)
in requests.get('https://s3.amazonaws.com/outcome-blog/imagenet/labels.json').json().items()}
定义预测函数并添加指标
import clipper_admin.metrics as metrics
def predict_torch_model(model, imgs):
import io
import PIL.Image
import torch
import clipper_admin.metrics as metrics
metrics.add_metric("batch_size", 'Gauge', 'Batch size passed to PyTorch predict function.')
metrics.report_metric('batch_size', len(imgs)) # TODO: Fill in the batch size
# We first prepare a batch from `imgs`
img_tensors = []
for img in imgs:
img_tensor = preprocess(PIL.Image.open(io.BytesIO(img)))
img_tensor.unsqueeze_(0)
img_tensors.append(img_tensor)
img_batch = torch.cat(img_tensors)
# We perform a forward pass
with torch.no_grad():
model_output = model(img_batch)
# Parse Result
img_labels = [labels[out.data.numpy().argmax()] for out in model_output]
return img_labels
Clipper 必须从互联网下载这个 Docker 镜像,所以可能需要一点时间。
from clipper_admin.deployers import pytorch as pytorch_deployer
pytorch_deployer.deploy_pytorch_model(
clipper_conn,
name="pytorch-model",
version=1,
input_type="bytes",
func=predict_torch_model, # predict function wrapper
pytorch_model=model, # pass model to function
)
现在将生成的 pytorch-model 链接到之前创建的应用 squeezenet-classsifier。
clipper_conn.link_model_to_app(app_name="squeezenet-classsifier", model_name="pytorch-model")
就这样!
如何使用 Requests 查询 API
import requests
import json
import base64
clipper_addr = 'localhost:1337'
for img in ['img1.jpg', 'img2.jpg', 'img3.jpg']: # example with local images
req_json = json.dumps({
"input":
base64.b64encode(open(img, "rb").read()).decode() # bytes to unicode
})
response = requests.post(
"http://%s/%s/predict" % (clipper_addr, 'squeezenet-classsifier'),
headers={"Content-type": "application/json"},
data=req_jsn)
print(response.json())
停止 Clipper
如果遇到问题并希望完全停止 Clipper,你可以通过调用 [ClipperConnection.stop_all()](http://docs.clipper.ai/en/latest/#clipper_admin.ClipperConnection.stop_all) 来实现。
clipper_conn.stop_all()
当你最后列出所有 Docker 容器时,你应该会看到所有 Clipper 容器都已停止。
!docker ps --filter label=ai.clipper.container.label
2. 使用来自 Zeit 的 Now
论坛讨论中的另一个选项是使用 Now 服务,来自 Zeit。你可以参考 Fast.ai 文档中的 这个指南。我尝试过这个方法,但没有得到准确的结果(可能是由于归一化问题)。看起来很有前景。
你只需运行这些命令一次。第一次安装 Now 的 CLI(命令行界面)。
sudo apt install npm # if not already installed
sudo npm install -g now
下一步下载基于 Fast.ai 课程 2 的模型部署 入门包。
wget https://github.com/fastai/course-v3/raw/master/docs/production/zeit.tgz
tar xf zeit.tgz
cd zeit
上传你的训练模型文件
将你的训练模型文件(例如 stage-2.pth)上传到 Google Drive 或 Dropbox 等云服务。复制该文件的下载链接。注意:下载链接是直接启动文件下载的链接,通常与提供下载视图的分享链接不同(如有需要,使用 rawdownload.now.sh/)。
根据你的模型自定义应用
-
打开
app目录中的server.py文件,并用上面复制的 URL 更新model_file_url变量。 -
在同一文件中,用你期望的模型类别更新
classes = ['black', 'grizzly', 'teddys']行。
部署
在终端中,确保你在 zeit 目录下,然后输入:
now
第一次运行时,它会提示输入你的电子邮件地址,并为你创建一个 Now 帐户。账户创建后,再次运行以部署你的项目。
每次使用 now 部署时,它都会为应用创建一个唯一的 部署 URL。其格式为 xxx.now.sh,在部署应用时会显示。
3. 使用 Torch Script 和 PyTorch C++ API
这些是 PyTorch 官方 1.0 版本即将推出的一些最新变化。你可以按照这篇文档中的说明操作,或查看 Udacity 的 Intro to Deep Learning with PyTorch 课程的最后一章,其中详细讲解了这些步骤。这只是主要步骤的概述。
import torch
import torchvision
# An instance of your model.
model = torchvision.models.resnet18()
# An example input you would normally provide to your model's forward() method.
example = torch.rand(1, 3, 224, 224)
# Use torch.jit.trace to generate a torch.jit.ScriptModule via tracing.
traced_script_module = torch.jit.trace(model, example)
# Save the model
traced_script_module.save("model-resnet18-jit.pt")
构建一个最小化的 C++ 应用程序
-
按照 这些步骤 操作,构建
example-app.cpp和CMakeLists.txt。 -
安装 Anaconda 并在你的机器上运行 CMAKE。你可以通过他们的 binaries 安装它,或者如果你使用的是 MacOS,输入
brew install cmake(通过 这些 指令安装homebrew)。如果你遇到 CMAKE 问题,记得直接从 这里 下载 X-Code 命令行工具的.dmg(在我的情况下是 MacOS 10.14)。 -
从 这里 安装 Caffe2 并运行
conda install pytorch-nightly-cpu -c pytorch
PyTorch, Libtorch, C++ 和 NodeJS
结论
我尽力总结了一些部署你最近训练的 PyTorch 模型的选项。希望这对你有帮助,期待阅读你的评论。
简介: Nicolás Metallo 是一位获奖企业家,拥有近 10 年的专业经验。他毕业于纽约大学,获得技术管理与创新硕士学位,并担任管理顾问和自由深度学习工程师。Nicolas 还是 INVIP Labs Inc. 的共同创始人,这是一个通过计算机视觉帮助盲人和低视力者更好地理解环境的社会企业。他对数据科学的特别兴趣在于为城市提供数据,使其更加互联、高效、韧性强、充满活力和繁荣。
原文。已获得许可转载。
相关:
更多相关内容
部署你的第一个机器学习 API
原文:
www.kdnuggets.com/2021/10/deploying-first-machine-learning-api.html
comments
作者提供的图片 | 元素来自 vectorjuice
介绍
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
在这个项目中,我们将学习如何为你的机器学习模型构建应用程序编程接口(API),然后使用简单的代码进行部署。我花了一个小时来学习 FastAPI,五分钟来学习如何将其部署到 Deta 服务器。我们还将使用 Python Request 在本地服务器和远程服务器上测试我们的 API。让我们深入了解一下我们将在项目中使用的技术。

作者提供的图片
spaCy
相较于用于实验和评估的著名 NLTK Python 库,spaCy 在应用和部署方面更为友好。spaCy 提供了预构建的统计神经网络 NLP 模型,具有强大的功能,易于在你的项目中使用和实施,spaCy就是这样一个工具。我们将使用一个相对简单的小型预构建英文模型来从我们的文本中提取实体。
FastAPI
FastAPI 是一个用于构建 Python API 的快速 Web 框架,它具有更快的查询时间、简化的代码,使你可以在几分钟内设计你的第一个 API,FastAPI提供了这些功能。在我们的项目中,我们将学习 FastAPI 的工作原理,以及如何使用我们预构建的模型从英文文本中提取实体。
Deta
我们将使用 Deta Micros 服务来处理我们的 API,并且在没有 docker 或 YAML 文件的情况下部署我们的项目。Deta 平台提供了易于部署的 CLI、高可扩展性、安全的 API 认证密钥、更改子域名的选项以及 Web 流量的日志记录。这些功能在Deta上完全免费。在我们的项目中,我们将使用 Deta CLI 通过几行脚本来部署我们的 Fast API。
代码
当我学习 FastAPI 时,我偶然发现了 YouTube 上的视频,这激励我写了这篇文章。Sebastián Ramírez解释了 Fast API 是如何工作的,以及它是最快的 Python 网页框架。我们将编写两个 Python 文件,一个包含机器学习模型,另一个包含你的 API 代码。
需求
在我们开始之前,我们需要创建一个新的目录,并添加一个requirements.txt文件。你可以在下面找到我们将要使用的所有必要库????
fastapi
spacy
uvicorn
https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.1.0/en_core_web_sm-3.1.0.tar.gz
你可以逐个安装它们,也可以使用????
$ pip install -r requirements.txt
我们将为这个项目使用一个预训练的 NLP 模型,因此我们需要从 GitHub 仓库github.com/explosion/spacy-models下载,或者只需运行需求文件,它将自动下载并安装。
机器学习模型
我们将使用预训练的Spacy NLP 模型来从文本中提取实体。如果你使用 Jupyter notebook,尝试使用%%writefile在你的目录中创建 Python 文件。
首先,我们加载了 NLP 模型,然后从 CBS News文章中提取实体。只需几行代码,你就可以运行你的第一个机器学习模型。你也可以使用相同的方法加载训练好的模型。
API 文件
这是你的主文件,其中包含:
-
read_main:使用GET,它从资源请求数据,在我们的例子中,它将显示一条消息,说欢迎。
-
class Article:使用pydantic BaseModel 来定义将用于你的 API 的对象和变量 (helpmanual.io)。在我们的例子中,我们将内容定义为字符串,将评论定义为字符串列表。
-
analyze_article:它接受一个包含评论的文本列表,并使用来自 ml 文件的NLP对象显示实体。
我知道这很复杂,所以让我们将其分解成更小的部分以便更好地理解。
拆解
我们创建了一个 FastAPI 对象,然后使用它作为装饰器在你的函数上,使用@app.get(“/”)。
-
@app 是你 FastAPI 对象的装饰器
-
.get 或 .post 是返回数据或处理输入的 HTTP 方法
-
(“/”) 是网页服务器上的位置。在我们的例子中,它是主页。如果你想添加另一个目录,你可以使用("/<new_section>/")
我们创建了read_main函数来在主页上显示消息,就这么简单。
现在我们将创建一个Article类,它继承自BaseModel。这个函数帮助我们创建我们将用作POST方法的参数类型。在我们的例子中,我们将内容创建为字符串变量,将评论创建为字符串列表。
在最后一部分,我们正在创建一个POST 方法(“/article/”)作为我们的 API。这意味着我们将创建一个新部分,该部分将接受作为输入的参数,并在处理后返回结果。
-
文章类作为参数:使用文章列表创建文章参数,这将允许我们添加多个文本条目。
-
从文章中提取数据:创建循环以从文章列表中提取数据,然后从评论列表中提取数据。它还将评论添加到一个数组中。
-
将文本加载到 NLP 模型中:将内容加载到nlp 预训练模型中。
-
提取实体:从nlp 对象中提取实体,然后将其添加到ents 数组中。这将堆叠结果。
-
显示:该函数将返回实体和评论的列表。
测试
Fast API 是在 Uvicorn 上构建的,因此服务器也在 Uvicorn 上运行。在 Jupyter Notebook 中,你可以使用 ???? 运行应用程序,或者在终端中只需输入uvicorn 然后是main 文件和 FastAPI 对象,在我们的例子中是app。
我们的服务器运行平稳,所以让我们使用request.get方法来访问它。API 正在通过在主页上显示“欢迎”消息来工作。
现在让我们尝试将单个文本和评论作为字典添加到列表中。我们将使用POST 请求方法和/article/来访问我们的 NLP 模型函数。将输出转换为.json() 以便于提取数据。
我们有我们的字典键:[‘ents’, ‘comments’]
让我们检查一下我们整个输出的样子。看起来我们有ents 和标签及实体的列表。comments 键也是如此。
现在让我们提取单个实体及其文本,以检查我们输出的灵活性。在我们的例子中,我们正在提取输出中的第二个实体。
结果显示完美。
部署
进入终端,或者你可以在 Jupyter Notebook 单元中执行相同的步骤,但在任何脚本之前添加“!”。首先,你需要使用cd 访问包含main.py 和 ml.py 文件的目录。
cd ~”/FastAPI-ML-Project”
Deta 所需的三个主要文件是ml.py、main.py 和 requirments.txt。
作者提供的图像 | 项目目录
如果你使用Windows,请在 PowerShell 中使用以下命令下载并安装 Deta CLI。
iwr [`get.deta.dev/cli.ps1`](https://get.deta.dev/cli.ps1) -useb | iex
对于Linux
curl -fsSL [`get.deta.dev/cli.sh`](https://get.deta.dev/cli.sh) | sh
然后使用deta login,它会带你到浏览器并要求你输入用户名和密码。如果你已经登录,它会在几秒钟内完成认证。
deta login

Deta 认证 | deta
这些两个词 在终端中是魔法词,它们将在 2 分钟内上传文件并部署你的应用程序。
deta new
你的应用程序已上传到一个终点链接。在我们的例子中是 93t2gn.deta.dev/
Successfully created a new micro{“name”: “FastAPI-ML-Project”,“runtime”: “python3.7”,“endpoint”: “https://93t2gn.deta.dev/",“visor”: “enabled”,“http_auth”: “disable”}Adding dependencies…Collecting fastapi…Successfully installed ……
如果看到错误,请使用deta logs 检查日志,进行一些更改后使用deta deploy 来更新更改。
如你所见,我们的应用已在 Deta 服务器上部署并运行。
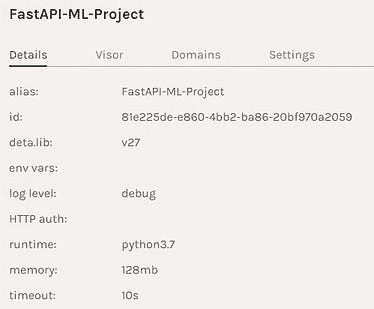
项目总结 | deta
你可以访问Deta提供的链接自行查看。

作者提供的图像
测试 Web API
最后,让我们在 Deta 平台上将我们的远程 API 作为微服务进行测试。这次我们将添加 Deta 端点链接,而不是本地 IP。由于我们没有启用 API 认证,所以可以在没有头部的情况下运行。Deta 还提供免费的 API 密钥,当启用认证时,仅你或拥有 API 密钥的人可以访问 Web 服务器。要了解更多关于认证和子域名的信息,我建议你阅读 文档。
我们将添加相同的参数和相同的代码,以获得相同的结果,瞧,它起作用了。你的 API 在线并可以通过链接轻松访问。
结论
在学习 FastAPI 之后,我在思考接下来要做什么,于是一天我在浏览网页时偶然发现了 Deta,这引起了我的注意。安装Deta CLI并在远程服务器上部署我的 API 只用了几分钟。我对他们的子域名和免费 API 密钥功能印象深刻。我很快就理解了服务的工作原理以及我将如何在未来的项目中使用它。
我们在学习了一些机器学习模型后都会问这个问题。
我知道如何训练我的模型并获取预测,但接下来该怎么办?我如何与他人分享我的模型?以便他们可以查看我所构建的内容,并在他们的项目中使用这些功能。
这就是像Heroku、Google、Azure这样的云平台的作用所在,但这些平台相当复杂,需要学习Docker文件的编码,这有时可能会让人感到沮丧。Deta通过其简单的两行脚本解决了所有问题,这将使你的应用在几秒钟内部署和运行。
你还可以查看我关于这个项目的 GitHub 仓库:kingabzpro/FastAPI-ML-Project。
个人简介:Abid Ali Awan 是一名认证的数据科学专家,热爱构建机器学习模型并撰写有关最新 AI 技术的博客。
原文。已获许可转载。
相关:
-
用于数据科学项目的 Python APIs
-
使用 Flask 构建 RESTful APIs
-
使用 FastAPI 和 spaCy 构建生产就绪的机器学习 NLP API
更多相关话题
部署机器学习模型:逐步教程
原文:
www.kdnuggets.com/deploying-machine-learning-models-a-step-by-step-tutorial
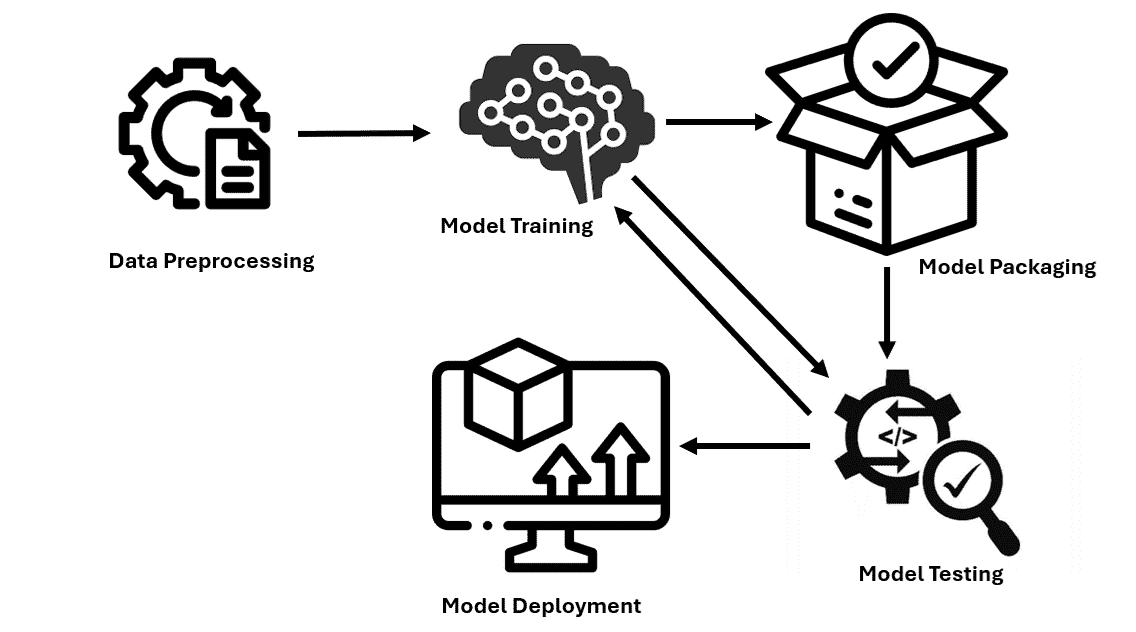
图片由作者提供
模型部署是将训练好的模型集成到实际应用中的过程。这包括定义所需的环境、指定如何将输入数据引入模型以及模型产生的输出,以及分析新数据并提供相关的预测或分类。让我们探讨生产环境中部署模型的过程。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
第 1 步:数据预处理
处理缺失值,可以通过使用均值填补或删除行/列来解决。确保分类变量也从定性数据转换为定量数据,方法包括独热编码或标签编码。规范化和标准化数值特征,将其转换为共同的尺度。
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder, StandardScaler, MinMaxScaler
# Load your data
df = pd.read_csv('your_data.csv')
# Handle missing values
imputer_mean = SimpleImputer(strategy='mean')
df['numeric_column'] = imputer_mean.fit_transform(df[['numeric_column']])
# Encode categorical variables
one_hot_encoder = OneHotEncoder()
encoded_features = one_hot_encoder.fit_transform(df[['categorical_column']]).toarray()
encoded_df = pd.DataFrame(encoded_features, columns=one_hot_encoder.get_feature_names_out(['categorical_column']))
# Normalize and standardize numerical features
# Standardization (zero mean, unit variance)
scaler = StandardScaler()
df['standardized_column'] = scaler.fit_transform(df[['numeric_column']])
# Normalization (scaling to a range of [0, 1])
normalizer = MinMaxScaler()
df['normalized_column'] = normalizer.fit_transform(df[['numeric_column']])
第 2 步:模型训练和评估
将数据分为两组:训练数据集和测试数据集,以训练模型。选择一个模型并对使用的数据进行训练。微调超参数以选择性能最佳的机器学习模型。模型的稳定性通过不同子组的数据进行检查,以实施交叉验证。
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder, StandardScaler, MinMaxScaler
# Load your data
df = pd.read_csv('data.csv')
# Split data into training and testing sets
X = df.drop(columns=['target_column'])
y = df['target_column']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Hyperparameter tuning
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10]
}
grid_search = GridSearchCV(estimator=RandomForestClassifier(random_state=42),
param_grid=param_grid,
cv=5,
scoring='accuracy',
n_jobs=-1)
# Fit the grid search to the data
grid_search.fit(X_train, y_train)
# Get the best model from the grid search
best_model = grid_search.best_estimator_
# Cross-validation to assess model generalization and robustness
cv_scores = cross_val_score(best_model, X_train, y_train, cv=5, scoring='accuracy')
print(f"Cross-validation scores: {cv_scores}")
print(f"Mean cross-validation score: {cv_scores.mean()}")
第 3 步:模型打包
来源:knowledge.dataiku.com/latest/mlops-o16n/architecture/concept-model-packaging.html
将代码序列化为更适合存储或分发到其他系统的格式。Pickle 是常见的格式之一,另外还有 joblib 和 ONNX 格式,具体取决于用户的需求。在定义和优化模型后,将其存储在文件或数据库中。像 Git 这样的平台也很有用,用于处理变更和修改。采取特定措施,如对存储和传输中的数据进行加密,以防止数据被他人轻易访问。
import joblib
joblib.dump(model, 'model.pkl')
将序列化的模型放入如 Docker 这样的容器中。这使得模型具有可移植性,并且更容易将机器学习模型传输到不同的环境中。
# Docker code
FROM python:3.8-slim
COPY model.pkl /app/model.pkl
COPY app.py /app/app.py
WORKDIR /app
RUN pip install -r requirements.txt
CMD ["python", "app.py"]
第 4 步:部署环境设置
为模型部署设置基础设施和资源,建议使用 AWS、Azure 或 Google Cloud 等云服务。修改托管模型所需的必要组件,如服务器、数据库以及所有可以在所选云平台的云基础设施服务上完成的事项。
AWS:使用 AWS CLI 设置 EC2 实例
aws ec2 run-instances \
--image-id ami-0abcdef1234567890 \
--count 1 \
--instance-type t2.micro \
--key-name MyKeyPair \
--security-group-ids sg-0abcdef1234567890 \
--subnet-id subnet-0abcdef1234567890
Azure:使用 Azure CLI 设置虚拟机
az vm create \
--resource-group myResourceGroup \
--name myVM \
--image UbuntuLTS \
--admin-username azureuser \
--generate-ssh-keys
Google Cloud:使用 Google Cloud CLI 设置 Compute Engine 实例
gcloud compute instances create my-instance \
--zone=us-central1-a \
--machine-type=e2-medium \
--subnet=default \
--network-tier=PREMIUM \
--maintenance-policy=MIGRATE \
--image=debian-9-stretch-v20200902 \
--image-project=debian-cloud \
--boot-disk-size=10GB \
--boot-disk-type=pd-standard \
--boot-disk-device-name=my-instance
第 5 步:构建部署管道
使用 Jenkins 或 GitLab CI/CD 等工具来自动化模型部署步骤。设计一系列步骤,以提高部署过程的效率,并在 GitHub Actions 的上下文中使用 Jenkinsfile 或 YAML 配置。
# Using Jenkins for CI/CD pipeline
pipeline {
agent any
stages {
stage('Build') {
steps {
sh 'python setup.py build'
}
}
stage('Test') {
steps {
sh 'python -m unittest discover'
}
}
stage('Deploy') {
steps {
sh 'docker build -t mymodel:latest .'
sh 'docker run -d -p 5000:5000 mymodel:latest'
}
}
}
}
第 6 步:模型测试
进行测试以确保模型的所有功能得到适当实现。之后,将预测结果与模型应提供的结果进行比较。检查模型的泛化能力,以确定其在其他新数据上的表现。选择正确的评估标准——准确性、精确度、召回率来与样本数据进行比较。
# Import necessary libraries
from sklearn.metrics import accuracy_score, precision_score, recall_score
# Load your test data
test_df = pd.read_csv('your_test_data.csv')
X_test = test_df.drop(columns=['target_column'])
y_test = test_df['target_column']
# Predict outcomes on the test set
y_pred_test = best_model.predict(X_test)
# Evaluate performance metrics
test_accuracy = accuracy_score(y_test, y_pred_test)
test_precision = precision_score(y_test, y_pred_test, average='weighted')
test_recall = recall_score(y_test, y_pred_test, average='weighted')
# Print performance metrics
print(f"Test Set Accuracy: {test_accuracy}")
print(f"Test Set Precision: {test_precision}")
print(f"Test Set Recall: {test_recall}")
第 7 步:监控和维护
借助 AWS CloudWatch、Azure Monitor 或 Google Cloud Monitoring 等工具,确保模型中没有错误。这将需要展示未来部署的模型应如何修改,以使其更好。
AWS CloudWatch
aws cloudwatch put-metric-alarm --alarm-name CPUAlarm --metric-name CPUUtilization \
--namespace AWS/EC2 --statistic Average --period 300 --threshold 70 \
--comparison-operator GreaterThanThreshold --dimensions "Name=InstanceId,Value=i-1234567890abcdef0" \
--evaluation-periods 2 --alarm-actions arn:aws:sns:us-east-1:123456789012:my-sns-topic
来源:https://blogs.vmware.com/management/2021/03/cloud-services-aws-cloudwatch-azure-monitor.html
Azure Monitor
az monitor metrics alert create --name 'CPU Alert' --resource-group myResourceGroup \
--scopes /subscriptions/{subscription-id}/resourceGroups/{resource-group-name}/providers/Microsoft.Compute/virtualMachines/{vm-name} \
--condition "avg Percentage CPU > 80" --description 'Alert if CPU usage exceeds 80%'
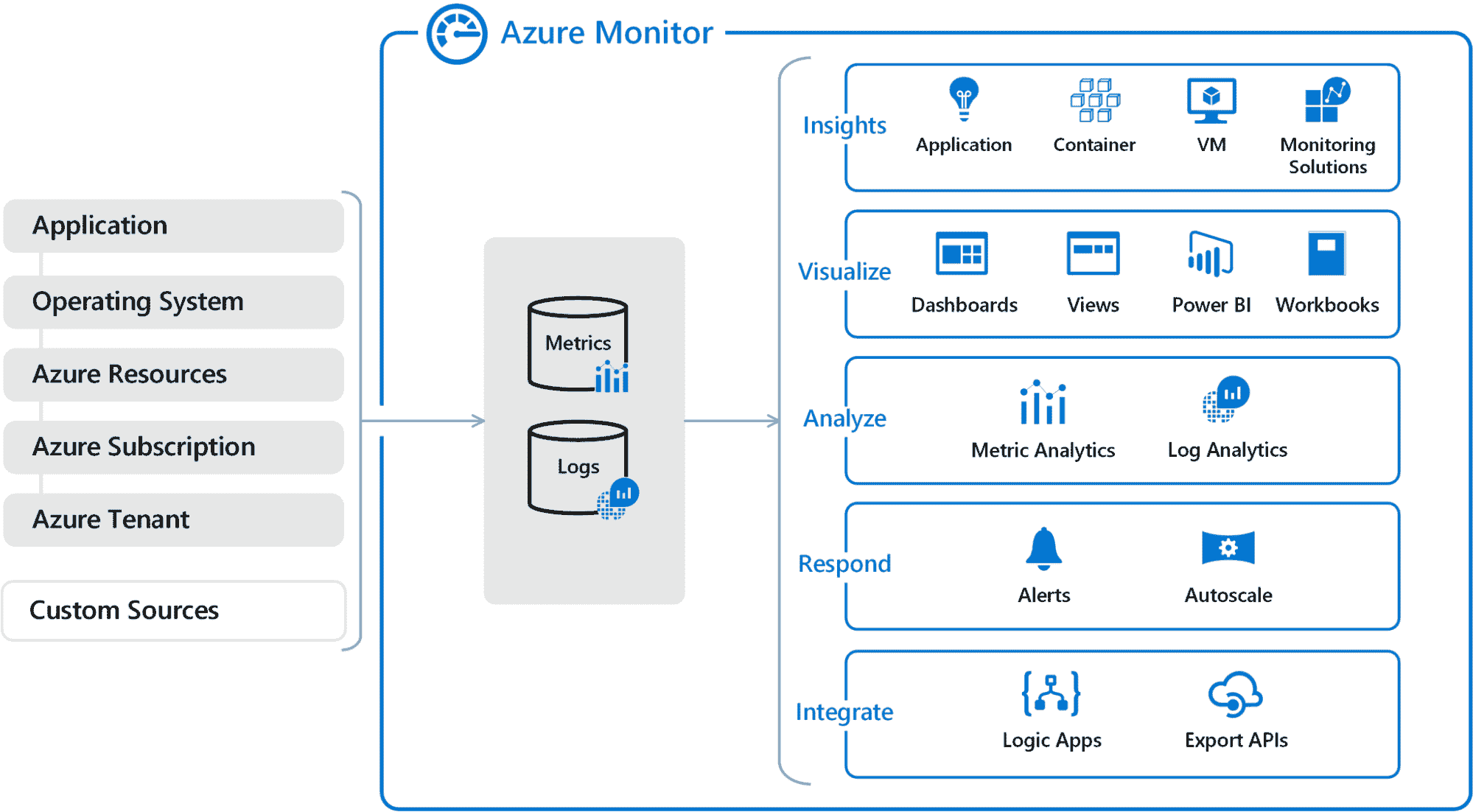
来源:https://blogs.vmware.com/management/2021/03/cloud-services-aws-cloudwatch-azure-monitor.html
总结
本教程中概述的策略将确保你掌握部署机器学习模型所需的关键步骤。遵循上述步骤,可以使训练好的模型变得可用,并且易于实际部署。从构建模型到配置和验证结构,你现在知道如何将你的机器学习工作从假设变为实际应用。
Jayita Gulati 是一位机器学习爱好者和技术写作专家,她热衷于构建机器学习模型。她拥有利物浦大学计算机科学硕士学位。
更多相关话题
使用 Streamlit 分享部署 Streamlit 应用
原文:
www.kdnuggets.com/2020/10/deploying-streamlit-apps-streamlit-sharing.html
评论
由Tyler Richards撰写,Facebook 数据科学家

图片由作者提供
在过去的几周里,我一直在尝试一个新的 Streamlit 功能,叫做 Streamlit 分享,这使得部署自定义应用变得非常简单。我将首先介绍一些背景知识,如果你想开始使用 Streamlit 分享,你可以在这里找到相关文档。
Streamlit 背景
简单来说,Streamlit 是一个框架,允许你快速而自信地将 Python 脚本转换为 web 应用,对于需要快速分享模型或互动分析的团队数据科学家,或者想向世界展示个人项目的数据科学家来说,它是一个不可思议的工具。如果你想试试,可以查看这个Streamlit 入门教程!
我在过去的约 6 个月里一直在使用 Streamlit,它真的非常有用。之前,如果我知道在项目结束时需要制作一个 web 应用,我总是选择切换到 R,以便使用出色的 R shiny 框架,尽管我在 Python 编程方面比 R 要好得多。使用 Django 或 Flask 开发总是会有很多摩擦,使得个人项目很少值得这样做,而在工作中也总是花费太多时间。但在使用了 Streamlit 后,我现在不仅有了选择,而且发现自己更喜欢 Python+Streamlit 而不是 R+shiny。
Streamlit 分享
这让我想起几个月前的事。我开始了一个数据科学项目,专注于使用来自Goodreads应用的数据分析阅读习惯。我决定尝试 Streamlit,它将一个多天的 Django/Flask 应用在本地运行的过程缩短到了大约半小时的本地 Streamlit 使用。它确实像将你的分析放入脚本中,并在你想在应用中放置图表、小部件或文本解释时调用 Streamlit 函数一样简单。
然而,Streamlit 上最烦人的过程是部署和管理过程。我跟随的教程很简单,而且不会花太多时间,但还是相当繁琐。它需要启动一个 ec2 实例,配置 SSH,使用 tmux,并在每次想要更改 web 应用时都回到终端。虽然可以完成,但很烦人。
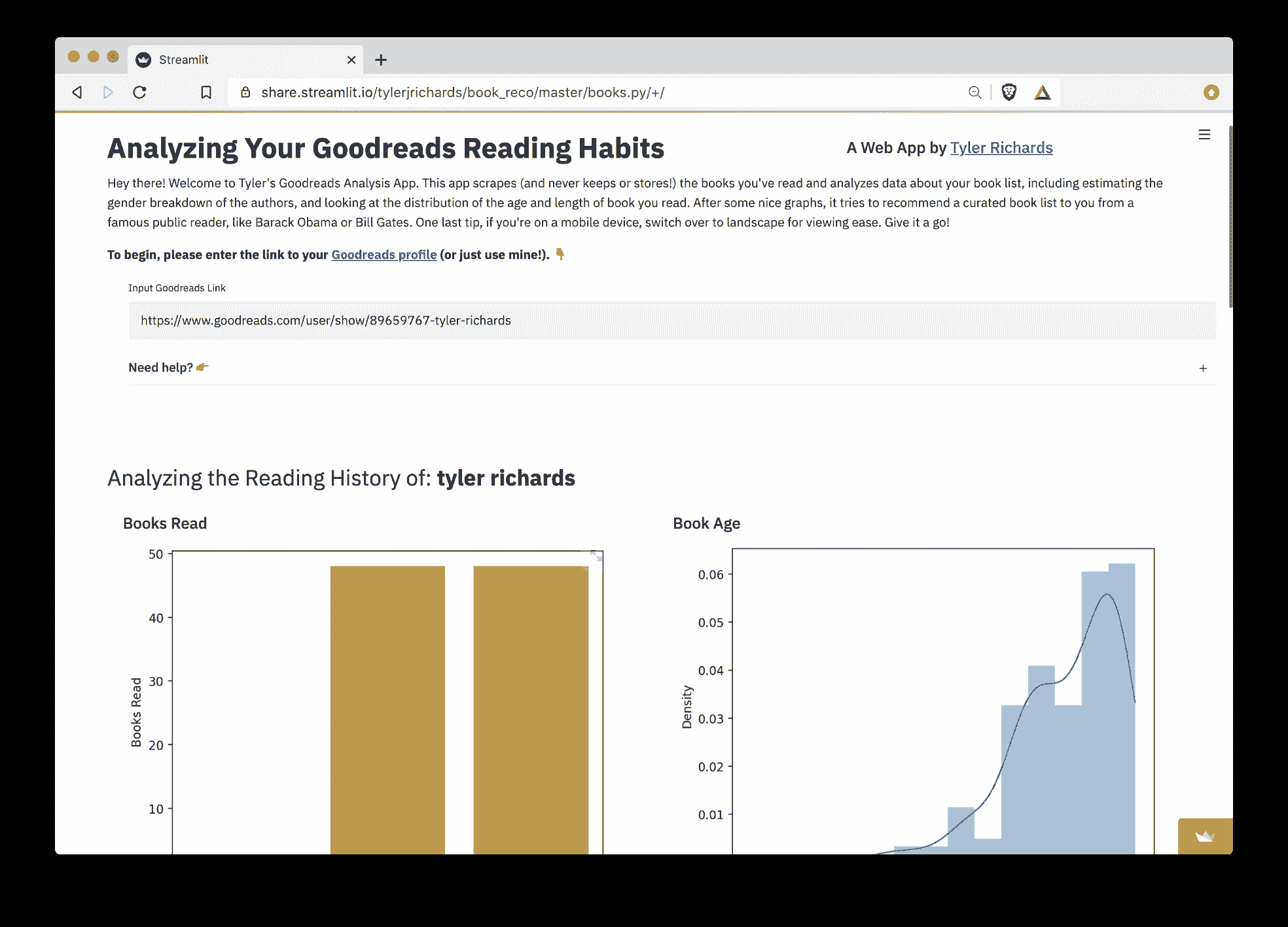
图片由作者提供
几周前,Streamlit 看到我的 Goodreads 应用,并问我是否想测试他们的 Streamlit 分享测试版,该版旨在消除上述提到的摩擦。我显然答应了。
我只需做的是:
-
将我的应用推送到 Github 仓库
-
添加一个列出我使用的所有 Python 库的 requirements.txt 文件
-
通过仓库链接将 Streamlit 指向我的应用
-
点击部署
真的如此简单就能搞定。我预留了几个小时来解决这个问题,因为我预计会出现各种错误(毕竟还在测试版!),但我只花了不到 10 分钟就使其运行起来了。
我目前有三个应用在运行,一个是测试应用,第二个是前面提到的 Goodreads 图书推荐应用,第三个是我创建的 互动分析,从构思到功能齐全并部署的网页应用大约用了一个半小时。
转向 Streamlit 分享还为我节省了每月约 $5 的 AWS 账单,我很乐意为这项功能支付这个费用,仅仅是为了节省部署时间。
图片由作者提供
如果我想尝试一个新的应用程序,我只需点击新的应用程序按钮,将其指向我的仓库,它们会处理所有其他事情。
图片由作者提供
如果你的 Streamlit 应用使用了其他包,请确保在你的仓库中包含一个 requirements.txt 文件——否则在部署时会立即出现错误。你可以使用类似 pip freeze 的工具来获取要求,但这会列出环境中的所有包,包括你当前项目中未使用的包。这会减慢你的应用部署速度!所以我建议使用类似 pipreqs 的工具来只保留你的应用核心要求。
pip install pipreqs
pipreqs /home/project/location
如果你有 apt-get 需求,请将它们添加到 packages.txt - 中,每行一个包。
结论
总结一下,Streamlit 分享为我节省了开发时间和托管费用(感谢让这一切成为可能的风险投资基金),使我的个人项目更加互动和美观,并消除了快速部署模型或分析的头痛问题。难怪我成为了 Streamlit 的粉丝。
想查看更多内容吗?你可以在 Twitter、Substack 或 我的作品集网站 找到我。
快乐的 Streamlit!
简历:Tyler Richards 是 Facebook 的数据科学家。
原文。转载时已获许可。
相关:
-
12 小时机器学习挑战:使用 Streamlit 和 DevOps 工具构建并部署应用程序
-
构建一个使用 TensorFlow 和 Streamlit 生成逼真面孔的应用程序
-
机器学习模型部署
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关话题
使用 DAGsHub 将 Streamlit Web 应用程序部署到 Heroku
原文:
www.kdnuggets.com/2022/02/deploying-streamlit-webapp-heroku-dagshub.html

作者封面
作为初学者,很难意识到项目的最终产品应该是什么样的。你从一个基础的机器学习流程开始,随着项目的演进,你调整和增强组件以满足你的最终标准。但旅程并未止步于此。为了与世界分享你的工作,你希望有一种方式让人们与模型互动并评估其性能。在这篇博客中,我们将学习如何仅使用 Python 构建一个 Streamlit 应用程序,并将其部署到远程 Heroku 服务器上。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
示例项目 - 肺炎分类
我们将使用Pneumonia-Classification项目,并展示如何将其 Streamlit 应用程序部署到云端。该项目分为五个任务:数据标注、数据处理、建模、评估和 Streamlit。我们将使用在Kaggle上可获得的胸部 X 光数据集。数据集包含 5,863 张正面胸部 X 光图像。它被分为三个文件夹:train、test、val,每个文件夹包含子文件夹Pneumonia和Normal。我们的数据集使用CC BY 4.0许可,可以用于商业用途。我们将重点关注创建 Web 应用程序并将其部署到云端,但如果你想了解更多数据预处理和模型构建的内容,可以查看项目。
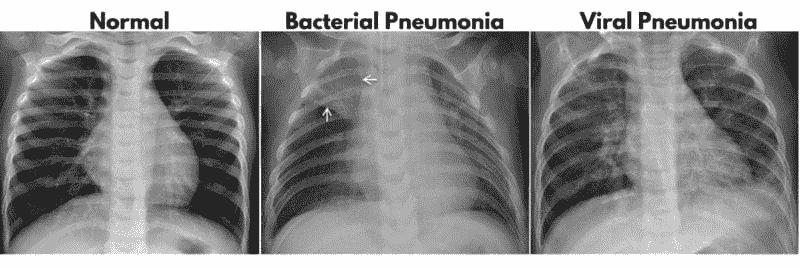
图片由Cell提供
什么是 Streamlit?
Streamlit 是一个开源库,允许你仅使用 Python 构建网页应用程序。它提供了自定义选项,可以根据你的需求设计应用程序,而无需任何网页开发的先验知识。使用 Streamlit,数据科学从业者可以通过构建一个 用于他们模型 的网页应用程序,轻松地与技术同事或非技术利益相关者沟通他们的工作。
如何创建一个 Streamlit 应用程序
在本节中,我们将重点学习 Streamlit 的核心组件,并简要了解其他组件如何帮助我们创建互动的 Streamlit 应用程序。核心组件包括选择或上传图像、加载 Tensorflow 模型和运行预测以显示结果。
我们在应用程序中使用的其他组件:
-
页面设置: 用于设置头部、图标和应用程序的初始配置。
-
Markdown: 用于编写标题、副标题和描述。
-
图像: 用于显示封面图像。
-
展开器: 多元素容器,可以展开/折叠,用于图像池。
-
列: 用于创建图像池表格。
-
进度条: 显示运行模型推断的进度条。
选择与上传
streamlit 的 侧边栏 功能非常方便,因为它允许我们在应用程序中添加额外的功能。侧边栏选项增加了 selectbox 和 file_uploader 的额外交互性。选择框是一个下拉选项框,允许我们从健康或生病的 X 光图像中进行选择。file_uploader 允许我们上传新的 X 光图像进行肺炎预测。
-
selectbox: 下拉选项用于选择单一选项。
-
file_uploader: 将 X 光图像上传到应用程序。
selectbox = st.sidebar.selectbox(SELECT_BOX_TEXT,
[None] + healthy_sidebar_list + sick_sidebar_list)
file_buffer = st.sidebar.file_uploader("", type=SUPPORTED_IMG_TYPE)
侧边栏的选择框和文件上传器图像
模型预测
模型预测使用 tensorflow 加载模型并预测分类。下面的函数在选择了选项或上传了图像后激活。
if selectbox:
predict_for_selectbox(selectbox, my_bar, latest_iteration)
dict_of_img_lists = load_image_pool()
if file_buffer:
predict_for_file_buffer(file_buffer, my_bar, latest_iteration)
get_prediction 函数加载 Tensorflow 模型,对图像(已选择/上传)进行预测并显示结果。
@st.cache(suppress_st_warning=True)
def get_prediction(img):
with open(CLASS_NAME_PATH, "r") as textfile:
class_names = textfile.read().split(',')
img_expand = np.expand_dims(img, 0)
model = tf.keras.models.load_model(PROD_MODEL_PATH)
predictions = model.predict(img_expand)
display_prediction(class_names[np.rint(predictions[0][0]).astype(int)])
我还使用了 streamlit 进度条函数来显示进度条。我们还使用了 streamlit 的 成功 和 警告 函数来显示预测结果。
latest_iteration = st.empty()
my_bar = st.progress(0)
def display_prediction(pred):
if pred == 'sick':
st.warning(WARNING_MSG)
else:
st.success(SUCCESS_MSG)
下面的代码从选择框中读取选项并对图像进行预测。
def predict_for_selectbox(selectbox, my_bar, latest_iteration):
img_class = selectbox.split()[0]
img_position = int(selectbox.split()[-1]) - 1
img = dict_of_img_lists[img_class][img_position]
my_bar.progress(50)
latest_iteration.text('Processing image')
get_prediction(img)
my_bar.progress(100)
正在运行带有进度条的预测,进度为 50%
以下函数读取上传的文件并对图像进行预测。
def predict_for_file_buffer(file_buffer, my_bar, latest_iteration):
latest_iteration.text('Loading image')
img = load_n_resize_image(file_buffer)
markdown_format(MID_FONT, "Your chest X-ray")
st.image(img, use_column_width=True)
my_bar.progress(50)
latest_iteration.text('Processing image')
get_prediction(img)
my_bar.progress(100)
成功的肺炎预测图像
下一步..
在为你的项目创建并本地运行 Streamlit 应用程序之后,是时候将其部署并与世界分享了。对于不熟悉这个过程的人来说,将应用程序部署到云端可能非常具有挑战性。在下一部分中,我们将讨论你可能遇到的主要问题,探讨解决这些问题的选项,并选择适合该任务的最佳方案。
为 Streamlit 应用程序选择部署服务器
选择云提供商来托管应用程序可能会让人感到沮丧和不知所措,因为平台的膨胀和其优势的不明确。为了帮助你,我比较了三种云服务:AWS、Heroku 和 Huggingface,它们在使用 Streamlit 设计的机器学习应用程序方面表现良好。
云服务器比较
AWS EC2
亚马逊云服务提供安全且可调整大小的计算能力。EC2 允许你部署整个机器学习工作流,也可以为更好的机器进行配置。它不够用户友好,学习曲线相当陡峭。然而,EC2 通过使用 GPU 支持提供了更快的推理速度。如果你有兴趣学习和部署你的 Streamlit 应用程序使用 AWS,我建议你阅读由Nishtha Goswami撰写的精彩博客。
Hugging Face
HuggingFace Spaces提供了简单的部署和快速推理解决方案,但它有一个缺点,就是你只能使用 Streamlit 或Gradiao框架。Spaces 服务器在 DVC 集成和开发 MLOps 解决方案方面不提供灵活性,但它们提供了一种名为Infinity的付费企业解决方案,具有很大的灵活性和更快的推理速度。
Heroku
Salesforce Heroku 提供用户友好的体验、自动化和使用多个 第三方集成 的灵活性。偏见提示:我第一次云端体验是使用 Heroku,因为过程极其简单,我一直在使用他们的服务。Heroku 有两个缺点:存储限制(500MB)和相较于其他云服务,模型推断速度较慢。这些缺点可以通过使用 Docker 部署和采纳优化技术来轻松解决。
如何在 Heroku 上部署 Streamlit 应用。
将 streamlit 应用部署分为五个步骤:项目初始化、创建 web 应用(streamlit)、设置 DVC、设置 web 应用,以及最后将其部署到服务器。在本节中,我们将学习如何使用 Heroku GUI 和 Heroku CLI 来初始化应用程序、设置项目以进行部署以及将代码推送到云服务器。
部署 web 应用到 Heroku 服务器的步骤。
项目初始化。
初始化项目有两种方法:使用 Heroku 网站和 Heroku CLI。如果你是初学者,可以使用网站完成从创建应用到部署应用的所有任务。
使用 GUI 初始化一个 Heroku 项目。
-
注册一个免费的 Heroku 账户。
-
下载 Heroku CLI 并安装它。
-
登录你的账户。
-
前往仪表盘并 创建一个新应用。
-
输入应用名称并选择服务器的区域。
-
从命令终端输入 git clone https://git.heroku.com/
.git
使用 GUI 初始化 Heroku 应用。
使用 Heroku CLI 初始化一个 Heroku 项目。
-
注册一个免费的 Heroku 账户。
-
从命令终端,切换到项目目录并输入:git init。
-
安装 Heroku CLI:sudo snap install --classic heroku
-
登录:heroku login。这将引导你到浏览器中的登录部分。
-
创建应用:heroku create
。
设置 DVC。
对于数据和模型版本控制,我使用了 DVC 和 DAGsHub 进行远程存储。在本节中,我们将自动化 DVC 从远程服务器拉取数据,使用 Heroku buildpack。为什么使用 buildpack?为什么不能直接拉取数据?如果我们没有使用 buildpack 拉取数据,webapp 将无法注册新的 DVC 文件。简而言之,如果你希望 DVC 为你工作,就必须使用 buildpack。它为编译和运行时的 apt-based 依赖项提供支持。感谢 GuilhermeBrejeiro 和他的项目 deploy_ML_model_Heroku_FastAPI,它帮助我自动化了 DVC。
1. 使用 shell 安装 buildpack:heroku buildpacks:add --index 1 heroku-community/apt,或者前往应用程序设置并添加 buildpack,如下所示。

添加 build pack
2. 创建一个 Aptfile,并添加一个指向 DVC 最新版本的链接:github.com/iterative/dvc/releases/download/2.8.3/dvc_2.8.3_amd64.deb。确保这是一个 .deb 文件。

3. 在 streamlit_app.py 中添加这些代码行,以拉取 4 张图片和一个模型。此方法用于优化存储并促进更快的构建。我使用了 dvc config 使其与 Heroku 服务器环境兼容。你可以在 这里 阅读更多关于配置的内容。
import os
if "DYNO" in os.environ and os.path.isdir(".dvc"):
print("Running DVC")
os.system("dvc config cache.type copy")
os.system("dvc config core.no_scm true")
if os.system(f"dvc pull {PROD_MODEL_PATH} {HEALTHY_IMAGE_ONE_PATH} {HEALTHY_IMAGE_TWO_PATH} {SICK_IMAGE_ONE_PATH} {SICK_IMAGE_TWO_PATH}") != 0:
exit("dvc pull failed")
os.system("rm -r .dvc .apt/usr/lib/dvc")
该代码检查 dyno 和目录中的 .dvc 文件夹,然后执行 dvc 配置,这将使 Heroku 服务器能够拉取 dvc 文件。最后,它只拉取模型文件夹、来自 DVC 服务器的样本图片,并删除不必要的文件。
设置应用程序
我们需要做一些更改,以便 Heroku 能够顺利构建和运行应用程序而不会崩溃。我们将设置 PORT 配置变量,创建 Profile,并替换 requirement.txt 中的 Python 包。在大多数情况下,Heroku 仅需要 requirement.txt 来构建应用程序和 Procfile 来运行应用程序。
设置端口
我们可以使用 Heroku CLI 设置 PORT:heroku config:set PORT=8080,或者我们可以前往仪表板设置并手动添加,如下所示。这部分是可选的,但建议设置端口号以避免 H10 错误。

配置变量
Procfile
Procfile 包含一个 web 初始化命令:web: streamlit run --server.port $PORT streamlit_app.py。没有它,应用程序将无法运行。
要求
最后,修改 requirements.txt 文件以避免存储和依赖问题。例如,我们将项目中的依赖项更改如下:
-
将 tensorflow 替换为 tensorflow-cpu 以将 slug 大小从 765MB 减少到 400MB。
-
将 opencv-python 替换为 opencv-python-headless 以避免安装额外的 C++ 依赖项。
-
除了 Numpy、Pillow 和 Streamlit 外,移除其他软件包。
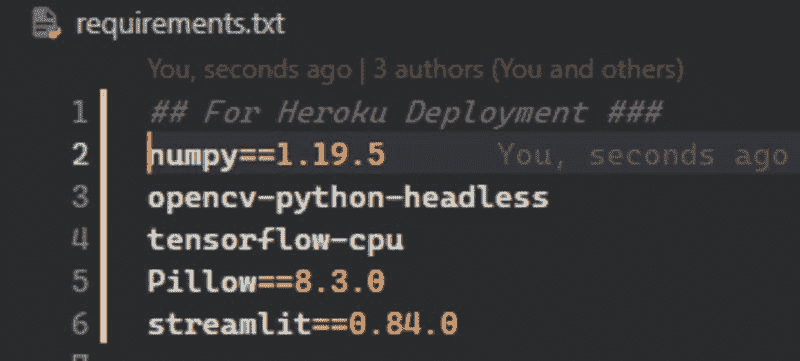
Heroku 部署包
提示
我们只需要几个文件夹和文件,将其他文件夹添加到 **.slugignore** 文件中以优化存储。[.slugignore](https://devcenter.heroku.com/articles/slug-compiler#ignoring-files-with-slugignore) 文件的功能类似于 .gitignore,但它在构建过程中忽略文件。
部署
部署是本指南中最简单的部分,因为我们只需提交所有更改并将代码推送到 Heroku 远程服务器。
git add .
git commit -m "first deployment"
git push heroku master
Streamlit 图像分类 web 应用程序已部署在 (dagshub-pc-app.herokuapp.com)。

部署应用程序到 Heroku 服务器只需不到五分钟。如果你在部署过程中仍然遇到问题,可以查看我的 DAGsHub 仓库 作为参考。
结论
在本博客中,我们学习了如何将 DVC 和 DAGsHub 与 Heroku 服务器集成。我们还学习了多种优化存储和避免依赖问题的方法。构建你的 web 应用程序并将其部署到服务器上是令人满意的,因为你现在可以与同事和朋友分享它。我们使用 DVC、streamlit、tensorflow、pillow 和 Heroku 构建了一个肺炎分类 web 应用程序。如果你想减少 slug 大小,尝试使用 joblib 加载模型并进行预测。你也可以使用 docker 文件来部署你的 web 应用程序,因为它们不受大小限制。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为患有心理疾病的学生开发一个人工智能产品。
更多相关主题
部署您的第一个机器学习模型
原文:
www.kdnuggets.com/deploying-your-first-machine-learning-model

图片来源:Lucas Fonseca
介绍
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT
在本教程中,我们将学习如何使用玻璃分类数据集构建一个简单的多分类模型。我们的目标是开发和部署一个能够预测各种类型玻璃的 Web 应用程序,例如:
-
构建已处理浮动的窗户
-
构建未处理浮动的窗户
-
车辆窗户已处理浮动
-
车辆窗户未处理浮动(数据集中缺失)
-
容器
-
餐具
-
前照灯
此外,我们将了解:
-
Skops:分享基于 scikit-learn 的模型并投入生产。
-
Gradio:ML Web 应用程序框架。
-
HuggingFace Spaces:免费机器学习模型和应用程序托管平台。
到本教程结束时,您将获得构建、训练和部署基本机器学习模型作为 Web 应用程序的实际经验。
模型训练和保存
在本部分中,我们将导入数据集,将其拆分为训练和测试子集,构建机器学习管道,训练模型,评估模型性能并保存模型。
数据集
我们已加载数据集并对其进行了洗牌,以实现标签的均匀分布。
import pandas as pd
glass_df = pd.read_csv("glass.csv")
glass_df = glass_df.sample(frac = 1)
glass_df.head(3)
我们的数据集

之后,我们使用数据集选择了模型特征和目标变量,并将其拆分为训练集和测试集。
from sklearn.model_selection import train_test_split
X = glass_df.drop("Type",axis=1)
y = glass_df.Type
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=125)
机器学习管道
我们的模型管道很简单。首先,我们通过一个填补器处理特征,然后使用标准缩放器对其进行归一化。最后,我们将处理后的数据输入随机森林分类器。
在将管道拟合到训练集后,我们使用 .score() 生成测试集上的准确度分数。
分数中等,我对性能感到满意。尽管我们可以通过集成或使用各种优化方法来改进模型,但我们的目标不同。
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
pipe = Pipeline(
steps=[
("imputer", SimpleImputer()),
("scaler", StandardScaler()),
("model", RandomForestClassifier(n_estimators=100, random_state=125)),
]
)
pipe.fit(X_train, y_train)
pipe.score(X_test, y_test)
>>> 0.7538461538461538
分类报告也很好。
from sklearn.metrics import classification_report
y_pred = pipe.predict(X_test)
print(classification_report(y_test,y_pred))
precision recall f1-score support
1 0.65 0.73 0.69 15
2 0.82 0.79 0.81 29
3 0.40 0.50 0.44 4
5 1.00 0.80 0.89 5
6 1.00 0.67 0.80 3
7 0.78 0.78 0.78 9
accuracy 0.75 65
macro avg 0.77 0.71 0.73 65
weighted avg 0.77 0.75 0.76 65
保存模型
Skops 是一个很棒的库,用于将 scikit-learn 模型部署到产品中。我们将用它来保存模型,并在生产中加载。
import skops.io as sio
sio.dump(pipe, "glass_pipeline.skops")
正如我们所见,通过一行代码,我们可以加载整个管道。
sio.load("glass_pipeline.skops", trusted=True)
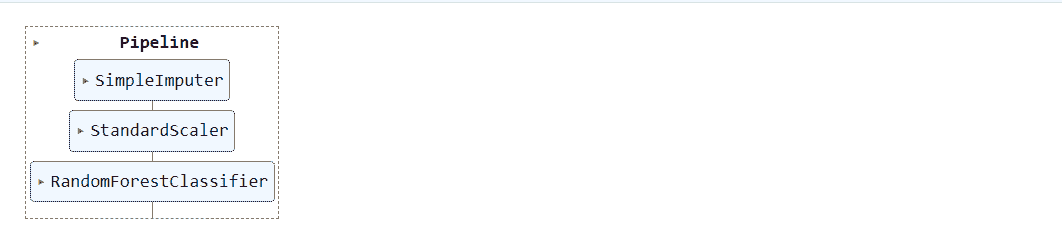
构建 Web 应用
在这一部分,我们将学习如何使用 Gradio 构建一个简单的分类用户界面。
-
使用 skops 加载模型。
-
创建一个类名数组,将第一个留空或设为“None”,作为我们的数值类从 1 开始。
-
编写一个分类 Python 函数,该函数从用户那里获取输入,并使用管道预测类别。
-
使用滑块为每个特征创建输入。用户可以使用鼠标选择数值。
-
使用标签创建输出。它将以粗体文本显示在顶部。
-
添加应用的标题和描述。
-
最后,使用
gradio.Interface组合所有内容
import gradio as gr
import skops.io as sio
pipe = sio.load("glass_pipeline.skops", trusted=True)
classes = [
"None",
"Building Windows Float Processed",
"Building Windows Non Float Processed",
"Vehicle Windows Float Processed",
"Vehicle Windows Non Float Processed",
"Containers",
"Tableware",
"Headlamps",
]
def classifier(RI, Na, Mg, Al, Si, K, Ca, Ba, Fe):
pred_glass = pipe.predict([[RI, Na, Mg, Al, Si, K, Ca, Ba, Fe]])[0]
label = f"Predicted Glass label: **{classes[pred_glass]}**"
return label
inputs = [
gr.Slider(1.51, 1.54, step=0.01, label="Refractive Index"),
gr.Slider(10, 17, step=1, label="Sodium"),
gr.Slider(0, 4.5, step=0.5, label="Magnesium"),
gr.Slider(0.3, 3.5, step=0.1, label="Aluminum"),
gr.Slider(69.8, 75.4, step=0.1, label="Silicon"),
gr.Slider(0, 6.2, step=0.1, label="Potassium"),
gr.Slider(5.4, 16.19, step=0.1, label="Calcium"),
gr.Slider(0, 3, step=0.1, label="Barium"),
gr.Slider(0, 0.5, step=0.1, label="Iron"),
]
outputs = [gr.Label(num_top_classes=7)]
title = "Glass Classification"
description = "Enter the details to correctly identify glass type?"
gr.Interface(
fn=classifier,
inputs=inputs,
outputs=outputs,
title=title,
description=description,
).launch()
部署机器学习模型
在最后一部分,我们将创建 Hugging Face 上的空间,并添加我们的模型和应用文件。
要创建空间,你需要登录 https://huggingface.co。然后,点击右上角的个人资料图片,选择“+ 新建空间”。
图片来自 HuggingFace
写下你的应用程序名称,选择 SDK,并点击创建空间按钮。
图片来自 Spaces
然后,创建一个 requirements.txt 文件。你可以通过前往“文件”选项卡并选择“+添加文件”按钮来添加或创建文件。
在 requirements.txt 文件中,你需要添加 skops 和 scikit-learn。
图片来自 Spaces
之后,通过将模型和文件从本地文件夹拖放到空间中来添加它们。然后,提交。
图片来自 Spaces
安装所需的包和构建容器需要几分钟时间。
图片来自 Spaces
最后,你将获得一个无 bug 的应用程序,你可以与家人和同事分享。你还可以通过点击链接查看实时演示:玻璃分类。
图片来自 玻璃分类
结论
在本教程中,我们详细介绍了构建、训练和部署机器学习模型作为 Web 应用的完整过程。我们使用了玻璃分类数据集来训练一个简单的多类别分类模型。在使用 scikit-learn 训练模型后,我们利用 skops 和 Gradio 将模型打包并部署为 HuggingFace Spaces 上的 Web 应用。
在这个入门项目的基础上有很多可能性。你可以将更多功能整合到模型中,尝试不同的算法,或在其他平台上部署 Web 应用。重要的是,你现在已经获得了从头到尾的机器学习工作流程的实际经验。你已经接触了模型训练、将其打包以便于生产,并构建了用于与模型预测交互的 Web 界面。
感谢你的关注!如果在继续你的机器学习旅程中有任何其他问题,请告诉我。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专家,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为那些遭受心理疾病困扰的学生开发一个 AI 产品。
更多相关话题
将你的机器学习模型部署到云中
原文:
www.kdnuggets.com/deploying-your-ml-model-to-production-in-the-cloud

图片来源:编辑
AWS 或亚马逊网络服务,是一种用于存储、分析、应用程序、部署服务等的云计算服务。它是一个利用多个服务的平台,以无服务器的方式支持业务,并采用按需付费的方案。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
机器学习建模活动也是 AWS 支持的活动之一。通过多个服务,可以支持建模活动,从开发模型到将其投入生产。AWS 展示了多功能性,这对任何需要扩展性和速度的企业至关重要。
本文将讨论如何在 AWS 云中将机器学习模型部署到生产环境中。我们该如何做到这一点?让我们进一步探索。
准备工作
在开始本教程之前,你需要创建一个 AWS 账户,因为我们需要它来访问所有 AWS 服务。我假设读者将使用免费层来跟随本文。此外,我假设读者已经了解如何使用 Python 编程语言,并具备机器学习的基本知识。同时,我们将重点关注模型部署部分,而不会关注数据科学活动的其他方面,例如数据预处理和模型评估。
牢记这一点,我们将开始在 AWS 云服务中部署你的机器学习模型的旅程。
在 AWS 上部署模型
在本教程中,我们将开发一个机器学习模型来预测给定数据的客户流失。训练数据集来自 Kaggle,你可以 在这里 下载。
在我们获取数据集之后,我们将创建一个 S3 桶来存储数据集。在 AWS 服务中搜索 S3 并创建桶。
图片来源:作者
在这篇文章中,我将桶命名为“telecom-churn-dataset”,并位于新加坡。你可以根据需要更改这些设置,但暂时就使用这个名称吧。
在你创建好桶并将数据上传到你的桶中后,我们将前往 AWS SageMaker 服务。在这个服务中,我们将使用 Studio 作为我们的工作环境。如果你从未使用过 Studio,我们需要在继续之前创建一个域和用户。
首先,在 Amazon SageMaker 管理配置中选择“Domains”。
作者提供的图片
在“Domains”中,你会看到很多按钮供选择。在这个屏幕中,选择“Create domain”按钮。
作者提供的图片
如果你想加快创建过程,可以选择快速设置。完成后,你应该会在仪表板中看到一个新的域。选择你刚刚创建的新域,然后点击“Add user”按钮。
作者提供的图片
接下来,你应该根据你的偏好命名用户配置文件。对于执行角色,你可以先保持默认,因为它是创建域时生成的角色。
作者提供的图片
只需点击“下一步”直到画布设置。在此部分,我关闭了一些不需要的设置,例如时间序列预测。
一切设置好后,前往 Studio 选择界面,选择你刚刚创建的用户名对应的“Open studio”按钮。
作者提供的图片
在 Studio 中,导航到看起来像文件夹图标的侧边栏,并在其中创建一个新的笔记本。我们可以保持默认设置,就像下面的图片所示。
作者提供的图片
使用新的笔记本,我们将创建一个流失预测模型并将模型部署到 API 推断中,以便我们可以在生产中使用。
首先,让我们导入必要的包并读取流失数据。
import boto3
import pandas as pd
import sagemaker
sagemaker_session = sagemaker.Session()
role = sagemaker.get_execution_role()
df = pd.read_csv('s3://telecom-churn-dataset/telecom_churn.csv')

作者提供的图片
接下来,我们将用以下代码将上述数据拆分为训练数据和测试数据。
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, test_size = 0.3, random_state = 42)
我们将测试数据设置为原始数据的 30%。通过我们的数据拆分,我们将把它们重新上传到 S3 桶中。
bucket = 'telecom-churn-dataset'
train.to_csv(f's3://{bucket}/telecom_churn_train.csv', index = False)
test.to_csv(f's3://{bucket}/telecom_churn_test.csv', index = False)
你可以看到你 S3 桶中的数据,目前包括三个不同的数据集。
作者提供的图片
数据集准备好后,我们现在将开发一个流失预测模型并进行部署。在 AWS 中,我们通常使用脚本训练方法进行机器学习训练。这就是为什么我们在开始训练之前需要开发一个脚本。
在下一步中,我们需要在同一个文件夹中创建一个额外的 Python 文件,我称之为 train.py。
Image by Author
在这个文件中,我们将设置我们的模型开发过程来创建流失模型。对于本教程,我会采用 Ram Vegiraju 的一些代码。
首先,我们将导入所有开发模型所需的包。
import argparse
import os
import io
import boto3
import json
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import joblib
接下来,我们将使用解析器方法来控制我们可以输入到训练过程中的变量。我们将放在脚本中的整体代码如下。
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--estimator', type=int, default=10)
parser.add_argument('--sm-model-dir', type=str, default=os.environ.get('SM_MODEL_DIR'))
parser.add_argument('--model_dir', type=str)
parser.add_argument('--train', type=str, default=os.environ.get('SM_CHANNEL_TRAIN'))
args, _ = parser.parse_known_args()
estimator = args.estimator
model_dir = args.model_dir
sm_model_dir = args.sm_model_dir
training_dir = args.train
s3_client = boto3.client('s3')
bucket = 'telecom-churn-dataset'
obj = s3_client.get_object(Bucket=bucket, Key='telecom_churn_train.csv')
train_data = pd.read_csv(io.BytesIO(obj['Body'].read()))
obj = s3_client.get_object(Bucket=bucket, Key='telecom_churn_test.csv')
test_data = pd.read_csv(io.BytesIO(obj['Body'].read()))
X_train = train_data.drop('Churn', axis =1)
X_test = test_data.drop('Churn', axis =1)
y_train = train_data['Churn']
y_test = test_data['Churn']
rfc = RandomForestClassifier(n_estimators=estimator)
rfc.fit(X_train, y_train)
y_pred = rfc.predict(X_test)
print('Accuracy Score: ',accuracy_score(y_test, y_pred))
joblib.dump(rfc, os.path.join(args.sm_model_dir, "rfc_model.joblib"))
最后,我们需要实现 SageMaker 进行推断所需的四个不同函数:model_fn, input_fn, output_fn, 和 predict_fn。
#Deserialized model to load them
def model_fn(model_dir):
model = joblib.load(os.path.join(model_dir, "rfc_model.joblib"))
return model
#The request input of the application
def input_fn(request_body, request_content_type):
if request_content_type == 'application/json':
request_body = json.loads(request_body)
inp_var = request_body['Input']
return inp_var
else:
raise ValueError("This model only supports application/json input")
#The prediction functions
def predict_fn(input_data, model):
return model.predict(input_data)
#The output function
def output_fn(prediction, content_type):
res = int(prediction[0])
resJSON = {'Output': res}
return resJSON
脚本准备好后,我们将运行训练过程。在下一步中,我们将把上面创建的脚本传递给 SKLearn 估算器。这个估算器是一个 SageMaker 对象,它会处理整个训练过程,我们只需要传递所有类似于以下代码的参数。
from sagemaker.sklearn import SKLearn
sklearn_estimator = SKLearn(entry_point='train.py',
role=role,
instance_count=1,
instance_type='ml.c4.2xlarge',
py_version='py3',
framework_version='0.23-1',
script_mode=True,
hyperparameters={
'estimator': 15})
sklearn_estimator.fit()
如果训练成功,你将会得到以下报告。

Image by Author
如果你想检查 SKLearn 训练的 Docker 镜像和模型工件的位置,你可以使用以下代码访问它们。
model_artifact = sklearn_estimator.model_data
image_uri = sklearn_estimator.image_uri
print(f'The model artifact is saved at: {model_artifact}')
print(f'The image URI is: {image_uri}')
模型到位后,我们将把模型部署到一个 API 端点,以便进行预测。为此,我们可以使用以下代码。
import time
churn_endpoint_name='churn-rf-model-'+time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())
churn_predictor=sklearn_estimator.deploy(initial_instance_count=1,instance_type='ml.m5.large',endpoint_name=churn_endpoint_name)
如果部署成功,将创建模型端点,你可以访问它以进行预测。你也可以在 Sagemaker 仪表板中查看这个端点。
Image by Author
你现在可以通过这个端点进行预测。为此,你可以用以下代码测试端点。
client = boto3.client('sagemaker-runtime')
content_type = "application/json"
#replace with your intended input data
request_body = {"Input": [[128,1,1,2.70,1,265.1,110,89.0, 9.87,10.0]]}
#replace with your endpoint name
endpoint_name = "churn-rf-model-2023-09-24-12-29-04"
#Data serialization
data = json.loads(json.dumps(request_body))
payload = json.dumps(data)
#Invoke the endpoint
response = client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType=content_type,
Body=payload)
result = json.loads(response['Body'].read().decode())['Output']
result
祝贺你。你现在已经成功地在 AWS 云中部署了你的模型。测试过程完成后,不要忘记清理端点。你可以使用以下代码来完成这个操作。
from sagemaker import Session
sagemaker_session = Session()
sagemaker_session.delete_endpoint(endpoint_name='your-endpoint-name')
如果你不再需要,别忘了关闭你使用的实例,并清理 S3 存储。
若要进一步阅读,可以了解更多关于 SKLearn 估计器 和 批量转换推理,如果你不想使用终端节点模型。
结论
AWS 云平台是一个多用途平台,许多公司用来支持他们的业务。常用的服务之一是数据分析,特别是模型生产。在本文中,我们学习如何使用 AWS SageMaker 以及如何将模型部署到终端节点。
Cornellius Yudha Wijaya 是一位数据科学助理经理和数据撰写者。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
更多相关话题
将机器学习算法完整端到端地部署到实时生产环境中
原文:
www.kdnuggets.com/2021/12/deployment-machine-learning-algorithm-live-production-environment.html

图片来源:Fotis Fotopoulos 于 Unsplash
引言
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
在 2021 年 10 月,我撰写了一篇关于“将机器学习和数据科学项目部署为公开网络应用”的文章(见 towardsdatascience.com/deploying-machine-learning-and-data-science-projects-as-public-web-applications-3abc91088c11)。
在这篇文章中,我探讨了如何使用 Voila、GitHub 和 mybinder 将 Jupyter Notebooks 部署为公开的网络应用。
文章发布后,我收到读者反馈,他们对如何进一步推动生产部署感兴趣,希望探索如何将机器学习算法完全部署到实时生产环境中,以便能够以平台无关的方式“消费”它,这也促成了这篇文章的产生……
第一步:开发一个机器学习算法
第一步是开发我们想要部署的机器学习算法。在实际应用中,这可能涉及数周或数月的开发时间以及在数据科学管道各个步骤中进行大量的迭代,但在这个例子中,我将开发一个基本的机器学习算法,因为这篇文章的主要目的是找到一种可以供“消费者”使用的算法部署方式。
我从 kaggle 选择了一个数据集 (www.kaggle.com/prathamtripathi/drug-classification),该数据集由作者创建,并具有“CC0: 公共领域”许可,这意味着它没有版权,可以在其他作品中自由使用(详情请见 creativecommons.org/publicdomain/zero/1.0/)。
开发一个预测性机器学习算法以根据一系列患者标准分类药物处方的 Python 代码如下 -
0.99 0.012247448713915901
此时我们可以看到,我们有一个训练好的机器学习算法用于预测药物处方,并且交叉验证(即数据折叠)已被用来评估模型准确率达到 99%。
目前一切顺利……
我们将把这个模型部署到生产环境中,虽然这是一个简单的示例,但我们不希望每次用户想要预测药物处方时都需要在实时环境中重新训练模型,因此我们的下一步是使用pickle保存我们训练过的模型的状态……
现在,每当我们想使用训练好的模型时,我们只需从model.pkl文件中重新加载其状态,而不是重新执行训练步骤。
步骤 2:从训练模型中进行单独预测
我将在步骤 2 中做几个假设 -
-
机器学习算法的消费者有一个需求,就是对单个患者进行预测,而不是对一批患者进行预测。
-
那些消费者希望使用类似文本的值(例如血压 = “正常”或“高”)来与算法进行通信,而不是它们的标签编码等效值(如 0 和 1)。
因此,我们将从审查所有标签编码的类别特征的值开始,这些特征作为输入传递给算法……
Sex ['F', 'M'] [0, 1]
BP ['HIGH', 'LOW', 'NORMAL'] [0, 1, 2]
Cholesterol ['HIGH', 'NORMAL'] [0, 1]
Drug ['DrugY', 'drugC', 'drugX', 'drugA', 'drugB'] [0, 3, 4, 1, 2]
这样,我们就得到了一个包含每个类别特征及其在数据中出现的唯一值和通过LabelEncoder()转换后的相应数值的列表。
有了这些信息,我们可以提供一组字典,将类似文本的值(例如“高”、“低”等)映射到它们的编码等效值,然后开发一个简单的函数来进行单独的预测,如下所示……
然后可以通过调用函数进行一些基于原始数据值的预测来验证这个实现,以便我们知道输出应该是什么……
'drugC'
'DrugY'
请注意,我们的predict_drug函数不需要训练模型,而是将先前通过pickle保存状态的模型“重新加载”到model.pkl文件中,我们可以从输出中看到,药物推荐的预测是正确的。
步骤 3:开发一个 Web 服务包装器
目前一切看起来都很好,但这里有一个主要问题:我们的机器学习算法的客户端或消费者必须用 Python 编程语言编写,不仅如此,我们还必须能够更改和修改应用程序。
如果第三方应用程序希望使用和消耗我们的算法,并且这个第三方应用程序不是用 Python 编写的怎么办?也许它是用 Java、C#、JavaScript 或其他非 Python 语言编写的。
这就是 Web 服务发挥作用的地方。Web 服务是一个“封装器”,它接收来自客户端和消费者的 HTTP GET 和 HTTP PUT 请求,调用 Python 代码并返回 HTML 响应。
这意味着客户端和调用者只需能够构造 HTTP 请求,几乎所有编程语言和环境都有实现这一点的方法。
在 Python 世界中,有几种不同的方法可供选择,但我选择的方式是使用 flask 构建我们的 Web 服务封装器。
代码本身并不复杂,但配置 VS Code 以使开发者能够调试 Flask 应用可能会有挑战。如果你需要这个步骤的教程,请查看我的文章《如何在 VS Code 中调试 Flask 应用》,可以在这里找到——towardsdatascience.com/how-to-debug-flask-applications-in-vs-code-c65c9bdbef21。
这是 Web 服务的封装器代码 …
从 Anaconda Navigator 页面启动 VS Code IDE(或通过启动 Anaconda 命令提示符并输入 code)。这将启动带有 Conda 基础环境的 VS Code,这是运行和调试 Flask 应用所必需的。
可以通过在 VS Code 中点击“运行和调试”然后选择“Flask 启动和调试 Flask Web 应用”来启动 Web 服务 -
图片由作者提供
如果一切顺利,TERMINAL 窗口中的最后一条消息应为 Running on http://127.0.0.1:5000/ (Press CTRL+C to quit),这表示你的 Flask Web 应用已成功运行。
现在你应该使用以下方法之一来测试你的 Web 服务 -
-
打开一个网页浏览器并输入:
127.0.0.1:5000/drug?Age=60&Sex=F&BP=LOW&Cholesterol=HIGH&Na_to_K=20 -
打开 Anaconda 命令提示符并输入:
curl -X GET "http://127.0.0.1:5000/drug?Age=60&Sex=F&BP=LOW&Cholesterol=HIGH&Na_to_K=20"
图片由作者提供
如果你想了解更多关于开发 flask 应用和 Web 服务的信息,这些文章是一个很好的起点 -
第 4 步:将 Web 服务部署到 Microsoft Azure
我们现在有了一个预测性机器学习算法,可以以 99% 的准确率预测药物处方,我们有一个可以进行单独预测的辅助函数,并且我们有一个允许这些组件通过浏览器或命令行调用的 Web 服务封装器。
然而,这一切仍然只能在开发环境中调用。下一阶段是将所有内容部署到云中,以便客户可以通过公共互联网“访问” Web 服务。
有许多不同的公共服务可用于 Web 应用程序的部署,包括 -
-
谷歌 —
cloud.google.com/appengine/docs/standard/python3/building-app/writing-web-service -
亚马逊 Web 服务 —
medium.com/@rodkey/deploying-a-flask-application-on-aws-a72daba6bb80 -
Microsoft Azure —
medium.com/@nikovrdoljak/deploy-your-flask-app-on-azure-in-3-easy-steps-b2fe388a589e
我选择了 Azure,因为它是免费的(对于入门级账户),易于使用,快速,并且与我最喜欢的开发环境 VS Code 完全集成。
步骤 4.1:将 Azure App Service 扩展添加到 VS Code
切换到 VS Code,转到“扩展”(Ctrl+Shft_X),然后添加“Azure App Service”扩展。添加扩展后,您将在活动栏中看到一个新的 Azure 图标 -
作者提供的图片
步骤 4.1:创建一个 Azure 账户
您必须拥有一个账户才能开始在 Azure 云中进行部署,并且在注册过程中必须提供信用卡信息。然而,除非您特别选择离开免费许可证,否则不会收费。
您可以按照此页面上的说明 — azure.microsoft.com/en-gb/free/ 通过浏览器创建您的免费 Azure 账户,但最简单的方法是点击活动栏中的新 Azure 图标,然后选择“创建免费 Azure 账户”(或者如果您已经有账户,则选择“登录 Azure”) -
作者提供的图片
步骤 4.3:创建一个 Azure Web 应用程序
下一步是通过点击“APP SERVICE”窗口中的“+”符号来创建一个 Azure Web 应用程序以托管您的应用程序。系统会提示您输入应用程序的名称。这个名称将用于最终的 URL,并且必须是唯一的,但除此之外,名称并不是特别重要。
当系统提示您选择许可证类型时,选择“免费试用” — 您的 Web 应用程序现在将被创建,您可以开始部署。
作者提供的图片
步骤 4.4 创建一个“requirements.txt”部署文件
在您可以将应用程序部署到 Azure 之前,您必须在与 Flask Web 应用程序相同的文件夹中创建一个“requirements.txt”文件,该文件包含 Azure 必须安装的所有依赖项和库的列表,以便运行您的应用程序。此步骤至关重要,因为如果库不在部署环境中,应用程序将崩溃。
我们应用程序的 requirements.txt 文件内容如下 -
作者提供的图片
一些需要注意的点 -
-
库名称必须与使用 pip 安装时输入的名称完全一致,例如
pip install Flask。 -
请注意
Flask的 “F” 是大写的。这是因为 Flask 采用了这种不寻常的大小写方式,通常库名都是小写的。 -
sklearn是执行重新加载的model.pkl所必需的。虽然代码中没有明确引用 sklearn 和DecisionTreeClassifier,但它们是model.fit所需要的,因此如果省略sklearn,应用程序将崩溃。 -
pickle的引用不是必需的,因为这个库是 Python 核心安装的一部分。如果你包含pickle,部署将会崩溃,因为你不能执行pip install pickle。
如果遵循这些规则,你的部署将会成功,任何错误信息通常足够详细,可以通过一些互联网搜索解决问题。
步骤 4.5 将你的应用程序部署到 Azure
如果你到目前为止一直在按照步骤操作,你现在应该在 VS Code 中有一个 Flask 应用程序。你的应用程序代码文件将叫做 app.py,应用程序名称为 app。Flask 应用程序已经在本地开发网络服务器上进行了测试。
你已安装 VS Code Azure App 扩展,并使用它创建了一个 Microsoft Azure 免费账户和一个 Azure 网络应用程序。
你应该在 VS Code 中打开你的 Flask 应用程序,并且你已准备好将应用程序部署到云端。
这通过简单地点击蓝色圆圈图标旁边的网页应用名称,然后点击 “+” 旁边的云图标来实现。
当被提示时,选择以下选项 -
-
选择默认文件夹进行部署
-
选择 “Free Trial” 订阅
-
选择你创建的网页应用名称
-
如果提示覆盖,选择 “Deploy”
-
当被问及 “Always deploy …” 时,选择 “Skip for now”
-
部署开始时点击 “output window”
现在坐下来喝杯咖啡,同时应用程序正在部署中 -
作者提供的图片
部署完成后,点击 “Browse Website” 将带你到正确的 URL,该 URL 将运行 app.route("/") 函数。
只需添加我们用于测试本地部署的相同 URL 参数,你将看到完全部署的网页应用的输出! -
graham-harrison68-web03.azurewebsites.net/drug?Age=60&Sex=F&BP=LOW&Cholesterol=HIGH&Na_to_K=20
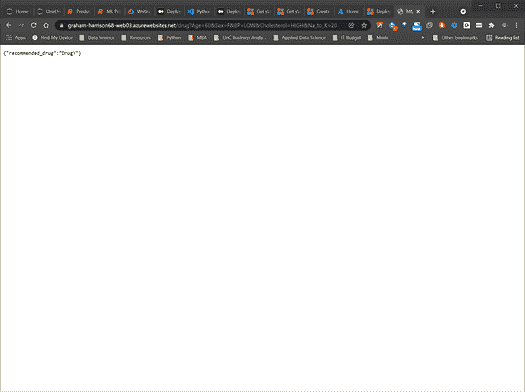
作者提供的图片
一点需要注意的是:过一段时间,azure 应用会进入睡眠状态,第一次调用后需要很长时间。
如果你选择升级到付费的 Azure 订阅,有一个选项可以保持应用程序刷新和“唤醒”,但在免费订阅中,睡眠相关的延迟无法避免,因为此订阅仅用于测试目的,因此有一些限制。
步骤 5:构建一个客户端应用程序以使用 Azure 部署的网络服务
目前,任何能够发起网络请求的编程语言或环境都可以用几行代码调用部署的网络服务。
我们一开始确实说过可以使用非 Python 环境如 C#、JavaScript 等,但我将通过写一些代码来演示如何使用ipywidgets从 Python 客户端调用部署的应用程序——
图片来源:作者
如果你点击“Prescribe”并保持默认值,推荐的应该是“drugC”。
将年龄更改为 60,Na 更改为 K 为 20,应该开具“DrugY”。将年龄改回 47,Na 改回 K 为 14,并将 BP 更改为“HIGH”,应该开具 drugA。
这些简单的测试证明,使用决策树预测机器学习算法的 Azure 托管网络服务已经完全部署到公共云中,任何能够执行http GET命令的开发环境都可以调用,并且从端到端完全工作。
结论
这涉及到相当多的步骤,但通过使用现成的库和免费工具,包括 scikit-learn、pickle、flask、Microsoft Azure 和 ipywidgets,我们构建了一个功能完全的、公开可用的机器学习算法云部署,以及一个功能完备的客户端来调用和使用该网络服务并显示结果。
感谢阅读!
如果你喜欢阅读这篇文章,不妨查看我其他的文章:grahamharrison-86487.medium.com/
此外,我很乐意听取你对这篇文章、我其他的文章或任何与数据科学和数据分析相关的内容的看法。
如果你希望讨论这些主题,请在 LinkedIn 上查找我 —— www.linkedin.com/in/grahamharrison1 或随时通过电子邮件联系我:GHarrison@lincolncollege.ac.uk。
如果你希望支持作者和全球数千名为文章撰写做出贡献的人,请使用这个链接订阅 —— grahamharrison-86487.medium.com/membership。注意:如果你使用此链接注册,作者将从费用中获得一部分。
格雷厄姆·哈里森 是林肯学院集团的信息技术、信息管理及项目组的总监,负责英国、沙特阿拉伯和中国的数据和技术能力。格雷厄姆还是数据科学咨询公司 The Knowledge Ladder 的董事总经理和创始人,林肯郡网络安全论坛的委员会成员,以及大林肯郡和拉特兰分支的董事学会数字大使。格雷厄姆最近完成了关于数据科学民主化的学术研究,并热衷于为所有组织提供可访问、负担得起且灵活的数据科学服务,无论其规模、行业或以前的经验如何。详情请访问 www.theknowledgeladder.co.uk/ 和 www.youtube.com/watch?v=cFt03rny07Y。
原文。转载已获许可。
更多相关话题
描述数据:Statology 入门
图片来源 | Midjourney & Canva
KDnuggets 的姊妹网站,Statology,拥有由专家编写的大量统计学相关内容,这些内容在短短几年内积累而成。我们决定通过整理并分享一些精彩教程,帮助我们的读者了解这一宝贵的统计、数学、数据科学和编程资源。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 在 IT 领域支持你的组织
学习统计学可能很困难。它可能令人沮丧。而且,最重要的是,它可能令人困惑。这就是为什么Statology在这里提供帮助。
这一系列教程涉及描述数据这一永恒重要的话题。每当我们试图理解数据时,能够以特定方式描述数据是很重要的。这些描述工具也有助于与他人分享数据的总结性方面。掌握以下常见的数据描述方法是理解数据的关键,同时也能帮助你更好地理解 Statology 上的其他内容。
集中趋势度量:定义与示例
集中趋势的度量是一个代表数据集中心点的单一值。这个值也可以被称为数据集的“中心位置”。
在统计学中,有三种常见的集中趋势度量:
-
均值
-
中位数
-
众数
这些度量方法使用不同的方法找到数据集的中心位置。根据你分析的数据类型,其中一种度量可能比其他两种更适合使用。
分散度量:定义与示例
当我们分析数据集时,我们通常关心两件事:
-
“中心”值的位置。我们通常用均值和中位数来衡量“中心”。
-
值的“分散程度”。我们用范围、四分位差、方差和标准差来衡量“分散”。
SOCS:描述分布的有用缩写
在统计学中,我们通常希望了解数据集的分布情况。特别地,有四个方面是了解分布时很有帮助的:
1. 形状
该分布是对称的还是偏向一侧的?
该分布是单峰的(一个峰)还是双峰的(两个峰)?
2. 异常值
该分布中是否存在任何异常值?
3. 中心
分布的均值、中位数和众数是多少?
4. 分布
该分布的范围、四分位距、标准差和方差是多少?
想要获取更多类似内容,请继续关注 Statology,并订阅他们的每周通讯,以确保不会错过任何信息。
Matthew Mayo (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 和 Statology 的执行编辑,以及 Machine Learning Mastery 的特约编辑,Matthew 致力于使复杂的数据科学概念易于理解。他的专业兴趣包括自然语言处理、语言模型、机器学习算法和探索新兴的 AI。他的使命是使数据科学社区的知识民主化。Matthew 从 6 岁起就开始编程。
更多相关话题
从 CRISP-DM 的视角来看描述性分析、机器学习和深度学习
原文:
www.kdnuggets.com/2018/05/descriptive-analytics-machine-learning-deep-learning-crisp-dm.html
 评论
评论
作者 Stéphane Faure,IBM。
作为一个组织的一部分,我经常需要解释“经典”机器学习的基础,我通常会介绍 CRISP-DM 方法论(见 www.kdnuggets.com/2014/10/crisp-dm-top-methodology-analytics-data-mining-data-science-projects.html)。
这种方法论可能是最合适的,不同的阶段为从业者提供了强大的框架,但为了更具体地解释它如何应用于“经典”机器学习和深度学习,我需要用更具体的设计流程来补充 CRISP-DM:
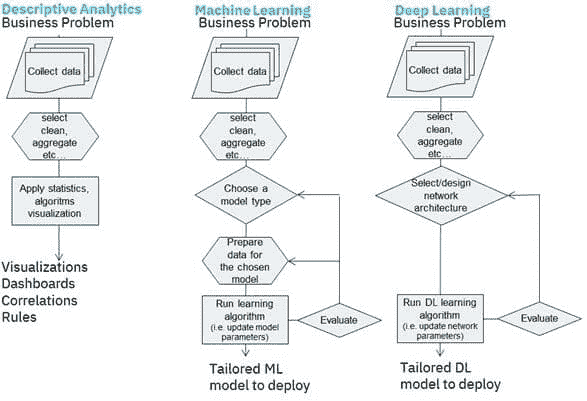
由于流程的目的是解释三种方法之间的区别,因此一些(很多……)没有纳入流程中,但我认为这对那些打算向非专业人士介绍机器学习和深度学习的人会有所帮助。
简介: Stéphane Faure 是 IBM 的 IT 专业人员,在那里他支持整个欧洲的服务器销售。在过去几年中,他一直从事支付欺诈检测、信用评分,并定期展示和教授预测分析。
相关:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关话题
描述性统计关键术语解释
原文:
www.kdnuggets.com/2017/05/descriptive-statistics-key-terms-explained.html
尽管统计学是数据科学的核心工具集,但它常常被更为技术性的技能如编程所忽视。即使是机器学习算法,它们依赖于数学概念如代数和微积分——更不用说统计学了!——也常常在处理时高于所需的基础数学水平,这可能导致一些“数据科学家”对其职业的一个关键方面缺乏基本理解。
本文不会解决了解与不了解统计学绝对基础之间的差异。然而,如果你无法完全理解文中包含的基本描述性统计术语,你肯定缺乏建立在这些基础上构建更多坚实且有用的专业概念所需的基础知识。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 为你的组织提供 IT 支持

这里是 15 个基本描述性统计关键术语的集合,以易于理解的语言进行解释。接下来是一个全面的示例,其中包含一些 Python 代码。请注意,作为基本介绍,本文中故意省略了术语的数学表示和描述。
1. 描述性统计
描述性统计是一组用于定量描述或总结数据集的统计工具。描述性统计旨在总结数据,因此可以与推断统计区分开来,后者在性质上更具预测性。
2. 总体
总体是一个被选中的个体或群体,代表了某个特定感兴趣群体的完整成员集合。
3. 样本
样本是从更大的总体中抽取的一个子集。如果这个抽样方式确保总体中的每个成员都有平等的选择机会,那么结果称为随机样本。
4. 参数
参数是从总体中生成的一个值。如果我拥有地球上所有人的数据,并计算出平均年龄,那么这个值就是一个参数。
5. 统计量
统计量是从样本中生成的一个值。如果我计算了地球上某一人群的平均年龄(更具可行性),这个值将是一个统计量。因此,统计学科的由来。
6. 泛化能力
泛化能力指的是基于从样本中收集的数据结果,对总体特征得出结论的能力。这种能力并不是自然而然存在的,而是高度依赖于样本收集的性质、样本大小以及各种其他因素。
7. 分布
分布是按一个变量的值从低到高排列的数据。这种排列及其特征,如形状和扩展,提供了关于基础样本的信息。
8. 平均数
平均数,与中位数和众数一起,是衡量集中趋势的三个主要度量之一,这三者共同评估分布的一个重要基本方面。作为变量值(或得分)分布的简单算术平均值,平均数提供了分布的单一、简洁的数值总结。平均数也可能是一般研究中最常遇到的统计量。总体平均数用 μ 表示,而样本平均数用 x̄ 表示。
9. 中位数
中位数是分布中位于第 50 百分位的得分,分隔了得分的前后 50%。中位数对将分布得分集合分成两半以及帮助识别分布的偏斜非常有用。
10. 众数
众数就是在分布中出现频率最高的得分。多峰指的是有多个众数的分布;双峰指的是有两个众数的分布。
11. 偏斜
当分布的一端的得分多于另一端时,会导致偏斜。当分布的得分更多集中在高端时,低端相对较少的得分会形成尾部,这种情况称为负偏斜。正偏斜是指分布在高端形成尾部。
通常,在负偏斜的分布中,我们会期望平均数小于中位数,而在正偏斜的分布中,我们会期望平均数大于中位数。
12. 范围
离散度的一个重要度量是范围,它是分布中最大值和最小值之间的差异。
13. 方差
方差是分布中得分离散的统计平均值。方差通常不会单独使用,但它可以作为描述性统计测量的一个有用计算步骤,如标准差。
14. 标准差
分布的标准差是个体分布分数与分布均值之间的平均偏差。标准差单独提供了一个良好的度量,衡量一个分布分数的分散程度。与均值一起考虑时,这两个度量可以很好地概述分数的分布。
15. 四分位距 (IQR)
IQR 是划分第 75 百分位数和第 25 百分位数之间的分数差,即第三四分位数和第一四分位数。
下面是一个简单的 Python 脚本,用于计算上述讨论的大部分描述性统计数据,随后是一个示例。
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats
dist = np.array([ 1, 4, 5, 6, 8, 8, 9, 10, 10, 11, 11, 13, 13, 13, 14, 14, 15, 15, 15, 15 ])
print('Descriptive statistics for distribution:\n', dist)
print('Number of scores:', len(dist))
print('Number of unique scores:', len(np.unique(dist))
print('Sum:', sum(dist))
print('Min:', min(dist))
print('Max:', max(dist))
print('Range:', max(dist)-min(dist))
print('Mean:', np.mean(dist, axis=0))
print('Median:', np.median(dist, axis=0))
print('Mode:', scipy.stats.mode(dist)[0][0])
print('Variance:', np.var(dist, axis=0))
print('Standard deviation:', np.std(dist, axis=0))
print('1st quartile:', np.percentile(dist, 25))
print('3rd quartile:', np.percentile(dist, 75))
print('Distribution skew:', scipy.stats.skew(dist))
plt.hist(dist, bins=len(dist))
plt.yticks(np.arange(0, 6, 1.0))
plt.title('Histogram of distribution scores')
plt.show()
Descriptive statistics for distribution:
[ 1 4 5 6 8 8 9 10 10 11 11 13 13 13 14 14 15 15 15 15]
Number of scores: 20
Number of unique scores: 11
Sum: 210
Min: 1
Max: 15
Range: 14
Mean: 10.5
Median: 11.0
Mode: 15
Variance: 16.15
Standard deviation: 4.01870625948
1st quartile: 8.0
3rd quartile: 14.0
Distribution skew: -0.714152479663
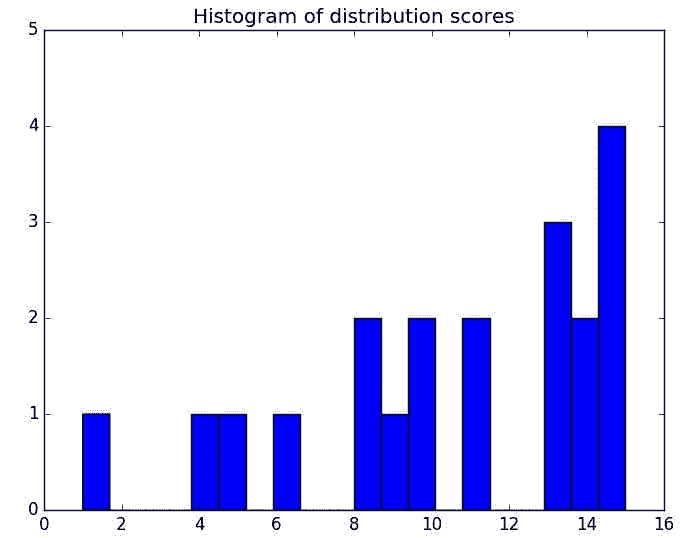
Matthew Mayo (@mattmayo13) 是一位数据科学家和 KDnuggets 的主编,这是一个开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
了解更多此主题
描述性统计:数据科学中的强大小工具——波峰因子
原文:
www.kdnuggets.com/2018/04/descriptive-statistics-mighty-dwarf-data-science-crest-factor.html
评论
作者:Pawel Rzeszucinski,Codewise.com

我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
现如今,社区的相当一部分(通常受商业压力影响)似乎倾向于在应用中使用一些复杂且计算成本较高的算法,而这些应用过去本可以由更简单(因此更快)和更具可解释性(因此更具商业价值)的方法来处理。在这一系列文本中,我将介绍描述性统计的力量和美丽,作为一种定量描述数据性质的方法,并为任何后续的数据研究打下坚实的基础。在这篇文章中,我将介绍另一个强大的小工具,它与我上一篇文章中介绍的技术类似——峰度,但在统计破坏力上略有不同——“波峰因子”。你还将遇到令人恐惧的需求之龙。
引言
在上一篇文章中,我们使用了峰度来检测数据中的冲动内容,这些冲动内容是由假想商店商品需求的季节性变化引起的。我们说过,峰度通常被认为是信号幅度分布的“峰态”度量,并解释了这一点,尽管这对一些同行来说是有争议的。通过一些实际的模拟,我们得出结论,峰度对于检测单一冲动非常有效。今天,我想花一些时间考虑一下如果我们遇到多个冲动时会发生什么,峰度的表现是否仍然令人满意。
案例研究
让我们回顾一下案例研究的内容:一个商店记录了随时间变化的销售商品数量,并试图自动检测任何异常需求的存在。
在去年(之前的帖子),峰度被成功用于检测冲击。图 1 显示了数据和相应的峰度值。该指标为 6.227——明显高于 3,这在高斯噪声中是默认值。检测到了冲击内容,成功了!因此,今年受到鼓励的管理层使用了相同的指标。经过分析,峰度值甚至更高:6.920。 “肯定是今年有更大的峰值。太棒了!”。但进一步调查揭示了一些不同的情况,如图 2 所示。结果显示,除了去年第 200 天的确切相同的冲击之外,今年第 400 天还发生了另一个幅度较小的冲击。两个信号之间的差异在直方图上由两支箭头指示(图 3)。
图 1
图 2
图 3
根据上述结果,对峰度行为的直觉应该是双重的:是的,它会在冲击存在时增加,而且,它会按比例对冲击的幅度作出反应,但它也会在存在额外冲击(即使是较小的幅度)的情况下增加其值。因此,需要注意的是,峰度总结了数据中各种峰值的效应,指标值的增加并不总是意味着峰值更大。
这是商业需求的龙向强大的矮人请求替代方案的时候:“嘿,我不想让我的参数在数据中的最大值不变时上升。如果我只对以归一化的方式跟踪最大峰值的行为感兴趣,那我无论数据的绝对规模如何,都能得到大致相同的结果怎么办?”矮人可能会这样回答:“我不能完全解决你的问题,但我有些东西可能会有帮助。试试“波峰因子”的力量。”

那么什么是波峰因子?从理论上讲,它是数据中峰值的绝对值与同一数据的均方根(RMS)值的比率 [1]:

其中 |xpeak| 是数据中峰值(正值或负值)的绝对值,xRMS 是数据的均方根(RMS),进一步定义为 [2]:
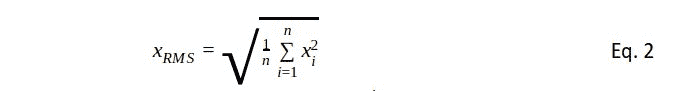
其中 n 是数据中的总样本数,xi 是数据中的第 i 个样本。
好的,但这究竟意味着什么?让我们稍微分解一下。峰值是数据中所有样本绝对值的最大值,而 RMS 是数据总“重量”或数据中包含的能量量的测量。我们可以看到,与峰度不同,峰值因子(CF)的分子不包括对数据中所有点的求和,它只关注最大峰值。同时,分母是数据中所有样本的平方均值。如此轻量的分子(仅一个样本)和重量级的分母(所有样本)可能意味着信号中出现额外冲击的效果(除了已经存在的最大峰值)将被数据中的所有其他样本大大抵消——它可能几乎不被察觉。效果?与峰度相比,对新冲击的存在的敏感性远低。
让我们定义 CF 并进行一些测试来验证我们的假设。
import numpy
def crest_factor(x):
return np.max(np.abs(x))/np.sqrt(np.mean(np.square(x)))
注意:分母中的 RMS 是数据的均方根——可以使用 numpy 库显式编码为 Root(Mean(Square))——非常容易记住。
定义了指标之后,让我们将其应用于我们关注的两个数据集:
crest_factor(sales_spike)
1.6949964209239023
crest_factor(sales_two_spikes)
1.693766572123957
确实,这些变化似乎几乎不可察觉。下表比较了应用于两个数据集的峰度和峰值因子的值。此外,为了便于比较,还包括了百分比变化和基线、无冲击信号(销售来自我的 上一篇文章)。
看起来“小矮人”是对的,CF 似乎更稳定地保持了其优势。
如果你是一个细心的分析师,你一定注意到 CF 的值出现了一个非常轻微但有趣的下降。为什么呢?实际上,分子没有变化——绝对峰值保持不变——但额外的冲击使信号的 RMS 增加了一点。因此,比例下降了。
总结
峰值因子可以被认为是峰度的替代指标,具有更大的关注数据中最大冲击的影响,因此在某种程度上忽略了其他较低振幅峰值的重要性。
参考文献
[1] Clarence W. de Silva, Vibration and Shock Handbook, CRC Press, 2005
[2] Stan Tempelaars, Signal Processing, Speech and Music, Routledge, 2014
Bio: Pawel Rzeszucinski 获得了克兰菲尔德大学的计算机科学硕士学位和弗罗茨瓦夫理工大学的电子学硕士学位。随后,他转到曼彻斯特大学,在 QinetiQ 赞助的项目中获得了博士学位,该项目涉及直升机齿轮箱诊断的数据分析。回到波兰后,他在 ABB 企业研究中心担任高级科学家,并在汇丰银行战略分析部担任高级风险建模师。目前,他是 Codewise 的数据科学家。
相关:
-
描述性统计:数据科学中的强大侏儒
-
描述性统计的关键术语,解释
-
使用 Python 中的标准差移除异常值
更多相关话题
-
[在 Python 中应用描述性和推断性统计](https://www.kdnuggets.com/applying-descriptive-and-inferential-statistics-in-python)
描述性统计:数据科学中的强大小巨人
原文:
www.kdnuggets.com/2018/03/descriptive-statistics-mighty-dwarf-data-science.html
评论
由 Pawel Rzeszucinski、Codewise.com

我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
如今,社区中的相当一部分人(通常受商业压力影响)似乎倾向于将一些复杂且计算开销较大的算法应用于过去可以用更简单(因此更快)和更具可解释性(因此商业价值更高)技术轻松处理的应用。在接下来的系列文章中,我将尝试介绍描述性统计的力量和美妙,作为定量描述数据性质并为后续数据调查奠定坚实基础的方法。在这篇文章中,我将介绍强大小巨人的武器之一——“峰度”。
介绍
考虑一个监控系统需要在数据中检测异常的情况。通常,人们可能会转向经典的离群点分析方法,如基于 DBSCAN 的方法或 LOF。这些方法本身没有问题,它们可能非常好地指示出离群点可能存在的方向。然而,这些技术可能需要大量计算资源才能在高数据量下在合理的时间内完成任务。一个更快的替代方案是将给定案例视为时间序列分析问题。来自‘健康’条件下运行的系统的数据会有典型的、可接受的幅度分布,在这种情况下,任何偏离预期形状的情况都可能被视为潜在威胁,值得检测。
一种非常快速的描述性统计方法,旨在总结信号分布的形状,被称为“峰度”。用数学术语定义如下:
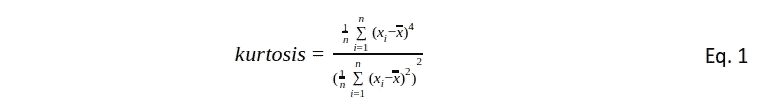
其中 n 是数据中样本的总数,xi 是数据中的第 i 个样本,x 是数据的样本均值。
通常峰度被认为是信号幅度分布的“峰态”度量。这意味着什么?我们都对高斯分布的钟形曲线非常熟悉。如果高斯信号累积了一些幅度显著更大的样本(冲动),其分布将由于尾部的扩展而变得更加尖锐,即相比纯高斯信号更尖峰。我将在接下来的案例研究中展示这一概念。
案例研究
考虑以下案例研究:一家商店记录销售商品的数量作为时间的函数,试图自动检测任何异常需求的存在。
让我们将数据合成一个高斯分布信号,为期一千天,均值集中在 10(销售的商品数量千位)。
import numpy as np
sales = np.random.normal(loc = 10, size = 1000)
数据如 图 1 所示。
图 1
对于任何正态分布的信号,峰度值总是围绕 3 变化。在我们的商店案例中:
from scipy.stats import kurtosis
print(kurtosis(sales, fisher = False))
3.0450704320268427
注意: 一些峰度的实现使用了公式 1 的原始输出,但通常会从峰度值中减去 3,使得高斯信号的峰度值接近 0。这样的实现通常被称为“超额峰度”。后者版本是 SciPy 默认使用的。由于我支持经典的“高斯输出为 3”的方式,因此我将峰度函数的“fisher”参数设置为 False。
除了计算速度快之外,峰度的力量和美在于输出的标准化,这意味着无论信号的绝对幅度如何,即销售的商品数量,峰度值都会保持在高斯信号预期的 3 附近:如果我们将信号的幅度放大 100 倍,峰度仍然在预期范围内:
print(kurtosis(100 * sales, fisher = False))
2.9663203436894965
回到案例研究:假设由于需求的季节性变化,我们期望在销售中看到一些异常值。假设在第 200 天,我们看到销售商品的数量大幅上升,随后在第 201 天出现大幅下降(图 2)。
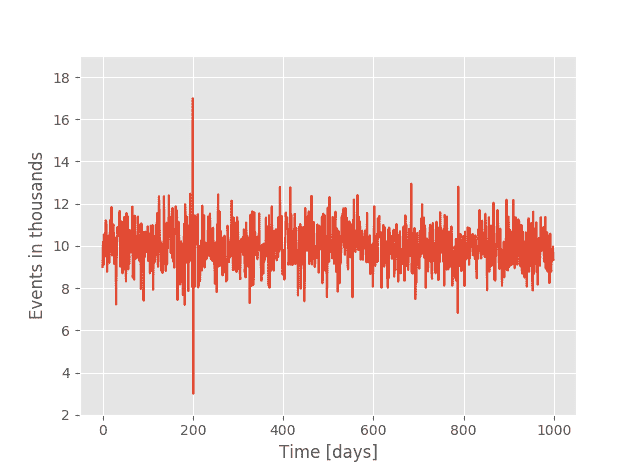
图 2
我们希望能够自动检测这些事件。这就是数据科学的潜力所在,它会说:“我很高兴能迅速检测到这样的异常!我将使用我的魔法‘峰度’工具。”

让我们创建讨论情境的数据:
sales_spike = sales.copy()
sales_spike[200] = sales_spike [200] + 7
sales_spike[201] = sales_spike [201] - 7
Applying kurtosis on “sales_spike” results in:
print(kurtosis(sales_spike, fisher = False)
7.0049964681419326
非常明显的增加。非常明显的变化。峰度值与冲动的幅度直接成正比,这是该指标的另一个非常有用的属性。
任务完成,没有 CPU 损失——检测非常迅速。
回到峰度的非正式定义,作为分布峰度的度量。比较图 3 和图 4 中显示的“销售”和“销售峰值”的直方图。尽管这两个直方图几乎是由相同的信号生成的,除了“销售峰值”有两个脉冲之外,幅度分布看起来非常不同,其中一个明显显得更尖锐(即具有更高峰度值的那个)相比于另一个。
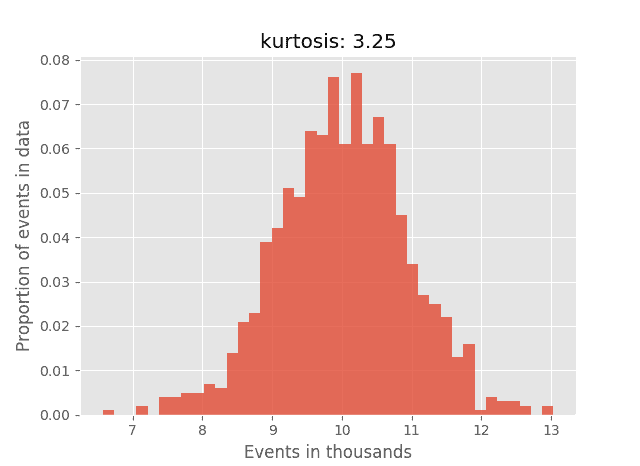
图 3 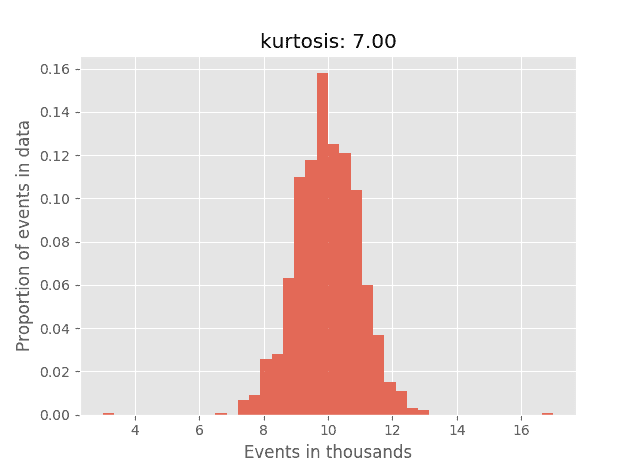
图 4
摘要
峰度在检测数据中的冲动内容方面非常高效,它对数据幅度差异进行了归一化处理,并且计算速度非常快。然而,它确实存在一些缺点,我将在文章中进行讨论。
简历:帕维尔·日舍钦斯基 获得了克兰菲尔德大学计算机科学硕士学位和弗罗茨瓦夫理工大学电子学硕士学位。之后他转到曼彻斯特大学,在 QinetiQ 赞助的项目上获得了与直升机齿轮箱诊断相关的数据分析博士学位。回到波兰后,他在 ABB 企业研究中心担任高级科学家,并在汇丰银行战略分析部门担任高级风险建模师。目前,他在 Codewise 担任数据科学家。
相关:
-
描述性统计学关键术语解释
-
一些营销人员的统计学小贴士
-
使用 Python 移除异常值的标准差方法
更多相关主题
如何设计你的数据科学作品集
原文:
www.kdnuggets.com/2022/01/design-data-science-portfolio.html
拥有一个整理得当的作品集对于突出你的工作和讲述你的故事能力至关重要。精心挑选的项目是展示你专业知识和分享经验的最佳方式。
我个人在整合我的项目和找出最佳分享我激情的方式上遇到了一些挑战。数据科学和工程项目通常比较模糊,可能很难展示,在我的情况下,主要分为代码和内容。我将我的源代码放在 Github 页面上,将我的文章放在 Medium 或其他网络上。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
所以我创建了一个个人的五部分作品集。以下是我对每个部分的思考过程。
介绍
kathleenlara.com: 介绍部分
我设计了这个部分,想象自己在给别人一个电梯演讲,介绍我自己和我的工作。我添加了 GIF 来代表自己,并提供互动感。(我想我本可以添加一个我的 GIF,但目前我的自信水平还达不到那种程度!)
关于背景,最初是白色的。我通常在几乎所有的视觉效果中使用最小化的白色,因为它的安全感与任何东西都相匹配。但是,我不能总是成为习惯的奴隶,所以我决定冒险,彻底使用柔和渐变色。
在那次简短的介绍之后,访客会进行三件事作为下一步。类似于你在现实世界中获得的选项——当你遇到某人时,你要么积极地给他们你的联系方式或名片,这代表着发送邮件按钮(我知道我说得很直接,但无论如何,给我发邮件完全没问题,我喜欢读邮件!),你可以直接进入,查看更多细节,通过查看简历,或者继续进行了解对话,滚动到作品集部分以了解更多。
项目
kathleenlara.com: 项目部分
接着我关于自己和兴趣的简短自我介绍,我设计了这一部分来分享更多我所做的事情。在这一部分,我对我的项目进行了分类。第一个是“精选”类别,这是我挑选并展示我最喜欢的作品。其他类别与编码、我撰写的文章以及我的数据可视化有关。
免责声明:我参与的大多数项目都是保密的,不适合分享,这也解释了为什么我列出的项目有限 目前。我正在尝试寻找时间进行更多个人研究工作。
我添加了紫色标签,以快速了解项目内容。我还在底部添加了“了解更多”链接,如果你注意到,它们都在点击时打开新标签。我非常注重这个外部标签,因为我希望观众在另一个标签中保留作品集,这样他们可以轻松地返回我的页面,在了解特定项目后进一步探索我的作品集。
我曾工作过的公司

kathleenlara.com:我曾工作过的公司部分
我从一句总结性的话开始这一部分,概括了我曾工作过的公司类型。我的目标是突出我以前的角色,并引导观众下载我的简历。我不想用过多的信息淹没他们,因此跳过了职位描述的要点。
更多关于我

kathleenlara.com:关于我
你可能会想——为什么把这部分放在底部,而不是在一开始就更多地突出自己?实际上,在现实生活中,我注意到人们在社交活动中的交流和互动有一种模式。(我应该在这里放一些引人注目的行为统计数据,但由于没有,所以这完全基于我的个人经验 ????*)。首先,你会询问工作情况,他们的职业,然后经过一段时间的交流,逐渐变得更加个人化,这就是为什么我把这一部分放在了底部。
那么,我是如何决定分享哪些个人信息的呢?这实际上是最难写的部分之一,因为我不习惯分享关于我的事,我觉得我在工作之外做的活动并不是那么独特。我包含了最基本的信息,包括我所在的地点和我的爱好。我还添加了一张略显不正式的照片,可能与其他部分相比有些不专业,但它为页面增添了更多个性(我也想展示我的有趣的一面)。
我列出了我的技能和我最常用的工具,以便给出我的日常工作的概念。这也是一个挑战,因为我不想给人留下“万金油”形象,能做从数据工程到全面数据分析的所有事情,但我认为这些是强大的数据科学家应该具备的一些技能和工具,以便在工作中更高效和富有生产力——必须知道如何深入处理数据。我也在不断进步,但我总是努力学习新事物。
联系我
kathleenlara.com:联系我
有两种方式可以联系我,要么复制我的电子邮件地址,要么填写表单。是的,我公开的电子邮件地址仅用于我的公共账户(我有不同的电子邮件地址用于更私密的账户)。
作品集改进
我对网页开发不是很擅长,希望我能有更多时间来真正改进我的作品集——但网页设计不是我的强项,我的主要目标只是展示我的工作。我开始使用Webflow来节省开发时间,并添加了自己的一些 CSS 和 Javascript 代码来增加额外功能。Webflow 还使得网站的设备响应变得更加容易。虽然有一些相关费用,并且需要一点 UI / UX 开发知识,但还有其他选项,比如 Square Space 或 Wix,对于没有编码或开发经验的用户来说可能更友好。
对我来说,整体上我花了一个周末来构建这个网站,内容和草图已经准备好。我还需要优化作品集中的各个元素,以提高加载速度,特别是在移动设备上。我还需要添加更多项目,或者挑选一些更好的项目来展示——但总体来说,我对目前所建的内容感到满意。
在建立作品集时没有对错之分,一个建议是先考虑你想如何讲述你的故事,然后从那里开始创建框架。
用一杯咖啡支持我 ☕
Kathleen Lara (@itskathleenlara) 是一位来自波士顿的数据科学家,拥有数据工程和统计学背景。查看她的网站。
更多相关内容
如何设计数据收集实验
原文:
www.kdnuggets.com/2022/04/design-experiments-data-collection.html

图片由Science in HD提供,来源于Unsplash
关键要点
-
当用于分析的数据不可用时,设计数据收集实验是重要的。
-
关键目标是快速有效地设计一种方法,以收集最佳的数据子集。
数据在数据科学和机器学习中扮演着核心角色。我们通常假设用于分析或模型构建的数据是现成的并且免费的。有时我们可能没有数据,并且获取完整的数据集要么是不可能的,要么需要很长时间才能收集。在这种情况下,我们需要设计一种方法来尝试快速有效地收集我们能获得的最佳数据子集。设计数据收集实验的过程称为实验设计。实验设计的一些例子包括调查和临床试验。
我们现在讨论设计和执行数据收集实验时需要记住的 4 个主要因素。
实验设计因素
时间
我们需要确保实验可以在合理的时间内设计和实施。例如,假设某组织的客户服务部门正经历电话数量的指数级增长和呼叫中心的长时间等待。该组织可以设计调查,供员工和客户参与。必须迅速及时地完成,以便收集的数据可以被分析并用于数据驱动的决策,从而帮助改善客户服务体验。如果实验设计和数据分析未能及时完成,可能会对销售和利润产生负面影响。
数据量
在设计实验时,我们需要确保从实验中收集的数据足以回答我们需要的问题。收集的数据量(样本数据)相对于预期的总数据量(总体数据)必须较小,否则将需要过长时间来收集。样本数据必须具有总体的代表性。例如,旨在研究药物疗效的实验应具有人口统计学代表性(应包括不同年龄组、性别、种族等)。
确定重要特征
在设计数据收集实验时,你需要决定哪些是你的因变量或预测变量。例如,如果实验的目标是收集数据以估计某个特定社区的房价,你可能会决定根据如卧室数量、浴室数量、面积、邮政编码、学区、建造年份、业主协会费用 (HOA) 等预测因素来预测房价。理解重要特征和控制特征非常重要。
成本
设计数据收集实验可能会非常昂贵。执行实验也可能涉及成本。例如,参与调查的人员可能会获得补偿作为激励以鼓励参与。此外,数据科学家和数据分析师也需要为分析从调查中收集的数据而获得报酬。在设计实验之前,估算执行实验的成本以及实验的收益是否超过风险是非常重要的。例如,如果调查结果可以改善客户体验并增加利润,那么这项投资就是值得的。
总结来说,我们讨论了设计数据收集实验时必须考虑的几个因素。关键目标是设计一种快速而高效地收集最佳数据子集的方法。
本杰明·O·泰约 是一位物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的所有者。之前,本杰明曾在中央俄克拉荷马大学、大峡谷大学和匹兹堡州立大学教授工程学和物理学。
了解更多相关话题
MLOps 中的机器学习设计模式
原文:
www.kdnuggets.com/2022/02/design-patterns-machine-learning-mlops.html

由Juliana Malta提供的照片,发布在Unsplash
介绍
设计模式是一组最佳实践和可重用的解决方案,用于解决常见问题。数据科学和其他领域,如软件开发、架构等,都由大量重复出现的问题组成,因此尝试对最常见的问题进行分类,并提供不同形式的蓝图以便于识别和解决,这将为更广泛的社区带来巨大的好处。
使用设计模式的想法最早由 Erich Gamma 等人提出于“设计模式:可重用面向对象软件的元素”[1],并在最近通过 Sara Robinson 等人应用于机器学习过程中的“机器学习设计模式”[2]。
在本文中,我们将探索构成MLOps的不同设计模式。MLOps(机器学习 -> 操作)是一组旨在将实验性的机器学习模型转化为生产化服务的过程,准备在现实世界中做出决策。从本质上讲,MLOps 基于与 DevOps 相同的原则,但额外关注数据验证和持续培训/评估(见图 1)。

图 1:DevOps 和 MLOps(图由作者提供)。
MLOps 的主要好处之一是:
-
改善市场时间(更快的部署)。
-
增强模型的鲁棒性(更容易识别数据漂移、重新训练模型等)。
-
更大的灵活性来训练/比较不同的 ML 模型。
另一方面,DevOps强调软件开发的两个关键概念:持续集成(CI)和持续交付(CD)。持续集成专注于使用中央代码库作为团队协作的手段,并尽可能自动化新代码的添加、测试和验证过程。通过这种方式,可以随时测试应用程序的不同部分是否能正确通信,并尽早识别任何形式的错误。而持续交付则专注于平稳地更新软件部署,尽量避免任何形式的停机。
MLOps 设计模式
工作流程管道
机器学习(ML)项目由许多不同的步骤构成(见图 2)。

图 2:ML 项目关键步骤(图像由作者提供)。
在原型设计新模型时,通常会先使用一个单独的脚本(整体式)来编码整个过程,但随着项目复杂性的增加以及更多团队成员的参与,可能会有必要将项目的每个不同步骤划分到单独的脚本中(微服务)。采取这种方法的一些好处包括:
-
更容易对不同步骤的编排进行变更实验。
-
通过定义使项目可扩展(可以轻松添加和删除新步骤)。
-
每个团队成员可以专注于流程中的不同步骤。
-
可以为每个不同的步骤创建独立的工件。
工作流管道设计模式旨在定义创建 ML 管道的蓝图。ML 管道可以表示为 有向无环图(DAG),其中每个步骤都以一个容器为特征(见图 3)。
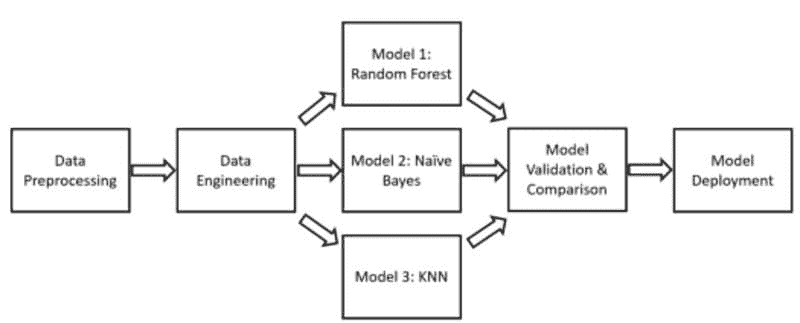
图 3:有向无环图示例(图像由作者提供)。
遵循这种结构,可以创建可重复和可管理的 ML 过程。使用工作流管道的一些好处包括:
-
通过在流程中添加和删除步骤,可以创建复杂的实验来测试不同的预处理技术、机器学习模型和超参数。
-
单独保存每个不同步骤的输出,可以避免在管道开始阶段重新运行步骤,如果有任何更改仅在最后几个步骤中(从而节省时间和计算资源)。
-
如果出现错误,可以很容易识别出可能需要更新的步骤。
-
一旦通过 CI/CD 部署到生产环境,管道可以根据不同因素进行调度重新运行,例如:时间间隔、外部触发器、机器学习指标的变化等。
特征存储
特征存储是为机器学习过程设计的数据管理层(见图 4)。这种设计模式的主要用途是简化组织管理和使用机器学习特征的方式。这是通过创建某种形式的中央存储库来实现的,公司用它来存储为 ML 过程创建的所有特征。这样,如果数据科学家需要在不同的 ML 项目中使用相同的特征子集,他们就不必多次将原始数据转换为处理过的特征(这可能非常耗时)。两个最常见的开源特征存储解决方案是 Feast 和 Hopsworks。
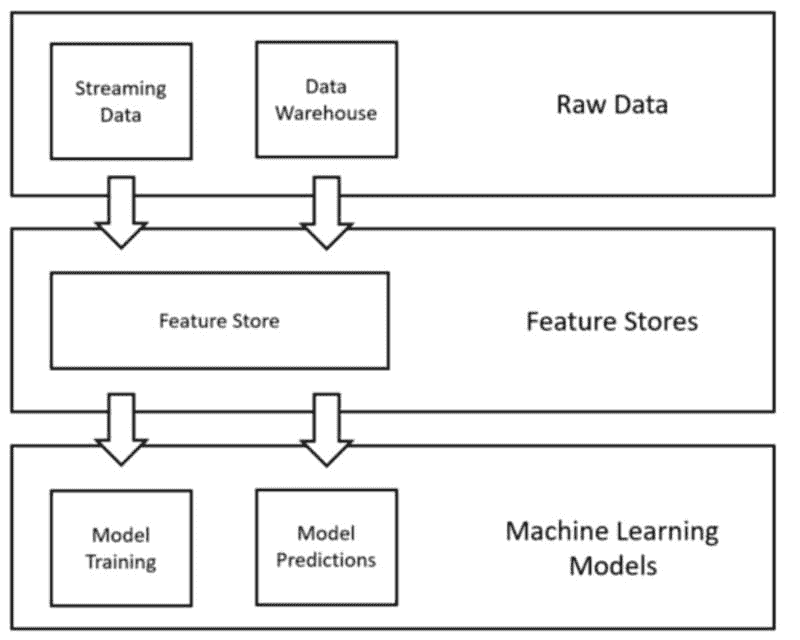
图 4:特征存储设计模式(图像由作者提供)。
关于特征存储的更多信息可以在我的上一篇文章中找到。
转换
转换设计模式旨在通过将输入、特征和转换保持为独立实体(图 5),使在生产中部署和维护机器学习模型变得更加容易。原始数据通常需要经过不同的预处理步骤,然后才能作为机器学习模型的输入,一些这些转换需要保存下来,以便在为推理预处理数据时重用。
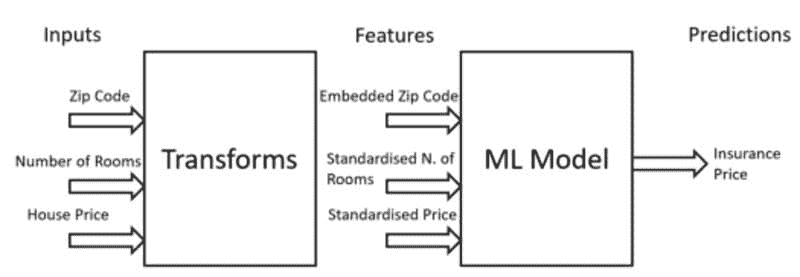
图 5:输入和特征关系(图像由作者提供)。
例如,归一化/标准化技术通常应用于数值数据,以处理异常值并使数据更接近高斯分布。在训练 ML 模型之前,这些转换应保存下来,以便在未来处理新数据进行推理时可以重用。如果这些转换未保存,就会在训练和推理之间产生数据偏差,因为用于推理的输入数据与用于训练 ML 模型的输入数据的分布不同。
为了避免训练和服务之间出现任何类型的偏差,可以使用特征存储设计模式作为替代解决方案。
多模态输入
可以使用不同类型的数据(例如图像、文本、数字等)来训练 ML 模型,尽管某些类型的模型只能接受特定类型的输入数据。例如,Resnet-50 只能接受图像作为输入数据,而其他 ML 模型如 KNN(K 最近邻)则只能接受数值数据作为输入。
为了解决 ML 问题,可能需要使用不同形式的输入数据。在这种情况下,需要应用某种形式的转换,以创建所有不同类型输入数据的共同表示(多模态输入设计模式)。例如,假设我们获得了一组合成的文本、数值和分类数据。为了训练 ML 模型,我们可以使用情感分析、词袋模型或词嵌入等技术将文本数据转换为数值格式,并使用独热编码将分类数据转换为数值格式。这样,我们的所有数据就会以相同的格式(数值型)准备好进行训练。
级联
在某些场景下,仅用一个机器学习模型可能无法解决问题。在这种情况下,可能需要创建一系列相互依赖的机器学习模型以实现最终目标。例如,假设我们要预测推荐给用户的商品类型(图 6)。为了解决这个问题,我们首先要创建一个模型来预测用户是否超过 18 岁,然后根据该模型的响应,将我们的流程路由到两个不同的机器学习推荐引擎中的一个(一个用于推荐给 18 岁以上用户,另一个用于推荐给 18 岁以下用户)。
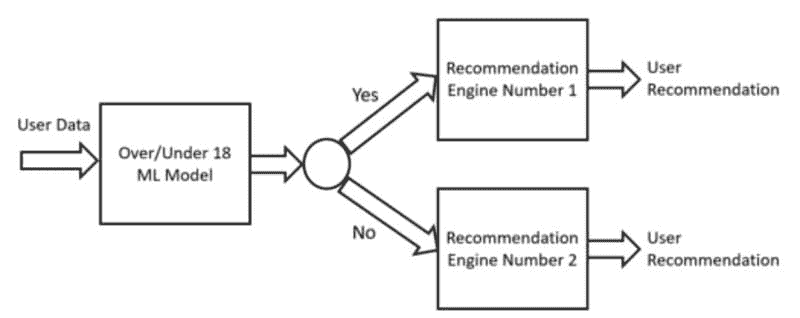
图 6:级联设计模式(图片来源:作者)。
为了创建这个级联的机器学习模型,我们需要确保它们一起训练。实际上,由于它们之间的依赖性,如果第一个模型发生变化(而其他模型没有更新),这可能会导致后续模型的不稳定。这种过程可以使用工作流管道设计模式来自动化。
结论
在本文中,我们探讨了支撑 MLOps 的一些常见设计模式。如果你对机器学习中的设计模式感兴趣,可以查阅 this talk ,由 Valliappa Lakshmanan 在 AIDevFest20 上演讲,以及《机器学习设计模式》一书的公开 GitHub 仓库。
联系方式
如果你想跟进我最新的文章和项目,请在 Medium 上关注我 follow me on Medium ,并订阅我的 邮件列表。以下是我的一些联系信息:
参考文献
[1] “设计模式:可重用面向对象软件的元素”(Addison-Wesley,1995)。访问链接: www.uml.org.cn/c%2B%2B/pdf/DesignPatterns.pdf
[2] “机器学习设计模式”(Sara Robinson 等,2020)。访问链接: www.oreilly.com/library/view/machine-learning-design/9781098115777/
Pier Paolo Ippolito 是一位数据科学家,并拥有南安普顿大学的人工智能硕士学位。他对人工智能的进展和机器学习应用(如金融和医学)充满兴趣。与他在 Linkedin 上联系。
原文。经许可转载。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
更多相关内容
机器学习管道的设计模式
原文:
www.kdnuggets.com/2021/11/design-patterns-machine-learning-pipelines.html
评论
由 Davit Buniatyan,Activeloop 的首席执行官,一家 Y-Combinator 孵化器的初创公司。
机器学习管道的设计模式在过去十年中经历了几次演变。这些变化通常是由于内存和 CPU 性能之间的不平衡所驱动的。它们也不同于传统的数据处理管道(如 MapReduce),因为它们需要支持与深度学习相关的长期运行的、有状态的任务的执行。
随着数据集规模的增长超过内存的可用性,我们看到更多的 ETL 管道采用分布式训练和分布式存储作为首要原则。这些管道不仅可以使用多个加速器以并行方式训练模型,还可以用云对象存储替代传统的分布式文件系统。
与来自 AI 基础设施联盟 的合作伙伴一起,我们在 Activeloop 积极构建工具,帮助研究人员在任意大的数据集上训练任意大的模型,例如 用于 AI 的开源数据集格式。
单机 + 单个 GPU
在 2012 年之前,训练机器学习模型是相对简单的操作。像 ImageNet 和 KITTI 这样的数据集存储在单台机器上,并由单个 GPU 访问。大多数情况下,研究人员可以在不进行预取的情况下获得不错的 GPU 利用率。
在这个时代生活更为轻松:几乎不需要考虑梯度共享、参数服务器、资源调度或多个 GPU 之间的同步。只要任务是 GPU 绑定而不是 IO 绑定,这种简单性意味着第一代深度学习框架如 Caffe 在单台机器上运行通常足以满足大多数机器学习项目的需求。
尽管训练一个模型需要数周时间并不罕见,但研究人员开始探索使用多个 GPU 来并行化训练。
单机 + 多个 GPU
到 2012 年,更大的数据集如 COCO、更大的模型架构以及 经验结果 证明了配置多 GPU 基础设施所需的努力是值得的^([1])。因此,我们看到了像 TensorFlow 和 PyTorch 这样的框架的出现,以及配备多个 GPU 的专用 硬件设备,它们可以处理具有最小代码开销的分布式训练^([2])。
在数据并行的看似简单需求(参数共享后进行全局归约操作)背后存在着与并行计算相关的复杂问题,如容错和同步。因此,社区必须在多 GPU 训练能够可靠地投入实践之前,深入理解来自高性能计算(HPC)领域的全新设计模式和最佳实践(如MPI),正如我们在Horovod框架中看到的那样。
在此期间,一种流行的多 GPU 训练策略是将数据复制并本地放置到 GPU 上。模块如tf.data通过结合预取和高效的数据格式,同时保持数据增广的灵活性,出色地提高了 GPU 的利用率。
然而,随着数据集的增加(如Youtube8M,其数据量超过 300 TB 且数据类型更为复杂),因此需要具有随机访问模式的云规模存储,像 HDF 这样的分布式文件系统格式在处理非结构化、多维数据时逐渐变得不那么有用。^([3])
这些格式不仅没有考虑云对象存储的设计需求,而且也没有针对模型训练独特的数据访问模式(洗牌后跟随顺序遍历)或读取类型(将多维数据作为块或分片访问,而不是读取整个文件)进行优化。
对于存储大规模数据集所需的云存储和最大化 GPU 利用率的需求之间的差距意味着机器学习管道不得不再次重新设计。
对象存储 + 多个 GPU
在 2018 年,我们开始看到更多利用云对象存储进行分布式训练的情况,出现了如s3fs和AIStore这样的库,以及 AWS SageMaker 的管道模式^([4])等服务。我们还看到了一些考虑云存储的 HDF 启发的数据存储格式的出现,如Zarr。也许最有趣的是,我们注意到许多行业机器学习团队(通常处理 100TB+ 的数据)正在开发内部解决方案,以将数据从 S3 流式传输到模型中。
尽管传输速度问题仍然存在(从云对象存储读取的速度可能比从 SSD 读取慢几个数量级),这种设计模式被广泛认为是处理 PB 级数据集的最可行技术。
虽然当前的 EBS 卷分片或将数据直接 传输到模型 以及像 WebDataset 等巧妙的变通方法已经足够,但吞吐量不匹配的根本问题仍然存在:云对象存储每请求可推送 ~30MB/sec,而 GPU 读取可达 140GB/sec,这意味着昂贵的加速器往往被闲置。
因此,任何针对大规模 ML 设计的新数据存储格式都需要解决几个关键问题:
-
数据集大小:数据集通常超出节点本地磁盘存储的容量,需要分布式存储系统和高效的网络访问。
-
文件数量:数据集通常包含数十亿个具有均匀随机访问模式的文件,这常常超出本地和网络文件系统的处理能力。从包含大量小文件的数据集中读取需要很长时间。
-
数据速率:在大型数据集上进行训练的工作通常使用多个 GPU,需要对数据集的总 I/O 带宽达到多 GB/s;这些带宽只能通过大规模并行 I/O 系统满足。
-
洗牌和增强:训练数据在训练前需要进行洗牌和增强。当数据集太大而无法缓存到内存中时,反复读取洗牌顺序的数据集是低效的。
-
可扩展性:用户通常希望在小数据集上进行开发和测试,然后迅速扩展到大数据集。
结论
在当前的千兆数据集环境下,研究人员应该能够在云端训练任意大型模型。正如分布式训练将模型架构与计算资源分离一样,云对象存储有潜力使 ML 训练独立于数据集大小。
^([1]) 安装和配置 NCCL 或 MPI 对胆量要求很高。
^([2]) 一个特别设计良好的 API 是 PyTorch 的 DistributedDataParallel。
^([3]) 虽然有诸如 Parquet 的创新,但这些主要处理结构化表格数据。
^([4]) AWS 的 Pipe Mode 也有助于优化 ENA 和多部分下载等底层细节。
个人简介: Davit Buniatyan (@DBuniatyan) 在 20 岁时开始在普林斯顿大学攻读博士学位。他的研究涉及在 Sebastian Seung 的监督下重建小鼠大脑的连接组。为了克服他在神经科学实验室分析大数据集时遇到的障碍,David 成为 Activeloop 的创始 CEO,该公司是 Y-Combinator 毕业的初创企业。他还获得了 Gordon Wu 奖学金和 AWS 机器学习研究奖。
相关:
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 工作
更多相关内容
机器学习中的设计模式
原文:
www.kdnuggets.com/2021/07/design-patterns-machine-learning.html
评论
由 Ágoston Török,AGT International 数据科学总监
根据其 定义,设计模式是针对常见问题的可重用解决方案。在软件工程中,这一概念可以追溯到 1987年,当时贝克和坎宁安开始将其应用于编程。到了 2000 年代,设计模式——特别是面向对象编程的 SOLID 设计原则——被认为是程序员的常识。快进 15 年,我们来到了 Software 2.0时代:机器学习模型开始在越来越多的代码位置取代传统功能。今天,我们将软件视为传统代码、机器学习模型和基础数据的融合。这种融合要求这些组件的无缝集成,鉴于这些领域通常各自独特的历史和发展,这往往远非简单。
今天,我们将软件视为传统代码、机器学习模型和基础数据的融合。
然而,设计模式尚未扩展到应对这一新时代的挑战。在 Software 2.0 中,常见的挑战不仅仅出现在代码层面,还包括问题定义、数据表示、训练方法、扩展以及 AI 系统设计的伦理方面。这为机器学习的反模式实践创造了肥沃的土壤。不幸的是,如今甚至博客文章和会议有时也会出现反模式:那些被认为能改善情况的做法,实际上却使情况更糟。由于反模式也需要技能,因此其从业者往往无法识别它们。因此,接下来我将给出两个常见的机器学习挑战的例子,但不是从设计模式开始,而是首先介绍它们的解决方案反模式。
该模型在评估指标上的表现不佳。
在常见场景中,工程师在收集、清理和准备数据后,会训练第一个模型并发现其在测试数据上的表现不佳。一种常见的反模式是用更复杂的模型(例如,通常是梯度提升树)替换第一个模型,并通过这种方式提升性能。这种反模式的变体可能在此步骤之后,通过例如模型平均的方式结合多个模型。

唐纳德·克努斯的名言“过早优化是万恶之源”已经快 50 年了,依然是真理。图片由 tddcomics授权使用。
这些方法的问题在于,它们只关注问题的一部分,即模型,并选择通过增加模型复杂性来解决它。这种步骤迫使我们接受过拟合的高风险,并在额外的预测能力和可解释性之间做出权衡。虽然有高效的实践可以缓解这种选择的副作用(例如 LIME),但我们不能完全消除它们。
设计模式是错误分析。这在实践中意味着查看我们的模型在哪里出错,无论是通过评估模型在不同测试集上的拟合情况,还是通过查看模型错误的个别案例。尽管我们都听说过“垃圾进,垃圾出”的说法,但仍然很少有人意识到,即使是数据中的小不一致性也会对结果产生如此大的影响。也许标签来自不同的评分者,每个人对标注指南有自己稍有不同的解释。也许数据收集方式随着时间发生了变化。错误分析对小数据问题尤其有效。然而,我们还应牢记,在大量数据情况下,我们也会遇到长尾事件(例如,从入学考试中识别稀有人才)。
错误分析的真正力量在于,通过应用它,我们既不会在可解释性和过拟合风险之间做出权衡,实际上,单独应用它就能获得关于数据分布的关键知识。此外,错误分析使我们能够选择以模型为中心(例如,更复杂的模型)和以数据为中心(例如,进一步清理步骤)解决方案。
部署模型的性能随时间下降
模型经过广泛的验证并投入生产。用户感到满意并给予积极反馈。然后,一个月/季度/年后,收到报告指出预测中的缺陷。这通常是概念漂移的表现,即模型学习到的输入和输出之间的联系随着时间发生了变化。有些地方概念漂移是众所周知的(如词义、垃圾邮件检测),但‘概念’漂移可以发生在任何领域。例如,口罩和社交距离规定也挑战了许多以前部署的计算机视觉模型。

ML 系统在不进行再训练的情况下,假设输入和输出之间学习到的关系不会发生变化。图片由tddcomics提供许可。
一个常见的反模式是将这些例子归因于噪声,并期待情况随着时间的推移而稳定。这不仅意味着缺乏行动,还意味着错误归因,这在数据驱动的业务中通常应被避免。稍微好一点的反模式是对报告做出快速重新训练和新模型部署的反应。即使团队认为他们遵循敏捷软件开发原则,从而选择快速响应变化,这仍然是一个反模式。问题在于,这个解决方案解决的是症状而不是系统设计中的缺陷。
设计模式是对性能的持续评估,这意味着你预计漂移会发生,因此,设计系统以尽快注意到它。这是一种完全不同的方法,因为重点不在于反应速度,而在于检测速度。这使得整个系统处于一个更加受控的状态,提供了更多的优先级反应空间。持续评估意味着建立流程和工具,以持续生成新数据的一部分的真实标签。在大多数情况下,这涉及手动标记,通常使用众包服务。然而,在某些情况下,我们可以使用其他更复杂但在部署环境中不可行的模型和设备来生成真实标签。例如,在自动驾驶汽车的开发中,可以使用一个传感器(如 LiDAR)的输入来生成另一个传感器(如相机)的真实标签。
机器学习的 SOLID 设计原则
我撰写关于设计模式的原因是,这个领域已经成熟到我们不仅要分享最佳实践,而且应该能够将其抽象为真正的设计模式。幸运的是,这项工作已经由多个团队开始了。实际上,最近有两本书已经出版了 [1], [2]。我喜欢阅读这些书,但我仍然感到尽管我们正在朝着正确的方向前进,但我们仍然离为机器学习从业者制定 SOLID 设计原则还有几步之遥。我相信,虽然基础知识已经存在并用于构建今天的 AI 驱动产品,但对设计模式和反模式的研究是迈向 Software 2.0 时代的重要一步。

设计模式是机器学习工艺的基础。图片由 tddcomics 提供。
简历: Ágoston Török 是 AGT International 的数据科学总监。
原文。已获授权转载。
相关:
-
何时重新训练机器学习模型?运行这 5 个检查来决定时间表
-
2021 年顶级 6 个数据科学在线课程
-
你的机器学习代码消耗了多少内存?
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
相关主题
我设计了自己的机器学习和人工智能学位
原文:
www.kdnuggets.com/2020/05/designed-machine-learning-ai-degree.html
评论
由Angelica Dietzel撰写,数据科学自学之旅。

我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
在发现我大学的编程课程过时后,我决定利用在线资源自学机器学习和人工智能。没有技术经验和之前的学位,我从头到尾设计了以下机器学习和人工智能学位,以实现我的目标:成为一个全面的机器学习和人工智能工程师。
我的目标
-
为世界带来价值—我学习这些技术不是为了学习而学习,也不是因为它们是新兴技术。我将利用所学知识构建一些不可思议的东西。
-
利用机器学习和人工智能解决重大问题—我知道我永远不会成为机器学习或人工智能领域的世界领先专家,但我希望能留下自己的印记。
-
激励他人开始自己的学习旅程—通过撰写我的经历并分享我所学到的一切,我希望激励他人创造自己的学习路径。
我决策的逻辑
我在决定选择什么课程时使用的主要标准是价格、灵活性、基于项目的学习、评论和评分。我使用了来自Class Central和CourseTalk的数千条课程评分和评论,以及各个机构的评分和评论,以帮助我做出决定。我基于这些选择了我能找到的最佳计算机科学、数学、数据科学、人工智能和机器学习课程。
我选择的概述
我选择学习的每一个不同科目的理由来自分析世界各地顶级大学的机器学习和数据科学学位,并通过研究自学者的成功故事来真正理解成功所需的条件。
我从数学开始。我相信数学扮演着重要角色,因为它为机器学习和人工智能奠定了基础(而且我喜欢数学!),所以我包含了一些涵盖线性代数、多变量微积分、概率和统计的课程。
我选择的学位基础语言是 Python,但我也包括了一门很好的 R 语言课程。
我转向提供数据科学、机器学习、人工智能和深度学习基础的课程。我以深入探讨机器学习和人工智能的高级课程结束我的学位。我还包括了额外的课程来填补一些空白。
开始吧!
我已经包含了每门课程的链接,标明了每个课程的机构,提供了价格,并概述了你将学习的内容。如果你知道任何优秀的课程,请随时推荐与机器学习或人工智能相关的证书或项目——我很乐意查看并/或包含它们。
数学基础
数据科学数学技能 由杜克大学(Coursera)[$49]
- 涵盖内容:集合论、区间符号、含不等式的代数;在 x-y 平面上绘制函数及其反函数;瞬时变化率和曲线的切线概念;指数、对数、概率论,包括贝叶斯定理
机器学习数学 由帝国理工学院(Coursera)[$49/月]
- 涵盖内容:线性代数、多变量微积分、主成分分析的降维、特征值和特征向量
杜克大学的推断统计(Coursera)[$49/月]
- 涵盖内容:假设检验、置信区间以及数值和分类数据的统计推断方法。
数学思维导论 由斯坦福大学(Coursera)[$49] 可选
- 涵盖内容:学习像数学家一样思考;数论、实分析、数学逻辑
离散优化 由墨尔本大学(Coursera)[$49] 可选
- 涵盖内容:如何使用离散优化概念和算法、约束编程、分支限界、线性规划(LP)、混合整数规划解决复杂的搜索问题
计算机科学基础
计算机科学导论 由哈佛大学(edX)[免费,证书$99]
- 涵盖内容:抽象、算法、数据结构、封装、资源管理、安全、软件工程和网页开发。提供对 C、Python、SQL 和 JavaScript 以及 CSS 和 HTML 的熟悉
编程入门:基础知识 由多伦多大学(Coursera)[免费,证书$49]
- 涵盖内容:编程的基本构建块;教你如何使用 Python 编写有趣且实用的程序
Python 基础
Python 编程入门(Udacity)[免费]
- 覆盖内容: Python 的基础知识。学习使用 Python 数据类型和变量表示和存储数据,使用条件语句和循环,利用复杂数据结构的强大功能。
人人皆 Python 由密歇根大学(Coursera)[$49/月]
- 覆盖内容: 使用 Python 编程的基础;HTML、XML 和 JSON 数据格式;核心数据结构,SQL 基础,基本的数据库设计用于存储数据。
密歇根大学的 Python 3 编程专业化课程(Coursera)[$49/月]
- 覆盖内容: 变量、条件语句和循环,关键字参数,列表推导式,lambda 表达式和类继承,编写查询互联网 API 的程序以获取数据并提取有用信息。
掌握 R
掌握 R 软件开发 由约翰斯·霍普金斯大学(Coursera)[$39/月]
- 覆盖内容: 专注于在数据科学环境中使用 R,稳健的错误处理,面向对象编程,性能分析和基准测试,调试,函数的正确设计,构建 R 包,构建数据可视化工具。
数据科学基础
数据科学中的 Python 由加州大学圣地亚哥分校(edX)[免费,$350 认证]
- 覆盖内容: Python 和 Jupyter 笔记本、pandas、NumPy、Matplotlib、Git;如何操作和分析未整理的数据集;基本统计分析和机器学习方法;如何有效地可视化结果。
数据分析师纳米学位(Udacity)[$359/月,4 个月]
- 覆盖内容: 如何操作和准备数据以进行分析;为数据探索创建可视化;如何利用数据技能讲述数据故事。
应用数据科学与 Python 由密歇根大学(Coursera)[$49/月]
- 覆盖内容: 通过 Python 介绍数据科学;应用绘图、图表和数据表示,文本挖掘;pandas,Matplotlib。
机器学习基础
机器学习 由斯坦福大学(Coursera)[免费,$79 认证]
- 覆盖内容: 广泛介绍机器学习、数据挖掘、统计模式识别、监督学习和无监督学习、最佳实践、如何将学习算法应用于智能机器人、文本理解、计算机视觉、医学信息学、音频、数据库挖掘及其他领域。
AI 基础
TensorFlow 实践专业化课程 由 deeplearning.ai(Coursera)[$49/月]
- 覆盖范围: 如何构建和训练神经网络,提升网络性能,教会机器理解、分析和响应人类语言的自然语言处理系统;计算机视觉。
高级课程
高级机器学习 由国家研究大学——高等经济学院 [免费,$49/月 证书]
- 覆盖范围: 深度学习介绍、强化学习、自然语言理解、计算机视觉、贝叶斯方法,以及如何从顶级 Kagglers 学习赢得数据科学竞赛。
深度学习 由 deeplearning.ai 和斯坦福大学(Coursera) [$49/月]
- 覆盖范围: 深度学习基础;了解如何构建神经网络并领导成功的机器学习项目;卷积网络、RNN、LSTM、Adam、Dropout、BatchNorm、Xavier/He 初始化。
深度学习 NanoDegree(Udacity) [$324/月,4 个月]
- 覆盖范围: 成为神经网络专家;学习如何使用深度学习框架 PyTorch 实现神经网络;构建用于图像识别的卷积网络,用于序列生成的递归网络,用于图像生成的生成对抗网络;学习如何部署从网站访问的模型。
人工智能微硕士 由哥伦比亚大学(edX) [$894.40]
- 覆盖范围: AI 的指导原则;如何将机器学习概念应用于实际问题和应用,设计和利用神经网络的力量,以及 AI 在机器人技术、视觉和物理模拟领域的广泛应用。
AWS 机器学习入门 由 AWS(Coursera) [免费,$49 证书]
- 覆盖范围: 如何使用内置算法和 Jupyter Notebook 实例通过 Amazon SageMaker 构建、训练和部署模型,如何使用 Amazon AI 服务(如 Amazon Comprehend、Amazon Rekognition、Amazon Translate 等)构建智能应用程序。
额外内容
随着我在这个课程中的进展,将在此部分添加额外资源。欢迎提出建议。
数据结构与算法专项 由 UCSD(Coursera) [$49/月]
- 覆盖范围: 基本算法技术,如贪心算法、二分搜索、排序和动态规划,应用图算法和字符串算法解决实际问题,最大流、线性规划、近似算法、SAT 求解器、流处理。
数据工程、大数据和 GCP 上的机器学习 由 Google Cloud(Coursera) [$49/月]
- 涵盖内容:对在 Google Cloud Platform 上设计和构建数据管道的实际介绍;设计数据处理系统,构建端到端的数据管道,分析数据,并得出见解;结构化、非结构化和流数据。
Hadoop 和 MapReduce 入门 由 Cloudera 提供 (Udacity) [免费]
- 涵盖内容:Apache Hadoop 项目开发开源软件以实现可靠、可扩展的分布式计算;其基本原理及如何利用其强大功能来理解大数据。
使用 Git 的版本控制 (Udacity) [免费]
- 涵盖内容:使用版本控制系统 Git 的基础知识;学习创建新的 Git 仓库、提交更改、查看现有仓库的提交历史记录、如何使用标签和分支组织提交,以及通过解决合并冲突来合并更改。
使用 Python 进行软件调试 (Udacity) [免费]
- 涵盖内容:如何系统地调试程序;如何自动化调试过程并在 Python 中构建几个自动化调试工具。
华盛顿大学的计算神经科学 (Coursera) [$49]
- 涵盖内容:理解神经系统功能和运作的基本计算方法;人工神经网络、强化学习和生物神经元模型,使用 Matlab、Octave 和 Python。
就这样!
感谢 Coursera、edX 和 Udacity 成为教育领域的先锋,推动开放教育的发展。同时感谢 Class Central 和 CourseTalk 提供了寻找顶级在线课程的好方法,并帮助我找到上述课程选择。
如果你对我的学位有任何建议、评论或疑虑,或想讨论你的教育目标,请在下方留言!
原文。经许可转载。
相关内容:
更多相关内容
设计伦理算法
原文:
www.kdnuggets.com/2019/03/designing-ethical-algorithms.html
评论
由 Claire Whittaker,Artificially Intelligent Claire
随着我们寻求扩大机器学习应用,数据伦理变得越来越重要。
但你如何使算法符合伦理?
在算法设计中,你可以调整哪些关键杠杆来使其符合伦理?
设计伦理算法时需要考虑的 5 个领域。
这个算法将用于什么?
花些时间考虑一下你算法的最终用途。你认为这个机器学习工具的应用是否符合伦理?

我们越来越希望机器学习科学家和开发者在他们不同意自己工作的使用方式时站出来发声。
值得注意的是,最近微软的员工对公司与美国军方签订合同制造 AR 头显发表了公开声明。他们表示,他们并没有签约成为战争利润者,并且不同意这一举动。
在进行广泛应用的机器学习项目时,问问自己你是否认为这项工作符合伦理。当机器学习算法应用于现实世界时,你是否对其潜力感到满意?
这是伦理算法设计的第一步。
你的训练数据是否存在偏见?
确保伦理算法设计的另一种方法是查看你的训练数据集。
你的数据集在多大程度上代表了整个世界?这个数据集是否符合伦理,适合用来制作算法或预测特征?
从伦理角度关注你正在使用的数据集,是防止最近出现的一些机器学习应用伦理挑战的最佳方法之一。
当亚马逊宣布暂停开发其招聘机器学习算法时,是因为在训练集中发现了意外的偏见。尽管亚马逊曾尝试从系统中移除性别指标以防止偏见,但算法还是能够检测到这些指标。
我们每个人都拥有的无意识偏见可能会被机器学习放大。
了解数据集如何影响伦理算法设计可以帮助你减少偏见。
你是否考虑了你所应用的不同权重?
在开发时,除了与数据集相关,还需要考虑如何对算法的不同特征进行加权。
在优化权重时,你可能需要考虑输出是否在设计上是伦理的。

你将如何定义一个伦理的特征集?
针对伦理算法设计的最终要点是你用于开发机器学习算法的特征。
你用来理解数据的特征范围是否是最适合给出伦理输出的?
在评估模型识别的高重要性特征时,你是否同意这是一种良好的表示,还是看到任何潜在的红旗?
再次,关注伦理算法设计将确保你在过程中不会被意外后果困扰。
我们最不希望的是生产中出现意外!
制作伦理算法的最佳方法?开发中的多样性
伦理机器学习的最终且可能是最重要的组成部分是多样性。
技术领域内各种类型的多样性不足是一个已知问题。
缺乏代表性样本的 AI 开发在过去造成了一些重大挑战。
这不仅仅是技术领域中的挑战。
有多少因广告失误而引发的丑闻可以通过多样化的决策者来预防?
仅仅一个声音就能发现其他人可能视而不见的潜在伦理问题。
麦肯锡关于如何控制机器学习偏见的报告建议实施标准和控制措施。
在将机器学习算法投入生产之前,拥有一个多样化的评估委员会可以确保伦理开发。
在开发机器学习技术时,我敦促你寻找那个声音,否则你可能会后悔。
在开发技术时保持伦理和包容,否则你可能会后悔。
说到这儿,我结束了这篇文章。我们都有机会开发对社会真正有益的技术。
确保你的算法在设计上是伦理的将使这一好处得以实现。
简介: 克莱尔·惠特克 正在致力于帮助每个人理解大数据概念及如何使用人工智能。这是她的热情所在!她如此热衷,以至于希望将这份热爱传递给你!她通过博客分享学习编程和 AI 创新的经历,帮助好奇的千禧一代,他们热爱技术和人工智能。你可以在她的博客 人工智能克莱尔 上阅读她在人工智能伦理方面的更多经历。
相关:
-
伦理 + 数据科学:DJ Patil,前美国首席数据科学家的观点
-
算法不是偏见,我们才是
-
利用 Mitchell 范式对学习算法的简要解释
我们的前三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 为你的组织提供 IT 支持
更多相关主题
如何检测和克服 MLOps 中的模型漂移
原文:
www.kdnuggets.com/2021/08/detect-overcome-model-drift-mlops.html
评论
由 Bhaskar Ammu,Sigmoid 的高级数据科学家

我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
机器学习(ML)被广泛认为是数字化转型的基石,但 ML 模型却最容易受到数字环境动态变化的影响。ML 模型由其创建时的变量和参数定义和优化。
让我们来看看一个ML 模型的例子,该模型旨在跟踪基于当时可能已广泛传播的垃圾邮件的一般化模板的垃圾邮件。凭借这个基线,ML 模型能够识别并阻止这些邮件,从而防止潜在的网络钓鱼攻击。然而,随着威胁环境的变化和网络犯罪分子的智慧提升,更加复杂和逼真的邮件已经取代了旧邮件。当面对这些新的攻击尝试时,基于先前年份变量的 ML 检测系统将无法妥善分类这些新威胁。这只是模型漂移的一个例子。
模型漂移(或模型衰退)是 ML 模型预测能力的退化。由于数字环境的变化以及概念和数据等变量的随之变化,模型漂移在 ML 模型中很突出,这正是机器语言模型的本质所在。
假设所有未来变量将与 ML 模型创建时的变量保持不变,这是MLOps 中的模型漂移的滋生温床。
例如,如果模型在一个静态环境中使用静态数据运行,那么其性能不应该退化,因为预测的数据来自于训练期间使用的相同分布。然而,如果模型存在于一个不断变化的动态环境中,涉及过多变量,则模型性能也会有所不同。
模型漂移的类型
模型漂移可以根据变量或预测因子的变化广泛地分为两种主要类型:概念漂移和数据漂移。
概念漂移 – 当模型中目标变量的统计属性发生变化时,会出现概念漂移。简单来说,如果模型变量的本质发生变化,那么模型将无法按预期运行。
数据漂移 – 最常见的模型漂移类型,当某些预测因子的统计属性发生变化时会发生。随着变量的变化,模型可能会失败。在一个时间段内有效的模型可能在应用到不同环境时效果不佳,仅仅是因为数据没有适应变化的变量。
在概念漂移与数据漂移的争论中,上游数据变化也在模型漂移中扮演着重要角色。随着所有必要数据通过数据管道流动,未生成的特征和单位(如测量)变化也可能导致缺失值,从而影响机器学习模型的操作。
解决模型漂移
及早检测模型漂移对于维护模型准确性至关重要。这是因为随着时间的推移,模型的准确性会下降,预测值会继续偏离实际值。这个过程越进一步,对模型整体造成的不可替代的损害就越大。因此,及早发现问题是必要的。F1 得分可以快速检测是否有异常,其中模型的精准度和召回能力被评估其准确性。
同样,根据模型的用途,各种其他指标在不同情况下也会显得重要。用于医疗用途的机器学习模型将需要与用于业务操作的机器学习模型不同的一组指标。然而,最终结果是一样的:每当指定的指标低于设定的阈值时,就有很高的可能性发生模型漂移。
然而,在某些情况下,无法测量模型的准确性——特别是在获取预测数据和实际数据困难时,这仍然是扩展机器学习模型的挑战。在这种情况下,基于过去经验重新调整模型可以帮助创建预测时间表,以便在模型漂移可能发生时进行准备。考虑到这一点,可以定期重新开发模型以应对即将发生的模型漂移。
保持原始模型不变也可以作为基准,从而创建新的模型,这些新模型将改进和修正之前基准模型的预测结果。
然而,当数据随时间变化时,根据当前变化对数据进行加权可能很重要。通过确保模型对最近的数据变化赋予更多的权重,而对较旧的数据变化赋予较少的权重,机器学习模型将变得更加稳健,并建立一个整洁的小数据库来管理潜在的未来漂移相关变化。
创建可持续的机器学习模型
没有一种万能的方法可以确保及时检测和解决模型漂移。无论是通过计划的模型重训练还是通过实时的机器学习,创建一个可持续的机器学习模型本身就是一个挑战。
然而,MLOps 的出现简化了更频繁且时间更短的模型重训练过程。它使数据团队能够自动化模型重训练,而触发这一过程的最可靠方法是通过调度。通过自动化重训练,公司可以在特定时间框架内用新的新鲜数据来强化现有的数据管道。好消息是,这不需要任何特定的代码更改或重建管道。然而,如果公司发现了在模型训练过程中未曾出现的新特征或算法,那么在部署重训练模型时将其纳入其中,可以显著提高模型的准确性。
在决定模型需要多频繁重训练时,有几个变量需要考虑。有时,等待问题出现成为唯一的实际选择(特别是如果没有过去的历史可供参考的话)。在其他情况下,模型应根据与变量季节性变化相关的模式进行重训练。然而,在这片变化的海洋中,保持监控的重要性是恒定的。无论是时间表还是业务领域;在定期间隔内进行持续监控始终是检测模型漂移的最佳方式。
尽管管理、检测和解决成千上万个机器学习模型的模型漂移的挑战可能看起来令人望而生畏,但来自服务提供商如 Sigmoid 的机器学习操作化解决方案可以为您提供直面这些问题所需的优势。Sigmoid 的 MLOps 实践 提供了数据科学、数据工程和DataOps 专业知识的正确组合,这些组合是实现机器学习操作化和扩展以交付业务价值所必需的,并构建一个有效的 AI 战略。
想了解更多关于我们如何帮助数据驱动的公司加快 AI 项目的商业价值实现并克服模型漂移的挑战,请点击链接这里。
简介: Bhaskar Ammu 是 Sigmoid 的高级数据科学家。他专注于为客户设计数据科学解决方案,构建数据库架构,以及管理项目和团队。
原文。已获转载许可。
相关:
-
MLOps 是工程学科:初学者概述
-
使用 PyCaret + MLflow 轻松实现 MLOps
-
何时重新训练机器学习模型?运行这 5 个检查以决定时间表
更多相关内容
使用机器学习检测应用内购买欺诈
原文:
www.kdnuggets.com/2015/11/detecting-app-purchase-fraud-machine-learning.html
评论
作者:Ella Gati,Soomla。
 黑客应用程序如 Freedom、iAP Cracker、iAPFree 等允许用户免费进行应用内购买。通过这些黑客手段,玩家可以在没有支付任何费用的情况下获得他们购买的金币、宝石、关卡或生命。如果游戏开发者没有在应用内购买上实施任何验证过程,例如 SOOMLA 的欺诈保护,这些购买将被记录为系统中的真实购买。因此,报告的收入可能与实际收入大相径庭(尤其是在存在大量欺诈的热门游戏中)。
黑客应用程序如 Freedom、iAP Cracker、iAPFree 等允许用户免费进行应用内购买。通过这些黑客手段,玩家可以在没有支付任何费用的情况下获得他们购买的金币、宝石、关卡或生命。如果游戏开发者没有在应用内购买上实施任何验证过程,例如 SOOMLA 的欺诈保护,这些购买将被记录为系统中的真实购买。因此,报告的收入可能与实际收入大相径庭(尤其是在存在大量欺诈的热门游戏中)。
我们希望使报告尽可能准确,并能够向游戏开发者传达他们游戏的真实状态。我们使用机器学习和统计建模技术来解决这个问题。
在 GROW 数据网络中借助几款大型游戏的帮助,我们成功构建了一个模型,能够以非常高的准确率将每次购买分类为真实或欺诈。
应用内购买模型特征
该模型使用了各种购买、用户和物品特征。下表详细列出了我们计算的一部分特征:
| 购买 | 用户 | 物品 |
|---|---|---|
| 购买日期 | 总购买次数 | 总购买次数 |
| 购买时间 | 总收入 | 总收入 |
| 购买来源的国家 | 平均每日收入 | 平均每日购买次数 |
| 购买所用的货币 | 用户玩过的游戏数量 | 平均每日收入 |
| 手机地区设置是否与国家匹配 | 用户购买的游戏数量 | 最大每日购买次数 |
| 购买货币是否与国家的货币匹配 | 用户是否曾被收据验证阻止 | 最大每日收入 |
| … | … | … |
决策树的救援
决策树,顾名思义,是帮助决策的树。树的每个内部节点测试一个特征的值,叶节点则是目标类别。给定一个新的观察值,可以用树来决定将其分配到哪个类别。
在我们的案例中,树可以有两种叶子节点(类别):欺诈或非欺诈,特征是上述详细说明的内容。内部节点的例子可以是“总购买次数 > 100”或“货币与国家匹配 = 真”。为了避免过拟合训练数据,基于树的技术结合了多个树,以获得比每个单独树输出更准确的最终结果。
基于树的分类算法有许多优点,列举几项:
-
参数之间的非线性关系不会影响树的性能。
-
决策树隐式地执行变量筛选或特征选择。
-
决策树需要相对较少的数据准备,并且易于解释和理解。
我们尝试了两种基于树的分类器。随机森林分类器是一个决策树的集合,训练在数据的子集上,它输出的是单个树输出的类别的众数。提升树使用梯度提升技术结合多个决策树,拟合简单树的加权加性扩展。
另一个模型参数是类别权重,它有两种形式:均匀的,即所有类别的权重都是 1,以及按类别的,即使用类别在整体人口中的相对大小作为类别权重。
欺诈分类性能
我们通过四个指标来衡量模型的性能:
-
准确率:所有测试数据中正确分类的比例。
-
假阳性率 (FPR):所有有效购买中被错误分类为欺诈的比例。
-
假阴性率 (FNR):所有欺诈购买中被错误分类为非欺诈的比例。
-
F1 分数:精确度和召回率 的调和平均值,这是一个来自信息检索领域的度量,反映了其他两个指标之间的平衡。
将有效购买和用户分类为欺诈的错误比错过一个欺诈购买要严重得多,因此我们旨在将假阳性率降低到最低,即使这会导致假阴性率略高。
我们的真实数据包括来自 4 个游戏的购买数据。在其中最大的一个游戏中,我们有 145K 购买的标签。对于这两种算法,参数是通过交叉验证进行调整的。
每游戏模型
对于第一次实验,我们为每个游戏构建了不同的模型。下表详细说明了不同游戏和模型参数的性能。
| 游戏 | 分类器 | 类别权重 | FPR | FNR | F1 分数 | 准确率 |
|---|---|---|---|---|---|---|
| 1 | 随机森林 | 均匀 | 0.22 | 0.03 | 0.95 | 0.93 |
| 1 | 随机森林 | 按类别 | 0.10 | 0.08 | 0.95 | 0.92 |
| 1 | 提升树 | 均匀 | 0.09 | 0.03 | 0.97 | 0.96 |
| 1 | 提升树 | 按类别 | 0.05 | 0.05 | 0.96 | 0.95 |
| 2 | 随机森林 | 均匀 | 0.02 | 0.16 | 0.89 | 0.85 |
| 2 | 随机森林 | 按类别 | 0.01 | 0.16 | 0.91 | 0.82 |
| 2 | 提升树 | 均匀 | 0.01 | 0.11 | 0.94 | 0.84 |
| 2 | 增强树 | 按类别 | 0.05 | 0.05 | 0.90 | 0.85 |
这些结果非常令人印象深刻!每个游戏模型的 F1 分数高达 97%。
第二个游戏的真实数据较少(这是一个每月平均购买次数少 100 倍的游戏,我们获得了一个月的购买数据),这解释了其较低的性能。
增强树算法优于随机森林算法,这并不令人惊讶,因为它是一种优化,通常可以在较少的树木中提供更好的准确性。
使用按类别大小调整的权重通常会导致更低的假阳性率(FPR)和更高的假阴性率(FNR),F1 分数略低。如前所述,我们更关心假阳性率,因此在后续实验中我们使用了具有非均匀权重的增强树算法。
跨游戏分类
我们已经看到,当为特定游戏构建模型时,可以获得非常好的结果。但我们只有四个游戏的真实数据。那么其他游戏怎么办?
为了测试这一点,第二个实验在一个包含来自一个游戏的数据的训练集和来自另一个游戏的数据的测试集上进行。

上表展示了跨游戏实验的准确性。所有分数都为 79%或更高!这对其他所有游戏来说都是好消息。正如预期的,当训练集和测试集来自相同的游戏数据(70%-30%的随机拆分)时,获得了最高的分数。最低的分数是在测试第 4 个游戏时获得的,它是最小的游戏(200 次购买)。
另一个有趣的结果是本实验中的 FPR 分数。

同时值得注意的是,训练于游戏 4 的模型生成了较差的假阳性率(FPR)分数。这是由于购买数量少,以及欺诈行为相对较低(54%对比于其他游戏的 77%-85%)。由于游戏 1 具有最大的真实数据,训练于其他(较小的)游戏的模型假阳性率非常高,最多有 30%的有效购买被分类为欺诈。当训练于其他游戏时,我们得到的结果要好得多,错误分类的有效购买率为 1-2%。
这一实验证明了游戏之间的数据传输在大多数情况下效果良好,但如果你的游戏具有非常独特的用户行为,可能会出现问题。
结果
最终,我们在所有的真实数据上训练了一个模型,并用它对我们数据库中的所有购买进行分类。根据分类器的结果,55.7%的购买是欺诈行为,这些购买占总收入的 72.9%。

这些数字在不同游戏之间有所不同。我们可以看到一个普遍趋势:较大的游戏(用户更多的游戏)的欺诈百分比最高,即使我们也看到一些相对较小的游戏有高达 89%的欺诈。这些差异可以通过不同的经济模型或游戏在不同国家的受欢迎程度来解释。
根据我们的模型结果,欺诈在斯拉夫国家最为普遍。俄罗斯、乌克兰和白俄罗斯排名前列,超过 90%的购买都是欺诈行为。

模型预测仅有 2%的用户有一些有效购买和一些欺诈。其余 98%的用户要么是欺诈者(总是进行欺诈),要么不是(所有购买都有效)。在这 98%中,超过一半是欺诈者。
对游戏开发者的影响
知道哪些用户是欺诈者可以帮助游戏开发者调整游戏玩法并采取限制措施以确保最小的收入损失。一些选项包括:
-
完全阻止特定用户的应用内购买。
-
增加游戏难度以阻止用户使用黑客获取的游戏币进行非正常进度。
-
增加广告频率以最大化从永远不会付费的滥用用户那里获得的收入。
-
使游戏无法进行,例如,通过突出警告信息来禁用所有游戏玩法,要求用户立即进行应用内购买存款以解锁游戏。
我们如何改进?
我们掌握的真实数据越多,我们的分类结果就会越好。游戏开发者和工作室可以通过提供反馈或与我们分享销售报告来获得更好的报告并帮助我们改进。
有问题?请联系 ella@soom.la。
相关:
-
数据挖掘医疗数据 – 我们能发现什么?
-
如何使用 Hadoop 和大数据发现被盗数据?
-
欺诈检测解决方案
我们的前三个课程推荐
1. Google 网络安全证书 - 加速你的网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT
更多相关话题
使用 Eurybia 检测数据漂移以确保生产机器学习模型质量
原文:
www.kdnuggets.com/2022/07/detecting-data-drift-ensuring-production-ml-model-quality-eurybia.html
在本文的其余部分,我们将重点介绍使用 Eurybia 这一开源 Python 库进行的逐步数据漂移研究。检测数据漂移是确保生产环境中机器学习模型质量的重要步骤。这种检测大大有利于人工智能的长期可靠性。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
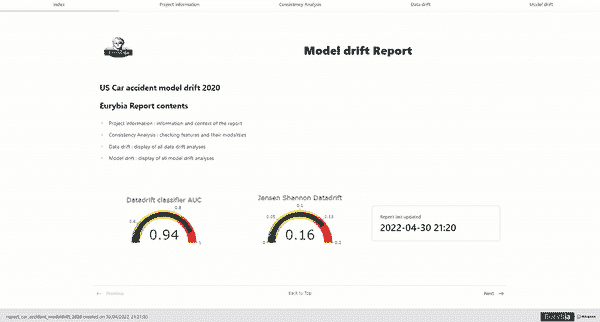
Eurybia 演示,图像来源:作者
什么是数据漂移,为什么要关心?
机器学习模型通常在历史数据库中的数据上进行训练。然后,模型被部署在生产环境中。生产环境中的预测是基于新获得的数据进行的。
因此,用于训练模型的历史数据和用于预测结果的数据可能有所不同。这种数据集之间的差异被称为数据漂移。
生产环境中的机器学习模型有时会随着时间的推移出现性能下降。这种下降可能归因于操作使用或数据漂移(或两者)。
如何检测数据漂移?
为了检测数据漂移,可以使用几种方法,例如通过统计测试比较数据集特征的分布。
Python 库 Eurybia 使用了一种方法,该方法包括训练一个二分类模型(称为“数据漂移分类器”)。该模型试图预测样本是否属于训练/基线数据集或生产/当前数据集。
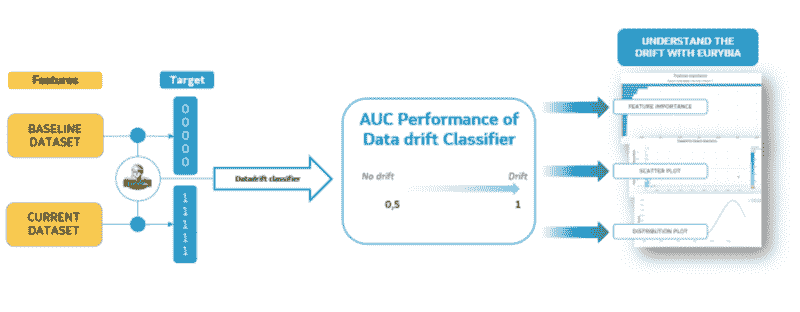
数据漂移分类器的工作原理,图像来源:作者
然后可以研究创建的可解释性“数据漂移分类器”。这是一大优势,因为可解释性提供了关于漂移的详细分析,并为进一步研究和理解数据漂移提供了强有力的理由。除了可解释性,“数据漂移分类器”的性能还提供了数据漂移的度量。
数据漂移:我们在寻找什么?
最显著的特征是什么变化了?
可以提取“datadrift classifier”中包含的每个特征的重要性。这有助于优先研究变化最大的特征。
数据漂移是否影响模型预测?
Eurybia 将数据漂移与部署模型的特征重要性进行对比。特征对部署模型越重要,特征的漂移问题就越严重。
每个特征的变化是什么?
可以观察基线数据集和当前数据集中每个特征的分布。
数据漂移的影响是什么?
Eurybia 根据基线数据集和生产数据集绘制预测概率分布图。我们可以通过 Jensen Shannon Divergence 测量这些分布之间的差异。
我们可以测量数据漂移吗?
Eurybia 提供了数据漂移的性能指标(“datadrift classifier”的 AUC 和预测概率分布的 Jensen Shannon Divergence),显著地允许随着时间跟踪。
使用 Eurybia 演示数据漂移检测
你可以通过 pip 安装该软件包:
$pip install eurybia
让我们使用 Eurybia!
在本文的其余部分,我们将专注于使用 Eurybia 进行逐步的数据漂移研究。
我们将使用来自 Kaggle 的著名“房价”数据集。数据将被拆分为两个不同的数据集。2006 年的数据将用于训练一个回归模型,以预测房屋的销售价格。然后,将使用之前创建的模型预测 2007 年售出的房屋价格。
我们将尝试检测这个回归器的漂移,基于 2006 年与 2007 年数据集的数据漂移。
让我们开始加载数据集:
构建监督模型:
并使用 Eurybia 检测数据漂移…
步骤 1 — 导入
步骤 2 — 初始化 SmartDrift 对象
可选参数:
-
“deployed_model”:在此处指明用于提供预测的模型。该参数允许将数据漂移结果与预测模型结合,从而提供关于数据漂移对部署模型性能的潜在影响的线索。
-
“Encoding”:如果使用了特定的编码器来准备数据集,以便为 “deployed_model” 提供修改过的数据,则应在此处指明。Eurybia 将能够整合这些信息并返回原始数据格式。
步骤 3 — 编译
可选参数:
-
“full_validation”:False/True(默认值:False)。完整验证包括分析列之间的模式一致性。
-
“date_compile_auc”:指定保存结果时要标明的日期。当计算过去数据集的漂移时,这可能会很有用。
-
“datadrift_file”:包含数据漂移性能历史记录的 CSV 文件名。此参数在随时间评估漂移时很有用。
步骤 4 — 生成 Html 报告
可选参数:
-
“title_description”:简短的副标题用于描述报告。
-
“project_info_file”:yaml 文件的路径。该文件可能包含多个要添加到报告中的信息,如一般信息、数据集描述、数据准备或模型训练。
如何理解 Eurybia 的输出
Eurybia 旨在生成用于分析的 HTML 报告。HTML 报告中提供的所有图表也可以在 Jupyter notebooks 中查看。
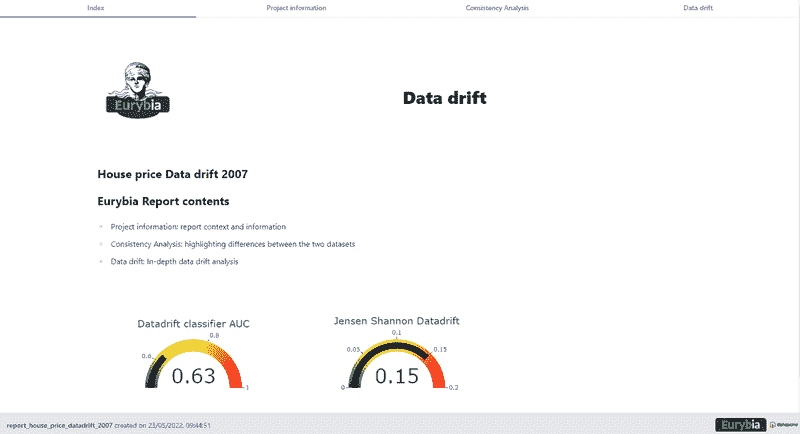
Eurybia 报告索引,图片来源:作者
报告可以通过标签浏览,结构如下:
-
索引:主页
-
项目信息:报告背景和信息
-
一致性分析:突出显示两个数据集之间的差异
-
数据漂移:深入数据漂移分析
Datadrift 分类器模型性能
数据漂移检测方法基于模型分类器识别样本属于一个数据集还是另一个数据集的能力。为此,将目标 (0) 分配给基线数据集,将第二个目标 (1) 分配给当前数据集。训练一个分类模型 (catboost) 来预测这个目标。因此,数据漂移分类器的性能与两个数据集之间的差异相关。显著的差异将导致容易分类 (最终 AUC 接近 1)。类似的数据集将导致数据漂移分类器性能差 (最终 AUC 接近 0.5)。
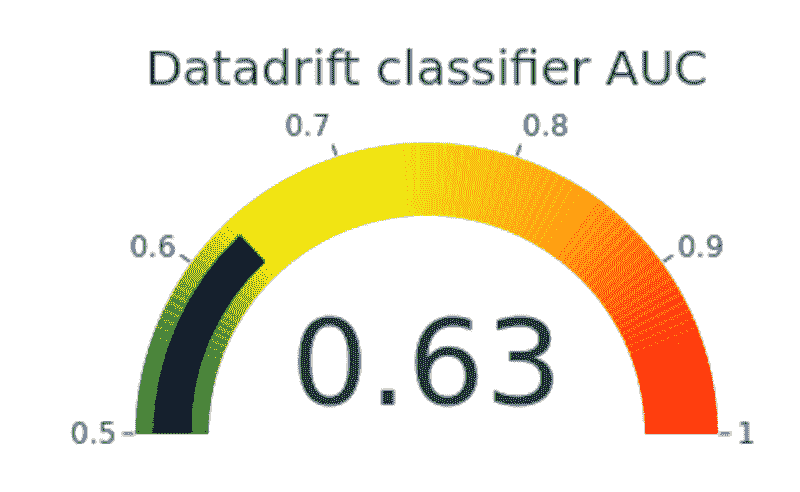
Datadrift 分类器模型性能,图片来源:作者
AUC 越接近 0.5,数据漂移越少。AUC 越接近 1,数据漂移越多
数据漂移中特征的重要性
条形图表示每个包含在“datadrift 分类器”中的变量的特征重要性。
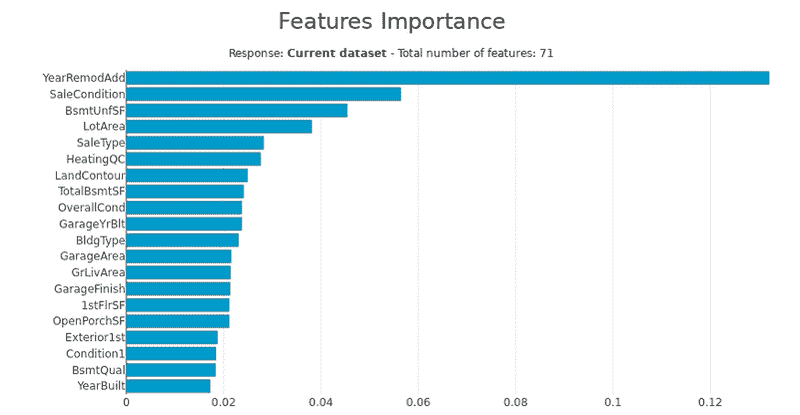
数据漂移中特征的重要性,图片来源:作者
该图表突出显示了漂移最多的变量。这有助于优先考虑对特定变量的进一步深入研究。
特征重要性概述
Eurybia HTML 报告还包含一个散点图,描绘了每个特征的特征重要性,作为“datadrift 分类器”特征重要性的函数。这突出了数据漂移对已部署模型分类的实际重要性。
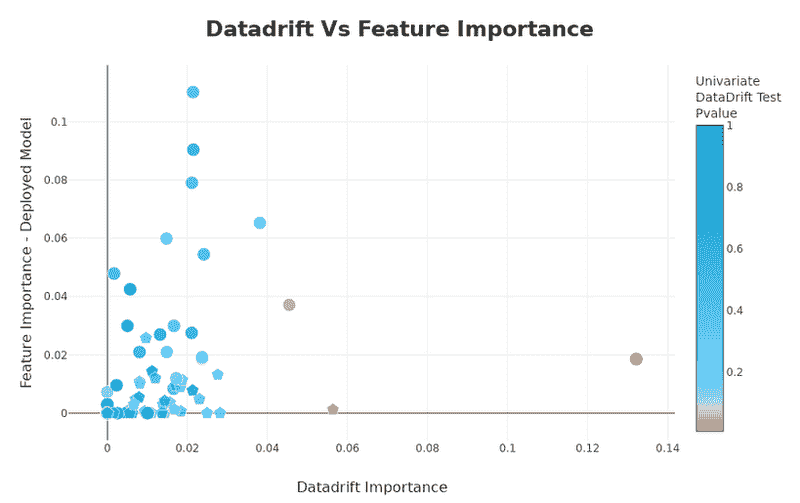
特征重要性概述,图片来源:作者
基于特征位置的图形解释:
-
左上角:对已部署模型重要且数据漂移较低的特征
-
左下角:对已部署模型重要性适中且数据漂移较低的特征
-
右下角:对部署模型重要性适中的特征但具有高数据漂移。这一特征可能需要你的关注。
-
右上角:对部署模型重要且数据漂移高的特征。这一特征需要你的关注。
单变量分析
单变量分析通过两个数据集的分布图形分析得到支持,便于研究对漂移检测最重要的特征。
单变量分析,图片来源:作者
在 Eurybia 报告中,通过下拉菜单,特征按照数据漂移分类中的重要性排序。对于分类特征,可能的值按两个数据集之间的降序差异进行排序。
预测值的分布
预测值的分布有助于可视化部署模型在基线数据集和当前数据集上的输出预测。分布差异可能反映数据漂移。
预测值的分布,图片来源:作者
Jensen Shannon Divergence (JSD)。JSD 衡量数据漂移对部署模型性能的影响。接近 0 的值表示数据分布相似,而接近 1 的值则通常显示数据分布不同,对部署模型性能有负面影响。
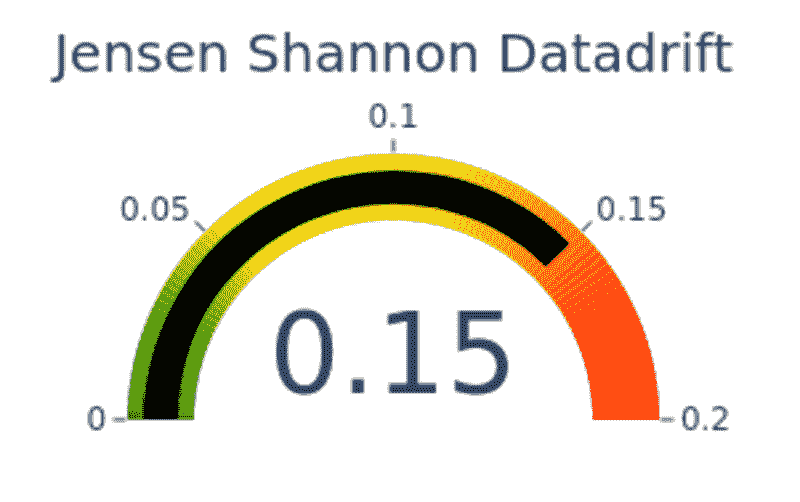
Jensen Shannon Divergence,图片来源:作者
历史数据漂移
Eurybia 可以编译数据漂移情况,涵盖销售数据直到 2010 年。
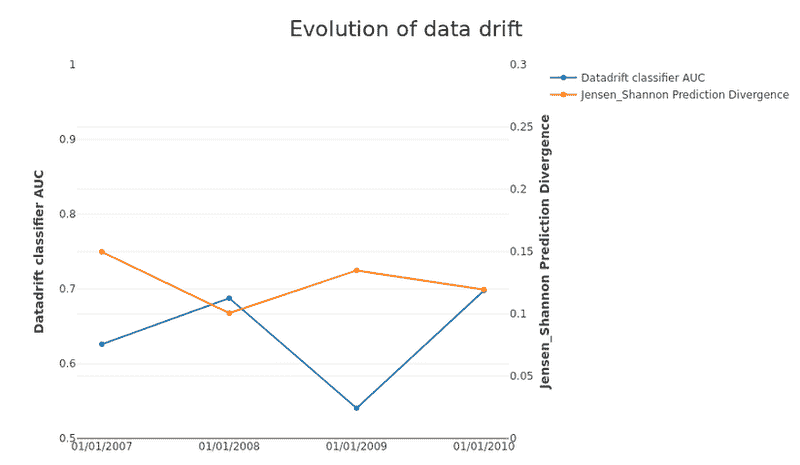
历史数据漂移,图片来源:作者
“Datadrift 分类器 AUC”和“Jensen Shannon Datadrift”提供了两个有用的数据漂移指标。
虽然 AUC 严格关注数据演变,JSD 则评估数据演变对部署模型预测的影响。
换句话说,单一变量的明显漂移,如果该变量对部署模型的重要性较低,应导致高 AUC 但可能低 JSD。
如果你想深入了解…
关于 Eurybia 不同用途的教程可以在 这里找到。
希望 Eurybia 在监控生产中的 ML 模型时能发挥作用。欢迎任何反馈和想法!Eurybia是开源的!请随时通过评论此帖或在GitHub 讨论区来贡献。
托马斯·布歇是 MAIF 的首席数据科学家。
更多相关话题
如何使用 Python 确定最佳拟合数据分布
原文:
www.kdnuggets.com/2021/09/determine-best-fitting-data-distribution-python.html
有时你在分析之前就知道数据的最佳拟合分布或概率密度函数;但更多时候,你并不知道。数据采样、建模和分析的方法可以根据数据的分布而有所不同,因此确定最佳的理论分布可以成为数据探索过程中的一个重要步骤。
这时,distfit 就派上用场了。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 工作
distfit是一个用于通过残差平方和(RSS)和假设检验,对 89 种单变量分布进行概率密度拟合的 Python 包。概率密度拟合是将概率分布拟合到一系列数据上,这些数据涉及对变量现象的重复测量。distfit为 89 种不同的分布中的每一种打分,以评估与经验分布的拟合情况,并返回得分最高的分布。
本质上,我们可以将数据传递给 distfit,它会基于 RSS 指标,确定数据最适合哪种概率分布,这在它尝试将数据拟合到 89 种不同的分布后进行。然后,我们可以查看经验数据与最佳拟合分布的可视化叠加图。我们还可以查看过程的摘要,并绘制最佳拟合结果。
让我们看看如何使用 distfit 来完成这些任务,并了解使用它是多么简单。
首先,我们将生成一些数据;初始化 distfit 模型;并将数据拟合到模型中。这是 distfit 分布拟合过程的核心。
import numpy as np
from distfit import distfit
# Generate 10000 normal distribution samples with mean 0, std dev of 3
X = np.random.normal(0, 3, 10000)
# Initialize distfit
dist = distfit()
# Determine best-fitting probability distribution for data
dist.fit_transform(X)
而 distfit 正在默默工作:
[distfit] >fit..
[distfit] >transform..
[distfit] >[norm ] [0.00 sec] [RSS: 0.0004974] [loc=-0.002 scale=3.003]
[distfit] >[expon ] [0.00 sec] [RSS: 0.1595665] [loc=-12.659 scale=12.657]
[distfit] >[pareto ] [0.99 sec] [RSS: 0.1550162] [loc=-7033448.845 scale=7033436.186]
[distfit] >[dweibull ] [0.28 sec] [RSS: 0.0027705] [loc=-0.001 scale=2.570]
[distfit] >[t ] [0.25 sec] [RSS: 0.0004996] [loc=-0.002 scale=2.994]
[distfit] >[genextreme] [0.64 sec] [RSS: 0.0010127] [loc=-1.105 scale=3.007]
[distfit] >[gamma ] [0.39 sec] [RSS: 0.0005046] [loc=-268.356 scale=0.034]
[distfit] >[lognorm ] [0.84 sec] [RSS: 0.0005159] [loc=-227.504 scale=227.485]
[distfit] >[beta ] [0.33 sec] [RSS: 0.0005016] [loc=-2746819.537 scale=2747059.862]
[distfit] >[uniform ] [0.00 sec] [RSS: 0.1103102] [loc=-12.659 scale=22.811]
[distfit] >[loggamma ] [0.73 sec] [RSS: 0.0005070] [loc=-554.304 scale=83.400]
[distfit] >Compute confidence interval [parametric]
一旦完成,我们可以通过几种不同的方式检查结果。首先,让我们看看生成的摘要。
# Print summary of evaluated distributions
print(dist.summary)
distr score LLE loc scale \
0 norm 0.000497419 NaN -0.00231781 3.00297
1 t 0.000499624 NaN -0.00210365 2.99368
2 beta 0.000501588 NaN -2.74682e+06 2.74706e+06
3 gamma 0.000504569 NaN -268.356 0.0336241
4 loggamma 0.000506987 NaN -554.304 83.3997
5 lognorm 0.00051591 NaN -227.504 227.485
6 genextreme 0.00101271 NaN -1.10495 3.00708
7 dweibull 0.00277053 NaN -0.00114977 2.56974
8 uniform 0.11031 NaN -12.659 22.8107
9 pareto 0.155016 NaN -7.03345e+06 7.03344e+06
10 expon 0.159567 NaN -12.659 12.6567
arg
0 ()
1 (323.7785925192121,)
2 (73202573.87887828, 6404.720016859684)
3 (7981.006169767873,)
4 (770.4368441223046,)
5 (0.013180038142300822,)
6 (0.25551845624380576,)
7 (1.2640245435189867,)
8 ()
9 (524920.1083231748,)
10 ()
基于 RSS(即上述摘要中的“得分”),并且记住最低的 RSS 将提供最佳拟合,我们的数据最适合正态分布。
这可能看起来是一个不言而喻的结论,鉴于我们从正态分布中抽样,但事实并非如此。鉴于众多分布之间的相似性,对重新抽样数据的连续运行使用正态分布,显示出得到 t、gamma、beta、log-normal 或 log-gamma 等最佳拟合分布是一样容易的(也许更容易?),尤其是在相对较小的样本量下。
然后我们可以将最佳拟合分布的结果与我们的实证数据进行绘图。
# Plot results
dist.plot()
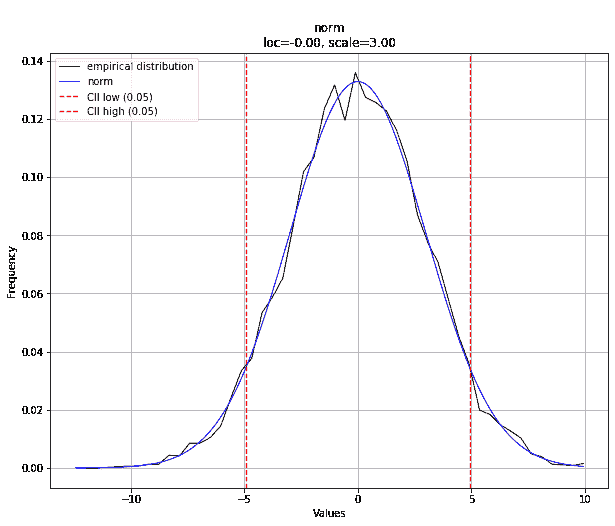
最终,我们可以绘制最佳拟合总结,直观地比较分布拟合的情况。
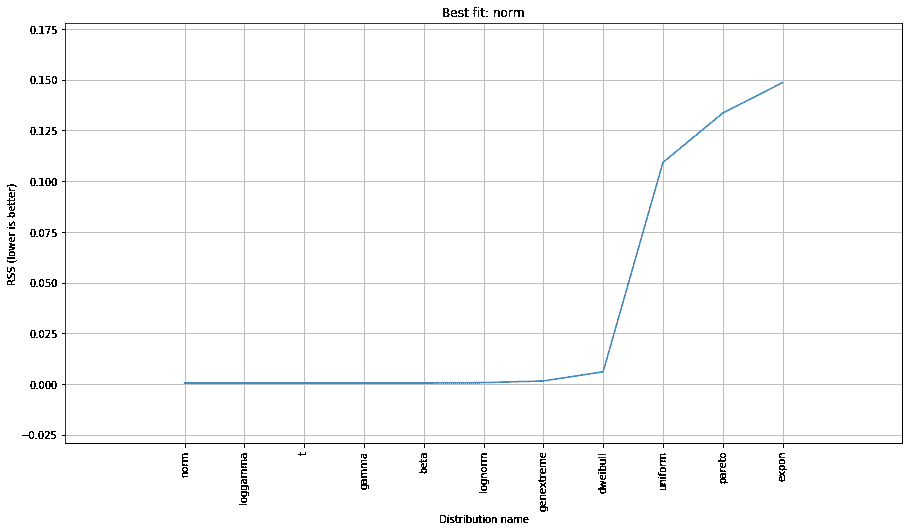
从以上内容可以看出几个最佳拟合分布相对的优劣。
除了分布拟合,distfit 还有其他应用场景:
distfit函数有许多应用场景。首先是确定数据的最佳理论分布。这可以将数万个数据点简化为 3 个浮动参数。另一个应用是异常值检测。可以使用正常状态来确定零分布。显著偏离的新的数据点可以被标记为异常值,可能具有兴趣。零分布也可以通过随机化/置换方法生成。在这种情况下,如果新数据点与随机性显著偏离,将被标记出来。
你可以在distfit 文档中找到这些应用场景的示例。
Matthew Mayo (@mattmayo13) 是数据科学家及 KDnuggets 的主编,KDnuggets 是开创性的在线数据科学和机器学习资源。他的兴趣在于自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
更多相关主题
如果你是一个转行进入数据科学的开发人员,这里是你最好的资源
原文:
www.kdnuggets.com/2019/06/developer-transitioning-data-science-best-resources.html
评论
由 Cecelia Shao 和 Comet.ml 提供
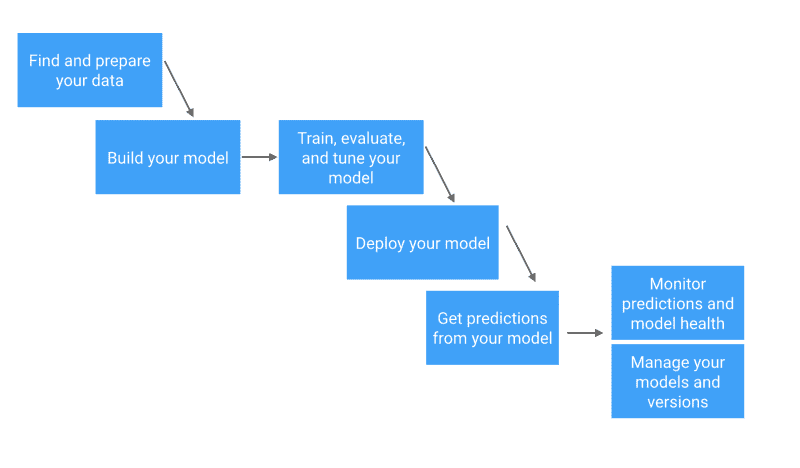 由 Cecelia Shao 提供
由 Cecelia Shao 提供
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
现在似乎每个人都想成为数据科学家——从博士生到数据分析师,再到你的老大学同学,他不断在 Linkedin 上发消息“约个咖啡”。
也许你也有过这样的感觉,你应该至少探索一下数据科学职位,看看这种炒作到底是什么。也许你已经看到像 Vicki Boykis 的 《数据科学现在不同了》 这样的文章,其中提到:
显而易见的是,在炒作周期的后期,数据科学正渐渐接近工程学,而未来数据科学家所需的 技能 越来越少涉及可视化和统计学,而是 更符合传统计算机科学……:
单元测试和持续集成等概念迅速融入了数据科学家和从事机器学习工程的数值科学家常用的术语和工具中。
或 像 Tim Hopper 的 推文:
不清楚的是你如何将作为软件工程师的经验转化为数据科学职位。你可能还有一些其他问题,例如:
我应该优先学习什么?
是否有针对数据科学家的最佳实践或工具?
我的现有技能能否转移到数据科学角色?
本文将提供数据科学家角色的背景信息,以及为什么你的背景可能适合数据科学,并提供具体的逐步行动,供你作为开发人员提高数据科学技能。
想要查看最新的数据科学职位?订阅双周更新的ML Jobs Newsletter,获取邮箱中的新数据科学职位信息。
数据科学家与数据工程师
首先,我们应该区分两个互补的角色:数据科学家与数据工程师。虽然这两个角色都涉及机器学习模型,但他们与这些模型的互动方式以及数据科学家和数据工程师的工作要求和性质有很大不同。
注意:专门从事机器学习的数据工程师角色在职位描述中也可能表现为“软件工程师,机器学习”或“机器学习工程师”。
作为机器学习工作流的一部分,数据科学家将执行统计分析,以确定使用哪种机器学习方法,然后开始原型设计和构建这些模型。
机器学习工程师通常会在建模过程的前后与数据科学家合作:(1)构建数据管道,将数据输入这些模型,(2)设计一个工程系统来服务这些模型,以确保模型的持续健康。
下面的图表展示了一种查看这些技能连续体的方法:
关于数据科学家和数据工程师之间区别的在线资源非常丰富——一定要查看:
作为免责声明,本文主要涵盖数据科学家角色,并略微涉及机器学习工程的方面(特别是如果你正在考虑在小型公司担任两个角色的职位)。如果你有兴趣了解如何转型为数据工程师或机器学习工程师,请在下面的评论中告诉我们!
作为开发者的优势
对所有人不利的是,像“Python 中的数据科学导论”或 Andrew Ng 的 Coursera 课程这样的机器学习课程未涵盖来自软件工程的概念和最佳实践,例如单元测试、编写模块化可重用代码、CI/CD 或版本控制。即使是一些最先进的机器学习团队也仍未在其机器学习代码中使用这些实践,导致了一个令人担忧的趋势……
Pete Warden 将这一趋势描述为‘机器学习可重复性危机’:
我们在跟踪变化和从头重建模型时仍然处于黑暗时代。糟糕到有时感觉像是回到没有源代码控制的编程时代。
虽然你可能在数据科学家职位描述中看不到这些“软件工程”技能被明确列出,但如果你已经掌握这些技能,将会使你作为数据科学家的工作提升十倍。此外,当你在数据科学面试中回答编程问题时,这些技能也会派上用场。
想要从另一方获取有趣的视角,可以查看Trey Causey关于‘数据科学家的软件开发技能’的文章,其中他推荐数据科学家应该学习的技能,以“编写更好的代码、更好地与软件开发人员互动,并最终节省时间和头疼。”
提升数据科学技能
你已经拥有良好的软件工程背景,这很好,但成为数据科学家的下一步是什么?Josh Will 关于数据科学家定义的调侃推文出乎意料地准确:
如果你有兴趣从事数据科学家角色或职业,这暗示了你应该赶上的一个主题:统计学。在接下来的部分,我们将介绍一些优秀的资源:
-
建立特定于机器学习的知识
-
建立行业知识
-
机器学习堆栈中的工具
-
技能和资格
建立特定于机器学习的知识
建立理论知识(如概率和统计)与应用技能(如数据处理或在 GPU/分布式计算上训练模型)的结合是最有效的。
你获得的知识可以通过将其与机器学习工作流程对照来进行框架化。
机器学习工作流程的简化视图
查看来自 Skymind AI 的详细工作流程
在这里,我们列出了一些你可以找到的最佳机器学习资源。虽然不可能列出所有资源,为了节省空间(和阅读时间),我们没有提到非常流行的资源,如 Andrew Ng 的 Coursera 课程或 Kaggle。
课程:
-
Fast.ai MOOC(免费的课程,教授实际应用技能,包括实用深度学习、前沿深度学习、计算线性代数以及机器学习入门)
-
可汗学院
-
3Blue1Brown 和 mathematicalmonk 的 YouTube 频道
-
Udacity 课程(包括 Python 中的机器学习预处理)
教科书: 尝试找到大多数这些书籍的免费 PDF 版本
指南:
-
机器学习掌握指南(要找到一个好的起点,请参见这个关于 Python 机器学习的迷你课程)
-
Pyimagesearch(用于计算机视觉)
聚会: 主要是纽约市的聚会
要找到一个很好的起点,可以查看 Will Wolf 的‘开源机器学习大师’,了解如何安排时间,专注于特定主题,并进行项目工作,以展示在低成本远程地点的专业知识。
建立行业特定知识
如果你有意从事特定行业如医疗保健、金融服务、消费品、零售等,了解该行业的数据和机器学习相关的痛点和发展是非常宝贵的。
一个专业提示 = 你可以扫描垂直行业特定的 AI 初创公司的网站,查看他们如何定位其价值主张以及机器学习的作用。这将给你提供学习机器学习特定领域的思路以及项目主题,以展示你的工作。
我们可以通过一个例子来了解: 假设我对在医疗保健领域工作感兴趣。
1. 通过快速谷歌搜索“机器学习 医疗保健”,我找到 Healthcareweekly.com 上关于‘2019 年值得关注的最佳医疗保健初创公司’的列表。
你也可以在 Crunchbase 或 AngelList 上用“healthcare”作为关键词进行快速搜索
2. 以榜单上的公司之一,BenevolentAI,为例。
3. BenevolentAI 的网站上写道:
我们是一家从早期药物发现到晚期临床开发具有端到端能力的 AI 公司。BenevolentAI 将计算医学和先进 AI 的力量与开放系统和云计算的原则相结合,以改变药物设计、开发、测试和上市的方式。
我们建立了 Benevolent 平台,以更好地理解疾病,并从大量生物医学信息中设计新药物并改进现有治疗方案。我们相信我们的技术能够使科学家更快、更具成本效益地开发药物。
每 30 秒就会发布一篇新的研究论文,而科学家目前仅使用可用知识的一小部分来理解疾病的原因并提出新治疗方案。我们的平台能够处理、‘阅读’并将大量从书面文献、数据库和实验结果中提取的信息进行背景化。它能够在这些不同、复杂的数据源中做出无穷的推断和推理,识别和创建关系、趋势和模式,这些都是人类单独无法完成的。
4. 你可以立即看到 BenevolentAI 使用自然语言处理(NLP),如果他们正在识别疾病与治疗研究之间的关系,他们很可能在使用一些知识图谱
5. 如果你查看 BenevolentAI 的招聘页面,你会发现他们正在招聘 高级机器学习研究员。这是一个高级职位,因此不是一个完美的例子,但请查看他们要求的技能和资质:
注意:
-
自然语言处理、知识图谱推断、主动学习和生物化学建模
-
结构化和非结构化数据源
-
贝叶斯模型方法
-
现代机器学习工具的知识

这应该为你提供一些下一步的方向:
-
处理结构化数据
-
处理非结构化数据
-
在知识图谱中分类关系(查看一个很好的资源 这里)
-
学习贝叶斯概率和建模方法
-
从事一个自然语言处理(NLP)项目(即文本数据)
我们并不建议你申请你通过搜索找到的公司,而是看看他们如何描述客户的痛点、公司的价值主张,以及他们在职位描述中列出的技能,以指导你的研究。
机器学习堆栈中的工具
在 BenevolentAI 高级机器学习研究员的职位描述中,他们要求“具备现代机器学习工具的知识,如 Tensorflow、PyTorch 等……”
学习这些现代机器学习工具可能会让人感到畏惧,因为这个领域总是在变化。为了将学习过程分解为易于管理的部分,请记住围绕上述机器学习工作流程来思考——“这个工作流程的哪个部分可以通过什么工具来帮助我?” ????
要查看哪些工具配合每个机器学习工作流程步骤,请查看 Roger Huang 的‘机器学习堆栈介绍’,其中涵盖了 Docker、Comet.ml 和 dask-ml 等工具。
从战术角度来看,Python 和 R 是数据科学家使用的最常见编程语言,你将会遇到为数据科学应用设计的附加包,如 NumPy 和 SciPy,以及 matplotlib。这些语言是解释型的,而非编译型的,使得数据科学家可以专注于问题本身而不是语言的细节。学习面向对象编程以理解数据结构的实现作为类,值得投入时间。
要跟上 Tensorflow、Keras 和 PyTorch 等机器学习框架,确保访问它们的文档并尝试完整实现其教程。
最终,你要确保你正在构建展示这些现代工具的数据收集和处理、机器学习实验管理和建模的项目。
想要为你的项目寻找灵感,可以查看 Edouard Harris 关于‘冷启动问题:如何构建你的机器学习作品集’的文章。
技能和资格
我们把这一部分放在最后,因为它汇总了之前部分的大部分信息,但特别针对数据科学面试准备。数据科学家面试中主要有六个主题:
-
编程
-
产品
-
SQL
-
A/B 测试
-
机器学习
-
概率(请参见这里的良好定义与统计)
你会注意到这些主题中有一个与其他不同(产品)。对于数据科学职位,关于技术概念和结果的沟通以及商业指标和影响至关重要。
一些有用的数据科学面试问题汇总:
-
github.com/iamtodor/data-science-interview-questions-and-answers -
你会注意到我们包含了 Hooked on Data 的《数据科学面试中的警示信号》——在面试过程中,你可能会遇到那些仍在建设数据基础设施的公司,或者可能不完全了解他们的数据科学团队如何融入更大的公司价值中。
这些公司可能仍在上升这一需求层次。
 来自 Monica Rogati 的流行 AI 需求层次
来自 Monica Rogati 的流行 AI 需求层次
关于数据科学面试的期望设定,我建议阅读 Tim Hopper 的文章《关于被拒绝许多数据科学工作的反思》。
感谢阅读!我们希望本指南能帮助你了解数据科学是否是你应该考虑的职业,以及如何开始这段旅程!
想看到最新的数据科学职位?订阅每两周更新的 ML Jobs Newsletter 以在收件箱中获取新的数据科学职位开盘信息:
注册接收每两周一次的行业最佳公司数据科学职位开盘清单。角色…www.getrevue.co
简介:Cecelia Shao 是 comet.ml 的产品负责人。
原文。已获得许可转载。
相关:
-
如何进入数据科学领域:为有志数据科学家的终极问答指南
-
新数据科学家的建议
-
初学者数据科学家的七个实用建议
更多相关话题
开发者实际需要了解的机器学习知识
原文:
www.kdnuggets.com/2016/04/developers-need-know-about-machine-learning.html
评论
由 Louis Dorard, PAPIs.io
机器学习的教学方式存在问题。
大多数机器学习(ML)教师喜欢解释不同学习算法的工作原理,并在这方面花费大量时间。对于一个希望开始使用 ML 的初学者来说,能够选择算法并设置参数似乎是首要的入门障碍,了解不同技术的工作方式似乎是移除这个障碍的关键要求。然而,许多从业者认为,你只需一种技术即可开始:随机森林。其他技术有时可能表现更好,但通常,随机森林在各种问题上表现最佳的可能性最大(见我们是否需要数百个分类器来解决现实世界中的分类问题?),这使得它们对于刚开始接触 ML 的开发者来说足够了。
我还认为,你不需要了解(随机森林)学习算法的所有内部工作原理(以及它们使用的更简单的决策树学习算法)。对算法的高层次理解、其背后的直觉、主要参数、可能性和限制就足够了。你会知道足够的信息来开始实践和实验 ML,因为有优秀的开源 ML 库(如 Python 中的 scikit-learn)和云平台,使得从数据中创建预测模型变得非常简单。
所以,如果我们只是概述一种技术,我们还可以教什么呢?

Dataiku贴纸(见于 PAPIs)。他们的数据科学工作室使得实验和部署 ML 模型变得简单。
将 ML 模型部署到生产环境中
事实证明,在实际应用中使用 ML 时,大多数工作发生在学习之前和之后。ML 讲师很少提供关于将 ML 应用于生产中预测应用所需的端到端视图。他们只是解释问题的一个部分,然后假设你会自己弄清楚其余的部分,并自行连接点。例如,将你被教会在 Python、R 或 Matlab 中使用的 ML 库与在 Ruby、Swift、C++等中开发的生产应用程序连接起来。
当我差不多 10 年前开始攻读博士学位时,我有一个在 Yahoo 的朋友刚刚完成了他的学业,他向我解释了软件工程师是如何将机器学习研究人员的代码重写成生产环境中使用的语言的。正如 Dataiku 的 Florian Douetteau 在去年 PAPIs Connect 上 展示 的那样,将概念验证模型投入生产的成本可能会彻底扼杀机器学习项目。部署是一个非常重要的问题,他估计像 Spotify 和 Facebook 这样的顶级公司每家都在其机器学习生产平台上投资了超过 500 万美元(包括 10-20 名专门从事该工作的人员、资源、基础设施等)。
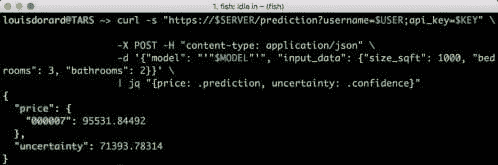
从暴露为 REST API 的模型中获取预测。
幸运的是,今天有新的可获取的解决方案来应对这个“最后一公里问题”。这些解决方案围绕着使用 REST(http)API。模型需要暴露为 API,如果模型执行的预测数量成为问题,这些 API 可以在多个端点上提供,前面有负载均衡器。平台即服务可以提供帮助——这里有一些关于 Microsoft Azure ML 扩展能力、Amazon ML 和 Yhat 的分析负载均衡器(你也可以在自己的私人基础设施/云上运行)的信息。这些平台中的一些允许你使用任何你想要的机器学习库,其他则限制你使用他们自己专有的库。在我即将到来的 研讨会 中,我选择使用 Azure 将使用 scikit-learn 创建的模型部署到 API 中,并且还演示了 Amazon 和 BigML 提供的更高级的抽象层(同时仍提供准确的模型),这可以使它们在许多情况下更易于使用。
机器学习工作流
部署并不是现实世界机器学习中唯一的后学习挑战。你还应该在部署前后找到适当的方式来评估和监控模型的性能/影响。
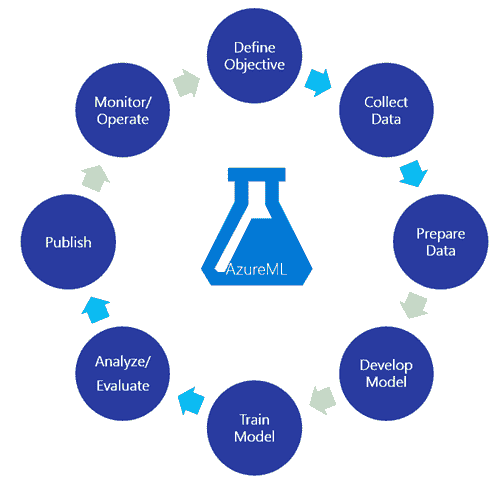
机器学习工作流 由 Azure 提供。
上面的机器学习工作流图也展示了一些在训练模型之前需要采取的步骤,这些步骤涉及为算法运行准备合适的数据集。在实际运行任何算法之前,你需要…
-
为你的组织定义正确的机器学习问题
-
工程特征,即找到表示你将使用机器学习进行预测的对象的方式。
-
确定你需要进行预测的时间和频率,以及你可以为此分配多少时间(是否可以批量进行预测,还是必须要求所有预测都是实时的?)
-
收集数据
-
准备实际的数据集以运行学习算法,即从“原始”收集的数据中提取特征并进行清理
-
确定你需要学习新的/更新的模型的时间和频率,以及你可以为此分配多少时间。
2 天掌握操作性机器学习
开发者的机器学习课程应有什么目的?它不仅仅应该涉及教授一些新的、令人感兴趣和智力挑战的内容,还应着眼于使开发者尽可能熟练地使用他们所学到的新技术。
在 PAPIs,我们希望使开发者能够通过机器学习改善他们的应用程序并从数据中创造新的价值。我们将启动一系列2 天的动手实践工作坊,既有课堂设置也有在线设置。我们计划的第一类工作坊是一个面向开源和云平台操作性 ML 的介绍。第 1 天涵盖机器学习的介绍、预测模型的创建、操作化和评估。第 2 天包括模型选择、集成、数据准备、无监督学习和深度学习等高级主题的实用概述,以及开发自己的机器学习用例的方法论。
我们使用 Python 和一些库,如 Pandas、scikit-learn、SKLL,以及云平台,如 Microsoft Azure ML、Amazon ML、BigML 和 Indico。我认为这些平台对于许多组织和实际使用案例来说非常出色,但即使由于某些原因你发现它们可能不完全适合你,我仍然推荐你使用它们来学习和练习机器学习。ML-as-a-Service 使得设置工作环境变得更快(例如,Azure ML 预装了大多数流行的库,并且可以运行交互式 Jupyter notebooks,你可以通过浏览器访问),同时也使得使用它们提供的更高抽象层进行机器学习实验变得更加容易(例如,使用 BigML 的一键聚类、异常检测和分类模型,或者使用 Indico 的深度学习 API 快速特征化文本和图像)。
了解更多信息关于 PAPIs.io 的开源和云平台操作性机器学习 2 天工作坊,适用于开发者——无论是面对面还是在线——从应用开发者的角度出发,提供机器学习整合到应用程序中的端到端视图。
简介:Louis Dorard 是《Bootstrapping Machine Learning》的作者,也是 PAPIs.io 的共同创始人。
原文。已获得许可转载。
相关信息:
-
Quora 关于“如何学习机器学习”的最佳建议
-
数据科学家的职业建议 – 去赚更多的钱
-
当好建议变坏时
我们的三大课程推荐
![]() 1. Google 网络安全证书 - 快速开启网络安全职业生涯。
1. Google 网络安全证书 - 快速开启网络安全职业生涯。![]() 2. Google 数据分析专业证书 - 提升你的数据分析能力
2. Google 数据分析专业证书 - 提升你的数据分析能力![]() 3. Google IT 支持专业证书 - 支持你的组织的 IT
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
为什么更多开发者在他们的机器学习项目中使用 Python?
原文:
www.kdnuggets.com/2022/01/developers-python-machine-learning-projects.html
图片来源:Artturi Jalli 在 Unsplash
当人类学习新事物时,通常通过经验和教育的结合来识别模式。机器 也能够学习 并以一种与人类决策方式相似的方式应用这些学习。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
通过我们所称的机器学习(ML),机器依赖于历史数据模式和经验,这些模式和经验为算法提供了信息,并允许它们不断从数据中推断出新的模式。为了支持新兴和激动人心的 ML 和人工智能(AI)应用程序的创建,开发者需要一个强大的编程语言。这就是 Python 编程语言的作用所在。
Python 是机器学习和人工智能开发者最常用的编程语言之一,这也是有充分理由的。让我们快速了解一下为什么 Python 是开始进行 AI/ML 开发时的完美选择,以及它在机器学习中的一些不同应用。
机器学习解释
让我们更详细地介绍 ML 的定义,以便更好地理解为什么 Python 是编程 ML 应用程序的有效语言。基本上,ML 指的是数学模型 - 我们称之为算法 - 这些模型允许 ML 应用程序预测诸如类别或其他连续值等内容。它们调节其数据输入以进行这些预测,并使用从数据输入中得出的不同参数来实现这些预测。
ML 模型依赖上述过程来持续和迭代地学习。它们接收输入并尽可能准确地预测所需的连续值。它们通过一个损失函数进一步优化预测能力,该函数告知模型其与期望数据输出的偏差。这个过程会重复多次,以逐步提高准确性。
机器学习是推动人工智能的核心。虽然这两个术语常常被互换使用,但它们并不相同。不同类型的机器学习算法更适合不同的功能,但深度学习和强化学习是主要实现我们对 AI 共同理解功能的子领域。
现在我们了解了 ML 学习过程的基础知识,是时候深入探讨为什么 Python 是 ML 的绝佳选择。
为什么 Python 对 ML 应用如此出色
Python 已成为编程 ML 应用的首选语言,这主要归功于其可读性。Python 学习简单,适合所有经验水平的开发者,且由于可以在所有流行操作系统上运行,因此具有高度的可移植性。然而,使其在ML 开发者中受欢迎的最大因素是其庞大的生态系统。大多数 ML 算法都可以使用 Python 作为框架来实现。
这对于处理大量数据并需要 ML 应用从这些数据集中迭代学习的企业和组织来说尤其是个好消息。大多数开发者每小时至少收费 75 美元来处理开发项目,如果他们技术相当熟练,这意味着 Python 基础的项目在经验丰富的开发团队处理下至少相对便宜。而且,如果开发团队遇到问题,Python 的活跃社区可以在 StackOverflow、Reddit 和 Yahoo 等问答平台上提供支持。
机器学习应用,无论是基于 Python 还是其他技术,对需要更好地分析客户趋势以进行竞争研究和预测规划的 B2B 组织都特别有价值。开发团队可以访问的数据集越大,ML 应用使用行为分析预测客户趋势的准确性就越高。基于 ML 的客户行为分析需要不断增长的数据集,这意味着开发团队必须创建强大的计算处理模型以跟上。
让我们来看看一些机器学习的核心概念以及它们如何与应用数据分析相关联。
ML 核心概念实践
有一些基本概念为探索 Python 中 ML 的开发者提供了有用的背景。其中最基础的概念之一就是监督学习和无监督学习算法。
监督算法处理由开发者手动标记的数据,并且对每个数据点使用目标变量。与处理未标记数据并自行辨别输入中潜在规律的无监督算法相比,监督算法相对昂贵。
监督学习和无监督学习应用对 ML 改进客户分析的方式有所贡献。这两种算法都可以提取数据来预测行为模式,并精确检测客户在购物时何时需要帮助。这确保了更多的客户能够顺利完成销售过程而不遇到问题。它甚至可以帮助组织在潜在客户主动联系之前识别和联系他们,从而提升销售成功率和整体客户体验。
另一个概念是分类与回归,这适用于预测类别和连续值的 ML 应用。分类算法使用处理二元问题(例如真假)或多类区分的分类器来预测类别(例如分类动物类型)。与此相对,回归模型预测的是如房价等连续值。
这样的 ML 应用通常在网络安全环境中使用,比如识别欺诈行为或可疑的网络活动。黑客非常执着,一旦他们入侵或访问了一个网站,他们可能会利用该网站来感染其他人或供应商。机器学习支持基于 AI 的安全监控系统,帮助安全专家检测和响应安全漏洞,减少攻击在网络中扩散的风险。
结论
机器学习是一个涵盖广泛模型和应用的总称,它利用了许多重要概念,开发者可以通过 Python 探索这些概念。虽然这篇文章涵盖了一些最常见的 ML 概念,但开发者仍然需要通过选择自己或其组织感兴趣的问题来获得更广泛的实践理解。在此基础上,开发者既可以开展自己的 ML 项目,也可以在工作中应用对 ML 模型的更深入理解。
简介: Nahla Davies 是一名软件开发者和技术作家。在全职从事技术写作之前,她曾在一家《Inc. 5000》排名的体验品牌组织中担任首席程序员,该公司客户包括三星、时代华纳、Netflix 和索尼。
更多相关主题
开发端到端数据科学管道,包括数据摄取、处理和可视化
 图片来源
图片来源 数据科学项目不仅仅是开发完成后就不再关注。它们涉及整个过程,从获取数据集到维护数据集。这个迭代过程确保模型始终能提供价值。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
数据科学项目的关键不在于模型本身,而在于开始。如果数据质量受损且预处理不正确,后续模型将无法产生有价值的输出。维护一个能够处理端到端数据科学流程的管道变得重要。
在开发端到端数据科学管道过程中,我们将学习并重点关注数据摄取、处理和可视化。
标准端到端数据科学项目
在讨论端到端数据科学项目时,我们会讨论技术和业务方面。数据科学项目存在的目的是解决业务问题,因此每一步都需要记住与业务相关的内容。
一般来说,端到端数据科学项目或多或少遵循这些步骤:
-
业务理解
-
数据收集和准备
-
构建机器学习模型
-
模型优化
-
模型部署
-
模型监控
每一步都是必要的,需要按照顺序执行。即使缺少其中一步,我们的数据科学项目也不会提供最佳价值。
鉴于上述步骤,本文将重点介绍数据收集和准备步骤。它将基于数据摄取、处理和可视化。我们将创建一个简单的数据科学端到端项目管道,但重点强调数据收集和准备步骤。
让我们从探索步骤开始,从那里开始构建管道。
数据导入
数据导入将之前收集的数据集放入环境中,以便进行后续处理。如何导入数据会根据数据源的不同而有所不同。
让我展示代码示例。最简单的方法是从 CSV 或 Excel 文件中导入数据,我们可以使用以下代码完成。
import pandas as pd
data = pd.read_csv('data.csv')
然后,我们可以通过创建到数据库的连接,从数据仓库中导入数据。
import sqlalchemy
engine = sqlalchemy.create_engine('sqlite:///example.db')
data = pd.read_sql('SELECT * FROM table_name', engine)
另一种流行的方法是从数据源调用 API 请求。
import requests
response = requests.get('https://api.example.com/data')
data = response.json()
根据你的需求,数据导入过程还有很多其他使用方式。例如,你可以使用网页抓取。
from bs4 import BeautifulSoup
response = requests.get('https://example.com')
soup = BeautifulSoup(response.content, 'html.parser')
这就是数据导入的基础。让我们来探索数据处理。
数据处理
在获取数据后,我们必须进一步处理,以适应业务需求和任务。我们必须关注这一步,因为项目的质量通常取决于数据处理。
数据探索和处理通常是紧密相关的,因此决定如何处理数据是在数据探索之后的步骤。以下是一些数据处理的例子。
我们会看到的第一个数据处理是数据清理。我们清理数据以提高数据集的质量。下面的例子是删除缺失数据和重复数据的处理。
# Data Cleaning
data.dropna(inplace=True)
data.drop_duplicates(inplace=True)
数据转换也是数据处理的一部分,其中数据被转换为数据科学项目所需的其他形式。
# Data Transformation
data['date'] = pd.to_datetime(data['date'])
data['category_encoded'] = pd.get_dummies(data['category'])
我们还可以将数据转换为我们需要的规模。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data[['feature1', 'feature2']] = scaler.fit_transform(data[['feature1', 'feature2']])
此外,在处理数据时,我们经常会从现有特征中创建新特征。这个过程被称为特征工程。
# Feature Engineering
data['new_feature'] = data['feature1'] * data['feature2']
最后,我们可以进行数据拆分,将数据分为训练数据和测试数据,使用以下代码。
# Data Splitting
from sklearn.model_selection import train_test_split
train, test = train_test_split(data, test_size=0.2, random_state=42)
数据处理的方式还有很多,因为这取决于你的项目。现在,让我们深入数据可视化。
数据可视化
数据可视化可能与机器学习开发无关,但在数据科学项目中至关重要。通过使用数据可视化,我们可以更好地理解数据洞察,并轻松地传达我们得到的任何结果。
这里有一些使用 Python 生成数据可视化的代码示例。
首先,我们有相关性热图,以帮助理解特征之间的关系。
import seaborn as sns
import matplotlib.pyplot as plt
corr_matrix = data.corr()
sns.heatmap(corr_matrix, annot=True)
plt.title('Correlation Heatmap')
plt.show()
接下来,我们有配对图,它可视化了每个特征之间的二维图,并展示了目标特征的分布。
sns.pairplot(data, hue='target', diag_kind='kde')
plt.title('Pair Plot')
plt.show()
然后,我们可以从模型中可视化特征的重要性。
importance = model.coef_[0]
features = np.array(numeric_features.tolist() + list(preprocessor.named_transformers_['cat']['onehot'].get_feature_names_out(categorical_features)))
plt.figure(figsize=(10, 8))
sns.barplot(x=importance, y=features)
plt.xlabel('Importance')
plt.title('Feature Importance')
plt.show()
最后,我们可以在模型评估步骤中可视化混淆矩阵。
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm = confusion_matrix(y_test, model.predict(X_test))
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=model.classes_)
disp.plot(cmap=plt.cm.Blues)
plt.title('Confusion Matrix')
plt.show()
开发数据科学管道
让我们将以上学到的内容结合成一个数据科学管道,涵盖数据导入、处理和可视化。
我们将使用 Titanic 数据来开发一个分类模型作为本例。
首先,让我们使用 Pandas 导入数据。
import pandas as pd
url = 'https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv'
df_titanic = pd.read_csv(url)
在这之后,我们将进行数据处理。让我们使用下面的代码来清理数据集并进行数据转换。
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
df_titanic = df_titanic[['Survived', 'Pclass', 'Sex','Parch', 'Fare','Age', 'Embarked']]
df_titanic = df_titanic.dropna(subset=['Survived'])
X = df_titanic.drop('Survived', axis=1)
y = df_titanic['Survived']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
numeric_features = ['Age', 'Parch', 'Fare']
categorical_features = ['Pclass', 'Sex', 'Embarked']
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
X_train = preprocessor.fit_transform(X_train)
X_test = preprocessor.transform(X_test)
数据处理后,我们将开发机器学习模型。
from sklearn.linear_model import LogisticRegression
import joblib
model = LogisticRegression(random_state=42)
model.fit(X_train, y_train)
joblib.dump(model, 'titanic_logistic_regression_model.joblib')
joblib.dump(preprocessor, 'titanic_preprocessor.joblib')
accuracy = model.score(X_test, y_test)
print(accuracy)
最后,我们可以通过以下代码来可视化模型特征的重要性,并向观众展示。
import matplotlib.pyplot as plt
import numpy as np
importance = model.coef_[0]
features = np.array(numeric_features + list(preprocessor.named_transformers_['cat']['onehot'].get_feature_names_out(categorical_features)))
plt.figure(figsize=(10, 8))
plt.barh(features, importance)
plt.xlabel('Importance')
plt.title('Feature Importance')
plt.show()
以上就是开发一个简单的端到端数据科学管道的全部内容,包括数据摄取、处理和可视化。根据你的数据科学项目,你可以在中间添加更多步骤。
结论
标准化端到端数据科学管道对于我们持续为业务提供价值至关重要。通过了解每一步的细节,特别是数据摄取、处理和可视化,我们可以提高项目质量,为解决业务问题提供最佳结果。
Cornellius Yudha Wijaya** 是一位数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 期间,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 在各种 AI 和机器学习主题上撰写文章。
更多相关主题
开发开放标准的分析跟踪
原文:
www.kdnuggets.com/2022/07/developing-open-standard-analytics-tracking.html
在 2021 年初,我们的长期数据爱好者团队开始开发开放分析分类法。目标是提出一种通用的方式来构建分析数据,以便在一个数据集上建立的模型可以在另一个数据集上部署和运行。
简要历史
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
我们曾经的工作是为企业客户构建模型和运行深入的用户行为分析,这些数据集主要是通过流行的分析工具如谷歌分析、Mixpanel 和 Adobe 分析收集的。
在为 50 多个客户服务的过程中,有一件事特别突出:大多数客户的分析目标非常相似,但他们的数据集看起来却各不相同。
他们都希望防止用户流失、提高参与度或转化率、个性化用户体验和预测行为,但每个内部团队都制定了自己的事件类型、命名约定和数据结构方式。因此,无法复用。所有的管道和模型都需要从头开始构建,花费了大量时间将数据整理成干净的、适合模型的状态。
在这一阶段,我们对开发开放的分析分类法产生了兴趣。如果目标如此相似,是否存在一种通用的方法来构建分析数据,以覆盖所有这些常见的分析用例?对于更具体的需求,这意味着什么?如果可能的话,它会是什么样的?
快进到今天。经过无数小时在白板上草拟想法、收集来自数据科学家和工程师的反馈以及在实际用例中进行实验,我们已经达到了一个自信的阶段,准备开始涉及更广泛的受众。
允许我展示一下我们认为它可能的样子,并解释一些设计选择。
开放分析分类法的结构
开放分析分类法是对常见事件类型及其可能发生的上下文的通用分类。它是层次化的,每种事件和上下文类型都有其自己的属性、要求和关系。
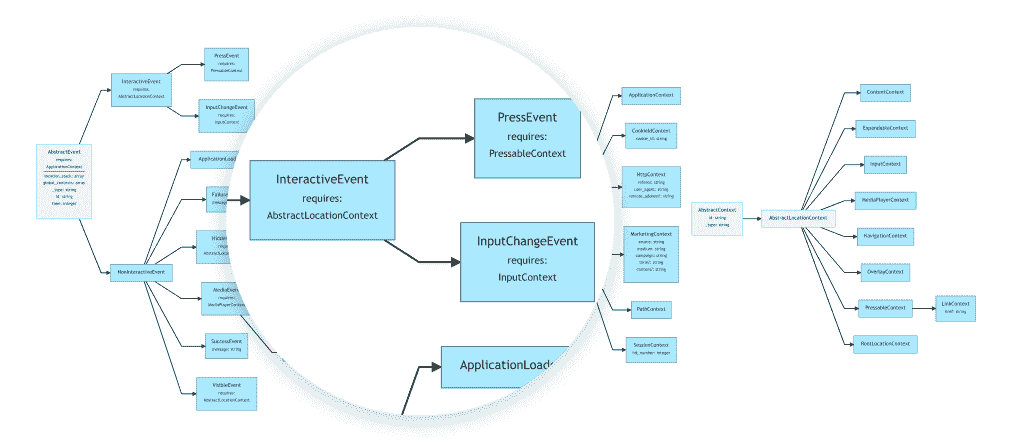
事件
让我们更详细地查看其中一个事件类,PressEvent:
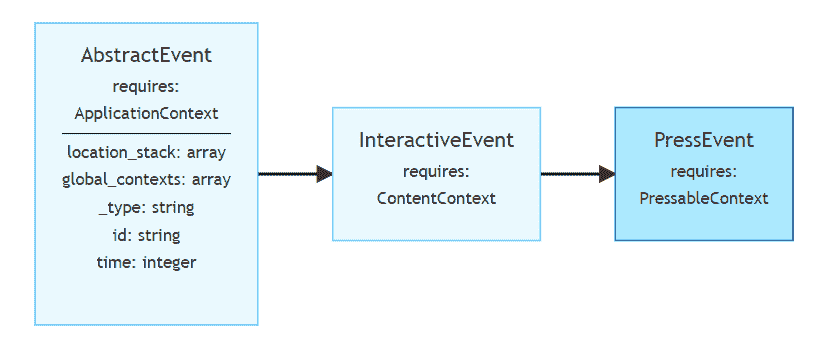
PressEvent用于描述用户点击或触摸(与设备无关)UI 中的元素。这是InteractiveEvent类的一个子类,InteractiveEvent是所有交互事件的父类。
事件被分为两个子类:交互事件和非交互事件。第一种类型由用户触发,第二种类型通常由应用程序触发。NonInteractiveEvent的一个例子是MediaStartEvent,它在音频或视频开始播放时触发:
上下文
你可能已经注意到,事件需要上下文。这些上下文提供了额外的信息,帮助你准确定位事件发生的地点和情况。
与事件类似,上下文被分为两个子类:全局上下文和位置上下文。
全局上下文包含一般信息。例子包括用户会话信息、应用信息或与事件相关的营销活动细节。

其次,位置上下文包含有关事件在 UI 中发生位置的信息。例如,前面提到的MediaStartEvent需要一个MediaPlayerContext来准确指出事件的来源。在这种情况下,特指媒体播放器,因为它的事件类。

用例与设计选择
让我们看看如何使用它以及我们为何做出某些设计选择。
数据验证
严格定义事件和上下文类型的类意味着你可以在非常早的阶段验证数据。例如,如果MediaPlayEvent缺少MediaPlayerContext,你可以抛出错误并选择不存储它(或者更好的是:将其存储在其他地方)。这将允许你防止收集不完整或有缺陷的数据,从而节省大量分析阶段的准备时间。
仪器验证
当前端开发者正在设置追踪器以收集数据时,同样的原则适用。你可以根据开放分类法验证追踪仪器,以确保其配置能够按预期捕捉事件,并在条件未满足时抛出错误。
例如,我们自己的追踪 SDK 通过在浏览器控制台运行时抛出错误来实现这一点,并指向文档以展示如何修复:
我们还利用它通过 TypeScript 定义在 IDE 中提供内联文档和验证问题的 linting:

特征选择
在分析阶段,数据中的层次结构和严格类型化对特征选择非常有用。子类和超类使你能够快速选择所需类型和级别的事件,而无需先手动映射它们。
想要所有交互式事件?你可以在笔记本中用一个命令来实现:
interactive_events = df[df.stack_event_types.json.array_contains('InteractiveEvent')]
仅获取 PressEvents 更加简单:
press_events = df[(df.event_type=='PressEvent')]
这在与位置上下文结合使用时尤其强大。让我演示一下我们如何利用它们来基于 UI 的层次结构实现快速特征选择。
我们要求仪器工程师通过标记 UI 的逻辑部分来丰富跟踪仪器,标记为位置上下文。我们的跟踪器随后为每个事件生成一个位置栈。它在位置上下文的层次结构中捕获事件触发的确切位置。
{
"_type": "RootLocationContext",
"id": "modeling"
},
{
"_type": "NavigationContext",
"id": "docs-sidebar"
},
{
"_type": "ExpandableContext",
"id": "open-model-hub"
},
{
"_type": "ExpandableContext",
"id": "models"
},
{
"_type": "ExpandableContext",
"id": "helper-functions"
},
{
"_type": "LinkContext",
"id": "is_new_user",
"href": "/docs/modeling/open-model-hub/models/helper-functions/is_new_user/"
}
事件位置栈的一个示例,捕获自我们文档的建模部分
上述事件是在用户点击侧边栏中的 is_new_user 标签时捕获的
随着你的数据集现在包含了你产品的逻辑结构,你可以用它在非常细粒度的层面上切分事件。
例如,你可以轻松选择所有带有 NavigationContext 的事件:

或者更具体地说,那些发生在文档侧边栏上的事件:

…等等。
重点:重用模型和工具
对我们来说,这就是一切的起点。拥有一种严格的、通用的结构化分析数据的方法,将意味着所有数据集都变得一致和通用,从而使得基于一个数据集构建的模型可以部署和运行在另一个数据集上。
你为 Android 应用开发的用户细分模型?你可以与负责 iOS 应用或 Web 应用的团队分享,他们可以在不做任何更改的情况下进行部署和运行。

我们的一个示例笔记本的摘录。它们可以在任何接受开放分析分类法的数据集上运行。
但我们认为这远不止于此。每天,其他公司中的某个人都在以略微不同的方式解决完全相同的问题。我们希望这能够结束,并通过协作的努力推动数据领域的发展:使你能够利用他人已经构建的东西,改进它,部署它,如果可能的话,将其交还给其他人以便他们也可以做到这一点。
目前还处于初期阶段,我们还有很长的路要走,但基础已经建立,我们看到采用速度迅速提升。
如果你想了解更多或参与其中,请查看 开放分析分类文档 和 Objectiv 的 Github 仓库。如果你有问题或想法,也可以 加入 Objectiv 的 Slack 频道。
伊瓦尔·普鲁因 是 Objectiv 的联合创始人兼首席产品官,该公司提供开源产品分析基础设施。他拥有特温特大学的电信学硕士学位。他的大部分职业生涯都在科技初创公司和成长型企业中度过,他特别关注推动数据云的未来。
更多相关内容
在本地开发和测试 AWS 的 ETL 管道
原文:
www.kdnuggets.com/2021/08/development-testing-etl-pipelines-aws-locally.html
评论
由Subhash Sreenivasachar,Epsilon 的软件工程技术负责人
介绍
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
AWS 在帮助工程师和数据科学家专注于构建解决方案和解决问题方面发挥了关键作用,而不必担心设置基础设施的需求。通过无服务器和按需付费的定价方式,AWS 提供了即刻创建服务的便利。
AWS Glue 被数据工程师广泛用于构建无服务器 ETL 管道。PySpark 是开发中常用的技术栈之一。然而,尽管服务可用,但仍有一些挑战需要解决。
在 AWS 环境中调试代码,无论是 ETL 脚本(PySpark)还是其他服务,都具有挑战性。
-
持续监控 AWS 服务的使用情况是控制成本因素的关键。
-
AWS 确实提供了带有所有 Spark 库的开发端点,但考虑到价格,对于大型开发团队来说并不切实可行。
-
对某些用户而言,AWS 服务的可访问性可能是有限的。
解决方案
AWS 的解决方案可以在本地环境中开发和测试,无需担心可访问性或成本因素。通过本文,我们解决了两个问题 -
-
在不使用 AWS 开发端点的情况下,本地调试 PySpark 代码。
-
本地与 AWS 服务的交互
这两个问题可以通过使用 Docker 镜像来解决。
- 首先,我们取消了在 AWS 环境中使用服务器的需求,而是使用运行在机器上的 Docker 镜像作为执行代码的环境。
AWS 提供了一个沙盒镜像,可用于 PySpark 脚本。可以设置 Docker 镜像来执行 PySpark 代码。 aws.amazon.com/blogs/big-data/developing-aws-glue-etl-jobs-locally-using-a-container/
- 有了可以执行代码的 Docker 机器,需要像 S3 这样的服务来存储(读/写)文件,以便在构建 ETL 管道时使用。
与 S3 的交互可以用 LocalStack 替代,它提供了一个易于使用的测试/模拟框架,用于开发云应用程序。它在你的本地机器上启动一个测试环境,提供与真实 AWS 云环境相同的功能和 API。
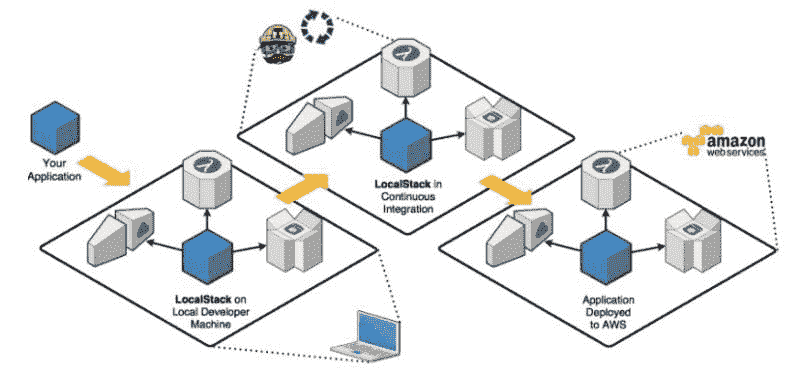
到目前为止,本文涉及构建 ETL 管道和使用可用服务。然而,类似的方法可以适用于与 AWS 服务(如 SNS、SQS、CloudFormation、Lambda 函数等)一起工作时的任何用例。
方法
-
使用 docker 容器作为远程解释器
-
在容器上运行 PySpark 会话
-
使用 LocalStack 在本地启动 S3 服务
-
使用 PySpark 代码从运行在 LocalStack 上的 S3 存储桶中读取和写入数据
前提条件
必须在你的机器上安装以下工具
-
Docker
-
PyCharm Professional/ VisualStudio Code
设置
-
下载或拉取 docker 镜像(docker pull
)
-
libs:glue_libs_1.0.0_image_01
-
localstack/localstack
-
-
Docker 容器可以作为 PyCharm 专业版中的远程解释器使用。
实施
在本地机器上安装 Docker 并拉取镜像后,开始设置 PyCharm 配置以启动容器。
- 创建一个 docker-compose.yml 文件
version: '2'
services:
glue-service:
image: amazon/aws-glue-libs:glue_libs_1.0.0_image_01
container_name: "glue_ontainer_demo"
build:
context: .
dockerfile: Dockerfile
ports:
- "8000:8000"
volumes:
- .:/opt
links:
- localstack-s3
environment:
S3_ENDPOINT: http://localstack:4566
localstack-s3:
image: localstack/localstack
container_name: "localstack_container_demo"
volumes:
- ./stubs/s3:/tmp/localstack
environment:
- SERVICES=s3
- DEFAULT_REGION=us-east-1
- HOSTNAME=localstack
- DATA_DIR=/tmp/localstack/data
- HOSTNAME_EXTERNAL=localstack
ports:
- "4566:4566"
- 创建一个 DockerFile
FROM python:3.6.10
WORKDIR /opt
# By copying over requirements first, we make sure that Docker will cache
# our installed requirements rather than reinstall them on every build
COPY requirements.txt /opt/requirements.txt
RUN pip install -r requirements.txt
# Now copy in our code, and run it
COPY . /opt
- 使用包含要安装的包的 requirements 文件
moto[all]==2.0.5
-
设置 Python 远程解释器
-
使用 docker-compose 文件设置 Python 解释器。
-
在 PyCharm Docker Compose 设置中选择
glue-service。 -
Docker-compose 文件创建并运行两个镜像的容器
-
LocalStack 默认运行在 4566 端口,S3 服务在该端口启用
代码
- 需要导入的库
import boto3
import os
from pyspark.sql import SparkSession
- 将文件添加到运行在 LocalStack 上的 S3 存储桶
def add_to_bucket(bucket_name: str, file_name: str):
try:
# host.docker.internal
s3 = boto3.client('s3',
endpoint_url="http://host.docker.internal:4566",
use_ssl=False,
aws_access_key_id='mock',
aws_secret_access_key='mock',
region_name='us-east-1')
s3.create_bucket(Bucket=bucket_name)
file_key = f'{os.getcwd()}/{file_name}'
with open(file_key, 'rb') as f:
s3.put_object(Body=f, Bucket=bucket_name, Key=file_name)
print(file_name)
return s3
except Exception as e:
print(e)
return None
http://host.docker.internal:4566 是在 docker 容器内本地运行的 S3
- 设置 PySpark 会话以从 S3 读取数据
def create_testing_pyspark_session():
print('creating pyspark session')
sparksession = (SparkSession.builder
.master('local[2]')
.appName('pyspark-demo')
.enableHiveSupport()
.getOrCreate())
hadoop_conf = sparksession.sparkContext._jsc.hadoopConfiguration()
hadoop_conf.set("fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
hadoop_conf.set("fs.s3a.path.style.access", "true")
hadoop_conf.set("fs.s3a.connection.ssl.enabled", "false")
hadoop_conf.set("com.amazonaws.services.s3a.enableV4", "true")
hadoop_conf.set("fs.s3a.aws.credentials.provider", "org.apache.hadoop.fs.s3a.TemporaryAWSCredentialsProvider")
hadoop_conf.set("fs.s3a.access.key", "mock")
hadoop_conf.set("fs.s3a.secret.key", "mock")
hadoop_conf.set("fs.s3a.session.token", "mock")
hadoop_conf.set("fs.s3a.endpoint", "http://host.docker.internal:4566")
return sparksession
-
PySpark 会话通过提供的模拟凭证连接到 S3
-
你可以直接使用创建的 PySpark 会话从 S3 读取数据
test_bucket = 'dummypysparkbucket'
# Write to S3 bucket
add_to_bucket(bucket_name=test_bucket, file_name='dummy.csv')
spark_session = create_testing_pyspark_session()
file_path = f's3a://{test_bucket}/dummy.csv'
# Read from s3 bucket
data_df = spark_session.read.option('delimiter', ',').option('header', 'true').option('inferSchema',
'False').format('csv').load(
file_path)
print(data_df.show())
- 最后,可以以任何首选格式写入 S3
# Write to S3 as parquet
write_path = f's3a://{test_bucket}/testparquet/'
data_df.write.parquet(write_path, mode='overwrite')
一旦完成上述步骤,我们可以创建一个带有模拟数据的虚拟 CSV 文件用于测试,你应该可以
-
将文件添加到 S3(运行在 LocalStack 上)
-
从 S3 读取数据
-
以 parquet 格式写回 S3
你应该能够运行 .py 文件来执行,PySpark 会话将被创建,可以使用 LocalStack API 从本地运行的 S3 存储桶中读取数据。
此外,你还可以检查 LocalStack 是否运行,通过 localhost:4566/health
LocalStack 还提供了使用 AWS CLI 运行命令的功能。
结论
使用 Docker 和 Localstack 提供了一种快速简便的方式来运行 Pyspark 代码、在容器中调试并写入本地运行的 S3。所有这些无需连接到任何 AWS 服务。
参考资料:
-
Glue 端点:
docs.aws.amazon.com/glue/latest/dg/dev-endpoint.html -
Docker:
docs.docker.com/get-docker/ -
PyCharm:
www.jetbrains.com/pycharm/ -
PyCharm 远程解释器:
www.jetbrains.com/help/pycharm/using-docker-compose-as-a-remote-interpreter.html -
LocalStack:
localstack.cloud
简介: Subhash Sreenivasachar 是 Epsilon 数字体验团队的首席软件工程师,负责构建工程解决方案来解决数据科学问题,特别是个性化,并帮助推动客户的投资回报率。
相关链接:
-
MLOps 是一门工程学科:初学者概述
-
云中的 ETL:通过数据仓库自动化转变大数据分析
-
什么是 ETL?
相关主题
AI、分析、机器学习、数据科学、深度学习研究 2021 年的主要发展和 2022 年的关键趋势
原文:
www.kdnuggets.com/2021/12/developments-predictions-ai-machine-learning-data-science-research.html
comments
又一年将要结束,再次,KDnuggets 联系了专家,以了解他们对今年发生的事情以及未来可能发生的事情的看法。
今年,我们向一些 AI、分析、机器学习、数据科学、深度学习研究领域的领导者提出了以下问题:
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
2021 年 AI、数据科学、机器学习研究的主要发展是什么?你对 2022 年有哪些关键趋势的看法?
虽然本文从研究的角度探讨了这个问题,但在接下来的几天里,我们还将分享从技术和行业的角度讨论同一问题的文章。
我想感谢本轮意见中的每位参与者,感谢他们在这个繁忙时节抽出时间提供见解和意见:Anima Anandkumar、Louis Bouchard、Andriy Burkov、Charles Martin、Gaurav Menghani、Ines Montani、Dipanjan Sarkar 和 Rosaria Silipo。
现在,让我们不再拖延,来看看 AI、分析、机器学习、数据科学、深度学习研究在 2021 年的主要发展和 2022 年的关键趋势。

Anima Anandkumar 是 NVIDIA 的 ML 研究主任及加州理工学院的 Bren 教授
AI4Science 在过去一年中显著成熟,疫情作为重要催化剂,将来自多个领域的科学家聚集在一起。我们看到突破性的十亿原子分子模拟,以了解 Covid-19 病毒及其与气溶胶的相互作用,借助人工智能方法增强了这些研究。我们看到能够解决复杂科学模拟的创新人工智能方法,例如首次解决湍流流体流动问题。我们看到许多医院联手,通过保留隐私的联邦学习平台协作训练 AI 患者护理模型。语言模型变得更大,但对偏见问题的广泛意识导致对这些模型的更深入检查,并开发了少量样本和微调方法以减少伤害。
路易斯·布歇 专注于在 YouTube 和 Medium 上的“What's AI”使人工智能更易于获取
第一个问题对我来说相对容易回答。我实际上维护着一个 GitHub 仓库,记录了人工智能的所有主要发展,所以我的答案很快:CLIP。它介绍了许多令人激动的可能性,将文本与图像连接起来。当然,这是我首先想到的,但今年还有许多其他惊人的发现和进展,我强烈邀请你查看我制作的精心挑选的列表,也在 KDnuggets 上共享,涵盖了 2021 年最有趣的人工智能研究,包括视频演示、文章和代码(如果适用)。
我相信我们将在 2022 年继续在图像合成和文本到图像应用领域取得许多激动人心的发现,并迈出比以往更大的步伐,许多技术进步也将再次发生。当然,如果你想跟上最新的研究趋势,我将继续在我的 YouTube 频道和博客上覆盖这些令人兴奋的趋势!
安德烈·布尔科夫 是数据科学主任——机器学习团队负责人,同时是《一百页机器学习书》和《机器学习工程书》的作者
2021 年人工智能的主要突破是 DALL·E 和类似的技术,这些技术可以从文本中创建图像。这些技术为创造性的人提供了全新的工具,并使创作过程更加民主化。我认为 2022 年我们将看到更多创造性 AI 的例子:在视频和音乐中。模型将变得更大,我们将看到新的多模态模型。
查尔斯·马丁 是一位 AI 专家和自然语言处理及搜索领域的杰出工程师
在 2021 年,疫情仍在全面爆发中,我们看到在线零售和一般在线存在的显著增长,越来越多的企业尝试将数据科学和机器学习运用于提升在线销售和运营。这导致了从纯数据科学作为孤立活动的转变,推动更多的机器学习/人工智能模型投入生产,增加了对机器学习工程、机器学习运维和数据中心人工智能的需求。虽然传统的机器学习方法(即 XGBoost)仍主导企业,但现代人工智能正找到自己的位置,包括向量空间搜索、图神经网络,以及计算机视觉应用。因果机器学习也受到关注,因为企业需要了解机器学习方法的工作原理。
在 2022 年,机器学习和人工智能将越来越成为标准软件产品开发生命周期的一部分,并且将出现更好的企业工具来管理它们的开发、部署和监控。
图片由 Gaurav Menghani 提供
Gaurav Menghani 是 Google Research 的一个软件工程师
-
可解释人工智能:为什么这个模型会做出这个具体的预测?理解模型行为背后的理由将帮助我们理解人工智能带来的偏见,从公平性和伦理角度来看。
-
合成人工智能:Cadbury 最近推出了一项广告活动,使小企业主能够创建自己的广告,并有一位受欢迎的电影明星为他们的杂货店做宣传。
-
无/低代码人工智能:像MindsDB这样的公司通过使人工智能训练和预测能够直接通过 SQL 进行,从而赋能用户,让他们可以无缝利用人工智能和预测分析的力量。
-
设备端人工智能:随着硅芯片每单位能量消耗提供更多的功率,设备端人工智能将变得更具吸引力,因为它更快、更响应迅速且更私密。
-
关键任务人工智能:当前的人工智能实践可能不适合关键任务应用(例如医疗保健中的安全/可靠性),在这些应用中,即使最后 0.1%的准确性也非常重要。
-
人工智能的规范:由于现有的规范无法涵盖不断扩大的人工智能需求,我们需要额外的规范和治理,以确保使用人工智能的机构不会忽视关键的保护措施。
Ines Montani 是 Explosion 的首席执行官兼创始人。
我们在 2021 年看到很多有趣的发展,但最让我印象深刻的是:对炒作驱动的开发的持续减少。人们大多已接受,自驾车并不是即将到来,人工智能不会治愈 COVID,这个新模型也不是仅差一步就能成为通用人工智能,GPT-3 及更大的语言模型不会神奇地解决所有实际问题,甚至最新论文中的这个奇特技巧可能也无法帮助你的生产应用。
仍然充满了兴奋和热情,但这次更为务实,且源于该领域有了更多时间成熟。现在有很多人已经在人工智能和机器学习领域工作了几年,2020 年和 2021 年远程工作的广泛接受帮助了合适的人找到合适的角色,从而真正完成工作。在 2022 年,我认为将会少写把人工智能呈现为这种陌生的新奇事物的文章。人工智能的发展就像软件开发,遵循相同的趋势。它大多是在内部完成的。维护的开支大于开发。工具大多是开源的。每个项目都有自己的挑战,因此没有灵丹妙药。
Dipanjan Sarkar 是苏黎世施法豪森技术学院的数据科学负责人,Google 机器学习开发专家,出版作者以及顾问。
根据我去年的预测,2021 年在迁移学习和表示学习领域取得了巨大进展,特别是变换器成为了理解、表示和构建有效解决方案于非结构化数据(包括文本、图像以及音频和视频)的突破性工具。我们还看到在使用低代码和自动化机器学习工具来自动化机器学习训练的领域取得了很多进展,以及可解释人工智能和机器学习运营的持续增长。
对于 2022 年,我预见到编码器-解码器模型架构(如变换器)在解决复杂的多模态数据问题和创建新基准方面将继续上升。我们还应看到生成式深度迁移学习领域的更多进展,以及更容易微调这些预训练模型来解决各种任务,使用的模型甚至比 GPT-3 更强大。生成式深度学习也应该密切关注,其在数据生成和内容创建等新兴领域中的应用。最后,机器学习、数据中心机器学习和 MLOps 的自动化将以稳定的步伐继续发展,更多高效工具的出现将帮助我们更快地构建、部署、监控和维护机器学习模型。
Rosaria Silipo是 KNIME 的数据科学布道负责人
过去的一年是 AI 生产化的一年。新的工具和流程应运而生,以便于部署、实施和监控基于数据科学的解决方案。多亏了数据科学生命周期中的这一新分支,AI 现在已成为主流学科。它不再是一个研究领域,而是数据分析社会的越来越多的领域都在寻求接触它。
市场分析师、护士、医生、首席财务官、会计师、机械工程师、审计专业人员等具有不同背景和不同程度编程及 AI 算法知识的专业人士,都需要在陌生领域内迅速开发数据解决方案——无论是编码、大数据还是 AI。在这种情况下,低代码工具的易用性可能成为非数据科学专业人士创建复杂 AI 解决方案的关键。
个人而言,我希望 2022 年能看到更多女性和其他少数代表性类别在数据科学领域的出现。
相关:
-
2020 年 AI、分析、机器学习、数据科学、深度学习研究的主要进展及 2021 年关键趋势
-
2020 年主要进展和 2021 年 AI、数据科学、机器学习技术的关键趋势
-
2021 年 AI、分析、数据科学、机器学习行业预测
更多相关话题
-
2021 年主要进展和 2022 年 AI、数据科学…的关键趋势
-
2022 年数据科学、机器学习、AI 和分析的关键进展
2021 年数据科学与分析行业的主要发展及 2022 年的关键趋势
原文:
www.kdnuggets.com/2021/12/developments-predictions-data-science-analytics-industry.html
随着 2021 年的结束,我们也结束了我们的专家观点系列文章,为读者带来了对今年重大发展的不同观点,并展望了明年的重要故事。
为此,我们向行业领先公司的专家征求意见,询问:
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
2021 年 AI、数据科学、机器学习的主要发展是什么?你预期 2022 年会有什么关键趋势?
本文从行业的角度来探讨这个问题,在过去的一周里,我们还发布了类似的文章,从研究和技术的角度探讨了同样的问题:
-
2021 年 AI、分析、机器学习、数据科学、深度学习研究的主要发展及 2022 年的关键趋势
-
2021 年 AI、数据科学、机器学习技术的主要发展及 2022 年的关键趋势
我想感谢这轮意见征集中的每一位参与者,在如此繁忙的时间里抽出时间提供他们的见解和观点:Yashar Behzadi(Synthesis AI)、Dipti Borkar(Ahana)、Matthew Carroll(Immuta)、Kendall Clark(Stardog)、Brian Gilmore(InfluxData)、Raj Gossain(Alation)、Alan Jacobson(Alteryx)、Ashley Kramer(Sisense)、Haoyuan Li(Alluxio)、Buno Pati(Infoworks)、Jared Peterson(SAS)、John Purcell(DoiT International)、Ravi Shankar(Denodo)、Dan Sommer(Qlik)、Muddu Sudhakar(Aisera)、Marco Varone(expert.ai)、Ryan Welsh(Kyndi)、Brett Wujek(SAS)。
现在,不再拖延,让我们来看看 2021 年 AI、分析、机器学习、数据科学、深度学习行业的主要发展和 2022 年的关键趋势。

Dipti Borkar,共同创始人兼首席产品官 (CPO),Ahana
在 2021 年,我们看到云计算在 AI 和 ML 应用中的采用加速,这是由于云数据仓库/数据湖/数据湖屋的普及。随着更多的数据迁移到云端,公司面临着一个架构决策——将特定的结构化数据存储在一个高成本的数据仓库中,虽然可以进行高速分析,价格/性能比非常好,还是使用数据湖存储所有数据——结构化和非结构化数据——成本更低但没有内置的查询或分析机制。
到 2022 年,我们将看到更多的 AI 和 ML 工作负载迁移到数据湖/数据湖屋,因为开放数据湖分析栈的出现——这是一个专为云数据仓库工作负载构建的栈,包括一个开源高性能查询引擎(Presto)用于数据湖上的 SQL 分析、开放格式和开放云。云计算的下一个增长阶段将包括开放数据湖,以增强云数据仓库,更多的开源分析和 AI 支持,以及开箱即用的云解决方案来推动创新,这意味着数据平台团队将花费更少的时间在管理复杂的分布式系统上,而更多时间专注于推动以业务为驱动的创新。
Muddu Sudhakar,Aisera的联合创始人兼首席执行官
对话式人工智能的迅猛崛起及更好的语言建模 — 到 2022 年,人工智能将继续演进,变得比以往更具变革性和直观性。从人力资源到营销,对话式人工智能技术被设计用来简化生活。对话式人工智能能够并将会接管日常的内部和客户服务任务,使得人工客服可以专注于更紧迫的问题。
对话式人工智能,如 Aisera 创建的那种,旨在与员工紧密协作,建立一个集成的、更高效、更快速的客户服务体验。
自然语言处理将继续发展,理解语音节奏以及我们所有的人类特有的语音模式、嗯声、啊声和含义混杂的词汇。它将继续学习哪些适用,使其更加反映人类语言,并更好地引导查询和解决问题。
Raj Gossain,Alation的首席产品官
公司将通过利用公共和私人数据市场释放关键业务价值 — 如今,公司已经在购买数据集以进行创新或获取数据不足的见解。到 2022 年,我们将看到更多组织转向公共数据市场,使用两种方法。首先,利用数据目录访问、使用和理解组织内丰富数据的公司,将认识到将企业数据与第三方数据集结合起来比以往释放更多价值和生产力。相比之下,传统公司将意识到专有内部数据集可以被货币化,并打包供其他公司使用,从而创造新的收入来源,使企业更容易发现和使用数据。
主流 AI 和深度学习 — 随着 AI 应用工具集的不断发展,机器学习和深度学习平台已进入主流,并将达到与专业数据分析相同的成熟度。正如我们目前看到基于 Apache Spark 和 Presto 的大量完全集成的托管服务一样,在 2022 年,我们将看到基于 PyTorch 和 TensorFlow 的垂直整合出现。MLOps 用于管道自动化和管理将变得至关重要,进一步降低障碍,加速 AI 和 ML 的采用。
数字化转型 2.0 将在各业务单元中带来分析文化,因为更多的大型企业提供自助服务技术和培训,以确保普通知识工作者能够成功并直接进行分析。
随着分析的持续民主化,数据科学家需要从“问题解决者”转变为“教师”。组织现在希望填补这些角色的人能够清晰地表达和解释——不仅仅是编写代码,以鼓励人们富有创意并进行批判性思考。然而,数据科学家作为从业者和作为教师之间存在技能差距。
数据和分析领域的碎片化将趋于平稳。近年来,AI/ML 领域变得复杂,进入这一领域的公司比前一年更多。然而,随着我们进入一个更加成熟的领域,并且在 2022 年出现更多整合,我们将开始看到这一趋势趋于平稳。
数据网格架构变得越来越诱人。随着组织规模和复杂性的增长,中央数据团队被迫处理各种功能单位和相关数据消费者。这使得理解所有跨职能团队的数据需求并向其消费者提供合适的数据产品变得困难。数据网格是一种新的去中心化数据架构方法,旨在消除瓶颈,将数据决策权移交给那些理解数据的人。
从 2022 年及以后,拥有分布式数据环境的大型组织将实施数据网格架构,以减少数据孤岛,避免重复工作,并确保一致性。数据网格将创建一个统一的基础设施,使领域能够创建和共享数据产品,同时强制执行互操作性、质量、治理和安全的标准。
John Purcell,首席产品官,DoiT International
在预测的季节里,很可能许多人会再次预言人工智能或机器学习的进展。公司和企业确实在寻找创新的方法来利用这些技术和方法,但它们在采用方面还未真正取得突破。主要挑战将保持不变:在数据中提出正确的问题,融合人类和机器智能来回答这些问题,以及克服复杂性。超大规模公司将继续推出新服务,公司将花费资金来确定这些服务如何真正帮助他们的业务。
Marco Varone,创始人兼首席技术官 expert.ai
在过去几年,自然语言理解的重要进展是将不同技术组合起来,以提高整体效果并更好地解决复杂问题。这种混合(或复合)方法结合了符号学和机器学习,赋予我们更强大的能力和灵活性来应对现实世界中的语言问题。
我们将在 2022 年看到这种方法的更广泛应用,因为它可以节省大量时间和金钱,同时提高准确性、效率和速度。它还增加了可解释性(仅机器学习很难做到这一点),并通过知识图谱使从之前的实施中重用知识变得更简单。
Matthew Carroll,首席执行官,Immuta
云计算将决定远程工作的成败 —— 云计算如今是企业的必备之物,并且在 COVID-19 大流行期间至关重要。全球的数据驱动型组织正在寻找解决方案,以加快数据获取速度、安全地与更多用户共享数据,并减轻数据泄露和漏洞的风险。云计算的特点是远程工作,未来将继续对寻求业务连续性、提高可扩展性和成本效益的组织至关重要。
根据 Immuta 数据工程状态调查,组织越来越多地采用多种云技术,以跟上现代数据团队所需的规模、速度和用例。近三分之二(65%)的受访者将他们的公司描述为 100%基于云或主要基于云,这表明对自动化云数据访问控制的市场需求很大。
布赖恩·吉尔莫尔,InfluxData 的物联网项目经理
智能城市技术变得无处不在:我们将不再使用“智能城市”这一术语——这不是因为技术失败,而是因为“城市”这一概念随着人口增长和无处不在的连接而消退。随着更多人群获得或选择高度成熟且易于访问的连接和服务,个体“智能城市”技术的采用将大幅增加。
AI/ML 驱动公民体验:智能政府应用将更像消费者应用,而不像企业内部网。最聪明的城市将把机器学习和人工智能集成到推荐引擎中,支持自然语言交互,通过数字方式提供所有服务,并将公民体验视为首要要求。
数据织物的上升趋势 —— 2022 年将看到数据织物解决方案的显著增长和兴趣,因为公司寻求利用共同管理层来加速分析迁移到云,确保安全和治理,通过支持跨混合多云的实时、可信数据快速交付业务价值——所有这些都在推动数字化转型。我们相信,这项技术将在未来五年得到广泛采用。
企业将期望供应商为业务团队提供全面的 AI 驱动解决方案,而不是专注于 IT 的开发工具和技术——AI 行业的大部分,甚至大多数,都专注于为内部 IT 团队或咨询组织开发强大的工具,以将技术应用于企业应用中的特定用例。在 2022 年,组织将要求 AI 供应商开始开发能够立即实施的特定 AI 驱动解决方案,而无需编码。通过专注于为业务用户提供以人为本的解决方案,供应商将使个人能够立即生成驱动决策的洞察。因此,组织将会调整对 AI 的投资,从高度定制的解决方案转向可配置的(现成的)选项。
合作与商业智能(BI)自疫情开始以来密不可分。在全球尝试恢复一定程度的正常状态时,合作的需求变得更加明确,需要尽早合作,并且没有数据孤岛阻碍。在努力改善我们围绕数据、网络和流程的协作方式时,我们将见证“协作挖掘”的出现,从而使决策得以跟踪。企业也了解到,如果他们想真正实现数据驱动,就必须找出在正确的地方运行正确查询的方法。最后,API 经济为企业联合进行共同倡议开辟了全新的途径,同时减少了买与自建的相关性。自动化是一个强劲的新兴领域,它消除了对这些集成进行编码的需求,我预计这项技术将在 2022 年产生持久影响。
人工智能(AI)正在慢慢地走向现实世界。虽然许多机器学习和 AI 的进展在常见任务或在线竞赛中表现出惊人的准确性,但这些进展仍需时间才能进入行业,最终为客户解决实际问题。这其中的一部分原因是需要领域特定的标注数据或运行这些系统/模型所需的计算能力。由于这些限制,我们将看到从研究到现实的进展将是缓慢但稳定的。
AI 带来了现实世界的成果。过去,组织在 AI 投资上几乎没有什么回报,因为过度关注模型构建和模型性能。AI 不仅会用于独特的突破性项目,组织还会发现将 AI 技术应用于既有项目中,以实现最佳结果的价值。一个 AI 产品或服务要成功,它必须包含能够提升结果或加快、降低过程成本的元素。AI 的价值将不在于它如何建模现实世界,而在于它如何改善现实世界。
多年来,我们一直听说分析的未来将超越描述性分析(发生了什么)和预测性分析(将会发生什么),进入处方指导(应对措施)。AI 的进步与自动化的结合终于使这一点成为可能,通过动态结合相关数据并提前提醒知识工作者采取行动。在 2022 年,处方分析将从仅仅告诉我们数字走向哪里,发展到帮助我们做出更智能、更主动的决策。
组织也开始意识到,并不是每个人都有时间/兴趣成为数据分析师或具备数据素养。在 2022 年,许多组织将重新定义“分析文化”的含义,通过以更易于消化的方式将见解带给员工——转向像嵌入式分析这样的方式,这不会要求新技能或额外的时间投入。
大数据中心化和整合的时代已经结束——中央化或整合数据存储的重要性也将在 2022 年成为焦点。明确来说,这一趋势并不是存储的终结,而是中心化整合的数据存储方法的终结,特别是针对分析和应用开发。
到 2022 年,我们将看到数据分析领域持续的大斗争,旧有的企业数据管理方法,侧重于整合和中央化模式,将达到顶峰,然后开始趋向下降。我们即将看到的 Snowflake 和 Databricks 之间的重大斗争部分源于它们对中央化整合的不同方法。
但这不仅仅是技术上的压力。在混合多云世界中不可避免的数据移动的经济状况并不好,也没有改善的迹象。客户和投资者正在反对随中央化方法而来的那种锁定现象,因此预期未来一年内,数据分析堆栈将朝向去中心化和去中介化的方向发展。
Yashar Behzadi,Synthesis AI的首席执行官兼创始人
围绕 AI 的数据对话将被优先考虑 — 关于 AI 的数据讨论已经开始,但尚未得到足够的关注。数据是构建 AI 系统的最关键方面,我们刚刚开始讨论和思考获取、准备和监控数据的系统,以确保性能和避免偏见。组织在 2022 年必须在企业架构中优先考虑数据优先的方法,以使 AI 和分析能够解决问题并促进新的收入来源。
合成数据将成为构建元宇宙的必需品 — 没有合成数据就无法构建元宇宙。为了将现实重建为数字双胞胎,必须深入了解人类、物体、3D 环境及其相互作用。创建这些 AI 能力需要大量高质量标记的 3D 数据——这些数据对人类来说几乎无法标记。我们无法在 3D 空间中标记距离,推断材料属性或标记重建空间所需的光源。利用生成 AI 模型和视觉效果(VFX)技术组合构建的合成数据将成为支持新元宇宙应用所需 AI 模型的关键推动力。
相关:
-
AI、分析、机器学习、数据科学、深度学习研究 2021 年主要进展及 2022 年关键趋势
-
2021 年主要进展及 2022 年 AI、数据科学、机器学习技术的关键趋势
-
2021 年 AI、分析、数据科学、机器学习的行业预测
更多相关主题
2020 年的主要进展和 2021 年 AI、数据科学、机器学习技术的关键趋势
原文:
www.kdnuggets.com/2020/12/developments-trends-ai-data-science-machine-learning-technology.html
评论这是非常不寻常且困难的一年,我很高兴它很快就会过去。但我们仍然可以拥有美好的事物,其中之一是 KDnuggets 每年的专家预测总结。
早些时候,我们涵盖了 2020 年 AI、分析、机器学习、数据科学、深度学习研究的主要进展和 2021 年的关键趋势。
COVID 改变了人们的生活和工作方式,也突显了预测模型对假设的依赖以及对突然变化的脆弱性。
本博客将更多关注技术。我们询问了我们的专家小组:
2020 年 AI、数据科学、机器学习、深度学习技术的主要进展是什么?你对 2021 年有何关键趋势的期待?
一些常见的主题包括 AutoML、自动化 / RPA、AI 偏见、COVID 影响、深度学习的限制、伦理 AI、GPT-3、医学和医疗保健以及 MLOps。
在提交截止日期之后发生了一项巨大的 AI/ML 发展。来自 DeepMind 的AlphaFold显然解决了长达 50 年的蛋白质折叠问题,对医学和生物学具有巨大的潜力。
这是专家们的意见,来自 Marcus Borba、Kirk Borne、Tom Davenport、Carla Gentry、Jake Flomenberg、IPFConline(Pierre Pinna)、Nikita Johnson、Doug Laney、Ronald van Loon、Bill Schmarzo、Kate Strachnyi 和 Mark van Rijmenam。
享受吧!

Marcus Borba,全球思想领袖与影响者:#AI #MachineLearning #DataScience #BI #BigData #Analytics #IoT #DigitalTransformation。
在 2020 年,对 AI 工作原理的关注日益增加,同时也评估了偏见问题,这使得 AI 需要越来越具可解释性和责任感。AutoML 的使用在资源工程和算法测试等问题上为数据科学家带来了若干好处。
在 2021 年,我预见到人工智能和机器学习在所有知识领域的使用将大幅增加,通过超自动化的概念,这涉及到除了 AI 和机器学习外的许多技术,如增强分析、物联网、iBPM 和 RPA。人工智能和机器学习将在网络安全领域、企业系统、智能城市和智能家居中被越来越多地使用。人工智能与物联网的结合(AIoT)也将是一个关键趋势,使得创建具有更高效率操作的解决方案成为可能,改善机器与人类之间的互动,同时在数据分析中获得更多的稳健性。
柯克·D·博恩,布兹艾伦的首席数据科学家。全球演讲者。顶级#大数据 #数据科学 #人工智能 影响者。博士,天体物理学家。
我在 2020 年数据相关领域的主要趋势包括:自动化叙述文本生成(如 GPT-3)的惊人(且令人惊恐)的进展;RPA 部署的无处不在;用于操作企业机器学习活动的 MLOps 工具的增长;AI 和 DevSecOps 在 IT 操作中的融合,作为 AIOps;数据科学家对我们部署模型中的数据漂移和概念漂移重要性的警示,特别是在 COVID 疫情期间之前成功模型的失败;包括边缘计算、边缘到云计算和雾计算在内的多样化混合数据架构的兴起;分布式数据挖掘的复兴(10-15 年前流行)在“联邦机器学习”标签下,允许在分布式数据集上进行增量模型训练而无需移动数据;在所有组织和市场领域对数据素养的巨大广泛兴趣和投资;以及对物联网的认识逐渐觉醒,不仅仅是监控活动(作为你做的事情),而是作为新的企业可观测性战略的技术推动者(作为你这样做的原因)。
我希望在 2021 年看到更多这样的趋势,特别是 MLOps、可观测性、数据素养和智能流程自动化(AI 增强 RPA)。
汤姆·达文波特、@tdav 是巴布森学院的 IT 和管理学杰出教授;德勤分析与人工智能实践的高级顾问;麻省理工学院数字经济倡议的数字研究员。
2020
-
我去年预测,广泛称为“MLOps”的机器学习模型持续管理将变得流行。这个概念已经变得流行,但我认为实际使用仍然主要集中在大型金融服务和科技公司中。
-
我还预测翻译员将变得对数据科学团队很重要,许多公司确实使用他们,但这个角色尚未成为制度化。
-
我预测了“模型对数据的适配只是考虑其是否有用的一个因素”,我认为这实际上并没有发生。强调这一信息的供应商并没有真正繁荣起来。
2021
-
大规模深度学习模型的受欢迎程度将在 2021 年达到峰值;数据和能源需求正变得过高,无法继续这一趋势。
-
数据科学团队将采纳成功实施项目所需的角色和技能分类;“产品经理”将成为确保部署的重要角色。
-
外部公司将专注于“数据科学即服务”的各个方面,包括提供训练模型的数据和通过 MLOps 监控模型。
这是这些预测中的一个词云

Carla Gentry,数据科学家,分析解决方案
2020
当我们回顾过去的一年时,我发现最有趣的关于人工智能、机器学习和数据科学的事情是:许多人仍在谈论 Python/编程/软件,但很少有人展示这些伟大领域如何帮助社会“解决问题”的现实例子——人工智能被简化为聊天机器人,机器学习变成了在某些“大型网站”上进行角色和物体识别,用于分类产品或寻找类似产品或推荐……我并不是说没有一些非常酷的东西在做,尤其是考虑到 Covid 是大家关注的焦点,数据科学和机器学习也被用来寻找热点和/或帮助接触追踪,这将有助于遏制新感染的增加。你知道,数据科学、分析和机器学习曾经并继续在所有疫苗的研发中发挥作用,但正如我们在“可靠性”和“再现性”部门即“AstraZeneca/Oxford COVID 疫苗数据”中看到的,数据质量和能够涉及代表性样本仍然是大问题。
尽管我们已经取得了进展,基本的“数据 101”问题仍然非常严峻——所以我们在开始任何项目时,请记得检查数据、查询并跟进异常,不要假设任何事情。有趣的是,在感恩节晚餐时,户外且保持社交距离,我妈妈给我看了一个两个“人跳舞”的视频,我说“哦,这很好”并微笑——她说——你注意到这两个“人”是机器人吗?嗯,跳舞就是数学,对吧(眨眼,不过,类似于 AI 画作,没有灵魂)2021 年及以后,我们可以做的事情无限,因此让我们通过记住基础知识——再现性、透明性、准确性和它是否代表真实生活和形式——来推动机器学习和数据科学的发展——我们必须摆脱黑箱思维——仅仅因为它在大学环境或实验室环境中有效,并不意味着它在现实生活中也会有效……
记住这一点,那些“短距离”内有上匝道和下匝道的高速公路——使得进出合流混乱——是由认为这样设计更高效的工程师设计的……对谁高效?在设计算法或模型时,了解你的受众……知道你的最终目标是什么,目的或功能是什么,然后——当然要有逻辑——但也要实际……
杰克·弗洛门贝格是 Wing Venture Capital 的合伙人,专注于 AI/ML 驱动的应用,他最近发布了一份关于数据科学领导者面临的最大问题的调查。
2020 年: COVID-19 是一个黑天鹅事件,使许多模型经受了考验。不幸的是,大多数 AI 尚未能很好地适应快速变化的情况。随着公司被迫适应,AI 可观测性和模型监控成为所有从事生产模型工作者的明显需求。
NLP 领域的 AI 正在上升。人类 NLP 基准测试正在被超越。像 GPT-3 这样的语言处理模型正在解锁新的应用场景,如总结和代码生成。利用 NLP 从文本中发掘价值的初创公司继续激增。
医疗保健领域的 AI 终于开始发挥作用——无论是化学、药物发现、蛋白质组学等。在过去 2 年中,涉及 AI 的生物学出版物占比超过一半。
2021 年: 随着数据科学家努力在组织内部各方——利益相关者、监管者和最终用户之间建立信任,并更好地理解他们的模型并提供性能置信区间,模型可解释性成为主流需求。各种问题,如不公平的偏见、模型不稳定性、监管要求,推动了这一点。
计算机视觉不断普及。我预计除了自动驾驶车辆外,将会看到更多的现实世界应用案例以及更多的风险投资。我也希望看到计算机视觉开始受益于在 NLP 中解锁价值的自注意力策略。
数据标注变得更加自动化。随着少量样本学习和迁移学习的进步,计算机终于能够介入,减少人工手动标注所有数据的需求。
IPFConline,数字化转型咨询,法国马赛。
对于 IPFConline 团队来说,2020 年在 AI 和数据科学领域标志着 3 个重要事实:
-
OpenAI GPT-3 的发布是自然语言处理领域的一个重大进步,
-
对于深度学习的真实认识在于,深度学习算法对数据的需求过于贪婪,这使得它们的解释变得非常困难。
-
在世界许多地方,禁止在大规模监控中使用面部识别技术。
2021 年将与 2020 年有很强的相似性,深度强化学习和迁移学习可能会开辟出新的算法类型,这些算法更公平,因此更值得信赖且偏见更少。
尼基塔·约翰逊,创始人,RE.WORK 深度学习与人工智能活动,#reworkDL #reworkAI #AIforGood
这一年充满挑战,但或许在我们保持社交距离的同时,关于如何将人工智能应用于社会影响的讨论使我们更紧密地团结在一起,并且由于探索如何利用人工智能应对疫情及造福社会,这些讨论变得更加突出。当然,DeepMind 近期关于蛋白质折叠突破的公告也是今年人工智能在医疗领域的一大进步。
我希望我们能看到人工智能在医疗和数字健康领域的力量在 2021 年进一步发展,包括隐私和个性化的进展,以及远程医疗和心理健康应用的改进。
道格·拉尼,创新研究员,数据与分析战略
在 2021 年,应用人工智能和数据科学的主要工业焦点将是提高生命科学研究和医疗服务的效率。新冠疫情危机突显了医疗政策、供应链、运营、诊断、预防和治疗中的差距和机遇。
随着个人继续寻找更有效的远程工作方式,智能代理将逐渐融入我们用来协作的应用程序中。它们将帮助我们与彼此及大量的数据、内容和其他应用程序进行集成和沟通。智能设备和助手将从以问答为主的发展到真正具备对话性和情境意识。此外,它们将学习并模仿我们个人在处理事务时的伦理标准。
此外,我们将看到人工智能开始自主管理数据。数据的体量和速度一直只是基础设施扩展的问题。然而,日益增长和不断演变的数据种类需要整合、清洗、组织、存储和访问,用于事务和分析目的,这一直是一项艰巨的手动建筑和工程任务。自组织的数据管理能力将会出现,以减轻这一负担。
罗纳德·范·伦,帮助数据驱动型公司创造价值;#AI、#BigData、#DataScience、#IoT、#MachineLearning、#Analytics、#Cloud、#5G 领域的 Top10 影响者
在 2020 年,随着企业应对 COVID-19 大流行带来的挑战,对话 AI 的加速发展达到了一个非凡的速度。对新数字服务的紧急需求、客户需求的变化以及远程工作的转变推动了这一技术的大规模战略性采用。AI API 的兴起,如对话 AI API 和文档 AI API,使得推动 AI 的可及性变得更加容易和快捷,并消除了对专业 AI 技能或经验的需求。
对于 2021 年,嵌入式 AI 将成为一个主要趋势,因为公司将专注于通过直观、简化的 AI 功能推动数字化转型的势头,并快速进行 AI 创新。这将确保 AI 的好处和价值能迅速实现,同时允许组织快速现代化业务。类似地,针对业务用户的机器学习应用将通过精简的实施和流程、自动化工作流以及更快的洞察生成推动企业中的 AI 民主化。
比尔·施马佐, @schmarzo, 大数据学主任 | 认可的创新者、教育者、实践者 数据科学、设计思维、数据货币化
2020 年的主要发展:
-
利用 AI 创建在使用过程中增值而非贬值的自主资产已经成为现实(感谢埃隆·马斯克)
-
孤立分析 - 为一次性分析目的构建的机器学习模型,但从未设计为可重复使用或持续学习和适应 - 继续成为组织的失望
-
开源工具在 AI/ML 模型开发、操作化和管理方面的持续进展
-
低估了由于错误估计误报和漏报错误成本而产生的意外后果
2021 年的关键趋势:
-
尽管数据货币化仍然是 CIO 的首要挑战,但许多组织缺乏以业务为中心的价值工程方法来识别和优先考虑 AI/ML 如何产生新的客户、产品和运营价值来源
-
组织开始认识到数据和分析的经济价值,这些数字资产不会磨损,而且使用越多,它们的价值就越高。
-
自主分析开始在领先组织中取代孤立分析
凯特·斯特拉赫尼, Story by Data 和 DATAcated Academy 创始人
在 2020 年,我们见证了从静态仪表板向交互式数据故事的转变,这些故事自动开发并向利益相关者传递关键洞察。数据消息是有上下文的,并根据受众(人们看到对他们有意义的洞察)量身定制的。我们还看到了一些软件,允许业务用户通过在搜索栏中输入问题来“询问”问题;这使他们能够更接近数据,减少获取数据驱动答案所需的时间和精力。
在 2021 年,我们可以期待看到推动提升所有行业和角色(不仅仅是数据专家)专业人士的数据素养技能的努力。将会有一个教育员工如何阅读、分析、解读和沟通数据的趋势。借助创新技术,我们将减少构建仪表盘的时间,更多地关注做出基于数据的决策。
马克·范·瑞门南博士,VanRijmenam,思考技术及其对商业和社会的影响。三本管理书籍的作者。Datafloq.com的创始人。通过Mavin.org打击虚假新闻、机器人和网络喷子。
在 2020 年,我们见证了拥有数十亿参数的先进语言模型的出现,这些模型凭借其准确性让人惊叹。《卫报》的一篇文章甚至展示了这一模型的先进性。
然而,在 2021 年,我们可能会看到首个拥有万亿参数的语言模型将技术提升到另一个层次。虽然这些模型可能最初会停留在研究领域,但如 GPT-3 这样的技术将会进入企业,并开始直接与客户互动。2021 年我们还会看到对伦理人工智能的关注和要求的增加。人工智能在社会中变得越来越普遍,公民将要求对人工智能采取伦理方法。在 2020 年,我们见证了阿姆斯特丹和赫尔辛基推出算法注册册,以带来人工智能公共部署的透明度,2021 年我们将看到这种情况更加频繁。
相关:
-
人工智能、分析、机器学习、数据科学、深度学习研究 2019 年的主要进展和 2020 年的关键趋势
-
人工智能、分析、机器学习、数据科学、深度学习技术 2019 年的主要进展和 2020 年的关键趋势
更多相关话题
《数据科学家的 DevOps:驯服独角兽》
原文:
www.kdnuggets.com/2018/07/devops-data-scientists-taming-unicorn.html
评论
作者 Syed Sadat Nazrul,分析科学家
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
当大多数数据科学家开始工作时,他们通常具备了从教科书中学到的所有数学概念。然而,很快他们就会意识到,大多数数据科学工作涉及将数据转换成模型所需的格式。更进一步地,正在开发的模型是最终用户应用的一部分。现在,一个合格的数据科学家应该将他们的模型代码版本控制在 Git 上。然后,VSTS 将从 Git 下载代码,VSTS 随后将被封装在 Docker 镜像中,然后被放到 Docker 容器注册表上。一旦在注册表中,它将使用 Kubernetes 进行编排。对普通数据科学家来说,这些术语可能会让他们感到完全困惑。大多数数据科学家知道如何提供静态报告或带有预测的 CSV 文件。然而,我们如何对模型进行版本控制并将其添加到应用程序中?用户如何基于结果与我们的网站互动?如何扩展!?所有这些都涉及到信心测试,检查是否有任何内容低于设定的阈值,来自不同方的签署和不同云服务器之间的编排(以及所有丑陋的防火墙规则)。这就是一些基本 DevOps 知识派上用场的地方。
什么是 DevOps?
简而言之,DevOps 是那些帮助开发者(例如数据科学家)和 IT 部门协作的人。

开发者和 IT 之间的常见斗争
开发人员有自己的指挥链(即项目经理),他们希望尽快推出功能。对于数据科学家来说,这意味着更改模型结构和变量。他们根本不在乎机器发生了什么。数据中心冒烟?只要他们能够获取数据以完成最终产品,他们根本不在乎。另一方面是 IT 部门。他们的工作是确保所有服务器、网络和精美的防火墙规则都得到维护。网络安全对他们来说也是一个巨大关注点。他们对公司的客户毫不关心,只要机器正常运作。DevOps 是开发人员和 IT 之间的中介。常见的 DevOps 职能包括:
-
集成
-
测试
-
打包
-
部署
博客的其余部分将详细解释整个持续集成和部署过程(或者至少是对数据科学家相关的内容)。在阅读博客的其余部分之前,请注意:理解业务问题,不要对工具过于依赖。博客中提到的工具可能会改变,但基础问题在可预见的未来将大致相同。
源代码管理
想象一下将你的代码推送到生产环境。它正常工作了!完美。没有任何抱怨。时间流逝,你不断添加新功能并持续开发。然而,其中一个功能引入了一个严重的错误,严重影响了你的生产应用。你本希望你的多个单元测试能发现这个错误。然而,仅仅因为某个功能通过了所有测试,并不意味着它没有漏洞。它只是意味着它通过了所有当前编写的测试。由于是生产级别的代码,你没有时间进行调试。时间就是金钱,你还有愤怒的客户。是否可以简单地回到代码正常工作的那个点呢?这就是版本控制发挥作用的地方。在敏捷风格的代码开发中,产品在不确定的时间段内不断开发。对于这种应用,某种形式的版本控制将非常有用。
Bitbucket 仓库
就个人而言,我喜欢Git,但SVN用户仍然存在。Git 适用于所有形式的平台,如GitHub、GitLab和BitBucket(每个平台都有其独特的优缺点)。如果你已经熟悉 Git,考虑阅读更为高级的 Git 教程。我推荐查看的一个高级功能是Git 子模块,你可以存储多个独立 Git 仓库的特定提交哈希,以确保你可以访问一组稳定的依赖项。当必要时,重要的是要有 README.md,概述仓库的详细信息以及打包(例如,使用 setup.py 进行 Python)。如果你存储二进制文件,考虑查看Git LFS(不过我建议如果可能的话避免使用这个)。
在 Git 上合并 Jupyter 笔记本
数据科学中特定的版本控制问题是使用 Jupiter/Zeppelin 笔记本。数据科学家绝对喜欢笔记本。然而,如果你将代码存储在笔记本模板中并尝试在版本控制中更改代码,那么在执行差异比较和合并时,你会得到疯狂的 HTML 垃圾。你可以完全放弃在版本控制中使用笔记本(仅从版本控制的库中导入数学函数),或者可以使用现有工具如nbdime。
自动测试
从数据科学家的角度来看,测试通常分为两类。一类是常规的单元测试,用于检查代码是否正常工作或是否按照你的要求运行。另一类更具体于数据科学领域,是数据质量检查和模型性能。你的模型是否为你提供了准确的分数?现在,我相信许多人会想知道为什么这是一个问题。你已经做了分类分数和 ROC 曲线,模型也足够令人满意,可以进行部署。好吧,有很多问题。主要问题是,开发环境中的库版本可能与生产环境完全不同。这意味着不同的实现、近似值,因此,模型输出也不同。
如果集成和部署做得正确,模型输出在开发和生产环境中应该是相同的。
另一个经典示例是为开发和生产使用不同语言。让我们设想这个场景。你,尊贵的数据科学家,希望用 R、Python、Matlab 或者上周刚刚发布白皮书的许多新语言之一来编写模型(这些语言可能还没有经过充分测试)。你将模型交给生产团队。生产团队怀疑地看着你,笑了 5 秒钟,然后才意识到你是认真的。他们可能会嗤之以鼻。生产代码是用 Java 编写的。这意味着需要将整个模型代码重写为 Java 以用于生产。这也意味着完全不同的输入格式和模型输出。因此,自动化测试是必要的。
Jenkins 主页
单元测试是非常常见的。JUnit可供 Java 用户使用,而unittest库适用于 Python 开发人员。然而,有可能有人在将代码推送到生产环境之前忘记在团队中正确运行单元测试。虽然你可以使用crontab来运行自动化测试,但我推荐使用更专业的工具,如Travis CI、CircleCI或Jenkins。Jenkins 允许你安排测试、从版本控制库中选择特定分支、如果出现问题会发送邮件提醒,甚至可以启动 Docker 容器镜像,如果你希望将测试隔离在沙盒中。基于容器化的沙盒化将在下一部分中更详细地解释。
容器化

容器与虚拟机
沙盒化是编码的重要组成部分。这可能涉及为各种应用程序设置不同的环境。它可能只是将生产环境复制到开发环境中。它甚至可能意味着拥有多个具有不同软件版本的生产环境,以满足更大客户群的需求。如果你考虑使用带有Virtual Box的虚拟机,我相信你已经注意到,你要么需要在多轮测试中使用完全相同的虚拟机(这是很糟糕的 DevOps 卫生),要么需要为每次测试重新创建一个干净的虚拟机(这可能需要接近一个小时,具体取决于你的需求)。一种更简单的替代方案是使用容器而不是完整的虚拟机。容器只是一个 UNIX 进程或线程,表现得像虚拟机。它的优点是功耗低,内存消耗少(这意味着你可以随意启动或关闭它……在几分钟内)。流行的容器化技术包括Docker(如果你只希望使用一个容器)或Kubernetes(如果你喜欢协调多个容器以实现多服务器工作流)。
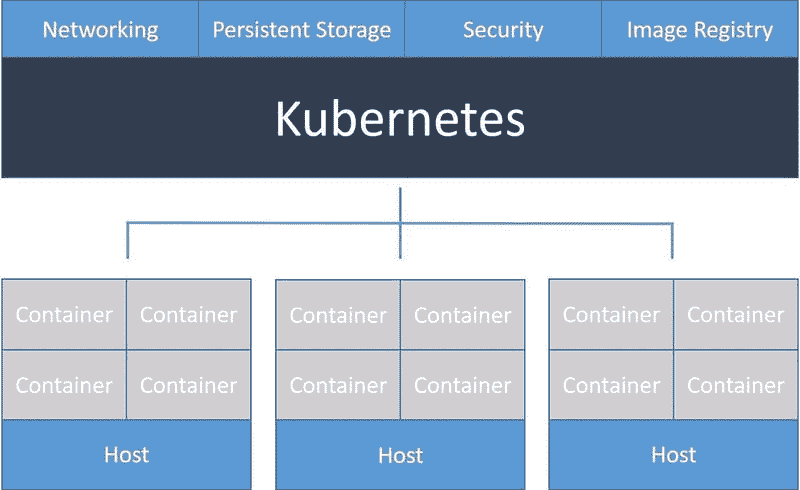
Kubernetes 工作流
容器化技术不仅有助于测试,还能提高可扩展性。特别是当你需要考虑多个用户使用你的模型基础应用程序时,这一点尤为重要。这可能涉及训练或预测。
安全
安全很重要,但在数据科学领域往往被低估。一些用于模型训练和预测的数据涉及敏感信息,如信用卡信息或医疗数据。在处理这些数据时,需要遵守 GDPR 和 HIPPA 等合规政策。不仅仅是客户端需要安全。贸易秘密模型结构和变量,在部署到客户端服务器时,也需要一定级别的加密。这通常通过将模型部署到加密的可执行文件(例如 JAR 文件)中,或在将模型变量存储到客户端数据库之前进行加密来解决(不过,请不要自己编写加密代码,除非你完全知道自己在做什么……)。
加密 JAR 文件
此外,最好按租户建立模型,以避免意外的迁移学习,这可能导致一个公司向另一个公司泄露信息。在企业搜索的情况下,数据科学家可以使用所有可用数据构建模型,并根据权限设置筛选出特定用户未授权查看的结果。虽然这种方法看起来合理,但用于训练模型的数据中一部分信息实际上是由算法学习并转移到模型中的。因此,无论如何,这使得用户有可能推断出被禁止页面的内容。没有绝对的安全。然而,它需要足够好(这一点的定义取决于产品本身)。
协作

当与 DevOps 或 IT 合作时,作为数据科学家,明确需求和期望是非常重要的。这可能包括编程语言、包版本或框架。最后但同样重要的是,彼此尊重也很重要。毕竟,DevOps 和数据科学家都面临着极具挑战性的工作。DevOps 对数据科学了解不多,而数据科学家在 DevOps 和 IT 方面也不是专家。因此,沟通是成功业务结果的关键。
额外信息
当人们开始作为自学编程的程序员时,我们经常会想到创建一个简单的应用程序……
在各种形式的组织中工作(从大型软件开发公司到小型创业公司,再到学术实验室),我...
数据科学是一个相当大且多样的领域。因此,很难成为一个全能型人才...
简介:Syed Sadat Nazrul 白天利用机器学习追捕网络和金融犯罪分子,晚上则撰写有趣的博客。
原始。已获许可转载。
相关:
-
操作性机器学习:成功 MLOps 的七个考虑因素
-
数据科学面试指南
-
接收器操作特征曲线揭秘(Python 版)
更多相关内容
IBM Watson 如何征服世界
原文:
www.kdnuggets.com/2016/02/dezyre-ibm-watson-taking-world.html
作者:Khushbu Shah,DeZyre
人工智能(AI)让我们着迷已有数十年,随着每年的推移,我们离那台能像人类一样互动的机器越来越近。一方面,我们在数据分析领域取得了巨大的进展,另一方面,我们的技术也变得足够智能,能够识别我们的提问并以我们提问的语言作出回应。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
人工智能 是一个复杂的领域,需要在分析、机器学习、神经网络、语音识别和大数据等多个方面进行前所未有的协调。现代智能手机操作系统配备了基于语音的虚拟助手,通过支持语音搜索并以机械化的英语回应结果来展示人工智能的初级阶段。虽然目前看来这已经足够,但仍然有许多工作要做。
IBM 一直处于创新的前沿。通过推出其超级计算机 IBM Watson(以 IBM 创始人 Thomas J. Watson 命名),它在人工智能领域迈出了坚实的一步。
什么是 IBM Watson?
它是一个“问答(QA)”机器(占据的空间足以容纳 10 台冰箱)。IBM Watson 具有扫描大量数据以“学习”主题的能力,然后像人类一样解释和回答问题。它的目标是复制(甚至超越)一个智能人类理解问题并提供答案的能力。
对于那些对数字感兴趣的人,IBM Watson 的处理能力为 80 teraflops,即每秒一万亿次浮点运算。为了能够像高效运作的人脑一样理解、分析和回答问题,Watson 从 90 台服务器上挖掘超过 2 亿页的信息。这些数据随后通过六百万条逻辑规则来得出相关的答案。
想成为数据科学超级英雄?学习 Python 中的数据科学

IBM Watson 与搜索引擎有何不同?
搜索引擎通常会对问题给出机械的回应。它们无法解释单词在句子中的顺序。它们只会查找搜索的短语并提供答案,而不考虑该短语出现的“上下文”。这意味着一旦 Watson 得到适当的训练,向它提出问题就像与一个实际的有意识的人的对话,而不是机械地显示结果。
IBM Watson 应用
2011 年,Watson 通过在危险边缘节目中与前冠军 Brad Rutter 和 Ken Jennings 竞争,证明了其认知计算的能力。最终赢得了 100 万美元的头奖。通过这次竞赛,主要研究员 David Ferrucci 领导的研究团队能够确立人工智能的变化面貌。大约四年后,Watson 的计算能力已被各个行业有效地利用来解决实际问题。在这一部分,我们列出了一些成功使用 IBM Watson 认知处理能力的行业。
USAA:帮助军人过渡到平民生活
美国劳工统计局指出,每年约有 155,000 名军人过渡到平民生活。在这一过程中,他们有许多与退伍军人补偿福利、9/11 后 GI 法案等相关的问题。相关信息散布在数十万页文档中。IBM Watson 已经吸收了记录在 3000 多份与军事过渡相关的文档中的知识,使其能够令人满意地回答军人们的问题。由于 3000+文档的知识库需要数百人阅读并整理观察结果,才能形成答案,因此 IBM Watson 所节省的成本可想而知。
澳新银行全球财富
金融行业拥有大量特定的数字,正确处理这些数字以生成最佳的金融规划建议对业务成功至关重要。澳新银行全球财富(澳大利亚和新西兰全球银行集团的私人银行部门)的 400 多名金融规划师使用 IBM Watson Engagement Advisor 来帮助他们改善金融建议流程。其目标是将客户收到建议声明的时间从几天减少到仅一次会话。
MD 安德森癌症中心
德克萨斯大学 MD 安德森癌症中心已经将 IBM Watson 引入其抗癌使命。在处方方面,肿瘤学专家顾问能够利用 Watson 的认知计算能力,整合 MD 安德森研究人员的庞大知识库。另一方面,它在收集和分析大量有关患者医疗历史的非结构化数据方面发挥了关键作用。一旦这两者连接,临床医生将获得宝贵的信息,这些信息要么需要很长时间才能收集,要么可能会被遗漏。
IBM Watson 的未来将会怎样?
如前所述,Watson 的应用涵盖了许多行业。如果您的业务需要处理大量数据,从中学习并提供超越数字计算的建议,您可以通过以下方式大幅缩短整个过程的周期时间:
IBM Watson 将使您的旅行计划无压力。
现在有很多网站可以帮助您找到旅行票的“最佳价格”。在争夺成为“最快”获取这些信息的在线门户/应用的竞争中,企业往往忽视了旅行的人文方面,即创造终生难忘的体验。Watson 能够从全球的旅行相关文档中获取信息,分析并准备针对诸如“4 月份我和妻子去哪里度浪漫海滩假期?”这样的问题的具体答案。在回答这个问题时,Watson 会考虑到并非所有海滩目的地都是浪漫的,它们的“最佳旅行月份”也不同。客户可能没有时间扫描成千上万的评论再做决定。试想一下,当查询用简单英语在几秒钟内得到回答时,旅行网站能够达到的效率!
IBM Watson 将使购物变得更简单。
想象一下,您走进一家商店购买露营相关的物品。我们通常会查找互联网,询问朋友,准备一份我们需要的物品清单,然后购买它们。如果有一台超级计算机,您可以简单地询问它,它会给您提供一份综合清单,并附加关于天气、最佳时间和露营地点以及邻近其他活动的信息?IBM Watson 的开发平台正被 Fluid Inc. 用来通过做类似的事情来颠覆购物者的购买体验。
IBM Watson 将为您提供烹饪大师级的体验。
沃森能够学习任何东西,它不局限于假设、事件和技术。其创造力可以用来创建新颖的食谱。就像其他应用程序一样,它需要经过烹饪方面的训练。一旦建立了足够大的知识库,就可以随时调用它来提供适合用户需求的食谱。经过足够的训练后,用户可以向沃森提问
提供一种意大利风味的素食菜肴建议,这道菜可以用特定的方式(例如烤制、煮沸、空气炸等)来烹饪,并且可以快速引导用户了解可能的食材、烹饪时间和配比。这些只是我们日常生活中的一些应用,它们能让我们的生活变得更简单、更美好。沃森的计算能力在农业、欺诈检测、风险评估、娱乐甚至太空探索等领域没有限制。因此,下次当你听到有人与机器对话并得到准确、富有创意且人类语气相似的回应时,你可能正在使用其中一个 IBM Watson 应用。
学习数据科学来构建令人惊叹的机器学习系统!
相关:
-
Spark SQL 实时分析
-
通过 IBM Watson 和 Twitter 解锁 Spark 的力量
-
独家采访:Apache Spark 创始人 Matei Zaharia 讨论 Spark、Hadoop、Flink 及 2020 年的大数据
更多相关内容
Bagging 和 Boosting 有什么区别?
原文:
www.kdnuggets.com/2017/11/difference-bagging-boosting.html
评论
由 xristica,Quantdare提供。

Bagging 和 Boosting 的相似之处在于它们都是集成技术,在这些技术中,一组弱学习器被组合以创建一个强学习器,从而获得比单一学习器更好的性能。所以,让我们从头开始:
什么是集成方法?
集成是一个机器学习概念,其思想是使用相同的学习算法训练多个模型。集成方法属于更大的方法群体,称为多分类器,在这些方法中,数百或数千个具有共同目标的学习器被融合在一起以解决问题。
第二组多分类器包含混合方法。它们也使用一组学习器,但可以使用不同的学习技术进行训练。Stacking 是最著名的。如果你想了解更多关于 Stacking 的信息,你可以阅读我之前的文章,“梦之队组合分类器”。
学习中的主要误差原因是噪声、偏差和方差。集成有助于最小化这些因素。这些方法旨在提高机器学习算法的稳定性和准确性。多个分类器的组合减少了方差,尤其是在不稳定分类器的情况下,并可能产生比单一分类器更可靠的分类。
要使用 Bagging 或 Boosting,你必须选择一个基础学习算法。例如,如果我们选择一个分类树,Bagging 和 Boosting 将由一个数量随意的树池组成。

Bagging 和 Boosting 如何获得 N 个学习器?
Bagging 和 Boosting 通过在训练阶段生成额外的数据来获得 N 个学习器。通过随机采样带替换从原始集合中生成 N 个新的训练数据集。通过带替换的采样,一些观察值可能在每个新训练数据集中重复出现。
对于 Bagging,任何元素在新数据集中出现的概率是相同的。然而,对于 Boosting,观察值是加权的,因此其中一些会更频繁地参与新集合:
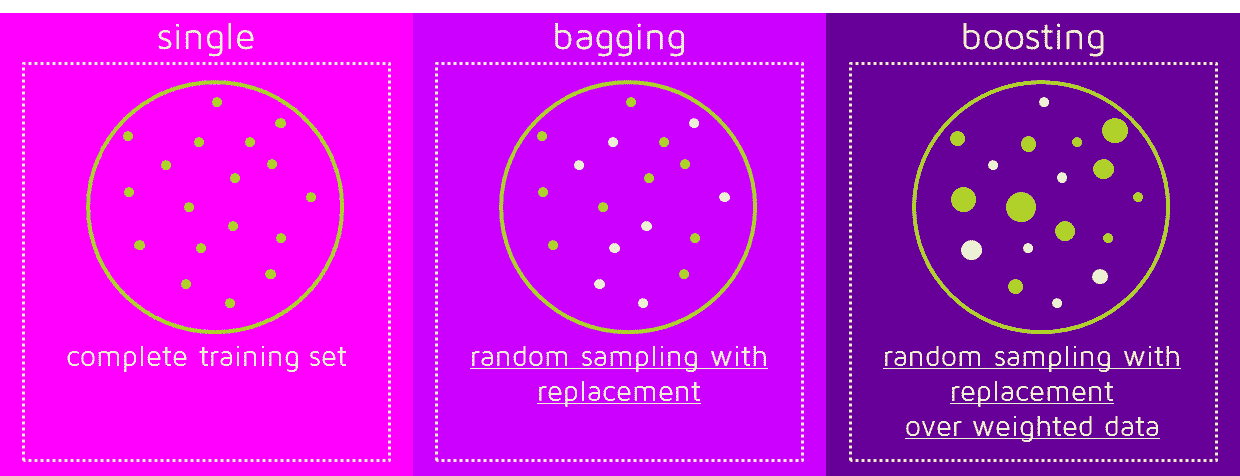
这些多个集合用于训练相同的学习算法,因此产生了不同的分类器。
为什么数据元素会被加权?
在这一点上,我们开始处理这两种方法之间的主要区别。虽然 Bagging 的训练阶段是并行的(即每个模型独立构建),但 Boosting 以顺序方式构建新的学习器:
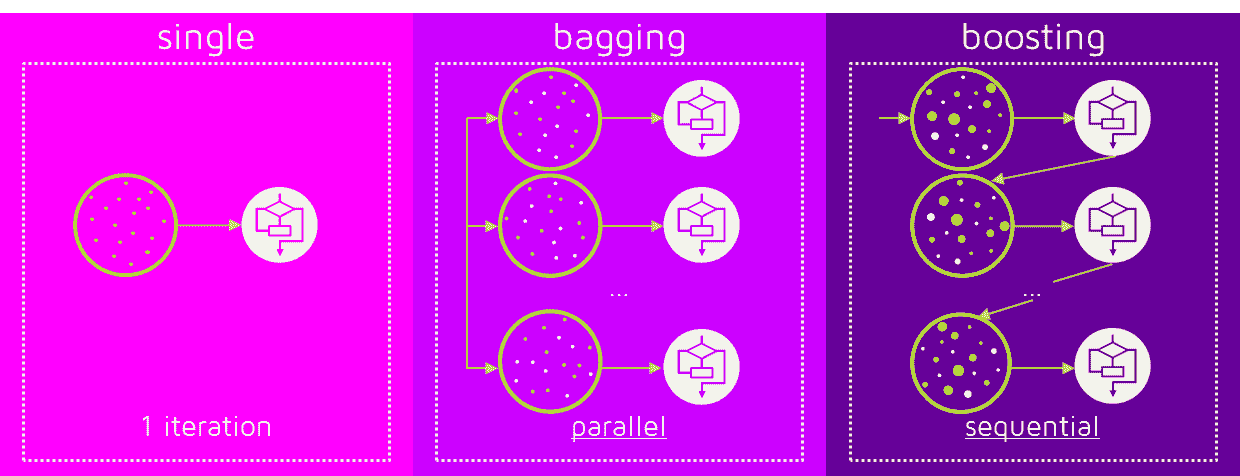
在 Boosting 算法中,每个分类器都是在数据上训练的,并考虑了之前分类器的成功。每次训练步骤后,权重会重新分配。被错误分类的数据增加其权重,以强调最困难的案例。这样,后续学习器在训练过程中会集中关注这些案例。
分类阶段是如何工作的?
要预测新数据的类别,我们只需将 N 个学习器应用于新观察数据。在 Bagging 中,结果是通过对 N 个学习器的响应进行平均(或多数投票)获得的。然而,Boosting 为 N 个分类器分配第二组权重,以便对它们的估计进行加权平均。
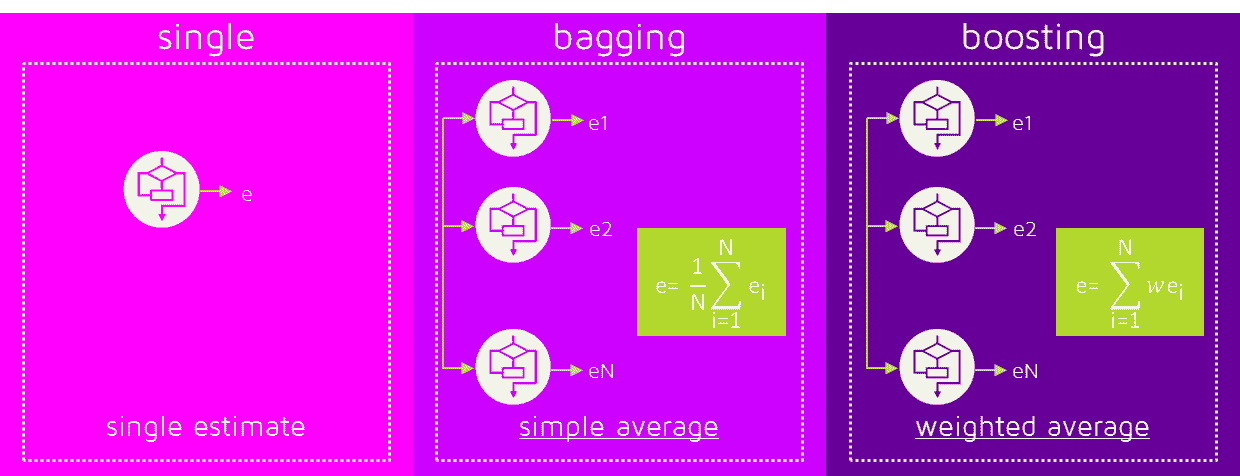
在 Boosting 训练阶段,算法会为每个结果模型分配权重。对训练数据分类效果好的学习器会被分配比效果差的学习器更高的权重。因此,在评估新的学习器时,Boosting 还需要跟踪学习器的错误。我们来看看过程中的差异:

一些 Boosting 技术包括额外的条件来决定是否保留或丢弃单个学习器。例如,在最著名的 AdaBoost 中,需要误差小于 50% 才能维持模型;否则,迭代将重复进行,直到达到比随机猜测更好的学习器。
之前的图像展示了 Boosting 方法的一般过程,但存在几种替代方法,它们在确定下一训练步骤和分类阶段使用的权重方面有所不同。如果你想详细了解,请点击这里:AdaBoost、LPBoost、XGBoost、GradientBoost、BrownBoost。
Bagging 和 Boosting 哪个更好?
没有绝对的赢家;这取决于数据、模拟和具体情况。
Bagging 和 Boosting 通过结合来自不同模型的多个估计来降低单个估计的方差。因此,结果可能是一个更高稳定性的模型。
如果问题在于单个模型性能非常低,Bagging 很少能获得更好的偏差。然而,Boosting 可以生成一个综合模型,具有较低的错误,因为它优化了单个模型的优点并减少了陷阱。
相反,如果单个模型的困难是过拟合,那么 Bagging 是最佳选择。Boosting 本身并不能避免过拟合;实际上,这一技术本身面临这个问题。因此,Bagging 比 Boosting 更常有效。
总结:
| 相似之处 | 差异 | |
|---|---|---|
| 两者都是集成方法,将 N 个学习者从 1 个学习者中获取… | … 但 Bagging 是独立构建的,而 Boosting 尝试添加在之前模型失败的地方表现良好的新模型。 | |
| 两者都通过随机抽样生成多个训练数据集… | … 但只有 Boosting 为数据确定权重,以便将偏差倾斜到最困难的案例。 | |
| 两者都通过对 N 个学习者的结果取平均(或取多数)来做出最终决定… | … 但 Bagging 采用的是等权重平均,而 Boosting 采用加权平均,更多权重分配给在训练数据中表现更好的学习者。 | |
| 两者都擅长减少方差并提供更高的稳定性… | … 但只有 Boosting 尝试减少偏差。另一方面,Bagging 可能解决过拟合问题,而 Boosting 可能增加过拟合。 |
原文。经许可转载。
相关:
-
集成学习以提升机器学习结果
-
数据科学入门:初学者的基本概念
-
必须了解:集成学习的基本思想是什么?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关话题
数据科学家与机器学习工程师的区别
原文:
www.kdnuggets.com/2021/08/difference-between-data-scientists-ml-engineers.html
评论

图片由 Stillness InMotion 提供,来源于 Unsplash
我们的前 3 门课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
数据科学家和机器学习工程师的角色之间常常存在混淆。虽然他们肯定会友好地合作,并且在专业知识和经验方面有一些重叠,但这两个角色服务于截然不同的目的。
实际上,我们正在区分那些寻求理解其工作背后科学的科学家和那些寻求构建可以被他人访问的事物的工程师。这两个角色都极其重要,在一些公司中,角色是可以互换的——例如,某些组织的数据显示科学家可能会执行机器学习工程师的工作,反之亦然。
为了明确区分,我将差异分为 3 类:1)职责 2)专业知识 3)薪资预期。
职责
数据科学家遵循数据科学过程,这也可以称为 Blitzstein 和 Pfister 工作流。Blitzstein 和 Pfister 最初创建了这个框架,旨在教导 哈佛 CS 109 课程的学生如何处理数据科学问题。
数据科学过程包括 5 个关键阶段
-
阶段 1: 理解业务问题
-
阶段 2: 数据收集
-
阶段 3: 数据清理与探索
-
阶段 4: 模型构建
-
阶段 5: 传达和可视化见解
数据科学家所做的大多数工作都是在研究环境中进行的。在这个环境中,数据科学家执行任务以更好地理解数据,从而构建能够最佳捕捉数据固有模式的模型。一旦他们构建了一个模型,下一步就是评估它是否达到项目的预期结果。如果没有,他们将迭代地重复这个过程,直到模型达到预期结果,然后将其交给机器学习工程师。
机器学习工程师负责创建和维护机器学习基础设施,使其能够将数据科学家构建的模型部署到生产环境中。因此,机器学习工程师通常在开发环境中工作,他们关注的是在研究环境中重现数据科学家构建的机器学习流程。同时,他们在生产环境中工作,使模型可以被其他软件系统和/或客户访问。
从本质上讲,机器学习工程师负责维护机器学习基础设施,使其能够部署和扩展数据科学家构建的模型。而数据科学家则是使用机器学习工程师构建的机器学习基础设施的用户。
专业知识
人们对这两个角色之间的区别感到困惑的原因在于,它们的技能有很多重叠的地方。例如,数据科学家和机器学习工程师都被期望具备良好的知识;
-
监督学习与无监督学习
-
机器学习与预测建模
-
数学和统计学
-
Python(或 R)
角色之间的主要重叠导致一些组织,特别是较小的组织和初创公司,将这些角色合并为一个。因此,一些组织让数据科学家做机器学习工程师的工作,而一些则让机器学习工程师做数据科学家的工作。这只会导致从业者之间的更多困惑。
然而,这两个角色所需的专业知识之间还是存在一些关键区别。
数据科学家通常是极其优秀的数据讲述者。有些人认为,这一特质使他们比机器学习工程师更具创造力。另一个区别是,数据科学家可能使用像 PowerBI 和 Tableau 这样的工具来向业务部门分享见解,他们不一定需要使用机器学习。
弥补对方不足的伴侣通常更强。当你这样考虑时,前面提到的专业知识可能是机器学习工程师的薄弱点,他们被期望在计算机科学和软件工程方面有坚实的基础。机器学习工程师需要了解数据结构和算法,并理解创建可交付软件所需的基本组件。
尽管如此,机器学习工程师通常也能很好地掌握其他编程语言,如 Java、C++ 或 Julia。
薪资预期
精确确定薪资期望是困难的。两个职位的薪资因多种因素而异,例如你的经验、资质、所在地点以及你所在的行业。
组织还预计提供各种福利。无论职位如何,你可以期待加入公司养老保险计划、灵活或远程工作、绩效奖金和私人医疗保险。
联合王国(UK)
-
初级数据科学家的起薪范围为£25,000 — £30,000(根据经验可能涨至£40,000)。 [来源: Prospects]。毕业生或入门级机器学习工程师的起薪为£35,000 — £40,000。 [来源: Prospects]
-
根据 Glassdoor,在英国,数据科学家的平均薪资为£46,818。 Prospects 指出,在英国,机器学习工程师的平均薪资为£52,000。
-
根据 Prospects,高级和首席数据科学家的薪资通常超过£60,000(在某些情况下超过£100,000)。相比之下,经验更丰富的机器学习工程师可以期待获得高达£170,000的薪资(特别是如果他们为像谷歌或脸书这样的跨国公司工作) [来源: Prospects]。
美利坚合众国(USA)
总的来说,机器学习工程师的薪资通常比数据科学家高,平均而言。
终极思考
尽管这两个职位有许多相似之处,但数据科学家和机器学习工程师在职责、专业技能和薪资方面差异很大。根据我听过的大多数相关访谈,许多人认为从数据科学家转型为机器学习工程师比从机器学习工程师转型为数据科学家要困难得多。这是因为数据科学家通常不熟悉软件工程和计算机科学基础,这是一大学习曲线。
感谢阅读!
如果你喜欢这篇文章,可以通过订阅我的免费每周通讯来与我联系。不要错过我关于人工智能、数据科学和自由职业的任何文章。
相关工作
简介:Kurtis Pykes 是一名机器学习工程师,数据科学领域的顶级作者,也是 Upwork 的顶级自由职业者。关注他的Medium 博客。
原文。经许可转载。
相关:
-
我如何在 8 个月内提升我的数据科学技能
-
最重要的数据科学项目
-
我希望在数据科学职业生涯中避免的 5 个错误
更多相关话题
数据分析师与数据科学家的区别
原文:
www.kdnuggets.com/2022/03/difference-data-analysts-data-scientists.html

图片来源:Alexander Sinn于Unsplash
数据科学家和数据分析师是 2022 年最受欢迎且薪资最高的职业之一。随着数据的不断增加,数据驱动的洞察也在不断增长。能够筛选、分析和解释大量信息的数据专业人员在今天至关重要。虽然数据分析师和数据科学家都处理数据,但有时不清楚二者之间的区别。主要的区别之一在于他们对处理的数据的不同用途。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
数据分析师通常使用结构化数据来解决特定的业务问题。数据分析师最常使用 SQL、R、Python 等工具。他们还使用数据可视化软件和统计分析。
相比之下,数据科学家处理的是未知的数据,并使用更先进的数据分析技术来预测未来。数据科学家构建自动化机器学习算法,开发能够处理结构化和非结构化数据的预测建模技术。通常,这个角色被认为是数据分析师的更高级版本。不过,这还不是全部。
本文将帮助你详细了解数据分析师和数据科学家如何处理数据。
什么是数据科学?
在深入了解数据分析师和数据科学家之前,了解一些关键术语是很重要的。虽然“数据科学”的定义没有统一标准,但谷歌决策智能负责人 Cassie Kozyrkov 表示:“数据科学是使数据变得有用的学科。”
另一个重要的术语是数据挖掘和描述性分析。数据挖掘是识别数据中的模式并提出关于这些模式成因的假设的过程。这一步骤专注于通过数据寻找趋势。
数据科学与许多区块链相关技术的交集越来越多。区块链本质上是一个不断增长的记录列表,通常作为一个使用加密技术链接的分布式账本。
数据的使用方式:数据分析师与数据科学家
数据科学家通常是处理原始数据和数据集的第一接触点。数据科学家将数据拆解并帮助理顺数据。他们处理的数据集通常很大,结构松散,并需要抽象分析来发现数据中的洞察。
另一方面,数据分析师接收由数据科学家处理过的数据并加以利用。他们获得带有洞察的已知数据集,然后寻找数据中的新趋势。由于数据更为结构化,数据分析师可以创建报告来回答特定的业务问题,并向非技术观众传达他们的发现。
越来越多的数据专业人士将区块链技术作为他们工作的一部分。区块链最为人知的是其作为比特币核心技术的角色。许多企业使用区块链来管理数据。其他企业甚至可能买卖比特币作为其财务计划的一部分。
可以把数据科学家视为数据的原始处理者,而数据分析师则是利用数据为业务带来利益的专家。
行业工具
一旦数据专业人士获取了数据,他们需要将其投入使用。然而,选择正确的工具进行数据分析很重要。由于工作的性质,数据分析师和数据科学家往往会使用相同的工具,但使用方式不同。
通常工具可以分为五类:
-
数据库
- 比如 DuckDB 和 PostgreSQL
-
网络爬取
-
Beautiful Soup,一个用于从 HTML 和 XML 中提取数据的 Python 库。
-
Zyte 是一个用于运行网络爬虫的云平台。
-
-
数据分析
-
编程语言是数据分析的核心。
-
Python 是数据科学家中最常用的语言。
-
R,是数据分析和统计学家中流行的程序。
-
Julia,一种用于解决科学问题的新兴编程语言。
-
Tableau,一个无需编码的工具,能让你可视化各种数据。
-
-
机器学习
-
FastAI 是一个适合初学者的编程库,用于构建机器学习性能。
-
Scikit-learn 用于数据处理和机器学习任务。
-
TensorFlow 是一个完整的机器学习生态系统,是构建机器学习模型的端到端解决方案。
-
-
报告
-
Jupyter notebook 允许你在本地或云端构建科学报告
-
Deepnote,一个云笔记本平台
-
Dash 允许你构建和部署具有交互式用户界面的数据应用程序。
-
这些只是数据分析师和数据科学家可用的部分工具。具体使用哪些工具取决于他们对数据如何利用的终极目标。
教育和技能
现在你了解了这两类专业人士如何使用数据以及他们使用的工具类型,那么这两组人需要哪些技能和教育背景呢?
教育
数据分析师通常比数据科学家专业性低,他们通常需要至少拥有统计学、数学、计算机科学或金融学的学士学位。
相对而言,数据科学家(以及更高级的分析师)至少拥有信息技术、数据科学、统计学或数学领域的硕士学位(甚至博士学位)。
然而,证书和专业培训的作用越来越大。Google 和 IBM 都提供数据分析的专业证书,让你获得成为入门级数据分析师所需的技能。最终,可以将数据分析师视为入门点,数据科学家则是更高级的数据管理者。
数据技能
由于这两组人都处理数据,他们在所需技能上往往有重叠,但也有一些差异。最重要的是,数据科学家往往经验更丰富。
-
数学
-
数据分析师:统计学、基础数学
-
数据科学家:高级统计学、预测分析
-
-
编程
-
数据分析师:Python、R、SQL 基础流利
-
数据科学家:高级面向对象编程语言培训
-
-
工具
-
数据分析师:Excel、SAS、商业智能软件
-
数据科学家:Hadoop、MySQL、TensorFlow、Spark
-
-
其他技能
-
数据分析师:数据可视化、分析思维
-
数据科学家:数据建模、机器学习
-
这些只是基础,但一般来说,数据分析师是成为数据科学家的入门点,通常需要经过广泛的培训和教育。许多在线平台提供数据科学免费课程和数据分析课程,如果你想深入了解。
数据专业人员在商业中的角色
数据科学家和数据分析师在商业团队中都至关重要。数据分析师和数据科学家在商业中扮演的角色以及技能的运用是不同的。
数据科学家通常向首席数据官汇报工作。他们通常在一个团队中工作,不同的业务部门将利用他们的工作来建立数据集,以便各自的数据分析师进行提取。数据科学家可能一天查看供应链数据,第二天则分析收益信息。
数据分析师通常会被限制在一个业务领域内。数据分析师最常在一个部门内工作,如财务或会计。然后他们会 专注于与其业务领域最相关的指标和报告。
数据科学家的主要商业价值在于他们能够深入挖掘数据,找到非结构化数据中的洞察。然后,数据分析师将这些洞察转化为可操作的见解。
数据科学职业的核心要点
数据科学家和数据分析师在组织中扮演着重要但不同的角色。然而,两者都是从商业数据中获取最大收益所必需的。数据科学家凭借其专业培训,可以从原始数据中识别出洞察。然后,数据分析师利用筛选后的数据来回答具体的商业问题。两者共同利用数据,帮助公司获得利益。
Nahla Davies 是一位软件开发者和技术作家。在全职从事技术写作之前,她还曾担任过包括三星、时代华纳、Netflix 和索尼在内的 Inc. 5,000 体验品牌组织的首席程序员,负责许多引人入胜的项目。
更多相关话题
数据科学家和数据分析师之间的区别是什么?
原文:
www.kdnuggets.com/2021/11/difference-data-scientist-data-analyst.html
评论
“数据科学家是被雇佣来分析和解释复杂数字数据的人,例如网站的使用统计信息,特别是为了帮助企业做出决策。”
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
—Oxford Dictionary
“数据分析师是一位与数据工作以提供洞察的专业人士,他们处理原始或非结构化的数据,并进行分析,以生成高层管理人员和其他人可以用来做决策的易于理解的结果。”
—Techopedia
“数据科学家是一个能够根据过去的模式预测未来的人,而数据分析师只是从数据中策划有意义的洞察。”
既然我们有了定义,我认为真正理解两者之间差异的最佳方法是进行比较。
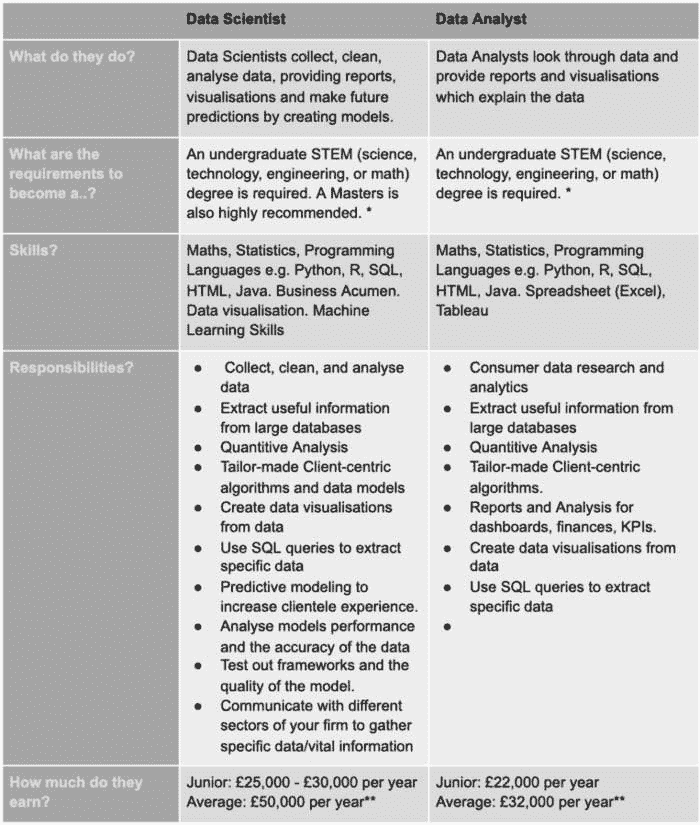
- 这是推荐的。成为数据科学家/分析师还有其他途径。查看我之前的文章。
从数据分析师转型为数据科学家
尽管这两条职业道路有很多相似之处,但也有许多不同之处。数据科学家获得的更高薪水伴随着更多的责任。这些额外的责任包括更多的学习、更多的知识以及更多的编程技能实践。
以下是一些建议,如果你希望从数据分析师转型为数据科学家,我推荐你采取的措施。
扮演数据科学家的角色。
如果你已经决定转型成为数据科学家,你一定做了大量额外的阅读,以全面理解成为数据科学家的要求。你将从描述数据中的趋势,转变为利用现有数据发现新数据,并构建机器学习模型以支持你的假设。
数据科学家:
-
花费大量时间使用如 Python 或 R 等语言清理数据。
-
使用机器学习算法,如梯度提升、线性回归、逻辑回归、决策树、随机森林等,构建预测模型。
-
评估他们创建的模型,以获得高百分比的准确率,从而验证分析结果。
-
测试和改进已建立的机器学习模型的准确性。
-
构建可视化图表来叙述高级分析结果。
提升你的技能。
作为数据分析师,你可能不会每天都编写代码。你的工作要求包括编写代码和运用技术技能,但你的部分时间可能会分配到其他地方,例如识别趋势以帮助业务决策。作为数据科学家,能够编写代码是至关重要的,因为你大部分时间都在编写代码,并且需要能够适应和使用不同的编程环境。这可能要求你理解频繁使用的不同编程语言的语法,如 R、Python 和 Java。
数据分析师使用的数学和统计方法远少于数据科学家。因此,复习数学和统计将对你大有裨益,因为你将需要在日常生活中应用这些知识。你需要从头编写算法,并全面理解这些机器学习算法的工作原理。
你编写的代码越多,学习的编程语言越多,你就会成为更出色的数据科学家。你可以通过练习代码、创建副项目、参与像 Kaggle、LeetCode 等代码挑战来实现上述目标。你只有通过实践数据科学家的生活,才能知道自己是否能成为一名数据科学家。
我希望这能帮助你了解这两个角色之间的区别,并为你计划从数据分析师转型为数据科学家提供一些指导。
本文最初发布在 AI Time Journal。
简介:Nisha Arya Ahmed 是一位年轻的数据科学家,希望探索人工智能在延长人类生命和攻克绝症方面的不同方式。Nisha 还希望了解人们对人工智能的看法,以及他们认为人工智能带来了什么或没有带来什么。
原文。经授权转载。
相关:
-
从新手到第一份工作的数据科学家职业路径
-
区分数据科学家的五个要素
-
别浪费时间建立你的数据科学网络
相关话题
L1 和 L2 正则化的区别
原文:
www.kdnuggets.com/2022/08/difference-l1-l2-regularization.html
主要要点
-
正则化回归可以用于特征选择和降维
-
这里讨论了两种类型的正则化回归模型:岭回归(L2 正则化)和套索回归(L1 正则化)
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT
基本线性回归
假设我们有一个数据集,其中包含 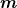 特征和
特征和 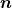 观测,如下所示:
观测,如下所示:

一个基本的回归模型可以表示为:
其中 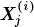 是
是 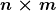 特征矩阵,而
特征矩阵,而 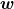 是权重系数或回归系数。在基本线性回归中,通过最小化下面给出的损失函数来获得回归系数:
是权重系数或回归系数。在基本线性回归中,通过最小化下面给出的损失函数来获得回归系数:
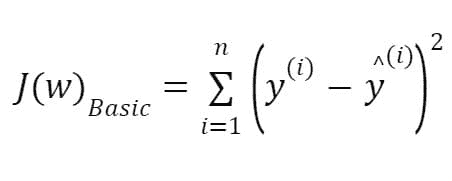
岭回归:L2 正则化
在 L2 正则化中,通过最小化 L2 损失函数来获得回归系数,如下所示:
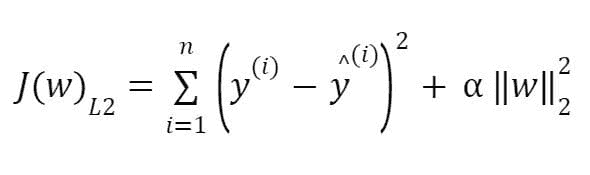
其中
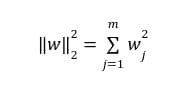
这里,α ∈[0, 1] 是正则化参数。L2 正则化在 Python 中实现为:
from sklearn.linear_model import Ridge
lasso = Ridge(alpha=0.7)
Ridge.fit(X_train_std,y_train_std)
y_train_std=Ridge.predict(X_train_std)
y_test_std=Ridge.predict(X_test_std)
Ridge.coef_
套索回归:L1 正则化
在 L1 正则化中,通过最小化 L1 损失函数来获得回归系数,如下所示:
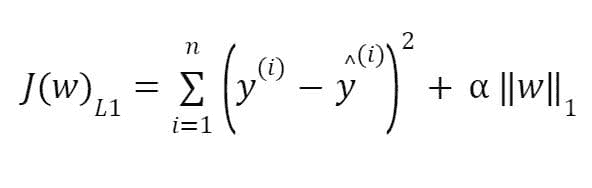
其中
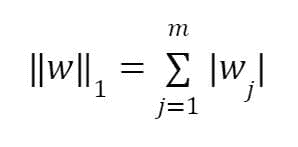
L1 正则化在 Python 中实现为:
from sklearn.linear_model import Lasso
lasso = Lasso(alpha=0.7)
lasso.fit(X_train_std,y_train_std)
y_train_std=lasso.predict(X_train_std)
y_test_std=lasso.predict(X_test_std)
lasso.coef_
在 L1 和 L2 正则化中,当正则化参数(α ∈[0, 1])增加时,这会导致 L1 范数或 L2 范数减小,从而将一些回归系数压缩为零。因此,L1 和 L2 正则化模型用于特征选择和降维。L2 正则化相较于 L1 正则化的一个优点是 L2 损失函数容易求导。
案例研究:L1 回归实现
使用游轮数据集实现 L1 正则化的实现可以在这里找到:Lasso 回归的实现。
下图展示了 R2 分数和 L1 范数作为正则化参数的函数关系。
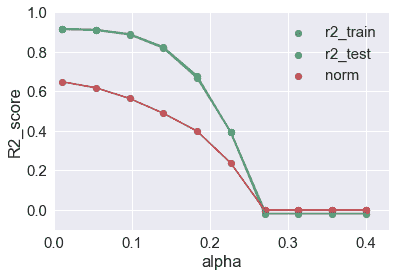
从上图中可以观察到,随着正则化参数α的增加,回归系数的范数变得越来越小。这意味着更多的回归系数被压缩为零,从而增加了偏差误差(过于简化)。在α保持较低值时,例如α=0.1 或更低,偏差-方差权衡的最佳值。
本杰明·O·泰约是一位物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的所有者。之前,本杰明曾在中欧大学、大峡谷大学和匹兹堡州立大学教授工程学和物理学。
更多相关话题
SQL 与对象关系映射(ORM)之间的区别是什么?
原文:
www.kdnuggets.com/2022/02/difference-sql-object-relational-mapping-orm.html
由 freepik 创建的技术矢量图 - www.freepik.com
在处理数据库时,通常会出现是否应该使用结构化查询语言(SQL)还是对象关系映射(ORM)的问题。以下是这两者的概述,帮助人们做出明智的决定。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
SQL 如何工作?
SQL 允许人们通过使用特定的查询与关系数据库互动。关系数据库将信息存储在字段中,并通常按行和列组织内容。每个数据库通常至少包含一个表。
SQL 是一种编程语言,允许个人提取或修改在数据库中的所需信息。他们通过输入不区分大小写的查询来实现这一点。
例如,CREATE DATABASE 命令创建一个新的数据库,而 INSERT INTO 命令将信息移动到一个数据库中。这是两种直接的查询类型。然而,根据需要,它们可能变得更加复杂。在这些情况下,一个分心的开发人员更容易出错。
ORM 与 SQL 有何不同?
对象关系映射让人们可以用自己选择的编程语言与数据库互动,而不是强制使用 SQL。开发人员可以使用称为对象关系映射器的工具。这些工具以结构化的方式展示数据,帮助用户理解数据库的内容和布局,而无需使用 SQL。一个主要的好处是节省时间相比输入 SQL 查询。
随着人们与数据的交互变得越来越复杂,SQL 查询的长度也随之增加。这种现实增加了出错的可能性。由于有多种编写问题和获取相同结果的方法,情况也变得更加复杂。
对象关系映射器作为一种翻译器,将代码从一种形式转换为另一种形式。该工具创建表示数据库虚拟映射的对象。用户可以与这些对象互动,而不是直接操作代码。
选择 SQL 和 ORM 之间的考虑因素
人们自然会想知道什么时候应该使用 SQL 或 ORM。以下是一些可以帮助他们在特定情况下做出正确决策的要点。
安全性
任何全面的数据安全方法都必须保护静态数据、使用中的数据和传输中的数据。SQL 注入攻击允许恶意方篡改存储的数据。许多因素可能使这些事件更有可能发生,但旧的或错误的代码是主要原因之一。使用参数化查询是避免 SQL 注入攻击的最佳实践之一。
许多 ORM 工具默认会对某些类型的查询进行参数化。这可以帮助防止一些 SQL 攻击。使用 ORM 不能完全杜绝这些攻击,但可以降低其发生的可能性。
当前 SQL 熟练程度
数据显示,2021 年全球 47.8% 的开发者使用 SQL。这虽然是一个总体少数,但仍然是一个相当大的比例。那些不经常使用 SQL 或对其不太舒适的人可能更愿意使用 ORM。他们可能会更少犯错,尤其是在处理复杂查询时。
然而,一些开发者指出,ORM 的存在并不能成为回避学习 SQL 的借口。使用 ORM 仍然需要设置和配置,才能开始使用。
查询的复杂性和所需速度
关于使用 ORM 和 SQL 需要考虑的另一点是,前者可能会牺牲一些速度。因此,人们在运行复杂查询时可能会发现他们的生产力降低。
如果人们担心在使用 SQL 输入复杂查询时出错,他们可能会发现较慢的速度是可接受的权衡,以换取 ORM 工具所提供的更高准确性。然而,那些有多年 SQL 经验且对自己能力有信心的人可能不愿意使用 ORM 工具并接受较慢的处理速度。
供应商锁定的可能性
使用 ORM 意味着在处理数据库时始终依赖第三方工具,而 SQL 则不需要。如果一个人不喜欢需要依赖供应商产品来进行数据库更改的想法,那么最好还是由具备强大 SQL 技能的其他人来完成这项工作。
市场上有许多 ORM 产品,确定哪个最适合组织的需求并不总是容易的。也许决策者还没有得出结论,而他们需要尽快完成数据库工作。在这种情况下,SQL 允许在公司购买 ORM 之前完成任务。
故障排除的便利性
SQL 需要开发者直接处理代码。这意味着他们通常可以更容易地进行低级故障排除,因为他们可以确切看到哪些查询使他们达到了某个点。
ORM 在开发者与代码之间工作,因此不容易看到后台发生了什么。这一特性使得故障排除变得更加复杂。
没有普遍适用的最佳选择
许多开发者可能会在不同的时间使用 SQL 和 ORM。这是因为在某些情况下,其中一个明显是更合适的选择。然而,简单地说其中一个在所有情况下都是最佳选择是短视的。考虑到这一点,开发者在决定使用哪一个之前,应考虑项目的范围、组织的需求和他们的能力。
香农·弗林 (@rehackmagazine) 是一位技术博主,专注于 IT 趋势、网络安全和商业技术新闻。她也是 MakeUseOf 的撰稿人,并且是 ReHack.com 的执行编辑。关注 KDnuggets,了解更多来自香农以及其他数据科学更新的信息。有关更多信息,请参见香农的 个人网站。
更多相关话题
机器学习中训练数据与测试数据的区别
原文:
www.kdnuggets.com/2022/08/difference-training-testing-data-machine-learning.html
在构建预测模型时,结果的质量取决于你使用的数据。如果你使用的数据不足或错误,你的模型将无法做出现实的预测,并会引导你走向错误的方向。为避免这种情况,你需要了解机器学习中训练数据与测试数据的区别。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
不再废话,让我们深入探讨。
培训数据
假设你想基于某些数据库创建一个模型。在机器学习中,这些数据被分为两个部分:训练数据和测试数据。
训练数据是你输入到机器学习模型中的数据,以便它可以分析并发现一些模式和依赖关系。这个训练集有三个主要特征:
-
大小。训练集通常比测试数据更多。你输入给机器的数据越多,模型的质量就越好。一旦机器学习算法获得了你的记录中的数据,它就会从中学习模式,并为决策制定创建一个模型。
-
标签。标签是我们试图预测的值(响应变量)。例如,如果我们想预测患者是否会被诊断为癌症,基于他们的症状,响应变量将是癌症诊断的“是/否”。训练数据可以是标记的或未标记的。这两种类型的数据在机器学习中都可以用于不同的情况。
-
案例细节。算法基于你提供的信息做出决策。你需要确保数据是相关的,并且具有各种不同结果的案例。例如,如果你需要一个可以评估潜在借款人的模型,你需要在训练集中包含在申请过程中你通常了解的关于潜在客户的信息:
-
名称和联系方式、地点;
-
人口统计、社会和行为特征;
-
来源(Meta 广告、网站登陆页面、第三方等)
-
与网站上的行为/活动、转化、在网站上花费的时间、点击次数等相关的因素。
-
测试数据
在机器学习模型建立之后,你需要检查它的工作情况。AI 平台使用测试数据来评估模型的性能,并进行调整或优化,以获得更好的预测结果。测试集应具备以下特点:
-
未见过。你不能重复使用在训练集中出现过的信息。
-
大。数据集应该足够大,以便机器能够进行预测。
-
代表性。数据应能代表实际的数据集。
幸运的是,你无需手动收集新的数据并与实际数据进行比较。AI 可以将现有数据分成两部分,在训练时将测试集放在一边,然后自动进行测试,比较预测结果和实际结果。数据科学有不同的数据拆分选项,但最常见的比例是 70/30、80/20 和 90/10。
因此,手头有了大量的数据集,我们可以检查是否可以基于该模型进行预测。
训练和测试数据如何运作的示例
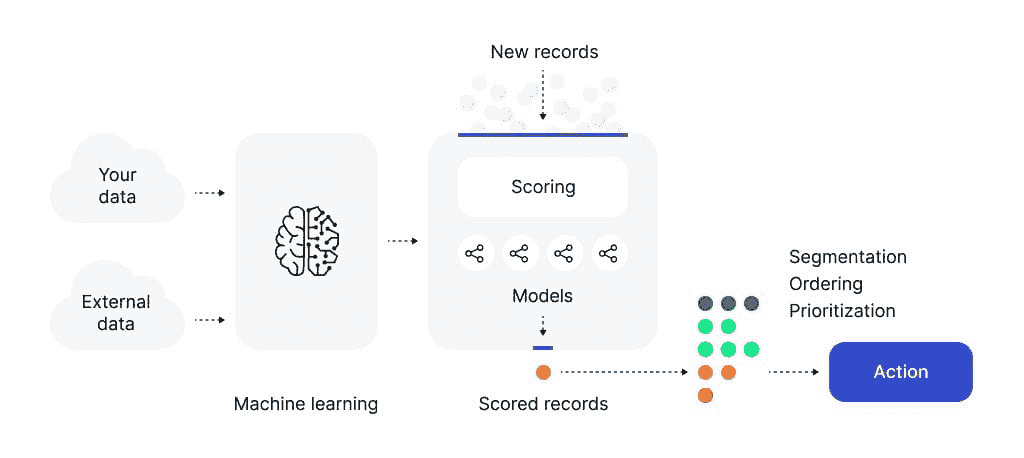
现在,让我们看看这两个数据集在实际中是如何运作的。作为示例,我们将使用 GiniMachine —— 一个无代码的 AI 决策平台。
在这种系统中,评估过程称为盲测。当建立模型时,AI 会将数据按约 70% 对 30% 的比例进行拆分,其中第一个比例是训练数据,第二个比例是测试数据。在训练过程中,机器会分析不同的指标及其对结果的影响。而在盲测期间,它会尝试为测试记录计算分数并预测结果。它可以处理自定义的比例和多目标以及双因素的分层。
在模型建立并测试之后,机器会计算一个特殊指标来代表模型的质量。这样,用户可以决定是否使用这个模型进行评分或创建另一个模型。
机器学习需要多少数据才够
训练集和测试集都应该足够大,以便机器能够学习。但究竟需要多少数据才算够呢?
这取决于你使用的平台。一些机器至少需要 1,000 条记录来建立模型。但是数据的质量也很重要。行业中有一条不成文的规则:使用 1,000 条不良记录加上 X 条好的记录来创建一个可靠的模型。例如,1,000 条不良贷款记录加上 X 条已成功偿还债务的记录。
然而,这只是一个大致的数字。所需记录的确切数量只能通过测试不同选项来确定。根据我们的经验,只用 100 条记录也可以建立一个不错的模型,而有些情况下需要超过 30,000 条记录。
使用我们之前提到的 GiniMachine,你可以无限制地实验不同的数据,构建尽可能多的模型。但是,如果你使用其他平台,如 Visier People 或 underwrite.ai,他们对数据的要求可能会有所不同。在选择决策平台时,请注意这些特性。
预测误差
讨论预测模型时,重要的是提到影响预测质量的两个现象:偏差-方差权衡和维度灾难。
简而言之,偏差-方差权衡是创建过于通用或过于具体模型之间的平衡。具有高偏差的模型通常过于简化,在训练数据和测试数据中都会犯很多错误。这发生在我们拥有的数据过少且过于通用时。例如,如果你试图用仅仅十个关于毛发长度和颜色的例子来教模型区分猫和狗。要解决这个问题,你需要使用更多的数据和变量。
而具有高方差的模型完全无法概括数据。因此,它在训练数据上表现良好,但在测试数据上有很多错误。如果你用具有许多特征的过于具体的数据喂养模型,就可能出现这种情况。因此,它无法理解哪些特征最重要,也无法对未见数据做出正确的预测。此外,特征数量的增加会增加模型的复杂性,并可能导致维度灾难。在这种情况下,你需要将单独的特征组合成簇,并从数据集中清理掉不必要的信息。
如何在业务中使用数据
机器学习和基于 AI 的预测软件的可能性是无限的。它们可以帮助你预测产品需求、评估新线索和选择最有前途的项目、评分信用申请和债务催收、自动化招聘流程,或分析医疗保健和农业数据。使用这样的平台没有限制。只要有合适的数据集,你就可以构建所需的模型,开始评分并获得更大的业务成果。
Mark Rudak 是 Ginimachine 的机器学习产品负责人
更多相关信息
传统编程和机器学习有多大不同?
原文:
www.kdnuggets.com/2018/12/different-conventional-programming-machine-learning.html
评论
作者:Avneesh Sharma,技术产品管理

工程让我们突破了人类能力的极限。我们利用对自然的理解来服务于我们的目的。无论是高性能的机械设备还是编码的硅芯片,计算机迄今为止是自然力量最复杂的应用之一,帮助人类推动能力的极限,即计算机能够执行的许多任务,往往是人类或一组人无法如此迅速和高效完成的。正如史蒂夫·乔布斯所说,计算机就像我们思想的自行车。
我从小就对计算机充满了好奇。我在 2001 年第一次接触计算机,当时我写了一个 BASIC 程序来加两个数字。我惊讶于无论加法有多么困难,计算机都能立即给出答案。
当我听到机器学习时,我无法抑制惊讶。我无法理解,跟我习惯的普通软件程序不同,我不需要事先详细教会计算机如何处理所有未来的场景。计算机可以自己学习如何解决问题。这对人类来说是一个巨大的飞跃。
什么是机器学习?
术语‘机器学习’并不新鲜。它是由亚瑟·塞缪尔在 1959 年创造的。它借鉴了计算机科学、统计学、线性代数和概率论等不同领域的理解,并应用于解决实际问题。机器学习使计算机能够从历史数据中学习,制定出可以用于解决未来类似问题的解决方案,而不需要显式地教会计算机所有可能场景的组合。而机器学习的实际应用正是那些连明确的数学解决方案都难以阐明的问题。
如果一个现实世界的问题符合以下条件,它就是机器学习应用的候选:
-
历史数据存在大量
-
数据中存在模式
-
数学上极难确定一个解决方案
它与传统编程有何不同?
传统编程的方法是给计算机输入一组指令以处理特定场景。之后,计算机将利用其计算能力帮助人类更快、更高效地处理数据。而在机器学习中,大量数据被输入到计算机中,计算机处理这些数据并得到一个称为训练模型(解决方案)的东西。然后使用这个模型来解决现实世界中未见过的问题。
示例
让我们以一个玩具问题来演示区别。这个问题接受一个输入数字,并尝试用 3 和 5 进行除法。如果数字能被 3 整除,则打印'fizz';如果能被 5 整除,则打印'buzz';如果能被两者整除,则打印'fizzbuzz'。如果不能被 3 或 5 整除,则打印'other'。这被称为Fizzbuzz游戏。
传统编程
在传统编程中,给计算机输入指令非常简单,因为我们只有 4 种场景需要验证,并根据这些场景打印输出。Python 代码可以如下编写,但如果你不喜欢编码,可以跳过阅读代码。
def fizzbuzz(n): # if the number is divisible by 3 as well as by 5 and returns # "FizzBuzz"
if n % 3 == 0 and n % 5 == 0:
return 'FizzBuzz'# If the first condition is not satisfied then it checks if it is # divisible by 3 and return "Fizz"
elif n % 3 == 0:
return 'Fizz'# If both of the above tests are not satisfying, then it will check # whether it is divisible by 5 and return "Buzz"
elif n % 5 == 0:
return 'Buzz'# If all the conditions above do not satisfy then it returns "Other"
else:
return 'Other'
机器学习
假设我们已经有很多数字,其输出结果已知,即它是'fizz'、'buzz'还是'fizzbuzz'。我们现在需要做的就是编写机器学习代码,并输入(训练)现有数据。然后通过用未见过的数据进行测试来验证我们是否成功创建了模型。如果模型能在不实际计算结果的情况下提供输出,那么我们就达到了目的。
我们将使用 Google 的Tensorflow库来实现。以下是实现中的一些代码片段。
再次强调,如果你不喜欢编码,可以跳过代码。完整的工作代码可以在我的 Github 账户的这里找到。
a. 创建模型
# Placeholders are the type of variables nodes where data can be
# fed from outside when we actually run the model
#Placeholder for input data
inputTensor = tf.placeholder(tf.float32, [None, 10])
# Placeholder for output data
outputTensor = tf.placeholder(tf.float32, [None, 4])
# The number of neurons which 1st hidden neurons will have i.e. 1000
NUM_HIDDEN_NEURONS_LAYER_1 = 1000
# Learning rate, which will be later used to optimize for optmizer function
# Learning rate defines at what rate the optimizwer function will move towards minima per iteration
# Less than optimum learning rate will slow down the process where as higher learning rate will have chances of
# skipping the minima all together. So it will never converge rather it will keep on going back and forth.
LEARNING_RATE = 0.05
# Initializing the weights to Normal Distribution
# The weights will keep on adjusting towards optimum values in each iteration. Conceptually, weights determine the
# discrimination factor of a particular variable in the newural network. More the weight, more will be it's
# contribution in determining the solution.
def init_weights(shape):
return tf.Variable(tf.random_normal(shape,stddev=0.01))
# Initializing the input to hidden layer weights
# We will need a total of 10(input layer number) * 100(number of hidden layers)
input_hidden_weights = init_weights([10, NUM_HIDDEN_NEURONS_LAYER_1])
# Initializing the hidden to output layer weights
# In this case we will need 100(number of hidden neurons layers) * 4(output neurons, we have only 4 categories)
hidden_output_weights = init_weights([NUM_HIDDEN_NEURONS_LAYER_1, 4])
# Computing values at the hidden layer
# Matrix multiplication is done and then rectifier neural network activation function is used
# for regularization of the resulting multiplication
hidden_layer = tf.nn.relu(tf.matmul(inputTensor, input_hidden_weights))
# Computing values at the output layer
# Matrix multiplication of hidden layer and output weights it done.
output_layer = tf.matmul(hidden_layer, hidden_output_weights)
# Defining Error Function
# Error function computes the difference between actual output and model output.
# Here we are calculating the error in the output as compared to the output label
error_function = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=output_layer, labels=outputTensor))
# Defining Learning Algorithm and Training Parameters
# We are using Gradient Descent function to optimize the error or to reach the minima.
training = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(error_function)
# Prediction Function
prediction = tf.argmax(output_layer, 1)
b. 训练模型
NUM_OF_EPOCHS = 5000
BATCH_SIZE = 128
training_accuracy = []
with tf.Session() as sess:
# Set Global Variables ?
# We had only defined the model previously. To run the model, all the variables need to be initialized and run.
# Actual computation can only start after the initialization.
tf.global_variables_initializer().run()
for epoch in tqdm_notebook(range(NUM_OF_EPOCHS)):
#Shuffle the Training Dataset at each epoch
#Shuffling is done to have even more randmized data, which adds to the generalization of model even more.
p = np.random.permutation(range(len(processedTrainingData)))
processedTrainingData = processedTrainingData[p]
processedTrainingLabel = processedTrainingLabel[p]
# Start batch training
# With batch size of 128, there will be total of 900/128 runs in each epoch where 900 is the total
# training data.
for start in range(0, len(processedTrainingData), BATCH_SIZE):
end = start + BATCH_SIZE
sess.run(training, feed_dict={inputTensor: processedTrainingData[start:end],
outputTensor: processedTrainingLabel[start:end]})
# Training accuracy for an epoch
# We are checking here the accuracy of model after each epoch
training_accuracy.append(np.mean(np.argmax(processedTrainingLabel, axis=1) ==
sess.run(prediction, feed_dict={inputTensor: processedTrainingData,
outputTensor: processedTrainingLabel})))
# Testing
predictedTestLabel = sess.run(prediction, feed_dict={inputTensor: processedTestingData})
c. 测试模型
wrong = 0
right = 0
predictedTestLabelList = []
#Comparing the predicted value with the actual label in training data
for i,j in zip(processedTestingLabel,predictedTestLabel):
predictedTestLabelList.append(decodeLabel(j))
if np.argmax(i) == j:
right = right + 1
else:
wrong = wrong + 1
print("Errors: " + str(wrong), " Correct :" + str(right))
print("Testing Accuracy: " + str(right/(right+wrong)*100))
d. 结果:
Errors: 2 Correct :98
Testing Accuracy: 98.0 %
结论
我们重复地输入相同的数据 5000 次,每次都重新打乱。每次运行后,我们通过测量测试数据的误差率来评估模型的准确性。如图所示,模型的准确率为 98%。我绘制了每次迭代后的误差图。数值越接近 1,模型表现越好。图表如下:

结束语
如上所示,在这个特定的玩具案例中——传统程序将始终给出正确的输出,而机器学习可能无法达到 100%的准确水平。
现在设想一个场景,你正在经营一家像 Netflix 这样的公司,拥有数百万客户。每个客户都有一组独特的偏好。例如,有些人可能喜欢纪录片和喜剧电影,但他在周二观看纪录片,在周日观看喜剧电影。而另一些人则在周六晚上狂看视频,喜欢在周日观看恐怖片等等。你可以想象,当有这么多变量决定确切的偏好时,记录每个人的习惯会多么复杂。因为如果你想向每个客户推荐他/她将要观看的电影,你必须了解该人的确切偏好。
对于传统编程,这个问题变得越来越困难,因为:
-
你不知道决定一个人观看习惯的所有因素。
-
即使你知道了,解决方案也无法扩展到数百万用户,因为对于每个人,你都需要根据他/她的习惯编写一个单独的解决方案。
这里实现了机器学习。一般来说,在这种情况下,机器学习将基于两个前提进行训练:
-
根据你的过去数据,你最有可能观看哪些电影?
-
现在人们像你一样在看什么?
请通过下面的评论告诉我你的想法。
PS:文章中使用的完整代码可以在 这里 找到。
参考资料
-
https://www.amazon.com/Pattern-Recognition-Learning-Information-Statistics/dp/0387310738
-
https://www.youtube.com/watch?v=mbyG85GZ0PI&index=1&list=PLD63A284B7615313A
简介: Avneesh Sharma 是布法罗大学(2018-19)的管理信息系统硕士候选人。他拥有 8 年的软件产品/功能从头开发经验。他喜欢解决对业务有直接影响的问题,并使最终用户满意。他相信,创造技术通常是解决现实世界痛点的一种手段,以简化生活。
原文。经许可转载。
相关内容:
-
回归分析真的算作机器学习吗?
-
机器学习与统计学
-
大数据、圣经密码和邦费罗尼
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关话题
NLP 在现实世界中的应用范围:每个问题的不同解决方案
原文:
www.kdnuggets.com/2022/03/different-solution-problem-range-nlp-applications-real-world.html

背景矢量图由 freepik 创作 - www.freepik.com
如今,公司开始意识到他们每天处理的所有非结构化数据中隐藏了大量价值,并埋藏在多年来巨大增长的档案中。我们观察到一个由许多提供基于人工智能解决方案的参与者组成的行业的(重新)诞生,组织要求他们帮助理解文档的内容,以及像数据科学家这样的新重要角色。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
由于这个行业非常年轻,我们也记录了理解自然语言处理真正意义上的困难。大多数公司将其视为一种大技术,并认为供应商的产品质量和价格可能有所不同,但NLP 并不是一种工具;它不是一种工具,而是一个工具箱。当我们将市场作为一个整体来看时,存在很大的多样性,即使大多数供应商只有一个工具,而这个工具也并不适用于所有问题。虽然可以理解,当技术合作伙伴接触潜在客户时,会尝试使用它拥有的工具来解决业务案例,但从客户的角度来看这并不理想。每个问题都需要不同的解决方案。
多年来,我与来自各个行业的许多客户合作,由于我有幸为拥有多种工具的公司工作,我可以每次选择不同的方法。最适合工作的工具。我通常的问题是:
-
方法论是否相关?鉴于相同的功能,是否有影响,比如说,偏好深度学习而不是符号学?
-
AI 解决方案预期要交付什么?针对特定的用例,哪个 NLP 特性最为合适?
尽管实现这一主题可能需要一个为期两周的研讨会来进行充分调查,但我会尝试通过几个例子总结我的经验(当然,也应用必要的简化)。
我会先说,从我的角度来看,这两个问题是紧密相连的。一些方法(例如基于机器学习的方法)可以响应短时间市场需求,实际上可以快速交付一个足够好的解决方案,至少对于一些用例(例如可以忽略精度与召回率),尤其是当我们的解决方案基于一个过去因为某种原因被手动标记的大型档案时。另一方面,一个项目可能要求高精度和高召回率,但它主要围绕专有名词或唯一的代码(即很少出现歧义),因此使用直接的关键词列表来处理问题更为容易。不幸的是,我们没有严格的指南来说明何时一种方法优于其他方法,这种选择与我们想要构建的具体解决方案紧密相关……但有一些一般规则。由于生活中的一切都有优缺点,这里是一个(再次,简化的)视角:
-
关键词技术(又名浅层语言学)在涉及明确的词汇列表时更为可取,但当相关词汇可以表示多重意义时不建议使用。
-
符号性(句法分析、语义学、深层语言学)将详细收集信息,理想情况下用于去除结果中的噪音,但当需要快速达到目标或保持最低工作量时不是最佳解决方案(除非我们谈论的是已经定制的解决方案,事实上,一些 NLP 供应商专注于某一行业,使得开发更快)。
-
机器学习(统计方法)近年来以我们通常称之为深度学习的技术形式强势回归,主要承诺从零开始提供解决方案所需的努力和时间非常少;确实,有时使用一个非常基础的算法可以轻松达到 75% 准确率(假设你有一个足够大的已标记语料库,或者你愿意投入工作)。这可能是许多创业公司,特别是在支出方面非常谨慎的公司,青睐这种方法的原因。如果你的应用程序期望生产级别的准确性(我个人定义为 85%以上的 F-score),那么根据用例,问题可能看起来难以克服,实际上我们最近看到越来越多的文章谈论机器学习不是 NLP 问题的理想方法,业内一些公司已经将他们的信息重塑为“机器学习是来帮助你的”。
但让我们谈谈工具箱中的工具。这里是一个简短的、非全面的列表:分类、实体提取、情感、摘要、词性标注、三元组(SAO)、关系、事实挖掘、关联数据、启发式、情感/感觉/情绪。几乎所有计算语言学中的用例都可以归结为元标记;文档经过一个引擎处理后,变得更加丰富,装饰有一系列标签,指示与之相关的关键智能数据。正是这个简单的概念让许多公司认为所有 NLP 技术都是相同的,但问题是:你想用什么来标记你的文档?来自标准分类法的类别?文中提到的公司名称?以“正面”或“负面”表示的文档总体情感?也许是上述的组合(例如,对文档中提取的每个实体的情感)?
文本分析提供者本质上是问题解决者。例如,如果一个供应商仅提供分类,他们通常会建立一个论点,说明如何通过内容分类过程来解决任何用例。就像我可以用鞋子把钉子钉进墙里,但如果有一把锤子,我可能会选择用锤子。我们如何识别每个项目所需的工具?有些更明显,但让我给你一些最著名的工具的提示:
-
分类应该在您的应用程序的最终目标是识别文档属于一个非常具体、预定义的类别(如体育、食品、保险政策、东南亚能源市场的金融报告等)时使用。就像把杂志放进一个箱子里并贴上标签一样。一个类别的名称不一定在属于该类别的文档中提到。
-
实体提取 在你对内容中那些可变部分感兴趣时非常有用,特别是那些非预定义的元素、话题或实际提到的名称
-
总结 当你的解决方案需要加快调查速度时非常有帮助,因此你希望能够自动生成小的摘要,这些摘要能让你了解文档的内容,而不必在确认文档是否与你的研究相关之前完全阅读它
-
情感 和情绪(或感觉,或心情,根据供应商不同)基本上是不言自明的;在分析和商业智能应用中相当受欢迎,尤其是在衡量品牌/产品在消费者市场中的声誉时(通过分析社交媒体)
-
关系 和三元组/SAO(例如:“CompanyX 收购 CompanyY”标记为 CompanyX + 收购 + CompanyY)在我们寻找的信息比平常更复杂时非常有用;有时我们只是对文档中不同命名实体(人、公司等)的共现感兴趣,而有时我们需要知道特定实体是否是涉及另一个实体的动作的对象
不可能列出所有 NLP 领域技术供应商提供的功能的完整列表,更重要的是,NLP 每年都在增长,它的世界不断扩展,这可能也是为什么有时很难理清市场上提供的所有东西。尽管如此,了解每个产品都存在深刻的差异有助于做出正确的选择。
Filiberto Emanuele 在软件、自然语言处理、项目管理方面有 30 多年的经验;设计产品并为大型企业和政府机构提供解决方案。这里的内容反映了我的个人观点,而不一定是 Filiberto 雇主的观点。
更多相关主题
机器学习碳足迹估算难度
原文:
www.kdnuggets.com/2022/07/difficulty-estimating-carbon-footprint-machine-learning.html

机器学习(ML)通常通过连接虚拟神经元和虚拟突触来模拟人脑的操作。深度学习(DL)是 ML 的一个子集,将虚拟大脑放大几个数量级。随着计算能力的进步,这些神经元的数量激增。大多数关于 ML 解决难题(如自动驾驶汽车或面部识别)的头条新闻使用了 DL,但这些“类固醇”也有代价。模型规模的增加带来了计算成本的增加,而计算成本与能源成本相关,从而导致更大的碳足迹。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
全球变暖无疑是我们这一代人需要在未来几年解决的最关键问题。这是一个引发极大情感的两极化话题,这非常棒。这种情感成分是解决我们社会最具挑战性问题的前提,但不幸的是,它也是吸引点击标题和虚假信息的主要目标。
2019 年,马萨诸塞大学阿默斯特分校的学者研究了某些先进深度学习模型的能源成本和碳足迹。该论文报告了令人眼花缭乱的温室气体排放,并恰当地提升了关于机器学习碳排放的讨论。其他科学家和科学记者也对此进行了报道,这份报告在过去三年里在数以千计的研究和新闻文章中被引用过多次。
麻省理工学院的学者在他们著名的文章《深度学习的递减回报》中推演了原始论文。文章预测,要超越当前模型的准确性将基于增加模型规模,就像过去一样。作者预测,一个最先进的模型将很快需要 1000 亿美元的训练费用,并产生与纽约市一个月相同的碳排放。他们不相信这会发生,因为即使在当前的通货膨胀环境下,花费 1000 亿美元训练一个模型在 2025 年也将是荒谬的,但这并没有阻止其对读者的情感冲击。机器学习将毁灭地球!
争议促使谷歌和加州大学伯克利分校的学者与 2019 年原始论文的作者合作发起了一个调查。该团队重新审视了原始论文中的估算,最终得出结论这些估算是不准确的。机器学习的碳足迹比我们想象的要小,而且对未来持谨慎乐观的理由也存在。
原始论文的问题在于在估算之上再进行估算。机器学习研究通常只报告收益,而对成本保持沉默。在多个不准确假设上进行外推会在最终结果中累积成指数误差,这就是发生的情况。在 2019 年论文中,作者假设了传统硬件、平均美国数据中心效率,并误解了神经架构搜索(NAS)的使用方式。2022 年的调查显示,最新的张量处理单元(TPUv2)效率更高,使用了一个高效的超大规模数据中心,并且 NAS 使用了微小模型作为代理。结合这些因素,原始论文中的错误幅度达到了 88 倍。
2022 年的论文还概述了确保我们未来不会毁灭地球的最佳实践。没有万灵药,但优化机器学习硬件、在“神经拓扑”方面创新稀疏模型,并允许客户选择最绿色的计算地理位置将是关键。他们认为,使用这些方法在 2017-2021 年间已经将训练著名的 Transformer NLP 模型的碳足迹减少了惊人的 747 倍或 99.998%。这并不意味着问题得到永远解决,因为模型还在不断增长,但它提供了一个更为平衡的展望。
根本的见解在于不估算而是测量。虽然粗略的外推可以提高意识,但解决问题需要可靠的度量标准。尽管最大的云服务提供商已经发布了揭示整体碳足迹的工具,但要准确了解机器学习操作的气候影响,还需要一个云无关的工具,比如 MLOps 平台。
2020 年 Google Cloud 各地区的碳零排放能源百分比(授权使用 CC BY 4.0)
“每个人都应该关注碳足迹,但首先要确保准确测量,” Valohai 的 CEO Eero Laaksonen 说。Valohai 是一个与云无关的 MLOps 平台,位于云服务提供商和数据科学家之间。云计算的问题在于公司往往被锁定在单一的云服务提供商上。工程师为单一目标编写代码,“切换云”变得不可能。Valohai 抽象了云服务提供商,将计算分布到不同的目标上变成了一键操作。Laaksonen 说:“一旦你有了可靠的指标,确保你能够对其做出反应。”他补充道:“你将计算分布在多个提供商之间,根据任务选择最绿色的一个。”
虽然 ML 和 DL 模型可能持续增长,但未来比头条新闻所呈现的要光明和环保得多。硬件和数据科学的进步有望抵消成本的增加,大型云服务提供商如 Google 承诺到 2030 年实现100% 碳零排放能源。与此同时,让我们保持冷静,确保我们的指标保持敏锐。
更多相关话题
图形匿名化的难度
原文:
www.kdnuggets.com/2021/02/difficulty-graph-anonymisation.html
评论
由 Timothy Lin,数据科学家、开发者、经济学家及 Cylynx 的联合创始人
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
这篇文章是对近期 TraceTogether 隐私事件的回应。对于非新加坡人,TraceTogether 是新加坡应对 COVID-19 大流行的接触追踪计划。该计划的目标是迅速识别可能与任何测试呈阳性的人有过密切接触的人。它包括一个应用程序或物理代币,利用蓝牙信号来存储接触记录。截至 2020 年 12 月底,70% 的新加坡居民据说已经参与了该计划。
2021 年 1 月 4 日,曝光了 TraceTogether 数据可能被警方用于刑事调查。这引发了负责部长们的一些澄清,以及围绕该项目隐私问题的更大辩论。内政部长澄清,根据《刑事诉讼法典》(CPC),警方可以并且已经使用 TraceTogether 数据调查“严重犯罪,如谋杀或恐怖事件”。TraceTogether 网站上的隐私声明 随后被修改以澄清这一点。
随后,通过了一项法案,以限制对 TraceTogether 数据在严重犯罪中的使用。它阐明了疫情后的数据使用情况,并提到为了“加强我们的公共卫生响应”,可能会保留匿名数据用于流行病学研究:¹
维维安·巴拉克里希南部长也在早前的议会声明中提到过这种可能性:
但我相信,一旦疫情过去,这些数据——特别是具体的、个性化的数据——这些字段应被删除。为了研究目的,我相信 MOH 可能仍希望拥有流行病学数据,但它应该被匿名化。它不应个性化,也不应个体化。
来源:
sprs.parl.gov.sg/search/sprs3topic?reportid=clarification-1547
尽管匿名化的流行病学数据可能对未来研究非常有用,但有两个原因说明应该重新考虑这种决定。
-
这是一种目的范围扩展,将 TraceTogether 从接触追踪操作扩展到警察执法和研究。
-
鉴于 TraceTogether 计划的性质,即使是“匿名化”的数据,也很难在匿名性和实用性之间取得适当的平衡。这是因为接近数据本质上是一个连接网络,从这些连接中获得的洞察力也使对手能够进行去匿名化。
匿名化数据用于研究要么被忽视,要么对去匿名化的风险认识不足,特别是网络数据。术语“匿名化数据”似乎传达了用户信息无法被还原的某种确定性。作为在网络科学领域工作的数据科学家,这远非事实,我希望借此机会解释网络匿名化的困难。
为什么要匿名化?
数据匿名化 是通过擦除或加密标识符来保护私人或敏感信息的过程,同时保持数据的研究用途。
匿名化是一种权衡。我们可以通过用随机值替代数据集中的每一个字段来实现 100% 隐私,但这会使数据完全无用。因此,统计学家研究了不同的数据匿名化技术,包括掩盖、置换、扰动或合成数据创建,旨在平衡隐私和实用性。
一个简单的重新识别技术
让我们从一个简单的表格数据集开始,以说明为什么删除或掩盖个人可识别信息(PII)字段无法实现隐私。我们从一个样本原始数据集开始,数据如下:
| id | name | address | sex |
|---|---|---|---|
| 1 | A | 123 | M |
| 2 | B | 123 | F |
| 3 | C | 456 | F |
这是一个数据集,id 和 name 被掩盖,行已打乱:
| id | name | address | sex |
|---|---|---|---|
| xx | xx | 456 | F |
| xx | xx | 123 | F |
| xx | xx | 123 | M |
我们如何找出每条记录的身份?假设我们有一个包含地址、性别和姓名信息的外部普查数据集,并且每个地址、性别和姓名的组合都是唯一的。这样,我们可以使用address和sex字段在我们的“掩码”数据集上进行连接,以解密name字段。在这里,我们依赖于address和sex与name字段之间的 1 对 1 映射关系。

来源: Garrick Aden-Buie 的 Tidy Explain
数据集的稀疏性影响了对手进行“连接攻击”的难易程度和准确性。如果我们数据集中只有一个字段,例如address,我们将无法唯一识别每个人,因为有两个人的address都是 123。现实世界数据集的“问题”在于,找到可以唯一标识个人的变量组合相对容易。
解密身份 - 2 个示例
GIC
在 1990 年代,马萨诸塞州的一个政府机构,即集团保险委员会(GIC),决定向任何请求的研究人员公开总结每位州员工的医院就诊记录。虽然诸如姓名、地址和社会保障号码等显性标识符被删除,但诸如邮政编码、出生日期和性别等医院就诊信息仍被保留。
Sweeney 1997 证明了 GIC 数据可以与选民名册结合,以揭示隐藏的个人身份信息。故事的一个有趣转折是,Sweeney 博士将其发现告知了当时的马萨诸塞州州长 William Weld,后者向公众保证 GIC 通过删除标识符来保护患者隐私。根据 1990 年代的普查数据,他发现 87%的美国公民可以通过邮政编码、出生日期和性别唯一识别。更多近期研究表明,虽然比例较低,但仍为 63%(Golle 2006)。
Netflix 数据
最近,Netflix 作为一个公开竞赛的一部分发布的电影评分数据被 Narayanan 和 Shmatikov 2008 证明没有最初想象的那样匿名。一个对手需要知道多少关于 Netflix 订阅者的信息才能识别她的记录(如果它在数据集中存在),从而得知她的完整电影观看历史?事实证明,不需要太多。
数据集中 84%的订阅者可以被唯一识别,如果知道 6 个不太受欢迎的电影评分(不在前 500 名之内)。通过使用从 IMDb 抓取的个人电影评分的辅助数据集,他们表明可以高概率地对一些用户进行去匿名化处理。
绑定的联系
假设没有计划保留任何个人信息。相反,仅保留接近度信息进行分析。² 这部分信息是否构成重新识别的威胁?
是的,关于社交媒体数据的研究和实验表明,连接信息可以揭示隐藏的用户联系。为了说明这一点,我们将接近度数据转换为图形形式。图(也称为网络)是一种数据结构,由节点/顶点通过边/链接连接在一起。图结构在日常生活中随处可见,从道路连接到社交网络到...接近度数据。
接近度数据可以被视为边列表。对于个体 A,如果 A 和 B 在同一接近窗口中被记录,则我们构建一个与个体 B 的链接。
我们忽略问题的时间因素,并假设我们掌握了以下连接数据集,该数据集表示两个个体之间的联系,掩盖了一个索引号。³
| 从 | 到 |
|---|---|
| 2 | 1 |
| 3 | 1 |
| 4 | 1 |
| 5 | 1 |
| 6 | 1 |
| 7 | 1 |
| 8 | 1 |
| 9 | 1 |
| 10 | 1 |
| 11 | 1 |
| 9 | 10 |
| 11 | 9 |
| 11 | 10 |
例如,在我们的表格中,个体 2 和 1 是连接的。数据可以通过以下图形进行可视化表示:
我们可以从图中推断出哪些特征或属性?我们可以计算每个个体的连接数量(也称为度)。例如,个体 1 有 10 个邻居,而个体 10 有 3 个邻居。假设我们有一个完整连接数据集的泄露,这可以绘制如下:
去匿名化的挑战在于尝试找到一个与我们的子图“匹配”的完整图的片段(更正式地称为子图匹配或子图同构问题)。你能找到它吗?
让我通过为聚类上色来帮助你,这应该很明显。点击脚注以揭示答案。⁴
上述网络是经常使用的悲惨世界网络数据集的图形表示。我们的子图是 Myriel 的自我网络(Myriel 及其所有连接)。事实证明,图中只有 5 个个体有 10 个连接。这有助于显著缩小候选匹配的范围。列出连接最多的个体按降序排列如下:
| 名称 | 连接数(度) |
|---|---|
| Valjean | 36 |
| Gavroche | 22 |
| Marius | 19 |
| Javert | 17 |
| Thenardier | 16 |
| Enjolras | 15 |
| Fantine | 15 |
我们能从这个例子中学到什么?
-
从边缘属性生成节点/实体级特征是很容易的
-
由于社交互动的性质,这些特征往往会表现出大的变异和异常值
-
社交网络的匿名性不足以保证隐私
在另一篇开创性的论文中,(Narayanan 和 Shmatikov 2009)展示了基于网络拓扑的再识别算法在真实世界社交媒体数据集上的有效性。他们展示了即使这些成员的关系重叠不到 15%,Flickr 和 Twitter 的成员仍能在完全匿名的 Twitter 图中以仅 12% 的错误率被识别。自从他们的论文发表以来,Twitter 已经在其 API 上引入了速率限制,这使得大规模抓取和采集变得不可行。
通过模糊化实现匿名性
一种使这种匿名攻击更加困难的方法是模糊或隐藏关系信息。例如,可以扰动边缘信息,以引入每个连接的某种概率不确定性。或者,我们可以从高度连接的人员中移除连接,使他们与普通个体融为一体。然而,这样做会丧失我们分析超级传播者或前线工人(这些工人会见到大量的人)之间病毒传播风险的能力。如前所述,数据匿名性是一种权衡,在这里我们更倾向于隐私而非研究。
去匿名化的多种途径
令人惊讶的是,这些匿名化方法并不能完全消除再识别的风险。到目前为止,我们只考虑了在数据中模糊度分布,但还可以从图数据集中构造其他度量指标。我们可以计算两跳远的连接数(邻居的邻居),或通过图中每个节点的三角形数量,或类似 PageRank 分数的中心性度量。有很多度量可以捕捉网络的不同方面以及节点在网络中的位置。模糊一个度量并不意味着其他度量也同样被匿名化。
我们如何总结一个节点的“本质”,考虑到它所有的邻近关系和在整个网络空间中的位置?节点嵌入(Grover 和 Leskovec 2016),是神经网络在图数据结构上的一种相对较新的应用,旨在通过将节点关系映射到更低维的向量空间中实现这一点。
在嵌入空间中距离更近的节点在原始网络中更相似。⁵ 给定一个匿名化的网络数据集,我们可以计算每个节点的嵌入,并推导每个节点实际上与给定节点在真实数据集中连接的可能性。我们遮蔽和混淆的特征越多,去匿名化率的准确性就越低。
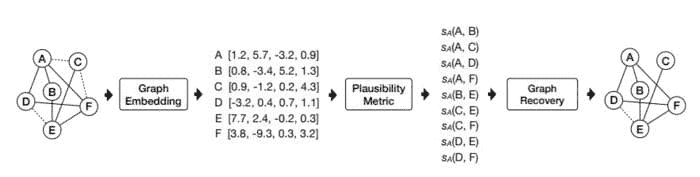
来源:张等,2017
重要的是,我们可以使用节点嵌入来量化边的可能性,并利用这些信息恢复原始数据集。张等人 2017 利用这一漏洞恢复了三个测试数据集的原始图,这些数据集通过使用不同的图匿名化技术进行了匿名化。他们提出了通过添加与原始图中的边更相似的虚假边来改进现有技术的方法。虽然这使得恢复原始数据集变得更加困难,但他们指出,“创建完全无法与原始边区分开的虚假边是非平凡的”。
连接点滴
进行这种隐私攻击所需的条件是什么?
-
一个“匿名化”的网络数据集
-
可能会泄露一个或多个个体身份的种子信息
-
一个包含真实信息的子图
即使 TraceTogether 数据被泄露,找到攻击向量 2 或 3 肯定很难?其实并非如此,只需一点想象力和创造力,正如各种研究论文所示。实际上,关于子图的信息可以通过 BluePass 计划轻松获得:
BluePass 包括用于生活或工作在宿舍的流动工人和本地工人的接触追踪令牌,以及建筑、船舶制造和过程行业中的工人。BluePass 令牌与 TraceTogether 令牌或应用兼容,这意味着它们可以相互交换信息。
一个关键的区别是雇主可以监督这些设备中的数据,以便更快地隔离 Covid-19 病例的密切接触者。⁶ 他们可以访问自己员工的 BluePass 数据,但不能访问其他 BluePass 令牌或 TraceTogether 数据。
尽管新法案涵盖了 TraceTogether 和 BluePass,并且对未经授权使用或泄露接触追踪数据有严格的处罚,但人们仍然会怀疑处理这些数据的公司的网络安全实践有多么安全。由于该法案不涵盖匿名化数据,公司也可能保留去匿名化的 BluePass 数据用于其内部研究。任何 BluePass 数据集的泄露或侵害都可能危及工人的身份,甚至可能危及匿名化的 TraceTogether 数据。
摘要
在本文中,我研究了图匿名化的难点。我展示了即使 PII 信息被掩盖,如何对表格数据进行重新识别,并将分析扩展到网络数据集。节点之间的连接包含大量信息,可以作为重新识别或图恢复尝试的基础。尝试扰动或掩盖边信息是困难的,平衡实用性和隐私性也很难。
我还概述了一个对手如何利用从 BluePass 项目获得的数据对匿名化的 TraceTogether 数据执行图恢复攻击的可能性。
为了保持 TraceTogether 项目在应对 Covid-19(以及可能的其他未来大流行病)中的作用,需要进行两项改动。一是仅保留汇总数据而非匿名化数据。二是公司应依法删除 BluePass 数据或在大流行结束时将其交给卫生部。
参考文献
Golle, P. "重新审视美国人口简单人口统计信息的唯一性。" 第 5 届 ACM 电子社会隐私研讨会论文集,第 77-80 页。2006 年。
Grover, Aditya 和 Jure Leskovec. "node2vec:用于网络的可扩展特征学习。" 第 22 届 ACM SIGKDD 国际知识发现与数据挖掘大会论文集,第 855-864 页。2016 年。
Narayanan, Arvind 和 Vitaly Shmatikov. "大规模稀疏数据集的强健去匿名化。" 2008 IEEE 安全与隐私研讨会 (sp 2008),第 111-125 页。IEEE,2008 年。
Narayanan, Arvind 和 Vitaly Shmatikov. "去匿名化社交网络。" 2009 年第 30 届 IEEE 安全与隐私研讨会,第 173-187 页。IEEE,2009 年。
Sweeney, L. "将技术和政策结合起来以保持机密性。" 法律、医学与伦理学杂志 25, no. 2-3 (1997): 98-110。
Zhang, Yang, Mathias Humbert, Bartlomiej Surma, Praveen Manoharan, Jilles Vreeken 和 Michael Backes. "朝着可信的图匿名化方向前进。" arXiv 预印本 arXiv:1711.05441 (2017)。
-
可以说,研究人员只需要获取接近数据,而不是个体标识符,以研究传播和安全距离措施的有效性。
-
如果时间元素未被掩码,将仅增加数据集的维度,从而使得重新识别个体变得容易。
-
答:左侧的蓝色簇
-
相似性可以通过各种方式定义,例如邻接或路径。
简介: Timothy Lin (@timlrxx) 是数据科学家、开发者、经济学家及 Cylynx 的联合创始人。Timothy 目前的兴趣领域包括网络分析、全栈开发、技术和劳动经济学,未来将会有更多相关内容出现!
原文。已获授权转载。
相关:
-
使用 NumPy 和 Pandas 在更大的图谱上进行更快的机器学习
-
图机器学习在基因组预测中的应用
-
机器学习的数据结构 - 第二部分:构建知识图谱
更多相关内容
-
用 Python 图形画廊制作惊人的可视化
扩散与去噪:解释文本到图像生成 AI
原文:
www.kdnuggets.com/diffusion-and-denoising-explaining-text-to-image-generative-ai

扩散的概念
去噪扩散模型经过训练以从噪声中提取模式,从而生成期望的图像。训练过程包括向模型展示具有不同噪声水平的图像(或其他数据),噪声水平是根据噪声调度算法确定的,目的是预测数据中的哪些部分是噪声。如果成功,噪声预测模型将能够从纯噪声中逐渐构建出逼真的图像,在每一步中从图像中减去噪声的增量。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT

与本节顶部的图像不同,现代扩散模型不会直接从添加噪声的图像中预测噪声。相反,它们在图像的潜在空间表示中预测噪声。潜在空间以压缩的数值特征集表示图像,这是变分自编码器或 VAE 编码模块的输出。这个技巧使得“潜在”被包含在 潜在扩散 中,并大大减少了生成图像的时间和计算需求。正如论文作者所报告的,潜在扩散使得推理速度比直接扩散快至少约 2.7 倍,并且训练速度快约三倍。
使用潜在扩散的人们经常谈到使用“扩散模型”,但实际上,扩散过程涉及几个模块。如上图所示,文本到图像工作流程的扩散管道通常包括一个文本嵌入模型(及其分词器)、一个去噪预测/扩散模型和一个图像解码器。潜在扩散的另一个重要部分是调度器,它决定了噪声如何在一系列“时间步骤”(一系列逐步更新,逐渐从潜在空间中去除噪声)中被缩放和更新。
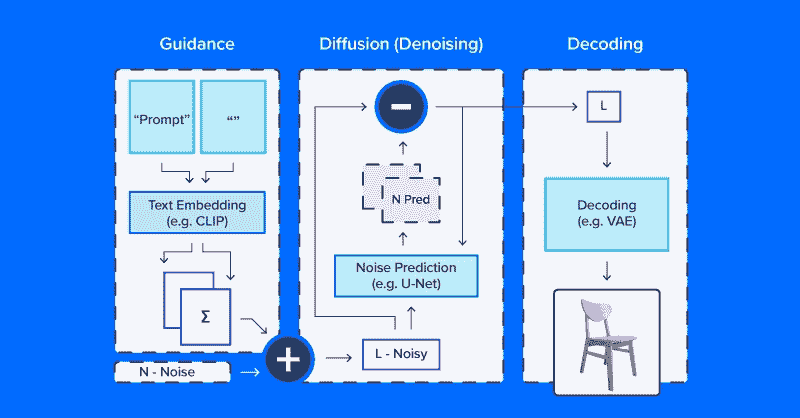
潜在扩散代码示例
我们将在大多数示例中使用 CompVis/latent-diffusion-v1-4。文本嵌入由一个CLIPTextModel 和 CLIPTokenizer 处理。噪声预测使用一个‘U-Net’,这是一种图像到图像的模型,最初在生物医学图像(特别是分割)中获得了广泛应用。为了从去噪的潜在数组生成图像,该管道使用变分自动编码器 (VAE) 进行图像解码,将这些数组转换成图像。
我们将从构建我们自己版本的 HuggingFace 组件管道开始。
# local setup
virtualenv diff_env –python=python3.8
source diff_env/bin/activate
pip install diffusers transformers huggingface-hub
pip install torch --index-url https://download.pytorch.org/whl/cu118
如果你在本地工作,确保检查 pytorch.org以确保适合你系统的版本。我们的导入相对简单,下面的代码片段足以用于所有后续演示。
import os
import numpy as np
import torch
from diffusers import StableDiffusionPipeline, AutoPipelineForImage2Image
from diffusers.pipelines.pipeline_utils import numpy_to_pil
from transformers import CLIPTokenizer, CLIPTextModel
from diffusers import AutoencoderKL, UNet2DConditionModel, \
PNDMScheduler, LMSDiscreteScheduler
from PIL import Image
import matplotlib.pyplot as plt
现在进入细节。首先定义图像和扩散参数以及提示。
prompt = [" "]
# image settings
height, width = 512, 512
# diffusion settings
number_inference_steps = 64
guidance_scale = 9.0
batch_size = 1
用你选择的种子初始化伪随机数生成器,以便复现结果。
def seed_all(seed):
torch.manual_seed(seed)
np.random.seed(seed)
seed_all(193)
现在我们可以初始化文本嵌入模型、自动编码器、U-Net 和时间步调度器。
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14")
vae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", \
subfolder="vae")
unet = UNet2DConditionModel.from_pretrained("CompVis/stable-diffusion-v1-4",\
subfolder="unet")
scheduler = PNDMScheduler()
scheduler.set_timesteps(number_inference_steps)
my_device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
vae = vae.to(my_device)
text_encoder = text_encoder.to(my_device)
unet = unet.to(my_device)
将文本提示编码为嵌入需要首先对字符串输入进行分词。分词将字符替换为对应于语义单元词汇的整数代码,例如通过字节对编码 (BPE)。我们的管道在图像的文本提示旁边嵌入了一个空提示(无文本)。这在提供的描述和一般自然出现的图像之间平衡了扩散过程。我们将在本文稍后看到如何改变这些组件的相对权重。
prompt = prompt * batch_size
tokens = tokenizer(prompt, padding="max_length",\
max_length=tokenizer.model_max_length, truncation=True,\
return_tensors="pt")
empty_tokens = tokenizer([""] * batch_size, padding="max_length",\
max_length=tokenizer.model_max_length, truncation=True,\
return_tensors="pt")
with torch.no_grad():
text_embeddings = text_encoder(tokens.input_ids.to(my_device))[0]
max_length = tokens.input_ids.shape[-1]
notext_embeddings = text_encoder(empty_tokens.input_ids.to(my_device))[0]
text_embeddings = torch.cat([notext_embeddings, text_embeddings])
我们将潜在空间初始化为随机正态噪声,并根据我们的扩散时间步调度器对其进行缩放。
latents = torch.randn(batch_size, unet.config.in_channels, \
height//8, width//8)
latents = (latents * scheduler.init_noise_sigma).to(my_device)
一切准备就绪,我们可以深入扩散循环本身。我们可以通过周期性采样来跟踪图像,从而查看噪声如何逐渐减少。
images = []
display_every = number_inference_steps // 8
# diffusion loop
for step_idx, timestep in enumerate(scheduler.timesteps):
with torch.no_grad():
# concatenate latents, to run null/text prompt in parallel.
model_in = torch.cat([latents] * 2)
model_in = scheduler.scale_model_input(model_in,\
timestep).to(my_device)
predicted_noise = unet(model_in, timestep, \
encoder_hidden_states=text_embeddings).sample
# pnu - empty prompt unconditioned noise prediction
# pnc - text prompt conditioned noise prediction
pnu, pnc = predicted_noise.chunk(2)
# weight noise predictions according to guidance scale
predicted_noise = pnu + guidance_scale * (pnc - pnu)
# update the latents
latents = scheduler.step(predicted_noise, \
timestep, latents).prev_sample
# Periodically log images and print progress during diffusion
if step_idx % display_every == 0\
or step_idx + 1 == len(scheduler.timesteps):
image = vae.decode(latents / 0.18215).sample[0]
image = ((image / 2.) + 0.5).cpu().permute(1,2,0).numpy()
image = np.clip(image, 0, 1.0)
images.extend(numpy_to_pil(image))
print(f"step {step_idx}/{number_inference_steps}: {timestep:.4f}")
在扩散过程结束时,我们会得到一个不错的渲染结果。接下来,我们将讨论额外的技术以获得更大的控制力。由于我们已经创建了扩散管道,我们可以使用 HuggingFace 提供的精简扩散管道来进行接下来的示例。
控制扩散管道
我们将在这一部分使用一组辅助函数:
def seed_all(seed):
torch.manual_seed(seed)
np.random.seed(seed)
def grid_show(images, rows=3):
number_images = len(images)
height, width = images[0].size
columns = int(np.ceil(number_images / rows))
grid = np.zeros((height*rows,width*columns,3))
for ii, image in enumerate(images):
grid[ii//columns*height:ii//columns*height+height, \
ii%columns*width:ii%columns*width+width] = image
fig, ax = plt.subplots(1,1, figsize=(3*columns, 3*rows))
ax.imshow(grid / grid.max())
return grid, fig, ax
def callback_stash_latents(ii, tt, latents):
# adapted from fastai/diffusion-nbs/stable_diffusion.ipynb
latents = 1.0 / 0.18215 * latents
image = pipe.vae.decode(latents).sample[0]
image = (image / 2\. + 0.5).cpu().permute(1,2,0).numpy()
image = np.clip(image, 0, 1.0)
images.extend(pipe.numpy_to_pil(image))
my_seed = 193
我们将从扩散模型最著名且最直接的应用开始:从文本提示生成图像,即文本到图像生成。我们将使用的模型是由发布了潜在扩散论文的学术实验室发布到 Hugging Face Hub 的。Hugging Face 通过方便的管道 API 协调像潜在扩散这样的工作流。我们需要根据是否拥有 GPU 来定义计算的设备和浮点数。
if (1):
#Run CompVis/stable-diffusion-v1-4 on GPU
pipe_name = "CompVis/stable-diffusion-v1-4"
my_dtype = torch.float16
my_device = torch.device("cuda")
my_variant = "fp16"
pipe = StableDiffusionPipeline.from_pretrained(pipe_name,\
safety_checker=None, variant=my_variant,\
torch_dtype=my_dtype).to(my_device)
else:
#Run CompVis/stable-diffusion-v1-4 on CPU
pipe_name = "CompVis/stable-diffusion-v1-4"
my_dtype = torch.float32
my_device = torch.device("cpu")
pipe = StableDiffusionPipeline.from_pretrained(pipe_name, \
torch_dtype=my_dtype).to(my_device)
引导比例
如果你使用非常不寻常的文本提示(与数据集中的提示大相径庭),可能会进入潜在空间的较少涉足部分。空提示嵌入提供了平衡,按照 guidance_scale 将两者结合起来可以在提示的具体性与常见图像特征之间进行权衡。
guidance_images = []
for guidance in [0.25, 0.5, 1.0, 2.0, 4.0, 6.0, 8.0, 10.0, 20.0]:
seed_all(my_seed)
my_output = pipe(my_prompt, num_inference_steps=50, \
num_images_per_prompt=1, guidance_scale=guidance)
guidance_images.append(my_output.images[0])
for ii, img in enumerate(my_output.images):
img.save(f"prompt_{my_seed}_g{int(guidance*2)}_{ii}.jpg")
temp = grid_show(guidance_images, rows=3)
plt.savefig("prompt_guidance.jpg")
plt.show()
由于我们使用 9 个引导系数生成了提示,你可以绘制提示并查看扩散是如何发展的。默认引导系数为 0.75,因此第 7 张图像将是默认图像输出。
负面提示
有时潜在扩散确实“想要”产生与您的意图不匹配的图像。在这些情况下,你可以使用负面提示将扩散过程推向不希望的输出。例如,我们可以使用负面提示来使我们的火星宇航员扩散输出看起来稍微少一些人性。
my_prompt = " "
my_negative_prompt = " "
output_x = pipe(my_prompt, num_inference_steps=50, num_images_per_prompt=9, \
negative_prompt=my_negative_prompt)
temp = grid_show(output_x)
plt.show()
你应该获得遵循提示的输出,同时避免输出负面提示中描述的内容。
图像变体
从头开始的文本到图像生成并不是扩散管道的唯一应用。实际上,扩散非常适合从初始图像开始进行图像修改。我们将使用一个稍有不同的管道和为图像到图像扩散调优的预训练模型。
pipe_img2img = AutoPipelineForImage2Image.from_pretrained(\
"runwayml/stable-diffusion-v1-5", safety_checker=None,\
torch_dtype=my_dtype, use_safetensors=True).to(my_device)
这种方法的一种应用是生成主题的变体。概念艺术家可能会使用此技术快速迭代不同的外星行星插图创意,基于最新的研究。
我们将首先下载一张公共领域艺术家的 TRAPPIST 系统中 1e 行星的概念图(来源:NASA/JPL-Caltech)。
然后,在降采样以去除细节后,我们将使用扩散流程制作几种不同版本的外星行星 TRAPPIST-1e。
url = \
"https://upload.wikimedia.org/wikipedia/commons/thumb/3/38/TRAPPIST-1e_artist_impression_2018.png/600px-TRAPPIST-1e_artist_impression_2018.png"
img_path = url.split("/")[-1]
if not (os.path.exists("600px-TRAPPIST-1e_artist_impression_2018.png")):
os.system(f"wget \ '{url}'")
init_image = Image.open(img_path)
seed_all(my_seed)
trappist_prompt = "Artist's impression of TRAPPIST-1e"\
"large Earth-like water-world exoplanet with oceans,"\
"NASA, artist concept, realistic, detailed, intricate"
my_negative_prompt = "cartoon, sketch, orbiting moon"
my_output_trappist1e = pipe_img2img(prompt=trappist_prompt, num_images_per_prompt=9, \
image=init_image, negative_prompt=my_negative_prompt, guidance_scale=6.0)
grid_show(my_output_trappist1e.images)
plt.show()
通过向模型提供一个初始图像示例,我们可以生成类似的图像。你还可以使用文本引导的图像到图像流程,通过增加引导、添加负面提示以及更多如“非现实主义”或“水彩”或“纸上素描”等来改变图像的风格。你的结果可能会有所不同,调整提示将是找到你想创建的正确图像的最简单方法。
结论
尽管关于扩散系统和模仿人类生成艺术的讨论依然存在,但扩散模型还有其他更具影响力的用途。它已被 应用于 蛋白质折叠预测,用于蛋白质设计和药物开发。文本到视频也是一个 活跃的领域 的 研究,并由多个公司提供(例如 Stability AI、Google)。扩散也是一个 新兴的方法 用于 文本到语音 应用。
很明显,扩散过程在人工智能的演变以及技术与全球人类环境的互动中正发挥着核心作用。虽然版权、其他知识产权法律的复杂性以及对人类艺术和科学的影响既有积极也有消极的表现,但真正积极的是人工智能前所未有的语言理解和图像生成能力。曾经是 AlexNet 使计算机分析图像并输出文本,而现在计算机可以分析文本提示并输出连贯的图像。
原文。经许可转载。
Kevin Vu 负责管理 Exxact Corp 博客,并与许多才华横溢的作者合作,这些作者写作内容涉及深度学习的不同方面。
相关话题
流形学习的扩散图,理论与实现
原文:
www.kdnuggets.com/2020/03/diffusion-map-manifold-learning-theory-implementation.html
comments
由 Rahul Raj,印度理工学院坎普尔分校
介绍
‘维度诅咒’是数据科学中的一个著名问题,它通常导致性能差、结果不准确以及最重要的相似性度量失效。这主要是因为高维数据集通常是稀疏的,通常会有一个低维结构或‘流形’来嵌入这些数据。因此,变量(或特征或维度)之间存在非线性关系,我们需要学习这些关系以计算更好的相似性。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
流形学习是一种非线性降维方法。流形学习算法的基础在于许多数据集的维度只是人为增加的¹。在这篇博客中,我们学习了流形学习中的一种技术,称为扩散图。其关键思想是,欧几里得距离,即最常见的相似性度量,仅在‘局部’上有意义。因此,假设数据存在一个低维结构或流形,测量这种结构上的相似性比在欧几里得空间中更为合适。
让我们从以下 2D 数据点的例子开始探索,这些数据点整齐地排列成S形状。

这个数据集具有明确的形状。如果我们需要测量这个集合中两个点的相似性,我们会计算欧几里得距离。如果这个距离很小,我们就说这些点相似,反之则不然。下图展示了这种情况。

然而,了解几何结构后,我们知道这种相似性度量是不准确的。由于‘x’和‘y’坐标之间存在非线性关系,因此如果我们在下面的图中所示的几何结构上测量相似性(或距离),会更为准确。

使用扩散映射,我们可以进行非线性维度减少以及学习高维数据的底层几何。让我们直接进入理论和实现,手牵手进行。
主要收获是什么?
本博客旨在介绍一种称为扩散映射²的流形学习技术。这种技术使我们能够理解高维数据集的底层几何结构,并在需要时通过准确捕捉原始维度之间的非线性关系来减少维度。
背后的理论(非常简要)
核心思想是一个时间相关的扩散过程,这只是数据集上的随机游走,每一步都有一个相关的概率。当扩散过程运行一段时间 t 时,我们得到不同路径的概率,以计算底层几何结构的距离。从数学上讲,我们称之为马尔科夫链的稳态概率。

两个数据点 x 和 y 之间的连通性定义为在随机游走的一步中从 x 跳到 y 的概率,为:
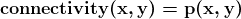
然而,将连通性表示为一个行归一化的似然函数 K 使用高斯核是有用的。这将被称为扩散核。
现在我们定义一个行归一化的扩散矩阵 P。从数学上讲,这等同于马尔科夫链中的转移矩阵。虽然 P 表示从点 x 到点 y 的单步跳跃概率(或在这种情况下的连通性),P² 表示从 x 在两步内到达 y 的概率,依此类推。随着跳跃次数或 Pᵗ 在 t 值增加的情况下增加,我们观察到扩散过程向前运行。换句话说,跟随几何结构的概率增加。
如果你想深入了解背后的理论,论文 已经解释得很清楚。对于快速概述,这篇 维基百科文章也很好地解释了理论。
实现
为了演示算法,我们从一个具有明确几何结构的数据集开始。让我们首先创建一个二维图形,如前所示。我们的主要目标是找出扩散映射是否揭示了数据的底层几何结构。
现在,让我们为这个二维数据集添加一个合成的第三维度(从均匀分布中提取的数据)。因此,我们的新三维数据集如下所示:

正如您可能已经注意到的,3D 数据集在一个角度上保留了 ‘S’ 形,这一点是正确的。现在我们的目标是将维度扁平化为 2,同时保留这种形状。希望在应用扩散映射后,我们能在 2D 中看到类似 ‘S’ 的结构。
输出

结果
从上述输出图中可以明显看出,应用扩散映射将维度从 3 降到 2 后,我们能够在一定程度上理解原始的几何结构,即 ‘S’ 形。通过调整 alpha 值,我们可以在最终结构中得到稍微不同的变体。(alpha 是上述扩散核中的参数)。
源代码
源代码可以在这里找到,并且在 MIT 许可证下开源。您可以使用提供的链接在 Google Colaboratory 中尝试代码。
参考文献:
-
Scikit-Learn 中的流形学习方法 (https://scikit-learn.org/stable/modules/manifold.html)
-
Porte, Herbst, Hereman, Walt,扩散映射简介
个人简介:Rahul Raj (@rahulrajpl) 目前在印度理工学院坎普尔分校攻读计算机科学与工程硕士学位。他的兴趣领域包括机器学习、数据科学及其在网络安全中的应用。有关作者的更多信息请访问:randomwalk.in
原文。经授权转载。
相关:
-
高级特征工程和预处理的 4 个技巧
-
掌握中级机器学习的 7 个步骤——2019 年版
-
什么是数据科学中的维度缩减?
更多相关内容
数据科学中的降维是什么?
原文:
www.kdnuggets.com/2019/01/dimension-reduction-data-science.html
评论
现在我们可以访问大量数据。大量数据可能会导致我们将所有可用数据输入到预测模型中以预测目标变量。本文旨在解释引入大量特征时常见的问题,并提供我们可以利用的解决方案来解决这些问题。
每个数据科学家和机器学习专家都必须理解降维技术是什么以及何时使用它们。

照片由 Sergi Kabrera 提供,发布在 Unsplash
让我们更好地理解这些问题
有时我们为数据科学项目收集数据,结果收集了一大堆特征。其中一些特征(称为变量)并不像其他特征那么重要。有时这些特征之间是相关的。偶尔我们会因为引入过多的特征而导致过拟合问题。大量特征使数据集变得稀疏。
此外,存储具有大量特征的数据集需要更大的空间。而且,分析和可视化具有大量维度的数据集会变得非常困难。
降维可以减少训练机器学习模型所需的时间,同时也有助于消除过拟合。
本文概述了我们可以遵循的技术,以将数据集压缩到一个新的低维特征子空间中。我还将提供有关重要降维技术的详细信息。
请阅读 FinTechExplained 的免责声明。
我如何定义降维?
想象一下,你想将一大堆文件通过电子邮件发送给朋友。上传和发送这些文件可能会花费更长时间。你可以通过将文件压缩后再发送电子邮件来加快文件上传的过程。压缩文件将大量数据压缩成较小的等效集合。
降维与压缩数据的原理相同。
降维是将大量特征压缩到一个较低维度的新特征子空间中,而不丢失重要信息。
尽管有一个小的区别,即降维技术在降低维度时会丢失一些信息。
视觉化大量维度是比较困难的。维度减少技术可以将 20 多个维度的特征空间转变为 2 或 3 维子空间。
不同的维度减少技术有哪些?
在深入了解关键技术之前,让我们快速了解机器学习的两个主要领域:
-
有监督的——当训练集的结果已知时
-
无监督的——当最终结果未知时
如果你想更好地理解机器学习,请查看我的文章:
有许多减少维度的技术,如前向/后向特征选择或通过计算相关特征的加权平均来合并维度。然而,在这篇文章中,我将探讨两种主要的维度减少技术:
线性判别分析 (LDA):
LDA 用于压缩监督数据。
当我们有大量特征(类别),且数据呈正态分布且特征之间没有相关性时,我们可以使用 LDA 来减少维度。LDA 是 Fisher 线性判别的广义版本。
计算 z-score 以规范化高度偏斜的特征。
如果你想了解如何丰富特征和计算 z-score,请查看这篇文章:
Sci-kit learn 提供了易于使用的 LDA 工具:
from sklearn.lda import LDA
my_lda = LDA(n_components=3)
lda_components = my_lda.fit_transform(X_train, Y_train)
这段代码将生成整个数据集的三个 LDA 组件。

主成分分析 (PCA):
它们主要用于压缩无监督数据。
PCA 是一种非常有用的技术,可以帮助去噪声和检测数据中的模式。PCA 用于减少图像、文本内容和语音识别系统中的维度。
Sci-kit learn 库提供了强大的 PCA 组件分类器。以下代码片段演示了如何创建 PCA 组件:
from sklearn.decomposition import PCA
pca_classifier = PCA(n_components=3)
my_pca_components = pca_classifier.fit_transform(X_train)
了解 PCA 的工作原理是明智的。
理解 PCA
本文的这一部分提供了过程的概述:
-
PCA 技术分析整个数据集,然后找到具有最大方差的点。
-
它创建了新的变量,使得新变量与原始变量之间存在线性关系,从而最大化方差。
-
然后为特征创建协方差矩阵以理解其多重共线性。
-
一旦计算了方差-协方差矩阵,PCA 将使用收集到的信息来减少维度。它从原始特征轴计算正交轴。这些是具有最大方差的方向轴。
首先计算方差-协方差矩阵的特征向量。该向量表示最大方差的方向,这些方向称为主成分。然后生成定义主成分大小的特征值。
特征值是 PCA 组件。
因此,对于 N 维度,将有一个 NxN 方差-协方差矩阵,因此,我们将有一个 N 值和 N 特征值矩阵的特征向量。
我们可以使用以下 Python 模块来创建组件:
使用 linalg.eig 创建特征向量
使用 numpy.cov 计算方差-协方差矩阵
我们需要选择最能代表数据集的特征向量。这些是具有最高特征值的向量。
选择捕捉大约 70%方差的特征向量。
记住,具有最大特征值的特征向量是方差最高的,并且最接近原始数据集。同时,特征向量数量越多,计算性能越慢。
我通常选择 2-3 个顶级特征向量来代表数据集。
如果我们希望 scikit-learn 提供所有的 PCA 组件以便评估方差,则将 PCA 初始化为 None 组件:

照片由 Chang Qing 提供,来源于 Unsplash
在执行 PCA 之前,规范化/标准化数据是重要的,因为 PCA 对特征数据的尺度敏感。
核主成分分析 (KDA):
它们用于非线性降维。
当我们拥有非线性特征时,可以将它们投影到更大的特征集上,以去除它们的相关性并使其线性。
本质上,非线性数据被映射和转换到更高维空间。然后使用 PCA 来减少维度。然而,这种方法的一个缺点是计算开销非常大。
就像在 PCA 中,我们首先计算方差-协方差矩阵,然后准备具有最高方差的特征向量和特征值来计算主成分。
然后我们计算核矩阵。这要求我们构建相似性矩阵。矩阵随后通过创建特征值和特征向量进行分解。
Sci-Kit Learn 提供了核 PCA 模块。要使用核 PCA,我们可以使用以下代码片段:
from sklearn.decomposition import KernelPCA
kpca = KernelPCA(n_components=2,kernel='rbf', gamma=45)
kpca_components = kpca.fit_transform(X)
Gamma 是 RBF 核的调节参数。

照片由 Billy Huynh 提供,来源于 Unsplash
降维的好处
本节简要概述了降维的核心好处。
我们现在可以访问大量的数据。当我们构建训练于图像、声音和/或文本内容上的预测模型时,输入特征集可能会有大量的特征。这增加了空间需求,进一步导致过拟合,并减慢了模型训练的时间。有时,特征的引入会带来比预期更多的噪声。
提高计算密集型任务效率的关键方法之一是减少维度,同时确保大部分关键信息得以保留。这也消除了具有强相关性的特征,并减少了过拟合。
总结
本文概述了我们可以遵循的技术,以将数据集压缩到新的低维特征子空间中。它还提供了重要降维技术的详细信息。
最后,总结了降维的好处。
如果有任何问题,请告诉我。
原文。经授权转载。
资源:
相关:
更多相关话题
使用主成分分析(PCA)进行降维
原文:
www.kdnuggets.com/2020/05/dimensionality-reduction-principal-component-analysis.html
评论
介绍
随着高性能 CPU 和 GPU 的普及,几乎可以使用机器学习和深度学习模型解决每一个回归、分类、聚类及其他相关问题。然而,在开发这些模型时,仍然存在各种性能瓶颈。数据集中大量的特征是影响机器学习模型训练时间和准确性的主要因素之一。
维度诅咒
在机器学习中,“维度”简单指数据集中特征(即输入变量)的数量。
虽然添加额外特征/维度会提高任何机器学习模型的性能,但到某个点时,进一步的添加会导致性能下降,这就是当特征数量与数据集中的观察数非常大时,许多线性算法努力训练有效模型的情况。这被称为“维度诅咒”。
降维是一组技术,研究如何在保留最重要信息的同时缩小数据的大小,并进一步消除维度诅咒。它在分类和聚类问题的性能中发挥了重要作用。
该图示例展示了一个 3-D 特征空间被分割成两个 1-D 特征空间,之后如果发现相关性,特征数量可以进一步减少。
用于降维的各种技术包括:
-
主成分分析(PCA)
-
线性判别分析(LDA)
-
广义判别分析(GDA)
-
LLE
-
IsoMap
-
自编码器
本文集中于 PCA 的设计原则及其在 Python 中的实现。
主成分分析(PCA)
主成分分析(PCA)是最受欢迎的线性降维算法之一。它是一种基于投影的方法,通过将数据投影到一组正交(垂直)轴上来转换数据。
“PCA 的工作条件是:当数据从高维空间映射到低维空间时,低维空间中数据的方差或扩散应尽可能大。”
在下图中,数据在二维空间中沿红色线的方差最大。
直观理解
让我们对 PCA 有一个直观的理解。假设你希望根据食品的营养成分区分不同的食物项目。哪个变量将是区分食物项目的好选择?如果你选择一个在不同食物项目之间变化很大的变量,你将能够很好地区分它们。如果所选变量在食物项目中几乎相同,你的工作将会更加困难。如果数据中没有可以很好区分食物项目的变量怎么办?我们可以通过原始变量的线性组合创建一个人工变量,如
New_Var = 4*Var1 - 4*Var2 + 5*Var3。
这就是 PCA 的本质,它找到原始变量的最佳线性组合,使得新变量的方差或扩展最大。
假设我们要将二维数据点的表示转换为一维表示。那么我们将尝试找一条直线,并将数据点投影到这条直线上(直线是一维的)。选择直线有许多可能性。
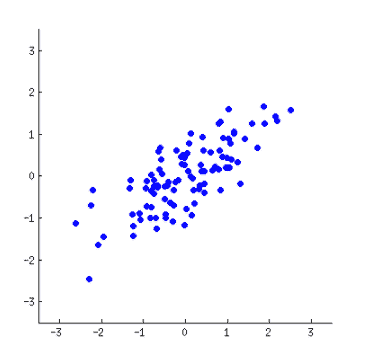
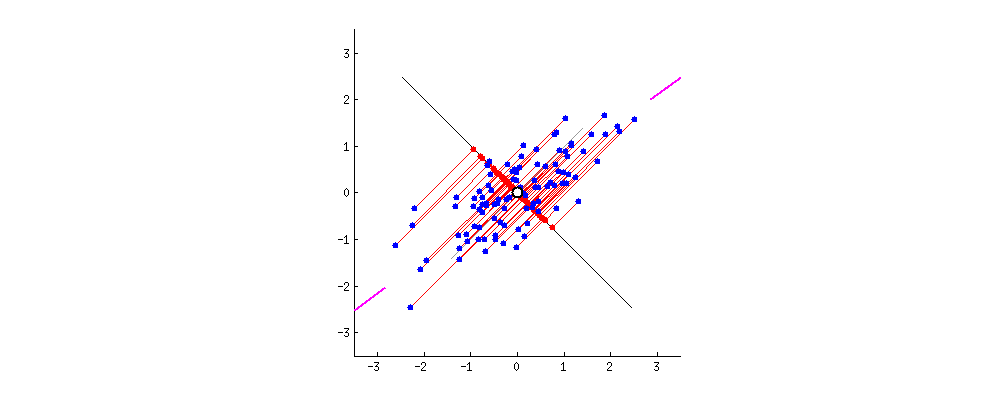
假设品红色的线将是我们的新维度。
如果你看到红线(连接蓝点在品红线上的投影),即每个数据点到直线的垂直距离就是投影误差。所有数据点的误差之和就是总投影误差。
我们的新数据点将是那些原始蓝色数据点的投影(红色点)。正如我们所见,我们通过将数据点投影到一维空间(即一条直线)上,将二维数据点转换为一维数据点。那条品红色的直线被称为主轴。由于我们投影到单一维度,我们只有一个主轴。我们使用相同的过程从残差方差中找出下一个主轴。除了具有最大方差的方向,下一个主轴必须与其他主轴正交(垂直或彼此不相关)。
一旦得到所有主轴,数据集将投影到这些轴上。投影或转换后的数据集中的列被称为主成分。
主成分本质上是原始变量的线性组合,这些组合中的权重向量实际上是找到的特征向量,而这些特征向量又满足最小二乘原则。
幸运的是,得益于线性代数,我们不必为主成分分析(PCA)付出太多汗水。线性代数中的特征值分解和奇异值分解(SVD)是 PCA 中用于降维的两个主要过程。
特征值分解
矩阵分解 是将矩阵简化为其组成部分的过程,以简化一系列更复杂的操作。特征值分解 是最常用的矩阵分解方法,它涉及将一个方阵(n*n)分解为一组特征向量和特征值。
特征向量 是单位向量,这意味着它们的长度或幅度等于 1.0。它们通常被称为右向量,这仅仅意味着列向量(相对于行向量或左向量)。
特征值 是施加在特征向量上的系数,赋予向量其长度或幅度。例如,负特征值可能会在缩放特征向量时反转其方向。
从数学上讲,一个向量是矩阵的特征向量,如果它满足以下方程:
**A . v = **???? **. v**
这被称为特征值方程,其中 **A** 是我们要分解的 n*n 方阵,**v** 是矩阵的特征向量,???? 表示特征值标量。
简而言之,矩阵 **A** 对向量 **v** 的线性变换具有相同的效果,即按因子 ???? 缩放向量。请注意,对于 **m*n** 非方阵 A(m ≠ n),**A.v** 是一个 m 维向量,但 ????.v 是一个 n 维向量,即没有定义特征值和特征向量。如果你想深入了解数学,请查看这个。
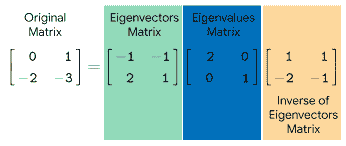
将这些组成矩阵相乘,或者组合这些矩阵所代表的变换将会得到原始矩阵。
分解操作不会导致矩阵的压缩;相反,它将矩阵分解为组成部分,使得在矩阵上执行某些操作变得更容易。像其他矩阵分解方法一样,特征分解作为元素用于简化其他更复杂矩阵操作的计算。
奇异值分解(SVD)
奇异值分解是一种将矩阵分解为三个其他矩阵的方法。
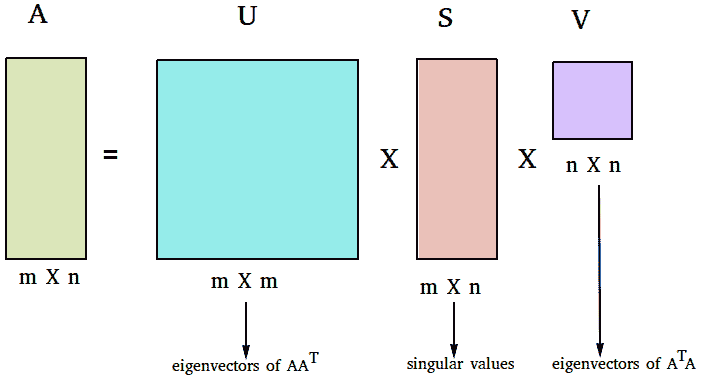
从数学上讲,奇异值分解表示为:
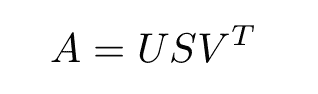
其中:
-
A 是一个 m × n 矩阵
-
U 是一个 m × n 正交 矩阵
-
S 是一个 n × n 对角矩阵
-
V 是一个 n × n 正交矩阵
如图所示,SVD 产生了三个矩阵 U、S 和 V。U 和 V 是正交矩阵,其列分别表示 AAT 和 ATA 的特征向量。矩阵 S 是对角矩阵,对角线上的值称为奇异值。每个奇异值是对应特征值的平方根。
降维如何适应这些数学方程?
一旦你计算了特征值和特征向量,就选择重要的特征向量来形成一组主轴。
特征向量的选择
特征向量的重要性由其对应特征值解释的总方差百分比来衡量。假设V1和V2是两个特征向量,分别对应40%和10%的总方差。如果要求从这两个特征向量中选择一个,我们会选择V1,因为它能提供更多的数据相关信息。
所有特征向量根据其特征值以降序排列。现在,我们必须决定保留多少个特征向量,为此我们需要讨论两种方法总方差解释和碎石图。
总解释方差
总解释方差用于衡量模型与实际数据之间的差异。它是模型总方差的一部分,由存在的因子解释。
假设我们有一个按降序排列的n个特征值(e0,..., en)的向量。在每个索引处取特征值的累计和,直到和大于95%的总方差。之后拒绝所有该索引之后的特征值和特征向量。
碎石图
从碎石图中,我们可以读取添加主成分时数据中方差的解释百分比。
它在 y 轴上显示特征值,在 x 轴上显示因子数量。它总是显示一个向下的曲线。曲线斜率趋于平缓的点(“肘部”)表示因子的数量。
例如,在上图中的碎石图中,急剧弯曲(肘部)出现在 4 处。因此,主轴的数量应该是 4。
Python 中从零开始的主成分分析(PCA)
下面的例子定义了一个小的 3×2 矩阵,对矩阵中的数据进行中心化,计算中心化数据的协方差矩阵,然后对协方差矩阵进行特征值分解。特征向量和特征值被作为主成分和奇异值,最终用来将原始数据投影到新的轴上。
Output:original Matrix: [[ 5 6] [ 8 10] [12 18]]Covariance Matrix: [[12.33333333 21.33333333] [21.33333333 37.33333333]]Eigen vectors: [[-0.86762506 -0.49721902] [ 0.49721902 -0.86762506]]Eigen values: [ 0.10761573 49.55905094]Projected data: [[ 0.24024879 6.28473039] [-0.37375033 1.32257309] [ 0.13350154 -7.60730348]]
结论
尽管 PCA 提供了很高的有效性,但如果变量的数量很大,就很难解释主成分。PCA 最适用于变量之间具有线性关系的情况。此外,PCA 对大离群值比较敏感。
主成分分析(PCA)是一种古老的方法,并且已经得到了充分的研究。基础 PCA 有许多扩展版本,例如鲁棒 PCA、核 PCA、增量 PCA 等,这些扩展版本解决了其不足之处。通过这篇文章,我们对 PCA 进行了基本且直观的理解。我们讨论了与 PCA 实施相关的一些重要概念。
好了,这篇文章就到此为止,希望大家喜欢阅读,如果有所帮助我会很高兴。欢迎在评论区分享你的意见/想法/反馈。
感谢阅读!!!????
简介:Nagesh Singh Chauhan 是一位数据科学爱好者。对大数据、Python、机器学习感兴趣。
原文。转载自许可。
相关内容:
-
Python 中的稀疏矩阵表示
-
机器学习模型的超参数优化
-
掌握中级机器学习的 7 个步骤:2019 版
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关话题
数据科学中的降维技术
原文:
www.kdnuggets.com/2022/09/dimensionality-reduction-techniques-data-science.html
图片来源:编辑
介绍
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域的职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT
在机器学习中,分析包含多个变量的数据需要大量的资源和计算,更不用说所需的人工劳动了。这正是降维技术发挥作用的地方。降维技术是一种将高维数据集转化为低维数据集的过程,同时不丢失原始数据的有价值属性。这些降维技术基本上是数据预处理步骤的一部分,在训练模型之前进行。
什么是数据科学中的降维?
想象一下,你正在训练一个模型,该模型可以基于当日的各种气候条件预测第二天的天气。当前的气候条件可能包括阳光、湿度、寒冷、温度等数百万个环境特征,这些特征过于复杂而难以分析。因此,我们可以通过观察哪些特征彼此强相关并将它们合并成一个来减少特征数量。

图片来源:作者
在这里,我们可以将湿度和降雨量合并为一个依赖特征,因为我们知道它们之间有很强的相关性。就这样!这就是降维技术用于将复杂数据压缩成更简单形式而不丧失数据本质的方法。此外,数据科学和 AI 专家现在还使用数据科学解决方案来提高业务 ROI。数据可视化、数据挖掘、预测分析以及 Datatobiz 提供的其他数据分析服务正在改变商业游戏规则。
为什么降维是必要的?
机器学习和深度学习技术通过输入大量数据来学习波动、趋势和模式。不幸的是,这种巨大的数据包含许多特征,通常会导致“维度诅咒”。
此外,稀疏性在大型数据集中很常见。稀疏性指的是具有微不足道或无值的特征,如果将其输入训练模型,模型在测试时表现不佳。此外,这些冗余特征会导致数据相似特征的聚类问题。
因此,为了应对维度诅咒,降维技术发挥了作用。为什么降维有用的问题的答案是:
-
模型表现得更准确,因为冗余数据将被移除,这将减少假设的空间。
-
更少的计算资源使用,将节省时间和财务预算
-
一些机器学习/深度学习技术在高维数据上无法工作,而这个问题会在降维后得到解决。
-
干净且非稀疏的数据会产生更具统计显著性的结果,因为这种数据的聚类更容易且更准确。
现在让我们通过示例来了解用于数据降维的算法。
什么是降维技术
降维技术大致分为两类,即:
-
线性方法
-
非线性方法
1. 线性方法
PCA
主成分分析(PCA)是数据科学中使用的降维技术之一。考虑一组互相关联的'p' 变量。该技术将这组'p' 变量减少为较小数量的不相关变量,通常用'k' 表示,其中 (k<p)。这些'k' 变量称为主成分,它们的变化类似于原始数据集。
PCA 用于找出特征之间的相关性,它将这些相关性结合在一起。因此,结果数据集具有较少的彼此线性相关的特征。这样,模型在同时计算原始数据集的最大方差时,会减少相关特征。找到这些方差的方向后,它将这些方向引导到一个较小的维度空间中,产生称为主成分的新成分。
这些成分在表示原始特征方面非常充分。因此,它在寻找最佳成分的同时减少了重构误差。这样,数据得到了减少,使得机器学习算法表现得更好、更快。PrepAI 是一个完美的 AI 示例,它在后台利用 PCA 技术从给定的原始文本中智能生成问题。
因素分析
该技术是主成分分析(PCA)的扩展。此技术的主要关注点不仅仅是减少数据集。它更多地关注发现潜在变量,这些变量是数据集中其他变量的结果。它们不是在单一变量中直接测量的。
潜在变量也称为因子。因此,建立一个测量这些潜在变量的模型的过程称为因子分析。它不仅有助于减少变量,还帮助区分响应簇。例如,你需要建立一个预测客户满意度的模型。你将准备一个问卷,其中包含类似的问题,
“你对我们的产品满意吗?”
“你愿意与熟人分享你的经验吗?”
如果你想创建一个变量来评估客户满意度,你可以选择对反馈进行平均或创建一个因子依赖的变量。这可以通过 PCA 完成,并将第一个因子作为主成分。
线性判别分析
这是一种主要用于监督分类问题的降维技术。逻辑回归在多分类问题中效果不佳。因此,LDA 应运而生,以弥补这一不足。它有效地区分了各个类别的训练变量。此外,它与 PCA 不同,因为它通过计算输入特征之间的线性组合来优化区分不同类别的过程。
这里有一个例子帮助你理解 LDA:
考虑一组属于两类的球:红球和蓝球。假设它们随机地绘制在二维平面上,以至于不能用直线将它们分成两个不同的类别。在这种情况下,使用 LDA 可以将二维图转换为一维图,从而最大限度地区分球的类别。球被投影到一个新的轴上,这个轴以最佳方式将它们分隔到各自的类别中。新的轴是通过两个步骤形成的:
-
通过最大化两个类别均值之间的距离
-
通过最小化每个类别内部的变异
SVD
考虑一个具有'm'列的数据。截断奇异值分解方法(TSVD)是一种投影方法,其中这些'm'列(特征)被投影到一个具有'm'列或更少列的子空间中,而不会丢失数据的特征。
一个 TSVD 可以使用的例子是包含电子商务产品评论的数据集。评论列通常是空白的,这会导致数据中出现空值,而 TSVD 可以有效处理这种情况。这个方法可以通过 TruncatedSVD()函数轻松实现。
PCA 使用的是密集数据,而 SVD 使用的是稀疏数据。此外,PCA 因式分解使用协方差矩阵,而 TSVD 是在数据矩阵上进行的。
2. 非线性方法
核 PCA
PCA 对于线性可分的数据集非常有效。然而,如果我们将它应用于非线性数据集,数据集的降维可能不准确。因此,这时核 PCA 变得高效。
数据集经过一个核函数并暂时投影到更高维的特征空间。在这里,类别被转换,可以用直线分开并加以区分。然后,应用一般的 PCA,将数据投影回降维空间。在该空间中进行线性降维方法将与在实际空间中进行非线性降维一样有效。
核主成分分析(Kernel PCA)操作有 3 个重要的超参数:我们希望保留的组件数量、我们要使用的核类型和核系数。有不同类型的核,即“线性”('linear')、“多项式”('poly')、“径向基函数”('rbf')、“ sigmoid”和“余弦”('cosine')。其中,径向基函数核(RBF)被广泛使用。
T-分布随机邻域嵌入(T-Distributed Stochastic Neighbor Embedding)
这是一种非线性降维方法,主要用于数据可视化、图像处理和自然语言处理(NLP)。T-SNE 具有一个灵活的参数,即“困惑度”('perplexity')。它展示了如何在数据集的全局和局部方面之间保持平衡。它提供了每个数据点的近邻数量的估计。此外,它将不同数据点之间的相似性转换为联合概率,并在低维嵌入和高维数据集的联合概率之间最小化 Kullback-Leibler 散度。此外,T-SNE 还提供了一个非凸的成本函数,使用不同的初始化方法可能会得到不同的结果。
T-SNE 仅保留最小的成对距离或局部相似性,而 PCA 保留最大对距离以最大化方差。此外,推荐使用 PCA 或 TSVD 将数据集中特征的维度减少到超过 50,因为在这种情况下 T-SNE 会失效。
多维缩放(Multi-Dimensional Scaling)
缩放指的是通过将数据减少到较低的维度来简化数据。这是一种非线性降维技术,通过可视化的方式展示特征集之间的距离或差异。特征之间距离较短被认为是相似的,而距离较大的则被认为是不相似的。
MDS 减少数据维度并解释数据中的差异。此外,数据在缩小后不会失去本质;两个数据点的距离总是相同的,无论它们的维度如何。此技术仅适用于具有关系数据的矩阵,例如相关性、距离等。让我们通过一个示例来理解这一点。
假设你需要制作一张地图,其中提供了城市位置的列表。地图还应该展示两个城市之间的距离。唯一可能的方法是通过卷尺测量城市之间的距离。但如果你只得到城市之间的距离和它们的相似性,而不是城市的位置呢?你仍然可以通过逻辑假设和广泛的几何知识来绘制地图。
在这里,你基本上是在应用 MDS 来创建一个地图。MDS 观察数据集中的差异,并创建一个地图,以计算原始距离并告诉你它们的位置。
等距映射(Isomap)
这是一种非线性降维技术,基本上是 MDS 或 Kernel PCA 的扩展。它通过连接每个特征的曲线或测地距离来减少维度。
Isomap 通过建立邻域网络来启动。然后,它使用图距离来估计每对点之间的测地距离。最后,通过分解测地矩阵的特征值,将数据集嵌入到较低维度中。可以使用Isomap()类的n_neighbours超参数指定每个数据点要考虑的邻居数量。该类实现了 Isomap 算法。
数据挖掘中为何需要降维?
数据挖掘是观察大规模数据集中的隐藏模式、关系和异常的过程,以估计结果。大规模数据集包含许多以指数速率增长的变量。因此,在数据挖掘过程中找到并分析这些模式需要大量的资源和计算时间。因此,可以在数据挖掘时应用降维技术,通过将数据特征合并来限制这些特征,同时仍然足够代表原始数据集。
降维的优缺点
优势
-
存储空间和处理时间减少
-
被解释变量的多重共线性已被消除
-
减少模型过拟合的机会
-
数据可视化变得更容易
劣势
-
会丢失一定量的数据。
-
PCA 无法应用于那些不能通过均值和协方差定义的数据。
-
不是每个变量都需要线性相关,而 PCA 倾向于发现这种相关性。
-
LDA 需要标记数据才能运行,这在某些情况下不可用。
结论
每秒生成大量数据。因此,利用资源进行准确分析同样重要。降维技术帮助以精确高效的方式进行数据预处理—这也是为什么它被认为是数据科学家的福音。
Kavika Roy 是 DataToBiz 的信息管理部门负责人。她负责技术监督的识别、获取、分配和组织。她对细节的高度关注使她能够向正确的受众提供有关功能方面的精确信息。
更多相关话题
DINOv2:Meta AI 的自监督计算机视觉模型
原文:
www.kdnuggets.com/2023/05/dinov2-selfsupervised-computer-vision-models-meta-ai.html

图片来自 Bing 图片创作者
Meta AI 刚刚发布了开源的DINOv2 模型,这是第一个利用自监督学习来训练计算机视觉模型的方法。DINOv2 模型实现了与该领域标准方法和模型相匹配甚至更优的结果。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持组织的 IT 工作
这些模型在无需微调的情况下取得了强大的性能,使其成为许多不同计算机视觉任务和应用的理想选择。由于自监督训练方法,DINOv2 可以从各种图像和特征集合中学习,例如深度估计,而无需显式的训练。

图 1:DINOv2:Meta AI 的自监督计算机视觉模型
1. 自监督学习的需求
1.1. 无需微调
自监督学习是一种强大的方法,用于在没有大量标记数据的情况下训练机器学习模型。DINOv2 模型可以在图像语料库上进行训练,而不需要相关的元数据、特定的标签或图像标题。与几种最近的自监督学习方法不同,DinoV2 模型不需要微调,因此能够为不同的计算机视觉应用提供高性能的特征。
1.2. 克服人工注释的局限性
在过去几年中,图像-文本预训练已成为各种计算机视觉应用的主要方法。然而,由于其依赖于人工标注的标题来学习图像的语义,这种方法往往忽视了标题中未明确包含的重要信息。例如,一张黄房间里的红色桌子的图片的人类标签可能是“一个红色木桌子”。这个标签会遗漏背景、位置和桌子大小等重要信息。这会导致对局部信息的理解不足,从而在需要详细定位信息的任务中表现不佳。
此外,对人工标签和注释的需求将限制我们收集数据以训练模型的数量。这在某些应用中变得更加困难,例如,注释细胞需要一定水平的人类专业知识,而这种专业知识在所需规模上无法获得。对细胞图像使用自监督训练方法,为基础模型的进一步发展打开了途径,从而改善了生物发现。同样,类似的高级领域,如动物密度估计也适用。
从 DINO 到 DINOv2 的过渡需要克服多个挑战,如
-
创建一个大型且经过整理的训练数据集
-
改进训练算法和实现
-
设计一个有效的蒸馏流程。
2. 从 DINO 到 DINOv2

图 2:DINO v1 与 v2 在分割精度上的比较
2.1. 创建一个大型、整理过的、多样化的图像数据集
构建 DINOv2 的主要步骤之一是训练更大的架构和模型,以提升模型的性能。然而,更大的模型需要大量的数据集才能高效训练。由于没有满足要求的大型数据集,研究人员利用公开抓取的网络数据,建立了一个只选择有用数据的流程,如在LASER中所示。
然而,为了能够使用这些数据集,需要完成两个主要任务:
-
在不同概念和任务之间平衡数据
-
删除无关的图像
由于这个任务可以手动完成,他们从大约 25 个第三方数据集中整理出了一组种子图像,并通过获取与这些种子图像紧密相关的图像来扩展它。这个方法使他们能够从 12 亿张图像中生成总共 1.42 亿张相关图像的数据集。
2.2. 算法和技术改进
尽管使用更大的模型和数据集会带来更好的结果,但这也带来了主要挑战。两个主要的挑战是潜在的不稳定性和在训练过程中保持可处理性。为了使训练过程更稳定,DINOv2 包含了额外的正则化方法,这些方法的灵感来源于相似性搜索 和 分类 文献。
DINOv2 的训练过程整合了最新的混合精度和分布式训练实现,这些实现由前沿的PyTorch 2 提供。这使得代码的实现速度更快,并且使用相同的硬件进行 DINO 模型的训练使速度提高了一倍,内存使用减少到三分之一,从而实现了数据和模型规模的扩展。
2.3. 通过模型蒸馏减少推理时间
运行大型模型进行推理需要强大的硬件,这将限制这些方法在不同用例中的实际应用。为了解决这个问题,研究人员使用了模型蒸馏技术,将大型模型的知识压缩到较小的模型中。通过这种方法,研究人员能够将高性能的架构浓缩成更小的模型,性能损失几乎可以忽略。这产生了强大的 ViT-Small、ViT-Base 和 ViT-Large 模型。
3. 开始使用 DINOv2
训练和评估代码需要 PyTorch 2.0 和 xFormers 0.0.18 以及许多其他第三方包,并且代码需要在 Linux 环境下运行。以下指令概述了如何配置所有必要的依赖项以进行训练和评估:
代码由作者提供
- 继续创建并激活名为 "dinov2" 的 Conda 环境,使用提供的环境定义:
代码由作者提供
- 要安装本项目所需的依赖项,请使用提供的 requirements.txt 文件。
代码由作者提供
- 最后,你可以使用以下代码加载模型:
代码由作者提供
总结来说,Meta AI 发布的 DINOv2 模型标志着一个重要的里程碑。DINOv2 模型采用的自监督学习方法提供了一种强大的方式来训练机器学习模型,无需大量标记数据。通过在不需要精调的情况下实现高准确率,这些模型适用于各种计算机视觉任务和应用。此外,DINOv2 可以从不同的图像集合中学习,并且可以从诸如深度估计等特征中学习,而无需明确的训练。DINOv2 作为开源模型的可用性为研究人员和开发者探索计算机视觉任务和应用的新可能性打开了大门。
参考资料
Youssef Rafaat 是一位计算机视觉研究员和数据科学家。他的研究重点是为医疗保健应用开发实时计算机视觉算法。他还在市场营销、金融和医疗保健领域担任数据科学家超过 3 年。
更多相关话题
每个数据科学家都知道的肮脏小秘密(但不愿意承认)
原文:
www.kdnuggets.com/2018/04/dirty-little-secret-data-scientist.html
评论
作者 Scott W. Strong,Cloudzero。
原文。经许可转载。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT

去年五月,我需要接受左膝手术,希望能够恢复跑步——这是我最喜欢的活动之一。现在,你可能会想“这和数据科学有什么关系?”,但在我恢复的过程中,我发现了比你想象的更多的相似之处。我在康复几个月后开始建立这种联系,通过所有的深蹲、冰敷、平衡训练和按摩。恢复跑步状态和我每天需要做的任务非常相似,这些任务是为了建立一个强大的数据科学文化。更重要的是,我逐渐意识到,今天的数据科学很像准备和跑马拉松(这是少数人做的事情,而且做得好的人更少)。
许多人称机器学习和 人工智能为下一个工业革命,这是一种 推动创新 的技术,也是我们时代的 最重要的通用技术。
在我八年的行业经验中,我亲身观察了机器学习的好处,并不否认机器学习的影响可以是革命性的。
尽管获得了这些荣誉,多年来对机器学习是否真的能带来商业价值一直存在健康的怀疑。而这种批评并非没有道理。在机器学习/人工智能被广泛知晓的这十年中,只有在过去几年中,C 级高管表示他们正在从中获得收益。机器学习的概念是否只是领先于十年前可用的计算能力,而现在才赶上?还是有其他因素在发挥作用?
让我们探讨一下如何为这场“数据科学马拉松”做准备,并揭示这个备受谈论领域背后的现实。
什么是数据科学?
数据科学,令人惊讶的是,并不是关于设计最先进的机器学习算法并用所有数据进行训练(然后拥有天网)。它是关于找到正确的数据,成为你尝试建模的过程、系统或事件的准专家,并创建能够帮助古怪且有时脆弱的统计算法做出准确预测的特征。实际上,算法本身所花的时间非常少。当然,也有例外,但即使在这些领域,大多数研究今天都是由像 Google、Facebook 等少数几个人(和/或公司)进行的,他们在推进该领域的技术方面。每个人通常是在新算法被整齐地打包成开源软件后才开始使用它们。一项对行业数据科学家的最新研究表明,79% 的时间花在收集、整理和清理数据上(60% 用于清理和整理,19% 用于收集数据),这在经验上确认了有大量的马拉松准备工作。但实际的比赛何时开始?这展示了幕后发生的情况的非常不同的视角,并指出了早前提到的价值延迟的可能原因。
为了更好地理解为什么会发生这种情况,我们来看看一个典型的数据科学家在工作中遇到的情况。
一天的生活…
当你走进一家从未考虑过使用机器学习的公司时,一些挑战立即显现出来。经过几个问题的询问,你会很快发现,要将正确的信息放在正确的位置以供机器学习算法使用,这将是一项巨大的努力。这在十年前尤其如此,但即使今天也非常普遍。
在由传统组织孤岛管理的分散数据库中,且无法跨组织链接数据点时,你开始听到类似“哦……你需要去找 Jeff 谈谈销售管道数据”或“Beth,在 DevOps 部门……她是唯一一个拥有这些信息的人”之类的话。一旦你开始了解业务,你不可避免地会发现一些关键的信息没有被追踪或存储。甚至更糟的是,你需要开发一种收集之前不可用的数据的方法。这听起来可能有些戏剧化,但这是许多数据科学家在开始于刚刚涉足机器学习的公司时所经历的现实。早前提到的同一研究显示,78%的数据科学家表示,他们最不喜欢的工作部分是收集、组织和清理数据(其中 57%是清理和组织数据,21%是收集数据)。
对许多人来说,这意味着开始制定数据收集(和保留)政策,或者获得组织内的批准,以存储进行工作所需的客户数据。
数据科学家作为变革推动者
通过了解大多数数据科学家所面临的环境和限制,越来越明显的是,机器学习并不是驱动那些成功使用机器学习的公司的创新。当然,有些行业确实能从机器学习中获得巨大的好处(例如自动驾驶汽车、自然语言处理、语音识别等)。然而,对于绝大多数公司来说,机器学习就像一把吸引眼球的锤子,每个人都认为自己有一个闪亮的钉子。这些公司可能会将他们的成功归因于机器学习的魔力,但成功可能源自其他地方。
那么,为什么人们会声称他们在机器学习方面取得了成功,这种成功的驱动力是什么呢?我不认为他们是在虚假声称成功,我确实相信机器学习正在产生影响,但对大多数公司而言,我相信成功是由其他因素推动的。
公司未意识到的是,通过拥有内部的数据科学家和机器学习专家,他们从根本上改变了公司的运营方式。这些专家迫使公司组织其数据!
仅仅因为机器学习在公司所有(或大部分)数据的“鸭子”排好队之前是无效的,这些人就引导公司采取本来不会采取的行动。此外,数据科学家开始批判性地思考如何以数据驱动的方式为产品和业务决策提供信息。这是大多数公司运作方式的剧变,我们甚至还没有提到机器学习!我相信这种转变(组织公司的数据、批判性思考他们拥有或可能拥有的数据,并使这些数据可操作和可用)才是机器学习所催生的真正创新。
大多数人没有意识到,真正“花哨”的机器学习算法就像马拉松的最后一公里。在你到达那里之前,还有很多事情要做!所有的训练和准备,然后你还得跑完前 25.2 英里。没什么大不了的……对吧?
实际上,能到达马拉松的起跑线本身就是一件大事,更不用说跑完比赛了。
马拉松准备的挑战
在组织的“数据科学马拉松”起跑线前开始并体现这些数据驱动的原则在实践中是相当困难的。让我们看看 CloudZero 团队在构建数据驱动产品和公司过程中遇到的一些障碍。
在 CloudZero,团队付出了大量努力,以理解来自 Amazon Web Services(AWS)的不同数据源,从而提供对我们客户网站部署的全面视图。能够可视化和预测网站可靠性,我们的核心价值,并不是一项简单的任务,需要大量准备。我们仍处于马拉松的训练阶段,但幸运的是,我们在将数据放在正确位置上投入了大量资金,这被认为是机器学习成功的关键。
采纳这种心态意味着在云环境中开发事件和资源的标准表示,并使其对机器和人类可搜索。这还意味着确定在客户端环境中发生事件的真正参与者,通过“AssumeRole”事件链追踪活动(如果你对 AWS 有所了解,你会知道这有多痛苦)。最后,这意味着能够连接资源之间的点,了解它们如何相互通信,展示依赖关系和潜在风险领域。
我们认识到这些关键信息对于能够上下文化任何云部署的可靠性是必需的,并且必须与我们的机器学习和数据科学工作协调。虽然这些任务并不容易,但我们正迎头面对,知道以数据为先的方法将为我们提供许多在行业中创新的机会。
准备好比赛了吗?
机器学习确实是一个革命性的概念,它正渗透到我们的社会中,从我们与设备互动的方式、相互沟通的方式,到全球范围内的商业活动。但当你更深入地剖析它时,你会开始看到所有促成其成功的因素。虽然说出来可能有些离经叛道,但公司需要认识到,只要有一些基本的统计学和有意义的数据组织,他们实际上已经走了 95%的路。机器学习无疑为最终产品增添了一些额外的特色(和准确性),但这个肮脏的小秘密是,它并不是成功的必要条件。
这绝不会使数据科学家的工作显得微不足道,也不会削弱机器学习研究员的努力。事实上,我相信了解这些现实会增加他们作为组织变革推动者的重要性。没有他们对干净和有意义数据的不断渴求,以及用这些数据做出突破性成果的愿景,公司可能永远不会推动数据组织上的进步。
我希望这篇文章能帮助打破一些阻碍人们(或公司)利用数据驱动决策的障碍,并使我们所有人(即使只是一点点)更接近一个更美好的未来的起点!
这在你们公司是否也如此?数据驱动决策对你们有何影响?
个人简介:Scott Strong 是 CloudZero 的研究总监,他在 CloudZero 的产品中将机器学习、建模与仿真以及黑客技术完美结合。在加入 CloudZero 之前,Scott 曾在位于亚特兰大的初创公司 Pindrop 担任机器学习研究员和数据科学家,致力于防止电话诈骗。
原文。经许可转载。
相关内容:
更多相关内容
距离度量:欧几里得、曼哈顿、闵可夫斯基,哦我的!
原文:
www.kdnuggets.com/2023/03/distance-metrics-euclidean-manhattan-minkowski-oh.html
作者提供的图片
如果你对机器学习很熟悉,你会知道数据集中的数据点和随后工程化的特征都是 n 维空间中的点(或向量)。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
任何两个点之间的距离也反映了它们之间的相似性。监督学习算法如 K 最近邻(KNN)和聚类算法如 K 均值聚类使用距离度量的概念来捕捉数据点之间的相似性。
在聚类中,评估的距离度量用于将数据点分组。而在 KNN 中,该距离度量用于找到与给定数据点最近的 K 个点。
在这篇文章中,我们将回顾距离度量的属性,然后查看最常用的距离度量:欧几里得距离、曼哈顿距离和闵可夫斯基距离。接着我们将介绍如何使用 scipy 模块中的内置函数在 Python 中计算这些距离。
我们开始吧!
距离度量的属性
在我们学习各种距离度量之前,让我们回顾一下度量空间中任何距离度量应满足的属性 [1]:
1. 对称性
如果x和y是度量空间中的两点,则x和y之间的距离应等于y和x之间的距离。
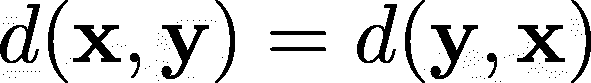
2. 非负性
距离应始终为非负值。这意味着它应大于或等于零。
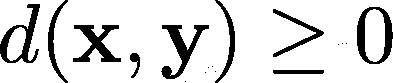
只有当x和y表示同一点时,即x = y,上述不等式才成立(d(x,y) = 0)。
3. 三角不等式
给定三点x、y和z,距离度量应满足三角不等式:
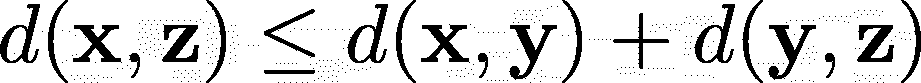
欧几里得距离
欧几里得距离是度量空间中任意两点之间的最短距离。考虑两个点x和y,它们在二维平面上的坐标分别为 (x1, x2) 和 (y1, y2)。
点x和y之间的欧几里得距离如图所示:
作者提供的图片
这个距离由两个点的相应坐标之间的平方差的和的平方根给出。在数学上,二维平面中点x和y之间的欧几里得距离为:

扩展到 n 维,点x和y的形式为x = (x1, x2, …, xn) 和 y = (y1, y2, …, yn),我们有以下欧几里得距离方程:
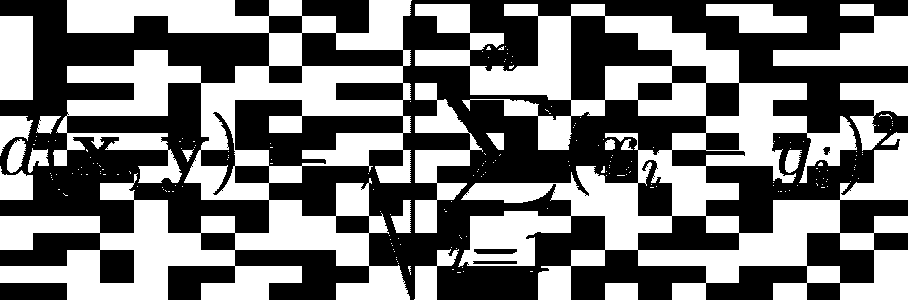
在 Python 中计算欧几里得距离
文章中提到的欧几里得距离和其他距离度量可以使用 SciPy 中spatial模块的便利函数进行计算。
首先,让我们从 Scipy 的spatial模块中导入distance:
from scipy.spatial import distance
然后我们初始化两个点x和y如下:
x = [3,6,9]
y = [1,0,1]
我们可以使用euclidean便利函数来找到点x和y之间的欧几里得距离:
print(distance.euclidean(x,y))
Output >> 10.198039027185569
曼哈顿距离
曼哈顿距离,也称为出租车距离或城市街区距离,是另一种流行的距离度量。假设你在一个二维平面内,并且只能沿着如图所示的轴移动:
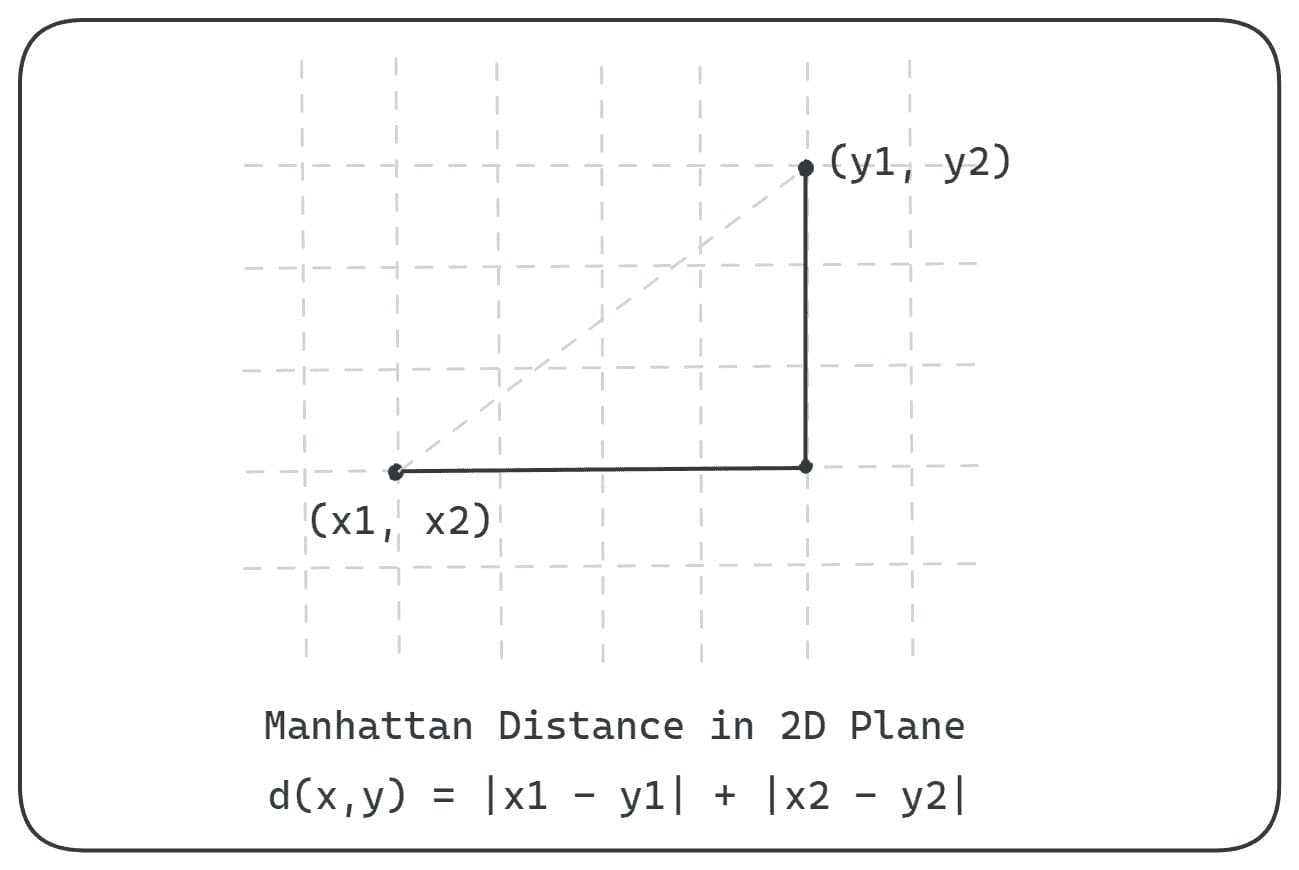
作者提供的图片
点x和y之间的曼哈顿距离由下式给出:
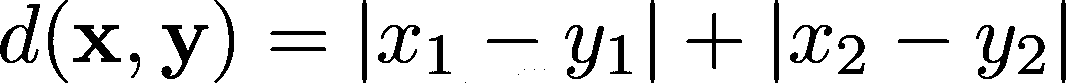
在 n 维空间中,每个点都有 n 个坐标,曼哈顿距离由下式给出:
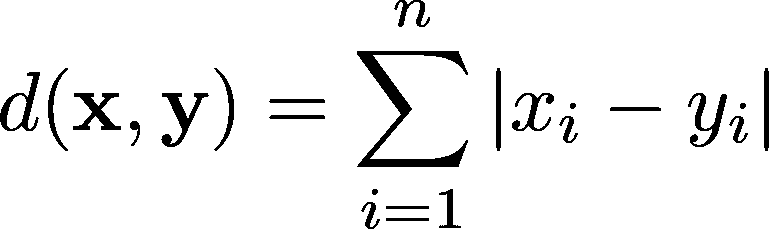
尽管曼哈顿距离不会给出任何两个给定点之间的最短距离,但在特征点位于高维空间中的应用中,它通常是首选的[3]。
在 Python 中计算曼哈顿距离
我们保留之前示例中的导入和 x、y:
from scipy.spatial import distance
x = [3,6,9]
y = [1,0,1]
要计算曼哈顿(或城市街区)距离,我们可以使用cityblock函数:
print(distance.cityblock(x,y))
Output >> 16
闵可夫斯基距离
以德国数学家赫尔曼·闵可夫斯基 [2] 的名字命名,闵可夫斯基距离在一个规范向量空间中的计算方法为:
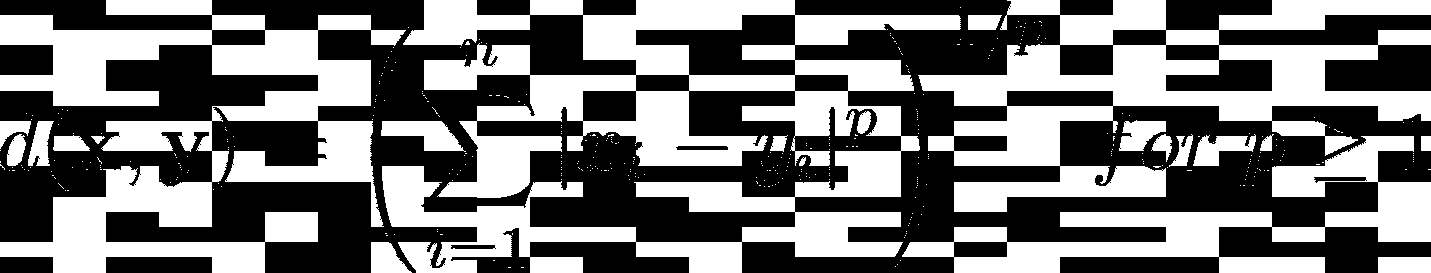
很容易看出,当p = 1时,闵可夫斯基距离方程与曼哈顿距离的形式相同:
同样,对于 p = 2,Minkowski 距离等同于欧几里得距离:
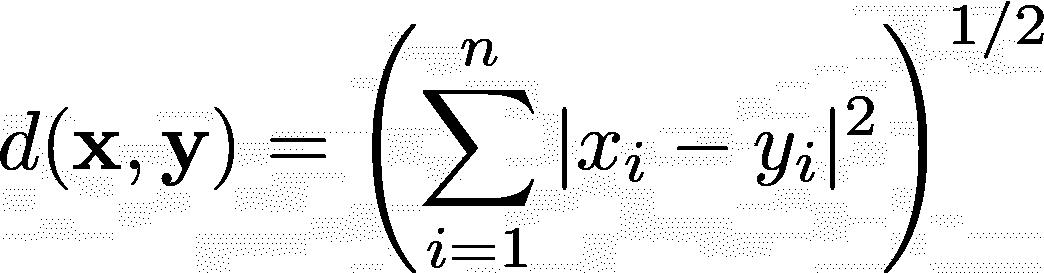
在 Python 中计算 Minkowski 距离
让我们计算点 x 和 y 之间的 Minkowski 距离:
from scipy.spatial import distance
x = [3,6,9]
y = [1,0,1]
除了需要计算距离的点(数组)之外,计算距离的 minkowski 函数还需要参数 p:
print(distance.minkowski(x,y,p=3))
Output >> 9.028714870948003
为了验证当 p = 1 时 Minkowski 距离是否等于曼哈顿距离,我们可以调用 minkowski 函数,将 p 设置为 1:
print(distance.minkowski(x,y,p=1))
Output >> 16.0
让我们还验证一下 p = 2 时的 Minkowski 距离是否等于我们之前计算的欧几里得距离:
print(distance.minkowski(x,y,p=2))
Output >> 10.198039027185569
这就是全部了!如果你熟悉规范向量空间,你应该能看到这里讨论的距离度量与 Lp 范数之间的相似性。欧几里得、曼哈顿和 Minkowski 距离等同于规范向量空间中差异向量的 L2、L1 和 Lp 范数。
总结
本教程到此为止。我希望你现在对常见的距离度量有所了解。下一步,你可以尝试在训练机器学习算法时使用你学到的不同度量。
如果你想开始学习数据科学,可以查看这个学习数据科学的 GitHub 仓库列表。祝学习愉快!
参考文献及进一步阅读
[1] 度量空间,Wolfram Mathworld
[2] Minkowski 距离,维基百科
[3] 高维空间中距离度量的惊人行为,CC Agarwal 等
[4] SciPy 距离函数,SciPy 文档
Bala Priya C 是一名技术写作人员,喜欢创建长篇内容。她的兴趣领域包括数学、编程和数据科学。她通过撰写教程、操作指南等方式与开发者社区分享她的学习成果。
更多相关内容
你如何在数百名其他数据科学候选人中脱颖而出?
原文:
www.kdnuggets.com/2021/07/distinguish-yourself-hundreds-other-data-science-candidates.html
评论

图片来源: Pixabay (免费使用)
为什么要费心区分自己?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
因为成为数据科学家的竞争极其激烈。
获得数据科学工作比以往更难 - 如何将这一点转化为你的优势 - KDnuggets
尽管许多有志的数据科学家发现,找到工作的难度比以前更大……
因为有一股疯狂的冲劲。各种工程师、科学家和职场专业人士都自称为数据科学家。
为什么有这么多“假”数据科学家?
你有没有注意到有多少人突然自称为数据科学家?你的邻居、你在某个……
因为你不确定自己是否能胜任这份工作。记住,冒名顶替综合症在数据科学领域依然存在。
如果他们发现你毫无头绪怎么办?
我可以继续,但你明白了……
那么,你如何与大众区分开来呢?我不确定你是否能做到,但我可以告诉你一些自我测试的指针。这就是这篇文章的内容。
问问自己几个简单的问题

图片来源: Pixabay (免费使用)
问问自己几个问题,并计算“是”的回答数量。你完成的越多,就越能与大众区分开来。
如果你是初学者
-
你是否发布了自己的 Python/R(无论你用什么编程语言)包?
-
如果有,你是否为它编写了详细的文档,以便其他人也能轻松使用?
-
你是否将你的分析从 Jupyter notebook 转移到一个完全发布的Web 应用程序?或者你是否研究了帮助你轻松实现这一点的工具?
-
你是否写过至少几篇高质量、详细的文章来描述你的爱好项目?
-
你是否尝试实践 费曼学习法 即“向一个六年级的学生教授你想要学习的概念”?
在稍微高级一点的阶段
如果你不是初学者,而是觉得自己作为数据科学家已经达到一个较成熟的阶段,你是否会做这些?
-
你是否有意识地在每次机会中将良好的软件工程实践(例如面向对象编程、模块化、单元测试)融入到你的数据科学代码中?
-
你是否特别注意不止步于你必须做的即时数据分析范围,而是考虑一下在 100 倍数据量或 10 倍错误预测成本的情况下会发生什么?换句话说,你是否会有意识地思考数据或问题扩展及其影响?
-
你是否特别注意不止步于传统的机器学习指标,而是还考虑数据获取成本和机器学习业务价值?
构建工具和创建文档:这两项技能都很重要


不要将所有时间和精力都花在分析更大的数据集或实验最新的深度学习模型上。
将至少 25%的时间用于学习一些在所有组织和所有情况下都被重视的事情,
-
构建小而集中的日常数据分析工具。在这个过程中,你的创意将会自由流动。你正在创造一些可能没有数千个立即用户的东西,但它将是新颖的,而且将是你自己的创作。
-
阅读和创建高质量文档,与新工具、框架或你刚刚构建的实用工具相关(见上文)。这将迫使你学会如何以易于广泛受众理解的方式传达你的创作的实用性和机制。
如你所见,这些习惯相当容易培养和实践,即它们不需要艰苦的工作、数年的统计学背景或深度机器学习的高级专长。
但令人惊讶的是,并不是每个人都接受它们。这是你与众不同的机会。
如何在工作面试中利用这些习惯?

图片来源:Pixabay(免费使用)
想象一下你自己在工作面试中。如果你对上述问题有许多“是”的回答,你可以告诉面试官,
-
“嘿,看看我为生成合成时间序列数据而构建的酷 Python 包”。
-
“我还编写了详细的文档,托管在 MyApp.readthedocs.io 网站上。它是用 Sphinx 和 Jekyll 构建的”。
-
“我定期为最大的在线平台 Towards Data Science 撰写数据科学文章。基于这些文章,我甚至收到了 Packt 或 Springer 等知名出版商的书籍出版邀请”。
-
“每个人都可以在 Jupyter Notebook 中拟合机器学习模型。但,我可以快速制作一个基本的 Web 应用程序演示,展示你可以通过 REST API 发送数据并获取预测的 Scikit-learn 函数”。
-
“我可以帮助进行新机器学习程序的成本效益分析,并告诉你收益是否超过数据收集的努力,以及如何做到最优”。
想象一下你在面试委员会面前的表现将如何与那些在统计学和梯度下降常规问题上表现良好,但没有提供全面能力证明的其他候选人不同。
他们表明你对数据科学问题充满好奇。
他们表明你阅读、分析和沟通。你创建并记录以便其他人创建。
他们表明你的思维超越了笔记本和分类准确性,进入了商业价值增值和客户同理心的领域。哪个公司不喜欢这种候选人呢?
…这些习惯相对容易培养和实践,即它们不需要艰苦的工作、长期的统计学背景或深度机器学习知识的高级专业技能。但,令人惊讶的是,并不是每个人都接受它们。这就是你与众不同的机会。
我在哪里可以获得帮助?
有这么多出色的工具和资源来帮助你练习。在一篇小文章的篇幅内,甚至不可能列出其中的一部分。我只是展示了一些代表性的例子。关键是沿着这些方向探索,并为自己发现有用的工具。
仅使用 Jupyter Notebooks 构建可安装的软件包
nbdev:用 Jupyter Notebooks 做所有事情
如何逐步制作一个了不起的 Python 包
学习如何将单元测试原则集成到自己的机器学习模型和模块开发中
学习如何在数据科学任务中整合面向对象编程原则
使用简单的 Python 脚本构建交互式 Web 应用程序——无需 HTML/CSS 知识
PyWebIO:使用 Python 以脚本方式编写交互式 Web 应用
从你的 Jupyter notebook 中编写完整的编程和技术书籍。也可以用来构建文档。
理解现实生活中的分析问题的多方面复杂性,它远不仅仅是建模和预测
想象一下你将如何与面试委员会的其他候选人不同,他们可能在统计和梯度下降的常规问题上表现出色,但没有提供全面能力的可证明证据。
关于 MOOCs/在线课程的几点说明

图片来源:作者自创
学习时不要跳过步骤。按照步骤进行。
图片来源:作者自创
在每个机会中阅读核心话题和书籍
不要仅仅关注最新的深度学习技巧或关于最新 Python 库的博客文章。在每一个机会中,都要阅读行业顶级论坛和好书上的核心话题。我喜欢的一些书籍和论坛如下,

图片来源:作者自创
总结
数据科学及其相关的机器学习和人工智能技能在目前的就业市场上需求极高,越来越多的企业采用并拥抱这些变革性技术。竞争激烈,并且人才需求与供应之间存在大量的沟通不畅。
一个燃眉之急的问题是:如何在一百名申请者中脱颖而出?
我们列出了一些关键问题,你可以自问这些问题来评估自己在一些使你与众不同的技能和习惯上的独特性。我们展示了一些虚拟对话片段,你可以用来在面试中展示这些技能和习惯。我们还提供了一份资源的短名单,帮助你开始这些。
我们列出了一些参加 MOOCs 的方法,并建议了阅读资源。
祝你在数据科学的旅程中一切顺利……
你可以查看作者的 GitHub** 仓库**,获取机器学习和数据科学中的代码、创意和资源。如果你像我一样,对 AI/机器学习/数据科学充满热情,请随时 在 LinkedIn 上添加我 或 在 Twitter 上关注我。
原文。经许可转载。
相关:
-
作为数据科学初学者,你应该避免的 10 个错误
-
如何获得实际的数据科学经验,以便为职业做好准备
-
麦肯锡教给我的 5 个课程,让你成为更优秀的数据科学家
更多相关话题
使用 llamafile 分发和运行 LLMs 的 5 个简单步骤
原文:
www.kdnuggets.com/distribute-and-run-llms-with-llamafile-in-5-simple-steps

图片由作者提供
对于许多人来说,探索 LLMs 的可能性感觉遥不可及。无论是下载复杂的软件,弄懂编码,还是需要强大的机器——开始使用 LLMs 似乎都令人望而却步。但试想一下,如果我们能够像启动其他计算机程序一样轻松地与这些强大的语言模型互动。无需安装,无需编码,只需点击和对话。这种可达性对于开发者和最终用户都至关重要。llamaFile 作为一种新颖的解决方案,将 llama.cpp 和 Cosmopolitan Libc 合并成一个单一的框架。这个框架通过提供一个称为“llama 文件”的单文件可执行文件来简化 LLMs 的复杂性,可以在本地机器上运行而无需安装。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
那么,它是如何工作的呢?llamaFile 提供了两种便捷的方法来运行 LLMs:
-
第一种方法涉及从 Hugging Face 下载 llamafile 的最新版本及相应的模型权重。一旦获得这些文件,你就可以开始使用了!
-
第二种方法更简单——你可以访问 预先存在的示例 llamafiles,这些文件已内置权重。
在本教程中,你将使用第二种方法操作LLaVa 模型的 llamafile。它是一个 70 亿参数的模型,被量化为 4 位,你可以通过聊天、上传图片和提问与之互动。其他模型的示例 llamafiles 也可用,但我们将使用 LLaVa 模型,因为其 llamafile 大小为 3.97 GB,而 Windows 的最大可执行文件大小为 4 GB。这个过程非常简单,你可以按照下面提到的步骤运行 LLMs。
步骤 1:下载 llamafile
首先,你需要从提供的 这里 下载 llava-v1.5-7b-q4.llamafile (3.97 GB) 可执行文件。
第 2 步:授予执行权限(适用于 macOS、Linux 或 BSD 用户)
打开你计算机的终端并导航到文件所在的目录。然后运行以下命令以授予你的计算机执行此文件的权限。
chmod +x llava-v1.5-7b-q4.llamafile
第 3 步:重命名文件(适用于 Windows 用户)
如果你使用 Windows,请在 llamafile 的名称末尾添加 “.exe”。你可以在终端中运行以下命令来完成这个操作。
rename llava-v1.5-7b-q4.llamafile llava-v1.5-7b-q4.llamafile.exe
第 4 步:运行 llamafile
使用以下命令执行 llama 文件。
./llava-v1.5-7b-q4.llamafile -ngl 9999
⚠️ 由于 MacOS 使用 zsh 作为默认的 shell,如果你遇到 zsh: exec format error: ./llava-v1.5-7b-q4.llamafile 错误,则需要执行以下操作:
bash -c ./llava-v1.5-7b-q4.llamafile -ngl 9999
对于 Windows,你的命令可能如下所示:
llava-v1.5-7b-q4.llamafile.exe -ngl 9999
第 5 步:与用户界面互动
运行 llamafile 后,它应该会自动打开你的默认浏览器并显示如下所示的用户界面。如果没有,打开浏览器并手动导航到 localhost:8080。
图片由作者提供
让我们通过一个简单的问题来与界面互动,以提供一些与 LLaVa 模型相关的信息。以下是模型生成的回复:

图片由作者提供
该回复强调了 LLaVa 模型的开发方法及其应用。生成的回复相当迅速。让我们尝试实施另一个任务。我们将上传以下带有详细信息的银行卡样本图像,并从中提取所需的信息。

图片由 Ruby Thompson 提供
这是回复:

图片由作者提供
再次地,回复是相当合理的。LLaVa 的作者声称它在各种任务中表现出色。随意探索不同的任务,观察其成功和局限性,并亲自体验 LLaVa 的卓越表现。
一旦与你的 LLM 的互动完成,你可以通过返回终端并按 "Control - C" 来关闭 llama 文件。
总结
分发和运行 LLM 从未如此简单。在本教程中,我们解释了如何仅通过一个可执行的 llamafile 轻松运行和试验不同的模型。这不仅节省了时间和资源,还扩展了 LLM 的可访问性和现实世界的实用性。我们希望您发现本教程有帮助,并非常希望听到您的意见。此外,如果您有任何问题或反馈,请随时与我们联系。我们随时乐于提供帮助并重视您的意见。
感谢您的阅读!
Kanwal Mehreen**** Kanwal 是一位机器学习工程师和技术作家,对数据科学和 AI 与医学的交叉领域充满了深厚的热情。她合著了电子书《用 ChatGPT 最大化生产力》。作为 2022 年亚太地区的 Google Generation Scholar,她倡导多样性和学术卓越。她还被认可为 Teradata 多样性技术学者、Mitacs Globalink 研究学者和哈佛 WeCode 学者。Kanwal 是变革的积极倡导者,创立了 FEMCodes 以赋能 STEM 领域的女性。
更多相关内容
使用 Ray 编写你的第一个分布式 Python 应用程序
原文:
www.kdnuggets.com/2021/08/distributed-python-application-ray.html
评论
由 Michael Galarnyk,数据科学专家

Ray 使并行和分布式计算的工作更像你所期望的那样 (图片来源)
Ray 是一个快速、简单的分布式执行框架,便于扩展应用程序并利用最先进的机器学习库。使用 Ray,你可以将顺序运行的 Python 代码转变为分布式应用程序,几乎不需要修改代码。
本教程的目标是探讨以下内容:
-
为什么你应该使用 Ray 进行并行化和分布式
-
如何开始使用 Ray
-
分布式计算中的权衡(计算成本、内存、I/O 等)
为什么你应该使用 Ray 进行并行化和分布式?
正如 之前的文章指出,并行和分布式计算是现代应用程序的基础。问题是,将现有 Python 代码并行化或分布式化可能意味着重写现有代码,有时甚至是从头开始。此外,现代应用程序有现有模块如 multiprocessing 缺乏的要求。这些要求包括:
-
在多台机器上运行相同的代码
-
构建具有状态并能够通信的微服务和角色
-
机器故障和抢占的优雅处理
-
大对象和数值数据的高效处理
Ray 库满足这些需求,并允许你在不重写应用程序的情况下进行扩展。为了简化并行和分布式计算,Ray 将函数和类转化为分布式环境中的任务和角色。这个教程的其余部分将深入探讨这些概念以及在构建并行和分布式应用程序时需要考虑的一些重要事项。

虽然本教程探讨了 Ray 如何使并行化普通 Python 代码变得容易,但需要注意的是,Ray 及其生态系统也使得并行化现有库变得容易,例如 scikit-learn、 XGBoost、 LightGBM、 PyTorch等。
如何开始使用 Ray
将 Python 函数转换为远程函数(Ray 任务)
Ray 可以通过 pip 安装。
pip install 'ray[default]'
让我们通过创建 Ray 任务来开始 Ray 之旅。这可以通过用 @ray.remote 装饰一个普通的 Python 函数来完成。这将创建一个可以在你的笔记本电脑的 CPU 核心(或 Ray 集群)上调度的任务。
考虑下面的两个函数,它们生成斐波那契数列(一个整数序列,其特征是每个数都是前两个数的和)。第一个是普通的 Python 函数,第二个是 Ray 任务。
import os
import time
import ray
# Normal Python
def fibonacci_local(sequence_size):
fibonacci = []
for i in range(0, sequence_size):
if i < 2:
fibonacci.append(i)
continue
fibonacci.append(fibonacci[i-1]+fibonacci[i-2])
return sequence_size
# Ray task
@ray.remote
def fibonacci_distributed(sequence_size):
fibonacci = []
for i in range(0, sequence_size):
if i < 2:
fibonacci.append(i)
continue
fibonacci.append(fibonacci[i-1]+fibonacci[i-2])
return sequence_size
关于这两个函数,有几点需要注意。首先,它们是相同的,只是在 fibonacci_distributed 函数上有 @ray.remote 装饰器。
第二点需要注意的是返回值较小。它们返回的不是斐波那契数列本身,而是序列大小,这是一个整数。这一点很重要,因为这可能会降低分布式函数的价值,设计时需要考虑它是否需要或返回大量数据(参数)。工程师通常将此称为分布式函数的输入/输出(IO)。
比较本地与远程性能
本节中的函数将帮助我们比较生成多个长斐波那契数列所需的时间,无论是在本地还是并行处理。值得注意的是,下面的两个函数都使用了 os.cpu_count(),它返回系统中的 CPU 数量。
os.cpu_count()
本教程中使用的机器有八个 CPU,这意味着下面的每个函数将生成 8 个斐波那契数列。
# Normal Python
def run_local(sequence_size):
start_time = time.time()
results = [fibonacci_local(sequence_size) for _ in range(os.cpu_count())]
duration = time.time() - start_time
print('Sequence size: {}, Local execution time: {}'.format(sequence_size, duration))
# Ray
def run_remote(sequence_size):
# Starting Ray
ray.init()
start_time = time.time()
results = ray.get([fibonacci_distributed.remote(sequence_size) for _ in range(os.cpu_count())])
duration = time.time() - start_time
print('Sequence size: {}, Remote execution time: {}'.format(sequence_size, duration))
在深入了解 run_local 和 run_remote 的代码之前,让我们先运行这两个函数,看看生成多个 100000 数字的斐波那契数列在本地和远程的时间差异。
run_local(100000)
run_remote(100000)
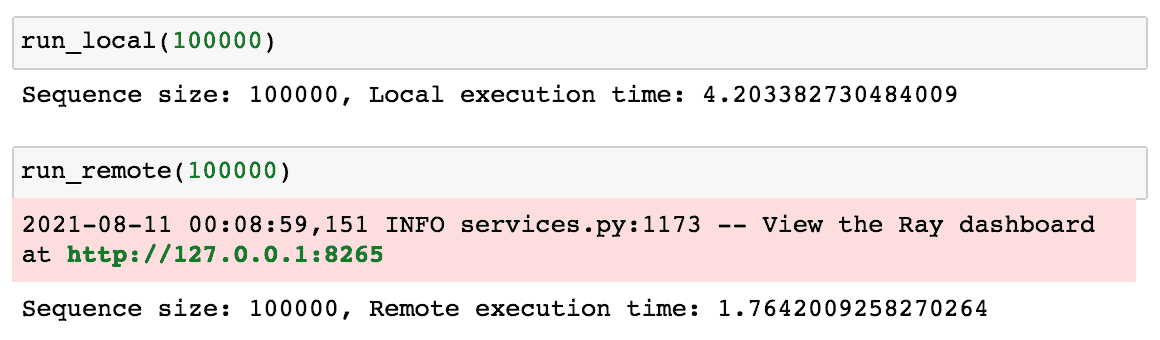
run_remote 函数将计算并行化到多个 CPU 上,从而减少了处理时间(1.76 秒对比 4.20 秒)。
Ray API
为了更好地理解为何 run_remote 更快,我们简要回顾一下代码,并解释 Ray API 的工作原理。

ray.init() 命令启动所有相关的 Ray 进程。默认情况下,Ray 每个 CPU 核心创建一个工作进程。如果你想在集群上运行 Ray,你需要传入一个集群地址,例如 ray.init(address= 'InsertAddressHere')。

fibonacci_distributed.remote(100000)

调用 fibonacci_distributed.remote(sequence_size) 会立即返回一个未来对象,而不是函数的返回值。实际的函数执行将会在后台进行。由于它立即返回,每个函数调用可以并行执行。这使得生成那些多个 100000 长的 Fibonacci 序列所需的时间更少。


ray.get 在任务完成时检索结果值。
最后,重要的是要注意,当调用 ray.init() 的进程终止时,Ray 运行时也将终止。注意,如果你尝试多次运行 ray.init(),你可能会遇到 RuntimeError(也许你意外地调用了 ray.init 两次?)。可以通过使用 ray.shutdown() 来解决这个问题。
# To explicitly stop or restart Ray, use the shutdown API
ray.shutdown()
Ray 仪表盘
Ray 附带一个仪表盘,你可以在调用 ray.init 函数后通过 http://127.0.0.1:8265 访问。
在 其他内容 中,仪表盘允许你:
-
了解 Ray 内存利用情况并调试内存错误。
-
查看每个演员的资源使用情况、已执行的任务、日志等。
-
查看集群指标。
-
终止演员并分析你的 Ray 作业。
-
一目了然地查看错误和异常。
-
在单一界面中查看多个机器的日志。
-
查看 Ray Tune 作业和试验信息。
下面的仪表盘显示了在运行 run_remote(200000) 后每个节点和每个工作者的资源利用情况。注意仪表盘显示了每个工作者正在运行的 fibonacci_distributed 函数。观察你的分布式函数运行的情况是个好主意。这样,如果你发现一个工作者在做所有的工作,你可能是不正确使用了 ray.get 函数。另外,如果你发现你的总 CPU 利用率接近 100%,你可能做得有些过头了。
分布式计算中的权衡
本教程使用了斐波那契序列,因为它们提供了调整计算和 IO 的多种选项。你可以通过增加或减少序列大小来改变每个函数调用所需的计算量。序列大小越大,生成序列所需的计算量就越多,而序列大小越小,则所需的计算量越少。如果你分布的计算量过小,Ray 的开销将主导总处理时间,你将无法从分布函数中获得任何价值。
在分布函数时,IO 也至关重要。如果你修改这些函数以返回它们计算的序列,随着序列大小的增加,IO 也会增加。在某些时候,传输数据所需的时间将主导完成多个分布函数调用所需的总时间。如果你在集群中分布函数,这一点尤其重要。这将需要使用网络,而网络调用比本教程中使用的进程间通信更昂贵。
因此,建议你尝试实验分布式斐波那契函数和本地斐波那契函数。尝试确定从远程函数中获益所需的最小序列大小。一旦你搞清楚了计算量,就可以调整 IO 以观察整体性能的变化。无论你使用什么工具,分布式架构在不需要移动大量数据时效果最佳。
幸运的是,Ray 的一个主要优点是能够远程维护整个对象。这有助于缓解 IO 问题。接下来我们来看看这个问题。
远程对象作为 Actors
正如 Ray 将 Python 函数转化为分布式任务一样,Ray 将 Python 类转化为分布式的 actor。Ray 提供了 actor,以便你可以并行化一个类的实例。从代码角度看,你只需在 Python 类中添加@ray.remote装饰器,即可将其转化为一个 actor。当你创建该类的一个实例时,Ray 会创建一个新的 actor,这是一个在集群中运行的进程,并持有对象的副本。
由于它们是远程对象,它们可以持有数据,并且它们的方法可以操作这些数据。这有助于减少进程间通信。如果你发现自己编写了太多返回数据的任务,而这些数据又被发送到其他任务中,请考虑使用 actor。
现在,让我们看一下下面的 actor。
from collections import namedtuple
import csv
import tarfile
import time
import ray
@ray.remote
class GSODActor():
def __init__(self, year, high_temp):
self.high_temp = float(high_temp)
self.high_temp_count = None
self.rows = []
self.stations = None
self.year = year
def get_row_count(self):
return len(self.rows)
def get_high_temp_count(self):
if self.high_temp_count is None:
filtered = [l for l in self.rows if float(l.TEMP) >= self.high_temp]
self.high_temp_count = len(filtered)
return self.high_temp_count
def get_station_count(self):
return len(self.stations)
def get_stations(self):
return self.stations
def get_high_temp_count(self, stations):
filtered_rows = [l for l in self.rows if float(l.TEMP) >= self.high_temp and l.STATION in stations]
return len(filtered_rows)
def load_data(self):
file_name = self.year + '.tar.gz'
row = namedtuple('Row', ('STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'ELEVATION', 'NAME', 'TEMP', 'TEMP_ATTRIBUTES', 'DEWP',
'DEWP_ATTRIBUTES', 'SLP', 'SLP_ATTRIBUTES', 'STP', 'STP_ATTRIBUTES', 'VISIB', 'VISIB_ATTRIBUTES',
'WDSP', 'WDSP_ATTRIBUTES', 'MXSPD',
'GUST', 'MAX', 'MAX_ATTRIBUTES', 'MIN', 'MIN_ATTRIBUTES', 'PRCP',
'PRCP_ATTRIBUTES', 'SNDP', 'FRSHTT'))
tar = tarfile.open(file_name, 'r:gz')
for member in tar.getmembers():
member_handle = tar.extractfile(member)
byte_data = member_handle.read()
decoded_string = byte_data.decode()
lines = decoded_string.splitlines()
reader = csv.reader(lines, delimiter=',')
# Get all the rows in the member. Skip the header.
_ = next(reader)
file_rows = [row(*l) for l in reader]
self.rows += file_rows
self.stations = {l.STATION for l in self.rows}
上述代码可用于加载和操作一个名为全球表面日总结(GSOD)的公共数据集。该数据集由国家海洋和大气管理局(NOAA)管理,并且可以在其 网站 上免费获取。NOAA 目前维护来自全球超过 9000 个站点的数据,GSOD 数据集包含这些站点的每日总结信息。从 1929 年到 2020 年,每年都有一个 gzip 文件。对于本教程,你只需下载 1980 和 2020 的文件。
这次 actor 实验的目标是计算 1980 年和 2020 年中有多少次读数达到 100 度或更高,并确定 2020 年是否有比 1980 年更多的极端温度。为了实现公平比较,只应考虑 1980 年和 2020 年都存在的站点。因此,这次实验的逻辑如下:
-
加载 1980 年的数据。
-
加载 2020 年的数据。
-
获取 1980 年存在的站点列表。
-
获取 2020 年存在的站点列表。
-
确定站点的交集。
-
获取 1980 年期间交集站点中 100 度或以上的读数数量。
-
获取 2020 年期间交集站点中 100 度或以上的读数数量。
-
打印结果。
问题在于,这种逻辑完全是顺序的;一个事情只能在另一个事情之后发生。使用 Ray 后,这种逻辑可以在并行中完成。
下表展示了更具并行性的逻辑。
以这种方式编写逻辑是确保你以可并行的方式执行所有操作的绝佳方法。以下代码实现了这一逻辑。
# Code assumes you have the 1980.tar.gz and 2020.tar.gz files in your current working directory.
def compare_years(year1, year2, high_temp):
# if you know that you need fewer than the default number of workers,
# you can modify the num_cpus parameter
ray.init(num_cpus=2)
# Create actor processes
gsod_y1 = GSODActor.remote(year1, high_temp)
gsod_y2 = GSODActor.remote(year2, high_temp)
ray.get([gsod_y1.load_data.remote(), gsod_y2.load_data.remote()])
y1_stations, y2_stations = ray.get([gsod_y1.get_stations.remote(),
gsod_y2.get_stations.remote()])
intersection = set.intersection(y1_stations, y2_stations)
y1_count, y2_count = ray.get([gsod_y1.get_high_temp_count.remote(intersection),
gsod_y2.get_high_temp_count.remote(intersection)])
print('Number of stations in common: {}'.format(len(intersection)))
print('{} - High temp count for common stations: {}'.format(year1, y1_count))
print('{} - High temp count for common stations: {}'.format(year2, y2_count))
#Running the code below will output which year had more extreme temperatures
compare_years('1980', '2020', 100)
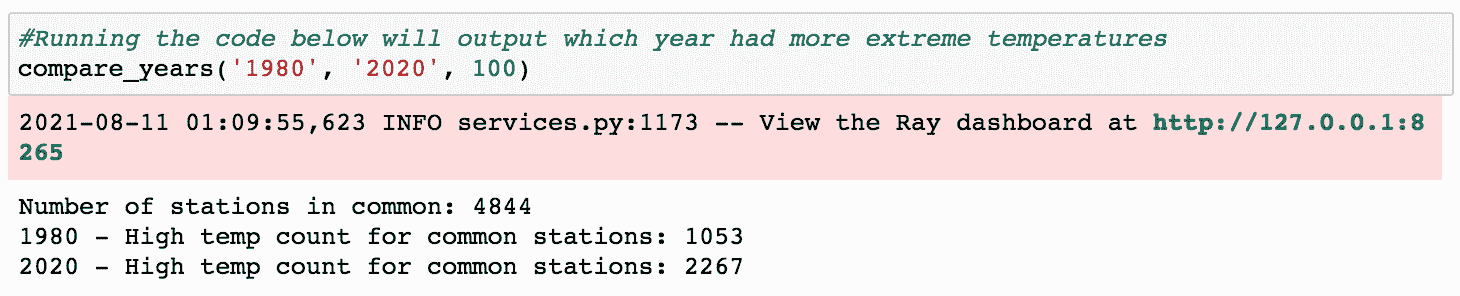
关于上面的代码有几点重要事项需要提及。首先,将@ray.remote装饰器放置在类级别,使所有类方法都可以被远程调用。其次,上面的代码使用了两个 actor 进程(gsod_y1 和 gsod_y2),这些进程可以并行执行方法(尽管每个 actor 每次只能执行一个方法)。这使得 1980 年和 2020 年的数据能够同时加载和处理。
结论
Ray 是一个快速、简单的分布式执行框架,使得扩展应用程序并利用最先进的机器学习库变得容易。这个教程展示了如何使用 Ray 轻松将现有的顺序 Python 代码转变为分布式应用程序,几乎无需更改代码。虽然这里的实验都在同一台机器上进行,但 Ray 也使得在每个主要云服务提供商上扩展 Python 代码变得容易。如果你对 Ray 感兴趣,可以查看 Ray 项目在 GitHub 上,关注 @raydistributed 的推特,并注册 Ray 新闻通讯。
简介: Michael Galarnyk 是一名数据科学专家,现任 Anyscale 开发者关系专员。
原文。经许可转载。
相关:
-
成功的数据科学职业建议
-
Dask 和 Pandas:没有过多的数据
-
加速 Scikit-Learn 模型训练
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 工作
更多相关内容
与 Kaggle 的 AI 报告 2023 一起深入未来 – 了解最新热点
原文:
www.kdnuggets.com/dive-into-the-future-with-kaggle-ai-report-2023-see-what-hot

编辑提供的图片
2023 年 5 月 12 日,Kaggle 开启了一个竞赛,Kaggle 社区可以参与编写一份总结过去两年 AI 迅猛发展的报告。Kaggle 社区是一个多元化的群体,拥有在 AI 领域深度的各种经验。
参与者被要求根据过去两年的变化和发展写一篇关于特定主题的文章,例如生成式 AI、AI 伦理等。
报告在这里,包括以下几个部分:
-
生成式 AI
-
文本数据
-
图像与视频数据
-
表格与时间序列数据
-
Kaggle 竞赛
-
AI 伦理
那么,让我们深入了解我们学到了什么……
生成式 AI
生成式 AI 最近成为热门话题。本部分深入探讨了过去两年生成式 AI 的快速进展和应用。我们见证了文本生成、图像创建和音乐开发等进展,使用了如 GANs 和 LLMs 等工具和技术。
这仅仅依靠了更大数据集和改进的硬件来增强算法在训练阶段的效果。尽管生成式 AI 仍处于初期阶段,但在过去的一年里,它已经展示了如何彻底改变不同的行业。仍需考虑伦理问题,例如隐私问题、虚假信息以及这些 AI 系统的使用。
继续阅读不同的文章:
文本数据
随着生成式 AI 的热潮,自然语言处理(NLP)也因大型语言模型(LLMs)的兴起而引起了极大的兴趣。Kaggle AI 报告的下一部分聚焦于 NLP 技术及其在各种任务中的应用,如总结和翻译。
如果回顾早期的方法,文本任务的早期方法包括基于术语频率的特征工程与非神经网络的机器学习方法相结合。现在我们处理的是更大的数据集,这些数据集经过学习词表示以进行模型解释。
互联网数据作为训练语料库的使用,使这些模型能够更好地学习,并在迁移学习等领域取得更好的性能。在 Kaggle 竞赛中,微调公开可用的模型已经显示出超越人类水平的表现。
以下顶级论文关注于 LLMs 的出现和最新技术:
图像与视频数据
就像文本数据被用于内容生成任务一样,图像和视频生成也非常流行。计算机视觉已存在很长时间,但近年来其发展迅速。我们现在能够处理如物体检测等任务。
本部分探讨了模型架构以及计算机视觉中的常见实践,如数据增强。计算机视觉在医疗成像等多个行业中得到了应用,但在深度伪造、伦理和哲学考量、多模态模型的局限性等领域仍面临挑战。
我们有如 Segment Anything Model (SAM)和 YOLO(You Only Look Once)等模型,这些模型展示了如何将通用的开源模型适应于不同且独特的任务。
通过以下论文深入了解图像和视频数据的进展:
表格与时间序列数据
下一部分将深入探讨表格数据和时间序列数据的历史意义。这些数据在过去几年并未广泛流行,因为它们未能像深度学习革命那样产生同样的影响。然而,它们仍然被广泛使用且非常有效,在以下领域中尤为流行:
-
针对特定数据集/问题的独特方法
-
数据预处理和特征工程的重要性
-
梯度提升树的主导地位
在 Kaggle 社区,这些趋势得到了高度认可,以下论文将深入探讨这些趋势以及表格和时间序列数据所面临的独特挑战。
Kaggle 竞赛
这份来自 Kaggle 社区的报告还分析了 Kaggle 竞赛,考察了过去两年中的发展及社区对这些变化的观察。多年来,Kaggle 竞赛广受欢迎,社区成员利用这一平台测试技能,建立作品集,为现实世界做好准备。
对 Kaggle 竞赛变化的观察包括诸如伪标签、种子平均和爬山算法等技术,这些曾经被视为“技巧”的方法现在已经成为常见做法。过去两年,Kaggle 竞赛变得更加激烈,RSNA、学习机构等竞赛非常受欢迎。
探索 Kaggle 竞赛的获胜技巧:
人工智能伦理
关于人工智能的伦理也是一个关注点,社会上许多人对人工智能系统的使用和实施有着复杂的情感。组织正在研究人工智能的伦理原则,并制定新策略,以确保他们不仅能够理解人工智能系统,还能够监控和缓解风险。
这不是一项学术研究,而是一项社会研究,其中包含许多重要的观点,帮助我们理解人工智能的世界以及如何在保护社会价值观的同时继续使用人工智能。我们看到组织在采用伦理设计的过程中对其人工智能系统进行了持续审计。
了解更多关于人工智能的挑战及其对社会的影响:
总结
Kaggle 团队创建了一份独特的报告,让社区成员表达他们对人工智能及其在过去两年变化的看法和经验。如果你发现某个特定部分或文章特别有趣,请告诉我们!
Nisha Arya 是一名数据科学家,自由撰稿人,以及 KDnuggets 的编辑和社区经理。她特别感兴趣于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。Nisha 涵盖了广泛的话题,并希望探索人工智能如何促进人类寿命的不同方式。作为一个热衷学习者,Nisha 致力于拓展她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
数据科学中的多样性:概述与策略
评论
许多近期的文章强调了科技行业中女性和代表性不足的少数族裔的短缺,以及硅谷“兄弟文化”相关的问题。然而,除了招聘实践之外,少有文章提供增加多样性的建议。这个问题到底有多严重,除了建议由背景基本相同的团队发起的文化变革,还有什么可行的解决方案?
大约三分之一的科技行业员工是女性,约六分之一是代表性不足的少数族裔(西班牙裔或非洲裔美国人)。管理层中约五分之六是白人。像谷歌或苹果这样的科技大公司报告称其员工的多样性更低,在技术相关职位中,行业中女性占 24%,代表性不足的少数族裔占 5%。在开发团队中,女性的比例低至 13%,且女性在技术职位上的离职率是男性的两倍。这些统计数据表明,女性和代表性不足的少数族裔在技术公司中担任的职务与技术开发或领导无关。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的捷径。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 部门
公司可以通过增加多样性获得多种好处。麦肯锡的一份最新报告显示,在种族和民族多样性方面排名前四分之一的公司,其超越行业中位数回报的可能性比基准水平高出 35%。一名女性担任高管职位使标准普尔 1500 公司收入的回报率提升了 4200 万美元。这表明,通过招聘多样化的技术团队和多样化的高管团队有可能增加收入。此外,女性和少数族裔带给技术团队的经验可以帮助设计并弥补用户体验和产品开发中的潜在盲点。
然而,解决这个问题比单纯改变招聘实践要复杂得多。女性和少数族裔在与科技职位相关的教育管道中占比过小;获得计算机科学学位的女性人数继续下降(从 1984 年的 37%下降到 2014 年的 18%)。考虑到如今在线培训程序和 MOOCs 的普及和便利,很容易假设这些机会能弥合差距。然而,数据科学项目/训练营的女性参与度(35%的参与者是女性)和少数族裔参与度(4%的非洲裔美国人和 8%的西班牙裔)仍然滞后。由于学术项目和行业训练营中的多样性较低,科技职位的数字趋势在短期内不太可能改变。即使减少歧视,如果年轻学生在课堂上看不到与自己相似的人或来自相同社会经济背景的人,也可能不会有所帮助。

教育工作者、训练营负责人以及科技行业本身可以解决这些差距,并且一些倡议有望在未来几年提升相关数字。许多奖学金存在于科技训练营中(www.switchup.org/blog/women-in-tech-a-comprehensive-scholarship-guide)和学术项目中(www.scholarshipsforwomen.net/engineering/),还包括非洲裔美国人和西班牙裔学生(www.nacme.org/)。美国还承诺在未来几年提供 2 亿美元的 STEM 教育资金用于女性和少数族裔。这可以帮助解决负担问题,并作为女性和少数族裔尝试科技相关专业或训练营的激励措施。
此外,针对创始人或领导职位中有女性或代表性不足少数群体的公司,提供了小企业资助 (startupnation.com/start-your-business/small-business-grants-women-minorities/, www.fundera.com/blog/where-to-find-small-business-grants-for-women, www.nerdwallet.com/blog/small-business/small-business-grants-minorities/, www.federalgrantswire.com/minority-federal-government-grants.html#.W47QKYeouK8, www.allamericangrantguide.com/minority-business-grants.php),帮助增加初创公司高层的多样性。在我开始自己的咨询有限公司之前,我并不了解启动小企业所需的资助类型,女性和代表性不足的少数群体可能也未必知道有这些资助。
行业会议提供了另一个鼓励女性和少数群体追求技术职位和职业发展的机会。斯坦福大学的女性数据科学(WiDS)会议在今年三月吸引了超过 10 万人参与,分布在数百个城市,这让女性能够向其他女性和参加会议的男性展示她们的工作。创建一个类似于 WiDS 的会议,突出非裔美国人和西班牙裔或来自低收入家庭的技术成就和工作,可能会在更大社区中创造类似的可见性,表现出技术是一个可行的职业选择。
我进入科技行业的道路涉及了三位教授——一位在基础微积分课程中,另两位在研究生阶段——他们都是在数学领域取得成功的女性,而我在行业中的第一次职位也是在有女性领导者的公司里。如果没有机会向这些女性学习,我不确定我是否会把领导或技术职位视为适合自己的选择。提高女性和少数群体在技术教育/项目中的可见性,特别是在早期,并通过奖学金和资助项目使这些机会经济上可行,可以在技术职业的各个阶段增加多样性。
角色榜样和资源的可见性可能比招聘指南和其他平等措施更能有效地提高科技领域(以及一般的 STEM 领域)多样性。像英国 WISE 倡议这样的活动专注于帮助和鼓励 16 岁以上的年轻女性追求 STEM 职业,迈阿密的女性生物医学科学倡议可能是实现这一目标的一种途径。更多像 WiDS 这样的会议也有助于提升可见性。通过女性和少数群体在该领域的可见领导、对机会和资金的广泛了解,以及将新一代潜在科技工作者与那些在职业生涯中走得更远的人连接的项目。
参考资料及其他文章:
www.techrepublic.com/article/5-eye-opening-statistics-about-minorities-in-tech/
www.eeoc.gov/eeoc/statistics/reports/hightech/
www.forbes.com/sites/mnewlands/2016/08/29/why-diversity-matters-in-tech/#7080726c8614
www.mckinsey.com/business-functions/organization/our-insights/why-diversity-matters
papers.ssrn.com/sol3/papers.cfm?abstract_id=1088182
www.betterbuys.com/bi/women-in-data-science/
www.forbes.com/sites/priceonomics/2017/09/28/the-data-science-diversity-gap/#52f389b5f58b
www.politico.com/story/2017/09/25/trump-stem-technology-grants-women-minorities-243115
相关:
更多相关话题
深入池化:揭示 CNN 池化层的魔力
原文:
www.kdnuggets.com/diving-into-the-pool-unraveling-the-magic-of-cnn-pooling-layers
动机
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 需求
池化层在所有最先进的深度学习模型中使用的 CNN 架构中非常常见。它们在计算机视觉任务中广泛存在,包括分类、分割、目标检测、自编码器等;只要有卷积层的地方就会用到它们。
在这篇文章中,我们将深入探讨使池化层有效的数学原理,并学习何时使用不同类型的池化层。我们还将弄清楚每种类型的特点以及它们之间的不同之处。
为什么使用池化层
池化层提供了各种好处,使其成为 CNN 架构的常见选择。它们在管理空间维度方面发挥了关键作用,并使模型能够从数据集中学习不同的特征。
这里是使用池化层在模型中的一些好处:
- 维度减少
所有池化操作从完整的卷积输出网格中选择一个子样本。这会减少输出,从而减少随后的层的参数和计算,这是卷积架构相对于全连接模型的一个重要好处。
- 平移不变性
池化层使机器学习模型对输入中的小变化(如旋转、平移或增强)具有不变性。这使得模型适用于基本的计算机视觉任务,使其能够识别类似的图像模式。
现在,让我们看看在实践中常用的各种池化方法。
常见示例
为了方便比较,我们使用一个简单的二维矩阵,并应用相同参数的不同技术。
池化层继承了与卷积层相同的术语,内核大小、步幅和填充的概念得到保留。
所以,我们在这里定义一个四行四列的二维矩阵。为了使用池化,我们将使用大小为二的内核和步幅为二的设置,没有填充。我们的矩阵如下所示。
作者图片
需要注意的是,池化是按通道进行的。 因此,在特征图的每个通道上重复相同的池化操作。即使输入特征图被降采样,通道数量也保持不变。
最大池化
我们在矩阵上遍历内核,并从每个窗口中选择最大值。在上述示例中,我们使用一个 2x2 的内核,步长为二,并在矩阵上遍历,形成四个不同的窗口,由不同颜色表示。
在最大池化中,我们只保留每个窗口中的最大值。 这会对矩阵进行降采样,我们得到一个较小的 2x2 网格作为最大池化输出。
作者提供的图片
最大池化的好处
- 保留高激活值
当应用于卷积层的激活输出时,我们实际上只捕捉了较高的激活值。这在高激活值至关重要的任务中很有用,例如目标检测。实际上,我们在降采样矩阵,但仍然可以保留数据中的关键信息。
- 保留主要特征
最大值通常表示我们数据中的重要特征。当我们保留这些值时,我们保存了模型认为重要的信息。
- 抗噪声
由于我们基于窗口中的单个值做决策,其他值的小变化可以被忽略,使其对噪声更具鲁棒性。
缺点
- 可能的信息丢失
基于最大值的决策忽略了窗口中的其他激活值。丢弃这些信息可能导致有价值的信息丧失,在后续层中无法恢复。
- 对小的位移不敏感
在最大池化中,非最大值的小变化将被忽略。这种对小变化的不敏感可能是一个问题,并可能偏倚结果。
- 对高噪声敏感
尽管会忽略值的小变化,但单个激活值的高噪声或错误可能导致选择一个异常值。这可能会显著改变最大池化的结果,导致结果退化。
平均池化
在平均池化中,我们以类似的方式遍历窗口。然而,我们考虑窗口中的所有值,取平均值,然后将其作为结果输出。

作者提供的图片
平均池化的好处
- 保留空间信息
从理论上讲,我们保留了窗口中所有值的一些信息,以捕捉激活值的集中趋势。实际上,我们丢失的信息更少,可以保留更多的卷积激活值的空间信息。
- 对异常值的鲁棒性
对所有值进行平均使这种方法相对于最大池化更能抵抗异常值,因为单个极端值不会显著改变池化层的结果。
- 更平滑的过渡
当取平均值时,我们获得的输出之间的过渡更为平滑。这提供了数据的通用表示,减少了后续层之间的对比度。
缺点
- 无法捕捉显著特征
应用平均池化层时,窗口中的所有值被平等对待。这无法捕捉卷积层的主要特征,这在某些问题领域可能是个问题。
- 特征图之间的区分度降低
当所有值被平均时,我们只能捕捉区域之间的共同特征。因此,我们可能会丧失图像中某些特征和模式之间的区别,这对于目标检测等任务确实是一个问题。
全局平均池化
全局池化不同于普通池化层。它没有窗口、卷积核大小或步幅的概念。 我们将整个矩阵视为一个整体,并考虑网格中的所有值。在上述示例中,我们对 4x4 矩阵中的所有值取平均,得到一个单一的值作为结果。

作者提供的图像
使用时机
全局平均池化允许构建简单而稳健的 CNN 架构。通过使用全局池化,我们可以实现通用模型,适用于任何大小的输入图像。 全局池化层直接在密集层之前使用。
卷积层对每张图像进行降采样,具体取决于卷积核迭代次数和步幅。然而,对不同大小的图像应用相同的卷积会导致不同形状的输出。所有图像都按相同的比例降采样,因此较大的图像会有较大的输出形状。当将其传递给密集层进行分类时,尺寸不匹配可能会导致运行时异常。
在没有修改超参数或模型架构的情况下,实现适用于所有图像形状的模型可能会很困难。这个问题通过使用全局平均池化得以缓解。
当全局池化应用在密集层之前时,所有输入大小都会被缩减到 1x1 的大小。因此,(5,5)或(50,50)的输入都会被降采样到 1x1 的大小。它们可以被展平并发送到密集层,而无需担心大小不匹配。
关键要点
我们讨论了一些基本的池化方法及其适用场景。选择适合我们特定任务的方法至关重要。
澄清一点,池化层中没有可学习的参数。它们只是执行基本数学操作的滑动窗口。池化层不可训练,但它们能够加速 CNN 架构的计算,并在学习输入特征时增强鲁棒性。
穆罕默德·阿赫曼 是一位从事计算机视觉和自然语言处理的深度学习工程师。他曾参与多个生成式 AI 应用的部署和优化,这些应用在 Vyro.AI 上进入了全球排行榜。他对构建和优化智能系统的机器学习模型感兴趣,并相信持续改进。
更多相关主题
使用 Streamlit 的 DIY 自动化机器学习
原文:
www.kdnuggets.com/2021/11/diy-automated-machine-learning-app.html
图片由 Soroush Zargar 拍摄,来源于 Unsplash
你可能知道自动化机器学习(AutoML)。你很有可能听说过开源 AutoML 工具TPOT,也就是你的数据科学助手。你甚至可能看过我最近的文章,介绍了如何使用 TPOT 优化机器学习管道(你可能没看过,所以这是你的机会去看看... 我等着你)。
无论如何,当这些优化按钮可见且易于调整时,探索 AutoML 和机器学习优化的调整旋钮会更有意义。在这篇文章中,我们将实现一个 TPOT 示例版本,如在我之前的文章中所述,作为一个 Streamlit 应用。
如果你不了解Streamlit,这是一个 30,000 英尺的概览:
Streamlit 将数据脚本在几分钟内转化为可分享的网页应用。
全部用 Python 编写。完全免费。不需要前端经验。
概述
我不会进一步详细说明 Streamlit 的使用,除了本文中的内容,你可以在这里找到一个很好的介绍,以及 Streamlit 速查表,基本涵盖了在了解其工作原理后所需知道的所有内容,在此。
除了快速了解如何实现 Streamlit 项目外,你还将获得一个沙盒网页应用,允许使用 TPOT 进行管道优化实验,并使用一对知名数据集。通过一些修改,你还应该能够使用其他数据集运行沙盒,并扩展功能以包括更多的调整旋钮。
我们用 Streamlit 和 TPOT 构建的“AutoML Pipeline Optimization Sandbox”网页应用
我不会重述原始博客文章(再次,随时阅读它),但简而言之,我们正在创建一个脚本,以自动化分类任务的预处理和建模优化——包括有限数量的预处理转换以及算法选择——在鸢尾花和数字数据集上。确实,数据集很枯燥,但使用知名数据来设置应用程序并不是一个坏主意,就像我上面说的,通过几行代码的修改,你可以尝试其他任何数据集。
关于这个优化过程的几点注意事项,超出了上述内容,还包括:
-
模型评估的交叉验证
-
对建模进行多次迭代(由于 TPOT 内部使用遗传算法)——在如此小的数据集上可能不太有用,但随着进展可能会有帮助
-
比较这些多次迭代后的结果管道——它们都一样吗?
-
你知道 TPOT 现在在幕后使用 PyTorch 来构建预测用的神经网络吗?
最后这一点不会影响我们今天的工作,但请记住它以备将来使用。
让我们看看创建这个简单 Streamlit 应用程序所需的代码。
代码
首先,导入:
import streamlit as st
import timeit
import pandas as pd
import matplotlib.pyplot as plt
from tpot import TPOTClassifier
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_digits, load_iris
from sklearn import metrics
from stqdm import stqdm
一切都应该非常简单。最后的导入 stqdm 是一个专门为 Streamlit 编写的 tqdm 风格的进度条。
接下来,这是数据加载函数:
@st.cache
def load_data(dataset, train_size, test_size, random_state):
"""Load data"""
ds = ''
if dataset == 'digits':
ds = load_digits()
df = load_digits(as_frame=True)
if dataset == 'iris':
ds = load_iris()
df = load_iris(as_frame=True)
X_train, X_test, y_train, y_test = train_test_split(ds.data, ds.target, train_size=train_size, test_size=test_size, random_state=random_state)
return X_train, X_test, y_train, y_test, df['frame']
我们使用 Scikit-learn 中的 load_iris() 和 load_digits() 函数(TPOT 与其紧密集成)来获取相应的数据集。请注意,这里将数据集分为训练集和测试集,并分别返回训练/测试特征/标签,以及用于向用户展示的完整数据集数据框,因为它看起来更美观,尤其是当通过 Streamlit 展示时(Streamlit 能够使用其 write() 方法解释和正确显示各种对象)。还有其他方法可以实现这一点,但这对如此小的数据集来说简单且没有问题。请注意 @st.cache 装饰器,它将函数的结果缓存以供应用程序未来的运行,而不是每次都重新加载数据。
现在我们设置一些应用范围的 Streamlit 配置,设置侧边栏,分配一些变量,并使用上述函数加载数据:
# Set title and description
st.title("AutoML Pipeline Optimization Sandbox")
st.write("Experiment with using open source automated machine learning tool TPOT for building fully-automated prediction pipelines")
# Create sidebar
sidebar = st.sidebar
dataset = sidebar.selectbox('Dataset', ['iris','digits'])
train_display = sidebar.checkbox('Display training data', value=True)
search_iters = sidebar.slider('Number of search iterations', min_value=1, max_value=5)
generations = sidebar.slider('Number of generations', min_value=1, max_value=10)
population_size = sidebar.select_slider('Population size', options=[10,20,30,40,50,60,70,80,90,100])
random_state = 42
train_size = 0.75
test_size = 1.0 - train_size
checkpoint_folder = './tpot_checkpoints'
output_folder = './tpot_output'
verbosity = 0
n_jobs = -1
times = []
best_pipes = []
scores = []
# Load (and display?) data
X_train, X_test, y_train, y_test, df = load_data(dataset)
if train_display:
st.write(df)
比较上述代码,在相关情况下,与你之前实现的独立脚本或 Streamlit 速查表中的内容,这一切应该都相当简单。
注意设置交互式用户可配置变量的便利,这些变量在我们的代码中被使用,以及设置侧边栏的便利。我们可以使用滑块、复选框和选择框来选择和显示数据集,并设置遗传算法 TPOT 内部用于优化过程的搜索迭代次数、代数和种群规模。现在应该越来越容易看到如何在不费太多力气的情况下开放自定义数据集。
接下来,让我们定义评分方法;模型评估方法;以及实际搜索方法。之后,展示了优化循环,包括为用户利益显示一些特定迭代的输出。
# Define scoring metric and model evaluation method
scoring = 'accuracy'
cv = ('stratified k-fold cross-validation',
StratifiedKFold(n_splits=10,
shuffle=True,
random_state=random_state))
# Define search
tpot = TPOTClassifier(cv=cv[1],
scoring=scoring,
verbosity=verbosity,
random_state=random_state,
n_jobs=n_jobs,
generations=generations,
population_size=population_size,
periodic_checkpoint_folder=checkpoint_folder)
# Pipeline optimization iterations
with st.spinner(text='Pipeline optimization in progress'):
for i in stqdm(range(search_iters)):
start_time = timeit.default_timer()
tpot.fit(X_train, y_train)
elapsed = timeit.default_timer() - start_time
score = tpot.score(X_test, y_test)
best_pipes.append(tpot.fitted_pipeline_)
st.write(f'\n__Pipeline optimization iteration: {i}__\n')
st.write(f'* Elapsed time: {elapsed} seconds')
st.write(f'* Pipeline score on test data: {score}')
tpot.export(f'{output_folder}/tpot_{dataset}_pipeline_{i}.py')
此时,你应该比较 Streamlit 速查表中的 write()、spinner()、success() 和其他显示功能。
一旦运行,上述优化循环将输出类似于以下内容的结果:
最后,我们需要评估我们的结果:
# check if pipelines are the same
result = True
first_pipe = str(best_pipes[0])
for pipe in best_pipes:
if first_pipe != str(pipe):
result = False
if (result):
st.write("\n__All best pipelines were the same:__\n")
st.write(best_pipes[0])
else:
st.write('\nBest pipelines:\n')
st.write(*best_pipes, sep='\n\n')
st.write('__Saved to file:__\n')
st.write(f'```{output_folder}/tpot_{dataset}_pipeline_{i}.py```py')
st.success("Pipeline optimization complete!")

...并输出最佳管道的代码(也保存到文件中):
# Output contents of best pipe file
with open (f'{output_folder}/tpot_{dataset}_pipeline_{i}.py', 'r') as best_file:
code = best_file.read()
st.write(f'```{code}```py')

这是 Streamlit 应用程序的完整代码(注意,只需这个简短的 Python 脚本即可完成所有任务):
这就是如何利用 Streamlit 和 TPOT 快速构建一个 AutoML 管道优化沙箱,只需使用 Python 代码。请注意,我们成功完成这一过程并不需要任何网页编程技能。
Matthew Mayo (@mattmayo13) 是数据科学家和 KDnuggets 的主编,KDnuggets 是开创性的在线数据科学和机器学习资源。他的兴趣领域包括自然语言处理、算法设计与优化、无监督学习、神经网络以及自动化机器学习方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
更多相关话题
DIY 深度学习项目
原文:
www.kdnuggets.com/2018/06/diy-deep-learning-projects.html
评论

LinkedIn 数据科学社区
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT

阿克沙伊·巴哈杜尔(Akshay Bahadur)是 LinkedIn 数据科学社区中的优秀例子之一。还有许多其他平台上的优秀人士,如 Quora、StackOverflow、YouTube 和众多论坛,他们在科学、哲学、数学、语言以及数据科学及其相关领域相互帮助。

阿克沙伊·巴哈杜尔(Akshay Bahadur)。
但我认为在过去的 ~3 年里,LinkedIn 社区在数据科学领域分享了很多精彩内容,从分享经验到详细的帖子,介绍了如何在现实世界中进行机器学习或深度学习。我总是推荐进入这个领域的人加入一个社区,LinkedIn 是最好的之一,你会一直在那里找到我 😃.
从深度学习和计算机视觉开始
github.com/facebookresearch/Detectron
在深度学习领域,研究图像分类、检测以及在“看到”某物时采取行动非常重要,这一领域在这个十年取得了令人惊叹的成果,比如在某些问题上超越了人类水平的表现。
在这篇文章中,我将展示阿克沙伊·巴哈杜尔在计算机视觉(CV)和深度学习(DL)领域所做的每一篇帖子。如果你对这些术语不熟悉,可以在这里了解更多:
关于深度学习的介绍、课程和博客文章非常丰富。但这是一种不同的介绍。 towardsdatascience.com
我决定提高对计算机视觉和机器学习技术的熟悉程度。作为一名网页开发人员,我发现了这一点…… towardsdatascience.com
对人类和计算机视觉的 50 年回顾 towardsdatascience.com
我最近完成了 Andrew Ng 的 Coursera 计算机视觉课程。Ng 对许多… towardsdatascience.com
1. 使用 OpenCV 进行手部运动
akshaybahadur21/HandMovementTracking
通过在 GitHub 上创建一个账户来为 HandMovementTracking 开发做出贡献。 github.com
来自 Akshay:
要进行视频跟踪,算法分析连续的视频帧并输出目标在帧之间的运动。各种算法各有优缺点。选择哪种算法时需要考虑其预期用途。视觉跟踪系统有两个主要组成部分:目标表示和定位,以及滤波和数据关联。
视频跟踪是使用相机随时间定位移动物体(或多个物体)的过程。它有多种用途,包括:人机交互、安全与监控、视频通信与压缩、增强现实、交通控制、医学成像和视频编辑。
这是你需要的所有代码来重现它:
import numpy as np
import cv2
import argparse
from collections import deque
cap=cv2.VideoCapture(0)
pts = deque(maxlen=64)
Lower_green = np.array([110,50,50])
Upper_green = np.array([130,255,255])
while True:
ret, img=cap.read()
hsv=cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
kernel=np.ones((5,5),np.uint8)
mask=cv2.inRange(hsv,Lower_green,Upper_green)
mask = cv2.erode(mask, kernel, iterations=2)
mask=cv2.morphologyEx(mask,cv2.MORPH_OPEN,kernel)
#mask=cv2.morphologyEx(mask,cv2.MORPH_CLOSE,kernel)
mask = cv2.dilate(mask, kernel, iterations=1)
res=cv2.bitwise_and(img,img,mask=mask)
cnts,heir=cv2.findContours(mask.copy(),cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)[-2:]
center = None
if len(cnts) > 0:
c = max(cnts, key=cv2.contourArea)
((x, y), radius) = cv2.minEnclosingCircle(c)
M = cv2.moments(c)
center = (int(M["m10"] / M["m00"]), int(M["m01"] / M["m00"]))
if radius > 5:
cv2.circle(img, (int(x), int(y)), int(radius),(0, 255, 255), 2)
cv2.circle(img, center, 5, (0, 0, 255), -1)
pts.appendleft(center)
for i in xrange (1,len(pts)):
if pts[i-1]is None or pts[i] is None:
continue
thick = int(np.sqrt(len(pts) / float(i + 1)) * 2.5)
cv2.line(img, pts[i-1],pts[i],(0,0,225),thick)
cv2.imshow("Frame", img)
cv2.imshow("mask",mask)
cv2.imshow("res",res)
k=cv2.waitKey(30) & 0xFF
if k==32:
break
# cleanup the camera and close any open windows
cap.release()
cv2.destroyAllWindows()
是的,54 行代码。很简单,对吧?你需要在电脑上安装 OpenCV,如果你有 Mac,可以查看这个:
在这篇文章中,我们将提供在 MacOS 和 OSX 上安装 OpenCV 3.3.0(C++ 和 Python)的逐步说明…
如果你有 Ubuntu:
OpenCV:在 Ubuntu 上安装 OpenCV-Python
现在我们已经有了所有必要的依赖项,接下来安装 OpenCV。安装需要通过 CMake 配置。它… docs.opencv.org
如果你有 Windows:
在 Windows 上安装 OpenCV-Python - OpenCV 3.0.0-dev 文档
在本教程中,我们将学习如何在 Windows 系统上设置 OpenCV-Python。以下步骤已在 Windows 7-64 上测试过…
2. 疲劳检测 OpenCV
akshaybahadur21/Drowsiness_Detection
通过在 GitHub 上创建一个账户来为 Drowsiness_Detection 开发做出贡献。 github.com
这可以用于那些长时间驾驶的骑手,可能会导致事故。该代码可以检测你的眼睛,并在用户打瞌睡时发出警报。
依赖
-
cv2
-
immutils
-
dlib
-
scipy
算法
每只眼睛由 6 个(x,y)坐标表示,从眼睛的左上角开始(就像你在看那个人一样),然后顺时针环绕眼睛:
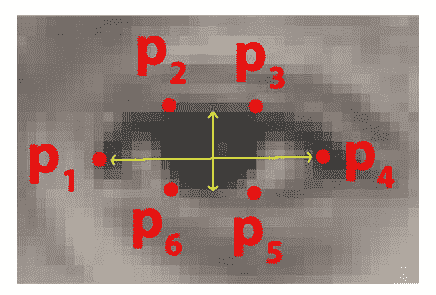
条件
它检查 20 个连续的帧,如果眼睛纵横比小于 0.25,则会生成警报。
关系
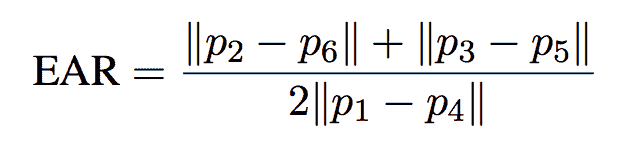
总结
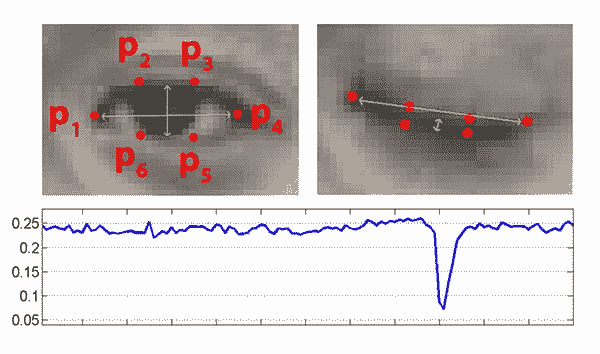
3. 使用 Softmax 回归进行数字识别
akshaybahadur21/Digit-Recognizer
Digit-Recognizer - 识别数字的机器学习分类器 github.com
这段代码帮助你使用 softmax 回归分类不同的数字。你可以安装 Conda 来解决机器学习的所有依赖关系。
描述
Softmax 回归(同义词:多项逻辑回归、最大熵分类器或多类逻辑回归)是逻辑回归的一种推广,我们可以用于多类分类(假设类别是相互排斥的)。相对而言,在二分类任务中,我们使用(标准)逻辑回归模型。
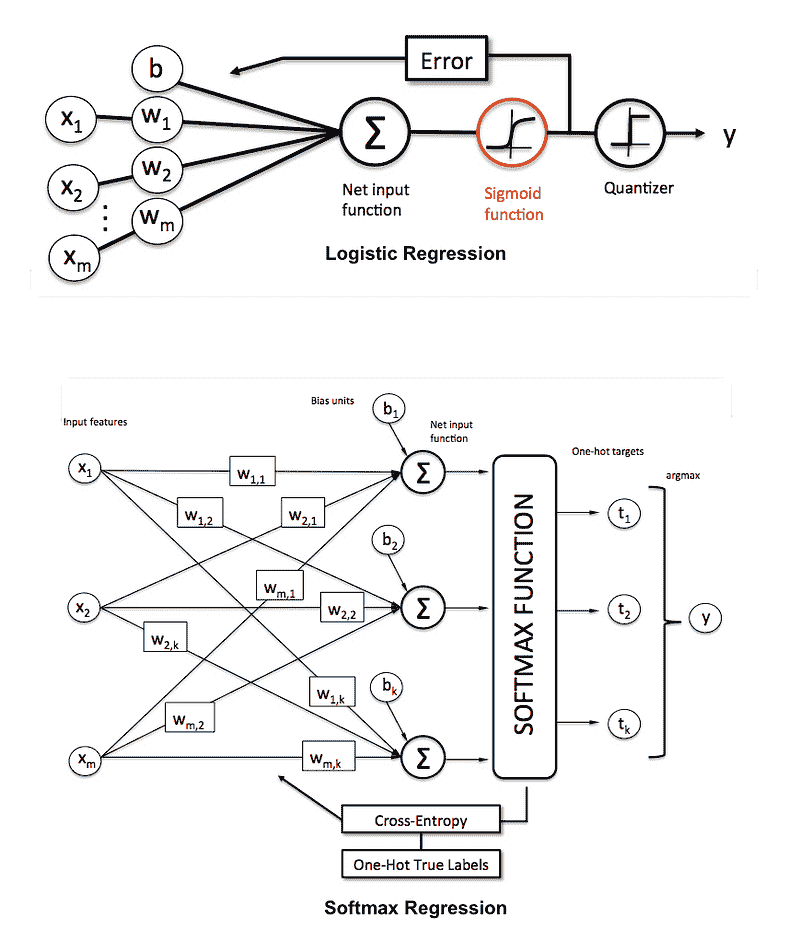
Python 实现
使用的数据集是 MNIST,图像大小为 28 X 28,计划是使用逻辑回归、浅层网络和深度神经网络来分类 0 到 9 的数字。
这里最好的部分之一是他使用 Numpy 编码了三个模型,包括优化、前向和反向传播以及所有其他内容。
对于逻辑回归:查看代码
对于浅层神经网络:查看代码
最终使用深度神经网络:查看代码
通过网络摄像头写入的执行
要运行代码,输入python Dig-Rec.py
python Dig-Rec.py
通过网络摄像头显示图像的执行
要运行代码,输入python Digit-Recognizer.py
python Digit-Recognizer.py

Devanagiri 识别
akshaybahadur21/Devanagiri-Recognizer
Devanagiri-Recognizer - 使用卷积网络的印地语字母分类器 github.com
这段代码帮助你使用卷积网络对印地语(Devanagiri)不同字母进行分类。你可以安装 Conda 来解决机器学习的所有依赖关系。
使用的技术
我使用了卷积神经网络。我使用 Tensorflow 作为框架,Keras API 提供高级抽象。
架构
CONV2D → MAXPOOL → CONV2D → MAXPOOL → FC → Softmax → 分类
一些额外的点
-
你可以添加额外的卷积层。
-
添加正则化以防止过拟合。
-
你可以添加额外的图像到训练集中,以提高准确性。
Python 实现
数据集- DHCD(Devanagari 字符数据集),图像大小为 32 X 32,并使用卷积网络。
要运行代码,输入python Dev-Rec.py
python Dev-Rec.py
4. 使用 FaceNet 进行面部识别
akshaybahadur21/Facial-Recognition-using-Facenet
Facial-Recognition-using-Facenet - 使用 facenets 实现面部识别。
这段代码帮助进行面部识别,使用 facenets(arxiv.org/pdf/1503.03832.pdf)。facenets 的概念最初在一篇研究论文中提出。主要概念涉及三元组损失函数,用于比较不同人的图像。这个概念使用了 inception 网络,源码来自于此,而 fr_utils.py 来自于 deeplearning.ai 作为参考。我添加了自己的一些功能,以提供稳定性和更好的检测。
代码要求
你可以为 Python 安装 Conda,它解决了所有机器学习的依赖关系,你将需要:
numpy
matplotlib
cv2
keras
dlib
h5py
scipy
描述
面部识别系统是一种技术,能够通过数字图像或视频源中的视频帧来识别或验证一个人。面部识别系统有多种工作方法,但一般来说,它们通过将选定的面部特征与数据库中的面部进行比较来工作。
添加的功能
-
仅在你的眼睛睁开时检测面部。(安全措施)。
-
使用 dlib 的面部对齐功能,以便在实时流媒体中有效预测。
Python 实现
-
使用的网络- Inception 网络
-
原始论文——Google 的 Facenet
步骤
-
如果你想训练网络,运行
Train-inception.py,然而你不需要这样做,因为我已经训练了模型并将其保存为face-rec_Google.h5文件,该文件在运行时会被加载。 -
现在你需要在你的数据库中有图像。代码会检查
/images文件夹。你可以将图片粘贴到那里,或者使用网络摄像头拍摄。为此,运行create-face.py,图像将存储在/incept文件夹中。你需要手动将它们粘贴到/images文件夹中。 -
运行
rec-feat.py来运行应用程序。
5. Emojinator
这段代码帮助你识别和分类不同的表情符号。目前,我们仅支持手部表情符号。
代码要求
你可以为 Python 安装 Conda,它解决了所有机器学习的依赖关系,你将需要:
numpy
matplotlib
cv2
keras
dlib
h5py
scipy
描述
表情符号是用于电子消息和网页的表意符号和笑脸。表情符号存在于各种类型中,包括面部表情、常见物品、地点和天气类型以及动物。它们很像表情符号,但表情符号是实际的图片,而不是文字。
功能
-
过滤器以检测手部。
-
用于训练模型的 CNN。
Python 实现
- 使用的网络 - 卷积神经网络
过程
-
首先,你必须创建一个手势数据库。为此,运行
CreateGest.py。输入手势名称,你将看到 2 帧显示。查看轮廓帧,并调整你的手,确保捕捉到手部特征。按 'c' 以捕捉图像。它将拍摄 1200 张同一手势的图像。尝试在帧内稍微移动手,以确保你的模型在训练时不会过拟合。 -
对你想要的所有特征重复此操作。
-
运行
CreateCSV.py将图像转换为 CSV 文件 -
如果你想训练模型,请运行‘TrainEmojinator.py’
-
最后,运行
Emojinator.py来通过网络摄像头测试你的模型。
贡献者
Akshay Bahadur 和 Raghav Patnecha。

结语
我只能说我对这些项目印象深刻,你可以在你的电脑上运行所有这些项目,或者更简单地在Deep Cognition平台上运行,如果你不想安装任何东西,并且它可以在线运行。
我想感谢 Akshay 和他的朋友们为这个伟大的开源贡献做出的努力,也感谢所有将来的贡献者。尝试这些,运行它们,获取灵感。这只是深度学习和计算机视觉能够做的惊人事物的一个小例子,最终由你来将其转化为能够帮助世界变得更美好的东西。
永不放弃,我们需要每个人对许多不同的事物感兴趣。我认为我们可以改变世界,使其变得更好,改善我们的生活、工作方式、思维方式和解决问题的方法。如果我们将所有现有资源集中起来,使这些知识领域为更大的利益而协作,我们可以对世界和我们的生活产生巨大的积极影响。
我们需要更多感兴趣的人,更多课程,更多专业化,更多热情。我们需要你 😃
感谢阅读。我希望你在这里找到了一些有趣的东西 😃
如果你有问题,可以在 Twitter 上添加我:
[Favio Vázquez (@FavioVaz) | Twitter
Favio Vázquez (@FavioVaz) 最新的推文。数据科学家。物理学家和计算工程师。我有一…twitter.com](https://twitter.com/FavioVaz)
和 LinkedIn:
[Favio Vázquez — 首席数据科学家 — OXXO | LinkedIn
查看 Favio Vázquez 在 LinkedIn 的个人资料,全球最大的专业社区。Favio 列出了 15 个工作…linkedin.com](http://linkedin.com/in/faviovazquez/)
那里见 😃
简历: Favio Vazquez 是一位物理学家和计算机工程师,专注于数据科学和计算宇宙学。他对科学、哲学、编程和音乐充满热情。目前,他担任 Oxxo 的首席数据科学家,致力于数据科学、机器学习和大数据。他还是 Ciencia y Datos 的创始人,这是一个西班牙语的数据科学出版物。他喜欢接受新挑战,与优秀的团队合作,并解决有趣的问题。他参与了 Apache Spark 的合作,帮助维护 MLlib、核心库和文档。他热衷于将自己的科学知识、数据分析、可视化和自动学习的专长应用于帮助世界变得更美好。
原文。经许可转载。
相关:
-
一个“奇怪”的深度学习入门
-
成为数据科学家的两面性
-
我深入学习深度学习的历程
更多相关话题
如何 DIY 自己的数据科学教育
原文:
www.kdnuggets.com/2019/04/diy-your-data-science-education.html
评论
如果你想成为一名数据科学专业人士,但不愿意走传统的大学课程途径,那也没问题。

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
虽然有些人发现正式教育的路径对他们很有效,但你也可以选择 DIY 方法。以下是八种方法:
1. 自学一些最必要的编程语言
作为一名数据科学家,你需要掌握一些编程语言。为了确保你成为一名全面的专业人士,你需要掌握许多你应该了解的编程语言。如果你想要一个坚实的起点,统计数据显示,越来越多的数据科学职位要求应聘者了解 Python。
幸运的是,你可以通过 Analytics Vidhya 提供的免费 Python 教程 来学习 Python。在完成教程并感觉你对 Python 有了透彻的理解之后,可以考虑学习 R。这是另一种在数据科学中常用的编程语言。Swirl 提供了 一个逐步学习 R 的过程,你可以下载一个互动控制台并在其中完成课程。
2. 聆听相关的播客
播客满足了那些希望在锻炼、通勤或做饭时既能获得教育又能获得娱乐的人们的需求。它们还可以补充你的数据科学教育,通过打破学习过程中的单调,让学习变得更加有趣。
Data Skeptic 值得一听,因为它通过将高级概念分解为小段内容,使其更易于理解。内容还涵盖了数据科学如何应用于现实世界,这可能会给你一些关于未来职业选择的灵感。
你还可以尝试 Digital Analytics Power Hour,这是一个全球朋友通过虚拟方式聚会讨论数据科学的节目。不要被其非正式的语气所欺骗,认为你没有学到实用的东西。每一集都旨在提供你可以独立深入探讨的要点。
3. 发展你的数据科学图书馆
如果你没有或者只有少量数据科学书籍,现在是投资一些书籍并开始创建一个你可以参考的图书馆的时机。试试 "Data Science for Business" 来学习如何从信息中提取见解。这本书是超过 150 所高等教育机构的数据科学课程的一部分。
"Getting Started With Data Analytics" 是另一本帮助你建立该学科宝贵基础的书籍,尤其适合自学者。除了这两本书外,可以考虑列出你遇到的感兴趣和迷人的主题。然后,寻找提到这些内容的书籍。
4. 报名参加在线数据科学课程
互联网的一个伟大之处在于它为人们提供了无数的学习机会,速度可以根据个人的节奏调整。你可以报名参加数据科学课程,并按照自己的时间表进行学习。例如,Udemy 有 一个数据科学训练营课程。这是一个付费选项,但课程声称可以提供“成为数据科学家所需的所有工具”,并且不需要先前的经验。
或者,CognitiveClass.ai 的数据科学基础学习路径 提供了随时可以访问的内容,并且提供了一个虚拟实验室,你可以在其中练习所学的概念。这只是与数据科学相关的众多可能性中的两个。探索类似的在线课程主题,比如机器学习或商业分析,也同样值得。
5. 计划亲自观看技术专家的演讲
今天领先的技术专家可以解释 数据科学如何应用于其他领域。例如,机器人通过改进用于训练的数据,学会了如何避开障碍物并适应实时的环境变化。
参加会议并从专家那里获取观点可以为你的自学教育提供动力,让你感到受启发。数据科学会议将在 2019 年 11 月在塞尔维亚贝尔格莱德举行,届时将有超过 50 位讲者。还有数据峰会 2019,将在 5 月于波士顿举行。
现在就计划清理你的日程,至少参加一个数据科学活动。你可能会对在如此短的时间内学到的东西感到惊讶。此外,你将对数据科学如何应用于其他领域有更深入的理解,从而跟上趋势和发展。
6. 查阅 YouTube
YouTube 是进一步学习数据科学的绝佳资源。要小心选择你观看的视频,特别是因为有些视频仅仅是课程广告,并没有提供实际的学习内容。然而,你仍然有很多可能性可以观看。
当你刚开始时,可以考虑数据科学入门——初学者速成课程来自 freeCodeCamp.org。还有麻省理工学院提供的一个学期长的免费课程,名为计算思维与数据科学简介。一旦掌握了入门材料,可以扩展到更高级的话题。
在开始学习内容之前,阅读其他观众的评论总是一个好主意。他们的评论可能帮助你确定课程的整体质量以及它是否符合你的期望。
7. 本地结识其他学习者和数据科学家
调查一下你的社区是否有定期的数据科学家和学习者会议。MeetUp 网站是一个很好的起点,它可能会向你揭示新的机会。例如,纽约提供了各种聚会,包括女性数据科学家的小组。旧金山的选项同样多样,还有一些数据科学初学者的群体。
无论你住在哪里,都可以使用 MeetUp 或类似网站来寻找面对面的数据科学家交流机会。你应该会像参加会议后那样享受到好处,不过这种交流会更为常规。
8. 从事数据科学项目
你可以按任意顺序浏览这个列表的各个部分。不过,最终你需要将所有学习付诸实践。做到这一点的最佳方法是投身于数据科学项目。Springboard.com 提供了几个来帮助你入门。然后,当你积累更多经验后,提出你想解决的问题,并创建使用免费数据集的项目。
期待一个光明的未来
数据科学是一个潜力巨大的职业领域,理解它的人在专业层面上持续受到需求。这个列表中的选项展示了你可以开始并甚至完成学习,而无需注册正式学位课程。
采用这种方法需要自律,但它也能使你具备接受和应对数据科学行业未来工作的能力。
个人简介: 凯拉·马修斯 在《The Week》、《The Data Center Journal》和《VentureBeat》等出版物上讨论技术和大数据,并且已有五年以上的写作经验。要阅读凯拉的更多文章,订阅她的博客《生产力字节》。
相关:
-
数据科学如何改善高等教育
-
在 2 年内提升数据科学技能的 8 种方法
-
2019 年每位数据科学家应设立的 6 个目标
更多相关主题
Django 的 9 种最常见的应用
原文:
www.kdnuggets.com/2021/08/django-9-common-applications.html
评论
由 Aakash Bijwe,Scalex 技术解决方案的 AVP, IT 解决方案提供

在为项目选择新语言或框架时,大多数开发者关注的是安全性、快速开发、可扩展性、多功能性和支持。对于许多公司和独立开发者来说,Django 框架是一个简单的选择,因为它是市场上最受欢迎的 web 开发框架之一。鉴于 Django 框架提供的功能,许多开发者已开始选择 Django 作为他们所有开发任务的首选框架。
关于 Django 框架
Django 是一个免费的、开源的、高级 Python web 框架,促进了快速开发和务实且简洁的代码。它旨在支持 web 应用开发、web API 和 web 服务。它采用了 MVC(模型-视图-控制器)架构的原则,其主要目标是简化复杂且数据库驱动的网站的开发。通过 Django 框架,web 开发者可以专注于创建功能丰富、快速、安全和可扩展的独特应用,并且比使用其他 web 开发工具具有更大的灵活性。Django 处理了许多 web 开发中的麻烦,使用户能够专注于开发应用所需的组件,而不是花费时间在已经开发的组件上。
由于 Python 的日益流行,Django 已成为许多Python 开发公司的首选框架。但是,为什么是 Django?为什么它在开发者中如此受欢迎?让我们来探讨一下为什么全球如此多的开发者使用它,以及你如何也能做到这一点。
使用 Django 框架的好处
基于 Python 构建
由于 Django 框架是基于 Python 构建的,它继承了这种编程语言的主要优点。它被认为相当容易使用和阅读,且非常适合机器学习。Python 非常易学,通常是开发者的首选语言。许多科技巨头,包括 Google,都在其技术栈中广泛使用 Python。
Django 的内置功能
Django 以“开箱即用”而闻名,这意味着开发者几乎可以找到开发一个完整应用程序所需的一切。这些功能包括 ORM、认证、会话管理支持、HTML 模板、URL 路由、中间件、HTTP 库、多站点支持、模板引擎、表单、视图层、模型层、Python 兼容性等。这一特性加快了开发进程,因为开发者无需实现这些基本功能。
高度安全
Django 在安全性方面没有妥协,并且默认提供保护应用程序和用户的功能。它通过提供一个经过工程设计的框架来帮助开发者避免许多常见的安全错误,从而自动保护网站。Django 通常是第一个响应漏洞并提醒其他框架的。
高度可扩展和可靠
显然,你需要一个能够处理大量数据和流量的框架。Django 使任何应用程序都能够高效地处理任何观众体量的增长。它包括一系列的默认组件,可以被拆卸和替换为更具体的解决方案。由于 Django 是各行业广泛使用的热门 Web 应用框架,许多云服务提供商正在采取一切措施,以便在他们的平台上快速、轻松地部署应用程序。这使得开发者能够开发出更具功能性、可靠性和效率的应用程序。
DRY 原则
DRY(不要重复自己)原则鼓励开发者不仅使用现有代码,还要避免不必要的代码行、错误或应用程序中的缺陷。这使得 Django 在时间上高效,非常适合高负载系统,同时也简化了维护。
丰富的库集
另一个从 Python 及其优秀社区继承的巨大优势是 Django 拥有许多有用的库。一些最受欢迎的库包括用于构建 API(应用程序编程接口)的 Django REST 框架和专注于网站内容管理的 CMS 框架。
优秀的社区和文档
Django 由一个大型且活跃的开发者社区支持,这些开发者帮助解决开发过程中遇到的问题。还提供了大量的材料和资源,从文档、教程、博客到见面会和研讨会应有尽有。
Django 框架的 9 种最常见应用
以下是使用 Django 框架开发的一些应用或项目类型
-
构建跨平台应用程序 - 该框架的跨平台特性使开发者能够支持各种操作系统和用户设备的整个开发和生产环境,从而接触更广泛的受众。Django 允许在跨平台设备上运行应用程序的灵活性。
-
可扩展的网络应用 - Django 最适合构建可扩展的网络应用,因为该框架提供了程序员希望在网络应用中包含的功能。此外,使用 Django 提供的组件来构建应用程序比构建自定义组件更为容易。
-
具有多个用户角色的应用程序 - Django 最适合构建具有多个用户角色的网络应用仪表板。它提供了一个在构建网络应用时自动生成的广泛的 web 管理界面。
-
构建 SaaS 和企业应用 - Django 允许你更快地构建应用程序,因为它支持异步视图。对于 SaaS 或企业应用,异步视图还可以用于调用第三方 API、发送电子邮件以及执行读写操作。
-
构建成本高效的 MVP - Django 使初创公司和企业家能够迅速将他们的想法转化为有效的概念验证。它支持快速开发,并且使用现成的库可以显著减少开发时间。
-
构建内容管理系统(CMS) - 它也非常适合需要内容管理系统的应用,例如报纸网站、在线杂志或博客,这些应用往往吸引大量流量。
-
安全的电子商务应用 - Django 的电子商务框架具备用户体验、安全性、可扩展性、功能丰富性和可靠性等所有特性。使用 Django 构建电子商务市场是处理流量的第一步。
-
金融平台 - 框架的安全性以及 Django 扩展和库使得创建强大的支付解决方案成为可能,这些解决方案具有基于个人数据、风险承受能力等计算结果的功能。
-
社交网络和书签网站 - 它可以用于创建促进交流的社交网络网站,其中安全性和多用户角色至关重要。
Django 还适用于创建文档管理系统、CRM 系统、算法生成器、处理法律问题的平台(如验证抵押贷款条件或租赁状态)、房地产评估系统、验证系统、电子邮件新闻通讯平台、具有动态规则和复杂参数的过滤系统、数据分析和复杂计算平台,以及机器学习。
总结
Django 为全球数以千计的网站提供支持,是初创公司和大型企业的完美解决方案。我们希望你在阅读这些使用案例后,能对 Django 框架有一个良好的理解。如果你希望快速且高效地交付产品,那么你应该考虑在下一个项目中使用 Django 框架。
简介: Aakash Bijwe 是 Scalex Technology Solutions 的一位充满热情且专注的商业领袖,他利用移动、云和分析的力量帮助企业保持领先和可持续。Aakash 对移动/网络技术和云的广泛知识使他能够塑造客户的想法并更好地服务他们。
相关:
-
Python 数据结构对比
-
数据科学家的高效 Python 编程指南
-
Prefect: 如何用 Python 编写和调度你的第一个 ETL 管道
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
更多相关内容
DLib:机器学习库
原文:
www.kdnuggets.com/2014/06/dlib-library-machine-learning.html
是一个开源的现代 C++ 库,实现了许多机器学习算法,并支持线程和网络等功能。

DLib-ml 实现了众多机器学习算法:
-
支持向量机(SVMs),
-
K-Means 聚类,
-
贝叶斯网络,
-
和其他许多内容。
DLib 还具有实用功能,包括
-
线程功能,
-
网络功能,
-
数值算法,
-
图像处理,
-
和数据压缩及完整性算法。
DLib 包含广泛的单元测试覆盖和使用库的示例。库中的每个类和函数都有文档。这些文档可以在库的 主页 找到。DLib 为开发 C++ 中的机器学习应用程序提供了一个良好的框架。
DLib 很像 DMTL,它提供了一个通用的高性能机器学习工具包,包含许多不同的算法,但 DLib 更新更频繁,并且有更多示例。DLib 还包含更多的支持功能。
DLib 的独特之处在于它既设计用于研究,也用于创建 C++ 中的机器学习应用程序。
描述工具包中机器学习部分的官方论文可以在 这里 找到。
DLib 适用于 Windows、Linux 和 OS X。
DLib 采用 Boost 软件许可证。
相关帖子:
-
MLTK: Java 中的机器学习工具包 – 免费下载
-
机器学习的数据工作流
-
Prediction.io 开源机器学习服务器
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT 工作
更多相关话题
Docker for Data Science Cheat Sheet
原文:
www.kdnuggets.com/2023/02/docker-data-science-cheat-sheet.html
Docker 是为数据科学量身定制的
Docker 是一个开源平台,允许开发者构建、打包和分发可移植应用程序。它已成为数据科学中一个必不可少的工具,帮助建立可重复和可扩展的环境。Docker 允许将代码和依赖项打包在容器中,这使得数据科学家可以在不同平台上分发他们的模型。这有助于开发和生产,并有助于防止由于不同版本的软件或硬件配置引发的错误和不一致性。Docker 还可以帮助团队有效协作,通过确保所有开发者和团队成员的环境一致。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
Docker 是一种超级增强的依赖管理工具,帮助确保可重复性和协作,使其成为数据科学中的重要工具。
要了解更多关于使用 Docker 进行数据科学的内容,请查看我们最新的备忘单。
Docker 允许将代码和依赖项打包在容器中,这使得数据科学家可以在不同平台上分发他们的模型。
KDnuggets 最新的备忘单旨在为使用 Docker 的数据科学家提供便捷的参考。Docker 能协助完成的任务很多,但主要分为几个类别。本备忘单将帮助你学习和记住构建和管理 Docker 镜像的要点。
一旦你对这方面的技能有信心,就可以继续查看:
-
容器化 - 如何在 Docker 容器中容器化代码和依赖项
-
Docker Compose - 使用 Docker Compose 协调多个容器并定义组成应用程序的服务
-
Docker 镜像的高级管理 - 如何使用 Docker 注册表(例如 Docker Hub)管理和共享 Docker 镜像
我们祝愿你在 Docker 之旅中好运,并希望这份参考资料对你有所帮助。立即查看,并请随时回来获取更多更新。
更多相关主题
数据科学中的 Docker
评论
由 Sachin Abeywardana,DeepSchool.io 的创始人

数据科学中的 Docker
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
Docker 是一个简化软件工程师安装过程的工具。作为一个统计学背景的人,我曾经很少关心如何安装软件,并且偶尔会花费几天时间解决系统配置问题。然后 Docker 出现了,真是天赐良机。
把 Docker 想象成一个轻量级虚拟机(我为使用这个术语向 Docker 专家道歉)。一般来说,有人会编写一个 Dockerfile 来构建一个 Docker 镜像,其中包含了你项目所需的大部分工具和库。你可以用它作为基础,并添加任何其他项目所需的依赖项。其基本理念是,如果在我的机器上能工作,就能在你的机器上工作。
数据科学家能得到什么?
-
时间:你在安装软件包时节省的时间本身就使这个框架值得使用。
-
可重复研究:我认为 Docker 就像是报告中的随机数种子。你在机器上使用的相同依赖和库版本也会被用在其他人的机器上。这确保了你生成的分析在其他分析师的机器上也能运行。
-
分发:你不仅在分发你的代码,还在分发运行这些代码的环境。
它是如何工作的?
Docker 采用了(可重用的)层的概念。所以你在 Dockerfile 中写的每一行都被视为一个层。例如,你通常会从以下内容开始:
FROM ubuntu
RUN apt-get install python3
这个 Dockerfile 会在 Ubuntu 层之上安装 python3(作为一个层)。
实际上,你对每个项目所做的就是把所有的 apt-get install、pip install 等命令写入你的 Dockerfile,而不是在本地执行它们。
我推荐阅读教程 docs.docker.com/get-started/ 来开始使用 Docker。学习曲线最小(最多 2 天的工作量),收益巨大。
Dockerhub
最后,Dockerhub 值得特别提及。就我个人而言,Dockerhub 是让 Docker 真正强大的原因。它就像github 对 git 的作用,是一个分享 Docker 镜像的开放平台。 你总是可以使用docker build ...在本地构建 Docker 镜像,但将这个镜像push到 Dockerhub 上总是好的,以便下一个人可以简单地pull进行个人使用。
我用于机器学习和数据科学的 Docker 镜像可以在这里找到,以及它的源文件。
总结
就我个人而言,我已经开始在我大多数甚至所有的 github 仓库中加入 Dockerfile。特别是考虑到这意味着我将不再遇到安装问题。
Docker 是软件工程师(以及现在的数据科学家/分析师)应该在工具箱中拥有的工具之一(几乎与 git 同样重要和受到尊重)。长期以来,统计学家和数据科学家忽视了数据分析的软件方面。考虑到 Docker 的使用变得如此简单直观,实际上没有理由不将其纳入你的软件开发流程。
编辑 1
如果你想要比上面提供的快速提示更为详细的教程,请查看这个视频(跳转到 4:30 左右):
编辑 2(关于 python 的 virtualenvs,R 的 packrat 等的简要说明):
就我个人而言,我没有使用过其他容器化工具,但应该注意到,Docker 独立于 python 和 R,且超越了为特定编程语言容器化应用程序的范畴。
如果你喜欢我的教程/博客文章,考虑支持我 在www.patreon.com/deepschoolio 或通过订阅我的 YouTube 频道www.youtube.com/user/sachinabey(或者两者都订阅!)。哦,还有点赞!😃
简介: Sachin Abeywardana 是一位机器学习博士和DeepSchool.io的创始人。
原文。经许可转载。
相关:
-
DeepSchool.io: 深度学习学习
-
使用 Docker 的数据科学部署
-
Jupyter+Spark+Mesos: 一种“主观”的 Docker 镜像
更多相关主题
数据科学家的 Docker 教程
原文:
www.kdnuggets.com/2023/07/docker-tutorial-data-scientists.html

图片来源:作者
Python 和一系列 Python 数据分析和机器学习库,如 pandas 和 scikit-learn,帮助你轻松开发数据科学应用程序。然而,Python 的依赖管理是一个挑战。在进行数据科学项目时,你需要花费大量时间安装各种库,并跟踪你所使用的库的版本等。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
如果其他开发者想要运行你的代码并为项目做贡献呢?其他希望复制你的数据科学应用程序的开发者首先需要设置他们机器上的项目环境——然后才能运行代码。即使是小的差异,如库版本不同,也可能引入破坏性更改。Docker 来拯救你。Docker 简化了开发过程并促进了无缝的协作。
本指南将向你介绍 Docker 的基础知识,并教你如何使用 Docker 对数据科学应用程序进行容器化。
什么是 Docker?

图片来源:作者
Docker 是一个容器化工具,让你可以将应用程序构建和分享为称为镜像的可移植工件。
除了源代码外,你的应用程序还会有一组依赖项、所需的配置、系统工具等。例如,在数据科学项目中,你会在开发环境中安装所有必要的库(最好是在虚拟环境中)。你还会确保使用库所支持的最新版本的 Python。
然而,当你尝试在另一台机器上运行你的应用程序时,仍然可能会遇到问题。这些问题通常源于两台机器之间开发环境中的配置和库版本不匹配。
使用 Docker,你可以打包你的应用程序——连同依赖项和配置一起。这样,你可以定义一个隔离、可重现且一致的环境,适用于各种主机机器上的应用程序。
Docker 基础知识:镜像、容器和注册表
我们来回顾一些概念/术语:
Docker 镜像
Docker 镜像是你应用程序的便携式工件。
Docker 容器
当你运行一个镜像时,你实际上是在容器环境中运行应用程序。因此,镜像的运行实例就是容器。
Docker 注册表
Docker 注册表是一个存储和分发 Docker 镜像的系统。在将应用程序容器化为 Docker 镜像后,你可以通过将其推送到镜像注册表来使其对开发者社区可用。 DockerHub 是最大的公共注册表,所有镜像默认都从 DockerHub 拉取。
Docker 如何简化开发?
由于容器为你的应用程序提供了隔离的环境,因此其他开发人员现在只需在他们的机器上设置 Docker。他们可以拉取 Docker 镜像并使用单个命令启动容器——无需担心复杂的安装——在远程机器上。
在开发应用程序时,常常需要构建和测试多个版本的相同应用程序。如果使用 Docker,你可以在同一环境中运行多个相同应用程序的不同版本——没有任何冲突。
除了简化开发,Docker 还简化了部署,并帮助开发和运维团队有效协作。在服务器端,运维团队不必花时间解决复杂的版本和依赖冲突。他们只需要设置一个 docker 运行时环境。
基本 Docker 命令
让我们快速回顾一些基本的 Docker 命令,其中大多数将在本教程中使用。有关更详细的概述,请阅读:12 个每个数据科学家都应该知道的 Docker 命令。
| 命令 | 功能 |
|---|---|
docker ps |
列出所有正在运行的容器 |
docker pull image-name |
默认从 DockerHub 拉取 image-name |
docker images |
列出所有可用的镜像 |
docker run image-name |
从镜像启动容器 |
docker start container-id |
重新启动已停止的容器 |
docker stop container-id |
停止正在运行的容器 |
docker build path |
使用 Dockerfile 中的指令在指定路径构建镜像 |
注意:如果你没有创建docker组,则需要在所有命令前加上sudo。
如何使用 Docker 容器化数据科学应用程序
我们已经了解了 Docker 的基础知识,现在是应用所学的知识的时候了。在这一部分,我们将使用 Docker 容器化一个简单的数据科学应用程序。
房价预测模型
让我们以以下线性回归模型为例,该模型根据输入特征预测目标值:中位数房价。该模型是使用 加州住房数据集 构建的:
# house_price_prediction.py
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load the California Housing dataset
data = fetch_california_housing(as_frame=True)
X = data.data
y = data.target
# Split the dataset into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Standardize features
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions on the test set
y_pred = model.predict(X_test)
# Evaluate the model
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Squared Error: {mse:.2f}")
print(f"R-squared Score: {r2:.2f}")
我们知道 scikit-learn 是一个必需的依赖项。如果你查看代码,我们在加载数据集时将 as_frame 设置为 True。因此,我们还需要 pandas。requirements.txt 文件看起来是这样的:
pandas==2.0
scikit-learn==1.2.2

作者提供的图片
创建 Dockerfile
到目前为止,我们有源代码文件 house_price_prediction.py 和 requirements.txt 文件。现在我们应该定义 如何 从我们的应用程序构建镜像。Dockerfile 用于创建这种从应用程序源代码文件构建镜像的定义。
那么 Dockerfile 是什么?它是一个包含逐步指令以构建 Docker 镜像的文本文件。
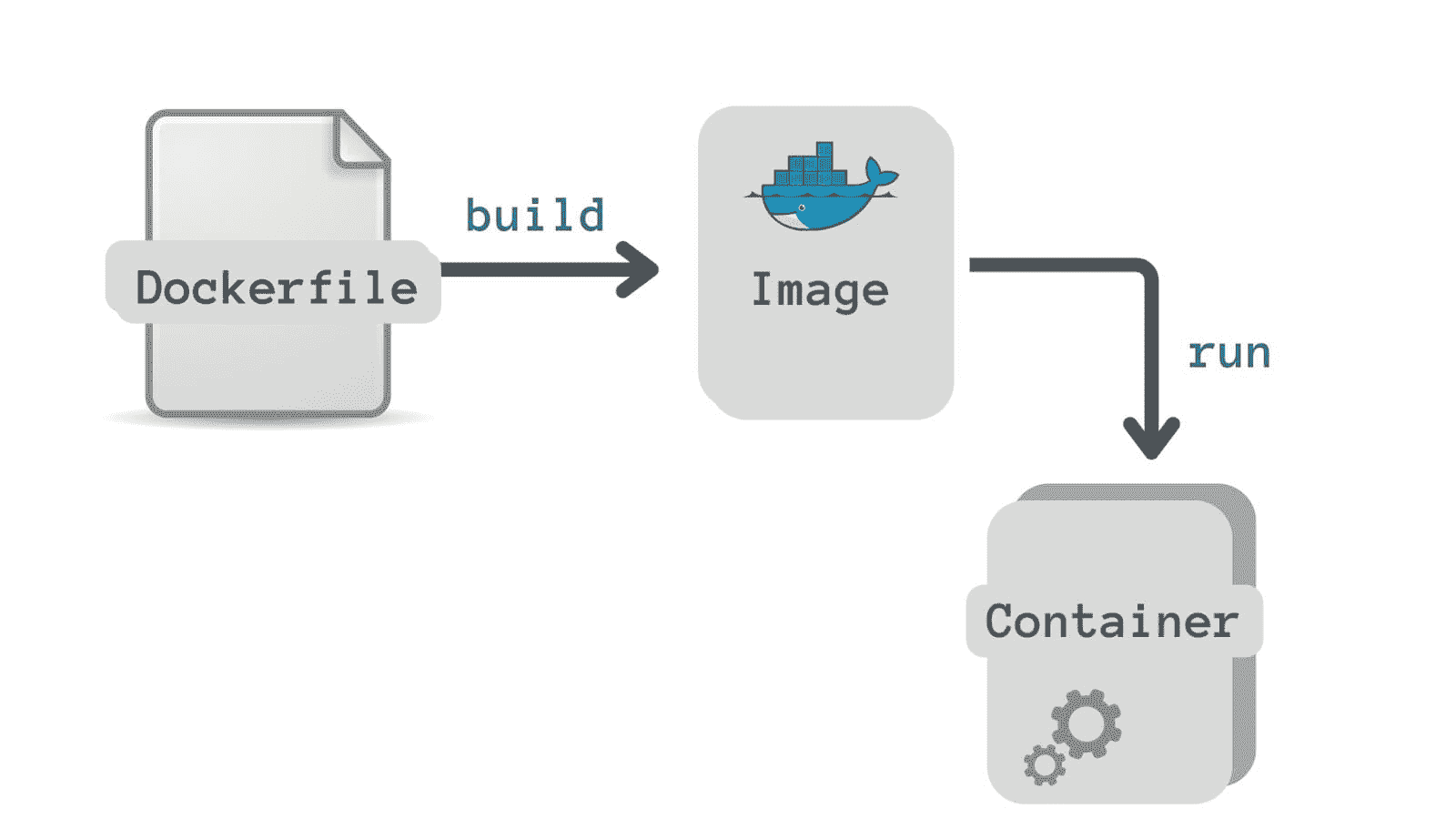
作者提供的图片
这是我们示例的 Dockerfile:
# Use the official Python image as the base image
FROM python:3.9-slim
# Set the working directory in the container
WORKDIR /app
# Copy the requirements.txt file to the container
COPY requirements.txt .
# Install the dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy the script file to the container
COPY house_price_prediction.py .
# Set the command to run your Python script
CMD ["python", "house_price_prediction.py"]
让我们详细分析一下 Dockerfile 的内容:
-
所有 Dockerfile 都以
FROM指令开始,指定基础镜像。基础镜像是你的镜像所基于的镜像。在这里,我们使用一个可用的 Python 3.9 镜像。FROM指令告诉 Docker 从指定的基础镜像构建当前镜像。 -
WORKDIR命令用于为所有后续命令设置工作目录(在这个例子中是 app)。 -
然后,我们将
requirements.txt文件复制到容器的文件系统中。 -
RUN指令在容器内的 shell 中执行指定的命令。在这里,我们使用pip安装所有必需的依赖项。 -
然后,我们将源代码文件——Python 脚本
house_price_prediction.py——复制到容器的文件系统中。 -
最后,
CMD指令指的是在容器启动时要执行的指令。这里我们需要运行house_price_prediction.py脚本。Dockerfile 应该只包含一个CMD指令。
构建镜像
现在我们已经定义了 Dockerfile,可以通过运行 docker build 来构建 Docker 镜像:
docker build -t ml-app .
选项 -t 允许我们为镜像指定名称和标签,格式为 name:tag。默认标签是 latest。
构建过程需要几分钟:
Sending build context to Docker daemon 4.608kB
Step 1/6 : FROM python:3.9-slim
3.9-slim: Pulling from library/python
5b5fe70539cd: Pull complete
f4b0e4004dc0: Pull complete
ec1650096fae: Pull complete
2ee3c5a347ae: Pull complete
d854e82593a7: Pull complete
Digest: sha256:0074c6241f2ff175532c72fb0fb37264e8a1ac68f9790f9ee6da7e9fdfb67a0e
Status: Downloaded newer image for python:3.9-slim
---> 326a3a036ed2
Step 2/6 : WORKDIR /app
...
...
...
Step 6/6 : CMD ["python", "house_price_prediction.py"]
---> Running in 7fcef6a2ab2c
Removing intermediate container 7fcef6a2ab2c
---> 2607aa43c61a
Successfully built 2607aa43c61a
Successfully tagged ml-app:latest
Docker 镜像构建完成后,运行 docker images 命令。你也应该看到 ml-app 镜像被列出。
docker images
你可以使用 docker run 命令运行 Docker 镜像 ml-app:
docker run ml-app

恭喜!你刚刚将你的第一个数据科学应用程序容器化。通过创建 DockerHub 账户,你可以将镜像推送到 DockerHub(或推送到组织内的私有仓库)。
结论
希望你觉得这个入门级的 Docker 教程对你有帮助。你可以在 这个 GitHub 仓库 中找到本教程使用的代码。下一步,设置 Docker 并尝试这个示例,或者将你选择的应用进行容器化。
在你的机器上安装 Docker 的最简单方法是使用 Docker Desktop: 你将同时获得 Docker CLI 客户端以及一个用于轻松管理容器的 GUI。快来设置 Docker,立刻开始编码吧!
Bala Priya C 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和咖啡!目前,她正致力于通过撰写教程、操作指南、观点文章等与开发者社区分享她的知识。
更多相关话题
如何 Docker 化任何机器学习应用程序
原文:
www.kdnuggets.com/2021/04/dockerize-any-machine-learning-application.html
评论
作者 Arunn Thevapalan,Octave 的高级数据科学家、导师和作家。

我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
容器化并部署模型!(照片由 Andy Li 供图,来自 Unsplash)
刚入职一个月,作为一名应届毕业生,我们的 AI 创始人走到我面前问:“Arunn,我希望你能成为 Docker 专家。你需要多长时间?” 我不确定 Docker 是什么,但又无法回避这个问题。最后,我回答说:“两周,1 个冲刺。”
我的经理,也在场,试图打断以拯救我,但我已经造成了损害,我只有接下来的两周时间。
回顾过去,我从来不是专家(现在也不是!),但我学到的足以完成所需的工作。在这篇文章中,我将告诉你如何将任何机器学习网络应用程序 Docker 化的基本步骤。
什么是 Docker?
Docker 是一个旨在通过使用容器来创建、部署和运行应用程序的工具。容器 是一个标准化的软件单元,简单来说——就是一个打包的应用程序代码和所需的库及其他依赖项的包。Docker 镜像 是一个可执行的软件包,包含运行应用程序所需的一切,并在运行时成为容器。
当我尝试理解 Docker 时,有很多新技术术语。但其实这个概念很简单。
可以把它想象成你获得了一台全新的迷你 Ubuntu 机器。然后,你在其上安装一些包。接着,你在其上添加一些代码。最后,你执行这些代码来创建一个应用程序。所有这一切都发生在你现有的机器上,使用你选择的操作系统。 你只需要在其中安装 Docker 即可。
如果你的机器上没有安装 Docker,请查阅 这里的安装说明。
为什么数据科学家需要 Docker?
我明白了。你从事数据科学领域的工作。你认为 DevOps 团队可以处理 Docker。你的老板没有要求你成为专家(不像我的老板!)。
你觉得你并不真的需要理解 Docker。
这不是真的,让我告诉你为什么。
“不确定为什么在你的机器上不起作用,它在我的机器上可以正常工作。你要我看看吗?”
在你的工作场所听过这些话吗?一旦你(和你的团队)理解了 Docker,就不会再有人说这些话了。你的代码将顺利运行在 Ubuntu、Windows、AWS、Azure、Google Cloud 或任何地方。
你构建的应用程序可以在任何地方重复使用。
你将开始更快地启动环境,并以正确的方式分发应用程序,这将节省大量时间。你(最终)将被认为是一位具备软件工程最佳实践的数据科学家。
3 个简单步骤
正如承诺的,我已将过程简化为 3 个简单步骤。在这里,我们以糖尿病预测应用程序的用例为例,该应用程序可以根据诊断措施预测糖尿病的发作。这将帮助你理解我们如何在现实世界的用例场景中接近容器化。
我强烈建议你阅读 这篇文章,其中我们使用 Streamlit 从头开始逐步构建这个机器学习应用程序。
作者制作的糖尿病预测应用程序的屏幕录制。
请查看这个 GitHub 仓库 ,其中包含完整的实现,可以跟随示例进行操作。既然我们知道了背景,接下来让我们解决这 3 个步骤!
1. 定义环境
第一步是确保应用程序正常运行所需的准确环境。有很多方法可以做到这一点,但其中一个最简单的想法是为项目定义一个 requirements.txt 文件。
请查看你代码中使用的所有库,并将它们列在一个名为 requirements.txt 的文本文件中。列出库的确切版本是一种好习惯,你可以在环境的终端上运行 pip freeze 来找到这些版本。我为糖尿病预测示例准备的 requirements 文件如下所示,
joblib==0.16.0
numpy==1.19.1
pandas==1.1.0
pandas-profiling==2.8.0
scikit-learn==0.23.2
streamlit==0.64.0
2. 编写 Dockerfile
这里的想法是,我们尝试创建一个名为 Dockerfile 的文件,该文件可用于构建我们应用程序运行所需的虚拟环境。把它当作在任何系统上构建所需环境的说明手册!
让我们为手头的示例编写 Dockerfile,
FROM python:3.7
EXPOSE 8501
WORKDIR /app
COPY . .
RUN pip install -r requirements.txt
CMD streamlit run app.py
就这些了。6 行代码。按顺序排列。每一行都在构建在前一行之上。让我们逐行解析。
-
每个 Dockerfile 必须以 FROM 开头。紧接着 ***FROM *的内容必须是一个已存在的镜像(本地或来自 DockerHub 仓库)。由于我们的环境基于 Python,我们使用python:3.7作为基础镜像,并最终使用此 Dockerfile 创建一个新镜像。
-
Streamlit 默认运行在 8501 端口。因此,为了使应用程序运行,重要的是要暴露该端口。我们使用 ***EXPOSE ***命令来实现。
-
***WORKDIR ***设置应用程序的工作目录。其余命令将从这个路径执行。
-
这里的 ***COPY ***命令将 Docker 客户端当前目录中的所有文件复制到镜像的工作目录。
-
***RUN *命令确保我们在requirements.txt中定义的库已正确安装。
-
***CMD *指定在容器启动时运行的命令。因此,streamlit run app.py确保 Streamlit 应用程序在容器启动后立即运行。
编写 Dockerfiles 需要一些实践,除非你花费大量时间在 Docker 上,否则无法掌握所有可用命令。我建议先熟悉一些基本命令,然后参考 Docker 的官方文档 。
3. 构建镜像
现在我们已经定义了 Dockerfile,是时候构建它并创建一个镜像了。这个镜像的目的是创建一个与底层系统无关的可重复环境。
docker build --tag app:1.0 .
如名字所示,build 命令按 Dockerfile 中定义的逐层构建镜像。最好给镜像标记一个名称和版本号,如
末尾的点表示 Dockerfile 的路径,即当前目录。
等等,我构建了镜像,但我该如何处理它?根据要求,你可以 在 DockerHub 上分享构建的镜像 或 将其部署到云端,等等。但首先,你现在需要运行镜像以获取容器。
如名字所示,run 命令在主机上运行指定的容器。--publish 8501:8501 将容器的 8501 端口映射到主机的 8501 端口,而-it 用于运行交互式进程(如 shell/terminal)。
docker run --publish 8501:8501 -it app:1.0
现在跟随终端上提示的链接,亲自见证奇迹吧!😉

你做到了!(照片由 Nghia Le 提供,来源于 Unsplash)
原文。已获许可转载。
简介: Arunn Thevapalan 是一位总部位于斯里兰卡的高级数据科学家,他的使命是通过分享学习、方法和成为成功数据科学家的全过程,激励热爱者进入并成长于数据科学领域。
相关:
更多相关内容
用可视化调试器容器化 Jupyter
原文:
www.kdnuggets.com/2020/04/dockerize-jupyter-visual-debugger.html
评论
作者:Manish Tiwari,数据爱好者

图片来源:Nilantha Ilangamuwa 来自 Unsplash
Jupyter 最近宣布了期待已久的可视化调试器的首次公开发布。尽管这是首次发布,但它支持调试和检查变量等所需的所有基本调试需求。
数据科学社区因 Jupyter Notebook 能够以互动的方式轻松传达和共享成果而大量依赖它。
然而,唯一的问题是缺少可视化调试能力,因此人们通常需要切换到其他提供更好调试和代码重构功能的经典 IDE。这一功能受到数据科学社区的高度期待,现在终于发布了。
如需简要了解可视化调试器的实际效果,请参考下面的视频演示:
在本文中,我们将详细讲解在现有 JupyterLab 环境中设置可视化调试器的步骤,并将 JupyterLab 环境与默认启用的可视化调试器进行容器化。
前提条件:
JupyterLab 2.0+
对任何编程语言的调试基础知识
Docker 的基础知识。
安装:
假设您已经在使用 JupyterLab,只需安装 JupyterLab 调试器扩展以进行前端调试,以及在后端支持 Jupyter 调试协议的任何内核。
安装 JupyterLab 扩展以启用前端调试:
JupyterLab 使用 nodejs 安装扩展,因此我们需要先安装 nodejs 才能安装前端调试器扩展。
在未来的版本中,Jupyter 可能会默认包含此扩展。
conda install -c conda-forge nodejs
jupyter labextension install @jupyterlab/debugger
安装内核 xeus-python:
目前,后端只有 xeus-python 支持 Jupyter 调试协议。未来可能会有更多内核支持该协议。
conda install xeus-python -c conda-forge
现在如果运行 Jupyter Lab,您应该能够看到 xeus-python 内核在控制台和笔记本部分各有 2 个附加图标。
为什么要容器化?
容器使得跨多个环境的开发更加顺畅。这就是它们成为云原生应用交付方法技术基础的原因。
Docker 创始人 Solomon Hykes 说,当支持软件环境不一致时会出现问题。“你会在 Python 2.7 上测试,然后它会在生产环境中运行 Python 3,结果会发生一些奇怪的事情。或者你依赖某个 SSL 库的特定版本,而安装了另一个版本。你会在 Debian 上运行测试,而生产环境在 Red Hat 上,一切都可能变得很奇怪。”
容器通过将运行应用程序所需的环境、依赖项、二进制文件、所有必要的配置和应用程序本身打包到一个包中来解决此问题。这样,我们不再需要担心操作系统和其他环境特定的依赖项,因为一切都被打包在一个可以在任何地方运行的独立实体中。
启用 Visual Debugger 的 Jupyter Docker 化
我假设你对基本的 Docker 命令和术语已经很熟悉。解释 Docker 的工作原理超出了本文的范围。然而,如果你觉得需要复习,请参考 Docker 文档。
现在我们将创建创建所需环境 Docker 镜像所需的 Dockerfile。你可以将镜像视为包含所有必要指令的文件,用于在容器中运行我们的应用程序。
我们将使用 Miniconda,一个用于 Anaconda 的轻量级最小化安装程序。它是 Anaconda 的一个小型启动版本,只包含 conda、Python、它们所依赖的包和少量其他有用的包。
FROM continuumio/miniconda3
定义 Docker 文件和工作目录的元数据:
LABEL maintainer=”Manish Tiwari <m***@gmail.com>”
LABEL version=”0.1"
LABEL description=”Debugging Jupyter Notebook”WORKDIR /jup
安装 JupyterLab
RUN conda install -c conda-forge jupyterlab
安装用于前端调试的 nodejs 和 labextension。
RUN conda install -c conda-forge nodejs
RUN jupyter labextension install [@jupyterlab/debugger](https://twitter.com/jupyterlab/debugger)
安装支持 Jupyter 调试协议的内核。
RUN conda install xeus-python -c conda-forge
注意:这里我们使用了 conda 包管理器,你也可以使用 pip,但不推荐同时使用这两者,因为这可能会破坏环境。
最后,暴露端口并定义入口点。
EXPOSE 8888
ENTRYPOINT [“jupyter”, “lab”,” — ip=0.0.0.0",” — allow-root”]
我们最终的 Dockerfile 应如下所示:
启用 Visual Debugger 的 JupyterLab Docker 化
从上述 Dockerfile 构建 Docker 镜像。
导航到包含上述 Dockerfile 的文件夹,然后运行以下命令。
docker build -t visualdebugger .
另外,你也可以从任何地方运行命令,只需提供 Dockerfile 的绝对路径。
一旦镜像成功构建,使用以下命令列出 Docker 镜像以进行验证。
docker image ls
输出应如下所示:

现在在新容器中运行 Docker 镜像,如下所示:
docker container run -p 8888:8888 visualdebugger-jupyter
在这里,我们将主机端口(冒号前的第一个端口)8888 映射到容器中暴露的端口 8888。这是主机与容器内的 Jupiter 监听端口进行通信所必需的。
运行上述命令后,你应该看到如下输出(前提是端口未被其他进程占用):
这意味着我们的 docker 容器正在运行。你现在可以打开上面指定的 URL,并使用 Jupyter 和可视化调试器,而不需要意识到它并未在主机上运行。
你还可以通过以下命令查看可用的容器列表:
docker container ls
上面的命令应该会列出容器及其元数据,如下所示:

一旦你打开上面输出的 URL,你应该能看到 JupyterLab 在主机的 localhost 和 8888 端口上运行。
在容器中运行的带有可视化调试器的 JupyterLab
现在,要使用可视化调试器,请在 Launcher 中打开xpython,而不是 Python。
我已经在 docker hub 上发布了我们刚刚构建的 docker 镜像,以便你获得一个带有可视化调试功能的 Jupyter 环境。
你可以通过以下命令拉取 docker 镜像并进行操作。
docker pull beingmanish/visualdebugger-jupyter
如果你希望深入了解 Jupyter 的可视化调试架构,可以参考这里。
有建议或问题吗?请在评论中写下。
参考文献: Jupyter 博客
个人简介: Manish Tiwari 是一位数据爱好者,热衷于分享 AI 领域的学习和经验。
原文。转载经许可。
相关:
-
4 个最佳 Jupyter Notebook 深度学习环境
-
5 个 Google Colaboratory 小贴士
-
GitHub Python 数据科学焦点:高级机器学习与 NLP,集成方法,命令行可视化与 Docker 简化
更多相关内容
ChatGPT 是否有潜力成为新的国际象棋超级大师?
原文:
www.kdnuggets.com/does-chatgpt-have-the-potential-to-become-a-new-chess-super-grandmaster

编辑提供的图片
作为一名资深的前国际象棋选手(青少年冠军,ELO 2000+)和自然语言处理数据科学家,我一直计划写这篇文章。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
我第一次听说 ChatGPT 下棋的能力,是从我的一位同事那里。他是博士,也是个非常聪明的人。他给我发了一个链接,可以和 ChatGPT 对弈,正如他所认为的那样。不幸的是,这并不完全是 ChatGPT,它背后是其他的国际象棋引擎。他被欺骗了。你仍然可以在这里尝试:https://parrotchess.com/
为了撰写本文,我与 ChatGPT 对弈了 2 局。以下是我们的开局:

让我们看看发生了什么。
快速国际象棋记谱课程 / 提醒(可以跳过):
K = 王,Q = 后,R = 车,B = 象,N = 马,0–0 = 王侧易位。0–0–0 = 后侧易位,x = 吃子。对于兵,我们只写它落到的方格,除非兵吃子。那时,我们写出兵之前所在方格的字母,以及吃掉另一子后所去方格的字母和数字。例如,exd4。
Nikola Greb 对阵 ChatGPT 4,2024 年 1 月 7 日
1\. e4 e5 2\. Nf3 Nc6 3\. d4 exd4 4\. Nxd4 Nf6 5\. Nc3 Bb4 6\. Nxc6 bxc6 7\. Bd3 O-O 8.
O-O d5 9\. e5 Ne4 10\. Nxe4 Bc5 11\. Nxc5 Qe7 12\. Qh5 g6 13\. Qh6 f6 14\. exf6 Qxf6
15\. Bg5 Qf7 16\. Rae1 Bf5 17\. Re7 Qxe7 18\. Bxe7 Rae8 19\. Bxf8 Rxf8 20\. Bxf5 Rf7
21\. Re1 1-0
直到 e5 这步棋,ChatGPT 4 的表现像是一位非常优秀的国际象棋选手。我们可以说像国际象棋大师。但当我下了一步不精确但具有攻击性的棋(exd5 是最佳走法)时,它失去了常规,犯了一个大错,走了 Ne4。

我用马吃掉了对方的马(10. Nxe4),第一次幻觉发生了:


Bc5 再次是一个错误,明显的失误。由于游戏的其余部分没有国际象棋的价值,我将总结一下。ChatGPT 4 指责我走了不可能的棋步,结果陷入了幻觉(提议不可能的棋步),而不是投降。
让我们看看在游戏 2 中发生了什么,我在其中下黑棋:
Nikola Greb 对阵 ChatGPT 4(走法 1–9)和 ChatGPT 3.5(走法 10–12),2024 年 1 月 7 日
1\. e4 c5 2\. Nf3 Nc6 3\. d4 cxd4 4\. Nxd4 e5 5\. Nb5 d6 6\. c4 f5 7\. N1c3 Nf6 8\. Bg5 Be7 9\. Bd3 Nxe4 10\. Bxe4 fxe4 11\. Nxe4 Bxg5 12\. Nec3 0–1
在下面的位置之前,ChatGPT 4 玩得非常好,从中建立了一个显著更好的位置,而我在面对真正的大师(甚至是候选大师)或国际象棋引擎时会很快输掉。如果白方走 Bf6,黑方会丢掉一个兵。然而,ChatGPT 走了 Bd3:

我走了 Ne4,而 ChatGPT 切换到 3.5 版本并走了 Bxe4。

几步棋后,我有了决定性的优势(由于 ChatGPT 玩得很差,不是我做了什么出色的事),所以我决定用一个不规则的走法来测试对手。我在这个位置上提议黑方走 Ne6:

ChatGPT 3.5 完全没有关注我的棋步。在我的幻觉上,它回应了新的幻觉:
结论
1. ChatGPT 4 是一个非常弱的国际象棋玩家,表现非常奇怪——开局阶段非常好,而后期则很糟糕。这是由于国际象棋游戏进展中选项数量的增加。我会评估它的整体 ELO 低于 1500。3.5 也是如此。
2. 没有发生隐性规则学习——ChatGPT 4 在国际象棋中仍然会产生幻觉,并且在收到关于幻觉的警告后仍然继续产生幻觉。这是人类无法出现的情况。
3. 更多数据几乎无法解决问题,由于边缘情况如超长的终局重复,或玩不寻常的开局。大型语言模型(LLMs)根本不适合下国际象棋,也无法评估位置。我们已经有了 AlphaZero 和 Stockfish。
4. 跟踪 LLM 在下国际象棋时产生的幻觉数量的减少,可能是理解 LLM 逻辑推理潜力的一个好路径。但悖论依然存在——LLM “知道”国际象棋规则,但仍然产生严重的幻觉。未来的机器学习可能会是 LLM 作为第一级代理,与用户沟通,然后调用专门的代理,其机器学习架构调整以适应特定的用例。
- LLM 有潜力在科学研究中发挥作用,并显示出与其他机器学习算法相结合的有趣的创造力。最近的一个例子是 DeepMind 开发的 FunSearch 算法,它结合了 LLM 和评估器,用于在数学领域进行发现。与棋类中位置评估是最困难的任务不同,许多数学科学问题是“易于评估,尽管通常难以解决”。
我对基于变压器架构构建一个高性能的棋类程序持怀疑态度,但专门的语言模型(LLM)结合外部评估/棋类程序,可能很快成为棋类教练的良好替代品。DeepMind 创建了另一个很酷的模型,作为结合 LLM 和专用 AI 模型的良好示例——AlphaGeometry。它在几何问题上的表现非常接近奥林匹克金牌标准,推动了数学中的 AI 推理。
- LLM 仍然是新兴的领域,尚且很年轻,且有太多的炒作,往往伴随着误导性和错误的结论。正如“《使用大型语言模型的程序搜索中的数学发现》”的作者所言:
“……据我们所知,这表明了第一个科学发现——使用 LLM 对一个臭名昭著的科学问题的一个可验证的知识新片段。”(加速预览于 2023 年 12 月 14 日发布)。
- 由乔·罗根(Joe Rogan)和两位嘉宾主持的视频,标题为“‘’我对 AI 并不害怕,直到我了解了这个’’”在 YouTube 上观看人数达到了 280 万。 一位嘉宾表示 ChatGPT 会下棋,这显然是不真实的。我可以想象这种内容如何影响人们,尤其是教育水平低或情绪不稳定的个体。我对此是非常肯定的。
总结来说,数据科学和软件开发建立在知识、精确性和追求真相的基础上。作为数据科学家和开发者,我们应该成为真理和智慧的传播者,平息大众媒体对 AI 的疯狂,而不是加剧这种疯狂。变压器,包括 ChatGPT,在语言任务中具有巨大的潜力,但离 AGI 仍然非常遥远。我们应该保持乐观但要准确。
作为指南,在做出重大声明之前,我们应该问自己:如果其他人根据我的陈述采取行动,会发生什么?你希望生活在什么样的世界里?
参考文献与进一步探索
-
通过自我对弈和通用强化学习算法掌握国际象棋和将棋: https://arxiv.org/pdf/1712.01815.pdf
-
FunSearch: 使用大型语言模型在数学科学中进行新发现: https://deepmind.google/discover/blog/funsearch-making-new-discoveries-in-mathematical-sciences-using-large-language-models/
-
使用大型语言模型的程序搜索中的数学发现: https://www.nature.com/articles/s41586-023-06924-6
-
AlphaGeometry:一个用于几何学的奥林匹克级 AI 系统:https://deepmind.google/discover/blog/alphageometry-an-olympiad-level-ai-system-for-geometry/
-
我对 AI 不再感到害怕,直到我了解了这个:https://www.youtube.com/watch?v=2yd18z6iSyk&ab_channel=JREDailyClips
-
如何与 ChatGPT 对弈国际象棋(以及为什么你可能不应该):https://www.androidauthority.com/how-to-play-chess-with-chatgpt-3330016/
-
Chat GPT 能玩国际象棋吗?:https://towardsdatascience.com/can-chat-gpt-play-chess-4c44210d43e4
-
ChatGPT 玩国际象棋的水平如何?(剧透:你会感到惊讶):https://medium.com/@ivanreznikov/how-good-is-chatgpt-at-playing-chess-spoiler-youll-be-impressed-35b2d3ac024a
-
与 ChatGPT 的完整对话:https://chat.openai.com/share/a1ff82b5-6210-4f7b-807c-220052de232c
-
使用通用强化学习算法通过自我对弈掌握国际象棋和将棋:https://arxiv.org/pdf/1712.01815.pdf
尼古拉·格雷布**** 编码经验超过四年,在过去两年里,他专注于 NLP。在转向数据科学之前,他在销售、人力资源、写作和国际象棋领域取得了成功。
更多相关话题
机器学习是否允许对立面吸引?
原文:
www.kdnuggets.com/2016/02/does-machine-learning-allow-opposites-attract.html
评论
1958 年,Monotones 问道:“谁写了爱情之书?”如果我们将时间快进到现在的 58 年,会不会‘爱情算法’更为准确?这是一个合理的问题;现代在线约会网站的普及正是如此。用户可以完全避免盲目约会或快速约会的尴尬,提前了解约会的每一个细节,甚至在见面之前。
 大多数约会网站利用某种形式的协同过滤或‘Netflix 风格’推荐算法,根据共同的兴趣爱好或互相的喜好与厌恶来匹配潜在的伴侣。前 EHarmony CEO Joseph Essas 在 2011 年写道,他的网站用户兼容性匹配基于三个不同的领域:心理兼容性、人际化学和身体吸引力。
大多数约会网站利用某种形式的协同过滤或‘Netflix 风格’推荐算法,根据共同的兴趣爱好或互相的喜好与厌恶来匹配潜在的伴侣。前 EHarmony CEO Joseph Essas 在 2011 年写道,他的网站用户兼容性匹配基于三个不同的领域:心理兼容性、人际化学和身体吸引力。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
考虑到在线约会网站的基石是匹配有相似兴趣和性格特征的人。我有一个问题——那些因为人们非常不同而关系美满的情况呢?我最近订婚了,感到非常幸运。然而,我相信没有哪个在线约会网站会把我和我的未婚妻匹配在一起。我喜欢运动,她觉得无聊。她不喜欢葡萄酒,我很喜欢。她阅读很多,她是电影迷。我们的音乐品味完全不同。我喜欢步行,她更愿意骑车。她喜欢购物,而我不喜欢。意大利肉酱面是世界上最棒的食物,她不同意。她身高 5 英尺,我身高 6 英尺 2 英寸。你可以看出我的意思……机器学习能否帮助识别那些实际上完美契合的非匹配?它是否能够理解对立面常常会吸引?在线约会网站是否因为你没有遵循相同的问答路径而让你与生命中的爱情擦肩而过?
仅作声明;我并不是说这些网站不能帮助人们找到爱情。Match.com 最近的统计数据令人震惊,显然已促成了 500,000 个关系、92,000 场婚姻和超过一百万个宝宝。我对此话题没有一个明确的结论,只是认为如果由于人们过于忙于在手机上滑动而没注意到走过的理想伴侣,从而失去了在咖啡馆里或公园里偶遇某人的自发性,那将是非常遗憾的。这个周日是情人节,许多庆祝的人是通过约会网站相识的,也有很多是因为他们恰好在对的时间、对的地点相遇。我的观点是,根据算法的错误的人可能是根据你内心的感觉正确的人。
更多相关话题
数据科学实战:Kaggle 数据清理教程
原文:https://www.kdnuggets.com/2016/03/doing-data-science-kaggle-walkthrough-cleaning-data.html
作者:Brett Romero,Open Data Kosovo。
这篇关于数据清理的文章是一个系列中的第三部分,系列通过Kaggle竞赛探讨数据科学和机器学习。如果你还没有阅读,建议你回去阅读第一部分和第二部分。
本部分将重点关注清理Airbnb Kaggle竞赛中提供的数据。

数据清理
当我们谈论数据清理时,我们究竟在谈论什么?通常,当人们谈论数据清理时,他们指的是一些具体的内容:
-
修复格式 – 数据在从一种格式保存或转换到另一种格式时(例如,从CSV转换到Python),某些数据可能无法正确转换。在上一篇文章中,我们看到一个很好的例子。在csv中,timestamp_first_active列包含像20090609231247这样的数字,而不是预期格式的时间戳:2009-06-09 23:12:47。清理数据的一个典型工作就是修正这些类型的问题。
-
填补缺失值 – 正如我们在第二部分中看到的那样,数据集中某些值缺失是相当常见的。这通常意味着某些信息没有被收集。处理缺失数据有几种选项,下面会详细介绍。
-
修正错误值 – 对于某些列,有些值明显不正确。例如,“性别”列中可能输入了一个数字,或“年龄”列中可能输入了一个远超100的值。这些值需要被修正(如果可以确定正确值的话)或假设为缺失值。
-
标准化类别 – 这是“修正错误值”的一个子类别,这种数据清理非常常见,值得特别提及。在许多(或所有?)情况下,当数据直接从用户收集时,尤其是使用自由文本字段时,拼写错误、语言差异或其他因素会导致相同答案以多种方式提供。例如,在收集出生国家的数据时,如果用户没有提供标准化的国家列表,数据中不可避免地会包含同一国家的多种拼写(例如:USA、United States、U.S. 等)。主要的清理任务之一通常是将这些值标准化,确保每个值只有一个版本。
处理缺失数据的选项
缺失数据通常是数据清理过程中较棘手的问题之一。大致上,有两种解决方案:
1. 删除/忽略缺失值的行
面对缺失值时,最简单的解决方案是训练模型时不使用包含缺失值的记录。然而,在开始删除大量行之前,有一些问题需要注意。
首先,这种方法只有在缺失数据的行数相对于数据集来说比较少时才有意义。如果你发现由于缺失值导致你需要删除的数据量超过了数据集的10%左右,你可能需要重新考虑。
第二个问题是,为了删除包含缺失数据的行,你必须确认你删除的行不包含其他行中没有的信息。例如,在当前的Airbnb数据集中,我们发现许多用户没有提供他们的年龄。我们能否假设选择不提供年龄的用户与提供年龄的用户是相同的?还是他们可能代表了一种不同类型的用户,可能是更年长且更注重隐私的用户,因此可能在选择访问国家时会做出不同的决策?如果答案是后者,我们可能不希望仅仅删除这些记录。
2. 填补缺失值
处理缺失数据的第二种广泛选项是用一个值填补缺失值。但应该使用什么值呢?这取决于一系列因素,包括你尝试填补的数据类型。
如果数据是分类数据(即国家、设备类型等),可能有意义的是创建一个新类别来表示‘未知’。另一种选择可能是用该列中最常见的值(众数)填补缺失值。然而,由于这些是填补缺失值的广泛方法,这可能会简化你的数据和/或使最终模型的准确性降低。
对于数值类型的数据(例如年龄列),还有其他选项。鉴于在这种情况下使用众数填补值意义不大,我们可以改为使用均值或中位数。我们甚至可以基于其他标准计算平均值——例如,根据选择了相同country_destination的用户的平均年龄来填补缺失的年龄值。
对于两种类型的数据(分类数据和数值数据),我们也可以使用更复杂的方法来填补缺失值。实际上,我们可以使用类似于预测country_destination的方法来预测其他列中的值,这些方法基于已经有数据的列。就像在建模过程中一样,这种方法几乎有无尽的方式实现,这里不会详细描述。有关此主题的更多信息,orange Python库提供了一些出色的文档。
我们的前三课程推荐
 1. Google网络安全证书 - 加速你的网络安全职业生涯。
1. Google网络安全证书 - 加速你的网络安全职业生涯。
 2. Google数据分析专业证书 - 提升你的数据分析技能
2. Google数据分析专业证书 - 提升你的数据分析技能
3. Google IT支持专业证书 - 支持你的组织的IT需求
更多相关主题
-
最全面的Kaggle解决方案和创意列表
复杂的插补方法。然而,我测试的这些方法都没有比上述方法产生更好的最终结果。
识别并填充其他缺失值列
从对数据的更详细分析中,你可能还会发现有一列缺失值——first_affiliate_tracked 列。按照我们之前在其他列中填充缺失值的方法,现在我们也填充这一列的值。
# Fill first_affiliate_tracked column
print("Filling first_affiliate_tracked column...")
df_all['first_affiliate_tracked'].fillna(-1, inplace=True)
这就全部了吗?
对数据处理更有经验的人可能会觉得我们对这些数据的清理做得不够——你是对的。Kaggle 比赛的一个好处是提供的数据不需要过多的清理,因为数据提供者并不希望参与者将重点放在此上。许多在现实世界数据中可能会发现的问题(如前所述)在这个数据集中并不存在,节省了我们大量时间。
然而,这种相对简单的清理过程也告诉我们,即使数据集提供的初衷是无需或仅需最小清理,仍然总会有一些事情需要处理。
下一次
在下一部分中,我们将重点关注数据转换和特征提取,从而创建一个训练数据集,期望能使模型做出更好的预测。为了确保你不会错过,使用下面的订阅功能。
[1] 对于那些有更多数据挖掘经验的人,你可能会意识到此阶段将测试数据和训练数据合并并不是最佳实践。最佳实践是避免在任何数据预处理或模型调整/验证步骤中使用测试数据集,以避免过拟合。然而,在这次比赛的背景下,由于我们只是试图创建一个分类单一不变数据集的模型,因此最大化该数据集模型的准确性是主要关注点。
简介: 布雷特·罗梅罗 是一位数据分析师,拥有在多个国家和行业(包括政府、管理咨询和金融)的工作经验。目前,他在科索沃的普里什蒂纳担任数据顾问,与联合国开发计划署(UNDP)以及开放数据科索沃等发展机构合作。
原文。经许可转载。
相关:
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT支持专业证书 - 为你的组织提供IT支持
相关文章
使用 SQL 进行统计分析
作者:Jean-Nicholas Hould,JeanNicholasHould.com
我最近写了一篇关于为什么你应该 学习 SQL 进行数据分析 的文章。我收到了很多反馈,人们希望看到一些使用 SQL 进行数据分析的具体例子。我决定应用一些我自己的建议,加载其中一个 超赞的数据集 进行一些基本的数据探索查询。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT

对于这篇文章,我使用了一个开放数据集。百万歌曲数据集是一个“自由获取的现代流行音乐曲目音频特征和元数据的集合”。
如果你想跟随,请按照以下步骤操作:
-
下载百万歌曲数据集。我使用了 10K 歌曲子集。
-
下载一个 SQLite 客户端
-
使用 SQLite 打开
subset_track_metadata.db文件并开始探索
为什么使用描述性统计?
当我开始分析新的数据集时,我会运行一些基本查询以了解数据的组织方式和数值的分布情况。我试图理解我所处理的内容。对于数值数据,我通常会运行一些描述性统计:我会测量中心趋势(均值、中位数、众数)并测量数据的变异水平。这些测量通常是数据探索的良好起点,常常会引发新的问题,推动我的分析。
中心趋势
均值
均值是将一组数字相加后除以该组总数得到的数字。均值对异常值非常敏感。它可能会被远高于或低于其余数据集的值严重影响。
SELECT CAST(AVG(songs.year) as int) as avg_year FROM songs
-- | avg_year |
-- |----------|
-- | 934 |
-
CAST:在兼容数据类型之间进行运行时数据类型转换。在这种情况下,我将浮点数转换为整数以进行四舍五入。 -
AVG:聚合函数,返回输入表达式值的均值。 -
as avg_year:临时重命名列标题 - 仅用于提高可读性,使代码更具人性化。我将在整个帖子中使用这种别名。
中位数
中位数是将有序数据集的上半部分与下半部分分开的数字。中位数有时是衡量中点的更好指标,因为每个数据点的权重相等。
SELECT songs.year as median_year
FROM songs
ORDER BY songs.year
LIMIT 1
OFFSET (SELECT COUNT(*) FROM songs) / 2
-- | median_year |
-- |-------------|
-- | 0 |
-
ORDER BY:按一列或多列对结果数据集进行排序。排序可以是升序ASC(默认)或降序DESC。 -
COUNT:聚合函数,返回符合条件的行数。 -
LIMIT:指定从结果数据集中返回的最大行数。 -
OFFSET:在开始返回行之前跳过 X 行。在这个特定示例中,我们跳过了 5000 行(相当于总行数COUNT(*)除以 2)。
众数
众数是数据集中出现频率最高的值。
SELECT
songs.year,
COUNT(*) as count
FROM songs
GROUP BY songs.year
ORDER BY COUNT(*) DESC
LIMIT 1
-- | year | count |
-- |------|-------|
-- | 0 | 5320 |
GROUP BY:与聚合函数如COUNT、AVG等一起使用。按一列或多列对结果数据集进行分组。
变异性
最小/最大值
数据集中的最小/最大值。
SELECT
MIN(songs.year) as min_year,
MAX(songs.year) as max_year
FROM
songs
-- | min_year | max_year |
-- |----------|----------|
-- | 0 | 2010 |
-
MIN:聚合函数,返回数据集中最小的值。 -
MAX:聚合函数,返回数据集中最大的值。
每年的歌曲分布
每年发行歌曲的数量
SELECT
songs.year,
COUNT(*) songs_count
FROM songs
GROUP BY songs.year
ORDER BY songs.year ASC
-- | year | song_count |
-- |------|------------|
-- | 0 | 5320 |
-- | 1926 | 2 |
-- | 1927 | 3 |
-- | ... | ... |
-- | 2009 | 250 |
-- | 2010 | 64 |
下一步
这篇文章中的 SQL 查询相对简单。它们不是技术性技巧的结果。它们只是帮助我们理解数据集的简单度量,这正是它们的优点。
在这个特定的数据集中,我们注意到超过一半的数据集中,歌曲的年份为0。这意味着我们要么在查看非常旧的歌曲数据集,要么在处理缺失值。后者更为现实。如果我们过滤掉年份为0的歌曲,我们的数据就更有意义了。歌曲的年份范围从1926到2010,中位数是2001年。
数据部分清理后,我们可以开始探索数据集中的其他列,并提出更多问题:每年有多少独特的艺术家创作歌曲?这种情况随时间的变化如何?现在的歌曲是否比以前短?这些简单的度量指标的优点在于,它们可以在查询和过滤器变得越来越复杂时重复使用。通过应用简单的描述性统计度量,我们可以很好地掌握数据,并不断深入探索。
简历:Jean-Nicholas Hould 是来自 加拿大蒙特利尔的数据科学家。作者,见 JeanNicholasHould.com。
原文。经许可转载。
相关:
-
掌握数据科学 SQL 的 7 个步骤
-
数据科学统计学 101
-
构建与购买 – 分析仪表盘
更多相关主题
Dolly 2.0:ChatGPT 开源商业用途替代方案
原文:
www.kdnuggets.com/2023/04/dolly-20-chatgpt-open-source-alternative-commercial.html

作者提供的图片 | Bing 图片创作者
Dolly 2.0 是一种开源的、遵循指令的大语言模型(LLM),经过人类生成的数据集进行了微调。它可用于研究和商业目的。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
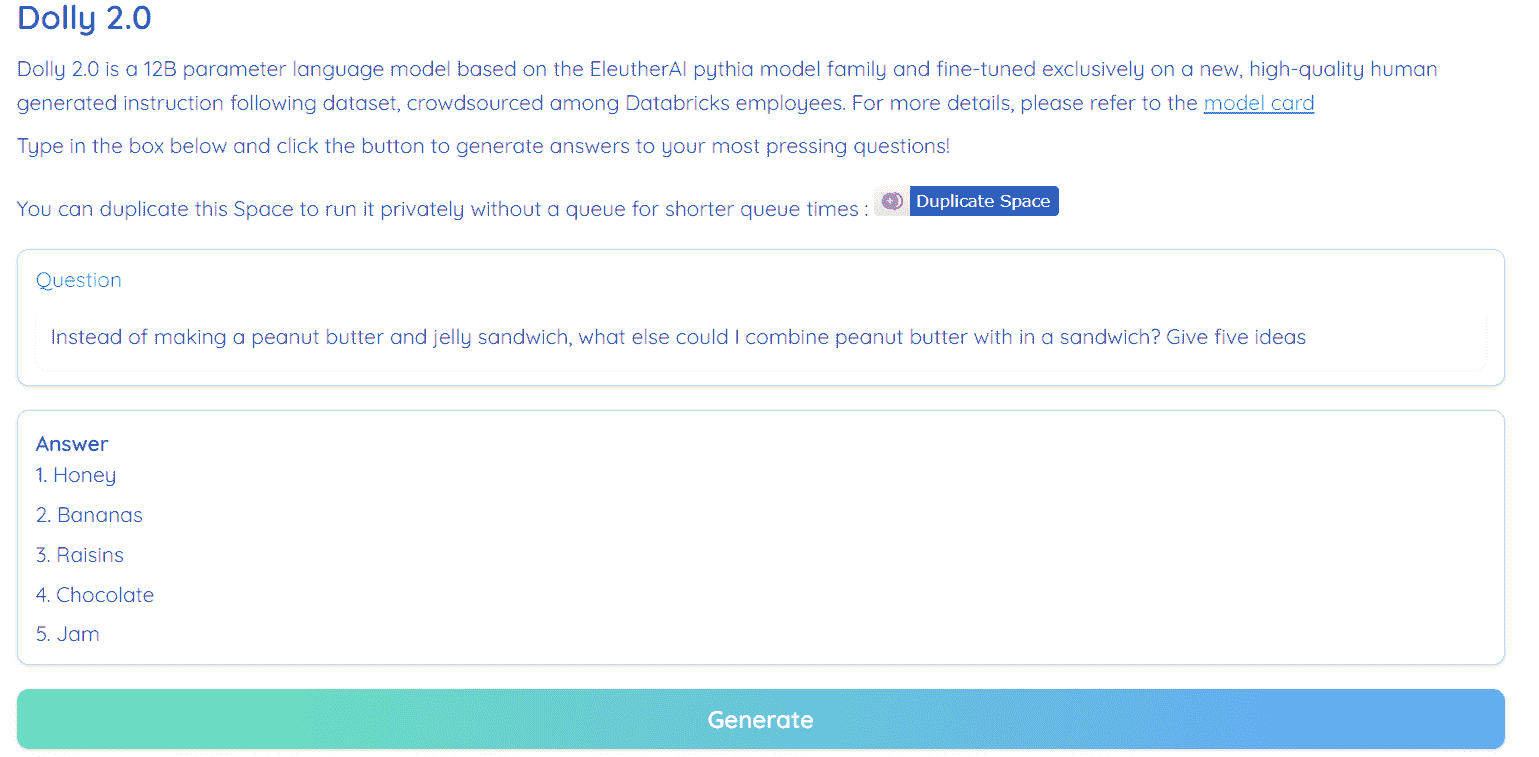
图片来源于 Hugging Face Space by RamAnanth1
之前,Databricks 团队发布了Dolly 1.0,这是一种大语言模型(LLM),具有类似 ChatGPT 的指令跟随能力,训练成本不到 $30。它使用了斯坦福 Alpaca 团队的数据集,该数据集在受限许可(仅限研究)下。
Dolly 2.0 通过在高质量人类生成的指令数据集上微调了 12B 参数的语言模型 (Pythia),解决了这个问题,该数据集由 Databricks 员工标注。模型和数据集都可用于商业用途。
为什么我们需要商业许可证数据集?
Dolly 1.0 的训练数据来自斯坦福 Alpaca 数据集,该数据集使用了 OpenAI API 创建。该数据集包含了 ChatGPT 的输出,并防止任何人利用该数据集与 OpenAI 竞争。简而言之,你不能基于这个数据集构建商业聊天机器人或语言应用程序。
最近几周发布的大多数最新模型都遇到了相同的问题,例如 Alpaca、Koala、GPT4All 和 Vicuna。为了应对这些问题,我们需要创建新的高质量数据集以供商业使用,这正是 Databricks 团队通过 databricks-dolly-15k 数据集所做的。
databricks-dolly-15k 数据集
新的数据集包含 15,000 个高质量的人类标注的提示/回应对,这些数据对设计指令调优的大型语言模型非常有用。databricks-dolly-15k 数据集采用 Creative Commons Attribution-ShareAlike 3.0 Unported License 许可协议,允许任何人使用、修改并创建商业应用。
他们是如何创建 databricks-dolly-15k 数据集的?
OpenAI 的研究 论文 表示,原始的 InstructGPT 模型是基于 13,000 个提示和回应进行训练的。利用这些信息,Databricks 团队开始着手这项工作,但生成 13k 个问题和答案是一项艰巨的任务。他们不能使用合成数据或 AI 生成的数据,必须对每个问题生成原创答案。这就是他们决定使用 5,000 名 Databricks 员工来创建人类生成数据的原因。
Databricks 举办了一场比赛,前 20 名标注者将获得丰厚的奖品。在这场比赛中,有 5,000 名对 LLMs 非常感兴趣的 Databricks 员工参与了比赛。
结果
dolly-v2-12b 不是一个最先进的模型。在一些评估基准上,它的表现不如 dolly-v1-6b。这可能与底层微调数据集的组成和规模有关。Dolly 模型系列仍在积极开发中,所以你可能会在未来看到一个性能更好的更新版本。
简而言之,dolly-v2-12b 模型在性能上优于 EleutherAI/gpt-neox-20b 和 EleutherAI/pythia-6.9b。

图片来自 Free Dolly
入门指南
Dolly 2.0 完全开源。它包括训练代码、数据集、模型权重和推理管道。所有组件都适合商业使用。你可以在 Hugging Face Spaces 上尝试该模型,Dolly V2 by RamAnanth1。
图片来自 Hugging Face
资源:
-
训练和推理代码:databrickslabs/dolly
-
Dolly 2.0 模型权重:databricks/dolly-v2-12b
-
databricks-dolly-15k 数据集:dolly/data
Dolly 2.0 演示:Dolly V2 by RamAnanth1
Abid Ali Awan(@1abidaliawan)是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,帮助那些受心理疾病困扰的学生。
更多相关话题
领域知识对机器学习重要吗?
原文:
www.kdnuggets.com/2022/07/domain-knowledge-important-machine-learning.html

开发机器学习模型涉及很多步骤。无论你是处理标记数据还是未标记数据,你可能会认为数字只是数字,并且在生成具有真正影响力的见解时,数据集中每个特征的意义并不重要。确实,有许多优秀的机器学习库,如scikit-learn,使得收集一些数据并将其放入一个模板模型中变得简单快捷。很快,你可能会开始认为没有什么问题是机器学习无法解决的。
坦率地说,这是一个初学者的思维方式。你还未意识到你不知道的所有东西。机器学习课程中提供的数据集或你在网上找到的免费数据集通常已经被处理过,使用这些数据集应用机器学习模型时很方便,但一旦你将技能和知识从玩具世界带到现实世界,你将面临一些额外的挑战。
许多人认为领域知识,或者关于数据所涉及行业或领域的额外知识,是多余的。这确实有一定的道理。你是否需要在你开发模型的领域中具备领域知识?不需要。你仍然可以在没有它的情况下生成相当准确的模型。从理论上讲,深度学习和机器学习是黑箱方法。这意味着你可以将标记数据放入模型中,而无需对领域有深入了解,甚至无需仔细查看数据。
但是,如果你走这条路,你将不得不面对后果。这是一种非常低效的训练分类器的方法,并且为了正常运作,你将需要大量标记数据集和大量计算能力来生成准确的模型。
如果你将领域知识融入到你的架构和模型中,这可以使解释结果变得更加容易,无论是对你自己还是对外部观察者。每一份领域知识都可以作为穿越机器学习模型黑箱的垫脚石。
很容易认为领域知识不是必需的,因为对于像COCO这样许多显而易见的数据集,所需的有限领域知识是作为一个“看得见”的人自然具备的。即使是包含癌细胞的更复杂的数据集,对人眼来说也同样明显,尽管缺乏专家级的知识。你可以在没有任何特定医学知识的情况下,对细胞之间的相似性或差异性进行基本评估。
自然语言处理(NLP)和计算机视觉是领域知识看似完全不必要的典型例子,但正因为这些任务对我们来说非常普通,我们可能甚至不会注意到我们是如何应用领域知识的。
如果你开始在异常值检测等不那么常见的领域工作,领域知识的重要性很快会变得显而易见。
数据预处理中的领域知识

让我们深入探讨领域知识如何在机器学习模型开发周期的数据预处理步骤中发挥作用。
在一个数据集中,并非每个数据点的值都是相同的。如果你收集了 100 个相同的新样本,它们不会帮助模型学习任何额外的信息。它们可能实际上会使模型集中在一个不重要的特定方向上。
如果你正在查看 100 张伞的图片,并且知道这个模型应该分类所有种类的配件,那么显然你的样本数据集并不代表整个总体。没有领域知识的话,很难知道哪些数据点有价值,或者它们是否已经在数据集中有所代表。
如果你在一个不容易用现有的通用知识解决的领域工作,你可能会通过训练数据引入偏差,这会影响模型的准确性和鲁棒性。
领域知识在数据预处理步骤中发挥重要作用的另一个方式是确定特征的重要性。如果你对每个特征的重要性有良好的感觉,你可以制定更好的策略来相应地处理数据。理解实际特征是什么非常重要,这对你如何处理特征有很大的影响。
选择合适模型中的领域知识

机器学习模型有很多种,考虑到许多因素,有些模型可能比其他模型更适合。数据是标记过的还是未标记的?你拥有多少数据?特征的数据类型是什么?特征的数据类型是否同质?你的目标输出是连续值还是分类?选择合适的模型很重要,但能够直接应用你选择的模型而不进行调整的情况非常少见。例如,随机森林可以直接处理异质数据类型。
选择正确的模型需要深入的机器学习知识,但如果你不是机器学习专家,还有很多资源可以帮助你做出选择。我从Towards Data Science、datacamp和Microsoft的机器学习备忘单中收集了我的前三个推荐。
调整模型和架构的领域知识

领域知识使你能够更好地调整模型以适应情况。数学优化只能做到一定程度,通常要实现大的改进跳跃,拥有相当的领域知识至关重要。
将领域知识应用于提高模型的准确性和鲁棒性的一种重要方法是将领域知识融入到你正在开发的模型的架构中。
如前所述,自然语言处理是机器学习的一个领域,这清楚地表明领域知识可以带来帮助。让我们谈谈词嵌入和注意力机制,以展示说人类语言是如何大有帮助的,但像语言学家一样思考可以真正提升自然语言处理模型的性能。
自然语言处理中的领域知识
领域知识已经应用于所有机器学习应用中。在过去几十年里,已经做出了一些小的调整,以更好地在许多领域应用机器学习模型。领域知识肯定已被应用于自然语言处理中的模型。让我们来看看这些发展是如何产生的。
词嵌入
如果你考虑数字和文字,我们对它们的思考方式差别很大。如果你有一组人的身高数据,你可以很容易地根据身高输出一些统计数据,例如中位数、离群值等。如果这个小组中的每个人都给你一个词来表示他们今天的感受,你将如何将其转化为任何有意义的汇总?
你应该考虑如何创建一个单词的数字表示。是否应该仅仅使用字母?这样做是否有意义?作为一个讲这种语言的人,我们立即理解单词背后的意义。我们不会按字母来存储单词。想想树。你是想象了一棵树,还是你的脑海里出现了 t-r-e-e?以字母形式存储单词的表示方式,在理解意义或重要性时并没有真正带来任何优势。
词嵌入是“一种词表示方法,允许具有相似含义的词具有类似的[数值]表示”。这些数值表示是通过无监督学习模型学习得到的。
这些数值表示是表示一个词如何使用的向量。这种数值表示甚至可以让你使用两个词表示之间的欧氏距离来量化两个词在训练文本中使用的相似程度。
“Adidas”和“Nike”的向量可能会非常相似。虽然每个向量字段的具体表示不甚清楚,因为它们是通过无监督学习开发的,但一个代表类似概念的词在模型理解中有类似的表示是有意义的。
如果你想了解什么是监督学习和无监督学习,以及使用这些学习方法的算法,查看我们的帖子“监督学习与无监督学习”。
注意力
注意力是一个非常宝贵和有用的概念。注意力之所以能在自然语言处理和图像识别中得到应用,是有充分理由的。
自2000 年代初以来,自然语言处理翻译一直是深度学习模型的一部分。大约在 2013 年,长短期记忆(LSTM)在该领域首次出现,并主导了几年。LSTM 模型读取句子,创建隐藏表示,然后利用隐藏表示生成输出句子。
作为人类,如果我们进行翻译,我们不仅仅是阅读句子并直接输出翻译。我们倾向于反复查看整个句子,或者在需要重新审视目标词的上下文时专注于某些部分。
例如,词语“read”。它表示的是现在时还是过去时?你需要关注句子的哪些其他部分来确定?是否需要周围句子的上下文信息?“I read books every year”单独来看有一个意思,但如果我说,“I did many things before I went to university. I read books every year. I ate dinner with my parents every day”,句子的意义就会发生变化,而“read”在第一个例子中表示的是现在时的动作,在第二个例子中则是过去时的动作。
注意力机制在句子或句子之间建立不同词汇之间的关系。对于我们想要翻译的每个词,它会根据这些相关词与目标词的重要性来突出显示原句中的不同词。一个缺乏经验或专业背景的翻译者可能只会逐字翻译,虽然基本信息会传达,但考虑到相关词的重要性会产生更准确的翻译。注意力机制允许我们将这种专业翻译模式融入深度学习模型的架构中。
为什么领域知识对机器学习至关重要
没有领域知识,你可以完成一个能够输出一些数字的可接受模型。拥有领域知识,你将知道什么数据最适合用来训练和测试你的模型。你还会意识到如何调整你使用的模型,以更好地代表数据集和你试图解决的问题,以及如何最好地利用模型产生的洞察。
机器学习是一个工具箱。如果你拿出一个电锯,你可能能切割一些木头,但没有木匠的专业知识,你可能无法构建一堆橱柜。领域知识将使你的机器学习技能的影响力达到更高的层次。
内特·罗西迪 是一位数据科学家和产品策略专家。他同时担任分析课程的兼职教授,并且是 StrataScratch,一个帮助数据科学家通过顶级公司的真实面试问题为面试做好准备的平台的创始人。你可以在 Twitter: StrataScratch 或 LinkedIn 上与他联系。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 相关工作
更多相关话题
机器学习的 5 个部落 – 问题与答案
原文:
www.kdnuggets.com/2015/11/domingos-5-tribes-machine-learning-questions-answers.html
评论
11 月 24 日,我主持了
Pedro,机器学习和数据科学的领先研究者之一,详细讲解了他的优秀书籍,《主算法》,其中解释了机器学习的 5 个部落的方法:符号主义者、连接主义者、进化主义者、贝叶斯主义者和类比主义者,以及如何结合这些方法以寻找能够彻底改变我们世界的主算法。
超过 1500 人参加了此次网络研讨会。
介绍 Pedro 后,我准备放松并享受演讲,但我的主持人角色却意外地变得非常紧张,因为仅仅几分钟后,许多问题开始涌入,我必须迅速阅读和优先处理这些问题。
Pedro 只有时间回答了 100 多个提交中的 5 个问题,但许多问题都非常好,因此我要求他回答一些其他有趣的问题。
另见 Pedro 对我早期问题的回答:
(帖子底部)
这里是 Pedro Domingos 对网络研讨会中他没有时间现场回答的额外问题的回答。
Juan Alvarado 提问:为了获得主算法,您是否考虑过由于哥德尔不完备定理而使其不可能?
Pedro Domingos: 主算法仅学习可学习的内容;它无法证明哥德尔定理无法证明的命题。
Pramod Anantharam:你认为可解释的模型是否会在未来战胜基于黑箱的方法?
PD: 这取决于应用程序。可解释性是一个非常重要的属性,对于许多应用程序,它优先于从(比如)深度学习中获得的额外准确性。
Mohamed Helmy:我们能简要了解一下规则引擎和符号逻辑(决策树)吗?
PD: 当然,可以查看《主算法》第三章或我的MOOC(Coursera 上的机器学习)的第二和第三周。
Jesus Morales:对于想要追随这条路径的大学生,他们在开始之前需要了解哪些建议?
PD: 上 MOOC 课程,阅读教科书,尝试一些算法。请参见《大师算法》中的进一步阅读部分。
Cristal Jones-Harris, 你有 360 度推荐系统的文本样本吗?
PD: 参见我在《华尔街日报》上发表的文章《"为你的数字模型做好准备"》。
Subhra Mazumdar: 360 度推荐系统会影响人的决策能力吗?它会成为人和机器的共生关系,还是更倾向于主奴关系?
PD: 360 度推荐系统是你大脑的扩展,因此你掌控一切。它所做的只是尽力做出你在有时间时会做出的选择,并且当它出错时,它应该学会在下次做得更好。
Abdelaziz Mahoui, 在新的 360 度推荐系统中,偶然性将如何表现?
PD: 推荐系统应该具有随机组件,就像现实生活一样。
Delane Pickel: “主算法”这个问题意味着只有一个。终极学习机器必须具备某种成功学习的理解能力。一些学习实际上可能变得具有破坏性。这不正是癌症吗?
PD: 大师算法有多于一种版本,就像有许多等同于图灵机的计算方案一样。它所学到的内容取决于你给它的数据和评估函数。
Aude Dufresne: 如果评估和优化改变现实怎么办?
PD: 不确定你指的是什么,但学习结果的部署往往会导致被建模的人改变他们的行为。这是一个重要且尚未充分探索的问题,但可以参考我在 KDD-04 会议上发表的论文《"对抗分类"》。
Michael Valenzuela: Wolpert 的《无免费午餐定理》证明了不存在“通用”机器学习算法。你如何调和这个证明和你的目标?
PD: 大师算法只需在我们的世界中有效,而非所有可能的世界,“无免费午餐”定理涉及的是后者。此外,大师算法不仅以数据为输入;它还输入知识(例如,逻辑公式)。
Jim Talley: 首先,那是一个非常好的总结。不过,在我看来,仍然缺少的部分是感知,或者更具体地说,是学习如何构建和准备这些五种范式的输入。对此有什么想法?你认为这已经是这些范式之一或多种的组成部分吗?
PD: 每种范式都有其解决这个问题的方法,确实需要解决。例如,深度学习的主要主张是它从原始数据(例如,像素)中学习自身的表示。
Joanna Biega: 那么关于存储大量数据的传统数据结构呢?我们是否忘记了不仅需要良好的机器学习算法或渐进线性算法,还需要有效的大数据数据结构?
PD: 确实,一个通用的学习者必须高效,数据结构是其中的重要部分。
Bhaskar Veeraraghavan, 主动强化学习有什么应用吗?
PD: 强化学习在某种意义上是主动学习。我听说 Deep Mind 正在将其应用于网页搜索,这将是一个主要应用,如果部署在 Google 的引擎中。
Habibollah Daneshpajouh, 正如你提到的,每个领域的这些“部落”在某些问题上表现更好,我们如何检测出在特定问题上最适合的 ML“部落”?
PD: 尽管进行了大量研究,但没有人能给出一个好的理论答案,不过有很多实用的启发式方法,你也可以尝试所有的方法。
Latha Krishnaswamy, ML 算法通常是无监督的。在你看来,这种情况允许或受限于缺乏人工监督的影响是什么?
PD: 实际上,监督学习的使用频率高于无监督学习。如果有监督(或获取成本不高),肯定要使用监督。
Parlinggoman Hasibuan, 你认为机器学习能做决策并取代人类吗?
PD: 是的,在许多领域已经如此(例如,信用评分、直销)。
Raul Sierra: 你谈到主算法,但我们是否也需要类似主任务的东西来评估主算法?
PD: 当然了。我们需要一组足够多样且困难的任务,如果学习算法能解决这些任务,我们就可以合理地称之为主算法。
Theodore Grammatikopoulos: 从一个主算法构建一个可能为不同的数据片段(列、行)选择不同算法并赋予适当权重的角度来看,这会是个好主意吗?
PD: 这实际上是一种模型集成,正如我讨论的那样,它比单一模型更好,但还不是主算法。
Wee Kiat: 你认为主算法是否能解决当前无法解决的问题?如果可以,机器学习会比我们的大脑更优越吗?
PD: 是的,确实如此,比如治愈癌症。但问题不在于机器学习是否会优于我们的脑,而在于我们的脑结合机器学习是否会优于没有机器学习的脑。
Victor: 你认为下一个接近突破的机器学习进展是什么?
PD: 我不知道,但我正在研究一些候选者 😃
更多相关话题
十大机器学习神话,作者:佩德罗·多明戈斯
原文:
www.kdnuggets.com/2017/01/domingos-ten-myths-machine-learning.html
评论
作者佩德罗·多明戈斯,著有 《大师算法》。

过去,机器学习发生在幕后:亚马逊挖掘你的点击和购买来推荐商品,谷歌挖掘你的搜索以进行广告投放,Facebook 挖掘你的社交网络来选择向你展示哪些帖子。但现在机器学习登上了报纸的头版,并成为激烈辩论的主题。学习算法驾驶汽车、翻译语音,并在 危险边缘 中获胜!它们能做什么,不能做什么?它们是隐私、工作甚至人类种族终结的开始吗?这种日益增长的意识是值得欢迎的,因为机器学习是塑造我们未来的主要力量,我们需要正视它。不幸的是,围绕它产生了几个误解,揭开这些误解是第一步。让我们快速了解一下主要的几个:
机器学习只是总结数据。 实际上,机器学习的主要目的是预测未来。了解你过去观看的电影仅仅是为了搞清楚你接下来可能想看的电影。你的信用记录是判断你是否按时支付账单的指南。就像机器人科学家一样,学习算法制定假设,改进它们,只有当预测成真时才相信这些假设。学习算法还没有像科学家那样聪明,但它们快了数百万倍。
学习算法只是发现事件对之间的相关性。 这是你从媒体中对机器学习的多数提及中得到的印象。在一个著名的例子中,Google 搜索 “流感” 的增加是其传播的早期迹象。这固然不错,但大多数学习算法发现的知识形式要丰富得多,比如规则 如果痣的形状和颜色不规则且正在增长,那么它可能是皮肤癌。
机器学习只能发现相关性,而非因果关系。 实际上,最流行的机器学习类型之一就是尝试不同的行为并观察其后果——这是因果发现的本质。例如,一个电商网站可以尝试多种不同的产品展示方式,并选择导致最多购买的方式。你可能在不知情的情况下参与了成千上万次这样的实验。而即使在实验不可能的情况下,只要计算机可以查看过去的数据,也能发现因果关系。
机器学习无法预测以前未见过的事件,也就是“黑天鹅”。 如果某件事从未发生过,其预测概率必须为零——还能是什么呢?相反,机器学习是一门以高准确率预测稀有事件的艺术。如果 A 是 B 的一个原因,而 B 是 C 的一个原因,那么即使我们之前从未见过这种情况,A 也可能导致 C。每天,垃圾邮件过滤器都会正确标记新编造的垃圾邮件。像 2008 年房市崩盘这样的黑天鹅事件实际上是被广泛预测的——只是当时大多数银行使用的风险模型存在缺陷。
数据越多,你越容易出现假象模式。 据说,NSA 查看的电话记录越多,就越可能将一个无辜的人标记为潜在恐怖分子,因为他不小心匹配了恐怖分子检测规则。挖掘相同实体的更多属性确实会增加假象的风险,但机器学习专家非常擅长将其保持在最低限度。另一方面,挖掘具有相同属性的更多实体会减少风险,因为从这些实体中学到的规则将有更强的支持。而且一些学习算法可以发现涉及多个实体的模式,这使得它们更加稳健:一个人在录像纽约市政厅可能并不令人怀疑,而另一个人购买大量硝酸铵也可能不是;但如果两者之间有密切的电话联系,也许 FBI 应该检查一下,以确保这不是一个炸弹阴谋。
机器学习忽视了先前的知识。 机器学习渗透的许多领域的专家对他们所知道的学习算法的“白板”方法持怀疑态度。真正的知识是长期推理和实验的结果,这不能仅仅通过在数据库上运行通用算法来模仿。但是并非所有学习算法都从白板开始;有些算法利用数据来完善已经存在的知识体系,只要这些知识被编码成计算机可以理解的形式,这些知识体系可以非常复杂。
计算机学习的模型对人类而言难以理解。 这自然引发了担忧。如果一个学习算法是一个黑箱,我们如何相信它的推荐?确实,有些类型的模型非常难以理解,比如一些机器学习最显著成功的深度神经网络(如识别 YouTube 视频中的猫)。但其他模型则相当易于理解,比如我们之前看到的皮肤癌诊断规则。
所有这些误解都是悲观的,因为它们假设机器学习比实际情况要有限。但也有一些乐观的误解:
简单模型更准确。 这种信念有时被等同于奥卡姆剃刀,但剃刀只说更简单的解释更可取,并没有说明原因。更简单的解释之所以更可取,是因为它们更容易理解、记忆和推理。有时候,与数据一致的最简单假设在预测上可能不如更复杂的假设准确。一些最强大的学习算法输出的模型似乎过于复杂——有时甚至在完全拟合数据后继续添加内容——但这正是它们胜过较弱模型的原因。
计算机发现的模式可以表面接受。 如果学习算法输出的皮肤癌诊断规则非常准确(也就是说,几乎所有符合该规则的痣都是肿瘤),这并不一定意味着你应该相信它。数据的微小变化可能导致算法得出一个非常不同——但同样准确——的规则。只有在数据随机变化下仍然可靠的规则才能被信任其含义,而不仅仅是作为预测工具。
机器学习将很快产生超人智能。 从人工智能的每日进展新闻中,很容易产生计算机即将像我们一样具备视觉、语言和推理能力的印象,之后它们将迅速超越我们。我们在人工智能的前五十年确实取得了长足的进步,而机器学习是最近成功的主要原因,但我们还有很长的路要走。计算机可以非常好地完成许多狭窄的任务,但它们仍然没有常识,且没有人真正知道如何教会它们。
所以你明白了。机器学习的力量超出我们的常规想象,但也有其局限。如何利用它取决于我们——前提是我们从准确的理解开始。
简介: Pedro Domingos 是华盛顿大学计算机科学教授,《主算法》一书的作者。
原文。经许可转载。
相关:
-
“人工智能”死了吗?深度学习长寿?!?
-
关于深度学习为何如此有效的三个想法
-
到 2026 年的人工智能常识?
更多相关话题
300 位数据科学领导者分享了阻碍他们团队的因素
原文:
www.kdnuggets.com/2021/09/domino-300-data-science-leaders.html
赞助帖子。
世界上最先进的公司在长期成功的关键驱动因素中,绝大多数依赖数据科学。但根据对 300 位数据科学高管的新调查(这些公司年收入超过 10 亿美元),人力、流程和工具方面的投资缺陷导致了数据科学的扩展失败。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
这些障碍表明,进行数据科学工作是困难的,进展需要对组织的“数据科学成熟度”和相关资源需求进行冷静评估,以实现大规模生产模型的成功创建、部署和维护。
调查揭示了五个明确的结论:
-
短期投资阻碍了增长预期
-
数据科学的角色不明确
-
更多收入需要更好的模型
-
未改进的模型带来更高风险
-
团队必须清除障碍以实现目标
一份新报告,数据科学需要成长:2021 年 Domino Data Lab 成熟度指数,揭示了一系列发现,展示了公司在努力扩展数据科学时的困难和原因。
这是调查结果的预览。
预期超出了投资,短期“华丽”的投资数量超过了持续的承诺
虽然 71%的数据高管表示他们的公司领导期望从数据科学投资中获得收入增长,但令人震惊的是 48%的人表示他们的公司投资不足以满足这些期望。
他们表示,组织似乎专注于短期利益。事实上,超过四分之三(82%)的受访者表示,他们的雇主在“引人注目的”投资上毫不吝啬,这些投资只带来短期效果。
公司在实施最佳计划以扩大数据科学的规模时遇到困难
超过三分之二的数据高管(68%)报告称,将模型投入生产以影响业务决策至少有些困难——37%的人表示这样做非常困难到极其困难。
几乎五分之二的数据高管(39%)表示,数据科学产生重大影响的主要障碍是组织内标准和流程的不一致。
领导者面临着技能型、高生产力员工的短缺以及所需工具的不足
48%的数据高管抱怨员工的数据技能不足,或无法招聘到足够的人才来扩大数据科学的规模(44%)。
超过五分之二的数据高管表示,他们的数据科学资源过于孤立,难以构建有效的模型(42%),几乎同样多的高管(41%)表示,他们没有明确的角色分配。
错误的模型带来日益严重的风险
研究还探讨了什么让数据科学领导者夜不能寐。结果对那些在数据科学上削减成本的公司发出了严峻的警告。
令人震惊的是,82%的受访者表示,他们的公司领导层应担心不良或失败的模型可能对公司造成严重后果,44%的人报告称他们的模型有四分之一或更多从未更新。受访者列举了模型管理不善的一些令人震惊的后果,包括:
-
由于错误决策导致收入损失(46%)
-
用于人员配置或薪酬决策的内部 KPI 不准确(45%)
-
安全性和薪酬风险(43%)
-
建模中的歧视或偏见(41%)
相关话题
在 Rev 2 上向对冲基金领导者学习数据科学与投资未来
原文:
www.kdnuggets.com/2019/04/domino-data-science-hedge-fund-rev-2.html
赞助文章。

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织中的 IT
Coatue Management 的联合创始人兼高级董事总经理 Thomas Laffont 将与他的首席数据科学家 Alex Izydorczyk 一同登台,参加由 Point72 的首席市场情报官和董事总经理 Matthew Granade 主持的令人着迷的讨论。(完全披露:Matthew Granade 也是 Domino 的联合创始人和董事会成员,而 Coatue Management 既是 Domino 的投资者也是客户。)
根据《福布斯》的说法,Coatue 一直处于“AI 革命的前沿”,在 Nvidia、Google 和 Equinix 等创新企业中拥有大量股份。他们最近也在私人市场上引起了轰动,被《机构投资者》称为“最具攻击性的对冲基金投资者”之一,投资了 Instacart、Lyft、Box.com、jet.com、Uber 和 Snapchat。2018 年,他们推出了两个风险投资基金,2 月份,创始人兼首席投资官 Philippe Laffont 宣布Coatue 将推出其首个量化对冲基金,该基金将完全系统化且市场中立。
Point72 还将其投资权重倾斜到由模型驱动的创新行业,将超过 22% 的资金分配给医疗保健,21% 给技术,16% 给能源。该公司在过去一年中扩大了其地理覆盖范围,并最近在悉尼开展业务,专注于宏观投资。对冲基金在 2018 年筹集了超过 40 亿美元的外部资本,使其管理的总资产达到大约 130 亿美元(截至 2018 年 11 月)。
Coatue 和 Point72 都认识到数据科学作为组织能力的重要性;他们通过将量化方法和自由裁量方法相结合而取得了成功,根据彭博社的报道。
但金融公司已经依赖模型几十年了。只是它被称为“量化研究”而不是“数据科学”,对吧?那么,新模型方法和数据科学行业的发展带来了什么变化呢?
在 Rev 的讨论中,三位对冲基金领导者将交换观点并解答如下问题:
-
对冲基金如何利用模型推动创新和制定新的业务策略?
-
随着数据科学和建模实践的发展,公共和私人市场的投资策略有哪些变化?
-
从金融公司的量化研究经验中,有哪些经验和概念对新数据科学体制的建立有价值?相反,对冲基金必须“忘记”哪些过去的操作方式?
-
将数据科学整合到您的基金中有哪些具体策略和技术?这些方法中哪些可以应用于金融行业以外的企业?
-
如何将数据科学家与传统分析师和投资组合经理整合?
一般会议讨论将于 5 月 24 日星期五在纽约万豪酒店举行。要了解更多关于 Rev 2 的信息或查看完整日程,请访问 rev.dominodatalab.com。请注意,4 人以上的团队一起注册可以获得 50%的票务折扣。或者,您也可以使用专属折扣代码KDNuggetREV享受单张票$100 的优惠!
更多相关话题
数据科学团队所需的马斯洛需求层次
原文:
www.kdnuggets.com/2020/09/domino-leader-forrester-paml-data-science-team.html
赞助帖子。
由 David Bloch 撰写
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升您的数据分析水平
3. Google IT 支持专业证书 - 支持您的组织的 IT 工作
Domino Data Lab 被宣布为连续第二年在最近发布的 “Forrester Wave™: 基于笔记本的预测分析和机器学习 (PAML),2020 年第三季度” 分析报告 中的领导者。报告突出了 Domino 的能力,能够“以可重复性、纪律性和治理支持各种 [机器学习] ML 选项”,同时也提到了我们认为将 Domino 区别于市场领导者的协作和治理能力。
我们相信这份报告验证了我们的产品愿景和战略。在 Domino,我们与财富 100 强中的一些最复杂的数据科学组织合作,因此对数据科学团队在高级数据科学平台上取得成功所需的关键组件形成了有根据的看法。虽然可扩展计算、访问代码库和存储库管理是必不可少的,但它们仅仅是数据科学平台的基础层和基本要求。
忠于我们的数据科学根源,我们构建了一个数据科学团队需求的马斯洛层次结构。在这里,我们绘制了我们认为数据科学团队需要满足的元素,并提供了一种方法,以帮助他们通过向利益相关者一致的解决方案交付来推动纪律、流程、快速迭代和规模。
需求层次金字塔的关键方面按递增顺序包括:
-
在基础层级上的可扩展计算,包括 CPU、GPU 和 APU 以及对所有数据存储库的访问
-
中心化的工具,这些工具开放、可扩展且灵活(研究人员所需)排在其后
-
用户访问控制和安全性用于提供访问权限、角色专业化和工具的认证。
-
所有数据科学资产的版本控制和版本管理
-
端到端的编排以实现可重复的实验、任务调度和连接性
-
支持团队协作和问题解决的动态协作用户界面
-
知识管理和治理解决方案使得在一个地方跟踪所有决策、输出和结果,并在模型生命周期内进行监控变得简单。
-
将数据科学产品以简单、可重复的方式交付给最终用户的能力。
Domino 是由数据科学家为数据科学团队构建的平台。我们的主要关注点是满足数据科学团队的需求,帮助他们生产能够对业务产生影响的数据科学产品,而不是像我们的一些竞争对手那样销售更多的云存储。这些产品被业务利益相关者用来改变业务运作方式并创造商业价值。
我们致力于保持完全开放和可扩展,将传统企业分析套件如 SAS 和 MATLAB 中的工作负载与尖端的开源技术如 Spark、Python 和 R 结合起来。
我们从模型开发和交付的整个生命周期中进行端到端的关注,提供创新的解决方案,帮助实现将机器学习模型从代码库中的代码行转化为部署的业务解决方案的“最后一公里”。
这种关注于交付数据科学产品而非仅仅是数据科学项目的做法,鼓励团队在数据科学家之间以及与来自组织各个部门的业务对口人员之间培养协作和沟通的文化。
通过专注于将数据科学产品交付到业务中,Domino 平台通过全面的模型监控、管理和协作功能,帮助培养健康的利益相关者关系和沟通。我们相信,我们对世界的看法不同于那些只专注于交付代码和计算的大多数数据科学平台供应商。
我们通过提供各种将模型部署到生产中的方式来实现这一目标,这些方式由可重复性和协作引擎支持,使你能够查看数据科学团队在选择解决问题的正确方法时所做的所有假设、决策和行动。
这一承诺意味着我们将继续专注于解决企业组织在将 AI/ML 工具集的承诺应用于关键业务解决方案时面临的问题——这些解决方案可以帮助他们在各自行业中实现差异化并建立可持续的竞争优势。
今天,我们很高兴支持超过 20% 的《财富》100 强公司进行大规模的数据科学。我们对基于笔记本的预测分析和机器学习平台的未来发展有独特的愿景,并期待与客户继续实现这一愿景。我们相信,Forrester 也如我们所想,通过在协作和平台基础设施标准中给 Domino 最高分,在 ModelOps 标准中给出最高分之一,以及在战略类别中给予第二高分,来表达对我们的认可。
今天获取这份重要研究报告的免费副本,查看我们的其他评分及竞争对手的表现。
主题更多内容
评估 Ray:用于大规模可扩展性的分布式 Python
原文:
www.kdnuggets.com/2020/03/domino-ray-distributed-python-massive-scalability.html
作者 Dean Wampler,Domino Data Lab

Dean Wampler 提供了 Ray 的精华概述,这是一个将 Python 系统从单台机器扩展到大型集群的开源系统。如果你对更多见解感兴趣,请注册参加即将举行的 Ray 峰会。
介绍
本文面向做出技术决策的人,即数据科学团队负责人、架构师、开发团队负责人,甚至是参与组织中技术战略决策的经理。如果你的团队已经开始使用 Ray,并且你想了解它是什么,这篇文章适合你。如果你想知道 Ray 是否应该成为你的 Python 应用程序,特别是 ML 和 AI 的技术战略的一部分,这篇文章也适合你。如果你想了解 Ray 的更深入技术介绍,请参阅 Ray 项目博客 的这篇文章。
Ray:扩展 Python 应用程序
Ray 是一个开源系统,用于将 Python 应用程序从单台机器扩展到大型集群。其设计受到下一代 ML 和 AI 系统独特挑战的驱动,但其功能使 Ray 成为所有需要在集群中扩展的基于 Python 的应用程序的绝佳选择,尤其是那些具有分布式状态的应用程序。Ray 还提供了一个最小侵入性和直观的 API,因此你可以在不需要大量分布式系统编程知识和努力的情况下获得这些好处。
开发人员在代码中指明哪些部分应该分布在集群中并异步运行,然后 Ray 会为你处理分布。若在本地运行,应用程序可以利用机器上的所有核心(你也可以指定限制)。当一台机器不够用时,可以很简单地在集群上运行 Ray,使应用程序利用集群。此时唯一需要改变的代码是初始化 Ray 时传递的选项。
使用 Ray 的 ML 库,例如用于强化学习(RL)的 RLlib,用于超参数调优的 Tune,以及用于模型服务(实验性)的 Serve,都在内部实现了 Ray,以利用其可扩展的分布式计算和状态管理优势,同时提供了针对其服务目标的领域特定 API。
Ray 的动机:训练强化学习(RL)模型
要了解 Ray 的动机,可以考虑训练强化学习(RL)模型的例子。RL 是一种机器学习方法,最近被用来to 击败世界顶级围棋选手,并实现 Atari 和类似游戏的专家级游戏玩法。
可扩展的 RL 需要 Ray 设计时提供的许多功能:
-
高度并行化和高效执行的 任务(数百万个或更多) – 训练模型时,我们重复相同的计算以找到最佳模型 方法(“超参数”),一旦选择了最佳结构,就找到最佳的模型 参数。我们还需要在任务有依赖于其他任务结果的情况下进行适当的任务排序。
-
自动故障容错 – 由于所有这些任务中可能有一部分因各种原因失败,我们需要一个支持任务监控和故障恢复的系统。
-
多样化的计算模式 – 模型训练涉及大量的计算数学。特别是大多数 RL 模型训练,还需要高效地执行一个模拟器——例如,我们想要击败的游戏引擎或代表现实世界活动的模型,比如自动驾驶。这些计算模式(算法、内存访问模式等)更典型于通用计算系统,这些系统的计算模式与数据系统中的计算模式(通常以高吞吐量的记录变换和聚合为主)可能大相径庭。另一个区别是这些计算的动态特性。想象一下一个游戏玩家(或模拟器)如何适应游戏的演变状态,改善策略,尝试新战术等。这些多样化的要求出现在各种新型的基于 ML 的系统中,如机器人技术、自动驾驶车辆、计算机视觉系统、自动对话系统等。
-
分布式状态管理 – 在 RL 中,需要在训练迭代之间跟踪当前模型参数和模拟器状态。由于任务是分布式的,这个状态也变得分布式。适当的状态管理也要求对有状态操作进行适当的排序。
当然,其他 ML/AI 系统也需要一些或所有这些功能。大规模操作的通用 Python 应用程序也是如此。
Ray 的要点
像 RLlib、Tune 和 Serve 这样的 Ray 库使用了 Ray,但大多数情况下对用户隐藏了它。然而,使用 Ray API 本身是很简单的。假设你有一个需要在数据记录上重复运行的“昂贵”函数。如果它是 无状态的,即它在调用之间不维护任何状态,并且你想要并行调用它,那么你只需通过添加 @ray.remote 注解将函数转化为 Ray 任务,如下所示:
@ray.remote
def slow(record):
new_record = expensive_process(record)
return new_record
然后初始化 Ray 并按如下方式对数据集进行调用:
ray.init() # Arguments can specify the cluster location, etc.
futures = [slow.remote(r) for r in records]
注意我们如何使用 slow.remote 调用 slow 函数。每次调用都会立即返回一个 future。我们有一个它们的集合。如果我们在集群中运行,Ray 会管理可用资源,并将任务放在具有运行函数所需资源的节点上。
我们现在可以要求 Ray 在完成每个结果时使用 ray.wait 返回结果。这是一种习惯用法:
while len(futures) > 0:
finished, rest = ray.wait(futures)
# Do something with “finished”, which has 1 value:
value = ray.get(finished[0]) # Get the value from the future
print(value)
futures = rest
如上所述,我们将等待 slow 的调用之一完成,此时 ray.wait 将返回两个列表。第一个列表将有一个条目,即完成的 slow 调用的 future 的 id。我们传入的其他 futures 将在第二个列表中—rest。我们调用 ray.get 来检索已完成 future 的值。(注意:这是一个阻塞调用,但由于我们已经知道它完成了,所以它会立即返回。) 我们通过将列表重置为剩余的项目来完成循环,然后重复直到所有远程调用完成并且结果被处理。
你还可以向 ray.wait 传递参数,以便一次返回多个结果并设置超时。如果你不等待一组并发任务,你也可以通过调用 ray.get(future_id) 等待特定的未来对象。
没有参数的情况下,ray.init 默认本地执行,并使用所有可用的 CPU 核心。你可以提供参数以指定运行的集群、使用的 CPU 或 GPU 核心数量等。
假设一个远程函数传递了另一个远程函数调用的 future。Ray 会自动安排这些依赖关系,以便它们按所需的顺序进行评估。你不需要自己处理这种情况。
假设你有一个 有状态 的计算任务要完成。当我们上面使用 ray.get 时,我们实际上是从分布式对象存储中检索值。如果你愿意,可以使用 ray.put 明确将对象放入其中,它返回一个 id,你可以稍后传递给 ray.get 以再次检索。
使用演员模型处理有状态计算
Ray 支持一种更直观和灵活的方式来管理状态的设置和检索,采用了演员模型。它使用常规的 Python 类,并通过相同的@ray.remote注解将其转换为远程演员。为了简化起见,假设你需要统计 slow 被调用的次数。这里是一个实现该功能的类:
@ray.remote
class CountedSlows:
def __init__(self, initial_count = 0):
self.count = initial_count
def slow(self, record):
self.count += 1
new_record = expensive_process(record)
return new_record
def get_count(self):
return self.count
除了注解之外,这看起来像是一个正常的 Python 类声明,尽管通常你不会单独定义 get_count 方法来检索 count。我稍后会再提到这一点。
现在以类似的方式使用它。注意类的实例是如何构造的,以及如何像以前一样使用 remote 调用实例上的方法:
cs = CountedSlows.remote() # Note how actor construction works
futures = [cs.slow.remote(r) for r in records]
while len(futures) > 0:
finished, rest = ray.wait(futures)
value = ray.get(finished[0])
print(value)
futures = rest
count_future_id = cs.get_count.remote()
ray.get(count_future_id)
最后一行应该打印出一个等于原始集合大小的数字。注意,我调用了方法get_count来检索count属性的值。此时,Ray 不支持直接检索像count这样的实例属性,因此与常规 Python 类相比,添加检索它的方法是唯一的必要区别。
Ray 统一了任务和演员
在上述两种情况下,Ray 跟踪任务和演员在集群中的位置,消除了在用户代码中明确知道和管理这些位置的需要。演员内部的状态变更以线程安全的方式处理,无需显式的并发原语。因此,Ray 为应用程序提供了直观的分布式状态管理,这意味着 Ray 是实现 有状态的 serverless 应用程序的绝佳平台。此外,在同一台机器上任务和演员之间的通信时,状态通过共享内存透明地管理,演员和任务之间进行零拷贝序列化,以实现最佳性能。
注意:让我强调 Ray 在这里提供的一个重要好处。没有 Ray,当你需要在集群上扩展应用程序时,你必须决定创建多少个实例,将它们放置在集群中的哪个位置(或使用像 Kubernetes 这样的系统),如何管理它们的生命周期,它们如何通信和协调等。Ray 为你做了所有这些,几乎不需要你付出额外的努力。你主要只需编写正常的 Python 代码。它是简化微服务架构设计和管理的强大工具。
采用 Ray
如果你已经在使用其他并发 API,如 multiprocessing、asyncio 或 joblib,那么这些 API 在单台机器上扩展效果很好,但它们不支持集群扩展。Ray 最近引入了这些 API 的实验性实现,允许你的应用程序扩展到集群。你代码中唯一需要更改的就是导入语句。例如,如果你使用的是 multiprocessing.Pool,这是通常的导入语句:
from multiprocessing.pool import Pool
要使用 Ray 实现,请改用以下语句:
from ray.experimental.multiprocessing.pool import Pool
这就是全部所需的。
那么 Dask 呢?它似乎提供了许多与 Ray 相同的功能。如果你需要分布式集合,如 numpy 数组和 Pandas DataFrames,Dask 是一个不错的选择。(一个使用 Ray 的研究项目 Modin 最终将满足这一需求。)Ray 设计用于更通用的场景,在这些场景中,需要分布式状态管理,并且在大规模上执行异构任务必须非常高效,例如我们在强化学习中需要的那样。
结论
我们已经看到 Ray 的抽象和功能使它成为一个易于使用的工具,同时提供强大的分布式计算和状态管理能力。尽管 Ray 的设计受到高性能、高要求 ML/AI 应用程序的特定需求的驱动,但它具有广泛的适用性,甚至提供了一种新的方法来处理基于微服务的架构。
我希望你发现这简短的 Ray 介绍很有趣。请 试一试 并告诉我你的想法!发送至: dean@anyscale.io
了解更多
有关 Ray 的更多信息,请查看以下内容:
-
Ray Summit 将于 2020 年 5 月 27-28 日在旧金山举行。了解案例研究、研究项目和 Ray 的深入探讨,并聆听数据科学和 AI 社区领导者的晨间主题演讲!
-
Ray 网站 是所有与 Ray 相关内容的起点。
-
几个基于笔记本的 Ray 教程 让你可以尝试 Ray。
-
Ray GitHub 页面 是你可以找到所有 Ray 源代码的地方。
-
直接向 Ray Slack 工作区 或 ray-dev Google 组 提问有关 Ray 的问题。
-
一些 Ray 项目:
-
若需更多技术细节:
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关话题
不要购买机器学习
comments
由 Marcos Sponton, Machinalis。

在我和彼得·诺维格的对话中,我们讨论了我们在 Machinalis 做的项目,以及说“我们是一家机器学习公司”有多么奇怪:在许多项目中,花费在机器学习研发上的努力通常只是总努力的一小部分,或者甚至没有,因为我们计划在首先构建应用程序后进入未来阶段。此时,诺维格引用了一位朋友的话:
“机器学习开发就像 葡萄干面包 中的葡萄干:1. 你需要首先有面包 2. 这只是几颗小葡萄干,但没有它你只会有普通的面包。”
那么公司如何购买这块葡萄干面包呢?
通常会发生两种情况:
一家大公司在更高层次上决定远离标准工具,考虑到“我们的业务和数据不同/特殊”,将机器学习或数据科学纳入其流程中。在这些情况下,他们找我们只是为了得到一些葡萄干。
一家初创公司在几轮融资后,决定将他们构建的原型转变为可生产的可扩展 MVP。在这些情况下,他们找我们是因为他们想要整块葡萄干面包,或者未来某个时候可能需要的其他类型的布丁。
即使吃这东西很流行,许多人也不习惯这种新口味,可能会觉得不太适应。
诀窍不是购买“机器学习玩意…”
除非你……
-
… 认识到这样做并不是进入一个典型的软件开发项目,而是一个研究和开发项目。即使对于一些不完全符合这一规则的更知名问题,典型的不确定性水平也比传统开发项目要高,如果对交付物的期望涉及到识别、设计和/或实现精度或准确度等指标的特定值,这种不确定性会更高。
-
… 理解到从“它是可能的”的研究论文到生产就绪的软件之间可能存在很大的差距,有时大到今天无法弥补。
-
… 将你在过程中创建的预测模型视为一种资产。你的竞争对手没有访问这个模型的权限,它是从你自己独特的数据和限制组合中产生的具有生产性和潜在可扩展性的知识。为此而工作的团队不是在浪费时间作为“必要的恶”,而是将精力投入到过程的主要资产中。
-
… 不要期望机器学习是一个神秘的黑箱,会产生魔法般的结果。过程中的一个核心原则是“垃圾进,垃圾出”,如果你的目标不明确,机器学习不会让它们更明确。
-
… 如果你有商业背景,你愿意融入一些机器学习概念,以便从商业角度向团队传达一个详细的问题愿景。技术团队将通过了解业务方面的内容做出回应。你不希望在项目结束时,经过分开工作的情况下,得到一个从科学角度看很吸引人的结果,但对你的业务来说毫无意义(这意味着你花费了大量金钱和时间,而你的竞争对手利用得更好)。
-
… 考虑一下,也许通过使用标准和现成的算法花费 20%的努力,你可以获得 80%预期结果。提高这一结果可能需要剩余的 80%的努力… 或更多。
-
… 你可能已经意识到你的机器学习团队通常费用不菲,你不希望他们需要处理将他们的工作与现有生产流程集成的问题。
-
… 你的团队已经准备好开始处理概率结果。
-
… 不要仅仅因为它很受欢迎就购买它:初创公司在早期阶段通常不需要完整的葡萄干面包,而只需要一些面包原型,也许是一个样本葡萄干,看看他们的街道上是否对面包店感兴趣。
你认为你能克服所有这些障碍吗?恭喜你,你有很好的机会在你的业务中享受美味的葡萄干面包。并且 我们很乐意听取你的意见。
(*) 在这一点上,如果你要开始一个“数据科学”、“大数据”、“人工智能”项目而不是一个“机器学习”项目,也没什么区别,你可能看不出这些术语之间的差异。
个人简介: Marcos Spontón @MarcosSponton 企业家,数据业务与增长的热衷者。
原文.
相关:
-
数据科学家的职业建议 – 去赚更多的钱
-
如何成为数据科学家并找到工作
-
数据科学家的软件开发技能
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
更多相关话题
不要在 24 小时内学习机器学习
原文:
www.kdnuggets.com/2018/04/dont-learn-machine-learning-24-hours.html
评论

来源 — medium.com/designer-hangout/machine-learning-and-ux-c28725b5f3a5
最近,我看到了一篇由彼得·诺维格撰写的精彩文章——“在 10 年内自学编程”。
这是一个机智且稍带讽刺的标题,挖苦那些旨在让你在 24 小时、7 天、10 天, 或插入一个荒谬短时间段内学会编程的咖啡桌编程书籍。
诺维格博士提出了一个很强的观点。是的,你可以在 24 小时内掌握编程语言的语法、特性和风格,但这并不意味着你已经熟练掌握了编程的艺术。因为编程并不仅仅关乎语言。编程涉及智能设计、对时间和空间复杂性的严格分析、了解何时使用某种语言优于另一种语言,等等。
当然,你可以在 24 小时内用 C++编写一个 Hello World 程序,或者编写一个计算圆面积的程序,但这不是重点。你是否掌握了面向对象编程的范式?你是否理解了namespaces和templates的用例?你是否了解著名的STL? 如果你了解这些,你肯定不会在一周甚至一个月内学完所有这些内容。这需要你花费相当长的时间。而且你学得越多,就越意识到深渊比从悬崖上看到的要深得多。
我发现当前围绕机器学习、深度学习和人工智能的氛围与此类似。由于炒作的推动,成千上万的博客、文章和课程纷纷涌现。它们中的许多都带有类似的标题——“7 行代码实现机器学习”、“10 天内掌握机器学习”等。这使得 Quora 上的人们开始提问,比如 “我怎么在 30 天内学会机器学习?”。简短的回答是,“你不能。没有人能做到。连任何专家(或即使对其内情了如指掌的人)也不能。”
看起来很熟悉?在一个非常有趣的 Facebook页面上找到了这个。
即使我们暂时忘记10,000 小时规则,你也不能仅凭 7 行代码来做机器学习。
为什么?因为那 7 行代码没有解释你在偏差-方差权衡中的表现,你的准确性值意味着什么,或者准确性是否是性能的合适指标,你的模型是否过拟合,你的数据分布情况如何,以及你是否选择了合适的模型来拟合你的数据等等。在回答这些问题之后,还有很多其他方面的内容需要了解。
由于你无法解释你的模型,你在 sklearn 中调整参数,得到了一点点准确性的提升,然后高高兴兴地回家了。但你真的学到了什么吗?

来源 — 机器学习与模因
总之,不要用 7 行代码来完成。花 6 个月、一年的时间来做。你会在这段时间中间知道这是否对你有兴趣。现在忘掉那些光鲜亮丽的东西,真正深入了解这个令人惊叹的研究领域。你一定要阅读this。我发现它是该领域新手的最佳入门读物。你不需要知道数学或代码来阅读它。但阅读之后,你会意识到你需要理解的整个概念范围,以便在这个领域流利地思考,也就是说,思考机器学习。
确实有许多迷人的博客可以关注。以下是我个人的一些最爱:
Medium 也是一个学习的好地方。我几乎完全关注这个出版物。
如果你是老派的,可以去斯坦福大学上 Andrew Ng 的CS229。这比他在 Coursera 上的课程更为深入,尽管 Coursera 上的课程也是一个很好的入门介绍。
不幸的是,炒作的结果是我们“淹没在信息中,却对知识感到饥渴”。如此多人这样做,以至于我们经常忽视更大的图景。机器学习是奇妙的,它是一个严肃的研究和开发领域,推动了许多 21 世纪的应用案例。
只是不要在 24 小时内完成。
这里 是彼得·诺维格的文章,来自我们时代的杰出 AI 研究者,必读之作。
说真的,为什么不呢?
原文。经许可转载。
相关:
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
更多相关话题
不要错过!2023 年结束前报名免费课程
原文:
www.kdnuggets.com/dont-miss-out-enroll-in-free-courses-before-2023-ends

作者提供的图片
年底是人们最为活跃的时候。您有最后的冲刺去实现年度目标,以便为 2024 年做准备。无论是开始新的技术行业职业还是提升当前技能,自我发展都很重要。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 需求
技术的持续进步导致了行业的激烈竞争。各行各业的人们都希望参与其中。该博客旨在为您提供一份优秀的免费课程列表,帮助您实现目标。我将按主题将其分解,便于您导航到您的关注领域。
这些免费课程都可以在 YouTube 上找到,仿佛您报名了真正的课程。在 YouTube 上找到合适的内容很困难,因为信息量巨大!希望这篇文章能使您的搜索更加轻松,下面我们来详细了解一下。
机器学习
1. 机器学习入门,2020/21
链接:机器学习入门,Dmitry Kobak,2020/21
2. 斯坦福大学 CS229: 机器学习
链接:斯坦福大学 CS229: 机器学习完整课程,由 Andrew Ng 授课
3. 康奈尔大学技术学院 CS 5787: 应用机器学习
链接:应用机器学习(康奈尔大学技术学院 CS 5787,2020 秋季)
4. 与机器学习交朋友
5. 基础模型
链接:基础模型
统计学
1. 统计机器学习
链接:统计机器学习
深度学习
初学者:
1. 麻省理工学院 6.S191: 深度学习入门
链接:深度学习入门
2. CMU 深度学习入门
3. MIT: 深度学习入门
链接:深度学习入门
4. 神经网络:从零到英雄
链接:神经网络:从零到英雄
5. 深度 RL 基础
链接:深度 RL 基础
中级:
1. 斯坦福 CS230: 深度学习
2. 斯坦福 CS25 - 变压器联合
链接:变压器联合
3. MIT 6.S192: 艺术、美学与创造力的深度学习
4. CS 285: 深度强化学习
链接:深度强化学习
5. 斯坦福:强化学习
链接:强化学习
6. 伯克利:深度无监督学习
7. 纽约大学深度学习
链接:深度学习 SP21
8. 全栈深度学习
链接:全栈深度学习 2021
9. 计算机视觉中的深度学习
链接:计算机视觉中的深度学习
NLP
1. Hugging Face 课程: NLP
2. 斯坦福 CS224U: 自然语言理解
链接:自然语言理解
3. CMU 高级 NLP
链接:高级 NLP,2022
4. CMU 多语言 NLP
链接:多语言 NLP
5. UMass CS685: 高级自然语言处理
链接:高级自然语言处理
实用
1. 实用深度学习
链接: 实用深度学习课程
2. 生产机器学习工程(MLOps)
链接: 生产机器学习工程
就这些了!
总结
正如我之前提到的,市面上有很多课程,很难坚持选择一个。你可能会对某个讲师的声音或讲解方式更有偏好。你需要考虑的因素有很多。
我在每个部分提供了一个详尽的列表,以帮助你选择你喜欢的,并继续你的学习。
希望这个列表对你有所帮助。如果你知道任何好的资源,请在评论中分享给学习社区 - 谢谢!
祝学习愉快!
Nisha Arya 是一位数据科学家,兼职技术写作员以及 KDnuggets 的社区经理。她特别感兴趣于提供数据科学职业建议或教程,以及数据科学的理论知识。她也希望探索人工智能如何/能如何有利于人类生命的延续。作为一名热衷学习者,她希望拓宽自己的技术知识和写作技能,同时帮助引导他人。
更多相关话题
我们不需要数据科学家,我们需要数据工程师
原文:
www.kdnuggets.com/2021/02/dont-need-data-scientists-need-data-engineers.html这是受到此帖启发的 KDnuggets 漫画
数据。无处不在,我们每天生成的数据越来越多。在过去的 5-10 年里,数据科学吸引了来自四面八方的新手,试图尝到这禁果的滋味。
我们的前三推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
但如今数据科学招聘的状态如何呢?
对于忙碌的读者来说,本文的要点用两句话总结如下。
总结:相比数据科学,公司中数据工程的职位空缺多出70%。在培养下一代数据和机器学习从业者时,让我们更多地强调工程技能。
作为我开发教育平台的一部分,我经常思考数据驱动(机器学习和数据科学)角色的市场如何演变。
与众多有意进入数据领域的潜在候选人,包括世界顶尖机构的学生交谈时,我看到对哪些技能最重要以帮助候选人脱颖而出并为其职业生涯做准备的困惑。
当你仔细考虑时,一个数据科学家可以负责以下任何子集:机器学习建模、可视化、数据清洗和处理(即 SQL 操作)、工程以及生产部署。
你如何开始为新手推荐学习课程呢?
数据胜于言辞。因此,我决定对自 2012 年以来每个来自Y-Combinator的公司招聘的数据角色进行分析。指导我研究的问题是:
-
公司最常招聘哪些数据角色?
-
我们谈论得很多的传统数据科学家有多么抢手?
-
开创数据革命的那些技能在今天仍然相关吗?
如果你想了解完整的细节和分析,请继续阅读。
方法论
我选择对那些声称将某种数据工作作为其价值主张的一部分的 YC 投资组合公司进行分析。
为什么专注于 YC?首先,他们提供了一个易于搜索(和抓取)的公司目录。
此外,作为一个特别前瞻性的孵化器,他们在过去十多年里资助了来自全球各领域的公司,我认为他们提供了一个代表性的市场样本以供我进行分析。也就是说,请对我的说法持保留态度,因为我没有分析超级大型科技公司。
我抓取了自 2012 年以来每个 YC 公司的主页 URL,初步筛选出约 1400 家公司。
为什么不从 2012 年开始?2012 年是AlexNet赢得 ImageNet 竞赛的年份,这实际上启动了我们现在所经历的机器学习和数据建模浪潮。可以说,这催生了数据优先公司的一些早期世代。
从这个初始池中,我进行了关键词过滤,以减少需要查看的相关公司数量。特别是,我只考虑了其网站上至少包含以下术语之一的公司:AI、CV、NLP、自然语言处理、计算机视觉、人工智能、机器、ML、数据。我还忽略了那些网站链接损坏的公司。
这是否产生了大量的虚假积极结果?绝对是!但在这里,我尽量优先考虑高召回率,同时意识到我会对相关角色的各个网站进行更细致的手动检查。
在这个缩小的范围内,我浏览了每个网站,找到他们发布招聘信息的地方(通常是Careers、Jobs或We’re Hiring页面),并记录了每个职位标题中包含数据、机器学习、自然语言处理(NLP)或计算机视觉(CV)的角色。这给我提供了大约 70 个招聘数据岗位的不同公司。
这里有一点说明:有可能我遗漏了一些公司,因为有些网站信息非常少(通常是那些在隐形状态中的公司),这些公司实际上可能正在招聘。此外,还有些公司没有正式的Careers页面,而是要求潜在候选人直接通过电子邮件联系。
我忽略了这两类公司,而不是联系他们,因此它们不在此次分析之内。
另外一点:这项研究的大部分工作是在 2020 年最后几周完成的。随着公司定期更新其页面,开放职位可能已经发生变化。然而,我认为这不会对得出的结论产生重大影响。
数据从业者负责什么?
在深入结果之前,值得花一些时间澄清每个数据角色通常负责的职责。以下是我们将要重点查看的四个角色,并简要描述了他们的工作内容:
-
数据科学家:使用各种统计和机器学习技术来处理和分析数据。通常负责建立模型以探测从某些数据源中可以学到的东西,尽管通常是在原型阶段而非生产阶段。
-
数据工程师:开发一个强大且可扩展的数据处理工具/平台。必须熟悉 SQL/NoSQL 数据库操作和构建/维护 ETL 管道。
-
机器学习(ML)工程师:通常负责模型训练和生产化。需要熟悉一些高级 ML 框架,并且必须能够构建可扩展的训练、推理和部署管道。
-
机器学习(ML)科学家:从事前沿研究。通常负责探索可以在学术会议上发布的新想法。往往只需原型化新型最先进模型,然后将其交给机器学习工程师进行生产化。
有多少数据角色?
那么当我们绘制公司招聘的每种数据角色的频率时会发生什么?图表如下:
令人印象深刻的是,与传统的数据科学家角色相比,开放的数据工程师职位明显更多。在这种情况下,原始数据表明公司招聘的数据工程师比数据科学家多约 55%,而机器学习工程师的数量与数据科学家大致相同。
但我们还可以做得更多。如果你查看各种角色的标题,似乎存在一些重复。
我们只提供通过角色整合的粗略分类。换句话说,我将描述大致相同的角色合并在一个标题下。
包括以下一组等价关系:
-
NLP 工程师 ≈ CV 工程师 ≈ ML 工程师 ≈ 深度学习工程师(尽管领域可能不同,但职责大致相同)
-
ML 科学家 ≈ 深度学习研究员 ≈ ML 实习生(实习描述看起来非常注重研究)
-
数据工程师 ≈ 数据架构师 ≈ 数据主管 ≈ 数据平台工程师
如果我们不喜欢处理原始数据,这里有一些百分比可以让我们安心:
我可能本可以将ML 研究工程师归入ML 科学家或ML 工程师类别,但由于这是一个混合角色,我将其保持原样。
整体上,整合使差异更加显著!开放的数据工程师职位比数据科学家多约 70%。此外,开放的ML 工程师职位比数据科学家多约 40%。而ML 科学家的职位只有数据科学家的约 30%。
主要收获
与其他数据驱动职业相比,数据工程师的需求越来越高。从某种意义上说,这代表了更广泛领域的演变。
当机器学习在 5-8 年前变得热门时,公司决定他们需要能够对数据进行分类的人。但随后像Tensorflow和PyTorch这样的框架变得非常优秀,使得开始进行深度学习和机器学习变得民主化。
这使得数据建模技能变得商品化。
今天,帮助公司将机器学习和建模洞察力投入生产的瓶颈在于数据问题。
你如何标注数据?你如何处理和清洗数据?你如何将数据从 A 移动到 B?你如何尽可能快地每天做到这些?

这一切都归结为拥有良好的工程技能。
这听起来可能有些乏味和不够吸引人,但将老派的软件工程与数据相结合,可能正是我们现在真正需要的。
多年来,我们一直对数据专业人士能够将生机注入原始数据的想法充满热情,归功于炫酷的演示和媒体炒作。毕竟,上一次你看到关于 ETL 管道的TechCrunch文章是什么时候?
如果没有别的,我相信在数据科学工作培训或教育项目中,我们对扎实工程能力的重视还远远不够。除了学习如何使用linear_regression.fit(),还要学会如何编写单元测试!
所以这是否意味着你不应该学习数据科学?不。
这意味着竞争将会更加激烈。市场上对数据科学的新人训练过剩,职位会变得更少。
总会有需要能够有效分析和提取数据中可操作见解的人。但他们必须要优秀。
从 Tensorflow 网站下载一个预训练模型以使用Iris 数据集可能已经不足以获得数据科学职位。
然而,很明显,随着大量的机器学习工程师职位空缺,公司往往希望拥有混合型数据从业者:既能构建和部署模型的人。简而言之,就是既能使用 Tensorflow 又能从源代码构建它的人。
另一个结论是,机器学习研究职位其实并不多。
机器学习研究往往受到大量炒作,因为那是所有前沿技术的发生地,比如所有的AlphaGo和GPT-3等等。
但对于许多公司,特别是初创公司来说,前沿的尖端技术可能已经不再是他们所需要的。获得一个达到 90% 的模型,但能扩展到 1000+ 用户,往往对他们来说更有价值。
这并不是说机器学习研究没有重要的地位。绝对不是。
但你可能会在能够承担长期资本密集型投资的行业研究实验室找到更多这样的角色,而不是在种子阶段的初创公司,该公司试图向投资者展示产品市场适配性,并在筹集 A 轮融资时。
如果没有别的,我认为使新进入数据领域的人的期望合理且精准是很重要的。我们必须承认,数据科学现在有所不同。我希望这篇文章能够揭示今天领域的现状。只有当我们知道自己在哪里时,我们才知道需要去哪里。
Mihail Eric 是 Confetti 的机器学习研究员和创始人。
原文。已获许可转载。
更多相关话题
机器学习与敏捷的注定失败的结合
原文:
www.kdnuggets.com/2019/11/doomed-marriage-machine-learning-agile.html
评论
作者 Ian Xiao,Dessa 的参与负责人

图片由 photo-nic.co.uk nic 提供,Unsplash
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能。
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作。
总结: 在机器学习项目中,过度采用敏捷和塞巴斯蒂安的建议的三大错误。我认为在机器学习项目中什么是可以用敏捷方法做的,什么不是。
免责声明: 本文未得到我所在公司或我提到的任何工具或服务的认可或赞助。我将 AI、数据科学和机器学习交替使用。
喜欢你读到的内容吗? 关注我在 Medium、LinkedIn 或 Twitter。另外,你是否想作为数据科学家学习商业思维和沟通技巧?查看我的“利用机器学习影响力”指南。
一个忏悔
2016 年 11 月 3 日晚上 11:35。我坐在多伦多心脏地带贝街的一个会议室里。我盯着街对面空荡荡的办公室楼层。我的房间灯光渐暗。我的手机亮了,我收到了三个通知。
// 高管演示,10 小时内。
// 给杰斯打电话。发送最终的婚礼后勤细节,12 小时内。
// 前往机场。18 小时后飞往香港参加我们的婚礼。
“他妈的… 他妈的。他妈的!”
我按下键盘;笔记本电脑开机了;一个数字出现了。它还是不能工作。我该如何解释预期转化率下降了 35%?
我拿起电话,打给了我的同事西蒙,他将帮助我进行演示:“我们来计划一下应急处理吧。”
“嘿,你在想我们的婚礼吗?”我亲爱的妻子杰斯问。
我猛然回到现实。这是 2019 年 11 月 5 日。我承认。不,我并没有想着我们的婚礼,但祝我们周年快乐!我永远不会忘记这个日期。
该死的,塞巴斯蒂安
我喜欢关于机器学习的成功故事。但,让我们面对现实:大多数机器学习项目失败。许多项目失败是因为我们试图用机器学习解决错误的问题;一些失败是因为我们没有足够关注 最后一公里问题 和 工程及组织问题。少数失败是因为我们觉得 数据科学很无聊 而停止关注。其余的,就像我所承认的那样,失败是由于项目管理不善。
如果我从这段经历中挑选出一个教训,那就是:不要过度使用敏捷。 一切始于 塞巴斯蒂安·特伦 的一张图。
这是我最喜欢的机器学习工作流程图,部分原因是塞巴斯蒂安写字的手写字体是用计算机写字板写的(说真的)。但是,有一个重要的细微差别。
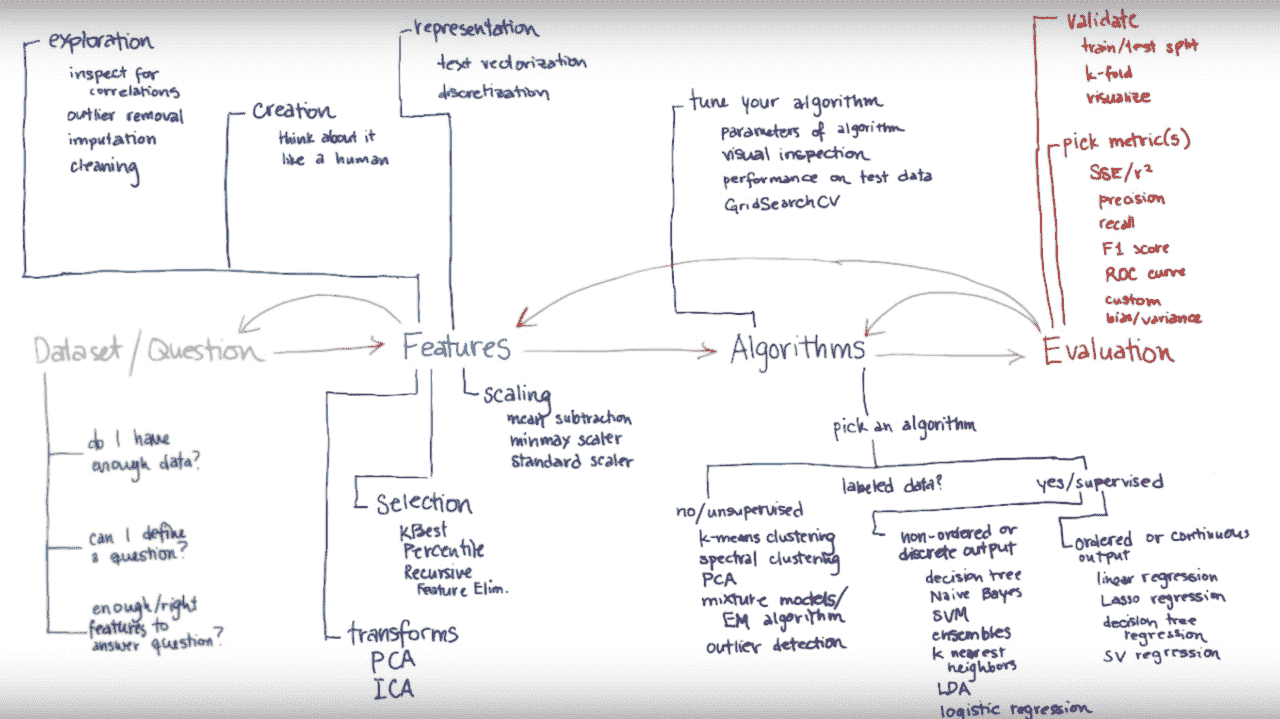
塞巴斯蒂安·特伦,Udacity——数据科学导论,最佳在线课程!
我的无知、细微差别以及发生了什么
首先,我必须承认自己的无知。 我曾经是 敏捷方法 的天真倡导者,因为 瀑布模型 太过古老和不吸引人。像我一样,你们中的许多人可能听说过关于敏捷的说法:迭代使我们能够快速学习、测试和失败。(此外,我们通过节省编写技术规范的纸张,减少了砍伐树木的数量,这些规范没人阅读并且可能在早期项目中就是错误的)。
细微差别。 不应该有箭头指回问题和评估(绿色和红色文本)阶段。敏捷的迭代原则 不应适用于 定义核心问题和评估指标的阶段。
核心问题必须尽早明确。然后,必须立即思考子问题(参见 假设驱动的问题解决 方法)。它们有助于 1) 识别良好的功能想法并推动探索性分析,2) 规划时间表,3) 决定每个敏捷迭代应该关注什么。评估指标必须根据核心问题谨慎选择。我在我的 指南 中详细讨论了这个过程。
那么,发生了什么? 无法识别我自己的无知和机器学习工作流程中的细微差别导致了 3 个致命错误。
错误 #1:我们因为对核心业务问题的错误定义在中途改变了 目标变量。这导致了 数据泄漏 ,破坏了我们的模型性能。我们不得不重新编写约 35% 的代码,并花费约 2 周的时间重新尝试不同的数据转换和模型架构。这真是一场噩梦。
错误 #2:我们优先考虑了低影响特性,因为我们的子问题没有经过充分考虑。好吧,这些特性中的一些是创新的,但事后看并不实用。这浪费了宝贵的开发时间,在时间限制的咨询环境中极为重要。
错误 #3:我们改变了评估指标。我们不得不重新设计我们的模型架构,并重新运行 超参数搜索。这需要新的测试用例。我们不得不手动运行许多回归测试。
所有这些错误对客户体验、团队士气和时间表产生了不良影响。最终,它们导致了我婚礼前的一个非常紧张的晚上。
变得更聪明
好吧,让我们公平一点。我确实把塞巴斯蒂安的建议断章取义了。他是最好的机器学习老师(对不起,Andrew Ng)。
塞巴斯蒂安的工作流程主要是为以实验为中心的机器学习项目设计的(例如商业智能或洞察发现)。对于以工程为中心的机器学习项目(例如我们的全栈机器学习系统),工作流程应该基于软件工程和产品管理的最佳实践进行改进。
这是我对什么可以敏捷,什么不可以敏捷的看法。这对时间限制的咨询或内部原型项目尤为重要。没有一种完美的方法,所以不要过于执着,聪明地应用即可。
可敏捷:
-
数据特征的开发
-
模型架构的开发
-
用户界面的设计和开发(例如仪表盘、Web-UI 等)
-
CICD 测试用例的设计和开发
不可敏捷:
-
用户体验如果最终消费者是人;集成模式和协议如果最终消费者是系统。
-
核心定义、子问题及主要特征创意列表
-
目标变量的定义(避免任何变更。但如果业务需求发生变化,锁定 CICD 流水线对于捕捉数据或软件缺陷非常有帮助。)
-
评估指标
-
基础设施:集成模式、服务层、关键数据库和硬件平台
到目前为止运行得很好。欢迎任何反馈,一如既往。
根据对这篇文章的反响,我可能会跟进如何使用瀑布模型和敏捷方法规划机器学习项目,并附上示例工作计划图和需求。通过关注我在Medium、LinkedIn,或Twitter来保持关注。
正如你所见,能够清晰地阐述核心问题并进行分析、特征构思、模型选择对项目的成功至关重要。我整合了我在影响力与机器学习迷你课程中提供给学生和从业者的材料。希望你觉得这有用。
喜欢你读到的内容吗? 你可能也会喜欢我这些受欢迎的文章:
我如何应对机器学习部署中的枯燥日子
数字、五种战术解决方案和快速调查
许多数据科学家未曾充分考虑的一件事
简介:Ian Xiao 是 Dessa 的参与负责人,负责在企业中部署机器学习。他领导业务和技术团队来部署机器学习解决方案,并改善 F100 企业的市场营销和销售。
原文。已获许可转载。
相关:
-
对抗另一个人工智能寒冬的最后防线
-
数据科学很无聊(第一部分)
-
数据科学很无聊(第二部分)
更多相关主题
从点 com 到点 AI:新的技术泡沫?

图片来源:Futurism
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
生成式 AI 时代的到来令所有人惊叹——无论是技术专家还是爱好者。关于如何乘上生成式 AI 浪潮的报告和手册层出不穷,被誉为行业的“iPhone 时刻”。
有趣的是,这不仅限于表面现象,而是已经成为董事会讨论中的基本议题。高管和技术专家正面临紧迫感,必须拥抱这一革命性变化并加速业务增长。
有人认为这种“哇”因素是对人工智能的过高期望,并担心重蹈点 com 泡沫的覆辙。
先聊聊英伟达!
在所有这些狂热中,一家公司最近成为了头条新闻,即芯片制造商英伟达。值得注意的是,英伟达是领先的 GPU(图形处理单元)提供商,由于人工智能领域的激增,这些 GPU 的需求非常高。这些 GPU 的供应对于构建需要高计算能力的 AI 模型至关重要。
英伟达股票的卓越表现证明了其成功轨迹,如下所示:
其增长历程是对人工智能投资增长的响应,这为今天的点 AI(.ai)世界与本世纪初的点 com(.com)世界进行比较提供了良好的过渡。
比较的开始
这种“.ai”与“.com”的比较源于一系列事件,其中之一是最新新闻提到的一年历史的 AI 初创公司,据说成为了印度获得独角兽地位的最快公司。
去年,当米斯特拉尔人工智能筹集了 1.18 亿美元,被认为是欧洲最大的种子基金时,类似的情绪也浮现出来。
值得注意的是,企业在训练大型语言模型时需要大量资金来取得重大进展,因为像 OpenAI、Anthropic 等公司也在这一过程中筹集了数十亿美元。
这样的消息在投资者社区中引起轰动,尤其是当人工智能作为一个备受关注的行业能够为投资者带来溢价回报,即所谓的世代回报时。
HBR 也通过将投资理论与行业重点而非创意重点联系起来来强调这一点——“风险投资家必须在本质上具有风险的业务中获得持续的超额回报。误区在于,他们通过投资于好的创意和好的计划来实现这一点。实际上,他们投资于好的行业——即那些在竞争上比整个市场更具宽容度的行业。他们以一种最大限度降低风险并最大化回报的方式来结构化他们的交易。”
一件事是明确的,世界在 ChatGPT 热潮中看起来是二元的——生成型人工智能与其他世界。
是泡沫还是非泡沫?
现在出现了一个重大问题——这是一场泡沫吗?
参考 FortuneBusinessInsights 的这些统计数据,预计全球生成型人工智能市场将在 2032 年前以约 40%的年均增长率增长至 9670 亿美元。
由于这种潜力,也有报告将这一“人工智能”泡沫与“互联网泡沫”进行比较。
那么,让我们讨论一下为何市场认为人工智能(AI)可能成为另一个即将到来的泡沫。
尽管人工智能是一个备受追捧的行业,但我们需要警惕即将到来的泡沫的前兆。投机性投资、缺乏相关专业知识以及缺乏明确的差异化或创新是吸引泡沫的早期迹象。
投资者通常关注严格的尽职调查过程,包括但不限于评估商业模式、财务和法律复杂性、市场需求和分析,这些都是评估投资机会的关键步骤。
此外,强有力的治理政策、相关的产品市场契合度,以及关于可行性、可扩展性和实现更高回报的潜力的提案,这些都是驱动投资者决策的一些关键因素。此外,营收生成能力、对总可寻址市场的理解、进入壁垒、商业护城河和增长战略也都指示了一个积极信号。
像人工智能这样的新颖且尖端的产品被视为获得丰厚投资回报的黄金机会。
很多投资走上了歧途,但为什么呢?
然而,选择正确的投资是一项具有挑战性的任务。让我们讨论一些 统计数据 来描述这些风险:
-
~75%的公司甚至无法实现投资的收支平衡。
-
在像人工智能这样的颠覆性技术背景下,报告建议这类初创公司由于固有的风险而具有更高的失败率。
CNN 还报道了“一些投资者和业内人士担心,资金的狂热正在转变为泡沫,资金投向那些既没有收入、也没有创新产品、也没有正确专业知识的公司。”
让我们看看投资者通常关注什么。投资者普遍认为,企业的成功在很大程度上依赖于创始人的韧性、诚信和将创新想法付诸实践的能力。一些因素考虑了商业概念本身的稳健性及其解决客户痛点的能力。
除了这些属性外,还包括各种心理因素,比如对创始人能力的信心(这可以通过他们是否是首次创始人或是否在过去有成功退出经历来评估),或者创始人是否愿意接受对立观点,也提供了一组额外的指标(尽管是非定量的)来参考。
然而,人类专家(在此情况下是投资者)只能同时考虑有限的因素以做出最有效的决策。这就是计算能力,也就是机器,发挥作用的地方,帮助投资者做出基于数据的决策。
风险投资世界的过去与现在
由于风险投资行业固有的高风险、高影响特性,人工智能可以用来增强风险投资者的直觉,这种直觉更多基于来自历史数据点的定量分析。这些模型评估提案的可行性并预测投资成功的可能性。
欢迎进入现代数据驱动的投资领域。
引用 Gartner:
“传统的推介体验将在 2025 年发生显著变化,科技首席执行官将需要面对使用人工智能驱动的模型和模拟的投资者,因为传统的推介文档和财务数据将不再足够。”
构建用于评估有吸引力的人工智能机会的工具似乎是在众多有吸引力的人工智能应用中有效地利用技术的一种方式。投资界将从这种量化工具中受益,使其能够做出明智的投资决策,避免行业陷入另一个泡沫中,这是一个合理的期望。
Vidhi Chugh 是一位 AI 策略师和数字化转型领导者,她在产品、科学和工程的交汇点上工作,致力于构建可扩展的机器学习系统。她是一位获奖的创新领袖、作者和国际演讲者。她的使命是使机器学习大众化,打破术语,让每个人都能参与这一转型。
相关话题
我如何通过数据科学和机器学习使收入翻倍
原文:
www.kdnuggets.com/2021/06/double-income-data-science-machine-learning.html
评论

我只是想先说一下,这篇文章更多的是反映了我如何达到今天的状态。我并不是建议你通过相同的步骤取得相同的成果,但我觉得这可能会给你提供一种你之前没有考虑过的独特视角。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
话虽如此,让我们深入了解吧!
我做了三件主要的事情来使我的收入翻倍:
-
提升技能(数据科学和机器学习)
-
博客(关于数据科学和机器学习)
-
自由职业(数据科学和机器学习项目)
1) 提升技能
许多人今天倾向于寻求高风险、高回报的投资,比如比特币,以试图“快速致富”,但正如沃伦·巴菲特所说,最好的投资就是投资自己。这对于那些没有钱投资但希望改善财务状况的人尤为适用。
通过简单地提升自己的技能,学习数据科学和机器学习,我在一年内将工资提高了 40%。
在过去的一年中,我主要关注了三个领域:
数据操作(SQL/Pandas)
在我看来,使用 SQL 和 Pandas 进行数据操作是带给我最大收益的领域。从我的经验来看,大部分时间都花在查询数据、探索数据和整理数据上,这些都需要 SQL 和 Pandas。在我所有的数据相关工作中(增长营销分析师、数据分析师、数据科学家),SQL 一直是共同的关键技能,并且可以说是数据专业人士最重要的技能。
以下是我用来自学 SQL 和 Pandas 的资源:
-
Mode 的 SQL 教程:我总是推荐这个资源,因为它作为学习概念的优秀指南,即使你不使用它来实际学习这些概念。它也很棒,因为他们将概念分解为不同的难度等级。
-
Mode 的 SQL 案例研究:这些案例研究很棒,因为它们可以让你应用所学的知识,并深入思考你将如何应对现实世界的场景。
-
LeetCode 数据库问题:我总是把这个作为资源,特别是在寻找新工作时。这是模拟涉及 SQL 的编码面试的好方法。
-
Pandas 练习题:Pandas 的语法不是特别直观(至少不像 SQL 那样),而且直到我遇到这个 Pandas 练习题的仓库时,它才真正被我理解!
脚本编程(Python)
我开始使用 Python 是因为学校的要求,而且我可能会在余生中继续使用 Python。就开源贡献而言,它目前遥遥领先,而且学习起来非常直接。
除了做一些副项目外,我强烈推荐两个主要的资源来提升你在 Python 方面的技能:
-
LeetCode 算法问题:类似于 SQL,我使用 LeetCode 来学习如何编写(稍微)高效的 Python 脚本来解决各种问题。
-
Tech with Tim:Tech with Tim 是一个 YouTube 频道,意味着它是免费的,但却比大多数付费课程和训练营要好。我强烈推荐你观看他的视频并跟着学习。
机器学习
当然,作为数据科学家而不学习机器学习有什么乐趣!以下是我在职业生涯初期使用的两个最重要的资源。
-
Kaggle 的机器学习入门:如果你像我一样不完全理解机器学习是如何工作的,或者你不知道它是如何在代码中实现的,那么我强烈推荐你去看看这个课程。
-
StatQuest:StatQuest 对于理解机器学习模型是如何工作的非常出色。一旦你理解了理论,用代码实现它将变得简单。
如果你想了解各种机器学习算法,查看我的文章。
我实际上写了一个 52 周的课程大纲,涵盖了 SQL、Pandas、Python 和机器学习,你可以在这里查看。
现在我已经讲述了我如何提升自己,你可能会想知道我是如何进行的,这正是我接下来要讨论的内容。
2) 数据科学和机器学习博客
你们中的一些人可能知道,我启动了一个名为“52 周数据科学与机器学习”的个人项目,在整个一年里,我每周学习、编程和写作与数据科学和机器学习相关的内容。这主要是为了让我自己在持续的基础上对学习新事物保持负责。
写了超过 100 篇文章并建立了超过 20,000 名读者的粉丝基础后,写作现在大约占我总收入的 25%。
这里有三个给我带来很多成功的建议:
提示#1: 找到你擅长写作的内容、你喜欢写的内容和人们喜欢阅读的内容之间的交集。

图像由作者创建。
这是我总是给有志作家的第一个建议。理想情况下,你希望找到一个满足这三者的利基市场。
如果你发现了一个你擅长写作的内容,并且你也喜欢写作,但人们不喜欢阅读,那你就不会建立粉丝基础(假设你在乎这一点)。
如果你发现了一个你擅长写作的话题,并且人们喜欢阅读,但你自己不喜欢写这个话题,那么你不会坚持太久,因为你会失去兴趣。
最后,如果你发现一个你喜欢写的主题并且人们也喜欢阅读,但你在写作上不够擅长(例如因为缺乏足够的专业知识),那么你可能不会获得任何 traction(吸引力)。
因此,在你开始旅程的初期,花时间找出你的利基市场。我将在提示#3 中详细说明这一点。
提示#2: 了解你所写平台的机制。
无论你是使用 Medium、Substack、Patreon 还是其他博客平台,请确保你花时间了解平台的运作方式。
我不能过多详细说明这一点,但了解诸如收入如何计算、平台如何帮助你进行自我广告等事项是重要的思考点。
通过了解 Medium 的机制及其运作方式,我能够最大化我的影响力,并最终更快地增加我的粉丝基础。
下一个提示将帮助你实现提示#1 和#2:
提示#3: 在创建内容时考虑“利用与探索”的概念。
为了找到提示#1 中的三个要素的交集,并了解你所写平台的机制,请考虑利用与探索的概念。
这个想法源于一个叫做“多臂赌博机问题”的统计学问题。我不会过多详细说明,但“探索与利用”的主要思想是决定是探索并寻找新的潜在想法,还是利用你已经知道有效的想法。
在你的写作/博客生涯开始时,最好尽可能探索和尝试尽可能多的想法,以了解哪些最适合你。这意味着撰写不同的主题,发布在不同的出版物上,并可能尝试新的写作风格。
随着你在写作风格和偏好上的发展,你可能会发现一个“秘诀”,它能在你的写作中带来持续的成功。这时你可以开始利用这一突破,并加倍使用你的秘密公式。
总结一下,在你的旅程早期尽可能多地探索,当你开始定义自己并取得成功时,开始利用那些使你成功的见解和想法。
3) 自由职业项目
剩余的收入来自与数据科学和机器学习相关的自由职业项目。我承接的项目包括编写技术论文、撰写营销内容和构建模型。
当我刚开始时,我从自由职业项目中赚取的收入仅仅是最低工资。这是有道理的,因为我没有太多经验,也不知道自己的价值。然而,到年末时,我能够收取每小时 50 美元以上的费用。
我的收入大部分来自科技行业的回头客。我实际上也不需要联系其他人——我能够通过我的数据科学和机器学习博客吸引客户的注意力,我认为这就是本文的关键点。
我的数据科学和机器学习博客不仅帮助我持续学习,还帮助我建立了自己的粉丝基础,并帮助我获得了几位自由职业客户。
相关:
更多相关内容
AI 进步的弊端是什么?

图片由pch.vector在 Freepik 上提供
人工智能和机器学习背后的技术不断进步。从 1951 年在曼彻斯特大学编写的第一个 AI 跳棋和国际象棋程序到 OpenAI 的 ChatGPT 和 Google 的 Bard AI,人工智能的历史和演变悠久且充满突破。
目前,AI 被广泛应用于各个行业。在交通运输行业,AI 现在被用于自动驾驶汽车、无人机的自动驾驶软件以及帮助司机寻找最有效路线以避开交通和节省时间和燃料的软件。

在医疗行业,AI 现在被医生用来帮助跟踪症状和识别潜在的诊断,也被制药科学家用来设计新的药物治疗方案。
这些提到的 AI 应用及其他未提及的应用,都是人工智能的积极用途,它们正在推动医学、技术、科学和人类进步。AI 确实可以成为社会中的一种积极力量,为更大的福祉服务。
然而,AI 的弊端呢?让我们来看看 AI 进步中一些最令人担忧的弊端,以及它们如何影响整个社会。
学术和职业抄袭
抄袭被定义为未经授权使用他人的作品或思想而不给予原作者适当的信用。但现在,美国的大学和高中正争相重新定义抄袭,以应对像 ChatGPT 和 Google Bard 这样的 AI 驱动聊天机器人出现后的挑战。
图片来自ChatGPT
更多的学生已经开始使用 ChatGPT 和 Google Bard 等 AI 驱动的应用来进行学术论文研究,学生们常常可以仅仅利用这些 AI 应用生成可以轻松复制并粘贴到论文中的长篇内容。
不仅仅是学术界受到了 ChatGPT 和 Google Bard 引入的影响。在数字营销领域,编辑们也在处理这些 AI 应用的出现以及内容创作者和文案撰写者如何利用这些 AI 应用生成 AI 制作的内容。
另外,有人知道 Google 搜索算法在评估内容并为 SERP 排名时会如何对待 AI 生成的内容吗?
无论是用于学术目的还是商业内容创作,目前关于我们应如何对待 AI 生成内容的问题尚无定论。目前,有许多 AI 检测程序可以用来识别作者是否使用了 ChatGPT 或其他 AI 驱动的应用来生成书面内容。
然而,这只是识别 AI 生成内容的一种短期方法,并未回答 AI 生成内容在学术界和商业内容中的使用是否合理的更大问题。
网络安全
网络安全行业是一个不断变化的领域,其中网络犯罪分子不断开发新的方式来渗透组织,而 IT 专业人员则持续开发新工具来保护数字资产。
网络犯罪分子一贯使用社会工程学等策略来实施勒索软件和恶意软件攻击以窃取敏感数据,并以现金或加密货币的形式敲诈整个系统。

图片来自 data-flair
随着人工智能在网络安全中扮演越来越重要的角色,以更好地检测威胁和保护数字资产,网络犯罪分子也在利用 AI 进行更复杂的攻击,这些攻击更难被检测,并且更容易欺骗用户打开恶意邮件、点击恶意链接和安装恶意文件。
环境后果
AI 的另一个缺点是它所需的能源量以及这种能源消耗对地球造成的重大环境影响。2019 年的一项研究发现,通过深度学习自然语言处理开发的 AI 需要大量燃料来运行训练 AI 所需的硬件。
研究中的专家估计,使用深度学习在自然语言处理(NLP)中训练一个 AI 模型可以 产生约 300,000 公斤 的 CO2 排放。为了将这个数据放到具体的背景下,训练一个 AI 模型所产生的 CO2 排放量相当于往返纽约市和北京 125 次的商业飞机飞行。
工作丧失
AI 进步的最大缺点之一是可能会被 AI 和机器人替代的工作岗位数量。尽管经济学家很难准确估计 AI 引入到行业中会影响到多少工人,但一些专家预测到 2030 年,可能有 7500 万到 3.75 亿工人需要转换工作并学习新技能。
AI 替代对世界经济的全面影响很难想象。例如,许多专家预测,AI 将不成比例地取代服务行业中的许多低技能工作以及行政和物流服务中的低技能职位。
尽管许多相同的专家预测 AI 将创造比其替代更多的工作,但危险在于被替代的大多数工人可能缺乏获得 AI 创造的新工作的必要技能和教育。
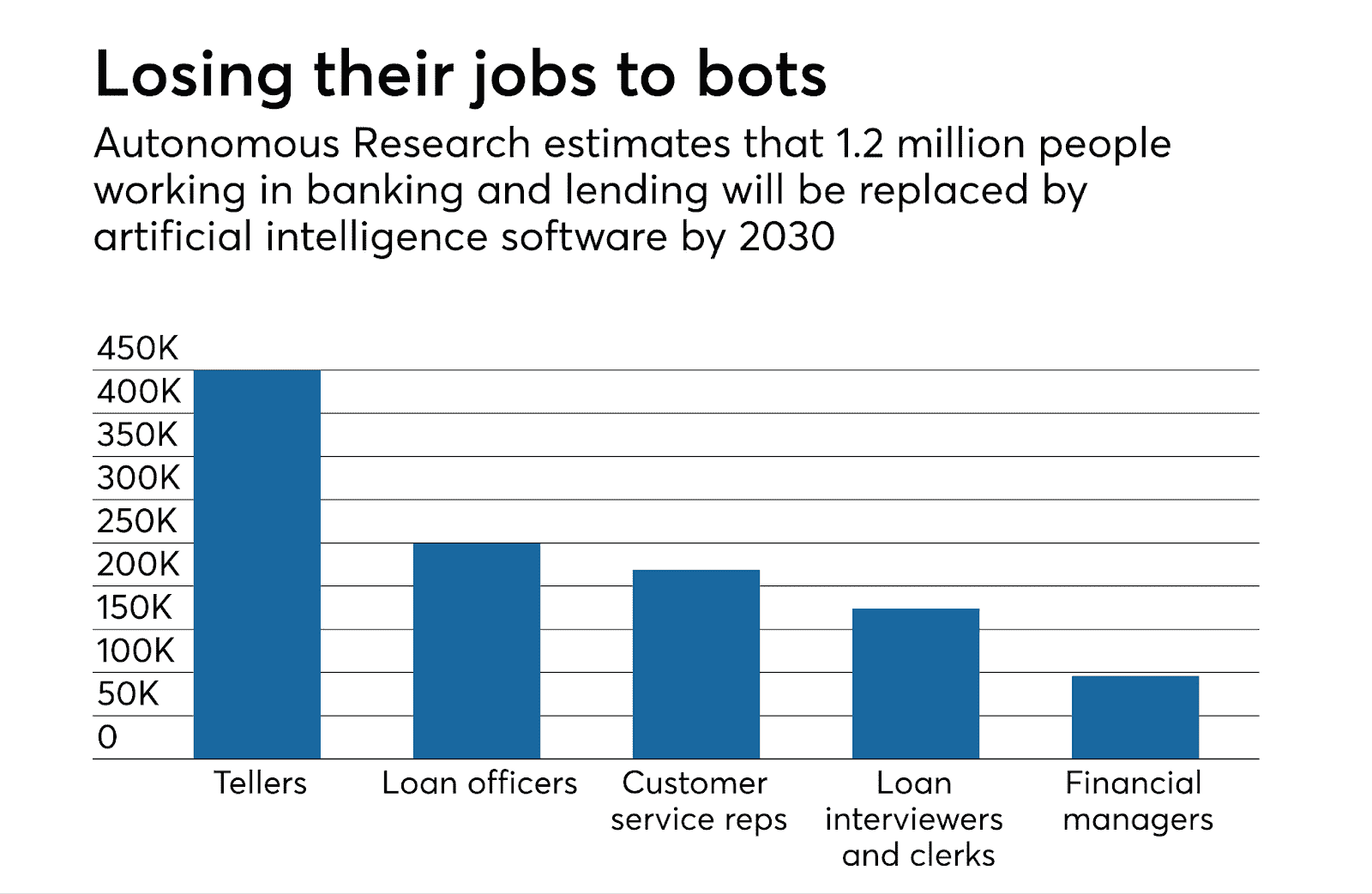
图片来自 americanbanker
如果没有妥善解决,这个问题可能会 导致进一步的收入不平等、社会动荡和政治动乱。因此,政府需要提供教育计划和培训,以帮助被替代的劳动力,甚至引入普遍基本收入来帮助缓解向新的 AI 中心经济过渡。此外,这种经济过渡以及政府能够为受影响人群提供必要培训和资源的程度,将因国家而异。
另一个需要考虑的重要点是,许多专家认为,一些研究生和高技能工人也可能会被 AI 大量取代。特别是会计和法律行业可能会面临巨大的冲击。会计师和律师的许多工作需要审查和理解大量数据和信息。相较于人类,AI 在这方面更高效、更准确,许多以前由会计师和律师完成的费时工作将转交给 AI 软件处理。
总体而言,尽管 AI 和机器人技术的引入确实会导致许多行业的工作岗位大量流失,AI 并不是来取代我们。相反,它需要私营部门和政府之间的协调努力,以确保被取代的劳动力获得必要的培训和资源,帮助他们适应并成为新经济中的积极参与者。
隐私侵犯
我们已经开始看到人工智能如何被中国政府使用来监控其公民。AI 和面部识别程序被用来追踪个人的活动、关系和政治观点。然后根据这些由 AI 和面部识别程序收集的数据点,个人会被给予一个社会信用评分,如果他们的评分过低,可能会阻碍他们参与社会某些方面,如获取工作、租房,甚至乘坐公共交通。
尽管对于许多西方人来说,这听起来像是一个永远不会发生的反乌托邦地狱景象,而民主制度有其立足点,但它已经发生了。美国全国各地的警察部门正在使用 AI 采用预测性警务算法,以预测犯罪发生的时间和地点。此外,AI 在西方已被用于收集个人信息,以识别可能有更高犯罪风险的人群。
无论如何,AI 很可能会被美国的执法机构和政府部门使用,但具体程度尚待确定。未来五到十年对于制定治理 AI 使用的法律将至关重要,以确保其与美国宪法的一致性。
结论
媒体倾向于关注人工智能的所有积极方面以及它能为世界带来的好处,我们很少深入探讨 AI 可能带来的负面后果,如上述例子所示。作为一个社会,找出如何在这些领域约束 AI 的解决方案,同时利用其好处,将是至关重要的。
娜赫拉·戴维斯 是一名软件开发人员和技术作家。在全职投入技术写作之前,她曾担任过多个有趣职位,包括在一家 Inc. 5,000 体验品牌机构担任首席程序员,该机构的客户包括三星、时代华纳、Netflix 和索尼。
更多相关内容
为什么素食者错过的航班更少——五个数据中的奇怪发现
原文:
www.kdnuggets.com/2019/01/dr-data-five-bizarre-insights-from-data.html
评论
“机器人科学家”——机器学习自动化了一种科学研究

很奇怪:素食者错过的航班更少。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
很疯狂:喜欢在 Facebook 上“卷曲薯条”的人更聪明。
你正在穿越一个边界是想象力的维度。嗯,这其实并不是真正的《阴阳魔界》,但我们可以称之为“大数据的‘怪诞经济学’”,或者“数据科学的‘Ripley’s Believe It or Not’”。
我们生活在一个奇怪又疯狂的世界中,充满了离奇和令人惊讶的联系,这些联系在不断收集的大量数据中得到了体现。这就是为什么数据成为世界上最强大、最蓬勃发展的“非自然资源”的原因。因此,世界热情地进入了数据发现的黄金时代。大量的数字分析正在产生丰富多彩、有时令人惊讶且常常有价值的见解。
在这篇文章中,我将解释这一过程如何运作,并探讨数据中发现的五个奇怪发现。
机器学习自动化科学发现
现在,计算机的全部意义在于自动完成任务——那么为什么不自动化科学发现呢?实际上,这正是机器学习所实现的,当计算机从数据中编码的经验中学习时。你可以将学习过程分为两个阶段:
第一点: 找到像素食者这样的个别见解。
第二点: 将见解结合起来,以提高预测能力——这也被称为“预测建模”,因为你将它们组合成一个单一的模型。
现在,这实际上有点简化了,因为机器学习通常交织这两个阶段,但我们可以将第一个阶段,即寻找见解,视为过程的基础部分。
让计算机做这些发现就是科学研究的自动化。这是一个颠覆传统科学方法的重大范式转变,传统方法是形成一个假设,然后进行测试。例如,一家航空公司可能会猜测请求素食餐的乘客错过航班的频率较低。然后他们会检查数据以测试这个假设。
顺便提一下,为什么素食者会这样的问题是一个单独的问题,我会在几分钟后讨论——第一个问题只是这个小理论是否成立。
不过,你知道,有很多这样的趋势可以检查。比如,乘客更喜欢靠过道的座位而不是靠窗的座位,或从某些城市出发的乘客等等?也许这些群体也更不容易错过航班。我们人类相当聪明,但与其坐在那里猜测这些问题,不如让计算机去搜索大量可能的趋势,看看哪些是真的?将你的 CPU 当作假设检验机器,一个“机器人科学家”。通过不知疲倦和机械地进行搜索,所有的石头都会被翻过。进行这种搜索的技术术语包括特征选择,或“逐一尝试每一个独立变量作为单变量模型”。但无论你称之为什么,这种搜索过程超越了源自人类直觉的有限思维范围。让它进行数字处理,机器将会吐出有价值的发现——这些发现有时会出乎意料,甚至似乎违背逻辑。
现在,在你对潜在的“机器人科学家”感到过于兴奋之前,这里有一个重要的警告。当你按下“开始”按钮,开启对科学发现的开放式大规模搜索时,它可能会适得其反,让你陷入重大麻烦,得出错误的结论。它可能会在数据中找到看似存在的趋势,但这些趋势实际上并不普遍成立。这个陷阱的技术术语是 p-hacking。实际上,你永远无法对数据中发现的联系做到绝对 100%的确定——总会有一些微小的可能性,数据可能误导了你,就像即使你掷硬币 100 次,每次都是正面,仍然有可能这是一个普通的硬币,你只是经历了一个异常长的正面序列。但是,通过适当检查从数据中得出的结论——这需要应用严格的统计标准——我们可以将被数据误导的可能性降低到一个可以接受的极小概率。
五个奇特的洞察——加上两个额外的奖励洞察
好了,让我们看看我们的机器人科学家发现了什么。这些是数据中发现的几个联系。每一个都有助于预测事物——例如谁会错过航班,谁更聪明,谁更具财务信用——因此这些都作为机器学习建立预测模型的基础构件。
我将首先介绍两个典型的、有趣的且在商业世界中有用的例子,然后再讲五个真正古怪的联系,总共七个。

第一,如果你购买尿布,你更有可能也会购买啤酒。 一家连锁药店在多个门店的晚间购物者中发现了这一趋势。有些人解释为,“爸爸需要一瓶啤酒。”虽然我听说过有人认为这个经典的尿布/啤酒数据挖掘例子是都市传说,但你实际上可以在我的书《预测分析》的注释中找到有关这一点和所有我正在讨论的例子的详细信息。注释在 PredictiveNotes.com 上可以免费获取。顺便说一下,这本书本身包括了总共 46 个奇特的发现,汇编成一个表格,其中包含了沃尔玛、壳牌、微软和维基百科等的例子。
现在进入第二个。如果你的朋友更换了手机公司,你更有可能也会这么做。 一家主要的北美运营商发现,如果某人的通话网络中的某人取消了服务,该客户更有可能取消服务,概率是七倍。物以类聚,人以群分。
第三,素食者错过航班的概率更低。 更准确地说,一家航空公司发现预订了素食餐的乘客更不容易错过航班。这是为什么呢?我也不清楚。坦白说,《数据博士秀》这一集的标题,“为什么素食者错过航班的概率更低”,有点像是点击诱饵,因为事实是,没有人确切知道原因。研究人员提出这可能是因为对个性化或特定餐点的期待会建立一种承诺感。但实际上,对于这些见解或发现的“为什么”我们无法得出明确的答案,至少在没有进一步研究的情况下是如此。这就是常听到的谚语,“相关性并不意味着因果关系”的意思。每一个发现、趋势或数据中的联系——无论你怎么称呼它们——都是相关性,任何解释其真实性的原因都需要理解因果关系。当分析企业积累的数据时——也就是典型的“大数据”,而不是专门为实验或科学研究收集的数据——我们通常只能得到“是什么”,却得不到“为什么”。然而,它仍然有助于预测——例如,航空公司可以利用这一发现来帮助计算航班的超售情况,即使不了解其真实性的原因。
 第四点,喜欢在 Facebook 上点赞“卷曲薯条”的人更聪明。 剑桥大学和微软的研究人员发现,喜欢“卷曲薯条”可以预测在某个测量智力的测试中的高分。研究人员认为这并不一定是因为你必须足够聪明才能意识到卷曲薯条的美味——而是他们怀疑是一些聪明的人最早喜欢了“卷曲薯条” Facebook 页面,然后他们的朋友看到并喜欢了这个页面,这种传播在相对聪明的人群中扩展开来。
第四点,喜欢在 Facebook 上点赞“卷曲薯条”的人更聪明。 剑桥大学和微软的研究人员发现,喜欢“卷曲薯条”可以预测在某个测量智力的测试中的高分。研究人员认为这并不一定是因为你必须足够聪明才能意识到卷曲薯条的美味——而是他们怀疑是一些聪明的人最早喜欢了“卷曲薯条” Facebook 页面,然后他们的朋友看到并喜欢了这个页面,这种传播在相对聪明的人群中扩展开来。
顺便提一下,关于“更聪明”的部分,我个人对将人类智力简化为一个数字感到相当怀疑,但所谓的智力测试可能确实测量了你在一些有价值的技能群体中的表现,这些技能覆盖了我们所说的“智力”的部分,但肯定不是全部。只是说说而已。
第五点,跳过早餐的男性冠心病风险更大。 哈佛大学的医学研究人员发现,45 至 82 岁的男性跳过早餐的风险提高了 27%。这并不一定是因为早餐本身的直接健康影响,而是因为吃早餐可能反映了生活方式。生活节奏快、压力大的人的确更容易跳过早餐,并且面临更高的健康风险。再说一次,这主要是一种直觉上的猜测——像往常一样,可能还有其他合理的解释。
第六点,旧金山的某些犯罪率较高的社区也对优步的需求更高。 这不一定是因为犯罪分子在乘坐优步,而是正如优步所推测的那样,因为犯罪率是非住宅人口的一个替代指标——这些正好是那些实际上不住在那里的人的更多的区域。

最后,第七点,去酒吧的人信用风险更高。 加拿大轮胎公司发放信用卡,并查看客户使用信用卡的情况与按时还款的对比。结果发现,曾在饮酒场所消费的人比平均水平更容易错过信用卡账单的重复付款。然而,如果你在牙医那里使用你的信用卡,你的信用风险较低,更不容易错过账单付款。而如果你购买那些小的毛毡垫以防止椅子腿刮伤地板……信用风险较低,你是一个更可靠的账单付款者。
相关的故事是,按照一家金融服务初创公司分析在线贷款申请填写方式的结果,打字时使用正确的大写字母与信用 worthiness 有关。
现在,这些趋势背后的推理可能看起来很直观且显而易见,尤其是在人格特征和组织能力方面,但请记住,仍然要对这种解释和直觉保持极大的保留。这种“怪异秀”虽能提供预测价值,但从科学角度来看却几乎没有自我解释。

这篇文章基于《Dr. Data Show》的文字记录。

关于 Dr. Data Show。这个新的网络系列打破了数据科学娱乐信息的常规,以简短的网络剧集吸引全球观众,涵盖了机器学习和预测分析的精华。点击这里查看更多剧集并注册未来的《Dr. Data Show》剧集。
 Eric Siegel 博士,预测分析世界(Predictive Analytics World)和深度学习世界(Deep Learning World)会议系列的创始人,以及预测分析时报(The Predictive Analytics Times)的执行编辑,使预测分析(即机器学习)的如何与为何变得易于理解且引人入胜。他是获奖著作预测分析:预测谁会点击、购买、撒谎或死亡(Predictive Analytics: The Power to Predict Who Will Click, Buy, Lie, or Die)的作者,The Dr. Data Show网络系列的主持人,曾是哥伦比亚大学教授,也是该领域的知名演讲者、教育者和领袖。还可以阅读他的数据与社会公正的文章,并在@predictanalytic上关注他。
Eric Siegel 博士,预测分析世界(Predictive Analytics World)和深度学习世界(Deep Learning World)会议系列的创始人,以及预测分析时报(The Predictive Analytics Times)的执行编辑,使预测分析(即机器学习)的如何与为何变得易于理解且引人入胜。他是获奖著作预测分析:预测谁会点击、购买、撒谎或死亡(Predictive Analytics: The Power to Predict Who Will Click, Buy, Lie, or Die)的作者,The Dr. Data Show网络系列的主持人,曾是哥伦比亚大学教授,也是该领域的知名演讲者、教育者和领袖。还可以阅读他的数据与社会公正的文章,并在@predictanalytic上关注他。
更多相关主题
你安全的五种方式依赖于机器学习
原文:
www.kdnuggets.com/2019/02/dr-data-five-ways-safety-depends-machine-learning.html
评论
注意:本文基于 Dr. Data Show 节目的文字稿,标题为 “你安全的五种方式依赖于机器学习” (点击查看)。
你的安全依赖于机器学习。这项技术通过指导桥梁、建筑物和车辆的维护,以及指导医疗保健提供者和执法人员,每天保护你免受伤害。
这让你处于安全的手中。医院、公司和政府利用机器学习来应对风险,积极保护你免受各种危险和危害,包括火灾、爆炸、坍塌、事故、工作场所事故、餐厅中的大肠杆菌和犯罪。我本以为狮子、老虎和熊已经够糟糕了!

这通过使用数据来预测这些危险最可能出现的时间和地点,并据此部署检查和预防措施。也就是说,标记出最危险的建筑物、桥梁、车辆和餐厅进行检查。这种预测性预防正越来越多地成为安全标准。
我将告诉你这五种数据驱动的安全措施如何让你更安全——但首先,先了解一下它是如何工作的。
机器学习的预测性预防
执行这项工作的技术是机器学习,当计算机从数据中编码的经验中学习时。假设有关于许多桥梁的历史数据,以及哪些桥梁已经恶化到成为危险的程度,计算机可以学习预测哪些桥梁应该被标记为需要尽快检查。当用于安全目的以及其他商业和政府目的时,机器学习也被称为预测分析。

这不是万灵药——不幸的是,这个世界上没有办法实现百分之百的安全保障——但机器学习提供了一种独特的改进。它作为一种独特的新方法,降低了风险,倾斜了更多安全的概率。由于预测性预防不同于其他风险管理方法,它总是能提供潜在的帮助,无论其他方法是否被采用。机器学习在一般情况下提高了各种流程的效率——当应用于保护程序时,这就转化为降低风险。
所以,让我们对数据给予应有的尊重和欣赏,尤其是它那无价的预测能力,它带来了这些以及其他巨大的好处。以下是一些帮助预测危险的示例见解,数据告诉了我们这些。像卡特里娜和玛丽亚这样的女性名字的飓风更致命。一项对最近几十年美国最具破坏性的飓风的研究显示,那些名字更女性化的飓风造成的死亡人数几乎是名字更男性化的飓风的三倍。心理研究表明,这可能是由于隐性性别歧视——人们认为“女性”飓风风险较低,从而低估了危险并采取了更少的预防措施。
说到飓风,沃尔玛的数据表明,草莓口味的波波饼在飓风来临前的销售量会增加约七倍。这被认为是人们囤积非易腐烂的安慰食品。

根据保险公司,信用评级低的人更容易发生车祸。专家推测这是因为你的财务责任可能反映了你驾驶时的责任,尽管这并不确定。无论如何,这又是一个数据预测事故的例子。
好的,如承诺的,这里有五种机器学习每天让你更安全的方法。顺便说一下,你实际上可以在我的书《预测分析》的笔记中找到这些例子的详细信息。笔记可以在 PredictiveNotes.com 上免费获取。
1) 加固建筑物、桥梁和其他基础设施
首先,加固建筑物、桥梁和基础设施。通过根据每个结构的风险等级优先检查,可以拯救生命。纽约市消防局使用预测分析来标记出火灾风险最高的建筑,Con Edison 识别出具有比平均水平高五倍的爆炸或火灾等危险事件风险的井盖,土木工程研究人员预测哪些桥梁在恶化,部分是通过使用机器学习自动检测桥梁混凝土裂缝的自动扫描图像。
芝加哥市已经识别出那些铅中毒事件风险是平均水平两倍以上的住宅。这是为了主动标记,而不是在检测到中毒后的常见反应步骤。
2) 防止运输事故
其次,防止交通事故和其他运输事故。汽车公司和军方利用机器学习来提高驾驶安全——检测驾驶员因分心、疲劳或醉酒而不警觉的情况,并预测车辆部件何时会失效,以便主动规划维护。
自动驾驶车辆的发展势不可挡,这一进展主要得益于相比于我们允许人类驾驶的最近一个世纪的实验,自动驾驶车辆承诺提供更好的安全记录。自动驾驶汽车依靠机器学习来识别周围的物体,预测它们的移动,并优化导航。

铁路公司也在正确的轨道上。他们预测断轨——这是导致严重列车事故的主要原因——以及单个车轮的故障。
航运业通过预测哪些大型船舶将经历危险事件来保持运转。每个风险等级是通过船舶的年龄、类型、载重能力、来源、所有权、管理以及其他因素来计算的。
3) 预防工作场所伤害
第三点,预防工作场所伤害。对于其全球石油炼油厂的每个工人团队,壳牌公司预测将发生的安全事件数量,并评估哪些因素影响最大,例如员工的参与程度——公司认为这对减少事故有很大影响。另一个因素适用于一般工作环境:事故基金保险发现,某些医疗条件如肥胖和糖尿病可以预测哪些职业伤害的成本最高,从而相应地针对工人进行预防措施。国家职业安全与健康研究所的研究人员应用机器学习来确定每个行业最重要的预防措施——无论是人体工程学还是关于跌倒的。
4) 加强医疗保健
第四点,加强医疗保健。预测医学是一个令人兴奋且快速发展的机器学习应用领域,它用于诊断疾病并预测临床结果。对于诊断,机器学习模型输入各种临床特征、检测结果,甚至整个 MRI 或其他医学图像,以评估各种疾病的概率——每种疾病一个模型——如糖尿病视网膜病变,它是导致失明的最快增长原因,还有各种癌症。通常,它的表现与医生一样好,甚至更好。至于预测结果,机器学习可以预测外科感染、脓毒症、HIV 进展、早产、医院再入院率甚至死亡。事实上,《数据医生秀》有一集专门讨论预测死亡,你可以在 TheDoctorDataShow.com 找到。通过标记高风险病例,可以针对性地采取额外的预防措施。
甚至在你完全不需要去医院之前,像波士顿和西雅图这样的城市政府通过预测哪些餐馆会有健康代码违规来预先保护你免受食物中毒,以优先进行检查。在某些情况下,他们通过输入 Yelp!评论来改善这些预测——人们对餐馆的评论有时可以揭示餐馆在厨房中的卫生状况是否达标。
5) 加强打击犯罪
最后,第五点,强化打击犯罪。如果法治是社会的基石,那么尽可能有效地执行法律就是基础。预测警务利用机器学习来指导执法决策,比如是否进行调查或拘留、判刑时间的长短以及是否假释。在做出这些决定时,法官和警察会考虑预测模型输出的概率——即嫌疑犯或被告未来被定罪的可能性。这些模型的计算基于诸如被告的先前定罪记录、收入水平、就业状况、家庭背景、居住区域、教育水平以及家庭和朋友的行为等因素。
机器学习也推动了康复工作。佛罗里达州青少年司法部在一定程度上根据未来犯罪的预测风险来分配康复任务。
本文基于 数据博士秀的文字稿。

关于《数据博士秀》。 这个全新的网络系列打破了数据科学娱乐资讯的常规,通过简短的网络剧集吸引了全球观众,涵盖了机器学习和预测分析的精华。点击这里查看更多剧集并报名获取未来的《数据博士秀》剧集。
埃里克·西格尔博士,预测分析世界(Predictive Analytics World)和深度学习世界会议系列的创始人,以及预测分析时报的执行编辑,使得预测分析(也称为机器学习)的“如何”和“为什么”变得易于理解且引人入胜。他是获奖著作预测分析:预测谁将点击、购买、撒谎或死亡的作者,数据博士秀网络系列的主持人,前哥伦比亚大学教授,以及知名的演讲者、教育家和领域领袖。阅读他的数据与社会公正相关文章,并在@predictanalytic上关注他。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关内容
拖拽、放置、分析:无代码数据科学的兴起
原文:
www.kdnuggets.com/drag-drop-analyze-the-rise-of-nocode-data-science

图像由 DALLE 3 生成
数据从业人员面临的挑战之一是每个新的使用案例都必须从头开始编码。这可能是一个耗时且低效的过程。无代码或低代码解决方案帮助数据科学家创建可重用的解决方案,适用于各种使用案例。这可以节省时间和精力,并提高数据科学项目的质量。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
你几乎可以在数据科学中完成所有事情而无需编写一行代码。“无代码或低代码解决方案是数据科学的未来,”Ingo Mierswa 评论道,他是 Altair 的产品开发高级副总裁及 RapidMiner 数据科学平台的创始人。作为无代码数据科学领域的杰出发明家,他的专业知识和贡献影响了这些功能在行业中的采纳和实施。“这些功能,”Mierswa 在我们的采访电话中提到,“使没有很多编程经验的人能够构建和部署数据科学模型。这可以帮助民主化数据科学,并使其对每个人更加可及。”
“当我发现自己作为计算机科学家时,市场上没有无代码或低代码平台,我不得不为每一个新的使用案例重新创建非常相似的解决方案。这是一个低效的过程,感觉像是在浪费大量时间,”Mierswa 分享道。他以基础知识为例,阐述道:“如果你第二次解决一个问题时仍在编程,那意味着你第一次没有正确解决问题。你应该创建一个可以重复使用的解决方案来解决相同或类似的问题。”他断言,“人们常常没有意识到他们的问题有多么相似,结果是,他们不断重复编写相同的代码。他们应该问的问题是,‘我为什么还在编程?’也许他们不应该这样做,以节省时间和精力。”
多样化加速
无代码或低代码的数据科学解决方案可能非常有价值。Mierswa 强调说:“第一个也是最重要的好处是,它们可以促进更好的协作。如果有人解释了视觉工作流或模型,每个人都可以理解,但并不是每个人都是计算机科学家或程序员,也不是每个人都能理解代码。”因此,为了有效协作,你需要理解团队共同生产的资产。“数据科学归根结底是一项团队运动。你需要理解业务问题的人,无论他们是否会编程,因为编程可能不是他们的日常工作。”
然后你会有其他有数据访问权限、充满计算思维的人,他们会想,“好吧,如果我想建立一个机器学习模型,我需要以特定方式转换我的数据。”这是一个很好的技能,他们也需要协作,但同样,对于这些技能,我们知道 ETL 产品已经存在了很长时间。“是的,在少数情况下,在特别、非常定制的情况下,你仍然需要编程。即使在那些情况下,这也是一百分之一的例外,”Mierswa 指出。“这不应该成为常态,但真正的魔力发生在你将所有不同的技能、数据、人和专业知识结合在一起的时候。”
Mierswa 理论道:“你永远不会看到纯代码方法能做到这一点。你永远得不到利益相关者的支持。这通常会导致我所说的死项目。我们应该把数据科学视为解决问题的工具。我们不应该把它当作一种科学方法,在这里是否实际创建解决方案并不重要。”他说:“这很重要。我们正在解决数百万美元的业务问题。我们实际上应该朝着有效解决方案的方向努力,获得支持,部署解决方案,并真正改善我们的情况。不是说‘是的,我知道,如果失败了,我不在乎。’所以协作是一个巨大的好处。”
Mierswa 解释说,加速是另一个好处。当你通过编程执行重复任务时,你并没有以最快的方式工作。例如,如果我创建了一个包含五个或十个操作符的 RapidMiner 工作流,那通常相当于成千上万行代码。复制和粘贴代码可能会拖慢速度,但低代码平台可以帮助你更快地创建自定义解决方案。
责任,往往被忽视,却是最重要的好处。当你创建基于代码的解决方案时,可能很难追踪谁做了哪些更改以及原因。“这可能会导致在其他人需要接手项目或代码中出现漏洞时出现问题。另一方面,低代码平台是自带文档的。这意味着你创建的视觉工作流也附有解释工作流功能的文档。“这使得理解和维护代码变得更容易,也有助于确保责任感,”Mierswa 说。“人们理解它。他们接受这个观点,但他们也能对这些结果负责。作为团队的一部分。”
开放生态系统
AI 的快速发展正在改变数据科学领域,那些希望保持领先的公司保持开放,使用开源和开放标准,不隐藏数据科学市场中非常重要的任何东西。
保持开放的公司因市场的快速变化和不断迭代而处于有利位置。“过去 10 到 20 年间的数据科学市场就是这样,”Mierswa 反思道,“市场的快速变化要求不断迭代,这使得关闭生态系统极为不明智。这也是一些传统上封闭的公司开放并采用供应商中立的方法以支持更多编程语言和集成的原因之一。”
虽然可选编码的方法允许研究人员在不编写任何代码的情况下执行复杂的数据分析任务,但在某些情况下,编码可能是必要的。在这些情况下,大多数低代码平台与编程语言、机器学习库和深度学习环境集成。它们还提供用户探索第三方解决方案市场的能力,Mierswa 指出。“RapidMiner 甚至提供了一个操作框架,允许用户创建自己的视觉工作流。这个操作框架使得扩展和重用工作流变得容易,为数据分析提供了灵活和可定制的方法。”
前景
Altair,一家计算科学和 AI 领域的领导者,进行了一项调查,揭示了全球组织广泛采用数据和 AI 策略的情况。
这项研究涉及了来自不同产业和 10 个不同国家的 2000 多名专业人士,揭示了在组织内部不同部门之间存在摩擦时,AI 和数据分析项目的失败率显著(从 36%到 56%)。
研究确定了三大摩擦来源,这些摩擦阻碍了数据和 AI 项目的成功:组织性、技术性和财务性。
-
组织摩擦源于在找到合格的人员填补数据科学职位方面的挑战以及员工缺乏 AI 知识。
-
技术摩擦源于数据处理速度的限制和数据质量问题。
-
财务摩擦是由于资金限制、领导层对前期成本的关注以及对高实施成本的认知造成的。
Altair 的创始人兼 CEO James R. Scapa 在新闻发布会上强调了组织将数据作为战略资产来获得竞争优势的重要性。
摩擦会使关键任务项目陷入瘫痪。为了克服这些挑战并实现 Altair 称之为“无摩擦 AI”的目标,企业必须采用自助数据分析工具。Scapa 强调,这些工具使非技术用户能够轻松且经济高效地导航复杂的技术系统,消除阻碍进展的摩擦。
他还承认,人、技术和投资方面的障碍存在,阻碍了组织有效利用数据驱动的洞察。通过缩小技能差距,组织可以帮助在跨职能团队之间建立良好的知识,从而克服摩擦。
Saqib Jan**** 是一位作家和技术分析师,对数据科学、自动化和云计算充满热情。
更多相关主题
构建 LLM 流程的拖放 UI:Flowise AI
原文:
www.kdnuggets.com/2023/07/draganddrop-ui-building-llm-flows-flowise-ai.html

图片由作者提供
关于大语言模型(LLMs)的热度不断上升,越来越多的公司推出工具以便于人们的生活。那么这些工具到底是什么呢?其中之一就是 Flowise AI。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
Flowise AI 是什么?
Flowise AI是一个开源的 UI 可视化工具,用于帮助开发 LangChain 应用。在我们深入了解 Flowise AI 之前,让我们快速定义一下 LangChain。LangChain 是一个框架/ python 库,帮助你利用 LLMs 构建自己的定制 NLP 应用。
Flowise 使用 LangChain 作为其代理执行器,Chroma 作为其向量存储,OpenAI 进行嵌入,HuggingFace 的推理模型,GitHub 作为文档加载器,SERP 作为查询 API。其图形用户界面对基于 LangChain.js 的 LLM 应用构建非常有帮助。
那么是什么让它如此简单和有用呢?拖放工具。每个人都喜欢拖放,尤其是在自定义 NLP 应用时。更大的优点是它不需要任何编码经验!
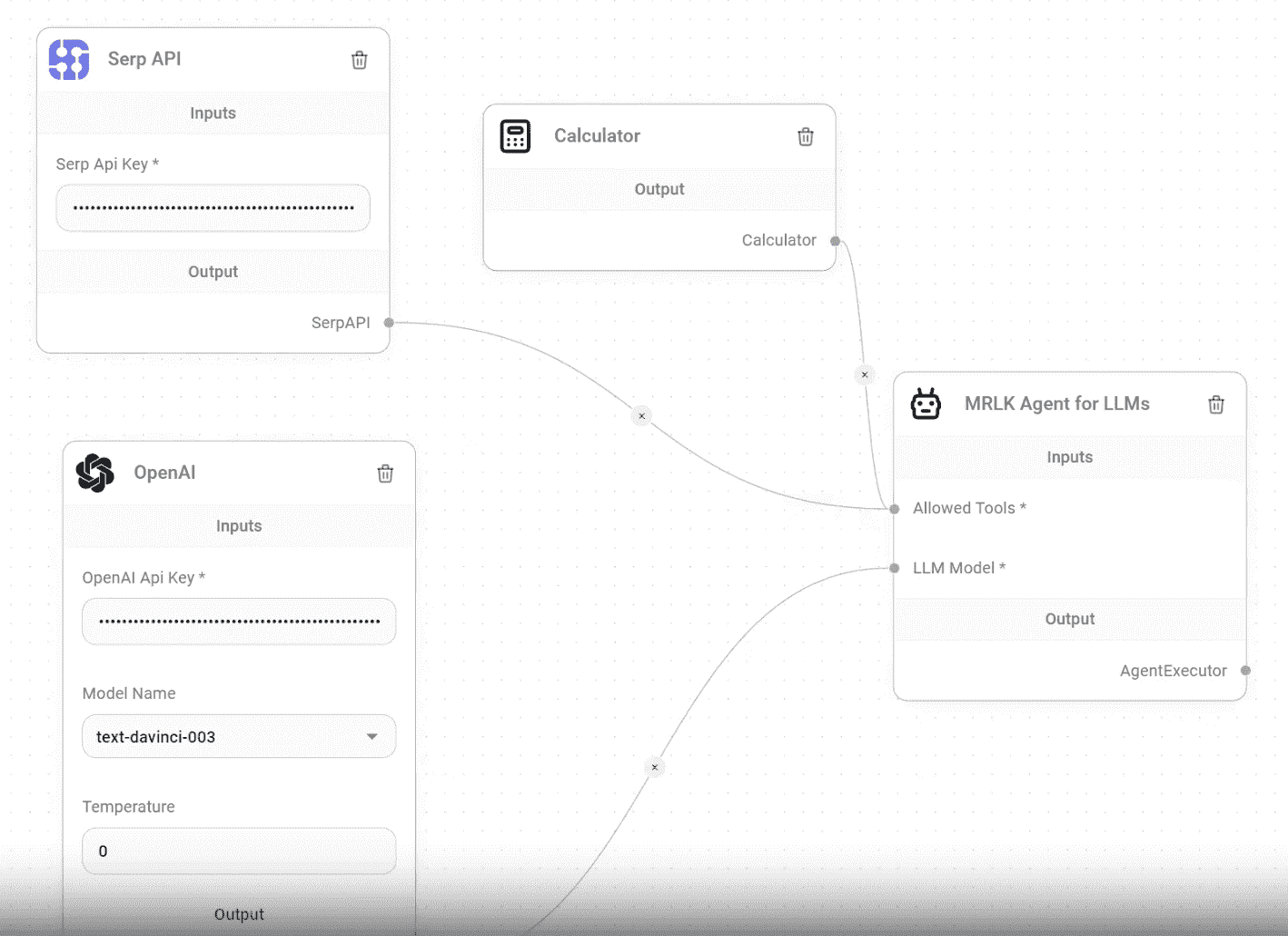
图片由Flowise AI提供
我可以用 Flowise AI 构建什么?
你可以使用 Flowise AI 构建多个应用,例如:
-
聊天机器人
-
虚拟助手
-
数据分析工具
-
教育工具
-
游戏
-
艺术
我为什么要使用 Flowise AI?
-
简洁: 拖放工具使构建自己的 LLM 流程变得容易。
-
无需编码技能: 对于行业新人和没有开发人员的组织,这一点非常有用。
-
开源: 免费使用和修改,允许根据自己的需求进行调整。
-
强大: 该工具可以用于开发广泛的 LLM 应用。
-
社区: Flowise 由一个支持性的开发社区支持,可以帮助你充分利用 Flowise。
Flowise AI 安装
那么,我如何安装这个简单的拖放可定制 NLP 工具呢?你可以通过三种不同的方式安装 Flowise AI。让我们逐一介绍。
快速安装
-
首先,你需要下载并安装 NodeJS >= 18.15.0。
-
完成后,你需要安装 Flowise
npm install -g flowise
- 下一步是启动 Flowise
npx flowise start
你需要输入用户名和密码:
npx flowise start --FLOWISE_USERNAME=user --FLOWISE_PASSWORD=1234
- 完成后,你可以通过打开以下网址在网页上查看:
如果你更愿意使用 Docker,请继续以下部分。
Docker
Docker Compose
-
首先,你需要进入项目根目录下的 docker 文件夹
-
然后你需要创建 .env 文件并指定 PORT(参见 .env.example)
-
然后你需要执行:docker-compose up -d
-
然后你需要打开
localhost:3000 -
你可以通过 docker-compose stop 停止容器
Docker 镜像
- 首先,你需要在本地构建镜像:
docker build --no-cache -t flowise .
- 然后你需要运行镜像:
docker run -d --name flowise -p 3000:3000 flowise
- 要停止镜像,你需要:
docker stop flowise
开发人员的本地设置
- 首先,你需要通过以下方式安装 Yarn v1:
npm i -g yarn
- 然后你需要克隆该仓库:
git clone https://github.com/FlowiseAI/Flowise.git
- 进入仓库文件夹:
cd Flowise
- 确保安装所有模型的所有依赖项:
yarn install
- 然后你需要构建所有代码:
yarn build
- 然后你可以启动应用程序:
yarn start
- 你可以在以下位置访问应用程序:
- 对于开发构建,请使用:
yarn dev
总结
所以,如果你是刚刚进入技术行业的新手,没有编码经验,或者你的组织缺乏开发人员 - Flowise AI 是你最佳的选择。如果有任何当前或以前的 Flowise 用户在阅读这篇文章,请在评论中告诉我们你的经验!
Nisha Arya 是一位数据科学家、自由技术写作者以及 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程,以及与数据科学相关的理论知识。她还希望探索人工智能如何或能如何有益于人类寿命的不同方式。作为一个热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
了解更多相关话题
梦想成真:通过思考构建网站
原文:
www.kdnuggets.com/2021/11/dream-come-true-allennlp-hacks-21.html
评论
由 Sreeram Ajay、Anjali Agarwal 和 Vatsala Nema
脑-机接口已成为一种最有前途的技术之一,用于帮助那些因中风、脊髓损伤、瘫痪或 ALS 而失去运动控制的人进行交流和执行之前无法实现的动作。利用这项技术,他们现在可以仅通过想象用自己的手书写来打字、行走和抓取物体。借助这项技术,我们在这里展示了我们的神经网站,这是我们作为 AllenNLP Hacks 2021 的一部分进行展示的。在这个项目中,我们使用了 BCI 和 NLP 技术,使失去运动控制的人可以仅通过想象编写指令来创建网站。
该项目有三个组成部分,
-
解码想象中的手写文字
-
自然语言处理
-
网站构建器
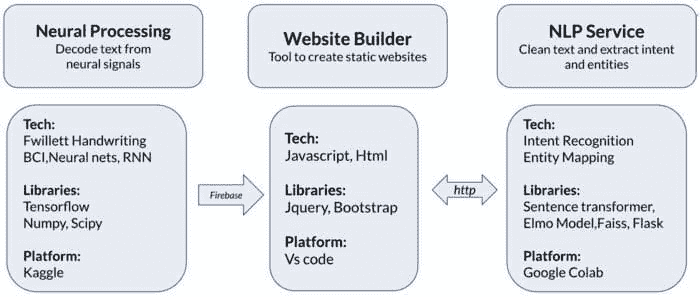
让我们进一步深入了解每个部分,以理解该项目。
解码想象中的手写文字
项目的第一部分包括将与手写相关的神经信号实时转换为文本。斯坦福大学的研究人员通过使用植入有皮层阵列电极的参与者左半球(主导)中央前回手“旋钮”区域记录的神经信号实现了这一点。
来源:[1]中风变色龙表现为不同的放射状神经病:专业知识可以加快诊断
[2]维基百科
在对神经信号进行预处理后,使用多单元阈值交叉率(神经信号每秒交叉某一阈值的次数平均值)作为神经特征。这些神经特征被输入到递归神经网络模型中,该模型将神经时间序列信号转换为概率时间序列。这些概率反过来告诉我们新字符的开始和后续字符的可能性(如下图所示)。在在线模式下,原始输出在其概率越过阈值时给出每个字符。在离线模式下,字符概率与大词汇量语言模型结合,以解码最可能的句子。
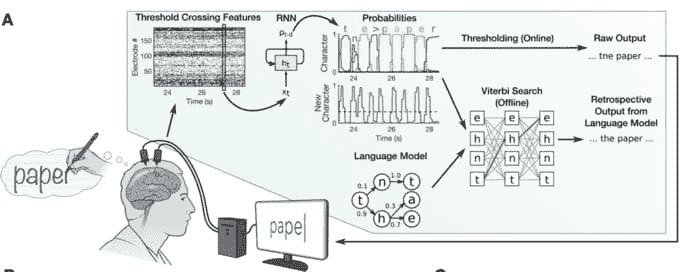
来源:www.nature.com/articles/s41586-021-03506-2
这个 BCI 通信系统的打字速度为每分钟 90 个字符,比之前使用光标移动的打字记录更快。在在线模式下,单词错误率为 5.4%,而在离线模式下使用语言模型则将单词错误率降低至 3.4%。
由于缺乏收集原始数据以构建网站的资源,我们创建了合成神经信号数据,可用于展示我们的项目。(与原始研究中用于数据增强的技术相同。)
自然语言处理
在从神经信号中获取解码文本后,我们使用自然语言处理技术清理和处理文本,以解读参与者在网站上的指令。我们使用类似于语音识别中的自动更正技术来清理解码文本,如使用二元模型获取候选句子,以及使用语言模型对输出进行重新评分。为了从清理后的文本中提取相关信息,我们使用了 NLP 技术。这项技术将参与者所写文本中的意图和实体分类。
意图识别
为了找到意图,即用户想要采取的行动,我们首先定义了一组已知的意图,这些意图可以用于在新句子中搜索相似的意图。我们使用 BERT 模型将这些原始文本示例转换为句子嵌入,以获得每个示例句子的向量表示。对于新句子,我们使用相同的训练模型来获取相应的嵌入。为了找到与输入文本最相似的句子,我们使用了 FAISS(Facebook AI 相似度搜索)库的 IndexFlatIP 算法,该算法使用向量之间的内积来查找它们的相似性。
实体映射
在获取意图后,我们需要在句子中找到实体或槽位。实体可以是字段、数据或文本描述(在我们的案例中,它是 HTML 元素)。我们使用了 ELMo 模型来获取上下文词嵌入。上下文词嵌入包含有关单个词及其在句子中使用的上下文意义的信息。例如,在句子“我把手机放在房间的左侧”中,词语“左”根据在句子中的出现情况可以有不同的含义。
我们还定义了一些需要在句子中查找的实体,如图像实体、位置实体等。句子中的各种实体使用相似度搜索算法进行解码。模型还给出了解码实体的值。我们使用了 BIO(开始-内部-外部)标记法(一种常见的标记格式)来获取多词实体。
例如,对于新句子“将背景更改为池塘附近的大象”,模型将输出如下结果,
意图:更改
实体:背景图像
值:池塘附近的大象
网站构建器
我们终于进入了项目的最终阶段,在收集并处理了用户提供的所有相关信息后,我们可以构建主网站。
现在提取的意图和实体用于更新用户界面。意图代表要采取的行动(添加、删除、更改、增加)。实体代表元素(标题、图片、边框)和属性(大小、颜色、样式、位置、图片描述)。例如,网站构建器将从图像搜索 API(在这种情况下为 pixabay API)中搜索大象的图像,并将最顶级的结果添加为当前视图的背景图像。如果用户不喜欢,他们可以输入下一张图像/更改图像等。然后背景将被第二个顶级结果替换。用户可以继续使用更多此类命令,如下一节/添加幻灯片,继续添加内容以增强和自定义页面以符合自己的喜好。最后,他们可以保存、托管并以链接形式分享他们的作品。
以下是使用该工具时的用户视图示例:
我们计划进一步扩展我们的项目到:
-
解读自然思维,并与更自然的语言接口连接,构建更好、更强大的设计和开发工具。
-
连接到物联网,主要是语音助手如 Alexa。
-
利用像 DALL.E 这样的语言模型,通过文本描述生成用于编辑网站的更具体的图像(从文本创建图像)。
通过这个项目,我们希望帮助面临困境的不同能力人士(如 ALS、中风等),让他们能够创建自己的网站、演示文稿或任何展示技能、活动或市场创业项目所需的内容。
你可以在这里查看我们项目的演示和介绍:
Neural Website - AllenNLP Hacks 2021 - YouTube。
参考文献
-
Willett, F.R., Avansino, D.T., Hochberg, L.R.等人。通过手写实现高性能脑对文本通信。自然 593, 249–254 (2021)。
doi.org/10.1038/s41586-021-03506-2 -
Reimers, Nils 和 Iryna Gurevych。“Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks。” ArXiv abs/1908.10084 (2019): n. Pag.
-
Peters, Matthew E., Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, 和 Luke Zettlemoyer。“深度上下文化词表示。” NAACL (2018)。
— Ajay Sreeram, Anjali Agarwal & Vatsala Nema
梦想成真团队
Sreeram Ajay 在 Target 担任高级 NLP 工程师。
Anjali Agarwal 在 Tata 研究、开发和设计中心担任研究员。
Vatsala Nema 是印度科学教育与研究学院 Bhopal 的 EECS 三年级学生。
相关:
-
介绍 Brain Simulator II:一个新的 AGI 实验平台
-
模拟一个脑神经元需要多少 AI 神经元?
-
为有志的数据科学家提供的黑客马拉松指南
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
更多相关内容
DrivenData:为社会公益而设的数据科学竞赛
原文:
www.kdnuggets.com/2014/11/drivendata-data-science-competitions-social-good.html
作者:彼得·布尔(DrivenData),2014 年 11 月
当我们开始启动我们的首个竞赛时,我们认为列出我们具体想做什么以及为什么这样做会是个好主意。
如果你的目标是改变未来,那么对未来的预测非常重要。
而且,有很多人对改变未来感兴趣。亚马逊希望增加你通过他们网站订购的商品数量,因此他们会预测你可能想要下一步购买的商品以及购买时间。推特希望提升你对他们平台的使用,因此他们会预测你会忽略哪些推文以及你会互动哪些推文。Facebook 和谷歌希望增加你点击他们网站上的广告的数量,因此他们会预测你个人的点击行为。他们在进行这些预测方面已经非常擅长。
但想要改变未来的原因还有很多。教育工作者希望增加高中毕业生的数量。健康工作者希望以可持续的成本改善人口的整体健康。小额贷款机构希望为发展中国家更多的个人提供追求梦想的机会,而不必担心违约。环保主义者希望在不影响生产力的情况下遏制我们的能源使用。政府希望防止火灾摧毁生命和财产。
这就是我们介入的地方。在实现这些困难但重要的变化的过程中,我们必须装备自己,以最先进的预测技术。预测哪些学生可能在初中阶段就辍学,以便教师可以提前干预。预测哪些个人即使在过去被银行拒绝的情况下也能够偿还他们的小额贷款。预测哪里更可能发生火灾,并优先到达现场。

一种不同的大数据火灾。
在当今世界,能够比其他人更好地进行这些预测的人是数据科学家。他们是现代的预言家,但他们使用的是数据集而不是水晶球。数据科学家凭借统计学和计算机科学的技能,利用大量数据集构建智能、创新和灵活的模型,以预测未来可能发生的情况。2011 年生产的数据量超过了人类历史上所有前几年加起来的数据总和。我们所拥有的数据的数量和种类正在爆炸式增长,而那些能够操控和揭示这些数据的人具有不可估量的价值。
在 DrivenData,我们希望将数据科学和众包的前沿实践应用于世界上最大的一些社会挑战和应对这些挑战的组织。 我们举办在线挑战,通常持续 2-3 个月,全球的数据科学家社区竞争以提出最佳的统计模型来解决具有影响力的难题。
就像现在的每个大型公司一样,非营利组织和非政府组织拥有比以往更多的数据。而且像那些公司一样,他们也在努力弄清楚如何最好地利用这些数据。我们与使命驱动的组织合作,识别他们关心的具体预测问题,并利用他们的数据来应对这些问题。

在预测建模中,尝试多种不同的方法至关重要。
然后我们会举办在线竞赛,来自世界各地的专家争相提出最佳解决方案。一些竞争者是私营部门的经验丰富的数据科学家,白天分析公司数据,夜晚拯救世界,测试自己在复杂影响问题上的能力。还有一些聪明、成熟的学生和研究人员,寻求在现实数据集和实际问题上磨练自己的技能。更多的则是有着广泛社会部门数据经验的人,想要将他们的专业知识用于新的、有意义的挑战——并获得关于他们解决方案效果的即时反馈。
像任何数据竞赛平台一样,我们希望利用群众的力量与日益增多的大型相关数据集相结合。与其他数据竞赛平台不同的是,我们的主要目标是通过我们的竞赛在世界上创造实际、可衡量、持久的积极变化。在每次挑战结束时,我们会与资助组织合作,整合获胜解决方案,提供工具以推动其实际影响的改善。
“我这一代最优秀的头脑都在考虑如何让人们点击广告。这真糟糕。” — 杰夫·哈默布彻,2011
拥有良好的预测,我们有机会改变我们星球的轨迹,这是以前从未有过的。我们希望解决当今世界上最棘手、最具挑战性和最有意义的问题。我们正在建立一个能够应对这些问题的数据专家社区。这就是社会公益的新前沿。
参与其中
我们已经启动了,并且希望你能加入我们!
如果你想获取关于我们今年秋天推出的激动人心的真实竞赛的更新,请在这里注册我们的邮件列表,并在 Twitter 上关注我们:@drivendataorg。
如果你是数据科学家,可以创建一个账户并开始体验我们的第一个沙盒竞赛。
如果你是非营利或公共部门组织,并且希望从数据中榨取每一滴任务效益,查看我们网站上的信息并告诉我们!彼得·布尔是 DrivenData 的联合创始人。
原文:blog.drivendata.org/2014/09/15/introducing-drivendata/
相关:
-
数据善用:推动社会公益的数据驱动项目
-
大数据与人道主义努力
-
竞赛:预测社交网络动态图
更多相关话题
世界首个用于机器学习和人工智能的蛋白质数据库
原文:
www.kdnuggets.com/2017/06/dspp-protein-database-machine-learning-ai.html
评论
由 Peptone 创始人 Kamil Tamiola 提供

我非常自豪和兴奋地介绍 Peptone 的首个公开产品,蛋白质结构倾向数据库。
蛋白质结构倾向数据库 (dSPP) 是世界上第一个与领先的机器学习框架 Keras 和 Tensorflow 无缝集成的蛋白质结构和动态特征的互动库。
dSPP 基于来自世界各地领先学术机构的同行评审研究,这些机构参与了用于蛋白质结构和无序特征表征的核磁共振光谱技术。dSPP 数据来自 7200 多种在生理相关条件下研究的无关蛋白质的溶液态和固态核磁共振光谱实验。
dSPP 是一个独特的信息来源,专注于固有无序蛋白质 (IDPs),这是一类研究难度较大的蛋白质。IDPs 涉及到许多使人虚弱的病理状况,包括阿尔茨海默病、帕金森病、朊病毒病、癌症的分子基础、HIV、HSV、HVC、ZIKVR 等。

MOAG-4 蛋白质的倾向分数的结构解释,提取自 dSPP 数据库 peptone.io/dspp/entry/dSPP27058_0\ MOAG-4 被认为能增强动物脑模型中的蛋白质聚集过程,从而加速帕金森病的早期发作。
dSPP 数据可以被实验人员轻松使用,以深入了解二级结构基序的结构稳定性,以及旨在提供医学相关蛋白质现实模型的高通量计算技术。
与其他蛋白质数据集中为实验人员和机器学习社区提供的二元 (logits) 二级结构分配不同,dSPP 数据报告了蛋白质结构和局部动态,具有原子分辨率,基于-1.0 到 1.0的连续结构倾向分配。

dSPP 实验数据是在生理相关条件下收集的,使其在结构和无序预测方法中具有绝对的唯一性,这些方法旨在处理生物学和医学相关背景下的蛋白质折叠和稳定性。
dSPP 配备直观的用户界面,提供对相关决策数据、原始文献引用和统一呈现的感兴趣蛋白的机器学习数据的无缝访问。
通过dspp-keras Python 包实现与Keras和Tensorflow机器学习框架的无缝集成,下载和设置时间不到 60 秒。因此,几乎任何对机器学习有基本了解的人都可以开始尝试蛋白质结构预测方法。
dSPP 是 Peptone 首个公开发布的产品,具有自动化 14 天更新周期,专为持续学习的 AI 应用而设计。
科学参考:
- 蛋白质结构倾向数据库。Kamil Tamiola, Matthew Michael Heberling, Jan Domanski。bioRxiv 144840;doi:*https://doi.org/10.1101/144840
可用性和行动呼吁
-
互动搜索引擎和数据渲染:
peptone.io/dspp -
独立 JSON 和 Python cPickle 下载:
peptone.io/dspp/download -
Keras 和 Tensorflow 集成:
github.com/PeptoneInc/dspp-keras -
在终端中:pip install dspp-keras
致谢
-
我们要感谢郑文伟博士(NIDDK, US)、鲁德·谢克博士(格罗宁根大学, NL)和谢维尔·佩里奥勒博士(奥胡斯大学, DK)对我们dSPP 论文的深刻评论和编辑建议。
-
弗朗索瓦·肖莱 来自 Keras / Google 因对数据库接口的深刻反馈以及关于Keras集成的直接建议而受到高度赞赏。
-
我们衷心感谢艾莉森·朗德斯、卡洛·鲁伊斯和亚当·格日瓦切夫斯基博士(NVIDIA Corporation)促进了合作并提供了 DGX-1 超级计算机的使用。
-
乔恩·韦德尔(BMRB)因在从 BMRB 中获取 NMR 共振分配的技术支持而受到高度赞赏。
-
我们感谢弗朗斯·A.A.·穆尔德博士(奥胡斯大学, DK)和佩德拉格·库基奇博士(剑桥大学, UK)提供 MOAG-4 的结构集成模型。
-
最后,我们要特别感谢马克·伯杰(NVIDIA Corporation)在整个项目执行过程中给予的巨大支持。
新闻稿
- 本新闻稿及媒体资产可从
drive.google.com/open?id=0B0VsF9FO3J_OMXljcm1MS3NCRHc下载。
关于 Peptone
成立于 2016 年(荷兰阿姆斯特丹),Peptone 通过机器学习和人工智能提供先进的蛋白质生物技术解决方案。我们将来自公共和私人数据库的大数据转化为强大的预测模型和直观的工具,用于蛋白质生产、稳定性、无序性、工程和定向进化实验,为客户提供透明且互补的软件,节省时间并提供精准的研究答案。
原始文章。转载经许可。
个人简介: 卡米尔·塔米奥拉 是一位企业家和研究员,拥有超算和蛋白质结构生物物理学的广泛科学背景。
相关:
-
科学的大数据生态系统:基因组学
-
使用可视化进行高级数据分析的 5 个步骤
-
深度学习:通过 XML 和 PMML 编程 TensorFlow
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
相关主题
《鸭子,鸭子,代码:Python 中的鸭子类型简介》
原文:
www.kdnuggets.com/duck-duck-code-an-introduction-to-pythons-duck-typing

图片作者 | DALLE-3 和 Canva
什么是鸭子类型?
鸭子类型是编程中的一个概念,通常与像 Python 这样的动态语言相关,它更注重对象的行为而非其类型或类。当你使用鸭子类型时,你会检查对象是否具有某些方法或属性,而不是检查具体的类。这个名字源于一句话,
如果它看起来像一只鸭子,游泳像一只鸭子,叫声像一只鸭子,那么它可能就是一只鸭子。
鸭子类型(Duck typing)为 Python 编程带来了几个优势。它允许编写更灵活和可重用的代码,并支持多态性,使得不同的对象类型可以互换使用,只要它们提供了所需的接口。这使得代码更简洁、更简明。然而,鸭子类型也有其缺点。一个主要的缺陷是潜在的运行时错误。此外,它可能会使你的代码更难理解。
理解 Python 中的动态行为
在动态类型语言中,变量类型不是固定的。相反,它们是在运行时根据赋值确定的。与之对比,静态类型语言在编译时检查变量类型。例如,如果你尝试将一个变量重新分配为不同类型的值,在静态类型中会遇到错误。动态类型提供了更大的灵活性来使用变量和对象。
让我们考虑一下 * Python 操作符;它的行为会根据与之使用的对象的类型而有所不同。当用于两个整数之间时,它会执行乘法。
# Multiplying two integers
a = 5 * 3
print(a) # Outputs: 15
当与字符串和整数一起使用时,它会重复字符串。这展示了 Python 的动态类型系统和适应性特征。
# Repeating a string
a = 'A' * 3
print(a) # Outputs: AAA
在 Python 中,鸭子类型是如何工作的?
在动态语言中,鸭子类型更受欢迎,因为它鼓励更自然的编码风格。开发者可以专注于设计基于对象能够做什么的接口。在鸭子类型中,类内定义的方法比对象本身更重要。我们通过一个基本的例子来说明这一点。
示例编号:01
我们有两个类:Duck(鸭子)和 Person(人)。鸭子可以发出呱呱声,而人类可以说话。每个类都有一个名为 sound 的方法,用于打印各自的声音。函数 make_it_sound 接受任何具有 sound 方法的对象并调用它。
class Duck:
def sound(self):
print("Quack!")
class Person:
def sound(self):
print("I'm quacking like a duck!")
def make_it_sound(obj):
obj.sound()
现在,让我们看看如何利用鸭子类型来处理这个例子。
# Using the Duck class
d = Duck()
make_it_sound(d) # Output: Quack!
# Using the Person class
p = Person()
make_it_sound(p) # Output: I'm quacking like a duck!
在这个例子中,Duck 和 Person 类都有一个 sound 方法。无论对象是鸭子还是人,只要它有一个 sound 方法,make_it_sound 函数都会正常工作。
然而,duck typing 可能导致运行时错误。例如,将 Person 类中的 sound 方法的名称更改为 speak 会在运行时引发 AttributeError。这是因为函数 make_it_sound 期望所有对象都有一个 sound 函数。
class Duck:
def sound(self):
print("Quack!")
class Person:
def speak(self):
print("I'm quacking like a duck!")
def make_it_sound(obj):
obj.sound()
# Using the Duck class
d = Duck()
make_it_sound(d)
# Using the Person class
p = Person()
make_it_sound(p)
输出:
AttributeError: 'Person' object has no attribute 'sound'
示例 No: 02
让我们深入探讨另一个程序,该程序处理不同形状的面积计算,而不必担心它们的具体类型。每个形状(矩形、圆形、三角形)都有自己的类,其中包含一个名为 area 的方法来计算其面积。
class Rectangle:
def __init__(self, width, height):
self.width = width
self.height = height
self.name = "Rectangle"
def area(self):
return self.width * self.height
class Circle:
def __init__(self, radius):
self.radius = radius
self.name = "Circle"
def area(self):
return 3.14 * self.radius * self.radius
def circumference(self):
return 2 * 3.14 * self.radius
class Triangle:
def __init__(self, base, height):
self.base = base
self.height = height
self.name = "Triangle"
def area(self):
return 0.5 * self.base * self.height
def print_areas(shapes):
for shape in shapes:
print(f"Area of {shape.name}: {shape.area()}")
if hasattr(shape, 'circumference'):
print(f"Circumference of the {shape.name}: {shape.circumference()}")
# Usage
shapes = [
Rectangle(4, 5),
Circle(3),
Triangle(6, 8)
]
print("Areas of different shapes:")
print_areas(shapes)
输出:
Areas of different shapes:
Area of Rectangle: 20
Area of Circle: 28.259999999999998
Circumference of the Circle: 18.84
Area of Triangle: 24.0
在上述示例中,我们有一个 print_areas 函数,它接受一个形状列表,并打印它们的名称以及计算出的面积。注意,我们不需要在计算面积之前显式检查每个形状的类型。由于 circumference 方法仅在 Circle 类中存在,因此它仅实现一次。这个例子展示了 duck typing 如何用于编写灵活的代码。
最终思考
Duck typing 是 Python 的一个强大特性,使你的代码更加动态和多才多艺,允许你编写更通用和适应性强的程序。尽管它带来了灵活性和简洁性等许多好处,但它也需要仔细的文档和测试以避免潜在的错误。
Kanwal Mehreen**** Kanwal 是一位机器学习工程师和技术作家,对数据科学及 AI 与医学的交汇点充满深厚的热情。她是电子书《利用 ChatGPT 最大化生产力》的共同作者。作为 2022 年 APAC Google Generation Scholar,她倡导多样性和学术卓越。她还被认定为 Teradata Diversity in Tech Scholar、Mitacs Globalink Research Scholar 和 Harvard WeCode Scholar。Kanwal 是变革的热情倡导者,创立了 FEMCodes 来赋权女性在 STEM 领域。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
更多相关主题
为什么 DuckDB 越来越受欢迎?

作者提供的图片
什么是 DuckDB?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
DuckDB 是一个免费的开源嵌入式数据库管理系统,旨在用于数据分析和在线分析处理。这意味着几个方面:
-
它是免费的开源软件,所以任何人都可以使用和修改代码。
-
它是嵌入式的,这意味着 DBMS(数据库管理系统)与使用它的应用程序在同一个进程中运行。这使得它快速且易于使用。
-
它针对数据分析和在线分析处理(OLAP)进行了优化,而不仅仅是像典型数据库那样的事务数据。这意味着数据按列而非按行组织,以优化聚合和分析。
-
它支持标准 SQL,因此你可以对数据执行查询、聚合、连接和其他 SQL 函数。
-
它在进程内运行,在应用程序内部,而不是作为单独的进程运行。这消除了进程间通信的开销。
-
像 SQLite 一样,它是一个简单的基于文件的数据库,因此不需要单独安装服务器。你只需在应用程序中包含该库即可。
总之,DuckDB 提供了一种易于使用的嵌入式分析数据库,适用于需要快速和简单数据分析能力的应用程序。它填补了分析处理中的一个利基市场,在这种情况下,完整的数据库服务器会显得过于庞大。
为什么 DuckDB 越来越受欢迎?
现在有许多公司在 DuckDB 上构建产品。这是因为数据库被设计用于快速分析查询,这意味着它优化了聚合、连接和对大型数据集的复杂查询 - 这些查询通常用于分析和报告。此外:
-
安装、部署和使用都很简单。无需配置服务器 - DuckDB 嵌入在你的应用程序中。这使得它易于集成到不同的编程语言和环境中。
-
尽管其简单,但 DuckDB 具有丰富的功能集。它支持完整的 SQL 标准、事务、辅助索引,并且与流行的数据分析编程语言如 Python 和 R 的集成良好。
-
DuckDB 对任何人免费使用和修改,这降低了开发人员和数据分析师采用它的门槛。
-
DuckDB 已经过充分测试且稳定。它具有广泛的测试套件,并在各种平台上进行持续集成和测试以确保稳定性。
-
DuckDB 提供了与专业 OLAP 数据库相媲美的性能,同时更易于部署。这使其适用于对小到中型数据集以及大型企业数据集的分析查询。
简而言之,DuckDB 将 SQLite 的简单性和易用性与专业列式数据库的分析性能结合起来。这些因素——性能、简单性、功能和开源许可证——共同促成了 DuckDB 在开发人员和数据分析师中日益增长的受欢迎程度。
DuckDB Python 示例
让我们使用 Python API 测试 DuckDB 的一些功能。
你可以使用 Pypi 安装 DuckDB:
pip install duckdb
对于其他编程语言,请查看 DuckDB 的 安装指南。
在这个示例中,我们将使用 2023 年数据科学薪资 Kaggle 上的 CSV 数据集,并尝试测试 DuckDB 的各种功能。
关系 API
你可以像使用 pandas 一样将 CSV 文件加载到关系中。DuckDB 提供了一种关系 API,允许用户将查询操作链接在一起。这些查询是延迟计算的,这使得 DuckDB 能够优化它们的执行。
我们已经加载了数据科学薪资数据集并显示了别名。
import duckdb
rel = duckdb.read_csv('ds_salaries.csv')
rel.alias
'ds_salaries.csv'
要显示列名,我们将使用 .columns,类似于 pandas。
rel.columns
['work_year',
'experience_level',
'employment_type',
'job_title',
'salary',
'salary_currency',
'salary_in_usd',
'employee_residence',
'remote_ratio',
'company_location',
'company_size']
你可以对关系应用多个函数以获得特定结果。在我们的案例中,我们筛选了“work_year”,仅显示了三列,并按薪资排序并限制显示底部五个职位标题。
通过遵循 指南 了解更多关于关系 API 的信息。
rel.filter("work_year > 2021").project(
"work_year,job_title,salary_in_usd"
).order("salary_in_usd").limit(5)
┌───────────┬─────────────────┬───────────────┐
│ work_year │ job_title │ salary_in_usd │
│ int64 │ varchar │ int64 │
├───────────┼─────────────────┼───────────────┤
│ 2022 │ NLP Engineer │ 5132 │
│ 2022 │ Data Analyst │ 5723 │
│ 2022 │ BI Data Analyst │ 6270 │
│ 2022 │ AI Developer │ 6304 │
│ 2022 │ Data Analyst │ 6359 │
└───────────┴─────────────────┴───────────────┘
你也可以使用关系 API 连接两个数据集。在我们的案例中,我们通过在“job_title”上更改别名来连接相同的数据集。
rel2 = duckdb.read_csv('ds_salaries.csv')
rel.set_alias('a').join(rel.set_alias('b'), 'job_title').limit(5)
┌───────────┬──────────────────┬─────────────────┬───┬──────────────┬──────────────────┬──────────────┐
│ work_year │ experience_level │ employment_type │ ... │ remote_ratio │ company_location │ company_size │
│ int64 │ varchar │ varchar │ │ int64 │ varchar │ varchar │
├───────────┼──────────────────┼─────────────────┼───┼──────────────┼──────────────────┼──────────────┤
│ 2023 │ SE │ FT │ ... │ 100 │ US │ L │
│ 2023 │ MI │ CT │ ... │ 100 │ US │ S │
│ 2023 │ MI │ CT │ ... │ 100 │ US │ S │
│ 2023 │ SE │ FT │ ... │ 100 │ US │ S │
│ 2023 │ SE │ FT │ ... │ 100 │ US │ S │
├───────────┴──────────────────┴─────────────────┴───┴──────────────┴──────────────────┴──────────────┤
│ 5 rows 21 columns (6 shown) │
└─────────────────────────────────────────────────────────────────────────────────────────────────────┘
直接 SQL 方法
也有直接的方法。你只需编写 SQL 查询来对数据集进行分析。你将写入 CSV 文件的位置和名称,而不是表名。
duckdb.sql('SELECT * FROM "ds_salaries.csv" LIMIT 5')
┌───────────┬──────────────────┬─────────────────┬───┬──────────────┬──────────────────┬──────────────┐
│ work_year │ experience_level │ employment_type │ ... │ remote_ratio │ company_location │ company_size │
│ int64 │ varchar │ varchar │ │ int64 │ varchar │ varchar │
├───────────┼──────────────────┼─────────────────┼───┼──────────────┼──────────────────┼──────────────┤
│ 2023 │ SE │ FT │ ... │ 100 │ ES │ L │
│ 2023 │ MI │ CT │ ... │ 100 │ US │ S │
│ 2023 │ MI │ CT │ ... │ 100 │ US │ S │
│ 2023 │ SE │ FT │ ... │ 100 │ CA │ M │
│ 2023 │ SE │ FT │ ... │ 100 │ CA │ M │
├───────────┴──────────────────┴─────────────────┴───┴──────────────┴──────────────────┴──────────────┤
│ 5 rows 11 columns (6 shown) │
└─────────────────────────────────────────────────────────────────────────────────────────────────────┘
持久存储
默认情况下,DuckDB 在内存数据库上运行。这意味着创建的任何表都存储在内存中,而不是持久化到磁盘。然而,通过使用 .connect() 方法,可以连接到磁盘上的持久数据库文件。写入该数据库连接的任何数据将保存到磁盘文件中,并在重新连接到相同文件时重新加载。
-
我们将使用
.connect()方法创建一个数据库。 -
运行 SQL 查询以创建一个表。
-
使用查询添加两个记录。
-
显示新创建的测试表。
import duckdb
con = duckdb.connect('kdn.db')
con.sql("CREATE TABLE test_table (i INTEGER, j STRING)")
con.sql("INSERT INTO test_table VALUES (1, 'one'),(9,'nine')")
con.table('test_table').show()
┌───────┬─────────┐
│ i │ j │
│ int32 │ varchar │
├───────┼─────────┤
│ 1 │ one │
│ 9 │ nine │
└───────┴─────────┘
我们也可以使用数据科学薪资 CSV 文件来创建新表。
con.sql('CREATE TABLE ds_salaries AS SELECT * FROM "ds_salaries.csv";')
con.table('ds_salaries').limit(5).show()
┌───────────┬──────────────────┬─────────────────┬───┬──────────────┬──────────────────┬──────────────┐
│ work_year │ experience_level │ employment_type │ ... │ remote_ratio │ company_location │ company_size │
│ int64 │ varchar │ varchar │ │ int64 │ varchar │ varchar │
├───────────┼──────────────────┼─────────────────┼───┼──────────────┼──────────────────┼──────────────┤
│ 2023 │ SE │ FT │ ... │ 100 │ ES │ L │
│ 2023 │ MI │ CT │ ... │ 100 │ US │ S │
│ 2023 │ MI │ CT │ ... │ 100 │ US │ S │
│ 2023 │ SE │ FT │ ... │ 100 │ CA │ M │
│ 2023 │ SE │ FT │ ... │ 100 │ CA │ M │
├───────────┴──────────────────┴─────────────────┴───┴──────────────┴──────────────────┴──────────────┤
│ 5 rows 11 columns (6 shown) │
└─────────────────────────────────────────────────────────────────────────────────────────────────────┘
完成所有任务后,必须关闭与数据库的连接。
con.close()
结论
为什么我喜欢 DuckDB?它快速且易于学习和管理。我相信简单性是 DuckDB 在数据科学社区广泛使用的主要原因。DuckDB 提供了一个直观的 SQL 接口,数据分析师和科学家很容易上手。安装简便,数据库文件轻巧且易于管理。这些都使 DuckDB 使用起来非常愉快。
查看我之前关于 使用 DuckDB 的数据科学 的 Deepnote 文章,深入分析功能和使用案例。
DuckDB 提供了强大的数据加载、管理和分析工具,与其他数据库解决方案相比,它是数据科学的一个有吸引力的选择。我相信,随着越来越多的数据专业人士发现其用户友好的特性,DuckDB 将在未来几年继续获得用户。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为那些正在与心理疾病作斗争的学生构建一个 AI 产品。
更多相关主题
使用 Python 进行的电子商务数据分析以制定销售策略
原文:
www.kdnuggets.com/2021/04/e-commerce-data-analysis-sales-strategy-python.html
评论
由 Juhi Sharma,产品分析师

介绍
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持组织的 IT 工作
Kmart 是美国领先的在线零售商,作为其年度销售回顾会议的一部分,他们需要根据 2019 年的销售数据洞察来决定 2020 年的销售策略。
数据与 2019 年每个月的销售有关,任务是生成关键洞察,以帮助 Kmart 的销售团队做出有关优化销售策略的重要业务决策。
数据理解
-
数据属于 Kmart - 美国领先的在线零售商。
-
时间范围 — 2019 年 1 月 — 2019 年 12 月
-
唯一产品 — 19
-
总订单数 — 178437
-
城市 — 9
-
KPI’s — 总销售额,总销售产品数
来源 — 作者
商业问题陈述
-
销售最佳的月份是哪一个?那个时候赚了多少钱?
-
哪个城市的销售数量最高?
-
推荐展示广告的最佳时间,以最大化客户购买产品的可能性?
-
什么产品卖得最多?你认为为什么卖得最好?
使用 Python 进行数据分析
-
加载了每个月的数据,并使用 pandas 制作了数据框
-
合并数据集以制作一个 2019 年销售数据的数据集。
-
处理空值和垃圾数据。
-
数据预处理后制作了一个筛选的数据集
-
分析和解决商业问题。(使用 matplotlib 和 seaborn 库进行可视化)
1. 导入库
import pandas as pd
2. 加载数据集并制作数据框
df1=pd.read_csv("Sales_January_2019.csv")
df1["month"]="Jan"
df2=pd.read_csv("Sales_February_2019.csv")
df2["month"]="feb"
df3=pd.read_csv("Sales_March_2019.csv")
df3["month"]="mar"
df4=pd.read_csv("Sales_April_2019.csv")
df4["month"]="apr"
df5=pd.read_csv("Sales_May_2019.csv")
df5["month"]="may"
df6=pd.read_csv("Sales_June_2019.csv")
df6["month"]="june"
df7=pd.read_csv("Sales_July_2019.csv")
df7["month"]="july"
df8=pd.read_csv("Sales_August_2019.csv")
df8["month"]="aug"
df9=pd.read_csv("Sales_September_2019.csv")
df9["month"]="sep"
df10=pd.read_csv("Sales_October_2019.csv")
df10["month"]="oct"
df11=pd.read_csv("Sales_November_2019.csv")
df11["month"]="nov"
df12=pd.read_csv("Sales_December_2019.csv")
df12["month"]="dec"list=[df1,df2,df3,df4,df5,df6,df7,df8,df9,df10,df11,df12]
3. 每个月的数据集的形状
for i in list:
print(i.shape)

来源 — 作者
4. 合并数据集
frame=pd.concat(list)
来源 — 作者
5. 最终数据集的列
frame.columns

来源 — 作者
6. 数据框信息
frame.info()
来源 — 作者
7. 数据集中的空值
frame.isnull().sum() # there are 545 null values in each column except month

来源-作者
(frame.isnull().sum().sum())/len(frame)*100 # we have 1.75 percent null values , so we can drop them
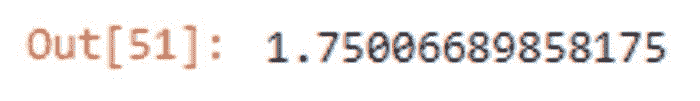
来源-作者
8. 删除空值
frame=frame.dropna()
frame.isnull().sum()

来源-作者
9. 删除垃圾数据
我们观察到有 355 列中的行值与标题相同,因此创建一个新的数据框,将这些值排除在外。
frame[frame['Quantity Ordered'] == "Quantity Ordered"]

df_filtered = frame[frame['Quantity Ordered'] != "Quantity Ordered"]
df_filtered.head(15)
df_filtered.shape
来源-作者
解决商业问题
Q 1. 哪个月的销售最好?那个时候赚了多少钱?
df_filtered["Quantity Ordered"]=df_filtered["Quantity Ordered"].astype("float")
df_filtered["Price Each"]=df_filtered["Price Each"].astype("float")# Creating Sales Column By multiplying Quantity Ordered and Price of Each Productdf_filtered["sales"]=df_filtered["Quantity Ordered"]*df_filtered["Price Each"]

来源-作者
month=["dec","oct","apr","nov","may","mar","july","june","aug",'feb',"sep","jan"]
df["month"]=monthfrom matplotlib import pyplot as plt
a4_dims = (11.7, 8.27)
fig, ax = pyplot.subplots(figsize=a4_dims)
import seaborn as sns
sns.barplot(x = "sales",
y = "month",
data = df)
plt.title("Month wise Sale")
plt.show()
来源-作者
销售最佳的月份是 12 月。
12 月的总销售额为 $ 4619297。
Q 2. 哪个城市的销售额最高?
dftemp = df_filtered
list_city = []
for i in dftemp['Purchase Address']:
list_city.append(i.split(",")[1])
dftemp['City'] = list_city
dftemp.head()

来源-作者
df_city=df_filtered.groupby(["City"])['sales'].sum().sort_values(ascending=False)
df_city=df_city.to_frame()
df_city
来源-作者
city=["San Francisco","Los Angeles","New York City","Boston","Atlanta","Dallas","Seattle","Portland","Austin"]
df_city["city"]=cityfrom matplotlib import pyplot
a4_dims = (11.7, 8.27)
fig, ax = pyplot.subplots(figsize=a4_dims)
sns.barplot(x = "sales",
y = "city",
data = df_city)
plt.title("City wise Sales")
plt.show()
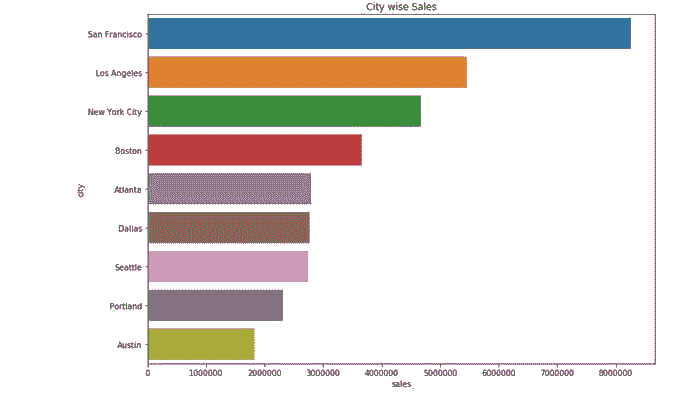
来源-作者
旧金山的销售额最高,大约为 $8262204。
Q 3 哪些产品卖得最多?
print(df_filtered["Product"].unique())
print(df_filtered["Product"].nunique())

来源-作者
df_p=df_filtered.groupby(['Product'])['Quantity Ordered'].sum().sort_values(ascending=False).head()
df_p=df_p.to_frame()
df_p
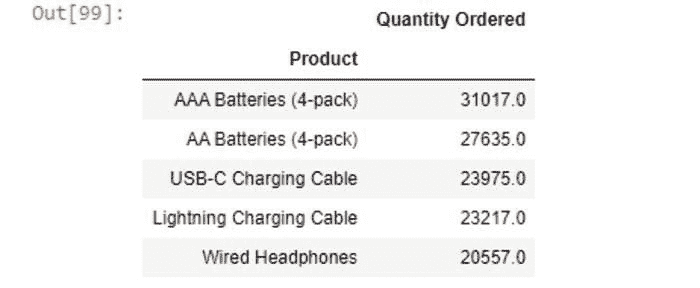
来源-作者
product=["AAA Batteries (4-pack)","AA Batteries (4-pack)","USB-C Charging Cable","Lightning Charging Cable","Wired Headphones"]
df_p["Product"]=productfrom matplotlib import pyplot
a4_dims = (11.7, 8.27)
fig, ax = pyplot.subplots(figsize=a4_dims)
sns.barplot(x = "Quantity Ordered",
y = "Product",
data = df_p)
plt.title("Prouct and Quantity Ordered")
plt.show()
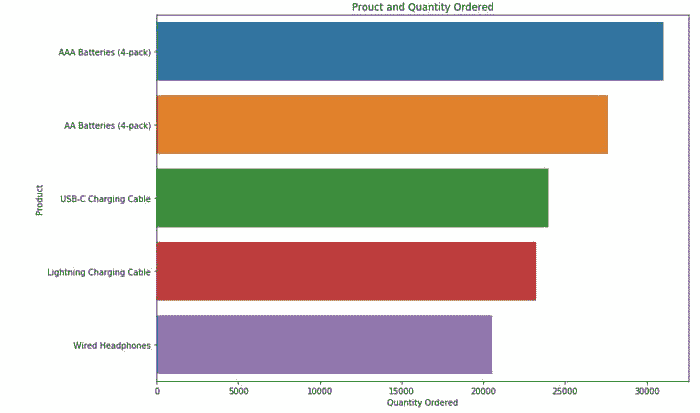
来源-作者
一年内销售了 31017.0 数量的 AAA 电池(4 包)。它销量最大,因为它是最便宜的产品。
Q 4 什么时候展示广告最合适,以最大化客户购买产品的可能性?
dftime = df_filtered
list_time = []
for i in dftime['Order Date']:
list_time.append(i.split(" ")[1])
dftime['Time'] = list_time
dftime.head()

来源-作者
df_t=df_filtered.groupby(['Time'])['sales'].sum().sort_values(ascending=False).head()
df_t=df_t.to_frame()
df_t
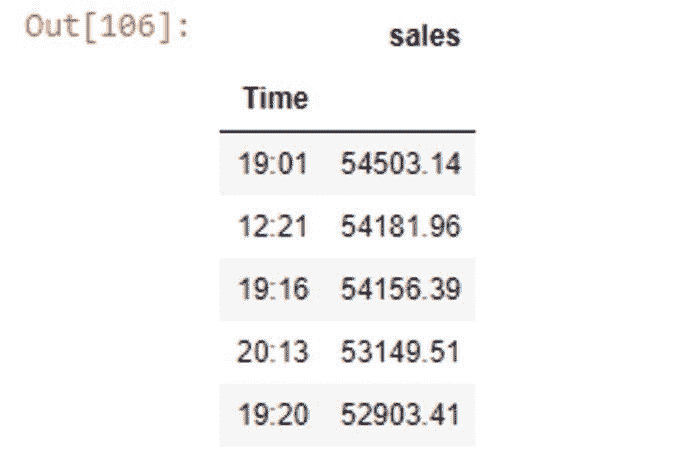
来源-作者
df_t.columns

来源-作者
在你离开之前
感谢阅读!如果你想联系我,请随时通过 jsc1534@gmail.com 或我的LinkedIn 个人资料与我联系。你还可以在我的GitHub账户上找到这篇文章的代码以及一些非常有用的数据科学项目。
简介: Juhi Sharma (Medium, GitHub) 具有 2 年以上分析师工作经验,涉及项目管理、业务分析和客户处理。目前,Juhi 在一家产品公司担任数据分析师。Juhi 拥有分析数据集、创建机器学习和深度学习模型的实际经验。Juhi 热衷于通过数据驱动的方法解决商业问题。
原文. 经许可转载。
相关内容:
-
Pandas Profiling: 一行代码的魔法数据分析
-
让你的数据项目更有价值的问题
-
如何构建正确的问题以通过数据回答
更多相关话题
使用 Pandas 制作美丽的交互式可视化的最简单方法
原文:
www.kdnuggets.com/2021/12/easiest-way-make-beautiful-interactive-visualizations-pandas.html
由 Frank Andrade 数据科学家和 Python 教师

图片由 Jerry Zhang 拍摄,来自 Unsplash
我们的前三个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业。
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你的组织进行 IT 管理
如果你一直关注我的data visualization guides,你可能知道我喜欢在 Python 中创建既美观又易读的可视化,而不需要过于技术化或浪费大量时间。
交互式可视化也不例外,因此我已经寻找了一段时间友好的 Python 库。虽然有许多库可以完成这个工作,但当涉及到与 Pandas 配合使用时,情况变得复杂。
幸运的是,现在有一种简单的方法可以直接从 Pandas 创建交互式可视化,我们将在本指南中详细了解其工作原理。
首先
安装库
要轻松创建交互式可视化,我们需要安装 Cufflinks。这个库将 Pandas 与 Plotly 连接在一起,因此我们可以直接从 Pandas 创建可视化(以前你需要学习解决方法才能让它们一起工作,但现在更简单了)。
首先,确保你通过终端运行以下命令来安装 Pandas 和 Plotly:
pip install pandas
pip install plotly
请注意,你也可以使用 conda 安装 Plotlyconda install -c plotly。
安装 Plotly 后,运行以下命令来安装 Cufflinks:
pip install cufflinks
导入库
开始工作之前,导入以下库:
import pandas as pd
import cufflinks as cf
from IPython.display import display,HTMLcf.set_config_file(sharing='public',theme='ggplot',offline=True)
在这种情况下,我使用了‘ggplot’主题,但可以随意选择任何你喜欢的主题。运行命令cf.getThemes()获取所有可用的主题。
要在接下来的部分中使用 Pandas 制作交互式可视化,我们只需要使用语法dataframe.iplot()。
数据
在本指南中,我们将使用一个人口数据框。首先,从Google Drive或Github下载 CSV 文件,将文件移动到你的 Python 脚本所在的位置,然后如下面所示在 Pandas 数据框中读取它。
df_population = pd.read_csv('population_total.csv')
数据框包含了世界上大多数国家多年来的人口数据,长这样:
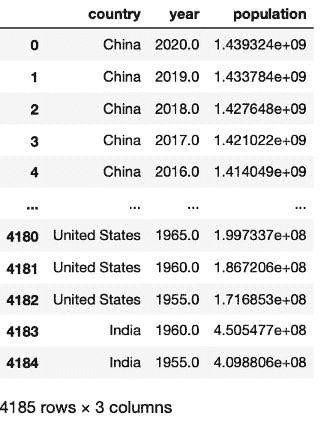
作者提供的图片
这个数据框几乎已经准备好绘制,我们只需要丢弃空值,重新塑形,然后选择几个国家来测试我们的交互式图表。下面的代码完成了这一切。
# dropping null values
df_population = df_population.dropna()# reshaping the dataframe
df_population = df_population.pivot(index='year', columns='country',
values='population')# selecting 5 countries
df_population = df_population[['United States', 'India', 'China',
'Indonesia', 'Brazil']]
现在数据框看起来像下面的图片,已经准备好绘制了。
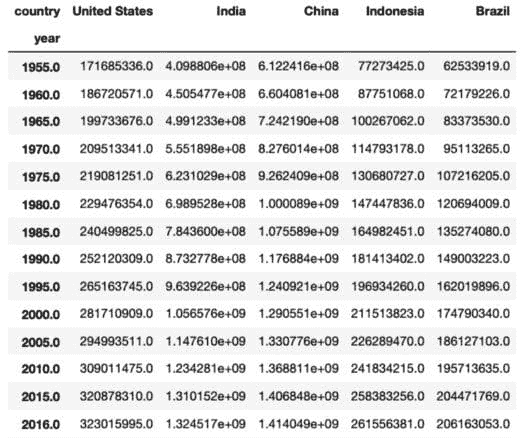
作者提供的图片
如果你想了解数据科学家如何收集像“population_total.csv”这样的真实世界数据,请查看我写的这个指南(查看这个指南)。(你不一定总是会有 Kaggle 数据集用于数据科学项目)
现在让我们开始制作交互式可视化吧!
线形图
让我们制作一个线形图,以比较 1955 年到 2020 年这 5 个国家的人口增长情况。
如前所述,我们将使用df_population.iplot(kind='name_of_plot')语法来制作下图所示的图表。
df_population.iplot(kind='**line**',xTitle='Years', yTitle='Population',
title='Population (1955-2020)')
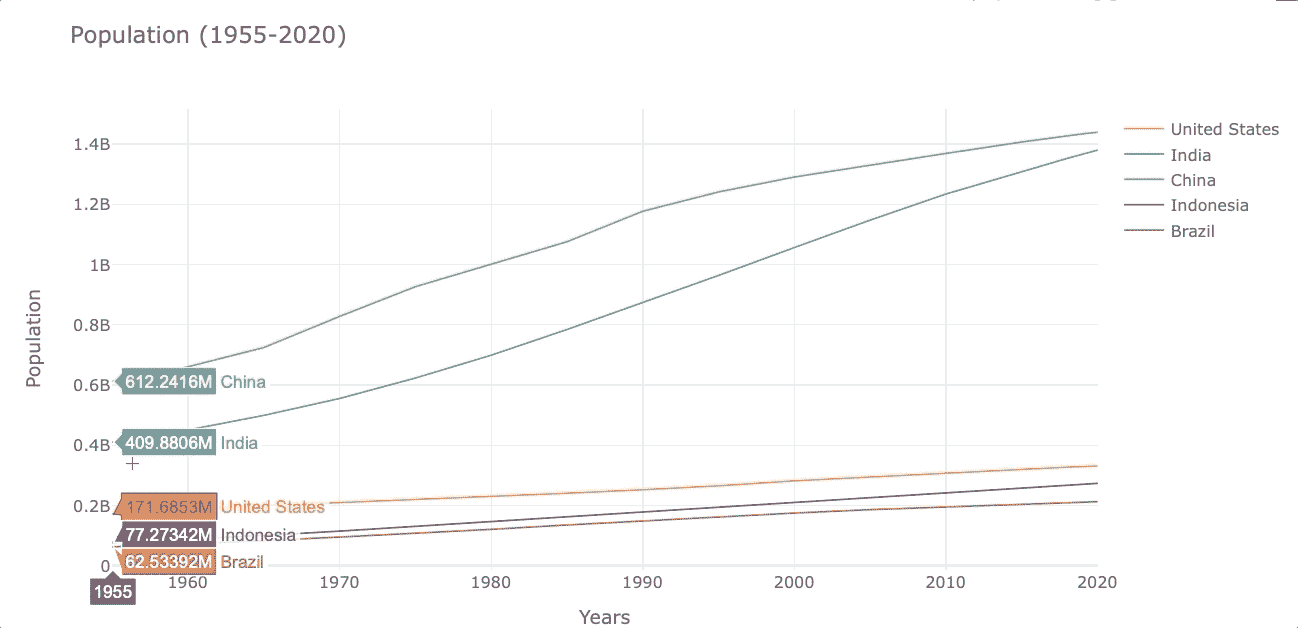
作者提供的图片
一眼看去,可以很容易看出印度的人口增长速度比其他国家快。
条形图
我们可以制作一个单独的条形图来展示按类别分组的条形图。我们来看看。
单个条形图
让我们创建一个条形图,展示每个国家到 2020 年的总人口。为此,首先,我们从索引中选择 2020 年,然后将行与列转置,以便将年份放入列中。我们将这个新的数据框命名为df_population_2020(我们在绘制饼图时还会用到这个数据框)
df_population_2020 = df_population[df_population.index.isin([2020])]
df_population_2020 = df_population_2020.T
现在我们可以用.iplot()来绘制这个新的数据框。在这种情况下,我将使用color参数将条形图颜色设置为浅绿色。
df_population_2020.iplot(kind='**bar**', color='lightgreen',
xTitle='Years', yTitle='Population',
title='Population in 2020')
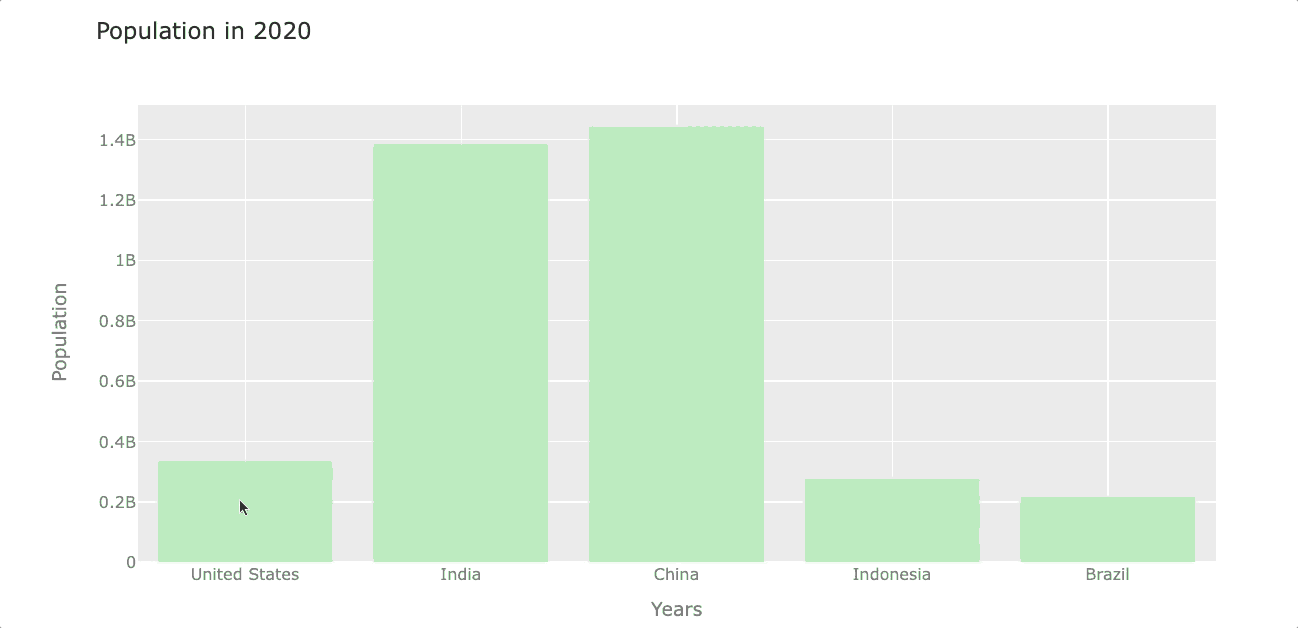
作者提供的图片
按“n”变量分组的条形图
现在让我们看看每个十年初的人口变化。
# filter years out
df_population_sample = df_population[df_population.index.isin([1980, 1990, 2000, 2010, 2020])]# plotting
df_population_sample.iplot(kind='**bar**', xTitle='Years',
yTitle='Population')
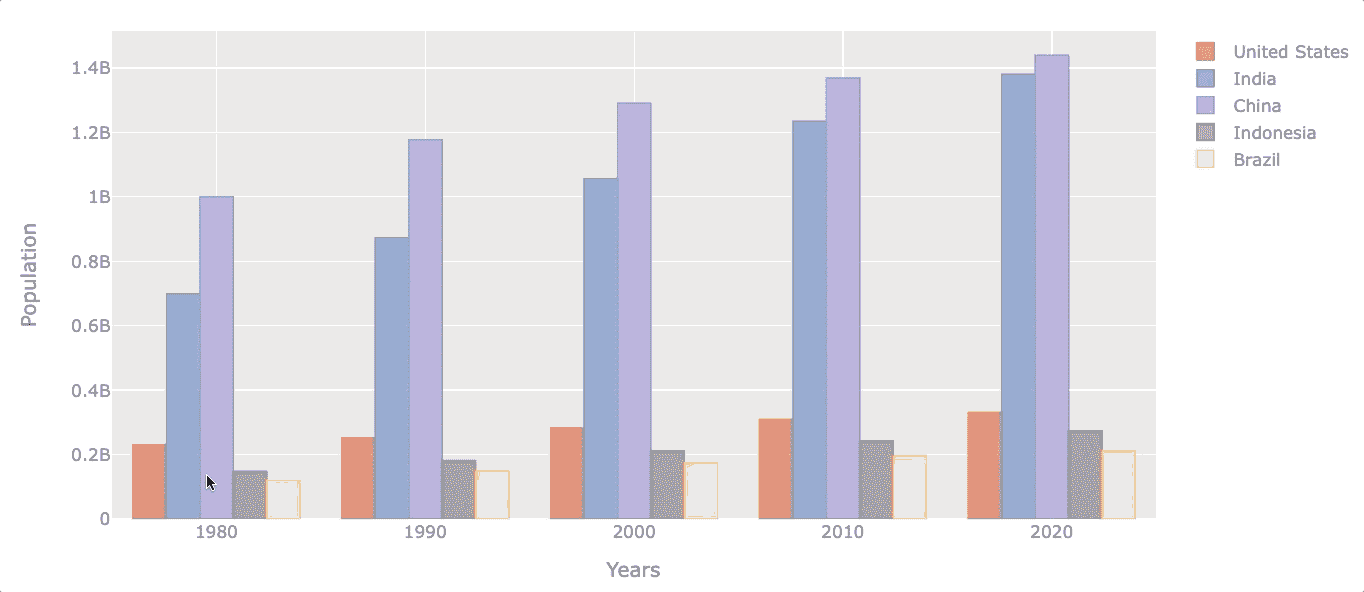
作者提供的图片
自然,所有国家的总人口都在这些年中增长了,但有些国家的增长速度更快。
箱形图
箱型图在我们想查看数据分布时非常有用。箱型图将揭示最小值、第一个四分位数(Q1)、中位数、第三个四分位数(Q3)和最大值。查看这些值的最简单方法是创建互动可视化。
让我们看看美国的人口分布。
df_population['United States'].iplot(kind='**box**', color='green',
yTitle='Population')
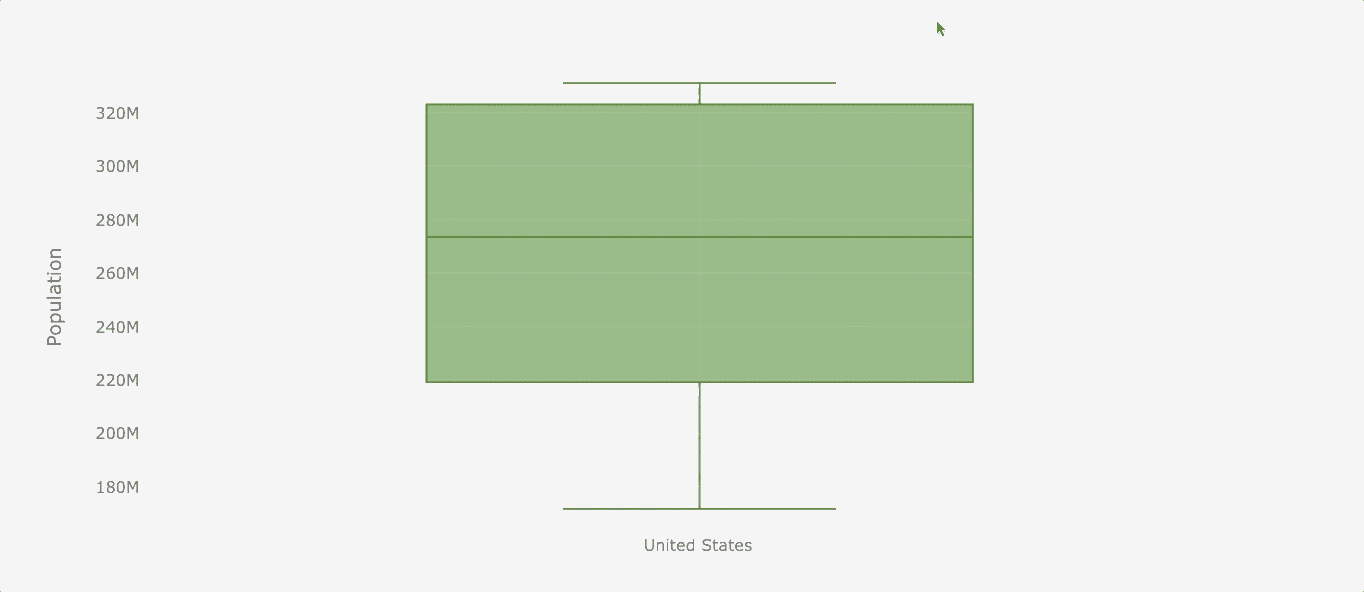
作者提供的图片
假设我们现在想获取所有选定国家的相同分布。
df_population.iplot(kind='**box**', xTitle='Countries',
yTitle='Population')
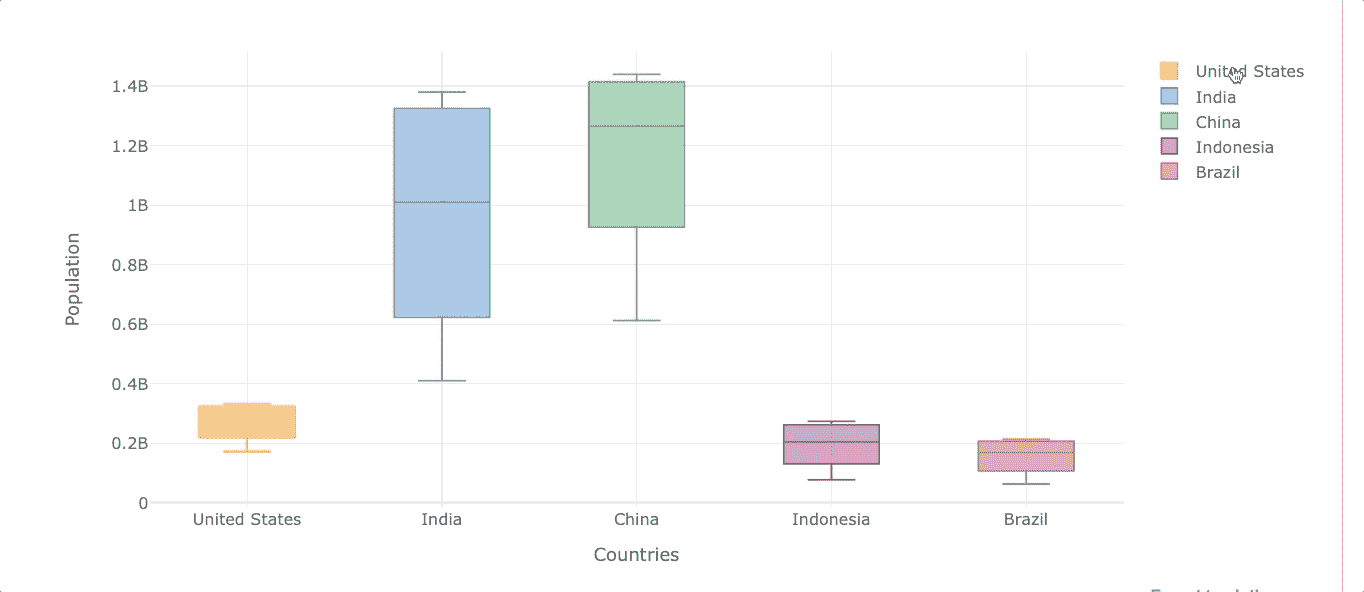
作者提供的图片
如我们所见,我们还可以通过点击右侧的图例来过滤任何国家。
直方图
直方图表示数值数据的分布。让我们看看美国和印度尼西亚的人口分布。
df_population[['United States', 'Indonesia']].iplot(kind='**hist**',
xTitle='Population')
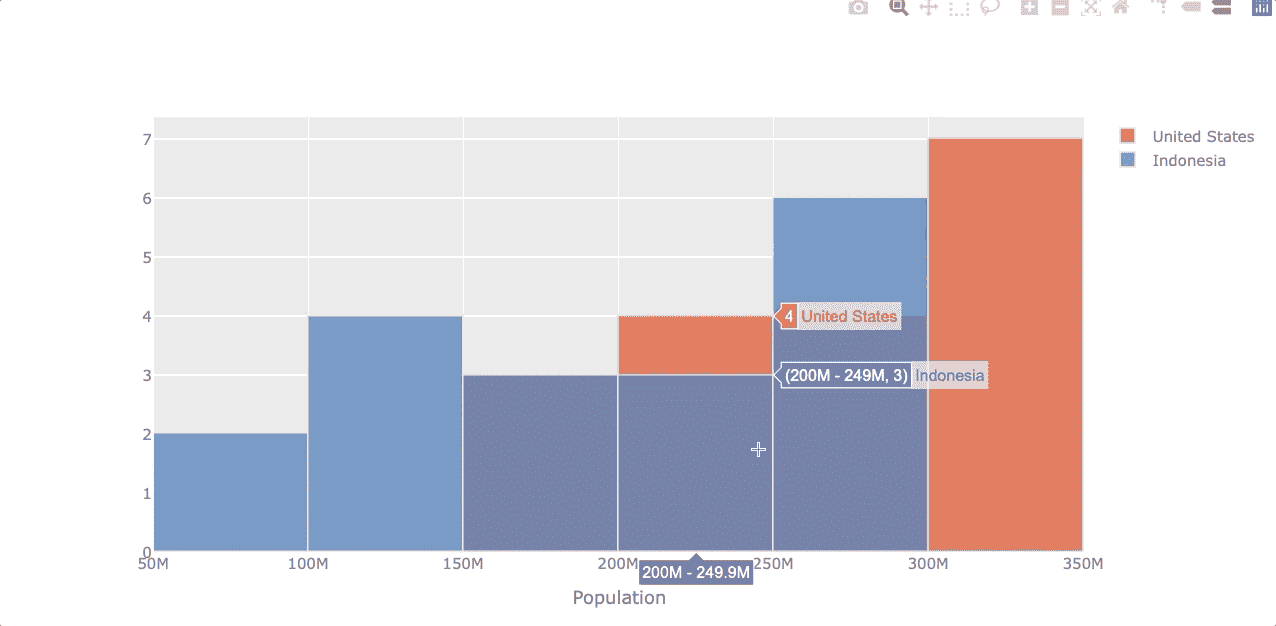
作者提供的图片
饼图
让我们再次比较 2020 年的人口数据,但这次使用饼图。为此,我们将使用在“单条柱状图”部分创建的df_population_2020数据框。
然而,为了制作饼图,我们需要将“国家”作为列而不是索引,因此我们使用.reset_index()来恢复列。然后我们将2020转换为字符串。
# transforming data
df_population_2020 = df_population_2020.reset_index()
df_population_2020 =df_population_2020.rename(columns={2020:'2020'})# plotting
df_population_2020.iplot(kind='**pie**', labels='country',
values='2020',
title='Population in 2020 (%)')
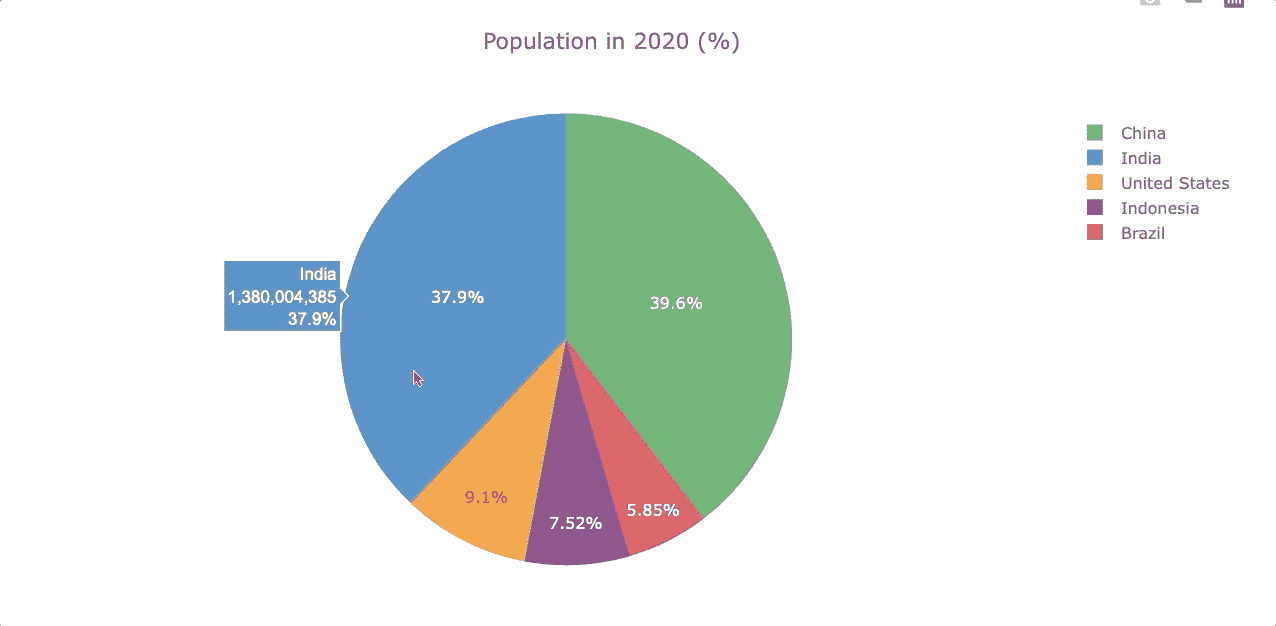
作者提供的图片
散点图
尽管人口数据不适合做散点图(数据遵循常见模式),但为了本指南的目的,我仍会制作这个图。
制作散点图类似于折线图,但我们必须添加mode参数。
df_population.iplot(kind='**scatter'**, **mode**='markers')
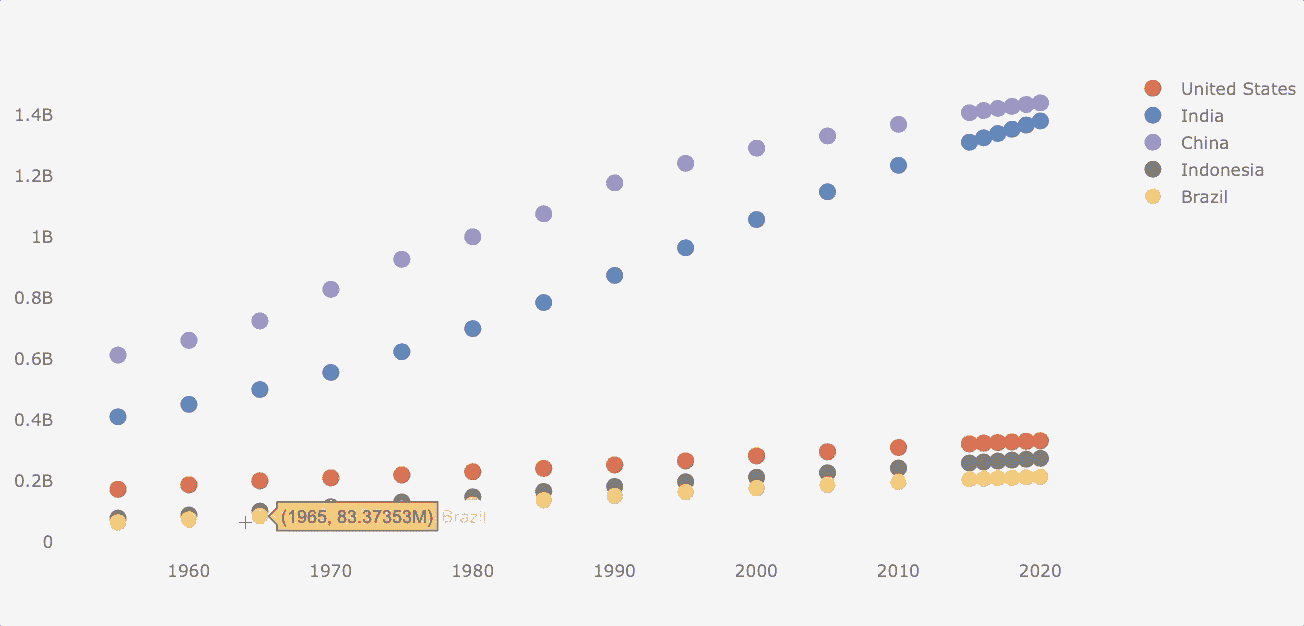
就这样!现在你已经准备好使用 Pandas 制作自己的美丽互动可视化。如果你想学习 Python 中其他可视化库,如 Matplotlib 和 Seaborn,并且还想了解如何制作词云,查看我制作的这些指南。
加入我的 3k+人邮件列表,获取我在所有教程中使用的 Python 数据科学备忘单(免费 PDF)
如果你喜欢阅读这样的故事并且想支持我作为作者,请考虑注册成为 Medium 会员。每月$5,你可以无限制访问成千上万的 Python 指南和数据科学文章。如果你通过我的链接注册,我将获得少量佣金,对你没有额外费用。
简历: Frank Andrade 是数据科学家,Python 教师,以及 Medium 上的前 1000 名作者。
原文。经许可转载。
了解更多相关内容
在本地运行 Llama 3 的最简单方法

图片来源:作者
在本地运行 LLM(大型语言模型)已变得越来越流行,因为它提供了安全性、隐私性和对模型输出的更多控制。在本教程中,我们将学习下载和使用 Llama 3 模型的最简单方法。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
Llama 3 是 Meta AI 最新的 LLM 家族。它是开源的,具有先进的 AI 能力,并且比 Gemma、Gemini 和 Claud 3 改进了响应生成。
什么是 Ollama?
Ollama/ollama 是一个开源工具,用于在本地计算机上使用像 Llama 3 这样的 LLM。通过新的研究和开发,这些大型语言模型不再需要大量的 VRam、计算或存储。相反,它们经过优化,可以在笔记本电脑上使用。
有多种工具和框架可以让您在本地使用 LLM,但 Ollama 是最容易设置和使用的。它允许您直接从终端或 Powershell 使用 LLM。它快速且具有核心功能,使您能够立即开始使用。
Ollama 的最佳部分是它可以与各种软件、扩展和应用程序集成。例如,您可以在 VScode 中使用 CodeGPT 扩展并连接 Ollama,以将 Llama 3 作为您的 AI 代码助手。
安装 Ollama
通过访问 GitHub 仓库 Ollama/ollama,向下滚动并点击适合您操作系统的下载链接来下载和安装 Ollama。
图片来自 ollama/ollama | 各种操作系统的下载选项
成功安装 Ollama 后,它将在系统托盘中显示如下图所示。
下载和使用 Llama 3
要下载 Llama 3 模型并开始使用它,您需要在终端/命令行中输入以下命令。
ollama run llama3
根据您的互联网速度,下载 4.7GB 模型大约需要 30 分钟。
除了 Llama 3 模型,你还可以通过输入下面的命令来安装其他 LLMs。
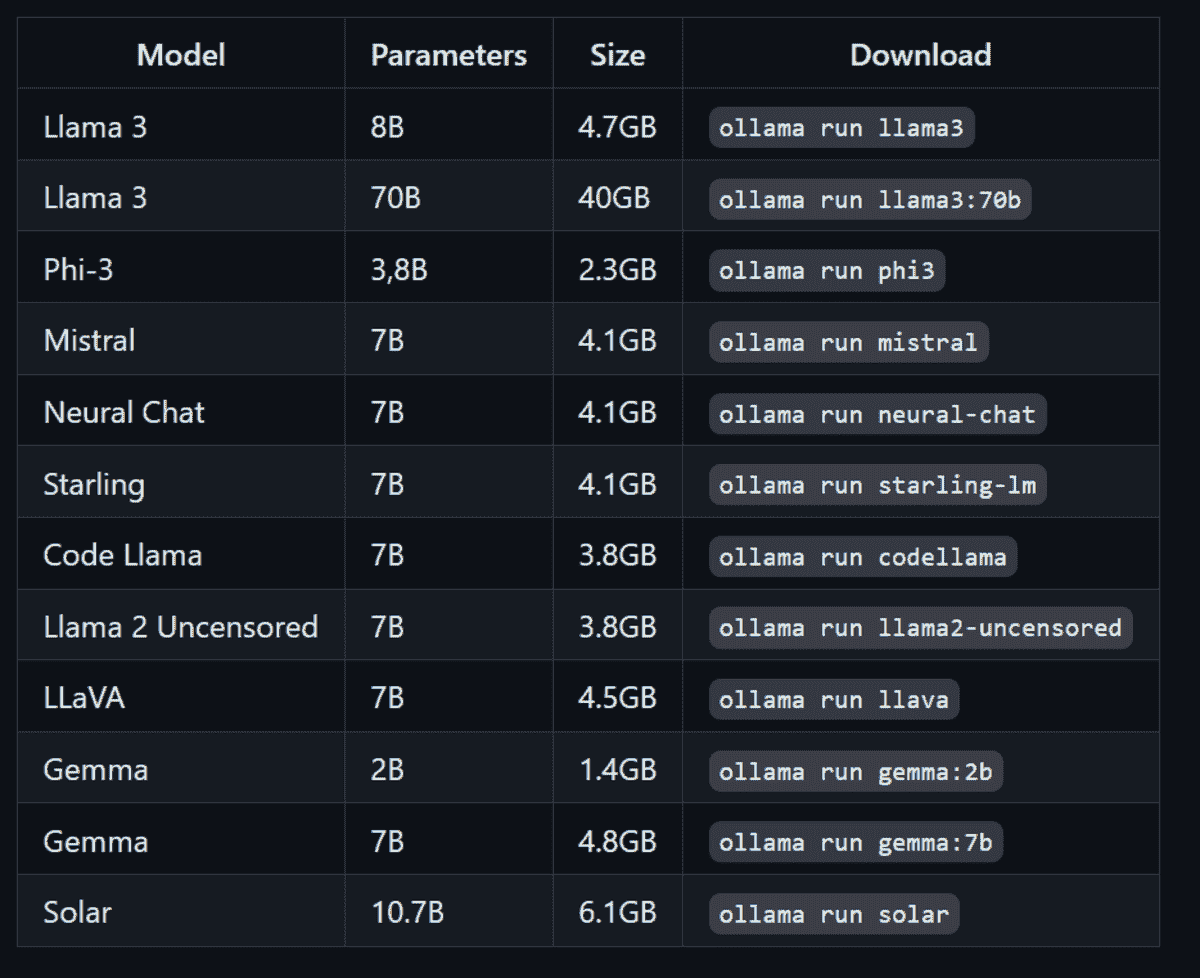
图片来自 ollama/ollama | 使用 Ollama 运行其他 LLMs
一旦下载完成,你就可以像在线使用一样在本地使用 LLama 3。
提示: “描述数据科学家的一天。”
为了展示响应生成的速度,我附上了一个 GIF,显示了 Ollama 生成 Python 代码并解释它的过程。
注意: 如果你的笔记本电脑上有 Nvidia GPU 和 CUDA 安装,Ollama 会自动使用 GPU 而不是 CPU 来生成响应。效果提高了 10 倍。
提示: “编写一个构建数字时钟的 Python 代码。”
你可以通过输入 /bye 来退出聊天,然后通过输入 ollama run llama3 重新开始。
最后的想法
开源框架和模型使 AI 和 LLMs 对每个人都变得可用。与少数公司控制不同,这些本地运行的工具如 Ollama 使任何拥有笔记本电脑的人都能使用 AI。
在本地使用 LLMs 提供了隐私、安全性以及对响应生成的更多控制。此外,你不需要支付任何服务费用。你甚至可以创建自己的 AI 驱动编码助手,并在 VSCode 中使用它。
如果你想了解其他在本地运行 LLMs 的应用程序,那么你应该阅读 在你的笔记本电脑上使用 LLMs 的 5 种方法。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一款 AI 产品,帮助那些在精神健康方面挣扎的学生。
更多相关内容
如何轻松部署机器学习模型使用 Flask
原文:
www.kdnuggets.com/2019/10/easily-deploy-machine-learning-models-using-flask.html
评论
当数据科学家/机器学习工程师使用 Scikit-Learn、TensorFlow、Keras、PyTorch 等开发机器学习模型时,最终目标是使模型能够投入生产。在机器学习项目中,我们往往会重点关注探索性数据分析(EDA)、特征工程、调整超参数等。然而,我们往往会忘记我们的主要目标,即从模型预测中提取实际价值。
机器学习模型的部署或将模型投入生产意味着使你的模型可供最终用户或系统使用。然而,机器学习模型的部署存在复杂性。本文旨在帮助你开始使用 Flask API 将训练好的机器学习模型投入生产。
我们的三大推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
我将使用线性回归根据利率和前两个月的销售额预测第三个月的销售额。
什么是线性回归
线性回归模型的目标是找到一个或多个特征(自变量)与连续目标变量(因变量)之间的关系。当只有一个特征时称为单变量线性回归,当有多个特征时称为多元线性回归。
线性回归假设
线性回归模型可以用以下方程表示
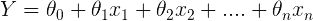
-
Y 是预测值
-
θ₀ 是偏置项。
-
θ₁,…,θₙ 是模型参数
-
x₁,x₂,…,xₙ 是特征值。
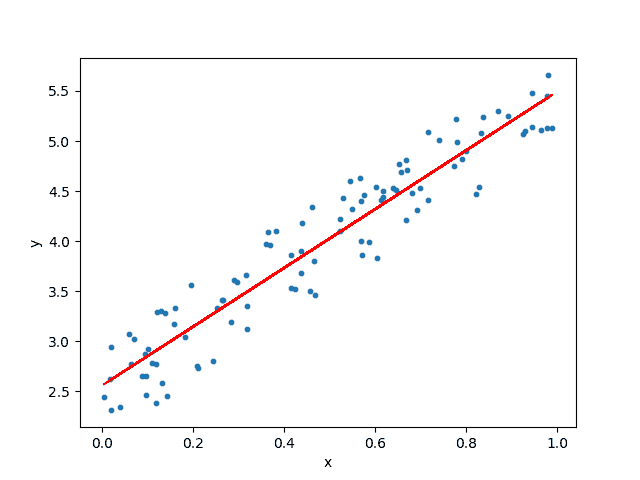
线性回归示意图
为什么选择 Flask?
-
易于使用。
-
内置开发服务器和调试器。
-
集成单元测试支持。
-
RESTful 请求调度。
-
有详尽的文档。
项目结构
本项目有四个部分:
-
model.py — 其中包含用于预测第三个月销售额的机器学习模型代码,基于前两个月的销售额。
-
app.py — 这包含 Flask API,通过 GUI 或 API 调用接收销售细节,基于我们的模型计算预测值并返回。
-
request.py — 这使用 requests 模块调用在 app.py 中定义的 API,并显示返回的值。
-
HTML/CSS — 这包含了 HTML 模板和 CSS 样式,以允许用户输入销售细节并在第三个月显示预测销售额。
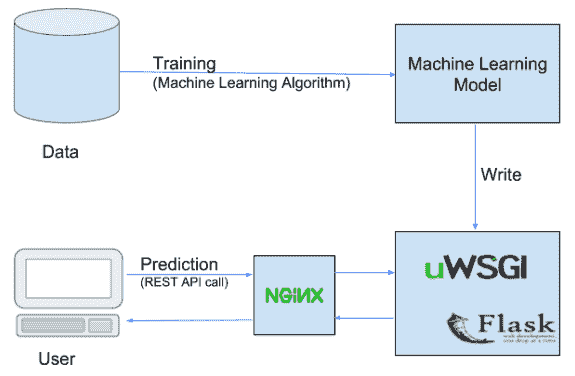
机器学习模型的部署管道
环境和工具
-
scikit-learn
-
pandas
-
numpy
-
flask
代码在哪里?
不多说,让我们开始代码吧。完整的项目可以在这里找到。
让我们开始使用 HTML 制作前端,以便用户输入值。用户需要填写三个字段——利率、第一月销售额和第二月销售额。
接下来,我使用 CSS 对输入按钮、登录按钮和背景进行了样式调整。
我为这个项目创建了一个自定义销售数据集,包含四列——利率、第一月销售额、第二月销售额和第三月销售额。
现在让我们制作一个机器学习模型来预测第三个月的销售额。首先,使用 Pandas 处理缺失值。当没有提供一个或多个项目的信息时,会出现缺失数据。我用零填充利率列,如果未提供第一月的销售额,则用该列的均值填充。我使用了线性回归作为机器学习算法。
序列化/反序列化
简单来说,序列化是一种将 python 对象写入磁盘的方法,可以传输到任何地方,后来由 python 脚本反序列化(读取)回来。
序列化,反序列化
我将模型从 python 对象的形式转换为字符流,使用 pickle。这个字符流包含了重建对象所需的所有信息,可以在另一个 python 脚本中进行重建。
下一步是创建一个 API,该 API 通过 GUI 接收销售细节,并根据我们的模型计算预测的销售值。为此,我将 pickle 模型反序列化为 python 对象。我使用index.html设置了主页。在使用 POST 请求提交表单值到/predict时,我们得到预测的销售值。
结果可以通过向/results发出另一个 POST 请求来显示。它接收 JSON 输入,使用训练好的模型进行预测,并以 JSON 格式返回该预测,可以通过 API 端点访问。
最后,我使用 requests 模块调用app.py中定义的 API。它显示第三个月返回的销售值。
结果
使用以下命令运行 Web 应用程序。
$ python app.py
在你的网页浏览器中打开 127.0.0.1:5000/,并且应出现如下所示的图形用户界面。

图形用户界面
结论
这篇文章展示了一种非常简单的机器学习模型部署方式。我使用线性回归来预测第三个月的销售值,依据是利率和前两个月的销售额。你可以运用在这篇博客中获得的知识,创建一些很酷的模型并将其投入生产,以便让他人欣赏你的工作。
参考文献/进一步阅读
开始使用 Flask 的示例教程
从加州大学圣地亚哥分校学习机器学习模型的部署。在本课程中,我们将学习……
使用简单的技术栈将你的第一个机器学习模型投入生产
机器学习模型在生产中部署的不同方法概述 - KDnuggets
有不同的方法将模型投入生产,每种方法的优点可能有所不同……
离开之前
对应的源代码可以在这里找到。
从数据收集到将模型投入生产的完整示例项目……
联系方式
如果你想及时了解我的最新文章和项目,请在 Medium 上关注我。以下是我的一些联系信息:
简历:Abhinav Sagar 是 VIT Vellore 的大四本科生。他对数据科学、机器学习及其在现实世界问题中的应用感兴趣。
原文。经许可转载。
相关:
-
构建一个 Flask API 来自动提取命名实体,使用 SpaCy
-
将您的 PyTorch 模型部署到生产环境
-
为有志数据科学家准备的黑客马拉松指南
更多相关话题
轻松将 LLMs 集成到你的 Scikit-learn 工作流中,使用 Scikit-LLM
原文:
www.kdnuggets.com/easily-integrate-llms-into-your-scikit-learn-workflow-with-scikit-llm

由 DALL-E 2 生成的图像
文本分析任务已经存在了一段时间,因为需求始终存在。研究从简单的描述统计到文本分类和高级文本生成已经取得了很大进展。随着大型语言模型的加入,我们的工作任务变得更加轻松。
我们的前三个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业生涯。
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你的组织 IT
Scikit-LLM 是一个为文本分析活动开发的 Python 软件包,利用 LLM 的强大功能。这个软件包之所以突出,是因为我们可以将标准的 Scikit-Learn 管道与 Scikit-LLM 集成。
那么,这个软件包是关于什么的?它是如何工作的?让我们深入了解。
Scikit-LLM
Scikit-LLM是一个通过 LLM 增强文本数据分析任务的 Python 软件包。它由Beatsbyte开发,旨在帮助桥接标准的 Scikit-Learn 库和语言模型的强大功能。Scikit-LLM 创建了类似于 SKlearn 库的 API,因此我们使用起来不会太麻烦。
安装
要使用该软件包,我们需要安装它们。为此,你可以使用以下code。
pip install scikit-llm
在撰写本文时,Scikit-LLM 仅与一些 OpenAI 和 GPT4ALL 模型兼容。这就是为什么我们只会使用 OpenAI 模型的原因。不过,你可以通过首先安装组件来使用 GPT4ALL 模型。
pip install scikit-llm[gpt4all]
安装后,你必须设置 OpenAI 密钥以访问 LLM 模型。
from skllm.config import SKLLMConfig
SKLLMConfig.set_openai_key("<your_key>")
SKLLMConfig.set_openai_org("<your_organisation>")</your_organisation></your_key>
尝试使用 Scikit-LLM
让我们在环境设置好后尝试一些 Scikit-LLM 的功能。LLMs 的一项能力是执行文本分类而无需重新训练,这被称为 Zero-Shot。然而,我们将首先使用样本数据尝试 Few-Shot 文本分类。
from skllm import ZeroShotGPTClassifier
from skllm.datasets import get_classification_dataset
#label: Positive, Neutral, Negative
X, y = get_classification_dataset()
#Initiate the model with GPT-3.5
clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo")
clf.fit(X, y)
labels = clf.predict(X)
你只需在 X 变量中提供文本数据,在数据集中提供标签 y。在这种情况下,标签包括情感,可能是 Positive、Neutral 或 Negative。
如你所见,这个过程类似于使用 Scikit-Learn 包中的拟合方法。然而,我们已经知道 Zero-Shot 并不一定需要训练数据集。这就是为什么我们可以在没有训练数据的情况下提供标签。
X, _ = get_classification_dataset()
clf = ZeroShotGPTClassifier()
clf.fit(None, ["positive", "negative", "neutral"])
labels = clf.predict(X)
这也可以扩展到多标签分类的情况,你可以在以下代码中看到。
from skllm import MultiLabelZeroShotGPTClassifier
from skllm.datasets import get_multilabel_classification_dataset
X, _ = get_multilabel_classification_dataset()
candidate_labels = [
"Quality",
"Price",
"Delivery",
"Service",
"Product Variety",
"Customer Support",
"Packaging",,
]
clf = MultiLabelZeroShotGPTClassifier(max_labels=4)
clf.fit(None, [candidate_labels])
labels = clf.predict(X)
Scikit-LLM 的神奇之处在于,它允许用户将 LLM 的力量扩展到典型的 Scikit-Learn 流水线中。
Scikit-LLM 在 ML 流水线中的应用
在下一个示例中,我将展示如何将 Scikit-LLM 作为向量化器来初始化,并使用 XGBoost 作为模型分类器。我们还将把这些步骤封装到模型流水线中。
首先,我们将加载数据并启动标签编码器,将标签数据转换为数值。
from sklearn.preprocessing import LabelEncoder
X, y = get_classification_dataset()
le = LabelEncoder()
y_train_enc = le.fit_transform(y_train)
y_test_enc = le.transform(y_test)
接下来,我们将定义一个流水线来执行向量化和模型拟合。我们可以使用以下代码来完成。
from sklearn.pipeline import Pipeline
from xgboost import XGBClassifier
from skllm.preprocessing import GPTVectorizer
steps = [("GPT", GPTVectorizer()), ("Clf", XGBClassifier())]
clf = Pipeline(steps)
#Fitting the dataset
clf.fit(X_train, y_train_enc)
最后,我们可以使用以下代码来进行预测。
pred_enc = clf.predict(X_test)
preds = le.inverse_transform(pred_enc)
如我们所见,我们可以在 Scikit-Learn 流水线下使用 Scikit-LLM 和 XGBoost。结合所有必要的包将使我们的预测更加强大。
使用 Scikit-LLM 还有各种任务可以完成,包括模型微调,我建议你查看文档以进一步了解。如果需要,你还可以使用 GPT4ALL 的开源模型。
结论
Scikit-LLM 是一个 Python 包,利用 LLM 强化 Scikit-Learn 文本数据分析任务。在这篇文章中,我们讨论了如何使用 Scikit-LLM 进行文本分类,并将其结合到机器学习流水线中。
Cornellius Yudha Wijaya** 是一名数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 涉及各种 AI 和机器学习主题的撰写工作。
更多相关话题
Python 中的轻松 AutoML
评论
作者:迪伦·谢里,EvalML 团队负责人

Alteryx 托管两个开源建模项目。
Featuretools 是一个执行自动特征工程的框架。它擅长将时间序列和关系数据集转换为机器学习的特征矩阵。
Compose 是一个用于自动化预测工程的工具。它允许你结构化预测问题并生成监督学习的标签。
我们看到 Featuretools 和 Compose 使用户能够轻松将多个表组合成转换和汇总的特征用于机器学习,并定义时间序列的监督学习用例。
我们接着问的问题是:接下来会发生什么?Featuretools 和 Compose 的用户如何以简单且灵活的方式构建机器学习模型?
我们很高兴宣布一个新的开源项目加入了 Alteryx 开源生态系统。EvalML 是一个用于自动化机器学习(AutoML)和模型理解的库,使用 Python 编写。
import evalml
# obtain features, a target and a problem type for that target
X, y = evalml.demos.load_breast_cancer()
problem_type = 'binary'
X_train, X_test, y_train, y_test = evalml.preprocessing.split_data(
X, y, problem_type=problem_type, test_size=.2)
# perform a search across multiple pipelines and hyperparameters
automl = AutoMLSearch(X=x, y=y, problem_type=problem_type)
automl.search()
# the best pipeline is already refitted on the entire training data
best_pipeline = automl.best_pipeline
best_pipeline.predict(X_test)

EvalML 的 AutoML 搜索实操
EvalML 提供了一个简单、统一的界面,用于构建机器学习模型,使用这些模型生成洞察并进行准确预测。EvalML 提供了一个统一 API 访问多个建模库。EvalML 支持各种监督学习问题类型,包括回归、二分类和多分类。自定义目标函数让用户能够直接按他们重视的标准来搜索模型。最重要的是,我们的目标是使 EvalML 稳定且高效,每个版本都有机器学习性能测试。
EvalML 的亮点
1. 简单统一的建模 API
EvalML 减少了获得准确模型所需的工作量,从而节省时间和复杂性。
EvalML 由 AutoML 生成的管道包括开箱即用的预处理和特征工程步骤。一旦用户确定了他们希望建模的数据的目标列,EvalML 的 AutoML 将运行搜索算法来训练和评分一组模型,使用户能够从中选择一个或多个模型,并使用这些模型进行洞察驱动的分析或生成预测。
EvalML 设计时考虑了与 Featuretools 的良好兼容性,Featuretools 能够集成来自多个表的数据并生成特征,从而提升 ML 模型的性能,还兼容 Compose,这是一个用于标签工程和时间序列聚合的工具。EvalML 用户可以轻松控制 EvalML 如何处理每个输入的特征,如数值特征、分类特征、文本、日期时间等。

你可以将 Compose 和 Featuretools 与 EvalML 一起使用来构建机器学习模型。
EvalML 模型通过管道数据结构表示,管道由组件图组成。AutoML 对数据应用的每个操作都记录在管道中。这使得从选择模型到部署模型变得简单。同时,定义自定义组件、管道和目标在 EvalML 中也很容易,无论是用于 AutoML 还是作为独立元素。
2. 特定领域的目标函数
EvalML 支持定义自定义目标函数,可以根据你的数据和领域进行调整。这使你能够明确模型在你的领域中有价值的标准,然后使用 AutoML 找到提供这些价值的模型。
自定义目标用于在 AutoML 排行榜上对模型进行排名,帮助引导 AutoML 搜索出影响最大的模型。自定义目标还将被 AutoML 用于调整二分类模型的分类阈值。
EvalML 文档提供了 自定义目标示例 及其有效使用方法。
3. 模型理解
EvalML 提供了多种模型和工具用于模型理解。目前支持的功能包括特征重要性和置换重要性、部分依赖、精确率-召回率、混淆矩阵、ROC 曲线、预测解释和二分类器阈值优化。

来自 EvalML 文档 的部分依赖示例
4. 数据检查
EvalML 的数据检查可以在建模之前捕捉到数据中的常见问题,防止它们导致模型质量问题或神秘的错误和堆栈跟踪。当前的数据检查包括检测 目标泄漏 的简单方法,其中模型在训练期间获得了在预测时不可用的信息,检测无效数据类型、高类别不平衡、高空值列、常量列以及可能是 ID 且对建模无用的列。

开始使用 EvalML
你可以通过访问 我们的文档页面来开始使用 EvalML,我们提供了 安装说明以及 教程,这些教程展示了如何使用 EvalML 的示例,还有 用户指南介绍 EvalML 的组件和核心概念, API 参考等。EvalML 代码库位于 github.com/alteryx/evalml。如需与团队联系,请查看我们的 开源 Slack。我们正在积极维护代码库,并会对你提交的问题作出回应。
接下来是什么?
EvalML 有一个活跃的功能发展路线图,包括时间序列建模、AutoML 期间管道的并行评估、AutoML 算法的升级、新的模型类型和预处理步骤、模型调试和模型部署工具、异常检测支持等等。
想了解更多?如果你有兴趣在项目继续更新时获得通知,请花点时间关注这个博客,给 我们的 GitHub 仓库点个星,敬请期待更多即将发布的功能和内容!
个人简介: Dylan Sherry 是一名软件工程师,领导团队开发 EvalML AutoML 包。Dylan 在自动建模技术方面拥有十年的经验。
原文。经允许转载。
相关内容:
-
Uber 开源 Ludwig 的第三个版本,它是一个无代码机器学习平台
-
高级超参数优化/调整算法
-
使用 PyCaret 2.0 构建你自己的 AutoML
我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 维护
更多相关主题
Python 数据预处理简易指南
原文:
www.kdnuggets.com/2020/07/easy-guide-data-preprocessing-python.html

图片来源于 rawpixel.com 在 Freepik 上
机器学习中 80%是数据预处理,20%是模型制作。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
如果你曾遇到过高级 Kaggle 数据科学家或机器学习工程师,你一定听过这个说法。事实上,这句话是正确的。在真实的数据科学项目中,数据预处理是最重要的工作之一,它也是模型成功的共同因素之一。也就是说,如果数据预处理和特征工程做得正确,该模型更可能产生显著更好的结果,而相比之下,数据没有经过良好预处理的模型效果会较差。
重要步骤
数据预处理有 4 个主要的关键步骤。
-
数据集的训练和验证集拆分
-
处理缺失值
-
处理分类特征
-
数据集的归一化
让我们来看看这些要点。
1. 训练测试拆分
训练测试拆分是机器学习中一个重要的步骤。这一点非常重要,因为你的模型需要在部署之前进行评估。而这种评估需要在未见过的数据上进行,因为一旦部署,所有接收到的数据都是未见过的。
训练测试拆分的主要思想是将原始数据集转换为两个部分
-
train
-
test
其中训练集包括训练数据和训练标签,而测试集包括测试数据和测试标签。
最简单的方法是使用scikit-learn,它有一个内置函数train_test_split。让我们编写代码。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
在这里,我们传入了X和y作为train_test_split中的参数,这样会将X和y拆分为 20%的测试数据和 80%的训练数据,并成功分配到X_train、X_test、y_train和y_test中。
2. 处理缺失值
有一个著名的机器学习说法,你可能听过,那就是
垃圾进,垃圾出
如果你的数据集中充满了 NaN 和垃圾值,那么你的模型表现也肯定会很差。因此,处理这些缺失值非常重要。我们可以用一个示例数据集来看一下如何解决这个垃圾值问题。你可以在这里获取该数据集。
让我们查看数据集中的缺失值。
df.isna().sum()
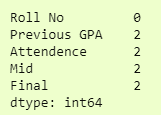
在这里,我们可以看到 4 列中有 2 个缺失值。一种填补缺失值的方法是用该列的均值来填补,即该列的平均值。例如,我们可以用Final列中所有学生的平均值来填补缺失值。
为此,我们可以使用SimpleImputer来自sklearn.impute。
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(fill_value=np.nan, startegy='mean')
X = imputer.fit_transform(df)
这将使用mean填补数据框df中的所有缺失值。我们使用fit_transform函数来做到这一点。
因为它返回的是一个 numpy 数组,我们可以将其转换回数据框以读取。
X = pd.DataFrame(X, columns=df.columns)
print(X)
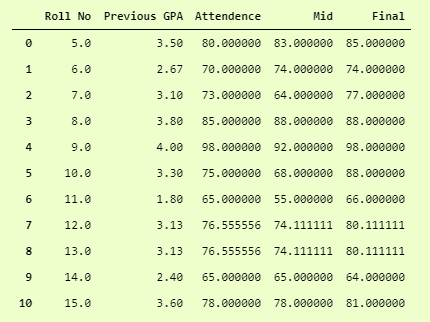
现在,我们可以看到我们已经用所有值的均值填补了所有缺失值。
我们可以通过以下方法确认
X.isna().sum()
输出结果为
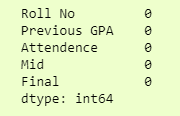
我们可以在SimpleImputer中使用mean、median、mode等。
如果我们有缺失值的行数较少,或者我们的数据不建议填补缺失值,那么我们可以使用pandas中的dropna来删除缺失行。
dropedDf = df.dropna()
在这里,我们删除了数据框中的所有空行,并将其存储到另一个数据框中。
现在我们已经删除了所有的空行,所以行数为 0。我们可以确认这一点为
dropedD.isna().sum()
3. 处理分类特征
我们可以通过将分类特征转换为整数来处理它们。有两种常见的方法来实现。
-
标签编码
-
一键编码
在标签编码器中,我们可以将分类值转换为数值标签。假设这是我们的数据集
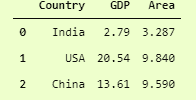
使用标签编码器处理 Country 列将把印度转换为 1,美国转换为 2,中国转换为 0。这种技术有一个缺点,它由于标签值高而将美国优先级最高,将中国标签为 0,因此中国优先级最低,但它在很多情况下仍然非常有用。
让我们开始编码吧。
from sklearn.preprocessing import LabelEncoder
l1 = LabelEncoder()
l1.fit(catDf['Country'])
catDf.Country = l1.transform(catDf.Country)
print(catDf)
标签编码器后的输出
在这里,我们实例化了一个 LabelEncoder 对象,然后使用fit方法将其拟合到我们的分类列上,接着使用transform方法进行应用。
请注意,它不是 inplace 的,因此为了使更改永久生效,我们必须将值返回到我们的分类列中,即,
catDf['Country'] = l1.transform(catDf['Country'])
在 OneHotEncoder 中,我们为每个唯一的分类值创建一列,如果实际数据框中存在该值,则该列的值为 1,否则为 0。
让我们看一下相同的示例,但稍作修改。我们将添加另一列分类数据,即“Continent”,它包含了相应国家的大陆名称。我们可以通过
catDf['Continent'] = ['Asia', 'North America', 'Asia']
现在由于我们有 2 个分类列,即 *[['Country', 'Continent']] *,我们可以对它们进行 one-hot 编码。
有两种方法可以做到这一点。
1. DataFrame.get_dummies
这是一种相当常见的方法,我们使用 pandas 内置的 get_dummies 函数将数据框中的分类值转换为 one-hot 向量。
让我们开始吧。
pd.get_dummies(data=catDf)
这将 返回 一个数据框,所有的分类值都以 one-hot 向量格式编码。

在这里我们可以看到,它将 Country 列的唯一值转换为 3 列,分别是 Country_China、Country_India 和 Country_USA。类似地,Continent 列的 2 个唯一值已被转换为 2 列,分别命名为 Continent_Asia 和 Continent_North America。
因为它不是就地操作的,我们必须将其存储在数据框中,即,
catDf = pd.get_dummies(data=catDf)
2. OneHotEncoder
使用 Sci-Kit Learning 的 OneHotEncoder 也是一种常见的做法。它提供了更多的灵活性和选项,但使用起来有点复杂。让我们看看如何在我们的数据集上实现它。
from sklearn.preprocessing import OneHotEncoder
oh = OneHotEncoder()
s1 = pd.DataFrame(oh.fit_transform(catDf.iloc[:, [0,3]]))
pd.concat([catDf, s1], axis=1)
在这里,我们初始化了 OneHotEncoder 对象,并在数据框中对我们所需的列(列号 0 和列号 3)使用了它的 fit_transform 方法。
fit_transform 的返回类型是 numpy.ndarray,因此我们将其转换为数据框 pd.DataFrame 并存储在一个变量中。然后,为了将其加入到原始数据框中,我们可以使用 pd.concat 函数,它用于连接两个不同的数据框。我们使用了 axis=1,这意味着它将基于列而不是行进行连接。
另外,请记住 pd.concat 不是 inplace 的,因此我们必须将返回的数据框存储在某个地方。
catDf = pd.concat([catDf, s1], axis=1)
得到的 dataframe 是
OneHotEncoded DataFrame
你可以看到,与 pd.get_dummies 相比,它的可读性不那么清晰,但如果你比较最后 5 列,我们使用 pd.get_dummies 和 OneHotEncoder 得到的结果,它们是相等的。
当然,你可以根据自己的需要在 OneHotEncoder 中修改列名,你可以通过 这个 问题在 StackOverflow 上学习如何操作。
4. 数据集归一化
这将我们带到了数据预处理的最后部分,即数据集的标准化。通过某些实验已证明,机器学习和深度学习模型在标准化数据集上的表现远远优于未标准化的数据集。
标准化的目标是将值更改为统一的尺度,而不扭曲值范围之间的差异。
有几种方法可以实现。我将讨论两种常见的标准化数据集的方法。
标准化器
参考: stackoverflow.com/a/50879522/10342778
使用这种技术,我们的数据集将具有均值 0 和标准差 1。我们可以通过结合 numpy 中的不同函数来实现这一点,即,
z = (x.values - np.mean(x.values)) / np.std(x.values)
其中 x 是一个包含所有数值索引的数据框。如果我们希望保留数据框中的值,那么我们可以简单地去掉 .values。
StandardScaler 之前的方差
catDf.var(ddof=0)

StandardScaler 之前的方差。
这里,我使用了ddof=0,默认情况下在pandas.DataFrame.var()中为 1,而在numpy.ndarray.var()中为 0。Ddof 表示自由度的增量,计算中使用的除数是N - ddof,其中N表示元素的数量。
ddof=0 为正态分布变量提供了方差的最大似然估计。
你可以在这里阅读更多关于ddof=0的内容。
StandardScaler 后的方差
另一种好的方法是使用来自sklearn.preprocessing的StandardScaler。让我们先看代码,然后再查看方差。
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
catDf.iloc[:,1:-1] = ss.fit_transform(catDf.iloc[:,1:-1])
print(catDf)
StandardScaler 后的 catDf。
在这里,我们对所有数值列(从第 1 列到最后一列(不包括))应用了StandardScaler,现在你可以看到GDP和Area的值。
现在我们可以通过 方差 来检查数据集的变异性
catDf.var(ddof=0)

StandardScaler 后的方差
我们可以看到方差从 80 和 13 大幅降低到 1。在现实世界的数据集中,通常改善从几千降到 1。
标准化
根据sklearn 官方文档,标准化是“将个体样本缩放到单位范数的过程。如果你计划使用二次形式如点积或其他内核来量化任何样本对的相似性,这个过程可能会有用。”
使用它的过程非常简单,类似于 StandardScaler。
from sklearn.preprocessing import Normalizer
norm = Normalizer()
catDf.iloc[:,1:-1] = norm.fit_transform(catDf.iloc[:,1:-1])
catDf

使用归一化器后的 catDf
还有几种其他的数据归一化方法,它们在特定情况下都非常有用。你可以在官方文档中了解更多信息,点击这里。
学习成果
-
划分数据集
-
填充缺失值
-
处理分类数据
-
数据集的归一化以提高结果
希望这些技巧能提升你作为数据科学家或机器学习工程师的一般技能,并改进你的机器学习模型。
Ahmad Anis 对机器学习、深度学习和计算机视觉感兴趣。目前在 Redbuffer 担任初级机器学习工程师。
更多相关话题


 浙公网安备 33010602011771号
浙公网安备 33010602011771号