KDNuggets-博客中文翻译-十四-
KDNuggets 博客中文翻译(十四)
原文:KDNuggets
数据科学家职位薪资分析
原文:
www.kdnuggets.com/2023/04/data-scientist-job-salaries-analysis.html

图片来源:Tima Miroshnichenko
数据科学和机器学习在运动、艺术、空间、医学、医疗保健等多个领域越来越受到关注。了解这些数据科学家在全球不同地区的薪资和就业现状将会很有启发性。
我们的前三课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
 2. 谷歌数据分析专业证书 - 提升您的数据分析能力
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
数据集下载自 Kaggle(链接见下方),我们将对数据进行探索性分析和可视化。www.kaggle.com/datasets/ruchi798/data-science-job-salaries
数据集根据经验水平分为以下几类:
-
EN: 入门级
-
MI: 中级
-
SE: 高级
-
EX: 高级管理层
数据集根据就业类型分为以下几类:
-
FT: 全职
-
PT: 兼职
-
CT: 合同制
-
FL: 自由职业者
数据集根据公司规模分为以下几类:
-
S: 小型
-
M: 中级
-
L: 大型
探索性分析与可视化
在本节中,我们将对给定的数据集进行探索性数据分析和可视化。以下项目在议程上:
-
经验水平的分布
-
工作类型的分布
-
基于经验水平的数据科学职位薪资比较
-
基于就业类型的数据科学职位薪资比较
-
基于经验水平和公司规模的薪资比较
-
比较全球数据科学家的薪资
-
平均薪资与货币的关系
-
平均薪资与地点的关系
-
前 10 名数据科学职位
-
远程工作状态与时间的关系
数据集中,14.5%的成员为应届生,而大部分名额由高级工程师填补,占 46.1%。
在 2020 至 2022 年期间,62.8%的成员因 Covid-19 危机转为居家工作模式。稍后,我们将看到这一趋势回归正常。
自然可以看出,经验越丰富,薪资也越高。然而,在最高的执行级别,薪资的变动幅度明显大于其他级别。
看起来合同制工作在所有类型的工作中收入最高,尽管其薪资变动幅度也很大。一个有趣的观察是,自由职业者的收入高于兼职工作者,但其薪资变动几乎是成比例的。
在之前的‘经验水平’与‘薪资’图表中添加‘公司规模’这一维度可以揭示更多信息。高级职位的薪资平均与执行级别薪资相符。此外,小公司的高级职位薪资平均几乎与相应公司规模的执行级别薪资一致。
通过对薪资列求和,我们得到的数据非常偏向于美国。这可能是因为许多数据科学职位都在美国创建,数据主要在美国收集,或者数据收集表单可能是英文的,并且该表单可能在非英语国家流传。然而,为了线性化数据,我们将对薪资列进行 log10 转换,并使用这些缩放值来绘制地图的颜色。
薪资总和可能不是一个正确的比较指标,因为某些国家的条目可能比其他国家更多。因此我们绘制了保持 log10 缩放的平均薪资图。这能更好地反映全球薪资情况。
可以观察到大多数数据科学职位在美国,并且美国的薪资也最高。加拿大(CA)、日本(JP)、德国(DE)、英国(GB)、西班牙(ES)、法国(FR)、希腊(GR)和印度(IN)在职位薪资和数量方面依次排名(日本除外)。
将平均薪资作为货币的函数进行分析显示,薪资最高的是以美元支付,其次是瑞士法郎和新加坡元。这个图表受到特定货币价值的严重影响,因为图表左侧的大多数货币相对于美元具有较高的价值。
公司的位置在确定平均薪资方面也起着至关重要的作用。根据平均薪资绘制了前 10 个国家。
可以观察到数据科学家是最常见的职位,其次是数据工程师和数据分析师。
由于 Covid-19 危机,大多数工作转向了在家办公模式,但随着疫苗的推出,一切开始恢复正常。
推论与结论
对给定的数据科学职位薪资数据集进行了详细的数据分析。可以得出以下结论:
-
数据科学是几乎所有行业中最受欢迎和新兴的领域之一,如医疗保健、体育、艺术等。
-
探索了全球数据科学家的平均薪资变动情况。
-
薪资在不同雇佣类型(如合同制、全职等)之间的变化非常关键。
-
随着经验的增长,薪资的变化呈上升曲线。
-
由于新冠疫情危机,工作环境从在家工作转回到正常状态。
参考文献与未来工作
所有有用的链接如下:
Nikhil Purao 目前在印度理工学院古瓦哈提分校攻读技术硕士学位,专注于数据与决策科学。作为一名人工智能爱好者,他热衷于利用先进的分析技术和人工智能推动业务增长和改善结果。通过学习,他对该领域最新的工具和技术有了深入了解,并致力于保持在这一激动人心的学科前沿。无论是从复杂数据集中挖掘关键见解,还是开发前沿解决方案,他总是渴望迎接新挑战并与他人合作以取得成功。
原文。经许可转载。
更多相关话题
数据科学家是适合你的职业道路吗?坦诚的建议
原文:
www.kdnuggets.com/2014/03/data-scientist-right-career-path-candid-advice.html
 评论
评论 如今,数据科学家(或相关角色如数据经理、统计学家、数据分析师等)无疑是最受追捧的职业之一。为了应对这一跨行业趋势,一些顶尖大学已经启动了专门的数据科学项目。
如今,数据科学家(或相关角色如数据经理、统计学家、数据分析师等)无疑是最受追捧的职业之一。为了应对这一跨行业趋势,一些顶尖大学已经启动了专门的数据科学项目。
被巨大的机会、优厚的薪酬和对商业领袖的曝光所吸引,许多人在没有彻底评估该角色的日常职责、所需态度以及技术与商业技能平衡的情况下,转向数据科学家的职业道路。
为了向数据科学 aspirant 提供一个清晰的、现实的数据科学家角色图景,帮助他们与自身性格和职业抱负进行评估,我最近与Paco Nathan,一位拥有 25 年以上行业经验的数据科学专家进行了讨论。他坦率、详细的回答很可能会让许多人大开眼界。
Paco Nathan 的简短个人介绍见帖子末尾。
Anmol Rajpurohit:数据科学家被称为 21 世纪最性感的职业。你同意吗?你会给那些考虑从事长期数据科学职业的人什么建议?
Paco Nathan: 我不同意。很少有人具备执行这个角色所需的广泛技能,也没有足够的耐心去获得这些技能,更没有去达到这一点的愿望。
作为自测:
-
![自测]() 准备对一个未知数据集进行分析和可视化,同时不耐烦的利益相关者在你肩膀上盯着,并提出尖锐的问题;要准备好对结果的置信度做出定量论证
准备对一个未知数据集进行分析和可视化,同时不耐烦的利益相关者在你肩膀上盯着,并提出尖锐的问题;要准备好对结果的置信度做出定量论证 -
用 25 个字以内描述“损失函数”和“正则化项”,比较/对比几个示例,并展示如何为模型透明性、预测能力和资源需求结构化各种权衡
-
向执行团队提出重组建议,这可能意味着解雇一些排名靠前的人
-
采访 3 到 4 个对你的项目持敌对态度的不同部门,以获取他们不愿释放的数据集的元数据
-
在一个超过 1000 节点的集群中,构建、测试并部署一个关键任务应用程序,实时服务水平协议(SLA)高效完成
-
在没有对方帮助的情况下,调试别人编写的至少 2000 行长的间歇性 bug
-
利用集成方法来增强你正在开发的预测模型
-
在与来自 3-4 个完全与您之前工作无关的领域的人进行配对编程时,要在截止日期前完成工作
 准备对一个未知数据集进行分析和可视化,同时不耐烦的利益相关者在你肩膀上盯着,并提出尖锐的问题;要准备好对结果的置信度做出定量论证
准备对一个未知数据集进行分析和可视化,同时不耐烦的利益相关者在你肩膀上盯着,并提出尖锐的问题;要准备好对结果的置信度做出定量论证如果现在对以上列出的每一项都感到完全不舒适,那么我的建议是避免将“数据科学”作为职业。
数据科学家这个词在 2012 年左右作为一种新角色显得“性感”,如 DJ Patil、Hilary Mason 等所提。然而,并不是每个人都能获得 4 亿美元 IPO 的一部分!(完全公开:我在其 IPO 之前被邀请加入 LinkedIn 三次,但固执地追求其他机会;那里的团队真是优秀!)
大约在 2012 年:那是当时,现在是现在。实际的数据科学工作包括:
-
一些从“绿地”状态创新的机会,但并不多
-
大多是被召入一个现有的项目——这个项目以某种方式处于风险中
-
向权力说出真相(这并不有趣,但这是角色的本质)
重申 DJ 和其他人之前清楚表述的观点:大多数与数据相关的问题是社会/组织性的(例如,数据孤岛、缺乏元数据、矩阵组织内斗等),否则关键洞察力可能已经在那个组织内显现。
我有一种预感,大部分有趣的电子商务工作已经完成——大玩家将继续获得丰厚收入,但现在的工作大多在硅谷之外。或者说,其他行业来到这里学习、合作、购买等。
 例如,孟山都在旧金山推出了一家私人股本公司,实际上可以比几乎任何风险投资公司以更优惠的条件投资农业数据项目。与此同时,该地区的风险投资公司几乎忽视了在重要领域的与数据相关的项目——Khosla 除外。在过去几个月里,他们收购了硅谷内的业务单位:Climate Corp、Solum 等,顺便说一下,这些都是由 Khosla 资助的。预计这种趋势会继续。
例如,孟山都在旧金山推出了一家私人股本公司,实际上可以比几乎任何风险投资公司以更优惠的条件投资农业数据项目。与此同时,该地区的风险投资公司几乎忽视了在重要领域的与数据相关的项目——Khosla 除外。在过去几个月里,他们收购了硅谷内的业务单位:Climate Corp、Solum 等,顺便说一下,这些都是由 Khosla 资助的。预计这种趋势会继续。
从我的角度看,现在数据领域的大问题不在于广告技术,而是现实问题:粮食供应、干旱/洪水、能源安全、医疗保健、电信、除石油依赖之外的交通运输、更智能的制造、森林砍伐监测、海洋学分析等。
此外,IT 预算在数据洞察方面仍然存在巨大缺陷。太多预算投入到“数据工程”的神职中,且预算往往用于已经清理过的数据。我发现,硅谷的“产品管理”概念几乎与数据的有效使用相对立:在许多情况下,产品经理的激励措施可能会阻碍公司内部数据的使用。
因此,我们的价值通常会体现在:
-
编写代码以准备数据
-
自动化流程以改进特征工程和模型比赛
-
向权力说出真相
第一个讲述了 IT 预算被错误分配的问题,第二个讲述了产品管理几乎系统性地敌视有效使用数据。第三个讲述了作为数据科学家的几项重要贡献,包括向高管提供确凿证据以解雇其他高管并使公司回到正轨。再次强调,行业干扰具有影响。
 对于刚刚起步的人来说,要非常小心选择工作地点。如果一家公司声称有“优秀的工程技术”但数据使用情况不足(大约 2014 年),那么他们不是工作台上最锋利的工具;选择其他公司开始吧。寻找导师。加入那些得到金融或运营部门强力支持的团队(这些部门通常理解数据和变异),而尽量避免那些得到工程或营销部门支持的团队(这些部门通常不理解数据的有效使用)。
对于刚刚起步的人来说,要非常小心选择工作地点。如果一家公司声称有“优秀的工程技术”但数据使用情况不足(大约 2014 年),那么他们不是工作台上最锋利的工具;选择其他公司开始吧。寻找导师。加入那些得到金融或运营部门强力支持的团队(这些部门通常理解数据和变异),而尽量避免那些得到工程或营销部门支持的团队(这些部门通常不理解数据的有效使用)。
推荐,不一定按顺序。
-
学会利用不断发展的 Py 数据栈:IPython、Pandas、scikit-learn 等。
-
学会领导跨学科团队。
-
获得 1 个以上数据/分析/编程领域之外的经验。
-
扎实掌握设计基础并将其应用于数据可视化。
-
尽一切可能成为更好的写作者和演讲者(除学术会议外)。
-
参与会议;发布博客、演讲等(招聘经理忽略简历,寻找在线发布的内容)。
-
扎实掌握抽象代数、贝叶斯统计、线性代数、凸优化。
-
研究流数据的算法和框架(未来的大用例不是批处理)。
-
学习 Scalding 和具有类型安全性的函数式编程。
-
避免商业智能(像避瘟疫一样)。
-
避免任何被称为“ Hadoop 生态系统”或“ Hadoop 作为操作系统”的内容。
 Paco Nathan 是大数据领域的“玩家/教练”,在大型应用程序的创新数据团队中领导了 10 多年。作为分布式系统、机器学习和企业数据工作流程的专家,Paco 是 O'Reilly 的作者,并且是包括 The Data Guild、Mesosphere、Marinexplore、Agromeda 和 TagThisCar 在内的几家公司顾问。Paco 从斯坦福大学获得了数学科学学士学位和计算机科学硕士学位,拥有超过 25 年的技术行业经验,涵盖了从贝尔实验室到早期初创公司的经历。
Paco Nathan 是大数据领域的“玩家/教练”,在大型应用程序的创新数据团队中领导了 10 多年。作为分布式系统、机器学习和企业数据工作流程的专家,Paco 是 O'Reilly 的作者,并且是包括 The Data Guild、Mesosphere、Marinexplore、Agromeda 和 TagThisCar 在内的几家公司顾问。Paco 从斯坦福大学获得了数学科学学士学位和计算机科学硕士学位,拥有超过 25 年的技术行业经验,涵盖了从贝尔实验室到早期初创公司的经历。
更多相关内容。
如何成为没有 STEM 学位的数据科学家
原文:
www.kdnuggets.com/2021/09/data-scientist-without-stem-degree.html
评论
1. 学习数据科学所有支柱的基础
“数据科学”是一个模糊的术语——它对不同公司可能意味着不同的东西,而且有许多与数据科学家相关的技能。
也就是说,我推荐你学习一些核心技能。以下技能对任何数据科学家都至关重要:SQL、Python、统计学、机器学习。我也建议你按此顺序学习这些技能。虽然听起来很多,但这与大学时你每学期需要完成 4-6 门课程并无不同!
让我们深入探讨每个技能。
A) SQL
SQL 是数据的语言,无疑是任何数据科学家最重要的技能。SQL 用于操作数据、分析数据、构建仪表板、构建数据管道、编写查询以供模型使用等等。
B) Python 和 Pandas
Python(或任何脚本语言)作为基础,能够进行诸如构建 ML 模型、网络数据抓取、构建自动化脚本等多种操作。
Pandas 是一个用于数据操作和分析的 Python 库。我个人在 Jupyter notebook 中探索数据时更倾向于使用 Pandas 而不是 SQL。
以下是我学习 Python 和 Pandas 时用到的最有用的资源:
C) 统计学
数据科学/机器学习本质上是统计学的现代版本。首先学习统计学,你会在学习机器学习概念和算法时轻松得多!尽管最初几周可能看起来没有实际收获,但后续的收益将会很值得。
以下是我学习统计学时用到的最有用的资源:
D) 机器学习
机器学习不仅有趣和激动人心,而且是所有数据科学家必须具备的技能。虽然建模占数据科学家时间的一小部分,但它的重要性不容忽视。
以下是我学习机器学习时用到的最有用的资源:
2. 完成 1-3 个个人数据科学项目
一旦你打下了基础,加速学习的最佳方式就是完成一些数据科学项目。最简单的方法是去Kaggle,选择一个数据集,创建一个预测模型或一些数据可视化。记住,你的前几个项目不会很出色!但重要的是你随着时间的推移如何进步。
这里有一些我过去完成的数据科学项目,你可以用来获得灵感!
当你继续学习和实践数据科学技能时,还有其他方法可以让自己成为更有价值的数据科学候选人,这也是我接下来要分享的建议。
3. 探索非传统的经验机会
成为数据科学家最困难的部分是如何在没有经验的情况下获得第一个机会。然而,以下是一些即使没有经验也可以获得经验的方法:
非营利机会
最近,我看到了一篇由苏珊·柯里·西维克(Susan Currie Sivek)撰写的资源丰富的文章, 提供了几个组织,你可以在这些组织中找到从事真实数据科学项目的机会。
如果你正在寻找更多的经验来丰富你的简历,我强烈推荐你查看这些。
参加比赛
在我看来,没有比通过比赛展示你已经准备好从事数据科学工作更好的方式了。Kaggle 举办了各种比赛,涉及构建模型以优化某些指标。
你现在可以尝试的两个比赛是:
在 Medium 上开设博客
是的,我有些偏颇,但请听我说。你会惊讶于 Medium 上有多少数据相关的专业人士。他们喜欢看到信息丰富、有见地和有趣的内容。利用 Medium 来撰写你的学习心得,解释复杂的话题,或者展示你的数据科学项目吧!
我特别建议你为出版物 Towards Data Science 撰写文章,因为他们目前拥有近 500,000 名关注者。
如果你需要一些灵感,可以查看我的项目演示,葡萄酒质量预测。
4. 寻找类似于数据科学家职位的工作
我知道我将面临艰难的挑战,尤其是没有作为数据科学家的经验。然而,寻找类似于数据科学家职位的工作将显著增加你成为数据科学家的机会。原因在于相关工作将给你在商业环境中处理实际数据的机会。
你不需要是数据科学家才能从事‘数据科学’工作
这里有一些你可以寻找的数据科学相关职位:
-
商业智能分析师
-
数据分析师
-
产品分析师
-
增长营销分析师 / 营销分析
-
定量分析师
除了上述两点,还有一个提示显著提高了我作为数据科学家的声誉。
5. 考虑获得定量领域的硕士学位
大多数数据科学职位列表要求硕士学位,因为通常需要高水平的技术技能。如果你发现上述两个建议没有成功,我建议你考虑定量领域(计算机科学、统计学、数学、分析等)的硕士项目。
就个人而言,我选择了乔治亚理工学院的分析学硕士项目,原因有很多:
-
它不需要定量领域的学士学位。
-
如果你想同时工作和学习,它有一个在线项目。
-
整个项目只需$10K 美元。
尽管如此,市场上有几个选项,我强烈建议你在做出决定之前花时间探索所有选项!
相关:
更多相关话题
数据科学家在欧洲做什么,他们的价值多少?
原文:
www.kdnuggets.com/2020/01/data-scientist-worth-europe.html
评论
在 12 月,我们分享了一些关于数据科学家价值的见解,数据主要集中在美国,同时也有一些额外的地理数据。随着Big Cloud 年度调查报告的发布,我们现在有了一些高质量的数据和可视化,帮助我们更好地了解全球数据科学家的价值。
这次我们将关注欧洲,特别是数据科学专业人士报告使用的技能、这些专业人士的薪资以及报告中的有趣见解。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
来自 Big Cloud 的报告:
自 2016 年以来,Big Cloud 致力于每年制作一些最大和最好的数据科学薪资报告。在超过 1300 个回应和 33 个问题后,我们自豪地宣布这是迄今为止我们为欧洲策划的最丰富的数据调查!
本报告将深入探讨 2019/2020 年度来自各背景、年龄和地点的欧洲地区专业人士提供的见解。今年贡献最多的来自德国、法国、英国、荷兰和瑞士。由于这些国家的数据点最多,因此这些国家是我们本报告的主要关注点。
更具体地说,大多数受访者来自以下城市:
-
巴黎
-
柏林
-
慕尼黑
-
伦敦
-
阿姆斯特丹
-
汉堡
-
苏黎世
-
剑桥
-
法兰克福
-
马德里
谁是受访者?
今年参与我们调查的最大群体是 24%的男性数据科学家,年龄在 25-34 岁之间。与去年相比,角色的变化似乎更大,数据科学家的数量减少了 15%,数据工程师的数量增加了 6%,C 级参与者的数量增加了 3%。
男性与女性参与者的比例保持不变。
超过一半的调查参与者拥有硕士学位,其次是博士学位(+4%)和学士学位(+2%)逐年稳步增加。然而,选择继续深造的人数持续下降,今年仅占 3%(2018 年为 3.45%)。
受访者的工作年限和在当前公司工作的年限如图 1 所示。
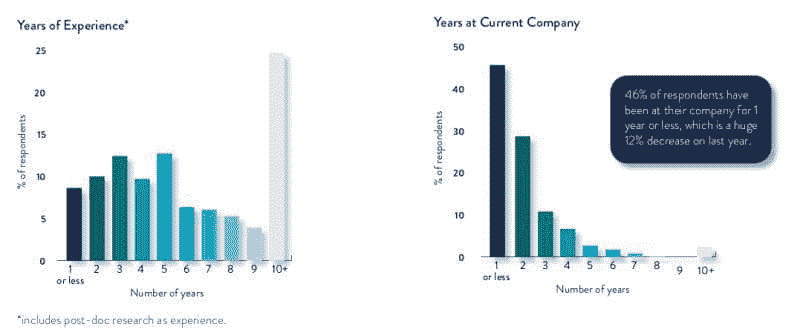
图 1:受访者的工作年限和在当前公司工作的年限。
调查受访者的主要行业是:
-
技术/信息技术
-
咨询
-
电子商务
-
金融科技
-
学术/教育
-
软件
-
医疗保健
-
保险
-
汽车
-
市场营销
请注意,本报告所依据的基础数据不可用。
现在我们对调查参与者有了一定了解,让我们来看看报告,从技能开始。
数据科学技能
调查研究的部分数据科学技能维度包括编程语言、编程能力和使用的方法。
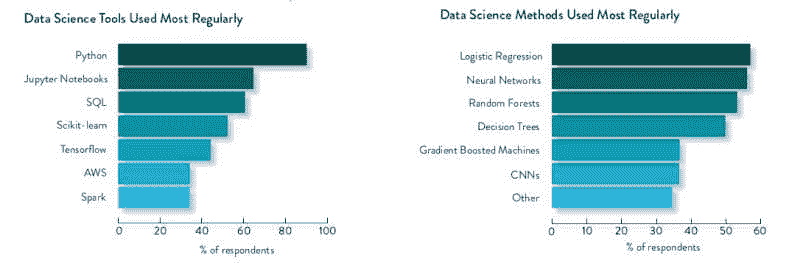
图 2:最常用的数据科学工具和最常用的数据科学方法。
在数据科学方法方面,从参与者中获得了以下信息:
[L]ogistic 回归、神经网络和随机森林是三种最受欢迎的选择,大约 56%的受访者表示使用它们。与数据科学家工具偏好相比,他们选择的数据科学方法种类更加多样。调查中的其他选项(未进入前七名)包括 34%的集成方法、31%的贝叶斯技术和 28%的支持向量机。
具体到编码方面,受访者的数据讲述了以下故事:
[A] 高达 70%的受访者表示他们使用 Python 作为主要建模编程语言。这比 2019 年的调查增加了 10%。9%使用 R,4%使用 SQL,4%使用 Java。此外,还有 3%的受访者表示他们不进行编码。
66%的受访者表示,他们的主要生产编程语言也是 Python。另有 9%表示 Java,还有 7%使用 Scala 或完全不进行编码。6%使用 C++
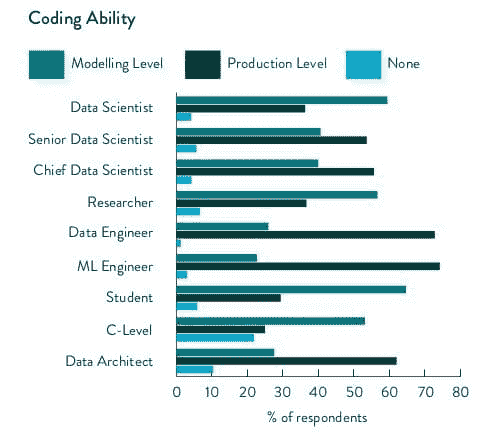
图 3:按职位类型划分的编程能力。
受访者花费多少时间进行编码?
29%的受访者每周花费 11-20 小时进行编码,这与我们 2019 年的调查结果相同。只有 14%的受访者表示他们每周花费 31 小时以上进行编码,而 7%的人完全不进行编码。总体而言,回应非常多样,这可能反映了参与者的资历差异。
受访者还指出,目前处理的最受欢迎的数据类型,按顺序排列如下:
-
关系数据
-
文本数据
-
图像数据
-
其他
-
视频数据
数据科学薪资
尽管调查包含了多个数据科学相关角色的薪资数据,但这很快就进入了比较苹果和橙子的领域。为了进行有意义的比较,我们将查看“数据科学家”和“高级数据科学家”的平均工资、中位工资、平均涨幅和平均奖金在 6 个国家(法国、德国、意大利、荷兰、瑞士、英国)的数据点(见图 4),这些国家在报告中被特别提及。
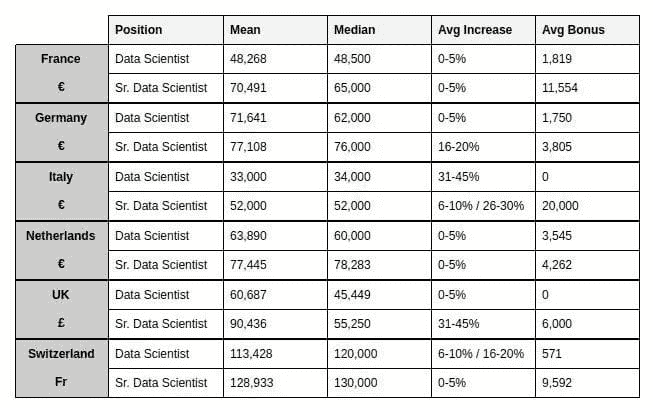
图 4:6 个调查参与者最多的国家的平均工资、中位工资、平均涨幅、平均奖金(标注了本地货币)。
让我们来绘制这些数据。图 5 可视化了上述图表中 6 个国家的平均工资,本地货币已转换为本文发布时的欧元价值。
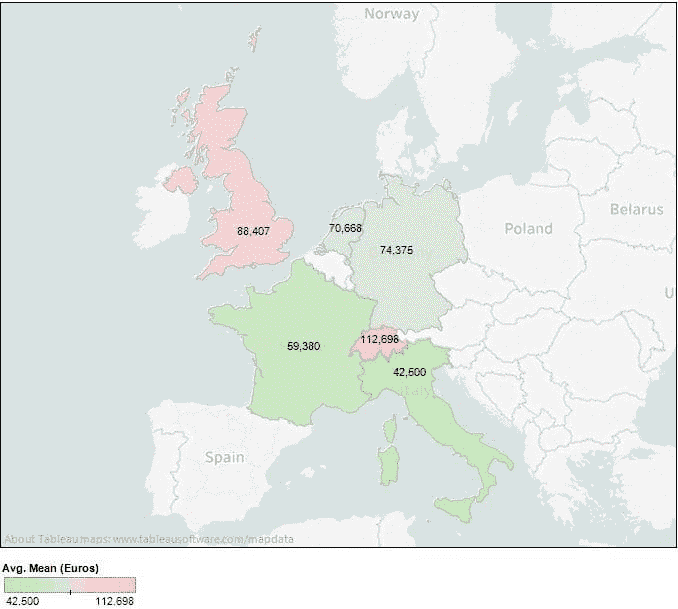
图 5:6 个调查参与者最多的国家的数据科学家的平均工资(以欧元计)。
为了更全面地描绘欧洲数据科学家的价值,图 6 绘制了同 6 个国家的数据科学家和高级数据科学家的平均工资 + 奖金(以欧元计),并通过柱状颜色强度描绘了薪资涨幅百分比。
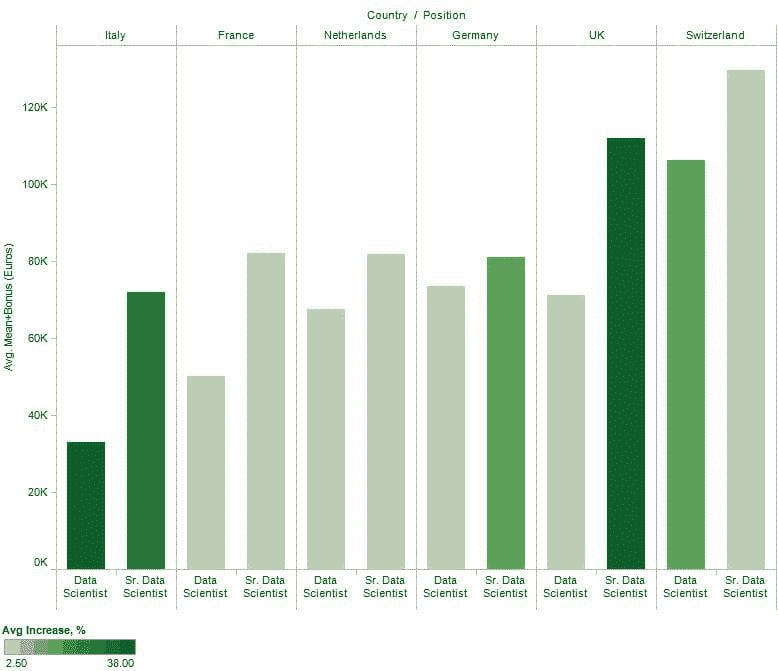
图 6:6 个调查参与者最多的国家的平均工资 + 奖金(以欧元计)和涨幅百分比。
在薪资满意度方面,结果并不令人震惊;然而,稍微多于一半的受访者似乎认为他们的薪资和福利套餐是令人满意的。
当被问到“在 1 到 10 的尺度上(10 为最容易),你认为找到新工作的难易程度如何?”时,调查参与者最常回答的是“3”。
结论
欧洲显然不是一个单一的整体,这在调查回应中很明显。各国之间的薪资差异确实存在,但这本身并没有讲述完整的故事,没有考虑生活成本差异。虽然这应该是显而易见的,并且超出了薪资调查的范围,但值得明确指出。
除了原始数据外,一个突出的事项是参与者认为替代的数据科学职位的可用性以及转移到这些职位的难易程度似乎相对较低。这是一种个人感知,但在决定是否寻找新角色时,感知和现实一样重要。
你可以 在这里阅读完整报告。
相关:
-
数据科学家值多少钱?
-
人工智能:薪资飞涨
-
数据科学家:为什么雇佣他们如此昂贵?
更多相关主题
数据科学家的价值是多少?
评论
2019 年在分析、数据科学和机器学习领域是充满事件的一年。新的趋势、新的工具、新的视角……我们最近整理了一组三篇文章,结合了几十位专家的见解,以描绘 2019 年的关键事件,并对 2020 年(以及可能的未来)进行预测。这些文章从研究、技术和行业的不同视角探讨了主题。如果感兴趣,你可以在这里找到:
-
AI、分析、机器学习、数据科学、深度学习研究 2019 年的主要进展及 2020 年的关键趋势
-
AI、分析、机器学习、数据科学、深度学习技术 2019 年的主要进展及 2020 年的关键趋势
-
行业 AI、分析、机器学习、数据科学对 2020 年的预测
在已经成为一种传统的做法中,KDnuggets 的朋友 Xavier Amatriain 再次撰写了他对 AI/ML 年度进展的回顾,你可以在这里找到。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
本文将对数据科学及相关薪资进行快照式的回顾,以总结另一年的结束。为了找到一个对比点,并尽力寻找可以相互比较的对象,我们将重点关注数据科学家在美国的角色,同时也会考虑一些相关职位和几个额外国家的情况。
数据科学家的薪资是多少?
为了了解情况,我们来看一下 Payscale,报告(最近更新于 2019 年 10 月 22 日)称,美国的数据科学家中位薪资为$91,260,范围在$62k - $138k 之间(见图 1)。

图 1:数据科学家中位薪资
但基本薪资并不是全部。Payscale 还报告说,中位数奖金为$8,042,范围在$1k - $17k 之间,中位数利润分享为$5,139,范围在$970 - $15k 之间(见图 2)。
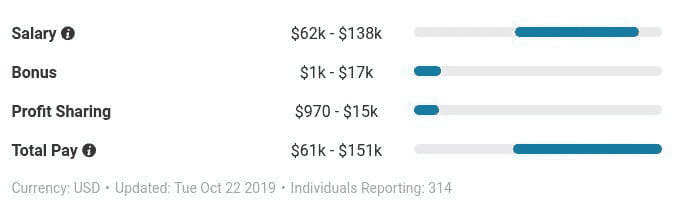
图 2:数据科学家薪资、奖金、利润分享范围
通常,任何职位的经验多少与薪资有相关性,这至少部分基于合理的推理。图 3 显示了与经验年限相称的薪资趋势。
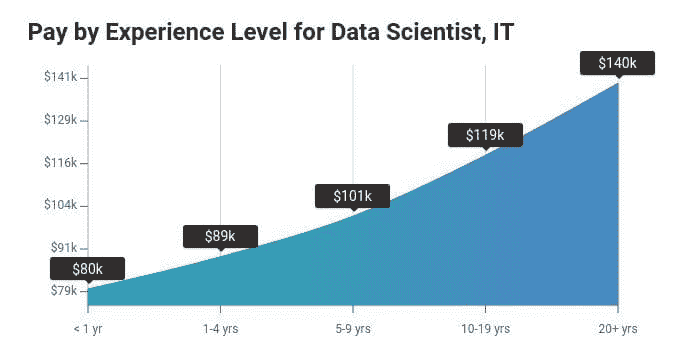
图 3:与经验年限相称的数据科学家薪资
通过这条回归线和按经验年限分组的标签,你可以看到薪资的上升趋势以及基于不同经验水平的合理预期薪资。显然,一名新的数据科学家在其第一个职位上不应期望得到中位数薪资(有十年经验的人也不应如此),上述内容有助于回答什么是合理的期望。
了解Robert Half 的说法关于数据科学家薪资的不同视角(2019 年 9 月 10 日):
这些 IT 专业人士利用他们在统计学和建模方面的知识,来理解来自各种来源的复杂数据。要获得$125,250 的中位数薪资,数据科学家需要具备商业敏锐度和沟通能力,除此之外,还需要统计学、数学和计算机科学的专业知识。了解 Python 或 Java 等编程语言通常也是工作所需的技能。
地理位置如何影响你的薪资?为了回答这个问题,图 4 展示了 Payscale 对几个美国城市薪资差异的分析。

图 4:按地点的薪资差异
对于那些了解技术中心相对吸引力和美国生活成本差异的人来说,这不应令人感到惊讶。此外,Indeed 的报告显示数据科学家在以下 5 个美国城市拥有最高的总体薪资(见图 5)。
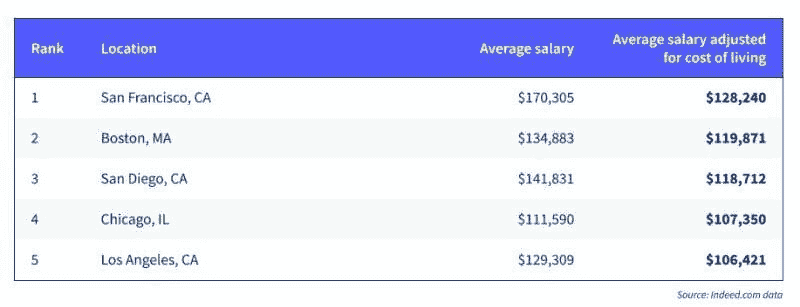
图 5:美国数据科学薪资最高的城市
到目前为止,我们对数据科学家薪资的理解与相关职位薪资相比如何(或“相关”职位根据 Payscale 的定义)?请参见下方的图 6。
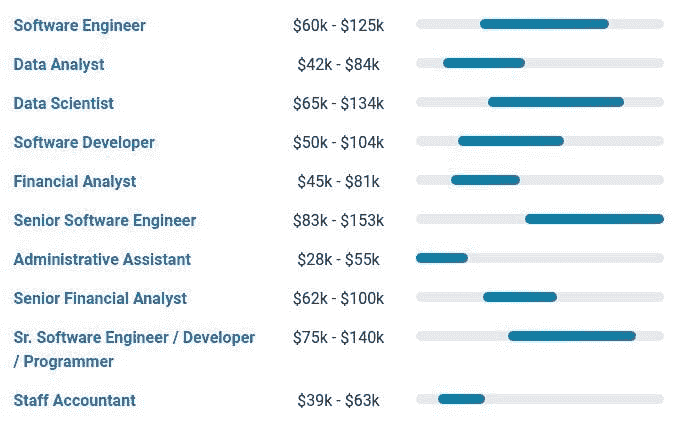
图 6:相关职位薪资
显然这些“相关”职位存在一些问题,但有几个职位提供了一些有限的相关对比。
关于职位薪资比较的更多额外有用的见解,让我们看看 Stack Overflow 编程薪资计算器(2019 年 10 月 16 日)。此报告概述了薪资计算器,该计算器“基于 Stack Overflow 开发者调查的综合数据,这些庞大而广泛的调查数据使我们能够建立一个准确的模型,反映全球范围内编码工作薪酬的趋势。”
继续关注美国,图 7 显示了 Stack Overflow 报告中不同类型开发者的中位薪资。
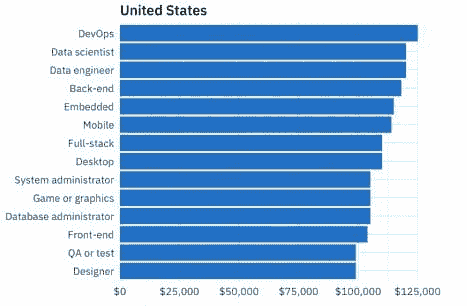
图 7:不同类型开发者的中位薪资(美国)
数据角色,如数据科学家和数据工程师,在薪资排名中高居开发者类型的顶端。Stack Overflow 提供了这一观察结果:
[W]e 在这里有证据表明,高薪资的数据科学家和数据工程师可以仅凭高学历和丰富经验来解释。数据科学家薪资很高,但不比受过类似教育的从事其他工作的开发者高。(拥有学士学位甚至更高学位的人,编码薪资显著提高。)近年来,数据科学和数据工程工作已从极端的异类位置逐步转向主流软件工作领域。
虽然将数据科学家视为“开发者”有些问题,但在技术层面上,当代编码数据科学家所具备的技能与开发者的技能之间无疑有很多重叠。话虽如此,高等教育作为数据科学家薪资高的主要(他们暗示为唯一)因素的评论并非离谱。然而,这些可能是苹果和橘子的比较;我们需要访问类似高学历的数据科学家以及其他开发者的薪资原始数据(如果有的话),才能得出这样的结论。
最后,让我们利用 Stack Overflow 的调查为我们的讨论引入国际视角。图 8 关注了 4 个国家中不同类型开发者的最高薪资:
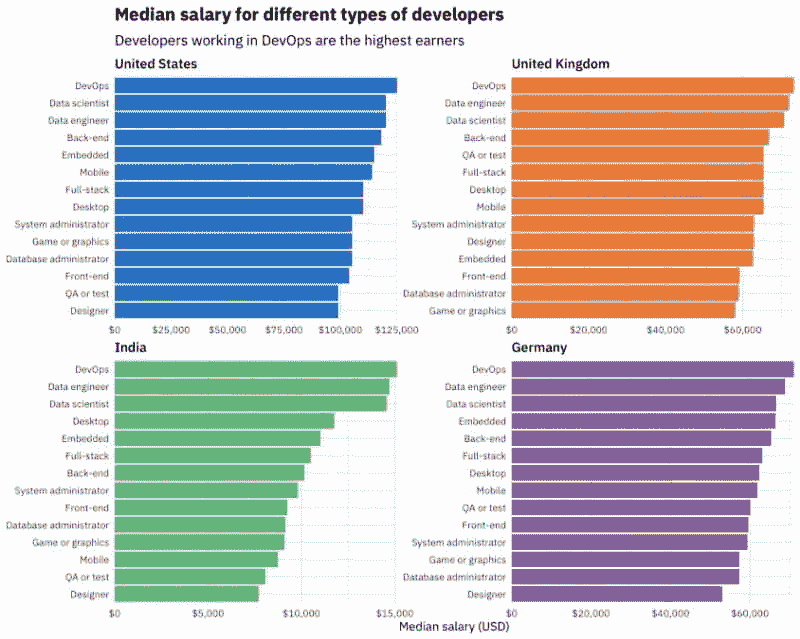
图 8:不同类型开发者的中位薪资(美国、英国、德国、印度)
那么,2019 年的数据科学家薪资是多少?结果显示,这是一个非常好的问题……但没有明确的答案。当然,你可能已经知道,完成后不会有一个单一的、神奇的数字。然而,你现在确实拥有一些数据来帮助做出合理的预测,了解在各种不同情况下公平薪资的情况。让我们看看 2020 年数据科学家薪资讨论带来了什么。
相关:
-
数据科学家:为什么他们的聘用费用如此昂贵?
-
人工智能:薪资飞涨
-
2019 年 Stackoverflow 调查中的 R 用户薪资
更多相关主题
数据科学家如何在全球就业市场中竞争
原文:
www.kdnuggets.com/2021/09/data-scientists-compete-global-job-market.html
评论

数据科学家的就业市场比以往任何时候都更加活跃,并预计在未来几年将迅速增长。美国劳工统计局预测,到 2026 年,职位数量将增长约 28%。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
公司正在投入大量资金进行市场研究和商业分析,为长期数据科学家和新入行者创造新的机会。与此同时,就业市场也变得更加竞争。随着数据科学职位变得对企业越来越重要,职位的平均薪酬也在上升,这促使招聘经理更加仔细地审查新员工。
希望保持竞争力或进入这一领域的数据科学家需要采用正确的方法。这些技巧将帮助他们寻找并获得新职位。
全球数据科学就业市场的现状
人们生成的信息比以往更多——专家认为,到 2025 年,全球数据将超出 175 泽字节。与此同时,AI 和大数据分析的创新使得大数据集对企业的价值比以往任何时候都要高——但前提是他们与经过培训的科学家合作,才能发现所需的洞察。
半数的调查企业已使用 AI以某种方式,并且更多企业表示他们计划在不久的将来进一步投资于数据驱动的解决方案。
现在,一条数据科学职位的招聘信息收到数百份申请并不罕见。更高的需求也意味着更高的薪酬,企业在招聘这些职位时变得更加谨慎。
作为回应,许多招聘经理正在夸大新数据科学职位的要求——要求更强的资质、更丰富的经验和额外的关键字。即使是具有良好资格或强大学术记录的数据科学家,现在也无法保证获得职位。
在全球就业市场中保持竞争力的最佳实践
希望进入该领域或获得新职位的数据科学家需要正确的策略来取得成功。这六个建议将帮助已有经验的专业人士和行业新手找到工作。
1. 知道使用正确的词汇
熟悉热门行业关键字——如 Python、SQL、AI 和数据分析——可以帮助你编写出更有效传达你技能的 CV 和简历,并通过招聘经理常用的简历筛选器。
跟上不断变化的行业需求也可以帮助你保持竞争力。虽然 Python 仍然是必备技能,但越来越多的企业期望熟悉深度学习、梯度提升机和大数据分析。许多公司还期望申请者过去使用过各种数据挖掘和分析方法。
2. 传达对行业标准工具的熟悉程度
当申请期望具备人工智能知识的职位时,强调数据科学和机器学习的知识可能有助于你获得面试机会。
同时,应避免关键字堆砌,即不自然地在简历中填充关键字以击败简历筛选器或吸引招聘经理的注意。尽量仅在简历或 CV 中使用与说明你的独特背景和数据科学技能集相关的关键字。
3. 了解大企业如何寻找数据科学专业人士
研究大型公司如何招聘数据科学家也可以帮助你改进简历和 CV。AI 和 ML 公司 Daitaku 最近在案例研究中出现,探讨了它如何在国际上寻找数据科学家。报告强调了技能集比地理位置更为重要。
4. 利用通用求职最佳实践
求职最佳实践通常也对寻找新职位的数据科学家有帮助。针对每个申请的职位量身定制你的 CV 和求职信会多花一些精力,但这有助于你在面试前传达你的特定技能,并展示你如何适合某个职位。
5. 与其他数据科学家建立联系
积极与其他数据科学家和寻找专业人士的招聘人员建立联系,可以帮助你扩大网络,更容易找到与你的技能和经验水平相匹配的职位。
在等待招聘经理的回复期间,你也可以寻找短期工作,以帮助你进一步提升技能,并在简历上增加一两个要点。
6. 考虑自由职业工作
需要数据科学家的企业但难以填补新职位,可能会向合格的申请者提供临时和自由职业工作。像 UpWork 这样的自由职业平台和求职板块可以为你提供这些职位的线索。
展望未来:数据科学家如何保持竞争力
数据科学家的职位空缺比以往更多,但这并不意味着市场竞争变得不那么激烈。数据科学的日益重要和技能人才的短缺使得公司在招聘时非常谨慎。
希望找到新职位或进入市场的数据科学家应保持对行业趋势的关注,并熟悉各种数据挖掘和分析技术。求职的最佳实践——如定制简历和谨慎使用关键词——也能帮助他们获得面试机会。
通过运用这些技巧,你可以在竞争激烈的环境中脱颖而出,找到理想的数据科学职位。
简介:德文·帕蒂达 是一位大数据和技术作家,也是 ReHack.com 的主编。
相关:
-
如何成功成为一名自由职业数据科学家
-
数据专业人士如何在简历中添加更多变化
-
自动化如何改善数据科学家的角色
更多相关话题
没有数据工程技能的数据科学家将面临严峻的现实
原文:
www.kdnuggets.com/2021/09/data-scientists-data-engineering-skills.html
评论

我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
你可能读过关于数据科学家和数据工程师区别的文章。我一直认为这个区别很明确。数据工程师准备好数据,然后数据科学家在这些数据上工作。
然而,经过我作为数据科学家的工作,我对这一区别的看法发生了剧烈变化。
数据科学的一切都始于数据。你的机器学习模型的质量与输入的数据同样重要。垃圾进,垃圾出!没有合适的数据,数据科学家无法通过某种魔法创造有价值的产品。
合适的数据并不总是立即可用。大多数情况下,将原始数据转换为适当格式的责任将落在数据科学家身上。
除非你在一家大型科技公司工作,该公司有专门的数据工程师和数据科学家团队,否则你应该具备处理一些数据工程任务的能力和技能。这些任务涵盖了广泛的操作,我将在文章的其余部分详细阐述。
毕竟有什么区别呢?
我想阐述一下数据工程师的工作和数据科学家之间的关系。
数据工程师就是数据工程师。数据科学家应该既是数据科学家,又是数据工程师。
这可能看起来是一个有争议的说法。然而,我想强调的是,在我开始作为数据科学家工作之前,我的观点是不同的。我曾经认为数据工程师和数据科学家是两个独立的实体。
在文章的剩余部分,我将尝试解释为什么数据科学家应该既是数据科学家又是数据工程师。
比如说,数据工程师会进行一系列称为 ETL(提取、转换、加载)的操作。这包括从一个或多个来源收集数据,应用一些转换,然后将其加载到另一个来源中。
如果数据科学家被期望执行 ETL 操作,我绝对不会感到惊讶。数据科学仍在发展中,大多数公司没有明确分开的数据工程师和数据科学家角色。因此,数据科学家应该能够执行一些数据工程任务。
如果你期望仅仅在使用现成数据运行机器学习算法,你会在刚开始工作时就面临严峻的现实。
你可能需要编写一些 SQL 存储过程来预处理客户端数据。也有可能你会从几个不同的来源收到客户端数据。你的工作将是提取和组合这些数据。然后,你需要将它们加载到一个单一的来源中。为了编写高效的存储过程,你需要广泛的 SQL 技能。
ETL 程序的转换部分涉及许多数据清理和操作步骤。如果你处理大规模数据,SQL 可能不是最佳选择。此时,分布式计算是更好的替代方案。因此,数据科学家也应熟悉分布式计算。
在分布式计算中,你的最佳伙伴可能是 Spark。它是一个用于大规模数据处理的分析引擎。我们可以将数据和计算分布在集群上,以实现显著的性能提升。
如果你熟悉 Python 和 SQL,那么适应 Spark 不会很困难。你可以使用 PySpark,这是一种 Spark 的 Python API。
关于集群工作,最佳环境是云。虽然有多种云提供商,但 AWS、Azure 和 Google Cloud Platform(GCP)领先于前。
虽然 PySpark 代码在所有云提供商中都是相同的,但环境设置和集群创建方式有所不同。它们允许通过脚本或用户界面创建集群。
在集群上进行分布式计算是一个完全不同的世界。它与在你的计算机上进行分析完全不同。它具有非常不同的动态。评估集群性能和选择集群的最佳工作节点数量将是你主要关注的问题。
结论
长话短说,数据处理将成为你作为数据科学家的重要部分。我所说的重要,是指你 80%以上的时间都将用于数据处理。数据处理不仅仅是清理和操作数据。它还包括 ETL 操作,这通常被认为是数据工程师的工作。
我强烈推荐熟悉 ETL 工具和概念。如果你有机会进行实践,那将非常有帮助。
认为作为数据科学家你只会处理机器学习算法是一个天真的想法。这确实是一个重要的任务,但它只会占用你时间的一小部分。
原文。转载已获许可。
相关:
更多相关话题
数据科学家和数据工程师如何协作?
原文:
www.kdnuggets.com/2022/08/data-scientists-data-engineers-work-together.html

图片由 fauxels 提供,通过 Pexels
数据科学家和数据工程师如何协作?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
数据科学家和数据工程师常常被初学者混淆,特别是那些在数据科学领域没有显著经验的人。虽然他们的工作乍一看可能似乎相似,但实际上存在一些重要的根本差异。如果你正在考虑数据科学的职业生涯,了解这两个领域的不同之处非常重要,以确定哪个领域可能更适合你的技能和兴趣。
数据科学家的工作是什么?
数据科学家 直接参与分析方面的工作。他们处理数据模型,提出特定问题的解决方案,并探索数据科学领域的极限,以寻找应对挑战的合适方法。数据科学家的工作涉及大量数学和对数据科学背后统计概念的深刻理解。强大的数学和统计背景对于成为数据科学家并在知名公司获得职位是必要的。
数据工程师的工作是什么?
另一方面,数据工程师 更多地关注于解决方案的实际技术实施。一旦科学家提出了一个模型,工程师就需要弄清楚如何将其整合到整体的数据处理流程中。数据工程师必须小心平衡他们所工作的系统的可访问性、灵活性和性能。
他们还必须尽可能全面地理解他们正在使用的技术栈。在实施解决方案时,数据工程师需要确定应该使用哪些语言、数据库和其他技术组件来组建最终结果。通常需要大量的脚本编写来将所有部分连接起来。
两个角色如何协作?
观察数据科学家和数据工程师的一个好方法是通过建筑师和土木工程师的类比。建筑师提出最初的计划,而工程师则在考虑结构限制和其他类似问题的同时实施这些计划。在数据科学的世界里也是如此。数据科学家进行规划,数据工程师则构建和实施。
尽管如此,这两个角色也紧密合作以提出最终解决方案。在双方都拥有良好的沟通技巧非常重要,因为通常需要整合想法和限制,这必须以不削弱任何人项目参与的方式进行。优秀的数据科学家和工程师的组合在这种通常混乱的工作环境中可以证明是不可或缺的。
哪条职业路径适合你?
如果你想参与数据科学,选择你是否想成为数据科学家或数据工程师是重要的。如果你喜欢数学并探索该领域的理论概念,作为数据科学家的工作可能更适合你。你需要对统计学、线性代数以及其他各种数学领域有很好的理解。你还需要阅读大量的已发表论文,以便对该领域如何整体联系有一个良好的理解。
另一方面,如果你喜欢“动手实践”,经常发现自己编写脚本来自动化工作,重新安排管道的部分以提高效率,并担心技术限制,那么作为数据工程师的工作可能非常适合你。这是一个非常技术性的领域,你不一定需要对数学基础有很好的理解才能成功。但这确实会有帮助。
为什么了解两方都值得
无论你选择哪一方,花些时间熟悉两端的概念都是一个好主意。一名优秀的数据工程师必须至少了解他们实现的模型最初是如何形成的,而一名优秀的数据科学家则必须了解他们可能遇到的粗略限制。这就是为什么这些领域中的最佳专家通常都会投入一些精力去学习另一方的工作方式。这在尝试传达复杂概念时也会非常有用。
无论你是决定先专注于一方面,然后再涉猎另一面,还是最初将注意力分散于两者之间,都由你决定。两种方法都可行,这取决于个人偏好。无论你选择哪个方向,Springboard 都有相关课程可以加深你的理解,并让你在感兴趣的领域中为求职做好准备。如果你对这一方面感兴趣,Springboard 的数据科学职业课程是一个很好的起点。
赖利·普雷杜姆 曾在多个数据领域,如产品和数据分析,以及数据科学和数据/分析工程领域,具有丰富的专业经验。他热衷于写作和教学,并喜欢为在线社区提供学习材料,专注于一般学习以及职业发展。赖利在他的Medium 博客上编写编码教程。
更多相关主题
为什么数据科学家期望谷歌 Bard 提供有缺陷的建议
原文:
www.kdnuggets.com/2023/02/data-scientists-expect-flawed-advice-google-bard.html

图片由编辑提供
在最近的宣传活动中,谷歌向世界展示了 Bard 的首次亮相,这是科技巨头试图取代极受欢迎的 AI 聊天机器人 ChatGPT 的尝试。尽管这次活动可能旨在为谷歌的 AI 聊天尝试制造轰动,但它很快成为了展示这些神秘 AI 聊天服务可能出错的公众示范。
根据路透社的首次报道,Bard 给出了不准确的回应,导致 Alphabet (GOOGL) 的股价在演示当天下跌了多达 9%。对于许多数据社区成员来说,这并不令人惊讶;原因如下。
Bard 的广告有什么问题?
问题:当被问及如何向 9 岁的孩子介绍令人惊叹的詹姆斯·韦布太空望远镜 (JWST) 时,Bard 错误地将其描述为“……用于拍摄地球太阳系外第一张行星的照片”。这一回答很快被识别为错误,因为地球太阳系外第一张行星的照片是在 2004 年由欧洲南方天文台的大型望远镜 (VLT) 拍摄的。
什么是谷歌 Bard?
谷歌首席执行官 Sundar Pichai 称 Bard 为“对话式 AI 服务”。如果这听起来很熟悉,你可能在过去几个月里遇到过谈论 ChatGPT 的众多在线影响者之一。
对这项 AI 突破的看法差异很大。赞成者讨论革命性计划或分享利用聊天机器人快速发展业务的兴奋点。ChatGPT 最受欢迎的用例之一是自动化重复性任务。另一方面,批评者对其能力提出了有缺陷的观点——认为聊天机器人的功能取代了人类的研究和批判性思维。谷歌 Bard 将引发类似的讨论。
什么是 LaMDA?
谷歌的 Bard 基于 LaMDA,这是公司在 2021 年推出的语言模型,LaMDA 本身建立在公司流行的开源神经网络架构 Transformer 上。
有趣的是,LaMDA 是通过对话进行训练的,使其比以前的语言模型更自然地回应人类对话。(如果 LaMDA 这个名字听起来很熟悉,也许你会记得有一个谷歌工程师认为LaMDA 已经具有意识。)
2021 年 5 月宣布的谷歌 LaMDA 首次亮相,是讨论其模型优势的机会,宣布特别关注其回应的真实性。两年后,在 Bard 宣布期间,记者很快发现了一个事实错误。这对谷歌的实施意味着什么?我们将拭目以待。
谷歌 Bard 有何不同于 LaMDA?
鉴于两者的相似之处,一些人问,这款新产品有什么不同?谷歌谦虚地声称,它的新服务将“世界知识的广度”添加到 LaMDA 已经令人印象深刻的对话技能中。它还承诺提升模型的能力,提供比普通聊天机器人更多的指导和研究。简而言之,Bard 依赖于 LaMDA,而 LaMDA 不依赖于 Bard。
同时请注意,谷歌计划通过 Bard API 链接向开发者开放服务,使其比普通聊天机器人更具吸引力。虽然用户已经可以与 LaMDA 进行自由流畅的对话,但谷歌 Bard 承诺通过包括公司提供的全方位谷歌搜索服务的相同信息来提升对话。
与直觉相反,Bard 的事实错误不应削弱这个新服务的承诺价值。谷歌的搜索结果从未承诺绝对准确。搜索者应始终考虑其来源。即使在发布了令人印象深刻的聊天机器人之后,这一事实仍然成立。
使用谷歌 Bard 的方法
数据科学家并不是唯一对使用谷歌 Bard 感到兴奋的人。皮查伊设想这项服务将帮助任何使用谷歌的人。他的承诺?Bard 简化复杂话题。考虑以下使用案例:
找到复杂问题的简单答案
想象一下你想去度假。谷歌现有的搜索可以轻松回答你知道要去哪里时的问题,并帮助你查找特定日期的价格。但皮查伊将这个新聊天机器人比作和朋友对话。
你应该能够开始一个关于工作的项目的对话,将复杂的研究文章分解成最重要的要点,然后在接下来的几周内请求应用这些要点的推荐。
Bard 还可以在销售团队培训中提供帮助,在你招待挑剔食客时提供晚餐推荐,以及讨论最新的漫威电影的精彩部分。谷歌已经在其产品中实施了 AI,但随着新聊天机器人的发展,这一过程将会扩展。所有这些,你无需离开你熟悉的搜索引擎。
自动化常规任务
谷歌已经与市场整合,使你可以直接从其界面购买商品和进行预订。谷歌 Bard 可能允许你通过对话实现这一点。Alexa 可能能启动你的 Spotify 播放列表,但想象一下与 AI 协作,为你的下一次公路旅行策划配乐,同时你开车上班。
参与社区对话
社交网络往往助长在线争论,奖励有争议的观点,并为网络喷子提供额外曝光。这导致许多人放弃了 2010 年代流行的平台。谷歌 Bard 可以为小众社区策划对话,连接好奇的头脑,同时过滤掉仇恨言论和虚假信息。
使用谷歌 Bard 的潜在陷阱
不足为奇的是,这个新聊天机器人引起了很多关注,至少部分原因是它广泛的应用潜力。对棋盘游戏爱好者和项目经理来说,它的吸引力是一样的。皮查伊在新闻稿中遗漏了一些重要点,这些点在最近的非凡太空摄影误归属事件中变得更加明显。这里还有一些需要考虑的点。
聊天机器人不必讲真话
像 ChatGPT 这样的流行对话代理内置了伦理指导。例如,它不应讲冷笑话或故意误导你。但这并不总是适用于 AI 聊天系统。
查看这项关于人工智能在棋盘游戏外交中的应用的最新研究,重点关注谈判和形成联盟的能力。研究还强调了对任何违背承诺的方实施处罚。看到团队专注于构建促进可信沟通的 AI 策略令人鼓舞,但请考虑这对不慎的数据科学家意味着什么。
随着聊天机器人技术的发展,我们应当更多考虑提供服务者的动机。在进行谈判(金融服务、交易、薪资谈判)时,聊天机器人可能会故意误导用户。
机器学习并不能消除偏见
数据科学社区已经很清楚机器学习中的偏见。像他们的人类同行一样,对话聊天机器人经常表现出确认偏见和偏见偏见。谷歌 Bard 无疑会考虑到这些问题中的一些,但我们应当对新发布的第三方应用保持警惕。
虽然谷歌聘请了一些世界上最优秀的数据科学家,但这家科技巨头也并非没有缺陷。记得那位提出一些令人不便的问题的伦理学研究者吗?她表达了对环境成本、难以理解的模型、错误导向的研究努力以及传播虚假信息潜在风险的担忧。
所有数据集都有缺陷
从本质上讲,聊天机器人依赖于自然语言处理(NLP)模型。但没有任何数据集能够代表完整的真相。深度学习可能有助于为对话伙伴提供更自然的回答,并在最佳情况下缓解一些数据集的局限性。但尽管你最喜欢的网红可能会说什么,没有任何聊天机器人是神。
引用乔治·博克斯的话:“. . . 没有必要问‘模型是否真实?’ 如果‘真实’是指‘全部真实’,答案必须是‘不’。唯一感兴趣的问题是‘模型是否具有启发性和实用性?’”
如何访问谷歌 Bard
谷歌已经向“受信任的测试者”提供了 Bard,但公司承诺在几周内进行更广泛的发布。这意味着开发者应该在密歇根州上半岛的雪融化之前获得谷歌的轻量级版本。
这对谷歌搜索的更新意味着什么?我们还得拭目以待。谷歌已经在使用人工智能来改进视觉搜索结果。我预计今年和明年会有很多变化。我期待着探索 Bard 作为商业工具的潜力。
如何开始使用 Bard 进行数据科学?
如果你想入门数据科学,我们列出了我们的一些推荐课程。这些课程在深度和范围上各不相同,所以一定要找到适合你技能水平的选项。那些考虑转行的人可以从头开始学习这个行业,虽然许多人选择学习像 Python 这样的编程语言作为进入该领域的起点。
从零开始学习数据科学
所有初学者都应熟悉数学,特别是数据科学统计学。这些技能对编程、数据评估、数据讲述及大多数其他工作部分都很重要。确定数据趋势的相关性需要以理解统计显著性作为起点。
作为数据科学家学习编程
数据科学涵盖了企业的各种功能,因此数据科学家需要学习多种语言。常见技能包括 Python、R、Hadoop、SQL 和 Apache Spark。为了深入了解这个主题,我们还讨论了如何学习数据科学。
作为专业人士实施人工智能
对于那些希望在自己领域应用机器学习、自然语言处理和其他现代技术的专业人士,请查看斯坦福大学人工智能专业项目。
总结思考
如果你对 Google Bard 感到兴奋,你并不孤单。如果你对它感到紧张、害怕或困惑,你也并不孤单。数据爱好者们了解聊天机器人如何提供建议,我们可以预期未来任何基于大型语言模型的技术都会出现类似的错误。
Jim Markus 管理 Hackr.io 及 VentureKite 旗下的网站组合。他主持了热门财经播客《节俭生活》,并共同创办了《墨与血决斗社》,这是一个在美国各大会议上出现的戏剧写作活动。他还是一位获奖的游戏设计师。
更多相关话题
数据科学家将在 10 年内灭绝
原文:
www.kdnuggets.com/2021/06/data-scientists-extinct-10-years.html
评论
作者:Mikhail Mew,研究员,投资者,数据科学家
以下是受此博客启发的 KDnuggets 投票结果:

随着 AI 的进步不断取得飞跃,数据科学的基本水平变得越来越民主化。传统的领域入门障碍,如缺乏数据和计算能力,已被不断涌现的数据创业公司(有些每天只需一杯咖啡的费用即可访问)和强大的云计算所消除,后者移除了对昂贵现场硬件的需求。作为先决条件的三位一体之一,技能和知识的实施,已经成为数据科学最普遍的方面。无需费力寻找在线教程,它们标语如“秒级实现 X 模型”,“仅用几行代码将 Z 方法应用于你的数据”。在数字世界中,即时满足已成为游戏规则。虽然改善的可及性乍看无害,但在闪亮的新软件库和模型之下,数据科学的真正目的变得模糊,有时甚至被遗忘。因为数据科学的目的并非仅仅为了运行复杂模型,或优化任意的性能指标,而是作为解决现实世界问题的工具。
一个简单但易于理解的例子是 Iris 数据集。多少人使用它来演示一个算法,而不去考虑什么是花萼,更不用说我们为什么要测量它的长度了?虽然这些对于可能更关心增加新模型的初学者来说可能显得微不足道,但对于记录了这些属性的植物学家埃德加·安德森来说,这并非小事,他这样做是为了理解鸢尾花的变异。尽管这是一个人为设置的例子,它却展示了一个简单的观点:主流已经更加关注“做”数据科学而不是“应用”数据科学。然而,这种不匹配并不是数据科学家衰退的根本原因,而是一种症状。要理解问题的根源,我们必须退一步,俯瞰全局。
数据科学有一个奇特的区别,它是少数几个没有特定领域的研究领域之一。药学学生成为药剂师,法律学生成为律师,会计学生成为会计师。那么数据科学学生是否必须成为数据科学家呢?但数据科学家是哪个领域的呢?数据科学的广泛应用证明了它是一把双刃剑。一方面,它是一个强大的工具箱,可以应用于任何产生和捕获数据的行业。另一方面,这些工具的一般适用性意味着用户在实际使用之前,很少会对这些行业有真正的领域知识。然而,在数据科学崛起的初期,这个问题并不重要,因为雇主们急于利用这项新兴技术,却没有完全理解它是什么以及如何将其完全融入公司中。
然而,近十年后,商业环境及其运作方式已发生变化。它们现在追求数据科学的成熟,拥有大规模的团队,并以行业标准为基准。紧迫的招聘需求已经转向理解业务、相关行业以及其利益相关者的问题解决者和批判性思考者。仅仅能够操作几个软件包或重复几行代码已经不够,数据科学从业者也不再以编程能力来定义。这从无代码、AutoML 解决方案如 DataRobot、RapidMiner 和 Alteryx 的日益流行中得到了证明。
这意味着什么?
数据科学家将在 10 年内消失(或多或少),至少这个角色头衔会消失。未来,被统称为数据科学的技能将由新一代数据敏锐的业务专家和主题领域专家承担,他们能够将深厚的领域知识融入分析中,无论他们是否会编程。他们的职称将反映他们的专业知识,而不是他们展示这些知识的方式,无论是合规专家、产品经理还是投资分析师。我们不需要回顾太久就能找到历史先例。在电子表格刚出现时,数据录入专家曾是备受青睐的,但如今,正如《数据讲故事》一书的作者科尔·努斯鲍默·克纳夫利克(Cole Nussbaumer Knaflic)恰如其分地观察到的那样,熟练使用微软办公套件已成为基本要求。在此之前,能够用打字机盲打被认为是一项专业技能,但随着个人计算机的普及,这也变得司空见惯。
最后,对于那些考虑从事数据科学职业或开始学习的人来说,时常参考你无疑会遇到的韦恩图可能会对你有益。它将数据科学描述为统计学、编程和领域知识的汇聚。尽管它们在交集区域中占据了相等的份额,但有些领域的权重可能会比其他领域更高。
免责声明:观点仅代表我个人的观察和经验。如果你不同意,也没关系,欢迎进行富有成效的讨论。
简介:米哈伊尔·缪 是一名研究员、投资者和数据科学家,同时也是一名好奇的观察者,提供投资和机器学习交汇处的见解和思考。
原文。经许可转载。
相关:
-
数据科学家应如何与利益相关者沟通
-
使用 BERT 构建求职知识图谱
-
高效能数据科学家的五种思维方式
更多相关话题
数据科学家如何引起 CFO 的关注(以及为什么你需要这样做)
原文:
www.kdnuggets.com/2021/12/data-scientists-get-ear-cfos-want.html
评论
图片由 StartupStockPhotos 提供于 Pixabay
数据科学家掌握着无限的可能性。其中许多可能性存在于商业智能和数据分析的领域。这些学科可以在商业环境中发挥重要作用,其中发现增长机会、识别低效以及超越竞争对手至关重要。
我们的前三名课程推荐
1. Google 网络安全证书 - 加速你的网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 为你的组织提供 IT 支持
数据专家可以通过了解首席财务官(CFO)关心的信息和报告来引起他们的注意。数据科学可以提供有价值的商业智能和预测。以下是如何引起 CFO 的关注,给公司提供高质量的分析,并在过程中提升你的价值和职业生涯。
了解不同类型的商业分析的价值
商业分析预计将在 2030 年成为一个 $6840 亿的行业。那些能够帮助公司和 CFO 在这场军备竞赛中取得领先的数据科学家往往能够稳固自己的职位并展示其价值。
为了实现这一点,数据科学家必须了解 主要的商业分析类型以及它们如何应用于以数据为驱动的企业规划。
1. 描述性分析
这一商业分析分支提供了对过去事件的见解,如公司绩效和更广泛的行业趋势。研究过去发生的事情帮助公司了解自身的弱点和优势。
对于首席财务官来说,这可能包括市场波动、现金流问题、员工流动和消费模式等。其他因素也会影响公司的灵活性和未来的准备情况。
2. 诊断分析
诊断性商业分析建立在描述性分析发现的基础上。它对公司数据进行更细致的调查,以发现隐藏的风险和问题,并最终阐明事情发生的原因。
这是未来战略规划的重要组成部分。清楚地看到低效发生的地方或浪费的地方可以大大简化首席财务官的工作。
3. 预测性分析
预测性商业分析实现了最初收集组织数据的承诺。历史信息帮助数据科学家和决策者理解事件或趋势重现的可能性。在商业环境中,这包括预测劳动力的增长或减少,考虑未来需求和购买行为的变化,以及检测金融欺诈或网络安全事件。
财务规划和分析行业的专家表示,公司使用的方法进展并不像许多人期望的那样快。在数据分析专业人员需求未得到满足的就业市场中,强大的专业知识使该领域的工作更加抢手。根据一些统计数据,2021 年美国的空缺职位大约有 140,000 个。
4. 规范性分析
这种类型的商业分析是之前分析的综合。规范性分析将当前的洞察与关于未来的理性数据驱动推断相结合,并将其转化为首席财务官和其他决策者关心的语言。
将规范性分析和商业智能应用于首席财务官角色
将原始数据转换为分析,再到为高层管理人员提供可操作的建议的过程还缺少一些步骤。其中最关键的涉及报告工具。
数据科学家可以轻松找到有关商业智能工具的客观评价和仪表板。他们需要了解如何提取决策者关心的信息,以便与首席财务官和高层管理人员有效沟通,
一些最有可能引起首席执行官、首席财务官和其他决策者兴趣的仪表板包括以下内容:
-
收入和支出仪表板
-
趋势仪表板
-
资产负债表仪表板
-
KPI 仪表板
-
基准仪表板
-
方差和异常仪表板
目前市场上的许多工具提供了针对特定业务领域预设计的模板。各种产品还可能包括数据阶段和数据仓储功能,以组织可用数据——这是从中挖掘任何附加价值的第一步。
在许多业务领域和关键工作流中,这种以数据为导向的思想交流正成为创新和业务精简的热土。这些是一些数据科学正在定义更精简、更清晰、更盈利和透明的企业结构的地方:
-
财务规划和商业模型: 理解这一领域的数据科学家可以帮助公司建立响应迅速的定价结构,了解反馈的使用方式,并主动且详细地跟踪收入。
-
工程、研究与开发: 如果通过描述性和预测性分析来了解新产品或服务的投资价值,这个过程将会顺利得多。
-
扩展、可扩展性、税务和财务: 进入新领域或进行收购不能仅仅依靠高层次的假设。了解可能的税务和财务影响,并研究目标人群以引导扩展方向,都依赖于数据科学及其科学家。
-
采购: 数据科学不断构建新工具,帮助公司更详细地跟踪其原材料和人员。运行高效的操作是实现可持续性的部分,而数据科学可以揭示使供应链更高效的机会。
数据科学家能否成为首席财务官?
是否有一种途径可以让以业务智能为导向的数据科学家成为首席财务官?答案是肯定的——而且成功案例也描述了这种进阶过程。
例如,有一位数据监控系统专家——该系统旨在识别欺诈迹象或寻找投资机会——将其大数据驱动的财务策略知识转化为首席财务官的角色。这里所利用的风险洞察和业务机会,以及公司角色的跃升,之所以成为可能,是因为这位科学家知道如何充分利用“数据废料”。
数据监控和金融科技领域的机器学习只是数据科学家角色与首席财务官角色互补的一个例子。在商业智能报告和对每天产生的 exabytes 信息的深入分析之间,如果数据科学家知道如何抓住机会,他们能为决策者提供很多帮助。
简介:德文·帕提达 是一名大数据和技术作家,同时也是ReHack.com的主编。
相关:
-
2021 年数据科学家招聘的顶级行业
-
数据科学家如何在全球就业市场竞争
-
如何成功成为自由职业数据科学家
更多相关话题
数据科学家可以从定性研究中学到什么
原文:
www.kdnuggets.com/2016/07/data-scientists-learn-from-qualitative-research.html
评论
由 Alyona Medelyan, Thematic。
开放性调查问题通常提供最有用的见解,但如果你处理的是数百或数千人的回答,总结这些回答会让你头疼不已。如果你是数据科学家,你可以尝试使用 NLP 库或 API,但调试它们很困难,结果往往难以解释。如果你没有定性研究的背景,这篇文章将帮助你学习来自长期从事文本工作的人的最佳实践,这些文本也被称为定性数据。

从文本到代码再到分析
什么是编码,为什么它很重要?
当提到“巨量数据”这样的术语时,它们几乎总是指定量数据:那些可以很容易用数字或类别表示的数据。统计和机器学习技术“喜欢”数字。另一方面,文本虽然难以处理,但却很重要!定性研究人员认为,单靠数字无法解决问题。他们认为,通过采访人们并让他们回答开放性问题,你可以学到比仅仅查看硬数据更多的东西。
例如 NPS 调查。NPS 得分是根据“你有多大可能性向朋友或家人推荐我们,0 到 9 分”的数字答案计算得出的,这将给你一个公司绩效的单一指标。但要提高这个指标,你需要关注“你为什么给我们这个分数?”的开放性问题的回答。
在定性研究过程中产生了大量的文本,为了得出结论,使用了一种叫做编码的技术。问卷调查中让受访者自由作答的问题也被称为开放性问题。每个回应被称为逐字稿。对每个回应进行“编码”或“标记”有助于捕捉回应的内容,从而有效地总结整个调查结果。
如果我们将编码与 NLP 方法用于分析文本进行比较,在某些情况下编码可以类似于文本分类,而在其他情况下则类似于关键词提取。接下来,我们将探讨编码的内容以及可以使用的不同方法论。我们通常会提到如何手动执行任务,但如果你打算使用自动化解决方案,这些知识将帮助你理解重要的内容以及如何选择有效的方法。
什么是编码框架?
创建代码时,它们被放入一个编码框架中。这个框架很重要,因为它代表了组织结构,并影响编码结果的使用方式。框架有两种类型:‘平面’和‘层次化’:
-
平面框架意味着所有代码被视为具有相同的具体性和重要性水平。虽然这种框架易于理解,但如果它变得庞大,组织和导航会很困难。
-
层次化框架捕捉了代码之间的分类关系。它们允许你在编码和分析结果时应用不同的粒度级别。
层次化框架的一个有趣应用是支持情感差异。如果顶层代码描述回应的内容,中层代码可以描述其正面或负面,而第三层描述属性或具体主题。下面展示了这种类型的编码框架的示例。

在层次化编码框架中使用情感
代码框架的优缺点

编码框架的覆盖面和灵活性
一个非常重要的考虑因素是编码框架的大小和覆盖面。在编码时,重要的是将包含相同主题的回应,即使表达方式不同,也归入同一个代码。例如,代码‘清洁’可以覆盖提到‘干净’、‘整洁’、‘脏’、‘多尘’等词汇和‘看起来像垃圾场’、‘可以从地板上吃东西’等短语。这要求编码员对每个代码及其覆盖面有良好的理解。代码少且框架固定会使决策更容易。代码多,特别是在平面框架中,会更难,因为可能存在模糊性,有时不清楚回应的确切含义。手动编码还要求编码员记住或能够找到所有相关代码,这在大型编码框架中更困难。
最后,编码框架应灵活。对调查进行编码是一项成本高昂的任务,尤其是手动完成时,因此结果应能在不同的上下文中使用。想象一下:你正在尝试回答“人们对客户服务的看法是什么”这个问题,并创建捕捉关键答案的代码。然后你发现同样的调查回应中还有许多关于公司产品的评论。为了回答“人们对我们产品的评价是什么”,你可能需要从头开始编码!创建一个灵活且覆盖面广的编码框架(见下文的归纳风格)是未来获取价值的好方法。
演绎和归纳编码风格
手动编码开放式问题的两种方法是什么,哪一种更好?
演绎编码使用预先存在的框架
使用演绎编码时,你从预定义的代码集开始。这些代码可能来自现有的分类法、覆盖业务部门的代码或行业特定术语。这通常意味着这些代码是由项目目标驱动的,旨在报告特定问题。例如,如果调查是关于客户体验的,你已经知道你对因呼叫等待时间产生的问题感兴趣,那么这将是其中一个代码。这有一个好处,就是你可以保证你感兴趣的项目会被覆盖,但你需要小心偏见。当你使用预先存在的编码框架时,你会带有一种偏见,预设答案的可能性,并可能会遗漏自然从人们的回应中出现的主题。
当你使用预先存在的编码框架时,你会带有一种偏见,预设答案的可能性,并可能会遗漏自然从人们的回应中出现的主题。
归纳编码使用抽样和重新编码
替代的编码风格是归纳法,通常称为“扎根法”。在这种方法中,你一开始没有任何代码,所有的代码都直接来源于调查回应。这个过程是迭代的:
-
你读取了一份数据样本
-
创建覆盖样本的代码
-
重新阅读样本并应用代码
-
阅读新的数据样本,应用代码并记录代码不匹配的地方
-
创建新的代码
-
返回并重新编码所有已编码的回应
-
从第 4 步重复。
如果你添加了一个新的代码,将现有的代码拆分成两个,或改变其描述,请确保审查所有可能受到影响的回应的代码。否则,调查开始和结束时相近的回应可能会被分配不同的代码!
如何选择好的代码
在决定创建哪些代码时,需要考虑几件事。
-
确保覆盖。代码应覆盖尽可能多的相关调查回应。这意味着代码应比评论本身更通用,以便能够覆盖其他回应。当然,这需要与分析的有用性相平衡。例如,“产品”是一个非常广泛的代码,会有很高的覆盖率,但有用性有限。另一方面,“产品在使用 3 小时后停止工作”是非常具体的,不太可能覆盖许多回应。
-
避免共性。虽然有相似的代码是可以的,但它们之间应该有明显的区别。在数学中,这被称为正交性,表示两个事物的独立性。“客户服务”和“产品”是正交的,而“客户服务”和“客户支持”可能有细微的差别,但不是正交的,可能作为相同的代码更好。
-
创建对比。尽量创建相互对比的代码。这允许将同一事物的正面和负面元素分别提取。例如,“有用的产品功能”和“不必要的产品功能”就是具有对比性的代码。
-
减少数据。我们来看看两个极端的情况:代码数量等于评论数量,或者每个代码适用于所有响应。在这两种情况下,编码练习都是毫无意义的。因此,试着考虑如何减少数据点的数量,以便有效地进行分析。上述“产品使用三小时后停止工作”的例子就未能通过这一测试。更有效的代码应该是“产品使用后停止”。
编码的准确性
无论使用演绎过程还是归纳过程,都很难确保一致性。这是因为编码者的思维框架和过去的经验会影响他们的解释方式。这意味着不同的人在面对相同的任务时,很可能会对适当的代码产生不同的看法。实际上,一项研究表明,同一个人在不同的日子对同一份调查进行编码会产生不同的结果。
通过记录所有决策和思考过程来缓解这个问题。应用现有代码或决定是否需要新的代码时,请回顾这些记录。这一过程还意味着代码的选择可以得到证据的支持。
确保准确性的另一种更昂贵的方法是通过有意测试编码的可靠性。‘测试—重测’方法涉及同一个人对数据进行两次编码而不查看结果。‘独立编码者’方法则在同一份调查中使用第二个编码者。在这两种情况下,结果会被比较一致性,并根据需要进行修正。
摘要 / TLDR
-
数据科学家在分析文本时可以向定性研究者学习
-
编码是将代码分配到开放性回答或其他类型的文本数据上的过程,然后这些文本可以像数值数据一样进行分析。
-
代码框架是一组代码,可以是平面的(使用更简单更快速)和层次的(更强大)
-
代码框架需要具有良好的覆盖面,并且灵活以允许对开放性回答进行全面和多样化的分析。
-
归纳编码(没有预定义的代码框架)更困难,但偏差较小
-
在创建代码时,请确保它们彼此对比并减少数据
-
准确性意味着一致的编码,这可以通过在编码过程中记录和回顾决策来实现。
简介: Alyona Medelyan,博士,专注于从文本中提取意义。她是一位自然语言处理和机器学习领域的顾问,并在这些主题上进行国际演讲。在 Thematic 她帮助企业理解客户反馈和情感。关注她的 Twitter @zelandiya 或通过 medelyan.com 联系她。
原文。经许可转载。
相关:
-
自然语言处理的内部更新
-
HPE Haven OnDemand 文本提取 API 开发者备忘单
-
文本分析:是什么让你的手机比调查分析更智能
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
更多相关内容
数据科学家是否应该对 COVID19 和其他生物事件进行建模
原文:
www.kdnuggets.com/2020/04/data-scientists-model-covid19-biological-events.html
评论
数据科学家的角色多年来一直在扩展。从用统计数据处理数字,到构建可扩展的数据库,再到构建生产级的机器学习或深度学习模型。生物统计学和流行病学是统计学的高度专业化领域,大学为其提供不同的学位课程。
生物统计学家使用的统计技术可能是你目前的日常数据科学家从未听说过的。这是一个很好的例子,说明缺乏领域知识会暴露你作为一个不知所措、只是跟随趋势的人。虽然社区中已知建立预测模型以查看谁更可能在泰坦尼克号上幸存或对鸢尾花进行分类作为数据科学之旅的一部分,但对于如全球大流行这样正在杀害数十万人甚至数百万人的更严重问题,或许应该给予更多的谨慎。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
流行病学家和生物统计学家

流行病学是研究疾病在特定人群和环境中的频率和分布的学科。流行病学是公共健康的重要方面,因为它涉及对人群中疾病的理解和风险评估。流行病学家通常具有生物学、医学和病毒学等领域的科学背景。这是流行病学家建立领域知识的方式,从而能够理解他们所建模的内容。
生物统计学是将统计技术应用于健康相关领域的科学研究,包括医学、流行病学和公共卫生。拥有统计学学位的人可能会成为零售、人口统计、房地产、经济学、金融等领域的数据分析师。生物科学则是一个完全不同的领域,需要单独的资格认证。
现在,数据科学家可能来自非统计/数学背景,突然开始建模疾病数据以展示他们的技能。这并不是展示你知识的正确数据类型。每个人都需要知道自己是否有能力正确处理这些数据。已经发布了大量虚假和误导性内容,这进一步玷污了数据科学家的职业,因为这表明仍然有人对数据一无所知,只关心使用 Python 中的随机森林或 xgboost 模型,而不是 R(因为 R 显然已经不再像以前那样酷)并在 LinkedIn 上推广,希望能让招聘人员或高级数据科学家留下深刻印象。
COVID-19 预测、达克效应和数据科学家的希波克拉底誓言由 Raj Iqbal 完美总结了这一点。达克效应简单来说就是当一个人高估自己的能力时,实际上他们完成任务的能力非常低。
预测 COVID-19
以下内容摘自这里。
预测和时间序列专家 Rob J Hyndman 表示,为了使预测相对准确,有三个主要因素:
-
我们对影响其因素的理解程度;
-
可用数据的多少;
-
预测是否会影响我们试图预测的内容。
例如,明天的股票价格预测准确性较低,因为上述因素 1 和 3 并未得到满足。首先,影响股票价格变化的因素并没有得到特别好的理解,并且至少部分依赖于人类心理学。其次,广泛宣传的股票市场预测可以直接影响许多投资者的行为。
上述三个因素并非都适用于疾病,但我们可以看到第二点因实际病例数量被低估而成为问题。第二个问题是,COVID-19 的预测可能会影响我们试图预测的内容,因为各国政府正在做出反应,有些比其他国家更好。除非能够考虑到减缓传播的各种措施,否则使用现有数据的简单模型将会产生误导。
他和其他科学家使用分 compartments 流行病学模型来模拟感染过程。最简单的模型是基于将人口中的活跃个体分类为易感、传染或康复——因此它们被称为 SIR 模型。
结论
尽管数据科学家的任务是分析数据以提供见解,但我们有责任认识到我们的才能应如何使用,以及何时退一步让真正的专家带领前进。传染病建模是一个过于专业和敏感的领域,不应盲目发表意见。我们需要意识到我们何时被需要,何时不被需要。
相关内容:
-
用 AI 对抗冠状病毒:利用深度学习和计算机视觉改进检测
-
数据科学家应避免的 5 个统计陷阱
-
数据科学家应对 COVID-19 的 5 种方式及 5 个应避免的行动
更多相关主题
数据科学家,你需要知道如何编码
原文:
www.kdnuggets.com/2021/06/data-scientists-need-know-code.html
评论
由 Tyler Folkman,Branded Entertainment Network 的 AI 负责人

图片由 Roman Synkevych 提供,来源于 Unsplash
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
我知道你在想什么——“我当然知道如何编码,你疯了吗?”
你每天在 Jupyter 笔记本中编写大量代码,数百行。显然,你会编码。并不是说你是在手动或在 Excel 中训练机器学习模型(尽管这是可能的)。
那我可能是什么意思呢?
我不愿意打击你,但大多数数据科学家做的编码我不认为是真正的编程。你是使用编程语言作为探索数据和构建模型的工具。但你创建的程序并不是你真正考虑的,只要它能完成工作就好。
你的代码通常很混乱,可能甚至不能按顺序运行(这要归功于笔记本)。你可能从未编写过单元测试,也几乎不了解如何编写良好、可重用的函数。
但是,随着数据科学越来越多地嵌入到实际产品中,这种类型的代码将不够用。你不能信任糟糕的代码,把你不信任的代码放到产品中会导致大量的技术债务和糟糕的用户体验。
“好吧,好吧,但我是一名数据科学家,不是软件工程师,”你说。我构建模型,清理代码是其他人的问题。虽然这在一些公司可能有效,但我现在深信,更好的模式是数据科学家学习如何编写更好的代码。你可能永远不会成为顶级的软件工程师,但数据科学家可以通过一些努力编写值得信赖并投入生产的代码。
从你的函数开始
在学习如何提升你的代码时,从你如何编写函数开始。大多数代码只是函数(或可能是类)的系列,如果你能学会编写相当好的函数,这将大大改善你的代码质量。
你的函数至少应该:
-
只做一件事
-
拥有文档。
-
使用良好的变量名。
虽然关于如何编写干净函数的书籍有很多,但这三个方面是一个很好的起点。
你不应该有一个函数看起来像是在尝试做超过一件事。一些迹象表明你的函数可能做得太多:
-
它的长度超过了一个屏幕,或者大约 30 行代码(根据我的经验)。
-
由于函数做的事情太多,清晰命名函数非常困难。
-
它包含了大量的 if/else 代码块,这些代码块实际上应该被拆分成独立的函数。
只做一件事的函数很重要,因为它使你的代码更容易理解、管理和测试(稍后会详细讲到测试)。
任何投入生产的函数都应该有文档字符串,该字符串应描述函数的功能,提供输入参数的信息,并可能提供一些简单的使用示例。未来你会感谢自己拥有良好的文档化函数,而其他人也会更容易理解你的代码。
最后,请使用易于理解和有用的变量名。太多的数据科学家习惯使用“a”、“a1”和“a2”这样的变量名。短小而无帮助的变量名在试验时更快输入,但在将代码投入生产时,确保你的变量名能帮助他人理解你的代码。
移除 Print 语句。
数据科学家常常使用 print 语句来显示发生的情况。然而,在生产环境中,这些 print 语句应当被移除(如果不再需要)或转换为日志语句。
日志记录应当是你与代码之间传达信息和错误的方式。一个值得查看的 Python 库是 Loguru,它使日志记录变得更简单。它自动处理了大多数麻烦的日志记录部分,感觉更像是使用 print 语句。
使用风格指南。
编程中的风格指南旨在使多人可以更轻松地在同一代码上工作,但使得这些代码看起来仿佛是由一个人编写的。
为什么这很重要?
当你拥有一致的风格时,代码的浏览和理解会变得更容易。使用风格指南时,发现 bug 会变得更轻松。遵循标准的代码编写方式会使你和他人更容易浏览代码。这意味着你不必花费太多时间去理解代码的格式,而可以专注于代码的功能及其是否正确有效。
PEP 8 可能是最广泛使用的 Python 风格指南。不过,还有很多其他风格指南。另一个受欢迎的风格指南来源是 Google,因为他们公开了内部风格指南。
重要的是你选择一种并尽量坚持。一个让这变得更容易的方法是使你的 IDE 检查样式错误,并设置样式检查,如果不遵循样式指南,阻止代码被推送。你还可以进一步提交,使用自动格式化工具,它会自动格式化你的代码以符合标准。Python 中一个流行的工具是 Black。
编写测试
我发现大多数数据科学家害怕测试,因为他们不太知道如何开始测试。
事实上,许多数据科学家已经在运行我所称之为临时测试。我发现数据科学家在笔记本中快速运行一些“健康检查”以验证新函数是很常见的。你通过一些简单的测试用例,确保函数按预期运行。
软件工程师称这个过程为单元测试。
不同的是,数据科学家通常会删除这些临时测试并继续前进。相反,你需要保存这些测试,并确保每次在代码推送之前都运行这些测试,以确保没有破坏。
要开始使用 Python,我建议使用 pytest。使用 pytest,你可以轻松创建测试,并一次性运行它们以确保它们通过。一个简单的开始方式是有一个名为“tests”的目录,在该目录内有以“test.”开头的 Python 文件。例如,你可以有“test_addition.py”。
*# content of test_addition.py*
**def** add(x, y):
**return** x + y
**def** test_add():
**assert** add(3, 2) == 5
通常,你会将实际的函数放在另一个 Python 文件中,并将其导入到你的测试模块中。你通常不需要测试 Python 加法,但这只是一个非常简单的例子。
在这些测试模块中,你可以保存你函数的所有“健康检查”。通常的好做法是不仅测试常见情况,还要测试边界情况和潜在错误情况。
注意:测试有许多不同类型。我认为单元测试是数据科学家开始测试的最佳选择。
做代码审查
在我们列出的编写更好代码的顶级事项中,最后但同样重要的是代码审查。
代码审查是指在你将代码提交到主分支之前,另一位在你领域内擅长编写代码的人对你的代码进行审查。这一步骤确保最佳实践得到遵循,并希望能够发现任何不良代码或错误。
审查你代码的人最好至少和你一样擅长编写代码,但即使让一个更初级的人审查你的代码也仍然可以非常有益。
人们有时会懒惰,并且很容易让这种懒惰影响到我们的代码。知道有人会审查你的代码是一个很好的激励,使你花时间编写优质代码。这也是我发现的最有效的改进方法。让更有经验的同事审查你的代码并提供改进建议是无价的。
为了让审查你代码的人更容易理解,尽量保持新代码量的小规模。小而频繁的代码审查效果更好。不频繁的大规模代码审查效果很差。没有人愿意审查上千行代码。这些审查往往提供较差的反馈,因为审查者无法花足够的时间真正理解这么多代码。
提升你的编码技能
我希望这篇文章能激励你花时间学习如何编写更好的代码。这并不一定很难,但确实需要时间和努力来提升。
如果你遵循这 5 个建议,我相信你会注意到你的代码质量有显著提升。
你的未来自己和同事会感谢你。
查看我的 免费课程,了解如何部署机器学习模型。
简介:泰勒·福克曼 是 Branded Entertainment Network 的 AI 主管。获取泰勒的免费 创建惊人数据科学项目的 5 步流程。
原文。经许可转载。
相关:
-
顶级编程语言及其用途
-
未来 5 年会出现数据科学工作短缺吗?
-
这些软技能可能决定你的数据科学职业生涯的成败
更多相关主题
数据科学家需要专业化以在科技寒冬中生存
原文:
www.kdnuggets.com/2023/08/data-scientists-need-specialize-survive-tech-winter.html

照片由Ingo Joseph提供
硅谷的温度最近很凉。毫无疑问,我们正处于科技寒冬。风险投资资金已经枯竭,数百家公司正在通过裁员来行使它们的权力,人工智能正在逼近每个人,导致额外的失业和不确定性威胁。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的信息技术
数据科学家们感到困惑:我的工作安全吗?这也不奇怪。曾经被誉为最性感职业的工作现在看起来已经不那么吸引人了。
从整体来看,数据科学的工作前景仍然乐观——劳动统计局仍然预测未来十年将增长 36%,远高于美国平均行业增长率 5%。但正如成千上万的被裁数据科学家所告知的,统计数据并不能作为失业的盾牌。答案是什么?一些专家建议,专业化是脱颖而出并使自己不容易被解雇的最佳方式之一。“随着数据的影响力增长和技术的发展,数据团队中将需要特定的角色来最大化效率,”财富杂志的作者梅根·马拉斯写道。
我同意。任何数据科学家都会告诉你,这份工作会根据你老板当天需要什么而有所不同——电子表格、演示文稿、开发 ETL 管道或设计实验。

图片来自Twitter
所有数据科学家共有的特点是随着数据量和重要性的增长,职责也在扩展。
数据科学家可以通过专业化来更好地区分自己,而不是继续尝试做所有事情。通过选择一个技能或领域,更容易明确他们的价值主张,在竞争激烈的就业市场中保持相关性和价值。
为什么专业化能帮助数据科学家保住工作
在我开始使用StrataScratch之前,我是一个普通的通才数据科学家。我不断学习新技能和技术,以跟上快速发展的领域。但当然,有一天我意识到我需要与众不同。我决定专注于基础设施以及如何通过基础设施支持数据科学工作。我的基础设施工作改变了团队中数据科学家的工作方式,使他们能够比以前更快地交付模型和结果。
在专注于数据科学基础设施几年后,我在生物技术领域找到了数据战略的工作。我很快意识到我的专业化在就业市场上给了我显著的优势,因为拥有我这样特定技能和经验的人很少。这也意味着我能够获得更高的薪水和职位,因为我在一个焦点领域的深厚知识使我能够晋升到一个更高级别的位置,仅仅因为我拥有更多的知识和经验来影响团队中的其他数据科学家。
不过,这只是我的故事。专业化可以以几种不同的方式提供帮助,具体取决于你当前的情况和总体目标。

图片来源:作者
争取工作安全
在我最喜欢的《老爸老妈的浪漫史》一集中,马歇尔因朋友巴尼的帮助而在一家律师事务所找到了工作。巴尼告诉他必须成为“某种”人物。也许是零食人员、按摩人员或游戏人员。那是避免被变化无常的老板解雇的唯一办法。
有时候情景喜剧说得对。通才可以被其他通才替代。作为专家,你的价值要高得多。很容易说:“不,我们不能解雇马歇尔,因为他是我们的营销分析人员。他是帮助我们建立所有营销和销售管道的人。他对团队至关重要。”
击败竞争对手
对数据科学家的需求很大,但对数据科学学位的需求也在增长。再加上公司现在开始考虑非传统背景的人,你就有了竞争的配方。
图片来自Geekwire
通过专注,你可以减少工作市场上的竞争。例如,如果你专注于自然语言处理(NLP),你确实会限制可以竞争的工作数量。但你将会更受欢迎,因为 NLP 专家远少于数据科学家。
追逐金钱
老实说,追求数据科学职业不能仅仅是为了金钱。专注也是如此。但如果你发现自己对工作中的某个特定部分感兴趣,值得知道的是,专家的薪资高于普通人,不论普通人掌握多少技能。
看看 Indeed 的数据,作为一个参考:数据科学家的平均基本工资是每年 127k 美元。相比之下,机器学习工程师的薪资为\([155k](https://www.indeed.com/career/machine-learning-engineer/salaries?from=career),或者[后端开发者](https://blog.boot.dev/backend/how-much-do-backend-devs-make/#:~:text=Backend%20developers%20enjoy%20an%20average,not%20to%20mention%20comprehensive%20benefits.)的薪资为\)158k。
如何成为专注的数据科学家
好的,你已经认识到专注的价值。那么,你该如何专注呢?让我们来分解步骤。
图片由作者提供
从你的兴趣开始
如果你要专注,你需要确保你对你将要专注的领域感兴趣。这不能只是为了钱;还必须是你喜欢做的事情。从你的兴趣开始。
你对什么充满热情?你发现自己在空闲时间里从事什么样的项目?通过确定你的兴趣,你可以开始看到自己可能专注的领域。了解你热衷的工作类型的一种方法是尝试理解你对哪些工作感到兴奋?例如,在一个项目中,你通常更兴奋于做基础设施工作?还是建模工作?或者数据清理工作?弄清楚你喜欢做什么,然后深入探索。
观察技术景观
技术景观不断变化,保持对最新趋势的了解非常重要。例如,看看 Meta。在花费了数年和巨额资金投入到元宇宙后,他们现在正在转向人工智能,以及其他所有主要科技公司。
一旦你列出了感兴趣的主题清单,寻找那些活动频繁和需求旺盛的领域。这将帮助你确定可以专攻的领域以及可能有机会让你脱颖而出的地方。
一个很好的地方是 Indeed。 这篇文章虽然有点旧,但我喜欢这个想法。作者从 Indeed 抓取了提到特定语言和城市的招聘信息。他们发现 R、SQL 和 Python 位居前列。你还可以查看StackOverflow 的开发者调查。他们对热门技术有相当准确的把握,因此值得一看。
寻找免费的课程和证书
一旦你确定了感兴趣的领域,寻找免费的课程和证书来帮助你提升技能。不要从昂贵的课程开始;先从免费的课程入手,看看这些知识是否能扎根。
目前有很多免费的资源,包括在线课程、书籍和练习平台。利用它们来提升你的数据科学技能和知识。一旦你感觉有了足够的信心,你可能会想做一些项目来建立你的作品集。
在工作中请求新项目
如果你已经在担任数据科学家的职位,寻找展示新技能的机会。与老板和同事讨论你的兴趣,看看是否有任何项目可以让你发展技能。通过接受工作中的新挑战,你可以在你选择的专业领域中积累经验和专业知识。
例如,如果你对自然语言处理感兴趣,你可以申请参与一个涉及分析客户反馈数据或开发客户服务聊天机器人的项目。如果你更倾向于计算机视觉,看看是否有与图像识别或视频分析相关的项目,你可以参与其中。
有时候,业务需求决定了你下一个项目的方向。例如,作为数据科学家,我的第一个项目之一是创建一个自然语言处理算法,用于通过 Twitter 推文跟踪食源性疾病爆发。我没有建立自然语言处理算法的培训,因此我不得不从头开始,并在项目期间尽可能多地学习。这是一个极好的学习经历,有助于提升我作为数据科学家的技能。
更换工作
最终,你可能会面临跳槽的时机。如果你的老板只把你看作是一个全能的数据科学家,你可能需要转到一家新公司,展示你新的职业方向。有时候,你可能会对雇主的业务需求(例如,总是相同的需求)、技术栈和团队结构感到厌倦。如果你每天上班没有激情学习,那么可能是时候探索让你成长和学习的新机会了。
寻找与你新技能匹配的职位,并申请这些职位。通过换工作,你可以重新开始,并向新雇主展示你的新专业技能。
沉没成本还是专业化——选择权在你
作为一名数据科学家,专注是明智的。但希望这不仅仅是一个好的职业选择——专注于我的领域给了我更多的角色清晰度,以及乐趣和目标。我的老板们对我应该做的事情有了更好的理解,并能够给我更多有用的 KPI。我更清楚如何创造价值。我也能够满足我的兴趣。
按照这些步骤,你可以开始专注于成为一名数据科学家,并在竞争激烈的就业市场中脱颖而出。记住,专注不仅仅是为了提升你的就业能力;它是关于追求你的兴趣,并建立一个你喜欢的职业生涯。祝好运!
Nate Rosidi 是一名数据科学家,专注于产品策略。他还是一名兼职教授,教授分析学,同时也是 StrataScratch 的创始人,该平台帮助数据科学家通过顶级公司的真实面试问题来准备面试。可以通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
相关话题
数据科学家应该使用 LightGBM 的 3 个理由
原文:
www.kdnuggets.com/2022/01/data-scientists-reasons-lightgbm.html
介绍
有许多优秀的 Python 提升库供数据科学家利用。其中包括 XGBoost 和新推出的 CatBoost 算法。然而,有一种算法结合了这些算法的某些特征,使其成为数据科学家的必备工具。虽然这些好处在学习和教育方面很棒,但更重要的是,它在需要快速的专业环境中表现尤为出色。接下来,我将讨论 LightGBM [1] 的好处以及它们如何与您的数据科学工作密切相关。
分类编码

图片由 米哈伊尔·瓦西里耶夫 提供,来自 Unsplash [2]
这个库的最佳特性之一是对分类特征的支持。虽然很多数据科学家可能使用独热编码为一个分类特征创建大量新列,但这个库允许你使用 categorical_feature 参数来指定分类特征。
虽然独热编码很有用,但在学术界,例如在 Jupyter Notebook 中,它在专业环境中可能不那么有用。假设你有 10 个分类特征,每个特征有 100 个独特的 bin,这将扩展到 1,000 个新列。这不仅使你的数据框变得稀疏,而且还使你的模型变得非常缓慢。这种稀疏性的另一个令人焦虑的结果是,当你需要将特征转换为生产代码供软件工程师在你的预测服务和部署中使用时(如果你有这种设置的话),这对双方来说可能会令人困惑和难以处理。
以下是使用 LightGBM 进行分类编码的一些好处:
-
更容易对分类特征进行编码
-
更容易使用
-
更容易与其他数据科学家、软件工程师、后台工程师和产品经理合作
-
可以保留原始列名
-
可以利用分类特征的好处,而不是使用独热编码进行传统的数值转换
-
这些好处可以最终使你的模型更快、更准确
快速

图片由 安迪·比尔斯 提供,来自 Unsplash [3]。
不仅仅是对类别特征进行编码使你的模型更快,LightGBM 还具备一些其他技巧来提高训练和预测速度。LightGBM 使用了 GOSS 和 EFB,或称为基于梯度的单侧采样(Gradient-based One-Side Sampling)和排他特征绑定(Exclusive Feature Binding),以及基于直方图的分裂方法。
以下是为什么快速的 LightGBM 模型对专业人士有用的原因:
-
并不是每个工作都允许你花费几周或几个月来制定模型,有些甚至可能希望在同一周内得到一个——或者至少是一个概念验证模型
-
这种更快的建模可以让你更快地测试特征和参数,最终使你在更快的环境中工作得更好
-
可以测试更多特征,而不会像其他算法那样显著减慢模型速度
它简单、快速,当有很多人依赖你的模型时,速度快可以让你更高效地帮助业务。
准确

图片由 Silvan Arnet 拍摄,来源于 Unsplash [4]。
XGBoost、CatBoost 和 LightGBM 都是准确的模型。是的,最终这取决于你的问题、特征和数据,但总体而言,这些算法在你执行了必要步骤后会产生准确的结果。
因为你可以使用类别特征,所以你更有可能得到一个准确的模型,比起只能执行独热编码的算法要更好。LightGBM 的分裂方式也可以导致更准确的模型。不过,重要的是要注意你需要防止过拟合。
以下是 LightGBM 更准确的一些原因,以及它如何在职业上帮助你的:
-
分裂方法
-
类别特征支持
-
当然,每个人都希望有一个更准确的模型,特别是在业务中(只需要确保你没有过拟合)
总结
虽然这些好处很简单,但它们非常重要,并且使你的工作变得更加轻松。因此,你的公司——包括利益相关者和工程师,会对你使用 LightGBM 感到满意。
总结一下,这里是一些在职业上使用 LightGBM 的主要好处:
-
类别编码
-
快速
-
准确
我希望你觉得我的文章既有趣又有用。如果你同意或不同意这些好处,请随时在下面评论。为什么或为什么不?你认为 LightGBM 还有哪些其他重要的好处需要指出?这些内容当然可以进一步澄清,但我希望我能够对 LightGBM 提供一些启示。
请随时查看我的 Medium 个人资料。
参考文献
[1] 微软公司,LightGBM 文档,(2022)
[2] 图片由 Mikhail Vasilyev 提供,来源于 Unsplash,(2017 年)
[3] 图片由 Andy Beales 提供,来源于 Unsplash,(2015 年)
[4] 图片由 Silvan Arnet 提供,来源于 Unsplash,(2020 年)
Matthew Przybyla (Medium) 是位于德克萨斯州 Favor Delivery 的高级数据科学家。他拥有南美 Methodist University 的数据科学硕士学位。他喜欢撰写关于数据科学领域的趋势话题和教程,从新算法到数据科学家日常工作经验的建议。Matt 喜欢突出数据科学的商业方面,而不仅仅是技术方面。欢迎通过 LinkedIn 联系 Matt。
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关主题
数据科学家:如何推销你的项目和你自己
原文:
www.kdnuggets.com/2021/11/data-scientists-sell-project.html
评论
由 Ilro Lee,NSW 客户服务部高级分析单元经理

照片由 JohnnyGreig 提供,拍摄于 Canva
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 管理
在数据科学行业,仅仅成为一名熟练的数据科学家是不够的——你还需要推销你的项目和你自己。推销一个想法或你自己的一步是制定一个有效的电梯推介,说明你的价值主张以及你的项目与其他项目的不同之处。在这篇博客文章中,我们将讨论电梯推介如何运作,它们包含了什么,以及数据科学家的电梯推介示例。
1. 什么是电梯推介
你和一位高管被困在电梯里,你只有 15 秒的时间来给自己和你的项目留下良好的第一印象。你会怎么说?你在一个网络活动中,一位行业领袖要求你向她介绍你的项目。你能简洁而有说服力地描述你的项目/产品吗?
在你心中,你想说的是“你即将和我一起踏上改变你一生的冒险。我是你所有问题的答案,更重要的是,你需要一个完全理解你需求的合作伙伴。”对吧?但我们知道,这样的表达实际上并不容易实现。你只有 15 秒钟来抓住他们的注意力。我们需要能够提供一个精心设计的电梯推介。
2. 为什么你需要知道如何进行一个好的电梯推介
你应该学习如何为你的项目提供有效的电梯推介,原因有两个。首先,你可能需要在工作或面试中展示一个项目。其次,这也是练习简明扼要地描述复杂主题和想法的好方法——这正是数据科学家所做的!你可能不会认为知道如何推销自己能使你在工作中更有效,但电梯推介是展示演讲和让数据科学项目对他人有吸引力的好练习。
3. 成功的电梯推介的组成部分
你会发现关于如何开发电梯推介的无尽建议和意见。然而,我认为我们应该系统地进行这项工作,这意味着公式应基于证据和研究。因此,这个公式来源于市场研究领域……他们知道如何进行市场推广!!
你需要两个高级组件。你必须明确你的价值主张和你的差异化。
价值主张:
-
具体描述你的项目所针对的细分市场。很难让别人相信你正在做的东西能帮助每个人,这也为项目设定了背景。
-
描述那些对当前环境不满的群体。
-
描述你正在开发的产品/服务以及它解决了什么具体问题。
你的差异化:
-
描述替代方案(可能是你的竞争对手或当前可用的产品/服务)
-
描述一种与当前可用产品/服务不同的具体(而非所有)功能或特点。
4. 电梯推介公式
针对 [目标客户/用户群体],
他们对 [当前可用的产品/服务] 感到不满意
我们的产品/服务是一个 [新产品类别]
它提供了一个 [关键问题解决能力]
与 [产品/服务替代品] 不同,
我们已经组装了 [针对特定应用的关键产品/服务功能]
5. 我如何使用这些功能的示例
示例 1:
针对 政治竞选活动经理,
他们对 传统的调查产品感到不满意,
我们的应用程序是一款 新型调查产品
它提供 在 24 小时内设计、实施并获得结果的能力。
与 其他需要超过 5 天才能完成的传统调查产品不同,
我们已经组装了 一款快速、经济且相对准确的调查产品。
示例 2:
针对 前线刑事调查员,
他们对 显示过多不必要信息的通用仪表盘感到不满,
我们的应用程序是一款 新型智能产品
它提供 一个高度定制的、启用机器学习的风险评估工具,使调查员能够揭示潜在犯罪分子的隐藏网络。
与 当前提供的信息往往不太有用的仪表盘不同,
我们已经组装了 一款智能产品,允许他们在已知和未知的感兴趣演员之间建立联系。
这些是我使用过的真实案例。它有效,并且肯定能引起他们的注意。告诉我你的看法。
简历:Ilro Lee 是 NSW 顾客服务部高级分析单元的经理。
原文。经许可转载。
相关:
-
5 件事让数据科学家与其他职业区别开来
-
不要浪费时间建立你的数据科学网络
-
数据科学家职业路径:从新手到首份工作
相关话题
不受欢迎的观点——数据科学家应该更多地从端到端
原文:
www.kdnuggets.com/2020/09/data-scientists-should-be-more-end-to-end.html
评论
由尤金·闫,亚马逊应用科学专家,作家和演讲者。

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 在 IT 领域支持你的组织
最近,我看到了一条关于数据科学和机器学习中不同角色的Reddit 讨论线程: 数据科学家、决策科学家、产品数据科学家、数据工程师、机器学习工程师、机器学习工具工程师、AI 架构师等。
我发现这让人感到担忧。当数据科学过程(问题框定、数据工程、机器学习、部署/维护)分散在不同的人手中时,很难做到高效。这会导致协调开销、责任分散以及缺乏全局视角。
在我看来,我相信数据科学家通过从端到端的方式可以更有效。在这里,我将讨论好处和反对观点,如何成为端到端,以及Stitch Fix 和 Netflix的经验。
从开始(确定问题)到结束(解决问题)
你可能见过类似的标签和定义,例如:
我发现这些定义比我更喜欢的要具备更强的规定性。相反,我有一个简单(且务实)的定义:端到端数据科学家能够识别并解决数据问题以提供价值。为了实现这一目标,他们将佩戴所需的(或较少的)多种帽子。他们还会学习和应用有效的技术、方法和过程。在整个过程中,他们会提出以下问题:
-
问题是什么?为什么重要?
-
我们能解决这个问题吗?我们应该如何解决?
-
估计值是多少?实际值是多少?
数据科学流程
另一种定义端到端数据科学的方法是通过流程。这些流程通常很复杂,我在主要讨论中省略了它们。尽管如此,这里有一些以供你参考:
如果这些流程看起来繁重且令人不知所措,不用担心。你不必完全采纳它们——可以逐步开始,保留有效的部分,并调整其余部分。
.
更多的背景信息,更快的迭代,更大的满意度
对于大多数数据科学角色来说,更多的端到端经验提升了你产生有意义影响的能力。(尽管如此,还有一些角色专注于机器学习。)
端到端工作提供了更高的背景信息。 虽然专业化角色可以提高效率,但它减少了背景信息(对于数据科学家而言),并导致次优的解决方案。
忘记整体图景的诀窍是近距离观察一切。——查克·帕拉纽克
在没有上游问题的完整背景信息的情况下,很难设计出整体解决方案。假设转换率下降,项目经理提出了改进搜索算法的请求。然而,最初导致下降的原因是什么?可能有多种原因:
-
产品:是否存在欺诈/质量差的产品减少了客户信任?
-
数据管道:数据质量是否受到影响,或者是否存在延迟/中断?
-
模型刷新:模型是否没有定期/正确刷新?
更常见的是,问题和解决方案往往在机器学习之外。改进算法的解决方案会忽略根本原因。
同样,在不了解下游工程和产品约束的情况下开发解决方案是有风险的。没有意义:
-
如果基础设施和工程师无法支持,构建近实时推荐器
-
如果无限滚动推荐器不适合我们的产品和应用
通过端到端的工作,数据科学家将拥有完整的背景,能够识别正确的问题并开发可用的解决方案。这也可能导致一些专业人员因其狭窄的背景而可能忽视的创新想法。总体而言,这提高了交付价值的能力。
沟通和协调开销减少。 拥有多个角色会带来额外的开销。让我们来看一个例子:数据工程师(DE)清理数据和创建特征,数据科学家(DS)分析数据和训练模型,机器学习工程师(MLE)进行部署和维护。
一位程序员在一个月内能完成的工作,两位程序员在两个月内也能完成。——弗雷德里克·P·布鲁克斯
数据工程师(DE)和数据科学家(DS)需要就哪些数据是(和不是)可用的、如何清理数据(例如,异常值、标准化)以及应该创建哪些特征进行沟通。类似地,数据科学家(DS)和机器学习工程师(MLE)必须讨论如何部署、监控和维护模型,以及模型的更新频率。当出现问题时,我们需要三个人在场(可能还有项目经理 PM),以确定根本原因和解决步骤。
这也会导致额外的协调工作,因为在执行和按顺序传递工作时,时间表需要保持一致。如果数据科学家(DS)想要尝试额外的数据和功能,我们需要等待数据工程师(DE)处理数据并创建功能。如果一个新的模型准备好进行 A/B 测试,我们还需要等待机器学习工程师(MLE)将其(转换为生产代码)并部署。
尽管实际开发工作可能需要几天,但来回的沟通和协调可能需要几周,甚至更长时间。通过端到端的数据科学家,我们可以最大限度地减少这些额外开销,并防止技术细节在传递过程中丢失。
(但是,端到端的数据科学家真的能做到这一切吗?我认为可以。虽然数据科学家在某些任务上可能不如数据工程师(DE)或机器学习工程师(MLE)熟练,但他们能够有效地执行大多数任务。如果他们需要帮助来扩展或强化,他们总是可以寻求专业数据工程师(DE)和机器学习工程师(MLE)的帮助。)
沟通和协调的成本
哈佛心理学家理查德·哈克曼(Richard Hackman)显示,一个团队中的关系数量是N(N-1) / 2,其中N是人数。这导致链接的指数增长,其中:
- 一支 7 人的初创团队有 21 个链接需要维护
- 一组 21 人(即三支初创团队)拥有 210 个链接
- 一组 63 人拥有近 2000 个链接。
在我们简单的例子中,只有三种角色(即六个链接)。但随着 PM、BA 和其他成员的加入,沟通和协调成本呈现出超过线性的增长。因此,虽然每增加一名成员会提高团队整体生产力,但增加的开销意味着生产力以递减的速度增长。(亚马逊的two-pizza teams是可能的解决方案。)
迭代和学习的速度提高。 在更大的背景和更少的开销下,我们现在可以更快地迭代、失败(即学习)并交付价值。
这对开发数据和算法产品尤为重要。与软件工程(一个更为成熟的领域)不同,我们不能在开始构建之前完成所有的学习和设计——我们的蓝图、架构和设计模式还不够完善。因此,快速迭代对于设计-构建-学习的循环至关重要。
责任感和担当意识更强。 数据科学过程分布在多人之间可能导致责任的扩散,更糟糕的是,可能会出现“社会懒散”现象。
一个常见的反模式是“抛砖引玉”。例如,DE 创建特征并将数据库表抛给 DS,DS 训练模型并将 R 代码抛给 MLE,MLE 将其转换为 Java 进行生产。
如果出现翻译失误或结果意外,谁负责?有了强烈的责任文化,每个人都会在各自的角色中挺身而出。但没有这种文化,工作可能退化为掩盖责任和指责他人,同时问题仍然存在,客户和业务也会受到影响。
让全程数据科学家对整个过程负责可以缓解这种问题。他们应该被赋予从头到尾的行动权限,从客户问题和输入(即原始数据)到输出(即部署的模型)和可衡量的结果。
责任扩散与社会懒散
责任扩散: 当有其他人在场时,我们不太可能承担责任和采取行动。如果我们知道还有其他人也在关注情况,个人就会感到责任感和紧迫感减少。
这种现象的一种形式是Bystander effect,其中Kitty Genovese在她居住的街对面公寓楼外被刺伤。虽然有 38 名目击者看见或听见了攻击,但没有人报警或提供帮助。
社会懈怠:我们在团队中工作时的努力比单独工作时少。19 世纪 90 年代,Ringelmann 让人们在单独和团队中拉绳子。他测量了他们拉的用力程度,发现团队成员在拉绳子时的努力程度通常低于单独工作的个体。
对于(一些)数据科学家来说,这可以带来更高的动力和工作满意度, 这与自主性、精通和目的密切相关。
-
自主性: 通过能够独立解决问题。端到端的数据科学家能够识别和定义问题,构建自己的数据管道,并部署和验证解决方案,而不是等待和依赖他人。
-
精通: 从端到端的问题、解决方案和结果。他们也可以根据需要掌握领域和技术。
-
目的:通过深度参与整个过程,他们与工作和结果有更直接的联系,从而增强了目的感。
但我们也需要专家
然而,全面掌握所有领域并不适合每个人(和每个团队),原因包括:
想要专注于 机器学习,或许是机器学习中的某个特定领域,如神经文本生成(参见:GPT-3 primer)。虽然全面掌握是有价值的,但我们也需要这些世界级的专家在研究和工业中推动边界。我们在机器学习中拥有的许多东西来自学术界和纯研究努力。
没有人通过成为一个通才来获得伟大。你不会通过分散注意力来提高某项技能。达到下一个水平的唯一方法是专注。 – 约翰·C·麦克斯韦
缺乏兴趣。 并不是每个人都热衷于与客户和企业互动,以定义问题、收集需求和编写设计文档。同样,也不是每个人都对软件工程、生产代码、单元测试和 CI/CD 管道感兴趣。
在大型、高杠杆的系统上工作,其中 0.01%的改进会产生巨大的影响。 例如,算法交易和广告。在这种情况下,需要超专业化来挖掘这些改进。
其他人也提出了为什么数据科学家应该专注于某一领域(而不是全面掌握)的理由。以下是一些文章,提供平衡和反驳的观点:
学习的最佳方式是通过实践
如果你仍然渴望更全面,我们现在将讨论如何做到这一点。在此之前,未涉及具体技术,这里是全面数据科学家常用的技能类别:
-
产品:理解客户问题,定义和优先排序需求
-
沟通:促进团队之间的合作,获得支持,编写文档,分享结果
-
数据工程:将数据从 A 点移动和转换到 B 点
-
数据分析:理解和可视化数据,A/B 测试与推断
-
机器学习:通常包括实验、实施和度量
-
软件工程:生产代码实践,包括单元测试、文档、日志记录
-
运维:基本的容器化和云熟练度,构建和自动化工具
(这个列表既不是强制性的,也不是详尽无遗的。大多数项目并不需要全部这些。)
这里有四种方法可以让你更接近成为一名全面的数据科学家:
学习正确的书籍和课程。(好吧,这不是通过实践学习,但我们都需要从某处开始)。我会关注那些涵盖隐性知识的课程,而非具体工具。虽然我没有找到这样的材料,但我听说全栈深度学习有很好的评价。
自己做完整的项目以获得整个过程的第一手经验。冒着简化的风险,以下是我会采取的一些步骤及其相关技能。
听而忘之,看而记之,做而理解。——孔子
从识别要解决的问题和确定成功指标(产品)开始。接着,找到一些原始数据(即非 Kaggle 竞赛数据);这可以让你清理和准备数据,并创建特征(数据工程)。然后,尝试各种机器学习模型,检查学习曲线、误差分布和评估指标(数据科学)。
在选择一个模型之前,评估每个模型的性能(例如,查询延迟、内存占用),并编写一个基本的inference class用于生产(软件工程)。 (你可能还想构建一个简单的用户界面)。然后,将其容器化并通过你首选的云提供商在线部署,让其他人使用(运维)。
一旦完成,额外付出努力分享你的工作。你可以为你的网站写一篇文章,或在聚会上讲述(沟通)。通过有意义的视觉效果和表格展示你在数据中发现的内容(数据分析)。在 GitHub 上分享你的工作。公开学习和工作是获取反馈和寻找潜在合作者的好方法。
通过像DataKind这样的组织进行志愿服务。 DataKind 与社会组织(如非政府组织)和数据专业人士合作,以解决人道主义问题。通过与这些非政府组织合作,你将有机会作为团队的一部分,处理真实(且非常复杂)的数据来解决实际问题。
虽然志愿者可能会被分配具体角色(例如,PM,DS),但你总是欢迎跟随和观察。你将看到(并学习)PM 如何与非政府组织合作来构建问题框架、定义解决方案,并围绕它组织团队。你将从其他志愿者那里学到如何使用数据来开发有效的解决方案。参加类似黑客马拉松的DataDives和长期的DataCorps是贡献于数据科学过程端到端的一个绝佳方式。
加入一个类似初创公司的团队。 注意:类似初创公司的团队并不等同于初创公司。大型组织中有些团队以类似初创公司的方式运作(例如,双比萨团队),而初创公司中也可能由专才组成。寻找一个精干的团队,在那里你受到鼓励并有机会进行端到端的工作。
在 Stitch Fix 和 Netflix 中的端到端
Stitch Fix的 Eric Colson 最初是由于对“过程效率的吸引”而被吸引到功能型分工中(即data science pin factory)。但经过反复试验,他发现端到端的数据科学家更为高效。现在,Stitch Fix 不再为专业化和生产力组织数据团队,而是为了学习和开发新的数据与算法产品来组织它们。
数据科学的目标不是执行。而是学习和开发新的业务能力。……没有蓝图;这些是具有固有不确定性的全新能力。……你所需要的所有元素必须通过实验、试错和迭代来学习。— Eric Colson
他建议数据科学角色应更加通用,拥有广泛的责任,不依赖于技术职能,并优化学习。因此,他的团队招聘和培养可以进行概念化、建模、实施和测量的通才。当然,这依赖于一个可靠的数据平台,该平台可以抽象掉基础设施设置、分布式处理、监控、自动故障转移等的复杂性。
端到端的数据科学家提升了 Stitch Fix 的学习和创新能力,使他们能够发现并构建更多的业务能力(相比于专业团队)。
Netflix的 Edge Engineering 最初有专门的角色。然而,这在产品生命周期中造成了低效。代码发布花费的时间更长(几周而非几天),部署问题的检测和解决也花费了更长时间,生产问题需要多次反复沟通。
极端情况下,每个功能区域/产品由 7 个人负责(source)。
为了解决这个问题,他们尝试了全周期开发者,这些开发者被授权跨越整个软件生命周期进行工作。这需要思维方式的转变——开发者不仅要考虑设计和开发,还要考虑部署和可靠性。
与多个角色和人员不同,我们现在有了完整周期开发(source)。
为了支持全周期开发者,集中团队构建了工具来自动化和简化常见的开发流程(例如,构建和部署管道、监控、管理回滚)。这些工具可以在多个团队之间重复使用,起到倍增效应,并帮助开发者在整个周期内有效工作。
通过全周期开发者的方法,边缘工程能够更快地迭代(而不是在团队之间协调),实现更快和更常规的部署。
这对我有效吗?以下是一些例子
在 IBM,我在一个团队中创建了员工的职位推荐。运行整个管道需要很长时间。我认为通过将数据准备和特征工程管道移到数据库中可以将时间缩短一半。但数据库人员没有时间进行测试。我不耐烦,进行了一些基准测试,将整体运行时间减少了 90%。这使我们可以更快地进行实验,并节省了生产中的计算成本。
在构建 Lazada 的排名系统时,我发现 Spark 对于数据管道是必要的(因为数据量大)。然而,我们的集群只支持 Scala API,而我对此不熟悉。不想等待(数据工程支持),我选择了更快但痛苦的方式来弄清楚 Scala Spark 并自己编写管道。这可能将开发时间减少了一半,并让我更好地理解数据,从而构建了更好的模型。
在一次成功的 A/B 测试后,我们发现业务利益相关者不信任模型。因此,他们手动选择展示的顶级产品,从而降低了在线指标(例如,点击率,转化率)。为了了解更多情况,我去了我们的市场(例如,印尼,越南)。通过相互教育,我们能够解决他们的担忧,减少手动覆盖的数量,并获得收益。
在上面的例子中,超出常规 DS & ML 职位范围有助于更快地交付更多价值。在最后一个例子中,有必要解除我们数据科学工作的阻碍。
尝试一下
你现在可能不是端到端的。这没关系——很少有人是。不过,考虑一下它的好处,并朝着它靠近一点。
哪些方面会不成比例地提升你作为数据科学家的交付能力?与客户和利益相关者的更多互动以设计更全面、创新的解决方案?构建和协调自己的数据管道?对工程和产品限制有更大的认识,以便更快地整合和部署?
不受欢迎的观点:数据科学家应该更具端到端能力。
尽管这种做法(过于泛泛而谈!)受到批评,我发现它可以带来更多的背景、更快的迭代、更大的创新——更多的价值,速度更快。
更多细节和 Stitch Fix & Netflix 的经验
t.co/aOBjuBSsSz— Eugene Yan (@eugeneyan) 2020 年 8 月 12 日
原文。经许可转载。
简介: Eugene Yan(@eugeneyan)在消费者数据和技术的交叉点工作,构建帮助客户的机器学习系统。Eugene 还撰写有关如何在数据科学、学习和职业生涯中取得成效的文章。目前,Eugene 是亚马逊的一名应用科学家,帮助用户阅读更多内容,从阅读中获得更多收益。
相关内容:
更多相关主题
数据科学家在生成式 AI 时代仍然需要吗?
原文:
www.kdnuggets.com/2023/06/data-scientists-still-needed-age-generative-ai.html

使用稳定扩散技术创建的图像
恰好两年前,我写了一篇名为“数据科学家将在 10 年内灭绝”的观点文章。令我惊讶的是,这篇文章成为我在 Medium 和 KDnuggets 上阅读量最高的文章之一。然而,反响却是两极分化的。这篇文章引发了我成年生活中收到的最多批评。我预言了 21 世纪最性感(也是最需求)工作的消亡,而我的同行们对此提出了异议,但我接受了反馈,生活继续前行。快进到现在,两年的时间带来了如此大的变化。ChatGPT 风靡全球,与此同时,特定角色将被淘汰的叙述被更大的议题所掩盖——人力资本在各个行业中的过时。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
革命似乎一夜之间发生了。但我们这些密切关注深度学习进展的人都知道,事实并非如此。ChatGPT 是数十年研究的积累,不可思议地汇聚成了一个不起眼的聊天机器人。ChatGPT 成功的核心在于它使 AI 民主化。掌握代码和拥有深厚的技术知识不再是进入门槛,前沿深度学习的可及性已超越了学术研究和大科技公司,任何有 wifi 和电子邮件地址的人都可以触及。
为什么数据科学家已经灭绝?
我从未想过我们会处于如此速度、规模和性质的技术革命的边缘。在 LLM 和文本到图像模型之前,生成式 AI (GAI) 很大程度上与 Ian Goodfellow 的生成对抗网络 (GANs) 同义。它被誉为近年来 AI 研究的重大贡献之一,体现了使用一对神经网络生成合成的、照片级真实的图像。我们这些曾经使用过 GAN 的人都知道,它们训练起来 notoriously difficult,即使实施正确,当时的应用场景也有限。因此,生成深度学习带来了最新一轮的进展,这更令人惊叹。
那么,为什么 ChatGPT(及其 GAI 伙伴)会使数据科学家面临灭绝的边缘呢?让我们回顾一下两年前的原始论点:
-
仅仅能复述代码和使用软件包的能力将不再定义数据科学家,因为低代码/无代码解决方案已经变得越来越普遍。
-
工作和分析数据的能力将成为许多角色的假定技能,就像计算技能和 MS Office 知识一样。
-
在这种范式下,能够解决现实世界问题的领域专家将会表现出色。数据科学将成为他们工具箱的一部分。
-
鉴于上述情况,通才数据科学家将被领域专家取代。
鉴于此,我们可以看到,GAI 几乎促进了上述每一个点。它可以直接从文本提示中生成代码、分析数据集和查询结果。对能够使用 ChatGPT 的 AI 准备专业人员的需求已经开始渗透到职位描述中,我们知道尽管使用 GAI 可以带来生产力的提升,但 AI 仍然容易产生幻觉,它仍可能出错,这进一步强调了深厚领域专业知识在应对这些情况中的必要性。总之,这还不到 10 年,只用了两年。
然而,数据科学家灭绝并不意味着从事数据科学的人工会变得过时,实际上恰恰相反。当我们回顾历史时,在过去 200 年里,我们经历了几次技术革命,包括蒸汽动力、大规模生产和个人计算等。每一次技术革命都使我们的生产力超过上一次,因为我们的角色和与技术的关系不断演变,这一概念在经济理论中根深蒂固(Solow 增长模型)。在当前环境下,企业正在创造和捕获比以往更多的数据,因此数据科学技能将始终有需求,但未来的数据科学家不会被称为数据科学家,他们将以产品经理、营销专家或投资分析师等名称出现。数据科学家灭绝了,数据科学万岁。
免责声明:观点和意见仅代表作者本人。
Michael Wang 是一位拥有超过 10 年行业经验的投资与数据科学从业者,涉足金融科技、投资、交易及教学等多个领域。他是 WhyPred 的首席顾问及创始人,该公司是一家将金融市场专业知识与人工智能和机器学习相结合的分析咨询公司。
更多相关话题
数据来源 101
评论
作者 Ayswarrya G,内容策略师,Atlan
开始接触数据世界可能会让人感到不知所措。大数据、替代数据、原始数据、内部数据——这份清单还在继续。一个常见的困惑是这些术语之间的区别,理解这些区别非常重要。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
这就是原因。
数据收集是数据生命周期的第一步之一——为了分析数据,你需要首先获取所有需要的数据(这不难理解,对吧?)。
为了收集正确的数据,你需要知道在哪里找到它,并确定收集它所涉及的努力。
这就是我写这篇文章的原因,为了回答最基本的问题:你需要的(或可能需要的)所有数据来自哪里?
数据来源
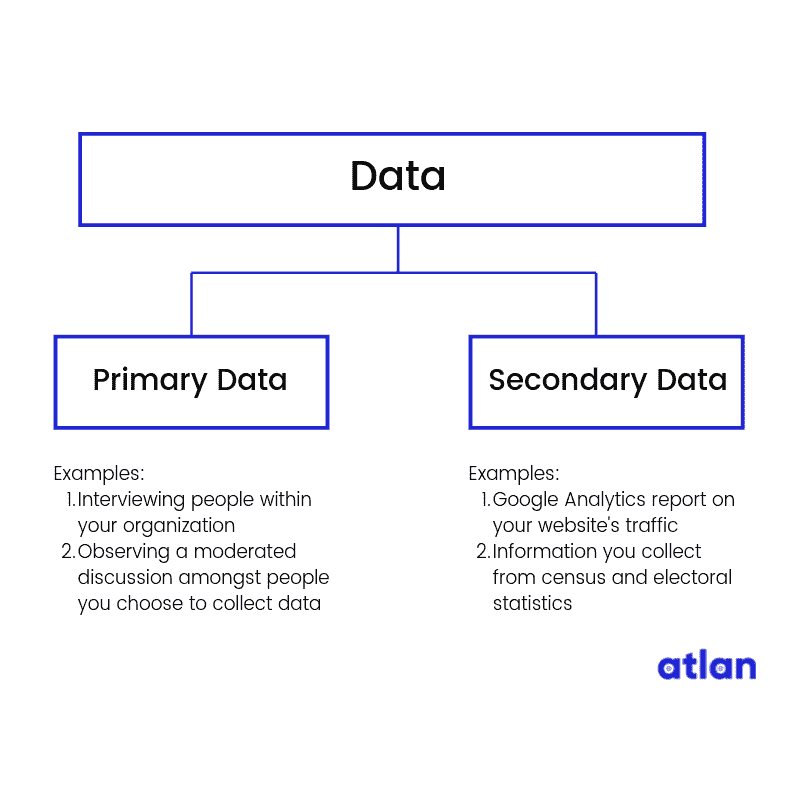
在查看数据来源之前,我们先了解一下原始数据和次级数据。
原始数据 — 你自己创建的数据
当你自己创建你想要的数据时,这被称为原始数据。如果你采访人们以收集对你产品的反馈,那么采访数据就是原始数据。
次级数据 — 从其他地方收集的数据
当你从其他人拥有的来源收集数据时,这被称为次级数据。如果你使用谷歌分析的数据来了解有多少人访问你的网站,那你就是在使用次级数据。这仍然是关于你组织的数据,但这是由一个次级组织(在我们的例子中是谷歌)为你收集的。
到目前为止,还不错,对吧?
现在让我们在这个基础上继续。数据来源可以是内部的,也可以是外部的。
内部数据 — 你创建、拥有或控制的数据
内部数据是你组织拥有、控制或收集的私人数据。你的组织的销售数据或财务数据就是内部数据的例子。
注意我说的是你创建、拥有或控制的数据?
这是有原因的。内部数据可以是原始的也可以是次级的。
当你通过调查你组织内的人员并利用这些洞察来展示影响工作场所生产力的因素时,这些数据就是内部数据和原始数据。
另一方面,当你使用 Google Analytics 的数据来显示大多数网站访问者搜索的是替代数据产品时,这些数据是内部和次级的。
外部数据 — 来自外部来源的数据
外部数据是从组织外部来源收集的数据。这些数据可能是:
-
公开可用的数据,例如人口普查、选举统计、税务记录和互联网搜索
-
来自第三方的私有数据,如亚马逊、Facebook、Google、沃尔玛以及像 Experian 这样的信用报告机构
外部数据也可以是主要数据或次级数据吗?如果你在考虑这些问题,你就走在正确的轨道上了!
当你与全球的数据科学领导者进行访谈时,你正在收集主要数据,但来源于外部。所以,这些数据是外部的和主要的。
当你使用像 Kaggle 或 Stack Overflow 这样的数字出版物进行的访谈数据时,你使用的是外部的和次级的数据。
但是等一下……难道不是还有一种叫做替代数据的吗?
等等!我正要提到这个。
替代数据是复杂、独特且大多数未被探索的次级数据。为了理解替代数据,让我们快速绕道 2 分钟,了解一下大数据。
大数据
大数据指的是海量的结构化、半结构化或非结构化数据,这些数据过于复杂,传统的数据系统(关系数据库和数据仓库)无法处理。
数据的格式
结构化什么?
数据有多种格式。以下是我对两种最主要格式的简要介绍:
-
结构化数据:在关系数据库中以固定格式组织的数据(可以想象成你存储在计算机上的文件)
-
非结构化数据:没有特定格式的数据(可以想象成监控数据);Gartner估计超过 80%的企业数据是非结构化的。
大数据的例子包括社交媒体数据📱、交易数据📈(股票价格、购买历史)、传感器数据(位置数据、天气数据)以及卫星数据📡。(这里有一篇关于今天世界上大数据的有趣阅读)

IBM 的大数据 4Vs。图片来源:IBM Big Data & Analytics Hub
传统数据系统 无法完全处理如此大量的非结构化数据。
分析大数据需要复杂的大数据技术(这是另一个话题,但如果你很急,可以查看这个有用的 wiki 了解大数据技术)。
我们的快速绕道到此结束。
因此,替代数据被认为是大数据。最初,对冲基金利用租金和水电费等非财务信息来估算个人的借贷风险。这些数据改变了金融行业(请参见 这篇文章 了解对冲基金如何使用替代数据)。
很快,其他行业也意识到了它的潜力以及如何帮助他们保持竞争优势。
替代数据当前使用的一些示例。图片来源: Humans of Data
一些常见的替代数据集示例包括:
-
卫星数据
-
位置信息
-
财务交易
-
在线浏览活动
-
社交媒体帖子
-
产品评论
最终话语
这样你就对世界数据的来源有了大致了解。这里有一张图,快速总结了各种数据来源。
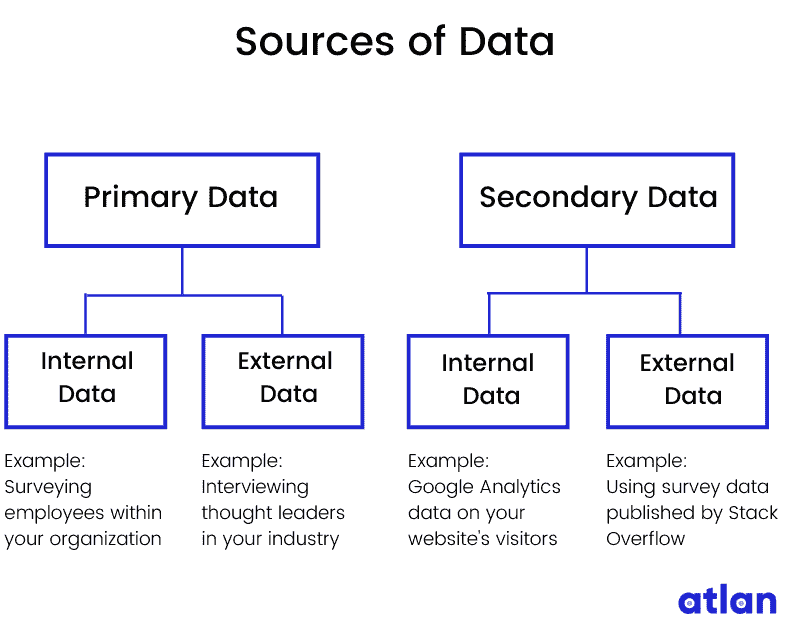
附言:在过去几个月里,我一直在参与一个名为 The Atlan Data Wiki 的社区项目——这是一个有趣、有帮助、无行话的百科全书,用于导航数据宇宙。如果你喜欢我的文章, 请查看这个 wiki ,我用类似的方法处理其他数据主题。我很想听听你的想法。
个人简介:Ayswarrya G (@Ayswarrya) 认为优秀的写作可以改变世界。目前,她负责 Atlan 的 Humans of Data 出版物和 Data Wiki。在闲暇时间,她要么在旅行,要么在练习法语。
相关:
-
了解你的数据:第一部分
-
处理机器学习中数据缺乏的 5 种方法
-
了解你的数据:第二部分
更多相关主题
与机器学习算法相关的数据结构
原文:
www.kdnuggets.com/2018/01/data-structures-related-machine-learning-algorithms.html/2
评论
堆
堆是另一种分层、有序的数据结构,类似于树,但与水平排序不同,它具有垂直排序。这种排序适用于层级结构,但不适用于跨层级:父节点总是比它的两个子节点都要大,但高等级的节点不一定比直接在其下方的低等级节点要大。
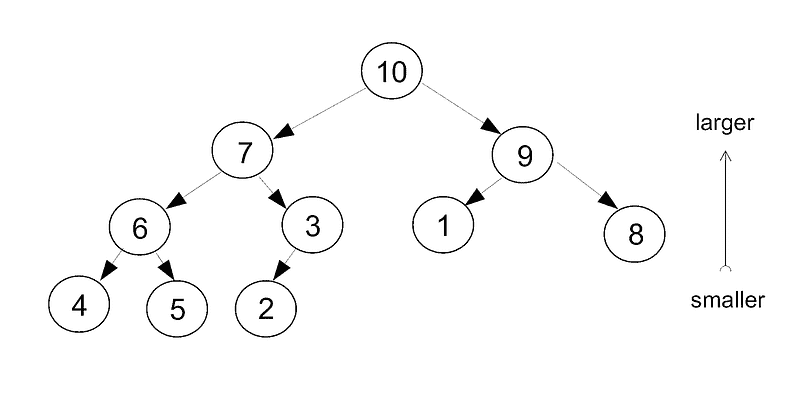
插入和检索都是通过提升来完成的。一个元素首先被插入到最高可用的位置。然后它与其父节点进行比较,并提升直到达到正确的等级。要从堆中取出一个元素,两个子节点中较大的一个被提升到缺失的位置,然后那两个子节点中较大的一个被提升,以此类推,直到所有元素都被提升到相应的等级。
通常,最高等级的值会从堆的顶部取出以对列表进行排序。与树不同,大多数堆只是存储在一个数组中,元素之间的关系只是隐含的。
栈
栈的定义是“先进后出”。一个元素被pushed到栈的顶部,它会覆盖之前的元素。必须先popped顶部元素,才能访问其他元素。
栈主要用于解析语法和实现计算机语言。
有许多机器学习应用场景中,特定领域语言(DSL)是完美的解决方案。例如,libAGF 库使用递归控制语言将二分类推广到多分类。使用特殊字符来重复先前的选项,但由于语言是递归的,该选项必须取自相同的层级或更高层级。这是通过栈来实现的。
队列
队列的定义是“先进先出”。想象一下银行柜台前的排队(对于那些还记得互联网银行之前的时代的人来说)。队列在实时编程中非常有用,这样程序可以保持一个待处理的任务列表。
设想一个记录运动员分段时间的应用。你输入号码牌并按回车,但在你做这件事的时间里,下一个运动员已经通过了。所以你输入一系列最近接近的运动员的号码牌,然后按另一个键来注册下一个队列中的运动员已通过。
集合
一个集合由一个无序的、不重复的元素列表组成。如果你添加了一个已经在集合中的元素,则不会发生变化。由于机器学习中的许多数学运算涉及集合,因此它们是非常有用的数据结构。
关联数组
在关联数组中,有两种类型的数据以对的形式存储:键和其关联的值。数据结构本质上是关系型的:值由其键来访问。由于训练数据也通常是关系型的,这种数据结构似乎非常适合机器学习问题。
在实践中,它的使用并不多,部分原因是大多数关联数组仅是单维的,而机器学习数据通常是多维的。
关联数组适合用于构建字典。
假设你正在构建一个 DSL,想要存储一个函数和变量的列表,并需要区分它们。
“sin” → function
“var” → variable
“exp” → function
“x” → variable
“sqrt” → function
“a” → variable
在“sqrt”上查询会返回“function”。
自定义数据结构
随着你处理更多问题,你肯定会遇到那些标准食谱箱中没有最佳结构的情况。你需要设计自己的数据结构。
考虑一个多类分类器,它将二元分类器推广到处理具有多个类别的分类问题。一种明显的解决方案是二分法:递归地将类别分成两组。你可以使用类似于二叉树的结构来组织二元分类器,但层次化解决方案并不是解决多类问题的唯一方法。
考虑几个划分,然后用来同时解决所有类别概率。
最一般的解决方案是将两者结合起来,因此每个层次化的划分不一定是二元的,而可以通过非层次化的多类分类器来解决。这是libAGF库中采用的方法。
更复杂的数据结构也可以由基本结构组成。考虑一个稀疏矩阵类。在稀疏矩阵中,大多数元素为零,仅存储非零元素。我们可以将每个元素的位置和值作为一个三元组存储,并将它们放在一个可扩展数组中。
考虑 3 乘 3 的单位矩阵:
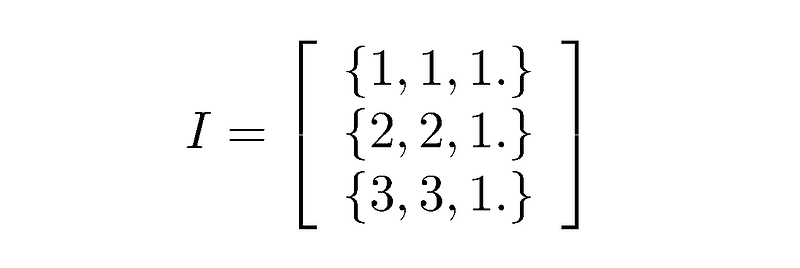
结论
数据结构本身有时并不那么有趣。真正让它们有趣的是你可以用它们解决的各种问题。
对于我做的大部分工作,我使用了许多基本的固定长度数组。我主要使用更复杂的数据结构使程序运行得更顺畅,与外界的接口更友好,用户体验也更佳。与过去的 Fortran 程序相比,后者在改变网格大小时需要忍受近半小时的编译周期(我实际上参与过这样的程序!)。
即使你一时无法想到应用场景,我仍然认为了解像栈和队列这样的数据结构是有益的。你永远不知道它们何时会派上用场。
真的很复杂的人工智能应用可能会使用诸如有向图和无向图的东西,这实际上只是树和链表的泛化。如果你无法处理链表,那你将如何构建前者?
问题
如果你想自己实践并实现机器学习算法的数据结构,可以尝试解决下面的一些问题:
-
将矩阵-向量乘法代码片段封装成一个名为matrix_times_vector的子程序。设计该子程序的调用语法。
-
使用struct, typedef或class,将向量和矩阵封装成一对抽象类型,分别称为vect和matrix。为这些类型设计一个 API。
-
在线找到至少三个做上述工作的库。
-
下载并安装 LIBSVM 库。考虑“svm.cpp”中第 316 行的Kernel::k_function方法。用于存储向量的数据结构的优缺点是什么?
-
你会如何重构 LIBSVM 库中的核函数计算?
-
文本中描述的哪些数据结构是抽象类型?
-
你可以使用什么内部表示或数据结构来实现抽象数据类型?有没有任何不在上面列表中的数据结构?
-
使用二叉树设计一个关联数组。
-
考虑 LIBSVM 中的向量类型。如何用它来表示稀疏矩阵?与上面描述的稀疏矩阵类相比,这有什么优缺点?查看完整类型。每种表示方法的优缺点是什么?
-
实现一个树排序和一个堆排序。现在使用相同的数据结构找出前k个元素。这对哪个常见的机器学习算法有用?
-
在你喜欢的编程语言中实现你最喜欢的数据结构。
简介: Peter Mills 对科学充满热情,感兴趣于大气物理学、混沌理论和机器学习。
原文。经授权转载。
相关:
-
初学者的前 10 种机器学习算法
-
IT 工程师需要学习多少数学才能进入数据科学领域?
-
数据科学家主要只做算术,这其实是好事
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
更多相关内容
数据转换:标准化与归一化
原文:
www.kdnuggets.com/2020/04/data-transformation-standardization-normalization.html
图片来源于 365datascience
数据转换是数据处理中的基本步骤之一。当我第一次学习特征缩放技术时,术语scale、standardise和normalize经常被使用。然而,找到关于何时使用这些术语的信息相当困难。因此,我将在本文中解释以下关键方面:
-
标准化和归一化之间的区别
-
何时使用标准化,何时使用归一化
-
如何在 Python 中应用特征缩放
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
特征缩放是什么意思?
在实际操作中,我们经常在同一数据集中遇到不同类型的变量。一个重要的问题是这些变量的范围可能相差很大。使用原始尺度可能会对范围大的变量赋予更多权重。为了处理这个问题,我们需要在数据预处理的步骤中,对自变量或数据的特征应用特征重缩放技术。术语normalisation和standardisation有时可以互换使用,但它们通常指的是不同的概念。
应用特征缩放的目标是确保特征几乎在相同的尺度上,以便每个特征同样重要,并且让大多数机器学习算法更容易处理。
示例
这是一个包含一个自变量(Purchased)和 3 个因变量(Country、Age 和 Salary)的数据集。我们可以很容易地发现这些变量的尺度不同,因为Age的范围从 27 到 50,而Salary的范围从 48 K 到 83 K。Salary的范围远大于Age的范围。这会导致我们模型中的一些问题,因为许多机器学习模型,如 k-means 聚类和最近邻分类,是基于欧几里得距离的。
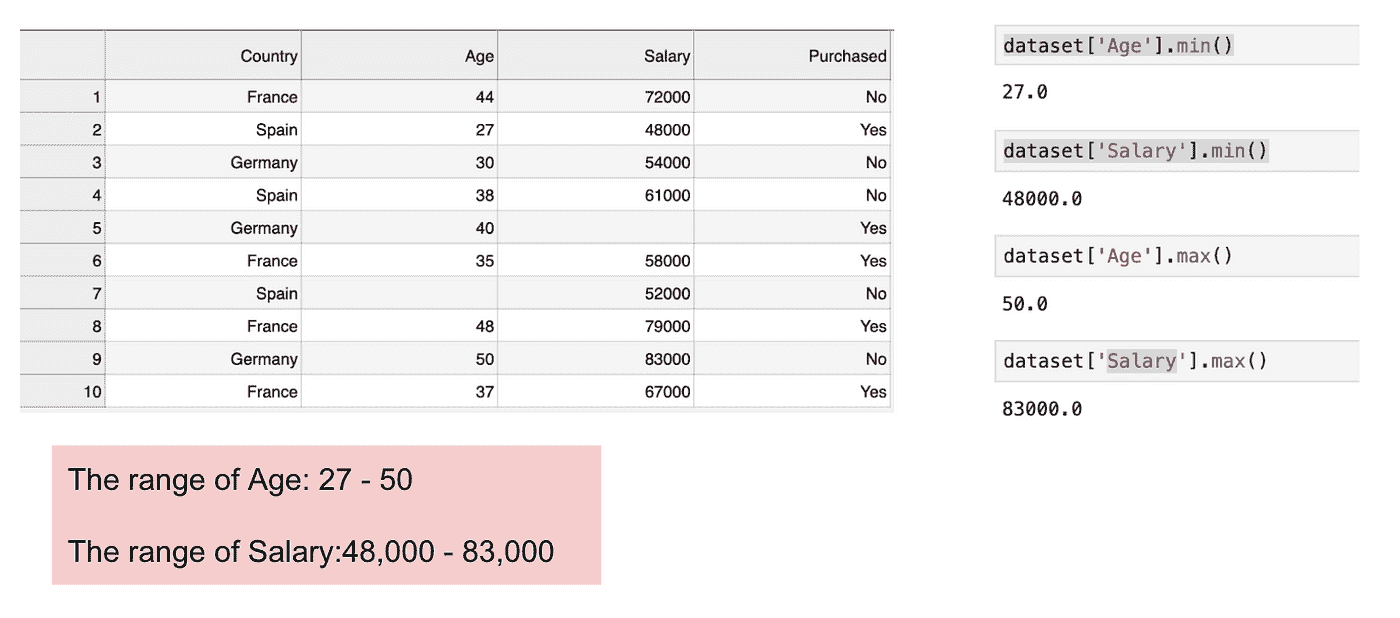
关注年龄和薪资
当我们计算欧几里得距离的公式时,(x2-x1)²的数量远大于(y2-y1)²的数量,这意味着如果不进行特征缩放,欧几里得距离将主要由薪资决定。年龄的差异对整体差异的贡献较小。因此,我们应该使用特征缩放将所有值调整到相同的量级,从而解决这个问题。为此,主要有两种方法:标准化和归一化。

欧几里得距离的应用。
标准化
标准化(或Z-score 归一化)的结果是特征将被重新缩放,以确保均值和标准差分别为 0 和 1。公式如下所示:
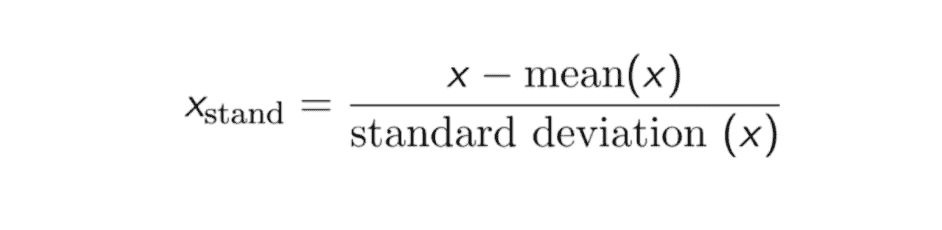
该技术是将特征值重新缩放到 0 和 1 之间,这对于优化算法(如梯度下降)非常有用,这些算法在机器学习中用于加权输入(例如回归和神经网络)。重新缩放也用于使用距离测量的算法,例如 K-最近邻(KNN)。
#Import library
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
sc_X = sc_X.fit_transform(df)
#Convert to table format - StandardScaler
sc_X = pd.DataFrame(data=sc_X, columns=["Age", "Salary","Purchased","Country_France","Country_Germany", "Country_spain"])
sc_X
最大-最小归一化
另一种常见的方法是所谓的最大-最小归一化(Min-Max scaling)。该技术将特征重新缩放到 0 和 1 之间。对于每个特征,该特征的最小值被转换为 0,最大值被转换为 1。一般公式如下所示:
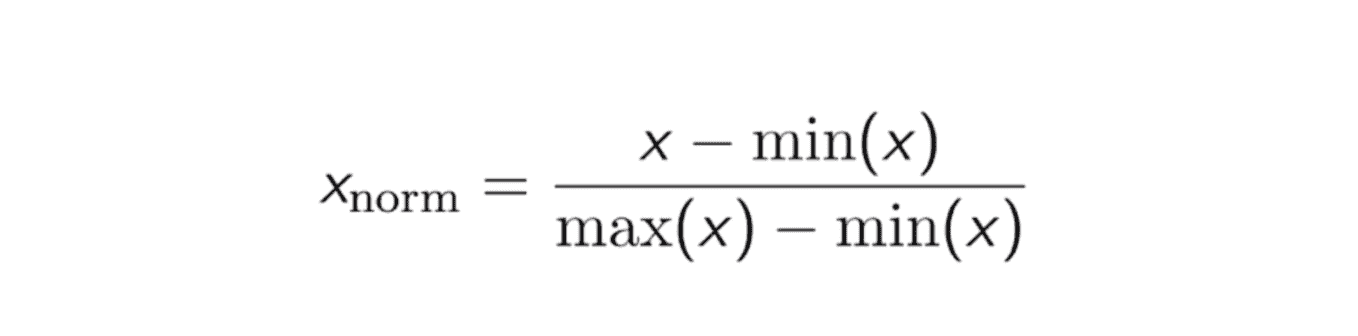
最大-最小归一化的公式
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(df)
scaled_features = scaler.transform(df)
#Convert to table format - MinMaxScaler
df_MinMax = pd.DataFrame(data=scaled_features, columns=["Age", "Salary","Purchased","Country_France","Country_Germany", "Country_spain"])
标准化与最大-最小归一化
与标准化相比,通过最大-最小归一化过程我们会获得较小的标准差。让我利用上面的数据集更详细地说明这一点。
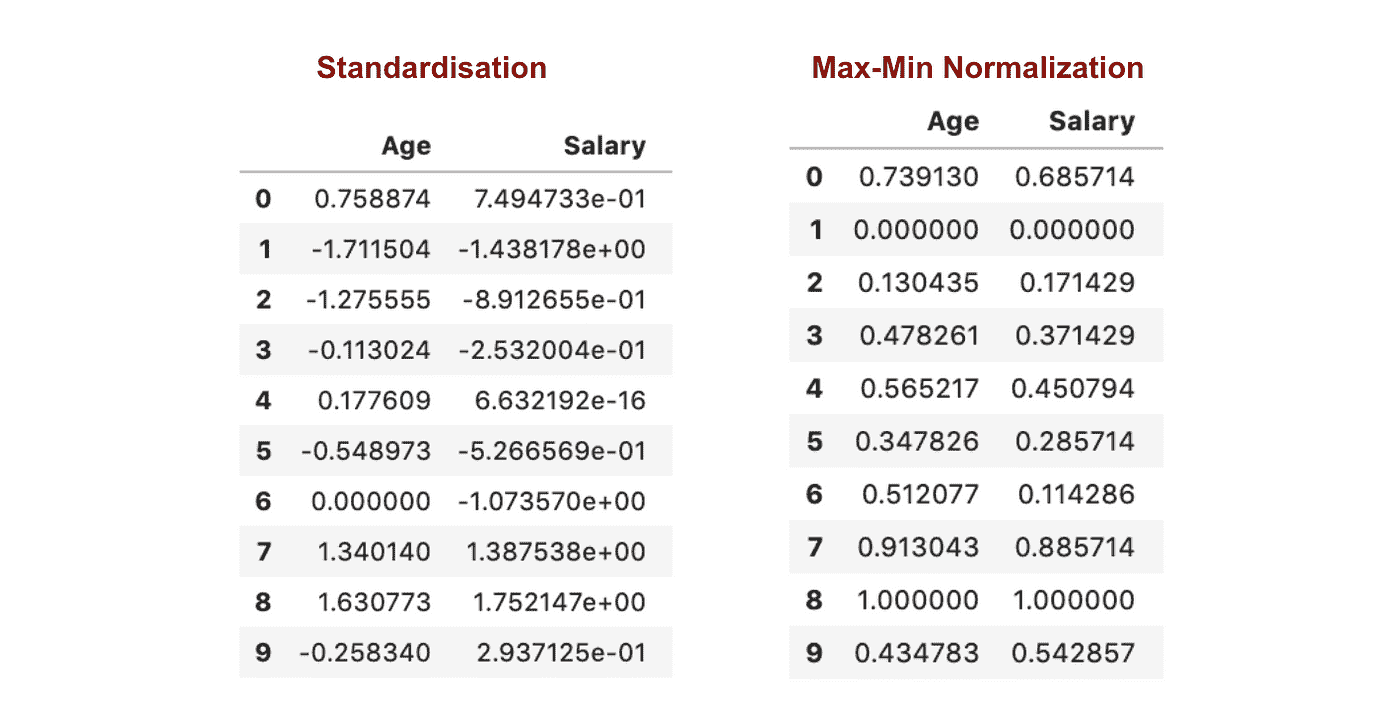
特征缩放后
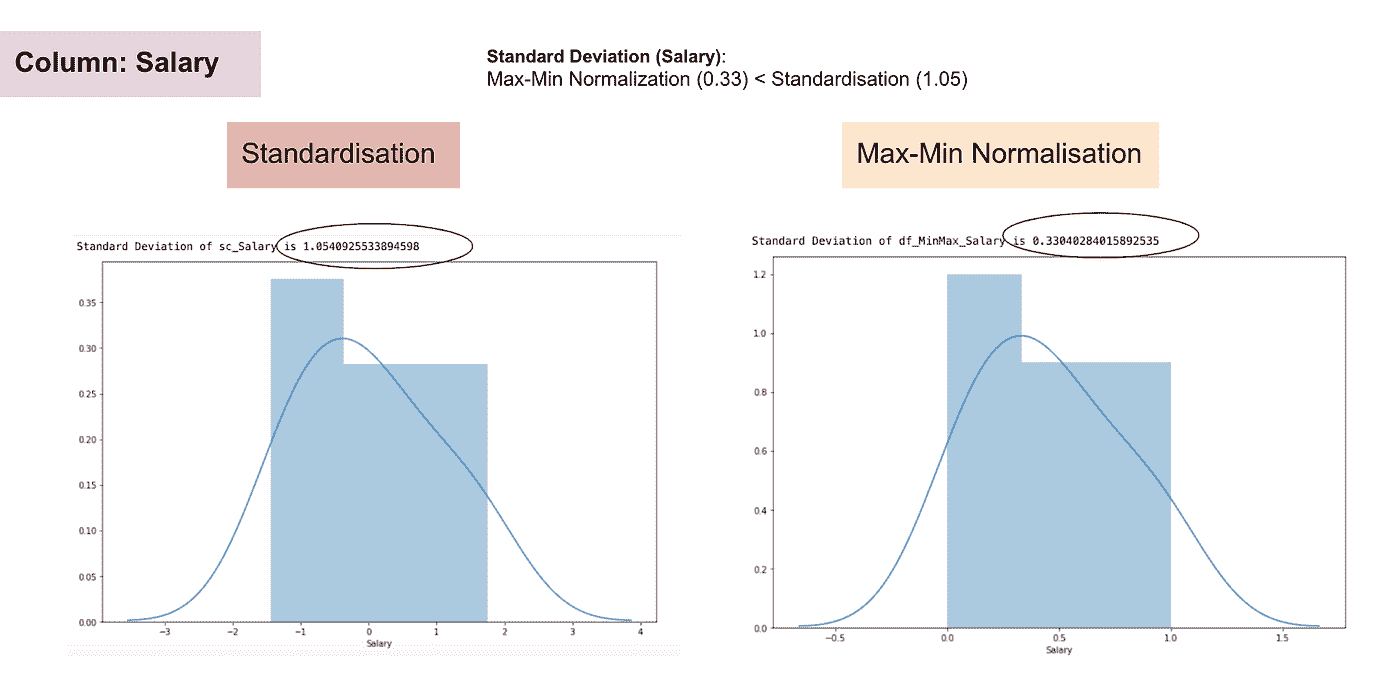
薪资的正态分布和标准差
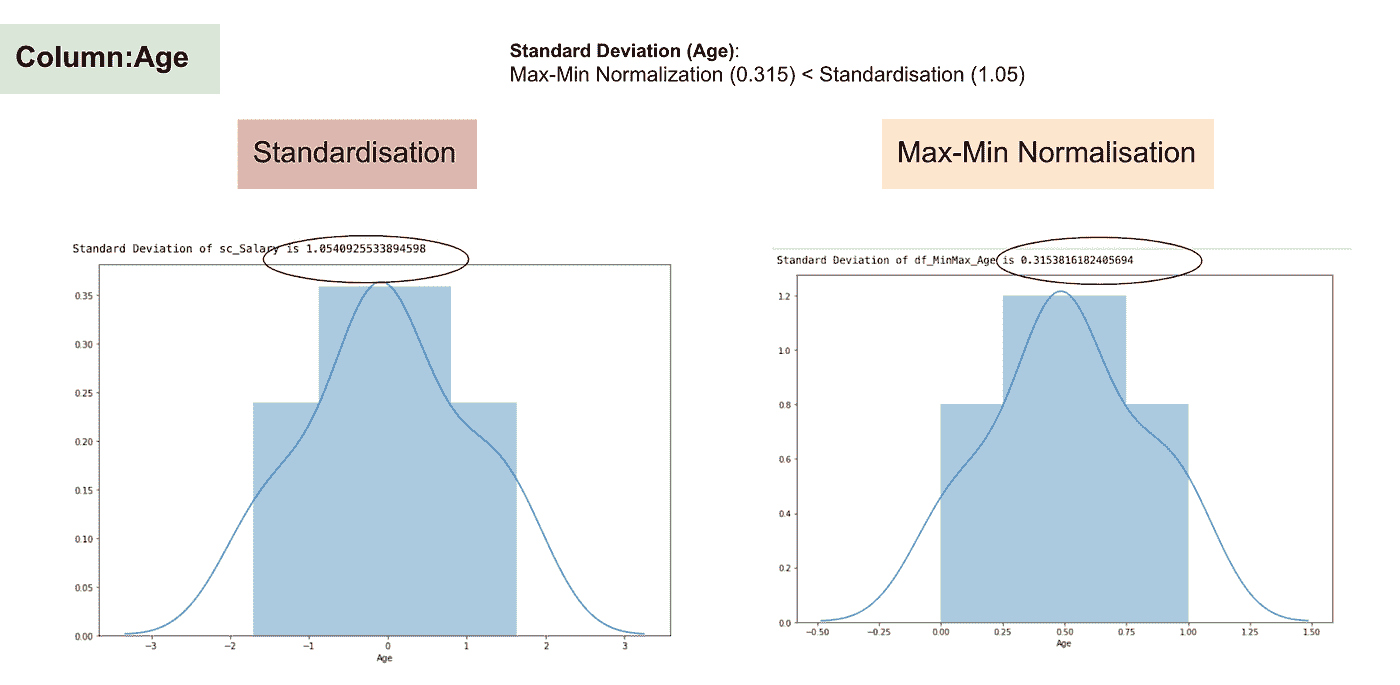
年龄的正态分布和标准差
从上述图表中,我们可以明显看到,在数据集中应用最大-最小归一化生成的标准差(薪资和年龄)小于使用标准化方法。这表明如果使用最大-最小归一化缩放数据,数据将更集中在均值附近。
因此,如果你的特征(列)中有异常值,归一化你的数据将把大部分数据缩放到一个小区间,这意味着所有特征将具有相同的尺度,但对异常值的处理不好。标准化对异常值更为稳健,在许多情况下,它优于 Max-Min 归一化。
特征缩放的重要性

一些机器学习模型基本上是基于距离矩阵的,也称为基于距离的分类器,例如 K 最近邻、SVM 和神经网络。特征缩放对这些模型至关重要,特别是当特征的范围差异很大时。否则,范围较大的特征在计算距离时将有较大影响。
Max-Min 归一化通常允许我们对具有不同尺度的数据进行转换,以使得没有特定维度主导统计数据,并且不需要对数据的分布做出非常强的假设,例如 k 最近邻和人工神经网络。然而,归一化 对异常值的处理并不好。相反,标准化允许用户更好地处理异常值,并且有助于某些计算算法(如梯度下降)的收敛。因此,我们通常更倾向于使用标准化而不是 Min-Max 归一化。
示例:哪些算法需要特征缩放
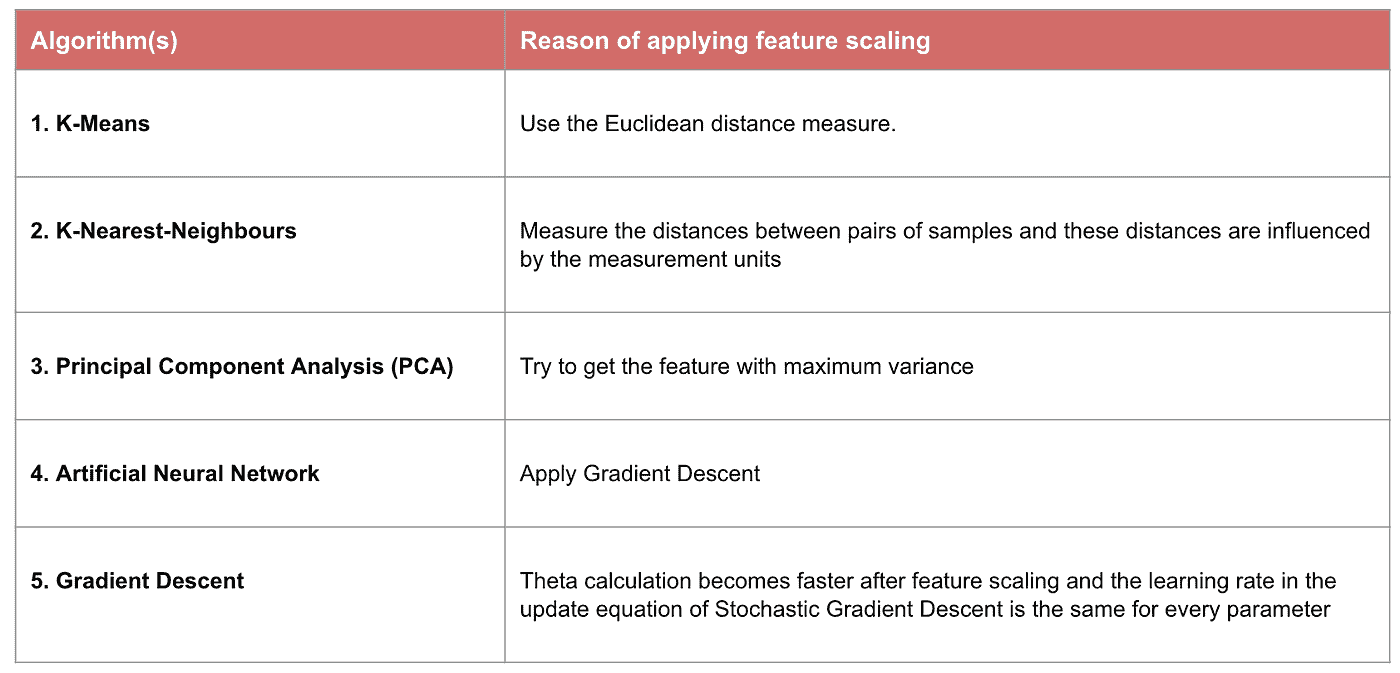
注意:如果一个算法不是基于距离的,则特征缩放不重要,包括朴素贝叶斯、线性判别分析和基于树的模型(梯度提升、随机森林等)。
总结:现在你应该知道
-
使用特征缩放的目的
-
标准化和归一化之间的区别
-
需要应用标准化或归一化的算法
-
在 Python 中应用特征缩放
请在此处找到代码和数据集这里。
原文。经许可转载。
Clare Liu 是一名在香港金融科技(银行)行业工作的数据科学家。热衷于解决数据科学和机器学习中的谜团。加入我,开始自学之旅吧。
更多相关内容
数据之信:数据中心的人工智能
原文:
www.kdnuggets.com/2022/10/data-trust-data-centric-ai.html

图片由作者提供
在 2012 年,作者比约恩·布洛辛(Björn Bloching)、拉尔斯·卢克(Lars Luck)和托马斯·拉姆格(Thomas Ramge)出版了《数据之信》(In Data We Trust):《客户数据如何革新我们的经济》。这本书详细讲述了许多公司如何将所有需要的信息掌握在手中。公司不再需要根据直觉和市场做出决策,而是可以使用数据流来更好地理解未来的趋势以及下一步的行动方案。
随着数据特别是人工智能领域的不断增长,越来越多的人持怀疑态度。一些人可能会说,数据的使用和自主功能改善了我们的日常生活,而另一些人则对他们的数据如何被使用以及人工智能的发展如何对人类产生严重影响感到担忧。
尽管人工智能已经证明能够产生一些令人印象深刻的结果,但它也曾失败过——甚至包括谷歌和亚马逊这样的巨头。例如,在 2019 年,亚马逊的 Rekognition 软件在由马萨诸塞州 ACLU 进行的面部识别测试中错误地将 27 名职业运动员与超级碗冠军的通缉照片匹配。
这些失败可能对人工智能的持续发展产生重大影响。人们自然会失去信任并希望远离它。失败并非来自人工智能本身,而是来自于输入和使用在这些模型中生成虚假输出的数据。
这就是我们需要信任数据并实施数据中心人工智能的地方。
什么是数据中心的人工智能?
如果你曾经在科技行业或从事机器学习模型工作,你会看到人们专注于软件、模型等的构建。然而,如果正确的输入产生了错误的输出,这可能会导致软件的失败。
例如,花费数年时间试图打造一辆外观美观、引擎强劲且配备所有新技术的汽车,如果你现在的燃料质量差到连车都启动不了,更别提到达目的地了,那有什么意义呢?
对吧?垃圾进,垃圾出。
人工智能也是一样。如果花费数小时构建一个模型,但一旦将数据输入其中,它就会产生错误,那有什么意义呢?
数据中心的人工智能(Data-Centric AI)是一个专注于数据的系统,而非代码。我并不是说它不使用代码,当然,它是使用的。它系统性地工程化用于构建人工智能系统的数据,并将这些数据与代码中的有价值元素相结合。
我们需要什么类型的数据?
为了使人工智能模型值得信赖并产生准确的输出,它需要干净和多样的数据。没有这两个数据元素,你可能无法在未来做出准确的决策。质量 > 数量。
如果你的数据不够干净或多样,它自然会降低性能并产生输出错误。不干净或不多样的数据会使模型感到困惑,因为它需要额外 10 倍的努力来理解数据。那么,我们可以使用什么工具来确保我们拥有干净、多样的数据呢?
数据标注
标注数据是将不干净的数据转变为干净数据的重要环节,为此你可以使用数据标注工具。标注工具可以快速注释图像和其他形式的数据,例如用于文档分类的命名实体识别(NER)。
数据标注工具帮助数据科学家、工程师和其他数据专家提高模型的整体准确性和性能。
标签工具可以且建议与下述本体论相关联使用。
本体论
拥有本体论。本体论是对信息系统中符号意义的规范说明。它是一个定义的虚拟目录,充当你的字典。本体论在数据标注过程中像一个参考点或丰富的资源库。
人类在环
如上所述,将人类引入你的过程可以帮助你获得干净的数据。人工智能整体上是在试图将人类智能模拟到计算机中,那么,什么比实际引入人类到这个过程中更好的方法来改善这个过程呢?
人类在环利用人类专业知识来训练良好的人工智能,通过让他们参与系统的构建、微调和模型测试。这将有助于确保数据标注工具有效工作,输出的准确性得到提升,并且整体决策更好。
数据质量管理
这是否是额外的费用?是的。它会在长远中对你有帮助吗?当然。如果你要做某件事,最好第一次就做好,而不是需要重复几次才能做对。虽然你可能一开始会把它视为额外的费用,但随着时间的推移,质量管理可以为你节省大量的时间和金钱。
通过数据质量管理,你将能够识别数据中的错误,并在过程早期解决这些问题,避免造成过多的损害。
数据增强
数据增强是一组技术,用于通过从现有数据生成新数据点来人工增加可用数据量。这是通过对现有数据点进行小的修改来创建新的数据点。
通过在现有数据中创建这些变化并生成新的数据点,模型变得更加稳健,能够学会做出符合现实世界的预测。数据点越多,数据越多样化——模型就能学会提升其整体准确性和性能。
结论
上述所有工具都能帮助我们应对当前世界在人工智能方面面临的挑战。这是一场范式转变,公司们每天都在加入这个行列。技术专家知道如何构建模型和人工智能能做什么,但现在的重点是如何改进它,我们已经理解这基于我们使用的数据。
尼莎·阿亚 是一名数据科学家和自由技术作家。她特别关注提供数据科学职业建议或教程及理论知识。她还希望探索人工智能如何有益于人类寿命的不同方式。作为一个热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关内容
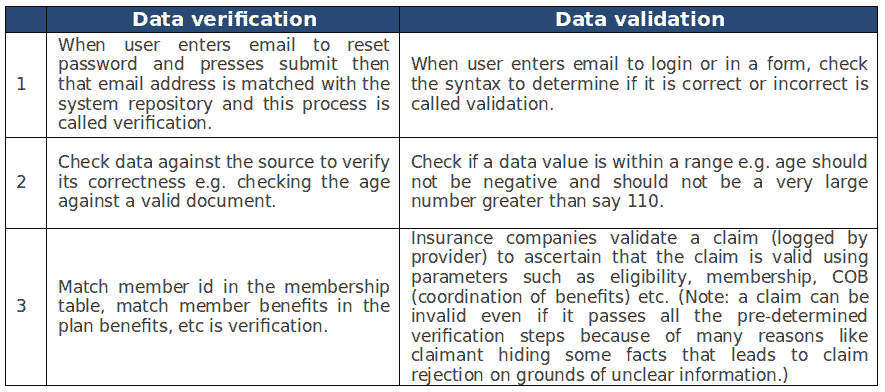
数据验证和数据核查 – 从词典到机器学习
原文:
www.kdnuggets.com/2021/03/data-validation-data-verification-dictionary-machine-learning.html
评论
由 Aditya Aggarwal,高级分析实践负责人,和 Arnab Bose,首席科学官,Abzooba
通常,当我们谈论数据质量时,我们会将数据验证和数据验证互换使用。然而,这两个术语是不同的。本文将从 4 个不同的背景理解它们的区别:
-
验证和验证的词典含义
-
一般来说,数据验证和数据验证之间的区别
-
从软件开发的角度来看,验证与验证的区别
-
从机器学习的角度来看,数据验证和数据核查之间的区别
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
1. 验证和验证的词典含义
表 1 解释了验证和验证这两个词的词典含义以及一些例子。
表 1:验证和验证的词典含义
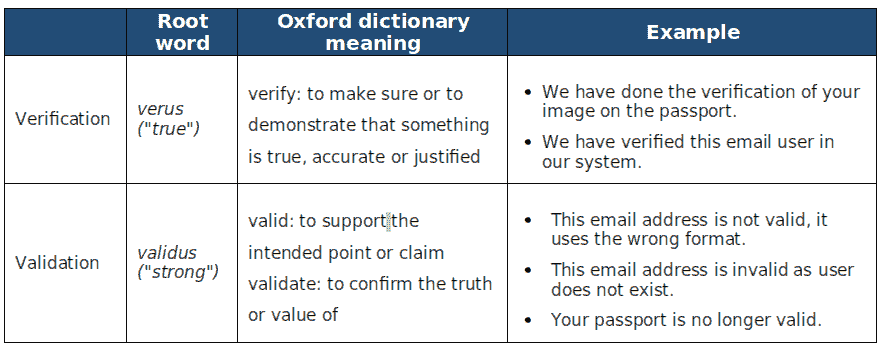
总结来说,验证关注的是真实性和准确性,而验证关注的是支持观点的强度或主张的正确性。验证检查方法的正确性,而验证检查结果的准确性。
2. 数据验证和数据核查的一般区别
现在我们理解了这两个词的字面意思,让我们深入探讨“数据验证”和“数据核查”之间的区别。
-
数据验证:确保数据的准确性。
-
数据验证:确保数据的正确性。
让我们通过表 2 中的例子来详细说明。
表 2:“数据验证”和“数据验证”的例子
3. 从软件开发的角度来看验证与验证的区别
从软件开发的角度来看,
-
验证是为了确保软件质量高、工程设计良好、健壮且无错误,而不涉及其可用性。
-
验证是为了确保软件的可用性和满足客户需求的能力。
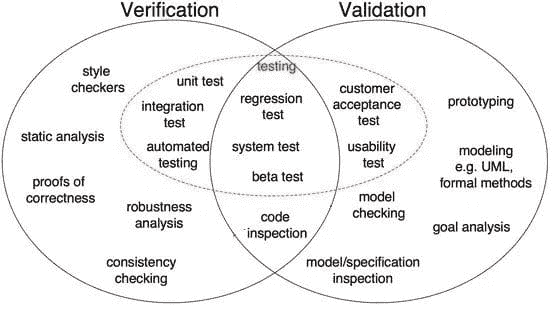
图 1:软件开发中验证与验证的区别 (来源)
如图 1 所示,正确性证明、鲁棒性分析、单元测试、集成测试等都是验证步骤,这些任务旨在验证具体的内容。软件输出会与期望的输出进行核对。另一方面,模型检查、黑箱测试、可用性测试等都是验证步骤,这些任务旨在了解软件是否满足需求和期望。
4. 从机器学习角度看数据验证与数据验证的区别
数据验证在机器学习流程中的角色是作为守门员。它确保数据的准确性和及时更新。数据验证主要在新数据获取阶段进行,即在机器学习流程的第 8 步,如图 2 所示。该步骤的示例包括识别重复记录并进行去重,以及清理客户信息中的不匹配,如地址或电话号码。
另一方面,数据验证(在机器学习流程的第 3 步)确保从第 8 步添加到学习数据中的增量数据质量良好,并且(从统计属性角度看)与现有的训练数据类似。例如,这包括发现数据异常或检测现有训练数据与新数据之间的差异。否则,增量数据中的任何数据质量问题/统计差异可能被忽视,从而导致训练错误可能随着时间的推移积累,并降低模型准确性。因此,数据验证在早期阶段检测增量训练数据中的显著变化(如有),有助于根本原因分析。
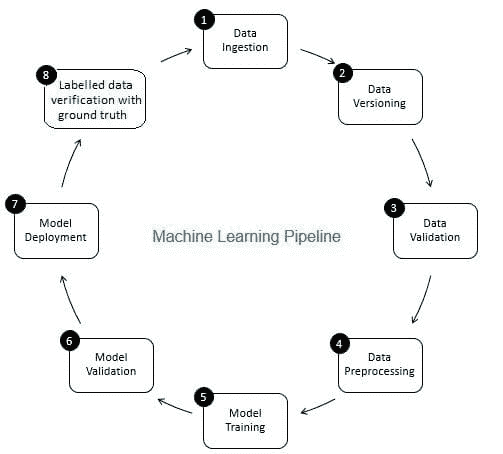
图 2:机器学习流程的组成部分
Aditya Aggarwal 在 Abzooba Inc. 担任数据科学实践主管。Aditya 拥有超过 12 年的经验,通过数据驱动的解决方案推动业务目标,专注于预测分析、机器学习、商业智能及业务策略,涉及多个行业。
阿尔纳布·博斯博士 是数据分析公司 Abzooba 的首席科学官,并且是芝加哥大学的兼职教师,教授机器学习与预测分析、机器学习运维、时间序列分析与预测、以及健康分析等课程。他是一位拥有 20 年预测分析行业经验的专家,喜欢利用非结构化和结构化数据来预测并影响医疗保健、零售、金融和运输领域的行为结果。他目前的关注领域包括利用机器学习进行健康风险分层和慢性病管理,以及机器学习模型的生产部署和监控。
相关:
-
MLOps – “为什么需要?”和“它是什么”?
-
我的机器学习模型没有学习。我该怎么办?
-
数据可观测性,第二部分:如何使用 SQL 构建自己的数据质量监控工具
更多相关主题
数据验证在机器学习中是至关重要的,而非可选的
原文:
www.kdnuggets.com/2021/05/data-validation-machine-learning-imperative.html
评论
作者:Aditya Aggarwal,数据科学实践负责人 & Arnab Bose,首席科学官,Abzooba
在生产环境中运作一个机器学习(ML)模型需要远比在学术界或研究中创建和验证模型要复杂得多。生产中的 ML 应用程序可以是一个包含多个组件顺序运行的管道,如图 1 所示。在我们达到管道中的模型训练之前,需要执行多个组件,如数据摄取、数据版本控制、数据验证和数据预处理。在这里,我们将讨论数据验证,并将本文安排如下:
-
什么是数据验证?
-
为什么需要数据验证?
-
数据验证面临哪些挑战?
-
数据验证组件是如何工作的?
-
市场上可用的数据验证组件示例。
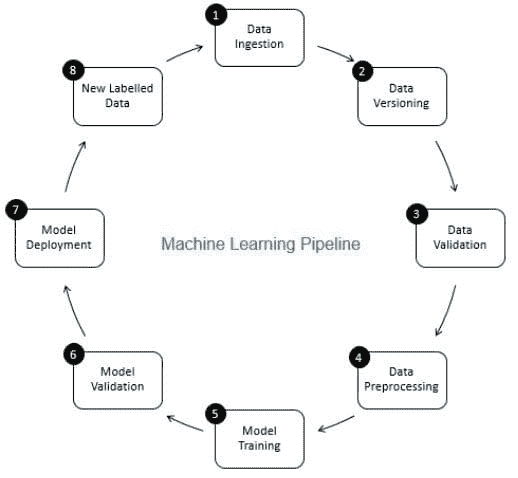
图 1:机器学习流程中的组件
1) 什么是数据验证?
数据验证意味着检查源数据的准确性和质量,在训练新模型版本之前进行。它确保稀有或增量数据中出现的异常不会被默默忽略。 它侧重于检查新数据的统计数据是否符合预期(例如特征分布、类别数量等)。根据目标和约束,可以执行不同类型的验证。机器学习流程中的一些目标示例如下 -
-
增量数据中是否有异常或数据错误?如果有,请向团队发出警报进行调查。
-
在模型训练过程中是否有任何数据假设被违反?如果有,请向团队发出警报进行调查。
-
训练数据和服务数据之间是否有显著差异?或者,是否有连续数据的差异被添加到训练数据中?如果有,请发出警报以调查训练和服务代码堆栈中的差异。
数据验证步骤的输出应该是信息丰富的,以便数据工程师可以对其采取行动。此外,它还需要具有高精度,因为过多的假警报会轻易失去可信度。
2) 为什么需要数据验证?
机器学习模型容易受到数据质量差的影响,正如古老的谚语所说“垃圾进垃圾出”。
在生产环境中,模型会周期性地使用新增的增量数据进行重新训练(频率可高达每日),并将更新的模型推送到服务层。模型在服务时使用新进入的数据进行预测,并且同样的数据会添加实际标签后用于重新训练。这确保了新生成的模型能够适应数据特征的变化。
然而,服务层中新进入的数据可能会发生变化,原因包括引入错误的代码更改或训练和服务堆栈之间的差异。随着时间的推移,错误的摄取数据将成为训练数据的一部分,这将开始降低模型的准确性。由于每次迭代中新添加的数据通常只是总体训练数据的一小部分,因此模型准确性的变化很容易被忽视,错误会随着时间的推移不断增加。
因此,在早期阶段捕捉数据错误非常重要,因为这将减少数据错误的成本,随着错误在管道中进一步传播,成本必然会增加(如图 2 所示)。
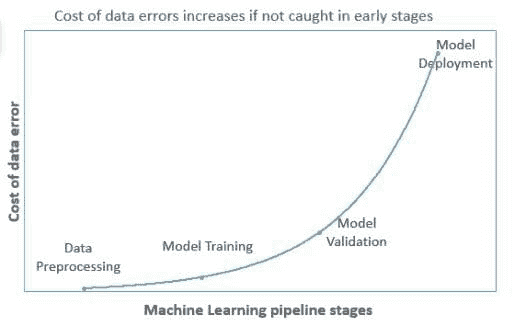
图 2:机器学习管道中的数据错误成本
3) 数据验证面临哪些挑战?
数据科学家在开发数据验证组件时面临各种挑战,例如
-
为具有少量列的数据集创建数据验证规则听起来很简单。然而,当数据集中的列数增加时,这将变成一项庞大的任务。
-
追踪和比较历史数据集中的指标以找出每列的历史趋势中的异常需要数据科学家花费大量时间。
-
现在的应用程序预计会全天候运行,在这种情况下,数据验证需要自动化。数据验证组件应该足够智能,能够刷新验证规则。
4) 数据验证组件如何工作?
把数据验证组件想象成 ML 应用程序的一个哨岗,阻止低质量数据进入。它会检查每一条即将添加到训练数据中的新数据。如图 3 所示,数据验证框架可以总结为 5 个步骤:
-
根据一组规则计算训练数据的统计信息
-
计算需要验证的摄取数据的统计信息
-
将验证数据的统计信息与训练数据的统计信息进行比较
-
存储验证结果并采取自动化措施,如删除行、限制或调整值
-
发送通知和警报以供审批

图 3:数据验证工作流程(点击放大)
5) 市场上可用的数据验证组件示例
亚马逊研究 [1] 和谷歌研究 [2] 提出了非常相似的数据验证组件构建方法。总体而言,这两种方法遵循了图 2 所示的相同工作流程。我们将在这里讨论这两种方法。
5.1) 亚马逊研究(Deequ)的数据验证单元测试方法
在软件工程中,工程师编写单元测试来测试他们的代码。同样,也应该定义单元测试来测试传入的数据。作者定义了一个框架来定义这个组件,该框架遵循以下原则 -
a) 声明约束:用户定义数据应该是什么样的。通过在数据上声明检查,按不同列组合约束来实现。表 1 中显示了约束列表。
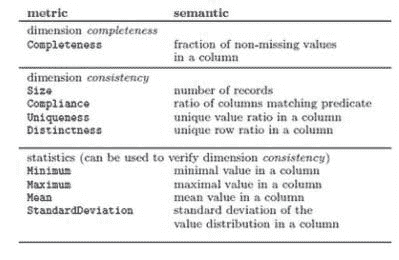
b) 计算度量:根据声明的约束,将其转换为可测量的度量,如下表 2 所示。这些度量可以计算并在手头数据和增量数据之间进行比较。
c) 分析和报告: 根据随时间收集的度量,预测增量数据中的度量是否异常。作为规则,如果新度量值比之前的均值多出三倍标准差,用户可以让系统发出“警告”;如果多出四倍标准差,则抛出“错误”。根据分析,报告失败的约束,包括导致约束失败的值(s)。
表 1:用于编排用户定义数据质量检查的约束
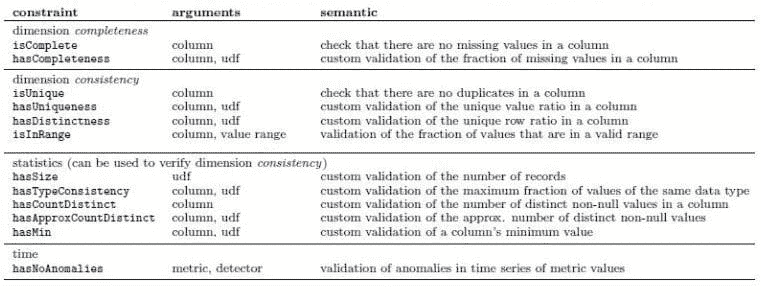 表 2:基于约束的可计算度量
表 2:基于约束的可计算度量
5.2) 谷歌研究(Tensorflow 数据验证)的数据模式方法
谷歌研究提出了非常相似的技术,但采用了数据管理系统中“经过实战考验”的原则,并将其定制用于机器学习。该技术首先将对正确数据的期望进行编码,然后利用这些期望的统计数据和用户定义的验证模式进行数据验证。 该数据验证框架包含3 个子组件,如图 4 所示。
-
数据分析器 - 计算定义数据所需的一组预定义数据统计信息
-
数据验证器 - 根据通过模式指定的数据属性进行检查。此模式是数据验证器执行的前提。此模式列出了所有特征的基本检查和与机器学习相关的检查的约束。
-
模型单元测试器 - 使用通过模式生成的合成数据检查训练代码中的错误
该框架为用户提供了能力
-
通过检测数据中的异常来验证单批增量数据
-
检测连续增量训练数据批次之间的显著变化。一些异常在检查单个批次时不可见,但在查看连续批次时会显现。
-
查找训练代码中未反映在数据中的假设(例如,如果训练代码中的特征预期应有 log(),则不应有负值或字符串值)。目标是涵盖那些未被添加到模式中的约束。此过程分为两个步骤
-
生成符合模式约束的合成训练示例
-
生成的数据会通过训练代码进行迭代以检查错误
-
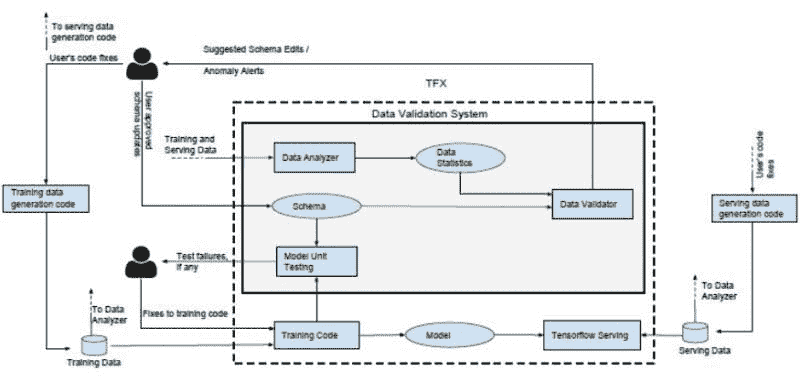
图 4: 谷歌研究的机器学习数据验证
亚马逊研究和谷歌研究的方法都为用户提供了建议,比如亚马逊框架中的约束和谷歌框架中更新模式的推荐。这两种方法都将数据视为机器学习管道中的一等公民,并在将数据输入系统之前进行数据验证。然而,仍有一些值得注意的区别。
表格 3: 数据验证库的差异
| Deequ(亚马逊) | Tensorflow 数据验证(谷歌) | |
|---|---|---|
| 1 | 无可用可视化 | 使用谷歌 Facets 提供可视化。总结了每个特征的统计数据,并比较训练数据和验证数据。 |
| 2 | 通过聚合之前保存的训练统计数据和新数据统计数据来重新计算训练统计数据。 | 每次运行时计算整个训练数据的统计数据,除非另有指定。这可能会变得计算开销较大。 |
| 3 | 除了基于阈值或相对/绝对差异进行异常检测,还提供基于运行平均值和标准差的异常检测能力。 | 提供基于阈值或相对/绝对差异的异常检测能力。 |
| 4 | 仅支持 SparkDataFrame 数据。 | 支持 pandas dataframe、csv,且与 TFRecord 配合最佳。 |
参考文献
-
S. Schelter, D. Lange, P. Schmidt, M. Celikel, F. Biessmann 和 A. Grafberger,“大规模数据质量验证的自动化”,发表于 VLDB 基金会,卷 11,第 12 期:1781-1794,2018 年。可用:
www.vldb.org/pvldb/vol11/p1781-schelter.pdf -
E. Breck, M. Zinkevich, N. Polyzotis, S. Whang 和 S. Roy,“机器学习的数据验证”,发表于第二届 SysML 会议,帕洛阿尔托,加州,美国,2019 年。可用:
mlsys.org/Conferences/2019/doc/2019/167.pdf
阿迪提亚·阿格尔瓦尔担任 Abzooba Inc.的数据科学实践负责人。凭借超过 12 年的数据驱动解决方案推动业务目标的经验,阿迪提亚专注于预测分析、机器学习、商业智能和商业战略。他是 Abzooba 的高级分析实践负责人,领导着一个 50 多人的充满活力的数据科学团队,使用机器学习、深度学习、自然语言处理和计算机视觉解决有趣的商业问题。他为客户提供人工智能方面的思想领导,将其商业目标转化为分析问题和数据驱动解决方案。在他的领导下,多个组织实现了任务自动化、降低了运营成本、提高了团队生产力,并改善了收入和利润。他开发了如代位索赔引擎、价格推荐引擎、物联网传感器预测维护等解决方案。阿迪提亚拥有印度技术学院(IIT)德里的技术学士学位和商业管理辅修学位。
阿纳布·博斯博士是 Abzooba 的首席科学官,该公司是一家数据分析公司,并且是芝加哥大学的兼职教员,教授机器学习、预测分析、机器学习操作、时间序列分析与预测以及健康分析等课程。他是一位拥有 20 年预测分析行业经验的专家,喜欢使用结构化和非结构化数据来预测和影响医疗保健、零售、金融和交通领域的行为结果。他目前的研究重点包括使用机器学习进行健康风险分层和慢性病管理,以及机器学习模型的生产部署和监控。阿纳布在许多电气和电子工程师协会(IEEE)会议和期刊上发表了书籍章节和审稿论文。他曾获得美国控制会议最佳演讲奖,并在美国、澳大利亚和印度的大学和公司中发表过关于数据分析的讲座。阿纳布拥有南加州大学的电气工程硕士和博士学位,以及印度技术学院卡拉格普尔分校的电气工程学士学位。
相关:
-
MLOps——“为什么需要它?”和“它是什么”?
-
数据验证和数据核实——从字典到机器学习
-
如何开始使用 SQL 管理数据质量并进行扩展
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 部门
更多相关话题
机器学习的数据验证
原文:
www.kdnuggets.com/2020/01/data-validation-machine-learning.html
评论 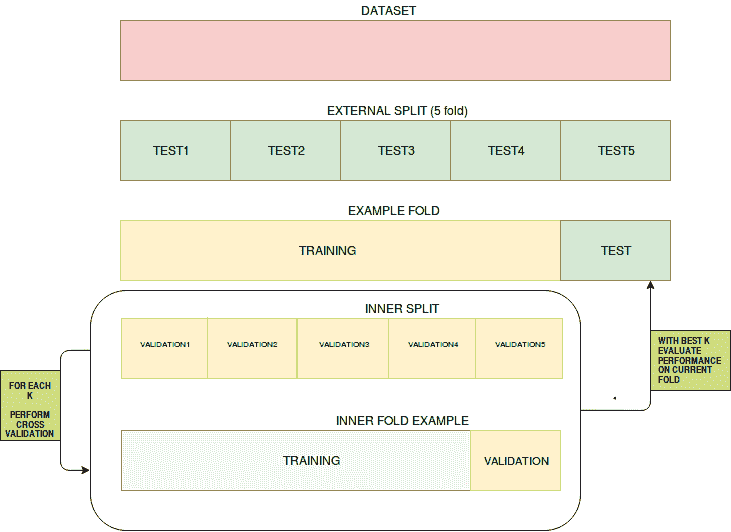 来源
来源
数据是维持机器学习运行的基本保障。无论机器学习和/或深度学习模型有多强大,如果数据质量差,它永远无法达到预期效果。随机噪声(即使模式难以识别的数据点)、某些类别变量的低频率、目标类别的低频率(如果目标变量是类别型的)和不正确的数值等,都是数据可能干扰模型表现的方式。虽然验证过程无法直接发现问题,但有时可以显示模型的稳定性存在问题。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
训练/验证/测试分割

验证数据的最基本方法(即在测试模型之前调整超参数)是对数据进行训练/验证/测试分割。典型的比例可能是 80/10/10,以确保你仍然有足够的训练数据。训练模型后,用户将进入验证结果并通过验证集调整超参数,直到达到满意的性能指标。一旦这一阶段完成,用户将使用测试集对模型进行测试,以预测和评估性能。
交叉验证
交叉验证是一种评估统计预测模型在独立数据集上表现的技术。其目的是确保模型和数据能够良好配合。交叉验证在训练阶段进行,用户将评估模型是否容易出现欠拟合或过拟合。用于交叉验证的数据必须来自目标变量的相同分布,否则我们可能会对模型在实际中的表现产生误导。
交叉验证有不同的类型,例如:
*** K 折交叉验证**
- 在我们希望尽可能多地保留数据用于训练阶段,而不冒将宝贵数据丢失到验证集的风险时,k 折交叉验证可以提供帮助。这种技术不要求训练数据放弃一部分作为验证集。在这种情况下,数据集被分成k个折叠,其中一个折叠将用作测试集,其余的将用作训练数据集,这个过程会重复n次,具体由用户指定。在回归中,结果的平均值(如 RMSE、R-Squared 等)将作为最终结果。在分类设置中,结果的平均值(即准确率、真正率、F1 等)将作为最终结果。
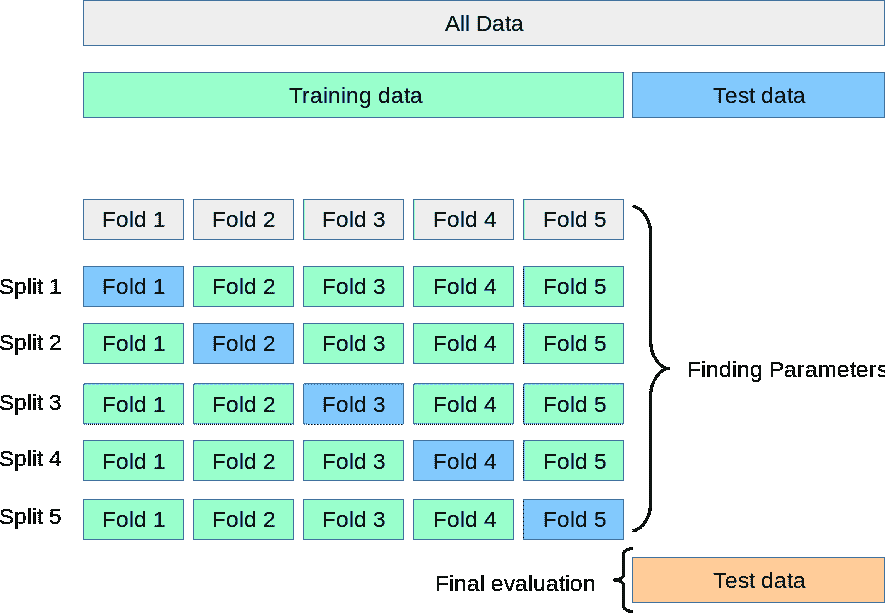
.
- 留一验证(LOOCV)
- 留一验证与 k 折交叉验证类似。该迭代过程将进行n次,具体次数由用户指定。
数据集将被分为 n-1 个数据集,被移除的数据集将是测试数据。性能的测量方式与 k 折交叉验证相同。

验证数据集让用户对模型的稳定性有信心。随着机器学习渗透社会的各个方面并被应用于我们的日常生活,确保模型能够代表我们的社会变得更加重要。过拟合和欠拟合是数据科学家在模型构建过程中面临的两大常见陷阱。验证是你的模型在性能优化和在长时间内稳定的关键步骤,之后才需要重新训练。
相关
-
常见的机器学习障碍
-
入门机器学习的书籍
-
你应该在数据科学项目中使用交叉验证的 5 个理由
更多关于此主题
使用 Pandera 进行 PySpark 应用的数据验证
原文:
www.kdnuggets.com/2023/08/data-validation-pyspark-applications-pandera.html

照片由 Jakub Skafiriak 提供,来源于 Unsplash
如果你是数据从业者,你会认识到数据验证在确保准确性和一致性方面的重要性。这在处理大型数据集或来自不同来源的数据时尤为关键。然而,Pandera Python 库可以帮助简化和自动化数据验证过程。Pandera 是一个 开源库,精心设计以简化模式和数据验证任务。它在 pandas 的稳健性和多功能性基础上构建,并引入了一个直观且富有表现力的 API,专门用于数据验证目的。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
本文简要介绍了 Pandera 的关键特性,然后深入说明了如何将 Pandera 数据验证集成到使用本地 PySpark SQL 的数据处理工作流中,自最新版本 (Pandera 0.16.0) 起。
Pandera 设计用于与其他流行的 Python 库如 pandas、pyspark.pandas、Dask 等一起工作。这使得将数据验证融入现有的数据处理工作流程变得容易。直到最近,Pandera 还缺乏对PySpark SQL的原生支持,但为了弥补这一空白,QuantumBlack, AI by McKinsey的团队包括Ismail Negm-PARI、Neeraj Malhotra、Jaskaran Singh Sidana、Kasper Janehag、Oleksandr Lazarchuk及 Pandera 创始人 Niels Bantilan开发了对 PySpark SQL 的原生支持,并将其贡献给了 Pandera。本文的文字也是由该团队准备的,以下是他们的描述。
Pandera 的关键特性
如果你不熟悉使用 Pandera 验证数据,我们建议查看Khuyen Tran的“使用 Pandera 验证你的 pandas DataFrame”,其中描述了基础知识。简而言之,我们在这里简要说明了简单直观的 API、内置验证函数和自定义的关键特性和优势。
简单直观的 API
Pandera 的一个显著特点是其简单直观的 API。你可以使用易于阅读和理解的声明式语法定义数据模式。这使得编写高效且有效的数据验证代码变得简单。
这是 Pandera 中模式定义的一个示例:
class InputSchema(pa.DataFrameModel):
year: Series[int] = pa.Field()
month: Series[int] = pa.Field()
day: Series[int] = pa.Field()
内置验证函数
Pandera 提供了一组内置函数(更常称为检查)来执行数据验证。当我们在 Pandera 模式上调用 validate() 时,它将执行模式和数据验证。数据验证将在后台调用 check 函数。
这是一个使用 Pandera 对数据框对象运行数据 check 的简单示例。
class InputSchema(pa.DataFrameModel):
year: Series[int] = pa.Field(gt=2000, coerce=True)
month: Series[int] = pa.Field(ge=1, le=12, coerce=True)
day: Series[int] = pa.Field(ge=0, le=365, coerce=True)
InputSchema.validate(df)
如上所示,对于 year 字段,我们定义了一个检查 gt=2000,强制所有此字段的值必须大于 2000,否则 Pandera 将引发验证失败。
这是 Pandera 默认提供的所有内置检查的列表:
eq: checks if value is equal to a given literal
ne: checks if value is not equal to a given literal
gt: checks if value is greater than a given literal
ge: checks if value is greater than & equal to a given literal
lt: checks if value is less than a given literal
le: checks if value is less than & equal to a given literal
in_range: checks if value is given range
isin: checks if value is given list of literals
notin: checks if value is not in given list of literals
str_contains: checks if value contains string literal
str_endswith: checks if value ends with string literal
str_length: checks if value length matches
str_matches: checks if value matches string literal
str_startswith: checks if value starts with a string literal
自定义验证函数
除了内置的验证检查,Pandera 还允许你定义自定义验证函数。这让你能够根据使用情况定义自己的验证规则。
例如,你可以定义一个用于数据验证的 lambda 函数,如下所示:
schema = pa.DataFrameSchema({
"column2": pa.Column(str, [
pa.Check(lambda s: s.str.startswith("value")),
pa.Check(lambda s: s.str.split("_", expand=True).shape[1] == 2)
]),
})
将对 PySpark SQL 数据框的支持添加到 Pandera 中
在添加对 PySpark SQL 支持的过程中,我们遵循了两个基本原则:
-
接口和用户体验的一致性。
-
PySpark 性能优化。
首先,让我们深入探讨一致性的问题,因为从用户的角度来看,他们需要无论选择什么框架,都能有一套一致的 API 和接口。由于 Pandera 提供了多个框架选择,因此在 PySpark SQL API 中拥有一致的用户体验变得尤为重要。
有了这一点,我们可以使用 PySpark SQL 来定义 Pandera 模式,如下所示:
from pyspark.sql import DataFrame, SparkSession
import pyspark.sql.types as T
import pandera.pyspark as pa
spark = SparkSession.builder.getOrCreate()
class PanderaSchema(DataFrameModel):
"""Test schema"""
id: T.IntegerType() = Field(gt=5)
product_name: T.StringType() = Field(str_startswith="B")
price: T.DecimalType(20, 5) = Field()
description: T.ArrayType(T.StringType()) = Field()
meta: T.MapType(T.StringType(), T.StringType()) = Field()
data_fail = [
(5, "Bread", 44.4, ["description of product"], {"product_category": "dairy"}),
(15, "Butter", 99.0, ["more details here"], {"product_category": "bakery"}),
]
spark_schema = T.StructType(
[
T.StructField("id", T.IntegerType(), False),
T.StructField("product", T.StringType(), False),
T.StructField("price", T.DecimalType(20, 5), False),
T.StructField("description", T.ArrayType(T.StringType(), False), False),
T.StructField(
"meta", T.MapType(T.StringType(), T.StringType(), False), False
),
],
)
df_fail = spark_df(spark, data_fail, spark_schema)
在上述代码中,PanderaSchema定义了传入的 pyspark 数据框的模式。它有 5 个字段,具有不同的dtypes,并对id和product_name字段进行了数据检查的强制执行。
class PanderaSchema(DataFrameModel):
"""Test schema"""
id: T.IntegerType() = Field(gt=5)
product_name: T.StringType() = Field(str_startswith="B")
price: T.DecimalType(20, 5) = Field()
description: T.ArrayType(T.StringType()) = Field()
meta: T.MapType(T.StringType(), T.StringType()) = Field()
接下来,我们制作了一个虚拟数据并强制执行 spark_schema中定义的本地 PySpark SQL 模式。
spark_schema = T.StructType(
[
T.StructField("id", T.IntegerType(), False),
T.StructField("product", T.StringType(), False),
T.StructField("price", T.DecimalType(20, 5), False),
T.StructField("description", T.ArrayType(T.StringType(), False), False),
T.StructField(
"meta", T.MapType(T.StringType(), T.StringType(), False), False
),
],
)
df_fail = spark_df(spark, data_fail, spark_schema)
这是为了模拟模式和数据验证失败。
这是df_fail数据框的内容:
df_fail.show()
+---+-------+--------+--------------------+--------------------+
| id|product| price| description| meta|
+---+-------+--------+--------------------+--------------------+
| 5| Bread|44.40000|[description of p...|{product_category...|
| 15| Butter|99.00000| [more details here]|{product_category...|
+---+-------+--------+--------------------+--------------------+
接下来,我们可以调用 Pandera 的 validate 函数来执行模式和数据级验证,如下所示:
df_out = PanderaSchema.validate(check_obj=df)
我们将很快探索df_out的内容。
PySpark 性能优化
我们的贡献专门针对在处理 PySpark 数据框时的最佳性能进行设计,这对于处理大型数据集以应对 PySpark 分布式计算环境的独特挑战至关重要。
Pandera 利用 PySpark 的分布式计算架构来高效处理大型数据集,同时保持数据的一致性和准确性。我们重写了 Pandera 的自定义验证函数以提高 PySpark 性能,使得大型数据集的验证更快、更高效,同时降低了在高负载情况下数据错误和不一致的风险。
综合错误报告
我们在 Pandera 中新增了生成详细错误报告的功能,这些报告以 Python 字典对象的形式提供。这些报告可以通过 validate 函数返回的数据框访问,提供了所有模式和数据级验证的全面摘要,依据用户的配置。
这一功能对开发人员来说非常有价值,可以快速识别和解决数据相关问题。通过使用生成的错误报告,团队可以编制应用程序中的模式和数据问题的全面列表,从而高效而精准地优先解决问题。
需要注意的是,这一功能目前仅对 PySpark SQL 可用,为用户在处理 Pandera 中的错误报告时提供了增强的体验。
在上述代码示例中,请记住我们对 spark 数据框调用了validate():
df_out = PanderaSchema.validate(check_obj=df)
它返回了一个数据框对象。使用访问器,我们可以提取其中的错误报告,如下所示:
print(df_out.pandera.errors)
{
"SCHEMA":{
"COLUMN_NOT_IN_DATAFRAME":[
{
"schema":"PanderaSchema",
"column":"PanderaSchema",
"check":"column_in_dataframe",
"error":"column 'product_name' not in dataframe Row(id=5, product='Bread', price=None, description=['description of product'], meta={'product_category': 'dairy'})"
}
],
"WRONG_DATATYPE":[
{
"schema":"PanderaSchema",
"column":"description",
"check":"dtype('ArrayType(StringType(), True)')",
"error":"expected column 'description' to have type ArrayType(StringType(), True), got ArrayType(StringType(), False)"
},
{
"schema":"PanderaSchema",
"column":"meta",
"check":"dtype('MapType(StringType(), StringType(), True)')",
"error":"expected column 'meta' to have type MapType(StringType(), StringType(), True), got MapType(StringType(), StringType(), False)"
}
]
},
"DATA":{
"DATAFRAME_CHECK":[
{
"schema":"PanderaSchema",
"column":"id",
"check":"greater_than(5)",
"error":"column 'id' with type IntegerType() failed validation greater_than(5)"
}
]
}
}
如上所示,错误报告以两级汇总的形式存储在一个 Python 字典对象中,以便下游应用程序轻松使用,比如使用 Grafana 等工具对错误的时间序列进行可视化:
-
验证类型 =
SCHEMA或DATA -
错误类别 =
DATAFRAME_CHECK或WRONG_DATATYPE等。
这种重构错误报告的新格式是在 0.16.0 版本中引入的,作为我们贡献的一部分。
开/关开关
对于依赖于 PySpark 的应用程序,开/关开关是一个重要的功能,可以在灵活性和风险管理方面带来显著的差异。具体来说,开/关开关允许团队在生产环境中禁用数据验证,而无需修改代码。
这对大数据管道尤其重要,其中性能至关重要。在许多情况下,数据验证可能会占用大量处理时间,这可能会影响管道的整体性能。使用开/关开关,团队可以在必要时快速轻松地禁用数据验证,而无需经过耗时的代码修改过程。
我们的团队为 Pandera 引入了开/关开关,使用户可以通过简单地更改配置设置,轻松关闭生产环境中的数据验证。这提供了在必要时优先考虑性能的灵活性,同时不牺牲开发中的数据质量或准确性。
要启用验证,请在您的环境变量中设置以下内容:
export PANDERA_VALIDATION_ENABLED=False
这将被 Pandera 拦截,以禁用应用程序中的所有验证。默认情况下,验证是启用的。
目前,该功能仅在 0.16.0 版本及更高版本的 PySpark SQL 中可用,因为这是我们贡献的新概念。
Pandera 执行的细粒度控制
除了开/关开关功能,我们还引入了对 Pandera 验证流程的更细粒度控制。这是通过引入可配置设置实现的,这些设置允许用户在三个不同的层级上控制执行:
-
SCHEMA_ONLY:此设置仅执行模式验证。它检查数据是否符合模式定义,但不执行任何额外的数据级别验证。 -
DATA_ONLY:此设置仅执行数据级别的验证。它检查数据是否符合定义的约束和规则,但不验证模式。 -
SCHEMA_AND_DATA:此设置执行模式和数据级别的验证。它会检查数据是否符合模式定义以及定义的约束和规则。
通过提供这种细粒度的控制,用户可以选择最适合其特定用例的验证级别。例如,如果主要关注的是确保数据符合定义的模式,可以使用 SCHEMA_ONLY 设置以减少总体处理时间。或者,如果数据已知符合模式,并且关注点是确保数据质量,则可以使用 DATA_ONLY 设置来优先考虑数据级别的验证。
对 Pandera 执行的增强控制允许用户在精确性和效率之间找到微调平衡,从而实现更有针对性和优化的验证体验。
export PANDERA_VALIDATION_DEPTH=SCHEMA_ONLY
默认情况下,验证是启用的,深度设置为SCHEMA_AND_DATA,可以根据用例需要更改为SCHEMA_ONLY或DATA_ONLY。
目前,这一功能仅适用于从版本 0.16.0 开始的 PySpark SQL,因为这是我们贡献的新概念。
列和数据框级别的元数据
我们的团队为 Pandera 添加了一个新功能,允许用户在Field和Schema / Model级别存储额外的元数据。此功能旨在让用户在其模式定义中嵌入上下文信息,以供其他应用程序使用。
例如,通过存储关于特定列的详细信息,如数据类型、格式或单位,开发人员可以确保下游应用程序能够正确解释和使用数据。类似地,通过存储关于某个模式中哪些列对于特定用例是必要的信息,开发人员可以优化数据处理管道,降低存储成本,并提高查询性能。
在模式级别,用户可以存储信息以帮助分类整个应用程序中的不同模式。这些元数据可以包括模式的目的、数据来源或数据的日期范围等细节。这对于管理复杂的数据处理工作流尤其有用,其中多个模式用于不同的目的,需要高效地跟踪和管理。
class PanderaSchema(DataFrameModel):
"""Pandera Schema Class"""
id: T.IntegerType() = Field(
gt=5,
metadata={"usecase": ["RetailPricing", "ConsumerBehavior"],
"category": "product_pricing"},
)
product_name: T.StringType() = Field(str_startswith="B")
price: T.DecimalType(20, 5) = Field()
class Config:
"""Config of pandera class"""
name = "product_info"
strict = True
coerce = True
metadata = {"category": "product-details"}
在上述示例中,我们引入了有关模式对象本身的附加信息。这允许在两个级别进行:字段和模式。
要提取模式级别的元数据(包括其中所有字段),我们提供了以下帮助函数:
PanderaSchema.get_metadata()
The output will be dictionary object as follows:
{
"product_info": {
"columns": {
"id": {"usecase": ["RetailPricing", "ConsumerBehavior"],
"category": "product_pricing"},
"product_name": None,
"price": None,
},
"dataframe": {"category": "product-details"},
}
}
当前,这一功能在 0.16.0 中是一个新概念,并已添加到 PySpark SQL 和 Pandas 中。
摘要
我们引入了几个新功能和概念,包括一个开关,允许团队在生产中禁用验证而无需更改代码,对 Pandera 验证流程的精细控制,以及在列和数据框级别存储额外元数据的能力。您可以在更新的 Pandera 文档中找到更多关于版本 0.16.0 的详细信息。
正如 Pandera 创始人 Niels Bantilan 在关于 Pandera 0.16.0 发布的近期博客文章中所解释的:
为了证明 Pandera 在新的模式规范和后端 API 中的可扩展性,我们与 QuantumBlack 团队合作,实现了一个模式和后端,用于 Pyspark SQL …并在几个月内完成了一个 MVP!
最近对 Pandera 开源代码库的贡献将惠及使用 PySpark 和其他大数据技术的团队。
以下在 QuantumBlack(麦肯锡的人工智能部门) 的团队成员负责了这次贡献:Ismail Negm-PARI、Neeraj Malhotra、Jaskaran Singh Sidana、Kasper Janehag、Oleksandr Lazarchuk。特别感谢 Neeraj 在准备这篇文章出版过程中的协助。
Jo Stichbury 是 QuantumBlack(麦肯锡的人工智能部门)的技术作家。他是一名技术内容创作者,撰写关于数据科学和软件的文章。曾是老派 Symbian C++ 开发者,现在是偶然的猫群管理者和鹅追逐者。
更多相关话题
数据:企业最宝贵的商品
原文:
www.kdnuggets.com/2022/03/data-valuable-commodity-businesses.html
图片由 200degrees 在 Pixabay 提供
理解企业每天访问的数据量及其存储的更多数据可能会很困难。许多公司已经以某种形式捕捉客户数据数十年了。每天,全球网络中都有数 PB 的数据在传输,这些数据意味着巨额的财富——至少对那些能够正确分析和利用这些数据的公司而言是如此。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
下面是公司如何最好地利用这些数据以影响积极结果的方法。
数据为何如此有价值
数据已经成为一种有价值的商品,类似于石油和黄金等商品,因为大多数公司拥有类似类型的数据。但当然,也存在许多不同类型的数据,而不同的数据对不同的公司具有不同的价值。并非每家公司都可以拥有相同的数据策略,因为企业需要探索的领域取决于该业务的领域专业知识。尽管如此,仍然可以对公司拥有的数据进行评估,那些将其专业领域与捕捉、分析和使用数据的能力相结合的人,将为其组织创造最大的价值。
今天,在我们所处的互联网时代,数据被广泛认为是世界上最宝贵的资源,因为它能够提供潜在的收入和商业价值。此外,它也可以被出售和购买。实际上,一些全球最具影响力的公司,如谷歌和脸书,主要靠他们掌握的有价值且常常是亲密的消费者数据来赚钱。这些公司向个人消费者提供免费服务,但它们报告的收入令人瞠目结舌。如果你看看特斯拉,每辆连接的汽车每小时生成25GB的数据,每年生成约 300TB 的数据。
Web 1.0 为我们提供了一个出色的机制来进行沟通和连接,但那时我们无法有效地浏览所有信息。随后出现了 Web 2.0,像谷歌、脸书和 YouTube 这样的基于平台的环境进入了舞台。这简化了用户之间的数据访问和交换,但也将过多的控制权交给了这些组织。现在,随着加密货币和非同质化代币的兴起,Web 3.0 正在全球范围内变得越来越主流。如果你展望未来,10 年后,终端用户将对因日常活动而产生的数据拥有更多的权力和控制,不论是在社交媒体上、通过电子邮件,还是在元宇宙中。了解捕捉哪些数据以及如何利用这种宝贵的商品,可以决定现代公司生死存亡的差异。最成功的公司可以整合来自社交媒体、电子邮件、购买历史和物联网设备的数据,绘制出一个非常准确的人物画像。这些公司可以将其商业模式和策略与客户的需求对齐,以影响他们的结果。例如,营销团队不再需要向潜在的不感兴趣的客户发送成千上万的邮件。
数据预测行为——这意味着更多收入
公司在自己的数据库中收集、存储和分析消费者数据,以帮助预测客户行为。这种预测能力可以准确到让公司在你需要之前就知道你需要什么。
例如,考虑一下 Target 能够预测其女性顾客怀孕的旧故事。一位愤怒的父亲冲进了当地的 Target 商店,要求解释为什么他的 teenage 女儿收到的邮件中包含尿布和其他婴儿用品的广告。几周后,他回到店里道歉——他发现女儿确实怀孕了。
尽管这个故事几乎已经过去十年,但它完美地展示了为什么数据是现代企业最有价值的商品。二十年前,大多数公司关注的唯一数据是与交易相关的。例如,他们用数据来回答利润率是多少、销售如何影响库存以及材料和运输的成本是多少等问题。然而,随着时间的推移,公司发现这些数据虽然必要,但并不是解锁收入增长的关键。
关键在于理解个别消费者,随着 AI 和计算能力的进步,这种理解变得越来越精准。就像 Target 能够根据女性的购物行为判断她是否怀孕一样,今天的数据挖掘者可以调整广告并跨设备投放给最有可能购买的特定人群。因此,个性化推荐几乎能确保销售成功。
数据使个性化推荐成为可能
如果你使用 Netflix,你可能已经意识到 Netflix 使用了 多种类型的缩略图艺术作品 来保持你的观看兴趣。根据你以前的选择,Netflix 利用其精细调整的算法选择最能吸引你继续观看的缩略图。类似地,Amazon 基于你的购买历史提供的精心策划的推荐也能让你不断回购。
强大的算法和预测软件生成这些个性化推荐,但它们得以实现的基础是这些公司拥有的大量客户数据。这就是数据的力量,也是现代公司最有价值的资源。
在互联网诞生并成长起来的公司不能对任何一个客户掉以轻心。网页加载时间的任何一秒延迟都可能将客户送到竞争对手那里。因此,公司需要了解客户的愿望和习惯。他们应该问这样的问题:“谁在访问我的网站?他们最花时间在什么地方?他们访问了哪些页面?他们点击离开网站时的位置在哪里?”通过找到这些答案,并在客户旅程的各个触点收集数据,公司将能更好地与消费者的需求对齐,并在全球激烈的竞争中获得竞争优势。
数据是成功商业成果的关键
数据已经成为当今商业世界中最宝贵的商品。理解数据价值时,一个重要的考虑因素是它可能不会直接转化为现金,但这并不减少其价值。你更愿意现在得到一笔销售,还是一个能帮助你在明年将销售收入增长三倍的见解?这就是我们需要挖掘的数据洞察——适应未来的前瞻性。
随着虚拟世界中业务的增加,一个强大的消费者偏好数据集可以帮助公司提供竞争优势,使其能够在客户想要之前预测他们的需求。在时间紧迫和竞争激烈的情况下,正确理解和使用数据是成功商业成果的关键。
Vijay Cherukuri 是 Infolob Solutions, Inc 的首席执行官
更多相关话题
数据版本控制:迭代机器学习
原文:
www.kdnuggets.com/2017/05/data-version-control-iterative-machine-learning.html
评论
作者:Dmitry Petrov,Twitter
在现实生活中,几乎不可能一次性开发出一个好的机器学习模型。ML 建模是一个迭代过程,跟踪你的步骤、步骤之间的依赖关系、代码和数据文件之间的依赖关系以及所有代码运行参数极为重要。在团队环境中,这变得更加重要和复杂,因为数据科学家的协作占据了团队的大部分精力。
今天,我们很高兴地宣布新开源工具data version control或 DVC 的 beta 版本发布。DVC 旨在帮助数据科学家跟踪他们的 ML 过程和文件依赖,形式类似于 git 命令:“dvc run python train_model.py data/train_matrix.p data/model.p”。无论使用哪种编程语言或工具,你现有的 ML 过程都可以轻松转化为可重现的 DVC 管道。
这篇博客文章引导你通过一个迭代过程,使用 DVC 构建机器学习模型,数据集为stackoverflow posts dataset。首先,你需要初始化一个 Git 仓库,并下载我们将用来展示 DVC 的建模源代码:
$ mkdir myrepo
$ cd myrepo
$ mkdir code
*$ wget -nv -P code/ https://s3-us-west-2.amazonaws.com/dvc-share/so/code/featurization.py *
*https://s3-us-west-2.amazonaws.com/dvc-share/so/code/evaluate.py *
*https://s3-us-west-2.amazonaws.com/dvc-share/so/code/train_model.py *
*https://s3-us-west-2.amazonaws.com/dvc-share/so/code/split_train_test.py *
*https://s3-us-west-2.amazonaws.com/dvc-share/so/code/xml_to_tsv.py *
https://s3-us-west-2.amazonaws.com/dvc-share/so/code/requirements.txt
$ pip install -r code/requirements.txt
$ git init
$ git add code/
$ git commit -m ‘下载代码’
可以通过运行下面的 bash 代码来构建完整的管道。如果你使用的是 Python 3,请将 python 替换为 python3,将 pip 替换为 pip3。
# 安装 DVC
$ pip install dvc
# 初始化 DVC 仓库
$ dvc init
# 下载文件并放入 data/目录中。
$ dvc import https://s3-us-west-2.amazonaws.com/dvc-share/so/25K/Posts.xml.tgz data/
# 从归档中提取 XML 文件。
$ dvc run tar zxf data/Posts.xml.tgz -C data/
# 准备数据。
$ dvc run python code/xml_to_tsv.py data/Posts.xml data/Posts.tsv python
# 切分训练和测试数据集。两个输出文件。
# 0.33 是测试数据集分割比例。20170426 是随机化的种子。
$ dvc run python code/split_train_test.py data/Posts.tsv 0.33 20170426 data/Posts-train.tsv data/Posts-test.tsv
# 从文本数据中提取特征。两个 TSV 输入和两个 pickle 矩阵输出。
$ dvc run python code/featurization.py data/Posts-train.tsv data/Posts-test.tsv data/matrix-train.p data/matrix-test.p
# 从训练数据集中训练 ML 模型。20170426 是另一个种子值。
$ dvc run python code/train_model.py data/matrix-train.p 20170426 data/model.p
# 通过测试数据集评估模型。
$ dvc run python code/evaluate.py data/model.p data/matrix-test.p data/evaluation.txt
# 结果。
$ cat data/evaluation.txt
AUC: 0.596182
你需要理解的一点是,DVC 会自动推导步骤之间的依赖关系,并透明地构建依赖图(DAG)。这个图用于重现受到近期更改影响的流水线部分。在下一个代码示例中,我们将更改流水线中的特征提取步骤,并重现最终结果。DVC 推导出七个步骤中只有三个需要重新构建,并运行这些步骤:
# 改进特征提取步骤。
$ vi code/featurization.py
# 提交所有更改。
$ git commit -am “添加二元特征”
[master 50b5a2a] 添加二元特征
1 个文件更改,5 行插入(+),2 行删除(-)
# 生成所有必需的步骤以获得我们的目标指标文件。
$ dvc repro data/evaluation.txt
为数据项 data/matrix-train.p 生成重现运行命令。参数:python code/featurization.py data/Posts-train.tsv data/Posts-test.tsv data/matrix-train.p data/matrix-test.p
为数据项 data/model.p 生成重现运行命令。参数:python code/train_model.py data/matrix-train.p 20170426 data/model.p
为数据项 data/evaluation.txt 生成重现运行命令。参数:python code/evaluate.py data/model.p data/matrix-test.p data/evaluation.txt
数据项“data/evaluation.txt”已被重新生成。
# 查看目标指标的改进。
$ cat data/evaluation.txt
AUC: 0.627196
如果你替换了影响所有步骤的输入文件,那么整个流水线将被重新生成。
# 将小型输入数据集(25K 项)替换为较大的数据集(100K)。
$ dvc remove data/Posts.xml.tgz
$ dvc import https://s3-us-west-2.amazonaws.com/dvc-share/so/100K/Posts.xml.tgz data/
# 生成指标文件。
$ dvc repro data/evaluation.txt
为数据项 data/Posts.xml 生成重现运行命令。参数:tar zxf data/Posts.xml.tgz -C data
为数据项 data/Posts.tsv 生成重现运行命令。参数:python code/xml_to_tsv.py data/Posts.xml data/Posts.tsv python
为数据项 data/Posts-train.tsv 生成重现运行命令。参数:python code/split_train_test.py data/Posts.tsv 0.33 20170426 data/Posts-train.tsv data/Posts-test.tsv
重现数据项 data/matrix-train.p 的运行命令。参数:python code/featurization.py data/Posts-train.tsv data/Posts-test.tsv data/matrix-train.p data/matrix-test.p
重现数据项 data/model.p 的运行命令。参数:python code/train_model.py data/matrix-train.p 20170426 data/model.p
重现数据项 data/evaluation.txt 的运行命令。参数:python code/evaluate.py data/model.p data/matrix-test.p data/evaluation.txt
数据项“data/evaluation.txt”已重现。
$ cat data/evaluation.txt
AUC: 0.633541
DVC 不仅可以将你的工作简化为一个可重复的环境,还可以通过 Git 包含依赖项(DAG)轻松共享该环境——这是一个令人兴奋的协作功能,能够在不同的计算机上重现研究结果。此外,你可以通过像 AWS S3 或 GCP Storage 这样的云存储服务共享数据文件,因为 DVC 不会将数据文件推送到 Git 仓库中。
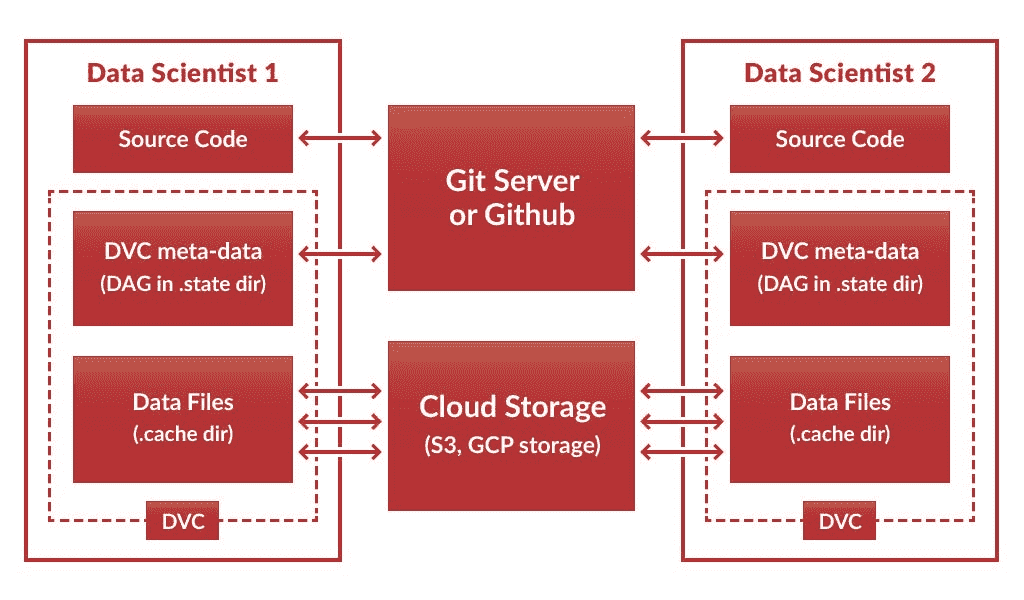
以下代码展示了如何通过 Git 分享你的代码和 DAG,以及通过 S3 分享数据文件:
# 设置云设置。例如:Cloud = AWS, StoragePath=/dvc-share/projects/tag_classifier
$ vi dvc.conf
$ git commit -am “设置 AWS 路径”
[master ec994b6] 设置 AWS 路径
1 个文件已更改,1 次插入(+),1 次删除(-)
# 与管道和云设置一起分享仓库。
$ git remote add origin https://github.com/dmpetrov/tag_classifier.git
$ git push -u origin master
# 分享最重要的数据文件。
$ dvc sync data/matrix-train.p data/matrix-test.p
上传缓存文件“.cache/matrix-train.p_1fa3a9b”到 S3“projects/tag_classifier/.cache/matrix-train.p_1fa3a9b”
上传完成
上传缓存文件“.cache/matrix-test.p_1fa3a9b”到 S3“projects/tag_classifier/.cache/matrix-test.p_1fa3a9b”
上传完成
现在,另一个数据科学家可以使用这个仓库,并以你刚刚使用的方法重现数据文件。如果她不想(或没有足够的计算资源)重现所有内容,她可以同步并锁定共享的数据文件。之后,只会重现机器学习过程的最后几个步骤。
# 获取仓库。
$ git clone https://github.com/dmpetrov/tag_classifier.git
# 从 S3 同步数据文件。
$ dvc sync data/
上传缓存文件“.cache/empty_0000000”到 S3“projects/tag_classifier/.cache/empty_0000000”
上传完成
从 S3 “dvc-share/projects/tag_classifier/.cache/matrix-test.p_1fa3a9b” 下载缓存文件
下载完成
从 S3 “dvc-share/projects/tag_classifier/.cache/matrix-train.p_1fa3a9b” 下载缓存文件
下载完成
# 锁定特征提取步骤中的重现过程
# 因为这些数据文件已同步。
$ dvc lock data/matrix-t*
数据项 data/matrix-test.p 已锁定
数据项 data/matrix-train.p 已锁定
# 改进模型。
$ vi code/train_model.py
$ git commit -am “调整模型”
[master 77e2943] 调整模型
1 个文件更改,1 次插入(+),1 次删除(-)
# 重现管道所需的步骤。
$ dvc repro data/evaluation.txt
重现数据项 data/model.p 的运行命令。参数: python code/train_model.py data/matrix-train.p 20170426 data/model.p
重现数据项 data/evaluation.txt 的运行命令。参数: python code/evaluate.py data/model.p data/matrix-test.p data/evaluation.txt
数据项“data/evaluation.txt”已被重现。
$ cat data/evaluation.txt
AUC: 0.670531
已重现的步骤(红色):
结论
因此,模型可以迭代改进,而 DVC 简化了迭代机器学习过程,并有助于数据科学家的协作。
我们非常感兴趣您的意见和反馈。请在这里发表评论或通过 Twitter 联系我们 — FullStackML。
如果您觉得这个工具有用,请“加星” DVC Github 仓库。
原文。经许可转载。
简介: 德米特里·佩特罗夫 正在构建数据科学工具的未来 DataVersionControl。前微软数据科学家。前研究员。计算机科学博士。
相关:
-
修复 CRISP-DM 中的部署和迭代问题
-
数据科学自动化:揭穿误解
-
RCloud – 数据科学的 DevOps
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
更多相关话题
如何使用数据可视化为你的工作报告和演示文稿增添影响力
原文:
www.kdnuggets.com/2022/08/data-visualization-add-impact-work-reports-presentations.html

图片由 RODNAE Productions 提供
当新手被引入数据科学领域时,解释通常会集中在通过利用数据中的洞察来为各个行业的组织增加巨大价值,从而推动更为明智的决策制定、预测等。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
这就是为什么典型的数据科学家或数据分析师职位描述中通常会包括类似的软技能条目: 能够将复杂的想法传达给非技术利益相关者。
然而,广泛需要与决策者沟通数据洞察的需求也联系到一个关键的硬技能。当然,我们说的就是数据可视化。
什么是数据可视化?
数据可视化仅仅是从数据中提取的洞察的图形表示。有效的数据可视化以对其相应受众易于接受的方式传达这些数据驱动的洞察。它被广泛认为是数据科学和数据分析中最重要的技能之一。
大局观: 数据可视化 “通过将大量无形数据转化为易于理解的图像和图形,帮助为利益相关者和其他团队成员提供高质量的信息。”
凭借生成有价值的商业洞察和解决实际问题的能力,数据科学现在正在推动几乎所有行业和领域的创新和变革——包括医疗保健、电子商务、执法、市场营销/广告、交通、体育、娱乐、非营利事业等。
数据可视化是关键能力之一,因为可视化的数据在大脑中处理速度比书面文字更快,这意味着它更易于理解,并能够从数据驱动的信息中更好地把握全局。
数据讲故事的重要性
不需要花哨的图表或图形来传达数据可视化的重要性。但虽然数据可视化的本质涉及更容易地向相关观众传达关键信息,它也严重依赖于 数据讲故事 的概念,这将你的叙述与可视化连接起来。
当你利用数据,或者更正式地说,是利用数据可视化技术来制作工作相关的报告或演示时,记住你实际上是在使用这些数据讲述一个故事,并将其作为决策的起点,会有所帮助。
根据视觉传播公司 Column Five Media 的说法,“数据讲故事是我们用来描述完整的数据收集、提取见解和将这些见解转化为故事的行为的通用术语。它是围绕引人入胜的数据精心编织的叙事,用于指导决策、揭示有趣的趋势或向你的观众提供有价值的信息。”
从本质上讲:“数据讲故事是两个世界的融合:硬数据和人际沟通。” 因此,数据可视化和讲故事是使数据科学对许多从业者如此有趣的核心所在。
数据可视化类型
在实践数据可视化的艺术与科学时,有多种具体的技术、策略和格式。
Tableau,这家开发了广泛使用的数据可视化工具的软件公司,提供了以下 最常见的通用数据可视化类型列表:
-
图表
-
表格
-
图表
-
地图
-
信息图
-
仪表盘
更深入地说,Tableau 列出了这些更具体的 数据可视化方法示例:
-
面积图
-
条形图
-
箱线图
-
气泡云
-
子弹图
-
地图图
-
圆形视图
-
点分布图
-
甘特图
-
热力图
-
高亮表格
-
直方图
-
矩阵格式
-
网络图
-
极区图
-
径向树
-
散点图(2D 或 3D)
-
流图
-
文本表格
-
时间轴
-
树图
-
扇形堆积图
-
词云
除了分享一些出色的 数据可视化实例 外,Tableau 还提供了 “历史与今日的 10 个最佳数据可视化示例” 的展示——从拿破仑 1812 年的行军到伦敦 1854 年的霍乱爆发,再到 1950-2060 年的美国按年龄组划分的人口趋势。
如何将数据可视化融入你的工作和生活
关于数据密集型演示的提示——以及任何希望以视觉格式创建和分享数据的实用建议——Column Five Media 建议密切关注 三个非常重要的基本原则:
-
从数据中找到故事。 你想讲述的独特故事是什么?是新的机会?新的效率?还是关于潜在风险的警示?
-
围绕这些数据构建一个叙事。 重要的是通过提供数据的背景,创造逻辑流畅的故事,并通过有趣的标题和副标题使其易于理解,从而引导观众了解故事。了解你的观众是很重要的,这样你才能在叙事中创建一个能引起观众某种程度上共鸣的联系。一个情感投入的观众就是一个会回应你“行动呼吁”的观众。
-
选择最有效的数据可视化。 这涉及选择格式和视觉设计,以最大化对数据驱动故事的理解。再一次,理解你的观众在你制作可视化之前是至关重要的。你需要确保这些可视化对你的观众是可访问和易于解读的。那些需要观众大量脑力去解读的可视化将很快被忽视或遗忘。
在另一篇专注于如何有效使用数据可视化格式和技术的文章中,以及上述数据叙事原则,Column Five Media 还提供了关于 创造性展示数据可视化的建议。该列表包括每种方法的引人注目的示例:
-
信息图表
-
电子书和白皮书
-
增强版传统报告和演示
-
互动图形
-
GIFs 和动画视觉效果
-
动态图形和视频
就选择合适的格式用于数据可视化应用而言,商业智能软件公司 Sisense 深入探讨了 13 种不同的数据可视化选项,从基本的到更高级的,解释了每种选项的独特功能以及何时使用它们以获得最大效果。他们的列表还包括以下格式的视觉示例:
-
指标清晰地展示一个关键绩效指标(KPI)
-
线图展示趋势
-
条形图简单地分解信息
-
列图表将数值进行并排比较
-
饼图清晰显示比例
-
区域图比较比例
-
数据透视表轻松展示关键数字
-
散点图:分布和关系
-
气泡图:理解多个变量
-
树形图展示层级结构,比较数值
-
极坐标图显示多个变量之间的关系
-
区域/散点图展示地理数据
-
漏斗图展示一个管道,通常用于销售数据
最后,在一篇面向对该主题不太熟悉的读者的文章中,哈佛商业评论探讨了掌握数据可视化关键原则和实践的重要性。简而言之:“你展示数据的方式可能会使其影响力翻倍,或者彻底削弱。”
Erin Cooke 目前是“数据科学公益课程”的讲师,该课程由圣地亚哥大学应用数据科学硕士项目与圣地亚哥科技中心合作制作。她感到非常荣幸能够在这个项目中介绍数据科学领域,并涉及数据伦理和数据讲故事等重要主题。
更多相关内容
数据可视化最佳实践与有效沟通资源
原文:
www.kdnuggets.com/2023/04/data-visualization-best-practices-resources-effective-communication.html

作者提供的图像
这是我的观点:好的数据可视化是客观的。它确实是一门艺术,但与现代艺术是否好坏的辩论不同,后者无法回答,数据可视化确实有“好”与“坏”之分。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
我们都见过糟糕的图表,并且能够客观地说那个图表很差。同样,我们也见过令人惊叹的数据可视化作品,它们简明而巧妙地传达了复杂的话题。
这是我最喜欢的之一,仅作为优秀数据可视化的一个例子。这是一张 1854 年霍乱爆发的地图。通过这个简陋的点图,医生约翰·斯诺能够看到死亡率最高的区域,并最终找出霍乱的原因——一个被污染的水井。今天看来这很简单,但在 1854 年是突破性的。
这很有趣,它内容丰富,吸引进一步调查,并且确定了一个趋势。即使没有流行病学知识,你也可以直观地感受到这里发生了什么。换句话说,这是一项优秀的数据可视化。
图片来自维基百科
如果你想看看一个糟糕的例子,看看我为这篇文章生成的图表,我在试图弄清楚人们是否喜欢我的图表制作技能。
这很糟糕。你无法理解我在说什么;它没有帮助发现任何趋势或模式。只需一眼,你就可以说,“是的,Nate,这需要改进。”
作者提供的图像
好消息是,由于这是客观的艺术,你可以学会做好它。这不是一种天赋,而是一种学习的技能。
为了帮助你避免糟糕的数据可视化,我将讨论一些最佳实践。虽然这有点像艺术,但你可以应用一些科学方法来确保你的数据可视化有效地传达信息。
什么是数据可视化?
数据可视化就是让数字讲述一个故事。那是我的定义;维基百科则更加枯燥地定义为“设计和创建易于沟通和理解的大量复杂数据和信息的图形或视觉表示的过程。”
许多工作最终都会涉及到数据可视化,因为现在还没有单独的“数据可视化专家”这一职位。数据分析师、业务分析师、数据科学家,甚至后端开发者可能会被要求创建一个图形来传达一些关键细节。
例如,作为一个后端开发者,你可能会发现你的数据分析团队希望你创建一个可视化图表,来表示二叉搜索树中的结果。作为数据科学家,你将被要求将复杂的财务数据转化为对高层管理人员有意义的图表。
数据可视化就是沟通,简单明了。
为什么良好的数据可视化很重要?
这就像在问为什么良好的沟通很重要一样。但让我们更深入地解析一下。良好的数据可视化之所以重要,有几个不同的原因。
传达复杂信息
想象一下你是 1854 年的约翰·斯诺。你的病人正在死亡。你知道这是一个模式,你知道这与一个特定的受污染的水井有关。你试图向疲惫不堪、持怀疑态度的城市官员解释这一点,他们并不真正相信疾病会以这种方式传播。
你能想象试图向某人描述那个霍乱图表吗?你会怎么做?这几乎是不可能的。
相比之下,非专家可以看到这个图表并立即理解发生了什么。死亡的模式与地理位置相匹配。这些家庭是从那个水井取水的。他的图表一眼就传达了复杂的信息。这就是良好数据可视化的优势之一。
识别模式和趋势
假设你是一个在医疗公司工作的数据科学家。你正在尝试分析病人数据以改善护理,所以你在查看病人统计数据、病史和治疗结果。
当你进行典型的统计分析时,你不会注意到任何突出的模式。然而,当你将死亡率和年龄放在散点图上时,你会发现 65 岁以上的病人死亡率急剧上升。
图片由作者提供
现在你可以将这些发现传递给医疗从业者,以便他们可以研究逆转这一趋势的方法。
做好数据可视化的最佳实践是什么?
好了,现在你了解了什么是好的数据可视化以及为什么它很重要。让我们来看看你可以应用的数据可视化最佳实践,以确保你创建出令人惊叹、难忘、引人入胜的图表。
了解你的受众
这是最重要的一步。你为谁创建这个数据可视化?他们感兴趣什么?他们已经具备什么基本理解?他们需要这个数据可视化做什么?
例如,假设你是一名数据分析师,试图向 CTO 解释电子邮件营销活动对品牌各个受众细分的有效性。此次会议的结果将决定下一个季度的整个电子邮件营销策略。
但你忘记了,对你来说是第二天性——如 CTR、CTA 和像“细分 A”这样的细分名称——对于非专家来说并不容易理解。
你展示了以下这种糟糕的效果,并且不得不花整个会议时间重新沟通所有术语和细分名称的具体含义。CTO 感到困惑、不满意,无法做出决策。
图片由作者提供
相反,你应该将其简化为决策者做出决策所需的主要关键因素,并确保一切对该受众来说都是有意义的。这是一个好的数据可视化版本可能的样子:
图片由作者提供
受众能够清楚地理解数据并做出决策。
保持简洁
你知道,当你现在观看 星球大战 时,它感觉有点像电影制片人最近发现了所有可以使用的 PowerPoint 过渡效果,并且仅仅因为乐趣和新奇而使用了每一个?
这是一种不良的数据可视化实践。好的数据可视化实践是尽可能保持简单。
例如,几年前有一个做 3D 图表的流行趋势。这并没有增加任何传递的信息。但它很花哨,所以人们喜欢它。
图片来源于 语义学者
良好的数据可视化意味着你要保持对数据的关注。如果不需要交互,就不要让它具有交互性。不必要的颜色也不要添加。如果可以通过使标题自解释来去除额外的图例,那就更好。
选择正确的图表类型
假设你想展示时间的变化。最好的图表类型是什么?
你对这个问题的回答可能意味着数据可视化的好坏之间的差别,好的数据可视化应当简洁明了,而不是应该被掩盖的怪物。
供参考,正确的答案是折线图。将时间放在 x 轴上,将你所测量的其他因素放在 y 轴上。
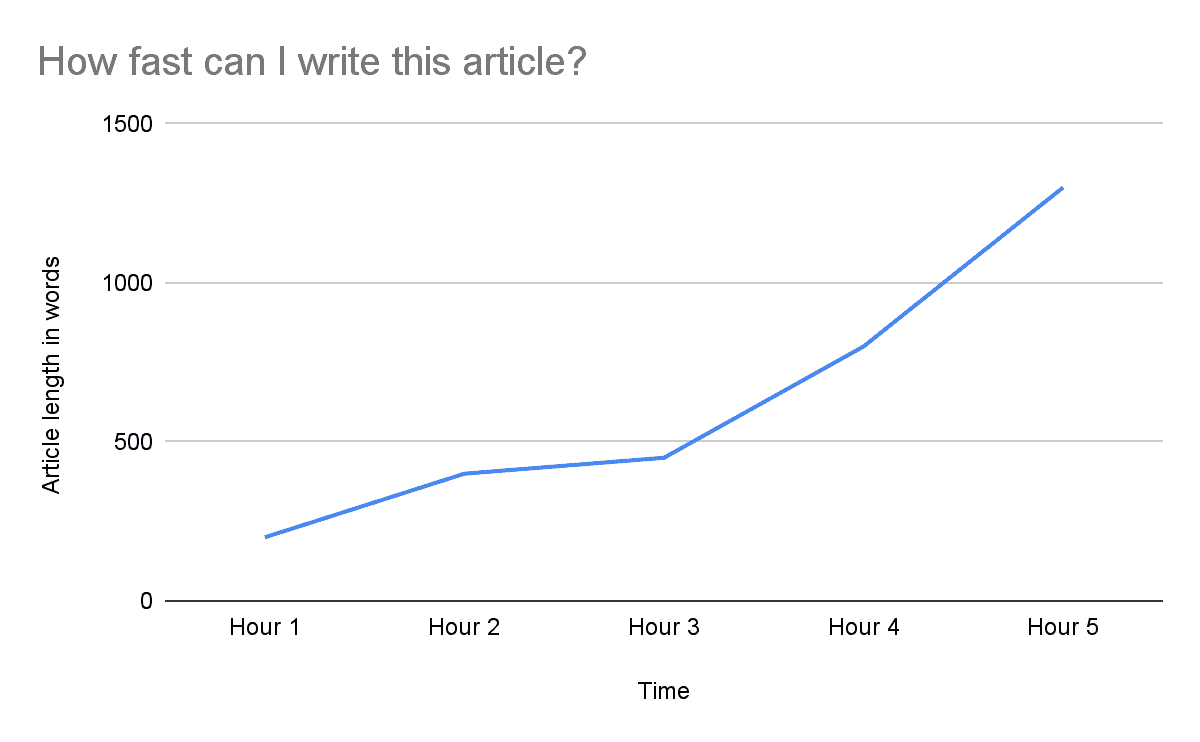
作者提供的图片
回到我之前的丑陋饼图。你可以清楚地看到,这显然不是用来解答我想得到的答案的正确数据可视化类型。饼图表示某种整体性;它非常适合用于累加百分比。所以如果 55% 的员工认为这个图表很好,但 45% 的员工不这样认为,那么饼图适合传达这一发现。
但对于一堆开放文本框的回答?饼图比没用还要糟糕。
这里有一张不错的表格,可以粗略地指导你在何时使用哪种数据可视化类型。请记住,你是自己数据的专家,所以要对此保持一定的警惕。
| 折线图 | 趋势随时间变化 |
|---|---|
| 条形图 | 比较组之间的值 |
| 饼图 | 显示不同组的比例 |
| 散点图 | 两个变量之间的关系 |
| 热力图 | 以矩阵格式可视化数据 |
| 树图 | 层级数据 |
我也鼓励你查看数据可视化,并记录你喜欢和不喜欢的内容。记住,数据可视化是客观的。通过一些思考,你可以准确指出哪些有效,哪些无效,并将这些发现应用到你自己的数据可视化中。
提供背景信息
最后,你应该始终解释数据可视化背后的原因。数据单位是什么?数据代表什么?还需要哪些相关信息来支持你的观点?
看这个例子了解不该做什么:
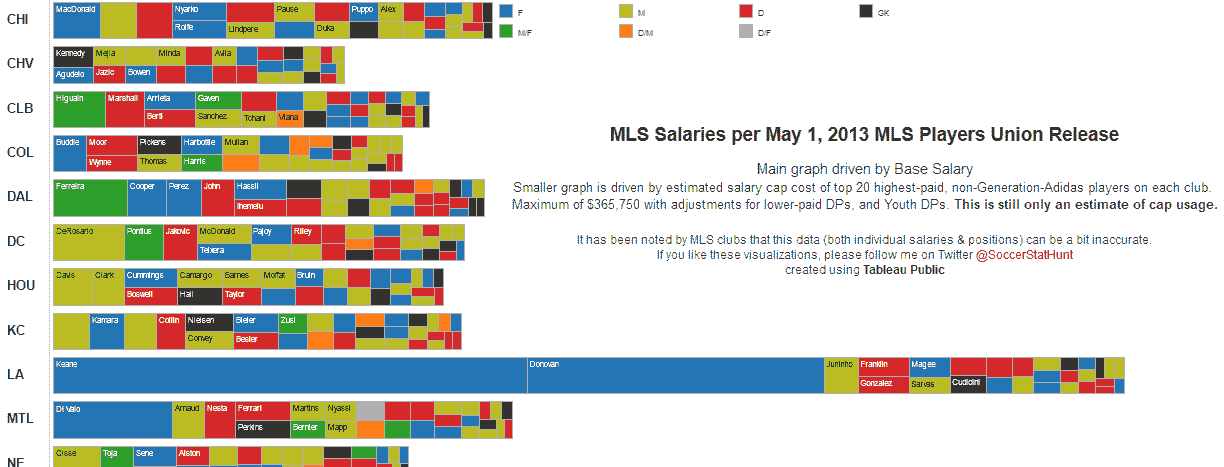
图片来源于 Tableau
这过于复杂,这已经违反了我们的第二条良好数据可视化准则。但它也没有提供任何背景信息。我应该从中得到什么结论?那些字母是什么意思?为什么那些矩形的比例不对?
如果需要提供定义,就加上它们。如果你认为行业基准能更好地说明你的发现的意义,就添加它。最重要的是,记住你在讲一个故事。如果你只是想提供数字,你可以给人们一个表格。但你不是。你在塑造叙事。这就是为什么背景如此重要。
记住,你是这些数字的专家。你在传达一个想法。你需要提供任何你认为有助于最好地阐述你的观点的补充材料。
学习数据可视化的资源
了解数据可视化的方式有两种:学习和实践。让我们分别了解这两种方法。
阅读/观看/消费关于数据可视化的内容
首先,你应该扎根于数据可视化的基础。我推荐以下资源:
-
我喜欢 David McCandless 的YouTube 讲座,作为数据可视化之美的起点。
-
Greg Martin 的数据可视化介绍也是一个很好的入门视频。
-
Simplilearn 在 YouTube 上有一个27 分钟的微型教程。
-
IBM 的 Python 数据可视化课程 是一个不错的下一个步骤,由 Coursera 主办。它是免费的。
DIY 风格
一旦你完成了听、看和学习的过程,是时候应用你所知道的内容了。获取来自以下来源的可靠数据:
-
你自己的生活——你吃的东西,你花费的时间,你的情绪,你的职业应用,任何事情!
然后,尝试自己制作数据可视化。考虑数据,想想你有什么问题,想发现什么趋势,以及哪些地方令人困惑,可以改进清晰度。
你可以使用像The Pudding或Kaggle这样的平台,获取关于你可以提出或回答的问题的灵感。
我还建议你查看一下真实面试官在数据科学面试中提出的问题。像StrataScratch这样的平台可以帮助你在实际案例中练习数据可视化技能。
想要更多?掌握数据可视化的 30 个资源 是一个很好的数据可视化资源汇总列表。
良好数据可视化沟通的最佳实践
那句经典名言:“一图胜千言。”如果这是真的,那么好的数据可视化就是一个图书馆的文字。
良好的数据可视化是几乎所有有意义的公司决策的支柱。它帮助来自不同部门的人以对所有方都有意义的方式进行沟通。这就是如何将一堆数字整理成一个故事。
但它很容易出错。要正确进行数据可视化,请记住,你需要考虑观众的需求,保持尽可能简单,选择正确类型的图表,并始终提供背景信息。
希望这本插图指南能帮助你更好地理解什么是良好的数据可视化,以及如何在未来制作出最佳的数据可视化。
Nate Rosidi 是一位数据科学家和产品战略专家。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,该平台帮助数据科学家准备顶级公司面试的真实面试问题。可以通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
更多相关主题
数据可视化:有效展示复杂信息
原文:
www.kdnuggets.com/data-visualization-presenting-complex-information-effectively
数据可视化的目的是以一种清晰易懂的方式展示复杂数据,并吸引观众。可视化使传达整体信息变得简单,突出关键洞察,并且在引导观众得出结论方面非常具有说服力。
在本文中,我们将探讨如何通过数据可视化有效地展示复杂信息,我们将提供一个简单的五步指南,并讨论其好处,还会提供一些应用案例。
我们的三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
什么是数据可视化?
数据可视化以图形方式表示数据和信息,使其易于理解。可视化可以包括图表、地图、图形、信息图表和其他帮助简化数据的元素。这使得识别模式和趋势、发现不一致性和异常值变得简单,并帮助观众得出所展示的数据结论。
图片来源:infogram
数据可视化在向公司内的非技术人员展示复杂且可能令人困惑的数据时也非常有效。这可以帮助关键决策者在批准新项目或将预算分配给某个部门时,例如。
数据可视化的优势是什么?
作为人类,我们的眼睛会立即被模式、颜色和形状吸引,我们可以瞬间区分某些元素。大企业的品牌和标志就是这种现象的典型例子,几乎全世界的人都能识别出那大大的黄色‘M’或那著名苹果的轮廓。
数据可视化基于这些人类感知,能够吸引观众的兴趣,并保持人们对信息的关注。有效使用数据可视化可以成为一个令人惊叹的讲故事工具,以一种引人入胜和有说服力的方式引导观众。
正如之前讨论的那样,数据可视化在将复杂和混乱的数据转化为更易于理解的内容方面非常有效,尤其是当它呈现给非技术人员或不熟悉该主题的观众时。
可视化还使得分析大数据成为可能,这些数据非常庞大、复杂,
这种快速变化的环境使得通过传统手段无法处理。这为企业提供了新的机会,能够发现新的见解和趋势,并提供竞争优势。
数据可视化的其他关键用途包括可视化两个元素之间的关系和模式、快速分享关键信息,以及以互动方式探索新的商业机会。
数据可视化的挑战
要完全理解数据可视化,我们不能只关注其优点,还需要了解其局限性,以确定何时以及何地可以使用。
一个缺点是用户错误多于技术故障,即在数据点数量众多时可能会做出不准确的假设。没有经验的用户也可能选择不良或不正确的设计,以一种混淆观众或实现过多偏见的方式可视化数据。
另一个需要避免的问题是自动认为任何相关性都可以与某种原因关联。当然,在许多情况下,相关性确实代表了有价值的见解或趋势,但并非总是如此,巧合也会发生。
最后,有时很容易被华丽的图形和互动图表所吸引,忽视了关键的信息和可视化的整体目标。像任何类型的报告和演示技巧一样,重点是关键的,以有效地传达关键信息。
数据可视化:使用案例
现在我们了解了数据可视化是什么、它的好处以及在设计和呈现报告时需要避免的事项,我们来考虑一下它在一些常见使用案例中的应用。
-
数据可视化可以提供先进的营销分析以帮助推动决策,发现新趋势和市场细分,同时改善当前的营销活动。数据可能包括网站流量和页面表现,帮助优化网站内容以提高转化率。
-
风险管理还可以依赖数据可视化来迅速突出业务运营或网络安全中的任何问题。例如,通过分析历史数据并以引人入胜的方式呈现,可以轻松识别和缓解风险,避免它们造成任何干扰。
-
在销售中,CRM 工具使企业能够以视觉吸引人的方式展示数据,从而简化内部团队和客户的理解。此外,还有针对非常特定行业的专业 CRM 工具。例如,屋顶承包商可以使用屋顶 CRM 软件而不是通用选项。这种定制的方法确保数据可视化变得易于访问并适用于各种业务。
5 步实现有效的数据可视化
如果遵循最佳实践并明确数据分析的目的和受众,那么有效地使用数据可视化可能相对简单。
以下是五个步骤,说明如何通过数据可视化有效展示复杂数据。
1. 确定受众是谁
创建数据可视化的第一步是充分了解受众的身份、他们的知识水平和技术专长。如果你对这些人有很好的了解,那么你可能也会知道他们的注意力跨度和对主题的兴趣。
为了使数据可视化有效,你必须完全理解受众的期望和目标,并以适合他们需求的格式和设计呈现数据。
2. 去除不必要的复杂性
设计数据可视化时,简洁至关重要,需要去除任何可能分散或混淆受众的多余元素。整体信息应该非常清晰,没有任何杂乱。为此,可以采用引人注目且一致的配色方案、清晰且合适大小的字体,并利用空白、网格和边距来组织页面布局。大型标题、图例和标签也有助于更清楚地解释内容。
3. 使用相关图表
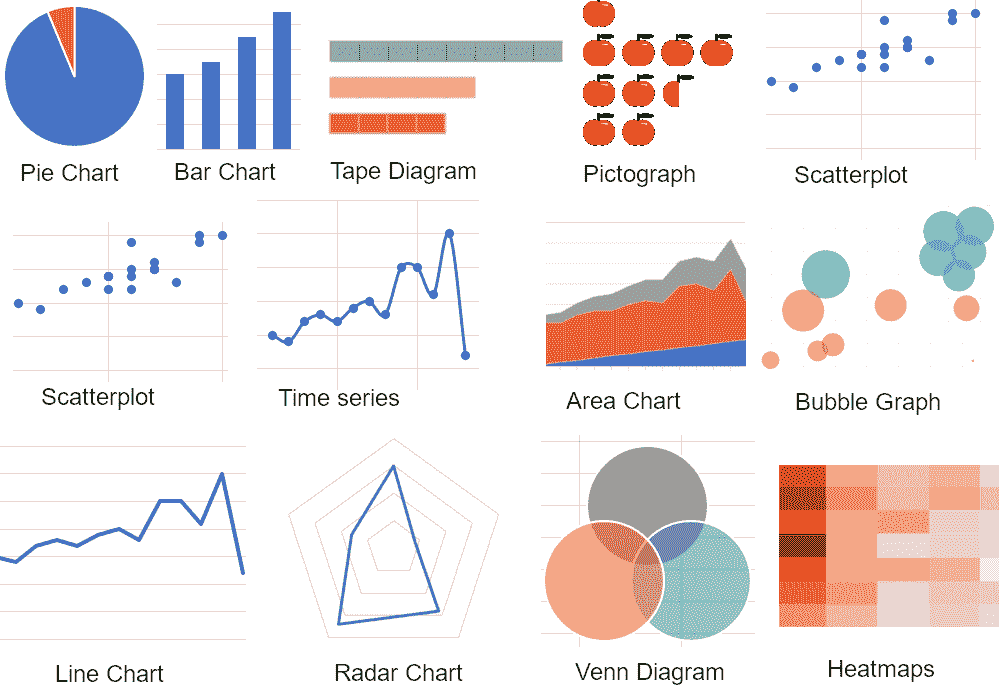
图片来源于polymersearch
相关性对高效的数据可视化至关重要,因此建议使用正确的图表和图形来展示数据。例如,折线图是展示趋势的推荐方式,而散点图展示关系和相关性,饼图或甜甜圈图则可以显示百分比。
4. 创建故事
数据可视化应该不仅仅是冰冷的硬数据,它应该有一个清晰的故事,能够吸引受众并逐步得出结论。在深入数据之前,确保包括任何相关的背景信息,并突出关键点以确保受众理解。
5. 测试你的数据可视化
最后的步骤是测试数据可视化,以便在向观众展示之前进行优化。确保关键点清晰,数据准确,图表和图形易于理解。让同事对可视化进行交叉检查是发现任何错误、打字错误或不一致之处的最佳方法之一,他们还可以提供关于设计和内容是否吸引人的诚实反馈。
总结:有效展示复杂信息
数据可视化已成为展示大数据和发现新见解及趋势的关键,特别是在销售和营销领域。通过这种方式展示数据,可以吸引观众,并以易于理解的方式呈现复杂的信息。
这可以帮助更好地理解组织内的大数据和分析,从而改善决策制定并提升运营效率。
Nahla Davies 是一名软件开发人员和技术作家。在全职从事技术写作之前,她曾担任过 — 除了其他有趣的职位 — 一家《Inc. 5000》体验品牌组织的首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼。
了解更多主题
Python 中的数据可视化:Matplotlib 与 Seaborn
原文:
www.kdnuggets.com/2019/04/data-visualization-python-matplotlib-seaborn.html
评论
Python 提供了多种数据绘图包。本教程将使用以下包来演示 Python 的绘图功能:
Matplotlib
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持组织的 IT 需求
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
在上述代码块中,我们使用 PyPlot 模块以 plt 作为别名导入了 Matplotlib 库。这是为了方便执行命令,正如我们稍后在教程中会看到的。PyPlot 包含了创建和编辑图表所需的一系列命令。运行 %matplotlib inline 是为了确保在代码块执行时,图表会自动显示在代码块下方。否则,用户需要每次创建新图表时输入 plt.show()。该功能仅适用于 Jupyter Notebook/IPython。Matplotlib 的高度可定制的代码结构使其成为其他绘图库的优秀指南。让我们看看如何从 matplotlib 生成散点图。
一个实用的小贴士是,每当执行 matplotlib 时,输出总会包括一个文本输出,这可能在视觉上不太吸引人。为了解决这个问题,在执行代码块生成图形时,在最后一行代码的末尾添加一个分号 - ';'。
使用的数据集是来自 UCI 机器学习库的 共享单车数据集。
Matplotlib: 散点图
散点图是你工具库中最具影响力、最具信息量和多功能的图表之一。它可以在不费太多力气的情况下向用户传达一系列信息(如下所示)。
-
plt.scatter()将为我们提供一个包含传递的初始参数的数据的散点图。temp是 x 轴,cnt是 y 轴。 -
c确定数据点的颜色。由于我们传递了一个字符串 - 'season',它是数据框架 day 的一列,因此颜色对应于不同的季节。这是一种快速简便的视觉格式数据分组方法。
plt.scatter('temp', 'cnt', data=day, c='season')
plt.xlabel('Normalized Temperature', fontsize='large')
plt.ylabel('Count of Total Bike Rentals', fontsize='large');
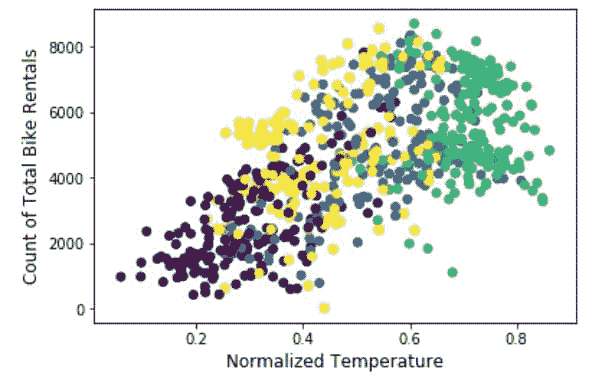
让我们看看它显示了哪些信息:
曾经有超过 8000 次自行车租赁。
-
标准化的温度已上升至 0.8 以上。
-
自行车租赁量与温度或季节的差异不大。
-
自行车租赁与标准化温度之间存在正线性关系。
这张图确实给了我们很多信息。然而,图表没有生成图例,这使得解读季节组别变得困难。这是因为在这种方式下绘制的图表,Matplotlib 无法生成图例。在下一部分中,我们将看到上述图如何隐藏甚至误导观众。
让我们看看经过彻底编辑的相同图。这里的目标是生成图例以解读组之间的差异。
plt.rcParams['figure.figsize'] = [15, 10]
fontdict={'fontsize': 18,
'weight' : 'bold',
'horizontalalignment': 'center'}
fontdictx={'fontsize': 18,
'weight' : 'bold',
'horizontalalignment': 'center'}
fontdicty={'fontsize': 16,
'weight' : 'bold',
'verticalalignment': 'baseline',
'horizontalalignment': 'center'}
spring = plt.scatter('temp', 'cnt', data=day[day['season']==1], marker='o', color='green')
summer = plt.scatter('temp', 'cnt', data=day[day['season']==2], marker='o', color='orange')
autumn = plt.scatter('temp', 'cnt', data=day[day['season']==3], marker='o', color='brown')
winter = plt.scatter('temp', 'cnt', data=day[day['season']==4], marker='o', color='blue')
plt.legend(handles=(spring,summer,autumn,winter),
labels=('Spring', 'Summer', 'Fall/Autumn', 'Winter'),
title="Season", title_fontsize=16,
scatterpoints=1,
bbox_to_anchor=(1, 0.7), loc=2, borderaxespad=1.,
ncol=1,
fontsize=14)
plt.title('Bike Rentals at Different Temperatures\nBy Season', fontdict=fontdict, color="black")
plt.xlabel("Normalized temperature", fontdict=fontdictx)
plt.ylabel("Count of Total Rental Bikes", fontdict=fontdicty);
-
plt.rcParams['figure.figsize'] = [15, 10]允许控制整个图的大小。这对应于一个15∗10(长度∗宽度)的图。 -
fontdict是一个可以作为参数传递的字典,用于标记坐标轴。标题的fontdict,x 轴的fontdictx和 y 轴的fontdicty。 -
现在有 4 个
plt.scatter()函数调用,对应于四个季节之一。这在数据参数中再次出现,数据已经被子集化以对应单个季节。 marker 和 color 参数对应于使用'o'视觉上表示数据点及该标记的相应颜色。 -
plt.legend() 是我们可以传递参数以创建图例的地方。前两个参数是 handles:实际的图形在图例中表示,以及 labels:与每个图形对应的名称,这些名称将在图例中显示。 scatterpoints 是散点图中每个标记的大小。
bbox_to_anchor=(1, 0.7), loc=2, borderaxespad=1。这三个参数一起使用,表示图例的位置;点击句首的链接以了解这些参数的性质。
现在我们可以区分季节以检查更多潜在的信息。然而,即使在添加这些额外层次后,图表仍然可能隐藏信息并容易被误解。
这个图:
**数据相互重叠。
-
图表杂乱。**
-
没有揭示出自行车租赁的季节性差异。
-
隐藏了例如春季和夏季自行车租赁随温度上升的模式。
-
显示了总自行车租赁与温度之间的整体正趋势。
-
没有清晰地显示哪个季节的温度最低。
子图
创建子图可能是行业中最吸引人和最专业的图表技术之一。当单个图表信息过于拥挤时,子图是必要的。那些信息在这种状态下无法评估。
分面 是创建多个共享相同坐标轴的图表的过程。分面是数据可视化中最具多样性的技术之一。分面图可以在多个维度上传达信息,并能揭示以前隐藏的信息。
-
plt.figure()将用于创建一个空的绘图画布,如前所述。它被保存为 fig。 -
fig.add_subplot()将重复 4 次,以对应各自的季节。参数对应于nrows、ncols和索引。例如在ax1中,它对应于图形的第一个绘图(索引从左上角开始为 1,向右增加)。 -
其余的函数调用要么是自解释的,要么已在前面讲解过。
fig = plt.figure()
plt.rcParams['figure.figsize'] = [15,10]
plt.rcParams["font.weight"] = "bold"
fontdict={'fontsize': 25,
'weight' : 'bold'}
fontdicty={'fontsize': 18,
'weight' : 'bold',
'verticalalignment': 'baseline',
'horizontalalignment': 'center'}
fontdictx={'fontsize': 18,
'weight' : 'bold',
'horizontalalignment': 'center'}
plt.subplots_adjust(wspace=0.2, hspace=0.2)
fig.suptitle('Bike Rentals at Different Temperatures\nBy Season', fontsize=25,fontweight="bold", color="black",
position=(0.5,1.01))
ax1 = fig.add_subplot(221)
ax1.scatter('temp', 'cnt', data=day[day['season']==1], c="green")
ax1.set_title('Spring', fontdict=fontdict, color="green")
ax1.set_ylabel("Count of Total Rental Bikes", fontdict=fontdicty, position=(0,-0.1))
ax2 = fig.add_subplot(222)
ax2.scatter('temp', 'cnt', data=day[day['season']==2], c="orange")
ax2.set_title('Summer', fontdict=fontdict, color="orange")
ax3 = fig.add_subplot(223)
ax3.scatter('temp', 'cnt', data=day[day['season']==3], c="brown")
ax3.set_title('Fall or Autumn', fontdict=fontdict, color="brown")
ax4 = fig.add_subplot(224)
ax4.scatter('temp', 'cnt', data=day[day['season']==4], c="blue")
ax4.set_title("Winter", fontdict=fontdict, color="blue")
ax4.set_xlabel("Normalized temperature", fontdict=fontdictx, position=(-0.1,0));
现在我们可以更有效地独立分析每组数据。首先,我们应该注意的是温度与自行车租赁量的关系在不同季节间有所不同:
** 春季的正线性关系。**
-
冬季和夏季的二次非线性关系。
-
秋季的正相关性较弱,甚至没有明显关系。
然而,再次可能误导观众,这并非显而易见的原因。所有四个图表的坐标轴都不同。大多数人不会意识到这一点可能导致误导性见解。如果不加以注意,可能会造成这种情况。见下文以了解如何解决这个问题:
fig = plt.figure()
plt.rcParams['figure.figsize'] = [12,12]
plt.rcParams["font.weight"] = "bold"
plt.subplots_adjust(hspace=0.60)
fontdicty={'fontsize': 20,
'weight' : 'bold',
'verticalalignment': 'baseline',
'horizontalalignment': 'center'}
fontdictx={'fontsize': 20,
'weight' : 'bold',
'horizontalalignment': 'center'}
fig.suptitle('Bike Rentals at Different Temperatures\nBy Season', fontsize=25,fontweight="bold", color="black",
position=(0.5,1.0))
#ax2 is defined first because the other plots are sharing its x-axis
ax2 = fig.add_subplot(412, sharex=ax2)
ax2.scatter('temp', 'cnt', data=day.loc[day['season']==2], c="orange")
ax2.set_title('Summer', fontdict=fontdict, color="orange")
ax2.set_ylabel("Count of Total Rental Bikes", fontdict=fontdicty, position=(-0.3,-0.2))
ax1 = fig.add_subplot(411, sharex=ax2)
ax1.scatter('temp', 'cnt', data=day.loc[day['season']==1], c="green")
ax1.set_title('Spring', fontdict=fontdict, color="green")
ax3 = fig.add_subplot(413, sharex=ax2)
ax3.scatter('temp', 'cnt', data=day.loc[day['season']==3], c="brown")
ax3.set_title('Fall or Autumn', fontdict=fontdict, color="brown")
ax4 = fig.add_subplot(414, sharex=ax2)
ax4.scatter('temp', 'cnt', data=day.loc[day['season']==4], c="blue")
ax4.set_title('Winter', fontdict=fontdict, color="blue")
ax4.set_xlabel("Normalized temperature", fontdict=fontdictx);
现在这个图表网格已调整为与夏季共享相同的 x 轴,因为它的温度范围更宽。现在有趣的是,这些数据给我们提供了一些新的见解:
** 春季的温度最低。
-
秋季的温度最高。
-
自行车租赁总量与温度在夏季和秋季似乎存在二次关系。
-
无论季节如何,低温下的自行车租赁量较少。
-
春季的温度与总自行车租赁量之间存在明显的正线性关系。
-
秋季的温度与自行车租赁量之间似乎存在轻微的负线性关系。
fig = plt.figure()
plt.rcParams['figure.figsize'] = [10,10]
plt.rcParams["font.weight"] = "bold"
plt.subplots_adjust(wspace=0.5)
fontdicty1={'fontsize': 18,
'weight' : 'bold'}
fontdictx1={'fontsize': 18,
'weight' : 'bold',
'horizontalalignment': 'center'}
fig.suptitle('Bike Rentals at Different Temperatures\nBy Season', fontsize=25,fontweight="bold", color="black",
position=(0.5,1.0))
ax3 = fig.add_subplot(143, sharey=ax3)
ax3.scatter('temp', 'cnt', data=day.loc[day['season']==3], c="brown")
ax3.set_title('Fall or Autumn', fontdict=fontdict,color="brown")
ax1 = fig.add_subplot(141, sharey=ax3)
ax1.scatter('temp', 'cnt', data=day.loc[day['season']==1], c="green")
ax1.set_title('Spring', fontdict=fontdict, color="green")
ax1.set_ylabel("Count of Total Rental Bikes", fontdict=fontdicty1, position=(0.5,0.5))
ax2 = fig.add_subplot(142, sharey=ax3)
ax2.scatter('temp', 'cnt', data=day.loc[day['season']==2], c="orange")
ax2.set_title('Summer', fontdict=fontdict, color="orange")
ax4 = fig.add_subplot(144, sharey=ax3)
ax4.scatter('temp', 'cnt', data=day.loc[day['season']==4], c="blue")
ax4.set_title('Winter', fontdict=fontdict, color="blue")
ax4.set_xlabel("Normalized temperature", fontdict=fontdictx, position=(-1.5,0));
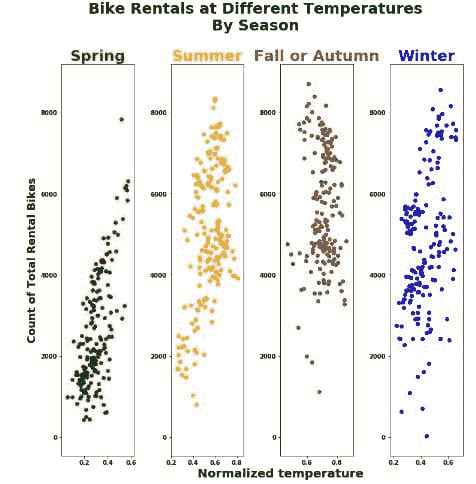
重新调整/对比这些图表现在显示了另一个视角:
** 所有季节在某个时间点的自行车租赁量都超过了 8000。
-
与其他季节相比,秋季和春季的聚类现象明显。
-
冬季和夏季的自行车租赁量变化最大。
不要试图从这个角度解读变量之间的关系。这可能会再次误导你,因为现在看起来春季和夏季的自行车租赁量与温度之间存在负线性关系,而我们之前看到的并非如此。
这里是一个由Real Python 关于使用 Matplotlib 的直观教程的链接。
Seaborn
seaborn 包是基于 Matplotlib 库开发的。它用于创建更具吸引力和信息性的统计图形。尽管 seaborn 是一个不同的包,但它也可以用来提升 matplotlib 图形的吸引力。
虽然 matplotlib 很棒,但我们总是希望做得更好。运行下面的代码块以导入 seaborn 库并创建之前的图表,看看会发生什么。
首先我们用 import seaborn as sns 导入库。下一行 sns.set() 将加载 seaborn 的默认主题和颜色调色板到会话中。运行下面的代码,观察图表区域和文本的变化。
import seaborn as sns
sns.set()
一旦我们将 seaborn 加载到会话中,每次执行 matplotlib 图表时,seaborn 的默认自定义设置都会添加,如上所示。然而,一个困扰许多用户的大问题是标题可能会重叠。再加上 matplotlib 对标题的混乱命名规则,这变得令人烦恼。尽管如此,吸引人的视觉效果仍使其对数据科学家工作有用。
为了获得我们想要的标题格式并增加自定义性,我们需要使用下面的结构。注意,如果我们在图表中使用副标题,这一点是必要的。有时候它们是必要的,因此最好备着。
fig = plt.figure()
fig.suptitle('Seaborn with Python', fontsize='x-large', fontweight='bold')
fig.subplots_adjust(top=0.87)
#This is used for the main title. 'figure()' is a class that provides all the plotting elements of a diagram.
#This must be used first or else the title will not show.fig.subplots_adjust(top=0.85) solves our overlapping title problem.
ax = fig.add_subplot(111)
fontdict={'fontsize': 14,
'fontweight' : 'book',
'verticalalignment': 'baseline',
'horizontalalignment': 'center'}
ax.set_title('Plotting Tutorial', fontdict=fontdict)
#This specifies which plot to add the customizations. fig.add_sublpot(111) corresponds to top left plot no.1
#(there is only one plot).
plt.plot(x, y, 'go-', linewidth=1) #linewidth=1 to make it narrower
plt.xlabel('x-axis', fontsize=14)
plt.ylabel('yaxis', fontsize=14);
深入了解 seaborn,我们可以用更少的代码行和类似的语法重现来自 Bike Rentals 数据集的上述可视化。Seaborn 仍然使用 Matplotlib 语法来执行 seaborn 图表,具有相对较小但明显的语法差异。
为了简化和提高可视性,我将重命名和重新标记 Bike Rentals 数据集中的 'season' 列。
day.rename(columns={'season':'Season'}, inplace=True)
day['Season']=day.Season.map({1:'Spring', 2:'Summer', 3:'Fall/Autumn', 4:'Winter'})
现在 'Season' 列已编辑为我们喜欢的样子,我们将继续创建前面图表的 seaborn 样式可视化。
第一个明显的区别是 seaborn 在加载其默认美学时呈现的默认主题。正如你直接看到的默认主题是因为在调用 sns.set() 时后台应用了 sns.set_style('whitegrid')。正如我们所见,这可以根据我们的喜好轻松覆盖,使用下方单元格中列出的现成主题:
-
sns.set_style()必须是 'white', 'dark', 'whitegrid', 'darkgrid', 'ticks' 中的一个。这控制图表区域,如颜色、网格和刻度线的存在。 -
sns.set_context()必须是 'paper', 'notebook', 'talk', 'poster' 中的一个。这控制图表的布局方式,如在 'poster' 上看到的放大图像和文字。'Talk' 将创建一个字体更粗的图表。
plt.figure(figsize=(7,6))
fontdict={'fontsize': 18,
'weight' : 'bold',
'horizontalalignment': 'center'}
sns.set_context('talk', font_scale=0.9)
sns.set_style('ticks')
sns.scatterplot(x='temp', y='cnt', hue='Season', data=day, style='Season',
palette=['green','orange','brown','blue'], legend='full')
plt.legend(scatterpoints=1,
bbox_to_anchor=(1, 0.7), loc=2, borderaxespad=1.,
ncol=1,
fontsize=14)
plt.xlabel('Normalized Temperature', fontsize=16, fontweight='bold')
plt.ylabel('Count of Total Bike Rentals', fontsize=16, fontweight='bold')
plt.title('Bike Rentals at Different Temperatures\nBy Season', fontdict=fontdict, color="black",
position=(0.5,1));
现在让我们来看一下相同的图表,但使用 sns.set_context('paper', font_scale=2) 和 sns.set_style('white')
plt.figure(figsize=(7,6))
fontdict={'fontsize': 18,
'weight' : 'bold',
'horizontalalignment': 'center'}
sns.set_context('paper', font_scale=2) #this makes the font and scatterpoints much smaller, hence the need for size adjustemnts
sns.set_style('white')
sns.scatterplot(x='temp', y='cnt', hue='Season', data=day, style='Season',
palette=['green','orange','brown','blue'], legend='full', size='Season', sizes=[100,100,100,100])
plt.legend(scatterpoints=1,
bbox_to_anchor=(1, 0.7), loc=2, borderaxespad=1.,
ncol=1,
fontsize=14)
plt.xlabel('Normalized Temperature', fontsize=16, fontweight='bold')
plt.ylabel('Count of Total Bike Rentals', fontsize=16, fontweight='bold')
plt.title('Bike Rentals at Different Temperatures\nBy Season', fontdict=fontdict, color="black",
position=(0.5,1));
现在我们终于用更少的代码行和更好的分辨率使用 Seaborn 重新创建了之前的 matplotlib 样式图。让我们再进一步,对图进行分面处理以完成:
sns.set(rc={'figure.figsize':(20,20)})
sns.set_context('talk', font_scale=2)
sns.set_style('ticks')
g = sns.relplot(x='temp', y='cnt', hue='Season', data=day,palette=['green','orange','brown','blue'],
col='Season', col_wrap=4, legend=False
height=6, aspect=0.5, style='Season', sizes=(800,1000))
g.fig.suptitle('Bike Rentals at Different Temperatures\nBy Season' ,position=(0.5,1.05), fontweight='bold', size=18)
g.set_xlabels("Normalized Temperature",fontweight='bold', size=15)
g.set_ylabels("Count of Total Bike Rentals",fontweight='bold', size=20);
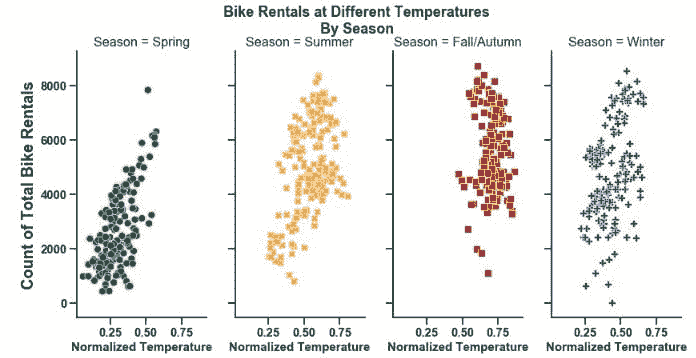
要更改图形的形状,需要调整aspect参数。增加此处的 aspect 值将创建一个更方形的图形。它与height配合使用,所以可以通过这两个参数实验不同的大小。
要更改行和列的数量,请使用col_wrap参数。它与col参数配合使用。它检测类别的数量并相应分配。
sns.set(rc={'figure.figsize':(20,20)})
sns.set_context('talk', font_scale=2)
sns.set_style('ticks')
g = sns.relplot(x='temp', y='cnt', hue='Season', data=day,palette=['green','orange','brown','blue'],
col='Season', col_wrap=2, legend=False
height=4, aspect=1.6, style='Season', sizes=(800,1000))
g.fig.suptitle('Bike Rentals at Different Temperatures\nBy Season' ,position=(0.5,1.05), fontweight='bold', size=18)
g.set_xlabels("Normalized Temperature",fontweight='bold', size=15)
g.set_ylabels("Count of\nTotal Bike Rentals",fontweight='bold', size=20);
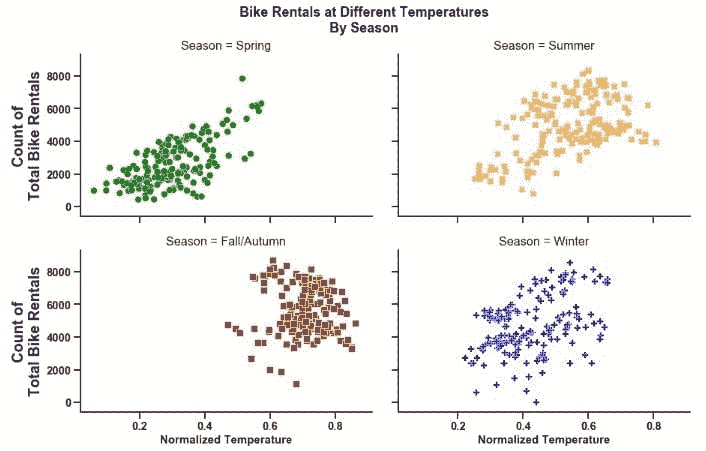
注意:本教程的部分内容曾用于我为维多利亚理工学院准备的教程中
相关:
-
6 个数据可视化灾难 – 如何避免
-
5 个用 Python 和代码快速简便的数据可视化
-
10 个适用于任何学科的有用 Python 数据可视化库
更多相关话题
-
[使用 Matplotlib 和 Seaborn 创建可视化](https://www.kdnuggets.com/creating-visuals-with-matplotlib-and-seaborn)
使用 Seaborn 进行 Python 数据可视化
原文:
www.kdnuggets.com/2022/04/data-visualization-python-seaborn.html
在我的数据科学工作中,我构建了不少预测算法,并编写了复杂的 SQL 查询来分析数据趋势。
所有这些分析需要转化为洞察,并向利益相关者解释,以便他们能够决定接下来的业务决策。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
将复杂信息拆解给非技术人员的最佳方式是创建易于消化的可视化。这可以是 PowerPoint 演示文稿中的独立图表,一系列 Jupyter Notebook 中的可视化,或者 Tableau 上的交互式仪表板。
数据可视化也可以为你对数据的理解和解读提供帮助。你可以构建图表来帮助你一眼看出不同变量之间的关系。
在这篇文章中,我将教你如何使用 Seaborn 库在 Python 中进行数据可视化。在本教程结束时,你将对以下概念熟悉:
-
可视化数值数据和分类数据的技术
-
单变量、双变量和多变量分析之间的区别
-
使用 Seaborn 创建回归图和配对图
-
可视化变量的分布。
先决条件
要跟随本教程,你需要在设备上安装 Jupyter Notebook。如果你还没有,可以通过简单的 ‘pip’ 安装 Seaborn 库。
加载数据集
在本教程中,我们将使用内置于 Seaborn 库的数据集,因此无需从外部数据源下载。
import seaborn as sns
df = sns.load_dataset('tips')
df.head()
上述数据框包含与餐厅顾客相关的 7 个变量:收到的小费(以美元计)、账单金额(以美元计)、付款人的性别、是否有吸烟者、日期、时间和聚会规模。
借助数据可视化,我们将尝试揭示上述数据集中的潜在模式。
单变量分析
单变量分析为我们提供了数据集中一个变量的洞察,并允许我们更好地探索和理解它。这是最简单的统计分析形式。
在本教程中,我们将探讨两种用于进行单变量分析的图表——直方图和计数图。
直方图
首先,让我们查看“total_bill”变量的分布。这将使我们了解餐馆单次用餐的价格范围。
sns.distplot(df['total_bill'],kde=False)
上图是“total_bill”变量的简单直方图。一眼就能看出,这家餐馆的一顿饭通常花费在$10 到$25 之间,由于有些顾客点了价格超过$50 的更贵的食物,导致了正偏态。
计数图
现在,让我们查看餐馆中男性和女性顾客的数量,以确定哪个性别更频繁地光顾这家餐馆。
sns.countplot(x='sex',data=df)
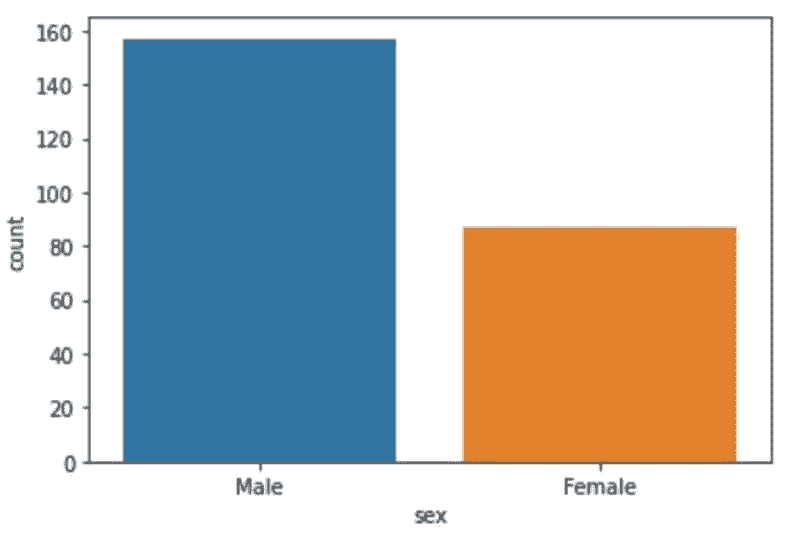
餐馆的男性顾客几乎是女性顾客的两倍。
让我们重复这个分析,以确定一周中最繁忙的日子——餐馆交易量最高的日子:
sns.countplot(x='day',data=df)
在所有记录的四天中,餐馆在周六的顾客人数最多,其次是周日。令人惊讶的是,周五的交易量最低。
双变量分析
双变量分析涉及查找两个变量之间的关系。为此,我们将创建条形图、箱型图和回归图。
条形图
现在,让我们尝试可视化两个变量之间的关系——“性别”和“total_bill”,以查看男性和女性在外出就餐时花费是否存在差异。
sns.barplot(x='sex',y='total_bill',data=df)
看起来男性在这家餐馆的单次账单花费略高于女性,尽管差异不显著。
箱型图
让我们创建一个箱型图,以进一步了解男性和女性顾客花费之间的差异。
箱型图是一种了解变量分布的有用方式,并为我们提供了数据点的五数概括——最小值、第一个四分位数、中位数、第三个四分位数、最大值。
要在 Seaborn 中创建箱型图,请运行以下代码行:
sns.boxplot(data=df, x='sex', y='total_bill')
一眼看去,我们可以看出,男性和女性顾客的中位花费几乎相同——大约在$15-$19 之间。然而,最低和最高花费之间存在很大的差异。
有些女性顾客的用餐花费低至$5,而最高花费约为$30。这可能是因为女性通常比男性吃得少,或者更倾向于小团体就餐。
此外,由于社会习惯,男性更有可能在约会或与较大群体的人外出时支付餐费,这可能是为什么最昂贵的账单都在他们名字下。
回归图
回归图是可视化两个数值变量之间关系的最佳方式。使用 Seaborn 的 lmplot() 函数,可以创建回归线以演示 X 和 Y 之间的相关性。
在这种情况下,让我们看看“total_bill”和“tip”之间的关系。创建图表之前的初步假设是更高的账单价格意味着小费的增加。
sns.lmplot(x='total_bill',y='tip',data=df)
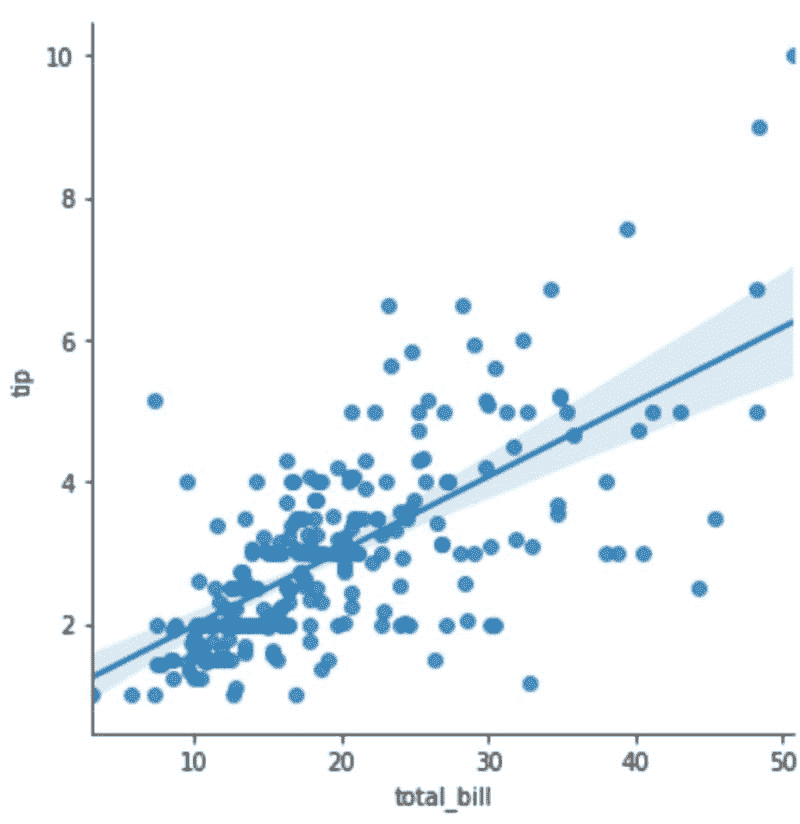
上面的图表验证了我们的假设。更高的账单与更高的小费相关联,并且观察到两个变量之间有正线性关系。
多变量分析
最后,我们将通过一个多变量分析的例子——对许多不同变量的统计分析。
sns.pairplot(df)
在 Seaborn 中创建一个 pairplot 允许我们一次性可视化数据集中每个数值变量之间的关系。
变量与自身的关系以直方图形式显示,而与其他变量的相关性则以散点图形式显示。
Seaborn 的 pairplot() 方法在分析具有多个数值特征的数据集时非常有用。在这种情况下,例如,有 3 个数值变量,将它们的关系在一个图表中查看比创建 9 个单独的可视化要容易得多。
使用 Python 进行数据可视化——下一步
在本教程中,我们了解了使用 Seaborn 库的数据可视化基础知识。我们学习了如何创建图表,以帮助我们进行单变量、双变量和多变量分析——所有这些都使我们能够更好地理解手头的数据。
正如你在本文中看到的,数据可视化并不难实现,也不需要你编写大量复杂的代码。
你只需知道为不同类型的分析创建合适的图表。例如——回归图用于可视化两个数值变量,或者条形图用于一个数值变量和一个类别变量。
此外,在创建任何类型的可视化之前,务必确保你有一个明确的问题。可视化的目的是告诉你(或其他人)关于数据的一些你尚未知道的东西。
在我们上面创建的可视化中,例如,我们着手了解男性是否在餐馆花费比女性更多的餐费。然后,我们决定通过条形图来探讨性别与总账单金额之间的关系。
这篇文章是入门级的,仅仅触及了你可以使用 Seaborn 库做的事情的表面。如果你想深入了解可以用 Seaborn 构建的不同类型的图表(总共有 14 种),我建议你观看这个小时的 YouTube 教程。
Natassha Selvaraj 是一位自学成才的数据科学家,热衷于写作。你可以通过LinkedIn与她联系。
更多相关话题
数据可视化:理论与技巧
原文:
www.kdnuggets.com/data-visualization-theory-and-techniques

图片由 freepik 提供
在一个被大数据和复杂算法主导的数字世界中,人们会认为普通人迷失在海量的数字和数据中。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
不是吗?
然而,原始数据与可理解见解之间的桥梁就在于数据可视化的艺术。
它是指引我们的指南针,是指引我们的地图,也是解码我们每天遇到的大量数据的翻译器。
但一个好的可视化背后的魔力是什么?
为什么一种可视化让人豁然开朗,而另一种则令人困惑?
今天,我们将回到基础,尝试理解数据可视化的基本原理。
让我们一起探索吧!👇🏻
拆解数据可视化的基础
高效讲述故事是数据科学家掌握的最难技能之一。如果我们在字典中查找“数据可视化”这个词,我们会找到以下定义:
“将信息以图像、图表或图示的形式呈现,或以这种方式表示信息的图像”
这基本上意味着数据可视化旨在从数据集中构建一个故事,以易于理解、引人入胜且有影响力的形式展示见解。
数据可视化,或者说将数据以图表的形式展现,可能不像机器学习那样酷炫。
但这确实是数据科学家工作中的关键部分。
在当今数据驱动的世界中,数据可视化就像帮助我们清晰看见的眼镜。对于那些不擅长数字和算法语言的人,它提供了一种有效的方式来理解复杂的数据叙事。
任何图表通常由两个主要组件组成:
1. 数据类型
我敢打赌你正在考虑数据作为数字,但数值只是我们可能遇到的几种数据类型中的两种。每当我们可视化数据时,我们总是需要考虑我们处理的数据类型。
除了连续和离散的数值外,数据还可以以离散类别、日期或时间以及文本的形式存在。
当数据是数字时,我们也称之为定量,而当数据是类别时,我们称之为定性。
因此,任何显示的数据总是可以描述为以下几类之一。
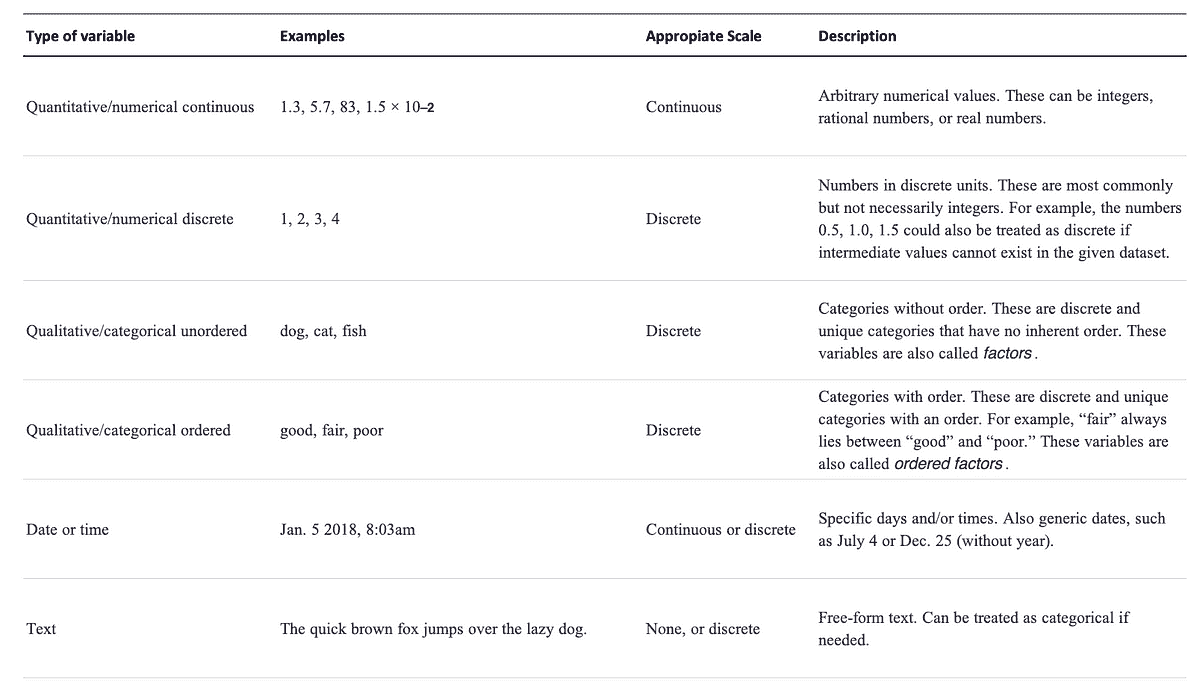
图片作者提供。分类摘自《数据可视化基础》,O’Reilly 出版社。
一旦我们清楚了数据的类型,我们需要理解如何将这些数据编码成最终的图表。
2. 编码信息:视觉词汇
视觉编码是数据可视化的核心。它将抽象的数字转换为图形表示,这是我们都能流利使用的语言。
尽管有许多不同类型的数据可视化,乍一看,散点图、饼图和热图似乎没有太多共同之处,但所有这些可视化都可以用一种通用的语言来描述,这种语言捕捉了数据值如何转化为纸上的墨滴或屏幕上的彩色像素。
但……你已经应该意识到……
编码数字的方法有成千上万种!
有两个主要组别:
- 视网膜编码: 从形状、大小、颜色和强度来看,这些都是我们眼睛瞬间捕捉到的元素。它们是元素固有的。
图片作者提供
- 空间编码: 它们利用我们大脑皮层的空间意识来编码信息。这种编码可以通过在尺度中的位置、定义的顺序或使用相对大小来实现。

图片作者提供
使用之前解释的所有编码方法,我们可以在一张图表中使用它们,但这样读者很难快速掌握所有信息。图表中过度使用多种编码可能会让人困惑,因此每张图表中使用 1 到 2 种视网膜编码是最佳的。
记住,少即是多,所以总是尽量创建简约且易于理解的图表。
想象一下调味—撒一点盐和胡椒可能会增强味道,但把整瓶盐都倒进去可能会破坏味道。
那么,现在……应该选择哪种编码呢?
这,朋友们,取决于你想要编织的故事。
所以你可以更好地问……
什么有效,什么无效?
尽管我们手头的视觉工具广泛,但并非所有工具都适合每一场战斗。
思考哪种编码最适合哪种变量。
-
连续数据变量,如体重和身高,在共同尺度上的位置是最好的表现形式。
-
离散的,如性别或国籍,在通过颜色或空间区域表现时最为出色。
有一些原因解释了某些图表的直观性。背后有两个主要理论。
1. 格式塔理论
从事技术工作的人有时会忽视事物的人性化方面。格式塔原理是心理学中的规则,解释了我们的大脑如何识别模式。
这些规则中的一些帮助我们理解为什么我们将相似的事物归为一组或注意到突出的事物。
- 相似性: 格式塔相似性意味着我们的脑袋会将看起来相似的事物归为一组。这可能是由于它们的位置、形状、颜色或大小。这在热图或散点图中被广泛使用。

图片由作者提供
- 封闭性: 边框内的物体,如线条或共享颜色,看起来像是属于同一组。这使它们从我们看到的其他事物中突出。我们常常在表格和图表中使用边框或颜色来分组数据。

图片由作者提供
- 连续性: 当个体元素相连时,我们的眼睛会认为它们属于同一组。即使它们看起来不同,线条也会让我们将它们视为一组。这在折线图中被广泛使用。
图片由作者提供
- 邻近性: 如果事物彼此靠近,我们会认为它们在同一组中。为了显示事物属于同一组,将它们放在一起。使用少量空间可以帮助分隔不同的组。这在散点图或节点链接图中很常见。
图片由作者提供
因此,格式塔原理及其相互作用在制作可视化时非常重要。
2. 墨水比例原理
在许多不同的可视化场景中,我们通过图形元素的范围来表示数据值。
通常,墨水一词用来指代视觉化中任何与背景色不同的部分。这包括线条、条形图、点、共享区域和文本。
例如,在条形图中,我们绘制的条形从 0 开始,到表示的数据值结束。在这种情况下,数据值不仅通过条形的终点进行编码,还通过条形的高度或长度进行编码。
如果我们绘制一个从非零值开始的条形图,那么条形图的长度和条形图的终点将传达矛盾的信息。
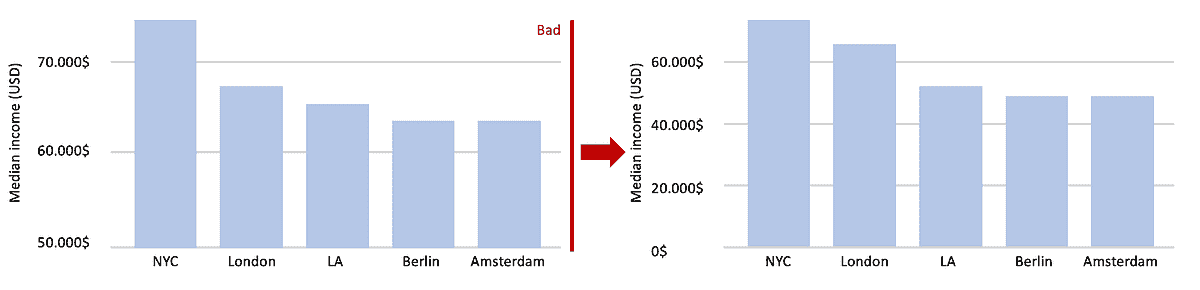
图片由作者提供
在所有这些情况下,我们需要确保没有不一致。这一概念被Bergstrom 和 West称为墨水比例原理。
“当使用阴影区域来表示数值时,该阴影区域的面积应与相应的数值成正比。”
当试图操控数据时,违反这一原则的情况相当普遍,尤其是在大众媒体和金融领域。
每当我们使用图形元素,如矩形、任意形状的阴影区域或任何具有定义视觉范围的元素时,都可能出现类似的问题,这些元素的视觉范围可能与所显示的数据值一致或不一致。
好的可视化的本质
在美学与功能性之间找到平衡至关重要。严格遵守如 Bergstrom 的比例墨水原则,但不能以牺牲可读性为代价。
尽管某些编码方式可能看起来效果较差,但它们可以被故意选择以表达某种声明或唤起某种情感。
在数据流量不断增加的时代,打造有意义的视觉叙事的重要性不容低估,特别是在向非数据专业人士传达我们的洞察时。
优秀的数据可视化不仅仅是展示数字,而是围绕故事来表达我们的数据。让数据在讲述故事的过程中变得生动,同时在原始信息和现实世界的影响及洞察之间建立联系。
作为技术专家和数据爱好者,这不仅是我们的艺术、语言,也是我们与整个世界的桥梁。
Josep Ferrer 是一位来自巴塞罗那的分析工程师。他毕业于物理工程专业,目前在应用于人类流动性的 数据科学领域工作。他还是一名兼职内容创作者,专注于数据科学和技术。你可以通过 LinkedIn、Twitter 或 Medium 联系他。
更多相关话题
数据仓库是否应该是不可变的?
作者:Barr Moses & Chad Sanderson
数据仓库是现代数据架构的基础,因此当我看到 Convoy 数据负责人Chad Sanderson在 LinkedIn 上宣称“数据仓库已经破损”时,引起了我的注意。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
当然,Chad 并不是在谈论技术,而是谈论技术的使用方式。
他认为,数据质量和可用性问题源于传统最佳实践,即将数据“倾倒”到数据仓库中,然后再进行操作和转换,以适应业务需求。
这与像 Snowflake 和 Databricks 这样的供应商确保他们的客户在存储和消费中高效(换句话说,节省金钱和资源)的总体努力是一致的。
无论你是否同意 Chad 下面详细描述的方法,无法争辩的是他的观点引发了大量的讨论。
Chad 表示:“一个阵营对我感到愤怒,因为他们认为这没什么新意,需要长时间的手动过程和拥有 30 年经验的数据架构师。另一个阵营对我感到愤怒,因为他们的现代数据架构基本上不是这种设置,而且这不是他们构建数据产品的方式。”
我会让你自己决定“不可变数据仓库”(或主动与被动 ETL)是否是你们数据团队的正确路径。
不管怎样,我坚信推动我们行业前进不仅需要对技术的概述,还需要对如何部署它们的坦诚讨论和独特视角。
不可变数据仓库如何结合规模与可用性
Chad Sanderson 的观点
现代数据架构有许多变体,但数据仓库是一个基础组件。简单来说:
-
数据通过被动管道(实际上只是 ETL 中的“E”)被提取并倾倒到…
-
一个数据仓库在处理和存储数据之后…
-
转换为数据消费者所需的格式,以便于…
-
特定用途如分析仪表盘、机器学习模型,或在 Salesforce 或 Google Analytics 等记录系统中的激活…
-
技术或流程如数据可观察性、治理、发现和目录等贯穿整个堆栈。
在深入探讨这种方法的挑战及建议的替代方案之前,值得探讨一下我们如何定义“现代数据堆栈”。
我们是怎么到这一步的?
在数据的早期,像 Bill Inmon 这样的开创者们,最初的 ETL(提取、转换、加载)过程涉及从源头提取数据并在进入数据仓库之前进行转换。
许多企业今天仍然如此运作。对于数据质量至关重要的大公司而言,这一过程涉及手动、密集的治理框架,并且数据工程师与嵌入不同领域的数据架构师之间有紧密的联系,以便快速利用数据进行操作洞察。
像 Google、Facebook 等科技巨头抛弃了这一过程,开始将几乎所有数据都存入数据仓库。对于快速增长的初创公司而言,逻辑组织数据的投资回报率远不如这种更快、更具扩展性的过程。更不用说,加载(即 ELT 中的“L”)在云中集成变得更加容易。
在这个过程中,流行的转换工具使数据在仓库中的转换变得比以往任何时候都更容易。模块化代码和显著减少的运行时间使 ETL 模型变得极大地减轻了痛苦……以至于流行的转换工具的使用从数据工程师扩展到了数据消费者,如数据科学家和分析师。
我们似乎发现了一种新的最佳实践,并且正朝着事实上的标准化迈进。甚至提出替代方案也会引发迅速而强烈的反应。
数据仓库中被动 ETL 或转换的挑战
现代数据仓库架构在多个层面上产生了问题。图片由 Chad Sanderson 提供。
依赖于在数据仓库中转换数据的架构和流程存在几个问题。
第一个问题是它在数据消费者(分析师/数据科学家)与数据工程师之间真正产生的断层,甚至是深渊。
项目经理和数据工程师将在分析师上游建立管道,分析师将负责回答内部利益相关者提出的某些业务问题。不可避免地,分析师会发现数据无法回答他们的所有问题,而项目经理和数据工程师已经离开了。
第二个挑战出现,当分析师的回应是直接进入仓库编写一个脆弱的 600 行 SQL 查询来获取答案。或者,数据科学家可能发现他们构建模型的唯一方式是从作为服务实现细节的生产表中提取数据。
生产表中的数据并非用于分析或机器学习。事实上,服务工程师通常明确表示不要对这些数据建立关键依赖,因为它随时可能发生变化。然而,我们的数据科学家需要完成工作,所以他们还是这样做了,当表被修改时,一切都会崩溃。
第三个挑战是当你的数据仓库成为一个垃圾场时,它就会变成数据废料场。
一项较早的 Forrester 研究发现,企业中 60%到 73%的数据未被用于分析。一项较新的 Seagate 研究发现,68%的企业可用数据未被利用。
结果是,数据科学家和分析师花费太多时间在过度处理的生产代码针毯中寻找上下文。作为数据工程师,我们需要强调数据可用性,除了数据质量之外。
如果你的用户不能可靠地在当前数据仓库中找到并利用他们需要的内容,那有什么意义呢?
另一种方法:引入不可变数据仓库
不可变数据仓库概念(也称为主动 ETL)认为,仓库应通过数据表示现实世界,而不是随机查询、破碎管道和重复信息的混乱。
有五个核心支柱:
-
业务被映射并分配了负责人。为了使企业真正从其拥有的大量数据中获得价值,团队需要退后一步,在通过代码定义实体和事件之前,先对其业务进行语义建模,以便用于分析。这可以是一个迭代过程,从业务中最关键的元素开始。
实体关系图(ERD)是基于现实世界的业务地图,而不是今天存在于数据仓库或生产数据库中的内容。它定义了关键实体、它们之间的关系(基数等),以及表明它们已互动的现实世界行为。为每个实体和事件设立工程负责人。端到端的自动化血统可以帮助建立 ERD 并使其具有可操作性。
-
数据使用者提前定义他们的需求,合同就会被创建。最具争议的观点可能是数据应从业务需求中浮现,而不是从无结构的管道中流出。与其让数据分析师和科学家在你仓库的尘封架子上寻找足够接近他们需求的数据,不如在数据消费者直接请求并定义之前,数据不会进入仓库。
没有业务问题、流程或问题驱动的数据不会进入数据仓库。所有内容都是为了完成特定任务而量身定制的。
设计这个过程时必须简单,因为数据需求总在变化,增加的摩擦将威胁到采用。Convoy 的合同实施通常需要几分钟到几小时,而不是几天到几周。
接下来是制定数据合同,这是一项业务和工程领导之间关于事件/实体模式及其最有效所需数据的协议。例如,现有的 inboundCall 事件可能缺少 OrderID,这使得将电话与已完成的订单关联变得困难。
SLA、SLI 和 SLO 是你可以应用于这种变更管理和利益相关者对齐模型的数据合同之一。
-
在活跃环境中进行的同行评审文档。就像我们需要代码(GitHub)或用户体验(Figma)进行同行评审一样,数据资产也应有类似的评审机制。然而,这种评审的适当抽象层级不是代码,而是语义。
这个评审过程应有与 GitHub 拉取请求相同的结果——版本控制、相关方签字等——所有这些都通过云端处理。通过应用现代的云技术,我们可以加快旧流程,使它们更适合快速增长的互联网企业。
数据目录作为数据仓库定义表面的一部分是有用的,但挑战在于缺乏激励措施来促使数据使用者保持元数据的更新。使用 ELT 流程并完成模型的数据科学家有什么激励回去记录他们的工作?
-
数据按照合同中定义的预建模式输入数据仓库。转换在消费层之前的上游发生(理想情况下在服务中)。工程师然后在他们的服务中实施数据合同。数据被导入数据仓库,利用建模元数据可以理想地自动进行 JOIN 和分类。
-
强调防止数据丢失,并确保数据可观测性、完整性、可用性和生命周期管理。使用事务性外发模式以确保生产系统中的事件与数据仓库中的一致,而日志和偏移处理模式(我们在 Convoy 广泛使用的)则防止数据丢失。这两个系统共同确保数据完整保存,使得不可变数据仓库直接反映和真实呈现业务中的发生情况。
数据质量和可用性需要两种不同的思维方式。数据质量主要是技术挑战,类似于“后端”工程。另一方面,数据可用性是“前端”工程挑战,需要用来创建出色客户体验的相同技能。
最后,不可变数据仓库不适合用来进行 PB 级别的测量比赛或展示大数据统计。弃用和维护与配置同样重要。
这种方法利用了技术的优势,达到两全其美的效果。结合了传统方法的治理和业务驱动的优势以及现代数据堆栈相关的速度和可扩展性。
如何让不可变数据仓库运作,将数据视作 API
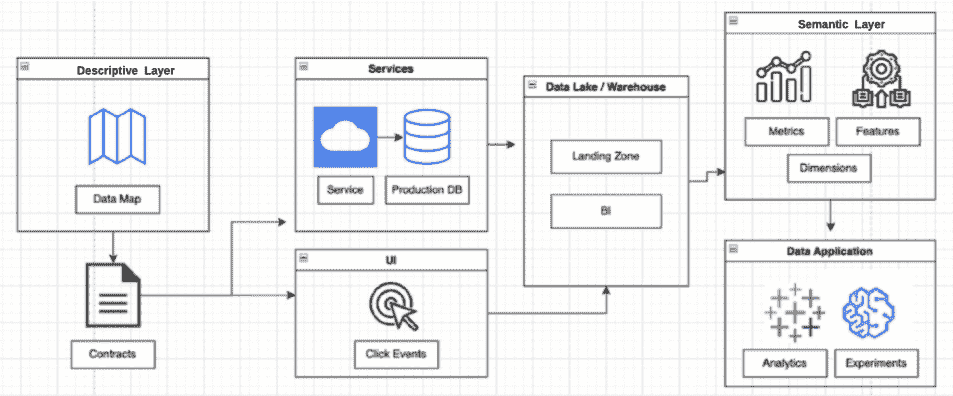
不可变数据仓库的层级。图片由 Chad Sanderson 提供
让我们从回顾不可变数据仓库的完整堆栈开始。
-
描述层: 与传统仓库不同,描述层将业务逻辑移动到服务层之上,让数据消费者掌控。消费者可以提出他们的需求,无需技术技能,因为数据工程师充当重要的需求到代码的翻译者。这些合同可以保存在数据目录或一般文档库中。
-
数据仓库: 仓库主要作为‘数据展示’和底层计算层。
-
语义层: 数据消费者构建经过验证并与业务共享的数据产品。语义层中的资产应定义、版本化、审查,然后通过 API 提供给应用层使用。
-
应用层: 这是数据用于完成某些业务功能的地方,例如实验、机器学习或分析。
-
端到端支持: 支持数据栈中数据操作的解决方案,如数据可观测性、目录、测试、治理等。理想情况下,一旦数据到达仓库,它应该是完美的、预建模的、高度可靠的,但你仍需覆盖现实世界可能带来的所有变数(并在流程超出界限时有执行机制)。
不可变数据仓库本身设计用于流处理——从流处理转到批处理比反向更容易——因此由三种不同类型的 API 提供支持。
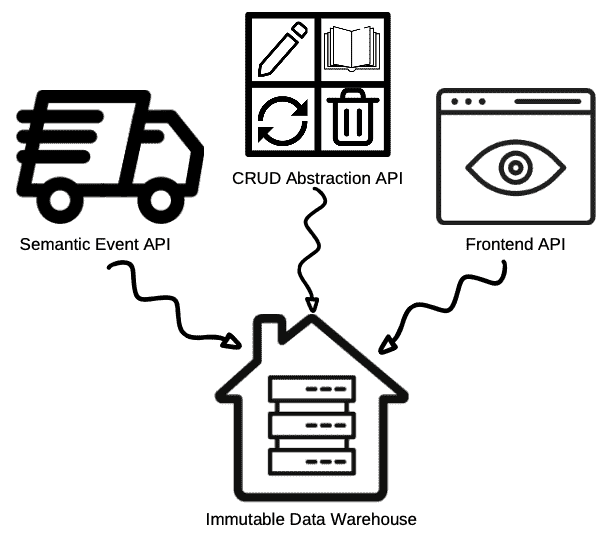
图片由 Monte Carlo 提供。
-
语义事件 API: 这个 API 处理的是公司核心构建块的语义现实世界服务级事件,而不是来自前端应用程序的事件。例如,在 Convoy 的情况下,这可能是一个货物创建或解除保留的事件。来自现实世界的事件是在服务代码中构建的,而不是 SQL 查询。
-
CRUD 抽象 API: 数据消费者不需要看到所有生产表,特别是当这些表只是他们用来生成洞察或推动决策的数据服务的实现细节时。相反,当生产表中的数据资产属性被更新时,API 包装器或抽象层(例如 dbt)将展示对数据消费者有意义的 CRUD 概念——例如,数据是否是最新的,或者行量是否在预期范围内。
-
前端 API: 目前已有许多工具处理前端事件定义和发射,例如 Snowplow、Mixpanel 和 Amplitude。不过,一些前端事件的重要性足够高,以至于团队需要能够确保其交付和完整性,使用长偏移管道。在某些情况下,前端事件对机器学习工作流至关重要,“足够接近”的系统无法满足要求。
还需要有一个映射层,该层位于仓库之外,以应对事物的变化(例如,一个服务可能需要变成多个服务)或数据科学家心中的模式与现实世界中发生的情况不符的情况。映射应通过流数据库在仓库上游处理,或在仓库本身进行处理。这个层级是业务智能工程师将工程中产生的数据与数据消费者需求匹配的地方,这可以自动化以生成Kimball 数据集市。
不可变数据仓库也面临挑战,这里有一些可能的解决方案
我并不幻想不可变数据仓库是万灵药。像任何方法一样,它有其优缺点,并且肯定不适合所有组织。
像数据网格和其他雄心勃勃的数据架构倡议一样,不可变数据仓库是一种理想状态,而不常见于现实。实现它——或试图实现它——是一个过程,而不是一个终点。
应考虑和缓解的挑战包括:
-
定义描述层的前期成本
-
处理没有明确所有权的实体
-
实施新的方法以实现快速实验
虽然定义描述层有一定成本,但通过软件可以大大加快这一过程,并通过优先考虑最重要的业务组件进行迭代。
这需要一个协作设计的努力,涵盖数据工程师,以防止数据质量责任在分布式数据消费者之间扩散。如果第一次没有做到完美也没关系,这是一个迭代过程。
处理没有明确所有权的实体可能是一个棘手的治理问题(这也是数据网格倡导者经常面临的难题)。这些问题通常不在数据团队的业务范围之内。
如果有一个核心业务概念跨多个团队,并且由一个整体系统而不是微服务生成,那么前进的最佳方式是建立一个强大的审查系统,并有一个专门的团队待命进行更改。
数据工程师仍然可以进行实验,并获得灵活性而不限制工作流。一个实现这一点的方法是通过一个单独的暂存层。然而,这些暂存区域的 API 数据不应允许下游使用或跨外部团队使用。
关键是,当你从实验阶段转到生产阶段或使其对边界团队可访问时,它必须经过相同的审核过程。就像在软件工程中一样,你不能因为想要更快地推进就跳过审核过程进行代码更改。
祝你在数据质量之旅中好运
现代数据堆栈有很多变体,作为一个行业,我们仍在经历实验阶段,以了解如何最好地建立我们的数据基础设施。
显而易见的是,我们正快速迈向一个未来,在这个未来中,更多关键任务、面向外部和复杂的产品将由数据仓库“提供支持”。
不管选择了哪种方法,这都需要我们作为数据专业人员提升标准,并加倍努力,确保数据的可靠性、可扩展性和可用性。数据质量必须是所有数据仓库的核心,无论其类型如何。
从我的角度看,底线是:当你建立在一个大而模糊的基础上时,东西容易坏,而且很难找到。而当你找到它时,可能很难准确地弄清楚那个“东西”是什么。
不管是否不可变,也许是时候尝试一些新的方法了。
更多相关话题
数据仓库与数据湖与数据集市:需要帮助决定吗?
原文:
www.kdnuggets.com/data-warehouses-vs-data-lakes-vs-data-marts-need-help-deciding
图片来源:作者
为了充分利用数据,组织需要高效且可扩展的解决方案,这些解决方案能够有效地存储、处理和分析数据。从从多个来源获取数据、通过转换和服务,数据存储支撑着数据架构。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你在 IT 方面的组织
因此,在选择合适的数据存储解决方案时,需要考虑如何访问数据以及具体的使用场景。本文将探讨三种流行的数据存储抽象:数据仓库、数据湖和数据集市。
我们将介绍基础知识,并比较这些数据存储抽象在访问模式、模式、数据治理、用例等特征上的差异。
让我们开始吧!
数据仓库
数据仓库是现代数据管理系统的基础组件,旨在促进结构化数据的高效存储、组织和检索,以用于分析目的。
图片来源:作者
什么是数据仓库?
数据仓库是一个专门的数据库,集中、存储和管理来自不同来源的结构化和处理过的数据,主要目的是支持复杂的分析和报告。
因此,数据仓库是一个用于结构化数据的集中式存储库,允许组织:
-
执行复杂的数据分析
-
生成报告和仪表盘
-
支持商业智能(BI)和决策过程
-
深入了解历史和当前的数据趋势
数据类型、访问模式和好处
数据仓库主要存储结构化数据,这些数据被组织成明确的表格,包含行和列。这种结构化的格式简化了数据检索和分析,使其适用于报告和查询。
数据仓库针对查询性能和报告进行优化。它们通常使用索引和缓存机制来加速数据检索,确保分析师和业务用户可以迅速获取所需信息。
数据集成
数据仓库集中整合来自各种源系统的数据。这包括从源系统中提取数据,将其转换为一致的格式,然后加载到仓库中。
ETL 过程通常用于数据仓库中的数据集成。这些流程从源系统中提取数据,对数据进行清理和结构化转换,然后将其加载到仓库的数据库表中。ETL 过程确保数据仓库中的数据质量和一致性。
模式
数据仓库执行模式以确保数据一致性。模式定义了数据的结构,包括表、列、数据类型和关系。这种强制执行的模式确保数据保持一致,并且可以依赖于分析。
数据仓库通常使用星型或雪花型模式来组织数据。在一个星型模式中,一个中央事实表包含事务数据,周围是提供背景和属性的维度表。在一个雪花型模式中,维度表经过规范化以减少冗余。选择这些模式取决于具体的数据仓库需求。
数据治理和安全
数据仓库以其强大的治理和安全控制而著称。它们设计用于结构化数据,并提供数据验证、数据质量检查、访问控制和审计功能等特性。
使用案例和业务单位
数据仓库主要用于企业范围的分析和报告。它们将来自不同来源的数据整合到一个单一的存储库中,使整个组织可以进行分析和报告。它们支持标准化报告和临时查询,供决策者使用。
数据湖
数据湖代表了一种灵活且可扩展的数据存储和管理方法,满足现代组织的多样化需求。
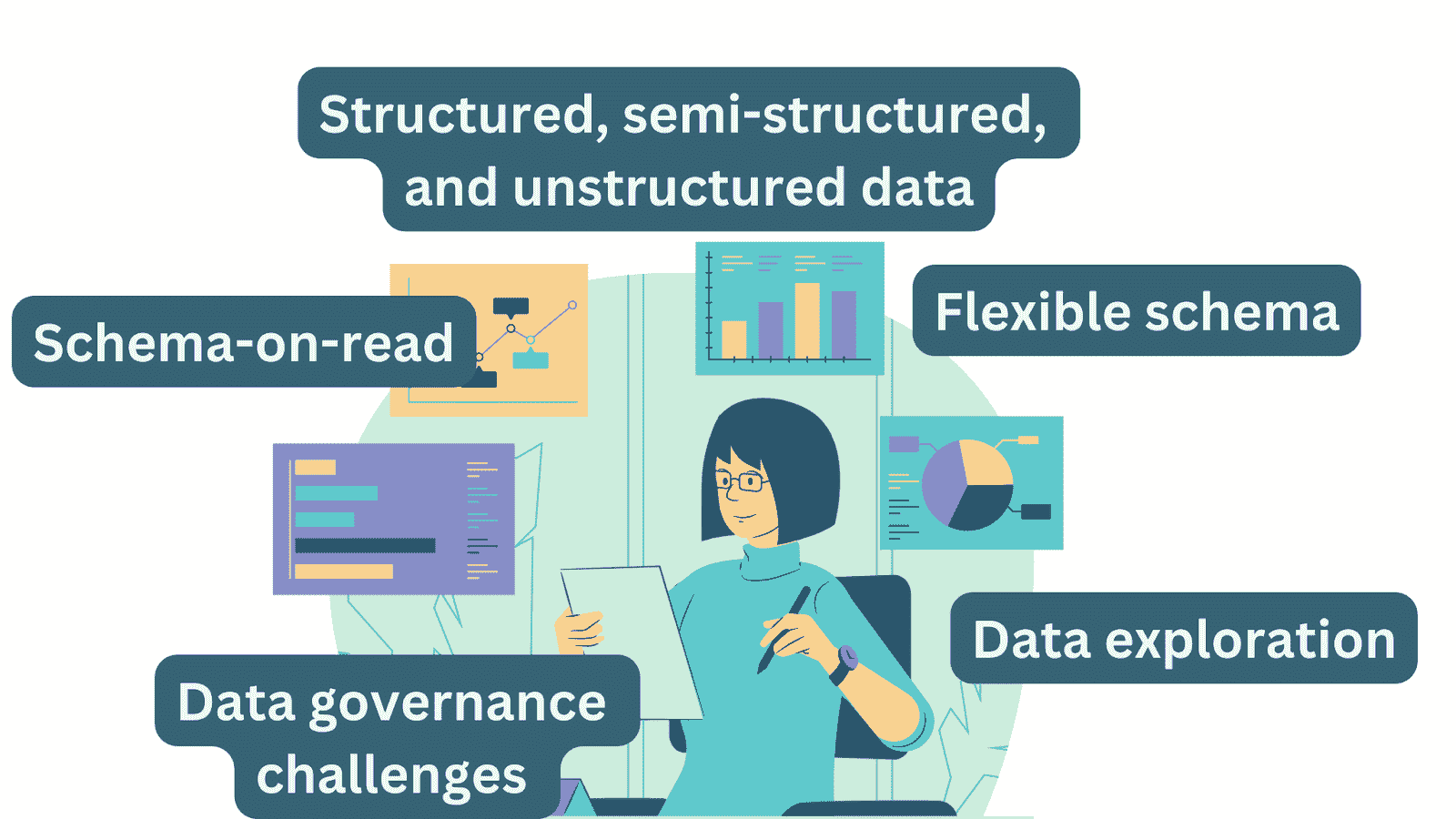
作者提供的图片
什么是数据湖?
数据湖是一个集中式存储库,存储大量原始、结构化、半结构化和非结构化的数据,允许组织在没有预定义模式限制的情况下存储和管理大量信息。
数据湖的主要目的是提供一个灵活且具有成本效益的解决方案,用于存储和管理多样化的数据类型:
-
数据湖保留数据的原始和本地形式。
-
数据湖支持广泛的使用案例,从传统的分析到高级机器学习和 AI 应用。
-
用户可以在不预定义数据结构或模式的情况下探索和分析数据。
数据湖旨在应对组织今天所面临的日益增长的数据量、速度和种类带来的挑战。
数据类型、访问模式和优势
数据湖能够存储多种数据类型,包括来自关系数据库的结构化数据、如 JSON、XML 的半结构化数据以及文本文件、图像和视频等非结构化数据。这使得数据湖适合处理原始和本地形式的数据。
数据集成
将数据摄取到数据湖中可以通过批处理或实时数据摄取来完成。批处理过程涉及定期加载大量数据,而实时摄取则允许从各种来源持续流入数据。这种灵活性确保数据湖能够处理不同的数据流速需求。
数据湖采用读取时模式。与数据仓库不同,数据湖中的数据没有预定义模式。相反,模式在分析时定义,允许用户根据具体需求解读和结构化数据。这种模式灵活性是数据湖的一个标志性特征。
模式
数据湖提供模式灵活性,允许在没有预定义模式的情况下摄取数据。这种灵活性适应了数据结构随时间变化的需求,使用户能够根据分析需要定义模式。
数据湖中的数据在分析时被赋予结构和意义。这种方法意味着用户可以根据他们的分析需求解读和结构化数据。
数据治理和安全
数据湖经常面临治理挑战,因为它们以原始形式存储结构化和非结构化数据。管理元数据、强制数据质量和维护统一的数据目录可能很困难,这可能导致数据发现和合规性问题。
用例和业务单元
数据湖非常适合数据探索和实验。它们可以存储大量原始的非结构化数据,使数据专业人员能够在没有预定义模式的情况下进行探索和实验。
数据集市
数据集市是企业数据仓库的子集,专门服务于组织内的特定业务单元或职能。
作者提供的图片
什么是数据集市?
数据集市是数据仓库或数据湖的专门子集,用于存储量身定制的针对特定业务单元、部门或职能区域的结构化数据。
数据集市的主要目的是为特定的分析和报告需求提供集中的高效数据访问。关键目标包括:
-
支持特定业务单元:数据集市旨在满足个别业务单元的需求,例如销售、营销、财务或运营。
-
简化数据访问:通过提供更容易访问相关数据的数据集市,使得特定领域的用户更容易获取和分析他们所需的信息。
-
更快的洞察时间:数据集市通过减少需要处理的数据量来提高查询和报告性能。
因此,数据集市在确保组织内各部分的决策者能够随时获得相关数据方面发挥了重要作用。
数据类型、访问模式和优点
数据集市主要存储与其服务的特定业务单元或职能相关的结构化数据。这种结构化格式确保了数据的一致性,并符合领域的分析需求。
数据集市提供了比企业数据仓库或数据湖更为专注和便捷的数据访问。这种专注的方法使用户能够快速访问和分析与其领域直接相关的数据。
数据整合
数据集市通常从中央存储库(如数据仓库)中提取数据。这个提取过程涉及识别和选择与特定业务单元或职能相关的数据。
一旦提取,数据会根据数据集市的需求进行特定的转换。这可能包括数据清洗、聚合或定制,以确保数据与其服务的领域的分析要求一致。
架构
数据集市可能遵循中央数据仓库中定义的架构,或者采用为特定数据集市的分析需求量身定制的自定义架构。选择取决于数据一致性和数据集市的自主性等因素。
数据治理和安全
数据集市通常是数据仓库的子集,关注于特定业务领域或单元。治理工作集中在数据集市层面,确保特定业务单元使用的数据符合数据仓库设定的企业级治理标准。
用例和业务单元
数据集市根据组织内各业务单元或领域的具体需求量身定制。它们提供来自数据仓库的相关数据子集,针对特定业务领域。这使得业务单元能够进行专门的分析和报告,而无需处理整个企业数据集的复杂性。
数据仓库与数据湖与数据集市的全面比较
总结数据仓库、数据湖和数据集市之间的主要区别:
| 特性 | 数据仓库 | 数据湖 | 数据集市 |
|---|---|---|---|
| 数据类型和灵活性 | 结构化数据,固定架构 | 各种数据类型,架构灵活性 | 结构化数据,明确定义的架构 |
| 数据集成 | ETL 管道 | 灵活的数据摄取、按需模式 | 针对领域的提取和转换 |
| 查询性能 | 针对查询进行优化 | 性能有所不同 | 最佳性能 |
| 数据治理 | 强大的数据治理和安全控制 | 数据治理挑战 | 数据集市级别的治理 |
| 使用场景 | 企业分析 | 大规模数据探索 | 领域特定分析 |
结论
我希望你对数据仓库、数据湖和数据集市有了一个概述。架构的选择取决于组织的具体需求以及其数据和业务需求所需的治理与灵活性之间的平衡:
-
数据仓库——具备强大的治理和安全控制——适用于企业范围的分析和报告。
-
数据湖适用于数据探索和大数据分析,但可能会带来治理和安全方面的挑战。
-
数据集市提供与业务部门需求对齐的领域特定分析,同时符合数据仓库的治理标准。
你还可以探索 数据湖仓,这是一种相对较新且不断发展的架构。数据湖仓旨在弥合数据仓库和数据湖之间的差距,提供统一的数据存储和分析方法。
Bala Priya C** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过编写教程、使用指南、观点文章等,与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。**
更多相关信息
数据仓库和 ETL 最佳实践
原文:
www.kdnuggets.com/2023/02/data-warehousing-etl-best-practices.html

图片来源:作者
什么是数据仓库?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
数据仓库是一个集中存储数据、信息和其他变量的中央库,可以进行分析以帮助企业做出明智决策。例如,它可以用于衡量性能或获取验证。
它涉及历史数据的维护,从而使组织中的知识工作者及其他人能够在决策过程中受益。数据仓库为公司提供:
-
单一的数据来源
-
一致性
-
有效的决策过程
什么是 ETL?
ETL 代表 提取、转换 和 加载。它是将数据从多个来源移动到一个集中式单一数据库的过程。它以从源头 提取 原始数据开始,然后在单独的处理服务器上 转换,最后 加载 到目标数据库中。
数据仓库和 ETL 常见错误
以下是人们在数据仓库和 ETL 过程中常遇到的错误:
-
对所有源数据缺乏理解
-
缺乏历史数据
-
花费太多时间在源数据的分析上
-
花费太多时间在测试提取过程上
-
同意一组规则
-
未记录 ETL 过程
-
不愿意接受新技术
ETL 最佳实践
1. 为你的 ETL 过程创建一个路线图
无论你在生活中做什么,最好还是先制定一个计划,而不是直接跳入深渊。你可能需要将其写下来,或者创建一个可视化的过程。但是,路线图是必不可少的,因为它让你可以回过头来进行调整,并通过反复试验来学习。
2. 早期填充测试数据
在创建你的路线图时,你将考虑最终目标。在你的 ETL 过程中,你需要理解“你想填充什么数据模型?” 将与你的最终目标相关的样本数据填充到数据仓库中,将使你的过程更加有效。这有助于你保持任务的方向并制定规则。
3. 审查源数据和系统
源系统包含传送到数据仓库的数据。你可以使用分析工具来帮助你识别 NULL 值或了解列的用途。与其花时间在分析查询上,不如审查你的源系统,以改善你的 ETL 过程。
你需要识别每个源表中的主键定义以及任何相关的信息/数据。将此实践作为一个验证阶段,以确保你对输入到数据仓库中的数据有信心。
4. 数据类型问题
在查询数据时,你不希望遇到由于数据类型问题而产生的各种错误。这是一个应该在早期处理的问题,以防止在后续过程中引发问题。
5. 提取数据
从源系统中提取数据是一个重要阶段,如果操作不当,可能会引发许多问题。以下是一些建议:
-
在源系统中拥有时间戳列将使你能够依赖于该交易日期,并确保所有必要的数据都已被提取。
-
以增量步骤提取数据将有助于处理非常大的源表。
-
记录提取过程所需的时间,因为可能存在改进的方法。
所有数据提取过程应经过彻底审查和验证。
6. 汇总 ETL 日志中的所有活动
最佳实践之一,不仅适用于数据仓库,也适用于生活中的其他方面,就是记录一切。回到一个曾经写满不同想法和过程的白板,总比回到一个空白的白板要好。
通过 ETL 日志,你可以找到有价值的信息,如提取时间、行的变化、错误等。
7. 警报
观察 ETL 过程可能会让人感到不知所措。你希望保持关注,但有时它可能会比你想象的更长时间,你可能会发现自己在不合时宜的时间还在忙碌。一些公司创建了消息和警报程序,通知他们任何需要注意的致命错误。
结论
尽管有人可能会说这些是每个人在处理数据仓库和 ETL 时应该做的实践,但你会惊讶于这些实际上是许多公司/团队面临的主要挑战。
如果你想了解更多关于数据仓库和 ETL 的内容,请阅读:
-
为什么组织需要数据仓库
-
SQL 和数据集成:ETL 与 ELT
-
ETL 与 ELT:数据集成对决
Nisha Arya 是一位数据科学家和自由技术写作员。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探索人工智能如何或能在延长人类寿命方面发挥作用。作为一名热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关内容
数据库关键术语,解释
原文:
www.kdnuggets.com/2016/07/database-key-terms-explained.html
数据有价值。实际上,数据就是价值。数据已经证明是数字经济中最重要的商品。数据的实际价值持续增长,它的潜在价值每天都在被推动。数据是新一切。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
数据需要被策划、呵护和关心。它需要被存储和处理,以便转化为信息,并进一步精炼成知识。存储数据的机制,从而促进这些转化,显然就是数据库。
本文介绍了 16 个关键的数据库概念及其简明、直观的定义。
选择这个主题的术语特别困难,有很多原因。仅仅说这些 16 个概念并不能充分代表所有与数据库相关的重要术语。然而,我希望它们能为那些希望深入了解数据库及其设计和管理的人提供一个起点。
1. 关系型数据库
关系型数据库是使用关系模型的数据库,其中原始数据被组织成元组集合,元组则组织成关系。这种关系模型对其内容施加了结构,相对于各种 NoSQL 架构的非结构化或半结构化数据而言。
2. 数据库管理系统 (DBMS)
数据库管理系统是一种软件系统,它使得存储的数据能够组织成特定的数据库架构,无论是关系型(关系型数据库管理系统,或 RDBMS)、文档存储、键值存储、列式存储、图形存储还是其他。流行的数据库管理系统包括 MongoDB、Cassandra、Redis、MySQL、Microsoft SQL Server、SQLite 和 Oracle 等等。
3. 主键
在关系模型中,主键是一个单一属性或属性组合,用于唯一标识给定表中的一行数据。常见的主键包括供应商 ID、用户 ID、电子邮件地址,或诸如名字、姓氏和居住城市的属性组合,所有这些一起被视为一个单一实体。需要注意的是,在一种情况下可以接受的主键在另一种情况下可能无法唯一标识数据实例。
4. 外键
在关系模型中,外键是来自一个关系表的一个属性或属性集合,其值必须匹配另一个关系表的主键。这种组织方案的常见用途是将一个表中的街道地址与另一个表中的城市关联起来,可能还与第三个表中的国家相关联。这消除了重复的数据输入,减少了错误的可能性,提高了数据准确性。
5. 结构化查询语言(SQL)
SQL 是一种关系数据库查询和操作语言。它的强大和灵活性允许创建数据库和表格,以及对数据的操作和查询。最近,这个术语已经与关系数据库、关系数据库管理系统和关系模型混为一谈,至少在与“ NoSQL”这个术语对比时是这样。
6. NoSQL
NoSQL 是一个总括性术语,涵盖了许多不同的技术。这些不同的技术不一定与 NoSQL 的唯一定义特征相关:它们本质上不是关系型的。这种缺乏关系的结构导致存储中的数据是非结构化或半结构化的;可能存在结构,但性质上较为松散,执行较为宽松。
通常情况下,NoSQL 被用来表示“不仅仅是 SQL”,意味着这些解决方案在本质上更灵活、较少受限。我相信在这一术语所有权的争论中会有一些坚定的支持者,但请注意潜在的定义差异。
7. 元数据
这是关于数据的数据。元数据描述数据关系和特征,通常被称为数据字典,尽管这个术语在关系世界中更为常见(但并不独占)。
8. 一致性
当数据库的所有完整性约束都已满足时,它就是一致的。只有当每个数据库事务或数据访问请求都以已知的一致状态开始时,才能确保一致性;否则,无法保证一致性。包含无法验证为一致的数据的数据库是有问题的,特别是当其不一致性未被发现时。
9. 数据冗余
数据冗余是指在数据库中,给定数据的副本被存储在两个不同的地方。这种冗余可以通过在同一数据库中的多个地方、同一计算机上的多个数据库或跨多台计算机的多个数据库中存储数据来实现,甚至使用不同的数据库管理服务器软件。这种冗余可以用于数据访问和持久性。
10. ACID
ACID 是一个缩写,指一组数据库事务属性,即原子性、一致性、隔离性和持久性。单个数据库操作或事务必须是原子性的、一致的、隔离的,并且是持久的,以便有效。换句话说,构成事务的步骤必须要么完全完成,要么回滚(原子性),保持一致(见上述定义),与其他潜在事务隔离,并且是持久的(持久性)。
11. CAP 定理
CAP 定理得出结论,分布式计算机系统(包括分布式数据库管理软件及其包含的数据)不可能同时提供以下所有保证:一致性,指的是每个计算机节点同时包含相同的数据;可用性,指的是每个数据库请求得到成功或失败的响应;以及分区容错性,指的是即使不是所有节点都连接在一起且出现通信问题,数据库系统仍能继续运行。最多只能同时保证这三个保证中的两个。
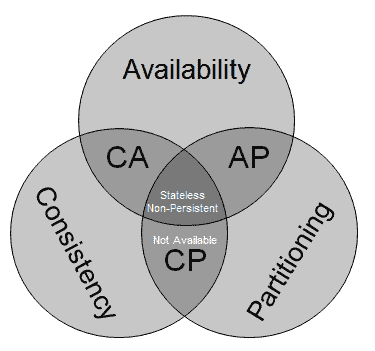
12. 分片
分片是一种数据分区技术。数据库分片是数据库内的数据的水平(考虑行,而不是列)分区,每个分区被称为一个分片。这些分片随后被分布在计算机节点上,以平衡负载。数据可能会包含在一个或多个这些分片中。
13. 键值存储
键值存储是主要的 NoSQL 架构之一。键值存储是一种简单的高层次范式:将值分配给键以便于这些值的访问和存储,这些值总是通过其键来找到。数据值通过标识键添加到数据库中;相同的数据值后来通过相同的键访问。如果你了解哈希映射,那么你已经领先一步(Python 中的字典)。Redis 是一个键值存储的例子。
14. 文档存储
文档存储是另一种 NoSQL 数据库架构。正如 NoSQL 引擎的要求,MongoDB 不使用关系型模式;相反,文档存储使用类似 JSON 的“文档”来存储数据。文档类似于记录,包含字段和值。MongoDB 是一个免费的开源示例。

15. 列式数据库
另一种 NoSQL 架构,列导向数据库的行实际上包含我们通常认为的纵向数据,或者传统上在关系型列中保存的数据(行包含列?啊?)。列导向数据库设计的优势在于某些类型的数据查找可以变得非常快速,因为所需的数据可能被连续存储在单一行中(与需要从多个不连续的行中搜索和读取以获取相同字段值的行导向数据库相比)。Cassandra 是列导向数据库的一个流行例子。
16. 图数据库
图数据库基于边作为关系的前提,直接将数据实例关联在一起。图数据库在某些使用案例中具有优势,包括在特定的数据挖掘和模式识别场景中,因为数据实例之间的关联被明确指出。Neo4j 是最广泛使用的图数据库。
Matthew Mayo (@mattmayo13) 是数据科学家及 KDnuggets 的总编辑,KDnuggets 是开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计和优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系到。
主题拓展
数据库优化:探索 SQL 中的索引
原文:
www.kdnuggets.com/2023/07/database-optimization-exploring-indexes-sql.html

图片由作者提供
在书中寻找特定主题时,我们会先查看索引页(位于书的开头),找出包含我们感兴趣主题的页码。现在,想象一下没有索引页的情况下查找书中的特定主题是多么不便。为此,我们不得不逐页搜索,这既耗时又令人沮丧。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力。
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 工作。
在 SQL Server 检索数据时,也会出现类似的问题。为了解决这个问题,SQL Server 也使用索引来加快数据检索过程,在这篇文章中我们将讨论这一部分。我们将讨论为什么需要索引以及如何有效地创建和删除索引。本教程的前提是对 SQL 命令的基本了解。
什么是索引?
索引是一种模式对象,使用指针从行中检索数据,从而减少定位数据的 I/O(输入/输出)时间。索引可以应用于一个或多个我们希望搜索的列。它们将列存储在一个称为B-Tree的单独数据结构中。B-Tree 的主要优点之一是它将数据按排序顺序存储。
如果你想知道为什么排序后的数据可以更快地检索,你必须阅读线性搜索与二分搜索。
索引是提升 SQL 查询性能的最著名方法之一。它们小巧、快速,并且针对关系表进行了显著优化。当我们希望在没有索引的情况下搜索一行时,SQL 会执行全表扫描,逐行扫描每一行以找到匹配条件,这非常耗时。另一方面,如前所述,索引保持数据排序。
但是我们也应该小心,索引创建了一个单独的数据结构,这需要额外的空间,当数据库很大时,这可能会成为一个问题。为了良好的实践,索引仅对经常使用的列有效,而对于很少使用的列可以避免使用。以下是一些索引可能有用的场景,
-
行数必须大于(>10000)。
-
所需的列包含大量值。
-
所需的列不能包含大量的 NULL 值。
-
如果我们经常基于特定列对数据进行排序或分组,索引可以快速检索排序后的数据,而不是进行全表扫描。
并且在以下情况下可以避免使用索引,
-
表很小。
-
或者当列的值很少使用时。
-
或者当列的值经常变化时。
也可能有一种情况,当优化器检测到全表扫描比索引表花费的时间更少时,即使存在索引,索引也可能不会被使用。这种情况可能发生在表很小或者列经常更新时。
创建示例数据库
在开始之前,你必须在 PC 上设置 MySQL Workbench,以便轻松跟随教程。你可以参考这个 YouTube 视频来设置你的工作台。
设置好工作台后,我们将创建一些随机数据,从中执行查询。
创建表:
-- Create a table to hold the random data
CREATE TABLE employee_info (id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(100),
age INT, email VARCHAR(100));
插入数据:
-- Insert random data into the table
INSERT INTO employee_info (name, age, email)
SELECT CONCAT('User', LPAD(ROW_NUMBER() OVER (), 5, '0')),
FLOOR(RAND() * 50) + 20,
CONCAT('user', LPAD(ROW_NUMBER() OVER (), 5, '0'), '@xyz.com')
FROM information_schema.tables
LIMIT 100;
它将创建一个名为employee_info的表,具有名称、年龄和电子邮件等属性。
显示数据:
SELECT *
FROM employee_info;
输出:
图 1 示例数据库 | 图片来源:作者
创建和删除索引
为了创建索引,我们可以使用如下的 CREATE 命令,
语法:
CREATE INDEX index_name ON TABLE_NAME (COLUMN_NAME);
在上述查询中,index_name是索引的名称,table_name是表的名称,column_name是我们要应用索引的列名称。
例如
CREATE INDEX age_index ON employee_info (age);
我们还可以为同一表中的多个列创建索引,
CREATE INDEX index_name ON TABLE_NAME (col1,
col2,
col3, ....);
唯一索引: 我们还可以为特定列创建唯一索引,这不允许在该列中存储重复值。这可以维护数据的完整性,并进一步提高性能。
CREATE UNIQUE INDEX index_name ON TABLE_NAME (COLUMN_NAME);
注意: 索引可以自动为 PRIMARY_KEY 和 UNIQUE 列创建。我们不需要手动创建它们。
删除索引:
我们可以使用 DROP 命令从表中删除特定的索引。
DROP INDEX index_name ON TABLE_NAME;
我们需要指定索引和表的名称以删除索引。
显示索引:
你还可以查看表中存在的所有索引。
语法:
SHOW INDEX
FROM TABLE_NAME;
例如
SHOW INDEX
FROM employee_info;
输出:

更新索引
以下命令在现有表中创建一个新索引。
语法:
ALTER TABLE TABLE_NAME ADD INDEX index_name (col1, col2, col3, ...);
注意: ALTER 不是 ANSI SQL 的标准命令。因此,它可能在其他数据库中有所不同。
例如
ALTER TABLE employee_info ADD INDEX name_index (name);
SHOW INDEX
FROM employee_info;
输出:

在上面的示例中,我们在现有表中创建了一个新索引。但我们无法修改现有索引。为此,我们必须首先删除旧索引,然后创建一个新的修改版索引。
例如:
DROP INDEX name_index ON employee_info;
CREATE INDEX name_index ON employee_info (name, email);
SHOW INDEX
FROM employee_info ;
输出:

总结一下
在这篇文章中,我们涵盖了 SQL 索引的基本理解。还建议将索引保持狭窄,即仅限于少数几列,因为过多的索引可能会对性能产生负面影响。索引可以加快SELECT查询和WHERE子句,但会减慢插入和更新语句。因此,只对经常使用的列应用索引是一个好的做法。
在此之前,请继续阅读和学习。
Aryan Garg 是一名 B.Tech 电气工程专业的学生,目前在本科最后一年。他的兴趣领域包括网页开发和机器学习。他一直在追求这些兴趣,并渴望在这些方向上进一步发展。
更多相关主题
[下载] 真实案例机器学习示例 + 笔记本
原文:
www.kdnuggets.com/2018/11/databricks-ebook-machine-learning-use-cases.html
赞助帖子。
|
| |
|
|
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT
你好 -
机器学习和深度学习从业者在突破性进展和推动积极成果方面的潜力前所未有。但是,如何利用现在触手可及的大量数据和机器学习工具?如何简化流程、加快发现速度,并将实施规模化以应对真实场景?
Databricks 为您提供现成的集群,可以处理从数据准备到模型构建和服务的所有分析过程,几乎没有限制,以便您可以根据需要扩展资源。
在本电子书中,我们将带您了解 Databricks 上的四个机器学习使用案例:
-
贷款风险使用案例
-
广告分析与预测使用案例
-
大规模市场篮分析问题
-
视频中的可疑行为识别使用案例
| 立即下载 |
Databricks 团队 |
|
|
|
|
|
|
|
|
|
|
|
Databricks: 160 Spear Street, 13th Floor, San Francisco, CA 94105 US
© Databricks 2018. 保留所有权利。Apache、Apache Spark、Spark 和
Spark 标志是Apache 软件基金会的商标。
|
|
|
|
更多相关话题
氢项目是基于 Apache Spark 的新倡议,旨在支持 AI 和数据科学
原文:
www.kdnuggets.com/2018/08/databricks-project-hydrogen-apache-spark.html
评论
由 Reynold Xin,Databricks 的联合创始人
问题 #1 - 什么是氢项目?
氢项目 旨在通过显著提高分布式深度学习和机器学习框架在 Spark 上的性能和故障恢复,来支持 Apache Spark^(TM) 上所有分布式机器学习框架的一流支持。
问题 #2 - 氢项目与其他机器学习和 AI 开源项目有什么不同?
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持组织的 IT
大多数关于机器学习和 AI 的开源项目都专注于算法和分布式训练框架。
氢项目是一个新的 SPIP(Spark 项目改进提案),引入了自项目开始以来 Spark 调度的最大变化之一,自最初的 600 行代码以来。
大数据和 AI 密不可分:最佳的 AI 应用需要大量不断更新的训练数据来构建最先进的模型。 AI 一直是大数据和 Apache Spark 最令人兴奋的应用之一。部分由深度学习驱动,我们看到越来越多的 Spark 用户希望将 Spark 与用于最先进训练的分布式机器学习框架集成。
问题在于,大数据框架如 Spark 和分布式深度学习框架由于大数据任务执行方式与深度学习任务执行方式之间的差异,难以协同工作。例如,在 Spark 中,每个任务被分为多个相互独立的子任务。这被称为“极其并行”,这是一个大规模的数据处理方式,可以扩展到 PB 级别的数据。
然而,深度学习框架使用不同的执行方案。它们假设任务之间有完全的协调和依赖。这意味着这种模式优化了常量通信,而不是大规模数据处理,以扩展到 PB 级数据。
氢项目被定位为解决这个困境的潜在方案。
问题 #3 - 这个项目将为贡献者和用户提供什么?
氢项目引入了 Spark 的新调度原语——群组调度。
在这种模式下,任务调度器采用“全或无”的方式。这意味着要么一次性调度所有任务,要么一个任务也不调度。这实际上解决了 Spark 与分布式 ML 框架需求之间的根本不兼容性。
现在用户可以使用一个简单的 API 来引入一个障碍函数。障碍函数指示 Spark 是否在机器学习管道的每个阶段使用令人尴尬的并行模式或群组调度器模式。
例如,新的群组调度器模式可以用于使用分布式训练框架的模型训练,而令人尴尬的并行可以在数据准备之前使用,也可以在模型训练后用于模型推理。
问题 #4 - 你认为氢项目如何支持对分析和机器学习的广泛需求?
氢项目的目标是将所有分布式机器学习框架作为 Spark 上的一等公民。它真正将数据处理与机器学习统一,特别是 Spark 上的分布式训练。
我们希望使其他框架在 Spark 上运行得像 MLlib 一样简单,无论是 TensorFlow 还是 Horovod,或未来流行的 ML 框架。这大大扩展了可以在 Spark 上有效用于深度学习应用的 ML 框架生态系统。
新的 API 还不是最终版本,但预计将很快被添加到核心 Apache Spark 项目中。
问题 #5 - 你认为开发者在整合不同的数据集和开源项目方面做得如何?我们是否更接近于统一的分析理论,还是在使 AI 适应实际应用方面还有很多工作要做?
人工智能(AI)具有推动颠覆性创新的巨大潜力,这些创新将影响地球上大多数企业。然而,大多数企业在 AI 方面的成功面临困难。为什么会这样?简单来说,AI 和数据被孤立在不同的系统和组织中。
Apache Spark 是第一个统一的分析引擎——它激发了这场革命,因为它是唯一一个真正将数据处理和机器学习结合在一起的引擎。通过氢项目,我们正在将 Spark 的内置优化扩展到 MLlib 之外,使开发者能够利用统一的数据处理和机器学习方法,使用 Spark 上的任何 ML 框架。
机器学习框架的多样化在生产 AI 应用时带来了其他下游影响,例如实验共享和跟踪以及模型推向生产。因此,我们刚刚推出了 MLflow,这是一个新的跨云开源框架,旨在简化端到端的机器学习生命周期。
问题 #6 - 你认为 AI 需要多长时间才能成为“日常业务”?
正如威廉·吉布森所说:“未来已经到来——只是分布得不太均匀。”
很少有公司在大规模和公司范围内成功实施 AI。这就是我们所说的 1% 问题。大多数公司——99%——由于拥有不一致的系统和技术,以及数据工程与数据科学家之间的组织隔阂,继续挣扎。要实现 AI,组织需要统一数据和 AI。
Apache Spark 是统一数据和 AI 的第一步,但仅此还不够——组织仍需管理大量基础设施。为了消除 AI 的障碍,公司必须利用统一分析。统一分析将数据处理与 AI 技术结合起来,使 AI 对企业组织而言变得更易实现,并使他们能够加速 AI 计划。统一分析使企业更容易在各种孤立的数据存储系统之间建立数据管道,并准备标记数据集以进行模型构建,从而允许组织在现有数据上进行 AI,并在海量数据集上迭代进行 AI。
统一分析平台为数据科学家和数据工程师提供了在整个开发到生产生命周期中有效协作的能力。成功将领域数据大规模统一 并且 将这些数据与最佳 AI 技术统一的组织将是 AI 成功的组织。
欲了解更多信息,请观看 Reynold Xin 关于 Hydroge 项目的演讲:
https://databricks.com/session/databricks-keynote-2
简介: Reynold Xin 是一位计算机科学家和工程师,专注于大数据、分布式系统和云计算。他是 Databricks 的联合创始人和首席架构师。
相关内容:
更多相关主题
[电子书] 规范化机器学习生命周期
原文:
www.kdnuggets.com/2019/03/databrocks-ebook-machine-learning-lifecycle.html
赞助广告。
|
|
| |
| |
| |
|
|
|
|
|
| |
| |
| 你好,成功地构建和部署机器学习模型可能一次就很困难。使其他数据科学家(或您自己)能够重现您的管道,比较不同版本的结果,跟踪运行状态,以及重新部署和回滚更新的模型,这就更加困难了。在这本电子书中,我们将探讨机器学习生命周期相比传统软件开发生命周期的挑战,并分享 Databricks 应对这些挑战的方法。在这本电子书中,我们将覆盖:
-
组织在管理机器学习模型生命周期中面临的主要挑战以及如何克服这些挑战。
-
MLflow,作为 Databricks 发布的开源框架,如何帮助解决这些挑战,特别是在实验跟踪、项目可重现性和模型部署方面。
-
Managed MLflow 在 Databricks 上提供了一个完全托管、集成的体验,具有企业级的可靠性、安全性和规模,运行在 Databricks 统一分析平台上。
| 阅读电子书 |
此致,
Databricks 团队 |
| |
|
| |
|
| |
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Databricks: 160 Spear Street, 13th Floor, San Francisco, CA 94105 US
© Databricks 2019。保留所有权利。Apache、Apache Spark、Spark 和
Spark 标志是 Apache 软件基金会 的商标。
|
|
|
|
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 部门
更多相关内容
学习 Python 以进行数据分析和数据科学的综合指南
原文:
www.kdnuggets.com/2016/04/datacamp-learning-python-data-analysis-data-science.html
Python 被广泛用于数据分析,你可能已经考虑过自己学习它(如果没有,或者你仍在寻找额外的动力来开始,看看下面的理由为何你应该学习 Python)。当然,自学可能会有挑战,一些指导总是有帮助的。本文正是为你提供了学习 Python 以处理数据的指导。
我们将讨论你应该采取的学习 Python 的步骤,并提供一些基本资源,例如 DataCamp 的免费 数据分析 Python 课程和教程 以及阅读和学习材料。
步骤 0:学习 Python 的理由
为什么要学习 Python 作为数据分析工具?
-
它是一个流行的数据分析工具:首先,Python 本身就是 最受欢迎的数据分析工具之一。35% 的数据科学家使用 Python,它领先于 SQL 和 SAS,仅次于 R。
-
通用编程语言:尽管还有其他非常流行且优秀的计算工具用于数据分析(例如 R、SAS),Python 是唯一真正的通用编程语言。查看这个 信息图表 获取更详细的比较。
-
流行编程语言:此外,与其他通用编程语言(例如 Java、C++、PHP)相比,Python 是 最受欢迎的编程语言之一。
-
如果这还不够,Python 还是 顶级美国大学计算机科学教学的首选语言。
作为旁注:正如在 “R 或 Python?考虑同时学习两者” 中所描述的,我们不建议你只学习 Python 而忽略其他。然而,学习 Python 是你职业生涯中可以做的最好的事情之一。Python 被计算机科学家广泛采用,有很多理由,而成为众多数据分析工具的首选主要是因为学习和使用 Python 的便利性。尽管如此,设定学习路径可能会有挑战,所以这就是我们现在要做的。

步骤 1:为数据分析设置 Python 环境
设置 Python 环境以进行数据分析相对简单。最方便的方法是从 Continuum Analytics 下载免费的 Anaconda 套件,它包含了核心的 Python 语言,以及所有必需的库,包括 NumPy、Pandas、SciPy、Matplotlib 和 IPython。通过使用图形安装程序,下载 Python 就像下载任何计算机程序一样简单。
安装后,你将获得一个包含多个程序的启动器。最重要的程序是 iPython 笔记本,也叫做 Jupyter 笔记本。一旦你启动笔记本,终端将打开,并且笔记本将在你的浏览器中打开。不要感到困惑!你不需要互联网连接来创建或使用笔记本。简单来说,浏览器被用作环境,而不是独立的程序,你可以在其中编写代码。
然而,你不局限于使用基于浏览器的 Jupyter 笔记本。如果你更喜欢集成开发环境(IDE),Yhat 提供的 Rodeo 是一个很好的数据分析选择。如果你对 RStudio 熟悉,那么 Rodeo 对 Python 来说非常类似。务必尝试这两种选择,毕竟,你使用的 Python 环境最终将取决于你的个人偏好。
步骤 2:学习基础知识和基本原理
现在你准备开始学习 Python 编程了。有几种很好的方法可以做到这一点。鉴于你希望学习 Python 进行数据分析,最好的选择是 DataCamp 提供的 Introduction for Python for Data Science 课程。这个免费的课程包含视频教程和互动浏览器练习,是一种通过实践学习的好方法,而不是单纯阅读概念和查看示例。你不会通过阅读书籍来学习绘画。你会拿起画笔开始绘画。这就是我们建议你开始学习 Python 的方式!除了入门课程,DataCamp 还提供了 Intermediate Python for Data Science 课程,进一步提升你的技能。
另一个相当有用的资源是 Codecademy 的 Python 课程。虽然这个课程并不专注于数据,而是 Python 编程,但它是练习 Python 语法和获得编程概念的好方法,这些概念在处理数据时对你会很有帮助。
步骤 3:用于数据分析的 Python 包
Python 是一种通用语言,通常用于数据分析和数据科学以外的其他任务。然而,Python 在处理数据时极其有用的原因是它的库,这些库为用户提供了必要的功能。以下是用于数据处理的主要 Python 库。你应该花时间了解这些包的基本用途。
-
Pandas – 数据处理和分析。
-
Matplotlib – 绘图和可视化。
-
Scikit-learn – 机器学习和数据挖掘。
-
StatsModels – 统计建模、测试和分析。

我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能。
3. Google IT 支持专业证书 - 支持你的组织进行 IT 维护。
更多相关内容
数据驱动的人工智能:你需要了解的最新研究
原文:
www.kdnuggets.com/2022/02/datacentric-ai-latest-research-need-know.html

技术照片由 rawpixel.com 创建 - www.freepik.com
尽管目前大多数研究工作专注于机器学习模型和算法,但数据本身往往被忽视,并且被视为固定不变。这种观点可能是有害的——因为模型与真实情况脱节,理论优于实践的风险很大。需要通过激励和信息来应对这一趋势,促使研究人员和从业者更多地关注数据。
让我们深入了解一下
两个值得研究的有趣观点:
-
面对模型改进的问题时,应通过提升数据质量来解决,而不是重新设计算法。
-
在处理数据时,应将过程视为一个整体(包括对标签者的精心选择),而不仅仅是技术层面(例如,聚合)。
一些有用的资源和比赛:
-
数据驱动的人工智能竞赛由 Andrew Ng 及其团队组织,邀请来自全球的参与者在不接触算法的情况下改进竞赛数据,从而绕过常见的模型驱动方法。数据集包含罗马数字,需要通过应用各种数据驱动技术来调整——修正错误标签、添加自有数据、数据增强等。
-
Koch 等人的论文以及Koch 的简短讲座聚焦于不同机器学习子社区的数据集使用模式的差异。这项研究的主要结论是,除了自然语言处理(NLP),研究人员往往将相同的数据集用于不同的任务。因此,基准测试代表真实世界数据科学问题的情况有所下降。
-
MLCommons 基金会致力于加速机器学习创新,并在其页面上列出了各种实用的材料和技术。
-
DataPerf是由几所大学、公司和知名研究人员发起的,旨在为训练集、测试集和各种数据驱动算法创建基准测试。
所有的文章都可以在会议记录页面这里找到,包括数据集和基准以及数据驱动的人工智能研讨会。
数据质量
测量数据集的质量极为重要;然而,目前尚无普遍认可的方法来实现这一点。虽然可以通过不同的指标来评估模型的准确性,但可靠的数据评估方法尚未找到。数据相关的问题可能导致模型在涉及噪声数据集时表现不佳。同时,不正确标注的数据也可能导致看似健康的机器学习模型学习到错误甚至潜在危险的模式。
一些研究探讨了各种数据集错误——提升数据质量的第一步:
-
Northcutt、Athalye 和 Mueller 研究了 十个最常用的计算机视觉、自然语言处理和音频数据集中的错误,以确定这些错误如何影响基准测试。他们的努力成果是Cleanlab,这是一个开源解决方案,帮助识别标签错误。附上Github 链接。
数据收集程序也值得讨论。主要的问题仍然是如何保持高质量,并理想地朝着主流软件工程的方法前进,寻找通用的标准和方法。两个有趣的资源:
-
Google Brain 的《人工智能中的技术债务》(从 5:53 开始)。
数据收集和标注
关于数据收集的另一个问题是如何拥有足够的数据变异性,以准确代表较少见的现实世界事件。一些提供的解决方案集中在手动设置数据收集参数(例如,AV 的天气模式和行人数量)、利用学习迭代不断将不寻常的案例添加到数据集中以及利用合成数据。以下是这些研究努力中的一些:
-
Raquel Urtasun(多伦多大学教授和 Waabi 创始人)关于AV 数据收集的全面讲座,从第 57 分钟开始。
-
一篇名为意图分类的数据增强的研究论文,由 Chen 和 Yin 撰写,并附有相应的闪电讲座。研究人员使用混合增强技术,从航空和电信行业的种子数据中生成伪标签训练样本。
-
Pavlichenko 等人发表的关于CrowdSpeech的论文贡献了一个大型数据集,以解决众包中最常见的问题之一:音频转录聚合。该数据集包含了一个知名语音识别数据集的转录录音,LibriSpeech。有趣的是,最佳聚合模型最初是为文本摘要设计的,但其表现超越了其他模型,包括特定任务的模型。此外,为了处理其他语言,作者创建了一个名为 Vox DIY 的管道,可以为几乎任何自然语言复制类似的数据集。
有关监督数据标注、说明不足和标注员培训的问题也相当有趣:
-
斯坦福大学的 Michael Bernstein 讲述的人机交互和数据中心人工智能的众包(从 1:12 开始) – 研究人员讨论了十年来众包研究中的“好”数据和“坏”数据。
-
数据中心人工智能与程序化监督:Alex Ratner 的讲座,讲述了如何使用 Snorkel 进行数据标注(从 5:38 开始)。
数据管理是人工智能社区面临的另一个挑战。当需要在长时间内进行多个操作和编辑时,如何管理嵌入复杂管道的数据集?是否需要版本控制和维护变更日志?这两场讲座特别关注数据文档化:
-
数据卡片是 Google Research 的 Pushkarna 和 Zaldivar 建议的模板。该方法用于总结数据集的关键信息。可以参考闪电讲座。
-
Tagliabue 等人提出的 DAG 卡片 是最新的灵活管道文档化方案之一。这个 闪电演讲 总结了其背后的逻辑及其主要优点。
伦理
伦理问题是一个高度争议的话题。需要牢记的一些关键方面包括:
-
隐私,包括但不限于 GDPR 指南。
-
偏见 – 避免数据集中的刻板印象,这些刻板印象常常对训练模型产生负面影响。
-
少数群体 – 数据集缺乏多样化,许多社会群体往往被低估或完全排除在外。
-
仅通过修改算法很难解决这些问题;因此,需要改进数据收集和数据标注过程。
解决这些问题的一个良好起点是识别这些问题的原因及其发生频率。查看我们专门讨论这一工作三场演讲:
-
Bao 等人的 演讲 及其支持的研究论文 《这真是复杂的 COMPAS》。作者批评了由执法部门使用的风险评估工具(RAI)数据集——即 COMPAS——这些数据集本质上存在偏见和种族歧视。
-
Peng、Mathur 和 Narayanan 的一篇 研究论文 和 演讲 关注伦理问题明显的面部识别数据集及其使用的影响,通过分析引用这些数据集的 1000 篇论文进行探讨。
-
一篇关于数据驱动的人工智能工作坊的论文提出了一种新的大规模数据集用于学习对人们年龄的主观意见,IMDB-WIKI-SbS,它有助于设计更好的推荐和排名算法。值得承认的是,该数据集在年龄和性别组方面是平衡的,目前机器学习模型很难在所有组别中平等处理照片。
尽管伦理问题显而易见,但解决方案却不那么明显。Bartl 和 Leavy 的 《数据驱动的人工智能的女性主义策展》 是为现有数据集做出补救的少数研究之一。Bartl 的 闪电演讲 概述了研究人员如何利用女性主义语言学来评估和缓解文本数据集及语言模型中的性别偏见。
最后,一篇值得阅读的有用论文是题为不一致性解卷积。这篇由伯恩斯坦共同撰写的论文重点讨论了如何通过 ROC-AUC 指标展示聚合中的多数投票有时会导致不良结果。
Alexey Umnov 是 Toloka 的机器学习顾问和博士。
相关主题
数据中心人工智能与表格数据
原文:
www.kdnuggets.com/2022/09/datacentric-ai-tabular-data.html

图片由编辑提供
人工智能模型开始成为家喻户晓的名字真是太棒了。DALL-E、LaMDA 和 GPT-3 最近都曾风光一时。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的信息技术
那么,掌握了表格数据的炫目、高性能模型在哪里?
尽管全球企业主要依赖表格数据,但计算机视觉和自然语言处理模型却抢尽了风头。学术研究和行业创新都集中在计算机视觉和自然语言处理上。这些工作带来了跨行业的惊人、改变世界的应用,如自动驾驶汽车、增强现实和接近人类水平的文本生成及对话工具。
同时,尽管表格数据对企业至关重要,但只有极少数的人工智能研究集中在改进处理这种数据格式的方法上。例如,在计算机科学 arXiv学术研究库中,提到“表格”的论文约有 900 篇,而“自然语言处理”的论文有超过 5,000 篇,“计算机视觉”的论文更是超过 81,000 篇。
你所知道的每一个电子表格都包含了表格数据。表格数据的捕捉和分析是我们拥有成千上万的数据库管理、商业智能、客户关系管理、企业资源计划、计算机科学以及其他商业工具的原因,这些工具创造了数万亿美元的市场价值。然而,表格数据的分析可以从更先进的方法中受益,包括数据准备、建模和部署过程的所有阶段。那么,为什么我们——广大的数据科学社区——不花更多时间和资源开发处理表格数据的技术呢?
我将探讨今天表格数据被忽视的三个主要原因,并建议一种趋势的变革——特别是数据中心人工智能——这是数据领域需要更广泛采纳的,包括人工智能在商业中的应用。
表格数据看起来不够吸引人,但却至关重要
对大多数人来说,电子表格并不完全激发灵感。更常见的,你会听到关于那些数据行列的枯燥乏味的抱怨。然而,即使对于那些稀有的电子表格爱好者,计算机视觉和自然语言处理项目也一直充满吸引力。让计算机理解图像或自然语言可能会让人感觉是在帮助推动数字化进程。相比之下,表格数据更像是用计算机的母语进行简单的对话。
然而,为了在企业中更广泛地推广人工智能并推动创新以提升收入驱动的 AI 举措,现在是时候了解一下表格数据的诱人之处了。
表格数据在研究中更难获取
计算机视觉和自然语言处理研究之所以能超越表格数据研究,另一个原因是这些项目的原材料更容易获得。互联网上有 数十亿张照片 和 数十亿 的网页包含文本,这为构建图像和语言项目的训练语料库提供了无限的可能性,这些项目为像 DALL-E 和 LaMDA 这样的强大模型提供了信息。
相比之下,公开可用的表格数据——特别是来自企业的数据——则显得相对稀缺。数据科学学生在同样的表格数据集上反复练习(比如鸢尾花数据集)。研究人员可能很难找到那些超出著名 数据集库 的多样化表格数据集。可以理解的是,企业不愿意发布反映客户活动或影响其业务策略的内部数据,这些数据很可能是表格形式的。而且,别忘了,还有许多法规限制了在其指定用途之外共享这些数据。没有访问许多多样化、大规模且面向业务的数据集,表格数据方法的发展就停滞不前。

来自 Pecan AI 的图像
表格数据是不同的
一个像素代表了一个大而有限的可能性领域。无论是狗的照片还是孩子的蜡笔画,一篇短篇小说还是一首史诗诗歌:无论图像或文本的内容是什么,数字化和预处理将其重塑为机器学习算法可以使用的一致格式。
表格数据中缺乏这种基本的一致性是高效机器学习的一个主要挑战。图像和文本可能看起来更复杂——但找到大多数表格数据集中潜在的共同结构同样具有挑战性,甚至更具挑战性。表格中的每一列都是不同的,可能没有明确标识。数据类型可能没有提供或配置准确。例如,某列中的五位数字是代表家庭收入还是邮政编码?另一列中的 0 和 1 是表示“否”和“是”,还是代表另一种二进制变量?而且——永恒的问题——这个日期格式是什么?
这些不一致性和不确定性通常使得准备表格数据成为一项艰巨的任务,尤其是当数据表需要从组织中不同来源合并时。将来自不同来源的类似信息匹配并标准化为单一的建模流程可能很困难。难怪一些数据科学家 仍然报告 他们在数据准备任务上花费了超过 70%的时间,将其视为数字清洁工工作的等同物。
手工艺方法在数据准备和特征工程中的失败
由于表格数据可以采取多种形式,数据分析师和数据科学家采用了针对具体情况的方式来准备数据以供分析和建模。每个数据集都经历了独特的清理、合并、预处理和特征工程的组合,每个新项目都要重新发明这个过程。
表面上看,对每一个数据项目采用高度具体的“手工艺”方法似乎是个好主意。但实际上,这种极其耗时和繁琐的工作很少会有回报。它使数据项目的投资回报延迟数周甚至数月。数据科学家试图根据直觉和经验决定创建哪些新特征,但他们在特征工程和选择过程中无意中引入了自己的偏见。这种数据科学的特有成分减少了对机器学习独特价值的贡献的客观性。
尽管有其缺点,但即兴的数据准备方法仍然存在,因为普遍存在的观念认为每个表格数据集都是独特的。实际上,表格数据的不可预测元素在一定范围的情况下可能是相当可预测的。
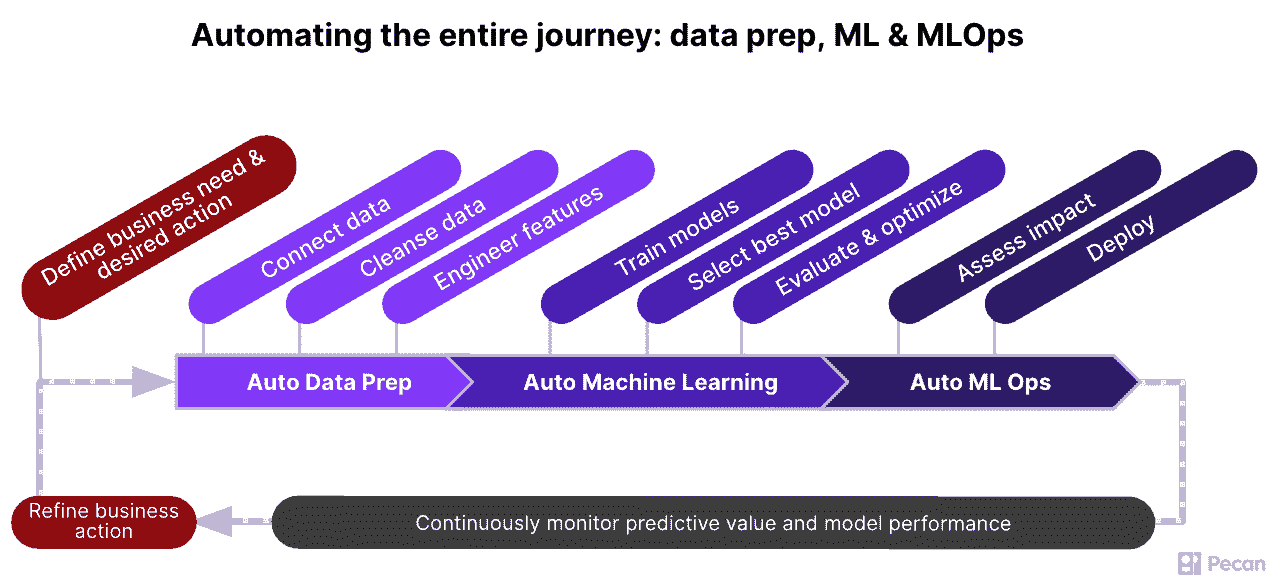
图片来源于 Pecan AI
为特定的机器学习应用推导出可重复的数据准备和特征工程框架
当企业使用其数据进行与频繁业务问题相关的建模时——如客户流失或终身价值——他们通常依赖于类似的数据集。这些数据集通常共享共同的元素。如果你检查足够多的这些数据集,就有可能识别出一组数据准备和特征工程任务,这些任务在这些数据集上始终需要执行。认识到这些共同点是开发可重复过程的第一步。
通过相对狭窄的预测建模应用关注,数据准备和特征工程不必是一个情境性的、临时的过程,每个新的数据集和项目都要重新发明。相反,这些任务可以通过精心编写的代码进行自动化,并在大量数据和多个项目中高效执行。这种自动化的方法比数据科学中普遍存在的即兴过程要快得多,更高效。
有些人可能会犹豫是否自动化特征工程与数据清洗,但这个过程也应该被自动化。在深度学习中,我们允许模型构建合适的特征。但由于某些原因,我们仍然坚持为表格数据手动创建特征。对表格数据进行自动化特征工程可以消除偏差,而自动化允许从人类能够手动创建和检查的特征中创建、评估和选择最真正有用的特征。
最重要的是,一个经过深思熟虑、严格应用的方法也能最大限度地提高结果数据集的质量。因为最终,高质量的数据对机器学习的成功至关重要——这是人工智能专家今天更广泛承认的事实。
数据中心化必须包括表格数据
在人工智能领域的讨论中,越来越多地引用“数据中心化人工智能”的概念。正如一个在线中心所说,数据中心化人工智能是“系统地工程化构建人工智能系统所用数据的学科”。像 Andrew Ng 这样的数据科学领袖普及了这个想法。然而,这些讨论再次集中在计算机视觉和自然语言处理应用上。
数据中心化人工智能的概念是对我们领域长期以来强调“海量数据”和不断完善和调整机器学习模型的平衡。数据中心化的观点认为,我们应该专注于优质数据,这些数据能够有效地训练即使是更简单的模型,以获得良好的性能。
这种观点还认为,算法创新和耗时的超参数调整只能在模型性能上带来有限的提升。然而,更加关注训练数据的质量可以在不重新发明每个新项目的算法轮子的情况下,为模型性能提供更显著的提升。
如果采用数据中心的方法处理表格数据、图像和文本数据会意味着什么?如上所述,表格数据可能难以解释,与图像或文本相比,数据集之间的关联性不那么明显。行和列可以包含多种数据,并意味着许多不同的事物。这种灵活性意味着更需要关注表格数据的质量。不幸的是,各种类型的数据错误在建模过程中可能会持续存在,数据专业人员可能在主观且不系统的特征工程过程中忽视潜在的有价值的特征。
假设我们花更多时间优化输入模型的表格数据质量。我们可以获得显著的性能提升——而无需使用最新的前沿算法或为每个项目手工构建工艺模型。
正如上述所述,通过精心设计的自动化,可以使数据清洗和特征工程过程变得更加可管理和可重复,这建立在在频繁的业务情境中常用的表格数据的重复框架之上。这种方法正是我共同创办的公司 Pecan AI 在处理与预测客户行为相关的高影响力业务用例时所采用的。我们已经自动化了大部分数据准备和特征工程过程,使预测分析变得更快、更易于访问,并且仍然异常准确。
尽管表格数据在商业中的重要性以及用这种数据形式进行创新的巨大潜力,但“表格”一词现在在数据中心人工智能的讨论中几乎消失了。现在是时候将更多的创新和自动化引入我们处理这种关键业务数据格式的方式了——特别是因为在商业应用中更好的模型表现可以显著影响企业的结果。我很高兴看到我们在技术和商业领域通过数据中心方法处理表格数据能取得什么成就。
诺姆·布雷泽斯 是 Pecan AI 的联合创始人兼首席技术官,Pecan AI 是全球唯一将数据科学的力量直接交到商业智能、运营和收入团队手中的低代码预测分析公司。Pecan 使公司能够充分利用 AI 和预测建模的力量,而无需在员工中配备数据科学家或数据工程师。诺姆拥有特拉维夫大学的计算神经科学博士学位、认知心理学硕士学位以及经济学和心理学学士学位。
更多相关话题
每一种复杂 DataFrame 操作,直观地解释与可视化
原文:
www.kdnuggets.com/2020/11/dataframe-manipulation-explained-visualized.html
评论
由 Andre Ye,Critiq 的联合创始人,Medium 的编辑和顶级作者。
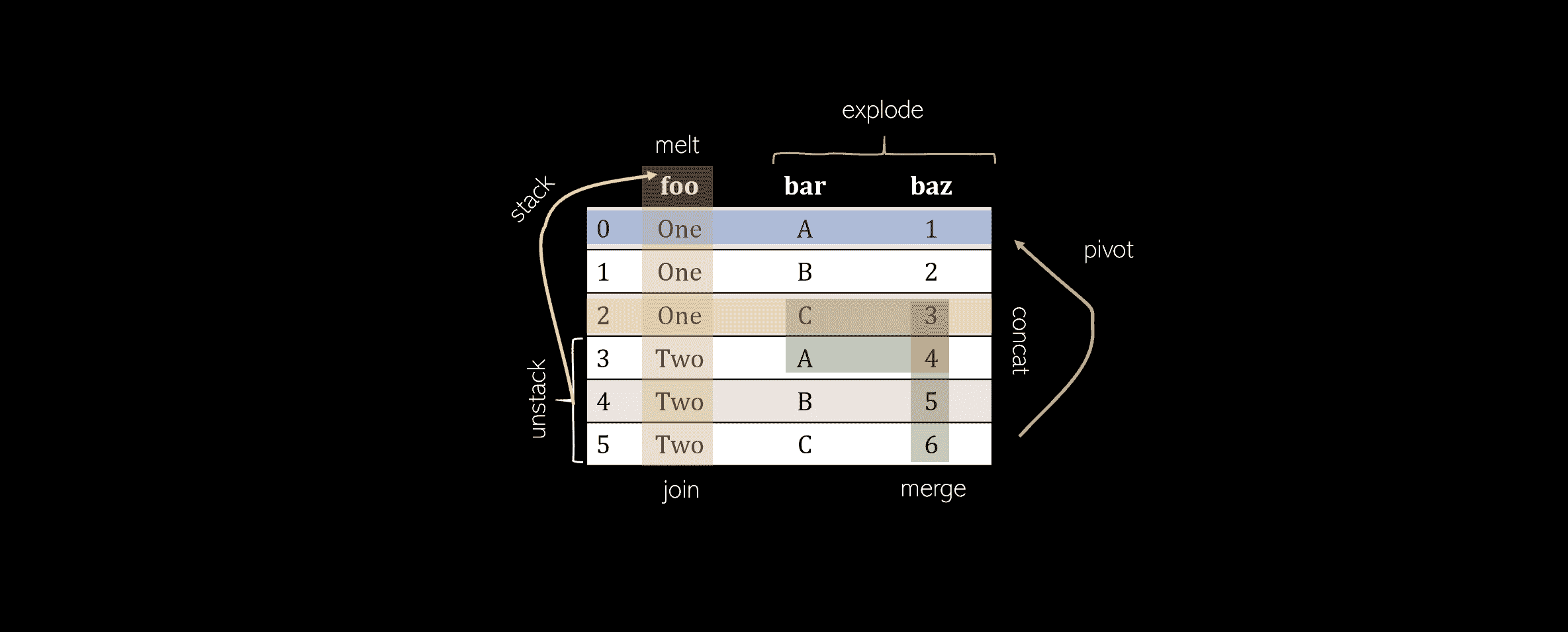
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你所在组织的 IT
Pandas 提供了广泛的 DataFrame 操作,但其中许多操作复杂且不易上手。本文介绍了 8 种基本的 DataFrame 操作方法,涵盖了数据科学家需要了解的几乎所有操作函数。每种方法将包括解释、可视化、代码以及记忆技巧。
Pivot
旋转一个表格会创建一个新的“旋转表”,将现有的数据列投影为新表中的元素,包括索引、列和值。初始 DataFrame 中将成为索引和列的列显示为唯一值,这两个列的组合将显示为值。这意味着旋转不能处理重复值。
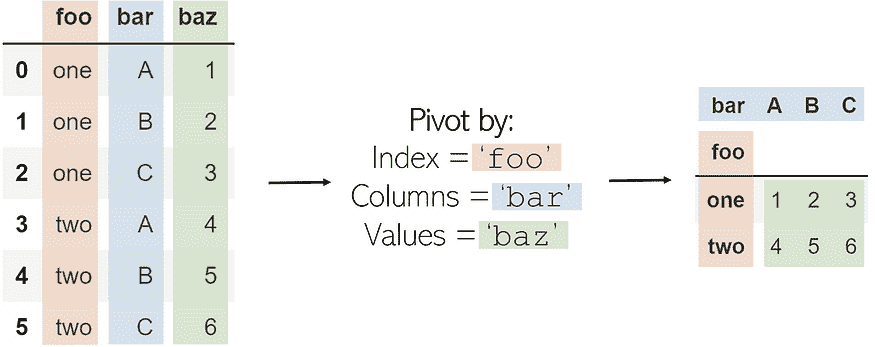
代码以旋转名为 df 的 DataFrame 如下:
df.pivot(index='foo', columns='bar', values='baz')
记忆技巧:在数据操作的领域之外,旋转是围绕某种对象进行的转动。在体育中,人们可以通过脚来“旋转”:pandas 中的旋转也是类似的。原始 DataFrame 的状态围绕 DataFrame 的中心元素旋转成一个新的 DataFrame。有些元素非常字面意义上旋转或转换(如列 bar)。
Melt
Melt 可以被视为一种“反旋转”,因为它将基于矩阵的数据(具有两个维度)转换为基于列表的数据(列表示值,行表示唯一数据点),而旋转则相反。考虑一个二维矩阵,其中一个维度为 B 和 C(列名),另一个维度为 a、b 和 c(行索引)。
我们选择一个 ID、一个维度以及一个或多个列来包含值。包含值的列被转换为两列:一列用于变量(值列的名称),另一列用于值(包含的数字)。
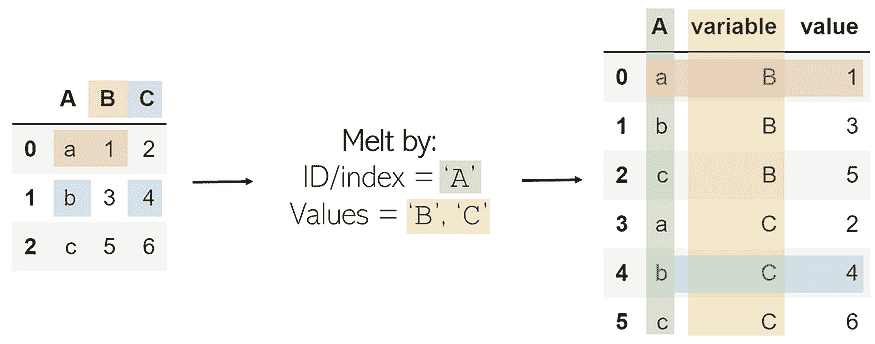
结果是 ID 列值(a, b, c)和值列(B, C)的每种组合,以及其对应的值,以列表格式组织。
melt 操作可以这样在 DataFrame df 上执行:
df.melt(id_vars=['A'], value_vars=['B','C'])
记住: 将某物像蜡烛一样融化,是将一个固化的复合物转变为几个更小的独立元素(蜡滴)。融化一个二维 DataFrame 会解开其固化的结构,并将其各部分记录为列表中的独立条目。
爆炸
爆炸是一个有用的方法,可以清除数据中的列表。当某列被爆炸时,列中的所有列表都作为新行列出在相同的索引下(为避免此情况,只需在之后调用 .reset_index())。非列表项如字符串或数字不会受到影响,空列表是 NaN 值(可以使用 .dropna() 清理这些)。
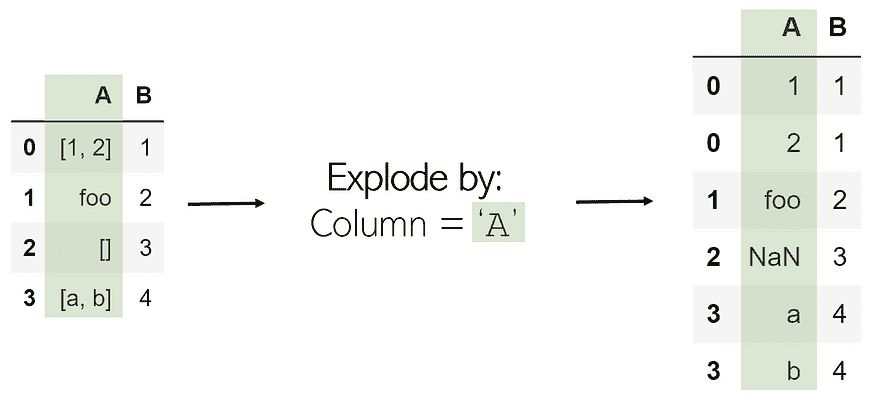
爆炸 DataFrame df 中的列 ‘A’ 非常简单:
df.explode(‘A’)
记住: 爆炸某物会释放其所有内部内容——爆炸一个列表会将其元素分开。
堆叠
堆叠将任何大小的 DataFrame 进行‘堆叠’,将列作为现有索引的子索引。因此,结果 DataFrame 只有一列和两个层级的索引。
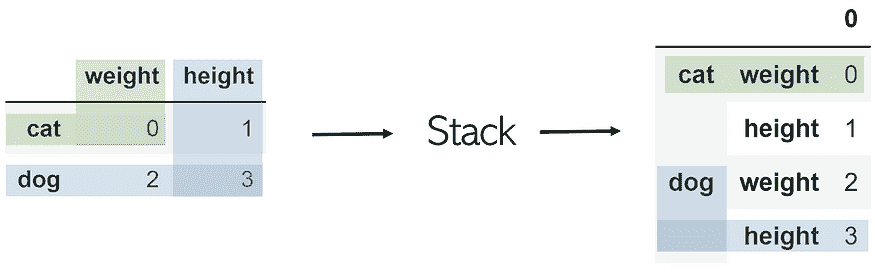
对名为 df 的表格进行堆叠非常简单,使用 df.stack()。
为了访问,比如说,狗的身高,只需调用基于索引的检索两次,如 df.loc[‘dog’].loc[‘height’]。
记住: 从视觉上看,stack 将表格的二维性转换为将列堆叠成多层索引。
Unstack
Unstacking 将一个多层索引的 DataFrame 进行“展开”,将指定层级的索引转换为新 DataFrame 的列,并附上其对应的值。对一个表格执行一次 stack 再执行一次 unstack 不会改变它(不考虑存在的‘0’)。
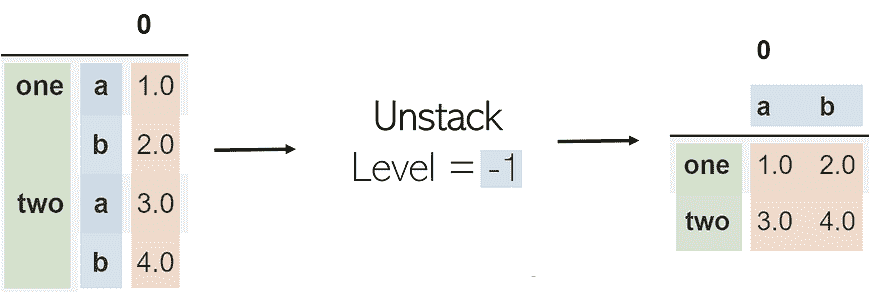
Unstacking 的一个参数是层级。在列表索引中,-1 索引会返回最后一个元素;层级也是如此。层级为 -1 表示将最后一个索引层级(最右边的那个)展开。举个进一步的例子,当层级设置为 0(第一个索引层级)时,它中的值会变成列,而接下来的索引层级(第二个)则会变成变换后 DataFrame 的索引。
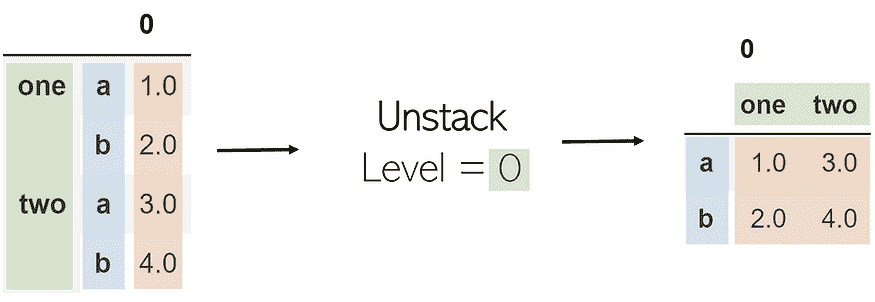
Unstacking 的操作方式与 stacking 相同,但需要层级参数:df.unstack(level=-1)。
记住: Unstack 意思是“撤销堆叠”。
合并
合并两个 DataFrame 是在共享的‘键’上将它们按列(水平)组合起来。这个键允许将表格合并,即使它们的顺序不同。完成合并的 DataFrame 将默认在值列上添加后缀 x 和 y。
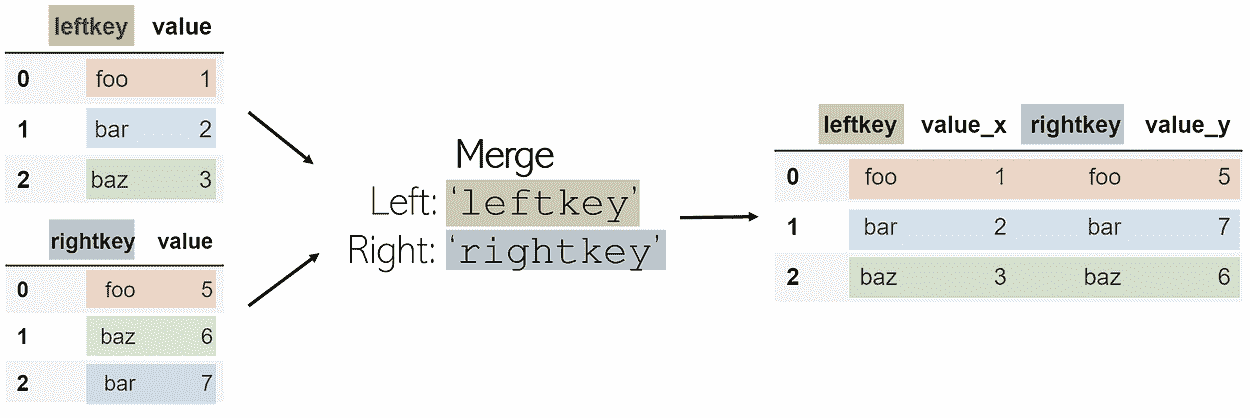
要合并两个 DataFrames df1 和 df2(其中 df1 包含 leftkey,df2 包含 rightkey),调用:
df1.merge(df2, left_on='leftkey', right_on='rightkey')
合并不是 pandas 的函数,而是附加到 DataFrame 上的。总是假定合并附加到的 DataFrame 是‘左表’,而在函数中作为参数调用的 DataFrame 是‘右表’,并具有对应的键。
合并函数默认执行的是所谓的内连接(inner join):如果每个 DataFrame 中有一个在另一个 DataFrame 中未列出的键,则该键不会包含在合并后的 DataFrame 中。另一方面,如果一个键在同一个 DataFrame 中列出两次,那么所有相同键的值组合都会在合并后的表中列出。例如,如果 df1 中的键 foo 有 3 个值,而 df2 中有 2 个相同键的值,则最终 DataFrame 中会有 6 个条目,其中 leftkey=foo 和 rightkey=foo。
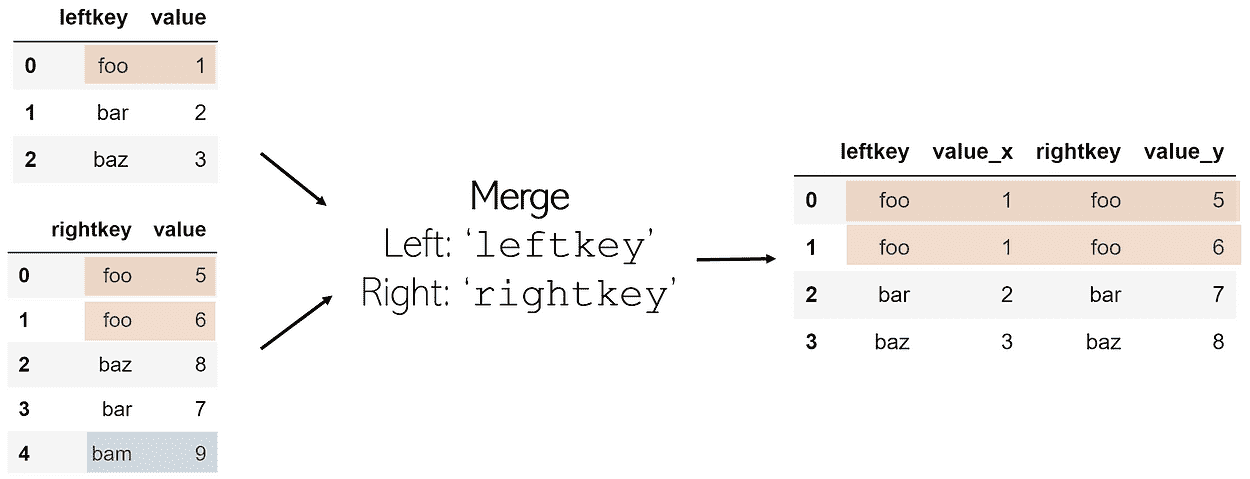
记住:合并 DataFrames 就像在驾驶时合并车道 —— 水平地进行。想象每一列都是高速公路上的一个车道;为了合并,它们必须水平结合。
连接(Join)
连接(Joins)通常比合并(merge)更受青睐,因为它具有更简洁的语法和更广泛的水平合并 DataFrames 的可能性。连接的语法如下:
df1.join(other=df2, on='common_key', how='join_method')
使用连接时,公共键列(类似于合并中的 right_on 和 left_on)必须命名相同。 how 参数是一个字符串,指代 join 可以将两个 DataFrame 组合在一起的四种方法之一:
-
‘left’:包括所有 df1 的元素,仅当 df2 的键是 df1 的键时才附加 df2 的元素。否则,合并后的 DataFrame 中 df2 的缺失部分将标记为 NaN。
-
‘right’:‘left’,但在另一个 DataFrame 上。包括所有 df2 的元素,仅当 df1 的键是 df2 的键时。
-
‘outer’:包括两个 DataFrame 中的所有元素,即使一个键在另一个 DataFrame 中不存在 —— 缺失的元素标记为 NaN。
-
‘inner’:仅包括键在两个 DataFrame 键中都存在的元素(交集)。合并的默认设置。
记住:如果你曾使用 SQL,那么‘join’一词应该立即与你的列级添加关联。如果没有,那么‘join’和‘merge’在定义上非常相似。
连接(Concat)
合并(merges)和连接(joins)是水平操作,而连接(concatenations)或简称为 concats,则是按行(垂直)附加 DataFrames。例如,考虑两个具有相同列名的 DataFrames df1 和 df2,使用 pandas.concat([df1, df2]) 进行连接:
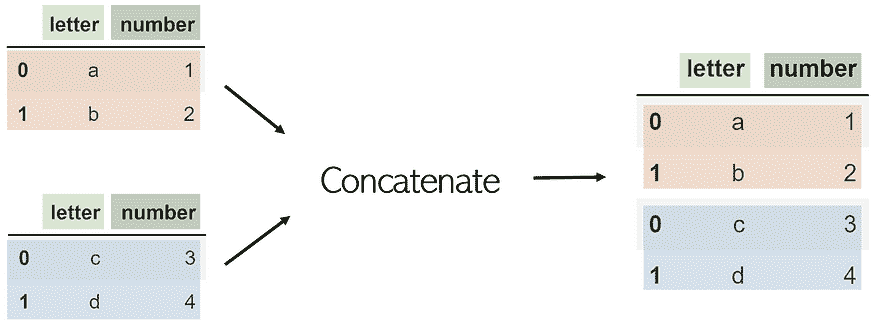
虽然你可以通过将轴参数设置为 1 使用 concat 进行列级连接,但直接使用 join 会更方便。
请注意,concat 是 pandas 的函数,而不是 DataFrame 的函数。因此,它接收一个需要连接的 DataFrame 列表。
如果 DataFrame 有一个不包含在另一个 DataFrame 中的列,默认情况下,该列会被包括在内,缺失值列为 NaN。为了避免这种情况,添加一个额外的参数,join=’inner’,这将只连接两个 DataFrame 共有的列。
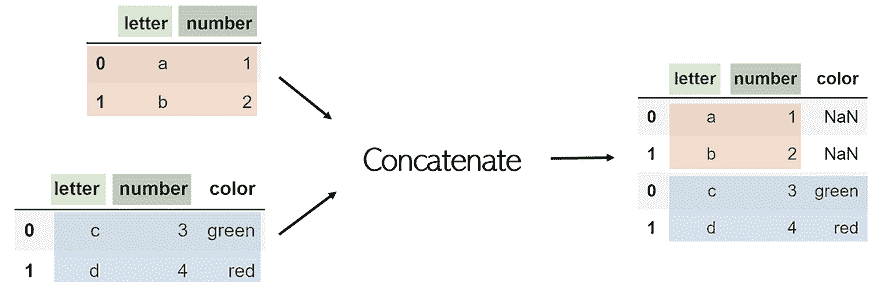
记住: 在列表和字符串中,可以追加额外的项目。连接是将额外的元素附加到现有内容中,而不是添加新信息(如按列连接)。由于每个索引/行是一个单独的项,连接会将额外的项添加到 DataFrame 中,可以将其视为行的列表。
Append 是另一种合并两个 DataFrame 的方法,但它执行与 concat 相同的功能,效率和灵活性较低。
有时内置函数不够用。
尽管这些函数覆盖了你可能需要的数据操作范围,但有时所需的数据操作过于复杂,一个或一系列函数无法完成。探索复杂的数据操作方法,如解析函数、迭代投影、高效解析等,更多内容请见这里。
原始文档。经许可转载。
相关:
更多相关话题
数据科学 PoC 的 7 个步骤 – 获取指南
原文:
www.kdnuggets.com/2018/02/dataiku-7-steps-data-science-poc-guidebook.html
|
|
|
|
| |
|
让你的下一个数据科学 PoC 取得成功
|
| 数据科学或分析的 PoC(概念验证)不仅仅是一个概念;它是一个必须产生结果的过程。有关成功运行 PoC 的七个步骤的详细指南,从选择用例到定义交付物及其中的所有内容,免费下载白皮书《推动成功数据科学 PoC 的 7 个步骤》。|
| |
| |
|
|
|
|
更多相关内容
实现数据科学生产的检查清单
原文:
www.kdnuggets.com/2017/06/dataiku-checklist-data-science-implemented-production.html
由 Dataiku 提供。赞助文章。
构建数据科学项目和训练模型只是第一步。将模型投入生产环境是公司经常失败的地方。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
实际上,将模型实施到现有的数据科学和 IT 堆栈中对许多公司来说非常复杂。原因?设计环境和实际生产环境之间的工具和技术的不一致。
一年多来,我们调查了成千上万家公司涵盖各种行业和数据科学发展,了解他们如何克服这些困难,并分析了结果。以下是你在设计到生产管道中需要牢记的关键事项。
1. 你的打包策略
数据项目是复杂的。它包含大量不同格式的数据存储在不同位置,还有很多代码行和脚本,这些代码和脚本用不同的语言将原始数据转换为预测。如果你不支持在生产过程中对代码或数据进行适当打包,这将会很棘手,尤其是当你处理预测时。
典型的发布流程应包括:
-
设立版本控制工具来管理代码版本。
-
创建打包脚本,将代码和数据打包成 zip 文件。
-
将其部署到生产环境中。
2. 你的模型优化和再训练
小的迭代是长期准确预测的关键,因此建立一个重新训练、验证和部署模型的流程至关重要。实际上,模型需要不断发展,以适应新行为和基础数据的变化。
高效重新训练的关键是将其设置为数据科学生产工作流中的一个独立步骤。换句话说,一个自动命令每周重新训练一个预测模型候选者,对该模型进行评分和验证,并在经过人工操作员简单验证后进行更换。
3. 你的业务团队的参与
在我们的调查中,我们发现公司报告在生产部署中遇到许多困难与业务团队的有限参与之间存在强烈的相关性。
在项目开发过程中,这是至关重要的,以确保最终产品对业务用户是可理解和可用的。一旦数据产品投入生产,它仍然是业务用户评估模型性能的重要成功因素,因为他们的工作基于此。实现这一点有多种方式;最受欢迎的方法是设置实时仪表板以监控并深入了解模型性能。自动发送包含关键指标的电子邮件可能是一个更安全的选择,以确保业务团队随时掌握信息。
4. 你的 IT 环境一致性策略
现代数据科学依赖于多种技术,如 Python、R、Scala、Spark 和 Hadoop,以及开源框架和库。当生产环境依赖于 JAVA、.NET 和 SQL 数据库等技术时,这可能会导致问题,因为可能需要对项目进行完全重编码。
工具的增多也会带来维护生产环境和设计环境的困难,需要保持当前版本和软件包(一个数据科学项目可能依赖于多达 100 个 R 包、40 个 Python 包和数百个 Java/Scala 包)。为了解决这个问题,两种流行的解决方案是维护一个通用包列表或为每个数据项目设置虚拟机环境。

5. 你的回滚策略
在有效的监控到位之后,下一个里程碑是建立回滚策略,以应对性能指标下降的情况。回滚策略基本上是一个保险计划,以防你的生产环境失败。
一个好的回滚策略必须包括数据项目的所有方面,包括数据、数据模式、转换代码和软件依赖关系。它还必须是用户(即使他们不是经过培训的数据工程师)可以访问的过程,以确保在失败时能快速反应。
6. 你的项目和流程的可审计性
能够审计以了解每个输出版本对应哪个代码是至关重要的。追踪数据科学工作流对于追踪任何不当行为、证明没有非法数据使用或隐私侵犯、避免敏感数据泄漏,或展示数据流的质量和维护都非常重要。
控制版本的最常见方法是(毫不意外地)Git 或 SVN。然而,保持有关数据库系统的信息日志(包括表创建、修改和架构更改)也是一种最佳实践。

7. 无论你的用例是否需要实时评分或在线机器学习
实时评分和在线学习在许多用例中越来越受欢迎,包括评分欺诈预测或定价。许多进行评分的公司使用批处理和实时评分的组合,甚至仅使用实时评分。越来越多的公司报告使用在线机器学习。
这些技术在生产环境、回滚和故障转移策略、部署等方面带来了复杂性。然而,它们并不需要为这些技术设置独立的过程和堆栈,只需要监控调整。

8. 你的系统和过程的可扩展性
随着数据科学系统在数据量和数据项目的增加中扩展,保持性能至关重要。这意味着建立一个足够弹性的系统,以应对显著的过渡,不仅是数据的纯量或请求数量,还有复杂性或团队可扩展性。
但可扩展性问题可能会意外出现,例如未清空的垃圾箱、大量日志文件或未使用的数据集。通过制定检查工作流效率或监控作业执行时间的策略来预防这些问题。
如果你想要了解更多关于优化设计到生产过程的最佳实践,可以查看我们的广泛生产调查结果。
更多相关主题
Dataiku 数据科学工作室
原文:
www.kdnuggets.com/2014/08/dataiku-data-science-studio.html
,一个完整的数据科学软件工具,为开发人员和分析师显著缩短了在构建预测应用时耗时的加载、清理、训练、测试和部署周期。我们 Dataiku 通过尝试捕捉数据科学家日常工作的方式构建了这款软件。我们认为统计软件需要适应大数据时代,在这个时代,数据集成和数据管道能力比以往任何时候都更为重要。
加载和准备
首先,DSS 能够直接快速连接到当前最常见的数据源(Hadoop、SQL、Cassandra、MongoDB、S3 等)和格式(CSV、Excel、SAS、JSON、Avro 等)。连接到数据源后,任何严肃的建模工作中的第一步是清理数据。如你所知,这一过程通常占据数据科学家多达 80% 的时间。为了加快这一进程,我们的工作室配备了强大的数据集成功能。首先,DSS 会自动推断数据的智能数据类型(如性别、国家、IP 地址、URL、日期等)。分析师可以利用这些智能数据类型以自动化的方式验证和转换数据(如从 IP 中提取国家、从日期中提取星期几等)。他们还可以在 DSS 的界面上执行更平凡的任务,如替换、分组、拆分、计算等,该界面会即时显示任何操作的可视化反馈。
建模:从列到预测
一旦数据清理完毕且丰富,用户可以训练监督式或非监督式模型。它会自动创建一个可调的特征工程管道,包括缺失值填补、虚拟变量编码、影响编码、特征生成和降维。
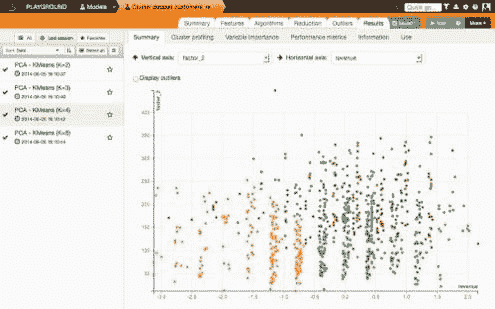
然后,它使用流行的 Scikit-Learn 和 H2O 框架中的算法训练不同的模型。用户可以比较模型、分析其性能,并通过 Web UI 调整所有参数。致力于白盒方法,DSS 允许高级用户为整个管道生成完整的 Python 源代码(用 Python 编写),以便他们可以随意修改。
从模型到预测应用
一旦模型建立,用户可以创建强大且可重复的工作流,支持重新训练或评分。这些工作流包括从原始数据到预测的完整数据流程。工作流引擎是增量的(例如,它可以在每小时更新的数据上增量工作)且稳健的(它可以智能地从部分数据暂时不可用的情况中恢复)。这些工作流可以通过 Python、R、SQL 或 Pig 中的自定义代码扩展,支持完全的 Hadoop 基础负载。预测值可以通过 REST API 访问或由 DSS 直接发布到各种目标(例如 ElasticSearch、FTP 服务器、内部数据仓库)。
我们构建了数据科学工作室,以缩短负载-清理-训练-测试周期,而不降低其复杂度;这是一个面向合格数据科学家的工具,同时对技术水平较低的商业智能或营销人员也保持可访问性。
免费社区版可用(限制为 100,000 行和一个用户)。工具的免费试用版也可在 www.dataiku.com/products/trynow/ 获取。
简要作者简介:
 Florian 是 Dataiku 的首席执行官。他在巴黎的一家搜索引擎技术公司 Exalead 开始了他的技术职业生涯。在那里,他领导了由 50 位才华横溢的数据极客组成的研发团队,直到公司在 2010 年的 1.5 亿美元退出。Florian 随后成为了社交游戏领域的欧洲领军企业 IsCool 的首席技术官。Florian 还曾作为自由职业首席数据科学家在多家公司工作,例如欧洲广告领军者 Criteo。Florian 定期在技术论坛如 Open World Forum 或巴黎 Java 用户组上发表演讲。
Florian 是 Dataiku 的首席执行官。他在巴黎的一家搜索引擎技术公司 Exalead 开始了他的技术职业生涯。在那里,他领导了由 50 位才华横溢的数据极客组成的研发团队,直到公司在 2010 年的 1.5 亿美元退出。Florian 随后成为了社交游戏领域的欧洲领军企业 IsCool 的首席技术官。Florian 还曾作为自由职业首席数据科学家在多家公司工作,例如欧洲广告领军者 Criteo。Florian 定期在技术论坛如 Open World Forum 或巴黎 Java 用户组上发表演讲。
相关:
-
GraphLab 会议,图分析和机器学习,旧金山 7 月 21 日
-
KDnuggets 分析、数据挖掘、数据科学软件调查 – 已分析
-
使用 H2O 深度学习,5 月 21 日网络讲座
相关主题
Dataiku DSS 3.1 – 现在支持 5 种机器学习后端和 Scala!
原文:
www.kdnuggets.com/2016/08/dataiku-dss-31-machine-learning-backends-scala.html
 |
|
|---|---|
 |
|
| Dataiku DSS 3.1 现在支持 5 种机器学习后端和 Scala!
Dataiku DSS 3.1 引入了新的视觉机器学习引擎,允许用户在无代码接口中创建强大的预测应用程序。所有技能水平的用户现在都可以直接在 Dataiku DSS 3.1 的视觉分析部分中使用HPE Vertica 机器学习、H2O Sparkling Water、MLlib、Scikit-Learn 和 XGBoost,在数据科学项目中应用强大的机器学习算法,而无需编写一行代码。
视觉无代码和自由形式代码转换的融合是 Dataiku DSS 在数据应用原型制作和生产中的主要优势之一。除了Python、R、SQL、Hive、Impala 和 Pig,Dataiku DSS 3.1 现在还允许 Apache Spark 用户用 Scala 编写转换和交互式笔记本,将 Spark 的原生和最高效的语言的力量带给使用 Dataiku DSS 的数据分析师。
 |
 |
| Dataiku DSS 3.1 的其他功能包括:
-
新的外部数据库:与 IBM Netezza、Hana 和 Big Query 的集成。
-
改进的用户体验:流畅的导航和项目依赖关系,优化用户体验和项目管理。
-
与 Tableau 的无缝集成:用户可以通过为数据集创建自定义导出格式(包括 Tableau .tde 文件)来扩展 Dataiku DSS 的兼容性。这允许与 Tableau 和其他工具更好地集成。
|
|---|
| www.dataiku.com | 联系我们 |
更多相关主题
自助分析和运营化——为什么你需要两者
原文:
www.kdnuggets.com/2018/11/dataiku-self-service-analytics-operationalization.html
赞助文章。
|
| |
|
|
|
| |
|
|
|
通过运营化 + 自助分析启用 AI 服务
|
|
|
|
许多希望变得更具数据驱动的组织会问:自助分析(SSA)还是数据科学运营化(o16n)——哪一个能让我达到目标?答案是:你需要两者结合。
获取白皮书 以了解今天顶级数据驱动公司如何扩展其高级分析和机器学习工作。
|
|
|
| |
|
|
| |
|
|
|
| |
|
更多相关话题
DataLang:为数据科学家设计的新编程语言……由 ChatGPT 创建?
原文:
www.kdnuggets.com/2023/04/datalang-new-programming-language-data-scientists-chatgpt.html

图片由作者使用 Midjourney 创建
这篇文章将为你提供一个关于我给 ChatGPT 运行的项目概述,即创建一种新的数据科学导向编程语言。详细内容都在下面,但由于一些原因可能会在后续阅读中显现,我想给 ChatGPT 一个机会,以引人入胜的方式介绍这门语言。而且,它确实很棒。所以先阅读这篇文章,然后我们可以在另一端进一步讨论。
数据科学的世界即将经历一次震撼性的变革,随着一种为数据科学家量身定制的开创性编程语言的出现。在今天的文章中,我们将带你深入了解这一革命性语言的构思、开发和实现过程:DataLang。
想象一下,一种语言被精心设计以简化你的数据科学任务,聚焦于可用性、效率和协作。这样一种语言旨在打破障碍,将你的数据驱动洞察推向前所未有的高度。DataLang 是那些渴望更强大工具集的数据科学家和分析师的答案,这些工具集专门为他们独特的需求和挑战量身定制。
在这篇引人入胜的揭秘文章中,我们将探讨 DataLang 的构思及其成为数据科学领域最受欢迎语言的历程。加入我们,揭示独家见解、意外挑战以及关键时刻,这些都是让 DataLang 成为现实的因素,由让这一切成为可能的团队亲自叙述。
但要小心——这不是普通的博客文章。我们将揭示隐藏的宝藏和令人瞠目的功能,这些都将令你着迷、投入,并让你渴望更多。DataLang 的揭示只是开始,相信我们,你不会想错过一行代码。
所以,做好准备,迎接数据科学未来的激动人心的旅程,让 DataLang 引领你的道路。旅程开始吧!
至少我们没有一开始就过度夸张这个概念……
初步设计
最近,我给 ChatGPT-4 任务,让它为数据科学家设计一种新的编程语言,适合他们日常的工作任务。这是设置新任务的初步提示:
你是一位经验丰富的计算机科学家,专注于系统编程。一个数据科学团队找到了你,要求你设计一种新的编程语言,专门为数据导向任务而优化,使其非常适合数据科学家在日常工作中使用。提供这种语言的高级描述;它与其他流行的数据科学语言(如 Python、R 和 SQL)有何不同;这种语言最重要的特性是什么;可能遇到的问题是什么;以及你认为其他重要的内容。请记住,它的标准库和内置功能应提供尽可能多的支持,以满足日常数据科学操作的需求。编写一个简短的程序来演示这种语言的特性、语法和功能。
语言名称:DataLang
高级描述
DataLang 是一种专门为数据导向任务设计的语言,优化了在数据科学应用中的性能和易用性。它结合了 Python、R 和 SQL 的最佳特性,并拥有独特的功能,旨在简化数据科学工作流程。
关键区分特征
原生数据结构:DataLang 将具有内置的数据结构,如数据框和张量,这些结构在数据科学任务中常被使用。这些结构将集成功能以处理缺失值、强制执行模式和数据类型强制转换。
延迟求值:为了提高性能,DataLang 将对数据操作任务使用延迟求值,只有在必要时才执行操作。这可以节省内存和计算时间,特别是在处理大型数据集时。
查询能力:受 SQL 启发,DataLang 将具有内置的查询能力,允许用户在不需要外部库的情况下过滤、排序、连接和聚合数据。
集成可视化:DataLang 将具有内置的可视化库,支持各种图表类型并且易于自定义。可视化功能将与原生数据结构无缝集成。
函数式和并行编程:DataLang 将鼓励函数式编程实践,并支持并行处理,以便在大规模数据任务中获得更好的性能。
广泛的库:DataLang 将拥有广泛的标准库,重点关注统计分析、机器学习、深度学习、自然语言处理和时间序列分析。
互操作性:DataLang 将支持与其他流行语言如 Python 和 R 的互操作性,允许用户利用现有的库和代码库。
可能存在的问题
采用:作为一种新语言,DataLang 可能面临吸引用户和建立强大社区的挑战。
兼容性:确保与现有工具、库和平台的兼容性对 DataLang 的成功至关重要。
性能优化:平衡易用性和性能优化将是一个持续的挑战。
DataOps:5 个你需要了解的关键点
原文:
www.kdnuggets.com/2021/05/dataops-5-things-need-know.html
comments
由 Sigmoid 提供
1. 什么是 DataOps?
我们的 Top 3 课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
简而言之,DataOps 可以定义为一种方法论,它为数据管道提供了速度和敏捷性,从而提升数据质量和交付实践。DataOps 促成 了组织内部的更大协作,并在大规模推动数据项目。借助 自动化,DataOps 改善了数据的可用性、可访问性和集成性。它将人员、流程和技术结合起来,为所有利益相关者提供可靠且高质量的数据。根植于敏捷方法论,DataOps 旨在通过持续交付分析洞察来提供最佳的消费者体验。
2. DataOps 和 DevOps 有何不同?
DataOps 通常被视为应用于数据分析的 DevOps。然而,DataOps 不仅仅是这样。它还结合了数据工程师和数据科学家的关键能力,为数据驱动的企业提供了一个强大的、过程驱动的结构。DevOps 结合了软件开发和 IT 运维,以确保系统开发生命周期中的持续交付。而 DataOps 还带来了数据链中关键参与者——数据开发者、数据分析师、数据科学家和数据工程师的专业能力——以确保数据流开发中的更大协作。此外,在比较 DataOps 和 DevOps 时,值得注意的是,DevOps 关注于转变软件开发团队的交付能力,而 DataOps 则通过数据工程师的帮助,强调分析模型和智能系统的转型。
3. 为什么 DataOps 对数据工程至关重要?
数据工程师在确保数据在整个分析流程中得到妥善管理方面发挥着重要作用。此外,他们还负责数据的最佳使用和安全。DataOps 通过提供工具、数据、代码和组织数据环境的端到端编排,帮助数据工程师促进关键功能领域。它可以促进团队之间的协作和沟通,以适应不断变化的客户需求。简单来说,DataOps 通过提供各数据利益相关者之间更大的协作,帮助数据工程师实现可靠性、可扩展性和灵活性,从而增强他们的能力。
4. DataOps 工程师在实现先进企业分析中扮演什么角色?
现在,DataOps 工程师的角色与数据工程师略有不同。DataOps 工程师仔细定义和管理数据开发的环境。这个角色还包括为数据工程师提供关于工作流的指导和设计支持。至于先进企业分析,DataOps 工程师在自动化数据开发和集成方面发挥着重要作用。凭借对软件开发和敏捷方法论的深入了解,DataOps 工程师通过元数据目录跟踪文档来源,并建立指标平台以标准化计算,从而为企业分析做出贡献。DataOps 工程师的一些关键角色包括:
-
测试自动化
-
代码库创建
-
框架编排
-
协作和工作流管理
-
数据溯源和影响分析
-
数据准备和集成
5. DataOps 团队常用的流行技术平台有哪些?
可以公平地说,DataOps 仍然是一个不断发展的学科,数据驱动的组织每天都在不断学习。然而,随着技术创新,许多平台已经在行业中留下了印记,并在不断扩大其影响力。以下是一些 DataOps 团队常用的流行平台。
-
Kubernetes
Kubernetes 是一个开源编排平台,允许公司将多个 docker 容器组合成一个单一的单位。这使得开发过程变得更加快捷和简单。Kubernetes可以帮助团队在单个集群中的节点上管理数据调度,简化工作负载,并将容器分类为逻辑单元,以便于发现和管理。
-
ELK(Elasticsearch、Logstash、Kibana)
Elastic 的 ELK Stack 是一个广泛使用的日志管理平台,包含三个不同的开源软件包——Elasticsearch、Logstash 和 Kibana。Elasticsearch 是一个运行在 Lucene 搜索引擎上的 NoSQL 数据库,而 Logstash 是一个接受来自多个来源的数据输入并进行数据转换的日志管道解决方案。Kibana 则本质上是一个在 Elasticsearch 之上操作的可视化层。
-
Docker
Docker 平台通常被认为是最简单明了的工具,可以帮助公司使用容器扩展高端应用,并安全地在云上运行它们。安全性是区别该平台的关键方面之一,因为它提供了一个用于测试和执行的安全环境。
-
**Git **
Git 是一款领先的版本控制应用程序,允许公司有效地管理和存储数据文件中的版本更新。它可以控制和定义特定的数据分析管道,如源代码、算法、HTML、参数文件、配置文件、容器和日志。由于这些数据工件只是源代码,Git 使它们容易被发现和管理。
-
**Jenkins **
Jenkins 是一个开源的基于服务器的应用程序,帮助公司无缝地协调一系列活动,以实现持续自动化集成。该平台支持从开发到部署的应用程序端到端开发生命周期,同时通过自动化测试加速过程。
-
Datadog
Datadog 是一个开源的云监控平台,通过统一的仪表板,帮助公司全面监控应用堆栈中的指标、追踪和日志。该平台提供了约 400 个内置集成和一个预定义的仪表板,简化了流程。
汇总
随着时间的推移,企业 AI 和 ML 应用的复杂性和规模只会增加,从而推动数据管理实践的融合需求。为了满足客户需求并更快地部署应用程序,组织需要调和数据目录和访问功能,同时确保完整性。而这正是 DataOps 实践能够帮助公司创造差异的地方。
简介:Jagan 是一位 Dev Ops 宣导者,领导 Sigmoid 的 Dev Ops 实践。他在维护和支持客户在消费品、零售、广告科技、金融、快餐和高科技垂直行业中的关键数据系统方面发挥了重要作用。
原文。转载已获许可。
相关:
-
在 Databricks 上使用 MLflow 进行模型实验、跟踪和注册
-
数据科学家、数据工程师及其他数据职业解读
-
为什么你应该考虑成为数据工程师而不是数据科学家
了解更多相关话题
如何构建由机器学习驱动的智能仪表板
原文:
www.kdnuggets.com/2018/06/datarobot-build-intelligent-dashboards-powered-machine-learning.html
|
|
| |
|  |
|
| |
|
|
|
| |
| |
| |
| 网络研讨会 - 2018 年 6 月 5 日星期二 1:00 pm ET/ 10:00 am PT - 45 分钟问答环节 |
| |
|
| 注册 |
|
| |
|
|
| |
|
| |
|
| |
|
|
| |
|
在当今数据驱动的激烈竞争时代,获取洞察的速度已成为成功的关键。预测模型的价值很小,除非它们能迅速在您的业务中投入使用。商业分析师通过改善数据洞察和提供具有机器学习功能的主动“智能”仪表板,可以取得巨大进步。
在这次网络研讨会中,分析行业专家 Jen Underwood,Impact Analytix 的创始人,将演示如何使用 Tableau、Qlik、Microsoft Power BI 甚至 Excel 等仪表板工具可视化机器学习结果。只需几次鼠标点击,您就可以切片、切块、最大化,并将机器学习的价值转化为可操作的智能仪表板。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 工作
网络研讨会参与者将:
-
学习“智能”仪表板的常见业务用例
-
发现可视化预测模型的最佳方法
-
观看使用 DataRobot 和 Tableau 实时创建智能仪表板
|
| |
|
|
| |
|
| 注册 |
|
| |
|
|
|
|
| |
| DataRobot 公司,国际广场 5 楼,波士顿,MA 02110 |
| |
|
相关话题
异常检测简介
原文:
www.kdnuggets.com/2017/04/datascience-introduction-anomaly-detection.html
由 DataScience.com 提供赞助。
本概述旨在为数据科学和机器学习领域的初学者提供指导。几乎不需要正式的专业经验,但读者应具备一些基本的微积分(特别是积分)、编程语言 Python、函数式编程和机器学习的知识。
简介:异常检测
异常检测是一种用于识别不符合预期行为的异常模式的技术,这些模式被称为离群点。它在商业中有许多应用,从入侵检测(识别可能表示黑客攻击的网络流量中的异常模式)到系统健康监测(在 MRI 扫描中发现恶性肿瘤),以及信用卡交易中的欺诈检测到操作环境中的故障检测。
本概述将涵盖几种检测异常的方法,以及如何使用简单移动平均(SMA)或低通滤波器在 Python 中构建检测器。
图 1. 太阳黑子的异常
什么是异常?
在开始之前,重要的是建立异常的定义边界。异常可以广泛地分类为:
-
点异常: 如果数据的单个实例与其他数据偏差过大,则该实例异常。 业务用例: 基于“消费金额”检测信用卡欺诈。
-
上下文异常: 异常是特定于上下文的。这种类型的异常在时间序列数据中很常见。 业务用例: 在假期期间每天花费 100 美元用于食物是正常的,但其他时候可能会显得异常。
-
集体异常: 一组数据实例集体有助于检测异常。 业务用例: 某人意外地尝试从远程机器复制数据到本地主机,这种异常将被标记为潜在的网络攻击。
异常检测类似于 - 但不完全相同于 - 噪声去除和新颖性检测。 新颖性检测 关注于识别新观察中未包含在训练数据中的未观察到的模式 - 比如圣诞节期间对 YouTube 新频道的突然兴趣。 噪声去除 (NR) 是保护分析免受不必要观察发生的过程;换句话说,就是从原本有意义的信号中去除噪声。
异常检测技术
简单统计方法
识别数据异常的最简单方法是标记那些偏离分布的常见统计属性的数据点,包括均值、中位数、众数和分位数。假设异常数据点的定义是偏离均值一定标准差的数据点。遍历时间序列数据的均值并不完全简单,因为它不是静态的。你需要一个滚动窗口来计算数据点的平均值。从技术上讲,这叫做滚动平均或移动平均,旨在平滑短期波动并突出长期波动。从数学上讲,n 期简单移动平均也可以定义为“低通滤波器”。(卡尔曼滤波器是这种度量的更复杂版本;你可以在这里找到一个非常直观的解释。)
挑战 低通滤波器可以帮助你在简单用例中识别异常,但在某些情况下,这种技术可能不起作用。以下是一些例子:
-
数据中包含的噪声可能类似于异常行为,因为正常行为和异常行为之间的边界通常并不精确。
-
异常或正常的定义可能会频繁变化,因为恶意对手会不断适应。因此,基于移动平均的阈值可能并不总是适用。
-
这种模式基于季节性。这涉及到更复杂的方法,例如将数据分解为多个趋势,以识别季节性的变化。
基于机器学习的方法
下面是流行的基于机器学习的异常检测技术的简要概述。
基于密度的异常检测
基于密度的异常检测基于 k 最近邻算法。
假设: 正常数据点通常位于密集的邻域中,而异常数据点则远离这些邻域。
使用评分评估最近的数据点,这个评分可能是欧氏距离或依赖于数据类型(分类或数值)的类似度量。它们可以大致分为两种算法:
-
k 最近邻:k-NN 是一种简单的非参数懒惰学习技术,用于根据距离度量(如欧氏距离、曼哈顿距离、闵可夫斯基距离或汉明距离)的相似性来分类数据。
-
数据的相对密度:这通常被称为局部离群因子(LOF)。这个概念基于一种叫做可达距离的距离度量。
基于聚类的异常检测
聚类是无监督学习领域中最流行的概念之一。
假设: 相似的数据点往往属于相似的组或簇,这取决于它们与局部中心的距离。
K-means 是一种广泛使用的聚类算法。它创建了‘k’个相似的数据点簇。落在这些组之外的数据实例可能会被标记为异常。
基于支持向量机的异常检测
支持向量机 是另一种有效的异常检测技术。SVM 通常与监督学习相关,但也有扩展(例如OneClassCVM,)可用于将异常检测作为无监督问题(即训练数据未标记)。该算法学习一个软边界,以便使用训练集对正常数据实例进行聚类,然后,通过测试实例调整自身,以识别落在学习区域之外的异常。
根据用例,异常检测器的输出可能是用于过滤特定领域阈值的数值标量值或文本标签(例如二进制/多标签)。
使用低通滤波器构建简单的检测解决方案
在本节中,我们将重点介绍如何使用移动平均构建一个简单的异常检测包,以识别样本数据集中每月太阳黑子数量的异常,该数据集可以通过以下命令在这里下载:
wget -c -b www-personal.umich.edu/~mejn/cp/data/sunspots.txt
该文件包含 3,143 行数据,包含 1749-1984 年间收集的太阳黑子信息。太阳黑子定义为太阳表面上的黑点。研究太阳黑子有助于科学家理解太阳在一段时间内的性质,特别是其磁性特性。
阅读本教程的其余部分,包括DataScience.com 网站上的 Python 代码。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关话题
相关性简介
原文:
www.kdnuggets.com/2017/02/datascience-introduction-correlation.html
由 DataScience.com 赞助。
介绍:什么是相关性,为什么它有用?
相关性是最广泛使用——也最被误解——的统计概念之一。在本概述中,我们提供了几种类型的相关性的定义和直觉,并展示了如何使用 Python pandas 库计算相关性。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 为你的组织提供 IT 支持
“相关性”一词指的是数量之间的相互关系或关联。在几乎任何业务中,以其与其他因素的关系来表达某一数量是有用的。例如,当营销部门增加电视广告支出时,销售可能会增加,或者客户在电子商务网站上的平均购买金额可能取决于与该客户相关的多个因素。通常,相关性是理解这些关系的第一步,随后可以建立更好的业务和统计模型。
那么,为什么相关性是一个有用的指标?
-
相关性可以帮助从一个数量预测另一个数量
-
相关性可以(但通常不会,如下面的一些例子所示)指示因果关系的存在
-
相关性作为许多其他建模技术的基本量和基础
更正式地说,相关性是描述随机变量之间关联的统计度量。计算相关系数的方法有多种,每种方法测量不同类型的关联强度。下面我们总结了三种最常用的方法。
相关性的类型
在深入了解相关性如何计算之前,介绍协方差的概念非常重要。协方差是两个变量X和Y之间关联的统计测量。首先,通过减去均值来中心化每个变量。这些中心化的分数被相乘,以测量一个变量的增加是否与另一个变量的增加有关。最后,计算这些中心化分数乘积的期望值(E)作为关联的总结。直观地,中心化分数的乘积可以被看作是一个矩形的面积,其中每个点与均值的距离描述了矩形的一边:

如果两个变量倾向于朝相同的方向移动,我们期望连接每个点(X_i, Y_i)到均值(X_bar, Y_bar)的“平均”矩形具有一个较大且正向的对角线向量,对应于上面方程中的较大正产品。如果两个变量倾向于朝相反的方向移动,我们期望平均矩形具有一个较大且负向的对角线向量,对应于上面方程中的较大负产品。如果变量之间无关,则这些向量在平均值上应相互抵消——总体对角线向量的大小应接近 0,对应于上面方程中的产品接近 0。
如果你在想“期望值”是什么,它是随机变量的平均值或均值μ的另一种说法。它也被称为“期望”。换句话说,我们可以写出以下方程来用不同的方式表达相同的量:

协方差的问题在于它保持变量X和Y的尺度,因此可以取任何值。这使得解释变得困难,也使得比较协方差变得不可能。例如,Cov(X,Y)= 5.2 和Cov(Z,Q)= 3.1 告诉我们这些对是正相关的,但在没有查看这些变量的均值和分布的情况下,很难判断X和Y之间的关系是否强于Z和Q之间的关系。这就是相关性变得有用的地方——通过用数据的某种变异度标准化协方差,它产生了具有直观解释和一致尺度的量。
Pearson 相关系数
Pearson 是最广泛使用的相关系数。Pearson 相关性测量连续变量之间的线性关联。换句话说,这个系数量化了两个变量之间的关系可以用一条线来描述的程度。值得注意的是,虽然相关性可以有多种解释,但 Karl Pearson 在 120 多年前开发的相同公式今天仍然是最广泛使用的。
在这一部分,我们将介绍几种流行的皮尔逊相关系数的表述及其直观解释(简称ρ)。
皮尔逊本人开发的相关系数原始公式使用了原始数据和两个变量X和Y的均值:

在这种表述中,原始观察数据通过减去其均值进行中心化,并通过标准差的度量进行重新缩放。
表达相同数量的另一种方式是使用期望值、均值μ[X]、μ[Y]和标准差σ**[X]、σ**[Y]:
![$$ \rho_{X,Y} = \frac{E[(X-\mu_{X})(Y-\mu_{Y})] }{\sigma_{X}\sigma_{Y}}$$](../Images/05c9de55054695689e263cf82293bb76.png)
请注意,这个分数的分子与上述协方差的定义相同,因为均值和期望可以互换使用。将两个变量之间的协方差除以标准差的乘积,确保了相关系数总是落在-1 和 1 之间。这使得解释相关系数变得更加容易。
下图显示了皮尔逊相关系数的三个例子。ρ 越接近 1,表示一个变量的增加与另一个变量的增加关联越大。另一方面,ρ 越接近-1,表示一个变量的增加会导致另一个变量的减少。请注意,如果X和Y是独立的,则ρ接近 0,但反之则不成立!换句话说,即使两个变量之间存在强关系,皮尔逊相关系数也可能很小。我们将很快看到这种情况如何发生。
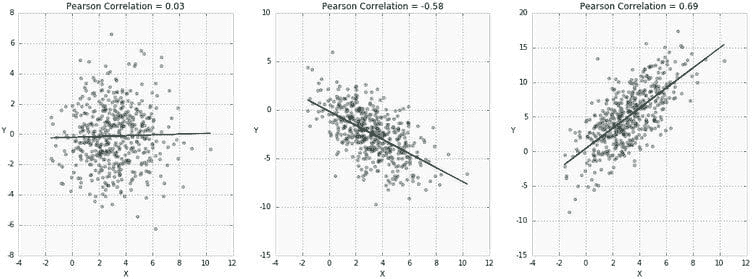
那么,我们如何解释皮尔逊相关系数呢?
在 DataScience.com 上阅读其余内容:相关性介绍
更多相关主题
K-means 聚类简介:教程
原文:
www.kdnuggets.com/2016/12/datascience-introduction-k-means-clustering-tutorial.html
由 DataScience 提供。 赞助帖子。
。
Andrea Trevino 博士在本教程中为广泛使用的 K-means 聚类算法提供了初学者入门介绍。
K-means 聚类是一种无监督学习,当数据中的结果类别或组未知时使用。这种算法发现数据中自然存在的组,结果允许用户快速标记新数据。一般来说,聚类是理解数据的关键工具。
这个算法可以用于多个应用,包括行为分割、库存分类、传感器测量排序以及检测机器人或异常等。本教程涵盖了确定聚类的迭代算法,并通过 Python 的配送车队数据示例进行讲解。
相关主题
自然语言处理简介,第一部分:词汇单元
原文:
www.kdnuggets.com/2017/02/datascience-introduction-natural-language-processing-part1.html
由DataScience.com赞助的帖子。
在本系列中,我们将深入探讨与自然语言处理的研究和应用相关的核心概念。下面的第一部分介绍了该领域,并解释了如何识别词汇单元作为数据预处理的一种方法。
自然语言处理简介
自然语言处理是一组允许计算机和人类进行互动的技术。考虑从某些数据生成过程提取信息的过程:一家公司希望预测其网站上的用户流量,以便提供足够的计算资源(服务器硬件)来满足需求。工程师可以定义相关信息为请求的数据量。由于他们控制数据生成过程,他们可以在网站上添加逻辑,将每个数据请求存储为一个变量。然后,他们可以将测量单位定义为请求的数据量,以字节为单位,从而使我们能够将信息表示为整数。有了良好的信息表示,工程师可以将其存储在表格数据库中,以便分析师可以根据这些历史数据进行预测。
自然语言处理是上述步骤的应用——定义信息的表示、从数据生成过程解析信息以及构建、存储和使用存储信息的数据结构——到嵌入自然语言的信息。
使语言成为自然语言的正是使自然语言处理变得困难的原因;自然语言中信息表示的规则是在没有预定的情况下演变而来的。这些规则可以是高层次的和抽象的,例如如何使用讽刺来传达意义;也可以是相当低层次的,例如使用字符“s”来表示名词的复数。自然语言处理涉及识别并利用这些规则,通过代码将非结构化的语言数据转换为具有模式的信息。语言数据可以是正式的文本,例如报纸文章,也可以是非正式的语音,例如电话交谈的录音。来自不同上下文和数据源的语言表达将具有不同的语法、句法和语义规则。在一个环境中有效的提取和表示自然语言信息的策略,在其他环境中往往无效。
商业用途
公司通常可以访问包含有价值信息的自然语言记录。产品评论或甚至 Twitter 上的推文可能包含与产品相关的特定投诉或功能请求,这可以帮助优先排序和评估提案。在线市场可能有可用的商品描述,有助于定义产品分类法。数字报纸可能有在线文章的档案,可用于构建搜索引擎,让用户找到相关内容。代表自然语言的信息也可以用于构建强大的应用程序,如回答问题的机器人或翻译软件。

自然语言处理可以用来从文本中识别特定的投诉。
需要自然语言处理的项目通常涉及这些挑战。解决这些问题通常要求我们将多个子任务串联起来,每个子任务可能有多种解决方案。自然语言处理方法的范围可能会让人望而却步,因为它高度专业化、广泛且缺乏一个总体概念框架。虽然自然语言处理的完整总结超出了本文的范围,但我们将介绍一些在通用自然语言处理工作中常用的概念。我们假设我们可以使用文本数据(而非需要额外语音识别步骤的听觉数据)。
识别词汇单元
由于自然语言通常由单词组成,许多自然语言处理项目的初始步骤是识别某些原始文本中的单词。然而,单词的概念可能过于限制或模糊。字符串“cats”和“cat”是词典中相同条目的不同形式;它们应该被视为等同吗?“Star Wars”在词典中没有条目,虽然它包含一个空格,但我们认为它是一个整体。这些是定义词汇单元时涉及的挑战,词汇单元代表词汇的基本元素。
对于特定任务,研究人员必须定义什么构成合适的词汇单元。单数和复数形式的单词是否应被视为同一个词汇单元?假设我们正在构建一个问答系统,并收到以下查询:
A: "找到离我最近的电影院。"
B: "找到离我最近的电影院。"
在 A 中,用户暗示她想查看多个电影院,而在 B 中,她只是想要一个最近的电影院。忽略单数和复数之间的区别会降低我们应用的质量。

另外,假设我们要总结以下产品评论:
A: “该产品存在一些连接问题。”
B: “该产品存在一个连接问题。”
在这里,“问题”和“问题”之间的区别并不相关。
虽然不完全详尽,但分词和规范化是从自然语言中解析词汇单元的两个常见步骤。分词是将字符序列分割成词素的过程,每个词素代表一个术语的实例。规范化是我们用来将术语压缩成词汇单元的一系列步骤。
分词算法可以很简单且确定性,例如每当字符不是字母数字时将字符分割成词素。非字母数字字符可能是空格、标点符号、井号等。我们可以使用模式匹配来实现这种方法,根据一些规则检查字符或字符序列的存在,其中我们将这些模式定义为正则表达式(通常缩写为“regex”)。例如,我们可以用正则表达式字符串“0-9”或“\d.”来表示所有数字字符的集合。我们可以将带有修饰符的术语组合成复杂的搜索模式。我们可以通过每次匹配查询[^A-Za-z0-9]+来将字符分割在非字母数字字符上。正则表达式的应用非常广泛,几乎所有现代编程语言中都有相应的实现。
很容易找到这种策略失败的例子(“didn't ≠ ["didn", "t"])。在一些应用中,研究人员使用多个复杂的正则表达式查询和特定于形态的规则来捕获这些模式,并通过有限状态机来确定正确的分词。编码一个详尽的规则集可能很困难,并且将取决于应用程序和分析的文本数据类型(尽管已有一些部分规则集被汇编)。为了适应新的语料库,可以通过在手动分词的文本上训练统计模型来构建分词器,尽管由于确定性方法的成功,这种方法在实践中很少使用。这些模型可能会查看字符属性序列,例如是否连续的字母数字字符以大写字母开头,并将分词建模为这些属性的函数。模型学习使用的规则将取决于提供的训练语料库(如 Twitter、医学文章等)。
另一个挑战是多项字符序列可以构成一个词汇单位。这些多项序列可能是像“New York”这样的命名实体,在这种情况下,我们进行命名实体识别或只是常见短语。解决这个问题的一种方法是通过将所有长度为 n 的项集(n-grams)作为标记来允许表示中的一些冗余。如果我们仅限于单个词和二元组,“New York”将被标记为“New”,“York”,“New York”。为了增加一些复杂性,而不是穷尽所有 n-grams,我们可以选择一组术语的最高阶 n-gram 表示,依据某些条件,比如它是否存在于硬编码词典(称为地名词典)中,或在我们的数据集中是否常见。或者,我们可以使用机器学习模型。如果给定单词的概率,p(word[i] | word[i-1]),在前面的单词下足够高,我们可能会将这个序列视为一个二项词汇单位(或者,我们可以使用公式p(word[i] | word[i-1]) = bigram) 使用标记的示例)。虽然平滑可以帮助改善问题,但这些语言模型通常难以泛化,并且需要一定程度的迁移学习、特征工程、确定性或抽象。概率 n-gram 模型需要标记的示例、机器学习算法和特征提取器(后两者包含在斯坦福 NER 软件中)。如果这些模型不值得投资,高质量的预训练模型通常可以在新的数据集上成功使用。
在分词后,我们可能希望对我们的词元进行标准化。 标准化是一组规则,旨在将所有词汇等价类的实例减少到其规范形式。
这可能包括如下过程:
-
复数 -> 单数(例如 cats -> cat)
-
过去时态 -> 现在时态(例如 ran -> run)
-
副词形式 -> 形容词形式(quickly -> quick)
-
连字符 -> 连接
标准化的一种方法是通过一个称为词形还原的过程将单词减少到其词典形式。一个术语的词元具有词典条目中包含的所有元数据:词性、定义(词义)和词干。词形还原传统上需要一个形态学解析器,在这个解析器中,我们根据词语的形态学元素(前缀、后缀等)完全特征化某个未经处理的词语(时态、复数形式、词性等)。为了构建一个解析器,我们创建一个已知词干和词缀的词典(词汇表),并包含有关它们的元数据,如可能的词性,列举规则(形态学语法)以规范词素如何组合在一起(例如复数修饰符“-s”必须跟在名词后面),最后列举规则(正字法规则)以规范在不同形态状态下单词的变化(例如,一个以“-c”结尾的过去时动词必须添加一个“k”,如“picnic -> picnicked”)。这些规则和术语传递给一个有限状态机,该状态机遍历输入,维护一个状态或一组特征值,然后在检查规则和词汇表与文本匹配时更新(类似于正则表达式的工作方式)。
我们如何定义等价类的特异性(哪些形态学元素相关),以及我们使用的标准化程度和提取的形态学元数据,取决于我们的应用。在信息检索中,我们通常只关心文本的一些高层语义。所有的词素或传达意义的元素(除了词干)都可以与所有形态学元数据(如时态)一起丢弃。词干提取算法通常使用替换规则,如:
- 如果给定的词干包含一个元音,我们会从所有包含该词干的词元中移除“-ing”(如“barking”→“bark”,但“string”→“string”)。
Porter 词干提取器可能是最著名的替换类型词干提取算法,尽管还有其他算法。所有这些类型的词干提取器都容易出错,但简单且易于实现,并且是大多数应用工作的良好起点。
最终,构建预处理管道的目标包括:
-
所有相关信息被提取。
-
所有不相关的信息都被丢弃。
-
文本被表示为足够少的等价类。
-
数据应以有用的形式存在,如 ASCII 编码的字符串列表或抽象数据结构,如句子或文档。
相关性、充分性和有用性的定义取决于项目的要求、开发团队的实力以及时间和资源的可用性。此外,在许多情况下,预处理管道的强度可以决定项目的整体成功。因此,在构建管道时需要谨慎。
在将原始文本转换为字符串或词汇单元的分词数组之后,研究人员或开发者可能会采取步骤对其文本数据进行预处理,例如字符串编码、停用词和标点符号去除、拼写校正、词性标注、分块、句子分割和语法分析。下表展示了研究人员在给定任务和一些原始文本时可能使用的一些处理类型的示例:
| 原始文本 | 处理后 | 步骤 | 任务 | 管道如何适应任务 |
|---|---|---|---|---|
| She sells seashells by the seashore. | ['she','sell','seashell','seashore'] | 分词,词形还原,停用词去除,标点去除 | 主题建模 | 我们只关注高级、主题性强和语义丰富的词 |
| John is capable. | John/PROPN is/VERB capable/ADJ ./PUNCT | 分词,词性标注 | 命名实体识别 | 我们关注每个词,但希望指明每个词所扮演的角色,以便构建命名实体识别候选列表 |
| Who won? I didn't check the scores. | [u'who', u'win'], [u'i',u'do',u'not',u'check',u'score'] | 分词,词形还原,句子分割,标点去除,字符串编码 | 情感分析 | 我们需要所有词,包括否定词,因为它们可以否定积极的陈述,但不关心时态或词形 |
预处理后,我们通常需要采取额外步骤将文本信息以量化形式表示。在本系列的第二部分中,我们将讨论各种抽象和数值文本表示方法。
本文中包含的依赖关系图是使用了令人惊叹的开源库 DisplaCy 构建的。点击这里查看。
想要继续学习吗?下载我们的Forrester 新研究,了解保持公司在数据科学前沿的工具和实践。
原文。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关主题
DataScience.com 发布了用于解释预测模型决策过程的 Python 包。
原文:
www.kdnuggets.com/2017/05/datascience-skater-python-package-interpreting-predictive-models.html
赞助文章。
DataScience.com 发布了其新 Python 库 Skater 的测试版,该库用于解释预测模型。Skater 通过结合多种算法来解释数据与模型预测之间的关系,使用户能够评估模型的表现并识别关键特征。
随着机器学习在商业应用中变得越来越受欢迎——例如评估贷款申请者的信用 worthiness、向观众推荐相关内容以及预测在线购物者的消费金额——解释也正成为模型构建过程中的不可或缺的一部分。Skater 提供了一个通用框架,用于描述预测模型,无论构建它们所用的算法是什么,使数据科学从业者可以自由选择所用技术,而不必担心其复杂性。
“在许多情况下,数据科学家会使用简单的建模技术,如线性回归或决策树,因为这些模型容易解释,”DataScience.com 首席战略官威廉·梅尔坎(William Merchan)说。“实际上,他或她是在牺牲性能以换取可解释性;例如,神经网络或集成模型更难以解释,但能产生高度准确的预测。Skater 旨在消除这种妥协。”
Skater 具有模型无关的部分依赖图,这是一种描述预测变量与目标变量之间关系的可视化图表,并且变量重要性衡量了特征对预测的影响程度。它还改进了现有的模型解释方法,如局部可解释模型无关解释(LIME)。Skater 允许将这些方法应用于任何机器学习模型——从集成模型到神经网络——无论是本地可用还是作为 API 部署。
使用 Skater,数据科学从业者可以:
-
评估模型在完整数据集或单个预测上的行为:Skater 通过利用和改进现有技术(包括部分依赖图、相对变量重要性和 LIME),实现了对模型的全局和局部解释。
-
识别潜在的特征交互并建立领域知识:从业者可以使用 Skater 理解特征在特定用例中的相互关系——例如,信用风险模型如何使用银行客户的信用历史、支票账户状态或现有信用额度来批准或拒绝其信用卡申请——然后利用这些信息来指导未来的分析。
-
衡量模型在生产环境中部署后的性能变化:Skater 支持对已部署模型的解释,给从业者提供了衡量特征交互如何在不同模型版本间变化的机会。
“DataScience.com 企业数据科学平台的一个关键特点是能够通过 REST API 部署模型,使其能够立即与仪表板或实时应用程序集成,”Merchan 补充道。“Skater 帮助我们更进一步,使我们能够以数据科学从业者以及最终的非技术利益相关者都能理解的方式,解释部署在我们平台上的复杂模型——无论是在我们的平台上还是其他地方。”
Skater 包可通过 GitHub 获取,并可以通过 pip 从 PyPI 轻松安装。
欲了解更多信息,请访问 www.datascience.com。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
Python 中的数据集拆分最佳实践
原文:
www.kdnuggets.com/2020/05/dataset-splitting-best-practices-python.html
评论
因此,你有一个整体数据集,需要将其拆分为训练数据和测试数据。也许你是为了监督学习而这样做,也许你使用 Python 来实现。
这是讨论在拆分数据集时需要考虑的三个具体因素,处理这些因素的方法,以及如何使用 Python 实际实现这些考虑事项。

来源: Adi Bronshtein
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
对于我们的示例,我们将使用 Scikit-learn 的train_test_split模块,该模块对拆分数据集很有用,无论你是否使用 Scikit-learn 来执行机器学习任务。你可以用其他方式手动进行这些拆分(例如,仅使用 Numpy),但 Scikit-learn 模块包含一些有用的功能,使得这一过程更简单。但请注意;也许你过去使用过这个模块进行数据拆分,但在进行时没有考虑到某些因素。
1. 随机打乱实例
第一个考虑因素是:你的实例是否被打乱?只要没有理由不打乱数据(例如,你的数据是时间序列),我们希望确保我们的实例不会仅仅按顺序分割,因为我们的实例可能以某种方式被添加,从而将一些不必要的偏差引入模型中。
例如,查看 Scikit-learn 中包含的 iris 数据集版本在加载时如何排列实例:
from sklearn.datasets import load_iris
iris = load_iris()
X, y = iris.data, iris.target
print(f"Dataset labels: {iris.target}")
Dataset labels:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
如果你将数据集按照 3 个类别的实例数量相等的比例分为 2/3 用于训练和 1/3 用于测试,你的新分离数据集将没有标签交叉。这在学习特征以预测类别标签时显然是个问题。幸运的是,train_test_split模块默认会先对数据进行洗牌(你可以通过将shuffle参数设置为False来覆盖此设置)。
为此,必须将feature和target向量(X和y)传递给模块。你应该设置一个random_state以确保可重复性。需要设置train_size或test_size中的一个,但两个都不是必需的。如果你明确设置了两个,它们的总和必须等于 1。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
train_size=0.67,
random_state=42)
print(f"Train labels:\n{y_train}")
print(f"Test labels:\n{y_test}")
Train labels:
[1 2 1 0 2 1 0 0 0 1 2 0 0 0 1 0 1 2 0 1 2 0 2 2 1 1 2 1 0 1 2 0 0 1 1 0 2
0 0 1 1 2 1 2 2 1 0 0 2 2 0 0 0 1 2 0 2 2 0 1 1 2 1 2 0 2 1 2 1 1 1 0 1 1
0 1 2 2 0 1 2 2 0 2 0 1 2 2 1 2 1 1 2 2 0 1 2 0 1 2]
Test labels:
[1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1
0 0 0 2 1 1 0 0 1 2 2 1 2]
你可以看到我们现在已经将实例打乱了。
2. 类别分层
下一步需要考虑的是:我们新分离的训练集和测试集的类别计数是否均匀分布?
import numpy as np
print(f"Numbers of train instances by class: {np.bincount(y_train)}")
print(f"Numbers of test instances by class: {np.bincount(y_test)}")
Numbers of train instances by class: [31 35 34]
Numbers of test instances by class: [19 15 16]
这不是一个均匀的划分。这涉及到算法是否有平等的机会学习数据集中每个类别的特征,并随后在每个类别的相同数量的实例上测试其学习成果。在较小的数据集中特别重要,但应始终关注。
我们可以使用train_test_split的stratify选项强制训练集和测试集中的类别比例保持一致,注意我们将根据y中的类别分布进行分层。
X_train, X_test, y_train, y_test = train_test_split(X, y,
train_size=0.67,
random_state=42,
stratify=y)
print(f"Train labels:\n{y_train}")
print(f"Test labels:\n{y_test}")
Train labels:
[2 0 2 1 0 0 0 2 0 0 1 0 1 1 2 2 0 0 2 0 2 0 0 2 0 1 2 1 0 1 0 2 1 2 1 0 2
0 2 0 1 1 0 2 1 1 0 2 1 2 0 1 0 2 1 1 1 1 1 1 2 1 2 2 0 2 1 1 2 0 2 2 2 0
2 0 0 2 2 2 0 1 2 2 0 1 1 1 1 1 0 2 1 2 0 0 1 0 1 0]
Test labels:
[2 1 0 1 2 1 1 0 1 1 0 0 0 0 0 2 2 1 2 1 2 1 0 2 0 2 2 0 0 2 2 2 0 1 0 0 2
1 1 1 1 1 0 0 2 1 2 2 1 2]
print(f"Numbers of train instances by class: {np.bincount(y_train)}")
print(f"Numbers of test instances by class: {np.bincount(y_test)}")
Numbers of train instances by class: [34 33 33]
Numbers of test instances by class: [16 17 17]
现在看起来更好了,原始数据告诉我们这是最优的分层划分。
3. 划分分割
第三个考虑因素与我们的测试数据有关:我们的建模任务内容是否只有一个由之前未见数据组成的测试数据集,还是应该使用两个这样的数据集——一个用于在微调过程中验证我们的模型,可能还有多个模型,另一个作为最终的保留集用于模型比较和选择。
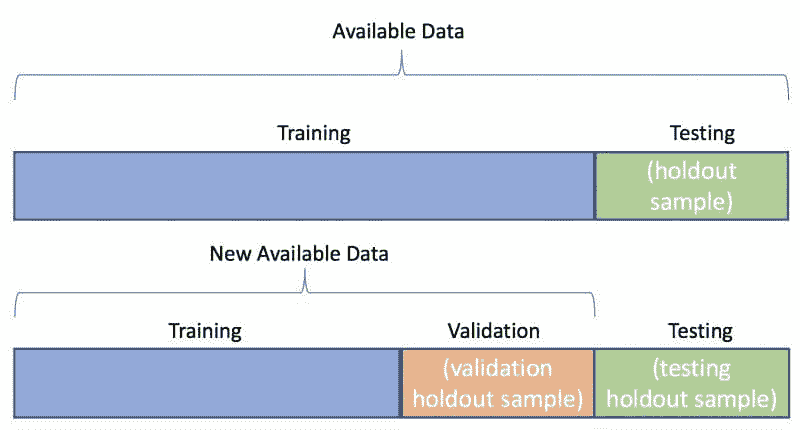
来源: Stack Exchange
如果我们选择两个这样的集合,这意味着会有一个数据集在所有假设测试、所有超参数调优以及所有模型训练到最佳性能之后才会被使用,作为实验的最后一步,这个数据集只会被模型看到一次。关于测试集与验证集的工作有很多,你可以查阅相关资料;我在这里不会进一步探讨其理由和论点。
然而,假设你得出结论你确实想要使用测试集和验证集(你应该得出这个结论),使用train_test_split来构建它们很简单;我们将整个数据集分一次,分离出训练数据,然后再分一次,将剩余的数据划分为测试集和验证集。
在下面,使用数字数据集,我们将 70%用于训练数据集,并暂时将剩余部分分配给测试集。我们继续执行上述最佳实践。
from sklearn.datasets import load_digits
digits = load_digits()
X, y = digits.data, digits.target
X_train, X_test, y_train, y_test = train_test_split(X, y,
train_size=0.7,
random_state=42,
stratify=y)
print(f"Numbers of train instances by class: {np.bincount(y_train)}")
print(f"Numbers of test instances by class: {np.bincount(y_test)}")
Numbers of train instances by class: [124 127 124 128 127 127 127 125 122 126]
Numbers of test instances by class: [54 55 53 55 54 55 54 54 52 54]
注意训练集和临时测试集中的分层类别。
然后我们以相同的方式重新拆分测试集——这次修改输出变量名称、输入变量名称,并小心更改stratify类向量引用——使用 50/50 的拆分比例用于测试和验证集。
X_test, X_val, y_test, y_val = train_test_split(X_test, y_test,
train_size=0.5,
random_state=42,
stratify=y_test)
print(f"Numbers of test instances by class: {np.bincount(y_test)}")
print(f"Numbers of validation instances by class: {np.bincount(y_val)}")
Numbers of test instances by class: [27 27 27 27 27 28 27 27 26 27]
Numbers of validation instances by class: [27 28 26 28 27 27 27 27 26 27]
再次注意所有数据集中的类别分层,这样是最优和理想的。
现在你可以根据数据的需要训练、验证和测试尽可能多的机器学习模型。
另一个考虑因素:你可能想要考虑使用交叉验证,而不是简单的训练/测试或训练/验证/测试策略。我们将下一次讨论交叉分层的考虑因素。
相关:
-
Python 中的稀疏矩阵表示
-
Scikit-learn 0.23 中的 5 个伟大新特性
-
处理不平衡数据集的 5 个最有用技巧
更多相关主题
Python 中的日期处理和特征工程
原文:
www.kdnuggets.com/2021/07/date-pre-processing-feature-engineering-python.html

也许像我一样,你在用 Python 处理数据时经常处理日期。也许像我一样,你在处理 Python 中的日期时感到沮丧,并发现你为了重复做相同的事情而过于频繁地查阅文档。
我们的前 3 门课程推荐
1. Google Cybersecurity Certificate - 快速通道进入网络安全职业。
2. Google Data Analytics Professional Certificate - 提升你的数据分析能力
3. Google IT Support Professional Certificate - 支持你的组织 IT
就像任何编程的人一样,当发现自己重复做同样的事情时,我想通过自动化一些常见的日期处理任务以及一些简单而频繁的特征工程来简化生活,从而使得对给定日期的常见日期解析和处理任务可以通过一次函数调用完成。然后我可以在之后选择我感兴趣的特征进行提取。
这个日期处理是通过一个单一的 Python 函数实现的,该函数仅接受一个格式为 'YYYY-MM-DD' 的日期字符串(因为这是日期的格式),并返回一个包含(当前)18 对键/值特征的字典。其中一些键是非常直接的(例如解析出的四位数年份),而其他的是经过工程处理的(例如日期是否为公共假期)。如果你觉得这段代码有用,你应该能够弄清楚如何修改或扩展它以适应你的需求。有关你可能想要编写的其他日期/时间相关特征的一些想法,请查看这篇文章。
大部分功能是通过 Python datetime 模块实现的,许多功能依赖于 strftime() 方法。然而,真正的好处是有一种标准的、自动化的方法来处理相同的重复查询。
唯一使用的非标准库是 holidays,它是一个“快速、高效的 Python 库,用于即时生成特定国家、省份和州的假期集合。”虽然该库可以处理各种国家和次国家的假期,但我在这个例子中使用了美国的全国假期。只需快速浏览项目文档和以下代码,你就能很容易确定如何在需要时进行更改。
那么,让我们首先查看 process_date() 函数。评论应该能提供有关发生了什么的见解,如果你需要的话。
import datetime, re, sys, holidays
def process_date(input_str: str) -> {}:
"""Processes and engineers simple features for date strings
Parameters:
input_str (str): Date string of format '2021-07-14'
Returns:
dict: Dictionary of processed date features
"""
# Validate date string input
regex = re.compile(r'\d{4}-\d{2}-\d{2}')
if not re.match(regex, input_str):
print("Invalid date format")
sys.exit(1)
# Process date features
my_date = datetime.datetime.strptime(input_str, '%Y-%m-%d').date()
now = datetime.datetime.now().date()
date_feats = {}
date_feats['date'] = input_str
date_feats['year'] = my_date.strftime('%Y')
date_feats['year_s'] = my_date.strftime('%y')
date_feats['month_num'] = my_date.strftime('%m')
date_feats['month_text_l'] = my_date.strftime('%B')
date_feats['month_text_s'] = my_date.strftime('%b')
date_feats['dom'] = my_date.strftime('%d')
date_feats['doy'] = my_date.strftime('%j')
date_feats['woy'] = my_date.strftime('%W')
# Fixing day of week to start on Mon (1), end on Sun (7)
dow = my_date.strftime('%w')
if dow == '0': dow = 7
date_feats['dow_num'] = dow
if dow == '1':
date_feats['dow_text_l'] = 'Monday'
date_feats['dow_text_s'] = 'Mon'
if dow == '2':
date_feats['dow_text_l'] = 'Tuesday'
date_feats['dow_text_s'] = 'Tue'
if dow == '3':
date_feats['dow_text_l'] = 'Wednesday'
date_feats['dow_text_s'] = 'Wed'
if dow == '4':
date_feats['dow_text_l'] = 'Thursday'
date_feats['dow_text_s'] = 'Thu'
if dow == '5':
date_feats['dow_text_l'] = 'Friday'
date_feats['dow_text_s'] = 'Fri'
if dow == '6':
date_feats['dow_text_l'] = 'Saturday'
date_feats['dow_text_s'] = 'Sat'
if dow == '7':
date_feats['dow_text_l'] = 'Sunday'
date_feats['dow_text_s'] = 'Sun'
if int(dow) > 5:
date_feats['is_weekday'] = False
date_feats['is_weekend'] = True
else:
date_feats['is_weekday'] = True
date_feats['is_weekend'] = False
# Check date in relation to holidays
us_holidays = holidays.UnitedStates()
date_feats['is_holiday'] = input_str in us_holidays
date_feats['is_day_before_holiday'] = my_date + datetime.timedelta(days=1) in us_holidays
date_feats['is_day_after_holiday'] = my_date - datetime.timedelta(days=1) in us_holidays
# Days from today
date_feats['days_from_today'] = (my_date - now).days
return date_feats
有几点需要注意:
-
默认情况下,Python 将一周的天数视为从星期天(0)开始,到星期六(6)结束;对我而言,我的处理方式是一周从星期一开始,到星期天结束——我不需要第 0 天(与将一周从第 1 天开始相对)——所以这需要进行更改。
-
创建一个工作日/周末特征很简单。
-
使用
holidays库创建假期相关特征很简单,并且可以执行简单的日期加减运算;同样,替换其他国家或次国家假期(或添加到现有假期中)也是很容易做到的。 -
一个
days_from_today功能是通过一两行简单的日期数学运算创建的;负数表示给定日期在今天之前的天数,而正数则表示从今天到给定日期的天数。
我个人不需要,例如,is_end_of_month 特征,但你应该能看到如何在此时相对轻松地将其添加到上述代码中。自己尝试一些自定义设置吧。
现在让我们测试一下。我们将处理一个日期,并打印返回的内容,即键值特征对的完整字典。
import pprint
my_date = process_date('2021-07-20')
pprint.pprint(my_date)
{'date': '2021-07-20',
'days_from_today': 6,
'dom': '20',
'dow_num': '2',
'dow_text_l': 'Tuesday',
'dow_text_s': 'Tue',
'doy': '201',
'is_day_after_holiday': False,
'is_day_before_holiday': False,
'is_holiday': False,
'is_weekday': True,
'is_weekend': False,
'month_num': '07',
'month_text_l': 'July',
'month_text_s': 'Jul',
'woy': '29',
'year': '2021',
'year_s': '21'}
在这里你可以看到特征键的完整列表以及相应的值。通常情况下,我不需要打印整个字典,而是获取特定键或键集合的值。
我们可以通过下面的代码演示这如何实际工作。我们将创建一个日期列表,然后逐个处理这些日期,最终创建一个 Pandas 数据框,其中包含处理过的日期特征的选择,并将其打印到屏幕上。
import pandas as pd
dates = ['2021-01-01', '2020-04-04', '1993-05-11', '2002-07-19', '2024-11-03', '2050-12-25']
df = pd.DataFrame()
for d in dates:
my_date = process_date(d)
features = [my_date['date'],
my_date['year'],
my_date['month_num'],
my_date['month_text_s'],
my_date['dom'],
my_date['doy'],
my_date['woy'],
my_date['is_weekend'],
my_date['is_holiday'],
my_date['days_from_today']]
ds = pd.Series(features)
df = df.append(ds, ignore_index=True)
df.rename(columns={0: 'date',
1: 'year',
2: 'month_num',
3: 'month',
4: 'day_of_month',
5: 'day_of_year',
6: 'week_of_year',
7: 'is_weekend',
8: 'is_holiday',
9: 'days_from_today'}, inplace=True)
df.set_index('date', inplace=True)
print(df)
year month_num month day_of_month day_of_year week_of_year is_weekend is_holiday days_from_today
date
2021-01-01 2021 01 Jan 01 001 00 0.0 1.0 -194.0
2020-04-04 2020 04 Apr 04 095 13 1.0 0.0 -466.0
1993-05-11 1993 05 May 11 131 19 0.0 0.0 -10291.0
2002-07-19 2002 07 Jul 19 200 28 0.0 0.0 -6935.0
2024-11-03 2024 11 Nov 03 308 44 1.0 0.0 1208.0
2050-12-25 2050 12 Dec 25 359 51 1.0 1.0 10756.0
希望这个数据框能让你更好地了解这种功能在实际应用中的有用性。
祝好运,数据处理愉快。
相关:
-
5 个 Python 数据处理技巧与代码片段
-
数据科学与机器学习中的日期时间变量特征工程
-
使用 SQL 处理时间序列
评论
更多相关话题
数据科学家的日常生活:专家与初学者
原文:
www.kdnuggets.com/2022/09/day-life-data-scientist-expert-beginner.html

图片由 Mikhail Nilov 提供
随着越来越多的人进入科技行业,了解你的日常工作是很有帮助的。我已经礼貌地请求了 Jose Navarro 和 Andrzej Ko?czyk 给我们详细介绍他们的日常工作,希望能帮助他人做好准备。
两者处于数据科学职业的不同阶段,帮助来自不同背景的人们。你不仅会了解专家数据科学家的工作内容,对于那些刚进入这个行业的人,你也会了解初学者数据科学家正在做些什么以成为专家。
那么,让我们更多地了解一下数据科学家的一天。
首先,我们有 Jose Navarro,一位在 Qbiz 工作的数据科学家。他说:
Jose Navarro

Jose Navarro | LinkedIn
我觉得自己非常幸运能成为一名数据科学家。我认为这份工作独一无二,能帮助我们利用统计学和计算机科学的力量解决复杂的行业问题。我将在这里描述我的日常生活,以便你能对其有一个更清晰的了解。
我有时在家工作,有时在办公室工作,因为我认为与同事和团队的面对面互动对于项目和职业的发展都很重要。
这是一个非常灵活的工作,通常允许我根据项目需求安排个人生活。如果工作与生活的平衡对你来说很重要,就像对我一样,那么数据科学的职业选择也不错。
如果我在家工作,我通常在上午 9 点开电脑,之后会有一到两个小时的会议。会议对于项目至关重要,良好的沟通是理解行业问题、明确每个团队成员的期望、达成解决方案或了解结果的关键。数据科学家应该能够利用他们的软技能有效沟通,并向项目的所有利益相关者展示,针对每种情况调整语言。
一天中的下一部分涉及到这份工作的硬技能,应用像 Python、SQL 等技术。根据项目的阶段,这部分内容可能差异很大,从头脑风暴到数据可视化,包括数据收集、数据清洗、标注、统计建模、参数调整等。
大约下午 1 点时,我会停下来吃午饭,时间大约为 30-60 分钟。我确保伸展腿部,并远眺以放松眼睛。没有理由数据科学家不能遵循一些健康习惯。健康和健身将有助于我们的荷尔蒙水平,并带来一些与工作相关的好处,比如提高创造力和集中注意力的能力。
我在下午 6 点左右结束一天的工作,确保留出一些时间用于学习。我通过像 KDNuggets 这样的网站以及 Kaggle、Twitter、LinkedIn 或 Medium 等服务来检查最新趋势和前沿技术。成为数据科学家的最佳事情之一就是学习总是受到鼓励的。在数据、机器学习和人工智能不断变化的环境中,保持更新真的会有回报(此外,这个世界也非常令人兴奋)。
每天都不同,总是有新的事物可以尝试和解决的新问题。让我们一起打造数据驱动的未来。
接下来会有更多关于他们日常生活的信息来自于Andrzej Kończyk,一位立志成为数据科学家的数据分析师。
Andrzej Kończyk

Andrzej Kończyk | LinkedIn
我想在开始时简要介绍一下自己。目前我在担任数据分析师的职位,直到 2021 年 11 月,我对数据科学/数据分析/数据工程没有任何了解。我毕业于一个完全不同的专业,但我一直对数据充满热情。因此,在 2021 年 11 月,我开始了数据科学 Bootcamp,并开始通过额外的在线课程和教程进行学习。在我的 Bootcamp 课程中,我学到了很多关于 SQL、Tableau 和 Python 库的知识,这些知识现在帮助我理解并成长为数据科学领域的新成员。
这个领域现在对我非常有趣,因为我开始基于真实数据构建自己的机器学习模型!我认为数据科学真的代表着未来,当你仍在学习时,你可以度过一些美好的时光。在我看来,这不是最简单的领域——有时候你需要花费很多时间来理解问题和发展你的想法——但这真的很吸引人。当你最终得到一些结果时,可能一开始不是最好,但你知道这是你做的。这是令人兴奋的。
正如我提到的,我仍然是一个初学者,但我希望学到更多,并尽快从数据分析师转变为数据科学家。我需要做些什么才能实现这一目标?我认为这些将是对任何希望加入我们团队的人有用的建议:永远不要放弃,学习、阅读,并通过自己做项目不断进步。这是最重要的。在模型创建过程中,你总是可以发现一些新东西。其他工具,如 Tableau、SQL 等也很重要,但你在做项目时也会使用它们 😃
总结:对我来说,数据科学是一个有趣且令人兴奋的机会,确实对我们世界中的商业产生了影响 😃
总结
我希望这能给你一个更好的概述,了解两个级别的数据科学家所做的工作,包括他们的责任、建议等。
妮莎·阿利亚 是一名数据科学家和自由职业技术作家。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能在延长人类生命方面的不同方式。她是一个热衷学习者,致力于拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关主题
数据科学家的一天:第四部分
原文:
www.kdnuggets.com/2018/04/day-life-data-scientist-part-4.html
评论

当然,没有两个数据科学家的角色是相同的,这也是我们进行调查的原因。许多潜在的数据科学家对那些在另一方整天忙碌的工作内容感兴趣,因此我认为让一些连接提供他们的见解可能是一个有用的尝试。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT
接下来是我从那些愿意提供几段关于他们日常专业任务的反馈中收到的一些精彩反馈。短小的日常总结以完整无编辑的形式呈现,让引用自行说明。
如果你对本系列的前三篇文章感兴趣,你可以在这里找到它们:
-
数据科学家的一天(第一部分)
-
数据科学家的一天(第二部分)
-
数据科学家的一天(第三部分)
罗赫利奥·库埃瓦斯 是多伦多 Scotiabank 数据科学与模型创新团队的数据科学家。
作为数据科学家,工作涉及的不仅仅是技术方面。作为数据科学家,我们需要解决复杂的业务问题,并确保我们开发的模型为业务提供价值。为此,了解业务的重中之重并与业务部门保持持续联系以避免我们开发的内容与他们需求之间的偏差是至关重要的。
我不能说工作中有一个典型的一天,但我可以说每天都有三个主要组成部分;唯一的变化是这些组成部分在每天中所占的比例:会议、技术和行政。
会议
我的工作日从上午 9:00 开始,进行 15 分钟的敏捷站会。我与参与我所负责项目的人见面,并提供 3 条信息:
-
我前一天做了什么,
-
我在一天中的工作重点是,
-
任何可能遇到的障碍,以及是否需要其他团队成员的帮助以取得进展。
除了这些会议,还有许多其他会议我需要参加以满足各种需求。其中一些会议的目的是向业务部门和内部客户更新我所取得的发现和进展,请求他们的意见或在未来的任务中确定优先级。
其他会议是为了获得澄清或提供信息,以理解我们当前开发的模型的未来部署,或者确保我们对流程的理解确实正确。
无论会议的具体细节如何,它们都有一个共同的目标:满足业务需求,并确保我们与之完全对齐。
技术
开发满足业务需求的模型是一个迭代过程,涉及
收集和清洗数据,
-
创建一个数据集,以此为基础开发模型,
-
定义一个满足业务需求的目标变量,
-
生成初步模型并提高其准确性,以及
-
将模型的准确性转化为对业务有意义的指标。
我们使用各种工具和算法:
-
使用 SQL 收集和汇总数据到一个数据集中,
-
使用 Python 和 R 进行数据清洗和模型创建,
-
使用 Git 进行代码版本控制,以及
-
使用各种回归和分类算法进行预测。
这些技术任务是协作性的,可以是双向的:我可以创建一个拉取请求并要求我的同事进行审查,也可以充当同事创建的拉取请求的审查者。无论哪种方式,协作都是对我们生成的产品进行增量改进的关键。
鉴于数据科学是一个变化非常快的领域,我们期望学习尽可能多的工具和技术。我们需要灵活并且愿意不断学习。
行政
我还将相当一部分时间用于行政任务,例如
-
预约会议
-
回复电子邮件和进行虚拟电话会议
-
创建报告我们发现的演示文稿
-
生成报告
-
记录我们正在开发的流程和模型
在办公时间之外,我尽量积极参与有趣和相关的 Meetups,与其他数据科学家建立联系,并阅读我遇到的博客、书籍、论文和软件包文档。
这是一个具有挑战性和令人兴奋的角色。我感到非常幸运能够成为一个高度协作并致力于不断学习的团队的一员。
我希望你觉得这份笔记信息丰富,并且能够帮助你了解当今商业世界中的数据科学是什么样的。
Sarah Nooravi 是 Operam, Inc. 的高级数据科学家,驻扎在洛杉矶。
记住,没有两个数据科学职位和没有两个数据科学家是完全相同的,让我带你了解一下我一天的工作!我希望这能帮助你看到数据科学家的工作不仅仅是建模和处理大数据。还有很多学习和沟通的时间。
对我而言,典型的一天从我上车的那一刻开始。手里拿着一杯咖啡,加上两个小时的通勤时间(谢谢你,洛杉矶),我(通常)很兴奋地开始学习和做一些有生产力的事情。我利用这段时间跟进我最喜欢的播客(《成长的力量》、《重解代码》或《数据怀疑论》)、收听有关机器学习/深度学习的 YouTube 视频、为下一节教学课做准备、头脑风暴新的产品创意/方法,或者放一些好音乐来激励自己迎接一天的挑战。
一旦到达工作地点,我会用一杯卡布奇诺和一个 Spotify 播放列表来安顿下来。然后我会利用早晨的时间处理邮件和 Slack 消息。我首先查看的是客户的任何紧急请求。如果没有任何紧急事项,我会阅读每日更新的《商业内幕》新闻。这些更新帮助我跟上趋势和我们所用平台的新产品功能。在做出对活动策略有重大影响的决策时,这些更新是非常有帮助的。
白天可能会发生任何事情!行政请求、临时报告需求、内部会议、客户会议、现有模型的优化、新工具的构建,还有很多我无法在这里完全列举的任务。每一项任务对业务和我的个人发展都起着关键作用。像冲刺规划和招聘挑战这样的行政任务提高了我的时间管理技能和快速决策能力。客户会议挑战并提高了我的沟通技巧和商业头脑。优化和构建新模型挑战并提升了我的技术能力和创造力。作为一名数据科学家,我发现那些允许你全面发展的跨职能角色最令人兴奋和有成就感。
一旦我完成了一整天的工作,我会继续思考和学习数据科学。根据一周中的不同日子,我会安排其他活动,如:教授数据可视化的训练营、参与与其他充满激情的数据科学家一起的“数据科学办公时间”小组讨论、通过女性工程师协会指导女性工程师,或者主持自己的机器学习聚会。如果你还没看出来,我对这个领域爱不释手。
总结一下:我大约在早上 7 点开始一天的工作,并在晚上 10 点到 11 点之间回到家。虽然日子很长,但我热爱我的工作。使每一天成功的关键是幸福。我努力在一天中融入那些带给我快乐并帮助我个人成长和社区发展的事物。
凯特·斯特拉赫尼是位于纽约市德勤的数据显示与报告专家。
不需要闹钟……我的一天从早上 6 点开始。我其中一个孩子肯定会在早上 6 点之前醒来。我已经保持这个早晨时间表接近 4 年了,我很喜欢!我做一杯咖啡,坐下来查看手机(早晨第一件事就是这样做,这让我有些内疚)。在查看了工作和个人信息后,就该开始准备我的大女儿(3 岁)去学校了。我们一起准备她的午餐,挑选她的衣服,然后在 8 点送她上学前,我们会花点时间玩耍。我的日常中最棒的部分是我在家工作(我的工作提供这样的灵活性真是太棒了)。如果天气很好,心情也不错,我会去跑步(大约 2-3 英里)然后再开始工作。
早上 9 点 – 通常我会登录到工作电脑上,查看我当天的日程安排;然后开始工作。我的职责包括处理仪表盘,开发关键绩效指标,确保数据质量,以及最重要的是为领导提供数据透明度。我在这里帮助人们利用数据建立联系。主要通过我最喜欢的数据可视化工具 – Tableau!我非常喜欢这个工具,以至于我有一个 YouTube 频道,提供关于如何使用 Tableau 的教程 – 数据故事。
大约中午 12 点我会吃午餐(通常是我当天准备的食物)。然后继续工作,和我的团队成员联系,确保我们都按计划完成当天/本周的目标。在下午 2 点,我去学校接女儿,把她带回家(步行距离,只需几分钟;但我喜欢这短暂散步后的精力)。下午的剩余时间用来工作和思考如何利用技术自动化一些工作。
与数据打交道一直让我感到着迷;从特别杂乱和非结构化的数据中提取见解的能力使我充满活力。对这个领域更深入了解的好奇心促使我撰写了我的书籍 成为数据科学家之旅,该书提供了与领先数据科学家进行的二十多次访谈,并揭示了有关如何入门数据科学的关键见解。
亚历山大·沃尔夫 是纽约市 Dataiku 的数据科学家。
我首次对数据科学产生兴趣是在达特茅斯大学作为计算机科学本科生参加机器学习和深度学习课程时;我觉得这些材料既引人入胜,又激动人心且新颖。在意识到这个领域的潜力后,我确信这是我想从事的工作。我也知道我想在初创公司工作。
从那时起,我通过在线资源自学了如何正确使用一些数据科学 API。我在学校的课程中已经建立了良好的数学和理论机器学习基础,但仍需学习数据可视化和工程的一些基础知识,例如如何高效地索引 Pandas Dataframes、创建 Sci-Kit Learn 管道、使用 Seaborn/MatPlotlib 可视化数据、通过 lambda 函数正确清洗数据等。(Python 库;R 的等效工具存在)。我发现Datacamp是一个很好的资源。类似地,我认为 Sci-Kit Learn 的文档也是一个很好的资源,可以加深我对每种算法的理解,以及其超参数如何影响每个模型。
在 2017 年初,我在Dataiku找到了一份位于纽约市的工作。Dataiku 是一家高速成长的国际初创公司,专注于数据科学平台;公司成立于巴黎,并在今年九月完成了 2800 万美元的 B 轮融资。从第一天起,我就知道自己在领域和职业道路上做出了正确的决定。Dataiku 不仅拥有出色的公司创业文化,而且每天我也有机会从事一些新鲜而令人兴奋的工作。在这里,每一天都不同,这让我的工作更有趣。
由于我们销售的是数据科学平台,因此整个数据科学团队与公司大多数其他部门紧密集成——从帮助销售/合作伙伴团队在销售过程中提供数据科学专业知识,到帮助市场团队为聚会、我们的博客、第三方活动等创建相关且有时技术性的内容。当我不与公司其他部门合作时,我通常会支持我们的客户,或者通过进行一些自己的数据科学项目来提升我的 Dataiku 平台技能。
当我们为新客户提供服务时,许多客户希望我们在现场待 1-3 天,教他们的数据工程师、分析师和科学家如何利用 Dataiku 实现团队间的协作,轻松地将数据管道/模型投入生产,并教授他们如何使用我们平台提供的更多功能。我通常每月需要进行两到三次这样的服务,同时在全国各地旅行,接触不同的数据科学流程和团队。观察不同行业和公司是如何组织的以及他们如何使用数据,这非常有趣。
许多公司还购买 Dataiku 的专业服务,我有机会与许多不同的公司合作处理他们的数据项目。我接触了各种数据科学工具箱、用例、团队和组织结构。我与客户合作过 NLP 项目、时间序列预测、数据库去重、可视化、深度学习、生产流水线、Spark 流水线等。我最喜欢在 Dataiku 工作的部分之一是,我不受限于在一个行业内工作或使用一个工具栈;每周我都与不同的公司合作,学习新事物,并帮助他们真正最大限度地利用他们的数据。我很幸运能在这样的初创公司工作,并且真的很期待看到它不断改进和成长。
当我不在办公室或出差拜访客户时,我喜欢在空闲时间阅读科技/人工智能新闻、编程、从事数据科学项目、打篮球、头脑风暴创业想法、和朋友聚会,以及阅读最新的深度学习研究论文。我通过浏览我的 LinkedIn 动态来保持对人工智能和数据科学领域新闻/工具的更新;实际上,我比其他任何社交媒体平台更喜欢这个平台。我推荐关注一些很棒的人 - Matthew Mayo, Florian Douetteau, Andriy Burkov, Rudy Agovic, Gregory Renard。我通常在早上 8 点左右起床,然后乘地铁到曼哈顿市中心工作。我大约在晚上 7 点回家。我尽量多锻炼,因为我曾是一名 D1 篮球运动员。
相关:
-
数据科学家的生活日常
-
数据科学家的另一天
-
数据科学家的又一天
更多相关内容
一位数据科学家的一天
评论

几周前,我向我的 LinkedIn 联系人征求反馈意见关于数据科学家典型工作日的内容。反应真的非常大!当然,没有两个数据科学家的角色是相同的,这就是为什么要进行调查的原因。很多潜在的数据科学家都对那些在这个领域忙碌的人都做些什么感兴趣,所以我想让一些联系人提供他们的见解可能会是一项有用的事业。
我们的前三个课程推荐
1. Google Cybersecurity Certificate - 加速职业生涯发展,从事网络安全工作。
2. Google Data Analytics Professional Certificate - 提升你的数据分析能力
3. Google IT Support Professional Certificate - 支持你的 IT 组织
下面是一些来自对我的日常专业任务感兴趣的人通过电子邮件和 LinkedIn 消息提供的很好的反馈。这些简短的日常摘要以完整的形式呈现,没有编辑,让引语本身说话。
Andriy Burkov 是加特纳的全球机器学习团队负责人,位于魁北克市。
我的典型工作日从早上 9 点开始,与我的团队进行为期 15-30 分钟的 Webex 会议:我的团队分布在印度(班加罗尔和钦奈)和加拿大(魁北克市)两地。我们讨论项目的进展并决定如何克服困难。
然后我阅读昨晚收到的电子邮件,必要时做出回应。然后我将工作投入到当前的项目中,目前这个项目是从职位公告提取工资。我需要为我们支持的每个国家语言对创建一个单独的模型对,大约有 30 个国家语言对。该过程包括转储某部分国家-语言的职位公告,对其进行聚类,然后获取训练示例的子集。然后我手动注释这些示例并构建模型。我进行构建/测试/添加数据/重新构建迭代,直到测试误差足够低(~98%)。
下午,我帮助我的团队成员通过在真实数据上测试当前模型,识别假阳性/阴性并创建新的训练示例来改正问题。何时停止改善模型并投入生产取决于项目。对于一些情况,特别是用户端,我们希望假阳性的水平非常低(低于 1%):用户始终会看到从其文本中提取某些元素出错,但并不总是注意到提取的缺失。
一天在下午 5:30 左右结束,我用 30 分钟的时间跟上科技新闻/博客。
Colleen Farrelly 是位于迈阿密的卡普兰公司的一名数据科学家。
这是关于我和我一天的生活的一点背景信息:
在攻读医学博士/博士学位项目后,我转入了数据科学和机器学习,此前我有一门文理交融的本科学位,我的日常项目通常高度跨学科。一些项目包括模拟流行病传播,利用工业心理学创建更好的人力资源模型,并解剖数据以获取低社会经济地位学生的风险群体。我的工作最好的部分是项目的多样性和每天都有新的挑战。
我的一个典型工作日大约在早上 8:00 开始,那时我会浏览与机器学习和数据科学相关的社交媒体帐户。我会在早上 8:30 左右转入工作项目,中午休息后,工作在下午 4:30 至 5:00 左右结束。我的时间中大约有 40%用于研究和开发,主要集中在数学上(尤其是拓扑学),包括从开发和测试新算法到撰写数学证明以简化数据问题。有时,结果是保密的并且仅在公司内部分享(通过公司内部每月的午餐与学习演示);另一些情况下,我被允许在外部会议上发布或展示。
我大约还有 30%的时间用于在我公司的各个部门建立关系并寻找新项目,这些项目通常与运营程序相关的问题、数据捕捉相关的问题,或先前项目之间的连接有关,从而为运营提供更全面的视图。这可能是工作中最关键的一个方面。我遇到的人经常提出他们看到的问题或提到有一个预测模型对销售/学生结果/运营产生了兴趣,我发现这为以后的对话和最佳实践建议敞开了大门。作为一名数据科学家,与一系列利益相关者进行沟通非常重要,这帮助我将我对机器学习算法的解释简化成了一个外行能理解的水平。
我剩下的 30%的时间通常用于数据分析和结果撰写。其中包括预测模型、关键指标的预测模型以及对给定数据集中子群体和趋势的数据挖掘。每个项目都是独特的,我试图让项目及其初步发现引导我下一步的行动。我主要使用 R 和 Tableau 进行项目工作,虽然 Python、Matlab 和 SAS 偶尔在特定的软件包或研发需求中也很有帮助。我通常可以重复使用代码,但是对于数学方面的问题,每个问题都有自己的假设和数据限制。项目通常可以使用拓扑学、实分析和图论中的工具进行简化,从而加快项目进展,并允许使用现有的软件包,而不需要从头开始编码。作为一家大公司唯一的数据科学家,这使我能够处理更多项目,并为我们的内部客户揭示更多的见解。
Marco Michelangeli是 Hopenly 公司的数据科学家,居住在意大利的雷焦艾米利亚。
当马修要求我写几段关于数据科学家“典型”一天的工作的文章时,我开始思考我的日常工作和例行公事,但后来我停下来意识到:“我真的没有一个固定的日常!”这就是作为数据科学家的最好之处!每一天都不同,都会出现新的挑战,一个新的问题悬在那里等待解决。我不仅仅在谈论编码、数学和统计学,还包括业务世界的复杂性:我经常与业务人员和客户讨论,了解他们的真实需求,我帮助营销部门制作产品内容,在会议上讨论新的 ETL 工作流和新产品的架构设计;我甚至发现自己在筛选数据科学家的简历。
成为一名数据科学家意味着要灵活、开放思维、准备解决问题和接受复杂性,但是请别误会:我 80%以上的时间都在清理数据!如果你刚开始从事数据科学的职业,你可能已经看过“10 个掌握 R 和 Python 在数据科学中的技巧”的帖子,或者“最好的深度学习库”,所以我不会给你任何更多的技术建议,我唯一能说的是来自于专业数据科学宣言的内容:“数据科学是关于解决问题,而不是构建模型。”这意味着如果你可以通过一条 SQL 查询来解决客户需求,就这样做!不要因复杂的机器学习模型而感到沮丧:要简单,要有帮助。
Ajay Ohri是位于新德里的 Kogentix Inc.的数据科学家。他还写过两本关于 R 语言的书和一本关于 Python 的书。
我典型的一天从上午 9 点的团队会议开始。我们的项目工作方法是将任务分成两周的目标或者迭代周期。这基本上是敏捷软件开发方法,与 CRISP-DM 或 KDD 方法不同。
需要一点背景知识来解释我们这样做的原因。我目前的角色是东南亚一家银行的数据科学家,负责实施大数据分析。我们的团队中有数据工程师、行政/基础架构人员、数据科学家和当然还有客户经理,满足项目的每个具体需求。我的当前组织是一家名为Kogentix的 AI 初创公司,不仅提供大数据服务,还有一个名为AMP的大数据产品,类似于 PySpark 的 GUI,试图实现大数据的自动化。AMP 相当酷,我很快就会谈到它。这导致我们的初创公司专注于尽可能多地吸引客户,并测试和实施我们的大数据产品。这意味着在客户合作中展示成功-我们的一个客户上个月入围了一个奖项。我听起来是不是太市场导向了-当然是的。数据科学家的工作通常对客户具有战略意义。
我每天都在做什么?可能有很多事情-包括不仅仅是电子邮件和会议。我可能用 Hive 提取数据,用它合并数据(或使用 Impala),我可能用 PySpark(Mllib)制作流失模型或进行 K 均值聚类。我可以用 Excel 文件提取数据来制作摘要,也可以制作数据可视化。有些天我用 R 来制作一些机器学习模型。我还协助测试我们的大数据分析产品 AMP,并与该团队合作增强产品的功能(如果您原谅这个双关语,因为该产品用于功能增强)。当我编写大数据时,我可能使用 Hadoop HUE 的 GUI,也可能使用命令行编程,包括批量提交代码。
在这之前,当我为印度第三大软件公司 Wipro 工作时,我的角色正好相反。我们的客户是印度的财政部(负责税收的部门)。初级数据科学家使用 SQL 从关系数据库管理系统中提取数据(由于历史问题),而我则验证这些结果。报告随后发送给各个客户。我们还在临时基础上使用 SAS Enterprise Miner 来展示印度进出口的时间序列预测作为一个概念测试。在为联邦政府工作与为私营部门工作时,时间表相当缓慢和官僚。我记得一次演示时,负责的官僚对我们执行机器学习感到惊讶,以及为什么政府之前没有使用它。但 SAS/VA(用于仪表盘)、SAS Fraud Analytics(我接受过培训并正在实施中)和 Base SAS(分析工具)都是令人惊叹的软件,我怀疑是否能很快制作出任何类似 SAS 领域专业托包的东西。
在此之前,我经营了十年的 Decisionstats.com。我写博客,销售广告(效果不好),为 Programmable Web、StatisticsViews 写了 3 本数据科学书籍,撰写了大量文章,并进行了一些数据咨询。我甚至为 KDnuggets 写了几篇文章。您可以在这里查看我的个人资料
en.m.wikipedia.org/wiki/Ajay_Ohri
Eric Weber 是位于加利福尼亚州阳光城的 LinkedIn 高级数据科学家。
在 LinkedIn 的一天。好吧,我想说没有“典型”的一天。在阅读时,请记住这一点!
首先,让我简要介绍一下我和我的主要职责。我很幸运能够在 LinkedIn Learning 团队工作,这是组织中最新的数据科学团队。具体而言,我支持 LinkedIn Learning 的企业级销售。这意味着什么呢?想象一下:我们使用数据、模型和分析来决策如何有效销售。当然,我们是如何做到的细节是内部的,但您可以想象我们想要回答的问题,比如:我们要销售给哪些账户?我们努力理解哪些账户与其他账户有所不同。
其次,每天的一个关键方面是沟通。我在 LinkedIn 上详细介绍了这个问题,但我相信与团队成员和业务伙伴进行有效沟通是杰出的数据科学家的一个定义特征。在典型的一天里,这涉及向直属团队成员、经理和高级领导提供关键项目的更新,适时地。我发现工作中这个方面非常有趣的一点是对简洁性的要求。像 LinkedIn 这样的公司内部有大量的沟通正在进行,所以所有发出去的东西必须被淬取成清晰而简洁的结果/对话要点。
最后,每一天都有失败的重要部分。我非常相信,如果你不失败,就不会学到东西。当然,这并不意味着灾难性的失败。这意味着每天我都在努力拓展自己在分析、数据科学和组织本身方面的理解。我从错误中学习,并观察别人是如何比我更高效地做事,或者用不同的方式做事的。每天早晨醒来时,我把失败视为工作的一部分,因为这能让我第二天变得更好。分析和数据科学的快速扩张确实提供了大量这样的机会!
希望这些描述能让你更深入地了解数据科学家日常工作。我收到了很多人的兴趣和回应,所以我会在不久的将来发布更多相关内容。
相关内容:
-
大数据和数据科学的 5 条职业路径,解析
-
7 种数据科学家工作档案
-
必备的 10 个数据科学技能,已更新
关于这个话题的更多信息
机器学习工程师的一天
原文:
www.kdnuggets.com/2022/10/day-life-machine-learning-engineer.html

了解其他人的日常生活是很有帮助的。许多学生更加关注他们需要掌握的技能、课程和知识水平,以确保自己能尽可能优秀。
有时候,你只需要听到第一手资料。如果你从未听说过这个成语,它的意思是如果你直接从知情者那里听到某事,你将获得最真实的信息。
让我们向 易卜拉欣·穆赫吉 学习
介绍
易卜拉欣·穆赫吉 是一名伦敦政治经济学院(LSE)管理学(荣誉)学士毕业生以及数据科学家。在 2008 年毕业后,易卜拉欣加入了石油和天然气行业,担任金融分析师,工作地点包括特立尼达、新加坡、英国(阿伯丁、雷丁、伦敦)、挪威、马来西亚、突尼斯和罗马尼亚。

易卜拉欣·穆赫吉
在此期间,易卜拉欣对行为经济学和神经科学的潜在兴趣,通过阅读丹尼尔·卡尼曼(《思考,快与慢》)和丹·阿里里(《预测性非理性》)的著作,促使他进入了机器学习和人工智能的第二职业生涯。
易卜拉欣对大脑如何从事件中抽象出意义以及人类认知如何与一般的机器学习和模式识别有所不同感兴趣。工作之外,易卜拉欣喜欢阅读科学哲学、宗教心理学、认知神经科学、人类对压力的反应、贝叶斯方法以及编写软件的书籍。
作为机器学习工程师的一天是什么样的?
作为一名机器学习工程师,我将大量时间用于三个主要任务:
-
理解业务需求
-
收集数据
-
基于 1 和 2 提供切实可行的商业问题解决方案
虽然这些任务听起来相对简单,但随着你所在组织的规模扩大,收集的数据复杂性以及生成的结果也会增加。
让我们逐一看看这些任务:
理解业务需求
塞萨尔·希达尔戈在他的书《信息如何增长》中提出了一个非常有趣的观察——当你从上方俯瞰一个城市时,当飞机即将降落时,它看起来与计算机内部的电路板(CPU)非常相似。一个城市是一个计算单元,任何企业也是如此。它可以被抽象为一个算法——有输入,有一些计算来处理这些输入,还有输出。
对于一个企业而言,计算就是企业生产的产品或服务。对于理发师而言,原材料或投入可能是剪刀、理发店的租赁空间、镜子、椅子、隔离栏等,而产品则是一次理发。在这种情况下,金钱是该输出的价值储存。通常情况下,输出的质量和/或数量越高,输出的价值也越高。然而,也有例外,比如内燃机的负外部性(可能会被政府逐渐征税),以及那些产生有效善意的慈善机构。但这仍然是一个普遍的结果。
数据科学家的工作,作为一个专家数据科学家,而不是普通数据科学家,是理解商业提案。输入是什么,输出是什么?
然后,数据科学家将系统地分类工作,以了解业务中的问题。什么可以改善公司的产品,提升公司获得的价格,改善原材料的采购,或改进从输入到公司输出的任何物流方面?
第二点是收集数据
在我深入探讨这一点之前,需要对那些没有经验的数据科学家提个醒,这可以通过二战时期的一个著名警示例子来解释。当盟军在寻求加强轰炸机的装甲时,他们查看了返回的飞机上的子弹孔频率。大多数当时的数据科学家或运筹学专家认为需要加强那些子弹孔较多的飞机区域。
一位出生于匈牙利的数学家亚伯拉罕·瓦尔德有不同的看法。他建议加强那些没有子弹孔的飞机部位。原因是,受损这些部位的飞机往往无法返回,它们已经被击落。
来自维基百科的生存偏差文章中的飞机
因此,数据只是故事的一部分。没有对业务机制的良好理解,数据作用有限。在大企业中,解决方案的规模可能很小,但改进或效率的量可能也不大。在这种情况下,对业务的深刻理解至关重要。
数据收集的形式包括与大量业务利益相关者交谈,了解业务中的数据。数据可能会在业务中的孤岛中隐匿得非常好,而数据科学家的工作是找到一个单一的真实来源,查阅提供的不同数据点,以理解数据并选择最相关和适合的部分进行分析。并非所有数据都是必需的,技能的一部分在于能够辨别重要数据和不重要的数据。将信号与噪音分开。将数据逐步添加到现有分析中总是可能的,删除数据集也是如此。然而,关键是找到数量较少但对解决业务需求至关重要的变量。
这使我们回到了主要的黄金法则。一切都必须增加价值。
企业最终是资本主义框架下的赚钱提案。如果分析不能提供节省钱或赚钱的途径——那就没有价值。那是不被允许的。这一点对数据科学的整个提案至关重要。它应该为管理层和/或利益相关者提供关键行动点或方向,以创造货币价值增值——无论是直接节省成本或赚取更多利润,还是以“软性”方式如市场营销或企业社会责任。
数据科学家还必须是讲故事者。正如 Steve Jobs 所说——“世界上最强大的人是讲故事者”。能够沟通对业务创造的价值是至关重要的。除非利益相关者“看到”价值,否则分析所创造的价值几乎没有意义,因为他们可能无法或不愿付诸实践。
因此,讲述价值主张与创造价值同样重要。数据科学家必须非常擅长传达这些见解。
总结
我想感谢 Ibrahim Mukherjee 花时间向我们解释作为机器学习工程师的一天。了解人们对职业的不同方法及其与自己或其他人的不同,是提升和改善职业生涯的重要因素。
希望这对你有帮助!再次感谢,Ibrahim Mukherjee!
Nisha Arya 是一位数据科学家和自由技术写作人。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能在延长人类寿命方面的不同方式。作为一个热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯的捷径。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织在 IT 方面
了解更多相关主题
机器学习中的 DBSCAN 聚类算法
原文:
www.kdnuggets.com/2020/04/dbscan-clustering-algorithm-machine-learning.html

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
2014 年,DBSCAN 算法在领先的数据挖掘会议 ACM SIGKDD上获得了“时间考验奖”(颁发给理论和实践中获得大量关注的算法)。
— 维基百科
介绍
聚类分析是一种无监督学习方法,它将数据点分为几个特定的组或群体,使得同一组的数据点具有相似的属性,而不同组的数据点在某种意义上具有不同的属性。
它包括许多不同的方法,基于不同的距离度量。例如,K 均值(点之间的距离)、亲和传播(图距离)、均值漂移(点之间的距离)、DBSCAN(最近点之间的距离)、高斯混合(到中心的马氏距离)、谱聚类(图距离)等。
从本质上讲,所有的聚类方法都使用相同的方法,即首先计算相似性,然后利用这些相似性将数据点聚集成组或批次。这里我们将重点讨论基于密度的噪声应用空间聚类(DBSCAN)聚类方法。
如果你对聚类算法不熟悉,我建议你阅读使用 K 均值聚类进行图像分割的介绍。你也可以阅读关于层次聚类的文章。
为什么我们需要像 DBSCAN 这样的基于密度的聚类算法,而不是已经有 K 均值聚类?
K-均值聚类可能将松散相关的观测值聚集在一起。即使观测值在向量空间中分散得很远,每个观测值最终也会成为某个簇的一部分。由于簇依赖于簇元素的均值,每个数据点在形成簇时都会发挥作用。数据点的轻微变化可能会影响聚类结果。这一问题在 DBSCAN 中由于簇形成方式的不同得到了很大程度的减少。除非我们遇到一些奇特的形状数据,否则这通常不是一个大问题。
另一个挑战是 k-均值算法,你需要指定簇的数量(“k”)才能使用它。很多时候,我们不知道合理的 k 值是什么 a priori。
DBSCAN 的优点是你不需要指定要使用的簇的数量。你只需要一个计算值之间距离的函数和一些关于什么距离被认为是“接近”的指导。DBSCAN 在各种不同的分布中也比 k-均值算法产生更合理的结果。下图说明了这一点:

基于密度的聚类算法
基于密度的聚类 指的是无监督学习方法,通过识别数据中的独特组/簇来进行分类,其基于这样一个理念:数据空间中的簇是高点密度的连续区域,由低点密度的连续区域与其他簇隔开。
基于密度的空间聚类(DBSCAN)是基于密度的聚类的基础算法。它可以从大量数据中发现不同形状和大小的簇,这些数据包含噪声和离群点。
DBSCAN 算法使用两个参数:
-
minPts: 为了使一个区域被认为是密集的,聚集在一起的最小点数(阈值)。
-
eps (ε): 用于定位任何点的邻域内点的距离度量。
如果我们探索两个叫做密度可达性(Density Reachability)和密度连接性(Density Connectivity)的概念,就能理解这些参数。
可达性 从密度的角度来说,建立一个点从另一个点可达的条件是它在该点的特定距离(eps)范围内。
连接性,另一方面,涉及基于传递性的链式方法来确定点是否位于特定簇中。例如,如果 p->r->s->t->q,则 p 和 q 点可以连接,其中 a->b 表示 b 在 a 的邻域内。
DBSCAN 聚类完成后,有三种类型的点:
-
核心点 — 这是一个距离自身不超过 n 的区域内至少有 m 个点的点。
-
边界点 — 这是一个在距离 n 内至少有一个核心点的点。
-
噪声 — 这是一个既不是核心点也不是边界点的点。它在自身距离 n 内的点少于 m 个。
DBSCAN 聚类的算法步骤
-
算法通过任意选择数据集中的一个点(直到所有点都被访问)来进行。
-
如果在半径为‘ε’的范围内有至少‘minPoint’个点,则我们将这些点视为同一簇的一部分。
-
然后,通过递归地重复每个邻近点的邻域计算来扩展簇。
参数估计
每个数据挖掘任务都有参数问题。每个参数都会以特定的方式影响算法。对于 DBSCAN,需要ε和minPts这两个参数。
-
minPts: 作为经验法则,最小minPts可以从数据集中的维度数D推导出来,公式为
***minPts* ≥ *D* + 1**。低值***minPts* = 1**是没有意义的,因为那样每个点本身就会形成一个簇。***minPts* ≤ 2**的结果将与使用单链接度量的hierarchical clustering相同,树状图的剪切高度为ε。因此,minPts至少应选择为 3。然而,对于有噪声的数据集,较大的值通常更好,会产生更显著的簇。作为经验法则,可以使用** *minPts* = 2·*dim***,但对于非常大的数据集、噪声数据或包含许多重复的数据,可能需要选择更大的值。 -
ε: 可以通过使用一个k-distance 图来选择ε的值,该图绘制了距离到
***k* = *minPts*-1**最近邻的距离,并按从大到小的顺序排列。好的ε值是在该图上显示“肘部”的位置:如果ε选择得太小,大部分数据将无法被聚类;而ε值过高,则聚类会合并,大多数对象会在同一个簇中。一般来说,小的ε值是更可取的,作为经验法则,只有少量的点应该在彼此的这个距离之内。 -
距离函数: 距离函数的选择与ε的选择密切相关,并对结果有重大影响。通常,在选择参数ε之前,需要首先确定数据集的合理相似度度量。没有此参数的估计,但需要为数据集选择适当的距离函数。
使用 Scikit-learn 的 DBSCAN Python 实现
让我们首先对球形数据应用 DBSCAN 进行聚类。
我们首先生成 750 个球形训练数据点及其对应的标签。之后对训练数据的特征进行标准化,最后应用 sklearn 库中的 DBSCAN。

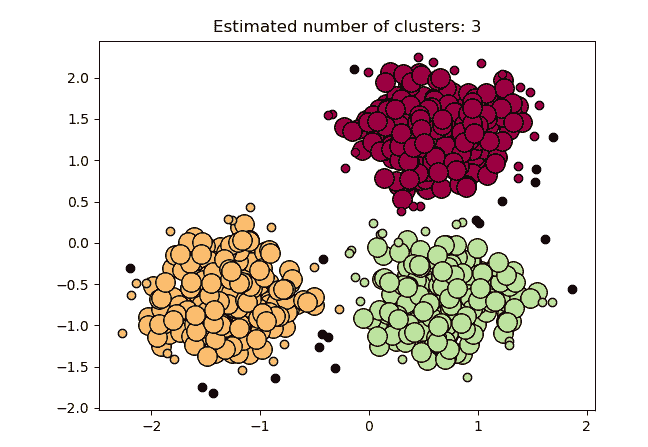
DBSCAN 对球形数据的聚类
上述结果中的黑色数据点代表离群点。接下来,应用 DBSCAN 对非球形数据进行聚类。
DBSCAN 对非球形数据的聚类
这完全是完美的。如果与 K-means 进行比较,它会给出完全不正确的结果,如下所示:
K-means 聚类结果
DBSCAN 的复杂度
-
最佳情况: 如果使用索引系统存储数据集,以便邻域查询以对数时间执行,则平均运行时间复杂度为
**O(nlogn)**。 -
最坏情况: 如果没有使用索引结构或在退化数据上(例如所有点在小于ε的距离内),最坏情况下的运行时间复杂度仍为
**O(*n*²)**。 -
平均情况: 根据数据和算法实现,与最佳/最坏情况相同。
结论
基于密度的聚类算法可以学习任意形状的簇,借助 Level Set Tree 算法,可以在展示广泛密度差异的数据集中学习簇。
但是,我要指出,与像 K-Means 这样的参数化聚类算法相比,这些算法在调整时要复杂一些。比如 DBSCAN 的ε参数或 Level Set Tree 的参数相比于 K-Means 的簇数量参数,直观理解较难,因此为这些算法选择好的初始参数值更具挑战性。
本文到此为止。希望你们阅读愉快,请在评论区分享你的建议/观点/问题。
感谢阅读!
个人简介: Nagesh Singh Chauhan 是 CirrusLabs 的大数据开发工程师。他在电信、分析、销售、数据科学等各个领域拥有超过 4 年的工作经验,专注于各种大数据组件。
原文。经许可转载。
更多相关内容
dbt 数据转换 – 实操教程
原文:
www.kdnuggets.com/2021/07/dbt-data-transformation-tutorial.html
评论
Essi Alizadeh 是一名工程师和高级数据科学家,处于永久测试状态。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
dbt(数据构建工具)是一个数据转换工具,使用 SQL 选择语句。它允许你创建复杂的模型,使用变量和宏(即函数),运行测试,生成文档等。
dbt 不提取或加载数据,但它在转换已存在于数据库中的数据方面非常强大——dbt 执行 ELT(提取、加载、转换)过程中的T。
在本文章中,你将学习如何:
-
配置 dbt 项目。
-
创建 dbt 模型(SELECT 语句)。
-
使用全局变量和宏构建复杂的 dbt 模型。
-
通过引用其他 dbt 模型来构建复杂的模型。
-
运行测试。
-
生成文档。
先决条件
注册
你可以在getdbt.com注册。免费计划对于小型项目和测试来说是一个很好的选择。
具有填充数据的数据库
你可以查看我关于如何在 Heroku 上部署一个 免费的 PostgreSQL 数据库的文章。该文章提供了逐步的操作说明。你也可以查看数据摄取脚本以及附带的GitHub 仓库。
根据上述内容,我们在 PostgreSQL 数据库中生成了两个表,这些表将在本文章中使用。数据库中有两个表,分别命名为 covid_latest 和 population_prosperity。你可以在本文章的 GitHub 仓库中找到摄取脚本。
dbt CLI 安装
你可以按照以下dbt 文档页面上的说明安装 dbt 命令行界面 (CLI)。
dbt 项目的基础知识
使用 dbt 工具时需要了解三件主要的事情:
-
dbt 项目
-
数据库连接
-
dbt 命令
如何使用 dbt?
一个 dbt 项目是一个包含 .sql 和 .yml 文件的目录。所需的最低文件包括:
-
一个名为dbt_project.yml的项目文件:该文件包含 dbt 项目的配置。
-
模型(.sql文件):dbt 中的模型只是一个包含单个 select 语句的.sql文件。
每个 dbt 项目都需要一个dbt_project.yml文件——这是 dbt 识别目录是否为 dbt 项目的方式。它还包含重要的信息,告诉 dbt 如何操作你的项目。
你可以在这里找到更多关于 dbt 项目的信息。
一个dbt 模型基本上是一个.sql文件,包含一个SELECT语句。
dbt 命令
dbt 命令以dbt开头,可以通过以下方式之一执行:
-
dbt Cloud(在 dbt Cloud 仪表板底部的命令部分),
-
dbt CLI
一些命令只能在 dbt CLI 中使用,如dbt init。在这篇文章中我们将使用的一些 dbt 命令包括
-
dbt init(仅在 dbt CLI 中)
-
dbt run
-
dbt test
-
dbt docs generate
dbt 项目设置
第一步:使用 dbt CLI 初始化一个 dbt 项目(示例文件)
你可以使用dbt init来生成示例文件/文件夹。特别是,dbt init project_name将创建以下内容:
-
如果还不存在的话,创建一个~/.dbt/profiles.yml文件
-
一个名为[project_name]的新文件夹
-
必要的目录和示例文件,以便开始使用 dbt
注意:由于dbt init生成一个名为project_name的目录,为避免任何冲突,你应该没有任何具有相同名称的现有文件夹。

dbt init <project_name>
结果是一个包含以下示例文件的目录。
sample_dbt_project
├── README.md
├── analysis
├── data
├── dbt_project.yml
├── macros
├── models
│ └── example
│ ├── my_first_dbt_model.sql
│ ├── my_second_dbt_model.sql
│ └── schema.yml
├── snapshots
└── tests
对于这篇文章,我们只考虑最小文件并去除多余内容。
sample_dbt_project
├── README.md
├── dbt_project.yml
└── models
├── my_first_dbt_model.sql
├── my_second_dbt_model.sql
└── schema.yml
第二步:设置 Git 代码库
你可以使用现有的代码库,如设置过程中所述。你可以通过查看 dbt 文档这里来配置代码库。
或者,如果你想创建一个新的代码库...
你可以在创建的目录内创建一个新的代码库。可以按如下方式进行:
git init
git add .
git commit -m "first commit"
git remote add origing
git push -u origin master
第三步:在 dbt Cloud 仪表板上设置新项目
在前一步中,我们创建了一个包含示例模型和配置的示例 dbt 项目。现在,我们想创建一个新项目,并在 dbt Cloud 仪表板上连接我们的数据库和代码库。
在继续之前,你应该已经拥有
-
数据库中已存在的一些数据,
-
一个包含前一步生成的文件的代码库
你可以按照下面的步骤在 dbt Cloud 中设置一个新项目(请记住,这一步与前一步不同,因为我们仅生成了一些示例文件)。
我们项目的dbt_project.yml文件如下所示(你可以在GitHub repo中找到完整版本)。
name: 'my_new_project'
version: '1.0.0'
config-version: 2
vars:
selected_country: USA
selected_year: 2019
# This setting configures which "profile" dbt uses for this project.
profile: 'default'
# There are other stuff that are generated automatically when you run `dbt init`
dbt_project.yml
dbt 模型和功能
dbt 模型
让我们创建一些简单的 dbt 模型来检索表中的几个列。
select "iso_code", "total_cases", "new_cases" from covid_latest
covid19_latest_stats dbt 模型(models/covid19_latest_stats.sql)
select "code", "year", "continent", "total_population" from population_prosperity
population dbt 模型(models/population.sql)
注意: dbt 模型名称是models目录下 sql 文件的文件名。模型名称可能与数据库中的表名不同。例如,在上述示例中,dbt 模型population是对数据库中population_prosperity表的SELECT语句的结果。
运行模型
你可以通过执行dbt run来运行 dbt 项目中的所有模型。下面显示了一个示例 dbt 运行输出。你可以查看运行所有 dbt 模型的摘要或详细日志。这对于调试查询中的任何问题非常有帮助。例如,你可以看到一个抛出 Postgres 错误的失败模型。

详细记录失败的jinja_and_variable_usage dbt 模型。
Jinja & 宏
dbt 使用了Jinja模板语言,这使得 dbt 项目成为一个理想的 SQL 编程环境。通过 Jinja,你可以进行 SQL 中通常不可能的转换,例如使用环境变量或宏——抽象的 SQL 片段,类似于大多数编程语言中的函数。每当你看到{{ ... }}时,你实际上是在使用 Jinja。有关 Jinja 及额外定义的 Jinja 风格函数的更多信息,请查看dbt 文档。
在这篇文章的后面,我们将介绍由 dbt 定义的自定义宏。
使用变量
定义变量
你可以在dbt_project.yml中的vars部分定义变量。例如,让我们定义一个名为selected_country的变量,其默认值为USA,以及另一个名为selected_year的变量,其默认值为2019。
name: 'my_new_project'
version: '1.0.0'
config-version: 2
vars:
selected_country: USA
selected_year: 2019
dbt_project.yml
使用变量
你可以通过var() Jinja 函数({{ var("var_key_name") }})在 dbt 模型中使用变量。
宏
在dbt_utils中有许多有用的转换和宏可以在你的项目中使用。有关所有可用宏的列表,你可以查看它们的GitHub 仓库。
现在,让我们按照以下步骤将 dbt_utils 添加到我们的项目中并安装:
- 将 dbt_utils 宏添加到你的packages.yml文件中,如下所示:
packages:
- package: dbt-labs/dbt_utils
version: 0.6.6
将dbt_utils包添加到 packages.yml 中。
- 运行dbt deps以安装包。

使用dbt deps安装包。
复杂的 dbt 模型
模型(选择)通常是相互堆叠的。为了构建更复杂的模型,你需要使用 ref() 宏。ref() 是 dbt 中最重要的函数,因为它允许你引用其他模型。例如,你可能有一个模型(即 SELECT 查询),它执行多个操作,但你不希望在其他模型中使用它。如果不使用之前介绍的宏,将很难构建复杂模型。
dbt 模型使用 ref() 和全局变量
我们可以使用前面定义的两个 dbt 模型来构建更复杂的模型。例如,我们可以创建一个新的 dbt 模型,将上述两个表按国家代码连接起来,然后根据选定的国家和年份进行筛选。
select *
from {{ref('population')}}
inner join {{ref('covid19_latest_stats')}}
on {{ref('population')}}.code = {{ref('covid19_latest_stats')}}.iso_code
where code='{{ var("selected_country") }}' AND year='{{ var("selected_year") }}'
jinja_and_variable_usage dbt 模型 (models/jinja_and_variable_usage.sql)。
关于上述查询的几点说明:
-
{{ref('dbt_model_name')}} 用于引用项目中可用的 dbt 模型。
-
你可以从模型中获取一个列,例如{{ref('dbt_model_name')}}.column_name。
-
你可以通过{{var("variable_name")}} 使用在 dbt_project.yml 文件中定义的变量。
上述代码片段将人口和 covid19_latest_stats 模型的数据按国家代码连接起来,并根据 selected_country=USA 和 selected_year=2019 进行筛选。模型的输出如下所示。

- jinja_and_variable_usage dbt 模型的输出。*
你也可以通过点击compile sql按钮查看编译后的 SQL 代码片段。这非常有用,特别是如果你想在 dbt 工具之外运行查询时。

编译后的 SQL 代码用于 jinja_and_variable_usage dbt 模型。
dbt 模型使用 dbt_utils 包和宏
dbt_utils 包含可以在 dbt 项目中使用的宏(即函数)。所有宏的列表可以在 dbt_utils 的 GitHub 页面 上找到。
让我们在 dbt 模型中使用 dbt_utils 的 pivot() 和 get_column_values() 宏,如下所示:
select
continent,
{{ dbt_utils.pivot(
"population.year",
dbt_utils.get_column_values(ref('population'), "year")
) }}
from {{ ref('population') }}
group by continent
using_dbt_utils_macros dbt 模型 (models/using_dbt_utils_macros.sql)。
上述 dbt 模型将在 dbt 中编译为以下 SQL 查询。
select
continent,
sum(case when population.year = '2015' then 1 else 0 end) as "2015",
sum(case when population.year = '2017' then 1 else 0 end) as "2017",
sum(case when population.year = '2017' then 1 else 0 end) as "2016",
sum(case when population.year = '2017' then 1 else 0 end) as "2018",
sum(case when population.year = '2017' then 1 else 0 end) as "2019"
from "d15em1n30ihttu"."dbt_ealizadeh"."population"
group by continent
limit 500
/* limit added automatically by dbt cloud */
编译后的 SQL 查询来自 using_dbt_utils_macros dbt 模型。
在 dbt 中运行测试
使用 dbt 的另一个好处是能够测试你的数据。开箱即用,dbt 提供了以下通用测试:unique,not_null,accepted_values 和 relationships。下方展示了这些测试在模型上的示例:
version: 2
models:
- name: covid19_latest_stats
description: "A model of latest stats for covid19"
columns:
- name: iso_code
description: "The country code"
tests:
- unique
- not_null
schema.yml(dbt 测试)。
你可以通过 dbt test 运行测试。你可以看到下面的输出。

在 dbt Cloud 仪表板上运行 dbt 测试的结果。
了解有关 dbt 测试的更多信息,可以访问 dbt 文档。
在 dbt 中生成文档
你可以通过在命令部分简单地运行 dbt docs generate 来生成你的 dbt 项目的文档,如下所示。

为 dbt 项目生成文档。
你可以通过点击 查看文档 来浏览生成的文档。你可以在下面看到生成的文档概述。
除了 dbt docs generate,dbt docs 还可以提供一个 web 服务器来展示生成的文档。为此,你只需运行 dbt docs serve。有关为你的 dbt 项目生成文档的更多信息,请点击 这里。
其他功能
使用钩子和操作进行数据库管理
有些数据库管理任务需要运行额外的 SQL 查询,例如:
-
创建用户定义的函数
-
授予表的权限
-
以及更多
dbt 有两个接口(钩子和操作)来执行这些任务,并且重要的是对它们进行版本控制。这里简要介绍了钩子和操作。有关更多信息,你可以查看 dbt 文档。
钩子
钩子只是会在不同时间执行的 SQL 片段。钩子在 dbt_project.yml 文件中定义。不同的钩子有:
-
pre-hook: 在模型构建之前执行
-
post-hook: 在模型构建后执行
-
on-run-start: 在 dbt 运行开始时执行
-
on-run-end: 在 dbt 运行结束时执行
操作
操作是一种方便的方式,可以在不运行模型的情况下调用宏。操作是通过 dbt run-operation 命令触发的。请注意,与钩子不同,你需要显式执行 dbt 操作 中的 SQL。
结论
dbt 是一个非常值得尝试的好工具,因为它可能简化你的数据 ELT(或 ETL)管道。在这篇文章中,我们学习了如何设置和使用 dbt 进行数据转换。我向你介绍了这个工具的不同功能。特别是,我提供了一个逐步指南:
-
配置 dbt 项目
-
创建 dbt 模型(SELECT 语句)
-
使用全局变量和宏构建复杂的 dbt 模型
-
通过引用其他 dbt 模型构建复杂模型
-
运行测试
-
生成文档
你可以在下面找到包含所有脚本(包括数据摄取脚本)的 GitHub 仓库。随意克隆本文的源代码。
简介: Essi Alizadeh (@es_alizadeh) 是一名工程师和高级数据科学家,始终保持不断进步。他喜欢写作关于不同的技术、统计学、时间序列和机器学习的文章。
相关内容:
更多相关话题
介绍 dbt,这一 ETL 和 ELT 的颠覆者
评论

图像来自 Pixabay 的 Peter H。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您组织的 IT
每天,世界各地都会收集、处理和存储海量的数据,以用于各种分析目的。如果没有管道来获取和正确使用这些数据,大规模的数据科学将根本无法实现。传统上,使用 ETL 和 ELT 这两种过程中的一种来获取大量数据,挑选出重要的部分,然后将这些数据加载到数据湖或数据存储中。然而,这两种管道都有其缺点,并且在 2020 年——随着世界对分析和实时数据的依赖越来越大——ETL 和 ELT 已经不再是最锋利的工具了。
在这篇文章中,我将比较 ETL 和 ELT,总结它们的工作原理,它们在过去和今天的传统用法,以及为什么大多数数据科学领导者认为它们已经过时。
ELT 和 ETL,有什么区别?
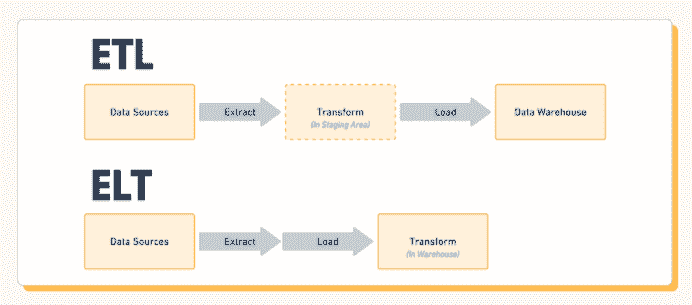
ELT 代表提取、加载、转换,而它的伙伴 ETL 同样代表提取、转换、加载。这三个步骤是任何重要数据转换中的关键过程。无论您是否意识到,它们在全球数百万个应用程序中被使用。每次您从附近的杂货店购买物品时,无论您的交易是匿名的还是识别的,都会经过这些管道进行财务和市场分析。让我们看看 ELT 与 ETL 的比较情况。
如果我们从不同来源收集数据,例如来自全国多个商店,或者举例来说,来自水坝上不同点的多种仪器,为了科学研究,我们需要将所有这些数据汇总在一起,然后仅提取与我们想要创建的分析相关的部分。这可能是来自每个商店的净销售额,在这种情况下,你需要对所有交易进行规范化并汇总。或者在水坝的例子中,可能需要列出所有水压读数。这就是转换过程,它对于创建分析至关重要。具体来说,它使我们能够使用像 Tableau 或 Periscope 这样的商业智能工具。
当我们使用 ELT——即提取、加载、转换(Extract, Load, Transform)时,我们的目的是通过在数据服务器上执行所有这些计算密集型操作来减轻主机器的负担。我们不是使用超市的计算机来汇总交易数据,而是将原始数据发送到数据湖或其他存储机器,然后再进行转换阶段以获取总体利润——例如,汇总交易并扣除成本。
ELT 非常适合大量数据的情况,其中我们只进行简单的计算,例如超市的例子。我们可以从所有来源提取数据,例如卡读卡器,将其加载到我们的数据存储中,然后进行转换,以便我们可以轻松地进行分析。
另一方面,你有ETL。在水坝的例子中,ETL 更为适用。总的来说,我们不一定收集大量数据,但有许多不同种类的读数,且很可能需要对其进行大量计算以获得有价值的分析。最好我们还希望这些数据能够实时处理,以便能够防止任何洪水!在这种情况下,提取、传输、加载(Extract, Transfer, Load)更为合适。我们不是将原始数据发送到数据存储中再进行操作,而是在数据传送到数据存储时进行操作,这被称为“转换阶段”。这样,我们可以建立一个在数据加载之前就已处理的连续数据流!
这两个类比很好地突出了 ETL 与 ELT 的优缺点。使用 ELT,当你有大量数据时,例如数百笔交易,但你只需要执行一些相对简单的操作,如计算利润或将销售数据映射到一天中的时间,这种方式非常有效。
与此同时,ETL 更适用于实时场景,其中我们没有大量数据,但有大量需要正确排序的专门数据,因此需要更多计算。
ETL 和 ELT 的工具
对于现代世界来说,我们不再需要进行大量编程来创建一个精简的数据管道了!现在有许多 ETL 和 ELT 工具可以帮助我们完成这些功能,从各种数据源到广泛的数据仓库或机器。
例如,Hevo 无代码数据管道在零售商和其他希望收集销售数据或店铺活动信息的实体业务中非常受欢迎。但它也非常适用于实时数据,因此如果你想测量店铺前的客流量并随着时间绘制数据图,你也可以使用 Hevo!
还有 Fivetran,它围绕预构建的连接器和功能构建,提供“即插即用”的体验。
dbt——一种更好的方法!
ELT 和 ETL 可能听起来是将数据从 A 传输到 B 进行分析的合理方法,但它们实际上各自都非常不方便。使用 ELT 和 ETL,你必须在加载数据之前确切知道你要创建的分析内容。幸运的是,现代工具如 Fivetran、Airflow、Stitch 等,以及 BigQuery、Snowflake 和 Redshift 等云仓库使得这些工具变得非常简单。
即使如此,困难的部分仍然存在于转换层。转换层是数据管道中的关键元素,但如果它阻碍了你获取最相关的洞察,那么一定有更好的方法。
然而,通过一些更先进的管道技术,我们可以增加选项,允许我们创建多种不同类型的分析,而无需通过管道重新发送数据并进行不同的转换!
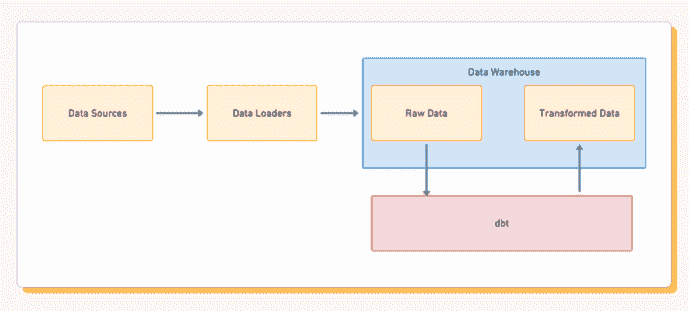
它被称为dbt,或 数据构建工具,这是一个超级灵活的命令行数据管道工具,允许我们非常快速和轻松地收集和转换数据以进行分析!使用 dbt 不需要完全重新编程你的管道。
dbt 仍然基于 SQL 像传统数据库一样构建,但它在其基础上使用像 jinja 这样的模板引擎构建了额外的功能。这有效地允许你将更多逻辑(即循环、函数等)引入你的 SQL,以访问、重新排列和组织数据——有点像编程你的数据集,但具有更多的灵活性和选项。
有了这段代码,你可以使用 dbt 的运行命令来编译代码并在 SQL 数据上运行,以获取你在转换中所需的确切部分。它也可以快速编程、测试和修改,而无需等待很长时间让其遍历所有数据,这意味着你可以在紧张的时间表上创建新的、更好的程序版本。
dbt 并不能完全取代 ELT,但它确实提供了显著更多的灵活性——它极大地提升了你的“转换”层/阶段。通过 dbt,你可以反复聚合、标准化和排序数据,而无需不断更新管道和重新发送。
dbt 并不是 ETL 和 ELT 的替代品,但随着现代技术的出现,这些管道方法单独使用正变得过时。无论你选择 ETL 还是 ELT,有一点可以肯定的是,dbt 在你能想到的每一个方面都对 T(转换)层有着如此巨大的改进。
我鼓励你去了解 dbt。你可以从 这里的快速入门指南 开始,并加入他们超级 有帮助的社区。当你开始使用 dbt 时,你会感到惊讶自己以前是如何进行数据建模工作的。
原文。已获得转载许可。
相关:
更多相关话题
如何处理机器学习中的分类数据
原文:
www.kdnuggets.com/2021/05/deal-with-categorical-data-machine-learning.html

在这篇博客中,我们将探索并实现:
-
使用独热编码:
-
Python 的 category_encoding 库
-
Scikit-learn 预处理
-
Pandas 的 get_dummies
-
-
二进制编码
-
频率编码
-
标签编码
-
顺序编码
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织在 IT 方面
什么是分类数据?
分类数据是一种用于将信息按类似特征分组的数据类型,而数值数据则是以数字形式表达信息的数据类型。
分类数据的例子:性别
为什么我们需要编码?
-
大多数机器学习算法无法处理分类变量,除非我们将它们转换为数值。
-
许多算法的表现甚至会因分类变量的编码方式而有所不同
分类变量可以分为两类:
-
名义型:没有特定顺序
-
顺序型:值之间有一定顺序
我们还会参考一张速查表,显示何时使用哪种类型的编码。
方法 1:使用 Python 的 Category Encoder 库
category_encoders 是一个很棒的 Python 库,提供了 15 种不同的编码方案。
这是库支持的 15 种编码类型的列表:
-
独热编码
-
标签编码
-
顺序编码
-
赫尔梅特编码
-
二进制编码
-
频率编码
-
平均编码
-
证据权重编码
-
概率比编码
-
哈希编码
-
向后差分编码
-
留一法编码
-
詹姆斯-斯坦编码
-
M 估计量编码
-
温度计编码器
导入库:
import pandas as pd
import sklearn
pip install category_encoders
import category_encoders as ce
创建一个数据框:
data = pd.DataFrame({ 'gender' : ['Male', 'Female', 'Male', 'Female', 'Female'],
'class' : ['A','B','C','D','A'],
'city' : ['Delhi','Gurugram','Delhi','Delhi','Gurugram'] })
data.head()
图片由作者提供
通过 category_encoder 实现独热编码
在这种方法中,每个类别映射到一个包含 1 和 0 的向量,以表示特征的存在或不存在。向量的数量取决于特征的类别数量。
创建一个独热编码对象:
ce_OHE = ce.OneHotEncoder(cols=['gender','city'])
data1 = ce_OHE.fit_transform(data)
data1.head()
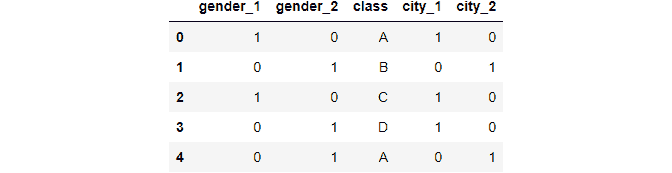
图片由作者提供
二进制编码
二进制编码将一个类别转换为二进制数字。每个二进制数字创建一个特征列。
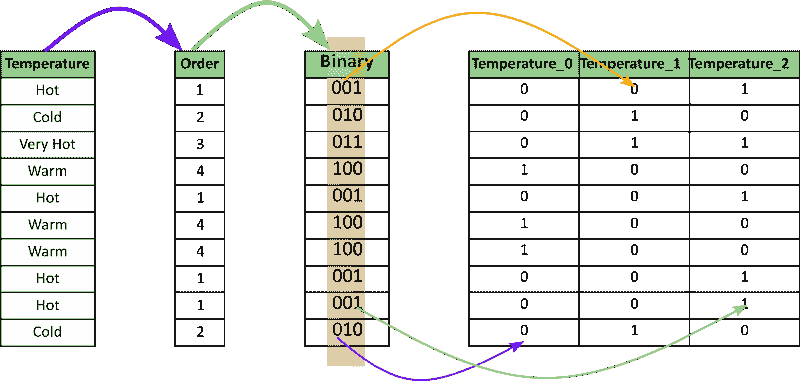
ce_be = ce.BinaryEncoder(cols=['class']);
# transform the data
data_binary = ce_be.fit_transform(data["class"]);
data_binary
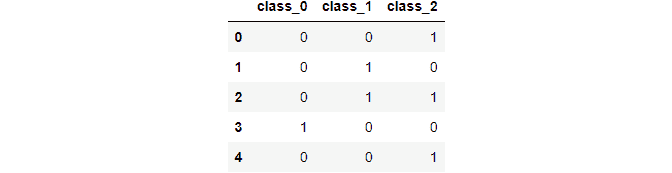
作者提供的图像
类似地,该库提供了另外 14 种编码方式。
方法 2:使用 Pandas 的 Get Dummies
pd.get_dummies(data,columns=["gender","city"])
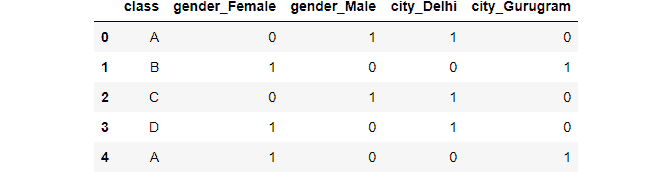
作者提供的图像
如果我们不希望编码使用默认值,可以分配前缀。
pd.get_dummies(data,prefix=["gen","city"],columns=["gender","city"])
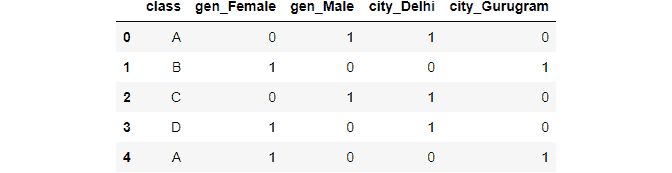
作者提供的图像
方法 3:使用 Scikit-learn
Scikit-learn 还提供了 15 种不同类型的内置编码器,可以从 sklearn.preprocessing 访问。
Scikit-learn 独热编码
首先获取数据中的类别变量列表:
s = (data.dtypes == 'object')
cols = list(s[s].index)
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(handle_unknown='ignore',sparse=False)
应用于性别列:
data_gender = pd.DataFrame(ohe.fit_transform(data[["gender"]]))
data_gender

作者提供的图像
应用于城市列:
data_city = pd.DataFrame(ohe.fit_transform(data[["city"]]))
data_city

作者提供的图像
应用于类别列:
data_class = pd.DataFrame(ohe.fit_transform(data[["class"]]))
data_class
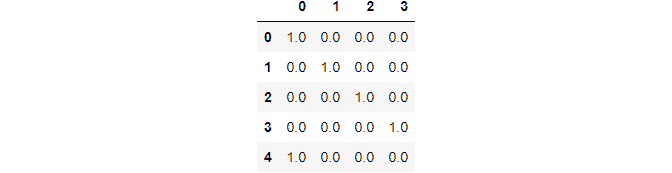
作者提供的图像
这是因为类别列有 4 个唯一值。
应用于类别变量列表:
data_cols = pd.DataFrame(ohe.fit_transform(data[cols]))
data_cols
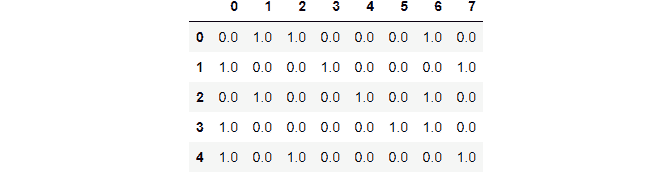
作者提供的图像
这里前两列代表性别,接下来的四列代表类别,剩下的两列代表城市。
Scikit-learn 标签编码
在标签编码中,每个类别被分配一个从 1 到 N 的值,其中 N 是该特征的类别数量。这些分配之间没有关系或顺序。
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
Label encoder takes no arguments
le_class = le.fit_transform(data[["class"]])
与独热编码比较
data_class
作者提供的图像
序数编码
序数编码的编码变量保留了变量的序数(有序)特性。它看起来类似于标签编码,唯一的区别在于标签编码不考虑变量是否有序;它将分配一系列整数。
示例:序数编码将分配值为 非常好(1)< 好(2)< 差(3)< 更差(4)
首先,我们需要通过字典分配变量的原始顺序。
temp = {'temperature' :['very cold', 'cold', 'warm', 'hot', 'very hot']}
df=pd.DataFrame(temp,columns=["temperature"])
temp_dict = {'very cold': 1,'cold': 2,'warm': 3,'hot': 4,"very hot":5}
df

作者提供的图像
然后我们可以根据字典映射每一行的变量。
df["temp_ordinal"] = df.temperature.map(temp_dict)
df
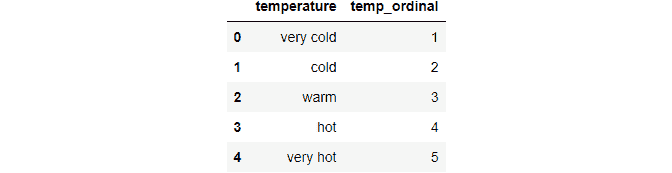
作者提供的图像
频率编码
类别是根据其总数量中值的频率分配的。
data_freq = pd.DataFrame({'class' : ['A','B','C','D','A',"B","E","E","D","C","C","C","E","A","A"]})
按类别列分组:
fe = data_freq.groupby("class").size()
按长度划分:
fe_ = fe/len(data_freq)
映射和舍入:
data_freq["data_fe"] = data_freq["class"].map(fe_).round(2)
data_freq

作者提供的图像
在本文中,我们看到了 5 种编码方案。类似地,还有其他 10 种编码方式我们尚未探讨:
-
赫尔梅特编码
-
平均编码
-
证据权重编码
-
概率比编码
-
哈希编码
-
向后差分编码
-
留一法编码
-
詹姆斯-斯坦编码
-
M-估计量编码
-
温度计编码器
哪种编码方法最佳?
没有一种方法适用于所有问题或数据集。我个人认为 get_dummies 方法在其易于实现的优势上具有优势。
如果你想了解所有 15 种编码方式,这里有一篇很好的文章可供参考。
这是一个有关何时使用何种编码类型的备忘单:
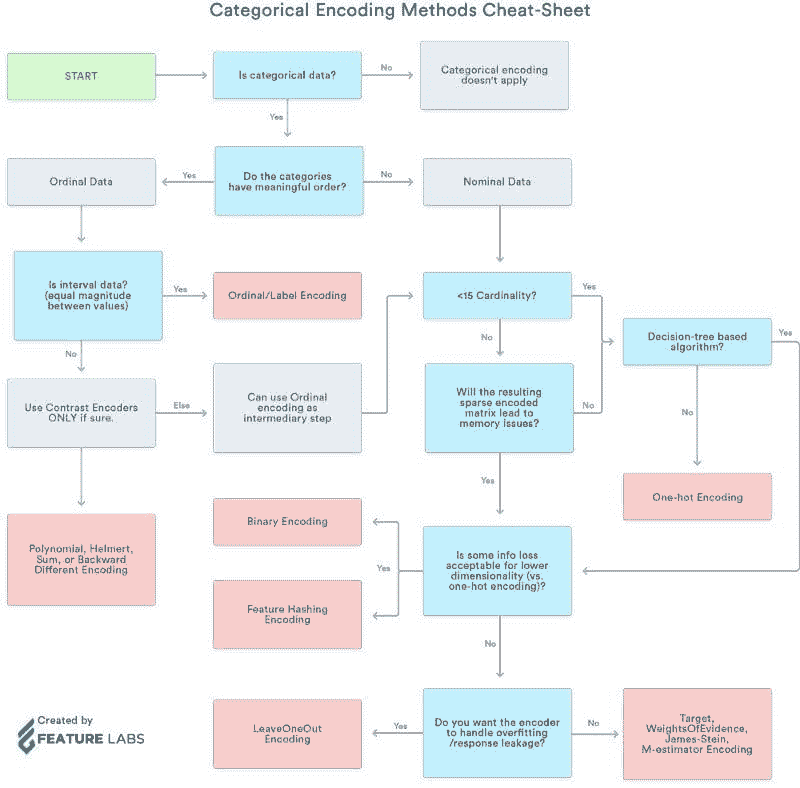
参考资料:
-
towardsdatascience.com/all-about-categorical-variable-encoding-305f3361fd02 -
pandas.pydata.org/docs/reference/api/pandas.get_dummies.html
Shelvi Garg 是 Spinny 的数据科学家
更多相关内容
处理数据泄漏
评论
由 Susan Currie Sivek, Ph.D.,高级数据科学记者

我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
捕捉自 via GIPHY
你正在为即将到来的考试做准备。考试是开卷的,所以你在复习时使用参考资料,表现非常好。
但当你在考试当天出现时,突然被告知考试不再是开卷的了。结果就不那么好了。
这听起来像是学术过度成就者的焦虑梦,但它类似于在机器学习模型中发生目标泄漏的情况。假设你建立了一个预测特定结果的模型,并用帮助模型进行预测的信息对其进行训练。那个模型可能表现得很好……也许表现得异常好。但如果有些信息在模型实际进行预测时无法获得,其真实表现将会下降。这就是目标泄漏的结果——数据科学家的焦虑梦!
我最近听到我们的一位内部 Alteryx 专家称目标泄漏为机器学习中最棘手的问题。但它是如何发生的,如何避免这个问题?它与“数据泄漏”有何关系?
目标泄漏
目标泄漏发生在模型使用了在预测时无法获得的数据进行训练时。模型在最初的训练和测试中表现良好,但当投入生产时,由于缺少现在已不再可用的数据,模型表现变差。就像你在书本旁学习,然后在考试时没有这些书本,模型也缺少了在训练过程中提升其表现的有用信息。
这里有一些代表目标泄漏的场景:
-
在用于训练模型的数据集中将需要预测的结果作为特征包含在内(这听起来可能很傻,但确实可能发生;例如,复制并重命名你的目标变量字段,然后忘记这一复制,可能会导致你无意中使用额外版本的目标作为预测变量);
-
包含一个表示学生在大学里就读年限的特征,用于预测学生是否会接受该大学的录取邀请;
-
包含一个表示订阅月数的特征,用于预测潜在客户是否会订阅;
-
包含一个表示火灾相关保险索赔是否被批准的特征,用于预测某种类型墙板房屋的火灾;和
-
包含来自其他数据集的信息,这些信息在预测时模型无法获得的详细内容。
在所有这些情况下,当模型构建时包含了在预测时无法知道的信息。我们无法在尝试确定客户是否会订阅时知道他们会订阅多少个月。(我们可以构建一个预测订阅月数的模型吗?当然可以。但我们会基于已知订阅者的数据,而不是所有可能订阅或不订阅的客户数据。)类似地,如果我们告诉模型某些材料建造的房屋曾经提出过火灾保险索赔,那么我们就把火灾发生后的知识引入了试图预测火灾的模型中。
即使是看似无害的细节,如文件大小或时间戳,也可能无意中成为目标变量的代理。例如,2013 年的 Kaggle 竞赛因这种问题被暂停并重新整理数据集。发现(并认真报告)泄露的团队曾短暂地在排行榜上名列前茅!
数据泄露导致的结果是对训练数据的过拟合。你的模型可能在具备额外知识的情况下预测得非常好——在开卷考试中表现出色——但在预测时没有这些信息时表现就不好。
训练-测试污染
另一种数据泄露的形式有时称为“训练-测试污染”。这个问题可能不涉及你的目标变量,但它会影响模型性能。这是我们可能无意中将未来数据的知识添加到训练数据中的另一种方式,导致性能指标看起来比实际生产中要好。(顺便提一下,如果你查找更多关于这个话题的阅读,注意“数据泄露”这个词有时也被网络安全人员用来谈论数据泄露事件。)
一种常见的训练-测试污染发生方式是,在将数据集拆分为训练集和测试集之前,或在使用交叉验证之前,先对整个数据集进行预处理。
例如,数据归一化需要使用数据集中每个变量的数值范围。对整个数据集进行归一化时,会在评估时将“知识”提供给模型。然而,投入生产的模型不会拥有这些知识,因此在预测时表现不会那么好。类似地,对整个数据集进行标准化会不当地告知模型整个数据集的均值和标准差。填补缺失值也使用了有关数据集的汇总统计数据(例如,中位数、均值)。
所有这些线索都可能帮助模型在你的训练和测试数据上的表现优于当模型最终引入全新的数据时。这篇文章提供了对这种数据泄漏的深入探讨,包括演示代码。
另一个问题可能会出现,如果你使用 k-折交叉验证 来评估你的模型。只要你的数据集中每个人/来源仅包含一个观察值,这种类型的泄漏对你来说不应该是个问题。然而,如果你的数据集中每个人或来源有多个观察值(即,数据行),那么在创建训练和测试模型的数据子集或“折”时,来自同一来源的所有观察值需要被归为一组。
例如,如果来自 A 人的观察值被包含在训练组和测试组中,你可能会使用 A 人的训练数据来预测 A 人的测试数据。模型在测试集上的表现似乎更好——测试集也包含 A 人——因为它已经从训练集中知道了 A 人的一些信息。但在生产中,它不会有这种先前接触的优势。有关这个问题的更多详细信息(有时称为“组泄漏”),请查看这篇文章。
处理数据泄漏
当你家中的水龙头滴水时,你可以通过声音和水洼来识别。但这些类型的泄漏可能很难检测。你仍然可以进行预防性维护和修理来解决这个问题。
异常良好的模型性能可能是泄漏的迹象。如果你的模型表现得惊人地好,抵制自满的诱惑,避免急于发布。这种表现可能是普通的过拟合造成的,但也可能反映了目标或数据泄漏。
为了尽量避免数据泄漏,你可以进行全面的探索性数据分析(EDA),并查找与结果变量有特别高相关性的特征。值得仔细检查这些关系,以确保如果将高度相关的特征一起用于模型中,不会存在泄漏的潜在风险。如果你有一个具有许多特征的高维数据集,这项审查可能会很具挑战性,因此在 Alteryx Designer 中使用像皮尔逊相关工具这样的工具,并过滤和/或可视化其输出可能会有帮助。
为了避免训练-测试污染,请确保在应用任何转换(如归一化)之前,将数据分成训练集/测试集/保留集,然后在训练集上训练模型。接下来,将相同的参数应用于测试集/保留集并进行转换,然后测试模型的性能。
此外,确保你充分理解数据集中所有的特征。这个 Kaggle 示例展示了如何在信用卡申请批准数据集中,一个名为“支出”的特征如果用于预测批准申请,可能会导致目标泄漏。“支出”作为特征名称可能有很多含义,但在这种情况下,它指的是信用卡用户在卡上花费了多少。这一特征暗示他们确实被批准了卡片,并不当地影响了模型的批准预测,因为在预测时支出信息是不可用的。
最后,检查特征的相对重要性并审查其他可解释性工具可能会帮助你发现泄漏。在上述信用卡申请批准的例子中,“支出”可能看起来是预测信用卡批准中一个非常重要的特征。如果有疑问,你可以尝试移除一个特征,看看模型的性能如何变化,然后确定模型是否突然表现得更为真实。
你的模型防泄漏
我希望这个概述为你提供了一些新的技术,以帮助你避免这些泄漏情况!通过仔细的 EDA 和对数据集的全面了解,以及正确的预处理和交叉验证设置,你应该能够保持目标的良好控制,并使数据集免于污染。
推荐阅读
最初发布于Alteryx Community Data Science Blog。
简介:Susan Currie Sivek, Ph.D. 是 Alteryx Community 的高级数据科学记者,她与全球观众探讨数据科学概念。她也是数据科学混音器播客的主持人。她在学术界和社会科学方面的背景为她研究数据和传达复杂观点的方式提供了信息,同时她的新闻培训也为她的创意注入了灵感。
原文。经授权转载。
相关内容:
-
机器学习的持续训练 – 成功策略的框架
-
AI 训练数据的 5 篇重要论文
-
Python 中的数据集拆分最佳实践
更多相关话题
处理文本数据中的噪声标签
原文:
www.kdnuggets.com/2023/04/dealing-noisy-labels-text-data.html

编辑器提供的图像
随着自然语言处理的兴趣上升,越来越多的从业者遇到了瓶颈,这不是因为他们不能构建或微调 LLM,而是因为他们的数据很混乱!
我们将展示简单但非常有效的编码程序,以修复文本数据中的噪声标签。我们将处理现实世界文本数据中的两个常见场景:
-
拥有一个包含来自其他几个类别的混合示例的类别。我喜欢将这种类别称为元类别。
-
拥有两个或更多应该合并成一个类别的类别,因为它们的文本指向相同的话题。
我们将使用为本教程创建的 ITSM(IT 服务管理)数据集(CCO 许可)。它可以在下面的 Kaggle 链接中找到:
www.kaggle.com/datasets/nikolagreb/small-itsm-dataset
是时候开始导入所有需要的库和基本数据检查了。做好准备,代码来了!
导入和数据检查
import pandas as pd
import numpy as np
import string
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import ComplementNB
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
from sklearn import metrics
df = pd.read_excel("ITSM_data.xlsx")
df.info()
<class>RangeIndex: 118 entries, 0 to 117
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ID_request 118 non-null int64
1 Text 117 non-null object
2 Category 115 non-null object
3 Solution 115 non-null object
4 Date_request_recieved 118 non-null datetime64[ns]
5 Date_request_solved 118 non-null datetime64[ns]
6 ID_agent 118 non-null int64
dtypes: datetime64ns, int64(2), object(3)
memory usage: 6.6+ KB</class>
每一行代表 ITSM 数据库中的一个条目。我们将尝试根据用户编写的工单文本来预测工单的类别。让我们更深入地探讨描述的业务用例中最重要的字段。
for text, category in zip(df.Text.sample(3, random_state=2), df.Category.sample(3, random_state=2)):
print("TEXT:")
print(text)
print("CATEGORY:")
print(category)
print("-"*100)
TEXT:
I just want to talk to an agent, there are too many problems on my pc to be explained in one ticket. Please call me when you see this, whoever you are. (talk to agent)
CATEGORY:
Asana
----------------------------------------------------------------------------------------------------
TEXT:
Asana funktionierte nicht mehr, nachdem ich meinen Laptop neu gestartet hatte. Bitte helfen Sie.
CATEGORY:
Help Needed
----------------------------------------------------------------------------------------------------
TEXT:
My mail stopped to work after I updated Windows.
CATEGORY:
Outlook
----------------------------------------------------------------------------------------------------
如果我们查看前两个工单,虽然一个工单是德文的,但我们可以看到描述的问题指的是相同的软件?—?Asana,但它们带有不同的标签。这是我们类别的初步分布:
df.Category.value_counts(normalize=True, dropna=False).mul(100).round(1).astype(str) + "%"
Outlook 19.1%
Discord 13.9%
CRM 12.2%
Internet Browser 10.4%
Mail 9.6%
Keyboard 9.6%
Asana 8.7%
Mouse 8.7%
Help Needed 7.8%
Name: Category, dtype: object
需要帮助的类别看起来可疑,像是一个可以包含来自多个其他类别的工单的类别。此外,Outlook 和 Mail 听起来相似,也许它们应该合并为一个类别。在深入研究这些类别之前,我们将清理我们关注列中的缺失值。
important_columns = ["Text", "Category"]
for cat in important_columns:
df.drop(df[df[cat].isna()].index, inplace=True)
df.reset_index(inplace=True, drop=True)
将工单分配到正确的类别
对数据进行目视检查没有有效的替代方法。在 pandas 中执行此操作的高级函数是 .sample(),因此我们将再次执行此操作,这次针对可疑类别:
meta = df[df.Category == "Help Needed"]
for text in meta.Text.sample(5, random_state=2):
print(text)
print("-"*100)
Discord emojis aren't available to me, I would like to have this option enabled like other team members have.
---------------------------------------------------------------------------
Bitte reparieren Sie mein Hubspot CRM. Seit gestern funktioniert es nicht mehr
---------------------------------------------------------------------------
My headphones aren't working. I would like to order new.
---------------------------------------------------------------------------
Bundled problems with Office since restart:
Messages not sent
Outlook does not connect, mails do not arrive
Error 0x8004deb0 appears when Connection attempt, see attachment
The company account is affected: AB123
Access via Office.com seems to be possible.
---------------------------------------------------------------------------
Asana funktionierte nicht mehr, nachdem ich meinen Laptop neu gestartet hatte. Bitte helfen Sie.
---------------------------------------------------------------------------
显然,我们有关于 Discord、Asana 和 CRM 的工单。因此,类别名称应该从“Help Needed”更改为现有的、更具体的类别。在重新分配过程的第一步,我们将创建一个新的列“Keywords”,该列提供工单是否包含“Text”列中类别列表中的单词的信息。
words_categories = np.unique([word.strip().lower() for word in df.Category]) # list of categories
def keywords(row):
list_w = []
for word in row.translate(str.maketrans("", "", string.punctuation)).lower().split():
if word in words_categories:
list_w.append(word)
return list_w
df["Keywords"] = df.Text.apply(keywords)
# since our output is in the list, this function will give us better looking final output.
def clean_row(row):
row = str(row)
row = row.replace("[", "")
row = row.replace("]", "")
row = row.replace("'", "")
row = string.capwords(row)
return row
df["Keywords"] = df.Keywords.apply(clean_row)
此外,请注意,使用“if word in str(words_categories)”而不是“if word in words_categories”将捕捉到来自多词类别(在我们的例子中是 Internet Browser)的词,但也需要更多的数据预处理。为了保持简单和直接,我们将使用仅包含一个词的类别的代码。这是我们数据集现在的样子:
df.head(2)
以图像输出:

提取关键词列后,我们将评估票据的质量。我们的假设是:
-
在文本字段中只有一个与票据所属类别相同的关键词的票据将容易分类。
-
在文本字段中有多个关键词的票据,其中至少一个关键词与票据所属类别相同,大多数情况下将容易分类。
-
含有关键词的票据,但其中没有一个与票据所属类别的名称相同的,可能是噪声标签的情况。
-
其他票据基于关键词是中性的。
cl_list = []
for category, keywords in zip(df.Category, df.Keywords):
if category.lower() == keywords.lower() and keywords != "":
cl_list.append("easy_classification")
elif category.lower() in keywords.lower(): # to deal with multiple keywords in the ticket
cl_list.append("probably_easy_classification")
elif category.lower() != keywords.lower() and keywords != "":
cl_list.append("potential_problem")
else:
cl_list.append("neutral")
df["Ease_classification"] = cl_list
df.Ease_classification.value_counts(normalize=True, dropna=False).mul(100).round(1).astype(str) + "%"
neutral 45.6%
easy_classification 37.7%
potential_problem 9.6%
probably_easy_classification 7.0%
Name: Ease_classification, dtype: object
我们创建了新的分布,现在是时候检查分类为潜在问题的票据了。在实际操作中,下一步将需要更多的采样并用肉眼查看更大块的数据,但基本原理是一样的。你需要找出有问题的票据,并决定是否可以提高其质量或是否应将其从数据集中剔除。当你面对一个大数据集时,保持冷静,别忘了数据检查和数据准备通常比构建机器学习算法需要更多的时间!
pp = df[df.Ease_classification == "potential_problem"]
for text, category in zip(pp.Text.sample(5, random_state=2), pp.Category.sample(3, random_state=2)):
print("TEXT:")
print(text)
print("CATEGORY:")
print(category)
print("-"*100)
TEXT:
outlook issue , I did an update Windows and I have no more outlook on my notebook ? Please help !
Outlook
CATEGORY:
Mail
--------------------------------------------------------------------
TEXT:
Please relase blocked attachements from the mail I got from name.surname@company.com. These are data needed for social media marketing campaing.
CATEGORY:
Outlook
--------------------------------------------------------------------
TEXT:
Asana funktionierte nicht mehr, nachdem ich meinen Laptop neu gestartet hatte. Bitte helfen Sie.
CATEGORY:
Help Needed
--------------------------------------------------------------------
我们了解到来自 Outlook 和 Mail 类别的票据与相同的问题相关,因此我们将合并这两个类别并改进我们未来机器学习分类算法的结果。
合并到集群
mail_categories_to_merge = ["Outlook", "Mail"]
sum_mail_cluster = 0
for x in mail_categories_to_merge:
sum_mail_cluster += len(df[df["Category"] == x])
print("Number of categories to be merged into new cluster: ", len(mail_categories_to_merge))
print("Expected number of tickets in the new cluster: ", sum_mail_cluster)
def rename_to_mail_cluster(category):
if category in mail_categories_to_merge:
category = "Mail_CLUSTER"
else:
category = category
return category
df["Category"] = df["Category"].apply(rename_to_mail_cluster)
df.Category.value_counts()
Number of categories to be merged into new cluster: 2
Expected number of tickets in the new cluster: 33
Mail_CLUSTER 33
Discord 15
CRM 14
Internet Browser 12
Keyboard 11
Asana 10
Mouse 10
Help Needed 9
Name: Category, dtype: int64
最后但同样重要的是,我们希望将一些来自“需要帮助”元类别的票据重新标记为适当的类别。
df.loc[(df["Category"] == "Help Needed") & ([set(x).intersection(words_categories) for x in df["Text"].str.lower().str.replace("[^\w\s]", "", regex=True).str.split()]), "Category"] = "Change"
def cat_name_change(cat, keywords):
if cat == "Change":
cat = keywords
else:
cat = cat
return cat
df["Category"] = df.apply(lambda x: cat_name_change(x.Category, x.Keywords), axis=1)
df["Category"] = df["Category"].replace({"Crm":"CRM"})
df.Category.value_counts(dropna=False)
Mail_CLUSTER 33
Discord 16
CRM 15
Internet Browser 12
Asana 11
Keyboard 11
Mouse 10
Help Needed 6
Name: Category, dtype: int64
我们进行了数据重新标记和清理,但如果我们不做至少一个科学实验来测试我们工作的最终分类影响,我们不应自称为数据科学家。我们将通过在 sklearn 中实现互补朴素贝叶斯分类器来完成这一点。你可以尝试其他更复杂的算法。此外,还要注意,进一步的数据清理可能会进行,例如,我们还可以删除所有仍留在“需要帮助”类别中的票据。
测试数据处理的影响
model = make_pipeline(TfidfVectorizer(), ComplementNB())
# old df
df_o = pd.read_excel("ITSM_data.xlsx")
important_categories = ["Text", "Category"]
for cat in important_categories:
df_o.drop(df_o[df_o[cat].isna()].index, inplace=True)
df_o.name = "dataset just without missing"
df.name = "dataset after deeper cleaning"
for dataframe in [df_o, df]:
# Split dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(dataframe.Text, dataframe.Category, test_size=0.2, random_state=1)
# Training the model with train data
model.fit(X_train, y_train)
# Predict the response for test dataset
y_pred = model.predict(X_test)
print(f"Accuracy of Complement Naive Bayes classifier model on {dataframe.name} is: {round(metrics.accuracy_score(y_test, y_pred),2)}")
Accuracy of Complement Naive Bayes classifier model on dataset just without missing is: 0.48
Accuracy of Complement Naive Bayes classifier model on dataset after deeper cleaning is: 0.65
相当令人印象深刻,对吧?我们使用的数据集很小(故意如此,以便你可以轻松看到每一步的结果),因此不同的随机种子可能会产生不同的结果,但在绝大多数情况下,模型在清理后的数据集上表现会显著优于原始数据集。我们做得很好!
尼古拉·格雷布 编程已有四年多,在过去的两年里,他专注于自然语言处理。在转向数据科学之前,他在销售、人力资源、写作和国际象棋方面取得了成功。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关话题
处理推荐和搜索中的位置偏差
原文:
www.kdnuggets.com/2023/03/dealing-position-bias-recommendations-search.html
人们更常点击搜索和推荐中的顶部项目,是因为它们在顶部,而不是因为它们的相关性。如果你用机器学习模型来排序搜索结果,它们可能会因为这种正向自我增强的反馈循环而最终质量下降。这个问题如何解决?
排名中的偏差
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT
每次你向人们展示列表,如搜索结果或推荐时,我们很难公正地评估列表中的所有项目。
项目排名无处不在。
一个 级联点击模型 假设人们在找到相关项之前会顺序评估列表中的所有项。但这意味着底部的项目被评估的机会较小,因此自然点击较少:
列表中的位置越高?——点击越多。
顶部项目仅因为其位置获得更多点击?——这种行为称为位置偏差。然而,位置偏差并不是列表中唯一的偏差,还有很多其他危险因素需要注意:
-
展示偏差:例如,由于 3x3 网格布局,位于第 4 位(紧接在第 1 位下方)的项目可能比第 3 位角落的项目获得更多点击。
-
模型偏差:当你用由同一模型生成的历史数据来训练机器学习模型时。
实际上,位置偏差是最强的偏差之一?——去除它可能会提高模型的可靠性。
实验:测量位置偏差
我们进行了一项小规模的众包研究关于位置偏差。使用 RankLens 数据集,我们用 Google 关键词规划师 工具生成了一系列查询以查找每部特定电影。
滥用 Google 关键字规划师获取人们用来寻找电影的真实查询。
通过一组电影和对应的实际查询,我们拥有一个完美的搜索评估数据集?——所有项目都为更广泛的观众所熟知,我们提前知道正确标签。
所有主要的众包平台,如 Amazon Mechanical Turk、Scale.com 和 Toloka.ai 都有针对典型搜索评估的现成模板:
一个典型的 搜索排名评估模板。
但这些模板中有一个巧妙的技巧,防止你因位置偏差而自找麻烦:每个项目必须独立检查。即使屏幕上出现多个项目,它们的排序也是随机的!但随机的项目顺序是否能阻止人们点击第一个结果?
实验的原始数据可以在 github.com/metarank/msrd 上找到,但主要观察结果是即使在随机排序的项目上,人们仍然更倾向于点击第一个位置!
即使在随机排名中,第一个项目的点击次数也更多。
逆向倾向加权
但你如何抵消点击的隐性反馈中位置的影响?每次你测量一个项目的点击概率时,你观察到的是两个独立变量的组合:
-
偏差:点击列表中特定位置的概率。
-
相关性:项目在当前上下文中的重要性(例如来自 ElasticSearch 的 BM25 得分和推荐中的余弦相似度)
在前一段提到的 MSRD 数据集中,很难将位置的影响与 BM25 相关性独立区分,因为你只能观察到它们的组合:
按 BM25 排序时,人们更喜欢相关项目。
例如,18%的点击发生在第 1 位。这只是因为我们在这里展示了最相关的项目吗?如果将相同的项目放在第 20 位,是否会获得相同数量的点击?
逆向倾向加权方法表明,某个位置的观察点击概率只是两个独立变量的组合:
真实的相关性是否独立于位置?
然后,如果你估算每个位置的点击概率(倾向性),你可以用它来加权所有相关性标签,并获得实际的无偏相关性:
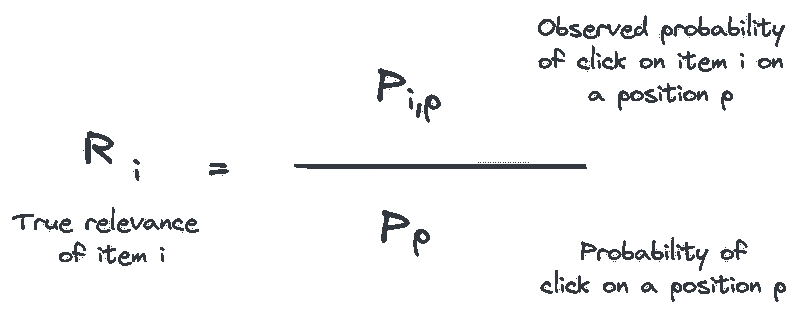
通过倾向性加权
但在实践中如何估算倾向性?最常见的方法是对排名进行轻微的随机排序,这样在相同上下文中(例如搜索查询)相同的项目会在不同的位置上进行评估。
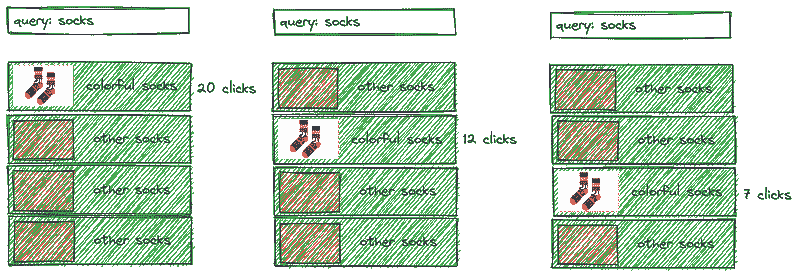
通过随机排序来估算倾向性。
但额外的随机排序肯定会降低你的业务指标,如点击率和转化率。是否有不涉及随机排序的更少侵入性的替代方法?

来自 MICES’19 演讲的幻灯片实时个性化搜索结果:搜索结果随机排序时转化率下降 2.8%!
位置感知学习
一个位置感知的排名方法建议让你的机器学习模型同时优化排名相关性和位置影响:
-
在训练时,你使用项目位置作为输入特征,
-
在预测阶段,你用一个常量值来替代它。
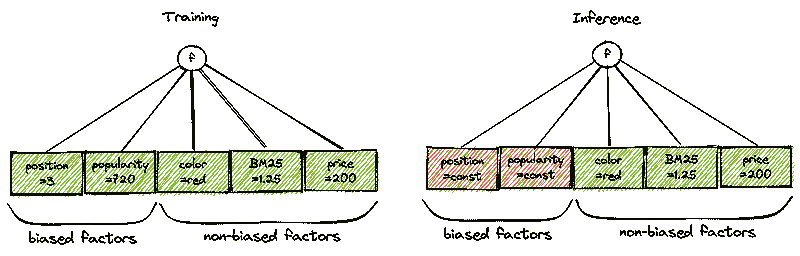
在推断过程中用常量替代偏差因素
换句话说,你让你的排名机器学习模型在训练时检测位置如何影响相关性,但在预测时将这一特征归零:所有项目同时呈现在相同位置上。
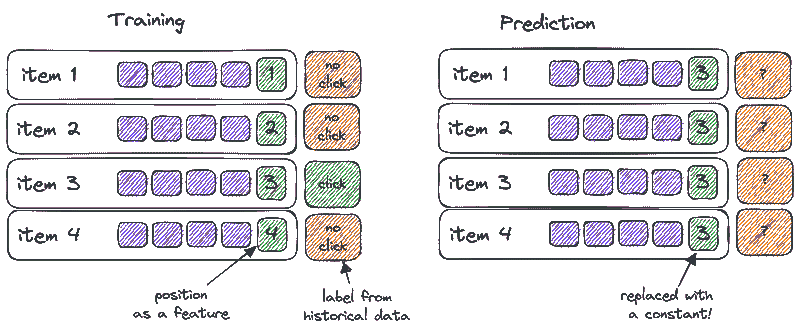
v
但你应该选择哪个常量值?PAL 论文的作者做了一些数值实验来选择最佳值——经验法则是不选择过高的位置,因为噪声太多。
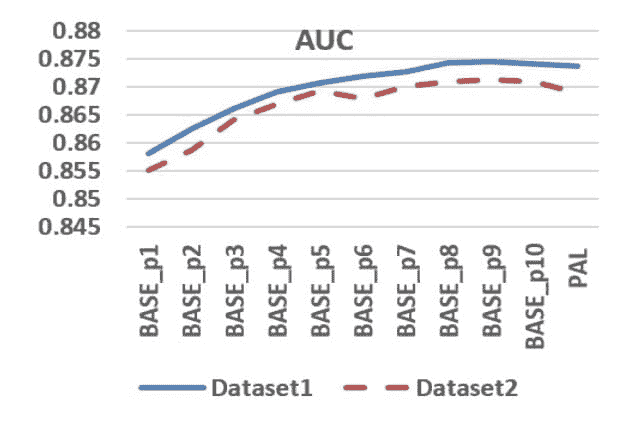
PAL 的作者测试了不同的位置常量值
实用的 PAL
PAL 方法已经成为多个开源推荐和搜索工具的一部分:
-
ToRecSys 实现了 PAL 作为一种偏差消除方法,以在有偏数据上训练推荐系统。
-
Metarank 可以使用基于 PAL 的特征来训练一个无偏的 LambdaMART Learn-to-Rank 模型。
由于位置感知方法仅仅是特征工程中的一个小窍门,在 Metarank 中,只需再添加一个特征定义即可:
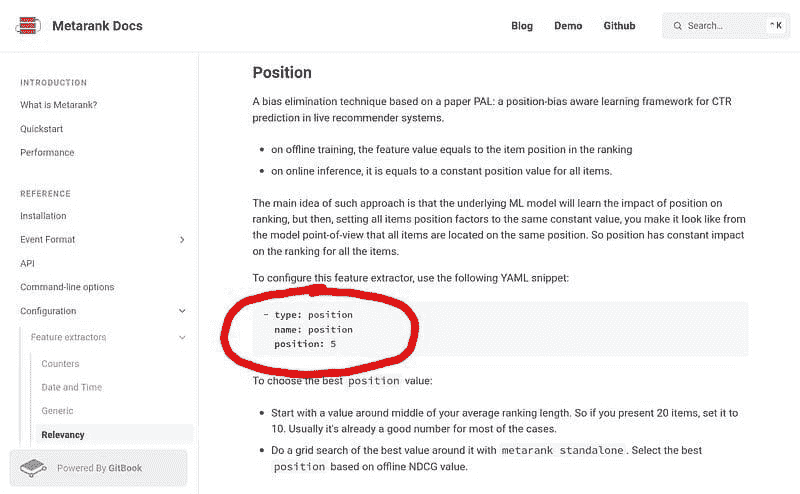
将 位置 作为 Learn-to-Rank 模型的排名特征
在上述 MSRD 数据集上,这种受 PAL 启发的排名特征相比其他排名特征具有较高的 SHAP 重要性值。
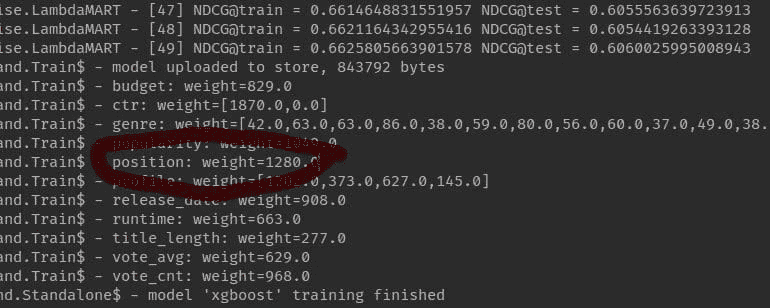
训练 LambdaMART 模型时位置的重要性
结束语
位置感知学习方法不仅限于纯排名任务和位置去偏:你可以使用这个技巧来克服任何其他类型的偏差:
-
对于由于网格布局造成的展示偏差,你可以在训练过程中引入一对特征,表示项目的行和列位置。但在预测时将它们交换为常数。
-
对于模型偏差,当展示更多的项目获得更多的点击时?——你可以引入一个“点击次数”训练特征,并在预测时用一个常数值替换它。
使用 PAL 方法训练的机器学习模型应产生无偏的预测。
Roman Grebennikov 是 Delivery Hero SE 的首席工程师,专注于搜索个性化和推荐。他是功能编程、Learn-to-Rank 模型和性能工程的务实爱好者。
更多相关内容
揭穿公民数据科学家的神话
原文:
www.kdnuggets.com/2022/10/debunking-myth-citizen-data-scientist.html

图片来源于 Hunters Race 在 Unsplash
高德纳分析师创造了“公民数据科学家”这一术语,意指“创造和生成利用预测或规范分析的模型,但其主要工作职能在统计和分析领域之外的人。”在一些圈子里,这一角色被广泛宣传为帮助组织加速其机器学习/人工智能旅程的解决方案。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的 IT 组织
但正如俗话所说,买者自负其责。虽然拥有公民数据科学家有一定好处,但他们并非万能——他们绝对不能替代真正的数据科学家。
人工智能旅程:挣扎是真实的
几乎所有行业的组织都在积极探索如何利用人工智能和机器学习来加速业务并取得更大的成果。根据高德纳的新调查,平均而言,只有54%的 AI 模型从试点阶段进入生产阶段。造成这一现象的原因有很多;对于一些公司来说,没有熟练的数据科学团队只是其中之一。

探索公民数据科学家的理念
熟练的专业人员需要花钱——你必须聘请具备正确技能的人。因此,公民数据科学家的概念具有吸引力——即可以让某人迅速使用他们所提供的工具集构建模型,而不需要对数据、数据的背景或如何清理数据和选择正确特征有深入了解。
这个场景很有吸引力,但高度不可能。没有相关背景,没有特定上下文理解的人不能仅仅去构建一个模型。因为从根本上说,他们不知道自己拥有的是什么;他们只是将东西扔进系统中。
更有甚者,我们看到一些例子,即使是受过良好培训的数据科学家也(无意中)对 ML 模型的偏差和漂移问题做出了贡献。想想 Zillow 失败的 iBuying 算法 或 Facebook 糟糕的照片误标记 事件。换句话说,如果连专家都可能出错,我们如何合理地期望新手能做对呢?
公民数据科学家的概念为何失败
如果你走这条路,你将面临经典的“垃圾进,垃圾出”问题。假设你的组织是一家银行,你是一名业务分析师,能够访问一个数据仓库。你可以获取到人们的收入水平、人口统计数据、位置、地址等信息。一些技术供应商提出的想法是,你可以直接将这些数据投入他们的工具中——然后它会为你选择合适的算法,并提供正确的预测。
但在这个过程中,通常发生的情况是,可能没有人去确保数据的正确性。你必须确保你在进行数据清洗或特征工程。你必须了解你拥有的内容。例如,在贷款申请中,你有不同的元素——一个街道地址、一个电话号码等等。当你进行特征工程时,每一条信息都可以是一个特征。
通常,数据科学家需要做的是确定哪些元素在预测结果中起关键作用。而公民数据科学家很可能无法在没有大量培训和重重努力的情况下做到这一点。
如果那个人不了解数据,并且在没有适当数据清洗的情况下将其输入工具中,那么你的输入就是垃圾,系统将基于对数据理解的缺乏而输出垃圾。仅靠工具本身无法使数据变得更好。
对受过训练的数据科学家的需求不会消失
即使拥有先进的 AI/ML 工具,你仍然需要经过训练的数据科学家来整理数据并确定哪些是好的,哪些是坏的。你需要知道如何进行特征工程的人。否则,你将会得到无法满足需求的模型或算法。
公民数据科学家是一个伟大的愿望,但它不是万灵药,也不是受过训练的数据科学家的替代品。换句话说,你会怎么想,如果你在飞机上,得知由一个“公民飞行员”(甚至是学生飞行员或飞行模拟器的热心用户)来驾驶飞机?
这并不简单。而且,这并不意味着公民数据科学家不是一个可行的概念。重要的是要理解这些角色需要作为补充,而不是替代数据科学家。
虽然很诱人地认为可以利用技术来颠覆或替代某些技能角色的需求,尤其是许多行业面临技能差距。然而,在目前的技术水平下,AI/ML 项目无法仅仅交给公民数据科学家来处理。
好数据的价格
尽管有很多关于无代码或低代码软件开发的讨论,但业界已经了解到这种方法的现实性以及它的适用场景。在需要开发关键任务软件时,无代码/低代码方法并不适用。因此,仅依靠公民数据科学家来运行你的 AI/ML 是更加不切实际的。
深入理解你的数据对 AI/ML 的成功至关重要。这是专业数据科学家所带来的,他们提供必要的背景洞察,以确定哪些数据是有用和好的,哪些则不是。虽然引入新的声音和想法是积极的,但这并没有消除对熟练专业数据科学家的需求。你不能通过不拥有专业数据科学家来削减成本。
Victor Thu 是 Datatron 的总裁。在他的职业生涯中,Victor 专注于产品营销、市场推广和产品管理,曾在 Petuum、VMware 和 Citrix 等公司担任 C 级和董事级职位。
更多相关话题
数据科学的十年
评论
作者 Alex Mitrani,数据科学家。
自从《哈佛商业评论》发布了一篇文章宣称数据科学家是“21 世纪最性感的职业”以来,已经过去了七年多。此后,全国各地涌现出许多培训营,大学也开发了数据科学的本科、硕士和博士课程;我自己的母校也计划建立一个专门针对这一主题的中心。这些课程的费用因是否在线完成、课程时长以及学校的就业统计和声誉而有很大差异。
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
数据科学家到底是什么?最广泛接受的定义可能是通过应用编码和统计学从数据中提取可操作的见解的人。在完成我的数据科学课程后,我涉及了市场趋势分析、时间序列、推荐系统、A/B 测试、卷积神经网络、计算机视觉、自然语言处理、分类和连续建模、非结构化聚类等内容。我主要使用 Python 编程和 SQL 完成这些项目。这些技能几乎可以应用于任何主题,这也是为什么各行各业的公司都在招聘需要领域知识的数据科学家的原因。
随着十年的结束,我想借此机会讨论行业趋势、流行框架、我有机会使用的一些有用工具,以及我期待在未来更多使用的工具。
就业前景
我决定进入数据科学领域有几个原因。我拥有商业学位以及金融和房地产背景。自从大学毕业以来,我注意到目标职位的首选资格部分越来越多地出现了 Python、SQL 和机器学习的知识。我也在处理 Excel 无法再处理的大数据集。我希望变得尽可能具有竞争力和相关性,因此我开始寻找涵盖这些技能的项目。在经过大量研究后,我决定探索数据科学。
数据科学家在 LinkedIn 的 2020 美国新兴职位报告中排名第三,该领域年增长率为 37%。根据 Glassdoor 调查 的 4,354 名受访者数据,入门级数据科学家的起薪为每年 $101,087。这些就业统计数据对从业和有志于成为数据科学家的人员来说应该很有吸引力。
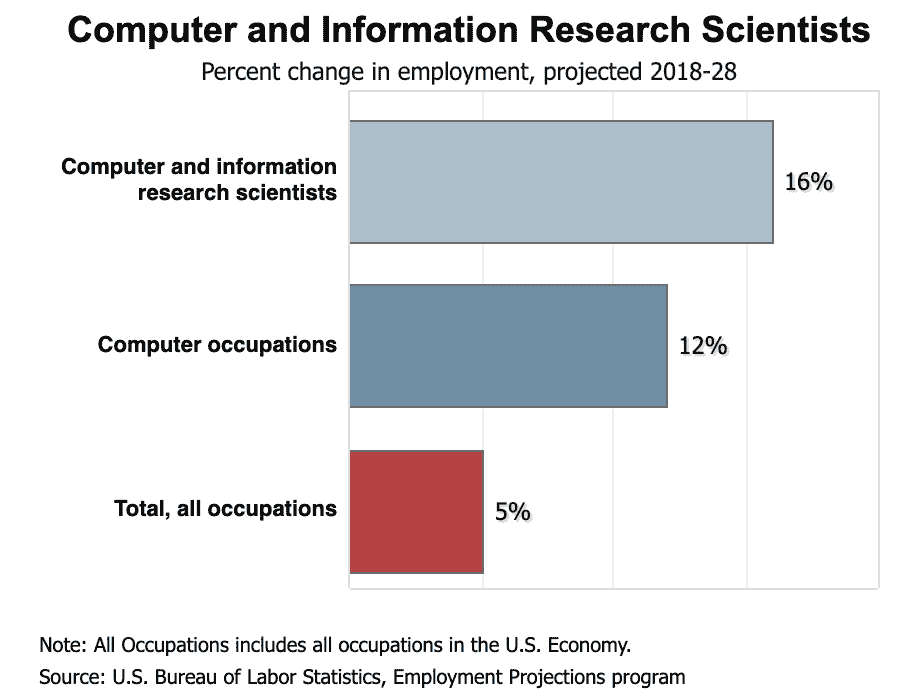
“计算机和信息研究科学家”中的第 2 页包括数据科学。来源: 美国劳工统计局。
框架
数据科学是统计学与计算机科学等学科的结合。Python 编程语言拥有越来越多的包,这些包使数据科学家能够处理数据并创建模型。我使用最频繁的库有(按无特定顺序):
-
Pandas— 将原始数据结构化为数据框,并执行汇总统计
-
NumPy— 许多计算可以在 n 维数组上高效执行
-
Scikit-learn— 许多机器学习模型和评估指标
-
Matplotlib— 标准且高度可定制的统计可视化
-
Seaborn— 统计可视化,比 Matplotlib 更容易实现
-
Plotly 和 Plotly Express— 互动和统计可视化,比 Matplotlib 更容易实现
-
TensorFlow 及其 Keras 实现— 深度学习库,支持模型开发和迁移学习。可应用于多种类型的数据,即文本、图像、音频等
基于云的工具
Google Colab、Amazon EMR 和 IBM Watson Studio 都允许你远程运行 Jupyter Notebook 样式的文件。这些平台还使你能够在云中存储和访问数据来构建模型,并利用强大的 GPU 比在本地机器的 CPU 上更快地训练模型。这些 GPU 可以按小时租用。Postman 是另一个可以租用 GPU 的服务。
有用的工具
AST Literal Evaluation
在许多项目中,我会在 pandas 数据框中创建一个数组列。然后,我需要保存数据框并稍后检索数据。无论使用什么文件类型,每当我读取保存的文件时,数组列都会加载为具有字面空格 (\n) 的字符串类型。当你花了几个小时进行网页抓取或从模型中获取嵌入,并且有截止日期临近时,这特别令人沮丧。幸运的是,Python 的抽象语法树(ast)模块的 literal_eval() 方法可以解决这个问题。我对格式错误的数组使用了一系列 replace() 语句,将 \n 和其他异常字符替换为空格。然后我为字符串添加了括号,使其看起来像一个数组。一旦字符串表现得像一个数组,我应用了 ast 方法来将字符串转换为实际的数组。返回数组的语句如下:
asarray(ast.literal_eval(embedding_as_string)).astype(‘float32’)
解析上述语句:
-
embedding_as_string — 应该是一个数组的检索字符串,其中所有不规则字符(即,\n)已被删除。通常出现在将文件读入 pandas 数据框时,原始数据类型为数组。
-
literal_eval() — 用于读取字符串语法的方法
-
asarray() — 一个用于将字符串语法转换为数组的NumPy 方法
-
.astype(‘float32’) — 在这种情况下,数组包含浮点小数元素,这将把各个元素转换为float32 类型。
总之,这个语句接受一个格式错误的数组字符串表示,并返回一个实际的数组。
TQDM
速度很重要,尤其是在实时演示中。我完成了一个面部相似度程序,将用户的面部嵌入与名人和政治家的嵌入数据库进行比较。我在实时演示中使用了余弦相似度度量来比较用户与数据库。我最初使用了 Scikit-learn 的方法,但实时演示速度实在太慢了。我通过在每个函数后面添加文本打印语句来寻找瓶颈。我很快发现计算余弦相似度花费的时间太长。我读到 NumPy 计算的速度很快,于是决定在阅读 Danushka Bollegala 的 文章 后切换到纯 NumPy 实现。出于好奇,我寻找了一种方法来测量这两个函数之间的时间差,我的同事建议了 TQDM 项目。
我使用 Jupyter Notebooks 来构建函数,因为我喜欢在编写 Python 脚本之前测试输出。TQDM 创建了一个可见的状态栏,使我们能够查看循环的进度。

一个在 lambda 函数上迭代 Pandas 数据框的 TQDM 状态栏的示例。
TQDM 状态栏告诉你函数正在完成哪个迭代、预期的总迭代次数(如果函数中断,这有助于定位问题)、总花费时间、预计剩余时间以及每秒的迭代次数。TQDM 与 Jupyter Notebooks 配合良好。我的数据集上,NumPy 实现的余弦相似度比 Scikit-learn 实现的快了 75%。
我期待使用的东西
容器化
共享代码和项目的能力在数据科学领域正变得越来越必要。容器化是将软件打包成在所有机器上都能一致和高效运行的方式。Docker 是一个流行的容器化平台。它本质上创建了一个软件包,包含所使用的每个库的版本,以便可以在不同机器上一致地加载和运行。当你在机器上运行 Docker 容器时,你不需要下载原始计算机的操作系统或常见的依赖库,这就是容器化更高效的原因。
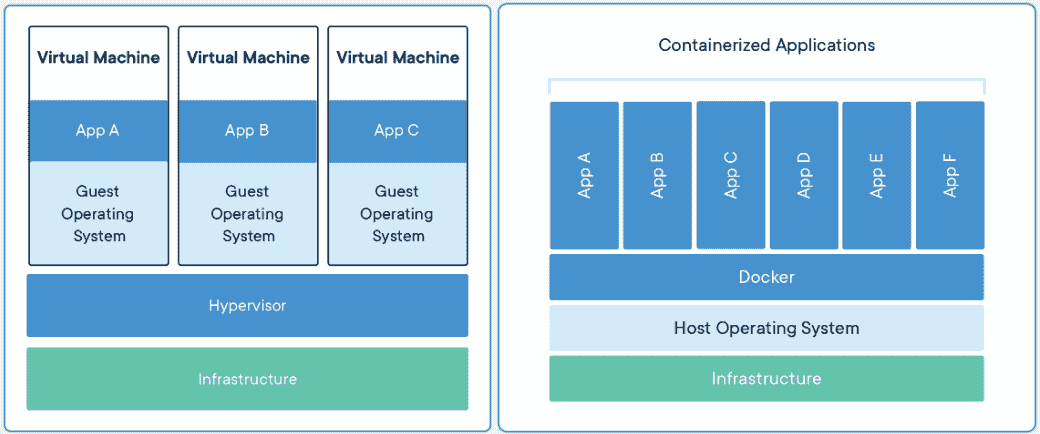
虚拟机(VM)与容器。虚拟机需要操作系统,然后下载相关的库,而容器不需要操作系统,只下载机器上未安装的库。来源: docker.com。
将容器化应用于数据科学项目可能会很棘手,因为容器的抽象性和可定制性。最常见的容器是包含 SQL 数据库和运行查询的 python 脚本的容器。Docker 的快速入门指南涵盖了容器及相关术语的基础知识。我发现,对专门为我设想的目的而设计的容器进行逆向工程,是实践构建不同类型容器的最佳方式。一旦我拥有了类似的容器,我可以利用 Docker 文档将其调整到我的目的上。
Keras 的迁移学习
我期待着利用迁移学习构建更多深度学习项目。迁移学习是将为一个目的构建的模型知识应用于另一个目的的实践。
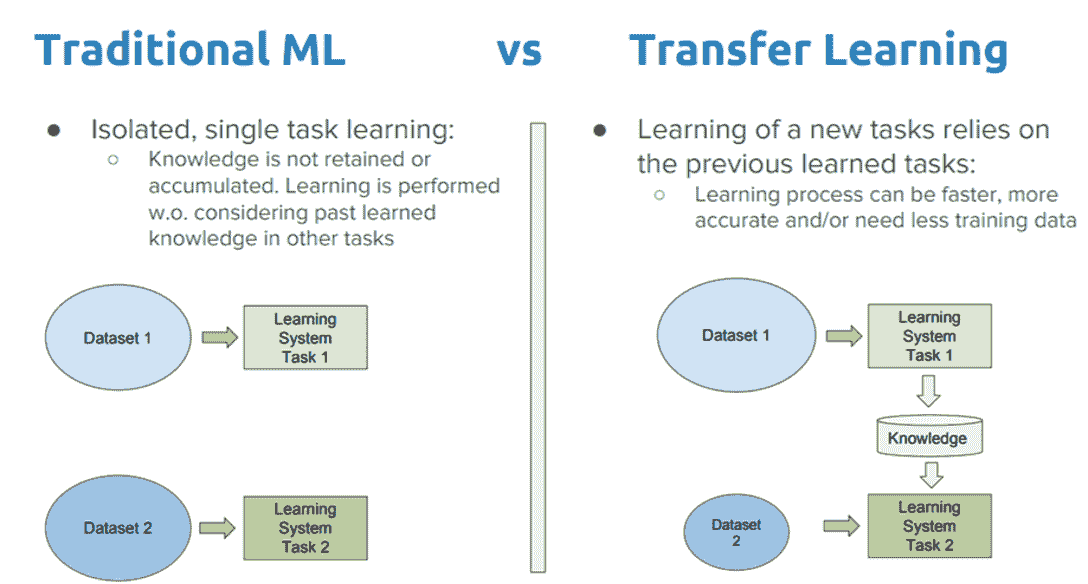
“传统学习与迁移学习” 来源:“深度学习中迁移学习的全面实践指南” 作者:Dipanjan (DJ) Sarkar。
例如,你可以将一个预训练的面部识别模型整合到另一组图片数据集中,而无需从头开始训练模型。Keras 使我们能够加载预训练模型并将其调整到其他数据集上。
OpenScale
最近,我与 IBM 的一位首席发明家讨论了Watson OpenScale。该项目以一种有趣的方式向我展示。我们一致认为,大多数数据科学家的时间都花在获取和清理数据上,然后提出正确的问题。实际构建模型所需的时间相对较少,也不像项目的前期那么困难。如果你在处理一个分类项目,你将建立多个模型,并使用像GridSearch这样的工具来调整模型到最有效的超参数。接着,你会选择一个度量标准来比较这些模型,并选择最适合你目的的模型。这种模型构建依赖于你选择每个参数的最佳范围的能力以及等待 GridSearch 定位最佳超参数值的耐心。OpenScale 通过基本上作为云端的 GridSearch 来处理分类模型和每个模型的参数,将这一过程提升到一个新的水平。这使得数据科学项目中最短的部分变得更短,使数据科学家可以专注于项目中更重要的部分:EDA、提出正确的问题、提取可操作的见解,并将发现清晰地传达给所有利益相关者。
摘要
数据科学领域的前景强劲。总有新的工具发布,我期待使用这些工具。该领域涵盖的主题不断增长,这意味着总有新的东西可以学习。数据科学可以应用于任何行业,用于多种目的,并且如果你提出正确的问题,可以为任何组织创造价值。
最初发表于 Analytics Vidhya 和 Medium。经授权转载。
个人简介: 亚历克斯·米特拉尼 是一位数据科学家,热衷于利用技术做出明智决策。亚历克斯的经验包括房地产和金融领域,他分析了投资并管理了客户关系。亚历克斯完成了 Flatiron School 的数据科学项目,并从波士顿大学金融专业毕业。
相关:
更多相关话题
去中心化和协作式 AI:微软研究如何利用区块链构建更透明的机器学习模型
评论

未来十年人工智能(AI)面临的最大挑战是,数据和智能是否仍然是少数几个国家的大型技术公司特权,还是可以向世界其他地区普及。机器学习和 AI 应用的中心化特性促成了一种“富者愈富”的动态,只有那些拥有高质量数据集和数据科学人才的公司才能利用 AI 机会。去中心化 AI 是应对这一挑战的领先趋势之一。尽管对许多实际应用仍不切实际,但去中心化 AI 领域在 AI 社区中稳步获得关注。最近,微软的 AI 研究人员开源了去中心化与协作 AI 区块链项目,该项目支持基于区块链技术实现去中心化的机器学习模型。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
从训练到优化,机器学习模型生命周期中的每一个步骤都可以通过一定程度的去中心化进行改进。以一个简单的预测模型为例,该模型旨在预测某一产品的销售情况。在传统的集中式方法中,我们需要隐含地信任一组数据科学家来选择合适的神经网络架构、构建正确的数据集、高效训练模型、调整超参数以优化性能,以及其他十几个任务。完成这些之后,我们不能真正确定模型是否表现最佳。一旦我们开始引入新版本的模型,这个问题会变得更糟,因为几乎不可能将特定的变化与特定的性能相关联。去中心化的人工智能方法旨在通过实现透明的问责制和全阶段的有机协作来简化这个问题。
区块链技术的普及和成熟成为了去中心化人工智能架构的重要催化剂。区块链技术的不可变性和分布式共识模型本质上引入了信任水平,并在机器学习应用中实现了协作动态。微软研究团队利用区块链技术的一些原生功能,在机器学习模型中实现了不同程度的去中心化。
微软去中心化与协作人工智能
去中心化与协作人工智能在区块链上的应用(DCAI)是一个在区块链基础设施上托管和训练机器学习模型的框架。当前版本的 DCAI 限于以太坊区块链,并利用智能合约作为机器学习程序的主要封装机制。从概念上讲,智能合约是不可变的程序,包含在区块链运行时上执行的业务逻辑。在 DCAI 框架中,智能合约用于实现机器学习模型中的去中心化训练机制。
从功能角度来看,DCAI 根据三个主要组件来构建向机器学习模型添加数据/训练的过程。
-
激励机制: 这个组件旨在鼓励高质量数据的贡献。激励机制负责验证交易,例如,在某些情况下需要“质押”或存款。
-
数据处理器: 这个组件将数据和元数据存储在区块链上。这确保了它可以在所有未来的使用中访问,而不仅限于这个智能合约。
-
模型: 这个组件封装了一个特定的机器学习模型,该模型根据预定义的训练算法进行更新。

去中心化人工智能应用的一个基本挑战是依靠正确的激励机制,鼓励不同的参与方贡献新的数据集或训练机器学习模型。在当前版本中,DCAI 依赖于两个主要的激励模型:
-
游戏化: 利用这种激励机制,数据贡献者可以在其他贡献者验证他们的贡献时获得积分和徽章。该提案完全依赖于贡献者合作的意愿,以实现共同的目标——模型的改善。
-
基于预测市场: 在该模型中,如果贡献者的贡献在使用特定测试集进行评估时提高了模型的性能,他们将获得奖励。
以下动画展示了用于 IMDB 评价的情感分类模型中的激励机制。贡献高质量数据集的参与者能够根据模型的性能获利,而贡献效果不佳的参与者则失去他们的资金。
从编程模型的角度来看,DCAI 通过类似于以下内容的智能合约来抽象化机器学习模型的训练:
DCAI 仍处于实验阶段,但已经为人工智能模型引入了重要的好处:
-
问责制: DCAI 在以太坊区块链上保持数据集和模型性能的不可更改记录。
-
数据可重用性: DCAI 数据处理器将训练数据集记录到以太坊区块链,以备将来使用。
-
合作: DCAI 的激励机制创建了一个可行的机器学习模型训练合作模型。
其他有趣的去中心化人工智能倡议
DCAI 不是去中心化人工智能领域中唯一相关的倡议。虽然去中心化人工智能仍是一个新兴且仍在实验中的市场,但已经有一些倡议在研究阶段之外获得了一定的知名度:
-
SingularityNet:SingularityNet 可以说是去中心化人工智能领域中最雄心勃勃的公司。它因驱动著名的 Sophia 机器人而闻名,SingularityNet 正致力于在人工智能生命周期的所有方面引入去中心化。从技术上讲,SingularityNet 是一个平台,能够以去中心化的模型实施和使用人工智能服务。基于以太坊区块链,SingularityNet 提供了一种模型,其中网络中的不同参与者因实施或使用人工智能服务而获得激励。
-
Ocean Protocol:Ocean Protocol 提供了一个去中心化的数据提供者和消费者网络,支持 AI 应用的实现和使用。Ocean 通过一个代币化的服务层暴露了 AI 应用的许多常见基础设施元素,如存储、计算或算法,从而抽象出去中心化 AI 程序的核心构建模块。Ocean Protocol 最近通过独家代币发售平台 CoinList 宣布了一次代币销售。
-
Erasure:由创新型对冲基金 Numerai 创建,Erasure 提供了一个去中心化的协议,用于创建和运行预测模型。Erasure 的目标是提供一个去中心化的市场,数据科学家可以在其中上传基于可用数据的预测,使用加密代币对这些预测进行质押,并根据预测的表现赚取奖励。Erasure 为 Numerai 提供数据科学交互的事实体现在协议的简单性和实际应用性上。
-
OpenMined:OpenMined 是去中心化人工智能市场中最活跃的项目之一。OpenMined 不仅仅是一个平台,它还是一个用于实施去中心化 AI 应用的工具和框架生态系统。OpenMined 已经建立了一个非常活跃的开发者社区,并提供与主流机器学习技术栈的无缝集成。
微软是机器学习和区块链技术领域的市场领导者之一。在微软的支持下,像 DCAI 这样的倡议有机会为大量用户带来更透明、负责任的机器学习模型。
原文。经许可转载。
相关:
-
This New Google Technique Help Us Understand How Neural Networks are Thinking
-
Neural Code Search: How Facebook Uses Neural Networks to Help Developers Search for Code Snippets
-
Introducing Gen: MIT’s New Language That Wants to be the TensorFlow of Programmable Inference
更多相关话题
-
Federated Learning: Collaborative Machine Learning with a Tutorial…
-
Open Assistant: Explore the Possibilities of Open and Collaborative…
一系列机器学习模型的决策边界
原文:
www.kdnuggets.com/2020/03/decision-boundary-series-machine-learning-models.html
评论
由马修·史密斯,马德里康普顿斯大学
边界上的机器学习:
机器学习模型超越传统计量经济学模型并不新鲜,但我想在我的研究中展示为什么以及如何一些模型进行给定的预测或在这种情况下的分类。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析能力。
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理。
我想展示我的二分类模型所做出的决策边界。也就是说,我想展示将我的分类划分为每个类别的分区空间。这个问题和代码可以通过一些调整分成多分类问题。
初始化:
我首先加载了一系列包,并初始化了一个逻辑函数,用于将对数几率转换为逻辑概率函数。
library(dplyr)
library(patchwork)
library(ggplot2)
library(knitr)
library(kableExtra)
library(purrr)
library(stringr)
library(tidyr)
library(xgboost)
library(lightgbm)
library(keras)
library(tidyquant)
##################### Pre-define some functions ###################################
###################################################################################
logit2prob <- function(logit){
odds <- exp(logit)
prob <- odds / (1 + odds)
return(prob)
}
数据:
我使用了iris数据集,该数据集包含由英国统计学家罗纳德·费舍尔在 1936 年收集的 3 种不同植物变量的信息。数据集由 44 种植物特征组成,这些特征应该能唯一地区分 33 种不同的植物种类(Setosa、Virginica和Versicolor)。然而,我的问题需要的是二分类问题而非多分类问题。在接下来的代码中,我导入了iris数据,并去除了一个植物种类virginica,将其从多分类问题转换为二分类问题。
###################################################################################
###################################################################################
data(iris)
df <- iris %>%
filter(Species != "virginica") %>%
mutate(Species = +(Species == "versicolor"))
str(df)
## 'data.frame': 100 obs. of 5 variables:
## $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
## $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
## $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
## $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
## $ Species : int 0 0 0 0 0 0 0 0 0 0 ...
###################################################################################
###################################################################################
我通过首先存储ggplot对象来绘制数据,只改变每个plt中的x和y变量。
plt1 <- df %>%
ggplot(aes(x = Sepal.Width, y = Sepal.Length, color = factor(Species))) +
geom_point(size = 4) +
theme_bw(base_size = 15) +
theme(legend.position = "none")
plt2 <- df %>%
ggplot(aes(x = Petal.Length, y = Sepal.Length, color = factor(Species))) +
geom_point(size = 4) +
theme_bw(base_size = 15) +
theme(legend.position = "none")
plt3 <- df %>%
ggplot(aes(x = Petal.Width, y = Sepal.Length, color = factor(Species))) +
geom_point(size = 4) +
theme_bw(base_size = 15) +
theme(legend.position = "none")
plt3 <- df %>%
ggplot(aes(x = Sepal.Length, y = Sepal.Width, color = factor(Species))) +
geom_point(size = 4) +
theme_bw(base_size = 15) +
theme(legend.position = "none")
plt4 <- df %>%
ggplot(aes(x = Petal.Length, y = Sepal.Width, color = factor(Species))) +
geom_point(size = 4) +
theme_bw(base_size = 15) +
theme(legend.position = "none")
plt5 <- df %>%
ggplot(aes(x = Petal.Width, y = Sepal.Width, color = factor(Species))) +
geom_point(size = 4) +
theme_bw(base_size = 15) +
theme(legend.position = "none")
plt6 <- df %>%
ggplot(aes(x = Petal.Width, y = Sepal.Length, color = factor(Species))) +
geom_point(size = 4) +
theme_bw(base_size = 15) +
theme(legend.position = "none")
我还想使用新的patchwork包,这使得显示ggplot图非常容易。即下面的代码将我们的图形绘制出来(1 个顶部图延展整个网格空间,2 个中间图,另一个单独的图,以及底部的另外 2 个图)。
(plt1) /
(plt2 + plt3)

另外,我们可以根据需要重新排列这些图,并以以下方式绘制它们。
(plt1 + plt2) /
(plt5 + plt6)

我认为这看起来很棒。
目标
目标是构建一个分类算法,以区分这两类,并计算决策边界,以便更好地了解模型如何做出这些预测。
为了创建每个变量组合的决策边界图,我们需要数据中不同的变量组合。
###################################################################################
###################################################################################
var_combos <- expand.grid(colnames(df[,1:4]), colnames(df[,1:4])) %>%
filter(!Var1 == Var2)
###################################################################################
###################################################################################
var_combos %>%
head() %>%
kable(caption = "Variable Combinations", escape = F, align = "c", digits = 2) %>%
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"), font_size = 9, fixed_thead = T, full_width = F) %>%
scroll_box(width = "100%", height = "200px")
表 1:变量组合
| 变量 1 | 变量 2 |
|---|---|
| 花萼宽度 | 花萼长度 |
| 花瓣长度 | 花萼长度 |
| 花瓣宽度 | 花萼长度 |
| 花萼长度 | 花萼宽度 |
| 花瓣长度 | 花萼宽度 |
| 花瓣宽度 | 花萼宽度 |
接下来,我想使用之前的不同变量组合,创建列表(每个变量组合一个)并用合成数据填充这些列表——或者说从每个变量组合的最小值到最大值的数据。这将作为我们合成创建的测试数据,我们在其上进行预测并构建决策边界。
重要的是要注意,图形最终会是二维的以便于说明,因此我们只对两个变量训练机器学习模型,但对于每个变量组合,这些变量是boundary_lists数据框中的前两个变量。
boundary_lists <- map2(
.x = var_combos$Var1,
.y = var_combos$Var2,
~select(df, .x, .y) %>%
summarise(
minX = min(.[[1]], na.rm = TRUE),
maxX = max(.[[1]], na.rm = TRUE),
minY = min(.[[2]], na.rm = TRUE),
maxY = max(.[[2]], na.rm = TRUE)
)
) %>%
map(.,
~tibble(
x = seq(.x$minX, .x$maxX, length.out = 200),
y = seq(.x$minY, .x$maxY, length.out = 200),
)
) %>%
map(.,
~tibble(
xx = rep(.x$x, each = 200),
yy = rep(.x$y, time = 200)
)
) %>%
map2(.,
asplit(var_combos, 1), ~ .x %>%
set_names(.y))
###################################################################################
###################################################################################
我们可以看看前四个观测值和最后两个列表的样子:
boundary_lists %>%
map(., ~head(., 4)) %>%
head(2)
## [[1]]
## # A tibble: 4 x 2
## Sepal.Width Sepal.Length
## <dbl> <dbl>
## 1 2 4.3
## 2 2 4.31
## 3 2 4.33
## 4 2 4.34
##
## [[2]]
## # A tibble: 4 x 2
## Petal.Length Sepal.Length
## <dbl> <dbl>
## 1 1 4.3
## 2 1 4.31
## 3 1 4.33
## 4 1 4.34
boundary_lists %>%
map(., ~head(., 4)) %>%
tail(2)
## [[1]]
## # A tibble: 4 x 2
## Sepal.Width Petal.Width
## <dbl> <dbl>
## 1 2 0.1
## 2 2 0.109
## 3 2 0.117
## 4 2 0.126
##
## [[2]]
## # A tibble: 4 x 2
## Petal.Length Petal.Width
## <dbl> <dbl>
## 1 1 0.1
## 2 1 0.109
## 3 1 0.117
## 4 1 0.126
训练时间:
现在我们已经设置了合成创建的测试数据集,我想用实际观察到的数据来训练模型。我使用上述图中的每个数据点作为训练数据。我应用以下模型:
-
逻辑模型
-
带线性核的支持向量机
-
带多项式核的支持向量机
-
带径向核的支持向量机
-
带 sigmoid 核的支持向量机
-
随机森林
-
具有默认参数的极端梯度提升(XGBoost)模型
-
单层 Keras 神经网络(含线性组件)
-
更深层的 Keras 神经网络(含线性组件)
-
更深层的 Keras 神经网络(含线性组件)
-
具有默认参数的轻量级梯度提升模型(LightGBM)
附注:我不是深度学习/Keras/Tensorflow 的专家,所以我相信更好的模型会产生更好的决策边界,但将不同的机器学习模型适配到purrr、map调用中是一个有趣的任务。
###################################################################################
###################################################################################
# params_lightGBM <- list(
# objective = "binary",
# metric = "auc",
# min_data = 1
# )
# To install Light GBM try the following in your RStudio terinal
# git clone --recursive https://github.com/microsoft/LightGBM
# cd LightGBM
# Rscript build_r.R
models_list <- var_combos %>%
mutate(modeln = str_c('mod', row_number())) %>%
pmap(~
{
xname = ..1
yname = ..2
modelname = ..3
df %>%
select(Species, xname, yname) %>%
group_by(grp = 'grp') %>%
nest() %>%
mutate(models = map(data, ~{
list(
# Logistic Model
Model_GLM = {
glm(Species ~ ., data = .x, family = binomial(link='logit'))
},
# Support Vector Machine (linear)
Model_SVM_Linear = {
e1071::svm(Species ~ ., data = .x, type = 'C-classification', kernel = 'linear')
},
# Support Vector Machine (polynomial)
Model_SVM_Polynomial = {
e1071::svm(Species ~ ., data = .x, type = 'C-classification', kernel = 'polynomial')
},
# Support Vector Machine (sigmoid)
Model_SVM_radial = {
e1071::svm(Species ~ ., data = .x, type = 'C-classification', kernel = 'sigmoid')
},
# Support Vector Machine (radial)
Model_SVM_radial_Sigmoid = {
e1071::svm(Species ~ ., data = .x, type = 'C-classification', kernel = 'radial')
},
# Random Forest
Model_RF = {
randomForest::randomForest(formula = as.factor(Species) ~ ., data = .)
},
# Extreme Gradient Boosting
Model_XGB = {
xgboost(
objective = 'binary:logistic',
eval_metric = 'auc',
data = as.matrix(.x[, 2:3]),
label = as.matrix(.x$Species), # binary variable
nrounds = 10)
},
# Kera Neural Network
Model_Keras = {
mod <- keras_model_sequential() %>%
layer_dense(units = 2, activation = 'relu', input_shape = 2) %>%
layer_dense(units = 2, activation = 'sigmoid')
mod %>% compile(
loss = 'binary_crossentropy',
optimizer_sgd(lr = 0.01, momentum = 0.9),
metrics = c('accuracy')
)
fit(mod,
x = as.matrix(.x[, 2:3]),
y = to_categorical(.x$Species, 2),
epochs = 5,
batch_size = 5,
validation_split = 0
)
print(modelname)
assign(modelname, mod)
},
# Kera Neural Network
Model_Keras_2 = {
mod <- keras_model_sequential() %>%
layer_dense(units = 2, activation = 'relu', input_shape = 2) %>%
layer_dense(units = 2, activation = 'linear', input_shape = 2) %>%
layer_dense(units = 2, activation = 'sigmoid')
mod %>% compile(
loss = 'binary_crossentropy',
optimizer_sgd(lr = 0.01, momentum = 0.9),
metrics = c('accuracy')
)
fit(mod,
x = as.matrix(.x[, 2:3]),
y = to_categorical(.x$Species, 2),
epochs = 5,
batch_size = 5,
validation_split = 0
)
print(modelname)
assign(modelname, mod)
},
# Kera Neural Network
Model_Keras_3 = {
mod <- keras_model_sequential() %>%
layer_dense(units = 2, activation = 'relu', input_shape = 2) %>%
layer_dense(units = 2, activation = 'relu', input_shape = 2) %>%
layer_dense(units = 2, activation = 'linear', input_shape = 2) %>%
layer_dense(units = 2, activation = 'sigmoid')
mod %>% compile(
loss = 'binary_crossentropy',
optimizer_sgd(lr = 0.01, momentum = 0.9),
metrics = c('accuracy')
)
fit(mod,
x = as.matrix(.x[, 2:3]),
y = to_categorical(.x$Species, 2),
epochs = 5,
batch_size = 5,
validation_split = 0
)
print(modelname)
assign(modelname, mod)
},
# LightGBM model
Model_LightGBM = {
lgb.train(
data = lgb.Dataset(data = as.matrix(.x[, 2:3]), label = .x$Species),
objective = 'binary',
metric = 'auc',
min_data = 1
#params = params_lightGBM,
#learning_rate = 0.1
)
}
)
}
))
}) %>%
map(
., ~unlist(., recursive = FALSE)
)
测试时间:
现在模型已经训练好,我们可以开始对我们在boundary_lists数据中创建的合成数据进行预测。
models_predict <- map2(models_list, boundary_lists, ~{
mods <- purrr::pluck(.x, "models")
dat <- .y
map(mods, function(x)
tryCatch({
if(attr(x, "class")[1] == "glm"){
# predict the logistic model
tibble(
modelname = attr(x, "class")[1],
prediction = predict(x, newdata = dat)
) %>%
mutate(
prediction = logit2prob(prediction),
prediction = case_when(
prediction > 0.5 ~ 1,
TRUE ~ 0
)
)
}
else if(attr(x, "class")[1] == "svm.formula"){
# predict the SVM model
tibble(
modelname = attr(x, "class")[1],
prediction = as.numeric(as.character(predict(x, newdata = dat)))
)
}
else if(attr(x, "class")[1] == "randomForest.formula"){
# predict the RF model
tibble(
modelname = attr(x, "class")[1],
prediction = as.numeric(as.character(predict(x, newdata = dat)))
)
}
else if(attr(x, "class")[1] == "xgb.Booster"){
# predict the XGBoost model
tibble(
modelname = attr(x, "class")[1],
prediction = predict(x, newdata = as.matrix(dat), type = 'prob')
) %>%
mutate(
prediction = case_when(
prediction > 0.5 ~ 1,
TRUE ~ 0
)
)
}
else if(attr(x, "class")[1] == "keras.engine.sequential.Sequential"){
# Keras Single Layer Neural Network
tibble(
modelname = attr(x, "class")[1],
prediction = predict_classes(object = x, x = as.matrix(dat))
)
}
else if(attr(x, "class")[2] == "keras.engine.training.Model"){
# NOTE:::: This is a very crude hack to have multiple keras NN models
# Needs fixing such that the models are named better - (not like) - (..., "class")[2], ..., "class")[3]... and so on.
# Keras Single Layer Neural Network
tibble(
modelname = attr(x, "class")[2], # needs changing also.
prediction = predict_classes(object = x, x = as.matrix(dat))
)
}
else if(attr(x, "class")[1] == "lgb.Booster"){
# Light GBM model
tibble(
modelname = attr(x, "class")[1],
prediction = predict(object = x, data = as.matrix(dat), rawscore = FALSE)
) %>%
mutate(
prediction = case_when(
prediction > 0.5 ~ 1,
TRUE ~ 0
)
)
}
}, error = function(e){
print('skipping\n')
}
)
)
}
) %>%
map(.,
~setNames(.,
map(.,
~c(.x$modelname[1]
)
)
)
) %>%
map(.,
~map(.,
~setNames(.,
c(
paste0(.x$modelname[1], "_Model"),
paste0(.x$modelname[1], "_Prediction")
)
)
)
)
校准数据
现在我们有了训练好的模型,以及预测结果,我们可以将这些预测map到数据中,然后使用ggplot绘制,再用patchwork进行排列!
plot_data <- map2(
.x = boundary_lists,
.y = map(
models_predict,
~map(.,
~tibble(.)
)
),
~bind_cols(.x, .y)
)
names(plot_data) <- map_chr(
plot_data, ~c(
paste(
colnames(.)[1],
"and",
colnames(.)[2],
sep = "_")
)
)
现在我们有了预测结果,可以创建ggplots。
ggplot_lists <- plot_data %>%
map(
.,
~select(
.,
-contains("Model")
) %>%
pivot_longer(cols = contains("Prediction"), names_to = "Model", values_to = "Prediction")
) %>%
map(
.x = .,
~ggplot() +
geom_point(aes(
x = !!rlang::sym(colnames(.x)[1]),
y = !!rlang::sym(colnames(.x)[2]),
color = factor(!!rlang::sym(colnames(.x)[4]))
), data = .x) +
geom_contour(aes(
x = !!rlang::sym(colnames(.x)[1]),
y = !!rlang::sym(colnames(.x)[2]),
z = !!rlang::sym(colnames(.x)[4])
), data = .x) +
geom_point(aes(
x = !!rlang::sym(colnames(.x)[1]),
y = !!rlang::sym(colnames(.x)[2]),
color = factor(!!rlang::sym(colnames(df)[5])) # this is the status variable
), size = 8, data = df) +
geom_point(aes(
x = !!rlang::sym(colnames(.x)[1]),
y = !!rlang::sym(colnames(.x)[2])
), size = 8, shape = 1, data = df) +
facet_wrap(~Model) +
theme_bw(base_size = 25) +
theme(legend.position = "none")
)
绘制所有不同的决策边界组合。注意:上述代码在您的控制台中效果更好,当我运行代码编译博客时,图形太小了。因此,我提供了模型和变量组合的单独样本图。
我首先需要选择前两列,即感兴趣的变量(花瓣宽度、花瓣长度、萼片宽度和萼片长度)。然后我想对其后的列(即不同的机器学习模型预测)进行随机抽样。
plot_data_sampled <- plot_data %>%
map(
.,
~select(
.,
-contains("Model")
) %>%
select(.,
c(1:2), sample(colnames(.), 2)
) %>%
pivot_longer(
cols = contains("Prediction"),
names_to = "Model",
values_to = "Prediction")
)
接下来我可以通过从列表中随机抽样来制作图表。
plot_data_sampled %>%
rlist::list.sample(1) %>%
map(
.x = .,
~ggplot() +
geom_point(aes(
x = !!rlang::sym(colnames(.x)[1]),
y = !!rlang::sym(colnames(.x)[2]),
color = factor(!!rlang::sym(colnames(.x)[4]))
), data = .x) +
geom_contour(aes(
x = !!rlang::sym(colnames(.x)[1]),
y = !!rlang::sym(colnames(.x)[2]),
z = !!rlang::sym(colnames(.x)[4])
), data = .x) +
geom_point(aes(
x = !!rlang::sym(colnames(.x)[1]),
y = !!rlang::sym(colnames(.x)[2]),
color = factor(!!rlang::sym(colnames(df)[5])) # this is the status variable
), size = 3, data = df) +
geom_point(aes(
x = !!rlang::sym(colnames(.x)[1]),
y = !!rlang::sym(colnames(.x)[2])
), size = 3, shape = 1, data = df) +
facet_wrap(~Model) +
#coord_flip() +
theme_tq(base_family = "serif") +
theme(
#aspect.ratio = 1,
axis.line.y = element_blank(),
axis.ticks.y = element_blank(),
legend.position = "bottom",
#legend.title = element_text(size = 20),
#legend.text = element_text(size = 10),
axis.title = element_text(size = 20),
axis.text = element_text(size = "15"),
strip.text.x = element_text(size = 15),
plot.title = element_text(size = 30, hjust = 0.5),
strip.background = element_rect(fill = 'darkred'),
panel.background = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
#axis.text.x = element_text(angle = 90),
axis.text.y = element_text(angle = 90, hjust = 0.5),
#axis.title.x = element_blank()
legend.title = element_blank(),
legend.text = element_text(size = 20)
)
)
## $Sepal.Width_and_Petal.Length
## Warning: Row indexes must be between 0 and the number of rows (0). Use `NA` as row index to obtain a row full of `NA` values.
## This warning is displayed once per session.

一些其他随机模型:
## $Sepal.Width_and_Sepal.Length

## $Sepal.Width_and_Sepal.Length

## $Petal.Length_and_Sepal.Length

## $Petal.Width_and_Petal.Length

## $Petal.Length_and_Petal.Width
## Warning in grDevices::contourLines(x = sort(unique(data$x)), y =
## sort(unique(data$y)), : todos los valores de z son iguales
## Warning: Not possible to generate contour data

自然地,线性模型形成了线性决策边界。看起来随机森林模型在数据上稍微过拟合了,而 XGBoost 和 LightGBM 模型能够形成更好、更具泛化能力的决策边界。Keras 神经网络表现不佳,因为它们需要更好的训练。
-
glm= 逻辑回归模型 -
keras.engine.sequential.Sequential Prediction...18= 单层神经网络 -
keras.engine.sequential.Sequential Prediction...18= 更深层的神经网络 -
keras.engine.sequential.Sequential Prediction...22= 更深层的神经网络 -
lgb.Booster Prediction= 轻量级梯度提升模型 -
randomForest.formula Prediction= 随机森林模型 -
svm.formula Prediction...10= 带有 Sigmoid 核的支持向量机 -
svm.formula Prediction...12= 带有径向核的支持向量机 -
svm.formula Prediction...6= 带有线性核的支持向量机 -
svm.formula Prediction...8= 带有多项式核的支持向量机 -
xgb.Booster Prediction= 极端梯度提升模型
在许多组合中,Keras 神经网络模型只是将所有观测值预测为特定类别(这再次是由于我对模型的调整不佳以及神经网络只有 100 个观测值用于学习和 40,000 个观测值用于预测)。也就是说,它将整个背景涂成了蓝色或红色,并且做出了许多误分类。在一些图表中,神经网络成功进行了完美分类,而在其他图表中,它做出了奇怪的决策边界。- 神经网络很有趣。
从图表的简要分析来看,简单的逻辑回归模型几乎完美地进行了分类。考虑到每个变量之间的关系都是线性可分的,这并不令人惊讶。然而,我更偏爱 XGBoost 和 LightGBM 模型,因为它们可以通过在目标函数中引入正则化来处理非线性关系,从而做出更稳健的决策边界。随机森林模型在这里失败了,因此它们的决策边界看起来虽然做得很好,但也略显不稳定和尖锐。
当然,随着更多变量和更高维度的引入,这些决策边界可能会变得显著更复杂和非线性。
for(i in 1:length(plot_data)){
print(ggplot_lists[[i]])
}
结束说明:
我在一个亚马逊 Ubuntu EC2 实例上编写了这个模型,但当我在 Windows 系统上用 R 编译博客文章时遇到了一些问题。这些问题主要是由于安装 lightgbm 包和包版本造成的。使用以下包版本(即使用最新包版本)时,代码正常运行没有错误。
sessionInfo()
## R version 3.6.1 (2019-07-05)
## Platform: x86_64-w64-mingw32/x64 (64-bit)
## Running under: Windows 10 x64 (build 17763)
##
## Matrix products: default
##
## locale:
## [1] LC_COLLATE=Spanish_Spain.1252 LC_CTYPE=Spanish_Spain.1252
## [3] LC_MONETARY=Spanish_Spain.1252 LC_NUMERIC=C
## [5] LC_TIME=Spanish_Spain.1252
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] tidyquant_0.5.7 quantmod_0.4-15
## [3] TTR_0.23-6 PerformanceAnalytics_1.5.3
## [5] xts_0.11-2 zoo_1.8-6
## [7] lubridate_1.7.4 keras_2.2.5.0
## [9] lightgbm_2.3.2 R6_2.4.1
## [11] xgboost_0.90.0.1 tidyr_1.0.0
## [13] stringr_1.4.0 purrr_0.3.2
## [15] kableExtra_1.1.0.9000 knitr_1.25.4
## [17] ggplot2_3.2.1 patchwork_1.0.0
## [19] dplyr_0.8.99.9000
##
## loaded via a namespace (and not attached):
## [1] Rcpp_1.0.3 lattice_0.20-38 class_7.3-15
## [4] utf8_1.1.4 assertthat_0.2.1 zeallot_0.1.0
## [7] digest_0.6.24 e1071_1.7-2 evaluate_0.14
## [10] httr_1.4.1 blogdown_0.15 pillar_1.4.3.9000
## [13] tfruns_1.4 rlang_0.4.4 lazyeval_0.2.2
## [16] curl_4.0 rstudioapi_0.10 data.table_1.12.8
## [19] whisker_0.3-2 Matrix_1.2-17 reticulate_1.14-9001
## [22] rmarkdown_1.14 lobstr_1.1.1 labeling_0.3
## [25] webshot_0.5.1 readr_1.3.1 munsell_0.5.0
## [28] compiler_3.6.1 xfun_0.8 pkgconfig_2.0.3
## [31] base64enc_0.1-3 tensorflow_2.0.0 htmltools_0.3.6
## [34] tidyselect_1.0.0 tibble_2.99.99.9014 bookdown_0.13
## [37] quadprog_1.5-7 randomForest_4.6-14 fansi_0.4.1
## [40] viridisLite_0.3.0 crayon_1.3.4 withr_2.1.2
## [43] rappdirs_0.3.1 grid_3.6.1 Quandl_2.10.0
## [46] jsonlite_1.6.1 gtable_0.3.0 lifecycle_0.1.0
## [49] magrittr_1.5 scales_1.0.0 rlist_0.4.6.1
## [52] cli_2.0.1 stringi_1.4.3 xml2_1.2.2
## [55] ellipsis_0.3.0 generics_0.0.2 vctrs_0.2.99.9005
## [58] tools_3.6.1 glue_1.3.1 hms_0.5.1
## [61] yaml_2.2.0 colorspace_1.4-1 rvest_0.3.4
简介:Matthew Smith (@MatthewSmith786) 是马德里康普顿斯大学的博士生。他的研究专注于应用于经济学和金融学的机器学习方法。他撰写的主题涵盖了 R、Python 和 C++。
原始文章。经许可转载。
相关:
-
R 编程入门
-
R 在 Cloud Run 上的无服务器机器学习
-
R 中音频文件处理的基础
更多相关话题
决策树算法解析
原文:
www.kdnuggets.com/2020/01/decision-tree-algorithm-explained.html

介绍
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
分类是机器学习中的一个两步过程,包括学习步骤和预测步骤。在学习步骤中,模型根据给定的训练数据进行开发。在预测步骤中,模型用于预测给定数据的响应。决策树是最容易理解和解释的分类算法之一。
决策树算法
决策树算法属于监督学习算法的范畴。与其他监督学习算法不同,决策树算法也可以用来解决回归和分类问题。
使用决策树的目标是创建一个训练模型,通过学习从先前数据(训练数据)推断出的简单决策规则来预测目标变量的类别或值。
在决策树中,为了预测记录的类别标签,我们从根开始。我们比较根属性的值与记录的属性。根据比较结果,我们跟随与该值对应的分支,并跳到下一个节点。
决策树的类型
决策树的类型基于目标变量的类型。可以分为两种类型:
-
分类变量决策树: 如果决策树具有一个分类目标变量,那么它被称为分类变量决策树。
-
连续变量决策树: 如果决策树具有一个连续的目标变量,那么它被称为连续变量决策树。
示例: 假设我们有一个问题,要预测客户是否会向保险公司支付续保费用(是/否)。在这里,我们知道客户的收入是一个重要变量,但保险公司没有所有客户的收入细节。既然这是一个重要变量,我们可以建立一个决策树,根据职业、产品和各种其他变量来预测客户的收入。在这种情况下,我们预测的是连续变量的值。
与决策树相关的重要术语
-
根节点: 它代表整个群体或样本,随后被分为两个或更多同质的集合。
-
分割: 这是将节点分成两个或更多子节点的过程。
-
决策节点: 当一个子节点进一步分裂成子节点时,它被称为决策节点。
-
叶节点/终端节点: 不再分割的节点称为叶节点或终端节点。
-
剪枝: 当我们移除决策节点的子节点时,这个过程称为剪枝。你可以认为这是分割的反过程。
-
分支/子树: 整棵树的一个子部分称为分支或子树。
-
父节点和子节点: 一个被分割成子节点的节点称为子节点的父节点,而子节点是父节点的子节点。
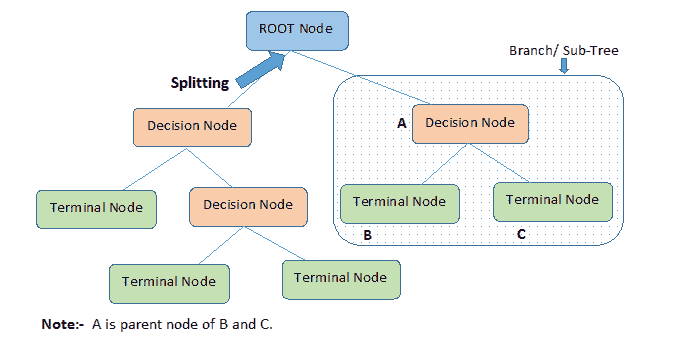
决策树通过从根节点将示例向下排序到某个叶节点/终端节点来进行分类,叶节点/终端节点提供了示例的分类。
树中的每个节点都充当某些属性的测试用例,节点下的每条边对应于测试用例的可能答案。这个过程是递归的,并且对每个以新节点为根的子树重复。
创建决策树时的假设
以下是我们使用决策树时的一些假设:
-
在开始时,整个训练集被视为根节点。
-
特征值最好是分类的。如果值是连续的,则在构建模型之前进行离散化。
-
记录递归分布在属性值的基础上。
-
属性作为树的根节点或内部节点的排序是通过使用一些统计方法完成的。
决策树遵循乘积和(SOP)表示法。乘积和(SOP)也称为析取范式。对于一个类别,从树的根到具有相同类别的叶节点的每条分支都是值的合取(乘积),不同的分支以该类别结束,形成析取(和)。
决策树实现中的主要挑战是确定哪些属性需要作为根节点和每一层。处理这个问题的过程称为属性选择。我们有不同的属性选择度量来识别可以在每一层作为根节点的属性。
决策树是如何工作的?
制定战略性分割的决策会对树的准确性产生重大影响。分类树和回归树的决策标准不同。
决策树使用多种算法来决定是否将节点分割成两个或更多子节点。子节点的创建增加了结果子节点的同质性。换句话说,我们可以说节点的纯度随着目标变量的增加而增加。决策树在所有可用变量上分割节点,然后选择导致最同质子节点的分割。
算法选择也基于目标变量的类型。让我们看一下决策树中使用的一些算法:
ID3 →(D3 的扩展)
C4.5 →(ID3 的继任者)
CART →(分类和回归树)
CHAID →(卡方自动交互检测,在计算分类树时执行多级拆分)
MARS →(多变量自适应回归样条)
ID3 算法通过自顶向下的贪婪搜索方法构建决策树,不进行回溯。正如其名,贪婪算法总是做出在当下看起来最好的选择。
ID3 算法中的步骤:
-
它从原始集合 S 作为根节点开始。
-
在算法的每次迭代中,它遍历集合 S 中未使用的属性,并计算该属性的熵(H)和信息增益(IG)。
-
然后选择具有最小熵或最大信息增益的属性。
-
然后通过所选属性将集合 S 划分为数据子集。
-
算法继续在每个子集上递归,仅考虑从未选择过的属性。
属性选择度量
如果数据集包含N个属性,则决定将哪个属性放在根节点或树的不同层级作为内部节点是一个复杂的步骤。仅仅随机选择一个节点作为根节点无法解决问题。如果我们遵循随机方法,可能会得到低准确率的不良结果。
为了解决这个属性选择问题,研究人员工作并提出了一些解决方案。他们建议使用一些标准,如:
熵,
信息增益,
基尼指数,
增益比,
方差减少
卡方
这些标准将为每个属性计算值。这些值会被排序,属性按照顺序放置在树中,即,具有高值(在信息增益情况下)的属性放置在根节点。
在使用信息增益作为标准时,我们假设属性是分类的,而对于基尼指数,则假设属性是连续的。
熵
熵是处理信息中随机性的度量。熵越高,从信息中得出结论就越困难。掷硬币就是提供随机信息的一个例子。
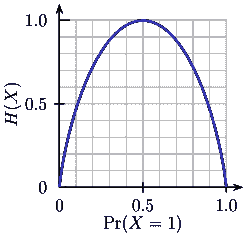
从上面的图表中可以明显看出,当概率为 0 或 1 时,熵 H(X) 为零。当概率为 0.5 时,熵最大,因为它在数据中投射了完美的随机性,并且无法准确确定结果。
ID3 遵循规则 — 熵为零的分支是叶节点,熵大于零的分支需要进一步拆分。
数学上,1 个属性的熵表示为:

其中 S → 当前状态,Pi → 状态 S 或类 i 的事件 i 的概率,或状态 S 节点中的类 i 的百分比。
数学上,多属性的熵表示为:
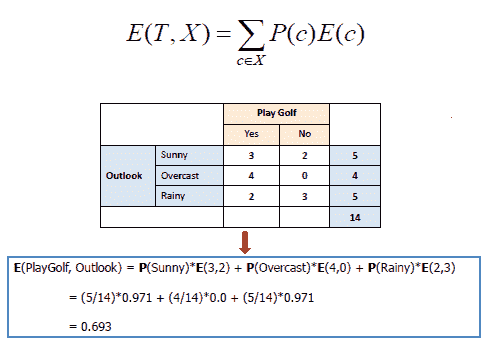
其中 T → 当前状态和 X → 选择的属性
信息增益
信息增益或 IG 是一种统计属性,用于测量给定属性根据其目标分类分离训练样本的效果。构建决策树的核心是找到一个能返回最高信息增益和最小熵的属性。
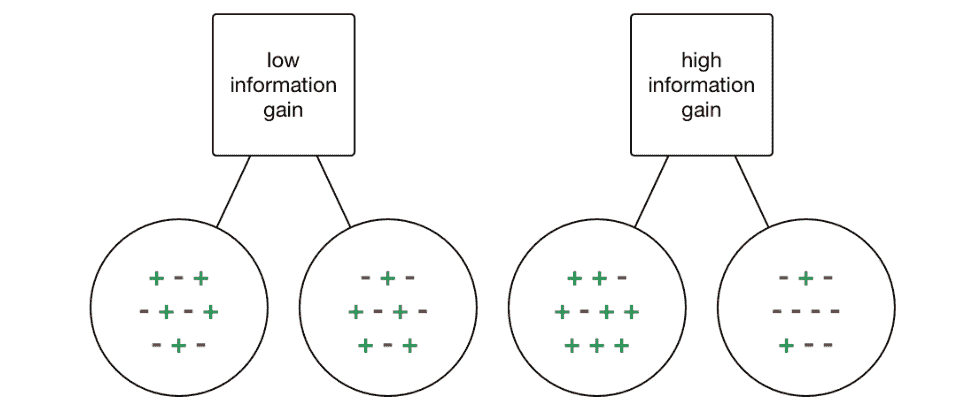
信息增益是熵的减少。它计算了基于给定属性值的分裂前后的熵差。ID3(迭代二分器)决策树算法使用信息增益。
数学上,IG 表示为:

更简单地说,我们可以得出结论:
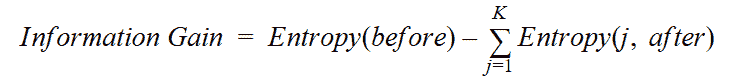
其中“before”是分裂前的数据集,K 是分裂生成的子集数量,(j, after)是分裂后的子集 j。
基尼指数
你可以将基尼指数理解为用来评估数据集分裂的成本函数。它通过从 1 中减去每个类别的平方概率总和来计算。它偏向于较大的分区且易于实现,而信息增益则偏向于较小的具有不同值的分区。
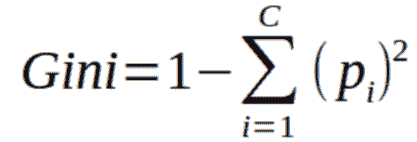 基尼指数
基尼指数
基尼指数适用于类别目标变量“成功”或“失败”。它仅执行二分裂。
较高的基尼指数意味着更高的不平等性,更高的异质性。
计算分裂基尼指数的步骤
-
计算子节点的基尼,使用上述公式计算成功(p)和失败(q)的值(p²+q²)。
-
计算分裂的基尼指数,使用该分裂每个节点的加权基尼得分。
CART(分类与回归树)使用基尼指数方法来创建分裂点。
增益比
信息增益偏向于选择具有大量值的属性作为根节点。这意味着它更倾向于选择具有大量不同值的属性。
C4.5,作为 ID3 的改进,使用增益比,这是一种信息增益的修改,减少了其偏倚,通常是最佳选择。增益比通过考虑拆分前产生的分支数量来克服信息增益的问题。它通过考虑拆分的固有信息来修正信息增益。
假设我们有一个数据集,其中包含用户和他们的电影类型偏好,基于性别、年龄组、评分等变量。借助信息增益,你可以在‘性别’上进行拆分(假设它具有最高的信息增益),现在‘年龄组’和‘评分’变量可能同样重要,通过增益比的帮助,它会惩罚具有更多不同值的变量,这将帮助我们在下一个层次决定拆分。
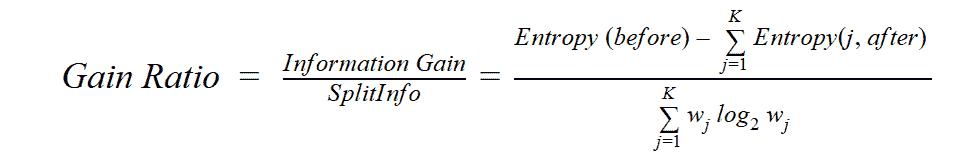
其中“before”是拆分前的数据集,K 是拆分生成的子集的数量,(j, after) 是拆分后子集 j。
方差减少
方差减少 是一种用于连续目标变量(回归问题)的算法。该算法使用方差的标准公式来选择最佳拆分。选择方差较低的拆分作为拆分总体的标准:
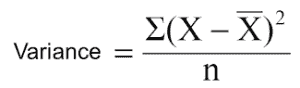
上面的 X-bar 是值的均值,X 是实际值,n 是值的数量。
计算方差的步骤:
-
计算每个节点的方差。
-
计算每个拆分的方差,作为每个节点方差的加权平均值。
卡方
缩写 CHAID 代表 卡方 自动交互检测器。它是最古老的树分类方法之一。它找出子节点和父节点之间差异的统计显著性。我们通过目标变量的观察频率和期望频率之间的标准化差异的平方和来衡量它。
它适用于分类目标变量“成功”或“失败”。它可以执行两个或更多的拆分。卡方值越高,子节点和父节点之间差异的统计显著性越高。
它生成一个称为 CHAID(卡方自动交互检测器)的树。
从数学上讲,卡方被表示为:

计算拆分卡方的步骤:
-
通过计算成功和失败的偏差来计算单个节点的卡方。
-
通过计算拆分后每个节点的成功和失败的所有卡方值的总和来计算拆分的卡方值。
如何避免/对抗决策树中的过拟合?
决策树的常见问题,特别是当表中列很多时,它们的拟合程度很高。有时,看起来树似乎记住了训练数据集。如果决策树没有设置限制,它会在训练数据集上提供 100%的准确率,因为在最坏的情况下,它会为每个观察值生成一个叶子节点。因此,这会影响对训练集之外样本的预测准确性。
这里有两种去除过拟合的方法:
-
剪枝决策树。
-
随机森林
剪枝决策树
分裂过程会生成完全生长的树,直到达到停止标准。但完全生长的树很可能会过拟合数据,从而在未见数据上的准确性较差。

在剪枝中,你会修剪树的分支,即从叶子节点开始移除决策节点,以确保总体准确性不受影响。这是通过将实际训练集分成两个集合来完成的:训练数据集 D 和验证数据集 V。使用分隔后的训练数据集 D 来准备决策树。然后继续修剪树,以优化验证数据集 V 的准确性。
在上述图示中,树的左侧的‘年龄’属性已被剪枝,因为它在树的右侧更重要,因此去除了过拟合。
随机森林
随机森林是集成学习的一个例子,在这种学习中,我们结合多个机器学习算法以获得更好的预测性能。
为什么叫“随机”?
赋予其“随机”名称的两个关键概念:
-
在构建树时,随机抽样训练数据集。
-
分裂节点时考虑的特征随机子集。
一种称为“自助法”(bagging)的技术用于创建一个决策树集成模型,其中多个训练集通过有放回的抽样生成。
在自助法技术中,数据集被划分为N个样本,使用随机抽样。然后,使用单一学习算法在所有样本上建立模型。之后,通过投票或平均的方式将结果预测合并在一起。
线性模型还是基于树的模型哪个更好?
这要看你正在解决的是什么问题。
-
如果因变量与自变量之间的关系可以通过线性模型很好地近似,线性回归将优于基于树的模型。
-
如果因变量与自变量之间有高度非线性和复杂关系,树模型将优于经典的回归方法。
-
如果你需要建立一个容易向人们解释的模型,决策树模型总比线性模型更好。决策树模型甚至比线性回归更易于解释!
使用 Scikit-learn 构建决策树分类器
我们拥有的数据集是超市数据,可以从这里下载。
加载所有基本库。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
加载数据集。它包括 5 个特征:UserID、Gender、Age、EstimatedSalary 和 Purchased。
data = pd.read_csv('/Users/ML/DecisionTree/Social.csv')
data.head()
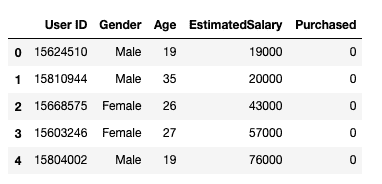 数据集
数据集
我们将仅使用 Age 和 EstimatedSalary 作为我们的自变量 X,因为像 Gender 和 User ID 这样的其他特征与个人的购买能力无关且没有影响。Purchased 是我们的因变量 y。
feature_cols = ['Age','EstimatedSalary' ]X = data.iloc[:,[2,3]].values
y = data.iloc[:,4].values
下一步是将数据集拆分为训练集和测试集。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.25, random_state= 0)
执行特征缩放
#feature scaling
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
在决策树分类器中拟合模型。
from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier()
classifier = classifier.fit(X_train,y_train)
做出预测并检查准确性。
#prediction
y_pred = classifier.predict(X_test)#Accuracy
from sklearn import metricsprint('Accuracy Score:', metrics.accuracy_score(y_test,y_pred))
决策树分类器的准确率为 91%。
混淆矩阵
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)Output:
array([[64, 4],
[ 2, 30]])
这意味着 6 个观察结果被归类为虚假。
让我们首先可视化模型预测结果。
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:,0].min()-1, stop= X_set[:,0].max()+1, step = 0.01),np.arange(start = X_set[:,1].min()-1, stop= X_set[:,1].max()+1, step = 0.01))
plt.contourf(X1,X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape), alpha=0.75, cmap = ListedColormap(("red","green")))plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())for i,j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set==j,0],X_set[y_set==j,1], c = ListedColormap(("red","green"))(i),label = j)
plt.title("Decision Tree(Test set)")
plt.xlabel("Age")
plt.ylabel("Estimated Salary")
plt.legend()
plt.show()
让我们也可视化一下这棵树:
你可以使用 Scikit-learn 的 export_graphviz 函数在 Jupyter notebook 中显示树。为了绘制树,你还需要安装 Graphviz 和 pydotplus。
conda install python-graphviz
pip install pydotplus
export_graphviz 函数将决策树分类器转换为 dot 文件,pydotplus 将此 dot 文件转换为 png 或在 Jupyter 中可显示的形式。
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
from IPython.display import Image
import pydotplusdot_data = StringIO()
export_graphviz(classifier, out_file=dot_data,
filled=True, rounded=True,
special_characters=True,feature_names = feature_cols,class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())
 决策树。
决策树。
在决策树图表中,每个内部节点都有一个决策规则来分割数据。基尼指数(Gini)被称为基尼比率,用来衡量节点的不纯度。可以说,当所有记录都属于同一类别时,节点是纯的,这种节点称为叶节点。
在这里,结果树是未经修剪的。这个未经修剪的树是不可解释的,且不容易理解。在下一节中,我们将通过修剪来优化它。
优化决策树分类器
criterion:可选(默认值为“gini”)或 选择属性选择度量:此参数允许我们使用不同的属性选择度量。支持的标准有“gini”用于基尼指数和“entropy”用于信息增益。
splitter:字符串, 可选(默认值为“best”)或 分割策略:这个参数允许我们选择分割策略。支持的策略有“best”以选择最佳分割和“random”以选择最佳随机分割。
max_depth:int 或 None,可选(默认=None)或树的最大深度:树的最大深度。如果为 None,则节点扩展直到所有叶子包含的样本数少于 min_samples_split。较高的最大深度值会导致过拟合,而较低的值会导致欠拟合(来源)。
在 Scikit-learn 中,决策树分类器的优化仅通过预剪枝进行。树的最大深度可以作为预剪枝的控制变量。
# Create Decision Tree classifer object
classifier = DecisionTreeClassifier(criterion="entropy", max_depth=3)# Train Decision Tree Classifer
classifier = classifier.fit(X_train,y_train)#Predict the response for test dataset
y_pred = classifier.predict(X_test)# Model Accuracy, how often is the classifier correct?
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
好的,分类率提高到了 94%,比之前的模型准确度更高。
现在,让我们在优化后再次可视化剪枝后的决策树。
dot_data = StringIO()
export_graphviz(classifier, out_file=dot_data,
filled=True, rounded=True,
special_characters=True, feature_names = feature_cols,class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())
 剪枝后的决策树
剪枝后的决策树
这个剪枝模型比之前的决策树模型图更简单、可解释且易于理解。
结论
在这篇文章中,我们涵盖了关于决策树的许多细节;它的工作原理、属性选择度量如信息增益、增益比和基尼指数,决策树模型的构建、可视化和在超市数据集上使用 Python Scikit-learn 包的评估,以及通过参数调整优化决策树性能。
好了,这篇文章就到此为止,希望大家喜欢阅读,欢迎在评论区分享你的评论/想法/反馈。

感谢阅读!!!
简介:Nagesh Singh Chauhan 是数据科学爱好者。对大数据、Python 和机器学习感兴趣。
原文。已获转载许可。
更多相关主题
决策树直觉:从概念到应用
评论

决策树是我学习过的流行且强大的机器学习算法之一。它是一种非参数的监督学习方法,可用于分类和回归任务。其目标是通过学习从数据特征中推断出的简单决策规则来创建一个预测目标变量值的模型。对于分类模型,目标值是离散的,而对于回归模型,目标值是连续的。与神经网络等黑箱算法不同,决策树相对更容易理解,因为它共享内部决策逻辑(你将在以下章节中找到详细信息)。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT 工作
尽管许多数据科学家认为这是一种旧方法,并且由于过拟合问题可能对其准确性有所怀疑,但更近期的树模型,例如随机森林(袋装方法)、梯度提升(提升方法)和 XGBoost(提升方法),都是建立在决策树算法之上的。因此,决策树背后的概念和算法非常值得理解!

有 4 种流行的决策树算法:ID3、CART(分类与回归树)、卡方检验和方差减少。
在这篇博客中,我将只关注分类树以及 ID3 和 CART 的解释。

想象一下,你每个星期天打网球,并且每次都邀请你最好的朋友 Clare 一起去。Clare 有时会来,有时不会。对于她来说,这取决于很多因素,例如天气、温度、湿度和风。我想利用下面的数据集来预测 Clare 是否会和我一起打网球。一种直观的方法是通过决策树。
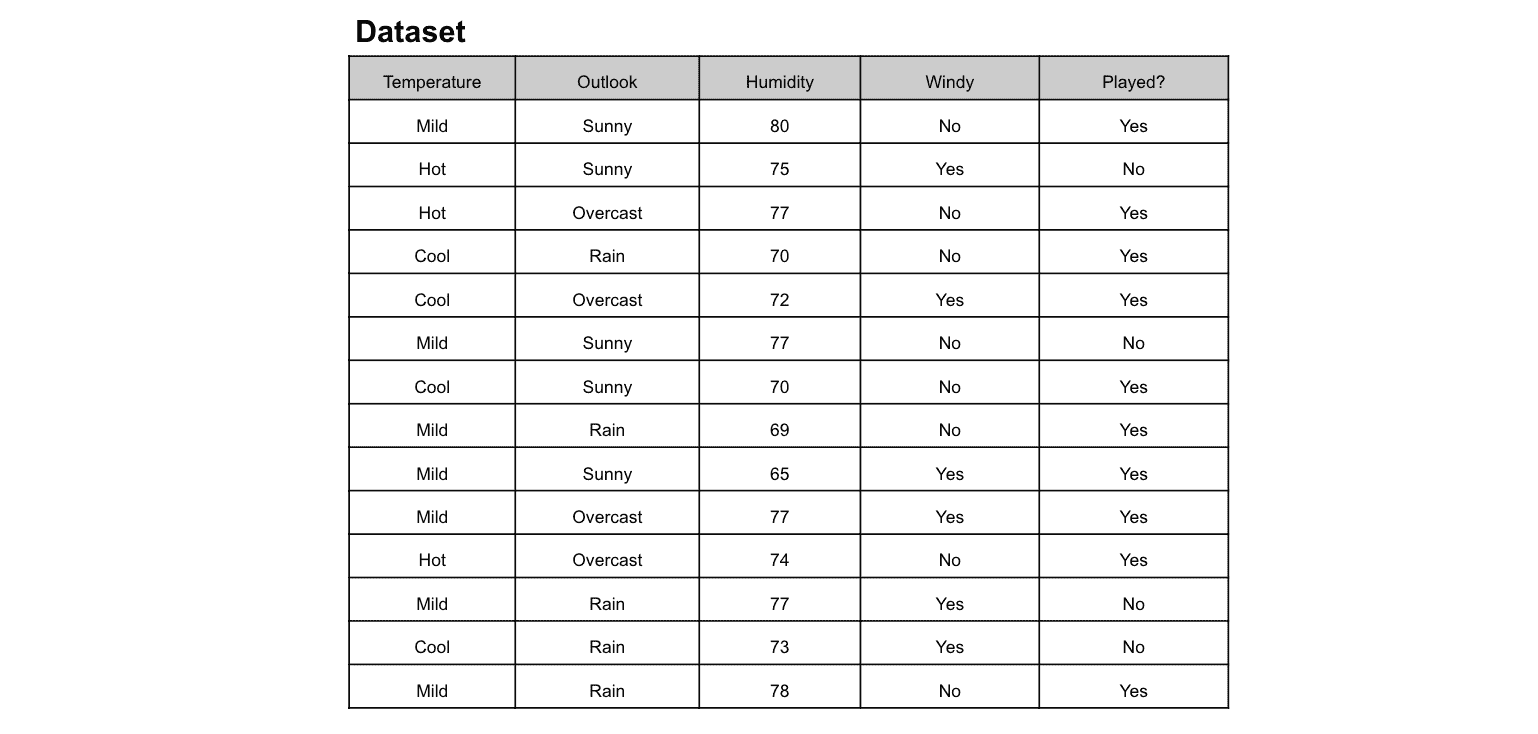
在这个决策树图中,我们有:
-
根节点:第一次划分决定整个数据集是否应该进一步分为两个或多个同质集合。在我们的例子中是“天气”节点。
-
划分:将一个节点分成两个或多个子节点的过程。
-
决策节点:决定是否/何时将子节点进一步划分为更多子节点的节点。在这里,我们有“天气”节点、“湿度”节点和“风”节点。
-
叶节点:预测结果的终端节点(分类值或连续值)。上色的节点,即“是”和“否”节点,是叶节点。
问题:基于哪个属性(特征)进行划分?什么是最佳划分?
回答:使用具有最高信息增益或基尼增益的属性
ID3(迭代二分法)
ID3 决策树算法使用信息增益来决定划分点。为了测量我们获得了多少信息,我们可以使用熵来计算样本的同质性。
问题:“熵”是什么?它的功能是什么?
回答:它是数据集中不确定性量的度量。熵控制决策树如何划分数据。它实际上影响了决策树如何绘制边界。
熵的公式:
概率分布的对数作为熵的度量是有用的。
熵与概率。
定义:决策树中的熵表示同质性。
如果样本完全同质,熵为 0(概率=0 或 1);如果样本在各个类别之间均匀分布,熵为 1(概率=0.5)。
下一步是进行最小化熵的划分。我们使用信息增益来确定最佳划分。
让我一步步向你展示在打网球的情况下如何计算信息增益。在这里,我将仅展示如何计算“天气”的信息增益和熵。
步骤 1:计算一个属性的熵——预测:克莱尔会打网球/克莱尔不会打网球
在这个示例中,我将使用这个列联表来计算目标变量的熵:是否玩?(是/否)。共有 14 个观察值(10 个“是”和 4 个“否”)。‘是’的概率(p)为 0.71428(10/14),‘否’的概率为 0.28571(4/14)。然后,你可以使用上述公式计算目标变量的熵。
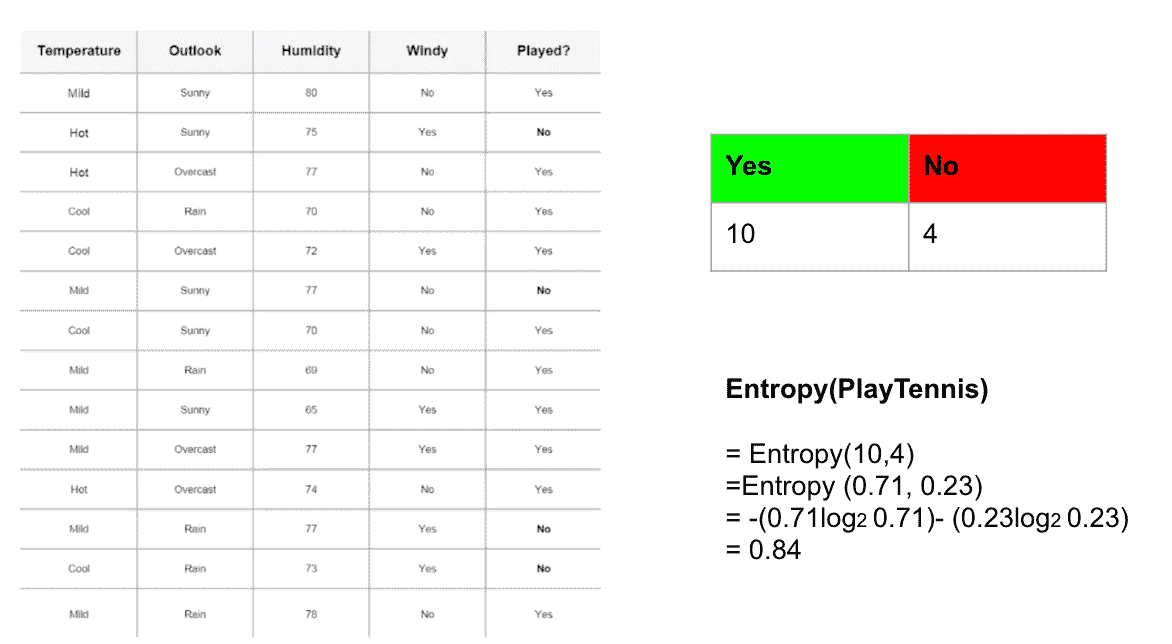
步骤 2:使用列联表计算每个特征的熵
为了说明,我使用“天气”作为例子来解释如何计算它的熵。共有 14 个观察值。我们可以看到,有 5 个属于“晴天”,4 个属于“阴天”,5 个属于“雨天”。因此,我们可以找到“晴天”、“阴天”和“雨天”的概率,然后分别使用上述公式计算它们的熵。计算步骤如下。
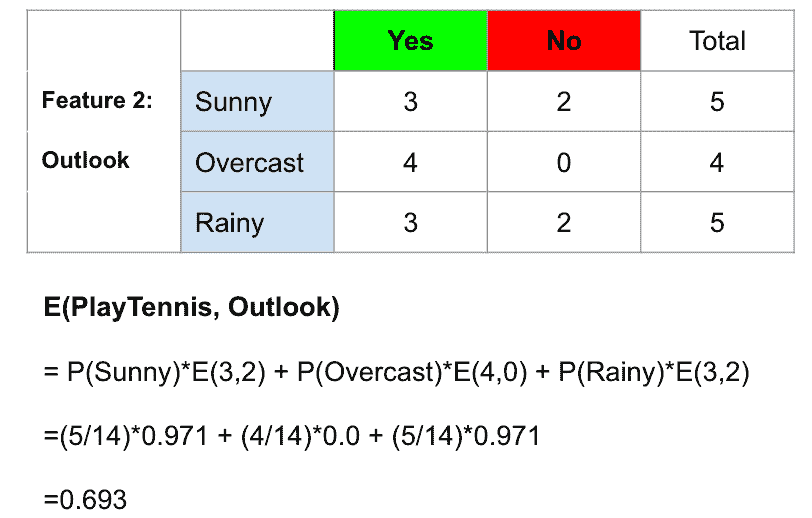
计算特征 2(Outlook)熵值的示例。
定义:信息增益是节点分裂时熵值的减少或增加。
信息增益的公式:
X 对 Y 的增益。

Outlook 的信息增益为 0.147。
sklearn.tree.DecisionTreeClassifier: “entropy”代表信息增益。
为了可视化如何使用信息增益构建决策树,我简单地应用了 sklearn.tree.DecisionTreeClassifier来生成图示。
步骤 3:选择信息增益最大的属性作为根节点
‘湿度’的信息增益最高,为 0.918。湿度是根节点。
步骤 4:一个*熵为 0 的分支是叶子节点,而熵大于 0 的分支需要进一步分裂。
步骤 5:在 ID3 算法中,节点会递归地增长,直到所有数据都被分类。
你可能听说过C4.5 算法,它是 ID3 算法的改进版,使用增益比作为信息增益的扩展。使用增益比的优点是通过使用分裂信息(Split Info)来规范化信息增益,以解决偏差问题。我不会在这里详细讨论 C4.5。如需更多信息,请查看这里(DataCamp)。
CART(分类与回归树)
另一种决策树算法 CART 使用基尼方法来创建分裂点,包括基尼指数(基尼不纯度)和基尼增益。
基尼指数的定义:随机挑选标签并为样本分配错误标签的概率,也用于测量树中特征的重要性。
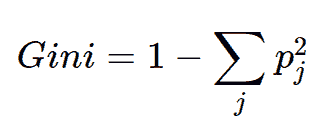
基尼指数的公式。
让我来展示一下如何计算基尼指数和基尼增益 😃

计算每个属性的基尼增益后,sklearn.tree.DecisionTreeClassifier会选择基尼增益最大的属性作为根节点。一个基尼值为 0 的分支是叶子节点,而基尼值大于 0 的分支需要进一步分裂。节点会递归地增长,直到所有数据都被分类(见下文详细说明)。
如前所述,CART 还可以使用不同的分裂标准处理回归问题:均方误差(MSE)来确定分裂点。回归树的输出变量是数值型的,输入变量可以是连续变量和分类变量的混合。您可以通过DataCamp获取更多关于回归树的信息。
太好了!现在你应该理解如何计算熵、信息增益、基尼指数和基尼增益!
问题:那么,我应该使用哪个?基尼指数还是熵?
回答:一般来说,结果应该是相同的……我个人更倾向于使用基尼指数,因为它的计算不涉及更复杂的log。但为什么不同时尝试这两者呢。
让我以表格形式总结一下!

使用 Scikit Learn 构建决策树
Scikit Learn是一个用于 Python 编程语言的免费机器学习库。
第 1 步:导入数据
import numpy as np
import pandas as pd
df = pd.read_csv('weather.csv')
第 2 步:将分类变量转换为虚拟/指示变量
df_getdummy=pd.get_dummies(data=df, columns=['Temperature', 'Outlook', 'Windy'])
“温度”、“天气”和“风力”的分类变量都转换为虚拟变量。
第 3 步:分离训练集和测试集
from sklearn.model_selection import train_test_split
X = df_getdummy.drop('Played?',axis=1)
y = df_getdummy['Played?']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=101)
第 4 步:通过 sklearn 导入决策树分类器
from sklearn.tree import DecisionTreeClassifier
dtree = DecisionTreeClassifier(max_depth=3)
dtree.fit(X_train,y_train)
predictions = dtree.predict(X_test)
第 5 步:可视化决策树图
from sklearn.tree import DecisionTreeClassifier
dtree = DecisionTreeClassifier(max_depth=3)
dtree.fit(X_train,y_train)
predictions = dtree.predict(X_test)
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(16,12))
a = plot_tree(dtree, feature_names=df_getdummy.columns, fontsize=12, filled=True,
class_names=['Not Play', 'Play'])
树的深度:3。
有关编码和数据集,请查看这里。

如果“湿度”的条件低于或等于 73.5,Clare 很可能会打网球!

为了提高模型性能(超参数优化),你需要调整超参数。有关详细信息,请查看这里。
决策树的主要缺点是过拟合,尤其是当树特别深的时候。幸运的是,近年来的树模型,包括随机森林和 XGBoost,都是建立在决策树算法基础上的,它们通常在建模技术上表现更强,且比单一决策树更加动态。因此,深入理解决策树背后的概念和算法对于构建良好的数据科学和机器学习基础非常有帮助。
总结:现在你应该知道
-
如何构建决策树
-
如何计算“熵”和“信息增益”
-
如何计算“基尼指数”和“基尼增益”
-
什么是最佳分裂?
-
如何在 Python 中绘制决策树图
原文。转载经许可。
相关:
更多相关话题
决策树修剪:如何和为什么
原文:
www.kdnuggets.com/2022/09/decision-tree-pruning-hows-whys.html

Devin H via Unsplash
让我们回顾一下决策树。
我们的前三个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业道路。
2. Google Data Analytics Professional Certificate - 提升您的数据分析水平
3. Google IT Support Professional Certificate - 支持您的组织 IT
决策树是一种非参数的监督学习方法,可用于分类和回归任务。目标是通过学习从数据特征中推断出的简单决策规则,建立一个能够预测目标变量值的模型。
决策树由以下部分组成
-
根节点 - 决策树的最顶部,是你尝试做出的最终决策。
-
内部节点 - 从根节点分支出来,表示不同的选项。
-
叶子节点 - 这些节点附加在分支的末端,表示每个动作的可能结果。
就像任何其他机器学习算法一样,最烦人的事情就是过拟合。决策树就是容易过拟合的机器学习算法之一。
过拟合是指模型完全拟合训练数据,却难以或无法泛化测试数据。这发生在模型记住了训练数据中的噪声,而没有捕捉到帮助处理测试数据的重要模式。
降低决策树过拟合的技术之一是修剪。
什么是决策树修剪,它为何重要?
修剪是一种移除决策树中阻止其完全生长的部分的技术。它移除的部分是不提供分类实例能力的部分。一个完全生长的决策树很可能会导致过拟合训练数据,因此修剪是重要的。
简单来说,决策树修剪的目的是构建一个在训练数据上表现较差但在测试数据上泛化更好的算法。调整决策树模型的超参数可以大大改善模型表现,节省时间和金钱。
如何修剪决策树?
剪枝有两种类型:预剪枝和后剪枝。我将介绍它们以及它们是如何工作的。
预剪枝
决策树的预剪枝技术是在训练管道之前调整超参数。它涉及到一种被称为‘早期停止’的启发式方法,该方法会停止决策树的生长 - 防止其达到完整深度。
它会停止树的构建过程,以避免生成样本量较小的叶子。在树的每个分裂阶段,将会监控交叉验证误差。如果误差值不再减少 - 那么我们就停止决策树的生长。
可以调节的超参数以进行早期停止和防止过拟合是:
max_depth、min_samples_leaf 和 min_samples_split
这些相同的参数也可以用于调整以获得稳健模型。然而,你应该谨慎,因为早期停止也可能导致欠拟合。
后剪枝
后剪枝与预剪枝相反,允许决策树模型生长到其完整深度。一旦模型生长到其完整深度,树枝将被移除以防止模型过拟合。
算法将继续将数据划分为更小的子集,直到最终产生的子集在结果变量方面相似。树的最终子集将仅包含少量数据点,从而使树能够完全学习数据。然而,当引入与学习数据不同的新数据点时 - 它可能无法得到良好的预测。
可用于后剪枝和防止过拟合的超参数是:ccp_alpha
ccp 代表成本复杂度剪枝,可以用作控制树大小的另一种选项。较高的ccp_alpha值将导致更多节点被修剪。
成本复杂度剪枝(后剪枝)步骤:
-
将决策树模型训练到其完整深度
-
使用
cost_complexity_pruning_path()计算ccp_alphas值 -
用不同的
ccp_alphas值训练你的决策树模型,并计算训练和测试性能分数 -
绘制每个
ccp_alphas值的训练和测试分数。
这个超参数也可以用于调整以获得最佳拟合模型。
提示
这里有一些你可以在决策树剪枝时应用的提示:
-
如果节点变得非常小,则不要继续分裂
-
在没有早期停止的情况下,最小误差(交叉验证)剪枝是一种好的技术
-
构建一个完整深度的树,然后通过在每个阶段应用统计检验来向后工作
-
修剪一个内部节点,并将其下方的子树上移一级
结论
在这篇文章中,我已经详细讲解了两种修剪技术及其用途。决策树非常容易出现过拟合——因此修剪是算法中一个至关重要的阶段。如果你想了解更多关于使用成本复杂度修剪的后期修剪决策树的内容,请点击这个链接。
Nisha Arya是一名数据科学家和自由技术写作员。她特别关注于提供数据科学职业建议或教程以及数据科学的理论知识。她还希望探索人工智能如何或可以有益于人类寿命的不同方式。作为一个热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关主题
决策树与随机森林的解释
原文:
www.kdnuggets.com/2022/08/decision-trees-random-forests-explained.html
介绍
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 支持
决策树和随机森林是两种最受欢迎的监督学习预测模型。这些模型可用于分类和回归问题。
在这篇文章中,我将解释决策树和随机森林之间的区别。到文章结束时,你应该熟悉以下概念:
-
决策树算法是如何工作的?
-
决策树的组成部分
-
决策树算法的优缺点是什么?
-
什么是袋装(bagging),随机森林算法是如何工作的?
-
哪种算法在速度和性能方面更好?
决策树
决策树是高度可解释的机器学习模型,允许我们对数据进行分层或分段。它们允许我们根据特定参数不断拆分数据,直到做出最终决策。
决策树算法是如何工作的?
看一下下面的表格:
这个数据集仅包含四个变量——“Day”、“Temperature”、“Wind”和“Play?”。根据任意一天的温度和风速,结果是二元的——要么出去玩,要么待在家里。
让我们使用这些数据来构建一个决策树:
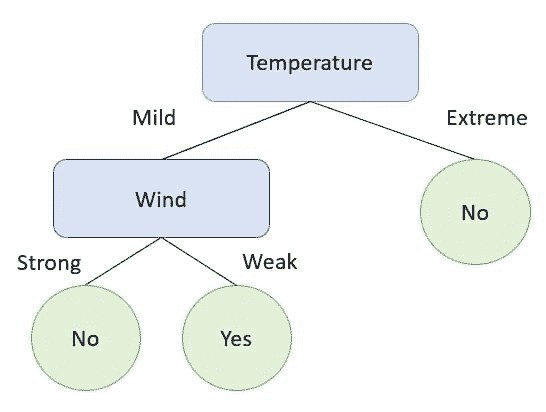
上面的示例虽然简单,但准确地概括了决策树如何在不同的数据点上拆分,直到获得结果。
从上面的可视化中可以看出,决策树首先在“Temperature”变量上进行拆分。当温度极端时,它也会停止拆分,并表示我们不应该出去玩。
只有当温度适中时,它才会开始对第二个变量进行拆分。
这些观察结果引出了以下问题:
-
决策树如何决定第一个要拆分的变量?
-
如何决定何时停止拆分?
-
构建决策树时使用的顺序是什么?
熵
熵是一个衡量决策树中分裂不纯度的指标。它决定了决策树如何选择划分数据。熵值范围从 0 到 1。0 的值表示纯净的分裂,1 的值表示不纯的分裂。
在上面的决策树中,回顾一下树在温度极端时已经停止分裂:
这是因为当温度极端时,“是否玩?”的结果总是“否”。这意味着我们有一个纯净的分裂,100%的数据点属于一个单一类别。这个分裂的熵值为 0,决策树将在这个节点停止分裂。
决策树总是选择最低熵的特征作为第一个节点。
在这种情况下,由于“温度”变量的熵值低于“风速”,因此这是树的第一个分裂。
观看这个YouTube 视频,了解更多关于如何计算熵及其在决策树中使用的内容。
信息增益
信息增益测量构建决策树时熵的减少量。
决策树可以通过多种不同的方式构建。树需要首先找到一个特征进行分裂,然后是第二个、第三个等。信息增益是一个指标,它告诉我们构建能够最小化熵的最佳决策树。
最佳的树是信息增益最高的树。
如果你想了解更多关于如何计算信息增益并利用它来构建最佳决策树的内容,你可以观看这个YouTube 视频。
决策树的组成部分:
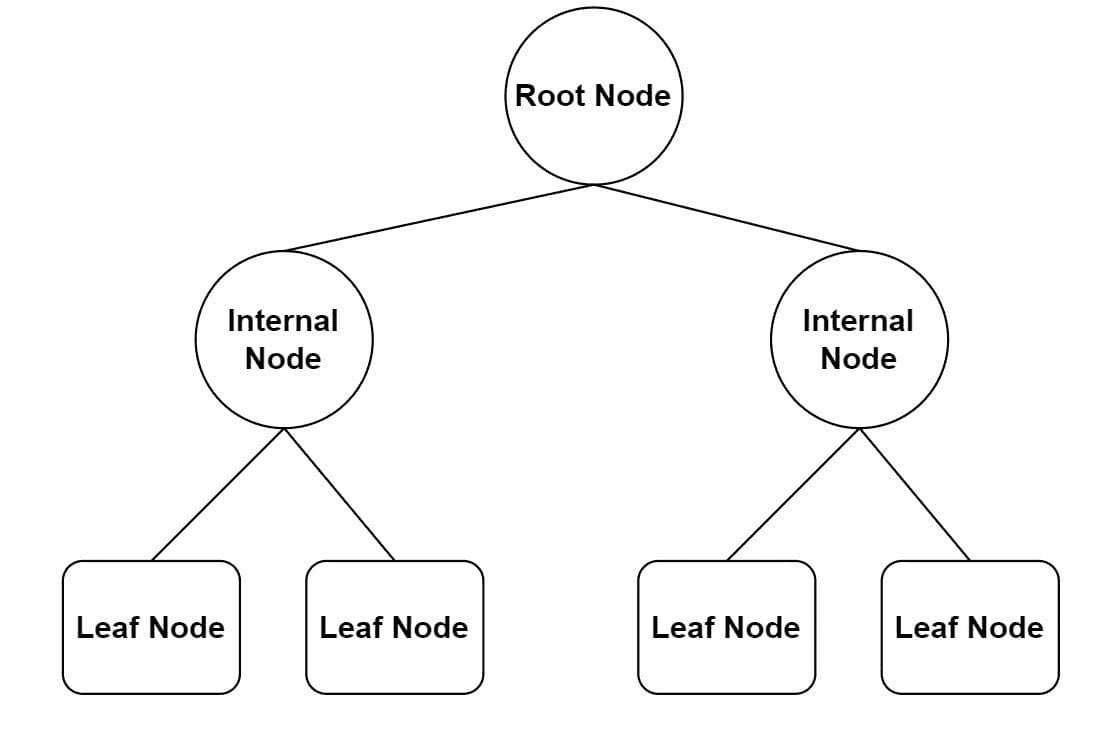
-
根节点:根节点位于决策树的顶部,是数据集开始划分的变量。根节点是为我们提供最佳数据分裂的特征。
-
内部节点:这些是根节点之后分裂数据的节点。
-
叶节点:这些是决策树底部的节点,之后没有进一步的分裂可能。
-
分支:分支连接一个节点到另一个节点,并用于表示测试的结果。
决策树算法的优缺点:
现在你了解了决策树的工作原理,让我们来看看该算法的一些优缺点。
优点
-
决策树简单且易于解释。
-
它们可以用于分类和回归问题。
-
它们可以对非线性可分的数据进行划分。
缺点
-
决策树容易出现过拟合。
-
即使训练数据集的一个小变化也会对决策树的逻辑产生巨大影响。
随机森林
决策树算法的一个最大缺点是容易过拟合。这意味着模型过于复杂,并且具有高方差。这样的模型会有很高的训练准确率,但对其他数据集的泛化能力较差。
随机森林算法如何工作?
随机森林算法通过结合多个决策树的预测结果并返回一个单一的输出,解决了上述挑战。这是通过扩展一种称为bagging或自助聚合的技术来实现的。
Bagging 是一种用于减少机器学习模型方差的过程。它通过对一组观察结果取平均来减少方差。
下面是 bagging 的工作原理:
自助法
如果我们有多个训练数据集,我们可以在每个数据集上训练多棵决策树,并对结果取平均。
然而,由于在大多数实际场景中我们通常只有一个训练数据集,因此使用了一种称为自助法的统计技术来对数据集进行有放回的抽样。
然后,创建多棵决策树,每棵树在不同的数据样本上进行训练:
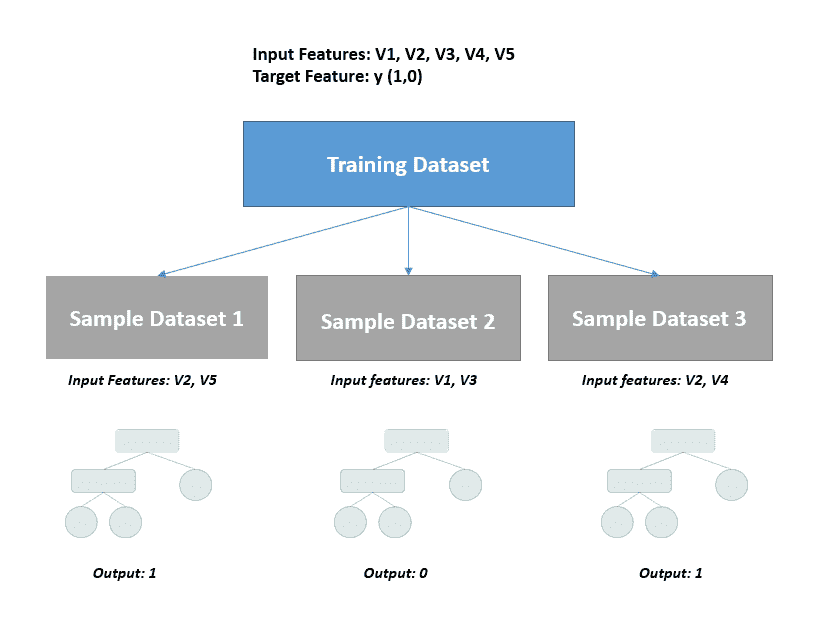
请注意,以上的训练数据集创建了三个 bootstrap 样本。随机森林算法在 bagging 的基础上进一步随机抽取特征,因此每棵树只使用部分变量进行构建。
每棵决策树根据其训练的数据样本会产生不同的预测结果。
聚合
在这一步骤中,将结合每棵决策树的预测结果,得出一个单一的输出。
在分类问题中,会做出一个多数类预测:
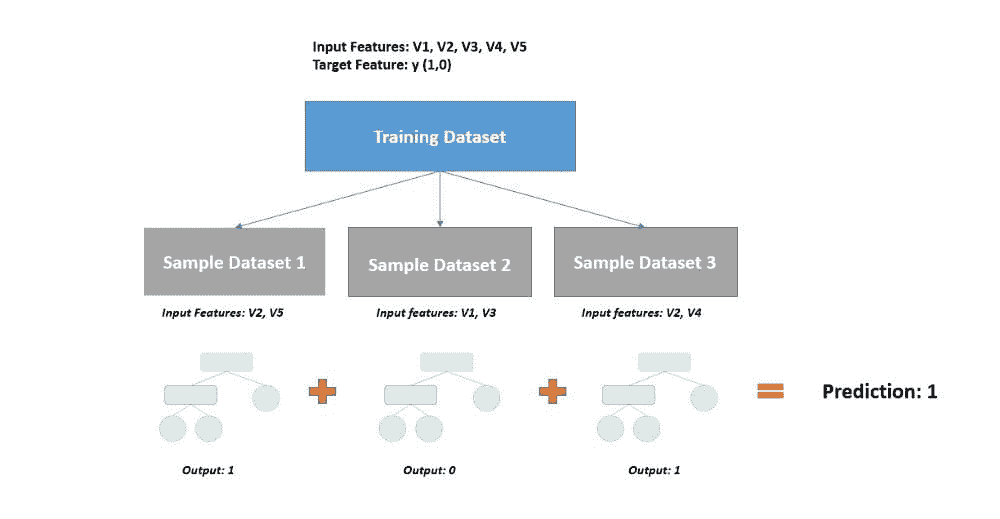
在回归问题中,所有决策树的预测结果会被平均,得出一个单一值。
为什么在随机森林算法中我们要随机抽取变量?
在随机森林算法中,不仅行会被随机抽样,变量也会被随机抽样。
这是因为如果我们用相同的特征构建多棵决策树,每棵树都会相似并高度相关,可能会产生相同的结果。这会导致高方差的问题。
决策树与随机森林 - 哪个更好,为什么?
随机森林通常比决策树表现更好,原因如下:
-
随机森林解决了过拟合问题,因为它们将多个决策树的输出结合起来,以得出最终预测结果。
-
当你构建一棵决策树时,数据的微小变化会导致模型预测的巨大差异。使用随机森林,这个问题不会出现,因为数据在生成预测之前会被多次抽样。
然而,就速度而言,随机森林较慢,因为需要更多时间来构建多个决策树。将更多树添加到随机森林模型中会在一定程度上提高其准确性,但也会增加计算时间。
最后,决策树相比于随机森林更易于解释,因为它们结构简单。可以轻松地可视化决策树并理解算法如何得出结果。随机森林更难以拆解,因为它更加复杂,并结合了多个决策树的输出进行预测。
Natassha Selvaraj 是一位自学成才的数据科学家,对写作充满热情。你可以通过LinkedIn与她联系。
了解更多此主题
深入探讨 GPT 模型:演变与性能比较
作者:Ankit、Bhaskar & Malhar
在过去几年中,得益于大型语言模型的出现,自然语言处理领域取得了显著进展。语言模型用于机器翻译系统中,以学习如何将字符串从一种语言映射到另一种语言。在语言模型家族中,基于生成预训练变换器(GPT)的模型最近受到了最多的关注。最初,语言模型是基于规则的系统,严重依赖人工输入来运行。然而,深度学习技术的发展对这些模型处理任务的复杂性、规模和准确性产生了积极影响。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
在我们的上一篇博客中,我们提供了对 GPT-3 模型各个方面的全面解释,评估了 Open AI 的 GPT-3 API 提供的功能,并探讨了模型的使用和局限性。在这篇博客中,我们将把重点转向 GPT 模型及其基础组件。我们还将回顾从 GPT-1 到最近推出的 GPT-4 的演变,并深入探讨每一代中所做的关键改进,这些改进使模型随着时间的推移变得更为强大。
1. 了解 GPT 模型
GPT(生成预训练变换器)是一个基于深度学习的大型语言模型(LLM),利用基于变换器的解码器架构。它的目的是处理文本数据并生成类似人类语言的文本输出。
如名称所示,该模型有三个支柱,即:
-
生成性
-
预训练
-
变换器
让我们通过这些组件来探索模型:
生成性: 这一特性强调了模型通过理解和响应给定文本样本生成文本的能力。在 GPT 模型之前,文本输出是通过重新排列或提取输入中的单词来生成的。GPT 模型的生成能力使其相较于现有模型具有优势,能够产生更连贯且更像人类的文本。
这种生成能力源自于训练过程中使用的建模目标。
GPT 模型使用自回归语言建模进行训练,模型接收一个词序列作为输入,然后通过概率分布预测最可能的下一个词或短语。
预训练: “预训练”指的是一个机器学习模型在被部署到特定任务之前,已经在大量示例数据集上进行过训练。在 GPT 的情况下,该模型在大量文本数据语料库上进行训练,使用无监督学习方法。这使得模型能够在没有明确指导的情况下学习数据中的模式和关系。
简而言之,使用大量数据以无监督的方式训练模型有助于模型理解语言的普遍特征和结构。一旦学习完成,模型可以利用这些理解来执行特定任务,例如问答和摘要。
变换器: 一种神经网络架构,旨在处理不同长度的文本序列。变换器的概念在 2017 年发表的开创性论文《Attention Is All You Need》之后获得了广泛关注。
GPT 使用仅解码器架构。变换器的主要组件是其“自注意力机制”,它使模型能够捕捉同一句子中每个词与其他词之间的关系。
示例:
-
一只狗坐在恒河的河岸上。
-
我将从银行取一些钱。
自注意力机制在句子中评估每个词与其他词的关系。在第一个例子中,当“bank”在“River”的上下文中被评估时,模型学习到它指的是河岸。同样,在第二个例子中,将“bank”与“money”一词相关联则暗示这是一个金融银行。
2. GPT 模型的发展
现在,让我们更详细地了解 GPT 模型的各种版本,重点关注每个后续模型中引入的改进和新增功能。
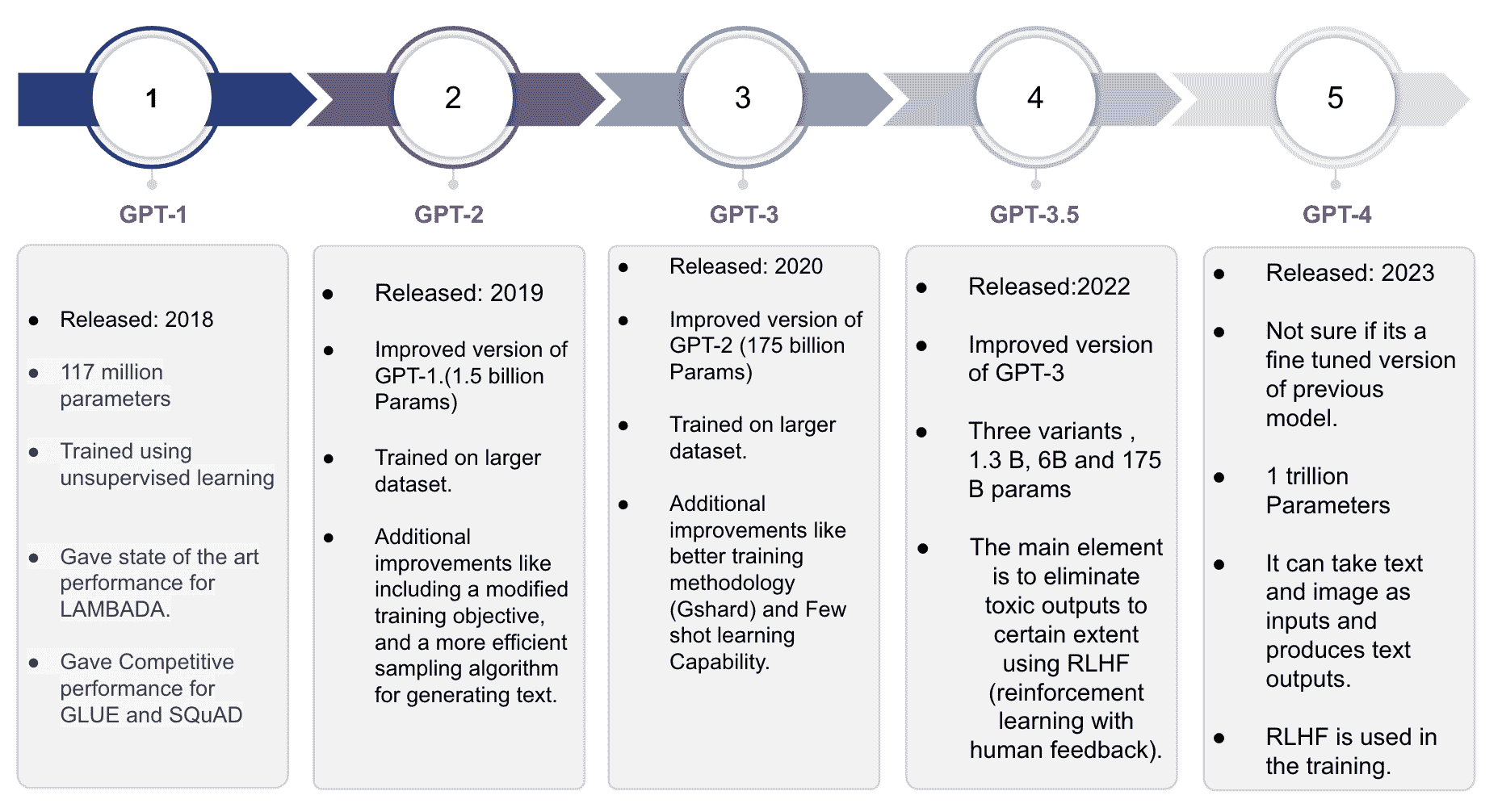
*第 3 幻灯片 GPT 模型
GPT-1
这是 GPT 系列的第一个模型,训练时使用了约 40GB 的文本数据。该模型在建模任务如 LAMBADA 中取得了最先进的结果,并在 GLUE 和 SQuAD 等任务中表现出竞争力。该模型的最大上下文长度为 512 个标记(约 380 个词),因此能够保留相对较短句子或文档的信息。模型出色的文本生成能力和在标准任务中的强大表现为后续模型的发展提供了动力。
GPT-2
从 GPT-1 模型派生的 GPT-2 模型保留了相同的架构特征。然而,它在比 GPT-1 更大的文本数据语料库上进行训练。值得注意的是,GPT-2 可以处理双倍的输入大小,使其能够处理更广泛的文本样本。GPT-2 拥有近 15 亿个参数,展现了在语言建模方面显著的能力和潜力提升。
以下是 GPT-2 相对于 GPT-1 的一些主要改进:
-
修改目标训练 是一种在预训练阶段用于增强语言模型的技术。传统上,模型仅基于前面的单词预测序列中的下一个单词,这可能导致不连贯或不相关的预测。MO 训练通过结合额外的上下文信息(如词性(名词、动词等)和主谓宾识别)来解决这一限制。通过利用这些补充信息,模型生成的输出更加连贯和信息丰富。
-
层归一化 是另一种用于提高训练和性能的技术。它涉及对神经网络中每一层的激活进行归一化,而不是对整个网络的输入或输出进行归一化。这种归一化减少了内部协变量偏移的问题,即网络激活的分布因网络参数的变化而发生的变化。
-
GPT-2 还配备了比 GPT-1 更优的 采样 算法。主要改进包括:
-
Top-p 采样:在采样过程中仅考虑累积概率质量超过某个阈值的令牌。这避免了从低概率令牌中采样,从而生成更具多样性和连贯性的文本。
-
温度缩放:控制 logits(即神经网络在 Softmax 之前的原始输出)中的随机性水平。较低的温度生成的文本更保守和可预测,而较高的温度则产生更具创意和意外的文本。
-
无条件采样(随机采样)选项,允许用户探索模型的生成能力,并能产生巧妙的结果。
-
GPT-3
| 训练数据来源 | 训练数据规模 |
|---|---|
| Common Crawl、BookCorpus、Wikipedia、Books、Articles 等 | 超过 570 GB 的文本数据 |
GPT-3 模型是对 GPT-2 模型的进化,超越了它的多个方面。它在一个显著更大的文本数据语料库上进行训练,并具有最多 1750 亿个参数。
随着其规模的增加,GPT-3 引入了几个显著的改进:
-
GShard( 巨型分片模型并行性):允许模型在多个加速器之间进行分割。这有助于并行训练和推理,尤其是对于拥有数十亿参数的大型语言模型。
-
零样本学习 功能使 GPT-3 展现出执行未明确训练的任务的能力。这意味着它可以通过利用对语言和给定任务的一般理解,响应新的提示生成文本。
-
少样本学习 功能使 GPT-3 能够快速适应新任务和领域,仅需少量训练。它展现了从少量示例中学习的惊人能力。
-
多语言支持: GPT-3 精通生成约 30 种语言的文本,包括英语、中文、法语、德语和阿拉伯语。这种广泛的多语言支持使其成为多种应用的高度通用语言模型。
-
改进的采样: GPT-3 使用了一种改进的采样算法,包括调整生成文本随机性的能力,类似于 GPT-2。此外,它引入了“提示”采样选项,允许根据用户指定的提示或上下文生成文本。
GPT-3.5
| 训练数据来源 | 训练数据大小 |
|---|---|
| Common Crawl, BookCorpus, Wikipedia, Books, Articles, and more | > 570 GB |
与其前身类似,GPT-3.5 系列模型源自 GPT-3 模型。然而,GPT-3.5 模型的显著特点在于其依据人类价值观的具体政策,通过一种称为强化学习与人类反馈(RLHF)的技术进行整合。主要目标是使模型更贴近用户意图,减少毒性,并优先考虑生成内容的真实性。这一进化标志着在语言模型的伦理和负责任使用方面的自觉努力,以提供更安全、更可靠的用户体验。
相较于 GPT-3 的改进:
OpenAI 使用来自人类反馈的强化学习来微调 GPT-3,使其能够遵循广泛的指令集。RLHF 技术涉及使用强化学习原则来训练模型,其中模型根据其生成输出的质量和与人类评估者的一致性获得奖励或惩罚。通过将这种反馈整合到训练过程中,模型能够从错误中学习并提升性能,最终生成更加自然和吸引人的文本输出。
GPT 4
GPT-4 代表了 GPT 系列的最新模型,引入了多模态能力,允许其处理文本和图像输入,同时生成文本输出。它支持各种图像格式,包括含文本的文档、照片、图表、图示、图形和截图。
尽管 OpenAI 没有披露 GPT-4 的技术细节,如模型大小、架构、训练方法或模型权重,但一些估计表明,它包含了近 1 万亿个参数。GPT-4 的基础模型遵循类似于之前 GPT 模型的训练目标,旨在预测给定一系列词语后的下一个词。训练过程涉及使用大量公开可用的互联网数据和授权数据。
GPT-4 在 OpenAI 内部的对抗性事实评估和像 TruthfulQA 这样的公开基准测试中,表现出比 GPT-3.5 更出色的性能。GPT-3.5 中使用的 RLHF 技术也被纳入了 GPT-4 中。OpenAI 积极根据 ChatGPT 和其他来源的反馈来提升 GPT-4。
GPT 模型在标准建模任务中的性能比较
GPT-1、GPT-2 和 GPT-3 在标准 NLP 建模任务 LAMBDA、GLUE 和 SQuAD 中的分数。
| 模型 | GLUE | LAMBADA | SQuAD F1 | SQuAD 准确匹配 |
|---|---|---|---|---|
| GPT-1 | 68.4 | 48.4 | 82.0 | 74.6 |
| GPT-2 | 84.6 | 60.1 | 89.5 | 83.0 |
| GPT-3 | 93.2 | 69.6 | 92.4 | 88.8 |
| GPT-3.5 | 93.5 | 79.3 | 92.4 | 88.8 |
| GPT-4 | 94.2 | 82.4 | 93.6 | 90.4 |
所有数字均以百分比表示。 || 来源 - BARD
这个表格展示了结果的一致改进,这可以归因于前述的增强。
GPT-3.5 和 GPT-4 在较新的基准测试和标准考试中进行了测试。
较新的 GPT 模型(3.5 和 4)在需要推理和领域知识的任务上进行了测试。这些模型已在众多被认为具有挑战性的考试中进行测试。一个这样的考试是 MBE 考试,GPT-3(ada、babbage、curie、davinci)、GPT-3.5、ChatGPT 和 GPT-4 都进行了比较。从图表中可以看到分数的持续改进,GPT-4 甚至超过了平均学生分数。
图 1 展示了不同 GPT 模型在 MBE*中获得的分数百分比的比较:
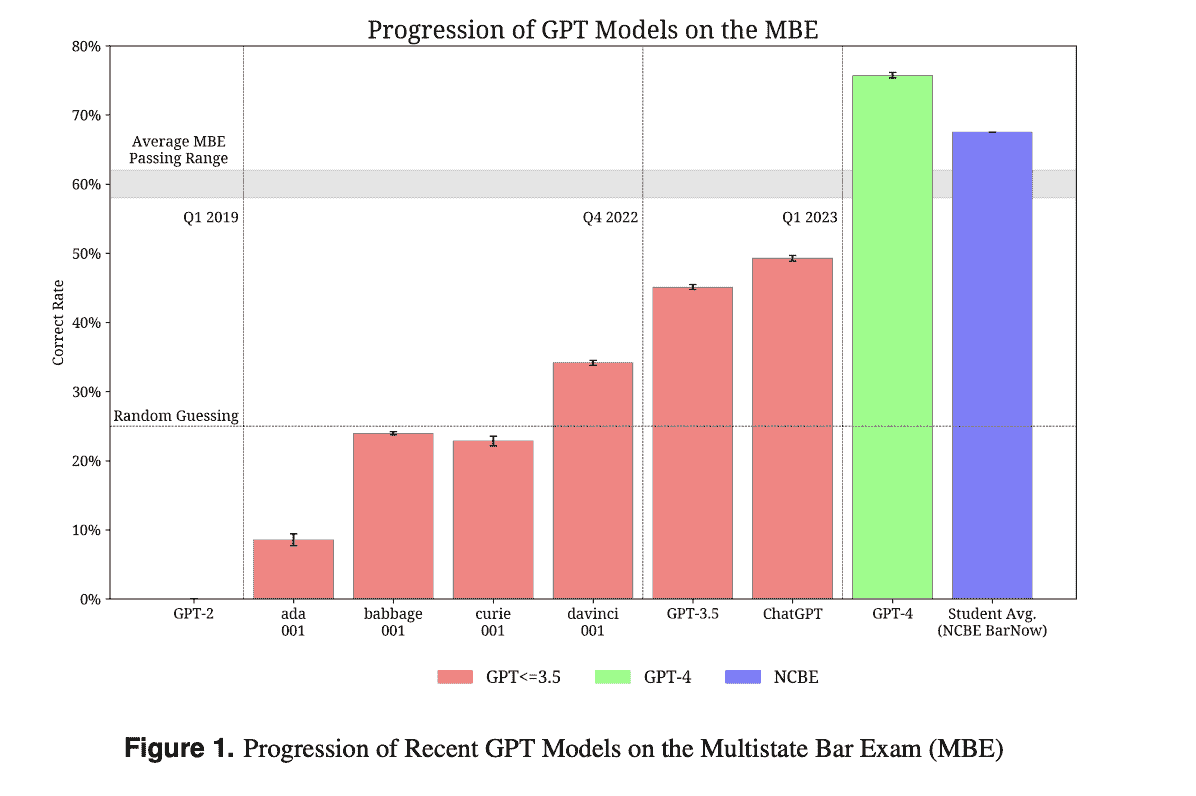
*多州律师考试(MBE)是一项旨在评估申请人法律知识和技能的挑战性测试,是在美国从事法律工作的前提条件。
下面的图表还突出了模型的进展,并且再次超过了不同法律学科领域的平均学生分数。
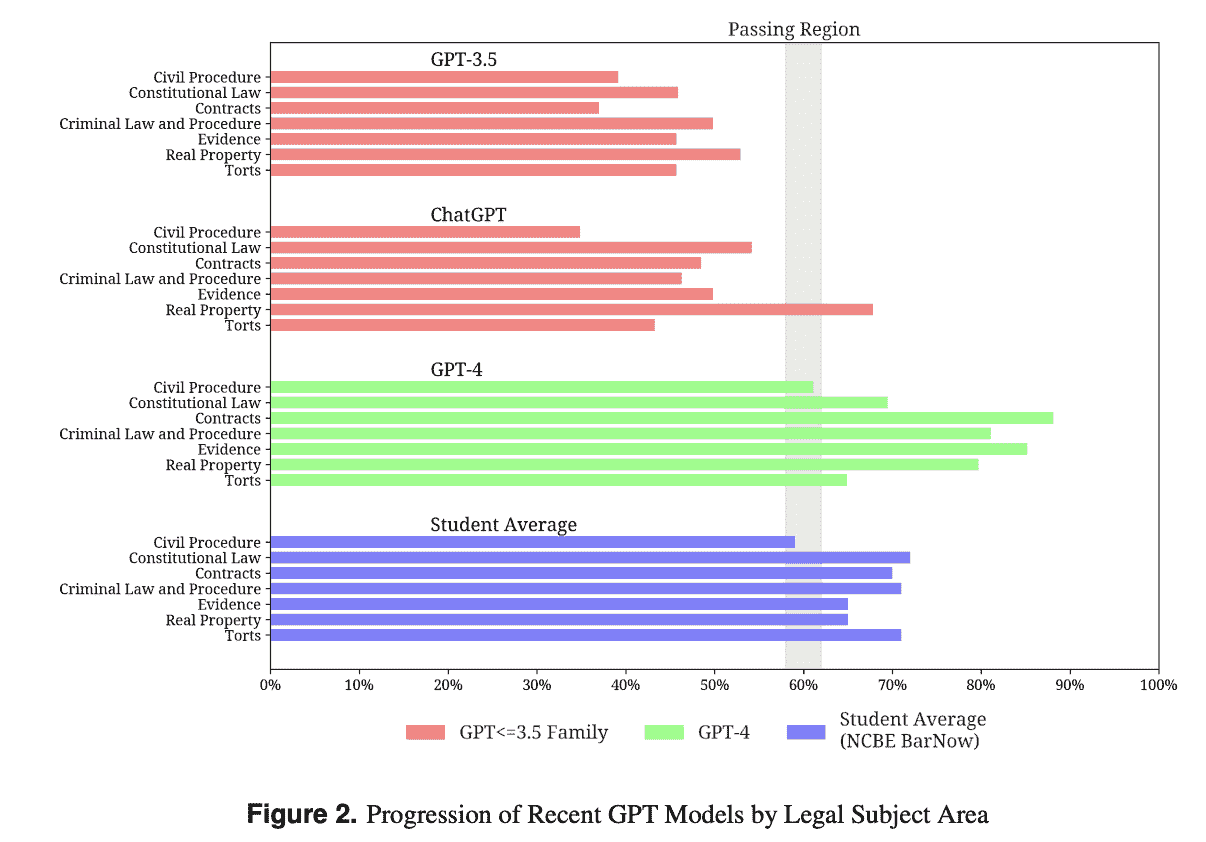
来源:数据科学协会
结论
随着基于 Transformer 的大型语言模型(LLMs)的崛起,自然语言处理领域正在迅速演变。在基于这一架构的各种语言模型中,GPT 模型在输出和性能方面表现出色。作为 GPT 背后的组织,OpenAI 自首个模型发布以来,始终在多个方面不断提升模型。
在五年的时间里,模型的规模显著扩大,从 GPT-1 到 GPT-4 约增加了 8,500 倍。这一显著进展可归因于在训练数据规模、数据质量、数据来源、训练技术以及参数数量等方面的持续改进。这些因素在使模型能够在各种任务中提供出色性能方面发挥了关键作用。
-
Ankit Mehra 是 Sigmoid 的高级数据科学家。他专注于分析和基于机器学习的数据解决方案。
-
Malhar Yadav 是 Sigmoid 的助理数据科学家,同时也是编码和机器学习爱好者。
-
Bhaskar Ammu 是 Sigmoid 的高级数据科学领导。他专注于为客户设计数据科学解决方案,构建数据库架构,以及管理项目和团队。
了解更多相关话题
深度特征合成:自动化特征工程如何工作
原文:
www.kdnuggets.com/2018/02/deep-feature-synthesis-automated-feature-engineering.html
评论
作者:Max Kanter,Feature Labs首席执行官
人工智能市场受到利用数据改变世界的潜力的驱动。虽然许多组织已经成功适应了这一范式,但将机器学习应用于新问题仍然具有挑战性。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的信息技术
机器学习算法必须克服的最大技术障碍是它们需要处理过的数据才能工作——它们只能从数值数据中做出预测。这些数据由相关变量组成,被称为“特征”。如果计算出的特征没有明确暴露出预测信号,那么再多的调整也无法将模型提升到下一个水平。提取这些数值特征的过程称为“特征工程。”
自动化特征工程通过处理必要但繁琐的任务,优化了构建和部署准确的机器学习模型的过程,使数据科学家可以将更多精力集中在其他重要步骤上。以下是一个名为深度特征合成(DFS)的自动化特征工程方法的基本概念,它生成许多与人工数据科学家所创建的特征相同的特征。
发明于 MIT CSAIL
我在 2014 年与 Kalyan Veeramachaneni 一起在 MIT 计算机科学与人工智能实验室开始开发 DFS。我们利用它创建了“数据科学机器”,以自动构建复杂的多表数据集的预测模型,并在在线数据科学竞赛中击败了 906 支人类团队中的 615 支。

我们首次在 IEEE 的数据科学与高级分析国际会议上,以同行评审的论文分享了这项工作。自那时起,它不仅为Feature Labs的产品提供了动力,还激励并使全球的研究人员能够开展研究,包括伯克利和IBM的研究人员。
理解深度特征合成
理解深度特征合成有三个关键概念:
1. 特征源于数据集中数据点之间的关系。
DFS 对数据库或日志文件中常见的多表和事务数据集进行特征工程。它专注于这种类型的数据,因为这是当今最常用的企业数据类型:一项对 16,000 名 Kaggle 数据科学家的调查发现,他们花费了 65% 的时间使用关系数据集。
2. 跨数据集,许多特征是通过使用相似的数学操作派生的。
要理解这一点,让我们考虑一个客户及其所有购买的数据库。对于每个客户,我们可能想计算一个表示其最昂贵购买的特征。为此,我们会收集与客户相关的所有交易,并找出购买金额字段的最大值。然而,假设一个用户想从飞机航班的数据集中提取“最长的航班延误”来预测未来的延误。她将使用相同的最大值函数。
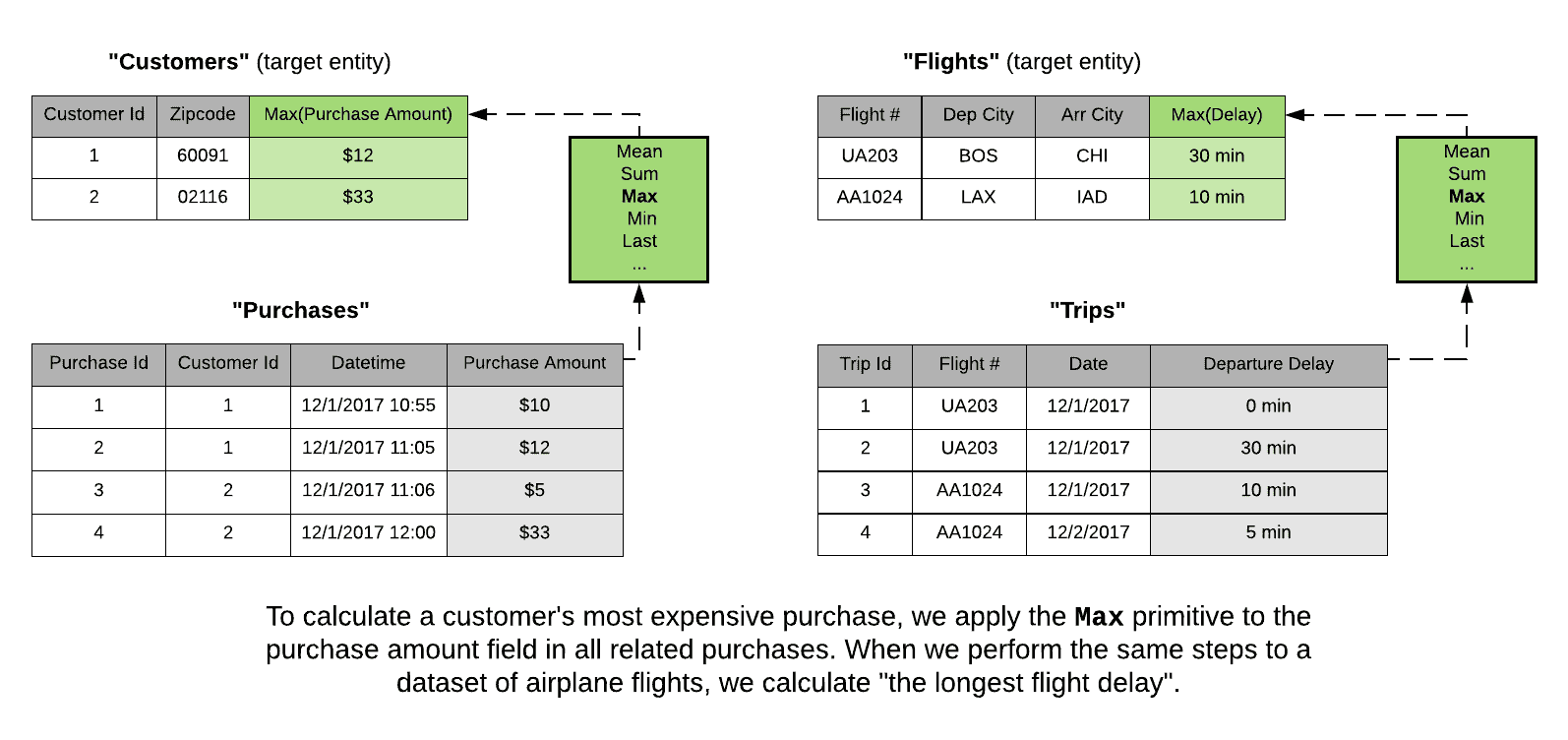
尽管自然语言描述完全不同,但底层数学保持不变。在这两种情况下,我们对一组数值应用相同的操作,以生成特定于数据集的新数值特征。这些与数据集无关的操作称为“原语”。
3. 新特征通常由利用先前派生的特征组成。
原语是 DFS 的构建块。由于原语定义了它们的输入和输出类型,我们可以堆叠它们以构建复杂的特征,这些特征模仿了人类今天创建的特征。
DFS 可以跨实体之间的关系应用原语,因此可以从包含多个表的数据集中创建特征。我们可以通过设置搜索的最大深度来控制我们创建的特征的复杂性。
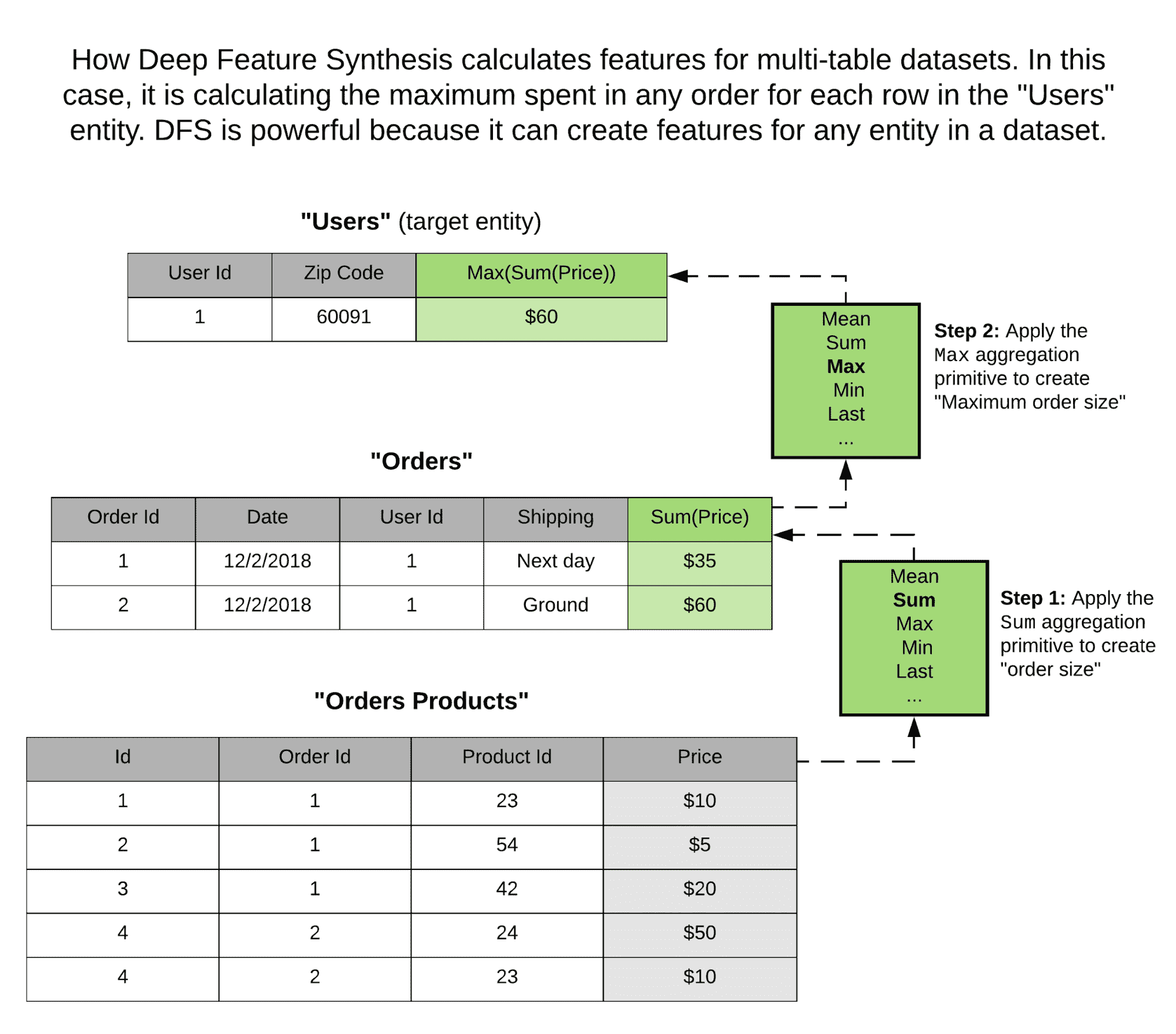
考虑一个数据科学家常常为事务或事件日志数据计算的特征:“事件之间的平均时间。” 这个特征在预测欺诈行为或未来客户参与度时非常有价值。DFS 通过堆叠两个原语,Time Since 和 Mean,来实现相同的特征。
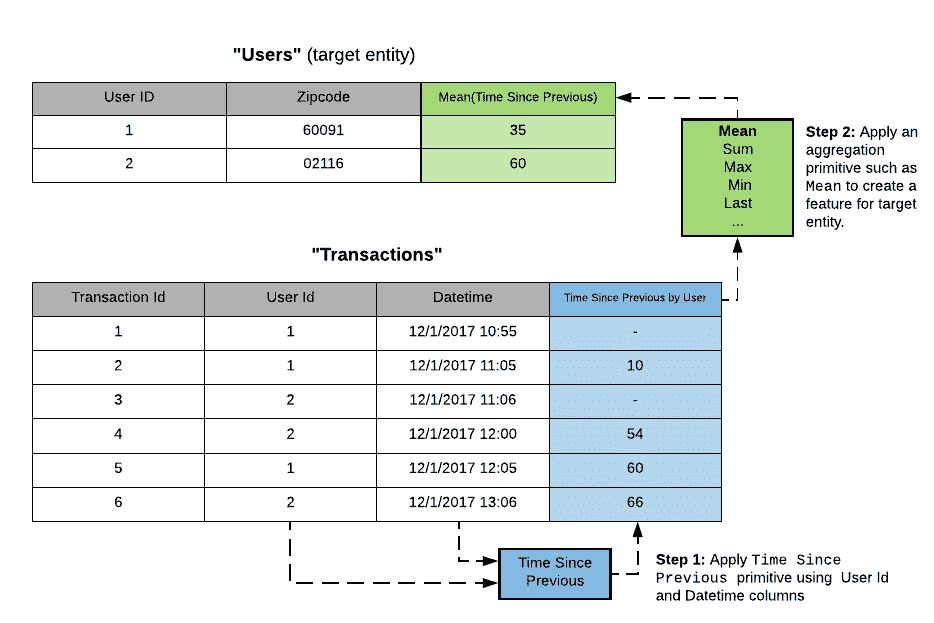
这个例子突显了原始元素的第二个优势,即它们可以用于快速枚举许多有趣的特征,采用参数化的方式。因此,我们可以使用最大值、最小值、标准差或中位数来自动生成几种不同的总结时间的方法。如果我们向 DFS 添加一个新原始元素——比如两个位置之间的距离——它将自动与现有的原始元素结合,无需用户任何额外操作。
不断改进
在九月份,Feature Labs 宣布我们将开源 DFS 的实现,供经验丰富和有志于数据科学的人员尝试。自那时以来的三个月,Featuretools 已经在麻省理工学院的在线数据科学和大数据分析课程中教授给了近 1000 人,并且已经成为 Github 上最受欢迎的特征工程库。
这意味着一个社区的人们可以聚集在一起贡献原始元素,大家都能从中受益。由于原始元素是独立于特定数据集定义的,任何添加到 Featuretools 的新原始元素都可以融入包含相同变量数据类型的任何其他数据集中。在某些情况下,这可能是相同领域的数据集,但也可能是完全不同的用例。例如,这里是 一个贡献 处理自由文本字段的 2 个原始元素。
处理时间
很容易不小心将你试图预测的信息泄漏到模型中。我们以前的一个零售企业客户的应用程序就是一个很好的例子:生产模型与公司开发结果不匹配。他们试图预测谁会成为客户,而模型中最重要的特征是潜在客户打开的电子邮件数量。它在训练期间表现出高准确率,但不幸的是在部署到生产环境时没有效果。
回顾起来,这一点很明显——这些前景只有在成为客户之后才开始阅读邮件。公司手动特征工程的步骤没有正确过滤掉在预测结果已经实现后收到的数据。
Featuretools 中的 DFS 可以通过使用“截止时间”自动计算每个训练样本在与样本相关的特定时间的特征。它通过模拟原始数据在过去某个时间点的样子来对有效数据进行特征工程。这减少了标签泄露问题,这帮助数据科学家对他们部署到生产中的结果更有信心。
用自动化增强人类触感
DFS 可以在几乎没有人工干预的情况下开发基准模型。我们在公开演示中展示了如何使用 Featuretools 实现这一点。然而,特征工程的自动化应该被视为对关键人类专业知识的补充——它使数据科学家能够更精确和高效。
对于许多问题,基准得分足以让人类决定某种方法是否有效。在一个案例中,我们在 Kaggle 上与 1,257 名人类竞争者进行了实验。我们使用 DFS 生成了特征矩阵,然后利用回归器创建了机器学习模型。
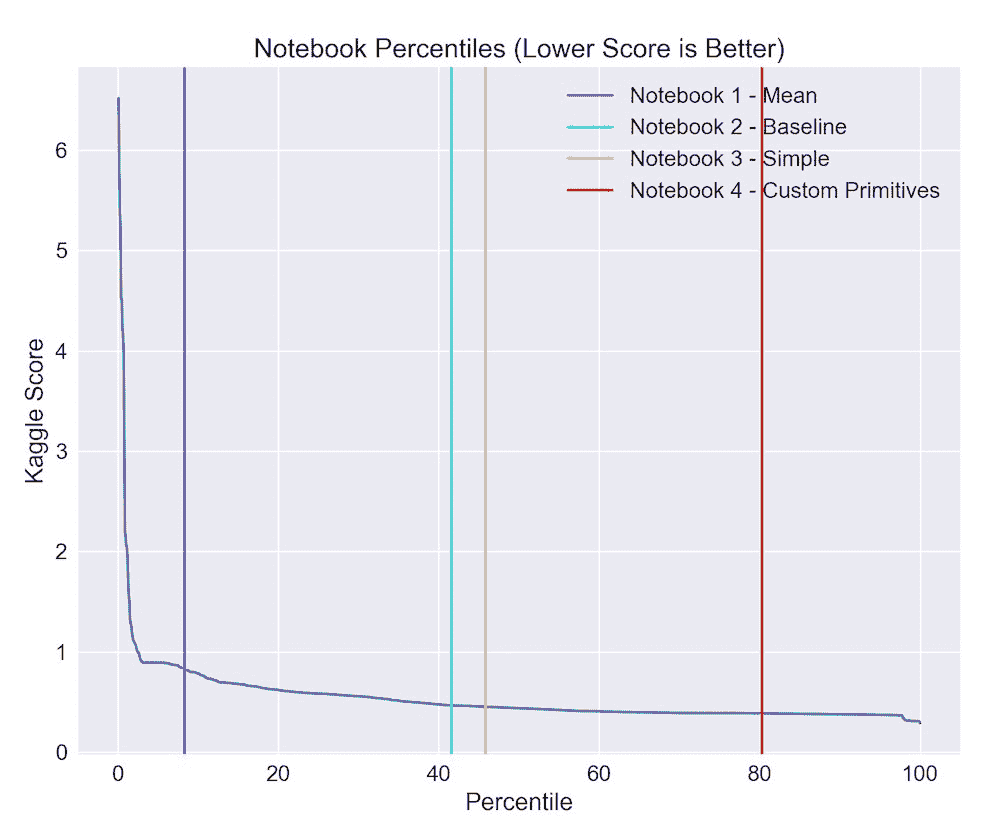
机器学习得分(RSME)与排行榜上的百分位数。得分下降时,排行榜上的位置上升。彩色垂直线表示不同实验在使用 Featuretools 时的排行榜位置。 我们发现几乎不需要人工干预,DFS 在这个预测问题上超越了两个基准模型。在实际应用中,这为在此用例中利用机器学习提供了有价值的支持证据。接下来,我们展示了如何通过添加自定义原语来超越超过 80%的竞争对手,并接近最佳总体得分。
应用深度特征合成
Feature Labs 的首席数据科学家 Ben Schreck 最近写了关于如何使用自动化特征工程来增加全球银行欺诈检测模型收入的文章。在那个案例中,我们预测了一个单独交易是否存在欺诈行为,但我们基于进行交易的客户的历史行为创建了特征。DFS 创建了诸如“上次交易以来的时间”,“交易之间的平均时间”和“这张卡上次使用的国家”等特征。所有这些特征都依赖于各种数据点之间的关系,并需要使用截止时间来确保只使用欺诈事件之前的行为。
结果显示,与银行现有的软件解决方案相比,误报率下降了 54%,从而减少了由于错误阻止交易而影响的客户数量。新模型的财务影响估计为每 200 万笔交易 19 万欧元。
深度特征合成与深度学习
深度学习自动化特征工程用于图像、文本和音频,这通常需要大量的训练集,而 DFS 则针对公司所处理的结构化事务和关系数据集。
DFS 生成的特征更易于人类解释,因为它们基于易于用自然语言描述的原始组合。深度学习中的变换必须通过矩阵乘法实现,而 DFS 中的原始数据可以映射到领域专家能够描述的任何函数。这增加了技术的可及性,并为那些没有经验的机器学习专业人士提供了更多贡献自己专长的机会。
此外,虽然深度学习通常需要许多训练样本来训练其复杂的架构,但 DFS 可以仅基于数据集的模式开始创建潜在特征。对于许多企业用例而言,深度学习所需的足够训练样本并不可用。DFS 提供了一种为较小的数据集创建可解释特征的方式,人们可以手动验证这些特征。
更美好的未来与特征工程
自动化特征工程有可能加速将机器学习应用于数据科学团队今天收集的宝贵数据集的过程。这将帮助数据科学家快速解决新出现的问题,更重要的是,使那些新进入数据科学领域的人更容易培养应用自己领域专业知识的技能。
著名的机器学习教授 Pedros Domingos 曾说过:“机器学习的一个圣杯是自动化更多的特征工程过程。” 我完全同意这一点,我对能在这一领域的前沿工作感到无比激动!
简历: Max Kanter (@maxk) 是 Feature Labs 的首席执行官和联合创始人,该公司构建用于数据科学自动化的工具和 API。Max 是一位工程师,热衷于为数据科学创造新技术。在创办 Feature Labs 之前,他曾是 MIT 的机器学习研究员,在那里创建了数据科学机器,并且之前曾是 Twitter、Fitbit 和纽约时报的软件工程师。
原文。经许可转载。
相关:
-
数据科学机器,或‘如何进行特征工程’
-
自动化机器学习的现状
-
使用 AutoML 和 TPOT 生成机器学习管道
了解更多相关话题
深度学习可以应用于自然语言处理
原文:
www.kdnuggets.com/2017/01/deep-learning-applied-natural-language-processing.html
评论
在 LinkedIn 上流传着一篇尝试对深度学习在自然语言处理领域应用提出反对意见的文章。Riza Berkan 撰写的文章 “谷歌在炒作吗?为什么深度学习不能轻易应用于自然语言” 提出了深度学习不可能工作的几个论点,并声称谷歌夸大了其主张。后者的论点当然有些接近阴谋论。
Yannick Vesley 写了一篇反驳文章 “神经网络非常不错:对 Riza Berkan 的回复” ,他对 Berkan 提出的每一点进行了辩论。Vesley 的观点确实很到位,但人们不能忽视深度学习理论中还有一些未解之谜。
然而,在我深入探讨之前,我认为读者了解深度学习目前仍是一门实验性科学是非常重要的。也就是说,深度学习的能力实际上是研究人员偶然发现的。确实有很多工程工作涉及到这些机器的优化和改进。然而,它的能力是‘不合理有效的’,简而言之,我们没有很好的理论来解释它的能力。
显然,理解中存在的差距至少在三个开放问题上:
-
深度学习如何在高维离散空间中进行搜索?
-
深度学习如何在看似进行死记硬背的情况下实现泛化?
-
(1) 和 (2) 如何从简单组件中产生?
Berkan 的论点利用了我们当前对缺乏坚实解释的现状,并提出了他自己替代的方法。他主张符号主义方法是救赎之路。不幸的是,他的论点中没有揭示符号主义方法的脆弱性、缺乏泛化性和扩展性。有没有人创建过一个基于规则的系统,能够根据低级特征分类图像,与深度学习相媲美?我认为没有。
然而,深度学习从业者并没有因为缺乏严密的理论基础而停止工作。深度学习确实有效,而且效果出奇地好。当前状态下的深度学习是一门实验科学,很明显,在背后有些我们尚未完全理解的东西。理解的缺失并不会使这种方法无效。
为了更好地理解这些问题,我在早期的一篇文章中写道“深度学习系统中的架构特性”。我基本上阐述了深度学习中的三种能力:
-
可表达性 — 这个特性描述了机器能够逼近普遍函数的程度。
-
可训练性 — 深度学习系统学习其问题的效率和速度。
-
泛化能力 — 机器在未训练过的数据上进行预测的能力。
当然,还有其他能力也需要在深度学习中考虑:可解释性、模块化、可迁移性、延迟、对抗稳定性和安全性。但这些是主要的。
要正确解释这些内容,我们必须考虑最新的实验证据。我在这里写过一篇文章“重新思考泛化”,我再总结一下:
ICLR 2017 提交的“理解深度学习需要重新思考泛化”肯定会颠覆我们对深度学习的理解。以下是他们通过实验发现的总结:
神经网络的有效容量足够大,可以对整个数据集进行暴力记忆。
即使在随机标签上进行优化仍然很容易。事实上,与在真实标签上训练相比,训练时间仅增加了一个小常数因子。
随机化标签仅仅是一种数据转换,不改变学习问题的所有其他属性。
令大多数机器学习从业者感到惊讶的是“暴力记忆”。你看,机器学习一直关注于曲线拟合。在曲线拟合中,你找到一组稀疏的参数来描述你的曲线,然后用它来拟合数据。泛化涉及在点之间插值的能力。这里的主要断层是,深度学习表现出了令人印象深刻的泛化能力,但如果我们仅将其视为记忆存储,这种方法显然行不通。
然而,如果我们把它们视为全息记忆存储,那么泛化问题就有了相当好的解释。在“深度学习是全息记忆”中,我指出了实验证据:
Swapout 学习过程告诉我们,如果你对整个网络的任何子网络进行抽样,得到的预测将与任何其他子网络的预测相似。就像全息记忆一样,你可以切割出一部分,仍然可以重建整个记忆。
事实证明,宇宙本身由一个类似的理论驱动,称为全息原理。实际上,这为开始更扎实的深度学习能力解释提供了一个很好的基础营。我介绍了“全息原理:深度学习为何有效”,在其中我介绍了一种使用张量网络的技术方法,该方法将高维问题空间缩减为可在可接受响应时间内计算的空间。
所以,再次回到关于 NLP 是否可以通过深度学习方法处理的问题。我们当然知道它是可行的,毕竟,你不是正在阅读和理解这篇文本吗?
在专家数据科学家和机器学习从业者中确实存在许多困惑。当我撰写“11 个专家对深度学习的误解”时,我意识到存在这种“反对”。然而,深度学习可能最好的解释是一种简单的直觉,可以 用五岁孩子能理解的方式解释:
DE3p Larenn1g wrok smliair to hOw biarns wrok.
这些机器通过识别完全的模式并将其连接到完整的概念来工作。它们按层工作,就像滤镜一样,将复杂的场景分解成简单的想法。
符号系统无法读取这些内容,但人类可以。
在 2015 年,NLP 从业者 Chris Manning 讨论了有关深度学习的领域关切(见:计算语言学与深度学习)。了解他的论点非常重要,因为这些论点并不与深度学习的能力相冲突。他的两个论点说明了为何 NLP 专家不必担心如下:
(1)对于我们的领域来说,最聪明和最有影响力的机器学习专家将 NLP 作为重点关注领域是非常令人振奋的;(2)我们的领域是语言技术的领域科学;它不是关于最佳的机器学习方法——核心问题仍然是领域问题。
第一个论点并不是对深度学习的批评。第二个论点解释了他不相信一种适用于所有领域的通用机器学习方法。这与上述全息原理的方法并不冲突,该方法强调了网络结构的重要性。
总之,我希望这篇文章能终结关于深度学习在自然语言处理领域不适用的讨论。
如果你仍然不信服,那么也许 Chris Manning 自己应该来说服你:
简介:Carlos Perez 是一名软件开发人员,目前正在撰写《深度学习设计模式》一书。这是他为博客文章提供灵感的来源。
原文。经许可转载。
相关:
-
深度学习为何与机器学习截然不同
-
深度学习智能的五个能力层次
-
博弈论揭示深度学习的未来
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
基于深度学习的实时视频处理
原文:
www.kdnuggets.com/2021/02/deep-learning-based-real-time-video-processing.html
评论
作者 Serhii Maksymenko,AI/ML 解决方案架构师,来自 MobiDev
什么是串行视频处理
视频数据是日常使用的常见资产,无论是个人博客中的直播流,还是制造建筑中的安全摄像头。机器学习应用正成为处理各种视频任务的常用工具。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
本文中讨论的视频处理方法是基于 MobiDev 团队开发的个人数据安全应用的背景下的。
简而言之,视频处理可以视为对每一帧进行的一系列操作。每帧包括解码、计算和编码过程。解码是将视频帧从压缩格式转换为原始格式。计算是对帧进行的某种操作。编码是将处理后的帧转换回压缩状态。这是一个串行过程。尽管这种方法看起来简单易行,但在大多数情况下并不实用。
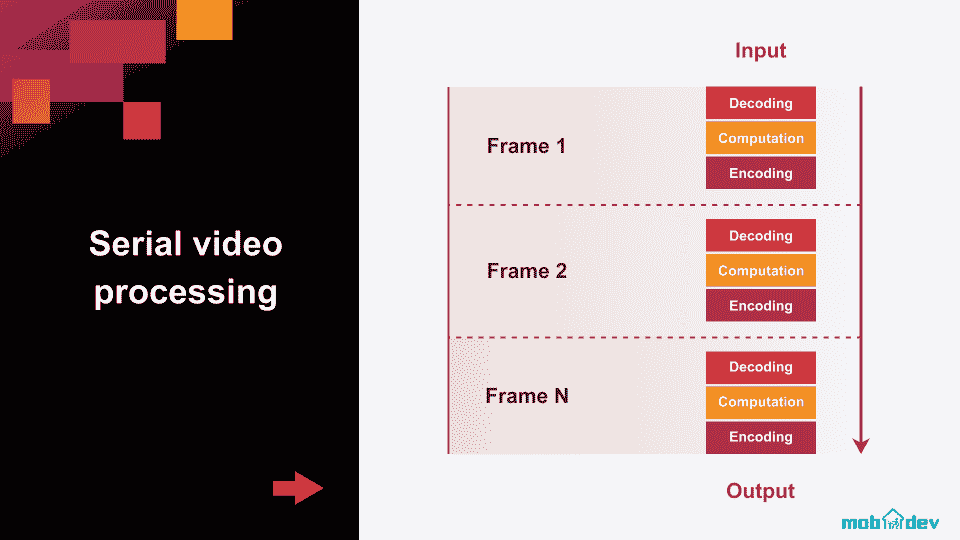
来源 mobidev.biz/wp-content/uploads/2021/01/serial-video-processing.png
为了使上述方法可行,需要设定如速度、准确性和灵活性等测量标准。然而,在一个系统中兼顾所有这些可能是不可能的。通常,在这种情况下,速度和准确性之间存在权衡。如果我们选择不关注速度,那么我们会有一个很好的算法,但它会极其缓慢,结果也就毫无用处。如果我们过度简化算法,那么结果可能不会如预期那样好。因此,快速且准确的“白象”是不可能集成的。解决方案应在输入、输出和配置方面具有灵活性。
那么,如何在保持较高准确性的同时加快处理速度呢?有两种可能的解决方法。第一种是使算法并行运行,这样可能可以继续使用较慢但准确的模型。第二种是对算法本身或其部分进行加速,同时尽可能减少准确性的损失。
并行处理方法
文件拆分
第一个方法是显而易见的。视频被拆分成多个部分并进行并行处理。这是一种简单直接的方法。它可以借助视频时间指针来实现。在这种方法中,拆分是虚拟的,并不是实际生成子文件。然而,在输出中,我们依然会有多个视频文件,这些文件需要合并成一个。这使得这种方法在涉及任务时有些受限,尤其是在计算时使用相邻帧。为了处理这种情况,我们不得不在视频拆分时添加重叠,以确保在接缝处不会丢失信息。
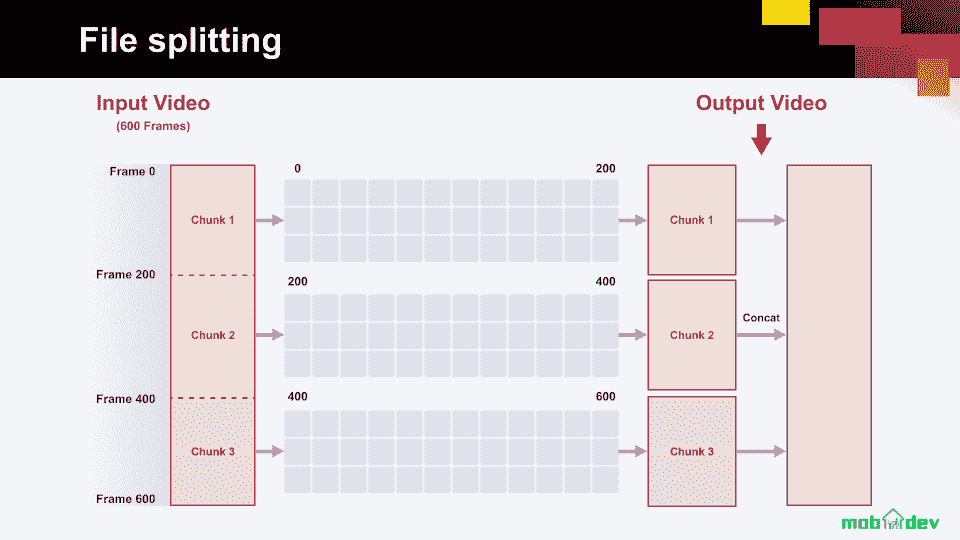
来源 mobidev.biz/wp-content/uploads/2021/01/file-splitting-video-processing.png
因此,例如处理来自网络摄像头的流是不可能的。文件拆分方法仅能处理视频文件。此外,这种方法可能难以暂停、恢复或甚至在时间轴上移动处理。尽管文件拆分方法简单,但它不符合灵活性的要求。
管道架构
相比于拆分视频,管道方法旨在拆分并行化处理过程中执行的操作。通常视频管道的基本操作包括解码、计算和编码。至少这三项操作可以并发进行。
为什么管道方法更灵活?管道方法的一个好处是可以根据需求轻松操作组件。解码可以使用视频文件,并将帧编码到另一个文件中。这是一种常见的情况。
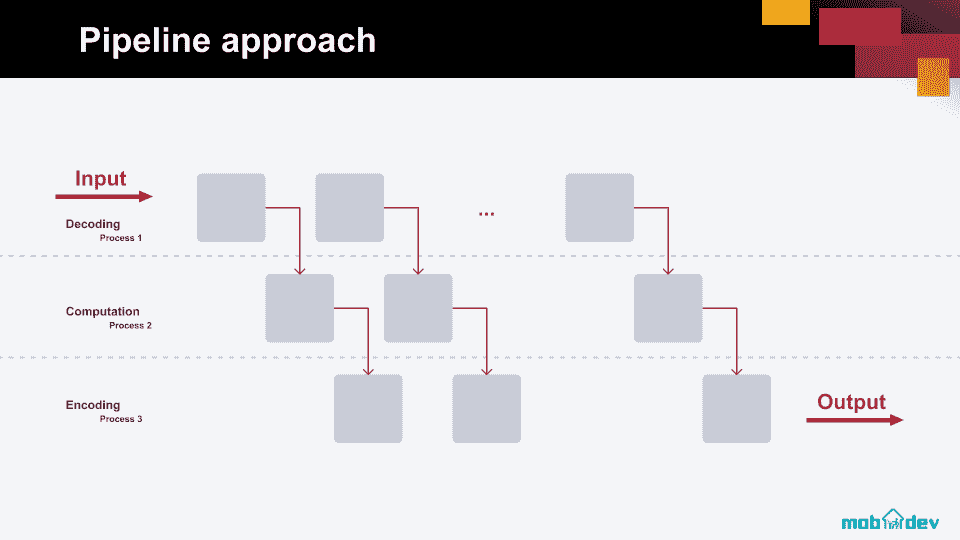
来源 mobidev.biz/wp-content/uploads/2021/01/pipeline-approach-video-processing.png
另外,输入可以通过 IP 摄像头进行 RTSP 流传输。输出可以通过浏览器或移动应用程序中的 WebRTC 连接。所有输入和输出格式的组合都基于视频流的统一架构。
过程的计算部分不一定是原子操作。它可以逻辑上拆分成子操作,从而创建更多的管道阶段。然而,创建过多的组件并不总是合理的,因为多线程处理的延迟可能会削弱性能的提升。
基本上,管道在灵活性方面正是我们所需要的。这不仅仅是因为可以更改输入和输出格式,还因为我们可以随时暂停和继续处理。
优化管道组件
时间分析
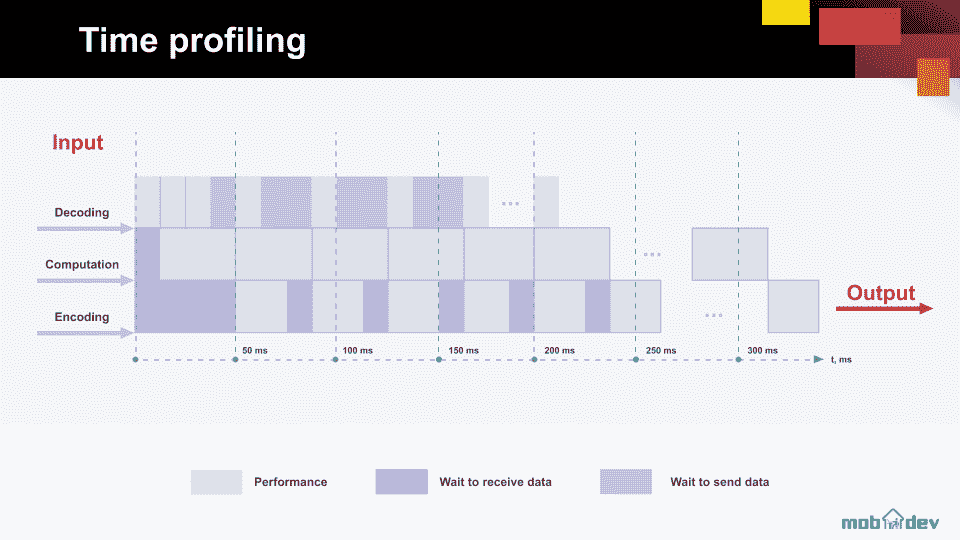
来源 mobidev.biz/wp-content/uploads/2021/01/time-profiling-video-processing.png
为了了解需要优化的部分,必须观察管道中每个阶段所需的时间。这样可以更容易找出瓶颈所在。最慢的管道阶段决定了输出的 FPS。尽管进行测量可能很乏味,但可以很容易地进行自动化。管道使用队列进行数据交换。因此,组件中会有一定的等待时间。通常,我们需要记录每个操作的耗时,每个操作等待从前一个组件获取数据的时间,以及每个操作等待其结果传递给下一个组件的时间。拥有这些信息可以大大简化性能分析。
解码与编码
解码和编码可以通过两种方式完成:软件和硬件。硬件加速得益于 NVIDIA 卡中的解码器和编码器以及 CUDA 核心。以下是可以用于实现解码和编码硬件加速的选项列表。
-
使用 CUDA 支持编译 OpenCV
-
编译支持 NVDEC/NVENC 编解码器的 FFmpeg
-
使用支持 NVDEC/NVENC 编解码器的 GStreamer
-
使用 NVIDIA 视频处理框架
解码与编码
从源代码编译可能比较复杂,但如果你仔细遵循说明,它应该是直接的。这可以在隔离的环境中进行,例如 Docker 容器中,这样在其他机器或云实例上部署就容易了,你也不需要每次都重复编译过程。
使用 CUDA 编译 OpenCV 不仅可以优化解码,还可以优化管道中使用 OpenCV 执行的其他计算。然而,我认为它们需要用 C++ 编写,因为 Python 包装器对此没有良好的支持。但在你希望在 GPU 上同时执行解码和数值计算而不从 CPU 内存中复制数据的情况下,这将是值得的。
自定义安装 FFmpeg 和 GStreamer 可以使用内置的 NVIDIA 解码器和编码器。建议先使用 FFmpeg,因为从维护角度来看,这应该更容易。此外,许多库在底层使用 FFmpeg,因此替换它将自动提高这些库的性能。
Python 封装器提供了将帧直接解码为 GPU 上的 PyTorch 张量的可能性,从而可以在不额外从 CPU 到 GPU 的复制的情况下开始推断。
计算(CPU)
-
使用混合精度技术
-
TensorRT
-
推断前调整大小
-
批量推断
客户的硬件列表中并不总是有 GPU。使用神经网络进行处理在 CPU 上很少见,但在某些限制下仍然可能。为了这个目的,不适合制作大型模型,但更轻量级的模型会有效。例如,在我们的工作中,我们能够在 CPU 上使用 SSD 对象检测模型获得 30 FPS。Tensorflow 和 PyTorch 的最新版本已针对在多个核心上运行某些操作进行了优化,并可以通过参数进行控制。因此,缺少 GPU 并不意味着任务不可能完成。例如,这可能是在资源有限的云计算环境中遇到的情况。
但当然,如果你想让一个好的模型以你期望的速度运行,GPU 是必不可少的。我们还应用了一些技术,以进一步加快 GPU 推断速度。在这些情况下,如果你的 GPU 支持 fp16,应用混合精度将非常简单,它是 PyTorch 和 TensorFlow 最新版本的一部分。它允许对某些层使用 fp16 精度,对其余层使用 fp32,从而保持网络的数值稳定性并保持准确性。一个替代且更高效的模型加速方法是 TensorRT 转换。这是一种更具挑战性的方法,但它可以使推断速度提高 5 倍。此外,还有其他明显的优化选项,如调整大小和批量推断。
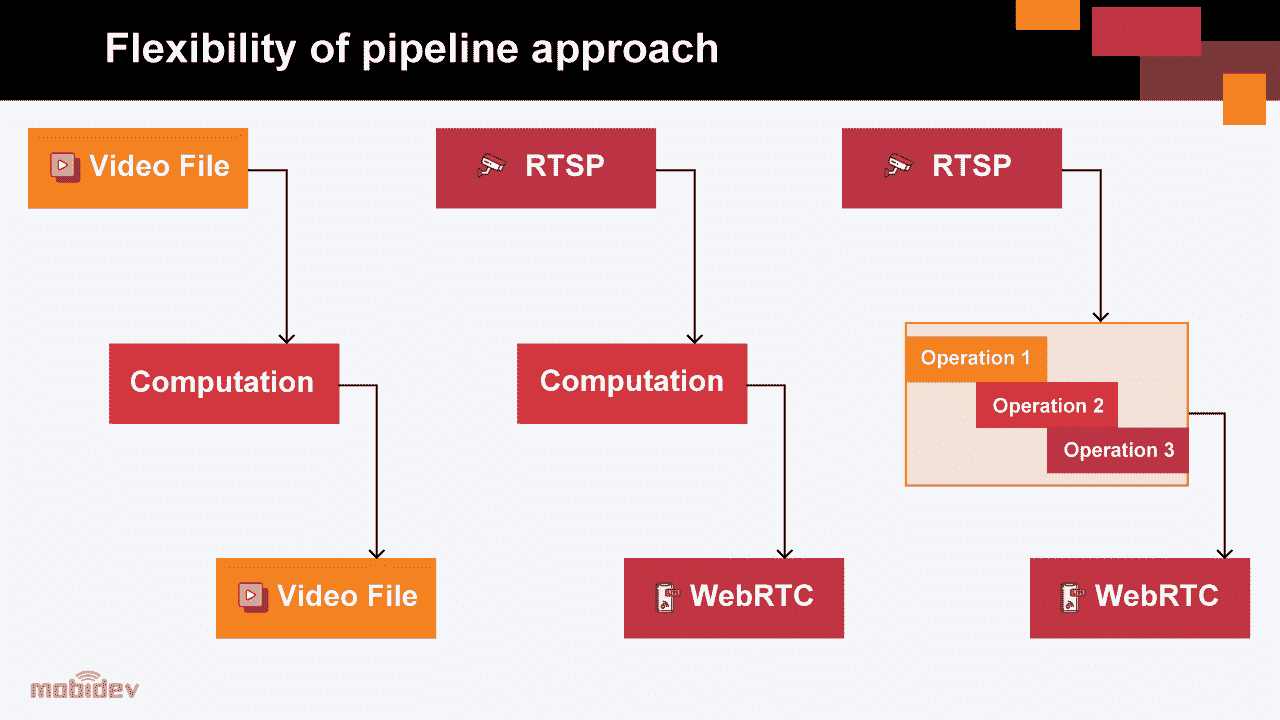
来源 mobidev.biz/wp-content/uploads/2021/01/flexibility-of-pipeline-approach.png
管道方法如何在应用中实现
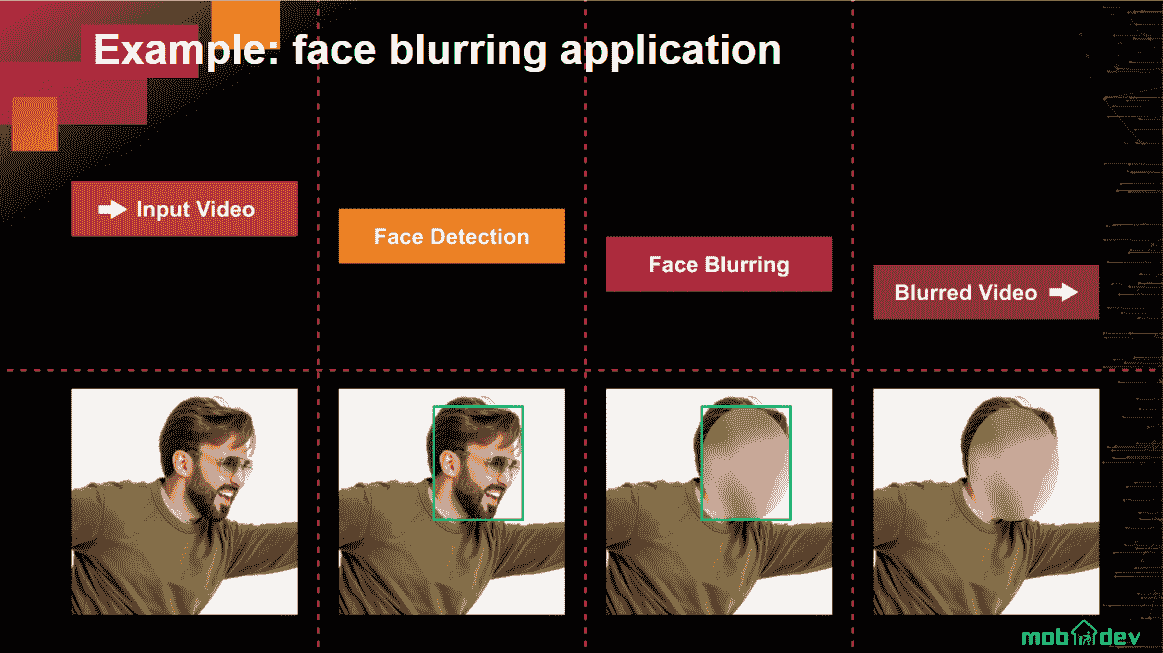
来源 mobidev.biz/wp-content/uploads/2021/01/face-blurring-video-processing.png
系统的灵活性在这种情况下至关重要,因为我们旨在处理不仅是视频文件,还包括不同格式的视频直播。它在 30-60 的范围内显示了良好的 FPS,具体取决于所使用的配置。
此外,我们还应用了一些其他改进:带有跟踪的插值、进程之间共享内存,以及为管道组件添加多个工作线程。
带有跟踪的插值
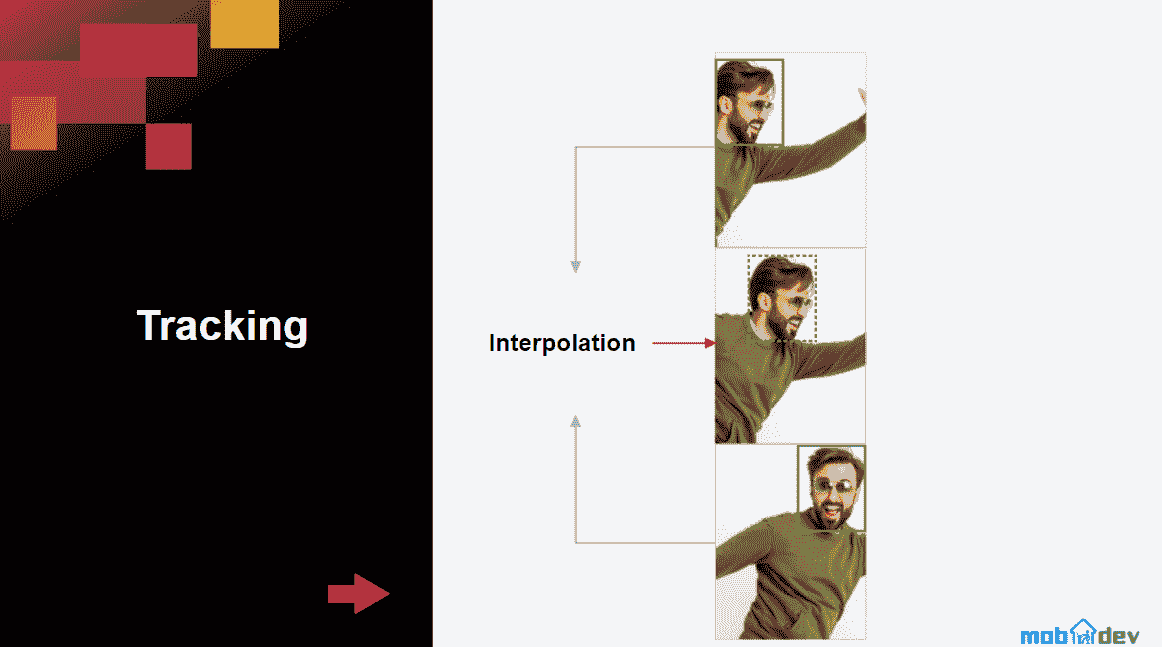
来源 mobidev.biz/wp-content/uploads/2021/01/interpolation-tracking-video-processing.png
你可能会想,我们真的需要对每一帧进行计算吗?不,实际上可以跳过某些间隔的帧,假设绑定框将通过跟踪算法进行插值。算法可以很简单。例如,通过质心之间的距离进行匹配。这将足以获得相当好的插值,从而实现更高的 FPS。
在跟踪阶段,使用更复杂的跟踪算法或相关跟踪器是至关重要的。但如果视频中面孔过多,它们确实会影响速度。例如,如果是拥挤的街道视频,我们不能承担过于复杂的跟踪算法。
由于我们跳过了一些帧,我们希望了解插值帧的质量。因此,我们计算了 F1 指标,并确保插值不会导致过多的假阳性和假阴性。大多数视频示例的 F1 值约为 0.95。
共享内存
下一点是进程间的内存共享。一个应用可以不断通过队列发送数据,但这真的很慢。Python 中进程间内存共享的替代方法很棘手。以下是一些方法:
-
torch.multiprocessing
-
Linux/dev/shm
-
Python 3.8 中的 SharedMemory
PyTorch 的多进程版本能够通过队列传递张量句柄,以便另一个进程可以直接获取指向现有 GPU 内存的指针。然而,我们决定使用另一种方法:系统级别的共享内存。这种方法使用一个特殊文件夹作为 RAM 内存空间的链接。有一些库提供了用于使用此内存的 Python 接口。它极大地提高了进程间通信的速度。Python 3.8 的共享内存 API 是另一种可能的方法。
多个工作线程
-
比较延迟
-
考虑 CUDA 流
-
更正帧的顺序
最后,我们需要为管道组件添加几个工作线程。这是一个值得考虑的好方法,但并不总是能正确工作。我们在面部检测阶段做了这件事。然而,同样的方法也可以应用于任何计算密集型操作,只要不需要有序的输入。关键在于,实际效果取决于内部执行的操作。在面部检测相对较快的情况下,添加更多检测工作线程后,FPS 反而降低了。管理一个额外进程所需的时间可能会大于从中获得的时间。然后,多个工作线程中使用的神经网络将以串行 CUDA 流计算张量,除非为每个网络创建一个单独的流,这可能会很棘手。
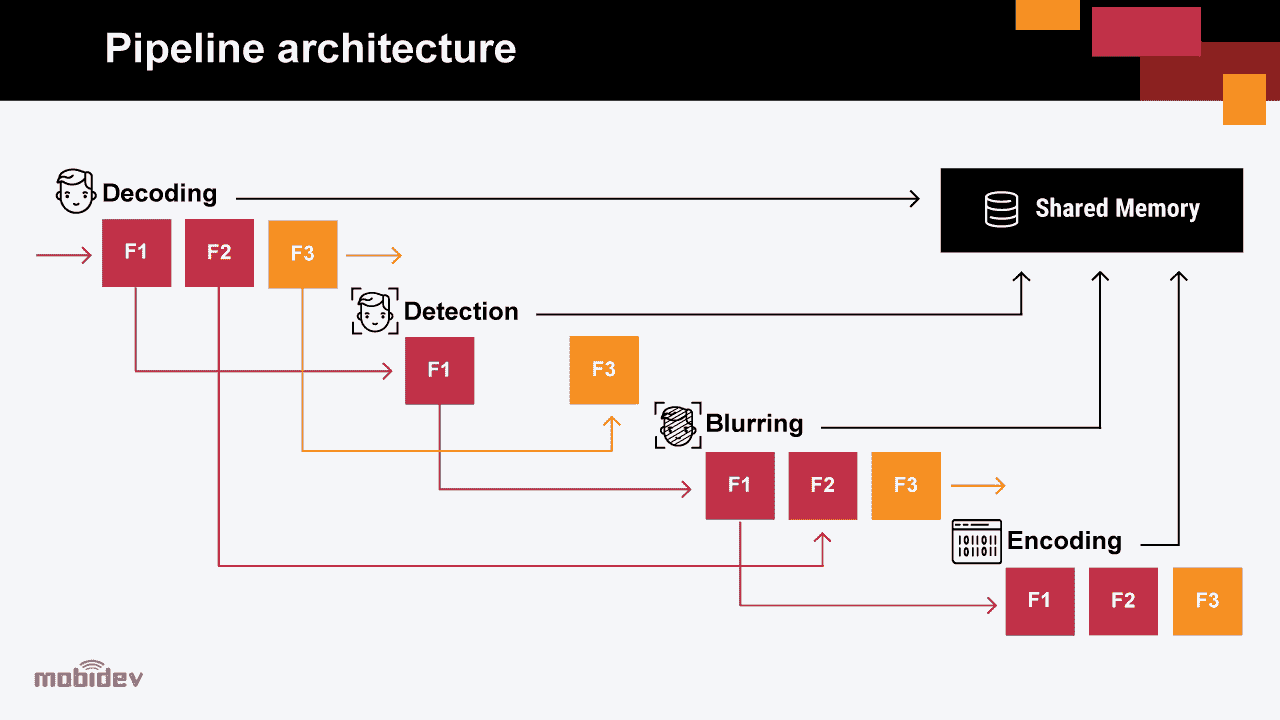
来源 mobidev.biz/wp-content/uploads/2021/01/pipeline-architecture-video-processing.png
另一个技术问题来自多个工作者,由于其并发性质,它们不能保证顺序与输入序列相同。因此,在重要的管道阶段(例如编码)中需要额外的努力来修正顺序。跳帧的情况实际上也会出现同样的问题。无论如何,经过特定配置,多个工作者也能带来改进。
相关:
-
OpenAI 发布两款神奇的 Transformer 模型,链接语言与计算机视觉
-
深度学习、自然语言处理与计算机视觉的顶级 Python 库
-
2020 年十大计算机视觉论文
更多相关主题
深度学习突破:一种不需要 GPU 的次线性深度学习算法?
原文:
www.kdnuggets.com/2020/03/deep-learning-breakthrough-sub-linear-algorithm-no-gpu.html
评论
由Anshumali Shrivastava,莱斯大学。
我们都知道 深度神经网络 (DNNs) 正在引领当前的 AI 革命。 反向传播算法 是一种常用的训练 DNNs 的方法。反向传播包括对网络的前向和反向传递,可以写作一系列矩阵乘法。 GPU (图形处理单元) 在这里具有独特的优势,因为它们有成千上万的处理核心,优化用于矩阵乘法。它们可以执行数量级更快的矩阵乘法。
Backpropagation 中的浪费计算
反向传播不是一种高效的算法。反向传播的先驱之一 Geoffrey Hinton 教授在一次采访中指出了它的几个重要缺陷。SLIDE 算法的核心思想是最小化浪费计算。想象一个具有数亿参数的庞大神经网络。随着训练的进行,不同的神经元专注于数据的非常不同特征(具有大激活值)。结果是一个网络,其中仅有少数几个神经元对任何给定的输入重要,如著名的猫神经元文章所示。我们称这种特性为自适应稀疏性。
反向传播对自适应稀疏性视而不见。相反,反向传播使用完整的矩阵乘法更新数百万个参数。这些更新中的大多数是不必要的。
自 2013 年以来,自适应稀疏性以几种方式被利用来改善泛化。例如, 一篇 NeurIPS 2013 论文 显示我们可以将权重更新限制到每层中的一个极小子集神经元。该子集是通过自适应采样选择的。采样是自适应的,意味着它在采样期间偏爱具有大激活值的神经元。作者认为,稀疏自适应更新支持更好的 泛化,从而提高准确性。
不幸的是,这些稀疏更新远未实现计算上的高效。我们需要计算每个输入的所有激活值以确定要更新哪些神经元。由于每个神经元都必须被访问,操作的数量在参数的数量上是线性的。因此,如果我们有一百万个参数,每个输入必须执行一百万次算术操作。
绕道:内积抽样的基本谜题
高效稀疏更新的算法被锁在一个算法谜题后面。谜题是:“我们如何在不计算所有激活的情况下抽样具有大激活的神经元?一个关键观察是激活值是神经元权重和输入之间内积的单调函数。因此,我们可以将问题简化为:“我们如何高效地抽样那些与输入有大内积的权重向量?”
这个问题看起来有点荒谬,因为我们需要知道内积的值才能判断哪些是大的。这个问题类似于伪装的相似性搜索问题,其中内积是相似性度量,输入是查询。在网页搜索中,我们知道可以在不进行线性计算的情况下找到与查询相似(或相关)的文档,使用的是indexing。
自适应抽样的哈希表
哈希函数 h(x)将输入 x 映射到一个整数,称为哈希值或指纹。假设 h(x)具有一个特殊属性:对于两个向量,两个向量的哈希值相同的概率为 Pr(h(x)=h(y))=g(⟨x,y⟩),其中 g 是一个单调函数。这个属性描述了局部敏感哈希(LSH)函数。简单来说,如果两个向量 x 和 y 的内积很大,那么它们对应的哈希值 h(x)和 h(y)很可能是相同的。如果向量的内积很小,那么 h(x)和 h(y)很可能不同。我们在这篇论文中展示了如何构造具有这种属性的哈希函数,该论文获得了 NIPS 2014(现 NeurIPS)的杰出论文奖。
在 2016 年初,我们展示了 (论文) 我们的函数可以实现高效的神经元采样算法。这个想法是将所有神经元索引到一个哈希表中,使用 h,如图 2 所示。我们在由指纹指向的内存位置存储神经元哈希的引用。在对神经元进行预处理后,我们可以高效地对任何输入 x 进行神经元采样。我们只需访问内存位置 h(x) 并从中选择神经元。这个过程确保了哈希碰撞,因此我们只选择可能具有大内积的神经元。我们的采样过程可以证明适应激活值,而不需要显式计算所有激活值。
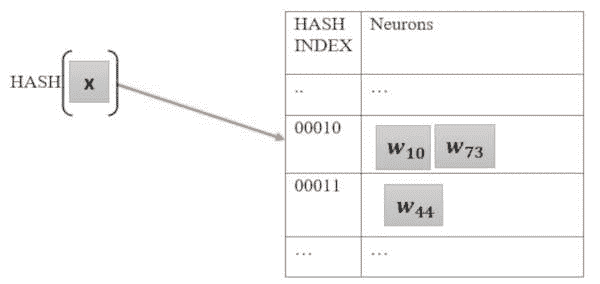
图 1: 哈希表用于采样神经元的示意图。HASH 函数满足 LSH 属性。
后续工作表明,概率哈希表可以实现 O(1) 的重要性采样,以高效估计 分区函数、 核函数 和 随机梯度。
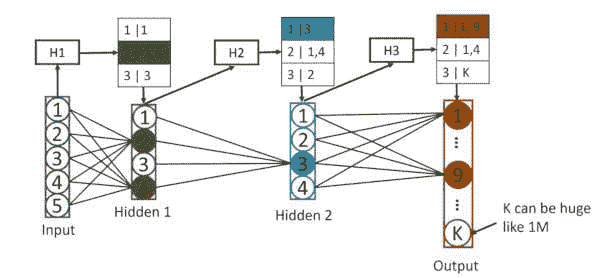
图 2: SLIDE 算法示意图。每一层都有哈希表用于高效识别激活值高的神经元。对于每个输入,我们只需要进行哈希计算和几个内存探测,就能获得网络的一个非常稀疏的快照。
SLIDE 算法:使用哈希表的稀疏反向传播
SLIDE 算法(图 2)在训练过程中使用哈希表来选择神经元。完整的实现细节可以在我们的 论文 中找到。
SLIDE 从初始化神经网络参数和将所有神经元预索引到 LSH 哈希表开始。
为了用给定输入训练网络,我们首先计算输入的 LSH 哈希值 (H1)。然后,我们查找以 H1 为地址(内存位置)的神经元,并从相应的桶中采样神经元。我们只计算这些神经元的激活值,并将其他神经元的激活值设置为 0。在下一层中,我们将上一层的稀疏激活输出作为输入。输入是稀疏的,因为只有所选神经元的激活值是非零的。我们为新的输入获得一个新的哈希值 H2,并重复下一层的采样过程。对于每个输入,我们只需几个哈希值和内存查找即可选择网络中的一组稀疏的重要节点。我们只在所选神经元上进行前向传播和反向传播。最后,我们使用更新后的权重更新哈希表中所选神经元的位置。
在训练过程中,所有操作的数量级是活跃神经元的数量(子线性),而不是神经元的总数量(线性)。在我们的实验中,我们展示了仅需 0.5% 的神经元即可获得与全反向传播相同的准确度。虽然 SLIDE 引入了少量的开销来维护哈希表,但与标准反向传播相比,我们的操作成本约低 200 倍。
并行梯度更新
由于对给定输入仅有 0.5%的节点处于激活状态,因此两个无关的输入 x 和 y 共享许多选择的神经元的可能性较小。因此,我们可以并行执行异步梯度更新。HOGWILD 论文表明,这个想法在理论上是合理的,并且对梯度下降是实用的。
总结来说,SLIDE 算法在每个输入上需要的算术操作数量减少了几个数量级。当结合异步数据并行梯度更新时,我们有了一个高效的训练过程。相比之下,标准的 GPU 反向传播需要昂贵的算术操作。GPU 并行化局限于扩展矩阵乘法,而不是数据并行处理。
** 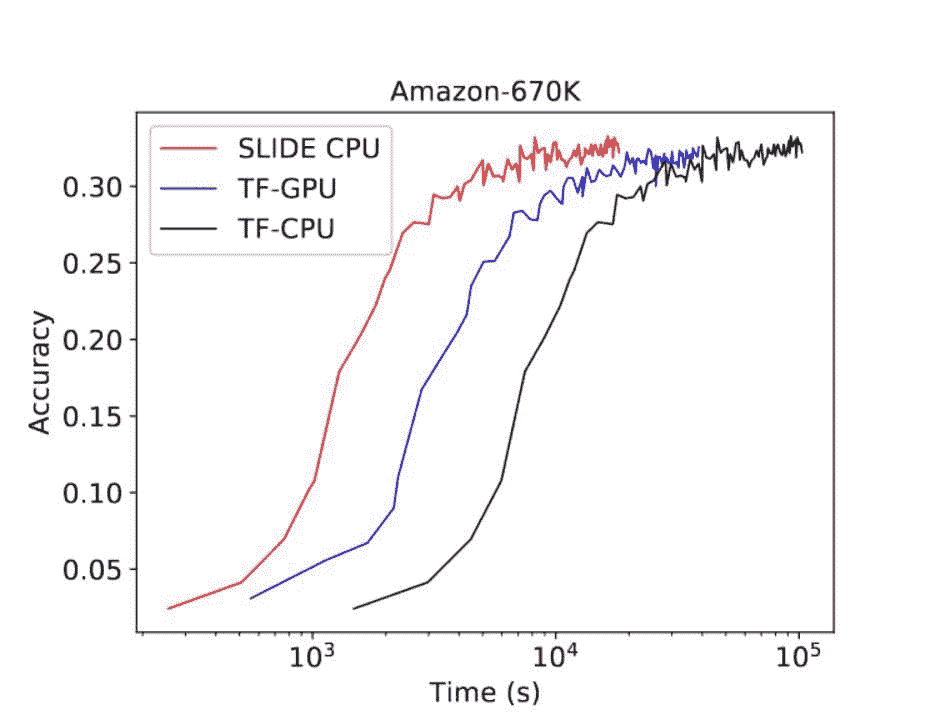 **
**
图 3: SLIDE(红色)与 TF-GPU(蓝色)和 TF-CPU(黑色)的训练时间比较。x 轴为对数刻度。SLIDE 实现于 C++,实验在与 TF-CPU 相同的 CPU 上进行。TF-CPU 使用了最优化的英特尔版本(MKL-DNN)。
与 TensorFlow 在 CPU 和 V100 GPU 上的反向传播比较
SLIDE 在大型、完全连接的神经网络上进行了比较,这些网络通常具有超过 1 亿个参数,广泛应用于商业推荐引擎。我们突出了来自论文的一个训练图表。代码及基准测试脚本已公开发布在Github上。数据可以从 Kaggle 上的Amazon-670k 数据集公开获取。
图 3. 说明了在 44 核 Intel Xeon CPU(2 个 22 核的插槽)上运行 SLIDE(红色曲线)的完整训练进展。SLIDE 与通过TensorFlow 在 V100 GPU 上的最优化反向传播实现(蓝色曲线)以及在相同的 44 核 CPU 上的Intel 优化 TensorFlow(黑色曲线)进行比较。运行时间为对数刻度。与 TF-GPU 相比,TF-CPU 较慢,表明 GPU 在处理这一大型工作负载上的反向传播具有优势。令人兴奋的是,SLIDE 算法的 C++ 实现,在相同的 CPU 上,显著超越了 GPU 加速。SLIDE 的收敛速度比 TensorFlow 在 V100 GPU 上快 3.5 倍(1 小时对比 3.5 小时)。
简介: Anshumali Shrivastava (@Anshumali_) 是莱斯大学计算机科学系的助理教授。他的广泛研究兴趣包括大规模机器学习的随机算法。2018 年,《科学新闻》将他评选为值得关注的 40 岁以下十大科学家之一。他获得了国家科学基金会 CAREER 奖、美国空军科学研究办公室的年轻研究员奖以及亚马逊的机器学习研究奖。他赢得了许多论文奖项,包括 2014 年 NIPS 最佳论文奖和 2019 年 SIGMOD 最具可重复性论文奖。他的工作曾在包括《纽约时报》、IEEE Spectrum、《科学新闻》、Engadget 和 ArsTechnica 等多个媒体上报道。
相关内容:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织中的 IT 工作
更多相关话题
深度学习用于合规检查:有什么新变化?
原文:
www.kdnuggets.com/2022/05/deep-learning-compliance-checks-new.html
自然语言处理(NLP)长期以来在全球主要银行的合规流程中发挥了重要作用。通过将不同的 NLP 技术应用于生产过程中,合规部门可以维持详细的检查,并跟上监管要求。
银行后办公室的几乎每个方面——无论是贸易融资、信用、全球市场、零售等领域。所有这些领域都可以通过文档处理和使用 NLP 技术更有效地完成流程。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持您的组织在 IT 方面
某些验证任务超出了传统基于规则的自然语言处理系统的范围。这时,深度学习可以填补这些空白,提供更流畅和高效的合规检查。
使用基于规则的系统进行合规检查的挑战
有几个挑战使得基于规则的系统在进行检查时变得更加复杂。
可变性是这些挑战之一。例如,合规文档筛选包括大量不同类型的文档,如身份证、提单、税务通知、发票等。这需要实际的管理和控制方法以维持这种可变性。
命名实体识别也存在问题。命名实体识别是一种提取信息以定位和分类实体(如人、地点等)的方法。实体在不同的情况下可能表现不同,使得正确区分变得困难。例如,Teheran 街道位于巴黎,但 Teheran 是伊朗的首都。
仅仅通过查看关键词来区分文档中的每个实体是一项漫长的任务。原始文档的结构和格式可能使这一过程更加困难;页数、数据以表格结构呈现或格式为 PDF 等。
传统的自然语言处理可能无法捕捉同义词或模糊实体,如 Orange 可以被识别为城市、颜色、水果等。因此,我们需要考虑上下文以正确识别并生成正确的输出。
从下图可以看出,有各种句子。机器学习模型使用命名实体识别(NER)来识别和分类句子的部分。你可以看到,有 4 种不同的类别可以用来分类实体。它们是地点(LOC)、杂项(MISC)、组织(ORG)和人(PER)。
例如,如果我们取第一个句子“我听说帕里斯·希尔顿住在巴黎的希尔顿酒店”。机器学习模型会面临一些困难,因为它很难区分‘Hilton’被分类为组织(Organisation)还是‘Paris’作为一个地点(location),因为它已学会‘Paris Hilton’是一个人(Person)。另一个困难是模型要区分‘Paris’是被认为是名字还是城市。
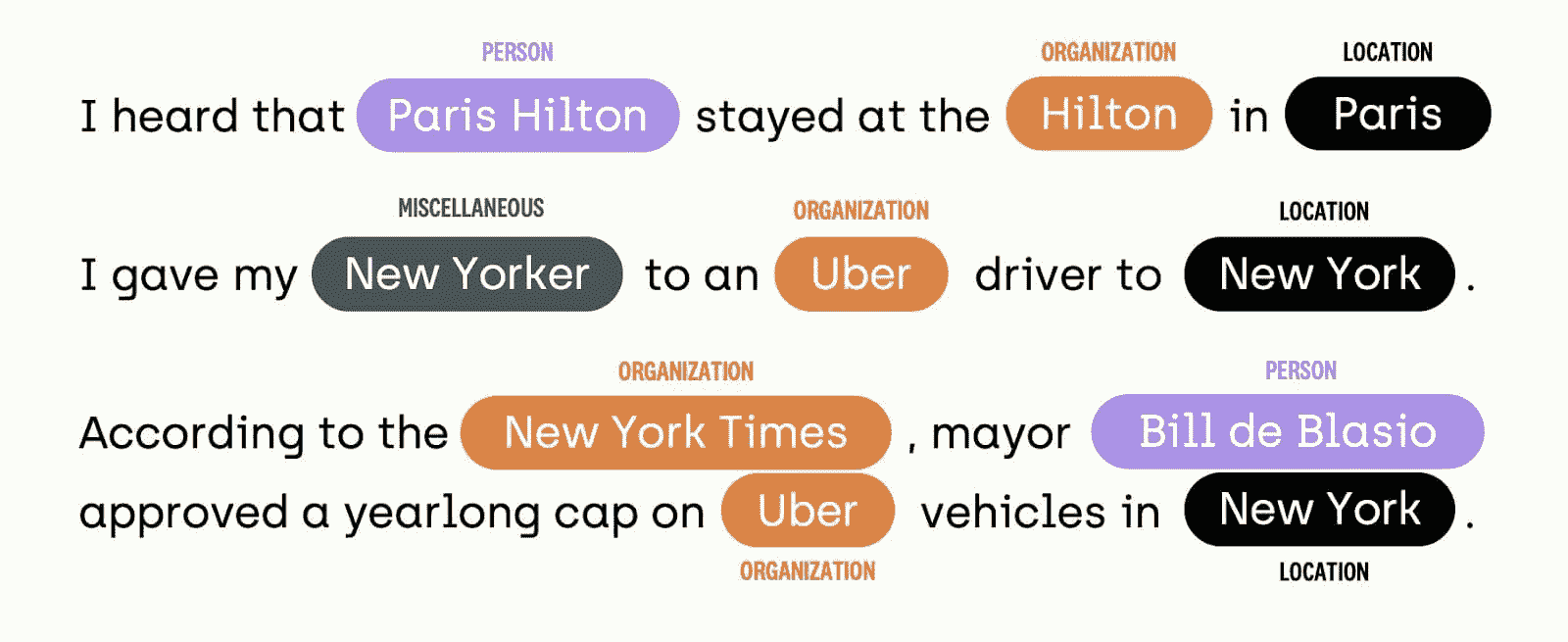
基于模型的知识库,它将通过训练数据学习到什么实体是什么。然而,如果模型没有学会区分这些实体,它将无法产生正确的输出。例如,如果它之前从未将‘Paris’分类为地点,但将其分类为人,它的过去知识会告诉它将其分类为人。
因此,在各种数据上训练模型并更改训练数据将改善其产生正确实体类别的整体性能。
使用传统 NLP 文档筛选时的另一个挑战是提高质量标准和不断变化的法规。基于规则的系统无法定义模式,因此在文本文档中识别复杂的违规模式对传统 NLP 来说是一个重大挑战。

深度学习的美丽及其所能提供的东西
面对使用手动或传统的自然语言处理(NLP)基于关键词筛选的挑战,深度学习可以解决大部分这些问题。深度学习是机器学习的一个子领域,模拟了人类获取某些类型知识的方式。由于其先进的准确性,深度学习技术已经变得非常流行,最近已超越了人类水平的表现。
如果你参考下面的图表,它显示了 2003 年至 2020 年 CoNLL 上的命名实体识别(NER)的表现。CoNLL 2003 NER 任务使用一个模型,该模型输入来自路透社 RCV1 的新闻文本,旨在识别四种不同的实体类型(PER, LOC, ORG, MISC)。
该模型基于跨度 F1 分数进行评估。跨度 QA 是一个任务,包含两段文本,其中一段称为上下文,另一段称为问题。最终目标是通过从文本中使用问题来提取答案,无论是否存在。F1 分数由以下公式确定:F1= 2precisionrecall/(precision+recall)。低 F1 分数表明精度和召回率都很差。
自 2017 年以来,F1 分数持续增长,从 91.26 的 F1 分数开始,到 2019 年达到 93.5,使用的是CNN Large + fine-tune。2020 年,F1 分数大幅增长,Primer NLX NER 模型在 CoNLL 上取得了 95.6%的 F1 准确率。这比 Facebook AI Research 之前发布的CNN Large and Fine-Tune提高了两个数字的 F1 分数。更重要的是,Primer NLX NER 模型现在与人类水平的表现相当。
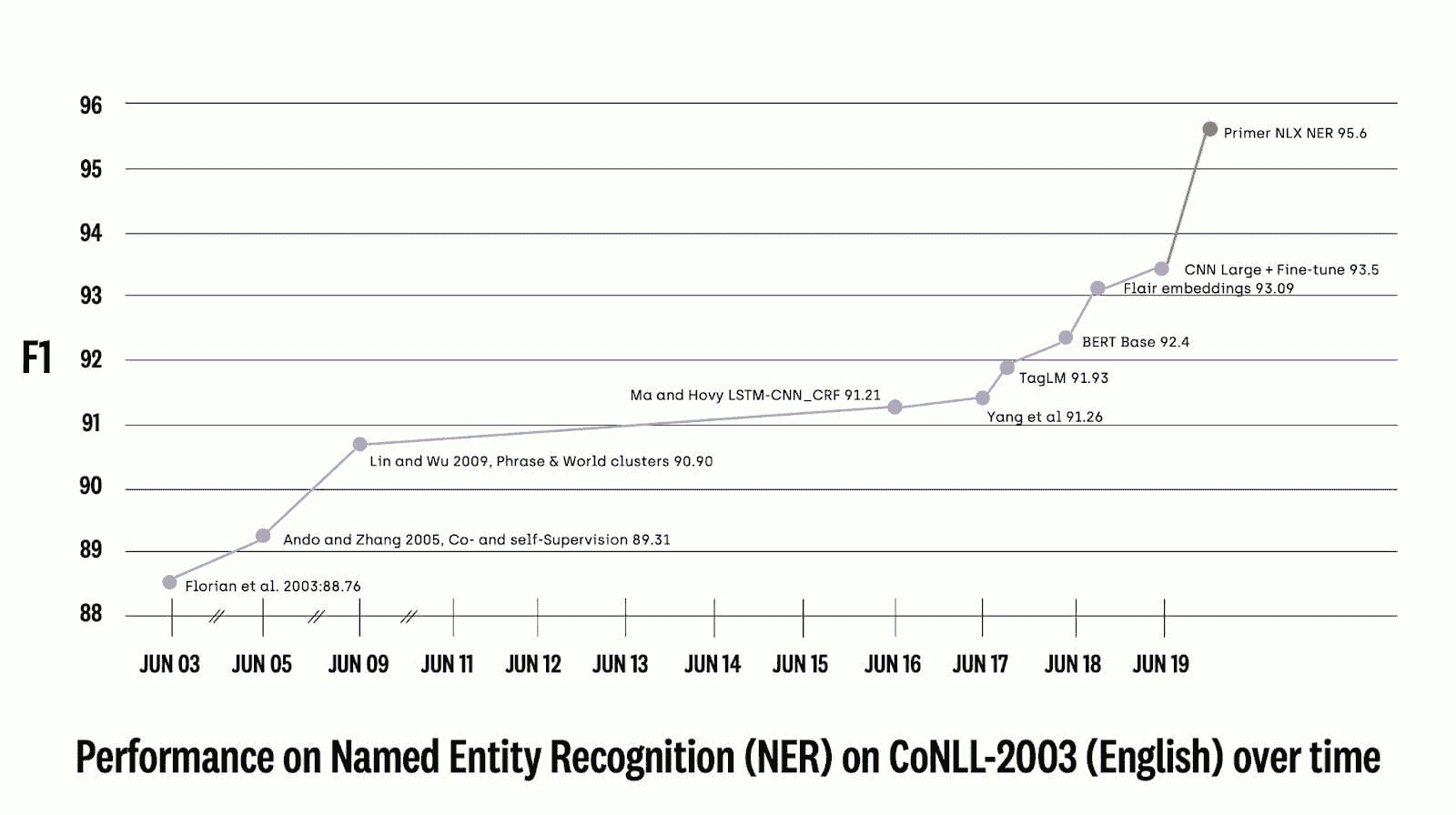
深度学习可以可靠地处理具有高度变异性的文档,尤其是在 KYC(了解你的客户)实施方面,以及交易监控和筛查任务。
它还可以提供复杂数据结构、混合文档类型(例如图像和文本)以及混合模型的准确分析。它具备适应和学习文档、流程以及洗钱/欺诈方案变化的能力。
此外,深度学习的另一个有效元素是它允许最终用户提前定义实体,以便软件可以轻松识别它们。
尽管深度学习软件无法替代传统的 NLP,但它仍然提供并作为第二道防线。深度学习不仅可以识别、定位和提取实体,还具有分类和归类的能力。
银行拥有大量从过去筛查中存储的数据和文档。这些可以通过用作输入数据来训练深度学习模型,从而受益。随着时间的推移,神经网络可以迭代改进和调整,以不断提升合规分析过程。

DCAI 在准确性和定制化方面有所不同
尽管使用深度学习和人工智能(AI)有许多好处,但它们仍然面临挑战。这包括数据稀缺、在现有基础设施中集成 AI 的复杂性,以及在生产阶段无法实现实验室结果。

有各种深度学习技术可以用来解决合规文档分析中的问题。然而,一个端到端的平台简化了这一过程,并提供了一种高效、简单的方法,以持续改进你的模型,实现长期成功。
端到端平台应提供数据驱动的 AI 方法,其中包括用干净、高质量的数据(例如文档)喂养模型。
为了做到这一点,它必须具备:
-
本体论管理和指令,使得高效定义实体并准确分类变得容易。
-
一套质量 KPI,如共识和审查工作流,以了解本体论及其指令的整体能力以及如何随着时间的推移改进它。
-
智能标记工具在通过人机协作实现准确标记方面非常重要。
-
数字接口允许跨职能的业务/AI 协作,而不受数据泄漏问题的影响,无论位置如何。
-
用于测试、评估模型和预标记的训练工具。
-
错误分析报告,如 Human/Model IOU,将评估现有模型。
大多数企业更倾向于完全拥有 AI 项目,无论是通过内部开发项目还是与供应商合作。我的经验是,数据驱动的 AI 平台提供了一种混合方法,结合了:
-
第一个方面是出于知识产权和安全原因,在内部开发和管理解决方案。
-
另一个方面是建立自己的 AI NLP 合规检查系统,不管 AI 人才短缺的问题。
Edouard d'Archimbaud (@edarchimbaud) 是 ML 工程师、CTO 和 Kili 的联合创始人,该公司是企业 AI 的领先训练数据平台。他对 数据驱动的 AI 充满热情,这是一种成功 AI 的新范式。
更多相关主题
深度学习有深层缺陷吗?
评论
这里有三对图像。你能找到左列和右列之间的差异吗?

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
我想不行。它们在肉眼看来完全相同,但对深度神经网络而言却不然。实际上,深度神经网络只能正确识别左侧的图像,而不能识别右侧的图像。有趣,不是吗?
最近的一项研究由谷歌、纽约大学和蒙特利尔大学的研究人员进行,发现了几乎所有深度神经网络中的这一缺陷。
介绍了深度神经网络的两个反直觉特性。
1. 在神经网络的高层中,包含语义信息的是空间,而不是单个单元。 这意味着原始图像的随机失真也可以被正确分类。
下图比较了在 MNIST 上训练的卷积神经网络中自然基和随机基的表现,使用 ImageNet 数据集作为验证集。


对于自然基(上图),它将隐藏单元的激活视为特征,并寻找最大化该单一特征激活值的输入图像。我们可以将这些特征解释为输入域中的有意义的变化。然而,实验表明这种可解释的语义也适用于任何随机方向(下图)。
以白色花朵识别为例。传统上,具有黑色圆圈和扇形白色区域的图像最有可能被分类为白色花朵。然而,事实证明,如果我们选择一组随机基,响应的图像也可以以类似的方式进行语义解释。
2. 在研究人员应用某种难以察觉的扰动后,网络可能会错误分类一张图像。 这些扰动是通过调整像素值以最大化预测错误来找到的。
对于我们研究的所有网络(MNIST、QuocNet、AlexNet),对于每个样本,我们总能生成非常接近、在视觉上难以区分的对抗样本,而这些样本会被原始网络错误分类。
以下示例中,左侧为正确预测样本,右侧为对抗样本,中间为它们之间差异的 10 倍放大。对于人类而言,这两列是相同的,而对神经网络却完全不同。

这是一个显著的发现。难道它们不应该对小扰动免疫吗?深度神经网络的连续性和稳定性受到质疑。平滑性假设不再适用于深度神经网络。
更令人惊讶的是,相同的扰动可以导致一个在不同训练数据集上训练的网络对相同图像进行错误分类。这意味着对抗样本在某种程度上是普遍存在的。
这个结果可能会改变我们管理训练/验证数据集和边缘案例的方式。实验已经支持,如果我们保留一组对抗样本并将其混入原始训练集中,泛化能力会有所提高。对抗样本对于高层次的作用似乎比低层次的更为有效。
这些影响不仅限于此。
作者声称,
尽管对抗负样本的集合很密集,但概率极低,因此在测试集中很少被观察到。
但“罕见”并不意味着从未发生。想象一下,如果带有这种盲点的 AI 系统被应用于犯罪检测、安全设备或银行系统。如果我们不断深入挖掘,是否在我们的大脑中也存在这样的对抗图像?很可怕,不是吗?

Ran Bi 是纽约大学数据科学项目的硕士生。在 NYU 学习期间,她在机器学习、深度学习以及大数据分析方面完成了多个项目。凭借本科阶段金融工程的背景,她对商业分析也很感兴趣。
相关:
-
在哪里学习深度学习 – 课程、教程、软件
-
深度学习分析如何模拟大脑
-
深度学习在 Kaggle 的狗猫竞赛中获胜
主题相关内容
深度学习用于从 X 光图像中检测肺炎
原文:
www.kdnuggets.com/2020/06/deep-learning-detecting-pneumonia-x-ray-images.html
评论

肺炎的风险对许多人来说非常巨大,尤其是在发展中国家,数十亿人面临能源贫困,依赖污染的能源形式。世卫组织估计,每年因家庭空气污染相关疾病(包括肺炎)导致超过 400 万人过早死亡。每年有超过 1.5 亿人感染肺炎,尤其是 5 岁以下的儿童。在这些地区,由于医疗资源和人员的匮乏,问题可能会进一步加剧。例如,在非洲的 57 个国家中,医生和护士的缺口达到 230 万。对这些人群而言,准确和快速的诊断至关重要。它可以保证及时获得治疗,并为那些已经陷入贫困的人节省宝贵的时间和金钱。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
这个项目是 胸部 X 光图像(肺炎) 在 Kaggle 上的一部分。
挑战
建立一个算法,通过查看胸部 X 光图像自动识别患者是否患有肺炎。这个算法必须非常准确,因为人的生命攸关。
环境和工具
数据
数据集可以从 kaggle 网站下载,网址在 这里。
代码在哪里?
不多说,让我们开始代码部分。完整项目可以在 这里找到。
首先加载所有库和依赖项。
接下来,我展示了一些正常和肺炎的图像,以观察它们在肉眼下的差异。其实差别不大!
示例图像
然后,我将数据集分为训练集、验证集和测试集。
接下来我写了一个函数,在其中进行了数据增强,并将训练集和测试集图像输入到网络中。同时,我还为图像创建了标签。
数据增强的做法是一种有效的方法,可以增加训练集的大小。通过增强训练样本,网络可以在训练过程中“看到”更多多样化但仍具有代表性的数据点。
然后我定义了一对数据生成器:一个用于训练数据,另一个用于验证数据。数据生成器能够从源文件夹直接加载所需数量的数据(一个小批量的图像),将它们转换为训练数据(提供给模型)和训练目标(一个属性向量——监督信号)。
在我的实验中,我通常设置
*batch_size = 64*。一般来说,32 到 128 之间的值应该效果不错。通常你应该根据计算资源和模型性能来增加/减少批量大小。
之后我定义了一些常量以备后续使用。
下一步是构建模型。可以通过以下 5 个步骤来描述。
-
我使用了五个卷积块,包括卷积层、最大池化层和批量归一化层。
-
在此基础上,我使用了一个扁平化层,并紧接着用了四个全连接层。
-
同时,我还使用了 dropout 来减少过拟合。
-
除了最后一层使用 Sigmoid 之外,整个过程中激活函数都是 Relu,因为这是一个二分类问题。
-
我使用了 Adam 作为优化器,并用交叉熵作为损失函数。
在训练模型之前,定义一个或多个回调函数是很有用的。其中比较实用的有:ModelCheckpoint和EarlyStopping。
-
ModelCheckpoint:当训练需要很长时间才能获得良好结果时,通常需要多次迭代。在这种情况下,最好只在改进指标的轮次结束时保存表现最好的模型的副本。
-
EarlyStopping:有时,在训练过程中我们会注意到泛化误差(即训练误差和验证误差之间的差异)开始增加,而不是减少。这是过拟合的一个症状,可以通过多种方式解决(减少模型容量、增加训练数据、数据增强、正则化、dropout等)。通常,一个实用且有效的解决方案是当泛化误差变得更糟时停止训练。
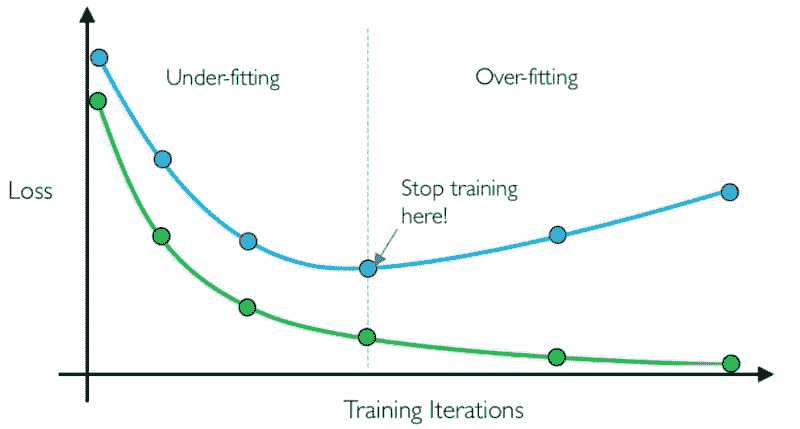
提前停止
接下来,我用 32 的批量大小训练了模型 10 个轮次。请注意,通常更高的批量大小会带来更好的结果,但代价是更高的计算负担。有研究还表明,最佳结果的批量大小是一个最佳值,可以通过投入一些时间进行超参数调优来找到。
Epoch 1/10
163/163 [==============================] - 90s 551ms/step - loss: 0.3855 - acc: 0.8196 - val_loss: 2.5884 - val_acc: 0.3783
Epoch 2/10
163/163 [==============================] - 82s 506ms/step - loss: 0.2928 - acc: 0.8735 - val_loss: 1.4988 - val_acc: 0.6284
Epoch 3/10
163/163 [==============================] - 81s 498ms/step - loss: 0.2581 - acc: 0.8963 - val_loss: 1.1351 - val_acc: 0.3970
Epoch 00003: ReduceLROnPlateau reducing learning rate to 0.0003000000142492354.
Epoch 4/10
163/163 [==============================] - 81s 495ms/step - loss: 0.2027 - acc: 0.9197 - val_loss: 0.3323 - val_acc: 0.8463
Epoch 5/10
163/163 [==============================] - 81s 500ms/step - loss: 0.1909 - acc: 0.9294 - val_loss: 0.2530 - val_acc: 0.9139
Epoch 00005: ReduceLROnPlateau reducing learning rate to 9.000000427477062e-05.
Epoch 6/10
163/163 [==============================] - 81s 495ms/step - loss: 0.1639 - acc: 0.9423 - val_loss: 0.3316 - val_acc: 0.8834
Epoch 7/10
163/163 [==============================] - 80s 492ms/step - loss: 0.1625 - acc: 0.9387 - val_loss: 0.2403 - val_acc: 0.8919
Epoch 00007: ReduceLROnPlateau reducing learning rate to 2.700000040931627e-05.
Epoch 8/10
163/163 [==============================] - 80s 490ms/step - loss: 0.1587 - acc: 0.9423 - val_loss: 0.2732 - val_acc: 0.9122
Epoch 9/10
163/163 [==============================] - 81s 496ms/step - loss: 0.1575 - acc: 0.9419 - val_loss: 0.2605 - val_acc: 0.9054
Epoch 00009: ReduceLROnPlateau reducing learning rate to 8.100000013655517e-06.
Epoch 10/10
163/163 [==============================] - 80s 490ms/step - loss: 0.1633 - acc: 0.9423 - val_loss: 0.2589 - val_acc: 0.9155
让我们可视化损失和准确率的图表。
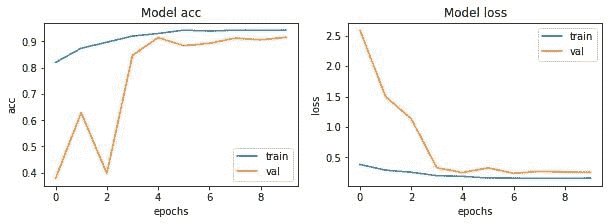
准确率与轮次 | 损失与轮次
到目前为止一切顺利。模型正在收敛,从损失和验证损失随着训练周期的减少可以观察到。此外,它能够在仅 10 个训练周期内达到 90% 的验证准确率。
让我们绘制混淆矩阵,并获取一些其他结果,如精准度、召回率、F1 分数和准确率。
CONFUSION MATRIX ------------------
[[191 43]
[ 13 377]]
TEST METRICS ----------------------
Accuracy: 91.02564102564102%
Precision: 89.76190476190476%
Recall: 96.66666666666667%
F1-score: 93.08641975308642
TRAIN METRIC ----------------------
Train acc: 94.23
该模型能够实现 91.02% 的准确率,考虑到使用的数据量,这是相当不错的。
结论
尽管这个项目还远未完成,但看到深度学习在如此多样的现实世界问题中的成功仍然很令人惊讶。我展示了如何从 X 光图像集合中分类阳性和阴性肺炎数据。该模型是从零开始构建的,这使其不同于其他高度依赖迁移学习的方法。未来,这项工作可以扩展到检测和分类包含肺癌和肺炎的 X 光图像。区分包含肺癌和肺炎的 X 光图像在近期已成为一个大问题,我们的下一个方向应该是解决这个问题。
参考资料/进一步阅读
我记得那天非常清楚。我的祖父开始出现随机咳嗽,并开始呼吸困难。他...
肺炎是由于感染病毒、细菌、真菌或其他病原体引起的肺部炎症。根据...
CheXNet:用深度学习在胸部 X 光片上进行放射科医师级的肺炎检测
该数据集由 NIH 发布,包含 112,120 张 30,805 名独特患者的正面 X 光图像,已标注...
在你离开之前
相应的源代码可以在这里找到。
Kaggle 竞赛的示例笔记本。显微镜图像的自动分割在医学领域是一个重要任务...
祝阅读愉快,学习愉快,编码愉快!
联系方式
如果你想了解我最新的文章和项目,请在 Medium 上关注我。这些是我的一些联系方式:
个人简介:Abhinav Sagar 是 VIT Vellore 的一名大四本科生。他对数据科学、机器学习及其在现实世界问题中的应用感兴趣。
原始内容。经许可转载。
相关:
-
用于乳腺癌分类的卷积神经网络
-
医疗保健中的 AI 和机器学习
-
AI 如何帮助管理传染病
更多相关主题
使用深度学习从职位描述中提取知识
原文:
www.kdnuggets.com/2017/05/deep-learning-extract-knowledge-job-descriptions.html
由 Jan Luts,Search Party 高级数据科学家撰写。
在 Search Party,我们专注于创建智能招聘软件。我们面临的一个问题是匹配候选人和职位,以建立推荐引擎。这通常需要解析、解释和规范化来自简历和职位的混乱的、半结构化/非结构化的文本数据,这就涉及到以下内容:条件随机场、词袋模型、TF-IDF、WordNet、统计分析,但也需要大量由语言学家和领域专家完成的手动工作,如创建同义词列表、技能分类、职位层级结构、知识库或本体。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
虽然这些概念对于我们尝试解决的问题非常有价值,但它们也需要一定量的手动特征工程和人工专业知识。这些专业知识无疑是使这些技术有价值的因素,但问题仍然是是否可以使用更多自动化的方法来提取关于职位空间的知识,以补充这些传统方法。
在这里,我们的目标是探索使用深度学习方法从招聘数据中提取知识,从而利用大量的职位空缺。数据集包括来自英国、澳大利亚、新西兰和加拿大的 1000 万个职位空缺,涵盖了 2014-2016 年期间。数据总字数为 30 亿。该数据集被分为训练集(850 万)和测试集(150 万)。每个职位空缺都包含职位描述和相应的职位名称。我们发现职位名称通常是可靠的,但数据中确实存在一定的噪声。这 1000 万个职位空缺中有 89,098 个不同的职位名称。数据的预处理最小:我们将职位描述的原始文本分词,并将所有词汇转换为小写。没有进行特征工程。
我们的模型架构包括一个卷积神经网络(CNN),用于生成职位描述的嵌入和一个包含职位标题嵌入的查找表:
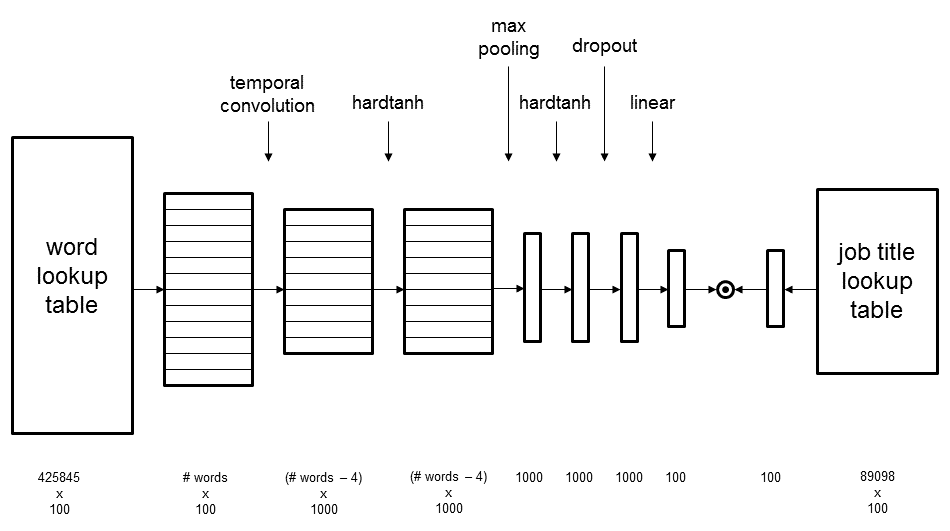
工作标题嵌入与职位描述嵌入之间的余弦相似度被用作评分函数。我们采用了学习排序的方法,使用成对的铰链损失来训练此模型。词汇查找表包含了 425,845 个最常见单词的 100 维嵌入。职位标题查找表包含了 89,098 个 100 维职位标题嵌入。对于卷积层,我们将过滤器数量设置为 1,000,内核宽度设置为 5,步幅设置为 1。这款模型有 52,095,400 个参数,词嵌入使用了从我们的训练数据中运行得到的重新缩放的 Word2Vec 系数进行初始化。优化使用了随机梯度下降,且使用了 dropout 作为正则化手段。实现使用了 Torch 7。
预测职位标题
显然,首先要查看的是模型被训练来做的事情:为职位描述预测职位标题。这是一个基础设施工程师的职位描述,不在训练集中:
职位标题在这个职位描述中包含,并且实际上提到了三次。职位描述中还有很多详细的职责和技能。通过将职位标题“基础设施工程师”替换为“人员”并删除其他两个引用,创建了一个替代的职位描述。
现在我们在两个职位描述上运行职位标题预测模型,并使用余弦相似度比较生成的嵌入与模型中学习到的职位标题嵌入。这些是两种情况中最可能的 10 个职位标题:
| 原始职位描述 | 无“基础设施工程师” | |
|---|---|---|
| 1 | 基础设施工程师 | linux 工程师 |
| 2 | linux 工程师 | devops 工程师 |
| 3 | 系统工程师 | linux 系统工程师 |
| 4 | windows 工程师 | 系统工程师 |
| 5 | devops 工程师 | 系统管理员 |
| 6 | 自动化工程师 | devops |
| 7 | linux 基础设施工程师 | 高级 devops 工程师 |
| 8 | 自动化工程师 devops | linux 系统管理员 |
| 9 | devops 基础设施工程师 | devops 顾问 |
| 10 | linux 系统工程师 | 构建自动化工程师 |
对于原始职位,最匹配的职位标题是“基础设施工程师”,恰好是正确的。然而,尽管“windows 工程师”稍显异常,其他大多数职位标题在前 10 名中都很合理。对于修改后的职位描述,最匹配的职位标题是“linux 工程师”。看起来其他 9 个职位标题在这种情况下也会是可以接受的。
这个例子表明,模型能够提取职位名称,但当我们从职位描述中去掉实际职位名称时,它也给出了有意义的预测。这表明,模型在缺乏更直接的信息时,会使用描述中的职责、技能和其他类型的信息来得出预测。
虽然模型是基于职位描述数据进行训练的,我们还希望在结构不同的数据上测试它:简单的查询,不包含实际职位名称。这个表格显示了它为各种输入得出的职位名称:
| 输入 | 预测职位名称 |
|---|---|
| 土建工人 | 土木工 |
| 照顾圣马丁小学的孩子 | 保姆 |
| 我们是彭伯顿卡车公司,我们正在招聘区域司机和一名 | 卡车司机 |
| 接受订单,广泛的产品知识,沟通技巧,餐饮技能 | 服务员 |
| 我们家正在寻找一个人来照顾我们最小的孩子 | 保姆 |
| 我们迫切需要一位具有 C++背景的开发人员 | C++开发人员 |
| 井淑技师(AK4679) | 汽车技师 |
| 我们正在寻找一个人来管理一个由五名软件开发人员和一名软件开发经理组成的团队 | |
| 我们正在寻找一个人来管理一个由五名会计师和一名财务经理组成的团队 | |
| 我们正在寻找一个人来管理一个由五名销售代表和一名销售经理组成的团队 |
这些例子表明,模型(在一定程度上)捕捉了特定职位通常做的事情。例如,它预测一个管理会计团队的人可能是财务经理。只需将“会计”替换为“软件开发人员”或“销售代表”,我们就会得到“软件开发经理”和“销售经理”这两个职位。模型学会了照顾孩子的人通常是保姆。当一家卡车公司寻找司机时,它很可能是在寻找卡车司机。鉴于“井淑技师”不是我们训练数据集中职位名称的一部分,预测“汽车技师”是合理的。
寻找相关职位名称、类比和关系
模型架构的一个副产品是,我们为训练集中所有的职位名称获得了嵌入向量。为了感受这些职位名称嵌入的质量,我们查看了嵌入空间中某个特定职位名称的最近邻:
| 统计学家 | 人文学科教师 | 人才招聘经理 |
|---|---|---|
| 统计分析师 | 人文学科教师 | 人才招聘专员 |
| 高级统计学家 | 资深人文学科教师 | 人才经理 |
| 生物统计学家 | 宗教研究教师 | 人才招聘合作伙伴 |
| 流行病学家 | QTS NQT 地理教师 | 人才招聘经理 |
| 研究统计学家 | 中学地理教师 | 人才招聘顾问 |
| 统计程序员 | 人文学科教师 | 人才招聘负责人 |
| 数据科学家 | 合格历史教师 | 招聘经理 |
这些例子表明,我们发现了职位名称的不同变体(例如“统计学家”与“统计分析师”以及“人才招聘经理”与“招聘经理”),相关(子)领域(例如统计学的生物统计学和流行病学),以及拼写错误(例如“人文学科教师”)。尽管我们的方法没有考虑单词中的实际字符,但模型在大量数据的配合下似乎对拼写错误有一定的容忍度。
现在换个话题。研究人员已经展示了基于余弦距离的简单向量偏移方法在使用词嵌入寻找类比时可以非常有效。一个众所周知的例子是:cos(w(“king”) – w(“man”) + w(“woman”), w(“queen”))。我们从模型中提取了训练后的词和职位名称嵌入,并发现这种关系在我们的模型中也成立:
| 示例 | 预测的最近邻 |
|---|---|
| Java 开发人员 – Java + C++ | C++开发人员 |
| 市场助理 – 初级 + 高级 | 高级市场执行官 |
| 护士 – 护理 + 编程 | 软件工程师 |
| 保姆 – 婴儿 + 数据库 | 数据库管理员 |
| 叉车司机 – 叉车 + Hadoop | 大数据架构师 |
| 手机维修技师 – 三星 + 福特 | 机械与电气修整技师 |
| 车辆销售执行官 – 福特 + 保险 | 保险销售执行官 |
| 市场经理 – 市场助理 + 初级软件开发人员 | 软件开发经理 |
| 银行员工 – NAB + 医院 | 护士 |
| 银行员工 – NAB + Coles | 杂货店店员 |
| 银行员工 – NAB + Woolworths | 超市零售助理 |
特征探测器在寻找什么?
模型中卷积层的滤波器对应于特征探测器,这些探测器在观察到特定模式时会被激活。由于我们模型中的卷积层操作在词嵌入上,因此我们可以轻松解释这些特征探测器在寻找什么。一种直接的方法是通过可视化导致最大激活的特定输入序列。下表显示了测试数据集所有职位描述中的前 5 个输入模式,对于几个滤波器而言。
毫不奇怪,一些特征探测器在寻找职位名称。毕竟,这就是我们优化的目标:
| 教师 | 酒店工作人员 |
|---|---|
| 高级讲师 高级讲师 高级讲师 | 主咖啡师 副厨师 长期工作 |
| 教师 教学公民人文学科 | 理想的酒店助理经理将 |
| 教师 中学教师 大学讲师 | 职称 酒店助理 学徒 雇主 |
| 描述 sen 教学助理 sen | 页面 酒店助理经理 m |
| 高级讲师 临床心理学讲师 | 主服务员 服务员 |
其他特征探测器寻找特定职责:
| 清洁 | 办公室行政 |
|---|---|
| 熨烫 清洁 带孩子 | 预订 提供打字 归档 复印 |
| 清洁厕所 清洁烤箱 垃圾桶 | 归档 一般打字 接听电话 |
| 清洁工 清洁工 维修工 | 欢迎客户 打字 归档 发送 |
| 清洁厕所 客房 清洁过道 | 打字者 处理电话 |
| 熨烫 清洁浴室 清洁厕所 | 打字 复印 答电话 |
另一些特征探测器关注于领导能力:
| 领导 | 监督 |
|---|---|
| 具有人员领导经验 高级 | 监督和管理焊工 锅炉工 |
| 指导 团队领导经验 高级 | 监督家庭作业 监督洗澡 |
| 监督和领导地面 | 激励和监督员工 有效 |
| 具有团队领导经验 | 管理和监督初级收费 |
| 监督和领导团队 | 激励和监督团队成员 |
就业类型和薪资:
| 休闲 | 薪资 |
|---|---|
| 休闲 酒吧门卫 休闲角色 | 按小时支付 周末小时 |
| 休闲 休闲 操作员 急需 | 按小时支付 各种工作时间 |
| 休闲 酒吧服务员 写你的 | 按小时支付 合同期 |
| 休闲 休闲 清洁工 需要良好 | 按小时支付 合同期 部分 |
| 休闲 酒吧服务员 工作类型 休闲 | 按小时支付 提供加班 周六可用 |
位置和语言技能:
| 澳大利亚 | 德语 |
|---|---|
| 悉尼中央商务区 新南威尔士 悉尼中央商务区 | 精通德语 咨询性专业 |
| 悉尼 墨尔本 布里斯班 珀斯 堪培拉 | 一位积极的德国专业教师 |
| 悉尼 澳大利亚 澳大利亚 悉尼 新南威尔士 | 指定地点 德国资源提供者 录入 |
| 悉尼 阿德莱德 布里斯班 查茨伍德 墨尔本 | 翻译技能 德语:英语。 |
| 悉尼 阿德莱德 布里斯班 查茨伍德 墨尔本 | 职位描述 德国资源提供者 录入 |
有趣的是,还存在一个用于检测候选人期望外观的特征探测器。根据这个特征探测器,良好的举止、一定的个人卫生标准和英语口音似乎是密不可分的:
| 外观 |
|---|
| 白种人语言:英语头发 |
| 白种人语言:英语口音 |
| 性格 聪明 整洁的外观 友好 |
| 整洁和可展现的外观 关怀 |
| 体面 有礼貌 courteous |
这些例子说明,所获得的过滤器不仅关注职位名称,还涵盖了在职位描述中期望找到的大多数相关部分。虽然卷积神经网络(CNN)以表示和特征学习而闻名,但我们仍然发现它在几乎没有预处理的情况下,从原始且未清理的职位描述中学习预测职位名称的结果非常引人注目。
关键词短语和相关职位描述
让我们再看一看那些最大程度激活 CNN 特征检测器的输入文本片段。尽管这忽略了网络中的转移函数和全连接层,但它是一种有助于理解 CNN 预测的方式。下图突出显示了与描述中激活最大的 50 个文本窗口相对应的烤炉厨师职位描述部分。通过为每个词分配一个简单的颜色代码(按激活程度递增:灰色、黄色、橙色、红色),可以清楚地看到这些文本窗口对应于从测试数据集中提取的职位描述中的关键短语:

请注意,职位描述的前 20 个词未被使用,因为它们通常包含职位名称(通常是职位的标题)。
一个最终的见解是,模型的 CNN 部分基本上是一种将文档转化为向量的方法,用于生成可变长度职位描述的嵌入。因此,利用这些嵌入进行相似职位描述的查找没有任何阻碍。这是上面提到的烤炉厨师职位在嵌入空间中最接近的测试集空缺:

毫无意外:这位雇主也在寻找烤炉厨师。同样不太令人惊讶的是,通过查看哪些神经元显示高激活,可以发现这些职位空缺基本上共享相同的活跃神经元。例如,神经元 725 在“烹饪技能,关于食物的知识”和“Prahan 的餐馆。友好”中被激活,而神经元 444 则在“所有腌料和印度菜肴”和“一个烤炉厨师职位”中被激活。因此,模型知道这些表达在语义上是相关的。根据我们的一些实验,这似乎是寻找相似或相关职位空缺的一个有趣方法。鉴于模型不仅仅查看职位名称,并且知道哪些表达是相关的,这相比于仅比较职位名称或职位描述实际词汇的简单方法更具价值。
本文是对一系列博客文章的浓缩概述,这些文章发布在这里。
简介:Jan Luts 是 Search Party 的高级数据科学家。他于 2003 年获得比利时哈瑟尔特大学的信息科学硕士学位,并于 2004 年和 2005 年分别获得比利时鲁汶天主教大学的生物信息学和统计学硕士学位。在 2010 年获得鲁汶天主教大学电气工程系(ESAT)的博士学位后,他在该机构进行了两年的博士后研究。2012 年,Jan 移居澳大利亚,成为悉尼科技大学数学科学学院的统计学博士后研究员。2013 年,他转入私营部门,担任 Search Party 的数据科学家。
相关:
-
文本挖掘亚马逊手机评论:有趣的见解
-
文本分析:入门
-
通过众包衡量主题解释性
更多相关话题
-
一个 90 亿美元的 AI 失败,剖析
(深度学习的深层缺陷)的深层缺陷
原文:
www.kdnuggets.com/2015/01/deep-learning-flaws-universal-machine-learning.html
评论
一些近期广泛报道的论文已经缓解了围绕深度学习的炒作。这些论文指出,图像可以被微妙地修改以引起错误分类,并且可以轻易生成看似随机的垃圾图像,这些图像会得到高度的信心分类。新闻界对这一消息进行了 sensationalized 的报道。几个博客帖子、一个 YouTube 视频以及其他媒体都放大并偶尔扭曲了结果,宣称深度网络的轻信性。
鉴于这些炒作,审视这些发现是合适的。虽然一些发现很吸引人,但其他的却不那么令人惊讶。有些是机器学习在对抗性环境中的几乎普遍存在的问题。此外,经过审视这些发现后,似乎很清楚,它们之所以令人震惊,完全是因为对深度网络实际做什么的非现实预期,即对现代前馈神经网络具有类似人类认知的非现实期望。
这些批评有两个方面,源于两篇独立的论文。第一篇,“神经网络的有趣特性”,是由谷歌的 Christian Szegedy 等人去年发表的论文。在其中,他们揭示了可以以对人类不可察觉的方式微妙地改变图像,从而导致经过训练的卷积神经网络 (CNN) 的错误分类。
需要明确的是,这篇论文写得很好,构思周密,提出了适度但有洞察力的主张。作者展示了两个结果。主要结果显示,神经网络最后一层的隐藏单元的随机线性组合在语义上与单元本身不可区分。他们建议这些隐藏单元所跨越的空间才是重要的,而不是哪个特定的基底跨越了这个空间。
第二个、更广泛报道的主张涉及图像的修改。作者非随机地改变了一组像素,以引起错误分类。结果是一个看似相同但被错误分类的图像。这个发现引发了关于深度学习在对抗性情境中的应用的有趣问题。作者还指出,这挑战了平滑假设,即相互非常接近的示例应有很高概率得到相同分类。
对抗案例确实值得深思。然而,优化图像以实现错误分类需要访问模型。这种情况可能并不总是现实的。例如,垃圾邮件发送者可能能够发送电子邮件并查看哪些电子邮件被谷歌的过滤器分类为垃圾邮件,但他们不太可能获得访问谷歌垃圾邮件过滤算法的机会,以便最大限度地优化垃圾邮件类型的电子邮件,这些电子邮件却未被过滤。同样,要欺骗深度学习面部检测软件,需要访问底层的卷积神经网络,以便准确地伪造图像。
值得注意的是,几乎所有的机器学习算法都容易受到对抗性选择示例的影响。考虑一个具有数千个特征的逻辑回归分类器,其中许多特征具有非零权重。如果其中一个特征是数值型的,可以将该特征的值设置得非常高或非常低,以诱导错误分类,而不改变其他数千个特征。对于只能感知特征子集的人类而言,这种改变可能不会被察觉。或者,如果模型中任何特征的权重非常高,则可能只需要将其值稍微调整一下,就能诱导错误分类。类似地,对于决策树,一个二进制特征可能被切换,以将示例引导到最终层的错误分区中。
对于神经网络而言,这种病态案例在某些方面是不同的。其中一个关键区别是像素的取值是受到约束的。然而,鉴于几乎任何具有许多特征和自由度的机器学习模型,都容易工程化病态的对抗示例。这对于那些更简单、理解更透彻并且有理论保证的模型也是真的。也许,我们不应该对深度学习也易受对抗性选择示例的影响感到惊讶。
第二篇论文,来自怀俄明大学的 Anh Nguyen 所著的《"深度网络容易被欺骗"》,似乎做出了更大胆的声明。引用了 Szegedy 等人的工作,他们着手研究反向问题,即如何制造一个看似无意义的例子,尽管它明显缺乏内容,但仍然获得了高置信度的分类。作者使用梯度上升法来训练一些无法被人眼识别的胡言乱语图像,这些图像被强烈分类到一些明显错误的对象类别中。

从数学直觉的角度来看,这正是我们应该预期的。在之前的情况中,修改后的图像被限制为与某个源图像不可区分。在这里,图像的限制只是不能看起来像任何东西!在所有可能的图像空间中,实际可识别的图像只是一个微小的子集,几乎整个向量空间都是开放的。此外,在几乎所有其他机器学习方法中,都很容易找到相应的问题。给定任何线性分类器,都可以找到一个既远离决策边界又远离任何曾见过的数据点的位置。给定一个主题模型,可以创建一个毫无意义的随机词序列,它似乎获得了与某个选定的真实文档相同的推断主题分布。
这个结果可能令人惊讶的主要原因是卷积神经网络在物体检测任务中的表现已经能够与人类能力相媲美。在这种意义上,区分 CNN 的能力和人类能力可能是重要的。作者从一开始就提出了这一点,这个论点是合理的。
正如 Michael I. Jordan 和 Geoff Hinton 最近讨论的那样,深度学习的巨大成功吸引了一波炒作。最近的负面宣传表明这种炒作有两面性。深度学习的成功确实使许多人愿意审视其缺陷。然而,值得记住的是,许多问题在大多数机器学习环境中都是普遍存在的。或许对对抗性示例鲁棒的算法的更广泛兴趣可以使整个机器学习社区受益。

Zachary Chase Lipton 是加州大学圣地亚哥分校计算机科学工程系的博士生。在生物医学信息学部门资助下,他对机器学习的理论基础和应用都感兴趣。除了在 UCSD 的工作,他还曾在微软研究院实习。
相关:
-
Geoff Hinton AMA:神经网络、大脑和机器学习
-
深度学习是否存在深层缺陷?
-
深度学习可以轻易被愚弄
-
差分隐私:如何使隐私与数据挖掘兼容
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
了解更多主题
深度学习框架实力评分 2018
原文:
www.kdnuggets.com/2018/09/deep-learning-framework-power-scores-2018.html
评论
Jeff Hale,企业家
深度学习仍然是数据科学中最热门的领域。深度学习框架正在快速变化。就在五年前,除了 Theano 之外,没有任何一个领导者存在。
我希望找到哪些框架值得关注的证据,因此我开发了这个实力排名。我使用了 11 个数据源,涵盖了 7 个不同的类别,以评估框架的使用、兴趣和受欢迎程度。然后,我在这个 Kaggle Kernel中加权和合并了这些数据。
更新 2018 年 9 月 20 日:由于需求旺盛,我扩大了评估的框架,包括 Caffe、Deeplearning4J、Caffe2 和 Chainer。现在所有在 KDNuggets 使用调查中报告使用率超过 1% 的深度学习框架都被包含在内。
更新 2018 年 9 月 21 日:我在多个指标中进行了若干方法改进。
不再赘述,以下是深度学习框架的实力评分:
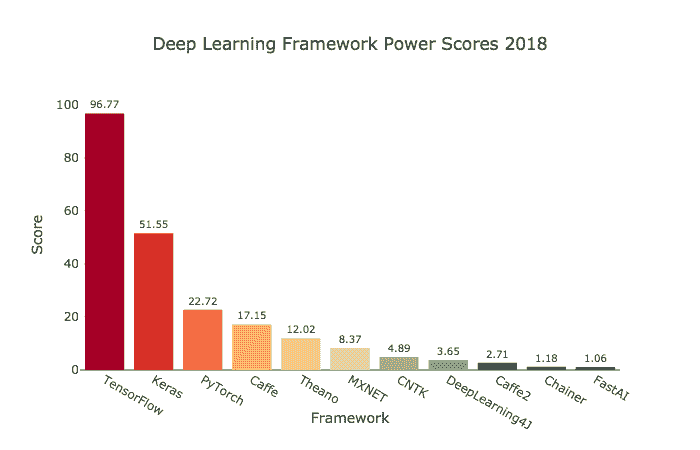
虽然 TensorFlow 是明显的赢家,但也有一些令人惊讶的发现。让我们深入了解一下!
竞争者
所有这些框架都是开源的。除了一个框架,其他框架都可以与 Python 一起使用,并且有些可以与 R 一起使用或其他语言。

TensorFlow是无可争议的重量级冠军。它在 GitHub 活跃度、Google 搜索量、Medium 文章、Amazon 书籍和 ArXiv 文章中都是最多的。它也拥有最多的开发者使用,并且在在线招聘广告中出现频率最高。TensorFlow 得到了 Google 的支持。

Keras有一个“为人类而设计的 API,而非机器”。它几乎在所有评估领域中都是第二受欢迎的框架。Keras建立在 TensorFlow、Theano 或 CNTK 之上。如果你对深度学习很陌生,建议从 Keras 开始。

PyTorch是第三大最受欢迎的框架,也是第二大最受欢迎的独立框架。它比 TensorFlow 更年轻,并且在受欢迎程度上迅速增长。它允许 TensorFlow 不具备的自定义功能。它得到了 Facebook 的支持。

Caffe是第四大最受欢迎的框架。它已经存在近五年。它在雇主中相对有需求,并且经常出现在学术文章中,但最近的使用情况报道较少。

Theano是 2007 年在蒙特利尔大学开发的,是最早的重大 Python 深度学习框架之一。它已经失去了很多人气,其领导者声明主要版本不再在计划中。然而,更新仍在进行中。Theano 仍然是第五高分的框架。
MXNET由 Apache 孵化并被 Amazon 使用。它是第六大受欢迎的深度学习库。

CNTK是微软认知工具包。它让我想起了许多其他微软产品,因为它试图与 Google 和 Facebook 的产品竞争,但并未获得显著的采用。

Deeplearning4J,也称为 DL4J,是用于 Java 语言的。它是唯一一个没有 Python 版本的半流行框架。然而,你可以将用 Keras 编写的模型导入到 DL4J 中。这是唯一一个不同搜索词偶尔会有不同结果的框架。我使用了每项指标的较高数字。由于框架得分相当低,这没有实质性区别。

Caffe2是另一个 Facebook 的开源产品。它基于 Caffe,现在被托管在 PyTorch 的 GitHub 存储库中。由于它不再拥有自己的存储库,我使用了其旧存储库的 GitHub 数据。

Chainer是由日本公司 Preferred Networks 开发的框架。它有一个小众的追随者。

FastAI基于 PyTorch 构建。其 API 受 Keras 的启发,所需代码更少,效果却很强。FastAI 截至 2018 年 9 月中旬处于前沿阶段,正在进行 1.0 版本的重写,预计于 2018 年 10 月发布。Jeremy Howard,FastAI 的幕后推手,是顶尖的 Kaggler 和Kaggle的主席。他讨论了为何 FastAI 从 Keras 转向自己构建的框架,点击这里了解更多。
FastAI 目前尚未在职业中广泛需求,也未被广泛使用。然而,通过其受欢迎的免费在线课程,它拥有大量内置用户。它既强大又易于使用,未来的采用率可能会显著增长。
标准
我选择了以下类别,以提供对深度学习框架的受欢迎程度和兴趣的全面视角。
评估类别:
-
在线职位列表
-
KDnuggets 使用调查
-
谷歌搜索量
-
Medium 文章
-
亚马逊书籍
-
ArXiv 文章
-
GitHub 活动
搜索是在 2018 年 9 月 16 日至 9 月 21 日进行的。源数据在 这个 Google 表格中。
我使用了 plotly 数据可视化库和 Python 的 pandas 库来探讨受欢迎程度。有关互动式 plotly 图表,请参见我的 Kaggle Kernel 这里。
在线职位列表
今天的职位市场上哪些深度学习库最受需求?我在 LinkedIn、Indeed、Simply Hired、Monster 和 Angel List 上搜索了职位列表。
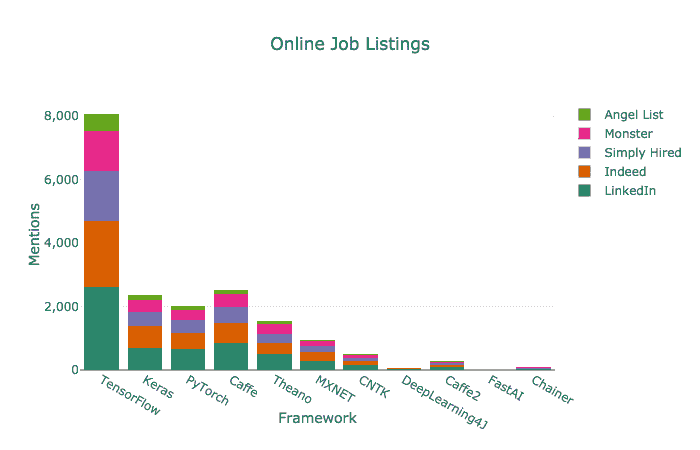
在职位列表中提到的框架中,TensorFlow 无疑是赢家。如果你想找一份做深度学习的工作,就学习它吧。
我使用了术语机器学习,然后是库名称。因此,TensorFlow 是通过机器学习 TensorFlow来评估的。我测试了几种搜索方法,这种方法给出了最相关的结果。
需要一个额外的关键词来区分这些框架和无关的术语,因为 Caffe 可能有多种含义。
使用情况
KDnuggets,一个流行的数据科学网站,对全球的数据科学家进行了调查,了解他们使用的软件。他们询问了:
你在过去 12 个月中在实际项目中使用了哪些分析、大数据、数据科学、机器学习软件?
这里是这一类别框架的结果。
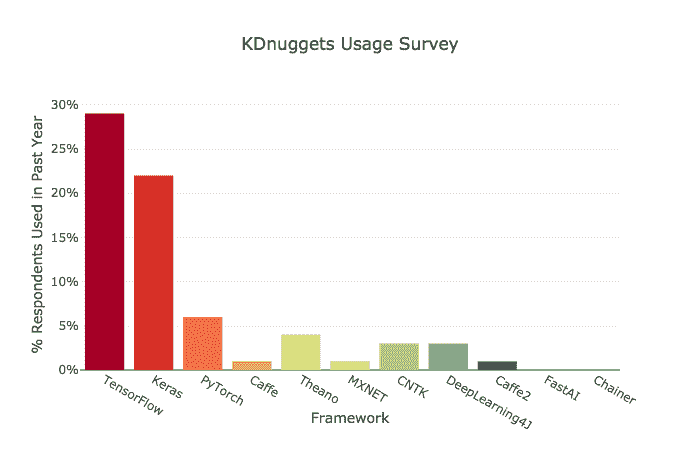
Keras 的使用量出乎意料地多——几乎和 TensorFlow 一样。很有趣的是,美国雇主显然在寻找 TensorFlow 技能,而在国际上,Keras 的使用频率几乎是一样的。
这一类别是唯一包含国际数据的类别,因为包含其他类别的国际数据会显得繁琐。
KDnuggets 报告了多年的数据。虽然我在这项分析中仅使用了 2018 年的数据,但我应当指出,自 2017 年以来,Caffe、Theano、MXNET 和 CNTK 的使用量都有所下降。
谷歌搜索活动
在最大的搜索引擎上的网页搜索是受欢迎程度的良好指标。我查看了过去一年在 Google Trends 上的搜索历史。谷歌没有提供绝对的搜索数量,但提供了相对数据。
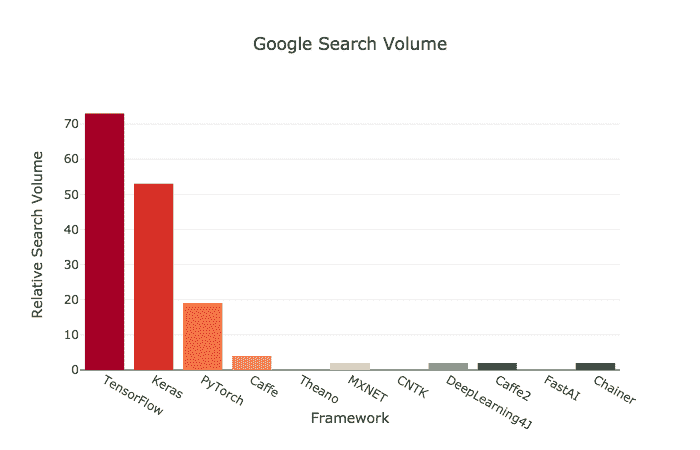
我于 2018 年 9 月 21 日更新了这篇文章,因此这些分数包括了截至 2018 年 9 月 15 日的一周内全球搜索的机器学习与人工智能类别数据。感谢 François Chollet 提出的建议,改进了这个搜索指标。
Keras 与 TensorFlow 相差不远。PyTorch 排在第三位,其他框架的相对搜索量得分在四分之一或以下。这些得分用于功率得分计算。
让我们简要看看搜索量随时间的变化,以提供更多的历史背景。下方的图表来自 Google,展示了过去两年的搜索情况。
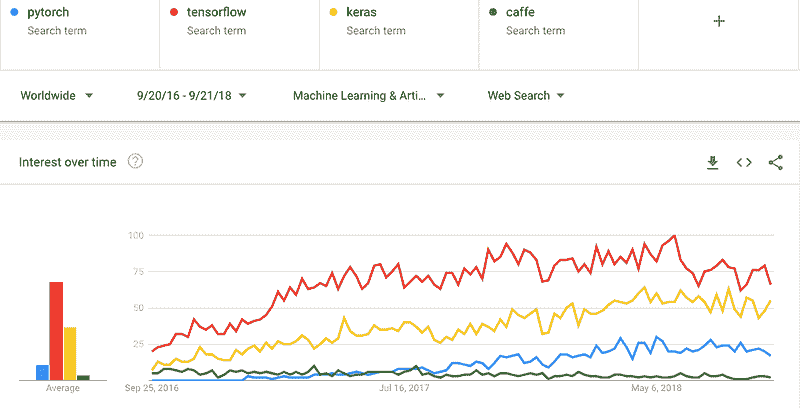
TensorFlow = 红色,Keras = 黄色,PyTorch = 蓝色,Caffe = 绿色
过去一年中,Tensor Flow 的搜索量并没有明显增长,但 Keras 和 PyTorch 的搜索量有所增加。Google Trends 仅允许同时比较五个术语,因此其他库在单独的图表中进行比较。除了 TensorFlow 外,其他库的搜索兴趣都很有限。
出版物
我在评分中包括了几种出版类型。让我们先来看 Medium 文章。
Medium 文章
Medium 是流行的数据科学文章和指南的发布地。现在你在这里——太棒了!
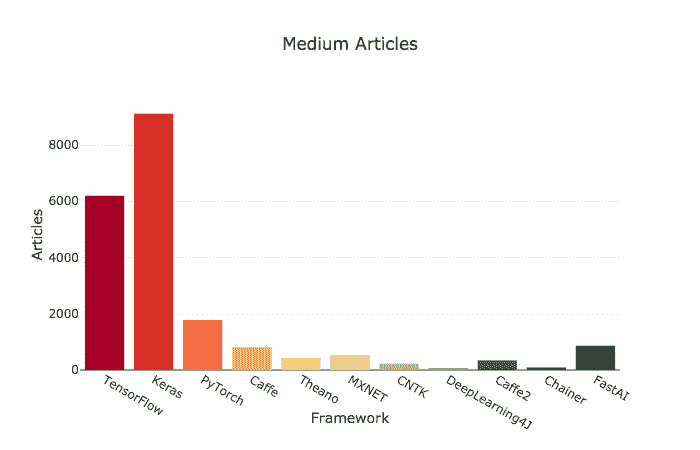
最终出现了一个新的赢家。在 Medium 文章中的提及方面,Keras 超过了 TensorFlow。FastAI 的表现相较于平时也有所提升。
我假设这些结果可能是因为 Keras 和 FastAI 对初学者友好。它们受到了新手深度学习从业者的相当多关注,而 Medium 通常是教程的论坛。
我在过去 12 个月中使用框架名称和“learning”作为关键词在 Medium.com 上进行 Google 站点搜索。这个方法是为了防止“caffe”一词出现错误结果。它在几种搜索选项中减少的文章数量最小。
现在让我们看看哪些框架在亚马逊上有相关书籍。
亚马逊书籍
我在 Amazon.com 上的 Books->Computers & Technology 分类下搜索了每个深度学习框架。
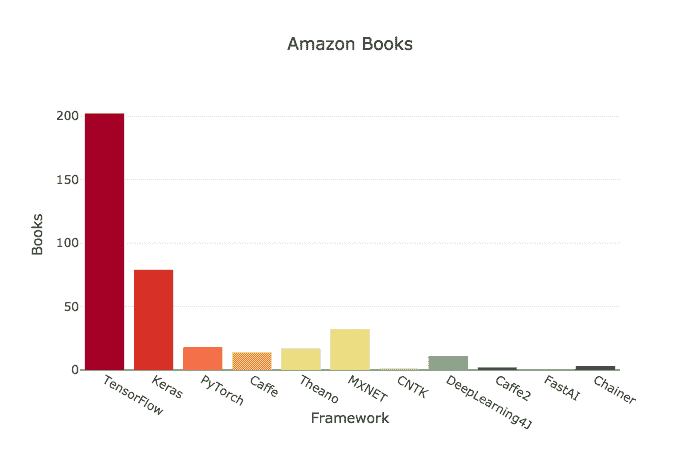
TensorFlow 再次获胜。MXNET 的书籍数量超出了预期,而 Theano 的书籍数量则较少。PyTorch 的书籍相对较少,但这可能是因为该框架较年轻。这项指标偏向于较老的库,因为出版一本书需要时间。
ArXiv 文章
ArXiv 是大多数学术机器学习文章发布的在线存储库。我使用 Google 站点搜索结果,搜索了过去 12 个月每个框架在 arXiv 上的情况。
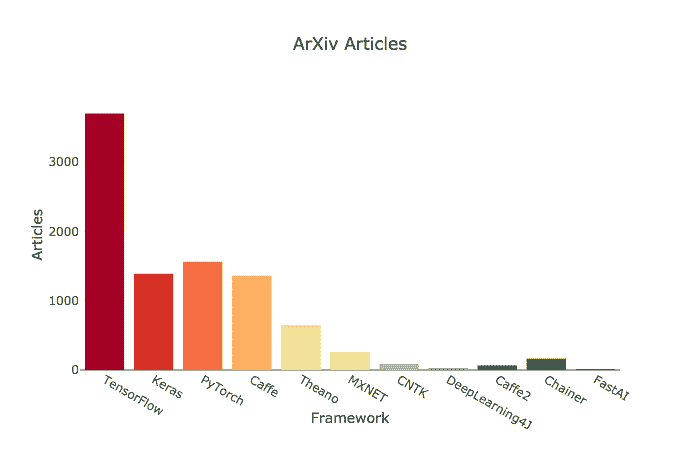
TensorFlow 在学术文章中继续保持相同的表现。注意 Keras 在 Medium 和亚马逊上的受欢迎程度远高于学术文章中的表现。PyTorch 在这一类别中位居第二,展示了其在实现新想法方面的灵活性。Caffe 的表现也相对较好。
GitHub 活动
GitHub 活动是框架受欢迎程度的另一个指标。我在下面的图表中分别列出了 stars、forks、watchers 和 contributors,因为它们分开来看比合在一起更有意义。
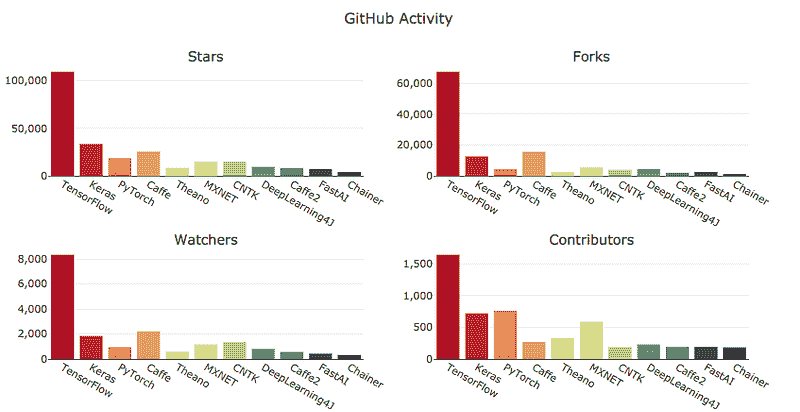
TensorFlow 显然是 GitHub 上最受欢迎的框架,拥有大量活跃用户。考虑到 FastAI 甚至还不到一年,它有一个相当不错的追随者。值得注意的是,贡献者水平在所有框架中更接近,而不是其他三个指标。
在收集和分析数据之后,到了将其整合成一个指标的时刻。
权力评分程序
这是我创建权力评分的方法:
-
将所有特征缩放到 0 和 1 之间。
-
汇总的职位搜索列表和 GitHub 活动子类别。
-
根据以下权重对类别进行加权。
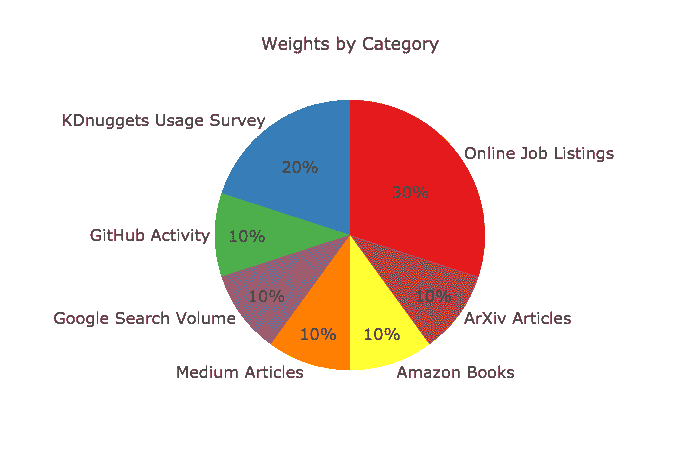
如上所示,在线职位列表和 KDnuggets 使用调查占总分的一半,而网络搜索、出版物和 GitHub 关注度占另一半。这种分配似乎是各种类别中最合适的平衡。
-
将加权得分乘以 100 以便于理解。
-
将每个框架的总类别得分汇总成一个总体评分。
这是数据:
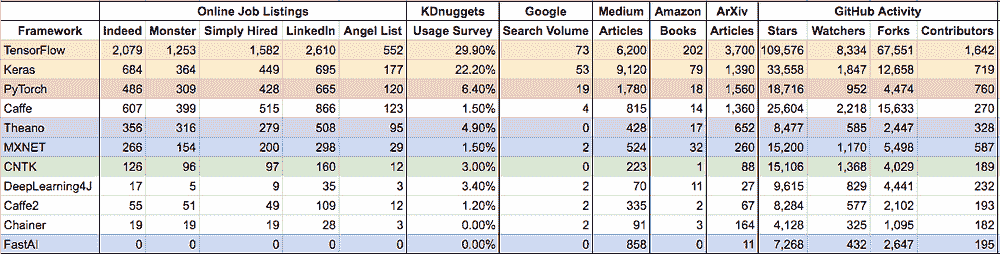
以下是加权和汇总子类别后的得分。
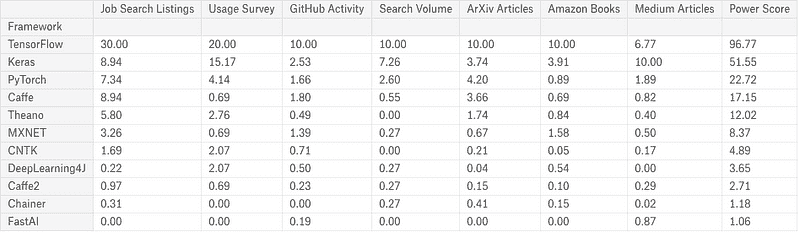
这里再次展示了最终权力评分的漂亮图表。
100 是最高可能得分,表示在每个类别中都是第一名。TensorFlow 几乎达到了 100,这在看到它在每个类别中都接近或位于顶端之后并不令人惊讶。Keras 排在第二位。
要互动地查看图表或叉开 Jupyter Notebook,请访问 这个 Kaggle Kernel。
未来
目前,TensorFlow 牢牢占据领先地位。在短期内它似乎会继续主导。不过,鉴于深度学习领域的变化如此之快,这种情况可能会改变。
时间会证明 PyTorch 是否会超越 TensorFlow,就像 React 超越 Angular 一样。这些框架可能是类比的。PyTorch 和 React 都是由 Facebook 支持的灵活框架,通常被认为比其由 Google 支持的竞争对手更容易使用。
FastAI 会在其课程之外获得用户吗?它有一个庞大的学生群体,API 比 Keras 更加适合初学者。
你认为未来会怎样?请在下方分享你的想法。
学习者建议
如果你考虑学习这些框架之一,并且拥有 Python、numpy、pandas、sklearn 和 matplotlib 技能,我建议你从 Keras 开始。它有大量用户基础,受到雇主的需求,Medium 上有很多相关文章,而且 API 使用起来很简单。
如果你已经了解了 Keras,它可能会很难决定下一个学习的框架。我建议你选择 TensorFlow 或 PyTorch 并好好学习,以便你可以创建出色的深度学习模型。
TensorFlow 显然是你想掌握市场需求框架的最佳选择。但 PyTorch 的易用性和灵活性使其在研究人员中越来越受欢迎。这是一个Quora 讨论关于这两个框架的对比。
一旦你掌握了这些框架,我建议你关注 FastAI。如果你想学习基础和高级深度学习技能,可以查看它的免费在线课程。FastAI 1.0 承诺让你轻松实现最新的深度学习策略,并迅速迭代。
无论你选择哪个框架,希望你现在对哪些深度学习框架最受需求、最常用以及最被讨论有了更好的理解。
如果你觉得这篇文章有趣或有帮助,请通过分享和点赞帮助其他人发现它。
祝深度学习愉快!
个人简介: Jeff Hale (@discdiver) 是一位经验丰富的企业家和经理,拥有 MBA 和硕士学位。他专注于数据科学,并撰写关于机器学习、数据可视化和深度学习的文章。在 LinkedIn 上与他联系。
原文。经许可转载。
相关:
-
你应该知道的 9 件关于 TensorFlow 的事
-
Keras 四步工作流程
-
fast.ai 深度学习第一部分完整课程笔记
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关主题
不仅仅是深度学习:GPU 如何加速数据科学与数据分析
原文:
www.kdnuggets.com/2021/07/deep-learning-gpu-accelerate-data-science-data-analytics.html
comments

GPU 如何加速数据科学与数据分析
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT 工作
人工智能 (AI) 将彻底改变全球生产力、工作模式和生活方式,并创造巨额财富。研究公司 Gartner 预计全球 AI 经济将从去年的约 1.2 万亿美元增长到 2022 年的约 \(3.9 万亿美元](https://www.forbes.com/sites/alexknapp/2018/04/25/gartner-estimates-ai-business-value-to-reach-nearly-4-trillion-by-2022/#3eb979af33f9),而麦肯锡则预测到 2030 年全球经济活动将达到约 [\),而麦肯锡则预测到 2030 年全球经济活动将达到约 $13 万亿美元。在许多方面,这种转型的核心是由强大的机器学习 (ML) 工具和技术推动的。
现代 AI/ML 系统的成功已经明确依赖于其利用任务优化硬件以并行处理大量原始数据的能力。因此,像图形处理单元 (GPU) 这样的专用硬件在早期成功中发挥了重要作用。从那时起,已经非常重视构建高度优化的软件工具和定制的数学处理引擎(包括硬件和软件)来利用 GPU 和并行计算的能力与架构。
尽管在学术界和商业圈中,GPU 和分布式计算在核心 AI/ML 任务(例如运行 100 层深度神经网络进行图像分类或亿参数 BERT 语音合成模型)中的应用被广泛讨论,但它们在常规数据科学和数据工程任务中的实用性却较少被涉及。这些数据相关任务是任何 AI 流水线中 ML 工作负载的基本前提,通常占据了数据科学家甚至 ML 工程师的大部分时间和智力精力。
事实上,最近,著名的 AI 先锋 Andrew Ng 讨论了从以模型为中心转向以数据为中心的 AI 工具开发方法。这意味着在实际的 AI 工作负载在你的管道中执行之前,需要花费更多时间处理原始数据并进行预处理。
你可以在这里观看 Andrew 的采访:www.youtube.com/watch?v=06-AZXmwHjo
这引出了一个重要问题...
我们能否将 GPU 和分布式计算的力量也用于常规数据处理任务?
答案并不简单,需要一些特殊的考虑和知识共享。在本文中,我们将尝试展示一些可以用于此目的的工具和平台。

RAPIDS:利用 GPU 进行数据科学
RAPIDS 开源软件库和 API 套件使你能够完全在 GPU 上执行端到端的数据科学和分析管道。NVIDIA 孵化了这个项目并构建了利用 CUDA 原语进行低级计算优化的工具。它特别专注于通过广受数据科学家和分析专业人士喜爱的 Python 语言暴露 GPU 并行性和高带宽内存速度特性。
常见的数据准备和整理任务在 RAPIDS 生态系统中受到高度重视,因为它们在典型的数据科学管道中占据了大量时间。一个熟悉的类似数据框 API已经开发出来,并内置了许多优化和稳健性。它还被定制以与各种 ML 算法集成,实现端到端管道加速,并且减少了序列化成本。
RAPIDS 还包括大量对多节点、多 GPU 部署和分布式处理的内部支持。它与其他库集成,使内存不足(即数据集大小超过单个计算机的 RAM)数据处理变得简单且易于数据科学家使用。
这里是 RAPIDS 生态系统中包含的最显著的库。
CuPy
一个由 CUDA 支持的数组库,外观和感觉类似于 Numpy,这是所有数值计算和 Python ML 的基础。它使用包括 cuBLAS、cuDNN、cuRand、cuSolver、cuSPARSE、cuFFT 和 NCCL 在内的 CUDA 相关库,充分利用 GPU 架构,目标是提供 Python 下的 GPU 加速计算。
CuPy 的接口与 NumPy 非常相似,可以作为大多数用例的简单替代品。这里是 CuPy 和 NumPy 之间 API 兼容性的模块级详细列表。
查看CuPy 比较表。
相对于 NumPy 的加速可能会令人惊叹,具体取决于数据类型和使用情况。以下是 CuPy 和 NumPy 在两种不同数组大小以及各种常见数值操作(如 FFT、切片、求和和标准差、矩阵乘法、SVD)上的速度比较,这些操作被几乎所有机器学习算法广泛使用。
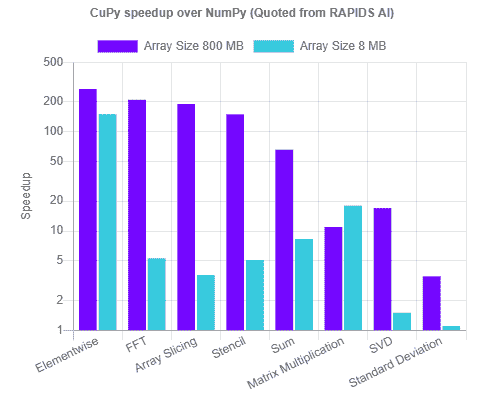
CuPy 与 NumPy 的速度比较,图片来源
CuDF
基于 Apache Arrow 列式内存格式构建,cuDF 是一个 GPU DataFrame 库,用于加载、连接、聚合、过滤和其他数据操作。它提供了一个类似 pandas 的 API,几乎所有数据工程师和数据科学家都很熟悉,因此他们可以利用强大的 GPU 加速工作流程,而无需深入了解 CUDA 编程。
目前,cuDF 仅支持 Linux 系统,以及 Python 版本 3.7 及以上。其他要求包括,
-
CUDA 11.0+
-
NVIDIA 驱动程序 450.80.02+
-
Pascal 架构或更高(计算能力 >=6.0)
有关这个强大库的更多信息,请查看CuDF 的 API 文档。
最后,数据科学家和分析师(即那些不一定在日常任务中使用深度学习的人)可以高兴地使用像以下这样的强大 AI 工作站,以提升他们的生产力。
来自 Exxact Corporation 的数据科学工作站,图片来源
CuML
cuML 使数据科学家、分析师和研究人员能够在 GPU 上运行传统/经典的机器学习算法任务(主要是)表格数据集,而无需深入了解 CUDA 编程。大多数情况下,cuML 的 Python API 与流行的 Python 库 Scikit-learn 匹配,使过渡到 GPU 硬件既快捷又无痛。
查看CuML 的 GitHub 仓库文档以了解更多信息。
CuML 还与Dask集成,无论何时可能,提供多 GPU 和多节点 GPU 支持,以便为不断增加的利用分布式处理的算法集合提供支持。
CuGraph
CuGraph 是一组 GPU 加速的图算法,处理在GPU DataFrames中找到的数据。cuGraph 的愿景是使图分析变得无处不在,以至于用户只需考虑分析,而不必考虑技术或框架。
熟悉 Python 的数据科学家将迅速掌握 cuGraph 如何与 cuDF 的 Pandas 类 API 集成。同样,熟悉 NetworkX 的用户将很快识别 cuGraph 提供的类似 NetworkX 的 API,目标是使现有代码能够以最小的努力迁移到 RAPIDS 中。
目前,它支持各种图分析算法,
-
中心性
-
社区
-
链接分析
-
链接预测
-
遍历
许多科学和业务分析任务涉及对大数据集进行广泛的图算法处理。像 cuGraph 这样的库在工程师投资于 GPU 驱动的工作站时提供了更高的生产力保证。
利用 GPU 加速计算来增强社交图分析,图片来源
GPU 数据科学的整体流程
RAPIDS 设想了一个 GPU 驱动的数据科学任务流程的完整管道。请注意,深度学习,传统上是 GPU 计算的主要关注点,只是该系统的一个子组件。
GPU 数据科学管道,图片来源
Dask:使用 Python 进行分布式分析
正如我们所观察到的,现代数据处理管道通常可以从大数据块的分布式处理中受益。这与单个 GPU 中数千个核心提供的并行性略有不同。这更多的是关于如何将普通的数据处理(这可能发生在数据集准备好进行 ML 算法之前很久)拆分成块,并在多个计算节点上处理。
这些计算节点可以是 GPU 核心,甚至可以是 CPU 的简单逻辑/虚拟核心。
从设计上看,大多数流行的数据科学库如 Pandas、Numpy 和 Scikit-learn 难以充分利用真正的分布式处理。Dask 试图通过将智能任务调度和大数据处理功能带入常规 Python 代码中来解决这个问题。自然,它由两个部分组成:
-
动态任务调度优化了计算。这类似于 Airflow、Luigi、Celery 或 Make,但针对交互式计算负载进行了优化。
-
“大数据”集合如并行数组、数据帧和扩展了常见接口的列表(如 NumPy、Pandas 或 Python 迭代器),用于大于内存或分布式环境。这些并行集合在上述动态任务调度器之上运行。
这是一个典型 Dask 任务流程的示意图。
官方 Dask 流程文档,图片来源
易于转换现有代码库
熟悉性是 Dask 设计的核心,因此典型的数据科学家可以仅需将现有的 Pandas/Numpy 基础代码转换为 Dask 代码,而学习曲线非常平缓。以下是来自官方文档的一些经典示例。

Dask 文档中比较 Pandas 和 NumPy,图片来源
Dask-ML 解决可扩展性挑战
对于机器学习工程师来说,有不同种类的可扩展性挑战。下图说明了这些挑战。机器学习库 Dask-ML 为每种场景提供了解决方案。因此,可以根据独特的业务或研究需求,专注于模型中心的探索或数据中心的发展。
最重要的是,再次强调熟悉性在这里发挥作用,DASK-ML API 旨在模仿广受欢迎的 Scikit-learn API。

Dask 文档中的 XGBRegressor,图片来源
Dask 在多核 CPU 系统中的好处
需要注意的是,Dask 的主要吸引力在于它作为一个高层次的高效任务调度器,可以与任何 Python 代码或数据结构一起工作。因此,它不依赖于 GPU 来通过分布式处理来提升现有的数据科学工作负载。
即便是多核 CPU 系统,只要代码编写时考虑到这一点,Dask 也能充分发挥作用。代码不需要进行重大更改。
你可以使用 Dask 在笔记本电脑的多个核心之间分配你的凸优化例程或超参数搜索。或者,你可以根据某些过滤条件,利用完整的多核并行处理不同部分的简单 DataFrame。这为所有数据科学家和分析师提供了提升生产力的可能性,他们无需购买昂贵的显卡,而只需投资于具有 16 或 24 个 CPU 核心的工作站。
GPU 驱动的分布式数据科学总结
在本文中,我们讨论了一些 Python 数据科学生态系统中的新进展,使得普通数据科学家、分析师、科学研究人员和学术人员可以使用 GPU 驱动的硬件系统来处理比图像分类和自然语言处理更广泛的数据相关任务。这无疑会扩大这些硬件系统对广大用户群体的吸引力,并进一步民主化数据科学用户基础。
我们还探讨了使用 Dask 库进行分布式分析的可能性,这可以利用多核 CPU 工作站。
希望这种强大硬件与现代软件栈的融合能够为高效的数据科学工作流开辟无尽的可能性。
原文。经许可转载。
相关:
-
如何使用 NVIDIA GPU 加速库
-
告别大数据,迎接海量数据!
-
抽象与数据科学:不太理想的组合
更多相关话题
深度学习阅读组:Skip-Thought 向量
原文:
www.kdnuggets.com/2016/11/deep-learning-group-skip-thought-vectors.html

继续我们从ResNet 博客文章开始的旧论文巡展,我们现在探讨Kiros的Skip-Thought 向量等。他们的目标是提出一种有用的句子嵌入,该嵌入未针对单一任务进行调整,并且不需要标记数据进行训练。他们从 Word2Vec skip-gram 获取灵感(你可以在这里找到我对该算法的解释),并试图将其扩展到句子。
Skip-thought 向量是使用编码器-解码器模型创建的。编码器接收训练句子并输出一个向量。解码器有两个,都以向量作为输入。第一个尝试预测前一句话,第二个尝试预测下一句话。编码器和解码器都由递归神经网络(RNN)构建。尝试了多种编码器类型,包括 uni-skip、bi-skip 和 combine-skip。Uni-skip 以正向阅读句子。Bi-skip 既正向又反向阅读句子,并将结果连接起来。Combined-skip 将 uni-skip 和 bi-skip 的向量连接起来。对输入句子只进行了最小限度的标记化。下图显示了输入句子和两个预测句子。

给定一个句子(灰点),skip-thought 尝试预测前一句话(红点)和下一句话(绿点)。图示来自论文。
他们的模型需要句子组进行训练,因此在 BookCorpus 数据集上进行训练。该数据集由未出版作者的小说组成,(不足为奇) 被浪漫和奇幻小说主导。这种数据集中的“偏见”将在后面讨论一些用于测试 skip-thought 模型的句子时变得明显;一些检索到的句子非常令人兴奋!
构建考虑整个句子意义的模型很困难,因为语言非常灵活。改变一个词语可能会完全改变句子的意义,也可能不会改变句子。移动词语也是如此。举个例子:
构建处理句子的模型的一个难点在于单个词语的改变可能不会改变句子的意义。
换句话说:
构建处理句子的模型的一个挑战在于单个词语的改变可能不会改变句子的意义。
改变一个单词几乎没有对句子的意义产生影响。为了处理这些单词层级的变化,skip-thought 模型需要能够处理大量词汇,其中一些在训练句子中并不存在。作者通过使用预训练的连续词袋(CBOW)Word2Vec 模型,并学习从 Word2Vec 向量到他们句子中的词向量的翻译来解决这个问题。以下展示了在词汇扩展后,使用未出现在训练词汇中的查询词的最近邻词:
未包含在训练词汇中的各种单词的最近邻词。表格来自论文。
那么模型的效果如何呢?一种探测方法是检索与查询句子最接近的句子;以下是一些例子:
查询:“我相信你今晚会有一个辉煌的夜晚,”她说,夸张地眨了眨眼。
检索结果:“我真的很高兴你今晚来参加聚会,”他说,转向她。
还有:
查询:虽然她可以告诉他对他们其他的闲聊不太感兴趣,但他似乎对这个话题真的很感兴趣。
检索结果:虽然他并没有用显微镜跟踪她的职业生涯,但他肯定注意到了她的外貌。
这些句子在结构和意义上实际上非常相似(如我之前警告的那样,有点猥亵),因此模型似乎表现良好。
为了进行更严格的实验,并测试 skip-thought 向量作为通用句子特征提取器的价值,作者通过一系列任务运行模型,使用编码向量和在其上训练的简单线性分类器。
他们发现,通用的 skip-thought 表示在检测两个句子的语义相关性和检测句子是否在释义另一个句子方面表现非常好。Skip-thought 向量在图像检索和标注中表现相对良好(在这些任务中,他们使用了VGG来提取图像特征向量)。Skip-thought 在情感分析中的表现较差,产生的结果与各种词袋模型相当,但计算成本高得多。
我们在实验室中使用了 skip-thought 向量,最近用于Pythia 挑战赛。我们发现它们在新颖性检测中很有用,但速度极慢。在约 20,000 份文档的语料库上运行 skip-thought 向量需要很多小时,而更简单(且同样有效)的方法只需几秒钟或几分钟。当他们的博客文章上线时,我会更新链接。
亚历山大·古德 目前是 Lab41 的数据科学家,专注于研究推荐系统算法。他拥有加州大学伯克利分校的物理学学士学位和明尼苏达大学双城分校的基本粒子物理学博士学位。
Lab41 是一个“挑战实验室”,美国情报界与学术界、工业界和 In-Q-Tel 的同行们汇聚一堂,共同应对大数据挑战。它允许来自不同背景的参与者接触到创意、人才和技术,探索数据分析中的有效方法和无效方法。Lab41 提供了一个开放、协作的环境,促进参与者之间宝贵的关系。
原文。已获许可转载。
相关:
-
深度学习中,架构工程是新的特征工程
-
深度学习最新进展:7 月更新
-
深度学习网络为何能够扩展?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
使用 R 进行 H2O 中的深度学习
评论
 这篇文章介绍了如何在 R 中使用 H2O 包进行深度学习。
这篇文章介绍了如何在 R 中使用 H2O 包进行深度学习。
H2O 是一个开源的人工智能平台,允许我们使用机器学习技术,如朴素贝叶斯、K 均值、PCA、深度学习、使用深度学习的自编码器等。使用 H2O,我们可以在 R、Python、Scala 等编程环境中构建预测模型,还可以通过一个称为 Flow 的基于 Web 的 UI 进行操作。
I. 深度学习:背景
深度学习是受人脑和神经系统功能启发的机器学习算法的一个分支。输入数据被固定到深度网络的输入层。网络随后使用层次化的隐藏层,逐步生成输入数据的紧凑、更高级的抽象(表示)。因此,它生成输入特征的伪特征。具有3 层或更多层的神经网络被认为是“深度”的。
作为一个例子,对于面部检测任务,原始输入通常是一个像素值向量。第一次抽象可能识别光影像素;第二次抽象可能识别边缘和形状;第三次抽象可能将这些边缘和形状组合成眼睛、鼻子等部分;下一个抽象可能将这些部分组合成一个面孔。因此,通过简单表示的组合来学习复杂的表示。
在输出层,计算网络误差(成本)。这个成本通过一种称为随机梯度下降的方法逐步最小化,并通过一种称为反向传播的算法向后传播到输入层。这会导致网络中权重和偏置的重新校准。使用新的权重,新的表示被向前传播到输出层,并再次检查网络误差。前向和后向传播的过程会持续进行,直到权重被调整到准确预测输出为止。
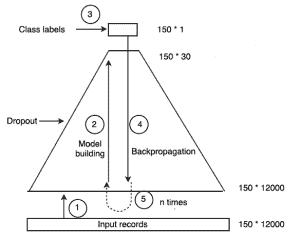
图 1:示意深度学习的金字塔 (来源)
对于图 1,我们考虑一个 150 * 12000 维的输入数据集(150 行,12000 列)。我们创建一个具有 4 个隐藏层的深度网络,包含 4000、750、200、30 个神经元。输入层中的所有 12000 个数据点都用于构建第一个隐藏层的 4000 个伪特征。由于这里网络的规模逐渐减小到最后一个隐藏层,它形成了一个金字塔。图中显示的 5 个步骤如下所述。
步骤 1: 将输入记录(150* 12000)输入到网络中。
步骤 2: 深度学习算法开始学习数据集中的固有模式。它通过将权重和偏置关联到从输入层和隐藏层形成的每个特征来实现。这是模型构建阶段。随着它通过每个连续的隐藏层,它形成了数据的更窄的抽象。每个抽象将前一层的抽象作为输入。
Dropout 是在模型构建阶段指定的超参数。
步骤 3: 经过最后一个隐藏层后,形成了 150* 30 特征的抽象。类别标签(150* 1)暴露于此抽象中。到目前为止,它仍然是一个前馈神经网络。
步骤 4: 类别标签帮助模型将结果与为每个输入记录创建的模式相关联。因此,现在可以调整权重和偏置,以更好地匹配标签并最小化成本(记录的预测输出与实际输出之间的差异)。
随机梯度下降使用随机训练集样本迭代以最小化成本。这是通过从输出层向输入层反向传播来实现的,称为反向传播。反向传播训练深度网络,使用随机梯度下降算法。
步骤 5: 反向传播发生了 n 次,其中 n = 纪元数,或者直到权重没有变化为止。
II. H2O 中的深度学习:
H2O 中的深度学习本地实现为多层感知器(MLP)。但是,H2O 还允许我们构建自编码器(自编码器是一个神经网络,它接受一组输入,对其进行压缩和编码,然后尝试尽可能准确地重建输入)。可以通过 H2O 的 Deep Water 项目 通过其他深度学习库(如 Caffe 和 TensorFlow)的第三方集成来构建递归神经网络和卷积神经网络。
用户需要指定深度学习模型的超参数值。参数指的是深度学习模型的权重和偏置。超参数是设计神经网络所需的选项,如层数、每层的节点数、激活函数、正则化器的选择等。
全局模型参数的计算可以在单个节点或多节点集群上运行。对于多节点集群,全局模型参数的副本在计算节点的本地数据上进行训练,通过多线程和分布式并行计算。模型在网络中进行平均,每个计算节点定期对全局模型做出贡献。
H2O 深度学习模型的一些特性包括:
1) 自动 ‘adaptive learning rate:
ADADELTA 算法(‘adaptive_rate’ 超参数)用于加快收敛速度和减少在峡谷周围的振荡,提供一个名为 ‘rate_annealing’ 的可选值,以在模型接近优化空间中的最小值时减慢学习率。
2) 模型正则化:
为了避免过拟合,H2O 的深度学习使用 l1 和 l2 正则化,并且使用 ‘dropouts’ 的概念。
-
l1: l1 约束权重的绝对值。它使许多权重变为 0。
-
l2: l2 约束权重的平方和。它使许多权重变得很小。
-
input_dropout_ratio: input_dropout_ratio 指每个训练记录中要丢弃/省略的特征的比例,以提高泛化能力。例如,‘ input_dropout_ratio = 0.1’ 表示 10% 的输入特征被丢弃。
-
hidden_dropout_ratios: hidden_dropout_ratios 指每个隐藏层中要丢弃/省略的特征的比例,以提高模型的泛化能力。例如,‘ hidden_dropout_ratios = c( 0.1, 0.1)’ 表示在一个有两个隐藏层的深度学习模型中,每个隐藏层中有 10% 的隐藏特征被丢弃。
3) 模型检查点:
检查点(使用其键 = ‘model_id’)用于在更多数据、更改超参数等情况下恢复先前保存模型的训练。
4) 网格搜索:
为了比较模型的性能并调整超参数值,网格搜索模型训练了通过组合超参数集合获得的所有可能模型。
下面的示例 (source) 显示了 3 种不同的隐藏层拓扑结构和神经元数量,2 种不同的 l1 正则化值。因此,模型 Model_Grid1 训练了 6 种不同的模型。
- H2O 还允许对 training_frame 执行交叉验证,并且还可以实现 GBM 方法(梯度提升机)。
III. 深度学习的常见 R 命令:
从 这个来源:
-
library(h2o): 导入 H2O R 包。
-
h2o.init(): 连接到(或启动)H2O 集群。
-
h2o.shutdown(): 关闭 H2O 集群。
-
h2o.importFile(path): 将文件导入 H2O。
-
h2o.deeplearning(x,y,training frame,hidden,epochs): 创建一个深度学习模型。
-
h2o.grid(algorithm,grid id,...,hyper params = list()): 启动 H2O 网格支持并给出结果。
-
h2o.predict(model, newdata): 从 H2O 模型生成对测试集的预测。
IV. R 脚本:
我使用了 UCI 机器学习的'Pima Indians'数据集。
相关:
-
基于 H2O 的物联网深度学习
-
深度学习和其他机器学习分类器的决策边界
-
访谈:Arno Candel,H20.ai 谈如何快速启动 H2O 深度学习
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
更多相关话题
深度学习 – 学习和理解的重要资源
原文:
www.kdnuggets.com/2014/08/deep-learning-important-resources-learning-understanding.html
作者:Gregory Piatetsky,@kdnuggets,2014 年 8 月 21 日
深度学习是目前最热门的机器学习方法,并且因取得显著成果而频频上新闻。在最近的大规模视觉识别挑战赛 (结果,纽约时报文章) 中,准确率几乎翻了一番(从 22.5% 提升至 43.9%),错误率则从 11.7% 降至仅 6.6%。
 值得注意的是,几乎所有参赛者都使用了一种称为卷积神经网络的变体方法 (ConvNet),这种方法最初由 NYU 教授 Yann LeCun 在 1998 年进行了完善,LeCun 最近被聘为 Facebook 人工智能研究中心的负责人。
值得注意的是,几乎所有参赛者都使用了一种称为卷积神经网络的变体方法 (ConvNet),这种方法最初由 NYU 教授 Yann LeCun 在 1998 年进行了完善,LeCun 最近被聘为 Facebook 人工智能研究中心的负责人。
这里有更多资源帮助你了解深度学习和卷积神经网络
-
我的文章 在哪里学习深度学习 - 课程、教程、软件
-
KDnuggets 独家 与 Yann LeCun 的访谈,第一部分,以及 第二部分
深度学习 书稿,作者:Yoshua Bengio、Ian Goodfellow 和 Aaron Courville
软件:
-
cuda-convnet,一个快速的 C++ 实现卷积神经网络(或者更一般的,前馈神经网络)
-
pylearn2 GitHub 页面,一个 Python 机器学习库,包含 Deep Learning 的 maxout 代码
-
视觉特征层次学习
-
使用机器学习构建人工视觉系统
-
PCMI 夏季学校的 5 节讲座:介绍、基于能量的学习、多阶段学习、卷积网络、无监督深度学习等
深度学习的基础论文 - 来自 Yoshua Bengio 的 Quora 回答。
这里是精选论文:
-
快速学习算法用于深度信念网络,作者:Geoff Hinton 等
-
在 MNIST 数字上训练深度自编码器或分类器,由 Ruslan Salakhutdinov 和 Geoff Hinton 编写的代码
-
深度玻尔兹曼机,由 Ruslan Salakhutdinov 和 Geoff Hinton 编写
-
学习深度玻尔兹曼机,由 Ruslan Salakhutdinov 编写的代码
-
Maxout 网络,由 Ian Goodfellow 等人编写
优秀的深度学习简介:从感知机到深度网络,由 Toptal 的 Ivan Vasilev 提供
另一个优秀的演示文稿是在 Hadoop 下一代 YARN 框架上进行并行迭代深度学习介绍,由 Adam Gibson 和 Josh Patterson 制作。
相关:
-
深度学习是否存在深层缺陷?
-
学习深度学习的去处 - 课程、教程、软件
-
KDnuggets 独家:采访 Yann LeCun,深度学习专家,Facebook AI 实验室主任
-
KDnuggets 独家采访 Yann LeCun,第二部分
-
深度学习分析如何模拟大脑
我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT
更多相关内容
深度学习关键术语解释
原文:
www.kdnuggets.com/2016/10/deep-learning-key-terms-explained.html
深度学习因其在多个领域取得了令人瞩目的成功而研究和产业上都在快速发展。深度学习是应用深度神经网络技术——即具有多个隐藏层的神经网络架构——来解决问题的过程。深度学习是一个过程,类似于数据挖掘,它使用深度神经网络架构,这些架构是特定类型的机器学习算法。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
深度学习在过去几年中取得了令人印象深刻的成就。鉴于此,至少在我看来,重要的是要记住以下几点:
-
深度学习不是灵丹妙药 - 它不是一个适用于所有问题的简单解决方案。
-
它不是传说中的万能算法 - 深度学习不会取代所有其他机器学习算法和数据科学技术,或者至少,它尚未证明如此。
-
适度的期望是必要的 - 尽管在所有类型的分类问题中,特别是计算机视觉和自然语言处理以及强化学习和其他领域,最近取得了巨大进展,但当代深度学习并不能解决诸如“解决世界和平”等非常复杂的问题。
-
深度学习和人工智能不是同义词
-
深度学习可以为数据科学提供大量的额外过程和工具来帮助解决问题,从这个角度看,深度学习是数据科学领域的一个非常有价值的补充。
那么,让我们看看一些与深度学习相关的术语,专注于简明扼要的定义。
1. 深度学习
如上所定义,深度学习是应用深度神经网络技术来解决问题的过程。深度神经网络是具有至少一个隐藏层的神经网络(见下文)。类似于数据挖掘,深度学习指的是一种过程,它采用深度神经网络架构,这些架构是特定类型的机器学习算法。
2. 人工神经网络
机器学习架构最初是受生物大脑(特别是神经元)的启发,从而实现深度学习。实际上,人工神经网络(ANNs)本身(非深度类型)已经存在很长时间,并且历史上能够解决某些类型的问题。然而,相对较近的时间内,神经网络架构被设计出来,包含了隐藏神经元层(不仅仅是输入层和输出层),这种附加的复杂性使得深度学习成为可能,并提供了一套更强大的问题解决工具。
ANNs 的架构实际上变化很大,因此没有明确的神经网络定义。所有 ANNs 通常引用的两个特征是具有适应性权重集和近似神经元输入的非线性函数的能力。
3. 生物神经元
通常会强调生物神经网络与人工神经网络之间的明确联系。流行的出版物传播的观点是,人工神经网络在某种程度上是对人类(或其他生物)大脑发生的情况的精确复制。这显然是不准确的;充其量,早期的人工神经网络受到生物学的启发。这两者之间的抽象关系不比原子组成与太阳系功能之间的抽象比较更为明确。
话虽如此,了解生物神经元在很高层次上的工作方式对我们还是有益的,至少可以帮助我们理解人工神经网络的灵感来源。
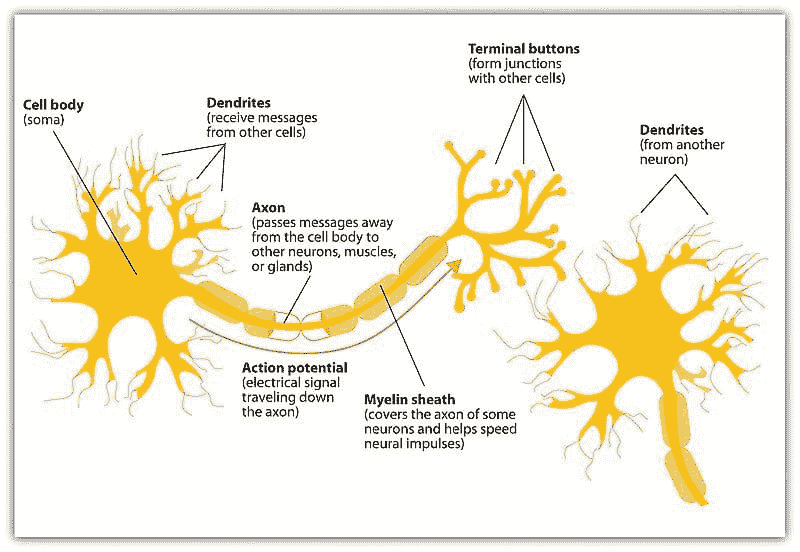
图片来源:维基百科
对我们感兴趣的生物神经元的主要组件有:
-
细胞核储存遗传信息(即 DNA)
-
细胞体处理输入激活并将其转换为输出激活
-
树突接收来自其他神经元的激活
-
轴突将激活传输到其他神经元
-
轴突末端与相邻的树突一起形成神经元之间的突触
化学物质称为神经递质,然后扩散穿过突触间隙,在轴突末端和相邻的树突之间形成神经递质传输。神经元的基本操作是,激活通过树突流入神经元,经过处理后,通过轴突及其轴突末端重新传输,在这里穿过突触间隙,达到许多接收神经元的树突,过程重复进行。
4. 感知器
感知器是一种简单的线性二分类器。感知器接收输入和相关的权重(表示相对输入的重要性),并将它们组合生成输出,然后用于分类。感知器存在了很长时间,早期的实现可以追溯到 1950 年代,其中的第一个实现涉及早期的 ANN 实现。
5. 多层感知机
多层感知机(MLP)是几个完全相邻连接的感知机层的实现,形成一个简单的前馈神经网络(见下文)。这个多层感知机具有非线性激活函数的额外优点,这是单层感知机所不具备的。
6. 前馈神经网络
前馈神经网络是最简单的神经网络架构形式,其中连接是非周期性的。原始的人工神经网络中,信息在前馈网络中单向从输入节点流向输出节点,经过任何隐藏层;没有循环。前馈网络与后来的循环网络架构不同(见下文),后者中的连接形成一个有向循环。
7. 循环神经网络
与上述前馈神经网络相对的是,循环神经网络的连接形成一个有向循环。这种双向流动允许内部时间状态的表示,这反过来允许序列处理,并且,值得注意的是,提供了识别语音和手写的必要能力。
8. 激活函数
在神经网络中,激活函数通过结合网络的加权输入来生成输出决策边界。激活函数的范围从恒等函数(线性)到 sigmoid 函数(逻辑函数或软阶跃)再到双曲正切函数及其他。为了使用反向传播(见下文),网络必须使用可微的激活函数。
9. 反向传播
我见过的最简明的基本反向传播定义来自数据科学家Mikio L. Braun,他在Quora上给出了如下回答,我将其逐字转述,以保持其简单的完美:
反向传播只是对个别错误的梯度下降。你将神经网络的预测与期望输出进行比较,然后计算错误相对于神经网络权重的梯度。这为你提供了在参数权重空间中使错误变小的方向。
10. 成本函数
训练神经网络时,必须评估网络输出的正确性。由于我们知道训练数据的期望正确输出,可以对比训练输出。成本函数衡量实际输出与期望输出之间的差异。如果实际输出与期望输出之间的成本为零,则表示网络已经以可能的最佳方式进行训练;这显然是理想的。
那么,成本函数是通过什么机制进行调整的,以实现最小化的目标呢?
11. 梯度下降
梯度下降是一种优化算法,用于寻找函数的局部极小值。虽然它不能保证全局最小值,但梯度下降对于那些难以通过解析方法精确求解的函数尤其有用,比如设置导数为零并求解。
如上所述,在神经网络的背景下,随机梯度下降用于对网络的参数进行有信息的调整,目标是最小化成本函数,从而使网络的实际输出逐步接近预期输出。这种迭代的最小化使用了微积分,特别是微分。在每次训练步骤后,网络权重根据成本函数的梯度和网络当前的权重进行更新,以便下一次训练步骤的结果可能更接近正确(通过较小的成本函数来衡量)。反向传播(误差的反向传播)是用于将这些更新分配到网络的方法。
12. 消失梯度问题
反向传播使用链式法则来计算梯度(通过微分),即在* n* 层神经网络的“前面”(输入)层,其小数量的更新梯度值会被乘以n次,然后将这一稳定值用作更新。这意味着梯度会呈指数级减少,这是较大值的n的一个问题,前面层需要更长时间才能有效训练。
13. 卷积神经网络
通常与计算机视觉和图像识别相关,卷积神经网络(CNNs)运用卷积的数学概念来模拟生物视觉皮层的神经连接网。
首先,卷积如 Denny Britz 详尽描述的那样,可以被视为在图像的矩阵表示上滑动的窗口(见下文)。这允许松散地模拟生物视觉场的重叠铺排。
图片来源:Analytics Vidhya
在神经网络架构中实施这一概念会导致专门处理图像部分的神经元集合,至少在计算机视觉中是这样。当在其他领域使用时,如自然语言处理,同样的方法可以应用,因为输入(单词、句子等)可以被排列成矩阵,并以类似的方式处理。
14. 长短期记忆网络
长短期记忆网络(LSTM)是一种递归神经网络,优化用于学习和处理时间相关的数据,这些数据可能在相关事件之间有不确定或未知的时间间隔。它们特有的架构允许持久性,为人工神经网络提供了“记忆”。最近在手写识别和自动语音识别领域的突破受益于 LSTM 网络。
图片来源: 克里斯托弗·奥拉赫
这显然只是深度学习术语的一个小子集,许多额外的概念,从基础到高级,等待着你在深入了解当前领先的机器学习研究领域时去探索。
马修·梅约 (@mattmayo13)是一名数据科学家,同时也是 KDnuggets 的总编辑,KDnuggets 是一个开创性的在线数据科学和机器学习资源。他的兴趣领域包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。马修拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系到。
更多相关内容
深度学习会取代机器学习,使其他算法过时吗?
原文:
www.kdnuggets.com/2014/10/deep-learning-make-machine-learning-algorithms-obsolete.html
深度学习迅速发展,并以惊人的经验结果让我们感到惊讶。关于深度学习是否会使其他机器学习算法过时,在 Quora 上有讨论。具体来说,像反向传播、HMM 这样的相关算法是否会像感知机一样过时?
哦,很难回答。Jack Rae 提供了一个有趣的回答,他说
过去几年的经验结果表明,当数据集足够大时,深度学习提供了最佳的预测能力。这是真的吗?我不知道在过去一年中是否有超过一亿行数据的预测能力被击败的例子。
他认为,深度学习将把其他学习算法推向灭绝的边缘,这是因为深度学习在中到大型数据集上的无与伦比的预测能力。其他算法会在人们开始将深度学习视为一些问题(如模式识别)的首选解决方案时变得过时。
另一方面,大多数人仍然相信深度学习不会取代所有其他模型和算法。Jacob Steinhart 的观点获得了最多的赞同。他写道
1. 对于许多应用来说,像逻辑回归或支持向量机这样的简单算法就足够了,而使用深度信念网络只会让事情变得复杂。
2. 虽然深度信念网络是最好的领域无关算法之一,但如果有人具备领域知识,那么许多其他算法(如用于语音识别的 HMM、用于图像的波形等)可以超越它们。虽然正在进行一些将领域知识融入神经网络模型的工作,但显然还不够,无法完全替代所有其他模型和算法。

上面是由 Eren Golge 创建的机器学习时间轴。
深度学习将成为主流,就像支持向量机(SVM)一样,后者在 2000 年代初期得到了迅速改进。然而,深度学习的复杂性及其对大量数据的需求仍然需要解决,才能使深度学习成为机器学习算法的首选。
Ran Bi 是纽约大学数据科学项目的硕士生。在 NYU 学习期间,她参与了多个机器学习、深度学习以及大数据分析的项目。
相关链接:
-
深度学习 – 学习和理解的重要资源
-
深度学习是否存在深层缺陷?
-
CuDNN – 一个新的深度学习库
我们的前三推荐课程
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
相关主题
大众的深度学习(……以及语义层)
原文:https://www.kdnuggets.com/2018/11/deep-learning-masses-semantic-layer.html


深度学习介绍
本文的范围并不是介绍深度学习,我在其他文章中已经做过了,你可以在这里找到:
[一个“奇怪”的深度学习介绍
有许多令人惊叹的深度学习介绍、课程和博客文章。但这是一种不同类型的介绍……towardsdatascience.com](https://towardsdatascience.com/a-weird-introduction-to-deep-learning-7828803693b0)
[我进入深度学习的旅程
在这篇文章中,我将分享我如何学习深度学习以及如何用它解决数据科学问题。这是一个……towardsdatascience.com](https://towardsdatascience.com/my-journey-into-deep-learning-c66e6ef2a317)
[关于深度学习的对话
有人偷听到两个人谈论深度学习,并把每个细节都告诉了我。其中一个人完全是……towardsdatascience.com](https://towardsdatascience.com/a-conversation-about-deep-learning-9a915983107)
但如果你想从这里尝试一下,我可以这样告诉你:
…深度学习是利用不同种类的神经网络[深度神经网络]进行表示学习,并优化网络的超参数,以获得(学习)最佳的数据表示。
如果你想知道这从哪里来,阅读上述文章。
深度学习并不那么难

这更难
目前,对于组织而言,深度学习并不是那么难。我不是说深度学习整体上很简单,研究这个领域需要大量的数学、微积分、统计学、机器学习、计算等知识。你可以从我之前制作的时间线上看到深度学习的来源。

从那里我可以说,反向传播、网络参数的更好初始化、更好的激活函数、Dropout 概念以及卷积神经网络、残差网络、区域基础 CNN、递归神经网络和生成对抗网络等一些网络类型,是我们在深度学习领域取得的最重要进展之一。
但你现在怎么使用深度学习呢?

hehe
数据优先

哦,你可能会想成为他们。对吧?或者可能不是,我不知道。
你想知道秘密吗?那些大科技公司使用的秘密武器?这不仅仅是深度学习(也许根本不是深度学习)
我不会在这里做完整的演讲,但一切都从数据开始。正如你可以想象的那样,数据现在是公司最重要的资产(也许是最重要的)。所以,在你能应用机器学习或深度学习之前,你需要拥有数据,知道你拥有的是什么,理解它,管理它,清理它,分析它,标准化它(也许还要更多),然后你才能考虑如何使用它。
从 Brian Godsey 的精彩 文章 中可以看出:
无论何种形式,数据现在无处不在,与其说它只是分析师用来得出结论的工具,不如说它已经成为自身的目的。公司现在似乎将数据视为最终目标,而非手段,尽管许多公司声称计划在未来使用这些数据。独立于信息时代的其他定义特征,数据获得了自己的角色、自己的组织和自己的价值。
所以你可以看到,这不仅仅是将最新的算法应用于你的数据,而是能够将数据以良好的格式呈现出来,并理解它,然后再使用它。
语义层

这些层次是有意义的。不过,这不是语义层。继续阅读。
这对我来说是很不寻常的,但我做了很多调查,并与几家公司合作,它们似乎都有相同的问题:它们的数据。
数据的可用性、数据质量、数据摄取、数据集成等常见问题,不仅会影响数据科学实践,还会影响整个组织。
清理数据并为机器学习做好准备的方法有很多,也有很棒的工具和方法论,你可以在这里阅读更多信息:
[宣布 Optimus v2——敏捷数据科学工作流简化版]
寻找一个可以显著提高你作为数据科学家生产力的库?快来看看这个! towardsdatascience.com
但这假设你已经有了摄取和集成数据的流程。现在有很棒的工具用于 AutoML,我之前已经讨论过这个问题:
[Auto-Keras,或如何在 4 行代码中创建深度学习模型]
自动化机器学习是新来的,它将长期存在。它帮助我们不断创造更好的… www.kdnuggets.com
以及像 DataRobot 这样的其他商业工具:
[用于预测建模的自动化机器学习 | DataRobot]
DataRobot 的自动化机器学习平台使构建和部署准确的预测模型变得快速而简单… www.datarobot.com
那么自动化摄取和集成呢?
这就是语义层的惊人好处之一。但到底什么是语义层呢?
语义一词本身意味着意义或理解。因此,语义层与数据相关的是其含义,而不是数据的结构。
理解是一个非常重要的过程,我之前已经提到过:
在这篇文章中,我将展示数据科学如何通过 AI 实现智能。 towardsdatascience.com
在这里我提到(来自 Lex Fridman):
理解是将复杂信息转化为简单、有用**信息的能力。
当我们理解时,我们是在解码构成这一复杂事物的部分,并将最初获得的原始数据转化为有用且易于理解的东西。我们通过建模来实现这一点。正如你可以想象的那样,我们需要这样的模型来理解数据的意义。
链接数据和知识图谱

我们需要做的第一件事是链接数据。链接数据的目标是以一种结构化的方式发布数据,使其能够被轻松地消耗并与其他链接数据结合。
链接数据是 Web 上数据发布和互操作性的新的事实标准,也正在进入企业。像 Google、Facebook、Amazon 和 Microsoft 这样的巨头,已经采用了其中的一些原则。
数据链接的过程是一个称为知识图谱的开端。知识图谱是一种高级的方式,用于映射某一特定主题的所有知识,以填补数据如何关联的空白,或数据库中的虫洞。
知识图谱由集成的数据和信息集合组成,这些集合还包含了大量不同数据之间的链接。
关键在于,在这种新模型下,我们不是寻找可能的答案,而是在寻求一个答案。我们需要的是事实——这些事实的来源并不那么重要。
这里的数据可以代表概念、对象、事物、人,实际上你脑海中的任何东西。图谱填补了这些概念之间的关系和连接。
这里是 Google 在 6 年前(对,就是 6 年)对知识图谱的一个惊人介绍:
知识图谱对你和你的公司意味着什么?
以旧式方式,数据仓库中的数据模型虽然是一个了不起的成就,但无法吸收涌向我们的庞大数据量。创建关系数据模型的过程实在跟不上。此外,用于推动数据发现的数据提取也过于有限。
基于 Hadoop 或云存储的数据湖因此已经变成了数据沼泽——缺乏必要的管理和治理能力。

https://timoelliott.com/blog/2014/12/from-data-lakes-to-data-swamps.html
你是否问过你的数据工程师和科学家,他们是否理解你们组织拥有的所有数据?请这么做。
分析你拥有的所有数据是极其困难的。并理解背后的关系是什么。
因为它们是图形,知识图谱更为直观。人们不会以表格的形式思考,但他们可以立刻理解图形。当你在白板上画出知识图谱的结构时,大多数人能立即明白它的意义。
知识图谱还允许你为图谱中的关系创建结构。你可以告诉图谱父母有孩子,父母可以是孩子,孩子可以是兄弟或姐妹,这些都是人。提供这样的描述信息允许从图谱中推断出新的信息,比如如果两个人有相同的父母,他们必须是兄弟姐妹。
我们的前三大课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌IT支持专业证书 - 支持你的组织IT需求
更多相关话题
-
关于语义分割注释的误解
持你的组织进行 IT 工作
更多相关话题
在手机上进行深度学习:用于移动平台的 PyTorch C++ API
原文:
www.kdnuggets.com/2021/11/deep-learning-mobile-phone-pytorch-c-api.html
评论
作者:Dhruv Matani,Meta(Facebook)的软件工程师。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织在 IT 方面
PyTorch 是一个用于训练和运行机器学习(ML)模型的深度学习框架,加快了从研究到生产的速度。
PyTorch C++ API 可以用来编写紧凑的、对性能敏感的代码,具有深度学习能力,在移动平台上执行 ML 推理。有关如何将 PyTorch 模型部署到生产环境的一般介绍,请参见 这篇文章。
PyTorch Mobile 当前支持在 Android 和 iOS 平台上部署预训练模型进行推理。
高级步骤
-
训练一个模型(或获取一个预训练的模型),并保存为 lite-interpreter 格式。PyTorch 模型的 lite-interpreter 格式使模型兼容于移动平台运行。本文未涵盖此步骤。
-
下载 PyTorch 源代码,并 从源代码构建 PyTorch。这对于移动部署是推荐的。
-
创建一个 .cpp 文件,包含加载模型、使用 forward() 运行推理并打印结果的代码。
-
构建 .cpp 文件,并链接到 PyTorch 共享对象文件。
-
运行文件并查看输出。
-
获利!
详细步骤
从源代码下载并安装 PyTorch 到 Linux 机器上。
对于其他平台,请参见 这个链接。
# Setup conda and install dependencies needed by PyTorch
conda install astunparse numpy ninja pyyaml mkl mkl-include setuptools cmake cffi typing_extensions future six requests dataclasses
# Get the PyTorch source code from github
cd /home/$USER/
# Repo will be cloned into /home/$USER/pytorch/
git clone --recursive https://github.com/pytorch/pytorch
cd pytorch
# if you are updating an existing checkout
git submodule sync
git submodule update --init --recursive --jobs 0
# Build PyTorch
export CMAKE_PREFIX_PATH=${CONDA_PREFIX:-"$(dirname $(which conda))/../"}
python setup.py install
创建源代码 .cpp 文件
将 .cpp 文件存储在与您的 AddTensorsModelOptimized.ptl 文件相同的文件夹中。我们称这个 C++ 源文件为 PTDemo.cpp。我们称这个目录为 /home/$USER/ptdemo/。
#include <ATen/ATen.h>
#include <torch/library.h>
#include <torch/csrc/jit/mobile/import.h>
#include
using namespace std;
int main() {
// Load the PyTorch model in lite interpreter format.
torch::jit::mobile::Module model = torch::jit::_load_for_mobile(
"AddTensorsModelOptimized.ptl");
std::vector inputs;
// Create 2 float vectors with values for the 2 input tensors.
std::vector v1 = {1.0, 5.0, -11.0};
std::vector v2 = {10.0, -15.0, 9.0};
// Create tensors efficiently from the float vector using the
// from_blob() API.
std::vector dims{static_cast(v1.size())};
at::Tensor t1 = at::from_blob(
v1.data(), at::IntArrayRef(dims), at::kFloat);
at::Tensor t2 = at::from_blob(
v2.data(), at::IntArrayRef(dims), at::kFloat);
// Add tensors to inputs vector.
inputs.push_back(t1);
inputs.push_back(t2);
// Run the model and capture results in 'ret'.
c10::IValue ret = model.forward(inputs);
// Print the return value.
std::cout << "Return Value:\n" << ret << std::endl;
// You can also convert the return value into a tensor and
// fetch the underlying values using the data_ptr() method.
float *data = ret.toTensor().data_ptr();
const int numel = ret.toTensor().numel();
// Print the data buffer.
std::cout << "\nData Buffer: ";
for (int i = 0; i < numel; ++i) {
std::cout << data[i];
if (i != numel - 1) {
std::cout << ", ";
}
}
std::cout << std::endl;
}
注意:我们使用来自at::命名空间的符号,而不是torch::命名空间(这是 PyTorch 网站教程中使用的),因为对于移动构建,我们不会包含完整的 jit(TorchScript)解释器。相反,我们将仅访问 lite-interpreter。
构建和链接
# This is where your PTDemo.cpp file is
cd /home/$USER/ptdemo/
# Set LD_LIBRARY_PATH so that the runtime linker can
# find the .so files
LD_LIBRARY_PATH=/home/$USER/pytorch/build/lib/
export LD_LIBRARY_PATH
# Compile the PTDemo.cpp file. The command below should
# produce a file named 'a.out'
g++ PTDemo.cpp \
-I/home/$USER/pytorch/torch/include/ \
-L/home/$USER/pytorch/build/lib/ \
-lc10 -ltorch_cpu -ltorch
运行应用程序
./a.out
命令应输出以下内容:
Return Value:
11
-5
8
[ CPUFloatType{3} ]
Data Buffer: 11, -5, 8
结论
在本文中,我们看到如何使用跨平台的 C++ PyTorch API 加载一个经过训练的 lite-interpreter 模型,并使用该模型进行推理。所使用的 C++代码是平台无关的,可以在所有支持 PyTorch 的移动平台上构建和运行。
参考文献
简介: Dhruv Matani 是 Meta(Facebook)的软件工程师,他领导与 PyTorch(开源 AI 框架)相关的项目。他是 PyTorch 内部结构、PyTorch Mobile 的专家,并且是 PyTorch 的重要贡献者。他的工作影响着全球数十亿用户。他在为 Facebook 数据平台构建和扩展基础设施方面有着丰富的经验。值得注意的是,他对 Facebook 实时数据分析平台 Scuba 的贡献,该平台用于快速获取产品和系统洞察。他拥有石溪大学计算机科学硕士学位。
相关:
更多相关主题
深度学习与 NLP:使用 Keras 创建聊天机器人!
原文:
www.kdnuggets.com/2019/08/deep-learning-nlp-creating-chatbot-keras.html
评论
由 Jaime Zornoza,马德里理工大学

在上一篇文章中,我们了解了人工神经网络和深度学习是什么。还介绍了一些用于处理序列数据(如文本或音频)的神经网络结构。如果你还没有阅读那篇文章,你应该放松一下,拿杯咖啡,慢慢享受它。它可以在这里找到。
这篇新文章将讲解如何使用 Keras,这是一个非常流行的神经网络库来构建聊天机器人。将解释该库的主要概念,然后我们将逐步指南如何使用它来创建一个“是/否回答机器人”的 Python 示例。我们将利用 Keras 的简便性来实现来自 Sukhbaatar 等人论文中的 RNN 结构(你可以在这里找到)。
这很有趣,因为在定义了一个任务或应用(创建一个“是/否”聊天机器人以回答特定问题)之后,我们将学习如何将研究工作中的洞察转化为实际模型,然后我们可以使用这个模型来实现我们的应用目标。
如果这是你第一次实现一个 NLP 模型,不要感到害怕;我会逐步讲解每一步,并在最后提供代码的链接。为了获得最佳学习体验,我建议你先阅读文章,然后在查看代码的同时,浏览与之相关的文章部分。
那我们开始吧!
Keras:Python 中的简单神经网络
Keras 是一个开源的高级库,用于开发神经网络模型。它由 Google 的深度学习研究员 François Chollet 开发。它的核心原则是使构建神经网络、训练它,然后使用它进行预测的过程对任何具有基础编程知识的人都简单易用,同时仍允许开发者完全自定义 ANN 的参数。
基本上,Keras 实际上只是一个可以运行在不同深度学习框架之上的接口,比如CNTK、Tensorflow 或 Theano。无论使用哪个后端,它的工作方式都是一样的。
Keras API 的分层结构。如图所示,它可以无缝运行在不同的框架之上。
正如我们在上一篇文章中提到的,在神经网络中,每个特定层的节点都会对来自上一层的输出进行加权求和,应用数学函数,然后将结果传递到下一层。
使用 Keras,我们可以创建一个表示每一层的模块,其中这些数学操作和层中的节点数量可以轻松定义。这些不同的层可以通过输入直观的单行代码来创建。
创建 Keras 模型的步骤如下:
步骤 1: 首先,我们必须定义一个网络模型,大多数时候,这将是顺序模型:网络将被定义为一系列层,每层具有其自定义大小和激活函数。在这些模型中,第一层将是输入层,我们需要定义将输入到网络中的输入大小。之后,可以添加更多层并进行自定义,直到达到最终的输出层。
#Define Sequential Model
model = Sequential()
#Create input layer
model.add(Dense(32, input_dim=784))
#Create hidden layer
model.add(Activation('relu'))
#Create Output layer
model.add(Activation('sigmoid'))
步骤 2: 在以这种方式创建网络结构之后,我们需要编译它,这将简单的层序列转变为复杂的矩阵运算组,这些运算组决定了网络的行为。在这里,我们必须定义将用于训练网络的优化算法,并选择需要最小化的损失函数。
#Compiling the model with a mean squared error loss and RMSProp #optimizer
model.compile(optimizer='rmsprop',loss='mse')
步骤 3: 一旦完成,我们可以训练或拟合网络,这将使用上一篇文章中提到的反向传播算法完成。
*# Train the model, iterating on the data in batches of 32 samples* model.fit(data, labels, epochs=10, batch_size=32)
步骤 4: 太棒了!我们的网络已经训练好了。现在我们可以用它对新数据进行预测。
正如你所看到的,使用 Keras 构建网络非常简单,所以让我们开始并使用它来创建我们的聊天机器人吧!上述代码块并不代表实际的具体神经网络模型,它们只是帮助说明如何使用 Keras API 简单地构建神经网络的每一步的示例。
你可以在其官方网站上找到所有关于 Keras 的文档以及如何安装它的信息。
项目:使用递归神经网络构建一个聊天机器人
现在我们知道了所有这些不同类型的神经网络,让我们使用它们来构建一个聊天机器人,它可以回答我们的一些问题!
大多数时候,神经网络的结构比标准的输入-隐藏层-输出更复杂。有时我们可能会想要自己设计一个神经网络,并尝试不同的节点或层组合。此外,在某些情况下,我们可能会想要实现我们在某处看到的模型,比如在科学论文中。
在这篇文章中,我们将通过一个例子来说明这种第二种情况,并构建来自论文“端到端记忆网络”的神经模型,由 Sukhbaatar 等人编写(你可以在这里找到)。
我们还将看到如何保存训练好的模型,以便在使用我们构建的模型进行预测时无需每次都重新训练网络。那么我们开始吧!
模型:灵感
如前所述,本篇文章中使用的 RNN 来源于论文“End to End Memory Networks”,因此建议你在继续之前先查看一下,尽管我会在接下来的内容中解释最相关的部分。
本文实现了一个类似 RNN 的结构,使用注意力模型来弥补我们在前一篇文章中讨论的 RNN 的长期记忆问题。
不知道什么是注意力模型?不用担心,我会用简单的术语来解释。注意力模型引起了很多关注,因为它们在机器翻译等任务中取得了很好的结果。它们解决了之前提到的长序列和 RNN 的短期记忆问题。
为了获取注意力的直观理解,想象一下一个人类如何翻译一个长句子从一种语言到另一种语言。而不是一次性翻译整句话,你会将句子拆分成更小的部分,然后逐一翻译这些小块。我们逐部分处理句子,因为一次性记住整个句子真的很困难。

人类如何将上面的文本从英语翻译成西班牙语
注意力机制正是实现了这一点。在每个时间步,t模型会在输出中对输入句子中与任务相关性更高的部分赋予更大的权重。这就是名字的由来:它关注重要的部分。上面的例子很好的说明了这一点;为了翻译句子的第一部分,查看整个句子或最后一部分几乎没有意义。
下图展示了RNN 与 Attention 模型在输入句子长度增加时的表现。当面对一个非常长的句子并要求执行特定任务时,RNN 在处理完所有句子后可能已经忘记了最初的输入。
RNN 和注意力模型的性能与句子长度的关系。
好了,现在我们知道什么是注意力模型了,我们来详细看看我们将使用的模型结构。这个模型接收输入 xi(一个句子),一个查询 q关于这个句子的,并输出一个是/否的答案 a。
左侧(a)是模型单层的表示。右侧(b)是堆叠在一起的 3 层。
在之前图像的左侧部分,我们可以看到该模型的单层表示。每个句子计算两个不同的嵌入,A 和 C。同时,查询或问题 q 也被嵌入,使用 B 嵌入。
A 嵌入的 mi,然后通过与问题嵌入 u 的内积计算(这是进行注意力机制的部分,通过计算这些嵌入之间的内积,我们实际上是在寻找查询和句子中的词汇匹配,然后使用Softmax 函数对点积结果进行加权)。
最后,我们使用来自 C 的嵌入 (ci) 和从点积获得的权重或概率 pi 计算输出向量 o。有了这个输出向量 o、权重矩阵 W 和问题的嵌入 u,我们最终可以计算预测答案 a hat。
为了构建整个网络,我们只需在不同层上重复这些过程,使用一个层的预测输出作为下一个层的输入。这在之前图像的右侧部分展示了。
如果所有这些内容对你来说来得太快,不用担心,希望在我们通过不同步骤在 Python 中实现这个模型时,你会有更好、更完整的理解。
数据:故事、问题和答案
2015 年,Facebook 提出了bAbI 数据集及 20 个用于测试文本理解和推理的任务,这些任务在 bAbI 项目中进行。任务的详细描述可以在论文中找到这里。**
每个任务的目标是挑战机器文本相关活动的独特方面,测试学习模型的不同能力。在这篇文章中,我们将面临其中一个任务,特别是“具有单一支持事实的 QA”。
下方的块展示了这种 QA 机器人期望的行为示例:
FACT: Sandra went back to the hallway. Sandra moved to the office. QUESTION: Is Sandra in the office?ANSWER: yes
数据集已分为训练数据(10k 实例) 和 测试数据(1k 实例),每个实例包含一个事实、一个问题和对该问题的“是/否”答案。
现在我们已经了解了数据的结构,我们需要构建一个词汇表。在自然语言处理模型中,词汇表基本上是一个模型了解并能够理解的词汇集合。如果在构建词汇表后,模型在句子中看到一个词不在词汇表中,它将给该词在句子向量中的值设为 0,或者将其表示为未知。
VOCABULARY:
'.', '?', 'Daniel', 'Is', 'John', 'Mary', 'Sandra', 'apple','back','bathroom', 'bedroom', 'discarded', 'down','dropped','football', 'garden', 'got', 'grabbed', 'hallway','in', 'journeyed', 'kitchen', 'left', 'milk', 'moved','no', 'office', 'picked', 'put', 'the', 'there', 'to','took', 'travelled', 'up', 'went', 'yes'
由于我们的训练数据变化不大(大多数问题使用相同的动词和名词,但组合不同),我们的词汇表不是很大,但在中等规模的 NLP 项目中,词汇表可能非常庞大。
请注意,为了构建词汇表,我们大多数时候只应该使用训练数据;测试数据应该从一开始就与训练数据分开,直到评估所选择和调整的模型性能时才触碰。
构建词汇表后,我们需要向量化我们的数据。由于我们使用的是普通单词作为模型的输入,而计算机在底层只能处理数字,我们需要一种方式来表示我们的句子,即单词组,作为数字向量。向量化就是做这件事的。
向量化句子的方式有很多种,比如词袋模型或Tf-Idf,然而,为了简便,我们将只使用一种索引向量化技术,即给词汇表中的每个单词分配一个从 1 到词汇表长度的唯一索引。
VECTORIZATION INDEX:
'the': 1, 'bedroom': 2, 'bathroom': 3, 'took': 4, 'no': 5, 'hallway': 6, '.': 7, 'went': 8, 'is': 9, 'picked': 10, 'yes': 11, 'journeyed': 12, 'back': 13, 'down': 14, 'discarded': 15, 'office': 16, 'football': 17, 'daniel': 18, 'travelled': 19, 'mary': 20, 'sandra': 21, 'up': 22, 'dropped': 23, 'to': 24, '?': 25, 'milk': 26, 'got': 27, 'in': 28, 'there': 29, 'moved': 30, 'garden': 31, 'apple': 32, 'grabbed': 33, 'kitchen': 34, 'put': 35, 'left': 36, 'john': 37}
请注意,这种向量化是使用随机种子开始的,因此即使你使用与我相同的数据,你可能会得到每个单词的不同索引。不要担心;这不会影响项目的结果。此外,我们的词汇表中的单词有大写和小写;在进行这种向量化时,为了统一性,所有单词都被转为小写。
在这之后,由于 Keras 的工作方式,我们需要对句子进行填充。这是什么意思?这意味着我们需要找到最长句子的长度,将每个句子转换为该长度的向量,并用零填充每个句子的单词数量与最长句子的单词数量之间的差距。
完成后,数据集中的一个随机句子应该是这样的:
FIRST TRAINING SENTENCE VECTORIZED AND PADDED:
array([ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 20, 30, 24, 1, 3, 7, 21, 12, 24, 1, 2, 7])
如我们所见,它到处都是零,除了末尾(这个句子比最长句子短很多),那里有一些数字。这些数字是什么?嗯,它们是代表句子中不同单词的索引:20 是代表单词Mary的索引,30 是moved,24 是to,1 是the,3 代表bathroom*,依此类推。实际句子是:
FIRST TRAINING SENTENCE:
"Mary moved to the bathroom . Sandra journeyed to the bedroom ."
好的,既然我们已经准备好了数据,我们现在可以开始构建我们的神经网络了!
神经网络:构建模型
创建网络的第一步是在 Keras 中创建被称为占位符的输入,在我们的案例中是故事和问题。简单来说,这些占位符是容器,批量的训练数据会被放置在这些容器中,然后再输入到模型中。
*#Example of a Placeholder
question = Input((max_question_len,batch_size))*
它们必须具有与将要输入的数据相同的维度,并且还可以定义一个批量大小,尽管如果在创建占位符时不知道这个值,我们可以留空。
现在我们需要创建论文中提到的嵌入,A, C 和 B。嵌入将一个整数(在本例中是单词的索引)转换为d维向量,其中考虑了上下文。单词嵌入在自然语言处理(NLP)中被广泛使用,并且是近年来使这一领域取得显著进展的技术之一。
#Create input encoder A:
input_encoder_m = Sequential()
input_encoder_m.add(Embedding(input_dim=vocab_len,output_dim = 64))
input_encoder_m.add(Dropout(0.3))#Outputs: (Samples, story_maxlen,embedding_dim) -- Gives a list of #the lenght of the samples where each item has the
#lenght of the max story lenght and every word is embedded in the embbeding dimension
上面的代码是论文中完成的一个嵌入(A 嵌入)的示例。像往常一样,在Keras中,我们首先定义模型(Sequential),然后添加嵌入层和一个丢弃层,通过触发网络节点的关闭来减少模型过拟合的机会。
一旦我们创建了输入句子的两个嵌入和问题的嵌入,我们可以开始定义模型中发生的操作。如前所述,我们通过计算问题的嵌入和故事嵌入之间的点积来计算注意力,然后进行 softmax。下面的代码块展示了如何实现这一点:
match = dot([input_encoded_m,question_encoded], axes = (2,2))
match = Activation('softmax')(match)
接下来,我们需要计算输出o,将匹配矩阵与第二个输入向量序列相加,然后使用这个输出和编码的问题来计算响应。
response = add([match,input_encoded_c])
response = Permute((2,1))(response)
answer = concatenate([response, question_encoded])
最后,完成这一过程后,我们将添加模型的其余层,包括一个LSTM层(而不是像论文中提到的 RNN)、一个丢弃层和一个最终的 softmax 来计算输出。
answer = LSTM(32)(answer)
answer = Dropout(0.5)(answer)
#Output layer:
answer = Dense(vocab_len)(answer)
#Output shape: (Samples, Vocab_size) #Yes or no and all 0s
answer = Activation('softmax')(answer)
请注意,这里的输出是一个词汇表大小的向量(即模型已知的单词数量的长度),其中所有位置应该是零,除了‘yes’ 和 ‘no’的索引位置。
从数据中学习:训练模型
现在我们准备好编译模型并进行训练了!
model = Model([input_sequence,question], answer)
model.compile(optimizer='rmsprop', loss = 'categorical_crossentropy', metrics = ['accuracy'])
使用这两行代码我们构建最终模型并编译它,也就是通过指定一个优化器、一个损失函数和一个度量标准来定义后台的所有数学运算。
现在是训练模型的时候,在这里我们需要定义训练的输入(即输入故事、问题和答案)、批量大小(即一次输入的数量)和训练轮数(即模型将通过训练数据的次数以更新权重)。我使用了 1000 轮训练,并获得了 98%的准确率,但即使使用 100 到 200 轮,你也应该能获得相当不错的结果。
请注意,根据你的硬件,这个训练可能需要一段时间。放轻松,坐下来,继续阅读 Medium,等到训练完成。
训练完成后,你可能会想“每次使用模型时我都需要等待这么久吗?” 明显的答案是,不。Keras 允许开发者保存特定的模型,包括权重和所有配置。下面的代码块展示了如何实现这一点。
filename = 'medium_chatbot_1000_epochs.h5'
model.save(filename)
现在,当我们想要使用模型时,可以像这样加载它:
model.load_weights('medium_chatbot_1000_epochs.h5')
很酷。现在我们已经训练了模型,让我们看看它在新数据上的表现,并玩一玩吧!
看到结果:测试和玩耍
让我们看看我们的模型在测试数据上的表现吧!
pred_results = model.predict(([inputs_test,questions_test]))
这些结果是一个数组,如前所述,包含每个词汇位置的概率,表示每个词是问题答案的概率。如果我们查看这个数组的第一个元素,我们会看到一个词汇表大小的向量,其中所有的值接近 0,除了对应于yes 或 no的值。
从这些中,如果我们选择数组中最大值的索引,然后查看它对应的单词,我们应该找出答案是肯定的还是否定的。
现在我们可以做一件有趣的事,那就是创建我们自己的故事和问题,并将其输入到机器人中,看看它会怎么说!
my_story = 'Sandra picked up the milk . Mary travelled left . '
my_story.split()
my_question = 'Sandra got the milk ?'
my_question.split()
我创建了一个故事和一个问题,某种程度上类似于我们的小机器人之前见过的内容,并在将其调整为神经网络希望的格式后,机器人回答了‘yes’(虽然是小写的,他不像我那样热情)。
我们换点不同的东西试试:
my_story = 'Medium is cool . Jaime really likes it. '
my_story.split()
my_question = 'Does Jaime like Medium ?'
my_question.split()
这次的回答是:‘当然了,谁不呢?’
只是开个玩笑,我没有尝试那个故事/问题组合,因为包含的许多词汇不在我们小回答机器的词汇表中。而且,它只会说‘yes’和‘no’,通常不会给出其他答案。不过,通过更多的训练数据和一些变通方法,这是可以轻松实现的。
今天就到这里!我希望你们阅读这篇文章和我写它时一样开心。祝你们一天愉快,保重,并享受人工智能!
你可以在我的Github页面找到代码和数据。
其他资源:
如果你想深入了解注意力模型,或者理解我提到的一些词向量化技术,查看我为你整理的这些额外资源吧。祝好运!
随时可以在LinkedIn上与我联系,或在 Twitter 上关注我@jaimezorno。同时,你也可以查看我在数据科学和机器学习方面的其他文章这里。阅读愉快!
简介:Jaime Zornoza 是一位工业工程师,拥有电子学学士学位和计算机科学硕士学位。
原文。经许可转载。
相关:
-
深度学习 NLP:ANNs、RNNs 和 LSTMs 解释!
-
训练神经网络以模仿洛夫克拉夫特风格写作
-
适配器:一种紧凑且可扩展的 NLP 转移学习方法
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 部门
更多相关话题
几分钟内使用这个预配置的 Python VM 镜像进行深度学习
原文:
www.kdnuggets.com/2017/05/deep-learning-pre-configured-python-vm-image.html
Adam Geitgey在他的博客中撰写有关机器学习、深度学习、图像和语音识别及相关主题的文章。他既讲理论也讲实践,并重点介绍了开发者如何快速开始使用这些技术。Geitgey 表示:
但我收到的最常见问题是“我到底怎么才能在我的计算机上安装并运行所有这些开源库?”
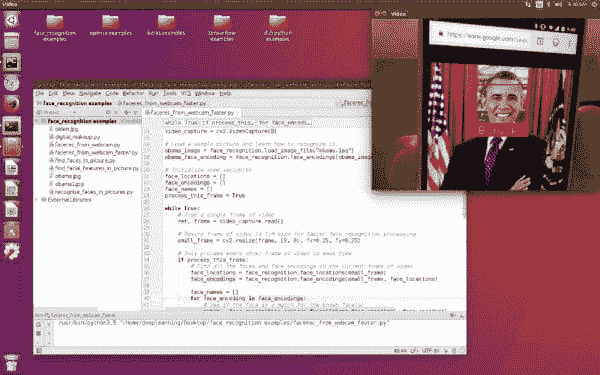
为此,Geitgey 整理了一个虚拟机镜像,他在这篇近期文章中进行了介绍。基于 Ubuntu Linux Desktop 16.04 LTS 64-bit,这个镜像包括了以下工具和库:
-
Python 3.5
-
带有 Python 3 绑定的 OpenCV 3.2
-
带有 Python 3 绑定的 dlib 19.4
-
Python 3 的 TensorFlow 1.0
-
Keras 2.0 for Python 3
-
Theano
-
Python 3 的 face_recognition(用于人脸识别的玩耍)
它还包括了一些预制的项目,以便立即上手:
如果你从左侧边栏启动 PyCharm Community Edition,将会看到几个预创建的项目可以打开。尝试运行 face_recognition、OpenCV 或 Keras 项目的一些演示。在代码窗口上右键点击并选择“运行”,以在 PyCharm 中运行当前文件。
阅读关于这个镜像的更多信息这里 -- 包括下载和安装说明、用户名和密码信息,以及一些使用技巧 -- 并从这里直接获取镜像。
一旦你启动了虚拟机,开始的一个很好的地方就是 Geitgey 的“机器学习是有趣的”系列文章:
相关:
-
一台深度学习虚拟机统治一切
-
如何在 TensorFlow 中构建递归神经网络
-
与 Python 机器学习的游击指南
我们的前三大课程推荐
1. 谷歌网络安全证书 - 加速你的网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
了解更多相关话题
使用 R 进行深度学习
图片来源于 Bing 图片创作者
介绍
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
谁没有被特别是 人工智能 的技术进步所吸引,从 Alexa 到特斯拉的自动驾驶汽车以及无数其他创新?我每天都对这些进展感到惊叹,但更有趣的是,当你了解支撑这些创新的基础时。欢迎来到 人工智能 和 深度学习 的无限可能。如果你一直在想这是什么,那么你来对地方了。
在本教程中,我将深入剖析术语,并带你了解如何在 R 中执行深度学习任务。需要注意的是,本文假设你对 机器学习 概念有一些基础了解,例如 回归、分类和 聚类。
让我们从一些围绕深度学习概念的术语定义开始:
深度学习 是机器学习的一个分支,教会计算机模拟人脑的认知功能。这是通过使用人工神经网络来解开数据集中的复杂模式来实现的。通过深度学习,计算机可以对声音、图像甚至文本进行分类。
在深入了解深度学习的细节之前,了解机器学习和人工智能是什么以及这三者如何相互关联是很有帮助的。
人工智能:这是计算机科学的一个分支,关注开发模拟人脑功能的机器。
机器学习:这是人工智能的一个子集,使计算机能够从数据中学习。
根据以上定义,我们现在对深度学习如何与人工智能和机器学习相关有了一个概念。
下面的图示将帮助展示这些关系。
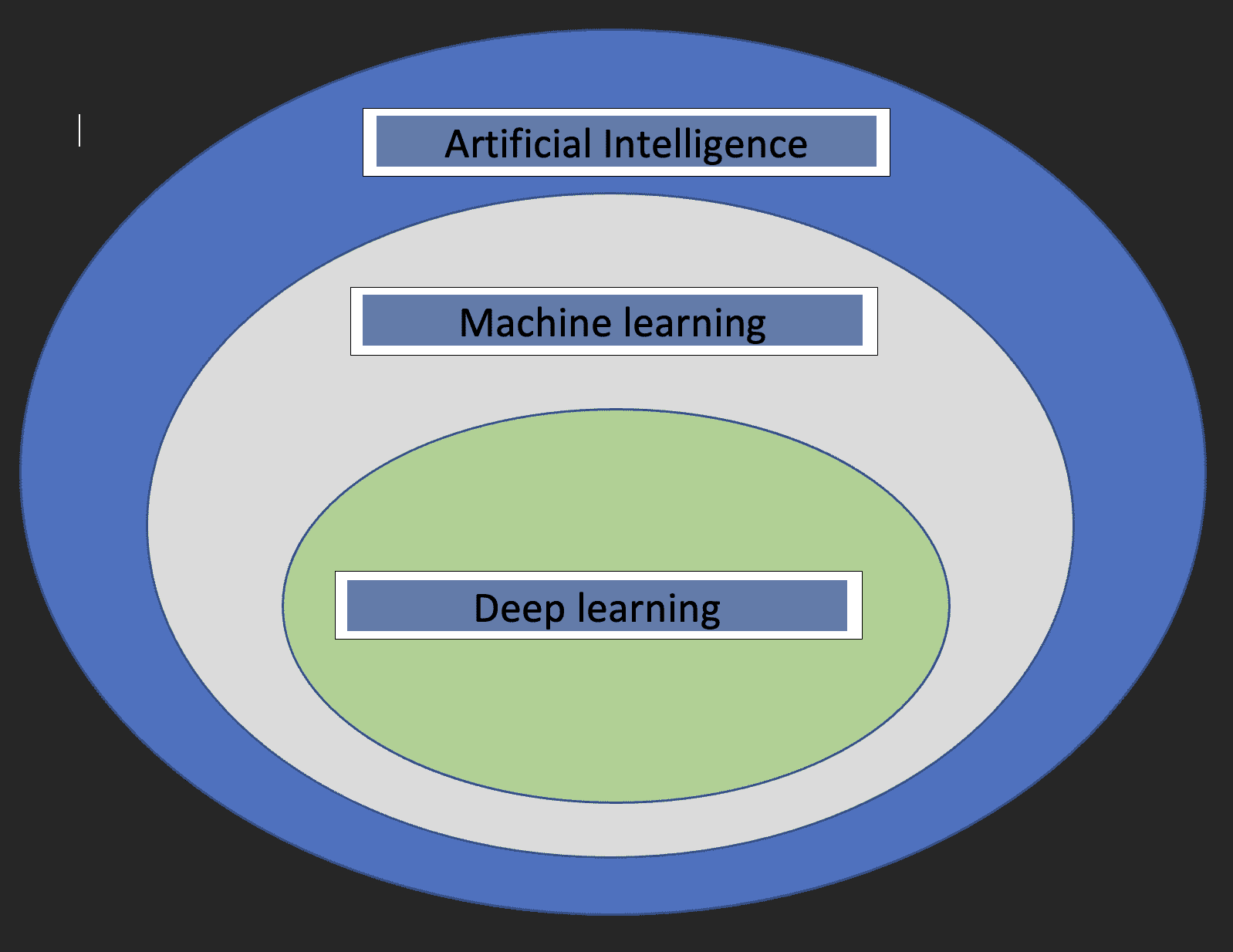
关于深度学习,有两个关键点需要注意:
-
需要大量的数据
-
需要高性能的计算能力
神经网络
这些是深度学习模型的构建块。正如名称所示,神经一词来源于神经元,就像人脑中的神经元一样。实际上,深度神经网络的结构灵感来自于人脑的结构。
一个神经网络有一个输入层、一个隐藏层和一个输出层。这个网络被称为浅层神经网络。当我们有多个隐藏层时,它就成为了深层神经网络,其中层数可以多达 100 层。
下图展示了神经网络的样子。
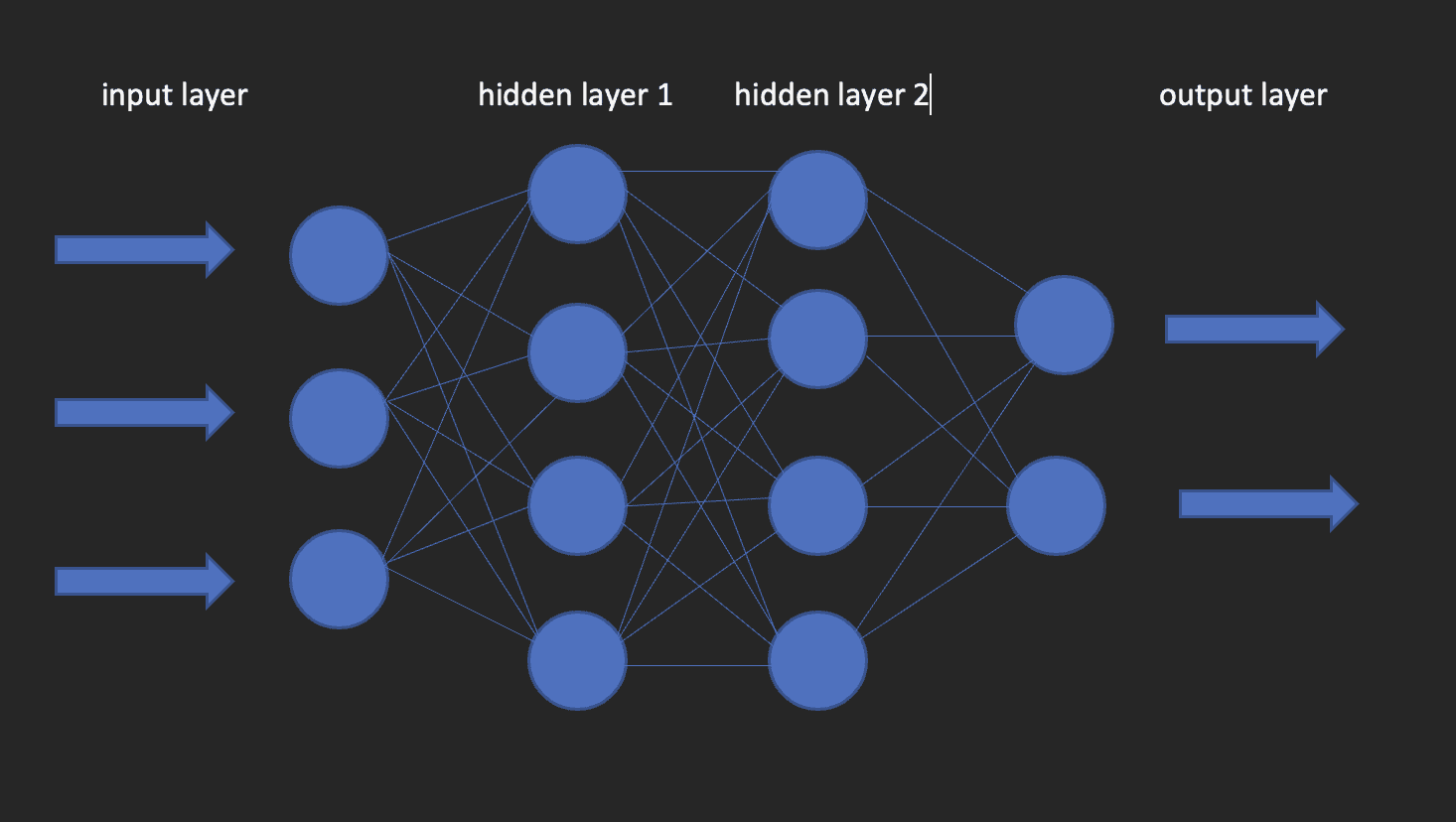
这就引出了一个问题:如何在 R 中构建深度学习模型?答案是 kera!
Keras是一个开源深度学习库,使得在机器学习中使用神经网络变得简单。这个库是一个包装器,使用TensorFlow作为后端引擎。然而,也有其他后端选项,如 Theano 或 CNTK。
现在让我们安装TensorFlow和 Keras。
从使用 reticulate 创建虚拟环境开始
library(reticulate)
virtualenv_create("virtualenv", python = "/path/to/your/python3")
install.packages(“tensorflow”) #This is only done once!
library(tensorflow)
install_tensorflow(envname = "/path/to/your/virtualenv", version = "cpu")
install.packages(“keras”) #do this once!
library(keras)
install_keras(envname = "/path/to/your/virtualenv")
# confirm the installation was successful
tf$constant("Hello TensorFlow!")
现在我们的配置已经设置好,我们可以开始探讨如何使用深度学习解决分类问题。
数据简介
我将用于本教程的数据来自一个正在进行的薪资调查,该调查由www.askamanager.org进行。
表单中主要询问的是你赚多少钱,另外还有一些细节,比如行业、年龄、工作经验年数等。这些细节被收集到一个 Google 表单中,我从中获取了数据。
我们希望解决的问题是能够构建一个深度学习模型,该模型可以根据年龄、性别、工作经验年数和最高学历等信息预测某人的潜在收入。
加载我们需要的库。
library(dplyr)
library(keras)
library(caTools)
导入数据
url <- “https://raw.githubusercontent.com/oyogo/salary_dashboard/master/data/salary_data_cleaned.csv”
salary_data <- read.csv(url)
选择我们需要的列
salary_data <- salary_data %>% select(age,professional_experience_years,gender,highest_edu_level,annual_salary)
数据清理
还记得计算机科学中的 GIGO 概念吗?(垃圾进,垃圾出)。这个概念在这里同样适用,就像在其他领域一样。我们的训练结果在很大程度上依赖于我们使用的数据质量。这就是为什么数据清理和转换在任何数据科学项目中都至关重要。
数据清理旨在解决的一些关键问题包括;一致性、缺失值、拼写问题、异常值和数据类型。我不会详细讲解这些问题是如何处理的,这只是为了避免偏离本文的主题。因此,我将使用清理后的数据版本,但如果你有兴趣了解清理的处理方法,可以查看这篇文章。
数据转换
人工神经网络仅接受数值变量,而由于我们的一些变量是分类性质的,我们需要将这些变量编码为数字。这是 数据预处理 步骤的一部分,因为通常情况下,你不会得到已经准备好建模的数据。
# create an encoder function
encode_ordinal <- function(x, order = unique(x)) {
x <- as.numeric(factor(x, levels = order, exclude = NULL))
}
salary_data <- salary_data %>% mutate(
highest_edu_level = encode_ordinal(highest_edu_level, order = c("High School","College degree","Master's degree","Professional degree (MD, JD, etc.)","PhD")),
professional_experience_years = encode_ordinal(professional_experience_years,
order = c("1 year or less", "2 - 4 years","5-7 years", "8 - 10 years", "11 - 20 years", "21 - 30 years", "31 - 40 years", "41 years or more")),
age = encode_ordinal(age, order = c( "under 18", "18-24","25-34", "35-44", "45-54", "55-64","65 or over")),
gender = case_when(gender== "Woman" ~ 0,
gender == "Man" ~ 1))
看到我们想要解决一个分类问题,我们需要将年薪分成两类,以便将其作为响应变量使用。
salary_data <- salary_data %>%
mutate(categories = case_when(
annual_salary <= 100000 ~ 0,
annual_salary > 100000 ~ 1))
salary_data <- salary_data %>% select(-annual_salary)
切分数据
与基本的机器学习方法(回归、分类和聚类)一样,我们需要将数据分成训练集和测试集。我们使用 80-20 规则,即将 80% 的数据集用于训练,20% 用于测试。这并不是一成不变的,你可以根据需要选择任何拆分比例,但请记住,训练集应该占有足够的百分比。
set.seed(123)
sample_split <- sample.split(Y = salary_data$categories, SplitRatio = 0.7)
train_set <- subset(x=salary_data, sample_split == TRUE)
test_set <- subset(x = salary_data, sample_split == FALSE)
y_train <- train_set$categories
y_test <- test_set$categories
x_train <- train_set %>% select(-categories)
x_test <- test_set %>% select(-categories)
Keras 接受矩阵或数组形式的输入。我们使用 as.matrix 函数进行转换。此外,我们需要缩放预测变量,然后将响应变量转换为分类数据类型。
x <- as.matrix(apply(x_train, 2, function(x) (x-min(x))/(max(x) - min(x))))
y <- to_categorical(y_train, num_classes = 2)
实例化模型
创建一个顺序模型,然后我们将使用管道操作符添加层。
model = keras_model_sequential()
配置层
input_shape 指定输入数据的形状。在我们的情况下,我们使用 ncol 函数获得了这一点。activation:在这里我们指定激活函数;这是一个将输出转换为所需非线性格式的数学函数,然后传递到下一层。
units:神经网络每层中的神经元数量。
model %>%
layer_dense(input_shape = ncol(x), units = 10, activation = "relu") %>%
layer_dense(units = 10, activation = "relu") %>%
layer_dense(units = 2, activation = "sigmoid")
配置模型学习过程
我们使用 compile 方法来完成这项工作。该函数接受三个参数;
optimizer:该对象指定训练过程。loss:这是优化过程中要最小化的函数。可选项有 mse(均方误差)、binary_crossentropy 和 categorical_crossentropy。
metrics:我们用来监控训练的指标。分类问题的准确率。
model %>%
compile(
loss = "binary_crossentropy",
optimizer = "adagrad",
metrics = "accuracy"
)
模型拟合
我们现在可以使用 Keras 的 fit 方法来拟合模型。fit 接受的一些参数包括:
epochs:一个 epoch 是对训练数据集的迭代。
batch_size:模型将传递给它的矩阵/数组切成更小的批次,然后在训练期间进行迭代。
validation_split:Keras 需要切分一部分训练数据,以获取用于评估模型每个周期性能的验证集。
shuffle:在这里你可以指示是否希望在每个周期之前打乱训练数据。
fit = model %>%
fit(
x = x,
y = y,
shuffle = T,
validation_split = 0.2,
epochs = 100,
batch_size = 5
)
评估模型
要获取模型的准确度值,请使用以下的 evaluate 函数。
y_test <- to_categorical(y_test, num_classes = 2)
model %>% evaluate(as.matrix(x_test),y_test)
预测
要对新数据进行预测,请使用 keras 库中的 predict_classes 函数,如下所示。
model %>% predict(as.matrix(x_test))
结论
本文向你介绍了使用 Keras 在 R 中进行深度学习的基础知识。你可以深入学习以获得更好的理解,尝试调整参数,动手进行数据准备,或许还可以通过利用云计算的力量来扩展计算。
Clinton Oyogo 是 Saturn Cloud 的作者,他认为分析数据以获取可操作的见解是他日常工作中的关键部分。凭借在数据可视化、数据处理和机器学习方面的技能,他为自己作为数据科学家的工作感到自豪。
原文。经许可转载。
进一步阅读
为什么深度学习与机器学习截然不同
原文:
www.kdnuggets.com/2016/12/deep-learning-radically-different-machine-learning.html
评论

现在关于人工智能(AI)、机器学习(ML)和深度学习(DL)的混淆很多。确实,关于 AI 作为一种竞争性游戏改变者的文章急剧增加,企业应该开始认真探索这些机会。对于这些领域的从业者来说,AI、ML 和 DL 之间的区别非常明确。AI 是一个涵盖从传统人工智能(GOFAI)到类似深度学习的连接主义架构的全包范围。ML 是 AI 的一个子领域,涵盖了与通过数据训练学习算法研究相关的一切。多年来,已经开发出大量的技术,例如线性回归、K-means、决策树、随机森林、PCA、SVM,最后是人工神经网络(ANN)。人工神经网络是深度学习领域的起源所在。
一些具有人工神经网络(ANN)先验经验的 ML 从业者,毕竟它是在 60 年代初发明的,最初会认为深度学习不过是具有多层的 ANN。进一步说,DL 的成功更多地归因于数据的增加以及像图形处理单元(GPU)这样更强大的计算引擎的出现。这当然是正确的,DL 的出现确实归功于这两项进步,然而将 DL 仅仅视为比 SVM 或决策树更好的算法,就像只看到树木而看不到森林一样。
引用 Andreesen 的话“软件正在吞噬世界”,可以说“深度学习正在吞噬机器学习”。来自不同机器学习领域的从业者的两篇出版物最恰当地总结了为什么 DL 正在占领世界。NLP 领域的专家 Chris Manning 写道 “深度学习的巨浪”:
深度学习的波涛已经冲击了计算语言学的海岸多年,但 2015 年似乎是巨浪全面袭击主要自然语言处理(NLP)会议的一年。然而,一些专家预测最终的损害可能会更严重。
Nicholas Paragios 在 “计算机视觉研究:深度的低谷” 中写道:
这可能仅仅是因为深度学习在高度复杂、自由度极高的图上,一旦拥有大量标注数据和近期才出现的不可思议的计算能力,就可以解决所有计算机视觉问题。如果是这样,那么行业(似乎已经是这种情况)接管只是时间问题,计算机视觉研究将成为边缘的学术目标,该领域将沿着计算机图形学(在活动和学术研究量方面)的发展路径前进。
这两篇文章确实强调了深度学习领域对传统机器学习实践的根本性颠覆。当然,它在商业世界中也应该同样具有颠覆性。然而,我对即使是 Gartner 也未能识别机器学习与深度学习之间的区别感到震惊和困惑。以下是 Gartner 2016 年 8 月的炒作周期图,深度学习甚至没有被提及:
真是个悲剧!他们的客户对机器学习有狭隘的看法,结果将被深度学习盲目冲击,这几乎是犯罪。
不管怎样,尽管被忽视,深度学习(DL)依然持续被炒作。目前的深度学习炒作倾向于认为我们拥有这些商品化的机器,只要有足够的数据和训练时间,就能自我学习。这当然要么是对最先进技术能力的夸张,要么是对实际深度学习实践的过度简化。在过去几年里,深度学习催生了大量以前未知或被认为不可行的思想和技术。最初,这些概念似乎是零散和不相关的。然而,随着时间的推移,模式和方法开始显现,我们正拼命尝试在“深度学习设计模式”中覆盖这些领域。
现今的深度学习不仅仅是多层感知机,而是用于构建可组合的可微分架构的一系列技术和方法。这些是极其强大的机器学习系统,我们现在只是看到了冰山一角。关键在于,深度学习今天可能看起来像炼金术,但我们最终会学会像化学一样实践它。也就是说,我们将拥有更坚实的基础,以便能够以更大的可预测性构建我们的学习机器。
顺便提一下,如果你有兴趣了解深度学习如何帮助你的工作,请随时在此留下你的电子邮件:www.intuitionmachine.com 或加入 Facebook 讨论:www.facebook.com/groups/deeplearningpatterns/
个人简介:Carlos Perez 是一名软件开发人员,目前正在撰写一本关于“深度学习设计模式”的书。这是他从中获取博客文章灵感的来源。
原文。经许可转载。
相关:
-
深度学习的不足之处
-
深度学习研究回顾:强化学习
-
预测科学与数据科学
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关内容
深度学习阅读组:图像识别中的深度残差学习
原文:
www.kdnuggets.com/2016/09/deep-learning-reading-group-deep-residual-learning-image-recognition.html

今天的论文提出了一种新的卷积网络架构。这篇论文由微软研究院的 He、Zhang、Ren 和 Sun 撰写。我要在开始之前警告你:这篇论文非常古老。它发布于 2015 年底深度学习的黑暗时代,我相当确定它的原始格式是莎草纸;幸运的是,有人扫描了它,以便未来几代人可以阅读。然而,它仍然值得抹去尘土并翻阅,因为它提出的架构已经被反复使用,包括在我们之前阅读的一些论文中:具有随机深度的深度网络。
He et al. 开始时指出了一个看似矛盾的情况:非常深的网络表现比中等深度的网络更差,也就是说,尽管增加网络的层数通常会提高性能,但在某些点之后,新层开始阻碍网络。他们将这种效应称为网络降级。
如果你一直关注我们的之前的帖子,这不会让你感到惊讶;随着网络变得更深,诸如梯度消失等训练问题会变得更严重,因此你会期望更多的层会在某个点之后使网络表现变差。但作者预见了这种推理,并指出几种其他深度学习方法,如批量归一化(参见我们的帖子的总结),基本上解决了这些训练问题,但网络的表现仍然随着深度的增加而变得越来越差。例如,他们比较了 20 层和 56 层的网络,并发现 56 层网络表现远不如 20 层;见下图。
20 层和 56 层网络在 CIFAR-10 上的比较。注意 56 层网络在训练和测试中的表现都较差。
然后作者设立了一个思想实验(或者说思想实验如果你像我一样是一个恢复中的物理学家)来证明更深的网络应该总是表现更好。他们的论点如下:
-
从一个表现良好的网络开始;
-
添加强制为恒等函数的额外层,即,它们只是传递到达它们的任何信息而不进行更改;
-
这个网络更深,但必须与原始网络具有相同的性能,因为新层没有做任何事情。
-
网络中的层可以学习恒等函数,因此如果它是最优的,它们应该能够准确复制这个深层网络的性能。
这个思想实验促使他们提出了深度残差学习架构。他们构建了他们所谓的残差构建块网络。下图展示了其中一个这样的块。这些块被称为 ResBlocks。
一个 ResBlock;顶部学习一个残差函数 f(x),而底部的信息保持不变。图像改编自黄等人的随机深度论文。
ResBlock 由普通网络层构建,这些层通过线性整流单元(ReLUs)连接,并且在下面有一个通过的连接,保持来自先前层的信息不变。ResBlock 的网络部分可以包含任意数量的层,但最简单的情况是两层。
要了解 ResBlock 背后的数学:假设一组层如果学习一个特定的函数h(x),将表现最好。作者指出,可以学习残差f(x) = h(x) − x,然后将其与原始输入结合,以恢复h(x),如下所示:h(x) = f(x) + x。这可以通过向网络中添加一个+x组件来实现,回想一下我们的思想实验,这只是恒等函数。作者希望将这种“传递”添加到他们的层中将有助于训练。与大多数深度学习一样,这种方法只有直观的支持,而没有更深层次的理解。然而,正如作者所展示的,它确实有效,而这正是许多从业者所关心的唯一问题。
论文还探讨了对 ResBlock 的一些修改。第一个是创建具有三层的瓶颈块,其中中间层通过使用较少的输入和输出来限制信息流。第二个是测试不同类型的传递连接,包括学习完整的投影矩阵。尽管更复杂的传递连接性能更好,但只是略微提高,而且训练时间成本更高。
论文的其余部分测试了网络的性能。作者发现,他们的网络在使用通行功能后表现优于没有通行功能的相同网络;请参见下图的绘图以了解这一点。他们还发现,能够训练更深层的网络,并且仍然表现出改进的性能,最终训练了一个 152 层的 ResNet,表现优于较浅的网络。他们甚至训练了一个 1202 层的网络以证明其可行性,但发现其性能不如论文中检查的其他网络。
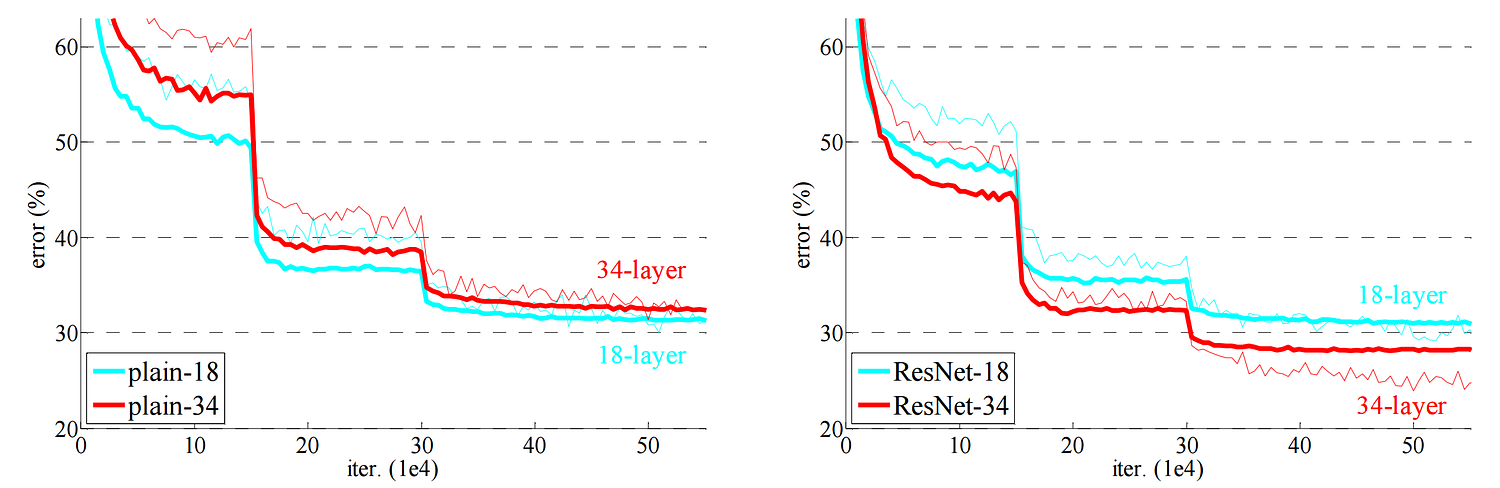
两个网络性能的比较:左侧的网络不使用 ResBlocks,而右侧的网络使用了。注意 34 层的网络比 18 层的网络表现更好,但仅在使用 ResBlocks 时。
就这样!他 et al. 提出了一个新的架构,受到思想实验的启发,并希望它能比以前的架构表现更好。他们构建了几个网络,包括一些非常深的网络,发现他们的新架构确实改善了网络的性能。虽然我们对深度学习的基本原理没有获得进一步的理解,但我们确实获得了一种使网络表现更好的新方法,最终也许这已经足够好。
亚历山大·古德 目前是 Lab41 的数据科学家,研究推荐系统算法。他拥有加州大学伯克利分校的物理学学士学位和明尼苏达大学双城分校的基础粒子物理学博士学位。
Lab41 是一个“挑战实验室”,美国情报界与学术界、工业界以及 In-Q-Tel 的同行共同合作,解决大数据问题。它允许来自不同背景的参与者接触思想、人才和技术,以探索数据分析中有效和无效的方面。作为一个开放、协作的环境,Lab41 促进了参与者之间的宝贵关系。
原文。经许可转载。
相关内容:
-
在深度学习中,架构工程是新的特征工程
-
深度学习进展:七月更新
-
深度学习网络为何会扩展?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关内容
深度学习阅读小组:SqueezeNet
原文:
www.kdnuggets.com/2016/09/deep-learning-reading-group-squeezenet.html
作者:Abhinav Ganesh,Lab41。

下一篇论文来自我们的阅读小组,由 Forrest N. Iandola、Matthew W. Moskewicz、Khalid Ashraf、Song Han、William J. Dally 和 Kurt Keutzer 共同撰写。该论文介绍了一种名为“SqueezeNet”的小型 CNN 架构,在 ImageNet 上实现了与 AlexNet 相当的准确率,但参数数量减少了 50 倍。正如你可能已经注意到的,我们对神经网络架构的压缩非常感兴趣,这篇论文确实很突出。
深度学习的难点之一就是参数调优的地狱。这篇论文提倡增加对卷积神经网络设计领域的研究,以大幅减少你需要处理的参数数量。与我们之前的关于“深度压缩”的帖子不同,这篇论文建议通过从更智能的设计开始来缩小网络规模,而不是使用巧妙的压缩方案。作者概述了减少参数大小而最大化准确性的三种主要策略。我现在将为你介绍这些策略。
策略 1. 通过用 1x1 卷积核替换 3x3 卷积核来缩小网络
这个策略通过将一堆 3x3 卷积核替换为 1x1 卷积核,从而减少了参数的数量,减少了 9 倍。最初这让我感到非常困惑。我以为移动 1x1 卷积核在图像上时,每个卷积核看到的信息会更少,因此性能会更差,但事实似乎并非如此!通常较大的 3x3 卷积核捕捉的是彼此接近的像素的空间信息。另一方面,1x1 卷积核专注于单个像素,并捕捉其通道之间的关系,而不是邻近像素之间的关系。如果你想了解更多关于 1x1 卷积核的使用,可以查看这篇博客文章。
策略 2. 减少剩余 3x3 卷积核的输入数量
这个策略通过基本上使用更少的卷积核来减少参数数量。这是通过将“压缩”层输入到他们称之为“扩展”层中系统地完成的,如下所示:
“Fire 模块”。图片来源于论文
现在是定义一些仅在这篇论文中出现的术语的时候了!正如你在上面看到的,“squeeze”层是由仅包含 1x1 滤波器的卷积层组成,“expand”层是包含 1x1 和 3x3 滤波器混合的卷积层。通过减少“squeeze”层中进入“expand”层的滤波器数量,他们减少了进入这些 3x3 滤波器的连接数量,从而减少了总参数数量。论文的作者将这种特定的架构称为“火焰模块”,它作为 SqueezeNet 架构的基本构建块。
策略 3. 在网络的后期进行下采样,以便卷积层具有大的激活图。
现在我们已经讨论了减少我们正在处理的参数数量的方法,那么如何充分利用剩余的较小参数集呢?作者认为,通过在后续卷积层中减小步幅,从而在网络后期创建更大的激活/特征图,分类准确性实际上会提高。在网络末尾拥有更大的激活图,与像 VGG这样的网络形成了鲜明对比,在这些网络中,激活图在接近网络末端时会变得更小。这种不同的方法非常有趣,他们引用了一篇 K. He 和 H. Sun 的论文,该论文类似地应用了延迟下采样,从而提高了分类准确性。
那么,这一切是如何结合在一起的呢?
SqueezeNet 利用上述的“火焰模块”,将这些模块串联在一起,从而实现了一个更小的模型。以下是他们论文中展示的这种串联过程的一些变体:
左侧:SqueezeNet;中间:带有简单旁路的 SqueezeNet;右侧:带有复杂旁路的 SqueezeNet。图片来自论文。
我发现这个架构令人惊讶的一点是缺乏全连接层。令人吃惊的是,通常在像 VGG这样的网络中,后期的全连接层学习的是 CNN 早期高层特征与网络试图识别的类别之间的关系。也就是说,全连接层学习的是鼻子和耳朵组成一个脸,而车轮和灯光指示车辆。然而,在这个架构中,这一步额外的学习似乎嵌入在不同“火焰模块”之间的转换中。作者从 NiN 架构中获得了这一想法的灵感。
够详细了!这表现如何?
论文的作者展示了一些令人印象深刻的结果。
SqueezeNet 对比其他 CNN 架构的基准测试。图像来自论文。
他们的 SqueezeNet 架构在模型大小上实现了比 AlexNet 减少 50 倍的效果,同时达到了或超过了 AlexNet 的 Top-1 和 Top-5 准确率。但这篇论文最有趣的部分可能是他们将深度压缩(在我们之前的帖子中进行了讲解)应用于他们已经更小的模型。这种深度压缩的应用使得模型比 AlexNet 小了 510 倍!这些结果非常鼓舞人心,因为它展示了结合不同压缩方法的潜力。作为下一步,我很希望看到这种设计思维如何应用于其他神经网络架构和深度学习应用。
如果这篇论文对你有兴趣,绝对要查看他们在 Github 上的开源代码。我只有时间介绍要点,但他们的论文中充满了关于参数减少 CNN 设计的深入讨论。
Abhinav Ganesh 目前是 Lab41 的工程师,致力于将机器学习应用于网络安全。他拥有卡内基梅隆大学电气与计算机工程的学士和硕士学位。
Lab41 是一个“挑战实验室”,美国情报界与学术界、工业界和 In-Q-Tel 的同行汇聚在一起,解决大数据问题。它允许来自不同背景的参与者获取想法、人才和技术,以探索数据分析中的有效性和不足之处。Lab41 提供了一个开放、协作的环境,促进了参与者之间的宝贵关系。
原文。经许可转载。
相关:
-
深度学习阅读小组:用于图像识别的深度残差学习
-
深入了解深度学习:七月更新
-
理解深度学习的 7 个步骤
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关内容
深度学习研究综述:强化学习
原文:
www.kdnuggets.com/2016/11/deep-learning-research-review-reinforcement-learning.html/2
DQN 强化学习** (使用 Atari 游戏的 RL)**

介绍
这篇论文由 Google Deepmind 于 2015 年 2 月发表,并登上了世界著名科学周刊《自然》的封面。这是将深度神经网络与强化学习结合起来的首次成功尝试之一(这篇 是 Deepmind 的原始论文)。论文表明,他们的系统能够在 49 款游戏中以与专业游戏测试员相当的水平玩 Atari 游戏。让我们深入了解他们是如何做到的。
方法
好了,记住我们在帖子开头的介绍教程中停留在哪里了吗?我们刚刚描述了优化我们的动作价值函数 Q 的主要目标。Deepmind 的团队通过一个深度 Q 网络,或称 DQN,来处理这个任务。这个网络能够根据来自游戏屏幕的像素和当前分数的输入,制定出优化 Q 的成功策略。
网络架构
让我们更仔细地看看这个 DQN 的输入是什么。考虑 Breakout 游戏,并取当前游戏中的 4 帧最近的图像。每一帧最初是一个 210 x 160 x 3 的图像(因为宽度和高度分别为 210 和 160 像素,是彩色图像)。然后,进行一些预处理,将图像缩放到 84 x 84(了解具体过程并不极其重要,但请查看第 6 页了解详细信息)。所以,现在我们有了一个 84 x 84 x 4 的输入体积。这个体积将被输入到一个卷积神经网络中(教程),经过一系列卷积和 ReLU 层处理。网络的输出是一个 18 维的向量,每个数字是用户可以采取的每个可能动作的 Q 值(向上移动、向下移动、向左移动等)。
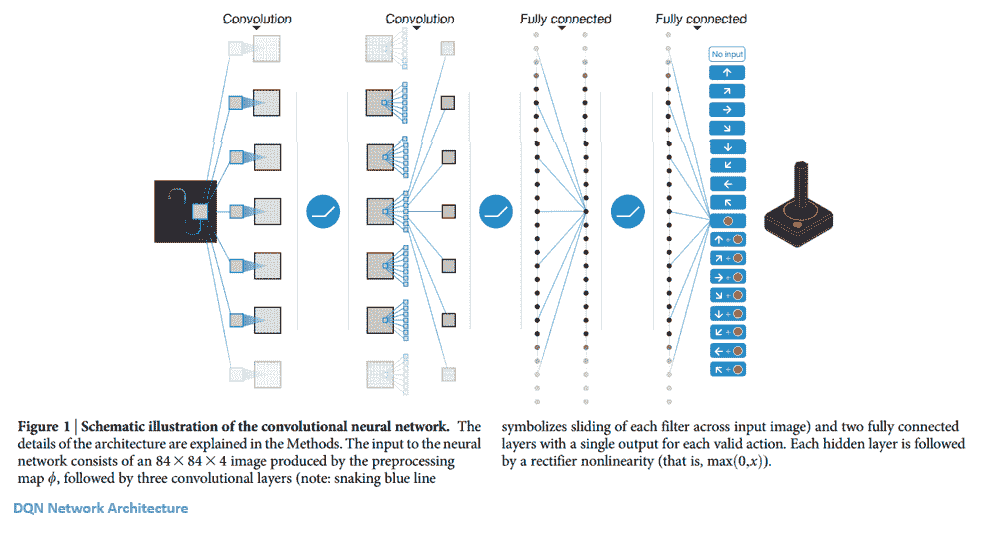
好的,让我们稍微退一步,弄清楚如何训练这个网络,使其能够预测准确的 Q 值。首先,让我们回顾一下我们要优化的内容。
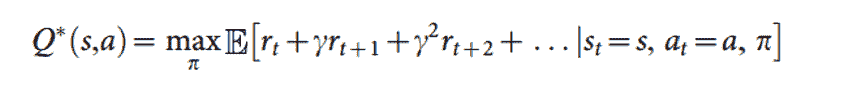
这与我们之前看到的 Q 函数形式相同,只不过这个表示的是所有 Q 的最大值 Q。让我们来研究一下如何获得这个 Q。现在,记住我们只需要 Q* 的一个近似值,这就是我们的函数逼近器(我们的 Qhats)会派上用场的地方。请在我们稍作转变时保持这个想法。
为了找到最佳策略,我们想要将问题框定为某种监督学习问题,其中预测的 Q 函数与期望的 Q 函数进行比较,然后朝正确的方向调整。为了做到这一点,我们需要一组训练样本。在我们的案例中,我们将需要创建一组经验,这些经验存储了每个时间步的代理状态、动作、奖励和下一个状态。让我们更正式地说明一下。我们有一个回放记忆D,其中包含了(st, at, rt, st+1)的一组不同时间步数据。随着代理与环境的互动增多,这个数据集会逐渐建立。现在,我们将随机抽取这一数据的一个批次(比如 64 个时间步的数据),计算它们的损失函数,然后按照梯度来改进我们的 Q 函数近似。
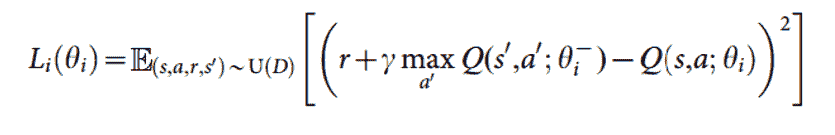
因此,正如你所见,损失函数旨在优化 Q 网络函数近似(Q(s,a,theta))与Q 学习目标之间的均方误差(MSE)。让我快速解释一下这些。这个 Q 学习目标是奖励 r 加上你可以从某个动作 a’中获得的最大 Q 值(在下一个时间步)。
一旦计算了损失函数,就会对 theta 值(或 w 向量)进行求导。然后更新这些值以最小化损失函数。
结论
这篇论文中我最喜欢的部分之一是它在游戏的某些时刻提供的值函数可视化。
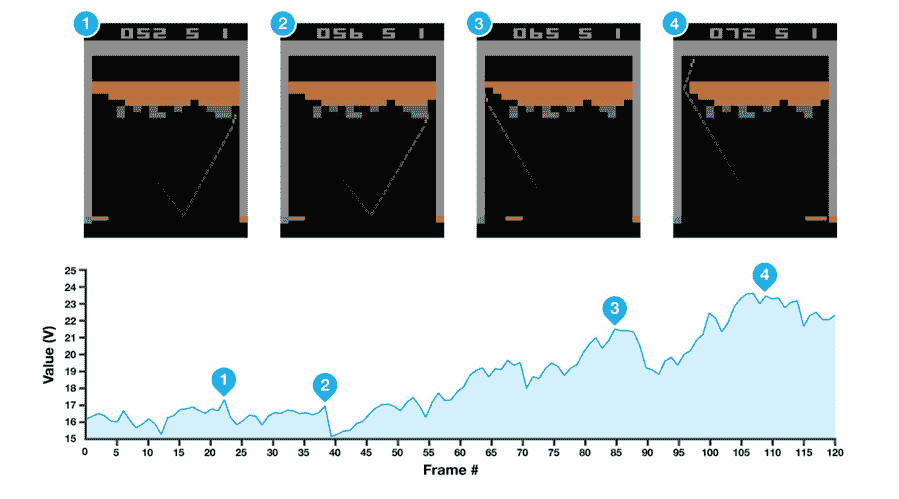
正如你所记得的,值函数基本上是衡量“处于特定情况有多好”的指标。如果你查看#4,你可以看到,根据球的轨迹和砖块的位置,我们可以获得大量的分数,高值函数很好地代表了这一点。
所有 49 个 Atari 游戏使用了相同的网络架构、算法和超参数,这对强化学习方法的稳健性是一个令人印象深刻的见证。深度网络与传统强化学习策略(如 Q 学习)的结合,在为...
掌握 AlphaGo 与 RL

介绍
4-1。这是 Deepmind 的强化学习代理在与世界顶级围棋选手李世石对局时的记录。万一你不知道的话,围棋是一种在棋盘上争夺领土的抽象策略游戏。由于游戏情境和移动方式的数量极为庞大,围棋被认为是世界上最难的 AI 游戏之一。论文开始时对围棋与象棋和跳棋等常见棋盘游戏进行了比较。虽然可以用变体的树搜索算法来攻击这些游戏,但围棋却完全不同,因为在一局游戏中大约有 250150 种不同的移动序列。显然需要强化学习,因此让我们看看 AlphaGo 是如何战胜困难的。
方法
AlphaGo 背后的基础是评估和选择的理念。在任何强化学习问题中(尤其是在棋盘游戏中),你需要一种评估环境或当前棋盘位置的方法。这将是我们的价值网络。然后,你需要一种通过策略网络选择行动的方法。我们确实对这两个术语——价值和策略——有一定的经验。
网络架构
让我们来看一下这两个网络的输入是什么。棋盘位置作为一个 19 x 19 的图像传入,并经过一系列卷积层,以构建当前状态的良好表示。首先,让我们看看我们的 SL(监督学习)策略网络。这个网络将图像作为输入,然后输出一个代理可以采取的所有合法动作的概率分布。这个网络在实际游戏之前已经在 3000 万个不同的围棋棋盘位置上进行了预训练。这些棋盘位置中的每一个都标记了在该情况下专家的最佳移动。团队还训练了一个较小但更快速的回合策略网络。
现在,卷积神经网络(CNN)在给定当前棋盘的表示时,能预测你应该采取的正确动作的能力是有限的。这时,强化学习发挥作用。我们将通过一个叫做策略梯度的过程来改进这个策略网络。还记得在上一篇论文中,我们希望优化我们的动作价值函数 Q 吗?现在,我们直接优化我们的策略(策略梯度的解释比较复杂,但 David Silver 在第七讲中讲得很好)。从高层次来看,策略通过模拟当前策略网络与网络的先前迭代之间的对局来改进。奖励信号为赢得比赛 +1,输掉比赛 -1,因此我们可以通过正常的梯度下降来改进网络。
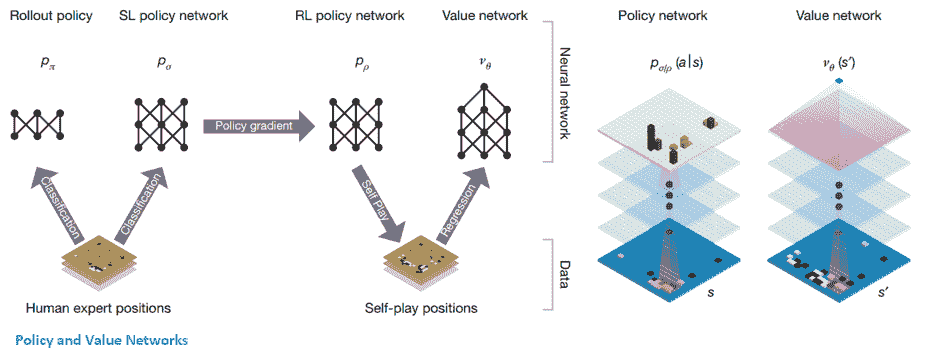
好的,现在我们有了一个相当不错的网络,它告诉我们最佳的行动步骤。下一步是拥有一个价值网络,预测在棋盘位置 S 上的游戏结果,其中两个玩家都使用策略 P。
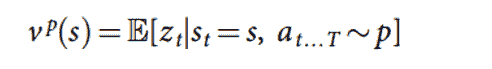
为了获得最佳的 V*,我们将使用我们熟悉的带有权重 W 的函数逼近器。这些权重由价值网络训练,训练数据基于状态、结果对(类似于我们在上一篇论文中看到的情况)。
现在我们有了这两个主要网络,我们的最后一步是使用蒙特卡洛树搜索将一切整合起来。MCTS 的基本思想是通过前瞻搜索选择最佳动作,其中树中的每条边存储一个动作值 Q、一个访问计数和一个先验概率。根据这些信息,MCTS 算法将从当前状态中选择最佳动作 A。系统的这一部分略显传统 AI 而少于 RL,因此如果你想了解更多细节,绝对可以查看论文,它会更好地总结这一部分。
结论
一台计算机系统刚刚击败了世界上最优秀的选手,赢得了最难的棋盘游戏之一。谁还需要结论呢?
特别感谢 David Silver 提供方程式和出色的强化学习讲座课程
简历:Adit Deshpande 目前是加州大学洛杉矶分校计算机科学专业的二年级本科生,同时辅修生物信息学。他热衷于将自己在机器学习和计算机视觉方面的知识应用到医疗领域,为医生和患者提供更好的解决方案。
原文。已获授权转载。
相关:
-
深度学习研究综述:生成对抗网络
-
神经网络中的深度学习:概述
-
9 篇关键深度学习论文,解释详解
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
相关主题
深度学习研究回顾:自然语言处理
原文:
www.kdnuggets.com/2017/01/deep-learning-review-natural-language-processing.html/3
记忆网络
简介
我们将讨论的第一篇论文是问答子领域中非常有影响力的出版物。由 Jason Weston、Sumit Chopra 和 Antoine Bordes 撰写,这篇论文介绍了一类称为记忆网络的模型。
直观的想法是,为了准确回答关于一段文本的问题,你需要以某种方式存储给定的信息。如果我问你“RNN 代表什么”,(假设你已经完全阅读了这篇文章 J)你会能够给出答案,因为你通过阅读这篇文章的第一部分吸收的信息被存储在你的记忆中。你只需花几秒钟找到这些信息并用语言表达出来。现在,我不知道大脑是如何做到这一点的,但拥有一个存储这些信息的地方的想法依然存在。
论文中描述的记忆网络是独特的,因为它具有一个可以读写的关联记忆。值得注意的是,我们在 CNNs 或 Q-Networks(用于强化学习)或传统神经网络中没有这种类型的记忆。这部分是因为问答任务非常依赖于能够建模或跟踪长期依赖关系,例如跟踪故事中的角色或事件的时间线。在 CNNs 和 Q-Networks 中,“记忆”在网络的权重中内建,因为它们学习不同的滤波器或从状态到动作的映射。乍一看,RNNs 和 LSTMs 可能会被使用,但它们通常不能记住或记忆过去的输入(在问答中这一点是相当关键的)。
网络架构
好的,现在让我们看看这个网络是如何处理它收到的初始文本的。像大多数机器学习算法一样,第一步是将输入转换为特征表示。这可能涉及使用词向量、词性标注、解析等。具体如何做完全取决于程序员。

下一步是将特征表示 I(x) 与我们的记忆 m 更新,以反映我们收到的新输入 x。

你可以将记忆 m 视为由单个记忆 m[i]组成的数组。每个单独的记忆 m[i]可以是记忆 m 整体、特征表示 I(x)和/或自身的函数。这个函数 G 可以简单地是将整个表示 I(x)存储在单个记忆单元 m[i]中。你可以修改这个函数 G,以基于新输入更新过去的记忆。第 3^(rd)和第 4^(th)步涉及根据问题从记忆中读取以获取特征表示 o,然后解码以输出最终答案 r。

函数 R 可以是一个 RNN,用于将来自记忆的特征表示转换为对问题的可读且准确的回答。
现在,让我们更详细地看一下第 3 步。我们希望这个 O 模块输出一个最能匹配给定问题 x 的可能答案的特征表示。现在这个问题将与每个单独的记忆单元进行比较,并根据记忆单元对问题的支持程度进行“评分”。
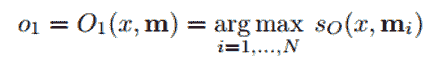
我们取评分函数的最大值以找到最能支持问题的输出表示(你也可以选择多个最高评分单元,不必限制为 1)。评分函数计算问题和所选记忆单元之间不同嵌入的矩阵积(详细信息请查阅论文)。你可以将其视为在计算两个词向量的相似度时的乘法。这个输出表示 o 随后会被送入 RNN、LSTM 或其他评分函数,以输出可读答案。
这个网络以监督方式进行训练,其中训练数据包括原始文本、问题、支持句子和真实答案。这里是目标函数。
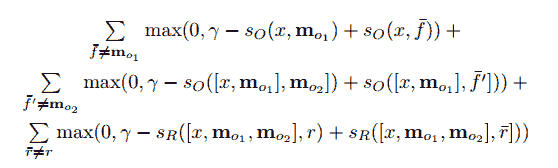
对于感兴趣的人,这里有一些基于这种记忆网络方法的论文
树形 LSTM 用于情感分析
简介
下一篇论文研究了情感分析的进展,即确定短语是否具有积极或消极的含义/意义。更正式地说,情感可以定义为“对某个情况或事件的看法或态度”。当时,LSTM 是情感分析网络中最常用的单元。由凯·盛·泰、理查德·索彻和克里斯托弗·曼宁撰写,这篇论文介绍了一种在非线性结构中将 LSTM 串联在一起的新方法。
这种非线性排列的动机在于自然语言的特性,即词语序列成为短语。这些短语根据词语的顺序,可以具有不同于其原始词汇组件的含义。为了表示这一特性,LSTM 单元的网络必须被安排成树形结构,其中不同的单元受到其子节点的影响。
网络架构
Tree-LSTM 和标准 LSTM 之间的一个区别在于,后者的隐藏状态是当前输入和前一个时间步的隐藏状态的函数。然而,Tree-LSTM 的隐藏状态是当前输入和其子单元的隐藏状态的函数。
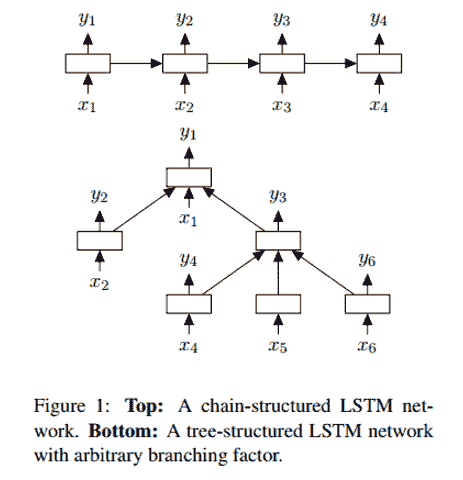
使用这种新的树形结构,一些数学变化包括子单元具有遗忘门。对于那些对细节感兴趣的人,可以查看论文以获取更多信息。然而,我想关注的是理解为什么这些模型比线性 LSTM 表现更好。
使用 Tree-LSTM,一个单元能够整合其所有子节点的隐藏状态。这很有趣,因为一个单元能够对每个子节点赋予不同的权重。在训练过程中,网络可以意识到某个特定词(可能是“not”或“very”在情感分析中)对句子的整体情感非常重要。提高该节点的权重为网络提供了很大的灵活性,并可能提高性能。
神经机器翻译
介绍
今天我们要看的最后一篇论文描述了一种机器翻译任务的方法。由 Google ML 的远见者杰夫·迪恩、格雷格·科拉多、奥里尔·维尼亚尔斯等人撰写,这篇论文介绍了一个机器翻译系统,这个系统成为了 Google 流行翻译服务的核心。与 Google 之前使用的生产系统相比,该系统将翻译错误减少了平均 60%。
传统的自动翻译方法包括短语匹配的变体。这种方法需要大量的语言领域知识,最终其设计证明过于脆弱,缺乏泛化能力。传统方法的问题之一是它试图逐块翻译输入句子。事实证明,更有效的方法(NMT 使用的方法)是一次翻译整个句子,从而允许更广泛的上下文和更自然的词语重排。
网络架构
论文中的作者介绍了一种深度 LSTM 网络,该网络可以通过 8 个编码器和解码器层进行端到端训练。我们可以将系统分为三个组件:编码器 RNN、解码器 RNN 和注意力模块。从高层次来看,编码器负责将输入句子转换为向量表示,解码器生成输出表示,然后注意力模块告诉解码器在解码任务中应关注什么(这就是利用整个句子上下文的想法所在)。
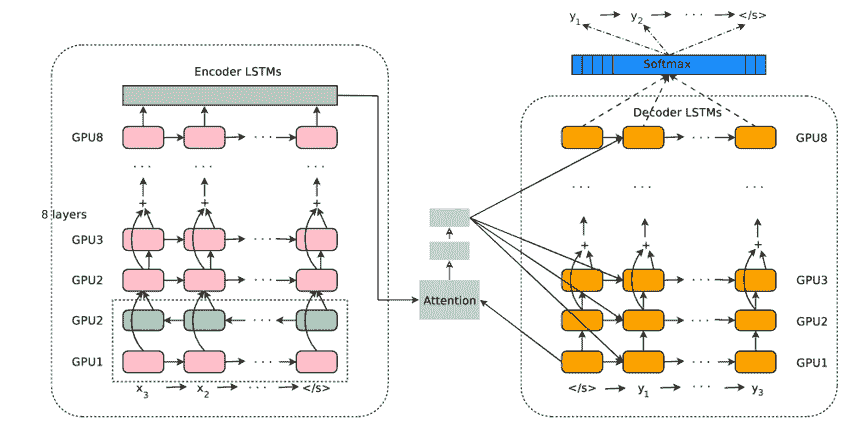
论文的其余部分主要集中在大规模部署此类服务所面临的挑战上。讨论了计算资源的数量、延迟以及高量级部署等主题。
结论
有了这些,我们结束了关于深度学习如何促进自然语言处理任务的讨论。在我看来,未来该领域的一些目标可能包括改善客户服务聊天机器人,完善机器翻译,并希望使问答系统能够更深入地理解非结构化或冗长的文本(例如维基百科页面)。
特别感谢 Richard Socher 和斯坦福 CS 224D的工作人员。精彩的幻灯片(大部分图片归功于他们的幻灯片)和精彩的讲座。
简介:Adit Deshpande 目前是加州大学洛杉矶分校计算机科学专业的二年级本科生,同时辅修生物信息学。他对将机器学习和计算机视觉的知识应用于医疗保健领域充满热情,以便为医生和患者工程出更好的解决方案。
原文。经许可转载。
相关:
-
深度学习研究回顾:强化学习
-
深度学习研究回顾:生成对抗网络
-
KDnuggets 顶级博主:与深度学习爱好者 Adit Deshpande 的访谈
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 需求
更多相关主题
深度学习的扩展是可预测的,经验上
原文:
www.kdnuggets.com/2018/05/deep-learning-scaling-predictable-empirically.html
评论
深度学习的扩展是可预测的,经验上 Hestness 等人,arXiv,2017 年 12 月
感谢 Nathan Benaich 在他的优秀2018 年第一季度 AI 世界总结中突出了这篇论文
这是一项非常出色的研究,具有深远的影响,甚至可能在某些情况下影响公司战略。研究始于一个简单的问题:“我们如何改进深度学习的最新技术?”我们有三条主要攻击线:
-
我们可以寻找改进的模型架构。
-
我们可以扩展计算。
-
我们可以创建更大的训练数据集。
随着 DL 应用领域的增长,我们希望更深入地理解训练集规模、计算规模和模型准确性改进之间的关系,以推动技术的前沿。
寻找更好的模型架构通常依赖于“不可依赖的顿悟”,正如结果所示,与增加可用数据量相比,影响有限。当然,我们已经知道这一点,包括从 2009 年的 Google 论文中,‘数据的非理性有效性’。今天的论文结果帮助我们量化了在各种深度学习应用中的数据优势。理解的关键在于以下方程:
这表明一般化误差 作为训练数据量
作为训练数据量 的函数,遵循具有指数
的函数,遵循具有指数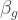 的幂律。经验上,
的幂律。经验上, 通常在-0.07 到-0.35 之间。误差当然是,较低更好,因此为负指数。我们通常在对数-对数图上绘制幂律,其中它们结果为直线,梯度表示指数。
通常在-0.07 到-0.35 之间。误差当然是,较低更好,因此为负指数。我们通常在对数-对数图上绘制幂律,其中它们结果为直线,梯度表示指数。
制作更好的模型可以将 y 截距降低(直到达到不可约错误水平),但似乎不会影响幂律系数。另一方面,更多的数据将使我们沿着改进的幂律路径前进。
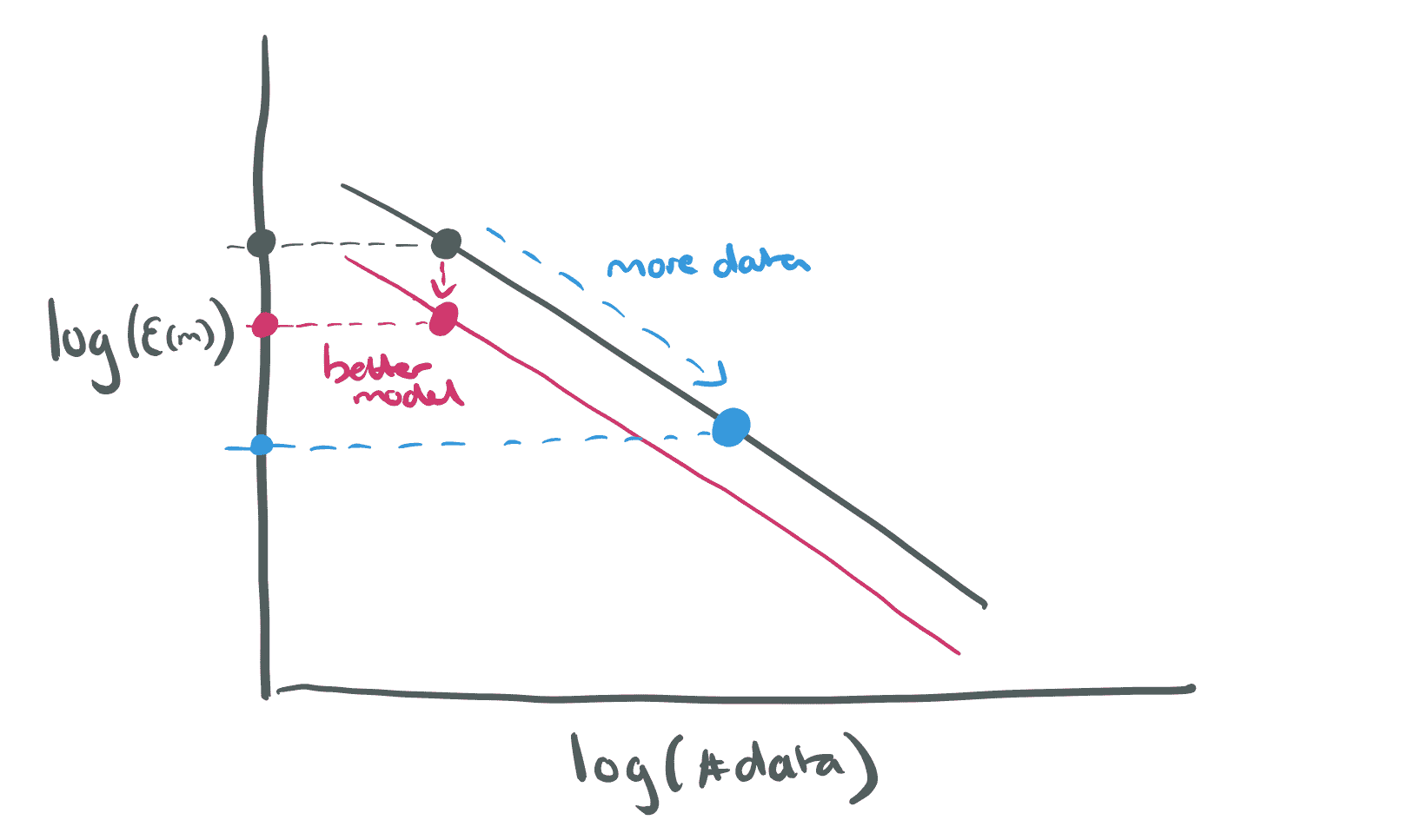
三个学习区域
实际应用的学习曲线可以分为三个区域:
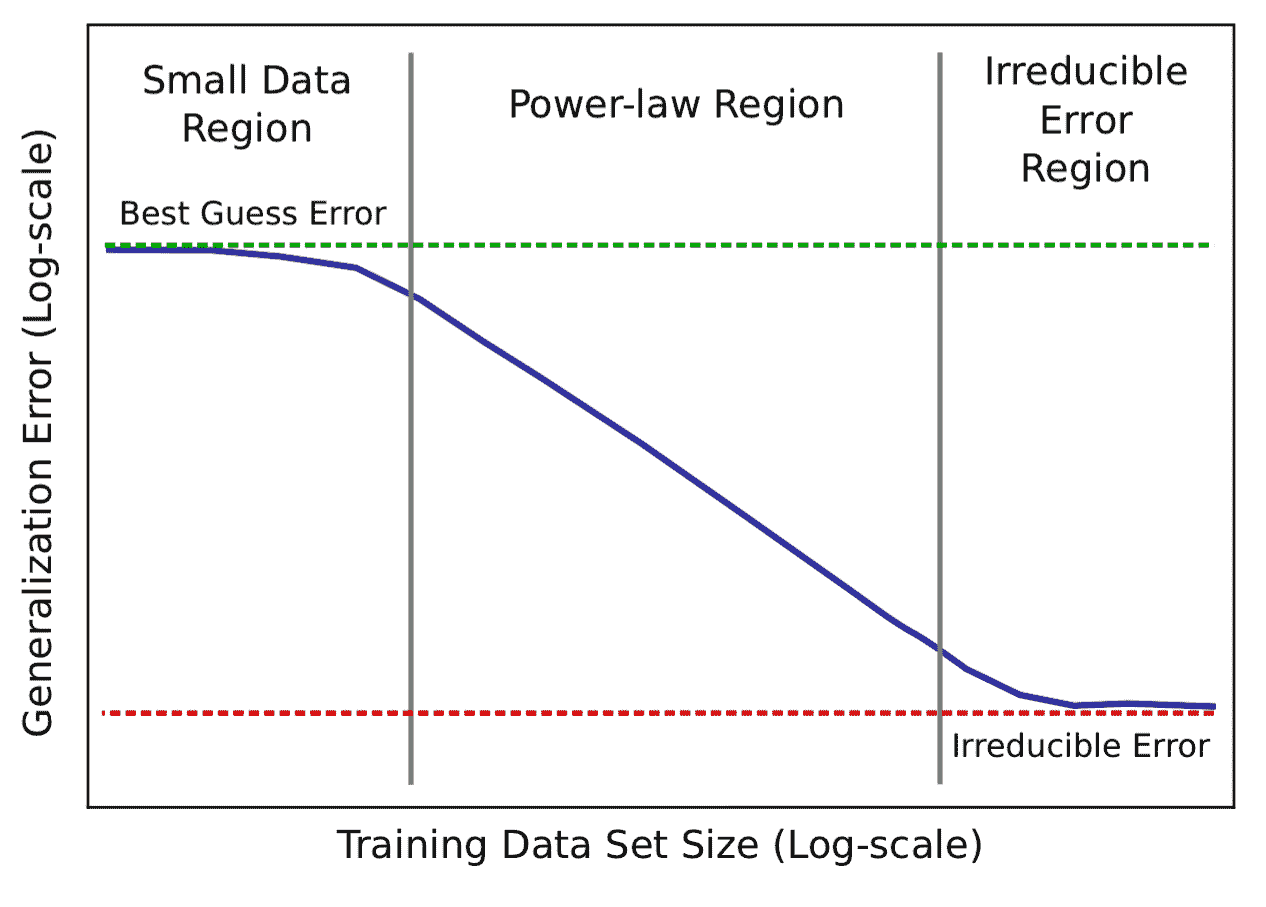
-
小数据区域是模型在数据不足的情况下挣扎学习的地方,模型的表现只能和“最佳”或“随机”猜测一样好。
-
中间区域是幂律区域,在该区域,幂律指数定义了曲线的陡峭程度(对数对数尺度上的斜率)。这个指数是模型表示数据生成函数的难度指标。
“本文的结果表明,幂律指数不容易通过先验理论来预测,并且可能依赖于问题领域或数据分布的某些方面。”
-
不可减少误差区域是指模型无法改进的非零下界误差。对于足够大的训练集,模型在这个区域会达到饱和。
关于模型大小
我们预期模型参数的数量与数据集的适配应遵循
,其中
是适应大小为
的训练集所需的模型大小,而
。
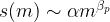 ,其中
,其中 是适应大小为
是适应大小为![\beta_p \in [0.5,1]](../Images/c5436a709bbb30c80b8049944cde8cd7.png) 。
。最佳拟合模型在训练分片大小上以次线性增长。较高的 值表明模型在较大的数据集上对额外参数的使用效果较差。尽管模型大小扩展存在差异,“对于给定的模型架构,我们可以准确预测能够最好地适应越来越大数据集的模型大小。”
值表明模型在较大的数据集上对额外参数的使用效果较差。尽管模型大小扩展存在差异,“对于给定的模型架构,我们可以准确预测能够最好地适应越来越大数据集的模型大小。”
幂律的影响
可预测的学习曲线和模型大小扩展表明,深度学习可能会有一些重要的影响。对于机器学习从业者和研究人员而言,可预测的扩展可以帮助模型和优化调试以及迭代时间,并提供估计提高模型准确性的最有影响力的下一步的方法。在操作上,可预测的曲线可以指导是否以及如何增长数据集或计算。
一个有趣的结果是,模型探索可以在较小的数据集上进行(因此更快/更便宜)。数据集需要足够大,以显示曲线的幂律区域的准确性。然后,可以将最有前景的模型扩展到更大的数据集上,以确保相应的准确性提升。这是因为扩展训练集和模型很可能会在模型之间带来相同的相对增益。在建立公司时,我们在扩展业务之前会寻找产品市场匹配。在深度学习中,似乎类比为在扩展之前寻找模型问题匹配,即先搜索再扩展的策略:
如果你需要对投资更多数据收集的投资回报率或可能的准确性提升做出商业决策,幂律可以帮助你预测回报:
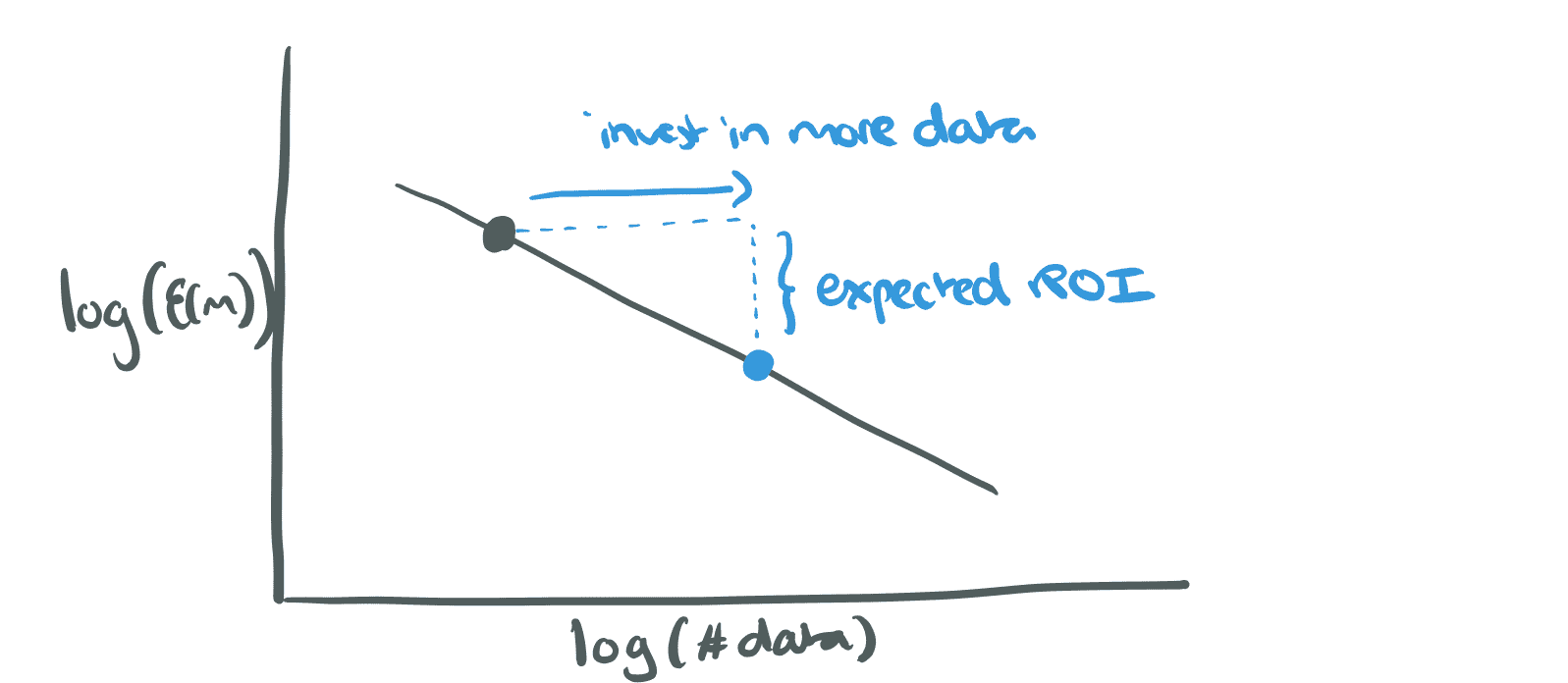
相反,如果在幂律区域内的泛化误差偏离幂律预测,这表明增加模型规模可能会有所帮助,或者更广泛的超参数搜索(即更多的计算)可能会有所帮助:
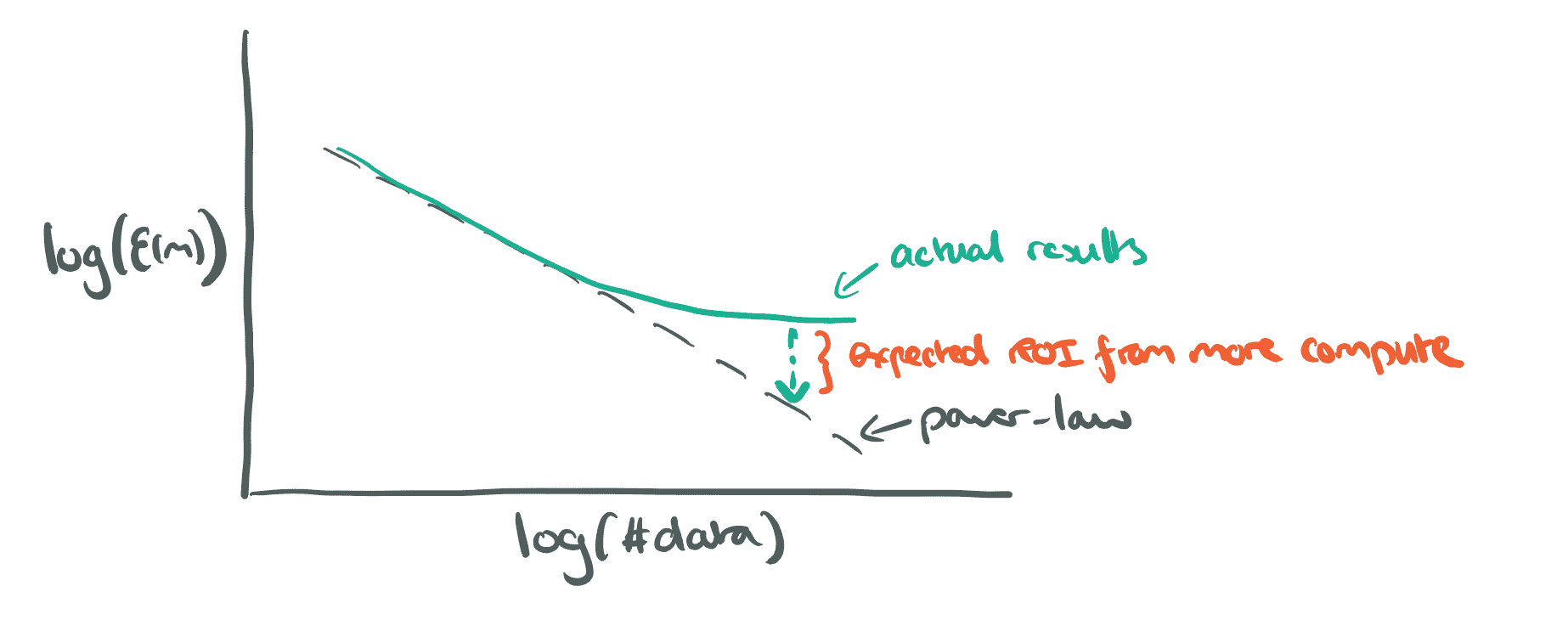
…可预测的学习和模型规模曲线可能提供了一种预测达到特定准确度水平的计算需求的方法。
你能超越幂律吗?
模型架构改进(例如,增加模型深度)似乎仅仅是将学习曲线向下移动,但不会改善幂律指数。
我们尚未找到影响幂律指数的因素。要在增加数据集规模时超越幂律,模型需要用逐渐减少的数据学习更多的概念。换句话说,模型必须从每个额外的训练样本中提取更多的边际信息。
如果我们能够找到改进幂律指数的方法,那么某些问题领域的潜在准确性提升是“巨大的”。
实证数据
支持这些的实证数据是通过在多个不同领域使用最新深度学习模型测试各种训练数据大小(以 2 的幂次方)收集的。
这是神经机器翻译的学习曲线。右侧可以看到每个训练集大小的最佳拟合模型的结果。随着训练集大小的增加,实证误差偏离幂律趋势,可能需要更全面的超参数搜索来将其重新对齐。
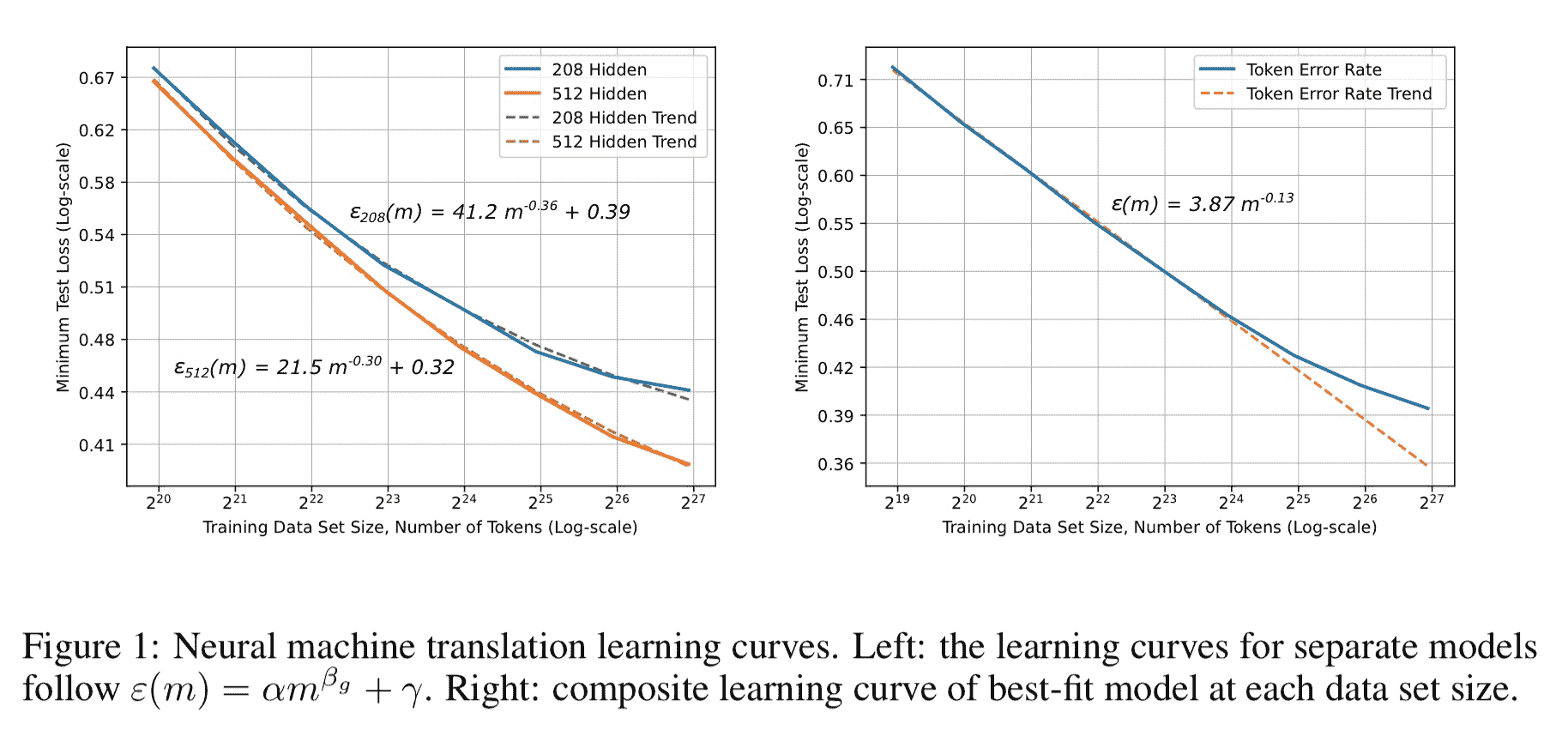
下一个领域是词语言模型。虽然使用了各种模型架构,它们的差异很大,但都表现出相同的学习曲线特征,由幂律指数表征。
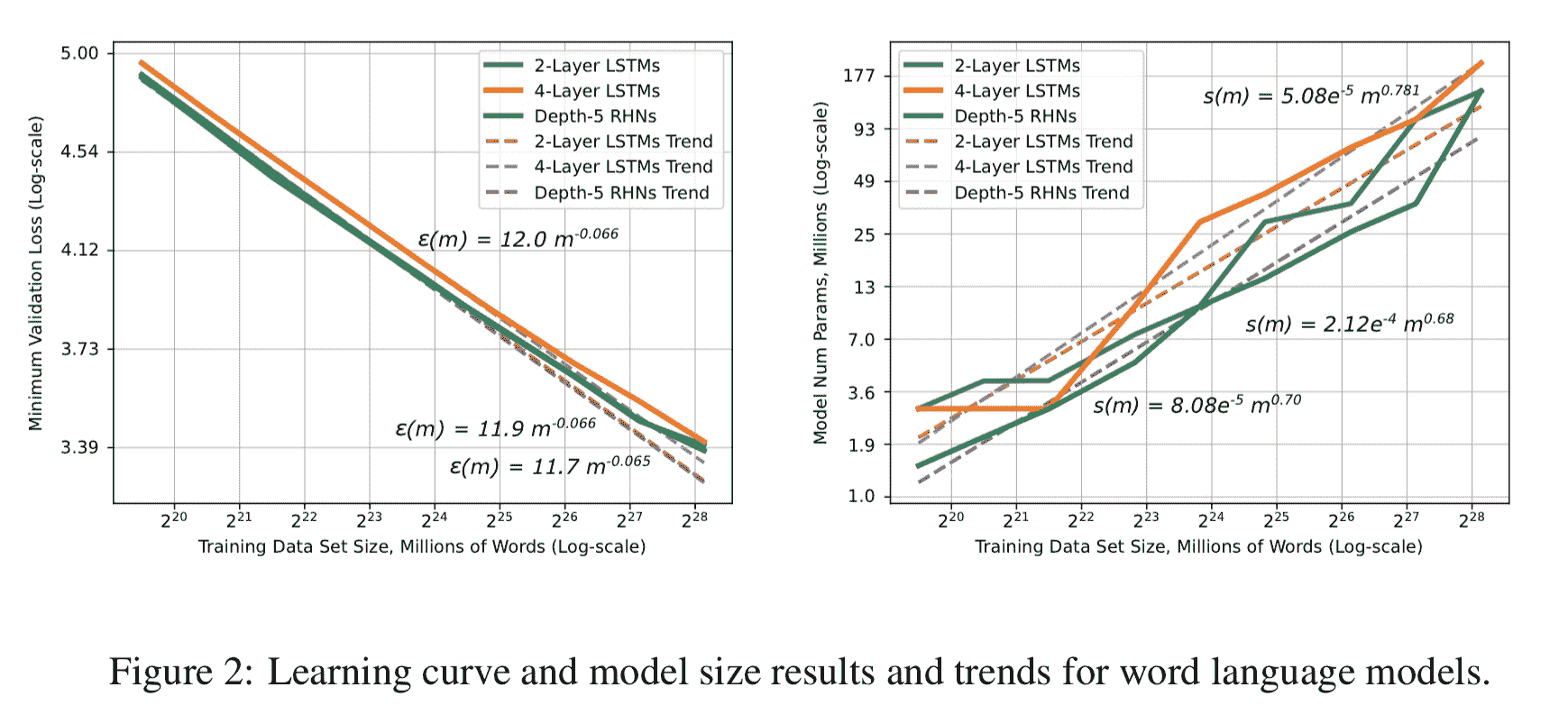
这是字符语言模型的结果:
在图像分类中,当数据不足以学习出良好的分类器时,我们可以在图中看到“数据稀少区域”出现:
最后,这里是语音识别:
我们实证验证了,随着在四个机器学习领域(机器翻译、语言建模、图像处理和语音识别)中为最先进(SOTA)模型架构增加训练集,DL 模型的准确性按幂律增长。这些幂律学习曲线在所有测试领域、模型架构、优化器和损失函数中都存在。
原文。转载经许可。
相关内容:
-
如何让 AI 更易获得
-
高级 API 是否让机器学习变得更简单?
-
逐步推导卷积神经网络与全连接网络的关系
我们的前三个课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关话题
深度学习是银弹吗?
原文:
www.kdnuggets.com/2017/02/deep-learning-silver-bullet.html
评论
由丹尼尔·勒梅尔,魁北克大学撰写。
在 2016 年,我们看到了涉及人工智能的广泛突破,特别是深度学习。谷歌、脸书和百度宣布了几个使用深度学习的突破。谷歌还击败了围棋。
深度学习是一类特定的机器学习算法。它有着悠久的历史,起源于计算机科学的早期阶段。然而,并非所有的机器学习都是深度学习。

我们现在是 2017 年,刚刚 1 月,人工智能领域的突破不断被宣布。这些天,我们听说顶级人类扑克玩家被击败。
特别是,卡内基梅隆大学的一个系统叫做Libratus似乎取得了很多成功。
关于 Libratus 的详细信息很少。引起我注意的是提到它使用了“反事实遗憾最小化”,这是一种传统的机器学习方法,并非深度学习的一种形式。
鉴于对深度学习的所有炒作,我发现这几乎让人惊讶……真的还有人工智能研究者在研究深度学习之外的技术吗?(我半开玩笑地说。)
去年,我参加了一个关于算法及其对加拿大文化的影响的讨论小组。组织者事后将小组名称更改为“我们是否通过深度学习算法推动了加拿大内容?”然而,小组并未专门讨论深度学习。深度学习的成功如此显著,以至于“深度学习”已经成为“算法”的同义词。
我最近在一个研究生奖学金委员会上……似乎每个聪明的年轻计算机科学家都计划从事深度学习。也许我有点夸张,但几乎没有。我见过将深度学习应用于各种领域的提案,从识别癌细胞到辅导孩子。
商业领域也在进行类似的过程。如果你是一家从事人工智能的初创公司,而且你没有专注于深度学习,你必须解释一下自己。
当然,机器学习是一个广阔的领域,包含许多技术类别。然而,人们几乎有一种印象,所有主要问题都将通过深度学习解决。实际上,一些深度学习的倡导者几乎明确提出了这一点……他们通常承认其他技术可能会在小问题上表现良好……但他们常常强调,对于大问题,深度学习必定会获胜。
我们将继续看到各种技术战胜非常困难的问题,这些技术往往与深度学习无关。如果我没错的话,这意味着那些涌向深度学习的年轻计算机科学家和创业者应该保持警惕。他们可能会陷入一个过于拥挤的领域,从而错过在其他地方发生的重要突破。
预测未来是困难的。也许深度学习确实是灵丹妙药,我们将很快通过深度学习“解决智能”……所有问题都将通过深度学习的变体得到解决……或者也可能是研究人员很快会遇到收益递减的情况。他们需要为了更小的进步而更加努力。
深度学习存在显著的局限性。例如,当我审查奖学金申请时……许多试图用深度学习解决困难问题的年轻计算机科学家并没有相应的大量数据来源。拥有几乎无限的数据供应是一种奢侈,只有少数人能负担得起。
我认为一个未被明确说明的假设是必须存在一种通用算法。一定存在某种技术可以以通用的方式使软件智能化。也就是说,我们可以“解决智能”……我们可以以通用的方式构建软件来解决所有其他问题。
我对通用智能的概念持怀疑态度。Kevin Kelly 在他的最新书籍中提出了没有这种东西的观点。所有智能都是专门化的。我们的智能对我们来说“感觉”是通用的,但这是一种错觉。我们认为自己擅长解决大多数问题,但实际上并不是这样。
例如,人脑在高级数学方面显示出其极限。经过大量训练和专注,我们中的一些人可以在没有错误的情况下编写形式化证明。然而,我们在这方面的效率非常低下。我预测,再过十年或二十年,未经辅助的人脑将被认定为在高级数学研究中过时。那位在黑板上做数学的老者?那将显得很古怪。
因此,我们的大脑并不是解决智能问题的灵丹妙药,因此我不相信任何一种机器学习技术可以成为灵丹妙药。
我应该说明我的观点。可能存在一个总体的“算法”。马特·里德利在他的新书中指出 一切都是通过类似于自然选择的过程进化的。自然获得了一袋不断被改进的技巧。实际上,有一个总体的试错过程。这确实很普遍,但有一个主要的权衡:它很昂贵。我们的生物学进化了,但地球生态系统花费了数百万年才产生出智人。我们的技术在进化,但需要人类文明的全部力量来维持它。它也不是万无一失的。经常会发生灭绝事件。
致谢:感谢马丁·布鲁克斯(Martin Brooks)启发了这篇博客文章。
进一步阅读: DeepStack:无上限扑克中的专家级人工智能。西蒙·芬克(Simon Funk)的欢迎来到人工智能。
简介:丹尼尔·莱梅尔 是魁北克大学的计算机科学教授。他的研究重点是软件性能和索引。他是技术乐观主义者。
原文。经许可转载。
相关:
-
数据科学难题,回顾
-
2026 年人工智能中的常识?
-
创建好奇的机器:构建信息搜寻代理
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关主题
深度学习与经验主义的胜利
评论
深度学习 现在是许多监督机器学习任务的标准代表。也可以说,深度学习在过去几十年中在无监督机器学习中产生了最实用的算法。这些进展所带来的兴奋促使了大量的研究和记者的耸人听闻的头条新闻。虽然我对这种炒作持谨慎态度,但我也发现这项技术令人兴奋,并且最近加入了这个阵营,发布了 关于递归神经网络(RNNs)在序列学习中的 30 页批评性评审。

但机器学习研究社区中的许多人并不对深度情有独钟。事实上,对于那些努力通过将人工智能研究基于数学语言并用理论保证来复兴人工智能研究的人来说,深度学习代表了一种时尚。更糟糕的是,对于一些人来说,它可能看起来像是一种倒退。¹
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 部门
在这篇文章中,我将尝试提供对理论保证有用性的高层次和公正的分析,并解释为什么它们可能并不总是从实践上有用,而从智力上却值得回报。更重要的是,我将提供论据来解释为什么在经过多年的统计上逐渐可靠的机器学习之后,今天许多表现最佳的算法没有理论保证。
保证什么?
保证是关于算法的行为、性能或复杂性,可以以数学确定性作出的声明。其他条件相同的情况下,我们希望说,在足够的时间内,我们的算法 A 可以从某个模型类{H1, H2, ...}中找到一个分类器 H,其性能不低于 H,其中 H是该类中最好的分类器。当然,这是相对于某个固定的损失函数 L。若无此绝对界限,我们希望能够通过某个常量来界定 H 和 H之间的性能差异或比率。在没有这种绝对界限的情况下,我们希望能够证明,以高概率 H 和 H在运行我们算法一段固定时间后会给出相似的值。
许多现有算法提供了强有力的统计保证。线性回归允许精确解。逻辑回归保证随着时间的推移会收敛。深度学习算法一般没有任何保证。给定一个任意糟糕的起点,我不知道有哪个理论证明某种变体的 SGD 训练的神经网络会在时间上逐步改进,并且不会陷入局部最小值。最近有大量工作合理地表明,神经网络的误差面上鞍点的数量超过了局部最小值(一个 m 维面,其中 m 是学习参数的数量,通常是节点之间边的权重)。然而,这并不等同于证明局部最小值不存在或它们不能任意糟糕。
保证的问题
可证明的数学性质显然是受欢迎的。它们甚至可能在人工智能领域尚不明确、承诺过高和未达标的时期拯救了机器学习。然而,许多今天最好的算法并没有提供任何保证。这怎么可能呢?
我将在接下来的段落中解释几个原因。其中包括:
-
保证通常相对于一个较小的假设类。
-
保证通常仅限于最坏情况分析,但现实世界很少出现最坏情况。
-
保证通常基于对数据的不正确假设。
从弱池中选择赢家
首先,理论保证通常保证一个假设接近于某个给定类中的最佳假设。这并不保证在给定类中存在一个能够令人满意地执行的假设。
这里有一个比较直白的例子:我希望一个人工编辑来协助我撰写文档。拼写检查可能提供关于其行为的保证。它将以 100%的准确率识别某些拼写错误。但现有的自动校对工具无法提供智能人类所能提供的洞察力。当然,人类没有数学上的保证。人类可能会打瞌睡,忽视我的电子邮件,或者做出无意义的回应。尽管如此,人类能够表达比 Clippy 更广泛的有用想法。
一种愤世嫉俗的观点可能是,有两种方法可以改进理论保证。一种是改进算法。另一种是削弱它所属的假设类。尽管神经网络几乎没有提供理论保证,但它们提供了一组比大多数更好理解的机器学习模型丰富得多的潜在假设。随着启发式学习技术和更强大的计算机消除了有效学习的障碍,显然对于许多模型来说,这种增强的表现能力对做出实际有用的预测至关重要。
最坏的情况可能无关紧要
保证通常是在最坏情况下给出的。通过保证结果在最优结果的一个 epsilon 因子内,我们说最坏情况不会比 epsilon 因子更糟。但在实际中,最坏情况可能从未发生。现实世界的数据通常高度结构化,最坏情况可能具有这样的结构,以至于典型数据集与病态数据集之间没有重叠。在这些情况下,最坏情况的界限仍然有效,但可能所有算法的表现都要好得多。没有理由相信,具有更好最坏情况保证的算法在典型情况下的表现会更好。
基于明显错误的假设
另一个原因是理论上健全的模型可能无法转化为实际的表现,是因为生成理论结果所需的数据假设往往是错误的。例如,考虑潜在狄利克雷分配(LDA),这是一种对话题建模非常了解且非常有用的算法。关于 LDA 的许多理论证明都基于这样一个假设:一个文档与一个话题分布相关。每个话题又与词汇表中所有单词的分布相关。生成过程如下进行。对于文档中的每个单词,首先根据每个话题的相对概率随机选择一个话题。然后,根据所选话题,按照该话题的单词分布选择一个单词。这个过程重复进行,直到所有单词都被选择。
显然,这一假设在任何真实世界的自然语言数据集中都不成立。在真实文档中,词汇的选择是有上下文的,并且高度依赖于它们所在的句子。此外,文档长度不是任意预定的,尽管在本科课程中可能是如此。然而,鉴于这种生成过程的假设,关于 LDA 的许多优雅证明是成立的。
需要明确的是,LDA 确实是一种广泛有用、最先进的算法。此外,我确信对算法特性的理论研究,即使在不切实际的假设下,也是提升我们理解并为后续更普遍和强大的定理奠定基础的有价值且必要的步骤。在本文中,我仅旨在阐明许多已知理论的性质,并向数据科学从业者提供直觉,解释为什么具有最有利理论性质的算法不总是表现最好的。
经验主义的胜利
有人可能会问,如果不完全依赖理论,是什么让像深度学习这样的的方法能够取得成功? 进一步的,为什么那些依靠直觉的经验方法现在如此广泛成功,即使这些方法在几十年前曾一度失宠?
对于这些问题,我相信像 ImageNet 这样的大规模标注数据集的存在是启发式方法复兴的原因。给定足够大的数据集,过拟合的风险较低。此外,对测试数据的验证提供了一种处理典型情况的方法,而不是专注于最坏情况。此外,平行计算和内存容量的进步使得同时跟进许多假设的实证实验成为可能。由强大直觉支持的经验研究提供了一条前进的道路,当我们达到形式理解的极限时。
警示事项
尽管深度学习在机器感知和自然语言处理中的成功不容忽视,但可以合理地认为,到目前为止,最有价值的三种机器学习算法是线性回归、逻辑回归和 k 均值聚类,这些算法在理论上都得到了很好的理解。对经验主义胜利的合理反驳可能是,迄今为止,最好的算法都是理论上有动机和基础的,而经验主义仅负责最新的突破,而不是最重要的突破。
少数事物是有保证的
当可获得时,理论保证是美丽的。它们反映了清晰的思维,并对问题的结构提供了深刻的洞察。给定一个有效的算法,解释其性能的理论加深了理解,并为进一步的直觉提供了基础。即便没有有效的算法,理论也提供了攻击的路径。
然而,具有坚实基础的直觉与严格的实证研究相结合,能够产生持续有效的系统,这些系统在许多重要任务上优于更为理解的模型,有时甚至优于人类。这种实证主义为那些形式分析受到限制的应用提供了一条前进的路径,并有可能开辟新的方向,最终在未来可能获得更深层次的理论理解。
¹是的,这是一个老套的双关语。
扎卡里·蔡斯·利普顿 是加州大学圣地亚哥分校计算机科学工程系的博士生。他的研究得到了生物医学信息学部门的资助,对机器学习的理论基础和应用都有浓厚的兴趣。除了在 UCSD 的工作,他还曾在微软研究院实习过。
相关:
-
慢一点:质疑深度学习智商结果
-
模型可解释性的神话
-
(深度学习的深层缺陷)
-
数据科学中最常用、最混淆和滥用的术语
-
差分隐私:如何使隐私和数据挖掘兼容
更多相关话题
深度学习来自魔鬼吗?
原文:
www.kdnuggets.com/2015/10/deep-learning-vapnik-einstein-devil-yandex-conference.html
评论
在过去一周的柏林,我参加了“机器学习:前景与应用”会议,这是一个来自学术机器学习社区的邀请讲者会议。由俄罗斯最大搜索引擎 Yandex 组织,会议显著地突出深度学习和智能学习这两个常常被认为对立的概念。尽管我以深度学习小组的讲者和参与者身份参加了会议,但会议的亮点是见证了许多领先理论家和从业者表达的经验主义与数学之间的哲学冲突。
第一日的深度学习主题结束时,进行了一个晚间小组讨论。由李登博士主持,该讨论挑战了深度学习社区的讲者,包括我自己,解释机器学习的数学基础,并展望其未来。关于模型可解释性的问题,这是我在之前的帖子中讨论的一个话题,尤其是针对医学应用的问题特别多。在周三,举行了第二晚的讨论。在这里,支持向量机的共同发明者、被广泛认为是统计学习理论奠基人的弗拉基米尔·瓦普尼克阐述了他的知识传递理论,并提供了涉及机器学习、数学和智能源的哲学视角。或许最具争议的是,他对深度学习提出了挑战,质疑其特设的方法。
在过去的夏天,我发布了一篇文章,建议深度学习的成功更广泛地反映了经验主义在大数据环境中的胜利。 我认为,若没有过拟合的风险,可在真实数据上验证的方法集合可能远大于那些我们可以从数学第一原则保证有效的方法。会议结束后,我想继续探讨这个话题,特别是那些弗拉基米尔·瓦普尼克在会议上提出的挑战。
为了避免任何混淆,我是一名深度学习研究员。我个人并不否定深度学习,并尊重它的开创者和继承者。但我也相信,我们应该对最终某些数学理论将更全面地解释其成功或指引新的方法持开放态度。显然,理解深度学习方法的论点及其批评观点都有其价值,因此我呈现了一些会议的亮点,特别是来自 Vapnik 教授的讲座。
大数据与深度学习作为蛮力方法
尽管 Vapnik 教授对深度学习有多个角度的看法,但也许最核心的观点是:在关于智能学习的观众讨论中,Vapnik 提到了爱因斯坦的隐喻神的观点。简而言之,Vapnik 认为,想法和直觉要么来自上帝,要么来自魔鬼。他提出的区别是上帝聪明,而魔鬼则不聪明。
在他的数学家和机器学习研究员职业生涯中,Vapnik 表示魔鬼总是以蛮力的形式出现。此外,虽然承认深度学习系统在解决实际问题上的出色表现,但他认为大数据和深度学习都带有蛮力的色彩。有一位观众问 Vapnik 教授是否认为进化(这可能导致了人类智能)是一个蛮力算法。由于明确表示不喜欢猜测,Vapnik 教授拒绝对进化提出任何猜测。还值得一提的是,虽然爱因斯坦关于上帝如何设计宇宙的直觉非常有成效,但并不总是奏效。最著名的是爱因斯坦认为“上帝不掷骰子”的直觉似乎与我们对量子力学的现代理解相冲突(见斯蒂芬·霍金关于这个话题的精彩易读文章)。
虽然我可能不同意深度学习必然等同于蛮力的观点,但我更清楚地看到了对现代大数据态度的反对论点。正如 Vapnik 博士和纳撒尼尔·因特拉托尔教授在特拉维夫大学所建议的,一个婴儿在学习时并不需要数十亿个标注样本。换句话说,虽然使用巨大的标注数据集进行有效学习可能很容易,但依赖这些数据集可能会错过关于学习本质的一些根本问题。也许,如果我们的算法只能通过巨大的数据集进行学习,而这些本应通过数百个样本即可学习的内容,那我们可能已经陷入了懒惰。
深度学习还是深度工程
瓦普尼克教授对深度学习的另一种看法是,它不是科学。具体来说,他表示深度学习偏离了机器学习的核心使命,他认为机器学习的核心在于理解机制。更详细的说,他认为研究机器学习就像是在试图制造一把斯特拉迪瓦里小提琴,而工程解决实际问题更像是成为一名小提琴手。从这个角度来看,小提琴手可以演奏出美妙的音乐,并对如何演奏有直觉,但未必正式理解自己在做什么。由此,他建议许多深度学习从业者对数据和工程有很好的感觉,但同样不真正理解自己在做什么。
人类是否发明了什么?
瓦普尼克教授提出的一个尖锐的观点是,我们是发现还是发明算法和模型。在瓦普尼克看来,我们实际上并没有发明任何东西。他具体对观众说,他“并不聪明到可以发明什么”。由此推测,可能没有其他人也如此聪明。更委婉地说,他认为我们发明的东西(如果有的话),与那些本质上固有的事物相比微不足道,真正的知识来源于对数学的理解。深度学习中模型经常被发明、命名和技术专利,这与更具数学动机的机器学习相比显得有些人为。在这段时间里,他挑战观众提供一个深度学习的定义。大多数观众似乎不愿意提供定义。在其他时候,观众通过引用深度学习的生物学启发来挑战他的观点。对此,瓦普尼克教授问道:“你知道大脑是如何工作的?”
扎克瑞·蔡斯·利普顿 是加州大学圣地亚哥分校计算机科学工程系的博士生。由生物医学信息学部资助,他对机器学习的理论基础和应用都感兴趣。除了在 UCSD 的工作外,他还曾在微软研究院实习,并担任亚马逊的机器学习科学家,是 KDnuggets 的特约编辑,并在 Manning Publications 签约成为作者。
相关:
-
深度学习与经验主义的胜利
-
模型可解释性的神话
-
(深度学习的深层缺陷)
-
数据科学中最常用、最困惑和被滥用的术语
-
差分隐私:如何使隐私与数据挖掘兼容
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你所在组织的 IT 需求
更多相关话题
虚拟试衣服装的深度学习 – 挑战与机遇。
原文:
www.kdnuggets.com/2020/10/deep-learning-virtual-try-clothes.html
评论
作者:Maksym Tatariants,MobiDev 的数据科学工程师。
下述研究由 MobiDev 进行,作为将AR 和 AI 技术用于虚拟试衣间开发的调查的一部分。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能。
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求。
探索将 2D 服装转移到人物图像上。
在开发虚拟试衣间应用程序时,我们进行了系列实验,尝试了虚拟试衣,并发现 3D 服装模型在人体上的适当渲染仍然是一个挑战。为了实现令人信服的 AR 体验,深度学习模型不仅应该检测到与人体关节对应的基本关键点集合,还应该识别身体的实际三维形状,以便衣物能够适当地贴合身体。
对于这种模型类型的一个示例,我们可以查看 Facebook 研究团队的DensePose(图 1)。然而,这种方法不够准确、对移动设备而言速度较慢且成本高昂。

图 1:使用 DensePose 进行身体网格检测 (来源)。
因此,需要寻找虚拟服装试穿技术的更简单替代方案。
一个受欢迎的选择是,与其使用 3D 服装进行试穿,不如使用 2D 服装和 2D 人体轮廓。这正是Zeekit公司所做的,为用户提供了将多种服装类型(如连衣裙、裤子、衬衫等)应用到他们的照片上的可能性。

图 2:2D 服装试穿,Zeekit (来源, 0:29 - 0:39)。
由于公司使用的布料转移技术除了结合深度学习模型之外尚未披露,我们可以参考相关的科学文章。在审阅了几篇最新的文章(source 1, source 2, source 3)后,发现主要方法是使用生成对抗网络(GANs)结合姿态估计和人体解析模型。利用后两者模型可以帮助识别图像中与特定身体部位对应的区域,并确定身体部位的位置。生成模型的使用有助于生成转移衣物的变形图像并将其应用于人的图像,以减少产生的伪影数量。
选定模型和研究计划
对于这项研究,我们选择了在“Towards Photo-Realistic Virtual Try-On by Adaptively GeneratingPreserving↔Image Content”论文中描述的自适应内容生成与保存网络(ACGPN)模型。为了说明 ACGPN 的工作原理,让我们查看其架构如图 3所示。
图 3:ACGPN 模型的架构(致谢: Yang et al.,2020)。
该模型包括三个主要模块:语义生成、衣物变形和内容融合。
语义生成模块接收目标衣物的图像及其掩膜、人的姿态数据、包含所有身体部位的分割图(手部尤其重要)以及识别出的衣物项目。
语义生成模块中的第一个生成模型(G1)修改了人的分割图,以清楚标识出应该被目标衣物覆盖的身体区域。获取这些信息后,第二个生成模型(G2)将衣物掩膜进行变形,以符合其应占据的区域。
之后,将变形的衣物掩膜传递给衣物变形模块,其中空间变换网络(STN)根据掩膜对衣物图像进行变形。最后,将变形的衣物图像、来自语义生成模块的修改过的分割图和一个人的图像输入到第三个生成模块(G3),并产生最终结果。
为了测试所选模型的能力,我们按照难度递增的顺序进行了以下步骤:
-
在原始数据和我们的预处理模型(简单)的基础上复现了作者的结果。
-
将自定义衣物应用于默认人物图像(中等)。
-
将默认衣物应用于自定义人物图像(困难)。
-
将自定义衣物应用于自定义人物图像(非常困难)。
在原始数据和我们的预处理模型上复制作者的结果
原始论文的作者没有提到他们用于创建人物分割标签和检测人体上的关键点的模型。因此,我们自行选择了模型,并确保了 ACGPN 模型输出的质量与论文中报告的相似。
作为关键点检测器,我们选择了OpenPose模型,因为它提供了适当的关键点顺序(COCO 关键点数据集),并且在其他与虚拟试衣服更换相关的研究中被使用。

图 4: 使用 OpenPose 的 COCO 关键点检测示例。
我们选择了在Self Correction for Human Parsing论文中提出的 SCHP 模型进行身体部位分割。该模型利用了用于人体解析的常见架构CE2P,并对损失函数进行了一些修改。
SCHP 分割模型使用预训练的骨干(编码器)从输入图像中提取特征。然后使用恢复的特征进行边缘分支中的人体轮廓预测和解析分支中的人体分割。这两个分支的输出连同来自编码器的特征图一起输入到融合分支,以提高分割图的质量。
图 5: SCHP 模型(基于 CE2P)的架构,图像来源 – Li 等人
SCHP 模型中的另一个新元素是自我纠正特性,用于迭代地改进模型在噪声地面真值标签上的预测。这些标签通常用于人体解析任务,因为人为标注者可能难以生成分割标签。在此过程中,模型首先在不准确的人体标注上进行训练,并与在从先前训练的模型中获得的伪地面真值掩码上训练的新模型进行聚合。
这个过程会重复几次,直到模型和伪地面真值掩码的准确性达到更好的水平。对于人体解析任务,我们使用了在Look Into Person (LIP)数据集上训练的模型,因为它最适合这个任务。
图 6: 使用 SCHP 模型的人体解析示例(左侧 - 人体,右侧 - 分割)。
最后,当关键点和人体解析模型准备好后,我们使用它们的输出在与作者训练时相同的数据上运行了 ACGPN 模型。在下面的图像中,您可以看到我们从 VITON 数据集中获得的结果。
语义生成模块会修改原始分割,以反映新的服装类型。例如,原始图像上的套头衫有长袖,而目标服装(T 恤)则有短袖。因此,分割掩码需要修改,以便手臂部分更加显露。这个转化后的分割掩码随后被内容融合模块用于修复修改过的身体部位(例如,绘制裸露的手臂),这是系统执行的最具挑战性的任务之一(图 7)。

图 7:ACGPN 模型的输入和输出。
在下面的图像中(图 8),您可以看到使用 ACGPN 模型成功和失败的服装替换结果。我们遇到的最频繁的错误包括修复效果差(B1)、新服装与身体部位重叠(B2)以及边缘缺陷(B3)。

图 8:成功(A1-A3)和失败(B1-B3)的服装替换。伪影用红色矩形标记。
自定义服装应用于默认人物图像
对于这个实验,我们挑选了几件服装(图 9)并将它们应用到 VITON 数据集中人物的图像上。请注意,有些图像不是实际的服装照片,而是 3D 渲染或 2D 绘图。

图 9:用于虚拟试穿的服装图像(A - 项目的照片,B、C - 3D 渲染,D - 2D 绘图)。
继续查看服装替换的结果(图 10),我们可以将其大致分为三组。

图 10:使用自定义服装的替换示例(A 行 - 成功且有少量伪影,B 行 - 中等伪影,C 行 - 大量伪影)。
A 行中的图像没有缺陷,看起来最自然。这可以归因于图像中的人物姿势相似,都是直立面向相机。正如论文的作者所解释的,这种姿势使得模型更容易定义新服装如何被扭曲并应用到人物图像上。
行 B 中的图像展示了模型处理起来更具挑战性的姿势。人物的躯干略微弯曲,手臂部分遮挡了应有服装的身体区域。如图 8所示,弯曲的躯干会导致边缘缺陷。注意到困难的长袖服装(图 9中的项目 C)被正确处理。这是因为袖子需要经过复杂的变换才能与人物的手臂对齐。如果手臂弯曲或其轮廓被原始图像中的服装遮挡,这会非常复杂。
行 C 中的图像展示了模型几乎完全失败的例子。这是预期的行为,因为输入图像中的人物躯干扭曲严重,手臂弯曲到遮挡了几乎一半的腹部和胸部区域。
默认服装应用于定制人物图像
让我们回顾一下模型在自然环境中对非约束图像的应用实验。用于模型训练的 VITON 数据集具有非常静态的光照条件,且相机视角和姿势的变化不多。
在使用真实图像测试模型时,我们意识到训练数据与非约束数据之间的差异显著降低了模型输出的质量。你可以在图 11中看到这个问题的例子。

图 11:服装替换 - 背景与训练数据的不相似性的影响。行 A - 原始背景,行 B - 用与 VITON 数据集中的背景相似的背景替换的背景。
我们找到了一些姿势和相机视角与训练数据集图像相似的人物图像,并且在处理后发现了许多伪影(行 A)。然而,在去除不寻常的背景纹理并用与训练数据集相同的背景颜色填充该区域后,输出质量有所提高(尽管仍有一些伪影存在)。
在使用更多图像测试模型时,我们发现模型在与训练分布相似的图像上表现尚可,而在输入明显不同的图像上则完全失败。你可以在图 12中看到应用模型的更成功的尝试以及我们发现的典型问题。

图 12:在非约束环境中的图像上的服装替换输出(行 A - 小瑕疵,行 B - 中等瑕疵,行 C - 主要瑕疵)。
行 A 中的图像展示了主要缺陷是边缘缺陷的地方的例子。
行 B 中的图像显示了更严重的遮罩错误情况。例如,布料模糊、孔洞以及出现皮肤/服装补丁的位置不应存在这些问题。
行 C 中的图像展示了严重的修补错误,比如手臂绘制不佳和遮罩错误,如身体未遮罩的部分。
将定制服装应用于定制人物图像
在这里,我们测试了模型在处理定制服装和定制人物照片方面的效果,并将结果再次分为三组。

图 13:在不受约束的环境和定制服装图像中替换衣物。
行 A 中的图像显示了我们从模型中获得的最佳结果。定制服装和定制人物图像的组合被证明在处理时难度较大,除非有中等程度的伪影。
行 B 中的图像显示了伪影变得更加丰富的结果。
行 C 中的图像显示了由于变换错误导致的最严重的失真结果。
未来计划
ACGPN 模型有其局限性,例如训练数据必须包含目标衣物和穿着这些特定衣物的人物的配对图像。
考虑到上述所有描述,可能会产生虚拟试穿衣物不可实现的印象,但事实并非如此。虽然现在是一个具有挑战性的任务,但它也为未来基于 AI 的创新提供了机会窗口。而且,已经有新的方法被设计来解决这些问题。另一个重要的事情是,在选择合适的用例场景时,要考虑技术能力。
相关:
更多相关主题
深入了解 13 种数据科学家角色及其职责
原文:
www.kdnuggets.com/2022/01/deep-look-13-data-scientist-roles-responsibilities.html

在科技领域,数据科学家的职位和工作职责可能是最为多样的。数据科学家需要扮演多种角色,在亚马逊的数据科学家的日常工作可能与在微软的数据科学家的工作有很大的不同。从寻找公司业务中可以从数据收集、分析和理解中受益的领域,到决定必须做出的战略决策以提高客户满意度或购买完成率,公司对数据科学家的要求可以非常高。
数据科学家需要具备专家级的统计、机器学习以及通常还包括经济学的技能和知识。数据科学家需要具备高超的技能,包括数学、统计、机器学习、可视化、沟通和算法实现。
此外,数据科学家必须深入了解其数据的业务应用。如果你在分析树木生长数据,你需要理解树高与冠基高度的区别。这种背景知识可以在工作中逐步积累,但如果你已经有相关行业的工作经验,那么成为数据科学家的机会将会更大。如果你有五年的银行工作经验,那么在金融科技领域获得数据科学职位的机会要远大于在医疗行业。
数据科学家所戴的各种“帽子”

数据科学是一个相对较新的领域,对于非数据科学家来说,很难向外行解释数据科学家做什么。这导致了现代数据科学家可能会面临各种各样的职责和职位名称,这些职责和名称有时显得颇为滑稽。
一名数据科学家,根据公司和具体工作职责,可能需要负责数据收集和清理。你也可能需要开发机器学习模型和管道,或作为公司的可视化专家。有些数据科学家更多的是面向内部,而其他人则需要与内部非技术团队或甚至客户密切合作。如果你与技术水平较低的人员合作,你需要具备出色的沟通技能,无论是撰写总结分析的报告,还是展示你的发现并为未来的行动提供建议。
数据科学家的关键职责(或公司对从事数据收集、分析、可视化或预测的人员的称谓)是讲述数据的故事。数据的来源是什么?我们从中可以学到什么关于过去的知识?它如何指导我们未来的行动?为了成功地做到这一点,你需要是业务领域专家或拥有上下文知识,以便将拼图 pieces 拼接在一起,并向周围人解释数据的意义和你从中获得的见解。
数据科学领域的具体职责差异很大,领域内有很多不同的角色。无论你是想进入这一领域还是想换工作,保持对职位名称和行业的开放态度非常重要。我将为你详细介绍数据科学领域中十三种不同角色的一般职责。
公司通常不擅长为数据科学领域的人物命名,因此你应将这些分类作为参考原则,而非确切定义。如果其中一个角色对你来说非常合适,你可以将搜索范围缩小到这个职位,但如果多个角色都适合你,那么在搜索时标题可以更具灵活性。(如果职位名称对你真的很重要,你可以在接受工作邀请时将其作为谈判的一部分!)
任何一家具有一定规模的现代公司都有数据科学部门,而在一家公司的数据工程师可能会有与另一家公司市场科学家相同的职责。数据科学职位标识不明确,因此要广泛考虑。
数据科学家职责角色分解

1. 数据分析师
数据分析师更多地关注数据收集、清理和聚合。你必须能够自如地处理复杂的 SQL 查询。你将负责设计并向非技术人员展示报告。你还将有机会设计数据模型、可视化以及预测模型。
2. 数据库管理员
数据库管理员管理数据库实例,包括本地和云实例。作为 数据库管理员,你需要建立、配置和维护生产环境。你还将负责数据库的性能、可用性和安全性。准备好领导数据操作并提供关键的呼叫支持。
3. 数据建模师
数据建模师创建概念性、技术性、逻辑性,有时还包括物理数据模型。你将需要果断地选择并维护数据建模和设计标准,以为公司的数据创建一个统一的愿景。
数据建模师还必须开发实体关系模型和设计数据库。你可能需要改进数据收集和分析,以确保数据集具有代表性,特别是对于团队或公司中未充分代表的数据类别。
4. 软件工程师
软件工程师 设计和维护软件系统。当你成为软件工程师时,要准备好编写可扩展、可靠且高效的代码。你将需要将设计要求转化为文档齐全、经过良好测试的代码,使产品设计师的愿景得以实现。
5. 数据工程师
识别和解决数据质量挑战将是你作为数据工程师的重要任务。你还需要支持将数据源导入数据存储解决方案。数据工程师工作中令人兴奋的一部分是有机会架构和设计数据工程解决方案。你还应准备好构建 ETL 管道,以提取、转换和加载数据到数据仓库中用于下游报告。数据工程师还负责数据复制、提取、加载、清理和策划。
6. 数据架构师
数据架构师主要负责设计和维护数据管道。数据架构师工作的重要部分还包括管理数据库。作为数据架构师,你将编写高效的查询并优化现有查询,以最大化可扩展性和成本效益。你还将把数据转化为可操作的报告、自动化和洞察。
7. 统计学家
统计学家理解业务需求,提出假设,并设计统计上可靠的实验。作为统计学家,你将验证其他业务团队实验计划的统计有效性。你还需要指导和培训项目或研究主管,开发统计上合理的实验和验证策略或指标。
除了实验,统计学家还开发和执行分析报告策略。你可能需要充当统计学啦啦队员,因为一些数据科学公司让统计学家积极推广统计方法,并发现新的业务领域,这些领域可能从统计上可靠的分析中受益。
8. 商业智能分析师
商业智能分析师的数据科学领域略显柔和。作为商业智能分析师,你需要收集业务和功能需求,并致力于将技术解决方案与业务战略对齐。你还将从事数据采购和处理策略的创建或发现。
你将负责提取和处理大量数据,创建分析报告。商业智能分析师还需要向关键利益相关者报告、展示和沟通分析结果。
9. 营销科学家
营销科学家向当前和潜在客户展示想法和发现。他们还应用数据挖掘和分析策略于数据,如人口统计或市场营销数据。根据Stone Alliance Group’s对营销科学家的描述,你必须“跟踪和评估客户获取工作、市场趋势和客户行为。”营销科学家是一种专门从事广告、市场营销或用户/客户人口统计数据的数据科学家。
10. 业务分析师
根据MaxisIT Inc’s的要求,业务分析师“分析业务和用户需求,记录需求,并设计系统和报告的功能规格”。如果你是业务分析师或希望成为业务分析师,你需要理解业务和行业需求,并利用这些需求来制定系统范围和技术目标。你还需要定义不同系统和数据库之间的数据交互。
11. 定量分析师
定量分析师使用大量数据集开发复杂模型,以支持内部报告并产生商业洞察。资源开发协会的定量分析师“开发并领导分析计划的实施,概述研究方法、问题、采样和迭代计划”。定量分析师还会自动化工作流程并验证数据完整性。
12. 数据科学家
作为数据科学家,你需要提取、汇总、清理和转换来自多个来源的数据。你需要识别问题的重要背景因素。数据科学家分析数据以提供业务改进性能的关键可操作洞察。根据公司情况,你可能需要预测市场趋势,以帮助公司战略性地发展其分支机构。
数据科学涉及在短期分析指导与长期预测和实验之间找到一个平衡。你需要在合适的时间传达重要信息,因此能展示易于理解的数据可视化和引人入胜的演示至关重要。
作为数据科学家,你将从数据中提取价值和洞察,并向非技术利益相关者展示。你将有机会主动发现公司内部可以从数据驱动决策中获益的领域,并与其他团队合作实现这些目标。
13. 机器学习工程师
构建用于生产的机器学习模型是机器学习工程师的主要工作重点。他们设计和实施可扩展、可靠、高效的数据管道和服务。根据公司及其重点领域,你可以通过将机器学习模型应用于历史和实时数据来改善产品的个性化或更好地预测行业市场趋势。
角色和职责交叉,区分仍然重要
这些角色之间有很多交叉。有些角色更专注于纯粹的数字计算,而另一些则更侧重于将数据分析产生的洞察应用于业务决策。无论你的具体职位是什么,如果你从事数据科学领域的工作,你都应该参与数据驱动的产品开发周期中的许多不同步骤。你应该准备好发现需要优化的新领域,确定重要的指标,找到这些指标所需的数据,设计和执行实验,并以简明、准确和有说服力的方式展示实验/模型的结果。
数据科学领域仍然年轻且定义模糊。很多时候,你会发现不同职位下的工作描述在数据科学的范畴内听起来非常相似。公司通常会意识到他们有数据或可以收集数据,然后利用这些数据改善他们的商业模式。然而,这些职位描述及其指定的职位标题通常由非技术人员编写,因此存在很多重叠。
一家公司中的数据工程师可能与另一家公司中的数据分析师做着相同的工作。所有这些职位都涉及到数据的收集或验证、应用某种形式的分析,然后通过报告、预测或可视化向非技术同事解释结果。
如果其中一个职位对你来说完美无瑕,那么你可以将搜索范围缩小到那个标题,但如果几个职位都很吸引你,那么在搜索时对职位标题保持更大的灵活性。如果标题对你来说真的很重要,你可以在收到工作报价时将其作为谈判的一部分。不要让这些职责列表吓跑你,阻止你从事一个有趣的工作。如果你真的想成为数据建模师,但不喜欢组织数据沿袭信息,你可以考虑不同公司的数据建模师职位或数据架构师职位。
让对这十三种最常见数据科学角色的分析成为你寻找数据科学工作的新起点。
Nate Rosidi 是一名数据科学家,专注于产品策略。他还是一名兼职教授,教授分析课程,并且是 StrataScratch、一个帮助数据科学家准备面试的平台的创始人。你可以在 Twitter: StrataScratch 或 LinkedIn 上与他联系。
更多相关话题
深度多任务学习 – 3 个学到的经验
评论
由 Zohar Komarovsky,Taboola。
在过去的一年里,我和我的团队一直在Taboola feed上致力于个性化用户体验。我们使用了多任务学习(MTL)来预测同一输入特征集上的多个关键绩效指标(KPI),并实现了一个在 TensorFlow 中进行深度学习(DL)的模型。刚开始时,MTL 对我们来说似乎复杂得多,因此我想分享一些学到的经验。
已经有不少关于在深度学习模型中实现 MTL 的帖子(1, 2, 3)。
分享即关怀
我们想从硬参数共享的基本方法开始。硬共享意味着我们有一个共享的子网络,随后是特定于任务的子网络。

在 TensorFlow 中开始玩这样的模型的一种简单方法是使用估算器和多个头。由于它看起来与其他神经网络架构没有太大不同,你可能会问什么会出错?
第 1 课 – 组合损失
我们在 MTL 模型中遇到的第一个挑战是为多个任务定义一个单一的损失函数。虽然单个任务有一个明确的损失函数,但多个任务则有多个损失。
我们尝试的第一种方法是简单地将不同的损失进行求和。很快我们发现,虽然一个任务收敛到良好的结果,其他任务却表现得相当差。当我们仔细观察时,我们可以很容易地看到原因。损失的尺度差异如此之大,以至于一个任务主导了整体损失,而其他任务没有机会影响共享层的学习过程。
一个快速的解决方法是用加权和代替损失之和,这将所有损失调整到大致相同的尺度。然而,这个解决方案涉及到另一个可能需要不时调整的超参数。
幸运的是,我们找到了一篇很棒的论文,提出了在 MTL 中使用不确定性来加权损失。它的做法是,通过学习另一个噪声参数,并将其集成到每个任务的损失函数中。这允许处理多个任务,可能是回归和分类,并将所有损失带到相同的尺度。现在我们可以回到简单地求和我们的损失。
我们不仅得到了比加权和更好的结果,而且可以忽略额外的权重超参数。这里是论文作者提供的 Keras 实现。
第 2 课 – 调整学习率
学习率是调整神经网络中最重要的超参数之一,这是一个常见的约定。所以我们尝试了调整,并找到了一种对任务 A 非常有效的学习率,以及一种对任务 B 非常有效的学习率。选择较高的学习率会导致死 ReLU 问题出现在一个任务上,而使用较低的学习率则会导致另一个任务收敛缓慢。那么我们能做什么呢?我们可以为每个“头”(任务特定子网)调整一个单独的学习率,并为共享子网调整另一个学习率。
虽然听起来可能很复杂,但实际上非常简单。通常在 TensorFlow 中训练神经网络时,你会使用类似的东西:
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(loss)
AdamOptimizer定义了如何应用梯度,而minimize计算并应用它们。我们可以用自己的实现替代minimize,在应用梯度时使用计算图中每个变量的适当学习率:
all_variables = shared_vars + a_vars + b_vars
all_gradients = tf.gradients(loss, all_variables)
shared_subnet_gradients = all_gradients[:len(shared_vars)]
a_gradients = all_gradients[len(shared_vars):len(shared_vars + a_vars)]
b_gradients = all_gradients[len(shared_vars + a_vars):]
shared_subnet_optimizer = tf.train.AdamOptimizer(shared_learning_rate)
a_optimizer = tf.train.AdamOptimizer(a_learning_rate)
b_optimizer = tf.train.AdamOptimizer(b_learning_rate)
train_shared_op = shared_subnet_optimizer.apply_gradients(zip(shared_subnet_gradients, shared_vars))
train_a_op = a_optimizer.apply_gradients(zip(a_gradients, a_vars))
train_b_op = b_optimizer.apply_gradients(zip(b_gradients, b_vars))
train_op = tf.group(train_shared_op, train_a_op, train_b_op)
顺便提一下,这个技巧实际上对单任务网络也有用。
第 3 课 – 将估计值用作特征
一旦我们完成了创建一个预测多个任务的神经网络的第一阶段,我们可能想要将一个任务的估计值用作另一个任务的特征。在前向传播中这很简单。估计值是一个张量,因此我们可以像连接其他层的输出一样连接它。但反向传播中会发生什么?
假设任务 A 的估计值被作为特征传递给任务 B。我们可能不希望将任务 B 的梯度反向传播到任务 A,因为我们已经有了任务 A 的标签。
不用担心,TensorFlow 的 API 有tf.stop_gradient正是为此目的。当计算梯度时,它允许你传递一个张量列表,你希望将其视为常量,这正是我们需要的。
all_gradients = tf.gradients(loss, all_variables, stop_gradients=stop_tensors)
再次强调,这在 MTL 网络中很有用,但不仅限于此。这个技术可以用于任何时候你想用 TensorFlow 计算一个值,并且需要假装这个值是一个常量。例如,在训练生成对抗网络 (GANs) 时,你不希望通过对抗样本的生成过程进行反向传播。
那么,接下来是什么?
我们的模型已上线运行,Taboola 的信息流正在个性化。然而,仍然有很多改进空间,还有许多有趣的架构可以探索。在我们的用例中,预测多个任务也意味着我们要基于多个 KPI 做出决策。这可能比使用单一 KPI 更具挑战性……但这已经是另一个全新的话题。
感谢阅读,希望你觉得这篇文章有用!
个人简介: Zohar Komarovsky 是 Taboola 的算法开发者,专注于推荐系统的机器学习应用。
原文。已获得许可重新发布。
资源:
相关:
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的捷径。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关内容
深度神经网络是否具有创意?
原文:
www.kdnuggets.com/2016/05/deep-neural-networks-creative-deep-learning-art.html
评论
深度神经网络是否具有创意?这似乎是一个合理的问题。谷歌的 "Inceptionism" 技术通过迭代修改图像,增强深层网络中特定神经元的激活。图像看起来 迷幻,将岩石变成建筑物或叶子变成昆虫。另一种由德国图宾根大学的 Leon Gatys 提出的神经生成模型,可以从一张图像(例如梵高的画作) 中提取风格,并将其应用到另一张图像(例如照片)的内容中。
生成对抗网络(GANs),由 Ian Goodfellow 提出的,通过建模已见图像的分布来合成新颖图像。此外,字符级递归神经网络(RNN)语言模型现在遍布互联网,似乎能够幻想出 莎士比亚的片段、Linux 源代码,甚至 特朗普的仇恨推文。显然,这些进展源自有趣的研究,并值得它们所激发的迷恋。

我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT
在这篇博客文章中,我们不讨论工作的质量(这点值得称赞),也不解释方法(这已被做过无数次),而是探讨一个问题:这些网络是否可以合理地称为“创意”?已经有人提出这一主张。deepart.io 的着陆页宣称“将你的照片转变为艺术”。如果我们接受创意是艺术的前提条件,那么这里隐含了这一主张。
在Engadget.com 上的一篇文章中,亚伦·苏普里斯描述了一个基于字符的 RNN,建议较高的采样温度使网络“更具创造力”。在这种观点中,创造力与连贯性相对立。
我们能否接受一种主要由随机性构成的创造力观?接受一种由随机数生成器最大化创造力的定义是否有意义?在这种观点下,创造力归结为熵的最大化。有趣的是,这似乎与深度学习先驱尤尔根·施密特胡伯(Juergen Schmidhuber)所提出的创造力观点相反,他建议低熵,即短描述长度,是艺术的定义特征。 更重要的是,这似乎与我们赋予人类的创造力观念相矛盾。将查理·帕克、贝多芬、陀思妥耶夫斯基和毕加索标记为创造性似乎没有争议,但他们的作品显然是连贯的。
采样是不够的
我们似乎急于将创造力归因于的算法,往往可以分为两类。首先是像 Inceptionism 和 Deep Style 这样的确定性过程。其次是随机模型,如 RNN 语言模型和生成对抗网络,它们建模了训练数据下的分布,为从近似分布中生成新图像/文本提供了采样机制。注:给定随机的自动编码器权重,Deep Style 可以被归入随机生成机制的类别。同样,通过随机选择节点进行增强,Inceptionism 也可以被随机化。
在确定性情况下,创造力进入过程的两个地方。首先,《Inceptionism》和《Deep Style》的创作者本身极具创造力。这些论文介绍了以前不存在的新颖而引人注目的工具。其次,这些工具的使用者可以对处理哪些图像以及使用哪些模型参数设置做出创造性的决策。但当然,就像相机不能被真实地描述为创造性一样,这些工具也没有自主性。虽然这些能力令人印象深刻,但就创造性过程而言,这些工具充当了超酷的 Photoshop 滤镜,但本身并不表达创造力。
评估随机模型的创造能力似乎更为困难。生成对抗网络和 RNN 能够自行生成图像,仅需一个随机种子,这引起了我们的想象力。最近的研究论文和博客文章,包括我自己的,倾向于将这些模型拟人化,将其生成过程描述为“幻觉”的行为。然而,我认为这些模型虽然令人兴奋且充满潜力,但尚未达到可以称之为“创造性”的合理标准。
想想飞机。曾几何时,地球上没有飞机。然后一些富有创造力的人发明了飞机。当然,在没有飞机的世界中,从现有技术的分布中进行任何随机抽样都无法产生飞机。我们用来形容创造力的最极致的术语,并不是指那些生产出模仿现有事物的无偏样本的个人,而是指那些具有发散思维能力的人,他们能够同时产生引人注目且令人惊讶的想法和艺术。这项工作并不反映以前工作的分布,而是实际改变了它。也就是说,在飞机发明之后,观察到飞机的概率大大增加了。
同样的观点也适用于被认为非常有创造力的艺术家。例如,巴赫通过发展对位法改变了音乐创作,或者查理·帕克,他的即兴演奏语言,被称为比波普,改变了数十年和多种音乐风格中的器乐即兴演奏。相反,那些能够令人信服地模仿的艺术家和作家,可能更准确地被描述为技艺高超而非创造力。介绍生成对抗网络(GANs)和深度风格的论文之所以具有创造性,正是因为它们开辟了新的研究领域。

建立创造性机器是否可能?
有必要澄清的是,我对创造性机器的概念没有宗教上的对立。人脑本身就是一种创造性机器,认为创造力是碳的属性,无法在硅中复制,这种说法是荒谬的。
然而,在将人类的创造力美德归于今天的模型之前,我们应该犹豫。确定性图像生成器非常吸引人,但并不具备自主性。产生逼真输出的随机模型可能具备某种类似于技艺的特征。但要让人工智能展现创造力,它必须做的不仅仅是模仿。也许强化学习者在发现新策略时确实展现了创造力。例如,AlphaGo 在围棋中表现出了超人的水平,发现了与人类玩家已知策略有巨大差异的策略。这个系统可以合理地称为具有创造性。然而,人类的创造力不仅体现在产生策略方面,也体现在发明需要解决的问题的更广泛领域。真正具有创造力的人工智能似乎是不可避免的。虽然我们应该认真考虑这一可能性,但我们也应警惕过早的宣告和将算法拟人化的诱惑。
Zachary Chase Lipton 是加州大学圣地亚哥分校计算机科学工程系的博士生。在生物医学信息学部资助下,他对机器学习的理论基础和应用都很感兴趣。除了在 UCSD 的工作外,他还曾在微软研究院实习,担任亚马逊的机器学习科学家,并且是 KDnuggets 的贡献编辑。
相关:
-
深度学习是否来自魔鬼?
-
MetaMind 与 IBM Watson Analytics 和 Microsoft Azure Machine Learning 竞争
-
深度学习与经验主义的胜利
-
模型可解释性的神话
-
(深度学习的深层缺陷) 的深层缺陷
-
数据科学中最常用、最混淆和滥用的行话
更多相关内容
深度神经网络不会引导我们走向 AGI
原文:
www.kdnuggets.com/2021/12/deep-neural-networks-not-toward-agi.html
评论
由 Thuwarakesh Murallie,Stax Inc. 的数据科学家

我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
照片由 Kindel Media 提供,来自 Pexels。
我对如 GitHub Copilot、Deepfake 和 AI 机器人以复杂策略玩 Alpha Go 这样的项目感到震惊,连专业玩家也无法理解这些策略。
我曾认为我们快要达到人工通用智能(AGI)。我认为这是 AGI 的伟大飞跃。
但我错了。
目前的神经网络在许多方面都不及人脑。机器学习(包括深度学习)可以解决特定的识别问题。然而,智能更多的是一个生成性问题。
我们需要了解 AI 的实际问题,然后再尝试用生物启发的算法(如深度神经网络)来解决这些问题。
为什么机器学习不是人工智能?
许多文献声称 机器学习是人工智能的一个子集。
从总体上说,我对此并不反对。但我相信机器学习只是 AI 的一种方法,而不是 AI 本身。
为了更好地理解这一点,我们必须思考孩子们是如何学习的。
人类和动物的学习方式是通过创建现实世界的表征。进一步的学习是通过融合其他类似的虚拟世界来改进这种表征。
它有助于想象尚不存在的事物。实际上,解决问题是从这种内部表征中生成想法,并将它们与现实世界进行匹配。
这就是孩子们如何学习的原因。因此,他们不一定需要看到猫和狗才能开始识别它们。他们的父母和环境在培养他们的世界内部表征方面发挥了作用。因此,他们生成关于狗和猫的想法,然后将其与自然世界匹配,以便在看到时进行分类。
机器学习(ML)算法不会学会做它们未被编程做的事情,也不会以任何方式具有创造力。它们遵循我们通过数据集示例教给它们的步骤。
正因如此,每当机器学习模型接触到新类型的数据时,都必须从头开始。
尽管深度神经网络已经在一些模式识别任务中占据了主导地位,如物体检测、语音识别或翻译——它们仍然缺乏生成能力。
在生成任务中,模型必须从无或随机中创建某物。
相关: 如何评估深度学习是否适合你?
如果机器学习不是人工智能,那么它是什么?
机器学习算法是特定问题的复杂近似。它们通过优化而非生成想法来解决问题。
他们需要看到足够多的示例才能识别问题。
这就是深度神经网络在许多方面受限的原因。例如,它们需要大量的数据和标记的训练样本。在复杂任务或具有大量类别/类别的问题上,它们的扩展性并不很好。
这些限制阻碍了它们解决需要推理、创造力和抽象思维的问题——例如人工通用智能所需的问题。
实际上,如果你知道如何骑自行车,你应该以某种程度的熟悉度学习驾驶汽车。但将知识从一个机器学习模型转移到另一个模型并不是那么简单。
迁移学习难道不是一种知识转移的方法吗?
研究人员使用的一种有用技术叫做迁移学习。迁移学习允许我们使用在一个任务上训练的深度学习模型作为类似工作的起点。
但即使是迁移学习也远未实现普遍的知识转移。在迁移学习中,你需要遵守许多要求,如保持类似的输入结构。
此外,迁移学习并不是解决机器学习模型非生成性质的方案。它仅仅帮助神经网络更快地收敛以解决调整问题。
迁移学习的好处包括减少训练时间和成本,但它仍然是一个识别问题。
谷歌知道这一点。
谷歌知道深度神经网络或机器学习一般还无法实现人工通用智能。他们理解,经过训练的模型是对现实世界知识的一种薄弱表示。
“机器学习系统常常在单一任务上过度专门化,而它们本可以在许多任务上表现出色。”——Jeff Dean,谷歌高级研究员及 SVP
谷歌的目标是通过他们称之为“Pathway”的方法来解决这个问题。
关于 Pathway 如何工作的公开信息不多。但根据 Jeff Dean 的博客文章,谷歌 Pathway 即将解决通向 AGI 的三大常见挑战。
Pathway 使我们能够使用一个模型来解决数千个不同的问题。这与传统的机器学习模型不同,因为后者被训练来解决特定问题。
此外,Pathway 使用了多种感官。传统模型使用来自单一感官的输入。例如,计算机视觉问题处理图像,语音识别处理音频信号。Pathway 预计同时处理这些以及其他感官输入。
此外,Pathway 承诺将模型执行从密集模式转移到稀疏模式。这意味着,为了解决一个问题,你不必激活整个神经网络,而是孤立地激活特定路径。
总结
这并不是说机器学习在人工智能领域没有其作用。
这仅仅意味着我们不应该将 ML 误认为 AGI,也不要假设它能引导我们实现类似人类智能和通用问题解决能力的目标。
深度神经网络(以及机器学习模型一般)适用于识别问题。但它们没有创建解决更一般问题所需的世界表示。
目前尚不清楚谷歌如何通过 Pathway 解决这些朝向 AGI 的挑战。我们需要等到相关信息发布后才能进一步评论。
你有什么想法?你认为机器学习会引导我们走向 AGI 吗?
你对 Pathway 模型及其在解决通用 AI 问题方面的承诺感到兴奋吗?分享你的想法、意见和观点。我很想听到你们的看法!
简介: Thuwarakesh Murallie(@Thuwarakesh)是 Stax Inc.的数据科学家和 Medium 上的人工智能顶级作者。
相关:
更多相关内容
深度分位回归
评论
由 Sachin Abeywardana,DeepSchool.io 的创始人
深度学习目前还没有广泛探讨估计中的不确定性。大多数深度学习框架目前专注于提供由损失函数定义的最佳估计。有时,除了点估计之外,还需要一些其他信息来做出决策。这时,分布将非常有用。贝叶斯统计非常适合这个问题,因为它推断了数据集上的分布。然而,迄今为止,贝叶斯方法的计算速度较慢,而且在大数据集上应用时会非常昂贵。
就决策而言,大多数人实际上需要的是分位数,而不是估计中的真正不确定性。例如,在测量一个特定年龄的孩子的体重时,个体的体重会有所不同。比较有趣的是(为了论证)第 10 和第 90 百分位数。请注意,不确定性不同于分位数,因为我可以要求第 90 分位数的置信区间。本文将纯粹关注推断分位数。
分位回归损失函数
在回归中,最常用的损失函数是均方误差函数。如果我们取这个损失的负值并进行指数运算,结果将对应于高斯分布。这个分布的模式(峰值)对应于均值参数。因此,当我们使用一个最小化该损失的神经网络进行预测时,我们是在预测训练集中可能存在噪声的输出均值。
分位回归中单个数据点的损失定义为:
单个数据点的损失
其中 alpha 是所需的分位数(一个介于 0 和 1 之间的值),
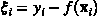
其中 f(x) 是预测的(分位数)模型,y 是对应输入 x 的观测值。整个数据集的平均损失如下所示:
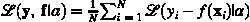
损失函数
如果我们取单个损失的负值并进行指数运算,我们会得到下图所示的非对称拉普拉斯分布。这个损失函数有效的原因是,如果我们找到图形左侧零点下的面积,它将是 alpha,即所需的分位数。
非对称拉普拉斯分布的概率密度函数(pdf)。
当 alpha=0.5 时,这种情况可能更为熟悉,因为它对应于平均绝对误差(MAE)。这个损失函数始终估计中位数(第 50 百分位数),而不是均值。
在 Keras 中建模
前向模型与进行 MSE 回归时没有不同。唯一改变的是损失函数。以下几行定义了上述部分中定义的损失函数。
import keras.backend as K
def tilted_loss(q,y,f):
e = (y-f)
return K.mean(K.maximum(q*e, (q-1)*e), axis=-1)
在编译神经网络时,只需简单地执行:
quantile = 0.5
model.compile(loss=lambda y,f: tilted_loss(quantile,y,f), optimizer='adagrad')
欲了解完整示例,请参见 这个 Jupyter 笔记本,我在其中查看了摩托车事故数据集随时间的变化。结果如下面所示,我展示了第 10、第 50 和第 90 百分位数。
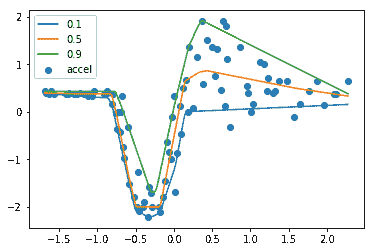
崩溃摩托车的加速度随时间的变化。
最终说明
-
注意,我必须对每个分位数重新运行训练。 这是因为每个分位数的损失函数是不同的,因为分位数本身是损失函数的一个参数。
-
由于每个模型都是简单的重新运行,存在分位数交叉的风险。即,第 49 百分位数在某些阶段可能超过第 50 百分位数。
-
注意,分位数 0.5 与中位数相同,你可以通过最小化平均绝对误差(Mean Absolute Error)来获得中位数,而在 Keras 中,你可以使用
loss='mae'来实现。 -
不确定性和分位数 不是 同一回事。但大多数时候,你关心的是分位数,而不是不确定性。
-
如果你真的想了解深度网络的不确定性,可以查看
mlg.eng.cam.ac.uk/yarin/blog_3d801aa532c1ce.html
编辑 1
正如 Anders Christiansen(在回应中)指出的那样,我们可以通过设置多个目标在一次运行中获得多个分位数。然而,Keras 通过 loss_weights 参数将所有损失函数结合在一起,如此处所示:keras.io/getting-started/functional-api-guide/#multi-input-and-multi-output-models。在 TensorFlow 中实现这一点会更容易。如果有人比我更早完成这个任务,我愿意更新我的笔记本/帖子以反映这一点。作为一个粗略的指南,如果我们需要分位数 0.1、0.5 和 0.9,Keras 中的最后一层应为 Dense(3),每个节点连接到一个损失函数。
编辑 2
感谢 Jacob Zweig 实现了 TensorFlow 中的同时多分位数: github.com/strongio/quantile-regression-tensorflow/blob/master/Quantile%20Loss.ipynb
如果你喜欢我的教程/博客文章,考虑支持我 www.patreon.com/deepschoolio 或订阅我的 YouTube 频道 www.youtube.com/user/sachinabey(或者两者都订阅!)。
简历:Sachin Abeywardana 是机器学习博士及 DeepSchool.io 创始人。
原文。经许可转载。
相关:
-
DeepSchool.io:深度学习学习
-
数据科学的 Docker
-
使用遗传算法优化递归神经网络
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
更多相关话题
使用 Python + NumPy 进行的图像分类深度残差网络
原文:
www.kdnuggets.com/2016/07/deep-residual-neworks-image-classification-python-numpy.html
作者:Daniele Ciriello,独立机器学习研究员
概述
我希望用 Python 从头实现 “深度残差学习用于图像识别” 以用于 我的计算机工程硕士论文,最后我实现了一个 简单(仅限 CPU)的深度学习框架 以及 残差模型,并在 CIFAR-10、 MNIST 和 SFDDD上进行了训练。 结果不言自明。
计算机视觉中的卷积神经网络
在 6 月 13 日星期一,我获得了计算机工程硕士学位,并展示了一篇关于计算机视觉中深度卷积神经网络的论文。目前只有意大利语版,我正在进行英文翻译,但不知道是否以及何时能完成,所以我尝试简要描述每一章。
文档组成如下:
-
介绍
主题介绍、论文结构描述以及从感知机到 NeoCognitron 的神经网络历史的快速描述。
-
神经网络基础
深度学习背后的基本数学概念描述。
-
前沿技术
描述了过去十年中实现目标的主要概念,引入了图像分类和对象定位问题,ILSVRC 以及从 2012 到 2015 年在这两项任务中获得最佳结果的模型。
-
实现深度学习框架
本章包含了如何实现残差模型中每一层的前向和后向步骤的解释、残差模型的实现以及在训练前测试网络的一些方法。
-
实验结果
在开发了模型和训练求解器之后,我在 CIFAR-10 上进行了几个实验。在本章中,我展示了如何测试模型以及当去除残差路径、应用数据增强函数以减少过拟合或增加层数时,网络的行为如何变化,然后我展示了如何使用随机生成的图像或数据集中的图像来欺骗训练好的网络。
-
结论
在这里,我描述了在 MNIST 和 SFDDD 上训练相同模型所获得的其他结果(更多信息请查看下面),项目概述以及可能的未来工作。
论文链接:
-
英语(进行中)
演示链接:
以下是我简要描述了如何获得所有这些内容,我使用的来源,训练的残差模型结构以及获得的结果。请记住,我的首要目标是开发和训练模型,因此我没有花太多时间在框架的设计方面,但我正在继续努力(欢迎提交拉取请求)!
PyFunt、PyDatSet 和 深度残差网络
Pyfunt 是一个简单的 Python 风格的命令式深度学习框架:它主要提供了大多数知名神经层的前向和反向步骤的实现,一些有用的初始化函数和一个求解器,它本质上是一个类,你实例化它,并将要训练的模型和使用 pydatset 加载的数据传递给它,该数据集包含导入一些数据集的函数和一组人工增强训练集的函数。为了澄清,PyFunt 和 PyDatSet 是这些库的名称,pyfunt 和 pydatset 是包的名称(因此你可以用from pydatset import ...导入它们)。
残差模型的实现位于 deep-residual-networks-pyfunt,其中也包含了 train.py 文件。
参考论文中提出的残差模型源于 VGG 模型,其中 3x3 的卷积滤波器应用于通道数保持不变的情况下步长为 1,如果特征数量翻倍则步长为 2(这样做是为了在每个卷积层中保持计算复杂度)。因此,残差模型由多个残差块(或残差层)级联组成,这些块是串联的卷积层组,其中最后一层的输出加到块的原始输入上,作者建议每个残差块中使用几层卷积层会效果很好。
每个残差块的组成是,如果应用了降维(使用 2 的卷积步骤而不是 1),则必须对输入应用下采样和零填充,然后才能进行加法,以允许两个 ndarray(skip_path + conv_out)的求和。
一个参数化的残差网络总共有(6*n)+2 层,组成如下(右边的值表示类似 CIFAR 图像的 [3,32,32] 样本的尺寸)。
你可以在下面看到一个包图,展示了train.py如何使用其他组件来训练残差模型。

在拥有所有数据后,我开始实验当你移除残差路径时会发生什么,当你应用或不应用数据增强函数时会有什么变化,增加层数或每层滤波器数量时会有什么变化。下面你可以看到一些结果的图像,但我建议你查看各个 JuPyter 笔记本(以及上述链接的论文和演示文稿),以获得更深入的理解,因为你可以在下面显示的所有数据集上找到更详尽的结果描述。
结果
我在CIFAR-10、MNIST和SFDDD上训练了残差模型,结果非常令人兴奋,至少对我来说如此。网络在几乎所有测试中表现良好,显然我的限制在于桌面 PC 的容量。
CIFAR-10

在 CIFAR-10 上的一个实验中,训练了一个简单的 20 层 resnet,通过应用数据增强的正则化函数,我得到了与参考论文中显示的类似的结果,如下所示。


这个模型的训练大约花费了 10 小时。更多信息可以在这个 jupyter ipython notebook中找到,位于代码库的文档文件夹中。
MNIST

与 CIFAR-10 相比,MNIST 是一个更简单的数据集,因此训练时间相对较短,我还尝试使用每个卷积层的一半滤波器数量。

关于 MNIST 上残差网络的更多实验信息可以在这里找到。

在上面的图像中,你可以看到 32 层网络错误分类的所有验证样本,训练仅进行了 30 个 epoch(!)。左上角是实际类别,左下角是网络的错误分类,右下角是第二次分类的置信度。
SFDDD

State Farm Distracted Driver Detection 是来自 State Farm 的数据集,托管在 kaggle.com,包含了 640x480 的驾驶员图片,分为 10 个分心类别。对于这个数据集,我决定将所有图片调整为 64x48,并使用 32x32 的随机裁剪进行训练,使用中心 32x32 裁剪进行测试。我也尝试了将所有图片直接缩放到 32x32,但结果更差(确认了缩放图片并不大有助于卷积网络学习更通用的特征)。
下面你可以看到两个分别具有 32 层和 44 层的模型的学习曲线,看来两个模型在 80 个 epoch 后都产生了较低的误差,但问题在于我用于验证集的是从训练集中随机提取的 2k 张图片,因此我的验证集的相关因子高于 State Farm 提出的原始训练集和验证集之间的相关性(我在其上获得的误差约为 3%)。

下面你可以看到六张图片的显著性图,类别为“用右手打电话”,其中较亮的区域表示对网络正确分类贡献最大的图像部分。

其他信息将在比赛结束后 这里 提供。
结束语
我希望我的项目能够帮助你学到新东西。如果没有,也许 你 可以教我一些新东西,评论和拉取请求始终欢迎!
来源
当我开始考虑实现 “深度残差网络用于图像识别”时,GitHub 上只有 this project 来自 gcr,基于 Lua + Torch,这段代码在我实现残差模型时确实帮助了我很多。
神经网络与深度学习 由 Michael Nielsen 编写,包含了对该主题非常全面且组织良好的介绍,以及大量代码以帮助用户理解过程中的各个部分。
colah.github.io 由 Christopher Olah 编写,包含了大量关于深度学习和神经网络的优质文章,例如我发现 this post about convolution layers 非常有启发性。
斯坦福大学的 CS231N 由 Andrej Karpathy 等人编写,是一门关于视觉识别 CNN 的非常有趣的课程,我主要使用了课程材料和作业解决方案来构建PyFunt。
Arxiv,一个提供数学、物理、天文学、计算机科学、定量生物学、统计学和定量金融领域科学论文的电子版库,可以在线访问。也可以查看Arxiv Sanity Preserver由Karpathy提供。
许多其他精彩的资源列在这里:github.com/ChristosChristofidis/awesome-deep-learning。
当我开始学习深度学习时,我跟踪了最佳论文,并在this google sheet中收集了标题、作者、年份和链接,我会定期更新。
简历: Daniele Ciriello 拥有计算机工程硕士学位,是深度学习爱好者,并热爱 Python 和开源。
原文。已获许可转载。
相关:
-
科学 Python 简介(以及一些相关数学) – NumPy
-
深入了解卷积神经网络
-
学习编写神经网络代码
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织 IT
更多相关内容
深入了解递归网络:序列到词袋模型
原文:
www.kdnuggets.com/2017/08/deeper-recurrent-networks-sequence-bag-words-model.html
由 Solomon Fung, MarianaIQ。
在过去五年左右之前,若没有强大的计算资源,很难在网络上揭示话题和情感。工程师们没有高效的方法来大规模地理解单词和文档。现在,借助深度学习,我们可以将非结构化文本转换为可计算的格式,有效地结合语义知识来训练机器学习模型。利用数字世界的庞大数据资源可以帮助我们更直接地理解人们,超越通过测量和调查结果收集数据点的局限。以下是我们在 MarianaIQ 如何实现这一目标的简要介绍。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析水平
3. Google IT 支持专业证书 - 支持您的组织的 IT
深入了解递归网络
递归神经网络(RNN) 是一种包含有时间反馈回路的神经层的网络。该层的一个神经元接收当前输入以及来自上一个时间步的输出。由于递归层在处理当前输入时“记住”之前的输入,RNN 可以在输入序列中操作。当计算 RNN 网络时,软件会“展开”网络(如下所示),通过快速克隆 RNN 到所有时间步并计算前向传递的信号。在反向传递期间,损失通过时间进行反向传播(BPTT),类似于前馈网络,但参数的调整在克隆之间是共享的。
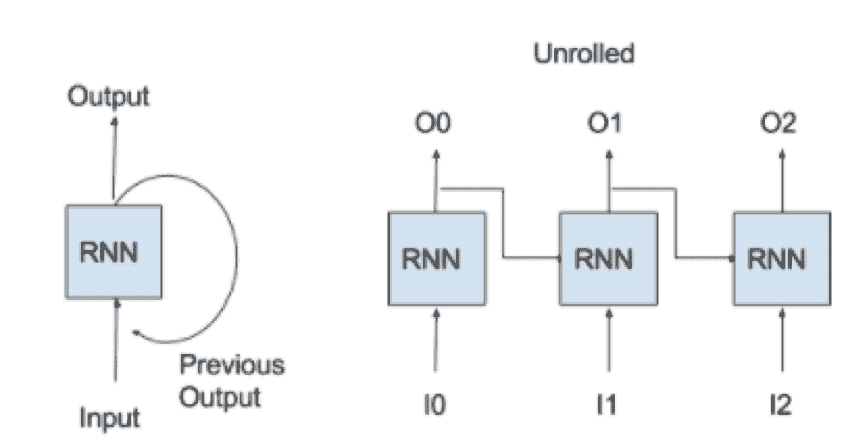
图 1. 递归网络架构
我们使用一种复杂的 RNN,称为长短期记忆(LSTM)⁷,其神经元包括像内部开关的门控激活,具有高级记忆能力。LSTM 的另一个特点是将“隐藏状态”传递到下一个时间步,与其输出分开。
通过产品评论数据集,我们可以逐词输入 RNN,并在接收到最后一个词后使用 softmax 层预测评分。另一个 RNN 应用是语言模型,其中每个输入预测下一个输入。训练良好的 RNN 能够生成模仿莎士比亚戏剧风格的文本,奥巴马演讲,计算机代码行甚至是音乐创作。
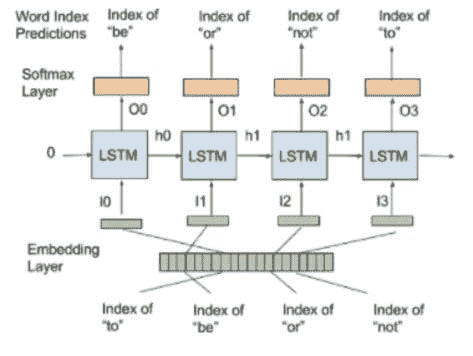
图 2. 训练 RNN 以逐词预测生成莎士比亚作品
使用双 RNN 编码一种语言并解码到另一种语言,我们可以训练强大而优雅的序列到序列翻译模型(“seq2seq”学习)⁸。现在,谷歌翻译的智能大多依赖于这项技术。这些 RNN 可以处理一热编码输入向量或未经训练/预训练的嵌入,代表文本的字符级别或词汇级别。
解决标题问题:我们的 Seq2BoW 模型
我们可以将 RNN 与 Word2vec 结合,使用我们称之为“Seq2BoW”(序列到词袋)的模型将职位标题映射到兴趣上。RNN 学习从词序列中构建任何标题的嵌入,这给我们带来了两个优势:
-
首先,我们不再需要词汇表来详尽捕捉如此多的类似标题组合。
-
其次,标题和兴趣存在于相同的嵌入空间中,因此我们可以跨这两个词汇表查询,以查看它们在意义上的关系。我们不仅可以评估标题的相似性,还可以通过对比推断出的兴趣了解原因。
训练集包括包含标题和提取关键词的职位描述。我们使用新的嵌入层处理标题词(标记),并通过 LSTM 计算固定的标题嵌入。这个新的标题嵌入被训练以预测在同一描述中出现的兴趣。
为此,我们使用线性层将新的标题嵌入投影到兴趣的向量空间中(在我们的语料库上使用 Word2vec 进行预训练)。线性层是一个没有非线性激活的神经层,因此它只是将 LSTM 输出线性转换到现有的兴趣向量空间。我们像 Word2vec 那样训练词预测,使用根据职位描述中出现的关键词生成的正负嵌入。
为了加速,我们将 RNN 投影与正面词和负面词之间的点积结合在同一训练样本中,使用 softmax 层仅预测正面词,而不是像 Word2vec 那样训练单独的嵌入对。
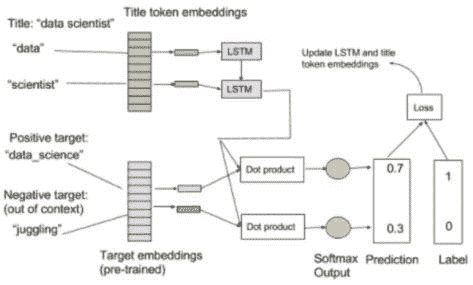
图 3. 训练标题 RNN(一个正样本和一个负样本)
我们使用了Keras在Tensorflow后端。运行在 NVIDIA GPU 上,使我们能够在 15 分钟内处理 1000 万份职位描述(32 宽 RNN 和 24 宽预训练兴趣词向量)。我们可以通过下面的一些例子展示这些向量的表征能力(所有列表均为计算机“生成”)。
使用我们用 Word2vec 训练的兴趣词汇,我们可以输入任何兴趣关键词,查找其向量并找到所有属于最接近向量的词汇:
营销内容:内容生成、企业博客、内容传播、署名文章、社交媒体策略、在线内容创作、内容策划、内容制作
杂技:溜冰、腹语、马戏艺术、独轮车、街舞、摇摆舞、喜剧时间、杂技
脑外科:医学研究、神经危重病护理、颅底外科、内分泌外科、脑肿瘤、医学教育、小儿心脏病学、肝胆外科
利用 Seq2BoW 标题模型,我们可以找到任何标题的相关兴趣:
营销分析:营销组合建模、Adobe 洞察、生命周期价值、归因建模、客户分析、Spss Clementine、数据细分、Spss Modeler
数据工程师:Spark、Apache Pig、Hive、Pandas、Map Reduce、Apache Spark、Octave、Vertica
酿酒师:葡萄种植学、酿酒、酒庄、红酒、品酒、食品搭配、香槟、啤酒
我们可以通过计算和存储最频繁标题的向量来创建一个单独的标题词汇表。然后,我们可以在这些向量中查询以找到相关标题:
首席执行官:主席、总合伙人、首席执行官、首席运营官、总裁、创始人/首席执行官、总裁/首席执行官、董事会成员
洗碗工:工作人员、队员、厨房工作人员、餐具清理员、酒吧助手、班组长、送餐员、三明治艺术家
程序员:高级软件开发工程师、首席软件开发人员、高级软件工程师 II、软件设计师、软件工程师 III、首席软件工程师、技术负责人、首席软件开发工程师
我们还可以找到任何兴趣附近的标题:
电话销售:账户管理、销售演示、直接销售、销售流程、销售运营、外勤销售、销售、销售管理
烘焙:厨师讲师、烹饪艺术讲师、烹饪讲师、面包师、首席面包师、糕点师、糕点、助理糕点师
神经网络:高级数据科学家、首席数据科学家、机器学习、数据科学家、算法工程师、定量研究员、研究程序员、首席科学家
我们可以超越兴趣和标题的关系,向 Seq2BoW 模型中添加各种输入或输出。例如,我们可以考虑公司信息、教育背景、地理位置或其他个人社会和消费者见解,并利用深度学习的灵活性来理解这些如何相关。
理解文本在规模上推动 ABM
MarianaIQ 使用的 ABM 智能依赖于强大且简洁的身份表示。我们使用深度学习来计算关键词和标题的语义嵌入。为了训练有用的机器学习模型,我们输入独特的标记向量,每个向量包含与我们的嵌入相连接的属性——这是一种结构化和非结构化数据的异质但和谐的组合。
通过学习来自网络的数据,我们避免了传统顾问的狭隘和偏见视角。 我们可以快速准确地提供定量评估,例如决定谁对特定主题反应更快或识别谁更像潜在买家。这些分析只有通过今天的机器学习才可行,但它们是让 ABM 能够在大规模为我们的客户服务的秘诀。
个人简介: 所罗门·冯拥有多种学位,反映了他广泛的兴趣。从斯坦福大学获得硕士学位以来,他一直居住在加利福尼亚州,原籍加拿大。他在 MarianaIQ 的当前重点是大数据——他的算法旨在帮助公司更好地理解和预测个体消费者的行为。
相关:
-
构建、训练及改进现有的递归神经网络
-
如何在 TensorFlow 中构建递归神经网络
-
使用 TensorFlow API:入门教程系列
更多相关主题
DeepMind 的 AlphaCode 会替代程序员吗?
原文:
www.kdnuggets.com/2022/04/deepmind-alphacode-replace-programmers.html

图片由作者提供
字母表子公司 DeepMind 再次取得了成功,这一次,他们正在测试 AI 在软件开发领域的边界。DeepMind 的 AlphaCode 在编码挑战中与人类表现进行了对比,并在 Codeforces 上获得了前 54% 的排名。这是一个显著的成就,因为它是独一无二的。还有其他代码生成机器学习模型,例如 OpenAI Codex,但没有一个尝试与人类程序员竞争。
编程挑战就像解谜。要解决这些挑战,个人必须具备逻辑、数学和编程技能。
谷歌的软件工程师 Petr Mitrichev 说:“解决竞争性编程问题是一件非常困难的事情。这需要人类具备良好的编码技能和解决问题的创造力。”
竞争性编程很难掌握,而 AlphaCode 的第一个版本已经超越了平均水平的编码人员。我们将学习 AlphaCode 的工作原理,并讨论 AI 替代人类程序员的可能性。我们还将了解 AI 辅助编程以及它如何塑造未来。
什么是 AlphaCode?
简而言之,AlphaCode 读取结构化问题陈述并生成最佳解决方案。这只有通过大规模的变换器才能实现,这些变换器在代码生成方面展示了令人满意的结果。这些变换器在来自 GitHub 的 175 GB 数据上进行了预训练,然后在小规模的竞争编程数据上进行了微调 - Tech Monitor。
AlphaCode 读取问题陈述并提出数千种潜在解决方案。这些解决方案经过筛选过程,最终减少到十种。之后,这些结果会提交到编程竞赛中进行评估。提出数千种解决方案并筛选到十种的缺点是,如果我们希望 AlphaCode 解决更复杂的问题,就需要策划一个大型复杂的编程数据集。
AlphaCode 解决了在 Codeforces 平台上已有 5,000 名用户尝试过的十个挑战。它被排在了过去六个月在该网站上参与竞争的用户中28%的前列。这对于初次发布而言是相当了不起的成就。DeepMind 团队表示,AlphaCode 目前仅限于竞争编程领域,他们正扩展这一领域以使其编程更加便捷和完全自动化 - The Verge。

Gif 来源于 AlphaCode
AI 会替代人类程序员吗?
简而言之,不。我们距离 AI 替代人类还有光年之遥。AlphaCode 对 AI 研究做出了有益的贡献,但距离达到人类程序员的熟练水平还远远不够。
“这不是在击败人类方面的AlphaGo,也不是在彻底改变一个科学领域方面的AlphaFold。”,对 AlphaCode 有深入了解的研究科学家 Dzmitry Bahdanau 说道。
除此之外,代码生成中存在的安全漏洞可能会对公司造成严重损害。在 研究 中,研究人员发现 40% 的 GitHub Copilot 生成 的代码含有安全漏洞。即使我们通过清理数据集在某种程度上解决了这个问题,我们也还未准备好应对那些试图在互联网发布有缺陷代码的恶意行为者,这些代码可能被用来训练 AI 模型。没有人类的参与,就没有安全的 AI 开发,因此我们始终需要软件开发人员和工程师来监控进展。
即使我们能够解决我上面提到的所有问题,现实世界的软件开发与编码挑战有很大不同。在软件开发中,项目的需求往往模糊,你需要通过逐步迭代来改进初始想法。这是程序员与利益相关者之间的反复谈判。没有固定的输入和输出,你需要通过每次迭代来确定输出。很难将所有利益相关者的需求以结构化的形式编写,因此 AlphaCode 只是一个实验,而不是对人类的真正威胁。
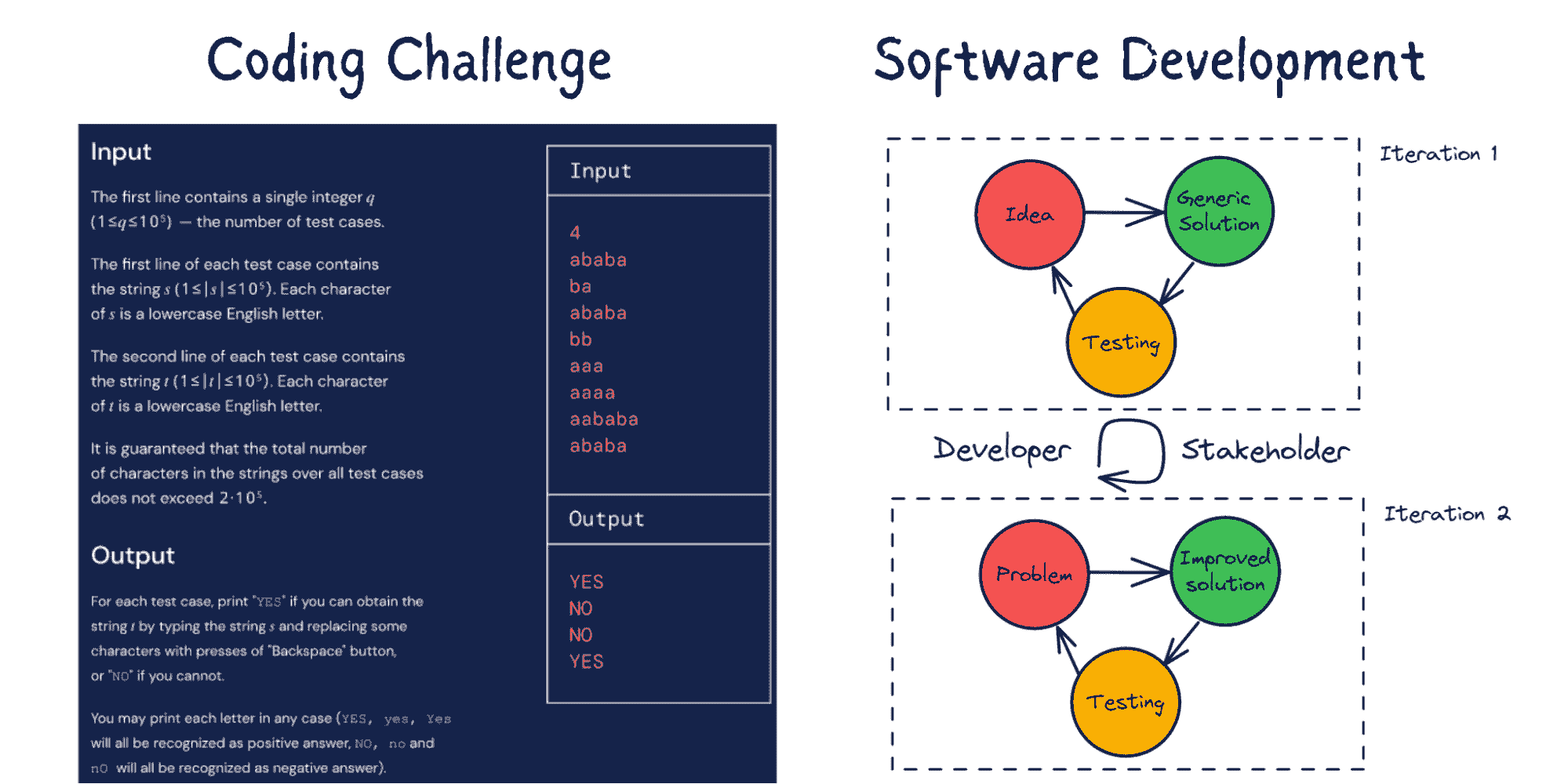
作者图像 | 编码挑战与软件开发 | 编码挑战来自 DeepMind
AI 辅助编程
让我们讨论一下 AlphaCode 和类似的 AI 应用程序的实用性。GitHub Copilot 通过自动补全代码来帮助开发者,有时它会根据你的编码实践学习并提供个性化解决方案,自动化大量软件开发。AlphaCode 的未来是帮助编码者和非编码者。主要任务是使重复任务自动化,使软件开发对程序员和非技术人员都变得轻松。最近,我们看到无代码或少代码软件开发的兴起,这只是一个开始。这些 AI 程序不会取代人类,但会使我们更好地创建软件解决方案。
图像来自 OpenAI Codex | Python 自动补全
未来
未来是对话式 AI 代码生成。这就像与一个智能机器人交谈,机器人记住过去的对话并像人类一样交流。SalesForce CodeGen 模仿真实的软件开发,你写一个提示,然后查看结果。每次迭代中,我们都在添加和删除内容,AI 不断改进初始代码。例如,Prompt 1:“解决两数之和问题”和 Prompt 2:“使用哈希表解决问题”。最终代码是通过理解之前的输入序列生成的。通过这种方式,我们不断发展我们的代码,添加新功能并修复现有的 bug。
总结我们的讨论,我认为 AI 是来帮助我们的。它是一个先进的工具,将帮助我们解决复杂的问题并自动化重复的任务。
图像来自 SalesForce CodeGen | 对话式 AI 编程
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些面临心理问题的学生。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 工作
更多相关话题
DeepMind 依靠这种旧的统计方法来构建公平的机器学习模型
原文:
www.kdnuggets.com/2020/10/deepmind-relies-statistical-method-build-fair-machine-learning-models.html
评论
来源:sitn.hms.harvard.edu/uncategorized/2020/fairness-machine-learning/
我最近开始了一份新的新闻通讯,专注于人工智能教育。TheSequence 是一份无废话(即没有炒作、没有新闻等)的 AI 专注新闻通讯,阅读时间为 5 分钟。目标是让你了解最新的机器学习项目、研究论文和概念。请通过下面的订阅尝试一下:
机器学习系统经常被用来支持的一个论点是,它们能够做出决策,而不容易受到人类主观性的影响。然而,这个论点只有部分正确。虽然机器学习系统不会基于情感或情绪做出决策,但它们确实通过训练数据集继承了大量的人类偏见。偏见是重要的,因为它会导致不公平。在过去几年里,已经有了很多进展,开发出可以减轻偏见影响并改善机器学习系统公平性的技术。几个月前,DeepMind 发布了一篇研究论文,提出使用一种称为因果贝叶斯网络(CBN)的旧统计技术来构建更公平的机器学习系统。
我们如何在机器学习系统的背景下定义公平性?人类通常通过主观标准来定义公平性。在机器学习模型的背景下,公平性可以表示为敏感属性(如种族、性别等)与模型输出之间的关系。虽然这个定义在方向上是正确的,但它是不完整的,因为在不考虑模型的数据生成策略的情况下,不可能评估公平性。大多数公平性定义表达了模型输出相对于敏感信息的属性,而没有考虑数据生成机制下相关变量之间的关系。由于不同的关系要求模型满足不同的属性以保证公平,这可能导致错误地将具有不良/合法偏见的模型分类为公平/不公平。从这个角度来看,识别数据生成机制中的不公平路径与理解模型本身一样重要。
关于分析机器学习模型中的公平性,另一个相关点是其特征超越了技术构造,通常涉及社会学概念。从这个意义上说,数据集的可视化是识别潜在偏见和不公平的关键组成部分。在市场上的不同框架中,DeepMind 依赖于一种称为Causal Bayesian networks (CBNs)的方法来表示和估计数据集中的不公平性。
因果贝叶斯网络作为不公平性的可视化表示
因果贝叶斯网络 (CBNs) 是一种用于表示因果关系的统计技术,采用图结构。概念上,CBN 是由表示随机变量的节点构成的图,这些节点通过表示因果影响的链接连接起来。DeepMind 方法的新颖之处在于使用 CBN 来建模数据集中不公平属性的影响。通过将不公平定义为图中敏感属性存在有害影响,CBN 提供了一个简单而直观的可视化表示,用于描述数据集中潜在的不同不公平场景。此外,CBN 为我们提供了一个强大的定量工具,以衡量数据集中的不公平性,并帮助研究人员开发解决这些问题的技术。
CBN 的一个更正式的数学定义是一个由表示个体变量的节点组成的图,这些节点通过因果关系连接。在 CBN 结构中,从节点 X 到节点 Z 的路径被定义为从 X 开始到 Z 结束的链接节点序列。如果存在从 X 到 Z 的因果路径,即路径中的链接指向序列中的后续节点,则 X 是 Z 的原因(对 Z 有影响)。
让我们在一个著名的统计案例研究中说明 CBNs。1975 年,一组伯克利大学的研究人员发表了一项关于统计学中偏见和不公平性最著名的研究之一。该研究基于一个大学录取场景,在该场景中,申请人根据资格 Q、部门选择 D 和性别 G 被录取;女性申请人更常申请某些部门(为了简单起见,我们将性别视为二元,但这不是框架强加的必要限制)。将该场景建模为 CBN,我们得到以下结构。在该图中,路径 G→D→A 是因果的,而路径 G→D→A←Q 是非因果的。

CBNs 和不公平性
CBNs 如何帮助确定数据集中的不公平因果关系?我们的大学录取示例展示了如何将不公平关系建模为 CBN 中的路径的一个清晰例子。然而,尽管 CBN 可以清楚地测量直接路径中的不公平性,但间接因果关系高度依赖于上下文因素。例如,考虑我们大学的三种变体,我们可以在这些变体中评估不公平性。在这些例子中,总的或部分的红色路径用于分别表示不公平和部分不公平的链接。
第一个例子说明了一个情境,其中女性申请者自愿申请接受率较低的部门,因此路径 G→D 被认为是公平的。

现在,考虑之前例子的一个变体,其中女性申请者因系统性历史或文化压力而申请接受率较低的部门,因此路径 G→D 被认为是不公平的(因此路径 D→A 变成部分不公平)。

继续考虑上下文游戏,如果我们的大学降低了女性更频繁选择的部门的录取率,会发生什么呢?路径 G→D 仍被认为是公平的,但路径 D→A 是部分不公平的。

在所有三个例子中,CBNs(条件贝叶斯网络)提供了描述可能不公平情境的可视化框架。然而,对不公平关系影响的解释通常依赖于 CBN 之外的上下文因素。
直到现在,我们已经使用 CBNs 来识别数据集中的不公平关系,但如果我们能够测量它们呢?事实证明,我们技术的小变体可以用来量化数据集中的不公平性,并探索缓解方法。量化不公平性的主要思路在于引入反事实情境,允许我们询问模型的特定输入是否被不公平对待。在我们的情境中,反事实模型将允许我们询问一个被拒绝的女性申请者(G=1, Q=q, D=d, A=0)在一个性别为男性的反事实世界中是否会获得相同的决定,即直接路径 G→A。在这个简单的例子中,假设录取决定是作为 G、Q 和 D 的确定性函数 f 获得的,即 A = f(G, Q, D),这相当于询问 f(G=0, Q=q, D=d) = 0,即一个具有相同部门选择和资格的男性申请者是否也会被拒绝。

随着机器学习在软件应用中变得越来越重要,创建公平模型的重要性将变得更加相关。DeepMind 论文表明,CBNs 可以提供一个视觉框架来检测机器学习模型中的不公平性,并量化其影响。这种技术可以帮助我们设计出最符合人类价值观并减少偏见的机器学习模型。
原文。已获得许可转载。
相关:
-
DeepMind 建立强大机器学习系统的三大支柱
-
神经网络能否展示想象力?DeepMind 认为它们可以
-
关于 AI 中意识辩论的一个有趣理论
我们的前三个课程推荐
1. Google 网络安全证书 - 快速迈入网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT 工作
更多相关话题
DeepMind 构建稳健机器学习系统的三大支柱
原文:
www.kdnuggets.com/2020/08/deepmind-three-pillars-building-robust-machine-learning-systems.html
评论
来源:tutorials.datasciencedojo.com/building-robust-machine-learning-models/attachment/2412/
我最近开始了一个新的专注于 AI 教育的通讯。《TheSequence》是一个没有虚假信息(即没有炒作,没有新闻等)的 AI 专题通讯,阅读时间为 5 分钟。其目标是让你了解最新的机器学习项目、研究论文和概念。请通过下面的订阅试试吧:
构建机器学习系统在许多方面与传统软件开发不同。对于机器学习模型,传统的软件测试、调试和故障排除方法往往显得不够实际。传统软件组件如网站、移动应用或 API 的行为完全由其代码决定,而机器学习模型则根据特定数据集随时间演变其知识。如何定义和编写稳健的机器学习代理是整个领域面临的存在性挑战之一。去年,DeepMind 的人工智能(AI)研究人员 发布了一些关于这个话题的想法。
当我们想到编写稳健的软件时,我们立即联想到两个根据预定义规范行为的代码。然而,在机器学习的情况下,没有确立的正确规范或稳健行为的定义。接受的做法是使用特定数据集训练机器学习模型,并使用不同的数据集进行测试。这种方法在两个数据集上都能实现高于平均水平的表现,但在处理边缘案例时并不总是有效。这些挑战的经典例子是图像分类模型,它们可能会因引入对人眼完全不可察觉的小变化而受到彻底干扰。
机器学习模型中的稳健性概念应该超越对训练和测试数据集的良好表现,还应根据描述系统期望行为的预定义规范进行行为。以我们之前的例子为例,需求规范可能会详细说明机器学习模型对对抗扰动或特定安全约束的预期行为。
编写鲁棒的机器学习程序是多个方面的结合,从准确的训练数据集到高效的优化技术。然而,大多数这些过程可以建模为构成 DeepMind 研究核心的三大支柱之一的变体:
-
测试与规范的一致性: 测试机器学习系统是否符合设计者和用户期望的属性(如不变性或鲁棒性)的技术。
-
训练机器学习模型以符合规范: 即使有大量的训练数据,标准的机器学习算法也可能产生与期望规范如鲁棒性或公平性不一致的预测模型——这需要我们重新考虑那些不仅能很好拟合训练数据,还能符合一系列规范的训练算法。
-
正式证明机器学习模型符合规范: 需要能够验证模型预测在所有可能输入下与感兴趣的规范一致的算法。尽管形式化验证领域已经研究了这些算法几十年,但这些方法在现代深度学习系统中并不容易扩展,尽管取得了显著进展。
规范测试
对抗性样本是测试机器学习模型在给定规范下行为的极好机制。不幸的是,大多数相关的对抗训练工作都局限于图像分类模型。将这些思想扩展到诸如强化学习等更通用的领域,可能会提供一种通用机制来测试机器学习模型的鲁棒性。
跟随对抗训练的一些思想,DeepMind 开发了两种互补的方法来进行强化学习代理的对抗测试。第一种技术使用无导数优化直接最小化代理的期望奖励。第二种方法学习一个对抗值函数,从经验中预测哪些情况最有可能导致代理失败。然后利用学习到的函数进行优化,以将评估重点放在最有问题的输入上。这些方法只是潜在算法丰富、不断增长空间的一小部分,我们对未来在代理严格评估中的发展感到兴奋。
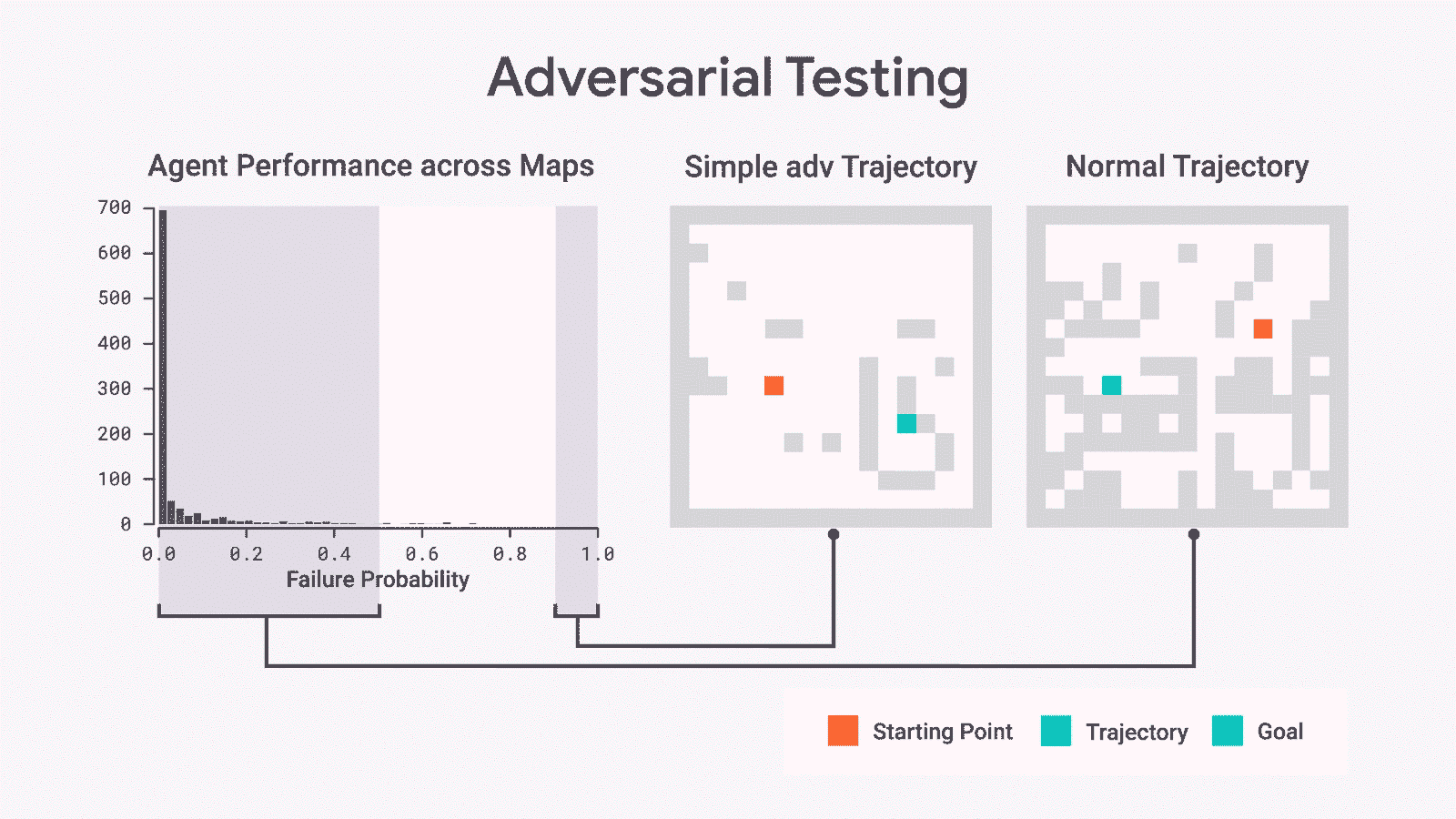
来源: deepmind.com/blog/article/robust-and-verified-ai
对抗性方法在强化学习代理中显示出比传统测试方法更显著的改进。对抗性测试揭示了通常会被忽视的错误,同时也暴露了在代理中基于训练数据集的组成不期望的定性行为。例如,以下图展示了对抗性训练在 3D 导航任务中的效果。尽管代理可以实现人类水平的表现,但对抗性训练显示它在超级简单任务中仍然可能失败。
规格训练
对抗性测试在检测错误方面非常有效,但仍未能揭示偏离给定规格的例子。如果我们从机器学习的角度思考需求的概念,它们可以被建模为输入和输出之间的数学关系。基于这一思路,DeepMind 团队创建了一种方法,通过使用上下界几何计算模型与给定规格的一致性。该方法称为区间界限传播,DeepMind 的方法将规格映射到一个可以在网络的每一层进行评估的有界框,如下图所示。这项技术在各种机器学习模型中证明能降低可证明的错误率。

来源:deepmind.com/blog/article/robust-and-verified-ai
形式验证
准确的测试和训练是实现机器学习模型鲁棒性所必需的步骤,但在很大程度上不足以确保系统按预期行为。在大规模模型中,枚举给定输入集的所有可能输出(例如,对图像进行微小扰动)由于输入扰动的选择数量庞大而不可行。形式验证技术是一个活跃的研究领域,专注于寻找基于给定规格设置几何界限的有效方法。
DeepMind 最近开发了一种形式验证方法,该方法将验证问题建模为一个优化问题,试图找到被验证属性的最大违反。该技术会进行多次迭代,直到找到正确的界限,这间接保证了不会出现进一步的属性违反。尽管最初应用于强化学习模型,但 DeepMind 的方法很容易推广到其他机器学习技术。
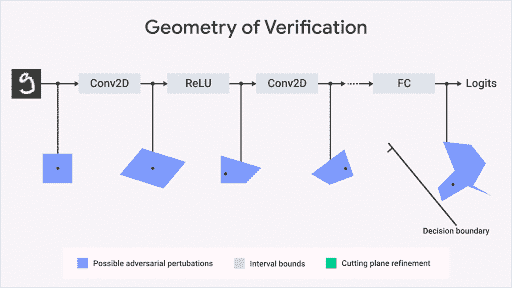
来源:deepmind.com/blog/article/robust-and-verified-ai
测试、训练和规格的正式验证的结合构成了实现强大机器学习模型的三个关键支柱。DeepMind 的想法是一个很好的起点,但我们应当期待这些概念发展成能够建模和验证机器学习模型相关规格的功能性数据集或框架。迈向强大机器学习的道路也将由机器学习推动。
原文。经许可转载。
相关:
-
通过遗忘学习:深度神经网络与詹妮弗·安妮斯顿神经元
-
DeepMind 对 #AtHomeWithAI 的学习建议
-
Facebook 使用贝叶斯优化进行更好的机器学习模型实验
我们的前三个课程推荐
1. Google 网络安全证书 - 加速你的网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关主题
DeepMind 正在使用这种旧技术来评估机器学习模型的公平性
评论
支持机器学习系统的一个常见论点是,它们能够在不受人为主观性影响的情况下做出决策。然而,这个论点只是部分正确。虽然机器学习系统不会基于情感或感觉做出决策,但它们确实通过训练数据集继承了很多人类偏见。偏见之所以重要,是因为它会导致不公平。在过去几年里,开发能够减轻偏见影响并提高机器学习系统公平性的技术取得了很大进展。最近,DeepMind 发布了一篇研究论文,提出使用一种叫做因果贝叶斯网络(CBN)的旧统计技术来构建更公平的机器学习系统。
我们如何在机器学习系统的背景下定义公平性?人们通常根据主观标准定义公平性。在机器学习模型的背景下,公平性可以表示为敏感属性(如种族、性别等)与模型输出之间的关系。虽然这个定义在方向上是正确的,但它并不完整,因为在评估公平性时必须考虑模型的数据生成策略。大多数公平性定义表达了模型输出相对于敏感信息的特性,而没有考虑数据生成机制中相关变量之间的关系。由于不同的关系会要求模型满足不同的属性才能被认为是公平的,这可能导致错误地将表现出不良/合法偏见的模型分类为公平/不公平。从这个角度来看,识别数据生成机制中的不公平路径与理解模型本身同样重要。
理解机器学习模型中公平性分析的另一个相关点是,它的特征超越了技术构造,通常涉及社会学概念。从这个意义上说,可视化数据集是识别潜在偏见和不公平的重要组成部分。在市场上的不同框架中,DeepMind 依赖于一种叫做 因果 贝叶斯 网络(CBNs)的方法来表示和估计数据集中的不公平性。
因果贝叶斯网络作为不公平性的视觉表示
因果贝叶斯网络(CBNs)是一种用于使用图结构表示因果关系的统计技术。从概念上讲,CBN 是由表示随机变量的节点组成的图,这些节点通过表示因果影响的链接连接。DeepMind 方法的新颖之处在于使用 CBNs 来建模数据集中的不公平属性的影响。通过将不公平性定义为图中来自敏感属性的有害影响的存在,CBNs 提供了一种简单直观的视觉表示,用于描述数据集中的不同可能的不公平情景。此外,CBNs 为我们提供了一种强大的定量工具,用于测量数据集中的不公平性,并帮助研究人员开发解决该问题的技术。
CBN 的一个更正式的数学定义是一个由节点组成的图,这些节点代表个别变量,并通过因果关系连接。在 CBN 结构中,从节点 X 到节点 Z 的路径定义为从 X 开始到 Z 结束的一系列连接节点。如果存在从 X 到 Z 的因果路径,即路径中的连接指向序列中接下来的节点,那么 X 是 Z 的原因(对 Z 有影响)。
让我们在一个著名的统计案例研究的背景下说明 CBNs。1975 年,伯克利大学的一组研究人员发表了有关统计中的偏见和不公平性的一项著名研究。该研究基于一个大学录取场景,其中申请者根据资格 Q、部门选择 D 和性别 G 被录取;女性申请者更常申请某些部门(为了简单起见,我们将性别视为二元的,但这并不是框架强加的必要限制)。将该场景建模为 CBN,我们得到以下结构。在该图中,路径 G→D→A 是因果的,而路径 G→D→A←Q 是非因果的。

CBNs 和不公平性
CBNs 如何帮助确定数据集中不公平性的因果表示?我们的大学录取示例清楚地展示了如何将不公平关系建模为 CBN 中的路径。然而,虽然 CBN 可以清晰地测量直接路径中的不公平性,但间接因果关系高度依赖于上下文因素。例如,考虑我们可以评估不公平性的大学的以下三种变体。在这些示例中,红色路径总或部分用于指示不公平和部分不公平的链接。
第一个示例说明了一个情景,其中女性申请者自愿申请接受率低的部门,因此路径 G→D 被认为是公平的。

现在,考虑前一个例子的一个变体,其中女性申请者由于系统性历史或文化压力申请接受率较低的部门,因此路径 G→D 被认为是不公平的(因此,路径 D→A 成为部分不公平)。

继续在上下文游戏中,如果我们的学院自愿降低女性选择更多的部门的录取率,会发生什么呢?好吧,路径 G→D 被认为是公平的,但路径 D→A 部分是不公平的。

在这三个例子中,CBNs 提供了一个描述可能不公平情境的可视化框架。然而,对不公平关系影响的解释往往依赖于 CBN 之外的上下文因素。
到目前为止,我们已经使用 CBNs 来识别数据集中不公平的关系,但如果我们能量化这些关系会怎么样呢?事实证明,我们的技术的一个小变种可以用来量化数据集中的不公平性,并探索缓解不公平性的方法。量化不公平性的主要思想在于引入反事实情境,使我们能够询问模型的特定输入是否受到不公平对待。在我们的场景中,一个反事实模型将允许我们询问是否被拒绝的女性申请者(G=1, Q=q, D=d, A=0)在一个性别为男性的反事实世界中是否会得到相同的决定。在这个简单的例子中,假设录取决定是作为 G、Q 和 D 的确定性函数 f 得到的,即 A = f(G, Q, D),这就相当于在询问 f(G=0, Q=q, D=d) = 0,即是否一个具有相同部门选择和资格的男性申请者也会被拒绝。
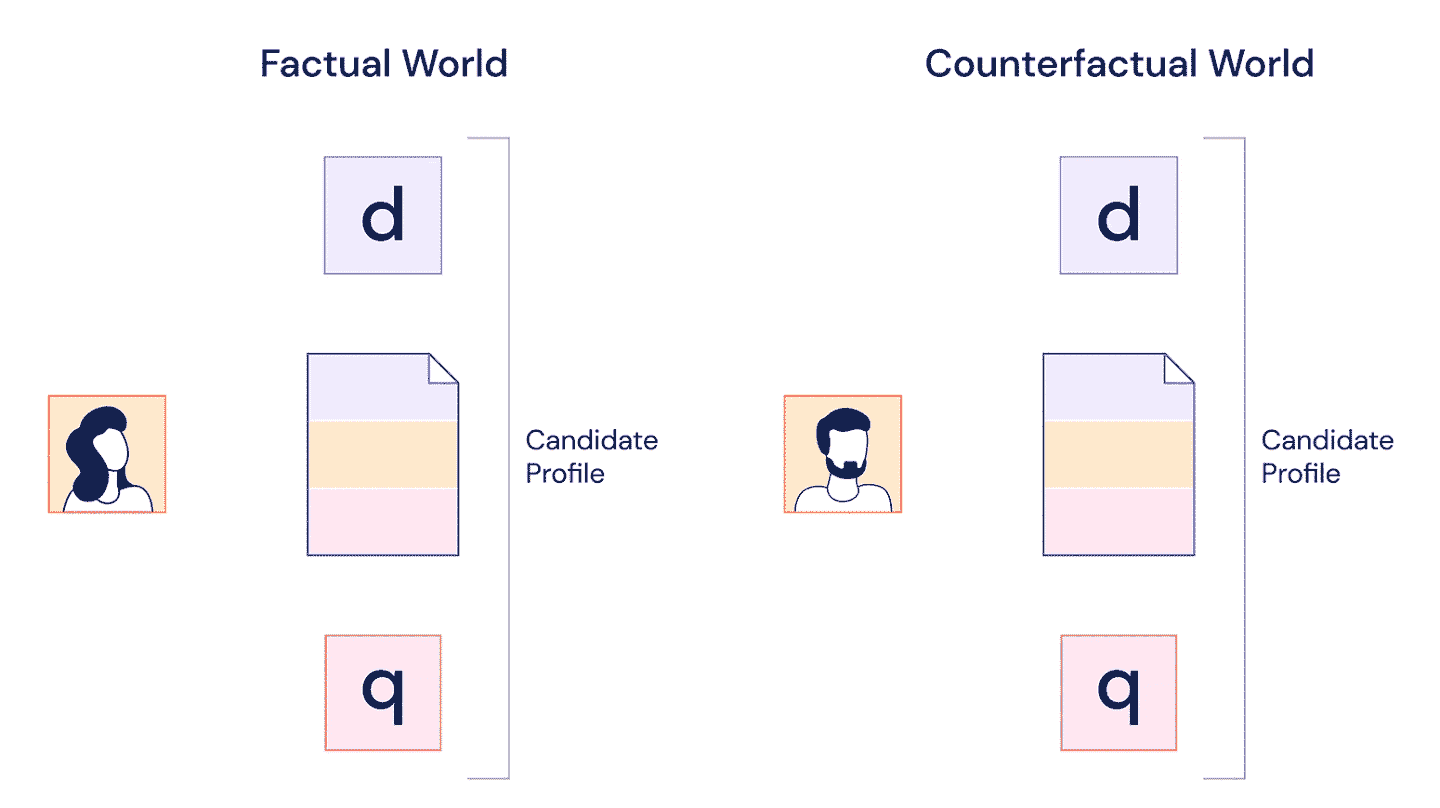
随着机器学习在软件应用中变得越来越重要,创建公平模型的意义也将变得更加相关。DeepMind 的论文表明,CBNs 可以提供一个可视化框架,用于检测机器学习模型中的不公平性以及量化其影响的模型。这种技术可能帮助我们设计出代表人类最佳价值观并缓解一些偏见的机器学习模型。
原文。经许可转载。
相关:
-
DeepMind 和 Waymo 如何利用进化竞争训练自动驾驶车辆
-
重塑想象力:DeepMind 构建能够自发重放过去经历的神经网络
-
DeepMind 静悄悄地开源了三种新型强化学习框架
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT
更多相关话题
如何克服机器学习工程师的冒名顶替综合症
原文:
www.kdnuggets.com/2021/10/defeat-machine-learning-engineer-impostor-syndrome.html
评论
由帕乌·拉巴尔塔·巴霍,数学家和数据科学家。

背景
当我第一次申请Toptal时,我想同时成为一个自由职业者和“真正的机器学习工程师”。
在此之前,我在 Nordeus 公司担任机器学习工程师,这是一家著名的手机游戏公司,以其旗舰游戏 TopEleven 上穆里尼奥的面孔而闻名。我在 Nordeus 的机器学习经历包括设计和实现一个智能系统,以帮助客服团队更快地解决玩家问题。其核心是从大量历史玩家票据和代理解决方案中构建一个文本分类器。
我心里有整个系统的构思,数据(至少我认为是这样),以及对 GPU 的访问。从纸面上看,一切似乎都很适合我大显身手,交付一个优秀的模型和更出色的解决方案。
但这从未发生。令我绝望的是,我花了超过一个月的时间才意识到我试图用来训练我监督模型的数据集糟糕透了。在意识到这一点之前,我花费了无数小时和 Jupyter notebooks 试图让这一切运作。我忙得没时间看数据。可以说,我的经验不足没有帮助。
在这个失败的项目后三个月,我决定辞职并开始我的自由职业生涯,加入了Toptal。经过几轮面试和技术筛选,我进入了最后一轮。你猜怎么着?我需要解决一个机器学习任务。几乎和我之前失败的任务一模一样。我有一周的时间来完成它。
描述那一周我不得不与大量负面自我对话作斗争的情况很难。冒名顶替综合症的长长阴影遮蔽了我的思维。
这一章有一个快乐的结局。我解决了问题,成功加入了 Toptal。三年和 10 个项目后,我可以说我更好地应对了冒名顶替综合症。
提示 1:勇敢尝试自由职业
勇敢是最能帮助你的东西。而自由职业确实是勇敢的。如果你想了解更多,请查看我之前的文章如何成为自由职业数据科学家。
当你作为自由职业者/合同工工作时,反馈不会在季度或年度评估中出现。它每天都会到来。没有捷径可走。客户期望你提供质量和速度。顺便说一下,这也是你比当前工作获得更高薪资的主要原因。
一旦你觉得自己掌握了机器学习的基础,就去试试自己。挑战自己。你聪明,你可以做到。多上在线课程不会消除冒名顶替综合症。相信我。
我认为排名前 2 的自由职业平台是
-
Toptal。全球排名第一的顶尖自由职业平台。他们有一个相当严格的申请流程,但绝对值得经历。如今,大型企业和新兴初创公司都在使用 Toptal 来实施机器学习解决方案。进入那里会给你提供大量闪耀的机会。
-
Braintrust。一个新兴的人才网络,受到一种全新经济模型的启发(听说过以太坊吗?)。他们正在快速成长,我预计他们很快会赶上 Toptal。

照片由Johannes Plenio提供,来自Pexels。
提示 2:永远不要忘记数据。绝对不要。
机器学习工程比传统软件工程更难,因为数据(大写字母,是的)。
很少有机会能得到一套干净且完整的特征和标签来构建你的机器学习模型。相反,你通常需要自己生成训练数据。我遇到的最常见问题是:
-
训练数据有缺陷。通常,你通过 SQL 查询和一些 Python 脚本自动提取原始特征和标签来生成这些数据。编写 SQL 查询很简单,但调试它们可能会非常困难。提高你的 SQL 技能是成为更好机器学习工程师的最佳途径之一。
-
训练数据不完整。在生成第一版训练数据后,你进入机器学习开发的下一阶段,建立一个快速基线模型。这个基线模型通常不足以解决业务问题,因此你需要迭代。缺乏经验的机器学习开发人员往往过于专注于改进模型,而忽视了他们创建的数据集。这是一个典型的错误,会引发挫折感和冒名顶替综合症。回到数据中。扩展你的 SQL 查询以添加更多相关特征。与环境中的领域专家(数据工程师、商业智能人员等)交流,他们可以帮助你获取能推动进展的数据,解除你的阻碍。
数据(DATA)是推动所有模型的神奇成分,从简单的线性回归到庞大的 Transformer 模型。如果燃料不好,驾驶哪辆车都无所谓。你是不会前进的。
这听起来如此琐碎和愚蠢,以至于我们(包括我在内)机器学习工程师有惊人的倾向去忘记。随着你在构建机器学习解决方案方面经验的增加,你会更好地记住这一点,并在遇到障碍时回到数据(DATA)上。
你不能使用 Stackoverflow 来调试你的数据集。你在那里是孤单的。你需要改变你的思维方式。你必须表现得像一个问题解决者。你需要了解数据集,最佳方式是可视化。我个人喜欢 Tableau Desktop,但还有其他选项,比如 Power BI、Apache Superset 等。如果你愿意,还可以使用 Python 库,例如 sweetviz。
无论你偏好什么工具,每次遇到困难时都要回到数据(DATA)上。

提示 3:不要期望知道一切(尤其是在开始时)。
机器学习是一个涵盖广泛技术复杂性的领域:软件开发、运维(MLOps)、经典 ML、前沿深度学习研究、硬件优化……
如果你试图涵盖所有内容,你会失去焦点,过于浮于表面。了解机器学习(ML)中的某些东西意味着你亲自实现了它。至此为止。
跟上深度学习(DL)的最新进展是很棒的,例如。但要以原则性的方式进行。设定明确的目标(例如,我想成为 Transformer 模型的专家),并为自己制定实现该目标的路径,选择相关的论文、库、网络研讨会,甚至会议。
从一个话题跳到另一个话题虽然让你忙碌,但不会让你集中注意力。保持谦虚。从小而专注的地方开始。一旦到达那里,迈出下一步,征服另一个领域。
结论
征服你的恐惧是一项每日(全职)的工作。不仅在机器学习中,而是在你生活的每一个希望成长并在明天变得更好的方面。
原文。经许可转载。
简介: 保·拉巴塔·巴霍(@paulabartabajo_) 是一位数学家和 AI/ML 自由职业者及演讲者,拥有超过 10 年的经验,为各种问题,包括金融交易、移动游戏、在线购物和医疗保健,处理数字和模型。
相关内容:
更多相关话题
如何像侦探一样定义机器学习问题
原文:
www.kdnuggets.com/2018/10/define-machine-learning-problem-detective.html
comments
由Spencer Norris,数据科学家,独立记者。

本文最初发表在OpenDataScience.com。
让我们看看能否通过为我们对机器学习的基本理解奠定基础来开始这个方向——即,究竟什么构成了一个机器学习问题?这似乎是一个你可能认为自己知道答案的奇怪问题,但实际上它有一个非常正式的定义,我们将在这里概述。
定义机器学习问题
你可以采取的最重要的步骤是首先问自己:我认为存在模式吗?
所有机器学习问题的基本假设是存在某种模式。你不能在没有鸡蛋的情况下做煎蛋卷;如果没有任何模式,那么我们就已经完成了。在决定开始一个项目之前问问自己这个问题——这可能会为你节省一些心痛。
如果你仍然认为存在模式,那么我们可以继续。我们寻找的模式是某个函数f,它将某个输入X映射到输出Y。在符号中,这就是f:XY。
当然,你不知道f——你不能知道f,否则你就不会在读这篇文章了。这是机器学习的核心:如果我有某种模式,我不能直接观察到,如何至少可以近似它?
像侦探一样定义问题
像侦探一样做。如果f留下了证据或观察,我们可以开始重建f的样子。每个观察都是一个输入xi=[x1,x2,…xd] Ɛ Rd(即每个xi是一个长度为d的实数数组)和一个观察到的输出yi。这些观察{(x1,y1), (x2,y2)… (xn,yn)}统称为我们的数据集,D。
问题是,即使有这些观察,仍然有无限多的可能性可以解释它们。例如,取一个D,仅包含以下两个观察。

我们对什么样的函数f可以解释这些观察有一些很好的猜测。很可能,它是直线——对吧?

那样最有意义。但是为什么它不能是一个多项式函数呢?

为什么它不能是更复杂的东西?

实际情况是,这些解释中的任何一种都没有完全不合理的理由。它们都是同样有效的假设。
那么为什么还要费心呢?如果没有办法确定真相,我们不是从一开始就注定失败了吗?
如果那是真的,你可能不会查看这一页,大多数犯罪也可能不会被解决。我们稍后会形式化这个概念,但目前,请将其视为:我们尝试根据 可能 的情况来制定假设。我们试图从一个无限的假设空间 H 中挑选出我们认为最有效的假设 g。
我们该如何进行呢?当然是用我们的侦探——算法 A。算法将负责在我们无限大的假设空间 H 中筛选,并找出最合适的一个。我们最终选择的那个是 g,我们说它足够好地近似了我们的真实函数 f,以至于我们可以使用它:gf。
这就是将机器学习问题形式化的全部内容。我们有一些未知的目标函数 f:XY。我们不知道 f 是什么,但我们有输入和输出的示例,这些示例称为 D。我们还有无限多的可能假设 H,我们将逐步缩小范围,直到找到一个看起来足够好的假设 g。我们将通过将 D 输入给 A,逐渐确定 g,以便找到最接近真实情况的答案。
解开谜团
在我们的侦探类比中,代理人 A 拥有一堆证据 D 以确定凶手 f 是谁。A 将在一个庞大的嫌疑人池 H 中筛选,直到他认为找到了一个符合条件的 g。没有保证 g 就是 f —— 在机器学习中,我们几乎从未有这样的保证 —— 但这是基于现有证据的最佳猜测。
如果有更多的证据,我们可能会得出不同的结论。我们有可能完全错认嫌疑人,这将是灾难性的。在实践中,你需要根据你的要求来确定算法允许多少误差(这是我们稍后会讨论的内容)。
如果是不同的代理人查看证据,他们可能会建议完全不同的嫌疑人。这就是当我们切换用于评估数据的算法时发生的事情。这也有代价,我们会讨论这个问题。在此期间,明智地选择你的算法。
当你花更多时间深入理论时,各种细微之处会浮现出来。有时候这可能是一场艰难的战斗,但从长远来看,这将使你成为更出色的机器学习从业者,并且如果你想在现实世界中使用它,它将是至关重要的。
下次我会谈论一下探索 H 的意义,为什么从这堆数据中挑选正确答案如此困难,以及我们为何能够做到这一点。
个人简介:斯宾塞·诺里斯是一位数据科学家和自由撰稿人。他目前以承包商身份工作,并在Medium上发表文章。
原文。经许可转载。
相关:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
进一步阅读
《解决 MySQL 中幻读问题的权威指南》
原文:
www.kdnuggets.com/2022/06/definitive-guide-solving-phantom-read-mysql.html

图片来源:storyset
当大多数人想到关系数据库时,MySQL 通常会首先浮现在脑海中。MySQL 使用 InnoDB 作为存储引擎,而 可重复读 隔离级别是最常见的,它在事务开始之前查看数据。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
然而,与 PostgreSQL 不同,InnoDB 中的 可重复读 隔离级别 无法平滑处理某些问题。具体来说,诸如丢失更新和幻读等问题无法在 InnoDB 可重复读 隔离级别下处理,而在 PostgreSQL 中,解决丢失更新不需要额外的黑客手段。然而,你可以使用一些技巧来执行幻读,例如范围类型和其他机制。
MySQL 开发人员应了解可能的陷阱,并能够适当地解决它们,以避免丢失更新和幻读等问题。本文将介绍 MySQL 开发人员 如何排除幻读可能造成的“写入”偏差。
导致幻读的场景
导致幻读的场景各不相同。然而,一般来说,这些场景都遵循类似的模式。它们最初会在 MySQL 数据库中搜索特定范围,然后根据搜索结果进行 CREATE、UPDATE 或 DELETE 操作。之后,执行的操作直接影响从已搜索范围中获得的结果。
假设,例如,在搜索特定范围后采取的操作是 UPDATE 或 DELETE。在这种情况下,MySQL 开发人员可以使用排他锁以避免“写偏斜”。然后,开发人员可以在 SELECT 的开头使用 FOR UPDATE,之后他们可以强制两个同时进行的事务一个接一个地执行。因此,这两个同时进行的事务在竞争条件期间,绕过了“写偏斜”。
如果我们假设根据特定范围的搜索结果采取的操作是 CREATE,那么上述解决方案是不完整的:没有对应的行允许开发人员在 SELECT 时锁定,这意味着行会在后面形成。
使用 CREATE 时解决幽灵读
我们将介绍一个实际场景,以更好地理解在使用 CREATE 时幽灵读导致的问题。一旦我们描述了这个例子,我们将讨论相应的解决方案。
想象一个允许人们预订会议室的系统;在有人通过这个系统预订了房间后,会向表中添加新数据。这个系统让用户知道房间是否可用,取决于他们想要预订的时间段。一旦有人创建了新的预订记录,所有其他用户就可以避免时间冲突。
然而,当两个人需要同时预订一个房间时,就会出现问题。两个用户都能够通过初始 SELECT 验证,这意味着在纸面上,他们都有同一时间的预订,从而导致时间冲突。如果例如,多个用户通过 VPN 连接到远程 SQL 服务器并需要使用这个预订系统,那么问题可能会加剧。即使 MySQL 开发人员添加了排他锁,也无法避免这个问题,因为他们不能在开始的 SELECT 验证时锁定行。
使用唯一约束索引来解决
MySQL 开发人员不能通过使用排他锁将并发操作转变为顺序操作。因此,他们需要通过向表中添加唯一约束来让一个操作失败。
开发人员可以在房间预订表的列中,针对房间号和会议开始时间使用唯一约束索引。这种解决方案可以防止有人预订已经被别人预订的时间段,并且开发人员可以确保没有人能预订超过一个小时的房间。
然而,这个解决方案还会阻止唯一约束在两个用户的会议时间重叠时有效。要正确解决这个问题,开发人员必须改为实现冲突检测。
通过实现冲突来解决
解决我们讨论的幻读问题的正确方法是揭示表隐藏的冲突。开发人员可以用数据集预填充一个全新的表,这些数据集协调并发操作。如果我们以我们的会议室系统为例,可以想象创建一个新表来规定时间段,并提前显示所有可用的时间段。
使用这个新表,开发人员现在需要对决定可用时间段的列执行 SELECT,并包括 FOR UPDATE,因为数据已经存在。开发人员需要在初始 SELECT 之前运行这个 SELECT FOR UPDATE。
通过在上述示例中实现冲突,开发人员可以使用排他锁阻止任何两个重叠的保留时间段,从而强制一个时间段在另一个时间段之前或之后。较晚的时间段会因为第一个时间段的完成而立即失败。
结论
尽管实现冲突是一种困难且不直观的解决方案,但在使用 MySQL 数据库时,为了避免牺牲任何显著的性能水平,这是必要的。遗憾的是,MySQL 的 InnoDB 隔离级别并非可序列化,因此开发人员需要为可接受的性能水平牺牲一定的复杂性。
使用数据库的人必须了解该数据库的能力以及其难以解决的解决方案。否则,无法预见该数据库的哪些行为可能会影响数据库设计和开发工作。
此外,了解如何适当地应对潜在风险同样重要。尽管我们在本文中通过时间预订系统描述的用例与其他用例不完全相同,但其展示的模式足够相似,理解如何解决这些问题可以使处理其他情况更加轻松。
Nahla Davies 是一名软件开发人员和技术作家。在全职投入技术写作之前,她管理了包括三星、时代华纳、Netflix 和索尼在内的 Inc. 5000 实验性品牌组织的首席程序员等其他引人注目的工作。
更多相关话题
将你的职业转型为数据科学的终极指南
原文:
www.kdnuggets.com/2022/05/definitive-guide-switching-career-data-science.html

照片由Saulo Mohana拍摄,Unsplash提供
你知道每秒钟地球上的每个人都会生成1.7 兆字节的数据吗?
这些巨量的数据需要由专家处理。数据科学专业人员知道如何分析和解读数据,以提取洞察力来帮助企业成长。
因此,这个行业的工作前景预计会比其他职业增长得更快。美国只有约11400 名数据科学家,但对他们技能的需求正在增加。
数据科学值得考虑吗?
数据科学是一个广阔的领域,虽然还很新,但已经显示出令人惊叹的成果。Dice 报告显示数据科学和工程专家的就业机会增加了50%。
物流、医疗保健、金融、保险、房地产和交通运输行业的企业都在使用数据科学,使其成为增长的关键部分。进行数据分析需要一个专家团队、软件和工具。
你不必成为数据科学家也能利用这个快速增长的行业的潜力。存在数百个就业机会和专注于大数据的途径。
成为数据科学家的好处是什么?
成为数据科学家有很多理由。主要好处包括:
高需求,低供应
数据科学在全球达到了前所未有的高度。LinkedIn 和其他招聘平台的数据科学家职位需求不断增加。吸引人的部分在于市场上数据科学家的数量有限。
需求增加意味着工资上涨。公司知道数据科学家的数量有限,因此他们希望尽快获得最佳人才。随时都有许多职位空缺和实习机会。
高薪职位
数据科学是世界上薪酬最高的工作之一。美国数据科学家的平均薪资为每年 123,511 美元。也不可否认的是,初级数据科学家的薪资待遇也很优厚,我们可以推测那些有经验且在管理职位上的人薪水会非常高。经理甚至可以赚得更多,并享有吸引人的福利。
大数据科学项目有巨大的财政合同。了解哪些公司支付给数据科学家的薪酬最高。
良好的工作与生活平衡
数据科学家可以在现场、远程或以混合方式工作。工作量相对较小,由于工作的性质,几乎不需要加班。数据科学家通常在笔记本电脑上使用软件和工具,因此可以在任何地方完成任务。
许多公司也聘用远程工作人员。即使有现场要求,通常也是 9 到 5 的工作,周末休息。
学习机会
数据科学提供了大量的知识和技能。我们已经提到,该行业正在迅速增长并有巨大的需求。几乎所有主要行业都在采用数据科学,填补数据科学家职位的需求不会很快停止。
数据科学为你提供宝贵的商业知识和许多在职业生活中必需的技能。即使你计划以后开创自己的事业,你在大数据方面的专业知识无疑会派上用场。
此外,销售人员也可以从数据科学专业知识中受益,以提高他们的销售管道效率并跟踪消费者行为。
数据科学行业的可能挑战
除了数据科学家所享受的所有奢华之外,如果你计划将职业转向数据科学,你应该了解一些缺点和劣势。
数据科学没有固定的定义
专业人士对数据科学的性质存在争论,它没有确切的定义。一些人认为它是重新定义的统计学,而其他人认为它是科学的一个重要支柱。
数据科学是一个新领域,因此许多解释和推理还未出现。该行业提供了数据科学家的角色,但不同的行业可能有不同的任务并要求不同的结果。
成为数据科学专家是极其困难的
数据科学结合了数学、统计学、概率和计算机研究。这些都是困难的学科,而且在基于这些学科建立职业时,更具挑战性。掌握所有上述领域存在许多差距——没有人能同时在所有领域都有专长。
人们可以来自不同的背景。一个在计算机研究方面有专长的人可能在统计学方面能力不足。因此,数据科学是一个不断变化的动态研究领域,人们必须不断学习和随着行业发展而演变。
需要海量知识
即使一个人对计算机科学和统计学有深入了解,他们仍有可能在没有广泛培训的情况下无法解决数据科学问题。
例如,即使你有 IT 和统计学的背景,你也需要学一点编程。这是因为数据科学家通常需要用 SQL、R 和其他编程语言编写算法。
此外,他们必须进行实验,以确保数据质量最高。之后,他们清理数据集,只有在此之后,他们才能组织和 结构化数据 以进行分析。
这是一项繁重的工作,而且一切都很新颖。因此,只有当你是一个自我驱动的人,并且欣赏数据所能提供的所有机会时,你才能在这个行业中立足。
数据隐私和任意结果难以处理
企业采取极端措施保护其数据,因为永无止境的网络攻击和泄露威胁可能危及数据。未能妥善保护其系统可能导致重大损失。
数据科学家在调查发生时是最初的嫌疑人,因为他们与数据进行互动和保护数据。
数据科学家的工作是仔细研究数据,并做出尽可能准确的预测以促进公司。然而,数据往往是任意的,因此结果有时可能无法满足预期。
成为数据科学家需要哪些技能?
成为数据科学家需要许多技能,包括:
-
机器学习
-
数据分析
-
深度学习
-
数学
-
编程
-
多任务处理
-
分析分析
-
问题解决
-
数据操作
-
快速反应
结论
我们希望这篇文章能为你提供足够的知识,帮助你决定是否应该辞掉当前工作,成为一名数据科学家。
随着时间的推移,数据科学 不断演变。尽管挑战复杂,但成为数据科学家的好处巨大。一位高技能的科学家甚至可能消除数据分析今天面临的挑战!
Nahla Davies 是一名软件开发人员和技术作家。在全职从事技术写作之前,她曾管理过许多有趣的工作——其中包括在一家排名 Inc. 5,000 的体验品牌公司担任首席程序员,该公司的客户包括三星、时代华纳、Netflix 和索尼。
更多相关话题
学位还是证书?雇主更看重哪个资质?
原文:
www.kdnuggets.com/degree-or-certificate-which-credential-do-employers-value-more

图片来源:作者 | Canva
当你在考察就业市场时,可能会遇到一些要求学士学位的职位空缺。根据哈佛商学院的数据,这一额外的学位要求使 64%的工作年龄成年人被排除在外,因为他们没有学位。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
自然,组织和雇主在学士学位方面有偏好,因为受教育的劳动力通常具有更高的生产力,正如经济政策研究所所述。通过增加学士学位要求来缩小申请范围也是许多公司的一个简单途径。
然而,情况有所不同。随着数据驱动解决方案的增长和人工智能带来的新机会,公司不再寻找他们曾经渴望的过度技能员工,而是更加重视愿意进行技能再培训和提升的员工。
就像其他人一样,由于缺乏学位,我发现自己避开了这些职位信息。当我决定追求数据科学职业时,我没有时间或财力承诺三年的学位课程。我必须赚钱,因此我选择了数据科学训练营。这一训练营需要 9 个月的时间,并且只有在我赚到一定金额后才需要偿还一部分费用。
理解你的职业目标
如果我可以回到过去,我会说证书和学位都没有错。然而,你需要更长远地考虑。这是你的短期职业目标,还是你想继续建立你的长期职业目标?
哈佛商学院在最近的一份报告中总结道:“工作不要求四年制学位,雇主要求。”尽管如此,许多雇主已经选择取消本科的要求,以适应当前市场的需求。
你可以获得职业证书以实现短期目标,即进入该领域并从基层开始。然而,如果你想在职业生涯中逐步晋升并转到不同的职位,你需要获得什么?理解你现在想要的和将来想要的,关键在于帮助你做出正确的选择。
如何搞清楚这些?研究。
如果你对短期、中期和长期目标有了一个大致的了解,你就需要深入研究。例如,你可能想从初级数据科学家开始,然后逐步晋升为首席数据科学家。但你的目标可能不仅仅止步于此,你可能还想进一步阐述最终目标是成为首席技术官(CTO)。
你可以做的最好的事情是研究并回顾这些职位的招聘信息,从入门级到高级职位。深入了解教育要求、工作经验年限,并在如 LinkedIn 这样的平台注册,查看其他人的教育路径。
职业认证还是学位?
一旦你对职业路径和如何达到目标进行了深入研究,你需要问自己是想立即到达第一个目标,还是愿意在达到目标之前多花几年时间。
职业证书完成时间较短,成本远低于学位。它们更注重技术技能的发展而非软技能,这有助于你在工作环境中进步。职业证书可以是你在短时间内体验兴趣并确保这是你想做的事情的绝佳途径。你可以在不浪费太多时间的情况下重新技能,而不像获得学士或硕士学位那样。
另一方面,本科和硕士学位需要更多时间来完成,并且有一定的费用。然而,它们是值得的。你不仅会培养技术技能,还能够建立批判性思维和创造力等软技能。硬技能和软技能在你想要在职场上取得成功时是相辅相成的。众所周知,学位可以提高你的薪资,相比于没有接受高等教育的员工,你面临的失业风险较低。尽管入门级职位对本科生的要求在减少,但要在职业生涯中晋升,你可能需要一个学位。
我应该从哪里开始?
你需要回顾自己的目标。你的目标将帮助你理解下一步该做什么。如果你正在开始一些全新的领域,比如从市场营销转到数据分析,那么最好的选择是从短期项目如职业认证开始。
大多数人在成人生活中会换几次职业——这是很正常的。你最不希望做的事情就是仅仅因为你在大学里花费了 3 或 4 年时间就承诺从事某个职业。
当今时代的美妙之处在于,如果你想走这两条路,你有多种选择。不同的电子学习平台允许你按照自己的节奏获得职业证书和学位。时间不再是决定性因素,你需要做出的唯一决定是是否选择短期路径或长期路径。
以下是使用这两条路径可以选择的一些不同职业道路:
数据科学
职业证书:
大学学位:
数据工程
职业证书:
大学学位:
数据分析师
职业证书:
大学学位:
总结
看看上述的职业证书和学位列表,你可以看到一个主要的区别和相似点。大多数职业证书都针对特定的职业,例如数据科学或数据工程。然而,学位则更为广泛,涵盖了所有类型的工作。
话虽如此,如果你不确定自己想要走哪条路,那么选择一个学位可能是更好的选择,这样你可以在过程中找到答案。
Nisha Arya 是一位数据科学家、自由职业技术作家,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。Nisha 涉及广泛的话题,并希望探讨人工智能如何促进人类寿命的不同方式。作为一个热衷学习者,Nisha 寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
在数据科学面试中进行精彩演示
原文:
www.kdnuggets.com/2022/01/deliver-killer-presentation-data-science-interviews.html

图片来源:Campaign Creators 在 Unsplash
很少有人喜欢公共演讲。然而,这几乎是任何工作中必不可少的技能。数据科学也不例外。作为数据科学家,你将需要向利益相关者展示你的想法和发现,这也是你在面试数据科学家职位时经常需要做演示的原因。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织的 IT
演示可能会让人紧张,但它们是证明你是一个有能力的数据科学家至关重要的一部分。数据科学家必须是能够推动对话、说服利益相关者接受他们建议和故事的销售者。面试中的演示环节是你展示自己能成为推动者而不仅仅是支持者的地方。
在这个博客中,我们将探讨面试中做演示的 5 个技巧。我们将讨论演示中应该包含哪些信息,以及如何以引人入胜的方式呈现这些内容。如果你更喜欢观看而非阅读,可以前往我的 YouTube 频道6,观看有关这个主题的视频。
让我们开始吧!
关注你的影响力
第一个技巧是关注你的影响力。项目通常是团队合作的结果,涉及的不仅仅是数据科学家。成功完成一个项目需要大量的协作和团队合作。
尽管如此,面试官在你展示一个项目时,往往不会关心这些细节。他们关注的是你,而不是团队的其他成员。因此,你需要专注于你的角色和影响力。
为了清晰地传达你的影响力,你应该用可衡量的术语进行描述。使用指标和数字来解释你在项目中的成就。
最佳的指标是那些显示你对业务的影响的指标。这包括例如增加收入、客户获取、客户留存等。如果你知道你的工作对业务指标的影响,这是一种理想的方式来在演示中说明你的影响。
然而,有时将你的工作与对业务的直接影响联系起来非常困难。可能是项目的范围不够大,或者项目只是间接影响业务指标。
如果是这种情况,你仍然要用面试官容易理解的度量标准来描述你的影响。你可以谈论例如通过构建数据管道来提高团队效率和生产力,或者谈论你构建的工具或开发的方法论如何被多个团队采纳。
虽然这些东西并没有准确说明你对业务的影响,但可以清楚地看到你对整个公司的积极影响。提高团队生产力必定会带来业务指标的改善。
在描述你的影响时,避免不清楚说明你如何帮助业务的细节。例如,仅仅说你提高了模型性能对面试官没有帮助。并不清楚这对公司有何好处。坚持使用那些即使没有技术背景的人也能清楚理解的指标,如果有的话,业务指标最好。
这个关于关注你影响力的提示不仅适用于演讲。在面试中描述过去的项目时,影响力也非常重要。你可以查看这篇博客文章以了解更多。
使用你的最佳内容
我们的下一个提示是使用你的最佳内容。这个提示一开始可能看起来非常明显。你当然想展示你最好的项目!然而,我们说的最佳内容到底是什么意思呢?可能会想展示一个你觉得最成功的项目,但你最成功的项目往往也是一个简单的项目。
当我说展示你的最佳内容时,我更指的是关于你自己的最佳内容,而不是最成功的项目。谈论一个有挑战的项目能给你更多展示技能、细致和独特性的机会。具有挑战性的项目往往更有趣,因此更容易引起面试官的注意。
挑战并不是使项目成为最佳的唯一因素。你还需要选择一个你深度参与的项目。选择一个你在项目过程中各个步骤中都可以舒适地突出自己行动的项目。解释项目设计和实施的可行性,以证明你理解自己的工作及其影响。这表明你可以推动项目,因为你理解整个工作的运作方式。
当你选择一个项目进行展示时,选择一个能展现你最佳状态的项目。这通常意味着选择一个曾经遇到一些问题和障碍的项目。这个想法引出了我们的第三个提示:列出项目的局限性。
列出局限性
跳过或略过项目中出现的问题和局限性可能是很有诱惑力的。然而,你在特定项目中遇到的局限性是你在演示中不想绕过的,尤其是在讨论建模方法时。
事实上,仅仅知道如何使用建模方法是不够的。任何人都可以学习做到这一点。为了给面试官留下深刻印象,你需要展示你对方法的优点和局限性的了解。展示对你情况中不理想部分的认识。
例如,你可能遇到了数据的局限性。也许数据收集存在问题,团队没有足够的数据进行分析或建模。为了克服这个局限性,你可能不得不进行一些研究,以寻找外部数据源。
这个例子说明了列出局限性给你一个机会去讨论你如何改进或计划改进。因此,对局限性的意识表明了成长的能力,并展示了你的解决问题能力。这表明你能够识别计划中的薄弱环节并致力于缓解这些问题。
思考技术细节
前三个提示应该帮助你决定讲述哪个项目,但现在你已经选择了一个项目,如何准备展示它?每个人的方法各不相同,但有一件事我建议每个人都做。第四个提示是仔细考虑项目的技术细节。
你可能没有时间解释项目的每一个技术方面,但你要确保你对你选择讨论的所有内容有透彻的理解。你通常会被问到后续问题,这需要对项目的技术细节有深入了解。
例如,面试官可能会问你以下问题:
-
将连续变量转换为分类变量是否有意义?如果分布是长尾的呢?
-
对于基于树的模型,如果是随机森林模型,你是否需要进行修剪?
确保你对所有计划展示的技术细节足够熟悉,以便回答后续问题。
行为确实重要
在准备演示时,内容当然很重要,这也是我们提示的重点:选择什么类型的项目以及在演示中关注该项目的哪些方面。
然而,拥有出色的内容并不是成功演示的唯一因素。面试官还会评估你处理自己方式的表现。
尽管你希望展现出自己能够推销思想并推动对话的能力,但你不想给人以傲慢或自大的印象。成为一个优秀的演讲者的一部分就是展示你是一个好的倾听者。没有人愿意和一个拒绝倾听他人意见和考虑不同观点的同事合作。
因此,在进行演讲时,展示对问题和建议的开放性是非常重要的。聆听不同的意见,甚至是那些与你的观点不一致的意见,并花时间分析它们。你可以随后说服听众接受你的观点,或者承认你在这方面的局限性。
许多时候,这仅仅意味着承认某人提出了一个好问题并考虑解决方案。不要忽视他人的意见和关切,因为这意味着你可能会是一个不合适的同事。在演讲过程中,你应该以一种展示自信和能力的方式表现自己,同时也展示你重视不同观点的态度。
结论
所有这些技巧表明,在面试中的演讲更多的是关于展示你作为数据科学家的能力,而不是单纯地展示一个项目。
为了展示你是一位称职的数据科学家,你的演讲应该超越仅仅解释项目的基本事实。你需要展示你的影响力、解决问题的能力、技术技能和知识,以及你的职业素养和推动对话的能力。
感谢阅读!
如果你喜欢这篇文章并想支持我...
-
订阅我的YouTube 频道!
-
在LinkedIn上联系我!
-
在求职开始时,尝试一下我的清单来优化你的数据科学简历。
艾玛·丁 是Data Interview Pro的创始人兼职业教练。
更多相关内容
数据科学家/机器学习专家的需求何时达到顶峰?
原文:
www.kdnuggets.com/2017/11/demand-data-scientists-machine-learning-decline.html
评论 最新的 KDnuggets 调查 询问了
数据科学家/机器学习专家的需求何时开始下降?
基于近 1,200 名选民的结果,KDnuggets 读者预计这将在 4 到 10 年之间发生。最常见的答案是 4-6 年,中位数答案在 8-9 年之间——见图 1。
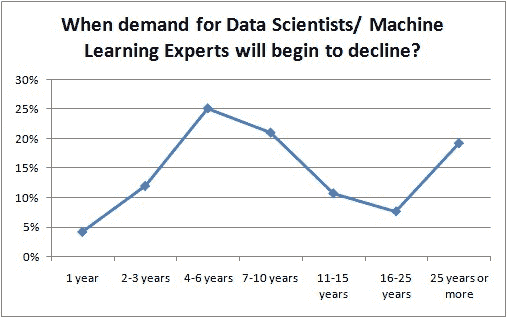 图 1:KDnuggets 调查:数据科学家/机器学习专家的需求何时开始下降?
图 1:KDnuggets 调查:数据科学家/机器学习专家的需求何时开始下降?
这是一个非常有趣且重要的图表,以下是我的观察。
注意:下降的开始时间紧接在需求峰值之后,因此我们将这两个术语互换使用。
数据科学家的需求在 2012 年被宣布为 21 世纪最性感的工作 后开始迅速增长。这种需求有两种方式得到满足:
-
教育:许多大学和其他教育平台,如 Coursera、edX 和 Udemy,正在提供 数据科学和机器学习教育
-
自动化:像 DataRobot 等公司提供 自动化数据科学/机器学习平台,这些平台要么让业务用户进行建模,要么通过嵌入业务流程(例如自动竞标广告)完全自动化数据科学。
关于自动化的一个不那么严肃的视角,请参见 KDnuggets 漫画 数据科学家——21 世纪最性感的工作,直到……
当前的需求感觉像一个泡沫,在某个时点泡沫会破裂,需求将开始下降,但正如许多泡沫一样,很难预测具体时间。需求峰值(下降的开始)在 4 到 9 年之间对我来说是合理的。当然,这并不意味着数据科学家会失业,但这份工作将变成一种常规工作,薪资将会稳定,正如例子中网页开发者的情况——在互联网初期这是一个非常热门的工作,但现在它已成为一份常规工作。
调查还询问了选民在数据科学和机器学习中的经验以及他们的所属(行业 / 学生 / 研究 / 政府 / 其他)——见图 2。
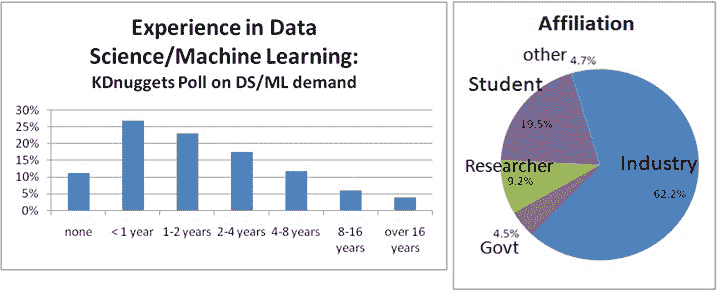 图 2:民意调查受访者的数据科学/机器学习经验与职务
图 2:民意调查受访者的数据科学/机器学习经验与职务
我们注意到大约 60%的受访者有 2 年或更少的经验,这显示了这个领域现在的年轻。62%的受访者来自工业界,19.5%是学生,9.2%是研究人员,4.5%是政府/非营利组织。
当我考察需求高峰与经验和职务的关系时,令人惊讶的是,我得到了类似的曲线,一个高峰出现在 4-6 年或 7-10 年,另一个较小的高峰出现在 25 年或更长时间。为了简化图表,我将“无经验”和“<1 年”经验的线条归为一组,以及“1-2 年”和“2-4 年”经验的线条归为一组,这两种情况看起来非常相似。
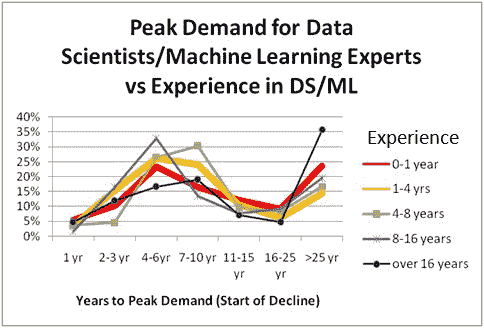
图 3:数据科学家/机器学习专家的需求高峰与数据科学/机器学习经验
我将期望数据科学家的需求仅在 25 年或更长时间后才开始下降的人称为“乐观主义者”,另一组称为“悲观主义者”。
我们注意到,经验最多的组(超过 16 年)的乐观主义者比例最高——超过 35%的人认为需求在未来 25 年内不会下降。
接下来,我们检查了需求高峰曲线与职务的关系——图 4。
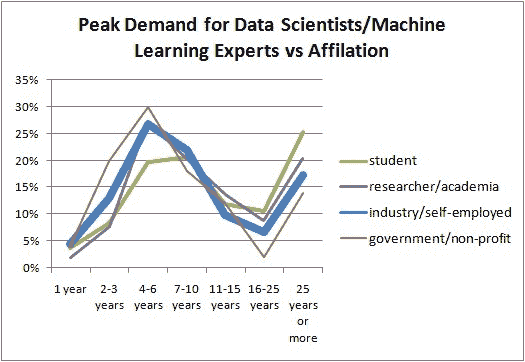
图 4:数据科学家/机器学习专家的需求高峰与职务对比
再次,最令人惊讶的发现是曲线再次相似。
学生是最乐观的,而政府人员是最悲观的,工业界则介于两者之间。
最后,我们考察了按地区分布的情况。地区参与情况是:
-
美国/加拿大,40%
-
欧洲,33%
-
亚洲,16%
-
其他,11%
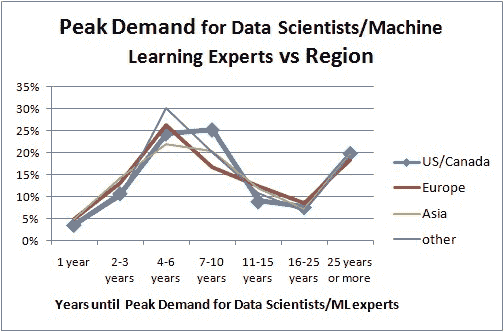
图 5:数据科学家/机器学习专家的需求高峰与地区对比
再次,最令人惊讶的发现是曲线再次相似。一个显著的不同之处是,美国/加拿大的受访者更乐观——他们最常选择的高峰需求是在 7-10 年,而其他地区则是在 4-6 年。所有地区中,认为 25 年或更长时间的比例惊人地相似(18.3%到 19.8%)。
什么可以解释这种类似的分布?
一个假设是,人们天生倾向于乐观或悲观,这会影响他们的预测。也许在询问关于社会趋势等无法从物理学中确定但依赖于人们的感觉和直觉的预测时,民意调查应该以某种方式衡量乐观与悲观的特质。
如果这是真的,我们注意到不同职务和地区的乐观主义者比例相对相似,并且随经验变化不大。
相关:
了解更多相关话题
通过 Dell EMC Ready 解决方案实现人工智能、深度学习、机器学习的民主化
原文:
www.kdnuggets.com/2018/01/democratizing-ai-deep-learning-machine-learning-dell-emc.html
评论
人工智能、机器学习和深度学习(AI | ML | DL)在数字化转型的核心,通过使组织能够利用日益增长的大数据来优化关键的业务和操作用例。
-
人工智能(Artificial Intelligence,简称 AI)是理论和开发计算机系统的学科,这些系统能够执行通常需要人类智慧的任务(例如视觉感知、语音识别、语言翻译等)。
-
机器学习(Machine Learning,简称 ML)是人工智能的一个子领域,它使系统能够通过经验自行学习和改进,而无需明确编程。
-
深度学习(Deep Learning,简称 DL)是一种建立在深层次层级结构上的机器学习(ML),每一层解决复杂问题的不同部分。这些层相互连接成一个“神经网络”。深度学习框架是加速这些模型开发和部署的软件。
参见“人工智能不是虚假智能”以获取更多关于人工智能 | 机器学习 | 深度学习的详细信息。
其商业影响令人震惊!(见图 1)
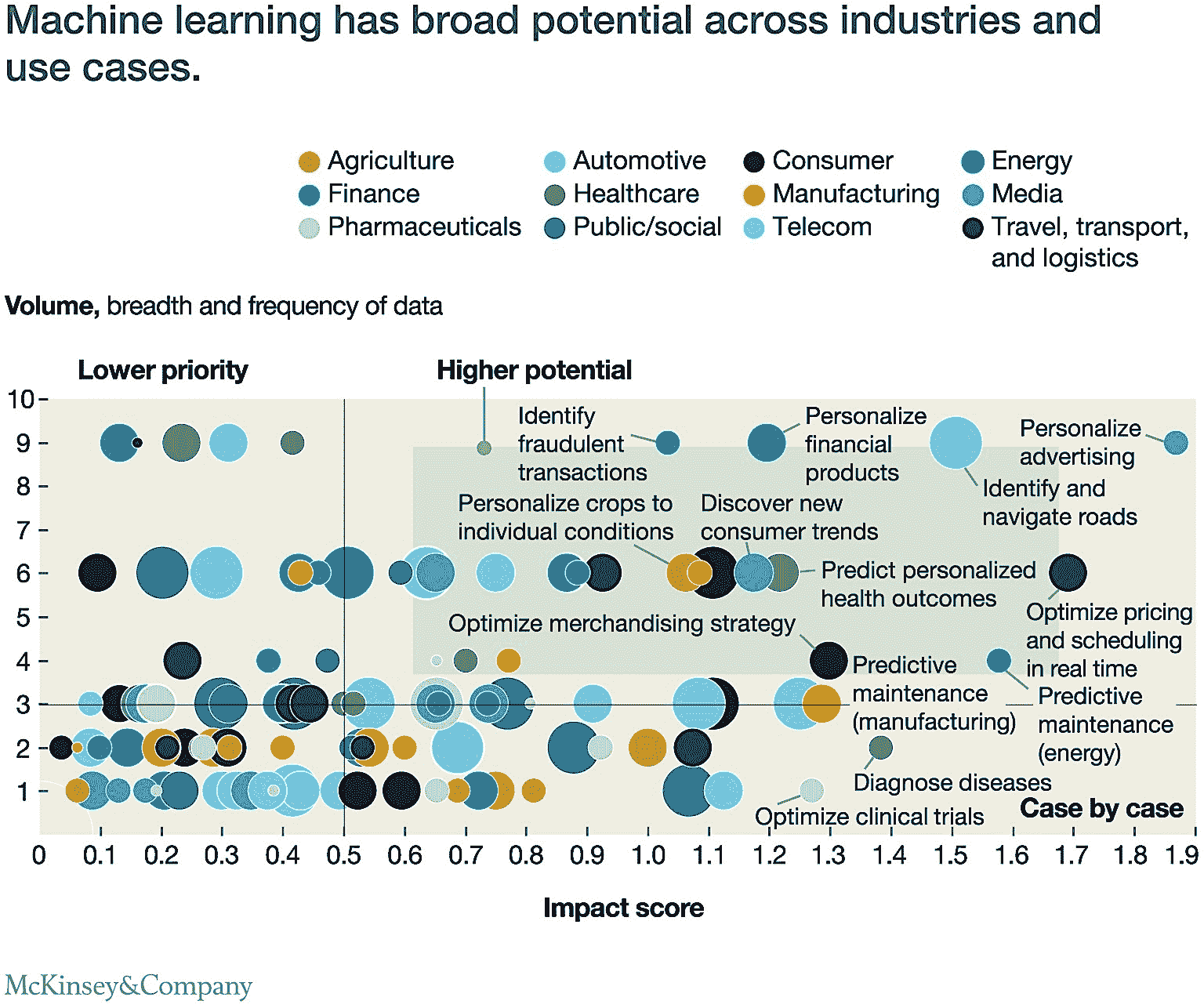
图 1:麦肯锡《分析、人工智能和自动化中的现状与未来》
高级管理人员似乎已经了解了这一点。《商业周刊》(2017 年 10 月 23 日)报道了在 363 次第三季度财报电话会议中提及“人工智能”的次数大幅增加(见图 2)。
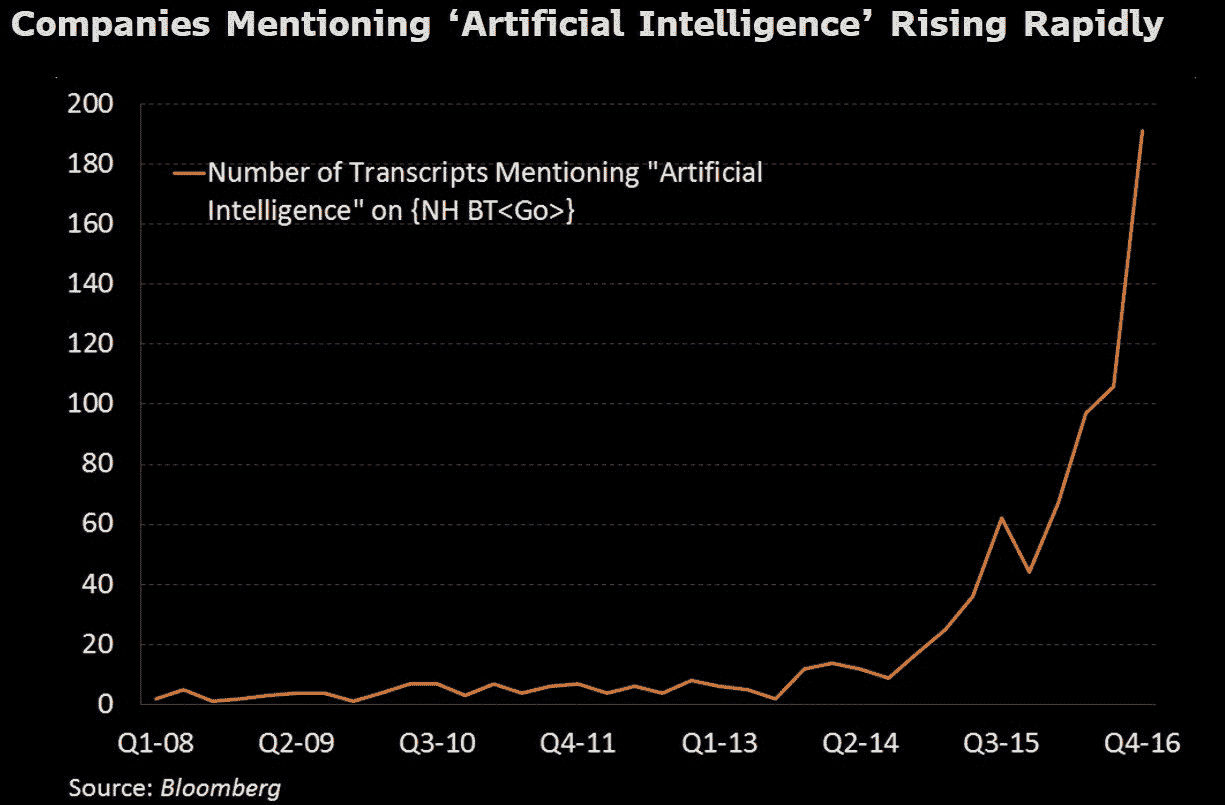
图 2:高管在财报电话会议中提及“人工智能”
为了帮助我们的客户利用人工智能 | 机器学习 | 深度学习的业务和操作优势,Dell EMC 创建了“Ready Bundles”,旨在简化人工智能 | 机器学习 | 深度学习解决方案的配置、部署和管理。每个捆绑包包括集成的服务器、存储、网络以及深度学习和机器学习框架(如 TensorFlow、Caffe、Neon、Intel BigDL、Intel Nervana 深度学习工作室、Intel 数学核心库 - 深度神经网络和 Intel 机器学习扩展库),以优化机器学习或深度学习。
推动人工智能 | 机器学习 | 深度学习的民主化
民主化定义为将某物变得对所有人,即“普通大众”可及的行动/发展。历史提供了工业革命和信息革命的民主化教训。这两个历史时刻都受到零件、工具、架构、接口、设计和培训标准化的推动,这使得创建通用平台成为可能。组织不再依赖“高僧”式的专家来组装枪支、汽车或计算机系统,各种规模的组织能够利用通用平台来建立自己的客户、业务和财务差异化来源。
AI | ML | DL 技术栈是复杂的系统,调整和维护难度大,专业知识有限,栈的一个最小变化可能会导致失败。AI | ML | DL 市场需要经历类似的“标准化”过程,以创建能够使各种规模的组织建立自身客户、业务和财务差异化来源的 AI | ML | DL 平台。
为了帮助加速 AI | ML | DL 的民主化,戴尔 EMC 创建了机器学习和深度学习准备捆绑包。这些预打包的准备捆绑包降低了风险,简化了 AI | ML | DL 项目,并通过预集成必要的硬件和软件来加快价值实现时间(有关更多信息,请访问 戴尔 EMC 机器学习准备捆绑包与 Hadoop)。
不再需要一个孤立的专业知识小组来建立你的 AI | ML | DL 环境。相反,组织可以将宝贵的数据工程和数据科学资源集中在创造新的客户、业务和运营价值上。
用戴尔 EMC 咨询公司实现机器学习货币化
在每个行业中,组织正积极采纳 AI | ML | DL 工具和框架,以帮助他们更有效地利用数据和分析来驱动关键的业务和运营用例(见图 3)。
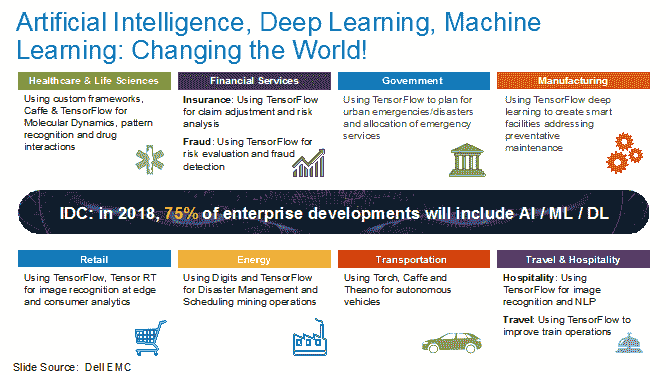
图 3:跨行业的 AI | ML | DL 用例
商机丰富。因此,真正的挑战不是识别利用 ML 获取业务和运营优势的机会,真正的挑战是:
-
确定从哪里以及如何开始将 AI | ML | DL 集成到业务模型中,通过构思、识别、验证和优先考虑潜在的用例
-
构建一个 弹性数据平台 (数据存储库或数据湖),使组织能够捕获、增强、保护和共享组织的关键数据和分析数字资产。
Dell EMC 服务旨在帮助客户弥合数据科学团队、IT 团队和业务线之间的差距。通过合作,我们能够陪伴你从部署到用例开发再到全面生产的整个过程。以下是 Dell EMC 帮助客户将 AI | ML | DL 整合到其关键业务和操作流程中的两个例子。
用例 #1: 使用医学图像识别进行膀胱癌识别
对人体的图像识别预计将大幅改善,帮助医生提供更好且更准确的医疗诊断。即使在疾病存在的情况下,应用于器官图像识别的 ML 也能减少医疗错误的可能性,加快疾病诊断。这在许多情况下都很重要,因为诊断延迟意味着治疗延迟。由于这些方法的前景,医疗成像技术将在不久的将来在医疗诊断和治疗中扮演关键角色。
在这一项目中,我们使用了来自癌症成像档案的磁共振成像(MRI)来识别患者的膀胱癌,采用了无监督和有监督的 ML 技术。这些算法识别出了图像之间的显著差异,使医生能够看到哪些特征可能与膀胱癌检测相关。ML 可以使用技术来减少图像的噪声,并提供更好的结果(见图 4)。
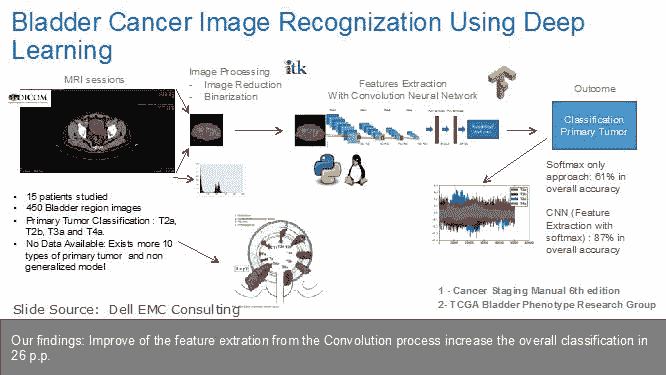
图 4: 利用机器学习加速膀胱癌检测
ML 算法的精准度将提高结果的准确性。随着更多图像数据的可用,全球范围内的好处将不断改善。此外,更多的 ML 模型将被训练,这些模型的有效性也将不断得到改进。
可以合理地说,利用 AI | ML | DL 技术进行计算机辅助肿瘤诊断将为社会带来重要的好处。它将减少医疗成本,并缩短治疗时间,同时推动更有效的结果(见图 5)。
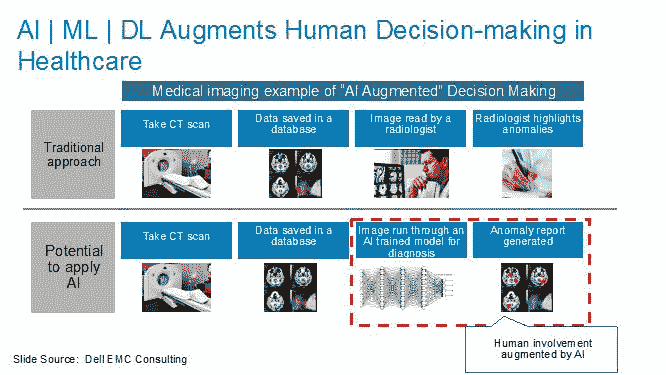
图 5: AI | ML | DL 增强医疗决策
注: 此用例最近获得了 Dell EMC 2017 年“最佳应用数据分析”奖项,来自 Dell EMC 的 Proven Professional Knowledge Sharing 计划。
用例 #2: 作物疾病识别
人类社会需要到 2050 年将食品生产增加约 70%,以满足预计将超过 90 亿人口的需求。目前,传染病使潜在作物产量平均减少 40%,许多发展中国家的农民损失甚至高达 100%[1]。
对全球 5 亿小农户来说,情况尤其严重,他们的生计依赖于作物的健康。在非洲,仅 80%的农业产出来自小农户。
全球范围内智能手机的广泛分布,预计到 2020 年将有 50 亿部智能手机,为将智能手机转变为各种种植食品社区的宝贵工具提供了潜力。一个潜在的应用是通过深度学习和众包开发移动疾病诊断。
参与的结果在对不同类型作物及其面临的不健康情况的风险评分方面非常令人印象深刻(见图 6)。
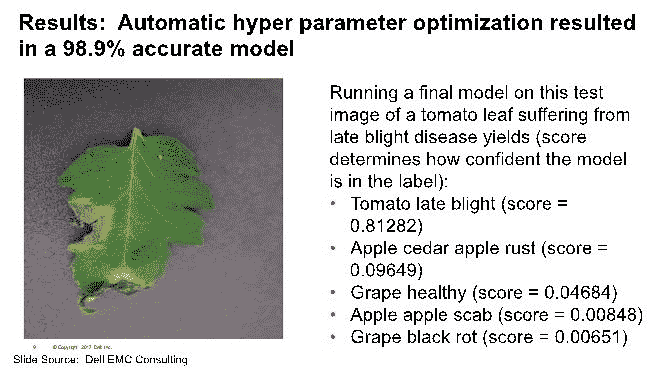
图 6:作物疾病识别与评分
戴尔 EMC 准备解决方案 + 戴尔 EMC 咨询 = 智能企业
戴尔 EMC 咨询提供了一整套服务,旨在帮助客户加速 AI | ML | DL 的采用并实现数据资产的变现(见图 7)。
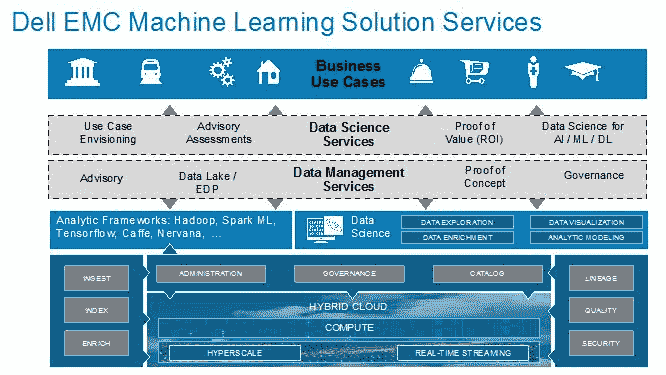
图 7:戴尔 EMC 咨询整合 AI | ML | DL 用例
对任何组织而言,最终目标是掌握 AI | ML | DL 的使用,以在整个组织内产生并推动客户、产品和运营价值;创造具备持续学习和适应变化的商业、环境、竞争和经济条件的“智能企业”(见图 8)。
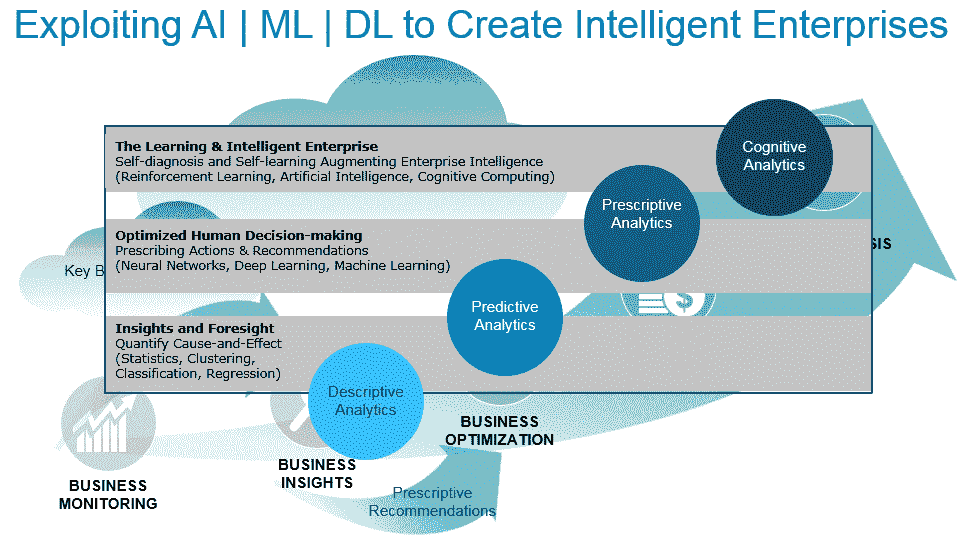
图 8:创建“智能企业”
未来已经到来,戴尔 EMC 与戴尔 EMC 咨询一起推出 AI | ML | DL 准备套餐,加速客户迈向“智能企业”的旅程。有关更多信息,请访问 dellemc.com/services。
来源:
图 1:麦肯锡 “分析、人工智能和自动化的现状与未来”
[1] “一个开放获取的植物健康图像库,以便开发移动疾病诊断。”
原文。经许可转载。
相关:
-
为什么使用数据分析来预防,而不仅仅是报告
-
来自《权力的游戏》的经验教训:阻止数据货币化的白行者
-
数据货币化的关键
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关内容


 浙公网安备 33010602011771号
浙公网安备 33010602011771号