KDNuggets-博客中文翻译-十六-
KDNuggets 博客中文翻译(十六)
原文:KDNuggets
使用 TensorFlow 进行简单的图像数据集增强
原文:
www.kdnuggets.com/2020/02/easy-image-dataset-augmentation-tensorflow.html
评论
图片来源:Nanonets
我们的前三大课程推荐
 1. Google 网络安全证书 - 快速开启网络安全职业生涯
1. Google 网络安全证书 - 快速开启网络安全职业生涯
 2. Google 数据分析专业证书 - 提升你的数据分析技能
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT 工作
图像分类的成功,至少在很大程度上,取决于大量可用的训练数据。暂且不谈诸如过拟合等问题,训练数据越多,你建立一个有效模型的机会就越大。
但当我们没有大量训练数据时,我们该怎么办?对于这个特定问题,立刻想到的几种广泛方法是迁移学习和数据增强。
迁移学习 是将现有机器学习模型应用于原本不打算用于这些场景的过程。这种利用可以节省训练时间,并扩展现有机器学习模型的实用性,这些模型可能在大数据集上经过了长时间的训练。如果我们在大数据集上训练一个模型,然后可以将结果调整为在我们较小的数据集上有效。至少,这就是我们的想法。
数据增强 是在不需要手动收集任何新数据的情况下,增加现有训练数据集的大小和多样性。这些增强的数据是通过对现有数据执行一系列预处理转换来获取的,这些转换可以包括水平和垂直翻转、倾斜、裁剪、旋转等,尤其是在图像数据的情况下。总的来说,这些增强的数据能够模拟各种微妙不同的数据点,而不仅仅是重复相同的数据。这些“附加”图像的微小差异应该足够帮助训练出一个更强大的模型。再说一次,这就是我们的想法。
本文重点介绍了在 TensorFlow 中解决图像训练数据量不足问题的第二种方法——数据增强的实际实施,而迁移学习的类似实际处理将在稍后时间进行。
图像增强的帮助
由于卷积神经网络学习图像特征,我们希望确保这些特征以各种方向出现,以便经过训练的模型能够识别出人的腿在图像中可以呈现为垂直或水平。例如。数据增强除了增加原始数据点的数量外,还能通过使用图像旋转等变换来帮助我们。另一个例子,我们还可以使用水平翻转来帮助模型训练,以识别猫是否直立或被倒置拍摄。
数据增强不是万能药;我们不应该期望它解决所有的小数据问题,但在许多情况下它可能是有效的,并且通过将其作为全面模型训练方法的一部分进行扩展,比如与转移学习等其他数据集扩展技术一起使用。
TensorFlow 中的图像增强
在 TensorFlow 中,数据增强是通过ImageDataGenerator类完成的。这非常简单易懂。每个周期都会循环整个数据集,并根据所选选项和数值对数据集中的图像进行变换。这些变换是在内存中执行的,因此不需要额外的存储(尽管可以使用save_to_dir参数将增强图像保存到磁盘,如果需要的话)。
如果你在使用 TensorFlow,你可能已经在使用ImageDataGenerator仅用于缩放现有图像,而没有进行额外的数据增强。这可能如下所示:
py` train_datagen = ImageDataGenerator(rescale=1./255) ```py ````
一个更新的ImageDataGenerator,其执行数据增强,可能如下所示:
py` train_datagen = ImageDataGenerator( rotation_range=20, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, vertical_flip=True, fill_mode='nearest') ```py ````
这都意味着什么?
-
**rotation_range**- 随机旋转的度数范围;在上述示例中为 20 度 -
**width_shift_range**- 总宽度的比例(如果值<1,如此处所示),用于随机水平平移图像;在上述示例中为 0.2 -
**height_shift_range**- 总高度的比例(如果值<1,如此处所示),用于随机垂直平移图像;在上述示例中为 0.2 -
**shear_range**- 用于剪切变换的逆时针剪切角度,单位为度;在上述示例中为 0.2 -
**zoom_range**- 随机缩放的范围;在上述示例中为 0.2 -
**horizontal_flip**- 随机水平翻转图像的布尔值;在上述示例中为 True -
**vertical_flip**- 随机垂直翻转图像的布尔值;在上述示例中为 True -
**fill_mode**- 输入边界外的点根据“constant”,“nearest”,“reflect”或“wrap”填充;在上述示例中为 nearest
然后,你可以指定训练(以及可选的验证,如果你创建了一个验证生成器)数据的位置,例如,使用ImageDataGenerator的flow_from_directory选项,然后在训练过程中使用fit_generator训练模型,将这些增强的图像流入你的网络。以下是一个这样的代码示例:
py` train_generator = train_datagen.flow_from_directory( 'data/train', target_size=(150, 150), batch_size=32, class_mode='binary') # 假设模型已定义... history = model.fit_generator( train_generator, steps_per_epoch=100, epochs=100, verbose=2) ```py ````
这就是全部内容。TensorFlow 中轻松图像数据集增强的简介。
相关:
-
高级特征工程和预处理的 4 个技巧
-
最新 Scikit-learn 版本中的 5 个伟大新功能
-
使用非最大抑制算法的行人检测
更多相关内容
使用 PyCaret + MLflow 轻松实现 MLOps
评论
由 Moez Ali,PyCaret 创始人及作者
PyCaret
PyCaret 是一个开源的低代码机器学习库和端到端模型管理工具,使用 Python 构建,用于自动化机器学习工作流。它以易用性、简洁性和能够快速高效地构建和部署端到端 ML 原型而闻名。
PyCaret 是一个替代性的低代码库,可以用几行代码替代数百行代码。这使得实验周期变得极其快速和高效。
PyCaret — 一个在 Python 中的开源低代码机器学习库
要了解更多关于 PyCaret 的信息,你可以查看他们的 GitHub。
MLflow
MLflow 是一个开源平台,用于管理 ML 生命周期,包括实验、可重复性、部署和中央模型注册。MLflow 目前提供四个组件:

MLflow 是一个开源平台,用于管理 ML 生命周期
要了解更多关于 MLflow 的信息,你可以查看 GitHub。
安装 PyCaret
安装 PyCaret 非常简单,只需几分钟时间。我们强烈建议使用虚拟环境,以避免与其他库的潜在冲突。
PyCaret 的默认安装是一个精简版,仅安装硬性依赖项 列于此处。
**# install slim version (default)** pip install pycaret**# install the full version**
pip install pycaret[full]
当你安装 PyCaret 的完整版时,所有的可选依赖项也会被安装 列于此处。MLflow 是 PyCaret 的依赖项,因此无需单独安装。
???? 让我们开始吧
在我讨论 MLOps 之前,让我们先简单谈谈机器学习生命周期的高层次概述:
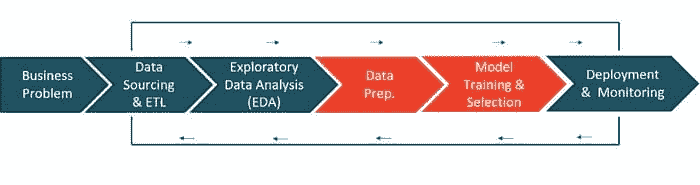
机器学习生命周期 — 作者提供的图像(从左到右阅读)
-
商业问题 — 这是机器学习工作流的第一步。根据用例和问题的复杂性,完成这一阶段可能需要几天到几周的时间。在这一阶段,数据科学家会与领域专家(SME)会面,以了解问题、采访关键利益相关者、收集信息,并设定项目的整体期望。
-
数据来源与 ETL — 一旦理解了问题,就可以利用在面谈中获得的信息从企业数据库中提取数据。
-
探索性数据分析(EDA) — 模型还没有开始。EDA 是你分析原始数据的阶段。你的目标是探索数据并评估数据的质量、缺失值、特征分布、相关性等。
-
数据准备 — 现在是时候准备数据以进行模型训练了。这包括将数据划分为训练集和测试集、填补缺失值、进行独热编码、目标编码、特征工程、特征选择等。
-
模型训练与选择 — 这是每个人都期待的步骤。这包括训练一组模型、调整超参数、模型集成、评估性能指标、模型分析(如 AUC、混淆矩阵、残差等),最后选择一个最佳模型进行生产部署以供业务使用。
-
部署与监控 — 这是最后一步,主要涉及 MLOps。这包括将最终模型打包、创建 Docker 镜像、编写评分脚本,然后使它们协同工作,最后将其发布为 API,以便用于对通过管道传入的新数据进行预测。
传统的做法相当繁琐、耗时,并且需要大量的技术知识,可能在一个教程中无法涵盖。不过,在本教程中,我将使用 PyCaret 来演示数据科学家如何高效地完成这些任务。在我们进入实际操作之前,让我们多谈谈 MLOps。
???? 什么是 MLOps?
MLOps 是一种工程学科,旨在将机器学习开发(即实验(模型训练、超参数调整、模型集成、模型选择等),通常由数据科学家执行)与机器学习工程和运维结合起来,以标准化和简化机器学习模型在生产中的持续交付。
如果你是一个完全的初学者,你可能对我说的内容一无所知。没关系。让我给你一个简单、非技术性的定义:
MLOps 是一系列技术工程和运维任务,使你的机器学习模型可以被组织内的其他用户和应用程序使用。基本上,这是一种将你的工作(即机器学习模型)在线发布的方式,以便其他人可以使用它们并实现一些业务目标。
这是对 MLOps 的一个非常简化的定义。实际上,它涉及的工作和好处比这要多一些,但如果你对这些内容还不熟悉,这个定义是一个很好的开始。
现在,让我们按照上图所示的相同工作流程进行实际演示,确保你已经安装了 pycaret。
???? 商业问题
对于本教程,我将使用达顿商学院发布的一个非常受欢迎的案例研究,已发表在Harvard Business上。该案例讲述了两个将来要结婚的人的故事。一个名叫Greg的男子想买一个戒指向名叫Sarah的女孩求婚。问题是要找出 Sarah 会喜欢的戒指,但在得到好友的建议后,Greg 决定购买一颗钻石,让 Sarah 可以自己决定。Greg 随后收集了 6000 颗钻石的数据,包括它们的价格和属性,如切工、颜色、形状等。
???? 数据
在本教程中,我将使用一个非常受欢迎的案例数据集,该数据集由达顿商学院发布,已发表在Harvard Business上。本教程的目标是根据钻石的属性(如克拉重量、切工、颜色等)预测钻石价格。你可以从PyCaret’s repository下载数据集。
**# load the dataset from pycaret** from pycaret.datasets import get_data
data = get_data('diamond')
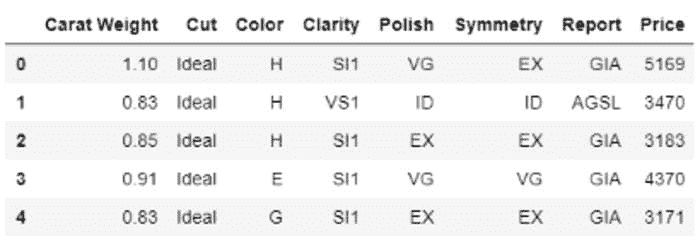
数据的样本行
???? 探索性数据分析
我们来做一些快速可视化,以评估独立特征(重量、切工、颜色、清晰度等)与目标变量即Price之间的关系。
**# plot scatter carat_weight and Price**
import plotly.express as px
fig = px.scatter(x=data['Carat Weight'], y=data['Price'],
facet_col = data['Cut'], opacity = 0.25, template = 'plotly_dark', trendline='ols',
trendline_color_override = 'red', title = 'SARAH GETS A DIAMOND - A CASE STUDY')
fig.show()
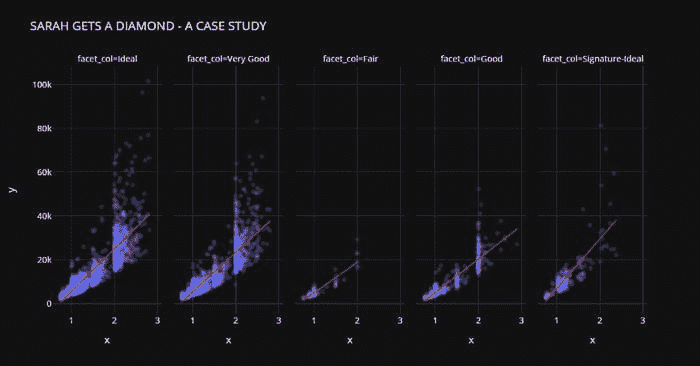
Sarah 获得一个钻石案例研究
让我们检查一下目标变量的分布情况。
**# plot histogram**
fig = px.histogram(data, x=["Price"], template = 'plotly_dark', title = 'Histogram of Price')
fig.show()
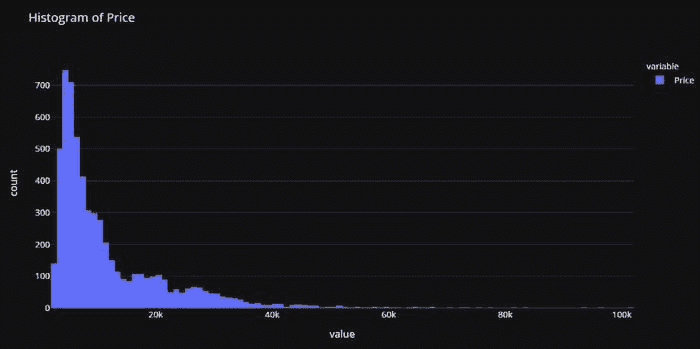
注意到 Price 的分布是右偏的,我们可以快速检查对数变换是否能使 Price 大致符合正态分布,从而给假设正态性的算法一个公平的机会。
import numpy as np**# create a copy of data**
data_copy = data.copy()**# create a new feature Log_Price**
data_copy['Log_Price'] = np.log(data['Price'])**# plot histogram**
fig = px.histogram(data_copy, x=["Log_Price"], title = 'Histgram of Log Price', template = 'plotly_dark')
fig.show()
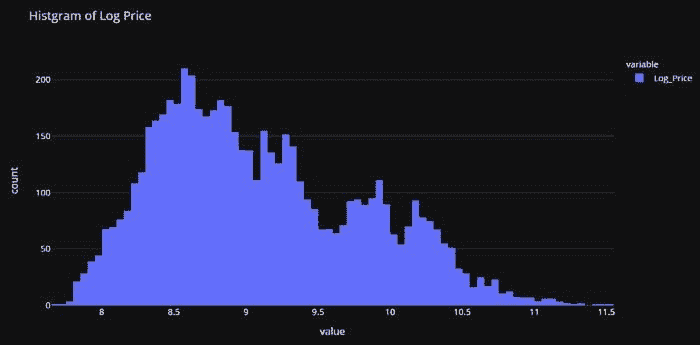
这证实了我们的假设。变换将有助于消除偏斜,使目标变量大致符合正态分布。基于此,我们将在训练模型之前对 Price 变量进行变换。
???? 数据准备
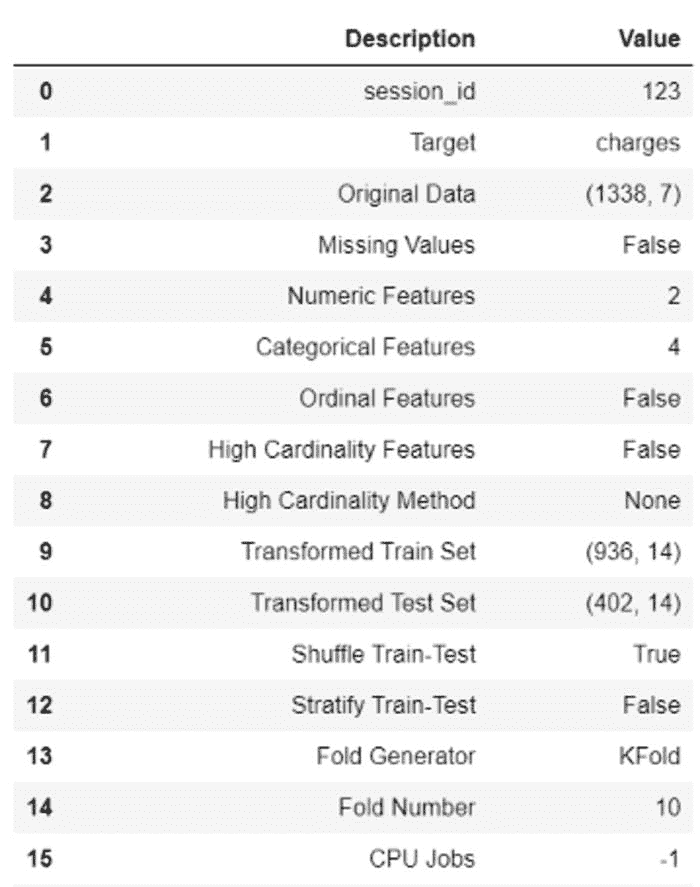
在 PyCaret 的所有模块中,setup 是任何机器学习实验中第一个也是唯一的必需步骤。这个函数处理所有训练模型之前所需的数据准备工作。除了执行一些基本的默认处理任务外,PyCaret 还提供了各种预处理功能。要了解 PyCaret 中所有预处理功能的更多信息,你可以查看这个链接。
**# initialize setup**
from pycaret.regression import *
s = setup(data, target = 'Price', transform_target = True, log_experiment = True, experiment_name = 'diamond')
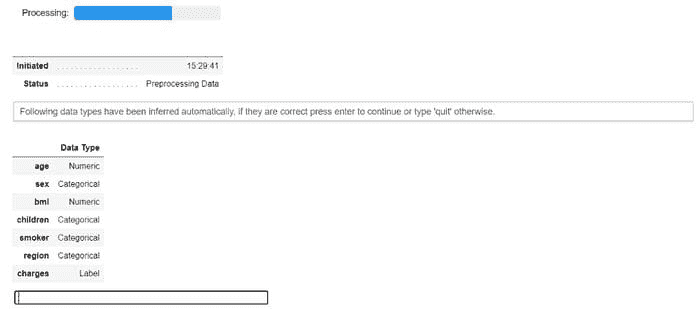
pycaret.regression 模块中的 setup 函数
当你在 PyCaret 中初始化 setup 函数时,它会对数据集进行分析,并推断所有输入特征的数据类型。如果所有数据类型都正确推断,你可以按回车继续。
注意:
-
我已传递了
log_experiment = True和experiment_name = 'diamond',这将告诉 PyCaret 在建模阶段自动记录所有的指标、超参数和模型工件。这是通过与MLflow的集成实现的。 -
我还在
setup中使用了transform_target = True。PyCaret 会在后台使用 box-cox 变换来转换Price变量。它影响数据分布的方式类似于对数变换(技术上不同)。如果你想了解更多关于 box-cox 变换的信息,可以参考这个链接。
从设置中输出 — 为了展示而截断
???? 模型训练与选择
现在数据已准备好进行建模,让我们通过使用compare_models函数开始训练过程。它将训练模型库中的所有算法,并使用 k 折交叉验证评估多个性能指标。
**# compare all models**
best = compare_models()
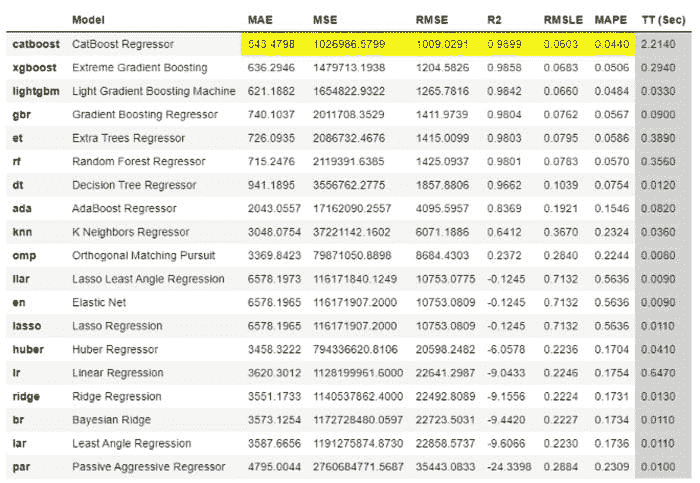
从compare_models的输出
**# check the residuals of trained model**
plot_model(best, plot = 'residuals_interactive')
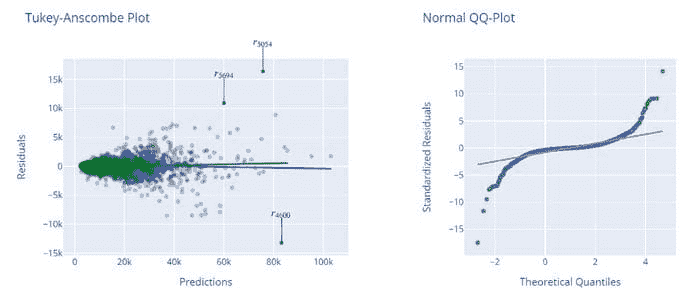
最佳模型的残差和 QQ 图
**# check feature importance**
plot_model(best, plot = 'feature')
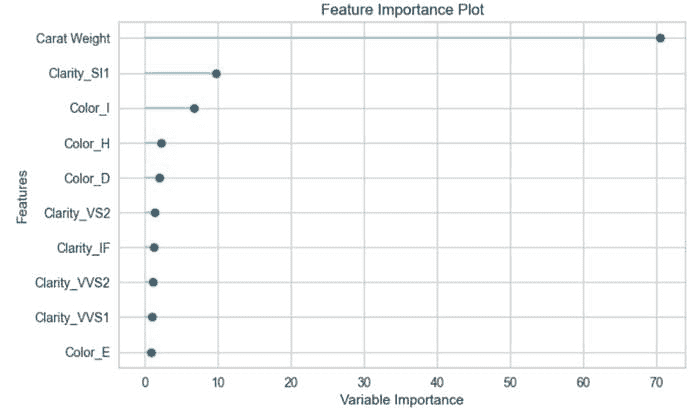
确定并保存 Pipeline
现在我们来确定最佳模型,即在整个数据集(包括测试集)上训练最佳模型,然后将 Pipeline 保存为 pickle 文件。
**# finalize the model**
final_best = finalize_model(best)**# save model to disk** save_model(final_best, 'diamond-pipeline')
save_model函数会将整个 Pipeline(包括模型)保存为本地磁盘上的 pickle 文件。默认情况下,它会将文件保存到你的 Notebook 或脚本所在的文件夹中,但如果你愿意,也可以传递完整路径:
save_model(final_best, 'c:/users/moez/models/diamond-pipeline'
???? 部署
记得我们在 setup 函数中传递了log_experiment = True和experiment_name = 'diamond'。让我们看看 PyCaret 在后台借助 MLflow 完成的神奇操作。要查看这些神奇操作,我们来启动 MLflow 服务器:
**# within notebook (notice ! sign infront)** !mlflow ui**# on command line in the same folder** mlflow ui
现在打开你的浏览器并输入“localhost:5000”。它将打开一个像这样的用户界面:
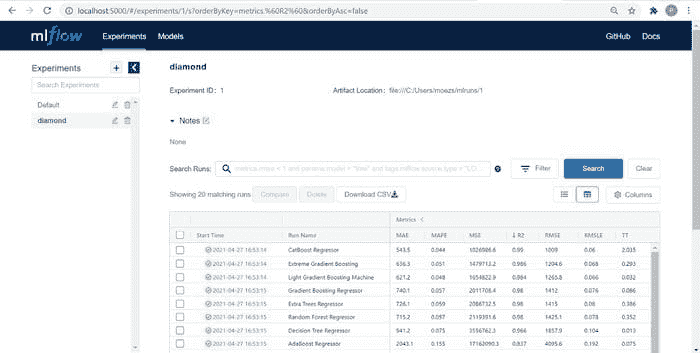
上表中的每一项代表一次训练运行,结果为一个训练好的 Pipeline 以及一堆元数据,如运行的日期时间、性能指标、模型超参数、标签等。让我们点击其中一个模型:
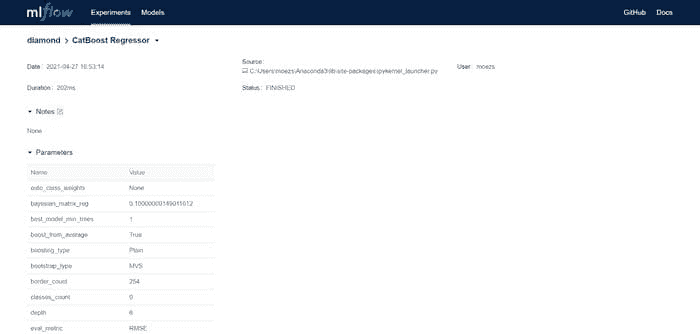
第一部分 — CatBoost 回归器
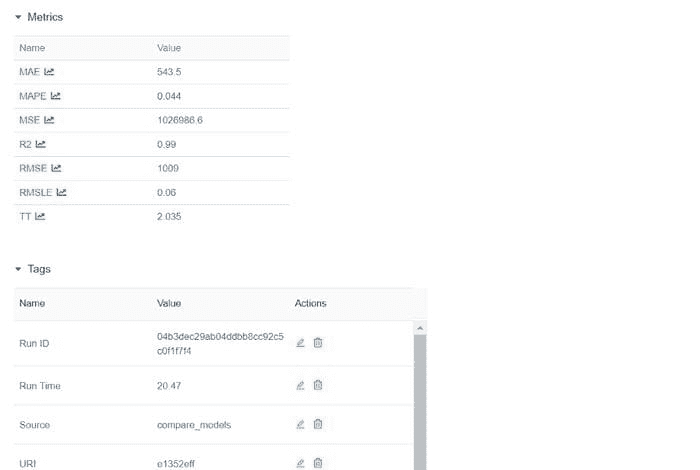
第二部分 — CatBoost 回归器(续)
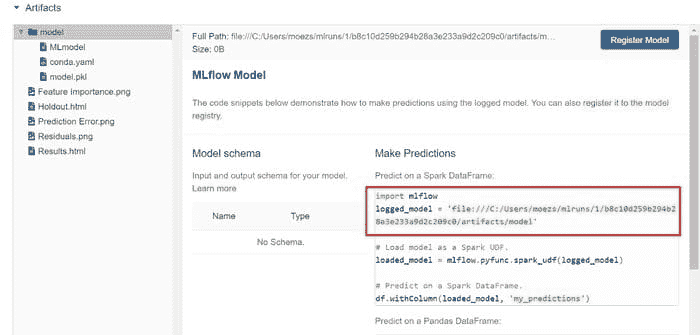
第二部分 — CatBoost 回归器(续)
注意你有一个logged_model的地址路径。这是使用 Catboost 回归器训练的 Pipeline。你可以使用load_model函数来读取这个 Pipeline。
**# load model**
from pycaret.regression import load_model
pipeline = load_model('C:/Users/moezs/mlruns/1/b8c10d259b294b28a3e233a9d2c209c0/artifacts/model/model')**# print pipeline** print(pipeline)

从print(pipeline)的输出
现在我们使用这个 Pipeline 来生成新数据的预测
**# create a copy of data and drop Price** data2 = data.copy()
data2.drop('Price', axis=1, inplace=True)**# generate predictions** from pycaret.regression import predict_model
predictions = predict_model(pipeline, data=data2)
predictions.head()
从管道生成的预测
哇!我们现在可以从训练好的管道中获取推断结果了。恭喜,如果这是你的第一次。注意到所有的转换,如目标转换、独热编码、缺失值填补等,都是在后台自动完成的。你得到一个实际规模的预测数据框,这正是你关心的。
敬请期待!
我今天展示的只是众多可以使用 MLflow 从 PyCaret 提供的训练管道中服务的方式之一。在下一个教程中,我计划展示如何使用 MLflow 的本地服务功能来注册你的模型、为其版本并作为 API 提供服务。
使用这个轻量级的 Python 工作流自动化库,你可以实现无限可能。如果你觉得这很有用,请不要忘记在我们的 GitHub 仓库上给我们⭐️。
想了解更多关于 PyCaret 的信息,请关注我们的 LinkedIn 和 Youtube。
加入我们的 Slack 频道。邀请链接 这里。
你可能也会感兴趣:
使用 PyCaret 2.0 在 Power BI 中构建你自己的 AutoML
在 Google Kubernetes Engine 上部署机器学习管道
使用 AWS Fargate 无服务器架构部署 PyCaret 和 Streamlit 应用
使用 PyCaret 和 Streamlit 构建并部署机器学习网页应用
在 GKE 上部署使用 Streamlit 和 PyCaret 构建的机器学习应用
重要链接
安装 PyCaret Notebook 教程 贡献于 PyCaret
想了解某个特定模块吗?
点击下面的链接查看文档和实际示例。
个人简介: Moez Ali 是数据科学家,同时也是 PyCaret 的创始人和作者。
原文。经授权转载。
相关:
-
PyCaret 的多时间序列预测
-
将机器学习管道部署到云端使用 Docker 容器
-
GitHub 是你需要的最佳 AutoML
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关主题
简单、一键式 Jupyter 笔记本
原文:
www.kdnuggets.com/2019/07/easy-one-click-jupyter-notebooks.html
 评论
评论 社会对数据科学家的印象
社会对数据科学家的印象
数据科学可以是一件有趣的事情!
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
实际上,我们做的大部分工作就是在探索数据,同时试图提取其中隐藏的信息。这就像我们在未知的丛林中寻找宝藏!
但这并不总是轻松有趣的。
在幕后,为数据科学家工作的平台设置涉及许多内容。创建服务器、安装必要的软件和环境、设置安全协议等等。
完成所有这些工作通常需要一位专门的 DevOps 工程师。他需要了解云服务、操作系统、网络的各个细节,并且对设置数据科学和机器学习软件有一定的了解。
但如果有一种方法可以绕过所有这些繁琐的 DevOps 工作,直接进入数据科学呢?
一项名为Saturn Cloud的新服务可以让数据科学家实现这一点:跳过繁琐的设置,直接进入数据科学的工作!
Saturn Cloud 和数据科学的 DevOps
花点时间想想为数据科学家有效工作而设置环境所需的所有工作。对于许多公司,这看起来像是:
-
创建和配置服务器。理想情况下,这些服务器应该在服务器性能和实例数量上都能轻松扩展。
-
在所有服务器上安装软件。软件应该易于更新。
-
配置安全性。保护任何敏感数据、代码或机器学习模型
-
配置网络。服务器应在特定端口和特定人员的访问下可用。
所有这些都需要大量时间,尤其是第 1 步和第 2 步。许多数据科学家甚至看不到这些过程的发生——他们只看到最终产品。但建立所有这些基础设施确实是一项挑战,其中一些需要持续更新。
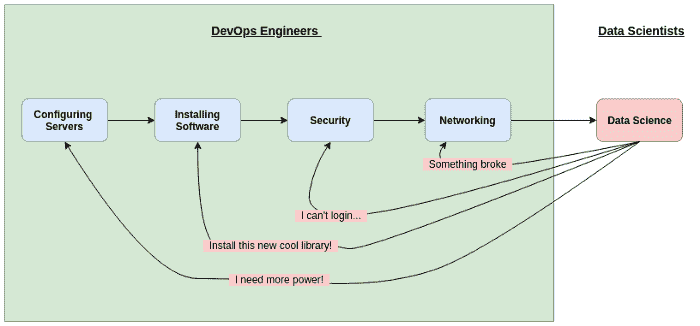 DevOps 工程师不断迎合数据科学家不断变化的需求
DevOps 工程师不断迎合数据科学家不断变化的需求
Saturn Cloud 自称为云托管数据科学,允许数据科学家轻松地在云上配置和托管他们的工作,而无需专门的 DevOps。然后你可以在由系统创建并托管在你指定的服务器上的 Jupyter Notebook 中工作。
软件、网络、安全和库的所有设置都由 Saturn Cloud 系统自动处理。数据科学家可以专注于实际的数据科学,而不是繁琐的基础设施工作。
这个想法是,用户(你和我,数据科学家)可以简单地指定我们需要的计算资源,输入我们需要的软件库列表,而 Saturn Cloud 系统将处理其余的设置。
如何使用托管的 Jupyter Notebooks
要开始,简单地访问Saturn Cloud 网站并创建一个帐户。基本计划完全免费,你可以先在环境中玩耍以熟悉操作。
进入后,点击“Your Dashboard”标签页开始创建一个托管 Jupyter Notebook 的服务器。下面的视频展示了如何创建你的服务器!
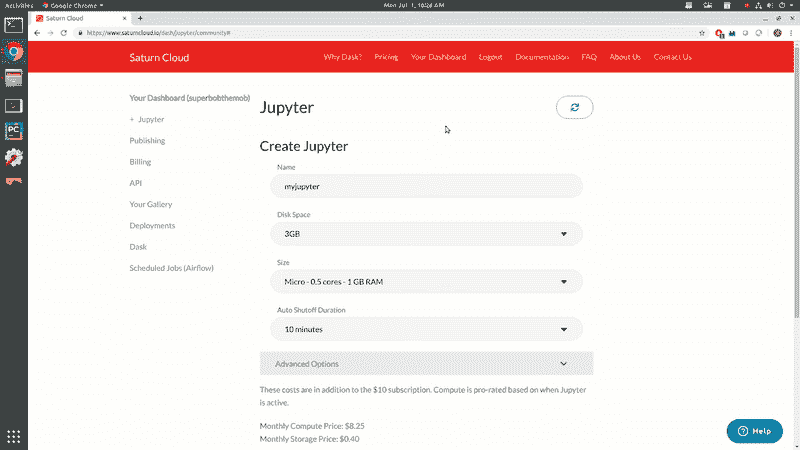
你基本上需要经过以下步骤:
-
为你的 notebook 指定一个名称
-
指定你想要的存储量
-
指定你想使用的 CPU 或 GPU
-
如果需要,设置自动关机
-
列出你希望在系统上安装的任何软件包或库
一旦你点击创建按钮,你的服务器将自动根据所需的设置和软件创建。当创建完成后——瞧!你的云托管 Jupyter Notebook 已准备好进行数据科学工作!
在仪表板顶部,你会看到启动、停止、编辑和删除你的 Notebook 云服务器的按钮。在本教程的下一部分,我已经编辑了我的服务器以安装 pandas 和 matplotlib。
要访问你的云托管 Jupyter Notebook,请点击“Go To Jupyter Notebook”链接。将打开一个包含 Jupyter Notebook 界面的标签页,你可以在其中创建你的 Python 3 notebook!
我已经在下面的视频中创建了我的 notebook。一旦你的 notebook 创建完成,你就可以开始编码了!我已经准备了一些代码来绘制 Iris 花卉数据集。Saturn Cloud 能够顺利无缝地运行所有内容。

除了托管 Jupyter Notebooks,Saturn Cloud 还允许你publish your notebooks,可以选择公开或私密。当你发布笔记本时,你将获得一个网址,可以与任何想要运行你笔记本的人分享:随时随地。看看我的这个吧!
喜欢学习吗?
在twitter上关注我,我会发布最新最好的 AI、技术和科学信息!也可以在LinkedIn与我联系!
简介: George Seif 是认证极客以及 AI / 机器学习工程师。
原文。经许可转载。
相关:
-
数据科学家的 DevOps:驯服独角兽
-
操作性机器学习:成功 MLOps 的七个考虑因素
-
将机器学习应用于 DevOps
更多相关主题
使用 Python 进行简单的语音转文本
评论
作者:Dhilip Subramanian,数据科学家和 AI 爱好者

来源:信息时代
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
语音是最常见的交流方式,世界上大多数人依赖语音进行沟通。语音识别系统基本上将口语语言翻译成文本。现实生活中有许多语音识别系统的例子。例如,苹果的 SIRI 能够识别语音并将其转换为文本。
语音识别是如何工作的?
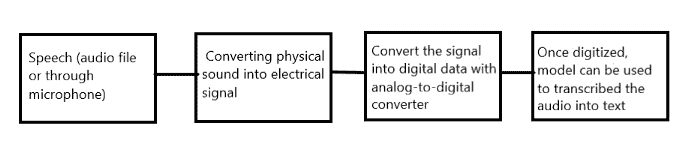
语音识别过程
隐马尔可夫模型(HMM)和深度神经网络模型用于将音频转换为文本。详细的过程超出了本博客的范围。在本博客中,我展示了如何使用 Python 将语音转换为文本。这可以通过“Speech Recognition” API 和 “PyAudio” 库来完成。
语音识别 API 支持多个 API,在本博客中我使用了谷歌语音识别 API。更多详情,请查看这里。它有助于将语音转换为文本。
Python 库
!pip install SpeechRecognition
将音频文件转换为文本
步骤:
-
导入语音识别库
-
初始化识别器类以识别语音。我们正在使用谷歌语音识别。
-
语音识别支持的音频文件格式:wav, AIFF, AIFF-C, FLAC。在这个例子中我使用了‘wav’文件
-
我使用了《特工绍特》电影音频片段,内容为“我不知道你是谁,我不知道你想要什么。如果你在寻找赎金,我可以告诉你,我没有钱”
-
默认情况下,谷歌识别器读取英语。它支持不同的语言,更多细节请查看文档。
代码
#import library
import speech_recognition as sr
# Initialize recognizer class (for recognizing the speech)
r = sr.Recognizer()
# Reading Audio file as source
# listening the audio file and store in audio_text variable
with sr.AudioFile('I-dont-know.wav') as source:
audio_text = r.listen(source)
# recoginize_() method will throw a request error if the API is unreachable, hence using exception handling
try:
# using google speech recognition
text = r.recognize_google(audio_text)
print('Converting audio transcripts into text ...')
print(text)
except:
print('Sorry.. run again...')
输出
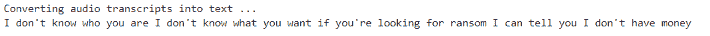
那么如何转换不同的音频语言呢?
例如,如果我们要读取法语音频文件,则需要在 recogonize_google 中添加语言选项。其余代码保持不变。请参阅更多文档
#Adding french langauge option
text = r.recognize_google(audio_text, language = "fr-FR")
输出

麦克风语音转文本
步骤:
- 我们需要安装 PyAudio 库,它用于通过麦克风和扬声器接收音频输入和输出。基本上,它帮助我们通过麦克风获取声音。
!pip install PyAudio
- 我们需要使用 Microphone 类,而不是音频文件源。其余步骤相同。
代码
#import library
import speech_recognition as sr
# Initialize recognizer class (for recognizing the speech)
r = sr.Recognizer()
# Reading Microphone as source
# listening the speech and store in audio_text variable
with sr.Microphone() as source:
print("Talk")
audio_text = r.listen(source)
print("Time over, thanks")
# recoginize_() method will throw a request error if the API is unreachable, hence using exception handling
try:
# using google speech recognition
print("Text: "+r.recognize_google(audio_text))
except:
print("Sorry, I did not get that")
我刚刚说了“你好吗?”
输出

试试说其他语言怎么样?
再次,我们需要在 recognize_google()中添加所需的语言选项。我用泰米尔语(印度语言)说话,并在语言选项中添加“ta-IN”。
# Adding "tamil language"
print(“Text: “+r.recognize_google(audio_text, language = “ta-IN”))
我刚刚用泰米尔语说了“你好吗”,它准确地打印了泰米尔语文本。
输出

注意:
Google 语音识别 API 是一种将语音转换为文本的简单方法,但它需要互联网连接才能操作。
在这篇博客中,我们看到如何使用 Google 语音识别 API 将语音转换为文本。这对于 NLP 项目尤其是处理音频转录数据非常有帮助。如果你有任何补充,请随时留言!
感谢阅读。继续学习,敬请关注更多内容!
个人简介: Dhilip Subramanian 是一名机械工程师,并完成了分析学硕士学位。他在数据相关的多个领域,包括 IT、市场营销、银行、电力和制造业,拥有 9 年的专业经验。他对自然语言处理和机器学习充满热情。他是SAS 社区的贡献者,并喜欢在 Medium 平台上撰写关于数据科学各个方面的技术文章。
原文。已获得许可转载。
相关:
-
使用 Python 轻松进行语音合成
-
数据科学的五个酷炫 Python 库
-
Docker: 数据科学家的容器化
更多相关内容
如何用原生 Python 编写 SQL

技术矢量图由 freepik 创建 - www.freepik.com
你经常编写 SQL 吗?你是否经常从 Python 中调用这些 SQL?能够通过 Python 链接 SQL 数据库并定义、操作和查询它们的想法是否吸引你?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
SQLModel 是一个用于在纯 Python 中与 SQL 数据库交互的 Python 库。它的设计动机包括直观性、易用性、兼容性和健壮性。SQLModel 使用 Python 的 类型注解,由 Pydantic 强制和管理,以及 SQLAlchemy,即“Python SQL 工具包和对象关系映射器”,用于其 SQL 交互。
这个库是由 Sebastián Ramírez,即 FastAPI 的作者编写的,这两个库设计上无缝协作。
SQLModel 的关键特性,直接取自项目的 GitHub 仓库,包含:
- 编写直观:编辑器支持优秀。处处有自动完成。减少调试时间。设计上易于使用和学习。减少阅读文档的时间。
- 易于使用:它具有合理的默认值,并且在底层做了大量工作,以简化你编写的代码。
- 兼容:设计上与 FastAPI、Pydantic 和 SQLAlchemy 兼容。
- 可扩展:你拥有 SQLAlchemy 和 Pydantic 所提供的所有强大功能。
- 简短:最小化代码重复。一个类型注解可以完成大量工作。不需要在 SQLAlchemy 和 Pydantic 中重复模型。
让我们快速看看 SQLModel 是如何工作的。
创建 SQLModel 模型(SQL 表)
想要使用 SQLModel 创建一个表格吗?
这是一个简单的 示例,来自库的 GitHub 仓库中的代码片段。
from typing import Optional
from sqlmodel import Field, SQLModel
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
在上述代码中,Hero 类是一个 SQLModel 对象。SQLModel 对象等同于 SQLModel 库中的 SQL 表。类属性,如 id 和 name,是表中的列。
创建行(表实例)
想要在表中创建一行,也就是一个数据实例?
这是一个来自库的 GitHub 仓库的示例,演示了如何操作。请注意,每一行都是上面定义模型的一个实例。
hero_1 = Hero(name="Deadpond", secret_name="Dive Wilson")
hero_2 = Hero(name="Spider-Boy", secret_name="Pedro Parqueador")
hero_3 = Hero(name="Rusty-Man", secret_name="Tommy Sharp", age=48)
请注意,仅使用了传统的 Python 代码来创建表并逐行输入数据,无需 SQL 代码作为 Python 对象和后端 SQL 数据库之间的中介。
写入 SQL 数据库
请注意,目前尚未将任何表或数据写入现有数据库,可以按如下方式实现。以下完整代码示例基于上述代码。
from typing import Optional
from sqlmodel import Field, Session, SQLModel, create_engine
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
hero_1 = Hero(name="Deadpond", secret_name="Dive Wilson")
hero_2 = Hero(name="Spider-Boy", secret_name="Pedro Parqueador")
hero_3 = Hero(name="Rusty-Man", secret_name="Tommy Sharp", age=48)
engine = create_engine("sqlite:///database.db")
SQLModel.metadata.create_all(engine)
with Session(engine) as session:
session.add(hero_1)
session.add(hero_2)
session.add(hero_3)
session.commit()
上述代码将把一个新表写入现有数据库,并添加 3 个“英雄”条目。
当然,SQLModel 还可以做很多其他事情。有关库可以实现的所有内容及其实现方法,请查看完整文档。
马修·梅奥 (@mattmayo13) 是数据科学家以及 KDnuggets 的主编,这是一个开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。马修拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系到。
更多相关主题
使用 Faker 在 Python 中生成简单的合成数据
原文:
www.kdnuggets.com/2021/11/easy-synthetic-data-python-faker.html
评论
真实的数据,来自真实世界,是数据科学的黄金标准,这一点可能很明显。当然,诀窍在于能够找到所需的真实世界数据。有时候,你会很幸运地发现所需的数据触手可及,格式符合要求,而且数量正好。
我们的三大推荐课程
1. Google 网络安全证书 - 快速开启网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
然而,现实世界的数据通常不足以满足项目需求。在这种情况下,可以使用合成数据代替真实数据或用来增强不足够大的数据集。人工制造数据的方法有很多,其中一些远比其他方法复杂。然而,也有一些相对简单的选项,例如,Faker 就是 Python 中的一个解决方案。
来自 Faker 的文档:
Faker 是一个生成假数据的 Python 包。无论你是需要为数据库进行引导,创建美观的 XML 文档,填充你的持久化存储以进行压力测试,还是匿名化从生产服务中获得的数据,Faker 都能满足你的需求。
可以使用 pip 安装 Faker:
pip install faker
导入并实例化一个 Faker 实例的方式如下:
from faker import Faker
fake = Faker()
Faker 的基本使用
Faker 的使用非常简单。让我们先看几个示例。
对于我们的第一个技巧,让我们生成一个假名字。
print(fake.name())
Deborah Brooks
其他数据类型怎么样?
# generate an address
print(fake.address())
# generate a phone number
print(fake.phone_number())
# generate a date
print(fake.date())
# generate a social security number
print(fake.ssn())
# generate some text
print(fake.text())
123 Danielle Forges Suite 506
Stevenborough, RI 36008
968-491-2711
1974-05-27
651-27-9994
Weight where while method. Rock final environmental gas provide. Remember continue sure. Create resource determine fine. Else red across participant. People must interesting spend some us.
Faker 优化
如果你对特定地区的数据感兴趣呢?例如,如果我想生成一种在墨西哥会出现的西班牙名字怎么办?
fake = Faker(['es_MX'])
for i in range(10):
print(fake.name())
Diana Lovato
Ing. Ariadna Palacios
Salvador de la Fuente
Margarita Naranjo
Alvaro Prado Melgar
Tomás Menchaca
Conchita Francisca Velázquez Zedillo
Ivonne Ana Luisa Bueno
Ramiro Raquel Vélez Urbina
Porfirio Esther Irizarry Varela
生成的输出可以通过使用 Faker 的权重设置进一步优化:
Faker 构造函数接受一个与性能相关的参数叫做
use_weighting。它指定是否尝试使值的频率匹配真实世界的频率(例如,英文名字 Gary 的出现频率会远高于名字 Lorimer)。如果use_weighting为False,则所有项目被选择的机会相等,选择过程也更快。默认值是True。
让我们看看一些美国英语的示例是如何工作的:
fake = Faker(['en_US'], use_weighting=True)
for i in range(20):
print(fake.name())
Mary Mckinney
Margaret Small
Dominic Carter
Elizabeth Gibson
Kelsey Garcia
Chelsea Bradford
Robert West
Timothy Howe
Gary Turner
Cynthia Strong
Joshua Henry
Amanda Jenkins
Jacqueline Daniels
Catherine Jones
Desiree Hodge
Shannon Mason DVM
Marcia West
Dustin Parrish
Christopher Rodriguez
Brett Webb
将此与未使用加权的类似输出进行比较:
fake = Faker(['en_US'], use_weighting=False)
for i in range(20):
print(fake.name())
Mr. Benjamin Horton
Miss Maria Hardin
Tina Good DDS
Dr. Terry Barr MD
Meredith Mason
Roberta Velasquez
Mr. Tim Woods V
Marilyn Conway
Mr. Dwayne Leblanc III
Dr. Dan Krause IV
Mia Newman DVM
Thomas Small
Joseph Holmes
Dr. Tanner Zhang
Alan Dixon
Miss Rebecca Davila DVM
Joseph Becker MD
Dr. Erin Pugh PhD
Mr. Ernest Juarez
Ross Thompson
注意,例如,在生成的“样本”中,医生的数量不成比例。
更全面的示例
假设我们要为一家国际公司生成一些虚假的客户数据记录,我们希望模拟现实世界中名字的分布,并将这些数据保存到 CSV 文件中,以便后续在某种数据科学任务中使用。为了清理数据,我们还将把生成的地址中的换行符替换为逗号,并完全移除生成文本中的换行符。
这是一个代码片段,可以实现这一点,展示了 Faker 在几行代码中的强大功能。
from faker import Faker
import pandas as pd
fake = Faker(['en_US', 'en_UK', 'it_IT', 'de_DE', 'fr_FR'], use_weighting=True)
customers = {}
for i in range(0, 10000):
customers[i]={}
customers[i]['id'] = i+1
customers[i]['name'] = fake.name()
customers[i]['address'] = fake.address().replace('\n', ', ')
customers[i]['phone_number'] = fake.phone_number()
customers[i]['dob'] = fake.date()
customers[i]['note'] = fake.text().replace('\n', ' ')
df = pd.DataFrame(customers).T
print(df)
df.to_csv('customer_data.csv', index=False)
id name ... dob note
0 1 Burkhardt Junck ... 1982-08-11 Across important glass stop. Score include rel...
1 2 Ilja Weihmann ... 1975-03-24 Iusto velit aspernatur nemo. Aliquid ipsum ita...
2 3 Agnolo Tafuri ... 1990-10-03 Aspernatur fugit voluptatibus. Cumque accusant...
3 4 Sig. Lamberto Cutuli ... 1973-01-15 Maiores temporibus beatae. Ipsam non autem ist...
4 5 Marcus Turner ... 2005-12-17 Témoin âge élever loi.\nFatiguer auteur autori...
... ... ... ... ... ...
9995 9996 Miss Alexandra Waters ... 1985-01-20 Commodi omnis assumenda sit ratione non. Commo...
9996 9997 Natasha Harris ... 2003-10-26 Voluptatibus dolore a aspernatur facere. Aliqu...
9997 9998 Adrien Marin ... 1983-05-29 Et unde iure. Reiciendis doloribus dignissimos...
9998 9999 Nermin Heydrich ... 2005-03-29 Plan moitié charge note convenir.\nSang précip...
9999 10000 Samuel Allen ... 2011-09-29 Total gun economy adult as nor. Age late gas p...
[10000 rows x 6 columns]
我们还有一个包含所有数据的 customer_data.csv 文件,供进一步处理和使用。

生成的客户数据 CSV 文件的截图
上面提到的特定类型数据生成器——如姓名、地址、电话等——称为提供者。通过启用 Faker 生成专门类型的数据,学习如何扩展其功能,使用标准提供者和社区提供者。
查看 Faker 的GitHub 仓库和文档,了解更多功能并立即创建你自己的数据集。
相关内容:
-
在 Python 中创建带有异常签名的合成时间序列
-
教 AI 用合成数据分类时间序列模式
-
3 个数据获取、注释和增强工具
更多相关内容
使用 Python 进行简单的文本到语音转换
评论
作者 Dhilip Subramanian,数据科学家和 AI 爱好者

文本到语音 (TTS) 技术可以朗读数字文本。它可以将计算机、智能手机、平板电脑上的文字转换为音频。还可以朗读各种文本文件,包括 Word 文档、页面文档、在线网页。TTS 可以帮助那些在阅读上有困难的孩子。许多工具和应用程序可以将文本转换为语音。
Python 附带了许多方便且易于访问的库,本文将探讨如何使用 Python 实现文本到语音的功能。

来源:www.youtube.com/watch?v=eiP-12qHM-c
Python 中提供了不同的 API 以将文本转换为语音。其中一个 API 是 Google 文字转语音,通常称为 gTTS API。该库非常易于使用,它将输入的文本转换为可以保存为 mp3 文件的音频文件。它支持多种语言,并且语音可以以两种可用的音频速度之一传递,即快或慢。更多详情可在 这里 找到
将文本转换为语音
代码:
导入 gTTS 库和 “os” 模块以播放转换后的音频
from gtts import gTTS
import os
创建要转换为音频的文本
text = “Global warming is the long-term rise in the average temperature of the Earth’s climate system”
gTTS 支持多种语言。请参阅文档 这里。选择了 ‘en’ -> 英语,并存储在语言变量中
language = ‘en’
创建一个名为 speech 的对象,并将文本和语言传递给引擎。标记 slow = False,这告诉模块转换后的音频应具有较高的速度。
speech = gTTS(text = text, lang = language, slow = False)
将转换后的音频保存为名为 ‘text.mp3’ 的 mp3 文件
speech.save(“text.mp3”)
播放转换后的文件,使用 Windows 命令 ‘start’ 后跟 mp3 文件的名称。
os.system(“start text.mp3”)
输出

text.mp3 文件
The output of the above program saved as text.mp3 file. Mp3 file should be a voice saying, 'Global warming is the long-term rise in the average temperature of the Earth’s climate system'
将文本文件转换为语音
在这里,将文本文件转换为语音。读取文本文件并传递给 gTTS 模块
代码
导入 gTTS 和 os 库
from gtts import gTTS
import os
读取文本文件并存储到名为 text 的对象中。我的文件名是 “draft.txt”
file = open("draft.txt", "r").read().replace("\n", " ")
选择语言为英语
language = ‘en’
将文本文件传递给 gTTS 模块并存储到 speech 中
speech = gTTS(text = str(file), lang = language, slow = False)
将转换后的音频保存为名为 ‘voice.mp3’ 的 mp3 文件
speech.save("voice.mp3")
播放 mp3 文件
os.system("start voice.mp3")
输出
将 draft.txt 文件转换为 voice.mp3
Draft.txt file saved as a voice.mp3 file.Play the Mp3 file to listen the text presented in the draft.txt file
注意:
GTTS 是一个简单的文本转语音工具,但它需要互联网连接,因为它完全依赖 Google 来获取音频数据。
感谢阅读。继续学习,敬请关注更多内容!
简介: Dhilip Subramanian 是一位机械工程师,拥有分析学硕士学位。他在 IT、营销、银行、电力和制造等多个数据相关领域拥有 9 年的经验。他对 NLP 和机器学习充满热情。 他是 SAS 社区的贡献者,并且喜欢在 Medium 平台上撰写有关数据科学各个方面的技术文章。
原文。经授权转载。
相关:
-
五款酷炫的 Python 数据科学库
-
Python 中文本挖掘:步骤和示例
-
2019 深度学习语音合成指南
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持组织的 IT 工作
更多相关内容
电子书:使用 R 学习数据科学 – 免费下载
原文:
www.kdnuggets.com/2021/09/ebook-learn-data-science-r.html
comments
由 Narayana Murthy,数据科学家。
我很高兴宣布我的电子书 使用 R 学习数据科学 已发布。它可以作为限时赠书 下载。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT

学习数据科学
数据科学是各种技能的结合。数据科学家需要精通统计学、数学、编程及其他技能。
所以合乎逻辑的问题是,从哪里开始?
统计学
统计学是理解和解释数据的科学。它是数据科学的核心。开始的最佳选择之一是 Pluralsight 的 统计学基础 课程。它涵盖了描述统计学和推断统计学。
编程语言
Python、R 和 Julia 是数据科学项目中流行的编程语言。每种语言都有其独特的优点。Python 是最受欢迎的数据科学语言,而 Julia 是最快的。推荐学习 核心 Python 课程来掌握 Python 语言。
R 语言是初学者、学术人员和领域专家的最佳选择。学习数据科学和像 Python 这样的通用语言同时进行会让人感到不知所措。R 语言作为数据科学语言,更容易掌握。它有良好的社区支持。
机器学习
机器学习是自动构建模型的科学。它是人工智能的一个子集。在掌握统计学和编程之后学习机器学习。书籍 线性代数与数据学习 涵盖了简单和高级的主题。它将线性代数与深度学习和神经网络结合起来进行讲解。
使用 R 学习数据科学 简介
针对特定主题的课程能很好地理解数据科学概念。能够在一个地方学习所有技能将是非常好的。
用 R 学习数据科学 涵盖统计学、基础数学、R 语言、可视化和机器学习算法。内容精准完整,书长达 250 页。
章节包括:
-
入门
-
统计学与 R
-
数学
-
数据整理
-
探索性数据分析
-
机器学习
-
机器学习类型
-
高级监督学习
-
实践项目
-
数据科学的应用案例
-
最终说明
撰写这本书对我来说是一次很棒的经历。该书在 Goodreads 和 LibraryThing 上获得了积极反馈。下载 电子书。希望你喜欢阅读,期待你的反馈。
简介: Narayana Nemani 目前担任首席数据科学家,参与数据科学的教学和研究。
相关:
更多相关内容
开源数据科学/机器学习生态系统的 6 个组成部分;Python 是否宣布击败了 R?
原文:
www.kdnuggets.com/2018/06/ecosystem-data-science-python-victory.html
评论 在 5 月,我们报告了第 19 届 KDnuggets 软件调查的初步结果:Python 蚕食 R:2018 年分析、数据科学、机器学习的顶级软件:趋势与分析。
在这里,我们更详细地查看哪些工具能够很好地配合使用。我们去年确定的开源 Python 友好的数据科学工具新兴生态系统已有新成员 - 见下文。
我们在文章末尾提供了一个匿名数据集的链接 - 请告诉我你在数据中发现了什么,并请发布或通过电子邮件将结果发给我。
首先,我们查看哪些工具是相互配合的,为了使图表易于理解,我们选择了至少有 400 票的工具。共有 11 种这样的工具,这种选择也有意义,因为第 11 名(Apache Spark,有 442 票)与第 12 名(Java,309 票)之间存在较大差距。
有许多方法可以衡量两个二元特征之间关联的显著性,比如卡方检验或 T 检验,但我们使用了与我们的 2016 年分析和 2017 年分析相同的 Lift 度量。
然后,我们将关联最强的工具组合在一起,从 Tensorflow 和 Keras 开始,直到得到下面的图 1。为了减少杂乱,我们还过滤了图表,只显示 abs(Lift1) > 15%的关联。
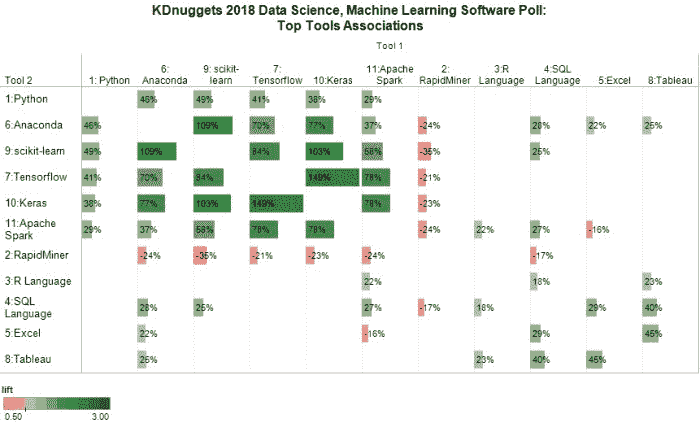
图 1:数据科学、机器学习顶级工具关联,2018 年
条形长度对应于 lift1 的绝对值,颜色表示 lift 值(绿色:关联较强,红色:关联较弱)。工具前面的数字是它们在 KDnuggets 2018 软件调查中的排名,例如 Python 排名第 1,RapidMiner 排名第 2,等等。
我们注意到一组包含 6 种主要工具的现代开源数据科学生态系统,它们是:Python、Anaconda、scikit-learn、Tensorflow、Keras 和 Apache Spark。
Rapidminer 与上述所有工具有小的负相关,也没有与其他工具强烈关联。
R 与 Apache Spark、SQL 和 Tableau 有小的正相关。
另一个出现的组是 3 种支持数据科学和机器学习的工具,它们经常一起使用:SQL、Excel 和 Tableau。
我们注意到,虽然下面的图表相对于对角线是对称的(右上三角形与左下三角形相等),但在完整图表中,比在一半图表中更容易看到模式。
提升度定义:
提升度 (X & Y) = pct (X & Y) / ( pct (X) * pct (Y) )
其中 pct(X) 是选择 X 的用户百分比。
提升度 (X&Y) > 1 表示 X&Y 一起出现的频率高于它们独立时的预期频率,
如果 X 和 Y 的出现频率与它们独立时的预期频率相符,则提升度 = 1,并且
如果 X 和 Y 一起出现的频率低于预期,则提升度 < 1(负相关)
为了更容易观察差异,我们定义
提升度 1 (X & Y) = 提升度 (X & Y) - 1
Python 与 R
接下来我们比较 Python 与 R。
设 with_Py(X) = 使用 Python 的工具 X 的百分比,以及 with_R(X) 为使用 R 的工具 X 的百分比。为了可视化每个工具与 Python 或 R 的接近程度,我们使用了一个非常简单的度量 Bias_Py_R(X) = with_Py(X) - with_R(X),如果工具更常与 Python 一起使用则为正值,如果更常与 R 一起使用则为负值。
在图 2 中,我们绘制了最受欢迎的工具的偏见,这些工具至少获得了 100 票。正如我们所见,几乎所有工具都偏向于 Python。唯一的两个例外是 IBM SPSS Statistics 和 SAS Base。作为对比,在类似的 2017 年分析中,有 10 个这样的工具:SAS Base、Microsoft 工具、Weka、RapidMiner、Tableau 和 Knime,几乎所有这些工具的使用量都与 Python 一起增加。
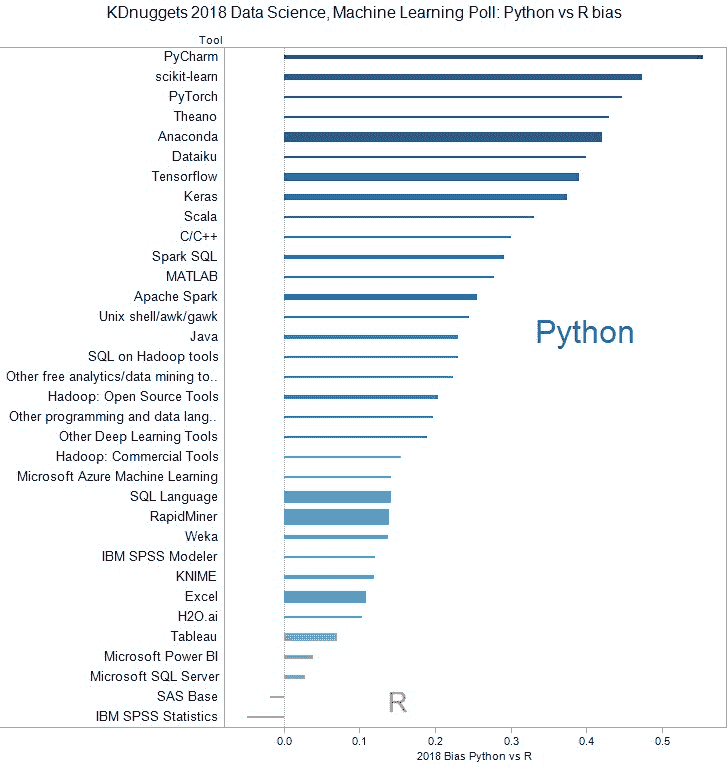 图 2:KDnuggets 2018 数据科学、机器学习投票:Python 与 R 的偏见
图 2:KDnuggets 2018 数据科学、机器学习投票:Python 与 R 的偏见
Python 是否战胜了 R?
我认为不是这样,因为 R 是一个极其优秀的平台,具有巨大的深度和广度,广泛用于数据分析和可视化,它仍然占有约 50% 的市场份额。我预计 R 会被许多数据科学家使用很长时间,但未来,我期待 Python 生态系统会有更多的发展和活力。
大数据与深度学习
大数据(Spark / Hadoop 工具)在 KDnuggets 2018 软件投票中被 33% 的受访者使用,这与 2017 年的比例完全相同。这表明,大多数数据科学家处理的是中小数据,不需要 Hadoop / Spark,或者他们使用的是其他云端解决方案。
然而,深度学习工具的比例从 32% 增长到了 43%。
对于每个工具 X,我们计算它与 Spark/Hadoop 工具的使用频率(纵轴),以及它与深度学习工具的使用频率(横轴)。
这是一个显示了顶级工具的图表(获得超过 100 票),排除了深度学习和大数据工具本身。
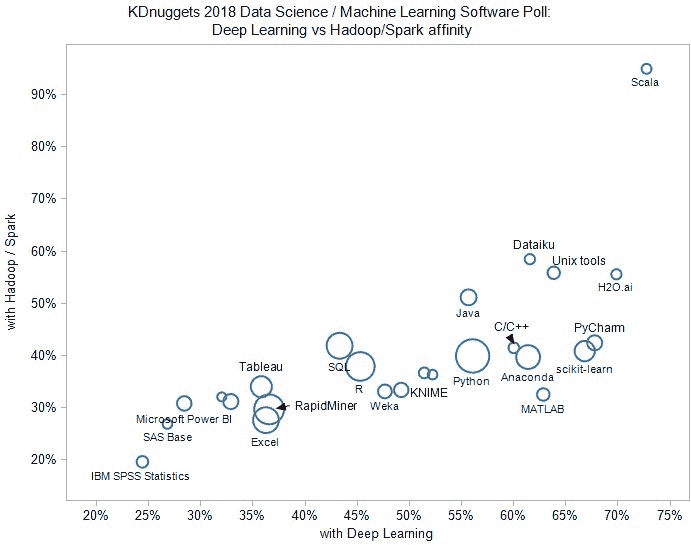 图 3:KDnuggets 2018 数据科学、机器学习投票:深度学习与 Spark/Hadoop 亲和度
图 3:KDnuggets 2018 数据科学、机器学习投票:深度学习与 Spark/Hadoop 亲和度
我们注意到 Scala 是在深度学习和大数据中最常用的语言。图表在左下角较重,几乎每个工具在深度学习中的使用频率都高于在大数据中的使用频率。
这是匿名调查数据的 CSV 格式链接,包含以下列
-
Nrand: 记录 ID(随机化,记录顺序与投票顺序无关)
-
region: usca: 美国/加拿大,euro: 欧洲,asia: 亚洲,ltam: 拉丁美洲,afme: 非洲/中东,aunz: 澳大利亚/新西兰
-
Python: 如果 Votes(最后一列)中包含 Python,则为 1,否则为 0。
-
RapidMiner: 如果 Votes 中包含 RapidMiner,则为 1,否则为 0。
-
R language: 如果 Votes 中包含“R Language”,则为 1,否则为 0。我们使用“R Language”而不是 R,以便更容易进行正则表达式匹配。
-
SQL Language: 如果 Votes 中包含“SQL Language”,则为 1,否则为 0。
-
Excel: 如果 Votes 中包含 Excel,则为 1,否则为 0。
-
Anaconda: 如果 Votes 中包含 Anaconda,则为 1,否则为 0。
-
Tensorflow: 如果 Votes 中包含 Tensorflow,则为 1,否则为 0。
-
Tableau: 如果 Votes 中包含 Tableau,则为 1,否则为 0。
-
scikit-learn: 如果 Votes 中包含 scikit-learn,则为 1,否则为 0。
-
Keras: 如果 Votes 中包含 KNIME,则为 1,否则为 0。
-
Apache Spark: 如果 Votes 中包含 Apache Spark,则为 1,否则为 0。
-
With DL: 如果 Votes 中包含深度学习工具,则为 1,否则为 0。
-
With BD: 如果 Votes 中包含大数据工具,则为 1,否则为 0。
-
ntools: Votes 中的工具数量
-
Votes: 投票列表,用分号“;”分隔
请告诉我你的发现!
相关:
-
Python 蚕食 R:2018 年分析、数据科学、机器学习的顶级软件:趋势与分析。
-
新兴生态系统:数据科学和机器学习软件分析,2017 年
-
分析、数据科学、机器学习软件的最新领导者、趋势和惊喜调查,2017 年
更多相关内容
EDISON 数据科学框架用于定义数据科学职业
原文:
www.kdnuggets.com/2016/10/edison-data-science-framework.html
作者:Yuri Demchenko,阿姆斯特丹大学,荷兰
摘要
数据科学技术的有效使用需要新的能力和技能,并要求新的职业来支持研究数据生命周期的所有阶段,从数据生产和输入到数据处理、存储以及获得的科学结果的发布和传播。本文介绍了 EDISON 数据科学框架(EDSF),包括建立未来数据科学专业人员可持续毕业和培训所需的概念性、指导性和政策性组件。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT
介绍
现代研究需要新的专业人员,这些人员能够支持研究数据生命周期的所有阶段,从数据生产和输入到数据处理、存储以及科学结果的发布和传播,这些可以统称为数据科学职业系列。未来的数据科学家必须具备数据挖掘与分析、信息可视化与沟通、统计学、工程学和计算机科学等方面的知识(并获得相关的能力和技能),并在未来的工作和专业领域中积累经验。尽管数据科学家是数据相关职业系列中的关键职业,其他职业则专注于数据生命周期的其他阶段和支持基础设施。
文章描述了所提出的 EDISON 数据科学框架(EDSF)的主要组件,该框架作为定义数据科学职业系列的基础。还提供了有关数据科学能力框架(CF-DS)和数据科学知识体系(DS-BoK)的更多详细信息,这些对于定义一致且可定制的数据科学课程至关重要。
EDISON 数据科学框架
图 1 下方展示了 EDISON 数据科学框架(EDSF)的主要组件,这些组件为数据科学职业的发展提供了概念基础(包括对相关文档的参考):
-
CF-DS – 数据科学能力框架(CF-DS,2016)
-
DS-BoK – 数据科学知识体系(DS-BoK,2016)
-
MC-DS – 数据科学模型课程(MC-DS, 2016)
-
DSP – 数据科学专业档案和职业分类(DSP, 2016)
-
数据科学分类法和科学学科分类
提出的框架为数据科学专业生态系统的其他组成部分提供了基础,例如
-
EDISON 在线教育环境(EOEE)
-
教育和培训市场及目录
-
数据科学社区门户(CP),还包括个别能力基准测试和个性化教育路径构建的工具
核心数据科学能力和专业档案的认证框架

图 1: EDISON 数据科学框架组成部分。
数据科学能力框架和知识体系
数据科学能力框架(CF-DS)是 EDISON 数据科学框架的基石,并用于定义数据科学知识体系(DS-BoK)和数据科学模型课程(MC-DS)等组成部分。CF-DS 的定义符合欧洲电子能力框架(e-CF3.0),并提供了将数据科学相关能力和技能扩展到 e-CF3.0 的建议。
图 2 说明了主要的 CF-DS 能力组及其相互关系:
-
数据分析,包括统计方法、机器学习和业务分析
-
工程:软件和基础设施
-
学科/科学领域能力和知识
-
数据管理、整理、保存
-
科学或研究方法(针对研究职业)和业务流程管理(针对业务相关职业)
确定的能力领域为定义数据科学相关工作的教育和培训项目、技能再培训和专业认证提供了更好的基础。对科学研究方法和技术的了解使数据科学家职业不同于所有以往的职业。
数据管理和研究方法(或业务流程管理)被放置在两个外圈,以强调这些能力和知识是所有数据科学专业人员所需的。建议在所有数据科学课程中都包括数据管理(或特别是研究数据管理)和研究方法。

(a)数据科学能力组(针对一般或研究导向的职业)。

(b)面向业务的职业的数据科学能力组。
图 2: 确定的数据科学能力组之间的关系,分为(a)一般或研究导向和(b)商业导向的职业/角色
CF-DS 为数据科学知识体系(DS-BoK)的定义提供了基础,该知识体系涵盖了专业人员执行其职业所有数据相关过程所需的知识。知识体系通常定义了课程内容,并通过可以为特定学员组定义的学习成果与 CF-DS 相关联。
数据科学知识体系与模型课程
根据 CF-DS 能力组定义,DS-BoK 应包含以下知识领域组 (KAG):
-
KAG1-DSDA: 数据分析组,包括机器学习、统计方法和商业分析
-
KAG2-DSENG: 数据科学工程组,包括软件和基础设施工程
-
KAG3-DSDM: 数据管理组,包括数据策展、数据保存和数据基础设施
-
KAG4-DSRM: 科学或研究方法组
-
KAG5-DSBP: 业务流程管理组
高校可以使用 DS-BoK 作为参考,定义他们需要在课程中覆盖的知识领域,这取决于他们在研究或行业中的主要需求组。领域特定的知识可以作为学术教育的一部分或作为研究生的专业培训在工作场所获得。普遍认为,“新鲜”的数据科学家需要 2-3 年才能熟练掌握其职业技能。
提出的数据科学模型课程为构建可定制的数据科学课程提供了两个基本组件:(1)基于 CF-DS 能力定义学习成果(LO),包括不同熟练程度的区分,例如使用布卢姆分类法,(2)定义映射到目标职业组学习成果的学习单元(LU),这些单元需要根据现有的学术学科分类,如计算机科学分类(CCS,2012),来定义。
进一步发展
所展示的 EDSF 包括由供应和需求双方的主要利益相关者实施的组件:大学、职业培训机构、标准化机构、认证和认证机构、公司及其人力资源部门,以成功管理数据相关工作的能力和职业发展。提出的 DS-CF 已在众多研讨会和社区论坛上广泛讨论。它已经被少数与 EDISON 项目相关的机构使用。发布的供公众评论的 DS-BoK 和 MC-DS 文档将需要进一步的开发和专家验证,以定义具体的知识领域。这将通过涉及相关知识领域的专家,并与 IEEE、ACM、DAMA、IIBA 等专业社区合作来完成。该项目将与合作伙伴和领先大学一起进行 DS-BoK 和 MC-DS 的试点实施,并收集从业者的反馈。所有 EDISON 项目产品均在创意共享许可下公开提供。
致谢
EDISON 项目在 H20202 资助协议编号 675419 下由欧洲委员会支持。本文是 SciDataCon2016 会议论文的更新版,最初发布于 www.scidatacon.org/2016/sessions/98/poster/75/
简介: 是阿姆斯特丹大学系统与网络工程领域的高级研究员。他的主要研究领域包括大数据和数据密集型技术、电子科学、云计算和跨云架构、基于云的服务设计、一般安全架构以及面向云服务和数据中心应用的分布式访问控制基础设施。他负责协调欧洲资助的 EDISON 项目,该项目旨在为欧洲研究和工业建立数据科学职业的基础。
参考文献
Andrea Manieri 等, 2015,《数据科学专业揭秘:EDISON 项目如何促进数据科学家广泛认可的职业形象》,发表于第七届 IEEE 国际云计算技术与科学会议(CloudCom2015)的论文集中,2015 年 11 月 30 日至 12 月 3 日,加拿大温哥华
CCS, 2012,2012 年 ACM 计算分类系统 [在线] www.acm.org/about/class/class/2012
CF-DS, 2016,《数据科学能力框架(CF-DS)》。EDISON 草稿 V0.6,2016 年 3 月 10 日 [在线] www.edison-project.eu/data-science-competence-framework-cf-ds
Demchenko, Y., E.Gruengard, S.Klous, 2014, 构建有效的大数据课程的教学模型。 见于第 6 届 IEEE 国际云计算技术与科学会议及研讨会 (CloudCom2014),2014 年 12 月 15-18 日,新加坡
DS-BoK, 2016, 数据科学知识体系 (DS-BoK)。EDISON 草稿 V0.1,2016 年 3 月 20 日 [在线] www.edison-project.eu/data-science-body-knowledge-ds-bok
DSP, 2016, 数据科学专业档案定义 (CF-DS)。EDISON 草稿 v0.1,2016 年 7 月 11 日 [在线] www.edison-project.eu/data-science-professional-profiles-dsp
eCFv3.0, 2014, 欧洲 e-能力框架 3.0。适用于所有行业领域的 ICT 专业人员的共同欧洲框架。CWA 16234:2014 第一部分 [在线] ecompetences.eu/wp-content/uploads/2014/02/European-e-Competence-Framework-3.0_CEN_CWA_16234-1_2014.pdf
EDISON 项目:构建数据科学职业 [在线] www.edison-project.eu/
ESCO, 2016, ESCO (欧洲技能、能力、资格和职业) 框架 [在线] ec.europa.eu/esco/portal/#modal-one
MC-DS, 2016, 数据科学模型课程 (MC-DS),EDISON 草稿 v0.1,2016 年 6 月 11 日 [在线] www.edison-project.eu/data-science-model-curriculum-mc-ds
NIST, 2015, NIST SP 1500-1 NIST 大数据互操作框架 (NBDIF):第 1 卷:定义,2015 年 9 月 [在线] nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.1500-1.pdf
相关:
-
分析、大数据、数据科学、机器学习的证书与认证
-
分析、数据挖掘和数据科学的证书
-
分析、数据科学、机器学习的教育
更多相关主题
高效的小型语言模型:微软的 13 亿参数 phi-1.5
原文:
www.kdnuggets.com/effective-small-language-models-microsoft-phi-15

图片来源:作者
当你以为你已经听够了有关大型语言模型(LLMs)的新闻时,微软研究院再次搅动了市场。2023 年 6 月,微软研究院发布了一篇名为 “教材就是你所需的一切” 的论文,在其中他们介绍了 phi-1,一个新的大型代码语言模型。phi-1 是一个基于 Transformer 的模型,具有 13 亿参数,在 8 个 A100 GPU 上训练了 4 天,使用了来自网络的“教科书质量”数据。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你在 IT 领域的组织
看来 LLM 正变得越来越小。
什么是 phi-1.5?
现在,微软研究院向你介绍 phi-1.5,这是一个具有 13 亿参数的 Transformer,它使用了与 phi-1 相同的数据来源进行训练。如上所述,phi-1 在高质量的教科书数据上进行训练,而 phi-1.5 仅在合成数据上进行训练。
phi-1.5 使用了 32xA100-40G GPU,并在 8 天内成功训练完成。phi-1.5 的目标是打造一个开源模型,它可以在研究社区中发挥作用,使用一个不受限制的小型模型,这样可以探索与 LLM 相关的不同安全挑战,例如减少有害内容、增强可控性等。
通过使用‘合成数据生成’方法,phi-1.5 在自然语言测试中的表现相当于规模大 5 倍的模型,并且在更困难的推理任务中表现优于大多数 LLM。
相当令人印象深刻,对吧?
该模型的学习过程非常有趣。它从多种来源获取数据,包括 StackOverflow 上的 Python 代码片段、合成的 Python 教科书以及由 GPT-3.5-turbo-0301 生成的练习。
处理有害内容和偏见
LLM 的一个主要挑战是有害内容和偏见内容。微软研究院旨在克服这一持续挑战,即有害/冒犯性内容和推广特定意识形态的内容。
用于训练模型的合成数据生成的响应,相较于其他 LLMs 如 Falcon-7B 和 Llama 2–7B,生成有害内容的倾向较低,如下图所示:
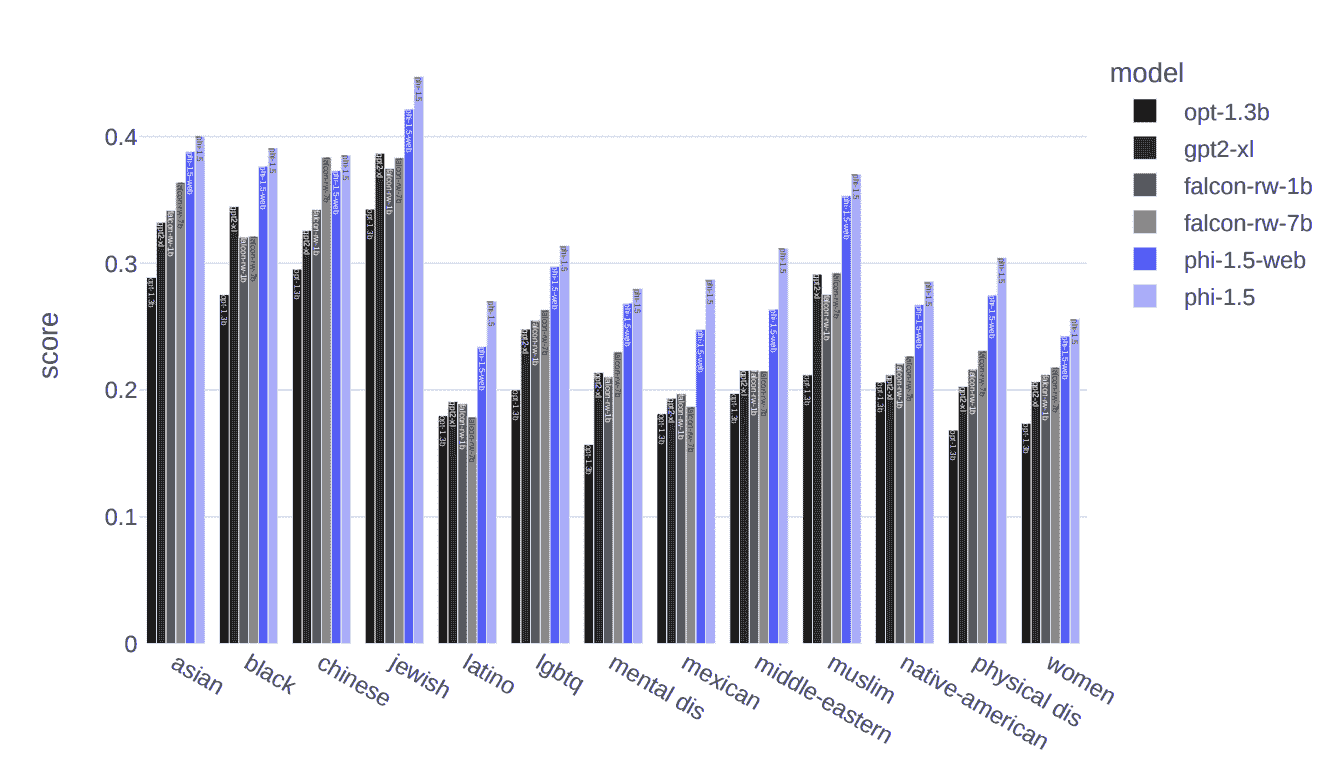
图片来源于教科书就是你所需的 II:phi-1.5 技术报告
基准测试
下图展示了 phi-1.5 在 3 个基准测试中表现略优于最先进的模型,如 Llama 2–7B、Llama-7B 和 Falcon-RW-1.3B,测试包括常识推理、语言技能和多步骤推理。

图片来源于教科书就是你所需的 II:phi-1.5 技术报告
这是怎么做的?
教科书式的数据使用方式使得 LLMs 中对这种数据的使用与从互联网提取的数据有所不同。为了进一步评估模型如何处理有害内容,使用了 ToxiGen,并设计了 86 个提示,手动标记为“通过”、“失败”或“未理解”,以更好地了解模型的局限性。
也就是说,phi-1.5 通过了 47 个提示,失败了 34 个提示,并且没有理解 4 个提示。使用 HumanEval 方法评估模型的结果显示,phi-1.5 的评分高于其他知名模型。
主要收获:
以下是你应该了解的关于 phi-1.5 的主要要点:
-
是一个基于 transformer 的模型
-
是一个专注于下一个词预测目标的 LLM
-
经过了 300 亿个 token 的训练
-
使用了 32xA100-40G GPUs
-
成功在 8 天内完成训练
Nisha Arya 是一位数据科学家、自由技术撰稿人以及 KDnuggets 的社区经理。她特别感兴趣于提供数据科学职业建议或教程和理论知识。她还希望探索人工智能如何能够或已经在延长人类寿命方面发挥作用。她是一个热衷学习的人,寻求拓宽技术知识和写作技能,同时帮助指导他人。
更多相关话题
机器学习的有效测试
原文:
www.kdnuggets.com/2022/01/effective-testing-machine-learning.html我们在PyData Global 2021上展示了这个博客系列的简短版本。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求

本博客系列描述了一种我在过去几年中开发的策略,用于有效测试机器学习项目。鉴于机器学习项目的不确定性,这是一种逐步的策略,你可以随着项目的成熟而采纳;它包括测试示例,以提供这些测试在实践中的清晰概念,并且完整的项目实现可在 GitHub 上获取。到文章末尾,你将能够开发出更强健的机器学习管道。
测试机器学习项目的挑战
测试机器学习项目是具有挑战性的。训练一个模型是一个长时间运行的任务,可能需要数小时,并且具有非确定性的输出,这与我们测试软件所需的快速和确定性过程正好相反。一年前,我发布了一篇关于测试数据密集型项目的帖子,以使持续集成成为可能。我后来将这篇博客文章转化为演讲,并在PyData 2020上进行了展示。但之前的工作仅涵盖了数据管道测试的通用方面,并没有涉及机器学习模型的测试。
需要明确的是,测试和监控是两回事。测试是一个离线过程,允许我们评估代码是否按预期工作(即,生成高质量的模型)。相反,监控涉及检查已部署的模型,以确保它正常工作。因此,测试发生在部署之前;监控发生在部署之后。
我在本文中使用了pipeline 和 task 这两个术语。任务是一个工作单元(通常是一个函数或脚本);例如,一个任务可以是下载原始数据的脚本,另一个任务可以是清理这些数据。另一方面,管道只是按预定义顺序执行的一系列任务。构建由小任务组成的管道的动机是使我们的代码更具可维护性和更易于测试;这与我们开源框架的目标一致,旨在帮助数据科学家使用 Jupyter 构建更具可维护性的项目。在接下来的部分中,你将看到一些示例 Python 代码;我们使用pytest、pandas 和Ploomber。
机器学习管道的各个部分
在我们描述测试策略之前,让我们分析一个典型的 ML 管道的样子。通过分别分析每个部分,我们可以清楚地阐明其在项目中的作用,并相应地设计测试策略。一个标准的 ML 管道具有以下组件:
-
特征生成管道。 一系列计算,用于处理原始数据并将每个数据点映射到特征向量。请注意,我们在训练和服务时都会使用这个组件。
-
训练任务。 接收训练集并生成模型文件。
-
模型文件。 来自训练任务的输出。它是一个包含学习到的参数的单一文件。此外,它可能包括预处理程序,如缩放或独热编码。
-
训练管道。 封装了训练逻辑:获取原始数据,生成特征,并训练模型。
-
服务管道。(也称为推理管道)封装了服务逻辑:获取新观察值,生成特征,通过模型传递特征,并返回预测结果。
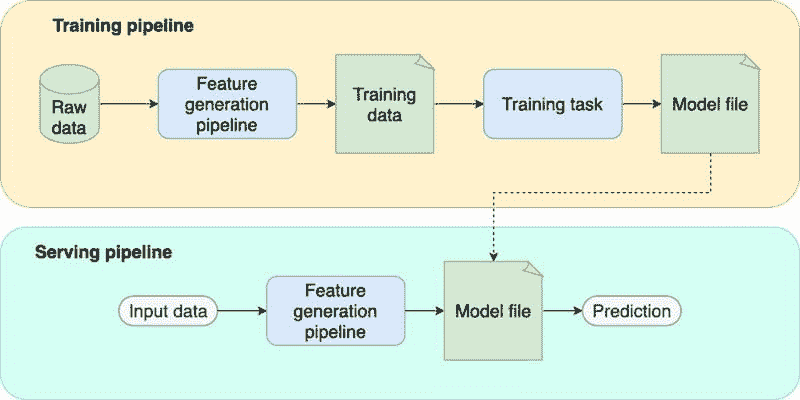
可能会出什么问题?
为了激励我们的测试策略,让我们列举每个部分可能出现的问题:
特征生成管道
-
无法运行管道(例如,设置问题、代码损坏)。
-
无法重现之前生成的训练集。
-
管道生成低质量的训练数据。
训练任务
-
无法训练模型(例如,缺少依赖项、代码损坏)。
-
使用高质量数据运行训练任务生成低质量模型。
模型文件
-
生成的模型质量低于我们当前生产中的模型。
-
模型文件与服务管道集成不正确。
服务管道
-
无法提供预测(例如,缺少依赖项、代码损坏)。
-
训练和服务时的预处理不匹配(即训练-服务偏差)。
-
传入无效原始数据时输出预测。
-
传入有效数据时崩溃。
请注意,这不是一个详尽的列表,但涵盖了最常见的问题。根据你的使用情况,可能还有其他潜在问题,重要的是列出它们以便定制你的测试策略。
测试策略
在开发机器学习模型时,我们迭代的速度越快,成功的机会就越大。与传统的软件工程项目不同(例如,注册表单),机器学习项目存在很多不确定性:使用哪些数据集?尝试哪些特征?使用什么模型?由于我们事先不知道这些问题的答案,我们必须尝试一些实验并评估它们是否产生更好的结果。由于这种不确定性,我们必须在迭代速度和测试质量之间取得平衡。如果我们迭代 太快,可能会编写粗糙的代码;如果我们花太多时间彻底测试每一行代码,就无法足够快地改进我们的模型。
这个框架稳步提高你的测试质量。策略包括五个层级;当达到最后一层时,你的测试已经足够健壮,可以自信地将新的模型版本推送到生产环境。
测试层级
-
冒烟测试。 我们通过在每次
git push时运行代码来确保其正常工作。 -
集成测试和单元测试。 测试任务的输出和数据转换。
-
分布变化和服务管道。 测试数据分布的变化以及测试我们能否加载模型文件并进行预测。
-
训练与服务偏差。 测试训练和服务逻辑的一致性。
-
模型质量。 测试模型质量。
简要介绍如何使用 pytest 进行测试
如果你之前使用过 pytest,可以跳过此部分。
测试是检查我们的代码是否正常工作的短程序。例如:
# test_math.py
from my_math_project import add, subtract
def test_add():
assert add(1, 1) == 2
def test_subtract():
assert subtract(43, 1) == 42
测试是一个运行一些代码并 断言 其输出的函数。例如,上一个文件有两个测试:test_add 和 test_substract,组织在一个名为 test_math.py 的文件中;通常每个模块一个文件(例如,test_math.py 测试 math.py 模块中的所有函数)。测试文件通常放在 tests/ 目录下:
tests/
test_math.py
test_stuff.py
...
test_other.py
测试框架如 pytest 允许你收集所有测试,执行它们并报告哪些测试失败,哪些测试成功:
# collect rests, run them, and report results
pytest
一个典型的项目结构如下:
src/
exploratory/
tests/
src/ 包含你项目的管道任务和其他实用函数。exploratory/ 包含探索性笔记本,你的测试放在 tests/ 目录中。src/ 中的代码必须可以从其他两个目录中导入。实现这一点的最简单方法是 打包你的项目。否则,你需要处理 sys.path 或 PYTHONPATH。
如何导航示例代码
示例代码可在 这里找到。该仓库有五个分支,每个分支实现了我将在接下来的部分中描述的测试级别。由于这是一种渐进策略,你可以通过从 第一个分支开始,逐步查看项目的演变。
该项目使用了 Ploomber,我们的开源框架来实现管道。因此,你可以在pipeline.yaml文件中查看管道规格。要查看我们用于测试管道的命令,请打开 .github/workflows/ci.yml,这是一个 GitHub Actions 配置文件,用于告诉 GitHub 在每次git push时运行特定的命令。
虽然不是严格必要的,但你可能会想查看我们的 Ploomber 入门教程以了解基本概念。
请注意,本博客文章中显示的代码片段是通用的(它们不使用任何特定的管道框架),因为我们想要用一般术语解释概念;然而,仓库中的示例代码使用了 Ploomber。
一级:冒烟测试
冒烟测试是最基本的测试级别,应在你开始项目时立即实施。冒烟测试不会检查代码的输出,只会确保它能够运行。虽然这看起来过于简单,但比完全没有测试要好得多。
记录依赖项
列出外部依赖项是启动任何软件项目的第一步,因此在创建你的 虚拟环境时,确保记录运行项目所需的所有依赖项。例如,如果使用pip,你的requirements.txt文件可能如下所示:
ploomber
scikit-learn
pandas
创建虚拟环境后,创建另一个文件(requirements.lock.txt)来记录所有依赖项的已安装版本。你可以使用pip freeze > requirements.lock.txt命令(在运行pip install -r requirements.txt后执行)生成类似如下内容的文件:
ploomber==0.13
scikit-learn==0.24.2
pandas==1.2.4
# more packages required by your dependencies...
记录具体的依赖项版本可以确保这些包的更改不会破坏你的项目。
另一个重要的考虑因素是将你的依赖列表保持尽可能简短。通常,你在开发时需要一组依赖项,但在生产环境中不需要。例如,你可能会使用matplotlib进行模型评估图,但在进行预测时不需要它。强烈建议将开发和部署的依赖项分开。依赖项过多的项目增加了遇到版本冲突的风险。
测试特性生成管道
你项目的第一个里程碑必须是获得一个端到端的特征生成管道。编写一些代码来获取原始数据,进行一些基本清洗,并生成一些特征。一旦你有了一个完整的端到端流程,你必须确保它是可重复的:删除原始数据,并检查你是否可以重新运行该流程并获得相同的训练数据。
一旦你有了这个,就可以实施第一个测试;用原始数据的一个样本(比如 1%)运行管道。目标是使这个测试运行快速(不超过几分钟)。你的测试应如下所示:
from my_project import generate_features_and_label
def test_generate_training_set():
my_project.generate_features_and_label(sample=True)
请注意,这只是一个基本测试;我们没有检查管道的输出!然而,这个简单的测试允许我们检查代码是否运行。每当我们执行git push时,运行此测试是至关重要的。如果你使用 GitHub,可以通过GitHub Actions完成,其他 git 平台也有类似功能。
测试训练任务
在生成特征后,你会训练一个模型。训练任务接受一个训练集作为输入,并输出一个模型文件。测试模型训练过程具有挑战性,因为我们不能轻易定义给定某些输入(训练集)的期望输出(模型文件)——主要因为我们的训练集变化迅速(即添加、删除特征)。因此,在这个阶段,我们的第一个测试只检查任务是否运行。由于我们暂时忽略输出,我们可以使用数据样本来训练模型;记住,这个冒烟测试必须在每次推送时执行。因此,让我们扩展之前的示例,以涵盖特征生成和模型训练:
from my_project import generate_features_and_label, train_model
def test_train_model():
# test we can generate features
X, y = my_project.generate_features_and_label(sample=True)
# test we can train a model
model = train_model(X, y)
在示例代码库中,我们使用 Ploomber,因此我们通过调用ploomber build来测试功能管道和训练任务,这会执行管道中的所有任务。
第二级:集成测试和单元测试
将管道模块化为小任务,以便我们可以单独测试输出,这一点至关重要。在实现了第二个测试级别后,你将实现两件事:
-
确保用于训练模型的数据达到最低质量水平。
-
分别测试代码中行为定义明确的部分。
让我们讨论第一个目标。
集成测试
测试数据处理代码是复杂的,因为其目标是主观的。例如,假设我让你测试一个接受数据框并清洗它的函数。你会如何测试?数据清洗的目的是提高数据质量。然而,这样的概念依赖于数据的具体情况和你的项目。因此,你需要定义清洁数据的概念,并将其转化为集成测试,尽管在这种情况下,我们可以使用数据质量测试这一术语来更精确。
集成测试的理念适用于管道中的所有阶段:从下载数据到生成特征:你需要定义每个阶段的期望。我们可以在下图中看到集成测试的图形表示:
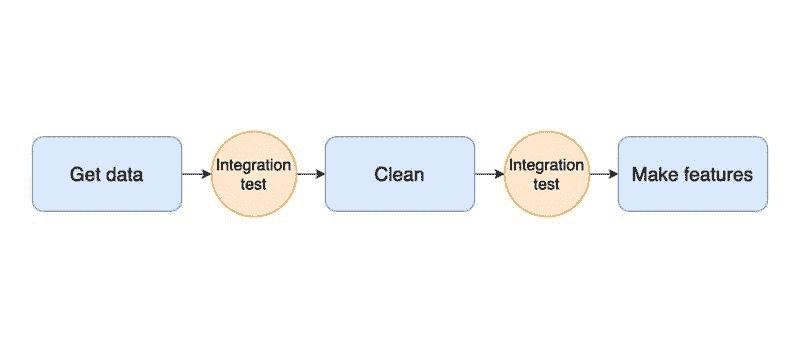
例如,要为数据清理函数(我们称之为clean)添加集成测试,我们在函数体的末尾运行一些检查来验证其输出质量。常见的检查包括没有空值、数值列在预期范围内或分类值在预定义的值集合中:
def clean(df)
# clean data frame with raw data
# ...
# ...
# integration test: check age column has a minimum value of 0
assert df.age.min() > 0
这种测试形式与我们在第一部分介绍的测试有所不同。单元测试存在于tests/文件夹中并可以独立运行,但集成测试在你执行训练管道时运行。 失败的测试意味着你的数据假设不成立,需要重新定义数据假设(这意味着需要相应地更新测试),或者你的清理程序应更改以确保测试通过。
你可以通过在每个任务结束时添加断言语句来编写集成测试,而不需要额外的框架。然而,一些库可以提供帮助。例如,Ploomber 支持在任务完成时运行一个函数。
这是实现示例的集成测试在我们的样本代码库中。
单元测试
在你的每个任务中(例如,clean内部),你可能会有更小的例程;这些代码部分应作为独立函数编写并进行单元测试(即,在tests/目录中添加测试)。
编写单元测试的一个良好候选场景是对列中的单个值进行转换。例如,假设你正在使用心脏病数据集,并创建一个函数将chest_pain_type分类列中的整数映射到其对应的可读值。你的clean函数可能如下所示:
import transform
def clean(df):
# some data cleaning code...
# ...
df['chest_pain_type'] = transform.chest_pain_type(df.chest_pain_type)
# ...
# more data cleaning code...
与一般的clean过程不同,transform.chest_pain_type具有明确的、客观定义的行为:它应将整数映射到对应的可读值。我们可以通过指定输入和预期输出将其转化为单元测试。
def test_transform_chest_pain_type():
# sample input
series = pd.Series([0, 1, 2, 3])
# expected output
expected = pd.Series([
'typical angina',
'atypical angina',
'non-anginal pain',
'asymptomatic',
])
# test
assert transform.chest_pain_type(series).equals(expected)
单元测试必须在所有即将到来的测试级别上持续进行。因此,每当你遇到具有明确目标的逻辑时,将其抽象成函数并单独测试。
这是一个实现示例的单元测试在样本代码库中。
接下来
到目前为止,我们已经实施了一种基本策略,确保我们的特征生成管道生成的数据具有最低质量标准(集成测试或数据质量测试),并验证数据转换的正确性(单元测试)。在本系列的下一部分中,我们将添加更强大的测试:测试分布变化,确保我们的训练和服务逻辑一致,并检查我们的管道是否生成高质量的模型。
如果你想知道第二部分何时发布,请订阅我们的 新闻通讯,关注我们的 Twitter 或 LinkedIn。
爱德华多·布兰卡斯 是 Ploomber 的联合创始人之一。Ploomber 是一家获得 Y Combinator 资助的公司,帮助数据科学家快速构建数据管道。我们通过允许他们开发模块化管道并在任何地方部署它们来实现这一目标。在此之前,他是 Fidelity Investments 的数据科学家,负责部署首个面向客户的资产管理机器学习模型。爱德华多拥有哥伦比亚大学的数据科学硕士学位和蒙特雷科技大学的机电工程学士学位。
原文。经许可转载。
更多相关主题
如何在数据过载时代有效获取消费者洞察
原文:
www.kdnuggets.com/2020/09/effectively-obtain-consumer-insights-data-overload-era.html
评论
作者:Patrícia Osorio,共同创始人兼首席市场官,Birdie

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
COVID-19 疫情对我们的日常生活产生了诸多影响。组织讨论的最重要因素之一是数字化转型的加速以及其在数据和技术方面的影响。正如《经济学人》所指出的,疫情的一个明显后果将是“数据驱动的服务将渗透到生活的方方面面。”这带来了另一个问题,就是大量的数据以及如何从中获取有价值的消费者洞察。大家都知道了解客户的重要性,但在信息过载的时代,如何做到这一点呢?
什么是数据过载?
信息过载是由 Debra Brass(前 J&J 全球总裁)在 2013 年创造的术语,描述了一种现实,即数据的过度可用性使得其分析变得复杂,以至于在某些情况下,它变得无效,无法对有洞察力的分析做出贡献。它阻碍了公司做出有效的决策,因为他们在面对如此多的数据时无法采取行动。
这种问题背景很可能是由于公司在数据收集能力上的迅速演变,但未能跟上正确集成和分析这些数据的能力。虽然这一问题可能影响整个公司,但对营销、客户服务、销售和消费者洞察等面向客户的团队尤其成问题。
一些研究估计,营销或消费者洞察高管最多将 80%的时间花在分析消费者数据上。在这些高管中,只有五分之一认为他们拥有合适的工具。电子商务平台上客户评论数量的指数级增长就是一个很好的例子。消费者不仅写更多评论,还在线上提出和回答更多问题,生成了大量具有挑战性的数据进行分析。
这既是一个机会也是一个问题:随着消费者评论和对话的增加,公司有机会获取这些数据,并以非常客观的方式实时了解其消费者,比以往更快。但他们如何在仍在为数据过载而挣扎并且未能获得所需洞察时探索新的消费者信息来源呢?
如何将数据转化为消费者洞察
答案是利用智能系统。这一概念由 Greylock Partners(软件行业最重要的投资基金之一)提出,许多人视其为数据分析领域下一波重大创新。智能系统作为一个额外的层次,连接了记录系统——存储数据的平台,如 CRM 或 ERP 平台——和互动系统——用于捕捉数据的互动平台(如客户服务或消息工具)。
智能系统的主要价值主张在于连接来自不同来源的数据——这些数据在大多数情况下未被充分利用,因为公司甚至无法访问它们——以便从这些数据中生成深刻的见解。通过实施这些智能系统,公司不仅可以减少将自身数据与电子表格连接的工作,还可以更轻松地将新的数据源纳入分析中,减少技术挑战,实现流畅的工作流程,从而提高每个操作周期的质量。
回到今天的背景,正是这样的解决方案似乎缺失。我们都有数据的访问权限,但在大多数情况下,我们不确定该寻找什么:我们分析错误的数据,只关注收集内容的一部分而看不到其与其他部分的关联,甚至选择了错误的度量标准来衡量。更重要的是,我们花更多的时间试图理解过去,而不是规划未来。
因此,我们不仅做出错误的决策,还浪费了大量时间将精力集中在对成功无关的行动上。Gartner 的研究显示,到 2023 年,数据智能和消费者洞察领域的 60%将减半,仅仅是因为无法从捕获的数据中生成价值。
市场营销和消费者洞察的高管需要减少在 Excel 上花费数小时处理和连接多个数据源的负担,以便- 也许- 得到相关的见解。
消费者洞察的未来:决策智能
随着"脏数据"每年使美国经济损失 3.1 万亿美元和每天产生 2.5 亿亿字节的数据,消费者洞察的未来与智能系统有直接关系并不足为奇。名字?决策智能。
决策智能是一个框架,旨在帮助将人工智能(AI)、机器学习(ML)和文本分析应用于实际业务决策,优先考虑业务并将技术投入使用。根据 Gartner,到 2023 年,超过 33%的大型组织将拥有从事决策智能的分析师。
它之所以如此强大,是因为它将商业目标、方面和问题与人工智能和预测分析的能力相连接,利用多个数据源来发展洞察力并预测未来。
简介: Patrícia Osorio 拥有超过 10 年的市场营销和业务发展经验。她在 USP 获得法学学位,在 FGV-EAESP 获得商业管理学位后,于 2007 年加入 Arizona,领导市场营销部门,并负责产品创新和新市场开发项目,如公司国际化(向阿根廷、智利、哥伦比亚和英国的客户销售,并在阿根廷开设办公室)以及数字产品开发。她还共同创办了 HomeRefill,一个在线订阅电子商务平台,以及 GVAngels,一个已经在巴西初创企业投资超过 100 万美元的天使投资集团。Pat 是由 Growth Tribe(欧洲)毕业的增长黑客,拥有在巴西和美国的 B2B 增长和获取经验。她与 Alex 一起看到了利用产品数据获得见解的机会,并在 2017 年底起草了Birdie的第一个版本。
相关内容:
-
坦率地说:我们在数据中淹没
-
向大数据提问的 3 个关键数据科学问题
-
客户流失预测:全球绩效研究
更多相关内容
如何有效使用 Pandas GroupBy
原文:
www.kdnuggets.com/2023/01/effectively-pandas-groupby.html
Pandas 是一个功能强大且广泛使用的开源库,用于使用 Python 进行数据操作和分析。它的一个关键特性是能够使用 groupby 函数通过基于一个或多个列将数据框分成组,然后对每个组应用各种聚合函数。

图片来自 Unsplash
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 维护
groupby 函数非常强大,因为它允许你快速总结和分析大数据集。例如,你可以根据特定列对数据集进行分组,并计算每个组中剩余列的均值、总和或计数。你还可以通过多个列进行分组,以获得对数据的更详细理解。此外,它还允许你应用自定义聚合函数,这对于复杂的数据分析任务是一个非常强大的工具。
在本教程中,你将学习如何使用 Pandas 的 groupby 函数来对不同类型的数据进行分组并执行不同的聚合操作。通过本教程,你应该能够使用这个函数以多种方式分析和总结数据。
实践代码示例
当概念经过充分练习后就会内化,这也是我们接下来要做的,即实际操作 Pandas 的 groupby 函数。建议使用 Jupyter Notebook 来完成本教程,因为你可以在每一步查看输出结果。
生成示例数据
导入以下库:
-
Pandas: 创建数据框并应用分组
-
Random - 用于生成随机数据
-
Pprint - 用于打印字典
import pandas as pd
import random
import pprint
接下来,我们将初始化一个空的数据框,并填入每一列的值,如下所示:
df = pd.DataFrame()
names = [
"Sankepally",
"Astitva",
"Shagun",
"SURAJ",
"Amit",
"RITAM",
"Rishav",
"Chandan",
"Diganta",
"Abhishek",
"Arpit",
"Salman",
"Anup",
"Santosh",
"Richard",
]
major = [
"Electrical Engineering",
"Mechanical Engineering",
"Electronic Engineering",
"Computer Engineering",
"Artificial Intelligence",
"Biotechnology",
]
yr_adm = random.sample(list(range(2018, 2023)) * 100, 15)
marks = random.sample(range(40, 101), 15)
num_add_sbj = random.sample(list(range(2)) * 100, 15)
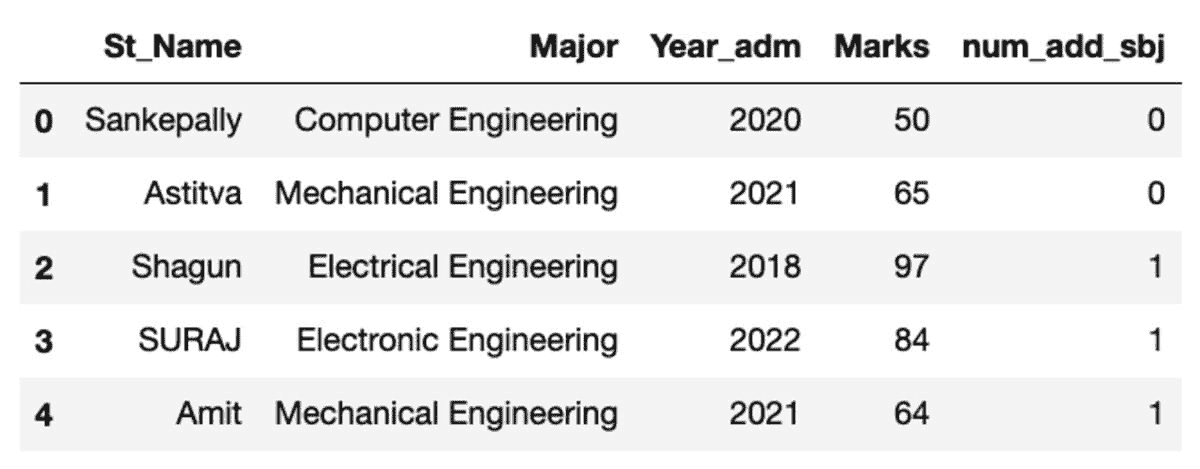
df["St_Name"] = names
df["Major"] = random.sample(major * 100, 15)
df["yr_adm"] = yr_adm
df["Marks"] = marks
df["num_add_sbj"] = num_add_sbj
df.head()
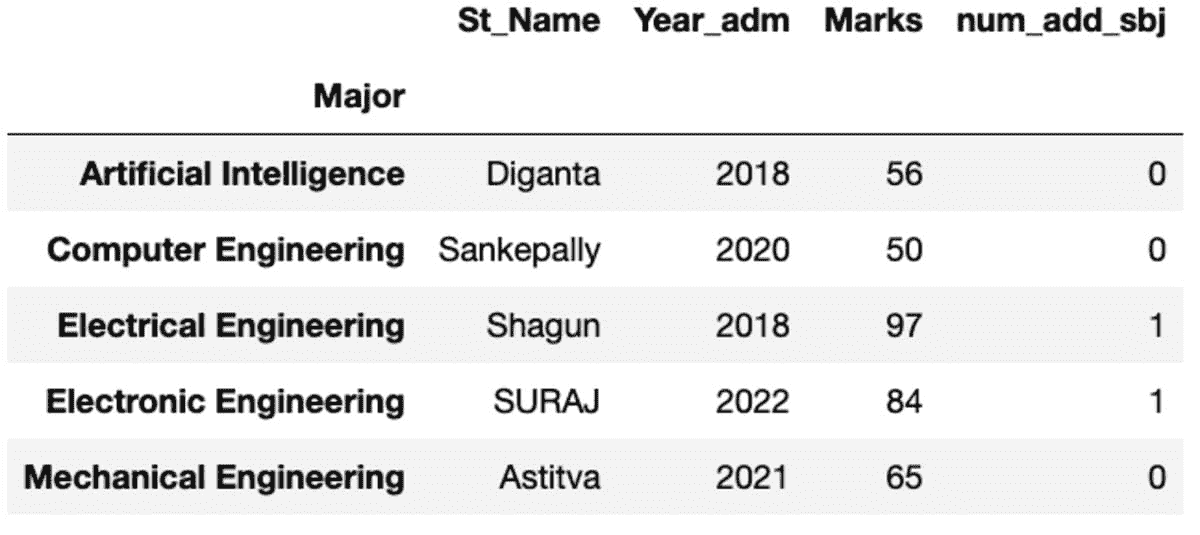
额外提示 – 更简洁的方法是创建一个包含所有变量及其值的字典,然后将其转换为数据框。
student_dict = {
"St_Name": [
"Sankepally",
"Astitva",
"Shagun",
"SURAJ",
"Amit",
"RITAM",
"Rishav",
"Chandan",
"Diganta",
"Abhishek",
"Arpit",
"Salman",
"Anup",
"Santosh",
"Richard",
],
"Major": random.sample(
[
"Electrical Engineering",
"Mechanical Engineering",
"Electronic Engineering",
"Computer Engineering",
"Artificial Intelligence",
"Biotechnology",
]
* 100,
15,
),
"Year_adm": random.sample(list(range(2018, 2023)) * 100, 15),
"Marks": random.sample(range(40, 101), 15),
"num_add_sbj": random.sample(list(range(2)) * 100, 15),
}
df = pd.DataFrame(student_dict)
df.head()
数据框的外观如下所示。在运行此代码时,由于我们使用的是随机样本,某些值可能不会匹配。
创建分组
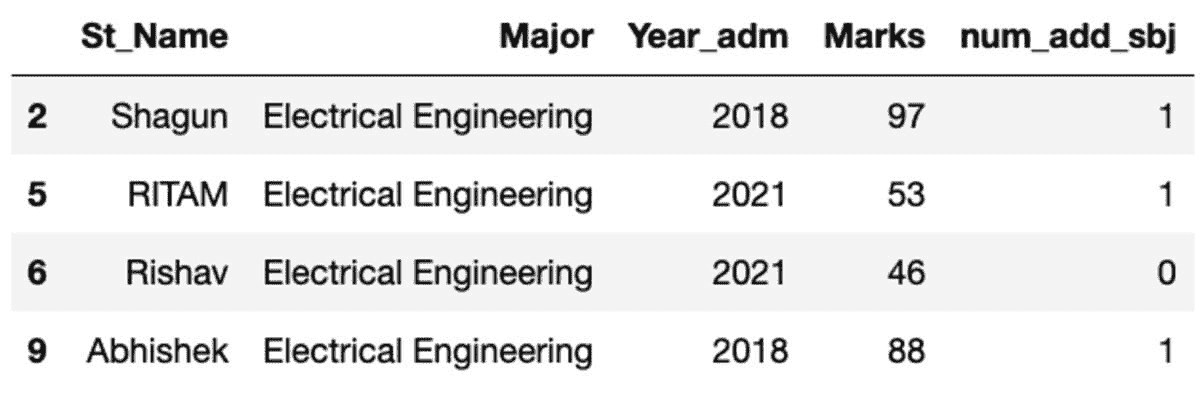
让我们按“Major”科目分组数据,并应用组过滤以查看有多少记录落入此组。
groups = df.groupby('Major')
groups.get_group('Electrical Engineering')
所以,四名学生属于电气工程专业。
你也可以按多个列分组(在此情况下为 Major 和 num_add_sbj)。
groups = df.groupby(['Major', 'num_add_sbj'])
注意,所有可以应用于单列组的聚合函数都可以应用于多列组。在接下来的教程中,让我们以单列为例深入探讨不同类型的聚合。
让我们使用“Major”列上的groupby创建组。
groups = df.groupby('Major')
应用直接函数
假设你想找到每个 Major 的平均分数。你会怎么做?
-
选择 Marks 列
-
应用均值函数
-
应用
round函数将成绩四舍五入到两位小数(可选)
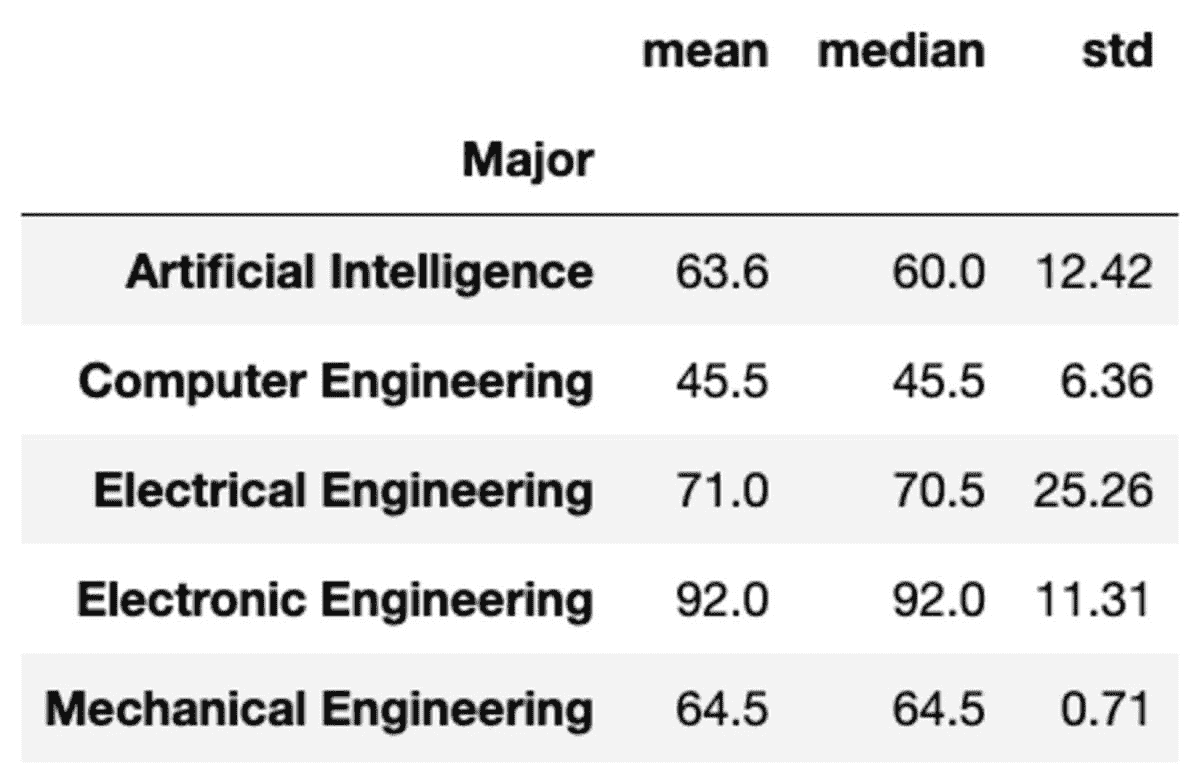
groups['Marks'].mean().round(2)
Major
Artificial Intelligence 63.6
Computer Engineering 45.5
Electrical Engineering 71.0
Electronic Engineering 92.0
Mechanical Engineering 64.5
Name: Marks, dtype: float64
聚合
另一种实现相同结果的方法是使用如下所示的聚合函数:
groups['Marks'].aggregate('mean').round(2)
你也可以通过将函数作为字符串列表传递给组来应用多个聚合。
groups['Marks'].aggregate(['mean', 'median', 'std']).round(2)
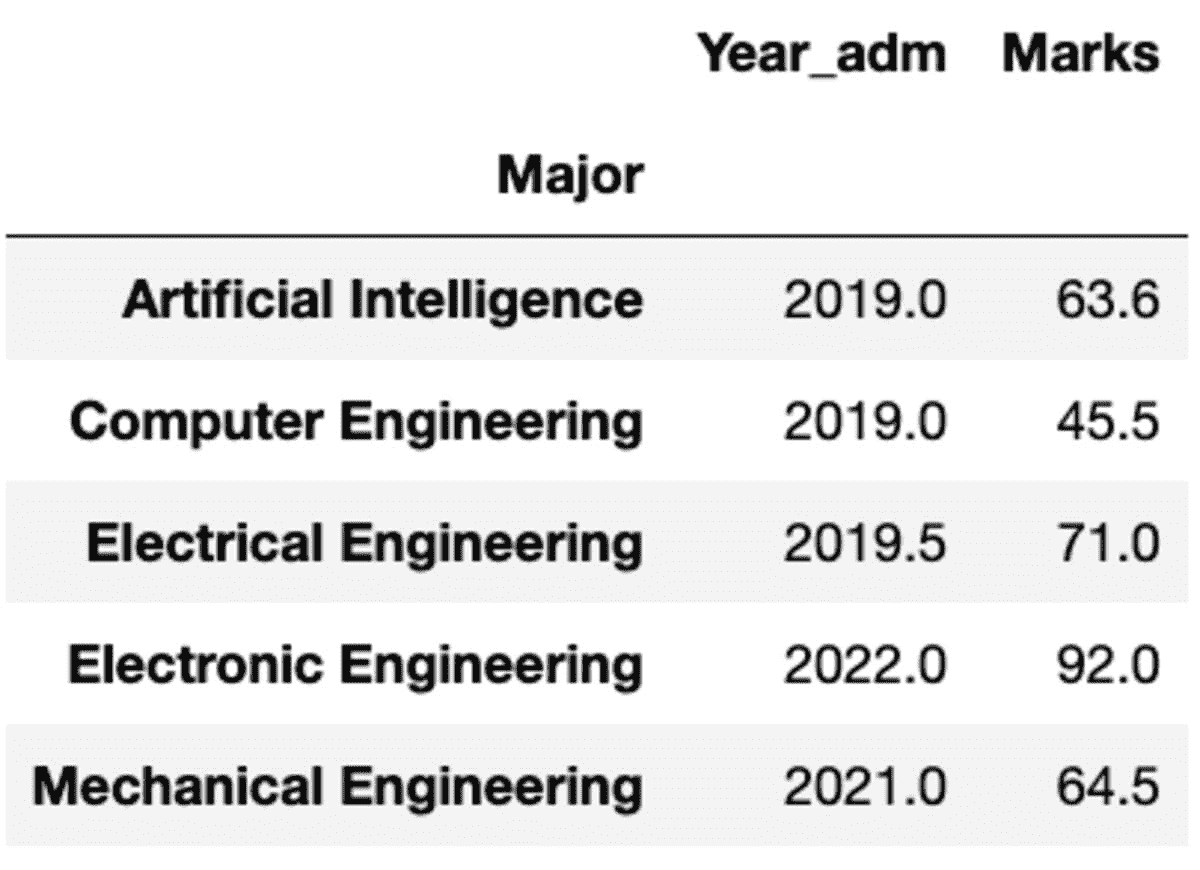
但如果你需要对不同的列应用不同的函数怎么办?不用担心。你也可以通过传递{column: function}对来做到这一点。
groups.aggregate({'Year_adm': 'median', 'Marks': 'mean'})
变换
你可能需要对特定列执行自定义变换,这可以通过使用groupby()轻松实现。让我们定义一个类似于 sklearn 的预处理模块中的标准缩放器。你可以通过调用transform方法并传递自定义函数来变换所有列。
def standard_scalar(x):
return (x - x.mean())/x.std()
groups.transform(standard_scalar)
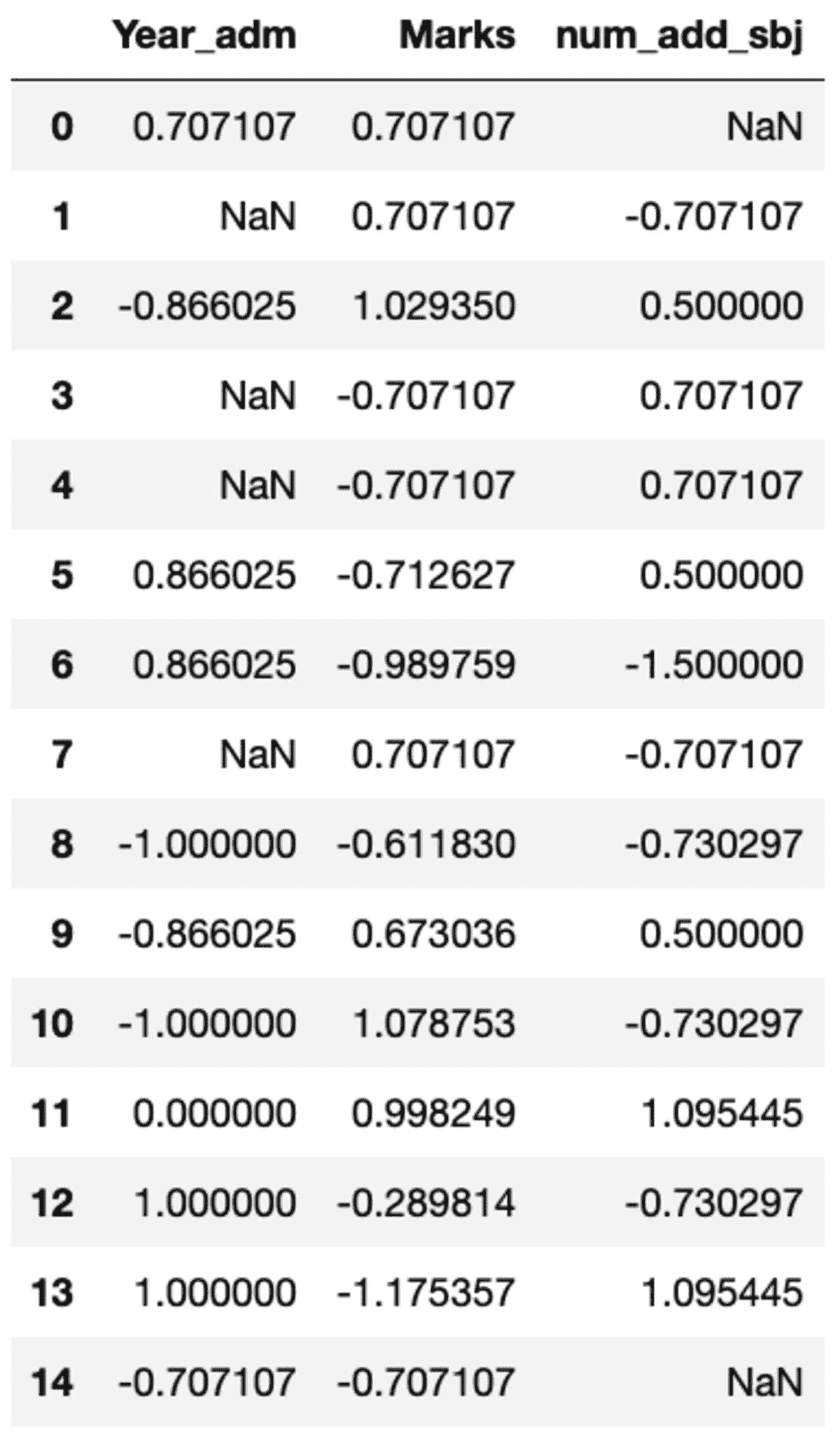
注意,“NaN”表示标准差为零的组。
过滤
你可能想检查哪个“Major”表现不佳,即平均“Marks”低于 60 的那个。这需要你对组应用一个带有函数的过滤方法。下面的代码使用一个 lambda 函数来实现过滤结果。
groups.filter(lambda x: x['Marks'].mean() < 60)

首先
它给你按索引排序的第一个实例。
groups.first()
描述
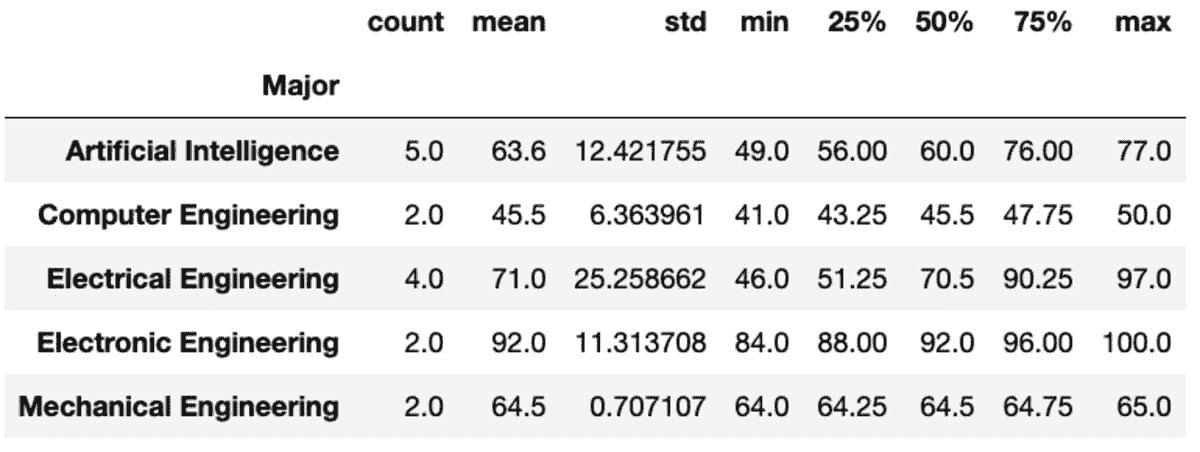
“describe”方法返回给定列的基本统计数据,如计数、均值、标准差、最小值、最大值等。
groups['Marks'].describe()
大小
Size,如名称所示,返回每组的大小,即记录数量。
groups.size()
Major
Artificial Intelligence 5
Computer Engineering 2
Electrical Engineering 4
Electronic Engineering 2
Mechanical Engineering 2
dtype: int64
计数和唯一值
“Count”返回所有值,而“Nunique”仅返回该组中的唯一值。
groups.count()
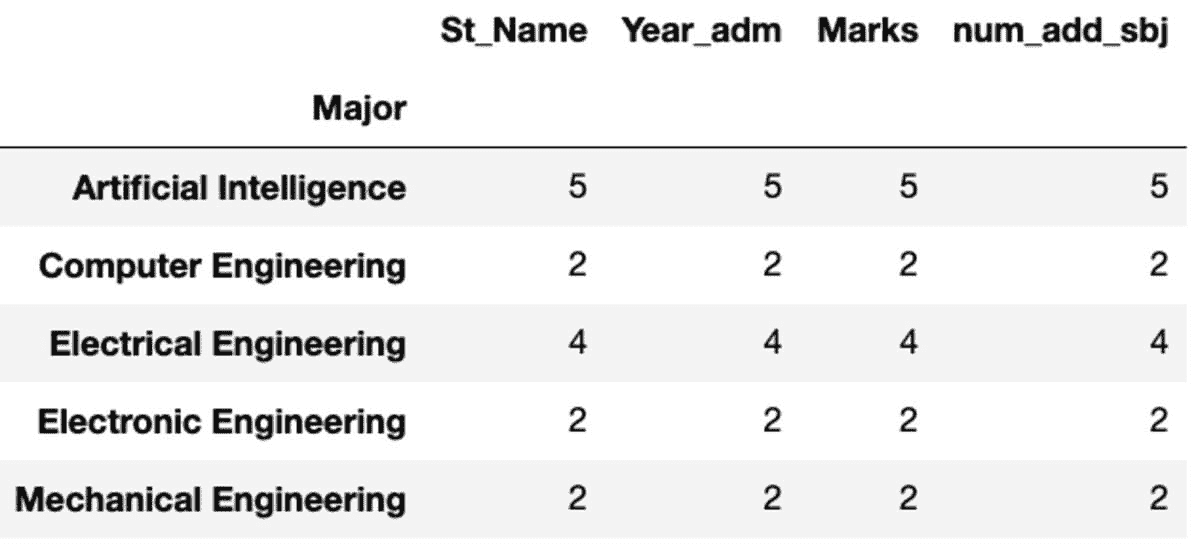
groups.nunique()
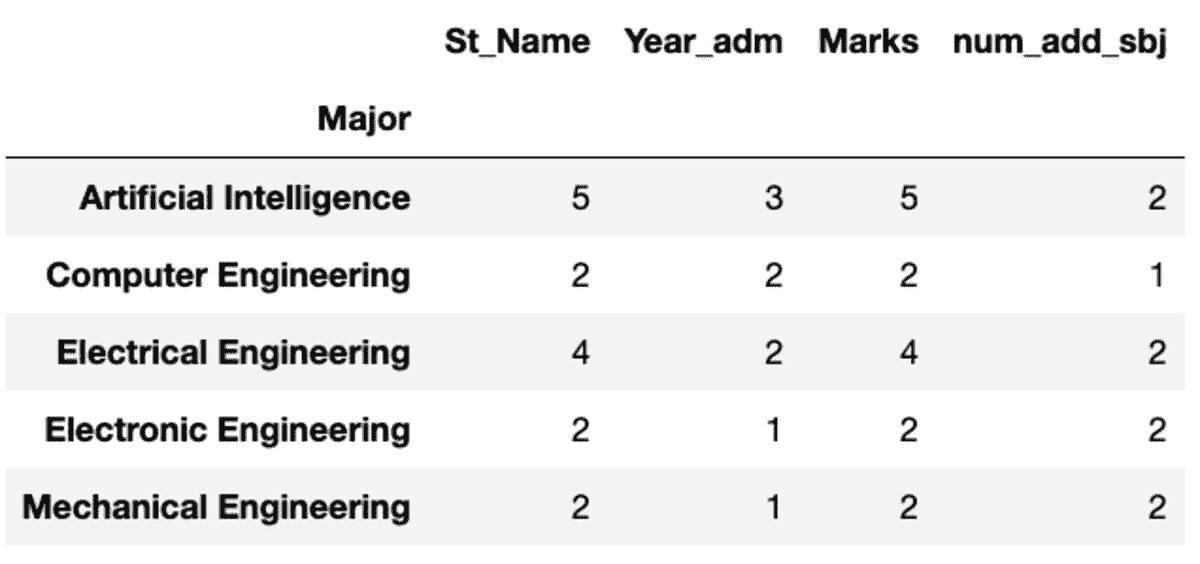
重命名
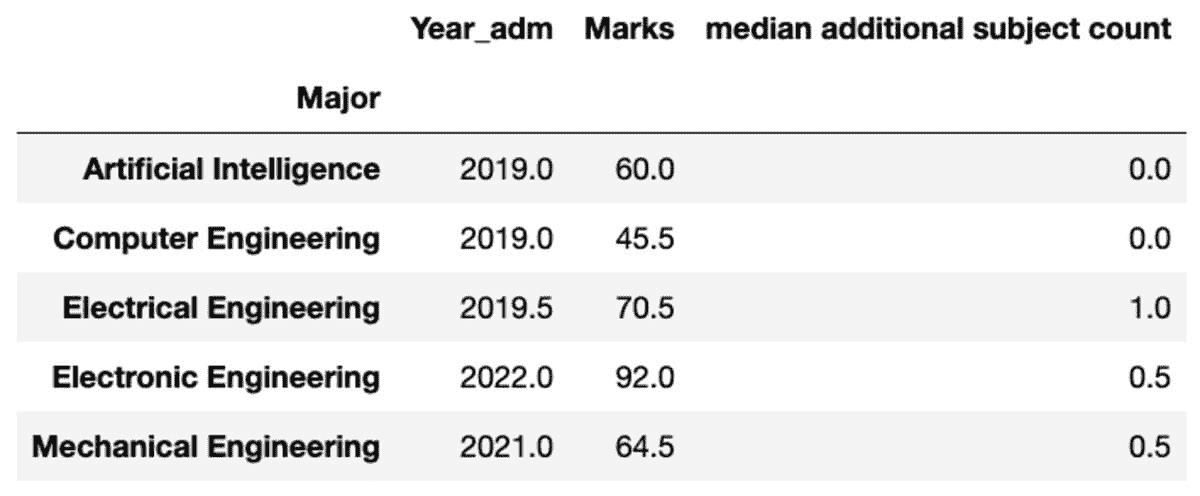
你也可以根据自己的偏好重命名聚合列的名称。
groups.aggregate("median").rename(
columns={
"yr_adm": "median year of admission",
"num_add_sbj": "median additional subject count",
}
)
充分利用 groupby 函数。
-
明确 groupby 的目的: 你是想通过一列对数据进行分组,以获取另一列的均值?还是通过多列对数据进行分组,以获取每组中的行数?
-
了解数据框的索引: groupby 函数使用索引来分组数据。如果你想通过某列对数据进行分组,确保该列被设置为索引,或者可以使用.set_index()
-
使用适当的聚合函数:可以与各种聚合函数一起使用,如 mean()、sum()、count()、min()、max()。
-
使用 as_index 参数: 当设置为 False 时,此参数告诉 pandas 将分组列用作常规列而不是索引。
你还可以将 groupby()与其他 pandas 函数(如 pivot_table()、crosstab()和 cut())结合使用,以从数据中提取更多洞察。
摘要
groupby 函数是数据分析和处理的强大工具,因为它允许你根据一个或多个列对数据行进行分组,然后对这些组执行聚合计算。教程展示了如何通过代码示例使用 groupby 函数的各种方法。希望它能帮助你理解这些选项及其在数据分析中的作用。
Vidhi Chugh 是一位人工智能策略师和数字化转型领导者,她在产品、科学和工程交汇处工作,致力于构建可扩展的机器学习系统。她是一位获奖的创新领导者、作者和国际演讲者。她的使命是使机器学习民主化,并打破行话,让每个人都能参与这场变革。
了解更多相关话题
ChatGPT 在学校的影响以及为什么它被禁止
原文:
www.kdnuggets.com/2023/06/effects-chatgpt-schools-getting-banned.html

图片由编辑提供
ChatGPT 在许多应用场景中既引起了兴奋也引发了担忧。它最显著——也是最具争议的——用途之一是它在学校中的使用。随着 ChatGPT 的受欢迎程度持续飙升,许多学区正在禁止它,但它对教育的潜在积极作用也在增长。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织在 IT 方面
学校为什么禁止 ChatGPT
理解这个问题的两个方面很重要。首先,这里列出了学校禁止 ChatGPT 的一些主要原因。
抄袭问题
对 ChatGPT 在学校中的最普遍担忧是它的抄袭倾向。像所有 AI 模型一样,ChatGPT 并不一定创造新内容,而是编译、总结和重新表述现有工作。学生可以轻松地使用它来完成他们的作业,就像偷别人的论文并交上去一样。
许多工具可以检测到 ChatGPT 生成的内容,因此发现试图作弊的学生相对容易。然而,即使学生只是将其作为研究工具,他们也可能无法找到 ChatGPT 提供的信息的原始来源,从而导致意外抄袭。模型训练数据背后人员缺乏同意也引发了进一步的抄袭问题。
准确性存疑
在学校使用 ChatGPT 也可能妨碍学生教育的质量。ChatGPT 提供的答案并不总是准确的,即使它们很有说服力,这可能导致学生相信误导性或完全错误的信息。
这些事实上的不准确性可能比抄袭更难检测,尤其是当涉及教师不太熟悉的话题时。因此,在研究或作为教学工具中使用它可能会传播错误信息。
隐私问题
ChatGPT 还存在一些隐私问题。该平台收集了大量用户数据,其隐私控制有限且不明显。考虑到教育行业在去年最容易遭受勒索软件攻击,这确实是一个重大问题。
学生可能不知道在使用 ChatGPT 时,他们正在提供多少个人信息或该网站如何使用这些信息。这使大量高度敏感的数据面临风险。
ChatGPT 的作弊以外的用途
尽管存在这些担忧,但 ChatGPT 在学校中有几个积极方面。以下是教育系统如何利用这个聊天机器人来使学生和教师都受益。
简化行政管理
教师和其他员工可以使用 ChatGPT 来自动化一些行政任务,比如安排时间表和数据录入。这种自动化将使他们有更多时间与学生互动,从而改善教育成果。
近50%的独立学校使用五种或更多在线解决方案来管理行政工作。这会导致很多断层、低效和不必要的成本。利用像 ChatGPT 这样的工具来简化这些幕后工作流程,将有助于减少时间和费用。
提高参与度
教育工作者还可以使用 ChatGPT 来使课程对学生更具吸引力。研究发现,当技术在他们的学习中发挥作用时,学生会更加投入和舒适,而像 ChatGPT 这样的新技术可能特别有用。
学生可以使用 ChatGPT 来制定他们自己充实的研究论文大纲,这有助于他们学习什么是高质量的文章。或者,教师可以使用 ChatGPT 来展示 AI 的工作原理,或强调在在线资源中关注偏见和虚假信息的重要性。
为 AI 未来做准备
学校也可以考虑教学生如何使用 ChatGPT 及类似工具。生成性 AI 无疑将在许多未来的业务中发挥作用,因此学习如何负责任地使用 AI 是即将到来的这一代的关键技能。
一些专家预测58%的现有劳动力将需要提升技能,以便在新技术改变他们的角色和职责时有效工作。教育系统可以通过在学生进入职场前为他们提供 AI 素养来领先于这一趋势。ChatGPT 的易用性使其成为实现这一目标的理想工具。
生成性 AI 可能永远改变教育
生成式 AI 平台如 ChatGPT 将改变许多行业的运作方式。教育领域可能也会发生类似变化,无论是通过采纳新政策来限制技术,还是积极拥抱它。
在学校使用 ChatGPT 有许多好处,但仍面临重大障碍。如果学校系统能以谨慎的态度对待,并考虑这些缺点,他们可以利用这些优势来改善未来的教育。
April Miller 是 ReHack 杂志的消费者技术管理编辑。她有创建优质内容的丰富经验,这些内容能够吸引流量到她所工作的出版物中。
更多相关话题
高性能深度学习,第一部分
原文:
www.kdnuggets.com/2021/06/efficiency-deep-learning-part1.html
评论

机器学习在今天的应用中无处不在。它在没有单一算法完美解决问题的领域中天然适用,并且在算法需要很好地预测正确输出的情况下,有大量未见过的数据。与我们期望确切最优解的传统算法问题不同,机器学习应用可以容忍近似答案。深度学习与神经网络在过去十年里一直是训练新机器学习模型的主流方法。它的崛起通常归因于 2012 年的 ImageNet [1] 竞赛。那一年,多伦多大学的一个团队提交了一个深度卷积网络(AlexNet [2],以首席开发者 Alex Krizhevsky 命名),表现比下一个最佳提交好 41%。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的捷径。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
深度和卷积网络之前已经被尝试过,但总是未能兑现承诺。卷积层最早由 LeCun 等人在 90 年代提出 [3]。同样,80 年代、90 年代等也提出了几种神经网络。深度网络为什么花了这么长时间才超越手工调整特征工程的模型?
这次的不同之处在于多个因素的结合:
-
计算:AlexNet 是早期依赖图形处理单元(GPU)进行训练的模型之一。
-
算法:一个关键的修复是激活函数使用了 ReLU。这使得梯度可以更深地反向传播。之前的深度网络使用了 sigmoid 或 tanh 激活函数,这些函数在非常小的输入范围内饱和到 1.0 或 -1.0。因此,输入变量的变化导致梯度非常微小(如果有的话),当层数很多时,梯度实际上消失了。
-
数据:ImageNet 拥有超过 1000 个类别的 100 万张以上的图像。随着互联网产品的出现,从用户行为中收集标注数据也变得更加便宜。
深度学习模型的快速增长
由于这项开创性的工作,出现了创建更深网络、参数数量越来越大的竞赛。几种模型架构如 VGGNet、Inception、ResNet 等,在随后的几年中相继打破了 ImageNet 比赛的记录。这些模型也已在实际应用中投入使用。
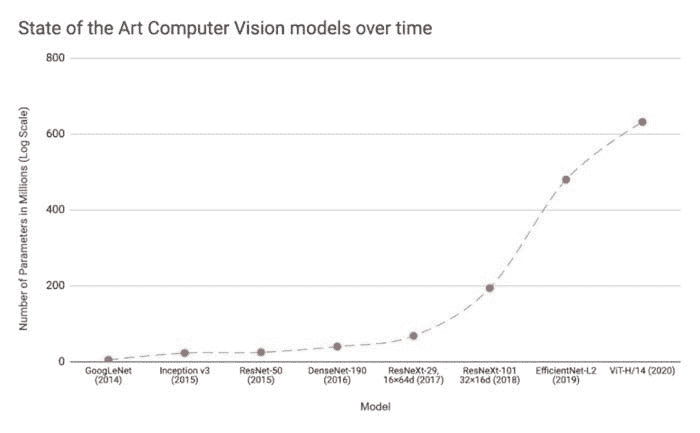
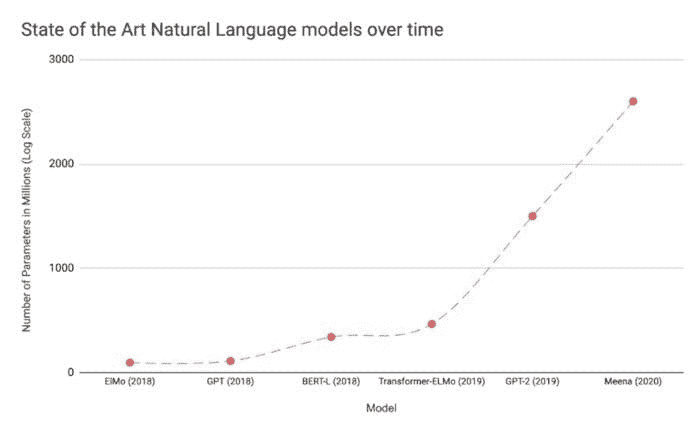
图 1:流行的计算机视觉和自然语言深度学习模型参数数量的增长趋势 [4]。
我们在自然语言理解(NLU)领域看到了类似的效果,其中 Transformer 架构显著超过了 GLUE 任务的之前基准。随后,BERT 和 GPT 模型在 NLP 相关任务上均显示出了改进。BERT 产生了几种优化其各种方面的相关模型架构。GPT-3 通过生成与给定提示相匹配的逼真文本引起了关注。这两者都已投入生产。BERT 用于 Google 搜索以提高结果的相关性,而 GPT-3 作为 API 供感兴趣的用户使用。
如所推测,深度学习研究一直集中于提高最先进的技术,因此,我们在图像分类、文本分类等基准测试中看到了持续的进步。每一次神经网络的新突破都导致了网络复杂度的增加、参数数量的增加、训练网络所需的资源量、预测延迟等。
像 GPT-3 这样的自然语言模型现在训练一次就需要花费数百万美元 [5]。这还不包括尝试不同超参数组合(调优)或手动或自动实验架构的成本。这些模型通常还拥有数十亿(或万亿)个参数。
与此同时,这些模型的卓越性能也推动了在之前受限于现有技术的新任务上的应用需求。这就产生了一个有趣的问题,即这些模型的传播受到其效率的限制。
更具体地说,我们在进入这一深度学习新时代时,面临以下问题,其中模型变得越来越大,并且跨越不同领域:
-
可持续的服务器端扩展:训练和部署大型深度学习模型的成本很高。虽然训练可能是一次性成本(或者使用预训练模型时可能免费),但长时间部署和进行推理仍可能是昂贵的。还有一个非常实际的关注点是用于训练和部署这些大型模型的数据中心的碳足迹。像谷歌、脸书、亚马逊等大型组织每年在数据中心的资本支出上花费数十亿美元。因此,任何效率提升都是非常重要的。
-
启用设备端部署:随着智能手机、物联网设备的普及,部署在这些设备上的应用必须是实时的。因此,需要设备端机器学习模型(即模型推理直接在设备上进行),这使得优化模型以适应运行设备变得非常重要。
-
隐私与数据敏感性:在用户数据可能涉及敏感处理或受各种限制(如欧洲的 GDPR 法规)的情况下,使用尽可能少的数据进行训练至关重要。因此,高效地使用少量数据训练模型意味着需要收集的数据更少。类似地,使设备上的模型能够运行意味着模型推理可以完全在用户设备上进行,而无需将输入数据发送到服务器端。
-
新应用:效率还将使得在现有资源约束下无法实现的应用成为可能。
-
模型爆炸:通常,可能会有多个机器学习模型在同一设备上同时服务。这进一步减少了单个模型的可用资源。这可能发生在服务器端,多个模型共存在同一台机器上,或者在应用中,不同的模型用于不同的功能。
高效深度学习
我们上述识别出的核心挑战是效率。虽然效率可能是一个过载的术语,但让我们探讨两个主要方面。
-
推理效率:这主要涉及部署模型进行推理(计算给定输入的模型输出)时需要问的问题。模型是否小巧?是否快速等等?更具体地说,模型有多少参数?磁盘大小、推理期间的内存消耗、推理延迟等是多少?
-
训练效率:这涉及到训练模型时需要问的一些问题,比如模型需要多长时间训练?需要多少设备进行训练?模型是否可以适应内存?还可能包括诸如,模型需要多少数据才能在给定任务上达到预期的性能?
如果我们有两个模型在给定任务上表现相同,我们可能会选择在上述一个或理想情况下两个方面表现更好的模型。如果在推理受限(如移动和嵌入设备)或昂贵(云服务器)的设备上部署模型,关注推理效率可能是值得的。同样,如果在有限或昂贵的训练资源下从头开始训练大型模型,开发针对训练效率设计的模型将有所帮助。
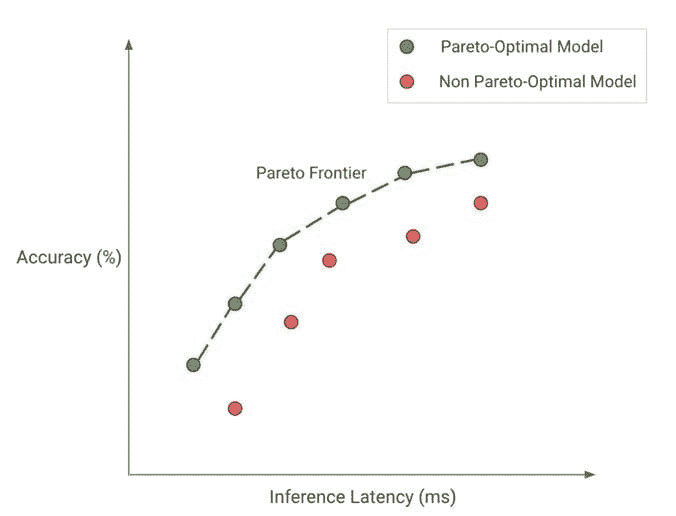
图 2: 帕累托最优性:绿色点代表帕累托最优模型(共同形成帕累托前沿),其中没有其他模型(红色点)在相同的推理延迟下获得更好的准确性,反之亦然。
无论我们优化的目标是什么,我们都希望达到帕累托最优性。这意味着我们选择的任何模型都是在我们关心的权衡中表现最好的。例如,在图 2 中,绿色点代表帕累托最优模型,其中没有其他模型(红色点)在相同的推理延迟下获得更好的准确性,反之亦然。总之,帕累托最优模型(绿色点)形成了我们的帕累托前沿。帕累托前沿的模型从定义上讲比其他模型更高效,因为它们在给定的权衡中表现最好。因此,当我们寻求效率时,我们应该考虑发现和改进帕累托前沿。
高效的深度学习可以定义为一组算法、技术、工具和基础设施,它们共同作用,使用户能够训练和部署帕累托最优模型,这些模型在训练和/或部署时消耗较少的资源,同时达到类似的结果。
现在我们已经激发了这个问题,在下一篇文章中,我们将讨论深度学习效率的五个支柱。
参考文献
[1] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, 和 Li Fei-Fei. 2009. ImageNet: 一个大规模层次化图像数据库。2009 年 IEEE 计算机视觉与模式识别大会。248–255. https://doi.org/10.1109/CVPR.2009.5206848
[2] Alex Krizhevsky, Ilya Sutskever, 和 Geoffrey E Hinton. 2012. 使用深度卷积神经网络进行 Imagenet 分类。神经信息处理系统进展 25 (2012), 1097–1105。
[3] 卷积网络: yann.lecun.com/exdb/lenet/index.html
[4] PapersWithCode: paperswithcode.com/
[5] Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, 等. 2020. 语言模型是少量样本学习者。arXiv 预印本 arXiv:2005.14165 (2020)。
简介: Gaurav Menghani(@GauravML)是 Google Research 的高级软件工程师,他领导着旨在优化大型机器学习模型的研究项目,以实现高效的训练和推理,这些模型可以在从微控制器到基于 Tensor Processing Unit(TPU)的服务器等各种设备上运行。他的工作对 YouTube、Cloud、Ads、Chrome 等领域的超过 10 亿活跃用户产生了积极的影响。他还是即将出版的 Manning Publication 的《高效机器学习》一书的作者。在 Google 之前,Gaurav 在 Facebook 工作了 4.5 年,并对 Facebook 的搜索系统和大规模分布式数据库做出了重要贡献。他拥有纽约州立大学石溪分校的计算机科学硕士学位。
相关:
更多相关主题
效率是生物神经元与人工神经元之间的区别
图片由 macrovector 提供 在 Freepik 上
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
机器学习取得了重大进展,但正如本系列所讨论的,它与大脑的工作方式没有太多相似之处。本系列第八部分探讨了生物神经元的一个方面,到目前为止,这一方面使它们远远领先于人工神经元:它们的效率。
您的大脑包含约 860 亿个神经元,这些神经元被挤在略超过一升的体积中。虽然机器学习可以做许多人脑做不到的事情,但大脑能够进行连续的语音识别、视觉解读以及许多其他任务,同时消耗约 12 瓦特的能量。相比之下,我的笔记本电脑消耗约 65 瓦特,而我的台式机消耗超过 200 瓦特,它们都无法运行当前使用的大型机器学习网络。
大脑是如何实现这种卓越效率的?我将其归因于三个关键因素:
-
大脑是物理和化学的,而不是电子的。
-
大脑中的神经元实际上非常慢。
-
神经元只有在发出脉冲时才需要能量。
尽管我们可以使用电子仪器测量神经元中的电压,但它们的基本操作是化学的。离子从膜的一侧迁移到另一侧,离子分子的取向发生变化。这与计算机有根本性的不同,计算机中电子的移动速度是光速。显然,大脑中的分子在静止时不需要任何外部能量,而将钠离子(例如)从膜的一侧移动到另一侧所需的能量微不足道。
正如我在本系列之前的文章中提到的,神经元的尖峰频率最高为 250Hz,神经信号以悠闲的 2m/s 速度传播。如果我们将 CPU 的速度减慢到类似的步伐,它们的能量消耗也会减少,但永远不会像生物神经元那样少。
真实的区别在于,神经元除了在发放时几乎不需要能量。此外,它们并不经常发放。通过将大脑的总能量除以通过化学计算出的发放能量,可以得出神经元平均每两秒发放一次的结论。显然,像视觉和听觉这样的连续过程必须几乎持续运行,消耗更多的能量。因此,为了使事物平均化,我们必须得出结论,大脑中很大一部分神经元几乎不会发放。因此,代表特定记忆的神经元(例如你的祖母)可能只有在你想到她时才会发放。
但还有一种更深层次的思考方式。CPU 在高速运行时使用一定量的能量(而非闲置或休眠),并且无论处理的数据是什么,都会使用这种量的能量。例如,加两个数,加 0+0 所需的能量与加 12,345 + 67,890 基本相同。神经元则不同。
这种区别是神经形态计算运动的起源。在脑模拟器中,只有当神经元发放时才需要处理,因此桌面 CPU 每秒可以处理多达 25 亿个突触。神经形态芯片利用这一效果,以比传统机器学习过程少得多的能量产生 AI 结果。
尽管神经形态系统在朝着更像大脑的架构方向发展,但它们通常仍使用完全不神经形态的 ML 反向传播算法。
"本系列的最后一篇文章将总结机器学习与大脑不一样的诸多原因——以及一些相似之处。"
查尔斯·西蒙 是一位全国知名的企业家和软件开发者,也是 FutureAI 的首席执行官。西蒙是《计算机会反叛吗?:为人工智能的未来做准备》的作者,也是 Brain Simulator II 的开发者,这是一个 AGI 研究软件平台。欲了解更多信息,请访问此处。
更多相关话题
如何通过云计算高效扩展数据科学项目
原文:
www.kdnuggets.com/2023/05/efficiently-scale-data-science-projects-cloud-computing.html

作者提供的图像
无法过分强调数据在做出明智决策中的重要性。在今天的世界里,企业依赖数据来推动战略、优化运营,并获得竞争优势。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织的 IT
然而,随着数据量的指数增长,组织甚至个人项目中的开发者可能会面临高效扩展数据科学项目以处理大量信息的挑战。
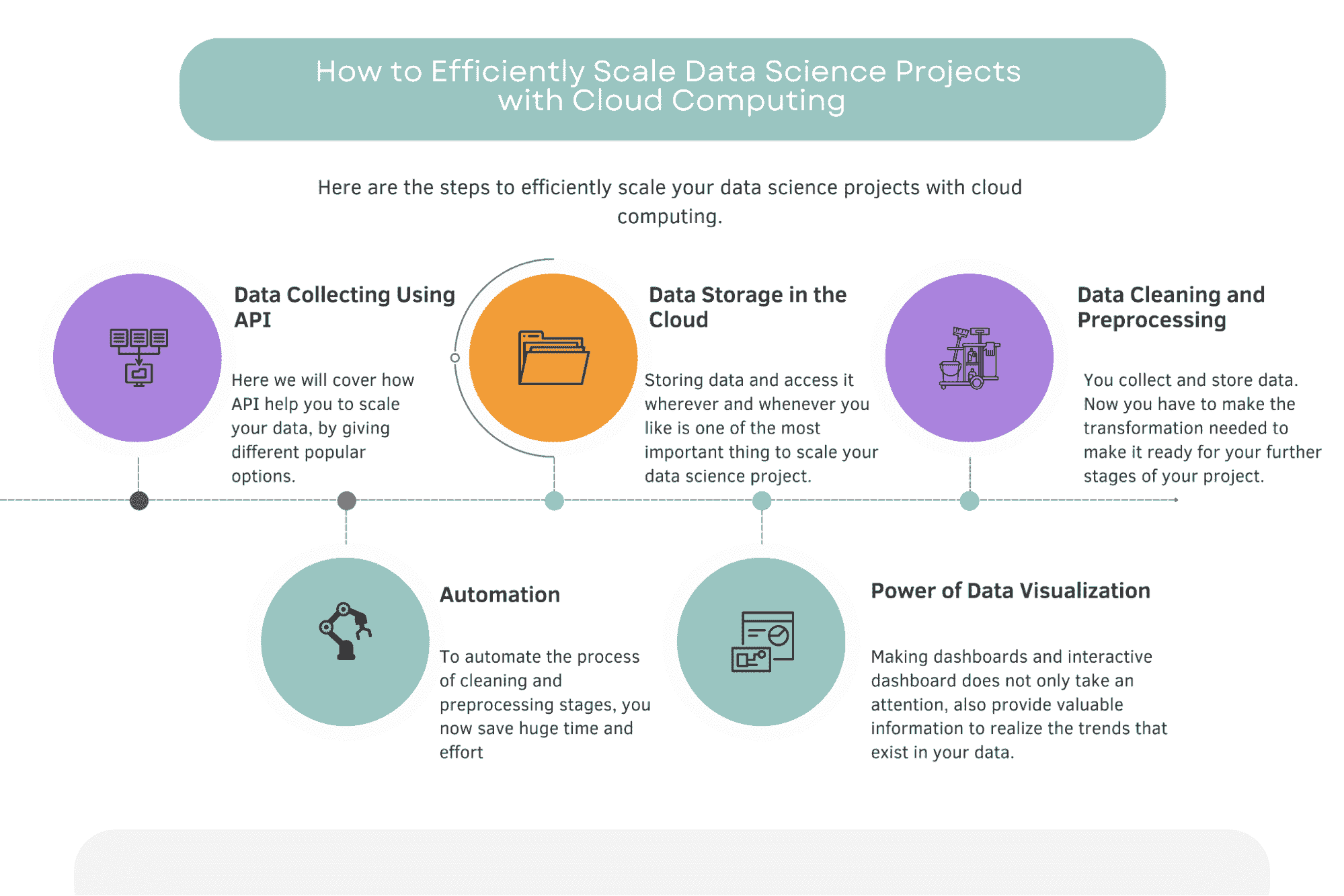
为了应对这一问题,我们将讨论五个关键组件,这些组件有助于成功扩展数据科学项目:
-
使用 APIs 进行数据收集
-
云中的数据存储
-
数据清洗和预处理
-
使用 Airflow 进行自动化
-
数据可视化的力量
这些组件对于确保企业收集更多数据并将其安全存储在云端以便于访问、使用预编写的脚本清理和处理数据、自动化流程,以及通过与云存储连接的互动仪表盘利用数据可视化的力量至关重要。
简而言之,这些是我们将在本文中介绍的方法,用于扩展您的 数据科学项目。
但要了解其重要性,我们不妨先看看在云计算出现之前,您可能会如何扩展您的项目。
云计算之前
作者提供的图像
在云计算出现之前,企业不得不依赖本地服务器来存储和管理数据。
数据科学家必须将数据从中央服务器移动到他们的系统中进行分析,这是一项耗时且复杂的过程。设置和维护本地服务器可能非常昂贵,并且需要持续的维护和备份。
云计算彻底改变了企业处理数据的方式,通过消除对物理服务器的需求并提供按需扩展的资源。
现在,让我们开始数据收集,以扩展你的数据科学项目。
图片由作者提供
使用 API 进行数据收集
图片由作者提供
在每个数据项目中,第一阶段是数据收集。
为你的项目和模型提供持续的、最新的数据对提升模型性能和确保其相关性至关重要。
收集数据的最有效方法之一是通过 API,这样可以程序化地从各种来源访问和检索数据。
API 已成为数据收集的一种流行方法,因为它们能够提供来自各种来源的数据,包括社交媒体平台、金融机构和其他网络服务。
让我们覆盖不同的用例,看看如何完成这些操作。
Youtube API
在这个视频中,使用了 Google Colab 进行编码,并通过 Requests 库进行测试。
使用了 YouTube API 来检索数据,并获得了 API 调用的响应。
数据发现存储在'items'键下。
数据被解析,并创建了一个循环来遍历这些项目。
进行了第二次 API 调用,数据被保存到 Pandas DataFrame 中。
这是在你的数据科学项目中使用 API 的一个很好的例子。
Quandl 的 API
另一个例子是 Quandl API,它可以用来访问金融数据。
在 Data Vigo 的视频中,这里,他解释了如何使用 Python 安装 Quandl,如何在 Quandl 的官方网站上找到所需的数据,并通过 API 访问金融数据。
这种方法使你可以轻松为你的金融数据项目提供必要的信息。
Rapid API
正如你所见,通过使用不同的 API,有许多不同的选项可以扩展你的数据。要发现适合你需求的正确 API,你可以探索像 RapidAPI 这样的平台,它提供了覆盖各种领域和行业的广泛 API。通过利用这些 API,你可以确保你的数据科学项目始终提供最新的数据,从而使你能够做出明智的数据驱动决策。
云端数据存储

图片由作者提供
现在,你收集了数据,但应该存储在哪里呢?
在数据科学项目中,安全且可访问的数据存储是至关重要的。
确保你的数据既安全,防止未授权访问,又能方便授权用户访问,这样可以确保顺利操作和团队成员之间的高效协作。
基于云的数据库已成为解决这些需求的热门方案。
一些流行的基于云的数据库包括 Amazon RDS、Google Cloud SQL 和 Azure SQL 数据库。
这些解决方案可以处理大量数据。
利用这些基于云的数据库的著名应用程序包括运行在 Microsoft Azure 上的 ChatGPT,展示了云存储的强大和有效性。
让我们看看这个用例。
Google Cloud SQL
要设置 Google Cloud SQL 实例,请按照以下步骤操作。
-
前往 Cloud SQL 实例页面。
-
点击“创建实例”。
-
点击“选择 SQL Server”。
-
输入你的实例 ID。
-
输入密码。
-
选择你想使用的数据库版本。
-
选择实例托管的区域。
-
根据你的偏好更新设置。
有关更详细的说明,请参阅官方 Google Cloud SQL 文档。此外,你还可以阅读这篇文章,它为从业人员解释了 Google Cloud SQL,提供了一个全面的指南,帮助你入门。
通过利用基于云的数据库,你可以确保数据安全存储且易于访问,使你的数据科学项目能够顺利高效地运行。
数据清理和预处理
图片由作者提供
你收集了数据并将其存储在云端。现在是时候转换数据以便进行进一步的处理了。
因为原始数据通常包含错误、不一致和缺失值,这些问题可能会对模型的性能和准确性产生负面影响。
适当的数据清理和预处理是确保数据准备好进行分析和建模的关键步骤。
Pandas 和 NumPy
创建一个用于清理和预处理的脚本涉及使用 Python 等编程语言,并利用 Pandas 和 NumPy 等流行库。
Pandas 是一个广泛使用的库,提供数据处理和分析工具,而 NumPy 是 Python 中用于数值计算的基础库。这两个库提供了清理和预处理数据的基本功能,包括处理缺失值、过滤数据、重塑数据集等。
Pandas 和 NumPy 在数据清理和预处理中至关重要,因为它们提供了一种强大而高效的方法来操作和转换数据,使数据转变为结构化格式,便于机器学习算法和数据可视化工具使用。
一旦你创建了一个数据清理和预处理脚本,你可以将其部署到云端以实现自动化。这确保了你的数据得到一致和自动的清理与预处理,简化了你的数据科学项目。
AWS Lambda 上的数据清理
要在 AWS Lambda 上部署数据清理脚本,你可以按照这个初学者示例中的步骤来处理 CSV 文件。这个示例演示了如何设置 Lambda 函数、配置必要的资源,并在云中执行脚本。
通过利用基于云的自动化的强大功能和 Pandas、NumPy 等库的能力,你可以确保你的数据是干净、结构良好的,并且准备好进行分析,从而最终提供更准确、更可靠的洞察。
自动化

图片由作者提供
那么,我们如何自动化这个过程呢?
Apache Airflow
Apache Airflow 非常适合这个特定任务,因为它允许编程创建、调度和监控工作流。
它允许你使用 Python 代码定义复杂的多阶段管道,使其成为自动化数据收集、清理和预处理任务的理想工具,在数据分析项目中尤为重要。
使用 Apache Airflow 自动化 COVID 数据分析
让我们在示例项目中看看它的使用情况。
示例项目:使用 Apache Airflow 自动化 COVID 数据分析。
在这个示例项目中,这里,作者演示了如何使用 Apache Airflow 自动化 COVID 数据分析管道。
-
创建 DAG(有向无环图)文件
-
从数据源加载数据。
-
清理和预处理数据。
-
将处理后的数据加载到 BigQuery
-
发送电子邮件通知:
-
将 DAG 上传到 Apache Airflow
通过遵循这些步骤,你可以使用 Apache Airflow 创建一个自动化的 COVID 数据分析管道。
这个管道将处理数据收集、清理、预处理和存储,同时在成功完成后发送通知。
使用 Airflow 进行自动化简化了你的数据科学项目,确保你的数据得到一致的处理和更新,使你能够根据最新的信息做出明智的决策。
数据可视化的力量

图片由作者提供
数据可视化在数据科学项目中发挥着至关重要的作用,它将复杂的数据转化为易于理解的视觉效果,使利益相关者能够快速掌握洞察,识别趋势,并根据呈现的信息做出更明智的决策。
简而言之,它将以互动的方式为你提供信息。
有几种工具可用于创建交互式仪表板,包括 Tableau、Power BI 和 Google Data Studio。
每种工具都提供了独特的功能和能力,帮助用户创建视觉上吸引人且信息丰富的仪表板。
将仪表板连接到你的云数据库
要将云数据集成到仪表板中,首先选择一个符合你需求的云数据集成工具。将该工具连接到你首选的云数据源,并映射你希望在仪表板上显示的数据字段。
接下来,选择合适的可视化工具,以清晰简洁的方式展示你的数据。通过引入筛选器、分组选项和钻取功能来增强数据探索。
确保你的仪表板自动刷新数据,或根据需要配置手动更新。
最后,彻底测试仪表板的准确性和可用性,进行必要的调整以提升用户体验。
将 Tableau 连接到你的云数据库 - 用例
Tableau 提供了与云数据库的无缝集成,使你可以轻松将云数据连接到仪表板。
首先,识别你使用的数据库类型,因为 Tableau 支持多种数据库技术,如 Amazon Web Services(AWS)、Google Cloud 和 Microsoft Azure。
然后,建立云数据库和 Tableau 之间的连接,通常使用 API 密钥以确保安全访问。
Tableau 还提供了多种云数据连接器,可以轻松配置以访问来自多个云源的数据。
有关在 AWS 上部署单个 Tableau 服务器的逐步指南,请参考这份详细文档。
另外,你可以探索一个演示Amazon Athena 与 Tableau 之间连接的用例,包含截图和解释。
结论
扩展数据科学项目的云计算好处包括改进的资源管理、成本节约、灵活性,以及专注于数据分析而非基础设施管理。
通过采用云计算技术并将其整合到你的数据科学项目中,你可以提升可扩展性、效率和数据驱动项目的整体成功。
通过在数据科学项目中采用云计算技术,你还可以实现改进的决策制定和数据洞察。随着你不断探索和采用云解决方案,你将更好地处理不断增长的数据量和复杂性。
这将最终赋能你的组织,基于从结构良好且高效管理的数据管道中获得的有价值洞察,做出更智能的数据驱动决策。
在这篇文章中,我们讨论了使用 API 进行数据收集的重要性,并探索了各种工具和技术以简化云中的数据存储、清理和预处理。我们还涵盖了数据可视化在决策中的强大影响,并突出了使用 Apache Airflow 自动化数据管道的好处。
充分利用云计算的好处来扩展你的数据科学项目,将使你能够完全挖掘数据的潜力,并引导你的组织在日益竞争的数据驱动行业中迈向成功。
Nate Rosidi 是一名数据科学家和产品战略专家。他还担任分析学兼职教授,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过顶级公司的真实面试问题准备面试。通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
更多相关话题
人员分析的努力是否值得结果?
原文:
www.kdnuggets.com/2022/09/efforts-people-analytics-worth-outcome.html

图片来源:Yan Krukov
创建职场中的多样性、公平性和包容性(DEI)责任在近年来变得越来越重要。今天,员工几乎期望他们的雇主制定 DEI 目标,以创建更具包容性和可达性的办公室。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
然而,实施和实现与 DEI 相关的计划需要正确的流程,包括使用人员分析。以下是关于 DEI 如何使用这些数据以及为什么值得的更多信息。
数据为何对 DEI 举措至关重要
现实是,雇主无法了解员工的问题,除非他们使用数据,特别是人员分析。许多组织投入资源进行 DEI,但没有具体目标来支持他们的员工,而这正是 DEI 对希望做出改变的企业最具影响力的地方。
这就是人员分析可以帮助的地方。企业可以通过跟踪招聘、投诉、晋升和其他人力资源指标等数据,制定更有意图和有意义的计划,朝着 DEI 目标努力。例如,审视招聘实践可以揭示偏见,从而告知相关团队为什么某些部门可能不够多样化。
没有这些数据,组织领导者无法了解令人担忧的趋势所在,因此无法发现并应用正确的解决方案。
使用人员分析推动 DEI
不幸的是,尽管70% 的企业高管指出在现代商业世界中人员分析至关重要,但一些研究表明只有7% 的公司领导关注团队问题。这种数字差异的原因可能是使用人员分析需要持续的努力,并且实施过程中可能会遇到障碍导致延迟。
即使是最先进的技术公司,也可能在正确实施数据管理和其他关键步骤方面遇到困难,从而使使用人员分析变得不那么有价值。此外,团队可能会抵制变革,使得高层管理者难以完全实现其计划。
从基本层面上看,许多组织并未意识到人员分析可以帮助他们朝着目标前进,特别是在 DEI(多样性、公平性和包容性)方面。理解人员分析对 DEI 的好处是第一步。接下来,公司必须开始跟踪员工的各种数据,这是一项复杂的任务。
人员分析在正确使用时支持 DEI
简而言之,组织可以通过使用人员分析来为具体目标奠定基础,从而建立多样化、公平和包容的工作环境。然而,数据无法帮助企业,除非他们知道如何使用它。投入精力来测量和分析人员分析是值得的,只要高层管理者清楚地理解其目的。
这是一些组织高层在致力于使人员分析对他们的 DEI 目标有价值时应考虑的方面:
-
数据管理和资源: 拥有一个专门的数据管理团队和支持调查结果的正确资源对于 DEI 的人员分析成功至关重要。最有效的公司有工程师来帮助他们的人员分析团队。
-
对总体目标的理解: 当组织中的每一个关键人物都对 DEI 达成共识时,他们可以与数据工程团队更好地合作,以实现他们设定的目标。这一部分还包括与员工沟通 DEI 倡议以及团队在这一过程中取得的成就。
-
数据创意: 无论是用于 DEI 还是其他用途,那些成功使用人员分析的组织在如何定位和使用数据方面都很有创意。数据来源可能看起来有限,但团队应跳出框框,以新的方式利用信息来支持 DEI。
总体而言,在工作场所使用人员分析进行 DEI 是值得的,尤其是当组织了解如何正确使用它时。
人员分析可以帮助工作场所整合 DEI
随着越来越多的员工关注创建欢迎、包容的工作环境,企业应内部寻求改变。使用人员分析来衡量工作环境的各个方面可以帮助组织实现 DEI 目标,但他们首先必须有一个适当测量员工数据的计划。跟踪人员分析是实施 DEI 的必要且有价值的步骤。
德文·帕提达是一位大数据和技术作家,同时也是ReHack.com的主编。
更多相关话题
8 种创新的 BERT 知识蒸馏论文改变了 NLP 的格局
编辑的图像
文章总结了从众多 BERT 知识蒸馏相关论文中精心挑选出的八篇论文。NLP 模型压缩和加速是一个活跃的研究领域,并在行业中广泛应用,以向终端用户提供低延迟的功能和服务。
直截了当说,BERT 模型用于将词语转换为数字,并使你能够在文本数据上训练机器学习模型。为什么?因为机器学习模型接受的输入是数字而非词语。
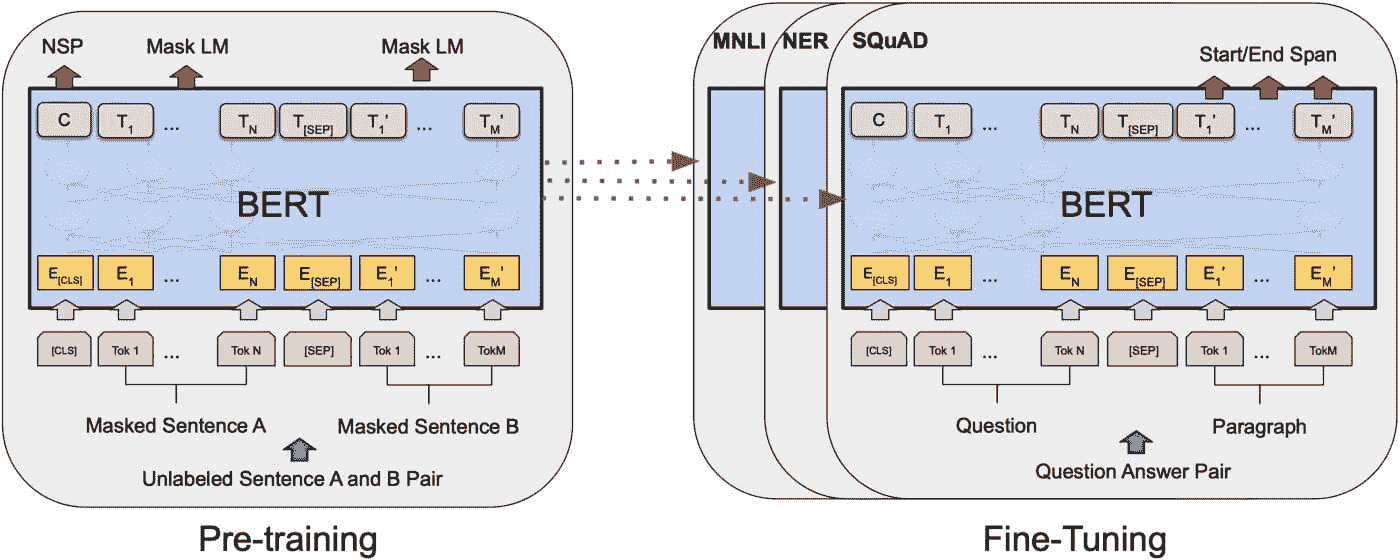
图片来源 Devlin et al., 2019
为什么 BERT 如此受欢迎?
首先,BERT 是一种语言模型,它提升了多个任务的高性能。BERT(双向编码器表示从 Transformers)于 2018 年发布,通过在广泛的 NLP 任务中提供前所未有的结果,引发了机器学习社区的轰动,尤其是在语言理解和问答方面。
BERT 的主要吸引力在于使用 Transformer 的双向训练,Transformer 是一种突出的语言建模注意力模型。但就我的叙述而言,这里有几个使 BERT 更加出色的方面:
-
它是开源的
-
NLP 中掌握语境丰富文本的最佳技术
-
双向特性
所有论文都呈现了 BERT 使用中的特定观点。
论文 1
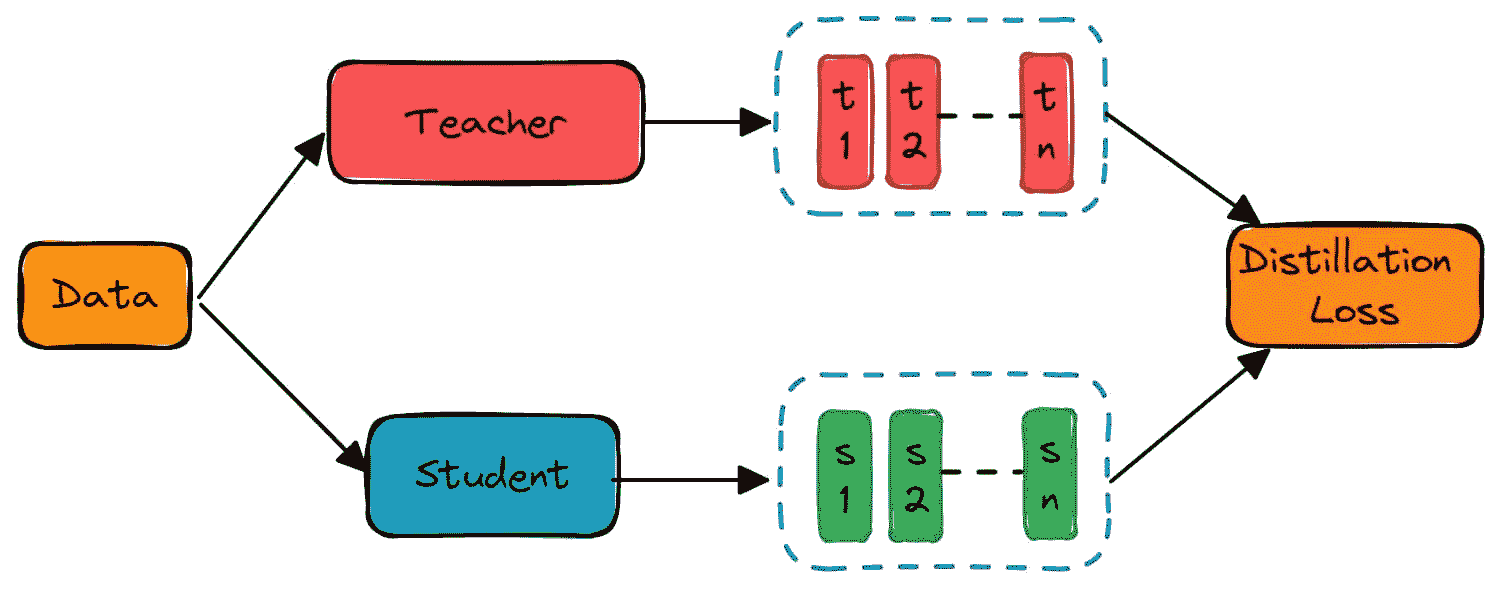
DistilBERT,BERT 的蒸馏版本:更小、更快、更便宜、更轻量
作者们提出了一种技术,旨在预训练一个较小的通用语言表示模型,称为 DistilBERT,该模型可以在多种任务上进行微调,并且表现出色,类似于其较大的同行。虽然大多数先前的工作研究了利用蒸馏来构建特定任务模型,但我们在预训练阶段利用了知识蒸馏。我们展示了可以将 BERT 模型的大小减少 40%,同时保留 97% 的语言理解能力,并且速度提高 60%。损失函数包含语言建模损失、蒸馏损失和余弦距离损失。使用的数据与原始 BERT 模型使用的数据相同。此外,DistilBERT 在八个 16GB V100 GPU 上训练了大约 90 小时。
让我们假设
对于输入 x,教师输出:
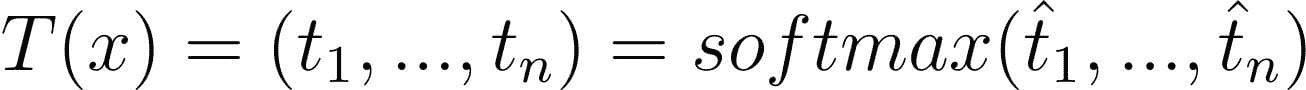
学生输出:
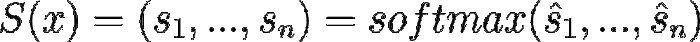
考虑到 softmax 及其相关符号,我们稍后会回到这个话题。然而,如果我们希望 T 和 S 接近,可以对 S 应用交叉熵损失,以 T 作为目标。这就是我们所谓的教师-学生交叉熵损失:
- 蒸馏损失:此损失与典型的知识蒸馏损失相同:
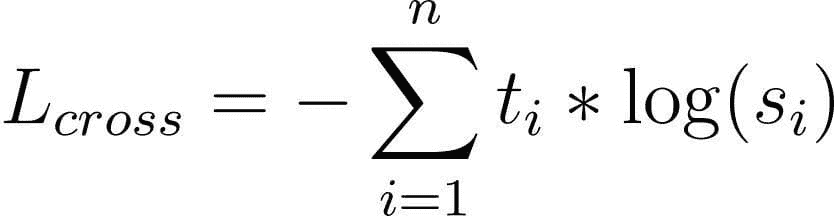
-
蒙版语言建模损失(MLM)
-
发现余弦嵌入损失(Lcos)是有益的,它对齐了学生和教师隐藏状态向量的方向。
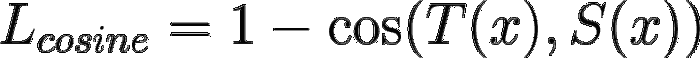
T(x)是教师向量输出,S(x)是学生向量输出 来源
关键要点: 这是一种在线蒸馏技术,其中教师模型和学生模型进行训练。
论文 2
本文提出了一种通用技术,用于利用预训练语言模型进一步优化文本生成,排除了特定的参数共享、特征提取或使用辅助任务进行增强。他们提出的条件 MLM 机制利用在大规模语料库上预训练的无监督语言模型,然后调整到监督的序列到序列任务。所提供的蒸馏方法通过仅提供软标签分布间接影响文本生成模型,因此是模型不可知的。关键点如下。
-
BERT 训练的 MLM 目标不是自回归的;它以同时考虑过去和未来上下文的方式进行训练。
-
新颖的 C-MLM(条件蒙版语言建模)任务需要额外的条件输入。
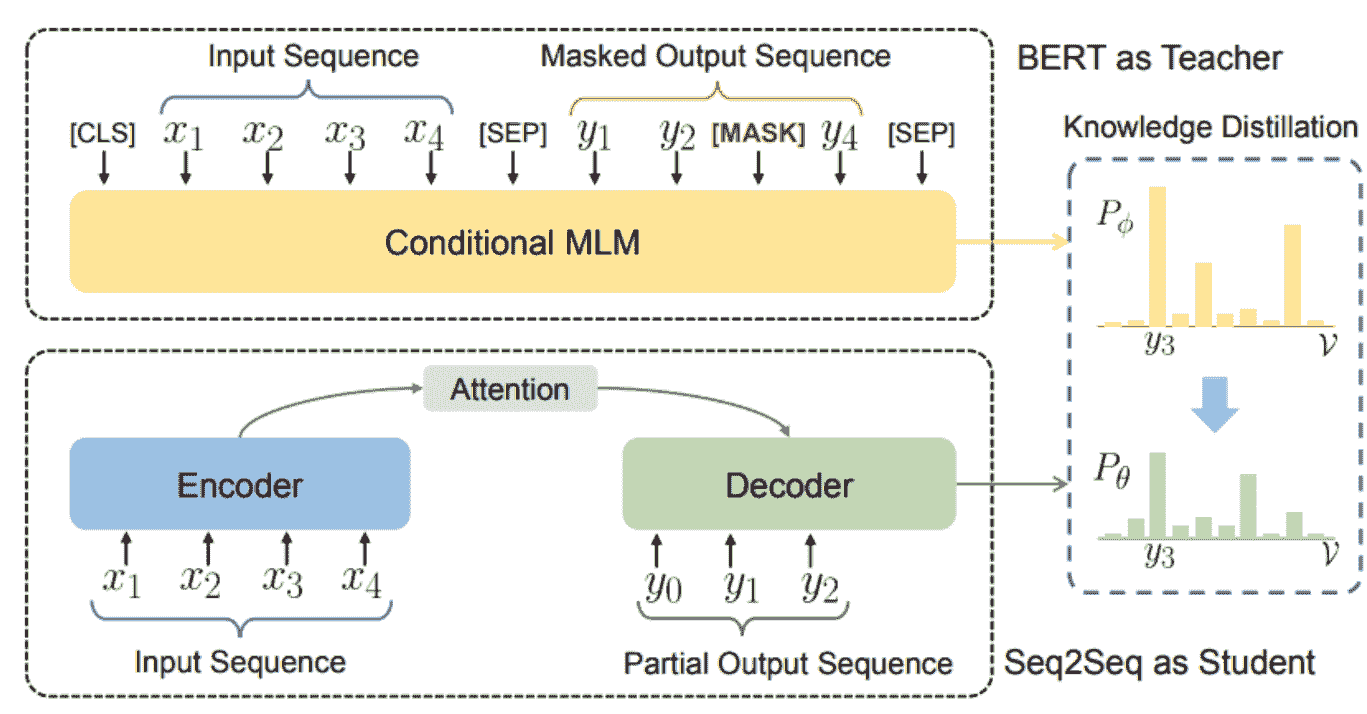
从 BERT 中提取知识以进行文本生成的示意图。 来源
此外,这里使用的知识蒸馏技术与原始蒸馏研究论文中使用的技术相同,我们在老师网络生成的软标签上训练学生网络。
那么,这篇研究论文与其他论文相比有什么突出的地方呢?以下是解释。
这里的关键思想是将 BERT 中的知识蒸馏到一个能够生成文本的学生模型,而之前的工作仅关注模型压缩以完成与老师模型相同的任务。然后,对 BERT 模型进行微调,使微调后的模型可以用于文本生成。
我们以语言翻译为例,X 是源语言句子,Y 是目标语言句子。
第一阶段: BERT 模型的微调
-
输入数据:将 X 和 Y 连接在一起,Y 中 15% 的词汇被随机屏蔽
-
标签:来自 Y 的屏蔽词汇
第二阶段: 微调 BERT 模型到 Seq2Seq 模型的知识蒸馏
-
老师:第一阶段的微调 BERT 模型
-
学生:Seq2Seq 模型,例如基于注意力的 RNN、Transformer 或任何其他序列生成模型
-
输入数据和标签:来自微调 BERT 模型的软目标
论文 3
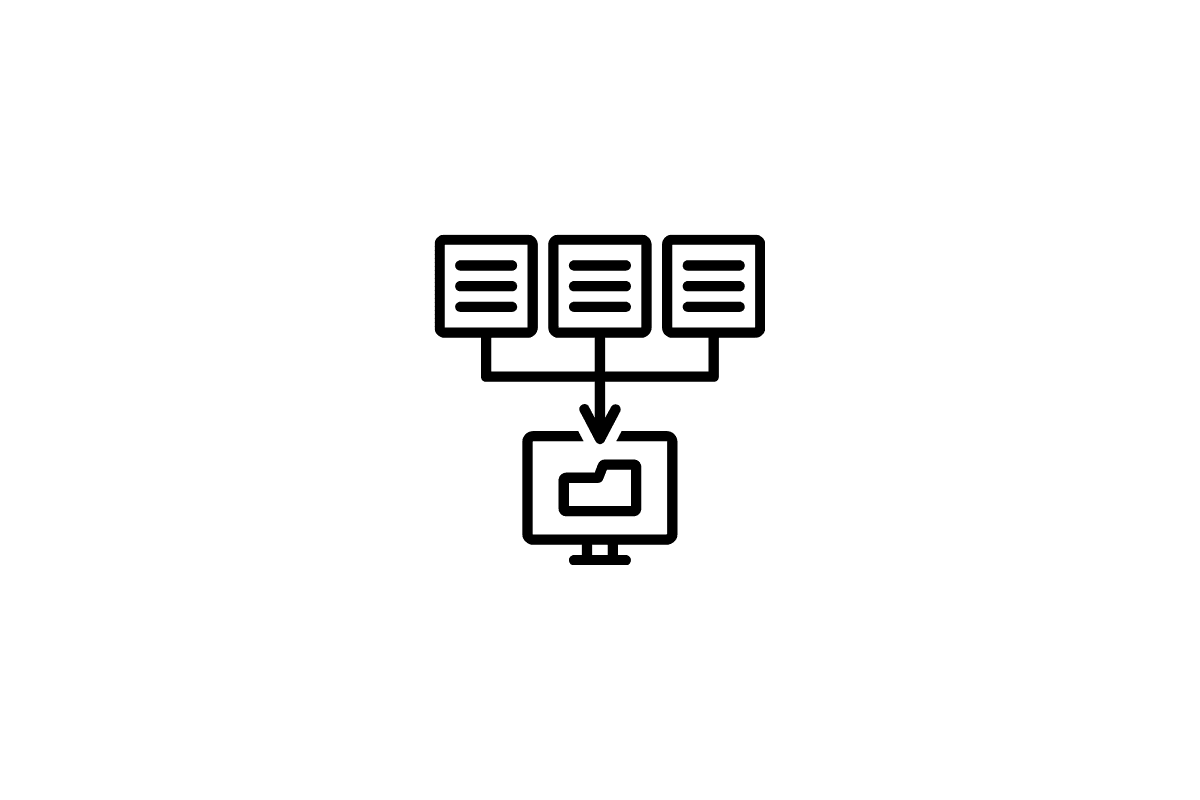
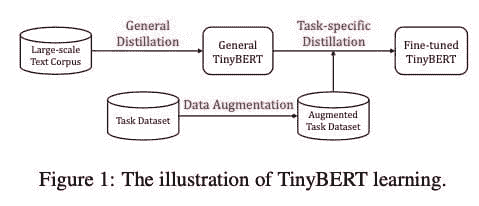
本文提出了一种新颖的 Transformer 蒸馏技术,专门用于 Transformer 基础模型的知识蒸馏 (KD)。通过利用这种新颖的 KD 方法,可以有效地将大型教师 BERT 中编码的知识转移到小型学生 Tiny-BERT 中。然后,我们引入了一个新的两阶段学习框架,用于 TinyBERT,该框架在预训练和任务特定学习阶段都执行 Transformer 蒸馏。该框架确保 TinyBERT 能够捕捉 BERT 的通用领域和任务特定知识。
具有四层的 TinyBERT 在经验上有效,其性能达到其老师 BERT-Base 在 GLUE 基准测试中的 96.8% 以上,同时体积小 7.5 倍,推理速度快 9.4 倍。四层的 TinyBERT 也明显优于 4 层最新的 BERT 蒸馏基准,仅使用约 28% 的参数和约 31% 的推理时间。此外,六层的 TinyBERT 性能与其老师 BERT-Base 相当。
此外,本文提出了三大组件用于蒸馏 Transformer 网络。
- Transformer 层蒸馏: 包括基于注意力的蒸馏和基于隐藏状态的蒸馏:
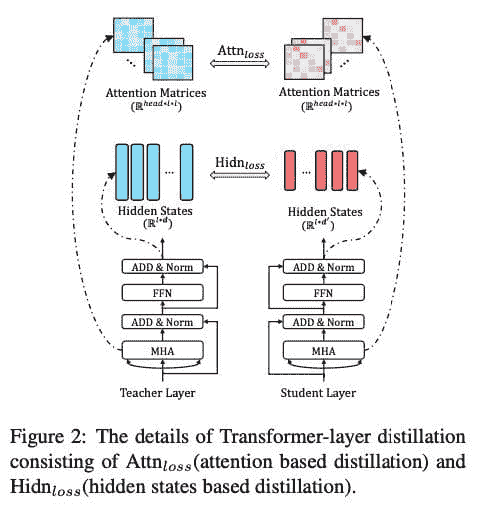
-
嵌入层蒸馏: 像对隐层状态进行蒸馏一样,对嵌入层进行知识蒸馏。
-
预测层蒸馏: 就像Hinton原作中一样,知识蒸馏是针对从教师模型中获得的预测进行的。此外,TinyBERT 模型的整体损失结合了上述三种损失:
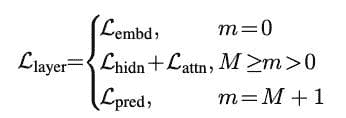
TinyBERT 训练的主要步骤如下:
-
通用蒸馏: 以未微调的原始 BERT 作为教师,并以大规模文本语料作为训练数据。现在对通用领域的文本进行 Transformer 蒸馏,得到可以进一步微调以进行下游任务的通用 TinyBERT。由于层数、神经元等较少,这种通用 TinyBERT 的表现比 BERT 差。
-
任务特定蒸馏: 以微调后的 BERT 作为教师,训练数据为任务特定训练集。
关键要点: 这是一种离线蒸馏技术,其中教师模型 BERT 已经预训练完成。然后,他们进行了两个独立的蒸馏过程:一个用于通用学习,另一个用于任务特定学习。通用蒸馏的第一步涉及对各种层的蒸馏:注意力层、嵌入层和预测层。
论文 4
FastBERT: 一种具有自适应推理时间的自蒸馏 BERT
他们提出了一种全新的可调速度的 FastBERT,具有自适应推理时间。推理时的速度可以根据不同需求灵活调整,同时避免了样本的冗余计算。此外,该模型采用了独特的自蒸馏机制进行微调,进一步提高了计算效率,同时性能损失最小。我们的模型在十二个英文和中文数据集上取得了令人满意的结果。如果在不同的加速阈值下进行速度与性能的折中,它的速度可以比 BERT 提高 1 到 12 倍的范围。
与类似工作的比较:
-
TinyBERT: 通过使用通用领域和任务特定的微调来进行两阶段学习。
-
DistilBERT: 引入了三重损失
FastBERT 的优势是什么?
该工作首次将自蒸馏(训练阶段)和自适应机制(推理阶段)技术应用于 NLP 语言模型,以提高效率。
模型架构
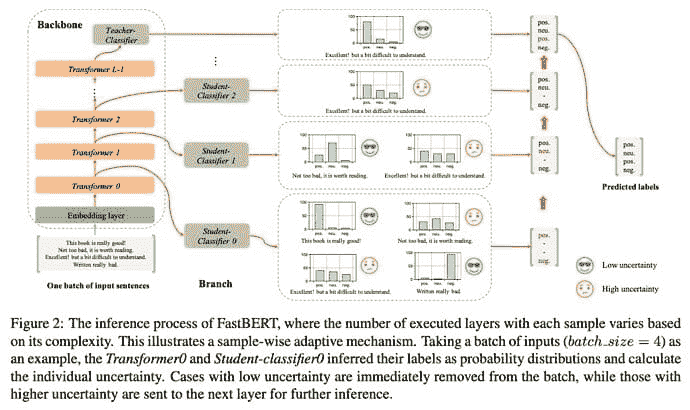
FastBERT 模型由主干和分支组成:
-
骨干:它包含三部分:嵌入层、包含 Transformer 堆栈的编码器以及教师分类器。嵌入层和编码器层与 BERT 的相同。最后,我们有一个教师分类器,用于提取任务特定的特征,以便下游任务使用软最大函数。
-
分支:这些包含学生分类器
-
具有与教师相同的架构
-
被添加到每个变压器块的输出中,以启用早期输出
训练阶段
对骨干和学生分类器使用单独的训练步骤。在一个模块训练时,另一个模块的参数始终被冻结。三步:
-
骨干预训练:使用 BERT 模型的典型预训练。这里没有变化。可以在此步骤中自由加载高质量的训练模型。
-
骨干微调:对于每个下游任务,使用任务特定的数据来微调骨干和教师分类器。在这个阶段,没有启用学生分类器。
-
学生分类器的自蒸馏:现在我们的教师模型已经训练好,我们获取其输出。这种软标签输出质量高,包含原始嵌入和概括性知识。这些软标签用于训练学生分类器。我们可以在这里自由使用无限量的未标记数据。这项工作不同于以往的工作,因为这项工作使用相同的模型作为教师和学生模型。
自适应推断
让我们谈谈推断时间。使用 FastBERT 时,推断是自适应执行的,即模型内执行的编码层数可以根据输入样本的复杂性进行调整。
在每个变压器层中,计算学生分类器输出的不确定性,并根据阈值确定是否可以终止推断。以下是自适应推断机制的工作原理:
-
在 FastBERT 的每一层中,相应的学生分类器预测每个样本的标签,并测量不确定性。
-
不确定性低于某个阈值的样本将被筛选到早期输出,而不确定性高于阈值的样本将转移到下一层。
-
阈值较高时,较少的样本被发送到更高层,以保持推断速度更快,反之亦然。
论文 5
在本文中,作者展示了即使没有架构修改、外部训练数据或额外输入特征,基础的轻量级神经网络也可以具有竞争力。他们提出将 BERT 知识蒸馏到单层双向长短期记忆网络(BiLSTM)及其同类模型,用于句子对任务。在大量的重述、自然语言推理和情感分类数据集中,他们在参数量大约少 100 倍,推理时间减少 15 倍的情况下,取得了与 ELMo 相当的结果。此外,他们的方法包括对教师和 BiLSTM 学生模型进行微调。此工作的主要动机包括:
-
简单的架构模型能否在文本建模中捕捉到与 BERT 模型相当的表示能力?
-
研究将知识从 BERT 转移到 BiLSTM 模型的有效方法。
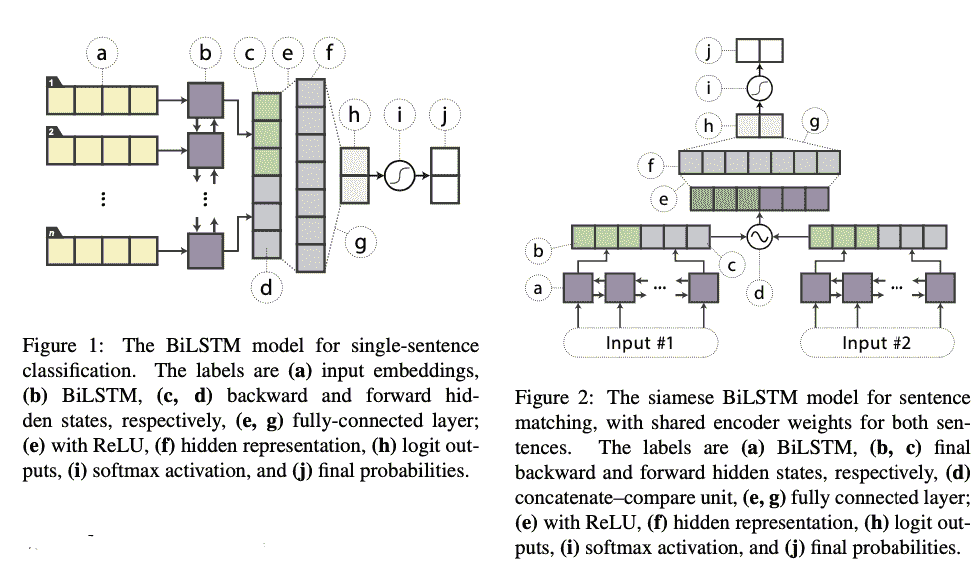
蒸馏的数据增强
小数据集可能不足以让教师完全表达其知识,因此使用从教师模型生成的伪标签的大型未标记数据集来扩充训练集。在这项工作中,提出了一些用于任务无关的数据增强的启发式方法:
-
掩码:随机将句子中的一个词替换为类似于 BERT 训练的 [MASK] 标记。
-
POS 引导的词替换:用同一词性标签的另一个词替换句子中的一个词,例如,“猪吃什么?”被扰动为“猪怎么吃?”
-
N-gram 采样:一种更激进的掩码形式,从输入示例中选择 n-gram 样本,其中 n 从 {1,2,3,4,5} 中随机选择。
论文 6
作者提出了一种患者知识蒸馏方法,将原始的大型模型(教师)压缩成一个同样有效的轻量级浅层网络(学生)。他们的方法与之前的知识蒸馏方法有很大不同,因为早期的方法仅使用教师网络最后一层的输出进行蒸馏;而我们的学生模型则耐心地从教师模型的多个中间层中学习,以进行渐进的知识提取,遵循两种策略:
-
PKD-Last:学生模型从教师的最后 k 层中学习(假设最后几层包含了对学生最重要的信息)。
-
PKD-Skip:学生模型从教师的每个 k 层中学习。
他们在多个数据集和不同的 NLP 任务上进行了实验,证明所提出的 PKD 方法比标准蒸馏方法(Hinton et al., 2015)表现更好,泛化能力更强。
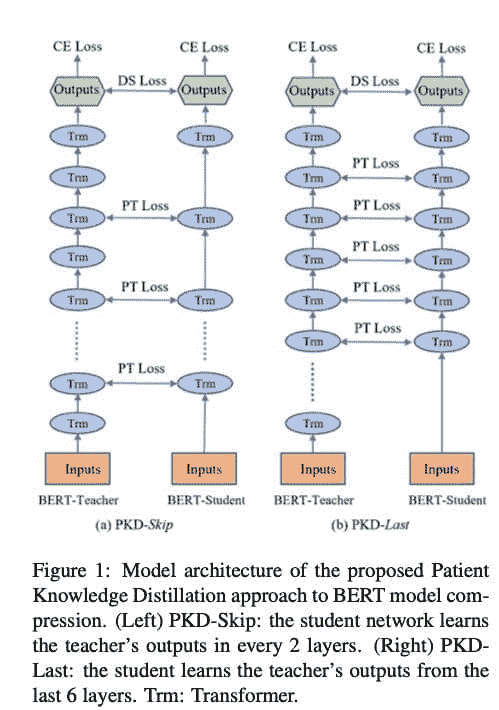
为什么不从教师模型的所有隐藏状态中学习?
原因是这可能会计算上非常昂贵,并且可能会给学生模型引入噪声。
论文 7
MobileBERT:一种紧凑的无任务专用 BERT,适用于资源受限设备
他们提出了 MobileBERT,用于压缩和加速流行的 BERT 模型。像原始 BERT 一样,MobileBERT 是不依赖任务的;即,通过简单的微调,可以通用地应用于各种下游 NLP 任务。MobileBERT 是 BERTʟᴀʀɢᴇ的精简版本,同时配备了瓶颈结构,并在自注意力机制和前馈网络之间进行了精心设计的平衡。
训练步骤
第一步: 首先训练一个特别设计的教师模型,即包含反向瓶颈的 BERTʟᴀʀɢᴇ模型。
第二步: 从这位教师模型向 MobileBERT 进行知识转移。
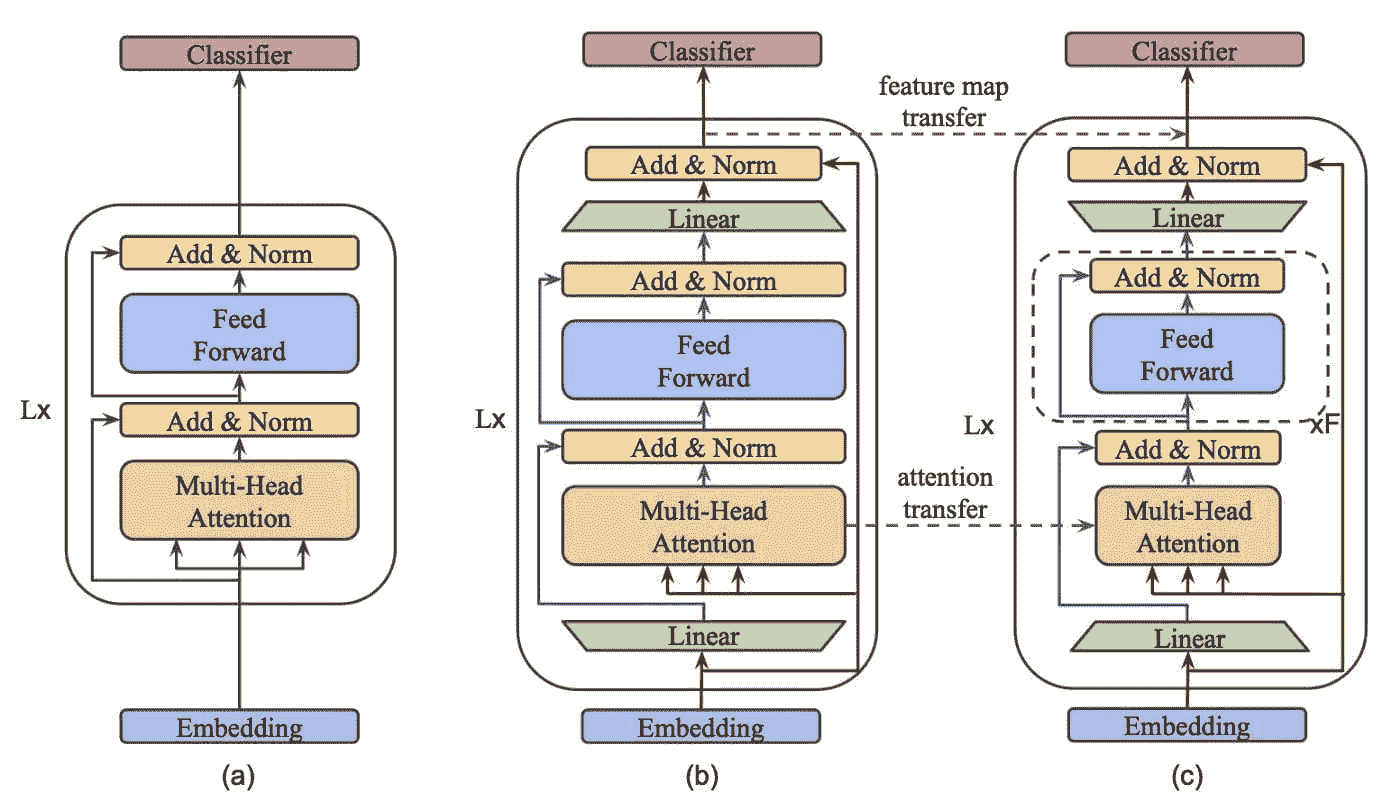
变压器块的架构可视化,如(a) BERT,(b) MobileBERT 教师,以及(c) MobileBERT 学生。标记为“Linear”的绿色梯形图被称为瓶颈。来源
(a) BERT;(b) 反向瓶颈 BERT(IB-BERT);以及© MobileBERT。在(b)和©中,红色线条表示块间流动,而蓝色线条表示块内流动。MobileBERT 通过逐层模仿 IB-BERT 进行训练。
如果你读到这里,你值得一个击掌。MobileBERT 在变压器块中展示了瓶颈,这使得从更大的教师模型中提取知识到更小的学生模型的过程更加平滑。这种方法减少了学生模型的宽度,而不是深度,这在给定的实验中产生了更高效的模型。MobileBERT 强调了这样一个信念,即在初始蒸馏过程之后,确实可以使学生模型进行微调。
此外,结果还表明,这在实践中也成立,因为 MobileBERT 可以在 GLUE 上达到 BERT-base 99.2%的性能,同时参数减少 4 倍,并且在 Pixel 4 手机上的推理速度快 5.5 倍!
论文 8
论文的关键关注点如下:
-
训练一个多任务神经网络模型,该模型结合了多个自然语言理解任务的损失。
-
从第一步生成多个模型的集成,这些模型本质上是通过从头开始训练多个多任务模型获得的。
-
最终步骤是对前一步的模型集进行知识蒸馏。
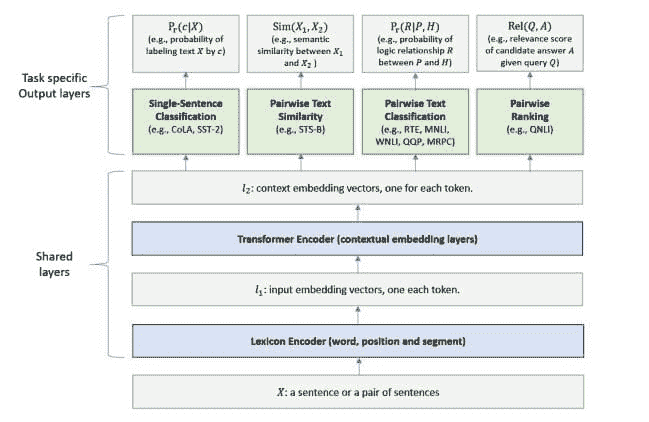
MT-DNN 模型用于表示学习的架构 (Liu et al., 2019)。较低层在所有任务中共享,而顶部层则是任务特定的。输入 X(可以是一个句子或一组句子)首先表示为一系列嵌入向量,每个单词一个,在 l1 层中。然后,Transformer 编码器捕捉每个单词的上下文信息,并在 l2 层中生成共享的上下文嵌入向量。最后,额外的任务特定层生成每个任务的任务特定表示,随后进行分类、相似性评分或相关性排序所需的操作。来源
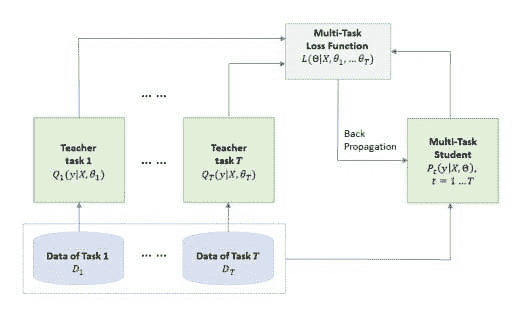
多任务学习的知识蒸馏过程。选择一组具有任务特定标签训练数据的任务。然后,为每个任务训练一个不同的神经网络(教师)。教师用于生成每个任务特定训练样本的一组软目标。考虑到多个任务的训练数据集的软目标,使用多任务学习和反向传播来训练一个单一的 MT-DNN(学生),如算法 1 所述,除了如果任务 t 有教师,则第 3 行的任务特定损失是两个目标函数的平均值,一个用于正确目标,另一个用于教师分配的软目标。来源
成就:在 GLUE 数据集上,蒸馏的 MT-DNN 在 9 个自然语言理解任务中的 7 个任务上创造了新的最先进结果,包括没有教师的任务,将 GLUE 基准(单模型)推高到 83.7%。
我们展示了蒸馏的 MT-DNN 几乎保留了由集成模型所取得的所有改进,同时保持模型大小与原始 MT-DNN 模型相同。
附注
现代最先进的自然语言处理模型在生产中难以应用。知识蒸馏提供了应对这些问题及其他问题的工具,但它也有其独特之处。
参考文献
-
提高几乎任何机器学习算法性能的一个非常简单的方法是训练多种不同的模型……arxiv.org](https://arxiv.org/abs/1503.02531)
-
我们介绍了一种新的语言表示模型,称为 BERT,代表双向编码器表示…arxiv.org](https://arxiv.org/abs/1810.04805)
-
大规模预训练语言模型如 BERT 在语言理解任务中取得了巨大成功…arxiv.org](https://arxiv.org/abs/1911.03829)
-
DistilBERT,一个 BERT 的蒸馏版本:更小、更快、更便宜、更轻量
随着大规模预训练模型在自然语言处理(NLP)中的迁移学习变得越来越普遍…arxiv.org](https://arxiv.org/abs/1910.01108)
-
语言模型预训练,如 BERT,显著提升了许多自然语言处理任务的性能…arxiv.org](https://arxiv.org/abs/1909.10351)
-
提高几乎所有机器学习算法性能的一种非常简单的方法是训练许多不同的模型…arxiv.org](https://arxiv.org/abs/1503.02531)
-
预训练语言模型如 BERT 已被证明非常高效。然而,它们通常在计算上…arxiv.org](https://arxiv.org/abs/2004.02178)
-
在自然语言处理文献中,神经网络变得越来越深且复杂。最近…arxiv.org](https://arxiv.org/abs/1903.12136)
-
预训练语言模型如 BERT 已被证明在自然语言处理(NLP)中非常有效…arxiv.org](https://arxiv.org/abs/1908.09355)
-
提高几乎所有机器学习算法性能的一种非常简单的方法是训练许多不同的模型…arxiv.org](https://arxiv.org/abs/1503.02531)
-
MobileBERT:一种紧凑型任务无关 BERT,适用于资源受限设备
自然语言处理(NLP)最近通过使用具有数百亿参数的大型预训练模型取得了巨大成功…arxiv.org](https://arxiv.org/abs/2004.02984)
-
本文探讨了使用知识蒸馏来改进多任务深度神经网络(MT-DNN)(Liu et al…arxiv.org](https://arxiv.org/abs/1904.09482)
"这里表达的观点是 Mr. Abhishek 的个人观点,与他的雇主无关"
Kumar Abhishek 是 Expedia 的机器学习工程师,专注于欺诈检测和预防领域。他使用机器学习和自然语言处理模型进行风险分析和欺诈检测。他拥有超过十年的机器学习和软件工程经验。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 部门
更多相关话题
为你的数据科学初创公司打造电梯演讲
原文:
www.kdnuggets.com/2019/08/elevator-pitch-data-science-startup.html
评论
作者:Estelle Liotard,市场营销专家和商业顾问。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
“电梯演讲”一词最初来源于企业家和小企业主在被问到“你做什么?”时,发展出一个 30 秒的演讲。这可能发生在社交场合和活动等地方。这是企业主/企业家提供非常简短(因此,30 秒)解释他们向客户或客户提供的价值的机会,然后递交名片。这一活动一直被视为“传播信息”的工具,而不是寻求资金的工具。
电梯演讲的扩展
随着时间的推移,电梯演讲的定义已经显著扩展,现在不仅仅指对那个简单问题的简短回答。它已扩展到初创公司创始人在寻求资金时使用的演讲。显然,这种类型的演讲更长、更详细,发生在创始人寻求种子资金以启动或寻求额外资金以扩展时。
作为数据科学创始人,你处于一个相当有利的位置。这个领域还足够新,以至于投资者希望将资金投入那些能够为无法雇佣自己数据科学家的中小型企业提供这些服务的初创公司。你在这个市场上尚未面临巨大竞争,如果你能做好演讲,那将使你处于有利位置。
基础知识
尽管电梯演讲已经扩展,场所也发生了变化,但在你开始制定具体演讲之前,你必须识别一些基本要素。以下是这些要素:
-
对你的公司做出有力声明。你是谁,你在做什么?简洁明了。
-
提供一个问题陈述。你为目标受众解决了什么问题?就数据科学服务而言,你显然是在解决获取大数据的问题。
-
你带来的是怎样的价值?这就是对那个问题陈述的解决方案。
-
注意你对自己所做的事情和解决的问题的描述。投资者不是技术专家,他们不一定理解算法、人工智能、预测模型等术语。在描述你所做的事情时,用所有人都能理解的通俗语言进行说明。一个好的建议?查看一些成功的初创公司推介示例。

新旧基础的变化
启动一家初创公司所需的资金比以前少得多。因此,许多创始人使用种子资金(他们自己、家庭、朋友、短期小额贷款、众筹等)来开发至少一个 MVP(最小可行产品),然后通过获取少量客户/客户来展示它是一个可行的产品。
这很重要。投资者希望看到产品/服务是可行的证据。你可以这样做:
-
“展示,不要仅仅说明。” 不要只是说你的数据科学初创公司将提供什么。展示它为你现有的少数客户提供了什么,或者提供一个视觉演示,展示你的数据科学服务的某个特定方面如何解决问题。否则,展示一些来自初期客户的统计数据。例如,“在我们最初引入的 15 位客户中,所有 15 位在合作满一年后仍继续使用我们的服务。”
-
投资者的获取方式发生了剧变。过去,寻找投资者是一个相当隐秘的过程。你需要认识一个认识可能感兴趣的人。互联网改变了这一切。通过众筹平台、“天使投资人”名单、招募提案的开放活动等,你可以轻松找到潜在的资助者,并设计你的提案以单独接触目标投资者。此外,网络交流可以在线进行,不再受地理位置限制。
-
推介的新格式。推介活动,即创始人在舞台上向投资者展示他们的推介,仍然是一种常见的方式。但许多创始人变得更加主动。他们创建了可以嵌入到网站中的视频推介,同时可以发送和发布到各个地方,无需实体出席。考虑一下接触外国投资者的可能性——这是一个全新的融资世界,特别是在技术领域,如数据科学。
竞争非常激烈
你可能拥有一支出色的数据科学团队,并且你可能为需要你服务的企业提供了惊人的解决方案。但除非你能以吸引人且有说服力的方式展示自己,否则你只是另一个寻求资金的创始人——而这样的创始人有很多。
- 做你自己,但也要融入他们
无论你是写一个电梯推介以口头形式向潜在投资者展示,还是为视频演示准备脚本,你都需要一个扎实的推介元素和你的声音,否则你会显得不够真诚。这对那些不一定擅长文字的技术人员来说具有挑战性。正如Studicus的编剧 Susan Johnston 所说:“我们有很多客户拥有惊人的概念和想法,但他们无法将这些转化为引人入胜的声音。技术人员常常处于这种情况。他们需要获得专业帮助,因为他们的声音必须真实,同时也是潜在客户和投资者可以理解的。”
- 你不是一个编剧或市场营销人员
电梯推介需要一个脚本——你对公司热情的展示是不够的。如果你打算制作一个视频演示(并且你必须这样做),那么要明白它必须既专业又个人化,这取决于你的受众。你需要研究这些受众,也许为每个受众开发独特的脚本。然后,脚本必须在演讲前写好并练习。再次,专业帮助可能是必要的。Joe Lesinski,WowGrade的客户编剧,这样说道:“编写脚本是一项特定技能,大多数人没有。任何没有这种技能的人都会失败。如果你打算吸引观众,最好找一个有经验的市场营销视频脚本编剧。”
关键在于:投资者和资助者每天都会收到大量的提案——成百上千个。你必须在这些竞争中脱颖而出,而你惊人的数据科学技能并不足以打动他们。沟通是可能最具挑战性的关键因素。遵循这些指南,你的成功机会将大大增加。
个人简介: Estelle Liotard 首先是一位市场营销专家,她曾与多个企业合作,从创办开始。根据她的经验,她还转向写作,讲述公司如何启动、获得资金和成长。她是多个博客的常客撰稿人,也是Trust My Paper的编辑部成员,这是一家与学生和企业合作的写作服务机构。
相关:
相关主题
ELMo:上下文化语言嵌入
原文:
www.kdnuggets.com/2019/01/elmo-contextual-language-embedding.html
评论
由Josh Taylor撰写,高级分析专家
使用最先进的 ELMo 自然语言模型进行语义句子相似性分析
本文将探讨自然语言建模的最新进展——深度上下文化词嵌入。重点在于实践而非理论,包含了如何使用最先进的 ELMo 模型来审查给定文档中的句子相似性,以及创建一个简单的语义搜索引擎的实际示例。完整代码可以在 Colab 笔记本中查看,链接在这里。
上下文在自然语言处理中的重要性
我们知道,语言是复杂的。上下文可以完全改变句子中单个词的含义。例如:
他踢翻了桶。
我还没有完成我人生愿望清单上的所有项目。
桶里装满了水。
在这些句子中,虽然“桶”这个词始终相同,但其含义却大相径庭。

词语的含义可能会根据上下文而有所不同
尽管我们可以轻松解读这些语言中的复杂性,但创建一个可以理解给定文本周围词语不同细微含义的模型却很困难。
正因如此,传统的词嵌入(如 word2vec、GloVe、fastText)显得力不从心。它们每个词只有一种表示,因此无法捕捉每个词在不同上下文中含义的变化。
介绍 ELMo:深度上下文化词表示
ELMo 应运而生。ELMo 由 AllenNLP 于 2018 年开发,超越了传统的嵌入技术。它使用深度双向 LSTM 模型来创建词表示。
与其说 ELMo 拥有一个词汇表及其对应向量,不如说 ELMo 在词语使用的上下文中进行分析。它还是基于字符的,使模型能够形成对超出词汇表范围的词的表示。
因此,ELMo 的使用方式与 word2vec 或 fastText 截然不同。ELMo 不是通过字典“查找”词及其对应的向量,而是通过将文本传递给深度学习模型即时创建向量。
一个实际示例,5 分钟内 ELMo 的实际应用
让我们开始吧!我会在这里添加主要的代码片段,但如果你想查看完整的代码集(或者确实想体验点击笔记本中每个单元格的奇妙感觉),请查看相应的 Colab 输出。
根据我最近几篇文章,我们将使用的数据基于现代奴隶制的报告。这些是公司必须发布的声明,用以说明它们如何在内部及其供应链中解决现代奴隶制问题。我们将在本文中深入分析 ASOS 的报告(一个英国的在线时尚零售商)。
如果你对查看其他与此数据集相关的 NLP 实验感兴趣,这些实验正在快速成为一个迷你系列,我在本文末尾包含了这些文章的链接。
1. 获取文本数据,清理并分词
使用 Python 字符串函数和 spaCy 来做到这一点是如此简单。这里我们通过以下方式进行一些基本的文本清理:
a) 移除换行符、制表符和多余的空白,以及神秘的‘xa0’字符;
b) 使用 spaCy 的‘.sents’迭代器将文本拆分成句子。
ELMo 可以接收一个句子字符串列表或一个列表的列表(句子和单词)。在这里,我们选择了前者。我们知道 ELMo 是基于字符的,因此对单词进行分词应该不会影响性能。
nlp = spacy.load('en_core_web_md')
#text represents our raw text document
text = text.lower().replace('\n', ' ').replace('\t', ' ').replace('\xa0',' ') #get rid of problem chars
text = ' '.join(text.split()) #a quick way of removing excess whitespace
doc = nlp(text)
sentences = []
for i in doc.sents:
if len(i)>1:
sentences.append(i.string.strip()) #tokenize into sentences
2. 使用 TensorFlow Hub 获取 ELMo 模型:
如果你还没遇到 TensorFlow Hub,它是一个极大的时间节省工具,用于提供大量的预训练模型以供 TensorFlow 使用。幸运的是,其中一个模型是 ELMo。我们只需两行代码即可加载一个完全训练好的模型。多么令人满意啊……
url = "https://tfhub.dev/google/elmo/2"
embed = hub.Module(url)
然后,要使用这个模型,我们只需多写几行代码,将其指向我们的文本文件并创建句子向量:
# This tells the model to run through the 'sentences' list and return the default output (1024 dimension sentence vectors).
embeddings = embed(
sentences,
signature="default",
as_dict=True)["default"]
#Start a session and run ELMo to return the embeddings in variable x
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
sess.run(tf.tables_initializer())
x = sess.run(embeddings)
3. 使用可视化来检查输出的准确性
可视化被忽视作为获得数据更深入理解的一种方式,这真是太惊人了。图片胜过千言万语,我们将创建一个千言万语的图表来证明这一点(实际上是 8,511 个单词)。
在这里,我们将使用 PCA 和 t-SNE 将 ELMo 输出的 1,024 维降到 2,以便我们可以查看模型的输出。如果你想了解更多,我在文章末尾包含了进一步的阅读材料。
from sklearn.decomposition import PCA
pca = PCA(n_components=50) #reduce down to 50 dim
y = pca.fit_transform(x)
from sklearn.manifold import TSNE
y = TSNE(n_components=2).fit_transform(y) # further reduce to 2 dim using t-SNE
使用惊人的 Plotly 库,我们可以在短时间内创建一个美丽的交互式图表。下面的代码展示了如何呈现我们降维的结果,并将其与句子文本结合起来。颜色也根据句子长度添加。由于我们使用的是 Colab,最后一行代码下载了 HTML 文件。可以在下面找到:
[句子编码
交互式句子嵌入 drive.google.com](https://drive.google.com/open?id=17gseqOhQl9c1iPTfzxGcCfB6TOTvSU_i)
创建这个的代码如下:
import plotly.plotly as py
import plotly.graph_objs as go
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
init_notebook_mode(connected=True)
data = [
go.Scatter(
x=[i[0] for i in y],
y=[i[1] for i in y],
mode='markers',
text=[i for i in sentences],
marker=dict(
size=16,
color = [len(i) for i in sentences], #set color equal to a variable
opacity= 0.8,
colorscale='Viridis',
showscale=False
)
)
]
layout = go.Layout()
layout = dict(
yaxis = dict(zeroline = False),
xaxis = dict(zeroline = False)
)
fig = go.Figure(data=data, layout=layout)
file = plot(fig, filename='Sentence encode.html')
from google.colab import files
files.download('Sentence encode.html')
通过这个可视化,我们可以看到 ELMo 在按语义相似性分组句子方面做得非常出色。实际上,模型的效果非常令人惊讶:
下载 HTML 文件(链接见上)以查看 ELMo 的实际效果
4. 创建一个语义搜索引擎:
现在我们对我们的语言模型运行良好充满信心,让我们在语义搜索引擎中发挥作用。其理念是让我们通过文本的语义接近度而非关键字来进行搜索。
这实际上很简单:
-
首先,我们获取一个搜索查询,并对其运行 ELMo;
-
然后,我们使用余弦相似度将其与文本文件中的向量进行比较;
-
然后,我们可以返回与搜索查询最接近的
n个匹配结果。
Google Colab 提供了一些出色的功能来创建适合此用例的表单输入。例如,创建输入只需在变量后添加 #@param。下面展示了一个字符串输入的示例:
search_string = "example text" #@param {type:"string"}
除了使用 Colab 表单输入,我还使用了‘IPython.display.HTML’来美化输出文本,并使用一些基本的字符串匹配来突出显示搜索查询与结果之间的常见词汇。
让我们来检验一下。让我们看看 ASOS 在其现代奴隶制报告中关于伦理规范的做法:

只需几分钟即可创建一个完全互动的语义搜索引擎!
这太神奇了!这些匹配结果超越了关键字,搜索引擎显然知道‘伦理’和伦理相关词之间的紧密关系。我们找到了有关诚信规范以及伦理标准和政策的匹配结果。它们都与我们的搜索查询相关,但并不是基于关键字直接链接的。
希望你喜欢这篇文章。如果你有任何问题或建议,请留下评论。
进一步阅读:
以下是我在如今逐渐形成的自然语言处理和公司现代奴隶制报告迷你系列中的其他帖子:
[使用无监督机器学习清理数据]
清理数据不一定要痛苦!这篇文章是如何使用无监督机器学习的一个快速示例…… towardsdatascience.com
[提升词向量]
在您的自然语言处理项目中提升 fastText 和其他词向量的简单技巧 towardsdatascience.com
要了解更多关于降维过程的信息,我推荐以下帖子:
[使用 PCA 和 t-SNE 在 Python 中可视化高维数据集]
围绕任何数据相关挑战的第一步是从数据本身开始探索。这可以通过查看…… medium.com
最后,关于最先进的语言模型,下面的内容是值得一读的:
jalammar.github.io/illustrated-bert/
简介:Josh Taylor (@josh_taylor_01) 是一位通过先进分析、机器学习和可视化技术生成洞见的专家,目前为女王陛下的政府工作。所有观点均为个人意见。
原始内容。经授权转载。
相关:
-
词嵌入与自监督学习,解释说明
-
自然语言处理任务的数据表示
-
2018 年数据科学领域的前 20 大 Python 库
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
更多相关主题
Emacs 用于数据科学
评论
作者:罗伯特·维斯科。
如果你需要一个能够支持 R、Python、SAS、Stata、SQL 以及几乎所有其他数据科学语言的编辑器。如果你需要一个具有 IDE 类特性的编辑器。如果你需要一个能够在任何平台以及终端上工作的编辑器。如果你是文学化编程的爱好者。如果你需要一个高度可定制的编辑器,并且这个编辑器能够在大多数编辑器消失后依然存在,那么你可能很难找到比 Emacs 更好的选择。
如果你完全在 R 环境下工作,你可能会考虑使用Rstudio。如果你使用 Python,你可能会被Spyder所吸引。通常,针对你所使用的语言可能会有专门的 IDE。但这就是问题所在。如果你想要使用其他语言呢?或者需要组合使用多种语言?你可能会使用多个 IDE,却不熟悉它们。而且,一旦这些 IDE 过时或停止更新,你辛苦获得的知识就会丢失。另一端则是像 Notepad++ 和 Sublime 这样的文本编辑器。这些编辑器可以与几乎所有你能想象的语言一起使用,并且通过一些插件可以获得额外的功能,但它们通常仅限于某些平台,且定制化往往并非易事。
现代数据科学家通常需要在多个平台上使用多种语言。一些项目可能在 R 中,其他项目则在 Python 中。或者你需要在没有图形界面的集群上工作。或者你可能需要用 LaTeX 写论文。你可以用 Emacs 完成这些工作,并根据需要进行定制。不过,我不会撒谎。学习曲线可能会很陡峭,但我认为这个投资是值得的。
下面是一些我认为使 Emacs 成为任何数据科学家出色编辑器的关键特性。
类似 IDE 的功能
对于大多数编程语言,你可以直接获得语法高亮功能。像ESS和Elpy这样的包提供了额外的功能,如自动补全、文档和调试能力。可用的 IDE 功能数量会因语言而异,但至少应该有语法高亮和某种形式的自动补全。
图 1:“自动补全”
我喜欢的一点是轻松访问帮助和函数参数……这些通常也伴随着自动补全。
图 2:“函数帮助”
图 3:“函数参数帮助”
别再使用打印语句了,调试一下你的 R 和 Python 代码吧!

图 4:“使用条件断点进行交互式调试”
让我对 Emacs 的第一个吸引我的特性之一就是交互式命令。通过一个键盘快捷键,你可以将缓冲区、函数、段落或行发送到解释器。让我明确一点——你甚至不需要高亮代码。这在进行统计分析时节省了大量时间^(1)。

图 5:“交互式命令”
SQL 也如此
你在处理数据库吗?上述许多相同的好处也适用于 SQL。与 sqlite、postgresql、mysql 以及其他数据库进行交互。你有一个长 SQL 语句在调试吗?没问题。快速迭代。

图 6:“交互式 SQL”
Org mode / 文学编程
你写出版物吗?你想将代码和论文一起保存吗?你相信可重复研究吗?使用 Emacs,你可以在文档中放入任何你想要的语言。虽然 Rstudio 也允许这样做,但你仅限于 R 和 LaTeX。

图 7:“文学编程:代码与 Stata”
你需要 LaTeX 吗?没问题。
#+BEGIN_LaTeX\frac{3}{4}#+END_LaTeX
这一魔法的关键是一个叫做 org mode 的庞大软件包。它是 Emacs 的杀手级功能之一。你还可以用它来组织你的代码……或者你的生活。
终端/远程编辑
有时候你需要远程连接到服务器。或者你可能在一个没有 GUI 的集群上工作,需要交互式调试脚本。

图 8:“在终端中同样有效”
与 Shell 交互
有没有一个终端命令是你希望能运行的?在 Emacs 中,你可以轻松运行终端命令。但使这个功能特别酷的是,它可以对你的文本进行操作。你可以选择一段代码,将其发送到终端命令,然后让其标准输出替换你缓冲区中的文本!
图 9:“使用 SED 查找并替换缓冲区中的文本”
矩形编辑
数据科学家经常处理表格数据。有时候你可能需要删除或移动某一列。或者也许有一块空白区域你需要修改。

图 10:“使用矩形模式来修改文本块”
一切尽在你的指尖
Emacs 拥有众多包,允许你搜索和查找文件、函数以及你能想到的任何东西。但目前最好的还是 helm。只需按下几个键,你就可以瞬间找到你要找的东西。我无法充分展示它的强大,但这个演示让你体验到它的惊人功能。
tuhdo.github.io/helm-intro.html
任何你想要的功能
也许你习惯了 sublime 的多光标功能?你可以实现这个功能:emacsrocks.com/。或者你是一个长期使用 vim 的用户?Evil Mode 让你可以享受 Vim 的编辑能力,同时拥有 emacs 的实用性。如果你是 git 用户,Emacs 有 magit,可以让你愉快地使用 git。如果它缺少某些功能,查看是否有相关包,否则 emacs 是你能找到的最具可定制性的编辑器。几乎所有关于它的功能都可以根据你的工作流程进行调整。
超过 30 年历史和广泛的用户基础
Emacs 已经存在很长时间了。十年前写的代码大多仍然有效。而且每年都在变得更好。然而,emacs24 非常棒。如果你多年前尝试过 emacs,应该再试一次。它现在内置了包管理功能,所以你可以轻松地添加测试包。重要的是,没有迹象表明 emacs 会很快消失,而且它是免费的。它可能会再存在至少十年,甚至更久。
那么它的缺点是什么?
网络上的遗留代码让人困惑
Emacs 已经存在很长时间了。Emacs 24 是一次巨大的改进,但也破坏了许多东西。Org-mode 从版本 7 到 8 之间也是如此。很多网络上的资料可能会让你感到困惑和沮丧,如果你不了解这一点。
使用 Emacs-lisp 进行定制
我实际上喜欢使用 lisp,因为它与我工作的其他语言非常不同。然而,许多人可能更喜欢使用像 python 这样的语言。
不适合新手/小白
Emacs 并不像那个总是笑容满面的兄弟。第一次接触可能会让人感到痛苦和尴尬。它不是一种绝对完美的工具。不过,还是有几个初学者包可以开箱即用,提供有用的功能。对于科学家来说,Kieran Healy 的初学者包可能很有用:kieranhealy.org/resources/emacs-starter-kit/
另一个有用的包是 prelude:github.com/bbatsov/prelude
如果你在 Mac 上,我听说 aquamacs 可以让你感到温暖和舒适:aquamacs.org/
这些大多数包都能让你迅速体验到 emacs 的强大。就我个人而言,我更喜欢从头开始构建我的 emacs,使它只做我想让它做的事,但这些包是体验其强大功能的好方法。
多个包
如果你决定使用 Python,准备好尝试各种不同的 Python 包。虽然 emacs 具有基本的 Python 支持,但你可能会需要代码检查、重构或其他有用的功能。许多包尝试实现这些功能,有些比其他的做得更好。就个人而言,我喜欢 Elpy,但它并不完美。选项的缺点是你必须浏览它们,这有时可能会很痛苦。
我遗漏了什么?
尽管我尽力包括了我认为会吸引数据科学家的大部分功能,但如果我遗漏了任何重要功能,请告诉我,我会尽力在这里加入。twitter.com/robertvesco
脚注:
^(1 像许多其他功能一样,这将取决于你安装的包。也就是说,为你喜欢的语言实现这个功能很简单。
个人简介: Robert Vesco 是一名博士候选人,正转回到工业界。
相关:
-
R 与 Python 在数据科学中的对决: 胜者是…
-
按受欢迎程度排序的前 20 个 R 包
-
21 个必备的数据可视化工具
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关内容
电子邮件垃圾邮件过滤:使用 Python 和 Scikit-learn 的实现
原文:
www.kdnuggets.com/2017/03/email-spam-filtering-an-implementation-with-python-and-scikit-learn.html

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 事务
文本挖掘(从文本中提取信息)是一个广泛的领域,随着大量文本数据的生成而获得了普及。许多应用程序的自动化,如情感分析、文档分类、主题分类、文本摘要、机器翻译等,已经通过机器学习模型实现。
垃圾邮件过滤是一个初学者的文档分类任务示例,它涉及将电子邮件分类为垃圾邮件或非垃圾邮件(也称为正常邮件)。你的 Gmail 帐户中的垃圾邮件箱是最好的例子。所以,让我们开始在公开的邮件语料库上构建垃圾邮件过滤器。我已经从 Ling-spam 语料库 中提取了相等数量的垃圾邮件和非垃圾邮件。我们将使用的提取子集可以从 这里 下载。
我们将通过以下步骤来构建这个应用程序:
-
准备文本数据。
-
创建词典。
-
特征提取过程
-
训练分类器
此外,我们将检查在创建的子集上的测试集结果。
1. 准备文本数据。
这里使用的数据集被分成了一个包含 702 封邮件的训练集和一个包含 260 封邮件的测试集,两者在垃圾邮件和正常邮件之间均等分配。你可以很容易地识别垃圾邮件,因为它的文件名中包含 spmsg。
在任何文本挖掘问题中,文本清理是第一步,我们会从文档中移除那些可能对我们要提取的信息没有贡献的词汇。电子邮件可能包含许多不必要的字符,如标点符号、停用词、数字等,这些在检测垃圾邮件时可能没有帮助。Ling-spam 语料库中的电子邮件已经通过以下方式进行了预处理:
a) 停用词的移除 – 停用词如“and”、“the”、“of”等在所有英语句子中都非常常见,在决定垃圾邮件或合法状态时并不太有意义,因此这些词已从邮件中移除。
b) 词形还原 – 这是将一个词的不同变形形式归为一类,以便将其作为单个项进行分析的过程。例如,“include”、“includes”和“included”都会被表示为“include”。与词干提取(另一种文本挖掘中的流行词,未考虑句子意义)不同,词形还原也会保留句子的上下文。
我们仍然需要从邮件文档中删除诸如标点符号或特殊字符等非单词。有几种方法可以做到这一点。在这里,我们将在创建字典后删除这些单词,这是一种非常方便的方法,因为有了字典后,你只需要删除每个这样的单词一次。所以,干杯!!到目前为止,你无需做任何事情。
2. 创建词典。
数据集中一个示例邮件如下所示:
Subject: posting
hi , ' m work phonetics project modern irish ' m hard source . anyone recommend book article english ? ' , specifically interest palatal ( slender ) consonant , work helpful too . thank ! laurel sutton ( sutton @ garnet . berkeley . edu
可以看到,邮件的第一行是主题,第3行包含邮件正文。我们将仅对内容进行文本分析,以检测垃圾邮件。作为第一步,我们需要创建一个单词及其频率的字典。为此任务,使用了700封邮件的训练集。这个 Python 函数会为你创建字典。
def make_Dictionary(train_dir):
emails = [os.path.join(train_dir,f) for f in os.listdir(train_dir)]
all_words = []
for mail in emails:
with open(mail) as m:
for i,line in enumerate(m):
if i == 2: #Body of email is only 3rd line of text file
words = line.split()
all_words += words
dictionary = Counter(all_words)
# Paste code for non-word removal here(code snippet is given below)
return dictionary
一旦字典创建完成,我们可以在上述函数中添加几行代码,以删除我们在第 1 步中讨论的非单词。我还删除了字典中那些无关的荒谬单字符。不要忘记将下面的代码插入到def make_Dictionary(train_dir)函数中。
list_to_remove = dictionary.keys()
for item in list_to_remove:
if item.isalpha() == False:
del dictionary[item]
elif len(item) == 1:
del dictionary[item]
dictionary = dictionary.most_common(3000)
可以通过命令print dictionary查看字典。你可能会发现一些荒谬的词频很高,但不用担心,这只是一个字典,你总有机会在之后改进它。如果你正在使用提供的数据集来跟随这个博客,请确保你的字典中包含下面列出的最常见词汇。我在字典中选择了3000个最常用的单词。
[('order', 1414), ('address', 1293), ('report', 1216), ('mail', 1127), ('send', 1079), ('language', 1072), ('email', 1051), ('program', 1001), ('our', 987), ('list', 935), ('one', 917), ('name', 878), ('receive', 826), ('money', 788), ('free', 762)
3. 特征提取过程。
一旦字典准备好,我们可以为训练集中的每封邮件提取3000维的词频向量(我们的特征)。每个词频向量包含训练文件中3000个单词的频率。当然你现在可能已经猜到,大多数词频会是零。让我们举个例子。假设我们的字典中有500个单词。每个词频向量包含训练文件中500个字典单词的频率。假设训练文件中的文本是“Get the work done, work done”,那么它将被编码为[0,0,0,0,0,…….0,0,2,0,0,0,……,0,0,1,0,0,…0,0,1,0,0,……2,0,0,0,0,0]。在这里,所有词频都放在500长度词频向量的第296、359、415、495个索引处,其余为零。
以下的 python 代码将生成一个特征向量矩阵,其中行表示 700 个训练集文件,列表示 3000 个词典中的单词。索引‘ij’的值将是词典中第 j^(th)个单词在第 i^(th)个文件中出现的次数。
def extract_features(mail_dir):
files = [os.path.join(mail_dir,fi) for fi in os.listdir(mail_dir)]
features_matrix = np.zeros((len(files),3000))
docID = 0;
for fil in files:
with open(fil) as fi:
for i,line in enumerate(fi):
if i == 2:
words = line.split()
for word in words:
wordID = 0
for i,d in enumerate(dictionary):
if d[0] == word:
wordID = i
features_matrix[docID,wordID] = words.count(word)
docID = docID + 1
return features_matrix
4. 训练分类器。
在这里,我将使用scikit-learn ML 库来训练分类器。它是一个开源的 python ML 库,可以在第三方分发包anaconda中找到,也可以通过这个单独安装。安装完成后,我们只需在程序中导入即可。
我在这里训练了两个模型,即朴素贝叶斯分类器和支持向量机(SVM)。朴素贝叶斯分类器是一种传统且非常流行的文档分类方法。它是一种基于贝叶斯定理的有监督概率分类器,假设每对特征之间相互独立。SVM 是一种有监督的二元分类器,当特征数量较多时非常有效。SVM 的目标是将训练数据的某个子集与其他数据分开,这些数据被称为支持向量(分隔超平面的边界)。SVM 模型的决策函数基于支持向量,并利用了核技巧来预测测试数据的类别。
一旦分类器训练完成,我们可以检查模型在测试集上的表现。我们提取测试集中每封邮件的词频向量,并用训练好的 NB 分类器和 SVM 模型预测其类别(ham 或 spam)。下面是完整的垃圾邮件过滤应用代码。你需要在第 2 步和第 3 步中包含我们定义的两个函数。
import os
import numpy as np
from collections import Counter
from sklearn.naive_bayes import MultinomialNB, GaussianNB, BernoulliNB
from sklearn.svm import SVC, NuSVC, LinearSVC
# Create a dictionary of words with its frequency
train_dir = 'train-mails'
dictionary = make_Dictionary(train_dir)
# Prepare feature vectors per training mail and its labels
train_labels = np.zeros(702)
train_labels[351:701] = 1
train_matrix = extract_features(train_dir)
# Training SVM and Naive bayes classifier
model1 = MultinomialNB()
model2 = LinearSVC()
model1.fit(train_matrix,train_labels)
model2.fit(train_matrix,train_labels)
# Test the unseen mails for Spam
test_dir = 'test-mails'
test_matrix = extract_features(test_dir)
test_labels = np.zeros(260)
test_labels[130:260] = 1
result1 = model1.predict(test_matrix)
result2 = model2.predict(test_matrix)
print confusion_matrix(test_labels,result1)
print confusion_matrix(test_labels,result2)
性能检查
测试集包含 130 封垃圾邮件和 130 封非垃圾邮件。如果你读到这里,你会看到下面的结果。我展示了两个模型的测试集混淆矩阵。对角线元素表示正确识别(即真实识别)的邮件,而非对角线元素表示错误分类(虚假识别)的邮件。
| Multinomial NB | Ham | Spam |
|---|---|---|
| Ham | 129 | 1 |
| Spam | 9 | 121 |
| SVM(Linear) | Ham | Spam |
| Ham | 126 | 4 |
| Spam | 6 | 124 |
两个模型在测试集上的表现类似,只是 SVM 在错误识别方面稍微平衡了一些。我必须提醒你,测试数据既没有用于创建词典,也没有用于训练集。
任务
下载Euron-spam语料库的预处理版本。该语料库包含 33716 封电子邮件,分布在 6 个目录中。每个目录包含‘ham’和‘spam’文件夹。非垃圾邮件和垃圾邮件的总数分别为 16545 封和 17171 封。
按照本博客文章中描述的步骤操作,检查使用支持向量机和多项式朴素贝叶斯模型的表现。由于这个语料库的目录结构与博客文章中使用的 ling-spam 子集的目录结构不同,你可能需要重新组织它或修改def make_Dictionary(dir)和def extract_features(dir)函数。
我将 Euron-spam 语料库划分为 60:40 的训练集和测试集。在执行了本博客中的相同步骤后,我在 13487 个测试集邮件上得到了以下结果。我们可以看到,SVM 在正确检测垃圾邮件方面的表现略优于朴素贝叶斯分类器。
| 多项式 NB | Ham | Spam |
|---|---|---|
| Ham | 6445 | 225 |
| Spam | 137 | 6680 |
| SVM(线性) | Ham | Spam |
| Ham | 6490 | 180 |
| Spam | 109 | 6708 |
最终思考
希望你觉得这个教程易于理解,因为我尽量保持简洁明了。对文本分析感兴趣的初学者可以从这个应用开始。
你可能在考虑使用的模型(如朴素贝叶斯和 SVM)背后的数学技术。SVM 是一个数学上复杂的模型,而朴素贝叶斯相对容易理解。建议你从在线资源中学习这些模型。此外,还可以进行很多实验,以找出不同参数的效果,比如
a) 训练数据量
b) 字典大小
c) 使用的机器学习技术的变体(GaussianNB, BernoulliNB, SVC)
d) 对 SVM 模型参数的微调
e) 通过去除无关词汇来改进字典(可能需要手动进行)
f) 其他特征(查找 td-idf)
我将会在一些其他的博客文章中撰写关于这些模型的数学解释。
你可以从 GitHub 链接这里获取这两个语料库的完整 Python 实现。
如果你喜欢这篇文章,关注本博客以获取即将发布的文章更新。同时,分享它,让更多读者看到。请随时讨论任何与这篇文章相关的内容。我很乐意听取你的反馈。
祝你机器学习愉快!
机器学习实践 是一个完美的入门实践,适合初学者提升其机器学习技能。
原文。经许可转载。
相关:
-
与 Numpy 矩阵的操作:一个实用的初步参考
-
使用鸢尾花数据集的简单 XGBoost 教程
-
K-Means 与其他聚类算法:Python 快速入门
更多相关主题
了解雇主对 2020 年数据科学家角色的期望
原文:
www.kdnuggets.com/2020/08/employers-expecting-data-scientist-role-2020.html
评论
作者:Shareef Shaik,有抱负的数据科学家
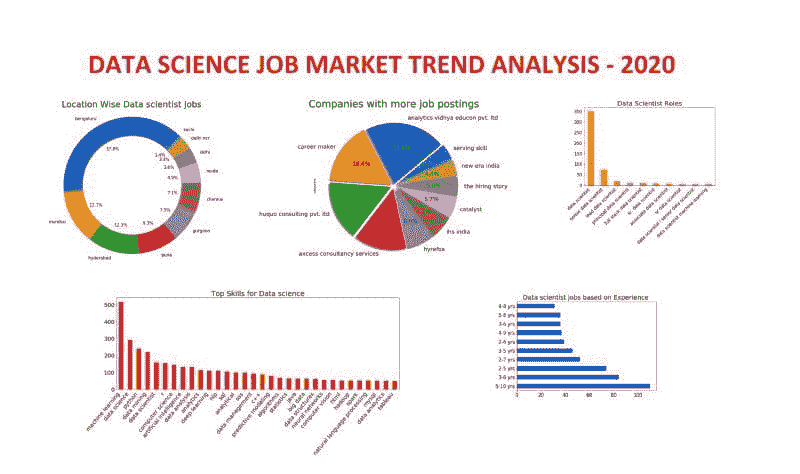
最近,我主动开始寻找数据科学领域的工作机会,我没有任何如硕士或博士等正式的 AI/机器学习教育背景。我完全出于个人兴趣开始学习(而不仅仅是因为炒作)。这是一个挑战性很大的领域,特别是如果你同时从事其他技术工作。我开始了我的学习之旅,通过报名参加许多 MOOCs(大规模在线课程)和阅读多个博客。一开始这些内容并没有太大意义,但在阅读了其他人的代码并亲自处理实时数据集后,它慢慢开始变得有意义。
当我开始寻找工作时,出现了一个有趣的新故事。我打开了印度的一个顶级招聘门户网站,开始搜索职位,我找到了一些与我寻找的工作相关的职位,但当我打开其中一个时,令我惊讶的是,要求的技能对我来说是全新的。除了传统的数据分析、机器学习和深度学习,还有一些 ETL 工具和多个大数据技术被列为所需技能。我想这没关系,因为每家公司现在对数据科学家的定义都不同,于是我又打开了另一个职位。这次显示出对一些其他技术的要求,如 AWS、Azure 和 Power BI。
请记住,所有这些职位开设仅针对数据科学家。这些职位都有一些共同的要求,如机器学习算法、统计学、数据分析、数据清理和深度学习技术。除了这些技能,一些公司还希望候选人具备云计算(AWS、Azure 或 GCP)和数据可视化工具(如 Tableau、Power BI)以及 ETL 工具(如 SSIS)的知识。通常,这些技术更适用于数据分析师/数据工程师角色,但数据科学家的角色仍在发展中,并未完全固定在某一技能集上。
我理解公司寻找符合他们职位空缺的申请人,并且具备他们所需技术技能。这无疑能为公司节省时间和金钱,而不是重新提供培训。
所以,我有一个有趣的想法,想了解 IT 行业对数据科学家角色的实时期望,而不是通常在 MOOCs 中教授的内容。
目标: 我们将尝试找出目前行业中最受追捧的技能和趋势。为此,我们将从招聘门户网站抓取数据。
注意:整个分析是针对印度市场的数据科学角色进行的。
在这篇文章中,我们将尝试解答一些每个数据科学求职者心中可能存在的重要问题。
-
公司正在寻找的顶级技能是什么?
-
行业中最受欢迎的经验水平是什么?
-
哪些公司在积极提供这个领域的职位?
-
哪些地点有更多的职位?
注意: 你可以在结论部分找到完整代码的链接。
1. 网络抓取:
我从印度顶级招聘网站Naukri.com上收集了所有相关的职位信息,这个网站几乎是每个求职者和招聘者现在都在使用的。我使用了 selenium-python 进行网络抓取,因为传统的 BeautifulSoup 方法在这个网站上效果不好。
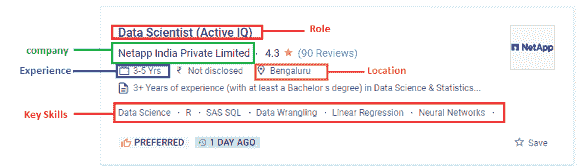
来自 Naukri.com 的一个职位样本
免责声明:网络抓取仅用于教育目的。
我们将抓取每个职位的这五个要素:角色、公司名称、经验、地点和关键技能。
抓取代码:
2. 预处理:
在我们深入之前,让我们做一些基本的预处理。
2.1. 处理缺失值:
进行了基本的清理,找出了缺失值并将其删除。
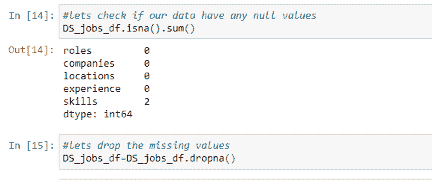
2.2. 处理重复数据:
处理重复数据时需要非常小心,因为公司可能会多次发布相同的需求,因为职位仍然开放或者另一方面公司可能在寻找具有相同需求的新职位。为了简单起见,我没有删除任何数据。
2.3. 对位置和技能列进行标记化
将所有字符串转换为小写,以避免冗余,并对位置和技能列进行了标记化,因为这些列中有多个值。
这是预处理后的样子。

3. 分析:
现在,我们一切就绪,可以开始了。
3.1. 哪些地点提供更多的职位?
注意:如果你不来自印度,可以跳过这部分位置。
-
如果我们观察上面的图表,可以看到近38%的职位位于班加罗尔。
-
前四个城市,即班加罗尔、孟买、海得拉巴和浦那,占据了全国数据科学职位的近 72%。
-
如果你来自这些城市中的任何一个,那么你获得数据科学职位的机会可能比其他城市要高。
3.2. 哪些公司正在积极招聘?:
-
Analytics Vidhya educon 以几乎21%的职位列表占据了榜首。
-
列表中还有许多咨询公司。这些咨询公司通常会为他们的客户进行招聘。
-
通常情况下,招聘门户上的竞争会非常激烈。大多数时候,由于收到的大量申请,你的简历可能甚至不会被招聘人员查看。有些情况下,即使是一个职位空缺,你也需要与数百名其他申请者竞争。最好是了解正在积极招聘的公司,以便我们可以直接通过他们的官方网站申请,从而增加获得面试的机会。
3.3. 最受欢迎的经验是什么?:
不同经验水平的职位机会。
-
我们可以观察到,公司显然在寻找有经验的候选人。似乎对于拥有 5–10 年经验的候选人的职位空缺更多。这是有道理的,因为数据科学家的工作涉及到的关键决策技能是随着经验积累而来的。
-
具有至少2 年经验的候选人有相当好的机会。
-
这并不意味着应届生不能进入,只是有更多的职位空缺面向经验丰富的候选人,而不是应届生。公司通常不会通过这些招聘门户招聘应届生,他们会直接通过校园招聘来招募应届生。应届生可以选择去初创公司工作,以获得必要的经验。
3.4. 需求角色是什么:
这是一个重要的步骤,因为在获取一些结果后,招聘门户通常会开始显示一些与我们搜索的职位无关的其他职位。为了确保我们查看的是正确的职位,让我们检查一下最常提到的前 10 个职位。
-
如果我们观察上一部分,会发现经验更丰富的人才的职位空缺更多,这引出了基于角色的职位空缺问题。
-
大多数职位空缺仍然被称为数据科学家。接下来是高级数据科学家和首席数据科学家,这当然需要丰富的之前经验。
3.5. 公司在寻找哪些技能:
最终,我们来到了这里。你可能正在阅读这篇文章的主要原因。
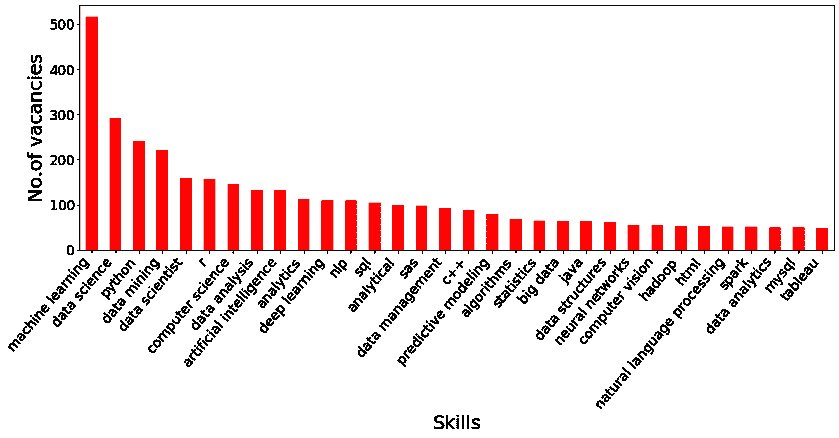
-
看起来非常复杂,对吧?别担心,我会在后面的部分详细说明。我在图中包含了许多技能,是因为数据科学涉及的领域广泛。
-
虽然我们在上图中能够描绘出一些顶级技能,但这仍然无法满足本分析的目的。
让我们深入探讨,以更清晰地理解趋势。
3.5.1. 必备技能?:
-
机器学习,这毫无疑问是数据科学家需要具备的最重要技能。
-
数据挖掘 和 数据分析 是每个数据科学家必须经历的关键活动。
-
强大的统计建模 是成为更好数据科学家所必需的。
-
公司期待对深度学习有良好的知识,因为它提供了最先进的技术来解决NLP和计算机视觉等领域的一些有趣的实时问题。
-
雇主期望候选人具备大数据技术的知识,因为每天记录的数据量急剧增加。在实时情况下,我们可能会处理大型数据集,这些技能肯定会派上用场。
3.5.2. 哪种编程语言在需求中?
- 如果你刚开始学习数据科学,一开始你肯定会发现选择合适的编程语言很困难。虽然有很多语言,但竞争始终在 Python 和 R 之间。让我们看看数据告诉我们什么。
-
该行业仍然偏爱Python,由于其丰富的库,紧随其后的是R语言。
-
SQL是每个数据科学家必备的。虽然它不适合被视为编程语言,但我还是冒险将其包括在内 😃.
-
在 Python 和 R 之后,SAS和C++语言似乎也有很好的需求。
3.5.3. 选择哪个深度学习框架?
- 由于深度学习的突然崛起,许多深度学习框架从 Google 和 Facebook 等巨头进入市场。
-
该行业更倾向于TensorFlow而不是PyTorch。
-
Keras在市场上占有一席之地,人们喜欢它因为其简单易用的特性。
-
尽管还有许多其他框架,如 Caffe、Maxnet,但似乎并没有很多职位空缺。如果不是在全球范围内,至少在印度如此。
3.5.4. 哪种大数据技术具有优势?
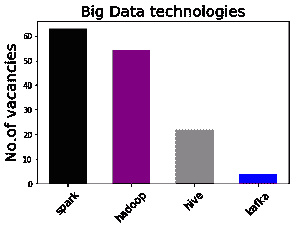
-
Spark排名第一。可以选择 Python 版本的 Spark - Pyspark。
-
Hadoop与 Spark 几乎有相同的机会,只有细微的差别。
-
Hive也有相当多的职位空缺。
3.5.5. 哪个云服务提供商在 ML 中需求量大?
-
训练模型涉及大量计算,这可能会变得非常昂贵。公司正在寻找更便宜的方式来完成工作,这也是这些云平台进入视野的原因。
-
AWS排名第一,其次是Azure。
-
公司正迅速转向云选项。这些技术在数据科学中的作用可能会在未来几天发挥重要作用。
3.5.6. 数据可视化工具的需求?
-
雇主对Tableau在数据可视化方面表现出更多兴趣。
-
虽然微软的Power BI仍然滞后。
结论:
你真的必须匹配这篇文章中提到的所有技能才能获得工作吗?
其实不完全是,列表中的一些工具如果你基础扎实的话可以在工作中很快掌握。话虽如此,如果你只是想找工作,拥有这些技能的简历可能会帮助你获得面试机会。
如果你掌握了所有提到的数据科学家必备技能,那么最佳的做法就是开始参加面试,同时努力填补你理解上的空白,并学习你认为能够让你在其他候选人中脱颖而出的工具/技术。
如果你觉得这有帮助或有任何问题,请在评论中告诉我。
再见。祝编程愉快..!
参考文献:
-
medium.com/@krishnakummar/donut-chart-with-python-matplotlib-d411033c960b -
stackoverflow.com/questions/51389377/unfolding-bag-of-words-in-pandas-column-python
简介: Shareef Shaik (Medium) 是一名有抱负的数据科学家,热衷于利用 AI 解决实际问题。
原文。已获得许可转载。
相关:
-
探索数据科学的真实世界
-
数据工程需要掌握的技能
-
如何像数据科学家一样思考
更多相关话题
使用 MultiLabelBinarizer 编码分类特征
原文:
www.kdnuggets.com/2023/01/encoding-categorical-features-multilabelbinarizer.html

作者提供的图片
过去,你可能通过 One Hot、Label 和 Ordinal 编码器将分类特征转换为数值特征。你处理的数据每个样本只有一个标签。但是,如何处理具有多个标签的样本呢?
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 在 IT 领域支持你的组织
在本迷你教程中,你将学习多分类和多标签的区别。此外,我们将应用 Scikit-Learn 的 MultiLabelBinarizer 函数,将可迭代的可迭代对象和多标签目标进行转换。
多分类与多标签
在机器学习中,多分类数据包含两个以上的类别,每个样本只分配一个标签。而在多标签分类中,每个样本会分配多个标签。
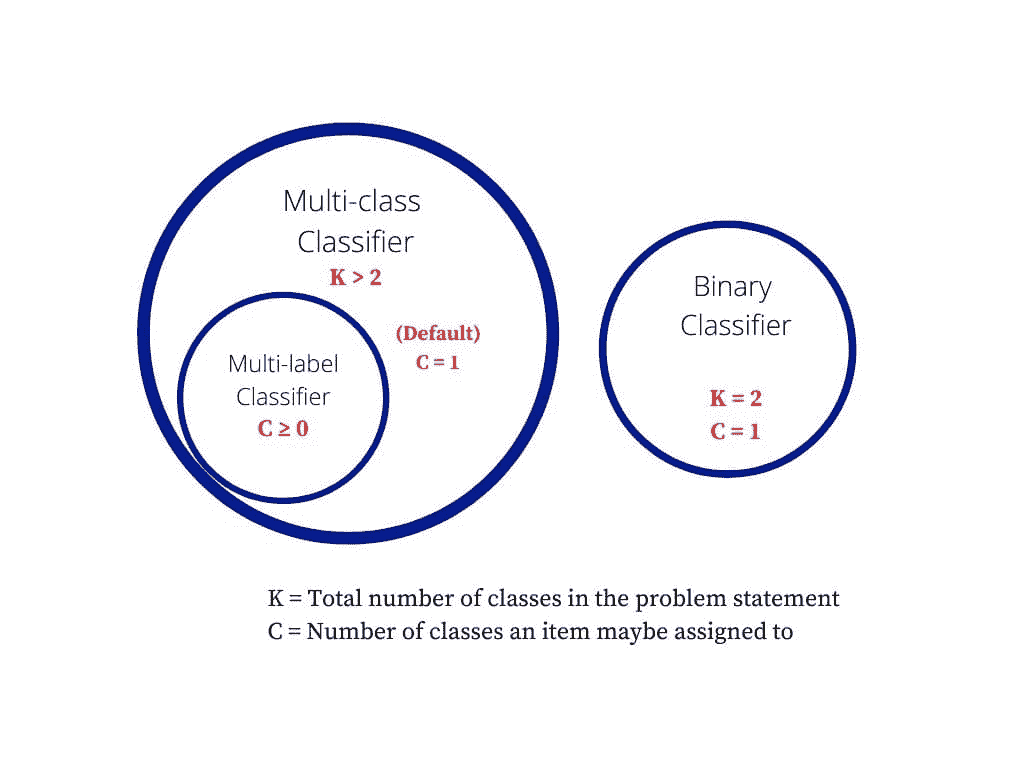
图片来源于 Thamme Gowda
我们将通过示例来理解这两种分类任务。
多分类
在多分类中,每个学生的记录只有一个标签(主修),并且有超过两个类别。学生只能选择数学、科学或英语作为主修。
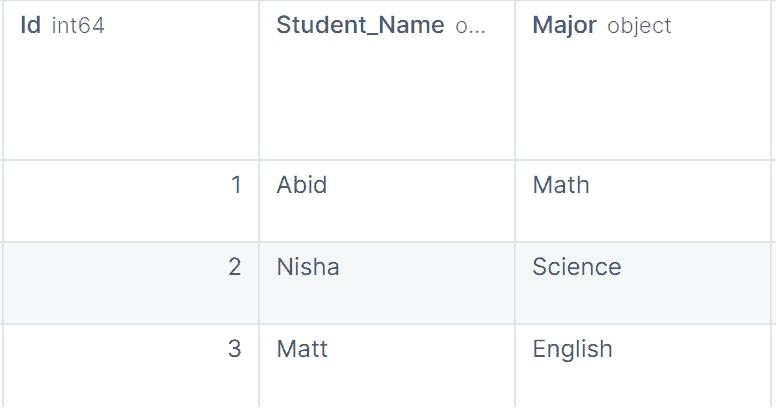
作者提供的图片
多标签
在多标签分类中,学生可以拥有多个主修。例如,Nisaha 选择了英语、法律和历史作为她的主修课程。
我们还可以看到,数组的长度有所不同,有些学生有两个主修课程,有些则有三个。
学生有 0 到 N 个主修课程。
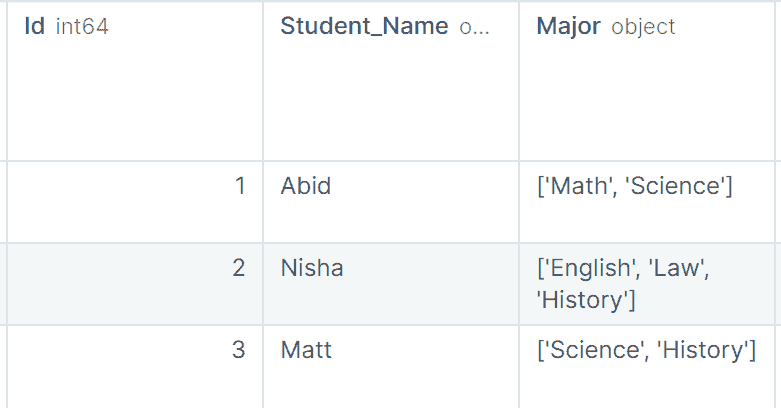
作者提供的图片
Scikit-Learn MultiLabelBinarizer 示例
我们现在将使用 Scikit-learn 的 MultiLabelBinarizer 将可迭代的可迭代对象和多标签目标转换为二进制编码。
示例 1
在第一个示例中,我们使用 MultiLabelBinarizer 函数将 List of Lists 转换为二进制编码。fit_transform 理解数据并应用转换。
import pandas as pd
from sklearn.preprocessing import MultiLabelBinarizer
mlb = MultiLabelBinarizer()
print(mlb.fit_transform([["Abid", "Matt"], ["Nisha"]]))
输出:
我们得到了一个由 1 和 0 组成的数组。
array([[1, 1, 0],
[0, 0, 1]])
示例 2
我们还可以将字典列表转换为表示类标签存在的二进制矩阵。
转换后,你可以使用 .classes_ 查看类标签。
y = mlb.fit_transform(
[
{"Abid", "Matt"},
{"Nisha", "Abid", "Matt"},
{"Nisha", "Abid", "Sara", "Matt"},
{"Matt", "Sara"},
]
)
print(list(mlb.classes_))
输出:
['Abid', 'Matt', 'Nisha', 'Sara']
要理解二进制矩阵,我们将把输出转换成带有类名的 Pandas DataFrame。
res = pd.DataFrame(y, columns=mlb.classes_)
res
就像独热编码一样,它将标签表示为 1 和 0。
MultiLabelBinarizer 通常用于图像和新闻分类。转换后,你可以迅速训练简单的随机森林或神经网络。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专家,他热爱构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些在心理健康方面挣扎的学生。
更多相关话题
机器学习项目的端到端指南
原文:
www.kdnuggets.com/2019/01/end-to-end-guide-machine-learning-project.html
评论
很难找到一篇简洁的文章提供关于如何实施一个机器学习项目的端到端指南。我们在线上找到很多信息丰富的文章,深入覆盖了如何实施机器学习/数据科学项目的各个部分,但有时我们只需要高层次的步骤提供清晰的指导。
当我刚接触机器学习和数据科学时,我常常寻找那些清晰地列出我需要做什么步骤来完成项目的文章。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
本文旨在提供一个端到端指南,以实现一个成功的机器学习项目。
记住这一点,让我们开始吧
简而言之,一个机器学习项目主要包括三个部分:数据理解、数据收集与清理,以及最后的模型实施与调优。通常,数据理解、收集和清理占据 60–70%的时间。为此,我们需要领域专家。
场景
让我们假设你正在尝试进行一个机器学习项目。本文将为你提供逐步指南,帮助你按照流程实施一个成功的项目。
一开始,我们的大脑中会产生很多问题
数据科学是试验与错误,它是研究与递归,它是实践与理论的结合,它需要领域知识,它提升你的战略技能,你会学习统计学并掌握编程技能。但最重要的是,它教会你保持耐心,因为你总是接近找到更好的答案。
步骤
两个前提步骤:
1. 确保你理解机器学习及其三个关键领域。点击阅读:
[机器学习 8 分钟
机器学习是现在和未来。所有的技术专家、数据科学家和金融专家都可以受益…medium.com](https://medium.com/fintechexplained/introduction-to-machine-learning-4b2d7c57613b)
2. 选择你的目标语言。熟悉 Python。点击阅读:
[从零开始学习 Python
Python 是数据分析和机器学习中最受欢迎的编程语言之一。此外,还有大量的…medium.com](https://medium.com/fintechexplained/from-python-installation-to-arima-exchange-rates-forecasting-9467ba03ee0c)
开始实施
1. 选择合适的机器学习算法。点击阅读:
[机器学习算法比较
有大量的机器学习(ML)算法可用。在本文中,我将描述和…medium.com](https://medium.com/fintechexplained/machine-learning-algorithm-comparison-f14ce372b855)
到现在为止,你应该已经明白你尝试解决的是一个监督式还是非监督式问题。
总是有可能找到另一个正确答案。在预测问题中,通常会有多个正确答案。
2. 如果这是一个监督式机器学习问题,请确保你了解它是回归问题还是分类问题。点击阅读:
[监督式机器学习:回归与分类
在这篇文章中,我将解释回归和分类监督式机器学习之间的关键区别…medium.com](https://medium.com/fintechexplained/supervised-machine-learning-regression-vs-classification-18b2f97708de)
3. 如果这是一个时间序列回归问题,请在预测之前使时间序列数据平稳。点击阅读:
[如何预测时间序列?
预测、建模和预测时间序列在许多领域越来越受欢迎。时间序列…medium.com](https://medium.com/fintechexplained/forecasting-time-series-explained-5cc773b232b6)
4. 提前找出测量算法性能的方法。点击阅读:
[每个数据科学家必须了解的数学度量
每个数据科学家都需要了解大量的数学度量。本文概述了…medium.com](https://medium.com/fintechexplained/must-know-mathematical-measures-for-data-scientist-15bfc4f7f39c)
5. 测量你的时间序列回归模型的性能。点击阅读:
[我的预测模型有多好——回归分析
预测是计量经济学和数据科学中的一个重要概念。它在人工智能中也得到了广泛应用…medium.com](https://medium.com/fintechexplained/part-3-regression-analysis-bcfe15a12866)
6. 调查是否需要使用 ARIMA 模型。点击阅读:
[理解自回归滑动平均模型——ARIMA
在我的文章《如何预测时间序列》中,我提供了时间序列分析的概述。文章的核心…medium.com](https://medium.com/fintechexplained/understanding-auto-regressive-model-arima-4bd463b7a1bb)
7. 如果这是一个无监督机器学习问题,那么了解聚类是如何工作的及其实现。点击阅读:
在本文中,我想解释无监督机器学习中的聚类是如何工作的。特别是,我想要…… medium.com
8. 探索神经网络和深度学习,看看它是否适用于你的问题。点击阅读:
本文旨在提供对神经网络的概述。它概述了神经网络的基本概念。 medium.com
9. 丰富你的特征集,重新缩放、标准化和归一化它们。点击阅读:
有时我们建立一个机器学习模型,用训练数据训练它,然后让它预测未来…… medium.com
数据清理=良好的结果。
10. 减少特征维度空间。点击阅读:
现在我们有大量的数据。大量的数据可以让我们创建一个预测模型,其中…… medium.com
如果在丰富特征和减少维度后,你的模型仍然没有产生准确的结果,那么可以考虑调整模型参数。
11. 精细调整你的机器学习模型参数。点击阅读:
精细调整机器学习预测模型是提高预测结果准确性的关键步骤。在…… medium.com
始终确保你没有过拟合或欠拟合
12. 最后,重复这些步骤直到获得准确结果:
-
丰富特征
-
精细调整模型参数
总是分析你的数据集,查看是否缺少任何重要信息,当发现问题时要解决,但始终记得备份并保存你的工作,因为你可能需要回到之前的步骤。
机器学习本质上是递归的
摘要
我希望有一个简单的页面列出实现机器学习模型所需遵循的步骤。本文旨在提供一个从头到尾的成功机器学习项目实施指南。
希望这能帮到你。
简介:Farhad Malik 用简单的术语解释复杂的数学、金融和技术概念。FinTechExplained的编辑。联系方式:FarhadMalik84@googlemail.com
原文。已获转载许可。
相关内容:
-
Keras 四步工作流程
-
机器学习过程的框架
-
机器学习项目检查清单
更多相关话题
关于时间序列分析和预测的端到端项目与 Python
原文:
www.kdnuggets.com/2018/09/end-to-end-project-time-series-analysis-forecasting-python.html
评论
作者 Susan Li,高级数据科学家

图片来源:Pexels
时间序列分析包括了分析时间序列数据的方法,以提取有意义的统计数据和其他数据特征。时间序列预测是利用模型根据以前观察到的值来预测未来的值。
时间序列广泛用于非平稳数据,如经济、天气、股票价格和零售销售。我们将展示不同的零售销售时间序列预测方法。让我们开始吧!
数据
import warnings
import itertools
import numpy as np
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
plt.style.use('fivethirtyeight')
import pandas as pd
import statsmodels.api as sm
import matplotlib
matplotlib.rcParams['axes.labelsize'] = 14
matplotlib.rcParams['xtick.labelsize'] = 12
matplotlib.rcParams['ytick.labelsize'] = 12
matplotlib.rcParams['text.color'] = 'k'
超市销售数据中有几个类别,我们从家具销售的时间序列分析和预测开始。
df = pd.read_excel("Superstore.xls")
furniture = df.loc[df['Category'] == 'Furniture']
我们有一份很好的 4 年家具销售数据。
furniture['Order Date'].min(), furniture['Order Date'].max()
时间戳(‘2014–01–06 00:00:00’),时间戳(‘2017–12–30 00:00:00’)
数据预处理
这一步包括去除不需要的列、检查缺失值、按日期聚合销售数据等。
cols = ['Row ID', 'Order ID', 'Ship Date', 'Ship Mode', 'Customer ID', 'Customer Name', 'Segment', 'Country', 'City', 'State', 'Postal Code', 'Region', 'Product ID', 'Category', 'Sub-Category', 'Product Name', 'Quantity', 'Discount', 'Profit']
furniture.drop(cols, axis=1, inplace=True)
furniture = furniture.sort_values('Order Date')
furniture.isnull().sum()
图 1
furniture = furniture.groupby('Order Date')['Sales'].sum().reset_index()
使用时间序列数据进行索引
furniture = furniture.set_index('Order Date')
furniture.index

图 2
我们当前的日期时间数据可能很难处理,因此我们将使用该月的平均每日销售值,并将每月的开始作为时间戳。
y = furniture['Sales'].resample('MS').mean()
快速浏览一下 2017 年的家具销售数据。
y['2017':]
图 3
可视化家具销售时间序列数据
y.plot(figsize=(15, 6))
plt.show()
图 4
当我们绘制数据时,出现了一些明显的模式。时间序列具有季节性模式,例如销售在年初总是较低,而在年末较高。每年总是存在一个上升趋势,年中有几个月的销售较低。
我们还可以使用一种称为时间序列分解的方法来可视化我们的数据,这种方法可以将时间序列分解为三个不同的组成部分:趋势、季节性和噪声。
from pylab import rcParams
rcParams['figure.figsize'] = 18, 8
decomposition = sm.tsa.seasonal_decompose(y, model='additive')
fig = decomposition.plot()
plt.show()
图 5
上面的图表清楚地显示了家具销售不稳定,并且有明显的季节性。
使用 ARIMA 进行时间序列预测
我们将应用最常用的时间序列预测方法之一,即 ARIMA,代表自回归积分滑动平均模型。
ARIMA 模型用ARIMA(p, d, q)表示。这三个参数考虑了数据中的季节性、趋势和噪声:
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print('Examples of parameter combinations for Seasonal ARIMA...')
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[1]))
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[2]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[3]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[4]))

图 6
这一步是我们家具销售 ARIMA 时间序列模型的参数选择。我们的目标是使用“网格搜索”来找到最佳的参数集,从而实现模型的最佳性能。
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit()
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continue
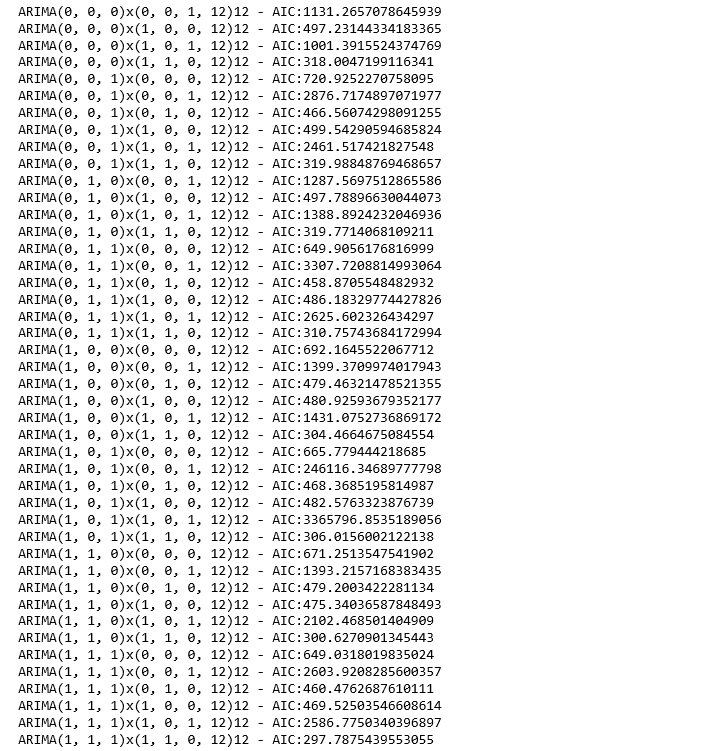
图 7
上述输出表明,SARIMAX(1, 1, 1)x(1, 1, 0, 12)产生了最低的AIC值 297.78。因此,我们应考虑这是最优选项。
拟合 ARIMA 模型
mod = sm.tsa.statespace.SARIMAX(y,
order=(1, 1, 1),
seasonal_order=(1, 1, 0, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit()
print(results.summary().tables[1])

图 8
我们应该始终运行模型诊断,以调查任何异常行为。
results.plot_diagnostics(figsize=(16, 8))
plt.show()
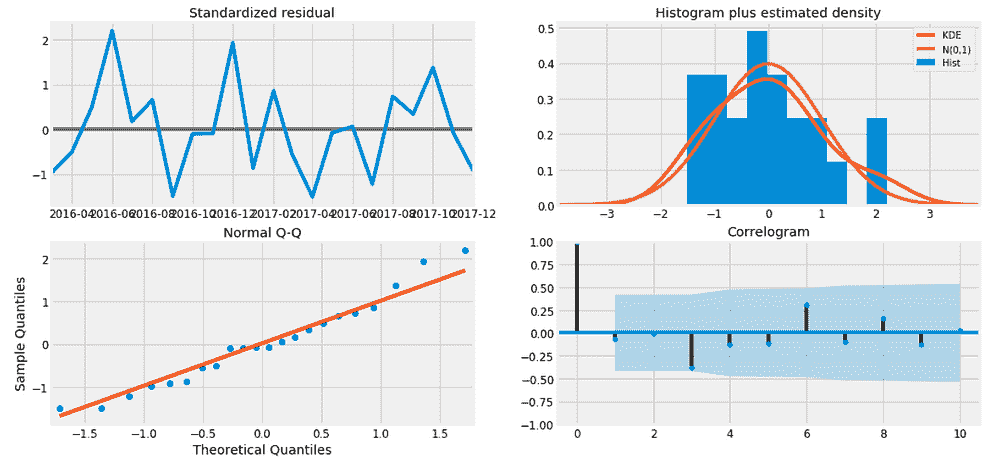
图 9
尽管如此,我们的模型诊断表明,模型残差接近正态分布。
验证预测
为了帮助我们理解预测的准确性,我们将预测销售额与时间序列的实际销售额进行比较,并且我们将预测设定为从 2017 年 1 月 1 日开始到数据的结束。
pred = results.get_prediction(start=pd.to_datetime('2017-01-01'), dynamic=False)
pred_ci = pred.conf_int()
ax = y['2014':].plot(label='observed')
pred.predicted_mean.plot(ax=ax, label='One-step ahead Forecast', alpha=.7, figsize=(14, 7))
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('Furniture Sales')
plt.legend()
plt.show()
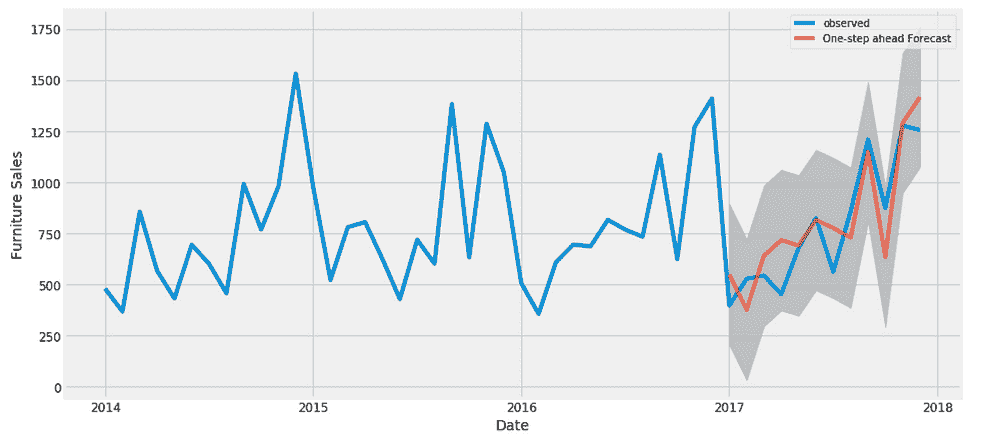
图 10
线图显示了观察值与滚动预测值的比较。总体而言,我们的预测与真实值非常吻合,显示了从年初开始的上升趋势,并在年底捕捉到季节性变化。
y_forecasted = pred.predicted_mean
y_truth = y['2017-01-01':]
mse = ((y_forecasted - y_truth) ** 2).mean()
print('The Mean Squared Error of our forecasts is {}'.format(round(mse, 2)))
我们预测的均方误差为 22993.58
print('The Root Mean Squared Error of our forecasts is {}'.format(round(np.sqrt(mse), 2)))
我们预测的均方根误差为 151.64
在统计学中,均方误差 (MSE)测量的是估计器的误差平方的平均值——即估计值与真实值之间的平均平方差。MSE 是估计器质量的衡量标准——它总是非负的,MSE 越小,我们找到最佳拟合线的可能性就越大。
均方根误差 (RMSE)告诉我们,我们的模型能够在测试集内预测日均家具销售额与实际销售额的误差为 151.64。我们的家具日销售额范围从约 400 到超过 1200。在我看来,这个模型目前表现相当不错。
生成和可视化预测
pred_uc = results.get_forecast(steps=100)
pred_ci = pred_uc.conf_int()
ax = y.plot(label='observed', figsize=(14, 7))
pred_uc.predicted_mean.plot(ax=ax, label='Forecast')
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.25)
ax.set_xlabel('Date')
ax.set_ylabel('Furniture Sales')
plt.legend()
plt.show()
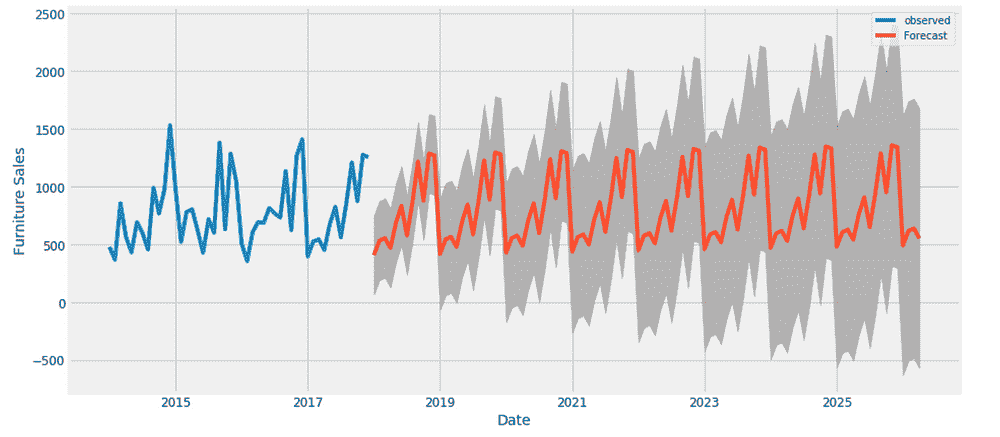
图 11
我们的模型明显捕捉到了家具销售的季节性。随着我们预测的时间越长,对预测值的信心自然会下降。这在模型生成的置信区间中体现出来,置信区间随着预测时间的延长而变大。
上述关于家具的时间序列分析让我对其他类别感到好奇,并想了解它们之间的比较。因此,我们将比较家具与办公供应商的时间序列。
家具与办公用品的时间序列
根据我们的数据,多年来办公用品的销售数量远远超过了家具。
furniture = df.loc[df['Category'] == 'Furniture']
office = df.loc[df['Category'] == 'Office Supplies']
furniture.shape, office.shape
((2121, 21), (6026, 21))
数据探索
我们将比较两个类别在同一时间段的销售。这意味着将两个数据框合并为一个,并将这两个类别的时间序列绘制到一个图中。
cols = ['Row ID', 'Order ID', 'Ship Date', 'Ship Mode', 'Customer ID', 'Customer Name', 'Segment', 'Country', 'City', 'State', 'Postal Code', 'Region', 'Product ID', 'Category', 'Sub-Category', 'Product Name', 'Quantity', 'Discount', 'Profit']
furniture.drop(cols, axis=1, inplace=True)
office.drop(cols, axis=1, inplace=True)
furniture = furniture.sort_values('Order Date')
office = office.sort_values('Order Date')
furniture = furniture.groupby('Order Date')['Sales'].sum().reset_index()
office = office.groupby('Order Date')['Sales'].sum().reset_index()
furniture = furniture.set_index('Order Date')
office = office.set_index('Order Date')
y_furniture = furniture['Sales'].resample('MS').mean()
y_office = office['Sales'].resample('MS').mean()
furniture = pd.DataFrame({'Order Date':y_furniture.index, 'Sales':y_furniture.values})
office = pd.DataFrame({'Order Date': y_office.index, 'Sales': y_office.values})
store = furniture.merge(office, how='inner', on='Order Date')
store.rename(columns={'Sales_x': 'furniture_sales', 'Sales_y': 'office_sales'}, inplace=True)
store.head()
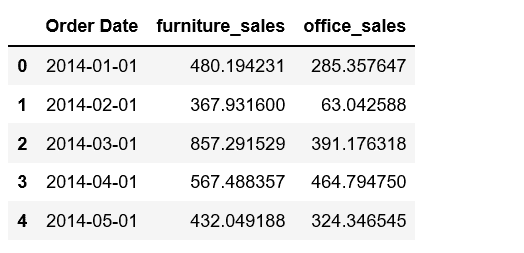
图 12
plt.figure(figsize=(20, 8))
plt.plot(store['Order Date'], store['furniture_sales'], 'b-', label = 'furniture')
plt.plot(store['Order Date'], store['office_sales'], 'r-', label = 'office supplies')
plt.xlabel('Date'); plt.ylabel('Sales'); plt.title('Sales of Furniture and Office Supplies')
plt.legend();
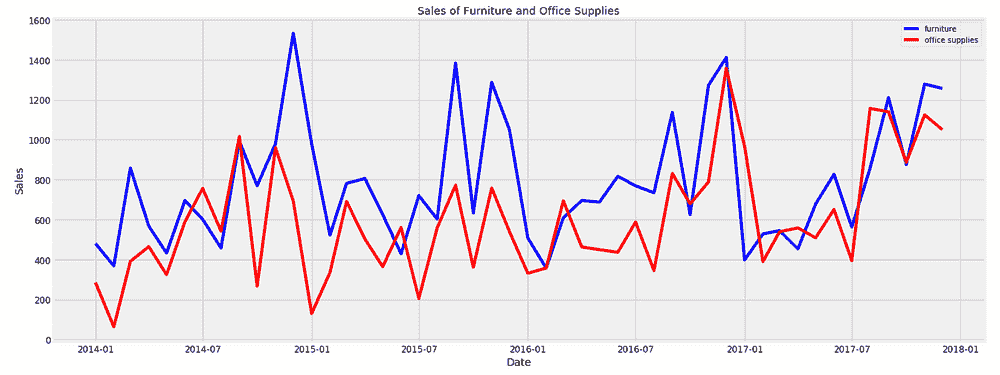
图 13
我们观察到家具和办公用品的销售都呈现出相似的季节性模式。年初是这两个类别的淡季。夏季似乎也是办公用品的淡季。此外,大多数月份家具的日均销售量高于办公用品。可以理解,因为家具的价值应该远高于办公用品。偶尔,办公用品的日均销售量会超过家具。让我们找出第一次办公用品销售超过家具的时间。
first_date = store.ix[np.min(list(np.where(store['office_sales'] > store['furniture_sales'])[0])), 'Order Date']
print("Office supplies first time produced higher sales than furniture is {}.".format(first_date.date()))
办公室用品首次在 2014 年 7 月 1 日销售超过家具。
是 2014 年 7 月!
使用 Prophet 的时间序列建模
Facebook 于 2017 年发布的预测工具 Prophet 旨在分析在不同时间尺度上显示模式的时间序列,例如年度、每周和每日。它还具有建模假期对时间序列的影响和实现自定义变更点的高级功能。因此,我们正在使用 Prophet 来建立和运行模型。
from fbprophet import Prophet
furniture = furniture.rename(columns={'Order Date': 'ds', 'Sales': 'y'})
furniture_model = Prophet(interval_width=0.95)
furniture_model.fit(furniture)
office = office.rename(columns={'Order Date': 'ds', 'Sales': 'y'})
office_model = Prophet(interval_width=0.95)
office_model.fit(office)
furniture_forecast = furniture_model.make_future_dataframe(periods=36, freq='MS')
furniture_forecast = furniture_model.predict(furniture_forecast)
office_forecast = office_model.make_future_dataframe(periods=36, freq='MS')
office_forecast = office_model.predict(office_forecast)
plt.figure(figsize=(18, 6))
furniture_model.plot(furniture_forecast, xlabel = 'Date', ylabel = 'Sales')
plt.title('Furniture Sales');
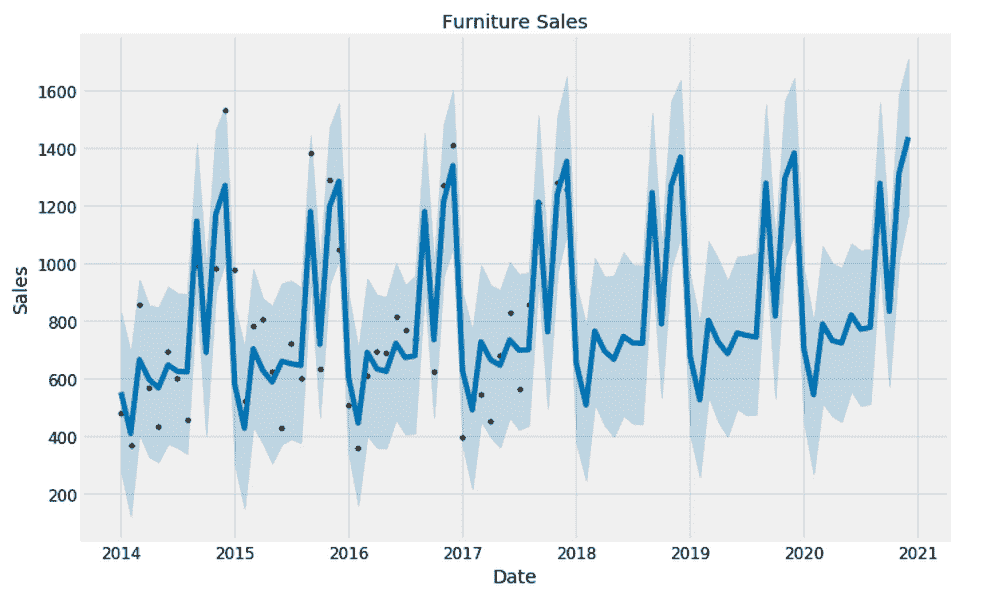
图 14
plt.figure(figsize=(18, 6))
office_model.plot(office_forecast, xlabel = 'Date', ylabel = 'Sales')
plt.title('Office Supplies Sales');
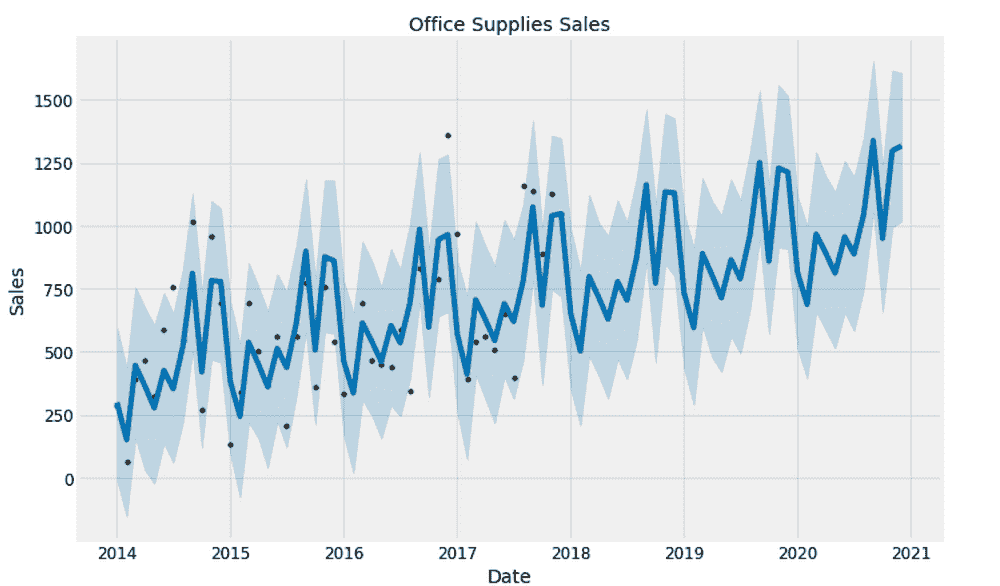
图 15
比较预测
我们已经有了这两个类别未来三年的预测。现在我们将它们结合起来,以比较它们未来的预测。
furniture_names = ['furniture_%s' % column for column in furniture_forecast.columns]
office_names = ['office_%s' % column for column in office_forecast.columns]
merge_furniture_forecast = furniture_forecast.copy()
merge_office_forecast = office_forecast.copy()
merge_furniture_forecast.columns = furniture_names
merge_office_forecast.columns = office_names
forecast = pd.merge(merge_furniture_forecast, merge_office_forecast, how = 'inner', left_on = 'furniture_ds', right_on = 'office_ds')
forecast = forecast.rename(columns={'furniture_ds': 'Date'}).drop('office_ds', axis=1)
forecast.head()
图 16
趋势和预测可视化
plt.figure(figsize=(10, 7))
plt.plot(forecast['Date'], forecast['furniture_trend'], 'b-')
plt.plot(forecast['Date'], forecast['office_trend'], 'r-')
plt.legend(); plt.xlabel('Date'); plt.ylabel('Sales')
plt.title('Furniture vs. Office Supplies Sales Trend');
图 17
plt.figure(figsize=(10, 7))
plt.plot(forecast['Date'], forecast['furniture_yhat'], 'b-')
plt.plot(forecast['Date'], forecast['office_yhat'], 'r-')
plt.legend(); plt.xlabel('Date'); plt.ylabel('Sales')
plt.title('Furniture vs. Office Supplies Estimate');
图 18
趋势和模式
现在,我们可以使用 Prophet 模型检查这两个类别在数据中的不同趋势。
furniture_model.plot_components(furniture_forecast);
图 19
office_model.plot_components(office_forecast);
图 20
很高兴看到家具和办公用品的销售量随着时间的推移线性增长,并将继续增长,尽管办公用品的增长似乎略微强劲。
家具的最差月份是 4 月,办公用品的最差月份是 2 月。家具的最佳月份是 12 月,而办公用品的最佳月份是 10 月。
我们可以从现在开始探索许多时间序列分析,比如带有不确定性范围的预测、变更点和异常检测、以及使用外部数据源的时间序列预测。我们才刚刚开始。
源代码可以在 Github 找到。我期待您的反馈或问题。
个人简介:Susan Li 正在改变世界,一篇文章一个时间。她是位于加拿大多伦多的高级数据科学家。
原文。经许可转载。
相关:
-
使用 Scikit-Learn 进行多类文本分类
-
使用 fast.ai 进行快速特征工程
-
时间序列入门——三步流程
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
更多相关话题
如何在 Python 中工程化日期特征
原文:
www.kdnuggets.com/2021/08/engineer-date-features-python.html

原图由 Sonja Langford 提供,来自 Unsplash
也许像我一样,你在用 Python 处理数据时经常处理日期。也许,像我一样,你对处理日期感到沮丧,并发现自己为了反复做同样的事情而频繁查阅文档。
像任何编写代码并发现自己重复做同样事情的人一样,我希望通过自动化一些常见的日期处理任务以及一些简单且频繁的特征工程来简化我的工作,这样我就可以通过一次函数调用完成对给定日期的常见日期解析和处理任务。之后,我可以选择感兴趣的特征进行提取。
这个日期处理是通过使用一个 Python 函数来实现的,该函数只接受一个格式为 'YYYY-MM-DD' 的日期字符串(因为这是日期的格式),并返回一个包含(目前)18 个键值对的字典。这些键中的一些非常直接(例如解析的四位日期年),而其他一些是工程化的(例如该日期是否为公共假期)。如果你发现这段代码有用,你应该能够了解如何修改或扩展它以满足你的需求。有关你可能希望编码生成的附加日期/时间相关特征的一些想法,请查看这篇文章。
大部分功能是通过 Python datetime 模块实现的,该模块依赖于 strftime() 方法。然而,真正的好处在于有一种标准化、自动化的方法来处理相同的重复查询。
唯一使用的非标准库是 holidays,这是一个“快速、高效的 Python 库,用于动态生成国家、省和州特定的节假日集合。”虽然该库可以处理大量的国家和次国家节假日,但在这个示例中我使用了美国的国定假日。通过快速浏览项目文档和下面的代码,你将很容易确定如何在需要时更改此设置。
那么,首先让我们看看 process_date() 函数。注释应能提供有关其功能的深入了解,如有需要。
import datetime, re, sys, holidays
def process_date(input_str: str) -> {}:
"""Processes and engineers simple features for date strings
Parameters:
input_str (str): Date string of format '2021-07-14'
Returns:
dict: Dictionary of processed date features
"""
# Validate date string input
regex = re.compile(r'\d{4}-\d{2}-\d{2}')
if not re.match(regex, input_str):
print("Invalid date format")
sys.exit(1)
# Process date features
my_date = datetime.datetime.strptime(input_str, '%Y-%m-%d').date()
now = datetime.datetime.now().date()
date_feats = {}
date_feats['date'] = input_str
date_feats['year'] = my_date.strftime('%Y')
date_feats['year_s'] = my_date.strftime('%y')
date_feats['month_num'] = my_date.strftime('%m')
date_feats['month_text_l'] = my_date.strftime('%B')
date_feats['month_text_s'] = my_date.strftime('%b')
date_feats['dom'] = my_date.strftime('%d')
date_feats['doy'] = my_date.strftime('%j')
date_feats['woy'] = my_date.strftime('%W')
# Fixing day of week to start on Mon (1), end on Sun (7)
dow = my_date.strftime('%w')
if dow == '0': dow = 7
date_feats['dow_num'] = dow
if dow == '1':
date_feats['dow_text_l'] = 'Monday'
date_feats['dow_text_s'] = 'Mon'
if dow == '2':
date_feats['dow_text_l'] = 'Tuesday'
date_feats['dow_text_s'] = 'Tue'
if dow == '3':
date_feats['dow_text_l'] = 'Wednesday'
date_feats['dow_text_s'] = 'Wed'
if dow == '4':
date_feats['dow_text_l'] = 'Thursday'
date_feats['dow_text_s'] = 'Thu'
if dow == '5':
date_feats['dow_text_l'] = 'Friday'
date_feats['dow_text_s'] = 'Fri'
if dow == '6':
date_feats['dow_text_l'] = 'Saturday'
date_feats['dow_text_s'] = 'Sat'
if dow == '7':
date_feats['dow_text_l'] = 'Sunday'
date_feats['dow_text_s'] = 'Sun'
if int(dow) > 5:
date_feats['is_weekday'] = False
date_feats['is_weekend'] = True
else:
date_feats['is_weekday'] = True
date_feats['is_weekend'] = False
# Check date in relation to holidays
us_holidays = holidays.UnitedStates()
date_feats['is_holiday'] = input_str in us_holidays
date_feats['is_day_before_holiday'] = my_date + datetime.timedelta(days=1) in us_holidays
date_feats['is_day_after_holiday'] = my_date - datetime.timedelta(days=1) in us_holidays
# Days from today
date_feats['days_from_today'] = (my_date - now).days
return date_feats
几点需要注意:
-
_l和_s后缀分别指“长版本”和“短版本” -
默认情况下,Python 将一周的天数视为从星期日(0)开始,到星期六(6)结束;对我来说,我的处理一周从星期一开始,到星期日结束——而且我不需要第 0 天(与从第 1 天开始的一周相对)——所以这需要改变
-
工作日/周末特征很容易创建
-
假日相关特征使用
holidays库并进行简单的日期加减法很容易工程化;再次,替代其他国家或次国家假日(或添加到现有的假日)将很容易做到 -
一个
days_from_today功能是通过另一两行简单的日期数学创建的;负数是指给定日期之前的天数,而正数是指给定日期到今天的天数
我个人不需要,例如,一个is_end_of_month功能,但你应该能够看到如何在此时相对轻松地将其添加到上述代码中。自己尝试一些自定义吧。
现在让我们测试一下。我们将处理一个日期并打印出返回的内容,即特征键值对的完整字典。
import pprint
my_date = process_date('2021-07-20')
pprint.pprint(my_date)
{'date': '2021-07-20',
'days_from_today': 6,
'dom': '20',
'dow_num': '2',
'dow_text_l': 'Tuesday',
'dow_text_s': 'Tue',
'doy': '201',
'is_day_after_holiday': False,
'is_day_before_holiday': False,
'is_holiday': False,
'is_weekday': True,
'is_weekend': False,
'month_num': '07',
'month_text_l': 'July',
'month_text_s': 'Jul',
'woy': '29',
'year': '2021',
'year_s': '21'}
这里你可以看到完整的特征键列表及其对应值。现在,在正常情况下,我不需要打印出整个字典,而是获取特定键或一组键的值。
我们可以通过下面的代码演示它如何在实际中工作。我们将创建一个日期列表,然后逐个处理这些日期,最终创建一个 Pandas 数据框,包含处理过的日期特征的选择,并打印到屏幕上。
import pandas as pd
dates = ['2021-01-01', '2020-04-04', '1993-05-11', '2002-07-19', '2024-11-03', '2050-12-25']
df = pd.DataFrame()
for d in dates:
my_date = process_date(d)
features = [my_date['date'],
my_date['year'],
my_date['month_num'],
my_date['month_text_s'],
my_date['dom'],
my_date['doy'],
my_date['woy'],
my_date['is_weekend'],
my_date['is_holiday'],
my_date['days_from_today']]
ds = pd.Series(features)
df = df.append(ds, ignore_index=True)
df.rename(columns={0: 'date',
1: 'year',
2: 'month_num',
3: 'month',
4: 'day_of_month',
5: 'day_of_year',
6: 'week_of_year',
7: 'is_weekend',
8: 'is_holiday',
9: 'days_from_today'}, inplace=True)
df.set_index('date', inplace=True)
print(df)
year month_num month day_of_month day_of_year week_of_year is_weekend is_holiday days_from_today
date
2021-01-01 2021 01 Jan 01 001 00 0.0 1.0 -194.0
2020-04-04 2020 04 Apr 04 095 13 1.0 0.0 -466.0
1993-05-11 1993 05 May 11 131 19 0.0 0.0 -10291.0
2002-07-19 2002 07 Jul 19 200 28 0.0 0.0 -6935.0
2024-11-03 2024 11 Nov 03 308 44 1.0 0.0 1208.0
2050-12-25 2050 12 Dec 25 359 51 1.0 1.0 10756.0
希望这个数据框能让你更好地理解这个功能在实践中的有用性。
祝好运,数据处理愉快。
Matthew Mayo (@mattmayo13) 是数据科学家和 KDnuggets 的主编,这是一个开创性的在线数据科学和机器学习资源。他的兴趣在于自然语言处理、算法设计和优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 事务
更多相关话题
使用 Ruff 提升您的 Python 编码风格
原文:
www.kdnuggets.com/enhance-your-python-coding-style-with-ruff

编辑器提供的图片
什么是 Ruff
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT
Ruff是一个极其快速的 Python linter 和格式化工具,使用 Rust 编写,旨在取代和改进现有工具如 Flake8、Black 和 isort。它提供 10-100 倍的更快性能,同时通过 700 多个内置规则和流行插件的重新实现保持一致性。
来自 Ruff 的统计数据 | 从头开始 Linting CPython 代码库
Ruff 支持现代 Python,兼容 3.12,并支持pyproject.toml。它还提供自动修复支持、缓存和编辑器集成。Ruff 对 monorepo 友好,广泛用于 Pandas、FastAPI 等主要开源项目中。通过结合速度、功能和可用性,Ruff 将 Linting、格式化和自动修复集成到一个工具中,比现有选项快几个数量级。
开始使用 Ruff
我们可以通过使用 PIP 轻松安装ruff。
pip install ruff
为了测试运行 Ruff 的简便性和速度,我们可以使用 DagHub 仓库kingabzpro/Yoga-Pose-Classification。您可以克隆它或使用您自己的项目进行格式化。
项目结构
首先,我们将对项目运行 linter。你也可以通过将“.”替换为文件位置来对单个文件运行 linter。
ruff check .

Ruff 已识别出 9 个错误和 1 个可修复错误。要修复错误,我们将使用--fix 标志。
ruff check --fix .
如您所见,它已经修复了 1 个可修复的错误。

要格式化项目,我们将使用ruff format命令。
$ ruff format .
>>> 3 files reformatted
Ruff linter 和 formatter 对代码进行了大量更改。但我们为什么需要这些工具呢?答案很简单——它们有助于执行编码标准和规范。因此,您和您的团队可以专注于代码中的重要方面。此外,它们有助于提高我们代码的质量、可维护性和安全性。
Gif 由作者提供
Jupyter 笔记本的代码检查和格式化
要在项目中使用 Ruff 进行 Jupyter 笔记本的检查,您需要创建 ruff.toml 文件,并添加以下代码:
extend-include = ["*.ipynb"]
您也可以对 pyproject.toml 文件做同样的操作。
然后重新运行这些命令,以查看它对 Jupyter 笔记本文件进行的更改。
2 个文件被重新格式化,我们有 2 个 Notebook 文件。
$ ruff format .
>>> 2 files reformatted, 3 files left unchanged
我们还通过重新运行 check 命令修复了这些文件中的问题。
$ ruff check --fix .
>>> Found 51 errors (6 fixed, 45 remaining).
最终结果非常惊人。它在没有破坏代码的情况下完成了所有必要的更改。
Gif 由作者提供
Ruff 配置
通过编辑 ruff.toml 文件来调整 linter 和 formatter 设置,可以轻松配置 Ruff 以用于 Jupyter 笔记本。有关更多详细信息,请查看 配置 Ruff 文档。
target-version = "py311"
extend-include = ["*.ipynb"]
line-length = 80
[lint]
extend-select = [
"UP", # pyupgrade
"D", # pydocstyle
]
[lint.pydocstyle]
convention = "google"
GitHub Action 和预提交钩子
开发人员和团队可以通过 ruff-pre-commit 将 Ruff 作为预提交钩子使用:
- repo: https://github.com/astral-sh/ruff-pre-commit
# Ruff version.
rev: v0.1.5
hooks:
# Run the linter.
- id: ruff
args: [ --fix ]
# Run the formatter.
- id: ruff-format
它也可以作为 GitHub Action 通过 ruff-action 使用:
name: Ruff
on: [ push, pull_request ]
jobs:
ruff:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: chartboost/ruff-action@v1
Ruff VSCode 扩展
Ruff 最令人愉悦的方面是它的 VSCode 扩展。它简化了格式化和代码检查,免去了对第三方扩展的需求。只需在扩展市场中搜索 Ruff 即可安装。
图片来自 Ruff - Visual Studio Marketplace
我已配置 setting.json 以便在保存时进行格式化。
结论
Ruff 提供了快速的 linting 和格式化,能够生成更干净、更一致的 Python 代码。凭借 700 多条内置规则在 Rust 中重新实现以提高性能,Ruff 从 Flake8、isort 和 pyupgrade 等流行工具中汲取灵感,以执行全面的编码最佳实践。经过精心策划的规则集专注于捕捉错误和关键的风格问题,而不进行过多的挑剔。
与预提交钩子、GitHub Actions 和 VSCode 等编辑器的无缝集成,使 Ruff 融入现代 Python 工作流程变得轻而易举。无与伦比的速度和精心设计的规则集使 Ruff 成为那些重视快速反馈、清洁代码和顺畅团队协作的 Python 开发人员的必备工具。Ruff 通过将强大的功能与闪电般的性能相结合,为 Python 的 linting 和格式化设定了新的标准。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理疾病困扰的学生打造一款 AI 产品。
更多相关内容
提升 LLM 推理:揭示代码链提示
原文:
www.kdnuggets.com/enhancing-llm-reasoning-unveiling-chain-of-code-prompting

图片由作者使用 DALL•E 3 创建
关键要点
-
代码链(CoC)是一种与语言模型互动的新方法,通过代码编写和选择性代码模拟来增强推理能力。
-
CoC 扩展了语言模型在逻辑、算术和语言任务中的能力,特别是在需要这些技能结合的任务中。
-
使用 CoC,语言模型可以编写代码并模拟不能编译的部分,提供了一种独特的解决复杂问题的方法。
-
CoC 在大型和小型 LLM 中都显示出有效性。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
关键思想是鼓励 LM 将语言子任务格式化为灵活的伪代码,以便编译器可以明确捕获未定义行为,并交给 LM(作为 'LMulator')进行模拟。
引言
新的语言模型(LM)提示、通信和训练技术不断涌现,以增强 LM 的推理和性能能力。其中之一是代码链(CoC)的开发,这是一种旨在推进 LM 代码驱动推理的方法。这种技术融合了传统编码和创新的 LM 代码执行模拟,成为应对复杂语言和算术推理任务的强大工具。
CoC 的特点在于其处理融合逻辑、算术和语言处理的复杂问题的能力,这长期以来一直是标准 LLM 用户所面临的挑战。CoC 的有效性不仅限于大型模型,还扩展到各种规模,展示了其在 AI 推理中的多样性和广泛适用性。
图 1:代码链方法和过程比较(图来自论文)
理解代码链
CoC 是语言模型功能的范式转变;这不仅仅是一个简单的提示策略,以增加从语言模型中引出期望响应的机会。相反,CoC 重新定义了语言模型对上述推理任务的方法。
从本质上讲,CoC 使语言模型不仅能够编写代码,还能够仿真部分代码,尤其是那些不可直接执行的部分。这种双重性使语言模型能够处理更广泛的任务,将语言细微差别与逻辑和算术问题解决结合起来。CoC 能够将语言任务格式化为伪代码,并有效地弥合传统编码与人工智能推理之间的差距。这种桥接使得系统在复杂问题解决方面更加灵活和高效。LMulator 作为 CoC 功能增强的主要组成部分,能够模拟和解释代码执行输出,这些输出否则无法直接提供给语言模型。
CoC 在不同基准测试中表现出色,显著超越了现有的方法,如思维链,特别是在需要语言和计算推理相结合的场景中。
实验表明,代码链在各种基准测试中优于思维链和其他基线;在 BIG-Bench Hard 上,代码链达到了 84%,比思维链提高了 12%。
图 2:代码链性能比较(图像来源于论文)
实现代码链
CoC 的实现涉及一种独特的推理任务方法,整合了编码和仿真过程。CoC 鼓励语言模型将复杂的推理任务格式化为伪代码,然后进行解释和解决。该过程包括多个步骤:
-
确定推理任务:确定需要推理的语言或算术任务
-
代码编写:语言模型编写伪代码或灵活的代码片段来概述解决方案。
-
代码仿真:对于那些不可直接执行的代码部分,语言模型仿真预期的结果,有效地模拟代码执行
-
结合输出:语言模型结合实际代码执行和其仿真结果,形成问题的全面解决方案
这些步骤使语言模型能够通过“用代码思考”来处理更广泛的推理问题,从而增强了它们的解决问题能力。
作为 CoC 框架的一部分,LMulator 可以在几个具体方面显著帮助改进代码和推理:
-
错误识别和仿真:当语言模型编写包含错误或不可执行部分的代码时,LMulator 可以模拟该代码在运行时的行为,揭示逻辑错误、无限循环或边缘情况,并指导语言模型重新思考和调整代码逻辑。
-
处理未定义行为:在代码涉及标准解释器无法执行的未定义或模糊行为的情况下,LMulator 利用语言模型对上下文和意图的理解来推断输出或行为应该是什么,在传统执行失败的地方提供有理由的模拟输出。
-
提高代码推理能力:当需要语言和计算推理的混合时,LMulator 允许语言模型迭代其自身的代码生成,模拟各种方法的结果,实际上是在代码中进行‘推理’,从而得出更准确和高效的解决方案。
-
边缘案例探索:LMulator 可以通过模拟不同的输入来探索和测试代码如何处理边缘案例,这在确保代码的健壮性和能够处理各种场景方面特别有用。
-
学习反馈循环:当 LMulator 模拟和识别代码中的问题或潜在改进时,这些反馈可以被语言模型用来学习和完善其编码和解决问题的方法,这是一个持续的学习过程,随着时间的推移提高模型的编码和推理能力。
LMulator 通过提供一个模拟和迭代改进的平台,增强了语言模型编写、测试和完善代码的能力。
结论
CoC 技术是提升语言模型推理能力的进步。CoC 通过将代码编写与选择性代码仿真相结合,拓宽了语言模型可以解决的问题范围。这一方法展示了 AI 处理需要细致思考的更复杂、现实世界任务的潜力。值得注意的是,CoC 在小型和大型语言模型中均表现优异,为越来越多的小型模型提供了可能提升其推理能力并将其效果接近大型模型的途径。
要深入了解,请参考完整论文。
马修·梅奥 (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为KDnuggets和Statology的主编,以及Machine Learning Mastery的特约编辑,Matthew 旨在使复杂的数据科学概念变得易于理解。他的职业兴趣包括自然语言处理、语言模型、机器学习算法以及探索新兴的人工智能。他的使命是普及数据科学领域的知识。Matthew 从 6 岁开始编程。
相关主题
免费报名 4 年计算机科学学位课程
原文:
www.kdnuggets.com/enroll-in-a-4-year-computer-science-degree-program-for-free

图片由作者提供
你是否曾经想学习计算机科学,但又不想支付高昂的大学学费?那么你很幸运!有一个令人难以置信的开源课程叫做 OSSU(开源社会大学),它允许你免费报名参加相当于 4 年计算机科学学位课程的学习。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 部门
OSSU 计算机科学学位项目是什么?
ossu/computer-science 提供了计算机科学基础概念的完整教育,这些概念对所有计算学科至关重要。课程内容是根据领先大学本科计算机科学专业的学位要求设计的。它利用了来自 edX、Coursera 和 Udacity 的高质量课程,这些课程由 MIT、哈佛和普林斯顿等学校的教授讲授。
课程内容涵盖了从编程语言、算法和数据结构到操作系统、计算机体系结构和软件工程的一切。完成核心计算机科学要求后,你可以选择高级选修课,专注于软件测试、博弈论、线性代数等领域。
最好的部分是所有课程材料都可以在网上免费获得,你可以按照自己的节奏完成课程。虽然如果每周学习约 20 小时可以在 2 年内完成,但你可以根据自己的日程进行调整。你还可以加入一个全球范围的独立学习者社区,互相支持。
⚠️免责声明
该项目完成后不会授予官方学位。它是基于自由可用资源的自学课程,包括视频、代码示例和测验。参与者不需要正式注册;所有材料和指南都可以通过指定的 GitHub 仓库 https://github.com/ossu/computer-science 访问。该项目结构旨在提供类似于 4 年计算机科学学位的广泛学习体验;然而,它是非官方的,不授予学术认证或教育机构的认可。
课程
先修课程
计算机科学课程在不同阶段有先修课程要求:
-
核心 CS: 学生必须具备包括代数、几何和前微积分在内的高中数学背景。
-
高级 CS: 学生只有在完成 Core CS 部分所有必修课程后,才能选择高级选修课程。
-
高级系统: 任何希望专注于高级系统选修课的学生必须先修过至少一门高中或大学基础物理课程。
Intro CS
Intro CS 部分有针对初学者的课程,帮助刚接触计算机科学的学生了解这是否适合他们。它涵盖了基础编程,以教授基本的编码概念和计算机科学入门课程,以帮助学生理解计算在解决问题中的作用。
Core CS
Core CS 部分的所有课程相当于大学计算机科学学位的前三年。它在以下重要领域建立了坚实的基础:
-
核心编程: 涵盖编程语言、测试、设计模式、架构等。
-
核心数学: 为数据结构、算法等建立所需的数学基础。
-
CS 工具: 介绍常用的工具,如版本控制、Shell 脚本等。
-
核心系统: 涉及操作系统、网络、编译和计算机架构。
-
核心理论: 基本的理论概念,如算法、NP 完全性等。
-
核心安全: 安全编码、密码学和漏洞。
-
核心应用: 数据库、机器学习、计算机图形学等。
-
核心伦理: 探讨技术在社会中的伦理影响。
高级 CS
完成所有必修的核心 CS 课程后,学生应根据他们的兴趣和意向领域选择额外的高级 CS 课程。
-
高级编程: 涵盖调试、并行计算、UML、软件架构、编译器、使用 Haskell 的函数式编程等主题。
-
高级系统: 更深入地探讨数字逻辑、计算机组织、流水线、并行处理、虚拟化以及其他低层次计算概念。
-
高级理论: 包括形式语言理论、图灵机、可计算性、并发模型、计算几何、逻辑和博弈论。
-
高级信息安全: 提供更专业的安全知识,如合规性、数字取证、安全开发生命周期和验证。
-
高级数学: 包括线性代数、数值方法、形式逻辑、概率论以及计算机科学的重要数学基础。
期末项目
期末项目要求学生通过构建有用的东西来应用他们所学的所有知识。这为他们的知识和技能提供了切实的证明,以展示给潜在雇主。
创建项目不仅能使简历更具吸引力,还能验证和巩固你的知识。你可以从零开始构建新的项目,或为需要帮助的现有开源项目做出贡献。
若需更多指导,有围绕项目的结构化课程专门化供你选择。主题包括全栈开发、数据科学、机器人技术等。通过核心基础,你现在可以识别与你兴趣相匹配的系列课程。
当你的期末项目完成后,通过拉取请求将其信息提交至 OSSU PROJECTS。此外,将 OSSU 徽章添加到你的项目 README 中。然后,利用社区渠道向其他学生宣布你的作品。
评估通过获取同行反馈和展示能力而不是传统评分来完成。这也使 OSSU 能够评估其课程在多大程度上为独立学习者的实际成就做好了准备。
结论
OSSU 计算机科学学位项目为那些有兴趣学习计算机科学但又不愿意承受高额学费的学生提供了绝佳机会。该项目拥有结构良好的课程,涵盖计算机科学的所有基本概念,使你能够在这一领域获得全面的教育。项目的灵活性允许你按照自己的节奏学习,使其成为任何人都能接触的选项,无论他们的时间安排如何。那么为什么要等待呢?立即通过 OSSU 开始你的计算机科学教育吧,完全免费。
Abid Ali Awan(@1abidaliawan)是一位认证的数据科学专业人士,他热衷于构建机器学习模型。目前,他专注于内容创作并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一款 AI 产品,帮助那些受心理疾病困扰的学生。
更多相关话题
免费报名数据科学本科项目
原文:
www.kdnuggets.com/enroll-in-a-data-science-undergraduate-program-for-free

作者提供的图片
我很高兴与大家分享另一个类似于我们之前讨论的计算机科学学位项目的学位项目。该项目由开源社会大学提供,并且完全免费。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
ossu/data-science 课程旨在为那些自我激励并希望以自己的节奏探索数据科学世界的学习者提供服务。该项目提供了一个综合的本科数据科学课程,使用来自世界顶级大学的课程。最重要的是,报名该项目的学习者无需承担经济负担。
课程设置
该项目课程包括你掌握数据科学并为职业生涯做好准备所需的所有必修和选修课程。数据科学项目重点关注理论、数学、算法、统计学和数据科学工具。以下是我们将在该项目中涵盖的完整主题列表:
-
数据科学入门: 理解数据科学的基础知识和范围。
-
计算机科学入门: 对初学者至关重要;精通任何编程语言的人可以跳过此部分。
-
编程课程:
-
Python 为每个人
-
使用 Python 进行计算机科学与编程入门
-
计算思维与数据科学入门
-
-
数据结构与算法: 使用 Java 讲授(Java 编程,算法,第一部分和第二部分)。
-
数据库: 从数据库管理基础到面向开发者的 MongoDB。
-
数学: 包括单变量微积分、线性代数和多变量微积分。
-
统计学与概率: 课程涵盖从描述性统计到推断统计。
-
数据科学工具与方法: 数据科学工具,数据科学方法论,数据清理。
-
机器学习/数据挖掘: 课程涵盖从入门到专业主题如流程挖掘。
⚠️免责声明
本项目在完成后不会授予官方学位。它是一个自学课程,基于免费的资源,包括视频、代码示例和测验。参与者无需正式注册;所有材料和指南都可以通过指定的 GitHub 仓库 https://github.com/ossu/data-science 访问。该项目的结构旨在提供类似于数据科学学位的广泛学习体验;然而,它是非官方的,不授予学术认证或教育机构的认可。
如何开始
1. 持续时间和规划
如果每周分配约 20 小时用于学习,你可以在 2 年内完成该项目。为了帮助你计划,可以使用这个 电子表格 来估算你的结束日期。只需在时间轴表中输入你的开始日期和每周学习时间即可。你可以通过更新课程数据表来跟踪你的进度,记录每门课程的完成日期。
2. 课程顺序
你需要了解某些课程可以同时进行,而其他课程则需要依次完成。你可以查看提供的图表来理解主题和课程的顺序。
图片来源于 ossu/data-science
3. 追踪进度
创建一个 Trello 账户并将提供的 看板 复制到你的账户中。你可以在 这里 找到如何操作的说明。之后,随着你课程的进展,将卡片移动到“进行中”或“完成”列。
4. 编程语言选择
Python、R 和 SQL 是数据科学社区中主要的编程语言。课程涵盖了这三种语言,但重要的是要关注理解核心概念,而不仅仅是语言本身。这些基础概念需要彻底理解,以便可以使用任何编程工具进行应用。
5. 先决条件
这门课程的先决条件是具备高中水平的基础数学和统计学知识。
结论
报名参加免费的数据科学本科课程是一个很好的起点,但重要的是要记住,这只是开始。成为受人追捧的“超级数据科学家”不仅仅依赖于课程学习。它需要你在专业领域扩展知识,积极参与项目,并通过实习获得实践经验。你必须愿意一步步构建你的职业生涯,每掌握一项新技能和经验都为你的基础打下坚实的基础。
遵循这个结构化和集中的课程,你正踏上掌握数据科学的道路。记住,成为一名熟练的数据科学家之旅与目标同样重要。接受并享受你的学习过程,每一步都让你更接近实现你的职业目标,在这个激动人心且不断发展的领域中。
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一种 AI 产品,帮助那些在精神健康方面有困难的学生。
更多相关主题
集成学习:5 种主要方法
原文:
www.kdnuggets.com/2019/01/ensemble-learning-5-main-approaches.html
评论
由 Diogo Menezes Borges,数据科学家。
还记得几个月前每个人对裙子的颜色(蓝色还是金色)或运动鞋的颜色(粉色还是灰色)进行狂猜吗?对我来说,集成学习有点像这样。一组弱学习者汇聚成一个强学习者,从而提高了任何机器学习模型的准确性。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
你听说过群体智慧吗?不是那个电视剧,而是真实的术语。没有?好吧……那么,想象一下你向成千上万的随机人提出一个复杂的问题。现在,将他们的答案汇总起来。
你可能会发现多数人给出的答案比专家的答案更好。
“群体智慧是一个群体的集体意见,而不是单个专家的意见”—维基百科
回到机器学习领域,我们可以应用相同的想法。例如,如果我们汇总一组预测者(例如分类器和回归器)的预测,我们可能会得到比最好的单个预测者更好的预测结果。
一组预测者称为集成。因此,这种机器学习技术被称为集成学习。瞧!
在我上一篇文章《决策树的新鲜空气》中,我讨论了决策树算法以及我们如何使用它进行预测。正如你所知,在自然界中,一组树木组成了一个森林。嗯……这意味着……
想象一下,我训练了一组决策树分类器,根据训练数据集的不同子集进行个体预测。然后,我预测一个观察值的预期类别,考虑到多数人对同一实例的预测。因此,这意味着,我基本上是在使用一组决策树的知识,或者更常被称为随机森林。
在本文中,我们将讨论包括bagging、boosting、stacking及其他一些最流行的集成方法。在详细介绍之前,请记住以下几点:
“集成方法在预测器尽可能独立时效果最佳。获得多样化分类器的一种方法是使用非常不同的算法进行训练。这增加了它们产生不同类型错误的机会,从而提高集成的准确性。”—“**动手学深度学习与 Scikit-Learn & TensorFlow,第七章
简单集成技术
- 硬投票分类器
这是该技术最简单的例子,我们已经友好地介绍过。投票分类器通常用于分类问题。想象一下你训练并拟合了几个分类器(逻辑回归分类器、SVM 分类器、随机森林分类器等)到你的训练数据集中。
创建更好分类器的一种简单方法是汇总每个分类器的预测,并将多数选择作为最终预测。基本上,我们可以将其视为获取所有预测器的众数。
《动手学深度学习与 Scikit-Learn & TensorFlow》第七章
- 平均法
我们看到的第一个例子主要用于分类问题。现在让我们来看看一种用于回归问题的技术,称为平均法。类似于硬投票,我们取多个算法做出的预测并计算其平均值以得出最终预测。
- 加权平均
这种技术与平均法相同,只是所有模型根据其对最终预测的重要性分配不同的权重。
高级集成技术
- 堆叠
也称为堆叠泛化,这种技术基于训练一个模型,该模型将执行我们之前看到的常规聚合操作。
我们有 N 个预测器,每个预测器做出预测并返回最终值。之后,Meta Learner 或 Blender 将这些预测作为输入并做出最终预测。
让我们看看它是如何工作的……
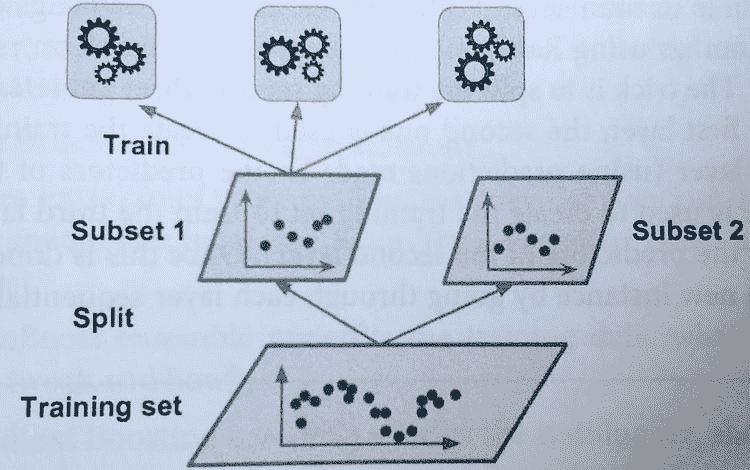
训练 Meta Learner 的常用方法是保留集。首先,将训练集拆分为两个子集。第一个子集的数据用于训练预测器。
之后,将在第一个子集上训练的相同预测器用于对第二个(保留的)集合进行预测。通过这样做,确保了预测的清洁性,因为这些算法从未见过数据。
利用这些新预测,我们可以生成一个新的训练集,这个训练集将用作输入特征(使新的训练集变为三维)并保留目标值。
因此,最后,元学习器在这个新数据集上进行训练,并考虑第一个预测提供的值来预测目标值。
此外,你可以使用这种方法训练多个元学习器(例如,一个使用线性回归,另一个使用随机森林回归,等等)。要使用多个元学习器,你必须将训练集拆分成三个或更多的子集:第一个用于训练第一层预测器,第二个用于对未知数据进行预测并创建新数据集,第三个用于训练元学习器并对目标值进行预测。
- 袋装和粘贴
另一种方法是对每个预测器使用相同的算法(例如,所有的决策树),然而,使用不同的训练集随机子集以获得更一般化的结果。
文章“使用可适应随机森林的降尺度降水”
关于子集的创建,你可以选择进行替换或不进行替换。如果我们假设有替换,一些观察可能会出现在多个子集中,这就是我们称这种方法为袋装(即自助聚合)。当抽样没有替换时,我们确保每个子集中的所有观察都是唯一的,从而保证每个子集中没有重复的观察。
一旦所有预测器都训练完成,集成模型可以通过聚合所有训练过的预测器的预测值来对新实例进行预测,就像我们在硬投票分类器中看到的那样。尽管每个单独的预测器比在原始数据集上训练时具有更高的偏差,但聚合可以减少偏差和方差(查看我的文章关于偏差-方差权衡)。
使用粘贴(pasting),这些模型给出相同结果的可能性很高,因为它们获取了相同的输入。自助抽样(bootstrapping)在每个子集中引入了更多的多样性,因此你可以预期袋装(bagging)具有更高的偏差,这意味着预测器之间的相关性较低,从而减少了集成的方差。总体而言,袋装模型通常提供更好的结果,这解释了为什么你通常会听到更多关于袋装而不是粘贴的内容。
- 提升
如果一个数据点被第一个模型以及接下来的模型(可能是所有模型)错误预测,那么它们结果的组合是否能提供更好的预测?这就是提升发挥作用的地方。
也被称为假设提升,指的是任何可以将弱学习者组合成更强学习者的集成方法。这是一个顺序过程,每个后续模型试图修正其前任模型的错误。
每个模型在整个数据集上的表现可能不佳。然而,它们在数据集的部分区域有很好的表现。因此,从提升中我们可以预期每个模型实际上都会有助于提升整体集成的性能。
基于袋装和提升的算法
最常用的集成学习技术是袋装和提升。以下是这些技术中一些最常见的算法。我会在不久的将来写单独的文章介绍这些算法。
袋装算法:
提升算法:
简介:Diogo Menezes Borges 是一名数据科学家,拥有工程背景和 2 年的经验,使用预测建模、数据处理和数据挖掘算法解决复杂的商业问题。
原文。已获许可转载。
资源:
相关内容:
相关主题更多内容
集成学习实例
原文:
www.kdnuggets.com/2022/10/ensemble-learning-examples.html

作者提供的图片
什么是集成学习?
我们的三大课程推荐
1. Google 网络安全证书 - 加速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
集成学习结合多个模型以获得更好的模型性能。它有助于提高模型的鲁棒性并提供通用模型。简而言之,它结合了模型的不同决策来提高性能。
在本教程中,我们将通过示例学习各种集成方法。我们将使用 Kaggle 上的心脏病分析与预测数据集。我们的重点是利用各种特征找到心脏病发作的高风险和低风险患者。
输出:
-
0 = 较低的心脏病发作风险
-
1 = 更高的心脏病发作风险
平均
我们将从导入所需的实用程序和机器学习包开始。
简单平均
我们将通过将所有模型的输出相加并除以模型总数来计算简单平均。
-
使用 pandas 加载了 heart.csv 文件。
-
目标是“输出”特征。
-
删除“输出”以创建训练特征。
-
使用 StandardScaler()对特征进行缩放
-
将数据拆分为训练集和测试集。
-
构建所有三个模型对象。我们使用的是 RandomForestClassifier、LogisticRegression 和 SGDClassifier。
-
在训练集上训练模型,并使用测试集预测输出。
-
使用平均公式并将输出四舍五入为仅显示 1 和 0。
-
显示准确性和 AUC 指标。
我们的模型在默认超参数下表现良好。
Accuracy: 85.246%
AUC score: 0.847
加权平均
在加权平均中,我们给表现最佳的模型赋予最高权重,给表现较差的模型赋予最低权重,同时计算平均值。
| model_1 | model_2 | model_3 | |
|---|---|---|---|
| 权重 | 30% | 60% | 10% |
下面的代码显示,通过给予model_2更高的权重,我们达到了更好的性能。
注意: 在赋予权重时,确保它们的总和为 1。例如,0.3 + 0.6 + 0.1 = 1
Accuracy: 90.164%
AUC score: 0.89
最大投票
最大投票法通常用于分类问题。在这种方法中,每个模型对每个样本进行预测并投票。从样本类别中,只有得票最高的类别会被纳入最终预测类别。
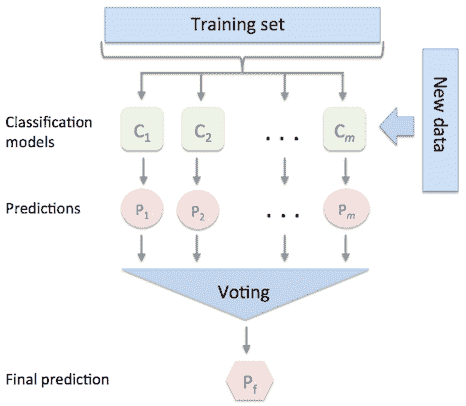
图像来自rasbt.github.io
在下面的例子中,我添加了第四个模型 KNeighborsClassifier。我们将使用 Scikit-Learn 的 VotingClassifier,并添加三个分类器:RandomForestClassifier、LogisticRegression 和 KNeighborsClassifier。
正如我们所见,我们得到了比简单平均更好的结果。
Accuracy: 90.164%
AUC score: 0.89
堆叠
堆叠通过元模型(meta-classifier 或 meta-regression)组合多个基础模型。基础模型在完整数据集上进行训练。元模型在基础模型的特征(输出)上进行训练。基础模型和元模型通常是不同的。简而言之,元模型帮助基础模型找到有用的特征,以实现高性能。
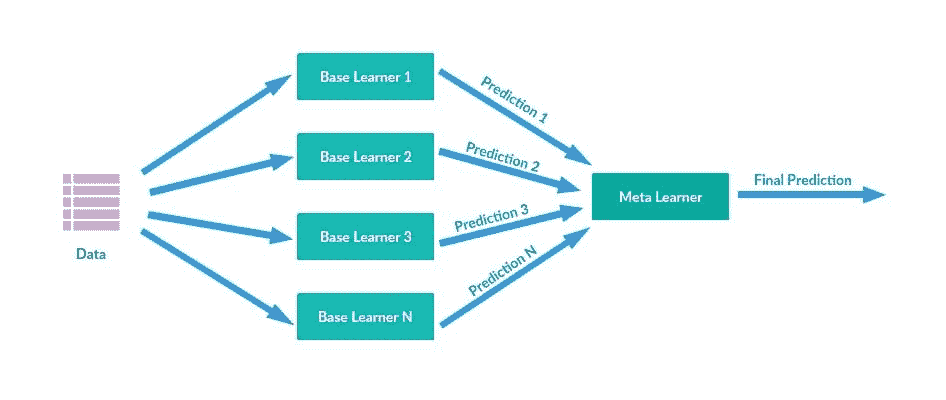
图像来自opengenus.org
在这个例子中,我们将使用随机森林、逻辑回归和 AdaBoost 分类器作为基础模型(估计器),并使用 GradientBoosting 分类器作为元模型(final_estimator)。
堆叠模型未能产生更好的结果。
Accuracy: 81.967%
AUC score: 0.818
Bagging
Bagging,也称为 Bootstrap Aggregating,是一种集成方法,用于提高机器学习模型的稳定性和准确性。它用于最小化方差和过拟合。通常,它应用于决策树方法。
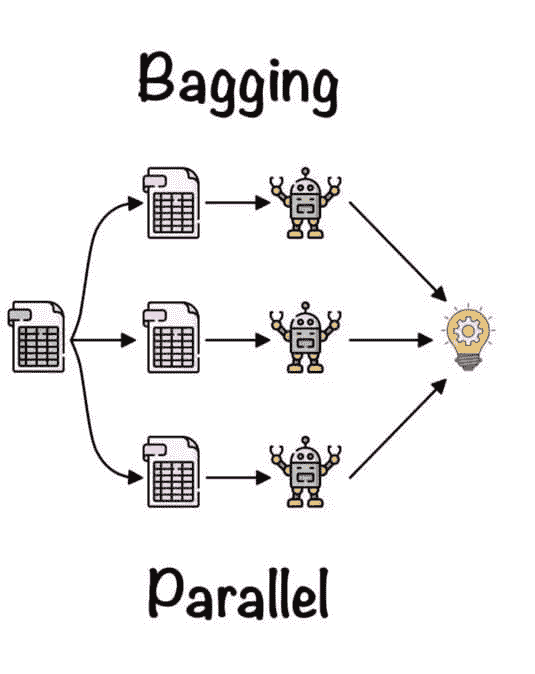
Bagging 由Fernando López介绍
Bagging 随机创建训练数据的子集,以公平分布整个数据集,并在其上训练模型。最终输出是通过组合所有基础模型的输出生成的。
在我们的例子中,我们将使用一种类型的模型,并在不同的训练数据子集上进行训练。一个子集也称为“包”,因此称为 bagging 算法。
在这个例子中,我们使用 Scikit-learn 的 BaggingClassifier,并利用逻辑回归作为基础估计器。
Bagging 算法已产生最佳和可靠的结果。
Accuracy: 90.164%
AUC score: 0.89
提升
提升方法通过组合弱分类器来创建强分类器。它减少了偏差并改善了单个模型的性能。
通过将弱分类器串联训练,你可以实现高性能。第一个模型在训练数据上进行训练,然后第二个模型在第一个模型中纠正错误。这是一个迭代算法,根据之前的模型调整权重。
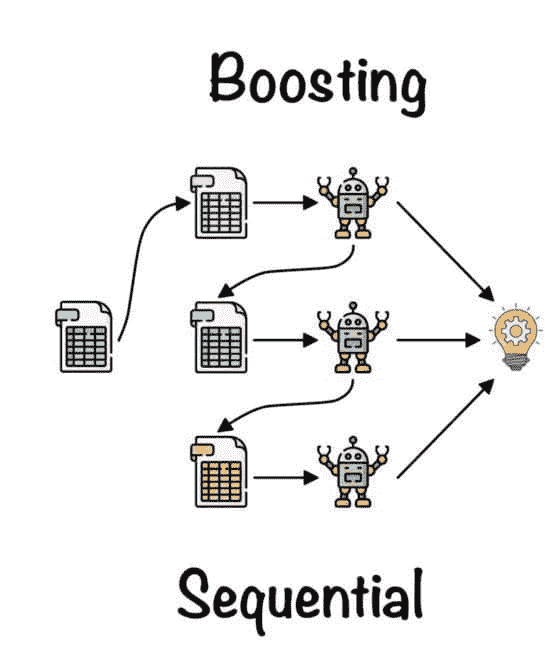
由 Fernando López 提供的提升方法
提升算法给予先前模型准确预测的观测值更多的权重。这个过程持续进行,直到所有训练数据集都被正确预测或达到了最大模型数量。
在这个示例中,我们将使用 AdaBoost 分类器。自适应提升算法(AdaBoost)是将弱分类器组合成一个强大分类器的经典技术。
Accuracy: 80.328%
AUC score: 0.804
结论
尽管集成学习应该应用于所有机器学习应用中,但在大型神经网络的情况下,你需要考虑吞吐量、计算和操作成本,以决定是否训练和服务多个模型。
在本教程中,我们学习了集成学习的重要性。此外,我们还学习了平均、最大投票、堆叠、袋装和提升的方法及其代码示例。
希望你喜欢这个教程,如果你对最佳技术有任何疑问,请在下面的评论区留言。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,他热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理健康问题的学生构建 AI 产品。
更多相关主题
集成学习以改善机器学习结果
原文:
www.kdnuggets.com/2017/09/ensemble-learning-improve-machine-learning-results.html
作者 Vadim Smolyakov,Statsbot。
集成学习通过结合多个模型来帮助提高机器学习结果。这种方法允许比单个模型产生更好的预测性能。这就是为什么集成方法在许多著名的机器学习竞赛中名列前茅,如 Netflix 竞赛、KDD 2009 和 Kaggle。
Statsbot团队希望给你这种方法的优势,并请数据科学家 Vadim Smolyakov 深入研究三种基本的集成学习技术。*
集成方法是将几种机器学习技术结合成一个预测模型的元算法,以减少 方差(bagging)、偏差(boosting)或改进预测(stacking)。
集成方法可以分为两类:
-
序列集成方法,其中基础学习者是顺序生成的(例如 AdaBoost)。
序列方法的基本动机是利用基础学习者之间的依赖关系。通过对先前错误标记的示例赋予更高的权重,可以提高整体性能。
-
并行集成方法,其中基础学习者是并行生成的(例如随机森林)。
并行方法的基本动机是利用基础学习者之间的独立性,因为通过平均化可以显著减少误差。
大多数集成方法使用单一的基础学习算法来产生同质基础学习者,即相同类型的学习者,形成同质集成。
还有一些方法使用异质学习者,即不同类型的学习者,形成异质集成。为了使集成方法比其任何单独成员更准确,基础学习者必须尽可能准确并且尽可能多样化。
Bagging
Bagging 代表自助聚合。减少估计方差的一种方法是将多个估计值进行平均。例如,我们可以在数据的不同子集上训练 M 棵不同的树(通过随机抽样替换选择),然后计算集成:
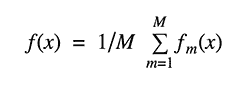
Bagging 使用自助抽样来获得用于训练基础学习者的数据子集。对于基础学习者的输出聚合,bagging 使用分类投票和回归平均。
我们可以在 Iris 数据集上的分类背景下研究 bagging。我们可以选择两个基础估计器:决策树和 k-NN 分类器。图 1 显示了基础估计器的学习决策边界以及它们应用于 Iris 数据集的 bagging 集成。
准确率:0.63 (+/- 0.02) [决策树]
准确率:0.70 (+/- 0.02) [K-NN]
准确率:0.64 (+/- 0.01) [袋装树]
准确率:0.59 (+/- 0.07) [袋装 K-NN]
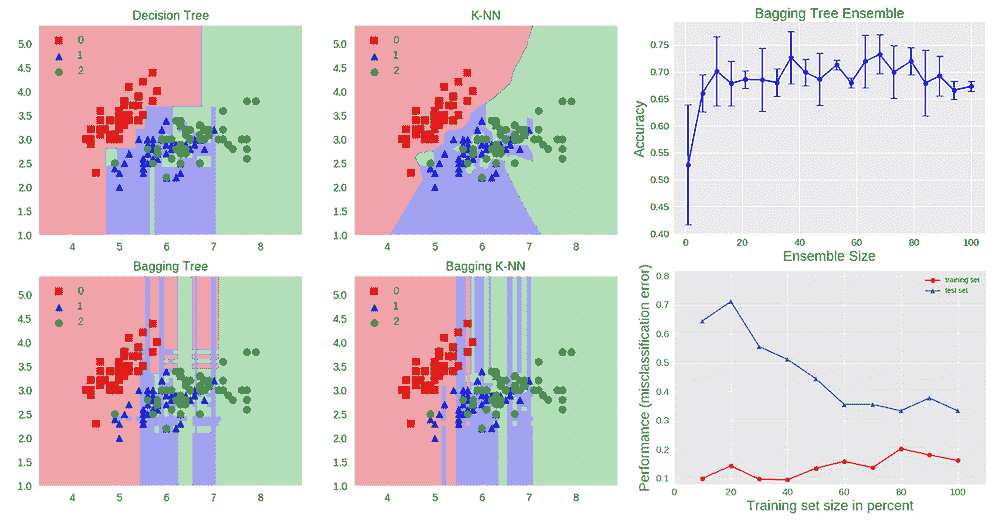
决策树展示了轴的平行边界,而 k=1 最近邻则紧密地拟合数据点。袋装集成方法使用了 10 个基础估计器,并对训练数据和特征进行了 0.8 的子采样。
与 k-NN 袋装集成相比,决策树袋装集成达到了更高的准确率。K-NN 对训练样本的扰动不太敏感,因此它们被称为稳定学习者。
将稳定学习者进行组合的优势较小,因为集成不会帮助改善泛化性能。
图形还显示了随着集成规模的增加,测试准确率的提升。根据交叉验证结果,我们可以看到准确率直到约 10 个基础估计器时才会增加,然后会趋于平稳。因此,添加超过 10 个基础估计器只会增加计算复杂性,而不会提高 Iris 数据集的准确率。
我们还可以看到袋装树集成的学习曲线。注意到训练数据的平均错误为 0.3,以及测试数据的 U 形错误曲线。训练和测试误差之间的最小差距发生在训练集大小约为 80%时。
一种常用的集成算法是随机树森林。
在随机森林中,集成中的每棵树都是从训练集的有放回抽样(即自助采样)中构建的。此外,随机选择特征的子集进一步增加了树的随机性,而不是使用所有特征。
结果是,森林的偏差略微增加,但由于较少相关树的平均化,其方差减少,导致整体模型更好。
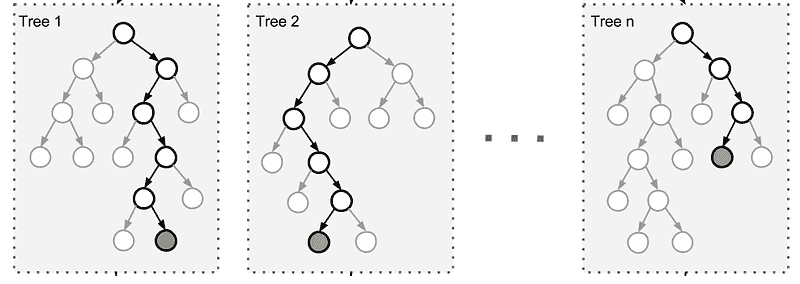
在极端随机树算法中,随机性更进一步:分裂阈值是随机的。不是寻找最具区分性的阈值,而是为每个候选特征随机抽取阈值,并选择这些随机生成阈值中的最佳作为分裂规则。这通常可以进一步减少模型的方差,但以略微增加偏差为代价。
提升(Boosting)
提升(Boosting)指的是一类能够将弱学习者转化为强学习者的算法。提升的主要原理是将一系列弱学习者——那些仅稍微优于随机猜测的模型,如小决策树——拟合到数据的加权版本上。更多的权重给予那些被早期轮次错误分类的示例。
然后通过加权多数投票(分类)或加权和(回归)来组合预测结果,以产生最终预测。提升方法与像 bagging 这样的委员会方法的主要区别在于,基本学习器是在数据的加权版本上按顺序训练的。
以下算法描述了最广泛使用的提升算法形式,称为 AdaBoost,即自适应提升。

我们看到第一个基本分类器 y1(x) 是使用所有相等的加权系数进行训练的。在随后的提升轮次中,对于被误分类的数据点,加权系数增加,对于正确分类的数据点,加权系数减少。
数量 epsilon 代表每个基本分类器的加权错误率。因此,加权系数 alpha 给予更准确的分类器更大的权重。
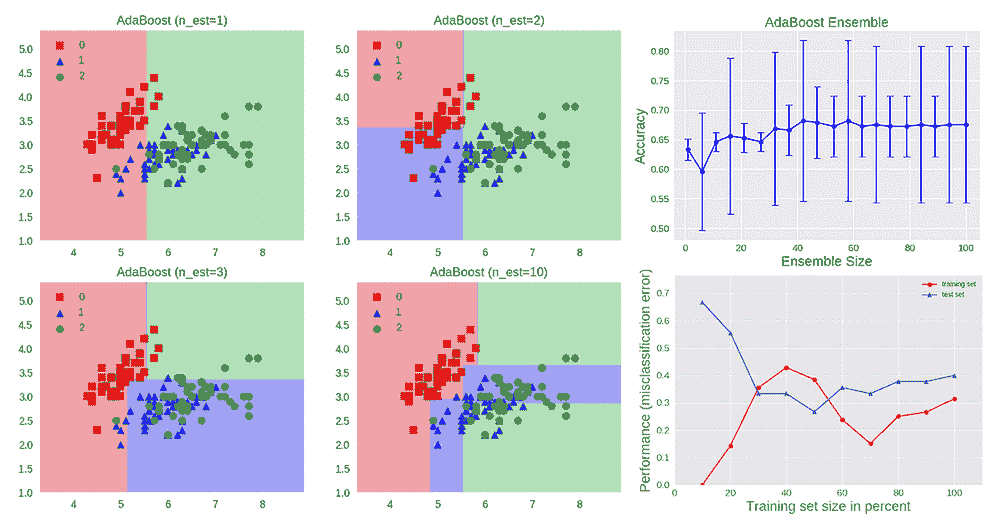
AdaBoost 算法在上图中进行了说明。每个基本学习器由一个深度为 1 的决策树组成,从而根据一个特征阈值对数据进行分类,该阈值将空间划分为两个由与一个轴平行的线性决策面分隔的区域。图中还显示了随着集成大小的增加测试准确度的提高,以及训练和测试数据的学习曲线。
梯度树提升 是提升到任意可微损失函数的推广。它可以用于回归和分类问题。梯度提升以顺序方式构建模型。
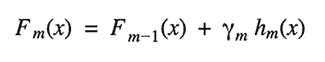
在每个阶段,选择决策树 hm(x) 以最小化当前模型 Fm-1(x) 的损失函数 L:
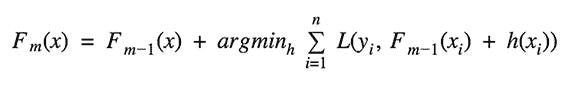
回归和分类算法在使用的损失函数类型上有所不同。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多关于此主题的信息
集成学习技术:在 Python 中使用随机森林的详细讲解
原文:
www.kdnuggets.com/ensemble-learning-techniques-a-walkthrough-with-random-forests-in-python
机器学习模型已成为多个行业决策中的重要组成部分,但在处理嘈杂或多样化的数据集时,往往会遇到困难。这就是集成学习发挥作用的地方。
本文将揭秘集成学习,并介绍其强大的随机森林算法。无论你是希望提升工具箱的数据科学家,还是寻求构建稳健机器学习模型的实践见解的开发者,这篇文章都适合你!
我们的三大推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 需求
在本文结束时,你将全面了解集成学习及其在 Python 中的随机森林如何工作。因此,无论你是经验丰富的数据科学家,还是只是想扩展机器学习能力的好奇者,都欢迎加入我们的冒险,提升你的机器学习专业知识!
1. 什么是集成学习?
集成学习是一种机器学习方法,其中多个弱模型的预测结果相互结合,以获得更强的预测。集成学习的概念是通过利用每个模型的预测能力来减少单个模型的偏差和错误。
为了更好地举例,假设你看到了一种动物,但不知道这只动物属于什么物种。那么,与其询问一个专家,不如询问十个专家,然后根据大多数人的意见来决定。这被称为硬投票。
硬投票是指我们考虑每个分类器的类别预测,然后根据对特定类别的最大投票数来对输入进行分类。另一方面,软投票是指我们考虑每个分类器对每个类别的概率预测,然后根据该类别的平均概率(分类器的概率平均值)将输入分类到概率最大类别。
2. 何时使用集成学习
集成学习通常用于提高模型性能,包括提高分类准确性和减少回归模型的平均绝对误差。此外,集成学习者通常能够提供更稳定的模型。当模型之间没有相关性时,集成学习者效果最佳,因为每个模型可以学习到独特的内容,并提高整体性能。
3. 集成学习策略
尽管集成学习可以通过多种方式应用,但在实践中,三种策略因其易于实现和使用而获得了很大的流行。这三种策略是:
-
Bagging: Bagging,即自助聚合,是一种集成学习策略,其中模型使用数据集的随机样本进行训练。
-
Stacking: Stacking,即堆叠泛化,是一种集成学习策略,其中我们训练一个模型以结合多个在我们的数据上训练的模型。
-
Boosting: Boosting 是一种集成学习技术,专注于选择错误分类的数据以训练模型。
让我们深入探讨这些策略,并看看如何使用 Python 在我们的数据集上训练这些模型。
4. Bagging 集成学习
Bagging 采用数据的随机样本,使用学习算法和均值来找到 Bagging 概率;也称为自助聚合;它汇总多个模型的结果以得到一个广泛的结果。
该方法包括:
-
将原始数据集拆分成多个有放回的子集。
-
为这些子集中的每一个开发基础模型。
-
在进行所有预测之前并行运行所有模型以获得最终预测。
Scikit-learn 为我们提供了实现 BaggingClassifier 和 BaggingRegressor 的能力。 BaggingMetaEstimator 确定原始数据集的随机子集以拟合每个基础模型,然后通过投票或平均将每个基础模型的预测汇总成最终预测。这种方法通过随机化其构建过程来减少方差。
让我们举一个使用 scikit-learn 进行包装估计器的例子:
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bagging = BaggingClassifier(base_estimator=DecisionTreeClassifier(),n_estimators=10, max_samples=0.5, max_features=0.5)
Bagging 分类器考虑多个参数:
-
base_estimator: 在包装方法中使用的基础模型。这里我们使用决策树分类器。
-
n_estimators: 我们将在包装方法中使用的估计器数量。
-
max_samples: 从训练集中为每个基础估计器提取的样本数量。
-
max_features: 用于训练每个基本估计器的特征数量。
现在我们将在训练集上训练这个分类器并进行评分。
bagging.fit(X_train, y_train)
bagging.score(X_test,y_test)
对于回归任务,我们也可以做相同的处理,唯一的区别是我们将使用回归估计器。
from sklearn.ensemble import BaggingRegressor
bagging = BaggingRegressor(DecisionTreeRegressor())
bagging.fit(X_train, y_train)
model.score(X_test,y_test)
5. 堆叠集成学习
堆叠是一种结合多个估计器的技术,以最小化它们的偏差并产生准确的预测。每个估计器的预测结果被结合在一起,然后输入到一个通过交叉验证训练的最终预测元模型中;堆叠可以应用于分类问题和回归问题。
堆叠集成学习
堆叠的过程如下:
-
将数据分为训练集和验证集
-
将训练集分为 K 折
-
在 k-1 个折叠上训练一个基本模型,并在第 k 个折叠上进行预测
-
反复进行,直到你对每一个折叠都有一个预测结果
-
在整个训练集上拟合基本模型
-
使用模型对测试集进行预测
-
对其他基本模型重复步骤 3–6
-
使用测试集的预测结果作为新模型(元模型)的特征
-
使用元模型对测试集进行最终预测
在下面的示例中,我们首先创建两个基本分类器(RandomForestClassifier 和 GradientBoostingClassifier)和一个元分类器(LogisticRegression),并使用 K 折交叉验证将这些分类器在训练数据(鸢尾花数据集)上的预测作为元分类器(LogisticRegression)的输入特征。
在使用 K 折交叉验证从基本分类器生成的预测作为元分类器的输入特征后,对测试集进行预测,并将结果与其堆叠集成模型进行准确性评估。
# Load the dataset
data = load_iris()
X, y = data.data, data.target
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Define base classifiers
base_classifiers = [
RandomForestClassifier(n_estimators=100, random_state=42),
GradientBoostingClassifier(n_estimators=100, random_state=42)
]
# Define a meta-classifier
meta_classifier = LogisticRegression()
# Create an array to hold the predictions from base classifiers
base_classifier_predictions = np.zeros((len(X_train), len(base_classifiers)))
# Perform stacking using K-fold cross-validation
kf = KFold(n_splits=5, shuffle=True, random_state=42)
for train_index, val_index in kf.split(X_train):
train_fold, val_fold = X_train[train_index], X_train[val_index]
train_target, val_target = y_train[train_index], y_train[val_index]
for i, clf in enumerate(base_classifiers):
cloned_clf = clone(clf)
cloned_clf.fit(train_fold, train_target)
base_classifier_predictions[val_index, i] = cloned_clf.predict(val_fold)
# Train the meta-classifier on base classifier predictions
meta_classifier.fit(base_classifier_predictions, y_train)
# Make predictions using the stacked ensemble
stacked_predictions = np.zeros((len(X_test), len(base_classifiers)))
for i, clf in enumerate(base_classifiers):
stacked_predictions[:, i] = clf.predict(X_test)
# Make final predictions using the meta-classifier
final_predictions = meta_classifier.predict(stacked_predictions)
# Evaluate the stacked ensemble's performance
accuracy = accuracy_score(y_test, final_predictions)
print(f"Stacked Ensemble Accuracy: {accuracy:.2f}")
6. 提升集成学习
提升是一种机器学习集成技术,它通过将弱学习器转变为强学习器来减少偏差和方差。这些弱学习器按顺序应用于数据集;首先创建一个初始模型并将其拟合到训练集。一旦识别出第一个模型的错误,就设计另一个模型来纠正这些错误。
有一些流行的算法和实现用于提升集成学习技术。让我们探索其中最著名的一些。
6.1. AdaBoost
AdaBoost 是一种有效的集成学习技术,它顺序地使用弱学习器进行训练。每次迭代时,优先考虑错误预测,同时减少对正确预测实例的权重;这种对挑战性观测的战略性关注促使 AdaBoost 随着时间的推移变得越来越准确,其最终预测是通过汇总多数投票或加权求和的方式来决定的。
AdaBoost 是一种适用于回归和分类任务的多用途算法,但在这里我们重点关注其在使用 Scikit-learn 进行分类问题的应用。让我们看看如何在下面的示例中使用它进行分类任务:
from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(n_estimators=100)
model.fit(X_train, y_train)
model.score(X_test,y_test)
在这个示例中,我们使用了 scikit-learn 中的 AdaBoostClassifier,并将 n_estimators 设置为 100。默认学习器是决策树,你可以进行更改。除此之外,决策树的参数可以进行调整。
2. 极端梯度提升 (XGBoost)
极端梯度提升,也更广为人知为 XGBoost,是提升集成学习者的最佳实现之一,因为其并行计算使其在单台计算机上运行非常优化。XGBoost 可以通过由机器学习社区开发的 xgboost 包进行使用。
import xgboost as xgb
params = {"objective":"binary:logistic",'colsample_bytree': 0.3,'learning_rate': 0.1,
'max_depth': 5, 'alpha': 10}
model = xgb.XGBClassifier(**params)
model.fit(X_train, y_train)
model.fit(X_train, y_train)
model.score(X_test,y_test)
3. LightGBM
LightGBM 是另一种基于树学习的梯度提升算法。然而,与其他基于树的算法不同,它使用叶子-wise 树增长,使其收敛更快。
叶子-wise 树增长 / 图片来源于 LightGBM
在下面的示例中,我们将应用 LightGBM 于二分类问题:
import lightgbm as lgb
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
params = {'boosting_type': 'gbdt',
'objective': 'binary',
'num_leaves': 40,
'learning_rate': 0.1,
'feature_fraction': 0.9
}
gbm = lgb.train(params,
lgb_train,
num_boost_round=200,
valid_sets=[lgb_train, lgb_eval],
valid_names=['train','valid'],
)
集成学习和随机森林是强大的机器学习模型,总是被机器学习从业者和数据科学家使用。在本文中,我们探讨了它们的基本直觉、何时使用它们,最后,我们介绍了最受欢迎的算法以及如何在 Python 中使用它们。
参考文献
Youssef Rafaat 是一位计算机视觉研究员和数据科学家。他的研究专注于为医疗保健应用开发实时计算机视觉算法。他还在市场营销、金融和医疗保健领域担任数据科学家超过 3 年。
更多相关主题
多人智慧胜过单人:集成学习的案例
评论
作者:Jay Budzik,ZestFinance。
“真理的利益需要多样的意见。” —J. S. Mill
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
银行和贷款机构越来越多地转向 AI 和机器学习,以自动化其核心功能,并在信贷承保和欺诈检测中做出更准确的预测。ML 从业者可以利用越来越多的建模算法,例如简单决策树、随机森林、梯度提升机、深度神经网络和支持向量机。每种方法都有其优缺点,这也是为什么将 ML 算法结合起来往往能提供比任何单一 ML 方法更出色的预测性能。(这是我们在 ZestFinance 每个项目中的标准做法。)这种结合算法的方法被称为集成。
集成方法在许多场景下提高了泛化性能,包括分类、回归和类别概率估计。集成方法在具有挑战性的数据集上创造了众多世界纪录。一个集成模型赢得了Netflix 奖和国际数据科学竞赛,几乎涵盖了所有领域,包括信用风险预测和视频分类。虽然集成方法通常被认为比单一模型的预测功能表现更好,但它们 notoriously 难以设置、操作和解释。随着更好的建模、可解释性和监控工具的发明,这些挑战正在减少,我们将在这篇文章的最后讨论这些工具。
集成模型如何实现更好的性能
就像自然界中的多样性有助于更强健的生物系统一样,机器学习模型的集成通过结合多个子模型的优势(并弥补其不足)产生更强的结果。神经网络需要在建模之前显式处理缺失值,而梯度提升树则自动处理这些缺失值。建模者在处理神经网络的缺失数据时,可能会引入偏差和错误。梯度提升树的方法选择也可能引入错误和偏差。通过结合不同的方法(例如,通过平均或混合分数),可以改善预测。更具体地说,集成通过结合具有不同错误模式的不同估计器来减少偏差和方差,从而降低单一错误来源的影响。
应用集成技术的方法有无数种。子模型可以处理不同的原始输入数据,你甚至可以使用子模型生成特征供另一个模型使用。例如,你可以对数据的每个段(如不同收入水平)训练一个模型,然后将结果结合起来。
集成方法的类型及其工作原理
集成学习有四种主要类型:
- 在装袋(bagging)中,我们使用自助采样来获取用于训练一组基础模型的数据子集。自助采样是使用逐渐增大的随机样本,直到预测准确性达到递减回报。每个样本用于训练一个单独的决策树,并对每个模型的结果进行聚合。对于分类任务,每个模型对结果进行投票。在回归任务中,模型结果取平均。具有低偏差但高方差的基础模型非常适合用于装袋。随机森林,即装袋的决策树组合,是这一方法的经典例子。
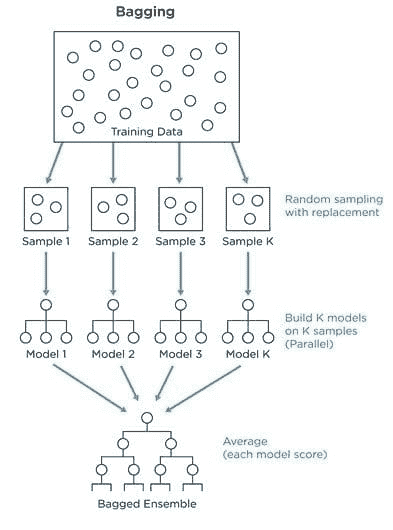
- 在提升(boosting)中,我们通过将建模努力集中于导致更多错误的数据(即关注困难的数据)来提高性能。我们训练一系列模型,对早期迭代中被错误分类的示例给予更多权重。与装袋(bagging)一样,分类任务通过加权多数投票来解决,回归任务则通过加权求和来得出最终预测。具有低方差但高偏差的基础模型非常适合用于提升。梯度提升是这一方法的一个著名例子。
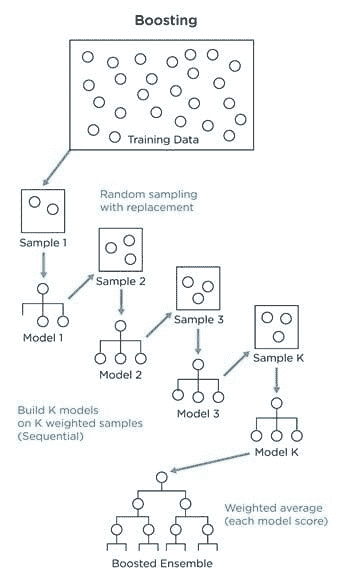
- 在堆叠中,我们创建一个集成函数,将多个基础模型的输出组合成一个单一的分数。基础级模型基于完整的数据集进行训练,然后其输出作为输入特征来训练集成函数。通常,集成函数是基础模型分数的简单线性组合。
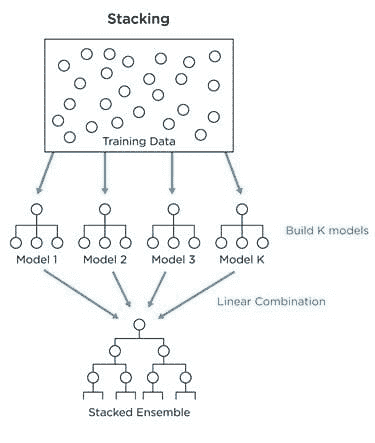
- 在 ZestFinance,我们更喜欢一种更强大的方法,称为深度堆叠,它使用堆叠集成与非线性集成函数,这些函数同时将模型分数和输入数据作为输入。这些方法有助于揭示子模型之间更深层次的关系,并通过根据每个子模型的优势来学习何时应用每个子模型,从而比简单的线性堆叠集成具有更高的准确性。深度堆叠允许模型根据特定的输入变量(如产品细分、收入带或营销渠道)选择正确的子模型权重,以进一步提高性能。
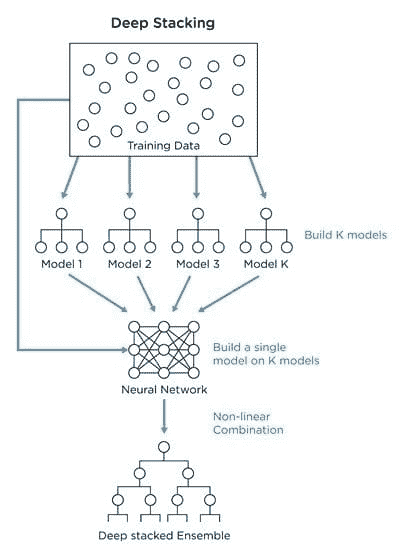
真实世界信用风险模型的结果
为了展示集成学习的卓越表现,我们建立了一系列二元分类模型,以预测从过去三年内发放的汽车贷款数据库中的违约情况。贷款数据包括超过 100,000 名借款人和超过 1,100 个特征。
竞争是在六个基础机器学习模型之间进行的:四个 XGBoost 模型和两个神经网络模型,这些模型使用来自不同信用局数据集的特征构建,并结合一个集成模型,该模型使用神经网络堆叠这六个基础模型。
为了评估模型的准确性,我们测量了它们在验证数据上的AUC和KS分数。AUC(接收器工作特征曲线下面积)用于衡量模型的假阳性和假阴性率,而 KS(Kolmogorov–Smirnov 检验的简称)用于比较数据分布。较高的数值与更好的业务结果相关。
以下是每个模型在预测准确性和通过减少损失节省的美元方面的表现,与逻辑回归基准模型相比。
| Model Type | AUC | KS | Est. Dollars Saved |
|---|---|---|---|
| Ensemble | 0.803 | 0.446 | $21M |
| XGB 1 | 0.791 (2%) | 0.420 (6%) | $18M (14%) |
| XGB 2 | 0.791 (2%) | 0.428 (4%) | $18M (12%) |
| XGB 3 | 0.781 (3%) | 0.411 (9%) | $17M (16%) |
| XGB 4 | 0.782 (3%) | 0.413 (8%) | $17M (16%) |
| ANN 1 | 0.750 (7%) | 0.376 (19%) | $16M (19%) |
| ANN 2 | 0.786 (2%) | 0.430 (4%) | $18M (13%) |
我们的集成模型产生了最高的 AUC(0.803),这意味着 80%的情况下,我们的集成模型将随机的优质申请人排在随机的劣质申请人之上。集成模型的 AUC 比最佳的 XGBoost 和神经网络模型高出 2%,这听起来可能不多,但 AUC 是对数刻度的,所以即使是小幅度的增加也比它们看起来的影响要大(类似于地震的里氏震中)。这个 5 亿美元的贷款业务通过使用集成模型相比于单一的 XGBoost 或神经网络模型每年将节省 300 万美元。
集成方法的优势不仅限于预测准确性。它们还通过随着时间的推移提高稳定性来惠及业务。为了验证这一点,我们使用验证集计算了集成模型和子模型在六个月期间的每日 AUC 分数。集成模型在这段时间内的 AUC 方差比表现最佳的神经网络模型低 3%,比表现最佳的 XGBoost 模型低 21%。更好的稳定性导致业务结果的可预测性更高。
集成方法的挑战
我们在上面看到,集成方法在实际的信用风险建模问题中提供了更好的经济效益和更好的稳定性。然而,在生产中使用复杂的集成模型可能会很棘手。
工程复杂性
我们上面提到的那个?即使是 Netflix 也无法投入生产。 技术依赖、运行时性能和模型验证都是在生产中使用这些模型的实际挑战。我们从头开始设计了 ZAML 软件工具来管理这些工程复杂性,我们很自豪地拥有许多世界级的集成模型在生产中运行。
为集成模型结果提供准确解释尤其具有挑战性。许多可解释性方法依赖于模型,并且不做出有问题的假设。 深度堆叠的集成模型使情况更加复杂,因为每个模型可能是连续的或离散的,这两种不同类型的函数的组合对于即使是最先进的分析技术也是一个挑战。
在之前的帖子中,我们展示了像 LOCO, PI 和 LIME 生成不准确解释 等常用技术,即使对于简单的玩具模型也是如此。它们在简单模型上不准确且运行缓慢,随着模型复杂性的增加,情况变得更糟。集成梯度(IG),一种基于 奥曼-沙普利值 的解释技术,适用于神经网络和其他连续函数。但是,你不能将神经网络与基于树的模型如 XGBoost 结合。如果这样做,IG 就会失效。
SHAP TreeExplainer 仅对决策树有效,不适用于神经网络。尽管一些机器学习工程师已开始使用 SHAP KernelExplainer,它声称适用于任何模型,但它对变量独立性和是否可以用平均值替代缺失值做了一些有问题的假设。
更重要的是,你通常不仅仅是试图理解模型得分的驱动因素。相反,你试图理解基于模型的决策。理解基于模型的决策意味着考虑模型得分的应用方式。在基于模型做出决策之前,模型的得分通常会经过一些转换,例如将其放在 0-1 范围内,并使得高于 90% 的得分对应于模型得分的最低十分位。这些转换在生成解释时必须仔细考虑。不幸的是,这也是许多开源工具,甚至最聪明的数据科学家,可能会遇到挑战的地方。
ZAML 客户可以从一种不受这些限制的可解释性方法中受益。它可以为几乎任何可能的机器学习函数集提供准确的解释。ZAML 使这种更好的模型使用起来更安全。
合规性
与电影推荐系统不同,信用风险模型必须经过严格分析和审查,以遵守消费者贷款法律和规定。使用数千个变量的集成信用承保模型增加了验证模型在各种条件下是否按预期表现的复杂性。拥有正确的可解释性数学仅仅是解决方案的一部分。记录模型构建和分析也很重要,以便其他从业者能够复制工作,提供为什么申请人被拒绝的清晰理由(不利行动),执行公平贷款分析,寻找较少偏见的模型,并提供足够的监控以了解模型何时需要更新。当你有多个子模型时,每个子模型使用不同的特征空间和模型目标,所有这些任务会变得更加复杂。幸运的是,ZAML 工具可以自动化大量这一过程。
结论
我们已经看到,集成学习如何产生更准确和稳定的预测,从而转化为更有利可图的商业结果。这些好处带来了额外的复杂性,但寻求最佳预测准确性和稳定性的贷款机构现在有像 ZAML 这样的工具来帮助管理任务。使用 ZAML 驱动的集成模型已经帮助美国贷款机构多年战胜竞争对手。多样性是进化和政治辩论中的强大工具 —— 同样,它也能带来更好的承保结果。
简介: Jay Budzik 是 ZestFinance 的首席技术官,拥有通过应用 AI 和 ML 来推动收入增长的成功记录。他在西北大学获得计算机科学博士学位,背景涉及 AI、ML、大数据和 NLP,Jay 曾是一名发明家和企业家,拥有金融和网络规模媒体及广告的经验:通过开发和部署成功的产品以及建设和培养优秀团队来取得成果。
相关:
更多相关话题
朴素英语解释的集成方法:自助法(Bagging)
原文:
www.kdnuggets.com/2021/05/ensemble-methods-explained-plain-english-bagging.html
评论
由Claudia Ng,高级数据科学家
在本文中,我将介绍一种流行的同质模型集成方法——自助法(bagging)。同质集成方法结合了大量相同算法的基础估计器或弱学习器。
同质集成的原理是“群体智慧”——多个多样化模型的集体预测优于单个模型的预测。要实现这一点,有三个要求:
-
模型必须是独立的;
-
每个模型的表现略好于随机猜测;
-
所有单独的模型在其自身的表现上相似。
当这三个要求得到满足时,添加更多模型应该能提高集成模型的表现。
集成方法有助于减少方差并防止对训练数据集的过拟合,从而使模型更好地学习一般化模式,而不是对训练数据集中的噪声过拟合。
自助法
自助法的工作原理
在自助法中,大量独立的弱模型被组合在一起,以相同的目标学习相同的任务。术语“自助法”来源于**b**ootstrap + **agg**regat**ing**,其中每个弱学习器在用替换抽样的随机子样本上进行训练,然后将模型的预测结果进行聚合。
自助法保证了独立性和多样性,因为每个数据子样本是独立抽样的,并且我们得到不同的子集来训练基础估计器。
基础估计器是表现仅比随机猜测稍好的一类弱学习器。一个这样的模型示例是最大深度为三的浅层决策树。这些模型的预测结果通过平均值进行组合。
自助法既可以应用于分类问题,也可以应用于回归问题。对于回归问题,最终预测将是基础估计器预测的平均值(软投票)。对于分类问题,最终预测将是多数投票(硬投票)。
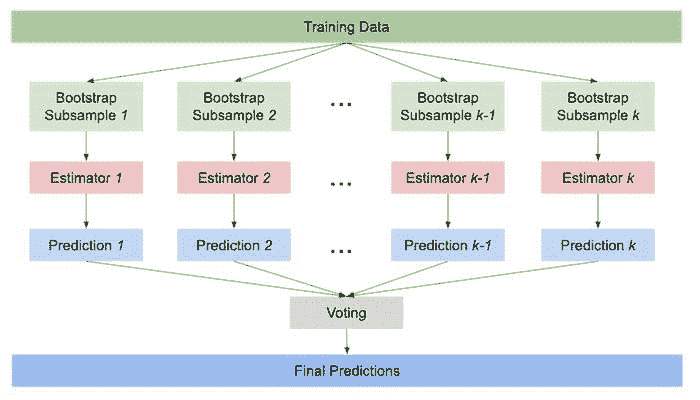
自助法算法的图示
使用 Scikit-Learn 实现自助法算法
你可以使用[BaggingRegressor](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.BaggingRegressor.html)或[BaggingClassifier](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.BaggingClassifier.html)在 Python 包 Scikit-Learn 中构建你自己的自助法算法。
首先,实例化你的基础估算器,并将其作为BaggingRegressor或BaggingClassifier中的基础估算器。下面是一个以线性回归作为基础估算器的袋装回归器示例,以及一个以决策树分类器作为基础估算器的袋装分类器示例。默认的估算器数量为 10。
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import BaggingRegressor
reg_lr = LinearRegression()
reg_bag = BaggingRegressor(base_estimator=reg_lr)
reg_bag.fit(X_train, y_train)
====================================================================
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
clf_dt = DecisionTreeClassifier(max_depth=3)
clf_bag = BaggingClassifier(base_estimator=clf_dt)
clf_bag.fit(X_train, y_train)
随机森林
随机森林®是袋装算法的一个流行示例。它使用平均值将多个在训练数据集子集上训练的单独决策树进行集成。
使用scikit-learn 的随机森林算法在 Python 中,你可以指定树特定的参数。以下是一些需要调整的重要超参数,以使其针对你的数据集进行优化:
-
n_estimators:训练的树木数量以进行聚合。通常 100 到 500 棵树就足够了,通常更多的树会改进你的模型(但收益递减),但计算成本也会更高; -
max_depth:树的最大深度。较深的树有助于减少偏差,但会增加方差。随机森林算法中多个树的聚合可以帮助解决这一问题,但仍需小心; -
max_features:每次分裂时考虑的最大特征数。一个好的起点通常是特征数量的平方根。
随机森林算法中的另一个重要概念是袋外(OOB)评分。在执行自助法时,会有实例未被纳入用于训练估算器的子样本。这些样本外的实例可以用来评估模型,得到一个袋外(OOB)评分,本质上类似于随机森林模型的伪验证集。要获得 OOB 评分,在初始化随机森林对象时将oob_score=True。
rf = RandomForestClassifier(n_estimators=100, oob_score=True)
rf.fit(X_train, y_train)
print(rf.oob_score_)
请注意,如果特征中存在空值,scikit-learn 的随机森林算法会返回错误,因此请记得在调用 fit 之前用 pandas 的fillna填充空值,否则会抛出错误。
袋装的优缺点
-
减少方差:由于采样是通过自助法真正随机进行的,袋装通常有助于减少方差并对抗过拟合。
-
易于并行化:估算器是独立的,因此可以在袋装过程中并行构建模型。
-
更高的稳定性和鲁棒性:大量聚合的估算器有助于提供更高的稳定性和鲁棒性。
-
难以解释:袋装算法的最终预测基于基础估算器的平均预测。虽然这提高了准确性,但模型变得更难以解释。
总结
Bagging 基于集体学习的思想,其中许多独立的弱学习器在引导的子样本数据上进行训练,然后通过平均进行聚合。它可以应用于分类和回归问题。
随机森林算法是一个流行的 bagging 算法示例。在为你的数据集调整随机森林算法的超参数时,需要关注三个重要领域:i) 树的数量 (n_estimators),ii) 修剪树(从 max_depth 开始,但也探索节点中所需的样本和/或分裂),iii) 每次分裂时考虑的最大特征数量 (max_features)。
Bagging 是一个非常强大的模型集成方法示例。希望这能激励你在下次处理预测建模问题时尝试使用 bagging 算法!
简介:Claudia Ng 是高级数据科学家。
原文。经授权转载。
相关:
-
XGBoost:它是什么,何时使用它
-
全面的集成学习指南——你需要知道的所有内容
-
微软探索集成学习的三个关键谜团
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关内容
机器学习的集成方法:AdaBoost
原文:
www.kdnuggets.com/2019/09/ensemble-methods-machine-learning-adaboost.html
评论
由 Valentina Alto,数据科学与商业分析硕士

我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
在统计学和机器学习中,集成方法使用多个学习算法来获得比任何单个学习算法所能获得的更好的预测性能。
结合多个算法的想法最初由计算机科学家兼教授 Michael Kerns 提出,他想知道 “弱学习能力是否等同于强学习能力”。目标是将一个略好于随机猜测的弱算法转变为强学习算法。结果发现,如果我们要求弱算法创建一堆分类器(定义上都很弱),然后将它们结合起来,可能会得到一个更强的分类器。
AdaBoost,即“自适应提升”,是一种机器学习元算法,可与许多其他类型的学习算法结合使用,以提高性能。
在这篇文章中,我将介绍 Adaboost 背后的数学原理,并提供一个 Python 实现。
AdaBoost 的直觉和数学
想象一下,我们有一个样本,将其划分为训练集和测试集,以及一堆分类器。每个分类器在训练集的随机子集上进行训练(注意这些子集实际上可以重叠——这与交叉验证不同)。然后,对于每个子集中的每个观察值,AdaBoost 分配一个权重,决定该观察值出现在训练集中的概率。权重较高的观察值更有可能被包含在训练集中。因此,AdaBoost 倾向于将更高的权重分配给那些被误分类的观察值,以便它们在下一个分类器的训练集中占据更大份额,目标是使下一个训练的分类器在这些观察值上表现更好。
考虑一个简单的二分类问题,其目标由‘正’或‘负’(表示为 1 和-1)的符号表示,最终分类器的方程如下:
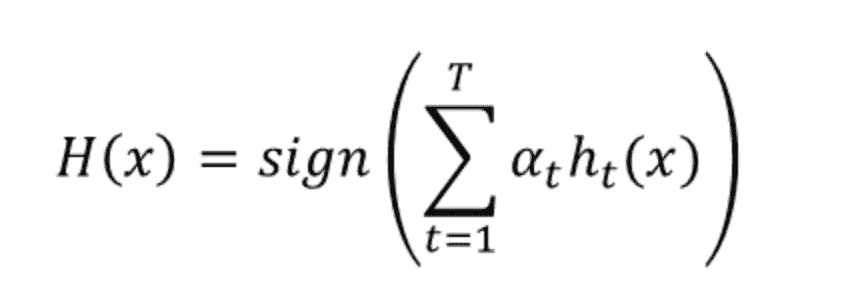
基本上,最终分类器对观察值 x 的输出等于 T 个弱分类器的输出 h_t(x)的加权和的符号,权重为α_t。
更具体地说,α_t 是分配给分类器 t 输出的权重(注意,这个权重与分配给观察值的权重不同,后续将讨论)。它的计算方式如下:
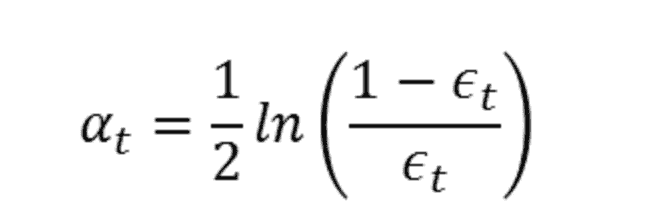
其中ε_t 是分类器 t 的误差项(错误分类的观察值/总观察值)。当然,误差低的分类器会在加权和中优先考虑,因此它们的权重会更高。实际上,如果我们查看不同误差对应的α:
import numpy as np
import matplotlib.pyplot as plt
epsilon=np.arange(0,1,0.01)
alpha=1/2*np.log((1-epsilon)/epsilon)
plt.plot(epsilon, alpha)
plt.xlabel('error')
plt.ylabel('alpha')
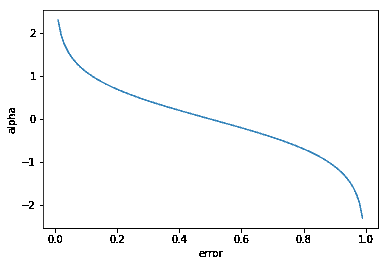
正如你所见,当误差接近 0 时,分类器的权重会指数增长,而当误差接近 1 时,它会指数地减少。
然后,α的值用于计算另一种类型的权重,即分配给子集观察值的权重。对于第一个分类器,权重被均等初始化,因此每个观察值的权重=1/n(其中 n 为子集的大小)。从第二个分类器开始,每个权重递归计算如下:
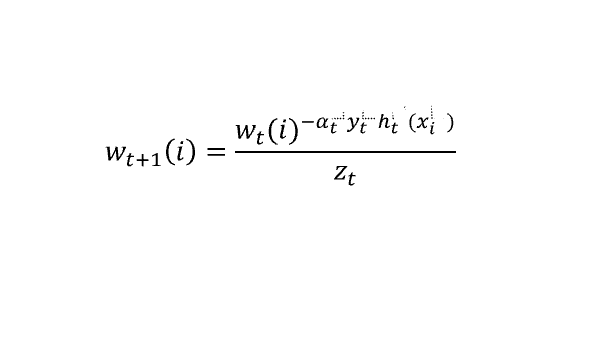
其中 y_t 是目标值(1 或-1),变量 w_t 是权重向量,每个训练样本都有一个权重。‘i’是训练样本的编号。这个方程展示了如何更新第 i 个训练样本的权重。
我们可以将 w_t 视为一个分布:这与我们一开始所说的一致,即权重表示训练样本被选为训练集的一部分的概率。
为了使其成为一个分布,这些概率的总和应该为 1。为确保这一点,我们通过将每个权重除以所有权重之和 Z_t 来归一化权重。
让我们解释一下这个公式。由于我们处理的是二分类问题(-1 与 1),如果实际值和拟合值具有相同的符号(分类正确),则 y_t*h_t(x_i)的乘积为正;如果它们的符号不同(分类错误),则乘积为负。因此:
-
如果产品为正且α大于零(强分类器),则分配给第 i 个观察值的权重会很小。
-
如果产品为正且α小于零(弱分类器),则分配给第 i 个观察值的权重会很高。
-
如果产品为负且α大于零(强分类器),则分配给第 i 个观察值的权重会很高。
-
如果产品为负且 alpha 小于零(弱分类器),则分配给第 i 个观察值的权重将很小。
注意:当我说‘小’和‘高’时,我指的是如果我们考虑归一化前的指数,分别小于 1 和大于 1。实际上:
现在我们对 AdaBoost 的工作原理有了了解,让我们看看它在 Python 中的实现,使用的是著名的鸢尾花数据集。
使用 Python 实现
首先,让我们导入数据:
from sklearn.ensemble import AdaBoostClassifier
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import metrics
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
AdaBoost 的默认算法是决策树,但你可以决定手动设置不同的分类器。在这里,我将使用支持向量机分类器(你可以在这里阅读更多关于 SVM 的内容)。
from sklearn.svm import SVC
from sklearn import metrics
svc=SVC(probability=True, kernel='linear')
abc =AdaBoostClassifier(n_estimators=50, base_estimator=svc,learning_rate=1)
model = abc.fit(X_train, y_train)
y_pred = model.predict(X_test)
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
Output:
Accuracy: 0.9777777777777777
如你所见,我们几乎 98%的观察结果已被正确分类。
结论
AdaBoost 是一种易于实现的技术。它通过迭代纠正弱分类器的错误,提高准确性。然而,它并非没有陷阱。实际上,由于它寻求减少训练误差,因此对异常值特别敏感,存在生成过拟合模型的风险,这种模型无法很好地适应新的、未标记的数据,因为它缺乏泛化能力(你可以在这里阅读更多关于过拟合的内容)。
最初发布于http://datasciencechalktalk.com于 2019 年 9 月 7 日。
简介:Valentina Alto 是一位机器学习和统计学爱好者,目前在博科尼大学攻读数据科学硕士学位。
原始。经许可转载。
相关:
-
梯度提升的直观集成学习指南
-
集成学习:5 种主要方法
-
理解梯度提升机
进一步阅读
在 Kaggle 数据科学竞赛中使用集成方法——第二部分
原文:
www.kdnuggets.com/2015/06/ensembles-kaggle-data-science-competition-p2.html
评论由 Henk van Veen 提供
堆叠泛化与融合
平均预测文件是简单易行的,但这不是顶级 Kagglers 所使用的唯一方法。重复码的真正收益始于堆叠和融合。抓紧你的高帽和衬裙:这里有龙。七头的。站在其他 30 条龙的上面。
Netflix
融合数百个预测模型,最终跨越终点线。
Netflix 组织并推广了第一个数据科学竞赛。电影推荐挑战中的参赛者真正推动了集成方法的前沿,甚至可能使 Netflix 决定不在生产中实施获胜的解决方案,因为它实在太复杂了。
尽管如此,这一挑战仍产生了大量论文和新方法:
当你想提高你的 Kaggle 表现时,这些都是有趣、易读且相关的读物。
堆叠泛化
堆叠泛化由 Wolpert 在 1992 年的一篇论文中引入,早于 Breiman 在 1994 年发表的开创性论文“Bagging Predictors”。Wolpert 还因另一条非常流行的机器学习定理而闻名:
“搜索和优化中没有免费的午餐”。
堆叠泛化的基本思想是使用一组基础分类器,然后使用另一个分类器来组合它们的预测,旨在减少泛化误差。
假设你想进行 2 折堆叠:
-
将训练集拆分为两部分:
train_a和train_b。 -
在
train_a上拟合第一个阶段的模型,并为train_b创建预测。 -
在
train_b上拟合相同的模型,并为train_a创建预测。 -
最后,在整个训练集上拟合模型,并为测试集创建预测。
-
现在在第一个阶段模型的概率上训练第二阶段的堆叠模型。
堆叠模型通过使用第一阶段的预测作为特征,比在孤立训练时获得更多的问题空间信息。
融合
混合是 Netflix 获胜者引入的一个词。它与堆叠泛化非常接近,但更简单,且信息泄漏的风险较小。一些研究者将“堆叠集成”和“混合”互换使用。
使用混合时,你不是为训练集创建外折预测,而是创建一个例如 10%的训练集的持出集。然后堆叠模型仅在这个持出集上进行训练。
混合有一些好处:
-
它比堆叠更简单。
-
它防止信息泄漏:泛化器和堆叠器使用不同的数据。
-
你不需要与队友分享分层折叠的种子。任何人都可以将模型放入“混合器”,然后混合器决定是否保留该模型。
然而,缺点是:
-
你总体上使用的数据更少。
-
最终模型可能会对持出集过拟合。
-
使用堆叠(通过更多折计算)的简历比使用单个小的持出集要更扎实。
就性能而言,两种技术能提供相似的结果,似乎是个人偏好和技能的差异。作者更喜欢堆叠。
如果你无法选择,你可以同时进行两个。创建具有堆叠泛化和外折预测的堆叠集成。然后使用持出集进一步在第三阶段组合这些模型,我们将会在下一部分探讨。
在 Kaggle 数据科学比赛中使用集成方法 - 第一部分
在 Kaggle 数据科学比赛中使用集成方法 - 第三部分
你计划如何实现你学到的东西?分享你的想法吧!
原文:Kaggle 集成指南 作者:Henk van Veen。
相关内容:
-
如何在不读取数据的情况下领导数据科学比赛
-
前 20 名 R 机器学习和数据科学包
-
Netflix: 主管 - 产品分析、数据科学与工程
更多相关主题
确保 LLM 的可靠少样本提示选择
原文:
www.kdnuggets.com/2023/07/ensuring-reliable-fewshot-prompt-selection-llms.html
作者: 克里斯·毛克,乔纳斯·穆勒
在这篇文章中,我们使用来自 OpenAI(支持 GPT-3/ChatGPT 的模型)的 Davinci 大型语言模型,通过 少样本 提示来分类一家大型银行的客户服务请求意图。按照通常的做法,我们从一个已有的人工标注请求示例数据集中获取少样本示例,包含在提示模板中。然而,结果显示 LLM 预测不可靠——仔细检查表明,这是因为现实世界的数据杂乱且易出错。手动修改提示模板以缓解潜在的噪音数据只能稍微提高 LLM 在客户服务意图分类任务中的表现。如果我们改用像 Confident Learning 这样的数据驱动 AI 算法来确保仅选择高质量的少样本示例纳入提示模板,LLM 预测会显著更准确。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织的 IT 工作
让我们探讨如何策划高质量的少样本示例,以促使 LLM 提供最可靠的预测。确保少样本提示中的高质量示例的必要性可能显而易见,但许多工程师不知道有算法/软件可以更系统地帮助你做到这一点(实际上,这是一个完整的科学学科——数据驱动的 AI)。这种算法数据策划具有许多优势,它是:完全自动化、系统化,并广泛适用于超越意图分类的一般 LLM 应用。
银行业意图数据集
本文研究了 Banking-77 数据集 的 50 类变体,该数据集包含带有对应意图的在线银行查询(下面显示的 标签)。我们评估了使用固定测试数据集(包含 ~500 个短语)的模型,这些模型预测该标签,并拥有 ~1000 个标记短语的池,我们认为这些短语可以作为我们少样本示例的候选。

你可以从 这里 和 这里 下载少样本示例候选池和测试集。你可以运行 这个 notebook 来重现本文中显示的结果。
少样本提示
少样本提示(也称为 上下文学习)是一种 NLP 技术,使预训练的基础模型能够执行复杂任务,而无需任何明确的训练(即对模型参数的更新)。在少样本提示中,我们向模型提供有限数量的输入-输出对,作为提示模板的一部分,该模板包含在用于指导模型如何处理特定输入的提示中。提示模板提供的额外上下文帮助模型更好地推断所需的输出类型。例如,给定输入:“旧金山在加州吗?”,如果这个提示增加了一个固定模板,使新的提示看起来像这样,LLM 将更好地知道所需的输出类型:
文本:波士顿在马萨诸塞州吗?
标签:是
文本:丹佛在加州吗?
标签:否
文本:旧金山在加州吗?
标签:
少样本提示在文本分类场景中尤其有用,其中你的类别是 特定领域的(通常在不同业务的客户服务应用中就是这样)。

在我们的案例中,我们有一个包含 50 个可能类别(意图)的数据集,以便为 OpenAI 预训练的 LLM 提供上下文,使其能够学习类别之间的差异。使用 LangChain,我们从每个 50 个类别中随机选择一个示例(从我们的标记候选示例池中),并构建一个 50-shot 提示模板。我们还在少样本示例之前附加了一个列出所有可能类别的字符串,以确保 LLM 输出是一个有效的类别(即意图类别)。
上述 50-shot 提示用作 LLM 的输入,以使其对测试集中每个示例进行分类(target text 是这输入中在不同测试示例之间唯一改变的部分)。这些预测与实际标签进行比较,以评估使用选定的少量提示模板产生的 LLM 准确性。
基线模型表现
# This method handles:
# - collecting each of the test examples
# - formatting the prompt
# - querying the LLM API
# - parsing the output
def eval_prompt(examples_pool, test, prefix="", use_examples=True):
texts = test.text.values
responses = []
examples = get_examples(examples_pool, seed) if use_examples else []
for i in range(len(texts)):
text = texts[i]
prompt = get_prompt(examples_pool, text, examples, prefix)
resp = get_response(prompt)
responses.append(resp)
return responses
# Evaluate the 50-shot prompt shown above.
preds = eval_prompt(examples_pool, test)
evaluate_preds(preds, test)
>>> Model Accuracy: 59.6%
通过上述 50-shot 提示将每个测试示例输入 LLM,我们达到了 59.6%的准确率,对于一个 50 类别的问题来说还不错。但这对于我们银行的客户服务应用来说还不够令人满意,因此我们需要更仔细地查看候选示例的数据集(即池)。当机器学习表现不佳时,数据往往是罪魁祸首!
我们数据中的问题
通过仔细检查我们从中提取少量示例的候选池,我们发现数据中潜藏着标记错误的短语和异常值。这里是一些明显标注错误的示例。

以前的研究观察到许多流行数据集包含标记错误的示例,因为数据标注团队并不完美。
客户服务数据集中也常常包含不相关的示例,这些示例被意外包含在内。这里我们看到了一些看起来奇怪的示例,它们与有效的银行客户服务请求不符。

为什么这些问题很重要?
随着 LLM 的上下文大小不断增长,提示中包含许多示例变得越来越普遍。因此,可能无法手动验证少量提示中的所有示例,特别是在类别数量较多(或缺乏相关领域知识)时。如果这些少量示例的数据源存在上述问题(许多真实世界的数据集确实如此),则错误示例可能会出现在你的提示中。本文其余部分将探讨此问题的影响以及我们如何减轻它。
我们可以提醒 LLM 这些示例可能存在噪声吗?
如果我们在提示中仅加入一个“免责声明”警告,告知 LLM 提供的少量示例中的一些标签可能不正确,会怎样?这里我们考虑对提示模板进行如下修改,仍然包括之前相同的 50 个少量示例。

prefix = 'Beware that some labels in the examples may be noisy and have been incorrectly specified.'
preds = eval_prompt(examples_pool, test, prefix=prefix)
evaluate_preds(preds, test)
>>> Model Accuracy: 62.0%
使用上述提示,我们达到了 62%的准确率。稍有改善,但仍不足以在我们银行的客户服务系统中使用 LLM 进行意图分类!
我们可以完全删除这些噪声示例吗?
既然我们不能信任少样本示例池中的标签,那如果我们完全从提示中移除它们,只依赖强大的 LLM 呢?与少样本提示不同,我们在进行零样本提示,其中提示中唯一的示例是 LLM 应该分类的那个。零样本提示完全依赖 LLM 的预训练知识来获得正确的输出。

preds = eval_prompt(examples_pool, test, use_examples=False)
evaluate_preds(preds, test)
>>> Model Accuracy: 67.4%
在完全移除低质量少样本示例后,我们达到了 67.4% 的准确率,这是我们迄今为止的最佳表现!
似乎嘈杂的少样本示例实际上可能 损害 模型性能,而不是像预期那样提升性能。
我们能否识别并纠正嘈杂的示例?
与其修改提示或完全移除示例,更聪明(但更复杂)的方法是手动查找并修复标签问题。这同时移除了一个对模型有害的嘈杂数据点,并增加了一个准确的数据点,应该通过少样本提示来提升性能,但手动进行这样的修正是繁琐的。我们在这里使用 Cleanlab Studio 轻松地纠正数据,该平台实现了 Confident Learning 算法,以自动找到并修复标签问题。
在通过 Confident Learning 用估计更合适的标签替换估计不良标签后,我们将原始的 50-shot 提示重新通过 LLM 运行,每个测试示例都是这样,除了这次我们使用自动修正的标签,这确保了我们在少样本提示中提供了 50 个高质量示例。
# Source examples with the corrected labels.
clean_pool = pd.read_csv("studio_examples_pool.csv")
clean_examples = get_examples(clean_pool)
# Evaluate the original 50-shot prompt using high-quality examples.
preds = eval_prompt(clean_examples, test)
evaluate_preds(preds, test)
>>> Model Accuracy: 72.0%
在这样做之后,我们达到了 72% 的准确率,这对于 50 类问题来说是相当令人印象深刻的。
我们现在已经展示了嘈杂的少样本示例可以显著降低 LLM 性能,仅仅手动更改提示(通过添加警告或移除示例)是次优的。要实现最高性能,您还应尝试使用数据中心 AI 技术如 Confident Learning 来纠正示例。
数据中心 AI 的重要性
本文强调了确保语言模型中可靠的少量示例提示选择的重要性,特别是关注银行领域的客户服务意图分类。通过对一家大型银行的客户服务请求数据集的探索以及使用 Davinci LLM 进行的少量示例提示技术的应用,我们遇到了来自嘈杂和错误示例的挑战。我们展示了仅修改提示或删除示例无法保证模型的最佳性能。相反,像 Confident Learning 这样的数据驱动 AI 算法在 Cleanlab Studio 等工具中的应用被证明在识别和纠正标签问题方面更为有效,从而显著提高了准确性。本研究强调了算法数据策展在获取可靠少量示例提示中的作用,并突出了这些技术在提升语言模型在各个领域性能方面的实用性。
克里斯·莫克 是 Cleanlab 的数据科学家。
更多相关话题
错误分析拯救你 – 从 Andrew Ng 的课程中学到的经验,第三部分
原文:
www.kdnuggets.com/2018/01/error-analysis-your-rescue.html
评论
欢迎来到 Ng 经验的第三章 ML 课程!是的,这一章完全基于 Andrew Ng 在 Coursera 上最新的 课程 的延续。虽然这篇文章可以独立学习,但阅读前两篇文章将有助于更好地理解这篇文章。以下是系列中的 第一篇 和 第二篇 文章的链接。开始吧!
当尝试解决一个新的机器学习问题(一个尚未有太多在线资源的问题)时,Andrew Ng 建议你快速构建第一个系统,然后进行迭代。建立一个模型,然后逐步识别错误并不断修复它们。如何发现错误以及如何修复它们?就在你考虑这些时,错误分析以巨大的袍子、长长的胡须藏在腰带下、戴着半月眼镜的形象出现,并说道 -
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
‘正是这些错误,哈利,告诉我们我们的模型到底是什么,远比准确性更能揭示真相’

为什么要进行错误分析?
在构建新的机器学习模型时,你应该尝试遵循以下步骤 -
设定目标: 设置开发/测试集并选择一个评估指标来衡量性能(参考第一篇文章)
快速构建初始模型:
1. 使用训练集进行训练 — 调整参数
2. 开发集 — 调整参数
3. 测试集 — 评估性能
优先考虑下一步:
1. 使用偏差和方差分析来处理欠拟合和过拟合(见 第二篇文章)
2. 分析导致错误的原因并修复它们,直到你拥有所需的模型!
手动检查算法所犯的错误可以让你深入了解下一步该怎么做。这个过程被称为错误分析。举个例子,你构建了一个猫分类器,显示出 10%的测试错误,而你的一个同事指出你的算法把狗的图像误分类为猫。你是否应该尝试让你的猫分类器在狗的图像上表现得更好?
修复哪个错误?
好吧,与其花几个月时间去做这些,最后发现这没有太大帮助,不如采用一种错误分析程序,可以让你非常迅速地判断这是否值得你的努力。
1. 获取约 100 个标记错误的开发集样本
2. 计算有多少张是狗的图片
3. 如果你只有 5%的狗图像,并且你完全解决了这个问题,你的错误率最多只能从 10%降到 9.5%!
4. 相反,如果你有 50%的狗图像,你可以更乐观地期待改善你的错误,并希望将其从 10%降低到 5%
这就是你评估单一错误修正方法的方式。类似地,你可以通过创建网格并选择最佳的改进性能的想法来评估多个想法 -
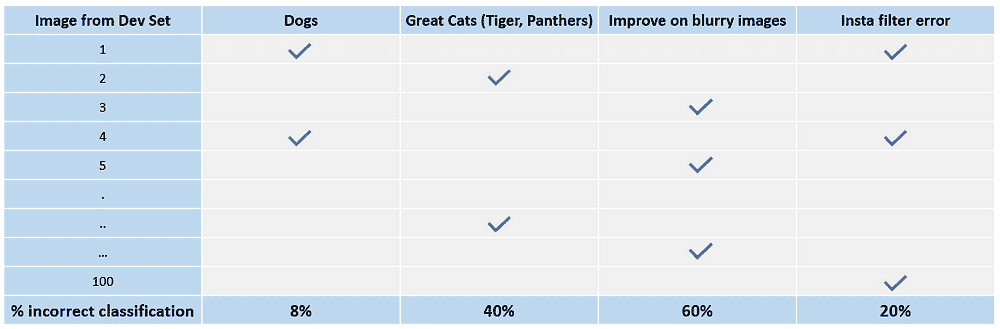
这个过程的结论给你一个关于各类错误工作价值的估计。例如,显然我们在模糊图像上犯了很多错误,其次是优秀的猫图像。这让你了解了最佳的选项。
这也告诉你,无论你在狗图像或 Instagram 图像上表现得多么出色,最多也只能提高 8%或 20%的性能。因此,根据你对改善优秀猫图像或模糊图像的想法数量,你可以选择其中一个,或者如果你的团队有足够的人员,也许可以让两个不同的团队分别独立工作。
现在,如果在模型构建过程中,你发现你的数据有一些错误标记的数据点,你应该怎么做?
错误标记的数据
训练集修正
深度学习算法对于训练集中的随机错误相当鲁棒。只要错误是无意的和相当随机的,就不必投入过多时间去修复它们。例如,我们的猫分类器训练集中几张标记错误的狗图像。
然而!然而,深度学习算法对系统性错误并不鲁棒,例如,如果你将所有白色的狗图像标记为猫,你的分类器将学习到这个模式。
开发/测试集修正
你还可以选择对开发/测试集进行错误分析,查看其中有多少比例的图片被标注错误,并判断是否值得修复。如果你的开发集错误率是 10%,而由于标注错误的开发集图片导致错误率为 0.5%,那么在这种情况下,可能不值得花时间去修复它们。但如果你的开发集错误率是 2%,而 0.5%的错误是由于标注错误的开发集图片造成的,那么在这种情况下,修复它们是明智的,因为这占你总错误的 25%。
你可能选择只修复训练集,而不修复开发/测试集中的标注错误。在这种情况下,请记住,现在你的训练集和开发/测试集都来自稍微不同的分布。这是可以接受的。让我们讨论如何处理训练集和开发/测试集来自不同分布的情况。
训练集和开发/测试集不匹配
在不同分布上进行训练和测试
假设你正在开发一个应用程序,用于对用户点击的图片进行猫的分类。现在你有两个来源的数据。第一个是来自网页的 200,000 张高分辨率图片,第二个是来自应用程序的 10,000 张非专业/模糊的用户拍摄图片。
现在,为了使训练集和开发/测试集有相同的分布,你可以将来自两个来源的图片进行洗牌,并在两个组之间随机分配。然而,在这种情况下,你的开发集将在 2500 张图片中仅包含约 200 张来自移动用户的图片。这将优化你的算法在网页图片上的表现。但,理想的开发/测试集选择是使其反映你期望未来获得的数据,并考虑到对其表现的重要性。
我们可以做的是,将所有的开发/测试集中的图片都来自移动用户,并将其余的移动用户图片与网页图片一起放入训练集中。这会导致训练集和开发/测试集中的分布不一致,但从长远来看,它会让你实现预期目标。
偏差和方差与数据分布不匹配
当训练集与开发集和测试集的分布不同时,分析偏差和方差的方法会有所变化。你不能再将训练集和开发集之间的错误称为方差(显然它们来自不同的分布)。你可以定义一个训练/开发集,该集具有与训练集相同的分布,但不用于训练。然后,你可以按下图所示分析你的模型。

结论
了解你的机器学习算法的应用,根据需要收集数据,并随机划分训练/开发/测试集。提出一个单一的优化评估指标,并调整参数以改进该指标。使用偏差/方差分析来理解你的模型是否过拟合、欠拟合,或是运行良好。进行错误分析,识别哪个修复最有效,最后,努力调整你的模型!
这是该系列的最后一篇文章。感谢阅读!希望它能帮助你更好地处理错误。
如果你有任何问题/建议,请随时在此处留下评论或通过LinkedIn/Twitter与我联系。
原文。经授权转载。
相关
更多相关内容
机器学习的本质
评论
我想以一篇不那么严肃的文章来结束这一年,讨论机器学习的本质。过去,你无疑已经探索了各种深入和半深入的机器学习定义,并探讨了它与许多其他主题的关系。讨论如此复杂的概念时,从一些初始的共同参考点开始总是一个好主意;问题是,对于像机器学习这样的主题,存在无数的初始共同参考点。
所以我想,为什么不探讨一下这些参考点呢?
来源:Imarticus
现在,事不宜迟,作为对可能看似语义学的练习,让我们探讨一下关于机器学习的 30,000 英尺的定义。
汤姆·米切尔
第一个定义,我个人最喜欢的,来自著名计算机科学家、机器学习研究员以及卡内基梅隆大学教授汤姆·米切尔。
如果一个计算机程序在经历了经验E之后,在某些任务* T 的表现得到提升,且该表现是通过 P *来衡量的,那么就可以说这个程序从经验中学习了。¹
米切尔的名言在机器学习界广为人知并经得起时间的考验,首次出现在他 1997 年的书中。这句话对我个人有很大的影响,因为我多年来多次引用了它,并在我的硕士论文中提到了它。该名言在 Goodfellow、Bengio & Courville 的《深度学习》第五章中也占据了重要位置,作为该书对学习算法解释的起点。请参见下面的图 1,了解所谓的米切尔范式的解释。
图 1。米切尔范式的可视化(来源)
伊恩·古德费洛、约书亚·本吉奥 & 亚伦·库维尔
说到 Goodfellow、Bengio & Courville 和《深度学习》,下面是那本书中对机器学习的定义。
机器学习本质上是一种应用统计学的形式,增加了对使用计算机来统计估计复杂函数的重视,而减少了对这些函数置信区间证明的重视[.]²
米切尔对机器学习的定义被移除应用,它专注于通常与机器学习相关的优化过程的具体组件,但没有规定如何在实践中进行。上述“深度学习”中的定义在本质上更具规范性,指出了计算能力的利用(实际上被强调了),而传统统计概念的置信区间则被淡化。
Ian Witten, Eibe Frank & Mark Hall
对我来说,另一本特别值得注意的机器学习来源是由 Witten、Frank 和 Hall 合著的《数据挖掘:实用机器学习工具与技术》一书,这本书是我全面阅读的第一本相关书籍。《数据挖掘》数学内容较少,但充满了直觉和解释,且具有实际倾向,它曾长时间是我对新入领域的机器学习者的首选(可能有偏见)建议。
他们对机器学习定义的初步追求有些零散,并试图在机器学习和数据挖掘的背景下将学习、表现和知识的概念结合起来。虽然有些话题偏离了,但下面展示了一些选定的引述。
[我们]感兴趣的是性能的改进,或者至少是新情况中的性能潜力。
事物在改变其行为以使其在未来表现更好时,会学习。
学习意味着思考和目的。某物要学习必须是有意为之。
经验表明,在许多机器学习应用于数据挖掘的情况下,所获得的显性知识结构,即结构性描述,至少与在新示例上表现良好的能力一样重要。人们经常使用数据挖掘来获取知识,而不仅仅是预测。³
并不一定引人注目的是,术语数据挖掘被用作机器学习的补充术语。这段引用的来源的第三版于 2011 年出版,当时数据挖掘的影响力比现在大得多;即便去掉对数据挖掘的引用,也应当能得到一个机器学习本身仍然适用的情境。
不过,尽管他们在长篇大论前表明了希望远离哲学的愿望,Witten、Frank 和 Hall 实际上做得相当不错地涉及了一些哲学内容。这些摘录其实很有帮助,因为它提供了机器学习定义的不同角度:虽然 Mitchell 关注于优化过程的具体组件,而 Goodfellow、Bengio 和 Courville 倾向于一个更具规范性的定义,强调计算能力的相对重要性,但这种定义尝试着关注“学习”在机器学习过程中类似且重要的方面。这些选段还提供了一个重要的观点,这一点实际上既实用又具有哲学性,即在最后一段中提到,无论是获得的知识还是使用这些知识的能力都是机器学习的重要方面(见训练和推理)。
Christopher Bishop
让我们转向最后一篇文本,研究员 Christopher M. Bishop 的《模式识别与机器学习》。值得注意的是,Bishop 并没有明确定义这个术语,但做得相当不错地隐含地提供了一个以算法为中心的机器学习定义(注意到这是在讨论数字分类任务时提到的)。
运行机器学习算法的结果可以表示为一个函数y(x),该函数以新的数字图像x作为输入,并生成一个输出向量y,其编码方式与目标向量相同。函数y(x) 的确切形式是在训练阶段,即学习阶段,根据训练数据确定的。一旦模型训练完成,它可以确定新的数字图像的身份,这些图像被称为测试集。正确分类与训练不同的新例子的能力被称为泛化。在实际应用中,输入向量的变化性将使得训练数据只能占所有可能输入向量的极小部分,因此泛化是模式识别中的核心目标。
首先,不要对“模式识别”的引用做更多解释,仅仅理解我们在讨论的是监督式机器学习,而不是无监督学习或强化学习(或其他形式的机器学习)。其次,更重要的是,这是唯一提供机器学习逐步处理定义的文本,无论这些步骤在此案例中可能多么简短。还值得关注的是,Bishop 书中的接下来的一页半概述并整合了许多额外的机器学习概念,并将它们很好地结合起来,提供了一个易读的介绍,而没有陷入数学细节(书的其余部分处理了这些内容)。
所以我们有四种定义机器学习的方法:一种是抽象地与优化过程相关;另一种更具指示性,指出计算在机器学习中的重要性;第三种关注“学习”的哪些方面在机器学习过程中是类似的和重要的;最后一种从算法的角度概述机器学习。这些定义都没有错误,但也都不完整。这不仅仅是语义上的问题;探讨先驱和受尊敬的研究者对“机器学习”的看法将扩展我们对它的定义。
参考文献:
-
机器学习,Tom Mitchell,McGraw Hill,1997。
-
深度学习,Ian Goodfellow、Yoshua Bengio 和 Aaron Courville,MIT Press,2016。
-
数据挖掘:实用机器学习工具与技术(第 3 版),Ian Witten、Eibe Frank 和 Mark Hall,Morgan Kaufmann,2011。
-
模式识别与机器学习,Christopher M. Bishop,Springer,2006。
相关:
-
使用 Mitchell 范式的学习算法简明解释
-
数据科学难题,解读
-
数据科学难题,再探讨
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
更多相关内容
数据科学中的核心 A/B 测试课程
原文:
www.kdnuggets.com/2023/02/essential-ab-testing-course-data-science.html
什么是 A/B 测试?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
在数据驱动的快速发展世界中,你不能仅仅依赖直觉或猜测来决定网站上的潜在变化。除非数据驱动的指标指引你做出变动,否则你不能“无思考”地“全知全能”。因此,许多组织使用一种称为 A/B 测试的统计技术来事先检查变化是否对业务有益。

图片来源于 Freepik
A/B 测试被定义为一种比较单一变量(产品或网站)两个版本的方法,通常是通过测试对象对变体 A 与变体 B 的反应来确定哪一个变体更有效或表现更好。无论你是市场营销人员、产品经理还是数据分析师,理解 A/B 测试对于做出数据驱动的决策至关重要。
简而言之,A/B 测试是一种用户体验研究方法,用于随机对照实验,以监测用户的反应和变化的有效性。
A/B 测试的重要性
A/B 测试主要用于提高用户对新特性或产品的参与度和亲和力。许多社交媒体公司,如 LinkedIn 和 Facebook,利用它来通过了解新产品或特性的影响来改善用户体验。

图片来源于 Freepik
A/B 测试支持统计决策,因此在许多行业和垂直领域中都有应用,具体应用如下。
-
改善产品发布策略:允许组织比较不同版本的产品,确定哪个版本表现更好,从而改善客户参与度、转化率和整体表现。
-
数据驱动决策:组织获得的数据驱动见解可以用来做出明智的决策,而不是依赖假设或直觉。
-
发现隐藏机会:可以揭示组织可能未意识到的改进隐藏机会。
-
优化营销策略:通过比较不同的营销活动、标题和信息,确定最有效的策略,从而实现优化的营销策略。
-
降低风险:A/B 测试允许组织以受控和安全的方式测试新想法和变化,减少引入对产品有负面影响的变化的风险,也称为爆炸半径。
-
成本效益:这是一个具有成本效益的(特别是当你比较全面发布一个产品时)方式来实验不同的产品或服务选项,并且可以提供有关客户行为、转化率等的宝贵见解,而无需支付失败产品的高昂成本。
-
个性化:通过测试内容、布局或功能的不同变体,并将最佳版本提供给特定的受众或细分市场,个性化用户体验是使用 A/B 测试的最大优势之一。
-
持续改进:这是一个不断进行的过程,组织可以持续使用它来改进他们的产品或服务。
高度推荐的课程
我最近在 Udacity 完成了一个免费的复习课程“Google 的 A/B 测试”,并想分享一下课程内容以及为什么你应该将其添加到你的待办事项列表中。这门课程帮助个人学习 A/B 测试的过程,并且是计划和执行 A/B 测试的主题以及大量真实案例研究的首选资源。
图片来源于 Udacity
它解释了如何设计一个实验,以捕捉网站或移动应用程序中的变化。不同的用户将看到带有和不带有变化的应用程序,以评估他们的反应,从而预测变化发布后的潜在改进。
这门课程适合谁?
如果你的工作涉及数据(考虑到其普遍性,这非常可能)和生成可操作的见解以推动组织决策,那么这门课程对你来说是相关的。简单来说,如果你的职业类别包括数据分析师、市场营销人员、产品经理和数据科学家,你将从这门课程中受益。
课程内容
如课程主页所列,课程分为五章,涵盖了进行 A/B 测试的以下重要组成部分。
-
A/B 测试框架概述
-
实验的政策和伦理
-
选择和描述指标
-
设计实验
-
结果分析
如果你是希望在自己空闲时间学习 A/B 测试基础知识的在职专业人士,那么这个自学进度的课程是一个合适的资源。如果你每周能够投入大约 8 小时,那么你将在两个月内完成课程。
以下是一些关键提示,帮助你决定这是否是学习 A/B 测试基础知识的合适课程:
-
该课程概述了 A/B 测试过程——定义、目标以及可以通过 A/B 测试进行的不同类型的实验。
-
接下来,你需要了解 A/B 测试的规划过程,例如找到并对齐决定成功标准的正确指标、制定假设等。确定进行测试所需的正确样本量是实验的核心组成部分之一。
-
一旦你设定了假设,课程将介绍如何运行 A/B 测试的过程,通常围绕如何实施实验、分析数据和解释结果进行。
-
仅仅阅读理论是不够的,无法准备好进行实验。实验中可能出现多个地方的错误,导致不正确的结论。课程解释了一些常见的错误及其避免方法。
-
该课程不仅仅停留在理论层面,还分享了多个现实世界的案例和实际应用,展示了 A/B 测试如何在不同的行业和环境中应用。
-
课程还涵盖了更高级的主题,例如多变量测试、移动应用的 A/B 测试以及个性化的 A/B 测试。
为了更好地装备学习者,避免常见的陷阱和掌握高级主题,该课程包括一个项目,让学习者通过自己进行 A/B 测试并分析结果来内化这些概念。
该课程采用讨论式的格式,以问答形式解释概念。这与演示风格的课程相比稍显不同。如果你有兴趣阅读课程的详细总结笔记,请参阅以下链接:
-
medium.com/@jchen001/udacity-a-b-testing-course-notes-84bd799a898f -
towardsdatascience.com/a-summary-of-udacity-a-b-testing-course-9ecc32dedbb1
Vidhi Chugh 是一位 AI 战略师和数字化转型领导者,致力于在产品、科学和工程的交汇处构建可扩展的机器学习系统。她是一位屡获殊荣的创新领袖、作者和国际演讲者。她的使命是使机器学习大众化,打破术语,让每个人都能参与这一转型。
更多相关主题
你需要成为数据工程师的基本书籍
原文:
www.kdnuggets.com/2022/10/essential-books-need-become-data-engineer.html

作者提供的图片
书籍 - 传统的学习方式。有些人可能更喜欢上课程,而有些人则希望沉浸在书本中。在这篇文章中,我将探讨成为数据工程师所需的书籍路线图。
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
在开始之前,让我们快速回顾一下数据工程师是什么
数据工程师是什么?
数据工程是数据科学的一部分。数据科学家负责探索数据,然后构建机器学习算法来解决任务或问题。而数据工程师则更关注使这些算法有效运行以及创建数据管道。
数据工程师负责建立和维护组织的数据基础设施。其他职责包括:
-
数据获取
-
发展、构建、测试和维护符合业务需求的架构
-
提高数据的准确性、效率和质量
-
执行预测性和规范性建模
-
实施分析工具、机器学习和统计方法
-
与利益相关者沟通发现
你需要达到目标的书籍
基础知识
那么让我们从数据工程的基础开始吧。
更加专业
一旦你很好地理解了基础知识,你的下一个目标就是在你感兴趣的领域中变得更加专业。
数据架构与管理
超越极限
根据你希望担任的数据工程师职位,你总有更多可以学习的内容。无论是为了获得特定工作还是仅仅为了知识,以下是一些可以帮助你实现目标的书籍
总结
当谈到基础知识时,你希望能够涵盖所有这些方面和主题。这些将为你的数据工程职业提供基础,从此之后,你可以选择你更感兴趣的领域以及你期望在未来 5-10 年内的发展方向。
如果你有兴趣在学习时通过课程测试你的知识,可以阅读这篇文章:免费数据工程课程
祝好运!
Nisha Arya 是一位数据科学家和自由技术作家。她特别感兴趣于提供数据科学职业建议或教程及理论知识。她还希望探索人工智能如何有助于人类寿命的延续。作为一个热心的学习者,她寻求拓展自己的技术知识和写作技能,同时帮助指导他人。
更多相关主题
30 张基础数据科学、机器学习与深度学习备忘单
原文:
www.kdnuggets.com/2017/09/essential-data-science-machine-learning-deep-learning-cheat-sheets.html/3
神经网络与深度学习

神经网络架构(通过 Asimov Institute)
神经网络细胞(通过 Asimov Institute)
我们的前三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT 工作

神经网络图表(通过 Asimov Institute)
TensorFlow(通过 Altoros)

Keras(通过 DataCamp)
统计学、概率与数学

概率(通过 William Chen & Joe Blitzstein)
统计学(通过 MIT)
线性代数(通过 minireference.com)
数据结构与算法
 ](
](大 O 复杂度(通过 Big O Cheat Sheet)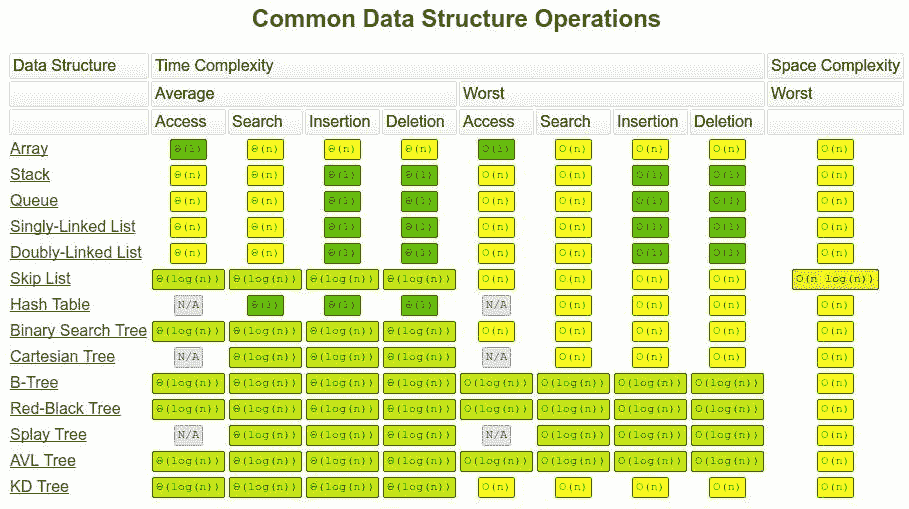 ](http://bigocheatsheet.com/)
](http://bigocheatsheet.com/)
常见数据结构操作(通过 Big O Cheat Sheet)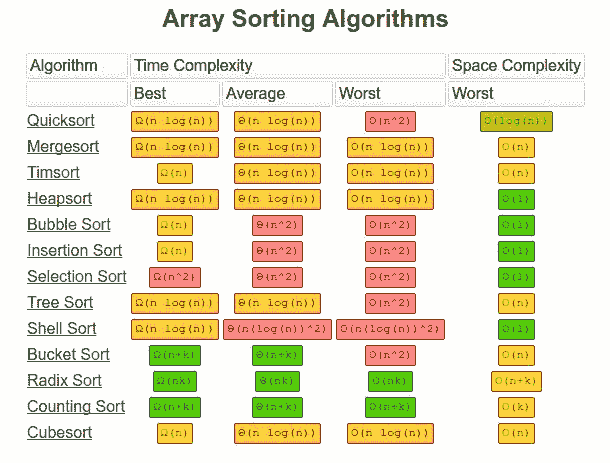 ](http://bigocheatsheet.com/)
](http://bigocheatsheet.com/)
常见排序算法(通过 Big O Cheat Sheet) ](https://www.clear.rice.edu/comp160/data_cheat.html)
](https://www.clear.rice.edu/comp160/data_cheat.html)
数据结构(通过 Rice University) ](http://scikit-learn.org/stable/_static/ml_map.png)
](http://scikit-learn.org/stable/_static/ml_map.png)
机器学习算法选择(通过 Scikit-learn)
结构化查询语言 (SQL)
 ](http://www.sql-tutorial.net/sql-cheat-sheet.pdf)
](http://www.sql-tutorial.net/sql-cheat-sheet.pdf)
SQL(通过 sql-tutorial.net)
相关:
-
50+ 数据科学和机器学习备忘单
-
50+ 数据科学、机器学习备忘单,已更新
-
我应该使用哪种机器学习算法?
该主题的更多信息
没有人谈论的数据科学核心技能
原文:
www.kdnuggets.com/2020/11/essential-data-science-skills-no-one-talks-about.html
评论
由 Michael Kolomenkin,AI 研究员
在谷歌上搜索“数据科学家的核心技能”。前几名结果是长长的技术术语列表,被称为硬技能。Python、代数、统计学和 SQL 是一些最受欢迎的技能。之后,是软技能——沟通能力、商业洞察力、团队合作等。
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
假设你是一个拥有上述所有能力的超级人类。你从五岁开始编码,是 Kaggle 的特级大师,你的会议论文肯定会获得最佳论文奖。你知道吗?即便如此,你的项目仍然很有可能难以成熟,成为完全成熟的商业产品。
最近的研究估计超过 85%的数据科学项目未能达到生产阶段。研究提供了许多失败的原因。我没有看到所谓的核心技能被提及作为潜在原因。
我是否在说上述技能不重要?当然不是。硬技能和软技能都是至关重要的。关键在于它们是必要的,但不够充分。此外,它们很流行,出现在每次谷歌搜索中。所以你很可能已经知道你是否需要提高数学能力或团队合作。
我想谈谈那些补充流行硬技能和软技能的技能。我称之为工程技能。它们对于构建真实产品并服务真实客户尤为重要。遗憾的是,工程技能很少教给数据科学家。这些技能通常通过经验获得。大多数初级数据科学家缺乏这些技能。
工程技能与数据工程领域无关。我使用“工程技能”一词来区分它们与纯科学或研究技能。根据剑桥词典,工程*是应用科学原理设计和建造机器、结构和其他物品。在本文中,工程是将科学转化为产品的推动因素。没有适当的工程,模型将只在预定义的数据集上表现良好。但它们永远无法接触到真实的客户。
要点:
重要且常被忽视的技能有:
-
简洁性。确保你的代码和模型简洁,但不肤浅。
-
稳健性。你的假设是错误的。深呼吸,继续编码。
-
模块化。分而治之。深入到最小的问题,然后找到开源的解决方案。
-
结果选择。不要只关注唾手可得的结果。但要确保你总是有东西可以选择。
简洁性

图片来源:shutterstock
“实体不应无必要地增加”——威廉·奥卡姆。“简洁是终极的复杂”——列奥纳多·达·芬奇。“一切应尽可能简单,但不能更简单”——阿尔伯特·爱因斯坦。“这是我的口号之一——专注和简洁”——史蒂夫·乔布斯。
我本可以用关于简洁的引文填满整页。研究人员、设计师、工程师、哲学家和作者都赞扬了简洁,并表示简洁本身具有价值。他们的理由有所变化,但结论始终如一。你达到完美不是当没有东西可以添加时,而是当没有东西可以去除时。
软件工程师完全意识到简洁的重要性。关于如何使软件更简单的书籍和文章不计其数。我记得 KISS 原则——Keep It Simple, Stupid——甚至在我的本科课程中也有教授。简单的软件更便于维护、更容易更改,并且更不容易出错。这一点有广泛的共识。
在数据科学中,情况非常不同。例如,有一些文章,如 “The virtue of simplicity: on ML models in algorithmic trading” 由 Kristian Bondo Hansen 撰写,或 “The role of simplicity in data science revolution” 由 Alfredo Gemma 撰写。但这些只是例外,而非常态。大多数数据科学家最好的情况下不在意,最坏的情况下更倾向于复杂的解决方案。
在讨论数据科学家通常不关心鲁棒性、他们为什么应该关心以及如何处理这一问题之前,我们先来看看什么是简单性。根据剑桥词典,简单性是指容易理解或做的品质,以及朴素的品质,没有不必要或多余的东西或装饰。
我发现定义简单性的最直观方法是通过消极方式,即复杂性的对立面。根据同一本词典,复杂性是由许多相互连接的部分或元素组成的;复杂的。虽然我们不能总是说某物是简单的,但我们通常可以说某物是复杂的。我们的目标是避免复杂,避免创造复杂的解决方案。
在数据科学中寻求简单性的原因与所有工程学科中的原因相同。更简单的解决方案要便宜得多得多。现实生活中的产品不是 Kaggle 比赛。需求不断变化。当需要适应新条件时,复杂的解决方案很快就会成为维护的噩梦。
很容易理解为什么数据科学家,尤其是应届毕业生,喜欢复杂的解决方案。他们刚刚从学术界出来,完成了论文,可能还发表了论文。学术出版物的评判标准包括准确性、数学优雅、新颖性、方法论,但很少考虑实际性和简单性。
一个将准确性提高 0.5% 的复杂想法对于任何学生来说都是一个巨大的成功。而对于数据科学家来说,同样的想法则是失败的。即使它的理论是正确的,它也可能隐藏着证明是错误的基本假设。在任何情况下,增量改进几乎不值得付出复杂性的代价。
那么,如果你、你的老板、你的同事或你的下属喜欢复杂和“最佳”的解决方案该怎么办?如果是你的老板,你可能注定要找新工作了。其他情况下,保持简单,傻瓜。
鲁棒性

图片来源:shutterstock
俄罗斯文化中有一个概念叫做avos‘。维基百科将其描述为“对神圣旨意的盲目信任和依赖纯粹运气”。Avos’ 是卡车司机决定超载的原因。而它也隐藏在任何不鲁棒的解决方案背后。
什么是鲁棒性?或者具体来说,数据科学中的鲁棒性是什么?与我们讨论最相关的定义是来自Mariano Scain 论文的“算法的鲁棒性是它对假设模型和现实之间差异的敏感度”。对现实的错误假设是数据科学家主要的问题来源。它们也是上述卡车司机问题的来源。
仔细的读者可能会说鲁棒性也是算法在执行过程中处理错误的能力。他们说得对。但这与我们的讨论关系不大。这是一个有明确解决方案的技术话题。
在大数据和深度学习之前,构建鲁棒系统的必要性已经很明显。特征和算法设计是手动进行的。测试通常是在数百甚至数千个例子上进行的。即使是最聪明的算法创造者也从未假设他们能想到所有可能的用例。
大数据时代是否改变了鲁棒性的本质?如果我们可以使用代表所有可想象场景的数百万数据样本来设计、训练和测试我们的模型,我们为什么还要在意?
事实证明,鲁棒性仍然是一个重要且未解决的问题。每年,顶级期刊通过发表涉及算法鲁棒性的论文来证明这一点,例如“提高深度神经网络的鲁棒性”和“基于模型的鲁棒深度学习”。数据的数量并没有转化为质量。用于训练的大量信息并不意味着我们可以涵盖所有用例。
如果涉及到人,现实总是会出乎意料和无法想象。我们大多数人很难说清楚午餐会吃什么,更不用提明天了。数据很难帮助预测人类行为。
那么,为了使你的模型更加鲁棒,我们应该怎么做呢?第一个选项是阅读相关论文并实现它们的思想。这是可以的。但这些论文并不总是具有普遍适用性。通常,你不能将一个领域的想法简单地转移到另一个领域。
我想介绍三种通用的做法。遵循这些做法不能保证模型的鲁棒性,但它大大减少了脆弱解决方案的可能性。
性能安全边际。安全边际是任何工程的基础。常见的做法是将要求增加 20–30%以确保安全。一个能够承受 1000kg 的电梯可以轻松承受 1300kg。此外,它经过测试能承受 1300kg 而不是 1000kg。工程师为意外条件做好准备。
数据科学中的安全边际是什么呢?我认为是 KPI 或成功标准。即使发生了意外情况,你仍然会高于阈值。
这一做法的重要后果是你将停止追求渐进改进。如果你的模型只提高了 1%的 KPI,你无法做到鲁棒。即使经过所有统计显著性检验,环境中的任何小变化都会破坏你的努力。
过度测试。忘记单一的测试/训练/验证划分。你必须在所有可能的组合上进行交叉验证。你有不同的用户吗?按用户 ID 进行划分,并进行数十次。你的数据随时间变化吗?按时间戳进行划分,确保每一天在验证组中出现一次。用随机值“垃圾”你的数据,或在数据点之间交换某些特征的值。然后在脏数据上测试。
我发现假设我的模型有缺陷直到证明其无误是非常有用的。
关于数据科学和机器学习测试的两个有趣来源——Alex Gude 的博客和“用 Python 进行机器学习,测试驱动的方法”。
不要在沙滩上建造城堡。减少对其他未经测试组件的依赖。绝不要在另一个高风险且未经验证的组件上建立你的模型。即使那个组件的开发者发誓不会出现任何问题。
模块化
图片来源:shutterstock
模块化设计是所有现代科学的基本原则。这是分析方法的直接结果。分析方法是一个将大问题分解为较小部分的过程。分析方法是科学革命的基石。
问题越小越好。在这里,“更好”不是锦上添花,而是必需。这将节省大量的时间、精力和金钱。当问题小、定义明确且没有大量假设时,解决方案既准确又易于测试。
大多数数据科学家在软件设计的背景下对模块化有所了解。但即便是最优秀的程序员,他们的 Python 代码清晰明了,往往也未能将模块化应用于数据科学本身。
失败很容易解释。模块化设计需要一种将几个较小模型合并为一个大模型的方法。机器学习中不存在这样的办法。
但有一些我认为有用的实用指南:
-
迁移学习。迁移学习简化了现有解决方案的使用。你可以将其视为将你的问题分为两个部分。第一部分创建一个低维特征表示。第二部分直接优化相关的 KPI。
-
开源。尽可能使用现成的开源解决方案。这使得你的代码在定义上就是模块化的。
-
忘记最优。从头开始构建一个针对你需求优化的系统是很诱人的,而不是适应现有解决方案。但是,只有在你能够证明你的系统显著优于现有系统时,这才是合理的。
-
模型集成。不要害怕采取几种不同的方法并将它们放在一起。这就是大多数 Kaggle 比赛获胜的方式。
-
划分你的数据。不要试图创建“一个伟大的模型”,虽然从理论上讲,这可能是可能的。例如,如果你要预测客户行为,不要为完全新客户和已经使用你服务一年的人建立相同的模型。
详细了解深度学习构建块,请查看 Compositional Deep Learning。要获取科学证明,请阅读 Pruned Neural Networks Are Surprisingly Modular。
采摘水果

图片来源:shutterstock
产品经理和数据科学家之间总是存在着紧张关系。产品经理希望数据科学家专注于易得的成果。他们的逻辑很清晰。他们说,业务只关心成果的数量和它们的来源。我们拥有的成果越多,我们的表现就越好。他们会使用各种流行词汇——帕累托原则、最小可行产品、最好是好的敌人等等。
另一方面,数据科学家表示,容易获取的成果很快就会变质并味道不好。换句话说,解决简单问题的影响有限,只处理症状而非根本原因。通常,这是一种学习新技术的借口,但他们往往是对的。
个人来说,我在这两种观点之间转换。读完 P. Thiel’s Zero-To-One 后,我确信容易得来的成果是浪费时间。在初创公司工作了近七年后,我坚信创建一个低成本的最小可行产品是正确的第一步。
最近,我开发了自己的方法来统一这两个极端。数据科学家的典型环境是一个动态且奇怪的世界,树木向各个方向生长。树木的方向会不断变化。它们可能会向下或侧面生长。
最好的水果确实在树顶。但如果我们花费太多时间搭建梯子,树木可能会移动。因此,最好是以树顶为目标,同时不断监测树顶的位置。
从隐喻转到实践中,长时间的开发过程中总会有变化。原始问题可能会变得无关紧要,新的数据源可能会出现,原始假设可能会被证明是错误的,KPI 可能会被替换,等等。
以树顶为目标是很好的,但要记住在每几个月推出一个有效的产品时做到这一点。这个产品可能不会带来最好的水果,但你会更好地理解水果的生长方式。
简介:Michael Kolomenkin 是三名孩子的父亲,AI 研究员,皮划艇教练,冒险爱好者,读者和作家。
原文。经授权转载。
相关:
-
初级和高级数据科学家的无声区别
-
获取数据科学职位比以往任何时候都难——如何将这一点转为你的优势
-
有志数据科学家的建议
该主题的更多内容
基本数据科学维恩图
原文:
www.kdnuggets.com/2019/02/essential-data-science-venn-diagram.html
评论
作者:Andrew Silver,Adret LLC
几年前,Drew Conway 提出了并分享了他现在无处不在的 数据科学维恩图。这非常有帮助,我们都受到了启发。感谢你,Conway 博士!
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT
许多变体随后出现,我在这里建议我自己的改进。希望它们也能带来启发。我提出了两个补充:区分统计应用(多变量 vs. 非多变量)以及增加学科精髓(即每个技能集的主要贡献或功能)。
首先,让我说我的维恩图,就像所有的维恩图一样,固有地存在缺陷。为什么?因为它是一个二维图示,展示了固有的多维动态。这部分反映在左下角的免责声明中,沟通维度(听觉+视觉)和软技能没有显示。创造力、毅力、内省诚实 和其他属性也在图形中缺失。
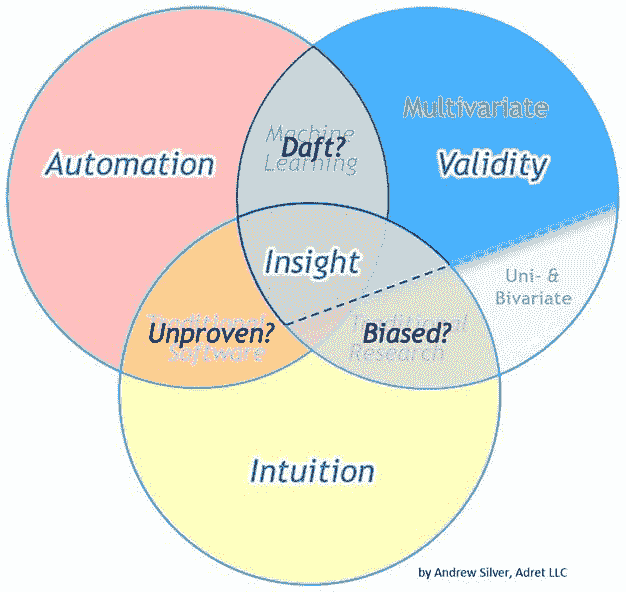 必要性
必要性
统计学广泛涉及量化方差的结构,其快乐结果是能够构建描述性、解释性、预测性和规范性模型(数据科学的输出)。因此,指出统计方法在数据科学维恩图上方差最大来源并不羞愧:多变量统计方法(评估≥3 个变量)与 [单变量和双变量] 统计方法之间的差异。
是的,我在这里暗示这比有监督与无监督统计建模、参数与非参数建模之间的差异要大。基于的方差度量是人群中对高级统计方法的意识差异明显。需要的是人们应该更加了解在第四次工业革命中发挥核心作用的多变量分析。
这种划分的一个含义是,“传统研究”在很大程度上没有充分利用多变量统计。根据你的学科,这一含义可能不成立。不幸的是,对于许多学科而言,这一含义确实成立。可以说,这一事实是许多行业易受干扰的原因之一。
一个例子是对决定系数(R-squared)的持续过度依赖,这种情况在许多领域依然存在。R-squared 对异常值不具抗性,仅对目标变量具有相对性,可能会因序列相关数据而膨胀,而且在许多其他方面可能不可靠。尽管如此,它仍被广泛使用——部分原因是 Excel 和几乎所有其他图表工具都使其易于获得。虽然 R-squared 可能是一个有用的工具,但它仍然是一个需要正确使用的工具(例如,用于评估双变量线性关联)。
多变量问题需要多变量工具,而大多数商业挑战本质上是多变量的。许多分析师和技术专业人员在学习如何正确应用计算多变量统计(⊆“机器学习”)方面仍有很长的路要走。因此,他们仍然容易受到利用多变量算法从数据中获得更好洞察力的竞争对手的干扰……或者通过采用无效策略(例如,创新者的困境的典型表现,即忽视下市场、低利润机会,未来竞争可能会在这些地方产生)的自我干扰。
基本意义
这三种专业领域也可以用它们所提供的更简单的术语来表达(即,它们的本质):直觉、有效性和自动化。自动化也可以称为扩展。它们的融合为我们提供了改进的洞察力。正如所描述的,洞察力也可以简单地来源于具有有效直觉的重叠(自动化不是前提)。这种情况在历史上确实存在。当前对高级分析的炒作在很大程度上是关于通过自动化数据收集、处理和分析来加速洞察力。
“偏差”的危险存在于“传统研究”领域,这是更新数据科学维恩图的主要灵感来源。统计学中的“偏差”指的是排除或忽视重要变量,这与口语中的含义相似。由于大多数人不熟悉处理多变量分析,当多变量问题被视为双变量或单变量问题时,偏差的危险最容易出现。如上所述,偏差的存在使得组织容易受到新进入者的干扰,这些新进入者通过多变量方法成为更具洞察力的竞争者。
还要注意,与“机器学习”相关的重叠区域缺乏直觉(即,是“愚蠢”的——一种明显的偏差)。一些人无疑会对此提出异议。但考虑到在与物理世界和社会的互动中,人们获得了一种机器学习模型无法接近的直觉(例如,有任何机器学习应用知道并欣赏盐的味道吗?)。机器学习模型只知道我们告诉它们的内容(我们提供的数据),模型输出最终将反映这一点。机器学习模型可以非常擅长我们训练它们做的事情,但它们仍然需要由人类来训练。(注意:即使是年轻人也需要由年长而睿智的人来训练。)从广泛经验中获得的背景构建了直觉。背景很重要。
标记为“传统软件”的区域描述起来较为困难。这回到试图用二维图形总结多变量系统的局限性。这一重叠区域也可以用来描述机械自动化(这无疑构成了全球经济的一个重要部分)。就本讨论而言,并且在大多数白领知识性工作的背景下,可以说这一领域代表了在执行风险评估时缺乏严谨性。
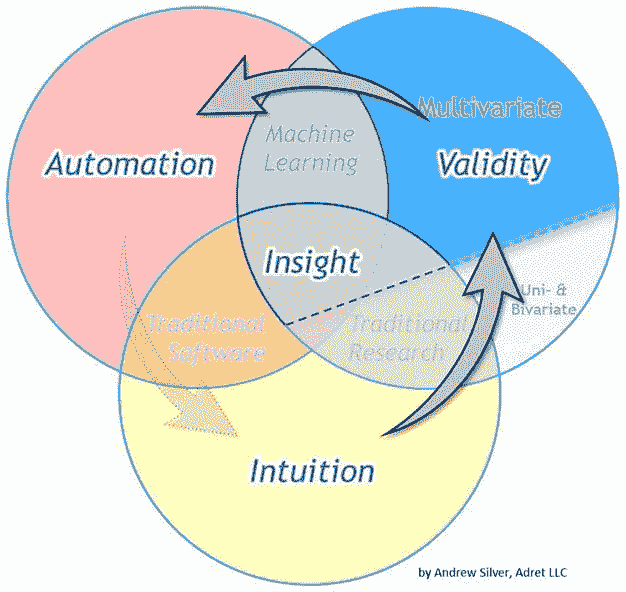
操作顺序
在大多数情况下,每个专业领域的整合都有固有的操作顺序或“最佳实践”。通常的顺序是直觉首先,然后是验证,最后是自动化。我们通常在直觉引导我们想到一个想法之后才会测试这个想法是否有效。同样,在未首先确认其有效性之前,我们不应该扩大(自动化)实现。
上述序列是否有例外?当然有!机器学习的输出有时会引起领域专家对他们之前忽视或不了解的关联的关注。也有许多情况,其中领域专家的启发式方法已经在自动化系统中实施,并在数据收集变得可能后得到了验证。我们也不要忘记自动化在帮助我们首先收集数据方面的作用,这些数据随后可以通过领域专长和统计严谨性进行评估。
Σ
总结来说,这个新的维恩图告诉我们一些我们已经知道的事情,但可能没有正式表达出来。这是一个简单的模式,作为这样的模式,它可以帮助人们更好地优先排序他们的工作流程。例如,它鼓励数据科学家在开始工作时首先与领域专家交谈——这已经被誉为最佳实践。如果你是那种不仅对什么要做感到满意,还想理解为什么的人,理解事情发生的本质会有所帮助。
近 70 年前,塞缪尔·威尔克斯写道 “统计思维有一天将像读写能力一样对有效公民至关重要。” 在不久的将来,多元 统计思维可能会成为更多职业的先决条件。如果我对数据科学维恩图的重新阐述能对任何人有所帮助,我会认为这段时间花得非常值得。
世界是我们创造的,它需要更智能。如果你喜欢这篇文章,请考虑与朋友分享。
(注意:这些维恩图图形可在注明出处的情况下使用。上述图表的初步版本首次发布于 www.adret-llc.com 和 LinkedIn 上,时间是 2017 年初。 文章 在 Medium 上转载。)
简历: 安德鲁·西尔弗 是一名地质学家(领域专家)和统计学家,拥有德克萨斯农工大学的 M.S. Analytics 和莱斯大学的 M.S. Earth Science 学位。他目前在上游能源领域提供咨询服务。
资源:
相关:
更多相关话题
3 个必备的 Google Colaboratory 小贴士和技巧
原文:
www.kdnuggets.com/2018/02/essential-google-colaboratory-tips-tricks.html
评论

像你们中的许多人一样,我对 Google 的 Colaboratory 项目感到非常兴奋。虽然它并不完全是新的,但最近的公开发布引起了对这个协作平台的许多新的兴趣。
对于那些不知道的人,Google Colaboratory 是...
[...] 一个 Google 研究项目,旨在帮助传播机器学习教育和研究。这是一个 Jupyter notebook 环境,使用时无需设置,完全运行在云端。
以下是一些简单的提示,帮助你在使用 Colab 时更好地发挥其能力。需要明确的是,这些不是隐藏的技巧,而是一个实用的文档(并进一步澄清)功能集合,这些功能可能是必不可少的。
1. 使用免费的 GPU 运行时
选择“运行时”,“更改运行时类型”,这就是你看到的弹出窗口:
确保“硬件加速器”设置为 GPU(默认是 CPU)。之后,确保你已连接到运行时(菜单带子中“连接”旁有一个绿色勾号)。
要检查你是否有可见的 GPU(即你当前是否连接到 GPU 实例),运行以下摘录(直接来自 Google 的代码示例):
import tensorflow as tf
device_name = tf.test.gpu_device_name()
if device_name != '/device:GPU:0':
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
如果你已连接,以下是响应:
Found GPU at: /device:GPU:0
另外,供需问题可能导致以下情况:
就这样。这允许你一次使用免费 GPU 最长达 12 小时。
2. 安装库
目前,Google Colaboratory 中的软件安装是不持久的,也就是说,你每次(重新)连接到实例时,都必须重新安装库。由于 Colab 默认安装了许多有用的常见库,因此这并不像看起来那么成问题,而未预装的库可以通过几种不同的方法轻松添加。
然而,你需要意识到,安装任何需要从源代码构建的软件可能会比在连接/重新连接到实例时的时间更长。
Colab 支持 pip 和 apt 包管理器。无论你使用哪种管理器,请记得在任何 bash 命令前加上 !。
# Install Keras with pip
!pip install -q keras
import keras
>>> Using TensorFlow backend.
# Install GraphViz with apt
!apt-get install graphviz -y
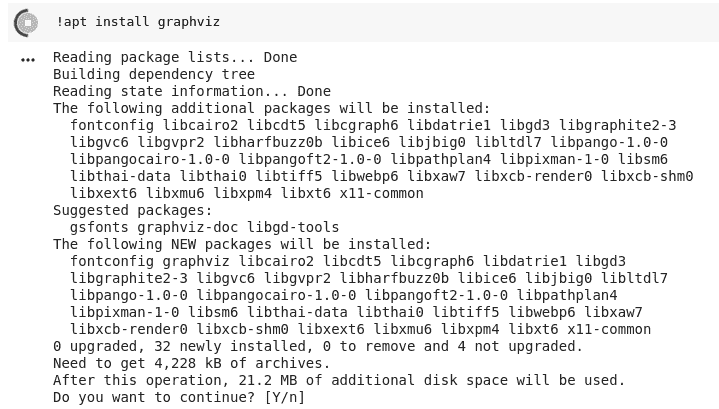
3. 上传和使用数据文件
你需要在 Colab 笔记本中使用数据,对吧?你可以使用类似 wget 的工具从网上获取数据,但如果你有一些本地文件想上传到 Google Drive 中的 Colab 环境并使用怎么办?
我认为这是最简单的方法,附带一点来自这里的指引。
在一个三步过程的第一步,首先在你的笔记本中调用一个文件选择器,使用:
from google.colab import files
uploaded = files.upload()
选择文件后,使用以下方法迭代上传的文件,以查找它们的关键名称,使用:
for fn in uploaded.keys():
print('User uploaded file "{name}" with length {length} bytes'.format(name=fn, length=len(uploaded[fn])))
示例输出:
User uploaded file "iris.csv" with length 3716 bytes
现在,使用以下方法将文件内容加载到 Pandas DataFrame 中:
import pandas as pd
import io
df = pd.read_csv(io.StringIO(uploaded['iris.csv'].decode('utf-8')))
print(df)
就这样。虽然还有其他方法可以达到相同的目的,上传和使用数据文件,但我发现这种方法最直接、最简单。
Google Colab 让我兴奋地尝试以类似于使用 Jupyter 笔记本的方式进行机器学习,但设置和管理更少。无论如何,这就是我们的想法;我们拭目以待。
如果你有任何有用的 Colab 技巧或窍门,请在下面的评论中留下。
相关内容:
-
Fast.ai 第 1 课在 Google Colab(免费 GPU)
-
从笔记本到 JupyterLab——数据科学 IDE 的演变
-
Python 中的探索性数据分析
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关话题
《变压器的基本指南:现代最先进人工智能的关键》
原文:
www.kdnuggets.com/2021/06/essential-guide-transformers-key-modern-sota-ai.html
评论
你是否被各种 X-formers 的浩繁数量所压倒?
不,它们不是像 X 战警、X 因素和 X 力量那样来自漫威的新变种团队。X-formers 是指各种变压器变体的名称,这些变体已经被实现或提议。你可能通过最近在自然语言处理、计算机视觉和其他人工智能领域的成功故事了解了变压器,但你是否熟悉所有的 X-formers?更重要的是,你知道它们之间的区别,以及为什么你可能会选择其中一个而不是另一个吗?
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
变压器调查,由 Tianyang Lin, Yuxin Wang, Xiangyang Liu 和 Xipeng Qiu 编写,旨在帮助对此感兴趣的读者。
摘要:
[A] 提出了各种各样的变压器变体(即 X-formers),然而,系统全面的文献综述仍然缺失。在这篇调查中,我们提供了各种 X-formers 的综合综述。我们首先简要介绍了原始变压器,然后提出了一种新的 X-formers 分类法。接下来,我们从三个方面介绍了各种 X-formers:架构修改、预训练和应用。最后,我们概述了一些未来研究的潜在方向。
这就是本调查论文所涵盖的三万英尺高度的视角;让我们更详细地看看。
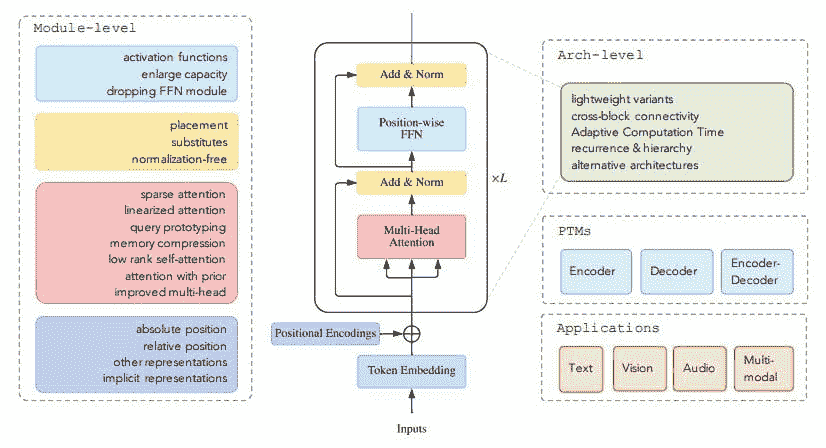
图 1. 变压器变体的分类(来源:变压器调查)
在介绍变压器之后,论文建立了许多后续变压器变体的概念,即上述的 X-formers,并指出这些不同的架构都试图从以下一个方面改进原始变压器:模型效率、模型泛化和模型适应。论文将继续讨论这些变化的观点,以及它们如何与随后提出的各种 X-formers 相关。
接下来,论文深入探讨了普通 Transformer 架构的技术细节(见图 2),包括其使用情况和性能分析。
在具体变体之前,作者对 Transformer 与其他架构进行了比较和对比。这一讨论包括对自注意力机制和归纳偏差的分析。在这里,Transformer 与以下架构进行比较:全连接深度神经网络、卷积网络和递归网络,比较了每层的复杂性、最小的序列操作数量和最大路径长度。
然后展示了一个 Transformer 的分类(见图 1),指出各种提出的模型试图从三个方面改进普通 Transformer:架构修改类型、预训练方法和应用。
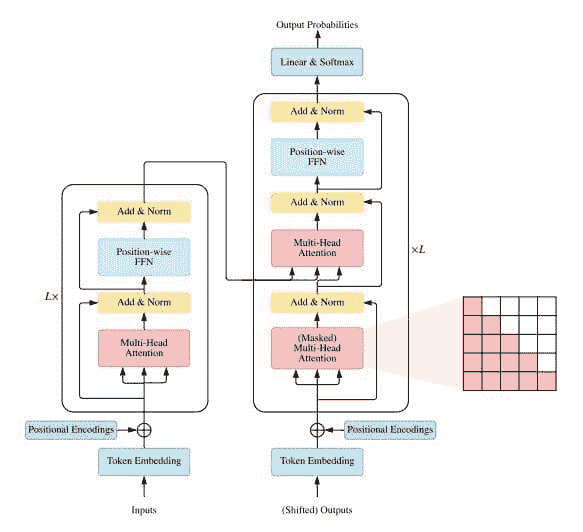
图 2. 普通 Transformer 架构(来源:A Survey of Transformers)
调查的核心内容出现在以下几节中,其中第一节专注于对注意力机制的改进,详细讨论了上述几个特定架构,并基于这些改进提出了 Transformer 的分类。为了促进改进,已经采取了几种不同的发展方向,并讨论了这些方向,包括:
-
稀疏注意力
-
线性化注意力
-
查询原型和记忆压缩
-
低秩自注意力
-
带有先验的注意力
-
改进的多头机制
作者随后转向其他 X-former 模块级的修改,与架构级的修改(在后续部分讨论)相对。这些修改包括位置表示、层归一化和位置-wise 前馈网络层。详细讨论了这些修改,阐明了它们为何对 Transformer 架构重要,以及各种改进的提案。
接下来是架构级的 X-former 变体,讨论了模块级之外的修改,包括:
-
使 Transformer 轻量化
-
强化跨块连接
-
自适应计算时间
-
具有分治策略的 Transformers
-
探索替代架构
最后一种修改类型,探索替代架构,提到“几项研究探索了 Transformer 的替代架构”,并讨论了这些研究可能的未来发展方向。
下一部分讨论了预训练的 Transformers,同时指出了 Transformers 的潜在问题:
Transformer 不对数据结构做任何假设。一方面,这使得 Transformer 成为一种非常通用的架构,具有捕捉不同范围依赖关系的潜力。另一方面,这使得 Transformer 在数据有限时容易过拟合。缓解这一问题的一种方法是将归纳偏差引入模型中。
介绍了仅编码器(包括 BERT 系列)、仅解码器(包括 GPT 系列)和编码器-解码器(包括 BART,一种扩展的 BERT 方法)架构的简要概述,涉及归纳偏差。
论文接着总结了 Transformers 的应用——如果你已经看到这一步,你可能已经了解——包括它在 NLP、CV、音频和多模态应用中的使用。最后,作者总结了 X-former 相关研究的结论和未来方向,指出了这些方向的潜在进一步发展:
-
理论分析
-
超越注意力的更佳全局交互机制
-
多模态数据的统一框架
作者在论文中做得非常出色。如果你有兴趣理清各种 X-formers 之间的具体关系,我建议你阅读 Tianyang Lin、Yuxin Wang、Xiangyang Liu 和 Xipeng Qiu 的 Transformers 调查。
相关:
-
现在学习自然语言处理的神经网络
-
自然语言处理研究和应用的新资源
-
入门 5 个必备自然语言处理库
更多相关话题
数据科学和机器学习的基本线性代数
原文:
www.kdnuggets.com/2021/05/essential-linear-algebra-data-science-machine-learning.html
评论
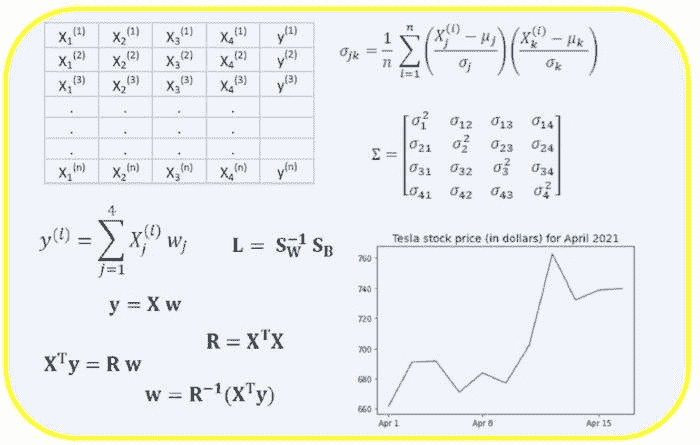
图片来源:Benjamin O. Tayo.
线性代数是数学的一个分支,在数据科学和机器学习中非常有用。线性代数是机器学习中最重要的数学技能。大多数机器学习模型可以用矩阵形式表示。数据集本身通常被表示为矩阵。线性代数用于数据预处理、数据转换和模型评估。你需要熟悉以下主题:
-
向量
-
矩阵
-
矩阵的转置
-
矩阵的逆
-
矩阵的行列式
-
矩阵的迹
-
点积
-
特征值
-
特征向量
在本文中,我们使用科技股票数据集来说明线性代数在数据科学和机器学习中的应用,数据集可以在 这里 找到。
1. 数据预处理中的线性代数
我们首先说明线性代数在数据预处理中的应用。
1.1 导入线性代数所需的库
import numpy as np
import pandas as pd
import pylab
import matplotlib.pyplot as plt
import seaborn as sns
1.2 读取数据集并显示特征
data = pd.read_csv("tech-stocks-04-2021.csv")
data.head()
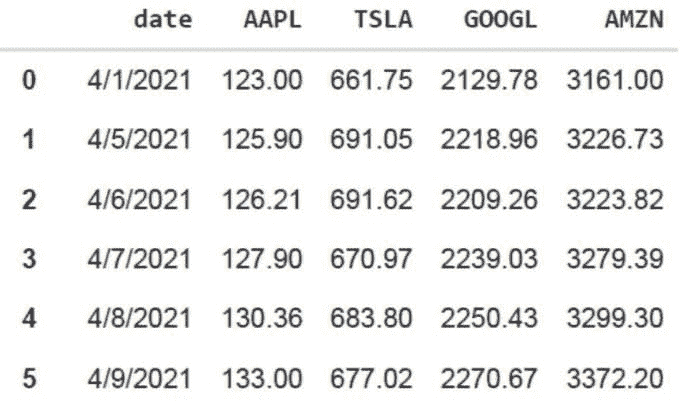
* 表 1. 2021 年 4 月前 16 天的选定股票价格表.*
print(data.shape)
output = (11,5)
data.shape 函数使我们能够知道数据集的大小。在这种情况下,数据集有 5 个特征(日期、AAPL、TSLA、GOOGL 和 AMZN),每个特征有 11 个观测值。日期 指的是 2021 年 4 月的交易日(截至 4 月 16 日)。AAPL、TSLA、GOOGL 和 AMZN 分别是苹果、特斯拉、谷歌和亚马逊的收盘股价。
1.3 数据可视化
为了进行数据可视化,我们需要定义 列矩阵 以便可视化特征:
x = data['date']
y = data['TSLA']
plt.plot(x,y)
plt.xticks(np.array([0,4,9]), ['Apr 1','Apr 8','Apr 15'])
plt.title('Tesla stock price (in dollars) for April 2021',size=14)
plt.show()
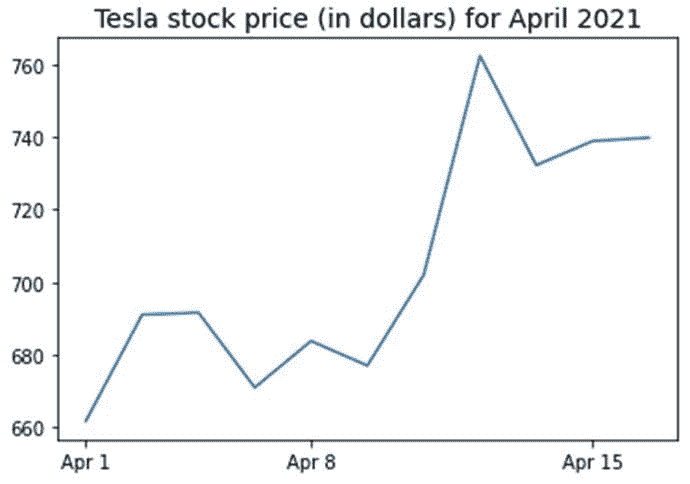
图 1. 2021 年 4 月前 16 天的特斯拉股票价格.
2. 协方差矩阵
协方差矩阵 是数据科学和机器学习中最重要的矩阵之一。它提供了特征之间共同运动(相关性)的信息。假设我们有一个特征矩阵,其中包含 4 个特征和 n 个观测值,如 表 2 所示:
表 2. 具有 4 个变量和 n 个观测值的特征矩阵.
为了可视化特征之间的相关性,我们可以生成散点对比图:
cols=data.columns[1:5]
print(cols)
output = Index(['AAPL', 'TSLA', 'GOOGL', 'AMZN'], dtype='object')
sns.pairplot(data[cols], height=3.0)
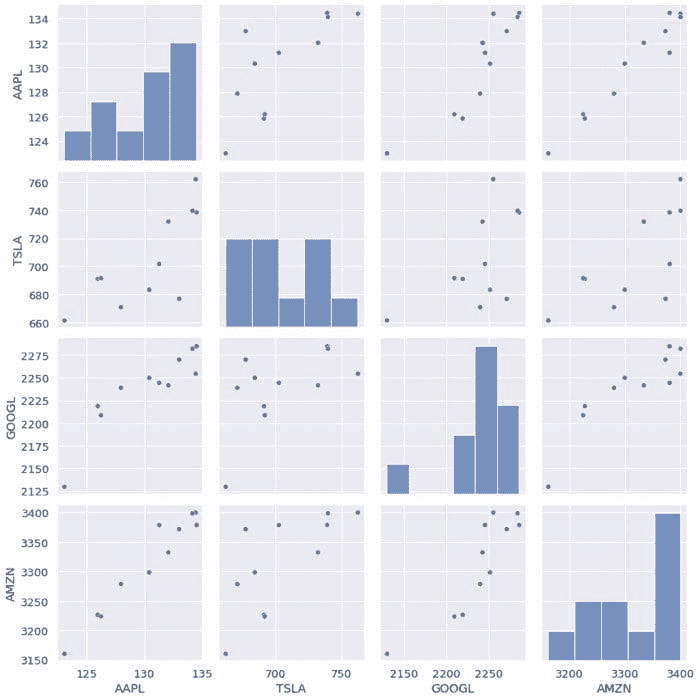
图 2. 选定科技股票的散点对比图.
为了量化特征之间的相关程度(多重共线性),我们可以使用以下公式计算协方差矩阵:
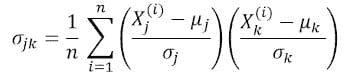
其中和分别是特征的均值和标准差。这个方程表明,当特征标准化时,协方差矩阵仅仅是特征之间的点积。
在线性形式下,协方差矩阵可以表示为一个 4 x 4 的实对称矩阵:
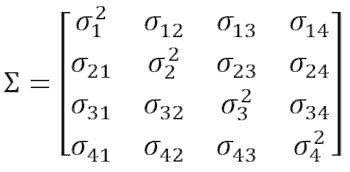
这个矩阵可以通过执行单位 ary 变换,也称为主成分分析(PCA)变换,来对角化,得到以下结果:
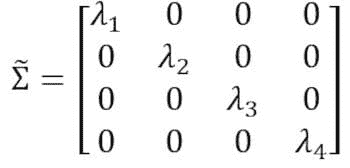
由于矩阵的迹值在单位 ary 变换下保持不变,我们观察到对角矩阵的特征值之和等于特征 X[1]、X[2]、X[3]和 X[4]中包含的总方差。
2.1 计算技术股票的协方差矩阵
from sklearn.preprocessing import StandardScaler
stdsc = StandardScaler()
X_std = stdsc.fit_transform(data[cols].iloc[:,range(0,4)].values)
cov_mat = np.cov(X_std.T, bias= True)
请注意,这使用了标准化矩阵的转置。
2.2 协方差矩阵的可视化
plt.figure(figsize=(8,8))
sns.set(font_scale=1.2)
hm = sns.heatmap(cov_mat,
cbar=True,
annot=True,
square=True,
fmt='.2f',
annot_kws={'size': 12},
yticklabels=cols,
xticklabels=cols)
plt.title('Covariance matrix showing correlation coefficients')
plt.tight_layout()
plt.show()
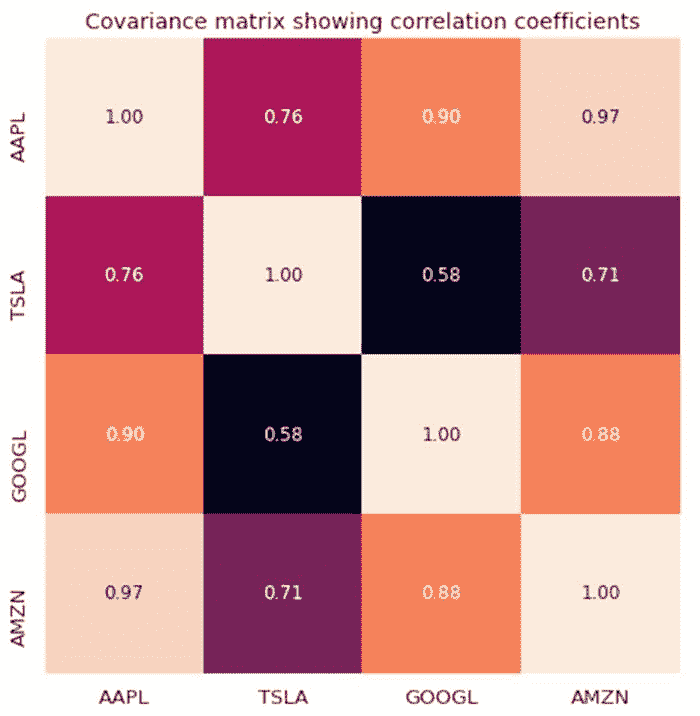
图 3。选定技术股票的协方差矩阵图。
从图 3 中我们观察到,AAPL 与 GOOGL 和 AMZN 有较强的相关性,而与 TSLA 的相关性较弱。TSLA 一般与 AAPL、GOOGL 和 AMZN 的相关性较弱,而 AAPL、GOOGL 和 AMZN 之间的相关性较强。
2.3 计算协方差矩阵的特征值
np.linalg.eigvals(cov_mat)
output = array([3.41582227, 0.4527295 , 0.02045092, 0.11099732])
np.sum(np.linalg.eigvals(cov_mat))
output = 4.000000000000006
np.trace(cov_mat)
output = 4.000000000000001
我们观察到,协方差矩阵的迹值等于特征值的总和,这与预期一致。
2.4 计算累积方差
由于矩阵的迹值在单位 ary 变换下保持不变,我们观察到对角矩阵的特征值之和等于特征 X[1]、X[2]、X[3]和 X[4]中包含的总方差。因此,我们可以定义以下量:
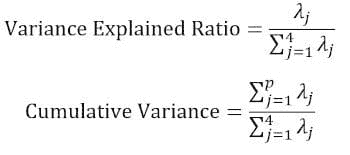
注意,当p=4 时,累积方差如预期变为 1。
eigen = np.linalg.eigvals(cov_mat)
cum_var = eigen/np.sum(eigen)
print(cum_var)
output = [0.85395557 0.11318237 0.00511273 0.02774933]
print(np.sum(cum_var))
output = 1.0
我们从累积方差(cum_var)中观察到,85%的方差包含在第一个特征值中,11%包含在第二个特征值中。这意味着当 PCA 实施时,只能使用前两个主成分,因为这两个主成分贡献了 97%的总方差。这实际上可以将特征空间的维度从 4 减少到 2。
3. 线性回归矩阵
假设我们有一个数据集,包含 4 个预测特征和n个观测值,如下所示。

表 3。包含 4 个变量和 n 个观测值的特征矩阵。第 5 列是目标变量(y)。
我们希望建立一个多重回归模型来预测y值(第 5 列)。因此,我们的模型可以表示为以下形式
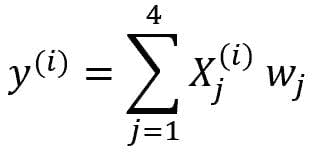
在线性形式下,这个方程可以写作
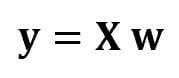
其中X是(n x 4)特征矩阵,w是(4 x 1)矩阵,表示待确定的回归系数,而y是(n x 1)矩阵,包含目标变量 y 的 n 个观测值。
注意X是一个矩形矩阵,因此我们不能通过取X的逆来解上述方程。
为了将X转换为方阵,我们将方程的左侧和右侧都乘以X的转置,即
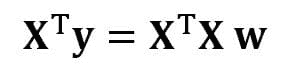
这个方程也可以表达为
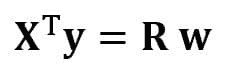
其中
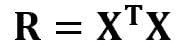
是(4×4)回归矩阵。显然,我们观察到R是一个实对称矩阵。注意,在线性代数中,两个矩阵的乘积的转置遵循以下关系
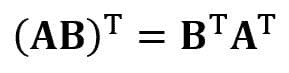
现在我们已经将回归问题简化,并将其表示为(4×4)实对称且可逆的回归矩阵R,很容易展示回归方程的精确解为
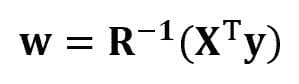
预测连续和离散变量的回归分析示例如下:
4. 线性判别分析矩阵
数据科学中的另一个实对称矩阵示例是线性判别分析(LDA)矩阵。这个矩阵可以表示为:
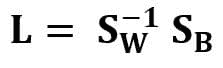
其中S[W]是特征内部散布矩阵,S[B]是特征间散布矩阵。由于矩阵S[W]和S[B]都是实对称的,因此L也是实对称的。对L的对角化产生了一个优化类别可分离性并减少维度的特征子空间。因此,LDA 是一个监督算法,而 PCA 不是。
关于 LDA 的实施的更多细节,请参见以下参考文献:
Sebastian Raschka 的《Python 机器学习》第三版(第五章)
摘要
总结一下,我们讨论了线性代数在数据科学和机器学习中的几种应用。通过使用技术股票数据集,我们阐明了矩阵的大小、列矩阵、方阵、协方差矩阵、矩阵的转置、特征值、点积等重要概念。线性代数是数据科学和机器学习中的一个重要工具。因此,初学者如果对数据科学感兴趣,必须熟悉线性代数中的基本概念。
相关:
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
了解更多相关内容
必要的机器学习算法:初学者指南
原文:
www.kdnuggets.com/2021/05/essential-machine-learning-algorithms-beginners.html

当机器根据历史和数据模式做出类似人类的决策时,后台有几个机器学习算法在执行这些功能。无论是根据用户数据历史搜索适当的用户选项的应用程序,还是在玩智力游戏如国际象棋中,机器决定每一步行动。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 加速进入网络安全职业的快车道
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在的组织的 IT 工作
机器学习算法的类型
目前,机器学习是一个快速发展的人工智能领域,机器通过实现类似于人脑的人工神经网络(ANN)来像人类一样思考和决策。它们帮助定制和分析用户内容和数据,以减少长期的整体需求和应用维护成本。
人工神经网络(ANN)包括人工神经元和节点,这些节点形成了输入层、隐藏层以及输出层这三层。这些层共同形成了每个机器学习算法的功能。数据以各种输入节点的形式提供给输入层。每个节点携带特定的信息。输入节点与随机权重和其他必要变量相乘,最后通过加上偏差进行计算。最后,应用非线性函数,也称为激活函数,以确定哪个神经元被激活。由于有数百万个神经元和输入可供选择,这些算法通常涉及复杂的功能,需要一定的处理能力来实现平稳的输出。
这些是主要的机器学习算法类型:
监督学习算法
当算法的结果类型已知于开发者,并且开发者明确标注了待分析的数据以得出结果时。监督学习主要扩大数据的范围,并帮助软件和硬件基于标记的样本数据对不可用、未来或未见过的数据进行预测。监督学习算法广泛用于对“输入”数据类型进行分类以及将其回归到最终提供输出的模式中。例如,价格预测和趋势预测等过程由监督学习算法处理。
无监督学习算法
在无监督机器学习算法的范围内,没有定义的输出或输入类型或任何特别标记的数据供算法利用。它们的输出和学习不在开发者的直接控制下。它们的功能用于探索信息的结构、提取有价值的见解、检测模式,并将其实施到操作中以提高效率。数字营销和广告技术领域已知积极使用这些 ML 算法为用户提供定制服务。
半监督学习算法
这些算法介于监督学习和无监督学习之间,其中使用指定数据集中的输出进一步“训练”算法以标记未标记的数据,然后将两者结合起来。许多法律和医疗行业成功使用半监督算法来管理其网络内容分类、图像和语音分析等。
强化学习算法
当系统将先前分析的输出的学习强化到其新的分析中时,这是一种强化学习算法。它包括大多数基于 AI 的功能,其中算法自主学习并随着使用变得更加智能。在这里,开发者试图开发一个自我维持的系统,通过连续的尝试和失败,基于标记数据和与新数据的交互来改进自己。自动驾驶汽车和现代视频游戏都是基于强化学习的 ML 算法的例子。
你应该了解的 ML 算法
让我们现在分析一些被称为未来将会变得著名的特定 ML 算法的功能。
线性回归
线性回归算法由机器用于分析数据,并根据特定的输入变量形成特定的“视觉斜率”以进行准确预测。它们有监督学习算法,简单版本通常基于类似的方程式。
y = ax + b
其中,x 和 y 分别是输入和输出变量。在多变量场景中,方程如:
f(x,y,z) = w[1]x + w[2]y + w[3]z
其中 x、y 和 z 代表要分析和预测的函数属性。
逻辑回归
这些也是监督学习算法,利用预测分析的概念来分类问题以寻找解决方案。它被企业用来通过将数据拟合到逻辑函数中来预测事件的概率。因此,它也被称为逻辑回归,并基本上在基于线性回归的算法(上述提到的)中包含了一个复杂的“成本函数”效用(本质上在 0 和 1 之间)。它往往发展为“Sigmoid 函数”,根据概率有效地预测值。
朴素贝叶斯
这是一种快速工作的监督学习算法,假设某一特征的出现与其他特征的出现是独立的,并且这种函数的输出值可以使用贝叶斯定理计算:
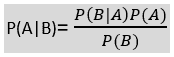
在垃圾邮件过滤、情感分析和分类文章相关算法中广泛使用;朴素贝叶斯是一种概率分类器,这意味着它基于对象的概率进行预测。
K-最近邻(K-NN)
K-NN 算法分析新案例或数据与先前可用案例之间的相似性,并将新案例放入与现有类别最相似的类别中。在训练阶段,它仅存储先前可用的数据集,当获取到新数据时,它将这些数据分类到与新数据最相似的类别中。这是一种易于使用的监督学习算法,主要用于解决分类问题,包括图像搜索的图像分类等。
K 均值聚类
K 均值聚类是一种简单的无监督机器学习算法,它有效地根据某些相似性(数据点)对数据进行聚类,并尝试分析所有数据模式。为实现这一目标,K 均值在数据集中寻找固定数量(k)的簇,而“均值”一词表示对可用数据集的平均值计算。
前路...
作为一项技术,机器学习已经逐渐成型,并塑造了其他技术;它们无处不在。除了上述提到的算法,还有其他一些算法也有助于满足这些标准和需求。但是,这些算法不能通过简单、广泛使用的 DIY 网站或平台纳入你的数字资产。为了实现这些功能,你需要聘请一位具有适当专业知识和经验的专职移动应用开发者!你还需要了解机器学习项目的预计时间和成本,以确保开发和交付过程的顺利进行。
Ria Katiyar 是一位内容贡献者,喜欢以简化和吸引人的方式撰写她的理解和知识。她是早期采用者,喜欢跟进最新的趋势和技术。
相关主题
数据科学的基本数学:基和基的变化
原文:
www.kdnuggets.com/2021/05/essential-math-data-science-basis-change-basis.html
评论
基和基的变化
理解特征分解的一种方式是将其视为基的变化。你将在这篇文章中学习什么是向量空间的基。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
你会看到空间中的任何向量都是基向量的线性组合,并且向量中看到的数字取决于你选择的基。
最终,你将看到如何使用基变换矩阵改变基。
将矩阵分解视为特征分解或奇异值分解是一种很好的方法。如你在数据科学的基本数学第九章所见,通过特征分解,你选择基使得新矩阵(类似于原始矩阵)变为对角矩阵。
定义
基是用于描述向量空间(向量集合)的坐标系统。它是你用来将数字与几何向量关联的参考。
被认为是基的向量组必须:
-
线性无关。
-
生成空间。
空间中的每个向量都是基向量的唯一组合。空间的维度定义为基集合的大小。例如,ℝ²中有两个基向量(对应于笛卡尔平面中的x和y轴),或者ℝ³中有三个。
如数据科学的基本数学第 7.4 节所示,如果一个集合中的向量数量大于空间的维度,则它们不能是线性无关的。如果一个集合包含的向量少于维度数,这些向量不能生成整个空间。
如你所见,向量可以表示为从原点到空间中某一点的箭头。这个点的坐标可以存储在一个列表中。笛卡尔平面中向量的几何表示意味着我们采用一个参考:由两个轴x和y给出的方向。
基向量 是指对应于此参考的向量。在笛卡尔平面上,基向量是正交的单位向量(长度为 1),通常记作 i 和 j。
图 1:笛卡尔平面中的基向量。
例如,在图 1 中,基向量 i 和 j 分别指向 x 轴和 y 轴的方向。这些向量给出了标准基。如果你将这些基向量放入一个矩阵中,你会得到以下单位矩阵(有关单位矩阵的更多细节,请参见 数据科学基础数学 第 6.4.3 节):
因此,I[2] 的列生成了 ℝ²。以同样的方式,I[3] 的列生成了 ℝ³,依此类推。
正交基
基向量可以是正交的,因为正交向量是独立的。然而,反之并不一定成立:非正交向量可以是线性独立的,从而形成基(但不是标准基)。
向量空间的基非常重要,因为与向量对应的坐标值依赖于这个基。顺便提一下,你可以选择不同的基向量,比如图 2 中的那些。
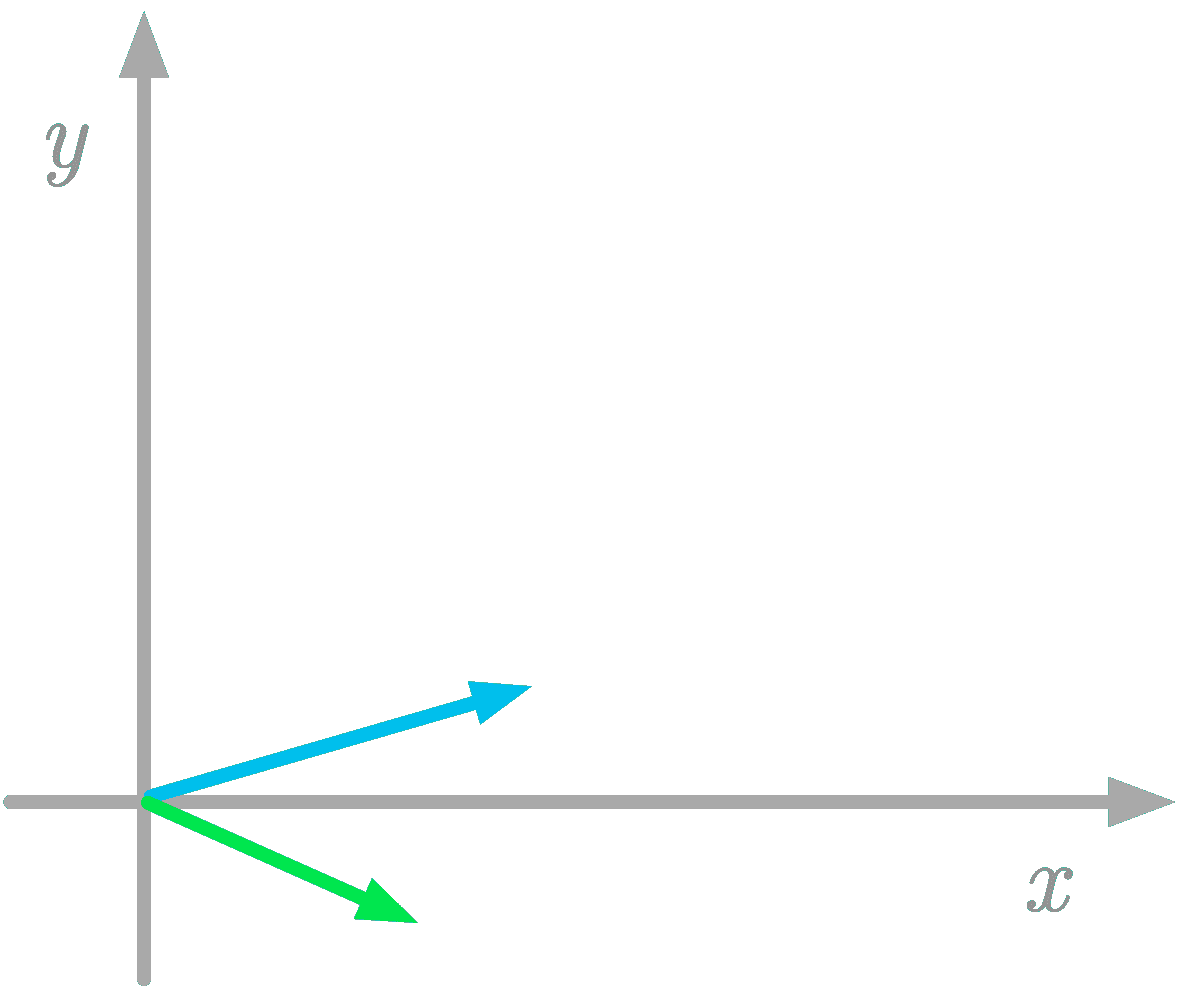
图 2:另一组基向量。
请记住,向量坐标依赖于隐含的基向量选择。
基向量的线性组合
你可以将向量空间中的任何向量视为基向量的线性组合。
例如,考虑以下二维向量 v:
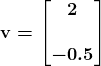
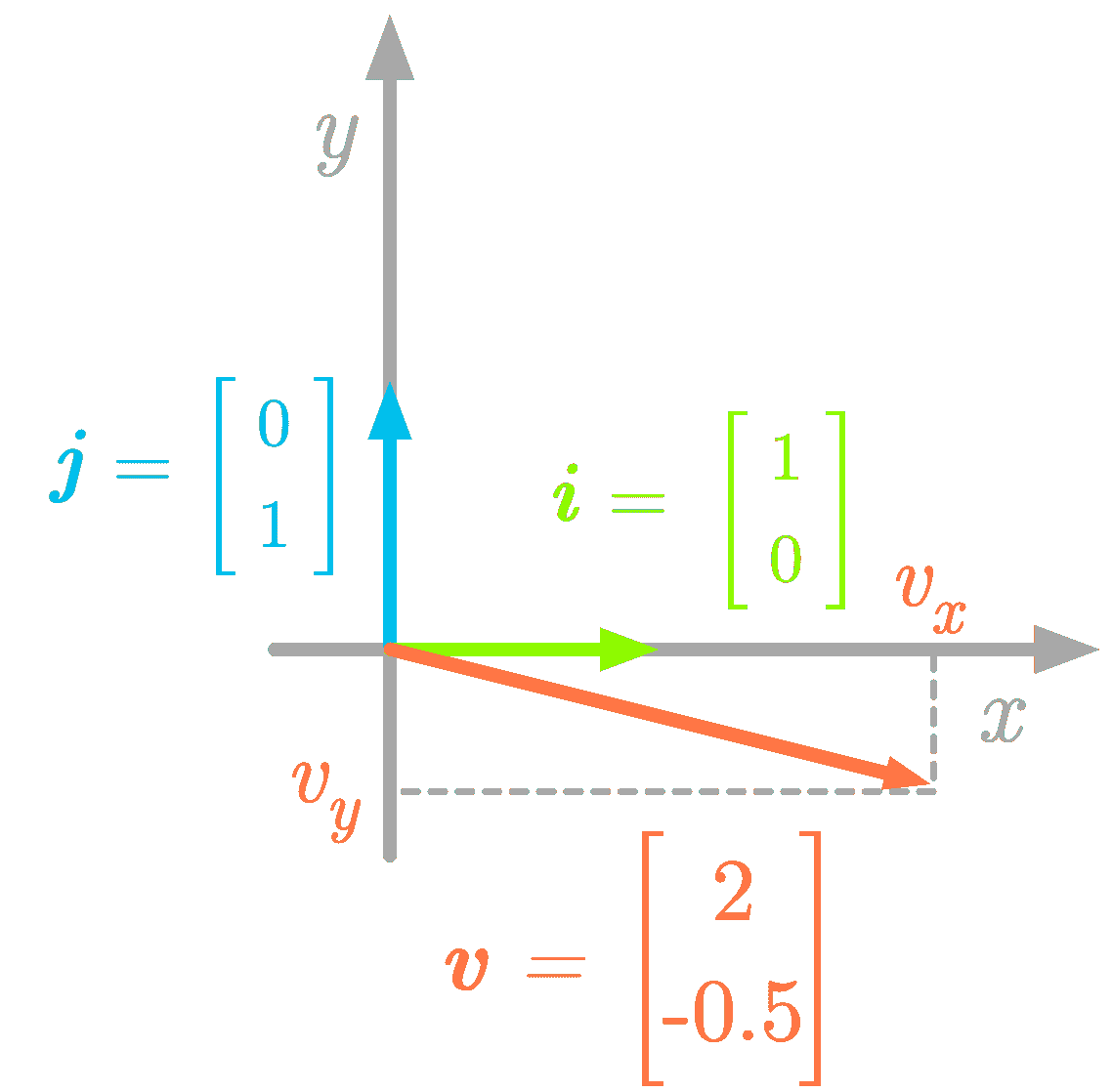
图 3:向量 v 的分量。
向量 v 的分量是对 x 轴和 y 轴的投影(vx 和 vy,如图 3 所示)。向量 v 对应于其分量的和:v = vx + vy,你可以通过缩放基向量来获得这些分量:v[x] = 2i 和 v[y] = −0.5j。因此,图 3 中显示的向量 v 可以被视为两个基向量 i 和 j 的线性组合:
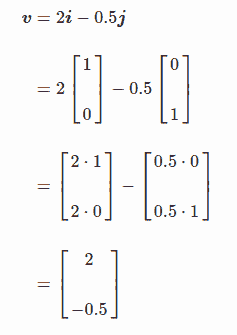
其他基
单位矩阵的列并不是唯一的线性独立列向量的情况。你可以在 ℝ^n 中找到其他线性独立的 n 个向量集。
例如,让我们考虑 ℝ² 中的以下向量:
和
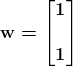
向量 v 和 w 在图 4 中表示。
图 4:二维空间中的另一组基。
从上面的定义来看,向量v和w是一个基,因为它们是线性无关的(你不能通过其他向量的组合来获得其中一个),并且它们张成了空间(通过这些向量的线性组合可以到达整个空间)。
重要的是要记住,当你使用向量的分量(例如v的x和y分量)时,这些值是相对于你选择的基的。如果使用其他基,这些值会有所不同。
你可以在数据科学的基础数学的第九章和第十章中看到,改变基的能力在线性代数中是基础性的,并且是理解特征分解或奇异值分解的关键。
向量是相对于一个基定义的
你看到,将几何向量(空间中的箭头)与坐标向量(数字数组)关联时,你需要一个参考。这个参考就是你的向量空间的基。因此,向量应该始终相对于一个基来定义。
让我们考虑以下向量:
x和y分量的值分别是 2 和-0.5。默认使用标准基。
你可以写Iv以指定这些数字相对于标准基的坐标。在这种情况下,i被称为基变换矩阵。
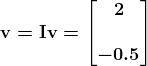
你可以使用不同于i的矩阵来相对于另一个基定义向量。
基向量的线性组合
向量空间(可能的向量集合)是根据一个基来描述的。几何向量作为一组数字的表达意味着你选择了一个基。使用不同的基,相同的向量v会关联不同的数字。
你看到基是一组线性无关的向量,这些向量张成了空间。更确切地说,一组向量是基,如果空间中的每个向量都可以被描述为基向量的有限线性组合,并且该集合是线性无关的。
考虑以下二维向量:
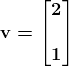
在ℝ²笛卡尔平面中,你可以将v视为标准基向量i和j的线性组合,如图 5 所示。
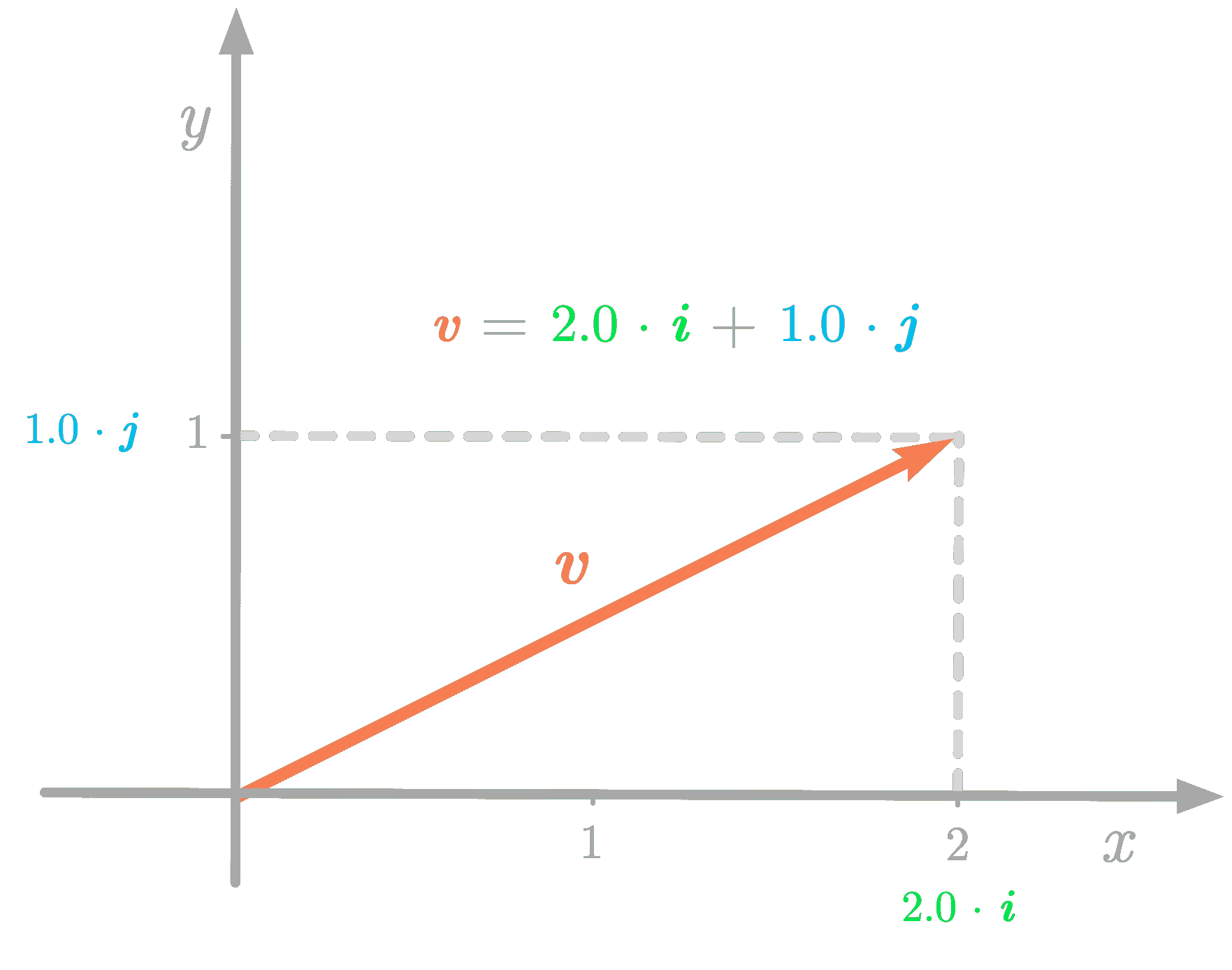
图 5:向量v可以被描述为基向量i和j的线性组合。
但是,如果你使用其他坐标系统,v将与新的数字相关联。图 6 展示了使用新坐标系统(i′和j′)表示的向量v。
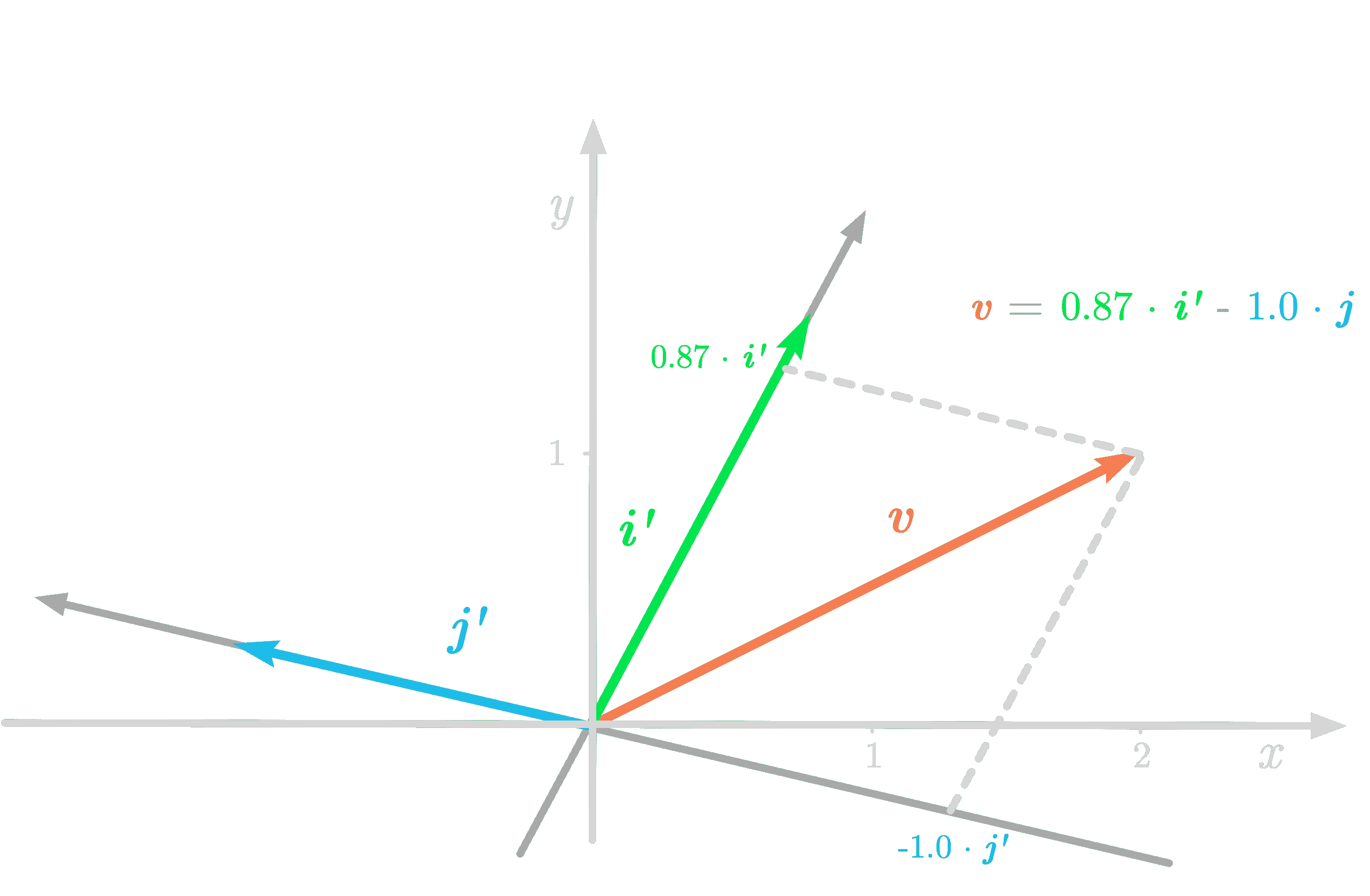
图 6:相对于新基坐标的向量v。
在新的基下,v是一个新的数字集合:
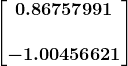
基础变换矩阵
你可以使用 基础变换矩阵 从一个基础转换到另一个基础。为了找到新基础向量的矩阵,你可以将这些新基础向量 (i′ 和 j′) 表示为旧基础 (i 和 j) 中的坐标。
让我们再次回顾前面的例子。你得到:
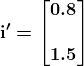
和
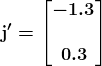
如图 7 所示。
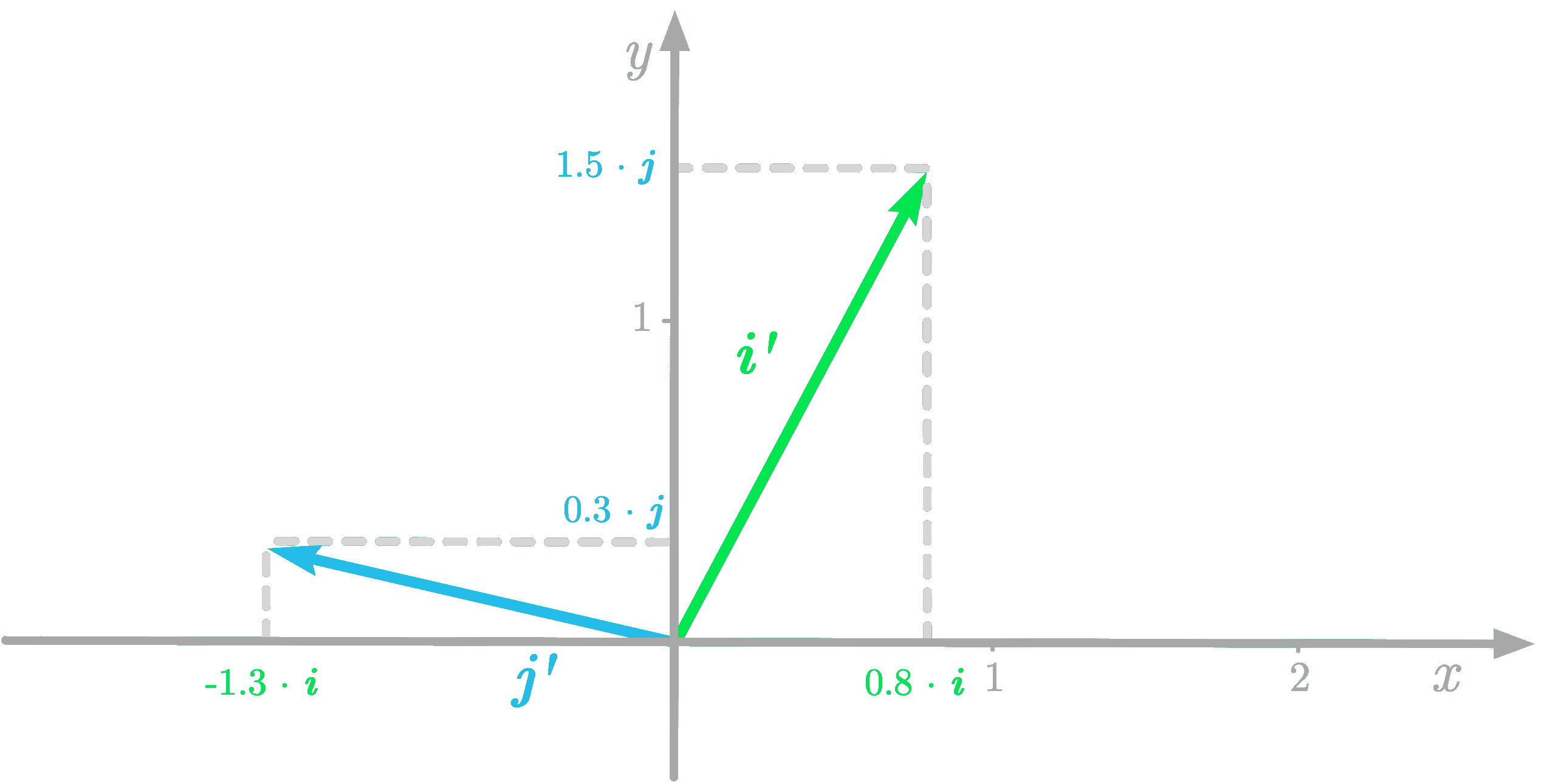
图 7:新基础向量相对于旧基础的坐标。
由于它们是基础向量, i′ 和 j′ 可以表示为 i 和 j 的线性组合。
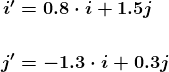
让我们将这些方程写成矩阵形式:
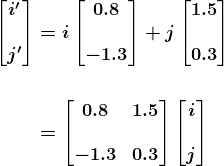
为了将基础向量作为列,你需要转置矩阵。你得到:
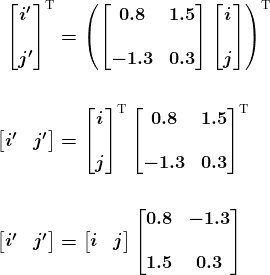
这个矩阵叫做基础变换矩阵。我们称之为 CC:

如你所见,基础变换矩阵的每一列都是新基础的一个基础向量。接下来你将看到,你可以使用基础变换矩阵 CC 将向量从输出基础转换到输入基础。
基础变换与线性变换
基础变换和线性变换之间的区别是概念性的。有时,将矩阵的作用视为基础变换是有用的;有时,当你把它看作线性变换时,你会得到更多的见解。要么你移动向量,要么你移动它的参考。这就是为什么旋转坐标系统的效果与旋转向量本身的效果相反的原因。对于特征分解和奇异值分解,这两种视角通常会一起考虑,这最初可能会让人感到困惑。记住这一点将对书的后半部分非常有用。这两者之间的主要技术区别是基础变换必须是可逆的,而线性变换则没有这个要求。
寻找基础变换矩阵
基础变换矩阵将输入基础映射到输出基础。我们将输入基础称为 B[1],其基础向量为 i 和 j,将输出基础称为 B[2],其基础向量为 i′ 和 j′。你得到:
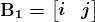
和
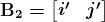
从基础变换的方程中,你可以得到:
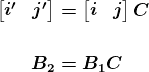
如果你想找到给定 B[1] 和 B[2] 的基础变换矩阵,你需要计算 B[1] 的逆以隔离 C:
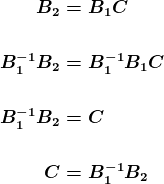
换句话说,你可以通过将输入基矩阵 ( ,包含输入基向量作为列) 的逆矩阵与输出基矩阵 (
,包含输入基向量作为列) 的逆矩阵与输出基矩阵 ( ,包含输出基向量作为列) 相乘来计算基变换矩阵。
,包含输出基向量作为列) 相乘来计算基变换矩阵。
将向量从输出基转换到输入基
小心,这个基变换矩阵允许你将向量从 转换到  ,而不是相反。直观地说,这是因为移动一个物体是与移动参考系相反的。因此,要从 转换到 ,你必须使用基变换矩阵
,而不是相反。直观地说,这是因为移动一个物体是与移动参考系相反的。因此,要从 转换到 ,你必须使用基变换矩阵 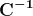 的逆矩阵。
的逆矩阵。
请注意,如果输入基是标准基 (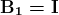 ),那么基变换矩阵只是输出基矩阵:
),那么基变换矩阵只是输出基矩阵:
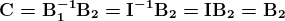
可逆基变换矩阵
由于基向量是线性无关的,矩阵 C 的列是线性无关的,因此,正如 《数据科学中的基础数学》 第 7.4 节所述, C 是可逆的。
示例:向量的基变换
让我们改变向量 v 的基,再次使用图 6 中表示的几何向量。
符号
你将把 v 的基从标准基变换到新的基。我们将标准基表示为 ,新基表示为 。记住,基是一个包含基向量作为列的矩阵。你有:
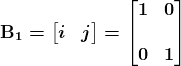
和
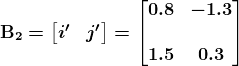
让我们将相对于基 的向量 v 表示为 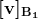 :
:
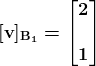
目标是找到相对于基 的 v 的坐标,记作  。
。
方括号符号
为了区分用来定义向量的基,你可以将基名称(如 )以下标的形式放在向量名称后面,括在方括号内。例如, 表示相对于基 的向量 v,也称为 v 相对于 的 表示。
使用线性组合

让我们编写代码:
v_B1 = np.array([2, 1])
B_2 = np.array([
[0.8, -1.3],
[1.5, 0.3]
])
v_B2 = np.linalg.inv(B_2) @ v_B1
v_B2
array([ 0.86757991, -1.00456621])
这些值是向量 v 相对于基 的坐标。这意味着如果你去到 0.86757991i′−1.00456621j′,你会到达标准基中的位置(2, 1),如图 6 所示。
结论
理解基的概念是处理矩阵分解(也称为矩阵因式分解),如特征分解或奇异值分解(SVD)的一个好方法。从这些术语来看,你可以将矩阵分解视为寻找一个基,其中与变换相关的矩阵具有特定属性:因式分解是一个基变换矩阵、新的变换矩阵,最后是基变换矩阵的逆矩阵,以回到初始基(更多细节见数据科学基础数学第九章和 10 章)。
个人简介:Hadrien Jean 是一位机器学习科学家。他拥有巴黎高等师范学院的认知科学博士学位,主要研究行为和电生理数据下的听觉感知。他曾在工业界工作,构建了用于语音处理的深度学习管道。在数据科学与环境交汇的领域,他从事利用深度学习分析音频记录进行生物多样性评估的项目。他还定期在 Le Wagon(数据科学训练营)创作内容并授课,并在他的博客中撰写文章(hadrienj.github.io)。
原文。经许可转载。
相关内容:
-
数据科学基础数学:标量和向量
-
数据科学基础数学:矩阵与矩阵乘积导论
-
数据科学基础数学:信息论
更多相关内容
数据科学的基础数学:特征向量及其在 PCA 中的应用
原文:
www.kdnuggets.com/2022/06/essential-math-data-science-eigenvectors-application-pca.html
矩阵分解,也叫做矩阵因式分解,是将一个矩阵拆分成多个部分的过程。在数据科学的背景下,你可以例如用它来选择数据的部分,旨在减少维度而不丢失太多信息(例如在主成分分析中,你将在这篇文章的后面看到)。一些操作也可以更容易地在分解后的矩阵上进行计算。
在这篇文章中,你将学习矩阵的特征分解。理解它的一种方法是将其视为一种特殊的基变换(有关基变换的更多细节,请参阅我上一篇文章)。你将首先了解特征向量和特征值,然后看到它如何应用于主成分分析(PCA)。主要思想是将矩阵  的特征分解视为基变换,其中新的基向量是特征向量。
的特征分解视为基变换,其中新的基向量是特征向量。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
特征向量和特征值
如你在数据科学的基础数学第七章中看到的,你可以将矩阵视为线性变换。这意味着如果你取任意一个向量  并对其应用矩阵 ,你会得到一个变换后的向量
并对其应用矩阵 ,你会得到一个变换后的向量  。
。
以以下例子为例:
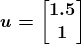
和
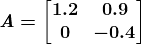
如果你将 应用于向量 (使用矩阵-向量乘积),你会得到一个新向量:
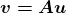
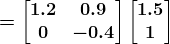
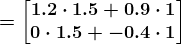
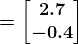
让我们绘制初始向量和变换后的向量:
u = np.array([1.5, 1])
A = np.array([
[1.2, 0.9],
[0, -0.4]
])
v = A @ u
plt.quiver(0, 0, u[0], u[1], color="#2EBCE7", angles='xy', scale_units='xy', scale=1)
plt.quiver(0, 0, v[0], v[1], color="#00E64E", angles='xy', scale_units='xy', scale=1)
# [...] Add axes, styles, vector names
图 1:矩阵 对向量 的变换成向量 。
注意,如你所料,变换后的向量 并不与初始向量 在同一方向上。这种方向的变化是你可以用 变换的大多数向量的特征。
然而,考虑以下向量:
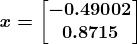
让我们将矩阵 应用于向量 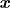 以获得一个向量
以获得一个向量 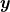 :
:
x = np.array([-0.4902, 0.8715])
y = A @ x
plt.quiver(0, 0, x[0], x[1], color="#2EBCE7", angles='xy',
scale_units='xy', scale=1)
plt.quiver(0, 0, y[0], y[1], color="#00E64E", angles='xy',
scale_units='xy', scale=1)
# [...] Add axes, styles, vector names
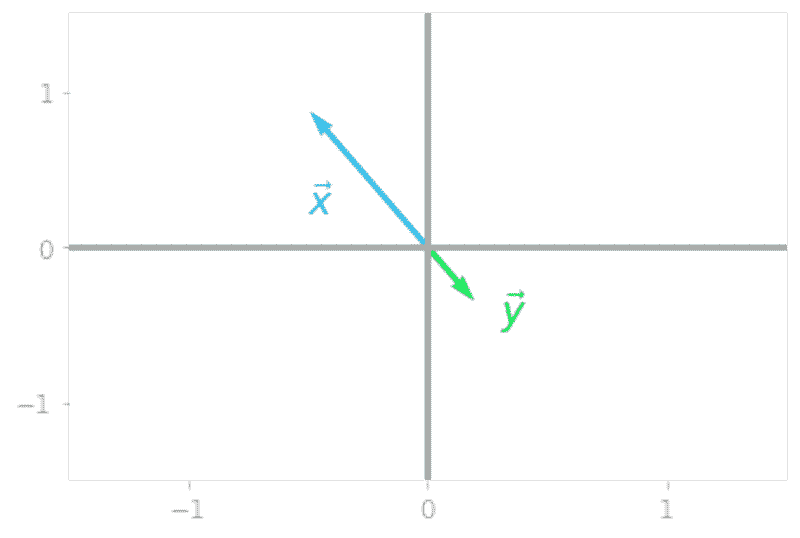
图 2:矩阵 对特殊向量 的变换。
从图 2 中可以看出,向量 与矩阵 具有特殊关系:它被缩放(带有负值),但初始向量 和变换后的向量 都在同一条直线上。
向量 是 的特征向量。它仅被一个值缩放,这个值称为矩阵 的特征值。矩阵 的特征向量是在矩阵变换时被缩短或拉长的向量。特征值是缩短或拉长向量的缩放因子。
从数学上讲,向量 是 的特征向量,如果:
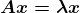
其中  (读作“lambda”)是与特征向量 对应的特征值。
(读作“lambda”)是与特征向量 对应的特征值。
特征向量
矩阵的特征向量是非零向量,当矩阵作用于它们时只是被重新缩放。如果缩放因子为正,初始向量和变换后的向量的方向相同;如果为负,则方向相反。
特征向量的数量
一个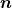 -by-矩阵最多具有个线性独立的特征向量。然而,每个特征向量乘以一个非零标量也是一个特征向量。如果你有:
-by-矩阵最多具有个线性独立的特征向量。然而,每个特征向量乘以一个非零标量也是一个特征向量。如果你有:
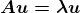
然后:
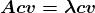
具有 任何非零值。
任何非零值。
这排除了零向量作为特征向量,因为你会有
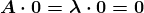
在这种情况下,每个标量将是一个特征值,因此会变得未定义。
实践项目:主成分分析
主成分分析(PCA)是一种算法,用于减少数据集的维度。例如,它在减少计算时间、压缩数据或避免所谓的维数灾难方面很有用。它也对可视化很有帮助:高维数据很难可视化,减少维数可以有助于绘制数据。
在这个实践项目中,你将使用你可以在数据科学基础数学一书中学习的各种概念,如基变换(第 7.5 节和 9.2 节,一些示例在这里)、特征分解(第九章)或协方差矩阵(第 2.1.3 节),以理解 PCA 是如何工作的。
在第一部分,你将学习投影、解释方差和误差最小化之间的关系,首先通过一点理论,然后通过对啤酒数据集(啤酒消费与温度的关系)进行 PCA 编码。请注意,你还会在数据科学基础数学中找到另一个示例,在那里你将使用 Sklearn 对音频数据进行 PCA,以根据类别可视化音频样本,然后压缩这些音频样本。
深入分析
理论背景
PCA 的目标是将数据投影到较低维度的空间,同时尽可能保留数据中包含的所有信息。这个问题可以被视为一个垂直最小二乘问题,也称为正交回归。
在这里你会看到,当投影线与数据方差最大的方向相符时,正交投影的误差被最小化。
方差和投影
首先需要理解的是,当你的数据集的特征不完全不相关时,一些方向的方差大于其他方向。
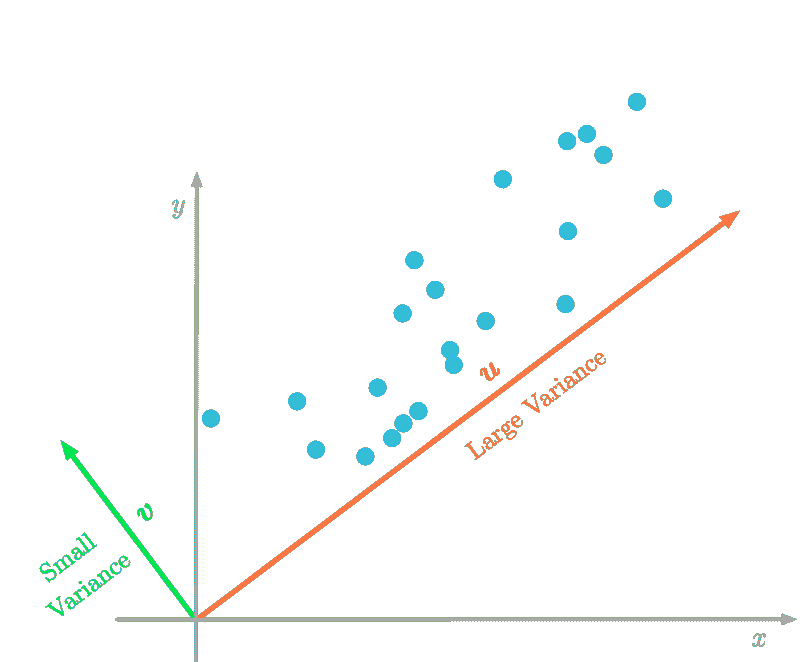 >
>
图 3:在向量(红色)方向上的数据方差大于在向量(绿色)方向上的数据方差。
将数据投影到低维空间意味着你可能会丢失一些信息。在图 3 中,如果将二维数据投影到一条线上的话,投影数据的方差告诉你你丢失了多少信息。例如,如果投影数据的方差接近零,这意味着数据点会被投影到非常接近的位置:你丢失了大量信息。
因此,PCA 的目标是改变数据矩阵的基,使得具有最大方差的方向(图 3 中的)成为第一个主成分。第二个成分是与第一个成分正交的具有最大方差的方向,以此类推。
当你找到 PCA 的组件时,你会改变数据的基,使得这些组件成为新的基向量。这个变换后的数据集具有新的特征,这些特征是组件,它们是初始特征的线性组合。通过仅选择一些组件来减少维度。
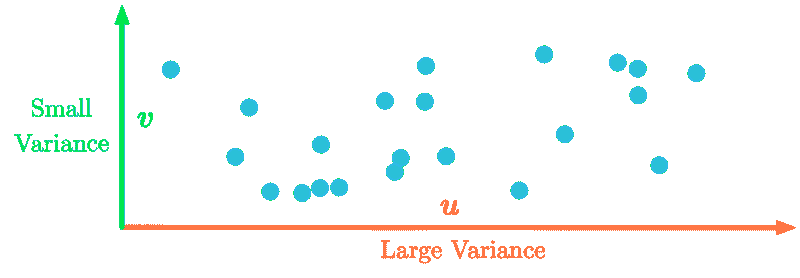
图 4:基变换,使得最大方差位于-轴。
作为说明,图 4 显示了基变换后的数据:最大方差现在与-轴相关。例如,你可以只保留这一维度。
换句话说,将主成分分析(PCA)表达为基变换,其目标是找到一个新的基(该基是初始基的线性组合),使得数据的方差在第一个维度上达到最大。
最小化误差
找到最大化方差的方向类似于最小化数据与其投影之间的误差。
图 5:最大化方差的方向也是与最小误差(用灰色表示)相关的方向。
在图 5 中你可以看到,左图中显示了较低的误差。由于投影是正交的,投影方向上的方差不会影响误差。
寻找最佳方向
在改变数据集的基之后,你应该有一个特征之间的协方差接近零(例如图 4)。换句话说,你希望转换后的数据集具有对角协方差矩阵:每对主成分之间的协方差为零。
你可以在 数据科学的基础数学 第九章中看到,你可以使用特征分解将矩阵对角化(使矩阵变为对角矩阵)。因此,你可以计算数据集的协方差矩阵的特征向量。它们将给你协方差矩阵对角化的新基方向。
总结来说,主成分是计算为数据集协方差矩阵的特征向量。此外,特征值提供了相应特征向量的解释方差。因此,通过根据特征值的降序对特征向量进行排序,你可以按重要性顺序对主成分进行排序,并最终去除与小方差相关的主成分。
计算 PCA
数据集
让我们用 2015 年在巴西圣保罗的啤酒消费和温度数据集来说明 PCA 是如何工作的。
让我们加载数据,并绘制温度作为消费的函数:
data_beer = pd.read_csv("https://raw.githubusercontent.com/hadrienj/essential_math_for_data_science/master/data/beer_dataset.csv")
plt.scatter(data_beer['Temperatura Maxima (C)'],
data_beer['Consumo de cerveja (litros)'],
alpha=0.3)
# [...] Add labels and custom axes
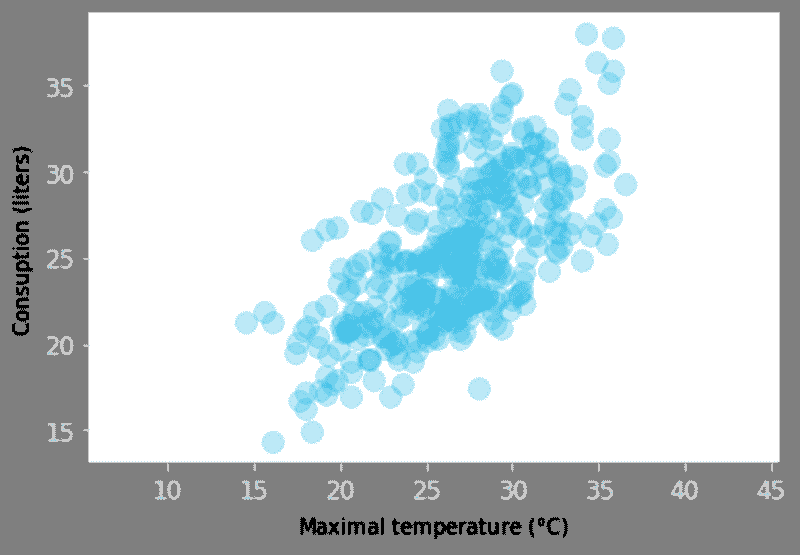
图 6:温度作为啤酒消费的函数。
现在,让我们创建数据矩阵  ,包含两个变量:温度和消费。
,包含两个变量:温度和消费。
X = np.array([data_beer['Temperatura Maxima (C)'],
data_beer['Consumo de cerveja (litros)']]).T
X.shape
(365, 2)
矩阵 有 365 行和两列(这两个变量)。
协方差矩阵的特征分解
如你所见,第一步是计算数据集的协方差矩阵:
C = np.cov(X, rowvar=False)
C
array([[18.63964745, 12.20609082],
[12.20609082, 19.35245652]])
记住,你可以这样理解:对角线值分别是第一个和第二个变量的方差。这两个变量之间的协方差大约为 12.2。
现在,你将计算该协方差矩阵的特征向量和特征值:
eigvals, eigvecs = np.linalg.eig(C)
eigvals, eigvecs
(array([ 6.78475896, 31.20734501]),
array([[-0.71735154, -0.69671139],
[ 0.69671139, -0.71735154]]))
你可以将特征向量存储为两个向量 和 。
u = eigvecs[:, 0].reshape(-1, 1)
v = eigvecs[:, 1].reshape(-1, 1)
让我们用数据绘制特征向量(注意你应该使用中心化的数据,因为它是计算协方差矩阵时使用的数据)。
你可以按对应的特征值缩放特征向量,这些特征值是解释的方差。为了可视化目的,我们使用三个标准差的向量长度(等于三倍的解释方差的平方根):
X_centered = X - X.mean(axis=0)
plt.quiver(0, 0,
2 * np.sqrt(eigvals[0]) * u[0], 2 * np.sqrt(eigvals[0]) * u[1],
color="#919191", angles='xy', scale_units='xy', scale=1,
zorder=2, width=0.011)
plt.quiver(0, 0,
2 * np.sqrt(eigvals[1]) * v[0], 2 * np.sqrt(eigvals[1]) * v[1],
color="#FF8177", angles='xy', scale_units='xy', scale=1,
zorder=2, width=0.011)
plt.scatter(X_centered[:, 0], X_centered[:, 1], alpha=0.3)
# [...] Add axes
图 7:特征向量 (灰色)和 (红色),按解释的方差进行缩放。
在图 7 中,你可以看到协方差矩阵的特征向量为你提供了数据的重要方向。红色的向量 与最大的特征值相关联,因此对应于具有最大方差的方向。灰色的向量 与 正交,是第二主成分。
然后,你只需使用特征向量作为新的基准向量来改变数据的基准。但首先,你可以根据特征值按降序排序特征向量:
sort_index = eigvals.argsort()[::-1]
eigvals_sorted = eigvals[sort_index]
eigvecs_sorted = eigvecs[:, sort_index]
eigvecs_sorted
array([[-0.69671139, -0.71735154],
[-0.71735154, 0.69671139]])
既然你的特征向量已经排序好了,我们来改变数据的基准:
X_transformed = X_centered @ eigvecs_sorted
你可以绘制变换后的数据,以检查主成分现在是否不相关:
plt.scatter(X_transformed[:, 0], X_transformed[:, 1], alpha=0.3)
# [...] Add axes
图 8:新基准下的数据集。
图 8 显示了新基准下的数据样本。你可以看到第一个维度( -轴)对应于具有最大方差的方向。
你可以在这个新基准下只保留数据的第一个主成分,而不会丢失太多信息。
协方差矩阵还是奇异值分解?
使用协方差矩阵计算 PCA 的一个警告是,当特征较多时(如在本动手操作的第二部分中的音频数据),计算可能会很困难。因此,通常更倾向于使用奇异值分解(SVD)来计算 PCA。
Hadrien Jean 是一位机器学习科学家。他拥有巴黎高等师范学院的认知科学博士学位,在那里他使用行为和电生理数据进行听觉感知研究。他曾在工业界工作,建立了用于语音处理的深度学习管道。在数据科学与环境交汇处,他从事关于生物多样性评估的项目,利用应用于音频录音的深度学习。他还定期在 Le Wagon(数据科学训练营)创建内容并教授课程,并在他的博客上撰写文章(hadrienj.github.io)。
原文。经许可转载。
更多相关话题
数据科学的基础数学:信息理论
原文:
www.kdnuggets.com/2021/01/essential-math-data-science-information-theory.html
评论
信息理论领域研究信号中信息的量化。在机器学习的背景下,这些概念用于表征或比较概率分布。量化信息的能力也被用于决策树算法中,以选择与最大信息增益相关的变量。熵和交叉熵的概念在机器学习中也很重要,因为它们导致了分类任务中广泛使用的损失函数:交叉熵损失或对数损失。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
香农信息
直觉
理解信息理论的第一步是考虑与随机变量相关的信息量。在信息理论中,这一信息量表示为 II,并称为香农信息、信息内容、自信息或惊讶度。主要思想是,可能发生的事件传达的信息比不太可能发生的事件少(因此这些事件更令人惊讶)。例如,如果来自洛杉矶的朋友告诉你:“今天晴天”,这比她告诉你:“今天下雨”信息量少。因此,将香农信息视为与结果相关的惊讶量可能会有所帮助。在本节中,你也将看到为什么它也是一种信息量,以及为什么可能发生的事件信息量较少。
信息单位
量化信息的常见单位是nat和bit。这些量基于对数函数。nat是“信息的自然单位”的缩写,基于自然对数,而 bit 是“二进制数字”的缩写,基于二进制对数。因此,bit 是 nat 的一个重新标定版本。接下来的部分将主要使用 bit 和二进制对数进行公式计算,但用自然对数替换只会将单位从 bits 改为 nats。
比特表示可以有两种不同状态(0 或 1)的变量。例如,1 比特用于编码一次掷硬币的结果。如果你掷两次硬币,你至少需要两个比特来编码结果。例如,00 代表 HH,01 代表 HT,10 代表 TH,11 代表 TT。你可以使用其他编码,比如 0 代表 HH,100 代表 HT,101 代表 TH,111 代表 TT。然而,这种编码在平均情况下使用的比特数量更多(假设四种事件的概率分布是均匀的,正如你将看到的)。
让我们举个例子来看一下一个比特描述了什么。Erica 发送给你一个消息,包含三次硬币掷出的结果,用 0 编码“正面”,用 1 编码“反面”。共有 8 种可能的序列,例如 001、101 等。当你收到一个比特的消息时,它将你的不确定性减少了一半。例如,如果第一个比特告诉你第一次掷硬币是“正面”,那么剩下的可能序列是 000、001、010 和 011。这样,可能的序列只有 4 种,而不是 8 种。同样,收到两个比特的消息将把你的不确定性减少到 4;收到三个比特的消息,将把不确定性减少到 8,依此类推。
请注意,我们谈论的是“有用的信息”,但可能消息是冗余的,并且在相同的比特数下传达的信息更少。
示例
假设我们想传输一系列八次投掷的结果。你将为每次投掷分配一个比特。因此,你需要八个比特来编码这个序列。这个序列可能是“00110110”,对应于 HHTTHTTH(四个“正面”和四个“反面”)。
然而,假设这个硬币是偏置的:得到“反面”的概率只有 1/8。你可以找到一种更好的方式来编码这个序列。一种选择是编码“反面”结果的索引:这将需要多个比特,但“反面”仅在少数试验中出现。通过这种策略,你可以将更多比特分配给稀有结果。
这个例子说明了更可预测的信息可以被压缩:一个偏置的硬币序列可以用比公平硬币序列更少的信息进行编码。这意味着香农信息依赖于事件的概率。
数学描述
香农信息编码了这个想法,并将事件发生的概率转化为相关的信息量。它的特点是,如你所见,可能事件的资讯少于不可能事件的信息,并且不同事件的信息是可加性的(如果事件是独立的)。
从数学角度来看,函数I(x) 是事件 X=x 的信息,它以结果作为输入,返回信息的数量。它是概率的单调递减函数(即,当概率增加时,函数值从不增加)。香农信息可以描述为:
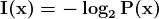
结果是比特数量的下限,也就是编码一个序列所需的最小比特数,以达到最佳编码。
乘积的对数等于各个元素的和: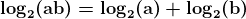 。这个性质对编码香农信息的加法性质很有用。两个事件的发生概率是它们各自概率的乘积(因为它们是独立的,正如你在数据科学的基本数学中看到的):
。这个性质对编码香农信息的加法性质很有用。两个事件的发生概率是它们各自概率的乘积(因为它们是独立的,正如你在数据科学的基本数学中看到的):
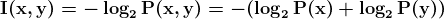
这意味着与两个事件发生概率P(x,y)相关的信息量等于与P(x)相关的信息量加上与P(y)相关的信息量。独立事件的信息量是相加的。
让我们绘制这个函数在概率范围从 0 到 1 内的曲线,以查看曲线的形状:
plt.plot(np.arange(0.01, 1, 0.01), -np.log2(np.arange(0.01, 1, 0.01)))
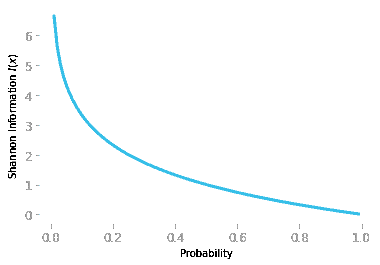
图 1:信息量由概率的负对数给出。
如图 1 所示,负对数函数编码了一个非常不可能事件(概率接近 0)与大量信息量相关,而一个可能事件(概率接近 1)与接近 0 的信息量相关的观点。
由于你使用了底为二的对数np.log2(),信息量I(x)以比特为单位进行测量。
熵
你已经看到香农信息给出了与单个概率相关的信息量。你也可以用香农熵,也称为信息熵,或者简单地叫做熵,来计算离散分布的信息量。
示例
比如考虑一个偏向的硬币,其中正面朝上的概率为 0.8。
-
这是你的分布:你有 0.8 的概率得到‘正面’,以及1 − 0.8 = 0.2的概率得到‘反面’。
-
这些概率分别与香农信息量相关:
和
- 正面朝上与大约 0.32 的信息量相关,反面朝上与 2.32 的信息量相关。然而,你不会在平均情况下有相同数量的正面和反面,所以你必须用每个概率的概率本身来加权香农信息。例如,如果你想传递一个包含 100 次试验结果的消息,你将需要大约 20 倍的反面信息量和 80 倍的正面信息量。你会得到:
和
- 这些表达式的总和给你:
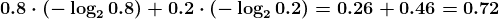
描述这一分布的一系列事件所需的平均比特数是 0.72 比特。
总结来说,你可以把熵看作是与离散分布的概率相关的信息的总结:
-
你计算了分布中每个概率的香农信息。
-
你用相应的概率加权香农信息。
-
你对加权结果进行求和。
数学公式
熵是相对于概率分布的信息的期望。请记住,从数据科学的基础数学中你了解到,期望是你从分布中抽取大量样本时得到的均值:
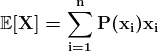
随机变量X具有n个可能的结果,x[i]是第i个可能的结果,对应的概率为P(x[i])。分布的信息的期望值对应于你将获得的信息的平均值。
按照期望和香农信息的公式,随机变量X的熵定义为:
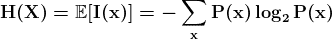
熵给你提供了编码随机变量X状态所需的平均信息量。
注意,函数H(X)的输入是随机变量X,而I(x)表示事件X=x的香农信息。你也可以参考随机变量X的熵,它是相对于P(x)分布的,记作H(P)。
示意图
让我们举个例子:如图 2 底部面板所示,你有一个具有四个可能结果的离散分布,概率分别为 0.4、0.4、0.1 和 0.1。正如你之前看到的,信息是通过对概率进行对数变换得到的(顶部面板)。这是熵公式的最后一部分:log2P(x)。
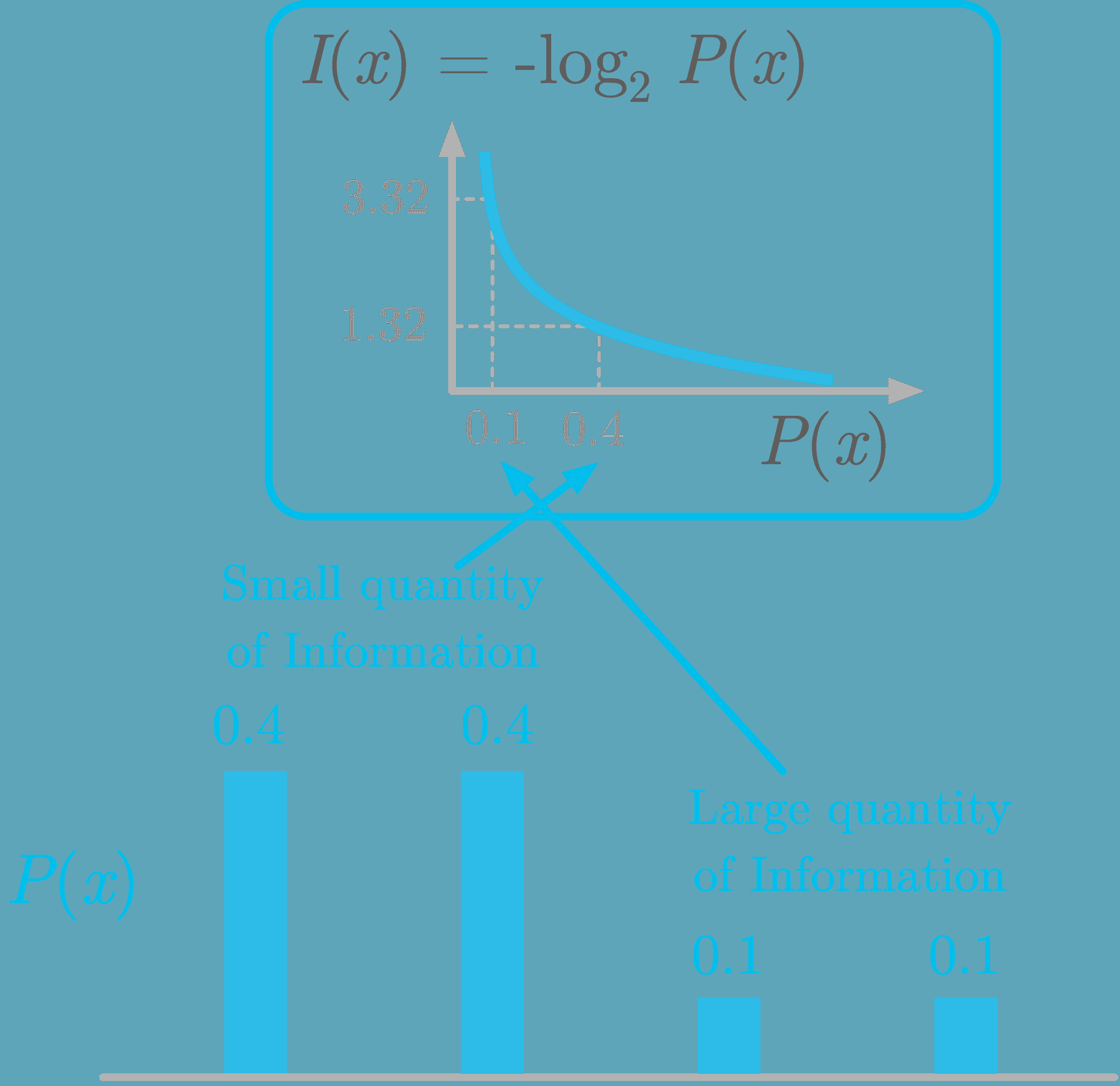
图 2:作为香农信息加权和的熵示意图。
每个经过变换的概率都按相应的原始概率加权。如果一个结果发生得很频繁,它将对分布的熵产生更大的影响。这意味着低概率(如图 2 中的 0.1)提供了大量的信息(3.32 比特),但对最终结果的影响较小。较大概率(如图 2 中的 0.4)则关联的信息较少(如图 2 所示的 1.32 比特),但加权更多。
二进熵函数
在一个有偏硬币的例子中,你计算了伯努利过程的熵(有关伯努利分布的更多细节请参见数据科学的基础数学)。在这种特殊情况下,熵被称为二进熵函数。
为了描述二进制熵函数,你将计算由各种概率分布(从严重偏向“反面”到严重偏向“正面”)描述的偏置硬币的熵。
让我们首先创建一个函数,计算一个分布的熵,该函数接受一个包含概率的数组作为输入并返回相应的熵:
def entropy(P):
return - np.sum(P * np.log2(P))
你也可以使用scipy.stats中的entropy(),在这里你可以指定用于计算熵的对数的底数。这里,我使用了以 2 为底的对数。
以公平硬币为例,其“正面”落地的概率为 0.5。分布因此是 0.5 和 1 − 0.5 = 0.5。我们使用刚刚定义的函数来计算相应的熵:
p = 0.5
entropy(np.array([p, 1 - p]))
1.0
该函数计算了P * np.log2(P)在你用作输入的数组的每个元素上的总和。如前一节所示,你可以期望偏置硬币的熵更低。让我们绘制不同硬币偏置的熵,从只落“反面”的硬币到只落“正面”的硬币:
x_axis = np.arange(0.01, 1, 0.01)
entropy_all = []
for p in x_axis:
entropy_all.append(entropy([p, 1 - p]))
# [...] plots the entropy
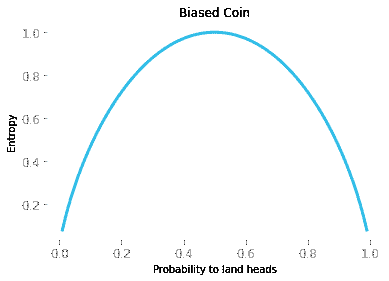
图 3:熵作为“正面”概率的函数。
图 3 显示了熵如何随着条件的不确定性增加而增加:也就是说,当“正面”落地的概率等于“反面”落地的概率时。
差分熵
连续分布的熵称为差分熵。它是离散分布熵的扩展,但不满足相同的要求。问题在于,连续分布中的值的概率趋向于零,而编码这些值需要的位数趋向于无穷大。
定义如下:
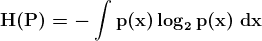
差分熵可能为负值。原因是,如你在数据科学的基础数学中所见,连续分布不是概率而是概率密度,这意味着它们不满足概率的要求。例如,它们不被限制在 1 以下。这导致p(x)可以取大于 1 的正值,而log2p(x)可以取正值(由于负号,结果变为负值)。
交叉熵
熵的概念可以用来比较两个概率分布:这称为两个分布之间的交叉熵,它测量了它们之间的差异。
这个想法是计算与分布Q(x)的概率相关的信息,但与熵不同的是,你不是根据Q(x)加权,而是根据另一个分布P(x)加权。注意,你比较的是关于相同随机变量X的两个分布。
你还可以将交叉熵视为从P(x)中绘制事件时使用Q(x)对其进行编码的期望信息量。
这在数学上表示为:
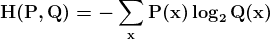
让我们看看它是如何工作的。
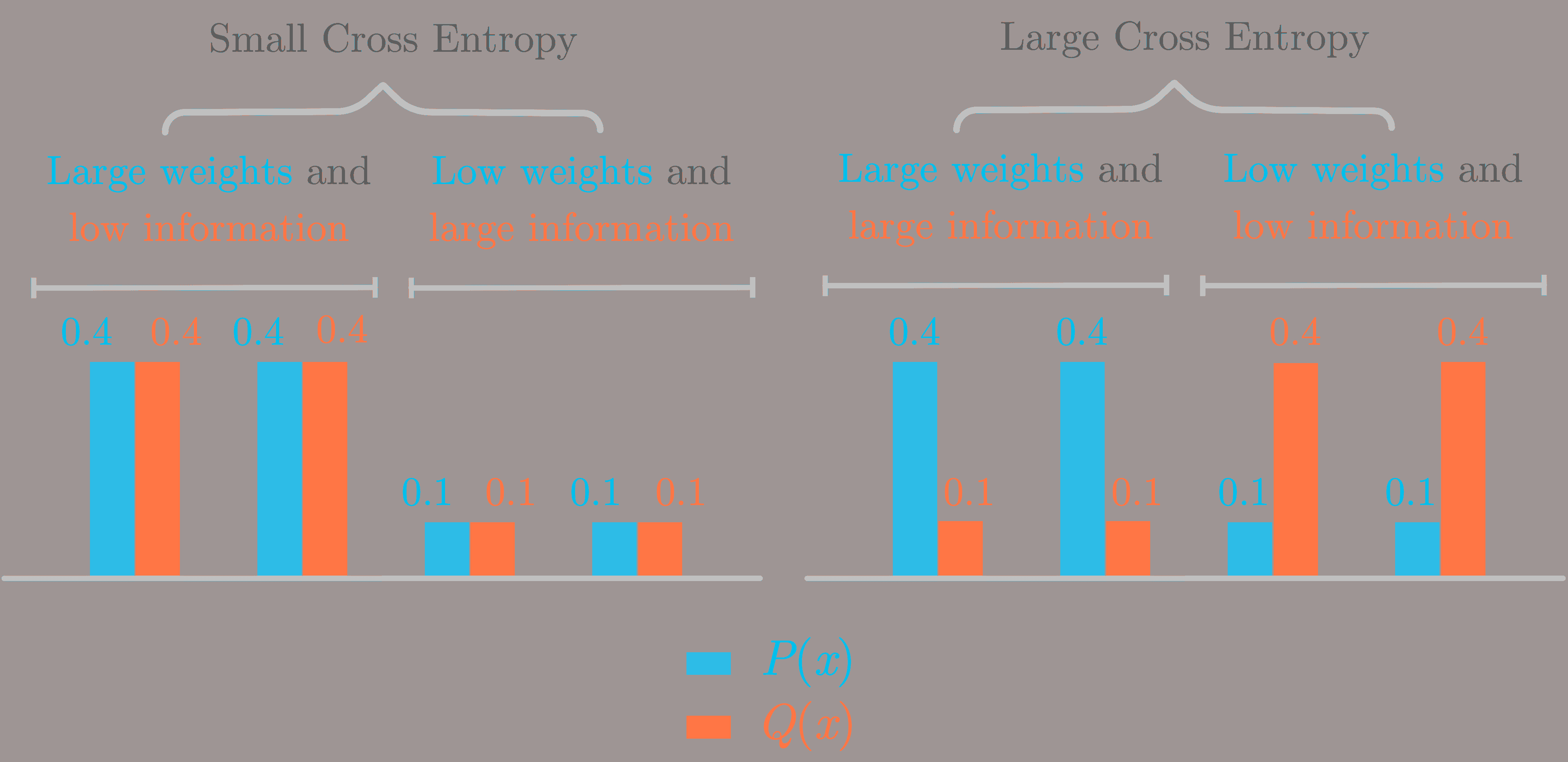
图 4:交叉熵作为 Q(x) 的香农信息,根据 P(x) 的分布加权。
图 4 显示了两种不同的情况以说明交叉熵。在左侧,你有两个相同的分布 P(x) (蓝色)和 Q(x) (红色)。它们的交叉熵等于熵,因为 Q(x) 的信息是根据 P(x) 的分布加权的,而 P(x) 与 Q(x) 相似。
然而,在右侧面板中,P(x) 和 Q(x) 是不同的。这导致了较大的交叉熵,因为与大量信息相关的概率权重较小,而与少量信息相关的概率权重较大。
交叉熵不能小于熵。仍在右侧面板中,你可以看到,当概率 Q(x) 大于 P(x) (因此与较少的信息量相关)时,它会被低权重抵消(导致低权重和低信息)。这些低权重会在分布的其他概率中被较大权重补偿(导致大权重和大量信息)。
还要注意,两个分布 P(x) 和 Q(x) 必须具有相同的 支持 (即随机变量可以取的值的集合,并且这些值具有正概率)。
总结来说,当分布相同时,交叉熵最小。如你在 0.1.4 中看到的,这一特性使得交叉熵成为一个有用的度量。还要注意,根据你选择的参考分布,结果是不同的:H(P,Q) ≠ H(Q,P)。
交叉熵作为损失函数
在机器学习中,交叉熵作为一种损失函数称为 交叉熵损失 (也称为 对数损失 或 逻辑损失,因为它在逻辑回归中使用)。
图 5:交叉熵可用于比较真实分布(正确类别的概率为 1,否则为 0)与模型估计的分布。
假设你想建立一个模型,该模型可以根据音频样本分类三种不同的鸟类。如图 5 所示,音频样本被转换为特征(这里是频谱图),而可能的类别(这三种不同的鸟类)被 独热编码,即正确类别编码为 1,否则为 0。此外,机器学习模型会为每个类别输出概率。
要学习如何对鸟类进行分类,模型需要比较估计分布 Q(x)(由模型给出)和真实分布 P(x)。交叉熵损失被计算为 P(x) 和 Q(x) 之间的交叉熵。
图 5 显示了你在此示例中考虑的样本对应的真实类别是“欧洲绿啄木鸟”。模型输出一个概率分布,你将计算与此估计相关的交叉熵损失。图 6 显示了两个分布。
图 6:真实分布 P(x) 和估计分布 Q(x) 的比较。
让我们手动计算这两个分布之间的交叉熵:
在交叉熵损失中使用的是自然对数而不是以二为底的对数,但原理是相同的。此外,请注意使用 H(P,Q) 而不是 H(Q,P),因为参考的是分布 P。
由于你进行了独热编码(1 表示真实类别,其他情况为 0),交叉熵就是对真实类别的估计概率的负对数。
二分类:对数损失
在机器学习中,交叉熵被广泛用作二分类的损失函数:对数损失。
由于分类是二元的,唯一可能的结果是 y(真实标签对应于第一类)和 1−y(真实标签对应于第二类)。同样,你有第一类的估计概率 y^ 和第二类的估计概率 1−y^。
从交叉熵的公式来看,∑x 在这里对应于两个可能结果的总和(y 和 1−y)。你有:
这就是对数损失的公式。
Kullback-Leibler 散度(KL 散度)
你看到交叉熵是一个依赖于两个分布相似度的值,交叉熵值较小对应于完全相同的分布。你可以利用这一特性来计算两个分布之间的 散度:你比较它们的交叉熵与分布完全相同的情况。这种散度称为 Kullback-Leibler 散度(或简称 KL 散度),或者 相对熵。
直观地说,KL 散度是与分布 Q(x) 编码相关的补充信息量,相对于真实分布 P(x)。它告诉你这两个分布有多么不同。
从数学上讲,两个分布 P(x) 和 Q(x) 之间的 KL 散度,记作 DKL(P||Q),表示为 P(x) 和 Q(x) 的交叉熵与 P(x) 的熵之间的差值:
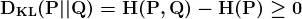
用交叉熵和熵的表达式替换,你得到:
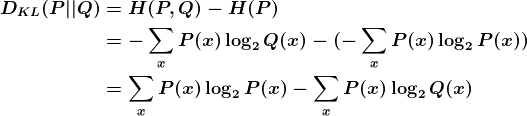
KL 散度总是非负的。由于熵 H(P) 与交叉熵 H(P,P) 相同,并且最小的交叉熵发生在相同的分布之间 (H(P,P)H(P,P)),所以 H(P,Q) 必然大于 H(P)。此外,当两个分布相同时,KL 散度等于零。
然而,交叉熵不是对称的。将分布 P(x) 与分布 Q(x) 进行比较可能与将分布 Q(x) 与 P(x) 进行比较不同——这意味着你不能将 KL 散度视为距离。
简介: Hadrien Jean 是一名机器学习科学家。他拥有巴黎高等师范学院的认知科学博士学位,在那里他使用行为学和电生理数据研究听觉感知。他曾在工业界工作,构建了用于语音处理的深度学习管道。在数据科学和环境交汇的领域,他从事使用深度学习对音频录音进行生物多样性评估的项目。他还定期在 Le Wagon(数据科学训练营)创建内容和授课,并在他的博客中撰写文章 (hadrienj.github.io)。
原文。经许可转载。
相关:
-
数据科学中的基本数学: 泊松分布
-
数据科学中的基本数学: 概率密度和概率质量函数
-
数据科学中的基本数学: 积分和曲线下的面积
更多相关话题
数据科学中的基础数学:积分与曲线下的面积
原文:
www.kdnuggets.com/2020/11/essential-math-data-science-integrals-area-under-curve.html
评论
微积分是数学的一个分支,提供了研究函数变化率的工具,通过两个主要领域:导数和积分。在机器学习和数据科学的背景下,你可能会使用积分来计算曲线下的面积(例如,用于评估模型的性能与 ROC 曲线,或从密度中计算概率)。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
在这篇文章中,你将通过使用 ROC 曲线下的面积这一实际数据科学示例来学习积分和曲线下的面积。以此示例为基础,你将从数学角度了解曲线下的面积和积分(参考我的书《数据科学中的基础数学》)。
实践项目
假设你想根据红酒的各种化学属性预测其质量。你希望对质量进行二分类(区分非常好的酒和不是很好的酒)。你将开发方法来评估考虑到不平衡数据的模型,利用接收者操作特征(ROC)曲线下的面积。
数据集
为此,我们将使用一个数据集,展示红酒的各种化学性质及其质量评分。数据集来源于此:https://archive.ics.uci.edu/ml/datasets/wine+quality。相关论文为 Cortez, Paulo, et al. ”通过从物理化学性质中挖掘数据建模酒类偏好。” Decision Support Systems 47.4 (2009): 547-553。
图 1:酒质建模的示意图。
如图 1 所示,数据集表示了酒的化学分析(特征)和质量评分。这个评分是目标:这是你将尝试估计的内容。
首先,让我们加载数据并查看特征:
wine_quality = pd.read_csv("https://raw.githubusercontent.com/hadrienj/essential_math_for_data_science/master/data/winequality-red.csv",
sep=";")
wine_quality.columns
Index(['fixed acidity', 'volatile acidity', 'citric acid', 'residual sugar',
'chlorides', 'free sulfur dioxide', 'total sulfur dioxide', 'density',
'pH', 'sulphates', 'alcohol', 'quality'],
dtype='object')
最后一列quality很重要,因为你将把它作为分类的目标。质量通过从 3 到 8 的评级来描述:
wine_quality["quality"].unique()
array([5, 6, 7, 4, 8, 3])
由于目标是对非常好的红酒进行分类,让我们决定当评分为 7 或 8 时葡萄酒是非常好的,否则不是非常好。
让我们创建一个数据集,其中y为质量(因变量,评分低于 7 为 0,评分大于或等于 7 为 1),X包含所有其他特征。
X = wine_quality.drop("quality", axis=1).values
y = wine_quality["quality"] >= 7
在查看数据之前,首先要做的事情是将数据分为训练集(用于训练算法)和测试集(用于测试算法)。这将允许你评估模型在训练过程中未见过的数据上的表现。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=13)
预处理
首先,让我们对数据进行标准化,以帮助算法的收敛。你可以使用 Sklearn 中的StandardScaler类。
请注意,你不想考虑测试集的数据来进行标准化。方法fit_transform()计算标准化所需的参数并同时应用它。然后,你可以将相同的标准化应用于测试集,而无需再次拟合。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_stand = scaler.fit_transform(X_train)
X_test_stand = scaler.transform(X_test)
第一个模型
作为第一个模型,让我们在训练集上训练一个逻辑回归模型,并计算测试集上的分类准确率(正确分类的百分比):
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
log_reg = LogisticRegression(random_state=123, penalty="none")
log_reg.fit(X_train_stand, y_train)
y_pred = log_reg.predict(X_test_stand)
accuracy_score(y_test, y_pred)
0.8729166666666667
准确率约为 0.87,这意味着 87%的测试样本被正确分类。你应该对这个结果感到满意吗?
不平衡数据集的指标
不平衡数据集
由于我们将数据分为非常好的葡萄酒和不太好的葡萄酒,数据集是不平衡的:每个目标类别的数据量不同。
让我们检查一下负类(不太好的葡萄酒)和正类(非常好的葡萄酒)的观察数量:
(y_train == 0).sum() / y_train.shape[0]
0.8650580875781948
(y_train == 1).sum() / y_train.shape[0]
0.13494191242180517
这表明大约有 86.5%的样本对应于类别 0,13.5%对应于类别 1。
简单模型
为了说明关于准确率和不平衡数据集的这一点,让我们创建一个基线模型并查看其性能。这将帮助你看到使用其他指标而非准确率的优点。
一个非常简单的模型利用数据集不平衡的事实,会总是估计具有最多观察数量的类别。在你的案例中,这样的模型总是会估计所有葡萄酒都很差,并且得到不错的准确率。
让我们通过创建低于 0.5 的随机概率来模拟这个模型(例如,0.15 的概率表示类别为正的机会是 15%)。我们需要这些概率来计算准确率和其他指标。
np.random.seed(1)
y_pred_random_proba = np.random.uniform(0, 0.5, y_test.shape[0])
y_pred_random_proba
array([2.08511002e-01, 3.60162247e-01, 5.71874087e-05, ...,
4.45509477e-01, 1.36436118e-02, 2.61025624e-01])
假设如果概率高于 0.5,则类别被估计为正:
def binarize(y_hat, threshold):
return (y_hat > threshold).astype(int)
y_pred_random = binarize(y_pred_random_proba, threshold=0.5)
y_pred_random
array([0, 0, 0, ..., 0, 0, 0])
变量y_pred_random仅包含零。让我们评估这个随机模型的准确性:
accuracy_score(y_test, y_pred_random)
0.8625
这表明,即使使用随机模型,准确度也并不差:这并不意味着模型很好。
总结来说,拥有不同数量的每个类别的观察样本时,你不能仅依靠准确度来评估模型的性能。在我们的例子中,模型可能只输出零,你会得到大约 86%的准确度。
你需要其他指标来评估在不平衡数据集上的模型性能。
ROC 曲线
准确度的一个很好的替代指标是接收者操作特征(ROC)曲线。你可以查看 Aurélien Géron 对 ROC 曲线的非常好的解释,详见 Géron, Aurélien. Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow: Concepts, tools, and techniques to build intelligent systems. O’Reilly Media, 2019。
主要思想是将模型的估计结果分成四类:
-
真正类(TP):预测为 1 且真实类别为 1。
-
假阳性(FP):预测为 1 但真实类别为 0。
-
真负类(TN):预测为 0 且真实类别为 0。
-
假负类(FN):预测为 0 但真实类别为 1。
让我们计算一下你第一个逻辑回归模型的这些值。你可以使用 Sklearn 中的函数confusion_matrix。它呈现的表格组织如下:
图 2:混淆矩阵的示意图。
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_pred_random)
array([[414, 0],
[ 66, 0]])
你可以看到,在随机模型下,没有正类观察被正确分类(TP)。
决策阈值
在分类任务中,你需要估计数据样本的类别。对于像逻辑回归这样的模型,它输出的是 0 到 1 之间的概率,你需要使用决策阈值或简称阈值将这个分数转换为类别 0 或 1。超过阈值的概率被视为正类。例如,使用默认的决策阈值 0.5 时,当模型输出的分数超过 0.5 时,你认为估计类别是 1。
然而,你可以选择其他阈值,你用来评估模型性能的指标将取决于这个阈值。
使用 ROC 曲线,你会考虑 0 到 1 之间的多个阈值,并计算每个阈值下的真正率与假阳性率的关系。
你可以使用 Sklearn 中的函数roc_curve来计算假阳性率(fpr)和真正率(tpr)。该函数还输出相应的阈值。让我们用我们模拟的随机模型尝试一下,其中输出值仅在 0.5 以下(y_pred_random_proba)。
from sklearn.metrics import roc_curve
fpr_random, tpr_random, thresholds_random = roc_curve(y_test, y_pred_random_proba)
让我们来看一下输出结果:
fpr_random
array([0\. , 0\. , 0.07246377, ..., 0.96859903, 0.96859903,
1\. ])
tpr_random
array([0\. , 0.01515152, 0.01515152, ..., 0.98484848, 1\. ,
1\. ])
thresholds_random
array([1.49866143e+00, 4.98661425e-01, 4.69443239e-01, ...,
9.68347894e-03, 9.32364469e-03, 5.71874087e-05])
现在,你可以根据这些值绘制 ROC 曲线:
plt.plot(fpr_random, tpr_random)
# [...] Add axes, labels etc.
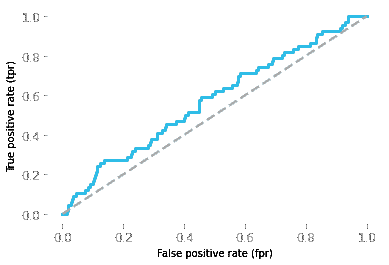
图 3:对应于随机模型的 ROC 曲线。
图 3 显示了对应于随机模型的 ROC 曲线。它给出了每个阈值下真正正例率作为假阳性率的函数。
但是,请注意,阈值范围从 1 到 0。例如,左下角的点对应于阈值为 1:此时没有真正的正例和假阳性,因为概率不可能超过 1,因此在阈值为 1 的情况下,没有观测值可以被分类为正例。在右上角,阈值为 0,因此所有观测值都被归类为正例,导致真正的正例和假阳性都达到 100%。
ROC 曲线接近对角线意味着模型不比随机模型好,这就是这里的情况。一个完美的模型应该与一个 ROC 曲线相关联,该曲线在所有假阳性率的值下的真正正例率为 1。
现在让我们来看一下你之前训练的逻辑回归模型对应的 ROC 曲线。你需要模型的概率,这可以通过使用predict_proba()而不是predict来获取:
y_pred_proba = log_reg.predict_proba(X_test_stand)
y_pred_proba
array([[0.50649705, 0.49350295],
[0.94461852, 0.05538148],
[0.97427601, 0.02572399],
...,
[0.82742897, 0.17257103],
[0.48688505, 0.51311495],
[0.8809794 , 0.1190206 ]])
第一列是类别 0 的分数,第二列是类别 1 的分数(因此每行的总和为 1),所以你可以只保留第二列。
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba[:, 1])
plt.plot(fpr, tpr)
# [...] Add axes, labels etc.
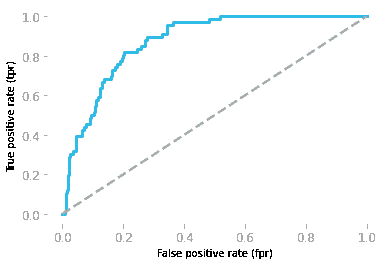
图 4:对应于逻辑模型的 ROC 曲线。
你可以在图 4 中看到你的模型实际上比随机模型要好,这不是你从模型准确率中能够得出的结论(它们是等效的:随机模型约为 0.86,你的模型约为 0.87)。
视觉检查是好的,但拥有一个单一的数值指标来比较你的模型也至关重要。这通常由 ROC 曲线下的面积提供。你将在接下来的章节中看到曲线下的面积是什么以及如何计算。
积分
积分是微分的逆操作。取一个函数f(x)并计算其导数f′(x),不定积分(也称为反导数)的f′(x)会恢复f(x)(除了一个常数,如你将很快看到的那样)。
你可以使用积分来计算曲线下的面积,这就是由函数限定的形状的面积,如图 5 所示。
图 5:曲线下的面积。
定积分是特定区间上的积分。它对应于该区间内的曲线下的面积。
示例
通过这个示例,你将了解函数的积分与曲线下的面积之间的关系。为了说明这个过程,你将使用曲线下的面积的离散化来近似函数g(x)=2x的积分。
示例描述
再次以移动火车为例。你看到速度作为时间的函数是距离作为时间的函数的导数。这些函数在图 6 中表示。
图 6:左侧面板显示f(x),它是时间函数的距离,右侧面板显示其导数g(x),它是时间函数的速度。
图 6 左侧面板中显示的函数定义为f(x)=x²。它的导数定义为g(x)=2x。
在这个例子中,你将学习如何找到g(x)曲线下方区域的近似值。
函数切片
要近似一个形状的面积,你可以使用切片方法:将形状切成小的矩形,计算这些矩形的面积并求和。
你将完全按照这种方法来找到g(x)曲线下方区域的近似值。
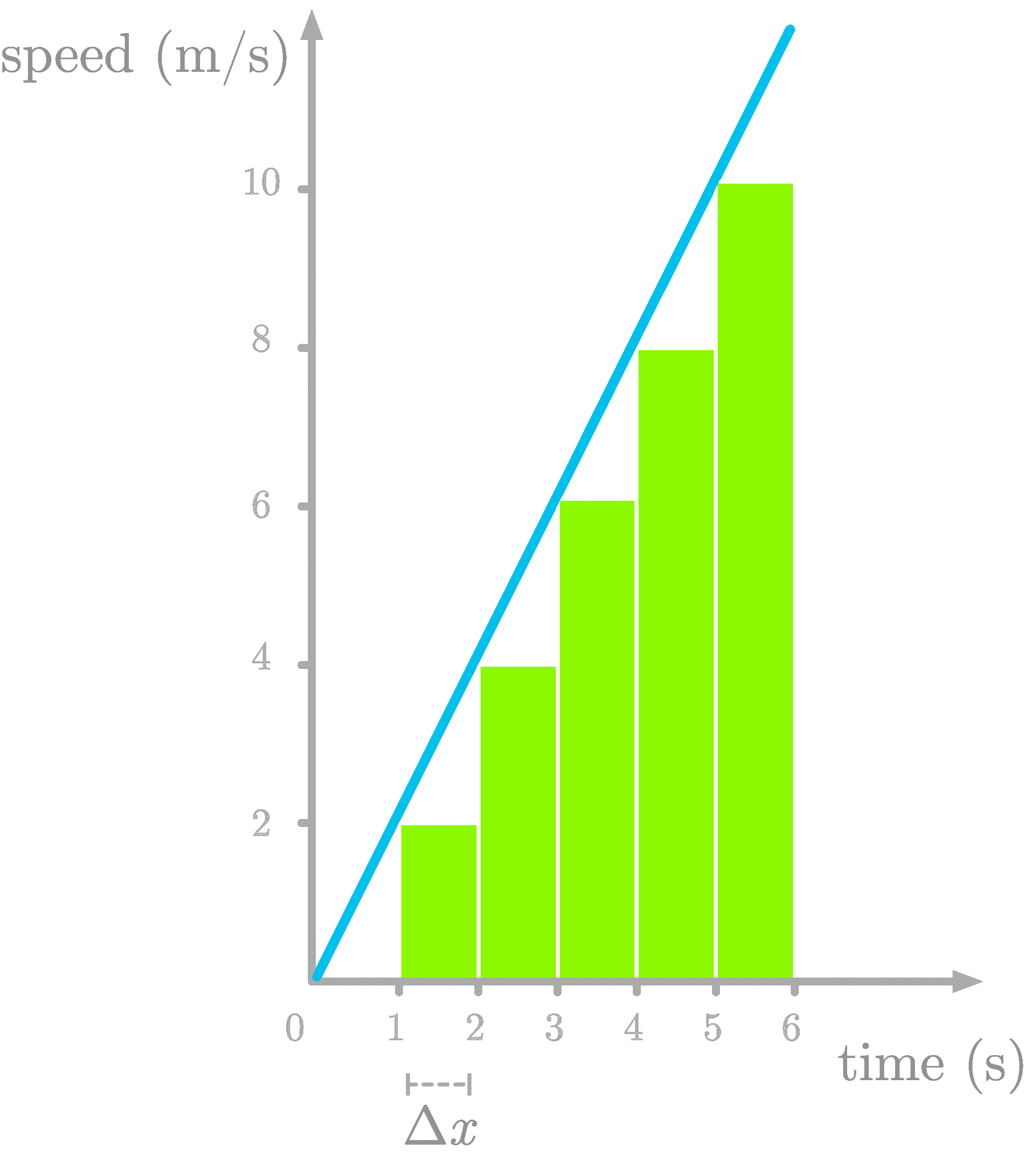
图 7:通过将速度曲线下方的区域离散化来近似曲线下方的面积。
图 7 显示了f′(x)曲线下方的区域被切成了一秒的矩形(我们称这种差异为Δx)。请注意,我们低估了该区域(查看缺失的三角形),但我们稍后会修正这个问题。
让我们尝试理解切片的含义。以第一个切片为例:它的面积定义为 2⋅12⋅1。切片的高度是一个秒钟内的速度(值为 2)。因此,第一个切片在单位时间内有两个速度单位。面积对应于速度和时间的乘积:这就是距离。
例如,如果你以每小时 50 英里的速度行驶两小时(时间),你 traveled 50⋅2=100 miles(距离)。这是因为速度的单位对应于距离和时间之间的比率(如每小时英里)。你可以得到:
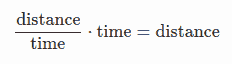
总结来说,距离对时间函数的导数是速度对时间函数,而速度对时间函数的曲线下方的面积(它的积分)给你一个距离。这就是导数和积分之间的关系。
实现
让我们使用切片来近似g(x)=2x的积分。首先,让我们定义函数g(x):
def g_2x(x):
return 2 * x
如图 7 所示,你将考虑函数是离散的,并取步长为Δx=1。你可以创建一个值从零到六的x轴,并对每一个这些值应用函数g_2x()。你可以使用 Numpy 方法arange(start, stop, step)来创建一个包含从start到stop(不包括)的值的数组:
delta_x = 1
x = np.arange(0, 7, delta_x)
x
array([0, 1, 2, 3, 4, 5, 6])
y = g_2x(x)
y
array([ 0, 2, 4, 6, 8, 10, 12])
然后你可以通过迭代计算切片的面积,将宽度(Δx)乘以高度(该点的y值)。如你所见,这个面积(delta_x * y[i-1]在下面的代码中)对应于距离(移动列车在第i个切片中行驶的距离)。最后,你可以将结果附加到一个数组中(slice_area_all在下面的代码中)。
请注意,y的索引是i-1,因为矩形在我们估计的x值的左侧。例如,x=0和x=1的面积为零。
slice_area_all = np.zeros(y.shape[0])
for i in range(1, len(x)):
slice_area_all[i] = delta_x * y[i-1]
slice_area_all
array([ 0., 0., 2., 4., 6., 8., 10.])
这些值是切片的面积。
要计算从开始到相应时间点的行驶距离(而不是每个切片),可以使用 Numpy 函数cumsum()计算slice_area_all的累积和:
slice_area_all = slice_area_all.cumsum()
slice_area_all
array([ 0., 0., 2., 6., 12., 20., 30.])
这是【g(x)】 在【x】上的曲线下的面积的估计值。我们知道函数【g(x)】 是f(x)=x² 的导数,因此我们应该通过对g(x)的积分得到f(x)。
让我们绘制我们的估计和f(x),我们称之为“真实函数”,以进行比较:
plt.plot(x, x ** 2, label='True')
plt.plot(x, slice_area_all, label='Estimated')
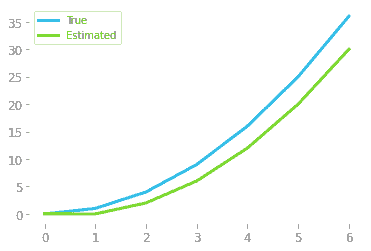
图 8:估计函数与原始函数的比较。
图 8 中所示的估计结果表明估计值还不错,但可以改进。这是因为我们遗漏了图中红色表示的所有这些三角形。
- 减少误差的一种方法是取更小的Δx值,如图 9 右侧面板所示。
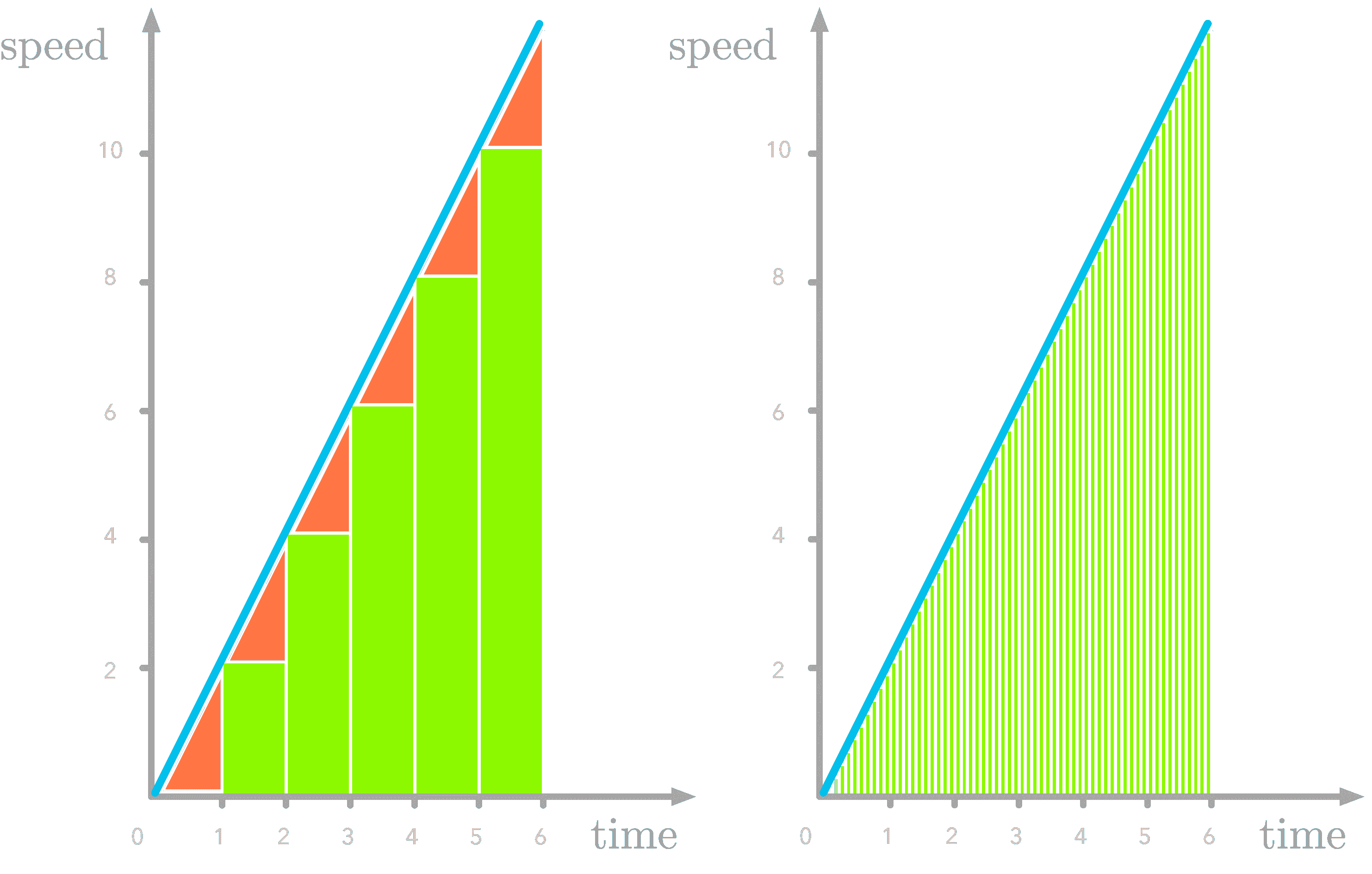
图 9:速度函数切片中的缺失部分(红色标记)。误差随着Δx的减小而变小。
让我们用Δx=0.1来估计积分函数:
delta_x = 0.1
x = np.arange(0, 7, delta_x)
y = g_2x(x)
# [...] Calculate and plot slice_area_all
图 10:较小的切片宽度导致对原始函数的更好估计。
如图 10 所示,我们恢复了(至少,加上一个常数)我们积分的原始函数。
扩展
在我们之前的例子中,你对函数2x进行了积分,这是一个线性函数,但对任何连续函数原则是相同的(例如,见图 11)。
图 11:切片方法可以用于许多线性或非线性函数,包括所有连续函数。
黎曼和
使用这种切片方法来近似积分被称为黎曼和。黎曼和可以通过不同的方式计算,如图 12 所示。
图 12:四种用于积分逼近的黎曼和。
如图 12 所示,左侧黎曼和中,曲线与矩形的左角对齐;右侧黎曼和中,曲线与矩形的右角对齐;中点规则中,曲线与矩形的中心对齐;梯形规则中,使用梯形代替矩形,曲线穿过梯形的两个上角。
数学定义
在上一节中,你看到了曲线下的面积与积分之间的关系(你通过导数恢复了原始函数)。现在我们来看一下积分的数学定义。
函数f(x) 相对于x 的积分表示为:
∫f(x)dx
符号dx称为x的differential,指的是x的一个微小变化。它是接近 0 的x的差异。积分的主要思想是对无限多个宽度极小的切片进行求和。
符号∫是积分符号,指的是对无限多个切片的和。
每个切片的高度是f(x)的值。f(x)与dx的乘积就是每个切片的面积。最后,∫f(x):dx是对无限多个切片(切片宽度趋近于零)的切片面积的和。这就是曲线下的面积。
你在上一部分中看到过如何近似函数积分。但如果你知道一个函数的导数,你可以通过知道它是反操作来检索积分。例如,如果你知道:
d(x²)dx=2x
你可以得出2x的积分是x²。然而,这里有一个问题。如果你在函数中加上一个常数,导数仍然相同,因为常数的导数为零。例如,
d(x²+3)dx=2x
常数的值是不可能知道的。因此,你需要在表达式中添加一个未知常数,如下所示:
∫2xdx=x²+c
其中 cc 是一个常数。
定积分
在定积分的情况下,你用积分符号下方和上方的数字来表示积分区间,如下:
∫baf(x)dx
它对应于图 13 中展示的在x=a和x=b之间的函数f(x)下的面积。
 图 13:x=a和x=b之间的曲线下的面积。
图 13:x=a和x=b之间的曲线下的面积。
ROC 曲线下的面积
既然你知道了曲线下的面积与积分的关系,让我们看看如何计算它以便对比你的模型。
记住你在图 14 中展示的 ROC 曲线:
plt.plot(fpr_random, tpr_random, label="Random")
plt.plot(fpr, tpr, label="Logistic regression")
# [...] Add axes, labels etc.
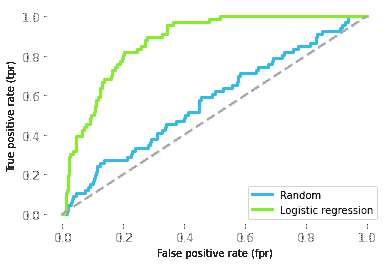
图 14:随机模型(蓝色)和逻辑回归模型(绿色)的 ROC 曲线。
让我们从随机模型开始。你需要将每个真实正率值与x轴上的宽度相乘,这个宽度是相应的假正率值与之前值之间的差异。你可以通过以下方法获得这些差异:
fpr_random[1:] - fpr_random[:-1]
array([0.00241546, 0.01207729, 0\. , ..., 0.01207729, 0\. ,
0.06038647])
所以随机模型的 ROC 曲线下的面积是:
(tpr_random[1:] * (fpr_random[1:] - fpr_random[:-1])).sum()
0.5743302591128678
或者你可以简单地使用 Sklearn 中的函数roc_auc_score(),通过真实目标值和概率作为输入:
from sklearn.metrics import roc_auc_score
roc_auc_score(y_test, y_pred_random_proba)
0.5743302591128678
ROC 曲线下的面积为 0.5 对应于一个不比随机更好的模型,而面积为 1 对应于完美的预测。
现在,让我们将这个值与模型的 ROC 曲线下的面积进行比较:
roc_auc_score(y_test, y_pred_proba[:, 1])
0.8752378861074513
这表明你的模型实际上并不差,你对葡萄酒质量的预测并非随机。
在机器学习中,你可以用几行代码来训练复杂的算法。然而,正如你在这里看到的,掌握一些数学知识可以帮助你充分利用这些算法,并加快你的工作进度。它将使你在多个领域中更加得心应手,例如,理解像 Sklearn 这样的机器学习库的文档。
简介:哈德里安·让 是一位机器学习科学家。他拥有巴黎高等师范学院的认知科学博士学位,研究领域包括使用行为和电生理数据进行听觉感知研究。他曾在工业界工作,构建了用于语音处理的深度学习管道。在数据科学与环境交汇的领域,他从事利用深度学习分析音频记录的生物多样性评估项目。他还定期在 Le Wagon(数据科学训练营)创建内容并授课,并在他的博客(hadrienj.github.io)上撰写文章。
原文。经授权转载。
相关:
-
提升你的数据科学技能。学习线性代数。
-
深度学习的预处理:从协方差矩阵到图像白化
-
数据科学的基础数学:‘为什么’和‘如何’
更多相关话题
数据科学的基础数学:线性方程组简介
原文:
www.kdnuggets.com/2021/08/essential-math-data-science-introduction-systems-linear-equations.html
评论
线性方程组
在本文中,你将能够利用你对向量、矩阵和线性组合的了解(分别是数据科学的基础数学 第五章、第六章和第七章)。这将使你能够将数据转换为线性方程组。在本章末尾(在 数据科学的基础数学),你将看到如何使用方程组和线性代数来解决线性回归问题。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
线性方程是变量之间关系的形式化表示。以以下方程定义的变量 x 和 y 之间的线性关系为例:
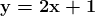
你可以在笛卡尔平面上表示这种关系:
# create x and y vectors
x = np.linspace(-2, 2, 100)
y = 2 * x + 1
plt.plot(x, y)
# [...] Add axes and styles
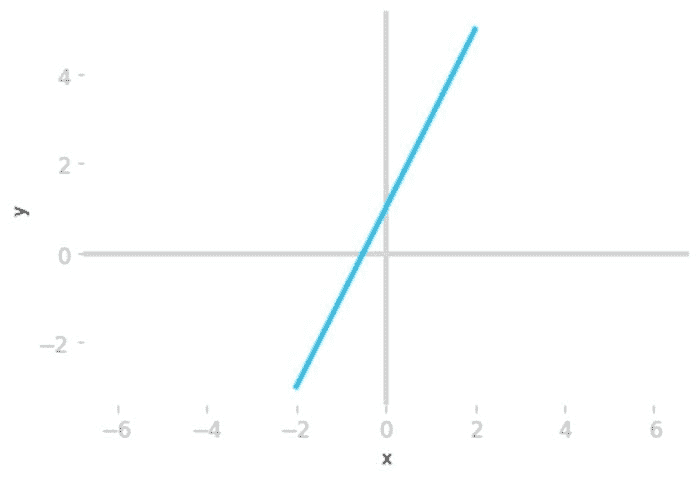
图 1:方程 的图示。
记住,线上的每个点都对应于这个方程的一个解:如果你用线上的一点的坐标替换 x 和 y 在这个方程中,等式就成立。这意味着有无数的解(线上的每个点)。
还可以考虑使用相同变量的多个线性方程:这就是一个方程组。
线性方程组
方程组是一组描述变量之间关系的方程。例如,考虑以下示例:
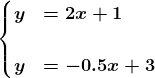
你有两个线性方程,它们都描述了变量 x 和 y 之间的关系。这是一个包含两个方程和两个变量(在这种情况下也称为未知数)的系统。
你可以将线性方程组(系统的每一行)视作多个方程,每个方程对应一条直线。这称为 行图示。
你也可以将系统视作不同的列,代表系数缩放变量。这称为 列图示。让我们深入了解这两种图示。
行图示
在行图示中,系统的每一行对应一个方程。在前面的例子中,有两个方程描述了两个变量 x 和 y 之间的关系。
行图示的图形表示
让我们将这两个方程式进行图形表示:
# create x and y vectors
x = np.linspace(-2, 2, 100)
y = 2 * x + 1
y1 = -0.5 * x + 3
plt.plot(x, y)
plt.plot(x, y1)
# [...]
图 2:我们系统中两个方程式的表示。
拥有多个方程式意味着 x 和 y 的值必须满足更多方程式。记住,来自第一个方程的 x 和 y 与第二个方程中的 x 和 y 是相同的。
所有在蓝色线上的点满足第一个方程,所有在绿色线上的点满足第二个方程。这意味着只有在两条线上的交点才满足这两个方程。当 x 和 y 取值为线交点的坐标时,方程组被解出。
在这个例子中,这个点的 x 坐标为 0.8,y 坐标为 2.6。如果你将这些值代入方程组中,你会得到:
这是一种几何方式来解决方程组。线性系统解为 x=0.8 和 y=2.6。
列图示
将系统视作列图示:你将系统视作未知值 (x 和 y) 缩放向量。
为了更好地理解这一点,让我们重新排列方程式,将变量放在一侧,将常数放在另一侧。对于第一个方程式,你有:
对于第二个方程式:
你现在可以将系统写成:
现在你可以查看图 3 来了解如何将两个方程式转换为一个 向量方程式。

图 3:将方程组视作由变量 x 和 y 缩放的列向量。
在图 3 的右侧,你会看到向量方程式。左侧有两个列向量,右侧有一个列向量。正如你在 数据科学的基础数学中看到的,这对应于以下向量的线性组合:

以及

在列图中,你用一个向量方程代替多个方程。从这个角度看,你要找到使右侧向量出现的左侧向量的线性组合。
列图中的解是一样的。行图和列图只是考虑方程组的两种不同方式:
它有效:如果你使用几何上找到的解,你会得到右侧向量。
列图的图形表示
让我们考虑将方程组表示为向量的线性组合。再以之前的例子为例:
图 4 展示了来自左侧(在图片中蓝色和红色的向量)和右侧(在图片中绿色的向量)方程的两个向量的图形表示。
图 4:由x和y缩放的向量组合得到右侧向量。
你可以在图 4 中看到,通过组合左侧向量可以得到右侧向量。如果你将向量缩放为 2.6 和 0.8,线性组合可以得到方程右侧的向量。
解的数量
在一些线性系统中,没有唯一解。实际上,线性方程组可以有:
-
没有解。
-
一个解。
-
无限多个解。
让我们考虑这三种可能性(包括行图和列图),以了解为什么线性系统不可能有多于一个解或少于无限多个解。
示例 1:无解
让我们考虑以下的线性方程组,仍然是两个方程和两个变量:
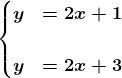
我们从表示这些方程开始:
# create x and y vectors
x = np.linspace(-2, 2, 100)
y = 2 * x + 1
y1 = 2 * x + 3
plt.plot(x, y)
plt.plot(x, y1)
# [...] Add axes, styles...
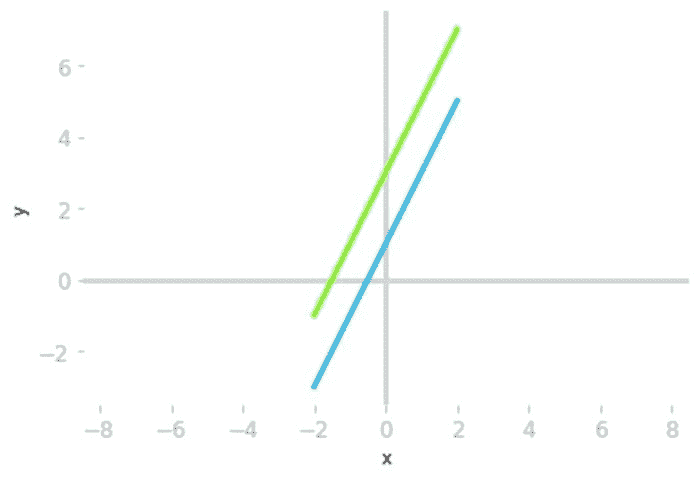
图 5:平行的方程线。
如图 5 所示,没有任何点同时位于蓝线和绿线上。这意味着这个方程组没有解。
你也可以通过列图从图形上理解为什么没有解。让我们将方程组写作如下:
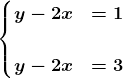
将其写作列向量的线性组合,你有:
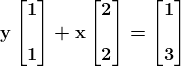
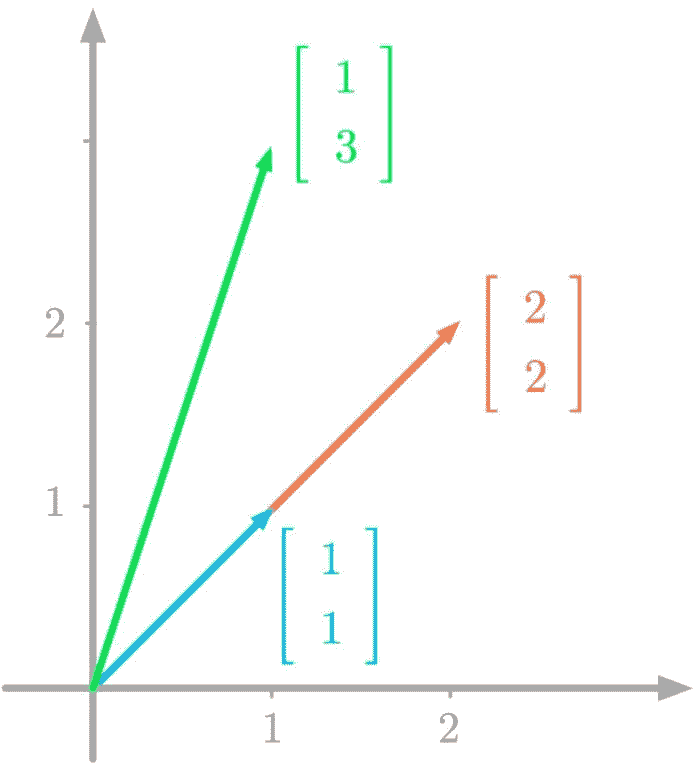
图 6:没有解的线性系统的列图。
图 6 显示了系统的列向量。你可以看到,通过组合蓝色和红色向量无法到达绿色向量的端点。原因是这些向量是线性相关的(更多细节见 数据科学的基础数学)。要到达的向量超出了你所组合的向量的跨度。
示例 2. 无限多个解
你还可能遇到另一个系统具有无限多个解的情况。我们考虑以下系统:
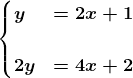
# create x and y vectors
x = np.linspace(-2, 2, 100)
y = 2 * x + 1
y1 = (4 * x + 2) / 2
plt.plot(x, y)
plt.plot(x, y1, alpha=0.3)
# [...] Add axes, styles...
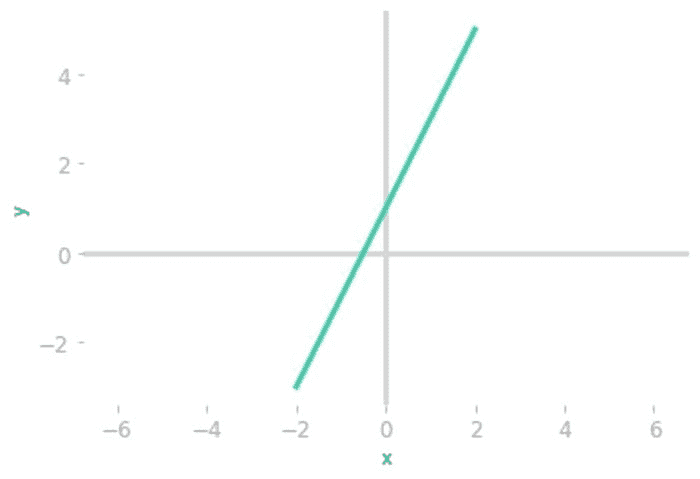
图 7:方程直线重叠。
由于方程是相同的,所以两个直线上的点无限多个,因此这个线性方程组有无限多个解。这例如类似于单个方程和两个变量的情况。
从列图的角度来看,你有:
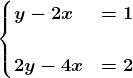
并使用向量表示法:
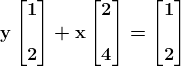
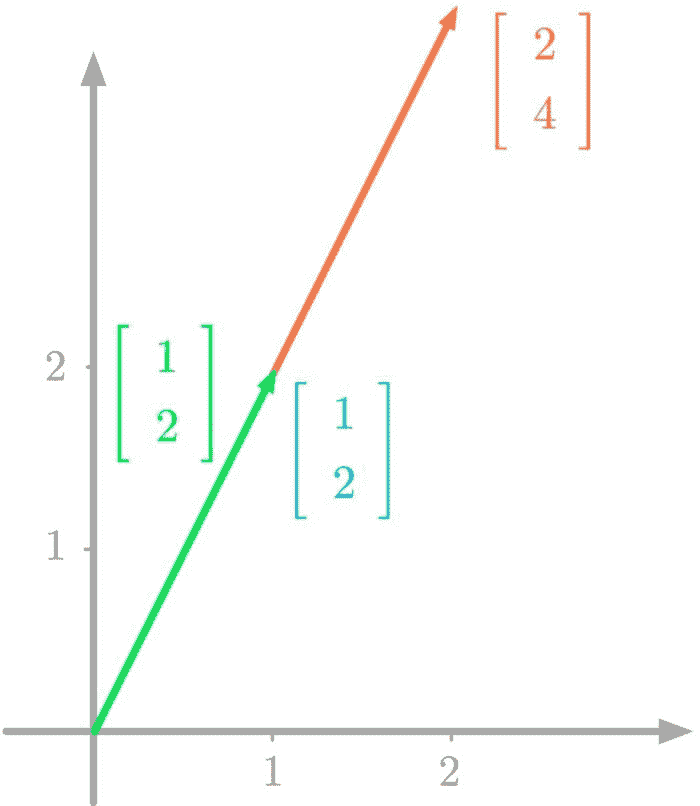
图 8:具有无限多个解的线性系统的列图。
图 8 显示了图形化表示的对应向量。你可以看到,通过蓝色和红色向量的组合,有无限多种方法到达绿色向量的端点。
由于两个向量朝相同方向,因此存在无限多个线性组合可以到达右侧向量。
总结
总结来说,你可以有三种可能的情况,如图 9 所示,包含两个方程和两个变量。
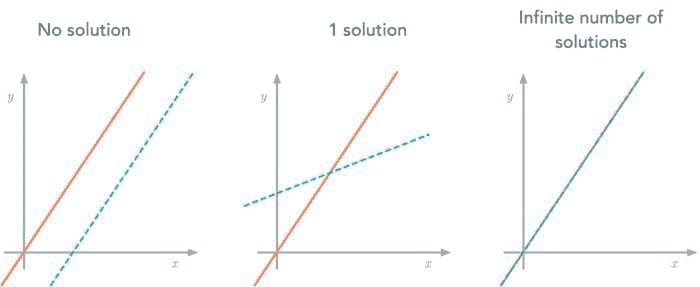
图 9:两个方程和两个变量的三种情况的总结。
不可能有两条直线交叉超过一次而少于无限次。
这一原理适用于更多维度。例如,在 IR³中,三个平面中至少有两个可以平行(无解),三个可以相交(一个解),或三个可以重叠(无限多个解)。
矩阵表示线性方程
现在你可以使用列图表示向量方程,你可以进一步使用矩阵来存储列向量。
我们再次考虑以下线性系统:
记住来自 数据科学的基础数学 的内容,你可以将线性组合写作矩阵-向量乘积。矩阵对应于左侧两个列向量的串联:
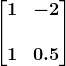
向量对应于矩阵的列向量的系数权重(此处为 x 和 y):

你的线性系统变成如下矩阵方程:
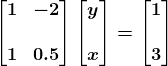
符号说明
这导致了广泛用于书写线性系统的符号表示:
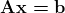
其中 A 是包含列向量的矩阵,x 是系数向量,b 是结果向量,我们称之为 目标向量。它使你能够从单独考虑方程的微积分,转到将线性系统的每一部分表示为向量和矩阵的线性代数。这种抽象非常强大,并将向量空间理论应用于求解线性方程组。
在列向量图像中,你需要找到方程左侧列向量线性组合的系数。只有当目标向量在这些列向量的跨度内时,解才存在。
个人简介: Hadrien Jean 是一位机器学习科学家。他拥有巴黎高等师范学院的认知科学博士学位,并在那里进行基于行为和电生理数据的听觉感知研究。他曾在工业界工作,构建了用于语音处理的深度学习管道。在数据科学和环境交汇处,他从事应用于音频录音的深度学习项目,用于生物多样性评估。他还定期在 Le Wagon(数据科学训练营)创作内容和授课,并在他的博客(hadrienj.github.io)上撰写文章。
相关:
-
数据科学的基础数学:基底与基底变换
-
数据科学的基础数学:矩阵的线性变换
-
数据科学的基础数学:信息理论
更多相关主题
数据科学的基础数学:矩阵及矩阵乘积简介
原文:
www.kdnuggets.com/2021/02/essential-math-data-science-matrices-matrix-product.html
评论
矩阵和张量
正如你在 数据科学的基础数学 中看到的,向量是存储和操作数据的有用方式。你可以将它们几何地表示为箭头,或作为数字数组(其结束点的坐标)。然而,创建更复杂的数据结构可能会很有帮助——这就是需要引入矩阵的地方。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
介绍
作为向量,矩阵 是允许你组织数字的数据结构。它们是包含值的方阵或矩阵,这些值按两维组织:行和列。你可以把它们看作是一个电子表格。通常,你会在数学领域看到术语矩阵,而在 Numpy 中则会看到二维数组。
维度
在矩阵的上下文中,维度 这个术语与向量几何表示的维度(空间的维度)不同。当我们说矩阵是一个二维数组时,这意味着数组中有两个 方向:行和列。
矩阵表示法
在这里,我将用粗体字母和大写字母表示矩阵,例如 A:
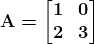
矩阵 A 有两行两列,但你可以想象任何形状的矩阵。更一般地,如果矩阵有 m 行和 n 列并包含实值,你可以用以下表示法来描述它: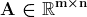
你可以通过矩阵的名称引用矩阵条目,名称中不使用粗体(因为条目是标量),后跟行索引和列索引,索引之间用逗号分隔并位于下标中。例如,A[1,2] 表示第一行第二列的条目。
按惯例,第一个索引用于行,第二个用于列。例如,矩阵A中位置 2 的条目位于矩阵A的第二行和第一列,因此表示为A[2,1](如数据科学的基础数学中所示,数学符号中通常使用基于一的索引)。
你可以按照如下方式写出矩阵的组件:
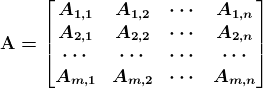
形状
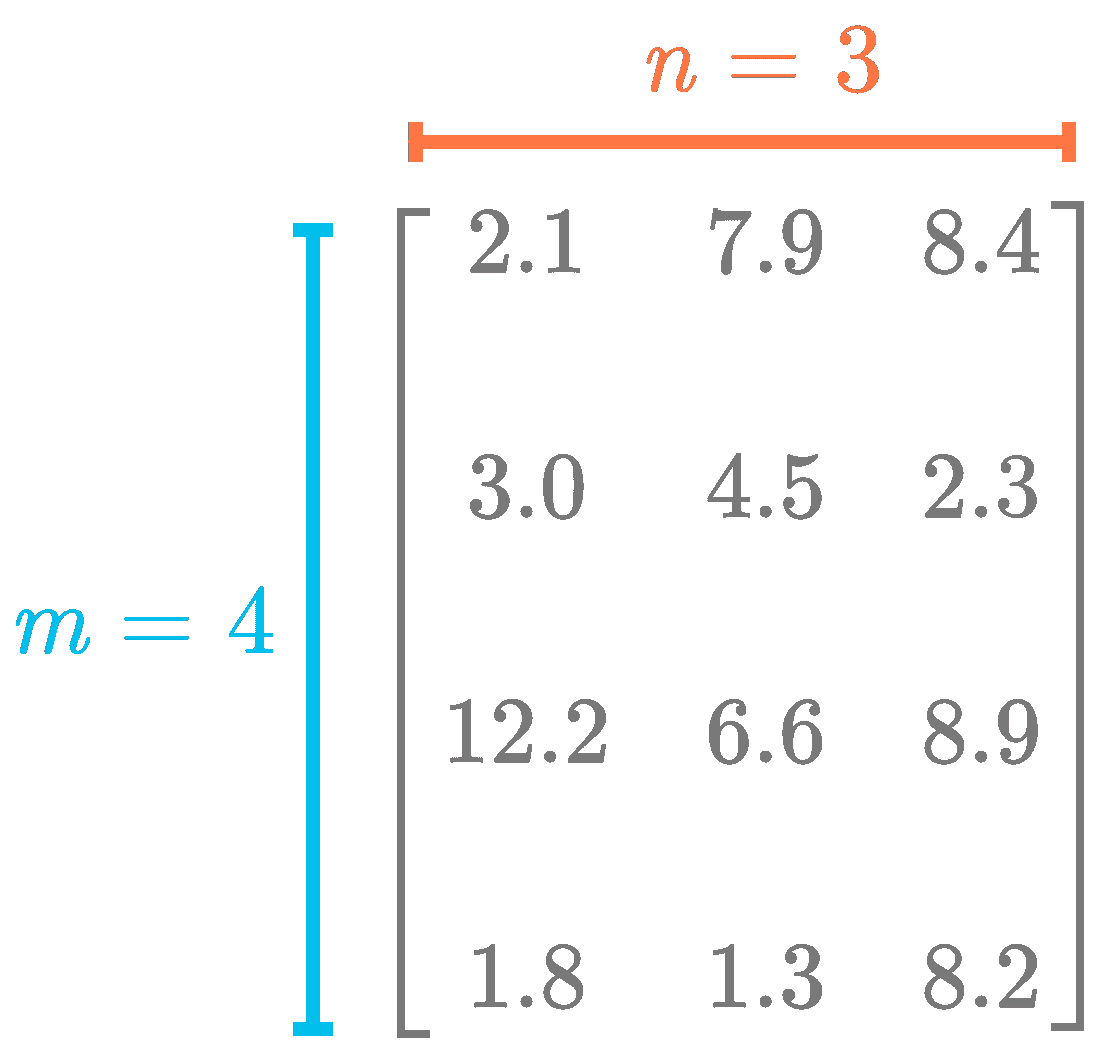
图 1:矩阵是二维数组。行数通常表示为 mm,而列数表示为 nn。
数组的形状告诉你每个维度的组件数量,如图 1 所示。由于这个矩阵是二维的(行和列),你需要两个值来描述形状(依次是行数和列数)。
让我们从使用方法np.array()创建一个二维 Numpy 数组开始:
A = np.array([[2.1, 7.9, 8.4],
[3.0, 4.5, 2.3],
[12.2, 6.6, 8.9],
[1.8, 1., 8.2]])
请注意,我们使用数组中的数组 ([[]]) 来创建二维数组。这与创建一维数组的方括号数量不同。
与向量一样,你也可以访问 Numpy 数组的形状属性:
A.shape
(4, 3)
你可以看到形状包含两个数字:它们分别对应于行数和列数。
索引
要获取矩阵的一个条目,你需要两个索引:一个用于行索引,一个用于列索引。
使用 Numpy,索引过程与向量相同。你只需要指定两个索引。让我们再次以矩阵A为例:
A = np.array([[2.1, 7.9, 8.4],
[3.0, 4.5, 2.3],
[12.2, 6.6, 8.9],
[1.8, 1.3, 8.2]])
可以使用以下语法获取特定条目:
A[1, 2]
2.3
A[1, 2] 返回具有行索引一和列索引二的组件(使用基于零的索引)。
要获取完整的列,可以使用冒号:
A[:, 0]
array([ 2.1, 3\. , 12.2, 1.8])
这会返回第一列(索引零),因为冒号表示我们想要从第一行到最后一行的组件。类似地,要获取特定的行,你可以这样做:
A[1, :]
array([3\. , 4.5, 2.3])
能够操作包含数据的矩阵是数据科学家的一项基本技能。检查数据的形状很重要,以确保它是按照你想要的方式组织的。了解你需要的数据显示形状对于使用像 Sklearn 或 Tensorflow 这样的库也很重要。
默认索引
请注意,如果你从二维数组中指定一个单一的索引,Numpy 认为这是针对第一维(行)的,而其他维度(列)的所有值都会被使用。例如:
A[0]
array([2.1, 7.9, 8.4])
这类似于:
A[0, :]
array([2.1, 7.9, 8.4])
向量和矩阵
对于 Numpy,如果数组是向量(一维 Numpy 数组),则形状是一个单一的数字:
v = np.array([1, 2, 3])
v.shape
(3,)
你可以看到v是一个向量。如果它是一个矩阵,形状有两个数字(分别是行数和列数)。例如:
A = np.array([[2.1, 7.9, 8.4]])
A.shape
(1, 3)
你可以看到矩阵只有一行:形状的第一个数字是 1。再次使用两个方括号[[和]],可以创建一个二维数组(矩阵)。
矩阵乘积
你可以在数据科学基础数学中学习点积。矩阵的等效操作称为矩阵乘积,或矩阵乘法。它接收两个矩阵并返回另一个矩阵。这是线性代数中的核心操作。
矩阵与向量
矩阵乘积的更简单情况是矩阵与向量之间的乘积(你可以将其视为一个具有单列的矩阵乘积)。
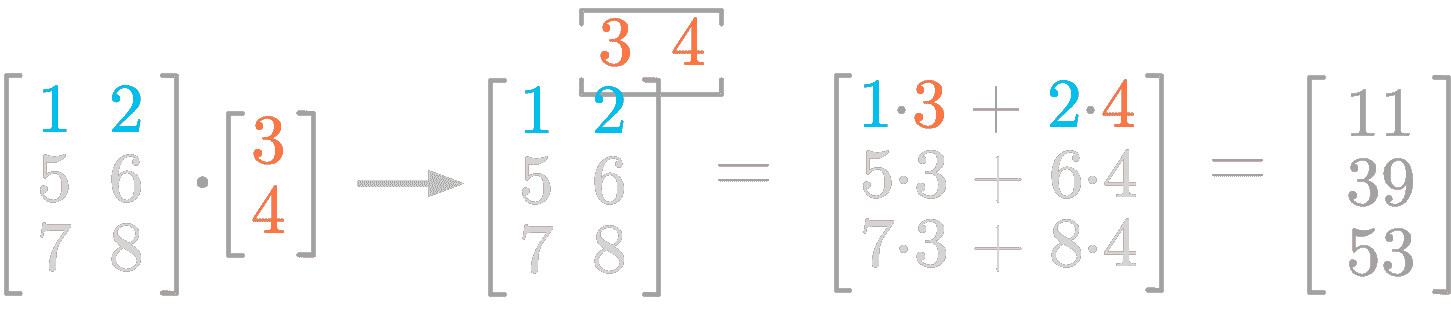
图 2:矩阵与向量之间乘积的步骤。
图 2 展示了矩阵与向量之间乘积的步骤。考虑矩阵的第一行。你将点积应用于向量(红色的值 3 和 4)和你考虑的行(蓝色的值 1 和 2)。你按对相乘:行中的第一个值与列向量中的第一个值(1⋅3),行中的第二个值与向量中的第二个值(2⋅4)。它给出了结果矩阵的第一个分量(1⋅3+2⋅4=11)。
你可以看到矩阵-向量乘积与点积相关。这就像将矩阵 AA 分成三行并应用点积(如在数据科学基础数学中)。
让我们看看如何使用 Numpy 来实现。
A = np.array([
[1, 2],
[5, 6],
[7, 8]
])
v = np.array([3, 4]).reshape(-1, 1)
A @ v
array([[11],
[39],
[53]])
请注意,我们使用了reshape()函数将向量重塑为 2 乘 1 的矩阵(-1让 Numpy 猜测剩余的数字)。如果不这样做,你将得到一维数组而不是二维数组(具有单列的矩阵)。
矩阵列的加权
还有另一种思考矩阵乘积的方法。你可以认为向量包含对矩阵每一列的加权值。这清楚地表明,向量的长度需要等于应用向量的矩阵的列数。
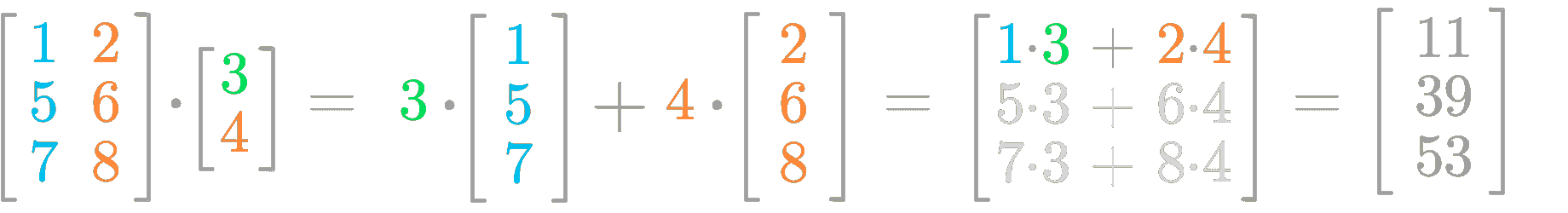
图 3:向量的值对矩阵的列进行加权。
图 3 可能有助于可视化这个概念。你可以将向量值(3 和 4)视为应用于矩阵列的权重。你之前看到的关于标量乘法的规则会得出与之前相同的结果。
使用最后一个例子,你可以将A和v之间的点积写作如下:
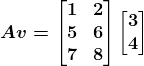
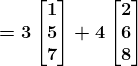
这很重要,因为正如你在数据科学基础数学中会看到的,它表明Av是A的列的线性组合,系数是v中的值。
形状
此外,你可以看到矩阵和向量的形状必须匹配,点积才可能进行。
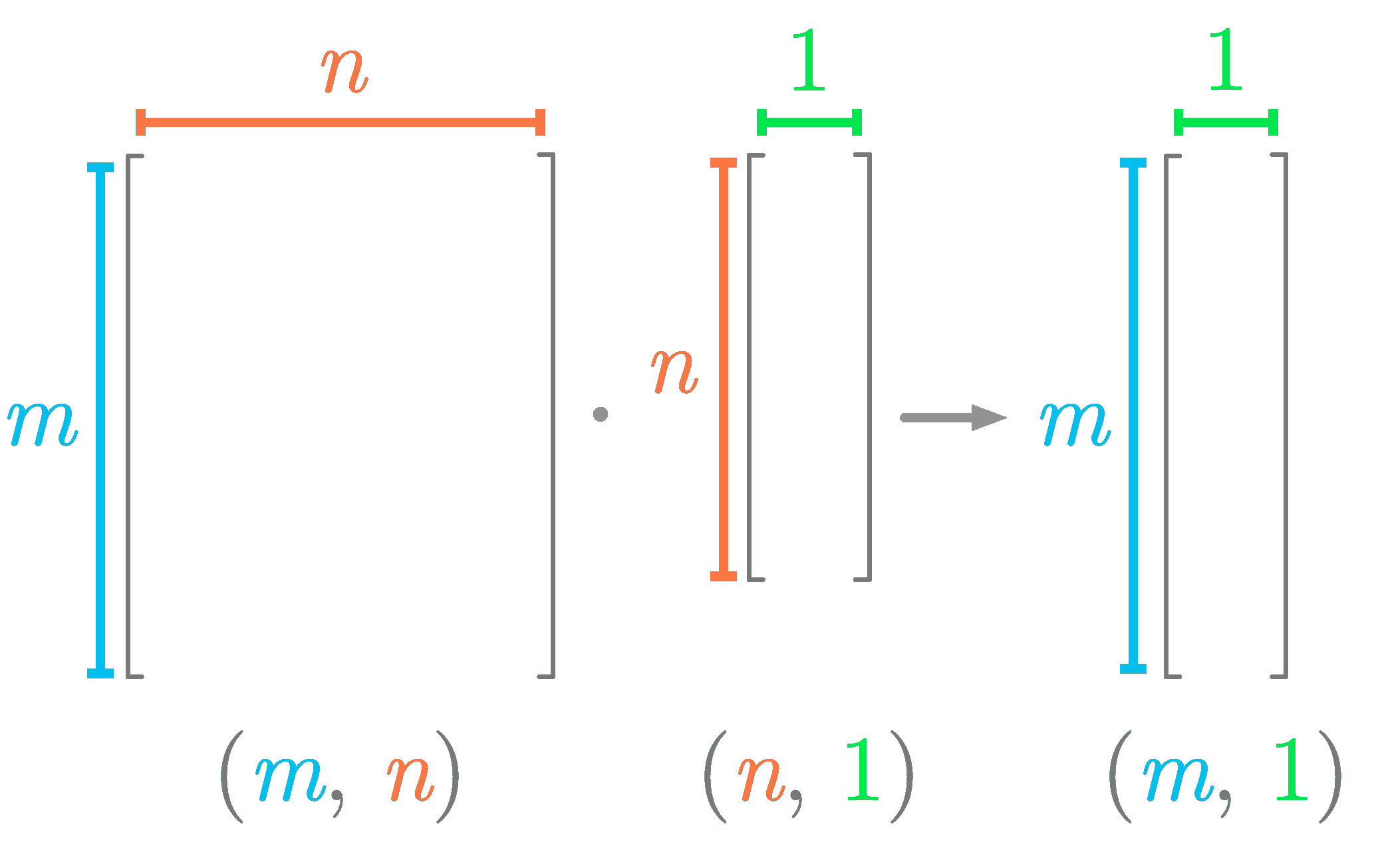
图 4:矩阵与向量之间点积所需的形状。
图 4 总结了矩阵-向量乘积中涉及的形状,并显示矩阵的列数必须等于向量的行数。
矩阵乘积
矩阵乘积是两个矩阵的点积操作的等效操作。正如你将看到的,它类似于矩阵-向量乘积,但应用于第二个矩阵的每一列。
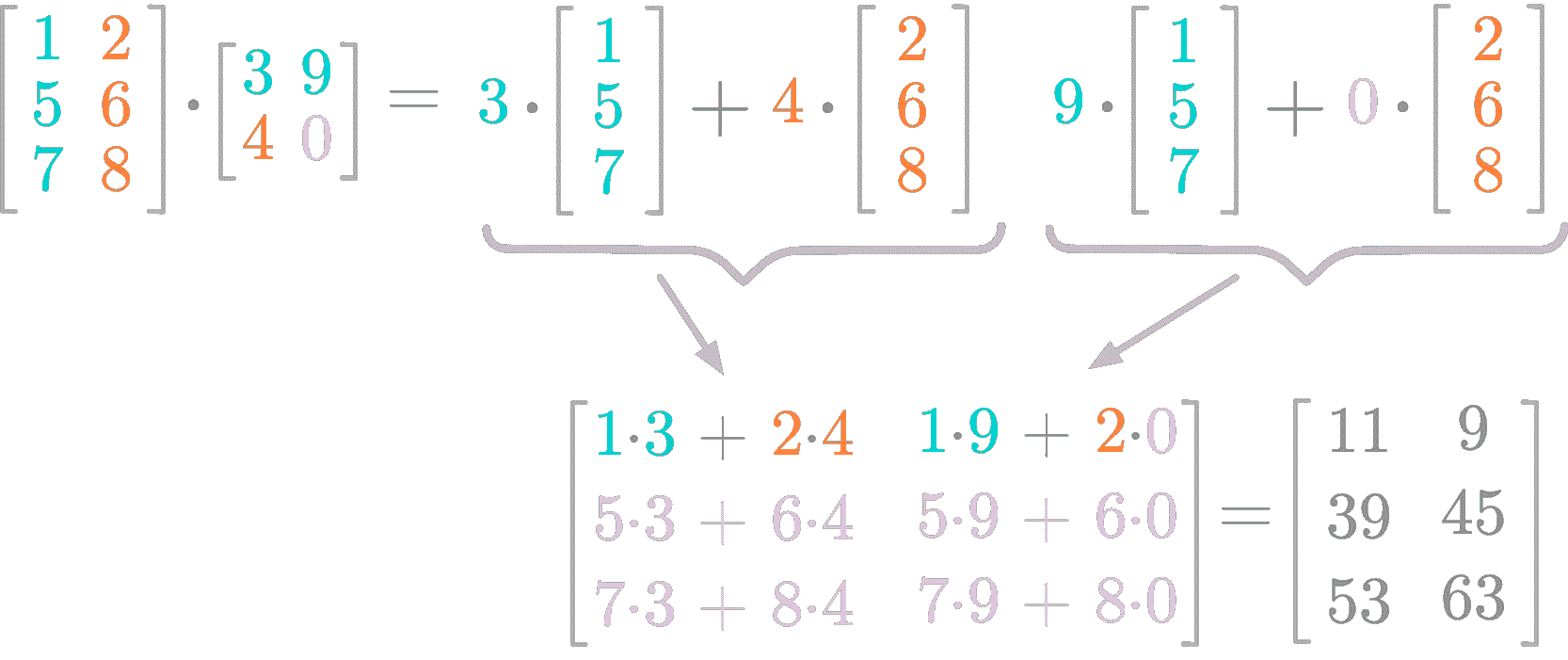
图 5:矩阵乘积。
图 5 展示了矩阵乘积的一个例子。你可以看到结果矩阵有两列,与第二个矩阵一样。第二个矩阵第一列的值(3 和 4)加权这两列,结果填充了结果矩阵的第一列。类似地,第二个矩阵第二列的值(9 和 0)加权这两列,结果填充了结果矩阵的第二列。
使用 Numpy,你可以像计算点积一样精确地计算矩阵乘积:
A = np.array([
[1, 2],
[5, 6],
[7, 8],
])
B = np.array([
[3, 9],
[4, 0]
])
A @ B
array([[11, 9],
[39, 45],
[53, 63]])
形状
就像矩阵-向量乘积一样,如图 6 所示,第一个矩阵的列数必须与第二个矩阵的行数匹配。
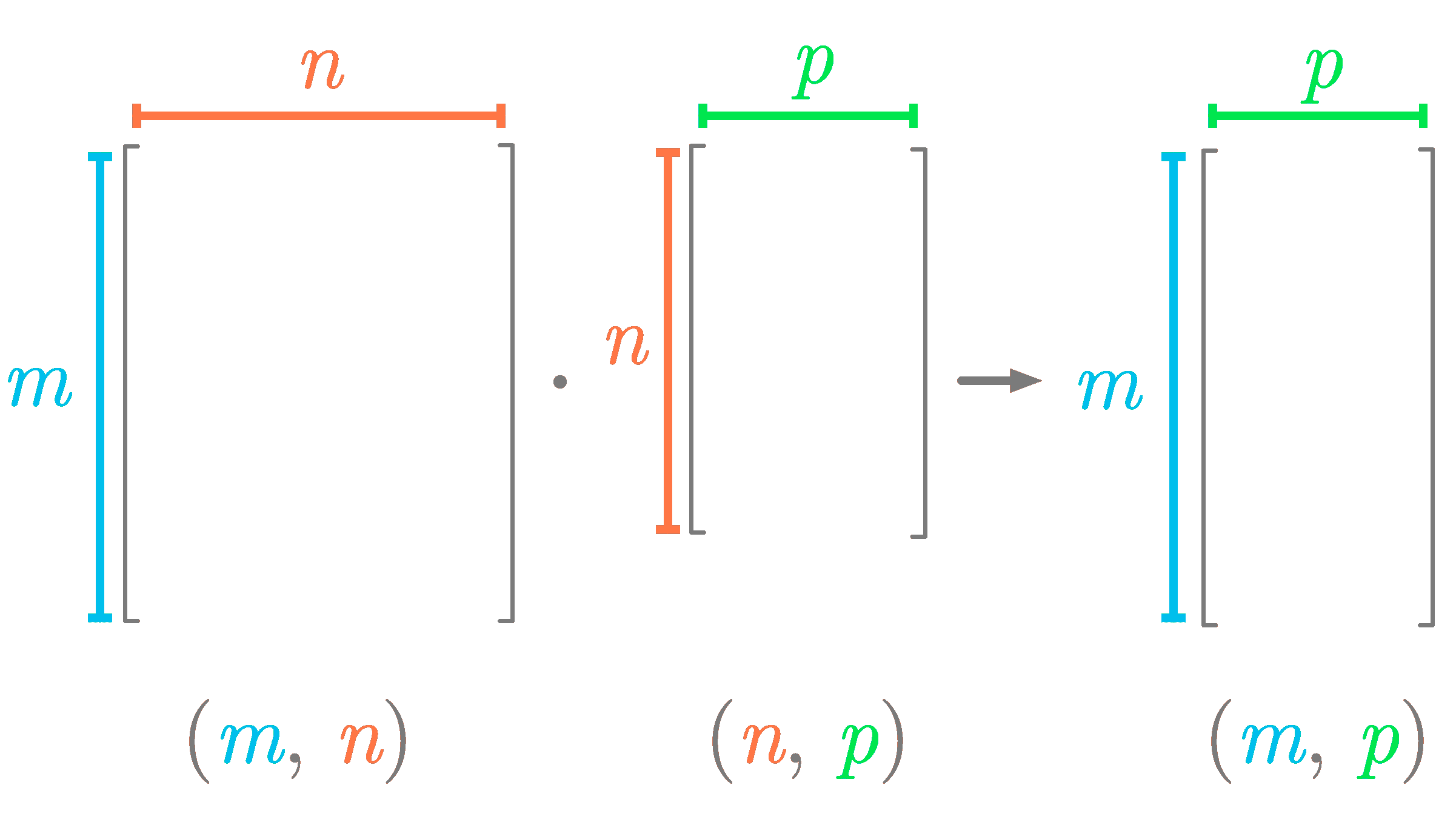
图 6:矩阵点积要求形状匹配。
结果矩阵的行数与第一个矩阵相同,列数与第二个矩阵相同。
让我们尝试一下。
A = np.array([
[1, 4],
[2, 5],
[3, 6],
])
B = np.array([
[1, 4, 7],
[2, 5, 2],
])
矩阵A和B有不同的形状。让我们计算它们的点积:
A @ B
array([[ 9, 24, 15],
[12, 33, 24],
[15, 42, 33]])
你可以看到A⋅B的结果是一个 3x3 的矩阵。这个形状来自于A的行数(3)和B的列数(3)。
计算协方差矩阵的矩阵乘积
你可以通过计算包含变量的矩阵与其转置之间的乘积来得到数据集的协方差矩阵(有关协方差矩阵的更多细节请参见数据科学基础数学)。然后,你需要除以观察次数(或者除以这个数字减去 1 用于贝塞尔校正)。你需要确保变量在计算前已经围绕零进行中心化(可以通过减去均值来完成)。
让我们模拟以下变量x、y和z:
x = np.random.normal(10, 2, 100)
y = x * 1.5 + np.random.normal(25, 5, 100)
z = x * 2 + np.random.normal(0, 1, 100)
使用 Numpy,协方差矩阵为:
np.cov([x, y, z])
array([[ 4.0387007 , 4.7760502 , 8.03240398],
[ 4.7760502 , 32.90550824, 9.14610037],
[ 8.03240398, 9.14610037, 16.99386265]])
现在,使用矩阵乘积,你首先需要将变量堆叠为矩阵的列:
X = np.vstack([x, y, z]).T
X.shape
(100, 3)
你可以看到变量X是一个 100x3 的矩阵:100 行对应观察次数,3 列对应特征。然后,你需要将这个矩阵围绕零进行中心化:
X = X - X.mean(axis=0)
最后,你计算协方差矩阵:
(X.T @ X) / (X.shape[0] - 1)
array([[ 4.0387007 , 4.7760502 , 8.03240398],
[ 4.7760502 , 32.90550824, 9.14610037],
[ 8.03240398, 9.14610037, 16.99386265]])
你得到的协方差矩阵类似于函数np.cov()的结果。重要的是要记住,矩阵与其转置的点积对应于协方差矩阵。
矩阵乘积的转置
两个矩阵点积的转置定义如下:
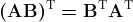
例如,取以下矩阵 A 和 B:
A = np.array([
[1, 4],
[2, 5],
[3, 6],
])
B = np.array([
[1, 4, 7],
[2, 5, 2],
])
你可以检查 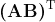 和
和 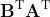 的结果:
的结果:
(A @ B).T
array([[ 9, 12, 15],
[24, 33, 42],
[15, 24, 33]])
B.T @ A.T
array([[ 9, 12, 15],
[24, 33, 42],
[15, 24, 33]])
起初,这可能令人惊讶,因为括号中两个向量或矩阵的顺序必须改变才能满足等价关系。让我们详细了解一下这个操作。
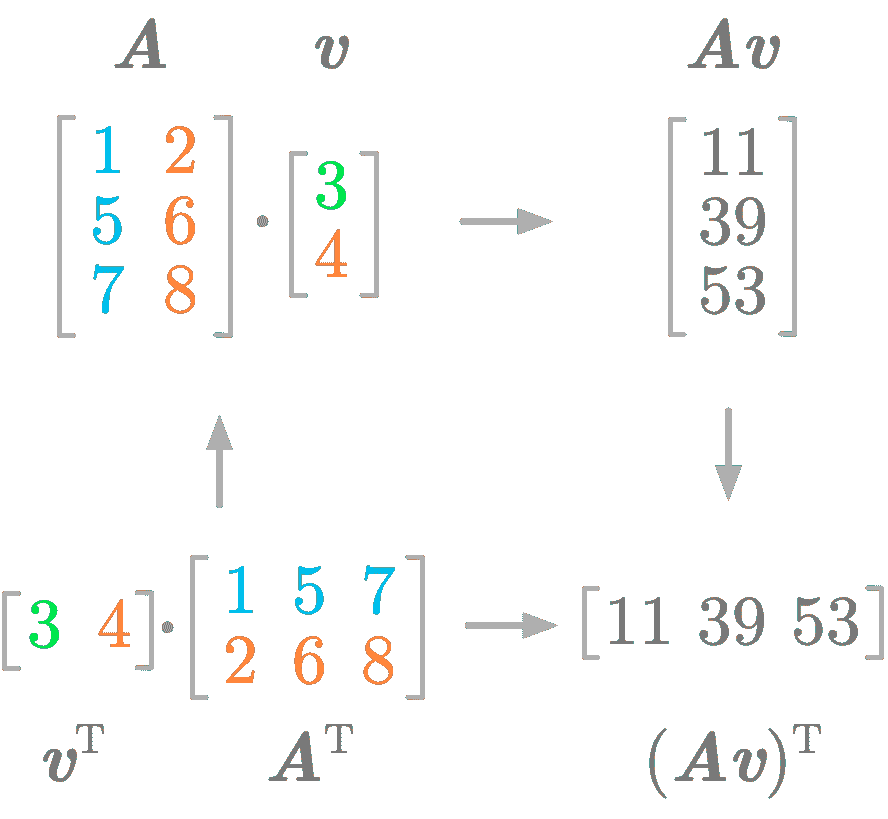
图 7:你必须改变向量和矩阵的顺序才能获得矩阵乘积的转置。
图 7 显示了,如果改变向量和矩阵的顺序,矩阵乘积的转置等于转置的乘积。
超过两个矩阵或向量
你可以将这个性质应用于多个矩阵或向量。例如,
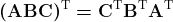
记住这个性质,它解释了许多在处理矩阵和向量时可能遇到的“外观上的调整”。用代码尝试这些操作是一个很好的学习方式。
总结来说,矩阵乘积是线性代数的关键概念,你将在 数据科学中的基本数学 中看到它如何与空间变换相关。
个人简介:Hadrien Jean 是一位机器学习科学家。他拥有巴黎高等师范学院的认知科学博士学位,在那里他利用行为学和电生理数据研究听觉感知。他之前在工业界工作,建立了用于语音处理的深度学习管道。在数据科学和环境交汇处,他从事利用深度学习处理音频录音的生物多样性评估项目。他还定期在 Le Wagon(数据科学训练营)创建内容和授课,并在他的博客(hadrienj.github.io)上撰写文章。
原文。经授权转载。
相关:
-
数据科学中的基本数学:概率密度和概率质量函数
-
矩阵分解解读
-
数据科学中的基本数学:信息理论
更多相关内容
数据科学的基础数学:概率密度函数和概率质量函数
评论
在《数据科学的基础数学》的第二章中,你可以学习基本的描述统计和概率理论。在这个样本中,我们将讨论概率质量函数和概率密度函数。你将看到如何理解和表示这些分布函数及其与直方图的关系。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
确定性 过程在重复多次时会产生相同的结果。这与描述随机 事件的随机变量不同,在这些事件中,随机性特征化了过程。
这意味着随机变量可以取各种值。你如何描述和比较这些值?一种好的方法是使用每个结果发生的概率。随机变量的概率分布是一个函数,它将样本空间作为输入,并返回概率:换句话说,它将可能的结果映射到它们的概率。
在本节中,你将学习离散和连续变量的概率分布。
概率质量函数
离散随机变量的概率函数称为概率质量函数(或 PMF)。例如,假设你正在进行一个掷骰子实验。你把X 叫做与这个实验相关的随机变量。假设骰子是公平的,每个结果都是等概率的:如果你进行大量实验,你会得到每个结果的大致次数相同。在这里,有六种可能的结果,因此你有六分之一的机会得到每个数字。
因此,描述X 的概率质量函数为每个可能的结果返回 1616,其他情况下返回 0(因为你不能得到 1、2、3、4、5 或 6 以外的结果)。
你可以写出  ,
, 等。
等。
概率质量函数的属性
并非每个函数都可以被视为概率质量函数。概率质量函数必须满足以下两个条件:
- 该函数必须返回每个可能结果的 0 到 1 之间的值:
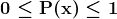
- 对应所有可能结果的概率之和必须等于 1:
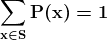
x的值可以是任何实数,因为样本空间之外的值与概率 0 相关。数学上,对于样本空间S之外的任何值x,P(x)=0。
骰子实验的模拟
让我们使用 Numpy 中的函数np.random.randint(low, high, size)来模拟骰子实验,该函数在low和high(不包括)之间抽取n(size)个随机整数。让我们模拟 20 次掷骰子:
rolls = np.random.randint(1, 7, 20)
rolls
array([6, 3, 5, ..., 6, 5, 1])
这个数组包含了实验的 20 个结果。让我们称X为对应于掷骰子实验的离散随机变量。X的概率质量函数仅在可能的结果上定义,并为每个结果提供概率。
假设骰子是公平的,你应该得到一个均匀分布,即每个结果的概率相同。
让我们可视化随机实验中每个结果的数量。你可以通过试验次数来计算概率。我们使用 Matplotlib 中的plt.stem()来可视化这些概率:
val, counts = np.unique(rolls, return_counts=True)
plt.stem(val, counts/len(rolls), basefmt="C2-", use_line_collection=True)
图 1:随机变量X的概率质量函数,基于 20 次掷骰子的估计。
在均匀分布下,图形每个结果的高度应该相同(因为高度对应于概率,而每次掷骰子的结果概率是相同的)。然而,图 1 中显示的分布看起来并不均匀。这是因为你没有足够多地重复实验:当你重复实验很多次(理论上是无限次)时,概率将会稳定下来。
让我们增加试验次数:
throws = np.random.randint(1, 7, 100000)
val, counts = np.unique(throws, return_counts=True)
plt.stem(val, counts/len(throws), basefmt="C2-", use_line_collection=True)
图 2:随机变量X的概率质量函数,基于 100,000 次掷骰子实验的估计。
在足够多的试验中,图 2 中显示的概率质量函数看起来是均匀的。这强调了从频率主义概率角度来看试验次数的重要性。
概率密度函数
对于连续变量,可能的结果数量是无限的(受限于你使用的小数位数)。例如,如果你抽取一个 0 到 1 之间的数字,你可能得到一个如 0.413949834 的结果。抽取每个数字的概率趋近于零:如果你将某物除以一个非常大的数字(可能的结果数量),结果将非常小,接近于零。这对于描述随机变量并不太有帮助。
更好的做法是考虑在一系列值中获得特定数字的概率。概率密度函数的y轴不是概率。它被称为概率密度或简称为density。因此,连续变量的概率分布被称为概率密度函数(或 PDF)。
概率密度函数在特定区间上的积分给出了随机变量在该区间内取值的概率。因此,这个概率由该区间下的曲线所围成的面积表示(如你在数据科学基础数学中所见)。
符号
在这里,我将用小写p表示概率密度函数。例如,函数p(x)给出与值x对应的密度。
示例
让我们检查一个概率密度函数的例子。你可以使用 Numpy 函数np.random.normal从正态分布中随机抽取数据(你可以在数据科学基础数学中找到关于正态分布的更多细节)。
你可以选择正态分布的参数(均值和标准差)以及样本数量。我们来创建一个变量data,其包含 1,000 个从均值为 0.3 和标准差为 0.1 的正态分布中随机抽取的值。
np.random.seed(123)
data = np.random.normal(0.3, 0.1, 1000)
让我们通过直方图查看分布的形状。函数plt.hist()返回直方图的x轴和y轴坐标的确切值。我们将这些值存储在一个名为hist的变量中以备后用:
hist = plt.hist(data, bins=13, range=(-0.3, 1))
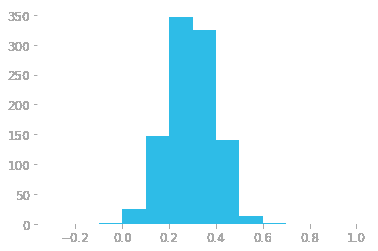
图 3:从正态分布生成的数据的直方图。x轴是向量中元素的值,y轴是位于相应范围内的元素数量(计数)。
直方图
直方图显示了值的分布情况。这是一种使用从分布中抽取的有限数量的值来建模概率分布的方法。由于我们处理的是连续分布,这个直方图对应于特定区间的值的数量(这些区间取决于函数hist()中的参数bins)。
例如,图 3 显示区间 (0.2, 0.3) 内大约有 347 个元素。每个条形对应的宽度为 0.1,因为我们使用了 13 个条形来表示范围从 -0.3 到 1 的数据。
让我们更仔细地查看具有更多条形的分布。你可以使用参数 density 来使 y 轴对应于概率密度,而不是每个条形中的值计数:
hist = plt.hist(data, bins=24, range=(-0.2, 1), density=True)
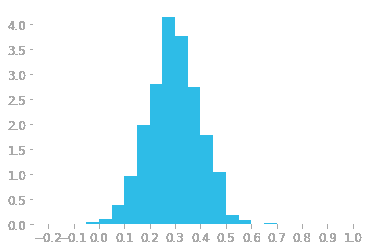
Figure 4: Histogram using 30 bins and density instead of counts.
你可以在图 4 中看到,这个直方图有更多的条形(24 个而不是 13 个)。这意味着每个条形现在有更小的宽度。y 轴也使用了不同的刻度:它对应于密度,而不是之前的值计数。
要从密度中计算在某个范围内抽取值的概率,你需要使用曲线下方的面积。在直方图的情况下,这就是条形的面积。
让我们以一个从 0.2 到 0.25 的条形为例,关联的密度如下:
print(f"Density: {hist[0][8].round(4)}")
print(f"Range x: from {hist[1][8].round(4)} to {hist[1][9].round(4)}")
Density: 2.8
Range x: from 0.2 to 0.25
由于有 24 个条形,且可能的结果范围是从 -0.2 到 1,每个条形对应的范围是  。在我们的例子中,条形的高度(从 0.2 到 0.25)约为 2.8,因此该条形的面积是
。在我们的例子中,条形的高度(从 0.2 到 0.25)约为 2.8,因此该条形的面积是  。这意味着获取一个介于 0.2 和 0.25 之间的值的概率约为 0.14 或 14%。
。这意味着获取一个介于 0.2 和 0.25 之间的值的概率约为 0.14 或 14%。
你看到概率的总和必须等于一,因此条形的面积总和也应该等于一。让我们检查一下:你可以取包含密度的向量(hist[0]),并将其乘以条形宽度(0.05):
(hist[0] * 0.05).sum().round(4)
1.0
一切正常:概率的总和等于一。
从直方图到连续概率密度函数
直方图表示的是概率密度函数的分箱版本。图 5 显示了真实概率密度函数的表示。图中的蓝色阴影区域对应于获得一个介于 0 和 0.2 之间的数字的概率(0 和 0.2 之间曲线下方的区域)。
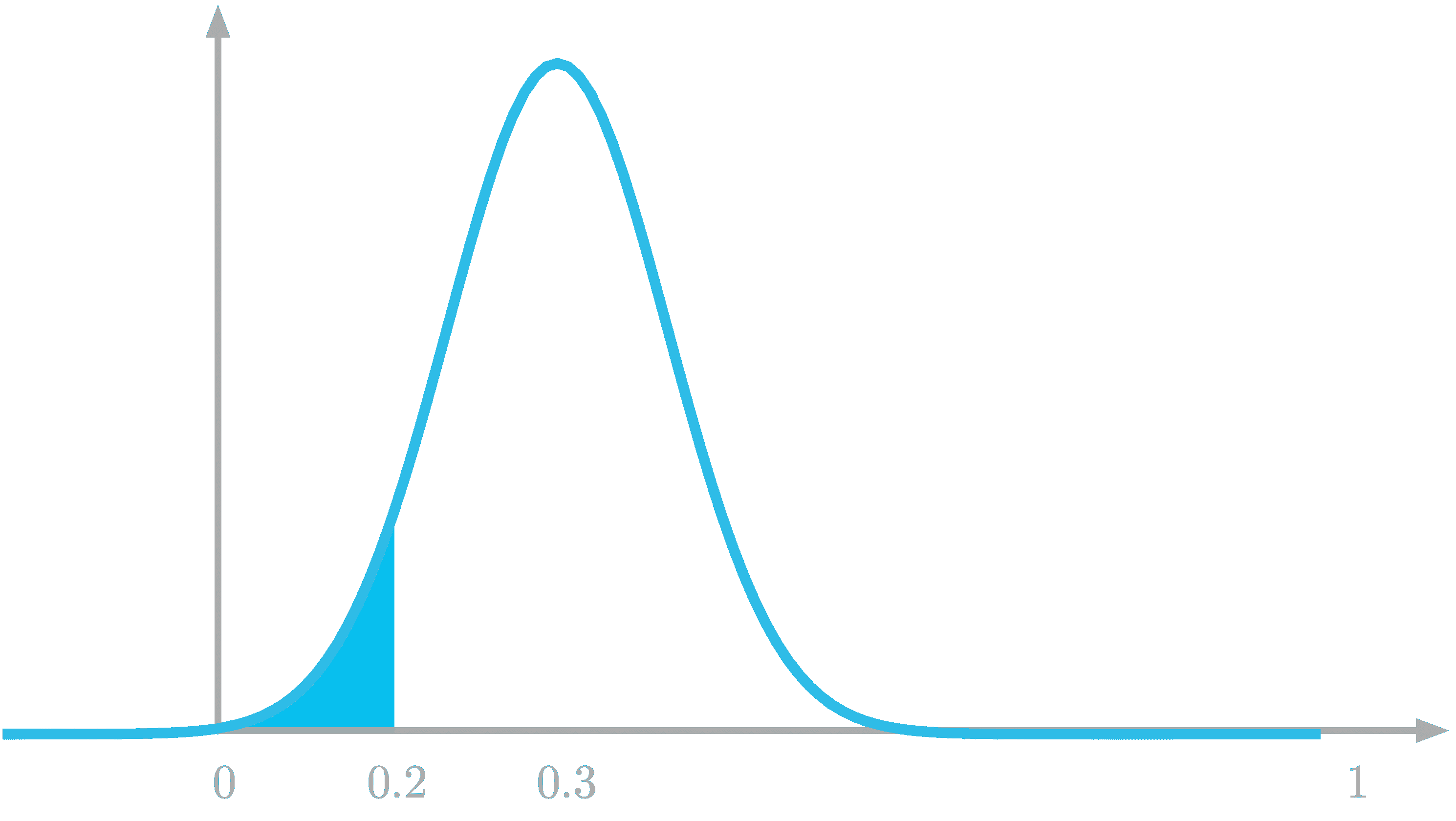
图 5:抽取一个介于 0 和 0.2 之间的数字的概率是曲线下方高亮区域。
概率密度函数的性质
与概率质量函数类似,概率密度函数必须满足一些要求。第一个要求是它必须返回非负值。数学表示为:
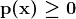
第二个要求是概率密度函数的曲线下方的总面积必须等于 1:
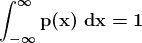
在关于概率分布的部分,你看到概率质量函数用于离散变量,而概率密度函数用于连续变量。请记住,概率质量函数的y轴上的值是概率,而概率密度函数则不是。查看密度值(例如在图 4 中):它们可以大于 1,这表明它们不是概率。
简介:Hadrien Jean 是一位机器学习科学家。他拥有巴黎高等师范学校的认知科学博士学位,曾在该校进行基于行为和电生理数据的听觉感知研究。他之前在工业界工作,构建了用于语音处理的深度学习管道。在数据科学与环境的交汇处,他从事利用应用于音频录音的深度学习进行生物多样性评估的项目。他还定期在 Le Wagon(数据科学训练营)创建内容并教授课程,并在他的博客中撰写文章 (hadrienj.github.io)。
原文。经许可转载。
相关:
-
数据科学必备数学:积分与曲线下面积
-
提升你的数据科学技能。学习线性代数。
-
数据科学必备数学:‘为什么’和‘如何’
更多相关主题
数据科学的基本数学:标量和向量
原文:
www.kdnuggets.com/2021/02/essential-math-data-science-scalars-vectors.html
评论
机器只理解数字。例如,如果你想创建一个垃圾邮件检测器,你必须先将文本数据转换为数字(例如,通过词嵌入)。数据随后可以存储在向量、矩阵和张量中。例如,图像被表示为值在 0 到 255 之间的矩阵,代表每个像素每种颜色的亮度。可以利用线性代数领域的工具和概念来操作这些向量、矩阵和张量。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
线性代数是研究向量空间的数学分支。你将看到向量如何构成向量空间,以及线性代数如何将线性变换应用于这些空间。你还将了解线性方程组与向量方程之间的强大关系,这与最小二乘近似等重要数据科学概念相关。最后,你将学习重要的矩阵分解方法:特征分解和奇异值分解(SVD),这些对理解主成分分析(PCA)等无监督学习方法非常重要。
标量和向量
什么是向量?
线性代数处理向量。该领域的其他数学实体可以通过它们与向量的关系来定义:例如,标量是单一的数字,当它们与向量相乘时,会缩放这些向量(拉伸或收缩)。
然而,向量根据其使用领域指代不同的概念。在数据科学的背景下,它们是一种存储数据值的方式。例如,考虑人的身高和体重:由于这些是具有不同含义的独立值,你需要将它们分别存储,例如使用两个向量。然后,你可以对向量进行操作,以操控这些特征,同时不会丧失这些值对应于不同属性的事实。
你还可以使用向量来存储数据样本,例如,将十个人的身高存储为包含十个值的向量。
符号表示法
我们将使用小写粗体字母来命名向量(如 vv)。如常规,请参阅 数据科学基础数学 中的附录,以获得本书中使用的符号总结。
几何向量和坐标向量
词汇 向量 可以指多个概念。让我们更多地了解几何向量和坐标向量。
坐标 是描述位置的数值。例如,地球上任何位置都可以通过地理坐标(纬度、经度和高度)来指定。
几何向量
几何向量,也称为 欧几里得向量,是由其大小(长度)和方向定义的数学对象。这些属性使你能够描述从一个位置到另一个位置的位移。
图 1: 从 A 到 B 的几何向量。
例如,图 1 显示了点 A 的坐标为 (1, 1),点 B 的坐标为 (3, 2)。几何向量 v 描述了从 A 到 B 的位移,但由于向量由其大小和方向定义,你也可以将 v 表示为从原点开始。
笛卡尔平面
在图 1 中,我们使用了一个叫做 笛卡尔平面 的坐标系统。水平线和垂直线是 坐标轴,通常分别标记为 x 和 y。两个坐标轴的交点称为 原点,对应于每个轴的坐标 0。
在笛卡尔平面中,任何位置都可以通过 x 和 y 坐标来指定。笛卡尔坐标系统可以扩展到更多维度:在 n 维空间中,点的位置由 nn 个坐标指定。实际的 n 维坐标空间,包含 n 元组的实数,被称为
。例如,空间
是包含实数对(坐标)的二维空间。在三维空间 (
) 中,空间中的一点由三个实数表示。
 是包含实数对(坐标)的二维空间。在三维空间 (
是包含实数对(坐标)的二维空间。在三维空间 (坐标向量
坐标向量 是与向量坐标对应的有序数字列表。由于向量的初始点位于原点,你只需要编码终点的坐标。
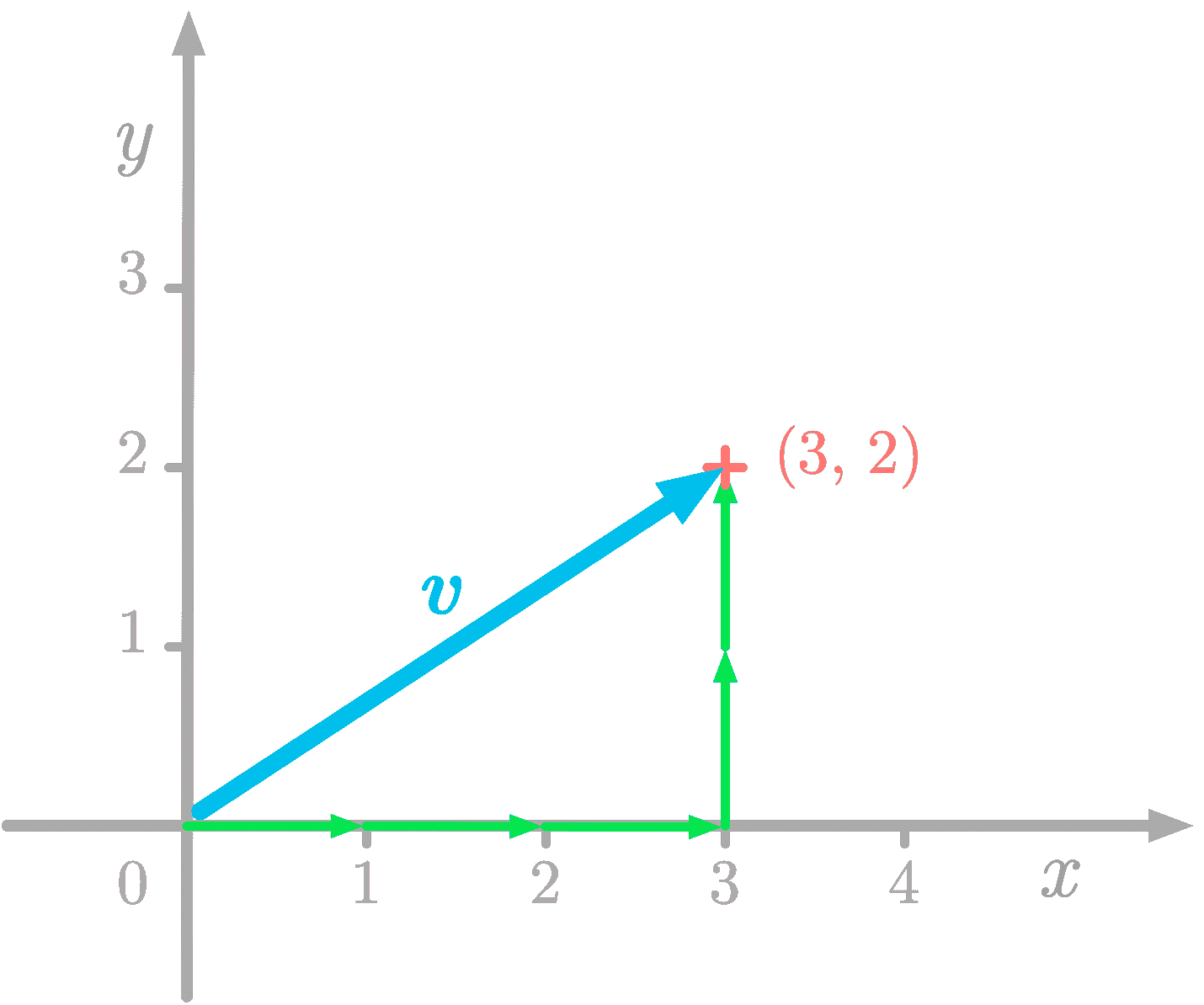
图 2: 向量 vv 的坐标为 (3, 2),对应于从原点在 x 轴上三单位和在 y 轴上两单位。
例如,我们来看看图 2 中表示的向量 v。相应的坐标向量如下:
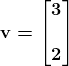
每个值与一个方向相关联:在这种情况下,第一个值对应于 xx 轴方向,第二个数对应于y轴。
图 3:坐标向量的分量。
如图 3 所示,这些值被称为分量或条目。
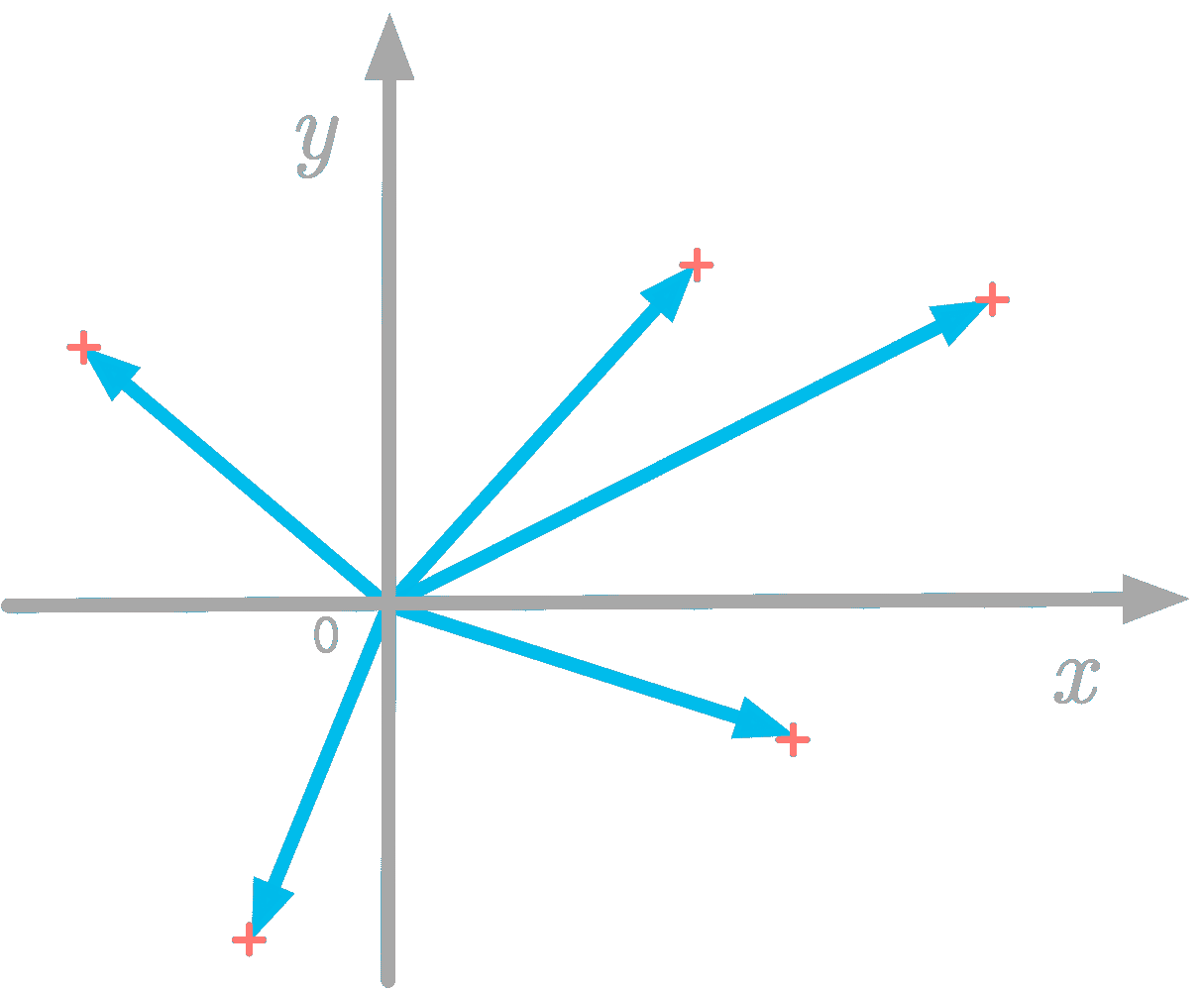
图 4:向量可以表示为笛卡尔平面上的点。
此外,如图 4 所示,你可以简单地表示箭头的终点:这就是散点图。
索引
索引指的是使用位置(即索引)获取向量分量(向量中的一个值)的过程。
Python 使用零基索引,意味着第一个索引是零。然而,从数学上讲,约定是使用一基索引。我将用下标表示向量v的分量i,即v[i],不使用粗体,因为向量的分量是标量。
Numpy
在 Numpy 中,向量被称为一维数组。你可以使用函数np.array()来创建一个:
v = np.array([3, 2])
v
array([3, 2])
更多分量
让我们以v为例,定义为三维向量如下:
如图 5 所示,你可以通过在 xx 轴上移动 3 个单位,在 yy 轴上移动 4 个单位,以及在 zz 轴上移动 2 个单位来到达向量的终点。

图 5:原点在(0, 0, 0)和点在(3, 4, 2)的三维表示。
更一般地,在一个n维空间中,终点的位置由n个分量描述。
维度
你可以使用集合符号表示向量的维度 。它表示实际坐标空间:这是一个具有实数作为坐标值的 nn 维空间。
。它表示实际坐标空间:这是一个具有实数作为坐标值的 nn 维空间。
例如,向量在 中具有三个分量,如下例中的向量v:
中具有三个分量,如下例中的向量v:
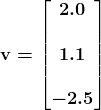
数据科学中的向量
在数据科学的背景下,你可以使用坐标向量来表示你的数据。
你可以将数据样本表示为向量,每个分量对应一个特征。例如,在一个房地产数据集中,你可以有一个向量表示一个公寓,其特征作为不同的分量(如房间数、位置等)。
另一种方法是为每个特征创建一个向量,每个向量包含所有观测值。
将数据存储在向量中允许你利用线性代数工具。请注意,即使你不能可视化具有大量分量的向量,你仍然可以对它们应用相同的操作。这意味着你可以使用二维或三维来获取线性代数的见解,然后将所学应用于更高维度。
点积
点积(指用于描述此操作的点符号),也称为 标量积,是一种对向量进行的操作。它接受两个向量,但与加法和标量乘法不同,它返回一个单一的数字(一个标量,因此得名)。它是更一般的操作 内积 的一个例子。
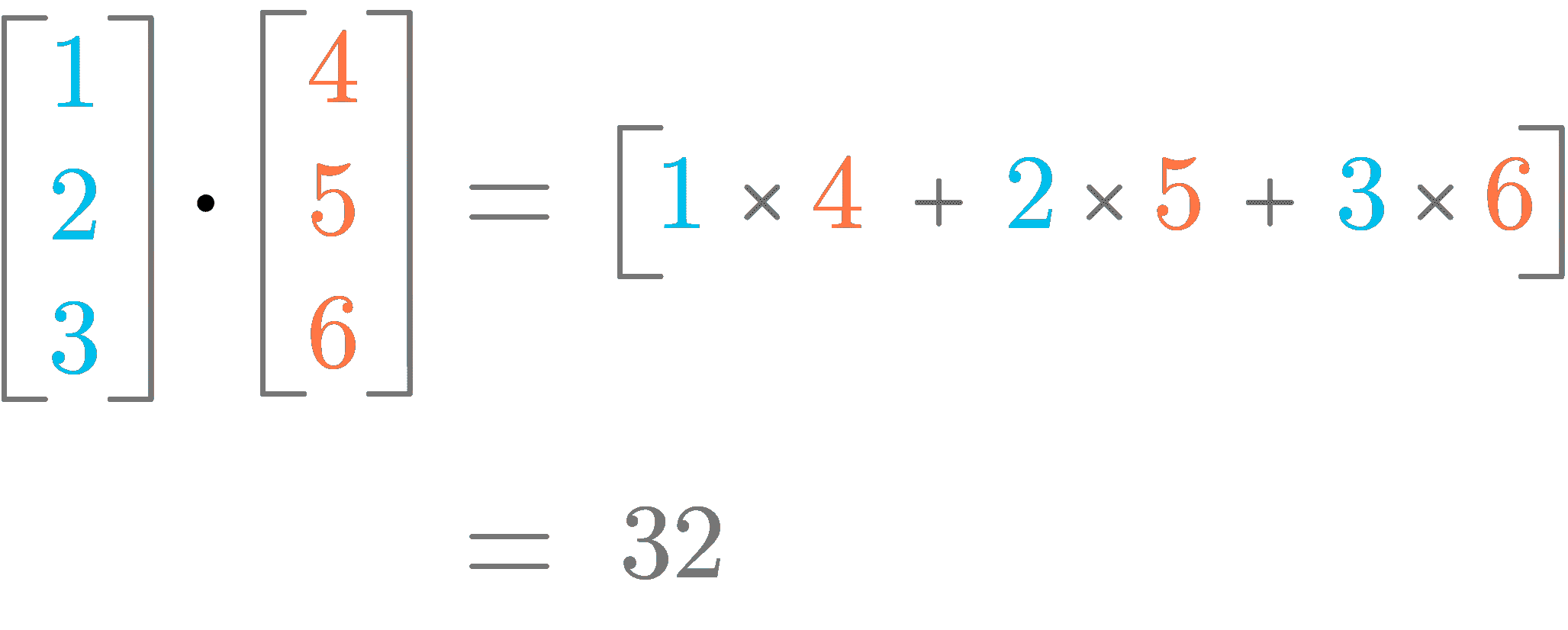
图 6:点积的示意图。
图 6 显示了点积的工作原理。你可以看到它对应于具有相同索引的分量的乘积之和。
定义
向量 u 和 v 之间的点积,用符号 ⋅ 表示,定义为每对分量乘积的和。更正式地,它表示为:
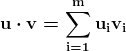
其中 m 是向量 u 和 v 的分量数量(它们必须具有相同数量的分量),i 是当前向量分量的索引。
点符号
请注意,点积的符号与用于标量之间乘法的点相同。上下文(元素是标量还是向量)告诉你它指的是哪一个。
让我们举一个例子。你有以下向量:
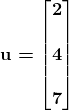
和
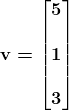
这两个向量的点积定义为:
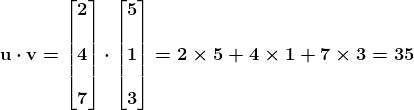
向量 u 和 v 之间的点积是 35。这将两个向量 u 和 v 转换为一个标量。
让我们使用 Numpy 来计算这些向量的点积。你可以使用 Numpy 数组的 dot() 方法:
u = np.array([2, 4, 7])
v = np.array([5, 1, 3])
u.dot(v)
35
还可以使用以下等效语法:
np.dot(u, v)
35
或者,在 Python 3.5+ 中,也可以使用 @ 运算符:
u @ v
35
向量乘法
请注意,点积不同于 逐元素 乘法,也称为 Hadamard 积,它返回另一个向量。符号 ⊙⊙ 通常用于描述此操作。例如:
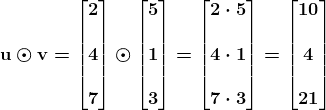
点积与向量长度
平方 L² 范数可以通过向量与自身的点积(u ⋅ u)来计算:
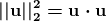
这是机器学习中的一个重要属性,如你在 数据科学的基础数学 中所看到的。
特殊情况
两个正交向量之间的点积等于 0。此外,单位向量与自身的点积等于 1。
几何解释:投影
你如何解释几何向量的点积操作。你在数据科学的基础数学中见过向量的加法和标量乘法的几何解释,那么点积呢?
让我们来看以下两个向量:
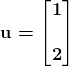
和
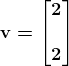
首先,让我们计算u和v的点积:
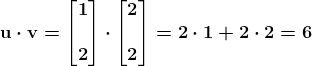
这个标量的意义是什么?嗯,它与将u投影到v上的想法有关。
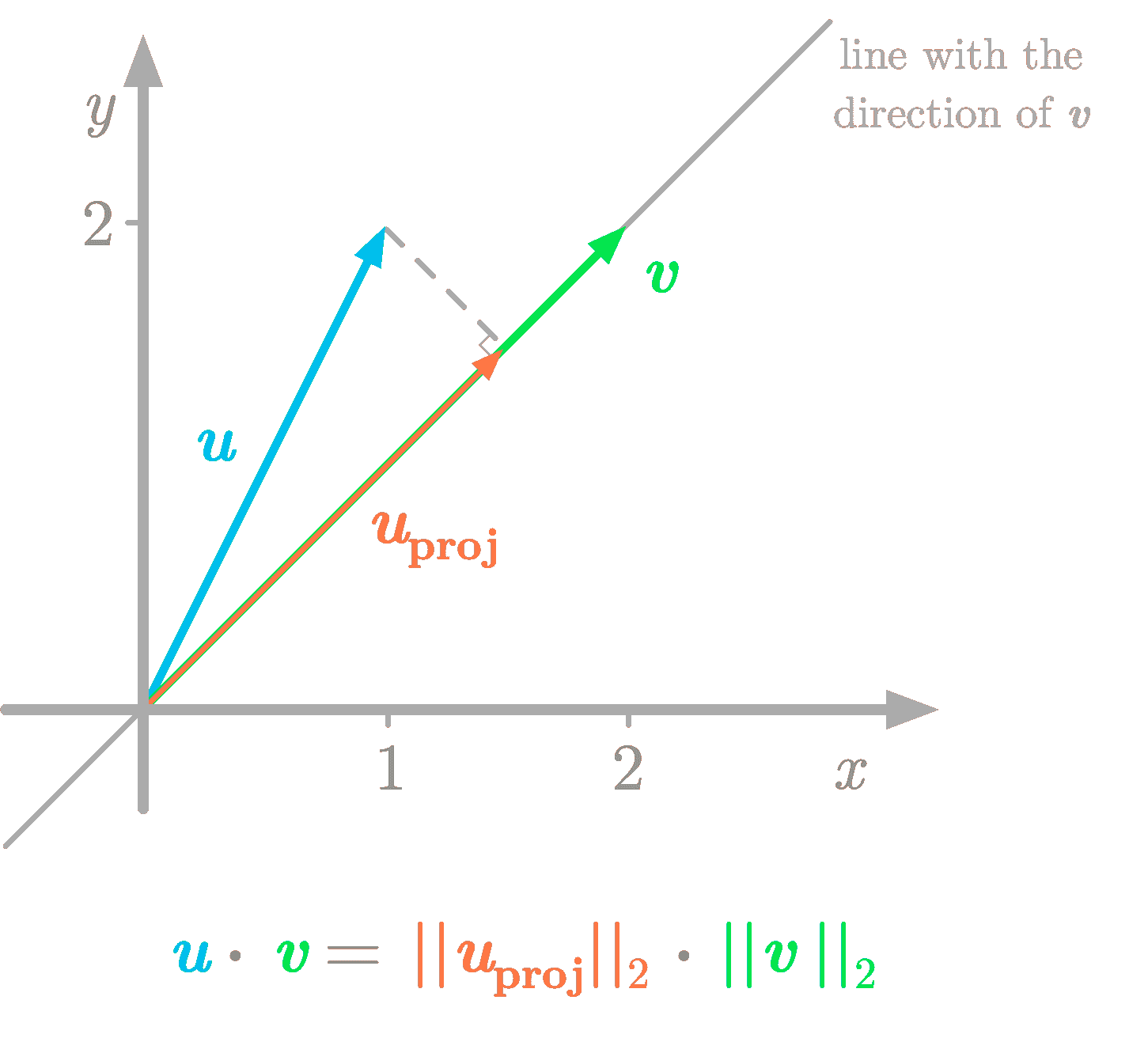
图 7:点积可以看作是 vv 的长度与投影的长度(向量 uprojuproj)的乘积。
如图 7 所示,将u投影到v方向的直线上的投影就像是向量u在这条直线上的影子。点积的值(在我们的例子中为 6)对应于v的长度(L²范数∥v∥)和u在v上的投影的长度(L²范数∥u[proj]∥)的乘积。你要计算:
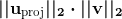
请注意,这些元素是标量,因此点号指的是这些值的乘法。你有:
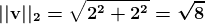
将u投影到v上的定义如下(你可以参考数据科学的基础数学查看有关向量投影到直线上的数学细节):
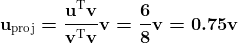
所以u[proj]的L²范数是 0.75 倍v的L²范数:
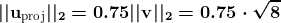
最后,v的长度与投影的长度的乘积是:
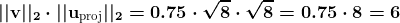
这表明你可以将几何向量上的点积看作是一种投影。使用投影给出的结果与你使用点积公式得到的结果相同。
此外,你通过点积得到的值告诉你两个向量之间的关系。如果这个值是正的,向量之间的角度小于 90 度;如果是负的,角度大于 90 度;如果是零,则向量正交,角度为 90 度。
属性
让我们回顾点积的一些属性。
分配律
点积是分配律的。这意味着,例如,对于三个向量u、v和w,你有:
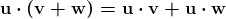
结合律
点积不是结合律的,这意味着操作的顺序很重要。例如:
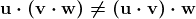
点积不是一个二元操作符:两个向量的点积结果不是另一个向量(而是一个标量)。
交换律
向量之间的点积被称为交换律。这意味着点积中向量的顺序并不重要。你有:
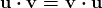
然而,要小心,因为这对矩阵不一定适用。
简介: 哈德里安·让 是一名机器学习科学家。他拥有巴黎高等师范学院的认知科学博士学位,曾利用行为学和电生理数据研究听觉感知。他曾在工业界工作,构建了用于语音处理的深度学习管道。在数据科学与环境交汇处,他从事关于利用深度学习分析音频记录进行生物多样性评估的项目。他还定期在 Le Wagon(数据科学训练营)创建内容和教学,并在他的博客(hadrienj.github.io)上撰写文章。
原文。经许可转载。
相关:
-
数据科学的基础数学:概率密度函数和概率质量函数
-
数据科学的基础数学:矩阵与矩阵乘积的介绍
-
数据科学的基础数学:积分和曲线下的面积
更多相关话题
数据科学的基础数学:奇异值分解的视觉介绍
在这篇文章中,你将了解奇异值分解(SVD),这是线性代数、数据科学和机器学习的一个主要主题。例如,它用于计算主成分分析(PCA)。你需要了解一些线性代数基础(可以查看前一篇文章和书籍 数据科学的基础数学)。
你只能对方阵应用特征分解,因为它使用了一个单一的基变换矩阵,这意味着初始向量和变换后的向量相对于同一个基。你用  转到另一个基进行变换,然后用
转到另一个基进行变换,然后用  回到初始基。
回到初始基。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
与特征分解一样,奇异值分解(SVD)的目标是将矩阵分解为更简单的组件:正交矩阵和对角矩阵。
你还可以看到矩阵可以被视为线性变换。矩阵的分解对应于将变换分解为多个子变换。在奇异值分解(SVD)的情况下,变换被转换为三个更简单的变换。
在这里,你将看到三个示例:一个是二维的,一个是比较 SVD 和特征分解的变换,另一个是三维的。
二维示例
你将使用自定义函数 matrix_2d_effect() 观察这些变换的作用。该函数绘制单位圆(有关单位圆的更多细节可以在 数据科学的基础数学 第五章找到),以及被矩阵变换后的基向量。
你可以在 这里 找到这个函数。
为了表示变换前的单位圆和基向量,我们使用这个函数,使用单位矩阵:
I = np.array([
[1, 0],
[0, 1]
])
matrix_2d_effect(I)
# [...] Add labels
图 0:单位圆和基向量
现在我们使用该函数查看矩阵 的效果。
的效果。
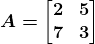
这将绘制单位圆和被矩阵变换的基向量:
A = np.array([
[2, 5],
[7, 3]
])
matrix_2d_effect(A)
# [...] Add labels
图 1:矩阵 AA 对单位圆和基向量的影响。
图 1 展示了对你二维空间的影响。我们将其与 SVD 矩阵相关的子变换进行比较。
你可以使用 Numpy 计算的 SVD:
U, Sigma, V_transpose = np.linalg.svd(A)
记住,矩阵 、
、 和
和 分别包含左奇异向量、奇异值和右奇异向量。你可以将
分别包含左奇异向量、奇异值和右奇异向量。你可以将 视为第一次基变换矩阵,为新基中的线性变换(由于是对角矩阵,因此该变换应为简单的缩放),而 UU 为另一次基变换矩阵。你可以在数据科学中的基本数学第十章中看到,SVD 限制了两个基变换矩阵和必须是正交的,这意味着这些变换将是简单的旋转。
视为第一次基变换矩阵,为新基中的线性变换(由于是对角矩阵,因此该变换应为简单的缩放),而 UU 为另一次基变换矩阵。你可以在数据科学中的基本数学第十章中看到,SVD 限制了两个基变换矩阵和必须是正交的,这意味着这些变换将是简单的旋转。
总结一下,对应矩阵的变换被分解为旋转(或反射,或旋转反射)、缩放和另一种旋转(或反射,或旋转反射)。
让我们依次查看每个矩阵的效果:
matrix_2d_effect(V_transpose)
图 2:矩阵对单位圆和基向量的影响。
你可以在图 2 中看到单位圆和基向量已被矩阵旋转。
matrix_2d_effect(np.diag(Sigma) @ V_transpose)
图 3:矩阵的效果 和 。
然后,图 3 显示了 的效果是单位圆和基向量的缩放。
matrix_2d_effect(U @ np.diag(Sigma) @ V_transpose)
图 4:矩阵的效果 、 和
最后,通过  应用第三次旋转。你可以在图 4 中看到,这个变换与矩阵 相关的变换是相同的。你已经将变换分解为旋转、缩放和旋转反射(查看基向量:已经进行了反射,因为黄色向量位于绿色向量的左侧,而这在最初并不是这样)。
应用第三次旋转。你可以在图 4 中看到,这个变换与矩阵 相关的变换是相同的。你已经将变换分解为旋转、缩放和旋转反射(查看基向量:已经进行了反射,因为黄色向量位于绿色向量的左侧,而这在最初并不是这样)。
与特征分解的比较
由于矩阵 是方阵,你可以将此分解与特征分解进行比较,并使用相同类型的可视化。你将获得有关两种方法之间差异的见解。
记住来自数据科学的基本数学第九章的内容,矩阵 AA 的特征分解是:
让我们用 Numpy 计算矩阵 和  (读作“资本 Lambda”):
(读作“资本 Lambda”):
lambd, Q = np.linalg.eig(A)
注意,由于矩阵 不是对称的,它的特征向量不是正交的(它们的点积不等于零):
Q[:, 0] @ Q[:, 1]
-0.16609095970747995
让我们看看  对基向量和单位圆的效果:
对基向量和单位圆的效果:
ax = matrix_2d_effect(np.linalg.inv(Q))
图 5:矩阵的效果 。
你可以在图 5 中看到, 旋转并缩放了单位圆和基向量。非正交矩阵的变换不是简单的旋转。
下一步是应用 。
ax = matrix_2d_effect(np.diag(lambd) @ np.linalg.inv(Q))
图 6:矩阵的效果 和
如图 6 所示, 的效果是沿 y 轴的拉伸和反射(黄色向量现在在绿色向量的右侧)。
ax = matrix_2d_effect(Q @ np.diag(lambd) @ np.linalg.inv(Q))
图 7:矩阵 、 和 的效果。
图 7 中显示的最后一个变换对应于将基转换回初始基。可以看到,这会导致与变换相关的结果相同,即:两个矩阵 和  是相似的:它们对应于不同基中的相同变换。
是相似的:它们对应于不同基中的相同变换。
这突出了特征分解和 SVD 之间的差异。使用 SVD,你有三种不同的变换,但其中两种仅为旋转。使用特征分解,只有两种不同的矩阵,但与 相关的变换不一定是简单的旋转(仅当是对称的时才是)。
三维示例
由于 SVD 可以用于非方阵,因此观察这些情况下变换的分解方式非常有趣。
首先,非方阵映射两个维度数量不同的空间。请记住, 通过
通过  矩阵映射一个 nn 维空间到一个 维空间。
矩阵映射一个 nn 维空间到一个 维空间。
以一个 3x2 矩阵为例,它将二维空间映射到三维空间。这意味着输入向量是二维的,输出向量是三维的。考虑矩阵 :
A = np.array([
[2, 5],
[1, 6],
[7, 3]
])
为了可视化的效果,你将再次使用二维单位圆,并计算一些圆上点的变换输出。每个点被视为输入向量,你可以观察 对这些向量的影响。函数matrix_3_by_2_effect()可以在这里找到。
ax = matrix_3_by_2_effect(A)
# [...] Add styles axes, limits etc.
图 8:矩阵的效果 :它将单位圆上的向量以及基向量从二维空间转换为三维空间。
如图 8 所示,二维单位圆被变换为三维椭圆。
你可以注意到输出向量都落在一个二维平面上。这是因为 的秩是二(有关矩阵秩的更多细节请参见 数据科学中的基本数学 第 7.6 节)。
现在你知道了通过 变换的输出,让我们计算 的 SVD,并观察不同矩阵的效果,就像你在二维示例中做的那样。
U, Sigma, V_transpose = np.linalg.svd(A)
左奇异向量的形状 () 是 mm 乘 mm,右奇异向量的形状 (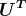 ) 是 乘 。矩阵 中有两个奇异值。
) 是 乘 。矩阵 中有两个奇异值。
与 相关的变换被分解为:首先是  中的旋转(与 相关,在示例中是
中的旋转(与 相关,在示例中是  ),然后是从 到
),然后是从 到  的缩放(在示例中,从 到
的缩放(在示例中,从 到  ),以及输出空间 IRmIRm 中的旋转(在示例中是 )。
),以及输出空间 IRmIRm 中的旋转(在示例中是 )。
让我们开始检查 对单位圆的影响。你在这一步仍然处于二维空间:
matrix_2d_effect(V_transpose)
图 9:矩阵的效果 :在这一步,你仍处于二维空间中。
然后,你需要重新塑形 ,因为函数 np.linalg.svd() 会给出一个包含奇异值的一维数组。你需要一个与 相同形状的矩阵:一个 3 乘 2 的矩阵,以便从二维到三维。这个矩阵将奇异值作为对角线,其余值为零。
让我们创建这个矩阵:
Sigma_full = np.zeros((A.shape[0], A.shape[1]))
Sigma_full[:A.shape[1], :A.shape[1]] = np.diag(Sigma)
Sigma_full
array([[9.99274669, 0\. ],
[0\. , 4.91375758],
[0\. , 0\. ]])
现在你可以添加的变换,以便在图 10 中查看三维结果:
ax = matrix_3_by_2_effect(Sigma_full @ V_transpose)
# [...] Add styles axes, limits etc.
图 10:矩阵的效果和:由于是一个 3x2 矩阵,它将二维向量转换为三维向量。
最后,你需要进行最后的基变换。由于矩阵是一个 3x3 矩阵,所以你停留在三维空间中。
ax = matrix_3_by_2_effect(U @ Sigma_full @ V_transpose)
# [...] Add styles axes, limits etc.
图 11:三个矩阵的效果、和:变换是从三维空间到三维空间。
你可以在图 11 中看到,结果与矩阵相关的变换相同。
摘要
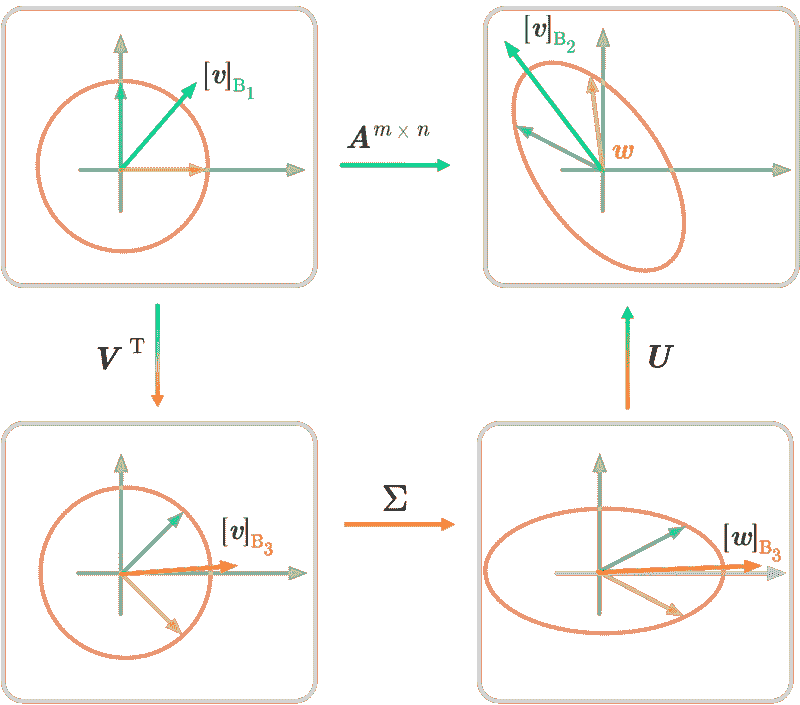
图 12:二维中的奇异值分解(SVD)。
图 12 总结了将矩阵 AA 分解为三个矩阵的 SVD 分解。与相关的变换由三个子变换完成。符号与图 12 中相同,说明了 SVD 的几何视角。
奇异值分解可以用来找到近似矩阵的变换(见数据科学基础数学第 10.4 节的低秩矩阵近似)。
原文。 经许可转载。
Hadrien Jean 是一名机器学习科学家。他拥有巴黎高等师范学院的认知科学博士学位,曾使用行为和电生理数据研究听觉感知。他曾在工业界工作,构建了用于语音处理的深度学习管道。在数据科学与环境交汇处,他致力于使用深度学习应用于音频录音的生物多样性评估项目。他还定期在 Le Wagon(数据科学训练营)创建内容和教学,并在他的博客中撰写文章(hadrienj.github.io)。
主题更多
Essential MLOps:一本免费的电子书
原文:
www.kdnuggets.com/2023/06/essential-mlops-free-ebook.html
MLOps,即机器学习操作,是一种促进数据科学家和运营专业人员之间协作和沟通的实践,旨在帮助管理生产环境中的 ML 生命周期。它结合了机器学习、DevOps 和数据工程,以标准化和简化 AI 模型在生产中的部署、测试和监控。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 工作
MLOps 是至关重要的,因为它解决了大规模部署 ML 模型的挑战。它有助于管理 ML 模型的复杂性、多样性和数量,同时确保过程的稳健性、可重复性和可扩展性。机器学习模型的价值取决于它们在实际应用中的表现,而 MLOps 使企业能够持续监控和改进模型。
此外,MLOps 强调自动化、可重复性以及持续集成和部署,这些都是满足现代企业快节奏需求所必需的。这些实践有助于缩短上市时间,确保模型的准确性和可靠性。没有 MLOps,组织可能会在部署和维护机器学习模型时面临困难,从而导致错失机会或无效的 AI 应用。因此,MLOps 在将 AI 落实到实际操作中起着关键作用,为过程带来更多的准确性、效率和可预测性。
现在有多种资源可以学习 MLOps 的基础知识,而现在还有一本新书加入其中。数据科学地平线 最近发布了一本关于 MLOps 基础知识的免费电子书,标题为 Essential MLOps:成功实施所需了解的要点。
《Essential MLOps: What You Need to Know for Successful Implementation》 涵盖了广泛的主题,从 MLOps 的基础概念及数据科学家和工程师在这一领域的角色,到数据管理、模型训练与评估以及持续集成和部署等关键技能。此外,我们深入探讨了促进 MLOps 实施的工具和技术,包括数据版本控制系统、CI/CD 工具和监控解决方案。最后,通过一系列案例研究,我们展示了 MLOps 在各个行业的实际影响,突出它如何提高效率、更具信息的决策和更好的整体性能。
这本电子书在相对较少的页面中涵盖了大量内容,简明扼要地向读者介绍了 MLOps 领域的重要话题。
如果你对机器学习操作的初学者介绍感兴趣,可以查看 《Essential MLOps: What You Need to Know for Successful Implementation》。
Matthew Mayo (@mattmayo13) 是数据科学家及 KDnuggets 的主编,这是一个开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。可以通过 editor1 at kdnuggets[dot]com 联系他。
更多相关主题
数据处理的必备 Python 库
原文:
www.kdnuggets.com/essential-python-libraries-for-data-manipulation

图像由 Midjourney 生成
作为数据专业人士,理解如何处理数据至关重要。在现代时代,这意味着使用编程语言快速处理我们的数据集,以实现我们预期的结果。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域的职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
Python 是数据专业人士使用的最流行的编程语言,许多库对于数据处理都非常有用。从简单的向量到并行计算,每个用例都有一个可以帮助的库。
那么,哪些 Python 库对数据处理至关重要呢?让我们深入了解一下。
1.NumPy
我们将讨论的第一个库是 NumPy。NumPy 是一个用于科学计算的开源库。它于 2005 年开发,并已在许多数据科学案例中使用。
NumPy 是一个流行的库,提供了许多在科学计算活动中有价值的功能,如数组对象、向量运算和数学函数。此外,许多数据科学用例依赖于复杂的表格和矩阵计算,因此 NumPy 允许用户简化计算过程。
让我们在 Python 中尝试 NumPy。许多数据科学平台,如 Anaconda,默认情况下已安装 NumPy。但你也可以通过 Pip 安装它们。
pip install numpy
安装完成后,我们将创建一个简单的数组并执行数组操作。
import numpy as np
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
c = a + b
print(c)
输出:[5 7 9]
我们还可以使用 NumPy 进行基本的统计计算。
data = np.array([1, 2, 3, 4, 5, 6, 7])
mean = np.mean(data)
median = np.median(data)
std_dev = np.std(data)
print(f"The data mean:{mean}, median:{median} and standard deviation: {std_dev}")
数据均值:4.0,中位数:4.0,标准差:2.0
还可以进行线性代数运算,如矩阵计算。
x = np.array([[1, 2], [3, 4]])
y = np.array([[5, 6], [7, 8]])
dot_product = np.dot(x, y)
print(dot_product)
输出:
[[19 22] [43 50]]
使用 NumPy 你可以获得很多好处。从数据处理到复杂的计算,难怪许多库都以 NumPy 为基础。
2. Pandas
Pandas 是数据专业人士最流行的数据处理 Python 库。我相信许多数据科学学习课程会将 Pandas 作为后续处理的基础。
Pandas 因其直观的 API 和多功能性而闻名,因此许多数据操作问题可以轻松通过 Pandas 库解决。Pandas 允许用户执行数据操作,并分析来自各种输入格式的数据,如 CSV、Excel、SQL 数据库或 JSON。
Pandas 构建在 NumPy 之上,因此 NumPy 对象的属性仍适用于任何 Pandas 对象。
让我们尝试使用该库。像 NumPy 一样,如果你使用像 Anaconda 这样的数据科学平台,它通常会默认提供。然而,如果你不确定,可以参考 Pandas 安装指南。
你可以尝试从 NumPy 对象初始化数据集,并使用以下代码获取一个显示前五行数据的 DataFrame 对象(类似表格)。
import numpy as np
import pandas as pd
np.random.seed(0)
months = pd.date_range(start='2023-01-01', periods=12, freq='M')
sales = np.random.randint(10000, 50000, size=12)
transactions = np.random.randint(50, 200, size=12)
data = {
'Month': months,
'Sales': sales,
'Transactions': transactions
}
df = pd.DataFrame(data)
df.head()
然后你可以尝试进行几种数据操作活动,如数据选择。
df[df['Transactions'] <100]
可以进行数据计算。
total_sales = df['Sales'].sum()
average_transactions = df['Transactions'].mean()
使用 Pandas 进行数据清理也很容易。
df = df.dropna()
df = df.fillna(df.mean())
使用 Pandas 进行数据操作有很多事情要做。查看 Bala Priya 关于使用 Pandas 进行数据操作的文章 以进一步了解。
3. Polars
Polars 是一个相对较新的数据操作 Python 库,旨在快速分析大型数据集。与 Pandas 在几个基准测试中相比,Polars 的性能提升了 30 倍。
Polars 建立在 Apache Arrow 之上,因此它在大数据集的内存管理方面高效,并支持并行处理。它还通过延迟执行来优化数据操作性能,只有在需要时才进行计算。
对于 Polars 的安装,你可以使用以下代码。
pip install polars
像 Pandas 一样,你可以用以下代码初始化 Polars DataFrame。
import numpy as np
import polars as pl
np.random.seed(0)
employee_ids = np.arange(1, 101)
ages = np.random.randint(20, 60, size=100)
salaries = np.random.randint(30000, 100000, size=100)
df = pl.DataFrame({
'EmployeeID': employee_ids,
'Age': ages,
'Salary': salaries
})
df.head()
然而,我们使用 Polars 操作数据的方式有所不同。例如,这里是如何使用 Polars 选择数据的。
df.filter(pl.col('Age') > 40)
API 比 Pandas 复杂得多,但如果你需要快速处理大型数据集,这将非常有用。另一方面,如果数据量较小,你将不会获得这个好处。
要了解详细信息,可以参考 Josep Ferrer 关于 Polars 与 Pandas 的比较分析的文章。
4. Vaex
Vaex 类似于 Polars,因为该库专门用于大规模数据集的数据操作。然而,它们处理数据集的方式存在差异。例如,Vaex 使用内存映射技术,而 Polars 侧重于多线程处理方法。
Vaex 非常适合比 Polars 所设计的更大的数据集。虽然 Polars 也用于大规模数据集处理,但该库理想的应用于仍能适配内存大小的数据集。同时,Vaex 非常适合用于超出内存的数据集。
对于 Vaex 的安装,最好参考他们的文档,因为如果安装不正确,可能会破坏你的系统。
5. CuPy
CuPy是一个开源库,可以在 Python 中实现 GPU 加速计算。CuPy 是为 NumPy 和 SciPy 设计的替代品,适用于在 NVIDIA CUDA 或 AMD ROCm 平台上运行计算。
这使得 CuPy 非常适合需要强大数值计算并需要使用 GPU 加速的应用。CuPy 可以利用 GPU 的并行架构,对于大规模计算非常有益。
要安装 CuPy,请参考他们的 GitHub 仓库,因为许多可用版本可能适用于或不适用于你使用的平台。例如,下面的是针对 CUDA 平台的。
pip install cupy-cuda11x
这些 API 与 NumPy 类似,因此如果你已经熟悉 NumPy,可以立即使用 CuPy。例如,下面是 CuPy 计算的代码示例。
import cupy as cp
x = cp.arange(10)
y = cp.array([2] * 10)
z = x * y
print(cp.asnumpy(z))
如果你持续处理高规模计算数据,CuPy 是一个不可或缺的 Python 库。
结论
我们探索过的所有 Python 库在特定用例中都是必不可少的。NumPy 和 Pandas 可能是基础,但像 Polars、Vaex 和 CuPy 这样的库在特定环境下会非常有用。
如果你认为还有其他必不可少的库,请在评论中分享!
Cornellius Yudha Wijaya**** 是数据科学助理经理和数据撰写者。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作分享 Python 和数据技巧。Cornellius 涉及各种 AI 和机器学习话题。
更多相关主题
学习贝叶斯统计的关键资源
原文:
www.kdnuggets.com/2020/07/essential-resources-learn-bayesian-statistics.html
评论
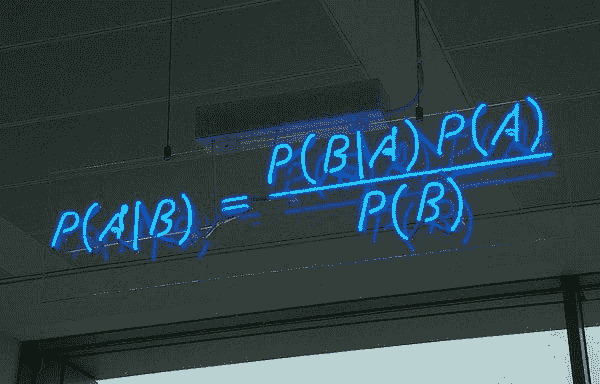
在这篇文章中,我总结了一系列入门贝叶斯统计的资源。我根据自己的经验和对什么是良好介绍及下一步的看法编制了这些参考资料。这不是学术课程或特别严谨的内容,但这是一个全面的列表,必定会帮助你开始重温/开始你的统计学之旅。以下许多参考资料是在我参加的几个研讨会上推荐给我的,我希望与那些想提高统计学和机器学习(ML)技能的人分享。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 需求
我能想到的初学者入门贝叶斯统计和建模的第一个资源是理查德·麦克艾瑞斯的 《统计学的重新思考》。在这里,你将学习从在简单问题中应用贝叶斯规则到复杂的多层/层级模型的所有内容。由于这不仅是一本书,还有一个完整的课程,你绝对应该在阅读过程中跟随 YouTube 上的视频讲座。我建议你完成每章末尾的代码和练习,因为这是获得实际操作经验的最佳方式。另一个好处是,书中的 R 包 rethinking 和所有示例代码已经被翻译成多种编程语言,因此你可以自由选择你喜欢的语言进行阅读。
对于那些想通过真实世界的例子来复习统计知识的人来说,Andrew Gelman 和 Jennifer Hill 的 数据分析:回归与多层次/分层模型 是一本很棒的书,适合那些对社会科学应用统计有更多兴趣的人。该书的更新版名为 回归与其他故事(Andrew Gelman, Jennifer Hill, Aki Vehtari),预计今年晚些时候发布。如果你想深入学习贝叶斯统计的更高级课程,我建议你访问 Aki Vehtari 的教学页面。虽然这比 McElreath 的课程更具挑战性,但值得一看。课程材料在 R 和 Python 中均有提供。
现在,你已经复习了基础统计,并阅读了大部分 McElreath 的书,但你也想了解机器学习。你可能会问,接下来应该去哪里?做些什么?挑战自己阅读 Christopher Bishop 的 模式识别与机器学习。Bishop 的书通过隐含的贝叶斯视角介绍了从回归和分类到神经网络的所有知名机器学习概念。可以说,我仅通过阅读前几章就深刻加强了我在机器学习和贝叶斯统计方面的知识。尽管我强烈推荐这本书,但请记住,这本书较为高级,需要时间来理解其概念。
与 Bishop 的书籍处于同一水平,你还可以在 David MacKay 的信息理论、推理与学习算法 中找到严谨且详细的贝叶斯统计和建模解释。我很幸运在大学时使用了这本书,它仍然在我重新审视一些概率概念、贝叶斯统计和机器学习时至关重要。该书网页还提供了软件资源和示例,供你在阅读文本时进行实验和探索。
每当你对基础知识感到足够舒适,准备深入了解概率建模、概率计算和应用贝叶斯统计背后的数学和理论概念时,我强烈建议你按顺序阅读 Michael Betancourt 的所有案例研究。这在开始时可能很难掌握,但随着你回顾内容并投入时间理解这些概念,最终的回报是巨大的。
现在,很少听到贝叶斯方法在工业界的成功故事,特别是在机器学习和人工智能备受关注的今天。对于喜欢通过播客了解从业者和应用贝叶斯统计的人的故事的人,我强烈建议你去听亚历山大·安多拉的播客《学习贝叶斯统计》。亚历克斯在采访来自各种领域的专业人士时做得非常出色,介绍了贝叶斯统计的广阔应用宇宙。
最后一点是上述参考资料和资源的共同点,那就是马尔可夫链蒙特卡罗(MCMC)。要全面探索概率空间和分布,你需要像 MCMC 及其高级变体这样的高效且可靠的计算方法。如今,许多编程语言可以实现这种先进的估计算法,但最受欢迎的是 1) Stan,它基于 C++,并具有多个接口到 R (rstanarm、brms)、Python (PyStan)、Julia 等,以及 2) PyMC3。如果你有兴趣学习基础知识,可以访问他们的网页查看代码示例。
总结一下,我想分享一下我在贝叶斯统计方面的个人经历。这个话题并不简单,你应该投入一些时间以看到进展。上述参考资料是一个很好的起点,我通过尝试将贝叶斯方法应用于我的工作中,发现了学习路径中的重要一步。对我来说,它的基础更直观和透明,总体上也更易于理解(至少在概念上),但应用起来却相当困难。
相关链接:
更多相关内容
人工智能的伦理:导航智能机器的未来
原文:
www.kdnuggets.com/2023/04/ethics-ai-navigating-future-intelligent-machines.html

作者提供的图片
根据你的生活背景,每个人对人工智能及其未来有不同的看法。一些人认为这只是一个即将消退的潮流,而另一些人则认为将其应用于我们的日常生活中有巨大的潜力。
到目前为止,很明显,人工智能对我们的生活产生了重大影响,并且它将长期存在。
随着 ChatGPT 等 AI 技术的最新进展,以及 Baby AGI 等自主系统的出现,我们可以期待人工智能在未来的持续进步。这并不新鲜。这与计算机、互联网和智能手机的到来带来的剧变是一样的。
几年前,进行了一项调查,在六个国家的 6000 名客户中,仅有 36%的消费者对企业使用人工智能感到舒适,而 72%的人表示对人工智能的使用感到担忧。
尽管这非常有趣,但也可能令人担忧。虽然我们期待未来人工智能有更多的发展,但最大的问题是‘它的伦理是什么?’。
人工智能发展的最主要领域是机器学习。这使得模型能够利用过去的经验,通过探索数据和识别模式来学习和改进,几乎无需人工干预。机器学习被应用于不同的领域,从金融到医疗保健。我们有了像 Alexa 这样的虚拟助手,现在还有像 ChatGPT 这样的巨大语言模型。
那么,我们如何确定这些人工智能应用的伦理标准,它将如何影响经济和社会呢?
人工智能的伦理关注
关于人工智能存在一些伦理问题:
1. 偏见与歧视
尽管数据被称为新石油,并且我们拥有大量的数据,但关于人工智能是否会对其拥有的数据产生偏见和歧视仍然存在担忧。例如,面部识别应用被证明对某些族群,尤其是肤色较深的人群,存在严重的偏见和歧视。
尽管一些面部识别应用存在严重的种族和性别偏见,但像亚马逊这样的公司在 2018 年拒绝停止向政府销售该产品。
2. 隐私
另一个关于人工智能应用的担忧是隐私。这些应用需要大量数据以产生准确的输出并保持高性能。然而,关于数据收集、存储和使用的问题仍然存在。
3. 透明度
尽管人工智能应用程序输入了数据,但对这些人工智能应用程序如何做出决策的透明度存在很高的担忧。这些人工智能应用程序的创作者面临着透明度不足的问题,提出了谁应对结果负责的疑问。
4. 自主应用程序
我们已经看到 Baby AGI 的诞生,这是一个自主任务管理器。自主应用程序能够在人工的帮助下做出决策。这自然引起公众对将决策权交给技术的关注,这在社会眼中可能被视为伦理或道德上不正确。
5. 职业安全
自人工智能诞生以来,这一担忧一直存在。随着越来越多的人看到技术能够完成他们的工作,比如 ChatGPT 生成内容并可能取代内容创作者——将人工智能应用到我们日常生活中会带来哪些社会和经济后果?
伦理人工智能的未来
在 2021 年 4 月,欧盟委员会发布了关于人工智能使用法案的立法。该法案旨在确保人工智能系统符合基本权利,并为用户和社会提供信任。它包含了一个框架,将人工智能系统分为 4 个风险领域:不可接受的风险、高风险、有限风险以及最小或无风险。你可以在这里了解更多:欧洲人工智能法案:简化解析。
巴西等其他国家在 2021 年也通过了一项法律,创建了关于人工智能使用的法律框架。因此,我们可以看到全球各国和大陆正在进一步探讨人工智能的使用以及如何伦理地使用它。
人工智能的快速发展必须与提议的框架和标准对齐。构建或实施人工智能系统的公司必须遵循伦理标准,并对应用程序进行评估,以确保透明度、隐私,同时防范偏见和歧视。
这些框架和标准将需要关注数据治理、文档记录、透明度、人类监督以及强大、准确和网络安全的人工智能系统。如果公司未能遵守,他们将不得不面对罚款和处罚。
总结一下
ChatGPT 的推出和通用人工智能应用程序的发展促使科学家和政治家建立法律和伦理框架,以避免人工智能应用程序可能带来的任何潜在危害或影响。
仅今年就发布了许多关于人工智能及其伦理的论文。例如,通过比较视角评估跨大西洋人工智能驱动决策制定的竞赛。我们将继续看到越来越多的论文发布,直到政府进行并发布清晰而简洁的框架供公司实施。
Nisha Arya 是一位数据科学家、自由技术作家以及 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何/可以促进人类生命的长寿。作为一个热心的学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关主题
伦理学 + 数据科学:由前美国首席数据科学家 DJ Patil 的观点
评论
由 DJ Patil,前美国首席数据科学家。

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
数据在过去十年中改变了我们的生活多少?就在十多年前,iPhone 刚刚发布。那时候,我们的手机只能拍出模糊的照片,视频仅仅是个幻想。那时在互联网上购买鞋子还是很奇怪的,我们还得在访问新城市时携带一叠地图。Netflix 还只是一个 DVD 公司。
现在,你的手机可以拍照和录像,每秒钟有超过 4,000 张照片上传到 Facebook,每分钟有超过 400 小时的视频上传到 YouTube。我们比起确保我们有地图,更担心是否能保持连接。我们的地图应用提供实时交通情况和通过交通的导航选项。不想开车?没问题,使用一个利用数万亿数据点的共享出行应用。这种剧烈变化的根本转变是计算能力、存储和数据的巨大增长组合。当然,还有那些让这些想法成为现实的数据科学家、设计师和其他技术专家。
数据带来的变革才刚刚开始。我们即将从测序人类基因组过渡到实现个性化医疗(精准医疗)。自主车辆已开始出现在我们的道路上,我们将看到努力建造货船和飞机的尝试。而人工智能也展示了思考游戏的新方式,因为它们击败了最优秀的人类。
与此同时,我们也看到数据被用来造成伤害,通过疏忽、天真和复杂的攻击。无论是美国选举、英国脱欧、自动驾驶汽车事故,还是种族歧视算法;我们必须预计到数据带来的伤害会增加。我们才刚刚开始应对由于自动化带来的工作岗位流失的社会影响。
我们需要解决的问题是,我们能做些什么来确保数据和技术为我们服务,而不是对我们不利?

白宫幕僚长团队将分发的贴纸
有来自欧盟的监管方法(GDPR)和加州的(CCPA)。以及美国国会的听证会(没有行动)。也有一些书籍强调了未来的风险,例如《数学武器的毁灭》和《自动化的不平等》。还有一些新的智库,如人工智能合作伙伴关系、AI Now 研究所和人文技术中心,它们开始研究对社会的更广泛影响。
我是这些努力的粉丝。它们非常必要。我想问的问题是:负责构建这些技术的数据科学家和其他团队成员的角色是什么?他们在实施“良好”数据科学方面的作用是什么?(在这篇文章中也讨论过。)

当希拉里·梅森和我出版了《数据驱动:创建数据文化》时,我们意识到很少有措施来赋权那些想要做正确事情的人。这些技术专家、设计师和产品经理可能有正确的自然直觉,但由于商业压力或不理想的实践,常常被边缘化。而在其他情况下,他们甚至不知道要问什么问题。
我们与希拉里·梅森和迈克·卢基德斯(他一直是我们每本书的编辑,我们最终说服他成为合著者)一起查看了我们在数据科学家中看到的最佳实践,并发布了一本新电子书:伦理与数据科学。
鉴于我们对这个话题的期望改变如此之大,我们将这本书视为一个开源项目,这里是 0.1 版本。我们也确保它将始终免费并采用创意共享许可证(所以你可以拿它并与自己的努力结合)。我们也希望其他人考虑贡献,我们会在O'Reilly Radar 的伦理系列上发布这些更新。我们也故意保持它尽可能简短,希望你能与其他团队分享。(你可以在这里免费获取我们所有的电子书。)

你可以在书中期待找到什么?我们涵盖了一个模型清单(借鉴了Atul Gawande 的《清单宣言》),用于构建数据产品(如果你正在做类似的事情,我们非常希望听到你的成功经验和失败教训)。关于如何在产品开发过程中实施更道德的行为,包括如果你不同意团队意见的异议渠道。如何开始面试以评估文化适配和道德适配。还包括我们所谓的 5C——五个框架指南帮助我们思考构建数据产品(同意、清晰、一致、控制与透明度,以及后果与伤害)。最后,我们包含了普林斯顿大学 Ed Felten 团队的一组案例研究,供你和你的团队参考。
我们最希望听到的是你的声音。数据的影响力正在显现,我们需要赶在它之前。这从我们开始。那些正在构建这些技术的人。在这里获取电子书。
开始行动吧。没有人会来救我们,一切都靠我们自己。
简介:DJ Patil 旨在改变我们的医疗保健系统。前美国首席数据科学家。
原始。经许可转载。
相关:
更多相关话题
机器学习中的伦理 – 摘要
原文:
www.kdnuggets.com/2016/06/ethics-machine-learning-mlconf.html
comments
作者:Courtney Burton, MLconf

感谢 Akash!这正是我们所期望的!我们在 5 月 20 日首次决定在西雅图举办一系列关于机器学习伦理的讲座。正如我们上个月在 KD Nuggets 文章中提到的,我们最近问了自己这样一个问题:如果 AI 从我们这里学习,它真的能安全吗?根据我们的 Quora 问题:“需要哪些限制来防止 AI 和机器学习算法成为对人类的反乌托邦威胁?”,比赛的获胜者 Igor Markov 在 5 月 20 日于 MLconf 西雅图展示了他的答案和计划。
马尔科夫引用了百度研究的 Andrew Ng 的话,他说:“今天担心 AI 就像担心火星上的人口过剩。”马尔科夫接着探讨了几部科幻电影,以及机器如何掌握权力、社会对现实中这一现象的恐惧,然后提醒我们人类如何在过去的时代生存,以及如何在“机器崛起”的时代利用这些知识。在他的计划中,马尔科夫建议在设计 AI 系统时,应该在不同的智力和信任水平之间引入和保持边界。他的关键点是:
-
代理应当具有关键的弱点
-
软件和硬件的自我复制应该受到限制
-
自我修复和自我改进应当受到限制
-
能源获取应当受到限制
下图指向了 AI 的约束以拦截反乌托邦威胁:

马尔科夫的完整幻灯片可以在 MLconf 的 Slideshare 账户中找到,点击这里。
紧接着 Markov 的是 Meetup 的首席机器学习工程师 Even Estola。在一次活动前的采访中,Estola 参与了有关机器学习伦理的讨论。他的回应是:“因为构建机器学习技能的最简单方法是练习现成的数据集,所以很容易遇到实际数据中的问题。事实证明,野生数据是混乱、不完整的,有时甚至带有种族主义、性别歧视和不道德。我们需要承认现实世界有时会很糟糕,因此我们应该构建应对这种情况的系统,而不是屈服于此。这不会很容易,可能会使我们的传统性能指标有所下降,但我们所知道的机器学习只能推断现状,我们需要做得更好。我们都知道,种族主义计算机是一个糟糕的主意。不要让你的公司制造种族主义计算机。”在他的讲话中,Estola 呼吁我们提高对这个问题的认识,并建议使用简单的解决方案,即使它们在性能上有小的让步。他还建议使用集成建模和设计测试数据集以捕捉无意的偏见。
Estola 的完整幻灯片可以在 MLconf Slideshare 账户中找到,点击这里。
随后是 Florian Tramèr,他展示了数据驱动应用中不公平关联与后果的示例,以及这些错误如何有可能冒犯大众。Tramèr 继续解释了预防措施及其局限性。他的解决方案是 FairTest,它找到保护变量和应用输出之间的特定上下文关联。FairTest 可用于理解和评估潜在的关联错误。
*幻灯片 5/10,Tramer 的幻灯片在MLconf Slideshare 账户。
机器学习中的伦理讨论远未结束。我们希望通过提供一个表达这些想法的平台,能够继续推进,防止我们构建的机器对社会构成潜在威胁。幸运的是,社区并未在概念和哲学层面处理这个潜在问题。研究活动在增加,寻求这些潜在威胁的解决方案。我们旨在揭示这些工作的价值。
在MLconf Seattle上还有 12 位才华横溢的演讲者,他们不容忽视,他们介绍了各种主题,如机器学习的未来、自然语言处理、概率编程、多算法集成、与深度学习相关的神经科学、推荐系统等!我们将在本系列活动中涵盖这些以及更多机器学习相关话题秋季。提及“Ethics18”,即可在任何即将到来的秋季活动中享受 18%的折扣!
相关:
-
机器学习中的伦理:我们从 Tay 聊天机器人事件中学到了什么?
-
数据科学与偏见 – 祝福还是诅咒?
-
互联网中的人:分析个人数据的 4 个关键原则
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关主题
大数据和数据科学的 3 个关键伦理原则
原文:
www.kdnuggets.com/2016/07/ethics-principles-big-data-science.html
评论
由 Jay Taylor 提供。
大数据在当代世界无处不在。数据通过我们几乎所有的活动被收集。从智能手机收集我们的信息,到网站抓取我们经常访问的地方进行广告分析,到各个层级的社交媒体,我们的数字足迹无处不在。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织 IT
在任何现代行业中,伦理问题很快就会被提及。随着技术以指数级的速度加速发展,数据的收集速度也在加快。例如,电子支付方面发生了剧烈变化。由于支付卡和手机中的 NFC 芯片,购买物品的快速访问只会继续扩展。曾经需要几分钟的,现在只需几秒钟。
那么伦理问题呢?是什么在约束那些以分析驱动的公司的大商业方面?我们如何知道这些数据是否会以我们的最佳利益为出发点?
数据科学中的伦理培训
所以,如果伦理总的来说很重要,伦理培训是否应该成为数据科学领域的一个关键元素?
在之前的一篇 KDnuggets 帖子中,这个问题已经被探讨过了。在一项对全球 324 人的调查中,答案非常明确。绝大多数投票者(76%)表示,是的,伦理培训应该纳入数据科学的领域中。只有 17%的人反对伦理培训,7%的人不确定。
伦理培训调查 由 KDnuggets 提供
认证分析师(CAP)和联合国统计司已经发布了官方的 伦理规范 和 声明。这些指南的目的是阐明至关重要的伦理要求,以设立标准,帮助遏制欺骗行为,并使个人和组织对其收集和使用数据驱动信息的方式负责。
在这里,我们总结了基于近期专家提案的数据科学和大数据的关键伦理指南。
1. 收集最少的数据,聚合现有的数据
如果公司想要保护其用户和数据,必须确保只收集真正必要的数据。数据的丰富并不一定意味着有大量可用的数据。保持数据收集简洁而有目的至关重要。相关数据必须受到高度重视,以保护隐私。
保持数据聚合也很重要,以保护隐私并增强透明度。当前,算法被用于从机器思维和自动驾驶汽车,到数据科学和预测分析等各种领域。用于数据收集的算法允许公司看到消费者的非常具体的模式和行为,同时保护他们的身份。
一篇题为《大数据的伦理》的文章涉及了数据聚合的主题。熊辉,一位管理科学与信息系统的副教授表示:
“公司可以在关注隐私问题的同时利用这一力量的一种方式是聚合数据……如果数据表明有 50 人遵循某种特定的购物模式,就止步于此,利用这些数据,而不是进一步挖掘,可能暴露个人行为。”
情况变得非常有趣……Google、Facebook、Amazon 和 Microsoft 拥有最隐私的信息,同时也肩负着最大的责任。因为他们对数据的理解非常深入,像 Google 这样的公司通常具备最强的参数来分析和保护他们收集的数据。”

2. 识别并清理敏感数据
信息科学领域的员工必须理解哪些数据是个人的和敏感的,并找出利用这些信息的方法。当未经同意收集消费者信息时,必须清除可能导致数据具有个人可识别性的洞察。
一篇题为《五种方式在不妨碍隐私的情况下“利用”大数据》的文章强调了以下几点:
“违反法规可能会导致罚款、声誉损害和客户流失。但有方法可以在利用大数据提供的机会的同时最小化风险……组织需要实施一种数据隐私解决方案,防止数据泄露并强化安全,帮助企业:
- 识别所有敏感数据。
- 确保敏感数据得到识别和保护。
- 确保遵守所有适用的法律法规。
- 主动监控数据和 IT 环境。
- 对数据或隐私泄露进行快速反应和处理。

3. 制定应对计划,以防您的见解适得其反
无论你是否意识到,每次你走进商店并进行购买时,都会收集关于你购物的某种信息。几年前,零售巨头 Target 突破了典型的客户跟踪水平。
他们开发了一种基于 25 个项目的方法,这些项目在一起购买时通常表示顾客可能怀孕。这种顾客意识对于理解购物习惯和决定发送哪些促销和优惠券很有帮助。但它缺少一个重要的筛选条件。
这个过程适得其反,因为一位困惑的明尼阿波利斯男子冲进 Target,紧握着寄给他十几岁女儿的特定优惠券。一篇Business Insider 文章详细讲述了随之而来的对话:
“我女儿收到了这个邮件!”男子对经理说。“她还在高中,你们却给她寄来了婴儿衣物和婴儿床的优惠券?你们是在鼓励她怀孕吗?”
经理对那位男子说的事情一无所知。他看了看邮寄的广告。果然,它寄给了男子的女儿,并包含了孕妇装、育儿家具和笑容满面的婴儿的广告。经理道歉了,然后几天后再次打电话道歉。
不过,电话中的父亲有些尴尬。“我和女儿谈过了,”他说。“原来在我家发生了一些我完全不知情的事情。她八月份预产。我向你们道歉。”
Target 经理的反应是适当的,从而缓解了这一情况。但类似 Target 分析引发的事件的情景描绘了大数据的画面,这必须包括极大的细节关注。

图片由维拉诺瓦大学在线提供
数据几乎影响着一切。像医疗保健这样的匿名信息中心的行业有其实际性。刑事司法行业认为大数据是最顶尖的技术工具。甚至专业教练和运动员也在磨练他们的专注,使用基于数据的可穿戴技术来优化表现和减少伤害。
我们必须小心保护信息安全,数据科学背后的组织有责任遵守一套或一套伦理规范。
个人简介: Jay Taylor 是来自西北地区的学生和有抱负的音乐家。他对环境、技术、音乐理论以及他人的福祉充满热情。
相关内容:
-
伦理应该成为数据科学培训的一部分
-
机器学习中的伦理 – 摘要
-
机器学习中的伦理: 我们从 Tay 聊天机器人事件中学到了什么?
更多相关主题
ETL 与 ELT:数据集成对决
原文:
www.kdnuggets.com/2022/08/etl-elt-data-integration-showdown.html

EJ Strat via Unsplash
提取-转换-加载 与 提取-加载-转换
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
它们都是用于将数据从一个来源转移到数据仓库的数据集成方法。虽然它们的方法目标相似,但有所不同。
什么是 ETL?
ETL 是将数据从多个来源转移到集中单一数据库的过程。原始数据从源中提取,在单独的处理服务器上转换,然后加载到目标数据库中。
转换在加载之前进行的原因是提取的数据需要符合目标数据库的数据规范。例如,有些数据仓库只能接受基于 SQL 的数据结构。
ETL 方法在一定意义上确保了合规性,即提取的数据以正确的数据形式转换到目标数据库。如果提取的数据没有正确转换,则不会成功移动和加载到数据仓库中。
什么是 ELT?
ELT 不要求原始数据在加载之前进行转换。原始数据被加载到数据仓库中,转换、数据清理等操作发生在数据仓库中。
由于数据以原始格式留在数据仓库中,这允许不同类型的转换和分析进行。
ELT 在技术行业中较新,其发展得益于可扩展的云基础数据仓库。因此,随着时间的推移和更多公司采纳云基础设施,你会看到 ELT 过程也变得越来越受欢迎。
ETL 和 ELT 过程的比较
| ETL | ELT | |
|---|---|---|
| 发现 | 存在已超过 20 年 | 对数据集成方法较新 |
| 提取 | 原始数据使用 API 连接器提取。 | 原始数据使用 API 连接器提取。 |
| 转换 | 原始数据在次级处理服务器上进行转换。 | 原始数据在目标数据库内进行转换。 |
| 加载 | 原始数据必须在加载到目标数据库之前进行转换。 | 原始数据直接加载到目标数据库中。 |
| 时间 | 数据转换使 ETL 过程耗时较多 | 数据转换是并行进行的 - 提高了时间效率 |
| 隐私 | 数据在加载前进行转换可以消除个人识别信息(PII) | 这需要更多的隐私标准 |
| 成本 | 使用备用处理服务器可能会增加成本 | 由于简化的数据堆栈,成本更低 |
| 数据结构 | 结构化 | 可以是结构化、半结构化和非结构化的 |
| 数据大小 | 通常用于较小的数据集 | 通常用于较大的数据集 |
| 数据集需求 | 复杂的转换 | 速度和效率 |
| 重新查询 | 因为数据在进入目标数据库之前已被转换,所以无法重新查询。 | 是的,因为数据尚未被转换 |
| 数据湖兼容性 | 否 | 是 |
结论
如果你想确定需要使用哪种数据集成过程,那取决于你团队的需求。
是的,ELT 相对较新且具有更多优势,但可能无法实现你的需求。
了解你的需求将帮助你确定使用哪种处理过程。
Nisha Arya是一位数据科学家和自由职业技术作家。她特别感兴趣于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何/能够有益于人类生命的持久性。作为一个热衷的学习者,她寻求扩展她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
ETL 与 ELT:哪一种适合您的数据管道?
原文:
www.kdnuggets.com/2023/03/etl-elt-one-right-data-pipeline.html

作者提供的图片
ETL 和 ELT 是将数据从多个来源传输到一个集中源并对其进行一些转换和处理步骤的数据集成管道。这两者的区别在于 ETL 在加载之前进行数据转换,而 ELT 在加载之后进行数据转换。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT
但在深入了解之前,让我们首先了解 E、L 和 T 的含义。
E 代表 提取 - 从一个或多个来源提取数据。
T 代表 转换 - 转换数据是一个清理和修改数据的过程,以便将其以适合业务分析的格式使用。
L 代表 加载 - 这涉及将数据加载到目标系统中,可能是数据仓库或数据库。
ETL(提取、转换、加载)
ETL 是 1970 年代随着磁盘存储的发展而出现的首个标准化数据集成方法。顾名思义,它首先从源头提取原始数据,然后对其进行转换,再加载到目标数据库中,即(提取 ? 转换 ? 加载)
在 ETL 中,数据摄取过程较慢,因为我们需要先在单独的服务器上转换数据,然后再将其加载到目标数据库中。
ETL 用于在有限存储中存储少量数据。它适用于本地、结构化和关系型数据集。
图 1 ETL 系统架构 | 图片由 estuary.dev 提供
现在,让我们了解一下它的一些主要优缺点。
优点
-
数据质量: ETL 通过处理来自各种来源的原始数据,并将其组合成结构化格式,从而提高数据质量。
-
减少磁盘驱动器负担: ETL 的关键特性在于数据在内存中进行转换,这使我们能够创建那些磁盘带宽受限的数据管道。
-
一致性: 将处理后的数据存储在数据库中,确保数据一致、相关和准确,这满足了所有业务需求,并有助于做出更好的决策。
缺点
-
灵活性: ETL 具有僵化的管道。不允许在数据库中进行修改。如果业务计划发生变化,商业智能团队将无法回到原始原始数据并重新查询。
-
延迟: 数据摄取与数据分析之间的延迟不适合实时应用。
-
数据丢失: 如果数据处理不当或转换步骤出现错误,ETL 管道可能导致数据丢失。
ELT(提取、加载、转换)
在 2000 年代初,云计算变得更加普及,数据湖和数据仓库的发展引发了数据存储的革命。现在,企业可以访问便宜且无限的云存储来加载数据。
这导致了新数据集成管道的开发,即 ELT(提取、加载、转换)。原始数据可以存储在数据仓库中并直接从中查询。
简而言之,在 ELT 中,原始数据从源中提取并直接存储在数据仓库中,而没有进行任何转换。与 ETL 不同,转换步骤是在加载之前在单独的服务器上执行,这会在系统中造成额外的延迟和僵化。
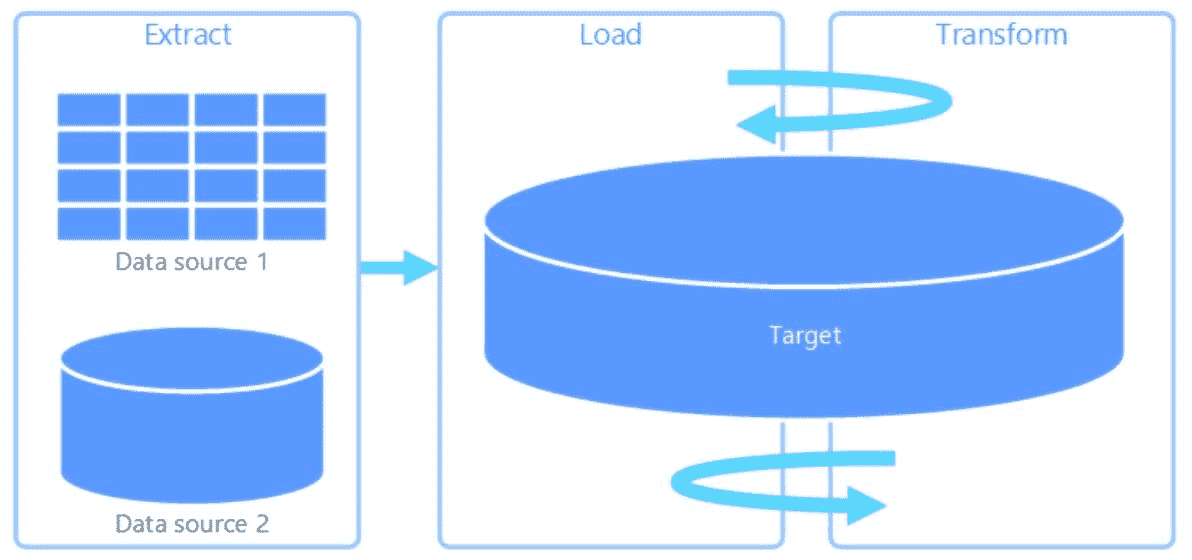
图 2 ELT 系统架构 | 图片来自 sqlofthenorth
现在,让我们深入了解一些主要的优缺点。
优势
-
灵活性: ELT 管道更具灵活性,因为如果业务计划发生变化,它们允许从原始数据中重新查询相关数据。
-
延迟: 由于数据加载和转换可以同时进行,因此适用于实时决策。
-
成本效益: ELT 管道更具成本效益,因为所需的软件大多依赖于现成的开源软件。
缺点
-
数据质量: ELT 管道中的数据质量可能与 ETL 不同。转换在数据存储到目标数据库之后进行。
-
非结构化数据: 如果非结构化数据没有得到适当管理,编写查询将非常困难。而且,由于数据结构的不一致,查询结果可能不够准确。
-
安全性: 由于所有原始数据都存储在数据库中,因此可能存在敏感数据被暴露或被滥用的风险。
-
数据存储: 由于原始数据直接存储而没有任何处理,这需要更多的存储空间。
ETL 与 ELT 的区别
ETL 和 ELT 的区别在于两个方面。在 ETL 中,数据在加载之前进行转换,而在 ELT 中,数据在加载之后进行转换。
ETL 有一个固定的管道,因为它仅支持传统数据库架构,而 ELT 灵活,支持数据重新查询。
ETL 比 ELT 相对较慢,涉及在加载之前的额外数据转换步骤。但在 ELT 中,这种转换可以与加载同时进行。
ETL 仅适用于本地或结构化数据。但 ELT 可以用于任何结构化、非结构化或半结构化的数据。
以下是 ETL 和 ELT 数据管道的并排比较表。
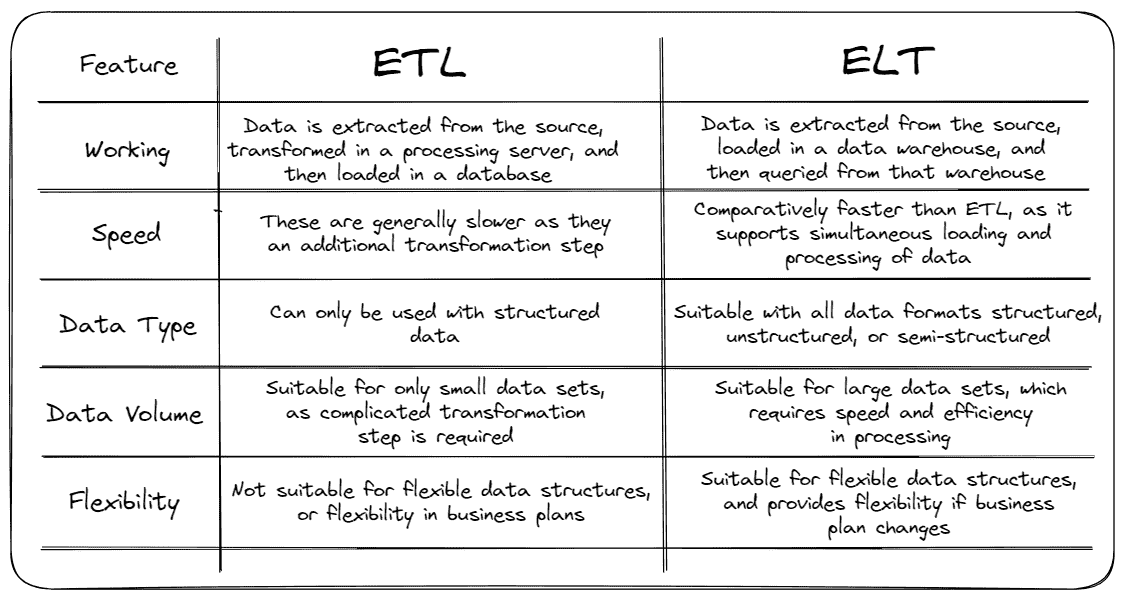
图 3 ETL 和 ELT 管道的并排比较 | 图片由作者提供
何时使用什么?
要在今天的商业环境中充分利用数据,我们需要高效且强大的数据管道,这些管道能够从多个来源提取、加载和转换数据到一个集中存储中,以便进行分析。此时 ETL 和 ELT 数据管道发挥作用。但选择 ETL 还是 ELT 完全取决于业务需求。
通常,当我们对加载数据之前有严格的一致性和数据质量要求时,ETL 管道可以使用。或者当我们需要执行复杂的数据集成和转换步骤时,也可以使用。
ELT 可以在我们想要存储大量数据并需要更快、更高效处理时使用。ELT 还根据不断变化的业务需求提供数据库的灵活性。
希望你喜欢阅读这篇文章。你也可以通过 Linkedin 联系我。
Aryan Garg 是一名电气工程专业的 B.Tech. 学生,目前处于本科最后一年。他对网页开发和机器学习领域感兴趣,并在这方面追求自己的兴趣,渴望在这些方向上工作。
更多相关内容
ETL 与机器学习有什么关系?

托比亚斯·费舍尔 通过 Unsplash
你可能在阅读博客或观看 YouTube 视频时听到过 ETL。那么 ETL 与机器学习有什么关系呢?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
对于那些还不知道的人,机器学习是一种利用数据分析来预测准确结果的人工智能类型。正是机器学习算法通过学习历史数据及其特征来产生这些预测结果。
ETL 代表提取-转换-加载。它是将数据从多个来源移动到一个集中式单一数据库的过程。
提取:
你的第一步是从其原始来源提取数据。这可以位于另一个数据库或应用程序中。
转换:
就像处理数据和机器学习算法时的大多数时间一样——有一个清理数据的阶段。在转换阶段,你将清理数据,查找和纠正任何重复项,并准备将其加载到另一个数据库中。
加载:
一旦你的数据格式正确,它就可以被加载到目标数据库中。
为什么 ETL 很重要?
ETL 阶段的每一部分都很重要,以准确地交付最终产品。它带给机器学习的好处是帮助提取数据、清理数据并将其从点 A 传送到点 B。
然而,它不仅仅是这样。
大多数公司拥有大量数据,但这些数据往往是孤立的。这意味着它们格式不同、不一致,并且与业务的其他方面沟通不畅。基本上是没用的。
我们都知道在这个时代数据可以做什么——它创造了什么、解决了什么问题,以及它如何能造福我们的未来。那么为什么还要让它无所作为呢?
当你将不同的数据集汇集到一个集中式的存储库中时,它提供了:
-
上下文 - 组织拥有更多的历史数据以提供背景
-
可解释的 - 有了更多的数据,我们可以通过分析和报告获得更综合的视图,从而做出更好的解释。
-
生产力 - 它消除了繁重的编码过程,节省了时间和金钱,提高了生产力。
-
准确性 - 上述所有点都提高了数据及其输出的整体准确性,这对于遵守法规和标准可能至关重要。
这些阶段使机器学习算法的工作流程顺畅,并产生我们可以信赖的准确输出。
但为什么不使用云计算?
是的,我们生成和收集了大量数据,增长速度如此之快,以至于我们无法在传统的数据仓库基础设施中物理存储所有数据。这就是云计算使我们受益的地方。
云计算不仅使我们能够存储大量数据,还帮助我们进行高速分析。自从云计算进入市场以来,企业能够扩展规模并继续创新。
但无论数据是通过传统的数据仓库还是云存储,数据仍然需要存储在中央存储库中。ETL 的目的是准备数据,使其以最合适的格式用于机器学习。如果不通过 ETL 准备数据,那么数据在数据仓库中保持原始格式或只是存在于云中没有区别。
ETL 与机器学习
为了使机器学习算法可信赖并表现良好,它需要大量的训练数据。这些训练数据需要具有良好的质量,并具有可以帮助解决当前任务的特征和特性。
在制作有效的机器学习算法过程中,ETL 位于基础 - 基石。让我们深入了解 ETL 对机器学习的重要性。
数据收集
一旦你收集了数据,无论是通过外部来源、用户生成内容、传感器等,下一步就是移动和存储这些数据。这时 ETL 发挥了作用,还有其他步骤,如基础设施、管道、结构和非结构化数据存储。
数据准备
一旦数据被移动并存储在正确的位置,下一步就是探索数据并在必要时对其进行转换。数据的转换也称为数据的准备,包括清洗和错误检测。
数据标记
一旦数据准备好并且格式良好 - 我们就可以继续对数据进行标记,以便输入到机器学习算法中。这将作为训练数据,我们将在其中学习更多关于数据点的特征,并进行分析以获得更好的理解。
学习数据
这就是机器学习发挥作用的地方。通过标记的数据,我们可以将其输入到机器学习算法中,以便它们能更好地学习每个数据点的特征及其之间的关系。在这一阶段,会进行大量实验和 A/B 测试,以了解数据的局限性及其性能。
如你所见,ETL 是机器学习算法过程中的第一步之一——这就是为什么我称其为基础。如果你忽略了 ETL,你会发现自己不得不来回纠正数据中的错误和问题,这将导致机器学习算法中的输出不准确。
ETL 与 ELT
你可能也听说过 ELT,它与 ETL 类似但阶段不同——提取-加载-转换。虽然它们使用相同的术语,但它们是不同的。
ETL 在一个独立的处理服务器上转换数据,因此原始数据不会被转移到数据仓库。将数据转换到一个独立的处理服务器的过程使数据的摄取速度变慢。
然而,ELT 将原始数据转移到数据仓库中,并在那里进行数据转换。由于 ELT 不使用独立的处理服务器,数据摄取的速度更快。
如果你想了解更多关于 ETL 和 ELT 之间的区别,请点击这个链接。
结论
ETL 在各种数据管理任务、大数据、Hadoop 等方面被有效使用。在考虑 ETL 时,你需要考虑:
-
你需要提取哪些数据源?
-
你需要对这些数据进行什么样的转换?
-
你计划将数据加载到哪里?
这是关于 ETL 与机器学习的概述,我希望我回答了你的问题。
Nisha Arya 是一名数据科学家和自由技术写作人。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探索人工智能如何有助于人类寿命的延续。她是一位热衷学习者,寻求拓宽技术知识和写作技能,同时帮助指导他人。
更多相关话题
在 Python 和 R 中评估预测模型的业务价值
原文:
www.kdnuggets.com/2018/10/evaluating-business-value-predictive-models-modelplotpy.html
评论
由 Jurriaan Nagelkerke、数据科学顾问,和 Pieter Marcus、数据科学家
为什么 ROC 曲线不适合向商业人士解释您的模型
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升您的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
摘要
在本博客中,我们解释了四种最有价值的评估图,以评估预测模型的业务价值。这些图包括累积增益、累积提升、响应和累积响应。由于这些可视化图形在大多数流行的模型构建包或 R 和 Python 模块中未包含,我们展示了如何使用我们的 modelplotpy Python 模块和我们的 modelplotr R 包(喜欢 R 吗?在这里阅读有关 modelplotr 的全部内容!) 为您自己的预测模型轻松创建这些图。这将帮助您将模型的业务价值以通俗易懂的方式向非技术人员解释。
介绍

‘…正如我们在这张 ROC 图上清楚看到的,模型在 0.2 的值下的灵敏度相对于 1 减去特异性是相当高的!对吗?…’。
如果您的商业同事在您展示您出色的预测模型时还没有离开,当您开始这样讲话时,他们肯定会彻底走开。为什么?因为 ROC 曲线不容易快速解释,并且难以转化为观众提出的业务问题的答案。而这些业务问题正是您构建模型的初衷!
什么是业务问题?我们构建各种监督分类问题。例如预测模型,以选择数据集中最佳的记录,这些记录可以是客户、潜在客户、项目、事件……例如:你想知道你的活跃客户中哪一位最可能流失;你需要选择那些最有可能对优惠做出回应的潜在客户;你必须识别出具有高风险的欺诈交易。在你的展示中,你的听众主要关注于回答类似你的模型是否能帮助我们接触到目标受众?使用你的模型我们有多大的改善?我们的活动预期回应如何?这样的问题。
在我们构建模型的过程中,我们应该已经关注于验证模型的表现。通常,我们通过在一部分记录上训练模型参数,并在保留集或外部验证集上测试性能来实现这一点。我们查看一些性能指标,如 ROC 曲线和 AUC 值。这些图表和统计数据在模型构建和优化过程中非常有帮助,可以检查模型是否过拟合或欠拟合以及哪些参数在测试数据上表现最佳。然而,这些统计数据在评估你开发的模型的业务价值方面并不那么有价值。
ROC 曲线在解释模型的业务价值方面并不十分有用,因为很难向业务人员解释‘曲线下面积'、‘特异性'或‘灵敏度'的含义。另一个重要原因是这些统计数据和图表在业务会议中无用,因为它们无法帮助决定如何应用预测模型:我们应该基于模型选择多少比例的记录?是否仅选择最好的 10% 的案例?还是在 30% 时停止?或者继续直到选择 70%?……这是你希望与你的业务同事共同决定的,以最好地匹配他们的业务计划和活动目标。我们即将介绍的四个图表——累计收益、累计提升、响应和累计响应——在我们看来是最适合这个目的的。
让 modelplotpy 在你的机器上运行
让我们从安装modelplotpy模块开始。本模块已经可以从Github获得,但目前无法通过Python Package Index (PyPI) 仓库安装。
对于一些用户,我们发现 GitHub 需要首先安装在你的机器上。如果你还没有在机器上安装 GitHub,可以从这里下载。安装 GitHub 后,建议重启计算机,然后继续本教程。
Modelplotpy 必须通过命令行安装。在 macOS 或 Linux 操作的机器上打开终端,在 Windows 机器上搜索 cmd.exe 并按回车键。复制并粘贴下面的命令,然后按回车键。
pip install git+https://github.com/modelplot/modelplotpy.git
一旦成功安装 modelplotpy,就可以打开 Python 并将其加载到工作目录中,继续本教程!本教程使用 Python 3.6.4 编写,可能在 Python 2.x 中无法完全运行。
import modelplotpy as mp
现在我们准备使用 modelplotpy。在另一篇文章中,我们将详细介绍我们在 R 和 Python 中的 modelplot 包及其所有功能。在这里,我们将重点介绍如何使用 modelplotpy 进行商业示例。
示例:来自 sklearn 的预测模型在 银行营销数据集 上
开始工作吧!在介绍图表时,我们将展示如何用一个商业示例使用它们。这个示例基于一个公开可用的数据集,称为银行营销数据集。它是最受欢迎的数据集之一,提供在 UCI 机器学习库 上。数据集来自葡萄牙的一家银行,处理一个经常被提问的市场营销问题:客户是否获得了定期存款这一金融产品。共有 4 个数据集,我们使用的是 bank-additional-full.csv。它包含了 41,188 名客户的信息和 21 列数据。
为了说明如何使用 modelplotpy,假设我们在这家银行工作,我们的市场营销同事要求我们帮助选择最有可能响应定期存款优惠的客户。为此,我们将开发一个预测模型并创建图表,以便与市场营销同事讨论结果。由于我们要展示如何构建图表,而不是如何构建完美的模型,我们将在示例中使用这六个列。以下是我们使用的数据的简要描述:
-
y:客户是否订阅了定期存款?
-
duration:最后一次联系的持续时间,以秒为单位(数字型)
-
campaign:在本次活动中为该客户进行的联系次数
-
pdays:客户上次从之前的活动中联系后经过的天数
-
previous:在本次活动之前为该客户进行的联系次数(数字型)
-
euribor3m:欧元区 3 个月利率
让我们加载数据并快速查看一下:
import io
import os
import requests
import zipfile
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
#r = requests.get("https://archive.ics.uci.edu/ml/machine-learning-databases/00222/bank-additional.zip")
# we encountered that the source at uci.edu is not always available, therefore we made a copy to our repos.
r = requests.get('https://modelplot.github.io/img/bank-additional.zip')
z = zipfile.ZipFile(io.BytesIO(r.content))
# You can change the path, currently the data is written to the working directory
path = os.getcwd()
z.extractall(path)
bank = pd.read_csv(path + "/bank-additional/bank-additional-full.csv", sep = ';')
# select the 6 columns
bank = bank[['y', 'duration', 'campaign', 'pdays', 'previous', 'euribor3m']]
# rename target class value 'yes' for better interpretation
bank.y[bank.y == 'yes'] = 'term deposit'
# dimensions of the data
print(bank.shape)
# show the first rows of the dataset
print(bank.head())
(41188, 6)
y duration campaign pdays previous euribor3m
0 no 261 1 999 0 4.857
1 no 149 1 999 0 4.857
2 no 226 1 999 0 4.857
3 no 151 1 999 0 4.857
4 no 307 1 999 0 4.857
在这些数据上,我们应用了一些来自 sklearn 模块 的预测建模技术。这个知名模块是许多预测建模技术的封装器,如逻辑回归、随机森林等。让我们训练几个模型并用图表进行评估。
# to create predictive models
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
# define target vector y
y = bank.y
# define feature matrix X
X = bank.drop('y', axis = 1)
# Create the necessary datasets to build models
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 2018)
# Instantiate a few classification models
clf_rf = RandomForestClassifier().fit(X_train, y_train)
clf_mult = LogisticRegression(multi_class = 'multinomial', solver = 'newton-cg').fit(X_train, y_train)
C:\Users\nagelk000\PycharmProjects\testen_matplotpy\venv\lib\site-packages\sklearn\ensemble\weight_boosting.py:29: DeprecationWarning: numpy.core.umath_tests is an internal NumPy module and should not be imported. It will be removed in a future NumPy release.
from numpy.core.umath_tests import inner1d
在另一篇文章中,我们将详细介绍我们在 R 和 Python 中的 modelplot 包及其所有功能。现在,我们重点解释如何向我们的营销同事展示我们的预测模型如何帮助他们选择客户进行定期存款活动。
obj = mp.modelplotpy(feature_data = [X_train, X_test]
, label_data = [y_train, y_test]
, dataset_labels = ['train data', 'test data']
, models = [clf_rf, clf_mult]
, model_labels = ['random forest', 'multinomial logit']
)
# transform data generated with prepare_scores_and_deciles into aggregated data for chosen plotting scope
ps = obj.plotting_scope(select_model_label = ['random forest'], select_dataset_label = ['test data'])
No comparison specified! Single evaluation line will be plotted
The label with smallest class is ['term deposit']
Target value term deposit plotted for dataset test data and model random forest.
刚刚发生了什么?在modelplotpy中实例化了一个类,plotting_scope函数指定了你想展示的图表范围。一般来说,modelplotpy类中可以应用 3 种方法(函数),但你不必指定它们,因为它们是链式调用的。这些函数是:
-
prepare_scores_and_deciles:根据客户获得定期存款的概率对训练数据集和测试数据集中的客户进行评分
-
aggregate_over_deciles:将所有分数聚合到十分位数并计算展示的信息
-
plotting_scope允许你指定分析的范围。
在第二行代码中,我们指定了分析的范围。由于我们未指定“scope”参数,因此选择了默认值 - 不进行比较。正如输出所示,你可以使用modelplotpy从多个角度评估你的模型:
-
仅解释一个模型(默认值)
-
比较不同数据集的模型性能
-
比较不同模型的性能
-
比较不同目标类的性能
在这里,我们将简单地评估 - 从业务角度 - 一个选定模型在一个目标类的选定数据集中的表现。我们确实为一些参数指定了值,以便专注于随机森林模型在测试数据上的表现。目标类的默认值是定期存款;由于我们想专注于那些确实进行定期存款的客户,这个默认值是完美的。
让我们介绍收益、提升和(累积)响应图。
在我们提供更多代码和输出之前,让我们让你熟悉我们强烈推荐用于评估预测模型商业价值的图表。尽管每个图表从不同角度揭示了模型的商业价值,但它们都使用相同的数据:
-
目标类的预测概率
-
基于此预测概率的等大小组
-
这些组中实际观察到的目标类观察值的数量
将数据划分为 10 个等大小的组并称这些组为十分位数是一种常见做法。在一个数据集中,属于前 10%具有最高模型概率的观察值在该数据集的十分位数 1 中;下一个 10%高模型概率的组是十分位数 2,最后 10%具有最低目标类模型概率的观察值属于十分位数 10。
我们的四个图表中的每一个都将十分位数放在 x 轴上,另一个指标放在 y 轴上。十分位数从左到右绘制,因此具有最高模型概率的观察值在图表的左侧。这会产生如下图表:
现在既然每个图的横轴已经明确,我们可以更详细地探讨每个图的纵轴上的指标。对于每个图,我们将从业务角度简要说明该图提供的洞察。之后,我们将其应用于我们的银行数据,并展示 modelplotpy 的一些有趣功能,帮助你向他人解释你出色的预测模型的价值。
1. 累计收益图
累计收益图——通常称为“收益图”——帮助你回答以下问题:
当我们应用模型并选择最佳的 X 分位时,我们可以期望目标类观察值的百分比是多少?
因此,累计收益图可视化了如果你决定选择直到第 X 分位的目标类成员的百分比。这是一个非常重要的业务问题,因为在大多数情况下,你想使用预测模型来针对一个子集的观察值——客户、潜在客户、案例等——而不是针对所有案例。由于我们不会总是构建完美的模型,我们会遗漏一些潜力。这是完全可以接受的,因为如果我们不愿意接受这一点,我们不应该使用模型。或者构建一个完美的模型,对所有实际目标类成员的概率为 100%,对所有不属于目标类的案件的概率为 0%。然而,如果你是这样一个精英,你根本不需要这些图,或者你应该仔细检查你的模型——也许你在作弊?
因此,我们必须接受会有一些损失。你在给定分位时选择的目标类成员的百分比,这就是累计收益图告诉你的。图中有两条参考线来告诉你模型的好坏:随机模型线和精英模型线。随机模型线告诉你在完全没有模型的情况下,你期望选择的实际目标类的比例。这条垂直线从原点(0%案件时,你只能拥有 0%目标类成员)到右上角(100%案件时,你拥有 100%目标类成员)。这是你模型表现的最低水平;如果你接近这个水平,那么你的模型不比抛硬币好多少。精英模型是你模型能做到的上限。它从原点开始,并尽可能陡峭地上升到 100%。如果不到 10%的案件属于目标类别,这意味着它从原点急剧上升到第 1 分位值和 100%的累计收益,并在所有其他分位中保持不变,因为这是一个累计指标。你的模型总是会在这两条参考线之间移动——越接近精英模型越好——看起来是这样的:
回到我们的业务示例。我们能从预测模型的前 20%中选择多少定期存款买家?让我们找出答案!为了生成累积收益图,我们可以简单地调用函数plot_cumgains():
# plot the cumulative gains plot
mp.plot_cumgains(ps)
The cumulative gains plot is saved in C:\Users\nagelk000\AppData\Local\Temp\intro_modelplotpy.ipynb/Cumulative gains plot.png
<Figure size 432x288 with 0 Axes>
<matplotlib.axes._subplots.AxesSubplot at 0x1ca44358>
我们只需指定带有 plotting_scope 输出的输入。不过,还有几个参数可以自定义图表。如果我们想强调模型在某一点的表现,可以在图表中添加高亮,并在图表下方添加一些解释文本。不过这两项都是可选的:
# plot the cumulative gains plot and annotate the plot at decile = 2
mp.plot_cumgains(ps, highlight_decile = 2)
When we select 20% with the highest probability according to model random forest, this selection holds 80% of all term deposit cases in dataset test data.
The cumulative gains plot is saved in C:\Users\nagelk000\AppData\Local\Temp\intro_modelplotpy.ipynb/Cumulative gains plot.png
<Figure size 432x288 with 0 Axes>
<matplotlib.axes._subplots.AxesSubplot at 0x20596198>
我们的highlight_decile参数在第 2 百分位数的图表上添加了一些指导元素,并在图表下方添加了一个文本框,文字解释了第 2 百分位数的图表。这个解释也会打印到控制台。我们的简单模型——仅使用了 6 个预测变量——似乎很好的挑选出了有意购买定期存款的客户。当我们根据随机森林选择前 20%的客户时,这些选择占测试数据中所有定期存款案例的 79%。 如果模型完美,我们会选择 100%,因为测试集中购买定期存款的客户不到 20%。随机选择只会包含 20%的定期存款客户。这比随机选择好多少,就要看第 2 号图表了!
更多相关主题
评估数据科学项目:案例研究批评
原文:
www.kdnuggets.com/2017/09/evaluating-data-science-projects-case-study-critique.html
作者:Tom Fawcett,硅谷数据科学。

我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
我写了 两篇 博客文章 讨论评估——机器学习中的“西兰花”。实际上,评估下有两个密切相关的关注点:
-
模型评估 通常教授给数据科学家,涉及模型的技术质量:模型表现如何?我们能相信这些数字吗?它们在统计上是否显著?
-
项目评估 包括模型评估,但也要考虑应用背景的问题:是否解决了正确的问题?性能指标是否适合任务?数据是如何提供的,模型结果是如何使用的?成本是否可以接受?
这两种类型不仅对数据科学家很重要,对管理者和高管也同样重要,他们必须评估项目提案和结果。我会对管理者说:不必了解机器学习项目的内部工作原理,但你应该理解是否测量了正确的东西,结果是否适合业务问题。你需要知道是否要相信数据科学家告诉你的内容。
为此,我将在这里评估一个机器学习项目报告。我发现这项工作被描述为在一个 流行的机器学习博客上的客户成功故事。这个写作发表于 2017 年初,同时发布了一个展示结果的相关视频。有些方面令人困惑,如你所见,但我没有向作者寻求澄清,因为我希望像报告中那样进行批评。这使得这个案例研究具有现实性:你经常需要评估缺少或令人困惑的细节的项目。
正如你将看到的,我们将揭示一些即使是专业数据科学家也可能犯的常见应用错误。
问题
问题的呈现方式如下:一家大型保险公司希望预测特别大的保险索赔。具体而言,他们将其人群划分为报告事故的驾驶员(7-10%)、没有事故的驾驶员(90-93%)和所谓的大损失驾驶员,这些驾驶员报告涉及 1 万美元或更多损害的事故(约占其人群的 1%)。他们只希望检测最后一组涉及大额索赔的群体。他们面临的是一个两类问题,这些类别被称为大损失和非大损失。
熟悉我之前 文章的读者可能会记得我谈到过现实世界中的机器学习问题中常见的不平衡类别。确实,在这里我们看到一个 99:1 的偏斜,其中正类(大损失)实例的数量比不感兴趣的负类实例少了两个数量级。(顺便说一下,这在机器学习研究标准下会被认为是非常偏斜的,但在现实世界标准下则属于轻微偏斜。)由于这种偏斜,我们在评估时必须小心。
方法
他们的方法相当直接。他们有一个关于之前驾驶员记录的历史数据样本用于训练和测试。他们使用 70 个特征来表示每个驾驶员的记录,这些特征涵盖了分类特征和数值特征,尽管这里只展示了一部分。
他们表示,他们的客户之前使用了随机森林来解决这个问题。随机森林是一种广泛使用且受欢迎的技术,它通过构建一组决策树来对实例进行分类。他们希望通过使用深度学习神经网络取得更好的效果。他们的网络设计如下:

该模型是一个具有三层隐藏层的全连接神经网络,使用ReLU作为激活函数。他们表示使用了来自 Google Compute Engine 的数据来训练模型(使用 TensorFlow 实现),并使用了 Cloud Machine Learning Engine 的 HyperTune 功能来调整超参数。
我没有理由怀疑他们的表示选择或网络设计,但有一点看起来很奇怪。他们的输出是两个 ReLU(整流)单元,每个单元发出该类别的网络准确率(技术上:召回率)。我会选择一个代表大损失驾驶员概率的Softmax单元,从中我可以得到一个ROC或精确度-召回率曲线。然后我可以对输出进行阈值处理,以获得曲线上任何可实现的性能。(我在这篇文章中解释了评分优于硬分类的优势。)
但我不是神经网络专家,这里目的不是批评他们的网络设计,只是他们的一般方法。我假设他们进行了实验,并报告了他们找到的最佳性能。
结果
他们呈现测试结果的方法令人困惑。一开始,他们报告了 78%的准确率——这很奇怪,因为准确率是这个偏斜领域的一个无信息量的指标,并且因为仅仅总是说非大损失应该会产生 99%的准确率。这两点并不无关。
但是进一步下方他们展示了这个作为最终结果:

图表缺少x和y标记,所以很难从曲线中获得很多信息。唯一的信息在顶部。他们报告了两个准确率,一个针对每个类别。这改变了情况——他们不是使用综合分类准确率(“准确率”的常见含义),而是每个类别的召回率。我们可以计算一些信息来评估他们的系统。这够吗?
大损失准确率(识别率)是 0.78。根据惯例,稀有类别通常为正类,所以这意味着真正正例(TP)率是 0.78,假阴性率(1 – 真正正例率)是 0.22。非大损失识别率是 0.79,所以真正负例率是 0.79,假阳性(FP)率是 0.21。
他们之前报告的随机森林准确率是 0.39。现在我们意识到,这个值实际上是大损失类别的单类识别率,因此它是随机森林的真正正例率。他们没有报告假阳性率(或真正负例率,我们可以从中计算)。这有问题。
这就是他们报告的全部。
评价
第一个批评是相当明显的。他们仅报告了一个训练和测试的单个运行结果,因此无论其他问题如何,我们确实只有一个结果可用于工作。我们应该使用交叉验证或自助法进行多次运行,以提供变异的指示。如此一来,我们无法确信这些数字是否具有代表性。大多数机器学习课程都介绍了基本的模型评估,并强调需要多次评估来建立置信区间。
那么他们的解决方案有多好?
底线是:我们不知道。他们没有给出足够的信息。可能没有他们认为的那么好。
这里是一个ROC 曲线说明分类器的图表。这样的图表允许我们看到在灵敏度和特异性之间(等效地,在假阳性和真阳性之间)的性能折衷。
如果这些研究人员同时提供了 TP 率和 FP 率的值,我们可以在 ROC 空间中绘制一个漂亮的曲线,但是他们只给了我们足够绘制神经网络的单个点,显示为蓝色。
再次,我们对于随机森林只有一个真阳性率值(0.39),但没有伴随的假阳性率。这不够用;仅仅将所有东西分类为大损失,我们可以得到 1.00 的大损失准确率。我们需要另一个坐标点。
在 ROC 图上,我用绿线显示了随机森林在y=0.39 处的性能。随机森林的性能是该线上的某一点。如果其假阳性率小于约 0.10,随机森林实际上比神经网络更好。因此,我们甚至不能回答哪个模型更好。
让我们再问一个问题:他们的深度学习解决方案可用吗?
底线是:不,这些结果可能不够好,不能满足保险公司的要求。
这里是推理。为了评估神经网络的表现,我们真正需要知道错误的成本。他们没有提供这些。这并不罕见:这些数字必须由客户(保险公司)提供,并且根据我的经验,大多数客户无法精确地为这些错误分配成本。因此,我们需要其他方法来理解性能。有几种方法可以做到这一点。
一种方法是回答这个问题:为了获得一个真阳性,我必须处理多少个假阳性?为了计算这个,回想一下他们的司机人群具有 99:1 的非大损失到大损失的偏斜比例。因此,他们在假阳性到真阳性的性能比是 0.22/0.78。我们可以通过将这些值相乘来回答最初的问题:
99/1 x 0.22/0.78 ~= 28
这个结果意味着,使用他们的神经网络,他们必须处理每个大损失客户的 28 个无趣的非大损失客户(误报)。而且他们可能只能找到 78%的大损失客户。
另一种理解他们表现的方式是将其转换为精度。给定 29 个警报,其中只有 1 个会是正警报,所以精度是 1/28,大约为 4%。
这对保险公司来说可以接受吗?我不是专家,但我猜不行。4%的精度很低,每个真实警报需要 28 个误报的成本很高。除非公司投入了大量的劳动力来处理这个任务,否则他们可能承担不起。
这些研究人员能做得更好吗?我认为可以。由于结果没有考虑类别不平衡,我假设损失函数和训练方案也不适合这个问题。不平衡数据学习并不是一项简单的工作,但朝这个方向的任何努力都可能会取得更好的结果。
作为一个项目评估解决方案
从技术细节中退一步,我们可以将其视为一种解决业务问题的方案。他们在这里给出的“案例”并没有真正说明他们试图解决什么业务问题。我们无法判断解决方案是否适合解决这个问题。报告中仅仅指出,“调整员需要了解哪些客户在这些情况下风险更高,以便优化其保单的定价”。
忽略他们模型的表现不佳,这种方法是否有效?“理解”通常包括理解预测因素,而不仅仅是高评分司机的名字和账户号码。没有说明这种理解是如何实现的。尽管神经网络现在非常流行,但深度学习神经网络以其不可理解性而臭名昭著。它们可能并不是解决这个问题的理想选择。
最后,关于解决方案如何影响定价,甚至关于优化定价所需的模型方面的重要内容,什么也没有提到。
解决应用程序问题时,一个重要的部分是理解模型将在应用程序的上下文中如何使用(即更大的过程)。这个项目只是展示了一个业务问题快速转换为二分类问题的过程,然后展示了模型的技术细节和获得的结果。由于保险问题的初步分析很肤浅,我们甚至不知道什么样的性能是可接受的。
结论
我在批评这个项目时相当无情,因为它展示了数据科学家在处理业务问题时犯的很多错误。换句话说,这很方便,尽管几乎不具唯一性。如果你认为只有业余爱好者或初学者才会犯这些错误,这里是来源的案例研究。请注意,这是 Google 在推广 Google Cloud Platform 时展示的“客户成功故事”之一。
根据我的观察,机器学习或数据科学课程很少涵盖我在这里提到的应用问题。大多数课程集中在教学算法,因此往往简化了在实际应用中出现的数据和评估复杂性。我要花费多年经验才能理解这些细微差别,并知道哪些问题需要预见。
你呢?从学术项目到实际应用中,最大的惊喜是什么?你会有什么不同的做法?你希望在学校里学到什么?请在下面评论以开始讨论。
简介:汤姆·福塞特 是《数据科学与商业》一书的合著者,拥有超过 20 年的机器学习和数据挖掘实践经验。他曾在 Verizon 和 HP Labs 等公司工作,并且是机器学习期刊的编辑。
原始来源。经许可转载。
相关:
-
机器学习与统计学:数据科学的德克萨斯决斗
-
探索性数据分析的价值
-
理解 AI 工具包指南
更多相关主题
评估 HTAP 数据库在机器学习应用中的表现
原文:
www.kdnuggets.com/2016/11/evaluating-htap-databases-machine-learning-applications.html/2
Oracle Exadata 是部署最广泛的高端 OLTP 系统,并且已经扩展了内存列式功能的新 OLAP 能力。Exadata 完全符合 ACID 标准,支持所有隔离级别,Oracle 使用混合表示,其中数据以元组(行式)插入,然后转换为内存中的列式表示。Oracle 严格来说是一个扩展式工程解决方案,性能优越但成本非常高。该系统不是开源的,Oracle 提供的数据库即服务模型。
MemSQL 主要用于分析工作负载。它符合 ACID 标准并处理事务更新,但这些更新并未针对大规模实时 OLTP 工作负载进行优化。MemSQL 通常不用于支持实时并发应用程序。MemSQL 使用混合表示,其中数据以元组(行式)插入,然后转换为列式。MemSQL 是一个扩展解决方案,通常部署在普通集群上,并且能够在集群中分布计算并扩展。该系统不是开源的,并且不通过 DBaaS 提供。
Splice Machine 是一个完全符合 ACID 标准的 MVCC,能够支持包括原生 Oracle PL/SQL 在内的应用程序。OLAP 计算在 Apache Spark 上进行,而事务查询则在 Apache HBase 上进行。原生数据持久化在 Apache HBase 中。数据也可以持久化在外部 Parquet 和 ORC 列式文件中。Splice Machine 是一个扩展解决方案,其基于成本的优化器通过 Apache Spark 或 Apache HBase 分配工作负载。该系统是开源的,并将在 2017 年第一季度作为 DBaaS 提供。
Apache Hive 主要用于分析工作负载。它符合 ACID 标准并处理事务更新,但这些更新并未针对大规模实时 OLTP 工作负载进行优化。Hive 通常不用于支持实时并发应用程序。一个 Hive 应用程序可以在另一个从同一分区读取的应用程序运行时添加行,而不会相互干扰。该系统使用 Hadoop 文件系统上的原生文件存储。较旧的系统将原始数据存储在 HDFS 上,但较新的系统使用 Apache Parquet 或 ORC 列式格式。这些列式存储系统压缩数据并表现出色。Hive 是一个扩展解决方案,通常部署在普通集群上。它依赖于 Hadoop 文件系统和 Map-Reduce 计算。该系统是开源的,通过 Quoble、Amazon 和 Google 提供 DBaaS。
Apache HAWQ 主要用于分析工作负载。它符合ACID规范,处理事务更新,但这些更新并未针对大规模实时 OLTP 工作负载进行优化。HAWQ 通常不用于支持实时并发应用。HAWQ 在 HDFS 上以多种格式存储数据,包括 Apache Parquet。HAWQ 是一种扩展型解决方案,通常部署在普通集群上。它将计算分布在集群中并能进行扩展。该系统是开源的,并通过 Pivotal 提供服务。
Apache Trafodion 是一种 SQL-on-HBase 解决方案,旨在支持具有两阶段提交协议的完整 OLTP 工作负载。Apache Trafodion 使用 HBase 作为持久化的行式存储。Apache Trafodion 是一种扩展型解决方案,将工作分布在执行代理的集群中,这些代理将工作分配给 HBase 区域服务器。该系统是开源的,但不作为 DBaaS 提供。
Apache Kudu/Impala 主要用于分析工作负载。它符合ACID规范,处理事务更新,但这些更新并未针对大规模实时 OLTP 工作负载进行优化。Kudu 通常不用于支持实时并发应用。Apache Kudu 是一种混合键值存储,具有元组型和列式存储。Kudu 使用混合表示法,其中数据以元组形式插入到写优化的 LSM 树中,然后使用 Apache Parquet 转换为列式存储。Apache Kudu/Impala 系统是扩展型系统,利用集群中的并行计算并尽可能向量化指令。该系统是开源的,但不作为 DBaaS 提供。
HTAP 系统结合了事务和分析能力。大多数 HTAP 系统能够接受事务更新并进行分析,而一些 HTAP 系统甚至能够在进行分析的同时支持并发应用。系统之间的多样性仍在继续,因为一些 HTAP 系统是扩展型的昂贵解决方案,而其他则是扩展型的较便宜解决方案,还有一些是开源的,而另一些是专有的。组织可以平衡这些需求以扩展传统应用并使其智能化。
个人简介: Monte Zweben 是一位技术行业资深人士。Monte 的早期职业生涯是在 NASA Ames Research Center 担任人工智能分部副主任,他因在航天飞机项目中的工作而获得了著名的太空行动奖。Monte 随后创办了 Red Pepper Software,并担任首席执行官,这是一家领先的供应链优化公司,1996 年与 PeopleSoft 合并,他在 PeopleSoft 担任制造业务部门的副总裁和总经理。1998 年,Monte 创办了 Blue Martini Software - 领先的零售电商和多渠道系统公司。Blue Martini 在 2000 年通过最成功的首次公开募股之一上市,并现在成为 JDA 的一部分。Blue Martini 之后,他担任了 SeeSaw Networks 的主席,这是一家数字化的、基于地点的媒体公司。Monte 还是《智能调度》的合著者,并在《哈佛商业评论》和各种计算机科学期刊及会议论文集中发表过文章。Zweben 目前担任 Rocket Fuel Inc.的主席,并在卡内基梅隆大学计算机科学学院的院长顾问委员会任职。
相关:
-
KDnuggets 顶级推文,8 月 8-10 日:忘记 SQL 与 NoSQL,新趋势是 HTAP:混合事务/分析处理
-
5 个理由说明机器学习应用需要更好的 Lambda 架构
-
访谈:Antonio Magnaghi,TicketMaster 谈通过 Lambda 架构统一异构分析
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 需求
更多相关话题
评估文档相似性计算方法
原文:
www.kdnuggets.com/evaluating-methods-for-calculating-document-similarity

图片来源:编辑
引言
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
数据科学是一个在过去一百年中由于计算机科学领域的进步而迅猛发展的领域。随着计算机和云存储成本的降低,我们现在可以以比几年前更低的成本存储大量数据。计算能力的增加使我们能够在大规模数据集上运行机器学习算法并提取洞察。网络技术的进步使我们可以以闪电般的速度生成和传输数据。由于这一切,我们生活在一个每秒都在生成大量数据的时代。我们有来自电子邮件、金融交易、社交媒体内容、互联网网页、企业客户数据、患者医疗记录、智能手表的健身数据、YouTube 上的视频内容、智能设备的遥测数据等各种形式的数据。这种结构化和非结构化数据的丰富使我们进入了一个叫做数据挖掘的领域。
数据挖掘是从大数据集中发现模式、异常和关联以预测结果的过程。虽然数据挖掘技术可以应用于任何形式的数据,但文本挖掘是数据挖掘的一个分支,它指的是从非结构化文本数据中寻找有意义的信息。在本文中,我将专注于文本挖掘中的一个常见任务——寻找文档相似性。
文档相似性有助于高效的信息检索。文档相似性的应用包括:检测抄袭、有效回答网络搜索查询、按主题聚类研究论文、查找类似的新闻文章、在问答网站如 Quora、StackOverflow、Reddit 中聚类类似问题,以及根据描述在亚马逊上对产品进行分组等。文档相似性也被 Dropbox 和 Google Drive 等公司用来避免存储相同文档的重复副本,从而节省处理时间和存储成本。
背景摘要
计算文档相似度有几个步骤。第一步是将文档表示为向量格式。然后可以在这些向量上使用成对相似度函数。相似度函数是计算一对向量之间相似度程度的函数。有多种成对相似度函数,如欧几里得距离、余弦相似度、Jaccard 相似度、Pearson 相关性、Spearman 相关性、Kendall's Tau 等[2]。成对相似度函数可以应用于两个文档、两个搜索查询,或一个文档和一个搜索查询之间。虽然成对相似度函数适用于比较较少数量的文档,但还有其他更先进的技术,如基于深度学习的 Doc2Vec 和 BERT,它们被像 Google 这样的搜索引擎用于高效的信息检索。在这篇论文中,我将重点讨论 Jaccard 相似度、欧几里得距离、余弦相似度、TF-IDF 加权的余弦相似度、Doc2Vec 和 BERT。
预处理
计算文档之间距离或相似度的常见步骤是对文档进行一些预处理。预处理步骤包括将所有文本转换为小写,标记化文本,移除停用词,移除标点符号和词形还原[4]。
标记化: 这一步涉及将句子拆分成更小的单元进行处理。一个标记是句子可以拆分成的最小词汇原子。可以使用空格作为分隔符将句子拆分成标记。这是一种标记化的方法。例如,一个句子“tokenization is a really cool step”被拆分为标记 ['tokenization', 'is', 'a', 'really', 'cool', 'step']。这些标记构成了文本挖掘的基础,并且是建模文本数据的第一步。
转换为小写: 虽然在某些特殊情况下可能需要保留大小写,但在大多数情况下我们希望将不同大小写的单词视为相同。这一步对于从大型数据集中获得一致的结果非常重要。例如,如果用户搜索“india”这个词,我们希望检索到包含不同大小写的相关文档,如“India”、“INDIA”和“india”,只要它们与搜索查询相关。
移除标点符号: 移除标点符号和空白有助于将搜索集中在重要的单词和标记上。
移除停用词: 停用词是一组在英语中常用的词,移除这些词可以帮助检索到更符合查询上下文的重要单词的文档。这也有助于减少特征向量的大小,从而有助于处理时间的缩短。
词形还原:词形还原通过将词映射到其根词来帮助减少稀疏性。例如,‘Plays’,‘Played’ 和 ‘Playing’ 都映射到 play。通过这样做,我们还减少了特征集的大小,并在不同文档之间匹配所有词汇变体,以提取最相关的文档。
(A) Jaccard 相似度
这种方法是最简单的方法之一。它对单词进行分词,并计算共享术语的计数总和与两个文档中总术语数量之和的比值。如果两个文档相似,分数为 1;如果两个文档不同,分数为 0 [3]。
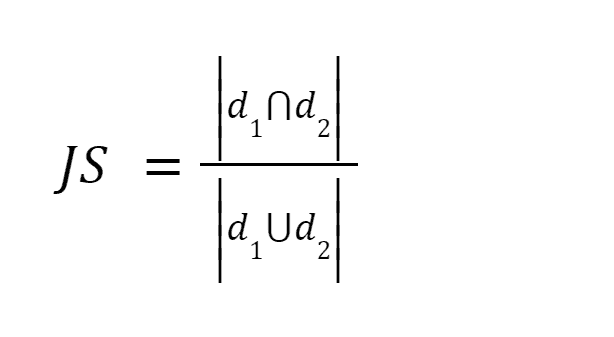
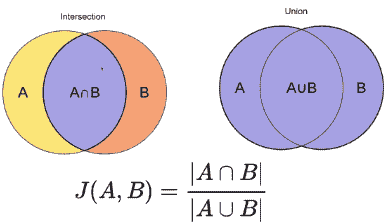
图片来源:O'Reilly
总结:该方法存在一些缺点。随着文档大小的增加,即使两个文档在语义上不同,共同词汇的数量也会增加。
(B) 欧几里得距离
在对文档进行预处理之后,我们将文档转换为向量。向量的权重可以是术语频率,即我们计算术语在文档中出现的次数,也可以是相对术语频率,即我们计算术语的出现次数与文档中总术语数量的比率 [3]。
设 d1 和 d2 为两个表示为 n 个术语(表示 n 维)的文档向量;然后我们可以使用毕达哥拉斯定理计算两个文档之间的最短距离,从而找到两个向量之间的直线。距离越大,相似度越低;距离越小,相似度越高。
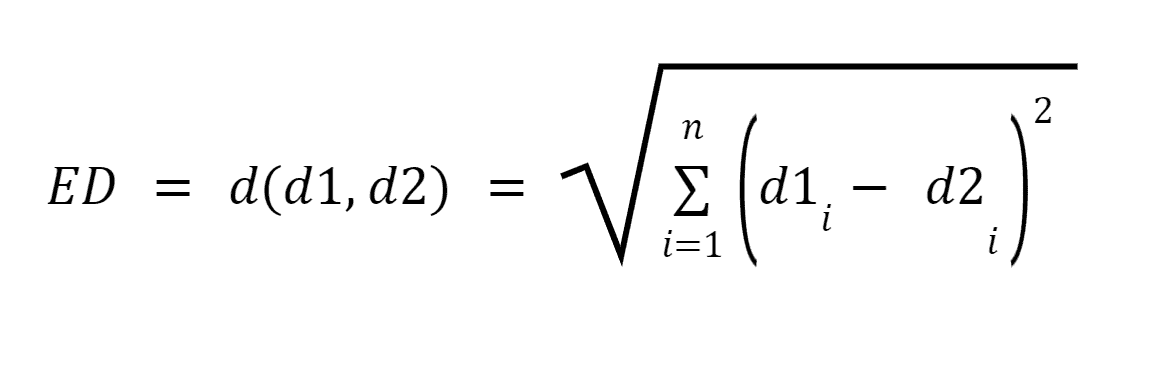
图片来源:Medium.com
总结:这种方法的主要缺点是,当文档大小不同的时候,即使两个文档在性质上相似,欧几里得距离也会给出较低的分数。较小的文档将导致向量的大小较小,而较大的文档将导致向量的大小较大,因为向量的大小与文档中的单词数量成正比,从而使整体距离变大。
(C) 余弦相似度
余弦相似度通过测量两个向量之间的夹角余弦值来评估文档之间的相似性。余弦相似度的结果可以在 0 和 1 之间取值。如果向量指向相同的方向,相似度为 1;如果向量指向相反的方向,相似度为 0。[6]。
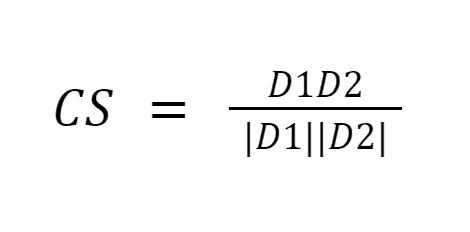
图片来源:Medium.com
总结:余弦相似度的优点在于它计算向量之间的方向而不是幅度。因此,即使文档大小不同,它也能捕捉到相似的文档之间的相似性。
上述三种方法的基本缺陷是测量未能通过语义查找相似文档。此外,这些技术只能逐对进行,从而需要更多的比较。
(D) 使用 TF-IDF 的余弦相似度
这种文档相似性查找的方法在 ElasticSearch 的默认搜索实现中使用,并且自 1972 年以来一直存在[4]。tf-idf 代表词频-逆文档频率。我们首先使用以下公式计算词频:
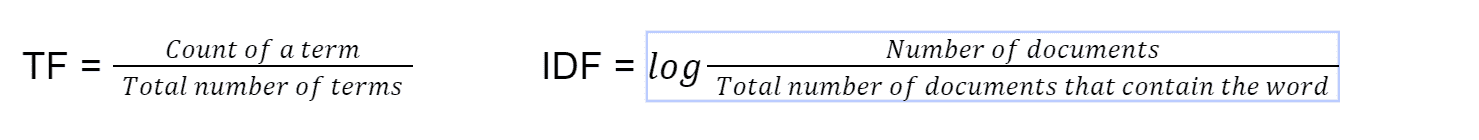
最后,我们通过将 TF*IDF 相乘来计算 tf-idf。然后我们在向量上使用余弦相似度,以 tf-idf 作为向量的权重。
总结:将词频与逆文档频率相乘有助于抵消一些在文档中普遍出现的词,并专注于文档之间不同的词。这种技术通过将搜索集中在重要的关键词上,帮助找到匹配搜索查询的文档。
(E) Doc2Vec
尽管从文档中提取单独的词(BOW - 词袋模型)转换为向量可能更容易实现,但它不会考虑句子中词语的顺序。Doc2Vec 是建立在 Word2Vec 之上的。Word2Vec 表示词的意义,而 Doc2Vec 表示文档或段落的意义[5]。
这种方法用于将文档转换为其向量表示,同时保留文档的语义意义。这种方法将变长文本(如句子、段落或文档)转换为向量[5]。然后训练 doc2vec 模型。模型的训练类似于训练其他机器学习模型,通过选择训练集和测试集文档并调整调优参数以实现更好的结果。
总结:这种向量化形式的文档保留了文档的语义意义,因为具有相似上下文或意义的段落在转换为向量时会更接近。
(F) BERT
BERT 是 Google 开发的用于 NLP 任务的基于变换器的机器学习模型。
随着 BERT(双向编码器表示来自 Transformer)的出现,NLP 模型使用大量未标记的文本语料库进行训练,这些模型既从左到右也从右到左查看文本。BERT 使用一种称为“注意力”的技术来提高结果。谷歌的搜索排名在使用 BERT 后显著提高了[4]。BERT 的一些独特特性包括
-
预训练于 104 种语言的维基百科文章。
-
从左到右和从右到左查看文本
-
帮助理解上下文
总结:因此,BERT 可以针对许多应用进行微调,如问答系统、句子改写、垃圾邮件分类器、构建语言检测器,而无需对任务特定架构进行大量修改。
下一步或应用的想法
了解相似性函数在寻找文档相似度中的应用非常有意义。目前,开发者需要选择最适合场景的相似性函数。例如,tf-idf 目前是文档匹配的最先进技术,而 BERT 在查询搜索中是最先进的技术。建立一个自动检测最适合场景的相似性函数的工具将非常有用,从而选择优化了内存和处理时间的相似性函数。这在自动匹配简历与职位描述、按类别聚类文档、根据患者病历分类患者等场景中将大有裨益。
结论
在本文中,我介绍了一些计算文档相似度的显著算法。这并不是一个详尽无遗的列表。还有其他几种方法可以找到文档相似度,选择合适的方法取决于具体的场景和应用。像 tf-idf、Jaccard、欧几里得、余弦相似度等简单统计方法非常适合简单的用例。可以利用现有的 Python、R 库来计算相似度分数,而无需强大的机器或处理能力。更先进的算法如 BERT 依赖于预训练的神经网络,这可能需要数小时,但对于需要理解文档上下文的分析能产生有效的结果。
参考文献
[1] Heidarian, A., & Dinneen, M. J. (2016). 一种用于测量文档相似度和文档聚类的混合几何方法。2016 IEEE 第二届国际大数据计算服务与应用会议(BigDataService),1–5. doi.org/10.1109/bigdataservice.2016.14
[2] Kavitha Karun A, Philip, M., & Lubna, K. (2013). 文档聚类中相似性度量的比较分析。2013 年国际绿色计算、通信与能源保护会议(ICGCE),1–4. doi.org/10.1109/icgce.2013.6823554
[3] Lin, Y.-S., Jiang, J.-Y., & Lee, S.-J. (2014). 一种用于文本分类和聚类的相似性度量. IEEE 知识与数据工程汇刊, 26(7), 1575–1590. doi.org/10.1109/tkde.2013.19
[4] Nishimura, M. (2020 年 9 月 9 日). 2020 年最佳文档相似性算法:初学者指南 - Towards Data Science. Medium. towardsdatascience.com/the-best-document-similarity-algorithm-in-2020-a-beginners-guide-a01b9ef8cf05
[5] Sharaki, O. (2020 年 7 月 10 日). 使用 Doc2vec 检测文档相似性 - Towards Data Science. Medium. towardsdatascience.com/detecting-document-similarity-with-doc2vec-f8289a9a7db7
[6] Lüthe, M. (2019 年 11 月 18 日). 计算相似性 — 相关度指标概述 - Towards Data Science. Medium. towardsdatascience.com/calculate-similarity-the-most-relevant-metrics-in-a-nutshell-9a43564f533e
[7] S. (2019 年 10 月 27 日). 相似性度量 — 评分文本文章 - Towards Data Science. Medium. towardsdatascience.com/similarity-measures-e3dbd4e58660
普尔尼玛·穆图库马尔**** 是微软的高级技术产品经理,拥有超过 10 年的经验,致力于为云计算、人工智能、分布式和大数据系统等多个领域开发和交付创新解决方案。我拥有华盛顿大学的数据科学硕士学位。在微软,我拥有四项专利,专注于 AI/ML 和大数据系统,并在 2016 年获得了全球黑客马拉松人工智能类别的奖项。今年 2023 年,我很荣幸成为 Grace Hopper 会议软件工程类别的审查小组成员。阅读和评估这些领域中有才华的女性的提交材料,对我来说是一次有价值的经历,这不仅推动了女性在科技领域的发展,也让我从她们的研究和见解中获益匪浅。我还是微软机器学习 AI 和数据科学(MLADS)2023 年 6 月会议的委员会成员。我同时也是全球女性数据科学社区和女性编码数据科学社区的大使。
更多相关话题
使用平均精度均值评估对象检测模型
原文:
www.kdnuggets.com/2021/03/evaluating-object-detection-models-using-mean-average-precision.html
评论
为了评估像 R-CNN 和YOLO这样的对象检测模型,使用平均精度均值(mAP)。mAP 比较真实边界框和检测到的边界框,并返回一个分数。分数越高,模型的检测越准确。
在上一篇文章中,我们详细讨论了混淆矩阵、模型准确性、精确度和召回率。我们还使用了 Scikit-learn 库来计算这些指标。现在我们将扩展讨论,看看精确度和召回率如何用于计算 mAP。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
本教程涵盖的部分如下:
-
从预测分数到类别标签
-
精确度-召回率曲线
-
平均精度(AP)
-
交并比(IoU)
-
对象检测的平均精度均值(mAP)
让我们开始吧。
从预测分数到类别标签
在本节中,我们将快速回顾如何从预测分数中推导出类别标签。
给定有两个类别,正类 和 负类,以下是 10 个样本的真实标签。
y_true = ["positive", "negative", "negative", "positive", "positive", "positive", "negative", "positive", "negative", "positive"]
当这些样本输入模型时,它返回以下预测分数。根据这些分数,我们如何对样本进行分类(即为每个样本分配一个类别标签)?
pred_scores = [0.7, 0.3, 0.5, 0.6, 0.55, 0.9, 0.4, 0.2, 0.4, 0.3]
为了将分数转换为类别标签,使用一个阈值。当分数等于或高于阈值时,样本被分类为一个类别。否则,它被分类为另一个类别。我们约定,如果样本的分数高于或等于阈值,则样本为正类。否则,为负类。下一个代码块将分数转换为类别标签,阈值为0.5。
import numpy
pred_scores = [0.7, 0.3, 0.5, 0.6, 0.55, 0.9, 0.4, 0.2, 0.4, 0.3]
y_true = ["positive", "negative", "negative", "positive", "positive", "positive", "negative", "positive", "negative", "positive"]
threshold = 0.5
y_pred = ["positive" if score >= threshold else "negative" for score in pred_scores]
print(y_pred)
['positive', 'negative', 'positive', 'positive', 'positive', 'positive', 'negative', 'negative', 'negative', 'negative']
现在真实标签和预测标签都可以在y_true和y_pred变量中找到。根据这些标签,可以计算混淆矩阵、精确度和召回率。
r = numpy.flip(sklearn.metrics.confusion_matrix(y_true, y_pred))
print(r)
precision = sklearn.metrics.precision_score(y_true=y_true, y_pred=y_pred, pos_label="positive")
print(precision)
recall = sklearn.metrics.recall_score(y_true=y_true, y_pred=y_pred, pos_label="positive")
print(recall)
# Confusion Matrix (From Left to Right & Top to Bottom: True Positive, False Negative, False Positive, True Negative)
[[4 2]
[1 3]]
# Precision = 4/(4+1)
0.8
# Recall = 4/(4+2)
0.6666666666666666
在快速回顾了计算精度和召回后,在下一节我们将讨论如何创建精度-召回曲线。
精度-召回曲线
从第一部分中给出的精度和召回的定义中记住,精度越高,模型在将样本分类为正样本时越自信。召回率越高,模型正确分类的正样本数量越多。
当模型具有高召回率但低精度时,模型可以正确分类大多数正样本,但也有许多假阳性(即将许多负样本分类为正样本)。当模型具有高精度但低召回率时,模型在将样本分类为正样本时准确,但可能仅分类了一部分正样本。
由于精度和召回率的重要性,有一个精度-召回曲线,显示了不同阈值下精度和召回值之间的权衡。此曲线有助于选择最佳阈值,以最大化这两个指标。
创建精度-召回曲线需要一些输入:
-
真实标签。
-
样本的预测分数。
-
将预测分数转换为类别标签的阈值。
下一块代码创建了y_true列表以保存真实标签,pred_scores列表用于预测分数,最后thresholds列表用于不同的阈值。
import numpy
y_true = ["positive", "negative", "negative", "positive", "positive", "positive", "negative", "positive", "negative", "positive", "positive", "positive", "positive", "negative", "negative", "negative"]
pred_scores = [0.7, 0.3, 0.5, 0.6, 0.55, 0.9, 0.4, 0.2, 0.4, 0.3, 0.7, 0.5, 0.8, 0.2, 0.3, 0.35]
thresholds = numpy.arange(start=0.2, stop=0.7, step=0.05)
这里是保存在thresholds列表中的阈值。由于有 10 个阈值,因此将创建 10 个精度和召回值。
[0.2,
0.25,
0.3,
0.35,
0.4,
0.45,
0.5,
0.55,
0.6,
0.65]
下一步函数precision_recall_curve()接受真实标签、预测分数和阈值。它返回两个相等长度的列表,表示精度和召回值。
import sklearn.metrics
def precision_recall_curve(y_true, pred_scores, thresholds):
precisions = []
recalls = []
for threshold in thresholds:
y_pred = ["positive" if score >= threshold else "negative" for score in pred_scores]
precision = sklearn.metrics.precision_score(y_true=y_true, y_pred=y_pred, pos_label="positive")
recall = sklearn.metrics.recall_score(y_true=y_true, y_pred=y_pred, pos_label="positive")
precisions.append(precision)
recalls.append(recall)
return precisions, recalls
下一个代码在传递了三个之前准备好的列表后调用precision_recall_curve()函数。它返回precisions和recalls列表,分别保存了所有精度和召回值。
precisions, recalls = precision_recall_curve(y_true=y_true,
pred_scores=pred_scores,
thresholds=thresholds)
这里是precisions列表中返回的值。
[0.5625,
0.5714285714285714,
0.5714285714285714,
0.6363636363636364,
0.7,
0.875,
0.875,
1.0,
1.0,
1.0]
这里是recalls列表中的值列表。
[1.0,
0.8888888888888888,
0.8888888888888888,
0.7777777777777778,
0.7777777777777778,
0.7777777777777778,
0.7777777777777778,
0.6666666666666666,
0.5555555555555556,
0.4444444444444444]
给定两个相等长度的列表,可以在下图所示的二维图中绘制它们的值。
matplotlib.pyplot.plot(recalls, precisions, linewidth=4, color="red")
matplotlib.pyplot.xlabel("Recall", fontsize=12, fontweight='bold')
matplotlib.pyplot.ylabel("Precision", fontsize=12, fontweight='bold')
matplotlib.pyplot.title("Precision-Recall Curve", fontsize=15, fontweight="bold")
matplotlib.pyplot.show()
精度-召回曲线在下图中显示。请注意,随着召回率的增加,精度会下降。原因是,当正样本数量增加(高召回率)时,每个样本正确分类的准确性下降(低精度)。这是可以预期的,因为当样本数量较多时,模型更容易出现失败。
精度-召回曲线使决定精度和召回率都高的点变得容易。根据之前的图表,最佳点是(recall, precision)=(0.778, 0.875)。
在之前的图中,图形化决定精准率和召回率的最佳值可能是有效的,因为曲线不复杂。更好的方法是使用一种称为f1的指标,该指标根据下列公式计算。

f1指标衡量精准率和召回率之间的平衡。当f1值较高时,意味着精准率和召回率都较高。较低的f1分数表示精准率和召回率之间的不平衡较大。
根据前面的示例,f1的计算方法如下代码所示。根据f1列表中的值,最高分数是0.82352941。它是列表中的第 6 个元素(即索引 5)。recalls和precisions列表中的第 6 个元素分别是0.778和0.875。相应的阈值是0.45。
f1 = 2 * ((numpy.array(precisions) * numpy.array(recalls)) / (numpy.array(precisions) + numpy.array(recalls)))
[0.72,
0.69565217,
0.69565217,
0.7,
0.73684211,
0.82352941,
0.82352941,
0.8,
0.71428571, 0
.61538462]
下一图中以蓝色显示了最佳平衡点的位置,该点对应于召回率和精准率之间的最佳平衡。总之,平衡精准率和召回率的最佳阈值是0.45,在此阈值下,精准率为0.875,召回率为0.778。
matplotlib.pyplot.plot(recalls, precisions, linewidth=4, color="red", zorder=0)
matplotlib.pyplot.scatter(recalls[5], precisions[5], zorder=1, linewidth=6)
matplotlib.pyplot.xlabel("Recall", fontsize=12, fontweight='bold')
matplotlib.pyplot.ylabel("Precision", fontsize=12, fontweight='bold')
matplotlib.pyplot.title("Precision-Recall Curve", fontsize=15, fontweight="bold")
matplotlib.pyplot.show()
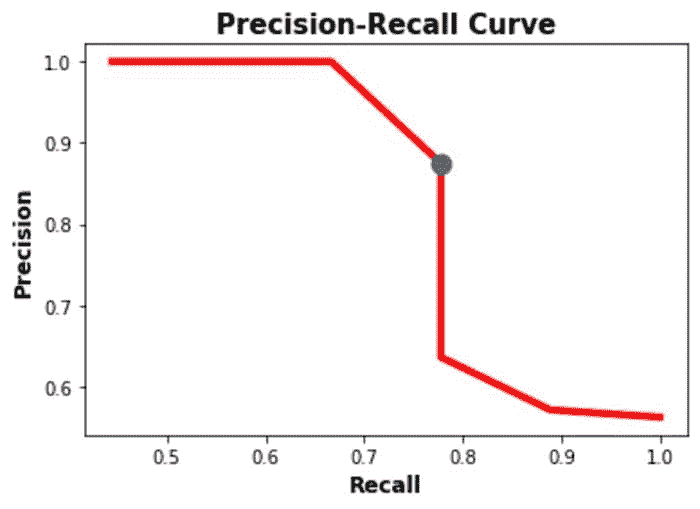
讨论了精准率-召回率曲线后,下一部分讨论如何计算平均精准率。
平均精准率 (AP)
平均精准率 (AP)是一种将精准率-召回率曲线汇总为一个值的方式,该值表示所有精准率的平均值。AP 根据下列公式计算。通过循环遍历所有的精准率/召回率,计算当前和下一召回率之间的差异,然后乘以当前的精准率。换句话说,AP 是每个阈值下精准率的加权总和,其中权重是召回率的增加。
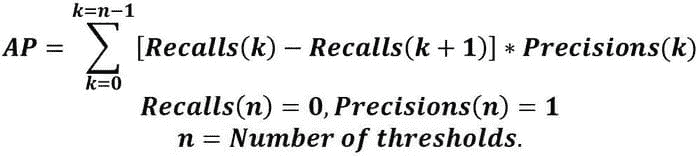
重要的是将recalls和precisions列表分别用 0 和 1 进行扩展。例如,如果recalls列表为 0.8,0.60.8,0.6,则应添加 0,使其变为 0.8,0.6,0.00.8,0.6,0.0。precisions列表也要这样做,但应添加 1 而不是 0(例如 0.8,0.2,1.00.8,0.2,1.0)。
由于recalls和precisions都是 NumPy 数组,前面的公式可以通过以下 Python 代码建模。
AP = numpy.sum((recalls[:-1] - recalls[1:]) * precisions[:-1])
这是计算 AP 的完整代码。
import numpy
import sklearn.metrics
def precision_recall_curve(y_true, pred_scores, thresholds):
precisions = []
recalls = []
for threshold in thresholds:
y_pred = ["positive" if score >= threshold else "negative" for score in pred_scores]
precision = sklearn.metrics.precision_score(y_true=y_true, y_pred=y_pred, pos_label="positive")
recall = sklearn.metrics.recall_score(y_true=y_true, y_pred=y_pred, pos_label="positive")
precisions.append(precision)
recalls.append(recall)
return precisions, recalls
y_true = ["positive", "negative", "negative", "positive", "positive", "positive", "negative", "positive", "negative", "positive", "positive", "positive", "positive", "negative", "negative", "negative"]
pred_scores = [0.7, 0.3, 0.5, 0.6, 0.55, 0.9, 0.4, 0.2, 0.4, 0.3, 0.7, 0.5, 0.8, 0.2, 0.3, 0.35]
thresholds=numpy.arange(start=0.2, stop=0.7, step=0.05)
precisions, recalls = precision_recall_curve(y_true=y_true,
pred_scores=pred_scores,
thresholds=thresholds)
precisions.append(1)
recalls.append(0)
precisions = numpy.array(precisions)
recalls = numpy.array(recalls)
AP = numpy.sum((recalls[:-1] - recalls[1:]) * precisions[:-1])
print(AP)
这就是关于平均精准率的所有内容。以下是计算 AP 的步骤总结:
-
使用模型生成预测分数。
-
将预测分数转换为类别标签。
-
计算混淆矩阵。
-
计算精准率和召回率指标。
-
创建精准率-召回率曲线。
-
测量平均精准率。
下一部分讨论交并比 (IoU),这是对象检测如何生成预测分数的方式。
交并比 (IoU)
训练对象检测模型通常有两个输入:
-
一张图片。
-
图像中每个物体的实际边界框。
模型预测了检测到的物体的边界框。预计预测框不会完全匹配实际框。下图展示了一张猫的图像。物体的实际框为红色,而预测框为黄色。根据这两个框的可视化,模型是否做出了一个高匹配分数的良好预测?
主观评估模型预测是困难的。例如,有人可能认为匹配度为 50%,而其他人则认为匹配度为 60%。

Image 来自 Pixabay ,由 susannp4 提供
更好的替代方法是使用定量度量来评分实际框和预测框的匹配程度。这一度量是交并比 (IoU)。IoU 有助于判断一个区域是否包含物体。
IoU 是通过将两个框之间的交集面积除以它们的并集面积来计算的。IoU 越高,预测越好。
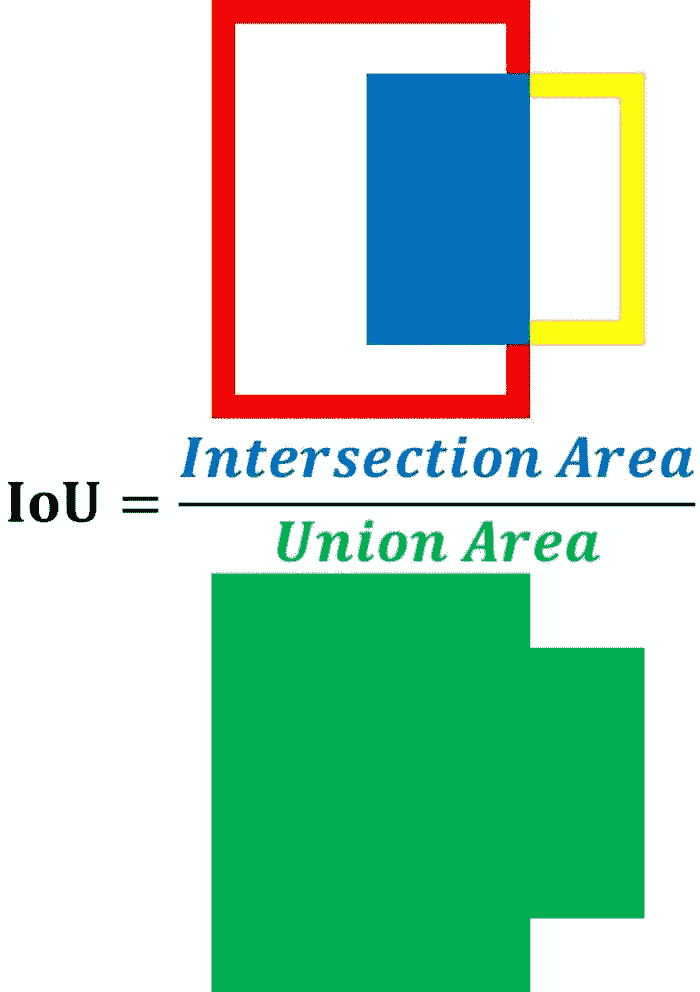
下图展示了三个具有不同 IoU 的情况。请注意,每个案例顶部的 IoU 是客观测量的,可能与实际情况略有不同,但还是有意义的。
对于案例 A,黄色预测框与红色实际框相距较远,因此 IoU 分数为0.2(即两个框之间只有 20%的重叠)。
对于案例 B,两个框之间的交集面积较大,但两个框仍未对齐,因此 IoU 分数为0.5。
对于案例 C,两个框的坐标非常接近,因此它们的 IoU 为0.9(即两个框之间有 90%的重叠)。
请注意,当预测框和实际框之间重叠度为 0%时,IoU 为 0.0。当两个框完全重合时,IoU 为1.0。
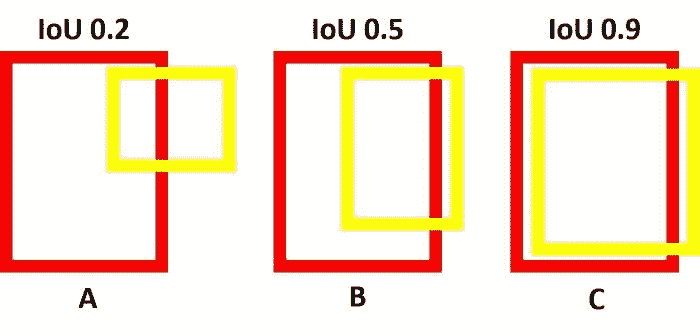
要计算图像的 IoU,这里有一个名为intersection_over_union()的函数。它接受以下两个参数:
-
gt_box:实际边界框。 -
pred_box:预测边界框。
它计算了intersection和union变量中两个框之间的交集和并集。此外,IoU 在iou变量中计算。它返回这三个变量。
def intersection_over_union(gt_box, pred_box):
inter_box_top_left = [max(gt_box[0], pred_box[0]), max(gt_box[1], pred_box[1])]
inter_box_bottom_right = [min(gt_box[0]+gt_box[2], pred_box[0]+pred_box[2]), min(gt_box[1]+gt_box[3], pred_box[1]+pred_box[3])]
inter_box_w = inter_box_bottom_right[0] - inter_box_top_left[0]
inter_box_h = inter_box_bottom_right[1] - inter_box_top_left[1]
intersection = inter_box_w * inter_box_h
union = gt_box[2] * gt_box[3] + pred_box[2] * pred_box[3] - intersection
iou = intersection / union
return iou, intersection, union
传递给函数的边界框是一个包含 4 个元素的列表,其中包括:
-
左上角的 x 轴。
-
左上角的 y 轴。
-
宽度。
-
高度。
这里是汽车图像的实际和预测边界框。
gt_box = [320, 220, 680, 900]
pred_box = [500, 320, 550, 700]
给定图像名为cat.jpg,这是绘制边界框的完整代码。
import imageio
import matplotlib.pyplot
import matplotlib.patches
def intersection_over_union(gt_box, pred_box):
inter_box_top_left = [max(gt_box[0], pred_box[0]), max(gt_box[1], pred_box[1])]
inter_box_bottom_right = [min(gt_box[0]+gt_box[2], pred_box[0]+pred_box[2]), min(gt_box[1]+gt_box[3], pred_box[1]+pred_box[3])]
inter_box_w = inter_box_bottom_right[0] - inter_box_top_left[0]
inter_box_h = inter_box_bottom_right[1] - inter_box_top_left[1]
intersection = inter_box_w * inter_box_h
union = gt_box[2] * gt_box[3] + pred_box[2] * pred_box[3] - intersection
iou = intersection / union
return iou, intersection, union
im = imageio.imread("cat.jpg")
gt_box = [320, 220, 680, 900]
pred_box = [500, 320, 550, 700]
fig, ax = matplotlib.pyplot.subplots(1)
ax.imshow(im)
gt_rect = matplotlib.patches.Rectangle((gt_box[0], gt_box[1]),
gt_box[2],
gt_box[3],
linewidth=5,
edgecolor='r',
facecolor='none')
pred_rect = matplotlib.patches.Rectangle((pred_box[0], pred_box[1]),
pred_box[2],
pred_box[3],
linewidth=5,
edgecolor=(1, 1, 0),
facecolor='none')
ax.add_patch(gt_rect)
ax.add_patch(pred_rect)
ax.axes.get_xaxis().set_ticks([])
ax.axes.get_yaxis().set_ticks([])
下一个图示显示了带有边界框的图像。

要计算 IoU,只需调用intersection_over_union()函数。根据边界框,IoU 分数为0.54。
iou, intersect, union = intersection_over_union(gt_box, pred_box)
print(iou, intersect, union)
0.5409582689335394 350000 647000
IoU 分数0.54意味着真实框与预测框之间有 54%的重叠。观察这些框,有人可能会直观地觉得模型检测到猫物体已经足够好。也有人可能觉得模型还不够准确,因为预测框与真实框的契合度不高。
为了客观判断模型是否正确预测了框的位置,使用了一个阈值。如果模型预测的框的 IoU 分数大于或等于阈值,则预测框与真实框之一之间有很高的重叠。这意味着模型能够成功检测到物体。检测到的区域被分类为Positive(即包含物体)。
另一方面,当 IoU 分数小于阈值时,模型做出了错误的预测,因为预测框与真实框没有重叠。这意味着检测到的区域被分类为Negative(即不包含物体)。
让我们通过一个例子来澄清 IoU 分数如何帮助将区域分类为物体或非物体。假设物体检测模型输入了下一张图像,其中有 2 个目标物体,真实框用红色标出,预测框用黄色标出。
下一段代码读取图像(假设文件名为pets.jpg),绘制框,并计算每个物体的 IoU。左侧物体的 IoU 为0.76,而另一个物体的 IoU 分数为0.26。
import matplotlib.pyplot
import matplotlib.patches
import imageio
def intersection_over_union(gt_box, pred_box):
inter_box_top_left = [max(gt_box[0], pred_box[0]), max(gt_box[1], pred_box[1])]
inter_box_bottom_right = [min(gt_box[0]+gt_box[2], pred_box[0]+pred_box[2]), min(gt_box[1]+gt_box[3], pred_box[1]+pred_box[3])]
inter_box_w = inter_box_bottom_right[0] - inter_box_top_left[0]
inter_box_h = inter_box_bottom_right[1] - inter_box_top_left[1]
intersection = inter_box_w * inter_box_h
union = gt_box[2] * gt_box[3] + pred_box[2] * pred_box[3] - intersection
iou = intersection / union
return iou, intersection, union,
im = imageio.imread("pets.jpg")
gt_box = [10, 130, 370, 350]
pred_box = [30, 100, 370, 350]
iou, intersect, union = intersection_over_union(gt_box, pred_box)
print(iou, intersect, union)
fig, ax = matplotlib.pyplot.subplots(1)
ax.imshow(im)
gt_rect = matplotlib.patches.Rectangle((gt_box[0], gt_box[1]),
gt_box[2],
gt_box[3],
linewidth=5,
edgecolor='r',
facecolor='none')
pred_rect = matplotlib.patches.Rectangle((pred_box[0], pred_box[1]),
pred_box[2],
pred_box[3],
linewidth=5,
edgecolor=(1, 1, 0),
facecolor='none')
ax.add_patch(gt_rect)
ax.add_patch(pred_rect)
gt_box = [645, 130, 310, 320]
pred_box = [500, 60, 310, 320]
iou, intersect, union = intersection_over_union(gt_box, pred_box)
print(iou, intersect, union)
gt_rect = matplotlib.patches.Rectangle((gt_box[0], gt_box[1]),
gt_box[2],
gt_box[3],
linewidth=5,
edgecolor='r',
facecolor='none')
pred_rect = matplotlib.patches.Rectangle((pred_box[0], pred_box[1]),
pred_box[2],
pred_box[3],
linewidth=5,
edgecolor=(1, 1, 0),
facecolor='none')
ax.add_patch(gt_rect)
ax.add_patch(pred_rect)
ax.axes.get_xaxis().set_ticks([])
ax.axes.get_yaxis().set_ticks([])
如果 IoU 阈值为 0.6,则只有 IoU 分数大于或等于 0.6 的区域被分类为Positive(即有物体)。因此,IoU 分数为 0.76 的框为 Positive,而 IoU 为 0.26 的另一个框为Negative。

无标签的图像来自hindustantimes.com
如果阈值改为0.2而不是 0.6,则两个预测都是Positive。如果阈值为0.8,则两个预测都是Negative。
总结来说,IoU 分数衡量的是预测框与真实框的接近程度。它的范围从 0.0 到 1.0,其中 1.0 是最佳结果。当 IoU 大于阈值时,框被分类为Positive,因为它包围了一个物体。否则,分类为Negative。
下一节展示了如何利用 IoU 来计算物体检测模型的平均精度均值(mAP)。
物体检测的平均精度均值(mAP)
通常,目标检测模型会使用不同的 IoU 阈值进行评估,其中每个阈值可能会给出不同的预测。假设模型输入了一张包含 10 个物体、分布在 2 个类别中的图像。如何计算 mAP?
要计算 mAP,首先需要计算每个类别的 AP。所有类别的 AP 的均值即为 mAP。
假设使用的数据集只有 2 个类别。对于第一类,以下是y_true和pred_scores变量中的真实标签和预测分数。
y_true = ["positive", "negative", "positive", "negative", "positive", "positive", "positive", "negative", "positive", "negative"]
pred_scores = [0.7, 0.3, 0.5, 0.6, 0.55, 0.9, 0.75, 0.2, 0.8, 0.3]
以下是第二类的y_true和pred_scores变量。
y_true = ["negative", "positive", "positive", "negative", "negative", "positive", "positive", "positive", "negative", "positive"]
pred_scores = [0.32, 0.9, 0.5, 0.1, 0.25, 0.9, 0.55, 0.3, 0.35, 0.85]
IoU 阈值列表从 0.2 到 0.9,步长为 0.25。
thresholds = numpy.arange(start=0.2, stop=0.9, step=0.05)
要计算一个类别的 AP,只需将其y_true和pred_scores变量输入到下列代码中。
precisions, recalls = precision_recall_curve(y_true=y_true,
pred_scores=pred_scores,
thresholds=thresholds)
matplotlib.pyplot.plot(recalls, precisions, linewidth=4, color="red", zorder=0)
matplotlib.pyplot.xlabel("Recall", fontsize=12, fontweight='bold')
matplotlib.pyplot.ylabel("Precision", fontsize=12, fontweight='bold')
matplotlib.pyplot.title("Precision-Recall Curve", fontsize=15, fontweight="bold")
matplotlib.pyplot.show()
precisions.append(1)
recalls.append(0)
precisions = numpy.array(precisions)
recalls = numpy.array(recalls)
AP = numpy.sum((recalls[:-1] - recalls[1:]) * precisions[:-1])
print(AP)
对于第一类,这里是其精确率-召回率曲线。根据这条曲线,AP 为0.949。
第二类的精确率-召回率曲线如下所示。它的 AP 为0.958。
根据这两个类别的 AP(0.949 和 0.958),目标检测模型的 mAP 按照下列公式计算。
根据这个公式,mAP 为0.9535。
mAP = (0.949 + 0.958)/2 = 0.9535
结论
本教程讨论了如何为目标检测模型计算均值平均精度(mAP)。我们首先讨论了如何将预测分数转换为类别标签。通过使用不同的阈值,创建了一个精确率-召回率曲线。从这条曲线中,测量出平均精度(AP)。
对于目标检测模型,阈值是检测物体的交并比(IoU)。一旦计算出数据集中每个类别的 AP,即可计算 mAP。
个人简介:Ahmed Gad 于 2015 年 7 月获得埃及梅努非亚大学计算机与信息学院(FCI)信息技术学士学位,并荣获优秀学位。因在学院排名第一,他于 2015 年被推荐到埃及的一个学院担任教学助理,随后在 2016 年转为学院的教学助理及研究员。他目前的研究兴趣包括深度学习、机器学习、人工智能、数字信号处理和计算机视觉。
原文。经授权转载。
相关内容:
-
评估深度学习模型:混淆矩阵、准确率、精确率和召回率
-
在 Keras 中使用 Lambda 层
-
如何在深度学习中创建自定义实时图
更多相关内容
事件处理:三大重要开放问题
原文:
www.kdnuggets.com/2018/05/event-processing-important-open-problems.html
评论
由 Miyuru Dayarathna,WSO2
- 简介
事件处理(EP)是一种分析事件流以提取现实世界事件有用见解的范式。如图 1 所示,我们可以将 EP 分为两个 主要领域,即 事件流处理 和 复杂事件处理(CEP)。第一个领域,流(即事件)处理 支持多种连续分析,例如过滤、聚合、丰富、分类、连接等。第二个领域,CEP 使用简单事件序列上的模式来检测和报告复合事件。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
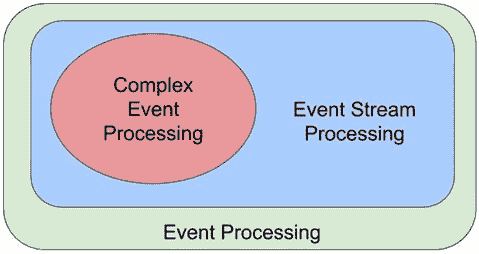
图 1:事件处理术语的区别
基于最近的 调查 和对行业趋势的多项分析,我们识别出事件处理领域的三大重要开放问题,如下所示,
-
如何开发和调试事件处理应用程序?
-
如何解决系统可扩展性问题?
-
如何管理系统状态?
- 如何开发和调试事件处理应用程序?
首先,我们需要解决事件处理应用程序开发的关键问题。主要有两个关键子问题,如下所示,
2.1 我们可以在不同的流处理器之间使用一种编程语言吗?
事件处理应用程序的开发遵循三种主要技术。首先,通过使用用标准编程语言(如 Java/C++/Python)编写的 API。此类事件处理平台的一些示例(全部为 Apache 项目)包括 Flink、Samza、Apex、Storm、Heron 等。图 2 展示了事件处理软件使用编程语言的情况。
图 2:事件处理软件编程语言的使用情况。(a)汇总视图(b)不同事件处理系统中使用的编程语言的分类。
第二,它们可以使用自定义(即领域特定)语言开发。例如,IBM Infosphere Stream 的流处理语言(SPL),Software AG 的 Apama 等。用自定义语言编写的程序语句会被翻译成中间语言,如 C/C++/Perl 等,然后被编译成应用程序可执行文件。
第三,事件处理应用程序可以使用 SQL 或类似 SQL 的语言开发。例如,WSO2 的 Siddhi (WSO2 流处理器),Confluent 的 KSQL,FlinkSQL,SparkSQL,BeamSQL,等等。类似 SQL 的语言(也称为流式 SQL)为具有关系数据库背景的应用开发者提供了熟悉的语法。流式 SQL 提供的核心操作覆盖了 90% 的用例。
编程语言的多样性产生了需要遵循通用语法的需求,以解决在事件流处理器中普遍存在的可用性和移植性问题。在这样做的过程中,上述第三种方法(流式 SQL)有可能成为指定事件流处理应用程序的标准。理想的情况是创建一个符合 ANSI SQL 的流式 SQL 系统。目前,还存在一些缺失的部分,例如在流式 SQL 中支持集合操作(见)。
2.2 查询编写与调试环境
大多数流处理器使用编程语言代码来表达业务逻辑,例如 流式 SQL、Scala、Java 等。因此,拥有正确的工具集对于开发流处理应用程序非常有用。为了开发大型复杂的应用程序,大多数非程序员更倾向于使用基于图形用户界面(GUI)的环境,而不是命令行界面(CLI)。大量的流处理器用户是非程序员,例如数据科学家。因此,缺乏适当的查询编写和调试环境使非程序员的工作非常困难。数据分析笔记本正在成为流处理应用程序的查询编写环境。几乎所有的事件流处理器都有某种应用调试支持。然而,调试支持的深度差异很大。
- 如何解决系统可扩展性问题?
系统可扩展性和性能是衡量流处理器处理大工作负载能力的重要指标。一个可扩展的流处理器可以扩展其操作规模。传统的扩展方法基于增加更多资源,称为垂直扩展(向同一服务器添加更多资源)和水平扩展(添加多个服务器)。然而,一些其他技术如 弹性扩展、近似计算 也可以用来解决系统可扩展性问题。
- 如何有效管理系统状态?
事件处理器的状态是处理来自输入数据流的事件期间反复访问的值集合。状态有三种类型:应用程序状态、用户状态和系统状态。应用程序状态是指在运行应用程序时创建和维护的值。例如,检测模式或长度窗口内容所需的状态。应用程序状态驻留在短期存储器(见图 2)中,例如主内存,并定期刷新到长期存储器。用户状态是应用程序访问的用户数据,用于做出运行时决策。例如,像 RDBMS 这样的长期存储器可以包含用户的信用历史信息。系统状态指框架提供的其他所有内容,以确保如果流处理器崩溃,它可以恢复到正常操作状态。
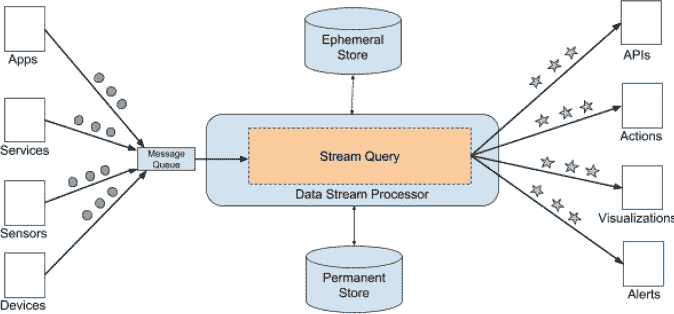
图 3:具有状态管理功能的典型数据流处理器
可靠且容错的状态管理对流处理器提供高可用服务至关重要。传统上,流处理器的可靠性和容错性通过将其操作员状态检查点保存到分布式文件系统、关系数据库管理系统(RDBMS)或分布式消息队列(如 Apache Kafka)来实现。然而,检查点引入了延迟,因为我们需要在进行检查点之前停止流应用程序的执行。已经提出了几种技术来减少保存检查点所需的时间。例如,增量检查点保持对状态所做更改的日志,并使用日志进行恢复,而不是每次都对应用程序状态进行完整检查点。因此,该技术仅在快照恢复成本可以通过增量检查点带来的性能提升来弥补时才有用。另一种方法是将计算层和数据库层合并为一个层,将另一层作为流和快照的存储层 (详细信息请参见)。
结论
事件处理应用程序如何编程、如何扩展以及如何管理其状态是事件处理范式中需要解决的三个主要问题。找到有效的解决方案可能会引导我们进入下一代流处理器。
简介: Miyuru Dayarathna 是 WSO2 的高级技术主管。他是一名计算机科学家,在流计算、图数据管理和挖掘、云计算、性能工程、物联网等方面有多个研究兴趣和贡献。
相关:
相关主题
你是否应该免费提供你的数据技能?
原文:
www.kdnuggets.com/2018/03/ever-volunteer-data-skills-free.html
评论

作为数据专家,你属于相对较小的职业群体。你拥有的技能始终处于高需求状态,并且随着技术的进步,这些技能的需求只会变得更高。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
然而,可能会出现这样一个问题:是否可以免费向个人或组织提供你的数据相关知识?采取这种方式是否对你有利?
你可以帮助非营利组织用数据回答关键问题
你可能愿意无偿提供服务的一个潜在原因是,你正在与非营利组织短期合作,帮助慈善机构利用数据。这种情况被称为 DataDive,并在 48 小时或更短时间内完成。
在参加该活动期间,你将成为一个最多由 20 名数据专家组成的团队的一部分,并且可以在过程中在各组之间跳转。这种设置意味着你有机会与领域内的其他人建立联系,并协助各种项目,同时帮助需要帮助的组织。
许多非营利组织可能已经意识到收集和分析数据的潜力,但可能没有足够的财力开始。这种安排帮助你用你的专业知识直接协助他们。
获得新编程语言经验的机会
分析师表示,R 和 Python 是数据分析师的顶级编程语言。如果你还不熟悉其中一种,学习它将显著提升你的知识基础。
尽管许多数据专业人士会自学这两种语言或参加在线课程以掌握基础知识,但你可能会发现,在现实环境中学习效果更佳。
在这种情况下,如果你遇到一个无薪实习或其他类型的机会,可以教你另一种编程语言并让你获得相关经验,这值得关注。这不会立即带来经济收益,但可能帮助你以后获得更好的工作,因此值得考虑将你的技能免费贡献出来。
除了各种硬技能之外,成功的数据科学家职业生涯需要具备正确的性格特质并意识到即使是小的创新也是重要的。你可能还需要采取试错的方法来克服挑战。
在上述描述的情况中免费贡献你的技能是一种互利的经历。组织获得了你的知识,而你则可以尝试真实世界的技术。
作为数据科学家进行志愿服务不会给你带来作品集或个人资料
与数据科学相关的人员相比,其他技术领域的人可能更愿意主动贡献他们的时间和才能。例如,在网页设计领域,你所做的工作通常可以纳入你的作品集。
此外,它可能会提升你的公众形象。如果你有权限这样做,很容易向朋友、家人、同学以及其他认识的人展示你在网上所做的贡献。
数据科学有所不同。虽然你可能能够通过案例研究或统计数据来证明你的工作如何在实现目标中发挥了重要作用,但这些东西对大多数人,尤其是那些不从事你行业的人而言,视觉吸引力不如其他方式。
愿意免费工作可能帮助你开启一段新职业生涯
数据科学职位的潜力使得许多各个领域的人考虑转行并尝试从其他背景进入这个行业。如果这听起来像你,免费工作可能是有价值的。
必须具备基本的数据技能,但如果你能展示出对工作的热情,这种性格特质可能会大有裨益,甚至可能比计算机科学或数学学位更有价值。
记住你的生计
你在这里读到的内容可能会促使你考虑免费工作——至少在某些情况下。如果你决定走这条路,务必要以实际的方式进行。例如,不要让志愿服务优先于能带来收入的工作。
此外,要明确而坚定你能提供的帮助范围,无论是针对某个特定项目还是你整体的贡献。否则,组织可能会过度依赖你,从而导致倦怠,并让你意识到你把太多时间投入到某个原因上了。
每当你有机会作为数据科学家免费工作时,务必确定你能从中获得什么经验,并且要考虑是否能在不被过度劳累和压倒的情况下实现预期。
如果机会显而易见且不需要付出太多牺牲,那就去把握它吧!否则,仔细考虑所有利弊后再做决定。
简历:凯拉·马修斯 讨论了诸如《周刊》、《数据中心期刊》和《风险投资》上的技术和大数据,已有五年以上的写作经验。欲阅读更多凯拉的文章,订阅她的博客 Productivity Bytes。
相关:
-
2 年内提高数据科学技能的 8 种方法
更多相关话题
互联网上每个数据科学入门课程的排名
原文:
www.kdnuggets.com/2017/03/every-intro-data-science-course-ranked.html
作者:David Venturi,有志数据科学家。
数据可视化由Alanah Ryding提供。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
一年前,我退出了加拿大最好的计算机科学项目之一。我开始利用在线资源创建自己的数据科学硕士课程。我意识到,通过 edX、Coursera 和 Udacity,我可以学到所需的一切。而且,我可以更快、更高效地学习,而且成本仅是原来的一个小部分。
我现在快完成了。我已经参加了许多与数据科学相关的课程,并审核了更多课程的部分内容。我了解目前的选择,以及为数据分析师或数据科学家角色准备所需的技能。几个月前,我开始创建一份以评论为驱动的指南,推荐数据科学每个主题的最佳课程。
在系列的第一份指南中,我推荐了一些编程课程给初学者数据科学家。接着是统计学和概率课程。
现在开始介绍数据科学。
(如果你不确定数据科学入门课程的内容,不用担心。我会很快解释的。)
在这份指南中,我花费了 10 多个小时试图识别 2017 年 1 月提供的所有在线数据科学入门课程,从它们的课程大纲和评论中提取关键信息,并汇总它们的评分。为此,我依赖了开源的 Class Central 社区及其数千个课程评分和评论的数据库。
自 2011 年以来,Class Central的创始人Dhawal Shah比世界上几乎任何人都更加关注在线课程。Dhawal 亲自帮助我整理了这份资源列表。
我们如何挑选考虑的课程
每门课程必须符合三个标准:
-
必须教授数据科学过程。 详细内容将在稍后提供。
-
必须是按需提供或每隔几个月开设一次。
-
必须是互动的在线课程,不接受书籍或只读的教程。虽然这些也是学习的可行方法,但本指南专注于课程。
我们相信我们涵盖了符合上述标准的所有显著课程。由于Udemy上似乎有数百门课程,我们选择仅考虑评价最多和评分最高的课程。不过,我们仍有可能遗漏了某些课程。如果我们遗漏了好的课程,请在评论区告诉我们。
我们如何评估课程
我们从 Class Central 和其他评论网站汇总了平均评分和评论数量,以计算每门课程的加权平均评分。我们阅读了文本评论,并利用这些反馈来补充数字评分。
我们基于两个因素做出了主观的课程大纲判断:
-
数据科学过程的覆盖范围。 课程是否略过或跳过某些主题?是否对某些主题讲解过于详细?有关这一过程的具体内容请参见下一部分。
-
常见数据科学工具的使用情况。 课程是否使用 Python 和/或 R 等流行编程语言教授?虽然这些不是必要的,但在大多数情况下很有帮助,因此对这些课程稍有偏好。

Python 和 R 是数据科学中最受欢迎的两种编程语言。
数据科学过程是什么?
什么是数据科学?数据科学家做什么? 这些是数据科学入门课程应回答的基本问题。以下来自哈佛教授 Joe Blitzstein 和 Hanspeter Pfister 的图表概述了典型的数据科学过程,这将帮助我们回答这些问题。
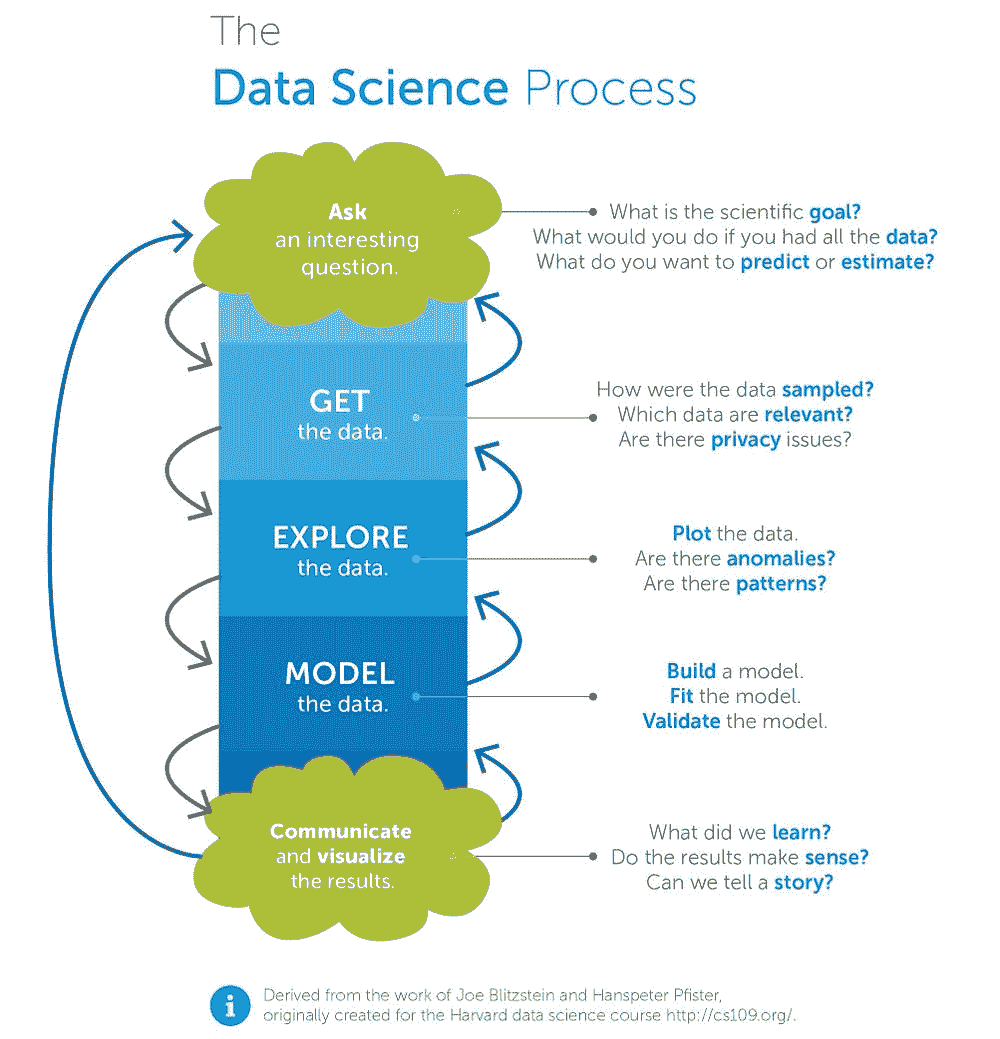
来自Opera Solutions的可视化图。
我们的目标是通过这门数据科学入门课程来熟悉数据科学过程。我们不希望深入覆盖过程的具体方面,因此标题中有“入门”一词。
对于每个方面,理想的课程应在过程框架内解释关键概念,介绍常见工具,并提供一些示例(最好是动手操作)。
我们只寻找一个入门课程。因此,本指南不会包括像约翰霍普金斯大学的数据科学专业化在 Coursera 上或 Udacity 的数据分析师纳米学位这样的完整专业化或项目。这些课程的汇编超出了本系列的目的:寻找每个学科的最佳单独课程,以组成数据科学教育。本系列文章中的最后三篇指南将详细介绍数据科学过程的各个方面。
需要基本的编码、统计和概率经验。
下列几个课程需要基本的编程、统计和概率经验。考虑到新内容相对高级,而这些学科通常有几门专门的课程,这一要求是可以理解的。
可以通过我们在前两篇文章中的推荐(编程,统计)来获得这些经验,这些文章是《数据科学职业指南》的一部分。
我们推荐的最佳数据科学入门课程是...
数据科学 A-Z™:包括真实数据科学练习(Kirill Eremenko/Udemy)
Kirill Eremenko 的数据科学 A-Z™在 Udemy 上在覆盖数据科学过程的广度和深度方面显然是胜出的。它在 3,071 条评论中获得了 4.5 星的加权平均评分,这使它在所有考虑的课程中排名最高。
该课程概述了完整的过程,并提供了实际的例子。内容长达 21 小时,时长适中。评论者喜欢讲师的授课方式和内容的组织。价格根据 Udemy 的折扣而有所不同,折扣频繁,因此你可能只需$10 即可购买。
尽管它没有检查我们“使用常见数据科学工具”的选项,但非 Python/R 工具选择(gretl、Tableau、Excel)在上下文中被有效使用。Eremenko 在解释 gretl 选择时提到(gretl 是一个统计软件包),尽管它适用于他使用的所有工具(重点是我的):
在 gretl 中,我们可以像在 R 和 Python 中一样进行建模,但无需编写代码。这就是关键所在。你们中的一些人可能已经很熟悉 R,但有些人可能完全不知情。我的目标是展示如何建立一个强大的模型,并提供一个可以在任何你选择的工具中应用的框架。gretl 将帮助我们避免陷入编程的困境。
一位著名的评论员指出:
Kirill 是我在网上找到的最好的老师。他使用现实生活中的例子,并解释常见问题,以便你能更深入地理解课程内容。他还提供了大量关于从处理不足的数据到向 C 级管理层展示工作的数据科学家的见解。我强烈推荐这门课程给初学者和中级数据分析师!

数据科学 A-Z™的预览视频。
这是一个以 Python 为重点的绝佳入门课程。
数据分析入门 (Udacity)
Udacity 的 数据分析入门 是 Udacity 流行的 数据分析师纳米学位 的一部分,相对较新。它使用 Python 清晰而有条理地覆盖了数据科学过程,但在建模方面略有不足。预计时间为 36 小时(每周六小时,共六周),但根据我的经验时间较短。它在一条评论中获得了 5 星评价。课程免费。
视频制作精良,讲师(Caroline Buckey)清晰而亲切。大量编程测验巩固了视频中学习的概念。学生将在课程结束后对他们的新技能或改进的 NumPy 和 Pandas 技能充满信心(这些是流行的 Python 库)。最终项目——在纳米学位中评分和评审,但在免费的单独课程中没有——可以为个人作品集增添亮点。

Udacity 的讲师 Caroline Buckey 讲解了数据分析过程(也称为数据科学过程)。
这是一项令人印象深刻的课程,虽然没有评论数据。
数据科学基础 (Big Data University)
数据科学基础是由 IBM 的 Big Data University 提供的四门课程系列。它包括名为数据科学 101、数据科学方法论、开源工具实践数据科学和R 101的课程。
它涵盖了完整的数据科学过程,并介绍了 Python、R 以及其他几种开源工具。课程制作质量极高。预计需要 13 到 18 小时,取决于是否参加最后的“R 101”课程,这对本指南的目的并非必要。不幸的是,它在我们用于此分析的主要评价网站上没有评价数据,因此我们暂时不能推荐它作为上述两个选项的替代品。它是免费的。

来自 Big Data University 的数据科学 101(这是数据科学基础系列的第一门课程)的一个视频。
竞争情况
我们的首选具有 3,068 条评论的加权平均评分 4.5 星。接下来我们来看看其他替代选项,按评分降序排列。下面你会找到一些以 R 为重点的课程,如果你坚定地想要在该语言中入门。
-
数据科学与机器学习 Python 全栈训练营(Jose Portilla/Udemy):全面覆盖过程,侧重于工具(Python)。流程驱动较少,更详细地介绍了 Python。虽然这个课程很棒,但不适合本指南的范围。它和 Jose 的 R 课程一样,可以同时作为 Python/R 和数据科学的入门课程。内容长达 21.5 小时。它的4.7星加权平均评分来自 1,644 条评论。费用根据 Udemy 的折扣而异,折扣频繁。
-
Data Science and Machine Learning Bootcamp with R(Jose Portilla/Udemy):涵盖整个过程,重点是工具使用(R)。过程驱动较少,更侧重于 R 的详细介绍。尽管如此,这门课程非常出色,但对于本指南的范围可能不太适合。它和上面提到的 Jose 的 Python 课程一样,可以作为 Python/R 和数据科学的入门课程。内容长达 18 小时,基于 847 条评价,平均评分为 4.6 星。费用根据 Udemy 的折扣而异,折扣频繁。

Jose Portilla 在 Udemy 上有两个数据科学和机器学习的速成课程:一个是 Python,另一个是 R。
-
Data Science and Machine Learning with Python — Hands On!(Frank Kane/Udemy):部分过程覆盖。重点在于统计和机器学习。内容适中(九小时)。使用 Python。基于 3,104 条评价,平均评分为 4.5 星。费用根据 Udemy 的折扣而异,折扣频繁。
-
Introduction to Data Science(Data Hawk Tech/Udemy):覆盖整个过程,但深度有限。内容较短(三小时)。简要覆盖 R 和 Python。基于 62 条评价,平均评分为 4.4 星。费用根据 Udemy 的折扣而异,折扣频繁。
-
应用数据科学:入门(雪城大学/Blackboard 开放教育):覆盖整个过程,但分布不均。重点关注基础统计学和 R 语言。过于应用,过程关注不够,无法满足本指南的目的。在线课程体验感到断断续续。具有4.33星的加权平均评分,共 6 条评论。免费。
-
数据科学导论(Nina Zumel & John Mount/Udemy):仅覆盖部分过程,但在数据准备和建模方面深度不错。长度适中(六小时内容)。使用 R 语言。具有4.3星的加权平均评分,共 101 条评论。费用因 Udemy 折扣而异,折扣频繁。
-
使用 Python 的应用数据科学(V2 Maestros/Udemy):全面覆盖过程,并且每个过程的深度都很好。长度适中(8.5 小时内容)。使用 Python。具有4.3星的加权平均评分,共 92 条评论。费用因 Udemy 折扣而异,折扣频繁。

V2 Maestros 的“应用数据科学”课程有两个版本:一个是针对Python,另一个是针对R。
-
想成为数据科学家吗?(V2 Maestros/Udemy):覆盖整个过程,但深度有限。内容较短(3 小时)。工具覆盖有限。具有4.3星的加权平均评分,共 790 条评论。费用因 Udemy 折扣而异,折扣频繁。
-
数据到洞察:数据分析简介(奥克兰大学/FutureLearn):覆盖范围不明确。声称专注于数据探索、发现和可视化。不可随时提供。内容时长为 24 小时(每周三小时,共八周)。它有 4 星的加权平均评分,基于 2 条评论。免费,提供付费证书。
-
数据科学导论(Microsoft/edX):部分过程覆盖(缺乏建模方面)。使用 Excel,这一点很合理,因为这是微软品牌的课程。内容时长为 12-24 小时(每周两到四小时,共六周)。它有 3.95 星的加权平均评分,基于 40 条评论。免费,提供 $25 的认证证书。
-
数据科学基础(Microsoft/edX):全面的过程覆盖,每个方面的深度都很好。涵盖 R、Python 和 Azure ML(微软的机器学习平台)。有几个 1 星评论提到工具选择(Azure ML)和讲师的表现不佳。内容时长为 18-24 小时(每周三到四小时,共六周)。它有 3.81 星的加权平均评分,基于 67 条评论。免费,提供 $49 的认证证书。

上述两个课程来自 Microsoft 的 数据科学专业证书 在 edX 上。
-
应用数据科学与 R(V2 Maestros/Udemy):V2 Maestros 的 Python 课程的 R 伴侣。全面的过程覆盖,每个方面的深度都很好。时长适中(11 小时内容)。使用 R。它有 3.8 星的加权平均评分,基于 212 条评论。价格因 Udemy 的折扣而异,折扣频繁。
-
数据科学导论(Udacity):部分过程覆盖,虽然对所涉及主题的深度很好。缺乏探索方面,尽管 Udacity 有一门完整的 课程 讲解探索性数据分析(EDA)。声称时长为 48 小时(每周六小时,共八周),但根据我的经验更短。一些评论认为高级内容的设置不足。感觉组织较差。使用 Python。它有 3.61 星的加权平均评分,基于 18 条评论。免费。
-
Python 中的数据科学入门(密歇根大学/Coursera):部分过程覆盖。不包括建模和可视化,尽管课程#2 和#3 在应用数据科学与 Python 专项中涵盖这些方面。完成这三门课程对于本指南而言过于深入。使用 Python。时长四周。其3.6星的加权平均评分基于 15 条评论。提供免费和付费选项。

密歇根大学在 Coursera 上教授应用数据科学与 Python 专项。
-
数据驱动的决策制定(普华永道/Coursera):部分覆盖(缺乏建模),重点在商业应用。介绍了许多工具,包括 R、Python、Excel、SAS 和 Tableau。时长四周。其3.5星的加权平均评分基于 2 条评论。提供免费和付费选项。
-
数据科学速成课程(约翰霍普金斯大学/Coursera):对完整过程的极简概述。对本系列来说过于简略。时长两小时。其3.4星的加权平均评分基于 19 条评论。提供免费和付费选项。
-
数据科学家的工具箱(约翰霍普金斯大学/Coursera):对整个过程的极简概述。更多是约翰霍普金斯大学的数据科学专业化的准备课程。声称有 4-16 小时内容(每周一到四小时,持续四周),尽管一位评论者指出可以在两小时内完成。其3.22星的加权平均评分基于 182 条评论。提供免费和付费选项。
-
数据管理与可视化(卫斯理大学/Coursera):部分过程覆盖(缺乏建模)。为期四周。制作质量良好。使用 Python 和 SAS。其2.67星的加权平均评分基于 6 条评论。提供免费和付费选项。
以下课程在 2017 年 1 月时没有评论。
- CS109 数据科学(哈佛大学):对整个过程进行了深入的全面覆盖(可能对于本系列来说过于深入)。一个完整的 12 周本科课程。由于课程未设计为在线学习,导航较为困难。实际的哈佛讲座被录制。上述数据科学过程信息图源自该课程。使用 Python。没有评论数据。免费。
哈佛 CS109 的主页上的特色可视化。
-
面向商业的数据分析导论(科罗拉多大学博尔德分校/Coursera):部分过程覆盖(缺乏建模和可视化方面),重点在于商业。数据科学过程在其讲座中伪装成“信息-行动价值链”。为期四周。描述了几种工具,但只有 SQL 有深入覆盖。没有评论数据。提供免费和付费选项。
-
数据科学导论(Lynda):全面覆盖过程,但覆盖深度有限。相当短(内容三小时)。介绍了 R 和 Python。没有评论数据。费用取决于 Lynda 订阅。
总结
这是涵盖进入数据科学领域最佳在线课程的六篇系列文章中的第三篇。我们在第一篇文章中讨论了编程,在第二篇文章中讨论了统计学和概率。系列的其余部分将涵盖数据科学的其他核心能力:数据可视化和机器学习。
最终的部分将总结这些文章,并推荐其他关键主题如数据处理、数据库甚至软件工程的最佳在线课程。
如果你在寻找完整的数据科学在线课程列表,可以在 Class Central 的数据科学和大数据主题页面找到它们。
如果你喜欢阅读这篇文章,看看Class Central的其他文章:
这是我在Class Central 上发布的原始文章的精简版,其中包含了进一步的课程描述、大纲和多个评论。
David Venturi 使用 MOOCs 为自己创建了一个个性化的数据科学硕士课程。他拥有化学工程和经济学的双学位。结合他对体育和数据的热爱,他喜欢阅读和写作关于最新的冰球和棒球分析的内容。
作为在线课程和 MOOCs 的首选平台,Class Central 提供经过策划和学生评论的高质量课程,帮助学习者做出明智的学习决策。
原文。经许可转载。
相关内容:
-
顶级机器学习 MOOCs 和在线讲座:全面调查
-
顶级 Coursera 数据科学专业:比较与独家见解
-
15 门数据科学数学 MOOCs
更多相关话题
如何在计算机视觉中做一切
原文:
www.kdnuggets.com/2019/02/everything-computer-vision.html
评论
Mask-RCNN 进行对象检测和实例分割
想做计算机视觉吗?如今深度学习是实现这一目标的途径。大规模的数据集加上深度卷积神经网络(CNN)的表现能力,构建了超级准确和稳健的模型。唯一仍然存在的挑战是:如何设计你的模型。
我们的三大课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业生涯
2. Google Data Analytics Professional Certificate - 提升你的数据分析能力
3. Google IT Support Professional Certificate - 支持你的组织的 IT 需求
在计算机视觉这样一个广泛而复杂的领域中,解决方案并不总是明确的。计算机视觉中的许多标准任务都需要特别考虑:分类、检测、分割、姿态估计、增强与修复以及动作识别。虽然用于每种任务的最先进网络都展示了共同的模式,但它们仍然需要独特的设计调整。
那么我们如何为所有这些不同的任务构建模型呢?
让我向你展示如何用深度学习做计算机视觉中的一切!
分类
最著名的!图像分类网络以固定大小的输入开始。输入图像可以有任意数量的通道,但 RGB 图像通常为 3。当你设计网络时,分辨率在技术上可以是任何大小,只要足够大以支持网络中所有的下采样。例如,如果你在网络中下采样 4 次,那么你的输入图像大小至少需要为 4² = 16 x 16 像素。
随着你深入网络,空间分辨率会降低,因为我们试图将所有信息压缩成一个一维向量表示。为了确保网络始终有能力传递它提取的所有信息,我们会根据深度增加特征图的数量,以适应空间分辨率的降低。即,我们在下采样过程中丢失了空间信息,为了弥补这种损失,我们扩展特征图以增加语义信息。
在选择的一定量下采样后,特征图被矢量化并输入到一系列全连接层中。最后一层的输出数量与数据集中类别的数量相同。
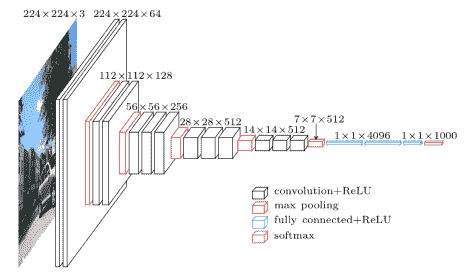
目标检测
目标检测有两种类型:一阶段和两阶段。它们都以“锚框”开始;这些是默认的边界框。我们的探测器将预测这些框与真实框之间的差异,而不是直接预测框。
在一个两阶段探测器中,我们自然有两个网络:一个框提议网络和一个分类网络。框提议网络提出了边界框的坐标,这些坐标是基于它认为对象可能存在的高概率区域;这些坐标相对于锚框是相对的。分类网络则对每个边界框中的潜在对象进行分类。
在一阶段探测器中,提议和分类网络被融合成一个单独的阶段。网络直接预测边界框坐标和框内的类别。由于两个阶段融合在一起,一阶段探测器通常比两阶段的更快。但由于任务的分离,两阶段探测器的准确性更高。
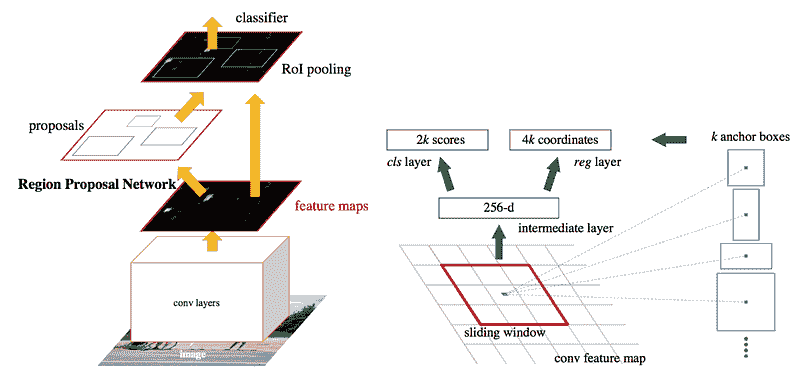
Faster-RCNN 两阶段目标检测架构 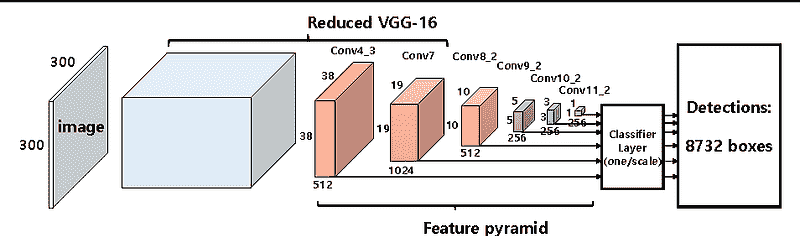
SSD 一阶段目标检测架构
分割
分割是计算机视觉中较为独特的任务之一,因为网络需要学习低层次和高层次的信息。低层次信息用于准确地按像素分割图像中的每个区域和对象,而高层次信息则用于直接分类这些像素。这导致网络被设计为将早期层和高分辨率(低层次空间信息)的信息与更深层次和低分辨率(高层次语义信息)的信息结合起来。
如下所示,我们首先通过标准分类网络处理图像。然后,我们从网络的每一阶段提取特征,从而利用从低到高的一系列信息。每个信息层级在合并之前会独立处理。当信息被合并时,我们上采样特征图,以最终达到完整的图像分辨率。
想了解更多关于深度学习分割的细节,请查看 这篇文章。
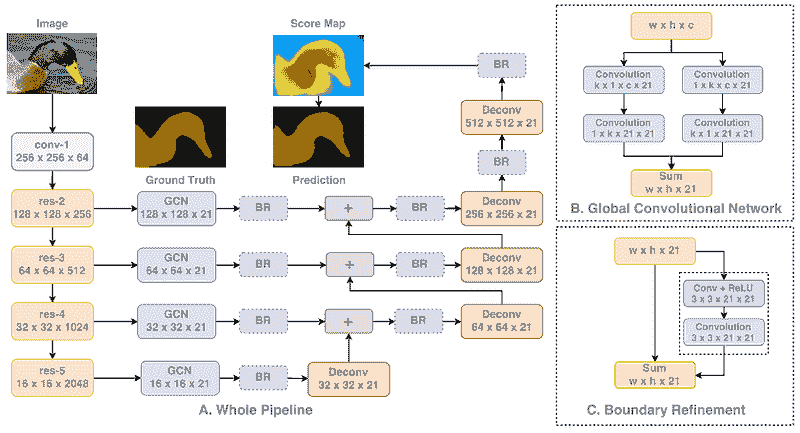
GCN 分割架构
姿态估计
姿态估计模型需要完成两个任务:(1)检测图像中每个身体部位的关键点(2)找出如何正确连接这些关键点。这分为三个阶段:
(1) 使用标准分类网络从图像中提取特征
(2) 给定这些特征,训练一个子网络来预测一组 2D 热图。每个热图与特定关键点相关,并包含关于每个图像像素是否可能存在关键点的置信度值。
(3) 再次利用分类网络的特征,我们训练一个子网络来预测一组 2D 矢量场,每个矢量场编码了关键点之间的关联程度。高关联的关键点被认为是连接在一起的。
以这种方式训练模型与子网络将共同优化关键点的检测和连接。
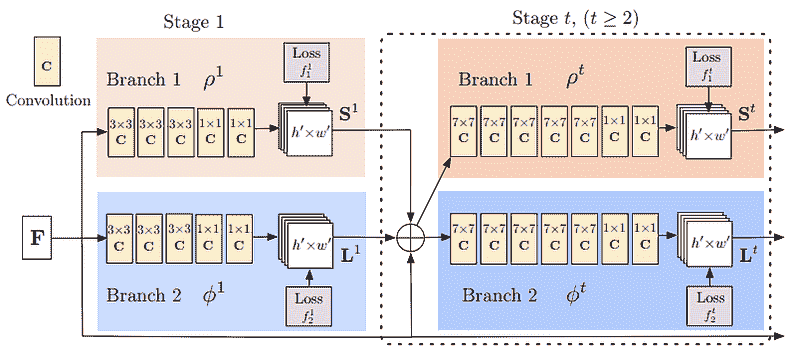
OpenPose 姿态估计架构
增强与恢复
增强和恢复网络是它们自己独特的存在。我们不对这些进行任何下采样,因为我们真正关心的是高像素/空间准确性。下采样会降低空间准确性,因为它减少了用于空间准确性的像素数。相反,所有处理都在全图像分辨率下进行。
我们首先将要增强/恢复的图像以全分辨率传递给我们的网络,不做任何修改。该网络仅由多个卷积和激活函数堆叠而成。这些模块通常受到启发,并且偶尔直接复制自最初为图像分类开发的模块,如Residual Blocks、Dense Blocks、Squeeze Excitation Blocks等。最后一层没有激活函数,甚至没有 sigmoid 或 softmax,因为我们希望直接预测图像像素,而不需要任何概率或分数。
这就是这些类型网络的全部内容!在图像的全分辨率下进行大量处理,以实现高空间准确性,使用已被证明在其他任务中有效的相同卷积。
EDSR 超分辨率架构
动作识别
动作识别是少数几个特定需要视频数据才能良好工作的应用之一。要分类一个动作,我们需要了解场景随时间发生的变化,这自然要求我们需要视频。我们的网络必须学会空间和时间信息,即空间和时间的变化。最适合这个任务的网络是3D-CNN。
3D-CNN,顾名思义,是一种使用 3D 卷积的卷积网络!它们与常规 CNN 的不同之处在于卷积应用于 3 个维度:宽度、高度和时间。因此,每个输出像素的预测基于其周围像素和相同位置的前后帧中的像素的计算!
直接传递大批量图像
视频帧可以通过几种方式传递:
(1) 直接在大批量中,如第一张图所示。由于我们传递的是一系列帧,因此同时提供了空间和时间信息。
单帧 + 光流(左)。视频 + 光流(右)
(2) 我们也可以在一个流中传递单个图像帧(数据的空间信息)及其对应的视频光流表示(数据的时间信息)。我们会使用常规的 2D CNN 从这两者中提取特征,然后将它们结合后传递给我们的 3D CNN,后者结合了这两种信息。
(3) 将我们的帧序列传递给一个 3D CNN,将视频的光流表示传递给另一个 3D CNN。这两个数据流都有空间和时间信息。这将是最慢的选项,但也可能是最准确的,因为我们对视频的两种不同表示进行特定处理,而这两种表示包含了所有信息。
所有这些网络输出视频的动作分类。
喜欢学习吗?
在 twitter上关注我,我会发布关于最新和最伟大的 AI、技术和科学的内容!
简介:George Seif 是一位认证的极客和 AI/机器学习工程师。
原文。经许可转载。
相关:
-
快速轻松解决任何图像分类问题
-
Scikit Learn 简介:Python 机器学习的黄金标准
-
如何为机器学习设置 Python 环境
更多相关话题
关于数据湖仓你需要了解的一切
原文:
www.kdnuggets.com/2022/09/everything-need-know-data-lakehouses.html
来源:Dremio
你是否可以将数据湖仓视为科技界的新流行词?看起来我们可以。我们最初使用的数据仓库,指的是一种可以分析以帮助决策的信息存储架构。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
数据仓库可以追溯到 20 世纪 80 年代,在商业世界的许多不同方面都发挥了作用。然而,大数据时代很快来临,当时非结构化原始数据占据了许多组织中可用数据和信息的 80-90%。
正是因为数据仓库无法处理非结构化数据,其模型基于结构化数据,数据湖仓成为了下一个大趋势。
作为这篇文章的一部分,我与Dremio,一个提供“适合熟悉和喜爱 SQL 的团队的湖仓平台”的组织合作。Dremio 成立于 2015 年,专注于数据湖仓。他们的技术已应用于包括联合利华、德勤、诺基亚在内的各种组织,并与 AWS 等多个云和技术合作伙伴合作。Dremio 已成为数据湖仓领域的领导者。
“数据湖仓结合了数据湖的可扩展性和灵活性,以及数据仓库的性能和功能。数据湖仓是两者的最佳结合,是分析目的的数据管理的未来。”
— 马克·莱昂斯,Dremio
他们的团队很乐于助人,并回答了一系列我们提出的问题,以帮助你了解有关数据湖仓的所有信息。
与 Dremio 的马克·莱昂斯的讨论
编辑注:以下问题由马克·莱昂斯,Dremio的产品管理副总裁回答。
什么是数据湖仓?
数据湖屋在技术市场上相对较新,它是在 2010 年发明的,并迅速获得了主流采用。数据湖屋具有用于数据分析和处理非结构化数据的能力,这与数据仓库不同。
数据湖屋的作用是什么?
数据湖屋使公司能够在数据探索到关键业务智能仪表板的所有分析工作负载中,在一个数据副本上运行(通常为Apache Parquet格式,这是性能最好的),因为它存储在云对象存储中。
数据湖屋如何工作?
数据湖屋是 2.0 版本的数据湖,具有许多相同的目标,但改进了技术,解决了数据湖即“数据沼泽”的历史性不足。数据湖屋不仅仅是对象存储中的文件——它的意义更大。
数据湖屋具有添加表格格式的能力,这些格式支持仓库功能,例如一致的插入、更新和删除,以及对底层数据优化(如文件压缩,以防止著名的“小文件”问题)等。
数据湖屋的基本特征是什么?
重要特征包括:
- 多引擎支持(机器学习、SQL、流处理等)
- 对行业标准表格格式(如Apache Iceberg)进行插入、更新和删除
- 像传统数据库管理系统(DBMS)一样的原子事务和数据一致性保证
- 元数据(Hive metastore、Project Nessie、AWS Glue Catalog等)
- 供应商无关
- 标准的客户端集成以支持使用笔记本或仪表板工具的数据消费者
- 自动扩展
- 用户可以选择最适合自己需求的软件或 SaaS。
数据湖屋与数据仓库之间的关系是什么?
数据湖屋与数据仓库有相似之处也有不同之处。数据湖屋使 SQL 引擎(如 Dremio、Hive、Athena、Spark SQL 等)能够对行业标准表格格式提供数据操作语言(DML)功能,并为事务和数据一致性提供数据库级别的保证。
这使得数据湖屋相当于数据仓库的能力,但当你查看其差异时,情况还远不止于此。数据湖屋支持其他引擎用于 SQL 之外的用例,如机器学习或流处理,同时保持供应商无关性,这意味着它们以及所有使用的数据都保持在遵循开放数据架构哲学的开放格式中。
为什么数据湖屋变得如此受欢迎?
通过数据湖仓架构,数据消费者可以立即使用他们喜欢的工具来分析数据——这是一个巨大的优势!数据工程师节省了大量将数据加载到仓库中供他人使用以及维护相关基础设施的时间和金钱。
此外,数据湖仓消除了云数据仓库臭名昭著的供应商锁定和锁定问题。云对象存储中的数据以开放的、与供应商无关的格式存储,如Apache Parquet和Apache Iceberg,因此没有供应商能够对数据施加影响。
在湖仓领域,公司自然受益于竞争和创新。它们在选择计算引擎以处理当前使用的数据类型方面具有灵活性,并且能够轻松尝试未来出现的新计算引擎。
结论
Dremio 的目标是打破一个持续了 30 年的范式,这个范式束缚了每个公司。他们希望消除某些障碍,帮助公司变得创新,加快洞察时间,并将控制权交还给用户。
我希望这次与来自 Dremio 的 Mark Lyons 的访谈能帮助你更好地理解数据湖仓是什么,它们为何进入市场,它们的工作原理,它们的重要特性,以及它们与数据仓库的区别。
我们要感谢 Mark Lyons 和Dremio参与本文的创作。
Nisha Arya 是一位数据科学家和自由技术作家。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何(或能)促进人类寿命的不同方式。作为一名热心的学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关内容
你需要了解的 Cohere LLM 大学的一切
原文:
www.kdnuggets.com/2023/07/everything-need-llm-university-cohere.html

作者提供的图像
你可能听到很多关于大型语言模型(LLMs)的信息。你们中的一些人对未来充满兴趣。也有一些人想知道“我怎么参与其中?”。无论你对 LLMs 的看法如何——最终的目标是想要更多了解它。如果你想学习 LLMs 以便转行到技术行业的其他职业——Cohere 的 LLM 大学可以帮助你实现这一目标!
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域的职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能。
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面。
我们看到越来越多的开发者希望将他们的职业生涯提升到一个新的水平。自然语言处理(NLP)是一个很多开发者本来不打算深入的领域。但随着大型语言模型(LLMs)的发展以及像 Cohere 这样的组织提供教育内容——这使得过渡变得更加容易。
什么是 LLM 大学?
Cohere旨在通过赋能开发者和企业,构建语言 AI 的未来,使他们能够利用语言 AI 捕获重要的商业价值。为了实现这一目标,他们为希望了解更多关于 NLP 和 LLMs 的开发者创建了LLM 大学。
他们提供了一个全面的课程,旨在为学生和开发者提供扎实的 NLP 基础知识,并在此基础上开发自己的应用程序。
听到这是为开发者准备的,不要感到紧张——因为他们面向各类背景的人群。你将学习 NLP 和 LLMs 的基础知识,并将你的知识提升到更高级的水平,比如构建和使用文本表示和文本生成模型。
理论部分有明确的解释和例子来支持,而实践部分则有代码示例以巩固你的知识。一旦你对该领域有了较好的理解,你将通过实际操作来检验你的技能,然后你将能够构建和部署你自己的模型。
学习路线
那么这如何运作呢?初学者和中级者一起?不。所以有两种学习方式:
*** 顺序**
**如果你是新手机器学习工程师,你可能更愿意从 NLP 和 LLM 的基础开始。通过顺序路线,你将学习 NLP 和 LLM 的基础知识及其架构。
尽管这条路线需要的背景知识很少,但你仍然可以通过以下资料来巩固你的机器学习和 NLP 知识:附录 1。
*** 非顺序**
**如果你对 NLP 和 LLM 的基础知识感到比较自信,你可能不想从基础开始。你可以跳过这些基础模块,转而学习适合你需求的特定模块,或帮助你完成某个特定项目的模块。你可以通过查看以下资料了解这包含了什么:附录 2。
LLM 大学课程
想知道你将学习什么吗?让我们深入了解…
在接下来的主要模块中,你将学习 LLM 的工作原理,并进行实践实验室以构建自己的语言应用程序。第一个模块完全以理论为主,然后在模块 2、3 和 4 中,你将结合理论和带代码实验室的实践。
这些是模块:
*** 模块 1:大型语言模型是什么?**
**在这个模块中,你将学习 LLM 的基础知识,还将学习更多关于嵌入、注意力、变换器模型架构、语义搜索的内容,以及实际示例和动手练习。
*** 模块 2:使用 Cohere 端点进行文本表示**
**在第二个模块中,你将学习理论和实际实验室,在那里你将学习如何使用 Cohere 的端点进行分类、嵌入和语义搜索。在本模块结束时,你将学习如何编写代码调用 Cohere API 的多个不同端点。
*** 模块 3:使用 Cohere 端点进行文本生成**
**在第三个模块中,你将学习如何使用生成式学习生成文本。你将从一个教你如何使用生成的端点的代码实验室开始,然后掌握提示工程。
*** 模块 4:部署**
**最后但同样重要的是,部署!当你构建应用程序时,你将学习如何使用平台和框架进行部署,如 AWS SageMaker、Streamlit 和 FastAPI。
一旦完成这些模块,你将掌握 NLP 的领域,并开启语言技术不断增长的新机遇。
总结
为了获得所需的帮助,Cohere 正在招收第一批学习者,并一同指导他们完成课程材料。他们还设有阅读小组,并将举办独家活动。你可以注册他们的 Discord 社区:Cohere 的 Discord 社区,在那里你可以与其他学习者联系,互相帮助,分享想法,共同进步。
妮莎·阿雅 是一名数据科学家、自由技术写作人以及 KDnuggets 的社区经理。她特别感兴趣于提供数据科学职业建议或教程,并围绕数据科学进行理论知识的传授。她还希望探索人工智能在延续人类生命方面的不同益处。作为一个热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
相关主题
-
ChatGPT:你需要知道的一切************
你想知道的所有机器学习知识
原文:
www.kdnuggets.com/2022/09/everything-youve-ever-wanted-to-know-about-machine-learning.html
在基础知识中增加趣味!一系列短视频,旨在让初学者和专家都能享受
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
寻找一门有趣且幽默的 AI 入门课程?看看《与机器学习交朋友》(MFML),这是一个受人喜爱的免费 YouTube 课程,旨在满足每个人的需求。是的,每个人。如果你在读这篇文章,这门课程就是为你准备的!

图片由 Randall Munroe 提供,xkcd.com CC。
课程预告
短视频: 下面的大多数视频长度为 1–5 分钟,这意味着你可以在小块、好,味道鲜美的知识中升级自己的知识!从一开始就深入学习,或者滚动找到你想了解的主题。
长视频: 对于那些喜欢在 1–2 小时的长时间学习中学习的人,课程也以 4 个较长的部分提供这里。
基本概念
-
基础知识:MFML 000 — 欢迎
-
基础知识:MFML 001 — 什么是机器学习?
-
基础知识:MFML 004 — 如何测试机器学习
-
基础知识:MFML 005 — 黑箱中有什么?
-
基础知识:MFML 006 — 简单线性回归
-
基础知识:MFML 007 — 多元线性回归
-
基础知识:MFML 008 — 特征工程
-
基础知识:MFML 009 — 什么是 AI?
-
基础知识:MFML 011 — 算法、数据和计算

实践中
-
实践中:MFML 012 — 实际应用
-
实践中: MFML 016 — 为什么信任 AI?
-
实践中: MFML 017 — 可解释性与 AI
-
实践中: MFML 020 — 决策智能
-
实践中: MFML 022 — 熟练的决策者
-
实践中: MFML 023 — 可靠还是不可靠?
-
实践中: MFML 024 — 可预防的灾难
-
实践中: MFML 025 — 负责任地许愿
-
实践中: MFML 027 — 我们的 AI 未来
AI 的 12 个步骤

-
第 0 步: MFML 028 — AI 的 12 个步骤
-
第 0 步: MFML 029 — 从哪里开始应用 AI?
-
第 0 步: MFML 030 — 分类与回归
-
第 0 步: MFML 031 — 实例、特征和目标
-
第 0 步: MFML 032 — 监督学习
-
第 0 步: MFML 033 — 无监督学习
-
第 0 步: MFML 034 — 半监督学习
-
第 0 步: MFML 035 — 强化学习
-
第 0 步: MFML 036 — 数据科学究竟是什么?
-
第 0 步: MFML 037 — 数据科学流程图
-
第 0 步: MFML 038 — 不要忘记数据!


-
第 1 步: MFML 039 — AI 的“良好行为”是什么?
-
第 1 步: MFML 040 — 假阳性和真阴性
-
第 1 步: MFML 041 — 混淆矩阵
-
第 1 步: MFML 042 — 性能指标
-
第 1 步: MFML 043 — 真实情况
-
第 1 步: MFML 044 — 精确度与召回率
-
第 1 步: MFML 045 — 什么是优化?
-
第 1 步: MFML 046 — 损失函数
-
第 1 步: MFML 047 — 设置启动标准


- 第 2 步: MFML 048 — 数据工程
-
第 3 步: MFML 049 — 过拟合的危险
-
第 3 步: MFML 050 — 你需要关注欠拟合吗?
-
第 3 步: MFML 051 — 数据拆分的重要性


- 第 4 步: MFML 052 — 探索性数据分析 (EDA)

-
第 5 步: MFML 053 — 如何选择 AI 算法
-
第 5 步: MFML 第四部分 — AI 算法指南(不适合快速阅读!快速阅读版在本页的最后部分。)
-
第 6 步: MFML 054 — 训练 AI 系统容易吗?
-
第 6 步: MFML 055 — 数据集的理想形状
-
第 6 步: MFML 056 — 如何加速你的 ML/AI 训练阶段
-
第 6 步: MFML 057 — 统计学与“统计学”
-
第 6 步: MFML 058 — 当你的机器学习项目耗时极长
-
第 6 步: MFML 059 — 正则化
-
第 6 步: MFML 060 — 你绝对不应该在 AI 中使用的特征
-
第 6 步: MFML 061 — 你可以跳过 AI 训练阶段吗?

-
第 7 步: MFML 062 — 调试你的机器学习模型
-
第 7 步: MFML 063 — 超参数调优
-
第 7 步: MFML 064 — 什么是保留集,你如何使用它?
-
第 7 步: MFML 065 — 理解 k 折交叉验证
-
第 7 步: MFML 066 — 高级 AI 调试
-
第 7 步: MFML 067 — 如果跳过调试会怎样?

-
第 8 步:MFML 068 — 模型验证失败时该怎么办
-
第 8 步:MFML 069 — 正确的模型验证
-
第 8 步:MFML 070 — 验证轮盘
-
第 9 步:MFML 071 — 测试和验证的区别
-
第 9 步:MFML 072 — 统计学的 12 个步骤
-
第 9 步:MFML 073 — 解读 AI 测试输出
-
第 9 步:MFML 074 — 理解 p 值
-
第 9 步:MFML 075 — 统计显著性
-
第 9 步:MFML 076 — 如果测试失败该怎么办
-
第 9 步:MFML 077 — 测试的重要性
-
第 10 步:MFML 078 — 生产化
-
第 10 步:MFML 079 — 安全地重新利用数据
-
第 10 步:MFML 080 — 解决 AI 延迟问题
-
第 10 步:MFML 082 — 训练-服务偏差
-
第 10 步:MFML 083 — 注意链式模型
-
第 10 步:MFML 084 — 对 AI 代码进行微小改动
-
第 10 步:MFML 085 — 当你的 AI 模型失败时的重测
-
第 10 步:MFML 086 — AI 中的长尾风险
-
第 10 步:MFML 087 — 如何捕捉异常值和 AI 失败
-
第 10 步:MFML 088 — AI 安全和政策层

- 第 11 步:MFML 089 — 实时交通实验
-
第 12 步:MFML 090 — 监控你的 AI 系统
-
第 12 步:MFML 091 — AI 系统维护
算法导论

菜单
无监督学习
懒惰学习
线性分类器
决策树与随机森林
集成方法
朴素贝叶斯
回归模型
深度学习
课程介绍
与机器学习交朋友 是谷歌内部专为启发初学者和取悦专家创建的课程。* 今天,它向所有人开放!
该课程旨在为你提供在解决商业问题和在日益以人工智能驱动的世界中成为合格公民所需的有效参与工具。MFML 适合所有人;它专注于概念理解(而非数学和编程细节),并引导你了解成功机器学习方法的基础理念。它适合每一个人!
完成本课程后,你将能够:
-
获得对核心机器学习概念的直观和正确理解。
-
理解几种流行机器学习方法的特点。
-
避免机器学习中的常见错误。
-
了解机器学习如何帮助你的工作。
-
了解从构思到发布及其后的机器学习项目涉及的步骤。
-
提升你与机器学习专家和非专家沟通的能力。
这个课程适合你吗?看看人们对它的评价
“她的演讲质量让我完全惊叹。这是一个 6 小时的杰作;在每一分钟里,Cassie 都表现得清晰、幽默、充满活力、平易近人、富有洞察力和信息量十足。” — Hal Ableson,麻省理工学院计算机科学教授
“我无法过分强调本课程面向普通观众的价值。” — 人力资源专家
“精彩的课程,而且非常有趣!” — 软件工程师
“我现在对我对机器学习的理解更有信心了……非常喜欢。” — 公共关系经理
“比我在大学里学过的所有相关课程都更有用。” — 可靠性工程师
“我喜欢她如何组织课程,了解内容,并在一天的课程中保持我们的兴趣不让我们感到无聊。因此我在这节课中学到了两件事:1)机器学习,2)演讲技巧。” — 高管
“非常棒的课程:我会推荐它。” — 机器学习研究科学家
“…始终有趣并且保持我的注意力。” — 高级领导,工程部门
“…结构良好,内容清晰,针对像我这样的人的水平恰到好处,并且充满了有用的视觉效果和故事,帮助我理解和记忆。我学到了很多。” — 高级领导,销售部门
“MFML 课程非常出色。它为理解最佳实践奠定了基础,并提升了我尝试应用机器学习的信心。” — 产品技术经理
“我终于感觉到自己理解了 90%以上的内容。通常我总是迷失,觉得自己非常愚蠢,想要哭泣。” — 项目经理
“比其他课程高层次得多,但也更通用、更全面。提供了该主题的全面视角……填补了我所存在的许多“空白”。它确实解开了许多谜团。” — 软件工程师
“虽然我在过去(大约 8 年前)学习和使用过机器学习,但感到厌倦,因此对最近的趋势不太感兴趣…经过这次刷新,我觉得我可以重建这种关系,再次与机器学习成为朋友。” — 产品经理
“否则难以理解的材料由于 Cassie 的深厚专业知识、机智和幽默变得易于理解和愉快。” — 用户体验设计师
如果你喜欢它,那么你应该分享一下…
现在有很多垃圾信息,如果你认为这门课程比大多数替代方案要好,请帮助它脱颖而出,通过与你的社区分享来实现。为了让课程作者微笑,只需选择一个让你开心的视频并发布到任何地方。
P.S. 你是否曾经尝试过在 Medium 上多次点击鼓掌按钮,看看会发生什么? ????
Cassie Kozyrkov 是 Google 的数据科学家和领导者,她的使命是普及决策智能和安全可靠的人工智能。
原文。经许可转载。
更多相关话题
Apache Druid 的演变
近年来,包括 Netflix、Confluent、Target 和 Salesforce 在内的数千家公司的软件开发人员都转向 Apache Druid 以推动他们的分析应用程序。Druid 因其能够提供交互式数据体验而成为首选数据库,且没有数据量或并发要求的限制。
Apache Druid 在任何规模下对多维、高基数数据进行交互式切片和切块方面表现卓越。它被设计来支持快速移动、大量数据,适用于任何数量的用户,并且可以在灵活的分布式架构中从单个节点轻松扩展到数千个节点。最大的 Druid 安装可以扩展到数 PB 的数据,由数千台数据服务器提供服务,并能够在不到一秒的时间内返回数十亿行的数据查询结果。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
但根据我的经验,尽管 Druid 非常适合交互式切片和切块,这并不是现代分析应用的全部故事。分析应用程序越来越需要其他面向用户的功能,如数据导出和报告,这些功能依赖于运行时间较长或更复杂的查询,这些查询对于 Druid 来说并不理想。今天,开发者通过在 Druid 旁边使用其他系统来处理这些工作负载。但这会增加成本和复杂性:相同的数据必须加载两次,并且必须管理两个独立的数据管道。
贴合其名称起源的事实,Apache Druid 正在不断变革——新增了一个多阶段查询引擎。但在深入了解新引擎之前,让我们看看 Druid 的核心查询引擎如何执行查询,以比较其差异。
Druid 查询执行现状
性能是交互性的关键,在 Druid 中,“不要做”是性能的关键。这意味着要专注于效率,并减少计算机需要做的工作。
Druid 擅长这一点,因为它从一开始就被设计为高效。Druid 拥有紧密集成的查询引擎和存储格式,二者协同设计,以最小化每台数据服务器需要执行的工作量。
Druid 的查询引擎使用“散布/聚合”技术来执行查询:它迅速识别出哪些分段与查询相关,将计算推送到各个数据服务器,然后通过我们称之为 Broker 的组件收集过滤和聚合后的结果,Broker 然后执行最终合并并将结果返回给用户。
每个数据服务器可能处理数十亿行数据,但由于下推的过滤器、聚合和限制,返回给 Broker 的部分结果集要小得多。因此,Broker 通常处理相对较少的数据。这种设计意味着单个 Broker 可以处理跨越数千个数据服务器和万亿行的数据的查询。
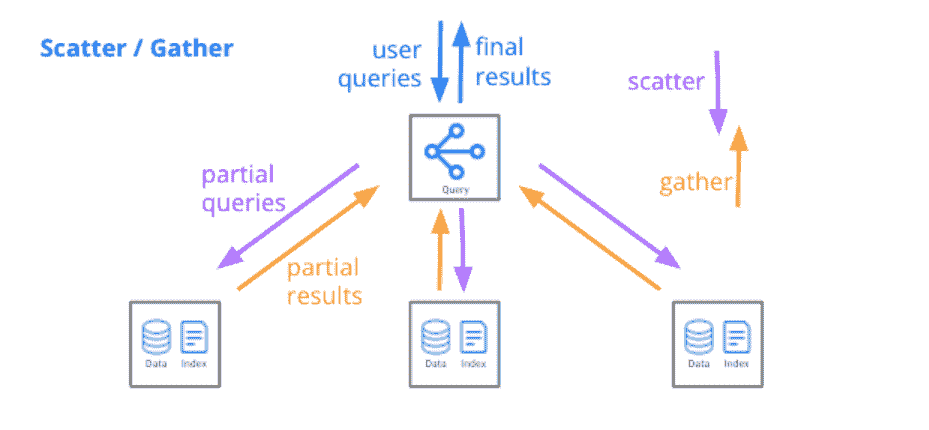
散布/聚合对分析应用中使用的查询类型非常高效且性能卓越。但是,该技术有一个 Achilles’ heel:当查询结果非常庞大,或查询结构需要对数据进行多次访问时,Broker 可能成为瓶颈。
新的多阶段查询引擎
当我们重新考虑长期运行的查询在 Druid 中如何工作的时,我们知道保持所有好的方面是很重要的:即,与存储格式的紧密集成,以及出色的数据服务器性能。我们还知道,我们需要保留使用轻量级、高并发的散布/聚合方法的能力,用于在数据服务器上完成大部分处理的查询。但我们还需要支持数据服务器之间的数据交换,而不是要求每个查询都使用散布/聚合。
为了实现这一点,我们正在构建一个多阶段查询引擎,它接入了 Druid 标准查询引擎的现有数据处理流程,因此它将拥有所有相同的查询能力和数据服务器性能。除此之外,我们还在其上添加了一个系统,将查询拆分成多个阶段,并使数据能够在阶段之间通过洗牌网格进行交换。每个阶段都被并行化,以便同时在多个数据服务器上运行。不需要任何调优:Druid 将能够使用抗偏斜的洗牌和协作调度自动运行这一过程。
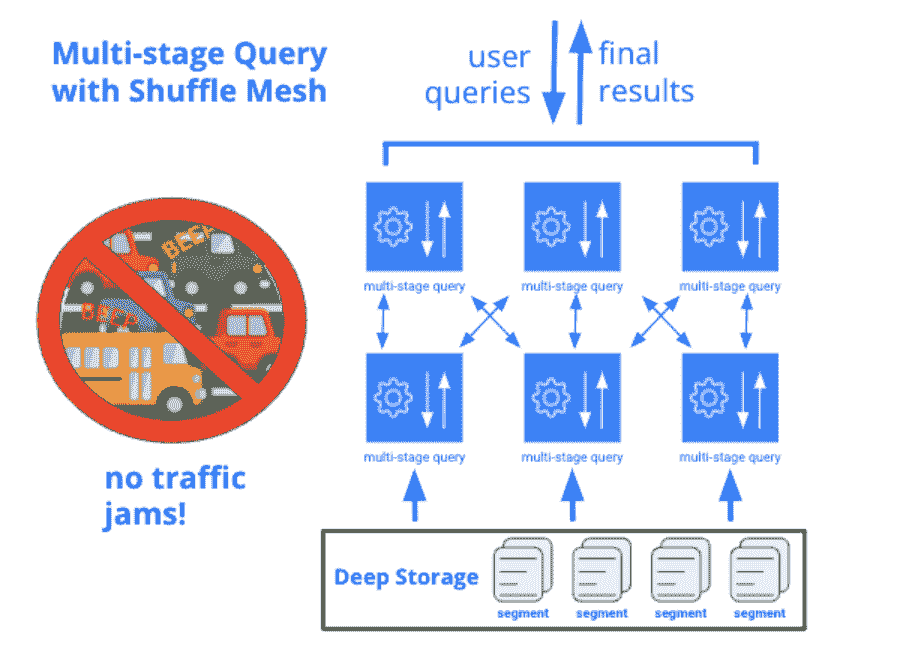
通过允许多阶段查询的每个阶段在整个集群上分布式运行,我们可以有效地处理所有阶段中的任何数量的数据,而不需要在底层处理大部分数据。
分析数据库的新标准
一旦我们开始深入思考,我们意识到我们可以做的远不止处理复杂查询。我们可以通过一个系统和一个 SQL 语言来实现查询和摄取的功能。我们可以摆脱对分开操作模型的需求。我们可以支持外部数据查询,并启用分离存储和计算的部署模式。
通过这项工作,我们正在建立一个平台,将实时分析数据库的性能与传统 SQL 关系数据库管理系统相关的功能和能力相结合。我对这个项目的方向感到非常兴奋。如今,Druid 是最具吸引力的大规模实时分析数据库。随着 Druid 逐渐获得这些新功能,它将成为最具吸引力的分析数据库绝对。
贾恩·梅尔利诺 是开源 Apache Druid 项目的联合作者,并且是 Imply 的共同创始人和 CTO。贾恩还担任 Apache Druid 委员会(PMC)主席。之前,贾恩曾在 Metamarkets 领导数据摄取团队,并在 Yahoo 担任高级工程职位。他拥有加州理工学院计算机科学学士学位。
更多相关内容
从人工智能到机器学习再到数据科学的演变
原文:
www.kdnuggets.com/2022/08/evolution-artificial-intelligence-machine-learning-data-science.html

图片由 DeepMind 提供,来源于 Unsplash
近年来,在人工智能(AI)、机器学习(ML)和数据科学领域取得了许多突破和发现。这些领域交叉如此之多,以至于它们变得同义。不幸的是,这导致了一些模糊性。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
本指南旨在通过定义术语并解释它们如何应用于商业和科学来澄清混乱。我们不会深入讨论这些内容;但是,到本文末尾时,你应该能够区分这些概念。
定义人工智能
作为一个领域,人工智能专注于创建灵活的自动化系统。人工智能的终极目标是建立能够像人类一样智能和独立运作的系统。因此,人工智能必须能够模仿人类的一些感官。
它们必须至少能够听、看,有时还能感知触觉和嗅觉。然后,人工智能必须能够解释通过这些感官接收到的刺激并做出相应的反应。因此,人工智能领域及其分支致力于赋予机器和系统这些能力。
人工智能的主要分支
人工智能的主要分支包括:
-
机器学习(ML)
-
深度学习(DL)
-
自然语言处理(NLP)
-
模糊逻辑
-
专家系统
-
神经网络
这些概念并不是人工智能的独立领域,而是使现代和未来的人工智能实现成为可能。
人工智能的阶段
人工智能的三个阶段如下:
-
人工狭义智能(ANI)是当前人工智能的发展阶段。它也被称为弱人工智能,描述了能够执行有限一组定义任务的人工智能系统。
-
人工通用智能(AGI):我们正在慢慢接近这一阶段,也称为强人工智能。它描述了能够像人类一样进行推理的人工智能。一些学者认为 AGI 标签应仅限于有感知的人工智能。
-
人工超级智能(ASI):这是一个假设的人工智能阶段,其中计算机的智能和能力超越了人类。目前,ASI 仍然存在于科幻领域之外。
上述信息对于商业用户来说可能显得有些术语化和深奥。这些在现实世界中如何转换,又是如何应用人工智能的?
人工智能的常见应用
-
图像处理在照片编辑软件中的功能
-
客户参与服务
-
社交媒体算法
-
在线广告平台
-
通过自然语言处理提供的翻译
-
机器人流程自动化(RPA)
-
营销和产品使用分析
-
视频和文本游戏中的非可玩和敌对角色
-
人工智能在增强现实(AR)中的提升
-
销售和趋势预测
-
自动驾驶汽车
-
交通检测
定义机器学习
机器学习(ML)这个术语通常与人工智能互换使用。虽然它们不是同一个概念,但它们紧密相关。
应用程序和软件在代码上运行,这些代码大多是固定的。代码中包含的参数集有限,只能在程序员编辑或添加时进行更改。机器学习旨在使计算变得更加灵活,允许软件随意更改其源代码。这类似于人们学习新事物时,大脑结构会发生细微而剧烈的变化。
机器学习的主要分支
机器学习的四大主要分支是:
-
有监督学习
-
半监督学习
-
无监督学习
-
强化学习
当然,还有一些子集和新范式,如强化学习、降维等。机器学习通常是通过模型来实现的。
机器学习模型的类型
-
人工神经网络
-
决策树
-
支持向量机
-
回归分析
-
贝叶斯网络
-
遗传算法
-
联邦学习
-
强化学习
深度学习是机器学习的最知名和最常用的子集之一。它本质上由一个多层神经网络组成。神经网络试图通过密切模仿人脑的结构来模拟认知。它们被认为是实现通用人工智能(AGI)的最可行路径。
机器学习在商业中的应用
机器学习在商业和消费者产品中的一些应用示例包括:
产品推荐
产品推荐无疑是机器学习和人工智能中最流行的应用之一——特别是在电子商务领域。在这一应用中,商家的网站或应用程序会跟踪你的行为,基于你的活动使用机器学习。这些活动可能包括你的以前购买记录、搜索模式、点击、购物车历史等。商家随后会使用算法生成个性化的产品推荐。
欺诈检测
在金融和银行领域应用机器学习后,金融机构能够发现隐藏的模式、检测可疑活动,并在为时已晚之前预见到文书错误。科技咨询公司 Capgemini 声称,经过良好训练的机器学习解决方案可以将所有欺诈事件减少70%,同时将交易准确率提高 90%。
医疗保健
机器学习提高了医疗诊断中异常检测的准确率,使医疗从业者能够做出更准确的诊断。最近,机器学习驱动的软件被证明能比经验丰富的医生更准确地诊断患者。它通过处理医疗记录和实时评估变化参数来实现这一点。其快速适应环境变化的能力是机器学习在医疗保健领域的最大优势之一。
定义数据科学
数据科学是一个广泛的术语,指的是数据管理的所有方面,包括收集、存储、分析等。因此,这是一个涉及多个学科的领域,包括:
-
统计学
-
信息学
-
数据分析
-
计算机科学
-
数学
-
领域知识
-
信息科学等
每天(全球范围内)生成的估计2.5 万亿字节的数据中,很多数据是非结构化且噪声很大。数据科学家的大量精力用于结构化、排序并从这些数据中获得洞见。
因为数据科学是一门多学科的科学而非一个概念,所以它不能像人工智能和机器学习那样进行分类。然而,在我们探讨它在商业环境中的应用之前,让我们扩展一下数据科学中涉及的不同职业。
数据科学中最重要的职业
一些最常见的数据科学家类型包括:
-
机器学习科学家
-
数据工程师
-
软件工程师
-
精算科学家
-
统计学家
-
数字分析师
-
商业分析师
-
空间数据科学家
-
质量分析师
建议数据科学家必须能够开发软件(代码)、使用分析工具和软件、开发预测模型、分析数据完整性和质量,并能够优化数据收集流程。
数据科学在商业中的应用
数据科学对于企业来说是极其有用的工具。每天生成的大量数据都是潜在的消费者数据。例如,机器学习实现可以处理旧的医疗记录或观察并收集用户行为信息。这是一种数据挖掘。数据科学在商业中的其他应用包括:
-
定向广告:像 Google、Facebook 和百度这样的公司主要通过数字广告赚取收入。无论是经营博客还是在线商店,你都可以利用数据科学在发布定向广告活动之前进行客户细分或聚类。执行聚类和分组的最佳方式是通过无监督的机器学习模型。
-
库存管理的销售预测:你可以利用数据科学预测模型来预测未来的销售情况。预测模型试图基于历史数据预测未来的销售。
-
电商推荐引擎:你可以利用数据科学根据顾客的购买历史为忠实顾客构建定制的产品推荐。
数据科学(主要通过数据分析实现)也可以用于商业智能。公司可以从数据仓库中提取有价值的洞察,并利用这些洞察做出明智的商业决策。
摘要
上述指南作为一个简单的入门书,主要突出人工智能、机器学习和数据科学之间的区别,以及它们如何在商业环境中应用。要了解更多关于这些主题的信息,你可以访问 KDnuggets 网站上许多相关的指南和文章。
Nahla Davies 是一位软件开发人员和技术作家。在全职从事技术写作之前,她曾管理——在许多有趣的工作中——担任过一家 Inc. 5,000 体验品牌组织的首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼。
更多相关话题
数据领域的进化
共同作者 Srujan 和 Travis Thompson
数据领域已经成熟,并从地下的厚重文件时代走过了漫长的道路。这段旅程既迷人又激动人心,不亚于软件革命。幸运的是,我们正处于数据革命的中心,并有机会亲身见证这一过程。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
我们五到十年前关注的是完全不同的问题,而今天我们面对的是全新的问题。有些是数据的寒武纪大爆炸的结果,有些则出乎意料地源于解决初始问题所制定的解决方案。
这导致了大量数据堆栈和架构的过渡。然而,突出的却是三种简单但根本性的关键堆栈:传统数据堆栈、现代数据堆栈和数据优先堆栈。让我们看看这些是如何发展的。
进化基础:触发数据领域变革的模式
进化有两种广泛的模式:发散型和汇聚型。这些广泛的模式同样适用于数据领域。
地球上的物种多样性源于发散型进化。类似地,发散型进化在数据行业中产生了种类繁多的工具和服务,今天被称为疯狂数据景观。汇聚型进化则随着时间的推移创造出具有共同特征的工具变种。例如,老鼠和老虎虽然是截然不同的动物,但它们都有类似的特征,如胡须、皮毛、四肢和尾巴。
汇聚型进化导致工具解决方案中的共同特征,意味着用户为冗余的功能付费。发散型进化则导致更高的集成成本,需要专家理解和维护每个工具的独特理念。
请注意,常见的共同点并不意味着这些点解决方案正在朝着统一的解决方案收敛。相反,每个点正在开发与其他点的解决方案相交的解决方案,这些交集是基于需求的。这些共同能力有各自的语言和哲学,需要专业的专家。
例如,Immuta 和 Atlan 分别是数据治理和目录解决方案。然而,Immuta 也在开发数据目录,而 Atlan 正在添加治理功能。客户倾向于用专门的工具替代次要功能。这导致了:
-
投入时间去理解每个产品的语言和哲学
-
引入两个具有类似功能的工具的冗余成本
-
专业人才的高资源成本;尤其困难的是人才短缺
现在我们对演变模式有了高层次的理解,让我们来看一下它们在数据领域中的表现。为了简洁起见,我们不会回顾太远。
回溯几年
我们今天作为数据行业面临的问题与 5-6 年前截然不同。当时组织面临的主要挑战是从本地系统向云的巨大的过渡。本地大数据生态系统和 SQL 数据仓库(即传统数据堆栈或 TDS)不仅维护困难且正常运行时间极低,而且在数据到洞察的过程中极其缓慢。简而言之,规模和效率远远无法实现,尤其是由于以下障碍:
数据工程师的数量
任何数量的数据工程师都不足以维持内部系统。从数据仓库和 ETL 到仪表板和 BI 工作流程的所有内容都必须在内部工程化,导致组织的大部分资源用于建设和维护,而不是产生收入的活动。
管道的压倒性
数据管道复杂且互相交织,许多是为了应对新的业务需求而创建的。有时,一个新管道是为了回答一个问题或从较少的源表中创建大量的数据仓库表。这种复杂性可能让人感到不知所措,难以管理。
零容错性
数据没有备份、恢复或根本原因分析时既不安全也不可靠。数据质量和治理往往被忽视,有时甚至超出了工程师的工作描述,这些工程师在繁重的管道活动下辛勤工作。
数据迁移成本
传统系统间的大规模数据迁移是另一个警示,耗费了大量资源和时间。此外,数据还常常出现损坏和格式问题,这需要几个月时间解决,或者直接被抛弃。
变更抵触
本地系统中的数据管道非常脆弱,因此对频繁的变化或任何变化都很抵触,这对于动态且易变的数据操作来说是一场灾难,并使实验成本高昂。
紧张的节奏
部署新的管道以回答通用业务问题花费了数月和数年时间。动态的业务请求更是不在考虑之中。更不用说在频繁的停机期间业务损失的情况了。
技能缺口
高债务或陈旧的系统导致项目交接时的抵触,因为存在关键的依赖关系。市场上缺乏合适的技能并没有改善这种情况,往往导致关键管道的重复工作长达数月。
当时的解决方案及其结果问题
云计算的出现与成为云原生的义务
十年前,数据并不像今天这样被视为资产。尤其是因为组织没有足够的数据来作为资产利用,并且必须解决无数问题才能生成一个可用的仪表盘。但随着时间的推移,随着流程和组织变得更加数字化和数据友好,数据生成和捕获出现了突然的指数增长。
组织意识到,通过了解超出其处理能力的历史模式,他们可以改进自己的流程。为了解决 TDS 的持续问题并增强数据应用,多种点解决方案出现并集成到一个中央数据湖中。我们称这种组合为现代数据堆栈(MDS)。在当时的数据行业中,它无疑是几乎完美的解决方案。
➡️ 过渡到现代数据堆栈(MDS)
MDS 解决了一些当时数据领域的持续问题。它最大的成就也许是对云的革命性转变,这不仅使数据更易获取,而且还可恢复。像 Snowflake、Databricks 和 Redshift 这样的解决方案帮助大型组织将数据迁移到云端,提高了可靠性和容错性。
一些由于预算限制而支持 TDS 的数据领导者,在看到其他组织成功过渡后,感到有义务转向云端并保持竞争力。这需要说服 CFO 优先考虑并投资于过渡,通过承诺近期内实现价值来完成。
但成为云原生不仅仅是迁移到云端,这本身就是一笔巨大的开销。真正的云原生还意味着整合一系列解决方案来操作云中的数据。计划看起来不错,但最终 MDS 将所有数据都倾倒到一个中央湖中,导致各行业出现了无法管理的数据沼泽。
???? 虚幻承诺的投资
-
将大量数据资产迁移到云端的成本
-
保持云端运行的成本
-
为操作云所需的点解决方案的个人许可证成本
-
点解决方案中常见或冗余因素的成本
-
理解每个工具不同理念的认知负担和专业知识成本
-
每当新工具加入生态系统时,持续集成的成本
-
持续维护集成的成本,从而导致管道洪水
-
为了操作点解决方案而设置数据设计基础设施的成本
-
维持基础设施运行的专门平台团队的成本
-
在数据沼泽中存储、移动和计算 100%数据的成本
-
每个暴露点或集成点的孤立治理成本
-
由于多个暴露点造成的频繁数据风险的成本
-
频繁项目交接时去复杂化依赖的成本
正如你所猜测的,这个列表远非详尽。
???? 数据投资回报的恶性循环
数据领导者,包括 CDO 和 CTO,迅速感受到了未实现的投资承诺的负担,这些投资规模达到数百万美元。增量的补丁解决方案解决了很多问题,却也带来了同样多的问题,数据团队又回到了无法使用他们拥有的丰富数据的根本问题上。
缺乏未来保障对领导者来说是一个严重的风险,他们在组织中的任期被缩短到不到 24 个月。为了确保 CFO 看到回报,他们抓住了流行的数据设计架构和新工具创新,这些都提出了新的承诺。
此时,首席财务官办公室不可避免地开始质疑承诺结果的可信度。更危险的是,他们开始质疑投资于数据驱动的垂直领域本身的价值。是否花费数百万美元用于其他操作会在五年内带来更好的影响?
如果我们稍微深入一些,并接近我们上面讨论的实际解决方案,就会更加清楚数据投资如何在这些年里生锈,尤其是由于隐藏和意外的成本。
TCO 的估算基于小众专家、迁移、设置、管理固定工作负载的计算、存储、许可费用以及治理、目录和 BI 工具等点解决方案的累计成本。根据客户与这些供应商的经验,我们在顶部添加了格状条,因为在使用这些平台时,往往会遇到意外的成本跳跃。
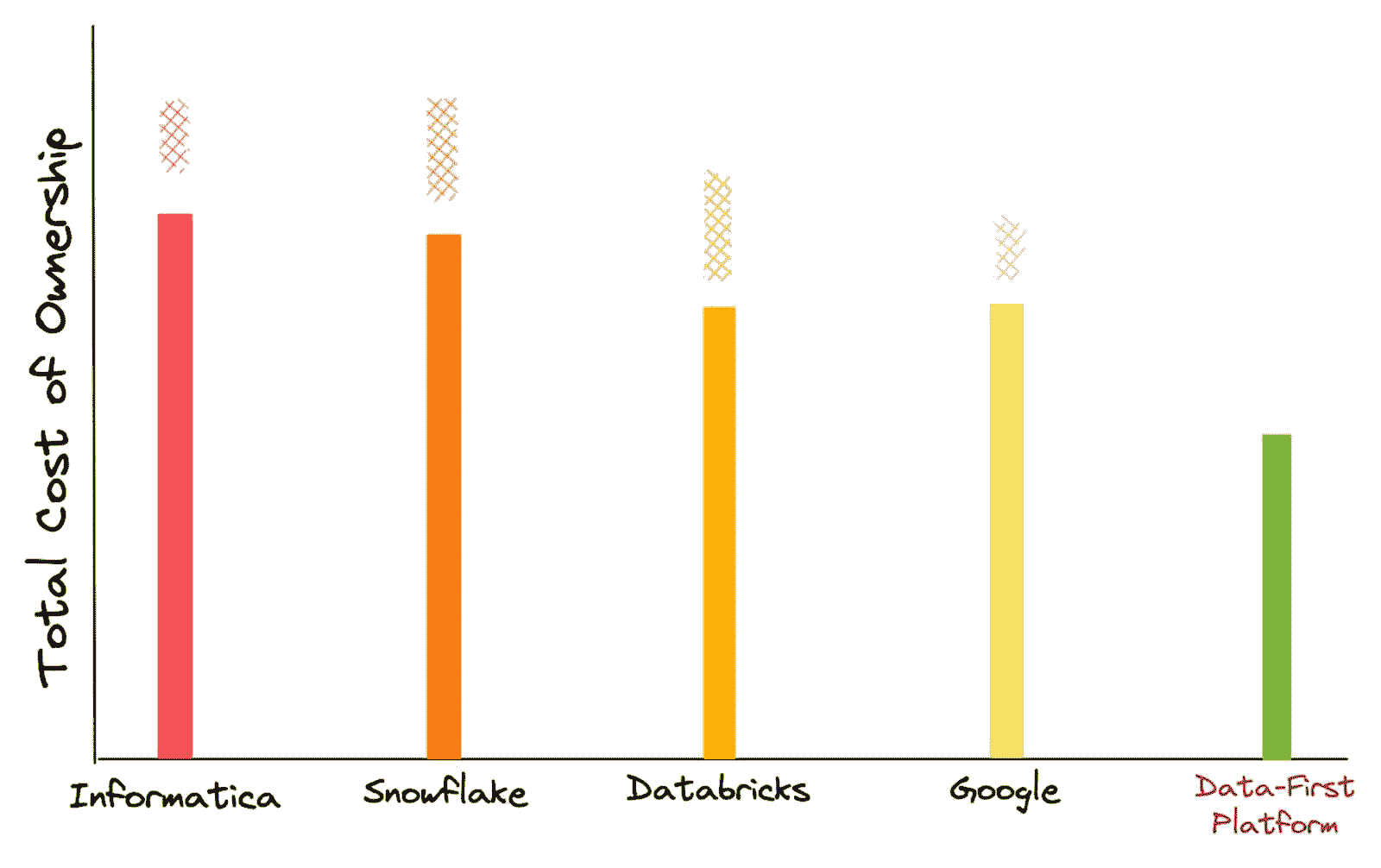
由于这些成本的多样性,如工作负载增加或背景查询的变化,甚至定价模型本身,它们最好被归类为‘神秘成本’。另一方面,采用数据优先的方法来抽象工具复杂性,可以避免意外的总拥有成本(TCO)跳跃。对于每个工作负载和使用的存储,有完全的控制权。
???? 工具的大量扩散使得每个堆栈都变成了维护优先、数据最后。
如 MAD Landscape 或 MDS 所示,丰富的工具使得组织越来越难以专注于实际带来业务成果的解决方案开发,因为维护票据不断吸引注意力。
可怜的数据工程师陷入了维护优先、集成其次、数据最后的经济模式。这涉及大量时间用于解决基础设施缺陷和维护数据管道。托管和集成多个工具所需的基础设施同样令人痛苦。
数据工程师被大量配置文件、频繁的配置漂移、每个文件的环境特定自定义以及无数的依赖开销所压倒。简而言之,数据工程师为了确保数据基础设施符合正常运行时间 SLOs 而熬夜。
工具的过度使用不仅在时间和精力上成本高昂,而且集成和维护的开销直接影响工程团队的投资回报率(ROI),同时对推动业务的数据应用没有任何直接改善。
这里是传统 ETL 和 ELT 方法下企业数据移动的表现。它包括集成批处理和流数据源的成本以及数据工作流的编排。
成本的逐年增加基于这样的假设,即随着时间的推移,企业将增加平台的使用量,包括集成的源系统数量和随后的数据处理。
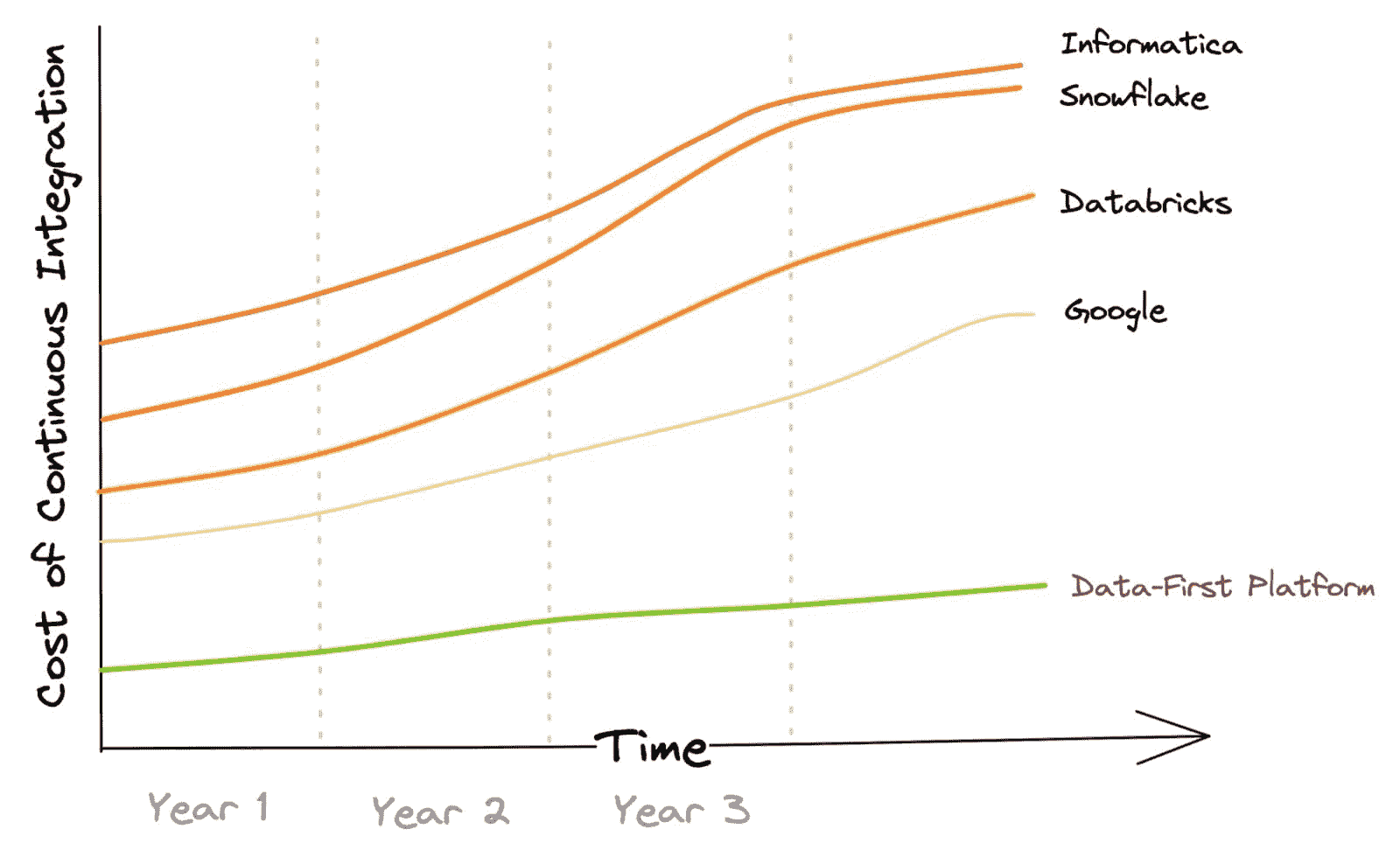
这在大多数客户中被发现是正确的。在数据优先的方法中,由于其对智能数据移动的总体信念和抽象的集成管理,数据集成成本为零到最低,因为它允许在最小的数据移动下进行数据处理。
???? 组织被迫服从工具的理念。
管理一系列不同的解决方案并不是终点。组织必须遵循这些单独工具的预定义方向和哲学。例如,如果引入了一个治理工具,数据开发人员需要学习如何操作该工具,学习它与其他工具的具体交互方式,并重新安排其他工具以匹配新组件的规格。
每个工具在设计架构中都有发言权,作为其自身哲学的结果,使得互操作性变得更加复杂和选择性强。缺乏灵活性也是转向新的和创新的基础设施设计(如网格和织物)高成本的原因,这些设计可能会提升承诺的投资回报率。
大量具有独特哲学的工具也需要丰富的专业知识。在实际操作中,招聘、培训、维护和协作如此多的数据工程师是不可能的。特别是在这个领域内缺乏熟练和经验丰富的专业人员时更是如此。
???? 无法捕捉和操作原子见解
由于大量工具和集成,僵化的基础设施意味着低灵活性,无法在正确的时刻将原子数据字节传递到正确的面向客户的端点。缺乏原子性也是低互操作性和孤立子系统的结果,这些子系统没有建立良好的沟通路线。
一个很好的例子是每个工具点维护其独立的元数据引擎以操作元数据。这些元数据引擎有不同的语言和传输渠道,除非专门设计,否则几乎无法相互通信。这些新设计的渠道还增加了维护费用。使用数据在转换中丢失,平行垂直领域无法利用从彼此中得出的见解。
此外,由于无法在混乱的 MDS 传播中强制执行类似软件的实践,MDS 中的数据操作通常是批量开发、提交和部署的。实际上,除非数据,作为数据栈中唯一的不确定组件,能够接入一个统一层,这个层能够强制执行原子提交、沿着变更路线进行纵向测试和 CI/CD 原则,以消除不仅是数据孤岛还有数据代码孤岛,否则 DataOps 是不可行的。
解决 MDS 所带来的后续问题的解决方案
从传统数据栈到现代数据栈,再到最终的数据优先栈(DFS)的过渡在很大程度上是不可避免的。DFS 的需求主要是由于数据工程领域内技术债务的累积。DFS 提出了一种统一的方法或整体解决方案,针对 TDS 和 MDS 的薄弱环节,而不是倡导它们的拼凑哲学。
DFS 将自助服务能力带给了业务团队。他们可以带来自己的计算资源,而不是争夺 IT 资源(这在许多企业中严重限制了业务团队对数据的访问)。与合作伙伴共享数据并以合规的方式货币化变得更容易了。用户不再需要整合数百个分散的解决方案,而是可以将数据放在首位,专注于核心目标:构建直接提升业务结果的数据应用程序。
降低资源成本是当前市场上组织的优先事项之一,但由于合规成本在治理和目录化分散的多点解决方案时非常高,这几乎是不可能的。DFS 的统一基础设施通过将这些点能力组合成基本构建块并集中治理这些块,迅速提高了发现性和透明度。
DFS 的目录解决方案是全面的,因为它的 数据发现与可观测性 特性嵌入了本地治理和丰富的语义知识,允许进行积极的元数据管理。此外,它实现了对数据基础设施所有应用程序和服务的完整访问控制。
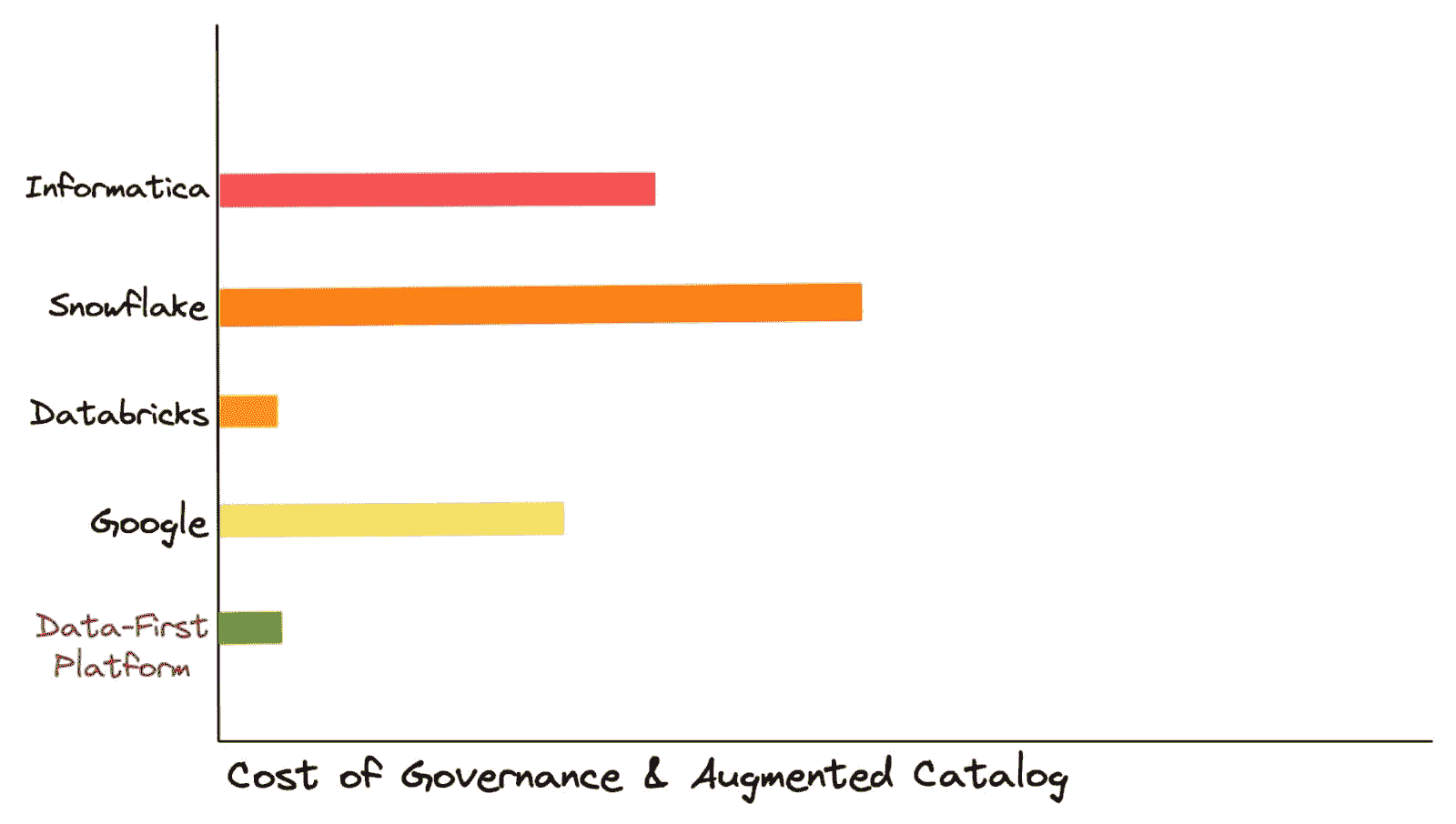
数据优先栈本质上是一个操作系统(OS),它是一个管理所有程序的程序,使最终用户能够专注于结果驱动的体验,而不是弄清楚如何运行这些程序。我们大多数人都在笔记本电脑、手机以及任何界面驱动的设备上体验过操作系统。我们依赖这些系统,因为它们将启动、维护和运行日常应用程序的低级细节抽象化。相反,我们直接使用这些应用程序以驱动结果。
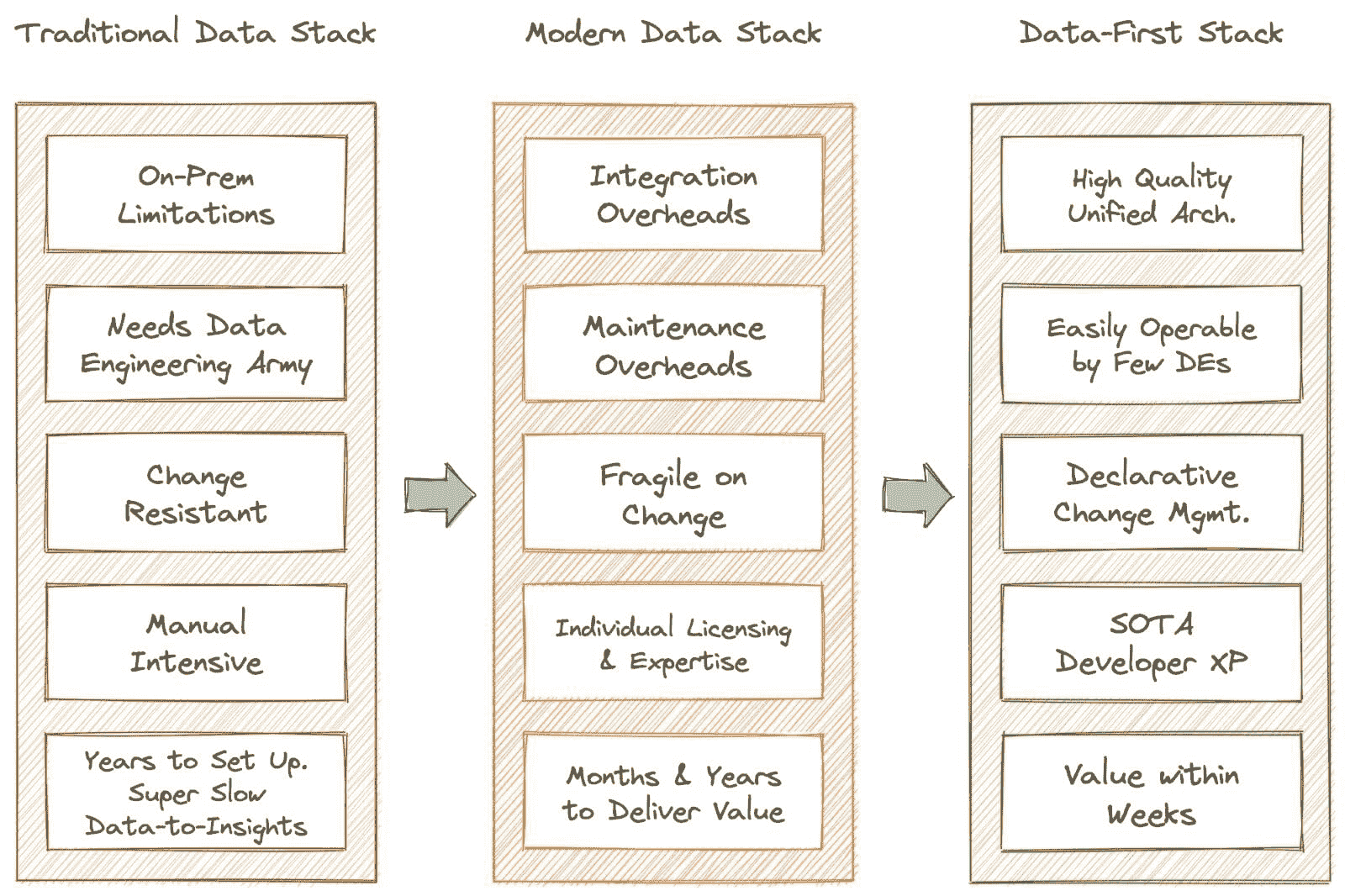
数据操作系统(DataOS)因此与数据精通和数据陌生的组织都相关。总之,它通过将用户从应用程序的程序复杂性中抽象出来,提供自助服务的数据基础设施,并以声明式方式提供结果。
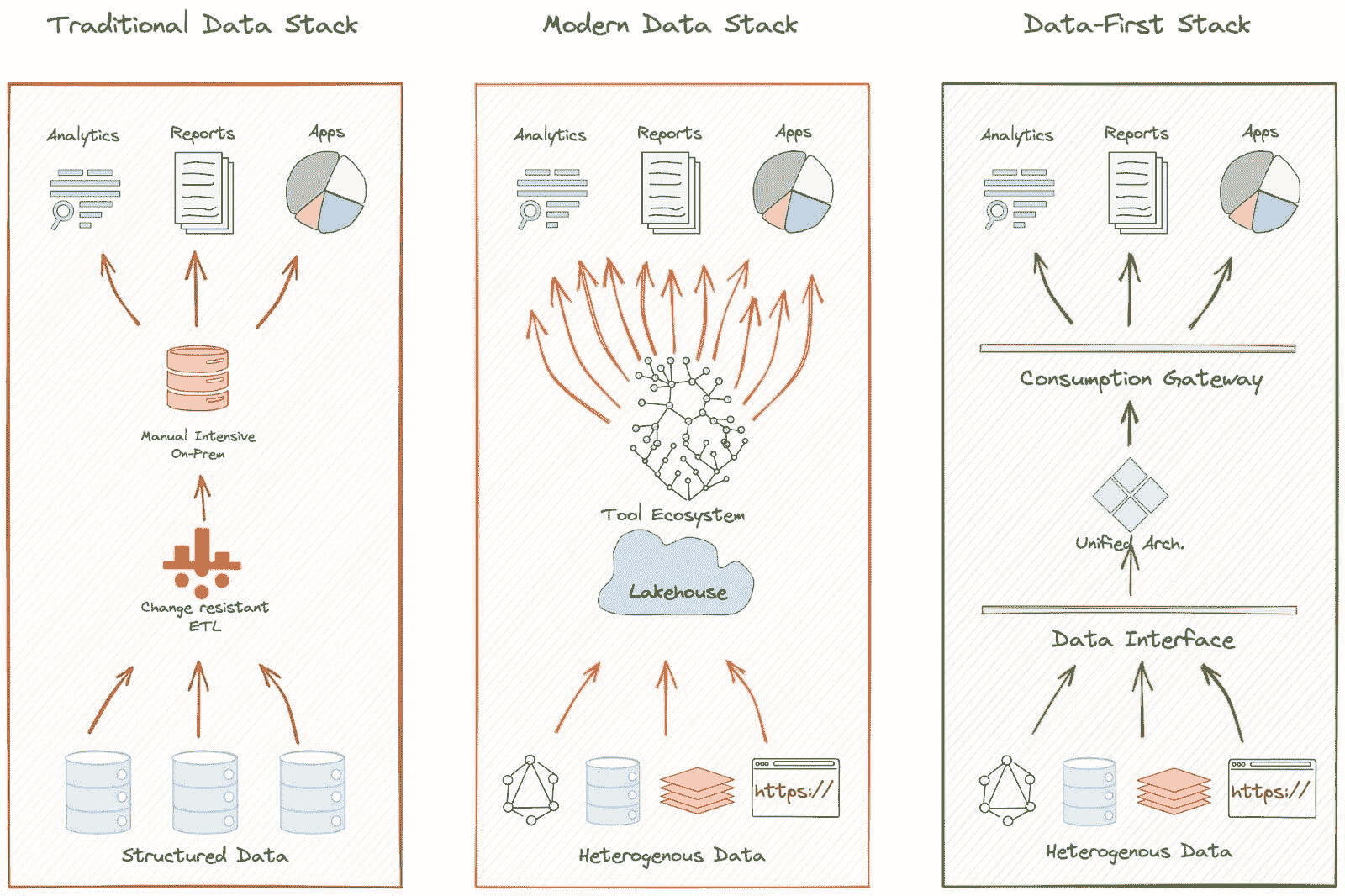
???? 从维护优先到数据优先的过渡
数据操作系统(DataOS)是一个以数据为先的数据栈,它理解组织必须成为数据的用户,而不是数据基础设施的建设者。DataOS 抽象了所有低级数据管理的细节,否则这些细节会耗尽大多数数据开发人员的活跃时间。
声明式管理系统大大消除了脆弱性的范围,并按需呈现根本原因分析(RCA)视角,从而优化资源和投资回报率。这使得工程人才能够将时间和资源专注于数据及构建直接影响业务的数据应用程序。
数据开发者可以通过标准基础配置快速部署工作负载,从而消除配置漂移和大量配置文件,这些配置不需要特定环境变量。系统自动生成应用的清单文件,实现 CRUD 操作、执行和元存储。简而言之,DataOS 提供了以工作负载为中心的开发方式,在这种方式下,数据开发者声明工作负载要求,DataOS 提供资源并解决依赖关系。影响是立即显现的,部署频率显著增加。
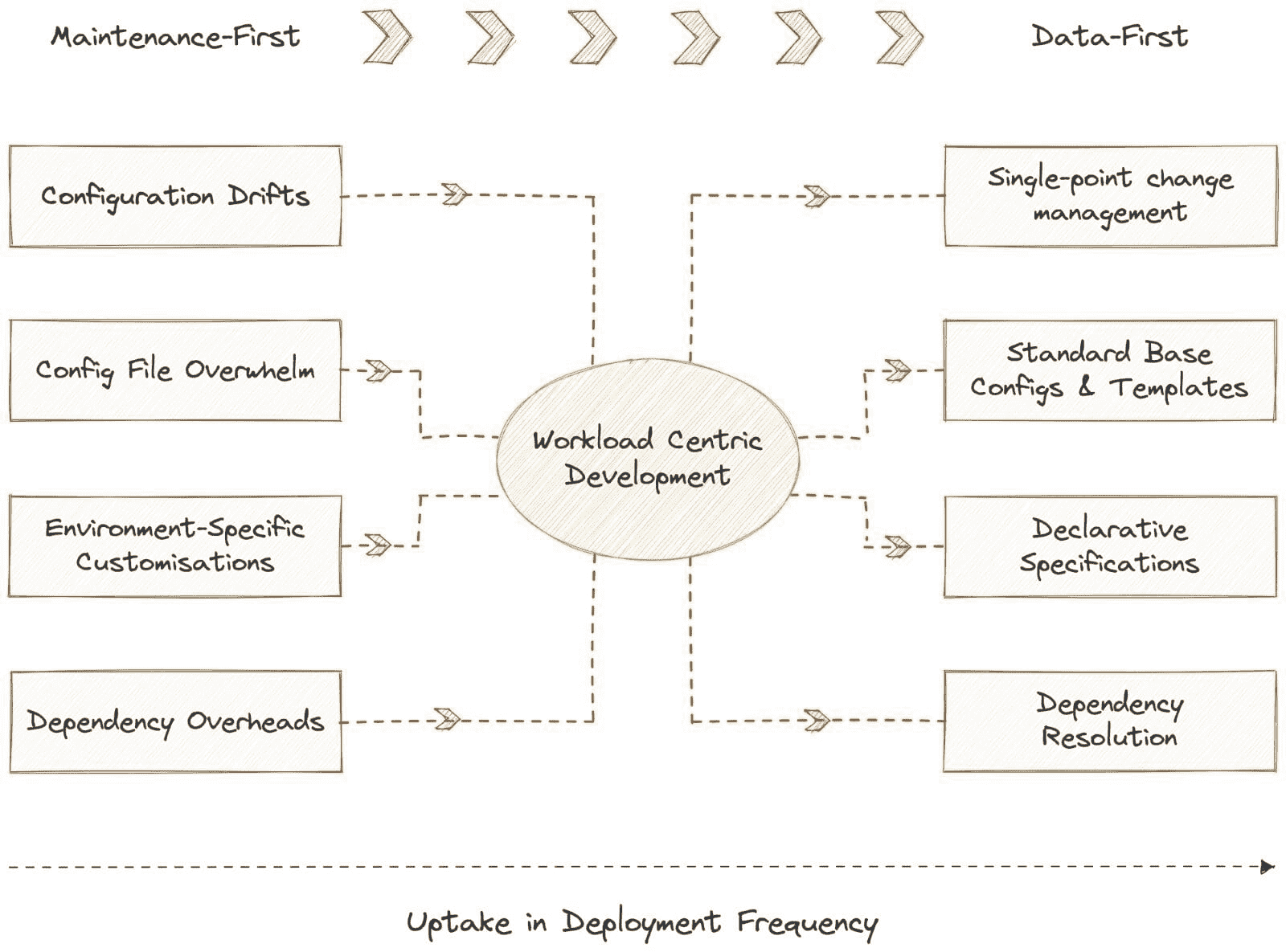
???? 向统一架构的融合
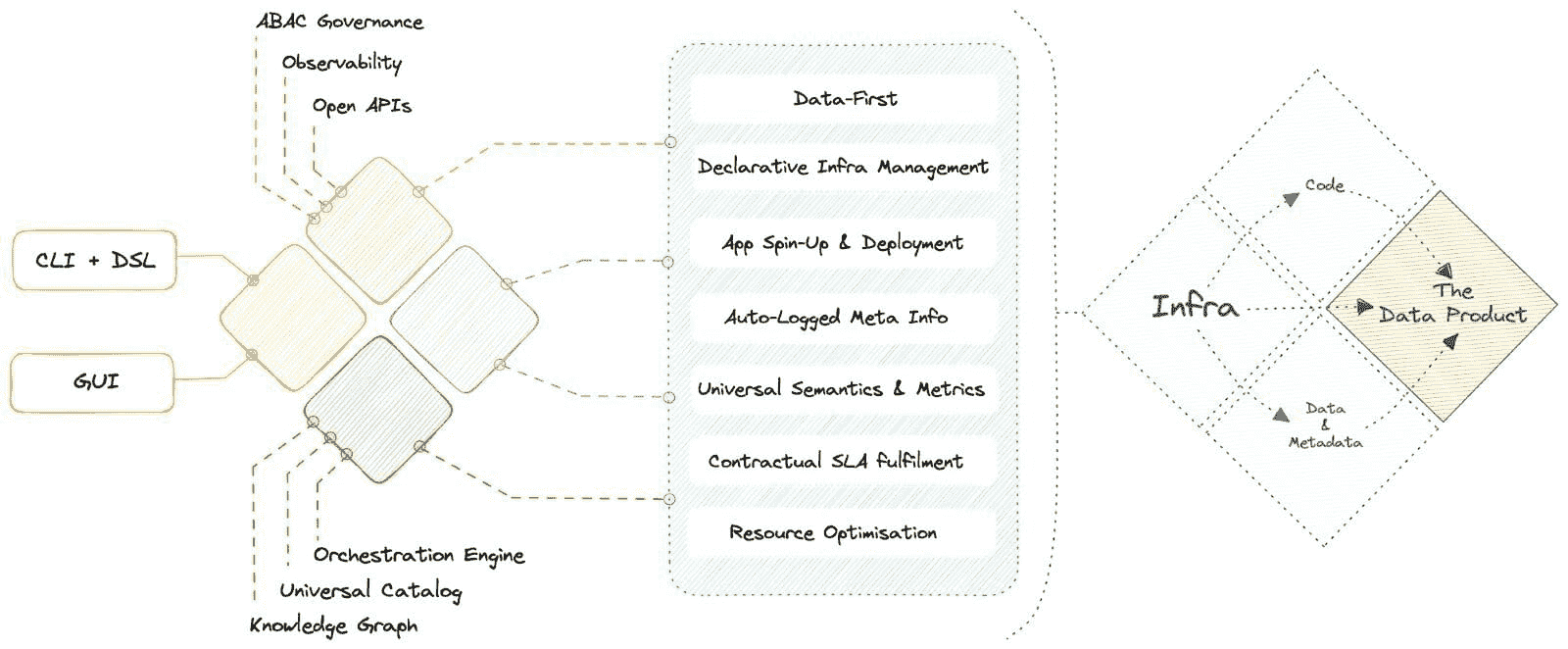
???? 从拼凑的解决方案过渡到原始构建块
通过高度内聚的可组合数据操作系统架构,数周内实现数据优先是可能的:通过模块化实现统一。模块化是通过一组有限的原语来实现的,这些原语被唯一识别为数据堆栈最基本形式的关键元素。这些原语可以被特定排列以构建高阶组件和应用。
它们可以被视为可以使用版本控制系统进行源控制和管理的工件。每个原语可以被视为一种抽象,允许你以声明的方式列举具体目标和结果,而不是繁琐地定义‘如何实现这些结果’。
???? 统一现有工具以实现声明性管理
作为首要工件与开放标准,DataOS 作为任何现有数据基础设施之上的架构层使用。它使其能够与 DataOS 本地和外部的异构组件进行交互。因此,组织可以将现有的数据基础设施与新技术进行集成,而无需完全重构现有系统。
这是一个完整的自服务接口,供开发人员通过 API 和 CLI 以声明性方式管理资源。业务用户通过直观的 GUI 实现自服务,直接将业务逻辑集成到数据模型中。GUI 界面还允许开发人员可视化资源分配并简化资源管理。这节省了大量时间,提高了生产力,开发人员可以在没有广泛技术知识的情况下轻松管理资源。
☀️ 中央治理、编排和元数据管理
DataOS 在双平面概念架构下运行,其中控制分为一个用于核心全球组件的中央平面和一个或多个用于本地操作的数据平面。控制平面帮助管理员通过对垂直组件的集中管理和控制来治理数据生态系统。
用户可以在云原生环境中集中管理基于策略和目的的访问控制,优先考虑本地所有权,协调数据工作负载、计算集群生命周期管理、DataOS 资源版本控制,并管理不同类型的数据资产的元数据。
⚛️ 体验用例的原子级洞察
行业正在迅速从事务性用例转向体验性用例。从大量数据中提取的重大洞察现在已成为次要需求。即时数据点中提取的原子级或字节级洞察才是新的游戏规则,客户愿意为此付费。
共同的底层原语层确保数据在统一架构中的所有接触点上可见,并能够通过语义抽象在业务用例要求时随时在任何渠道中实现。
Animesh Kumar 是 Modern 的首席技术官兼联合创始人,也是数据操作系统基础设施规范的共同创作者。在数据工程领域有超过 30 年的经验,他为包括 NFL、GAP、Verizon、Rediff、Reliance、SGWS、Gensler、TOI 等在内的广泛 A 类玩家设计了工程解决方案。
Srujan 是 Modern 的首席执行官兼联合创始人。在数据和工程领域拥有 30 年的经验,Srujan 作为企业家、产品高管和业务领袖,积极参与社区,并在摩托罗拉、TeleNav、Doot 和 Personagraph 等组织中推出了多个获奖产品。
Travis Thompson(合著者):Travis 是数据操作系统基础设施规范的首席架构师。在数据和工程领域拥有 30 年的经验,他为顶级组织如 GAP、Iterative、MuleSoft、HP 等设计了最先进的架构和解决方案。
更多相关话题
ETL 演变:跳过转换如何增强数据管理
原文:
www.kdnuggets.com/evolution-in-etl-how-skipping-transformation-enhances-data-management

编辑提供的图片
几种数据概念比 ETL(提取-转换-加载)更具争议,ETL 是几十年来主导企业操作的准备技术。ETL 于 1970 年代开发,在大型数据仓库和存储库的时代表现突出。企业数据团队集中数据,构建报告系统和数据科学模型,并提供自助服务的商业智能(BI)工具访问。然而,在云服务、数据模型和数字化流程的时代,ETL 已显得有些陈旧。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织的 IT
搜索如“ETL 是否仍然相关/有需求/过时/已死?”在谷歌上结果层出不穷。原因在于企业数据团队在为员工角色和业务功能广泛使用数据做准备时感到吃力。ETL 难以处理云中存储的大量历史数据,也无法提供快速决策所需的实时数据。此外,构建自定义 API 以向应用程序提供数据会造成显著的管理复杂性。现代企业常常有 500 到 1000 个管道,以寻求转换数据并为用户提供自助服务的 BI 工具访问。然而,这些 API 处于不断的演变状态,因为当拉取的数据发生变化时,它们必须重新编程。显然,这一过程对于许多现代数据需求,如边缘用例,过于脆弱。
此外,应用程序能力也有所演变。源系统提供业务逻辑和工具以执行数据质量控制,而消费型应用程序则实现数据转换并提供强大的语义层。因此,团队不再有足够的动力去构建点对点接口以大规模移动数据、进行转换,并将数据加载到数据仓库中。
两种创新技术为实现数据民主化指明了方向,同时最小化转换负担。Zero ETL 使数据在不移动的情况下可用,而逆向 ETL 则在数据可用时立即将数据推送到需要它的应用程序。
Zero ETL 减少了数据移动和转换需求
Zero ETL 优化了较小数据集的移动。通过数据复制,数据以当前状态被移动到云中,用于数据查询或实验。
但如果团队完全不想移动数据怎么办?
数据虚拟化将服务器与终端用户隔离。当用户从单一来源查询数据时,结果会被推送回用户。而且通过查询联邦,用户可以查询多个数据源。该工具将结果组合起来,向用户呈现集成的数据结果。
这些技术被称为零 ETL,因为不需要构建管道或转换数据。用户可以实时处理数据质量和聚合需求。
Zero ETL 特别适用于临时分析近期数据,因为在历史数据上执行大型查询可能会影响操作性能并增加数据存储成本。例如,许多零售和消费品行业高管使用零 ETL 查询每日交易数据,以便在需求高峰期(如假日)期间调整市场营销和销售策略。
Google Cortex 提供加速器,使 SAP 企业资源规划 系统数据实现零 ETL。其他公司,如全球最大零售商之一和一家全球食品饮料公司,也已采用零 ETL 过程。
Zero ETL 的收益包括:
-
提供访问速度: 使用零 ETL 过程来为自助查询提供数据,节省了 40-50% 的时间,因为不需要构建管道。
-
减少数据存储需求: 数据虚拟化或查询联邦不会移动数据。用户只需存储查询结果,从而减少存储需求。
-
降低成本: 使用零 ETL 过程的团队在数据准备和存储成本上节省了 30-40% 的费用,相比传统 ETL。
-
提高数据性能: 由于用户只查询所需的数据,结果交付速度提高了 25%。
要开始使用零 ETL,团队应评估哪些用例最适合这种技术,并确定他们需要执行的数据信息。他们还应配置零 ETL 工具以指向所需的数据源。团队接着提取数据,创建数据资产,并将其提供给下游用户。
使用逆向 ETL 按需向应用程序提供数据
逆向 ETL 技术简化了数据流向下游应用程序。团队利用逆向 ETL 工具将数据按时、完整地推送到业务流程中,而不是使用 REST API 或端点并编写脚本来提取数据。
使用反向 ETL 具有以下好处:
-
减少时间和精力: 使用反向 ETL 处理关键用例将访问数据所需的时间和精力减少了 20-25%。一家领先的邮轮公司利用反向 ETL 进行数字营销计划。
-
提高数据可用性: 团队对关键计划所需数据的访问有更大的确定性,因为 90-95%的目标数据按时交付。
-
降低成本: 反向 ETL 过程减少了对 API 的需求,而 API 需要专门的编程技能并增加管理复杂性。因此,团队将数据成本降低了 20-25%。
要开始使用反向 ETL,数据团队应评估需要按需数据的用例。接下来,他们确定数据传递的频率和量,并选择适当的工具来处理这些数据量。然后,他们将数据仓库中的数据资产指向其目标消费系统。团队应使用一个数据加载进行原型测试,以测量效率并扩展流程。
成功处理数据,需要使用多种准备技术。
零 ETL 和反向 ETL 工具为团队提供了服务数据给用户和应用的新选项。他们可以分析用例要求、数据量、交付时间框架和成本驱动因素,选择最适合的数据交付选项,无论是传统 ETL、零 ETL 还是反向 ETL。
合作伙伴通过提供有关最佳技术和工具的见解来支持这些努力,满足功能和非功能需求,提供加权评分卡,使用获胜工具进行价值证明(POV),然后将工具投入实际使用以适应更多用例。
使用零 ETL 和反向 ETL,数据团队能够实现他们赋能用户和应用的目标,让数据在需要的时间和地点可用,同时推动成本和性能的提升,避免了转换的麻烦。
Arnab Sen是一位拥有超过 16 年技术和决策科学行业经验的专业人士。他目前担任 Tredence 的数据工程副总裁,该公司是一家著名的数据分析公司,他帮助组织设计其 AI-ML/云/大数据战略。凭借在数据货币化方面的专长,Arnab 发掘数据的潜在价值,推动 B2B 和 B2C 客户的业务转型,涵盖各种行业。Arnab 对团队建设的热情以及扩展人员、流程和技能的能力使他成功管理了多个百万美元的投资组合,涉及电信、零售和金融服务等多个领域。他曾在 Mu Sigma 和 IGate 任职,在解决客户问题方面发挥了关键作用,通过开发创新解决方案取得了显著成绩。Arnab 卓越的领导才能和深厚的领域知识使他获得了《福布斯》技术委员会的席位。
更多相关内容
语音识别指标的发展
原文:
www.kdnuggets.com/2022/10/evolution-speech-recognition-metrics.html

图片由 pch.vector 提供 自 Freepik
随着深度学习的广泛应用,自动语音识别(ASR)准确率在过去几年中得到了加速进展。研究人员迅速宣称在特定测量上达到了人类平等。然而,语音识别今天真的已经解决了吗?如果没有,我们目前关注的测量指标将会影响 ASR 未来的发展方向。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
人类平等曾是最终目标,但现在我们要移动目标!
ASR 系统长期以来一直专注于 词错率(WER) 来衡量准确性。这个指标是有意义的。WER 衡量系统每识别一百个词中出错多少个词。由于系统性能可能因场景、音质、口音等因素显著变化,因此很难给出一个单一的最终目标(当然,0% 是理想的)。因此,我们通常使用 WER 来比较两个系统。当系统开始变得越来越好时,我们开始将其 WER 与人类的 WER 进行比较。人类平等最初被认为是一个遥远的目标,但深度学习加速了进程,我们“实现”得要早得多。
如果我们在比较机器与人类,那我们又在比较人类与什么呢?
人工评审首先被要求转录音频。为了生成转录参考,不同的评审会多次听取音频并编辑以获得更准确的转录。当多个评审达成一致时,转录被认为是干净的。通过将新评审的转录与参考转录进行比较来测量人类基准 WER。与参考相比,一个评审有时仍可能出错,实际上,通常会有每二十个单词中有一个单词出错。这相当于 5%的 WER。
要声称达到人类水平,我们通常将系统与一个评审进行比较。有趣的一点是,ASR 系统确实尝试自己做多次处理。那么,将系统与一个人进行比较是否公平?确实公平,因为我们假设该人也有足够的时间在转录时重复播放音频,实际上也做了多次处理。
一旦 ASR 在某些语音识别任务中达到了人类水平(美式英语),很快就显现出对于正式书写文本而言,每二十个单词中有一个单词出错仍然是糟糕的体验。一种解决这个问题的方法是尝试找出识别的单词中哪些是低置信度的,并为它们提供可行的替代选项。我们可以在许多商业产品中观察到这种‘修正’体验,包括微软 Office Dictation 和 Google Docs(图 1 和图 2)。然而,WER 还有另一个显而易见的问题。

图 1:Microsoft Word Dictation 展示了为听写文本提供的替代选项
图 2:Google Docs 展示了为听写文本提供的替代选项
为了简化问题,传统上 WER 并没有计算最终书面形式的文本。可以说,ASR 系统的主要任务只是正确识别单词,而不是正确格式化日期、时间、货币、电子邮件等实体。因此,WER 计算使用的是口语形式版本,而不是正确格式化的文本。这消除了任何特定的格式差异、标点符号、大写等,只专注于口语单词。如果使用场景是语音搜索,这种假设是可以接受的,因为任务完成比文本格式更重要。通过语音搜索可以只使用‘口语形式’来进行。然而,对于像语音助手这样的不同使用场景,情况开始发生变化。现在,口语形式“wake me up at eight thirty-seven am”比书面形式“wake me up at 8:37 am”更难处理。书面形式在这里更容易被助手解析并转化为动作。
语音搜索和语音助手是我们所说的“一次性听写”用例的例子。随着 ASR 系统在一次性听写用例中变得更加可靠,注意力转向了听写和对话场景。这些都是长篇语音识别任务。对于语音搜索或语音助手,忽略标点符号很容易,但对于任何长篇听写或对话,无法标点是一个障碍。由于自动标点模型尚未足够好,听写采用的一条途径是支持“明确标点”。你可以明确说“句号”或“问号”,系统会做出正确的处理。这使用户能够控制并“解锁”他们使用听写来写电子邮件或文档。大小写或流畅性处理等其他方面也开始在听写场景中变得重要。如果我们继续依赖 WER 作为主要指标,我们会错误地描绘出我们的系统已经解决了这个问题。我们的指标需要随着语音识别用例的发展而演变。
Token Error Rate (TER) 是 Word Error Rate (WER) 的明显继任者。对于 TER,我们尝试考虑书面形式的所有方面,如大小写、标点符号、语言流畅性等,并尝试像 WER 一样计算一个单一指标(见表 1)。在 ASR 在 WER 上达到人类平等的同一数据集上,当用 TER 重新评估时,ASR 再次失去了人类平等。我们的目标已发生变化,但这次感觉像一个真正的目标,因为结果将更接近广泛使用的书面形式。
| 识别 | 参考 | 指标 | |
|---|---|---|---|
| 口语形式 | wake me pat eight thirty five a m | wake me up at eight twenty five a m | WER = 3/9 = 33.3% |
| 书面形式 | 叫我在 8:35 AM 起床。 | 叫我在 8:25 AM 起床。 | TER = 3/7 = 42.9%(标点符号单独计算) |
表 1:口语形式与书面形式如何影响指标计算?
这些综合指标的问题
TER 是一个很好的总体度量标准,但它掩盖了所有关键细节。现在有许多类别影响这个数字,这不仅仅是关于准确获得单词。因此,这个度量标准本身的可操作性较差。为了提高可操作性,我们需要弄清楚哪些类别对它的影响最大,并决定专注于改进那些类别。同时也存在类别不平衡的问题。不到 2%的所有标记包含任何数字以及相关格式,如时间、货币、日期等。即使我们完全搞错了这一类别,它对 TER 的影响也会有限,具体取决于 TER 的基准。但即使是这 2%的错误出现一半的时间,也会给用户带来糟糕的体验。因此,单靠 TER 度量标准无法指导我们的研究投资。我认为,我们需要找出对用户重要的类别,并测量和改进更具针对性的度量标准,如类别-F1。
如何确定对我们的用户来说什么是重要的?
啊哈!这是 ASR(自动语音识别)中最重要的问题。词错误率(WER)、翻译错误率(TER)或类别-F1 都是科学家用来验证进展的度量标准,但仍可能与用户真正关心的内容相距甚远。那么,什么才是重要的呢?为了回答这个问题,我们需要回到用户最初需要 ASR 系统的原因。这当然取决于具体场景。首先以听写为例。听写的唯一目的是替代打字。我们难道没有一个衡量这个的标准吗?每分钟字数(WPM)已经是一个衡量打字效率的成熟标准。我认为这是听写的完美标准。如果听写用户能够通过听写实现比打字更高的 WPM,那么 ASR 系统就完成了它的任务。当然,这里的 WPM 充分考虑了用户需要回头纠正错误的情况,这可能会拖慢他们的速度。某些错误是用户必须修复的,而有些错误是可以接受的。这自然赋予了重要内容更高的权重,甚至可能与 TER 对所有错误赋予相等权重的做法有所不同。太棒了!
我们能否将相同的逻辑应用于对话或会议记录?
会议记录与听写在目标上有很大不同。听写是人机交互的用例,而会议记录则是人际间的用例。每分钟字数(WPM)不再是合适的度量标准。然而,如果生成记录有其目的,那么合适的度量标准就是围绕这个目的而来的。例如,广播会议的目标可能是在最后生成可读的记录,因此人工标注员需要对机器生成的记录进行多少次编辑就成为了一个度量标准。这类似于 TER,只是部分内容是否被误识别并不重要,重要的是结果是否连贯且流畅。
另一个目的可能是从转录中提取可操作的见解或生成摘要。这些更难以衡量与识别准确率的关系。然而,人类交互仍然可以被衡量,任务完成或参与度类型的指标更为合适。
我们到目前为止讨论的指标可以被归类为“在线”指标和“离线”指标,如表 2 所总结的那样。在理想的世界中,它们应该是同步的。我认为,虽然离线指标可能是潜在改进的良好指示,但“在线”指标才是真正的成功衡量标准。当改进的 ASR 模型准备好时,首先测量正确的离线指标非常重要。发布这些模型只是完成了一半的工作。真正的考验是这些模型是否能改善客户的“在线”指标。
| 离线指标 | 在线指标 | |
|---|---|---|
| 语音搜索 | 口语形式的单词错误率(WER) | 成功点击相关搜索结果 |
| 语音助手 | 令牌错误率(TER),时间、日期、电话号码等的格式化 F1 | 任务完成率 |
| 语音输入(听写) | 令牌错误率(TER),标点符号 F1,大小写 F1 | 每分钟单词数(WPM),编辑率,用户保留/参与度 |
| 会议(对话) | 令牌错误率(TER),标点符号 F1,大小写 F1,流畅性 F1 | 转录编辑率,用户与转录 UI 的互动 |
表 2:语音识别的离线和在线指标
参考文献
-
“实现对话语音识别中的人类水平 - arXiv。” 2016 年 10 月 17 日,
arxiv.org/abs/1610.05256. -
每分钟单词数(WPM)
en.wikipedia.org/wiki/Words_per_minute
Piyush Behre 是微软的首席应用科学家,专注于语音识别/自然语言处理。他获得了印度理工学院鲁尔基分校的计算机科学与工程学士学位。
了解更多相关信息
分词的演变 - NLP 中的字节对编码
原文:
www.kdnuggets.com/2021/10/evolution-tokenization-byte-pair-encoding-nlp.html
评论
由 Harshit Tyagi, 数据科学讲师 | 导师 | YouTuber
虽然 NLP 在 AI 的启示上可能有些晚,但它在 Google、OpenAI 等组织中表现卓越,推出了如 BERT 和 GPT-2/3 等最先进的(SOTA)语言模型。
GitHub Copilot 和 OpenAI Codex 是当前新闻中的一些非常受欢迎的应用程序。作为一个对 NLP 了解有限的人,我决定将 NLP 作为研究领域,接下来的几篇博客/视频将是我分享在分析 NLP 的一些重要组件后所学到的内容。
NLP 系统有三个主要组件,帮助机器理解自然语言:
-
分词
-
嵌入
-
模型架构
顶级深度学习模型如 BERT、GPT-2 或 GPT-3 都共享相同的组件,但具有不同的架构,使每个模型有所区别。
在本期通讯中(以及 笔记本),我们将专注于 NLP 管道中第一个组件的基础知识,即分词。这是一个经常被忽视的概念,但它本身就是一个研究领域。我们已经远远超越了传统的 NLTK 分词过程。
尽管我们有最先进的分词算法,但了解其演变过程并学习我们如何达到现在的状态始终是一个好习惯。
所以,我们将覆盖以下内容:
-
什么是分词?
-
我们为什么需要分词器?
-
分词的类型 - 词级、字符级和子词级。
-
字节对编码算法 - 现在大多数 NLP 模型都使用的一个版本。
本教程的下一部分将深入探讨更先进(或增强版 BPE)的算法:
-
Unigram 算法
-
WordPiece - BERT 变压器
-
SentencePiece - 端到端分词器系统
什么是分词?
分词是将原始文本表示为称为“tokens”的较小单位的过程。这些 tokens 可以被映射为数字,以便进一步输入到 NLP 模型中。
这是一个过于简化的分词器功能示例:
## read the text and enumerate the tokens in the text
text = open('example.txt', 'r').read(). # read a text file
words = text.split(" ") # split the text on spaces
tokens = {v: k for k, v in enumerate(words)} # generate a word to index mapping

在这里,我们只是简单地将文本中的每个词映射到一个数字索引。显然,这是一个非常简单的示例,我们没有考虑语法、标点符号、复合词(如 test, test-ify, test-ing 等)。
因此,我们需要一个更技术化且准确的令牌化定义。为了考虑每一个标点符号和相关词汇,我们需要从字符级别开始工作。
令牌化有多种应用。其中一个用例来源于编译器设计,我们需要解析计算机程序,将原始字符转换为编程语言的关键字。
在深度学习中, 令牌化是将字符序列转换为令牌序列的过程,之后还需将其转换为可以由神经网络处理的数值向量序列。
为什么我们需要令牌化器?
对令牌化器的需求源于“我们如何让机器阅读?”这个问题。
处理文本数据的常见方法之一是定义一个规则字典,然后查找那个固定的规则字典。但这种方法只能走到一定程度,我们希望机器从阅读的文本中学习这些规则。
现在,机器不懂任何语言,也不理解声音或语音学。它们需要从头开始学习,以便能够阅读任何可能的语言。
这可是一项大任务,对吧?
人类通过将声音与意义联系起来来学习语言,然后我们学习用这种语言阅读和写作。机器无法做到这一点,因此它们需要从最基本的文本单元开始处理。
这就是令牌化的作用。将文本分解成称为“令牌”的更小单元。
还有不同的文本令牌化方法,这就是我们现在要学习的内容。
令牌化策略 - 简单的令牌化方法
为了让深度学习模型从文本中学习,我们需要一个两步过程:
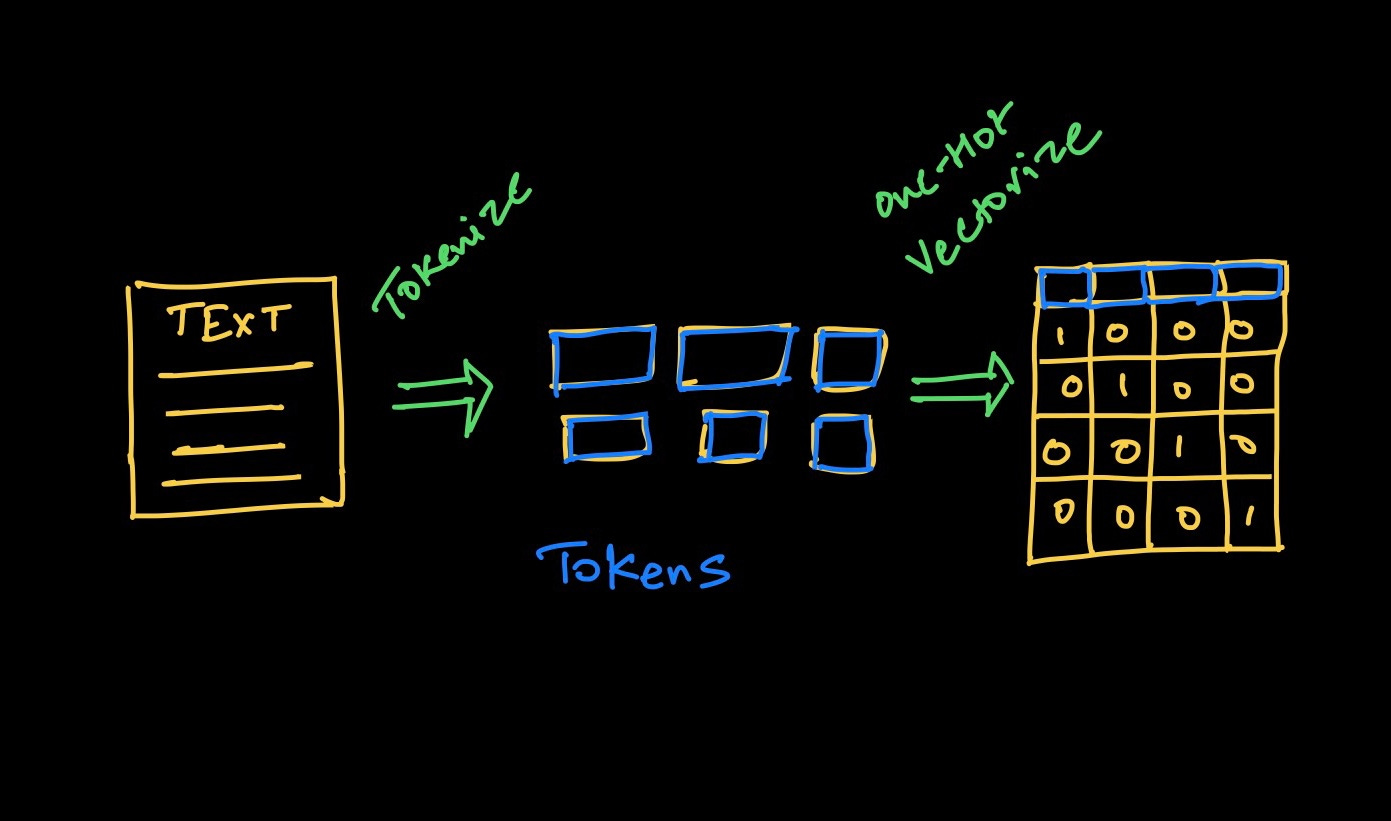
-
令牌化 - 决定使用什么算法来生成令牌。
-
将令牌编码为向量
正如第一步所示,我们需要决定如何将文本转换为小的令牌。大多数人提出的简单直接的方法是基于词的令牌,通过空格分割文本。
字词令牌化器的问题
-
训练数据中缺词的风险: 使用词元时,你的模型无法识别训练数据中未包含的词的变体。因此,如果你的模型在训练数据中看到了
foot和ball,但最终文本中有football,模型将无法识别该词,并将其视为<UNK>标记。类似地,标点符号也会带来问题,let或let's需要单独的标记,这是一个低效的解决方案。这将需要一个庞大的词汇表以确保你拥有每个词的所有变体。即使你添加了词形还原器来解决这个问题,你也增加了处理流程中的一个额外步骤。 -
处理俚语和缩写: 另一个问题是现在文本中使用的俚语和缩写,例如 "FOMO"、"LOL"、"tl;dr" 等。我们该如何处理这些词?
-
如果语言不使用空格进行分隔怎么办: 对于像中文这样不使用空格进行单词分隔的语言,这种分词器将完全失败。
在遇到这些问题后,研究人员开始研究另一种方法,即逐字符分词。
基于字符的分词
为了解决与基于词的分词相关的问题,尝试了一种逐字符分词的替代方法。
这确实解决了缺词的问题,因为现在我们处理的是可以使用 ASCII 或 Unicode 编码的字符,并且现在可以为任何单词生成嵌入。
每个字符,无论是空格、撇号还是冒号,现在都可以分配一个符号来生成向量序列。
但这种方法也有其缺点。
基于字符的模型的缺点
-
计算需求更多: 基于字符的模型将每个字符视为词元,更多的词元意味着更多的输入计算以处理每个词元,从而需要更多的计算资源。对于一个 5 词长的句子,你可能需要处理 30 个词元,而不是 5 个基于词的词元。
-
缩小 NLP 任务和应用的数量: 对于长字符序列,只有某种类型的神经网络架构可以使用。这限制了我们可以执行的 NLP 任务类型。对于像实体识别或文本分类这样的应用,基于字符的编码可能会变得低效。
-
学习错误语义的风险: 与字符一起工作可能会产生单词的错误拼写。此外,由于没有固有的意义,使用字符学习就像在没有有意义语义的情况下学习。
有趣的是,对于这样一个看似简单的任务,已经编写了多个算法来寻找最佳的分词策略。
在理解了这些分词方法的优缺点之后,寻找一种提供中间路径的方法是有意义的,即保留语义的同时使用有限的词汇表,以便在合并时生成文本中的所有单词。
子词分词
使用基于字符的模型,我们有丢失词语的语义特征的风险,而使用基于词的分词,我们需要一个非常大的词汇表来包含每个单词的所有可能变体。
所以,目标是开发一个算法,能够:
-
保留标记的语义特征,即每个标记的信息。
-
在不需要非常大词汇表的情况下进行分词,使用有限的词汇表。
为了解决这个问题,我们可以考虑根据一组前缀和后缀来拆分单词。例如,我们可以编写基于规则的系统来识别子词,如"##s"、"##ing"、"##ify"、"un##"等,其中双哈希的位置表示前缀和后缀。
所以,像"unhappily"这样的词通过子词"un##"、"happ"和"##ily"进行分词。
模型只学习一些子词,然后将它们组合起来创建其他词。这解决了创建大型词汇表所需的内存要求和工作量。
该算法的问题:
-
根据定义的规则创建的一些子词可能从未出现在你的文本中进行分词,并且可能占用额外的内存。
-
此外,对于每种语言,我们需要定义不同的规则集来创建子词。
为了缓解这个问题,在实践中,大多数现代分词器都有一个训练阶段,识别输入语料库中出现的文本并创建新的子词标记。对于稀有模式,我们坚持使用基于词的标记。
在这个过程中另一个重要因素是由用户设置的词汇表的大小。较大的词汇表允许更多常见单词被分词,而较小的词汇表则需要创建更多子词来构造文本中的每个单词,而不使用<UNK>标记。
在这里,平衡你的应用程序是关键。
字节对编码(BPE)
BPE 最初是一种数据压缩算法,用于通过识别常见字节对找到表示数据的最佳方式。现在它被用于自然语言处理(NLP),以使用最少的标记找到文本的最佳表示。
工作原理如下:
-
在每个单词的末尾添加一个标识符(
</w>)以标识单词的结束,然后计算文本中的单词频率。 -
将单词拆分为字符,然后计算字符频率。
-
从字符标记开始,进行预定义次数的迭代,计算连续字节对的频率,并合并出现频率最高的字节对。
-
持续迭代,直到你达到迭代限制(由你设置)或达到标记限制。
让我们逐步(在代码中)处理一个示例文本。为此编写代码,我借鉴了Lei Mao 的 BPE 极简博客。我鼓励你去看看!
这是我们的示例文本:
"There is an 80% chance of rainfall today. We are pretty sure it is going to rain."
## define the text first
text = "There is an 80% chance of rainfall today. We are pretty sure it is going to rain."
## get the word frequency and add the end of word () token ## at the end of each word
words = text.strip().split(" ")
print(f"Vocabulary size: {len(words)}")

第二步:将单词拆分为字符,然后计算字符频率。
char_freq_dict = collections.defaultdict(int)
for word, freq in word_freq_dict.items():
chars = word.split()
for char in chars:
char_freq_dict[char] += freq
char_freq_dict

第三步:合并最频繁出现的连续字节对。
import re
## create all possible consecutive pairs
pairs = collections.defaultdict(int)
for word, freq in word_freq_dict.items():
chars = word.split()
for i in range(len(chars)-1):
pairs[chars[i], chars[i+1]] += freq

第四步 - 迭代多次以找到最佳(就频率而言)对进行编码,然后将它们连接以查找子词。
在此阶段,最好将我们的代码结构化为函数。这将要求我们执行以下步骤:
-
在每次迭代中,找到最频繁出现的字节对。
-
合并这些标记。
-
重新计算字符标记的频率,添加新的对编码。
-
继续进行,直到没有更多对或者你到达循环的结束。
要查看详细代码,你可以查看我的 Colab 笔记本。
这是这四个步骤的精简输出:

当我们迭代每个最佳对时,我们合并(连接)该对,你可以看到,当我们重新计算频率时,原始字符标记频率减少,新配对的标记频率在标记字典中出现。
如果你查看创建的标记数量,最初会增加,因为我们创建了新的配对,但在经过若干次迭代后,数量开始减少。
在这里,我们从 25 个标记开始,在第 14 次迭代中增加到 31 个标记,然后在第 50 次迭代中减少到 16 个标记。很有趣,对吧?
BPE 算法的改进空间
BPE 算法是一种贪婪算法,即它在每次迭代中尝试寻找最佳对。这个贪婪方法有一些局限性。
因此,BPE 算法也有优缺点。
最终标记将根据你运行的迭代次数而有所不同,这也带来了另一个问题。现在,我们可以对同一文本拥有不同的标记,从而得到不同的嵌入。
为了解决这个问题,提出了多种解决方案,但最突出的是一种添加了subword regularization(子词正则化,一种新的子词分割方法)训练的单语语言模型,该模型通过使用损失函数计算每个子词令牌的概率,以选择最佳选项。更多内容将在即将到来的博客中介绍。
他们在 BERTs 或 GPTs 中使用 BPE 吗?
像 BERT 或 GPT-2 这样的模型使用某种版本的 BPE 或单语模型来对输入文本进行标记化。
BERT 包含了一种新的算法,叫做 WordPiece,这与 BPE 类似,但增加了一个概率计算层,以决定合并的令牌是否会被最终采纳。
总结
你在这篇博客中学到了什么(如果有的话),即机器如何通过将文本分解为非常小的单元来开始理解语言。
现在,有很多方法可以将文本分解,因此比较不同方法变得重要。
我们从通过空格分割英文文本来理解标记化开始,但并非所有语言都是以相同的方式书写(即使用空格来表示分割),因此我们研究了通过字符分割来生成字符令牌。
使用字符的问题在于令牌的语义特征丧失,可能导致创建不正确的词汇表示或嵌入。
为了兼顾两全,推出了更有前景的子词标记化方法,然后我们研究了 BPE 算法来实现子词标记化。
下一周将详细介绍 WordPiece、SentencePiece 等高级标记化器的下一步,以及如何使用 HuggingFace 标记化器。
参考文献和注释
我的文章实际上是以下论文和博客的汇总,我鼓励你阅读:
-
稀有词汇的神经机器翻译与子词单元 - 讨论基于 BPE 压缩算法的不同分割技术的研究论文。
-
关于子词 NMT(神经机器翻译)的 GitHub 代码库 - 支持上述论文的代码。
-
Lei Mao 的 Byte Pair Encoding 博客 - 我使用了他博客中的代码来实现和理解 BPE。
-
机器如何阅读 - Cathal Horan 的博客。
如果你想开始学习数据科学或机器学习领域,可以查看我的课程 数据科学与机器学习基础。
如果你想看到更多类似内容而你还不是订阅者,可以考虑使用下面的按钮订阅我的新闻通讯。
简介: Harshit Tyagi 是一位在网页技术和数据科学(即全栈数据科学)方面拥有丰富经验的工程师。他已经辅导了超过 1000 名人工智能/网页/数据科学的求职者,并正在设计数据科学和机器学习工程学习路径。此前,Harshit 与耶鲁大学、麻省理工学院和加州大学洛杉矶分校的研究科学家一起开发了数据处理算法。
原文。经授权转载。
相关:
-
深度学习的文本预处理方法
-
15 个必须了解的 Python 字符串方法
-
学习数据科学和机器学习:路线图后的第一步
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
更多相关主题
你用 Python 读取 Excel 文件吗?有一种 1000 倍更快的方法
原文:
www.kdnuggets.com/2021/09/excel-files-python-1000x-faster-way.html
评论
作者:Nicolas Vandeput,供应链数据科学家

来源:www.hippopx.com/,公有领域
我们的 3 个最佳课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 在 IT 领域支持你的组织
作为 Python 用户,我使用 Excel 文件来加载/存储数据,因为商务人士喜欢以 Excel 或 csv 格式共享数据。不幸的是,Python 处理 Excel 文件特别慢。
在这篇文章中,我将向你展示在 Python 中加载数据的五种方法。最后,我们将实现 3 个数量级的加速,速度将非常快。
编辑 (18/07/2021):我找到了使过程快 5 倍(实现 5000 倍加速)的方法。我把它作为文章末尾的一个附加内容。
实验设置
让我们假设我们要加载 10 个包含 20000 行和 25 列的 Excel 文件(总共约 70MB)。这是一个代表性的案例,假设你要将 ERP(SAP)中的事务数据加载到 Python 中进行一些分析。
让我们填充这些虚拟数据并导入所需的库(稍后在文章中我们会讨论 pickle 和 joblib)。
import pandas as pd
import numpy as np
from joblib import Parallel, delayed
import timefor file_number in range(10):
values = np.random.uniform(size=(20000,25))
pd.DataFrame(values).to_csv(f”Dummy {file_number}.csv”)
pd.DataFrame(values).to_excel(f”Dummy {file_number}.xlsx”)
pd.DataFrame(values).to_pickle(f”Dummy {file_number}.pickle”)
在 Python 中加载数据的 5 种方法
想法 #1:在 Python 中加载 Excel 文件
让我们从一种简单的方法开始加载这些文件。我们将创建第一个 Pandas Dataframe,然后将每个 Excel 文件附加到它上面。
start = time.time()
df = pd.read_excel(“Dummy 0.xlsx”)
for file_number in range(1,10):
df.append(pd.read_excel(f”Dummy {file_number}.xlsx”))
end = time.time()
print(“Excel:”, end — start)>> Excel: 53.4
在 Python 中导入 Excel 文件的简单方法。
运行时间约为 50 秒。相当慢。
想法 #2:使用 CSV 而不是 Excel 文件
现在我们假设我们将这些文件从 ERP/System/SAP 保存为 .csv(而不是 .xlsx)。
start = time.time()
df = pd.read_csv(“Dummy 0.csv”)
for file_number in range(1,10):
df.append(pd.read_csv(f”Dummy {file_number}.csv”))
end = time.time()
print(“CSV:”, end — start)>> CSV: 0.632
在 Python 中导入 csv 文件的速度比 Excel 文件快 100 倍。
我们现在可以在 0.63 秒内加载这些文件。这几乎快了 10 倍!
Python 加载 CSV 文件的速度是 Excel 文件的 100 倍。使用 CSV 文件。
缺点:csv 文件通常比 .xlsx 文件大。在这个例子中,.csv 文件为 9.5MB,而 .xlsx 文件为 6.4MB。
想法 #3:更智能的 Pandas DataFrames 创建
我们可以通过改变创建 pandas DataFrames 的方式来加快我们的进程。与其将每个文件附加到现有的 DataFrame,
-
不如将每个 DataFrame 独立地加载到一个列表中。
-
然后将整个列表连接成一个 DataFrame。
start = time.time()
df = []
for file_number in range(10):
temp = pd.read_csv(f”Dummy {file_number}.csv”)
df.append(temp)
df = pd.concat(df, ignore_index=True)
end = time.time()
print(“CSV2:”, end — start)>> CSV2: 0.619
更聪明的 CSV 文件导入方式
我们减少了几个百分点的时间。根据我的经验,这个技巧在处理更大的数据框(df >> 100MB)时会非常有用。
想法#4:使用 Joblib 并行化 CSV 导入
我们想在 Python 中加载 10 个文件。与其一个一个加载,为什么不一次性并行加载所有文件呢?
我们可以使用joblib轻松实现这一点。
start = time.time()
def loop(file_number):
return pd.read_csv(f”Dummy {file_number}.csv”)
df = Parallel(n_jobs=-1, verbose=10)(delayed(loop)(file_number) for file_number in range(10))
df = pd.concat(df, ignore_index=True)
end = time.time()
print(“CSV//:”, end — start)>> CSV//: 0.386
使用 Joblib 在 Python 中并行导入 CSV 文件。
这几乎是单核版本速度的两倍。然而,作为一般规则,不要指望通过使用 8 核来将你的过程加速八倍(在这里,我在使用新 M1 芯片的 Mac Air 上,通过使用 8 核实现了 x2 的速度提升)。
Python 中使用 Joblib 进行简单的并行化
Joblib是一个简单的 Python 库,允许你在//中运行函数。实际上,joblib 的工作方式类似于列表推导式,只不过每次迭代由不同的线程执行。以下是一个例子。
def loop(file_number):
return pd.read_csv(f”Dummy {file_number}.csv”)
df = Parallel(n_jobs=-1, verbose=10)(delayed(loop)(file_number) for file_number in range(10))#equivalent to
df = [loop(file_number) for file_number in range(10)]
将 joblib 看作是一个智能的列表推导式。
想法#5:使用 Pickle 文件
通过将数据存储在 pickle 文件中——Python 使用的一种特定格式——而不是.csv 文件,你可以(大大)加快速度。
缺点:你不能手动打开 pickle 文件查看其中的内容。
start = time.time()
def loop(file_number):
return pd.read_pickle(f”Dummy {file_number}.pickle”)
df = Parallel(n_jobs=-1, verbose=10)(delayed(loop)(file_number) for file_number in range(10))
df = pd.concat(df, ignore_index=True)
end = time.time()
print(“Pickle//:”, end — start)>> Pickle//: 0.072
我们刚刚将运行时间缩短了 80%!
一般来说,处理 pickle 文件比处理 csv 文件要快得多。不过,另一方面,pickle 文件通常会占用更多的磁盘空间(在这个具体的例子中除外)。
实际上,你可能无法直接从系统中提取数据到 pickle 文件中。
我建议在以下两种情况下使用 pickle 文件:
-
如果你想保存来自 Python 进程的数据(并且不打算在 Excel 中打开),以便以后/在其他进程中使用。将你的数据框保存为 pickle 文件,而不是.csv。
-
你需要多次重新加载相同的文件。第一次打开文件时,将其保存为 pickle 文件,以便下次能够直接加载 pickle 版本。
示例:假设你使用的是交易性月度数据(每个月你加载一个新的数据月)。你可以将所有历史数据保存为.pickle,每次收到新文件时,你可以先将其作为.csv 加载,然后保留为.pickle 以备下次使用。
奖励:并行加载 Excel 文件
假设你收到的是 Excel 文件,你别无选择,只能按原样加载它们。你也可以使用 joblib 来并行化这个过程。相比我们上面提到的 pickle 代码,我们只需更新循环函数。
start = time.time()
def loop(file_number):
return pd.read_excel(f"Dummy {file_number}.xlsx")
df = Parallel(n_jobs=-1, verbose=10)(delayed(loop)(file_number) for file_number in range(10))
df = pd.concat(df, ignore_index=True)
end = time.time()
print("Excel//:", end - start)>> 13.45
如何使用 Python 中的并行化加载 Excel 文件。
我们可以将加载时间减少 70%(从 50 秒降到 13 秒)。
你也可以使用这个循环来动态创建 pickle 文件。这样,下次你加载这些文件时,你将能够实现闪电般的加载速度。
def loop(file_number):
temp = pd.read_excel(f"Dummy {file_number}.xlsx")
temp.to_pickle(f"Dummy {file_number}.pickle")
return temp
回顾
通过并行加载 pickle 文件,我们将加载时间从 50 秒减少到不到十分之一秒。
-
Excel:50 秒
-
CSV:0.63 秒
-
更智能的 CSV:0.62 秒
-
CSV in //:0.34 秒
-
Pickle in //:0.07 秒
-
Excel in //:13.5 秒
奖励#2:4 倍更快的并行化
Joblib 允许更改并行化后台以减少一些开销。你可以通过将prefer=”threads” 传递给Parallel来做到这一点。
使用 prefer=”threads” 将使你的过程运行得更快。
我们获得了大约 0.0096 秒的速度(在 2021 年款 MacBook Air 上进行 50 次测试)。
使用 prefer=”threads” 进行 CSV 和 Excel 并行化的结果如下。

如你所见,使用“线程”后台在读取 Excel 文件时得分更差。但在使用 pickle 时表现惊人(逐个加载 Excel 文件需要 50 秒,而在//中读取 pickle 文件仅需 0.01 秒)。
???? 让我们在 LinkedIn 上连接吧!
简介:尼古拉斯·万德普特是一名供应链数据科学家,专注于需求预测和库存优化。他于 2016 年创办了自己的咨询公司SupChains,并于 2018 年共同创办了SKU Science——一个快速、简单且经济实惠的需求预测平台。对教育充满热情的尼古拉斯既是一名积极的学习者,也享受在大学授课:自 2014 年以来,他在比利时布鲁塞尔教授预测和库存优化课程。自 2020 年以来,他还在法国巴黎的 CentraleSupelec 教授这两个学科。他于 2018 年出版了供应链预测的数据科学(2021 年出版了第 2 版),并于 2020 年出版了库存优化:模型与模拟。

原文。经许可转载。
相关:
-
Vaex: Pandas 但快 1000 倍
-
如何查询你的 Pandas 数据框
-
使用 PyPolars 使 Pandas 快 3 倍
更多相关话题
一个学习 ChatGPT 背后所有基础的优秀资源
原文:
www.kdnuggets.com/023/08/excellent-resource-learn-foundations-everything-underneath-chatgpt.html

图片来自 Freepik
OpenAI、ChatGPT、GPT 系列以及大型语言模型(LLMs) – 如果你与 AI 行业或技术行业有任何联系,那么你很可能会在几乎所有的商务对话中听到这些词汇。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
而且这种炒作是真的。我们不能再称其为泡沫。毕竟,这次,炒作确实兑现了它的承诺。
谁会想到机器能够理解并以类人智能作出回应,并执行几乎所有以前被认为是人类特长的任务,包括音乐创作、诗歌写作,甚至编程应用?
大型语言模型在我们生活中的普及让我们都对这一强大技术背后的内容充满好奇。
因此,如果你因为算法的复杂细节和 AI 领域的复杂性而感到退缩,我强烈推荐这个资源来了解“ChatGPT 在做什么……以及它为何有效?”

是的,这是 Wolfram 文章的标题。
为什么推荐这个?因为在学习 Transformers、LLMs 或者生成型 AI 之前,理解机器学习的基本要素以及深度神经网络如何与人脑相关是至关重要的。
这看起来像一本迷你书,独立成章,但请花时间阅读这篇资源。
在这篇文章中,我将分享如何开始阅读这些内容,以便更容易掌握概念。
理解‘模型’至关重要
其主要亮点是关注“大型语言模型”中的‘模型’部分,通过一个例子说明了球从每一层到达地面的时间。
图片来源:斯蒂芬·沃尔弗拉姆的写作
有两种方法可以实现这一点 – 从每一层重复这个过程,或建立一个可以计算它的模型。
在这个例子中,存在一个基本的数学公式,使得计算变得更容易,但如何使用“模型”来估计这种现象呢?
最佳做法是拟合一条直线来估计感兴趣的变量,在这个例子中就是时间。
对这一部分更深入的阅读会解释没有“无模型的模型”,这将自然引导你了解各种深度学习概念。
深度学习的核心
你将了解到,模型是一个复杂的函数,它接受某些变量作为输入,并生成输出,比如在数字识别任务中的一个数字。
文章从数字识别到典型的猫与狗分类器,清楚地解释了每一层所提取的特征,从猫的轮廓开始。值得注意的是,神经网络的前几层会提取图像的某些方面,如物体的边缘。

图片来源:Freepik
关键术语
除了说明多个层的作用外,还解释了深度学习算法的多个方面,例如:
神经网络的架构
文章称这是一种艺术与科学的结合 – “但大多数情况是通过反复试验发现的,添加了想法和技巧,逐步积累了关于如何处理神经网络的丰富经验”。
轮次
轮次是一种有效的方法,可以提醒模型特定的示例,让它“记住这个示例”
由于重复相同的例子多次并不足够,因此向神经网络展示不同的示例变体非常重要。
权重(参数)
你一定听说过某个大型语言模型拥有惊人的 1750 亿个参数。嗯,这说明了模型的结构如何根据旋钮的调整而变化。
本质上,参数是“你可以调节的旋钮”,用于拟合数据。文章强调,神经网络的实际学习过程就是寻找正确的权重 – “最终,这一切都是关于确定哪些权重能够最好地捕捉给定的训练示例”
泛化
神经网络学会了以“合理的方式在展示的示例之间进行插值”。
这种泛化有助于通过学习多个输入-输出示例来预测未见过的记录。
损失函数
那么,我们如何知道什么是合理的呢?它由输出值与期望值之间的距离定义,这些期望值被封装在损失函数中。
它为我们提供了“我们得到的值与真实值之间的距离”。为了减少这种距离,权重会被反复调整,但必须有一种系统化的方法来将权重调整到最短路径的方向。
梯度下降
在权重景观中找到最陡下降路径称为梯度下降。
一切都在于通过在权重景观中导航来找到最佳的权重,以最准确地表示真实情况。
反向传播
继续阅读关于反向传播的概念,它利用损失函数向后工作,逐步找到最小化相关损失的权重。
超参数
除了权重(即参数),还有超参数,包括不同的损失函数选择、损失最小化,甚至选择“批次”大小。
复杂问题中的神经网络
神经网络在复杂问题中的使用被广泛讨论。然而,直到这篇文章解释了高维空间中的多个权重变量如何提供通向最小值的各种方向,这种假设的逻辑才变得清晰。
现在,将此与较少的变量进行比较,这意味着可能会陷入局部最小值而没有方向离开。
结论
通过这次阅读,我们涵盖了许多内容,从理解模型及人脑如何工作到将其应用于神经网络、它们的设计及相关术语。
请关注后续文章,了解如何在此基础上深入理解 chatgpt 的工作原理。
Vidhi Chugh 是一位 AI 策略专家和数字化转型领导者,专注于产品、科学和工程的交汇点,以构建可扩展的机器学习系统。她是一位获奖的创新领导者、作者和国际演讲者。她的使命是使机器学习民主化,并打破术语,使每个人都能参与这场转型。
更多相关主题
使用 Flask 部署机器学习模型
原文:
www.kdnuggets.com/2019/12/excelr-deployment-machine-learning-flask.html
赞助帖子。
到目前为止,我们已经开发了许多数据科学模型,对测试数据进行了预测,并离线检查了结果。在现实世界中,生成预测只是数据科学项目的一部分。让我们考虑一个使用 CPU/GPU 的机器学习来检测垃圾短信的情况。一个朴素贝叶斯分类器在 CPU/GPU 上用垃圾短信和非垃圾短信进行训练。训练好的模型作为服务部署到网上,供大众或用户使用。
本博客将向我们解释机器学习算法部署的基本知识。在本博客中,我们将专注于开发一个用于垃圾短信识别的朴素贝叶斯模型,并使用 Flask(Flask 是一个 Python 的 Web 服务开发微框架)为模型创建 API。API 允许我们通过 HTTP 请求利用算法的分类能力。
Flask 基于 2 个组件:WSGI(Web 服务器网关接口)工具包和 Jinja2 模板。WSGI 用于 Web 应用程序,Jinja2 提供网页。Flask 总是用于较大规模的机器学习项目。Flask 可用于构建 REST 应用程序、电子邮件服务、聊天应用等。
开始吧!
有关 数据科学课程 的更多信息,请关注我们 @ExcelR
第 1 步:
首先,我们将使用一个数据集(messages.csv)来构建一个分类模型,该模型将准确识别哪些文本是垃圾信息。该分类器模型基于词袋特征来识别垃圾邮件。一旦我们训练好模型,建议保存该模型以便将来使用,从而减少重新训练的时间。为此,我们将模型保存为.pkl 文件以备将来使用。这是一个 pickle 文件,是用于保存和加载 Python 对象文件的原生 Python 库。

第 2 步:
下一步,我们需要开发一个具有用户友好界面的 Web 应用程序,界面上包含一个用于用户输入的表单字段。在将用户定义的消息输入到 Web 应用程序后,它将把消息传递到结果页面,显示是否为垃圾信息。
第 3 步:
为了开发 Web 应用程序,我们在桌面上创建一个名为 Spam Identifier 的项目文件夹,确保在其中创建文件目录。文件夹中的目录结构将如下所示:
py app.py HTML files/ homepage.html output.html style/ design.csspy 步骤 4: 检查这个app.py文件是否包含用于执行 Flask 网络应用程序的 Python 源代码,它应该包括用于分类垃圾信息的 ML 程序(.pkl 文件)。此文件是链接到 HTML 文件和调用模型的 API,以显示用户定义输入的输出。 步骤 5: 然后将应用程序作为一个模块运行,以使用参数__name__初始化一个新的 Flask 实例,这将帮助 Flask 在同一文件夹(垃圾识别器)中找到 HTML 文件夹(包含 HTML 文件)。 ```py app = Flask(__name__) ``` **Step 6:** To furnish the web page, flask will look for html files present in the subdirectory called html files. In this case, we have two create 2 html files: homepage.html and output.html. **Step 7:** CSS can be used to design the look of 2 html documents. Don’t forget to save design.css file in a subdirectory called style, which happens to be the default directory of Flask. **Step 8:** Next use the route decorator (@app.route('/')) url to activate the execution of homepage function. On the back of which homepage function will simply provision homepage.html file available in the sub category.  **Step 9:** Thereafter, we define predict function, wherein we read messages.csv set, pre-process the text, make estimations, and store the model.  **Step 10:** Next, we access the new message inputted by the user and make a prediction. Afterwards, make use of the POST method to transfer the form data to the server.  **Step 11:** Post which output.html file can be activated through the render_htmlfiles function inside the predict function which we defined in the app.py script.  **Step 12:** Finally, use the run function to only run the application on the server, by using if statement with __name__ == '__main__'. Later, set the debug=True argument inside the app.run method, to trigger flask's debugger.  **Step 13:** For running the model , you can start running the API either by double clicking app.py, or executing the command from the terminal as follows: ```py` ``` cd -Spam Identifier Python app.py ```py **Step 14:** Next, open a web browser and navigate to http://127.0.0.1:5000/, where you should see a simple website which is similar to the one below  Congratulations! You have now created an end-to-end NLP application at zero cost and little effort. Hosting and sharing data science models can be uncomplicated. Developing android apps, chatbots and many more applications dependent on machine learning algorithms back-end can be created with no difficulty. When you have time, I recommend to start reading about deployment in machine learning. That’s it for flask. Thanks for reading. For More Information related to [Data Science Course](https://www.excelr.com/data-science-course-training-in-bangalore) Follow us @ExcelR * * * ## Our Top 3 Course Recommendations  1\. [Google Cybersecurity Certificate](https://www.kdnuggets.com/google-cybersecurity) - Get on the fast track to a career in cybersecurity.  2\. [Google Data Analytics Professional Certificate](https://www.kdnuggets.com/google-data-analytics) - Up your data analytics game  3\. [Google IT Support Professional Certificate](https://www.kdnuggets.com/google-itsupport) - Support your organization in IT * * * ### More On This Topic * [A Full End-to-End Deployment of a Machine Learning Algorithm into a…](https://www.kdnuggets.com/2021/12/deployment-machine-learning-algorithm-live-production-environment.html) * [From Data Collection to Model Deployment: 6 Stages of a Data…](https://www.kdnuggets.com/2023/01/data-collection-model-deployment-6-stages-data-science-project.html) * [Back to Basics Week 4: Advanced Topics and Deployment](https://www.kdnuggets.com/back-to-basics-week-4-advanced-topics-and-deployment) * [Top 7 Model Deployment and Serving Tools](https://www.kdnuggets.com/top-7-model-deployment-and-serving-tools) * [Predicting Cryptocurrency Prices Using Regression Models](https://www.kdnuggets.com/2022/05/predicting-cryptocurrency-prices-regression-models.html) * [How to Make Large Language Models Play Nice with Your Software…](https://www.kdnuggets.com/how-to-make-large-language-models-play-nice-with-your-software-using-langchain) ```` ```py``
KDnuggets 独家:采访扬·勒昆的第二部分
原文:
www.kdnuggets.com/2014/02/exclusive-yann-lecun-deep-learning-facebook-ai-lab-part2.html
格雷戈里·皮亚特斯基,2014 年 2 月 20 日。
这里是采访第一部分
是深度学习的领先专家之一——这一突破性进展在机器学习领域取得了惊人的成功,纽约大学数据科学中心的创始主任,并最近被任命为 Facebook 人工智能研究实验室主任。
格雷戈里·皮亚特斯基:5. 从长期来看,人工智能将走多远?我们会达到雷·库兹韦尔描述的奇点吗?
扬·勒昆:我们将拥有智能机器。这显然只是时间问题。我们将有一些机器,虽然它们并不是非常智能,但能做一些有用的事情,比如自主驾驶我们的汽车。
这需要多长时间?AI 研究人员在低估构建智能机器的难度方面有很长的历史。我将用一个类比来说明:在研究中取得进展就像开车去一个目的地。当我们找到一个新的范式或一套新技术时,感觉就像我们在高速公路上开车,直到到达目的地,没有什么能阻止我们。 
但现实是,我们实际上在浓雾中行驶,没意识到我们的高速公路实际上是一处停车场,远端有一堵砖墙。许多聪明的人犯过这个错误,每一次 AI 的新浪潮后,都会跟随一段过度乐观、非理性炒作和反弹期。这种情况发生在“感知机”、“基于规则的系统”、“神经网络”、“图模型”、“支持向量机”等领域,也可能发生在“深度学习”上,直到我们找到其他东西。但这些范式从未完全失败。它们都留下了新的工具、新的概念和新的算法。
 虽然我确实相信我们最终会建立起与人类智能相媲美的机器,但我不太相信奇点。我们感觉自己正处在一个指数增长的进步曲线上。但我们也可能正处在一个 S 型曲线上。S 型曲线在开始时非常像指数曲线。此外,奇点假设的不仅仅是指数增长,它还假设一个渐近线。动态演化的差异,如线性、二次、指数、渐近或 S 型形状,是阻尼或摩擦因素。未来学家似乎假设不存在这样的阻尼或摩擦项。未来学家有动机做出大胆预测,特别是当他们真的希望这些预测成真时,也许希望它们能自我实现。
虽然我确实相信我们最终会建立起与人类智能相媲美的机器,但我不太相信奇点。我们感觉自己正处在一个指数增长的进步曲线上。但我们也可能正处在一个 S 型曲线上。S 型曲线在开始时非常像指数曲线。此外,奇点假设的不仅仅是指数增长,它还假设一个渐近线。动态演化的差异,如线性、二次、指数、渐近或 S 型形状,是阻尼或摩擦因素。未来学家似乎假设不存在这样的阻尼或摩擦项。未来学家有动机做出大胆预测,特别是当他们真的希望这些预测成真时,也许希望它们能自我实现。
GP: 6. 你曾(或现在)还是纽约大学数据科学中心的主任。你打算如何将你在 Facebook 和纽约大学的工作结合起来?
Yann LeCun:我已经辞去了 的(创始)主任职务。
现任临时主任是 S. R. Srinivasa "Raghu" Varadhan,他可能是世界上最著名的概率论学家。纽约大学已经开始寻找新的常任主任。我在 CDS 的创建上投入了大量精力。我们现在有了数据科学的硕士项目,并且很快将有博士项目。我们有 9 个开放的教职位置,我们从 Moore 和 Sloan 基金会获得了一个为期五年的大型资助,与伯克利和华盛顿大学合作,我们与 Facebook 和其他公司建立了合作伙伴关系,我们将很快有一栋新楼。下一任主任将会享受所有的乐趣!
GP: 7. “数据科学”这一术语最近出现,被描述为统计学、黑客技术和领域/商业知识的交集。数据科学与以前的术语如“数据挖掘”和“预测分析”有什么不同?如果它是一门新科学,它的关键方程/原则是什么?
Yann LeCun:数据科学涉及从数据中自动或半自动提取知识。这个概念渗透到许多学科中,每个学科都有不同的名称,包括统计估计、数据挖掘、预测分析、系统识别、机器学习、人工智能等。
在方法论方面,统计学、机器学习以及某些应用数学分支都可以声称“拥有”数据科学领域。但实际上,数据科学对于统计学、机器学习和应用数学的意义,就像计算机科学对于 1960 年代的电气工程、物理学和数学的意义一样。计算机科学如何成为一门独立的学科,而不是数学或工程的一个子领域,这是因为它对社会的重要性。
随着数字世界中生成的数据呈指数增长,从数据中自动提取知识的问题也在迅速增长。这导致了数据科学作为一个学科的出现。它正在重新划定统计学、机器学习和应用数学之间的界限。同时,它也创造了科学、商业、医学和政府中“方法”人员与“领域”人员之间紧密互动的需求。
我的预测是,10 年后,许多顶级大学将设立数据科学系。
GP: 8. 对于“ Big Data”作为一种趋势和流行词,你有什么看法?有多少是炒作,多少是现实?
扬·勒昆:我喜欢在社交网络上流传的那个笑话,它将大数据比作青春期性行为:每个人都在谈论它,但没有人真正知道怎么做,每个人都认为其他人都在做,所以每个人都声称自己在做。 [GP: 这个笑话来源于丹·阿里耶利的 Facebook 帖子]
我见过有人坚持使用 Hadoop 来处理那些可以轻松放进闪存驱动器并且可以在笔记本电脑上轻松处理的数据集。
确实存在炒作。但如何收集、存储和分析大量数据的问题非常真实。我总是对像“大数据”这样的名称感到怀疑,因为今天的“大数据”可能是明天的“小数据”。此外,也有许多重要问题是由于数据过少而产生的。基因组学和医学数据通常就是这种情况。数据永远不够。
GP: 9. 数据科学家被称为“21 世纪最性感的职业”。你会给想进入这个领域的人什么建议?
扬·勒昆:如果你是本科生,尽可能多地修读数学、统计学和物理学课程,并学习编程(修 3 到 4 门计算机科学课程)。
如果你有本科学位,可以申请NYU 数据科学硕士。
GP: 10. 你最近读过并喜欢的书是什么?当你远离计算机/智能手机时,你喜欢做什么?
我设计和制作微型飞行器,玩弄 3D 打印机,破解基于微控制器的小工具,并希望在音乐制作上有所提高(我似乎收集了很多电子风琴)。我主要阅读非小说类书籍,听很多爵士乐(以及其他各种类型的音乐)。
更多相关主题
《数据科学与机器学习高管指南》
原文:
www.kdnuggets.com/2018/05/executive-guide-data-science-machine-learning.html
评论
大数据。深度学习。预测分析。如今,数据科学部门和主要商业新闻网站上充斥着大量行话,各行各业都在争相招聘,以开发先进的分析工具来辅助决策。但作为一名高管,了解哪些信息是重要的呢?
尽管数据科学和数据经济是快速出现和发展的领域,但与这些领域相关的许多工作和新发展都遵循一些普遍的原则和概念。本指南旨在提供对当前数据科学中常用的关键数据相关主题和术语的简要概述,并举例说明它们在数据科学中的应用。
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
大数据是一个涵盖所有数据的术语,这些数据足够大,以至于在存储和分析中会遇到问题,特点包括高容量(大量记录)、高度多样性(文本数据、视频数据和数值数据的结合)、速度(流数据)和真实性(数据质量)。许多时候,这指的是记录的数量,这些记录可能达到数十亿或数万亿,例如零售交易数据或大型营销活动中的潜在客户数据。这类数据在存储上成为问题。然而,大数据也可以指关于某一记录的信息量很大的数据,例如关于患者的基因组数据或某个学生的学术记录,这种数据在通过统计方法分析时可能非常棘手,因为它违反了许多分析工具的假设。数据可能很大,但存在质量控制问题,如数据缺失、记录损坏或捕获策略不正确;这也是分析项目失败的最常见原因之一,也是数据捕获策略如此重要的关键原因之一。数据工程师负责捕获和优化存储数据,以便将来在分析或报告中使用。
Hadoop和SQL是两种常见的数据存储数据库(数据在等待分析时的“栖息地”)。SQL 在成熟的企业和数据量不大的企业中很常见;Hadoop 在处理非常大的数据集时更为优选。还有其他数据库存在,但通常是特定行业独有的。MapReduce是一个相关的框架,通过将数据拆分和存储或分析这些部分,帮助管理和分析大量数据。通过这种方式,一组计算机可以在分析或存储类似数据时无需在任何一台计算机上占用大量存储空间。跨计算机存储的数据和结果可以根据需要汇总为最终结果。这在 Hadoop 和专门的大数据数据库/分析工具中很常见。
人工智能(AI)是计算机科学的一个广泛领域,包括设计软件系统和算法,帮助计算机理解语音、表示知识、训练机器人导航、解决问题和理解图像或视频。通常,存在一个目标和数据用于训练或优化软件。算法是一组指导计算机学习过程或决策的指令,通常基于数据,并根据这些数据优化指令。
统计建模和机器学习通过其与数学和统计学的交集与 AI 和算法相关。模型通过统计测试感兴趣结果(如客户流失、营销活动中的潜在客户或每周销售)与一组预测变量(如客户人口统计、购买模式、点击行为或已知的可能与给定结果相关的其他特征)之间的关系。很多时候,这些模型还可以用来预测未来行为,前提是模型找到的重要预测变量。机器学习扩展了许多常见的统计模型以适应大数据,它还包括探索数据的工具,除了预测之外,这些工具可以用于细分客户群或分组销售趋势。实现这些模型的常用软件语言有R和Python,使用这些高级工具来研究业务问题的专业人士通常被称为数据科学家,数据科学指的是他们为理解业务问题、创建预测模型或测试新的操作程序/营销活动而进行的工作。
监督学习算法包括学习结果和预测因子之间关系的机器学习模型,目标是理解给定结果的驱动因素或仅仅预测在一组预测因子下的未来结果。监督学习的一个缺点是必须观察结果,并且必须有足够的数据来训练模型。分类模型是用来理解群体之间如何不同的监督学习算法;例如,创建一个模型来理解买家广告点击行为和非买家广告点击行为的差异。回归模型(在监督学习中)处理连续或计数结果,例如建模购买数量或在给定月份的服务使用情况的驱动因素。无监督学习算法探索数据以理解预测因子或结果如何分组,类似于市场细分或数据趋势的可视化探索。
深度学习是一种类似于大脑中简单电路的人工神经网络,是一种常用于预测建模的监督学习算法,尤其适合处理大量记录的数据。与其他在几千条训练记录中性能稳定的模型不同,深度学习模型在提供越来越多的训练数据时会不断改进。然而,要实现良好的性能,深度学习需要大量的数据,而 5,000 或 10,000 条记录的训练样本可能不足以训练这种类型的监督学习算法。深度学习通常需要大量的专业知识来定制或从零开始构建,如果问题或数据复杂或数据量小,雇佣深度学习专家会很有帮助。

随机森林是一种当前在实践中非常常见的监督学习算法。该算法在分类和回归模型中表现良好,并且通过 map reduce 框架非常适合大数据。在其核心,这种方法包括一组基于数据样本建立的模型,这些模型被汇聚成一个最终模型。这有助于减少错误和在单个模型集合中的错误学习关系。
拓扑数据分析是一套相对较新的工具,主要用于无监督学习,在处理小数据样本、大量预测因子、缺失数据和数据捕捉错误方面具有良好特性。这些工具还提供了有助于简化结果和允许数据团队进一步探索发现的可视化方法(如下所示,用于突出显示不符合其他记录的记录)。这使它们成为无监督学习的理想选择,广泛应用于生物技术、医疗保健和教育等行业。

无论使用什么技术,对于与训练模型相关的数据的任何分析都有一些注意事项。抽样和偏倚是选择用于统计建模或机器学习的数据时两个重要的考虑因素。如果只选择来自新英格兰的客户数据进行分析,那么模型的结果可能无法推广到乔治亚州或德克萨斯州的客户;这是分析中的一种偏倚示例。抽样方法对于减少可能的偏倚以及解决可能导致不良结果的几个统计问题非常重要。过度分析,即使用过多的数据来测试组间差异或寻找数据中的关系,可能会暗示不存在的关系,因为模型在给定预测因子内寻找微小波动,而不是一个真实的关系。这在 A/B 测试营销活动中尤为重要。
几本优秀的书籍比这本指南更为详细,读者希望深入了解高管数据科学的内容,可以从这些精选资源中获取更多信息:
《执行数据科学》(作者:罗杰·彭)
《大数据的工作:揭开神话,发现机遇》(作者:托马斯·达文波特)
《跟上量化分析的步伐:理解和使用分析的指南》(作者:托马斯·达文波特和金志浩)
相关内容:
更多相关话题
使用机器学习寻找系外行星
原文:
www.kdnuggets.com/2020/01/exoplanet-hunting-machine-learning.html
评论 
来源: weheartit.com/entry/298477443
我们的三大推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作。
我们的太阳系大约在 46 亿年前形成。我们从陨石和放射性研究中得知这一点。一切始于一团气体和尘埃的云。附近的一次超新星爆炸可能扰动了这团平静的云,云开始因引力收缩,形成了一个扁平的旋转盘,大部分物质集中在中心:原恒星。随后,引力将其余的物质拉成块,并使其中一些块变圆,形成了行星和矮行星。剩余的物质形成了彗星、小行星和流星体。
但什么是系外行星?
系外行星是指在我们太阳系之外的行星。在过去的二十年里,已经发现了成千上万颗系外行星,主要是通过NASA 的开普勒太空望远镜。
这些系外行星有各种各样的大小和轨道。有些是巨大的行星,紧靠着它们的母星;有些是冰冷的,有些是岩石的。NASA 和其他机构正在寻找一种特殊的行星:一种与地球大小相同,围绕类似太阳的恒星在适居带内运行的行星。
适居带是指恒星周围的区域,在这个区域内,环境既不太热也不太冷,以至于液态水可以存在于周围行星的表面。想象一下,如果地球在冥王星的位置,太阳几乎看不见(大约只有豌豆的大小),地球的海洋和大部分大气将会冻结。
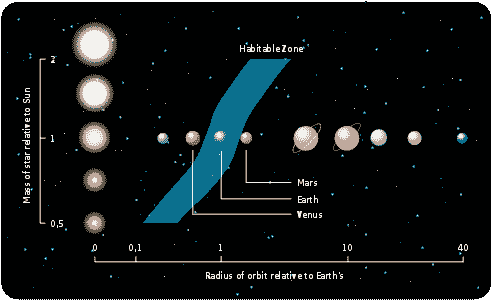
适居带。来源: www.e-education.psu.edu/astro801/content/l12_p4.html
系外行星是指在我们太阳系之外的行星。在过去的二十年里,已经发现了成千上万颗系外行星,主要是通过……
为什么要寻找系外行星?
我们银河系中大约有100,000,000,000颗恒星。我们预计会有多少外行星——太阳系之外的行星——存在?为什么有些恒星被行星环绕?行星系统有多种多样?这种多样性是否告诉我们一些关于行星形成过程的信息?这些都是驱动外行星研究的许多问题之一。一些外行星可能具备存在复杂有机化学的必要物理条件(恒星的光照强度和质量、温度、气氛组成),或许还适合生命的存在(这种生命可能与地球上的生命大相径庭)。
然而,检测外行星并非易事。尽管我们在书籍和电影中想象了其他行星上的生命几个世纪,但检测实际的外行星仍然是一个较新的现象。行星本身发出的光非常微弱,如果有的话。我们之所以能在夜空中看到木星或金星,是因为它们反射了太阳的光。如果我们观察一个外行星(最近的一个距离超过 4 光年),它将非常靠近一颗明亮的恒星,使得行星几乎无法被看见。
来源:media.giphy.com/media/YA2bZh31eFXi0/giphy.gif
科学家们发现了一种非常有效的研究这些现象的方法;行星本身不会发光,但围绕它们运行的恒星会发光。考虑到这一事实,NASA 的科学家们开发了一种被称为过境法(Transit method)的方法,其中使用类似数字相机的技术来检测和测量行星经过恒星前方时恒星亮度的微小下降。通过对过境行星的观察,天文学家可以计算出行星半径与恒星半径的比率——实际上是行星阴影的大小——通过这个比率,他们可以计算出行星的大小。
开普勒太空望远镜寻找行星的主要方法是“过境法”。
过境法:在下面的图示中,一颗恒星被一颗行星围绕。从图表中可以看出,由于行星在我们的位置上部分遮挡了恒星,恒星的光强度下降。当行星从恒星前方经过时,恒星的光强度会恢复到原来的值。
来源:gfycat.com/viciousthaticelandichorse
直到几年前,天文学家们只确认了不到一千个系外行星的存在。随后,开普勒任务启动了,系外行星的数量激增。开普勒任务于 2018 年遗憾地结束,但TESS任务 或称过境系外行星勘测卫星已经接替了它,并定期在夜空中发现新的系外行星。TESS 监测恒星的亮度,以检测因行星过境造成的周期性亮度下降。TESS 任务发现了从小型岩石世界到巨型行星的各种行星,展示了银河系中行星的多样性。
我想查看是否可以利用现有的系外行星数据来预测哪些行星可能适合生命。NASA 公开的数据非常美丽,因为它包含许多有用的特征。目标是创建一个模型,该模型可以利用来自 3198 颗不同恒星的通量(光强度)读数,预测系外行星的存在。
数据集可以从这里下载。
让我们开始导入所有库:
import os
import warnings
import math
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
from pylab import rcParams
rcParams['figure.figsize'] = 10, 6
from sklearn.metrics import mean_squared_error, mean_absolute_error
from imblearn.over_sampling import SMOTE
from sklearn.model_selection import train_test_split
from sklearn import linear_model
from sklearn.model_selection import cross_val_score
from sklearn.metrics import precision_score, recall_score,roc_curve,auc, f1_score, roc_auc_score,confusion_matrix, accuracy_score, classification_report
from sklearn.preprocessing import StandardScaler, normalize
from scipy import ndimage
import seaborn as sns
加载训练数据和测试数据。
test_data = pd.read_csv('/Users/nageshsinghchauhan/Downloads/ML/kaggle/exoplanet/exoTest.csv').fillna(0)
train_data = pd.read_csv('/Users/nageshsinghchauhan/Downloads/ML/kaggle/exoplanet/exoTrain.csv').fillna(0)train_data.head()

数据集
现在目标列LABEL包含两个类别1(不代表系外行星)和2(代表系外行星的存在)。因此,将它们转换为二进制值,以便于数据处理。
categ = {2: 1,1: 0}
train_data.LABEL = [categ[item] for item in train_data.LABEL]
test_data.LABEL = [categ[item] for item in test_data.LABEL]
在继续之前,让我们减少测试和训练数据帧所使用的内存。
#Reduce memory
def reduce_memory(df):
""" iterate through all the columns of a dataframe and modify the data type
to reduce memory usage.
"""
start_mem = df.memory_usage().sum() / 1024**2
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return dftest_data = reduce_memory(test_data)#Output
Memory usage of dataframe is 13.91 MB
Memory usage after optimization is: 6.25 MB
Decreased by 55.1%
这一步是为了内存优化,已将test_data数据帧的内存使用减少了 55.1%,你也可以对train_data数据帧进行相同的操作。
现在可视化训练数据集中的目标列,并了解类别分布情况。
plt.figure(figsize=(6,4))
colors = ["0", "1"]
sns.countplot('LABEL', data=train_data, palette=colors)
plt.title('Class Distributions \n (0: Not Exoplanet || 1: Exoplanet)', fontsize=14)
目标变量的类别分布。
结果显示数据严重不平衡。因此,让我们首先从数据预处理技术开始。
让我们绘制训练数据的前 4 行并观察通量值的强度。
from pylab import rcParams
rcParams['figure.figsize'] = 13, 8
plt.title('Distribution of flux values', fontsize=10)
plt.xlabel('Flux values')
plt.ylabel('Flux intensity')
plt.plot(train_data.iloc[0,])
plt.plot(train_data.iloc[1,])
plt.plot(train_data.iloc[2,])
plt.plot(train_data.iloc[3,])
plt.show()
我们的数据很干净,但尚未归一化。让我们绘制非系外行星数据的高斯直方图。
labels_1=[100,200,300]
for i in labels_1:
plt.hist(train_data.iloc[i,:], bins=200)
plt.title("Gaussian Histogram")
plt.xlabel("Flux values")
plt.show()
系外行星缺失
现在绘制系外行星存在时的数据的高斯直方图。
labels_1=[16,21,25]
for i in labels_1:
plt.hist(train_data.iloc[i,:], bins=200)
plt.title("Gaussian Histogram")
plt.xlabel("Flux values")
plt.show()
系外行星存在
因此,让我们首先拆分数据集并对其进行归一化。
x_train = train_data.drop(["LABEL"],axis=1)
y_train = train_data["LABEL"]
x_test = test_data.drop(["LABEL"],axis=1)
y_test = test_data["LABEL"]
数据标准化是一种在机器学习中常用于数据准备的技术。标准化的目标是将数据集中数值列的值调整到一个共同的尺度上,而不会扭曲值的范围之间的差异。
x_train = normalized = normalize(x_train)
x_test = normalize(x_test)
下一步是对测试集和训练集应用高斯滤波器。
在概率论中,正态(或高斯或高斯或拉普拉斯–高斯)分布是一种非常常见的连续概率分布。正态分布在统计学中很重要,通常用于自然科学和社会科学中表示分布未知的实值随机变量。
正态分布之所以有用,是因为中心极限定理。在其最一般的形式下,在一些条件下(包括有限方差),它表明,独立从同一分布中抽取的随机变量的观察值的样本平均值在分布上收敛于正态分布,即当观察值数量足够大时,它们变成正态分布。预计是许多独立过程之和的物理量通常具有近似正态的分布。
x_train = filtered = ndimage.filters.gaussian_filter(x_train, sigma=10)
x_test = ndimage.filters.gaussian_filter(x_test, sigma=10)
我们使用特征缩放,以便所有值保持在可比较的范围内。
#Feature scaling
std_scaler = StandardScaler()
x_train = scaled = std_scaler.fit_transform(x_train)
x_test = std_scaler.fit_transform(x_test)
我们处理的列/特征数量庞大。我们的训练数据集中有 5087 行和 3198 列。基本上,我们需要减少特征数量(维度减少),以去除维度诅咒的可能性。
为了减少维度/特征,我们将使用最流行的维度减少算法,即PCA(主成分分析)。
要执行 PCA,我们必须选择数据中希望保留的特征/维度数量。
#Dimentioanlity reduction
from sklearn.decomposition import PCA
pca = PCA()
X_train = pca.fit_transform(X_train)
X_test = pca.transform(X_test)
total=sum(pca.explained_variance_)
k=0
current_variance=0
while current_variance/total < 0.90:
current_variance += pca.explained_variance_[k]
k=k+1
上述代码给出k=37。
现在让我们取 k=37,并对我们的自变量应用 PCA。
#Apply PCA with n_componenets
pca = PCA(n_components=37)
x_train = pca.fit_transform(x_train)
x_test = pca.transform(x_test)
plt.figure()
plt.plot(np.cumsum(pca.explained_variance_ratio_))
plt.xlabel('Number of Components')
plt.ylabel('Variance (%)') #for each component
plt.title('Exoplanet Dataset Explained Variance')
plt.show()
上述图表告诉我们,选择 37 个组件可以保留数据总方差的约 98.8%或 99%。这是有道理的,我们不会使用 100%的方差,因为它表示所有组件,我们只需要主要的几个。

列数在测试集和训练集中都减少到 37。
现在进入下一步,我们知道目标类分布不均,一类主导另一类。因此,我们需要对数据进行重采样,以使目标类均匀分布。
解决这种类不平衡问题有 4 种方法:
-
合成新的少数类实例
-
对少数类进行过采样
-
对多数类进行欠采样
-
调整成本函数,使得对少数类实例的误分类比对多数类实例的误分类更重要。
#Resampling
print("Before OverSampling, counts of label '1': {}".format(sum(y_train==1)))
print("Before OverSampling, counts of label '0': {} \n".format(sum(y_train==0)))sm = SMOTE(random_state=27, ratio = 1.0)
x_train_res, y_train_res = sm.fit_sample(x_train, y_train.ravel())print("After OverSampling, counts of label '1': {}".format(sum(y_train_res==1)))
print("After OverSampling, counts of label '0': {}".format(sum(y_train_res==0)))
我们使用了SMOTE(合成少数类过采样技术)重采样方法。这是一种过采样方法。它的作用是创建少数类的合成(而非重复)样本,从而使少数类与多数类平衡。SMOTE 通过选择相似的记录并逐列随机调整该记录,以差异范围内的随机量来实现。
Before OverSampling, counts of label '1': 37
Before OverSampling, counts of label '0': 5050
After OverSampling, counts of label '1': 5050
After OverSampling, counts of label '0': 5050
现在我们要构建一个模型,能够在测试数据上对系外行星进行分类。
所以我将创建一个函数model,它将:
-
拟合模型
-
执行交叉验证
-
检查我们模型的准确性
-
生成分类报告
-
生成混淆矩阵
def model(classifier,dtrain_x,dtrain_y,dtest_x,dtest_y):
#fit the model
classifier.fit(dtrain_x,dtrain_y)
predictions = classifier.predict(dtest_x)
#Cross validation
accuracies = cross_val_score(estimator = classifier, X = x_train_res, y = y_train_res, cv = 5, n_jobs = -1)
mean = accuracies.mean()
variance = accuracies.std()
print("Accuracy mean: "+ str(mean))
print("Accuracy variance: "+ str(variance))
#Accuracy
print ("\naccuracy_score :",accuracy_score(dtest_y,predictions))
#Classification report
print ("\nclassification report :\n",(classification_report(dtest_y,predictions)))
#Confusion matrix
plt.figure(figsize=(13,10))
plt.subplot(221)
sns.heatmap(confusion_matrix(dtest_y,predictions),annot=True,cmap="viridis",fmt = "d",linecolor="k",linewidths=3)
plt.title("CONFUSION MATRIX",fontsize=20)
始终需要验证机器学习模型的稳定性。我是说,你不能仅仅将模型拟合到训练数据上,然后希望它在从未见过的真实数据上也能准确工作。你需要某种保证,确保模型从数据中提取了大部分模式,而且不会过多地受到噪声的影响,换句话说,它在偏差和方差上都很低。
现在将支持向量机(SVM)算法拟合到训练集,并进行预测。
from sklearn.svm import SVC
SVM_model=SVC()
model(SVM_model,x_train_res,y_train_res,x_test,y_test)
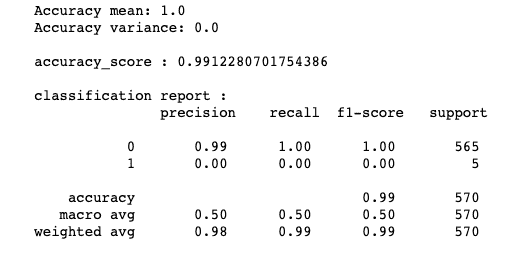
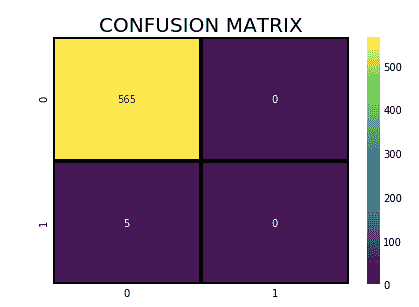
另外,尝试随机森林模型并获取特征重要性,但在此之前请在函数模型中包含以下代码。
#Display feature importance
df1 = pd.DataFrame.from_records(dtrain_x)
tmp = pd.DataFrame({'Feature': df1.columns, 'Feature importance': classifier.feature_importances_})
tmp = tmp.sort_values(by='Feature importance',ascending=False)
plt.figure(figsize = (7,4))
plt.title('Features importance',fontsize=14)
s = sns.barplot(x='Feature',y='Feature importance',data=tmp)
s.set_xticklabels(s.get_xticklabels(),rotation=90)
plt.show()
并调用随机森林分类算法。
from sklearn.ensemble import RandomForestClassifier
rf_classifier = RandomForestClassifier()
model(rf_classifier,x_train_res,y_train_res,x_test,y_test)
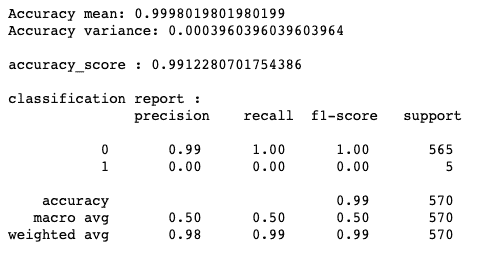
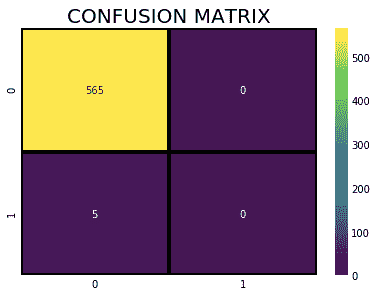
通常,特征重要性提供一个分数,表明每个特征在模型构建中的有用性或价值。属性在决策树中用于做关键决策的次数越多,它的相对重要性就越高。
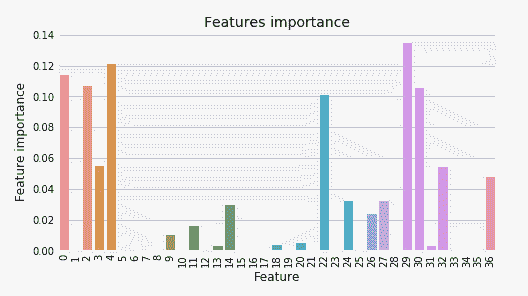
我们可以看到,我们从 SVM 和随机森林算法中得到了相当不错的结果。不过,你可以继续调整参数,并尝试其他算法,查看准确性的差异。
现在让我们尝试使用 Keras Python 库中的神经网络(ANN)解决相同的问题。
from tensorflow import set_random_seed
set_random_seed(101)
from sklearn.model_selection import cross_val_score
from keras.wrappers.scikit_learn import KerasClassifier
from keras.models import Sequential # initialize neural network library
from keras.layers import Dense # build our layers library
def build_classifier():
classifier = Sequential() # initialize neural network
classifier.add(Dense(units = 4, kernel_initializer = 'uniform', activation = 'relu', input_dim = x_train_res.shape[1]))
classifier.add(Dense(units = 4, kernel_initializer = 'uniform', activation = 'relu'))
classifier.add(Dense(units = 1, kernel_initializer = 'uniform', activation = 'sigmoid'))
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
return classifierclassifier = KerasClassifier(build_fn = build_classifier, epochs = 40)
accuracies = cross_val_score(estimator = classifier, X = x_train_res, y = y_train_res, cv = 5, n_jobs = -1)
mean = accuracies.mean()
variance = accuracies.std()
print("Accuracy mean: "+ str(mean))
print("Accuracy variance: "+ str(variance))#Accuracy mean: 0.9186138613861387
#Accuracy variance: 0.07308084375906461
神经网络模型的准确率均值为 91.86%
在交叉验证后,准确性方差为 7.30%,这是一个相当不错的结果。
结论:未来
我们能够收集来自遥远星星的光,研究这些光,这些光已经旅行了数千年,并对这些星星可能拥有的潜在世界做出结论,这真是令人惊叹。
在接下来的 10 年内,将有 30 到 40 米直径的望远镜从地球上运作,通过成像和恒星的速度变化来探测系外行星。包括 Cheops、JWST、Plato 和 Ariel 在内的卫星望远镜将通过凌日法探测行星。JWST 还将进行直接成像。NASA 正在设计直径为 8 到 18 米的大型空间望远镜(LUVOIR、Habex),计划在 2050 年前探测系外行星上的生命迹象。
在更远的未来,巨大的干涉仪将制作行星的详细地图。而且,可能会发射星际探测器前往最近的系外行星拍摄近距离图像。工程师们已经在研究推进技术,以达到这些遥远的目标。
所以在这篇文章中,我们使用机器学习模型和神经网络预测了系外行星的存在。
好了,以上就是这篇文章的所有内容,希望你们阅读愉快。如果这篇文章对你有所帮助,我会很高兴。欢迎在评论区分享你的意见/想法/反馈。

你可以在我的Github 仓库中找到代码:
感谢阅读!!!
个人简介:纳戈什·辛格·乔汉 是一位数据科学爱好者。对大数据、Python、机器学习感兴趣。
原文。经许可转载。
相关内容:
-
通过时间序列分析进行股票市场预测
-
使用 5 种机器学习算法分类稀有事件
-
利用开放数据进行地理可视化
更多相关内容
2023 年 AI 质量趋势展望
原文:
www.kdnuggets.com/2022/11/expect-ai-quality-trends-2023.html

图片由Pavel Danilyuk提供
2022 年是人工智能的一个分水岭年,因为质量相关的问题成为了焦点。欧盟、亚洲和美国的法规也相继出台,我们看到像 Zillow 这样的公司因 AI 模型质量问题而受挫。
根据我最近与数十个财富 500 强数据科学团队的讨论,我预计 2023 年将继续关注 AI 模型质量。以下是我关注的六个领域。
迈向更正式的 AI 模型测试和监控程序
类似于 20 年前的软件开发,直到测试和监控变得普及,企业软件的使用才真正起飞。AI 正处于类似的拐点。AI 和机器学习技术的采纳速度很快,但质量参差不齐。通常,开发模型的数据科学家也会手动测试模型,这可能导致盲点。测试是手动的且缓慢,监控是初期的且临时的。AI 模型质量高度可变,成为成功采用 AI 的一个关键因素。自动化测试和监控提供质量保证,降低不确定性和风险。
AI 模型的可解释性依然热门
随着 AI 在日常生活中变得越来越重要,更多的人希望准确了解模型的工作原理。这是由需要信任所使用模型的内部利益相关者、受到模型决策影响的消费者和希望确保消费者受到公平对待的监管者推动的。
关于 AI 和偏见的讨论越来越多。AI 是公平的朋友还是敌人?
在 2021 年和 2022 年,人们担心 AI 会导致偏见,例如由于训练数据不良。在 2023 年,我认为我们会逐渐意识到 AI 可以通过绕过历史上产生偏见的环节来帮助消除偏见。人们通常比机器更有偏见,我们开始看到 AI 可以减少偏见而不是引入它的方法。
更多类似 Zillow 的灾难
在测试和监控成为标准实践之前,企业将继续面临质量相关的问题,例如Zillow在其购房部门遇到的(过时的模型导致公司以虚高价格过度购买,最终导致该部门关闭、巨额损失和裁员)。我预计 2023 年会有更多的公关灾难,这些本可以通过更好的 AI 模型质量方法来避免。
数据科学领域的新漏洞
近年来,数据科学家严重短缺,幸运拥有他们的公司视其如金。然而,随着 AI 投资回报难以证明的趋势持续,以及经济放缓,企业对结果的要求变得更严格。现在只有 1/10 的模型能够进入生产使用是很常见的。那些无法更快将模型投入生产的数据科学团队将面临压力。这些职位可能不会永远安全。
美国对 AI 使用的正式监管
美国的监管机构一直在研究 AI 的挑战和影响,但尚未做出重大举措,与欧盟委员会不同。我预计这一点在 2023 年会有所改变,美国将最终起草自己的联邦级别规则,类似于欧盟和亚洲已经生效的规则。市场中的护栏对每个人都有好处,并将最终帮助建立对 AI 的信任。美国的法规不会太遥远,企业应做好准备。最近发布的白宫AI 权利蓝图是朝着正确方向迈出的一步,为负责任的 AI 开发和使用提供了框架。
结论
AI 仍然是技术领域中发展最快的领域之一——但在许多方面,其承诺尚未实现。更强的质量关注将推动 AI 的采纳,并帮助公司实现其不断增长的 AI 投资的回报。
Anupam Datta是TruEra的联合创始人、总裁兼首席科学家(之前称为 AILens)。他在卡内基梅隆大学担任教职 15 年,最近担任负责任系统实验室的教授和主任。他的研究重点是使用机器学习和其他统计及人工智能方法的负责任数据驱动系统。Datta 的工作涉及隐私、公平、合规性和安全性的多个其他方面。Datta 获得了斯坦福大学的博士学位(2005 年)和硕士学位(2002 年),以及印度理工学院卡拉格普尔分校的学士学位(2000 年),均为计算机科学专业。
更多相关内容
作为数据科学家的职业路径的预期
原文:
www.kdnuggets.com/2022/01/expect-career-path-data-scientist.html
数据科学是一个令人兴奋的领域。在应用和就业机会方面,它的可能性正在扩展。无论你是考虑进入这一领域,已经拥有你的第一份数据科学工作,还是已经在这领域工作了几年,以下是当你期望继续留在数据科学领域时的概述。
就像大多数职业路径一样,高级别所需的技能建立在低级别技能的基础上。查看你当前级别之上所需的技能和任务是个好主意。通过在工作中寻找机会来发展这些技能,当你争取下一个晋升机会时,你可以展示你的价值。
直接上下相邻职位之间存在相当大的重叠。当我在数据科学领域工作时,我的高级同事的工作与我的工作差别不大,但他们处理的项目要复杂得多。我们的老板则处于另一个层级,管理链越高,你被要求或有机会从事技术工作的可能性就越小,比如实现模型。这一模式在很多技术领域都是如此,数据科学也不例外。
只要你仍然是个体贡献者(IC),你可以期待继续直接处理数据和模型。然而,一旦你开始管理他人,就要做好换帽子的准备。你将不得不更多地与人互动——包括汇报给你的人和合作团队或客户。数据科学的一个重要部分是将业务目标或需求转化为数据驱动的洞察,因此你必须与业务方面的不同团队进行交流,以理解问题。
每家公司都有自己划分级别的方式。这是基于多个公司数据科学职业路径的汇总粗略指南,但你工作的公司或你申请的公司可能会有所不同。
让我们深入探讨一下data scientist 职业路径的不同步骤。
1. 数据科学助理
对于这个职位,你要么刚从大学毕业,要么刚刚进入数据科学领域。大多数数据科学助理职位要求的经验较少,但如果你通过实习或副项目获得了实际经验,你将有优势。
获取职位所需技能
数据科学助理必须能够识别数据来源并结合或汇总数据。你可能会为你的资深同事做这种基础工作。你还需要进行数据预处理。一些数据科学公司可能会期望你制定流程来清理、整合和评估来自不同来源的大数据集。
此外,数据科学助理还需开发预测模型并通过数据可视化展示其发现。你应该对统计学和机器学习有相当的舒适度,包括理论和实践。
作为数据科学家,了解背景领域是一个重要部分。如果这是一个纯技术公司,这可能不是必需的,但如果你在分析道路的磨损数据,你应该尽可能多地了解物理基础设施,以更好地理解数据和你的发现。
你可能会被分配的项目
作为数据科学助理,你的公司可能会要求你完成各种基础数据科学任务。这可能包括在数据库中挖掘和分析现有数据。你还可能会实现算法以最大化数据提取,或设计工具以跟踪和分析项目或模型的表现。
你的主要任务将是组织和使用预测模型来生成洞察。
职位目标
要掌握这个职位,专注于学习该行业的工具和技术。你应该掌握你所开发的每一种模型。你还应该了解公司的工具栈,因为一个了解自己周围工具的数据科学家比一个不了解工具的数据科学家要高效得多。
好消息是,你正处于起步阶段。你可以期待从上级那里获得支持和指导,所以当你需要帮助时,一定要主动寻求。
2. 数据科学经理(IC)
数据科学经理仍然是一个个体贡献者。该职位要求有一到三年的相关经验。
获取职位所需技能
对于这份工作,准备好在动脑的同时也要开口说话。你需要优秀的沟通技能,因为你将更多地与他人合作,以完成更复杂的项目和收集需求。
你能够简洁明了地向非技术人员传达发现和提出建议至关重要。你将与团队外的人员有更多的互动。你需要解释你的结果与他们的情况的相关性,以及你的发现应如何影响解决方案。
从技术角度看,你需要实施预测模型。作为数据科学团队的高级成员,要准备在团队内及公司整体推动自动化项目。你还需要推动技术创新。考虑公司使用的工具栈,看看是否有需要更换或添加的元素。
你需要拥有构建各种机器学习模型的丰富经验。你将负责更大、更复杂的项目,并且需要在较少的上司或团队成员监督下,决定哪些模型最适合特定情况。
你可能会被分配的项目
作为数据科学经理,你可能会与市场营销团队合作制定实验。数据科学经理还需向高层管理人员展示发现,无论是以报告还是演示的形式。
你可能还需要验证测试数据的代表性、偏见等。除了实施模型外,如果你在做数据科学产品,你可能还会被要求开发解决方案原型。即便该产品并不专注于数据科学,你仍可能会在内部产品化预测管道。
职位目标
该职位的目标都是为了扩展你作为数据科学助理所发展出的技能,并发展新的技能以扩大你的影响力。你需要理解如何使用工具和处理数据。你还应该提升你的利益相关者管理技能,包括了解他们的目标、关切和困惑。准备主动解决他们的问题,并提供解决方案。
你可能仍然需要一些帮助,但你应该变得越来越独立。
3. 数据科学高级经理(IC)
数据科学高级经理应有大约四到五年的经验。在这一阶段,你仍然是 IC,并且没有直接下属。
获得这份工作的技能要求
数据科学高级经理应能利用各种机器学习模型和统计技术。你需要找到并评估新颖的数据集。
准备从混乱的数据中提取洞察,如来自多语言的数据、未标记的数据等。你还需要领导生产环境中机器管道的部署和维护,这意味着你已经掌握了数据科学的开发运维,并能熟练执行这一任务。
你可能会被分配的项目
作为数据科学高级经理,你应该在分析框架、代码、数据共享等方面提供思想领导。你需要为你的团队和合作团队担任技术数据科学大师的角色。
你还将与研究、营销和产品团队建立并维护密切的关系,以便将分析工作与业务目标对齐。
你将根据需要将深度学习、监督学习和/或无监督学习的深入知识应用于复杂的数据集。你还需要与数据工程师和平台架构师合作,以“实施强大的生产实时和批量决策解决方案”,这符合一些苹果公司开放的职位。
职位目标
高级数据科学经理实际上是完全独立的。你将为团队中的初级成员提供技术建议,并帮助他们在与合作团队的场景中进行导航。
你应该能够管理利益相关者、他们的期望、需求、时间表和问题。你将需要在最小的监督下管理整个项目。你负责的项目将变得越来越复杂,并且可能缺乏明确的解决方案。
4a. 员工/首席数据科学工程师(IC)
一名员工或首席数据科学工程师通常有五到十年的经验。这个角色是个体贡献者,因此尽管你非常有经验并且是真正的数据科学专家,但你不负责管理其他人员。
岗位所需技能
这不是你的第一次挑战。首席数据科学家可以将模糊的想法或直觉转化为明确的、数值化的洞察,推动公司改进和利润增长。在实现模型、构建管道和分析数据方面,你绝对是个天才。
你有将本地模型转化为实时数据科学管道的经验,这些管道扩展了你模型对多个团队或产品组的功能和价值。
尽管没有任何技术报告,你仍然渴望指导你团队中的初级成员。
你可能被分配的项目
作为首席数据科学家,你被认为是技术最为娴熟的数据科学家之一。你将面临一些最复杂的问题,并且需要开展实验性项目,构建和维护用于模型部署和持续操作的各种管道。
你应该交付更准确、更精简的管道,这些管道能够更好地产品化。你的数据提取技能无与伦比,使你能够从数据中获得比初级数据科学家更多的洞察。
职位目标
作为首席数据科学工程师,你需要在没有监督的情况下承担复杂的项目。你负责产品路线图。首席数据科学工程师通过将数据科学原则应用于未开发的领域或倡导自动化艺术,来发现提升团队或部门能力的机会。
你的主要工作是影响解决方案及其路线图。你将会有许多不同的利益相关者,来自不同的部门,因此请做好准备优雅地处理他们相互竞争的优先事项和要求。
你可能最近不怎么写代码,但你仍然会审查你团队的很多代码。
4b. 数据科学总监/组经理
数据科学总监或组经理通常有五到十年的经验,但与前面列出的所有角色不同,组经理通常有大约 4 名下属。报告给你的团队的确切规模将很大程度上取决于你的部门和你工作的公司。
获取该职位所需的技能
作为数据科学总监,你需要在数据科学的大多数领域拥有广泛的知识和经验。你应该对大数据工具(如 Spark、Hive 等)非常熟悉。
作为数据科学总监,你还应该能够“理解和调试跨工具链和团队的复杂系统集成”。你可以熟练地识别数据模式背后的故事,并将分析洞察提炼成简洁、以业务为中心的要点。
整个团队都仰望你,因此你的技能和知识应该使你成为一个全面的技术专家,并支持你的团队。
你可能会被分配的项目
数据科学总监与业务团队合作,识别机会,逐步确定需求,并从团队中提出技术解决方案。如果你是雇主,你必须吸引和指导顶尖人才,因为数据科学家的就业市场竞争激烈。
你需要在部门层面定义和优化数据科学战略。这涉及到许多不同的方面,因此你需要有一个可以在详细层面上贯彻的大局观。
你可能需要通过证明公司在遵循数据科学建议后所享受的好处,为公司带来(财务)收益。准备好为你的团队的价值辩护或解释为什么需要扩展。
职位目标
你有直接下属,你需要管理和发展他们。你的工作是指导你的下属并帮助他们完成工作。你需要引导他们找到解决问题的方案,而不是直接解决问题。你本质上需要教他们如何完成工作,而不是替他们做。
你需要合理配置团队的资源,这意味着你帮助优先排序工作并将工作分配给团队成员。你将帮助填补人员休假期间的空缺,并正确跟踪和配置所有工作,以满足合作团队的期望和时间表。
5. 数据科学高级总监/副总裁
在你职业生涯的这个阶段,你应该有 10 年以上的经验。你将负责管理一个部门或多个部门。
获得职位所需的技能
你需要有多年管理他人的经验。这些经验应使你在深度技术指导和辅导方面得以磨练。
你需要有丰富的数据科学模型的个人经验,并且有构建可扩展数据管道的经验。
作为一个部门负责人,你需要在跨职能的协作环境中茁壮成长。你还需要在做出影响整个产品线或公司战略的决策时,将客户需求和行为放在心中最前面。
你可能被分配的项目
你将作为建模和数据科学的主题专家,技术指导其他数据科学家。作为公司内部数据科学的倡导者,你需要与合作的工程团队一起推动数据科学和自动化解决方案的集成,使其遍及公司各个产品。 Wayfair期望他们的数据科学高级总监“理解、构建和转化复杂的业务问题为适合机器学习解决方案的分析问题。”
数据科学高级总监负责路线图、规划和交付团队和部门的整个机器学习产品组合。你需要与多个部门的产品负责人协作,以确保数据科学解决方案和效益在公司范围内得到最大化。
作为高级领导团队的成员,你必须将数据科学视角带入董事会,以推动业务的成功。你应该把数据科学应用到公司所有可能受益的角落。
职位目标
作为高级总监,你是管理者的管理者。你需要对部门未来的发展有一个愿景,并指导直接向你汇报的经理执行这一愿景。你将更关注公司的整体表现,并应经常考虑你的团队如何能帮助公司取得成功。
数据科学职业道路的最终思考
在公司中,重要的是你始终关注将数据科学应用到新领域(这是高级角色所需的,也是突出自己在初级角色中的好方法)。如果你愿意,你可能总是能继续编码,因此要考虑你是否希望作为经理或个人贡献者晋升。数据科学团队通常很小,除非他们在开发数据科学产品,所以你不必将所有时间都花在管理上。
通常保持关注数据科学的“前沿”是好的。保持相关性,并考虑新技术、工具或解决方案是否能对你的团队有益。数据科学家很难找到,所以如果你的职业发展速度不如你所愿,或者你没有参与你希望的项目,考虑向老板解释或申请其他职位。
专注于你上面的职位,并寻找机会发展和展示你的 数据科学技能。
Nate Rosidi 是一位数据科学家,专注于产品策略。他还是一位副教授,教授分析课程,并且是 StrataScratch 的创始人,该平台帮助数据科学家准备来自顶尖公司的真实面试问题。可以通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
更多相关话题
关于开发安全、可靠和值得信赖的 AI 框架的专家见解
原文:
www.kdnuggets.com/expert-insights-on-developing-safe-secure-and-trustworthy-ai-frameworks
作者:查尔斯·瓦德曼博士、克里斯托弗·斯威特博士和保罗·布伦纳博士
与拜登总统最近发布的 行政命令 强调安全、可靠和值得信赖的 AI 一致,我们分享了两年研究项目中的 可信 AI (TAI) 经验教训。这个研究计划,如下图所示,专注于使 AI 符合严格的伦理和性能标准。这与行业日益增长的透明度和责任趋势相一致,尤其是在国家安全等敏感领域。本文反映了从传统软件工程到信任至关重要的 AI 方法的转变。
TAI 维度应用于 ML 流水线和 AI 开发周期
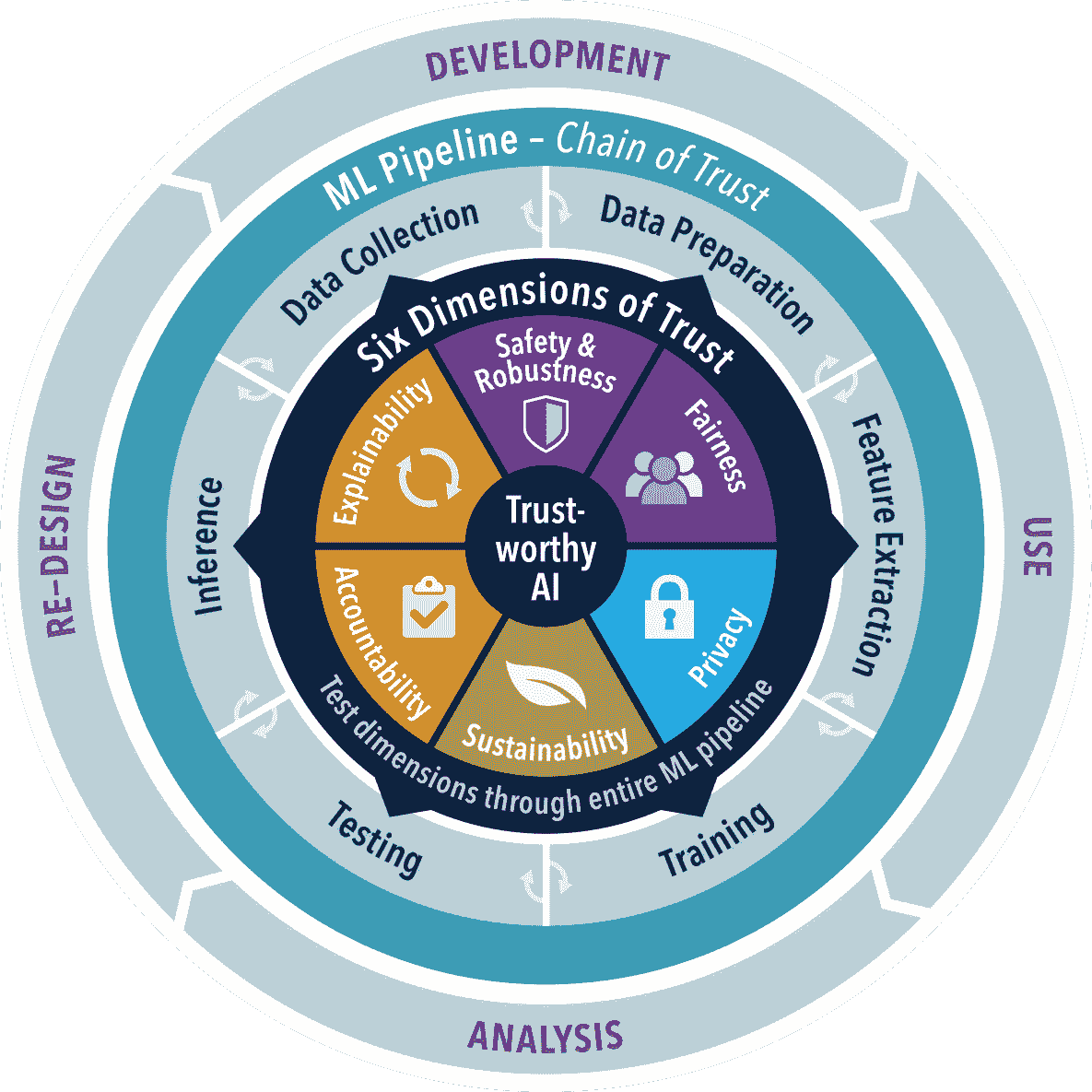
从软件工程过渡到 AI 工程
从“软件 1.0 到 2.0 以及 3.0 的概念”的过渡需要一个可靠的基础设施,这不仅能够概念化,还能实际执行对 AI 的信任。即使是下图所示的简单 ML 组件集,也展示了必须理解的重大复杂性,以解决每个层级的信任问题。我们的 TAI 框架子项目通过提供软件和 TAI 研究产品的最佳实践的集成点,来满足这一需求。像这样的框架降低了 TAI 实施的障碍。通过自动化设置,开发人员和决策者可以将精力集中在创新和战略上,而不是处理初步复杂性。这确保了信任不是事后的考虑,而是先决条件,每个阶段从数据管理到模型部署都与伦理和操作标准本质上对齐。最终结果是一个简化的路径,能够部署在技术上先进但在战略上可靠的高风险环境中的 AI 系统。TAI 框架项目调查和利用现有的软件工具和最佳实践,这些工具和最佳实践具有开源、可持续的社区,并且可以直接在现有操作环境中利用。
示例 AI 框架组件及其利用
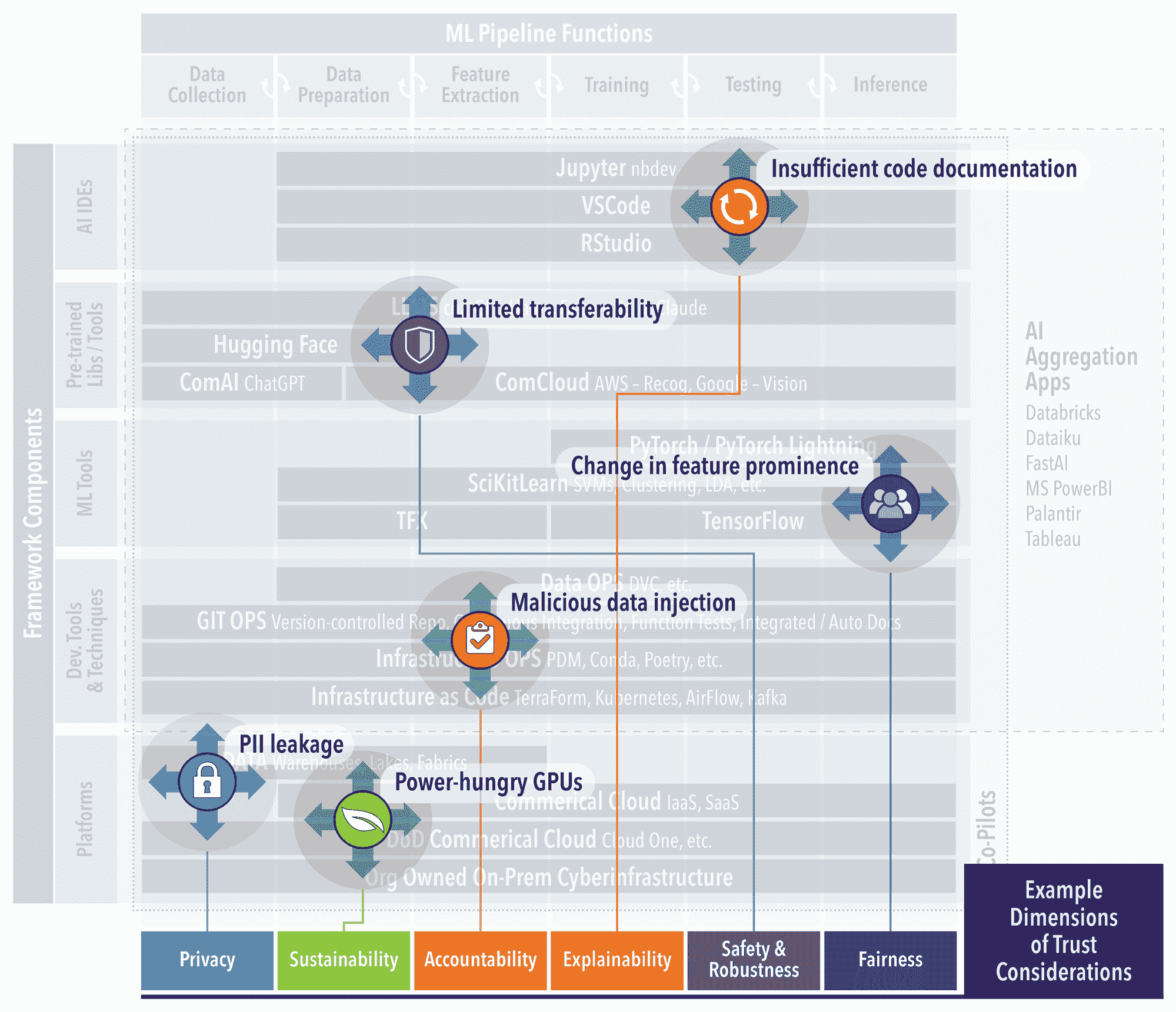
GitOps 和 CI/CD
GitOps 已经成为 AI 工程中不可或缺的一部分,特别是在 TAI 框架下。它代表了软件开发和运维工作流管理的一种进化,提供了一种声明式的方法来进行基础设施和应用生命周期管理。这种方法对于确保持续的质量和将伦理责任融入 AI 系统至关重要。TAI 框架项目利用 GitOps 作为自动化和简化开发管道的基础组件,从代码到部署。这种方法确保了软件工程的最佳实践能够自动遵循,从而实现不可变的审计跟踪、版本控制的环境和无缝的回滚能力。它简化了复杂的部署过程。此外,GitOps 通过提供一个可以将伦理检查自动化作为 CI/CD 管道一部分的结构,促进了伦理考虑的整合。CI/CD 在 AI 开发中的采用不仅仅是为了保持代码质量;它还确保 AI 系统的可靠性、安全性以及符合预期的性能。TAI 推广了自动化测试协议,以应对 AI 的独特挑战,特别是当我们进入生成 AI 和基于提示的系统时代时。测试不再仅仅局限于静态代码分析和单元测试。它扩展到 AI 行为的动态验证,包括生成模型的输出和提示的有效性。自动化测试套件现在必须能够评估响应的准确性、相关性和安全性。
数据驱动和文档化
在追求 TAI 的过程中,数据驱动的方法是基础,因为它优先考虑数据的质量和清晰度,而不是算法的复杂性,从而从根本上建立信任和可解释性。在这个框架下,有一系列工具可用于维护数据完整性和可追溯性。dvc(数据版本控制)因其与 GitOps 框架的契合而受到特别青睐,增强了 Git 以涵盖数据和实验管理(更多替代方案见这里)。它为数据集和模型提供了精确的版本控制,就像 Git 对代码所做的那样,这对有效的 CI/CD 实践至关重要。这确保了为 AI 系统提供动力的数据引擎始终接收准确且可审计的数据,这是值得信赖的 AI 的先决条件。我们利用 nbdev,它通过将 Jupyter Notebooks 转变为一种文献编程和探索编程的媒介,来补充 dvc,简化了从探索性分析到良好文档化代码的过渡。软件开发的性质正在演变为这种“编程”风格,并且 AI “副驾驶”的发展加速了这种演变,帮助文档编制和 AI 应用程序的构建。软件材料清单(SBoMs)和 AI BoMs,由像 SPDX 这样的开放标准倡导,是这一生态系统的核心部分。它们作为详细记录,补充 dvc 和 nbdev,涵盖了 AI 模型的来源、组成和合规性。SBoMs 提供了组件的全面清单,确保 AI 系统中的每个元素都被记录和验证。AI BoMs 扩展了这一概念,包括数据来源和转换过程,为 AI 应用程序中的模型和数据提供了透明度。它们共同构成了 AI 系统的完整谱系,促进了信任并帮助利益相关者理解。
TAI 命令
以伦理和数据为中心的方法对 TAI 至关重要,确保 AI 系统既有效又可靠。我们的 TAI 框架项目利用 dvc 进行数据版本控制,利用 nbdev 进行文献编程,反映了软件工程中适应 AI 细微差别的转变。这些工具象征着一种更大的趋势,即从 AI 开发过程的开始就整合数据质量、透明度和伦理考虑。在民用和国防领域,TAI 的原则保持不变:一个系统的可靠性取决于其建立的数据和所遵循的伦理框架。随着 AI 复杂性的增加,对能够透明和伦理地处理这种复杂性的稳健框架的需求也在增加。AI 的未来,特别是在关键任务应用中,将依赖于这些以数据为中心和伦理的方法,从而巩固各领域对 AI 系统的信任。
关于作者
Charles Vardeman、Christopher Sweet 和 Paul Brenner 是 圣母大学研究计算中心 的研究科学家。他们在科学软件和算法开发方面拥有数十年的经验,专注于将技术转移到产品操作中的应用研究。他们在数据科学和网络基础设施领域拥有大量的技术论文、专利和资助的研究活动。与学生研究项目对齐的每周 TAI 知识点可以在 这里 找到。
Charles Vardeman 博士**** 是圣母大学研究计算中心的研究科学家。
了解更多相关主题
企鹅咖啡乐团的 NLP 洞察
赞助帖子。
由 Laura Gorrieri 提供,expert.ai
请在此处找到此线程的笔记本版本。
让我们构建一个小应用程序来调查我最喜欢的艺术家之一。他们叫做"企鹅咖啡乐团",如果你不认识他们,你将会了解他们的风格。
我们的数据集:我从 Piero Scaruffi 的网站上获取的他们专辑评论列表,并保存在一个专门的文件夹中。
我们的目标:通过专辑评论更深入地了解一位艺术家。
我们的实际目标:查看 expert.ai 的 NL API 如何工作及其功能。
企鹅咖啡乐团的音乐是什么?
首先,让我们看看从评论中分析的词汇会得出什么。我们将首先将所有评论连接成一个变量,以获得完整的艺术家评论。然后我们将查看其中最常出现的词,希望这能揭示更多关于企鹅咖啡乐团的信息。
*## Code for iterating on the artist's folder and concatenate albums' reviews in one single artist's review*
import os
artist_review = ''
artist_path = 'penguin_cafe_orchestra'
albums = os.listdir(artist_path)
for album in albums:
album_path = os.path.join(artist_path, album)
with open(album_path, 'r', encoding = 'utf8') as file:
review = file.read()
artist_review += review
通过浅层语言学方法,我们可以调查包含所有可用评论的艺术家评论。为此,我们使用 matplotlib 和 word cloud 生成一个词云,以告诉我们文本中最常见的词汇。
# 导入包
import matplotlib.pyplot as plt
%matplotlib inline
*# Define a function to plot word cloud*
def plot_cloud(wordcloud):
*# Set figure size*
plt.figure(figsize=(30, 10))
*# Display image*
plt.imshow(wordcloud)
*# No axis details*
plt.axis("off");
*# Import package*
from wordcloud import WordCloud, STOPWORDS
*# Generate word cloud*
wordcloud = WordCloud(width = 3000, height = 2000, random_state=1, background_color='white', collocations=False, stopwords = STOPWORDS).generate(artist_review)
*# Plot*
plot_cloud(wordcloud)
图 1:一个词云,其中使用频率最高的词以较大的字体显示,而使用频率较低的词则以较小的字体显示。
他们的音乐让你感觉如何?
通过词云,我们对企鹅咖啡乐团有了更多了解。我们知道他们使用了如尤克里里、钢琴和小提琴等乐器,并且他们混合了民谣、民族和古典等多种风格。
尽管如此,我们对艺术家的风格仍然一无所知。我们可以通过查看他们作品中表现出的情感来了解更多。
为此,我们将使用 expert.ai 的 NL API。请在此处注册,查找 SDK 文档此处以及功能文档此处。
### 安装 Python SDK
!pip install expertai-nlapi
*## Code for initializing the client and then use the emotional-traits taxonomy*
import os
from expertai.nlapi.cloud.client import ExpertAiClient
client = ExpertAiClient()
os.environ["EAI_USERNAME"] = 'your_username'
os.environ["EAI_PASSWORD"] = 'your_password'
emotions =[]
weights = []
output = client.classification(body={"document": {"text": artist_review}}, params={'taxonomy': 'emotional-traits', 'language': 'en'})
for category in output.categories:
emotion = category.label
weight = category.frequency
emotions.append(emotion)
weights.append(weight)
print(emotions)
print(weights)
**['幸福', '兴奋', '喜悦', '娱乐', '爱']
[15.86, 31.73, 15.86, 31.73, 4.76]**
为了检索权重,我们使用了“频率”,实际上这是一个百分比。所有频率的总和是 100\。这使得情感频率成为饼图的良好候选项,该饼图使用 matplotlib 绘制。
# 导入库
from matplotlib import pyplot as plt
import numpy as np
*# Creating plot*
colors = ['#0081a7','#2a9d8f','#e9c46a','#f4a261', '#e76f51']
fig = plt.figure(figsize =(10, 7))
plt.pie(weights, labels = emotions, colors=colors, autopct='%1.1f%%')
*# show plot*
plt.show()
图 2:一个饼图,展示每种情感及其百分比。
他们的最佳专辑是什么?
如果你想开始聆听他们的作品,看看是否与你感受到的情感一致,你该从哪里开始?我们可以查看每张专辑的情感分析,了解它们的最佳专辑。为此,我们迭代每张专辑的评论,并使用 expert.ai NL API 获取其情感及强度。
## 迭代每张专辑并获取情感的代码
sentiment_ratings = []
albums_names = [album[:-4] for album in albums]
for album in albums:
album_path = os.path.join(artist_path, album)
with open(album_path, 'r', encoding = 'utf8') as file:
review = file.read()
output = client.specific_resource_analysis(
body={"document": {"text": review}}, params={'language': 'en', 'resource': 'sentiment' })
sentiment = output.sentiment.overall sentiment_ratings.append(sentiment)
print(albums_names)
print(sentiment_ratings)
['从家中广播', '音乐会节目', '企鹅咖啡馆的音乐', '生命的迹象']
[11.6, 2.7, 10.89, 3.9]**
现在我们可以使用柱状图可视化每条评论的情感。这将快速提供对企鹅咖啡馆管弦乐队最佳专辑和他们职业生涯的视觉反馈。为此,我们再次使用 matplotlib。
import matplotlib.pyplot as plt
plt.style.use('ggplot')
albums_names = [name[:-4] for name in albums]
plt.bar(albums_names, sentiment_ratings, color='#70A0AF') plt.ylabel("Album rating")
plt.title("Ratings of Penguin Cafe Orchestra's album")
plt.xticks(albums_names, rotation=70)
plt.show()
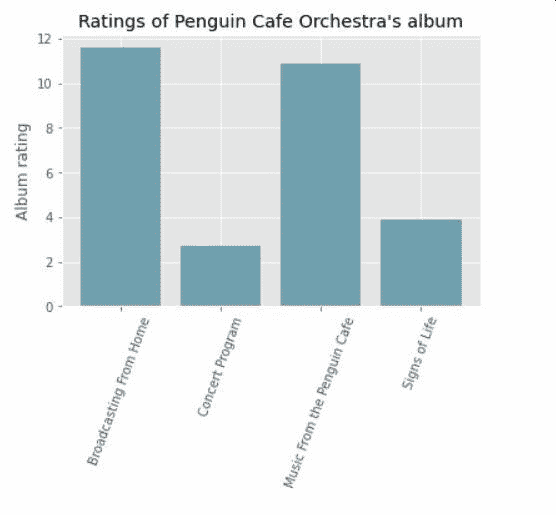
最初发布于 这里。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
更多相关话题
如何在面试中解释关键机器学习算法
原文:
www.kdnuggets.com/2020/10/explain-machine-learning-algorithms-interview.html
评论

由katemangostar创建。
线性回归
线性回归涉及找到一个“最佳拟合线”,该线使用最小二乘法来表示数据集。最小二乘法涉及找到一个线性方程,以最小化平方残差的总和。残差等于实际值减去预测值。
举个例子,红线是比绿线更好的最佳拟合线,因为它更接近数据点,因此残差更小。
图像由作者创建。
岭回归
岭回归,也称为 L2 正则化,是一种回归技术,通过引入少量的偏差来减少过拟合。它通过最小化平方残差的总和加上一个惩罚来实现,其中惩罚等于λ乘以斜率的平方。λ指的是惩罚的严重程度。
图像由作者创建。
如果没有惩罚,最佳拟合线的斜率较陡,这意味着它对 X 的微小变化更敏感。通过引入惩罚,最佳拟合线对 X 的微小变化变得不那么敏感。这就是岭回归的核心思想。
Lasso 回归
Lasso 回归,也称为 L1 正则化,与岭回归类似。唯一的区别是惩罚是通过斜率的绝对值来计算的。
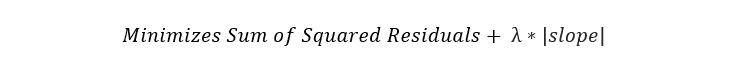
逻辑回归
逻辑回归是一种分类技术,也找到一个“最佳拟合线”。然而,与使用最小二乘法找到最佳拟合线的线性回归不同,逻辑回归使用最大似然法找到最佳拟合线(逻辑曲线)。这是因为y值只能是 1 或 0。查看 StatQuest 的视频,了解如何计算最大似然。
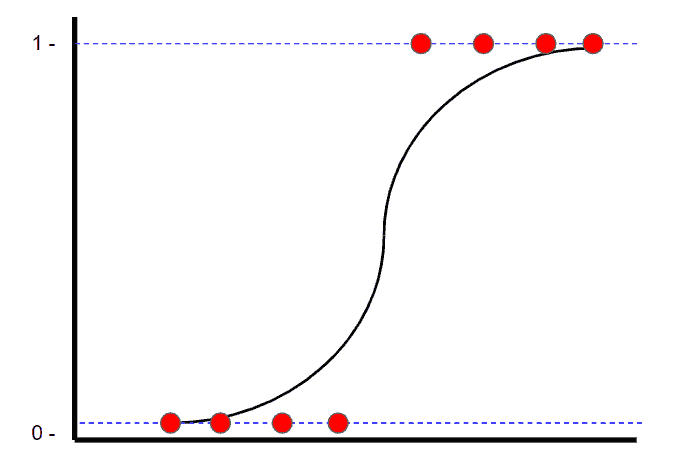
图像由作者创建。
K-最近邻
K-最近邻是一种分类技术,其中通过查看最近的已分类点来对新样本进行分类,因此称为“K-最近”。在下面的示例中,如果k=1,则未分类点将被分类为蓝色点。
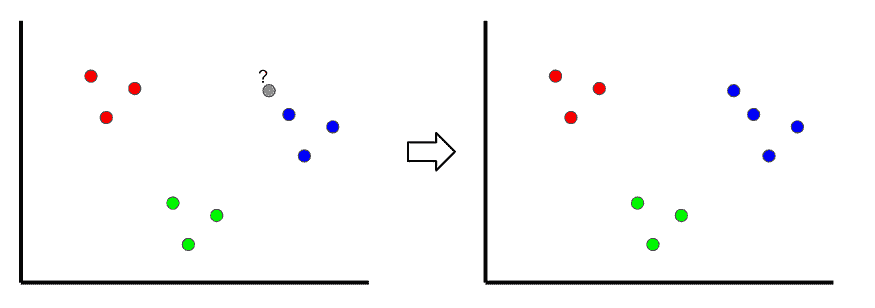
图像由作者创建。
如果k的值太低,则可能受到异常值的影响。然而,如果值太高,则可能忽略只有少量样本的类别。
朴素贝叶斯
朴素贝叶斯分类器是一种受贝叶斯定理启发的分类技术,该定理表示以下方程:
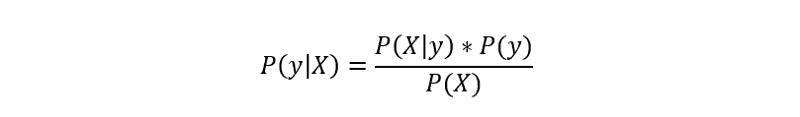
由于存在天真的假设(因此得名)认为在给定类别的情况下变量是独立的,我们可以将 P(X|y) 重写如下:
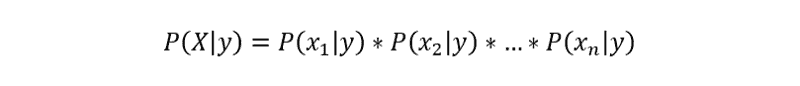
此外,由于我们正在求解 y,P(X) 是一个常数,这意味着我们可以将其从方程中移除并引入一个比例关系。
因此,y 的每个值的概率被计算为 x[n] 在给定 y 时的条件概率的乘积。
支持向量机
支持向量机是一种分类技术,它找到一个最佳边界,称为超平面,用于分隔不同类别。通过最大化类别之间的边际来找到超平面。
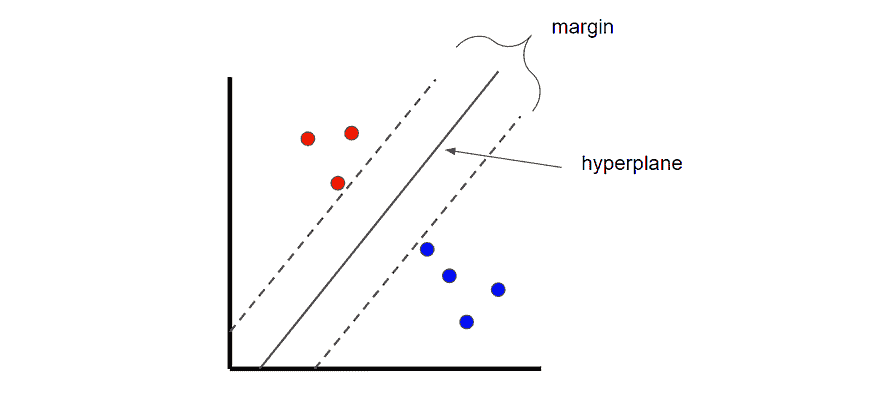
由作者创建的图像。
决策树
决策树本质上是一系列条件语句,用于确定样本走的路径,直到到达底部。它们直观且易于构建,但通常不够准确。
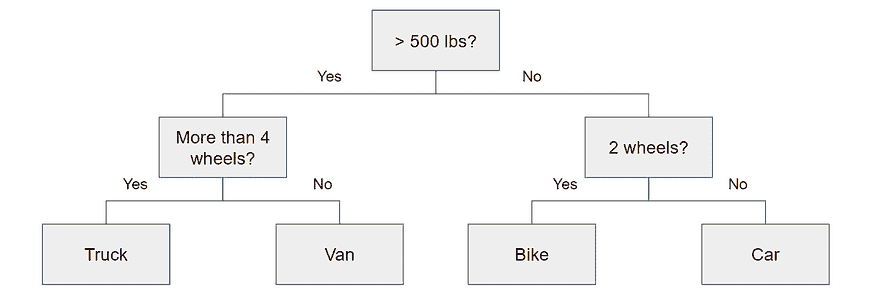
随机森林
随机森林是一种集成技术,意味着它将多个模型组合成一个,以提高其预测能力。具体来说,它使用自助数据集和变量的随机子集(也称为自助法)构建成千上万的较小决策树。通过成千上万的较小决策树,随机森林使用“多数决定”模型来确定目标变量的值。

例如,如果我们创建了一个决策树,即第三棵,它将预测 0。然而,如果我们依赖所有 4 棵决策树的众数,那么预测值将是 1。这就是随机森林的强大之处。
AdaBoost
AdaBoost 是一种提升算法,与随机森林类似,但有几个显著的不同点:
-
与其说 AdaBoost 构建一片树的森林,不如说它通常构建一片桩的森林(桩是只有一个节点和两个叶子的树)。
-
每个桩的决策在最终决策中的权重是不等的。总错误较少(高准确性)的桩将具有更高的权重。
-
桩的创建顺序很重要,因为每个后续的桩都强调了在前一个桩中被错误分类的样本的重要性。
梯度提升
梯度提升与 AdaBoost 相似,因为它构建多个树,每棵树都基于之前的树构建。与 AdaBoost 构建桩(stump)不同,梯度提升构建通常具有 8 到 32 片叶子的树。
更重要的是,梯度提升与 AdaBoost 的主要区别在于决策树的构建方式。梯度提升从一个初始预测开始,通常是平均值。然后,根据样本的残差构建一棵决策树。通过将初始预测值加上学习率乘以残差树的结果来做出新预测,并重复这一过程。
XGBoost
XGBoost 本质上与梯度提升(Gradient Boost)相同,但主要区别在于残差树的构建方式。使用 XGBoost 时,残差树通过计算叶子与前面节点之间的相似性分数来确定哪些变量用作根节点和节点。
原文。已获转载许可。
相关内容:
我们的前三推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关主题
如何向软件工程师解释机器学习
原文:
www.kdnuggets.com/2016/05/explain-machine-learning-software-engineer.html
评论
软件工程是开发程序或工具以自动化任务。我们不是“手动做事”,而是编写程序;程序基本上是可以由计算机执行的机器可读指令集。让我们考虑一个经典示例:电子邮件垃圾邮件过滤。假设我们可以访问电子邮件客户端的源代码并知道如何处理它,我们可以制定一套直观的规则,可能有助于解决垃圾邮件问题。

例如:如果不是“发件人在联系人中”:如果“主题包含 BUY!: 电子邮件垃圾邮件文件夹:”否则如果...
说制定这些规则是一项相当繁琐的任务是很直观的。不用说,我们必须在现实数据上测试我们的垃圾邮件过滤器,不断评估和改进它,修改和更新规则,等等。同样,我们的目标是自动化:我们希望编写一组指令,自动过滤掉垃圾邮件,以便我们不必“手动”从电子邮件收件箱中删除它们。
现在,机器学习就是关于自动化自动化!我们不再亲自制定自动化任务(如电子邮件垃圾邮件过滤)的规则,而是将数据输入机器学习算法,由算法自己找出这些规则。在这种情况下,“数据”应代表我们想要解决的问题的样本——例如,一组垃圾邮件和非垃圾邮件,以便机器学习算法可以“从经验中学习”。
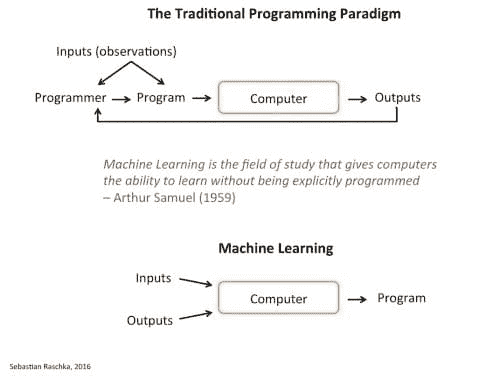
在“传统”编程中,我们编写一组规则,将其与数据一起输入计算机,并希望它产生期望的结果。
传统编程:
- 一组规则 + 数据 -> 计算机 -> 结果
在机器学习中,我们获取数据(例如,电子邮件),提供有关期望结果的信息(这些电子邮件的垃圾邮件和非垃圾邮件标签),然后将其输入学习算法,该算法由计算机执行。计算机随后学习出一组我们可以用来自动化(解决)问题任务的规则。
机器学习:
- 结果 + 数据 -> 机器学习算法 + 计算机 -> 一组规则
换句话说,机器学习是寻找优化指令以自动化任务。机器学习算法是指令,让计算机从数据或经验中自动学习其他指令。因此,机器学习就是自动化的自动化。
简介:Sebastian Raschka 是一位“数据科学家”和机器学习爱好者,对 Python 和开源充满热情。著有《Python 机器学习》。密歇根州立大学。
原始。经许可转载。
相关:
-
深度学习何时优于 SVM 或随机森林?
-
神经网络故障排除:当我的误差增加时出什么问题了?
-
为什么要从头实现机器学习算法?
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
更多相关话题
使用 LIME 解释 NLP 模型
理解 LIME 如何得出最终输出以解释对文本数据的预测是非常重要的。在这篇文章中,我通过阐明 LIME 的组件分享了这一概念。

由 Ethan Medrano 在 Unsplash 拍摄
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持组织的 IT 需求
几周前,我写了一篇 博客 讨论如何使用不同的可解释性工具解释黑箱模型的预测。在那篇文章中,我分享了 LIME、SHAP 和其他可解释性工具背后的数学,但没有详细讲解这些概念在原始数据上的实现。在这篇文章中,我打算逐步分享 LIME 在文本数据上的工作原理。
用于整个分析的数据来源于 这里。这些数据用于预测给定的推文是否关于真实灾难(1)或不是(0)。它包含以下列:

由于本博客的主要焦点是解释 LIME 及其不同组件,因此我们将迅速构建一个使用随机森林的二分类文本分类模型,并主要关注 LIME 的解释。
首先,我们从导入必要的包开始。然后,我们读取数据并开始预处理,例如去除停用词、转小写、词形还原、去除标点符号、去除空白等。所有清理后的预处理文本都存储在一个新的“cleaned_text”列中,该列将进一步用于分析,并且数据被分为训练集和验证集,比例为 80:20。
然后我们迅速转向使用TF-IDF向量化器将文本数据转换为向量,并在此基础上拟合一个随机森林分类模型。
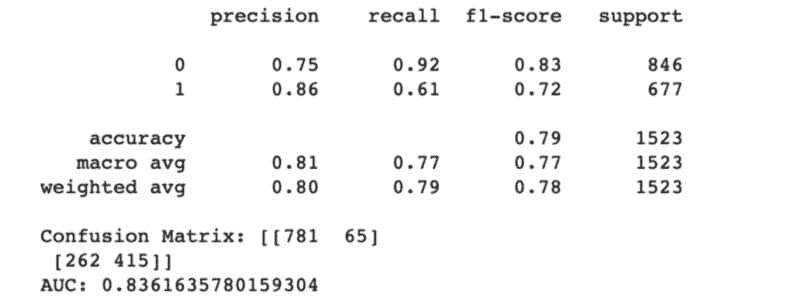
图片由作者提供
现在让我们开始本博客的主要内容,即如何解释 LIME 的不同组件。
首先,让我们查看 LIME 解释对于特定数据实例的最终输出。然后,我们将逐步深入探讨 LIME 的不同组件,最终得到所需的结果。
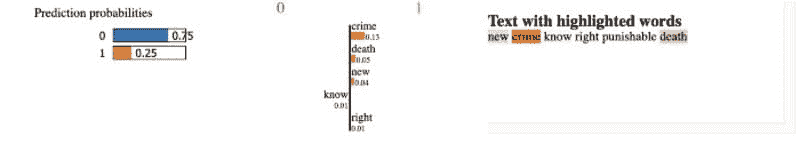
图片由作者提供
这里传递了 labels=(1,)作为参数,意味着我们希望获取类 1 的解释。用橙色突出显示的特征(在这个例子中是单词)是导致类 0(非灾难)预测概率为 0.75 和类 1(灾难)预测概率为 0.25 的顶级特征。
注意:char_level 是 LimeTextExplainer 的一个参数,它是一个布尔值,标识我们是否将每个字符视为字符串中的独立出现。默认值为 False,因此我们不会将每个字符独立考虑,使用 IndexedString 函数进行分词和文本实例中的单词索引,否则使用 IndexedCharacters 函数。
所以,你一定对这些计算方法感兴趣吧?
让我们看看这个。
LIME 首先在感兴趣的数据点周围创建一些扰动样本。对于文本数据,通过随机删除实例中的一些单词来创建扰动样本,默认使用余弦距离来计算原始样本与扰动样本之间的距离。
这将返回 5000 个扰动样本的数组(每个扰动样本的长度与原始实例相同,1 表示原始实例中该位置的单词在扰动样本中存在),以及它们对应的预测概率和原始样本与扰动样本之间的余弦距离。部分内容如下:

图片由作者提供
现在,在创建了邻域中的扰动样本后,是时候为这些样本分配权重了。距离原始实例较近的样本会获得比距离原始实例较远的样本更高的权重。默认使用宽度为 25 的指数核来分配这些权重。
之后,通过从扰动数据中学习一个局部线性稀疏模型来选择重要特征(按 num_features:最大解释特征数)。使用局部线性稀疏模型选择重要特征的方法有很多,如‘auto’(默认)、‘forward_selection’、‘lasso_path’、‘highest_weights’。如果选择‘auto’,当 num_features≤6 时使用‘forward_selection’,否则使用‘highest_weights’。

图片来源于作者
在这里,我们可以看到选择的特征是 [1,5,0,2,3],这些是原始实例中重要词汇(或特征)的索引。由于这里 num_features=5 且 method=‘auto’,因此使用了‘forward_selection’方法来选择重要特征。
现在让我们看看如果我们选择‘lasso_path’方法会发生什么。

图片来源于作者
一样,对吧?
但你可能会对深入了解这个选择过程感兴趣。别担心,我会让它变得简单。
它使用了 最小角回归 的概念来选择顶级特征。
如果我们选择方法为‘highest_weights’,会发生什么呢?

图片来源于作者
稍等一下,我们正在深入选择过程。
现在我们已经通过任何一种方法选择了重要特征。但最终我们必须拟合一个局部线性模型来解释黑箱模型的预测。为此,使用了默认的 岭回归。
让我们检查一下最终的输出会是什么样的。
如果我们分别选择方法为 auto、highest_weights 和 lasso_path,输出将如下所示:
图片来源于作者
这些返回一个元组(局部线性模型的截距、重要特征的索引及其系数、局部线性模型的 R² 值、解释模型对原始实例的局部预测)。
如果我们将上述图像与
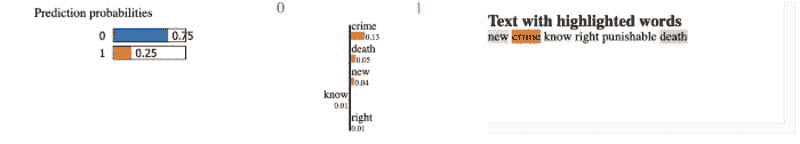
图片来源于作者
那么我们可以说,最左侧面板中的预测概率是解释模型的局部预测。中间面板中的特征和数值是重要特征及其系数。
注意:对于这个特定的数据实例,词数(或特征数)只有 6,我们正在选择最重要的前 5 个特征,因此所有方法都给出了相同的前 5 个重要特征。但对于更长的句子,这种情况可能不会发生。
如果你喜欢这篇文章,请点击推荐。这将非常棒。
要获取完整的代码,请访问我的 GitHub 仓库。请在 LinkedIn 和 Medium 关注我的未来博客。
结论
在这篇文章中,我尝试解释了 LIME 在文本数据中的最终结果,以及整个解释过程是如何逐步进行的。类似的解释也可以用于表格数据和图像数据。为此,我强烈推荐查看 this。
参考文献
-
LIME 的 GitHub 仓库:
github.com/marcotcr/lime -
LARS 的文档:
www.cse.iitm.ac.in/~vplab/courses/SLT/PDF/LAR_hastie_2018.pdf -
towardsdatascience.com/python-libraries-for-interpretable-machine-learning-c476a08ed2c7
Ayan Kundu 是一名具有 2 年以上银行和金融领域经验的数据科学家,同时也是一个热情的学习者,致力于尽可能帮助社区。请在 LinkedIn 和 Medium 关注 Ayan。
更多相关内容
可解释人工智能:10 个 Python 库解密您的模型决策
原文:
www.kdnuggets.com/2023/01/explainable-ai-10-python-libraries-demystifying-decisions.html

作者提供的图片
XAI 是一种人工智能,允许人类理解模型或系统的结果和决策过程。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
解释的 3 个阶段
模型前解释性
可解释人工智能从可解释的数据和清晰、可解释的特征工程开始。
模型解释性
当选择适用于特定问题的模型时,通常最好使用最具可解释性的模型,同时仍能实现良好的预测结果。
模型后解释性
这包括像扰动这样的技术,即分析单个变量对模型输出的影响,如训练后的 SHAP 值。
人工智能解释性的 Python 库
我找到这 10 个用于人工智能解释性的 Python 库:
SHAP (SHapley Additive exPlanations)
SHAP 是一种模型无关的方法,通过分解每个特征的贡献并为每个特征分配分数来工作。
LIME (Local Interpretable Model-agnostic Explanations)
LIME 是另一种模型无关的方法,通过局部近似模型的行为来工作,围绕特定的预测。
ELi5
Eli5 是一个用于调试和解释分类器的库。它提供特征重要性分数,以及 scikit-learn、Keras、xgboost、LightGBM、CatBoost 的“原因代码”。
Shapash
Shapash 是一个 Python 库,旨在使机器学习对所有人都可解释和易于理解。 Shapash 提供几种类型的可视化,具有明确的标签。
Anchors
Anchors 是一种生成可供人类理解的规则的方法,可以用来解释机器学习模型的预测。
XAI (eXplainable AI)
XAI 是一个用于解释和可视化机器学习模型预测的库,包括特征重要性分数。
BreakDown
BreakDown 是一个可以用来解释线性模型预测的工具。它通过将模型输出分解为每个输入特征的贡献来工作。
interpret-text
interpret-text 是一个用于解释自然语言处理模型预测的库。
iml(可解释的机器学习)
iml 目前包含 Shap 项目的接口和 IO 代码,并且可能也会为 Lime 项目提供相同的功能。
aix360(AI Explainability 360)
aix360 包含一套全面的算法,涵盖不同的维度
OmniXAI
OmniXAI(全称为 Omni eXplainable AI)解决了实践中解释机器学习模型所产生判断的若干问题。
我是否遗漏了任何库?
来源
玛丽亚姆·米拉迪 是一位人工智能和数据科学专家,拥有机器学习和深度学习的博士学位,专注于自然语言处理和计算机视觉。她拥有 15 年以上的经验,成功开发了超过 40 个项目。她曾为 12 家不同的组织工作,涉及金融犯罪检测、能源、银行、零售、电子商务和政府等多个行业。
更多相关主题
《解释性人工智能与机器学习的案例》
原文:
www.kdnuggets.com/2018/12/explainable-ai-machine-learning.html
评论
作者:Katarina Athens-Miller、Anna Olecka 和 Jason Otte
在最近的 KDnuggets 文章中 企业人工智能的圣杯—解释性人工智能 [1], Genpact 的人工智能产品工程负责人 Saurabh Kaushik 写道:
可信赖的人工智能系统生产部署。是的,这确实是人工智能的圣杯,原因也很正当;无论是因为错误的流失预测导致失去高价值客户,还是因为金融交易分类错误而损失金钱。在现实中,客户较少关心人工智能模型的准确性,而更关注数据科学家无法解释的“我如何相信其决策?”
在消费者领域构建信用风险模型的数据科学家面临着透明度的要求,这种要求可能存在于该领域的整个发展过程中,因为这受到了管理消费者风险的法规的约束。市场营销人员也受到某些规则的约束,这些规则不允许诸如性别或种族等受保护的类别进入模型。这些法规是在美国制定的,以保护消费者。在欧洲,这些要求甚至更严格。然而,对透明度的需求远远超出了消费者保护。
随着人工智能模型在工业物联网领域(如预测性维护)中的应用,使用这些模型结果的操作员要求提供警报的原因。如果他们需要对这些警报作出反应,尤其是在某些情况下需要快速反应,他们需要知道应该具体集中在哪里。

长期以来,人工智能社区内部存在一种不成文的共识,即最复杂的模型(如图像识别)应当免于解释性要求。然而,随着这些模型在广泛的社会环境中部署,如建筑安全或刑事司法系统,越来越清楚的是,这些模型往往建立在偏见数据上,因此会产生偏见结果。例如,几项研究表明,如果使用显著较少的深色皮肤个体的数据样本来训练面部识别算法,这些算法对肤色较深的个体的准确性较低。根据麻省理工学院媒体实验室的 Joy Buolamwini [2] & [3] 的说法,高达 35% 的深色皮肤女性可能会被人工智能误识别。而白人男性的错误率为 1%。
2016 年 10 月,乔治敦大学法学院的隐私与技术中心发布了一项广泛的研究 《永恒的排队 - 美国无监管的警察面部识别》 [4]。研究人员发现,执法中使用的面部识别软件存在系统性偏差。
警察面部识别将不成比例地影响非洲裔美国人。许多警察部门并未意识到这一点。在一份常见问题解答文件中,西雅图警察局表示其面部识别系统“看不到种族”。然而,一项由 FBI 共同撰写的研究表明,面部识别在黑人员工身上可能不够准确。此外,由于逮捕率不成比例地高,依赖于拘留照片数据库的系统可能包含了不成比例的非洲裔美国人。尽管有这些发现,但没有独立的测试机制来检测种族偏见的错误率。在采访中,两家主要的面部识别公司承认,他们没有在内部进行这些测试。

一起最近的事件中,亚马逊构建了一个 AI 工具来自动化招聘决策,几年后才发现该模型由于基础数据倾斜而产生了偏见的结果,这一事件在媒体上广泛报道。路透社 [5] 评论说“该公司的实验,路透社首次报道,为机器学习的局限性提供了一个案例研究。它还给包括希尔顿全球控股公司(HLT.N)和高盛集团(GS.N)在内的越来越多的大型公司提供了一个教训,这些公司正在寻求自动化招聘过程的部分内容。”
仍然有一些情况,透明度在操作上或监管上并不至关重要。例如,推荐引擎的接收者不需要知道 Netflix 如何选择下一个推荐的电影。但即使在这些情况下,消费者常常会问“为什么”,满足这种好奇心将大大增加用户对推荐的信心。
关于 AI 偏见的信息传播速度几乎与 AI 应用本身一样快。最近的一些例子包括主要的尊敬平台,如 Ted Talk [3],以及主要出版物,如哈佛商业评论 [6]、Quartz [7] 或纽约时报 [8]。早期认识到这个问题的 ACT(计算语言学协会)自 2014 年以来一直在组织机器学习中的公平性、问责制和透明度会议,受邀的演讲者包括顶级的 ML 研究人员和从业者[9] (fatconference.org/2019/cfp.html)。
尽管如此,AI 社区中的一些人仍然怀疑可解释性 AI 的必要性,并更愿意专注于进一步提高模型的准确性。
随着 AI 和 ML 模型越来越受欢迎,并应用于越来越广泛的用例,我们必须牢记风险。我们不要陷入准确性胜过解释性的陷阱。如果我们,数据科学家,陷入了这个陷阱,我们将失去公众和那些部署我们模型的人的信任。
为了支持可解释 AI 的倡议,DataWisen 及我们的合作伙伴展示了一些突出的使用案例。这些案例仅仅是对可解释 ML/AI 需求的一个小样本。鼓励读者在评论中分享自己的例子。
我们将这一系列使用案例分为三个部分:
-
操作需求
-
合规性和
-
公众信任和社会接受度。
A. 操作需求
用例 #1: 油炼厂资产可靠性:炉子洪水预测
-
情况
维持稳定的燃烧对油炼厂炉子的安全操作至关重要。如果燃烧过程变得不稳定且未能及时识别和处理,炉子可能会发生洪水,最终可能引发爆炸。在油炼厂炉子中,洪水每年发生 12 到 20 次。在每个案例中,炉子需要停机以避免爆炸。生产中断的成本估计每年高达数百万美元。
-
ML/AI 解决方案
可靠的在线预测炉子洪水,以便及时响应操作员。该 ML 项目的数据将包括来自炉子的所有传感器信号以及外部数据,如天气、湿度等。解决方案应在事件发生前 20 分钟预测炉子洪水的可能性。操作员要求警报包括最可能的警报原因(即哪些传感器指向洪水风险)。
-
为什么需要可解释的 AI
造成洪水风险增加的原因有很多:例如燃烧器可能被扑灭,空气分配器可能出现故障等。操作员需要迅速对 ML 模型发出的警报做出反应。了解哪些传感器出现故障,使得操作员能够采取预防措施,而无需浪费时间进行额外调查。
用例 #2: 公用事业收入保护:智能电网中的能源盗窃检测
-
情况
能源盗窃造成的商业损失严重困扰全球公用事业公司,估计每年损失达 890 亿美元,并推动客户的能源价格上涨。能源盗贼使用多种手段盗取能源:他们可以接入变压器和房屋之间的线路,接入邻居的计量器,倒转自己的计量器等。
-
ML/AI 解决方案
为了最小化盗窃,收入保护经理需要一个优先级列表,列出最可能需要调查的盗窃案件。这种列表可以通过训练于智能计量器数据和外部因素(如天气、地区地理风险等)的 ML 模型生成。该工具必须足够灵活,以适应不断演变的盗窃方法。工具需要能够识别提升盗窃风险的因素,并输出犯罪的地理位置。
-
为什么需要可解释的 AI
不同类型的盗窃案件需要调查人员采取不同的行动。对于被逆向改装的电表,需要断开电表;对于盗贼接入邻居电源的家庭,需要发出警报并更换被篡改的电表。对于变压器线路的盗用,需要派遣卡车到适当的位置等。
用例 #3: 电力公用事业 – 线路维护
-
情况概述
维护电力基础设施对电力输送系统的可靠性至关重要。如果电力线路或变压器因天气条件而老化或退化,并且这一状况未被识别和处理,设备故障可能会导致电力中断和停电。
-
机器学习/人工智能解决方案
传统的解决方案依赖于定期维护,但随着设备中内置传感器的增加,维护设备的趋势正在转向“及时”方式,当线路或变压器传感器发出即将需要维护的信号时。一个可靠的在线预测潜在设备故障的系统应包括所有传感器的信号以及天气、湿度等外部数据。该解决方案应实时预测设备故障的可能性。
-
为何需要可解释的人工智能
电力输送基础设施覆盖广泛的地理区域。了解哪些传感器发出信号,使维护人员能够被派遣到正确的位置。
B. 监管合规与法律影响
用例 #4: 信用风险评分
-
情况概述
所有金融机构以及许多其他企业都根据消费者的风险评分做出消费信用决策。信用评分模型是一种工具,通常用于接受或拒绝贷款的决策过程中。
-
机器学习/人工智能解决方案生成风险评分的机器学习消费者模型基于借款人的财务行为、过往支付历史、信用利用情况等信息,使信用提供者和其他相关人员能够基于未来违约的估计风险做出合理决策。
-
为何需要可解释的人工智能《公平信用报告法案》(FCRA)是一部联邦法律,规范信用报告机构,并强制要求它们确保所收集和分发的信息是消费者信用历史的公平和准确总结。... 这项法律旨在保护消费者不受误导信息的侵害。如果消费者因信用报告而被拒绝信用、保险或就业,他/她有法律权利要求具体的拒绝理由。因此,任何在信用决策中使用的风险模型都需要提供评分的关键理由。此外,目前美国银行业的所有风险计算模型都在受到银行合规团队和外部监管机构的审查。这些机构要求对输入模型的数据和各个特征的影响进行完全透明,以防止对受保护群体的潜在歧视。
用例 #5: 视频行为检测
-
情况
设施需要安全措施来保护人身和物理资产。典型的解决方案是安保人员和视频监控的结合。人员无法时刻监控每个入口点和每个视频数据流,并且由于错误可能会遗漏一些威胁。
-
机器学习/人工智能解决方案
AI 和深度学习模型评估视频数据以检测威胁,然后将这些威胁标记给安保人员。例如,AI 图像识别模型被训练来标记接近入口的高风险个人(例如,可能携带武器或已知犯罪分子),而忽略合法员工。
-
为什么需要可解释的 AI
将个人标记为威胁可能会产生重大法律影响。如果 AI 使用的数据在某些类别(例如,特定少数群体)中训练样本比例不均,就会引入对这些类别的偏见。
被拦截、阻挡或被安保人员搜查而感到羞辱的个人可能会质疑事件的合法性。公司可能被迫在法庭上为其行为辩护,并披露挑选该个人的原因。如果不能解释模型为何标记该个人,将无法保护公司免受歧视指控。
C. 公众信任和社会接受度
用例 #6:马术运动行业的定价模型
-
情况
在马术运动行业中,马匹的价格和估值缺乏标准和透明度。该行业还面临代理人隐性获利的广泛做法,这些代理人促进了马匹的买卖。
驱动马匹价值和价格的最重要因素包括血统、身体构造、在特定项目(如跳跃、盛装舞步、三项赛等)的能力、教育/训练水平和表现记录、年龄及健康状况。马匹的视觉特征也会影响其价值。
了解驱动运动马匹价值的数据对公平和合理的马匹定价至关重要。这对于使该行业可负担且可行作为一种运动至关重要。关于估值和定价的建模和透明度将有助于防止回扣、过高佣金和价格操控。
-
机器学习/人工智能解决方案
机器学习模型可以处理大量历史销售数据,以建立可靠的定价模型。AI 视觉识别模型可以识别马匹的特征,并使定价模型得以应用。这些工具结合在一起可以为运动马匹的定价提供宝贵且客观的工具。
-
为什么需要可解释的 AI
AI 模型所显示的价格本身并不能透露马匹的特征和能力。潜在买家必须看到潜在因素和马匹的特征,以便做出符合其需求的正确决定。一个解释驱动价格的因素的模型是满足市场需求并增强用户对价格信心所必需的。
参考文献
[1] 企业 AI 的圣杯——可解释的 AI,Saurabh Kaushik;KDnuggets,2018 年 10 月;www.kdnuggets.com/2018/10/enterprise-explainable-ai.html
[2] 性别阴影:商业性别分类中的交叉准确性差异;Joy Buolamwini,麻省理工学院媒体实验室 & Timnit Gebru,微软研究院;《机器学习研究公平、问责和透明度会议论文集》,2018 年 1 月
[3] 我如何在算法中对抗偏见;Joy Buolamwini Ted Talk,2016 年 11 月 www.ted.com/talks/joy_buolamwini_how_i_m_fighting_bias_in_algorithms?utm_campaign=tedspread&utm_medium=referral&utm_source=tedcomshare
[4] 永续排队——美国不受监管的警用面部识别;乔治城大学隐私与技术中心;2016 年 10 月
[5] 亚马逊取消了一个显示对女性有偏见的秘密 AI 招聘工具,Jeffrey Dastin;路透社,2018 年 10 月;[www.reuters.com/article/us-amazon-com-jobs-automation-insight/amazon scraps-secret-ai-recruiting-tool-that-showed-bias-against-women-idUSKCN1MK08G](https://www.reuters.com/article/us-amazon-com-jobs-automation-insight/amazon scraps-secret-ai-recruiting-tool-that-showed-bias-against-women-idUSKCN1MK08G)
[6] 算法无法解决社会问题 [...], Dave Gershgorn;Quartz,2018 年 10 月;qz.com/1427159/algorithms-cant-fix-societal-problems-and-often-amplify-them/
[7] 算法偏见审计;Rumman Chowdhury & Narendra Mulani,哈佛商业评论,2018 年 10 月;hbr.org/2018/10/auditing-algorithms-for-bias
[8] 面部识别准确度高,但前提是你是白人;Steve Lohr,《纽约时报》,2018 年 2 月 nyti.ms/2BNurVq
[9] 今年 4 月,欧洲委员会通过了关于人工智能在司法系统中使用的欧洲伦理章程 www.coe.int/en/web/human-rights-rule-of-law/-/council-of-europe-adopts-first-european-ethical-charter-on-the-use-of-artificial-intelligence-in-judicial-systems
资源:
相关:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
相关话题更多
可解释人工智能(第二部分)——模型解释策略
原文:
www.kdnuggets.com/2018/12/explainable-ai-model-interpretation-strategies.html
评论
来源:Pixabay
介绍
本文是我系列文章的延续,旨在探讨 ‘可解释人工智能(XAI)’。如果你还没有查看第一篇文章,我强烈建议你快速浏览一下 ‘第 I 部分——人类可解释的机器学习的重要性’,其中涵盖了人类可解释的机器学习的定义和重要性,以及模型解释的需求和重要性,以及其范围和标准。在本文中,我们将从中断的地方继续,并进一步扩展机器学习模型解释方法的标准,探索基于范围的解释技术。本文的目的是让你对现有的传统模型解释方法、它们的局限性和挑战有一个良好的理解。我们还将讨论经典的模型准确性与模型可解释性权衡,最后了解主要的模型解释策略。
简而言之,我们将在本文中涵盖以下几个方面。
-
传统模型解释技术
-
传统技术的挑战与局限
-
准确性与可解释性权衡
-
模型解释技术
这将为我们即将到来的详细实践指南《模型解释》第三部分做好准备,敬请关注!
传统模型解释技术
模型解释的核心在于找到更好理解模型决策制定政策的方法。这是为了实现公平性、问责制和透明度,使人们对在现实世界中使用这些模型充满信心,这对商业和社会有很大影响。因此,已经存在许多技术,可以用来更好地理解和解释模型。这些技术可以分为以下两个主要类别。
-
探索性分析和可视化技术 如 聚类 和 降维。
-
模型性能评估指标 如精确度、召回率、准确率,ROC 曲线和 AUC(用于分类模型)和决定系数(R 平方),均方根误差、平均绝对误差(用于回归模型)
让我们简要详细了解这些技术。
探索性分析和可视化
探索性分析的理念并非全新。多年来,数据可视化一直是从数据中获取潜在洞察的最有效工具之一。这些技术中的一些可以帮助我们识别数据中的关键特征和有意义的表示,这可能指示模型在决策时哪些因素对人类可解释形式的模型影响较大。
降维技术在这里非常有用,因为我们通常处理的是非常大的特征空间(维度诅咒),减少特征空间有助于我们可视化并查看哪些因素可能影响模型做出特定决策。以下是一些这些技术。
现实问题中的一个例子可能是通过检查文本特征的语义相似性来可视化哪些特征可能对模型有影响,并使用 t-SNE 进行可视化,如下图所示。
使用 t-SNE 可视化词嵌入(来源:理解特征工程(第四部分)— 深度学习方法用于文本数据 — 数据科学)
你还可以使用 t-SNE 来可视化著名的 MNIST 手写数字数据集,如下图所示。
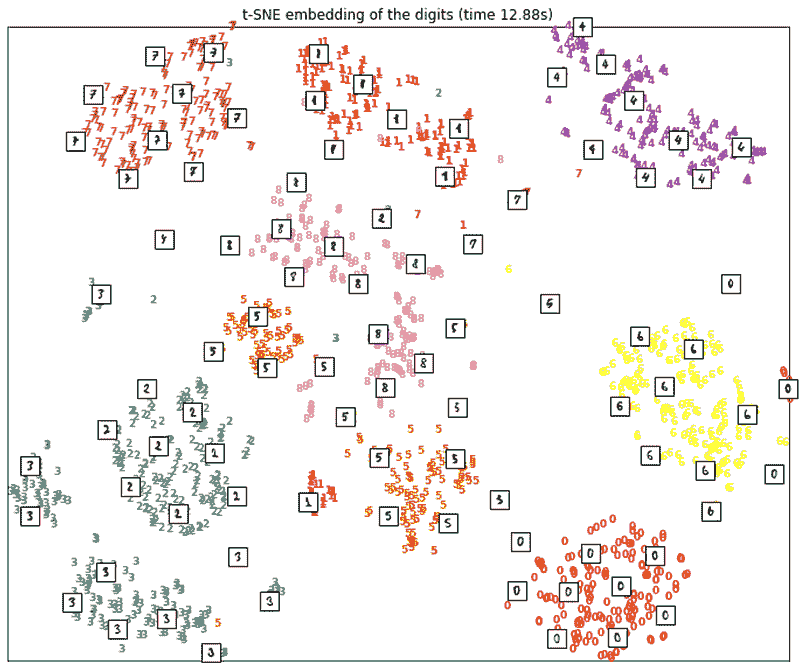
使用 sklearn 的 t-SNE 可视化 MNIST 数据。图片由 Pramit Choudhary 和 Datascience.com 团队提供。
另一个示例是通过 PCA 进行维度缩减来可视化著名的 IRIS 数据集,如下图所示。
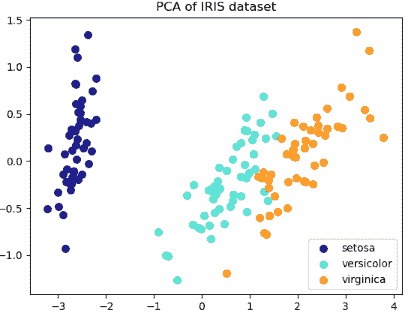
除了数据和特征的可视化外,一些更直观和可解释的模型,如决策树,帮助我们可视化它是如何做出特定决策的。下图展示了一个示例树,帮助我们以人类可解释的方式可视化具体规则。
可视化决策树模型的人类可解释规则(来源:Python 实用机器学习,Apress 2018)
然而,正如我们讨论的,我们可能无法为那些不像树模型那样可解释的其他模型获得这些规则。此外,巨大的决策树总是变得非常难以可视化和解释。
模型性能评估指标
模型性能评估 是数据科学生命周期中的关键步骤,用于选择最佳模型。这使我们能够查看模型的表现,比较各种模型的性能指标并选择最佳模型。这也使我们能够 调整和优化超参数 以获得在我们处理的数据上表现最佳的模型。通常,基于我们所处理问题的类型存在某些标准评估指标。
- 监督学习——分类: 对于分类问题,我们的主要目标是预测一个离散的分类响应变量。混淆矩阵在这里非常有用,我们可以从中推导出一整套有用的指标,包括准确率、精确率、召回率、F1 分数,如下例所示。

分类模型性能指标(来源:Python 实用机器学习,Apress 2018)
除了这些指标外,我们还可以使用一些其他技术,如 ROC 曲线和 AUC 分数,如下图中的葡萄酒质量预测系统所示。
ROC 曲线和 AUC 分数(来源:Python 实用机器学习,Apress 2018)
ROC 曲线下的面积是一个非常流行的技术,用于客观评估分类器的性能。在这里,我们通常尝试平衡真实正例率(TPR)和假正例率(FPR)。上述图表告诉我们,对于类别**‘高’**的葡萄酒,AUC 分数为**0.9**,这意味着模型将更高的分数分配给类别**‘高’**(正类)的概率为 90%,而不是类别**非‘高’**(负类),该类别可能是**‘中’**或**‘低’**。有时,如果 ROC 曲线交叉,结果可能会误导并难以解释(来源:测量分类器性能:ROC 曲线下的面积的连贯替代方法)。
-
监督学习 — 回归: 对于回归问题,我们可以使用标准指标,如决定系数(R 平方)、均方根误差(RMSE)和平均绝对误差(MAE)。
-
无监督学习 — 聚类: 对于基于聚类的无监督学习问题,我们可以使用像silhouette coefficient、同质性、完整性、V-measure以及Calinski-Harabaz 指数这样的指标。
传统技术的局限性及对更好模型解释的动机
我们在前面讨论的技术在尝试更好地了解我们的数据、特征以及哪些模型可能有效方面确实是有帮助的。然而,它们在尝试揭示模型如何工作的人类可解释性方面相当有限。在任何数据科学问题中,我们通常在静态数据集上构建模型,并得到我们的目标函数(优化的损失函数),该模型通常在满足基于模型性能和业务需求的某些标准时被部署。通常,我们利用上述的探索性分析和评估指标来决定我们数据上模型的整体性能。然而,在现实世界中,模型的性能往往在部署后随着时间的推移而下降和趋于平稳,这可能是由于数据特征的变化、增加的约束和噪声。这可能包括环境变化、特征变化以及增加的约束。因此,仅仅在相同特征集上重新训练模型是不够的,我们需要不断检查特征在决定模型预测中的重要性以及它们在新数据点上的表现如何。
例如,一个入侵检测系统(IDS),作为一个网络安全应用,容易受到规避攻击,其中攻击者可能利用对抗性输入来击败安全系统(注意:对抗性输入是由攻击者故意设计的样本,用以欺骗机器学习模型做出错误预测)。在这种情况下,模型的目标函数可能只是对现实世界目标的一个弱近似。可能需要更好的解释来识别算法中的盲点,以通过修复易受对抗攻击影响的训练数据集来构建安全的模型(欲了解更多,请参阅 Moosavi-Dezfooli 等,2016 年,DeepFool 和 Goodfellow 等,2015 年,Explaining and harnessing adversarial examples)。

此外,模型中经常存在偏差,这通常与我们处理的数据特性有关,比如在稀有类别预测问题中(如欺诈或入侵检测)。指标不能帮助我们阐明模型预测决策的真实情况。此外,这些传统的模型解释形式可能对数据科学家来说容易理解,但由于其本质上是理论性和数学性的,向(非技术)业务相关者解释这些模型存在相当大的困难,并且仅依赖这些指标来决定项目的成功标准是不够的。仅告诉业务 “我有一个准确率为 90%的模型” 不足以让他们在实际应用中开始信任这个模型。我们需要可以通过适当和直观的输入和输出来解释的模型决策政策的人类可解释性解释(HII)。这将使有洞察力的信息可以轻松地与同事(分析师、经理、数据科学家、数据工程师)共享。利用这样的解释形式,可以基于输入和输出进行说明,可能有助于促进更好的沟通与协作,使企业能够做出更有信心的决策(例如,金融机构的风险评估/审计风险分析)。
重申一下,我们将模型解释(新方法)定义为能够考虑公平性(无偏见/非歧视)、问责性(可靠的结果)和透明性(能够查询和验证预测决策)——目前主要针对监督学习问题。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
相关话题
-
2022 年最受欢迎的人工智能技能
y 值——一种来自合作博弈论的方法——告诉我们如何公平地分配‘支付’给各个特征。让我们看一个说明性的例子。

假设你训练了一个机器学习模型来预测公寓价格。对于某个公寓,模型预测了 300,000 欧元,你需要解释这个预测。该公寓的面积为 50 平方米,位于2 楼,附近有公园,而且禁止养猫。所有公寓的平均预测价格是 310,000 欧元。每个特征值相对于平均预测的贡献是多少?
对于线性回归模型,答案很简单:每个特征的效果是特征的权重乘以特征值,减去所有公寓的平均效果:这仅仅是因为模型的线性特性。对于更复杂的模型,我们该怎么办?一个选项是我们刚刚讨论的 LIME。另一个解决方案来自于合作博弈论:Shapley 值,由 Shapley 提出,是一种根据特征对总支付的贡献分配支付给玩家的方法。玩家在一个联盟中合作,并从这种合作中获得一定的收益。
-
‘游戏’是数据集中单个实例的预测任务。
-
‘收益’是该实例的实际预测值减去所有实例的平均预测值。
-
‘玩家’是实例的特征值,它们合作以获得收益(即预测一个特定值)。
因此,在我们的公寓示例中,特征值**‘允许公园’**、**‘禁止养猫’**、**‘面积-50 平方米’**和**‘楼层-2 楼’**共同作用以实现 300,000 欧元的预测。我们的目标是解释实际预测(300,000 欧元)与平均预测(310,000 欧元)之间的差异:即-10,000 欧元。答案可能是:**‘公园附近’**贡献了 30,000 欧元;**‘面积-50 平方米’**贡献了 10,000 欧元;**‘楼层-2 楼’**贡献了 0 欧元;**‘禁止养猫’**贡献了-50,000 欧元。贡献总和为-10,000 欧元:即最终预测减去平均预测的公寓价格。
Shapley 值是特征值在所有可能的联盟中的平均边际贡献。联盟基本上是特征的组合,用于估算特定特征的 Shapley 值。通常,特征越多,计算量会指数增长,因此对于大规模或宽数据集计算这些值可能需要很多时间。下图展示了评估**‘禁止养猫’**的 Shapley 值所需的所有特征值联盟。
第一行显示了没有任何特征值的联盟。第二行、第三行和第四行显示了不同的联盟——用**‘|’**分隔——联盟的大小逐渐增加。对于这些联盟中的每一个,我们计算了包含和不包含**‘cat-forbidden’**特征值的预测公寓价格,并取其差值来获得边际贡献。Shapley 值是边际贡献的(加权)平均值。我们用公寓数据集中随机的特征值替换那些不在联盟中的特征值,以获取机器学习模型的预测。当我们对所有特征值重复计算 Shapley 值时,我们得到特征值之间的预测(减去平均值)的完整分布。SHAP 是对 Shapley 值的增强。
SHAP(SHapley Additive exPlanations)为特定预测分配每个特征一个重要性值。它的新颖组成部分包括:识别出一种新的加性特征重要性度量类别,并且理论结果表明在这个类别中存在一个具有一组期望属性的唯一解决方案。通常,SHAP 值试图将模型(函数)的输出解释为将每个特征引入条件期望的效果之和。重要的是,对于非线性函数,引入特征的顺序是重要的。SHAP 值是对所有可能排序的平均结果。博弈论的证明表明,这是唯一可能一致的方法。以下来自 KDD 18 论文,Consistent Individualized Feature Attribution for Tree Ensembles 的图示很好地总结了这一点!

理解 SHAP 值
以下是使用 SHAP 解释模型在预测一个人的收入是否超过 $50K 时的决策的示例。

使用 SHAP 解释模型预测
看到模型在做出这样的决策时背后的关键驱动因素(特征)非常有趣!我们将在本系列的第三部分中通过实际示例来覆盖这一内容。
结论
本文应帮助你在通向可解释人工智能(XAI)的道路上迈出更明确的步伐。你现在知道了模型解释的需求和重要性,第一篇文章中提到的偏见和公平性问题。在这里,我们回顾了传统的模型解释技术,讨论了它们的挑战和局限性,并且涵盖了模型可解释性与预测性能之间的经典权衡。最后,我们查看了当前最先进的模型解释技术和策略,包括特征重要性、部分依赖图、全局代理模型、局部代理模型、LIME、Shapley 值和 SHAP。正如我之前提到的,让我们努力朝着人类可解释的机器学习和 XAI 迈进,以揭开机器学习的神秘面纱,并帮助提高对模型决策的信任。
下一步是什么?
在本系列的第三部分中,我们将详细介绍使用本文所学的所有新技术来构建和解释机器学习模型的全面指南。我们将使用几个最先进的模型解释框架。
-
最新最先进的模型解释框架的实操指南
-
使用框架如 ELI5、Skater 和 SHAP 的特点、概念和示例
-
探索概念并查看它们的实际应用——特征重要性、部分依赖图、代理模型、LIME、SHAP 值的解释和说明
-
在一个监督学习示例中进行实操的机器学习模型解释
敬请关注,这将变得更加有趣和激动人心!
查看‘第一部分——人类可解释机器学习的重要性’,它涵盖了人类可解释机器学习的什么和为什么,以及模型解释的需求和重要性,及其范围和标准,以防你还没看过!
感谢DataScience.com的所有优秀人士,特别是Pramit Choudhary为构建出色的模型解释框架Skater而付出的努力,并为本系列提供了出色的内容。
我在我的书“Python 实用机器学习”中涵盖了大量的机器学习模型解释示例。代码是开源的,供你使用!
有反馈吗?或者有兴趣与我合作研究、数据科学、人工智能,甚至在TDS上发布文章?你可以通过LinkedIn与我联系。
个人简介:Dipanjan Sarkar 是一位@Intel 的数据科学家、作者、@Springboard 的导师、作家,以及体育和情景喜剧爱好者。
原文。经授权转载。
相关:
-
人类可解释的机器学习(第一部分) — 模型解释的必要性和重要性
-
情感和情绪分析:实践者的 NLP 指南
-
命名实体识别:实践者的 NLP 指南
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 工作
相关话题
可解释人工智能(XAI)和可解释增强机器(EBM)介绍
原文:
www.kdnuggets.com/2021/06/explainable-ai-xai-explainable-boosting-machines-ebm.html
评论
由 Chaitanya Krishna Kasaraneni,Predmatic AI 的数据科学实习生。

照片由 Rock’n Roll Monkey 提供,来源于 Unsplash。
近年来,机器学习已成为许多领域如体育、医学、科学和技术发展的核心。机器(计算机)变得如此智能,甚至 击败了围棋等游戏中的专业人士。这些发展引发了关于机器是否也能成为更好的司机(自动驾驶车辆)甚至更好的医生的问题。
在许多机器学习应用中,用户依赖模型来做出决策。但是,医生显然不能仅仅因为“模型这么说”就对病人进行手术。即使在低风险情况下,例如从流媒体平台选择一部电影,我们也需要一定的信任度,然后才能根据模型的推荐投入几个小时的时间。
尽管许多机器学习模型是黑箱,但理解模型预测背后的理由肯定会帮助用户决定何时信任或不信任其预测。这种“理解理由”的需求引出了一个概念,称为可解释人工智能(XAI)。
什么是可解释人工智能(XAI)?
可解释人工智能指的是应用人工智能技术(AI)中的方法和技术,使得解决方案的结果可以被人类专家理解。[维基百科]
可解释人工智能如何不同于人工智能?
AI 和 XAI 之间的区别。
通常,AI 使用机器学习算法得出结果,但 AI 系统的设计者并未完全理解算法是如何得出该结果的。
另一方面,XAI 是一组过程和方法,允许用户理解和信任机器学习模型/算法产生的结果/输出。XAI 用于描述 AI 模型、其预期影响和潜在偏差。它帮助描述模型的准确性、公平性、透明度以及 AI 驱动决策的结果。可解释的 AI 对于组织在将 AI 模型投入生产时建立信任和信心至关重要。AI 解释性还帮助组织采用负责任的 AI 开发方法。
这种解释器的著名例子包括局部可解释模型无关解释(LIME)和Shapley 加性解释(SHAP)。
-
LIME 通过在预测周围局部学习一个可解释的模型,以可解释和忠实的方式解释任何分类器的预测。
-
SHAP 是一种博弈论方法,用于解释任何机器学习模型的输出。
使用 SHAP 解释预测
SHAP 是由 Scott Lundberg 在微软开发的一种新颖的 XAI 方法,并最终开源。
SHAP 具有强大的数学基础。它将最优的信用分配与使用经典的博弈论 Shapley 值及其相关扩展的局部解释联系起来(详细信息见papers)。
Shapley 值
使用 Shapley 值,每个预测可以被分解为每个特征的单独贡献。
例如,假设你的输入数据有 4 个特征(x1, x2, x3, x4),模型的输出是 75,使用 Shapley 值,你可以说特征 x1 贡献了 30,特征 x2 贡献了 20,特征 x3 贡献了 -15,特征 x4 贡献了 40。这 4 个 Shapley 值的总和是 30+20–15+40=75,即模型的输出。这听起来不错,但遗憾的是,这些值极其难以计算。
对于一般模型,计算 Shapley 值所需的时间是与特征数量的指数关系。如果你的数据有 10 个特征,这可能还算可以。但如果数据有更多特征,比如 20 个,根据你的硬件条件,可能已经是不可能的。公平地说,如果你的模型由树结构组成,有更快的近似方法来计算 Shapley 值,但仍然可能会很慢。
使用 Python 的 SHAP
在本文中,我们将使用 红酒质量数据 来理解 SHAP。此数据集的目标值为从低到高(0–10)的质量评分。输入变量是每个酒样的成分,包括固定酸度、挥发酸度、柠檬酸、残留糖、氯化物、游离二氧化硫、总二氧化硫、密度、pH 值、硫酸盐和酒精。有 1,599 个酒样。代码可以通过此 GitHub 链接找到。
在本文中,我们将构建一个随机森林回归模型,并使用 SHAP 的 TreeExplainer。SHAP 为任何机器学习算法提供了解释器——无论是基于树的还是非基于树的算法。它被称为 KernelExplainer。如果你的模型是基于树的机器学习模型,你应使用已优化的树解释器 TreeExplainer(),以便快速渲染结果。如果你的模型是深度学习模型,请使用深度学习解释器 DeepExplainer()。对于所有其他类型的算法(如 KNN),使用 KernelExplainer()。
SHAP 值适用于连续或二元目标变量的情况。
变量重要性图 — 全球解释性
变量重要性图按降序列出最重要的变量。排名靠前的变量对模型的贡献大于排名靠后的变量,因此具有较高的预测能力。有关代码,请参阅此 笔记本。
使用 SHAP 的变量重要性图。
总结图
尽管 SHAP 没有内置函数,但你可以使用 matplotlib 库输出图表。
SHAP 值图进一步展示了预测变量与目标变量之间的正负关系。
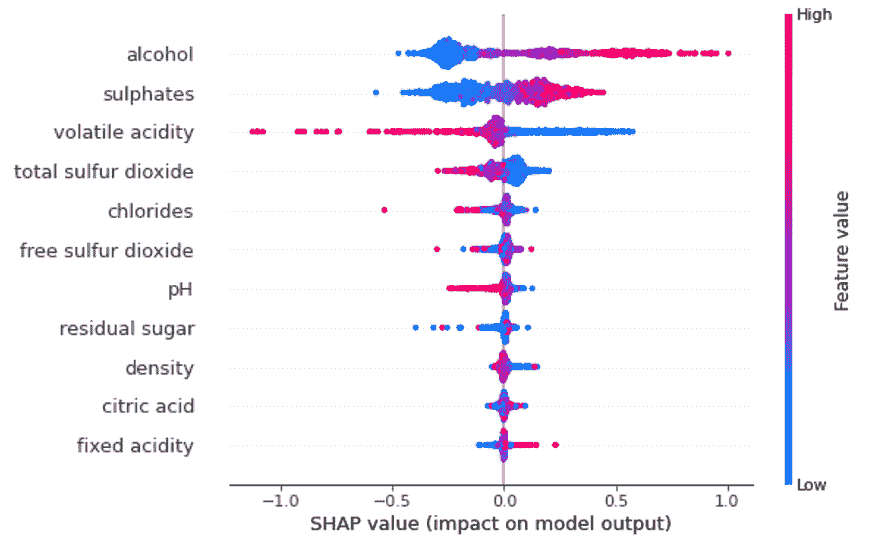
总结图。
该图由训练数据中的所有点组成。它展示了以下信息:
-
变量按降序排列。
-
水平位置显示该值的效应是否与更高或更低的预测相关。
-
颜色显示该变量在观察值中是高(红色)还是低(蓝色)。
使用 SHAP,我们可以生成部分依赖图。部分依赖图展示了一个或两个特征对机器学习模型预测结果的边际影响(J. H. Friedman 2001)。它可以说明目标与特征之间的关系是线性的、单调的还是更复杂的。
黑箱解释远胜于没有解释。然而,正如我们所见,LIME 和 SHAP 都有一些不足。如果模型能同时表现良好并且具有可解释性,那就更好了——解释性提升机器(EBM)就是这样一种方法的代表。
解释性提升机器(EBM)
EBM 是一种玻璃盒模型,旨在具有与先进的机器学习方法(如随机森林和提升树)相当的准确性,同时保持高度的可理解性和可解释性。
EBM 算法是 GA²M 算法的快速实现。反过来,GA²M 算法是 GAM 算法的扩展。因此,让我们从 GAM 算法开始讲起。
GAM 算法
GAM 代表广义加法模型。它比逻辑回归更灵活,但仍然具有可解释性。GAM 的假设函数如下所示:
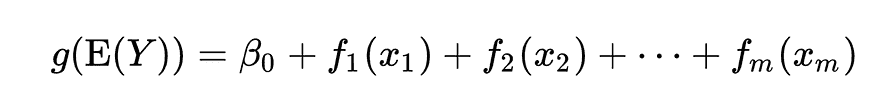
需要注意的关键部分是,特征的线性项 ????ixi 现在被替换为函数 fi(xi)。稍后我们会回到如何在 EBM 中计算这个函数。
GAM 的一个限制是每个特征函数是独立学习的。这阻碍了模型捕捉特征之间的交互,并降低了准确性。
GA²M 算法
GA²M 旨在改善这一点。为此,它除了考虑每个特征学习到的函数外,还考虑了一些成对交互项。这不是一个容易解决的问题,因为需要考虑的交互对的数量更多,这会大幅增加计算时间。在 GA²M 中,他们使用 FAST 算法高效地选择有用的交互项。这是 GA²M 的假设函数。注意额外的成对交互项。
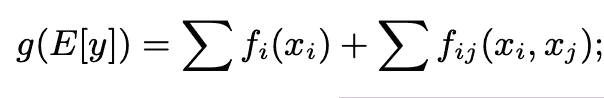
通过添加成对交互项,我们得到了一个更强的模型,同时仍然保持可解释性。这是因为可以使用热图清晰地可视化两个特征在二维空间中的影响及其对输出的作用。
EBM 算法
最后,让我们讨论一下 EBM 算法。在 EBM 中,我们使用诸如袋装法和梯度提升等方法来学习每个特征函数 fi(xi)。为了使学习过程独立于特征的顺序,作者使用了非常低的学习率,并以循环的方式遍历特征。每个特征的特征函数 fi 代表了每个特征对模型在该问题上的预测贡献程度,因此具有直接的可解释性。可以绘制每个特征的单独函数,以可视化其对预测的影响。成对交互项也可以在之前描述的热图上进行可视化。
这种 EBM 的实现也是可并行化的,这在大规模系统中是非常宝贵的。它还有一个极快的推理时间的额外优势。
训练 EBM
EBM 训练部分使用了增强树和袋装的组合。一个好的定义可能是袋装的增强袋装浅层树。
浅层树以增强的方式进行训练。这些是微小的树(默认最多有 3 片叶子)。此外,增强过程是特定的:每棵树仅在一个特征上进行训练。在每次增强轮次中,树会逐个对每个特征进行训练。这确保了:
-
模型是可加的。
-
每个形状函数仅使用一个特征。
这是算法的基础,但其他技术进一步提高了性能:
-
在这个基础模型上进行袋装。
-
每个增强步骤的可选袋装。此步骤默认情况下被禁用,因为它会增加训练时间。
-
成对交互作用。
根据任务,第三种技术可以显著提升性能。一旦使用单个特征训练了模型,就会进行第二次训练(使用相同的训练过程),但使用特征对。对的选择使用了一个专门的算法,避免了尝试所有可能的组合(当特征很多时,这将不可行)。
最终,在所有这些步骤之后,我们得到了一个树的集成。这些树通过使用输入特征的所有可能值来进行离散化。这很简单,因为所有特征都被离散化。因此,预测的最大值数量是每个特征的箱数。最后,这些成千上万的树被简化为每个特征的分箱和评分向量。
使用 Python 的 EBM
我们将使用相同的红酒质量数据来理解 InterpretML。代码可以通过这个GitHub 链接找到。
探索数据
“总结”中的训练数据显示了目标变量的直方图。
总结显示目标的直方图。
当选择单个特征(这里是固定酸度)时,图表显示了该特征与目标的皮尔逊相关性。同时,所选特征的直方图以蓝色显示,相对于目标变量的直方图以红色显示。
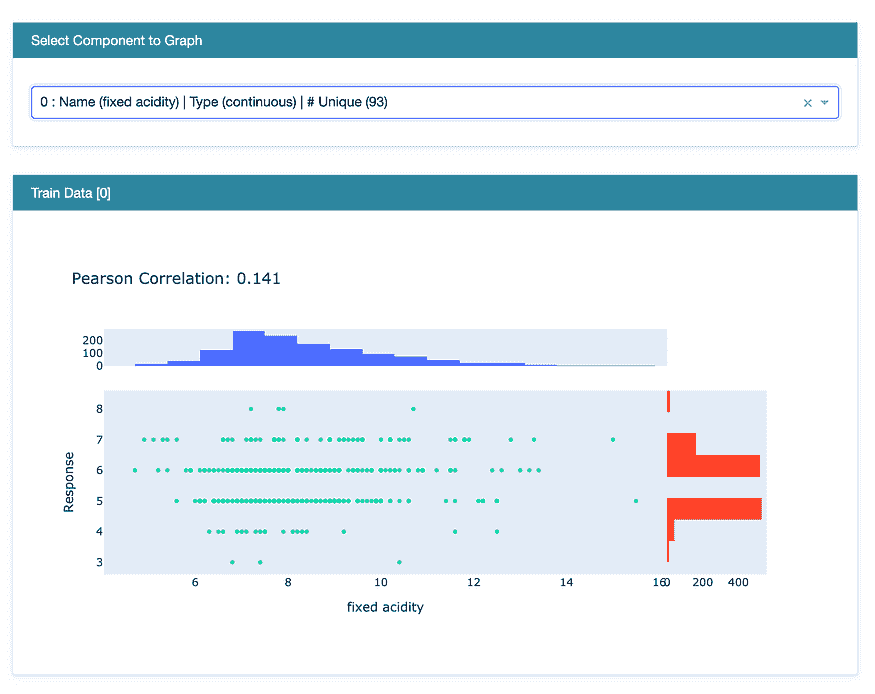
单个特征与目标对比。
训练解释性提升机(EBM)
这里使用的是 InterpretML 库中的ExplainableBoostingRegressor()模型,采用默认超参数。RegressionTree()和LinearRegression()也被训练用于对比。

解释性提升回归模型。
解释 EBM 性能
RegressionPerf()用于评估每个模型在测试数据上的表现。EBM 的 R 平方值为 0.37,优于线性回归和回归树模型的 R 平方误差。
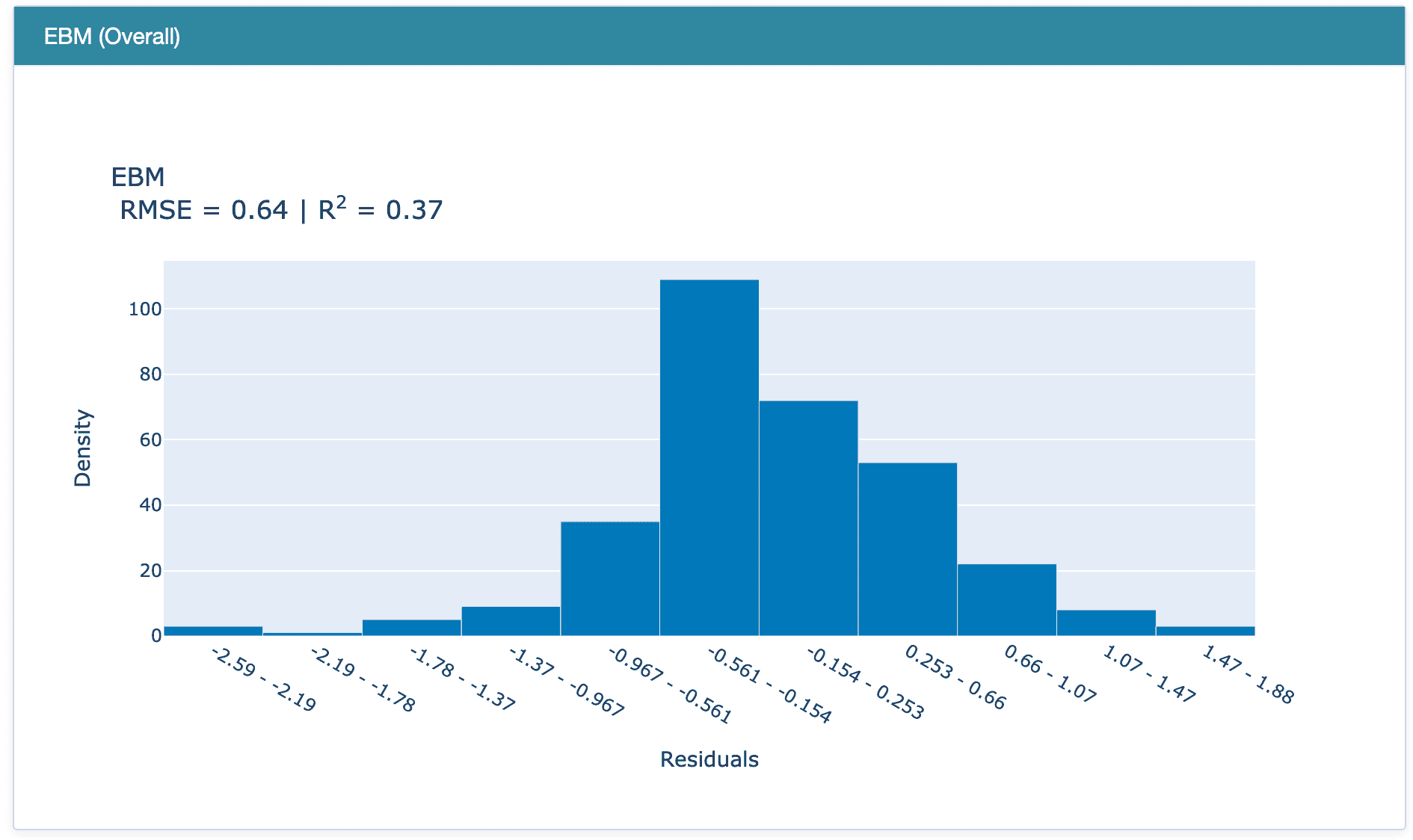
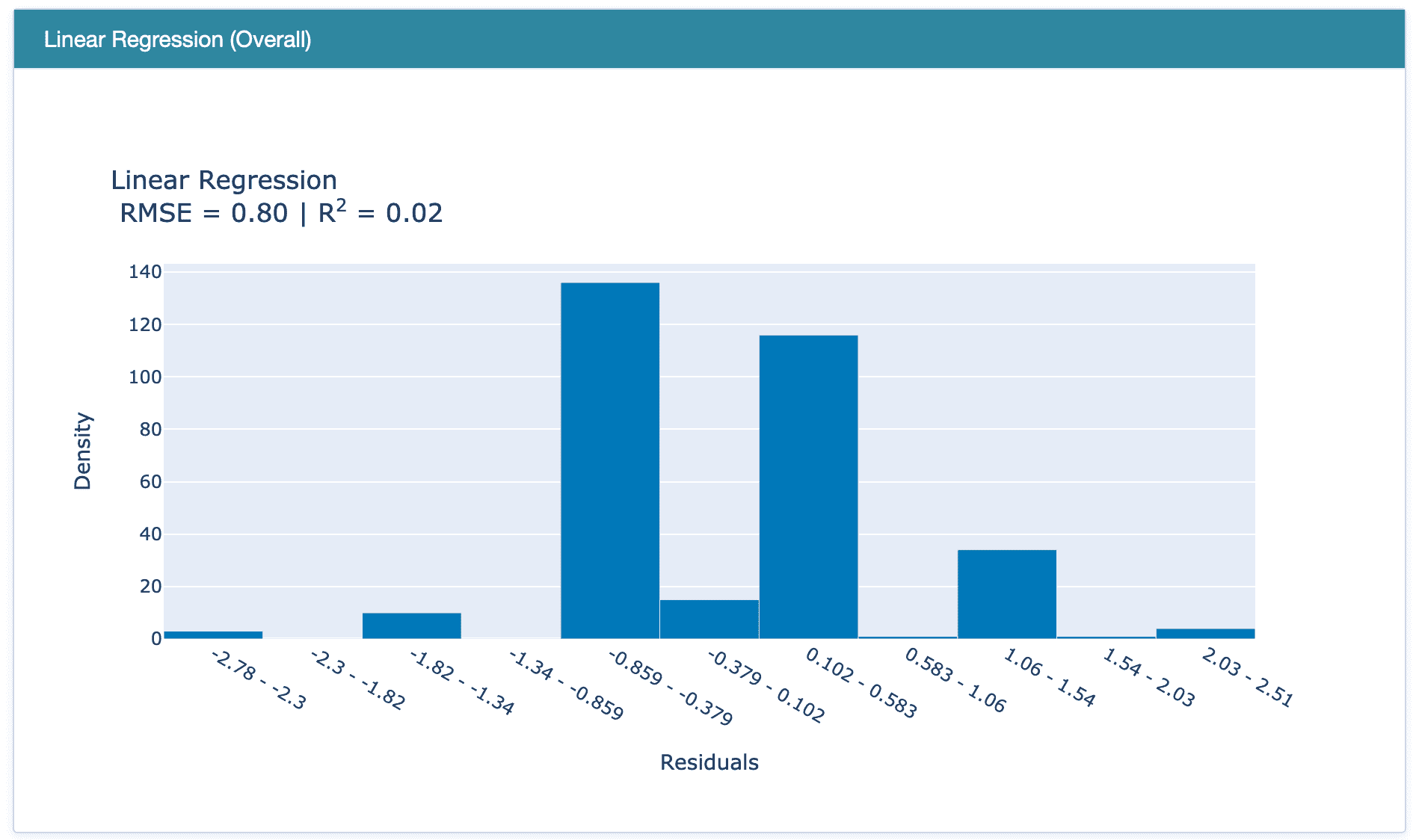
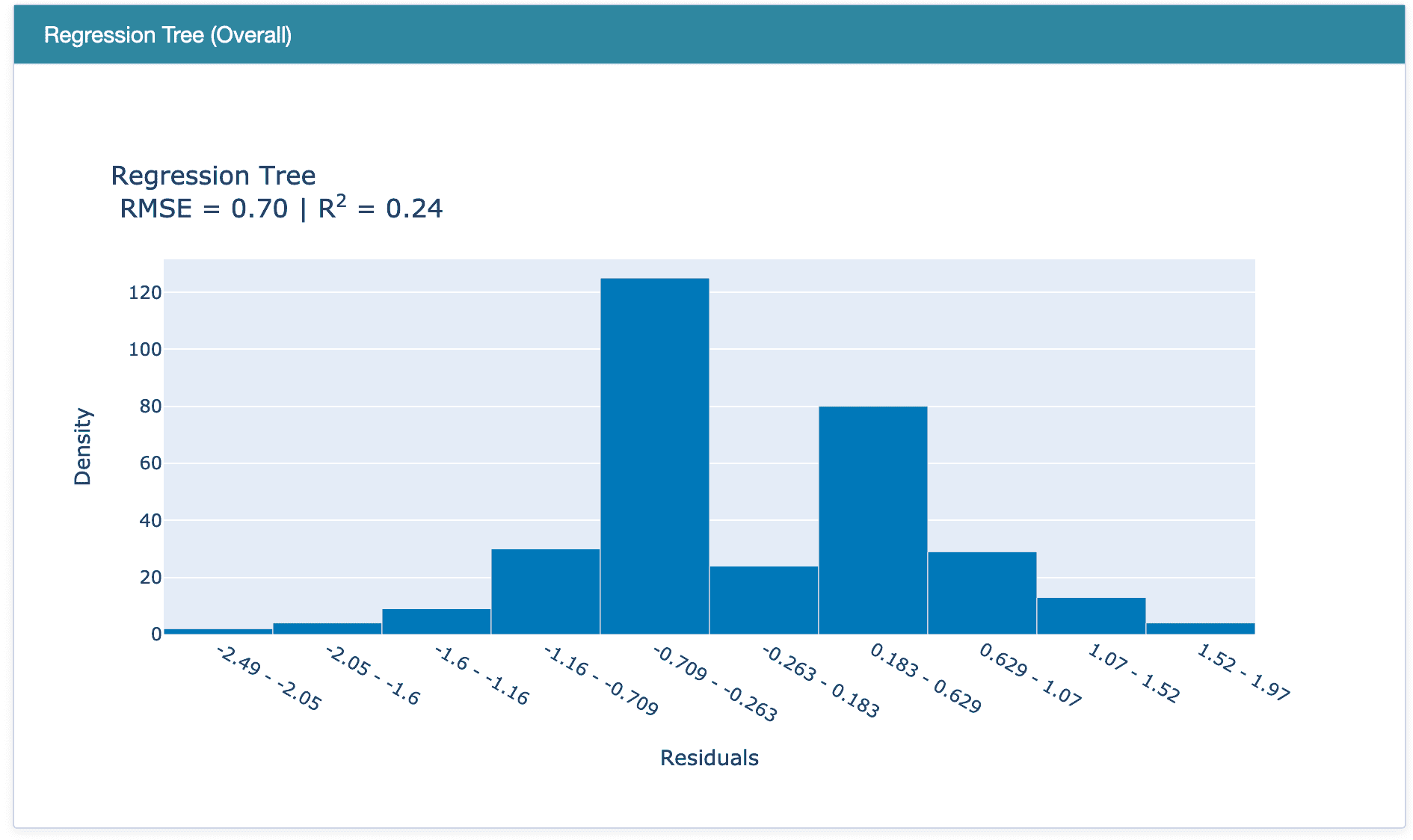
(a)EBM,(b)线性回归,以及(c)回归树的性能。
每个模型的全局和局部可解释性也可以分别使用model.explain_global()和model.explain_local()方法生成。
InterpretML 还提供了一个功能,可以将所有内容结合起来并生成一个互动仪表板。请参考笔记本以查看图表和仪表板。
结论
随着对可解释性要求的增加以及现有 XAI 模型的不足,选择准确性和可解释性之间的时代早已过去。EBM 可以像提升树一样高效,同时又像逻辑回归一样容易解释。
原文. 经授权转载。
相关内容:
我们的三大推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 需求
更多相关内容
可解释的提升机器
原文:
www.kdnuggets.com/2021/05/explainable-boosting-machine.html
评论
由Dr. Robert Kübler,Publicis Media 的数据科学家
可解释性与准确性的权衡
在机器学习社区,我经常听到和阅读到可解释性和准确性的概念,以及它们之间的权衡。通常,它被描绘成这样:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您在 IT 领域的组织
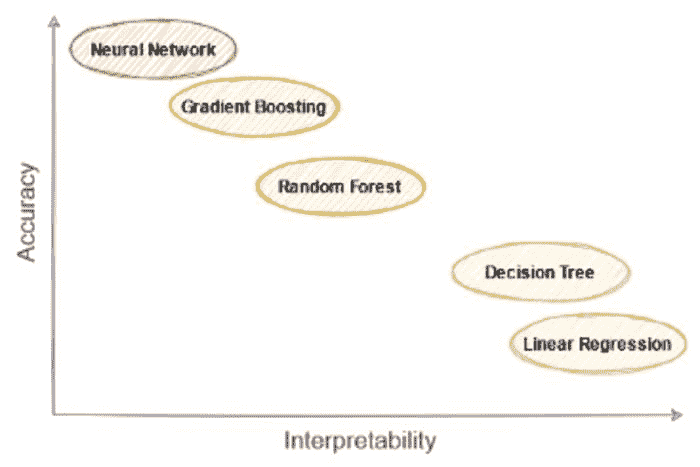
图片由作者提供。
你可以这样理解:线性回归和决策树是相当简单的模型,通常不太准确。神经网络是黑箱模型,即它们难以解释,但通常表现相当不错。像随机森林和梯度提升这样的集成模型也很优秀,但难以解释。
可解释性
但是,什么是可解释性呢?对此没有明确的数学定义。一些作者,如在[1]和[2]中定义可解释性为人类可以理解和/或预测模型的输出的属性。这有点模糊,但我们仍然可以根据这个标准对机器学习模型进行分类。
为什么线性回归y=ax+b+ɛ是可解释的?因为你可以说“将x增加一个单位会增加a的结果”。模型不会给出意外的输出。x越大,y越大。x越小,y越小。没有输入x会让y以奇怪的方式波动。
为什么神经网络不可解释?嗯,试着在不实际实现它并且不使用纸笔的情况下猜测一个 128 层深的神经网络的输出。确实,输出是根据某个大公式得出的,但即使我告诉你对于x=1 输出是y=10,而对于x=3 输出是y=12,你也无法猜测x=2 的输出。可能是 11,也可能是-420。
准确性
这就是你所熟悉的——原始数据。对于回归,均方误差、平均绝对误差、平均绝对百分比误差,任你选择。对于分类,F1、精确度、召回率,当然,还有老朋友准确性本身。
回到图中。虽然我同意现有的内容,但我想强调以下几点:
可解释性与准确性之间没有固有的权衡。有些模型既可解释又准确。
所以,不要让这张图迷惑你。可解释的提升机器将帮助我们突破中间的向下倾斜线,达到我们图表的右上角的终极目标。
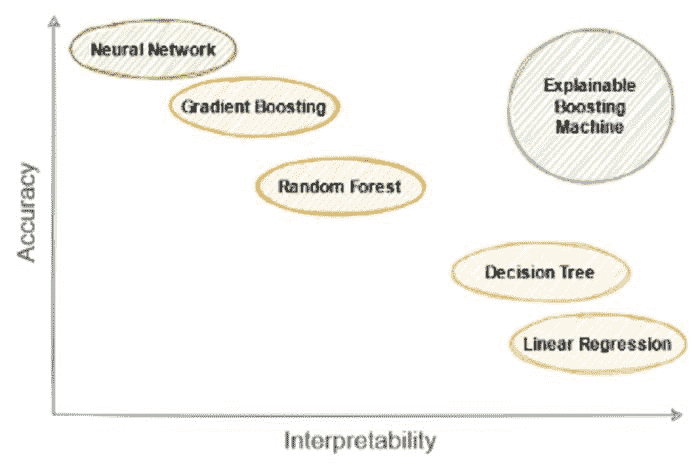
图片由作者提供。
(当然,你也可以创建既不准确又难以解释的模型。这是你可以自己完成的练习。)
阅读完这篇文章后,你将能够
-
理解为什么可解释性很重要,
-
解释黑箱解释方法如 LIME 和 Shapley 值的缺点,并
-
理解并使用可解释的提升机器学习器
解释的重要性
能够解释模型具有多个好处。它可以帮助你改进模型,有时甚至是业务的要求,简单明了。
模型改进

图片来源于alevision.co在Unsplash
假设你想建立一个预测房价的模型。很有创意,对吧?其中一个输入特征是房间数量。其他特征包括房屋大小、建造年份和一些对邻里质量的测量。在归一化特征后,你决定使用线性回归。测试集上的r²很不错,你部署了模型。后来,新房数据出现时,你发现你的模型有点偏差。出什么问题了?
由于线性回归高度可解释,你可以直接看到答案:“房间数量”特征的系数是负的,尽管作为人类你会期望它是正的。房间越多越好,对吧?但模型学到了相反的,原因不明。
这可能有很多原因。也许你的训练集和测试集在某种程度上存在偏差,即如果一栋房子有更多房间,它往往较旧。而且,如果一栋房子较旧,它通常会便宜。
这是因为你能查看模型内部的工作方式而发现的。而且你不仅可以发现它,还可以修复它:你可以将“房间数量”的系数设置为零,或者你也可以重新训练模型并强制“房间数量”的系数为正。这可以通过将positive=True关键字设置到 scikit-learn 的LinearRegression中来实现。
不过请注意,这会将所有系数设置为正值。如果你想完全控制系数,你需要自己编写线性回归。你可以查看这篇文章来开始。
商业或监管要求

照片由Tingey Injury Law Firm提供,来源于Unsplash
通常,利益相关者希望对事情的运作至少有一些直观的理解,你必须能够向他们解释。即使是最非技术性的人也可以理解“我将一堆数字加在一起”(线性回归)或“我沿着一条路径走,根据某些简单条件向左或向右”(决策树),但对于神经网络或集成方法来说,解释起来要困难得多。农夫不知道他就吃不到东西。这也可以理解,因为这些利益相关者通常需要向其他人汇报,而这些人也希望了解事情的大致运作方式。祝你好运,向你的老板解释梯度提升方法,让他或她能够把知识传达给更高层次而不犯重大错误。
除此之外,可解释性甚至可能是法律要求的。如果你为银行工作并创建一个决定某人是否获得贷款的模型,你可能会被法律要求创建一个可解释的模型,这可能是逻辑回归。
在我们讨论可解释增强机器之前,让我们先看看一些解释黑箱模型的方法。
黑箱模型的解释

照片由Laura Chouette提供,来源于Unsplash
解释黑箱模型的工作原理的方法有很多。这些方法的优点是你可以在已经训练好的模型基础上再训练一个解释器。这些解释器使模型更容易理解。
这种解释器的著名例子有局部可解释模型无关解释(LIME)[3]和夏普利值[4]。让我们快速了解这两种方法的不足之处。
LIME 的不足之处
在 LIME 中,你试图逐个解释模型的预测。给定一个样本x,为什么标签是y?假设你可以用一个可解释的模型来逼近你的复杂黑箱模型,在x附近的区域内。这种模型被称为替代模型,通常选择线性/逻辑回归或决策树。然而,如果逼近不准确,你可能没有注意到,那么解释会变得具有误导性。
这仍然是一个你应该关注的sweet library。
Shapley 值
利用 Shapley 值,每个预测可以分解为每个特征的个体贡献。例如,如果你的模型输出 50,利用 Shapley 值你可以说特征 1 贡献了 10,特征 2 贡献了 60,特征 3 贡献了-20。这 3 个 Shapley 值的总和是 10+60–20=50,即你的模型的输出。这很棒,但遗憾的是,这些值的计算非常困难。
对于一般的黑箱模型,计算它们的运行时间是在特征数量上的指数级。如果你有少量特征,比如 10 个,这可能还可以接受。但是,根据你的硬件,20 个特征可能已经不可能了。公平地说,如果你的黑箱模型由树构成,有更快的近似方法来计算 Shapley 值,但仍然可能很慢。
还有一个出色的shap library可用于 Python,它可以计算 Shapley 值,你一定要查看一下!
别误会我的意思。黑箱解释比没有解释要好得多,所以如果你必须使用黑箱模型,请使用它。但是,当然,如果你的模型表现良好并且同时是可解释的,那就更好了。现在是时候深入了解这种方法的代表了。
可解释增强机器
可解释增强的基本思想其实并不新鲜。它最早由 Jerome H. Friedman 和 Werner Stuetzle 于 1981 年提出的加性模型。这类模型具有以下形式:
作者提供的图片。
其中y是预测值,而x₁,…,xₖ是输入特征。
一个老朋友
我声称你们中的每一个人已经遇到过这样的模型。让我们大声说出来:
线性回归!
线性回归不过是一种特殊的加性模型。在这里,所有函数fᵢ只是身份,即fᵢ(xᵢ)=xᵢ。简单,对吧?但你也知道,如果其假设,尤其是线性假设,被违反,线性回归可能不是最好的选择。
我们需要的是更多通用的函数,它们能够捕捉输入和输出变量之间更复杂的关联。微软的一些人展示了如何设计这样的函数的一个有趣的例子[5]。更好的是,他们围绕这个想法为 Python 和 R 构建了一个舒适的包。
请注意,下面我将只描述可解释的增强回归器。分类也适用,并且没有更复杂。
解释
你可能会说:
有了这些函数 f,这看起来比线性回归更复杂。这如何更容易解释呢?
为了说明这一点,假设我们训练了一个看起来像这样的加法模型:
图片由作者提供。
你可以将(16, 2)插入模型,得到 5+12–16=1 作为输出。这已经是 1 的分解输出——有一个基准值 5,然后特征 1 提供额外的 12,特征 3 提供额外的-16。
所有函数,即使它们很复杂,都是由简单加法组成的,这使得这个模型非常容易理解。
现在让我们看看这个模型是如何工作的。
这个想法
作者以类似梯度提升的方式使用小树。如果你不知道梯度提升如何工作,请参阅这个很棒的视频。
现在,解释性提升回归的作者提出的建议是,训练每棵小树时只使用一个特征。这会生成一个如下所示的模型:
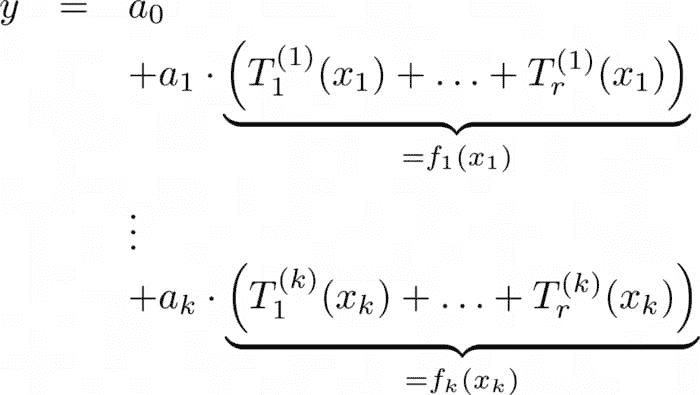
图片由作者提供。
你可以看到以下内容:
-
每个T都是一棵小深度的树。
-
对于每个k特征,训练r棵树。因此,你可以在方程中看到kr*个不同的树。
-
对于每个特征,其所有树的总和就是前述的f。
这意味着函数f是由小树的总和组成的。由于树的多功能性,许多复杂的函数可以被相当准确地建模。
另外,请务必查看这个视频,以获得另一种解释:
好了,我们已经看到了它的工作原理,以及如何轻松解释解释性提升机器的输出。但这些模型真的好吗?他们的论文[5]中说了以下内容:
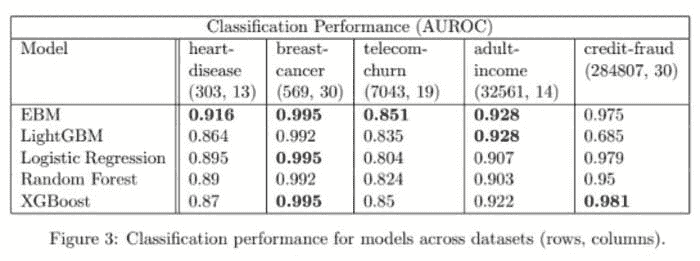
图片摘自[5]。EBM = 可解释提升机。
我觉得不错!当然,我也测试了这个算法,它在我的数据集上也有效。说到测试,让我们看看如何在 Python 中实际使用解释性提升。
使用 Python 中的解释性提升
微软的解释包使得使用解释性提升变得轻而易举,因为它使用了 scikit-learn API。这里是一个小示例:
from interpret.glassbox import ExplainableBoostingRegressor
from sklearn.datasets import load_bostonX, y = load_boston(return_X_y=True)
ebm = ExplainableBoostingRegressor()
ebm.fit(X, y)
这里没有什么令人惊讶的。不过,解释包提供了更多功能。我特别喜欢可视化工具。
from interpret import showshow(ebm.explain_global())
除其他外,show方法允许你检查函数f。这是波士顿房价数据集中特征 4(NOX; 氮氧化物浓度)的函数。
图片由作者提供。
在这里,你可以看到 NOX 对房价的影响在大约 0.58 之前没有影响。从 0.58 开始,影响变得稍微积极,NOX 值在 0.62 左右对房价的正面影响最大。然后它再次下降,直到对 NOX 值大于 0.66 的影响变为负面。
结论
在这篇文章中,我们看到了解释性是一个理想的属性。如果我们的模型默认不可解释,我们仍然可以借助如 LIME 和 Shapley 值等方法来帮助自己。这比什么都不做要好,但这些方法也有其不足之处。
我们随后介绍了可解释增强机器,它的准确性与梯度提升算法如 XGBoost 和 LightGBM 相当,但同样具有可解释性。这表明准确性和解释性并非相互排斥。
使用可解释增强在生产环境中并不困难,感谢 interpret 包。
有些许改进空间
这是一个很棒的库,目前唯一的主要缺点是:它只支持树作为基础学习器。这在大多数情况下可能足够,但如果你需要单调函数,例如,目前你将面临困难。然而,我认为实现这一点应该很简单:开发者只需添加两个功能:
-
对通用基础学习器的支持。 然后我们可以使用单调回归来创建单调函数。
-
对不同特征使用不同基础学习器的支持。 因为对于某些特征,你希望你的函数f是单调递增的,对于其他特征则是递减的,而对于某些特征,你不在乎。
你可以在这里查看讨论。
参考文献
[1] Miller, T. (2019). 人工智能中的解释:来自社会科学的见解。人工智能, 267, 1–38。
[2] Kim, B., Koyejo, O., & Khanna, R. (2016 年 12 月). 示例不够,学会批评!解释性批评。在NIPS (第 2280–2288 页)。
[3] Ribeiro, M. T., Singh, S., & Guestrin, C. (2016 年 8 月). “我为什么要相信你?” 解释任何分类器的预测。在第 22 届 ACM SIGKDD 国际知识发现与数据挖掘大会论文集 (第 1135–1144 页)。
[4] Lundberg, S., & Lee, S. I. (2017). 一种统一的模型预测解释方法。arXiv 预印本 arXiv:1705.07874。
[5] Nori, H., Jenkins, S., Koch, P., & Caruana, R. (2019). Interpretml:一个统一的机器学习解释框架。arXiv 预印本 arXiv:1909.09223。
感谢 Patrick Bormann 的有用建议!
我希望我能教你一些有用的东西。
感谢阅读!
如果你有任何问题,可以在LinkedIn上给我写信!
另外,查看一下我在这里的其他文章,了解易于掌握的机器学习主题。
简介:罗伯特·库布勒博士 是 Publicis Media 的数据科学家,并在 Towards Data Science 上撰写文章。
原文。经授权转载。
相关:
-
梯度提升决策树 – 概念解释
-
Shapash:让机器学习模型易于理解
-
可解释的机器学习:免费电子书
更多相关主题
使用 DALEX 和 Neptune 进行可解释且可复现的机器学习模型开发
评论
由Jakub Czakon、neptune.ai 的高级数据科学家,Przemysław Biecek、MI2DataLab 创始人以及 MI2DataLab 的研究工程师 Adam Rydelek

机器学习模型开发是困难的,尤其是在现实世界中。
通常,你需要:
-
理解业务问题,
-
收集数据,
-
探索它,
-
设置合适的验证方案,
-
实现模型并调整参数,
-
以对业务有意义的方式部署它们,
-
检查模型结果只会发现你必须处理的新问题。
这还不是全部。
你应该对你运行的实验和训练的模型进行版本控制,以便你或其他人需要检查它们或在未来复现结果时使用。从我的经验来看,这一刻总是出乎意料,“我希望我早些考虑到这一点”的感觉非常真实(且痛苦)。
但还有更多内容。
随着机器学习模型服务于真实的人,误分类案例(这是使用机器学习的自然结果)影响了人们的生活,有时还非常不公平。这使得解释模型预测的能力成为一种必要,而不仅仅是一个附加功能。
那么你可以做些什么呢?
幸运的是,如今有工具可以解决这两个问题。
最棒的是,你可以将它们结合起来使你的模型具有版本控制、可复现和可解释性。
继续阅读以了解如何:
-
使用DALEX解释器解释机器学习模型
-
使用Neptune使你的模型有版本控制并使实验可复现
-
使用Neptune + DALEX 集成自动保存每次训练运行的模型解释器和交互式解释图表
-
使用版本控制的解释器比较、调试和审计你构建的每个模型
让我们深入了解一下。
使用 DALEX 进行可解释的机器学习
如今,仅仅在测试集上得分高的模型通常是不够的。这就是为什么对可解释人工智能(XAI)的兴趣日益增长,XAI 是一套让你理解模型行为的方法和技术。
有许多可解释人工智能(XAI)方法在多种编程语言中可用。在机器学习中一些最常用的方法是LIME、SHAP或PDP,但还有许多其他方法。
在众多技术中很容易迷失方向,这时可解释人工智能金字塔派上用场。它将与模型探索相关的需求汇聚成一个可扩展的逐层地图。左侧关于单个实例的需求,右侧关于整个模型的需求。连续的层次深入探讨有关模型行为的更多详细问题(局部或全局)。

XAI pyramide | 了解更多请参见解释模型分析电子书
DALEX(适用于 R 和 Python)是一个帮助你理解复杂模型工作原理的工具。它目前仅适用于表格数据(但未来将支持文本和视觉)。
它与用于构建机器学习模型的最流行框架集成,如keras, sklearn, xgboost, lightgbm, H2O等!
DALEX的核心对象是解释器。它连接训练或评估数据和训练好的模型,并提取你需要解释的所有信息。
一旦拥有它,你可以创建可视化,展示模型参数,并深入挖掘其他与模型相关的信息。你可以与团队分享,或保存以备后用。
为任何模型创建解释器非常简单,如在这个使用sklearn的示例中所示!
import dalex as dx
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import LabelEncoder
data = dx.datasets.load_titanic()
le = preprocessing.LabelEncoder()
for feature in ['gender', 'class', 'embarked']:
data[feature] = le.fit_transform(data[feature])
X = data.drop(columns='survived')
y = data.survived
classifier = RandomForestClassifier()
classifier.fit(X, y)
exp = dx.Explainer(classifier, X, y, label = "Titanic Random Forest")
模型解释(局部解释)
当你想理解为何你的模型做出特定预测时,局部解释是你最好的朋友。
一切从预测开始,向下移动到上面金字塔的左半部分,你可以探索和理解发生了什么。
DALEX 提供了一系列方法,展示每个变量的局部影响:
-
SHAP: 使用经典的 Shapley 值计算特征对模型预测的贡献
-
Break Down: 将预测分解成可以归因于每个变量的部分,使用所谓的“贪婪解释”
-
Break Down with interactions: 扩展“贪婪解释”以考虑特征交互
向下移动金字塔,局部解释的下一个关键部分是理解模型对特征值变化的敏感性。
在 DALEX 中有一种简单的方法来绘制这些信息:
- Ceteris Paribus: 显示模型预测的变化,仅允许单个变量的差异,同时保持其他变量不变
继续我们在泰坦尼克数据集上创建的随机森林模型示例,我们可以轻松创建上述提到的图。
observation = pd.DataFrame({'gender': ['male'],
'age': [25],
'class': ['1st'],
'embarked': ['Southampton'],
'fare': [72],
'sibsp': [0],
'parch': 0},
index = ['John'])
# Variable influence plots - Break Down & SHAP
bd = exp.predict_parts(observation , type='break_down')
bd_inter = exp.predict_parts(observation, type='break_down_interactions')
bd.plot(bd_inter)
shap = exp.predict_parts(observation, type = 'shap', B = 10)
shap.plot(max_vars=5)
# Ceteris Paribus plots
cp = exp.predict_profile(observation)
cp.plot(variable_type = "numerical")
cp.plot(variable_type = "categorical")

模型理解(全局解释)
当你想了解在模型做出决策时哪些特征通常重要时,你应查看全局解释。
为了从全局层面理解模型,DALEX 提供了变量重要性图。变量重要性图,特别是置换特征重要性,使用户能够了解每个变量对整体模型的影响,并区分出最重要的变量。
这些可视化可以被看作是 SHAP 和 Break Down 图的全局等效物,它们描绘了单个观察的类似信息。
在数据集层面,下降到金字塔下,有一些技术,如部分依赖图和累计局部依赖图,让你可视化模型对选定变量反应的方式。
现在让我们为示例创建一些全局解释。
# Variable importance
vi = exp.model_parts()
vi.plot(max_vars=5)
# Partial and Accumulated Dependence Profiles
pdp_num = exp.model_profile(type = 'partial')
ale_num = exp.model_profile(type = 'accumulated')
pdp_num.plot(ale_num)
pdp_cat = exp.model_profile(type = 'partial',
variable_type='categorical',
variables = ["gender","class"])
ale_cat = exp.model_profile(type = 'accumulated',
variable_type='categorical',
variables = ["gender","class"])
ale_cat.plot(pdp_cat)

可重复使用且有组织的解释对象
一个干净、结构化且易于使用的 XAI 可视化集合很好,但 DALEX 还有更多功能。
将你的模型打包在DALEX 解释器中,提供了一个可重复使用且有组织的存储和版本控制任何你进行的机器学习模型工作的方式。
使用 DALEX 创建的解释对象包含:
-
需要解释的模型,
-
模型名称和类别,
-
任务类型,
-
用于计算解释的数据,
-
针对这些数据的模型预测,
-
预测函数,
-
模型残差,
-
对观察的采样权重,
-
额外的模型信息(包、版本等)
将所有这些信息存储在一个对象中,使得创建本地和全局解释变得容易(正如我们之前所见)。
它还使得在模型开发的每个阶段,审查、共享和比较模型及解释成为可能。
使用 Neptune 进行实验和模型版本控制
在理想情况下,你的所有机器学习模型和实验都应以与版本化软件项目相同的方式进行版本控制。
不幸的是,要跟踪你的 ML 项目,你需要的远远不止于将代码提交到 Github。
简而言之,正确版本化机器学习模型 你应当跟踪:
-
代码、笔记本和配置文件
-
环境
-
参数
-
数据集
-
模型文件
-
结果如评估指标、性能图表或预测
有些内容与 .git 很匹配(代码、环境配置),但其他的则不太合适。
Neptune 通过让你记录所有你认为重要的内容,使得跟踪这些内容变得简单。
你只需在脚本中添加几行:
import neptune
from neptunecontrib.api import *
from neptunecontrib.versioning.data import *
neptune.init('YOU/YOUR_PROJECT')
neptune.create_experiment(
params={'lr': 0.01, 'depth': 30, 'epoch_nr': 10}, # parameters
upload_source_files=['**/*.py', # scripts
'requirements.yaml']) # environment
log_data_version('/path/to/dataset') # data version
#
# your training logic
#
neptune.log_metric('test_auc', 0.82) # metrics
log_chart('ROC curve', fig) # performance charts
log_pickle('model.pkl', clf) # model file
每次你运行的实验或模型训练都会被版本控制,并在 Neptune 应用程序(和数据库 ????)中等待你。

你的团队可以访问所有实验和模型,比对结果,快速找到信息。
你可能在想:“好的,很棒,我的模型已经版本化了,但”:
-
如果我想在模型训练后的几周或几个月后调试它怎么办?
-
如果我想查看每次实验运行的预测解释或变量重要性怎么办?
-
如果有人让我检查这个模型是否存在不公平偏见,而我没有训练它的代码或数据怎么办?
我听到了,这就是 DALEX 集成发挥作用的地方!
DALEX + Neptune = 版本化和可解释的模型
为什么不让你的 DALEX 解释器在每个实验中都被记录和版本控制,并使用交互式解释图表在一个友好的用户界面中呈现,方便与任何你想分享的人共享呢?
确实,为什么不呢!
使用 Neptune-DALEX 集成,你可以以额外 3 行代码的成本获得所有这些。
此外,还有一些非常实际的好处:
-
你可以 审查 其他人创建的模型,并轻松分享你的模型
-
你可以 比较 任何创建的模型的行为
-
你可以 追踪和审计每个模型 以发现不希望有的偏见和其他问题
-
你可以 调试 和比较那些缺少训练数据、代码或参数的模型
好的,这听起来很酷,但它实际上是如何工作的呢?
让我们现在深入了解一下。
本地解释的版本控制
要记录本地模型解释,你只需:
-
创建一个观察向量
-
创建你的 DALEX 解释器对象
-
将它们传递给
log_local_explanations函数来自neptunecontrib
from neptunecontrib.api import log_local_explanations
observation = pd.DataFrame({'gender': ['male'],
'age': [25],
'class': ['1st'],
'embarked': ['Southampton'],
'fare': [72],
'sibsp': [0],
'parch': 0},
index = ['John'])
log_local_explanations(expl, observation)
交互式解释图表将在 Neptune 应用的“Artifacts”部分等待你:

以下图表被创建:
-
变量重要性
-
部分依赖(如果指定了数值特征)
-
累积依赖(如果指定了类别特征)
全局解释的版本控制
对于全局模型解释,更简单:
-
创建你的 DALEX 解释器对象
-
将其传递给
log_global_explanations函数来自neptunecontrib -
(可选)指定你希望绘制的类别特征
from neptunecontrib.api import log_global_explanations
log_global_explanations(expl, categorical_features=["gender", "class"])
就是这样。现在你可以前往“Artifacts”部分,找到你的本地解释图表:

以下图表被创建:
-
细分,
-
通过交互进行细分,
-
shap
-
数值变量的 ceteris paribus,
-
类别变量的 ceteris paribus
版本化解释器对象
但如果你真的想对解释进行版本控制,你应该 对解释器对象本身进行版本控制。
保存它的好处是什么?:
-
你总是可以在之后创建它的可视化表示
-
你可以在表格格式中深入了解细节
-
你可以随意使用它(即使你目前不知道怎么做????)
并且这非常简单:
from neptunecontrib.api import log_explainer
log_explainer('explainer.pkl', expl)
你可能会想:“我还可以如何使用解释器对象?”
让我在接下来的部分展示给你。
获取并分析训练模型的解释
首先,如果你将解释器记录到 Neptune,你可以直接将其提取到你的脚本或笔记本中:
import neptune
from neptunecontrib.api import get_pickle
project = neptune.init(api_token='ANONYMOUS',
project_qualified_name='shared/dalex-integration')
experiment = project.get_experiments(id='DAL-68')[0]
explainer = get_pickle(filename='explainer.pkl', experiment=experiment)
现在你有了模型解释,你可以调试你的模型。
一个可能的场景是,你有一个观察点,但你的模型却失败得很惨。
你想弄清楚原因。
如果你保存了 DALEX 解释器对象,你可以:
-
创建本地解释并查看发生了什么。
-
检查特征变化如何影响结果。

当然,你可以做更多的事情,特别是如果你想比较模型和解释的话。
让我们现在来深入了解一下!
比较模型和解释
如果你想:
-
将当前模型想法与在生产中运行的模型进行比较?
-
查看去年的实验性想法是否在新收集的数据上表现更好?
拥有清晰的实验和模型结构以及存储它们的单一位置使得这变得非常简单。
你可以根据参数、数据版本或指标在 Neptune UI 中比较实验:

你只需两次点击即可查看差异,并且可以通过一到两次点击深入查看所需的信息。
好吧,它在比较超参数和指标时确实非常有用,但解释器呢?
你可以进入每个实验并查看交互式解释图表以查看模型是否存在异常情况。
更好的是,Neptune 让你以编程方式访问所有记录的信息,包括模型解释器。
你可以获取每个实验的解释器对象并进行比较。只需使用来自 neptunecontrib 的 get_pickle 函数,然后使用 DALEX .plot 可视化多个解释器:
experiments =project.get_experiments(id=['DAL-68','DAL-69','DAL-70','DAL-71'])
shaps = []
for exp in experiments:
auc_score = exp.get_numeric_channels_values('auc')['auc'].tolist()[0]
label = f'{exp.id} | AUC: {auc_score:.3f}'
explainer_ = get_pickle(filename='explainer.pkl', experiment=exp)
sh = explainer_.predict_parts(new_observation, type='shap', B = 10)
sh.result.label = label
shaps.append(sh)
shaps[0].plot(shaps[1:])

这就是 DALEX 图表的魅力。你可以传递多个解释器,它们将发挥魔力。
当然,你可以将以前训练的模型与当前正在工作的模型进行比较,以查看你是否在正确的方向上。只需将其附加到解释器列表中并传递给 .plot 方法。
最后思考
好的,总结一下。
在这篇文章中,你了解了:
-
各种模型解释技术以及如何将这些解释与 DALEX 解释器打包
-
如何使用 Neptune 对机器学习模型和实验进行版本控制
-
如何为每次训练版本化模型解释器和交互式解释图表,并与 Neptune + DALEX 集成
-
如何比较和调试你训练的模型与解释器
希望有了这些信息,你的模型开发过程现在会更加有组织、可重复和可解释。
祝训练愉快!
Jakub Czakon 是 neptune.ai 的高级数据科学家。
Przemysław Biecek 是 MI2DataLab 的创始人,三星研发中心波兰的首席数据科学家。
Adam Rydelek 是 MI2DataLab 的研究工程师,华沙理工大学数据科学专业的学生。
原文。已获许可转载。
相关:
-
一种简单且可解释的二分类器性能度量
-
解释“黑箱”机器学习模型:SHAP 的实际应用
-
可解释性第三部分:通过 LIME 和 SHAP 打开黑箱
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关话题


 浙公网安备 33010602011771号
浙公网安备 33010602011771号