
KDNuggets-博客中文翻译-十八-
KDNuggets 博客中文翻译(十八)
原文:KDNuggets
你应该选择哪种 BERT 风格用于你的 QA 任务?
评论
作者 Olesya Bondarenko,Tangible AI

图片由 Evan Dennis 提供,来源于 Unsplash
得益于开源自然语言处理库的丰富、策划的数据集和迁移学习的强大功能,制作一个智能聊天机器人从未如此简单。使用 Transformers 库构建一个基本的问答功能可以像这样简单:
from transformers import pipeline# Context: a snippet from a Wikipedia article about Stan Lee
context = """
Stan Lee[1] (born Stanley Martin Lieber /ˈliːbər/; December 28, 1922 - November 12, 2018) was an American comic book
writer, editor, publisher, and producer. He rose through the ranks of a family-run business to become Marvel Comics'
primary creative leader for two decades, leading its expansion from a small division of a publishing house to
multimedia corporation that dominated the comics industry.
"""nlp = pipeline('question-answering')
result = nlp(context=context, question="Who is Stan Lee?")
下面是输出结果:
{'score': 0.2854291316652837,
'start': 95,
'end': 159,
'answer': 'an American comic book writer, editor, publisher, and producer.'}
哇!它工作了!
那个低信心评分有点令人担忧。稍后我们讨论 BERT 检测不可能问题和无关背景的能力时,你会看到它的影响。
然而,花时间选择适合你任务的正确模型将确保你能从你的对话代理中获得最佳的开箱即用性能。你对语言模型和基准数据集的选择将决定你的聊天机器人的表现。
BERT(双向编码表示转换器)模型在复杂的信息提取任务中表现非常出色。它们不仅能够捕捉单词的含义,还能捕捉上下文。在选择模型(或采用默认选项)之前,你可能需要评估候选模型的准确性和资源(RAM 和 CPU 周期),以确保它确实符合你的期望。在这篇文章中,你将看到我们如何使用斯坦福问答数据集(SQuAD)对我们的 QA 模型进行基准测试。还有许多其他优秀的问答数据集,你可能也想使用,包括微软的NewsQA、CommonsenseQA、ComplexWebQA等。为了最大化应用的准确性,你需要选择一个代表你期望的问题、答案和上下文的基准数据集。
Huggingface Transformers 库拥有大量针对各种任务的预训练模型:情感分析、文本总结、同义改写,当然还有问答。我们从可用的模型库中选择了一些候选问答模型。果然,许多模型已经在 SQuAD 数据集上进行了微调。太棒了!这里是我们将要评估的几个 SQuAD 微调模型:
-
distilbert-base-cased-distilled-squad
-
bert-large-uncased-whole-word-masking-finetuned-squad
-
ktrapeznikov/albert-xlarge-v2-squad-v2
-
mrm8488/bert-tiny-5-finetuned-squadv2
-
twmkn9/albert-base-v2-squad2
我们在 SQuAD 的两个版本(版本 1 和版本 2)上使用我们选择的模型进行了预测。它们之间的区别在于,SQuAD-v1 只包含可回答的问题,而 SQuAD-v2 还包含不可回答的问题。为了说明这一点,让我们来看下面来自 SQuAD-v2 数据集的例子。问题 2 的答案无法从维基百科提供的上下文中推导出来:
问题 1:“诺曼底位于哪个国家?”
问题 2:“谁在 1000 年代和 1100 年代将他们的名字给予了诺曼底?”
上下文:“诺曼人(Norman: Nourmands; French: Normands; Latin: Normanni)是指在 10 世纪和 11 世纪将他们的名字给予法国诺曼底地区的人。他们的祖先是来自丹麦、冰岛和挪威的诺斯(‘诺曼’源自‘诺斯人’)劫掠者和海盗,他们在他们的领袖罗洛的带领下,同意对西法兰克国王查理三世宣誓效忠。通过几代人与当地的法兰克人和罗马高卢人的融合,他们的后代逐渐与西法兰克的加洛林文化融合。诺曼人的独特文化和民族身份最初在 10 世纪上半叶出现,并在随后的几个世纪中不断发展。”
我们理想的模型应该能够充分理解上下文以生成答案。
让我们开始吧!
要在 Transformers 中定义模型和分词器,我们可以使用 AutoClasses。在大多数情况下,AutoModels 可以自动从模型名称中推导出设置。我们只需要几行代码来完成设置:
from tqdm import tqdm
from transformers import AutoTokenizer, AutoModelForQuestionAnsweringmodelname = 'bert-large-uncased-whole-word-masking-finetuned-squad'tokenizer = AutoTokenizer.from_pretrained(modelname)
model = AutoModelForQuestionAnswering.from_pretrained(modelname)
我们将以人类水平的表现作为我们的准确性目标。SQuAD 排行榜提供了这个任务的人类水平表现,即 87%的准确率和 89%的 F1 得分。
你可能会问,“他们怎么知道人类表现是什么?”以及“他们说的是哪些人?”那些斯坦福研究人员很聪明。他们只是使用了同一组标记 SQuAD 数据集的众包人群。对于测试集中的每个问题,他们让多个人工提供不同的答案。为了获得人类得分,他们只是将其中一个答案留出来,并检查它是否与其他答案匹配,使用了与评估机器模型相同的文本比较算法。这种“留一个人类答案”的数据集的平均准确性就是机器所要追求的人类水平得分。
为了在我们的数据集上运行预测,首先我们需要将下载的 SQuAD 文件转换为计算机可解释的特征。幸运的是,Transformers 库已经提供了一套方便的函数来完成这一任务:
from transformers import squad_convert_examples_to_features
from transformers.data.processors.squad import SquadV2Processorprocessor = SquadV2Processor()
examples = processor.get_dev_examples(path)
features, dataset = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=512,
doc_stride = 128,
max_query_length=256,
is_training=False,
return_dataset='pt',
threads=4, # number of CPU cores to use
)
我们将使用 PyTorch 及其 GPU 功能(可选)来进行预测:
import torch
from torch.utils.data import DataLoader, SequentialSamplereval_sampler = SequentialSampler(dataset)
eval_dataloader = DataLoader(dataset, sampler=eval_sampler, batch_size=10)all_results = []
def to_list(tensor):
return tensor.detach().cpu().tolist()for batch in tqdm(eval_dataloader):
model.eval()
batch = tuple(t.to(device) for t in batch) with torch.no_grad():
inputs = {
"input_ids": batch[0],
"attention_mask": batch[1],
"token_type_ids": batch[2]
} example_indices = batch[3] outputs = model(**inputs) # this is where the magic happens for i, example_index in enumerate(example_indices):
eval_feature = features[example_index.item()]
unique_id = int(eval_feature.unique_id)
重要的是,模型输入应该针对 DistilBERT 模型(例如 distilbert-base-cased-distilled-squad)进行调整。由于 DistilBERT 与 BERT 或 ALBERT 的实现差异,我们应该排除“token_type_ids”字段,以避免脚本出错。其他所有内容将保持完全相同。
最后,为了评估结果,我们可以应用来自 Transformers 库的 squad_evaluate() 函数:
from transformers.data.metrics.squad_metrics import squad_evaluateresults = squad_evaluate(examples,
predictions,
no_answer_probs=null_odds)
这是由 squad_evaluate 生成的示例报告:
OrderedDict([('exact', 65.69527499368314),
('f1', 67.12954950681876),
('total', 11873),
('HasAns_exact', 62.48313090418353),
('HasAns_f1', 65.35579306586668),
('HasAns_total', 5928),
('NoAns_exact', 68.8982338099243),
('NoAns_f1', 68.8982338099243),
('NoAns_total', 5945),
('best_exact', 65.83003453213173),
('best_exact_thresh', -21.529870867729187),
('best_f1', 67.12954950681889),
('best_f1_thresh', -21.030719757080078)])
现在让我们比较对我们两个基准数据集 SQuAD-v1 和 SQuAD-v2 生成的精确答案准确率(“exact”)和 f1 分数。所有模型在没有负面样本的数据集(SQuAD-v1)上的表现明显更好,但我们有一个明确的赢家(ktrapeznikov/albert-xlarge-v2-squad-v2)。总体而言,它在两个数据集上的表现都更好。另一个好消息是我们为这个模型生成的报告与作者发布的 报告 完全一致。准确率和 f1 分数稍微逊色于人类水平,但对于像 SQuAD 这样具有挑战性的数据集来说仍然是一个很好的结果。

表 1:5 个模型在 SQuAD v1 和 v2 上的准确率得分
我们将在下一个表格中比较 SQuAD-v2 预测的完整报告。看起来 ktrapeznikov/albert-xlarge-v2-squad-v2 在两个任务上表现几乎一样好:(1)识别可回答问题的正确答案,和(2)筛选出可回答的问题。有趣的是,bert-large-uncased-whole-word-masking-finetuned-squad 在第一个任务(可回答的问题)上提供了大约 5% 的显著提升,但在第二个任务上完全失败。

表 2:不可回答问题的单独准确率得分
我们可以通过调整 null 阈值来优化模型在识别不可回答问题方面的表现,以获得最佳的 f1 分数。请记住,最佳的 f1 阈值是由 squad_evaluate 函数计算的输出之一(best_f1_thresh)。以下是当我们应用来自 SQuAD-v2 报告的 best_f1_thresh 时 SQuAD-v2 预测指标的变化情况:

表 3:调整后的准确率得分
尽管这种调整有助于模型更准确地识别不可回答的问题,但它以回答问题的准确性为代价。这个权衡应该在你的应用背景下仔细考虑。
让我们使用 Transformers QA 流水线测试三种最佳模型,并提出一些我们自己的问题。我们从一篇关于计算语言学的维基百科文章中挑选了以下未见示例:
context = '''
Computational linguistics is often grouped within the field of artificial intelligence
but was present before the development of artificial intelligence.
Computational linguistics originated with efforts in the United States in the 1950s to use computers to automatically translate texts from foreign languages, particularly Russian scientific journals, into English.[3] Since computers can make arithmetic (systematic) calculations much faster and more accurately than humans, it was thought to be only a short matter of time before they could also begin to process language.[4] Computational and quantitative methods are also used historically in the attempted reconstruction of earlier forms of modern languages and sub-grouping modern languages into language families.
Earlier methods, such as lexicostatistics and glottochronology, have been proven to be premature and inaccurate.
However, recent interdisciplinary studies that borrow concepts from biological studies, especially gene mapping, have proved to produce more sophisticated analytical tools and more reliable results.[5]
'''
questions=['When was computational linguistics invented?',
'Which problems computational linguistics is trying to solve?',
'Which methods existed before the emergence of computational linguistics ?',
'Who invented computational linguistics?',
'Who invented gene mapping?']
请注意,最后两个问题在给定的上下文中是无法回答的。以下是我们测试的每个模型的结果:
Model: bert-large-uncased-whole-word-masking-finetuned-squad
-----------------
Question: When was computational linguistics invented?
Answer: 1950s (confidence score 0.7105585285134239)
Question: Which problems computational linguistics is trying to solve?
Answer: earlier forms of modern languages and sub-grouping modern languages into language families. (confidence score 0.034796690637104444)
Question: What methods existed before the emergence of computational linguistics?
Answer: lexicostatistics and glottochronology, (confidence score 0.8949566496998465)
Question: Who invented computational linguistics?
Answer: United States (confidence score 0.5333964470000865)
Question: Who invented gene mapping?
Answer: biological studies, (confidence score 0.02638426599066701)
Model: ktrapeznikov/albert-xlarge-v2-squad-v2
-----------------
Question: When was computational linguistics invented?
Answer: 1950s (confidence score 0.6412413898187204)
Question: Which problems computational linguistics is trying to solve?
Answer: translate texts from foreign languages, (confidence score 0.1307672173261354)
Question: What methods existed before the emergence of computational linguistics?
Answer: (confidence score 0.6308010582306451)
Question: Who invented computational linguistics?
Answer: (confidence score 0.9748902345310917)
Question: Who invented gene mapping?
Answer: (confidence score 0.9988990117797236)
Model: mrm8488/bert-tiny-5-finetuned-squadv2
-----------------
Question: When was computational linguistics invented?
Answer: 1950s (confidence score 0.5100432430158293)
Question: Which problems computational linguistics is trying to solve?
Answer: artificial intelligence. (confidence score 0.03275686739784334)
Question: What methods existed before the emergence of computational linguistics?
Answer: (confidence score 0.06689302592967117)
Question: Who invented computational linguistics?
Answer: (confidence score 0.05630986208743849)
Question: Who invented gene mapping?
Answer: (confidence score 0.8440988190788303)
Model: twmkn9/albert-base-v2-squad2
-----------------
Question: When was computational linguistics invented?
Answer: 1950s (confidence score 0.630521506320747)
Question: Which problems computational linguistics is trying to solve?
Answer: (confidence score 0.5901262729978356)
Question: What methods existed before the emergence of computational linguistics?
Answer: (confidence score 0.2787252009804586)
Question: Who invented computational linguistics?
Answer: (confidence score 0.9395531361082305)
Question: Who invented gene mapping?
Answer: (confidence score 0.9998772777192002)
Model: distilbert-base-cased-distilled-squad
-----------------
Question: When was computational linguistics invented?
Answer: 1950s (confidence score 0.7759537003546768)
Question: Which problems computational linguistics is trying to solve?
Answer: gene mapping, (confidence score 0.4235580072416312)
Question: What methods existed before the emergence of computational linguistics?
Answer: lexicostatistics and glottochronology, (confidence score 0.8573431178602817)
Question: Who invented computational linguistics?
Answer: computers (confidence score 0.7313878935375229)
Question: Who invented gene mapping?
Answer: biological studies, (confidence score 0.4788379586462099)
如你所见,仅凭单个数据点很难评估模型,因为结果差异很大。虽然每个模型对第一个问题(“计算语言学是什么时候发明的?”)给出了正确答案,但其他问题则更具挑战性。这意味着即使是我们最好的模型也可能需要在自定义数据集上进行进一步调整,以实现更好的效果。
要点:
-
开源预训练(和微调过的!)模型可以为你的自然语言处理项目提供快速启动。
-
在做其他事情之前,尽量复现作者报告的原始结果(如果可用)。
-
对模型进行准确性基准测试。即使是对完全相同的数据集进行微调的模型,也可能表现出很大的差异。
个人简介:Olesya Bondarenko 是 Tangible AI 的首席开发者,她负责推动 QAry 变得更智能。QAry 是一个你可以信赖的开源问答系统,适用于最私密的数据和问题。
原文。经允许转载。
相关:
-
BERT、RoBERTa、DistilBERT、XLNet:使用哪一个?
-
在 Python 中使用文本相似性检测的简单问答系统
-
利用 NLP 识别争议
我们的三大课程推荐
 1. Google 网络安全证书 - 快速进入网络安全职业。
1. Google 网络安全证书 - 快速进入网络安全职业。
 2. Google 数据分析专业证书 - 提升你的数据分析技能
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织中的 IT 工作
更多相关话题
FluDemic – 利用 AI 和机器学习抢占疾病先机
原文:
www.kdnuggets.com/2021/04/fludemic-ai-machine-learning-disease.html
评论
由DataDriven Health提供,AI 技术公司,致力于转变人口健康和综合监测。
2314 exabytes。这是估计在 2020 年生成的医疗数据量,来自世界经济论坛。换句话说,如果一个千兆字节相当于地球的大小,那么一个艾字节则相当于太阳的大小。

图片来源。
我们必须利用机器学习的力量来分析大量数据,从中获得有意义的见解,以帮助改善公共健康。COVID-19 大流行造成了全球灾难、严重的人员损失和前所未有的社会经济干扰。但如果我们能够在疫情扩散之前预测并阻止这一激增,那会怎样呢?
我们的动机
冠状病毒爆发使传染病建模成为焦点。这正是 FluDemic 大显身手的地方。我们的目标是通过数据协助政府、卫生系统管理者、社区领导和所有人做出前瞻性决策。我们的数据科学家和分析师密切合作,研究传播模式,了解各种社会经济影响,并使用专有的机器学习算法创建预测模型。FluDemic 目前提供了一个平台,用于跟踪和预测 COVID-19 和流感样疾病(ILI)。
我们如何增加价值?
FluDemic 在本质上有三种方式来发挥作用:
1. 疾病追踪:
对于 COVID-19,FluDemic 跟踪几个关键指标,如病例、死亡、检测数据、疫苗接种率和住院率。对于流感,跟踪的指标包括门诊访问中与 ILI 相关的比例、肺炎和流感死亡率、阳性检测率以及 ILI 活动水平。

COVID-19 的度量条。

流感的度量条。
除了原始值之外,我们还提供了标准化的时间和人口调整指标视图,使我们的观众能够真实地了解实际情况。这些指标在两个维度上进行跟踪:
-
空间:用于在县、市和国家之间进行地理视图。这种可视化评估哪个地区最有效地应对疾病。
-
时间:用于疫情的时间视图。这有助于评估关键政策决策的有效性。它还捕捉了疾病的趋势,无论是上升还是下降。
2. 热点检测与预测:
监测疾病的空间分布并识别病例集中最多的地方,为公共卫生官员提供了关键信息。提前一到两周预测这些热点有助于帮助官员有效和高效地将稀缺资源,如个人防护装备、医院床位和疫苗,分配到最需要的地区。FluDemic 关注多个群体并预测哪些地理区域最容易出现未来的激增、爆发和社会经济风险。

纽约州的人口调整 COVID-19 病例的 7 天预测。
3. 社区意识与影响:
由于疾病传播最终掌握在公众手中,无论他们是否遵守社交距离和戴口罩等各种政策,因此了解他们行为的潜在后果至关重要。流动数据通过地理位置和不同类别的地点(如零售和休闲、杂货和药店、公园、交通站点、工作场所和住宅)显示了随时间变化的移动趋势。此外,FluDemic 的社会经济风险指标提供了基于地点的感染和死亡风险的定性视图。
仅将冠状病毒大流行称为健康危机是过于天真的。根据世界卫生组织(WHO)的说法,“全球 33 亿劳动力中的近一半面临失去生计的风险。” FluDemic 通过跟踪失业率来揭示一些情况。许多企业已经破产,更多的企业面临生存威胁。这些影响通过综合领先指标(CLI)得到体现,CLI 显示了经济活动的波动,以及信心指数,这些指数反映了国家商业前景和家庭支出。
如果你对了解更多关于该网站的内容感兴趣,请查看这个简短的 FluDemic 教程:
数据和建模
供 FluDemic 使用的数据来源种类繁多。对于 COVID-19,多个不同的来源提供了病例、死亡、检测、住院、流动、失业、信心指数、社交距离措施和疫苗接种的关键数据。对于流感,数据来源包括流感样疾病(ILI)、肺炎和流感死亡、疫苗接种率和检测等指标。有关数据来源的详细信息,请查看FluDemic的关于部分。
尽管有各种可用的信息,但建模流行病过程仍然面临几个挑战。隐私和保密问题使得在个人层面公开数据变得困难。因此,许多可用的信息都是在总体水平上。像个人的既往病史这样的关键信息无法在公共模型中考虑。在处理大规模数据时,我们需要认识到数据的收集过程和质量在各州之间差异很大。例如,流感监测是一个自愿过程,每个州以不同的完整性和不同的延迟报告其信息。这种报告制度的差异往往会掩盖更细微的区域差异。
现代疫情的建模也受到高度互联的世界中的现实情况的复杂影响,在这种世界中,长途旅行的频率可以在几周内将疫情升高为全球现象。仅考虑局部传播是不够的。模型必须纳入人口的连通性。为了平衡这一点,我们现在拥有比以往更多、更好的数据来量化这种行为。
我们将传染病的发展分为四个阶段:暴露、感染、住院和致死(例如,使用公开数据估计 COVID-19 相关住院和死亡的个体风险)。这一过程始于暴露阶段,即一个或多个未感染者接触到一个感染者。虽然暴露可以发生在家中或杂货店,但当未受保护的人群在一起待较长时间时,暴露风险会加剧。室内用餐在酒吧和餐厅或参加现场活动可能会导致大量人同时暴露于疾病,即使只有很小一部分参与者感染。暴露之后,每种传染病都有一个潜伏期,在此期间病毒感染身体并繁殖。经过这段时间后,症状会出现,个人可能会接受检测并记录为病例。建模挑战在于识别潜伏期的统计分布,并将其纳入跟踪暴露诱发情况的模型中。
在一部分人群中,感染者健康状况严重恶化,导致住院,偶尔还会死亡。然而,住院和随后的死亡都存在时间延迟,这些延迟因人而异,通常与患者的既往病史、治疗护理的可及性和质量相关。在我们的人群模型中,我们利用时间延迟分布及其卷积来追踪从感染到死亡的进程。我们还注意到,对于像 COVID-19 这样的新型疾病,治疗方案随着疫情的进展而不断演变,病例致死率也是如此。由于疫情高峰期间医院床位——特别是 ICU 床位和呼吸机——的紧张,优质护理的可及性受到影响。尽管复杂,了解病例和住院情况的状态使我们能够展望预期的死亡情况。

纽约州每日按人口调整的 7 天滚动平均病例和死亡预测。
热点地区被定义为在考虑预期变化后,每日病例或死亡人数异常高的县。利用序列时间序列模型和时间延迟回归量来预测每个县的每日病例和死亡趋势。结果预测经过人口规模化处理,并使用七天滚动平均进行平滑,从而帮助我们识别新兴热点。

美国各地死亡风险的变异性。
为了将特定县的病例和死亡与基础的人口统计和社会经济因素联系起来,我们计算与人口规模化感染(发病率)和死亡(死亡率)相关的风险因素。主要的人口统计和社会经济因素包括县的人口及人口密度,以及年龄、收入和家庭规模分布。在疫情期间,行为因素如流动性和口罩使用等也会影响风险模型。
与社会经济风险相关的诸多因素并不是彼此独立的——每个因素提供一些独立信息,同时也是常见模式的度量。我们通过各种技术如主成分分析将这些信息拆解为独立组合,这也使我们能够减少独立模型参数的数量,从而使风险估计更为稳健(例如,COVID-19 大流行中的社会经济状况和心血管健康)。
建模风险的第二个重要方面是术语贡献的固有非线性。让我们考虑一下口罩使用情况、流动性和人口密度。每个术语单独都会对社会经济风险产生影响。然而,它们结合在一起时,效果更为强烈。一个人口密度大、流动性高的县会看到口罩使用的影响远大于一个人口稀少的县或一个人们倾向于呆在家的县。这些非线性效应通过使用包含所有交叉项的顺序多项式回归在我们的模型中得到考虑。
下一步是什么?
公开可用的数据常常存在报告错误、显著延迟和较低的地理颗粒度。这给模型的准确性和可操作性带来了挑战。通过 FluDemic 的高级版,我们专注于利用健康系统提供的大量临床级数据。这些数据经过匿名化、聚合处理,并输入到机器学习模型中,从而提供更高的准确性。使该解决方案更具可操作性的关键改进有:
-
数据是实时/接近实时的。
-
数据提供了患者人群的洞察——包括患者的年龄、性别和共病情况。机器学习模型提供了与不同队列相关的更多具体信息,这对于资源调动和有针对性的消息传递至关重要。
-
地理颗粒度为普查区和街区组级别。
-
住院数据仅在机构级别提供,而非在州级别,这对于资源调动尤其重要。
-
病例数据来源于“金源”系统,如确诊实验室测试结果或 COVID-19 和流感的处方。
-
基因组测序将加速开发病毒基因组监测网络,该网络将预测并提醒相关方未来的疫情高峰,评估新变种带来的威胁,并为我们未来不可避免的大流行做好准备。此模型将增强对其他当前传染病(如流感)的监测和预测。
除了 COVID-19 和流感,机器学习模型还将应用于糖尿病、癌症、慢性阻塞性肺病(COPD)和充血性心力衰竭(CHF)等不同的治疗领域。
Bio: 由 Data Driven Health 团队提供,该公司专注于通过人工智能技术转变人群健康和综合监测。
相关:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
更多相关内容
2018 年机器学习/人工智能的关注重点应该是什么?
 评论
评论
作者:Vijay Srinivas Agneeswaran,SapientRazorfish。

机器学习的生产化
这是 2018 年最重要的关注领域。大多数企业已经完成了机器学习的概念验证,并寻求通过全面的生产实施算法来实现数据的全部价值。这个领域的关键技术可能是 Clipper。Clipper 是来自伯克利大学 Rise 实验室的最先进的机器学习服务系统,利用分布式计算概念来扩展模型,使用容器化模型部署来处理任何平台创建的模型,并执行跨框架缓存和批处理,以利用像 GPU 这样的并行架构。最后,Clipper 还可以通过像集成和多臂强盗这样的机器学习技术执行跨框架模型组合。
另一个有趣的技术与模型选择有关,称为 autoML——类似于 Uber 的 Michelangelo。许多开源框架如 TPot 和 AutoSKLearn 已出现,帮助自动搜索多个模型的空间,使用适当的超参数并选择最适合当前任务的模型。模型管理是指跟踪生产中数百个模型的能力,包括模型/分析的传承——例如,每个模型在何种数据集上评估了哪些指标及结果,实质上是模型开发、再训练和更新的整个周期等。ModelDB 是该领域的一个可能选择。
另一个有趣的工作来自 MapR——名为机器学习物流(Machine Learning Logistics)的工作,其核心理念是 Rendezvous 架构。Rendezvous 架构的关键元素包括基于流的微服务和容器化,以及促进警报和诱饵的 DataOps 风格设计。诱饵是一个对输入数据不进行任何操作的模型——它用于保存输入流的副本。警报是一个提供参考或基准的模型,用于与其他模型进行比较。Rendezvous 架构允许模型被大程度地监控,并且可以测量模型漂移,使得新的模型能够逐步、无缝地接管。
深度学习将继续存在
最近有一些论文揭示了深度学习的局限性,包括著名的文章作者加里·马库斯和KDNuggets上的这篇文章。加里认为,深度学习的局限性主要来源于仅有有限的数据进行训练,而实际中可能需要无限的数据才能实现完美的泛化。KDNuggets 文章展示了深度学习网络在分类任务中如何容易受到输入图像扰动以及随机(无意义)图像的欺骗,这些扰动和图像会导致高置信度的错误分类。
然而,正如谷歌深度思维团队在使用深度学习结合强化学习进行 Atari 游戏系统或 AlphaGo 的研究中所展示的,深度学习是非常有用的,并且可以与其他已知的机器学习技术结合,产生出色的结果。
使用深度学习的一个常见问题是超参数调优。一种最近的方法展示了如何通过强化学习的方法组合某些形式的递归网络,这些网络可以在显著程度上超越现有系统。
另一篇最近的论文提出了如何使用深度学习来预测小分子的量子力学性质——它展示了深度学习(特别是消息传递神经网络这种特定形式的深度学习)可以应用于图结构数据,并且对图同构是不变的。
隐式信号与显式信号
人们会撒谎,尤其是在调查中。因此,使用调查来理解用户行为的传统方法似乎不再奏效。这在 Netflix 中尤为明显,当时他们发现经典影片的评分非常高,但实际上并未被观看。这在 Google 搜索中也很明显,并且是最近 Strata Data 主题演讲的内容。Google 研究人员指出,在对马里兰州毕业生的调查中,只有 2%的人表示他们的 CGPA 低于 2.5,而实际情况是 11%的人 CGPA 低于 2.5。类似地,在另一个调查中,40%的工程师表示他们是公司中前 5%的工程师。Google 搜索是数字真相血清,人们在上面比在任何调查或其他平台上更为诚实。这也告诉我们,我们应该关注隐性信号(如人们在 Netflix 上实际观看的内容),而不是依赖于调查的显性反馈来理解消费者行为。这在 Pinterest 开发的一些推荐系统中也有所体现,如在这场keynote speech中记录的那样;他们使用了用户如何与钉子互动的隐性信号(保存钉子、重新钉其他用户的钉子、搜索钉子以及用户不喜欢或忽略的推荐),并能够根据基于图的推荐引擎为用户推荐适当的个性化内容。
模型解释性
模型解释性或可解释性是机器学习算法解释其为何以某种方式做出预测的能力。由于训练数据中看到的多个欺诈案例,系统可能将其推断为欺诈交易。随着越来越多的机器学习模型在金融、保险、零售甚至医疗等多个领域投入生产,模型解释性变得越来越重要。这个领域的一个新兴技术包括Skater和Lime等。
超越深度学习的人工智能
Libratus,另一个最近的游戏系统,将纳什均衡和博弈论结合起来,解决了像扑克这样的不完全信息游戏,并在动态竞争定价和产品组合优化中得到应用。Libratus 的三个主要组件包括:
-
游戏抽象器——计算游戏的一个更小且易于解决的抽象,并为该抽象计算博弈论策略。
-
第二个模块构建了子游戏的精细抽象(几轮后的游戏状态),并使用一种称为嵌套子游戏求解的技术来解决它。
-
第三个模块是自我改进器,它为游戏创建蓝图策略,填充蓝图抽象的部分,并计算这些分支的博弈论方法。
强化学习是数据科学家工具包中的另一个重要工具。它现在与深度学习结合,开发出深度强化学习网络,例如来自谷歌的网络。
机器学习时代的隐私。
数据隐私及其相关的数据保护法律,包括《通用数据保护条例》(GDPR),在这方面非常重要。例如,GDPR 规定必须获得用户的同意才能收集个人数据。用户还拥有询问所收集数据的权利,以及修改、删除数据或反对使用个人数据进行定向的权利(如果他们愿意的话)。数据处理者根据 GDPR 也有一定的义务。GDPR 将在 2018 年影响所有数据产品的设计。
确保数据管道和基础设施的安全不仅重要,确保商业智能(BI)和分析的安全也同样重要。这时,隐私保护分析变得相关,并在 2018 年将变得极为重要。保障 BI 安全的相关技术是 Uber 与伯克利大学 Rise Labs 最近联合开发的,基于所谓的弹性敏感度,它结合了局部敏感度机制与一般等值连接,确保 SQL 查询的差分隐私。
对于深度学习模型,隐私保护分析是通过一种名为联邦学习的技术实现的,该技术由谷歌推广。它基于一个集中式参数服务器,托管所有学习所需的参数。每部手机可以下载这些参数,利用本地数据来改进模型,并生成一个小的更新消息,然后发送回参数服务器。服务器从多部手机中聚合更新,并在中心更新模型参数。联邦学习的有趣之处在于数据都是本地的,而学习是全球性的。每部手机通过使用自己的本地数据并在本地进行计算来更新模型——将机器学习与将数据存储在云端解耦。这一技术在 Android 的 Gboard(谷歌键盘)中得到了应用。
上述通过联邦学习进行的单一模型训练确实存在一些挑战,如高通信开销、滞后者和容错性问题,以及将模型与数据适配的统计挑战。这些问题通过 CMU 的近期研究得到解决,该研究使用联邦核化多任务学习来应对统计挑战,通过使用多个模型并同时更新它们,而系统挑战则由 MOCHA——分布式优化模型来解决。
原文。经授权转载。
相关:
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
一种美味的数据科学方法
原文:
www.kdnuggets.com/2017/01/foodpairing-tasty-approach-data-science.html
作者:Natalia Hernandez,Foodpairing。
当品牌准备创建新风味时,总会有一个构思阶段,开发者会问自己“我们接下来可以创造什么?”在 Foodpairing,我们通过结合消费者行为数据和科学分析的混合方法帮助品牌回答这个问题。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
当然,当公司试图自己回答这个问题时,他们会在模糊的前期阶段花费过多时间(这是新产品风味构思与开发开始之间的时间)。
在风味线开发的这一阶段,调查无效且昂贵,趋势报告过于笼统,无法为企业提供可操作的洞察。公司只能依赖直觉——这是一种高成本的风险。
我们将构建新风味线的方法命名为消费者风味智能(CFI),它缩短了产品开发过程中的模糊前期阶段。
方法
消费者行为数据是 CFI 核心要素之一,因为它提供了关于消费者对新风味和口味期望的大量洞察。
我们在注意到公司面临三大日益严重的挑战以开发新风味线后,开发了这种方法。
首先,消费者不再完全忠于品牌——千禧一代的风味口味迅速变化,为了跟上这一变化,新产品不断上架。
第二,76%的新产品线扩展在一年内失败——我们将其归因于市场模糊前期缺乏精准。
第三,新一代敏捷公司已进入市场。例如,当地的工艺生产商通过高质量、符合潮流的产品创建强大的品牌。他们的开发周期比跨国公司短,从而缩短了市场上市时间。
总体而言,这为公司尝试新风味线创造了一个普遍风险较高的环境。为了解决这些众多挑战,我们创建了一个从更全面的角度考察市场的解决方案。
我们的数据科学家挖掘公共在线数据,这为我们提供了总体趋势洞察。然后,我们使用分子方法对食品进行分析。在这里,我们分析气味并测量其与其他风味的兼容性。我们还进行品牌分析,使用定性方法描述品牌本身,包括其视觉识别和语调,以及特定产品的属性,如质地和口味。然后,我们可以根据品牌身份分析对风味选项进行评分。

图 1:Foodpairing 如何可视化其匹配食材的方法。他们的分析识别出潜在的气味(如水果味、蔬菜味等)及其在成分中的主导程度。然后,他们可以将其与具有互补成分的其他成分连接起来。
现在是数据科学与食品行业结合的时候了
采用科学、消费者数据、厨师灵感的市场研究方法的主要好处是它减少了研发团队试错的成本。
当前在模糊前端的工具箱已经不再足够。市场营销经理、研发厨师和研发经理缺乏可操作的市场和消费者洞察。如今,研究技术在评估阶段效果很好,但在创意生成阶段效果却不佳。
当数据成为创意的核心时,从市场营销到研发的利益相关者可以共同参与决策,对齐公司目标,并帮助提高成功推出的机会。
对我们来说,确保在正确的时刻将正确的风味推出到正确的市场是至关重要的。这是使新风味系列成功的关键。我们提供的市场研究与消费者当前和未来的偏好紧密相关。
我们不断投资于与市场关键参与者建立更多独特的数据合作伙伴关系。这使我们能够增强预测能力。
此外,我们真的希望快速消费品/食品行业对“大数据”的普遍不信任能减少。我们看到数据和数据驱动的策略如何改变了电影、音乐和汽车等行业。
我们觉得现在是时候在食品和饮料行业拥抱“数据科学”了。我们通过在市场研究组织中变得更加活跃来推动这一进程,以提高行业的可见性。作为市场研究圈的外部人士,我们对挑战该领域的参与者始终思考数据的下一个应用感到兴奋。
简介:Natalia Hernandez 是 Foodpairing 的数据科学家。她拥有来自马德里 IE 商学院的商业分析和大数据硕士学位以及工业工程学士学位。Natalia 的第一大热情是食物。在完成工程学学位之前,她曾就读于烹饪学校。
相关:
-
WCAI 研究机会,4 月 24 日:他说,她买了——用户生成的评论和购买行为
-
营养与主成分分析:教程
更多相关内容
预测未来事件:AI 和 ML 的能力与局限性
原文:
www.kdnuggets.com/2023/06/forecasting-future-events-capabilities-limitations-ai-ml.html

图片来自 Bing 图像创作者
ML 和 AI 能否应用于预测未来?
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
预测未来是一项具有挑战性的任务,但越来越多地使用机器学习和人工智能来尝试实现。这些技术有可能彻底改变我们在金融、医疗保健和自然灾害等各个领域的预测方式。它们能够基于数据中的模式和趋势进行预测,但这些预测的准确性可能会因使用的数据质量和数量以及模型的复杂性而有所不同。由于有许多变量可能影响结果,因此很难确定地预测未来事件。此外,关于未来事件的预测,例如自然灾害或世界领导人,也可能受到人类行为和决策的影响,这些是难以建模的,并且目前超出了 ML 和 AI 的能力,它们尚未足够先进,无法以高精度预测未来事件。
目前使用 ML 和 AI 的预测现状
如今,ML 和 AI 的预测应用已经出现在各个领域。一些例子包括在金融领域,算法被用于高精度地预测股票市场价格。在医疗保健领域,机器学习算法被用来预测患者发展某种疾病的风险。在自然灾害领域,算法被用来预测洪水或飓风的可能性。然而,这些预测并不总是准确的,还有若干挑战需要克服。

然而,重要的是要注意,虽然这些模型和算法可以提供有用的预测和预报,但它们也受到一些进一步讨论的因素的限制。
预测的局限性
机器学习和人工智能可以对未来事件做出预测,但这些预测的准确性高度依赖于用于训练模型的数据的质量和数量,以及被预测任务的复杂性。其中一个最新的案例是 ChatGPT,这是一个人工智能语言模型,无法观察世界或经历事件,它只能基于训练数据中的模式和关系生成预测。一些限制包括:
-
数据不足:为了做出准确的预测,机器学习和人工智能模型需要大量的数据进行学习。对于某些类型的事件,可能没有足够的数据来训练模型。
-
任务的复杂性:一些事件本质上比其他事件更复杂。例如,预测股票市场是一个高度复杂的任务,因为有许多不同的因素可以影响股价。
-
不可预测的事件:一些事件,如自然灾害,难以预测,因为它们是由不可预测的因素引起的。
-
人类行为难以建模:许多事件依赖于人类行为,而人类行为很难预测。例如,预测选举结果可能很困难,因为这取决于人们如何投票,而投票行为受情感、信仰和背景等多种因素的影响。
-
对世界的理解有限:我们对世界的许多事物仍然不了解,模型只能预测它们所训练的内容。
-
数据中的偏差:如果用于训练模型的数据有某种偏差,那么模型做出的预测也会有偏差。
这些限制是否足够强大以至于使预测未来事件成为不可能?
很难说预测未来事件是否是不可能的。预测基于不完整的信息,而未来的复杂性和不确定性使得准确预测变得具有挑战性。
然而,随着技术的进步和数据的日益丰富,预测未来事件变得越来越可能。
改进预测的方法
预测未来事件是一个复杂的任务,需要理解影响事件的基本因素以及建模这些因素之间相互作用的能力。没有一种通用的方法来预测未来事件,但可以使用的一些方法包括:
-
数据驱动的方法:这种方法涉及分析历史数据以识别模式和趋势,并利用这些模式对未来事件做出预测。这种方法在金融、天气预报和体育预测等领域被广泛使用。
-
专家意见:从在该领域拥有深厚理解的专家那里获得见解,可以用于做出预测。这些专家可能会利用他们自己的经验和知识,以及数据驱动的方法来做出预测。使用诸如机器学习(ML)、人工智能(AI)和专家知识等技术的组合非常重要。
-
模拟:构建计算机模型来模拟影响事件的因素之间的相互作用,可以用于做出预测。这种方法在天气预报、工程学和经济学等领域中被广泛使用。
-
情景规划:这种方法涉及创建一组合理的未来情景,然后利用这些情景来指导决策。这种方法可以用于预测未来事件,例如通过考虑不同的可能行动及其可能的结果,来预测世界领导人的行动。
-
持续监测和更新预测:未来是不断变化的,因此重要的是不断监测预测,并在有新信息出现时更新它们。
-
了解预测的局限性和不确定性:预测永远不会是 100%准确的,因此重要的是以一定的怀疑态度看待它们,并将其与其他信息来源结合考虑。
此外,即使预测是准确的,也可能无法采取行动。例如,如果一个预测说自然灾害即将发生,但没有办法采取措施预防,那么这个预测就没有用。因此,在做出预测时,考虑预测的可操作性非常重要。
结论
预测是决策的重要工具,但也存在局限性。机器学习和人工智能有潜力革新我们的预测方式,但理解这些预测的局限性也很重要。通过收集更多数据、开发更先进的模型、从专家那里获取见解以及纳入多个情景,预测可以得到改进。然而,使用这些预测时要谨慎,不要过于依赖它们。
Parisi Shalini 是一名数据工程师,对探索那些提出有趣问题但没有现成答案的领域充满热情。她喜欢深入未知领域的兴奋感,那些领域尚未被揭示的知识使她充满激情。
进一步了解此主题
忘掉 ChatGPT,这款全新的 AI 助手遥遥领先,将永远改变你的工作方式
原文:
www.kdnuggets.com/2023/08/forget-chatgpt-new-ai-assistant-leagues-ahead-change-way-work-forever.html

作者提供的图像
我使用 ChatGPT 和 Bard 已有一段时间,这些工具已成为我工作流程的重要部分。我依赖它们生成代码、进行统计测试、理解新术语,并制作分析报告和总结。然而,当我切换到 Poe 后,体验显著改善。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
在这篇文章中,我将解释为什么我停止使用 ChatGPT,并且为什么我认为 Poe 是各种数据科学任务的更佳替代方案。
什么是 Poe
Poe 是一个聊天机器人服务,允许你使用最先进的模型,如 Claude +、GPT-3.5-Turbo、GPT-4、LlaMA 2、PaLM 和所有新型 LLM 模型。此外,它将使用户能够使用初始提示创建和共享可定制的聊天机器人。Poe 速度快,易于使用,并提供准确的答案。

来自 Poe 的图像
我更喜欢使用 Poe 而非 ChatGPT 和 Bard,因为 Poe 更快、更准确,并且提供更多功能。Poe 允许我一键清除上下文,而在 ChatGPT 上,我必须开始一个新的聊天会话。Poe 让我可以一键在 Claude+ 和 Sage 等模型之间切换,而 ChatGPT 仅提供 GPT-4 和 GPT-3.5-Turbo。
Poe 的特点

来自 Poe 的图像
Poe 的主要特点:
-
速度: Poe 的加载和响应速度比 ChatGPT 快得多。
-
模型范围: Poe 提供了更多种类的 AI 模型,这些模型提供比 GPT-3.5-Turbo 更准确的答案。
-
模型切换的简便性: 你可以通过单击轻松切换 AI 模型。
-
自定义聊天机器人: 你可以根据个人偏好通过提供初始提示来创建可定制的聊天机器人。
-
社区聊天机器人: 你可以访问和探索其他 Poe 用户为特定任务创建的聊天机器人。
-
简洁性: 注册和开始使用 Poe 非常简单明了。
-
高级访问: 付费订阅可以让你访问更多高级模型,如 GPT-4 和 Claude。
-
应用程序: Poe 既有 Android 版也有 iOS 版。
-
稳定性: 它不会崩溃或出现 bug。
-
易用性: 清除上下文并开始新的聊天非常简单。
我如何用于数据科学任务
你需要了解这些生成型 AI 聊天机器人是你的助手。它们可以帮助你完成各种任务,从写文章到构建端到端的数据科学项目。
我通常使用 Poe 来编写和创建内容结构。如果我不喜欢 Claude-Instant 的回答,我会询问 ChatGPT 或 Google PaLM。这使我能够选择最佳回复。此外,我还使用 Poe 来:
-
代码生成: 我使用 Poe 生成 Python、R 和 SQL 代码,用于特定任务,如清理数据、执行统计测试和构建机器学习模型。它帮助调试我的代码,甚至生成完整的代码示例来构建网页应用。
-
内容写作: Poe 帮助改善我的博客文章和教程的语法和结构。它还总结了长文档,并生成更好的标题和摘录。
-
技术学习: 我请 Poe 解释新的数据科学技术和统计测试,帮助我学习新技能。
-
数据分析和探索: Poe 生成代码以清理、探索、分析和建模我的数据。它帮助验证数据质量并识别问题。
-
翻译: 我利用 Poe 进行代码和文本的翻译。
总的来说,Poe 是一个有用的助手,可以完成许多重复的任务,从而释放出我的时间用于更高层次的工作和决策。它显著提高了我作为数据科学家的生产力。
结束语
让我们开始使用它,感受不同。我已经使用 Poe Free 三个月了,并且不打算回到官方的 ChatGPT 或 Bard。如果我想从 ChatGPT 生成回复,我会在 Poe 中切换模型。就是这么简单快捷。
如果你有兴趣了解我如何利用其他 AI 工具来提升我的数据科学和内容创作技能,请在评论中告诉我,我将来会写关于这些工具的文章。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专家,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些与心理健康问题斗争的学生。
了解更多相关信息
为什么你应该忘记数据科学代码中的for-loop,而拥抱向量化
原文:
www.kdnuggets.com/2017/11/forget-for-loop-data-science-code-vectorization.html
评论

我们都曾经使用for-loops来处理需要遍历长列表元素的大多数任务。我相信几乎所有阅读这篇文章的人,在高中或大学时,都用 for-loop 编写了他们的第一个矩阵或向量乘法代码。for-loop 长久以来一直服务于编程社区。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
然而,它也带来了一些问题,当处理大型数据集(如当今大数据时代的数百万条记录)时,执行速度往往较慢。这对于像 Python 这样的解释型语言尤其如此,如果你的循环体很简单,循环本身的解释器开销可能是相当大的开销。
幸运的是,在几乎所有主要编程生态系统中都有替代方案。Python 有一个很棒的选择。
Numpy,简写自Numerical Python,是 Python 生态系统中进行高性能科学计算和数据分析所需的基础包。它是几乎所有更高级工具如Pandas和scikit-learn的基础。TensorFlow使用 NumPy 数组作为基本构建块,在此基础上构建了他们的 Tensor 对象和用于深度学习任务的 graphflow(这在长列表/向量/矩阵数字上的线性代数操作中使用频繁)。
Numpy 提供的两个最重要的优势是:
-
ndarray,一个快速且节省空间的多维数组,提供向量化的算术操作和复杂的广播功能 -
进行快速数据数组操作的标准数学函数无需编写循环
你会经常听到数据科学、机器学习和 Python 社区中的说法,即由于其向量化实现和许多核心例程用 C 编写,Numpy 的速度要快得多(基于CPython 框架)。
这确实是事实(这篇文章是一个很好的演示,展示了与 Numpy 一起使用的各种选项,甚至使用 Numpy API 编写裸骨的 C 例程)。Numpy 数组是同质类型的紧密打包数组。相比之下,Python 列表是指向对象的指针数组,即使它们都是同一类型。因此,你可以获得引用局部性的好处。许多 Numpy 操作是用 C 实现的,避免了 Python 中循环的通用开销、指针间接访问以及每个元素的动态类型检查。速度提升取决于你正在执行的操作。[对于数据科学和现代机器学习任务,这是一个宝贵的优势],因为数据集的大小通常达到百万,甚至亿万记录,你不想使用 for 循环及其相关负担来迭代处理它。
如何通过一个中等大小数据集的例子来明确证明这一点?
这是我 Github 代码的链接(Jupyter notebook),它展示了在几行简易代码中,Numpy 操作与常规 Python 编程构造如for 循环、map 函数或列表推导式的速度差异。
我只是概述基本流程:
-
创建一个中等数量的浮点数列表,最好从类似高斯或均匀随机的连续统计分布中抽取。我选择了 100 万个作为演示。
-
从列表中创建一个
ndarray对象,即向量化。 -
编写简短的代码块来遍历列表,并对列表执行数学操作,例如取 10 为底的对数。使用 for 循环、map 函数和列表推导式。每次使用
time.time()函数来确定处理 100 万条记录所需的总时间。
t1=time.time()
for item in l1:
l2.append(lg10(item))
t2 = time.time()
print("With for loop and appending it took {} seconds".format(t2-t1))
speed.append(t2-t1)
- 使用 Numpy 的内置数学方法 (
np.log10) 对ndarray对象执行相同操作。计时。
t1=time.time()
a2=np.log10(a1)
t2 = time.time()
print("With direct Numpy log10 method it took {} seconds".format(t2-t1))
speed.append(t2-t1)
- 将执行时间存储在列表中,并绘制一个条形图以显示比较差异。
这是结果。你可以通过运行 Jupyter notebook 中的所有单元格重复整个过程。每次都会生成一组新的随机数字,因此确切的执行时间可能会有些许变化,但总体趋势将始终相同。你可以尝试其他数学函数/字符串操作或其组合,以检查这种情况是否普遍适用。
这是一本由法国神经科学研究员编写的开源在线书籍,涉及这一主题。在这里查看。

简单数学操作的执行速度比较条形图
如果你有任何问题或想分享的想法,请通过tirthajyoti[AT]gmail.com联系作者。你也可以查看作者的GitHub 仓库,获取更多有趣的 Python、R 或 MATLAB 代码片段以及机器学习资源。
个人简介:Tirthajyoti Sarkar 是半导体技术专家、机器学习/数据科学热衷者、电气工程博士、博客作者和作家。
原文。经许可转载。
相关:
-
使用 Numpy 矩阵的实用参考
-
科学 Python 简介(及其背后的数学) – NumPy
-
Python 数据准备案例文件:基于组的插补
相关阅读
忘记 PIP、Conda 和 requirements.txt!改用 Poetry,稍后感谢我
原文:
www.kdnuggets.com/2023/07/forget-pip-conda-requirementstxt-poetry-instead-thank-later.html

图片由我使用 Midjourney 制作
库 A 需要 Python 3.6。库 B 依赖于库 A,但需要 Python 3.9,库 C 依赖于库 B,但需要与 Python 3.6 兼容的库 A 的特定版本。
欢迎来到依赖地狱!
由于没有外部数据科学包的原生 Python 很差劲,数据科学家经常发现自己陷入如上所示的两难依赖情况。
像 PIP、Conda 或可笑的 requirements.txt 文件这样的工具无法解决这个问题。实际上,依赖地狱在很大程度上正是由于它们的存在。因此,为了结束这些痛苦,Python 开源社区开发了名为 Poetry 的迷人工具。
Poetry 是一个集成的项目和依赖管理框架,在 GitHub 上拥有超过 25k 星标。本文将介绍 Poetry,并列出它为数据科学家解决的问题。
开始吧。
安装
虽然 Poetry 可以通过 PIP 安装为库,但建议将其系统范围内安装,以便你可以在任何地方的 CLI 上调用 poetry。以下是适用于 Unix 类系统的安装脚本命令,包括 Windows WSL2:
curl -sSL https://install.python-poetry.org | python3 -
如果因为某些奇怪的原因,你使用 Windows Powershell,以下是适用的命令:
(Invoke-WebRequest -Uri https://install.python-poetry.org -UseBasicParsing).Content | py -
要检查 Poetry 是否正确安装,你可以运行:
$ poetry -v
Poetry (version 1.5.1)
Poetry 还支持各种 Shell(如 Bash、Fish、Zsh 等)的 Tab 补全。了解更多信息 在这里。
1. 所有项目的结构一致
由于 Poetry 是一款集成工具,你可以从项目开始到结束都使用它。
当开始一个新项目时,你可以运行 poetry new project_name。它将创建一个几乎准备好构建和发布到 PyPI 的默认目录结构:
$ poetry new binary_classification
Created package binary_classification in binary_classification
$ ls binary_classification
README.md binary_classification pyproject.toml tests
$ tree binary_classification/
binary_classification
├── pyproject.toml
├── README.md
├── binary_classification
│ └── __init__.py
└── tests
└── __init__.py
但我们数据科学家很少创建 Python 包,因此建议你自己开始项目,并在其中调用 poetry init:
$ mkdir binary_classification
$ poetry init
CLI 会询问你一系列设置问题,但你可以将大多数留空,因为它们可以稍后更新:

GIF. 由我制作。
init 命令会生成 Poetry 的最重要文件 - pyproject.toml。该文件包含一些项目元数据,但最重要的是,它列出了依赖项:
$ cat pyproject.toml
[tool.poetry]
name = "binary-classification"
version = "0.1.0"
description = "A binary classification project with scikit-learn."
authors = ["Bex Tuychiev <bex>"]
readme = "README.md"
packages = [{include = "binary_classification"}]
[tool.poetry.dependencies]
python = "³.9"
[build-system]
requires = ["poetry-core"]
build-backend = "poetry.core.masonry.api"</bex>
目前,tool.poetry.dependencies 下唯一的依赖项是 Python 3.9(我们稍后将了解 ^ 的含义)。让我们添加更多库。
如果你想了解
pyproject.toml文件中的所有字段的作用,请跳转到 这里。
2. 依赖项规格说明
要为你的项目安装依赖项,你不再需要直接使用 PIP 或 Conda。相反,你将开始使用 poetry add library_name 命令。
这是一个示例:
$ poetry add scikit-learn@latest
添加 @latest 标志会从 PyPI 安装 Sklearn 的最新版本。也可以在没有任何标志(约束)的情况下添加多个依赖项:
$ poetry add requests pandas numpy plotly seaborn
add 的美妙之处在于,如果指定的包没有任何版本约束,它会找到所有包的版本,使其能够解决,即在一起安装时不会抛出任何错误。它还会检查 pyproject.toml 中已经指定的依赖项。
$ cat pyproject.toml
[tool.poetry]
...
[tool.poetry.dependencies]
python = "³.9"
numpy = "¹.25.0"
scikit-learn = "¹.2.2"
requests = "².31.0"
pandas = "².0.2"
plotly = "⁵.15.0"
seaborn = "⁰.12.2"
让我们尝试将 numpy 降级到 v1.24,看看会发生什么:
$ poetry add numpy==1.24
...
Because seaborn (0.12.2) depends on numpy (>=1.17,<1.24.0 || >1.24.0) ...
version solving failed.
Poetry 不会允许这种情况发生,因为降级版本会与 Seaborn 冲突。如果这是 PIP 或 conda,它们会很乐意安装 Numpy 1.24,然后对我们露出笑容,随着噩梦的开始。
除了标准安装,Poetry 提供了一种多功能的语法来定义版本约束。这种语法允许你指定确切版本,设置版本范围的边界(大于、小于或介于之间),并固定主版本、次版本或补丁版本。以下表格取自 Poetry 文档(MIT 许可证),作为示例。
脚本要求:

波浪号要求:

通配符要求:

欲了解更多高级约束规格说明,请访问 Poetry 文档的 这个页面。
3. 环境管理
Poetry 的核心特性之一是以最有效的方式将项目环境与全局命名空间隔离。
当你运行 poetry add library 命令时,发生的情况如下:
-
如果你在已经激活虚拟环境的现有项目中初始化了 Poetry,
library将被安装到该环境中(它可以是任何环境管理器,如 Conda、venv 等)。 -
如果你创建了一个空项目,使用
poetry new或在没有激活虚拟环境时使用init初始化 Poetry,Poetry 会为你创建一个新的虚拟环境。
当情况 2 发生时,结果环境将位于 /home/user/.cache/pypoetry/virtualenvs/ 文件夹下。Python 可执行文件也会在某处。
要查看当前激活的 Poetry 创建的环境,你可以运行poetry env list:
$ poetry env list
test-O3eWbxRl-py3.6
binary_classification-O3eWbxRl-py3.9 (Activated)
要在 Poetry 创建的环境之间切换,你可以运行poetry env use命令:
$ poetry env use other_env
你可以从这里了解更多关于环境管理的知识。
4. 完全可复现的项目
当你运行add命令时,Poetry 会生成一个poetry.lock文件。它不会像1.2.*那样指定版本约束,而是锁定你使用的库的确切版本,比如1.2.11。所有后续的poetry add或poetry update运行将修改锁定文件以反映变化。
使用这样的锁定文件可以确保使用你项目的人能够在他们的机器上完全复现环境。
人们长期以来使用像requirements.txt这样的替代品,但其格式非常松散且容易出错。一个典型的人为创建的requirements.txt并不全面,因为开发人员通常不愿意列出他们使用的确切库版本,只是说明版本范围,或者更糟糕的是,简单地写下库名称。
然后,当其他人尝试用pip install -r requirements.txt复现环境时,PIP 自身尝试解决版本约束,这就是为什么你最终可能会遇到依赖地狱的原因。
使用 Poetry 和锁定文件时,这种情况不会发生。因此,如果你在一个已经存在requirements.txt的项目中初始化 Poetry,你可以通过以下方式将依赖添加进去:
$ poetry add `cat requirements.txt`
并删除requirements.txt。
但请注意,像 Streamlit 或 Heroku 这样的服务仍然需要旧的requirements.txt文件用于部署。在使用这些服务时,你可以通过以下命令将你的poetry.lock文件导出为文本格式:
$ poetry export --output requirements.txt
要遵循的工作流程
我希望留下这篇文章,提供一个将 Poetry 集成到任何数据项目中的逐步工作流程。
步骤 0: 安装 Poetry 以适配你的系统。
步骤 1: 使用mkdir创建一个新项目,然后在其中调用 [poetry init](https://python-poetry.org/docs/cli/#init)来初始化 Poetry。如果你想将项目转换为 Python 包,可以使用`[poetry new project_name](https://python-poetry.org/docs/cli/#new)`创建项目。
py` 第 2 步:使用 poetry add lib_name 安装并添加依赖项。也可以手动编辑 pyproject.toml 文件,将依赖项添加到 [tool.poetry.dependencies] 部分。在这种情况下,你需要运行 poetry install 来解决版本约束并安装库。完成这一步后,Poetry 会为项目创建一个虚拟环境,并生成一个 `poetry.lock` 文件。 第 3 步:初始化 Git 和其他工具,如 [DVC](https://medium.com/towards-data-science/data-version-control-for-the-modern-data-scientist-7-dvc-concepts-you-cant-ignore-bb2433ccec88),并开始跟踪相关文件。将 `pyproject.toml` 和 `poetry.lock` 文件放到 Git 下。 第 4 步:开发你的代码和模型。要运行 Python 脚本,必须使用 `poetry run python script.py`,以便使用 Poetry 的虚拟环境。 第 5 步:测试你的代码并进行必要的调整。对数据分析或机器学习算法进行迭代,尝试不同的技术,并根据需要优化你的代码。 可选步骤: 1. 要更新已安装的依赖项,请使用 `poetry update library` 命令。`update` 仅在 `pyproject.toml` 内的约束条件下工作,因此请查看 [这里的警告](https://python-poetry.org/docs/managing-dependencies/)。 2. 如果你从带有 requirements.txt 的项目开始,可以使用 poetry add cat requirements.txt 来自动添加和安装依赖项。 3. 如果你想导出 `poetry.lock` 文件,可以使用 `poetry export --output requirements.txt`。 4. 如果你为项目选择了包结构 (`poetry add`),可以使用 `poetry build` 构建包,准备好推送到 PyPI。 5. 使用 `poetry env use other_env` 在虚拟环境之间切换。 通过这些步骤,你将确保不会再次陷入依赖地狱。 感谢阅读! **[Bex Tuychiev](https://www.linkedin.com/in/bextuychiev/)** 是 Medium 上的前 10 名 AI 作者和 Kaggle 大师,拥有超过 15k 的关注者。他喜欢撰写详细的指南、教程和笔记本,涉及复杂的数据科学和机器学习主题,风格略带讽刺。 [原文](https://medium.com/towards-artificial-intelligence/forget-pip-conda-requirements-txt-use-poetry-instead-and-thank-me-later-226a0bc38a56)。转载许可。 * * * ## 我们的前 3 个课程推荐  1. [Google 网络安全证书](https://www.kdnuggets.com/google-cybersecurity) - 快速进入网络安全职业的快车道。  2. [Google 数据分析专业证书](https://www.kdnuggets.com/google-data-analytics) - 提升你的数据分析技能  3. [Google IT 支持专业证书](https://www.kdnuggets.com/google-itsupport) - 支持你的组织 IT * * * ### 更多相关主题 * [用 Poetry 与 Conda 和 Pip 管理 Python 依赖项](https://www.kdnuggets.com/managing-python-dependencies-with-poetry-vs-conda-pip) * [停止在数据科学项目中硬编码 - 改用配置文件](https://www.kdnuggets.com/2023/06/stop-hard-coding-data-science-project-config-files-instead.html) * [你应该使用线性回归模型的 3 个理由,而不是…](https://www.kdnuggets.com/2021/08/3-reasons-linear-regression-instead-neural-networks.html) * [忘记 ChatGPT,这个新 AI 助手领先数倍,将…](https://www.kdnuggets.com/2023/08/forget-chatgpt-new-ai-assistant-leagues-ahead-change-way-work-forever.html) * [Pip 安装 YOU:创建 Python 库的初学者指南](https://www.kdnuggets.com/pip-install-you-a-beginners-guide-to-creating-your-python-library) * [KDnuggets™ 新闻 22:n06,2 月 9 日:数据科学编程…](https://www.kdnuggets.com/2022/n06.html) py
忘记讲故事;帮助人们导航
原文:
www.kdnuggets.com/2021/03/forget-telling-stories-help-people-navigate.html
评论
优秀的报告和可视化应该创建一个行动路径,引导用户通过分析过程并最终采取行动以改善业务。目标不仅仅是讲述故事,而是帮助用户从数据到行动。
以下是该框架的简单信息图:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT

点击图片放大
让我们从“当前状态”的一批关键绩效指标(KPI)开始。这些是你会放在高管仪表板上的主要可视化图表。它们让人们对业务中的关键指标有一个整体的了解。那么,哪些 KPI 能够讲述组织的当前故事呢?
下一步是寻找显著的信号、变化或事件。在我们的报告中,我们应该使用明亮的颜色和引人注目的图标来突出变化的数据。
每个主要 KPI 和警报都需要配备一个或多个深入挖掘的路径来探索细节。这些是补充的可视化图表。深入挖掘的路径需要简单且清晰地链接。理想情况下,每个部门或业务流程都有自己的深入挖掘区域或文件夹。
现在我们必须超越单纯的数据倾倒。人们希望被引导到推荐路线来解决问题。并不是每个图表中的每个变化都有一个自动推荐的最佳路线,但许多有。如果某个 SKU 的库存低,有几个跟随的路线,那为何不直接在报告上标记出来呢?如果一个部门的成本增长快于计划,你是否有标准的方法来解决问题?如果有,那么就列出那些标准行动,正好在信息需要和有用的地方,因为信息被消耗时。
最后,我们需要通过在报告中嵌入链接到相关应用程序来帮助用户采取行动。如果库存低,下面的 KPI 下方添加一个链接到仓库管理软件。如果某个地区的销售额下降,在 KPI 的底部添加一个链接到 Salesforce 或你的 CRM 系统以便后续跟进。
我们可以通过使用框架中的五个步骤将我们的报告工具转变为导航工具。
简介: Stan Pugsley 是一位数据仓库和分析顾问,隶属于总部位于犹他州盐湖城的Eide Bailly 技术咨询公司。他还是犹他大学 Eccles 商学院的兼职教授。你可以通过电子邮件联系作者。
相关:
-
讲述一个精彩的数据故事:一个可视化决策树
-
数据科学与商业智能的比较解析
-
每个数据科学家应该知道的 5 个概念
更多相关话题
被遗忘的算法
原文:
www.kdnuggets.com/2020/02/forgotten-algorithm-monte-carlo-simulation.html
评论
由 Ian Xiao,Dessa 的参与负责人
TL;DR — 当我们谈论机器学习时,我们通常会想到监督学习和无监督学习。在这篇文章中,我想讨论一个经常被遗忘但同样强大的算法:蒙特卡洛模拟。我将分享一个通用设计框架和一些技术,并提供一个互动工具。最后,你还可以在文章末尾找到一些好的模拟工具列表。
免责声明: 这不是由 Streamlit 赞助的,也不是我提到的任何工具或我工作的任何公司赞助的。我将数据科学和机器学习视为可互换的。*
喜欢你读到的内容? 关注我在 Medium、LinkedIn 和 Twitter 上。
不应得的那个
在近期的机器学习(ML)崛起中,监督学习和无监督学习算法,如使用 深度学习 的分类和使用 KNN 的聚类,得到了大多数关注。当这些算法获得热情社区的高度赞扬时,一些同样强大而优雅的技术却在角落里静静地等待。它的名字是 蒙特卡洛 — 这个在原子物理学、现代金融和赌博中被遗忘而不应得的英雄(或者说是恶棍,这取决于你对这些问题的看法)。
注意:为了简洁,我将监督学习和无监督学习方法称为“ML 算法”,将蒙特卡洛方法称为“模拟”。
简短历史
斯坦尼斯瓦夫·乌拉姆、恩里科·费米 和 约翰·冯·诺伊曼 — 洛斯阿拉莫斯的天才们 — 在 1930 年代发明、改进并推广了蒙特卡洛方法,目的并不那么高尚 (提示:不是为了原子弹)。观看视频了解更多。
蒙特卡洛模拟简短历史(YouTube)
什么是蒙特卡洛模拟?
如果我用一句话总结蒙特卡洛模拟,这里是:假装做一亿次,直到我们大概知道现实是什么。
在技术(和更严肃的)层面上,蒙特卡洛方法的目标是 近似 结果的期望,以考虑各种输入、不确定性和系统动态。这个视频介绍了一些对有兴趣的人来说的高级数学。
蒙特卡洛近似,YouTube
为什么使用模拟?
如果我必须强调仿较于机器学习算法的一个(过于简单化的)优势,那就是:探索。我们使用仿真来理解任何规模系统的内部工作(例如:世界、社区、公司、团队、个人、车队、汽车、车轮、原子等)
通过虚拟仿真重新创建系统,我们可以计算和分析假设结果,而无需实际改变世界或等待真实事件发生。换句话说,仿真允许我们提出大胆的问题并制定战术来管理各种未来结果,而风险和投资相对较小。
什么时候使用仿真,而不是机器学习?
根据本杰明·舒曼,一位著名的仿真专家,仿真是过程驱动的,而机器学习是数据中心的。要产生良好的仿真效果,我们需要理解系统的过程和基本原理。相比之下,我们可以仅通过使用数据仓库中的数据和一些现成的算法来创建合理的预测。
换句话说,创建良好的仿真在财务和认知上通常更昂贵。我们为什么还要使用仿真?
好吧,考虑三个简单的问题:
-
你是否在数据仓库中有数据来表示业务问题?
-
你是否有足够的数据——无论是数量上还是质量上——来构建一个好的机器学习模型?
-
预测是否比探索更重要(例如,提出假设性问题并制定支持业务决策的战术)?
如果你对这些问题的回答是“否”,那么你应该考虑使用仿真而不是机器学习算法。
如何设计蒙特卡洛仿真?
要创建一个蒙特卡洛仿真,至少需要遵循一个 3 步过程:

仿真过程,作者分析
如你所见,创建一个蒙特卡洛仿真仍然需要数据,更重要的是,需要对系统动态有一定了解(例如销售量和价格之间的关系)。要获得这种知识,通常需要与专家交谈,研究流程,以及观察实际业务操作。
Yet Another Simulator
要查看基本概念如何实现,你可以访问Yet Another Simulator——这是我使用Streamlit开发的一个交互式工具。
在欢迎页面上,你可以尝试各种输入设置,并观察根据你应用的函数,结果如何变化。

Yet Another Simulator的欢迎页面,作者的工作
除了基本示例外,该工具还包括 4 个案例研究,讨论了各种设计技术,如影响图、敏感性分析、优化和将机器学习与仿真相结合。
例如,在CMO 示例中,我讨论了如何使用影响图来帮助设计一个模拟以解决广告预算分配问题。

影响图,作者的工作
最终,你将踏入数据科学家的角色,建议首席营销官(CMO)。你的目标是帮助 CMO 决定广告支出金额,探索各种情景,并提出在不同不确定性下最大化回报的策略。

广告预算分配,作者的工作
我希望这些示例能说明蒙特卡罗模拟的工作原理,它相较于机器学习算法的优势,以及如何使用不同的设计技巧设计有用的模拟。
一些案例研究仍在积极开发中。请在此处注册,以便在它们准备好时接到通知。
总结
我希望这篇文章提供了对蒙特卡罗方法的另一种视角;在今天的机器学习讨论中,我们常常忽视这样一个有用的工具。模拟具有许多传统机器学习算法无法提供的优势——例如,在巨大不确定性下探索重大问题的能力。
在即将发布的文章中,我将讨论如何在实际商业环境中结合机器学习和模拟以获得两者的最佳效果,以及如何阐明不同模拟情景的含义。
通过关注我的Medium、LinkedIn或Twitter保持关注。**
下次见,
伊恩
如果你喜欢这篇文章,你可能也会喜欢这些:
如何使用 Streamlit 和 DevOps 工具构建和部署机器学习应用
如何不在机器学习项目中应用敏捷
我如何应对部署机器学习的无聊日子
数字、五种战术解决方案和快速调查
很多数据科学家没充分考虑的一件事
如何为现实世界设计和实现强化学习
流行工具
当我讨论仿真时,很多人会询问工具建议。这里有一份我了解的工具列表,选择适合你需求的工具。请享用。
-
AnyLogic (这可能是模拟专业人士的首选工具;免费增值)
-
Simio (免费增值)
-
Yasai (Excel 插件,免费)
-
Oracle Crystal Ball (免费增值)
-
SimPy (Python 包,免费)
-
Hash (创企,当前处于隐秘模式。创始团队相当强大。可能是免费增值)
参考资料
决策树的历史 — pages.stat.wisc.edu/~loh/treeprogs/guide/LohISI14.pdf
聚类的历史 — link.springer.com/chapter/10.1007/978-3-540-73560-1_15
将仿真与机器学习结合的时机 — www.benjamin-schumann.com/blog/2018/5/7/time-to-marry-simulation-models-and-machine-learning
仿真的分类 — gamingthepast.net/theory-practice/simulation-design-guide/
蒙特卡洛方法及其工作原理 — www.palisade.com/risk/monte_carlo_simulation.asp
简介:Ian Xiao 是 Dessa 的参与负责人,负责在企业中部署机器学习。他领导业务和技术团队部署机器学习解决方案,并为 F100 企业改进市场营销和销售。
原文. 经许可转载。
相关:
-
数据科学很无聊(第一部分)
-
我们创建了一个懒惰的 AI
-
12 小时机器学习挑战:使用 Streamlit 和 DevOps 工具构建并部署应用
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT 工作
更多相关话题
Forrester 与 Gartner 关于数据科学平台和机器学习解决方案的对比
原文:
www.kdnuggets.com/2017/04/forrester-gartner-data-science-platforms-machine-learning.html
评论 上个月,领先的分析公司 Forrester 发布了他们的“ Forrester Wave™”:2017 年第一季度预测分析和机器学习解决方案报告,由 Mike Gualtieri 编写。
预测分析和机器学习是现在最重要的技术之一,正如 KDnuggets 读者所知,Forrester 预计 PAML 市场在 2021 年前将实现 15% 的复合年增长率(CAGR)。
报告审查并评估了 14 家公司的战略、当前产品和市场表现。结果汇总在图 1 中。
图 1: Forrester Wave™:预测分析和机器学习解决方案,2017 年第一季度
(来源:Forrester Research, Inc. 未经授权的复制、引用或分发均被禁止)
领导者:
-
SAS 重新构想其数据科学产品组合 并将其数据科学解决方案整合到 SAS Visual Suite 下。它将世界一流的数据准备、可视化、数据分析、模型构建和模型部署集于一体。
-
IBM 喜爱开源。 SPSS 仍然是 IBM 数据科学平台的核心,但 IBM 还推出了来自 Spark 技术中心的 SystemML,并为数据科学编程者引入了数据科学体验。
-
SAP 将预测模型与业务应用直接连接。 SAP 提供全面的数据科学工具来构建模型,同时也是全球最大的企业应用公司。
-
Angoss 准备好成为你的主要解决方案。 Angoss KnowledgeSEEKER 是数据科学团队必备的工具,它通过美观且全面的可视化工具帮助构建决策和策略树。
-
RapidMiner 将广度和深度融入美丽的包装中。 RapidMiner 大力投资重新设计其视觉界面,使其成为我们在此次评估中见过的最简洁和流畅的界面。
-
KNIME 的充满活力的开源社区提高了生产力。 KNIME 不是大公司,但它拥有一个大社区的贡献者,不断推动平台向前发展,如生物信息学和图像处理等功能。
-
FICO 通过模型使企业决策更智能。 FICO 的广泛实际经验造就了一种解决方案,专注于大型组织中首席数据科学家和普通数据科学家的需求。
强劲表现者:
-
H2O.ai 将算法放在首位。 H2O.ai 以开发开源、集群分布式机器学习算法而闻名,这些算法早在 2011 年当大数据需求迫切时便已存在。H2O 还提供 Sparkling Water 用于在 Apache Spark 上创建、管理和运行工作流,并提供 Steam 用于部署模型。
-
Microsoft 不仅仅是企业的 R 解决方案。 Microsoft 为希望使用 R 编程语言的 数据科学家 提供 Microsoft R,该语言支持可调用的集群分布式算法。它还为希望使用更传统可视化开发工具的数据科学家提供 Azure Machine Learning。
-
Alpine Data 专注于协作。 Alpine Data 的可视化工具为数据工程师、数据科学家和业务利益相关者提供了分工合作构建模型的能力。
-
Dataiku 实现了代码与点击的完美结合。 Dataiku(名字受到日本俳句的启发)提供的数据科学平台允许编码人员在需要时使用笔记本,但在生产力关键时使用可视化工具来构建工作流。
-
Statistica 又一次找到了新家。 Statistica 成立于 1984 年,最初名为 Statsoft,并于 2014 年被 Dell 收购。现在,它成为了新重启的 Quest Software 的一部分。
竞争者:
-
Domino Data Labs 希望编码人员在开源环境中协作,该解决方案旨在整合最流行的开源编码工具和库,为数据科学编码团队提供统一的界面。
-
Salford Systems 强调准确性和自动化,并因其实施特定方法(如 CART、MARS、Random Forests 和 TreeNet)而受到大大小小客户的喜爱。
这些排名与
我尝试了类似 Gartner 报告 的重叠式比较,但结果图像过于拥挤,难以阅读。所以这里是一些亮点:
-
保持领导者地位:SAS、IBM、SAP
-
从 2015 年的强劲表现者到 2017 年的领导者:RapidMiner、KNIME、Angoss、FICO
-
保持强劲表现者地位:Microsoft(在产品提供上有所提升)、Alpine Data、Statistica/Quest(在战略上有所下降)
-
2017 年的新加入者:Domino Data Labs、Dataiku、H20.ai、Salford Systems
-
2017 年下滑的公司:Alteryx、Predixion Software、Oracle
Forrester 的评估与 Gartner 2017 Magic Quadrant for Data Science Platforms 的比较如何?
Gartner 和 Forrester 使用不同的方法论,但在两种情况下,代表公司距离图表左下角的圆圈越远,表现越好。我们测量了每家公司这一距离,将其标准化,使最大距离为 95,最小距离为 5,并在下图 Figure 2 中绘制。
在 Gartner 或 Forrester 图表中都未出现的公司距离值为负(-1)。

图 2:2017 年 Q1 Gartner 与 Forrester 对数据科学、预测分析和机器学习平台的评估
圆圈的大小对应于估计的供应商规模,颜色为 Forrester 标签,形状(圆圈的填充程度)为 Gartner 标签。
总共涉及 17 家公司:13 家同时出现在两个报告中,3 家仅出现在 Gartner(下文简称 G)中,1 家仅出现在 Forrester(下文简称 F)中。
我们看到几个集群:
-
强劲领导者:SAS、IBM、RapidMiner 和 KNIME 被 G 和 F 都评为领导者。
-
领导者:Angoss、SAP 和 FICO 在 F 中是领导者,但在 G 中仅为利基/远见者。
-
强劲竞争者:H2O.ai、微软和 Statistica/Quest 在 F 中是强劲表现者,在 G 中是远见者/挑战者
-
竞争者:Alpine Data、Domino、Dataiku:F 中的强劲表现者/竞争者,G 中的远见者
-
玩家:Salford Systems、Teradata、Alteryx、MathWorks:只有一个排名
如果您是客户,可以从Forrester获取 Forrester Wave™: 预测分析与机器学习解决方案,Q1 2017,或从SAP、RapidMiner或报告中好评提到的其他公司下载。
相关:
-
Forrester Wave™ 大数据预测分析 2015:赢家与输家
-
Gartner 数据科学平台 – 更深入的分析
-
Gartner 2017 年数据科学平台魔力象限:赢家与输家
更多相关话题
什么是基础模型,它们如何工作?

图片来自 Adobe Firefly
什么是基础模型?
基础模型是建立在大量数据基础上的预训练机器学习模型。这是人工智能(AI)领域的一项突破性发展。由于它们能够从大量数据中学习并适应广泛的任务,这些模型作为各种 AI 应用的基础。它们在庞大的数据集上进行预训练,并可以微调以执行特定任务,使其非常灵活和高效。
基础模型的例子包括用于自然语言处理的 GPT-3 和用于计算机视觉的 CLIP。在这篇博客中,我们将深入探讨基础模型是什么,它们是如何工作的,以及它们对不断发展的人工智能领域的影响。
基础模型的工作原理
基础模型,如 GPT-4,通过在大规模数据语料库上预训练一个巨大的神经网络,然后在特定任务上对模型进行微调,从而使其能够在语言任务上执行广泛的操作,且只需最少的任务特定训练数据。
预训练与微调
在大规模无监督数据上进行预训练:基础模型通过从大量无监督数据中学习来开始其旅程,例如来自互联网的文本或大型图像集合。这个预训练阶段使模型能够掌握数据中的基本结构、模式和关系,帮助它们形成强大的知识基础。
在任务特定标记数据上进行微调:预训练后,基础模型使用较小的标记数据集对特定任务进行微调,例如情感分析或物体检测。这一微调过程使模型能够提高技能,并在目标任务上表现出色。
迁移学习与零样本能力
基础模型在迁移学习中表现出色,迁移学习指的是它们将从一个任务中获得的知识应用于新的相关任务的能力。一些模型甚至展示了零样本学习能力,这意味着它们可以在没有任何微调的情况下处理任务,仅依赖于预训练期间获得的知识。
模型架构与技术
变换器在自然语言处理(例如,GPT-3,BERT):变换器以其创新的架构彻底改变了自然语言处理(NLP),使得语言数据的处理更加高效和灵活。NLP 基础模型的例子包括 GPT-3,它在生成连贯文本方面表现出色,而 BERT 在各种语言理解任务中表现出色。
视觉变换器和多模态模型(例如,CLIP,DALL-E):在计算机视觉领域,视觉变换器作为处理图像数据的强大方法已经出现。CLIP 是一种多模态基础模型,能够理解图像和文本。DALL-E 另一个多模态模型,展示了从文本描述生成图像的能力,展示了将自然语言处理和计算机视觉技术结合在基础模型中的潜力。
基础模型的应用
自然语言处理
情感分析:基础模型在情感分析任务中表现出色,它们根据文本的情感对其进行分类,如积极、消极或中立。这一能力在社交媒体监测、客户反馈分析和市场研究等领域得到了广泛应用。
文本摘要:这些模型还可以生成长文档或文章的简明摘要,使用户能够快速掌握要点。文本摘要具有许多应用,包括新闻聚合、内容策划和研究辅助。
计算机视觉
目标检测:基础模型在识别和定位图像中的对象方面表现出色。这一能力在自动驾驶汽车、安全监控系统和机器人等应用中尤为重要,因为准确的实时目标检测至关重要。
图像分类:另一个常见的应用是图像分类,基础模型根据图像内容对其进行分类。这一能力已被用于各种领域,从组织大型照片收藏到利用医学影像数据诊断医疗条件。
多模态任务
图像描述:通过利用对文本和图像的理解,多模态基础模型可以生成图像的描述性字幕。图像描述在视觉障碍用户的辅助工具、内容管理系统和教育材料中具有潜在用途。
视觉问答:基础模型还可以处理视觉问答任务,它们提供关于图像内容的问题的答案。这一能力为客户支持、互动学习环境和智能搜索引擎等应用开辟了新可能。
未来的前景和发展
模型压缩和效率的进展
随着基础模型变得越来越大和复杂,研究人员正在探索压缩和优化它们的方法,以便在资源有限的设备上部署,并减少其能源足迹。
改进应对偏见和公平性的技术
解决基础模型中的偏见对于确保公平和伦理的 AI 应用至关重要。未来的研究可能会集中于开发识别、衡量和减轻训练数据和模型行为中偏见的方法。
开源基础模型的合作努力
AI 社区正日益协作,创建开源基础模型,促进合作、知识共享和对尖端 AI 技术的广泛访问。
结论
基础模型代表了 AI 的重大进步,能够在自然语言处理、计算机视觉和多模态任务等多个领域应用高性能的多功能模型。
基础模型对 AI 研究和应用的潜在影响
随着基础模型的不断发展,它们可能会重塑 AI 研究并推动众多领域的创新。它们在启用新应用和解决复杂问题方面的潜力巨大,预示着一个 AI 日益融入我们生活的未来。
Saturn Cloud 是一个灵活的数据科学和机器学习平台,支持 Python、R 等多种语言。进行扩展、协作,并利用内置的管理功能来帮助你运行代码。启动一个具有 4TB RAM 的笔记本,添加 GPU,连接到分布式工作集群等等。Saturn 还自动化了 DevOps 和 ML 基础设施工程,让你的团队可以专注于分析。
原文。经授权转载。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关信息
数据科学基础:免费电子书
原文:
www.kdnuggets.com/2020/07/foundations-data-science-free-ebook.html
评论
我们本周再次推出了新的免费电子书。这次我们将讨论一本名为数据科学基础的书,作者是 Avrim Blum、John Hopcroft 和 Ravindran Kannan。这本书的名字本身就表明了它的重要性。幸运的是,它的内容也确实支持了这一点。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织的 IT
首先,这本书的结构与典型的数据科学书籍不同。在我看来,它的章节及其进展并不符合标准当代数据科学教材的模式。从下面列出的目录可以看出,该书真正地涵盖了广泛的不同主题,而不是简单地将数据科学与机器学习等同起来,并按照这种方式进行进展:
-
引言
-
高维空间
-
最佳拟合子空间和奇异值分解(SVD)
-
随机游走和马尔可夫链
-
机器学习
-
大规模数据问题的算法:流处理、草图绘制和抽样
-
聚类
-
随机图
-
主题模型、非负矩阵分解、隐马尔可夫模型和图模型
-
其他主题
-
小波
-
附录
书中涵盖了各种高级主题,并且早期就包括了关于高维空间、子空间以及随机游走或马尔可夫链的章节,这增强了该书的概述风格。这也让我想起另一部你可能熟悉的数据科学经典书籍,大规模数据集挖掘。强调这本书侧重于“基础”,你不会在其中找到最新的神经网络架构。然而,如果你希望最终理解一些更复杂的数据科学问题解决方法的原因和原理,那么你会发现《数据科学基础》是很有用的。
矩阵分解、图论、核方法、聚类理论、流处理、梯度下降、数据采样;这些都是你在解决数据科学问题时将会大有裨益的概念,它们也是实现更复杂方法的基本构建块。如果没有梯度下降,你无法理解神经网络。如果没有图论,你不能分析社交媒体网络。如果你不能理解何时及为何从数据中采样,你构建的模型将毫无价值。
与我们最近介绍的其他一些书籍(例如统计学习的元素和理解机器学习)类似,这本书无所顾忌地理论化。书中没有代码,没有依赖的 Python 库,也没有含糊其辞。只有深入的解释,帮助你理解这些不同的主题,只要你愿意花时间阅读。
作者撰写此书的动机在书籍介绍的这一摘录中得到了体现:
虽然计算机科学的传统领域仍然非常重要,但未来的研究人员将越来越多地涉及使用计算机从大量数据中理解和提取可用信息,而不仅仅是如何在特定明确定义的问题上使计算机有用。考虑到这一点,我们编写了这本书,涵盖我们预计在未来 40 年内会有用的理论,就像对自动机理论、算法和相关主题的理解在过去 40 年中给予学生优势一样。一个主要的变化是对概率、统计和数值方法的重视增加。
在许多当代书籍中,数据科学被简化为一系列编程工具,只要掌握了这些工具,就可以完成数据科学任务。这些书籍似乎较少关注与代码脱离的基本概念和理论。这本书则是与这种趋势相反的好例子,它无疑会为你提供必要的理论知识,使你以扎实的基础迎接数据科学的职业生涯。
相关:
-
统计学习入门:免费电子书
-
理解机器学习:免费电子书
-
统计学习的元素:免费电子书
更多相关话题
解释 AI 和机器学习的四种方法
原文:
www.kdnuggets.com/2018/12/four-approaches-ai-machine-learning.html
评论
作者:Jay Budzik,首席技术官,ZestFinance
高级机器学习(ML)是人工智能(AI)的一个子集,使用更多的数据和复杂的数学方法来做出更好的预测和决策。它驱动了自动驾驶汽车、Netflix 推荐系统以及大量的银行欺诈检测。银行和贷款机构可以利用 ML 与传统的信用评分技术结合,找到更好的借款人,并拒绝更多不良借款人,从而赚取更多的钱。但由于技术的“黑箱”特性,ML 的采用受到了阻碍。ML 模型极其复杂。如果无法解释其决策,你无法安全或准确地运行信用模型。
我们真正希望从 AI 可解释性中得到三样东西:一致性、准确性和性能。市场上有一些技术被宣传为解决这种“黑箱”问题。谨防上当。这些技术往往不一致、不准确、计算成本高,和/或未能发现不可接受的结果,例如基于种族和性别的歧视。其中一些技术已经使用了很长时间,对于旧的建模方法,如逻辑回归,非常有效。但它们在 ML 上效果不佳。
在 ZestFinance,我们在 ZAML 软件工具中构建了新的可解释性数学方法,这些方法可以快速地将 ML 模型的内部工作从创建到部署变得透明。你可以使用这些工具实时监控模型健康状况。你可以相信结果是公平和准确的。我们还自动化了报告生成,所以你只需按一下按钮即可生成所有符合规定所需的文档。
在这篇论文中,我们比较了几种流行的可解释性技术(包括我们的 ZAML 技术),描述了它们的相对优缺点,并展示了每种技术在一个简单建模问题上的表现。我们进行的测试显示,ZAML 比这些其他方法更准确、一致和快速。
四种可解释性技术的解释
目前推广的三种常见机器学习可解释性技术分别是 LOCO、置换影响和 LIME。LOCO,代表“留一列”的意思,通过将一个变量“遗漏”并重新计算模型的预测值。其思路是,如果分数变化很大,那么被遗漏的变量一定非常重要。置换影响(PI),也称为置换重要性,用一个随机选择的值替代一个变量,并重新计算模型的预测值。与 LOCO 类似,其思路是,如果分数变化很大,那么被扰乱的变量一定非常重要。LIME,代表局部可解释的模型无关解释,拟合一个新的线性模型在给定申请人的真实数据值和真实模型对这些合成值的得分周围的局部邻域内。然后使用这个新的线性近似模型来解释更复杂的模型的行为。本质上,你是将一个非常复杂的模型假装成简单的,以便进行解释。
ZestFinance 的 ZAML 软件使用了一种来自博弈论和多元微积分的专有解释方法,适用于实际的基础模型。ZAML 可解释性通过查看每个变量与其他变量的交互,来确定每个变量对最终得分的相对重要性。下方的清单比较了这四种可解释性技术在七个重要能力上的表现。我们还为每种技术添加了在解释两个常见机器学习模型时的准确性、一致性和速度的测试评分。准确性通过平均排名相关性来衡量,或者说解释与实际基准的偏差有多大。一致性通过方差来衡量,即解释的差异在所有申请人中的变化程度。速度是生成数据集中所有行解释所需的时间。

让我们解读一下这个清单
对于高风险业务应用(如信用风险建模),机器学习模型的解释必须满足多种要求,以便其具有可信性,其中最重要的是准确性、一致性和性能,即预测速度。上面的图表总结了你可能听说的四种技术在一个极其简单的模型上的表现。对于现实世界中的可解释性问题,例如信用风险建模中普遍存在的问题,性能差异可能更为明显。我们使用了一个简单的模型来展示这些差异,旨在说明即使是只有两个变量的模型,也无法像 ZAML 可解释性那样准确地用 LOCO、PI 或 LIME 解释。如果一种可解释性技术在解释最简单的“玩具”模型时都很困难,那么在涉及大量资金的现实世界应用中信任它可能是不明智的。
LOCO、LIME 和 PI 在准确性、一致性或速度方面都有缺陷。LOCO 和 PI 通过一次分析一个特征来工作。这意味着随着模型变量数量的增加,算法运行变得更慢、更昂贵。LOCO、LIME 和 PI 只关注模型的输入和输出,这意味着它们获取的信息比像 ZAML 这样查看模型内部结构的解释器少得多。外部探测模型(即输入和输出)是一个不完美的过程,容易导致潜在的错误和不准确性。分析重新拟合和/或代理模型,如 LOCO 和 LIME 所要求的,而不是分析你的最终模型,也存在问题。我们认为分析真实模型非常重要——如果不这样做,你将面临很多风险。
在尝试解释高级机器学习模型时,重要的是你的解释能全面捕捉特征的影响,或与其他特征的关系。单变量分析,如 LOCO 和 PI 通常采用的,将无法正确捕捉这些特征交互和相关效应。准确性再次受到影响。解释器还应从全局而不仅仅是局部角度计算特征解释。假设你建立了一个模型来理解为什么科比·布莱恩特是一位伟大的篮球运动员。仅仅使用局部特征重要性进行解释将表明他的身高并不是问题,因为从模型的角度看,所有与科比接近的 NBA 球员也都很高。但你不能否认科比的 6 英尺 6 英寸的身高与他为何打得这么好有关系。再一次,不准确性出现了。
大多数建模技术也有称为超参数的调节旋钮,可以自动调整以使模型更准确。对于解释器来说,没有实际等同于这种“自动调优”操作的东西。这使得对从解释器如 LIME 获得的结果充满信心变得非常困难,因为无法确定你是否正确设置了像数据区域大小这样的超参数。设置得过小,数据会在模型的高维空间中变得非常稀疏。设置得过宽,你将违反 LIME 的局部线性假设。
一致的解释器使用真实数据。LIME 和 PI 使用非真实数据来探测模型。假设你建立了一个包含收入、债务和债务收入比率的模型。PI 会独立地逐列打乱。这意味着当 PI 通过打乱分析债务收入比率时,它将不再是债务特征除以收入特征。由于训练数据中的所有数据保持了这种关系,因此以这种方式查询模型应该被视为未定义的行为。
即使解释中的轻微不准确也可能导致灾难性的结果,例如发布基于年龄、性别、种族或民族的歧视模型,或发布不稳定且产生高违约率的模型,这可能导致借贷业务的资金流失。一个模型可解释性技术应该在给定相同的输入和模型时提供相同的答案。不准确或不一致的模型可解释性技术可能看似提供了风险管理的一些保证,但如果结果不准确,它们对业务利益相关者和监管机构几乎没有价值或保证。
速度和效率也很重要。在模型构建过程中以及模型应用时,模型可解释性应被频繁使用,以便为每个基于模型的决策生成解释。缓慢和低效的技术限制了可解释性的实用性:如果你需要等待一整夜才能获得结果,你会减少分析的频率,从而获得关于模型运行的见解也会减少。这意味着你在改进模型上投入的时间会减少。
对可解释性技术进行测试
我们将对这四种可解释性技术的比较更进一步,并进行了一个实验,评估这些方法在简单建模问题上相对于真实值的表现。在这个测试中,我们使用了一个基于竞争博弈理论计算出的参考值作为真实值。参考值衡量了给定模型输入变量引入的平均边际效益。它通过穷举所有可能的变量组合来实现这一点。计算参考值需要创建指数数量的模型变体,每个变体包含不同的变量组合。通过了解模型的比较表现,我们可以量化模型中每个变量的价值。
在我们的实验中,我们评估了四种技术在解释两个机器学习模型和“月亮”数据集方面的表现。这是一个简单的、包含 100,000 行的双变量数据集,通常用于本科机器学习课程中,以演示线性模型的局限性。

“月亮”分类任务是建立一个模型,使用仅 X 和 Y 坐标将浅橙色数据点与深橙色数据点分开。线性模型无法很好地完成这一任务。要查看这一点,只需在上图中画一条直线,注意到直线两侧都有黄色和绿色数据点。没有一条直线可以分开橙色区域。月亮数据集提供了一个简单的例子,展示了机器学习方法对变量交互的敏感性,并且比只能创建线性模型的旧方法如逻辑回归更好地捕捉数据的真实形状。
我们构建了两个机器学习分类模型,分别使用了 XGBoost,一个流行的树集合诱导算法,以及 Tensorflow,一个流行的神经网络包。在撰写本文时,这两种方法都被认为是最顶尖的机器学习建模技术。随后,我们将各种可解释性方法应用于生成的树和神经网络模型。结果如下所示。

对于梯度提升树,LIME、PI 和 LOCO 在面对非常简单的建模问题时产生的错误率较高且方差更大,甚至与 ZAML 相比。还要注意的是,LIME 的计算速度要慢得多。虽然 PI 和 LOCO 在这种两变量模型测试中看起来更合理,但随着行列数的增加,这些方法的速度很快变得非常慢。对于像我们在信用风险建模工作中每天遇到的大型数据集,它们变得不切实际。我们曾经等待了几个小时甚至几天才获得 LOCO、PI 和 LIME 的解释。根据我们的经验,ZAML 方法在单台笔记本电脑或普通计算机上计算时间不超过几秒,即使是对具有数千个变量的模型也是如此。

对于神经网络,LIME、PI 和 LOCO 也产生了更高的错误率和方差。与在梯度提升树上的表现一致,LIME 的速度非常慢。对感兴趣的人来说,比较每种方法与参考值的散点图已包含在下面的附录中。
结论
并非所有可解释性技术都是一样的。即使在像二维“月亮”数据集这样简单的建模问题上,只有 100,000 行数据,我们也展示了 ZAML 的可解释性比其他方法更准确、更一致,且通常更快。在处理如信用风险建模等高风险业务问题时,确保核心可解释性方法正确至关重要,以便你了解模型的工作情况并能够管理其应用所带来的风险。如果你使用的核心可解释性数学产生了错误的答案,可能会让你的业务陷入严重麻烦。
简介:Jay Budzik 是一位产品和技术领导者,有通过应用 AI 和 ML 创建新产品和服务的优秀收入增长记录。
原文。转载已获许可。
资源:
相关:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力。
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求。
更多相关话题
数据准备中的四个基本步骤
原文:
www.kdnuggets.com/2021/10/four-basic-steps-data-preparation.html
评论
由Rosaria Silipo撰写,KNIME 数据科学布道主管
数据准备的步骤是什么?我们是否需要针对特定问题采取具体步骤?答案并不那么简单:实践和知识将为每种情况设计最佳方案。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
首先,数据准备有两种类型:KPI 计算用于从原始数据中提取信息,以及数据科学算法的数据准备。前者依赖于领域和业务,而后者则更为标准化。
在这篇博客文章中,我们专注于准备数据以供机器学习算法使用的操作。这些数据操作有很多,其中一些更为通用,而另一些则更针对特定情况。当你考虑到有整门大学课程专注于数据准备操作时,这个话题太广泛,无法在一篇简短的文章中涵盖所有内容。
我们希望在这里介绍四个非常基础且非常通用的机器学习算法数据准备步骤。我们将描述在特定示例中如何及为什么应用这些转换。
-
归一化
-
转换
-
缺失值插补
-
重采样
我们的例子:流失预测
让我们以数据科学中的一个简单例子来说明:流失预测。简单来说,流失预测旨在区分那些有流失风险的客户和其他客户。通常,使用公司 CRM 系统中的数据,包括客户行为、人口统计信息和收入特征。有些客户流失,有些则没有。这些数据然后用于训练一个预测模型,以区分这两类客户。
这个问题是一个二分类问题。输出类别(流失)只有两个可能的值:流失“是”和流失“否”。任何分类算法都适用:决策树、随机森林、逻辑回归等。逻辑回归有点像历史算法,运行快速且易于解释。我们将采用它来解决这个问题。
让我们开始构建我们的工作流程。首先,我们从两个独立的文件中读取数据,一个 CSV 文件和一个 Excel 文件,然后应用逻辑回归,最后将模型写入文件。
但别急,Nelly!让我们先查看数据。
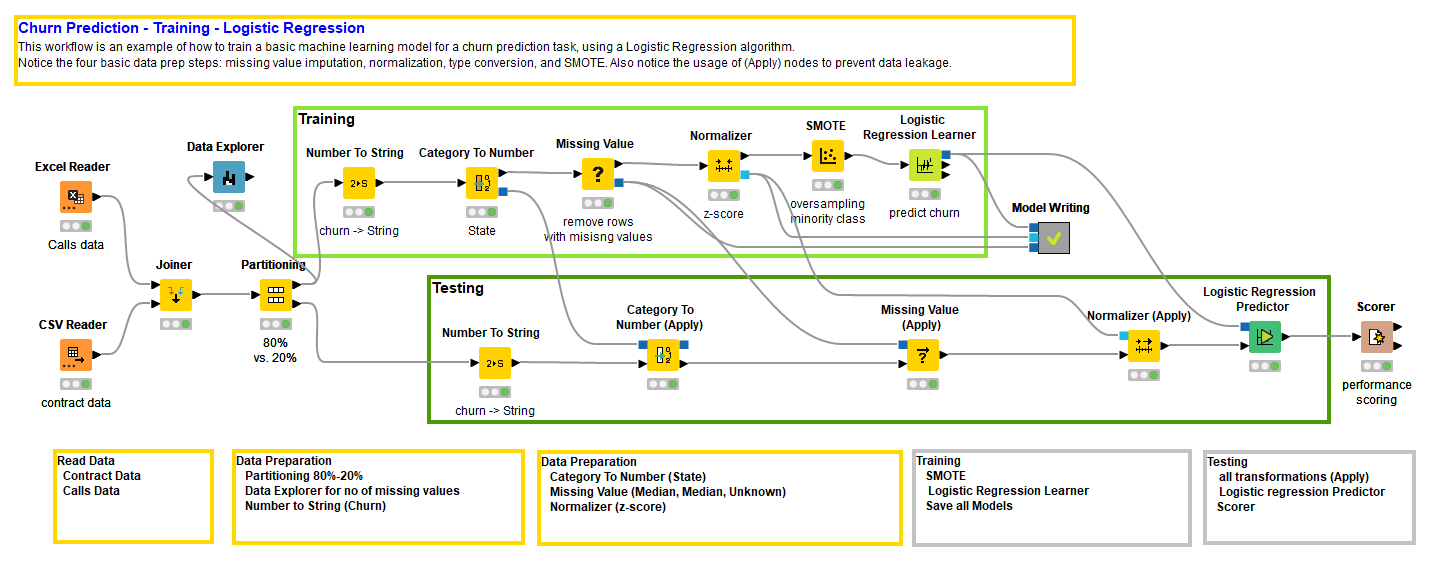
图 1. 训练和评估逻辑回归模型的工作流程,包括四个常见的数据准备步骤(点击放大)。
将数据分区以生成两个数据子集
训练一个模型还不足以声称我们有一个好的模型。我们还需要通过在单独的数据子集上使用准确性或误差度量来评估它。换句话说,我们需要创建一对不重叠的子集——训练集和测试集——从原始数据集中随机抽取。为此,我们使用分区节点。分区节点从输入数据表中随机提取数据,按其配置窗口中指定的比例,生成两个数据子集并在两个输出端口输出。
训练集将由逻辑回归学习器节点用于训练模型,测试集将由逻辑回归预测器节点和后续的评分节点用于评分模型。逻辑回归预测器节点生成客户流失预测,而评分节点评估这些预测的准确性。
在这里,我们没有将分区操作包含在数据准备操作中,因为它并不会真正改变数据。然而,这只是我们的看法。如果你想将分区包含在数据准备操作中,只需将标题从“四”改为“数据准备的五个基本步骤” 😃
1. 标准化
接下来,逻辑回归需要将输入数据标准化到区间[0, 1],如果能够高斯标准化则更好。任何包括距离或方差的算法都将在标准化的数据上有效。这是因为具有较大范围的特征会影响方差和距离的计算,可能会主导整个算法。由于我们希望所有输入特征被平等考虑,因此数据的标准化是必要的。
例如,决策树依赖于概率,不需要标准化数据,但逻辑回归依赖于方差,因此需要先前的标准化;许多聚类算法,如 k-Means,依赖于距离,因此需要标准化;神经网络使用激活函数,其参数落在[0,1]之间,因此也需要标准化;等等。你将学会识别哪些算法需要标准化及其原因。
逻辑回归确实需要高斯标准化的数据。因此,必须引入一个Normalizer节点来标准化训练数据。
2. 转换
逻辑回归在数值属性上工作。这对于原始算法来说是正确的。有时,在一些包中,你会看到逻辑回归也接受分类的,即名义输入特征。在这种情况下,逻辑回归学习函数内部实现了一个准备步骤,将分类特征转换为数字。通常,逻辑回归只在数值特征上工作。
由于我们希望掌控操作,而不是盲目地将转换操作委托给逻辑回归扩展包,因此我们可以自行实现这个转换步骤。实际上,我们希望将一个名义列转换为一个或多个数值列。这里有两个选项:
-
索引编码。每个名义值被映射为一个数字。
-
独热编码。每个名义值创建一个新列,其单元格根据原始列中该值的存在与否填充 1 或 0。
索引编码解决方案从一个名义列生成一个数值列。然而,由于映射函数,它在两个值之间引入了人为的数值距离。
独热编码解决方案不会引入任何人为距离。然而,它从一个原始列生成许多列,因此增加了数据集的维度,并人为地加重了原始列的权重。
没有完美的解决方案。最终这是在准确性和速度之间的妥协。
在我们的案例中,原始数据集中有两个分类列:State和Phone。Phone是一个唯一的 ID,用于识别每个客户。由于它不包含关于客户行为或合同的任何一般信息,我们在分析中不会使用它。State则相反,可能包含相关信息。某个州的客户可能由于当地竞争者的存在,更倾向于流失。
为了转换输入特征State,我们使用了基于索引的编码,通过Category to Number节点实现。
在光谱的另一端,我们有目标列Churn,其中包含有关客户是否流失(1)或未流失(0)的信息。许多分类器训练算法要求类别标签的目标列为分类的。在我们的案例中,Churn 列最初被读取为数值(0/1),必须转换为分类类型,通过Number To String节点。
3. 缺失值填充
逻辑回归的另一个缺点是它不能处理数据中的缺失值。一些逻辑回归学习函数包括缺失值策略。然而,正如我们之前所说的,我们希望控制整个过程。让我们也决定缺失值填补的策略。
文献中有很多缺失值填补的策略。你可以在文章“缺失值填补:综述”中查看详细信息。
最简单的策略就是忽略有缺失值的数据行。这是粗糙的,但如果我们有多余的数据,并不算错。当数据很少时,这就变得有问题了。在这种情况下,仅仅因为某些特征缺失而丢弃一些数据,可能不是最聪明的决定。
如果我们对领域有一些了解,我们就会知道缺失值的含义,并且能够提供一个合理的替代值。
由于我们一无所知,数据集也确实不大,我们需要找到一些替代方案。如果我们不想思考,那么采用中位数、均值或最频繁值是一个合理的选择。如果我们一无所知,就选择多数值或中间值。这是我们在这里采用的策略。
然而,如果我们想稍微思考一下,我们可能想通过 数据探索器 节点对数据集进行一些统计分析,以估计缺失值问题的严重性。如果缺失值问题严重,我们可以在受影响最严重的列中隔离那些有缺失值的行。从这些观察中,可能会得到一个合理的替代值的想法。当然,在实施缺失值策略后,我们这样做了。事实上,数据探索器节点的视图显示我们的数据集没有缺失值。完全没有。哦,好吧!让我们把缺失值节点留在那里以完成工作。
4. 重采样
现在最后一个基本问题:目标类别在数据集中是否均匀分布?
在我们的情况下,它们并不是这样。两个类别之间存在 85%(未流失)对 15%(流失)的不平衡。当一个类别比另一个类别少得多时,训练算法可能会忽视这个类别。如果不平衡不是很严重,那么在分区节点中使用分层抽样策略进行随机数据抽取应该足够了。然而,如果不平衡较强,如本例所示,则可能需要在训练算法之前进行一些重采样。
要进行重采样,你可以选择对多数类别进行欠采样,或者对少数类别进行过采样,这取决于你处理的数据量以及是否可以承担丢弃多数类别数据的奢侈。这种数据集不大,因此我们决定使用 SMOTE 算法对少数类别进行过采样。
防止数据泄漏
现在,我们必须对测试集重复所有这些变换,使用与工作流的训练分支中定义的完全相同的变换。为了防止数据泄漏,我们不能将测试数据用于任何这些变换的制作。因此,在工作流的测试分支中,我们使用了(应用)节点,仅仅将变换应用于测试数据。
请注意,没有 SMOTE(应用)节点。这是因为我们要么重新应用 SMOTE 算法来对测试集中的少数类进行过采样,要么采用考虑类别不平衡的评估指标,如 Cohen’s Kappa。我们选择用 Cohen’s Kappa 指标来评估模型质量。
打包和结论
我们已经完成了工作流的最后一步(你可以从 KNIME Hub 下载工作流 数据准备的四个基本步骤)。我们已经准备了训练数据,对其进行了预测算法训练,使用完全相同的变换准备了测试数据,将训练好的模型应用于测试数据,并将预测结果与实际类别进行评分。评分器 节点生成了多个准确度指标来评估模型的质量。我们选择了 Cohen’s Kappa,因为它可以衡量算法在两个类别上的表现,即使它们高度不平衡。
我们得到了接近 0.4 的 Cohen’s Kappa。这是我们能做的最好结果吗?我们应该尝试回到之前的步骤,调整一些参数,看看是否能得到更好的模型。与其手动调整参数,我们甚至可以引入优化周期。查看免费的电子书 从建模到模型评估,了解更多展示模型性能的评分技术。
我们现在结束这篇文章,介绍了四种非常基础的数据变换。我们邀请你深入了解这四种变换,并探索其他数据变换,例如降维、特征选择、特征工程、异常值检测、PCA 等。
简介: Rosaria Silipo 不仅是数据挖掘、机器学习、报告和数据仓库领域的专家,她还成为了 KNIME 数据挖掘引擎的公认专家,关于这一点她已出版了三本书:《KNIME Beginner’s Luck》、《The KNIME Cookbook》和《The KNIME Booklet for SAS Users》。之前,Rosaria 曾为欧洲多家公司担任自由数据分析师。她还曾在 Viseca(苏黎世)领导 SAS 开发组,在 Spoken Translation(加州伯克利)使用 C# 实现语音转文本和文本转语音接口,并在 Nuance Communications(加州门罗公园)开发了多种语言的语音识别引擎。Rosaria 于 1996 年获得意大利佛罗伦萨大学的生物医学工程博士学位。
首次发布于 KNIME 博客
原文. 经许可转载。
相关:
-
使用 dplyr 在 R 中进行数据准备,附带备忘单!
-
混乱的数据是美丽的
-
基于机器学习的自动数据标注
更多相关主题
数据科学家的四项工作
评论
由罗杰·D·彭、@jhubiostat教授;《R 编程数据科学》作者;@simplystats。

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
2019 年,我写了一篇关于数据科学的支柱的文章,尝试提炼数据科学家的关键技能。在文章中,我写道:
当我问自己“什么是数据科学?”时,我倾向于思考以下五个组成部分。数据科学是(1)将设计思维应用于数据问题;(2)创建和管理数据转换和处理的工作流程;(3)通过协商人际关系来识别背景、分配资源和描述数据分析产品的受众;(4)应用统计方法来量化证据;(5)将数据分析信息转化为连贯的叙述和故事。
我的观点是,如果你是一位优秀的数据科学家,那么你在数据科学的五个支柱方面都很出色。相反,如果你在所有五个支柱上都很擅长,那么你很可能是一位优秀的数据科学家。
我对这些技能的感觉还是一样的,但我现在的感觉是,这篇文章实际上让数据科学家的工作看起来比实际要简单。这是因为它将所有这些技能包裹成一个工作,而实际上,数据科学需要在四个工作中都表现出色。为了说明我的意思,我们必须退一步,问一个更基本的问题。
数据科学的核心是什么?
这是一个每个人都在问的问题,我认为也很难回答。任何领域中,总有一些问题的区分
-
这个领域的核心是什么?
-
那些人在该领域通常做些什么?
如果还不清楚,这些问题并不是一样的。例如,在统计学中,根据大多数博士项目的课程,领域的核心涉及统计方法、统计理论、概率论,也许还有一些计算。数据分析通常不会在正式课堂上教授(即在教室里),而是作为论文或研究项目的一部分来掌握。许多标记为“数据科学”或“数据分析”的课程只是教授更多的方法,如机器学习、聚类或降维。正式的软件工程技术通常也不会被教授,但在实践中往往会被使用。
可以说,数据分析和软件工程是统计学家做的事情,但这并不是该领域的核心。是否正确无关紧要。我只是想说,我们必须在某处做出区分。统计学家总是会做比该领域核心更多的工作。
在数据科学领域,我认为我们正在共同盘点数据科学家往往做什么。问题在于,目前看起来一片混乱。传统统计确实倾向于成为活动的核心,但计算机科学、软件工程、认知科学、伦理学、沟通等也一样。这几乎不能定义为领域的核心,而只是活动的枚举。
问题是,我们能否定义出所有数据科学家都在做的事情?如果我们必须教所有数据科学学生一些东西,而不知道他们未来可能去哪里,这会是什么呢?我认为在某个阶段,所有数据科学家都必须参与到基本的数据分析迭代中。
数据分析迭代
基本数据分析迭代分为四个部分。一旦问题确定并且获得或收集数据的计划可用,我们可以做以下事情:
-
构建一个预期结果集合
-
设计/构建/应用一个数据分析系统到数据上
-
诊断分析系统输出中的异常
-
做出一个决策关于下一步要做什么
虽然这个迭代对于许多人可能熟悉或显而易见,但这种熟悉掩盖了其中的复杂性。特别是,每一步迭代都需要数据科学家扮演不同的角色,涉及非常不同的技能。这就像是一场独角戏,其中数据科学家在从一个步骤到下一个步骤时需要换装。这就是我所说的数据科学家的四个角色。
四个角色
基本数据分析迭代的每一个步骤都要求数据科学家扮演四种不同的角色:(1) 科学家;(2) 统计学家;(3) 系统工程师;(4) 政治家。让我们更详细地了解每个角色。
科学家
科学家提出问题并负责了解科学的现状以及关键的知识缺口。科学家还设计任何收集新数据的实验并执行数据收集。科学家必须与统计学家合作,设计一个数据分析系统,并最终从任何数据分析中构建一个预期结果集。
科学家在开发一个能够产生我们预期结果集的系统中发挥着关键作用。这个系统的组件可能包括文献综述、元分析、初步数据或来自同事的轶事数据。我在这里广泛使用“科学家”这个术语。在其他环境中,这可能是政策制定者或产品经理。
统计学家
统计学家与科学家合作,设计分析系统来分析任何数据收集工作的生成数据。他们指定系统如何运行,生成什么输出,并获取实现系统所需的资源。统计学家利用统计理论和个人经验来选择将要应用的分析系统的不同组件。
统计学家在这里的角色是将数据分析系统应用于数据并生成数据分析输出。该输出可以是回归系数、均值、图表或预测。但必须生成某种可以与我们的预期结果集进行比较的东西。如果输出偏离了我们的预期结果集,那么接下来的任务是确定这种偏差的原因。
系统工程师
一旦将分析系统应用于数据,只有两种可能的结果:
-
输出符合我们的期望,或者
-
输出不符合我们的期望(异常)。
在出现异常的情况下,系统工程师的责任是基于对数据收集过程、分析系统和科学知识状态的了解,诊断异常的潜在根本原因。
最近,Emma Vitz 在推特上写道:
如何向初级人员教授调试技能?我觉得这是一项非常重要的技能,但似乎我们没有结构化的教学框架。
对于软件和数据分析来说,挑战在于错误或意外行为可能来自任何地方。任何复杂的系统由多个组件组成,其中一些可能是你的责任,而许多则是他人的。但错误和异常不会尊重这些边界!可能会有一个在一个组件中发生的问题,只有在你查看数据分析输出时才会被发现。
因此,如果你负责诊断问题,那么你有责任调查系统中每个组件的行为。如果这是你不太熟悉的内容,那么你需要变得熟悉它,要么通过自学,要么(更可能地)与实际负责的人交谈。
数据分析输出中常见的意外行为源于数据收集过程,但分析数据的统计学家可能不负责这一方面。尽管如此,识别异常的系统工程师必须回过头来,与统计学家和科学家沟通,以搞清楚每个组件的工作原理。
最终,系统工程师的任务是全面审视所有影响数据分析输出的活动,以识别任何偏差。一旦这些根本原因被解释清楚,我们就可以决定如何处理这些新信息。
政治家
政治家的工作是做出决策,同时平衡各方利益,以实现合理的结果。我认识的大多数统计学家和科学家会对被认为是政治家或认为政治会在任何形式的科学中发挥作用感到反感。然而,我的想法更基础:在任何数据分析迭代中,我们都在不断地做出关于该做什么的决策,同时考虑各种冲突因素。为了化解这些冲突并达成合理的协议,必须具备一种关键技能,即谈判。
在数据分析迭代的各个阶段,政治家必须就以下方面进行谈判:(1)分析中成功的定义;(2)执行分析的资源;以及(3)在看到分析系统的输出并诊断出任何异常的根本原因后,决定下一步该做什么。关于下一步该做什么的决定从根本上涉及数据和科学之外的因素。
政治家必须确定问题的利益相关者是谁,以及他们究竟想要什么(而不是他们的立场是什么)。例如,一位研究人员可能会说:“我们需要 p 值小于 0.05。”那是他们的立场。但他们想要的更可能是“在高影响力期刊上发表文章。”另一个例子可能是一个研究人员需要赶上紧迫的发表截止日期,而另一个研究人员则想进行耗时(但更可靠)的分析。显然,立场相冲突,但可以说,两位研究人员共享相同的目标,即严格的高影响力出版物。
识别职位与潜在需求是谈判合理结果的关键任务。根据我的经验,这一过程很少涉及数据(尽管数据可能用于某些论证)。这一过程的主导因素往往是各方之间的关系性质和资源的限制(如时间)。
应用迭代
如果你在阅读此内容时发现自己说“我不是 X”,其中 X 是科学家、统计学家、系统工程师或政治家,那么很可能你在数据科学方面存在不足。我认为一个好的数据科学家必须在这些领域中具备一些技能,以完成基本的数据分析迭代。
在任何给定的分析中,迭代可以从一次应用到几十次甚至几百次。如果你曾经制作过同一数据集的两个图,那么你可能已经进行了两次迭代。尽管迭代的具体细节和频率在应用中可能会有所不同,但核心性质和涉及的技能变化不大。
原文。经许可转载。
相关:
更多相关话题
分析、数据挖掘、数据科学的四种主要语言
原文:
www.kdnuggets.com/2014/08/four-main-languages-analytics-data-mining-data-science.html
评论作者:Gregory Piatetsky,@kdnuggets,2014 年 8 月 18 日。
有时高层次的数据科学平台对于特定的分析任务来说是不够的,数据科学家需要转向更低层次的统计/编程语言。
最后的 KDnuggets 投票调查询问了
你在 2014 年分析/数据挖掘/数据科学工作中使用了哪些编程/统计语言?
结果显示,主要的 4 种语言 - R、Python、SAS 和 SQL - 占据了主导地位 - 91% 的受访者使用了其中之一。
与类似的 KDnuggets 投票调查比较
在 2013 年:你在分析/数据挖掘中使用了哪些编程/统计语言,在 2012 年,我们注意到了一些变化和趋势。
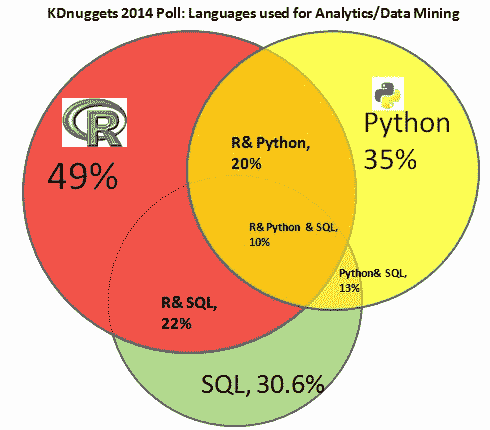
1. 2014 年 SAS 用户参与度大幅增加,这可能部分受到 KDnuggets 读者组成变化的驱动,也可能由于此调查在 SAS 用户中的知名度提高。SAS 用户中有很高比例的“孤立”投票 - 在 2014 年,58% 的人表示他们仅使用 SAS,而 2013 年这一比例为 26%。2014 年 R 的“孤立”投票比例为 20.5%,Python 为 14%,SQL 仅为 4.5%。
2. 四大主流语言的整合 - R、SAS、Python 和 SQL。91% 的所有投票者至少使用过其中一种。几乎所有其他语言在数据挖掘任务中的受欢迎程度有所下降,包括 Java、Unix shell、MATLAB、C/C++、Perl、Octave、Ruby、Lisp 和 F#。
这里是一个维恩图,显示了 R、Python 和 SQL 之间的显著重叠。百分比表示选择该选项的投票者比例,例如,20% 的所有投票者使用了 R 和 Python,而 10% 的人使用了 R、Python 和 SQL。圆圈和交集的面积大致对应投票者的比例。
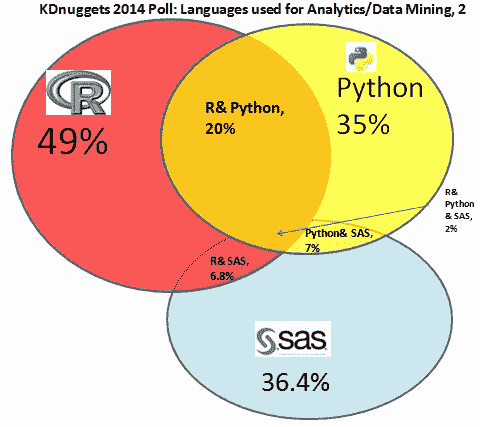
这里是一个类似的维恩图,展示了 R、Python 和 SAS 之间的重叠。我们看到 SAS 与 R 和 Python 的独立性更强,大约 2/3 的 SAS 用户没有使用 R 或 Python。
3. 2014 年增长最快的语言是
-
Julia,增长 316%,从 2013 年的 0.7% 增至 2014 年的 2.9%
-
SAS,增长 76%,从 2013 年的 20.8% 增至 2014 年的 36.4%
-
Scala,增长 74%,从 2013 年的 2.2% 增至 2014 年的 3.9%
4. 使用比例下降幅度最大的语言 为:
-
F#,下降 100%,从 2013 年的 1.7%降至 2014 年的零
-
C++/C,下降 60%,从 2013 年的 9.3%降至 2014 年的 3.6%
-
GNU Octave,下降 57%,从 2013 年的 5.6%降至 2014 年的 2.4%
-
MATLAB,下降 50%,从 2013 年的 12.5%降至 2014 年的 6.3%
-
Ruby,下降 44%,从 2013 年的 2.2%降至 2014 年的 1.3%
-
Perl,下降 41%,从 2013 年的 4.5%降至 2014 年的 2.6%
这里是更多详细信息的表格:
| 2014 年你在分析/数据挖掘/数据科学工作中使用了哪些编程/统计语言? |
|---|
| 使用语言 |  2014 年选民比例(总计 719 人)
2014 年选民比例(总计 719 人)  2013 年选民比例(总计 713 人)
2013 年选民比例(总计 713 人)
 2012 年选民比例(总计 579 人) |
2012 年选民比例(总计 579 人) |
| R(2014 年 352 名选民) | |
|---|---|
| SAS(262) | |
| Python(252) | |
| SQL(220) | |
| Java(89) | |
| Unix shell/awk/sed(63) | |
| Pig Latin/ Hive/其他基于 Hadoop 的语言(61) | |
| SPSS(58) | 未询问 未询问 |
| MATLAB(45) | |
| Scala(28) | |
| C/C++(26) | |
| Julia(21) | |
| 其他低级语言 (20) | |
| Perl (19) | |
| GNU Octave (17) | |
| Ruby (9) | |
| Lisp/Clojure (5) | |
| F# (0) | 0% 2012 年未被提及 |
除了其他编程语言,威廉·德温内尔提到了编译的 BASIC(PowerBASIC)。
地区参与情况为
-
美国/加拿大: 51.6%
-
欧洲: 26.7%
-
亚洲: 13.3%
-
拉丁美洲: 3.7%
-
非洲/中东: 3.5%
-
澳大利亚/新西兰: 2.0%
这与 2013 年类似,但亚洲和非洲/中东(以以色列和土耳其为主)的参与更多,而拉丁美洲的参与则减少(主要是巴西的减少,也许仍因世界杯失利而受到打击)。
更多相关话题
帮助准确确定分析工程项目范围的四个问题
原文:
www.kdnuggets.com/2019/10/four-questions-scope-analytics-engineering-project.html
评论
由 Tristan Handy,Fishtown Analytics 创始人兼首席执行官。

我们的前三个课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能。
3. Google IT 支持专业证书 - 支持你的组织 IT。
在 Fishtown Analytics,我们以两周的冲刺周期销售和交付分析工程项目,每个周期都有固定的价格和交付物。在如此紧凑的时间表和明确的结果下交付是非常紧张的!我们在这方面做得相当好:我们已经完成了超过 1000 个冲刺,其中超过 95% 准时交付。
结果是,我们在确定分析项目范围方面变得非常擅长。我们发现,如果我们提前回答四个问题,我们可以显著减少在为时已晚之前发现问题的机会。事实上,早期发现问题是按时交付分析工作的最重要因素。如果你花一周时间走上一条道路,结果发现是死胡同,那是一段巨大的浪费时间。关键是要在陷入困境之前预见到死胡同。
我们的主动问题识别方法已经变得直观——这是我们大家自然会做的事情,因为我们都曾在炉子上烫过手,知道这样做更好:“我本该知道我需要检查那些 ID 是否能匹配。操。”
这是一个如此重要的话题,以至于我想花时间使我们的直观、潜在知识更为明确,并与更大的社区分享。因为这项技能不仅仅是为顾问准备的:任何使用 敏捷方法进行数据团队管理 的人,或者任何管理数据项目截止日期的人,都应该关心。
为什么? 数据团队成功的关键在于建立信任储备 ——这就是你如何从所有业务利益相关者那里获得“受信任顾问”地位的方式,以及如何最终影响业务的轨迹。我们通过提供高质量、经过测试和准确的数据来赢得信任。我们还通过对项目的过程设定明确期望并一再兑现来建立信任。
以下是我们在 Fishtown Analytics 主动识别问题并按时交付分析工程项目时提出的四个问题。
1. 我是否从原始来源获得了数据?
数据相关但来自错误系统的情况并不罕见。一个常见的例子是:你的公司可能在 Marketo 中存储营销数据,但它通过现有的 Salesforce 集成被引入到数据仓库中。使用 Marketo 数据而非 Salesforce 数据并不错误,但却有风险。双重集成将有更多失败的机会,数据也可能不像原始数据那样详细或完整。最好是直接从数据的源头获取所有数据。
实际上,这里有很多这样的例子。你应该信任:
-
是 Shopify 的收费还是 Stripe 的? 我会选择 Stripe 的用于财务/收入相关的情况,而 Shopify 的用于电子商务相关的情况。
-
Mixpanel 的事件还是 Segment 的? 我几乎总是选择 Segment,因为大多数公司将数据通过 Segment 推送到 Mixpanel。
-
Hubspot 的归因还是 Snowplow 的? 我相信你的网络分析工具(在这种情况下是 Snowplow)需要成为你网络事件数据的权威来源,从而成为你的归因来源。
当你开始一个项目时,坚持直接从源头获取数据是一件有趣的事,因为在某些方面,这并不非常务实。支付额外的集成费用通常有明确的价格标签,而且一开始并不清楚它的价值。为什么你拥有的数据“不够好”?答案是,基于最基本的真实数据源建立你的分析将节省大量的时间、挫折、变通方法和混乱的代码。
如果你有真正的原始数据,你就几乎无所不能:如果一个问题可以回答,你就能回答它。如果你在与一位 VP 开会时,他问:“我们能按获取来源来切分潜在客户吗?”答案要么是“可以”,要么是“我们使用的系统没有提供这样的数据。”如果你没有原始数据,你有时只能回答“根据我们目前的分析管道无法做到这一点。”这并不令人信服。
如果你没有原始数据,请做两件事:
-
试着直接获取这些数据。这可能像设置 Stitch 或 Fivetran 集成一样简单,或者可能需要自定义集成。
-
如果你无法获取原始数据并需要依赖于次级数据源,请提醒你的利益相关者潜在的缺陷,以便每个人对项目有正确的期望。概述你能提供的分析范围,以及如果能够获取原始数据时需要的再加工量。只要你明确告知利益相关者潜在的下游影响,基于 expediency 做出决策本身没有什么问题。
2. 数据源是否足够细粒度?
根据Kimball,重要的是“坚持使用与原始来源和收集过程紧密相关的丰富、表达性强的原子级数据。” 我完全同意:细粒度数据给你更多的选择,而汇总数据则有限制。
实践中最常见的一个例子是 Google Analytics 通过 API 导出的数据与 Google Analytics 360 自动加载到 Bigquery 中的数据之间的差异。通过 API,GA 只会提供汇总指标,而 GA 360 会将每一个会话和每一个事件导出到 Bigquery 中。汇总数据仅在创建极高层次的分析时有用,例如页面浏览量或独立访客的趋势线。利用细粒度数据,你可以回答任何问题——多触点归因、漏斗分析、A/B 测试等。
理想情况下,你希望能访问来源数据系统中绝对最细粒度的数据。在这个早期阶段,你还不知道将来会被要求调查的所有后续问题,你希望能够跟踪任何可能的线索。即使你的顶层问题可以通过汇总导出得到答案,你的后续问题几乎肯定无法回答。
实际上了解你所交互的数据源系统非常重要。
-
如果是 SaaS 产品,阅读 API 文档。API 会提供什么数据?好的 API 会提供你所需的所有对象;优秀的 API 会在这些对象上提供变更跟踪。例如,Salesforce API 会提供一个包含所有机会及其状态变化的历史表。这表明,机会历史表对 Salesforce 管道报告的一个大部分至关重要。
-
如果是内部产品数据库,请阅读所有可用的内部文档或与有经验的工程师坐下来了解产品中存储的数据。
总体来说,你离事件越近,情况就越好。如果你拥有一个系统的所有状态变更,你总是可以在任何给定时间点重建该状态——这是一种非常强大的状态。例如,你实际需要的唯一 Stripe API 端点是事件端点:从那个单一端点,你可以在任何时间点推导出所有其他端点的输出。你可以用类似的方式使用 Mailchimp 的事件表来分析电子邮件营销表现。
幸运的是,大多数 Stitch 和 Fivetran 集成默认会提取最大粒度的数据——这两个产品都是为现代分析栈构建的,旨在给予你完全的控制。然而,还是需要自己进行检查。前不久,我在与客户制定销售管道报告的计划时,发现 Stitch Close.io 集成(这是社区支持的)不包含机会历史端点。这显著改变了项目的范围,因为我们实际上无法在不将该额外端点添加到集成中的情况下进行所需的分析。最好在一开始就发现这个问题。
3. 这个数据集以前用过吗?
如果你的组织以前没有使用过来自某个数据管道的数据,你应该将其视为有罪,直到证明其清白。数据未使用过的情况下,可能存在大量错误方式,而且许多错误是微妙的。主要有两个类别:
-
加载错误。在加载过程中可能会出现错误,导致你的数据仓库中的数据不正确。即使你处理的是 Stitch 和 Fivetran 集成,错误总会发生。每次我看到集成出现问题时,都是由于最奇怪、最深奥的问题,每个问题都是独一无二的。
-
意外的加载行为。有时,加载发生的方式是你意想不到的。例如,Stitch 将许多它称之为“报告表”的表作为不可变日志进行加载,然后提供如何从这些表中查询的具体指示。如果你不阅读它们的指示,而是直接开始编写查询,你会得到令人困惑的错误数据。
这两种类型的错误都可以通过在建立关键任务分析之前对新数据集进行数据审计来捕捉。审计数据集究竟意味着什么?对我们来说,这意味着在表格上生成直观的指标,并将这些指标与另一个系统(通常是数据提取自的系统)中的输出进行比较。例如,我们经常计算订单和收入,并将这些指标与我们在 Shopify 中本地获得的结果进行比较。这些指标计算起来非常简单,如果数字匹配,你可以立即对数据集的状态有很高的信心。
原始数据的问题通常是跨切的:它们会影响表中的所有记录或某个日期范围内的所有记录。如果你审核 2-3 个指标,你通常可以对数据质量感到相当满意。
如果你的组织曾经使用过来自某个数据摄取管道的数据,那么你有责任去学习已经建立的内容。如果你使用的是 dbt:
-
查阅使用 dbt 文档进行的现有建模工作。
-
阅读所有模型和列的描述文本,确保你真正理解代码。
-
查找 git 提交历史中的作者,询问是否有任何你需要知道的注意事项。
不要只是说“算了”,然后从头开始你的工作。 分析工程技术债务和错误的主要来源是多个代码库试图转化和分析本质上相同的数据。两个代码路径意味着双倍的错误面和无限的混淆机会。跟踪之前的工作并不总是容易,但将现有代码库融入其中,而不是从零开始,是至关重要的。我见过一些团队不愿意以这种方式协作编写代码,而是每个分析师都建立自己的孤岛。这是一种极其低效的数据团队做法。
4. 是否存在必要的关键字来将所有数据连接在一起?
新的分析通常会基于现有概念,通过将新数据附加到已经建模的数据上。通常的做法是从你的应用数据库或购物车开始,然后向外扩展到其他数据系统:事件跟踪、客户成功、广告、电子邮件等。当你将这些系统引入你的管道和数据模型时,你需要至少一个关键字来连接数据。
这看起来应该相当简单,但通常情况并非如此。以下是一些例子:
-
你在 Salesforce 实例中将试用注册登记为线索,但提交到 Salesforce 的营销网站上的网页表单在流程中的那个点没有用户的账户号码。没有关键字!
-
你的事件跟踪在过去一周只显示了 15,000 个识别用户,但你的应用数据库确信在同一时间段内有 20,000 个用户登录。你的事件跟踪管道的用户识别代码是“漏的”——一些识别调用丢失了!哪些?
-
你想跟踪整个漏斗中的客户获取成本(CAC),从广告支出开始。但当你整合来自各种广告来源的数据时,你意识到市场团队没有在他们使用的链接中添加 URL 参数!没有这些参数,你就无法将来自你仓库其余部分的数据与广告成本数据连接起来。
这种情况经常发生,知道在哪里寻找问题至关重要。如果两个系统之间缺少一个密钥,可能会使整个分析项目陷入停滞,因为通常 a) 添加密钥涉及从组织的其他部分引入利益相关者,b) 没有办法追溯获取数据。
确保在深入之前检查你的密钥。如果缺少密钥,请与利益相关者合作创建它们。这种“过程仪表化”是优秀分析工程师的关键部分:你不能总是指望业务流程自然输出所需的数据,有时你需要卷起袖子确保数据被收集。
在深入之前了解答案
作为顾问,我必须有一个强有力的流程:如果我对一个迭代范围估算错误,这可能意味着接下来的两周我将没有足够的睡眠。或者这可能意味着我们在项目上亏损——风险是真实的。这就是为什么我(以及 Fishtown 的每个人)如此专注于精确范围估算。
在内部数据团队中,风险同样很高,但反馈通常不如外部那样明确或即时。你的利益相关者会注意到如果你持续错过截止日期或未能交付关键结果,他们可能不会直接告诉你。给同事直接反馈往往很困难——你上次说“你们团队错过了那个截止日期导致我错过了季度承诺的 OKR,我很生气”是什么时候?
即使没有明确说明,数据团队一致未能交付可预测的结果也会损害信任,从而影响团队对更大组织的影响力。通过在项目范围确定阶段识别问题,并与利益相关者沟通你的方法的局限性,避免这种结果。
原文。经许可转载。
简介: Tristan Handy目前正在构建 Fishtown Analytics,以帮助获得风险投资的公司通过构建工具来实施先进的分析,从而促进一种有主见的分析工作流程。
相关:
更多相关话题
四种异常值检测技术
原文:
www.kdnuggets.com/2018/12/four-techniques-outlier-detection.html
评论
作者:Maarit Widmann, Moritz Heine, Rosaria Silipo,KNIME的数据科学家
异常值或离群值在训练机器学习算法或应用统计技术时可能是一个严重的问题。它们通常是测量误差或特殊系统条件的结果,因此不能描述基础系统的常见功能。实际上,最佳实践是在进行进一步分析之前实施异常值去除阶段。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
但等一下!在某些情况下,异常值可以为我们提供关于整个系统的局部异常的信息;因此,异常值检测是一个有价值的过程,因为它们可以提供关于数据集的额外信息。
有许多技术可以检测并选择性地去除数据集中的异常值。在这篇博文中,我们展示了KNIME Analytics Platform中四种最常用的 - 传统和新型 - 异常值检测技术的实现。
数据集和异常值检测问题
我们用于测试和比较所提议的异常值检测技术的数据集是著名的航空公司数据集。该数据集包括 2007 年至 2012 年间美国国内航班的信息,如起飞时间、到达时间、起始机场、目的地机场、空中时间、起飞延误、到达延误、航班号、船只号、承运人等。这些列中有些可能包含异常值,即离群值。
从原始数据集中,我们提取了 1500 个从芝加哥奥黑尔机场(ORD)出发的航班样本,数据来自 2007 年和 2008 年。
为了展示所选的异常值检测技术的工作原理,我们集中于在机场的平均到达延误时间方面寻找异常值,这些时间是基于所有降落在特定机场的航班计算得出的。我们寻找那些显示出异常平均到达延误时间的机场。
四种异常值检测技术
数值异常值
这是在一维特征空间中最简单的非参数异常值检测方法。这里,异常值是通过IQR(四分位距)来计算的。
计算第一个和第三个四分位数(Q1, Q3)。然后,异常值是位于四分位距之外的数据点 x[i]。即:

使用四分位数乘数值k=1.5,范围限制是箱形图的典型上须和下须。
该技术通过在KNIME Analytics Platform中构建的工作流中的 Numeric Outliers 节点实现(图 1)。
Z-Score
Z-score 是一种在一维或低维特征空间中的参数化异常值检测方法。
该技术假设数据服从高斯分布。异常值是分布尾部的数据点,因此远离均值。距离的远近取决于为标准化数据点 z[i]设置的阈值 z[thr],计算公式如下:

其中 x[i]是数据点,μ是所有 x[i]的均值, 是所有 x[i]的标准差。
异常值是一个标准化的数据点,其绝对值大于 z[thr]。即:

常用的 z[thr]值为 2.5、3.0 和 3.5。
该技术通过在 KNIME 工作流中的 Row Filter 节点实现(图 1)。
DBSCAN
该技术基于DBSCAN聚类方法。DBSCAN 是一种在一维或多维特征空间中基于密度的非参数异常值检测方法。
在 DBSCAN 聚类技术中,所有数据点被定义为核心点、边界点或噪声点。
-
核心点是距离ℇ内至少有MinPts个邻居的数据点。
-
边界点是核心点在距离ℇ内的邻居,但在距离ℇ内的邻居少于MinPts。
-
所有其他数据点都是噪声点*,也被识别为异常值。
异常值检测因此依赖于所需的邻居数MinPts、距离ℇ以及选择的距离度量,如欧几里得或曼哈顿距离。
该技术通过图 1 中的 KNIME 工作流中的 DBSCAN 节点实现。
隔离森林
这是一种用于大数据集的非参数方法,适用于一维或多维特征空间。
该方法中的一个重要概念是隔离数。
隔离数是隔离一个数据点所需的分裂次数。通过以下步骤确定分裂次数:
-
随机选择一个点“a”进行隔离。
-
随机选择一个数据点“b”,它位于最小值和最大值之间,并且与“a”不同。
-
如果“b”的值低于“a”的值,“b”的值将成为新的下限。
-
如果“b”的值大于“a”的值,“b”的值将成为新的上限。
-
只要在上限和下限之间存在其他数据点,程序就会重复执行。
与隔离非离群点相比,隔离离群点所需的拆分较少,即离群点的隔离数低于非离群点。因此,如果数据点的隔离数低于阈值,则定义为离群点。
阈值是基于数据中估计的离群点百分比定义的,这是该离群点检测算法的起点。
关于隔离森林技术的解释和图片可参考 quantdare.com/isolation-forest-algorithm/。
这一技术通过在 Python Script 节点内使用几行 Python 代码在图 1 中的 KNIME 工作流中实现。
from sklearn.ensemble import IsolationForest
import pandas as pd
clf = IsolationForest(max_samples=100, random_state=42)
table = pd.concat([input_table['Mean(ArrDelay)']], axis=1)
clf.fit(table)
output_table = pd.DataFrame(clf.predict(table))
Python Script 节点是 KNIME Python Integration 的一部分,它允许你在 KNIME 工作流中编写/导入 Python 代码。
在 KNIME 工作流中的实现
KNIME Analytics Platform 是一个开源的数据科学软件,涵盖了从数据摄取和数据混合到数据可视化、从机器学习算法到数据清理、从报告到部署等所有数据需求。它基于图形用户界面进行可视化编程,使其非常直观易用,大大缩短了学习时间。
它设计为支持不同的数据格式、数据类型、数据来源、数据平台,以及外部工具,例如 R 和 Python。它还包括用于分析非结构化数据(如文本、图像或图表)的多个扩展。
KNIME Analytics Platform 中的计算单元是小的彩色块,称为“节点”。将节点一个接一个地组装在管道中,实现了数据处理应用程序。管道称为“工作流”。
考虑到所有这些特性——开源、可视化编程和与其他数据科学工具的集成——我们选择了它来实现本文中描述的四种离群点检测技术。
实现这四种离群点检测技术的最终 KNIME 工作流见图 1。工作流:
-
在 Read data 元节点内读取数据样本。
-
在 Preproc 元节点内预处理数据,并计算每个机场的平均到达延误。
-
在下一个名为“延误密度”的元节点中,它标准化数据,并将标准化的平均到达延误的密度与标准正态分布的密度进行绘制。
-
使用四种选定的技术检测异常值。
-
使用 KNIME 与 Open Street Maps 的集成,在 MapViz 元节点中可视化美国的异常机场。

图 1: 实现四种异常检测技术的工作流程:数值异常值、Z-score、DBSCAN、孤立森林。该工作流程可在 KNIME EXAMPLES 服务器上找到,路径为 02_ETL_Data_Manipulation/01_Filtering/07_Four_Techniques_Outlier_Detection/Four_Techniques_Outlier_Detection。
检测到的异常值
在图 2-5 中,您可以看到不同技术检测到的异常机场。
蓝色圆圈代表没有异常行为的机场,而红色方块代表有异常行为的机场。平均到达延迟时间定义了标记的大小。
一些机场被所有技术一致识别为异常值:斯波坎国际机场 (GEG)、伊利诺伊大学威拉德机场 (CMI) 和哥伦比亚大都会机场 (CAE)。斯波坎国际机场 (GEG) 是最大的异常值,其平均到达延迟时间非常长 (180 分钟)。
然而,还有一些其他机场仅被部分技术识别。例如,路易斯·阿姆斯特朗新奥尔良国际机场 (MSY) 仅被孤立森林和 DBSCAN 技术发现。
请注意,对于这个特定的问题,Z-Score 技术识别出最少的异常值,而 DBSCAN 技术识别出最多的异常机场。
只有 DBSCAN 方法 (MinPts=3, ℇ=1.5, 距离度量欧氏) 和孤立森林技术 (估计异常值百分比 10%) 能在早到方向上找到异常值。

图 2: 使用数值异常值技术检测的异常机场 
图 3: 使用 z-score 技术检测的异常机场 
图 4: 使用 DBSCAN 技术检测的异常机场 
图 5: 使用孤立森林技术检测的异常机场
摘要
在这篇博客文章中,我们描述并实现了四种不同的异常检测技术在一维空间中:2007 年至 2008 年间所有美国机场的平均到达延迟时间,如航空公司数据集中所述。
我们研究的四种技术是数值异常值、Z-Score、DBSCAN 和孤立森林方法。其中一些适用于一维特征空间,有些适用于低维空间,还有一些扩展到高维空间。有些技术需要标准化和检查维度的高斯分布,有些需要距离度量,还有一些需要计算均值和标准差。
有三个机场被所有异常检测技术识别为异常值。然而,只有部分技术(DBSCAN 和 Isolation Forest)能够识别分布左尾中的异常值,即那些平均上航班到达时间早于预定到达时间的机场。
参考文献
本博客文章的理论基础来自:
- Santoyo, Sergio. (2017 年 9 月 12 日). 异常检测技术的简要概述 [博客文章]。
相关:
-
使用标准差在 Python 中去除异常值
-
如何让你的机器学习模型对异常值具有鲁棒性
-
8 个可能毁掉你预测的常见陷阱
更多相关内容
数据科学家的傅里叶变换
原文:
www.kdnuggets.com/2020/02/fourier-transformation-data-scientist.html
评论
图片来源:Shutterstock
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
介绍
傅里叶变换是数学中最深刻的见解之一,但不幸的是,其意义深藏在一些荒谬的方程式中。
傅里叶变换是一种将某物拆分为一堆正弦波的方法。像往常一样,名字来自很久以前的一个人,傅里叶。
在数学术语中,傅里叶变换是一种将信号转化为其组成成分和频率的技术。
傅里叶变换不仅广泛应用于信号(如无线电、声学等)处理,还用于图像分析,如边缘检测、图像过滤、图像重建和图像压缩。例如:傅里叶变换在透射电子显微镜图像中有助于检查样本的周期性。周期性——意味着模式。傅里叶变换可以扩展有关分析样本的信息。
为了更好地理解,考虑一个信号 x(t):

如果我们对另一个信号做同样的处理,并选择相同的时间点进行幅度测量。
另一个信号 y(t):

当我们同时发出这两个信号或将它们加在一起时会发生什么?
当我们在同一时间发出这两个信号时,我们得到一个新信号,即这两个信号的幅度之和。这是因为这两个信号被加在一起。
将两个信号相加:z(t) = x(t) + y(t)

如果我们只得到一个信号(即信号 x(t)和 y(t)的和),我们能恢复原始信号 x(t)和 y(t)吗?
是的,这就是傅里叶变换的作用。它接受一个信号并将其分解为组成它的频率。
在我们的例子中,傅里叶变换会将信号 z(t)分解成其组成频率,就像信号 x(t)和 y(t)一样。
傅里叶变换的作用是将我们从时间域移动到频率域。

如果有人想知道,我们如何从频率域返回到时间域?
我们可以通过使用逆傅里叶变换(IFT)来实现这一点。
你需要了解的数学知识。
“任何连续信号在时间域中可以通过无限正弦波序列唯一且明确地表示。”
这是什么意思?
这意味着,如果我们有一个由某个函数x(t)生成的信号,那么我们可以得到另一个函数f(t),使得:

因此,无论信号的强度如何,我们都可以找到一个函数f(t),它是无限正弦波序列的和,能够完美地表示信号。
现在,提出的问题是,我们如何在上述方程中找到系数,因为这些值将决定输出的形状,从而决定信号。

因此,为了获得这些系数,我们使用傅里叶变换,而傅里叶变换的结果是一组系数。因此,我们用X(w)表示傅里叶系数,它是频率的函数,通过解积分得到:
傅里叶变换表示为不定积分:
X(w):傅里叶变换
x(t):逆傅里叶变换


傅里叶变换和逆傅里叶变换
此外,当我们实际计算上述积分时,会得到这些复数,其中a和b对应于我们追求的系数。
连续傅里叶变换将无限持续时间的时间域信号转换为由无限多个正弦波组成的连续谱。在实际应用中,我们处理的是离散采样的信号,通常在固定间隔内采样,并且具有有限持续时间或周期性。为此,经典傅里叶变换算法可以表示为离散傅里叶变换(DFT),它将函数的有限序列等间隔采样转换为离散时间傅里叶变换的等长度序列:

所以,这本质上就是离散傅里叶变换。我们可以进行这种计算,它会产生一个形式为a + *i*b的复数,其中包含傅里叶级数的两个系数。
现在,我们知道如何采样信号和如何应用离散傅里叶变换。最后,我们想做的是,想要摆脱复数 *i*,因为它在 mllib 或 systemML 中不被支持,可以通过一种称为欧拉公式的方法来实现,该公式如下:

因此,如果我们将欧拉公式代入傅里叶变换方程并进行求解,它将产生实部和虚部。

如你所见,X 由格式为 a+ib 或 a-ib 的复数组成。因此,如果你解上述方程,你将得到傅里叶系数 a 和 b。


现在,如果你在f(t)方程中代入a和b的值,你可以根据其频率定义一个信号。
在实际操作中,我们使用快速傅里叶变换(FFT)算法,它递归地将离散傅里叶变换(DFT)分解为更小的 DFT,从而显著降低所需的计算时间。DFT 的时间复杂度是2N²,而 FFT 的时间复杂度是2NlogN。
为什么在表示信号时使用余弦和正弦函数?
尽管正弦和余弦函数最初是基于直角三角形定义的,但在当前情况下,考虑那个观点并不是最佳选择。你可能已经被教导识别正弦函数为“对边除以斜边”,但现在是时候换一个稍微不同的视角了。
考虑单位圆:

在笛卡尔平面上。假设一条通过原点的直线在逆时针方向上与 ????-轴成角θ,直线与圆的交点为 (cosθ, sinθ)。

想一想。这个观点与之前的观点相关吗?两种定义是相同的。
假设我们开始旋转这条直线,使θ线性增加。你会得到如下结果:

正弦函数和余弦函数在多种情况下可以说是最重要的周期函数:
-
SHM 振荡器中位移、速度和加速度随时间变化的周期函数是正弦函数。
-
每个粒子都有波动性,反之亦然。这是德布罗意的波粒二象性。波动总是某些物理量的正弦函数(如电磁波的电场和声波的压力)。
声音本身是通过能够压缩和扩展的材料介质传播的压力扰动。声音波沿点的压力随时间呈正弦变化。
傅里叶变换的收敛性
如果一个点以恒定速度绕圆圈移动,它离地面的高度描绘了一个正弦函数。点移动的速度对应于频率,圆圈的半径对应于振幅。

添加 1 个圆圈,

添加 2 个圆圈,

添加 9 个圆圈:

几乎是一个离散波形。
由于傅里叶定理,我们可以用适当频率和半径的圆生成任何信号。
我使用了 Dan Shiffman 的代码从coding challenge #125制作动画。你可以从他的GitHub获取 JavaScript 代码并自行尝试。
人工智能中的傅里叶变换
傅里叶变换是一个线性函数,为了引入非线性,使用了卷积。
两个信号的乘积的傅里叶变换是这两个信号的卷积。
设 x(t) 和 y(t) 为两个具有卷积 X(t)*Y(t) 的函数,F 代表傅里叶变换,那么
F{x(t).y(t)} = X(t)*Y(t)
记住,在时间域中的卷积在频域中是乘法。这就是傅里叶变换在机器学习,尤其是深度学习算法中最常用的方式。
我将以卷积神经网络,CNNs 为例;
CNNs 中 90% 的计算是卷积,并且已经有许多方法来减少这些计算的强度,其中之一就是快速傅里叶变换(FFT)。
替代卷积,输入和滤波矩阵通过 FFT 转换到频域中进行乘法运算。然后,输出通过反向FFT (IFFT) 转换回时间域。

FFT 的另一个用途是可以用于降维或特征提取。
当数据集中每个样本是一个信号(时间序列或图像等)时,它可能包含成千上万的样本。但它们实际上可能只对应傅里叶域中的几个点(尤其是如果有某种周期性)。这大大简化了问题。
或者,有时使用傅里叶域可能提供平移不变性。也就是说,即使信号之间有滞后,这些变异也不会影响它们在傅里叶域中的表现。
傅里叶变换的 Python 实现
最简单的 FFT 实现可以使用 numpy 和 scipy python 库完成。
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import scipy.fftpack
# Number of samplepoints
N = 600
# sample spacing
T = 1.0 / 800.0
x = np.linspace(0.0, N*T, N)
y = np.sin(50.0 * 2.0*np.pi*x) + 0.5*np.sin(80.0 * 2.0*np.pi*x)
yf = scipy.fftpack.fft(y)
xf = np.linspace(0.0, 1.0/(2.0*T), N/2)
fig, ax = plt.subplots()
ax.plot(xf, 2.0/N * np.abs(yf[:N//2]))
plt.show()

FFT 绘图
结论
FFT 用于数字录音、采样、加法合成 和音高校正软件。
FFT 的重要性源于其使在频域工作的计算复杂度与在时间域或空间域工作的计算复杂度相当。一些 FFT 的重要应用包括:
-
快速的大整数和多项式乘法
-
高效的 Toeplitz 矩阵、循环矩阵及其他结构化矩阵的矩阵-向量乘法
-
过滤算法
-
快速的切比雪夫逼近
-
解差分方程。
好了,本文就到这里,希望你们喜欢阅读,如果文章对你们有帮助我会很高兴。欢迎在评论区分享你的评论/想法/反馈。
感谢阅读!!!
个人简介:纳戈什·辛格·乔汉 是一名数据科学爱好者,对大数据、Python 和机器学习感兴趣。
原文。经许可转载。
相关:
-
数据科学难题 — 2020 版
-
贝叶斯背后的数学
-
2020 年数据科学的 5 大趋势
更多相关内容
接近文本数据科学任务的框架
原文:
www.kdnuggets.com/2017/11/framework-approaching-textual-data-tasks.html
今天有大量的文本数据可用,并且每天都会产生大量数据,这些数据从结构化到半结构化再到完全非结构化。我们可以用它做什么?实际上,可以做很多事情;这取决于你的目标,但有两个复杂相关但有所不同的任务类别,可以利用所有这些数据的可用性。
文本挖掘还是自然语言处理?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
自然语言处理(NLP)关注自然人类语言与计算设备之间的互动。NLP 是计算语言学的一个重要方面,也属于计算机科学和人工智能的领域。
文本挖掘与自然语言处理(NLP)处于相似的领域,因为它涉及识别文本数据中有趣的、非平凡的模式。
好的,很棒。但真正的区别是什么?
首先,这两个概念的确切边界并不明确且未达成一致(见数据挖掘与数据科学),并且在不同程度上相互交织,具体取决于与之讨论这些问题的从业者和研究者。我发现通过洞察的程度来区分是最简单的。如果原始文本是数据,那么文本挖掘是信息,NLP 是知识(见下方理解金字塔)。可以说是语法与语义的问题。
理解金字塔:数据、信息、知识。
另一种理解这两个概念之间差异的方法是通过下方的维恩图,它还考虑了其他相关概念,以展示多个密切相关领域和学科之间的关系和重要重叠。

我对这个图表并不完全信服——它将过程与工具混淆了——但它确实有其有限的用途。
关于文本挖掘与自然语言处理之间确切关系的各种解释存在,你可以找到对你更有效的解释。我们并不特别关注确切的定义——无论是绝对的还是相对的——而是更注重直观地认识到这些概念之间有某些重叠但仍然各自独立。
我们将继续前进的观点是:尽管自然语言处理和文本挖掘不是同一回事,但它们紧密相关,处理相同的原始数据类型,并且在使用上有一些交集。重要的是,针对这两大领域的任务的数据预处理大致相同。
尽量避免歧义是文本预处理的一个重要部分。我们希望保留预期的含义,同时消除噪音。为此,需要做以下工作:
-
关于语言的知识
-
关于世界的知识
-
结合知识来源的一种方式
文字还为什么难?

来源:CS124 斯坦福。
文本数据科学任务框架
我们能否制定一个足够通用的框架来处理文本数据科学任务?事实证明,处理文本与其他非文本处理任务非常相似,因此我们可以借鉴KDD 流程的灵感。
我们可以说这些是通用文本任务的主要步骤,属于文本挖掘或自然语言处理的范畴。
1 - 数据收集或汇编
- 获取或构建语料库,这可以是从电子邮件、整个英文维基百科文章集、公司的财务报告、莎士比亚的完整作品,到其他完全不同的内容。
2 - 数据预处理
-
在原始文本语料库上执行准备任务,以便进行文本挖掘或自然语言处理任务。
-
数据预处理包含多个步骤,任何步骤可能适用于给定任务,也可能不适用,但通常属于分词、规范化和替代的广泛类别。
3 - 数据探索与可视化
-
无论我们的数据是什么——文本还是其他——探索和可视化它是获得洞察的关键步骤。
-
常见任务可能包括可视化词频和分布,生成词云,并执行距离测量。
4 - 模型构建
-
这是我们核心的文本挖掘或自然语言处理任务进行的地方(包括训练和测试)。
-
还包括在适用时的特征选择与工程。
-
语言模型:有限状态机,马尔可夫模型,词义的向量空间建模
-
机器学习分类器:朴素贝叶斯,逻辑回归,决策树,支持向量机,神经网络
-
序列模型:隐马尔可夫模型、递归神经网络(RNNs)、长短期记忆神经网络(LSTMs)
5 - 模型评估
-
模型的表现是否符合预期?
-
指标会根据文本挖掘或 NLP 任务的类型而有所不同
-
即使在聊天机器人(一个 NLP 任务)或生成模型方面进行创新思考:某种形式的评估也是必要的

一个简单的文本数据任务框架。这些步骤并不完全是线性的,但为了方便起见进行了可视化。
下一次请加入我,我们将定义并进一步探索一个用于文本数据任务的数据预处理框架。
相关:
-
自然语言处理关键术语解释
-
5 个免费的资源,帮助你入门自然语言处理的深度学习
-
7 种用于自然语言处理的人工神经网络类型
更多相关主题
框架为数据科学家提供了编程语言所缺乏的什么?
原文:
www.kdnuggets.com/2017/05/frameworks-offer-data-scientists-programming-languages-lack.html
曾几何时,计算机编程全在于使用正确的语言。在 C、Lisp 和 Pascal 等系统之间,程序员可以选择其专长和格式。然而,随着计算能力的提升,使得系统能够理解并轻松切换所有语言,编程语言之间的差异已经大致消失。今天的重点是框架,它们通常更现代和前瞻,能够克服许多编程语言的过时做法。

今天你使用的编程语言不再像以前那样重要。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
框架是一组统一的库代码,它们简化了任何给定语言的编程,而语言则是编写代码的实际语法和语法结构。框架具有许多优势。尽管编程语言永远不会完全过时,但越来越多的程序员更倾向于使用框架,并认为它们是更现代和前沿的选择。这种转向框架的趋势是IT 转型的一部分,预计在未来几年将会加速发展。
框架深入探讨
编程曾经是关于如何从代码中获取最大收益的,但这种做法已经被自动化代码编写系统大大取代了。如今,程序员不再专注于如何编写一个 API,而是更关心这个 API 能做什么。这就像是拼写一个单词的正确与否和真正理解这个单词的意思以及如何在句子中使用它之间的区别。由于大多数编码是将一组 API 连接在一起,程序员可以更多地关注系统的框架,而不是担心在代码中间插入什么标点符号。关注 API 的功能使程序员能够突破极限,找到各种编码问题的原因和效果;这让他们更自由地理解发生了什么,以及如何操作以创建最有效的代码。
框架关注宏观
多亏了自动化系统和教程,对各种编程语言的深入了解已经不再像以前那样重要了。各种程序可以自动纠正错误,这些程序会不断地查找编码错误。与其花时间处理代码的细节,框架让程序员能够从更宏观的角度思考。通过更好地理解系统和 API 的能力,以及由自动化系统处理更繁琐的细节,程序员可以将更多精力投入到将程序发展成具有更多高级功能和潜力的更大项目中。
框架构建强大的算法
使用编程语言最重要的部分之一是理解算法,并确保代码符合这些算法。然而,算法可能会受到语言的限制,因为它们实际上是由框架定义的。将算法作为框架的一部分进行更改和建立,比在语言层面进行调整要安全和有效得多。框架已经开发多年,意味着它们经过了多次验证,是来自最佳编程思想的结合体。
框架是未来
无论他们专注于哪个语言,许多程序员都同意框架是编程的未来。如果代码是法律,编程语言是确保法律得到实施的执行者,而框架则是实际制定法律的系统。通过专注于框架,程序员可以在未来中拥有更大的发言权,并可以真正设定代码的规则,而不仅仅是实现它们。一旦规则设定完毕,每个人都必须遵循这些规则,因此理解框架为用户提供了设定所有人必须遵循的规则的机会。在一个快速发展且前瞻性的编程世界中,能够制定一些规则为用户提供了改变游戏的权力和机会。

一些可以在数据科学中利用的框架样本。
数据科学家的好处
这就引出了框架如何极大地促进数据科学家的工作。上述所有观点都可能对数据科学家有利。例如,专注于框架意味着数据科学家不必始终具有丰富的编码和编程语言经验。他们可以将自己在各自行业的经验带到工作中。框架还帮助数据科学家进行数据挖掘和数据分析,同时也让他们有时间关注更大的目标。
一些框架甚至是以大数据和数据科学为出发点开发的。例如,Hadoop 是第一个被各种企业广泛采纳的大数据处理框架之一。Hadoop 也催生了一个专注于大数据处理的技术生态系统,如 Hive 和 Pig。其他框架如 Spark、Samza 和 Flink 都各有其用处,并帮助数据科学家更好地取得积极成果,从大数据集中提取见解,以及高效管理大数据项目。
尽管编程语言曾经非常重要,但专注于它们细微的区别已逐渐过时且不必要,特别是当自动化程序可用时。相反,专注于框架以及事物为何如此工作的原因将引领计算未来,帮助数据科学家达到新的成功高度。
相关:
-
顶级大数据处理框架
-
Python 深度学习框架概述
-
机器学习专家的 15 个顶级框架
更多相关主题
从机器的视角看欺诈
评论
作者 Jakub Karczewski,机器学习工程师。

背景
确定某笔交易是否存在欺诈行为的方法有很多种。从基于规则的系统到机器学习模型——每种方法在特定条件下通常效果最佳。成功的反欺诈系统应当充分利用所有这些方法,并在最适合解决问题的地方加以应用。
在反欺诈系统中,网络和连接分析的概念至关重要,因为它有助于揭示通过其他方式无法获得的交易隐藏特征。在这篇博客文章中,我们将尝试揭示如何创建网络,然后利用它们来检测欺诈交易。
欺诈检测中的网络
让我们考虑一个交易——这是在线支付世界中的基本实体之一。每个交易可以通过一组属性来描述。在 Nethone,我们每笔交易收集超过 5000 个数据点,但为了简单起见,我们将重点关注几个常见的属性,例如:
-
支付的特征是什么(金额、卡片令牌),
-
谁发起了交易(姓名、电子邮件),
-
使用了哪种设备(IP 地址、设备操作系统、浏览器 Cookie)
记住这些示例交易属性,我们现在可以进入网络构建阶段。网络(或图)是一组通过边(“线”)连接的节点(“点”)。在在线支付的世界里,节点可以是交易或交易属性的特定值。边可以表示各种关系,但在这种情况下,我们将重点关注最常见的一种:共享属性值。让我们以这个简单的网络为例:

图 1 - 简单网络。
我们可以看到,处理过的交易(“带光环的点”)与其他几个交易(黑色节点)共享了 IP 地址(绿色节点)、电子邮件地址(紫色节点)和 Cookie(橙色节点)的值。创建这样一个网络的过程相当简单:
-
提取处理过的交易的属性值(如 IP 地址、Cookie、电子邮件等)。
-
查找其他共享某些属性值的交易。
-
绘制这些数据并通过代表特定属性值的中介节点连接到处理过的交易。
简而言之,这一切都是关于使用某些属性作为匹配键来连接交易。这种方法虽然在原则上简单,却提供了有价值的背景信息。
一旦图形创建完成,我们可以查询其各种属性。我们可以检查最长路径是什么,或者有多少节点连接到某个特定节点,例如 IP 地址。提取网络特征后,我们可以将其输入规则基础系统或机器学习模型中——如开头所述——混合方法效果最佳。
欺诈攻击的可视化

图 2 - 扩展网络 - 卡片诈骗方案。
该网络是使用不同的种子交易构建的,并通过增加深度参数进行扩展。这意味着我们现在可以连接与处理过的交易相关的交易——借用社交互动的类比,我们可以分析“朋友的朋友的朋友……等”,即与不同相关交易相关的交易。这样,我们可以扩展范围,获取更多洞察。让我们深入观察一些集群。

图 3 - 通过卡片令牌的可疑连接。
初看,我们可以看到一个电子邮件和 IP 地址(红色和绿色节点)连接到许多不同的信用卡令牌(蓝色节点)。由于人们拥有大量信用卡的情况相当少见,这种类型的网络可能是卡片诈骗的一个例子。在这种攻击中,欺诈者使用盗取的信用卡凭证执行大量交易。当数据结构化为网络时,我们可以轻松区分正常流量和卡片诈骗模式(少数人,多张卡片和交易)。在查询图形并遇到风险模式后,我们可以将可疑属性值添加到黑名单中。这样,如果系统遇到这些值,交易将自动标记为有风险。
连接分析的好处和挑战
我们可以从连接分析中提取大量洞察,但这并非毫无代价——还存在额外的挑战。一方面,从事务性、表格数据构建的网络中研究连接可能有助于揭示在保持数据平铺时难以提取的关系。网络的结构及其随时间变化可以是一个非常丰富的信息来源,以及一个对人类友好的数据界面。
另一方面,对于什么行为属于欺诈行为没有严格的规则。如果我们看到多个交易来自同一个 IP 地址,这可能意味着欺诈攻击,但也可能是员工利用他们的公司代理网络进行购买。重要的是尽可能考虑多个因素——忽视某些因素可能会严重扭曲我们通过网络感知数据的方式。一个关键因素的好例子是时间——在同一天进行第 10 次交易并在每次交易后清除浏览器 cookies 的情况与一个合法用户在同一年进行第 10 次购买(其 cookies 在连续交易之间自然过期)的情况看起来完全相同。
背景是关键。
原文. 经许可转载。
相关:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 支持
更多相关话题
免费人工智能入门课程

图片由@girlie_mac提供
如果你在寻找免费的入门人工智能课程,微软可以满足你的需求。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
名为初学者的人工智能的课程由 Microsoft Azure Cloud Advocates 精心编制,包括为期 12 周、24 节课的课程,旨在向学习者介绍人工智能的奇妙世界。
该课程将向学习者介绍各种人工智能概念,包括但不限于:
-
“经典”GOFAI(传统人工智能)方法,从符号方法到知识表示和推理
-
现代人工智能方法,其基础是神经网络及其深度学习技术
-
使用 TensorFlow 和 PyTorch 实施现代人工智能主题
-
图像和文本的神经网络架构
-
替代的人工智能方法,包括遗传算法和多智能体系统
你可以查看具体的课程内容,一节课一节课地列出,[点击这里](http://Microsoft Azure Cloud Advocates, and consists of a 12 week, 24 lesson curriculum)。
课程使用各种材料进行讲授。一些常见的资源包括:
-
课程的前阅读材料;这是知识表示和知识系统的一个示例
-
特定于 PyTorch 或 TensorFlow 的指导性 Jupyter 笔记本,通常每节课一个框架
-
实验室,作为学习者需要完成的作业,通常是需要完成的 Jupyter 笔记本
-
偶尔会有与相关主题相关的 Microsoft Learn 模块的链接;Microsoft Learn 提供对 GPU 支持环境的访问
你可以在这里找到课程的思维导图。
如果你有兴趣了解更多,可能想要观看下面的视频以了解课程的讲师。
现如今有许多涵盖各种数据科学、机器学习、人工智能和分析主题的课程,因此你需要认真研究以确保选择符合你目标的课程。我们希望通过这些文章帮助你筛选出优质的免费课程对你有帮助,但不要忘记在报名之前调查每个课程。这门来自微软的课程现在没有变化。然而,如果你是一个想了解当前概念、技术和话题的 AI 初学者,这门课程是一个有前途的选择。
Matthew Mayo (@mattmayo13) 是一位数据科学家和 KDnuggets 的总编辑,这是一个开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及自动化机器学习方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
了解更多相关话题
NVIDIA 提供的免费 AI 课程:适合所有级别
原文:
www.kdnuggets.com/free-ai-courses-from-nvidia-for-all-levels

作者图片
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT 需求
生成式 AI 在过去几个月中已成为主流,并且只会越来越好。那么,如何提升技能并跟上所有最新进展呢?
但好消息是:随着最近的进展,高质量免费学习资源的数量也在增加。这是一份来自 NVIDIA——NVIDIA 深度学习学院的免费 AI 课程汇编,帮助您掌握 AI 主题并开始构建有影响力的解决方案。
那么,让我们来看看这些课程及其内容吧!
生成式 AI 解释
生成式 AI 解释 是一门适合初学者的生成式 AI 基础课程,让您入门。此课程将介绍以下主题:
-
生成式 AI 及其工作原理
-
生成式 AI 应用
-
生成式 AI 中的挑战与机遇
到课程结束时,您将对生成式 AI 有一个良好的理解,了解它的工作原理以及如何使用它。
链接: 生成式 AI 解释
10 分钟内构建大脑
大型语言模型目前非常流行且极具帮助。然而,在深入了解 LLM 之前,对神经网络如何工作有一个基本的理解是必要的。
10 分钟内构建大脑 是构建神经网络的入门课程,涉及生物学启发,指导神经网络架构。
为了充分利用本课程,您需要对 Python 编程和回归模型感到舒适。这个短课程将帮助您学习以下内容:
-
神经网络如何从数据中学习
-
神经元背后的数学及神经网络的工作原理
链接: 10 分钟内构建大脑
使用检索增强生成来扩展您的 LLM
每当你想构建使用 LLM 的应用程序时,你也会使用检索增强生成(RAG)。通过 RAG,你可以基于特定领域的数据构建 LLM 应用程序,减轻 LLM 幻觉等。
通过检索增强生成增强你的 LLM课程将教你如何构建一个使用信息检索和响应生成的 RAG 管道。这将帮助你很好地掌握 RAG 的基础知识和 RAG 检索过程。
链接: 通过检索增强生成增强你的 LLM
使用 LLM 构建 RAG 代理
一旦你熟悉了之前课程中的 RAG 工作原理,你可以参加使用 LLM 构建 RAG 代理课程,通过构建端到端的 LLM 系统,深入探索 RAG。
要掌握这门课程,拥有中级的 Python 编程经验和一些 PyTorch 编程经验会很有帮助。在本课程中,你将探索设计 LLM 管道,并使用Gradio、LangChain和LangServe等工具。你还将尝试使用嵌入、模型和向量存储进行检索。
链接: 使用 LLM 构建 RAG 代理
总结
我希望你觉得这份来自 NVIDIA 深度学习学院的免费 AI 课程综合列表对你有帮助。
如果你有兴趣进一步探索 LLM 和生成 AI,以下是你可能会觉得有用的几篇文章:
祝学习愉快,编码顺利!
Bala Priya C** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过编写教程、操作指南、观点文章等与开发者社区分享她的知识。Bala 还制作了引人入胜的资源概述和编码教程。
更多相关话题
免费 Python 算法课程
原文:
www.kdnuggets.com/2022/09/free-algorithms-python-course.html

来自Python 中的算法的截图
随着“算法”这个词越来越深入公众的脑海和词汇中,它也越来越带有神秘的色彩。
人们听到这个词时通常会想到机器学习算法,这可能导致公众误以为是同样误导的术语——人工智能。但你和我知道这不应该是这样。算法是我们为解决特定问题所采取的具体步骤。就是这样,没有更多的东西。没有涉及魔法。
当然,我们可以谈论机器学习算法,这些是机器学习概念的实现所采取的具体步骤,但在算法术语中,这些只是另一组步骤,与机器学习或人工智能的神秘性无关。但我跑题了。
回到我们要讨论的主题:在我们的背景下,算法是特定计算概念的步骤在编程中的实现。我们到底在数据或某些资源上做了什么,以及确切的顺序是什么?如果你来自计算机科学背景,毫无疑问你在“编程导论 101”之后的第一个计算机科学课程之一是算法,或者可能是数据结构与算法,它们结合了数据方面的什么和如何。如果你不是计算机科学背景,可能是在自学编程、在线学习数据科学或通过其他方法时学到了算法。
总的来说:如果你以某种方式学习了算法,恭喜你!做得好!如果没有,你真的应该学习。让我们看看是否能帮忙。
freeCodeCamp 刚刚发布了Python 中的算法,这是一个免费学习算法的完整课程,使用的是现存的最流行的编程语言之一。该课程由Joy Brock与realtoughcandy.io合作开发,因此一定要查看他们的其他课程。
Python 不仅在作为通用编程语言方面享有广泛的受欢迎程度——意味着你可以用它完成各种编程任务,几乎是任何可以想象的任务(在合理范围内)——Python 也是数据科学和机器学习领域需求最高的语言之一。作为额外的好处,Python 是一个 notoriously 对初学者友好的语言,使得用它来理解算法和其他程序性及计算概念变得更容易。
在这个视频课程中,你将学习算法基础知识,如阶乘、排列、N 皇后问题和旅行推销员问题。你将深入探讨程序算法的核心内容:排序!接着你将学习一些数据结构,并了解算法和结构如何通过如哈希表的概念协同工作。你还会学习动态编程、矩阵乘法等话题,以及什么是贪心算法。
Python 已成为数据科学新手和经验丰富的从业者的首选语言(或者,更准确地说,是首选语言之一)。将你的算法学习与 Python 配对,迈出进一步提升自己的步伐。祝好运!
Matthew Mayo (@mattmayo13) 是数据科学家及 KDnuggets 的主编,KDnuggets 是一个开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及自动化机器学习方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。你可以通过 editor1 at kdnuggets[dot]com 联系他。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
更多相关主题
免费亚马逊课程以学习生成式 AI:适合所有级别
原文:
www.kdnuggets.com/free-amazon-courses-to-learn-generative-ai-for-all-levels

图片由作者提供
每个人都想分一杯生成式 AI 的蛋糕,从软件开发人员到非技术业务领导者。掌握所有提升你职业或组织中生成式 AI 的信息和技能,就是你所需要的。现在,你可以通过亚马逊的免费课程获取这些信息,这些课程涵盖了生成式 AI 的各个方面、领域以及不同的职位。
生成式 AI 基础
链接:生成式 AI 基础
关注亚马逊的生成式 AI 基础 YouTube 播放列表,该列表深入探讨了为已熟悉 AI 建模的人设计的技术细节。你将学习生成式 AI 的概念基础,并获得实用建议,以及如何预训练、微调和部署先进的基础模型,无论是在 AWS 还是其他平台。
提示工程基础
链接:提示工程基础
这是一个独立的课程,你将在其中学习有效提示工程的原则、技术和最佳实践。从基础知识开始,逐步进阶到更高级的技术。你还将学习如何防范提示滥用以及减轻偏见。
该课程面向中级技术专业人士,完成需时 4 小时。为了充分利用这门课程,建议你对生成式 AI 有良好的理解,知道如何在项目中处理生成式 AI 以及 Amazon Bedrock。
生成式 AI 开发者学习计划
从这门免费的亚马逊课程开始你的生成式 AI 学习路径,该课程涉及大规模语言模型、生成式 AI 项目的规划、提示工程的基础知识,以及如何使用 Amazon Bedrock。
包含 5 门课程,总计 11 小时。为了从这门课程中获得最大收益,建议先具备 AWS 技术基础 和中级 Python 水平。
在 AWS 上构建语言模型
了解如何在 Amazon SageMaker 上构建大型语言模型,这个平台帮助数据科学家构建、训练、部署和监控机器学习模型。数据科学家将负责在平台上构建大型语言模型,学习不同的存储、数据摄取和训练选项,以处理模型所需的大型文本数据。你还将学习在生成式人工智能任务中部署大型语言模型时遇到的挑战。
本课程面向高级技术专业人员,完成需要 5.5 小时。
决策者的生成式人工智能学习计划
链接: 决策者的生成式人工智能学习计划
在成为技术专业人员或处理数据驱动的结果时,做决策可能是最具挑战性的事情之一。在亚马逊提供的这门免费课程中,你将学习生成式人工智能如何在商业方面被使用,以及它如何用于做出技术决策。成为这些决策者之一,学习如何处理生成式人工智能项目,使组织做好生成式人工智能准备。
这条学习路径包括 3 门课程,每门课程需要 1 小时完成。
高管的生成式人工智能
链接: 高管的生成式人工智能
尽管目前关于生成式人工智能的宣传很多,但你可能仍然不了解它的真正能力以及如何实施以提升你的组织。在本课程中,你将获得生成式人工智能的高层次概述,了解它如何解决高管的关注和挑战,以及如何支持业务增长。这将通过各种用例和一个关于如何培训员工使用生成式人工智能的视频来支持。
总结
无论你在组织中的位置如何,你都必须了解当前技术领域的现状以及未来的期望。这些课程可以帮助你为组织实施新策略,或提升你作为软件开发人员的技能。
每个人都应该有免费访问今天世界的学习机会。
Nisha Arya 是一名数据科学家、自由技术写作人,同时也是 KDnuggets 的编辑和社区经理。她特别感兴趣于提供数据科学职业建议或教程及数据科学相关的理论知识。Nisha 涵盖了广泛的主题,并希望探索人工智能如何有利于人类寿命的不同方式。作为一个热衷于学习的人,Nisha 希望拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关内容
免费人工智能与深度学习速成课程
原文:
www.kdnuggets.com/2022/07/free-artificial-intelligence-deep-learning-crash-course.html
不论好坏,“人工智能”(AI)这个术语似乎正变得与现代机器学习同义。以前,AI 包含了许多用于模拟机器智能的计算技术,但现在几乎专指现代机器学习中的一个分支:深度学习。
深度神经网络在 Krizhevsky、Sutskever 和 Hinton 的ImageNet 胜利于 2012 年 10 月引发现代深度学习革命时,已经存在了一段时间。从那时起,深度学习在几乎所有 AI 子领域和领域中都取得了 SOTA 结果:计算机视觉;自然语言处理;语音识别;医学图像分析;图像重建;文本生成;以及更多。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
简而言之,如果你想参与现代 AI 发展,你需要理解深度学习。这就是 Simplilearn 的人工智能与深度学习完整课程的用武之地。

来自 Simplilearn 的人工智能与深度学习完整课程的静态图像
这是课程的 YouTube 页面对人工智能和深度学习以及它们的关系的定义:
人工智能是什么?
人工智能是从大量数据中构建智能机器的过程。系统从过去的学习和经验中学习,并执行类似于人类的任务。它提高了人类努力的速度、精确度和有效性。AI 使用复杂的算法和方法来构建能够自主决策的机器。机器学习和深度学习是人工智能的核心。
深度学习是什么?
深度学习可以被视为机器学习的一个子集。它是一个基于通过检查计算机算法来学习和自我改进的领域。虽然机器学习使用的是更简单的概念,深度学习则利用人工神经网络,这些网络旨在模拟人类的思维和学习方式。
Simplilearn 制作了这个视频课程,以帮助观众理解人工智能和深度学习的基础知识,以及如何在自己的模型中使用 AI 和深度学习算法。
从其网站直接获取的课程内容包括:
-
人工智能基础
-
人工智能的未来
-
详细的人工智能
-
什么是深度学习
-
神经网络
-
Tensorflow 目标检测
-
循环神经网络
-
什么是 GAN?
-
Keras 教程
-
OpenCV
-
深度学习面试问题
你可以在下面或直接在YouTube上观看这门 10.5 小时的课程。
不要等待,立即扩展你对人工智能及其最强大现代推动者——深度学习的理解。这门全面的课程肯定会将你引导到正确的道路上。
Matthew Mayo (@mattmayo13)是数据科学家和 KDnuggets 的主编,这是一个开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及自动化机器学习方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
了解更多相关主题
免费的 Python 自动化课程
原文:
www.kdnuggets.com/2022/07/free-automate-python-course.html

来自 Frank Andrade 的自动化备忘单
直白地说,计算机编程就是关于自动化的。如果你不需要自动化某件事,你就不会编写代码。你写的那个处理 CSV 文件的脚本?自动化。你写的那个解析文本输入的程序?自动化。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT
编程是自动化的全部内容,你能自动化的越多,作为程序员的生活就会越轻松(你也能为与你合作的人提供更多价值)。
没有人喜欢机械重复(好吧,也许有人喜欢)。手动做某事 X 次与花时间自动化它之间的平衡有点像艺术,但通常来说,如果你在电脑上反复做同一件事,你不妨自动化它。有什么比用 Python 自动化更好的选择呢?Python 是我们今天可用的最流行、最受支持且易于使用的编程语言之一。
freeCodeCamp 最近推出了一个免费的 Python 自动化课程,方便地命名为 使用 Python 自动化。课程由 Frank Andrade 教授,采用独特的方法来教授 Python 及其在将繁琐任务从重复中解放出来的实用性。该课程是基于项目的,设定了 4 个主要项目,每个部分都建立在完成这些项目所需的 Python 技能上。这里没有一次性代码行;所有内容都相互配合,进展顺利,逻辑清晰。
具体来说,本课程涵盖的四个项目是:
-
表格提取
-
网络自动化与网络抓取
-
自动化 Excel 报告
-
自动化 WhatsApp
在课程中学习如何具体自动化这些项目任务的同时,你还应该理解如何以自动化的思维方式来思考,磨练你的技能并改变视角,留意未来类似机会。你还将学习一些自动化友好的 Python 库,如 Path、Selenium 和 XPath。你还会沿途掌握一些其他有价值的技能,如基本的 HTML、将 Python 文件转换为 EXE、调度脚本、用 Python 编写 Excel 公式等。
该课程附带代码、数据和由课程作者 Frank Andrade 为其更长但紧密相关的用 Python 自动化生活课程创建的一个(单独提供)多页自动化备忘单。
freeCodeCamp 版本的课程时长不到 3 小时,你可以在YouTube上找到它,并嵌入在下方。
如果你仍然定期手动执行枯燥的任务,或经常编写临时代码来处理这些工作,那就加入那些酷炫的家伙吧,花时间学习如何用 Python 进行正确的自动化。你未来的自己会感谢你的。
Matthew Mayo(@mattmayo13)是数据科学家和 KDnuggets 的主编,KDnuggets 是开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络和自动化机器学习方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
相关话题
构建可重复和可维护的数据科学项目:一本免费在线书籍
原文:
www.kdnuggets.com/2022/08/free-book-build-reproducible-maintainable-data-science-project.html
确定如何结构化、管理和维护你的数据科学项目是一系列不简单的任务,如果执行得当,可以在项目展开和成熟的过程中大大简化你的工作。旨在确保可重复性会增加额外的复杂性和难度,但有助于项目的长期性和可信度。
如何找到关于实际确保数据科学项目的可重复性和可维护性的全面资源?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT

Python 项目文件结构(来源:构建可重复和可维护的数据科学项目 作者:Khuyen Tran)
Khuyen Tran 编写了一本名为构建可重复和可维护的数据科学项目的免费在线书籍,这本书相当贴切地提供了极好的资源。
本书介绍了用于开发高效工作流的 Python 工具,以支持可重复和可维护的数据科学项目。我们介绍了最佳实践和工具,使数据科学家能够适应日益增长的复杂性需求,同时确保他们的系统可靠。
听起来都很棒,你可能会想,这到底意味着什么?为了更深入了解本书提供的内容,我建议你快速查看第 2.1 节,如何构建一个具有可读性和透明度的数据科学项目。你将快速了解本书的结构、涵盖的内容、呈现方式以及 Tran 对标准和最佳实践(及其遵循)的重视。你会发现一份易读、结构良好且信息丰富的资源在等着你。
Tran 的书和随附的 数据科学 Cookie Cutter 模板依赖以下 Python 工具来实现其目标:
-
Cookiecutter
-
Poetry
-
Git
-
DVC
-
Hydra
-
Prefect
-
pre-commit 插件
-
pdoc
-
和更多
我是 Poetry 的忠实粉丝,因此 Tran 在项目中选择使用 Poetry 让我非常高兴(注意:对于那些更喜欢的用户,项目的 pip 版本确实存在)。Poetry 是一个出色的 Python 依赖管理工具,具有比 pip 更多的功能。你可以在 这里 了解更多关于 Poetry 的信息。
同样重视测试、配置文件管理、项目安装、数据和模型管理,以及代码的合规性和组织。简而言之,无论你应该做什么来确保你的代码是可重复和可维护的,Tran 在本书中都有覆盖。不仅涵盖了概念和实践,随附的 GitHub 存储库还包含一个有助于执行整个任务集的项目。

预提交任务(来源:构建一个可重复和可维护的数据科学项目 由 Khuyen Tran 提供)
确保你的代码符合 PEP-8 风格指南?已覆盖。
版本控制你的数据集并将其存储在线?完成。
提交之前删除笔记本输出?是的。
你在编写代码时记录文档?当然!
Tran 的免费在线书籍对初学者和经验丰富的从业者都是一个有用的资源。采用其中的方法无疑将提高你代码的可靠性、实施的可维护性和项目的可重复性,同时允许更高的复杂性。
不要让你可以完全控制的项目方面——即结构和实施——成为你的绊脚石;按照 Tran 在本书中提供的蓝图来帮助确保你构建一个可重复和可维护的数据科学项目。
Matthew Mayo (@mattmayo13) 是数据科学家及 KDnuggets 的主编,KDnuggets 是重要的数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
更多相关主题
免费 ChatGPT 课程:使用 OpenAI API 编写 5 个项目
原文:
www.kdnuggets.com/2023/05/free-chatgpt-course-openai-api-code-5-projects.html

图片由作者提供
介绍
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
ChatGPT 完全改变了我们工作和学习的方式。人工智能领域正在快速发展,OpenAI 正在引领这一进程。这个全球趋势不会很快消失,相反,我们期待指数级增长。但这一趋势与我们有何关系?事实上,这项技术正逐渐融入我们的日常生活中。随着周围世界的演变,我们也必须适应。正如 Mark Cuban 所说,我引用:
“世界变化非常快。大不再战胜小。将是快速战胜缓慢。”
因此,开发者和爱好者需要充分理解 OpenAI API 的潜力及其各种应用。无论你的背景或经验水平如何,这个课程将帮助你掌握技能,保持领先,并轻松创建出色的应用程序。
课程详情
FreeCodeCamp 最近与 Ania Kubow 合作推出了 ChatGPT 课程 – 使用 OpenAI API 编写 5 个项目。她是一位著名的软件开发者和课程创建者。你也可以在这里找到她的 YouTube 频道:与 Ania Kubów 一起编程。这个5 小时的课程深入探讨了 OpenAI API 的迷人世界。它提供了对 OpenAI API 的有见地的介绍及其应用,然后转到创建 5 个项目。
课程的详细大纲如下:
1. 介绍
它突出了课程的背景、目标及其受众。你还将概览 OpenAI API 及其实际应用。
2. 认证
讲师详细讲解了 OpenAI API 文档,解释了如何使用 API 密钥进行认证,以及如何生成并安全使用它。
3. 模型
它涵盖了 OpenAI 生态系统中可用模型的列表及其用例,例如 DALL-E、Whisper、GPT-4、GPT-3.5 等。所有支持的模型可以在这里找到。
4. 文本完成
生成文本、操作文本和标记化概念的细节被解释,以帮助你掌握文本完成的艺术。
5. 创建有效提示
ChatGPT 极其多才多艺,可以处理各种任务,因此你需要明确你的提示以生成有意义和准确的结果。本节涵盖了有关提示的用词、结构和背景的基本指导,以确保它们引发期望的回应。
6. 聊天完成项目
本节帮助你发现聊天完成的全部潜力,以及如何利用它创建交互式应用程序。为了将新学到的技能付诸实践,本教程将指导你构建两个聊天完成项目。在第一个项目中,你将使用 JavaScript 和 OpenAI API 创建一个简单的聊天完成克隆。在第二个项目中,你将提升到一个新的水平,使用 React 构建前端,Node.js 构建后端,制作一个 ChatGPT 克隆。
7. 图像生成项目
OpenAI 发布了一个 DALL-E 模型,可以根据文本描述生成图像。本节首先讲解使用 DALL-E 生成、编辑和创建图像变体的基础知识。为了巩固你的理解,提供了两个图像生成的实践项目。第一个项目教你如何使用 JavaScript 和 OpenAI API 构建一个图像生成应用。第二个项目是一个使用 React、Node.js、OpenAI npm 库和 OpenAI API 构建的图像生成和变体应用。这些项目将帮助你获得实践经验,使你在这个令人兴奋的领域中更加熟练。
8. SQL 生成器项目
在最后一节,你将创建一个 SQL 查询生成器项目,该项目将英文提示翻译为 SQL 查询。这个项目很好地总结了你到目前为止在课程中学到的所有技能。它使用 Typescript 作为前端,Node.js 作为后端,并在聊天完成端点使用 OpenAI API。
如果你想进一步探索这门课程,请观看下面的视频:
结论
如果你对如何使用 OpenAI API 构建实际项目感到好奇,这门课程是一个很好的基础。请观看课程视频,并在评论区告诉我你的想法。
Kanwal Mehreen 是一位有志的软件开发者,对数据科学和 AI 在医学中的应用充满兴趣。Kanwal 被选为 2022 年 APAC 区域的 Google Generation Scholar。Kanwal 喜欢通过撰写关于热门话题的文章分享技术知识,并热衷于提高女性在科技行业的代表性。
更多相关话题
更多关于大语言模型的免费课程
原文:
www.kdnuggets.com/2023/06/free-courses-large-language-models.html

图片由作者提供
鉴于大语言模型(LLMs)及其应用的潜力,现在是了解它们的最佳时机!无论是有趣的个人项目、学术研究还是工作,了解 LLM 更深入总是令人兴奋的,这样我们就能使用它们构建有趣的应用程序。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
在上一篇文章中,我们列举了帮助你学习大语言模型的免费课程和资源。我们又策划了一份新的免费课程列表,帮助你提升技能。
让我们开始吧!
ChatGPT 提示工程师开发人员
ChatGPT 提示工程师开发人员由 DeepLearning.AI 与 OpenAI 团队合作提供。
如果你已经在使用 ChatGPT 或 GPT-4,本课程教你如何更好地使用它们。你将学习如何通过最佳的提示工程实践有效使用 OpenAI API。
在这个过程中,你将有机会构建一个自定义聊天机器人,并学习使用 OpenAI API 处理常见用例,包括总结、推理、翻译、拼写和语法检查。
还可以查看 Josep Ferrer 的这篇详细的提示工程课程评测。
LangChain 用于 LLM 应用开发
DeepLearning.AI 的LangChain 用于 LLM 应用开发由 LangChain 的创始人 Harrison Chase 共同授课。该课程专注于通过利用 LangChain 生态系统构建应用程序,将帮助你掌握:
-
管理提示和解析响应、内存及上下文窗口约束
-
使用链条执行一系列操作
-
在文档语料库上进行问答
-
利用代理的推理能力
使用 ChatGPT API 构建系统
使用 ChatGPT API 构建系统 也由 DeepLearning.AI 与 OpenAI 合作提供。在这门免费的课程中,你将构建一个客服聊天机器人来应用课程中涵盖的以下概念:
-
使用大型语言模型构建系统
-
使用多阶段提示
-
通过将任务拆分为子任务来构建子任务管道
-
评估 LLM 输入和输出
注意:上述所有课程在有限时间内免费。
Google Cloud 生成 AI 学习路径
Google Cloud 最近发布了专门的 生成 AI 学习路径。构成该路径的一系列微课程旨在实现 Google Cloud 上生成 AI 解决方案的开发和部署。
如果你有兴趣学习大型语言模型,你会发现以下课程非常有帮助:
Google Cloud 上的大型语言模型简介
Google Cloud 上的大型语言模型简介 是 Udacity 免费课程库的一部分,涵盖了理解和构建 LLM 应用程序的入门内容,包括:
-
大型语言模型的基础知识和用例
-
提示调整
LLM 大学
Cohere 的 LLM 大学 提供了一个易于跟随的学习路径:从 LLM 的基础知识到使用它们构建应用程序。该课程涵盖:
-
词嵌入和句子嵌入等概念
-
大型语言模型的基础概念:变换器和注意力机制
-
LLM 在文本生成、分类和分析中的应用
-
使用 Cohere 的端点构建和部署应用程序
全栈 LLM 训练营
全栈 LLM 训练营涵盖了所有内容:从提示工程到最大限度地利用 GPT 助手,再到部署和监控 LLM 应用程序。以下是该训练营提供的概述:
-
提示工程
-
LLM 基础
-
LLMOps
-
增强型语言模型
-
语言用户界面的 UX
这里有一篇 文章 详细介绍了这个全栈 LLM 训练营的内容。
其他有用的资源
这里有一些其他有趣的资源,可以帮助你快速了解大型语言模型(LLMs):
-
GPT 状态 演讲:Andrej Karpathy 在微软 Build 2023 上的这次演讲提供了关于 GPT 助手训练流程的全面概述,包括标记化、预训练、微调和从人类反馈中强化学习。
-
实践深度学习教程,第二部分 由 fast.ai 提供:关于 注意力机制和变换器模型 的课程可能会有所帮助。
-
CS25: Transformers United V2 由斯坦福大学提供:一系列讲座涵盖了变换器的基础知识,以及大型语言模型的最新进展和应用——超越了常见的 NLP 任务。
-
Data Independent 的 LangChain 教程 在 YouTube 上:一系列简短的教程,使用 LangChain 构建基于不同自定义数据源的大型语言模型应用,并探索包括解决数学问题、总结和搜索在内的各种任务。
总结
希望你觉得这个汇总的资源对学习大型语言模型有帮助。我们很高兴整理了这个列表,希望你对学习和开始构建感到兴奋!祝学习愉快!
Bala Priya C 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和咖啡!目前,她正在通过编写教程、操作指南、评论文章等方式学习并与开发者社区分享她的知识。
更多相关主题
免费数据分析师训练营
原文:
www.kdnuggets.com/free-data-analyst-bootcamp-for-beginners

作者提供的图片
如果你打算进入数据分析领域,可能已经看过几个数据分析师的职位列表。你也许还见过列出的所需工具和编程语言:SQL、Excel、Power BI、Tableau、Python 等。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
你可以注册多个课程来学习这些技能。但如果能通过一个全面的训练营来学习所有这些技能,并建立项目组合,不是更好吗?
完全免费的初学者数据分析师训练营由 Alex the Analyst 提供,是启动数据分析师职业的理想选择。除了学习 SQL、Excel、Power BI、Tableau 和 Python,你还将构建项目、学习编写简历等。现在让我们深入了解这个训练营的内容。
链接: 初学者数据分析师训练营(SQL、Tableau、Power BI、Python、Excel、Pandas、项目等)
1. SQL
课程首先提供了关于如何成为数据分析师的一般路线图,然后详细介绍了每个所需工具,第一个是 SQL。
本教程的 SQL 部分分为三个部分:基础、初级 SQL 和高级 SQL。
基础 SQL 部分涵盖:
-
Select + From 语句
-
Where 语句
-
Group by 和 Order by
中级 SQL 教程部分涵盖以下内容:
-
内连接和外连接
-
联合
-
Case 语句
-
Having 子句
-
更新和删除数据
-
别名
-
Partition by
高级 SQL 部分将教你:
-
公共表表达式(CTEs)
-
临时表
-
字符串函数
-
存储过程
-
子查询
该模块通过几个关于数据探索和数据清洗的项目来结束,使用 SQL。
2. Excel
作为数据分析师,如果你发现整个工作都涉及在电子表格中处理数字,也不要感到惊讶。在掌握 SQL 基础知识后,你可以通过练习进一步提升,接下来学习 Excel。
几乎所有组织都使用 Excel 或类似的电子表格工具,因此学习如何使用这些工具非常有帮助。
Excel 部分涵盖以下主题:
-
数据透视表
-
公式
-
XLOOKUP
-
条件格式
-
图表
-
清洗数据
与 SQL 部分一样,你将进行一个关于使用 Excel 进行数据分析的完整项目。
3. Tableau
现在你已经很好地掌握了 SQL 和 Excel,这对于几乎所有基本的数据分析都足够了,是时候转向学习 BI 工具。
Tableau 教程部分从安装 Tableau 开始,并涵盖以下主题:
-
创建你的第一个可视化
-
使用计算字段和分箱
-
使用连接
接下来,你将从一个初学者友好的项目开始工作。
4. Power BI
Power BI 部分将指导你使用 Microsoft Power BI 进行数据分析和可视化,从安装 Power BI 开始。
下面是这一部分涵盖内容的概述:
-
创建你的第一个可视化
-
使用 Power Query
-
创建和管理关系
-
在 Power BI 中使用 DAX
-
使用钻取功能
-
条件格式和列表
-
Power BI 中的流行可视化
与之前的部分一样,你将在 Power BI 部分进行一个指导项目。
5. Python
现在你对数据分析中使用的大多数工具已经熟悉,是时候学习数据中最广泛使用的编程语言了。那就是 Python。
本部分涵盖了 Python 和 Pandas 数据分析,有机会进行简单项目。涉及的主题包括:Python 基础,包括 Python 基础知识和一些项目以应用所学内容。然后你将学习使用 Python 进行网页抓取。
pandas 教程涵盖以下主题:
-
读取文件
-
过滤列和行
-
索引
-
Groupby 和聚合函数
-
合并数据框
-
使用 pandas 创建可视化
-
数据清洗
-
探索性数据分析 (EDA)
然后你可以在两个投资组合项目中进行 API 和网页抓取的工作。
6. 职业建议
到此为止,你已经掌握了成为数据分析师所需的所有技能,并且还完成了项目以充实你的投资组合。那么接下来是什么呢?就是申请工作、面试并获得职位。
数据分析师训练营的最后一部分包含有用的职业建议,以指导你进行求职过程:
-
如何创建投资组合网站
-
如何创建优秀的数据分析师简历
-
使用 LinkedIn 找工作的技巧
这非常有帮助,因为很少有课程涵盖你在学习所需技能并建立项目后应该做的事情之后。
总结
希望你发现这个关于这次训练营的全面回顾对你有帮助。那么你还在等什么?现在就开始学习吧。
祝学习愉快和编程顺利!
Bala Priya C** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过撰写教程、操作指南、观点文章等方式学习并与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。**
更多相关话题
初学者免费数据工程课程
原文:
www.kdnuggets.com/free-data-engineering-course-for-beginners

Image by storyset 在 Freepik 上
现在是进入数据工程领域的好时机。那么你从哪里开始呢?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
学习数据工程有时会因为需要掌握大量工具而感到压倒性,更不用说那些令人畏惧的职位描述了!
如果你正在寻找一个适合初学者的数据工程入门课程,这个由 Airbyte 的开发者倡导者 Justin Chau 主讲的免费 数据工程初学者课程 是一个很好的起点。
在大约三小时内,你将学习到基本的数据工程技能:Docker、SQL、分析工程等。因此,如果你想探索数据工程并看看这是否适合你,这门课程是一个很好的入门选择。现在让我们来了解一下这门课程的内容。
课程链接:数据工程初学者课程
为什么选择数据工程?
这门课程首先介绍了你为什么应该考虑成为一名数据工程师。我认为在深入技术主题之前,了解这些是非常有帮助的。
教师 Justin Chau 讲解了:
-
确保大数据项目成功所需的高质量数据和数据基础设施
-
数据工程角色的需求不断增长,薪酬也很高
-
作为数据工程师,您可以为组织的数据基础设施增加的业务价值
Docker
当你学习数据工程时,Docker 是你可以添加到工具箱中的第一个工具之一。Docker 是一种流行的容器化工具,允许你将应用程序(包括依赖项和配置)打包成一个叫做镜像的单一工件。这样,Docker 让你能够创建一个一致且可重复的环境,在容器内运行你的所有应用程序。
本课程的 Docker 模块从基础知识开始,比如:
-
Dockerfile
-
Docker 镜像
-
Docker 容器
然后,讲师会讲解如何使用 Docker 对应用程序进行容器化:创建 Dockerfile 和使容器启动的命令。这个部分还涵盖了持久化卷、Docker 网络基础知识以及使用 Docker-Compose 管理多个容器。
总的来说,如果你对容器化是新手,这个模块本身就是一个很好的 Docker 快速入门课程!
SQL
在下一个关于 SQL 的模块中,你将学习如何在 Docker 容器中运行 Postgres,然后通过创建一个示例 Postgres 数据库并执行以下操作来学习 SQL 的基础知识:
-
CRUD 操作
-
聚合函数
-
使用别名
-
连接
-
联接和联合所有
-
子查询
从零开始构建数据管道
有了 Docker 和 SQL 基础,你现在可以从零开始学习构建数据管道。你将从构建一个简单的 ELT 管道开始,并在课程的其余部分进行改进。
此外,你将看到你迄今为止学到的所有 SQL、Docker 网络和 Docker-compose 概念如何结合在一起,构建一个在 Docker 中运行 Postgres 的管道,涵盖源和目标。
dbt
课程接下来进入分析工程部分,你将学习 dbt(数据构建工具)来组织你的 SQL 查询作为自定义数据转换模型。
教师将指导你开始使用 dbt:安装所需的适配器和 dbt-core,并设置项目。这个模块特别关注使用 dbt 模型、宏和 jinja。你将学习如何:
-
定义自定义 dbt 模型并在目标数据库中的数据上运行它们
-
将 SQL 查询组织为 dbt 宏以便重用
-
使用 dbt jinja 为 SQL 查询添加控制结构
CRON 作业
到目前为止,你已经构建了一个基于手动触发的 ELT 管道。但你肯定需要一些自动化,而最简单的方法就是定义一个定时任务(cron job),在每天的特定时间自动运行。
这个超级简短的部分介绍了 cron 作业。但是像 Airflow(你将在下一个模块中学习)这样的数据编排工具提供了对管道的更精细控制。
Airflow
为了编排数据管道,你将使用开源工具,如 Airflow、Prefect、Dagster 等。在这一部分你将学习如何使用开源编排工具 Airflow。
这一部分比之前的部分更为详细,因为它涵盖了你需要了解的一切,以便迅速掌握为当前项目编写 Airflow DAG 的方法。
你将学习如何设置 Airflow 的 Web 服务器和调度器以安排作业。接着你将学习 Airflow 操作符:Python 和 Bash 操作符。最后,你将定义进入 DAGs 的任务以进行示例。
Airbyte
在最后一个模块中,你将学习 Airbyte,一个开源的数据集成/迁移平台,它让你轻松连接更多的数据源和目标。
你将学习如何设置你的环境,并了解如何使用 Airbyte 简化 ELT 过程。为此,你需要修改现有项目的组件:ELT 脚本和 DAGs,以将 Airbyte 集成到工作流中。
总结
希望你觉得这篇关于免费数据工程课程的评测对你有帮助。我很喜欢这个课程——特别是构建和逐步改进数据管道的实践方法,而不仅仅是理论。代码也提供了供你跟随。所以,祝你数据工程愉快!
Bala Priya C** 是来自印度的开发者和技术写作员。她喜欢在数学、编程、数据科学和内容创作的交叉领域工作。她的兴趣和专长包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她致力于学习并通过编写教程、操作指南、观点文章等与开发者社区分享知识。Bala 还创建引人入胜的资源概述和编码教程。**
更多相关主题
免费数据工程课程
原文:
www.kdnuggets.com/2022/05/free-data-engineering-courses.html

图片来源于 freepik
在这篇博客中,你将学习适合初学者和专业人士的 3 门最佳免费数据工程课程。这些课程将教你数据摄取、数据管道、SQL、ETL/ELT、分析工程、批处理、数据流以及自动化。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
免费课程:
-
适合所有人的数据工程
-
数据工程 Zoomcamp
-
AWS 数据工程入门教程
1. 适合所有人的数据工程
适合所有人的数据工程课程由 DataCamp 提供,是一个无代码的可视化数据工程入门课程。没有先决条件,任何人都可以免费参加此课程,即使是纯管理专业人士。
你将了解数据工程师的工作以及他们为何如此受欢迎。你还将概述 SQL 数据库、数据仓库和数据湖、数据处理、并行计算、任务调度以及云计算。
课程时长为 2 小时,包含互动练习和视频教程。它将为你准备数据工程职业生涯的路线。
2. 数据工程 Zoomcamp
数据工程 Zoomcamp由 DataTalks.Club 提供,是最全面的数据工程课程之一。课程的所有材料都是免费的,包括项目文件、视频教程和工具。
在第一周,你将学习数据工程及环境搭建。第二周,你将学习数据摄取、数据湖、工作流编排,以及在本地和云上创建数据管道。第三周专注于数据仓库、BigQuery 和 Airflow。第四周,你将深入研究使用 dbt 的分析工程。在接下来的几周中,你将学习使用 Spark 进行批处理和使用 Kafka 进行数据流处理。最后三周将集中在使用你所学工具进行端到端项目的实践。项目将由你的同事进行评审。
你还将学习流行的数据工程工具,如 Airflow、PostgreSQL、BigQuery、Terraform、Docker、dbt(数据构建工具)、Spark 和 Kafka。
该课程为期 9 周,包括实际项目和视频教程。

图片来自 DataTalksClub/data-engineering-zoomcamp
3. AWS 数据工程初学者教程
AWS 数据工程初学者教程是一个 90 分钟的 YouTube 课程,将教你如何使用 Amazon Web Services 进行数据工程。该课程适合初学者和经验丰富的专业人士。
你将学习 AWS 工具,如 Kinesis、DMS 和 Glue,并结合理论和实际案例。你将使用这些工具学习流数据分析、数据摄取、转换、查询和可视化,以及自动化。
如果你想了解 AWS 数据工程生态系统,我建议你参加这个课程。
常见问题解答
数据工程师的薪资范围是多少?
平均而言,美国的数据工程师年薪为 114,832 美元。如果你是高级工程师,年薪可以达到 390K 美元以上。Meta 和思科系统在技术行业提供更高的薪资 - Glassdoor。
什么是数据工程?
数据工程的核心是清理、处理和准备数据以供分析、数据科学和机器学习任务使用。你将创建用于机器学习和数据质量检查的 ETL 或 ELT 数据管道。你将学习 SQL、数据库管理、Apache Kafka、Apache Airflow、Apache Hadoop、Apache Spark 和 Apache Hive。
最好的数据工程课程有哪些?
付费
免费
如何成为数据工程师?
成为数据工程师所需的技能:
-
SQL 和数据库管理。
-
构建、测试和维护数据管道。
-
确保数据管道符合业务需求。
-
收集和整理各种数据源到一个地方。
-
开发算法以分析和提取数据中的信息。
-
自动化重复任务。
如何获得数据工程师认证?
掌握数据工程技能和工具后,你可以报名参加专业认证项目:
这两项认证将帮助你获得数据工程相关职位。
Abid Ali Awan (@1abidaliawan) 是一位认证数据科学专家,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,帮助那些面临心理健康问题的学生。
更多相关话题
免费数据管理与数据科学学习 CS639
原文:
www.kdnuggets.com/2023/01/free-data-management-data-science-learning-cs639.html

作者提供的图片
数据科学有许多要学习的内容,具体取决于你希望深入了解哪些领域。尤其是数据管理。威斯康星大学麦迪逊分校有一门课程叫做:数据管理
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
数据科学。
课程分为 6 个部分,并有若干讲座。你可以下载讲座的 PDF,也建议你阅读额外的资料来帮助学习。
如果你对此感兴趣,请继续阅读!
CS639 先决条件
课程先决条件
为了从数据管理与数据科学课程中获得最大收益,CS 300 对你的学习至关重要。CS 400 也将有所帮助。
熟练掌握 Python 也是必要的。如果你还不熟练,大学建议你使用这里描述的资源。
教材
本课程没有指定教材,但推荐以下书籍:
-
Python 数据分析,Wes McKinney,2012
-
数据科学实战,Cathy O'Neil 和 Rachel Schutt,2013
CS639 讲座计划
课程分为 6 个部分,期末有一次考试。
数据科学简介
关系数据库与关系代数
MapReduce 模型与 No SQL 系统
-
讲座 8:关于规模的推理与 MapReduce 抽象
-
讲座 9:MapReduce 算法 1
-
讲座 10:MapReduce 算法 2
-
讲座 11:Spark
-
讲座 12:NoSQL 系统:键值存储与文档存储
在此主题后,你将进行 2 次期中考试。
预测分析
-
讲座 13:统计推断
-
讲座 14:采样
-
讲座 15:贝叶斯方法
-
讲座 16:机器学习与决策树入门
-
讲座 17:第 16 讲的总结及线性分类器与支持向量机
-
讲座 18:机器学习模型评估
-
讲座 19:其他学习方法:无监督学习与集成学习
-
讲座 20:优化/梯度下降
信息提取与数据集成
传达洞察
期末考试
你已经完成了所有关于数据管理与数据科学的内容学习。接下来你将进行一个三部分的最终复习。这里有一些样题以及答案。
在此之后,你将有一个附加项目,该项目开放式要求你使用密尔沃基市的数据创建酷炫的可视化图表。
结论
结构化的课程总是对你的学习有帮助。借助威斯康星大学的这些资源,你将能够获得结构化的课程以及大学级别的资源——完全免费!
如果你想了解更多关于成为数据科学家的信息,我建议阅读:完整的数据科学学习路线图
尼莎·阿亚 是一名数据科学家和自由职业技术作家。她特别感兴趣于提供数据科学职业建议或教程,并围绕数据科学进行理论知识的讲解。她还希望探索人工智能在延续人类生命方面的不同益处。作为一个热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
更多免费数据挖掘、数据科学书籍和资源。
原文:
www.kdnuggets.com/2015/03/free-data-mining-data-science-books-resources.html
下列列表基于 Pedro Martins 编制的列表,但我们添加了书籍作者和年份,按标题字母顺序排序,修正了拼写错误,并移除了失效的链接。描述由 Pedro 提供。
-
![数据挖掘书籍]() 《数据科学导论》 由 Jeffrey Stanton 和 Robert De Graaf 编著,2013 年出版。
《数据科学导论》 由 Jeffrey Stanton 和 Robert De Graaf 编著,2013 年出版。由 Syracuse University 开发的入门级资源。
-
《统计学习导论:R 语言应用》 由 Gareth James、Daniela Witten、Trevor Hastie 和 Robert Tibshirani 编著,2013 年出版。
基于大数据集的统计学习概述。使用 R 编程语言讨论数据的探索性技术。
-
《程序员的数据挖掘指南》 由 Ron Zacharski 编著,2012 年出版。
这是一本从编程角度讲解数据挖掘概念的指南。它提供了若干动手练习题来实践和测试在线书籍中讲授的主题。
-
《贝叶斯推理与机器学习》 由 David Barber 编著,2012 年出版。
重点应用于机器学习算法和过程。它是一个动手操作的资源,非常适合全面吸收书中的知识。
-
《大数据、数据挖掘与机器学习:为商业领袖和从业者创造价值》 由 Jared Dean 编著,2014 年出版。
本资源探讨了大数据的现实及其从市场营销角度的好处。它还解释了如何存储这类数据以及基于数据挖掘和机器学习的处理算法。
-
《数据挖掘与分析:基本概念与算法》 由 Mohammed J. Zaki 和 Wagner Meira, Jr. 编著,《数据挖掘与分析:基本概念与算法》,剑桥大学出版社,2014 年 5 月出版。
一本涵盖数据挖掘探索算法和机器学习过程的优秀书籍。这些解释还结合了一些统计分析。
-
《R 语言的数据挖掘与商业分析》 由 Johannes Ledolter 编著,2013 年出版。
另一本基于 R 的书,描述了所有的过程和实现方法来探索、转换和存储信息。它还关注商业分析的概念。
-
数据挖掘技术:市场营销、销售与客户关系管理 作者:迈克尔·J·A·贝瑞、戈登·S·林诺夫,2004 年。
一本专门针对市场营销和业务管理的数据挖掘书籍,包含了大量实际案例,以帮助理解如何在现实世界中应用这些技术。
-
用 Rattle 和 R 进行数据挖掘:挖掘数据以发现知识的艺术 作者:格雷厄姆·威廉姆斯,2011 年。
这本书的目的是提供大量有关数据操作的信息。它专注于 Rattle 工具包和 R 语言,以演示这些技术的实现。
-
高斯过程与机器学习 作者:卡尔·爱德华·拉斯穆森和克里斯托弗·K·I·威廉姆斯,2006 年。
一本理论性书籍,探讨了基于概率高斯过程的学习算法。涉及监督学习问题,描述了与机器学习相关的模型和解决方案。
-
归纳逻辑编程技术与应用 作者:纳达·拉夫拉克和萨索·德泽罗斯基,1994 年。
一本关于归纳逻辑编程的旧书,包含了大量理论和实践信息,并参考了一些重要工具。
-
信息理论、推理与学习算法 作者:大卫·麦凯,2009 年。
一种有趣的信息理论方法,融合了推理和学习概念。这本书教授了许多数据挖掘技术,揭示了信息理论的关系。
-
机器学习简介 作者:阿姆农·沙舒阿,2008 年。
一本简单但非常重要的书,旨在向每个人介绍机器学习这一主题。
-
机器学习 作者:阿卜杜勒哈米德·梅卢克和阿卜杜奈瑟·谢比拉,2009 年。
一本非常全面的机器学习书籍,涉及了多种特定且非常有用的技术。
-
机器学习、神经网络与统计分类 作者:唐纳德·米奇、戴维·斯皮格尔哈尔特、查尔斯·泰勒,1994 年。
一本关于统计方法、学习技术和其他与机器学习相关的重要问题的经典书籍。
-
一个由维基百科提供的极佳资源,将大量机器学习知识汇集成一本简单但非常有用和完整的指南。
-
大规模数据集挖掘 作者:朱尔·莱斯科维奇、阿南德·拉贾拉曼、杰夫·乌尔曼,2014 年。
本书的重点是提供必要的工具和知识,以管理、操控和处理数据库中的大量信息。
-
《数据建模》 作者:Ben Klemens,2008 年。
本书重点介绍解决应用于数据的分析问题的某些过程。特别是,解释了创建探索大数据集工具的理论。
-
《模式识别与机器学习(信息科学与统计)》 作者:Christopher Bishop,2006 年。
本书从贝叶斯网络的角度向你展示了大量模式识别的内容。许多机器学习概念得到了探讨和举例说明。
-
《概率编程与黑客的贝叶斯方法》 作者:Cam Davidson-Pilon,2013 年。
一本关于贝叶斯网络的书,提供了解决非常复杂问题的能力。还讨论了在 Python 语言上的编程实现。
-
《统计学习要素:数据挖掘、推断与预测,第 2 版》 作者:Trevor Hastie, Robert Tibshirani 和 Jerome Friedman,2009 年。
这是一本从数据挖掘和预测的统计视角出发的概念书籍。也涵盖了许多机器学习主题。
-
《强化学习:导论》 作者:Richard S. Sutton 和 Andrew G. Barto,2015 年。
一种扎实的强化学习主题方法,提供了解决方案方法。还描述了一些非常重要的案例研究。
-
《Think Bayes,贝叶斯统计简明指南》 作者:Allen B. Downey,2013 年。
一种 Python 编程语言的方法来应用贝叶斯统计方法,这些技术被用来解决实际问题和模拟。

个人简介:Pedro Martins 是 Data On Focus 团队的一员,对 IT 相关问题充满兴趣。他二十多岁,来自葡萄牙,具有信息工程背景,对数据挖掘和数据科学充满热情。
相关:
-
《神经网络与深度学习,免费在线书籍(草稿)》
-
《9 本学习数据挖掘和数据分析的免费书籍》
-
新书:《社交媒体挖掘 – 免费 PDF 下载》
更多相关话题
60+本关于大数据、数据科学、数据挖掘、机器学习、Python、R 等方面的免费书籍
评论
作者:布伦丹·马丁, (LearnDataSci).
从网上提取了一个很棒的电子书集合。虽然列表中的每一本书都是免费的,但如果你发现特别有帮助的书籍,可以考虑购买纸质版。作者们花了很多时间整理这些资源,我相信他们都会感激你的支持!
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT

数据科学概述
-
杰弗里·斯坦顿, 2013
-
数据学院,2015
-
DJ·帕蒂尔,2012
与数据科学家的访谈
组建数据科学团队
-
[在亚马逊购买]
希拉里·梅森 & DJ·帕蒂尔,2015
-
DJ·帕蒂尔,2011
-
朱莉·斯蒂尔, 2015
数据分析
分布式计算工具
-
汤姆·怀特, 2011
-
[在亚马逊购买]
吉米·林和克里斯·戴尔, 2010
学习语言
Python
R
-
罗杰·D·彭,
-
维基书籍, 2014
-
[在亚马逊购买]
哈德利·维克汉姆, 2014
SQL
-
泽德·A·肖, 2010
-
教程点
数据挖掘与机器学习
-
阿姆农·沙苏亚, 2008
-
阿卜杜勒哈米德·梅卢克 & 阿卜杜尔纳塞尔·谢比拉, 450
-
维基百科
-
[在亚马逊购买]
Reza Zafarani, Mohammad Ali Abbasi 和 Huan Liu, 2014
-
数据挖掘:实用机器学习工具与技术
[在亚马逊购买]
Ian H. Witten 和 Eibe Frank, 2005
-
[在亚马逊购买]
Jure Leskovec, Anand Rajaraman 和 Jeff Ullman, 2014
-
Ron Zacharski, 2015
-
[在亚马逊购买]
Graham Williams, 2011
-
[在亚马逊购买]
Mohammed J. Zaki 和 Wagner Meria Jr., 2014
-
[在亚马逊购买]
Cam Davidson-Pilon, 2015
-
[在亚马逊购买]
Michael J.A. Berry 和 Gordon S. Linoff, 2004
-
[在亚马逊购买]
Nada Lavrac 和 Saso Dzeroski, 1994
-
[在亚马逊上购买]
Christopher M. Bishop, 2006
-
[在亚马逊上购买]
D. Michie, D.J. Spiegelhalter, & C.C. Taylor, 1999
-
[在亚马逊上购买]
David J.C. MacKay, 2005
-
[在亚马逊上购买]
Johannes Ledolter, 2013
-
[在亚马逊上购买]
David Barber, 2014
-
[在亚马逊上购买]
C. E. Rasmussen & C. K. I. Williams, 2006
-
[在亚马逊上购买]
Richard S. Sutton & Andrew G. Barto, 2012
-
[在亚马逊上购买]
Csaba Szepesvari, 2009
-
大数据、数据挖掘与机器学习
[在亚马逊上购买]
Jared Dean, 2014
-
[在亚马逊购买]
本·克莱门斯, 2008
-
[在亚马逊购买]
罗伯托·贝洛, 2013
-
约书亚·本吉奥、伊恩·J·古德费洛 和 亚伦·库维尔, 2015
-
迈克尔·尼尔森, 2015
-
维基书籍, 2014
-
[在亚马逊购买]
穆罕默德·J·扎基 和 瓦格纳·梅拉二世, 2014
-
坂井重明, 2012
统计学与统计学习
-
[在亚马逊购买]
艾伦·B·唐尼, 2014
-
[在亚马逊购买]
艾伦·B·唐尼, 2012
-
[在亚马逊购买]
特雷弗·哈斯蒂、罗伯特·蒂布希拉尼 和 杰罗姆·弗里德曼, 2008
-
[在亚马逊购买]
加雷斯·詹姆斯、丹尼埃拉·维滕、特雷弗·哈斯蒂 和 罗伯特·蒂布希拉尼, 2013
-
[在亚马逊购买]
Gary W. Oehlert, 2010
数据可视化
大数据
计算机科学话题
-
Steven Bird, 2009
-
Richard Szeliski, 2010
-
简明计算机视觉 [在亚马逊购买]
Reinhard Klette, 2010
-
斯图尔特·拉塞尔,1995
好了,以上就是所有内容。数以千计的电子书等着你阅读。我们希望这里有适合每个人的书籍,无论你处于什么水平。如果你有任何免费书籍的建议或想要评论提到的书籍,请在下方评论告诉我们!
原始链接。
相关:
-
神经网络与深度学习,免费在线书籍(草稿)
-
9 本免费的数据挖掘和数据分析学习书籍
-
更多免费的数据挖掘、数据科学书籍和资源
-
预测警务——免费书籍
更多相关内容
免费数据科学面试书,助你获得理想工作
原文:
www.kdnuggets.com/free-data-science-interview-book-to-land-your-dream-job

作者提供的图片
如果你正在准备数据科学面试,你知道浏览所有可用资源可能有多么令人不知所措。很容易迷失在细节中。这就是为什么我很高兴向你介绍一个隐藏的宝藏资源:“数据科学面试书”由Dip Ranjan Chatterjee编写。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
这本免费提供的在线书籍涵盖了你在数据科学面试中需要了解的所有基本主题,从统计学和模型构建到算法、神经网络和商业智能。但与其他资源不同的是,它专注于提供仅有的相关信息,以帮助你为面试做好准备。这使得它成为忙碌的数据科学家快速复习广泛概念的完美资源。我认为这本书的独特之处在于:
-
实际面试问题: 本书包括来自 Google、DoorDash 和 Airbnb 等公司的实际面试问题,并附有详细的解决方案和案例研究。
-
更新内容: 这本书会不断更新,增加新章节、问题和更丰富的内容。
-
备忘单和参考资料: 书中包含了各种主题的备忘单和快速参考指南,以及对那些想深入研究主题的额外参考资料。
内容概览
如果遇到一个⚠️符号的部分,不要惊慌。这只是表示这些部分仍在处理过程中,并可能会有所更改。以下是本书涵盖的主要部分:
1. 统计学
本节涵盖了统计学基础,这对于数据分析和模型构建至关重要。主题包括概率基础、概率分布、中心极限定理、贝叶斯与频率论推理、假设检验和 A/B 测试。
2. 模型构建
本书的这一部分将指导你完成创建成功模型的过程,从数据收集到模型选择。它还教你数据预处理技术,这对任何数据科学家都是必需的,包括特征缩放、处理异常值、处理缺失值和编码分类变量。它还包括一个超参数优化的小节以及一些用于超参数优化的著名开源工具。
3. 算法
算法是数据科学的基础,理解它们对于在数据科学面试中取得成功至关重要。本节涵盖了各种机器学习算法,并为你提供了选择适合你用例的算法的实际建议。本节从偏差-方差权衡和生成模型与判别模型的基础知识开始,然后深入到回归、分类、聚类、决策树、随机森林、集成学习和提升方法等高级概念。此外,本节还讨论了时间序列分析和异常检测。最后,本节以一张关于 Big O 分析的综合表格作为结束,其中涵盖了不同机器学习算法的时间和空间复杂度。
4. Python
Python 是一种多功能语言,用于数据科学中的各种任务。本节包含以下子部分:
-
理论: 它涵盖了 Python 中的一些基本概念,例如网格、统计方法、range 与 xrange、switch case 和 lambda 函数。
-
基础: 有一些常见的编程技巧,你必须熟悉它们以解决面试中的 Python 问题,比如列表、元组和字典,并理解使用循环和条件语句的控制流程。
-
从零开始编码算法: 通常,公司会要求候选人在编码演示环节中从零开始编码算法。这里讨论了从零开始编码算法的一般步骤。
-
问题: 它涵盖了一些与统计、数据处理和自然语言处理相关的示例问题。
5. SQL
在数据科学面试中,SQL 查询通常用于评估候选人处理数据和解决复杂问题的能力。本节涵盖了 SQL 的基础知识,包括连接、临时表与表变量与 CTE、窗口函数、时间函数、存储过程、索引和性能优化。临时表与表变量与 CTE 部分解释了这三种临时数据结构之间的区别以及何时使用每一种。你还将学习如何创建和使用存储过程。性能优化部分涵盖了优化 SQL 查询的各种技巧。总体来说,它将为你提供 SQL 的坚实基础。
6. 分析思维
虽然这本书包含了多个持续更新的部分,如 Excel、神经网络、自然语言处理、机器学习框架、商业智能等,但我特别想突出这一部分。我认为它很独特,因为它涉及了商业场景和行为管理相关的问题,这在数据科学面试中越来越重要。公司不仅仅寻找技术专长,还希望找到能够战略性思考和有效沟通的候选人。
例如,这是 Salesforce 在其一次面试中提出的一个问题:
“作为 Salesforce 的数据科学家,你在与一位产品经理交谈,他想了解 Salesforce 的用户基础。你的方法是什么?”
通过审视这些基于场景的问题,你将为面试做好充分准备。
7. 备忘单
与其花费数小时在线搜索备忘单,你可以在一个地方找到关于 Numpy、Pandas、SQL、统计学、RegEx、Git、PowerBI、Python 基础、Keras 和 R 基础的快速而全面的指南。这些指南非常适合在面试前快速复习或在编码挑战中参考。
结论
我完全理解拥有一个可靠且全面的资源以准备面试的重要性,我相信这本书正符合这一要求。我相信它将帮助你成功。祝你在数据科学准备之旅中一切顺利!如有任何问题,请随时与我联系。
Kanwal Mehreen**** Kanwal 是一位机器学习工程师和技术作家,对数据科学以及人工智能与医学的交汇处充满深厚的热情。她合著了电子书《利用 ChatGPT 最大化生产力》。作为 2022 年 APAC 地区的 Google Generation 学者,她倡导多样性和学术卓越。她还被认可为 Teradata 多样性技术学者、Mitacs Globalink 研究学者和 Harvard WeCode 学者。Kanwal 是变革的积极倡导者,创立了 FEMCodes 以赋能女性在 STEM 领域的发展。
更多相关话题
免费电子书:10 个实用的 Python 编程技巧
原文:
www.kdnuggets.com/2023/04/free-ebook-10-practical-python-programming-tricks.html
图片由 fullvector 提供,来源于 Freepik
您是否是一名已经掌握基础知识并希望学习一些不那么明显但有用的技能的 Python 程序员?
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织在 IT 领域
也许您已经知道如何使用列表。也许您现在擅长创建函数。可能您能够轻松控制程序的执行流程。或许您掌握了 Python 的类型系统以及何时使用何种类型。此时,您可能只是希望获得一些更高级的 Python 技巧。
如果这听起来像是您,您可能会发现免费的电子书 10 个实用的 Python 编程技巧:提升效率和代码质量 对您有所帮助。
采用这些技巧来提升您的 Python 编程技能,成为一个能够轻松创建高质量、高性能应用程序的熟练开发者。
这是 Data Science Horizons 的一款产品,这本免费电子书涵盖了以下主题,旨在帮助提高读者的效率和代码质量:
-
列表推导式
-
Lambda 函数
-
海象运算符(赋值表达式)
-
Itertools 模块
-
F-strings(格式化字符串字面量)
-
上下文管理器和 'with' 语句
-
生成器和生成器表达式
-
装饰器
-
类型提示和静态类型检查
-
Python 一行代码
正如标题所暗示的,除了展示上述技能外,这本电子书还专注于代码的效率和质量:
编写高效代码意味着优化代码的执行速度并最小化资源消耗,例如内存使用。另一方面,干净的代码关注于可读性、可维护性和组织结构。这两者密不可分,因为高效的代码更容易理解、调试和修改,而干净的代码本质上会带来更好的性能。通过采纳本电子书中列出的最佳实践,您将能够编写高质量的 Python 代码,这些代码不仅快速且资源高效,同时也易于理解和修改。
如果您准备将 Python 编程提升到一个新的水平,可以查看免费的电子书 10 个实用的 Python 编程技巧:提升您的效率和代码质量。这可能正是您所寻找的。
马修·梅奥 (@mattmayo13) 是数据科学家和 KDnuggets 的主编,KDnuggets 是一个开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。马修拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系到。
更多相关话题
掌握生成式 AI 和提示工程:免费电子书
原文:
www.kdnuggets.com/2023/04/free-ebook-mastering-generative-ai-prompt-engineering.html
掌握生成式 AI 和提示工程:数据科学家的实用指南 电子书封面
自 2022 年 11 月底发布以来,ChatGPT 已经主导了个人、职业和公共讨论。每个人都在谈论它,它能做什么,我们如何利用它……以及为什么我们应该对它感到担忧。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
GPT 代表生成式预训练变换器,指的是一类在现有文本数据上进行训练的大型语言模型(LLMs),这些模型能够统计性地预测词序列中的下一个词或标记。这样描述起来确实没什么特别的。但 GPT 已经对我们的生活、工作和娱乐产生了深远的影响。我甚至不需要在这里引用任何例子,因为你已经熟悉了许多实例。
GPT(和其他 LLMs)并不是唯一的生成式 AI。在它们出现之前,已经有自然语言处理模型能够执行类似的任务,有些今天仍在使用。然而,在这种任务的最前沿现在完全是 GPT 的领域,它们在最近几个月迅速流行,尽管它们在 ChatGPT 爆发之前以较小的形式存在了多年。
文本并不是唯一的生成模型。你可能听说过并使用过图像生成模型,如 DALL-E、Stable Diffusion 和 Midjourney。它们同样依赖于精心设计的提示来进行有效的生成。
简而言之,生成型 AI —— 以及驱动它们的提示 —— 无处不在。但除了基础知识外,你对这些了解多少?也许你会发现一本简明、聚焦的电子书在这些主题上很有用。如果是这样,掌握生成型 AI 和提示工程:数据科学家的实用指南 来自 Data Science Horizons 是一个很好的起点。
本电子书将深入探讨生成型 AI 和提示工程的关键概念、最佳实践以及实际应用。它将探讨流行 AI 模型的能力和局限性,详细说明设计有效提示的过程,并讨论在使用这些技术时出现的伦理问题。[...] 阅读完本电子书后,你将对生成型 AI 和提示工程有一个扎实的理解,使你能够有效地将这些技术应用到自己的项目中。
这本书将深入探讨“生成型 AI 和提示工程的关键概念、最佳实践以及实际应用。”很好。但也许我们应该首先更清楚地阐明这两个虽然相关但又分开的主题,以避免误解。以下是本电子书对生成型 AI 的定义:
生成型 AI 包括一系列旨在基于现有输入数据生成新数据的模型和技术。这些模型在自然语言处理、图像生成等领域展现了显著的能力。通过理解生成型 AI 的机制和细节,数据科学家可以利用其力量为众多问题创造创新解决方案。
提示工程的定义如下:
提示工程另一方面涉及到有效提示的艺术,以指导 AI 模型生成期望的输出。随着 AI 模型变得越来越复杂,对于高效且精准的提示工程的需求变得愈加重要。通过掌握这一技能,数据科学家可以更好地引导 AI 模型产生目标结果,从而提高应用的有效性。
我们被承诺将查看上述概念、最佳实践和应用,但实际实施呢?这是一本提示手册吗?虽然书中涵盖了一些具体的提示示例,但它更好地提供了生成型 AI 和提示工程主题的高级视角。其主要章节包括:
-
理解生成型 AI
-
提示工程介绍
-
提示工程的实际应用
-
提示工程的挑战和局限性
-
提示工程的未来方向和新兴趋势
-
提示工程的实用技巧和最佳实践
在提供的指导中,值得注意的是,在对 GPT 的不切实际的高期望(和恐惧)的新时代背景下,他们的局限性得到了现实的阐述。从伦理到可预测性,一些主要的关注点被提及,以确保读者了解这些问题,并能进一步研究。
虽然提示工程可以显著提高生成式 AI 模型的性能和可用性,但必须承认这些模型固有的局限性和偏差。理解这些局限性可以帮助数据科学家设定现实的期望,做出明智的决策,并开发出更稳健、更可靠的 AI 解决方案。
如果你想了解更多关于通过掌握提示工程来利用生成式 AI 的信息,可以立即查看免费的电子书 掌握生成式 AI 和提示工程:数据科学家的实用指南。它包含了大量有用的信息,可以快速消化… 而且价格合理。你可能会发现它是你一直在寻找的相关指南。
Matthew Mayo (@mattmayo13) 是数据科学家及 KDnuggets 的主编,KDnuggets 是开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及自动化机器学习方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
更多相关主题
免费全栈 LLM 训练营
原文:
www.kdnuggets.com/2023/06/free-full-stack-llm-bootcamp.html

图片由作者提供
大型语言模型(LLMs)及其应用正是当前的热门话题!无论你是想将它们用于个人项目、在工作中提高生产力,还是快速总结搜索结果和研究论文——LLMs 为每个人提供了一些东西。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
这很棒!但是,如果你想更好地使用 LLMs,超越仅仅使用这些应用程序,开始构建自己的应用,那么来自全栈团队的免费LLM 训练营适合你。
从有效使用 LLMs 的提示工程到构建自己的应用程序和设计 LLM 应用的最佳用户界面,本次训练营涵盖了所有内容。让我们了解更多关于训练营提供的内容。
什么是全栈 LLM 训练营?
全栈 LLM 训练营最初作为 2023 年 4 月在旧金山的现场活动进行授课。现在,训练营的所有材料——讲座、幻灯片、项目源代码——都可以免费获取。

LLM 训练营 | 图片来源
LLM 训练营旨在提供全面的学习方法。它涵盖了提示工程技术、LLM 基础知识,以及构建和发布 LLM 应用程序到生产环境。
本次训练营由以下讲师授课:查尔斯·弗莱、乔希·托宾和谢尔盖·卡拉耶夫——他们都是加州大学伯克利分校的校友。他们的目标是让每个人掌握 LLM 的最新进展:
“我们的目标是使你 100%跟上最新的技术,并准备好构建和部署 LLM 应用程序,无论你对机器学习的经验如何。” – 全栈团队
更深入了解全栈 LLM 训练营
现在我们知道 LLM 训练营的内容了,让我们深入探讨课程内容。
先决条件
尽管没有强制性的先决条件——除了对学习 LLMs 的真正兴趣,相关的编程经验可以使你的学习过程更为顺畅。以下是一些这样的先决条件:
-
具有 Python 编程经验
-
了解机器学习、前端或后端开发将会有所帮助
学习拼写:提示工程
为了让语言模型产生理想的结果,提高提示的能力非常重要。
学习拼写:提示工程模块涵盖了以下内容:
-
对 LLM 输出进行概率思考
-
在预训练模型如 GPT-3 和 LLaMa、指令调整模型如 ChatGPT 以及模拟角色的代理中提示的基础知识
-
提示工程技巧和最佳实践,如分解、整合不同 LLM 的输出、使用随机性等
LLMOps
即使是简单的机器学习应用,构建模型也只是冰山一角。真正的挑战在于将模型部署到生产环境,并持续监控和维护其性能。
LLMOps模块涵盖了:
-
通过考虑速度、成本、自定义能力以及开源和限制性许可证的可用性,为你的应用选择最佳 LLM
-
通过将提示跟踪整合到工作流程中(使用 Git 或其他版本控制系统)来更好地管理提示
-
测试 LLM
-
在 LLM 应用中实施测试驱动开发(TDD)的挑战
-
LLM 的评估指标
-
监控性能指标、收集用户反馈并进行必要的更新
语言用户界面 UX
除了考虑基础设施和模型选择,应用的成功还依赖于用户体验。
语言用户界面 UX模块涵盖:
-
人本和同理设计的设计原则及产品接口
-
考虑如自动补全、低延迟等便利因素
-
案例研究以深入探讨有效的方法(以及无效的方法)
-
UX 研究的重要性
增强型语言模型
增强型语言模型是所有 LLM 驱动应用的核心。我们通常需要语言模型具备更好的推理能力,能够处理自定义数据集,并使用最新信息来回答查询。
增强型语言模型模块涵盖了以下概念:
-
AI 驱动的信息检索
-
嵌入的全部内容
-
将 LLM 调用链式连接到多个语言模型
-
有效使用 LangChain 等工具
一小时内启动 LLM 应用
本模块教你如何快速构建 LLM 应用,包括:
-
进行原型制作、迭代和部署的过程,以构建 MVP 应用
-
使用不同的技术栈构建有用的产品:从 OpenAI 的语言模型到利用无服务器基础设施
LLM 基础
如果你有兴趣了解大型语言模型的基础及多年来的突破,LLM 基础模块将帮助你理解以下内容:
-
机器学习基础
-
Transformers 和注意力机制
-
重要的 LLM,如 GPT-3 系列和 LLaMA 的重要突破元素
项目演示:askFSDL
该训练营还专门设置了一个部分,带你逐步了解项目askFSDL,这是一个基于 Full Stack Deep Learning 课程语料库构建的 LLM 驱动应用程序。
该团队的全栈深度学习课程是学习最佳实践以构建和部署深度学习模型的另一个优秀资源。
从数据收集和清理、ETL 和数据处理步骤,到构建前端和后端、部署和设置模型监控——这是一个完整的项目,你可以尝试复制并在过程中学到很多东西。
这是项目所使用的(不完全)概述:
-
OpenAI 的 LLM
-
使用 MongoDB 存储清理后的文档语料库
-
FAISS 索引以更快地搜索语料库
-
LangChain用于链式调用 LLM 和管理提示
-
在Modal上托管应用程序的后台
-
使用 Gantry 进行模型监控
总结
希望你对通过 LLM 训练营学习更多关于 LLM 的内容感到兴奋。祝学习愉快!
你还可以通过加入这个 Discord 服务器与其他学习者和社区成员互动。这里有来自行业专家(如 OpenAI 和 Repl.it)的邀请讲座,以及 LLM 领域工具的创造者。这些讲座也将很快上传到训练营的网站。
想了解更多关于 LLM 的课程吗?这里有一个 LLM 顶级免费课程列表。
Bala Priya C 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉点上工作。她的兴趣和专业领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过撰写教程、操作指南、意见文章等来学习和分享知识。
更多相关主题
Google 提供的免费生成式人工智能课程
原文:
www.kdnuggets.com/2023/07/free-generative-ai-courses-google.html

作者图片
在我们深入探讨免费课程之前,让我简要介绍一下生成式人工智能的定义。生成式人工智能可以根据用户的提示生成文本、图像或其他形式的媒体。它可以生成新的内容,替代重复的任务,处理定制的数据等。例如,PandasAI 最近发布了——一个将生成式人工智能能力集成到 Pandas 中的生成式人工智能 Python 库,以简化数据分析。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
就像 PandasAI 一样,我们预计会看到更多生成式人工智能工具和软件的发布,并将其集成到我们的日常生活中,使过程更加简单和顺畅。
现在我们来谈谈 Google 提供的关于生成式人工智能的免费课程。
Google 的生成式人工智能学习路径
Google 创建了生成式人工智能学习路径,其中包括围绕生成式人工智能产品和技术的一系列课程。你将学习大型语言模型(LLMs)的基础知识,并能够在 Google Cloud 上创建和部署生成式人工智能解决方案。
学习路径包括以下 10 门课程:
1. 生成式人工智能简介
链接: 生成式人工智能简介
这门课程将为你提供生成式人工智能基础知识的概述。如果你对生成式人工智能完全陌生,这将是最好的起点。你还将学习生成式人工智能如何与其他机器学习方法区分开来。
2. 大型语言模型简介
链接: 大型语言模型简介
随着 ChatGPT 和 Bard 等聊天机器人兴起,了解大型语言模型(LLMs)是什么,它们是如何构建的,以及它们的使用和提示调整是至关重要的信息。
3. 负责任人工智能简介
链接:负责任的 AI 介绍
最近对负责任的人工智能(AI)引发了一些愤慨。这个课程将介绍如何将负责任的 AI 实施到 Google 的产品中。你将学习 Google 的 7 个 AI 原则,深入了解社会责任、问责制和隐私设计原则。
4. 生成式 AI 基础
链接:生成式 AI 基础
完成前三门课程后,你将会在第四门课程中接受这三门课程的测验。你们中的一些人可能已有背景知识,能很快完成。然而,这对初学者和希望填补知识空白的人来说是有益的。
5. 图像生成简介
链接:图像生成简介
生成式 AI 的重要部分是能够使用稳定扩散生成图像。在这个课程中,你将进一步了解扩散模型,并深入研究机器学习、深度学习和卷积神经网络。
6. 编码器-解码器架构
链接:编码器-解码器架构
了解更多关于用于序列到序列任务的强大机器学习架构——编码器-解码器架构。有了这些,你将能更好地理解机器翻译、文本摘要和问答系统。
这个课程还包括一个实验室演练,你将在其中编写一个简单的编码器-解码器架构的实现,以完成特定任务。
7. 注意机制
链接:注意机制
我听到很多人谈论想要更多地了解这个主题。注意机制是一种技术,允许神经网络集中注意力于输入序列的特定部分。为了在课程中取得成功,你需要对机器学习、深度学习、自然语言处理和/或 Python 编程有良好的理解。
8. 变换器模型和 BERT 模型
随着术语的复杂化,此时你需要有更多经验。在课程中,你将学习变换器模型的主要组件以及双向编码器表示模型(BERT)。
比如,你将能够更深入地了解自注意机制,以及它如何用于构建 BERT 模型,还可以了解其他任务如文本分类。
9. 创建图像字幕模型
链接:创建图像字幕模型
这名字已经说明了一切。通过使用深度学习创建图像标注模型,分解图像标注模型的不同组件,如编码器和解码器。然后你将进行模型训练和评估,并创建你自己的图像标注模型,以生成图像的标题。
10. 生成式 AI 工作室介绍
链接: 生成式 AI 工作室介绍
最后但同样重要的是生成式 AI 工作室。在本课程中,你将介绍生成式 AI 工作室的演示,这些工作室用于帮助原型设计和定制生成式 AI 模型,以便你可以在应用程序中使用其功能。课程结束时还有一个动手实验和一个测验来测试你的知识。
总结
由 Google 提供的这 10 门课程不仅适合初学者,还适合那些希望在职业生涯中转型或学习新知识的机器学习工程师和数据科学家。与其落后,不如保持更新,而 Google 提供了出色的资源来帮助学生、员工和新手达到目标。
Nisha Arya 是一名数据科学家、自由技术作家及 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探索人工智能如何/能如何促进人类寿命的延续。作为一名热衷学习者,她寻求拓宽技术知识和写作技能,同时帮助指导他人。
更多相关内容
免费 Google Cloud Gemini 学习路径
原文:
www.kdnuggets.com/free-google-cloud-learning-path-for-gemini

图片由作者创建
Gemini 简介
我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业之路。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
现在是语言模型的时代,Gemini是谷歌迄今为止最新和最强大的模型。
Gemini 是谷歌各团队的大规模协作成果,包括谷歌研究部门的同事。它从头开始构建,具备多模态功能,这意味着它能够泛化并无缝理解、操作并结合不同类型的信息,包括文本、代码、音频、图像和视频。
如果你对了解 Gemini、语言模型以及如何利用它们感兴趣,谷歌推出了一条新的中级语言模型学习路径——Google Cloud Gemini 学习路径。请查看下方的学习路径信息。
学习路径
Google Cloud Gemini 学习路径展示了 Gemini 如何为多种不同角色提供助力。凭借其对话自然语言聊天界面,Gemini 可以快速处理与云相关的问题或提供最佳实践建议。它通过在你输入时提供代码补全或代码生成,或偶尔根据所做评论来帮助编码任务。这条学习路径可以促进开发者、数据分析师、云工程师、架构师和安全工程师等各种角色的工作。

在第一门课程中,Gemini for Application Developers,学习 Gemini 如何帮助你构建应用程序。了解所有关于提示、解释代码,甚至生成代码的内容。
在第二门课程中,Gemini for Cloud Architects,了解 Gemini 如何帮助配置基础设施。查看 Gemini 如何解释基础设施、更新基础设施,并部署 Google Kubernetes Engine 集群。该课程使用实践实验室来帮助巩固学习。
第三门课程“面向数据科学家和分析师的 Gemini”,探讨如何利用 Gemini 分析数据和进行预测。重点关注客户数据,学习如何在 Google BigQuery 的帮助下识别、分类和开发新客户。

下一门课程“面向网络工程师的 Gemini”,演示 Gemini 如何帮助网络工程师创建和管理虚拟私有云网络。学习提示策略,让 Gemini 协助你的网络任务。
第五门课程名为“安全工程师的 Gemini”,旨在展示如何将 Gemini 作为协作者来保护你的云环境和资源。你将看到 Gemini 如何帮助将示例工作负载部署到 Google Cloud 环境中,并识别安全配置错误。
第六门课程“面向 DevOps 工程师的 Gemini”,介绍 Gemini 如何帮助工程师管理基础设施。使用 Gemini 了解和管理应用日志,创建 Google Kubernetes Engine 集群等。

第七门课程“面向端到端 SDLC 的 Gemini”,展示如何与其他 Google 产品和服务一起使用 Gemini,从创建到部署,开发、测试、部署和管理自己的应用程序。
在学习路径的最后一门课程“使用 Gemini 和 Streamlit 开发 GenAI 应用程序”中,学习有关文本生成、使用函数调用以及创建和部署带有 Cloud Run 的 Streamlit 应用程序的全部内容。
总结
了解如何利用 Gemini 执行 Google Cloud 最新学习路径中的各种工程任务,查看 Google Cloud 的 Gemini 学习路径 的详细信息,看看这是否能对你的职业生涯有所帮助。
马修·梅奥 (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 和 Statology 的主编,以及 Machine Learning Mastery 的贡献编辑,马修致力于使复杂的数据科学概念易于理解。他的职业兴趣包括自然语言处理、语言模型、机器学习算法和探索新兴 AI。他的使命是让数据科学社区的知识民主化。马修从 6 岁开始编程。
更多相关内容
来自谷歌的免费:生成式 AI 学习路径
原文:
www.kdnuggets.com/2023/07/free-google-generative-ai-learning-path.html

作者插图
你是否有兴趣了解生成式 AI 模型及其应用的潜力?幸运的是,谷歌云发布了生成式 AI 学习路径,这是一个很棒的免费课程集合,涵盖了从解释生成式 AI 的基本概念到更复杂的工具,比如生成式 AI 工作室,以构建自定义生成式 AI 模型。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业之路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
本文将探讨七门现有课程,让你了解我们每天接触的大型语言模型背后的概念,并创建新的 AI 解决方案。让我们开始吧!
1. 生成式 AI 简介
课程链接:生成式 AI 简介
这第一门课程是由谷歌云的 AI 技术课程开发者 Dr. Gwendolyn Stripling 主讲的生成式 AI 入门课程。它将帮助你了解生成式 AI 是什么以及它的应用。课程从数据科学的基本概念(AI、机器学习、深度学习)开始,并介绍生成式 AI 与这些学科的不同之处。此外,它通过非常直观的插图解释了围绕生成式 AI 的关键概念,如变换器、幻觉和大型语言模型。
视频时长: 22 分钟
讲师: Gwendolyn Stripling
推荐阅读:
2. 大型语言模型简介
课程链接:大型语言模型简介
第二个课程旨在从高层次介绍语言模型是什么。特别是,它给出了 LLM 应用的例子,如文本分类、问题回答和文档摘要。最后,它展示了 Google 生成 AI 开发工具的潜力,可以在无需代码的情况下构建你的应用程序。
视频时长: 15 分钟
讲师: John Ewald
建议阅读:
3. 图像生成简介
课程链接:图像生成简介
第三个课程专注于解释最重要的扩散模型,这是一类生成图像的模型。最有前途的一些方法包括变分自编码器、生成对抗模型和自回归模型。
它还展示了可以分为两种类型的使用案例:无条件生成和有条件生成。前者包括人脸合成和超分辨率作为应用,而有条件生成的例子包括从文本提示生成图像、图像修复和文本引导的图像到图像。
视频时长: 9 分钟
讲师: Kyle Steckler
4. 注意力机制
课程链接:注意力机制
在这个简短的课程中,你将深入了解注意力机制,这是变换器和大型语言模型背后的一个非常重要的概念。它使得诸如机器翻译、文本摘要和问题回答等任务得以改进。特别是,它展示了注意力机制如何在解决机器翻译时发挥作用。
视频时长: 5 分钟
讲师: Sanjana Reddy
5. 变换器模型和 BERT 模型
课程链接:变换器模型和 BERT 模型
该课程涵盖了变换器架构,这是 BERT 模型背后的基本概念。在解释了变换器之后,它概述了 BERT 以及如何应用于解决不同任务,如单句分类和问题回答。
与之前的课程不同,这个理论课程配有一个实验室,需要具备 Python 和 TensorFlow 的基础知识。
视频时长: 22 分钟
讲师: Sanjana Reddy
建议阅读:
6. 创建图像字幕生成模型
课程链接:创建图像字幕模型
本课程旨在讲解图像字幕模型,这些生成模型通过输入图像来生成文本字幕。它利用编码器-解码器结构、注意力机制和变换器来解决为给定图像预测字幕的任务。与之前的课程一样,本课程也包括一个实验室,以将理论付诸实践。它同样面向具有 Python 和 Tensorflow 先验知识的数据专业人士。
视频时长: 29 分钟
讲师: Takumi Ohyama
7. 生成式 AI 工作室简介
课程链接:生成式 AI 工作室简介
这门课程介绍并探索生成式 AI 工作室。它首先重新解释什么是生成式 AI 及其用例,如代码生成、信息提取和虚拟助手。在概述这些核心概念后,Google Cloud 展示了即使没有 AI 背景也能解决生成式 AI 任务的工具。其中之一是 Vertex AI,这是一个管理机器学习生命周期的平台,从模型构建到部署。这个端到端平台包括两个产品:生成式 AI 工作室和模型花园。课程主要集中在解释生成式 AI 工作室,它允许轻松构建无需代码或少量代码的生成模型。
视频时长:15 分钟
推荐阅读:
最后的思考
希望你觉得这次对 Google Cloud 提供的生成式 AI 课程的快速概述有所帮助。如果你不知道从哪里开始理解生成式 AI 的核心概念,这条学习路径涵盖了各个方面。如果你已有机器学习背景,肯定能从这些课程中发现模型和用例。你知道其他关于生成式 AI 的免费课程吗?如果有有见地的建议,请在评论中分享。
尤金妮亚·安内洛 目前是意大利帕多瓦大学信息工程系的研究员。她的研究项目集中在结合异常检测的持续学习上。
更多主题
免费哈佛课程:Python 介绍人工智能
原文:
www.kdnuggets.com/free-harvard-course-introduction-to-ai-with-python

作者提供的图片
初学者在尝试学习人工智能时面临的最大问题之一是选择最佳的资源,因为资源实在太多了。 CS50 的 Python 人工智能介绍 是哈佛大学开设的一门优秀的 AI 学习资源。
我们的三大推荐课程
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT
在为期 7 周的课程中,您将首先学习数学逻辑和图搜索算法的基本概念。然后,您还将探索机器学习、神经网络和语言模型。更重要的是,您还将完成多个有趣的项目。
如果您想在参加这门课程之前刷新编程基础,请查看 CS50x 计算机科学导论—这也是免费的—以便快速掌握编程和计算机科学的基础知识。
接下来,我们来回顾一下课程内容。
课程链接:CS50 的 Python 人工智能介绍
1. 搜索
给定两个点 A 和 B,搜索算法旨在找到 A 和 B 之间的路径。最优解通常是 A 和 B 之间的最短路径。例子包括寻找任意两个地点之间最短路径的导航应用程序。
本模块关于搜索涵盖以下主题:
-
深度优先搜索 (DFS)
-
广度优先搜索 (BFS)
-
贪心最佳优先搜索
-
A* 搜索
-
Minimax
-
Alpha-beta 剪枝
以下是您将在本模块中完成的项目:
-
两位演员之间的分隔度(灵感来自于 凯文·贝肯六度分隔 游戏)
-
一个人工智能来玩井字棋
链接:搜索
2. 知识
第二个模块重点介绍利用现有知识进行推理的知识型智能体。
因此,搜索(第一个模块)和知识模块基于图算法和数学逻辑。你将在后续模块中学习机器学习和优化。
这个第二模块关于知识涵盖了以下内容:
-
命题逻辑
-
推断
-
推理
-
模型检查
-
解析
-
一阶逻辑
你将构建的项目包括:
-
骑士:一个解决逻辑谜题的程序,以及一个构建 AI 以玩扫雷的程序
-
构建一个玩扫雷的 AI
链接: 知识
3. 不确定性
概率是学习机器学习时最重要的概念之一。本模块教你概率和随机变量的基本概念。你将完成两个有趣的项目来总结本模块。
本模块涵盖:
-
概率
-
条件概率
-
随机变量
-
独立性
-
贝叶斯网络
-
采样
-
马尔可夫模型
-
隐马尔可夫模型
你将构建的项目包括:
-
一个按重要性排序网页的 AI
-
一个评估一个人是否具有遗传特征的 AI
链接: 不确定性
4. 优化
优化是一个重要的数学工具,它允许你解决广泛的问题。实际上,优化可以帮助你从一组解中找到最优解。
本模块涵盖以下优化算法:
-
局部搜索
-
攀升算法
-
模拟退火
-
线性规划
-
约束满足
-
回溯搜索
在本模块中,你将构建一个生成填字游戏的 AI。
链接: 优化
5. 学习
这是一个让你探索机器学习及各种机器学习算法细节的模块。你将学习监督学习、无监督学习和强化学习范式。
涵盖的主题包括:
-
最近邻分类
-
感知器学习
-
支持向量机
-
回归
-
损失函数
-
正则化
-
马尔可夫决策过程
-
Q 学习
-
K 均值聚类
本模块的项目包括:
-
预测客户是否会完成在线购买
-
使用强化学习的 Nim 游戏学习 AI
链接: 学习
6. 神经网络
本模块专注于深度学习基础知识。除了学习深度学习的基础知识外,你还将学习如何使用 TensorFlow 构建和训练神经网络。
这是神经网络模块涵盖的主题概述:
-
人工神经网络
-
激活函数
-
梯度下降
-
反向传播
-
过拟合
-
Tensorflow
-
图像卷积
-
卷积神经网络
-
循环神经网络
为了总结你的学习,你将进行一个交通标志识别项目。
链接: 神经网络
7. 语言
这个最终模块专注于处理自然语言。从语言处理基础到变压器和注意力机制,本模块涵盖了以下主题:
-
语法
-
语义学
-
上下文无关文法
-
N-grams
-
词袋模型
-
注意力机制
-
变压器
这是本模块的项目:
-
一个解析句子并提取名词短语的解析器
-
屏蔽词预测
链接:语言
总结
从图算法到机器学习、深度学习和语言模型——本课程涵盖了 AI 中的多个基础主题。
我相信每周进行讲座、复习讲义和进行项目将是一次极好的学习体验。祝学习愉快!
Bala Priya C**** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交集上工作。她的兴趣和专业领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和咖啡!目前,她正在通过撰写教程、操作指南、观点文章等与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关主题
免费中级 Python 编程速成课程
原文:
www.kdnuggets.com/2022/12/free-intermediate-python-programming-crash-course.html

编辑提供的图片
Python 是数据科学和机器学习中最受欢迎的编程语言。通过这个免费速成课程掌握 Python 的基础知识。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
关键要点
-
Python 是一种灵活的、开源的、解释型的高级编程语言,适用于各种现实世界的应用场景。
-
Python 现在被认为是数据科学和机器学习中最受欢迎的编程语言。
-
这个免费速成课程来自 freeCodeCamp.org,将帮助你学习 Python 编程的基础知识。
Python 现在被认为是最受欢迎的编程语言,尤其在统计、工程、数据科学、机器学习和人工智能领域。最近使用 LinkedIn 的数据进行的分析显示,Python 编程技能是全球大多数技术工作所需的前 10 项技能之一,美国的情况如下:

作者提供的图片

作者提供的图片
为什么 Python 脱颖而出
Python 是一种相对容易学习的高级编程语言。Python 是免费的且开源的,拥有一个庞大的开源社区,并且提供大量免费的教育资源,帮助初学者掌握 Python 编程。
Python 拥有多个专门的库,可用于各种应用,例如:
NumPy
NumPy 是 Python 中科学计算的基础包。它是一个提供多维数组对象、各种衍生对象(如掩码数组和矩阵)以及一系列用于快速操作数组的例程的库,包括数学、逻辑、形状操作、排序、选择、I/O、离散傅里叶变换、基本线性代数、基本统计操作、随机模拟等。
Matplotlib
Matplotlib 是一个用于在 Python 中创建静态、动画和交互式可视化的综合库。
Seaborn
Seaborn 是一个基于 matplotlib 的 Python 数据可视化库。它提供了一个高级接口,用于绘制吸引人且信息丰富的统计图形。
Pandas
Pandas 是一个快速、强大、灵活且易于使用的开源数据分析和处理工具,构建在 Python 编程语言之上。
Scikit-learn
Scikit-learn 提供简单高效的预测数据分析工具。
PyTorch
PyTorch 是一个用于深度学习、计算机视觉和自然语言处理等应用的机器学习框架。
TensorFlow
TensorFlow 是一个免费和开源的软件库,用于机器学习和人工智能。
对于大多数数据科学和机器学习职位来说,掌握 Python 编程非常重要。这就是为什么你现在应该学习 Python。
中级 Python 编程课程
中级 Python 编程课程来自 freeCodeCamp.com,将帮助你将 Python 技能提升到一个新水平。首先,你将复习基础概念,如列表、字符串和字典,但会强调一些鲜为人知的功能。然后,你将学习更高级的主题,如线程、多处理、上下文管理器、生成器等。
直接从其网站,这里是课程承诺涵盖的内容:
-
列表
-
元组
-
字典
-
集合
-
字符串
-
集合
-
Itertools
-
Lambda 函数
-
异常与错误
-
日志记录
-
JSON
-
随机数
-
装饰器
-
生成器
-
线程与多处理
-
多线程
-
多处理
-
函数参数
-
星号 (*) 运算符
-
浅拷贝与深拷贝
-
上下文管理器
正如你所看到的,课程内容从基础到高级概念。你可以在下面找到约 6 小时的速成课程,或直接在 YouTube 上查看。
如果你是一名有志的数据科学家,我真诚地鼓励你投入一些时间和精力来学习 Python 的基础知识。这是来自 freeCodeCamp 的免费课程,将帮助你获得 Python 编程的实际技能。
本杰明·O·塔约 是一名物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的拥有者。此前,本杰明曾在中央俄克拉荷马大学、峡谷大学和匹兹堡州立大学教授工程学和物理学。
更多相关内容
新的 Andrew Ng 机器学习书籍正在构建中,免费草稿章节
原文:
www.kdnuggets.com/2016/06/free-machine-learning-book-draft-chapters.html
Andrew Ng,硅谷百度研究院首席科学家,斯坦福大学副教授,Coursera 主席兼联合创始人,以及机器学习领域的重量级人物,正在撰写一本名为机器学习的渴望的新书。
然而,这不是一本典型的机器学习书籍;它专注于实现机器学习系统所需的技能和策略,而不是各种分类算法或艺术科学的概述。

来自书籍网站:
本书的目标是教你如何在组织机器学习项目时做出众多决策。你将学习到:
- 如何建立开发和测试集
- 基本误差分析
- 如何使用偏差和方差来决定下一步行动
- 学习曲线
- 比较学习算法与人类水平的表现
- 调试推理算法
- 何时应使用和不应使用端到端深度学习
- 部分误差分析
Ng 还提到,这本书将“约 100 页,包含许多易读的 1-2 页章节。”
然而,网站不仅提供了书籍的概述,还表示,如果你在 6 月 24 日(星期五)之前注册邮件列表,你将获得完成章节的免费访问权限。
这本书本身在完成后看起来可能填补当前类似书籍中的一个明显空白。鉴于提供免费预览章节的时间似乎有限,我建议迅速访问书籍的网站并加入列表。
相关:
-
新深度学习书籍完成,最终在线版本可用
-
数据爱好者十大必读书籍
-
掌握 Python 机器学习的 7 个步骤
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
更多相关话题
数据科学与机器学习的免费数学课程
原文:
www.kdnuggets.com/2020/02/free-mathematics-courses-data-science-machine-learning.html
评论
你是否有兴趣学习成功数据科学职业的基础知识?或者你是否希望复习数学知识,或者通过扩展基础来加深理解?
这是一个数学课程的精选合集,包括各种课程和专业化内容,这些内容都可以在网上免费获得,帮助你实现数据科学数学目标。它们被分为数学基础、代数、微积分、统计学与概率论,以及那些与数据科学和机器学习特别相关的主题。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
查看一下列表,并仔细检查那些可能对你感兴趣的课程。希望你能找到有用的东西。

数学基础
这些课程旨在帮助打下学习更高级数学的基础,同时促进数学思维的发展。课程描述直接来自各自的课程网站。
-
逻辑导论,斯坦福大学(课程)
这门课程从计算的角度介绍了逻辑学。它展示了如何以逻辑句子的形式编码信息;如何用这种形式的信息进行推理;并提供了逻辑技术及其在数学、科学、工程、商业、法律等领域应用的概述。
-
数学思维导论,斯坦福大学(课程)
职业数学家以某种方式解决实际问题,这些问题可能来自日常世界、科学或数学本身。学校数学成功的关键是学会在框框内思考。相反,数学思维的一个关键特征是跳出框框思考——这是今天世界中宝贵的能力。本课程有助于培养这种至关重要的思维方式。
-
高中数学,麻省理工学院(课程集合)
在本节中,我们提供了来自麻省理工学院的数学课程和资源集合。有些是用于教授麻省理工学院本科生的材料,而其他则专门为高中生设计。
代数
这些代数课程涵盖了从入门代数到线性模型和矩阵代数的范围。代数在计算和数据科学中很有帮助,并包含一些在推动某些机器学习算法(包括神经网络)中的主要概念。描述直接来源于各自课程的网站。
-
代数 I,可汗学院(课程)
课程涵盖代数基础、解方程和不等式、单位操作、线性方程和图形、线性方程的形式、方程组、不等式(系统与图形)、函数、序列、绝对值和分段函数、指数和根、指数增长与衰减、二次方程(乘法与因式分解)、二次函数和方程、无理数。
-
代数 II,可汗学院(课程)
课程涵盖多项式算术、复数、多项式因式分解、多项式除法、多项式图形、理性指数和根、指数模型、对数、函数变换、方程、三角学、建模、理性函数。
-
线性代数,麻省理工学院(课程)
这是一个关于矩阵理论和线性代数的基础课程。重点关注在其他学科中有用的主题,包括方程组、向量空间、行列式、特征值、相似性和正定矩阵。
-
通过短视频、练习、可视化和编程作业,你将学习向量和矩阵运算、线性变换、解方程组、向量空间、线性最小二乘法以及特征值和特征向量。此外,你还将瞥见线性代数库开发的前沿研究,这些库在计算科学中广泛使用。
-
线性模型与矩阵代数入门,哈佛大学(课程)
在这门数据分析的入门在线课程中,我们将使用矩阵代数来表示常用来模拟实验单位之间差异的线性模型。我们对这些差异进行统计推断。在整个课程中,我们将使用 R 编程语言来执行矩阵操作。
微积分
这些微积分课程涵盖了从预备微积分到微分、积分,再到多变量微积分和微分方程的主题。微积分有广泛的应用,一般来说,它包含了驱动神经网络工作的核心概念。描述直接来自各自的课程网站。
-
课程涵盖了复数、多项式、复合函数、三角学、向量、矩阵、级数、圆锥曲线、概率和组合数学。
-
课程涵盖了极限与连续性、导数:定义和基本规则、导数:链式法则和其他高级主题、导数的应用、函数分析、积分、微分方程、积分的应用。
-
课程涵盖积分复习、积分技巧、微分方程、积分的应用、参数方程、极坐标和向量值函数、级数。
-
课程涵盖了多变量函数的思考、多变量函数的导数、多变量导数的应用、多变量函数的积分、格林定理、斯托克斯定理和散度定理。
-
课程涵盖了一阶微分方程、二阶微分方程、拉普拉斯变换。
-
微积分入门,悉尼大学(课程)
《微积分入门》课程的重点和主题涉及数学在科学、工程和商业应用中的最重要基础。课程强调微积分的关键概念和历史动机,同时在理论和应用之间取得平衡,从而掌握基础数学中的关键阈值概念。
统计与概率
统计学和概率是数据科学的基础,比任何其他数学概念家族都重要。这些课程将帮助你从统计的角度和批判性的概率视角来观察数据。描述直接来自各自的课程网站。
-
统计学与概率,汗学院(课程)
课程涵盖分析分类数据、显示和比较定量数据、总结定量数据、建模数据分布、探索双变量数值数据、研究设计、概率、计数、排列与组合、随机变量、抽样分布、置信区间、显著性测试、两样本推断组间差异、分类数据推断、高级回归、方差分析
-
统计学基础,麻省理工学院(课程)
统计学是将数据转化为洞见和最终决策的科学。机器学习、数据科学和人工智能的最新进展背后是基本的统计原则。本课程的目的是在坚实的数学基础上发展和理解这些核心理念,从构造估计量和测试开始,以及对其渐近表现的分析。
-
数据科学:概率,哈佛大学(课程)
我们将介绍重要概念,如随机变量、独立性、蒙特卡罗模拟、期望值、标准误差和中心极限定理。这些统计学概念是进行数据统计测试的基础,有助于理解你所分析的数据是否由于实验方法或偶然性发生。
-
课程涵盖所有基本概率概念,包括:多个离散或连续随机变量、期望值和条件分布、大数法则、贝叶斯推断方法的主要工具、随机过程简介(泊松过程和马尔可夫链)
-
首先,我们将讨论如何正确解读 p 值、效应量、置信区间、贝叶斯因子和似然比,以及这些统计数据如何回答你可能感兴趣的不同问题。然后,你将学习如何设计实验以控制假阳性率,以及如何确定研究的样本量,例如为了实现高统计效能。随后,你将学习如何在科学文献中解读证据,考虑到广泛存在的发表偏倚,例如通过学习 p 曲线分析。最后,我们将讨论如何进行科学哲学、理论构建和累积科学,包括如何进行重复性研究,为什么以及如何预注册你的实验,以及如何按照开放科学原则分享你的结果。
-
概率与数据介绍,杜克大学(课程)
本课程介绍了数据采样与探索的基本知识,以及基本的概率理论和贝叶斯规则。你将研究各种采样方法,并讨论这些方法如何影响推断的范围。课程将涵盖多种探索性数据分析技术,包括数值汇总统计和基本数据可视化。你将被指导安装和使用 R 及 RStudio(免费的统计软件),并将使用这些软件进行实验练习和最终项目。本课程中的概念和技术将作为专业课程中推断和建模课程的基础。
-
概率论与数理统计,宾州州立大学(课程)
相关课程的教材涵盖了概率介绍、离散分布、连续分布、双变量分布、随机变量函数的分布、估计、假设检验、非参数方法、贝叶斯方法等内容。
数据科学与机器学习的数学基础
这些是与数据科学和机器学习直接相关的数学主题。它们可能包括上述课程的内容,也可能比上述内容更基础。然而,它们对于复习你可能已经有一段时间未学过的内容尤其有用,特别是对数据科学实践具有重要意义。描述直接来源于各自课程的网站。
-
数据科学数学技能,杜克大学(课程)
数据科学课程包含数学——这是无法避免的!本课程旨在教授学员在几乎所有数据科学数学课程中成功所需的基本数学知识,并专为具有基础数学技能但可能没有学习代数或预备微积分的学员设计。《数据科学数学技能》介绍了数据科学所依赖的核心数学,没有额外的复杂性,一次介绍一个陌生的概念和数学符号。
-
本课程不是完整的数学课程;它并不是为了替代学校或大学的数学教育。相反,它专注于你在机器学习学习中会遇到的关键数学概念。它旨在填补学生在正规教育中错过的这些关键概念的空白,或者在长时间未学习数学后需要刷新记忆的学生。
-
机器学习的数学,帝国理工学院(专业化)
对于许多高级机器学习和数据科学课程,你会发现需要重新温习数学基础——这些是你可能在学校或大学学习过的内容,但以不同的上下文或不太直观的方式教授,使你难以将其与计算机科学中的应用联系起来。本专业旨在弥合这一差距,使你掌握基础数学,建立直观理解,并将其与机器学习和数据科学相关联。
相关:
-
基于高中知识的机器学习和人工智能简介
-
贝叶斯背后的数学
更多相关内容
免费的 Microsoft Excel 初学者课程
原文:
www.kdnuggets.com/2022/09/free-microsoft-excel-beginners-course.html

图片来源:freeCodeCamp | 作者编辑
Excel 是每个数据分析师必备的工具。即使你不是数据专业人士,你也可能在学校项目、分析调查、研究论文、数据库或开票中使用过此软件。微软生态系统让我们很容易将 Excel 表格集成到日常任务中。
那么,为什么我们需要学习,即使我们已经在使用它?答案很简单,有许多 Excel 功能可以帮助我们改善日常任务。我们可以利用 Excel 的内置功能创建交互式图表,而不是使用第三方工具来创建数据可视化。
对于完全初学者来说,这将是进入数据科学世界的门户。在简历上拥有 Excel 技能是一个加分项。公司更喜欢能够使用 Excel 执行各种任务并提供良好展示的候选人。
freeCodeCamp.org 和 Programming Professor 联手推出了一个基于项目的 Microsoft Excel 课程。该课程共 7 部分,总时长 2.5 小时。
Microsoft Excel 课程将从基础开始教你所有内容。你将学习数据输入、电子表格快捷键、Excel 公式、数据可视化、数据导入和导出、数据透视表等更多内容……
该课程旨在教你 Excel 的基础知识。你将通过创建五个实际应用来学习基本功能。
-
工资单
-
成绩册
-
决策因素
-
销售数据库
-
汽车库存
之后,在问题解决模板部分,你将获得包含一半解决方案的作业。你将运用之前部分的课程内容来完成这些作业。
在课程结束时,你将学到:
-
如何输入数据和导航电子表格。
-
编写公式来解决问题。
-
创建图表和图形。
-
相对和绝对引用。
-
数据的导入和导出(CSV)。
-
实现 VLOOKUP。
-
数据透视表。
-
拆分和连接文本。
如果你感兴趣,请按下方的播放按钮,或前往 freeCodeCamp 的 YouTube 频道 开始学习。
基于项目的课程是快速学习技能的最佳方式。在 Excel 课程中,你将有充足的时间跟随并自行练习。前五个项目更多的是教程,而在课程结束时,你将获得指导性作业。你将运用你的创造力和新学到的知识来完成这些作业。
我总是建议我的读者进行实践和探索。对于认真学习者而言,Microsoft Excel 只是一个开始,你需要学习其他数据分析工具和数学概念,以确保能找到数据分析师的工作。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一款针对心理疾病学生的人工智能产品。
更多相关内容
免费 MIT 课程:TinyML 和高效深度学习计算
原文:
www.kdnuggets.com/free-mit-course-tinyml-and-efficient-deep-learning-computing

图片由作者提供
介绍
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
在今天的科技时代,我们被令人惊叹的 AI 技术奇迹所包围:语音助手回答我们的疑问,智能摄像头识别面孔,自驾车在道路上行驶。这些就像我们数字时代的超级英雄!然而,使这些技术奇迹在我们日常设备上顺利运行比看起来要困难得多。这些 AI 超级英雄有一个特殊需求:显著的计算能力 和 内存资源。这就像试图将整个图书馆塞进一个小背包。更糟糕的是,大多数我们的普通设备如手机、智能手表等并没有足够的‘脑力’来处理这些 AI 超级英雄。这在 AI 技术的广泛部署中带来了重大问题。
因此,提高这些大型 AI 模型的效率,使其更易获取至关重要。本课程:"TinyML 和高效深度学习计算" 由 MIT HAN 实验室解决了这一核心障碍。它介绍了优化 AI 模型的方法,确保其在实际场景中的可行性。让我们详细了解一下它提供的内容:
课程概览
课程结构:
持续时间: 2023 年秋季
时间: 星期二/星期四 下午 3:35-5:00 东部时间
讲师: 宋汉教授
由于这是一个进行中的课程,你可以通过这个 链接 观看直播。
课程方法:
理论基础: 从深度学习的基础概念开始,逐步深入到高效 AI 计算的复杂方法。
实践经验: 通过让学生在其笔记本电脑上部署和使用像 LLaMA 2 这样的语言模型,提供实际经验。
课程模块
1. 高效推理
本模块主要集中在提高 AI 推理过程的效率。它深入探讨了如剪枝、稀疏性和量化等技术,旨在加快推理操作并提高资源效率。涵盖的关键主题包括:
-
剪枝与稀疏性(第一部分和第二部分): 探索通过移除不必要的部分来减少模型大小的方法,同时不影响性能。
-
量化(第一部分和第二部分): 使用更少的位数表示数据和模型的技术,节省内存和计算资源。
-
神经架构搜索(第一部分和第二部分): 这些讲座探讨了发现特定任务最佳神经网络架构的自动化技术。它们展示了在 NLP、GAN、点云分析和姿态估计等各个领域的实际应用。
-
知识蒸馏: 本次会议专注于知识蒸馏,这是一种训练紧凑模型以模仿较大、更复杂模型行为的过程。旨在将知识从一个模型转移到另一个模型。
-
MCUNet:微控制器上的 TinyML: 本讲座介绍了 MCUNet,专注于在微控制器上部署 TinyML 模型,使 AI 能够在低功耗设备上高效运行。讲座内容包括 TinyML 的本质、挑战、创建紧凑的神经网络以及其多种应用。
-
TinyEngine 和并行处理: 本部分讨论 TinyEngine,探讨了在受限设备上高效部署和并行处理策略的方法,如循环优化、多线程和内存布局。
2. 领域特定优化
在领域特定优化部分,本课程涵盖了旨在优化特定领域 AI 模型的各种高级主题:
-
Transformer 和 LLM(第一部分和第二部分): 探讨了 Transformer 基础、设计变体,并涉及与 LLM 相关的高效推理算法的高级主题。还探讨了 LLM 的高效推理系统和微调方法。
-
视觉 Transformer: 本部分介绍了视觉 Transformer 基础、高效的 ViT 策略和各种加速技术。还探讨了自监督学习方法和多模态大语言模型(LLMs),以增强 AI 在视觉相关任务中的能力。
-
GAN、视频和点云: 本讲座专注于通过探讨高效的 GAN 压缩技术(使用 NAS+蒸馏)、动态成本的 AnyCost GAN 和数据高效的 GAN 训练的可微增强来提升生成对抗网络(GAN)。这些方法旨在优化 GAN、视频识别和点云分析模型。
-
扩散模型: 本讲座提供了对扩散模型结构、训练、领域特定优化以及快速采样策略的深入见解。
3. 高效训练
高效训练指的是应用方法优化机器学习模型的训练过程。本章节涵盖了以下关键领域:
-
分布式训练(第一部分和第二部分): 探索在多个设备或系统间分布训练的策略。提供了克服带宽和延迟瓶颈、优化内存消耗和实施高效并行化方法的策略,以提高在分布式计算环境中训练大规模机器学习模型的效率。
-
设备端训练和迁移学习: 本节主要关注直接在边缘设备上训练模型,处理内存限制,并采用迁移学习方法以高效适应新领域。
-
高效微调和提示工程: 本节重点介绍通过高效微调技术(如 BitFit、Adapter 和 Prompt-Tuning)来优化大型语言模型(LLMs)。此外,还强调了提示工程的概念,并说明了如何提升模型的性能和适应性。
4. 高级主题
本模块涵盖了量子机器学习这一新兴领域的主题。虽然该部分的详细讲座尚未提供,但计划涉及的主题包括:
-
量子计算基础
-
量子机器学习
-
噪声鲁棒量子机器学习
这些主题将提供对计算中量子原理的基础理解,并探讨这些原理如何应用于增强机器学习方法,同时解决量子系统中噪声带来的挑战。
如果你有兴趣深入了解这门课程,请查看下面的播放列表:
总结发言
这门课程收到了极好的反馈,特别是来自 AI 爱好者和专业人士。虽然课程正在进行中,计划于 2023 年 12 月结束,但我强烈推荐加入!如果你正在参加这门课程或有意参加,请分享你的经验。让我们一起聊聊 TinyML,讨论如何在小型设备上让 AI 变得更聪明。你的意见和见解将非常宝贵!
Kanwal Mehreen**** Kanwal 是一名机器学习工程师和技术作家,对数据科学及 AI 与医学的交汇处充满热情。她共同撰写了电子书《利用 ChatGPT 最大化生产力》。作为 2022 年 APAC 的 Google Generation Scholar,她倡导多样性和学术卓越。她还被认可为 Teradata 技术多样性学者、Mitacs Globalink 研究学者和 Harvard WeCode 学者。Kanwal 是变革的坚定倡导者,她创办了 FEMCodes,以赋能 STEM 领域的女性。
更多相关话题
免费的 MIT 微积分课程:理解深度学习的关键
原文:
www.kdnuggets.com/2020/07/free-mit-courses-calculus-key-deep-learning.html
数学无疑是机器学习的语言。统计学是机器学习建立的基础。线性代数也是一个核心贡献者。然而,为了全面理解神经网络和深度学习,必须对微积分有一定的知识。
就像生活中的所有事物一样,对微积分的理解有不同的层次,这些层次可以被认为对于理解不同深度的神经网络是足够的。例如,如果你仅仅使用流行的库来实现经过验证的策略来处理非新颖的使用案例,你可能会觉得拥有基本的导数直觉以及了解如何通过反向传播来更新神经元权重是合理的。翻译:你并不需要对微积分有深入的理解就能使用 Keras 的 ResNet 来进行图像分类。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
作为一个简单但有效的微积分解释的例子,这里是我遇到过的最好的单页微积分介绍,这个总结在几年前本来可以为我省去很多麻烦:

微积分简明版,第 2 版,1914 年,第一章(由文章作者编辑以去除不包容的语言)。
将其与神经网络联系起来可能有些困难,但可以获得微积分的基本直觉。如果你想要更全面地了解这一数学分支,你将需要寻找一些更为全面的学习工具。这里有 3 个课程和一本教科书可以帮助你,全部来自 MIT 的开放课程 计划,它们将涵盖你理解深度学习所需的所有微积分知识——以及远远超出这些内容。

来自 MIT Open Courseware 课程页面:
这个微积分课程涵盖了一元函数的微分和积分,并以对无限级数的简要讨论结束。微积分是许多科学学科的基础,包括物理学、工程学和经济学。
本课程提供了你对异步在线课程资源的所有期望:
- 讲座视频及支持性书面笔记
- 解题视频,提供解决问题的技巧
- 带详细解答的例题
- 习题集及解答
- 考试及解答
- 互动 Java 小程序("Mathlets"),以强化关键概念
更重要的是,这些(以及此处涵盖的其他课程)是OCW Scholar课程。这意味着什么?OCW Scholar 课程以提供独立学习所需的完整资源而著称,并且拥有与 MIT 学生在课堂上使用的相同材料。

来自课程的 MIT 开放课程网页:
本课程涵盖了多变量函数的微分、积分和矢量微积分。这些数学工具和方法在物理科学、工程、经济学和计算机图形学中被广泛使用。
这也是一门 OCW Scholar 课程,拥有与之前课程相同的完整课程资源类型。

来自课程的 MIT 开放课程网页:
自然法则以微分方程的形式表达。科学家和工程师必须知道如何将世界建模为微分方程,如何解这些方程并解释解答。本课程专注于在科学和工程中最有用的方程和技术。
这也是一门 OCW Scholar 课程,具有与前述课程相同的完整材料。

由麻省理工学院的吉尔伯特·斯特朗编写的关于单变量和多变量微积分的完整本科教材。可以作为上述课程的补充,也可以作为独立使用的文本学习资源。
书的目录:
-
微积分简介
-
导数
-
导数的应用
-
链式法则
-
积分
-
指数和对数
-
积分技巧
-
积分的应用
-
极坐标和复数
-
无限级数
-
向量和矩阵
-
曲线上的运动
-
偏导数
-
多重积分
-
矢量微积分
-
微积分后的数学
这本书的完整 PDF 可以直接访问这里。
一系列配套的短视频《微积分亮点》,展示了微积分在我们生活中的重要性,可以在这里找到。
确实,这比理解深度学习所需的微积分要多得多,但一旦开始,你可能不想停下来。
马修·梅奥 (@mattmayo13) 是一位数据科学家,并且是 KDnuggets 的主编,这是一项开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。马修拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系到。
了解更多相关话题
MIT 免费提供:计算思维与数据科学入门
原文:
www.kdnuggets.com/2020/10/free-mit-intro-computational-thinking-data-science-python.html
评论
编程是数据科学的重要组成部分,计算机科学的基本概念也是如此。如果我们计划实施计算解决方案来解决数据科学问题,那么编程显然是绝对必要的。为了帮助那些希望建立或巩固这些技能的人,我们最近分享了 MIT 开放课程中的一个很好的免费课程。
在学习了编程基础后,转向计算思维是解决复杂现实世界问题,包括从数据科学角度出发的良好过渡步骤。今天,我们分享计算思维与数据科学,这是 MIT 开放课程提供的另一门顶级课程,任何对学习感兴趣的人都可以免费获得。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT 支持
课程网站自我描述为:
6.0001 计算机科学与 Python 编程入门的续集,旨在为几乎没有编程经验的学生提供帮助。课程旨在使学生理解计算在解决问题中的作用,并帮助学生,无论他们的专业是什么,都能对自己编写小程序以实现有用目标的能力充满信心。该课程使用 Python 3.5 编程语言。
2016 年秋季的这门课程由 Eric Grimson、John Guttag 和 Ana Bell 教授。该课程仅使用 Python 作为实现编程语言。
讲座主题如下,取自教学大纲:
-
介绍和优化问题
-
优化问题
-
图论模型
-
随机思维
-
随机游走
-
蒙特卡洛模拟
-
置信区间
-
抽样与标准误差
-
理解实验数据
-
理解实验数据(续)
-
机器学习介绍
-
聚类
-
分类
-
分类与统计学的罪与罚
-
统计学的罪与罚及总结
我特别喜欢这门课程似乎分成了几个不同的部分。第一部分(直到第六讲)集中在计算概念上;下一部分(第七到第十讲)则具有统计性质;其余讲座组成了最后一部分关于机器学习的内容,尽管它从未远离统计学,并在最后适当地回到统计学上。
这种结构使学生能够在不混淆的情况下学习这些不同的概念。计算思维与机器学习无关;它有助于将问题分解成更小的问题,并思考解决这些更小问题的最有效方法。这是一项在生活或工作中的任何方面都值得培养的技能。然而——尽管它与机器学习没有内在联系——它确实为从业者提供了必要的洞察,以理解机器学习算法的内部工作原理、使用这些算法解决问题的方案,以及如何迭代和改进这些解决方案,使其更高效、准确和有用。
统计学总是与数据科学问题或其解决方案密切相关。对抽样误差、置信区间的讨论,以及对理解实验数据和统计学习结果潜在误用的关注,在入门数据科学课程中通常得不到应有的重视,这使得《计算思维与数据科学导论》与许多其他课程有所区别。

该课程的开放课程版本包括 讲义和所需文件、问题集、阅读材料(不幸的是,课程教材 并不免费),以及——特别值得注意的—— 讲座视频。从这个意义上说,免费提供的课程可以真正被视为完整的。
这些材料还构成了 同名 edX 课程 的基础。如果你对更有结构的学习环境或在课程完成时获得认证证书感兴趣,你可以在那里注册并选择此选项。
与麻省理工学院的 计算机科学与 Python 编程入门课程 配对,这些免费课程为学习编程、计算机科学、Python、计算、统计学和机器学习的基础提供了强有力的开端——这些都是成功的数据科学职业的关键要素。
相关内容:
-
麻省理工学院提供的免费计算机科学与 Python 编程入门课程
-
超越肤浅:具有实质性的 数据科学 MOOC 课程
-
亚马逊提供的免费机器学习入门课程
更多相关话题
MIT 免费课程:使用 Julia 的计算思维入门
原文:
www.kdnuggets.com/2020/11/free-mit-intro-computational-thinking-julia.html
评论
所以你已经尝试过其他在线数据科学课程,也许你喜欢其中的一些。也许它们帮助你从计算的角度思考问题。然后你能够过渡到自己的数据科学项目,尝试实现一些相关的概念和技能。
但让我问你:这些课程中使用了哪些编程语言?我敢打赌,大多数是使用 Python 进行教学的,一些少数课程使用了 R。我更敢打赌,没有一门课程使用 Julia。如你从这篇文章的标题和它所聚焦的课程中可能已经看出,Julia 是 MIT 这一免费课程的使用语言。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析职业证书 - 提升你的数据分析技能
3. Google IT 支持职业证书 - 支持你的组织 IT
无论你是刚开始学习编程,还是刚开始数据科学之旅,或者你是一个拥有高级编程技能的数据科学家,但使用的是其他语言而非 Julia,这门课程都能对你有用。加上课程集中在一个如此相关的话题——COVID-19,这绝对不是你遇到过的其他数据科学和编程入门课程的简单重复。
使用 Julia 的计算思维入门及 COVID-19 疫情建模应用 是 MIT 开放课程项目的另一门免费课程,由 Alan Edelman 教授和 David P. Sanders 教授讲授。鉴于课程标题中包含 COVID-19,你也许不会感到惊讶,这也是一门非常新的课程,已于 2020 年春季开设。

课程网站上有这样的描述:
这门半学期课程通过使用 Julia 编程语言的数据科学、人工智能和数学模型应用来介绍计算思维。这一 2020 年春季版本是一个加速的课程改编,重点关注 COVID-19 应对措施的应用。
课程中具体教授了什么?以下是课程大纲中的课程内容:
-
COVID-19 数据分析
-
模拟指数增长
-
概率
-
随机游走模型
-
表征变异性
-
用户自定义类型
-
马尔可夫链和连续随机变量
-
连续时间
-
指数分布
-
微分方程
-
优化与数据拟合
-
流行病建模中的网络
正如你所看到的,课程内容每周在编程基础、数据科学概念和 COVID 特定主题之间转换,这无疑有助于保持材料的新鲜感和高兴趣。课程材料包括讲义幻灯片、讲座视频、作业、外部资源和 Jupyter 笔记本。课程的Github 仓库包含了 Jupyter 笔记本和其他相关资源。

记住这门课程的标题是“计算思维”,因此课程中并没有直接涉及机器学习。然而,它专注于如何使用计算方法解决问题,这是一项非常有用的技能,无论你的具体编程角色是什么;它对于计算解决数据科学问题是必不可少的。有鉴于此,将这门课程与高质量的免费电子书《Statistics with Julia: The Free eBook》配合使用,对于那些希望将 Julia 用于数据科学的人来说似乎是一个不错的选择。
我仍然非常希望将 Julia 编程纳入我的技能组合……当我找到时间的时候。当我找到那段时间时,我会深入研究麻省理工学院的使用 Julia 进行计算思维入门,以及上面提到的免费电子书《Statistics with Julia》。我看不出你会做得有什么不同。
相关内容:
-
《Statistics with Julia: The Free eBook》
-
麻省理工学院免费提供:Python 计算机科学与编程入门
-
麻省理工学院免费提供:计算思维与数据科学入门
更多相关内容
免费来自 MIT:Python 计算机科学与编程导论
原文:
www.kdnuggets.com/2020/09/free-mit-intro-computer-science-programming-python.html
评论
我不必告诉你编程是数据科学的重要方面。
为了解决数据科学问题的计算解决方案,编程显然是绝对必要的。无论你是在可视化数据、进行探索性数据分析、还是实现机器学习模型,无论你是使用现有的代码库和库,还是从头开始编写代码,作为数据科学家编写代码都是必需的。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
但将通过谷歌搜索找到的不同代码片段拼凑在一起不应该是一个有志于数据科学家(或其他任何学习编程的人)的目标。理解计算机科学原理、计算问题解决方法和编程基础,所有这些与具体实现的编程语言无关,应该是任何真正希望真正学习如何编程的人的目标。
学习编程和掌握计算机科学概念有很多方法。显然,有些人会比其他方法更适合某些方法。彻底的大学课程,包括讲座、阅读材料、幻灯片和作业,就是一种这样的方式。

通过其开放课程计划,MIT 提供了计算机科学与 Python 编程导论,这是一种结构化学习计算机科学和编程概念的方法。由 Dr. Ana Bell、Prof. Eric Grimson 和 Prof. John Guttag 授课,这门课程旨在向编程新手传授全面的计算机科学基础。
OCW 网站对课程的描述如下:
6.0001《计算机科学与 Python 编程导论》旨在帮助没有或几乎没有编程经验的学生。这门课程旨在让学生理解计算在解决问题中的作用,并帮助学生,不论他们的专业如何,都能够对自己编写小程序以实现有用目标的能力充满信心。该课程使用 Python 3.5 编程语言。
课程主题如下:
-
什么是计算?
-
分支和迭代
-
字符串操作、猜测与检查、近似、二分法
-
分解、抽象、函数
-
元组、列表、别名、可变性、克隆
-
递归、字典
-
测试、调试、异常、断言
-
面向对象编程
-
Python 类和继承
-
理解程序效率,第一部分
-
理解程序效率,第二部分
-
搜索和排序
想直接跳到讲座视频播放列表?你可以 在 YouTube 上找到它。

再次注意,这些概念都是通过 Python 教授的,Python 是数据科学中主导的编程语言之一,也是 今天广泛使用的最流行的通用编程语言之一。
技术发展迅速。然而,尽管这门课程的版本是在 2016 年 9 月教授的,并使用 Python 3.5,但计算机科学和编程的基础知识要比外界普遍认为的更为稳定,因此不要被这门课程版本已有四年的事实所困扰。它确实仍然非常相关。
课程的配套教材,《使用 Python 进行计算与编程导论》,遗憾的是,并非免费。然而,如果你有兴趣跟读,可以在像 Amazon 这样的卖家处以合理价格购买。如果没有,讲座视频、笔记和其他资源仍然提供了丰富的学习体验。

如果你完成了这门课程并寻找下一步,MIT 的 计算思维与数据科学导论 是直接的后续课程,也可以在他们的 OCW 平台上免费获取。
学习编程不会出错,而如今学习 Python 也不会出错。如果你对掌握计算机科学和编程的基础感兴趣,这门 MIT 课程可能适合你。
相关:
-
免费 MIT 微积分课程:理解深度学习的关键
-
加速计算机视觉:来自亚马逊的免费课程
-
最佳深度学习自然语言处理课程是免费的
更多相关话题
免费的 MLOps 初学者速成课程

除非你过着隐居的生活,否则你一定听说过 MLOps,你可能至少对它有一个大致的了解。
对于那些隐居在洞穴中的隐士们,MLOps 是一系列用于机器学习模型部署和生命周期维护的程序、实施和实践。如果你熟悉 DevOps——一种用于软件持续开发的类似方法——你会注意到,MLOps 是机器学习(ML)与 DevOps 中相同的 'Ops' 的合成词。
根据 ml-ops.org,这是 Dr. Larysa Visengeriyeva、Anja Kammer、Isabel Bär、Alexander Kniesz 和 Michael Plöd 创建的一个信息性网站:
通过机器学习模型操作化管理(MLOps),我们旨在提供一个端到端的机器学习开发过程,以设计、构建和管理可复现、可测试和可演变的 ML 驱动的软件。
MLOps 不是一种流行的术语;它是一种哲学(哲学?),用于在现实世界中管理机器学习项目,从其起始到(希望!)随着时间的推移持续更新。不要被误导以为当代机器学习只是创建 Jupyter 笔记本中的模型;学习 MLOps 并在现实世界中发挥作用。这是开始学习之旅的一个不错的地方。
但如果你想快速、简洁地了解 MLOps 是什么,以及它如何有用呢?由 ZenML 的 Hamza Tahir 指导的免费 CodeCamp 课程 "免费 MLOps 初学者速成课程",在紧凑的一小时讨论中很好地回答了这些问题以及更多。
该课程基于 ZenML,这是一个允许你“构建可移植的、生产就绪的 MLOps 管道”的框架。
ZenML 帮助你将 ML 管道 标准化,由解耦的、模块化的 步骤 组成。这使你能够编写可移植的代码,并在几秒钟内将其从实验转移到生产环境。
不要被只有一个小时的时长所迷惑。尽管你不会在讨论结束时成为 MLOps 英雄,但你应该根据课程内容学到以下知识:
1. 什么是 MLOps(机器学习操作化),以及它为何必要。
2. 什么是机器学习管道。
3. 如何从零开始创建和部署一个完全可复现的 MLOps 管道。
4. 学习连续训练、漂移检测、警报和模型部署的基础知识。
涵盖的主题完整列表如下:
-
介绍
-
关于 MLOps
-
生产中的机器学习
-
部署后的问题
-
模型过时
-
模型中心 vs 数据中心
-
重点总结
-
ZenML 演示
你可以在这里查看课程幻灯片。
你可以在下面找到课程,或者点击链接到 YouTube 上观看。
Matthew Mayo (@mattmayo13) 是数据科学家及 KDnuggets 的主编,这是一个开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及自动化机器学习方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
更多相关主题
免费 Python 速成课程
Python 是一种灵活、开源、解释型的高级编程语言,适用于各种现实世界的环境。由于其简单的语法和快速原型开发的适应性,Python 在某种程度上成为了数据科学的语言。
Python 还恰好是世界上最流行的编程语言之一——如果不是最流行的编程语言的话——正如TIOBE 指数 2022 年 6 月排名 Python 第 1 所证明的那样。

TIOBE 编程社区指数(来源)
点击放大
Python 的吸引力是什么? 其继续广泛采用的贡献因素包括其庞大的生态系统、灵活性和性能、它作为倍增器的事实("Python 确实让你快速完成某些东西)以及开源社区。
对于大多数数据科学和机器学习职位来说,不懂 Python 是获得就业的主要障碍,无论你的其他资格如何。这就是为什么你应该现在学习 Python——如果你还不懂的话——或者巩固你的 Python 知识,如果你已经熟悉基础知识。
freeCodeCamp 和 Did Coding 的 Bobby Stearman 最近发布了Python 初学者教程,这是一个针对想要掌握语言的人的速成课程。
直接从其网站上,这门课程承诺涵盖以下内容:
-
安装
-
Python 解释器
-
文本编辑器
-
Git:支持文档
-
数字
-
字符串
-
列表
-
元组
-
集合
-
字典
-
条件语句
-
匹配语句
-
循环
-
循环子句
-
模块
-
循环子句
-
错误和异常
-
类
-
虚拟环境
-
构建项目
如你所见,这门课程从安装和基础知识开始,一直深入到项目构建,涵盖了语言的主要方面。除了学习 Python 的语言结构和语法,如基本类型、控制语句和异常处理外,你还会接触到一些稍微次要但同样重要的概念,比如 Git 和虚拟环境。
你可以在下面找到 ~3 小时的课程,或者直接在 YouTube 上观看。
我真诚地鼓励你学习 Python,如果你还不知道的话。freeCodeCamp 提供的这个免费课程看起来是一个很好的帮助你实现这个目标的方法,所以现在就去看看,确保你掌握了今天数据科学中最重要和最需求的技术技能之一。
Matthew Mayo (@mattmayo13) 是数据科学家以及 KDnuggets 的主编,KDnuggets 是一个开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及自动化机器学习方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系到。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关内容
免费 Python 数据科学课程
原文:
www.kdnuggets.com/2022/09/free-python-data-science-course.html

对于读者来说,Python 作为与数据科学实践关联最紧密的语言之一,应该不会感到意外。
我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
尽管可以合理地争辩说 Python 是绝对顶尖的数据科学编程语言,但与 R 和 SQL 一起,Python 无疑是前三名之一。
无论语言的具体排名如何,Python 作为一个有效的工具来实现数据科学实践是不容否认的。它的生态系统提供了丰富的库,覆盖了数据科学管道的整个范围以及相关的数据处理和分析任务。了解数据科学、Python 及其交集是确保你作为数据科学家有用的绝佳方式。
freeCodeCamp和Maxwell Armi负责整理并提供这 12 小时(没错,12 小时!)的Python 及其生态系统数据科学课程。
本 Python 数据科学课程将带你从对 Python 一无所知,到使用 Pandas、NumPy 和 Matplotlib 等工具进行数据编码和分析。
该课程设计为实践性强,逐步学习,并在学习过程中提供了坚实的 Python 语言概念基础。数据科学概念在课程中得到覆盖,并在课程的最后部分得到更专注的讲解。课程的最终项目是使用你学到的 Python 工具进行 COVID 趋势分析。
课程内容如下:
-
课程介绍及大纲
-
编程基础
-
为什么选择 Python
-
如何安装 Anaconda 和 Python
-
如何启动 Jupyter Notebook
-
如何在 iPython Shell 中编码
-
Python 中的变量与运算符
-
Python 中的布尔值与比较
-
其他有用的 Python 函数
-
Python 中的控制流
-
Python 中的函数
-
Python 中的模块
-
Python 中的字符串
-
其他重要的 Python 数据结构:列表、元组、集合和字典
-
NumPy Python 数据科学库
-
Pandas Python 数据科学库
-
Matplotlib Python 数据科学库
-
示例项目:一个使用 Python 库构建的 COVID19 趋势分析数据分析工具
请查看下面的课程视频,或前往 freeCodeCamp 的 YouTube 频道 观看。
freeCodeCamp 提供的 12 小时课程在其副标题中指出该课程适合初学者,并且将帮助你学习 Python、Pandas、NumPy 和 Matplotlib。根据我了解到的信息,它似乎兑现了承诺。如果你希望学习 Python 和数据科学,深入了解一下这个课程是值得的。
Matthew Mayo (@mattmayo13)是一位数据科学家,兼任 KDnuggets 的主编,这是一个开创性的在线数据科学和机器学习资源。他的兴趣领域包括自然语言处理、算法设计与优化、无监督学习、神经网络以及自动化机器学习方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。你可以通过 editor1 at kdnuggets[dot]com 与他联系。
更多相关内容
免费 Python 项目编码课程
原文:
www.kdnuggets.com/2022/08/free-python-project-coding-course.html

他们说,最好的学习方式是通过实践,实践能导致熟练(进而导致精通),试错是成功的关键。如果是这样,通过项目驱动的方法学习 Python 是非常有意义的。按照这个逻辑,你应该看看这个来自 feeCodeCamp 的免费 Python 项目驱动编码课程。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
由 Kylie Ying 整理的12 个初学者 Python 项目名副其实,时长几乎恰好为 3 小时。它会在这段时间内将你从 Python 新手带到可以称为熟练的中级 Python 开发者,同时关注大局。虽然许多 Python 新手——实际上是编程初学者——开始时学习语法,专注于理解孤立的概念,但基于项目的学习迫使人们从头开始思考这些概念在大局中的位置。
学习流程控制本身是一回事;将其实际应用到一个功能更全的项目中则是另一回事。
你将要处理哪些项目?按照顺序:
-
Madlibs
-
猜数字(计算机)
-
猜数字(用户)
-
剪刀石头布
-
猜字谜
-
井字棋
-
井字棋 AI
-
二分搜索
-
扫雷
-
数独解答器
-
Python 中的图像处理
-
马尔可夫链文本生成器
Kylie 是一位非常优秀的讲解者,采取了系统化的编程方法。如果你一直在寻找一个基于项目的课程来提高你的 Python 技能,不妨试试看这个课程。
不要忘记查看我们最近推荐的一些其他 Python 课程,包括这个免费 Python 速成课程和这个免费 Python 自动化课程。
马修·梅奥 (@mattmayo13)是一名数据科学家,同时也是 KDnuggets 的主编,这是一个开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。马修拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 与他联系。
更多相关话题
帮助你成为高手的免费 Python 资源
原文:
www.kdnuggets.com/free-python-resources-that-can-help-you-become-a-pro

图片由作者提供
Python 是最受欢迎的编程语言,学习它将给你的职业带来优势。你可以用它来构建 Web 应用程序、自动化任务、进行数据分析和构建机器学习模型;简而言之,Python 可以为你做任何事情。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
这怎么可能?因为开源社区的支持已经创建并维护了适用于各种任务和各个领域的 Python 包。你甚至可以访问来自 Java、C++和其他语言的流行包,因为所有这些语言都有 Python 包装器可用。
Python 是一项必要的技能,它将帮助你过渡到更专业的领域。然而,对于非技术人员或初学者来说,它仍然很棘手。你必须学习语法、函数和库。然后,你需要学习如何使用这些技能来构建项目,这将要求你参加课程并从各种资源中学习。
在本博客中,我们将回顾一些免费的 Python 课程、书籍、GitHub 仓库、项目、备忘单和在线编译器,这些资源将帮助你快速入门并成为语言专家。
Python 课程
我一直在指导学生从哪里开始学习数据科学,我总是建议他们从 Python 和 SQL 开始。他们中的大多数人不确定是否要支付巨额费用,因此我建议他们先参加一个顶级的免费课程,学习基础知识,如果他们想提高,可以付费参加课程。
本节中的免费课程涵盖了 Python 语言语法和库的基础知识。你还将学习如何使用 Python 进行数据分析和构建简单的机器学习模型。本节中的所有课程都很受欢迎,并且在参加过的人的评价中得到了高度评价。
-
Python 计算原理 由卡内基梅隆大学提供
-
使用 Python 进行数据分析 由 freecodecamp 提供
-
数据科学的 Python 由 freecodecamp 提供
Python 书籍
有些人偏爱书籍而不是课程,因为他们希望慢慢来,在尝试任何东西之前学会有关主题的所有内容。以下列出的书籍在业界很受欢迎,由顶级专家编写。它们包括示例、项目和额外资源,帮助你成为一名经验丰富的 Python 开发者。
-
人人皆可 Python 由 Dr. Charles Severance 编写
-
用 Python 自动化无聊的任务 由 Al Sweigart 编写
-
Python 数据科学手册 由 Jake VanderPlas 编写
-
Python 3 模式、配方和习语 由 Bruce Eckel 和朋友们编写
-
Python 编程入门指南 由 Kenneth Reitz 和 Tanya Schlusser 编写
Python GitHub 仓库
我总是推荐使用 GitHub 作为学习平台。在 GitHub 上,你可以找到各种社区支持的仓库,这些仓库对于 Python 初学者至关重要。这些仓库提供了“做中学”的方法,包括项目、练习和需要你解决的问题,帮助你学习语言。它们还附带了工具、框架、免费资源以及使用 Python 语言构建项目所需的一切。
Python 项目
在学习基础知识并熟悉 Python 语法之后,是时候通过构建项目来测试你的技能了。参与 Python 项目还能帮助你建立一个强大的作品集,这最终将帮助你获得高薪工作。以下列表包含了从初学者到专家的各类项目。
-
7 个适合初学者的 Python 项目 由 Abid Ali Awan 编写
-
5 个适合数据科学作品集的 Python 项目 由 Abid Ali Awan 编写
-
12 个初学者 Python 项目 由 freecodecamp 提供
-
你可以构建的 25 个 Python 项目 由 Jessica Wilkins 编写
-
Python 项目从初学到高级 由 GeeksforGeeks
Python CheatSheets
备忘单对于专家和希望在面试或考试前复习概念的学生都很有用。它们包含有关 Python 语法、库和函数的简明信息,方便快速复习。我用它们来准备工作面试或撰写技术内容。
-
使用 Python 进行网页抓取 由 The PyCoach
-
Pandas:数据处理 由 pydata
-
Python 机器学习 由 DataCamp
-
Python 中的神经网络 由 DataCamp
-
终极 Python 备忘单 由 wilfredinni
在线 Python 编译器
只有一些人可以使用个人电脑,即使他们有笔记本电脑,他们也希望避免安装 Python 和 IDE,甚至运行 Python 文件。在本节中,我提到了你可以通过浏览器访问的顶级和免费的 Python 开发环境,这些环境可以在几秒钟内使用。这些平台受欢迎且用户友好,所以我建议学生使用在线 Python 解释器,而不是设置环境来测试代码或学习编程。
最终想法
如果你是 Python 新手,我祝你好运。这个语言易于学习,我在本博客中提供的资源将帮助你快速学习。唯一需要的是你的专注。你需要付出努力和时间来学习和获得项目经验。
本博客包含了免费的 Python 资源列表,如课程、书籍、代码库、项目、资源和在线编译器。如果你对从哪里开始仍有疑问,你可以在 LinkedIn 上给我写一条合适的信息,我会尽力帮助你。
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些在心理健康方面挣扎的学生。
更多相关话题
学习自然语言处理的免费资源
原文:
www.kdnuggets.com/2018/09/free-resources-natural-language-processing.html
评论
由 Muktabh Mayank, ParallelDots 提供。

自然语言处理(NLP)是计算机系统理解人类语言的能力。自然语言处理是人工智能(AI)的一个子集。在线有许多资源可以帮助你在自然语言处理方面发展专长。
在这篇博客文章中,我们列出了供初学者和中级学习者使用的资源。
初学者的自然语言资源

初学者可以选择两种方法,即传统机器学习和深度学习,以开始自然语言处理。这两种方法有很大的不同。对于好奇者,这里是这两者之间的差异。
传统机器学习
传统机器学习算法复杂,且常常不易理解。以下是一些资源,将帮助你开始学习使用机器学习进行自然语言处理:
-
由 Jurafsky 和 Martin 编写的《语音与语言处理》是传统自然语言处理的经典之作。你可以通过这里访问它。
-
对于更实际的方法,你可以尝试Natural Language Toolkit。
深度学习
深度学习是机器学习的一个子领域,由于引入了人工神经网络,它比传统的机器学习方法要好得多。初学者可以从以下资源开始:
-
CS 224n:这是使用深度学习进行自然语言处理的最佳课程。该课程由斯坦福大学提供,访问这里。
-
Yoav Golberg 的免费和付费书籍是开始进行自然语言处理深度学习的优秀资源。免费版本可以通过这里访问,完整版可通过这里获取。
-
Jacob Einsenstein 在 GATECH 的 NLP 课程中的笔记对所有算法进行了非常全面的覆盖,涉及几乎所有的 NLP 方法。你可以在 GitHub 上通过这里访问这些笔记。
自然语言资源供从业者使用

如果你是一名数据科学家,你将需要三种类型的资源:
-
快速入门指南 / 了解最新热点
-
针对特定问题的方法综述
-
定期关注的博客
快速入门指南 / 了解最新热点
-
可以从 Otter 等人的《自然语言处理的深度学习》综述开始。你可以在 这里 访问这篇综述。
-
Young 等人的综述论文尝试总结深度学习自然语言处理中的所有前沿技术,推荐给实践者作为自然语言处理的入门读物。你可以在 这里 访问这篇论文。
-
你可以参考 这篇文章,以理解 LSTM 和 RNN 的基础知识,这些技术在自然语言处理(NLP)中被广泛使用。另一篇更常被引用(且声誉极高)的 LSTM 综述可以在 这里找到。这是一篇有趣的论文,可以帮助理解 RNN 的隐藏状态如何工作。阅读起来很愉快,可以在 这里 访问。我总是推荐以下两个博客文章给任何还没有读过的人:
-
卷积神经网络(Convnets)可以用于理解自然语言。你可以通过阅读这篇论文 这里 来可视化 Convnets 在 NLP 中的工作原理。
-
Convnets 和 RNN 的比较在 这篇 由 Bai 等人撰写的论文中得到了强调。所有的 pytorch 代码(我已经停止或大幅减少阅读非 pytorch 编写的深度学习代码)在 这里 开源,并且让你感受到哥斯拉对战金刚或福特野马对比雪佛兰 Camaro(如果你喜欢那种东西)。谁将赢得胜利!
针对特定问题的方法综述
实践者需要的另一类资源是对以下类型问题的解答:“我需要训练一个算法来做 X,我可以应用什么最酷(且易于访问)的东西?”。
你需要以下内容:
文本分类
人们首先解决的问题是什么?主要是文本分类。文本分类可以是将文本分类到不同的类别中,或检测文本中的情感/情绪。
我想强调一个关于不同情感分析综述的简单阅读,描述在这个 ParallelDots 博客 中。尽管这篇综述是关于情感分析技术的,但它可以扩展到大多数文本分类问题。
我们(ParallelDots)的调查问卷技术性稍弱,旨在引导您到有趣的资源以理解一个概念。我推荐给您的 Arxiv 调查论文将非常技术性,需要您阅读其他重要论文以深入理解一个主题。我们建议的方式是通过我们的链接来熟悉并乐在其中,但要确保阅读我们推荐的详细指南。(奥克利博士的课程讲解了块化学习,即您首先尝试从各处获取小块信息,然后再深入学习)。记住,虽然有趣很重要,但除非详细理解技术,否则在新情况中应用概念将会很困难。
另一个情感分析算法的调查(由 Linked University 和 UIUC 的人员编写)请见这里。
迁移学习革命已经影响了深度学习。就像在图像中,一个在 ImageNet 分类上训练的模型可以针对任何分类任务进行微调一样,针对维基百科的语言建模训练的 NLP 模型现在可以在相对较少的数据上进行文本分类。这里有两篇来自 OpenAI 和 Ruder 及 Howard 的论文,处理了这些技术。
Fast.ai 提供了更友好的文档来应用这些方法,详见这里。
如果您正在进行两个不同任务的迁移学习(不是从维基百科语言建模任务迁移),有关使用 Convnets 的技巧请参见这里。
恕我直言,这种方法将会慢慢取代所有其他分类方法(这是从视觉领域发生的情况进行的简单推测)。我们还发布了关于零样本文本分类的研究,能够在没有数据集训练的情况下获得良好的准确性,并且正在开发其下一代。我们建立了一个自定义文本分类 API,通常称为 Custom Classifier,您可以定义自己的类别。您可以在这里查看免费版。
SEQUENCE LABELING
序列标注是一个为单词标注不同属性的任务。这些属性包括词性标注、命名实体识别、关键词标注等。
我们对类似任务的方法进行了有趣的回顾,详见这里。
针对这些问题的一个优秀资源是今年 COLING 的研究论文,它提供了训练序列标注算法的最佳指南。你可以在这里获取。
机器翻译
- 最近自然语言处理领域最大的进展之一是发现了能够将文本从一种语言翻译到另一种语言的算法。Google 的系统是一个令人惊叹的 16 层 LSTM(因为他们有大量的数据进行训练,所以不需要丢弃)并且提供了最先进的翻译结果。
媒体专家夸大了这一炒作,发布了虚假报道声称“Facebook 不得不关闭发明了自己语言的 AI”。以下是一些相关报道。
我的一些最喜欢的论文在这里—
-
这篇Google 的论文告诉你当你有大量的钱和数据时,如何解决一个问题。
-
Facebook 的卷积神经机器翻译系统(仅仅因为其酷炫的卷积方法)及其代码作为库被发布在这里。
-
marian-nmt.github.io/是一个用于快速翻译的 C++框架www.aclweb.org/anthology/P18-4020 -
opennmt.net/使每个人都能训练他们的 NMT 系统。
问答系统
在我看来,这将是下一个“机器翻译”。问答任务有很多不同的类型。从选项中选择,基于段落或知识图谱选择答案,或基于图像回答问题(也称为视觉问答),有不同的数据集可以了解最前沿的方法。
-
SQuAD 数据集是一个测试算法阅读理解和回答问题能力的问答数据集。微软今年早些时候发布了一篇论文,声称他们已达到该任务的人类水平准确性。论文可以在这里找到。另一个重要的算法(我觉得非常酷)是 Allen AI 的BIDAF及其改进。
-
另一个重要的算法集是视觉问答,它回答关于图像的问题。Teney 等人的论文来自 VQA 2017 挑战赛,是一个很好的入门资源。你还可以在 Github 上找到它的实现这里。
-
对大文档进行抽取式问答(类似于谷歌如何在前几条结果中突出显示对查询的回答)在现实生活中可以使用迁移学习(因此只需少量标注),如这篇 ETH 论文中所示这里。一篇非常好的论文批评了问答算法的“理解”,请参阅这里。如果你在这个领域工作,必须阅读。
同义句生成、句子相似性或推理
句子比较任务。NLP 有三个不同的任务:句子相似性、同义句检测和自然语言推理(NLI),每个任务对语义理解的要求逐渐提高。MultiNLI及其子集斯坦福 NLI 是最知名的 NLI 基准数据集,最近成为了研究的重点。还有 MS 同义句语料库和 Quora 语料库用于同义句检测,以及 SemEval 数据集用于 STS(语义文本相似性)。有关该领域高级模型的良好调查可以在这里找到。在临床领域应用 NLI 非常重要。(查找正确的医疗程序、药物的副作用及交叉效应等)。如果你希望将技术应用于特定领域,这篇教程是一个不错的阅读选择。
这里是我在这个领域中最喜欢的论文列表
-
自然语言推理在交互空间中的应用 – 它展示了一种非常巧妙的方法,将 DenseNet(用于句子表示的卷积神经网络)应用于此。这个成果还是一个实习项目的结果,这让它更加酷炫!你可以在这里阅读这篇论文。
-
Omar Levy 小组的这篇研究论文表明,即使是简单的算法也能完成任务。这是因为算法仍然没有学习“推理”。
-
BiMPM 是一个很酷的模型,用于预测同义句,可以在这里访问。
-
我们也有一项关于同义句检测的新工作,它将关系网络应用于句子表示,并且已被今年的 AINL 会议接受。你可以在这里阅读。
其他领域
这里有一些更详细的调查论文,可以获取有关你可能在构建 NLP 系统时遇到的其他任务的研究信息。
-
语言建模(LM) – 语言建模的任务是学习语言的无监督表示。通过预测给定前 N 个单词后第 (n+1) 个单词来完成。这些模型有两个重要的实际应用,自动补全和作为文本分类转移学习的基础模型,如前所述。详细调查可以在这里找到。如果你有兴趣了解基于搜索历史的 LSTM 如何在手机/搜索引擎中进行自动补全,这里有一篇很酷的论文值得阅读。
-
关系抽取 – 关系抽取的任务是提取句子中存在的实体之间的关系。给定句子“A 与 B 的关系为 r”,给出三元组 (A, r, B)。该领域的研究工作调查可以在这里找到。这里是我发现非常有趣的一篇研究论文。它使用 BIDAFs 进行零样本关系抽取(即,它可以识别它未曾接受训练的关系)。
-
对话系统 – 随着聊天机器人革命的兴起,对话系统现在非常流行。许多人(包括我们)将对话系统构建为意图检测、关键词检测、问答等模型的组合,而其他人则尝试端到端建模。JD.com 团队对对话系统模型的详细调查可以在这里找到。我还想提到 Facebook AI 提供的框架 Parl.ai。
-
文本摘要 – 文本摘要用于从文档(段落/新闻文章等)中获取简洁的文本。有两种方法:提取式摘要和抽象式摘要。提取式摘要提供了信息含量最高的句子(这种方法已经存在几十年),而抽象式摘要则旨在像人类一样撰写摘要。这款演示来自 Einstein AI,将抽象式摘要引入主流研究。有关技术的详细调查报告这里。
-
自然语言生成 (NLG) – 自然语言生成是计算机旨在像人类一样写作的研究。这可能包括故事、诗歌、图像描述等。在这些方面,当前研究在图像描述上表现很好,LSTM 和注意力机制的结合已经提供了可以实际使用的输出。有关技术的调查报告这里。
推荐关注的博客
这里有一份博客推荐列表,适合任何对跟踪 NLP 研究新动态感兴趣的人。
Einstein AI – https://einstein.ai/research
Google AI 博客 – ai.googleblog.com/
WildML – www.wildml.com/
DistillPub – distill.pub/ (distillpub 是独特的,既是博客也是出版物)
Sebastian Ruder – ruder.io/
如果你喜欢这篇文章,必须关注我们的博客。我们经常在这里提供资源列表。
就这些了!享受让神经网络理解语言的乐趣。你还可以尝试基于自然语言处理的文本分析 API,这里。
你还可以阅读有关机器学习算法的文章,了解成为数据科学家应掌握的算法这里。
你还可以这里查看 ParallelDots AI API 的免费演示。
原创。已获授权转载。
简介: Muktabh Mayank 是 ParallelDots 的联合创始人,该公司致力于“简化每个人的机器学习”。Muktabh 是数据科学家、企业家、社会学家,不是传统的书呆子。
相关链接:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
相关主题
免费 SQL 和数据库课程
SQL 是数据科学家——或者任何编程人员——能够掌握的最受欢迎和最有用的语言之一。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 在 IT 领域支持你的组织
SQL 可能是数据科学家的最佳朋友,而且有充分的理由。 Jorge Torres 在他最近的文章中提到了两个非常重要的理由:首先,SQL 主导了数据库;其次,对 SQL 技能的需求很高,并且还在增长。
此外,数据科学家及 KDnuggets 贡献者 Natassha Selvaraj 在最近的教程中指出了以下内容:
我能给有志于数据科学的人的最大建议就是学习 SQL。这是大多数数据科学学习提供者经常忽视的技能,但可以说它与机器学习建模一样重要。
进一步量化一下,2022 年 9 月的 TIOBE 指数——编程语言受欢迎程度的指标——将 SQL 排在所有编程语言的第 9 位。SQL 不仅对数据科学家有好处,对应用程序开发者、数据库管理员、后端开发者等也同样重要。
如果你想将 SQL 和关系数据库管理系统(RDBMSs)深深地记在脑海里,这个来自 freeCodeCamp 的免费课程可能是你的最佳选择。
正如前面提到的,除了 SQL 之外,这门课程还涵盖了关系数据库管理系统,并特别使用 MySQL 来探讨这些概念。关系数据库,特别是 MySQL 数据库系统的需求有多大?DB-Engines 排名根据数据库管理系统的受欢迎程度进行排名,并且每月更新一次。截至目前,排名前十的数据库引擎中有 8 个基于 RDBMS,其中前五名全部都是。MySQL 本身总体排名第二,因此你在学习这个系统时绝对不会浪费时间。

DB-Engines 排名,2022 年 9 月。
回到相关课程。这门课程由 Mike Dane 开发,时长刚刚超过 4 小时,涵盖了以下内容:
-
介绍
-
什么是数据库?
-
表格与键
-
SQL 基础
-
MySQL Windows 安装
-
MySQL Mac 安装
-
创建表格
-
插入数据
-
约束
-
更新与删除
-
基本查询
-
公司数据库简介
-
创建公司数据库
-
更多基本查询
-
函数
-
通配符
-
联合
-
连接
-
嵌套查询
-
删除时
-
触发器
-
ER 图简介
-
设计 ER 图
-
将 ER 图转换为模式
这门课程确实涵盖了掌握 SQL 和关系数据库管理系统所需的所有主题。尽管你在操作 SQL 时可能需要超过 4 小时的视频时间,但对于初学者来说,这门课程绝对值得投资。
你可以在YouTube或以下找到免费的完整课程。
Matthew Mayo (@mattmayo13) 是一位数据科学家及 KDnuggets 的主编,KDnuggets 是一个开创性的在线数据科学和机器学习资源。他的兴趣领域包括自然语言处理、算法设计与优化、无监督学习、神经网络和自动化机器学习方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
更多相关主题
斯坦福大学提供:图计算机器学习
原文:
www.kdnuggets.com/2021/04/free-stanford-machine-learning-graphs.html
评论
许多顶级大学将部分课程免费提供给非学生,这一趋势近年来逐渐增加。虽然这可能不是这种提供方式的首个例子,但我们可以感谢安德鲁·恩(当然还有其他人),使他的斯坦福机器学习课程在课堂之外得以提供,最初通过第三方手段,然后作为 MOOC 平台 Coursera 上的首批课程之一。自那时以来,通过这种平台提供的课程以及具有公开访问课程网站的课程数量迅速增加。如今,优质的免费大学级课程不乏其例,特别是在计算机科学、数据科学、机器学习以及其他技术学科领域。
一开始,请注意我们说“免费”时指的是课程的大部分学习材料对大众开放,而无需费用。为了明确,你无法免费注册这门课程并获得结业证书。但来自顶级大学的高质量学习材料免费访问确实值得珍惜,尤其是这些材料由该领域的领先研究人员整理和教授。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
在这种情况下,我们讨论的是斯坦福大学的图计算机器学习课程,由尤尔·莱斯科维奇教授,顾问米歇尔·卡塔斯塔及一众敬业的助教协助。当前分享的是本学期的课程版本。
图,嗯?为什么要学习图?我觉得很多人没有意识到图在问题解决中能建模什么。一些例子包括:
-
推荐系统
-
流量预测
-
药物副作用
-
药物发现
-
蛋白质折叠
当我们将图与机器学习的力量结合时,我们(希望)能够更好地揭示人眼可能看不到的洞察。鉴于许多网络的潜在复杂性,这种组合可能非常有价值。

来自斯坦福大学的《图的机器学习》:介绍幻灯片
所以,你想了解更多关于这门课程的详细信息?直接来自课程网站:
复杂数据可以表示为对象之间关系的图。这些网络是建模社会、技术和生物系统的基础工具。本课程专注于分析大规模图的计算、算法和建模挑战。通过研究基础图结构及其特征,学生们将接触到机器学习技术和数据挖掘工具,这些工具能够揭示各种网络的洞察。
整个目录呈现了逐主题教学的更丰富的画面:
-
介绍;图的机器学习
-
图上的传统机器学习方法
-
节点嵌入
-
链接分析:PageRank
-
节点分类的标签传播
-
图神经网络 1:GNN 模型
-
图神经网络 2:设计空间
-
图神经网络的应用
-
图神经网络理论
-
知识图谱嵌入
-
知识图谱推理
-
使用 GNNs 的频繁子图挖掘
-
网络中的社区结构
-
图的传统生成模型
-
图的深度生成模型
-
GNNs 的高级主题
-
扩展 GNNs
-
特邀讲座:GNNs 在计算生物学中的应用
-
特邀讲座:GNNs 的工业应用
-
GNNs 在科学中的应用
这门课程有哪些资源?最初,只打算提供幻灯片和其他非视频内容,但上周Jure 在互联网上宣布:
应广大要求,我们发布了斯坦福 CS224W《图的机器学习》的讲座视频,重点关注图表示学习。每周新增两节讲座。
除了上述提到的视频,还提供了讲座幻灯片和一系列包含现成代码示例的 Colab 笔记本。此外,特别值得注意的是,作为课程用书的图表示学习书籍由麦吉尔大学的 William L. Hamilton 编写,可以免费获得预出版 PDF。

来自斯坦福大学的《图的机器学习》:介绍幻灯片
图和机器学习的结合可以是强大的,就像斯坦福的机器学习与图结合,以及汉密尔顿的图表示学习书籍的结合。无成本获取这些高质量的学习资源应该足以迅速让任何感兴趣的人了解如何使用机器学习解决基于图的问题。如果你感兴趣,我建议你现在就去看看这两者。
相关:
-
最佳 NLP 深度学习课程是免费的
-
免费 MIT 微积分课程:理解深度学习的关键
-
机器学习系统设计:一个免费的斯坦福课程
更多关于这个话题
免费 TensorFlow 2.0 完整课程
原文:
www.kdnuggets.com/2023/02/free-tensorflow-20-complete-course.html

作者提供的图片
介绍
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
AI 解决方案和机器学习系统已经彻底改变了我们的工作方式和学习方式。它已经达到一个转折点,并正在塑造人类的未来。全球顶级科技公司如 Google、Microsoft、Amazon、Apple、Meta、Tesla 等都在大量投资 AI 应用的升级和开发。此外,依据 Precedence Research 的报告:
“全球人工智能(AI)市场规模在 2022 年估计为 1197.8 亿美元,预计到 2030 年将达到 15971 亿美元,2022 至 2030 年的年均增长率为 38.1%”
当前市场上的这些趋势要求该领域的劳动力具备更高的技能,并成为最高薪资领域之一。也就是说,如果你是一个对机器学习和人工智能感兴趣的初学者 Python 程序员,那么这篇文章就是为你准备的,请继续阅读。
课程详情
FreeCodeCamp 已与 Tim Ruscica(也称为 “Tech With Tim”)合作发布了 免费 TensorFlow 2.0 完整课程 - 初学者 Python 神经网络教程。这个 7 小时 的课程讲解了机器学习和人工智能中的基本概念,如核心学习算法、使用神经网络的深度学习、使用卷积神经网络的计算机视觉、使用递归神经网络的自然语言处理以及强化学习。让我们深入了解课程内容:
先决条件
本课程要求你具备 Python 编程的基础知识。如果你之前没有使用过 Python,我个人建议你先学习 “Python 入门 - FreeCodeCamp 免费课程” 然后再学习本课程。
课程内容
该课程分为以下 8 个模块:
模块 1:机器学习基础
本模块首先解释了整个课程中将使用的基本术语,如机器学习、人工智能、神经网络等。还讨论了数据的重要性。标签和特征是什么?神经网络如何工作?
模块 2:TensorFlow 介绍
本模块讲解了以下主题:
-
TensorFlow 安装和设置
-
张量表示
-
张量的形状和秩
-
张量的类型
模块 3:核心学习算法
本模块涵盖了 4 种基本的机器学习算法。这些算法已应用于独特的问题和数据集,并突出每种算法的应用场景。讨论的 4 种算法是
-
线性回归
-
分类
-
聚类
-
隐马尔可夫模型
模块 4:使用 TensorFlow 的神经网络
本模块涵盖了以下子主题:
-
神经网络如何工作?
-
创建神经网络
-
数据预处理
-
构建和训练模型
-
评估模型
-
进行和验证预测
模块 5:深度计算机视觉 - 卷积神经网络
本模块讲解了如何使用卷积神经网络进行图像分类和物体检测/识别,并解释了以下概念:
-
图像数据
-
卷积层
-
池化层
-
CNN 架构
模块 6:使用 RNN 进行自然语言处理
介绍了一种新型的神经网络,能够更有效地处理文本或字符等序列数据,称为递归神经网络 (RNN)。解释了如何使用递归神经网络完成以下任务:
-
情感分析
-
字符生成
模块 7:使用 Q-学习进行强化学习
这是课程中的最后一个主题,涵盖了强化学习并使用不同的技术进行预测。本模块讨论的主题如下:
-
基本术语
-
Q-学习
-
Q-学习示例
模块 8:总结与下一步
本模块推荐了一些进一步学习 TensorFlow 的资源。
如果你有兴趣深入了解本课程,请查看下面的课程视频:
结论性备注
本课程包括对每个模块的全面解释和各种编码示例。完成后,你将对机器学习和 AI 的基本概念有深刻的理解,并能够将它们应用于你的数据和特定问题。
Kanwal Mehreen 是一位有抱负的软件开发人员,对数据科学和 AI 在医学中的应用充满热情。Kanwal 被选为 2022 年 APAC 区域的 Google Generation Scholar。Kanwal 喜欢通过撰写关于趋势主题的文章来分享技术知识,并热衷于改善女性在科技行业中的代表性。
相关主题
免费大学数据科学资源
原文:
www.kdnuggets.com/2022/05/free-university-data-science-resources.html

Dom Fou 通过 Unsplash
当你开始学习数据科学时,选择正确的课程可能会非常混乱,而且课程也可能非常昂贵。选择免费的选项总是最好的,这样你可以真正了解自己是否适合这门课程,以及是否愿意为证书付费。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
我将列出在线提供的免费数据科学资源和笔记,其中一些由大学提供。
数据科学资源和笔记
1. 斯坦福大学 - 计算机科学
斯坦福大学提供了一系列的数据科学课程。其中一门特别的课程是计算机科学课程,包含:
CS 221 — 人工智能
CS 229 — 机器学习
CS 230 — 深度学习
2. 哥伦比亚工程学院 - 应用机器学习
应用机器学习课程由安德烈亚斯·C·穆勒创建,他是 Python 机器学习库 Scikit-learn 的开发者之一,同时还是哥伦比亚大学的讲师。
课程覆盖了机器学习的基础知识,包括数据探索、数据清洗、模型评估和调优。其他涉及的方面还有 GitHub、单元测试等。
3. 伯克利 - 人工智能
伯克利大学提供一个名为 CS 188 - 人工智能导论的课程。该课程涵盖了智能计算机系统的基本理解和技术,特别强调统计学和决策理论建模范式。
如果你计划独立学习这些材料,你可以在Gradescope上创建一个账户,并使用此代码进行注册:93PWD8。然后,你可以使用以下链接进行学习:
www.gradescope.com/courses/33660
4. 巴黎综合理工学院 - 数据科学
巴黎综合理工学院提供一个名为 Master Year 2 Data Science 的课程。该课程将涵盖深度学习的基础知识,重点关注应用。
这门课程适合那些精通数据科学并对深度学习有更大兴趣的人。为了确保你理解讲座幻灯片和笔记,请确保你的数据科学技能完好无损。
5. 麻省理工学院(MIT) - 深度学习
麻省理工学院是位于剑桥的私立土地赠授研究型大学。他们提供一门名为深度学习和人工智能的课程,深入探讨深度学习的基础、自动驾驶汽车和人工智能。
有 2017 年的讲座提供了对深度学习多年来发展的洞察。
6. MIT 开放课程网
麻省理工学院(MIT)是学习的领先机构,2001 年,该大学推出了一个名为开放课程网的平台。他们分享开放教育资源(OER)来帮助人们学习、增加知识和改变生活,完全免费!
你可以搜索你想要的任何内容,然后点击课程;会有一个左侧下拉菜单提供课程大纲和其他资源。他们有一个课程列表,我会提供几个可以让你开始的课程:
1. 计算机科学数学
2. 计算机科学与编程导论
3. 计算机科学与 Python 编程导论
4. Python 计算机科学与编程入门
5. 统计思维与数据分析
6. 大数据和机器学习的数学
结论
在线有如此丰富的资源可以帮助你免费学习数据科学。如果你在考虑将数据科学作为职业,我建议你尝试一下这些来自顶尖大学的免费资源。
如果你对更多免费课程感兴趣,可以阅读:
-
如果你没有钱但想学习数据科学
-
学习数据科学的最佳 YouTube 频道
-
哈佛大学最受欢迎且免费的编程入门课程:CS50
Nisha Arya 是一位数据科学家和自由技术写作者。她特别感兴趣于提供数据科学职业建议或教程以及有关数据科学的理论知识。她还希望探索人工智能如何促进人类寿命的不同方式。她是一位热衷学习者,寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关主题
支持向量机的友好介绍
原文:
www.kdnuggets.com/2019/09/friendly-introduction-support-vector-machines.html
评论
图片来源:analyticsprofile
机器学习被认为是人工智能的一个子领域,涉及开发使计算机能够学习的技术和方法。简而言之,就是开发使机器能够学习并执行任务和活动的算法。机器学习在许多方面与统计学重叠。随着时间的推移,许多技术和方法被开发用于机器学习任务。
在本文中,我们将学习几乎所有关于一种监督学习算法的信息,这种算法可以用于分类和回归(SVR),即支持向量机或简称 SVM。我们将在本文中重点关注分类。
介绍
支持向量机(SVM)是最受欢迎和讨论最多的机器学习算法之一。
它们在 1990 年代开发时极为流行,并且至今仍然是一个高性能算法的首选方法,只需少量调整即可。
SVM 的目标是在 N 维空间(N-特征数)中找到一个超平面,该超平面可以明确地对数据点进行分类。
支持向量机是最大边界分类器的推广。这个分类器很简单,但由于类别必须由线性边界分隔,它无法应用于大多数数据集。不过,它确实解释了 SVM 的工作原理。
在support-vector machines的背景下,最优分隔超平面或最大边界超平面是一个超平面,它将两个凸包的点分开,并且与两个凸包之间的距离是equidistant的。

好的,什么是超平面?
在 N 维空间中,超平面是一个维度为 N-1 的平面仿射子空间。形象地说,在二维空间中,超平面将是一个线条,而在三维空间中,它将是一个平面。
简单来说,超平面是帮助分类数据点的决策边界。

现在,为了分离两类数据点,有许多可能的超平面可以选择。我们的目标是找到一个具有最大边际的平面,即两类数据点之间的最大距离,下面的图形清楚地解释了这一点。

最大边际的超平面在 3D 空间中看起来像这样:

注意:- 超平面的维度取决于特征的数量。
支持向量
支持向量是位于或最接近超平面的数据点,它们影响超平面的定位和方向。利用这些支持向量,我们最大化分类器的边际,删除这些支持向量会改变超平面的位置。这些实际上是帮助我们构建 SVM 的点。

支持向量与超平面等距。它们被称为支持向量,因为如果它们的位置发生变化,超平面也会发生变化。这意味着超平面仅依赖于支持向量,而不依赖于其他观察值。
直到现在我们讨论的 SVM 只能分类线性可分的数据。
如果数据是非线性可分的,怎么办?
例如:请看下面的图像,其中数据是非线性可分的,当然,我们不能用一条直线来分类数据点。

在支持向量机(SVM)中引入了核函数的概念,用于对非线性可分数据进行分类。核函数是一种将低维数据映射到高维数据的函数。
核函数 SVM 有两种方法来分类非线性数据。
-
软边际
-
核技巧
软边际
这允许 SVM 犯一定数量的错误,并保持尽可能宽的边际,以便其他点仍然可以被正确分类。
“换句话说,SVM 容忍少量点被误分类,并尝试在最大化边际和最小化误分类之间平衡权衡。”
可能发生两种类型的错误分类:
-
数据点在决策边界的错误一侧,但在正确的一侧
-
数据点在决策边界的错误一侧,并且在边际的错误一侧
容忍度
在寻找决策边界时,我们希望设置多少容忍度是 SVM(线性和非线性解决方案)的一个重要超参数。在 Sklearn 中,它被表示为惩罚项——‘C’。

C 值越大,SVM 在误分类时受到的惩罚就越大。因此,边界的间隔越窄,决策边界依赖的支持向量就越少。
核技巧
这个思想是将非线性可分的数据从低维空间映射到高维空间,在高维空间中,我们可以找到一个超平面来分隔数据点。
所以一切都在于找到将 2D 输入空间映射到 3D 输出空间的映射函数,而为了减少寻找映射函数的复杂性,SVM 使用了核函数。
核函数 是一种广义函数,它接受两个(任意维度的)向量作为输入,并输出一个分数(点积),表示输入向量的相似程度。如果点积较小,向量之间差异较大;如果点积较大,向量之间则较为相似。

核函数的数学表示
核技巧的图示表示:

核技巧的视觉表示:

核函数的类型:
-
线性
-
多项式
-
径向基函数(rbf)
-
Sigmoid
让我们来谈谈最常用的核函数,即 径向基函数(rbf)。
可以将 rbf 看作是一个转换器/处理器,通过测量所有其他数据点到特定点的距离,生成更高维的新特征。
最常用的 rbf 核是高斯径向基函数。从数学角度来看:

其中 gamma(????) 控制新特征对决策边界的影响。gamma 值越高,特征对决策边界的影响越大。
类似于软间隔中的正则化参数/惩罚项(C),Gamma(????) 是一个在使用核技巧时可以调节的超参数。
结论
SVM 有许多用途,包括面部检测、图像分类、生物信息学、蛋白质折叠、远程同源性检测、手写识别、广义预测控制(GPC)等。
这篇关于支持向量机的文章就到此为止,支持向量机是最强大的回归和分类算法之一。在下一篇文章中,我们将看到如何使用 SVM 解决实际问题。
希望大家喜欢阅读这篇文章,欢迎在评论区分享你的意见/想法/反馈。
如有任何问题,请通过 LinkedIn 与我联系。
感谢阅读!!!
简介:纳盖什·辛格·乔汉 是一名数据科学爱好者。对大数据、Python 和机器学习感兴趣。
原文。已获授权转载。
相关内容:
-
K 均值聚类图像分割介绍
-
使用 K-最近邻分类心脏病
-
使用卷积神经网络和 OpenCV 预测年龄和性别
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关主题
从 CSV 到完整分析报告,只需 5 个简单步骤
原文:
www.kdnuggets.com/from-csv-to-complete-analytical-report-with-chatgpt-in-5-simple-steps

图片由 rawpixel.com 提供,来源于 Freepik
无论你从事什么业务,在数据驱动的时代,了解如何分析数据比以往任何时候都更为重要。数据分析使企业能够保持竞争力,并提供做出更好决策的能力。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
数据分析的重要性驱使每个人都知道如何进行数据分析。然而,有时进行数据分析会花费过多时间。这就是为什么我们可以依赖 ChatGPT 来从数据文件中创建完整报告。
本文将探讨五个简单步骤,使用你的 CSV 文件创建完整的分析报告。这五个步骤包括:
第一步:导入 CSV 文件
第二步:数据摘要和预处理
第三步:数据分析
第四步:数据可视化
第五步:报告生成
作为前提条件,本文假设读者已经订阅了 ChatGPT Plus。考虑到这一点,让我们开始吧。
导入 CSV 文件
第一步是准备你要分析的 CSV 文件并创建报告。这个文件可以来自任何可信的来源,但本文将使用来自Kaggle的电信流失数据集。
确保数据结构化、组织良好,并且有明确的标题。如果你有特定的目标需要分析,别忘了在文件中包含这些数据。在我们的示例中,我们将尝试对流失列进行分析。
数据准备好后,将其附加到 ChatGPT 上,让模型进行处理。
数据摘要和预处理
下一步是从我们的 CSV 文件中获取数据摘要并进行预处理。在上传数据时输入以下提示。
Provide the data summary to this file and perform appropriate data processing for the dataset.
上述提示提供了以下结果:
这是你数据集的摘要:
行数: 3333
列数: 11
列名称:
流失
账户周数
合同续签
数据计划
数据使用
客服通话次数
日通话分钟
日通话次数
月度收费
超额费用
漫游分钟
数据类型:
整数:流失、账户周数、合同续签、数据计划、客服通话次数、日通话次数
浮点数:数据使用、日通话分钟、月度收费、超额费用、漫游分钟
缺失值: 所有列中没有缺失值。
ChatGPT 能够很好地读取数据,并提供了给定的数据集。接下来的结果是 ChatGPT 的数据预处理。
由于数据集中没有缺失值,数据清理和预处理的主要关注点将是:
-
检查数据中是否存在任何异常值或异常情况。
-
如果需要,可以对数据进行归一化或标准化,特别是对于具有连续数值的列。
-
将类别数据转换为适合分析的格式,如有必要。
让我们继续这些步骤。

箱型图提供了数据集中每个数值列潜在异常值的视觉概览。以下是一些观察结果:
-
账户周数、客服通话次数、日通话次数:这些列显示了相当正常的分布,但有一些异常值。
-
数据使用、日通话分钟、月度收费、超额费用、漫游分钟:这些列也显示了一些异常值,但考虑到数据的性质,它们似乎在合理范围内。
-
流失、合同续签、数据计划:由于这些列是类别/二进制数据,它们没有显示传统的异常值。
根据这些信息,数据清理和预处理的下一步可能包括:
-
处理异常值:我们可以根据你的具体分析需求和领域知识决定是删除、限制还是以其他方式处理异常值。
-
数据转换:如果需要,我们可以对像日通话分钟、月度收费等列进行归一化或标准化,特别是如果你计划使用对数据规模敏感的算法。
-
类别数据编码:将类别数据转换为适合分析的格式,如有必要进行此类转换。
你可以让 ChatGPT 执行额外的数据清理和预处理步骤,也可以保持现状。对于这个示例,我们将继续下一步。
数据分析
接下来,我们将使用 ChatGPT 进行数据分析。数据分析取决于你想要实现的目标。在我们的案例中,我们希望从流失的角度进行数据分析。
我们使用以下提示来执行上述情况的 ChatGPT 数据分析。
Please perform the data analysis based on the data above with respect to the churn data.
数据分析可以在以下结果中查看。
为了对流失数据进行数据分析,我们将重点了解不同因素如何与客户流失相关。流失作为一个二进制变量(0 表示无流失,1 表示有流失),通常通过分类方法分析,并通过检查与其他变量的关系。计划如下:
-
相关性分析:首先,我们将查看每个数值特征与流失的相关性。这可以帮助我们初步了解哪些因素可能与流失更为相关。
-
统计测试:对于像 ContractRenewal 和 DataPlan 这样的分类变量,我们可以使用统计测试来查看不同类别之间的流失率是否存在显著差异。
-
视觉分析:我们将创建一些可视化图表来进一步探讨这些关系。这包括比较不同组的流失率以及将关键变量与流失进行绘图。
-
汇总统计:我们将为不同组提供汇总统计,以查看是否存在明显的均值或分布差异。
我们从相关性分析开始,然后进行下一步。
与流失的相关性分析
不同变量与流失的相关性如下(从最强的负相关到最强的正相关):
负相关:
-
ContractRenewal:最强的负相关。表明未续签合同的客户更可能流失。
-
DataPlan:没有数据计划的客户稍微更可能流失。
-
DataUsage:更高的数据使用略微减少了流失的可能性。
正相关:
-
AccountWeeks,DayCalls:非常弱的正相关,表明对流失的影响很小。
-
RoamMins:漫游分钟数增加与流失可能性略有增加。
-
MonthlyCharge:月费增加略微提高流失率。
-
OverageFee:更高的超额费用与增加的流失有中等的相关性。
-
DayMins:更高的每日分钟数与增加的流失率有中等的相关性。
-
CustServCalls:强正相关。更多的客服电话与更高的流失率相关。
根据这些相关性,似乎合同续签、客服电话、每日分钟数和超额费用等因素与流失关系更为密切。我们可以通过视觉分析和统计测试进一步探讨这些因素,特别是像 ContractRenewal 和 DataPlan 这样的分类变量。
视觉分析

可视化图表提供了有关不同变量与流失之间关系的宝贵见解:
根据合同续签和 DataPlan 进行流失分析:
-
ContractRenewal:流失率存在显著差异。未续签合同的客户显示出更高的流失率。
-
DataPlan:根据客户是否拥有数据计划,流失率有明显差异,没有数据计划的客户流失率更高。
数值变量(CustServCalls,DayMins,MonthlyCharge,OverageFee)与流失:
-
CustServCalls:客户服务电话数量较多的客户更倾向于流失。
-
DayMins:更高的每日分钟数与更大的流失可能性相关。
-
每月费用:较高的每月费用与更高的流失率相关。
-
超额费用:较高的超额费用也与更高的流失率相关。
分析结论
-
合同续签状态和数据计划的存在是客户流失的重要因素。
-
高使用量(以每日分钟数计算)和高费用(每月费用和超额费用)与更高的流失率相关。
-
客户服务电话数量较多是潜在流失的强指标。
下一步
基于这些见解,可以制定针对性的策略来减少流失,例如改善客户服务、修订定价策略或提供合同续签和数据计划订阅的激励。
通过一个提示,我们可以查看 ChatGPT 如何完整地进行数据分析并得出数据洞察。你可以调整分析目标,并从中开始。
数据可视化
数据可视化是一项支持活动,有助于提升数据分析和整体报告质量。通过可视化,我们可以拥有更全面的报告来理解数据。
使用以下提示,我们可以利用 ChatGPT 进行数据可视化。
Please perform data visualization **from** the data analysis to explain the data better.
为了增强对数据分析结果的理解,我将创建一系列可视化图表,清晰地展示与客户流失相关的关键发现。这些可视化图表包括:
- 类别变量的条形图:
-
比较有无合同续签的客户流失率。
-
比较有无数据计划的客户流失率。
-
关键数值变量的箱形图:
- 客户服务电话与流失率。
-
每日通话时间与流失率。
-
每月费用与流失率。
-
超额费用与流失率。
- 相关性热图:
可视化所有变量与流失的相关性。

可视化将展示所有重要图表,概括整个数据集。我们可以要求每个图表提供更详细的描述,你可以尝试自行完成。
报告生成
最后一步是基于之前的步骤生成报告。不幸的是,ChatGPT 可能无法捕捉到所有数据分析中的描述和见解,但我们仍可以得到简化版的报告。
使用以下提示生成基于之前分析的 PDF 报告。
Please provide me with the pdf report from the first step to the last step.
你将获得包含之前分析的 PDF 链接结果。如果结果不满意或有想更改的地方,请尝试迭代步骤。
结论
数据分析是每个人都应掌握的技能,它是当前时代最需要的技能之一。然而,学习如何进行数据分析可能需要很长时间。使用 ChatGPT,我们可以减少这一活动时间。
在这篇文章中,我们讨论了如何通过 5 个步骤从 CSV 文件生成完整的分析报告。ChatGPT 为用户提供了从导入文件到生成报告的端到端数据分析活动。
Cornellius Yudha Wijaya**** 是一位数据科学助理经理和数据写作者。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 撰写了多种 AI 和机器学习主题。
更多相关话题
从虚构到现实:ChatGPT 与科幻梦中的真正 AI 对话
原文:
www.kdnuggets.com/from-fiction-to-reality-chatgpt-and-the-sci-fi-dream-of-true-ai-conversation

图像由 DALLE-3 生成并由编辑编辑
“对不起,戴夫。我恐怕不能这样做。”
HAL 9000
我们可以说,人工智能(AI)到达能够与机器对话的程度,激发了人类的想象力。我们中的许多人从小就看过关于高度智能机器/机器人科幻叙事的电影。
科幻在我成长过程中非常流行,我不确定这是否因为我们潜意识中知道我们正在接近这一现实的时刻。谁知道呢!但我们已经到了这里,所以让我们谈谈它。
科幻故事描绘了一个 AI 系统和人类携手合作的未来,有时这些设想完全走偏,例如《我,机器人》。但我们不能否认的是,我们被这些故事吸引了。它不仅为我们提供了娱乐,还推动了人脑深入思考人工智能的表现。
你还记得《2001 太空漫游》中的 HAL 9000 吗?或者《她》中的 Samantha 呢?这些科幻叙事不仅让我们探索了 AI 的能力,也让我们面临了 AI 在现实世界中的伦理挑战。
现在我们从屏幕过渡到诸如 ChatGPT 这样的对话模型,这些模型将这些虚构故事变成了现实。
对话 AI 的演变
我们可以肯定地说,实现对话 AI 的过程确实令人瞩目。让我们回到ELIZA,一个早期的自然语言处理计算机程序,由Joseph Weizenbaum于 1964 年至 1967 年间在麻省理工学院创建。ELIZA 是你的计算机治疗师,模拟了一个 Rogerian 心理治疗师。如果你还没试过,我建议你试试看,问 ChatGPT 相同的问题,会非常有趣。
以下是我与 ELIZA 的简短对话,我也用 ChatGPT 进行了类似的尝试。

多年后,我们开始遇到 Siri 和 Alexa,这些有时听不懂我们说话的助手。虽然我们已经取得了长足的进步,但这并不意味着我们已经走出了隧道的尽头。
机器学习和自然语言处理(NLP)领域已经取得了许多突破,得益于各种数据集的使用、硬件的增加和发展等。我们现在生活在大语言模型(LLM)时代,像 ChatGPT 和 Google Bard 这样的模型展示了令人印象深刻的人类对话能力。
ChatGPT:对话革命
如前所述,虽然有各种 LLM 存在并在开发中,但目前 ChatGPT 处于前沿。它提供快速响应,并可以根据你的喜好进行微调。它不仅是一个 AI 工具,也是一位合作伙伴。它可以处理各种任务,如创意标志设计、文本改进和生成以及教育材料。
我们中的许多人对它如何感知情感和幽默,并根据这些调整响应感到惊讶。但所有伟大的事物都有其局限性。
科幻梦境背后的现实
虽然我们看到 AI 在某种程度上反映了我们的科幻梦想,但它仍需克服一些挑战才能像人类一样进行对话。正如我之前提到的,我们还未到达隧道的尽头,研究人员和组织正在致力于克服这些挑战。LLM 面临许多伦理挑战,如就业替代、隐私、数据安全等。
AI 系统的可预测脚本与 AI 系统能够生成原创内容的自然流畅性之间仍存在差距。
在接下来的几年里,我们应该预期管理模糊的语言,避免偏见,并理解人类语言的细微差别。
所以我想我们可以继续梦想科幻的无限可能,对吧?我们是否迟早会达到我们心爱的科幻叙事中描绘的 AI 水平?
总结一下
当我们站在这场对话 AI 技术革命的风口浪尖时,重要的是回顾一下 AI 是如何发展到今天的。从科幻叙事,到 ELIZA 给我们的冷漠建议,再到 Siri 让我们重复自己。
使用像 ChatGPT 这样的对话 AI 工具,让我们在某种程度上将科幻梦境变为现实。
Nisha Arya是一名数据科学家、自由技术写作人,以及 KDnuggets 的编辑和社区经理。她特别感兴趣于提供数据科学职业建议或教程以及基于理论的数据科学知识。Nisha 涉猎广泛,希望探索人工智能如何有益于人类寿命的延续。作为一个热心的学习者,Nisha 希望拓宽她的技术知识和写作技能,同时帮助指导他人。
相关主题
从头开始:用于机器学习解释性的置换特征重要性
原文:
www.kdnuggets.com/2021/06/from-scratch-permutation-feature-importance-ml-interpretability.html
作者:Seth Billiau,数据科学家和统计学家

图片由Arno Senoner提供,来源于Unsplash
介绍
高级机器学习主题通常被黑箱模型主导。顾名思义,黑箱模型是复杂模型,很难理解模型输入如何组合以进行预测。深度学习模型如人工神经网络和集成模型如随机森林、梯度提升学习者和模型堆叠是黑箱模型的例子,它们在从城市规划到计算机视觉等多个领域提供了极其准确的预测。

黑箱模型的示意图
然而,使用这些黑箱模型的一个缺点是,很难解释预测因子如何影响预测结果——尤其是使用传统统计方法时。本文将解释一种解释黑箱模型的替代方法,称为置换特征重要性。置换特征重要性是一个强大的工具,允许我们检测数据集中哪些特征具有预测能力,无论我们使用什么模型。
我们将首先讨论传统统计推断与特征重要性之间的差异,以激发对置换特征重要性的需求。然后,我们将解释置换特征重要性并从头开始实现它,以发现哪些预测因子对预测 Blotchville 的房价很重要。最后,我们将讨论这种方法的一些缺点,并介绍一些未来可以帮助我们进行置换特征重要性的包。
统计推断与特征重要性
在使用传统的参数统计模型时,我们可以依靠统计推断来精确说明我们的输入与输出之间的关系。例如,当我们使用线性回归时,我们知道预测因子的单位变化对应于输出的线性变化。这个变化的幅度在模型拟合过程中被估计出来,我们可以使用概率理论为这些估计提供不确定性度量。

由 Javier Allegue Barros 在 Upsplash 上拍摄的照片
不幸的是,当使用黑箱模型时,我们通常无法做出这些声明。深度神经网络可能具有数百、数千甚至百万个可训练权重,这些权重将输入预测器连接到输出预测(ResNet-50 具有超过 2300 万个可训练参数),以及多个非线性激活函数。处理如此复杂的模型时,极其困难的是从分析角度绘制出预测器与预测之间的关系。
特征重要性技术的发展旨在帮助缓解解释性危机。特征重要性技术根据每个预测器改善预测的能力为其分配分数。这使我们能够根据预测器的相对预测能力对模型中的预测器进行排序。
生成这些特征重要性分数的一种方法是利用随机排列的强大功能。下一部分将解释如何使用 Python 执行排列特征重要性。
排列特征重要性
特征重要性的理念很简单。对预测有用的输入包含有价值的信息。如果你通过随机打乱特征值来破坏这些信息,那么预测质量应该会下降。如果质量下降很小,那么原始预测器中的信息在确定预测时并没有很大影响——你的模型即使没有这些信息也仍然很好。此外,如果质量下降很大,那么原始预测器中的信息对预测的影响很大。
这个理念可以通过三个简单的步骤来实现。假设你已经训练了一个 ML 模型,并记录了预测的某些质量度量(例如 MSE、对数损失等)。对于数据集中的每个预测器:
-
在保持其他预测器值不变的情况下,随机打乱预测器中的数据。
-
基于打乱的值生成新的预测,并评估新预测的质量。
-
通过计算新预测相对于原始预测质量的下降来计算特征重要性分数。
一旦你计算了所有特征的特征重要性分数,你可以根据预测的有用性对它们进行排名。为了更具体地解释排列特征重要性,请考虑以下合成案例研究。
案例研究:预测房价
注意:代码包括在内时最具指导性。请参考本指南的完整代码这里。
假设在Blotchville的 10,000 栋房子的价格由四个因素决定:房屋颜色、社区密度分数、社区犯罪率分数和社区教育分数。Blotchville 的房屋要么是红色,要么是蓝色,因此颜色被编码为二进制指示符。三个定量分数已标准化并近似呈正态分布。房屋价格 i c可以根据以下数据生成方程从这些因素中确定:

数据生成方程
数据集中还包含五个与房价无关且没有预测能力的预测变量。下面是数据集前五行的快照,df。

数据集快照
假设我们想训练一个模型,根据其他九个预测变量来预测房价。我们可以使用任何黑箱模型,但为了这个例子,我们训练一个随机森林回归模型。为此,我们将数据分为训练集和测试集。然后,我们使用 sklearn 拟合一个简单的随机森林模型。
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressorX = df.drop(columns = 'price')
# One-hot encode color for sklearn
X['color'] = (X['color'] == 'red')
y = df.price# Train Test Split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.33,
random_state=42)# Instantiate a Random Forest Regressor
regr = RandomForestRegressor(max_depth=100, random_state=0)# Fit a random forest regressor
regr.fit(X_train, y_train)
此时,您可以随意花些时间调整随机森林回归模型的超参数。但由于这不是关于超参数调整的指南,我将继续使用这个简单的随机森林模型——它对于说明置换特征重要性的用途足够了。
一个常用的度量回归预测质量的指标是 均方根误差 (RMSE),它是在测试集上评估的。让我们计算模型预测的 RMSE 并将其存储为 rmse_full_mod。
from sklearn.metrics import mean_squared_errorrmse_full_mod = mean_squared_error(regr.predict(X_test), y_test, squared = False)
现在,我们可以通过打乱每个预测变量并记录 RMSE 的增加来实现置换特征重要性。这将帮助我们评估哪些预测变量对于做出预测是有用的。下面是从头开始实现这一点的代码。看看你是否能将这段代码的注释与我们之前的算法对上。
# Initialize a list of results
results = []# Iterate through each predictor
for predictor in X_test:
# Create a copy of X_test
X_test_copy = X_test.copy()
# Scramble the values of the given predictor
X_test_copy[predictor] = X_test[predictor].sample(frac=1).values
# Calculate the new RMSE
new_rmse = mean_squared_error(regr.predict(X_test_copy), y_test,
squared = False)
# Append the increase in MSE to the list of results
results.append({'pred': predictor,
'score': new_rmse - rmse_full_mod })# Convert to a pandas dataframe and rank the predictors by score
resultsdf = pd.DataFrame(results).sort_values(by = 'score',
ascending = False)
结果数据框包含置换特征重要性分数。较大的分数对应于 RMSE 的显著增加——这是预测变量被打乱时模型性能变差的证据。检查表格时,我们看到四个数据生成的预测变量(教育、颜色、密度和犯罪)具有相对较大的值,这意味着它们在我们的模型中具有预测能力。另一方面,五个虚拟预测变量的值相对较小,这意味着它们在预测中不那么有用。

置换数据框结果
我们还可以使用 matplotlib 绘制置换特征重要性分数图,以便于比较。

排列特征重要性图
从这项分析中,我们获得了关于模型如何进行预测的宝贵见解。我们看到教育得分是预测房价时提供最有价值信息的预测变量。房屋颜色、密度得分和犯罪得分似乎也是重要的预测变量。最后,似乎这五个虚拟预测变量的预测能力并不强。事实上,由于删除虚拟预测变量 3 实际上导致了 RMSE 的下降,我们可能考虑在未来的分析中进行特征选择,移除这些不重要的预测变量。
排列特征重要性的缺点

尽管我们已经看到排列特征重要性的诸多好处,但同样重要的是承认其缺点(不是双关)。以下是使用排列特征重要性的一些缺点:
-
计算时间: 这个过程可能计算开销较大,因为它需要你对每个预测变量进行迭代并进行预测。如果预测成本不低或预测变量非常多,这可能会非常昂贵。
-
在多重共线性存在时表现不佳: 如果数据集中有相关特征,排列特征重要性可能表现不佳。如果一个预测变量的信息也存在于一个相关的预测变量中,那么当这些预测变量之一被打乱时,模型仍然可能表现良好。
-
得分是相对的,而非绝对的: 排列重要性得分显示了模型中特征的相对预测能力。然而,这些得分在没有上下文的情况下实际上没有任何有意义的价值——任何得分都可能因其他得分的不同而显得好或坏。
-
特征重要性仍不是统计推断: 特征重要性技术只能告诉你一个预测变量有多有用——它们不能提供关于关系的性质(例如线性、二次等)或预测变量效应的大小的任何见解。排列特征重要性不是统计推断的替代方案,而是当无法进行传统推断时的替代解决方案。
结论
排列特征重要性是分析黑箱模型和提供机器学习可解释性的有价值工具。通过这些工具,我们可以更好地理解预测变量与预测结果之间的关系,甚至可以进行更有原则的特征选择。
尽管我们是从零开始实现了排列特征重要性,但也有多个包提供了复杂的排列特征重要性实现及其他与模型无关的方法。Python 用户应查看 eli5、alibi、scikit-learn、LIME 和 rfpimp 包,而 R 用户则应转向 iml、DALEX 和 vip。
祝你在排列中愉快!如果你有任何问题,随时留言,我会尽力提供答案。
鸣谢:非常感谢出色的 Claire Hoffman 校对和编辑这篇文章,并忍受我对牛津逗号的忽视。我也感谢 Leo Saenger 阅读这篇文章并提供建议。
简介: Seth Billiau 是数据科学家和统计学家,哈佛大学统计学 A.B. 学位,前哈佛大学开放数据项目副总裁。电子邮件:sethbilliau [at] college.harvard.edu
原文。转载已获许可。
相关:
-
这种数据可视化是有效特征选择的第一步
-
特征选择 – 你想知道的一切
-
用于解释和比较机器学习模型的仪表盘
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关内容
如何从零到数据科学就业
原文:
www.kdnuggets.com/2019/01/from-zero-to-employment-data-science.html
评论

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 在 IT 领域支持你的组织
当你想进入一个新的工作领域时,会遇到一个鸡与蛋的问题:没有经验就无法找到工作,但没有工作就无法获得经验。我最近在从 R 转到 Python 并寻求 Python 工作的过程中遇到了这个问题,我想分享我如何克服这个问题。
我走过了五步的旅程,我推荐正是这种方法:
1. 学习基础知识
首先,你必须掌握基础知识,这需要你自己去做。找到一个好的课程,或询问有关好的课程的推荐,跟随它,每次遇到问题时,去stackoverflow.com提问。你可能会在开始时收到不礼貌的回应,但不要灰心——你需要学会如何在这里提问。这教会你如何清晰地将你的想法和问题表达给“不是在你脑海里”的人——提出好的问题是一项对你未来职业生涯至关重要的技能。
你可以将认证作为这一阶段的固定目标。例如,当我开始学习大数据技术时,我报名参加了 Cloudera 的 Spark 和 Hadoop 开发者考试。一些专业人士不喜欢证书,强调实际工作经验,但我认为证书特别是在开始阶段非常有帮助,它可以作为一个目标,指导你学习的内容,并标志着第一阶段的“完成”。
2. 寻找充满激情的项目
许多人停留在第 1 步——这是一种危险的陷阱。相反,尽量尽快脱离课程,创建一些你充满激情的项目。课程可以教你基础知识,但通常不擅长真正激励你。然而,如果你被困在对你重要的事情上,你会更快地解决问题,从而更快地学习。
如果你还想不到一个好的项目,可以看看现有的项目,阅读博客,扩展你对“现有”技术的了解。这可能需要一些时间,但这是非常值得的努力。当然,你还应将使用的技术与目标职位的要求对接。
不要害怕你第一个或第二个项目做得很糟。它们可能确实会很糟。我敢肯定我的项目也是如此。那些“大人物”的项目可能也是如此。要想完成那个第三个真正酷的项目,你必须先完成前两个项目。这两个项目是你学习最多的阶段。
3. 展示你的项目,并获得关注。
• 在本地聚会上做演讲(参见 https://meetup.com 寻找适合你第一次演讲的简单活动)
• 将你的工作发布到 Hacker News (https://news.ycombinator.com/showhn.html)。
• 在你所在地区寻找会议并申请成为演讲者。关于你的资历可以适当夸大(但不要撒谎),只要演讲本身有实质内容并且对听众有价值就可以。
4. 贡献开源
完成两三个个人项目后,考虑贡献到现有的大型开源项目中。将代码贡献给这些项目是获得顶级专家反馈的唯一途径。他们很少进行一对一辅导。这是继续学习的最佳方式,但需要时间才能达到那个水平。
5. 更新你的个人资料
将你的项目和演讲添加到你的 LinkedIn 和/或 Github 个人资料中,并展示你的项目为何有用。你需要了解谁会阅读你的个人资料。对于招聘人员,只需提到项目就像是“正常”工作一样。对于领域专家,只需说明这是一个无偿项目,但要链接到你的 GitHub 仓库,并可能提到获得了多少星标。
通过这种方法,你向潜在雇主表明你具备启动和完成项目的技能,并且能够很好地在团队中合作。这解决了开始时提到的鸡生蛋问题。
享受过程。这有时会让人沮丧,但非常值得。
个人简介: 亚历山大·恩格尔哈特 在慕尼黑大学获得了统计学硕士和博士学位,然后成为一名专注于 R 语言机器学习的自由数据科学家。
资源:
相关:
更多相关话题
从零到英雄:使用 PyTorch 创建你的第一个 ML 模型
原文:
www.kdnuggets.com/from-zero-to-hero-create-your-first-ml-model-with-pytorch

作者提供的图片
动机
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织中的 IT
PyTorch 是最广泛使用的基于 Python 的深度学习框架。它对所有机器学习架构和数据管道提供了极大的支持。在本文中,我们将讲解框架的基础知识,以帮助你开始实现自己的算法。
所有机器学习实现都有 4 个主要步骤:
-
数据处理
-
模型架构
-
训练循环
-
评估
在实现我们自己的 MNIST 图像分类模型时,我们会经历所有这些步骤。这将帮助你熟悉机器学习项目的一般流程。
导入
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
# Using MNIST dataset provided by PyTorch
from torchvision.datasets.mnist import MNIST
import torchvision.transforms as transforms
# Import Model implemented in a different file
from model import Classifier
import matplotlib.pyplot as plt
torch.nn 模块提供了对神经网络架构的支持,并且内置了对常用层如密集层、卷积神经网络等的实现。
torch.optim 提供了优化器的实现,如随机梯度下降和 Adam。
其他实用模块可用于数据处理支持和转换。稍后我们将详细介绍每个模块。
声明超参数
每个超参数将在适当的地方进一步解释。然而,最好在文件顶部声明它们,以便于更改和理解。
INPUT_SIZE = 784 # Flattened 28x28 images
NUM_CLASSES = 10 # 0-9 hand-written digits.
BATCH_SIZE = 128 # Using Mini-Batches for Training
LEARNING_RATE = 0.01 # Opitimizer Step
NUM_EPOCHS = 5 # Total Training Epochs
数据加载和转换
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: torch.flatten(x))
])
train_dataset = MNIST(root=".data/", train=True, download=True, transform=data_transforms)
test_dataset = MNIST(root=".data/", train=False, download=True, transform=data_transforms)
MNIST 是一个流行的图像分类数据集,在 PyTorch 中默认提供。它包含 10 个从 0 到 9 的手写数字的灰度图像。每张图像的尺寸为 28 像素 x 28 像素,数据集包含 60000 张训练图像和 10000 张测试图像。
我们分别加载训练和测试数据集,通过 MNIST 初始化函数中的 train 参数来表示。root 参数声明了数据集下载的目录。
然而,我们还传递了一个额外的转换参数。对于 PyTorch,所有输入和输出应该是 Torch.Tensor 格式。这相当于 numpy 中的 numpy.ndarray。这个张量格式提供了额外的数据操作支持。然而,我们加载的 MNIST 数据是 PIL.Image 格式。我们需要将图像转换为 PyTorch 兼容的张量。因此,我们传递了以下转换:
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: torch.flatten(x))
])
ToTensor() 转换将图像转换为张量格式。接下来,我们传递一个额外的 Lambda 转换。Lambda 函数允许我们实现自定义转换。在这里,我们声明一个函数来展平输入。图像的大小为 28x28,但我们将其展平,即转换为大小为 28x28 或 784 的一维数组。稍后在实现模型时,这一点将很重要。
Compose 函数按顺序组合所有转换。首先,数据被转换为张量格式,然后展平为一维数组。
将数据划分为批次
出于计算和训练目的,我们不能一次将整个数据集传递到模型中。我们需要将数据集划分为小批量,按顺序喂给模型。这可以加快训练速度,并为我们的数据集添加随机性,这有助于稳定训练。
PyTorch 提供了对数据批处理的内置支持。来自 torch.utils 模块的 DataLoader 类可以创建数据批次,给定一个 torch 数据集模块。如上所述,我们已经加载了数据集。
train_dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
我们将数据集传递给我们的数据加载器,并将 batch_size 超参数作为初始化参数。这创建了一个可迭代的数据加载器,因此我们可以使用简单的 for 循环轻松遍历每个批次。
我们的初始图像的大小为 (784, ),带有一个相关标签。批处理将不同的图像和标签组合在一起。例如,如果我们有一个批量大小为 64,那么批次中的输入大小将变为 (64, 784),并且我们将为每个批次有 64 个相关标签。
我们还会打乱训练批次,这会在每个 epoch 更改批次中的图像。这有助于稳定训练并加快模型参数的收敛。
定义我们的分类模型
我们使用一个由 3 个隐藏层组成的简单实现。虽然简单,但这可以让你对将不同层组合在一起以实现更复杂的实现有一个大致了解。
如上所述,我们有一个大小为 (784, ) 的输入张量和 10 个不同的输出类,每个类对应一个从 0 到 9 的数字。
**** 对于模型实现,我们可以忽略批次维度。**
import torch
import torch.nn as nn
class Classifier(nn.Module):
def __init__(
self,
input_size:int,
num_classes:int
) -> None:
super().__init__()
self.input_layer = nn.Linear(input_size, 512)
self.hidden_1 = nn.Linear(512, 256)
self.hidden_2 = nn.Linear(256, 128)
self.output_layer = nn.Linear(128, num_classes)
self.activation = nn.ReLU()
def forward(self, x):
# Pass Input Sequentially through each dense layer and activation
x = self.activation(self.input_layer(x))
x = self.activation(self.hidden_1(x))
x = self.activation(self.hidden_2(x))
return self.output_layer(x)
首先,模型必须继承自 torch.nn.Module 类。这为神经网络架构提供了基本功能。然后,我们必须实现两个方法,init 和 forward。
在 init 方法中,我们声明了模型将使用的所有层。我们使用 PyTorch 提供的线性(也称为 Dense)层。第一层将输入映射到 512 个神经元。我们可以将 input_size 作为模型参数传递,这样我们以后也可以用于不同大小的输入。第二层将 512 个神经元映射到 256。第三个隐藏层将前一层的 256 个神经元映射到 128。最后一层将最终减少到输出大小。我们的输出大小将是一个大小为 (10, ) 的张量,因为我们正在预测十个不同的数字。

作者提供的图片
此外,我们初始化一个 ReLU 激活层以增加模型的非线性。
前向函数接收图像,我们提供处理输入的代码。我们使用声明的层,并依次将输入通过每一层,其中包含一个中间的 ReLU 激活层。
在我们的主代码中,我们可以初始化模型,提供数据集的输入和输出大小。
model = Classifier(input_size=784, num_classes=10)
model.to(DEVICE)
一旦初始化完成,我们将更改模型设备(可以是 CUDA GPU 或 CPU)。在初始化超参数时,我们检查了设备。现在,我们必须手动更改张量和模型层的设备。
训练循环
首先,我们必须声明用于优化模型参数的损失函数和优化器。
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
首先,我们必须声明用于优化模型参数的损失函数和优化器。
我们使用交叉熵损失,主要用于多标签分类模型。它首先对预测值应用 softmax,并计算给定的目标标签和预测值。
Adam 优化器是最常用的优化函数,它允许稳定的梯度下降以趋向收敛。它现在是默认的优化器选择,并提供令人满意的结果。我们将模型参数作为参数传递,这些参数表示将被优化的权重。
对于我们的训练循环,我们逐步构建并填补缺失的部分,以加深理解。
作为起点,我们多次遍历完整的数据集(称为 epoch),并每次优化模型。然而,我们将数据分成了多个批次。因此,对于每个 epoch,我们还必须遍历每个批次。代码如下所示:
for epoch in range(NUM_EPOCHS):
for batch in iter(train_dataloader):
# Train the Model for each batch.
现在,我们可以使用单个输入批次训练模型。我们的批次包括图像和标签。首先,我们必须将这些分开。我们的模型只需要图像作为输入来进行预测。然后,我们将预测结果与真实标签进行比较,以估计模型的性能。
for epoch in range(NUM_EPOCHS):
for batch in iter(train_dataloader):
images, labels = batch # Separate inputs and labels
# Convert Tensor Hardware Devices to either GPU or CPU
images = images.to(DEVICE)
labels = labels.to(DEVICE)
# Calls the model.forward() function to generate predictions
predictions = model(images)
我们将一批图像直接传递给模型,这些图像将通过模型内部定义的前向函数进行处理。一旦获得预测结果,我们可以优化模型的权重。
优化代码如下所示:
# Calculate Cross Entropy Loss
loss = criterion(predictions, labels)
# Clears gradient values from previous batch
optimizer.zero_grad()
# Computes backprop gradient based on the loss
loss.backward()
# Optimizes the model weights
optimizer.step()
使用上述代码,我们可以计算所有的反向传播梯度,并使用 Adam 优化器优化模型权重。将所有上述代码结合起来,可以使我们的模型逐步收敛。
完整的训练循环如下所示:
for epoch in range(NUM_EPOCHS):
total_epoch_loss = 0
steps = 0
for batch in iter(train_dataloader):
images, labels = batch # Separate inputs and labels
# Convert Tensor Hardware Devices to either GPU or CPU
images = images.to(DEVICE)
labels = labels.to(DEVICE)
# Calls the model.forward() function to generate predictions
predictions = model(images)
# Calculate Cross Entropy Loss
loss = criterion(predictions, labels)
# Clears gradient values from previous batch
optimizer.zero_grad()
# Computes backprop gradient based on the loss
loss.backward()
# Optimizes the model weights
optimizer.step()
steps += 1
total_epoch_loss += loss.item()
print(f'Epoch: {epoch + 1} / {NUM_EPOCHS}: Average Loss: {total_epoch_loss / steps}')
损失值逐渐减少并接近 0。然后,我们可以在我们最初声明的测试数据集上评估模型。
评估我们的模型性能
for batch in iter(test_dataloader):
images, labels = batch
images = images.to(DEVICE)
labels = labels.to(DEVICE)
predictions = model(images)
# Taking the predicted label with highest probability
predictions = torch.argmax(predictions, dim=1)
correct_predictions += (predictions == labels).sum().item()
total_predictions += labels.shape[0]
print(f"\nTEST ACCURACY: {((correct_predictions / total_predictions) * 100):.2f}")
与训练循环类似,我们在测试数据集上逐批进行迭代以进行评估。我们为输入生成预测。然而,对于评估,我们只需要具有最高概率的标签。argmax函数提供了这个功能,以获取预测数组中值最高的索引。
对于准确性评分,我们可以比较预测标签是否与真实目标标签匹配。然后,我们计算正确标签的数量除以总预测标签的准确率。
结果
我只训练了五个周期,并取得了超过 96%的测试准确率,相比之下,训练前准确率为 10%。下图显示了训练五个周期后的模型预测结果。

就这样,你已经从零开始实现了一个可以仅通过图像像素值区分手写数字的模型。
这绝不是 PyTorch 的全面指南,但它确实为你提供了机器学习项目中结构和数据流的一般理解。尽管如此,这些知识足以让你开始实施深度学习中的最先进架构。
完整代码
完整代码如下:
model.py:
import torch
import torch.nn as nn
class Classifier(nn.Module):
def __init__(
self,
input_size:int,
num_classes:int
) -> None:
super().__init__()
self.input_layer = nn.Linear(input_size, 512)
self.hidden_1 = nn.Linear(512, 256)
self.hidden_2 = nn.Linear(256, 128)
self.output_layer = nn.Linear(128, num_classes)
self.activation = nn.ReLU()
def forward(self, x):
# Pass Input Sequentially through each dense layer and activation
x = self.activation(self.input_layer(x))
x = self.activation(self.hidden_1(x))
x = self.activation(self.hidden_2(x))
return self.output_layer(x)
main.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
# Using MNIST dataset provided by PyTorch
from torchvision.datasets.mnist import MNIST
import torchvision.transforms as transforms
# Import Model implemented in a different file
from model import Classifier
import matplotlib.pyplot as plt
if __name__ == "__main__":
INPUT_SIZE = 784 # Flattened 28x28 images
NUM_CLASSES = 10 # 0-9 hand-written digits.
BATCH_SIZE = 128 # Using Mini-Batches for Training
LEARNING_RATE = 0.01 # Opitimizer Step
NUM_EPOCHS = 5 # Total Training Epochs
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
# Will be used to convert Images to PyTorch Tensors
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: torch.flatten(x))
])
train_dataset = MNIST(root=".data/", train=True, download=True, transform=data_transforms)
test_dataset = MNIST(root=".data/", train=False, download=True, transform=data_transforms)
train_dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
model = Classifier(input_size=784, num_classes=10)
model.to(DEVICE)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
for epoch in range(NUM_EPOCHS):
total_epoch_loss = 0
steps = 0
for batch in iter(train_dataloader):
images, labels = batch # Separate inputs and labels
# Convert Tensor Hardware Devices to either GPU or CPU
images = images.to(DEVICE)
labels = labels.to(DEVICE)
# Calls the model.forward() function to generate predictions
predictions = model(images)
# Calculate Cross Entropy Loss
loss = criterion(predictions, labels)
# Clears gradient values from previous batch
optimizer.zero_grad()
# Computes backprop gradient based on the loss
loss.backward()
# Optimizes the model weights
optimizer.step()
steps += 1
total_epoch_loss += loss.item()
print(f'Epoch: {epoch + 1} / {NUM_EPOCHS}: Average Loss: {total_epoch_loss / steps}')
# Save Trained Model
torch.save(model.state_dict(), 'trained_model.pth')
model.eval()
correct_predictions = 0
total_predictions = 0
for batch in iter(test_dataloader):
images, labels = batch
images = images.to(DEVICE)
labels = labels.to(DEVICE)
predictions = model(images)
# Taking the predicted label with highest probability
predictions = torch.argmax(predictions, dim=1)
correct_predictions += (predictions == labels).sum().item()
total_predictions += labels.shape[0]
print(f"\nTEST ACCURACY: {((correct_predictions / total_predictions) * 100):.2f}")
# -- Code For Plotting Results -- #
batch = next(iter(test_dataloader))
images, labels = batch
fig, ax = plt.subplots(nrows=1, ncols=4, figsize=(16,8))
for i in range(4):
image = images[i]
prediction = torch.softmax(model(image), dim=0)
prediction = torch.argmax(prediction, dim=0)
# print(type(prediction), type(prediction.item()))
ax[i].imshow(image.view(28,28))
ax[i].set_title(f'Prediction: {prediction.item()}')
plt.show()
穆罕默德·阿赫曼 是一名从事计算机视觉和自然语言处理的深度学习工程师。他曾在 Vyro.AI 工作,负责多个生成 AI 应用的部署和优化,这些应用在全球排行榜上名列前茅。他对构建和优化智能系统的机器学习模型感兴趣,并相信持续改进。
更多相关话题
全栈一切?数据科学、开发与技术之间的组织交集
每家公司都有自己管理业务技术的术语和组织结构。这些术语可能已经演变了几十年,或者是由领导者强加以塑造部门品牌。组织结构可能符合行业规范,或可能是公司特殊需求所独有的。但所有组织的共同点是需要用共同的语言来谈论每个部门或团队的职责,并且一致努力弥合团队之间的差距。
下图展示了大型组织中技术职能的典型分解:
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织在 IT 领域
外层职能和内层职能同样重要,但外层主要扮演支持角色,而内层职能则创建核心技术成果。每个职能都致力于招聘和培训该职能核心技能的专业人才。 而且,组与组之间的界限经常因领土争夺而有意扩大,或因忽视关系建设而意外扩大。这些交集中会出现摩擦、延误和低效。
下图展示了成为创造业务价值的重要机会的共享交集。
该图并非全面,但展示了团队如何在关键业务需求上进行合作的示例。 没有合作,这些交集区域将不会如此有效或创新。
例如,在外层,项目管理职能如果没有其他职能的密切参与,无法提供权威的能力规划或 IT 路线图。而安全团队需要紧密合作,以了解风险管理的成本和优先级,并制定有效的身份管理方案。然而,各部门通常试图单独完成这些任务。
在内层维恩图中,我们有信息系统、商业分析和软件开发三个关键职能。每个职能都需要高度专业化的技能,找到一个“全数据堆栈”分析师/数据工程师/开发人员是非常稀有的。团队之间需要积极合作,以部署模型、工程数据管道和创建分析数据存储。
提高交叉点协作的重要措施:
-
在团队之间创建共同的语言和对部门角色及责任的认识
-
投资于跨团队活动和网络机会
-
鼓励员工在其他技术职能部门进行“轮岗”
-
用跨职能团队来配备项目,资源来自多个部门
-
定期举行部门间的知识共享和项目概况会议
鼓励技术职能交汇处的合作所需的时间和精力会随着时间的推移带来回报。第一步是使用这些图示作为沟通工具,开始讨论这些边界在哪里以及如何弥合这些边界。
斯坦·帕格斯利是总部位于犹他州盐湖城的自由数据工程和分析顾问。他还是犹他大学埃克尔斯商学院的讲师。您可以通过电子邮件联系作者。
相关话题
数据科学的基本方法:分类、回归和相似性匹配
由 Manu Jeevan 编写,2015 年 1 月。
在这篇文章中,我将讨论数据科学中的 3 种基本方法。这些方法是从数据中提取有用知识的基础,并且也为数据科学中许多著名算法奠定了基础。我不会深入探讨这些方法的数学细节;相反,我将重点介绍这些方法如何用于解决以数据为中心的业务问题。
那么,让我们开始吧,
 1. 分类与类别概率估计
1. 分类与类别概率估计
分类和类别概率估计尝试预测在一个总体中,每个个体属于哪个类别。通常这些类别彼此独立。一个分类问题的例子是:
“在所有的 Dish 客户中,哪些客户可能会对新优惠做出响应?”
在这个例子中,这两个类别可以称为“会响应”和“不会响应”。你在分类任务中的目标是给定一个新个体,确定该个体属于哪个类别。一个紧密相关的概念是评分或类别概率估计。
当应用于个人时,评分模型会产生一个分数,代表该个人属于每个类别的概率。在我们的客户响应示例中,评分模型可以评估每个客户,并产生每个客户对优惠响应的可能性分数。
2. 回归
回归是预测中最常用的方法。回归尝试预测某变量的实际值(数值)。一个回归问题的例子是:“给定一栋房子的费用是多少?”这里需要预测的变量是房价,模型可以通过查看其他类似房屋及其历史价格来建立。回归过程产生一个模型,该模型根据房屋估算房价。
回归与分类相关,但二者有所不同。简单来说,分类预测某件事是否会发生,而回归预测某件事会发生的程度。
牢记这一概念:“评分是一个分类问题,而非回归问题,因为底层目标(你试图预测的值)是分类的。”
 3. 相似性匹配
3. 相似性匹配
相似性匹配尝试根据已知的信息识别相似的个体。如果两个实体(产品、服务、公司)在某些方面相似,它们也会共享其他特征。
例如,Accenture 将会关注寻找与其现有的盈利客户相似的客户,以便开展有针对性的营销活动。Accenture 使用基于定义其现有盈利客户特征(如公司营业额、行业、地点等)的相似性匹配。
相似性是进行产品推荐的基础原则(即识别在购买或喜欢的产品方面相似的人)。像亚马逊和 Flipkart 这样的在线零售商使用相似性来向你推荐类似的产品。每当你看到“喜欢 A 的人也喜欢 B”或“与你的浏览历史相符的人也浏览过……”这样的表达时,实际上是在应用相似性概念。
结论
在这篇文章中,我讨论了分类、回归和相似性匹配。我坚信将这些基本方法应用于商业问题比它们的算法细节要重要得多。需要记住的重要事项包括:
-
评分是一种分类技术,而不是回归技术。
-
分类和回归之间的区别。
-
如何使用相似性匹配来寻找类似的客户。
Manu Jeevan 是一位自学成才的数据科学家和 BigDataExaminer 博主,他在该网站上撰写有关数据科学、统计学、Python 和机器学习的文章,以帮助他人学习数据科学。
相关:
-
书籍:数据分类:算法与应用
-
业务领导者的数据分析解读
-
参加 KDD Cup 或 Kaggle 竞赛,你不需要成为专家!
更多相关话题
你应该知道的 PyTorch 最重要的基础知识
评论

PyTorch 基础知识 – 介绍
自从 2017 年初由 Facebook AI 研究(FAIR)团队推出以来,PyTorch 已成为一个非常流行且广泛使用的深度学习(DL)框架。从 humble 开始,它吸引了全球各地的严肃 AI 研究人员和从业者,无论是工业界还是学术界,并且在这些年中显著成熟。
众多深度学习爱好者和专业人士从 Google TensorFlow(TF)开始了他们的旅程,但基础 TensorFlow 的学习曲线一直很陡峭。另一方面,PyTorch 自开始以来便以直观的方式进行深度学习编程,专注于基本的线性代数和数据流操作,易于理解,适合逐步学习。
由于这种模块化的方法,使用 PyTorch 构建和实验复杂的深度学习架构比遵循 TF 及其相关工具的相对僵化的框架要容易得多。此外,PyTorch 是为了与 Python 生态系统的数值计算基础设施无缝集成而构建的,而 Python 作为数据科学和机器学习的通用语言,它也顺应了这一日益增长的普及浪潮。
PyTorch 的张量操作
张量 是任何深度学习框架的核心。PyTorch 为程序员提供了巨大的灵活性,关于如何创建、组合和处理张量,它们在网络(称为计算图)中流动,同时配有相对高级的面向对象 API。
什么是张量?
在机器学习(ML),特别是在深度神经网络(DNN)中,表示数据(例如关于物理世界或某些业务过程的数据)是通过一种称为 张量 的数据/数学结构完成的。张量是一个可以容纳N维数据的容器。张量通常与另一个更为熟悉的数学对象 矩阵(具体是 2 维张量)交替使用。实际上,张量是对 2 维矩阵在 N 维空间的推广。
简单来说,可以将标量-向量-矩阵-张量视为一个流。
-
标量是 0 维张量。
-
向量是 1 维张量。
-
矩阵是 2 维张量
-
张量是广义的 N 维 张量。N 可以是 3 到无限大…
这些维度通常也被称为 秩。

图 1:各种维度(秩)的张量 (图片来源).
张量对 ML 和 DL 重要的原因是什么?
设想一个监督学习问题。你获得了一张包含一些标签的数据表(可能是数值实体或二元分类,如是/否回答)。为了让 ML 算法处理这些数据,数据必须以数学对象的形式输入。表自然等同于二维矩阵,其中每一行(或实例)或每一列(或特征)可以视作一维向量。
类似地,黑白图像可以视作一个包含数字 0 或 1 的二维矩阵。这可以输入到神经网络中进行图像分类或分割任务。
时间序列或序列数据(例如,来自监测机器的 ECG 数据或股票市场价格跟踪数据流)是二维数据的另一个例子,其中一个维度(时间)是固定的。
这些是使用二维张量的经典机器学习(例如线性回归、支持向量机、决策树等)和深度学习算法的示例。
超越二维,彩色或灰度图像可以视作三维张量,其中每个像素与所谓的‘颜色通道’相关联——一个由 3 个数字组成的向量,表示红绿蓝(RGB)光谱中的强度。这是一个三维张量的例子。
同样,视频可以看作是时间上的颜色图像(或帧)序列,可以视为四维张量。
简而言之,来自物理世界、传感器和仪器、商业和金融、科学或社会实验的各种数据,都可以通过多维张量轻松表示,以便让计算机中的 ML/DL 算法进行处理。
让我们看看 PyTorch 如何定义和处理张量。
在 PyTorch 中创建和转换张量
张量可以从 Python 列表定义如下,

实际元素可以按如下方式访问和索引,

可以轻松创建具有特定数据类型的张量(例如,浮点数),

大小和维度可以很容易地读取,

我们可以更改张量的视图。让我们从以下一维张量开始,

然后将视图更改为二维张量,

在 PyTorch 张量和 NumPy 数组之间来回转换是简单高效的。

从 Pandas 系列对象转换也很简单,

最后,可以完成转换回 Python 列表的操作,

PyTorch 张量的向量和矩阵数学
PyTorch 提供了一个易于理解的 API 和程序化工具箱,用于在数学上操作张量。我们在这里展示了 1 维和 2 维张量的基本操作。
简单的向量加法,

向量与标量的乘法,

线性组合,

元素逐位乘积,

点积,

将一个标量添加到张量的每个元素中,即广播,

从列表列表中创建 2-D 张量,

矩阵元素的切片和索引,

矩阵乘法,

矩阵转置,

矩阵的逆和行列式,

自动求导:自动微分
神经网络训练和预测涉及对各种函数(张量值)进行反复求导。Tensor 对象支持神奇的 Autograd 特性,即自动微分,这通过跟踪和存储张量在网络中流动时执行的所有操作来实现。你可以观看这个精彩的教程视频以获得可视化的解释:
PyTorch 的自动求导 官方文档在这里。
我们展示简单的示例来说明 PyTorch 的自动求导特性。

我们定义一个通用函数和一个张量变量 x,然后定义另一个变量 y,将其赋值为 x 的函数。

然后,我们在 y 上使用特殊的 backward() 方法来进行求导,并计算在给定 x 值下的导数值。

我们还可以处理偏导数!

我们可以将 u 和 v 定义为张量变量,定义一个结合它们的函数,应用 backward() 方法,并计算偏导数。见下图,

PyTorch 仅计算标量函数的导数,但如果我们传递一个向量,它实际上会逐元素计算导数并将其存储在相同维度的数组中。

以下代码将计算相对于三个组成向量的导数。

我们可以展示导数的图像。注意,二次函数的导数是一条直线,与抛物线曲线相切。

构建一个功能齐全的神经网络
除了张量和自动微分功能外,PyTorch 还有一些核心组件/特性,这些组件/特性共同作用于深度神经网络的定义。
构建神经分类器所需的 PyTorch 核心组件包括,
-
张量(PyTorch 中的核心数据结构)
-
张量的自动求导特性(自动微分公式内置于
-
nn.Module 类用于构建任何其他神经分类器类
-
优化器(当然,你可以选择很多)
-
损失函数(有很多选择供你挑选)
我们已经详细描述了张量和自动求导。接下来,我们快速讨论其他组件,
nn.Module 类
在 PyTorch 中,我们通过将神经网络定义为自定义类来构建神经网络。然而,这个类不是从原生 Python 的 object 继承,而是继承自 nn.Module 类。这使得神经网络类具有有用的属性和强大的方法。这样,在处理神经网络模型时可以保持面向对象编程(OOP)的全部力量。我们将在文章中看到这样的类定义的完整示例。
损失函数
在神经网络架构和操作中,损失函数定义了神经网络的最终预测与真实值(给定标签/类别或用于监督训练的数据)之间的距离。损失的定量度量有助于驱动网络更接近于最佳配置(神经元权重的最佳设置),以最佳方式分类给定数据集或以最小的总误差预测数值输出。
PyTorch 提供了所有常见的分类和回归任务的损失函数 —
-
二元和多类交叉熵,
-
均方误差和均绝对误差,
-
平滑 L1 损失,
-
负对数似然损失,甚至
-
Kullback-Leibler 散度。
优化器
优化权重以实现最低损失是训练神经网络的反向传播算法的核心。PyTorch 提供了大量的优化器来完成这个任务,通过 torch.optim 模块进行暴露 —
-
随机梯度下降(SGD),
-
Adam、Adadelta、Adagrad、SparseAdam,
-
L-BFGS,
-
RMSprop 等。
查看这篇文章 以了解更多关于在现代深度神经网络中使用的激活函数和优化器的信息。
五步过程
利用这些组件,我们将通过五个简单步骤构建分类器,
-
将我们的神经网络构建为自定义类(继承自nn.Module类),包含隐藏层张量和前向方法,用于通过各种层和激活函数传播输入张量
-
使用这个forward()方法将特征(来自数据集)张量传播通过网络 —— 假设我们得到一个输出张量作为结果
-
通过将输出与真实值进行比较并使用内置损失函数来计算损失
-
使用自动微分功能(Autograd)和反向传播方法传播损失的梯度
-
使用损失的梯度更新网络的权重 —— 这是通过执行所谓的优化器的一步 —— optimizer.step()来完成的。
就这样。这个五步过程构成了一个完整的训练周期。我们只需重复这个过程多次,以降低损失并获得高分类准确率。
思路如下,

实践示例
假设我们想构建并训练以下的 2 层神经网络。

我们从类定义开始,

我们可以定义一个属于这个类的变量并打印其摘要。

我们选择二元交叉熵损失,

让我们将输入数据集通过我们定义的神经网络模型,即进行一次前向传播并计算输出概率。由于权重已被初始化为随机值,我们会看到随机的输出概率(大多数接近 0.5)。这个网络尚未经过训练。


我们定义优化器,

接下来,我们展示如何使用一个优化器的步骤进行前向和反向传播。这段代码可以在任何 PyTorch 神经网络模型的核心中找到。我们按照另外一个五步过程进行,
-
将梯度重置为零(以防止梯度的累积)
-
将张量前向传播通过各层
-
计算损失张量
-
计算损失的梯度
-
通过将优化器更新一步(沿负梯度方向)来更新权重
上述五个步骤正是你在所有关于神经网络和深度学习的理论讨论(以及教科书)中观察到和阅读到的内容。而且,使用 PyTorch,你可以通过看似简单的代码一步步实现这个过程。
代码如下所示,

当我们在一个循环中运行相同类型的代码(多次周期)时,我们可以观察到熟悉的损失曲线下降,即神经网络逐渐被训练。

经过 200 轮训练后,我们可以再次直接查看概率分布,以查看神经网络输出的概率现在如何不同(试图与真实数据分布匹配)。

PyTorch 基础总结
PyTorch 是一个很棒的工具包,可以深入了解神经网络的核心,并根据你的应用进行定制,或尝试对网络的架构、优化和机制进行大胆的新想法。
你可以轻松构建复杂的互联网络,尝试新颖的激活函数,混合和匹配自定义损失函数等。计算图的核心思想、简便的自动微分以及张量的前向和后向流动将对你的任何神经网络定义和优化大有帮助。
在本文中,我们总结了一些关键步骤,这些步骤可以快速构建用于分类或回归任务的神经网络。我们还展示了如何使用这个框架轻松尝试新颖的想法。
本文的所有代码 可以在这个 GitHub 仓库找到。
原文。已获得许可转载。
相关:
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关主题
数据科学和分析师的统计学基础
原文:
www.kdnuggets.com/2023/08/fundamentals-statistics-data-scientists-analysts.html

图片来源 编辑
正如英国数学家卡尔·皮尔逊曾经指出的,统计学是科学的语法,这一点在计算机与信息科学、物理科学和生物科学中尤为重要。当你开始你的数据科学或数据分析之旅时,拥有统计知识将帮助你更好地利用数据洞察。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业领域。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
“统计学是科学的语法。” 卡尔·皮尔逊
统计学在数据科学和数据分析中的重要性不可低估。统计学提供了寻找结构和深入数据洞察的工具和方法。统计学和数学都喜爱事实而厌恶猜测。了解这两个重要学科的基础知识将让你在解决商业问题和做出数据驱动的决策时更加批判性和创造性。在本文中,我将涵盖数据科学和数据分析的以下统计学主题:
**- Random variables
- Probability distribution functions (PDFs)
- Mean, Variance, Standard Deviation
- Covariance and Correlation
- Bayes Theorem
- Linear Regression and Ordinary Least Squares (OLS)
- Gauss-Markov Theorem
- Parameter properties (Bias, Consistency, Efficiency)
- Confidence intervals
- Hypothesis testing
- Statistical significance
- Type I & Type II Errors
- Statistical tests (Student's t-test, F-test)
- p-value and its limitations
- Inferential Statistics
- Central Limit Theorem & Law of Large Numbers
- Dimensionality reduction techniques (PCA, FA)**
如果你没有任何统计学知识,并且希望从零开始识别和学习基本的统计概念,以准备你的求职面试,那么这篇文章适合你。这篇文章也适合任何希望刷新统计学知识的人。
在开始之前,欢迎来到 LunarTech!
欢迎来到LunarTech.ai,在这里我们理解在数据科学和人工智能领域中求职策略的力量。我们深入探讨了在竞争激烈的求职过程中所需的战术和策略。不论是定义职业目标、定制申请材料,还是利用求职网站和建立网络,我们的见解为你提供了获得梦想工作的指导。
正在为数据科学面试做准备吗?不用担心!我们将揭秘面试过程的复杂性,为你提供必要的知识和准备,以增加成功的机会。从初步的电话筛选到技术评估、技术面试和行为面试,我们都将一一讲解。
在LunarTech.ai上,我们不仅仅停留在理论层面。我们是你在技术和数据科学领域取得卓越成功的跳板。我们的全面学习旅程量身定制,能够无缝融入你的生活方式,让你在个人和职业承诺之间取得完美平衡,同时掌握前沿技能。我们致力于你的职业发展,包括职位推荐、专家简历制作和面试准备,你将成为一个行业准备就绪的精英。
今天就加入我们有抱负的社区,开始一起踏上这段激动人心的数据科学旅程。与LunarTech.ai一起,未来一片光明,你掌握着开启无限机会的钥匙。
随机变量
随机变量的概念是许多统计学概念的基石。虽然它的正式数学定义可能难以理解,但简而言之,随机变量是将随机过程的结果(如抛硬币或掷骰子)映射到数字的一种方式。例如,我们可以通过随机变量 X 来定义抛硬币的随机过程,如果结果是正面,则 X 取值为 1;如果结果是反面,则 X 取值为 0。

在这个例子中,我们有一个抛硬币的随机过程,这个实验可以产生两个 可能的结果:{0,1}。所有可能结果的集合称为实验的样本空间。每次重复随机过程时,称为事件。在这个例子中,抛硬币得到反面是一个事件。这个事件发生的概率称为该事件的概率。事件的概率是随机变量取特定值 x 的可能性,可以用 P(x)描述。在抛硬币的例子中,得到正面或反面的可能性相同,即 0.5 或 50%。因此我们有如下设置:

在这个例子中,事件的概率只能取值于[0,1]范围内。
统计学在数据科学和数据分析中的重要性不容低估。统计学提供了寻找结构和深入数据洞察的工具和方法。
均值、方差、标准差
为了理解均值、方差及许多其他统计主题的概念,了解总体和样本的概念非常重要。总体是所有观察值(个体、对象、事件或过程)的集合,通常非常大且多样,而样本是从总体中抽取的一个子集,理想情况下它真实地代表了总体。

图片来源:作者
由于对整个总体进行实验要么不可能,要么成本过高,研究人员或分析师在实验或试验中使用样本而不是整个总体。为了确保实验结果可靠且适用于整个总体,样本需要真实地代表总体。也就是说,样本需要没有偏倚。为此,可以使用统计抽样技术,如随机抽样、系统抽样、聚类抽样、加权抽样和分层抽样。
均值
均值,也称为平均值,是一个有限数集的中心值。假设数据中的随机变量 X 具有以下值:

其中 N 是样本集中的观察值或数据点的数量,也即数据频率。然后,样本均值由?定义,通常用于近似总体均值,可以表示如下:

均值也被称为期望,通常由E()或带顶线的随机变量定义。例如,随机变量 X 和 Y 的期望,即E(X)和E(Y),可以表示如下:

import numpy as np
import math
x = np.array([1,3,5,6])
mean_x = np.mean(x)
# in case the data contains Nan values
x_nan = np.array([1,3,5,6, math.nan])
mean_x_nan = np.nanmean(x_nan)
方差
方差度量数据点与平均值的分散程度,等于数据值与平均值(均值)之间差异的平方和。此外,总体方差可以表示如下:

x = np.array([1,3,5,6])
variance_x = np.var(x)
# here you need to specify the degrees of freedom (df) max number of logically independent data points that have freedom to vary
x_nan = np.array([1,3,5,6, math.nan])
mean_x_nan = np.nanvar(x_nan, ddof = 1)
要推导不同常见概率分布函数的期望和方差,请查看这个 Github 仓库。
标准差
标准差仅是方差的平方根,衡量数据偏离其均值的程度。由sigma定义的标准差可以表示如下:

标准差通常优于方差,因为它与数据点具有相同的单位,这意味着你可以更容易地解释它。
x = np.array([1,3,5,6])
variance_x = np.std(x)
x_nan = np.array([1,3,5,6, math.nan])
mean_x_nan = np.nanstd(x_nan, ddof = 1)
协方差
协方差是衡量两个随机变量联合变异性的指标,描述这两个变量之间的关系。它被定义为两个随机变量偏离其均值的乘积的期望值。两个随机变量 X 和 Z 之间的协方差可以通过以下表达式描述,其中E(X)和E(Z)分别表示 X 和 Z 的均值。

协方差可以取负值、正值或 0。协方差的正值表示两个随机变量倾向于朝相同方向变化,而负值则表明这些变量在相反方向变化。最后,值为 0 意味着它们不会一起变化。
x = np.array([1,3,5,6])
y = np.array([-2,-4,-5,-6])
#this will return the covariance matrix of x,y containing x_variance, y_variance on diagonal elements and covariance of x,y
cov_xy = np.cov(x,y)
相关性
相关性也是一种关系测量,它衡量两个变量之间线性关系的强度和方向。如果检测到相关性,则意味着两个目标变量的值之间存在关系或模式。两个随机变量 X 和 Z 之间的相关性等于这两个变量之间的协方差,除以这些变量的标准差乘积,可以通过以下表达式描述。

相关系数的值范围在-1 和 1 之间。请记住,变量与自身的相关性总是 1,即 Cor(X, X) = 1。在解释相关性时,还要记住不要将其与因果关系混淆,因为相关性并不意味着因果关系。即使两个变量之间存在相关性,也不能得出一个变量导致另一个变量变化的结论。这种关系可能是偶然的,或者可能有第三个因素导致这两个变量的变化。
x = np.array([1,3,5,6])
y = np.array([-2,-4,-5,-6])
corr = np.corrcoef(x,y)
概率分布函数
描述所有可能值、样本空间以及随机变量在给定范围内(介于最小值和最大值之间)可以取的相应概率的函数称为概率分布函数 (pdf)或概率密度。每个 pdf 需要满足以下两个标准:

第一个标准指出所有概率应在[0,1]范围内,第二个标准则指出所有可能概率的总和应等于 1。
概率函数通常分为两类:离散型和连续型。离散分布函数描述了具有可数样本空间的随机过程,例如投掷硬币的例子只有两种可能结果。连续分布函数描述了具有连续样本空间的随机过程。离散分布函数的例子包括Bernoulli、Binomial、Poisson、离散均匀。连续分布函数的例子包括正态、连续均匀、柯西。
二项分布
二项分布是n次独立实验中成功次数的离散概率分布,每次实验的结果是:成功(概率为p)或失败(概率为q = 1 ? p)。假设一个随机变量 X 遵循二项分布,则在 n 次独立试验中观察到k次成功的概率可以由以下概率密度函数表示:

二项分布在分析重复独立实验的结果时非常有用,特别是当关注于在特定错误率下达到某一特定阈值的概率时。
二项分布的均值与方差

下图展示了一个二项分布的例子,其中独立试验的次数为 8,每次试验的成功概率为 16%。

图片来源:作者
# Random Generation of 1000 independent Binomial samples
import numpy as np
n = 8
p = 0.16
N = 1000
X = np.random.binomial(n,p,N)
# Histogram of Binomial distribution
import matplotlib.pyplot as plt
counts, bins, ignored = plt.hist(X, 20, density = True, rwidth = 0.7, color = 'purple')
plt.title("Binomial distribution with p = 0.16 n = 8")
plt.xlabel("Number of successes")
plt.ylabel("Probability")
plt.show()
泊松分布
泊松分布是指定时间段内事件发生次数的离散概率分布,给定该时间段内事件的平均发生次数。假设一个随机变量 X 遵循泊松分布,则在指定时间段内观察到k次事件的概率可以由以下概率函数表示:

其中,e 是 欧拉数,? lambda 是到达率参数,是 X 的期望值。泊松分布函数因其在建模计数事件方面的使用而广受欢迎。
泊松分布均值与方差

例如,泊松分布可以用于建模在晚上 7 点到 10 点之间到达商店的顾客数量,或在晚上 11 点到 12 点之间到达急诊室的患者数量。下图展示了一个泊松分布的示例,我们计算网站访问者的数量,其中到达率 lambda 假设为每 7 分钟到达一次。

图片来源:作者
# Random Generation of 1000 independent Poisson samples
import numpy as np
lambda_ = 7
N = 1000
X = np.random.poisson(lambda_,N)
# Histogram of Poisson distribution
import matplotlib.pyplot as plt
counts, bins, ignored = plt.hist(X, 50, density = True, color = 'purple')
plt.title("Randomly generating from Poisson Distribution with lambda = 7")
plt.xlabel("Number of visitors")
plt.ylabel("Probability")
plt.show()
正态分布
正态概率分布是实值随机变量的连续概率分布。正态分布,也称为高斯分布,可以说是最常用的分布函数之一,广泛用于社会科学和自然科学的建模,例如,用于建模人们的身高或考试成绩。假设随机变量 X 遵循正态分布,则其概率密度函数可以表示如下。

其中,参数 ? (mu) 是分布的均值,也称为位置参数,参数 ? (sigma) 是分布的标准差,也称为 尺度参数。数字 ? (π) 是一个数学常数,约等于 3.14。
正态分布均值与方差

下图展示了一个均值为 0 (? = 0) 和标准差为 1 (? = 1) 的正态分布示例,这被称为** 标准正态 **分布,具有 对称性。

图片来源:作者
# Random Generation of 1000 independent Normal samples
import numpy as np
mu = 0
sigma = 1
N = 1000
X = np.random.normal(mu,sigma,N)
# Population distribution
from scipy.stats import norm
x_values = np.arange(-5,5,0.01)
y_values = norm.pdf(x_values)
#Sample histogram with Population distribution
import matplotlib.pyplot as plt
counts, bins, ignored = plt.hist(X, 30, density = True,color = 'purple',label = 'Sampling Distribution')
plt.plot(x_values,y_values, color = 'y',linewidth = 2.5,label = 'Population Distribution')
plt.title("Randomly generating 1000 obs from Normal distribution mu = 0 sigma = 1")
plt.ylabel("Probability")
plt.legend()
plt.show()
贝叶斯定理
贝叶斯定理,或称为贝叶斯法则,可以说是概率与统计中最强大的规则,得名于著名的英国统计学家和哲学家托马斯·贝叶斯。

图片来源:维基百科
贝叶斯定理是一个强大的概率法则,它将主观性的概念引入了统计学和数学这个以事实为基础的领域。它描述了一个事件的概率,基于可能与该事件相关的条件的先验信息。例如,如果已知感染冠状病毒或 Covid-19 的风险随着年龄的增长而增加,那么贝叶斯定理允许根据年龄来更准确地确定某一已知年龄个体的风险,而不是简单地假设该个体是整个群体中的一个普通成员。
条件概率在贝叶斯理论中扮演着核心角色,它是指在另一个事件已经发生的情况下,某事件发生的概率。贝叶斯定理可以用以下表达式来描述,其中 X 和 Y 分别代表事件 X 和 Y:

-
Pr (X|Y):事件 X 在事件或条件 Y 已发生或为真的情况下发生的概率
-
Pr (Y|X):事件 Y 在事件或条件 X 已发生或为真的情况下发生的概率
-
Pr (X) 和 Pr (Y):分别是观察到事件 X 和 Y 的概率
在前面的例子中,感染冠状病毒(事件 X)在某一特定年龄的条件下的概率是Pr (X|Y),它等于在感染冠状病毒的条件下处于某一特定年龄的概率Pr (Y|X),乘以感染冠状病毒的概率Pr (X),然后除以处于某一特定年龄的概率Pr (Y)。
线性回归
之前介绍了变量间的因果关系,即一个变量对另一个变量有直接影响。当两个变量之间的关系是线性时,线性回归是一种统计方法,可以帮助建模自变量独立变量对另一个变量因变量值的影响。
因变量通常被称为响应变量或解释变量,而自变量则通常被称为回归变量或解释性变量。当线性回归模型基于一个自变量时,该模型称为简单线性回归;当模型基于多个自变量时,它被称为多重线性回归。简单线性回归**可以用以下表达式来描述:

其中Y是因变量,X是数据中的自变量,?0是未知且恒定的截距,?1是未知且恒定的斜率系数或与变量 X 对应的参数。最后,u是模型在估计 Y 值时产生的误差项。线性回归的主要思想是找到通过一组配对(X, Y)数据的最佳拟合直线,回归线。线性回归应用的一个例子是建模鳍长对企鹅体重的影响,见下图。

图片来源:作者
# R code for the graph
install.packages("ggplot2")
install.packages("palmerpenguins")
library(palmerpenguins)
library(ggplot2)
View(data(penguins))
ggplot(data = penguins, aes(x = flipper_length_mm,y = body_mass_g))+
geom_smooth(method = "lm", se = FALSE, color = 'purple')+
geom_point()+
labs(x="Flipper Length (mm)",y="Body Mass (g)")
三个自变量的多重线性回归可以通过以下表达式描述:

普通最小二乘法
普通最小二乘法(OLS)是一种用于估计线性回归模型中未知参数(如?0 和?1)的方法。该模型基于最小二乘法的原则,该原则最小化观察到的因变量与其通过自变量的线性函数预测值之间的平方和,这些预测值通常称为拟合值。因变量 Y 的真实值和预测值之间的差异称为残差,OLS 的工作就是最小化残差的平方和。这个优化问题导致了对未知参数?0 和?1 的以下 OLS 估计,这些估计也被称为系数估计。

一旦这些简单线性回归模型的参数被估计,响应变量的拟合值可以通过以下方法计算:

标准误差
估计误差项或残差可以通过以下方法确定:

重要的是要记住误差项和残差之间的区别。误差项是无法观察到的,而残差是从数据中计算得出的。OLS 估计每个观察值的误差项,但并不估计实际的误差项。因此,真实的误差方差仍然未知。此外,这些估计受到抽样不确定性的影响。这意味着我们永远无法从样本数据中确定这些参数的确切估计值,即真实值。然而,我们可以通过以下方式计算样本残差方差来进行估计。

这个样本残差方差的估计值有助于估计参数估计的方差,通常表达如下:

该方差项的平方根称为标准误差,它是评估参数估计准确性的关键组成部分。它用于计算检验统计量和置信区间。标准误差可以表达为:

重要的是要记住误差项和残差之间的区别。误差项是无法观察的,而残差是从数据中计算出来的。
OLS 假设
OLS 估计方法做出了以下假设,满足这些假设才能获得可靠的预测结果:
A1: 线性假设声明模型在参数上是线性的。
A2: 随机 样本假设声明样本中的所有观察值都是随机选择的。
A3: 外生性假设声明自变量与误差项不相关。
A4: 同方差性假设声明所有误差项的方差是恒定的。
A5: 无完美多重共线性假设声明所有自变量都不是常数,并且自变量之间不存在精确的线性关系。
def runOLS(Y,X):
# OLS esyimation Y = Xb + e --> beta_hat = (X'X)^-1(X'Y)
beta_hat = np.dot(np.linalg.inv(np.dot(np.transpose(X), X)), np.dot(np.transpose(X), Y))
# OLS prediction
Y_hat = np.dot(X,beta_hat)
residuals = Y-Y_hat
RSS = np.sum(np.square(residuals))
sigma_squared_hat = RSS/(N-2)
TSS = np.sum(np.square(Y-np.repeat(Y.mean(),len(Y))))
MSE = sigma_squared_hat
RMSE = np.sqrt(MSE)
R_squared = (TSS-RSS)/TSS
# Standard error of estimates:square root of estimate's variance
var_beta_hat = np.linalg.inv(np.dot(np.transpose(X),X))*sigma_squared_hat
SE = []
t_stats = []
p_values = []
CI_s = []
for i in range(len(beta)):
#standard errors
SE_i = np.sqrt(var_beta_hat[i,i])
SE.append(np.round(SE_i,3))
#t-statistics
t_stat = np.round(beta_hat[i,0]/SE_i,3)
t_stats.append(t_stat)
#p-value of t-stat p[|t_stat| >= t-treshhold two sided]
p_value = t.sf(np.abs(t_stat),N-2) * 2
p_values.append(np.round(p_value,3))
#Confidence intervals = beta_hat -+ margin_of_error
t_critical = t.ppf(q =1-0.05/2, df = N-2)
margin_of_error = t_critical*SE_i
CI = [np.round(beta_hat[i,0]-margin_of_error,3), np.round(beta_hat[i,0]+margin_of_error,3)]
CI_s.append(CI)
return(beta_hat, SE, t_stats, p_values,CI_s,
MSE, RMSE, R_squared)
参数性质
在假设满足 OLS 标准 A1 — A5 的情况下,OLS 系数估计量 β0 和 β1 是最优线性无偏估计量和一致的。
高斯-马尔科夫定理
该定理突出了 OLS 估计的性质,其中术语最优线性无偏估计量表示最佳线性无偏估计量。
偏差
估计量的偏差是其期望值与被估计参数的真实值之间的差异,可以表示如下:

当我们说估计量是无偏的时,我们的意思是偏差等于零,这意味着估计量的期望值等于真实的参数值,即:

无偏性并不保证通过任何特定样本得到的估计值等于或接近?。它的意思是,如果从总体中重复抽取随机样本并每次计算估计值,那么这些估计值的平均值将等于或非常接近β。
效率
高斯-马尔可夫定理中的最佳一词与估计量的方差相关,并称为效率。*一个参数可以有多个估计量,但具有最低方差的那个被称为高效的。
一致性
一致性这一术语与样本大小和收敛这两个术语密切相关。如果估计量随着样本大小变得非常大而收敛于真实参数,那么该估计量被称为一致的,即:

在假设 OLS 标准 A1 — A5 得到满足的情况下,OLS 系数β0 和β1 的估计量是BLUE和一致的。
高斯-马尔可夫定理
所有这些性质都符合高斯-马尔可夫定理总结的 OLS 估计量。换句话说,OLS 估计量具有最小的方差,它们是无偏的,参数线性的,并且是一致的。这些性质可以通过使用之前做出的 OLS 假设来进行数学证明。
置信区间
置信区间是包含真实总体参数的范围,其具有一定的预设概率,称为实验的置信水平,并且是通过使用样本结果和误差范围获得的。
误差范围
误差范围是样本结果与如果使用整个总体时结果之间的差异。
置信水平
置信水平描述了实验结果的确定性水平。例如,95%的置信水平意味着如果将相同的实验重复进行 100 次,那么其中 95 次的试验将会得到类似的结果。请注意,置信水平在实验开始之前就已经定义,因为它会影响实验结束时误差范围的大小。
OLS 估计量的置信区间
如前所述,简单线性回归的 OLS 估计量,即截距?0 和斜率系数?1,是受采样不确定性的影响。然而,我们可以构建这些参数的置信区间,这些置信区间将在 95%的所有样本中包含这些参数的真实值。即,95%置信区间可以解释为:
-
置信区间是一组值,在这些值中,假设检验在 5%的水平上不能被拒绝。
-
置信区间有 95%的机会包含真实值?。
OLS 估计的 95%置信区间可以如下构建:

这个值基于参数估计、该估计的标准误差,以及代表 5%拒绝规则的误差边际值 1.96。这个值是通过使用正态分布表来确定的,这将在本文稍后讨论。与此同时,下图展示了 95% CI 的概念:

图片来源:维基百科
注意,置信区间还依赖于样本大小,因为它是通过基于样本大小的标准误差计算得出的。
置信水平在实验开始之前定义,因为它会影响实验结束时误差边际的大小。
统计假设检验
在统计学中,假设检验是一种测试实验或调查结果是否有意义的方法。基本上,是通过计算结果偶然出现的可能性来检验获得的结果是否有效。如果结果是偶然的,那么结果和实验都不可靠。假设检验是统计推断的一部分。
原假设与备择假设
首先,你需要确定要测试的论点,然后需要制定原假设和备择假设。**测试可以有两个可能的结果,基于统计结果你可以拒绝或接受所陈述的假设。作为经验法则,统计学家通常将需要拒绝的假设版本或表述放在原假设下,而接受和期望的版本放在备择假设下。*
统计显著性
让我们来看一下之前提到的例子,其中使用线性回归模型调查企鹅的鳍片长度(自变量)是否对体重(因变量)有影响。我们可以用以下统计表达式来制定这个模型:

然后,一旦 OLS 估计了系数,我们可以制定以下原假设和备择假设来测试鳍片长度对体重的** 统计学显著性 **影响:

其中 H0 和 H1 分别代表原假设和备择假设。拒绝原假设意味着鳍长的每单位增加对体重有直接影响。考虑到参数估计 ?1 描述了独立变量鳍长对因变量体重的影响。这一假设可以重新表述如下:

其中 H0 表示参数估计 ?1 等于 0,即鳍长对体重的影响是统计上不显著,而 H0 表示参数估计 ?1 不等于 0,暗示鳍长对体重的影响是统计上显著。
第一类错误和第二类错误
在进行统计假设检验时,需要考虑两种概念性错误:第一类错误和第二类错误。第一类错误发生在错误拒绝了原假设时,而第二类错误发生在错误未拒绝原假设时。一个混淆矩阵可以帮助清晰地可视化这两种错误的严重性。
作为经验法则,统计学家倾向于将假设的版本放在原假设下,这需要被拒绝,而可接受和期望的版本则陈述在备择假设下。
统计测试
一旦原假设和备择假设被陈述并且测试假设被定义,下一步是确定适当的统计测试并计算测试统计量。是否拒绝原假设可以通过将测试统计量与** 临界值 **进行比较来决定。这种比较显示了观察到的测试统计量是否比定义的临界值更极端,并且可能有两种结果:
-
测试统计量比临界值更极端时?可以拒绝原假设。
-
测试统计量不如临界值极端时?不能拒绝原假设。
临界值是基于预先指定的显著性水平 ?(通常选择为 5%)和检验统计量所遵循的概率分布类型。临界值将概率分布曲线下的区域分为拒绝区域和非拒绝区域。有许多统计检验用于检验各种假设。统计检验的示例包括学生 t 检验、F 检验、卡方检验、Durbin-Hausman-Wu 内生性检验、怀特异方差检验。在本文中,我们将介绍这两种统计检验。
当错误地拒绝了原假设时,发生的是 I 型错误,而当错误地未拒绝原假设时,发生的是 II 型错误。
学生 t 检验
最简单和最流行的统计检验之一是学生 t 检验。它可以用于检验各种假设,特别是在处理假设时,主要关注的是寻找单个变量的统计显著效应。*t 检验的统计量遵循学生 t 分布,可以按如下方式确定:

其中,分子中的 h0 是与之进行参数估计检验的值。因此,t 检验统计量等于参数估计值减去假设值,然后除以系数估计的标准误。在之前提到的假设中,我们想要检验鳍长是否对体重有统计显著影响。此检验可以使用 t 检验进行,在这种情况下,h0 等于 0,因为斜率系数估计值是与值 0 进行检验的。
t 检验有两个版本:双侧 t 检验和单侧 t 检验。你需要使用哪一种检验版本完全取决于你想要检验的假设。
双侧** 双尾 t 检验 **可以在假设检验相等与不相等关系时使用,类似于以下示例:

双侧 t 检验有** 两个拒绝区域**,如下图所示:

 
在这种 t 检验版本中,如果计算得到的 t 统计量太小或太大,则原假设被拒绝。

在这里,检验统计量与基于样本大小和选择的显著性水平的临界值进行比较。要确定确切的临界点值,可以使用双侧 t 分布表。
单侧或单尾 t 检验可以在假设检验正向/负向与负向/正向关系时使用,这类似于以下示例:

单侧 t 检验有一个单一的拒绝区域,根据假设的方向,拒绝区域要么在左侧,要么在右侧,如下图所示:

在这种 t 检验版本中,如果计算得到的 t 统计量小于/大于临界值,则原假设被拒绝。

F 检验
F 检验是另一种非常流行的统计检验,通常用于检验假设的a多个变量的联合统计显著性。 这种情况发生在你想检验多个自变量是否对因变量有统计学显著影响时。以下是一个可以通过 F 检验测试的统计假设示例:

在原假设中,这三个变量对应的系数在统计上是联合不显著的,而备择假设中这三个变量在统计上是联合显著的。F 检验的统计量遵循F 分布,可以如下确定:

其中,SSRrestricted 是限制模型的残差平方和,即从数据中排除被原假设认为不显著的目标变量的模型;SSRunrestricted 是非限制模型的残差平方和,即包含所有变量的模型,q 表示在原假设下被联合测试为不显著的变量数量,N 是样本量,k 是非限制模型中的变量总数。SSR 值在运行 OLS 回归后与参数估计一起提供,F 统计量也是如此。以下是 MLR 模型输出的示例,其中标记了 SSR 和 F 统计量值。

图片来源: Stock and Whatson
F 检验有一个拒绝区域,如下图所示:

图片来源:密歇根大学
如果计算的 F 统计量大于临界值,则可以拒绝原假设,这表明自变量在统计上是联合显著的。拒绝规则可以表示为:

p 值
另一种快速判断是否拒绝或支持原假设的方法是使用p 值。p 值是原假设下条件发生的概率。换句话说,p 值是在原假设为真的情况下,观察到至少与检验统计量一样极端的结果的概率。p 值越小,证据越强,建议可以拒绝原假设。
p-值的解释取决于选择的显著性水平。通常,1%、5%或 10%的显著性水平用于解释 p 值。因此,除了使用 t 检验和 F 检验外,还可以使用这些检验统计量的 p 值来检验相同的假设。
下图展示了一个包含两个独立变量的 OLS 回归的示例输出。在此表中,t 检验的 p 值测试了class_size变量参数估计的统计显著性,F 检验的 p 值测试了class_size和el_pct变量参数估计的联合统计显著性,这些值被下划线标出。

图片来源:Stock and Whatson
对于class_size变量的 p 值是 0.011,当将此值与显著性水平 1%或 0.01、5%或 0.05、10%或 0.1 进行比较时,可以得出以下结论:
-
0.011 > 0.01?t 检验的零假设不能在 1%的显著性水平下被拒绝。
-
0.011 < 0.05?t 检验的零假设可以在 5%的显著性水平下被拒绝。
-
0.011 < 0.10?t 检验的零假设可以在 10%的显著性水平下被拒绝。
所以,这个 p 值表明class_size变量的系数在 5%和 10%的显著性水平下是统计上显著的。对应于 F 检验的 p 值是 0.0000,由于 0 小于所有三个截止值;0.01、0.05、0.10,我们可以得出结论,在这三种情况下都可以拒绝 F 检验的零假设。这表明class_size和el_pct变量的系数在 1%、5%和 10%显著性水平下共同具有统计学显著性。
p 值的局限性
尽管使用 p 值有许多好处,但它也有局限性。即 p 值取决于关联的强度和样本大小。如果效应的大小很小且统计上不显著,p 值可能仍然显示显著影响,因为样本量很大。相反,如果样本量很小,一个效应可能很大,但仍然未能满足 p<0.01、0.05 或 0.10 的标准。
推论统计
推论统计使用样本数据对样本数据来源的总体做出合理的判断。它用于调查样本中变量之间的关系,并对这些变量如何与更大总体相关做出预测。
大数法则 (LLN)和中心极限定理 (CLM)在推论统计中具有重要作用,因为它们表明当数据量足够大时,实验结果无论原始总体分布的形状如何都能保持稳定。收集的数据越多,统计推断就越准确,从而生成的参数估计也越准确。
大数法则 (LLN)
假设X1, X2, . . . , Xn都是具有相同底层分布的独立随机变量,也称为独立同分布或 i.i.d,其中所有的 X 具有相同的均值?和标准差?。随着样本数量的增加,所有 X 的平均值等于均值?的概率趋近于 1。大数法则可以总结如下:

中心极限定理(CLM)
假设X1, X2, . . . , Xn都是具有相同底层分布的独立随机变量,也称为独立同分布或 i.i.d,其中所有的 X 具有相同的均值?和标准差?。随着样本量的增加,X 的概率分布在分布上收敛于均值为?和方差为?平方的正态分布。中心极限定理可以总结如下:

换句话说,当你有一个均值为?和标准差为?的总体,并且从这个总体中进行足够大的有放回随机抽样时,样本均值的分布将近似呈正态分布。
降维技术
降维是将数据从一个高维空间转换到一个低维空间,以便在这个低维表示中尽可能保留原始数据的有意义特性。
随着大数据的流行,这些降维技术的需求也增加了,这些技术可以减少不必要的数据和特征。流行的降维技术包括主成分分析、因子分析、典型相关分析和随机森林。
主成分分析(PCA)
主成分分析(PCA)是一种降维技术,通常用于减少大数据集的维度,通过将大量变量转换为较少的变量集,同时仍保留原始大数据集中的大部分信息或变异。
假设我们有一个数据 X,包含 p 个变量;X1, X2, …., Xp,具有特征向量 e1, …, ep 和 特征值 ?1,…, ?p。特征值表示某一数据字段在总方差中所解释的方差。PCA 的核心思想是创建新的(独立的)变量,称为主成分,它们是现有变量的线性组合。第 i个主成分可以表示如下:

然后使用肘部规则或凯泽规则,你可以确定最佳总结数据的主成分数量,而不会丢失过多信息。同样,查看总方差比例(PRTV) **被每个主成分解释的比例也很重要,以决定是否有必要包含或排除它。第 i个主成分的 PRTV 可以通过以下特征值计算:

肘部规则
肘部规则或肘部方法是一种启发式方法,用于确定 PCA 结果中的最佳主成分数量。这种方法的核心思想是将解释的方差作为主成分数量的函数绘制,并选择曲线的肘部作为最佳主成分的数量。以下是一个这样的散点图示例,其中 PRTV(Y 轴)与主成分数量(X 轴)绘制。肘部对应于 X 轴值 2,这表明最佳主成分的数量为 2。

图片来源:多变量统计 Github
因子分析(FA)
因子分析(FA)是另一种降维的统计方法。它是最常用的相互依赖技术之一,当相关变量集表现出系统性的相互依赖且目标是找出创建共同性的潜在因子时使用。假设我们有一个数据 X,包含 p 个变量;X1, X2, …., Xp。FA 模型可以表示如下:

其中 X 是一个[p x N]的 p 变量和 N 观测值的矩阵,µ是[p x N]的总体均值矩阵,A 是[p x k]的共同因子负荷矩阵,F [k x N]是共同因子的矩阵,u [pxN]是特定因子的矩阵。换句话说,因子模型是一系列多重回归,通过不可观测的共同因子 fi 预测每一个变量 Xi:

每个变量都有自己的 k 个公共因子,这些因子通过因子载荷矩阵与单个观察值相关联:在因子分析中,因子 是为了 最大化 组间方差而计算的,同时 最小化组内方差。它们被称为因子,因为它们将潜在变量分组。与 PCA 不同,在 FA 中数据需要标准化,因为 FA 假设数据集遵循正态分布。
Tatev Karen Aslanyan 是一位经验丰富的全栈数据科学家,专注于机器学习和人工智能。她还是 LunarTech 的联合创始人,该平台提供在线技术教育,并且是终极数据科学训练营的创建者。Tatev Karen 拥有经济计量学和管理科学的本科及硕士学位,在机器学习和人工智能领域取得了显著成长,专注于推荐系统和自然语言处理,并且有科学研究和发表的论文作为支持。经过五年的教学,Tatev 现在将她的热情投入到 LunarTech,帮助塑造数据科学的未来。
原文。经许可转载。
相关主题
对大数据和数据科学的幽默观察
评论
在假期周,我们为你带来一个不那么严肃的“大数据和数据科学”视角,感谢快乐数据科学家安德烈在 @TheSmartJokes 和 comic.browserling.com
如果你不明白一些笑话的含义,那么你可能需要提升你的数据科学技能。
好数据与坏数据仪表盘:

一个 SQL 查询走进酒吧,看到两个表。
它走向他们,说:“我可以加入你们吗?”

有一个乐队叫做 1023MB … 他们还没有演出过。


祝所有曾经遇到过偏差一(或两)错误的人新年快乐!

我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作。
更多相关话题
人工智能的未来:探索下一代生成模型
原文:
www.kdnuggets.com/2023/05/future-ai-exploring-next-generation-generative-models.html

图片来源:作者
如果你关注科技界,你会知道生成型人工智能是当前最热门的话题。我们听说了很多关于 ChatGPT、DALL-E 等的消息。
生成型人工智能的最新突破将彻底改变我们继续进行内容创作的方式以及各领域 AI 工具的增长速度。Grand View Research 在其《人工智能市场规模、份额与趋势分析报告》中指出:
“2022 年全球人工智能市场规模为 1365.5 亿美元,预计从 2023 年到 2030 年将以 37.3%的复合年增长率扩展。”
越来越多来自不同领域或背景的组织正在寻求通过使用生成型人工智能来提升技能。
什么是生成型人工智能?
生成型人工智能是用于创建新的独特内容的算法,如文本、音频、代码、图像等。随着人工智能的发展,生成型人工智能有潜力接管各个行业,帮助它们完成曾经被认为不可能的任务。
生成型人工智能已经在创作能够模仿像梵高这样的艺术家的艺术作品。时尚行业可以利用生成型人工智能为其下一系列创作新设计。室内设计师可以利用生成型人工智能在几天内为某人建造梦想家园,而不是几周或几个月。
生成型人工智能相对较新,仍在不断完善中。然而,像 ChatGPT 这样的应用已树立了高标准,我们应该期待在未来几年中看到更多创新应用的发布。
生成型人工智能的角色
当前没有关于生成型人工智能(Generative AI)具体限制的说明,如前所述,它仍在不断发展中。然而,截至今天,我们可以将其分为 3 个部分:
- 生成新内容/信息:
这可以包括创建新的博客、视频教程或一些新奇的墙面艺术。然而,它也可以帮助开发新药。
- 替代重复任务:
生成型人工智能可以接管员工的繁琐和重复任务,如电子邮件、演示总结、编码和其他类型的操作。
- 定制数据:
生成型人工智能可以为特定的客户体验创建内容,这可以作为数据来确保成功、投资回报率、营销技巧和客户参与度。利用消费者的行为模式,公司将能够区分有效的策略和方法。
以下是最流行的生成型人工智能模型之一,扩散模型的一个示例。
扩散模型
扩散模型旨在通过将数据集映射到较低维的潜在空间来学习其潜在结构。潜在扩散模型是一种深度生成神经网络,由慕尼黑大学的 CompVis 小组和 Runway 开发。
扩散过程是指逐渐向压缩的潜在表示中添加或扩散噪声,并生成一个仅由噪声组成的图像。然而,扩散模型则朝着相反的方向进行,执行扩散的反向过程。噪声以受控的方式逐渐从图像中减少,使图像慢慢呈现出原始的样子。

作者提供的图像
生成型 AI 的应用案例
生成型 AI 已被许多不同行业的组织广泛采用。这使他们能够采用这些工具来优化当前的流程和方法,并更有效地提升它们。例如:
媒体
无论是创建新文章、为网站准备新图像,还是制作酷炫的视频,生成型 AI 已经在媒体行业掀起了风暴,使他们能够以更快的速度高效地生产内容并降低成本。个性化内容使组织能够将客户参与提升到一个新水平,提供更有效的客户保留策略。
财务
AI 工具,如用于 KYC 和 AML 过程的智能文档处理(IDP)。然而,生成型 AI 使金融机构能够进一步分析客户,通过发现消费模式和确定潜在问题来推进客户分析。
医疗保健
生成型 AI 可以帮助处理 X 光和 CT 扫描等图像,提供更准确的可视化,更好地定义图像,并更快地检测诊断。例如,利用通过 GANs(生成对抗网络)进行插图到照片转换的工具,使医疗专业人员能够更深入地了解患者当前的医疗状态。
生成型 AI 的治理挑战
任何伟大的事物都会伴随一些负面影响,对吧?生成型 AI 的兴起引发了政府如何控制生成型 AI 工具使用的新问题。
近年来,AI 领域一直开放给组织自由操作。然而,直到有人介入并制定关于 AI 的固定法规只是时间问题。许多人担心生成型 AI 模型的监督及其对社会经济的影响,以及知识产权和隐私侵犯等其他问题。
生成型 AI 在治理方面面临的主要挑战是:
-
数据隐私 - 生成型 AI 模型需要大量数据才能成功输出准确的结果。由于可能滥用敏感信息,数据隐私成为所有 AI 公司和工具面临的挑战。
-
所有权 - 关于生成性 AI 创建的任何内容或信息的知识产权仍然是一个开放的讨论话题。有些人可能会认为这些内容是独特的,而另一些人则认为生成的文本内容是从各种互联网来源中改写的。
-
质量 - 随着大量数据输入到生成性 AI 模型中,首要关注的问题是调查数据的质量,然后是生成输出的准确性。医学等领域尤为关键,因为处理虚假信息可能产生重大影响。
-
偏见 - 在我们考察数据质量时,还需要评估训练数据中可能存在的偏见。这可能导致歧视性输出,使得 AI 在许多人眼中不受欢迎。
总结
生成性 AI 在被大家积极接受之前还有很多工作要做。这些 AI 模型需要更好地理解来自不同文化背景的人类语言。对于我们来说,与人交流时的常识是自然而然的,但对 AI 系统来说却不常见。它们很难适应不同的情况,因为它们被编程为基于事实信息进行训练。
未来生成性 AI 将扮演什么角色是值得关注的。我们只能拭目以待。
Nisha Arya 是一位数据科学家、自由撰稿人及 KDnuggets 的社区经理。她特别关注于提供数据科学职业建议或教程以及基于理论的数据科学知识。她还希望探索人工智能如何有益于人类生命的延续。作为一个热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助引导他人。
相关主题更多内容
数据科学与分析职业的未来
原文:
www.kdnuggets.com/2019/11/future-careers-data-science-analysis.html
评论
作者:弗兰基·华莱士,博主。

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
你是否在寻找一个能改变整个行业面貌的职业?如果是,那么数据科学和分析领域提供了许多影响几乎所有类型商业的机会,从零售到医疗保健。
对新数据科学家和数据分析师的需求逐年增长,聪明才智的填补这些空缺至关重要。这些领域复杂而精细,但任何能掌握必要技能的个人都有很多职业选择。为了更好地理解这些可能性,让我们深入探讨这些职位的细微差别以及你未来可能工作的地方。
数据科学家 vs. 数据分析师
尽管在许多行业中数据分析师和科学家都有大量的新职业,但对这些备受追捧职位感兴趣的人首先必须决定他们最感兴趣的工作。最基本的,这两个职位之间的区别在于数据科学家理解数据的需求并进行挖掘,而分析师利用他们找到的数据来理解趋势。这两个职位都显示出巨大潜力,有些预测称对这些职位的需求到 2020 年将提升 28%。
对数据科学感兴趣的人需要对数学有深入的理解,包括统计学和概率论,这些知识对于解释数据至关重要。此外,还需要掌握编程语言,包括Python 和 C/C++,因为编程是挖掘和整理数据所必需的。
科学家的职责是理解数据如何帮助特定领域。一旦他们了解需要寻找哪些数据,就会创建模型和编程系统,以便挖掘这些数据。最后,他们必须知道如何分离和解释数据,以验证所发现的数据是否如他们所期望的那样有用。
另一方面,数据分析师在数据产生后介入,对科学家生成的数据进行分析。他们在各种行业中工作,解决问题或预测趋势,然后以易于理解的格式向管理层和利益相关者提供统计分析。数据分析师需要理解数字,具备批判性思维能力,透视细节得出合理结论,并在需要更多信息时,能够清晰地向数据科学家沟通需求。

每个企业都需要数据
消费者所做的每一件事都会生成数据。无论是看医生、购买杂货还是在线观看视频,这些数据对公司产品的创建和发展至关重要。虽然许多商业专业人士都知道这一点,但管理者或首席执行官可能不理解如何获取和呈现这些信息,这也是数据分析师和数据科学家职业如此受欢迎的原因。
任何拥有营销部门的公司都高度需求这两个职业。利用这些技能可以确定客户的购买行为及其未来的购买兴趣,从而制定更好的营销活动。在营销活动创建之后,数据可以衡量客户对营销的反应,以及他们是否购买了公司尝试销售的产品。一个例子是 Netflix,它经常发送电子邮件推荐特定的电影或电视节目。他们通过分析数据了解订阅者的兴趣,目的是将用户吸引回他们的平台。
每个企业都需要制定一个风险管理计划,以分类潜在的产品或客户损害,并制定解决问题的行动计划。数据分析师和科学家也帮助解决这一问题。例如,银行可以使用数据分析师评估提供高额贷款的风险,或者运输公司可以更好地了解潜在事故的风险,以及如何简化索赔流程,以便他们的车辆保持在路上,提高整体效率。
主要行业需要分析
世界上最大的行业需要数据专业人士的原因有很多,因此寻求这两个职业的人可以挑选心仪的职位。例如,医疗保健行业已采用数据分析来研究多个领域,包括医生表现、患者和医院成本,以及全球某些地区的健康风险。大数据甚至在解决阿片类药物危机和理解可能治愈癌症的趋势方面取得了进展。
能源部门也在寻找能够帮助寻找替代能源源、提高现有电力效率以及在问题区域找到避免停电新方法的优秀人才。制造业也利用数据来了解他们生产的产品的供需关系,从而节省公司开支,客户也能获得所需产品。数据还可以帮助预测机器可能出现故障的时间,从而进行预防性维护,确保工厂高效运转。
一旦数据变得可用,保护数据至关重要,这就是为什么数据专业人士鼓励企业保护这些宝贵信息。为了避免数据丢失,专家建议花时间保持所有备份系统的最新状态,并且一旦发现服务器受损,要立即避免使用。保护数据是至关重要的,因为丢失信息,特别是用户记录,可能导致客户和收入的损失。
数据分析的未来非常光明,任何有动力和决心学习复杂领域的人都能蓬勃发展。看看这些有前途的职业和行业,成为这场变革的一部分吧。
相关:
更多相关主题
为什么 ETL 的未来不是 ELT,而是 EL(T)
评论
由John Lafleur,Airbyte.io 联合创始人。

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
在过去十年中,我们存储和管理数据的方式发生了彻底变化。我们从 ETL 世界转变到 ELT 世界,Fivetran 等公司推动了这一趋势。然而,我们认为这还不会就此停止;ELT 在我们看来是向 EL(T)过渡(将 EL 与 T 解耦)。要理解这一点,我们需要探讨这种趋势的根本原因,因为它们可能揭示了未来的发展方向。
这正是我们将在本文中讨论的内容。我是Airbyte的联合创始人,这是一个即将到来的数据集成开源标准。
ETL 存在什么问题?
历史上,数据管道过程包括提取、转换和加载数据到仓库或数据湖中。这个顺序存在严重的缺陷。
不灵活性
ETL 固有地很僵化。它迫使数据分析师事先了解他们将如何使用数据、将生成哪些报告。任何更改都可能代价高昂,并且可能会影响初始提取下游的数据消费者。
缺乏可见性
对数据进行的每一次转换都会掩盖一些底层信息。分析师不会看到仓库中的所有数据,只会看到在转换阶段保留下来的数据。这是有风险的,因为结论可能基于未正确切分的数据。
分析师缺乏自主性
最后但同样重要的是,建立一个基于 ETL 的数据管道通常超出了分析师的技术能力。这通常需要工程人才的密切参与,以及额外的代码来提取和转换每个数据源。
复杂的工程项目的替代方案是进行临时分析和报告,这种方法费时且最终不可持续。
什么改变了,为什么 ELT 更好
基于云的计算和数据存储
由于本地计算和存储的高成本,ETL 方法曾经是必要的。随着基于云的数据仓库(如 Snowflake)的快速增长和云计算及存储成本的急剧下降,继续在最终目的地加载之前进行转换的理由几乎不存在。实际上,交换这两个步骤使得分析师能够以更自主的方式做得更好。
ELT 支持分析师的敏捷决策
当分析师可以在转换数据之前加载数据时,他们不必事先确定确切需要生成的见解,从而决定所需的确切架构。
相反,底层源数据被直接复制到数据仓库中,形成一个“单一真实来源”。分析师可以根据需要对数据进行转换。分析师始终可以回到原始数据,并且不会因为可能损害数据完整性的转换而受到影响,从而拥有更大的自由度。这使得商业智能过程变得无与伦比地更灵活和安全。
ELT 促进了公司整体的数据素养
当与基于云的商业智能工具(如 Looker、Mode 和 Tableau)结合使用时,ELT 方法还扩展了跨组织的分析访问。即使是相对非技术用户也可以访问商业智能仪表板。
我们在 Airbyte 也是 ELT 的忠实粉丝。但 ELT并未完全解决数据集成问题并且有其自身的问题。我们认为 EL 需要与 T 完全解耦。
目前正在发生什么变化,以及为什么 EL(T)是未来趋势
数据湖和数据仓库的合并
Andreessen Horowitz 关于数据基础设施如何演变的分析非常出色。以下是他们在与行业领导者进行大量访谈后提出的现代数据基础设施架构图。

数据基础设施在高层次上有两个主要目的:
-
通过使用数据来帮助商业领导者做出更好的决策 - 分析用例
-
将数据智能构建到面向客户的应用程序中,包括通过机器学习 - 操作用例
围绕这些广泛用例形成了两个平行的生态系统。
数据仓库构成了分析生态系统的基础。大多数仓库以结构化格式存储数据。它们旨在从核心业务指标中生成见解,通常使用 SQL(尽管 Python 的受欢迎程度在增长)。
数据湖是操作生态系统的骨干。通过以原始形式存储数据,它提供了应用程序和更高级数据处理需求所需的灵活性、规模和性能。数据湖支持包括 Java/Scala、Python、R 和 SQL 在内的广泛语言。
令人真正感兴趣的是,现代数据仓库和数据湖开始彼此相似——两者都提供商品存储、原生水平扩展、半结构化数据类型、ACID 事务、交互式 SQL 查询等等。
所以你可能在想数据仓库和数据湖是否在趋向融合。它们会在堆栈中变得可互换吗?数据仓库也会用于操作用例吗?
EL(T) 支持两种用例:分析和操作 ML
与 ELT 相比,EL 完全将提取-加载部分与可能发生的任何可选转换解耦。
操作用例在利用传入数据的方式上都是独特的。有些可能使用独特的转换过程;有些可能根本不使用任何转换。
关于分析用例,分析师最终需要将传入的数据标准化以满足他们自己的需求。但将 EL 从 T 中解耦将允许他们选择任何他们想要的标准化工具。DBT 最近在数据工程和数据科学团队中获得了很多关注。它已成为转换的开源标准。即使是 Fivetran 也与他们集成,以便团队可以使用他们习惯的 DBT。
EL 比较快,并利用整个生态系统
转换是所有边缘情况所在的地方。对于公司内的每个特定需求,每个工具都有其独特的模式标准化。
将 EL 从 T 中解耦,使得行业可以开始覆盖连接器的长尾。在 Airbyte,我们正在建立一个 “连接器制造厂”,以便在几个月内实现 1,000 个预构建的连接器。
此外,如上所述,它将帮助团队以更轻松的方式利用整个生态系统。你开始看到每个需求的开源标准。从某种意义上说,未来的数据架构可能会是这样的:

最终,提取和加载将与转换解耦。你同意我们的观点吗?
原文。转载经许可。
简介: 约翰·拉弗勒 是 Airbyte 的联合创始人,该公司是数据集成的新开源标准。我还是 SDTimes、Linux.com、TheNewStack、Dzone 的作者……也是一个快乐的丈夫和父亲 😃
相关:
更多相关内容
机器学习的未来
评论
由 Benedict Neo,数据科学爱好者和博主。

我们的三大课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业轨道。
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你所在组织的 IT 需求
照片由 Arseny Togulev 提供,来自 Unsplash。
机器学习是人工智能时代的一个热门话题。计算机视觉和 自然语言处理 (NLP)领域正取得无法预料的突破。我们在生活中越来越多地看到它们,如智能手机中的面部识别、语言翻译软件、自驾车等。看似科幻的技术正变为现实,我们距离获得 通用人工智能 只有时间的问题。
在这篇文章中,我将深入探讨 Jeff Dean 的 主题演讲,内容涉及计算机视觉和语言模型的进展,以及机器学习如何从模型构建的角度走向未来。
计算机视觉

照片由 Alex Knight 提供,来自 Unsplash。
今天,机器学习领域,特别是计算机视觉领域,正经历指数级增长。目前,人类在计算机视觉中的错误率仅为 3%。这意味着计算机在识别和分析图像方面已经比人类更优秀。这真是一个了不起的成就!几十年前,计算机还只是一个房间大小的庞然大物;今天,它们能够以我们从未想过的方式感知周围的世界。
从 2011 年的 26%误差到 2016 年的 3%误差,我们取得了巨大的进展。我喜欢这样想,计算机现在拥有了能够工作的“眼睛”。 — Jeff Dean
现在,这项成就——得益于机器学习的进步——不仅仅是计算机迷和 AI 专家的庆祝,它还有实际应用,能挽救生命,让世界变得更美好。在我详细讲解计算机视觉的一个救生应用之前,让我先展示一下计算机视觉的力量。
假设我给你 1 万张狗的照片,并要求你将它们分类到相应的物种中,你能做到吗?你可以做到,但你必须是狗的专家,而且需要几天时间才能完成。但对于一台电脑(配有 GPU)来说,这只需几分钟。这种计算机视觉的惊人能力开启了大量的应用。
计算机视觉的应用
Jeff Dean 提供的一个计算机视觉的典型应用是糖尿病视网膜病——这是一种影响眼睛的糖尿病并发症。现在要诊断它,需要进行广泛的眼科检查。在医生稀缺的第三世界国家和农村地区,使用计算机视觉进行诊断的机器学习模型将极具帮助。与所有医学影像领域一样,这种计算机视觉也可以作为领域专家的第二意见,确保他们诊断的可信度。一般来说,计算机视觉在医学领域的目的是复制专家的专业知识,并在最需要的地方部署。
NLP 和 Transformers

语言模型 是帮助机器理解文本并执行各种操作的算法,例如翻译文本。根据 Jeff Dean 的说法,语言模型已经取得了很大进展。
今天,计算机能够以比以前更深层次的方式理解一段文字。尽管它们还达不到像我们人类那样阅读整本书并理解的水平,但理解几段文字的能力对于改进 Google 搜索系统等事物是至关重要的。
BERT 模型是 Google 发布的最新自然语言处理(NLP)模型,已被应用于他们的搜索排名算法中。这有助于提升对以前非常困难的各种查询的搜索结果。换句话说,搜索系统现在可以更好地理解用户的不同搜索,并提供更好、更准确的答案。
“深度学习和机器学习架构在接下来的几年里将发生很大变化。你已经可以看到这一点,现在在自然语言处理领域,基本上只有 Transformer 网络是主流。” — Yann LeCun
这些基于 Transformer 的模型在BLEU 分数上表现出色,BLEU 分数是衡量翻译质量的指标。因此,利用 Transformer 的机器学习架构,如 BERT,正在变得越来越流行和强大。
目前机器学习面临的问题

在主旨演讲中,Google 高级研究员提到了机器学习开发者今天用来执行各种单元任务的原子模型。他认为这些模型效率低下,计算开销大,而且需要更多的努力才能在这些任务中取得良好的结果。
具体来说,在当前的机器学习领域,专家们发现他们想解决的问题后,会专注于寻找合适的数据集来训练模型并执行特定任务。Dean 认为,这种做法基本上是从零开始——他们用随机浮点数初始化模型的参数,然后尝试从数据集中学习关于任务的所有内容。
为了详细说明这一点,他给出了一个很好的比较:
“这就像是当你想学习新东西时,你会忘记所有的教育背景,回到婴儿状态,现在你试图学习有关这个任务的一切。”
他将这种方法与人们每次想学习新东西时,变成婴儿并更换大脑的过程进行了比较。这种方法不仅计算开销大,而且需要更多的努力才能在这些任务中取得良好的结果。Jeff Dean 提出了一个解决方案。
机器学习的圣杯

照片由 Marius Masalar 提供,来源于 Unsplash。
Jeff 认为,机器学习的未来在于一个庞大的模型,一个能够做许多事情的多功能模型。这个超级模型将消除创建特定任务模型的需要,代之以用不同领域的专长训练一个大型模型。想象一下,一个计算机视觉模型不仅能诊断糖尿病视网膜病变,还能分类不同品种的狗,识别你的面孔,并同时用于自动驾驶汽车和无人机。
他还宣称,该模型通过稀疏激活所需的不同部分来操作。大部分时间模型将保持 99%的闲置状态,只在需要时调用相关的专业片段。
挑战
Dean 认为这个终极模型是机器学习的一个有前途的方向,工程挑战非常有趣。构建这样的模型将引发许多有趣的计算机系统和机器学习问题,例如可扩展性和模型结构。
提出的问题是:
模型将如何学习如何路由最合适的模型各部分?
要实现这样的突破,需要在机器学习研究和数学领域取得更多进展。
精华
计算机视觉和自然语言处理将继续在我们的生活中扮演重要角色。但这种进步也带来了负面影响,例如中国利用面部识别来实施对人民的评级系统(就像《黑镜》中的情节一样)以及虚假新闻的泛滥。我们必须在机器学习中取得进展,同时考虑算法偏见和伦理问题,提醒我们自己是上帝的创造物,而非创造者。
关于终极模型,有很多证据表明我们正一步步接近。例如,迁移学习——一种将模型重用于不同目的的方法,能够以更少的数据获得良好结果,多任务学习——一种在五个或六个相关事物的小规模操作的模型,通常能使事情运作良好。
因此,可以合理地说,通过扩展这些想法——迁移学习和多任务学习——并在其基础上进行开发,实现一个终极模型是切实可行的,这只是时间问题,而非如何实现。
感谢阅读我关于机器学习未来的摘录和对 Jeff Dean 主题演讲的概述。我希望你能一窥机器学习和人工智能的未来。
完整视频请观看 这里。
原始。已获许可重新发布。
相关:
更多相关内容
工作的未来:人工智能如何改变职位格局
原文:
www.kdnuggets.com/2023/04/future-work-ai-changing-job-landscape.html

图片由编辑提供
如果你仅仅考虑过去 5 年中,你与家人和朋友的对话如何发生了变化。有些人可能完全不谈论技术,但我们可以承认很难忽视它就在我们周围。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在的组织在 IT 方面
最近 ChatGPT 和 GoogleBard 的发布以其惊人的能力震撼了世界。你开始观察这些工具,并思考它们如何改善你的工作生活、公司的流程、个人生活等。
人工智能正在自动化曾经只能由人类完成的任务。自动化某些任务以简化人类生活的相关性将不断增加。有些人可能会称我们为懒惰,但有些人则认为这是更聪明的选择。
以下是人工智能如何改变职位格局的一些例子:
-
自动化: 自动化任务。这导致了大量的职位损失,但也为其他人创造了新的机会。
-
新的就业机会: 人工智能系统将要求人类员工与其合作,如数据科学家和机器学习工程师。
-
技能要求的转变: 随着人工智能应用的增加,现有和新员工需要更多地了解系统的运作方式、工程师、分析阶段等。
-
工作与生活平衡: 人工智能工具的兴起使更多人能够远程、兼职和/或自由职业,因为任务已被自动化。
人工智能自动化如何改变职位格局?
自动化目前是职位格局转变的最大原因。随着越来越多的任务由人工智能完成,而实际由人类完成的任务越来越少,你可以理解为什么公司会开始裁员。雇佣员工的成本包括工资、养老金、健康保险、产假/陪产假等。更多的公司将员工视为损失,自动化人工智能工具是他们最大的突破。
以下是一些已经实施自动化任务的领域:
客户服务
就在几周前,世界迎来了 ChatGPT 和 Google Bard。越来越多的行业正在采用人工智能驱动的聊天机器人来提供客户服务。随着大型语言模型的兴起,我们只能期待这些聊天机器人在处理客户查询、回答问题、解决问题,甚至进行销售方面变得越来越出色。
例如,聊天机器人也被用于金融行业,处理如新申请者的保险注册、了解你的客户(KYC)和反洗钱(AML)政策与流程等任务。自动化工具在这些敏感任务中的应用证明了人工智能的成功,并且这种趋势只会持续下去。
数据录入
数据录入任务曾经是手动完成的,这些任务非常繁琐和重复。由于任务的高度重复性和枯燥性,这一领域存在一些缺陷,工人更容易犯错误。
现在,人工智能能够自动化数据录入任务,通过从原始文件或文档中提取数据并将其输入数据库中来实现。
驾驶
我们都知道自动驾驶汽车。越来越多的汽车进入市场,如特斯拉、Waymo 和 Uber。这些汽车使用人工智能计算机视觉技术,安全地将乘客从 A 点送到 B 点,导航道路并避开障碍物。
金融
如我之前提到的,聊天机器人正在金融行业中用于自动化一些流程和任务,例如 KYC。人工智能也被用于帮助这些金融公司分析数据,以做出更好的当前和未来预测。
金融行业拥有大量的数据。历史数据越多,他们的分析结果就会越好。不幸的是,这将导致对与人工智能系统协作的需求发生变化,而不是人工智能系统为人类工作。
医疗
对于一个许多人对人工智能工具的整合感到震惊的行业,我们只能期待更多的变化。医疗行业的专业人士正在使用人工智能来诊断疾病,通过数据分析推荐治疗方案,甚至使用机器人进行手术。
人工智能如何创造新工作
随着人工智能的持续发展,大多数人的选择将是被解雇或与人工智能系统一起工作。这就是为什么你自然会看到数据专业人员的增加,更多的编程课程、训练营等。
你将自然会看到更多这些角色:
数据科学
数据科学是统计学、数据分析、机器学习和人工智能的结合。因此,数据科学家将负责整理、准备、清理和操作数据,以识别数据中的模式并进行高级数据分析。
机器学习工程师
机器学习 (ML) 工程师是精通研究、构建和设计自动化预测模型的软件的程序员。他们的角色是构建人工智能 (AI) 系统,这些系统消耗大量数据以生成和开发能够学习和进行未来预测的算法。
人工智能训练师
人工智能工具在学习所需知识后效果最佳。人工智能训练师将需要帮助教导人工智能系统如何执行任务。他们还将负责收集数据、标注数据,然后将数据输入到人工智能算法中,以便从标注数据中学习并确保生成准确的输出。
那么我们应该期待什么?
很难预见未来会发生什么,尤其是当人工智能参与其中时。不幸的是,我们将开始看到更多的人因人工智能而失去工作,同时也会出现与人工智能系统协作的工作岗位。
这将导致人们在学习新技能以确保工作安全方面产生变化。我们将开始看到更多人学习编程语言,理解人工智能及其在销售、市场营销等方面的应用。
随着疫情导致工作方式发生巨大变化,人工智能也对此产生了影响。未来将会有更多的人在家工作,同时利用人工智能系统的自动化功能在全球各地旅行。
有了这些信息,我认为无论当前职位如何,任何人都应该意识到人工智能将如何导致就业格局的变化,并了解如何准备以满足当前的技能需求。
Nisha Arya 是一名数据科学家、自由技术写作人以及 KDnuggets 的社区经理。她特别感兴趣于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何对人类寿命的延续产生益处。作为一名热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关主题
未来数据游戏:2023 年每位数据科学家需要的顶级技能
原文:
www.kdnuggets.com/futureproof-your-data-game-top-skills-every-data-scientist-needs-in-2023

编辑提供的图片
如果你还没听说,未来 3 年内,40%的员工预计将需要提升技能。这是为了跟上技术,特别是生成性 AI 的持续增长。
然而,IBM 报告指出,执行官估计,由于 AI 和自动化,40%的员工将需要重新技能培训。然而,它也指出,具备商业头脑的分析技能和一系列软技能将在未来 3 年内极具吸引力。
在这篇文章中,我将讨论 2023 年最受欢迎的技能,以及这些技能如何使你的未来职业受益。
那么让我们开始吧……
2023 年的数据科学技能
随着技术和生成性 AI 的崛起,很多事情正在发生变化。如果你在考虑开始或提升你的数据科学职业生涯,以下是 2023 年最受欢迎的技能。
编程语言
对于那些希望开始数据科学新职业的人,让我们从基础开始。
选择一种编程语言进行学习,并将其学得非常透彻。了解它的方方面面,所有的细节,尽你所能了解它。成为某一领域的高手总比成为多面手要好。
许多组织希望了解他们雇佣的员工能够带来多重好处。例如,这名员工在数据处理方面非常精通,但他们在为我们董事会会议创建数据可视化方面也非常出色。
如果你不确定选择哪种编程语言,可以阅读 2023 年数据科学需要学习的 8 种编程语言。
数据清理与处理
现在让我们深入了解作为数据科学家你将会被分配的任务。数据量巨大,随着大数据和其在生成性 AI 中的应用,组织将希望利用这些数据。数据清理和处理包括将原始数据转化为可以用于分析的格式。
尽管有人说数据科学家将多达 80%的时间花在数据清理上,但这并不总是正确的。尽管这是一项耗时的任务,但它并不会占据数据科学家全部的 80%时间。
尽管如此,在 2023 年,这仍然是数据科学家们所追求的技能。为什么?因为数据很少是干净整洁的。尤其是现在,组织正在筛选那些积满灰尘的旧数据,并试图找到利用这些数据的方法。拿出你的扫帚和簸箕吧,因为确实需要清理。
分析技能
正如我之前提到的,具有强大分析技能的员工将是未来三年高管们关注的重点。根据 IBM 报告,高管们优先关注的是提升员工在时间管理和沟通等各种软技能上的能力。之后是具有商业敏锐性的分析技能。
分析技能的领域包括:
-
统计分析
-
数据探索
-
特征选择与工程
-
机器学习
-
模型评估
-
数据可视化
以统计分析为例,它被称为数据科学的基石,允许你通过描述性统计探索数据,更好地理解数据并通过可视化进行表示。它们与数据清理和处理阶段的元素(如缺失值和处理异常)紧密配合。
分析技能是数据科学家工作的核心,因此同样的原则适用——了解细节、每一个角落,你将会在数据科学领域中脱颖而出。
机器学习与深度学习
由于我们生活在组织推动使用数据来提供见解和自动化任务的时代,掌握机器学习和深度学习的要素将至关重要。
机器学习和深度学习技能的领域包括:
-
数学和统计学
-
机器学习算法
-
深度学习架构
-
神经网络
-
GPU 和计算框架
-
部署
机器学习和深度学习在从数据中提取见解方面展现出了惊人的能力,使数据科学家能够构建能够自动学习的模型。
组织正在竞争性地寻求在各行业中建立具有卓越性能的先进模型。作为数据科学家,你将能够处理复杂问题,提高准确性,构建提升组织竞争力的模型,并不断推动创新。
如果你发现自己在机器学习或深度学习某一领域非常擅长并且喜欢,那就尽情发挥吧。正如我所说,与其是全能手,不如精通一门。
软技能
根据 IBM 报告,劳动力所需的最关键技能包括:
-
时间管理
-
优先级设定能力
-
有效地在团队环境中工作
-
有效沟通
-
灵活、敏捷并适应变化
我个人认为,管理者已经看到远程工作的变化可能对这些领域带来了限制。或者,这可能是一些能有效将想法变为现实的技能。
为了跟上生成式 AI 的步伐,高管们正在寻找能够完成生成式 AI 工具目前无法实现的任务的员工。技术可以帮助我们自动化任务,我们可以通过数据分析来了解哪些有效,哪些无效。
然而,如果员工不明智地利用他们的时间,不能在敏捷和灵活的团队环境中工作——所有这些洞察都会付诸东流。员工是创新的推动者,生成式 AI 系统是帮助我们的工具。
结论
这篇文章旨在让你关注未来几年即将发生的变化以及高管们所寻找的内容。如果你是数据科学领域的新手,你肯定有很多学习和工作的任务——然而,了解所有要素将使你在未来更具竞争力。
如果你目前是一名数据科学家,我希望这篇文章能让你了解到更多组织在寻找具备优秀软技能的候选人,这些软技能能够补充他们的硬技能。
我们都需要跟上世界的发展,因此,利用 AI 工具进行再培训或技能提升将非常有益。
Nisha Arya 是一名数据科学家、自由职业技术作家,并且是 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。Nisha 涵盖了广泛的主题,并希望探索人工智能如何有利于人类寿命的不同方式。作为一名热衷学习者,Nisha 寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
使用 d6tjoin 在 Python 中进行模糊连接
原文:
www.kdnuggets.com/2020/07/fuzzy-joins-python-d6tjoin.html
评论
由 Norman Niemer,首席数据科学家
合并不同的数据源是一项时间消耗大!
我们的前三个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业的快车道。
2. Google Data Analytics Professional Certificate - 提升你的数据分析水平
3. Google IT Support Professional Certificate - 支持你所在的组织的 IT
从不同来源合并数据对数据科学家来说是一个巨大的时间消耗。 d6tjoin 是一个 Python 库,让你可以快速高效地合并 pandas 数据框。
与 Haijing Li 合著,金融服务数据分析师,哥伦比亚大学商业分析硕士。
示例
我编造了这个例子来说明 d6tjoin 的能力。
假设我关注了几家公司的股票一段时间,并且制定了一个策略来对这些公司的表现进行 1-5 分的评分。对历史数据进行回测将帮助我评估股价是否真的反映了这些分数,并找出如何根据这些分数进行交易。我需要的回测信息包含在以下两个数据集中:df_price 包含 2019 年的历史股价,df_score 包含我定期更新的分数。


为了准备回测,我需要将“score”列合并到 df_price 中。显然,股票代码和日期应该是合并键。但存在两个问题:1. df_price 和 df_valuation 的“ticker”值不一致;2. 分数是按月记录的,我希望 df_price 中的每一行都分配上最近的分数,假设下一个分数在下一个更新日期之前不会出现。
预连接分析
d6tjoin 最好的地方之一是它提供了简单的预连接诊断。这对于检测潜在的数据问题特别有用,即使你并没有打算进行模糊连接。
import d6tjoin
j = d6tjoin.Prejoin([df_price,df_score],['ticker','date'])
try:
assert j.is_all_matched() # fails
except:
print('assert fails!')
在此之后,我们知道两个表在合并键上并非完全匹配。当你处理较大的数据集或混乱的字符串标识符时,这将更加有用,因为你无法一眼看出两个数据集是否具有不同的键值。
对于我们的情况,更有用的方法是 Prejoin.match_quality()。它总结了每个连接键的匹配/未匹配记录的数量。在我们的案例中,没有 ticker 名称完全匹配,且匹配的日期很少。这就是我们需要 d6tjoin 帮助进行模糊连接的原因。
j.match_quality()

连接具有不对齐的 ID(名称)和日期
d6tjoin 最适合对字符串、日期和数字进行最佳匹配连接。其 MergeTop1() 对象在 d6tjoin.top1 模块中非常灵活,可以让你定义如何合并:使用默认或自定义的差异函数,对多个键进行精确或模糊匹配。默认情况下,字符串的距离使用 Levenshtein 距离计算。
在我们的示例中,'ticker' 和 'date' 在两个数据集中都不对齐,因此我们需要对这两个字段进行模糊连接。
result=d6tjoin.top1.MergeTop1(df_price,df_score,fuzzy_left_on=['ticker','date'],fuzzy_right_on=['ticker','date']).merge()
结果以字典结构存储,包含两个键: {'merged': 合并结果的 pandas dataframe; 'top1': 每个连接键的性能统计和总结}
让我们来看一下结果:
result['top1']['ticker']
result['merged']
第一行返回关于 'ticker' 键的性能总结。它不仅显示了左右两边匹配的键值,还显示了在 _top1diff_ 列中计算的差异分数。默认情况下,左表中的每个键值应该与右表中的一个键值匹配。因此,即使 "SRPT-US" 和 "VRTX-US" 没有记录在 df_score 中,它们仍会与某些值匹配。我们可以通过设置 top_limit=3 来解决这个问题,这将使任何差异大于 3 的匹配被忽略。
第二行返回合并后的数据集。
原始的 df_price 数据集仅包含 1536 行,但为什么合并后变成了 5209 行?这是因为在原始数据集中,我们将 "date" 解析为字符串。d6tjoin 默认使用 Levenshtein 距离计算字符串的差异,因此左边的一个日期可能会与右边的多个日期匹配。这告诉你每次处理日期时应首先检查其数据类型。
将 "date" 数据类型从字符串更改为 datetime 对象,并为 "ticker" 设置 top_limit=3。让我们再次检查结果。
import datetime
df_price["date"]=df_price["date"].apply(lambda x: datetime.datetime.strptime(x,'%Y-%m-%d'))
df_score["date"]=df_score["date"].apply(lambda x: datetime.datetime.strptime(x,'%Y-%m-%d'))
result=d6tjoin.top1.MergeTop1(df_price,df_score,fuzzy_left_on=['ticker','date'],fuzzy_right_on=['ticker','date'],top_limit=[3,None]).merge()
result['top1']['ticker']
result['merged']


看起来不错!左侧的所有股票代码都匹配得很好,左侧的日期与右侧的最接近日期匹配。
高级使用选项:传递自定义差异函数
现在我们还有一个最后的问题。记住,我们希望假设分数在分配之前不会被提供。这意味着我们希望 df_price 中的每一行都与最近的分数进行匹配。但默认情况下,d6tjoin 不考虑日期的顺序,只是与前面或后面的最近日期进行匹配。
为了解决这个问题,我们需要编写一个自定义差异函数:如果左侧的日期早于右侧的日期,则计算出的差异应足够大,以便忽略匹配。
import numpy as np
def diff_customized(x,y):
if np.busday_count(x,y)>0: #x is left_date and y is right_date,np_busday_count>0 means left_date is previous to right date
diff_= 10000000000 #as large enough
else:
diff_=np.busday_count(x,y)
return abs(diff_)
现在让我们解析自定义差异函数并查看结果。
result=d6tjoin.top1.MergeTop1(df_price,df_score,fuzzy_left_on=['ticker','date'],fuzzy_right_on=['ticker','date'],fun_diff=[None,diff_customized],top_limit=[3,300]).merge()
result['top1']['date']
result['merged']


现在我们有了最终合并的数据集:未分配过分数的价格数据会被忽略,其它数据则各自分配了最近的分数。
结论
d6tjoin 提供的功能包括:
-
预连接诊断以识别不匹配的连接键
-
最佳匹配连接,找到最相似的错位 id、名称和日期
-
能够自定义差异函数、设置最大差异及其他高级功能
了解更多 d6t 库。它提供了包括以下内容在内的常见数据科学问题的解决方案:
简介: Norman Niemer 是一家大型资产管理公司的首席数据科学家,他提供数据驱动的投资见解。他拥有哥伦比亚大学的金融工程硕士学位和卡斯商学院(伦敦)的银行与金融学士学位。
原文。转载已获许可。
相关:
-
解释“黑箱”机器学习模型:SHAP 的实际应用
-
数据科学家常犯的前 10 个编码错误
-
数据科学家常犯的前 10 个统计错误
更多相关话题
GANs 也需要一些关注
原文:
www.kdnuggets.com/2019/03/gans-need-some-attention-too.html
评论
作者:Bilal Shahid(编辑:Taraneh Khazaei,Lindsay Brin)
自注意力生成对抗网络(SAGAN;Zhang 等人,2018)是使用自注意力范式来捕捉现有图像中的长程空间关系以更好地合成新图像的卷积神经网络。AISC 最近介绍并讨论了这篇论文,由 Xiyang Chen 主导。事件的详细信息可以在AISC 网站上找到,完整的演示可以在YouTube上查看。在这里,我们提供了这篇论文及其主要贡献的概述。
传统 GAN 的挑战
虽然传统的深度卷积 GAN 在生成相当逼真的图像方面表现优异,但它们无法捕捉图像中的长程依赖。这些传统的 GAN 对于不包含大量结构和几何信息的图像(例如,描绘海洋、天空和田野的图像)表现良好。然而,当图像中的信息变化率很高时,传统的 GAN 往往无法获取所有这些变化,从而未能忠实地表示全局关系。这些非局部依赖在某些类别的图像中始终出现。例如,GAN 可以绘制具有逼真毛发的动物图像,但通常无法绘制分开的脚部。

来自之前的最先进 GAN(具有投影判别器的 CGAN;Miyato 等人,2018)的输出图像
由于卷积运算符的表示能力有限(即感受野是局部的),传统的 GAN 只能在经过几层卷积之后才能捕捉长程关系。缓解此问题的一种方法是增加卷积核的大小,但这在统计和计算上都不高效。各种注意力和自注意力模型已被提出,以捕捉和利用结构模式和非局部关系。然而,这些模型通常无法在计算效率和建模长程关系之间取得平衡。
GAN 的自注意力
这个功能差距就是 SAGAN 的作用所在。Zhang et al. (2018) 提出了一种方法,其中 GAN 模型配备了一种工具来捕捉图像中的长程、多层次关系。这个工具就是自注意力机制。自注意力试图将输入特征的不同部分关联起来,以计算适合当前任务的输入表示。自注意力的思想已经成功应用于阅读理解(Cheng et al., 2016)、文本蕴含(Parikh et al., 2016)和视频处理(X. Wang et al., 2017)等领域。
将自注意力引入图像合成领域受到“非局部神经网络”(X. Wang et al., 2017)的启发,该网络利用自注意力捕捉视频序列中的时空信息。一般而言,自注意力只是计算单个位置的响应作为所有位置特征的加权和。这个机制允许网络关注图像中结构上相关但空间上相隔较远的区域。

《自注意力生成对抗网络中提出的自注意力模块》(Zhang et al., 2018)
在 SAGAN 中,自注意力模块与卷积网络协同工作,并使用键-值-查询模型(Vaswani et al., 2017)。该模块将卷积神经网络生成的特征图转换为三个特征空间。这些特征空间分别称为键 f(x)、值 h(x) 和查询 g(x),通过将原始特征图传递通过三个不同的 1x1 卷积图生成。然后,键 f(x) 和查询 g(x) 矩阵相乘。接下来,对乘法结果的每一行应用 softmax 操作。由 softmax 生成的注意力图确定了网络应该关注图像的哪些区域,如公式(1)所述,来自 Zhang et al. 2018:

因此,注意力图会与值 h(x) 相乘,生成自注意力特征图,如下所示(公式(2)来自 Zhang et al. 2018):

最终,输出是通过将原始输入特征图与缩放后的自注意力图相加来计算的。缩放参数 ???? 在开始时初始化为 0,以使网络首先关注局部信息。随着缩放参数 ???? 在训练过程中更新,网络逐渐学习关注图像的非局部区域(公式(3)来自 Zhang et al. 2018):


自注意力生成对抗网络输出图像 (Zhang, et al., 2018)
处理 GAN 训练中的不稳定性
SAGAN 论文的另一个贡献与生成对抗网络(GANs)训练不稳定的问题有关。论文提出了两种处理此问题的技术:光谱归一化和双时间尺度更新规则(TTUR)。
当生成器经过良好条件化时,表现更佳且训练动态得到了改善 (Odena, et al., 2018)。使用 SAGAN 时,生成器的条件化通过 光谱归一化 来实现。这种方法最初是在 (Miyato et al. 2018) 中引入的,但仅针对判别器网络,以解决生成器未能很好地学习目标分布的问题。SAGAN 在生成器和判别器网络中都采用光谱归一化,限制两个网络中权重矩阵的光谱范数。这一过程是有益的,因为它在不需要任何超参数调节的情况下限制了 Lipschitz 常数,防止了参数幅度和异常梯度的激增,并允许与生成器相比,判别器的更新次数减少。
除了光谱归一化,论文还使用了 TTUR (Heusel et al., 2018) 来解决使用正则化判别器时学习缓慢的问题。使用正则化判别器的方法通常需要每次生成器更新时多次更新判别器。为了加快学习速度,生成器和判别器使用不同的学习率进行训练。
结论
SAGAN 是图像生成技术的一项重大进步。有效整合自注意力技术使网络能够以计算高效的方式真实捕捉和关联长距离空间信息。在判别器和生成器网络中使用光谱归一化,以及 TTUR,不仅降低了训练的计算成本,还提高了训练稳定性。
原文。经授权转载。
相关:
-
对抗样本解释
-
生成对抗网络 – 论文阅读路线图
-
什么是一些“高级”人工智能和机器学习在线课程?
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在的组织的 IT
更多相关话题
深度学习与人类认知能力之间的差距
原文:
www.kdnuggets.com/2022/10/gap-deep-learning-human-cognitive-abilities.html

图片由 David Cassolato 提供
嗨!我是 AI HOUSE 社区的首席执行官博赫丹·波诺马尔。我们是由 Roosh 技术公司构建的生态系统的一部分。Roosh 创建 ML/AI 项目并投资于行业中的创新想法。我们的生态系统还包括 Pawa 风投工作室、Roosh Ventures 风投基金、SET University 科技大学、Reface 和 ZibraAI 初创公司,以及 Neurons Lab 公司。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
在 2022 年 8 月,我们启动了一个新的教育项目“AI for Ukraine”——一系列由国际人工智能专家主讲的研讨会和讲座,旨在支持乌克兰科技社区的发展。
系列的第一讲由蒙特利尔大学的教授约书亚·本吉奥主讲,他是魁北克人工智能研究所的创始人和科学主任,CIFAR 机器与大脑学习计划的负责人,以及 AI 行业的领先专家之一。2022 年,他成为全球 h-index 最高的计算机科学家。
在讲座中,教授介绍了他的研究项目,旨在弥合基于深度学习的现代 AI 与具有创造力的人类智能之间的差距。完整录音可以在 这里 通过捐款获取,本文中我们涵盖了讲座的主要内容。
系统性泛化
当前的机器学习在可靠性方面存在问题,因为 OOD(分布外样本)表示的表现不佳。我们习惯依赖 IID(独立同分布)假设,即测试分布和训练分布是相同的。但没有这个假设,我们需要一些替代假设来进行泛化。
这就引出了一个研究问题:分布如何具体变化?让我们考虑一下人类通常如何应对这些任务,因为这可以激发 AI 学习方法的发展。
多年来,语言学家一直在研究系统性概括,这在自然语言中很容易观察到。一个人可以将熟悉的概念重新排列,而声明的意思仍然完全明确。
我们甚至可以创建那些在训练分布中概率为零的配置。例如,一名司机将自己在本国的驾驶法律知识概括到其他国家,而这些国家的道路规则可能略有不同。然而,深度学习尚未实现类似的结果。这显示了最先进的 AI 系统与人类智能之间的差距本质。
组合知识表示
我们有大型语言模型,但它们需要大量数据,这使得它们的使用变得毫无意义。这是样本复杂性的问题——训练所需的样本数量。
因此,我们不应该考虑定量扩展,而是应该关注深度学习的定性发展。问题是:
-
这些系统如何能够泛化到新的分布外设置?
-
它们能多快适应这些设置(迁移学习)?
这些问题与人类建立和识别因果关系的能力直接相关。人类可以通过结合和重组之前的知识来得出新的结论。这种在自然语言中表示知识的组合能力也让我们能够考虑未来 AI 一代的发展方向。
有意识的信息处理
上述内容涉及到一个人类当前超越 AI 的关键能力。这就是我们大脑进行的有意识的信息处理。
比如,当一名司机开始在外国开车时会发生什么?假设司机习惯于左侧交通,但现在他必须适应右侧行驶。他不能完全依赖之前的经验,因为这样会使汽车驶入对向车道。但他可以专注于任务,不断提醒自己道路规则的不同。这就是他之前驾驶经验的帮助之处。
因此,当人们面对新的情况时,他们会在意识上注意,以便即兴结合相关的知识点,分析它们,并最终成功完成任务。这种有意识的信息处理本质上不同于我们在日常生活中依赖的处理方式(参见 D. Kahneman 的《思考,快与慢》)。
当前的深度学习系统在没有需要解决复杂问题的情况下,可以通过简单的动作序列成功模拟快速思维。但再现更复杂和算法性的慢思维对未来的行业发展来说是一项挑战。
为此,我们需要以一种方式组织知识,使其易于从训练分布中选择相关知识片段,以便在解决新问题时重新使用。类似的比喻可以是由独立模块和函数组成的程序代码。
因果关系
人类能够区分他们对世界的知识的两个视角:
-
这些依赖于不变的物理法则;以及
-
这些与动态变化条件相关。
这与常见的 IID 假设不同,因为那些在分布中保持不变并与物理法则相关的事物实际上是不变的。而与变量条件相关的事物则会发生变化。
因此,深度学习的目标是发现能够反映变量因素因果关系的知识表示。换句话说,结果取决于所采取的行动。
归纳偏差
人类可以通过语言接收和分享大量信息。最适合口头表达的是依赖于归纳偏差的知识,比如使用抽象命名对象。
例如,我手里拿着一个球。这句话包含了命名对象:我、手和球。每个对象都有自己的特征,如空间中的坐标。如果我突然掉下球,它们可以用来预测球在每一个下落时刻的坐标。这个预测是准确的,尽管它只基于几个变量。
但如果在像素级别应用这种方法,它将不起作用。无法准确预测一个像素本身的状态。但可以预测与抽象命名对象相关的像素状态,比如球。因为这种命名对象的统计结构与普通像素不同。
此外,抽象对象之间的因果关系是可重复使用的。无论是什么物体由于掉落而发生——球、电话或其他——机制保持不变。
GFlowNets
在神经科学中,有一个随机因素:在某种情况下,人类可能会有某种思维。因此,思维中存在某种离散随机的方面,无法事先预测。从机器学习的角度来看,我们需要一个能够从选择的分布中生成思想的概率神经网络,例如贝叶斯后验概率。
GFlowNets 是一个多功能的概率建模工具。这些网络使得通过复合对象建模分布以及估计如归一化常数或条件概率等量成为可能。最容易想象这种结构的是假图。
GFlowNets 如何生成像图这样的结构化对象?我们已经知道几年来,网络接受的不是固定大小向量的集合,而是图作为输入。现在我们考虑将图作为输出。这一过程类似于大脑生成思维的方式。为了创建复合结构,我们一次添加一个元素。即,我们将一个部分构建的思维作为输入,并推导出一个分布作为输出,确定所有可能的进一步行动。这样,我们一步步获得所需的结果。
GFlowNets 可以组织为专注于不同类型知识的不同模块。通过相互竞争,它们提供标准化的估计作为输出。此外,每个模块与其他模块共享信息——这就是短期工作记忆形成的方式。最后,某个估计会被随机选择,类似于人脑中启动意识处理的过程。
因果关系模型
在使用这样的神经网络时,主要挑战是正确识别和建模因果结构。因为如果你仅仅拿两个有相关性的 A 和 B 变量,那么无法确定哪个变量触发了另一个。然而,我们可以假设这种连接会由于外部因素而改变。例如,如果我们改变 A 的状态,这也改变了 B,那么 A 对 B 的影响更可能,而不是反过来。
因果关系是非对称的。如果你没有完全理解它,你可能会犯很大的错误。例如,这可能导致歧义,比如病人是因为新药治愈的,还是由于其他原因?
因此,有必要构建能够涵盖所有可能因果解释的模型。在思考中,人类能够提出类似的假设。对于人工智能,这一任务通过贝叶斯后验因果模型来解决。
结论
到目前为止,深度学习与人类认知能力之间的差距仍然很大。毕竟,人类可以概括他们的知识,应用慢思维并用来解决非平凡问题,意识处理信息,并理解现象之间的因果关系。
然而,世界领先的人工智能专家正在努力弥合这一差距,提升人工智能能力,灵感来自于对人脑功能原理的研究。蒙特利尔的Joshua Bengio团队研究概率神经网络,以迈向下一代深度学习。
博赫丹·波诺马尔 是AI HOUSE社区的首席执行官。他正在为学生和专家创建一个领先的人工智能生态系统,以在乌克兰建立世界一流的人工智能企业。
更多相关话题
Gartner 2015 炒作周期:大数据已过时,机器学习成为新趋势
原文:
www.kdnuggets.com/2015/08/gartner-2015-hype-cycle-big-data-is-out-machine-learning-is-in.html
评论 Gartner,这家领先的市场和技术研究公司,发布了 2015 年新兴技术的炒作周期报告。
图 1:Gartner 2015 炒作周期。
用于比较的是
图 2:Gartner 2014 炒作周期。
炒作周期是什么?
随着技术的进步,我们总是对新兴的流行词汇和技术趋势过于兴奋,然后在期望结果下降时感到失望。一些新兴技术确实带来了巨大的变化和显著的转变。
炒作周期让我们了解到这些技术中哪些实际上能够经受市场的炒作,并有可能成为我们日常生活的一部分。有关新兴技术的特别报告基于对 2000 多项技术的成熟度、采纳时间、商业利益和未来方向的评估,这些技术被分为 112 个领域。
Gartner 炒作周期的五个区域: 创新触发(潜在技术突破的开始)、过度期望的巅峰(通过早期宣传的成功故事)、幻灭低谷(兴趣下降)、启蒙斜坡(第二代和第三代产品出现)和生产力平台(主流采用开始)。
以下是一些与大数据相关的关键技术:
-
自动驾驶汽车,它们的定位从 2014 年的前期巅峰转移到了 2015 年的巅峰。根据 Gartner 的说法,“尽管自动驾驶汽车(如无人驾驶汽车)仍处于起步阶段,但这一运动仍代表了显著进步,所有主要汽车公司都将自动驾驶汽车列入了近期计划。”
-
物联网(我们周围协调活动的智能对象网络)在两年中几乎始终保持在巅峰期。它被认为是几十年来最具颠覆性的技术,一旦广泛部署。
-
自然语言处理问答,去年的赢家,正在滑向低谷。它可能无法通过。
-
大数据在 2015 年的炒作周期中无影无踪,而去年它被显示进入了幻灭低谷。这可能意味着最受关注的大数据相关技术现在已经投入实践,不再是炒作。
-
“机器学习”今年首次出现在图表上,但已经超过了夸大期的顶峰,现在取代了大数据的位置。
-
数字人文主义,根据 Gartner 的定义,是让人们变得更好,而不是让技术变得更好。可穿戴设备和物联网等已确立的趋势在周期的“夸大期顶峰”上,与机器学习和高级分析一起。所有这些趋势预计将在两到五年之间达到高原。
-
公民数据科学家:Gartner 在 2015 年首次提出这一新的公民数据科学家类别,但 2014 年并未出现,预计将在 2-5 年内达到高原。Gartner 研究总监 Alexander Linden 建议培养“公民数据科学家”——那些可能拥有一些数据技能的业务人员,可能来自数学或社会科学学位——并让他们探索和分析数据。
-
企业级 3D 打印和手势控制技术正快速接近高原,但目前仍处于“启蒙斜坡”中。
-
数字灵活性是新的,今天的员工拥有更高程度的数字灵活性,”Gartner 的研究副总裁 Matt Cain 说道。“他们在家中管理自己的无线网络,连接和管理各种设备,并在个人生活的几乎每个方面使用应用程序和网络服务。Gartner 已经概述了 IT 组织应如何利用员工的数字灵活性。
-
数据安全,这是今天一个相当重要的话题,似乎出乎意料地不那么炒作,被列为“数字安全”,在炒作周期的预期顶峰和接近触发区域。
-
与去年语音识别不同,这些技术都没有进入生产力高原。这种情况可能会随着更多技术的成熟而在未来几年发生变化。
你认为哪些技术被过度炒作,哪些技术可能会经受住炒作的考验?
相关:
-
Gartner 2015 高级分析平台魔力象限:谁获得了优势,谁失去了?
-
大数据项目失败的 3 个原因
-
大数据的 4 个问题(及其解决方案)
相关话题
Gartner 2018 年数据科学和机器学习平台的魔力象限中的赢家与输家
原文:
www.kdnuggets.com/2018/02/gartner-2018-mq-data-science-machine-learning-changes.html
评论 Gartner 不断更改此报告的名称(暗示市场细分)——最新的 2018 版本,发布于 2018 年 2 月 23 日,被称为“数据科学和机器学习平台的魔力象限”(Machine 和 Learning 之间用传统的连字符)。在 2017 年,它被称为“数据科学平台的 MQ”,在 2014-2016 年,它被称为“高级分析平台的 MQ”。这种变化反映了行业在内容和能力方面的快速变化,以及反映 AI 和机器学习增长的不断演变的品牌。
Gartner 将数据科学和机器学习平台定义为:
一款完整的软件应用程序,提供了一系列基本构建块,既对创建多种数据科学解决方案至关重要,又对将这些解决方案纳入业务流程、周边基础设施和产品中。
2018 年的变化相当显著,如下所述。
2018 年的报告评估了 16 家分析和数据科学公司,依据多项标准将其分为 4 个象限,基于愿景的完整性和执行能力。
请注意,虽然像 Python 和 R 这样的开源平台在数据科学市场中扮演着越来越重要的角色,但 Gartner 的研究方法并未包括它们。

图 1: 2018 年 Gartner 数据科学和机器学习平台的魔力象限
涉及的公司:
-
领导者(5): KNIME,Alteryx,SAS,RapidMiner,H2O.ai
-
挑战者(2): MathWorks,TIBCO Software(新增)
-
远见者(5): IBM,Microsoft,Domino Data Lab,Dataiku,Databricks(新增)
-
小众玩家(4): SAP,Angoss,Anaconda(新增),Teradata
2017 年新增了三家公司:TIBCO Software,Anaconda 和 Databricks。
2017 年 MQ 中的另外三家公司被淘汰:FICO,Quest 和 Alpine Data。我们注意到 Alpine Data 公司和 Quest 的 Statistica 资产被 TIBCO 收购,TIBCO 在 2017 年的 MQ 中的位置接近 Quest。
与我们之前的帖子 Gartner 2017 MQ 数据科学平台的赢家与输家 一样,我们比较了最新的 2018 年魔力象限与其前一版本。下面我们将审视这些变化、赢家和输家。

图 2: 2018 年与 2017 年的数据科学和机器学习平台的 Gartner 魔力象限比较
图 2 显示了 2017 MQ(灰色背景图像)和 2018 MQ(前景图像)的对比,箭头连接相同公司的圆圈。如果公司位置显著改善(离原点更远),箭头为绿色;如果位置变弱,箭头为红色。绿色圆圈表示新公司,而红色 X 标记的是在 2018 年被淘汰的供应商。
领导者:
自 2014 年以来,首次出现了变化。曾经属于领导者的 IBM 由于执行能力下降,降到了愿景者象限。KNIME 在愿景完整性轴上显著前进,SAS 在同一轴上后退,而 RapidMiner 在执行能力上稍有下滑。
2018 年有两家公司首次进入领导者行列:H2O.ai,从愿景者上升,Alteryx,从挑战者上升。
下面是每个公司的简要总结。完整报告请参见下方指引。
KNIME 提供开源的 KNIME Analytics Platform,全球用户超过 10 万。KNIME 提供商业支持和扩展,用于企业部署中的协作、安全和性能。在 2017 年,KNIME 为 AWS 和 Microsoft Azure 增加了平台的云版本,改进了数据质量功能,并扩展了深度学习能力。
Gartner 写道:
该供应商展示了对市场的深刻理解、强大的产品策略以及在所有用例中的优势。综合这些特性,它巩固了其作为领导者的位置。
Alteryx 平台使公民数据科学家能够在一个工作流程中构建模型。2017 年,Alteryx 成功上市,并随后收购了专注于模型部署和管理的数据科学供应商 Yhat。
Gartner 写道:
Alteryx 从挑战者象限上升到了领导者象限。这得益于强大的执行能力(无论是收入增长还是客户获取)、令人印象深刻的客户满意度以及一个致力于帮助组织培养数据和分析文化的产品愿景,而无需聘请专家数据科学家。
SAS 提供了许多用于分析和数据科学的软件产品。对于本次 MQ,Gartner 评估了 SAS Enterprise Miner(EM)和 SAS Visual Analytics 产品套件。
Gartner 写道:
SAS 依然是领导者,但在愿景完整性和执行能力方面有所下滑。Visual Analytics 套件由于其 Viya 云就绪架构而显示出潜力,这种架构比以前的 SAS 架构更加开放,使分析对更广泛的用户群体更易于访问。然而,令人困惑的多产品策略加剧了 SAS 的愿景完整性问题,高许可成本的认知也削弱了其执行能力。随着市场重点转向开源软件和灵活性,SAS 缺乏一个统一开放平台的迟缓应对也带来了负面影响。
RapidMiner 平台包括 RapidMiner Studio 模型开发工具(提供免费版和商业版),RapidMiner Server 和 RapidMiner Radoop。
高德纳写道:
RapidMiner 仍然是领导者,通过提供一个全面且易于使用的平台,服务于全体数据科学家和数据科学团队。RapidMiner 继续强调核心数据科学以及模型开发和执行的速度,通过引入新的生产力和性能功能来实现这一点。
H2O.ai 提供开源机器学习平台,包括 H2O Flow,它的核心组件;H2O Steam;H2O Sparkling Water,用于 Spark 集成;以及 H2O Deep Water,提供深度学习能力。
高德纳写道:
H2O.ai 从之前的魔力象限中的愿景者(Visionary)进步为领导者(Leader)。它继续通过显著的商业扩展取得进展,并巩固了其作为思想领袖和创新者的地位。
挑战者(Challengers):
-
MathWorks 仍然是挑战者(Challenger),得益于其在高级分析领域的高知名度、大量的已安装基础和强大的客户关系。然而,它从一些客户那里获得了较低的评分,并且其愿景的完整性受到其在工程和高端金融用例上的专注的限制。
-
TIBCO Software(新)通过于 2017 年 6 月收购 Quest Software 的知名 Statistica 平台进入了这一市场。2017 年 11 月,它还收购了 Alpine Data,后者在 2017 年魔力象限中被评为愿景者。对于执行能力,本次魔力象限仅评估了 TIBCO 在 Statistica 平台上的能力。TIBCO 的其他收购仅对其愿景完整性有所贡献。
愿景者(Visionaries)
-
IBM 提供许多分析解决方案。在这个魔力象限中,高德纳评估了 SPSS Modeler 和 SPSS Statistics,但没有评估 Data Science Experience (DSX),因为 DSX 没有满足高德纳在执行能力轴上的评估标准。高德纳写道:
IBM 现在是愿景者,较其他供应商在愿景完整性和执行能力方面有所下滑。然而,IBM 的 DSX 产品有潜力激发出更全面和创新的愿景。IBM 已宣布计划在 2018 年推出一个新的 SPSS 产品接口,该接口将 SPSS Modeler 完全集成到 DSX 中。
-
Microsoft 提供多个数据科学和机器学习产品。对于云计算,这些产品包括 Azure 机器学习、Azure 数据工厂、Azure Stream Analytics、Azure HDInsight、Azure 数据湖和 Power BI。
对于本地计算,微软提供了 SQL Server 及其机器学习服务(于 2017 年 9 月发布 - 在本次魔力象限的截止日期之后)。只有 Azure 机器学习工作室满足了本次魔力象限的包含标准。高德纳写道:
微软依然是一个愿景型公司。其在这方面的位置归因于市场响应性和产品可行性评分较低,因为 Azure 机器学习工作室仅限于云端,这限制了它在许多需要本地选项的高级分析用例中的可用性。
-
Domino(Domino 数据实验室) 数据科学平台是一个面向专家数据科学团队的端到端解决方案。该平台专注于整合来自开源和专有工具生态系统的工具、协作、可重复性以及模型开发和部署的集中化。Domino 仍然位于愿景型象限,但显著提高了执行能力。Gartner 写道
Domino …… 执行能力,尽管有所改善,但仍因机器学习生命周期初期(数据访问、数据准备、数据探索和可视化)功能较弱而受限。然而,在过去一年中,Domino 已展示出赢得新客户并在竞争激烈的市场中取得进展的能力。
-
Dataiku 提供以跨学科协作和易用性为重点的数据科学工作室(DSS)。Gartner 写道
Dataiku 仍然是一个愿景型公司……通过使用户能够快速启动机器学习项目。其在愿景完整性方面的位置得益于其协作和开源支持,这也是其产品路线图的重点。其整体愿景完整性评分低于之前的 MQ,原因在于用例的广度相对较差以及自动化和数据流的不足。
-
Databricks(新) 提供基于 Apache Spark 的 Databricks 统一分析平台,该平台在云端运行。它还提供了专有的安全性、可靠性、操作性和性能功能。Gartner 写道
Databricks 是此魔力象限的新进者。作为一个愿景型公司,它利用开源社区及其自身的 Spark 专业知识,提供一个对许多人来说易于访问且熟悉的平台。除了数据科学和机器学习外,Databricks 还专注于数据工程。2017 年的一轮 1.4 亿美元的 D 轮融资为 Databricks 提供了充足的资源,以扩大其部署选项并实现其愿景。
利基玩家
-
SAP 再次将其平台从 SAP Business Objects Predictive Analytics 更名为简单的 SAP Predictive Analytics。由于客户满意度较低、缺乏关注度、工具链破碎以及在云计算、深度学习和 Python 方面存在显著技术差距,它仍然是一个利基玩家。
-
Angoss 于 2018 年 1 月被 Datawatch 收购,但由于收购时间较晚,仍在本文档中以 Angoss 命名。Angoss 拥有忠实的客户,但仍然被视为利基玩家,因为它仍被认为是桌面环境的供应商。
-
Anaconda(新)提供了 Anaconda Enterprise 5.0,这是一个基于互动笔记本概念的开源开发环境。它还提供了一个发行环境,访问广泛的开源开发环境和开源库。
-
Teradata 提供了 Teradata Unified Data Architecture,这是一个企业级分析生态系统,结合了开源和商业技术以提供分析能力。由于其在数据科学开发方面缺乏一致性和易用性,它仍然是一个小众参与者。
你可以从 Domino、H2O.ai、Alteryx、Dataiku 以及报告中可能提到的其他供应商下载 Gartner 2018 年数据科学和机器学习平台魔力象限报告。
你还可以查看相关的 2018 年 Gartner 分析和商业智能平台魔力象限。
相关:
-
Gartner 2017 年数据科学平台魔力象限:赢家和输家
-
Gartner 2016 年高级分析平台魔力象限:赢家和输家
-
Gartner 2015 年高级分析平台魔力象限:谁赢了,谁输了。
-
Gartner 2014 年高级分析平台魔力象限。
更多相关内容
Gartner 2019 数据科学和机器学习平台魔力象限中的赢家、输家和趋势
原文:
www.kdnuggets.com/2019/02/gartner-2019-mq-data-science-machine-learning-changes.html
评论 近年来,Gartner 数据科学和机器学习平台魔力象限报告的名称首次与去年基本相同。2018 年的报告名为“数据科学和机器学习平台 MQ”(在 Machine 和 Learning 之间有一个老式的短横线)。2017 年为“数据科学平台 MQ”,2016 年为“高级分析平台 MQ”。也许名称的逐渐稳定反映了数据科学和机器学习领域的某种成熟感。然而,在行业中却没有稳定性,正如您将看到的那样,供应商排名发生了许多变化。
2019 年有哪些变化?
2019 年的报告评估了 17 家供应商(比往年多了一家),并将它们根据愿景完整性(简称 愿景)和执行能力(简称 能力)分为 4 个象限。
请注意,Gartner 仅包括那些拥有商业授权产品的供应商。像 Python 和 R 这样的纯开源平台,尽管在数据科学家和机器学习专家中非常受欢迎,但并未被纳入评估。

图 1:Gartner 2019 数据科学和机器学习平台魔力象限(截至 2018 年 11 月)
涵盖的公司:
-
领导者(4 家): KNIME, RapidMiner, TIBCO Software, SAS
-
挑战者(2 家): Alteryx, Dataiku
-
愿景者(7 家): Mathworks, Databricks, H2O.ai, IBM, Microsoft, Google(新增), DataRobot(新增)
-
利基玩家(4 家): SAP, Anaconda, Domino, Datawatch (Angoss)
2019 年报告新增了两家公司:Google 和 DataRobot。
2018 年魔力象限中的一家供应商被剔除:Teradata。
如同我们之前做的那样(见 2018 MQ 中的赢家和输家, Gartner 2017 MQ 赢家和输家),我们将最新的魔力象限与其之前的版本进行了比较。以下我们将探讨这些变化、赢家和输家。

图 2:Gartner 数据科学和机器学习平台魔力象限比较,2019 与 2018
图 2 显示了 2018 MQ(灰色背景图像)和 2019 MQ(前景图像)的比较,箭头连接了同一公司的圆圈。如果公司位置显著改善(离原点更远),箭头颜色为绿色;如果位置变弱,箭头颜色为红色。绿色圆圈表示 2 家新公司(Google 和 DataRobot),而红色 X 标记了今年下降的供应商(Teradata)。
我们看到 KNIME 和 RapidMiner 依然保持强大的领导地位,SAS 在能力上下降但仍在领导者中,TIBCO 最近收购了几家分析公司,首次进入领导者行列。Alteryx 移动到挑战者象限,并且 Dataiku 在能力轴上取得了很大进步。MathWorks 在愿景方面显著改善,并逐渐接近领导者。
3 年比较
如果我们审视所有三个最近年份中出现的主要公司,可以更清晰地看到长期趋势 - 参见图 3。

图 3:Gartner 数据科学和机器学习平台的魔力象限,比较了 2017、2018、2019 三年
Alteryx 在两年中在能力上都有所提升,但仍然是挑战者。
Dataiku 在 2018 年大幅下降,并在 2019 年在能力方面有了很大改善。
IBM 在两个维度上都显著下降,从领导者转变为愿景者。
H2O.ai 在 2018 年升至领导者,但在 2019 年降回到愿景者。
KNIME 在两年的愿景方面都有所进展,并且是强大的领导者。
MathWorks 在 2018 年能力上下降,但在 2019 年愿景上显著改善。
Microsoft 在每一年中在能力方面略有下降。
RapidMiner 实质上保持在领导者象限的同一位置。
SAS 在愿景和能力上都下降了,但仍然在领导者中。
这是 2019 年 Gartner MQ 中公司非常简短的总结
领导者:
这个象限在 2014-2017 年曾经有相同的 4 家公司(IBM、SAS、RapidMiner 和 KNIME),但在 2018 年发生了变化,今年再次发生了变化。
Rapidminer 在能力方面略有上升。Gartner 表示
RapidMiner 依然是领导者,通过在易用性和数据科学复杂性之间取得良好的平衡。其平台的易用性受到公民数据科学家的赞扬,同时其核心数据科学功能的丰富性,包括对开源代码和功能的开放,也使其对经验丰富的数据科学家具有吸引力。
KNIME 在能力轴上下降,但在愿景方面有所进展。Gartner 表示
KNIME 凭借丰富的全方位功能,保持了其作为市场“瑞士军刀”的声誉。其免费且开源的 KNIME Analytics Platform 涵盖了 85% 的关键功能,KNIME 的愿景和路线图与大多数竞争对手相比同样出色,甚至更好。
SAS 在能力上下降。Gartner 写道:
SAS 保持了长期以来的领导者地位。尽管公司面临来自其他大型供应商、成熟的颠覆者和开源解决方案的多方面威胁,但它在市场上仍保持强劲的存在。
TIBCO Software 加入了领导者行列,并在能力和愿景两个维度上都得到了提升。Gartner 写道:
通过收购企业报告和现代 BI 平台供应商(Jaspersoft 和 Spotfire)、描述性和预测性分析平台供应商(Statistica 和 Alpine Data)以及流分析供应商(StreamBase Systems),TIBCO 构建了一个全面而强大的分析平台。
挑战者:
Alteryx 由于其被认为缺乏创新,已经从领导者位置转变为挑战者。Gartner 写道,尽管如此
Alteryx 强调使数据科学对公民数据科学家和其他人可及,这种做法在市场上产生了共鸣。
Dataiku 在能力维度上取得了巨大的进步。Gartner 写道
Dataiku 出现在挑战者象限,主要是由于其在执行能力和可扩展性方面的强劲表现。
愿景者
Databricks 的基于 Apache Spark 的统一分析平台结合了数据工程和数据科学能力,使用各种开源语言。
Databricks 通过提供对端到端分析生命周期、混合云环境和广泛用户群体的支持,保持了愿景者的地位。
DataRobot (new):
DataRobot 平台自动化了关键任务,使数据科学家能够高效工作,公民数据科学家能够轻松构建模型。
Google (new):
Google 提供了丰富的 AI 产品和解决方案生态系统,从硬件(Tensor Processing Unit [TPU])和众包(Kaggle)到世界一流的机器学习组件,用于处理图像、视频和文本等非结构化数据。Google 也是自动化机器学习的先驱之一(拥有 Cloud AutoML)。
H2O.ai:
相比于该魔力象限中的其他供应商,H2O.ai 在执行能力方面有所下滑,主要由于参考客户对几个关键能力的评分较低。
IBM
IBM 仍然保持着愿景者的地位,但在愿景完整性和执行能力方面相较于其他供应商有所下滑。
MathWorks
MathWorks 通过无缝整合处理非常规数据源(图像、视频和物联网数据)的高级功能,增强了 MATLAB 平台在其工程专注受众中的一致性。
Microsoft
Microsoft 仍然保持着愿景者的地位,对开源技术的广度和易用性以及在深度学习方面的卓越承诺保持不变。对于需要严格本地产品的数据科学团队和使用案例,Azure Machine Learning 并不是一个选项。
小众玩家
SAP、Anaconda、Domino、Datawatch(Angoss)
你可以从 Dataiku、DataRobot 及其他在 Gartner 报告中受到青睐的供应商处下载 Gartner 2019 数据科学与机器学习平台魔力象限报告。
相关:
-
Gartner 2018 数据科学与机器学习平台魔力象限的赢家与输家
-
Gartner 2017 数据科学平台魔力象限:赢家与输家
-
Gartner 2016 高级分析平台魔力象限:赢家与输家
-
Gartner 2015 高级分析平台魔力象限:谁获益,谁失利
-
Gartner 2014 高级分析平台魔力象限
更多相关主题
2023 年 Gartner Hype Cycle 对 AI 的评估

作者提供的图像
我们都想知道技术的最新动态。有什么新东西,接下来会发生什么,我应该学习什么,公司们正在关注什么?
我们的三大推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织 IT 工作
你可以通过 2023 年 Gartner Hype Cycle 了解所有这些内容。Gartner Hype Cycle 为你提供技术和应用的图形表示,以及这些意味着实际业务问题和未来机会的内容。
2023 年 Gartner Hype Cycle™对人工智能(AI)的评估识别了当前为我们提供显著好处的创新和技术,同时考虑了相关风险。
你们中的许多人可能一直在想,现在技术会发生什么,特别是自从大型语言模型(LLMs)如 ChatGPT 兴起以来。生成式 AI 正在主导,我们都想了解更多!那么 Gartner Hype Cycle 告诉了我们什么?
首先,Gartner 建议生成式 AI 有两个方面:
-
生成式 AI 将推动的创新
-
推动生成式 AI 进步的创新
生成式 AI 推动的创新
生成式 AI 将改变很多事物,它将推动创新的一些领域包括:
-
人工通用智能
-
AI 工程
-
自主系统
-
云 AI 服务
-
复合 AI
-
计算机视觉
-
数据中心 AI
-
边缘 AI
-
智能应用程序
-
模型操作化
-
操作性 AI 系统
-
提示工程
-
智能机器人
-
合成数据
推动生成式 AI 进步的创新
那么哪些领域将推动生成式 AI 的进步?它们是:
-
AI 模拟
-
AI 信任、风险和安全管理(AI TRiSM)
-
因果 AI
-
数据标记和注释
-
原理性 AI(FPAI)
-
基础模型
-
知识图谱
-
多智能体系统(MAS)
-
神经符号 AI
-
负责任的 AI
想知道这些创新需要多长时间才能引发并达到高峰。请深入查看下面的 Gartner Hype Cycle 可视化图:

图片来源:Gartner Hype Cycle
总结一下
Gartner 为我们提供了一种全新的视角,了解生成型 AI 能为我们做什么以及它将如何塑造我们的未来。这些可视化图给出了对未来期望的估计时间框架。根据你在本文中学到的内容,你会提出挑战吗?在评论中告诉我们。
尼莎·阿里亚 是 KDnuggets 的数据科学家、自由技术写作人和社区经理。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何以及可能如何惠及人类寿命。作为一个热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
2020 年 Gartner 数据科学和机器学习平台魔力象限中的领导者、变化和趋势
原文:
www.kdnuggets.com/2020/02/gartner-mq-2020-data-science-machine-learning.html
评论 Gartner 上周发布了备受期待的数据科学和机器学习平台(DSML)魔力象限报告,如果你是客户,可以从 Gartner 处获取,或从文中提到的几家公司中获取 - 详见本博客底部的列表。
近年来,MQ 的名称不断变化,但 4 家领导者保持不变。现在名称与 2019 年 MQ 和 2018 年 MQ 报告中的名称保持一致,反映了对 DSML 领域更成熟的理解,但内容,特别是领导者象限,发生了剧烈变化,反映了该领域进展和竞争的加速。
2020 年 MQ 报告重新评估了 16 个供应商(比去年减少了 1 个),像往常一样,基于愿景(简写为“vision”)和执行能力(简写为“ability”)放置在 4 个象限中。
我们注意到报告仅包含具有商业产品的供应商,没有考虑像 Python 和 R 这样的开源平台,即使这些在数据科学家和机器学习专业人士中非常流行。

图 1: 截至 2019 年 11 月的数据科学和机器学习平台的 Gartner 魔力象限。
涵盖的供应商(每个象限中的字母顺序):
-
领导者(6 家):Alteryx, Dataiku, Databricks, MathWorks, SAS, TIBCO
-
挑战者(1 家):IBM
-
远见者(7 家):DataRobot, Domino, Google, H2O.ai, KNIME, Microsoft, RapidMiner
-
小众玩家(2 家):Anaconda, Altair(前 DataWatch/Angoss)
与去年相比,2020 年报告中没有新增条目,一家公司被删除:SAP。
我们像以前一样,将最新的魔力象限与其前一年版本进行比较 - 见图 2。

图 2: 2020 年与 2019 年数据科学和机器学习平台的 Gartner MQ 变化
绿色箭头表示供应商改善了他们的位置或进入了领导者象限,红色箭头 - 失去位置,黄色箭头 - 侧移。
今年 MQ 中有如此多的变化,以至于很难看到所有箭头,因此我们将上述图表分为两部分:1:领导者,2:挑战者和远见者。
以下是领导者象限中的 6 家供应商,其中两家是去年已在领导者象限中的(SAS 和 TIBCO),还有 4 家新进入的(Alteryx、Dataiku、Databricks 和 MathWorks)- 见图 3。

图 3:Gartner 数据科学和机器学习平台的领导者
领导者
六个领导者是:(按字母顺序排列)
-
Alteryx 基于其强大的公司和产品愿景,特别是在流程自动化以及 Gartner 称之为“增强型 DSML”方面,重新回到了 2018 年的领导者象限(从 2019 年的挑战者回归)。Alteryx 的收入增长继续高于几乎所有其他供应商,并且在国际上也取得了显著扩展。2019 年,Alteryx 完成了两项收购:ClearStory Data 和 Feature Labs。
-
Databricks 基于 Apache Spark,提供跨数据科学、机器学习和数据工程的统一数据分析平台。基于其强大的执行力、增长和超过 500 家公司的合作伙伴生态系统,Databricks 移动到领导者象限。Databricks 在实现机器学习的可扩展性方面也是一个领先者。
-
Dataiku 的核心产品是 Data Science Studio。基于易用性、愿景、数据治理以及支持多种用户类型(从数据工程师和数据科学家到业务用户及所谓的“公民数据科学家”)的协作能力,它今年从挑战者跃升为领导者。
-
MathWorks 的 MATLAB 被考虑用于此 MQ。MathWorks 今年进入了领导者象限,基于其适应性、使用最新技术(如深度学习和强化学习)以及强大的执行能力。MATLAB 是一个全面集成的平台,支持数据准备、模型构建、仿真和部署。
-
SAS 拥有许多产品,但此 MQ 评估了 SAS Visual Data Mining 和 Machine Learning。SAS 保持在领导者象限中,自该领域的首个 MQ 以来一直如此。根据 Gartner,SAS 的产品具有高度的企业准备度,并为客户提供了高商业价值。虽然开源替代方案是一个竞争威胁,但 SAS 仍然是一个强有力的竞争者。
-
TIBCO 在过去几年通过收购(包括 BI 公司(Jaspersoft 和 Spotfire)和分析/数据科学供应商(Insightful、Statistica 和 Alpine Data))建立了一个强大的平台(TIBCO Data Science)。TIBCO 在领导者象限中保持不变,因为它继续整合其广泛的产品组合。
接下来我们来看挑战者和愿景者中那些没有进入领导者象限但已改善其位置的公司。

图 4:Gartner 数据科学和机器学习平台的挑战者与愿景者
愿景者
愿景者象限中有 7 家公司:
-
DataRobot 数据科学和机器学习平台提供了整个分析过程的自动化,使业务用户和“公民”数据科学家能够完成所需的数据分析。DataRobot 还提供售前和售后支持。该公司最近收购了数据协作平台 Cursor、MLOps 平台 ParallelM 和数据准备平台 Paxata。DataRobot 在收入、用户数量和品牌知名度方面显示出显著增长。
-
Domino 提供工业级的强大平台,用于云端或本地的端到端数据科学和机器学习。Domino 可以作为大型独立数据科学团队的企业级数据科学和机器学习平台。Gartner 写道:“Domino 之所以被定位为愿景者,主要是因为其产品进展和路线图,这些都体现了供应商对数据科学和机器学习市场的深刻理解。”
-
谷歌一直在积极扩展其 AI/ML 产品,目前以 Google Cloud AI 作为其主要数据科学和机器学习平台。它包括 Cloud AutoML、BigQuery ML 和 TensorFlow。谷歌还拥有自己的 TPU 硬件和庞大的云基础设施。谷歌未被列入领导者,因为其 Cloud AI 平台并非独立产品。
-
H2O.ai 提供商业化的 AutoML 产品 H2O Driverless AI,并支持其开源产品 H2O-3(又名“Sparkling Water”)。H2O.ai 提供全球客户支持和一个社区 Slack 频道。H2O 保持了其愿景者的位置。
-
KNIME 提供开源的 KNIME Analytics Platform 和商业扩展 KNIME Server,具备包括协作、自动化和部署在内的高级功能。KNIME 由于相对于 Gartner 评估的其他供应商的低可见度和较慢的收入增长,从领导者象限降级为愿景者。
-
微软在本次 MQ 中核心产品是 Azure Machine Learning(Azure ML),以及支持产品 Azure ML Studio、Azure Data Factory、Azure HDInsight、Azure Databricks、Power BI 和其他相关组件。微软在愿景者象限中,在愿景和能力方面均有所进步。然而,它的执行能力受到以云优先的策略和一致性问题的限制。
-
RapidMiner 提供 RapidMiner Studio 的免费版和商业版,还有 RapidMiner Server,这是一个用于部署和维护模型及协作的企业扩展。RapidMiner 的支持产品包括 RapidMiner 实时评分、RapidMiner Radoop、RapidMiner Auto Model 等。RapidMiner 拥有庞大而活跃的用户社区。今年,RapidMiner 从领导者象限降级为愿景者,主要是由于其相对于本次 MQ 中的其他供应商增长较慢。
挑战者
只有一家企业在挑战者象限中:
-
IBM在本次 MQ 中主要产品为 Watson Studio,以及包括 Watson Machine Learning、SPSS(Modeler 和 Statistics)、IBM Decision Optimization for Watson Studio 和 IBM Streams 在内的众多支持产品。Gartner 写道
“改善其产品捆绑和相应的市场进入策略将进一步巩固 IBM 在改进其产品和跟上来自大型和小型供应商的日益激烈竞争方面的值得称赞的努力。”
小众玩家
最后,小众象限中有两家公司:
-
Anaconda 在此次 MQ 中评估的产品是 Anaconda Enterprise,这是一个基于交互式笔记本概念的数据科学开发环境。Anaconda 支持一个非常庞大且活跃的开源及企业用户社区。Anaconda 在此 MQ 中仍然是一个小众玩家。它非常适合使用 Python 或 R 的专家数据科学家,并能够利用不断更新的开源功能。然而,Anaconda 平台缺乏自动化,并且在应对不断变化的开源功能时面临复杂性。
-
Altair(DataWatch/Angoss)。2018 年 12 月,Altair 完成了对 Datawatch 的收购,而 Datawatch 于 2018 年 1 月收购了 Angoss。该公司主要的数据科学和机器学习产品叫做 Altair Knowledge Works,本次 MQ 中考虑的主要产品是 Knowledge Studio。由于在 2 年内经历了第二次收购,Altair 被视为一个小众玩家,因为这带来了风险和不确定性。
我们还注意到 SAP 在 2020 年 MQ 中被剔除。
你可以从报告中提到的几个供应商处获取 2020 年 Gartner MQ 报告,包括Alteryx,Dataiku,Databricks,Domino,RapidMiner,和TIBCO。
另见我们对往年分析的总结
-
Gartner 2018 数据科学和机器学习平台魔力象限中的赢家和输家
-
Gartner 2017 数据科学平台魔力象限:赢家和输家
-
Gartner 2016 高级分析平台魔力象限:赢家和输家
-
Gartner 2015 高级分析平台魔力象限:谁获胜,谁失利。
-
Gartner 2014 年高级分析平台魔力象限
更多相关话题
高斯朴素贝叶斯解释
原文:
www.kdnuggets.com/2023/03/gaussian-naive-bayes-explained.html

高斯朴素贝叶斯分类器的决策区域。图像由作者提供。
我认为这在每个数据科学职业生涯的开始阶段都是一个经典:朴素贝叶斯分类器。或者我应该更准确地说是朴素贝叶斯分类器家族,因为它们有很多不同的变体。例如,有多项式朴素贝叶斯、伯努利朴素贝叶斯,以及高斯朴素贝叶斯分类器,它们在一个小细节上有所不同,正如我们将要发现的那样。朴素贝叶斯算法在设计上相当简单,但在许多复杂的现实世界场景中证明了其有用性。
在这篇文章中,你可以学习到
-
朴素贝叶斯分类器是如何工作的,
-
为什么这样定义它们是有意义的,以及
-
如何使用 NumPy 在 Python 中实现它们。
你可以在 我的 GitHub 上找到代码。
查看我的贝叶斯统计入门文章 贝叶斯推断的温柔介绍 可能会有所帮助,以便熟悉贝叶斯公式。由于我们将以符合 scikit-learn 的方式实现分类器,因此查看我的文章 构建自定义 scikit-learn 回归器 也很有价值。不过,scikit-learn 的开销相当小,你仍然应该能够跟上。
我们将开始探索朴素贝叶斯分类的惊人简单理论,然后转向实现部分。
理论
我们在分类时真正感兴趣的是什么?我们实际在做什么,输入和输出是什么?答案很简单:
给定一个数据点 x,x 属于某个类别 c 的概率是多少?
这就是我们希望通过任何分类来回答的所有问题。你可以将这个陈述直接建模为条件概率:p(c|x)。
例如,如果有
-
3 个类别 c₁, c₂, c₃,以及
-
x 由 2 个特征 x₁ 和 x₂ 组成,
分类器的结果可能是这样的:p(c₁|x₁, x₂)=0.3,p(c₂|x₁, x₂)=0.5 和 p(c₃|x₁, x₂)=0.2。如果我们关心单一标签作为输出,我们会选择概率最高的那个,即这里的 c₂,概率为 50%。
朴素贝叶斯分类器尝试直接计算这些概率。
朴素贝叶斯
好的,给定一个数据点 x,我们想要计算所有类别 c 的 p(c|x),然后输出概率最高的 c。在公式中你经常看到这样的表达

图像由作者提供。
注意: max p(c|x) 返回最大概率,而 argmax p(c|x) 返回具有最高概率的 c。
但在我们能够优化 p(c|x)之前,我们必须能够计算它。为此,我们使用 贝叶斯定理:

贝叶斯定理。图片由作者提供。
这就是朴素贝叶斯中的贝叶斯部分。但是现在我们面临以下问题:p(x|c)和 p(c)是什么?
这就是朴素贝叶斯分类器训练的全部内容。
训练
为了说明所有内容,以下我们使用一个包含 两个实际特征 x₁、 x₂和 三个类别 c₁、 c₂、 c₃的玩具数据集。

数据的可视化。图片由作者提供。
你可以通过以下方式创建这个确切的数据集
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=20, centers=[(0,0), (5,5), (-5, 5)], random_state=0)
让我们从 类别概率 p(c)开始,这是观察到某个类别 c 在标记数据集中的概率。估计这个概率的最简单方法是计算类别的相对频率并将其作为概率。我们可以用我们的数据集来看这到底意味着什么。
数据集中有 20 个点中有 7 个标记为类别 c₁(蓝色),因此我们说 p(c₁)=7/20。类别 c₂(红色)也有 7 个点,因此我们设定 p(c₂)=7/20。最后一个类别 c₃(黄色)只有 6 个点,因此 p(c₃)=6/20。
这种简单的类别概率计算类似于最大似然方法。然而,如果你愿意,也可以使用其他 先验 分布。例如,如果你知道这个数据集不代表真实的总体,因为类别 c₃ 应该在 50%的情况下出现,那么你可以设定 p(c₁)=0.25、 p(c₂)=0.25 和 p(c₃)=0.5。任何有助于提高测试集性能的方法都是可行的。
现在我们转向 似然 p(x|c)=p(x₁, x₂|c)。计算这种似然的一种方法是过滤数据集中标签为 c 的样本,然后尝试找到一个能够捕捉特征 x₁、 x₂的分布(例如一个二维高斯分布)。
不幸的是,通常我们每个类别的样本不足以进行适当的似然估计。
为了建立一个更强健的模型,我们做出 朴素假设,即在给定 c 的情况下,特征 x₁、 x₂ 是随机独立的。这只是通过贝叶斯定理使数学更简单的一种花哨方式。

图片由作者提供
对于每个类别 c。这就是朴素贝叶斯中 朴素 部分的来源,因为这个方程在一般情况下是不成立的。不过,即便如此,朴素贝叶斯在实践中仍能产生良好,有时甚至是出色的结果。特别是对于具有词袋特征的自然语言处理问题,多项式朴素贝叶斯表现尤为出色。
上面给出的参数对于任何朴素贝叶斯分类器都是相同的。现在只是取决于你如何建模p(x₁|c₁), p(x₂|c₁), p(x₁|c₂), p(x₂|c₂), p(x₁|c₃)和p(x₂|c₃)。
如果你的特征只有 0 和 1,你可以使用一个Bernoulli 分布。如果它们是整数,则使用多项分布。然而,我们有实际的特征值,并决定使用高斯分布,因此称为高斯朴素贝叶斯。我们假设以下形式

图片由作者提供。
其中μᵢ,ⱼ是均值,σᵢ,ⱼ是标准差,我们需要从数据中估计。这意味着我们为每个特征i和一个类cⱼ获得一个均值,在我们的例子中是 2*3=6 个均值。标准差也是如此。这需要一个例子。
让我们尝试估计μ₂,₁和σ₂,₁。因为j=1,我们只对类c₁感兴趣,所以只保留此标签的样本。剩下的样本如下:
# samples with label = c_1
array([[ 0.14404357, 1.45427351],
[ 0.97873798, 2.2408932 ],
[ 1.86755799, -0.97727788],
[ 1.76405235, 0.40015721],
[ 0.76103773, 0.12167502],
[-0.10321885, 0.4105985 ],
[ 0.95008842, -0.15135721]])
现在,由于i=2,我们只需考虑第二列。μ₂,₁是这一列的均值,σ₂,₁是这一列的标准差,即μ₂,₁ = 0.49985176 和σ₂,₁ = 0.9789976。
如果你再次查看上面的散点图,这些数字是合理的。类c₁的样本的特征x₂大约在 0.5 左右,从图片中可以看出。
我们现在计算其他五种组合,就完成了!
在 Python 中,你可以这样做:
from sklearn.datasets import make_blobs
import numpy as np
# Create the data. The classes are c_1=0, c_2=1 and c_3=2.
X, y = make_blobs(
n_samples=20, centers=[(0, 0), (5, 5), (-5, 5)], random_state=0
)
# The class probabilities.
# np.bincounts counts the occurence of each label.
prior = np.bincount(y) / len(y)
# np.where(y==i) returns all indices where the y==i.
# This is the filtering step.
means = np.array([X[np.where(y == i)].mean(axis=0) for i in range(3)])
stds = np.array([X[np.where(y == i)].std(axis=0) for i in range(3)])
我们接收到
# priors
array([0.35, 0.35, 0.3 ])
# means
array([[ 0.90889988, 0.49985176],
[ 5.4111385 , 4.6491892 ],
[-4.7841679 , 5.15385848]])
# stds
array([[0.6853714 , 0.9789976 ],
[1.40218915, 0.67078568],
[0.88192625, 1.12879666]])
这是高斯朴素贝叶斯分类器训练的结果。
进行预测
完整的预测公式是

图片由作者提供。
假设一个新的数据点x=*(-2, 5)进入。

图片由作者提供。
为了确定它属于哪个类,让我们计算p(c|x)对于所有类。从图片来看,它应该属于类c₃ = 2,但我们来看一下。让我们暂时忽略分母p(x)。使用以下循环计算j = 1, 2, 3 的分子。
x_new = np.array([-2, 5])
for j in range(3):
print(
f"Probability for class {j}: {(1/np.sqrt(2*np.pi*stds[j]**2)*np.exp(-0.5*((x_new-means[j])/stds[j])**2)).prod()*p[j]:.12f}"
)
我们接收到
Probability for class 0: 0.000000000263
Probability for class 1: 0.000000044359
Probability for class 2: 0.000325643718
当然,这些概率(我们不应该这样称呼)不加起来是 1,因为我们忽略了分母。然而,这没有问题,因为我们可以将这些未标准化的概率除以它们的总和,这样它们的总和将加起来是 1。因此,将这三个值除以约 0.00032569 的总和,我们得到

图片由作者提供。
如我们所预期的那样,结果明显。现在,让我们实现它!
完整实现
这个实现目前还远远不够高效,也不够数值稳定,它只是用于教育目的。我们已经讨论了大部分内容,因此现在应该很容易跟进。你可以忽略所有的 check 函数,或者阅读我的文章 构建你自己的自定义 scikit-learn 如果你对它们的具体作用感兴趣。
请注意,我首先实现了一个 predict_proba 方法来计算概率。predict 方法只是调用这个方法,并使用 argmax 函数返回具有最高概率的索引(类别)。类别从 0 到 k-1,其中 k 是类别的数量。
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin
from sklearn.utils.validation import check_X_y, check_array, check_is_fitted
class GaussianNaiveBayesClassifier(BaseEstimator, ClassifierMixin):
def fit(self, X, y):
X, y = check_X_y(X, y)
self.priors_ = np.bincount(y) / len(y)
self.n_classes_ = np.max(y) + 1
self.means_ = np.array(
[X[np.where(y == i)].mean(axis=0) for i in range(self.n_classes_)]
)
self.stds_ = np.array(
[X[np.where(y == i)].std(axis=0) for i in range(self.n_classes_)]
)
return self
def predict_proba(self, X):
check_is_fitted(self)
X = check_array(X)
res = []
for i in range(len(X)):
probas = []
for j in range(self.n_classes_):
probas.append(
(
1
/ np.sqrt(2 * np.pi * self.stds_[j] ** 2)
* np.exp(-0.5 * ((X[i] - self.means_[j]) / self.stds_[j]) ** 2)
).prod()
* self.priors_[j]
)
probas = np.array(probas)
res.append(probas / probas.sum())
return np.array(res)
def predict(self, X):
check_is_fitted(self)
X = check_array(X)
res = self.predict_proba(X)
return res.argmax(axis=1)
测试实现
尽管代码非常简短,但仍然较长,无法完全确保没有任何错误。所以,让我们检查一下它与 scikit-learn 高斯 NB 分类器 的比较。
my_gauss = GaussianNaiveBayesClassifier()
my_gauss.fit(X, y)
my_gauss.predict_proba([[-2, 5], [0,0], [6, -0.3]])
输出
array([[8.06313823e-07, 1.36201957e-04, 9.99862992e-01],
[1.00000000e+00, 4.23258691e-14, 1.92051255e-11],
[4.30879705e-01, 5.69120295e-01, 9.66618838e-27]])
使用 predict 方法的预测结果是
# my_gauss.predict([[-2, 5], [0,0], [6, -0.3]])
array([2, 0, 1])
现在,让我们使用 scikit-learn。插入一些代码
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB()
gnb.fit(X, y)
gnb.predict_proba([[-2, 5], [0,0], [6, -0.3]])
结果
array([[8.06314158e-07, 1.36201959e-04, 9.99862992e-01],
[1.00000000e+00, 4.23259111e-14, 1.92051343e-11],
[4.30879698e-01, 5.69120302e-01, 9.66619630e-27]])
数字看起来与我们的分类器的结果有点类似,但在最后几个显示的数字上有一些偏差。我们做错了什么吗? 没有。 scikit-learn 版本只是使用了另一个超参数 var_smoothing=1e-09。如果我们将其设置为 零,我们就能得到完全相同的结果。完美!
看一下我们分类器的决策区域。我还标记了我们用于测试的三个点。你可以从 predict_proba 的输出中看到,那些接近边界的点只有 56.9% 的概率属于红色类别。其他两个点的分类信心要高得多。

带有三个新点的决策区域。图片来源:作者。
结论
在这篇文章中,我们了解了高斯朴素贝叶斯分类器的工作原理,并对其设计方式进行了直观的解释——这是一种直接建模感兴趣概率的方法。与逻辑回归相比,逻辑回归中概率是通过线性函数建模,并在其上应用了一个 sigmoid 函数。这仍然是一个简单的模型,但不像朴素贝叶斯分类器那样自然。
我们继续计算了几个例子,并在过程中收集了一些有用的代码片段。最后,我们实现了一个完整的高斯朴素贝叶斯分类器,并使其能够与 scikit-learn 良好配合。这意味着你可以在管道或网格搜索中使用它。
最后,我们通过导入 scikit-learn 自身的高斯朴素贝叶斯分类器,并测试我们的分类器和 scikit-learn 的分类器是否产生相同的结果,进行了一个小的正确性检查。这个测试是成功的。
罗伯特·库布勒博士 是 METRO.digital 的数据科学家以及 Towards Data Science 的作者。
原文。经许可转载。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
更多相关话题
GDPR 如何影响数据科学
评论
改编自原文发布于 Cloudera VISION 博客。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
如果你的组织收集有关欧盟(EU)公民的数据,你可能已经了解了通用数据保护条例(GDPR)。GDPR 定义并加强了对消费者的数据保护,并在欧盟内统一了数据安全规则。欧洲议会批准了这一措施,并于 2016 年 4 月 27 日通过。该条例将在不到一年的时间内生效,即 2018 年 5 月 25 日。

关于 GDPR 的大部分评论集中在新规则如何影响消费者个人信息(PII)的收集和管理。然而,GDPR 也将改变组织进行数据科学的方式。这正是本文的主题。
在开始之前有一个警告。GDPR 非常复杂。在某些领域,GDPR 定义了高层次的结果,但将详细的合规规则委托给了一个新的实体——欧洲数据保护委员会。GDPR 法规与许多国家的法律和规定交织在一起;在英国开展业务的组织还必须评估脱欧带来的未知影响。受 GDPR 约束的组织应寻求专家管理和法律顾问的帮助,以制定合规计划。
GDPR 与数据科学
GDPR 在三个领域影响数据科学实践。首先,GDPR 对数据处理和消费者画像施加了限制。其次,对于使用自动化决策的组织,GDPR 为消费者创造了“解释权”。第三,GDPR 要求公司对自动化决策中的偏见和歧视负责。
数据处理和分析。GDPR 对数据处理和消费者分析施加控制;这些规则补充了数据收集和管理的要求。GDPR 将分析定义为:
任何形式的个人数据自动化处理,包括使用个人数据评估与自然人相关的某些个人方面,特别是分析或预测有关自然人在工作中的表现、经济状况、健康、个人偏好、兴趣、可靠性、行为、位置或移动的方面。
一般而言,组织在能够证明合法商业目的(如客户或雇佣关系)且不与消费者的权利和自由相冲突时,可以处理个人数据。组织必须告知消费者分析及其后果,并提供选择退出的机会。
解释权。GDPR 赋予消费者“不得仅基于自动化处理作出决策,并对当事人产生法律效力”的权利。专家将这一规则称为“解释权”。GDPR 并未精确定义该部分涵盖的决策范围。英国信息专员办公室(ICO)表示该权利“很可能”适用于信用申请、招聘和保险决策。其他机构、法院或欧洲数据保护委员会可能会对这一范围作出不同的定义。
偏见和歧视。当组织使用自动化决策时,他们必须防止基于种族或民族出身、政治观点、宗教或信仰、工会成员身份、基因或健康状况或性取向的歧视性效果,或导致产生这种效果的措施。此外,他们不得在自动化决策中使用特定类别的个人数据,除非在规定的情况下。
GDPR 对数据科学实践的影响
新规则将如何影响数据科学团队的工作方式?让我们在三个关键领域探讨其影响。
数据处理和分析。新规则允许组织出于特定商业目的处理个人数据,履行合同义务,并遵守国家法律。信用卡发行机构可以处理个人数据以确定持卡人的可用信用额度;银行可以根据监管机构的要求筛查交易以防止洗钱。消费者不能选择退出在这些“安全港”下进行的处理和分析。
然而,组织不得在未经消费者额外许可的情况下将个人数据用于原意之外的目的。这一要求可能限制了可用于探索性数据科学的数据量。
GDPR 对数据处理和数据分析的限制仅适用于能够识别个人消费者的数据。
因此,数据保护原则不应适用于……以使数据主体无法识别或不再能够识别的方式匿名化的个人数据。因此,本法规不涉及此类匿名信息的处理,包括用于统计或研究目的。
明确的含义是,受 GDPR 约束的组织必须在数据工程和数据科学流程中建立稳健的匿名化机制。
可解释的决策。 对这一条款的影响存在一些争议。一些人欢呼它;另一些人不赞成;还有一些人否认GDPR 创造了这样的权利。一位欧盟法律专家认为,该要求可能迫使数据科学家停止使用不透明的技术(如深度学习),这些技术可能难以解释和理解。
毫无疑问,GDPR 将影响组织处理某些决策的方式。然而,对数据科学家的影响可能被夸大了:
“解释权”在范围上是有限的。如上所述,某些监管机构将法律解释为涵盖信用申请、招聘和保险决定。其他监管机构或法院可能会有不同的解释,但很明显,这项权利适用于特定场景,而不适用于所有自动化决策。
在许多司法管辖区,“解释权”已经存在且存在多年。例如,英国的信用决定监管规定与美国类似,美国的发行商必须提供对基于信用局信息的负面信用决定的解释。GDPR 扩大了这些规则的适用范围,但今天已经有商业化的合规工具。
大多数拒绝一些客户请求的企业理解,负面决定应该向客户解释。这在贷款和保险行业已经是普遍做法。一些企业将负面决定视为推广替代产品的机会。
— 需要提供解释会影响决策引擎,但不必影响模型训练的方法选择。现有技术使得即使数据科学家使用不透明的方法来训练模型,也可以“逆向工程”出可解释的模型评分解释。
尽管如此,数据科学家确实有充分的理由考虑使用可解释的技术。金融服务巨头 Capital One 认为这些技术是对抗隐性偏见(如下文所述)的有力武器。但不应因此得出结论,GDPR 将迫使数据科学家限制他们用于训练预测模型的技术。
偏见与歧视。 GDPR 要求组织必须避免在自动化决策中出现歧视性效果。这一规则对建立预测模型的数据科学家以及组织批准预测模型用于生产的程序施加了额外的尽职调查负担。
使用自动化决策的组织必须:
-
确保公平和透明的处理
-
使用适当的数学和统计程序
-
建立措施以确保在决策中使用的主题数据的准确性
GDPR 明确禁止在自动化决策中使用个人特征(如年龄、种族、民族和其他列举的类别)。然而,仅仅避免使用这些数据是不够的。禁止歧视性结果的规定意味着数据科学家还必须采取措施防止由代理变量、多重共线性或其他原因引起的间接偏倚。例如,使用看似中立的特征(如消费者的居住社区)的自动决策可能会无意中对少数民族群体造成歧视。
数据科学家还必须采取积极措施确认他们在开发预测模型时使用的数据是准确的;“垃圾进/垃圾出”或 GIGO,不能成为借口。他们还必须考虑以往结果的偏倚训练数据是否会影响模型。结果是,数据科学家需要关注数据血统,追踪数据从源头到目标的所有处理步骤。GDPR 还将推动对可重复性的更大关注,即准确复制预测建模项目的能力。
下一步
如果你在欧盟开展业务,现在是开始规划 GDPR 的时机。需要做的事情很多:评估你收集的数据,实施合规程序,评估你的处理操作等。如果你目前使用机器学习进行分析和自动决策,你现在需要做四件事。
限制对消费者个人身份信息(PII)的访问。
实施稳健的匿名化,以便默认情况下分析用户无法访问 PII。定义一个允许在特殊情况下在适当安全下访问 PII 的例外过程。
识别当前使用 PII 的预测模型。
在每种情况下,询问:
-
这些数据在分析上是否必要?
-
这些 PII 是否提供独特且不可替代的信息价值?
-
预测模型是否支持被允许的使用案例?
盘点面向消费者的自动化决策。
-
识别需要解释的决策。
-
实施程序以处理消费者的问题和担忧。
建立一个能够最小化错误和偏见风险的数据科学流程。
-
实施一个确保模型开发和测试正确的工作流程。
-
考虑训练数据中可能存在的“内建”偏见。
-
严格测试和验证预测模型。
-
实施同行评审,以独立评估每个模型。
即使你的组织不受 GDPR 约束,也可以考虑实施这些实践。这是正确的商业方式。
原文。经允许转载。
简介:托马斯·W·丁斯莫尔 最近加入 Cloudera,担任数据科学产品营销总监。此前,作为独立顾问,他为寻求机器学习市场情报的私人客户提供了市场见解。
相关:
-
数据科学治理 - 为什么重要?为什么现在?
-
数据匿名化与数据科学的未来
-
算法偏见的基础
更多相关主题
GDPR 会使机器学习变得非法吗?
原文:
www.kdnuggets.com/2018/03/gdpr-machine-learning-illegal.html
评论 欧盟通用数据保护条例,即 GDPR,是 21 世纪数据隐私法规中的重大变革,并将于 2018 年 5 月 25 日生效。
欧盟通用数据保护条例,即 GDPR,是 21 世纪数据隐私法规中的重大变革,并将于 2018 年 5 月 25 日生效。
这将对数据收集和处理欧盟公民数据的许多方面产生重大影响,并将影响到不仅是欧盟公司,还包括在欧盟运营的跨国公司。
GDPR 对机器学习的一个可能且重要的影响是“解释权”。
GDPR 的一些条款可以解释为要求对机器学习算法做出的决策进行解释,尤其是当其应用于人类对象时。
UW 的 Pedro Domingos 教授,一位领先的人工智能研究员,通过他的推文引发了轩然大波。
从 5 月 25 日起,欧盟将要求算法解释其输出,这将使深度学习成为非法行为。— Pedro Domingos (@pmddomingos) 2018 年 1 月 29 日
GDPR 是否真的要求对机器学习算法进行解释?
我们应该区分
-
全球解释:机器学习算法如何工作(这对于复杂的方法如深度学习可能非常困难)以及
-
本地解释:哪些因素影响了特定个人的决策(较容易)。已有一些算法,如 LIME: 本地可解释的模型无关解释,可以解释任何机器学习分类器的预测结果。
比如,如果一个人被拒绝抵押贷款,她是否应该知道哪些因素影响了这一决定?一方面,如果算法拒绝了你,你会想知道原因并有机会上诉。另一方面,过多的解释可能会使决策边界被逆向工程,从而让潜在的不法分子操控系统。在许多情况下这是非常不希望出现的(例如,安全应用)。
我向 ,一位欧盟律师,牛津大学大数据、人工智能与机器人伦理法律研究员,(@SandraWachter5 在 Twitter 上)询问了这个问题。
她说,GDPR 要求数据控制者采取适当措施保护数据主体的权利、自由和合法利益。这些措施应包括让数据主体获得人工干预、表达观点和争议决定的方法。
她的观点还包括第 15 条暗示了一种更一般形式的监督,而不是对特定决策的解释权。
因此,《GDPR》中的解释权在法律上并不具约束力,但可以自愿提供。
以下是 Sandra 博客的摘录,走向欧洲负责任的 AI?,经许可转载。
AI 及其挑战
基于 AI 的系统常常是不透明的“黑箱”,难以审查。随着我们经济、社会和公民互动越来越多地由算法进行——从信用市场和健康保险申请,到招聘和刑事司法系统——对技术透明度不足的担忧也随之增加,这使得个人对决策如何作出了解甚少。我们需要适当的保障措施,确保对我们作出的决策确实公平准确。
AI 与欧盟通用数据保护条例
2016 年,欧盟通用数据保护条例(GDPR),欧洲的新数据保护框架,已获批准。新法规将于 2018 年在整个欧洲——包括英国——生效。人们广泛且反复声称,新法规将强制要求对自动化或人工智能算法系统作出的所有决策提供“解释权”。这种“解释权”被视为增强自动化算法决策透明度和问责制的理想机制。
这种权利将使人们能够询问如何作出特定的决策(例如,保险被拒或晋升被拒)。
解释可以通过各种方式提供。至少有两种可能的算法解释:对“系统功能”的解释和对个体决策“理由”的解释。解释用于评估信用价值或设定利率的算法方法(系统功能)与解释“如何”设定某个利率或“为什么”信用卡申请被拒绝的解释并不相同。
我们与图灵研究人员 Dr. Brent Mittelstadt 和 Prof. Luciano Floridi 一起研究了这一声明。不幸的是,与预期相反,我们的研究揭示 GDPR 可能只会赋予个人有关自动决策存在性和“系统功能”的信息,但没有对决策理由的解释。事实上,在整个 GDPR 中,“解释权”只在第 71 前言中提到过一次,这一前言没有法律效力来建立独立的权利。前言的目的是在框架的操作部分存在歧义时提供解释,但在我们的研究中,我认为对于需要进一步澄清的最低要求并不存在歧义。
将“解释权”放在前言中,并且欧洲议会关于将这一权利具有法律约束力的建议未被采纳,这表明欧洲立法者并不想赋予这一概念与 GDPR 第 22 条中的其他保护措施相同的法律地位。当然,这并不意味着数据控制者不能自愿决定提供解释,或者未来的法律或以此前言为基础的法律可能会在未来创造这样的权利。
欲了解更多细节,请收听与 Sandra Wachter 讨论算法、解释和 GDPR 的播客。
一种可能的解释解决方案是反事实,例如
你被拒绝贷款是因为你的年收入为 30,000 英镑。如果你的收入是 45,000 英镑,你就会获得贷款。
由 Sandra Wachter、Brent Mittelstadt 和 Chris Russell 撰写的论文《无需揭开黑箱的反事实解释:自动决策与 GDPR》展示了即使使用高度复杂的系统,也能为人们提供有意义的解释,而无需理解算法的内部逻辑。使用反事实也不太可能侵犯商业秘密。另见关于反事实的访谈。
然而,Sandra 认为 GDPR 中没有解释权的观点并未被其他专家完全认同。
Andrew D. Selbst 和 Julia Powles 在《有意义的信息与解释权》中写道,
在欧洲新的《通用数据保护条例》(GDPR)中,没有单一明确标示为“解释权”的法定条款。但这并不意味着这样的权利是虚幻的。
第 13-15 条文章赋予了“关于自动化决策中涉及的逻辑的有意义信息”的权利。这是一种解释权,无论是否使用这一说法。
安德鲁·伯特在 GDPR 中是否存在机器学习的“解释权”? 中写道
像其他领域一样,GDPR 并不十分明确。因此,GDPR 是否要求机器学习模型提供“解释权”——即那些受模型显著影响的人员是否有权知道模型如何做出特定决策——已成为一个有争议的话题。例如,一些学者强烈反对这种权利的存在可能性。另一些人,如英国信息专员办公室,似乎认为这一权利是显而易见的。
最终,我有一些好消息要告诉律师和隐私专业人士……也有一些可能对数据科学家来说不太好的消息。
GDPR 中似乎存在足够的模糊性,使得律师们忙得不可开交。
敬请关注!
相关内容:
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关内容
机器学习过程的框架
原文:
www.kdnuggets.com/2018/05/general-approaches-machine-learning-process.html
比较机器学习过程的方法是否值得?这些框架之间是否存在根本性的差异?
尽管 经典方法 存在且存在已久,但从新的和不同的角度咨询仍然值得,原因有很多:我是否遗漏了什么?是否有之前未考虑的新方法?我是否应该改变处理机器学习的视角?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
我最近遇到的两个最相关的资源概述了处理机器学习过程的框架,分别是 Yufeng Guo 的 机器学习的 7 个步骤 和 Francois Chollet 的 用 Python 深度学习 第 4.5 节。这些是否与您目前处理类似任务的方式有所不同?
以下是这两种监督机器学习方法的概要、简要比较,以及尝试将它们融合成一个第三个框架,以突出(监督)机器学习过程中的最重要领域。
机器学习的 7 个步骤
实际上,我是通过先观看 他的一个视频 在 YouTube 上发现郭的文章的。该帖子与视频的内容相同,因此如果有兴趣,任一资源都足够。

郭的步骤如下(我稍作了些即兴发挥):
-
数据收集
→ 数据的数量和质量决定了我们的模型准确性
→ 这一阶段的结果通常是数据的表示(郭将其简化为指定一个表),我们将用来进行训练
→ 使用预先收集的数据,例如来自 Kaggle、UCI 等的数据集,仍然符合这一步骤
-
数据准备
→ 整理数据并为训练做好准备
→ 清理可能需要的内容(移除重复项、纠正错误、处理缺失值、标准化、数据类型转换等)
→ 随机化数据,这可以消除我们收集和/或准备数据时特定顺序的影响
→ 可视化数据以帮助检测变量之间的相关关系或类别不平衡(偏差警报!),或进行其他探索性分析
→ 划分为训练集和评估集
-
选择模型
→ 不同的算法适用于不同的任务;选择合适的算法
-
训练模型
→ 训练的目标是尽可能准确地回答问题或做出预测
→ 线性回归示例:算法需要学习m(或W)和b(x是输入,y是输出)
→ 每次过程迭代都是一个训练步骤
-
评估模型
→ 使用某种度量或度量组合来“衡量”模型的客观性能
→ 在之前未见过的数据上测试模型
→ 这些未见数据旨在某种程度上代表模型在实际世界中的表现,但仍有助于调整模型(与测试数据不同,测试数据没有这样的作用)
→ 良好的训练/评估划分?80/20、70/30 或类似的,取决于领域、数据可用性、数据集细节等
-
参数调整
→ 这一步指的是超参数调整,这是一种“艺术形式”,而不是科学
→ 调整模型参数以提高性能
→ 简单的模型超参数可能包括:训练步骤数、学习率、初始化值和分布等
-
进行预测
→ 使用进一步(测试集)数据,这些数据在此之前一直被保留在模型之外(且已知类别标签),用于测试模型;更好地近似模型在实际世界中的表现
机器学习的通用工作流程
在他的书的第 4.5 节中,Chollet 概述了机器学习的通用工作流程,他将其描述为解决机器学习问题的蓝图:
这个蓝图将我们在本章中学到的概念联系起来:问题定义、评估、特征工程和抗过拟合。
这与上述郭的框架相比如何?让我们看看 Chollet 的 7 个步骤(记住,虽然没有明确说明专门针对它们,但他的蓝图是为神经网络的书籍而写的):
-
定义问题并组建数据集
-
选择成功的衡量标准
-
决定评估协议
-
准备你的数据
-
开发一个表现优于基线的模型
-
扩展:开发一个过拟合的模型
-
正则化你的模型并调整参数
来源:斯坦福大学 Andrew Ng 的机器学习课程
Chollet 的工作流程更高层次,更多关注于将模型从良好提升到卓越,而 Guo 的方法则更关注于从零开始到良好。虽然它并不会为了做到这一点而舍弃其他重要步骤,但其蓝图更强调超参数调整和正则化以追求卓越。这里的简化似乎是:
良好模型 → “过于优秀”的模型 → 缩减回“可泛化”的模型
制定简化框架
我们可以合理地得出结论,Guo 的框架勾勒出了一种“初学者”机器学习过程,更明确地定义了早期步骤,而 Chollet 的方法则更为高级,强调了模型评估的明确决策和机器学习模型的调整。这两种方法都同样有效,并没有本质上的不同;你可以将 Chollet 的方法叠加在 Guo 的方法之上,虽然两个模型的 7 个步骤不完全对齐,但它们最终会覆盖相同的任务。
将 Chollet 的方法与 Guo 的方法对照,这里是我看到步骤对接的地方(Guo 的步骤编号,Chollet 的步骤则列在相应的 Guo 步骤下方,Chollet 工作流程步骤的编号在括号中):
-
数据收集
→ 定义问题并组装数据集(1)
-
数据准备
→ 准备你的数据(4)
-
选择模型
-
训练模型
→ 开发一个优于基线的模型(5)
-
评估模型
→ 选择成功的衡量标准(2)
→ 决定评估协议(3)
-
参数调整
→ 扩展:开发一个过拟合的模型(6)
→ 对你的模型进行正则化和参数调整(7)
-
预测
这并不完美,但我坚持这样做。
在我看来,这提出了一个重要的问题:这两个框架达成了一致,并共同强调了框架中的特定要点。应该明确的是,模型评估和参数调整是机器学习的重要方面。其他被一致认可的重要领域还包括数据的组装/准备以及原始模型的选择/训练。
一个简化的机器学习过程
让我们利用上述内容来组成一个简化的机器学习框架,即机器学习过程的 5 个主要领域:
-
数据收集与准备
→ 从选择数据来源到数据清理并准备进行特征选择/工程的整个过程
-
特征选择和特征工程
→ 这包括从数据清理完成后到数据被输入机器学习模型之间的所有变化
-
选择机器学习算法并训练我们的第一个模型
→ 获得一个“优于基线”的结果,基于此我们可以(希望)进行改进
-
评估我们的模型
→ 这包括度量的选择以及实际评估;看似比其他步骤小,但对我们的最终结果很重要。
-
模型调整、正则化和超参数调优
→ 这是我们从“足够好”的模型逐步过渡到最佳努力的过程。
那么,你应该使用哪个框架?是否真的存在重要的差异?郭和肖莱特所介绍的框架是否提供了之前所缺少的东西?这个简化的框架是否提供了实际的好处?只要涵盖了基础,并且处理了框架之间明确存在的任务,那么选择这两个模型中的任何一个,结果都会相同。你的视角或经验水平可能会偏好其中一个。
正如你可能已经猜到的,这实际上更多的是关于一个合理的机器学习过程应该是什么样子,而不是决定或比较特定框架。
Matthew Mayo (@mattmayo13) 是数据科学家以及 KDnuggets 的主编,KDnuggets 是一个重要的数据科学和机器学习在线资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及自动化机器学习方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系到。
了解更多相关话题
通才主导数据科学
原文:
www.kdnuggets.com/2018/02/generalists-dominate-data-science.html
评论
作者:拉塞尔·朱尔尼。
分析产品和系统最好由小型通才团队构建。大型专家团队容易受到沟通开销的主导影响,且“中文 whispers”的效果扭曲任务流程,阻碍创造力。数据科学家应发展通才技能,以成为数据科学团队中更高效的成员。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
数据科学:一项团队运动
构建数据产品需要一个涵盖广泛且多样化技能的团队。从一端的客户代表,到另一端的运营工程师,产品分析团队的角色范围如下:

大公司通常会为每个角色配备一双鞋子,从而形成一个像下面这样的十二人团队。这个设置的问题在于,达成共识和执行跨角色的任务变得更加困难。而在数据科学中,大多数任务都涉及跨角色的合作。

将图表添加到数据产品中
以一个具体的例子来看,让我们关注将图表作为数据产品的一部分进行创建。首先,产品经理创建一个规格说明,然后交互设计师设计图表,交给数据科学家填充数据(并且希望能探索数据并找到值得制作的图表),接着由后端工程师设置一个 API 以获取这些数据,然后由前端网页开发人员使用这些数据创建一个与设计图相符的网页,最后由体验设计师确保整个过程感觉合理且有意义。

图表需要迭代,因此这种沟通循环可能会重复发生。你可以看到沟通开销如何开始占据主导地位。一个由六人组成的会议就是一个完整的正式会议。在正式会议中完成事情非常困难。
在下一个图示中,我们看到一个数据产品团队可能由四名通才组成:一名数据工程师、一名数据科学家/后端开发人员、一名可以构建前端的设计师和一名能编写营销文案及洽谈交易的产品经理。这就是一个创业团队如何覆盖技能谱的方式,你可以看到这如何使他们更高效。

回到图表示例,创建一个图表成为产品经理、一个会编码的设计师和一个数据科学家的合作。这是那种 2 到 3 人的临时会议,在这种会议中,“事情会高效完成”。这个小组将比六人小组更高效。换句话说:这个小团队将击败大型团队。
在大公司系统中,有时唯一高效完成任务的方式就是成为“游击通才”,与其他通才合作以省略中间环节。这在政治上是不利的,也正是这部分原因使得高效的人才离开大公司。
结论
我们已经证明,小型通才团队比大型专业团队表现更好。事实上,通才技能是每个数据科学家都应该努力发展的。这并不意味着你不能专注于某一领域,而是应将专业化与通才结合,以发展“T 型技能”。T 型员工能够在多个项目中提供深度专业知识,同时在自己的角色中承担多重职责。
发展通才技能需要时间,这就是为什么成为数据科学家的道路不是六个月的训练营,而是十年的旅程。在这条道路上,记得努力成为 T 型人才!
附录
需要帮助构建分析产品或平台吗?数据综合症团队由数据科学家和数据工程师组成,提供数据产品和系统的服务。我们还为数据科学团队的所有成员提供敏捷数据科学培训。
简介: 拉塞尔·贾尼 是数据综合症的首席顾问,全栈数据产品黑客,以及数据科学团队领导。
原文。经许可转载。
相关
更多相关话题
介绍广义积分梯度(GIG):解释多样化集成机器学习模型的实用方法
原文:
www.kdnuggets.com/2020/01/generalized-integrated-gradients-explaining-ensemble-models.html
评论
由 Jay Budzik,Zest AI的首席技术官
-
集成机器学习模型提供比单一机器学习模型更高的预测准确性和稳定性,正如我们在之前的文章 集成模型更优中所展示的那样。 但集成模型使用常见的方法如 SHAP 和积分梯度难以解释和信任。
-
Zest 开发了一种新的方法来解释复杂的集成模型,称为广义积分梯度,使其在诸如信用风险承保等应用中安全使用。与其他方法不同,GIG 直接遵循一小套合理规则,无需任意假设。
为什么需要一种新的信用分配方法
机器学习已被证明能产生更好的承保结果并减少贷款中的偏见。但并非所有的机器学习技术,包括在无监管使用中广泛应用的那些,都建立在透明的基础上。许多部署的算法生成的结果难以解释。最近,研究人员提出了新颖而强大的方法来解释机器学习模型,特别是 Shapley 加性解释(SHAP 解释器)和 积分梯度(IG)。这些方法提供了分配模型用于生成评分的数据变量的机制。它们通过将机器学习模型表示为一个游戏来工作:每个变量是一个玩家,游戏的规则是模型的评分函数,游戏的价值是模型给出的分数。在 合作博弈中,信用分配是一个被很好理解的问题。
SHAP使用各种方法来计算 Shapley 值,这些方法在原子游戏中表现良好,通过系统地去除每个变量重新计算模型结果,从而识别出最重要的变量。当算法是神经网络时,它运行的是无穷小的微型游戏,这些游戏单独来看并不重要,但在整体中却有意义,因此你需要集成梯度来解释模型。IG 使用 Aumann-Shapley 值来理解两个申请人之间模型评分的差异。它量化了每个输入变量对模型评分差异的贡献。毕竟,根据模型的不同,一些变化比其他变化更重要,因此我们的任务是测量模型认为哪些变化更重要或不重要。
这两者在各自领域都是很好的创新,但它们都未能为混合类型模型提供令人满意的信用分配,这些模型通常能取得最佳效果。正如我们在早期文章中所解释的(为什么不直接使用 SHAP),SHAP 包中实现的解释器要么要求变量在统计上是独立的,要么要求缺失值可以用平均值替代。这两种情况在金融服务中都是不可行的。IG 要求模型在各处都是可微分的,这对决策树并不适用,因此它仅适用于像神经网络这样的模型。
像谷歌、Facebook 和微软这样的科技巨头多年来一直在利用集成机器学习的优势。它们构建了使用决策树、神经网络以及全套建模数学的模型,但它们不受像金融服务公司那样的监管约束。银行和贷款机构将极大受益于将这些同样高级的模型应用于信用审批和欺诈检测等领域。(请查看我们的近期文章,介绍了一种新的集成方法——深度堆叠,这种方法为一家小型贷款机构带来了 1300 万美元的利润,并提供了一个更准确且稳定的模型。)
所有的迹象都表明,需要一种新的方式来解释复杂的集成机器学习模型,以适用于高风险应用,例如信用和贷款。这就是我们发明 GIG 的原因。
介绍广义集成梯度
广义积分梯度(GIG)是 Zest AI 的新信用分配算法,通过应用测度理论的工具,克服了 Shapley 和 Aumann-Shapley 的局限性。GIG 是 IG 的正式扩展,能够准确分配更广泛模型类别的信用,包括当前机器学习领域几乎所有使用的评分函数。GIG 是唯一可以严格计算每个变量在多样化模型集中的贡献的方法。
GIG 在解释复杂机器学习模型方面的优势在于它避免了对数据进行不现实和潜在危险的假设。GIG 直接遵循其公理。使用 SHAP 和其他基于 Shapley 值的方法,你必须将输入变量映射到更高维空间中,以使值适用于机器学习函数。这种映射方式不计其数,尚不清楚哪一种是正确的映射。相比之下,GIG 完全由数学决定。
GIG 通过直接分析模型函数的各个部分来分配信用,以回答“哪些输入变量导致了模型得分的变化?”这个问题。它通过沿着从第一个输入到另一个输入的路径累积模型得分的变化来衡量每个变量的重要性,使用一种独特的公式计算每个变量导致预测函数得分变化的量。
应用于实际的信用风险模型
为了展示 GIG 的能力,我们用它来解释一个基于实际借贷数据的混合集成模型。该模型如下面所示,之前已被引用,是一个由 4 个 XGBoost 模型和 2 个神经网络模型组成的堆叠集成模型。

图 1:深度堆叠的集成模型:训练数据用于训练多个子模型,其中一些可能是树模型,如 XGBoost,其他则是神经网络,然后将这些模型与输入一起进行集成,形成一个更大的模型,使用神经网络。
在任何模型可解释性任务中的基本要求是准确量化模型中每个特征的重要性。我们进行了一系列实验(在我们的论文中描述),表明 GIG 准确量化了简单模型中变量的影响。这些实验基于已知的输入数据变化构建了一系列玩具模型,并显示 GIG 能够准确描绘模型从故意修改的数据中学到的内容。这里,我们查看了实际应用。表 1 显示了图 1 中更复杂集成模型的特征重要性。该表显示 GIG 甚至能够解释这个更复杂的实际模型。
| 特征定义 | 重要性 |
|---|---|
| 当前收入来源的比例 | 0.045763 |
| 全职工作的数量 | 0.028215 |
| 雇主的数量 | 0.025663 |
| 当前收入来源的数量 | 0.020645 |
| 申请人是否申请了破产 | 0.020339 |
| 申请人是否有第七章破产记录 | 0.020039 |
| 每月收入来源的数量 | 0.017467 |
| 大多数收入来源是当前的 | 0.016271 |
| 债务与收入比 | 0.015139 |
| 收入来源中来自就业的比例 | 0.011887 |
| 申请人是否被免除破产记录 | 0.010515 |
| 申请人是否有第十三章破产记录 | 0.010456 |
表 1:图 1 中显示的集合模型的特征重要性。除了计算整体特征重要性,GIG 还允许你量化每个申请人及不同人群(例如表现最好的贷款和表现最差的贷款,或者导致男女申请人批准率差异的变量)的特征重要性。
GIG 的工作原理
正如我们之前提到的,GIG 是基于 IG 和 奥曼-沙普利 的差异化信用分配函数。差异化信用分配解答了每个输入变化导致模型评分变化的多少。你比较两位申请人的输入集及模型返回的违约可能性(例如,一位申请人可能被拒绝,另一位申请人可能获得批准)。GIG 显示了每个输入变量对导致批准/拒绝决策的评分变化的贡献。
让我们可视化一下这一切是如何运作的。图 2 显示了一组绿色的获批申请人和一组红色的被拒绝申请人。被拒绝的申请人有较高的拖欠和破产记录。获批申请人则相反。

图 2。该模型考虑了两个变量:破产和拖欠。获得批准的申请人具有低破产和低拖欠记录。而被拒绝的申请人则有高破产和高拖欠记录。
差异化信用分配函数,如 GIG,通过比较每个获批申请人与每个被拒绝申请人之间的差异来解释两类申请人之间的区别:你基本上是在计算每对获批和被拒绝申请人之间的拖欠和破产差异,并取平均值。该过程在下面的图 3 中进行了说明。

图 3。被拒绝申请人(红色)与获批申请人(绿色)之间的评分差异可以通过拖欠和破产次数的差异来解释。
这仅用于说明,图表中缺少模型分数。图 4 显示了更现实的情况,它展示了模型分数如何随着违约和破产变量的变化而在被拒绝的申请人与批准的申请人之间的路径上变化。IG 方法使用 Aumann-Shapley 值来计算违约和破产对模型分数变化的贡献。

图 4. 这里模型分数由 y-轴表示。违约计数和破产在 x- 和 z- 轴上表示。沿被拒绝的申请人(红点)和批准的申请人(绿点)之间的路径的部分导数积分表示每个变量、违约 x 和破产 z 对模型分数 y 的 Aumann-Shapley 贡献。
一个模型可以具有任意数量的维度,Aumann-Shapley 可以适应它们。但正如我们之前所说,Aumann-Shapley 值仅适用于像神经网络这样的光滑函数。图 5 说明了 Aumann-Shapley(因此 IG)无法解释的函数组合的简单示例。

图 5. 函数组成的示例。这里的离散部分是红色的,表示在 x=1.75 处有跳跃不连续性的决策树。连续部分用蓝色表示。这两个函数的组合以绿色显示。组合函数在 x=1.75 处包含跳跃不连续性,就像它的离散部分一样。这些类型的函数不能通过 Shapley 或 Aumann-Shapley 充分解释,需要像 GIG 这样的不同方法。
GIG 首先枚举离散函数中的所有不连续点(例如,通过对模型决策树的深度优先搜索),并计算每个不连续点左右的离散函数值。它根据这两个值的平均值分配信用,如下图 6 的左面板所示。对连续部分分配的信用是使用 IG 计算的(图 6 的右面板)。然后将离散和连续的贡献合并,得到一个高度准确的综合贡献。

图 6. GIG 通过计算跳跃处的信用,方法是平均离散部分左右的值,然后与 Aumann-Shapley 在连续部分分配的信用相结合来工作。
详细信息包含在 GIG 可解释 ML 论文 中,该论文还数学证明了 GIG 是在一组合理公理下计算这些混合模型信用分配的唯一方法。
结论
集成模型比任何单一建模方法产生更好的结果,但之前一直难以准确解释。我们介绍了一种新方法,广义集成梯度,这是在一小组合理公理下唯一能够解释我们在实际机器学习应用中经常遇到的多样集成和函数组合的方法,例如在金融服务中。GIG 使得在你的贷款业务中使用这些先进、更有效的模型成为可能,从而在提供更多良好贷款的同时减少不良贷款,并且能够向消费者、监管者和业务负责人解释结果。
原文。经许可转载。
简介:Jay Budzik 是 Zest AI 的首席技术官。
相关:
-
机器学习中的集成方法:AdaBoost
-
可解释性:揭开黑箱,第一部分
-
众多智慧胜过一人:集成学习的案例
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关主题
广义且可扩展的最佳稀疏决策树 (GOSDT)
原文:
www.kdnuggets.com/2023/02/generalized-scalable-optimal-sparse-decision-treesgosdt.html

图片来源 fabrikasimf 在 Freepik
我经常谈论可解释 AI(XAI)方法及其如何被调整以解决一些阻碍公司构建和部署 AI 解决方案的痛点。如果你需要快速回顾 XAI 方法,可以查看我的 博客。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织的 IT
一种这样的 XAI 方法是决策树。由于其可解释性和简洁性,决策树历史上获得了显著的关注。然而,许多人认为决策树不能准确,因为它们看起来简单,而像 C4.5 和 CART 这样的贪婪算法不能很好地优化它们。
这个说法部分有效,因为某些变体的决策树,如 C4.5 和 CART,具有以下缺点:
-
易于过拟合,特别是当树变得过深且分支过多时。这可能会导致在新数据上的表现不佳。
-
由于需要根据输入特征的值做出多个决策,因此在大数据集上评估和预测可能会比较慢。
-
处理连续变量可能很困难,因为它们要求将变量划分为多个更小的区间,这可能会增加树的复杂性,并使识别数据中的有意义模式变得困难。
-
通常被称为“贪婪”算法,它在每一步做出局部最优决策,而不考虑这些决策对未来步骤的影响。次优树是 CART 的输出,但没有“真正的”指标来衡量它。
更复杂的算法,如集成学习方法,可以解决这些问题。但通常它们被认为是“黑箱”,因为算法的底层工作机制不透明。
然而,近期的研究表明,如果优化决策树(而不是使用像 C4.5 和 CART 这样的贪婪方法),它们可以在许多情况下与黑箱模型一样准确。GOSDT 是一个可以帮助优化并解决上述一些缺点的算法。GOSDT 是一个生成稀疏最优决策树的算法。
本博客旨在对 GOSDT 进行温和的介绍,并展示如何在数据集上实现它的示例。
本博客基于几位优秀人士发表的研究论文。你可以在这里阅读这篇论文。这个博客并不是该论文的替代品,也不会涉及极其数学化的细节。这是为数据科学从业者提供的指南,用于了解这个算法并在日常用例中加以利用。
简而言之,GOSDT 解决了几个主要问题:
-
能够很好地处理不平衡数据集并优化各种目标函数(不仅仅是准确率)。
-
完全优化树,而不是贪婪地构建它们。
-
它几乎与贪婪算法一样快,因为它解决了决策树的 NP-hard 优化问题。
GOSDT 树如何解决上述问题?
-
GOSDT 树通过哈希树使用动态搜索空间来提高模型的效率。通过限制搜索空间并使用边界来识别相似变量,GOSDT 树可以减少找到最佳切分所需的计算次数。这可以显著提高计算时间,特别是在处理连续变量时。
-
在 GOSDT 树中,切分的边界应用于部分树,并用于从搜索空间中消除许多树。这使得模型可以专注于剩余的树(这可以是部分树)并更高效地评估它。通过减少搜索空间,GOSDT 树可以快速找到最佳切分,并生成更准确、更易解释的模型。
-
GOSDT 树旨在处理不平衡数据,这在许多实际应用中是一个常见挑战。GOSDT 树通过加权准确度指标来解决不平衡数据,该指标考虑了数据集中不同类别的相对重要性。当有一个预定的准确度阈值时,这尤其有用,因为它允许模型专注于正确分类对应用更关键的样本。
总结 GOSDT 的观察结果
-
这些树直接优化了训练准确率和叶子数量之间的权衡。
-
以合理数量的叶子生成优秀的训练和测试准确率
-
非常适合高度非凸问题
-
最适合小型或中等数量的特征。但它可以处理多达数万个观测值,同时保持其速度和准确性。
是时候看到所有实际操作了!!在我之前的博客中,我使用 Keras 分类解决了一个贷款申请批准问题。我们将使用相同的数据集来构建一个使用 GOSDT 的分类树。
代码示例
作者代码
Supreet Kaur 是摩根士丹利的副总裁。她是一位健身和科技爱好者,同时也是名为 DataBuzz 的社区的创始人。
更多相关内容
如何使用 Python 生成自动化 PDF 文档
原文:
www.kdnuggets.com/2021/06/generate-automated-pdf-documents-python.html
评论
作者:Mohammad Khorasani,数据科学家/工程师混合型人才

由Austin Distel拍摄,发布在Unsplash。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的信息技术
上一次你处理 PDF 文档是什么时候?你可能不需要回顾太远就能找到答案。我们在日常生活中处理了大量文档,其中绝大多数确实是 PDF 文档。可以公平地说,这些文档中有很多是繁琐重复的,制定起来令人痛苦。是时候考虑利用 Python 的自动化功能来处理这些繁琐的工作,以便我们可以将宝贵的时间重新分配到生活中更紧迫的任务上。
请注意,不需要具备技术专长,我们要做的事情应该足够简单,足以让我们这些内行外行的人在短时间内完成。阅读本教程后,你将学会如何自动生成包含你自己数据、图表和图片的 PDF 文档,且拥有令人眼前一亮的外观和结构。
具体来说,本教程将自动化以下操作:
-
创建 PDF 文档
-
插入图片
-
插入文本和数字
-
数据可视化
创建 PDF 文档
在本教程中,我们将使用FPDF,这是 Python 中最通用和直观的生成 PDF 的包之一。在继续之前,请启动 Anaconda 提示符或你选择的任何 Python IDE,并安装 FPDF:
pip install FPDF
然后导入我们将用来渲染文档的一系列库:
import numpy as np
import pandas as pd
from fpdf import FPDF
import matplotlib as mpl
import matplotlib.pyplot as plt
from matplotlib.ticker import ScalarFormatter
随后创建你的 PDF 文档的第一页,并设置字体及其大小和颜色:
pdf = FPDF(orientation = 'P', unit = 'mm', format = 'A4')
pdf.add_page()
pdf.set_font('helvetica', 'bold', 10)
pdf.set_text_color(255, 255, 255)
如果你需要使用不同的字体,可以随时更改字体。
插入图片
下一步逻辑就是给我们的文档添加背景图像,以设定页面的结构。在这个教程中,我使用了 Microsoft PowerPoint 来渲染背景图像的格式。我简单地使用了文本框和其他视觉元素来创建所需的格式,一旦完成,我通过选择所有元素并按 Ctrl-G 将它们分组。最后,我通过右键点击它们并选择“另存为图片”将分组元素保存为 PNG 图像。

背景图像。图片由作者提供。
正如上面所示,背景图像为我们的页面设定了结构,并为稍后生成的图表、图形、文本和数字留出了空间。用于生成此图像的特定 PowerPoint 文件可以通过点击这里下载。
随后,将背景图像插入到你的 PDF 文档中,并使用以下方法配置其位置:
pdf.image('C:/Users/.../image.png', x = 0, y = 0, w = 210, h = 297)
请注意,你可以通过扩展上述方法来插入任意多的图像。
插入文本和数字
添加文本和数字可以通过两种方式完成。我们可以指定要放置文本的确切位置:
pdf.text(x, y, txt)
或者,我们可以创建一个单元格,然后在其中放置文本。这种方法更适合对齐或居中变量或动态文本:
pdf.set_xy(x, y)
pdf.cell(w, h, txt, border, align, fill)
请注意,在上述方法中:
-
‘x’ 和 ‘y’ 指的是页面上指定的位置
-
‘w’ 和 ‘h’ 指的是我们单元格的尺寸
-
‘txt’ 是要显示的字符串或数字
-
‘border’ 指示是否必须在单元格周围绘制线条(0: 不绘制,1: 绘制或 L: 左侧,T: 顶部,R: 右侧,B: 底部)
-
‘align’ 指示文本的对齐方式(L: 左对齐,C: 居中对齐,R: 右对齐)
-
‘fill’ 指示单元格背景是否应该被填充(True, False)。
数据可视化
在这部分,我们将创建一个条形图,以展示我们的信用、借记和余额值相对于时间的时间序列数据集。为此,我们将使用 Matplotlib 来渲染我们的图形,如下所示:
在上面的代码片段中,信用、借记和余额是具有日期和交易金额值的二维列表。一旦图表生成并保存后,可以使用前面部分显示的方法将其插入到我们的 PDF 文档中。
同样,我们可以使用以下代码片段生成甜甜圈图:
一旦完成,你可以通过生成自动化 PDF 文档来结束,如下所示:
pdf.output('Automated PDF Report.pdf')
结论
这就是你自己自动生成的 PDF 报告!现在你已经学会了如何创建 PDF 文档,向其中插入文本和图像,并且你还学会了如何生成和嵌入图表和图形。不过,你绝不仅仅局限于这些,事实上,你可以扩展这些技巧,以包含其他视觉元素和多页文档。天空才是真正的极限。

图片由作者提供。
如果你想深入了解 Python 和数据可视化,可以查看以下(附带推广链接)的课程: 面向每个人的 Python 专项课程 和 使用 Python 进行数据可视化。此外,也欢迎探索更多我的教程 这里。
简介:穆罕默德·霍拉萨尼 是数据科学家和工程师的混合体。后勤学家。直言不讳。现实主义者。逐步抛弃教条。阅读更多穆罕默德的文章。
原文。经授权转载。
相关内容:
-
数据科学家,你需要知道如何编程
-
使用 Python 自动化的 5 个任务
-
如何使 Python 代码运行得非常快
更多相关内容
如何在 Python 中生成 FiveThirtyEight 图表
原文:
www.kdnuggets.com/2017/12/generate-fivethirtyeight-graphs-python.html
评论
由Alex Olteanu,Dataquest.io 的学生成功专家
如果你阅读数据科学文章,可能已经碰到过FiveThirtyEight的内容。自然,你对他们的精彩可视化印象深刻。你想制作自己的精彩可视化,因此询问了Quora和Reddit怎么做。你收到了些回答,但它们相当模糊。你仍然无法自己制作图表。
在这篇文章中,我们将帮助你。使用 Python 的matplotlib和pandas,我们将看到复制任何 FiveThirtyEight(FTE)可视化的核心部分是相当简单的。
我们从这里开始:

然后,在教程结束时,达到这里:

要跟随教程,你至少需要一些 Python 的基础知识。如果你知道方法和属性之间的区别,那么你已经准备好了。
介绍数据集
我们将使用描述 1970 年至 2011 年间美国女性获得学士学位百分比的数据。我们将使用数据科学家Randal Olson编制的数据集,他从国家教育统计中心收集了这些数据。
如果你想自己动手编写代码,可以从Randal's blog下载数据。为了节省时间,你可以跳过下载文件,直接将直接链接传递给 pandas 的read_csv()函数。在下面的代码单元中,我们:
-
导入 pandas 模块。
-
将指向数据集的直接链接分配给名为
direct_link的变量。 -
使用
read_csv()读取数据,并将内容分配给women_majors。 -
通过使用
info()方法 打印数据集的信息。我们要找出行数和列数,同时检查空值。 -
使用
head()方法 显示前五行,以便更好地了解数据集的结构。
import pandas as pd
direct_link = 'http://www.randalolson.com/wp-content/uploads/percent-bachelors-degrees-women-usa.csv'
women_majors = pd.read_csv(direct_link)
print(women_majors.info())
women_majors.head()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 42 entries, 0 to 41
Data columns (total 18 columns):
Year 42 non-null int64
Agriculture 42 non-null float64
Architecture 42 non-null float64
Art and Performance 42 non-null float64
Biology 42 non-null float64
Business 42 non-null float64
Communications and Journalism 42 non-null float64
Computer Science 42 non-null float64
Education 42 non-null float64
Engineering 42 non-null float64
English 42 non-null float64
Foreign Languages 42 non-null float64
Health Professions 42 non-null float64
Math and Statistics 42 non-null float64
Physical Sciences 42 non-null float64
Psychology 42 non-null float64
Public Administration 42 non-null float64
Social Sciences and History 42 non-null float64
dtypes: float64(17), int64(1)
memory usage: 6.0 KB
None
| YEAR | AGRICULTURE | ARCHITECTURE | ART AND PERFORMANCE | BIOLOGY | BUSINESS | COMMUNICATIONS AND JOURNALISM | COMPUTER SCIENCE | EDUCATION | ENGINEERING | ENGLISH | FOREIGN LANGUAGES | HEALTH PROFESSIONS | MATH AND STATISTICS | PHYSICAL SCIENCES | PSYCHOLOGY | PUBLIC ADMINISTRATION | SOCIAL SCIENCES AND HISTORY | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1970 | 4.229798 | 11.921005 | 59.7 | 29.088363 | 9.064439 | 35.3 | 13.6 | 74.535328 | 0.8 | 65.570923 | 73.8 | 77.1 | 38.0 | 13.8 | 44.4 | 68.4 | 36.8 |
| 1 | 1971 | 5.452797 | 12.003106 | 59.9 | 29.394403 | 9.503187 | 35.5 | 13.6 | 74.149204 | 1.0 | 64.556485 | 73.9 | 75.5 | 39.0 | 14.9 | 46.2 | 65.5 | 36.2 |
| 2 | 1972 | 7.420710 | 13.214594 | 60.4 | 29.810221 | 10.558962 | 36.6 | 14.9 | 73.554520 | 1.2 | 63.664263 | 74.6 | 76.9 | 40.2 | 14.8 | 47.6 | 62.6 | 36.1 |
| 3 | 1973 | 9.653602 | 14.791613 | 60.2 | 31.147915 | 12.804602 | 38.4 | 16.4 | 73.501814 | 1.6 | 62.941502 | 74.9 | 77.4 | 40.9 | 16.5 | 50.4 | 64.3 | 36.4 |
| 4 | 1974 | 14.074623 | 17.444688 | 61.9 | 32.996183 | 16.204850 | 40.5 | 18.9 | 73.336811 | 2.2 | 62.413412 | 75.3 | 77.9 | 41.8 | 18.2 | 52.6 | 66.1 | 37.3 |
除了 Year 列外,其他每一列的名称表示学士学位的学科。学士列中的每个数据点表示授予女性的学士学位的百分比。因此,每一行描述了给定年份授予女性的各种学士学位的百分比。
如前所述,我们的数据从 1970 年到 2011 年。为了确认后一个限制,让我们使用 tail() 方法 打印数据集的最后五行:
women_majors.tail()
| YEAR | AGRICULTURE | ARCHITECTURE | ART AND PERFORMANCE | BIOLOGY | BUSINESS | COMMUNICATIONS AND JOURNALISM | COMPUTER SCIENCE | EDUCATION | ENGINEERING | ENGLISH | FOREIGN LANGUAGES | HEALTH PROFESSIONS | MATH AND STATISTICS | PHYSICAL SCIENCES | PSYCHOLOGY | PUBLIC ADMINISTRATION | SOCIAL SCIENCES AND HISTORY | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 37 | 2007 | 47.605026 | 43.100459 | 61.4 | 59.411993 | 49.000459 | 62.5 | 17.6 | 78.721413 | 16.8 | 67.874923 | 70.2 | 85.4 | 44.1 | 40.7 | 77.1 | 82.1 | 49.3 |
| 38 | 2008 | 47.570834 | 42.711730 | 60.7 | 59.305765 | 48.888027 | 62.4 | 17.8 | 79.196327 | 16.5 | 67.594028 | 70.2 | 85.2 | 43.3 | 40.7 | 77.2 | 81.7 | 49.4 |
| 39 | 2009 | 48.667224 | 43.348921 | 61.0 | 58.489583 | 48.840474 | 62.8 | 18.1 | 79.532909 | 16.8 | 67.969792 | 69.3 | 85.1 | 43.3 | 40.7 | 77.1 | 82.0 | 49.4 |
| 40 | 2010 | 48.730042 | 42.066721 | 61.3 | 59.010255 | 48.757988 | 62.5 | 17.6 | 79.618625 | 17.2 | 67.928106 | 69.0 | 85.0 | 43.1 | 40.2 | 77.0 | 81.7 | 49.3 |
| 41 | 2011 | 50.037182 | 42.773438 | 61.2 | 58.742397 | 48.180418 | 62.2 | 18.2 | 79.432812 | 17.5 | 68.426730 | 69.5 | 84.8 | 43.1 | 40.1 | 76.7 | 81.9 | 49.2 |
我们 FiveThirtyEight 图形的背景
几乎每个 FTE 图表都是文章的一部分。图表通过展示小故事或有趣的想法来补充文本。在复制我们的 FTE 图表时,我们需要注意这一点。
为了避免在本教程中跑题,我们假装已经写了大部分关于美国教育性别差距演变的文章。现在我们需要创建一个图表,帮助读者可视化 1970 年女性情况非常糟糕的学士学位的性别差距演变。我们已经设置了 20%的阈值,现在我们想要绘制所有 1970 年女性毕业生百分比低于 20%的学士学位的演变。
首先识别这些特定的学士学位。在以下代码单元中,我们将:
-
使用
.loc,这是一个基于标签的索引器,来:-
选择第一行(对应于 1970 年);
-
选择第一行中值小于 20 的项;
Year字段也将被检查,但显然不会包含在内,因为 1970 远大于 20。
-
-
将结果内容分配给
under_20。
under_20 = women_majors.loc[0, women_majors.loc[0] < 20]
under_20
Agriculture 4.229798
Architecture 11.921005
Business 9.064439
Computer Science 13.600000
Engineering 0.800000
Physical Sciences 13.800000
Name: 0, dtype: float64
使用 matplotlib 的默认样式
让我们开始制作我们的图表。我们将首先查看默认情况下可以构建的内容。在以下代码块中,我们将:
-
运行 Jupyter 魔法
%matplotlib来启用 Jupyter 和 matplotlib 的有效协作,并添加inline以使我们的图表显示在笔记本内部。 -
使用
plot()方法绘制图形,应用于women_majors。我们传入plot()以下参数:-
x- 指定用于 x 轴的women_majors中的列; -
y- 指定用于 y 轴的women_majors中的列;我们将使用under_20的索引标签,这些标签存储在该对象的.index属性中; -
figsize- 将图形的大小设置为tuple格式的(宽度, 高度),单位为英寸。
-
-
将绘图对象分配给名为
under_20_graph的变量,并打印其类型以显示 pandas 在幕后使用matplotlib对象。
%matplotlib inline
under_20_graph = women_majors.plot(x = 'Year', y = under_20.index, figsize = (12,8))
print('Type:', type(under_20_graph))

使用 matplotlib 的 fivethirtyeight 样式
上图具有一些特征,例如脊柱的宽度和颜色、y 轴标签的字体大小、没有网格等。所有这些特征构成了 matplotlib 的默认样式。
简短插曲,值得一提的是,在本文中我们将使用一些图形部分的技术术语。如果你在任何时候感到迷失,可以参考下面的图例。

除了默认样式外,matplotlib 还带有几个内置样式,我们可以直接使用。要查看可用样式的列表,我们将:
-
导入
matplotlib.style模块,并命名为style。 -
探索
matplotlib.style.available的内容(这是该模块的一个预定义变量),其中包含所有可用的内置样式列表。
import matplotlib.style as style
style.available
['seaborn-deep',
'seaborn-muted',
'bmh',
'seaborn-white',
'dark_background',
'seaborn-notebook',
'seaborn-darkgrid',
'grayscale',
'seaborn-paper',
'seaborn-talk',
'seaborn-bright',
'classic',
'seaborn-colorblind',
'seaborn-ticks',
'ggplot',
'seaborn',
'_classic_test',
'fivethirtyeight',
'seaborn-dark-palette',
'seaborn-dark',
'seaborn-whitegrid',
'seaborn-pastel',
'seaborn-poster']
你可能已经观察到,有一个内置样式叫做 fivethirtyeight。让我们使用这个样式,看看会发生什么。为此,我们将使用同一 matplotlib.style 模块中恰如其分命名的 use() 函数(我们以 style 名义导入)。然后我们将使用之前相同的代码生成图形。
style.use('fivethirtyeight')
women_majors.plot(x = 'Year', y = under_20.index, figsize = (12,8))


哇,这真是一个重大变化!与我们的第一个图形相比,我们可以看到这个图形有不同的背景颜色,有网格线,完全没有脊柱,主要刻度标签的粗细和字体大小也不同等。
你可以在 这里 阅读 fivethirtyeight 样式的技术描述,这也应能让你对使用此样式时运行的代码有一个很好的了解。样式表的作者,卡梅伦·大卫-皮隆,在 这里 讨论了一些特征。
有关在 Python 中生成 FiveThirtyEight 图形的更多信息,请参见 原始文章的其余部分。
简历: 亚历克斯·奥尔特亚努 是 Dataquest.io 的学生成功专员。他喜欢学习和分享知识,并为新的 AI 革命做准备。
原始文章。经授权转载。
相关:
-
分析科学研究人员的迁移
-
7 种技术可视化地理空间数据
-
Python 图表画廊
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT 部门
更多相关内容
如何使用 T5 Transformer 生成有意义的句子
原文:
www.kdnuggets.com/2021/05/generate-meaningful-sentences-t5-transformer.html
评论
由 Vatsal Saglani 编写,Quinnox 的机器学习工程师

由 Tech Daily 在 Unsplash 上拍摄(Tech Daily)
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
在博客中,使用 T5 Transformer 生成故事情节我们看到如何通过提供诸如类型、导演、演员和种族等输入来微调 Sequence2Sequence (Text-To-Text) Transformer (T5) 以生成故事情节/情节。在这篇博客中,我们将检查如何使用经过训练的 T5 模型进行推断。之后,我们还将看到如何使用gunicorn和flask进行部署。
如何进行模型推断?
- 让我们设置带有导入项的脚本
import os
import re
import random
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm_notebook, tnrange
from sklearn.utils import shuffle
import pickle
import math
import torch
import torch.nn.functional as F
from transformers import T5Tokenizer, T5ForConditionalGeneration
- 设置
*SEED*值并加载模型和分词器
torch.manual_seed(3007)model = T5ForConditionalGeneration.from_pretrained('./outputs/model_files')
tokenizer = T5Tokenizer.from_pretrained('./outputs/model_files')
- 使用
*model.generate*函数生成序列
text = "generate plot for genre: horror"
input_ids = tokenizer.encode(text, return_tensors="pt")
greedyOp = model.generate(input_ids, max_length=100)
tokenizer.decode(greedyOp[0], skip_special_tokens=True)
注意:阅读 这篇 令人惊叹的 Hugging Face 博客,了解如何使用不同的解码策略进行文本生成
- 让我们将其放入函数中
def generateStoryLine(text, seq_len, seq_num):
'''
args:
text: input text eg. generate plot for: {genre} or generate plot for: {director}
seq_len: Max sequence length for the generated text
seq_num: Number of sequences to generate
'''
outputDict = dict()
outputDict["plots"] = {}
input_ids = tokenizer.encode(text, return_tensors = "pt")
beamOp = model.generate(
input_ids,
max_length = seq_len,
do_sample = True,
top_k = 100,
top_p = 0.95,
num_return_sequences = seq_num
) for ix, sample_op in enumerate(beamOp):
outputDict["plots"][ix] = self.tokenizer.decode(sample_op, skip_special_tokens = True)
return outputDict
如何用 Flask 部署这个?
用户可以通过多种方式提供输入,模型可能需要生成情节。用户可以仅提供类型,或者可以提供类型和演员,甚至可以提供所有四项,即类型、导演、演员和种族。但为了实现这个功能,我要求至少提供一个类型。
你可以查看下面的链接,了解 API 将如何工作。
我在网上生成模糊的电影情节(但有时它们还不错)。但我可以向你保证,它总是会是……](https://movie-plot-generator.vercel.app/)
让我们开发一个后端来实现上述链接中使用的 API 调用
安装需求
pip install flask flask_cors tqdm rich gunicorn
创建一个 app.py 文件
- 导入项
# app.pyfrom flask import Flask, request, jsonify
import json
from flask_cors import CORS
import uuidfrom predict import PredictionModelObjectapp = Flask(__name__)
CORS(app)print("Loading Model Object")
predictionObject = PredictionModelObject()
print("Loaded Model Object")
- 添加 API 路由
@app.route('/api/generatePlot', methods=['POST'])
def gen_plot(): req = request.get_json()
genre = req['genre']
director = req['director'] if 'director' in req else None
cast = req['cast'] if 'cast' in req else None
ethnicity = req['ethnicity'] if 'ethnicity' in req else None
num_plots = req['num_plots'] if 'num_plots' in req else 1
seq_len = req['seq_len'] if 'seq_len' in req else 200 if not isinstance(num_plots, int) or not isinstance(seq_len, int):
return jsonify({
"message": "Number of words in plot and Number of plots must be integers",
"status": "Fail"
})
try:
plot, status = predictionObject.returnPlot(
genre = genre,
director = director,
cast = cast,
ethnicity = ethnicity,
seq_len = seq_len,
seq_num = num_plots
) if status == 'Pass':
plot["message"] = "Success!"
plot["status"] = "Pass"
return jsonify(plot)
else: return jsonify({"message": plot, "status": status})
except Exception as e: return jsonify({"message": "Error getting plot for the given input", "status": "Fail"})
- 运行
*flask*应用的主块
if __name__ == "__main__":
app.run(debug=True, port = 5000)
这个脚本还不能使用。你在执行脚本时可能会收到 ImportError,因为我们还没有创建带有*PredictionModelObject*的*predict.py**脚本
创建PredictionModelObject
- 创建一个
*predict.py*文件并导入以下内容
# predict.py
import os
import re
import random
import torch
import torch.nn as nn
from rich.console import Console
from transformers import T5Tokenizer, T5ForConditionalGeneration
from collections import defaultdictconsole = Console(record = True)torch.cuda.manual_seed(3007)
torch.manual_seed(3007)
- 创建
*PredictionModelObject*类
# predict.py
class PredictionModelObject(object): def __init__(self):console.log("Model Loading")
self.model = T5ForConditionalGeneration.from_pretrained('./outputs/model_files')
self.tokenizer = T5Tokenizer.from_pretrained('./outputs/model_files')
console.log("Model Loaded")
def beamSearch(self, text, seq_len, seq_num): outputDict = dict()
outputDict["plots"] = {}
input_ids = self.tokenizer.encode(text, return_tensors = "pt")
beamOp = self.model.generate(
input_ids,
max_length = seq_len,
do_sample = True,
top_k = 100,
top_p = 0.95,
num_return_sequences = seq_num
) for ix, sample_op in enumerate(beamOp):
outputDict["plots"][ix] = self.tokenizer.decode(sample_op, skip_special_tokens = True)
return outputDict def genreToPlot(self, genre, seq_len, seq_num): text = f"generate plot for genre: {genre}" return self.beamSearch(text, seq_len, seq_num) def genreDirectorToPlot(self, genre, director, seq_len, seq_num): text = f"generate plot for genre: {genre} and director: {director}"
return self.beamSearch(text, seq_len, seq_num) def genreDirectorCastToPlot(self, genre, director, cast, seq_len, seq_num): text = f"generate plot for genre: {genre} director: {director} cast: {cast}" return self.beamSearch(text, seq_len, seq_num) def genreDirectorCastEthnicityToPlot(self, genre, director, cast, ethnicity, seq_len, seq_num): text = f"generate plot for genre: {genre} director: {director} cast: {cast} and ethnicity: {ethnicity}" return self.beamSearch(text, seq_len, seq_num)
def genreCastToPlot(self, genre, cast, seq_len, seq_num): text = f"genreate plot for genre: {genre} and cast: {cast}" return self.beamSearch(text, seq_len, seq_num) def genreEthnicityToPlot(self, genre, ethnicity, seq_len, seq_num): text = f"generate plot for genre: {genre} and ethnicity: {ethnicity}" return self.beamSearch(text, seq_len, seq_num) def returnPlot(self, genre, director, cast, ethnicity, seq_len, seq_num):
console.log('Got genre: ', genre, 'director: ', director, 'cast: ', cast, 'seq_len: ', seq_len, 'seq_num: ', seq_num, 'ethnicity: ',ethnicity)
seq_len = 200 if not seq_len else int(seq_len)
seq_num = 1 if not seq_num else int(seq_num)
if not director and not cast and not ethnicity: return self.genreToPlot(genre, seq_len, seq_num), "Pass"
elif genre and director and not cast and not ethnicity: return self.genreDirectorToPlot(genre, director, seq_len, seq_num), "Pass" elif genre and director and cast and not ethnicity: return self.genreDirectorCastToPlot(genre, director, cast, seq_len, seq_num), "Pass" elif genre and director and cast and ethnicity: return self.genreDirectorCastEthnicityToPlot(genre, director, cast, ethnicity, seq_len, seq_num), "Pass" elif genre and cast and not director and not ethnicity: return self.genreCastToPlot(genre, cast, seq_len, seq_num), "Pass"
elif genre and ethnicity and not director and not cast: return self.genreEthnicityToPlot(genre, ethnicity, seq_len, seq_num), "Pass" else: return "Genre cannot be empty", "Fail"
保存predict.py文件,然后使用以下命令以调试模式运行app.py文件,
python app.py
测试你的 API
- 创建一个
*test_api.py*文件并执行
# test_api.py
import requests
import osurl = "<http://localhost:5000/api/generatePlot>"
json = {
"genre": str(input("Genre: ")),
"director": str(input("Director: ")),
"cast": str(input("Cast: ")),
"ethnicity": str(input("Ethnicity: ")),
"num_plots": int(input("Num Plots: ")),
"seq_len": int(input("Sequence Length: ")),
}r = requests.post(url, json = json)
print(r.json())
如何使用gunicorn运行?
使用gunicorn和flask非常简单。在开始时安装要求时,我们已经安装了gunicorn命令,现在需要通过终端进入包含app.py文件的文件夹,并运行以下命令
gunicorn -k gthread -w 2 -t 40000 --threads 3 -b:5000 app:app
我们上面使用的格式和标志表示如下
-
k: 类型(工作线程的类型)-
*gthread*,*gevent*等... -
w: 工作线程的数量
-
t: 超时
-
threads: 每个工作线程的数量
-
b: 绑定端口号
如果你的文件名是*server.py*或*flask_app.py*,则*app:app*部分将更改为*server:app*或*flask_app:app*
总结
在这篇博客中,我们介绍了如何使用之前训练好的 T5 变换器生成故事情节,并使用flask和gunicorn进行部署。此博客旨在易于跟随,以免你浪费时间在不同平台上查找问题。希望你阅读和实施时感到愉快。
简介: Vatsal Saglani (@saglanivatsal) 是 Quinnox 的机器学习工程师。
原文。转载已获许可。
相关:
-
Hugging Face Transformers 包 – 它是什么以及如何使用它
-
使用 Huggingface 和 PyTorch Lightning 的多语言 CLIP
-
GPT-2 与 GPT-3: OpenAI 对决
更多相关话题
使用 Google MusicLM 从文本生成音乐
原文:
www.kdnuggets.com/2023/06/generate-music-text-google-musiclm.html

图片来源于 Freepik
人工智能的发展比以往任何时候都更加迅猛,尤其是在生成 AI 领域。从生成类似于与人对话的文本到从文本生成图像,现在这一切都变得可能了。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织在 IT 方面
这种进步也进入了音乐生成领域,谷歌推出了一种名为 MusicLM 的音乐生成模型。该模型于 2023 年 1 月发布,自那时以来,人们一直在尝试其功能。那么,MusicLM 的详细情况是什么?您如何尝试它?让我们深入讨论。
Google MusicLM
MusicLM 首次在Agostinelli 等人 (2023)的论文中介绍,研究小组将 MusicLM 解释为一个从文本描述中生成高保真音乐的模型。该模型通常建立在AudioLM的基础上,实验表明,该模型可以生成多分钟高质量的音乐,采样率为 24 kHz,同时仍能遵循文本描述。
此外,研究还生成了公开的文本到音乐数据集 musicaps,供任何希望开发类似模型或扩展研究的人使用。数据由专业音乐家手动策划和挑选。
此外,MusicLM 的开发遵循了负责任的模型开发实践,以防对创意内容可能的不当使用感到担忧。通过扩展 Carlini 等人 (2022) 的工作,MusicLM 生成的 token 与训练数据有显著不同。
尝试 MusicLM
如果你想深入了解 MusicLM 的结果样本,Google 研究小组提供了一个简单的网站来展示 MusicLM 的能力。例如,你可以在网站上探索从文本标题生成的音频样本。

图片由作者提供(改编自 google-research.github.io)
另一个例子是我最喜欢的样本,故事模式音乐生成,通过使用多个文本提示将不同风格的音乐整合成一个整体。

图片由作者提供(改编自 google-research.github.io)
也可以根据绘画标题生成音乐,可能会捕捉到图像的情绪。

图片由作者提供(改编自 google-research.github.io)
结果听起来很棒,但我们如何尝试这个模型?幸运的是,自 2023 年 5 月以来,Google 已经接受了在 AI Test Kitchen 测试 MusicLM 的注册。前往网站,使用你的 Google 帐号进行注册。

图片由作者提供(改编自 aitestkitchen)
注册后,我们需要等待轮到我们试用 MusicLM 的机会。因此,请留意你的电子邮件。

图片由作者提供(改编自 aitestkitchen)
现在就这些;希望你能尽快轮到你试用令人兴奋的 MusicLM。
结论
MusicLM 是 Google 研究小组开发的一种模型,用于从文本生成音乐。该模型可以根据文本指令提供几分钟的高质量音乐。我们可以通过注册 AI Test Kitchen 试用 MusicLM。如果仅对样本结果感兴趣,我们可以访问 Google 研究网站。
Cornellius Yudha Wijaya 是一名数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
更多相关信息
使用 GAN 生成逼真的人脸
原文:
www.kdnuggets.com/2020/03/generate-realistic-human-face-using-gan.html
评论
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
“过去 20 年中深度学习中最酷的想法。” — Yann LeCun 谈 GAN
我们听说了关于艺术风格迁移和面部交换应用(也称为深伪技术)、自然语言生成(Google Duplex)、音乐合成、智能回复、智能写作等。
这种类型的人工智能背后的技术叫做GAN,或“生成对抗网络”。GAN 采用了不同于其他神经网络的学习方法。GAN 的算法架构使用两个神经网络,一个是生成器,另一个是鉴别器,它们相互“竞争”以创建期望的结果。生成器的任务是创建逼真的假图像,而鉴别器的任务是区分真实图像和假图像。如果两者都能高效运行,结果就是看起来几乎和真实照片一模一样的图像。
自从 2014 年由 Ian J. Goodfellow 及其合著者在文章《生成对抗网络》中介绍了生成对抗网络以来,这一技术取得了巨大的成功。
GAN 最初为什么会被开发出来?
已经注意到,大多数主流神经网络很容易被欺骗,只需在原始数据中添加少量噪声。令人惊讶的是,添加噪声后的模型对错误预测的信心比正确预测时更高。这种对抗的原因在于,大多数机器学习模型从有限的数据中学习,这是一个巨大的缺陷,因为它容易过拟合。此外,输入和输出之间的映射几乎是线性的。虽然看起来各种类别之间的分界线是线性的,但实际上,它们由线性组成,即使特征空间中的一点小变化也可能导致数据的错误分类。

GAN 是如何工作的?
GAN 通过将两个神经网络对抗起来来学习数据集的概率分布。
一个神经网络,称为生成器,生成新的数据实例,而另一个,称为判别器,评估这些实例的真实性;即判别器决定它审查的每个数据实例是否属于实际的训练数据集。
与此同时,生成器正在创建新的合成/假图像,并将其传递给判别器。它这样做是希望这些图像也能被认为是真实的,即使它们是假的。假图像是通过逆卷积生成的,称为转置卷积,来自一个 100 维的噪声(-1.0 到 1.0 之间的均匀分布)。
生成器的目标是生成可通过的图像:即在不被抓住的情况下进行欺骗。判别器的目标是识别来自生成器的图像为假图像。
以下是 GAN 的步骤:
-
生成器接收随机数字并返回图像。
-
这个生成的图像会与从实际的真实数据集中提取的一系列图像一起输入到判别器中。
-
判别器接收真实和假图像,并返回概率值,一个介于 0 和 1 之间的数字,其中 1 表示对真实性的预测,0 表示假图像。
所以你有一个双重反馈循环:
-
判别器与我们已知的图像的真实数据处于反馈循环中。
-
生成器与判别器处于反馈循环中。

GAN 的数学原理
让我们更深入地了解它是如何在数学上工作的。判别器的工作是执行二元分类,以检测真实和虚假的图像,因此其损失函数是二元交叉熵。生成器的工作是密度估计,从噪声到真实数据,并将其输入判别器以欺骗它。
设计中遵循的方法是将其建模为一个MiniMax 博弈。现在让我们来看一下成本函数:

J(D)中的第一个项表示将实际数据输入给判别器,判别器希望最大化预测为 1 的对数概率,表示数据是真实的。第二项表示由G生成的样本。在这里,判别器希望最大化预测为 0 的对数概率,表示数据是假的。另一方面,生成器则尝试最小化判别器正确的对数概率。这个问题的解决方案是博弈的均衡点,即判别器损失的鞍点。
目标函数

GANs 的架构
D() 给出给定样本来自训练数据 X 的概率。对于生成器,我们希望最小化log(1-D(G(z))),即当D(G(z))的值很高时,D将假设G(z)不过是 X,这使得1-D(G(z))非常低,我们希望最小化它,从而使其更低。对于判别器,我们希望最大化D(X)和(1-D(G(z)))。所以 D 的最优状态将是P(x)=0.5。然而,我们希望训练生成器 G,使其生成的结果能让判别器 D 无法区分 z 和 X。
那么问题是为什么这是一个最小最大函数?这是因为判别器尝试最大化目标,而生成器尝试最小化目标,因此我们得到最小最大项。它们通过交替梯度下降一起学习。
尽管理论上的 GAN 概念很简单,但构建一个有效的模型是非常困难的。在 GAN 中,有两个深度网络相互耦合,使得梯度的反向传播变得难度加倍。
深度卷积 GAN(DCGAN)是展示如何构建一个可以自学合成新图像的实际 GAN 模型之一。DCGAN 与GANs 非常相似,但特别专注于使用深度卷积网络来代替在 Vanilla GANs 中使用的全连接网络。
卷积网络有助于发现图像中的深层关联,即它们寻找空间相关性。这意味着 DCGAN 将是图像/视频数据的更好选择,而GANs 可以被视为DCGAN及许多其他架构(CGAN、CycleGAN、StarGAN 等)开发的基础性想法。
数据集
这个数据集非常适合用于训练和测试人脸检测模型,特别是识别面部特征,例如找出棕色头发、正在微笑或戴眼镜的人。图像涵盖了大范围的姿势变化、背景杂乱、多样的人群,并且支持大量的图像和丰富的注释。
数据集可以从Kaggle下载。我们的目标是创建一个能够生成现实中不存在的真实 人类图像的模型。
你没听错!
让我们加载数据集,看看输入图像的样子:
from tqdm import tqdm
import numpy as np
import pandas as pd
import os
from matplotlib import pyplot as plt
PIC_DIR = './drive/img_align_celeba/'
IMAGES_COUNT = 10000
ORIG_WIDTH = 178
ORIG_HEIGHT = 208
diff = (ORIG_HEIGHT - ORIG_WIDTH) // 2
WIDTH = 128
HEIGHT = 128
crop_rect = (0, diff, ORIG_WIDTH, ORIG_HEIGHT - diff)
images = []
for pic_file in tqdm(os.listdir(PIC_DIR)[:IMAGES_COUNT]):
pic = Image.open(PIC_DIR + pic_file).crop(crop_rect)
pic.thumbnail((WIDTH, HEIGHT), Image.ANTIALIAS)
images.append(np.uint8(pic)) #Normalize the images
images = np.array(images) / 255
images.shape #print first 25 images
plt.figure(1, figsize=(10, 10))
for i in range(25):
plt.subplot(5, 5, i+1)
plt.imshow(images[i])
plt.axis('off')
plt.show()

输入图像
下一步是创建生成器:
生成器的作用正好相反:它是试图欺骗判别器的艺术家。这个网络由 8 个卷积层组成。这里首先,我们将输入(称为gen_input)送入第一个卷积层。每个卷积层执行卷积操作,然后进行批量归一化和泄漏 ReLU 处理。最后,我们返回 tanh 激活函数。
LATENT_DIM = 32
CHANNELS = 3
def create_generator():
gen_input = Input(shape=(LATENT_DIM, ))
x = Dense(128 * 16 * 16)(gen_input)
x = LeakyReLU()(x)
x = Reshape((16, 16, 128))(x)
x = Conv2D(256, 5, padding='same')(x)
x = LeakyReLU()(x)
x = Conv2DTranspose(256, 4, strides=2, padding='same')(x)
x = LeakyReLU()(x)
x = Conv2DTranspose(256, 4, strides=2, padding='same')(x)
x = LeakyReLU()(x)
x = Conv2DTranspose(256, 4, strides=2, padding='same')(x)
x = LeakyReLU()(x)
x = Conv2D(512, 5, padding='same')(x)
x = LeakyReLU()(x)
x = Conv2D(512, 5, padding='same')(x)
x = LeakyReLU()(x)
x = Conv2D(CHANNELS, 7, activation='tanh', padding='same')(x)
generator = Model(gen_input, x)
return generator
接下来,创建判别器:
判别器网络由与生成器相同的卷积层组成。对于网络的每一层,我们将执行卷积操作,然后进行批量归一化以加快网络速度和提高准确性,最后执行 Leaky ReLU。
def create_discriminator():
disc_input = Input(shape=(HEIGHT, WIDTH, CHANNELS))
x = Conv2D(256, 3)(disc_input)
x = LeakyReLU()(x)
x = Conv2D(256, 4, strides=2)(x)
x = LeakyReLU()(x)
x = Conv2D(256, 4, strides=2)(x)
x = LeakyReLU()(x)
x = Conv2D(256, 4, strides=2)(x)
x = LeakyReLU()(x)
x = Conv2D(256, 4, strides=2)(x)
x = LeakyReLU()(x)
x = Flatten()(x)
x = Dropout(0.4)(x)
x = Dense(1, activation='sigmoid')(x)
discriminator = Model(disc_input, x)
optimizer = RMSprop(
lr=.0001,
clipvalue=1.0,
decay=1e-8
)
discriminator.compile(
optimizer=optimizer,
loss='binary_crossentropy'
)
return discriminator
定义一个 GAN 模型:
接下来,可以定义一个结合生成器模型和判别器模型的大型 GAN 模型。这个较大的模型将用于训练生成器中的模型权重,使用判别器模型计算的输出和误差。判别器模型单独训练,因此在这个较大的 GAN 模型中,模型权重标记为不可训练,以确保只有生成器模型的权重被更新。这个对判别器权重训练性的更改仅在训练组合 GAN 模型时生效,不在训练判别器模型时生效。
这个较大的 GAN 模型以潜在空间中的一个点作为输入,使用生成器模型生成图像,然后将其作为输入送入判别器模型,最后输出或分类为真实或伪造。
由于判别器的输出是 sigmoid 函数,我们使用二元交叉熵作为损失函数。RMSProp作为优化器在本案例中生成更逼真的伪造图像,相比之下Adam效果稍差。学习率为 0.0001。权重衰减和裁剪值在训练后期稳定学习。如果你想调整学习率,需要调整衰减值。
GAN 试图复制概率分布。因此,我们应该使用能够反映 GAN 生成的数据分布与真实数据分布之间距离的损失函数。
generator = create_generator()
discriminator = create_discriminator()
discriminator.trainable = False
gan_input = Input(shape=(LATENT_DIM, ))
gan_output = discriminator(generator(gan_input))
gan = Model(gan_input, gan_output)#Adversarial Model
optimizer = RMSprop(lr=.0001, clipvalue=1.0, decay=1e-8)
gan.compile(optimizer=optimizer, loss='binary_crossentropy')
我们不仅需要一个损失函数,而是需要定义三个:生成器的损失,使用真实图像时鉴别器的损失,以及使用虚假图像时鉴别器的损失。虚假图像和真实图像损失的总和即为总体鉴别器损失。
训练 GAN 模型:
训练是最困难的部分,由于 GAN 包含两个分别训练的网络,它的训练算法必须解决两个复杂问题:
-
GAN 必须兼顾两种不同的训练(生成器和鉴别器)。
-
GAN 的收敛性难以识别。
随着生成器的训练进步,鉴别器的性能会变差,因为鉴别器无法轻易区分真实和虚假。如果生成器成功完美,则鉴别器的准确率为 50%。实际上,鉴别器像掷硬币一样做出预测。
这种进展给整个 GAN 的收敛性带来了问题:随着时间的推移,鉴别器的反馈变得越来越没有意义。如果 GAN 继续训练到鉴别器提供完全随机反馈的地步,那么生成器开始在垃圾反馈上训练,其质量可能会崩溃。
iters = 20000
batch_size = 16RES_DIR = 'res2'
FILE_PATH = '%s/generated_%d.png'
if not os.path.isdir(RES_DIR):
os.mkdir(RES_DIR)
CONTROL_SIZE_SQRT = 6
control_vectors = np.random.normal(size=(CONTROL_SIZE_SQRT**2, LATENT_DIM)) / 2
start = 0
d_losses = []
a_losses = []
images_saved = 0
for step in range(iters):
start_time = time.time()
latent_vectors = np.random.normal(size=(batch_size, LATENT_DIM))
generated = generator.predict(latent_vectors)
real = images[start:start + batch_size]
combined_images = np.concatenate([generated, real])
labels = np.concatenate([np.ones((batch_size, 1)), np.zeros((batch_size, 1))])
labels += .05 * np.random.random(labels.shape)
d_loss = discriminator.train_on_batch(combined_images, labels)
d_losses.append(d_loss)
latent_vectors = np.random.normal(size=(batch_size, LATENT_DIM))
misleading_targets = np.zeros((batch_size, 1))
a_loss = gan.train_on_batch(latent_vectors, misleading_targets)
a_losses.append(a_loss)
start += batch_size
if start > images.shape[0] - batch_size:
start = 0
if step % 50 == 49:
gan.save_weights('gan.h5')
print('%d/%d: d_loss: %.4f, a_loss: %.4f. (%.1f sec)' % (step + 1, iters, d_loss, a_loss, time.time() - start_time))
control_image = np.zeros((WIDTH * CONTROL_SIZE_SQRT, HEIGHT * CONTROL_SIZE_SQRT, CHANNELS))
control_generated = generator.predict(control_vectors)
for i in range(CONTROL_SIZE_SQRT ** 2):
x_off = i % CONTROL_SIZE_SQRT
y_off = i // CONTROL_SIZE_SQRT
control_image[x_off * WIDTH:(x_off + 1) * WIDTH, y_off * HEIGHT:(y_off + 1) * HEIGHT, :] = control_generated[i, :, :, :]
im = Image.fromarray(np.uint8(control_image * 255))
im.save(FILE_PATH % (RES_DIR, images_saved))
images_saved += 1
我们还需要生成输出图像的 GIF。
import imageio
import shutil
images_to_gif = []
for filename in os.listdir(RES_DIR):
images_to_gif.append(imageio.imread(RES_DIR + '/' + filename))
imageio.mimsave('trainnig_visual.gif', images_to_gif)
shutil.rmtree(RES_DIR)
输出
你可以在我的 GitHub 仓库中获取代码。
nageshsinghc4/Face-generation-GAN
我们刚刚看到,如果训练充分,一个模型可以生成几乎像人类一样的面孔。由于计算限制,我已将模型训练了 15000 个周期。你可以尝试更多的周期以获得更好的结果。
“GANs 是危险的”
随着时间的推移,这些存在于我们周围的算法在其工作上会越来越好,这意味着这些生成模型可能会在生成模仿对象方面变得更好。另一个突破性的生成模型很可能就在前方。
这项技术可以用于许多有益的事情。然而,也存在不良的潜力。回想 2016 年的选举以及随后的许多国际选举,当时虚假新闻文章充斥几乎所有社交媒体平台。想象一下,如果这些文章还包含了伴随的“虚假图像”和“虚假音频”,其影响会有多大。宣传在这样的世界中可能传播得更快。实质上,这些新的生成模型,只要有足够的时间和数据,它们可以从几乎任何分布中生成非常可信的样本。
你可以访问 thispersondoesnotexist.com,体验 GAN 模型的强大,每次刷新网站时你都会看到一个不同的人物,这些人物甚至并不存在,而是通过 GAN 生成的。这确实很令人着迷。
结论:GAN 的未来
无监督学习是人工智能的下一个前沿,我们正朝着这个方向发展。
GAN 和生成模型通常非常有趣且令人困惑。它们代表了朝着一个越来越依赖人工智能的世界迈出的另一大步。GAN 在以下情况中有广泛的应用,如生成图像数据集的示例、生成真实照片、图像到图像的翻译、文本到图像的翻译、语义图像到照片的翻译、面部正面视图生成、生成新的人体姿势、面部衰老、视频预测、3D 对象生成等。
好的,这篇关于 GAN 的文章到此为止,我们讨论了这一酷炫的 AI 领域及其实际应用。希望大家喜欢阅读,欢迎在评论区分享你的评论/想法/反馈。
感谢阅读本文!!!
简介:纳格什·辛格·乔汉 是 CirrusLabs 的大数据开发人员。他在电信、分析、销售、数据科学等多个领域拥有超过 4 年的工作经验,并专注于各种大数据组件。
原文。转载经许可。
相关:
-
对抗性机器学习和生成对抗网络简介
-
使用卷积自编码器重建指纹
-
生成对抗网络的半监督学习
更多相关话题
使用开源工具生成合成时间序列数据
原文:
www.kdnuggets.com/2022/06/generate-synthetic-timeseries-data-opensource-tools.html

介绍
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 工作
时间序列数据,即在多个时间点对相同变量的测量序列,在现代数据世界中无处不在。就像表格数据一样,我们经常希望生成合成时间序列数据以保护敏感信息或在真实数据稀缺时创建更多训练数据。一些合成时间序列数据的应用包括传感器读数、时间戳日志消息、金融市场价格和医疗记录。时间维度的额外要求,其中趋势和时间间的相关性与变量之间的相关性同样重要,为合成数据带来了额外的挑战。
在 Gretel,我们之前发布了关于合成时间序列数据的博客(金融数据、时间序列基础),但我们始终在寻找可以改进合成数据生成的新模型。我们非常喜欢 DoppelGANger 模型及其相关论文(使用 GAN 共享网络时间序列数据:挑战、初步承诺和开放问题 由 Lin 等人撰写),并正在将该模型集成到我们的API和控制台中。作为这项工作的一个部分,我们在 PyTorch 中重新实现了 DoppelGANger 模型,并非常高兴将其作为我们开源gretel-synthetics库的一部分发布。
在本文中,我们简要概述了 DoppelGANger 模型,提供了我们 PyTorch 实现的示例用法,并展示了在合成每日维基百科网页流量任务中的优异合成数据质量,与 TensorFlow 1 实现相比,运行速度提升了约 40 倍。
DoppelGANger 模型
DoppelGANger 基于生成对抗网络 (GAN),并进行了些许修改以更好地适应时间序列生成任务。作为 GAN,该模型使用对抗训练方案,通过比较合成数据和真实数据,来同时优化鉴别器(或评论员)和生成器网络。一旦训练完成,可以通过将输入噪声传递给生成器网络来生成任意数量的合成时间序列数据。
在他们的论文中,Lin 等人回顾了现有的合成时间序列方法及其观察结果,以识别局限性并提出了几个特定的改进,这些改进构成了 DoppelGANger。这些改进范围从通用 GAN 改进到时间序列特定技巧。以下列出了其中的一些关键修改:
-
生成器包含一个LSTM来生成序列数据,但采用批处理设置,每个 LSTM 单元输出多个时间点,以改善时间相关性。
-
支持训练和生成中的可变长度序列(计划中,但在我们的 PyTorch 版本中尚未实现)。例如,一个模型可以使用和生成 10 或 15 秒的传感器测量数据。
-
支持不随时间变化的固定变量(属性)。这些信息通常在时间序列数据中找到,例如与金融价格历史数据中每个股票相关的行业或部门。
-
支持对连续变量的每个示例进行缩放,以处理具有大动态范围的数据。例如,流行与稀有维基百科页面的页面浏览量差异可以达到几个数量级。
-
使用带梯度惩罚的 Wasserstein 损失以减少模式崩溃并改善训练。
关于术语和数据设置的小说明。DoppelGANger 需要包含多个时间序列示例的训练数据。每个示例由 0 个或多个属性值、在时间上不变的固定变量和 1 个或多个在每个时间点观察到的特征组成。组合成训练数据集时,这些示例看起来像一个 2d 数组的属性(示例 x 固定变量)和一个 3d 数组的特征(示例 x 时间 x 时间变量)。根据任务和可用数据,此设置可能需要将几个较长的时间序列拆分成较短的块,以用作训练的示例。
总体而言,这些对基本 GAN 的修改提供了一个表达力强的时间序列模型,能够生成高保真度的合成数据。我们特别印象深刻的是 DoppelGANger 在不同尺度下学习和生成具有时间相关性的数据的能力,例如每周和每年的趋势。有关模型的详细信息,请阅读 Lin 等人撰写的出色论文。
示例用法
我们的 PyTorch 实现支持两种输入风格(numpy 数组或 pandas DataFrame)以及模型的多种配置选项。有关完整的参考文档,请参见synthetics.docs.gretel.ai/
使用我们的模型的最简单方法是将训练数据放在 pandas DataFrame 中。对于这种设置,数据必须是“宽格式”,其中每行是一个示例,一些列可能是属性,其余列是时间序列值。以下代码片段演示了如何从 DataFrame 进行训练和生成数据。
# Create some random training data
df = pd.DataFrame(np.random.random(size=(1000,30)))
df.columns = pd.date_range("2022-01-01", periods=30)
# Include an attribute column
df["attribute"] = np.random.randint(0, 3, size=1000)
# Train the model
model = DGAN(DGANConfig(
max_sequence_len=30,
sample_len=3,
batch_size=1000,
epochs=10, # For real data sets, 100-1000 epochs is typical
))
model.train_dataframe(
df,
df_attribute_columns=["attribute"],
attribute_types=[OutputType.DISCRETE],
)
# Generate synthetic data
synthetic_df = model.generate_dataframe(100)
如果你的数据还不是这种“宽格式”,你可以使用pandas pivot方法将其转换为预期的结构。目前,DataFrame 输入在某些方面有些限制,但我们计划在未来支持其他接受时间序列数据的方式。为了获得最大控制和灵活性,你也可以直接传递 numpy 数组进行训练(类似地,在生成数据时接收属性和特征数组),如下所示。
# Create some random training data
attributes = np.random.randint(0, 3, size=(1000,3))
features = np.random.random(size=(1000,20,2))
# Train the model
model = DGAN(DGANConfig(
max_sequence_len=20,
sample_len=4,
batch_size=1000,
epochs=10, # For real data sets, 100-1000 epochs is typical
))
model.train_numpy(
attributes, features,
attribute_types = [OutputType.DISCRETE] * 3,
feature_types = [OutputType.CONTINUOUS] * 2
)
# Generate synthetic data
synthetic_attributes, synthetic_features = model.generate_numpy(1000)
这些代码片段的可运行版本可在sample_usage.ipynb中找到。
结果
作为一种从 TensorFlow 1 转到 PyTorch 的新实现(其中可能存在底层组件如优化器、参数初始化等的差异),我们希望确认我们的 PyTorch 代码按预期工作。为此,我们复制了原始论文中的一部分结果。由于我们当前的实现仅支持固定长度的序列,因此我们专注于维基百科网页流量(WWT)数据集。
WWT 数据集由 Lin 等人使用,最初来自Kaggle,包含各种维基百科页面的每日流量测量。每个页面有 3 个离散属性(域名、访问类型和代理),以及一个持续 1.5 年(550 天)的每日页面浏览量时间序列特征。请参见图 1 了解 WWT 数据集中的一些示例时间序列。

图 1:3 个维基百科页面的缩放每日页面浏览量,页面属性列在右侧。
请注意,页面浏览量已基于整个数据集的最小/最大页面浏览量进行[-1,1]对数缩放。我们在实验中使用的 50k 页面训练数据(已缩放)可以作为csv 文件在 S3 上获得。
我们展示了 3 张图像,展示了合成数据的不同方面的保真度。在每张图像中,我们将真实数据与 3 个合成版本进行比较:1) 使用更大批量和更小学习率的快速 PyTorch 实现,2) 使用原始参数的 PyTorch 实现,3) TensorFlow 1 实现。在图像 2 中,我们查看了属性分布,其中合成数据与真实分布的匹配度较高(参考 Lin et. al. 的附录中的图 19)。

图像 2:实际和合成的 WWT 数据的属性分布。
WWT 数据的挑战之一是不同的时间序列具有非常不同的页面视图范围。有些维基百科页面始终接收大量流量,而其他页面则不那么受欢迎,但偶尔由于一些相关的时事,例如与页面相关的突发新闻,会出现流量激增。Lin 等人发现 DoppelGANger 在生成不同规模的时间序列方面非常有效(原始论文的图 6)。在图像 3 中,我们提供了类似的图表,显示时间序列中点的分布。每个示例中的中点是 550 天内获得的最小和最大页面视图之间的一半。我们的 PyTorch 实现显示了类似的中点保真度。

图像 3:实际和合成的 WWT 数据的时间序列中点分布。
最后,大多数维基百科页面的流量展示了每周和每年的模式。为了评估这些模式,我们使用自相关,即不同时间滞后的页面视图的皮尔逊相关性(1 天、2 天等)。3 个合成版本的自相关图显示在图像 4 中(类似于原始论文的图 1)。

图像 4:实际和合成的 WWT 数据的自相关。
两个 PyTorch 版本生成了与原始论文中观察到的每周和每年趋势一致的结果。TensorFlow 1 的结果并不完全匹配 Lin 等人的图 1,因为上述图表来自我们的实验。我们观察到使用原始参数进行训练时,模型偶尔无法捕捉到每年(甚至每周)的模式。我们快速版本中使用的较低学习率(1e-4)和较大批量(1000)使得重新训练更为一致。
生成本节图像以及训练 3 个模型的分析代码以笔记本形式共享在 github。
运行时
最后但同样重要的是,更复杂模型的一个关键方面是运行时间。一个需要几周才能训练的惊人模型在实践中比一个只需一小时训练的模型更受限。在这里,PyTorch 实现的表现极其出色(尽管正如作者在他们的论文中提到的,他们没有对 TensorFlow 1 代码进行性能优化)。所有模型都使用 GPU 进行训练,并在 GCP n1-standard-8 实例(8 个虚拟 CPU,30 GB 内存)上运行,配备 NVIDIA Tesla T4。将训练时间从 13 小时缩短到 0.3 小时对于使这个令人印象深刻的模型在实践中更具实用性至关重要!
| 版本 | 训练时间 |
|---|---|
| TensorFlow 1 | 12.9 小时 |
| PyTorch, batch_size=100(原始参数) | 1.6 小时 |
| PyTorch, batch_size=1000 | 0.3 小时 |
结论
Gretel.ai 已经在我们的开源 gretel-synthetics 库中添加了 DoppelGANger 时间序列模型的 PyTorch 实现。我们展示了这一实现能够生成高质量的合成数据,并且速度比之前的 TensorFlow 1 实现快了大约 ~40 倍。如果你喜欢这篇文章,请在我们的 gretel-synthetics GitHub 上留下一个 ⭐,如果你有任何问题,请在我们的 Slack 上告诉我们! 请关注更多关于时间序列的博客,我们会将 DoppelGANger 融入我们的 API 并添加更多功能,比如支持可变长度的序列。
致谢
感谢优秀 DoppelGANger 论文的作者:使用 GAN 共享网络时间序列数据:挑战、初步前景和开放问题 由 Zinan Lin, Alankar Jain, Chen Wang, Giulia Fanti, Vyas Sekar 合著。我们特别感谢 Zinan Lin 对论文和 TensorFlow 1 代码问题的回答。
Kendrick Boyd 是 Gretel.ai 的首席机器学习工程师。
更多相关主题
如何生成合成表格数据集
原文:
www.kdnuggets.com/2022/03/generate-tabular-synthetic-dataset.html

作者提供的图片
企业经常遇到这样的问题:他们没有足够的真实数据,或者由于隐私问题不能使用实际数据。这时,合成数据生成技术就派上用场了。研究人员和数据科学家利用合成数据来开发新产品、提升机器学习模型的性能、替代敏感数据,并节省数据获取成本。更多内容请阅读 终极合成数据指南。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
合成数据被应用于医疗保健、自驾车、金融行业、维持高水平隐私以及研究目的 - 数据科学探索。去年,整个 Kaggle 的 表格玩法系列 数据集是使用 CTGANs 开发的。Kaggle 团队利用来自各种比赛的旧数据集生成了人工数据集。这是 Kaggle 的一个聪明举动,因为它使作弊变得困难。在这篇博客中,我们将学习使用 SDV 的 Python 库生成表格数据的各种方法。
CTGANs
CTGAN 使用几种 基于 GAN 的方法从原始数据中学习,并生成高度真实的表格数据。为了生成合成表格数据,我们将使用开源 Python 库中的条件生成对抗网络,如 CTGAN 和合成数据库 (SDV)。SDV 允许数据科学家从单表、关系数据和时间序列中学习和生成数据集。它是各种表格数据的一站式解决方案。
通过几行代码,我们的深度学习模型可以学习并生成样本表格数据。在下面的示例中,我们初始化了模型,在真实数据上训练了它,保存了模型,然后生成了 200 个样本。这只是开始,我们还将学习生成人工数据的各种方法,然后评估结果。

图片来源于作者
教程
在本教程中,我们将使用 Food Demand Forecasting | Kaggle(根据 DbCL 许可)数据集来创建合成数据集。我们将尝试一个基础模型、自定义模型,最后评估结果。这些结果将帮助我们确定生成数据的质量。我们将使用 Deepnote 云笔记本生成结果。
CTGANSynthesizer
首先,我们需要通过使用 pip install ctgan 安装 CTGAN 库,然后使用 Pandas 加载我们的数据集。我们正在打乱数据集,以获得真正随机的两千个样本。我们使用较少的样本量来减少训练时间。
from ctgan import CTGANSynthesizer
import pandas as pd
data = pd.read_csv("/work/food-demand-forecasting/train.csv")\
.sample(frac=1).reset_index(drop=True)[0:2000]
在开始模型训练之前,让我们观察一下我们的实际数据集,以便我们可以看到真实数据和人工数据之间的差异。
data.head()

为了训练我们的 CTGAN 模型,我们需要提供离散列的列表、批量大小和训练轮数。API 类似于 Scikit-learn,我们用超参数初始化模型,然后使用 .fit() 训练模型。在成功训练模型后,我们将保存模型以重现类似的结果。通过 ctgan.sample(2000) 我们将生成 2k 个样本。
discrete_columns = ['week',
'Center_id',
'Meal_id',
'Emailer_for_promotion',
'homepage_featured']
ctgan = CTGANSynthesizer(batch_size=50,epochs=5,verbose=False)
ctgan.fit(data,discrete_columns)
ctgan.save('ctgan-food-demand.pkl')
samples = ctgan.sample(2000)
samples.head()
正如我们所观察到的,输出与原始数据非常相似。结果是可以接受的。

SDV
在这一部分,我们将使用 SDV 库生成数据。SDV 提供了多个单表模型,并且还提供了更多功能来进行数据生成实验。
首先,我们将通过提供主键和浮动特征的小数位数来初始化模型。然后,我们将训练模型并生成 200 个样本。
from sdv.tabular import CTGAN
model = CTGAN(primary_key='id',rounding=2)
model.fit(data)
model.save("sdv-ctgan-food-demand.pkl")
new_data = model.sample(200)
new_data.head()
正如我们所看到的,id 列以 0 开始,整体数据看起来很干净。为了完全理解我们的合成数据,我们需要使用相似度度量来评估数据集,并比较数据分布。

评估
我们将使用 SDV evaluate 函数来分析真实数据集与虚假数据集之间的相似度。此函数显示了所有相似度指标的汇总结果,范围从 0 到 1,其中 0 最差,1 最理想。在我们的情况下,相似度指标为(0.34),这表示较差,我们需要在超参数优化上投入更多工作,以获得更好的结果。
from sdv.evaluation import evaluate
evaluate(new_data, data)
>>>> 0.34091406940696406
TableEvaluator 用于评估合成数据集与真实数据集之间的相似度。它专门用于分析基于 GAN 的表格模型的性能。通过编写几行代码,我们可以比较两个数据集在绝对对数均值、所有特征的分布、相关矩阵和前两个 PCA 组件上的表现。
from table_evaluator import load_data, TableEvaluator
table_evaluator = TableEvaluator(data, new_data)
table_evaluator.visual_evaluation()
通过观察所有可视化结果,我们可以得出结论:数据特征的分布在某种程度上是相似的,但主成分分析的分布与真实数据完全不同。



自定义模型
我们来创建一个自定义模型,通过改变训练轮数、批量大小、生成器维度和判别器维度来改善相似度指标。
model = CTGAN(
epochs=500,
batch_size=100,
generator_dim=(256, 256, 256),
discriminator_dim=(256, 256, 256)
)
model.fit(data)
model.save("manual-CTGAN.pkl")
我们还可以通过创建常量来定制生成的数据集。假设我们想为center_id 161. 生成数据。我们将首先创建一个“条件”字典,并将其传递给下述样本函数。
conditions = {"center_id": 161}
model.sample(5, conditions=conditions)

通过轻量级超参数优化,我们已实现了更好的相似度评分(0.53),如下所示。如果您的生成数据集的评分在 0.6 到 0.7 之间,那么您的数据集已准备好用于生产。
new_data = model.sample(2000)
evaluate(new_data, data)
>>>> 0.517249739944206
SDV 用于关系数据和时间序列
我们还可以使用 SDV 库生成关系数据集,使用 sdv.relational.HMA1 和时间序列数据,使用 sdv.timeseries.PAR。API 的工作原理类似于 CTGAN 模型,我们只需训练模型,然后生成N个样本。
关系数据
层次建模算法 是一种允许递归遍历关系数据集并在所有表格上应用表格模型的算法。通过这种方式,模型学习所有表格中的字段如何相关。
时间序列
概率自回归模型 允许学习多类型、多变量的时间序列数据,然后生成具有与学习数据相同格式和属性的新合成数据。
结论
我使用 CTGAN 来提升我的机器学习模型性能,并评估模型在未见数据集上的准确性。这也帮助我处理不平衡的类数据集。如果你有有限的训练数据,并且希望在不投入大量资金的情况下开发人工智能产品,那么你应该考虑生成合成数据集。合成数据集不仅限于表格数据,我们现在可以使用 GAN 生成图像、音频和文本数据集。创建人工数据是一个不断发展的领域,未来它将超过真实数据集。
在这篇博客中,我们了解了 CTGAN 以及如何使用 SDV 库生成表格数据集。我们还了解到,我们可以使用类似的 API 生成关系数据和时间序列数据。希望你喜欢这个简短的教程,如果你对调试代码有任何问题,请在下方评论。
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为患有心理疾病的学生构建人工智能产品。
更多相关内容
生成美丽的神经网络可视化
原文:
www.kdnuggets.com/2020/12/generating-beautiful-neural-network-visualizations.html
评论
您是否为论文构建了神经网络,或需要通过技术报告或其他媒介与他人分享其架构?
Python 库 PlotNeuralNet 由 Haris Iqbal 提供,帮助通过生成 LaTeX 代码来绘制神经网络,从而解决这个问题。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
PlotNeuralNet 不能直接从现有的架构代码中工作。相反,您需要单独并明确地定义网络代码,以便程序能够使用它来输出其图示。这使得 PlotNeuralNet 库不依赖于特定架构,但也意味着您需要进行额外的手动工作。
这是由 Python 脚本生成的 LaTeX 渲染结果的示例图像(明白了吗?):

PlotNeuralNet 生成的样本卷积神经网络架构(来自库的 Github 页面)
架构定义是通过一个包含函数调用的 Python 列表完成的,如项目 Github 上的示例所示:
# Define your neural network architecture here
arch = [
to_head( '..' ),
to_cor(),
to_begin(),
to_Conv("conv1", 512, 64, offset="(0,0,0)", to="(0,0,0)", height=64, depth=64, width=2),
to_Pool("pool1", offset="(0,0,0)", to="(conv1-east)"),
to_Conv("conv2", 128, 64, offset="(1,0,0)", to="(pool1-east)", height=32, depth=32, width=2),
to_connection( "pool1", "conv2"),
to_Pool("pool2", offset="(0,0,0)", to="(conv2-east)", height=28, depth=28, width=1),
to_SoftMax("soft1", 10 ,"(3,0,0)", "(pool1-east)", caption="SOFT"),
to_connection("pool2", "soft1"),
to_end()
]
生成可视化所需的完整 Python 脚本仅略多于上述架构定义:
import sys
sys.path.append('../')
from pycore.tikzeng import *
# Define your neural network architecture here
...
def main():
namefile = str(sys.argv[0]).split('.')[0]
to_generate(arch, namefile + '.tex' )
if __name__ == '__main__':
main()
一旦您安装了 [先决条件](http://bash ../tikzmake.sh my_arch),并保存了上述架构脚本,剩下的就是执行控制 bash 脚本:
bash ../tikzmake.sh your_script_name
这是从 PlotNeuralNet 架构定义(如上述)生成的 LaTeX 的示例摘录:
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%% Draw Layer Blocks
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
\node[canvas is zy plane at x=0] (temp) at (-3,0,0) {\includegraphics[width=8cm,height=8cm]{cats.jpg}};
% conv1_1,conv1_2,%pool1
\pic[shift={(0,0,0)}] at (0,0,0) {RightBandedBox={name=cr1,caption=conv1,%
xlabel={{"64","64"}},zlabel=I,fill=\ConvColor,bandfill=\ConvReluColor,%
height=40,width={2,2},depth=40}};
\pic[shift={(0,0,0)}] at (cr1-east) {Box={name=p1,%
fill=\PoolColor,opacity=0.5,height=35,width=1,depth=35}};
% conv2_1,conv2_2,pool2
\pic[shift={(2,0,0)}] at (p1-east) {RightBandedBox={name=cr2,caption=conv2,%
xlabel={{"64","64"}},zlabel=I/2,fill=\ConvColor,bandfill=\ConvReluColor,%
height=35,width={3,3},depth=35}};
\pic[shift={(0,0,0)}] at (cr2-east) {Box={name=p2,%
fill=\PoolColor,opacity=0.5,height=30,width=1,depth=30}};
如果您不需要这些图片用于 LaTeX 文档的发布,但仍希望使用它们怎么办?很简单;只需使用像 Overleaf 这样的基于云的 LaTeX 编辑器生成图片,然后将其保存到计算机上。现在可以在您的博客帖子或其他任何需要的地方使用它。
相关:
-
如何在深度学习中创建自定义实时图
-
在 Tableau 中创建强大的动画可视化
-
用 Python 可视化决策树(Scikit-learn、Graphviz、Matplotlib)
更多相关主题
生成随机数据与 NumPy

图片由编辑提供 | Ideogram
随机数据由通过各种工具生成的值组成,这些值没有可预测的模式。值的出现取决于它们所抽取的概率分布,因为它们是不可预测的。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
在我们的实验中使用随机数据有很多好处,包括现实世界数据模拟、机器学习训练的合成数据或统计采样目的。
NumPy 是一个强大的包,支持许多数学和统计计算,包括随机数据生成。从简单的数据到复杂的多维数组和矩阵,NumPy 可以帮助我们满足随机数据生成的需求。
本文将进一步讨论如何使用 NumPy 生成随机数据。所以,让我们深入了解吧。
使用 NumPy 生成随机数据
你需要在环境中安装 NumPy 包。如果你还没有安装,可以使用 pip 来安装。
pip install numpy
当包成功安装后,我们将进入文章的主要部分。
首先,我们将设置种子号以便可重复性。当我们使用计算机进行随机事件时,我们必须记住我们所做的只是伪随机的。伪随机的概念是数据看起来随机,但如果我们知道起点(我们称之为种子),它是确定性的。
要在 NumPy 中设置种子,我们将使用以下代码:
import numpy as np
np.random.seed(101)
你可以将任何正整数作为种子,这将成为我们的起点。此外,NumPy 的 .random 方法将成为本文的主要函数。
一旦设置了种子,我们将尝试使用 NumPy 生成随机数数据。让我们尝试随机生成五个不同的浮点数。
np.random.rand(5)
Output>>
array([0.51639863, 0.57066759, 0.02847423, 0.17152166, 0.68527698])
使用 NumPy 可以获得多维数组。例如,以下代码将生成一个填充随机浮点数的 3x3 数组。
np.random.rand(3, 3)
Output>>
array([[0.26618856, 0.77888791, 0.89206388],
[0.0756819 , 0.82565261, 0.02549692],
[0.5902313 , 0.5342532 , 0.58125755]])
接下来,我们可以从某个范围生成一个整数随机数。我们可以使用以下代码来实现:
np.random.randint(1, 1000, size=5)
Output>>
array([974, 553, 645, 576, 937])
之前通过随机采样生成的所有数据都遵循均匀分布。这意味着所有数据发生的机会相似。如果我们将数据生成过程迭代到无限次,所有数字的频率将接近相等。
我们可以从各种分布生成随机数据。在这里,我们尝试从标准正态分布生成十个随机数据。
np.random.normal(0, 1, 10)
Output>>
array([-1.31984116, 1.73778011, 0.25983863, -0.317497 , 0.0185246 ,
-0.42062671, 1.02851771, -0.7226102 , -1.17349046, 1.05557983])
上述代码获取了均值为零和标准差为一的正态分布的 Z 分数值。
我们可以生成遵循其他分布的随机数据。下面是我们如何使用泊松分布生成随机数据。
np.random.poisson(5, 10)
Output>>
array([10, 6, 3, 3, 8, 3, 6, 8, 3, 3])
上述代码中的泊松分布随机样本数据会模拟特定平均率(5)的随机事件,但生成的数字可能会有所不同。
我们可以生成遵循二项分布的随机数据。
np.random.binomial(10, 0.5, 10)
Output>>
array([5, 7, 5, 4, 5, 6, 5, 7, 4, 7])
上述代码模拟了我们执行的基于二项分布的实验。假设我们进行十次掷硬币实验(第一个参数为十,第二个参数为概率 0.5);多少次会出现正面?如上面的输出所示,我们进行了十次实验(第三个参数)。
让我们尝试指数分布。使用这段代码,我们可以生成遵循指数分布的数据。
np.random.exponential(1, 10)
Output>>
array([0.7916478 , 0.59574388, 0.1622387 , 0.99915554, 0.10660882,
0.3713874 , 0.3766358 , 1.53743068, 1.82033544, 1.20722031])
指数分布解释了事件之间的时间。例如,上述代码可以表示等待公交车进入车站,这需要随机的时间,但平均需要 1 分钟。
对于更高级的生成,你可以随时结合分布结果来创建遵循自定义分布的样本数据。例如,下面生成的随机数据中有 70% 遵循正态分布,而其余部分遵循指数分布。
def combined_distribution(size=10):
# normal distribution
normal_samples = np.random.normal(loc=0, scale=1, size=int(0.7 * size))
#exponential distribution
exponential_samples = np.random.exponential(scale=1, size=int(0.3 * size))
# Combine the samples
combined_samples = np.concatenate([normal_samples, exponential_samples])
# Shuffle thes samples
np.random.shuffle(combined_samples)
return combined_samples
samples = combined_distribution()
samples
Output>>
array([-1.42085224, -0.04597935, -1.22524869, 0.22023681, 1.13025524,
0.74561453, 1.35293768, 1.20491792, -0.7179921 , -0.16645063])
这些自定义分布更为强大,特别是当我们想要模拟数据以符合实际情况数据(通常更为复杂)时。
结论
NumPy 是一个强大的 Python 包,用于数学和统计计算。它生成的随机数据可以用于许多事件,例如数据模拟、机器学习的合成数据等。
在本文中,我们讨论了如何使用 NumPy 生成随机数据,包括可以改善数据生成体验的方法。
Cornellius Yudha Wijaya**** 是一位数据科学助理经理和数据编写员。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 撰写了各种人工智能和机器学习主题的文章。
了解更多主题
使用 RNN 生成文本的 4 行代码
原文:
www.kdnuggets.com/2018/06/generating-text-rnn-4-lines-code.html
评论
生成文本是一个对机器学习和自然语言处理初学者来说似乎很有趣的项目,但它也相当令人畏惧。或者,至少对我来说是这样。
幸运的是,在线有各种优秀的材料可以学习如何使用 RNN 生成文本,这些材料涵盖了从理论到技术深度的内容,也有专注于实际应用的内容。其中一些非常好的文章 涵盖了所有内容 ,现已被认为是这一领域的经典。所有这些材料有一个共同点:在某个阶段,你必须构建和调整一个 RNN 来完成工作。
虽然这是一个显然值得做的任务,特别是为了学习,但如果你对更高层次的抽象感到满意呢,无论你出于什么原因?如果你是一个数据科学家,需要一个以 RNN 文本生成器形式存在的构建块来插入你的项目呢?或者,作为一个新手,你只是想稍微动手一下——但不要太深入——以测试水域或作为进一步挖掘的动机呢?
在这个背景下,让我们看看 textgenrnn 项目,它允许你“轻松训练自己生成文本的神经网络,无论大小和复杂度,使用几行代码即可。” textgenrnn 的作者是 Max Woolf,他是 BuzzFeed 的副数据科学家,曾是 Apple 软件 QA 工程师。
textgenrnn 基于 Keras 和 TensorFlow,可以用于生成字符级和词级文本(字符级是默认的)。网络架构使用了注意力加权和跳跃嵌入来加速训练和提高质量,并允许调整多个超参数,如 RNN 大小、RNN 层数以及是否包含双向 RNN。你可以在其 Github 仓库 或这篇 介绍博客文章 中阅读更多关于 textgenrnn 及其功能和架构的内容。

由于文本生成的“Hello, World!”(至少在我看来)似乎是生成特朗普的推文,我们就用这个吧。textgenrnn 的默认预训练模型可以很容易地在新文本上进行训练——虽然你也可以使用 textgenrnn 训练一个新模型(只需将 new_model=True 添加到其任何训练函数中)——由于我们想要快速生成推文,我们就这样做吧。
获取数据
我从特朗普推特档案中获取了一些唐纳德·特朗普的推文——2014 年 1 月 1 日至 2018 年 6 月 11 日(在撰写时的前一天),这明显包括了他作为美国总统就职前后的推文。这个网站可以轻松查询和下载总统的推文。我只提取了该日期范围内的推文文本,因为我不关心任何元数据,并将其保存到一个名为trump-tweets.txt的文本文件中。

训练模型
让我们看看使用 textgenrnn 生成文本有多简单。以下 4 行代码是我们需要的所有内容,用于导入库、创建文本生成对象、在trump-tweets.txt文件上训练模型 10 个周期,然后生成一些示例推文。
from textgenrnn import textgenrnn
textgen = textgenrnn()
textgen.train_from_file('trump-tweets.txt', num_epochs=10)
textgen.generate(5)
大约 30 分钟后,以下是生成的内容(在第 10 个周期):
My @FoxNews will be self finally complaining about me that so he is a great day and companies and is starting to report the president in safety and more than any mention of the bail of the underaches to the construction and freedom and efforts the politicians and expensive meetings should have bee
The world will be interviewed on @foxandfriends at 7:30pm. Enjoy!
.@JebBush and Fake News Media is a major place in the White House in the service and sense where the people of the debate and his show of many people who is a great press considering the GREAT job on the way to the U.S. A the best and people in the biggest! Thank you!
New Hampshire Trump Int'l Hotel Leadership Barrier Lou Clinton is a forever person politically record supporters have really beginning in the media on the heart of the bad and women who have been succeeded and before you can also work the people are there a time strong and send out the world with
Join me in Maryland at 7:00 A.M. and happened to the WALL and be true the longer of the same sign into the Fake News Media will be a great honor to serve that the Republican Party will be a great legal rate the media with the Best Republican Party and the American people that will be the bill by a
撇开政治不谈,鉴于我们只使用了约 12K 条推文进行仅 10 个周期的训练,这些生成的推文并不……糟糕。想试试温度(textgenrnn 的默认值为 0.5)来生成一些更具创意的推文吗?我们来试试吧:
textgen.generate(5, temperature=0.9)
“Via-can see this Democrats were the opening at GREAT ENSUS CALL!
.@GovSeptorald Taster is got to that the subcent Vote waiting them. @Calkers
Major President Obama will listen for the disaster!
Grateful and South Carolina so his real ability and much better-- or big crisis on many signing!
It is absolutely dumbers for well tonight. Love us in the great inherition of fast. With bill of badly to forget the greatest puppet at my wedds. No Turnberry is "bigger.” - Al
嗯,这说服力稍差。怎么样,我们试试一些更保守的,这样模型会更有信心的:
textgen.generate(5, temperature=0.1)
The Fake News Media is a great people of the president was a great people of the many people who would be a great people of the president was a big crowd of the statement of the media is a great people of the people of the statement of the people of the people of the world with the statement of th
Thank you @TrumpTowerNY #Trump2016 https://t.co/25551R58350
Thank you for your support! #Trump2016 https://t.co/7eN53P55c
The people of the U.S. has been a great people of the presidential country is a great time and the best thing that the people of the statement of the media is the people of the state of the best thing that the people of the statement of the statement of the problem in the problem and success and t
Thank you @TheBrodyFile tonight at 8:00 A.M. Enjoy!
现在,其中一些看起来更易读了。
当然,这并不完美。我们可以尝试各种其他方法,幸运的是,如果你不想实现自己的解决方案,textgenrnn 可以用来执行许多这些操作(再次参见Github 仓库):
-
从零开始训练我们自己的模型
-
使用更多的样本数据进行更多次迭代训练
-
调整其他超参数
-
对数据进行一些预处理(至少要去除虚假的网址)
有点有趣。我很想看看一个默认的 textgenrnn 模型在开箱即用时与一个定制的、经过良好调整的模型相比表现如何。也许下次可以尝试一下。
相关:
-
5 个你不应该忽视的机器学习项目,2018 年 6 月
-
使用 spaCy 进行自然语言处理入门
-
了解名人最常发布什么内容
我们的前三个课程推荐
1. 谷歌网络安全证书 - 加快你在网络安全领域的职业发展。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
更多相关内容
生成对抗网络 – 机器学习的热门话题
原文:
www.kdnuggets.com/2017/01/generative-adversarial-networks-hot-topic-machine-learning.html
作者:Al Gharakhanian。
NIPS2016(神经信息处理系统)是一个年度盛会,吸引了来自学术界和工业界的机器学习领域的顶尖人才。我上周第一次参加了这个活动,被演讲的数量和多样性震撼了。一个不寻常的观察是,大量展位是寻求机器学习人才的对冲基金。
有些论文高度抽象和理论化,而另一些则来自于如 Google 和 Facebook 等公司的务实研究。这些话题范围广泛,但有两个话题脱颖而出,吸引了大量关注。
第一个是“生成对抗网络”(简称 GANs),第二个是“强化学习”(简称 RL)。我的计划是这篇文章覆盖 GANs,希望未来的文章能同样介绍 RL。
GAN 是一种相对较新的神经网络机器学习架构,由 Ian Goodfellow 和他在蒙特利尔大学的同事们于 2014 年开创。为了全面理解 GANs,必须了解监督学习和无监督学习机器之间的区别。监督学习机器基于大量的“标记”样本进行训练和测试。换句话说,它们需要包含“特征”或“预测因子”以及相应标签的大型数据集。例如,一个监督图像分类引擎需要一组带有正确标签的图像(例如,汽车、花朵、桌子等)。无监督学习者没有这种奢侈条件,它们在实际操作中学习,从错误中吸取教训,力求不再犯类似的错误。
监督学习的缺点是需要大量的标记数据。标记大量样本既昂贵又耗时。无监督学习则没有这一缺点,但通常准确性较低。自然地,有强烈的动机去改进无监督机器,并减少对监督学习的依赖。你可以将 GANs 和 RLs 视为改进无监督机器(神经网络)的手段。
第二个值得记住的有用概念是“生成模型”。这些模型通过生成给定一系列输入样本的最可能结果来进行预测。例如,生成模型可以基于之前的帧生成下一个最可能的视频帧。另一个例子是搜索引擎在用户输入之前尝试预测下一个最可能的词。
牢记这两个概念,我们现在可以探讨 GAN。你可以将 GAN 视为一种新的无监督神经网络架构,相比传统网络能够实现更好的性能。更准确地说,GAN 是一种训练神经网络的新方式。GAN 包含两个独立的网络,它们各自工作并充当对手(见下图)。第一个神经网络称为判别器(D),它是需要接受训练的网络。D 是分类器,在训练完成后在正常操作过程中将承担繁重的任务。第二个网络称为生成器(G),其任务是生成随机样本,这些样本与真实样本相似,但带有一些变动,使其成为假样本。

例如,考虑一个设计用于识别各种动物图像的图像分类器 D。现在考虑一个对手(G),其任务是通过精心制作的图像来欺骗 D,这些图像看起来几乎正确但又不完全对。这是通过从训练集(潜在空间)中随机挑选一个合法样本,并通过随机改变其特征(添加随机噪声)来合成新图像。例如,G 可以获取一只猫的图像,并在图像上添加一个额外的眼睛,将其转换为假样本。结果是一个非常类似正常猫的图像,唯一的区别是眼睛的数量。
在训练过程中,D 会收到来自训练数据的真实图像与 G 生成的假图像的随机混合。其任务是识别正确和假输入。根据结果,两个网络都尝试微调它们的参数,变得更出色。如果 D 做出正确的预测,G 会更新其参数,以生成更好的假样本来欺骗 D。如果 D 的预测不正确,它会试图从错误中学习,以避免未来类似的错误。网络 D 的奖励是正确预测的数量,G 的奖励是 D 的错误数量。这个过程持续进行,直到达到平衡,D 的训练得到优化。
早期 GAN 的一个弱点是稳定性,但我们已经看到了一些非常有前景的工作可以缓解这个问题(详细信息超出了本文的范围)。从某种程度上来说,GAN 就像是一个拥有两个对立政党的国家的政治环境。每个党派不断尝试改善自己的弱点,同时试图发现和利用对方的漏洞,以推动自己的议程。随着时间的推移,两党都成为了更好的操作员。
至于 RL 和 GAN 对半导体的影响,这两种新架构需要显著更多的门、更高的 CPU 周期和更多的内存。这没什么好抱怨的。
原文。经许可转载。
简介: ****Al Gharakhanian** 是一位全面发展的高管,拥有在半导体、机器学习和数据科学领域的产品营销、销售和业务发展方面的丰富经验。
相关:
-
深度学习研究综述:生成对抗网络
-
深度神经网络是否具备创造力?
-
深度学习最新动态:8 月更新,第二部分
我们的 3 大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
更多相关内容
生成代理研究论文阅读推荐
原文:
www.kdnuggets.com/generative-agent-research-papers-you-should-read

图片来源于 pikisuperstar 在 Freepik
生成代理是由斯坦福大学和谷歌研究人员在他们的论文生成代理:人类行为的互动模拟(Park et al., 2023)中创造的术语。在这篇论文中,研究解释了生成代理是计算软件,能够可信地模拟人类行为。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
在这篇论文中,他们介绍了代理如何通过实施生成模型,尤其是大型语言模型(LLM),像人类一样进行写作、烹饪、演讲、投票、睡觉等行为。代理能够利用自然语言模型展示对自身、其他代理和环境的推断能力。
研究人员构建了一个系统架构,用于存储、综合和应用相关记忆,通过使用大型语言模型来生成可信的行为,从而实现生成代理。该系统由三个组件组成,它们是:
-
内存流。系统记录代理的经历,并作为代理未来行动的参考。
-
反思。系统将经历综合为记忆,以便代理可以学习和表现得更好。
-
计划。系统将前一系统的洞察转化为高层次的行动计划,并使代理能够对环境做出反应。
这些反思和计划系统与内存流协同工作,影响代理的未来行为。
为了模拟上述系统,研究人员专注于创建一个受《模拟人生》游戏启发的互动代理社会。上述架构与 ChatGPT 连接,并成功展示了其沙盒内的 25 个代理互动。以下图像展示了一整天代理活动的一个示例。

生成代理的日常活动和互动(Park et al., 2023)
用于创建生成代理并在沙箱中模拟它们的完整代码已经由研究人员开源,你可以在以下仓库中找到。说明非常简单,你可以顺利跟随。
随着生成代理成为一个令人兴奋的领域,基于这一点的研究也在不断进行。在本文中,我们将探讨一些你应该阅读的生成代理相关论文。这些论文有哪些呢?让我们深入了解一下。
1. 软件开发的交流代理
软件开发的交流代理论文(Quan et al., 2023)是一种通过生成代理来革命性改进软件开发的新方法。研究人员提出的前提是如何利用大型语言模型(LLM)的自然语言沟通来简化和统一整个软件开发过程。任务包括开发代码、生成文档、分析需求等。
研究人员指出,使用 LLM 生成整个软件面临两个主要挑战:幻觉和决策过程中缺乏交叉检查。为了解决这些问题,研究人员提出了一种基于聊天的软件开发框架,称为 ChatDev。
ChatDev 框架分为四个阶段:设计、编码、测试和文档编写。在每个阶段中,ChatDev 会建立几个具有不同角色的代理,例如代码审阅员、软件程序员等。为了确保代理之间的通信顺畅,研究人员开发了一个聊天链,将各个阶段划分为顺序原子子任务。每个子任务都实现了代理之间的协作和互动。
ChatDev 框架如下图所示。

提出的 ChatDev 框架(Quan et al., 2023)
研究人员进行了各种实验来测量 ChatDev 框架在软件开发中的表现。通过使用gpt3.5-turbo-16k,以下是软件统计实验的表现。

ChatDev 框架软件统计数据(Quan et al., 2023)
上述数字是关于 ChatDev 生成的软件系统的统计分析指标。例如,生成的代码行数最少为 39 行,最多为 359 行。研究人员还展示了生成的软件系统中有 86.66%正常工作。
这是一篇很棒的论文,展示了改变开发者工作方式的潜力。进一步阅读论文以了解 ChatDev 的完整实现。完整代码也可以在 ChatDev 的仓库中找到。
2. AgentVerse:促进多代理协作并探索代理中的涌现行为
AgentVerse 是 Chen et al., 2023 论文中提出的一个框架,用于通过大型语言模型模拟代理组,以便在组内进行动态问题解决程序,并根据进展调整组成员。这项研究旨在解决静态组动态的问题,即自主代理在解决问题时无法适应和演变。
AgentVerse 框架试图将框架拆分为四个步骤,包括:
-
专家招聘:代理调整阶段以与问题和解决方案对齐
-
协作决策:代理讨论以制定解决问题的方案和策略。
-
行动执行:代理根据决策在环境中执行行动。
-
评估:当前条件和目标被评估。如果目标仍未达到,反馈奖励将返回到第一步。
AgentVerse 的整体结构如下面的图像所示。

AgentVerse 框架(Chen et al., 2023)
研究人员对该框架进行了实验,并将 AgentVerse 框架与单一代理解决方案进行了比较。结果如下面的图像所示。

AgentVerse 性能分析(Chen et al., 2023)
AgentVerse 框架在所有展示的任务中通常优于单个代理。这证明了生成代理在解决问题时可能比单个代理表现更好。你可以通过他们的 repository 试用该框架。
3. AgentSims:一个用于大型语言模型评估的开源沙箱
评估 LLM 的能力仍然是社区和领域中的一个悬而未决的问题。限制评估 LLM 能力的三个因素是任务的评估能力有限、脆弱的基准和不客观的指标。为了应对这些问题,Lin et al., 2023 在他们的论文中提出了一种基于任务的评估作为 LLM 基准的方法。这种方法希望成为评估 LLM 工作的标准,因为它可以缓解提出的所有问题。为了实现这一点,研究人员引入了一个名为 AgentSims 的框架。
AgentSims 是一个具有互动和可视化基础设施的程序,用于策划 LLM 的评估任务。AgentSims 的总体目标是为研究人员和专家提供一个平台,以简化任务设计过程,并将其作为评估工具。AgentSims 的前端如下面的图像所示。

AgentSims 前端(林等人., 2023)
由于 AgentSims 的目标是为需要更简单 LLM 评估的方法的每个人提供服务,研究人员开发了可以与用户界面交互的前端。你还可以在他们的网站上尝试完整演示,或在 AgentSims 的代码库中访问完整代码。
结论
生成智能体是 LLMs 中模拟人类行为的一种新方法。最新的研究由 Park 等人., 2023 进行,展示了生成智能体的巨大潜力。这就是为什么许多基于生成智能体的研究不断涌现,并开启了许多新领域。
在这篇文章中,我们讨论了三种不同的生成智能体研究,包括:
-
软件开发中的交互智能体论文(全等人., 2023)
-
AgentVerse: 促进多智能体协作并探索智能体中的涌现行为(陈等人., 2023)
-
AgentSims: 一个开源的大型语言模型评估沙盒(林等人., 2023)
Cornellius Yudha Wijaya 是一名数据科学助理经理和数据撰稿人。虽然全职在印尼安联工作,他还是喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
更多相关话题
生成式 AI 关键术语解析

图片来源:作者
在过去几年,尤其是自 ChatGPT 出现以来,生成式 AI 模型用于创建逼真的合成文本、图像、视频和音频不断涌现,并迅速发展。最初仅是微不足道的研究,但很快发展成能够在上述各种媒介中生成高质量、类人输出的系统。特别是在神经网络的关键创新和计算能力的大幅提升的推动下,越来越多的公司现在提供这些模型的免费和/或付费访问,这些模型的能力以惊人的速度增长。
然而,生成式 AI 并非全是美好愿景。尽管它在多种应用中极具潜力,能够增强人类创造力,但如何恰当地评估、测试和负责任地部署这些生成系统仍然存在诸多担忧。尤其是对虚假信息传播的担忧,以及由这项技术带来的偏见、真实性和社会影响的忧虑。
然而,处理任何新技术的首要任务是尝试理解它,然后再决定是利用还是批评它。我们计划在本文中着手进行这一工作。我们打算列出一些关键的生成式 AI 术语,并尽力以直观的方式使初学者能够理解,从而提供一个基础框架,为进一步深入学习铺平道路。为此,在下文中的每个关键术语下,你将找到相关材料的链接,便于根据需要进一步调查。
现在让我们开始吧。
自然语言处理
自然语言处理(NLP)是一个专注于使机器理解、解释和生成自然语言的 AI 子领域,通过编程为这些机器提供所需的工具。NLP 构建了人类沟通与计算机理解之间的桥梁。NLP 首先使用基于规则的方法,其后采用了“传统”的机器学习方法,而如今最前沿的 NLP 则依赖于各种神经网络技术。
神经网络
神经网络是受(而非复制自)人脑启发的机器学习计算模型,用于从数据中学习。神经网络由层(许多层=深度学习)人工神经元组成,处理和传输小的个体数据,将这些数据适配到函数中,并重复更新与处理神经元相关的权重,以“更好地适配”数据到函数中。神经网络对于现代人工智能的学习和决策能力至关重要。没有十多年前开始的深度学习革命,我们所称之为人工智能的许多东西将不可能存在。
生成式人工智能
生成式人工智能是一类由神经网络驱动的人工智能,专注于创造新的内容。这些内容可以以多种形式出现,从文本到图像,再到音频等。这不同于专注于分类或分析现有数据的“传统”人工智能类型,它体现了“想象”并基于训练数据生成新内容的能力。
内容生成
内容生成是经过训练的生成模型实际生成合成文本、图像、视频和音频的过程,这些生成是基于从训练数据中学到的模式,对用户输入或提示进行上下文相关的输出。这些提示也可以是上述提到的任何形式。例如,文本可以作为提示生成更多的文本,或根据文本描述生成图像,或生成音频或视频。类似地,图像可以作为提示生成另一张图像、文本或视频等。多模态提示也是可能的,例如,可以使用文本和图像生成音频。
大型语言模型
大型语言模型(LLMs)是专门处理和“理解”人类语言的机器学习模型。LLMs 通过大量的文本数据进行训练,使其能够分析和复制复杂的语言结构、细微差别和语境。不论使用的具体 LLM 模型和技术是什么,这些模型的核心本质都是学习并预测当前词汇或标记(字母组合)之后的下一个词汇。LLMs 本质上是非常复杂的“下一个词汇猜测器”,而提升下一个词汇的猜测能力是目前一个非常热门的研究话题。
基础模型
基础模型是被设计为具有广泛能力的 AI 系统,这些能力可以适应多种特定任务。基础模型提供了构建更专业化应用的基础,例如将通用语言模型调整为特定的聊天机器人、助手或其他生成性功能。基础模型不仅限于语言模型,还存在于生成图像和视频等任务中。知名且被广泛依赖的基础模型包括 GPT、BERT 和稳定扩散。
参数
在这个背景下,参数是定义模型结构、操作行为和学习与预测能力的数值。例如,OpenAI 的 GPT-4 中的数十亿个参数影响其单词预测和对话生成能力。更技术性地说,神经网络中每个神经元之间的连接承载权重(如上所述),每个权重都是一个单一的模型参数。神经元越多 → 权重越多 → 参数越多 → 网络的学习和预测能力越强。
词嵌入
词嵌入是一种技术,通过将单词或短语转换为预定维度数量的数值向量,试图在远小于对词汇表中的每个单词(或短语)进行独热编码所需的空间中捕捉其含义和上下文关系。如果你创建一个 500,000 个单词的矩阵,其中每一行代表一个单词,每一行中的每一列都设置为“0”,除了一个表示该单词的列,这个矩阵将是 500,000 x 500,000 行 x 列,并且非常稀疏。这将是存储和性能上的灾难。通过将列设置为 0 到 1 之间的各种分数值,并将列数减少到例如 300(维度),我们获得了一个更为集中存储的结构,并本质上提高了操作性能。作为副作用,通过让神经网络学习这些维度嵌入值,相似的术语在维度值上会“更接近”,从而为我们提供关于相对单词含义的见解。
变换器模型
变换器模型是同时处理整句话的 AI 架构,这对于掌握语言上下文和长期关联至关重要。它们在检测单词和短语之间的关系方面表现优异,即使它们在句子中相隔很远。例如,当“她”在一段文本中早期被确立为指代特定个体的名词和/或代词时,变换器能够“记住”这种关系。
位置编码
位置编码是指变换器模型中的一种方法,帮助保持词汇的顺序。这是理解句子及句子之间上下文的关键组件。
从人类反馈中学习的强化学习
从人类反馈中学习的强化学习(RLHF)指的是一种训练大型语言模型(LLMs)的方法。与传统的强化学习(RL)类似,RLHF 训练并使用一个奖励模型,不过这个奖励模型直接来源于人类反馈。然后,该奖励模型作为奖励函数用于 LLM 的训练,借助优化算法。这个模型明确地将人类纳入模型训练的过程中,期望人类反馈能提供必要的、可能否则无法获得的反馈,以优化 LLM。
突现行为
突现行为指的是大型和复杂语言模型展示出的意外技能,这些技能在较简单的模型中并不存在。这些意外的技能可能包括编程、音乐创作和小说写作等能力。这些技能并没有被明确地编程到模型中,而是从其复杂的架构中自然出现的。然而,突现能力的问题可能超越这些更常见的技能;例如,心智理论是否是一种突现行为?
幻觉
幻觉是指大型语言模型由于数据和架构的限制而产生事实错误或不合逻辑的响应。尽管模型可能具备先进的能力,但这些错误仍然可能发生,无论是当遇到与模型训练数据无关的查询,还是当模型的训练数据包含错误或虚假的信息时。
拟人化
拟人化是指将类人特质归于人工智能系统的倾向。需要注意的是,尽管人工智能系统能够模仿人类情感或语言,以及我们本能地将模型视为“他”或“她”(或其他代词)而非“它”,人工智能系统并不具备情感或意识。
偏见
偏见在人工智能研究中是一个含义丰富的术语,可以指代多种不同的事物。在我们的上下文中,偏见指的是由于训练数据偏斜而导致的人工智能输出错误,进而导致不准确、冒犯或误导的预测。偏见的出现是因为算法将无关数据特征置于有意义的模式之上,或完全缺乏有意义的模式。
Matthew Mayo (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为KDnuggets和Statology的总编辑,以及Machine Learning Mastery的特约编辑,Matthew 致力于使复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、语言模型、机器学习算法以及探索新兴的人工智能。他的终极目标是将数据科学领域的知识普及化。Matthew 从 6 岁开始编程。
更多相关话题
大语言模型的生成性 AI:实践培训
原文:
www.kdnuggets.com/2023/07/generative-ai-large-language-models-handson-training.html

作者提供的图片
介绍
大型语言模型(LLMs)如 GPT-4 正在迅速改变世界和数据科学领域。在过去几年中,一度看似科幻的能力现在通过 LLMs 变成了现实。
大语言模型的生成性 AI:实践培训将向你介绍推动这一革命的深度学习突破,重点关注变换器架构。更重要的是,你将直接体验最新 LLMs 如 GPT-4 所能提供的惊人能力。
你将学习 LLMs 如何从根本上改变机器学习模型的开发和商业成功的数据产品。你将亲眼看到它们如何加速数据科学家的创造能力,同时推动他们成为成熟的数据产品经理。
通过利用 Hugging Face 和 PyTorch Lightning 的实际代码演示,本培训将涵盖处理 LLMs 的完整生命周期。从高效的训练技巧到在生产中优化部署,你将学习到直接适用的技能,释放 LLMs 的潜力。
在这场充满活力的会议结束时,你将对 LLMs 有基础性的理解,并获得利用 GPT-4 的实践经验。

训练中的图片
训练大纲
该培训有 4 个简短模块,介绍你大型语言模型,并教你如何训练自己的大型语言模型并将其部署到服务器。除此之外,你还将了解 LLMs 带来的商业价值。
1. 大型语言模型(LLMs)简介
-
自然语言处理的简要历史
-
变换器
-
子词标记化
-
自回归模型与自编码模型
-
ELMo, BERT 和 T5
-
GPT(生成预训练变换器)家族
-
LLM 应用领域
2. LLM 能力的广度
-
LLM 实验室
-
GPT 家族的惊人进展
-
GPT-4 的关键更新
-
调用 OpenAI API,包括 GPT-4
3. 训练和部署 LLMs
-
硬件加速(CPU、GPU、TPU、IPU、AWS 芯片)
-
Hugging Face 变换器库
-
高效 LLM 训练的最佳实践
-
低秩适应(LoRA)的参数高效微调(PEFT)
-
开源预训练 LLMs
-
使用 PyTorch Lightning 进行 LLM 训练
-
多 GPU 训练
-
LLM 部署注意事项
-
监控生产中的 LLMs
4. 从 LLMs 中获取商业价值
-
用 LLMs 支持机器学习
-
可以自动化的任务
-
可增强的任务
-
成功的人工智能团队和项目的最佳实践
-
下一步是什么?人工智能
资源
该培训包括指向外部资源的链接,如源代码、演示文稿幻灯片和 Google Colab 笔记本。这些资源使培训具有互动性,并对将生成性 AI 应用于工作空间的工程师和数据科学家非常有用。

培训中的图片
以下是使用 Huggingface 和 Pytorch Lighting 构建和部署自己的 LLM 模型所需的重要资源列表:
仅需 2 小时即可发现成功的秘诀!不要再等了!
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为面临心理问题的学生开发一个 AI 产品。
更多相关主题
IBM 为每个职业提供的生成式 AI 专业课程
原文:
www.kdnuggets.com/generative-ai-specialisation-courses-from-ibm-for-every-profession

作者提供的图像 | Canva
你可能在自己的岗位上,想知道如何在新的生成式 AI 热潮中提升技能。别担心,KDnuggets 的团队已经为你准备好了。AI 领域的发展速度快得让我们来不及反应——特别是生成式 AI。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT 部门
我们很多人都在日常工作和个人生活中使用生成式 AI。然而,如果你对如何提升技能、利用生成式 AI 最重要的是感觉你的工作不会受到威胁感兴趣,最好的办法就是学习它。
在这篇博客中,我将介绍针对特定职业的生成式 AI 专业课程。
数据分析师的生成式 AI
链接: 数据分析师的生成式 AI
组织使用生成式 AI 做出决策的方式正在上升。因此,作为数据分析师,你有责任了解生成式 AI 数据分析如何改善你的组织。
在 IBM 提供的这个专业课程中,你将学习实际的生成式 AI 使用案例以及流行的生成式 AI 模型和工具,涵盖文本、代码、图像、音频和视频生成。你将深入研究生成式 AI 提示工程概念,使用提示技术如零-shot 和 few-shot,并探索各种提示工程方法,以及像 IBM Watson、Prompt Lab、Spellbook 和 Dust 这样的工具。
然后,你将通过了解生成式 AI 的构建模块和基础模型,例如 GPT、DALL-E 和 IBM Watson Studio,以及在不同行业中使用生成式 AI 时的伦理影响、考虑因素和挑战来提升你的知识。
网络安全的生成式 AI
链接: 网络安全的生成式 AI
我认为网络安全并没有得到应有的重视。他们是确保组织能够有效运作的安全保障专家。作为网络安全专业人员,学习生成式 AI 技能对于你的日常工具包至关重要。
在 IBM 提供的这个专业课程中,你将从区分生成式人工智能和判别式人工智能的区别开始。然后你将深入探索真实世界中的生成式人工智能应用案例,并发现流行的生成式人工智能模型。你还将研究生成式人工智能的提示工程概念。最后,你将学习生成式人工智能在网络安全中的基本概念,以及如何将生成式人工智能技术应用于实际场景,包括 UBE、威胁情报、报告总结和剧本,并评估其影响和脆弱性。
数据工程师的生成式人工智能
链接: 生成式人工智能应用于数据工程师
作为数据工程师,你的角色和职责包括高效的数据收集、生成、转换和存储。在生成式人工智能的帮助下,你可以使用能够使每个数据工程任务在 ETL 管道上变得更加高效、有效和便捷的工具。
这门 IBM 专业课程不仅仅是为数据工程师设计的,还适用于任何对生成式人工智能在数据工程中应用感兴趣的人。该专业包括三个自学课程,你将从了解生成式人工智能与判别式人工智能的区别开始。你将深入探讨真实世界中生成式人工智能的应用案例,并探索流行的生成式人工智能模型和用于文本、代码、图像、音频和视频生成的工具。最后,你还将学习零样本和少样本等提示技术,探索各种提示工程方法,并了解包括 IBM Watsonx、Prompt Lab、Spellbook 和 Dust 在内的常用提示工程工具。
生成式人工智能应用于软件开发人员
链接: 生成式人工智能应用于软件开发人员
在当今时代,作为一名软件开发人员,你可以利用生成式人工智能这一革命性技术的诸多优势,例如编写更少漏洞的高质量代码。生成式人工智能已经被证明可以提高软件开发人员的整体效果和效率——使生成式人工智能成为软件工程师必备的技能。
这门 IBM 专业课程适用于那些希望在日常工作中利用生成式人工智能力量的软件开发领域人士。然而,这不仅仅针对软件开发人员,还包括现有和有志于成为网页开发人员、移动应用开发人员、前端开发人员、后端开发人员、全栈开发人员、DevOps 专业人员和站点可靠性工程师(SRE)。
在这个专业课程中,你将从生成式人工智能的基础知识开始,包括其用途、模型和用于文本、代码、图像、音频和视频生成的工具。然后你将深入学习提示工程,探索各种提示工程方法和提示工程工具,包括 IBM Watsonx、Prompt Lab、Spellbook 和 Dust。
产品经理的生成式 AI
链接: 产品经理的生成式 AI
想要一些关于产品构建、推出和市场交付的帮助吗?作为产品经理,你可以利用生成式 AI 来帮助减轻一些任务,无论是任务自动化还是用户体验个性化,生成式 AI 都能在产品开发过程中提供设计和开发的支持。
这门 IBM 专业课程将帮助产品经理,无论他们是新手还是有经验的,从而熟练掌握生成式 AI,并获得如何利用这一技术的洞察。你将从区分生成式 AI 和判别式 AI 开始,然后深入了解生成式 AI 的实际应用案例,并探索流行的生成式 AI 模型。
然后,你将掌握生成式 AI 提示工程概念在实际业务中的应用。了解提示技术,如零样本和少样本,各种提示工程方法,以及包括 IBM Watsonx 和 Spellbook 在内的工具。最后但同样重要的是,你将探索产品经理可以使用的具体生成式 AI 技术和流程,以便在更短的时间内交付更好的产品。
总结
5 个不同的专业课程,针对 5 种不同的工作。虽然这些专业课程的内容非常相似,但主要区别在于如何针对具体的职位定制,以确保你作为学习者能从中获得最大收益,并将其应用于你的日常工作流程中。
尼莎·阿亚是一位数据科学家、自由技术写作者,以及 KDnuggets 的编辑和社区经理。她特别感兴趣于提供数据科学职业建议或教程以及数据科学理论知识。尼莎涵盖了广泛的话题,并希望探索人工智能如何有利于人类寿命的延续。作为一名热衷的学习者,尼莎致力于拓宽自己的技术知识和写作技能,同时帮助他人。
更多相关主题
生成性 AI:初稿而非最终稿
原文:
www.kdnuggets.com/generative-ai-the-first-draft-not-final
作者:努玛·达哈尼 & 玛吉·恩格勒

可以说,人工智能正处于风口浪尖。自从 OpenAI 的对话代理 ChatGPT 在去年末意外走红以来,科技行业一直在热议 ChatGPT 背后的技术——大型语言模型(LLMs)。除了谷歌、Meta 和微软之外,还有像 Anthropic 和 Cohere 这样资金充裕的初创公司也推出了自己的 LLM 产品。各个行业的公司纷纷争相将 LLM 整合进他们的服务中:仅 OpenAI 就拥有从金融科技公司如 Stripe 提供客户服务聊天机器人,到教育科技公司如 Duolingo 和 Khan Academy 生成教育材料,再到视频游戏公司如 Inworld 利用 LLM 为 NPC(非玩家角色)提供对话的各类客户。凭借这些合作伙伴关系和广泛的采用,据报道 OpenAI 预计年收入将超过十亿美元。很容易被这些模型的活跃性所打动:关于 GPT-4 的技术报告显示,该模型在各种学术和专业基准测试中取得了令人印象深刻的分数,包括律师资格考试;SAT、LSAT 和 GRE;以及涉及艺术史、心理学、统计学、生物学和经济学的 AP 考试。
这些引人注目的结果可能暗示着知识工作者的终结,但 GPT-4 和人类专家之间存在一个关键区别:GPT-4 没有 理解。GPT-4 和所有 LLM 生成的回答并不是来源于逻辑推理过程,而是来自统计操作。大型语言模型是通过海量的互联网数据进行训练的。网络爬虫——访问数百万网页并下载其内容的机器人——生成了来自各种网站的文本数据集:社交媒体、维基和论坛、新闻和娱乐网站。这些文本数据集包含数十亿或数万亿个单词,这些单词大多以自然语言的形式排列:单词形成句子,句子形成段落。
为了学习如何生成连贯的文本,这些模型在数百万个文本补全示例数据上进行训练。例如,给定模型的数据集中可能包含像“这是一个黑暗而暴风雨的夜晚”和“西班牙的首都为马德里”这样的句子。模型不断尝试在看到“这是一个黑暗而暴风雨的”或“西班牙的首都为”之后预测下一个词,然后检查是否正确,并在每次错误时更新自己。随着时间的推移,模型在文本补全任务上变得越来越好,以至于在许多上下文中——尤其是那些下一个词几乎总是相同的上下文,如“西班牙的首都为”——模型认为最可能的响应是人类认为的“正确”响应。在那些下一个词可能有几个不同选择的上下文中,如“这是一个黑暗而”,模型将学习选择人类认为至少是合理的选择,也许是“暴风雨的”,但也可能是“阴险的”或“霉味的”。LLM 生命周期的这一阶段,模型在大型文本数据集上进行训练,被称为预训练。对于某些上下文,仅仅预测下一个词并不一定能产生期望的结果;模型可能无法理解它应该如何响应诸如“写一首关于狗的诗”这样的指令,而不是继续执行指令。为了产生某些行为,如遵循指令,并提高模型完成特定任务的能力,例如编写代码或与人进行轻松对话,LLM 随后会在针对这些任务设计的目标数据集上进行训练。
然而,LLM(大规模语言模型)通过预测可能的下一个词来生成文本的任务,导致了一种现象,称为幻觉。这是一个被广泛记录的技术陷阱,在这种情况下,LLM 在被提示时会自信地编造错误的信息和解释。LLM 预测和完成文本的能力基于训练过程中学到的模式,但当面临不确定或多种可能的补全时,LLM 选择看起来最可信的选项,即使它与现实无关。
例如,当谷歌推出其聊天机器人 Bard 时,它在首次公开演示中犯了一个事实错误。Bard 臭名昭著地声明詹姆斯·韦布太空望远镜(JWST)“拍摄了第一张来自我们太阳系外的行星的照片。”但实际上,第一张外行星的图像是在 2004 年拍摄的,由非常大望远镜(VLT)拍摄,而JWST 直到 2021 年才发射。
幻觉并不是大型语言模型(LLMs)唯一的缺陷——在大量互联网数据上训练还直接导致了偏见和版权问题。首先,让我们讨论一下偏见,它指的是模型在个人身份属性(如种族、性别、阶级或宗教)方面产生的不同输出。鉴于 LLMs 从互联网数据中学习特征和模式,它们也不幸地继承了类似于人类的偏见、历史不公和文化关联。虽然人类有偏见,但 LLMs更糟糕,因为它们往往会放大训练数据中的偏见。对于 LLMs 来说,男性是成功的医生、工程师和首席执行官,而女性则是支持性、美丽的接待员和护士,LGBTQ 人群则不存在。
在不可估量的互联网数据上训练 LLMs 还引发了版权问题的质疑。版权是对创作作品的独占权利,版权持有者是唯一有权在特定时间段内复制、分发、展览或表演该作品的实体。
目前,关于 LLMs 的主要法律问题不在于其输出的版权性,而在于现有版权的潜在侵犯,尤其是那些贡献了他们创作作品用于训练数据集的艺术家和作家。 作家协会呼吁 OpenAI、谷歌、Meta 和微软等公司,要求他们同意、标注并公平地补偿作家使用版权材料来训练 LLMs。一些作家和出版商也已将此事提上日程。
LLM 开发者目前正面临来自个人和团体的几起关于版权的诉讼——喜剧演员和演员萨拉·席弗曼 加入了一组作家和出版商起诉 OpenAI 的诉讼,声称他们从未授权将他们的版权书籍用于训练 LLMs。
尽管与幻觉、偏见和版权相关的担忧是与 LLMs 相关的最有文献记录的问题之一,但这绝不是唯一的担忧。举几个例子,LLMs 编码了敏感信息,产生了不良或有害的输出,并且可能被对手利用。毫无疑问,LLMs 在生成连贯且上下文相关的文本方面表现出色,应该毫无疑问地被用来提高效率等众多任务和场景中的效益。
研究人员也在致力于解决这些问题,但如何最佳控制模型输出仍然是一个未解的研究问题,因此现有的大型语言模型远非万无一失。它们的输出应始终检查准确性、事实性和潜在偏见。如果你获得的输出结果好得令人难以置信,那就要提高警惕,仔细审查。验证和修正任何由大型语言模型生成的文本是用户的责任,或者我们喜欢说的,生成式人工智能:这是你的初稿,而非最终稿。
玛吉·恩格勒是一位工程师和研究员,目前致力于大型语言模型的安全性。她专注于将数据科学和机器学习应用于在线生态系统中的滥用问题,是网络安全以及信任和安全领域的专家。玛吉还是一位热心的教育者和传播者,担任德克萨斯大学奥斯汀分校信息学院的兼职讲师。
努玛·达马尼****是一位在技术与社会交汇处工作的工程师和研究员。她是自然语言处理领域的专家,具有影响力操作、安全性和隐私方面的专业知识。努玛为财富 500 强公司、社交媒体平台、初创企业和非营利组织开发了机器学习系统。她曾为公司和组织提供咨询,担任美国国防部研究计划的首席研究员,并为多个国际同行评审期刊做出了贡献。
更多相关主题
遗传算法在 Python 中的实现
原文:
www.kdnuggets.com/2018/07/genetic-algorithm-implementation-python.html
评论

本教程将基于一个简单的例子实现遗传算法优化技术,我们的目标是最大化一个方程的输出。教程使用十进制表示基因,单点交叉和均匀变异。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 相关工作
遗传算法(GA)的流程图如图 1 所示。GA 的每一步都有一些变体。
图 1

例如,基因有不同类型的表示方式,如二进制、十进制、整数等。每种类型的处理方式不同。变异也有不同类型,如位翻转、交换、逆转、均匀、非均匀、高斯、缩小等。交叉操作也有不同的类型,如混合、单点、双点、均匀等。本教程不会实现所有这些变异和交叉类型,而是仅实现每一步中一种类型。教程使用了十进制表示基因,单点交叉和均匀变异。读者应对 GA 的工作原理有所了解。如果不了解,请阅读标题为“遗传算法优化简介”的文章,链接如下:
-
LinkedIn:
www.linkedin.com/pulse/introduction-optimization-genetic-algorithm-ahmed-gad/ -
KDnuggets:
www.kdnuggets.com/2018/03/introduction-optimization-with-genetic-algorithm.html -
TowardsDataScience:
towardsdatascience.com/introduction-to-optimization-with-genetic-algorithm-2f5001d9964b -
SlideShare:
www.slideshare.net/AhmedGadFCIT/introduction-to-optimization-with-genetic-algorithm-ga
教程开始时展示了我们将要实现的方程。方程如下所示:
Y = w1x1 + w2x2 + w3x3 + w4x4 + w5x5 + w6x6
方程有 6 个输入(x1 到 x6)和 6 个权重(w1 到 w6),输入值为(x1,x2,x3,x4,x5,x6)=(4,-2,7,5,11,1)。我们希望找到最大化该方程的参数(权重)。最大化该方程的想法似乎很简单。正输入应乘以尽可能大的正数,负数应乘以尽可能小的负数。但我们要实现的想法是如何让 GA 自己做到这一点,以便知道正权重与正输入配合使用,负权重与负输入配合使用。让我们开始实现 GA。
首先,让我们创建一个包含 6 个输入的列表和一个保存权重数量的变量,如下所示:
# Inputs of the equation.
equation_inputs = [4,-2,3.5,5,-11,-4.7]
# Number of the weights we are looking to optimize.
num_weights = 6
下一步是定义初始种群。根据权重的数量,种群中的每个染色体(解决方案或个体)将必定具有 6 个基因,每个基因对应一个权重。但问题是每个种群中有多少个解决方案?这个值没有固定的,我们可以选择适合我们问题的值。为了通用,我们可以在代码中保持它是可变的。接下来,我们创建一个变量来保存每个种群的解决方案数量,另一个变量保存种群的大小,最后一个变量保存实际的初始种群:
import numpy
sol_per_pop = 8
# Defining the population size.
pop_size = (sol_per_pop,num_weights) # The population will have sol_per_pop chromosome where each chromosome has num_weights genes.
#Creating the initial population.
new_population = numpy.ram.uniform(low=-4.0, high=4.0, size=pop_size)
在导入 numpy 库后,我们可以使用 numpy.random.uniform 函数随机创建初始种群。根据选择的参数,它将具有形状(8, 6)。即 8 个染色体,每个染色体有 6 个基因,每个基因对应一个权重。运行此代码后,种群如下:
[[-2.19134006 -2.88907857 2.02365737 -3.97346034 3.45160502 2.05773249]
[ 2.12480298 2.97122243 3.60375452 3.78571392 0.28776565 3.5170347 ]
[ 1.81098962 0.35130155 1.03049548 -0.33163294 3.52586421 2.53845644]
[-0.63698911 -2.8638447 2.93392615 -1.40103767 -1.20313655 0.30567304]
[-1.48998583 -1.53845766 1.11905299 -3.67541087 1.33225142 2.86073836]
[ 1.14159503 2.88160332 1.74877772 -3.45854293 0.96125878 2.99178241]
[ 1.96561297 0.51030292 0.52852716 -1.56909315 -2.35855588 2.29682254]
[ 3.00912373 -2.745417 3.27131287 -0.72163167 0.7516408 0.00677938]]
请注意,它是随机生成的,因此每次运行时都会有所变化。
在准备好种群后,接下来是遵循图 1 中的流程图。根据适应度函数,我们将选择当前种群中最优秀的个体作为配对的父母。接下来,应用 GA 变体(交叉和变异)来产生下一代的后代,通过附加父母和后代来创建新种群,并重复这些步骤若干次迭代/代。下一段代码应用了这些步骤:
import GA
num_generations = 5
num_parents_mating = 4
for generation in range(num_generations):
# Measuring the fitness of each chromosome in the population.
fitness = GA.cal_pop_fitness(equation_inputs, new_population)
# Selecting the best parents in the population for mating.
parents = GA.select_mating_pool(new_population, fitness,
num_parents_mating)
# Generating next generation using crossover.
offspring_crossover = GA.crossover(parents,
offspring_size=(pop_size[0]-parents.shape[0], num_weights))
# Adding some variations to the offsrping using mutation.
offspring_mutation = GA.mutation(offspring_crossover)
# Creating the new population based on the parents and offspring.
new_population[0:parents.shape[0], :] = parents
new_population[parents.shape[0]:, :] = offspring_mutation
当前的代数是 5。为了在教程中展示所有代的结果,选择了较小的代数。有一个名为 GA 的模块,其中包含算法的实现。
第一步是使用 GA.cal_pop_fitness 函数找到种群中每个解决方案的适应度值。GA 模块中该函数的实现如下:
def cal_pop_fitness(equation_inputs, pop):
# Calculating the fitness value of each solution in the current population.
# The fitness function calculates the sum of products between each input and its corresponding weight.
fitness = numpy.sum(pop*equation_inputs, axis=1)
return fitness
适应度函数接受方程输入值(x1 到 x6)以及种群。适应度值计算为每个输入与其对应基因(权重)之间的乘积和(SOP)。根据每个种群中的解数量,将会有若干 SOP。由于我们之前在名为 sol_per_pop 的变量中将解的数量设置为 8,将会有 8 个 SOP,如下所示:
[-63.41070188 14.40299221 -42.22532674 18.24112489 -45.44363278 -37.00404311 15.99527402 17.0688537 ]
请注意,适应度值越高,解越好。
在计算所有解的适应度值后,接下来是根据下一个函数GA.select_mating_pool选择最佳的解作为交配池中的父母。该函数接受种群、适应度值和所需父母的数量。它返回选择的父母。其在 GA 模块中的实现如下:
def select_mating_pool(pop, fitness, num_parents):
# Selecting the best individuals in the current generation as parents for producing the offspring of the next generation.
parents = numpy.empty((num_parents, pop.shape[1]))
for parent_num in range(num_parents):
max_fitness_idx = numpy.where(fitness == numpy.max(fitness))
max_fitness_idx = max_fitness_idx[0][0]
parents[parent_num, :] = pop[max_fitness_idx, :]
fitness[max_fitness_idx] = -99999999999
return parents
根据变量 num_parents_mating 中定义的所需父母数量,该函数创建一个空数组来保存它们,如下行所示:
parents = numpy.empty((num_parents, pop.shape[1]))
在当前种群中循环,函数获取最高适应度值的索引,因为这是根据这一行选择的最佳解:
max_fitness_idx = numpy.where(fitness == numpy.max(fitness))
这个索引用于使用这一行检索与该适应度值对应的解:
parents[parent_num, :] = pop[max_fitness_idx, :]
为了避免再次选择这样的解,其适应度值被设置为一个非常小的值,-99999999999,以避免再次被选择。最终返回的是parents数组,根据我们的例子,它将如下所示:
[[-0.63698911 -2.8638447 2.93392615 -1.40103767 -1.20313655 0.30567304]
[ 3.00912373 -2.745417 3.27131287 -0.72163167 0.7516408 0.00677938]
[ 1.96561297 0.51030292 0.52852716 -1.56909315 -2.35855588 2.29682254]
[ 2.12480298 2.97122243 3.60375452 3.78571392 0.28776565 3.5170347 ]]
请注意,这三个父母是在当前种群中适应度值最高的个体,分别为 18.24112489、17.0688537、15.99527402 和 14.40299221。
下一步是使用这些选定的父母进行交配,以生成后代。交配从交叉操作开始,根据GA.crossover函数进行。该函数接受父母和后代大小。它使用后代大小来确定从这些父母那里产生的后代数量。该函数在 GA 模块中的实现如下:
def crossover(parents, offspring_size):
offspring = numpy.empty(offspring_size)
# The point at which crossover takes place between two parents. Usually, it is at the center.
crossover_point = numpy.uint8(offspring_size[1]/2)
for k in range(offspring_size[0]):
# Index of the first parent to mate.
parent1_idx = k%parents.shape[0]
# Index of the second parent to mate.
parent2_idx = (k+1)%parents.shape[0]
# The new offspring will have its first half of its genes taken from the first parent.
offspring[k, 0:crossover_point] = parents[parent1_idx, 0:crossover_point]
# The new offspring will have its second half of its genes taken from the second parent.
offspring[k, crossover_point:] = parents[parent2_idx, crossover_point:]
这个函数首先根据后代大小创建一个空数组,如下行所示:
offspring = numpy.empty(offspring_size)
由于我们使用单点交叉,我们需要指定交叉发生的点。该点被选定以将解分成两个相等的部分,根据这一行:
crossover_point = numpy.uint8(offspring_size[1]/2)
然后我们需要选择两个父母进行交叉。这两个父母的索引根据这两行进行选择:
parent1_idx = k%parents.shape[0]
parent2_idx = (k+1)%parents.shape[0]
父代的选择方式类似于环状。首先选择索引为 0 和 1 的父代产生两个后代。如果仍需产生更多后代,则选择父代 1 和父代 2 生成另外两个后代。如果需要更多的后代,则选择索引为 2 和 3 的父代。到索引 3 时,我们达到了最后一个父代。如果需要产生更多的后代,则选择索引为 3 的父代,并返回到索引为 0 的父代,以此类推。
对父代应用交叉操作后的解决方案存储在后代变量中,它们如下:
[[-0.63698911 -2.8638447 2.93392615 -0.72163167 0.7516408 0.00677938]
[ 3.00912373 -2.745417 3.27131287 -1.56909315 -2.35855588 2.29682254]
[ 1.96561297 0.51030292 0.52852716 3.78571392 0.28776565 3.5170347 ]
[ 2.12480298 2.97122243 3.60375452 -1.40103767 -1.20313655 0.30567304]]
接下来是将第二种遗传算法变体——变异,应用到存储在后代变量中的交叉结果中,使用遗传算法模块中的变异函数。该函数接受交叉后的后代,并在应用均匀变异后返回。该函数的实现如下:
def mutation(offspring_crossover):
# Mutation changes a single gene in each offspring randomly.
for idx in range(offspring_crossover.shape[0]):
# The random value to be added to the gene.
random_value = numpy.random.uniform(-1.0, 1.0, 1)
offspring_crossover[idx, 4] = offspring_crossover[idx, 4] + random_value
它遍历每个后代,并根据这一行将一个均匀生成的随机数添加到范围 -1 到 1 之间:
random_value = numpy.random.uniform(-1.0, 1.0, 1)
然后将随机数添加到后代的索引 4 的基因中,依据这一行:
offspring_crossover[idx, 4] = offspring_crossover[idx, 4] + random_value
请注意,索引可以更改为任何其他索引。应用变异后的后代如下:
[[-0.63698911 -2.8638447 2.93392615 -0.72163167 1.66083721 0.00677938]
[ 3.00912373 -2.745417 3.27131287 -1.56909315 -1.94513681 2.29682254]
[ 1.96561297 0.51030292 0.52852716 3.78571392 0.45337472 3.5170347 ]
[ 2.12480298 2.97122243 3.60375452 -1.40103767 -1.5781162 0.30567304]]
这些结果被添加到变量 offspring_crossover 中,并由函数返回。
到目前为止,我们成功地从 4 个选择的父代中产生了 4 个后代,我们准备创建下一代的新种群。
请注意,遗传算法是一种基于随机的优化技术。它通过对当前解决方案应用一些随机变化来尝试改进它们。由于这些变化是随机的,我们不能确定它们会产生更好的解决方案。因此,建议在新种群中保留之前的最佳解决方案(父代)。在最坏的情况下,如果所有新的后代都不如这些父代,我们将继续使用这些父代。结果是,我们可以保证新一代至少保留之前的好结果,而不会变得更差。新种群将从之前的父代中获得前 4 个解决方案。最后 4 个解决方案来自应用交叉和变异后的后代:
new_population[0:parents.shape[0], :] = parents
new_population[parents.shape[0]:, :] = offspring_mutation
通过计算第一代所有解决方案(父代和后代)的适应度,其适应度如下:
[ 18.24112489 17.0688537 15.99527402 14.40299221 -8.46075629 31.73289712 6.10307563 24.08733441]
之前的最高适应度是18.24112489,但现在是31.7328971158。这意味着随机变化朝着更好的解决方案移动。这是很棒的。但通过经过更多的代数,这些结果可以得到进一步的提升。以下是另外 4 代每一步的结果:
Generation : 1
Fitness values:
[ 18.24112489 17.0688537 15.99527402 14.40299221 -8.46075629 31.73289712 6.10307563 24.08733441]
Selected parents:
[[ 3.00912373 -2.745417 3.27131287 -1.56909315 -1.94513681 2.29682254]
[ 2.12480298 2.97122243 3.60375452 -1.40103767 -1.5781162 0.30567304]
[-0.63698911 -2.8638447 2.93392615 -1.40103767 -1.20313655 0.30567304]
[ 3.00912373 -2.745417 3.27131287 -0.72163167 0.7516408 0.00677938]]
Crossover result:
[[ 3.00912373 -2.745417 3.27131287 -1.40103767 -1.5781162 0.30567304]
[ 2.12480298 2.97122243 3.60375452 -1.40103767 -1.20313655 0.30567304]
[-0.63698911 -2.8638447 2.93392615 -0.72163167 0.7516408 0.00677938]
[ 3.00912373 -2.745417 3.27131287 -1.56909315 -1.94513681 2.29682254]]
Mutation result:
[[ 3.00912373 -2.745417 3.27131287 -1.40103767 -1.2392086 0.30567304]
[ 2.12480298 2.97122243 3.60375452 -1.40103767 -0.38610586 0.30567304]
[-0.63698911 -2.8638447 2.93392615 -0.72163167 1.33639943 0.00677938]
[ 3.00912373 -2.745417 3.27131287 -1.56909315 -1.13941727 2.29682254]]
Best result after generation 1 : 34.1663669207
Generation : 2
Fitness values:
[ 31.73289712 24.08733441 18.24112489 17.0688537 34.16636692 10.97522073 -4.89194068 22.86998223]
Selected Parents:
[[ 3.00912373 -2.745417 3.27131287 -1.40103767 -1.2392086 0.30567304]
[ 3.00912373 -2.745417 3.27131287 -1.56909315 -1.94513681 2.29682254]
[ 2.12480298 2.97122243 3.60375452 -1.40103767 -1.5781162 0.30567304]
[ 3.00912373 -2.745417 3.27131287 -1.56909315 -1.13941727 2.29682254]]
Crossover result:
[[ 3.00912373 -2.745417 3.27131287 -1.56909315 -1.94513681 2.29682254]
[ 3.00912373 -2.745417 3.27131287 -1.40103767 -1.5781162 0.30567304]
[ 2.12480298 2.97122243 3.60375452 -1.56909315 -1.13941727 2.29682254]
[ 3.00912373 -2.745417 3.27131287 -1.40103767 -1.2392086 0.30567304]]
Mutation result:
[[ 3.00912373 -2.745417 3.27131287 -1.56909315 -2.20515009 2.29682254]
[ 3.00912373 -2.745417 3.27131287 -1.40103767 -0.73543721 0.30567304]
[ 2.12480298 2.97122243 3.60375452 -1.56909315 -0.50581509 2.29682254]
[ 3.00912373 -2.745417 3.27131287 -1.40103767 -1.20089639 0.30567304]]
Best result after generation 2: 34.5930432629
Generation : 3
Fitness values:
[ 34.16636692 31.73289712 24.08733441 22.86998223 34.59304326 28.6248816 2.09334217 33.7449326 ]
Selected parents:
[[ 3.00912373 -2.745417 3.27131287 -1.56909315 -2.20515009 2.29682254]
[ 3.00912373 -2.745417 3.27131287 -1.40103767 -1.2392086 0.30567304]
[ 3.00912373 -2.745417 3.27131287 -1.40103767 -1.20089639 0.30567304]
[ 3.00912373 -2.745417 3.27131287 -1.56909315 -1.94513681 2.29682254]]
Crossover result:
[[ 3.00912373 -2.745417 3.27131287 -1.40103767 -1.2392086 0.30567304]
[ 3.00912373 -2.745417 3.27131287 -1.40103767 -1.20089639 0.30567304]
[ 3.00912373 -2.745417 3.27131287 -1.56909315 -1.94513681 2.29682254]
[ 3.00912373 -2.745417 3.27131287 -1.56909315 -2.20515009 2.29682254]]
Mutation result:
[[ 3.00912373 -2.745417 3.27131287 -1.40103767 -2.20744102 0.30567304]
[ 3.00912373 -2.745417 3.27131287 -1.40103767 -1.16589294 0.30567304]
[ 3.00912373 -2.745417 3.27131287 -1.56909315 -2.37553107 2.29682254]
[ 3.00912373 -2.745417 3.27131287 -1.56909315 -2.44124005 2.29682254]]
Best result after generation 3: 44.8169235189
Generation : 4
Fitness values
[ 34.59304326 34.16636692 33.7449326 31.73289712 44.81692352
33.35989464 36.46723397 37.19003273]
Selected parents:
[[ 3.00912373 -2.745417 3.27131287 -1.40103767 -2.20744102 0.30567304]
[ 3.00912373 -2.745417 3.27131287 -1.56909315 -2.44124005 2.29682254]
[ 3.00912373 -2.745417 3.27131287 -1.56909315 -2.37553107 2.29682254]
[ 3.00912373 -2.745417 3.27131287 -1.56909315 -2.20515009 2.29682254]]
Crossover result:
[[ 3.00912373 -2.745417 3.27131287 -1.56909315 -2.37553107 2.29682254]
[ 3.00912373 -2.745417 3.27131287 -1.56909315 -2.20515009 2.29682254]
[ 3.00912373 -2.745417 3.27131287 -1.40103767 -2.20744102 0.30567304]]
Mutation result:
[[ 3.00912373 -2.745417 3.27131287 -1.56909315 -2.13382082 2.29682254]
[ 3.00912373 -2.745417 3.27131287 -1.56909315 -2.98105233 2.29682254]
[ 3.00912373 -2.745417 3.27131287 -1.56909315 -2.27638584 2.29682254]
[ 3.00912373 -2.745417 3.27131287 -1.40103767 -1.70558545 0.30567304]]
Best result after generation 4: 44.8169235189
在上述 5 代之后,最佳结果的适应度值现在为44.8169235189,相比之下,第一代后的最佳结果为18.24112489。
最佳解决方案具有以下权重:
[3.00912373 -2.745417 3.27131287 -1.40103767 -2.20744102 0.30567304]
实现遗传算法的完整代码如下:
import numpy
import GA
"""
The y=target is to maximize this equation ASAP:
y = w1x1+w2x2+w3x3+w4x4+w5x5+6wx6
where (x1,x2,x3,x4,x5,x6)=(4,-2,3.5,5,-11,-4.7)
What are the best values for the 6 weights w1 to w6?
We are going to use the genetic algorithm for the best possible values after a number of generations.
"""
# Inputs of the equation.
equation_inputs = [4,-2,3.5,5,-11,-4.7]
# Number of the weights we are looking to optimize.
num_weights = 6
"""
Genetic algorithm parameters:
Mating pool size
Population size
"""
sol_per_pop = 8
num_parents_mating = 4
# Defining the population size.
pop_size = (sol_per_pop,num_weights) # The population will have sol_per_pop chromosome where each chromosome has num_weights genes.
#Creating the initial population.
new_population = numpy.random.uniform(low=-4.0, high=4.0, size=pop_size)
print(new_population)
num_generations = 5
for generation in range(num_generations):
print("Generation : ", generation)
# Measing the fitness of each chromosome in the population.
fitness = GA.cal_pop_fitness(equation_inputs, new_population)
# Selecting the best parents in the population for mating.
parents = GA.select_mating_pool(new_population, fitness,
num_parents_mating)
# Generating next generation using crossover.
offspring_crossover = GA.crossover(parents,
offspring_size=(pop_size[0]-parents.shape[0], num_weights))
# Adding some variations to the offsrping using mutation.
offspring_mutation = GA.mutation(offspring_crossover)
# Creating the new population based on the parents and offspring.
new_population[0:parents.shape[0], :] = parents
new_population[parents.shape[0]:, :] = offspring_mutation
# The best result in the current iteration.
print("Best result : ", numpy.max(numpy.sum(new_population*equation_inputs, axis=1)))
# Getting the best solution after iterating finishing all generations.
#At first, the fitness is calculated for each solution in the final generation.
fitness = GA.cal_pop_fitness(equation_inputs, new_population)
# Then return the index of that solution corresponding to the best fitness.
best_match_idx = numpy.where(fitness == numpy.max(fitness))
print("Best solution : ", new_population[best_match_idx, :])
print("Best solution fitness : ", fitness[best_match_idx])
遗传算法模块如下:
import numpy
def cal_pop_fitness(equation_inputs, pop):
# Calculating the fitness value of each solution in the current population.
# The fitness function caulcuates the sum of products between each input and its corresponding weight.
fitness = numpy.sum(pop*equation_inputs, axis=1)
return fitness
def select_mating_pool(pop, fitness, num_parents):
# Selecting the best individuals in the current generation as parents for producing the offspring of the next generation.
parents = numpy.empty((num_parents, pop.shape[1]))
for parent_num in range(num_parents):
max_fitness_idx = numpy.where(fitness == numpy.max(fitness))
max_fitness_idx = max_fitness_idx[0][0]
parents[parent_num, :] = pop[max_fitness_idx, :]
fitness[max_fitness_idx] = -99999999999
return parents
def crossover(parents, offspring_size):
offspring = numpy.empty(offspring_size)
# The point at which crossover takes place between two parents. Usually it is at the center.
crossover_point = numpy.uint8(offspring_size[1]/2)
for k in range(offspring_size[0]):
# Index of the first parent to mate.
parent1_idx = k%parents.shape[0]
# Index of the second parent to mate.
parent2_idx = (k+1)%parents.shape[0]
# The new offspring will have its first half of its genes taken from the first parent.
offspring[k, 0:crossover_point] = parents[parent1_idx, 0:crossover_point]
# The new offspring will have its second half of its genes taken from the second parent.
offspring[k, crossover_point:] = parents[parent2_idx, crossover_point:]
return offspring
def mutation(offspring_crossover):
# Mutation changes a single gene in each offspring randomly.
for idx in range(offspring_crossover.shape[0]):
# The random value to be added to the gene.
random_value = numpy.random.uniform(-1.0, 1.0, 1)
offspring_crossover[idx, 4] = offspring_crossover[idx, 4] + random_value
简历:Ahmed Gad 于 2015 年 7 月获得埃及梅努菲亚大学计算机与信息学院(FCI)信息技术学士学位,并以优异成绩获得荣誉。因在学院中排名第一,他在 2015 年被推荐到埃及的一所学院担任助教,随后于 2016 年在他所在的学院担任助教和研究员。他目前的研究兴趣包括深度学习、机器学习、人工智能、数字信号处理和计算机视觉。
原文。经授权转载。
相关:
-
从完全连接网络逐步推导卷积神经网络
-
学习率在人工神经网络中是否有用?
-
通过正则化避免过拟合
更多相关话题
遗传算法关键术语,解析
原文:
www.kdnuggets.com/2018/04/genetic-algorithm-key-terms-explained.html
遗传算法,受到自然选择的启发,是一种常用的近似优化和搜索问题解决方案的方法。它们的必要性在于存在一些问题,它们的计算复杂性过高,以至于无法在任何可接受(或确定的)时间内解决。
以著名的旅行商问题为例。随着涉及的城市数量的增加,确定解决方案所需的时间迅速变得不可管理。例如,解决 5 个城市的问题是一项微不足道的任务;而解决 50 个城市的问题则需要的时间如此不合理,以至于永远无法完成。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
事实证明,使用遗传算法来近似这种优化问题是一种合理的方法,可以得到合理的近似值。遗传算法在机器学习的工具库中已经存在了几十年,但最近作为优化机器学习超参数(和遍历神经网络架构搜索空间)的工具的复兴,引起了新一代机器学习研究人员和从业者的关注。
本文介绍了 12 个遗传算法关键术语的简单定义,以帮助更好地向新手介绍这些概念。
1. 遗传算法
遗传算法(GA)通过二进制字符串表示来描述潜在的问题假设,并在潜在假设的搜索空间中进行迭代,以试图识别“最佳假设”,即优化预定义数值衡量标准或适应度的假设。遗传算法总体上是进化算法的一个子集。
2. 进化算法
进化算法(EA)是任何类型的学习方法,其动机来自于它们与生物进化的明显和有意的相似性,包括但不限于遗传算法、进化策略和遗传编程。
3. 遗传编程
遗传编程是一种特定类型的进化算法,利用进化学习策略来优化计算机代码的制作,结果是能在预定义的任务或任务集上表现最佳的程序。
4. 种群
在遗传算法中,每次迭代或世代产生一系列可能的假设来最佳近似一个函数,而“种群”指的是在给定迭代后生成的这些假设的完整集合或池。
5. 染色体
在明显向生物学致敬的情况下,一个染色体是许多组成一个种群的单一假设。
6. 基因
在遗传算法中,潜在的假设由染色体组成,染色体又由基因组成。实际上,在遗传算法中,染色体通常表示为二进制字符串,即一系列 1 和 0,表示字符串中位置的特定项的包含或排除。基因是这种染色体中的单个位。
例如,遗传算法的Hello World 通常被认为是背包问题。在这个问题中,会有一组N项,这些项可能被或不被放入小偷的背包中,这些N项会表示为一个长度为N的二进制字符串(染色体),字符串中的每个位置表示一个特定的项,位置上的位(1 或 0;基因)表示该项是否包含在特定假设中。
-
种群 → 当前世代(算法迭代)的背包问题所有提议解决方案
-
染色体 → 背包问题的特定提议解决方案
-
基因 → 在特定解决方案的背包中,特定项的定位表示(及其包含或排除)
7. 世代
在遗传算法中,通过选择一些完整的染色体(通常具有高适应度)前进到新世代(选择)、通过翻转现有完整染色体的一位并将其前进到新世代(突变)或最常见的,通过使用现有集合的基因作为父代来繁殖新世代的子染色体,来形成新的假设集。
世代则是遗传算法迭代结果的完整集合。
8. 繁殖
繁殖指的是创建新染色体的一般最常见的方法,即使用一对染色体作为父代,并利用交叉方法从中生成新的子染色体。
9. 选择
以自然选择为启示,选择的概念确保表现最好的(适应度最高的)染色体有更高的概率被用于繁殖下一代。通常情况下,表现最好的染色体可能会被选中并直接推进到新一代,而不被用于繁殖,以确保后续代的假设至少能够维持与当前代相同的表现水平。

10. 交叉
选定的染色体如何用于繁殖下一代?交叉方法,如下所示,是一般的选择。会选择一对长度为N比特的选定字符串,并生成一个随机整数c作为交叉点(假设 0 < c < N)。然后,在这个交叉点c将两个字符串独立地拆分,并使用一个字符串的头部和另一个字符串的尾部重新组装,形成一对新的染色体。这些新假设的适应度将在下一代中进行评估。

11. 变异
就像在生物学术语中一样,变异在遗传算法(GAs)中用于推动假设朝着最优方向发展。通常情况下,变异会简单地翻转一个随机基因的位,并将整个染色体推进到下一代,这是一种逃脱潜在局部最小值的策略。
12. 适应度
我们需要一些度量标准来评估假设的最佳适应度。使用某种适应度函数来评估每个染色体,并确定最佳适应度,以便在创建新一代染色体时更为依赖。适应度函数高度依赖于任务。
Matthew Mayo (@mattmayo13) 是数据科学家以及 KDnuggets 的主编,该网站是开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及自动化机器学习方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系到。
更多相关内容
使用遗传算法优化递归神经网络
原文:
www.kdnuggets.com/2018/01/genetic-algorithm-optimizing-recurrent-neural-network.html
评论
由 Aaqib Saeed,特温特大学
最近,自动化机器学习的工作增多了,从选择合适的算法到特征选择和超参数调整。有多个工具(如AutoML和TPOT),可以帮助用户高效地进行数百次实验。同样,深度神经网络架构通常由专家通过试错方法设计。虽然这种方法在多个领域产生了最先进的模型,但却非常耗时。最近,由于计算能力的增加,研究人员正在使用强化学习和进化算法来自动搜索最佳神经网络架构。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
在本教程中,我们将探讨如何应用遗传算法(GA)来寻找基于长短期记忆(LSTM)的递归神经网络(RNN)的最佳窗口大小和单元数量。为此,我们将使用Keras训练和评估时间序列预测问题的模型。GA 将使用一个名为DEAP的 Python 包。教程的主要目的是使读者熟悉使用 GA 自动寻找最佳设置;因此,仅探索两个参数。此外,假设读者对 RNN 的理论和应用知识有所了解。如果不熟悉,请参阅以下资源[1]和[2]。
带有完整代码的 ipython 笔记本可在以下链接获取。
遗传算法
遗传算法是一种启发式搜索和优化方法,灵感来自自然选择过程。它们广泛用于寻找具有大参数空间的优化问题的近似最优解。通过依赖生物启发的组件(例如交叉)来模拟物种(在我们的例子中是解决方案)的进化过程。此外,由于它不考虑辅助信息(例如导数),因此可以用于离散和连续优化。
使用 GA 需要满足两个前提条件:a)解决方案表示或定义一个染色体;b)一个用于评估生成解决方案的适应度函数。在我们的例子中,二进制数组是解决方案的遗传表示(见 图 1),模型在验证集上的均方根误差(RMSE)将作为适应度值。此外,构成 GA 的三种基本操作如下:
-
选择:它定义了哪些解决方案将被保留以供进一步繁殖,例如轮盘赌选择。
-
交叉:它描述了如何从现有的解决方案中生成新的解决方案,例如 n 点交叉。
-
突变:其目的是通过随机交换或关闭解决方案位引入多样性和新颖性,例如二进制突变。

有时还使用一种称为“精英主义”的技术,它保留一些最佳解决方案,并传递给下一代。图 2 描述了一个完整的遗传算法,其中,初始解决方案(种群)是随机生成的。接下来,它们根据适应度函数进行评估,然后执行选择、交叉和突变。这个过程会重复定义的迭代次数(在 GA 术语中称为代)。最后,选择适应度得分最高的解决方案作为最佳解决方案。要了解更多信息,请查看以下资源 [3] 和 [4]。

实现
现在,我们对 GA 的工作原理有了基本了解。接下来,让我们开始编码。
我们将使用风电预测数据,数据可以在以下 链接中找到。数据包括来自七个风电场的风电测量值(归一化在零和一之间)。为了简化起见,我们将使用第一个风电场的数据(名为 wp1 的列),但我鼓励读者尝试并扩展代码,以预测所有七个风电场的能源。
让我们导入所需的包,加载数据集并定义两个辅助函数。第一个方法 prepare_dataset 将数据分段以创建用于模型训练的 X、Y 对。X 将是过去的风力值(例如 1 到 t-1),Y 将是时间 t 的未来值。第二个方法 train_evaluate 完成三件事,1)解码 GA 解以获取窗口大小和单位数量。2)使用 GA 找到的窗口大小准备数据集,并将其分为训练集和验证集,3)训练 LSTM 模型,计算验证集上的 RMSE,并将其作为当前 GA 解的适应度得分返回。
import numpy as np
import pandas as pd
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split as split
from keras.layers import LSTM, Input, Dense
from keras.models import Model
from deap import base, creator, tools, algorithms
from scipy.stats import bernoulli
from bitstring import BitArray
np.random.seed(1120)
data = pd.read_csv('train.csv')
data = np.reshape(np.array(data['wp1']),(len(data['wp1']),1))
# Use first 17,257 points as training/validation and rest of the 1500 points as test set.
train_data = data[0:17257]
test_data = data[17257:]
def prepare_dataset(data, window_size):
X, Y = np.empty((0,window_size)), np.empty((0))
for i in range(len(data)-window_size-1):
X = np.vstack([X,data[i:(i + window_size),0]])
Y = np.append(Y,data[i + window_size,0])
X = np.reshape(X,(len(X),window_size,1))
Y = np.reshape(Y,(len(Y),1))
return X, Y
def train_evaluate(ga_individual_solution):
# Decode GA solution to integer for window_size and num_units
window_size_bits = BitArray(ga_individual_solution[0:6])
num_units_bits = BitArray(ga_individual_solution[6:])
window_size = window_size_bits.uint
num_units = num_units_bits.uint
print('\nWindow Size: ', window_size, ', Num of Units: ', num_units)
# Return fitness score of 100 if window_size or num_unit is zero
if window_size == 0 or num_units == 0:
return 100,
# Segment the train_data based on new window_size; split into train and validation (80/20)
X,Y = prepare_dataset(train_data,window_size)
X_train, X_val, y_train, y_val = split(X, Y, test_size = 0.20, random_state = 1120)
# Train LSTM model and predict on validation set
inputs = Input(shape=(window_size,1))
x = LSTM(num_units, input_shape=(window_size,1))(inputs)
predictions = Dense(1, activation='linear')(x)
model = Model(inputs=inputs, outputs=predictions)
model.compile(optimizer='adam',loss='mean_squared_error')
model.fit(X_train, y_train, epochs=5, batch_size=10,shuffle=True)
y_pred = model.predict(X_val)
# Calculate the RMSE score as fitness score for GA
rmse = np.sqrt(mean_squared_error(y_val, y_pred))
print('Validation RMSE: ', rmse,'\n')
return rmse,
接下来,使用 DEAP 包来定义运行 GA 所需的内容。我们将使用长度为十的二进制表示。它将通过伯努利分布随机初始化。同样,使用有序交叉、洗牌突变和轮盘选择。GA 参数值被任意初始化;我建议你尝试不同的设置。
population_size = 4
num_generations = 4
gene_length = 10
# As we are trying to minimize the RMSE score, that's why using -1.0\.
# In case, when you want to maximize accuracy for instance, use 1.0
creator.create('FitnessMax', base.Fitness, weights = (-1.0,))
creator.create('Individual', list , fitness = creator.FitnessMax)
toolbox = base.Toolbox()
toolbox.register('binary', bernoulli.rvs, 0.5)
toolbox.register('individual', tools.initRepeat, creator.Individual, toolbox.binary,
n = gene_length)
toolbox.register('population', tools.initRepeat, list , toolbox.individual)
toolbox.register('mate', tools.cxOrdered)
toolbox.register('mutate', tools.mutShuffleIndexes, indpb = 0.6)
toolbox.register('select', tools.selRoulette)
toolbox.register('evaluate', train_evaluate)
population = toolbox.population(n = population_size)
r = algorithms.eaSimple(population, toolbox, cxpb = 0.4, mutpb = 0.1,
ngen = num_generations, verbose = False)
通过 GA 找到的 K 个最佳解可以通过 tools.selBest(population,k = 1) 轻松查看。之后,可以使用最佳配置在完整的训练集上进行训练,并在保留的测试集上进行测试。
# Print top N solutions - (1st only, for now)
best_individuals = tools.selBest(population,k = 1)
best_window_size = None
best_num_units = None
for bi in best_individuals:
window_size_bits = BitArray(bi[0:6])
num_units_bits = BitArray(bi[6:])
best_window_size = window_size_bits.uint
best_num_units = num_units_bits.uint
print('\nWindow Size: ', best_window_size, ', Num of Units: ', best_num_units)
# Train the model using best configuration on complete training set
#and make predictions on the test set
X_train,y_train = prepare_dataset(train_data,best_window_size)
X_test, y_test = prepare_dataset(test_data,best_window_size)
inputs = Input(shape=(best_window_size,1))
x = LSTM(best_num_units, input_shape=(best_window_size,1))(inputs)
predictions = Dense(1, activation='linear')(x)
model = Model(inputs = inputs, outputs = predictions)
model.compile(optimizer='adam',loss='mean_squared_error')
model.fit(X_train, y_train, epochs=5, batch_size=10,shuffle=True)
y_pred = model.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print('Test RMSE: ', rmse)
在本教程中,我们探讨了如何使用遗传算法(GA)自动找到 RNN 中的最佳窗口大小(或回溯期)和单位数量。为了进一步学习,我建议你尝试不同的 GA 参数配置,将遗传表示扩展到包括更多参数进行探索,并在下方评论区分享你的发现和问题。
参考文献:
-
理解 LSTM 网络,作者 Christopher Olah
-
Tensorflow 中的递归神经网络 I,作者 R2RT
-
遗传算法:理论与应用,作者 Ulrich Bodenhofer
-
《机器学习》一书第九章,遗传算法,作者 Tom M. Mitchell
 简介: Aaqib Saeed 是荷兰特温特大学(University of Twente)计算机科学(专注于数据科学和智能服务)的研究生。
简介: Aaqib Saeed 是荷兰特温特大学(University of Twente)计算机科学(专注于数据科学和智能服务)的研究生。
原文。转载已获许可。
相关:
-
使用 Tensorflow 中的神经网络进行城市声音分类
-
在 Tensorflow 中实现 CNN 进行人类活动识别
-
今天我在午休时间用 Keras 构建了一个神经网络
更多相关话题
使用 AllenNLP 启动 NLP 项目的温和指南
原文:
www.kdnuggets.com/2019/07/gentle-guide-starting-nlp-project-allennlp.html
评论
由谷本康文,NLP 工程师

照片由Jamie Templeton在Unsplash上拍摄
你是否知道这个库,AllenNLP? 如果你在从事自然语言处理(NLP)工作,你可能听说过这个名字。然而,我想实际使用它的人并不多。或者,有些人尝试过但不知道从哪里开始,因为功能众多。对于那些不熟悉 AllenNLP 的人,我将简要介绍这个库,并让你了解将其集成到你的项目中的优点。
AllenNLP 是一个用于 NLP 的深度学习库。Allen Institute for Artificial Intelligence(人工智能领先研究机构之一)开发了这个基于PyTorch的库。使用 AllenNLP 开发模型比从头开始使用 PyTorch 构建模型要容易得多。它不仅提供了更简单的开发方式,还支持实验管理和开发后的评估。AllenNLP 具有专注于研究开发的特性。更具体地说,它可以快速原型化模型,并使管理大量不同参数的实验变得更容易。此外,它考虑了使用可读的变量名。
我们可能会遇到混乱的代码或丢失重要实验结果的情况,尤其是从头开始编码时。

当我了解了AllenNLP
在 AllenNLP 中,我们应该遵循下面的发展和实验流程。

典型流程与 AllenNLP 流程的比较
根据你自己的研究项目,你只需实现 DatasetReader 和 Model,然后使用配置文件运行各种实验。基本上,我们需要了解以下三个特性才能使用 AllenNLP 启动项目。
-
定义你的 DatasetReader
-
定义你的模型
-
设置你的配置文件
换句话说,一旦你理解了它,你就能进行可扩展的开发。在这篇文章中,我将通过处理情感分析任务来解释上述三个关键特性。此外,你可以查看帖子中使用的代码,如下所示:
最简单的 AllenNLP 配方。通过在 GitHub 上创建帐户来贡献 yasufumy/allennlp_imdb 的开发。](https://github.com/yasufumy/allennlp_imdb)
开始吧!
0. 快速回顾:情感分析
在这里,我将解释情感分析任务的基础知识,以便那些不熟悉的人了解。如果你已经非常了解这一点,请跳过到下一部分:1. 定义 DatasetReader。
情感分析是一个尝试分类给定文档极性(正面或负面)的任务。在这篇文章中,我们使用IMDB中的电影评论作为给定文档。例如,我们将查找复仇者联盟:终局之战的用户评论中的正面和负面评论。这次,我们将使用下面链接提供的数据集。
[情感分析
这是一个用于二元情感分类的数据集,比以前的基准数据集包含了更多的数据…](https://ai.stanford.edu/~amaas/data/sentiment/)
我们将构建一个模型,该模型以文档(评论)作为输入,并预测标签(极性)作为输出。我们应该准备文档和标签的对作为数据集。
1. 定义你的 DatasetReader
下图展示了 AllenNLP 中的 DatasetReader 类。这个类主要用于处理任务中的数据。

DatasetReader 以原始数据集作为输入,并应用预处理操作,如小写转换、分词等。最终,它输出包含预处理数据的 Instance 对象列表。在这篇文章中,Instance 对象将文档和标签信息作为属性。
首先,我们应该继承 DatasetReader 类来创建我们自己的类。然后,我们需要实现三个方法:__init__、_read和text_to_instance。让我们来看一下如何实现我们自己的 DatasetReader。我会跳过read方法的实现,因为它与 AllenNLP 的使用关系不大。但如果你感兴趣,可以参考这个链接。
实现的__init__方法如下。我们可以通过配置文件来控制该方法的参数。
@DatasetReader.register('imdb')
ImdbDatasetReader(DatasetReaer):
def __init__(self, token_indexers, tokenizer):
self._tokenizer = tokenizer
self._token_indexers = token_indexers
在这篇文章中,我设置了token_indexers和tokenizer作为参数,因为我假设我们在实验中改变了索引或分词的方式。token_indexers执行索引操作,而tokenizer执行分词操作。我实现的类具有装饰器(DatasetReader.register('imdb')),这使我们可以通过配置文件来控制它。
实现text_to_instance将如下所示。该方法是 DatasetReader 的主要过程。text_to_instance接受每个原始数据作为输入,进行一些预处理,并将每个原始数据输出为Instance。在 IMDB 中,它接受评论字符串和极性标签作为输入。
@DatasetReader.register('imdb')
ImdbDatasetReader(DatasetReaer):
...
def text_to_instance(self, string: str, label: int) -> Instance:
fields = {}
tokens = self._tokenizer.tokenize(string)
fields['tokens'] = TextField(tokens, self._token_indexers)
fields['label'] = LabelField(label, skip_indexing=True)
return Instance(fields)
在 AllenNLP 中,Instance 的属性对应于 Field。我们可以从 Fields 的字典中创建 Instance。Instance 的属性代表每个数据,如文档或标签。在 IMDB 中,Instance 有两个属性:评论和标签。评论和标签分别对应于 TextField 和 LabelField。
上述提到的是定义我们 DatasetReader 的方式。您可以通过这个链接查看完整代码。
2. 定义你的模型
下图展示了 AllenNLP 中的 Model 类。这个类主要构建解决任务的模型。

模型接受数据作为输入,并输出前向计算的结果和评估指标作为字典。
首先,我们应该继承 Model 类以创建自己的类。然后我们需要实现三个方法:__init__、forward和get_metrics。在这里,我们实现了一个用于 IMDB 评论的极性分类模型,采用了递归神经网络(RNN)。
实现__init__将如下所示。我们可以通过配置文件控制该方法的参数,与 DatasetReader 相同。
@Model.register('rnn_classifier')
class RnnClassifier(Model):
def __init__(self, vocab, text_field_embedder,
seq2vec_encoder, label_namespace):
super().__init__(vocab)
self._text_field_embedder = text_field_embedder
self._seq2vec_encoder = seq2vec_encoder
self._classifier_input_dim = self._seq2vec_encoder.get_output_dim()
self._num_labels = vocab.get_vocab_size(namespace=label_namespace)
self._classification_layer = nn.Linear(self._classifier_input_dim, self._num_labels)
self._accuracy = CategoricalAccuracy()
self._loss = nn.CrossEntropyLoss()
在这篇文章中,我设置了text_field_embedder和seq2vec_encoder作为参数,因为我假设我们在实验中会更改嵌入方式或 RNN 类型。text_field_embedder将标记嵌入为向量,而seq2vec_encoder使用 RNN 对标记序列进行编码(技术上你可以使用除 RNN 之外的其他类型)。我实现的类具有装饰器(Model.register('rnn_classifier')),这使我们能够通过配置文件来控制它。
forward的实现将如下所示。该方法是模型的主要过程。forward接受数据作为输入,通过前向计算进行计算,并将预测标签和评估指标的结果输出为字典。大部分实现方式与 PyTorch 相同。然而,请注意,我们应将结果返回为字典。
def forward(self, tokens, label=None):
embedded_text = self._text_field_embedder(tokens)
mask = get_text_field_mask(tokens).float()
encoded_text = self._dropout(self._seq2vec_encoder(embedded_text, mask=mask))
logits = self._classification_layer(encoded_text)
probs = F.softmax(logits, dim=1)
output_dict = {'logits': logits, 'probs': probs}
if label is not None:
loss = self._loss(logits, label.long().view(-1))
output_dict['loss'] = loss
self._accuracy(logits, label)
return output_dict
上述实现计算了极性分类的概率、交叉熵损失和准确率。我们通过 softmax 从 RNN 的输出中计算分类概率。如果给定标签,我们还计算模型的分类准确率。最后,它将每个计算结果输出为字典(output_dict)。
实现get_metrics将如下所示。
def get_metrics(self, reset=False):
return {'accuracy': self._accuracy.get_metric(reset)}
它返回一个字典形式的准确率值。这是因为我们在这次实验中使用了模型的准确率作为指标。我们可以在get_metrics方法中使用多个值。
上述内容是定义我们模型的方法。你可以从这个链接中查看完整的代码。
3. 设置你的配置文件
下图展示了如何在 AllenNLP 中运行我们的实验。我们可以通过将配置文件传递给allennlp train命令来运行实验。

我将解释如何制作我们的配置文件来控制实验。我们可以通过下面的命令使用 GUI 界面创建配置文件。但我将从头开始解释,以便更好地理解。
allennlp configure --include-package allennlp_imdb
配置文件主要包括dataset_reader字段、model字段和trainer字段。
{
"dataset_reader": {...},
"model": {...},
"trainer": {...}
}
dataset_reader字段和model字段分别指定了我们目前实现的 DatasetReader 和模型的设置。同时,trainer字段指定了优化器、训练周期数和设备(CPU/GPU)的设置。你可以从这个链接中查看完整的配置文件。接下来,我将分别解释这三个字段的重要部分。
DatasetReader 的设置如下。
"dataset_reader": {
"type": "imdb",
"token_indexers": {
"tokens": {
"type": "single_id"
}
},
"tokenizer": {
"type": "word"
}
}
首先,我们在type中指定使用的 DatasetReader。我们可以使用 ImdbDatasetReader 将type设置为imdb,因为它已经通过@DatasetReader.register('imdb')准备好使用了。AllenNLP 已经提供了很多流行的数据集。你可以从文档中查看这些数据集。
然后,我们为ImdbDatasetReader.__init__方法指定参数。我们使用[SingleIdTokenIndexer](https://github.com/allenai/allennlp/blob/master/allennlp/data/token_indexers/single_id_token_indexer.py#L12)作为token_indexers,因为我们希望令牌对应于单个 ID。同时,我们使用[WordTokenizer](https://github.com/allenai/allennlp/blob/master/allennlp/data/tokenizers/word_tokenizer.py#L12)作为tokenizer,因为我们希望令牌是一个单词。
模型的设置如下。
"model": {
"type": "rnn_classifier",
"text_field_embedder": {
"token_embedders": {
"type": "embedding",
...
}
},
"seq2vec_encoder": {
"type": "gru",
...
}
}
首先,我们在type中指定使用的模型,与 DatasetReader 相同。我们可以使用 RnnClassifier 将type设置为rnn_classifier,因为它已经通过@Model.register('rnn_classifier')准备好使用了。
然后,我们为RnnClassifier.__init__方法指定参数。我们使用[Embedding](https://allenai.github.io/allennlp-docs/api/allennlp.modules.token_embedders.html#embedding)作为text_field_embedder,因为我们希望将单词嵌入为向量。同时,我们使用[GRU](https://allenai.github.io/allennlp-docs/api/allennlp.modules.seq2vec_encoders.html)作为seq2vec_encoder,因为我们希望通过 GRU 对嵌入的单词序列进行编码。
Trainer 的设置如下。
"trainer": {
"num_epochs": 10,
"optimizer": {
"type": "adam"
}
}
num_epochs 指定训练的周期数。optimizer 指定更新参数的优化器,在此情况下,我们选择使用 adam。
上述内容是设置配置文件的方法。
我们可以通过执行以下命令来运行实验:
allennlp train \
--include-package allennlp_imdb \
-s /path/to/storage \
-o '{"trainer": {"cuda_device": 0}} \
training_config/base_cpu.jsonnet
当我们想要更改实验设置时,需要创建新的配置文件。但如果更改较少,可以通过以下命令进行更改。以下命令将 GRU 更新为 LSTM。
allennlp train \
--include-package allennlp_imdb \
-s /path/to/storage \
-o '{"trainer": {"cuda_device": 0}} \
-o '{"model": {"seq2vec_encoder": {"type": "lstm"}}}' \
training_config/base_cpu.jsonnet
解释完毕。感谢阅读我的文章。希望你了解如何构建数据加载器和模型,并在 AllenNLP 中管理实验。
感谢 BrambleXu。
个人简介:谷口康文 是一家日本公司的 NLP 工程师。他的兴趣在于问答、信息检索和开源开发。
原文。转载已获许可。
相关内容:
-
NLP 与 NLU:从理解语言到处理语言
-
Python 实践语音识别:基础知识
-
检查 Transformer 架构 – 第二部分:Transformer 如何工作简要描述
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
更多相关话题
Bloom 过滤器的温和介绍
原文:
www.kdnuggets.com/2016/08/gentle-introduction-bloom-filter.html
Bugra Akyildiz, Hinge App.
Bloom 过滤器
Bloom 过滤器是概率性空间高效的数据结构。它们与哈希表非常相似;它们专门用于集合中的成员存在性检测。然而,它们具有一个非常强大的特性,即在成员存在性检测时可以在空间和假阳性率之间进行权衡。由于它可以在空间和假阳性率之间进行权衡,因此它被称为概率数据结构。
我们的前三大课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业生涯的捷径。
2. Google Data Analytics Professional Certificate - 提升您的数据分析能力
3. Google IT Support Professional Certificate - 支持您的组织在 IT 领域

空间效率
让我们详细说明一下空间效率。如果你想在集合中存储长列表的项目,你可以采用多种方式。你可以将其存储在哈希映射中,然后检查哈希映射中的存在性,这将使你能够非常高效地插入和查询。然而,由于你将按原样存储这些项目,它将不会非常节省空间。
如果我们还想提高空间效率,可以在将项目放入集合之前对其进行hash。还有什么呢?我们可以使用位数组来存储项目的哈希值。还有,还有什么?让我们在位数组中也允许哈希冲突。这就是 Bloom 过滤器的工作原理,它们在底层是允许哈希冲突的位数组;这会产生假阳性。哈希冲突在 Bloom 过滤器中是设计上的一部分,否则它们不会那么紧凑。
每当使用列表或集合,并且空间效率重要且显著时,应考虑使用 Bloom 过滤器。
Bloom 过滤器基础知识
Bloom 过滤器是一个N位的位数组,其中N是位数组的大小。它还有另一个参数,即哈希函数的数量,k。这些哈希函数用于在位数组中设置位。当将元素x插入过滤器时,k个索引h1(x),h2(x), ..., hk(x)中的位会被设置,这些位的位置由哈希函数确定。请注意,随着哈希函数数量的增加,这种概率的假阳性率趋近于零。然而,插入和查找所需的时间增加,同时 Bloom 过滤器也会更快填满。
为了在布隆过滤器中检查成员存在性,我们需要检查所有的位是否都已设置;这与我们插入项目到布隆过滤器中的方式非常相似。如果所有的位都已设置,那么这意味着该项目 probably 在布隆过滤器中;如果并非所有位都设置,那么这意味着该项目不在布隆过滤器中。
基本的 Python 实现
如果我们想实现一个基本的布隆过滤器,我们可以轻松做到这一点。
# 3rd party
import mmh3
class BloomFilter(set):
def __init__(self, size, hash_count):
super(BloomFilter, self).__init__()
self.bit_array = bitarray(size)
self.bit_array.setall(0)
self.size = size
self.hash_count = hash_count
def __len__(self):
return self.size
def __iter__(self):
return iter(self.bit_array)
def add(self, item):
for ii in range(self.hash_count):
index = mmh3.hash(item, ii) % self.size
self.bit_array[index] = 1
return self
def __contains__(self, item):
out = True
for ii in range(self.hash_count):
index = mmh3.hash(item, ii) % self.size
if self.bit_array[index] == 0:
out = False
return out
def main():
bloom = BloomFilter(100, 10)
animals = ['dog', 'cat', 'giraffe', 'fly', 'mosquito', 'horse', 'eagle',
'bird', 'bison', 'boar', 'butterfly', 'ant', 'anaconda', 'bear',
'chicken', 'dolphin', 'donkey', 'crow', 'crocodile']
# First insertion of animals into the bloom filter
for animal in animals:
bloom.add(animal)
# Membership existence for already inserted animals
# There should not be any false negatives
for animal in animals:
if animal in bloom:
print('{} is in bloom filter as expected'.format(animal))
else:
print('Something is terribly went wrong for {}'.format(animal))
print('FALSE NEGATIVE!')
# Membership existence for not inserted animals
# There could be false positives
other_animals = ['badger', 'cow', 'pig', 'sheep', 'bee', 'wolf', 'fox',
'whale', 'shark', 'fish', 'turkey', 'duck', 'dove',
'deer', 'elephant', 'frog', 'falcon', 'goat', 'gorilla',
'hawk' ]
for other_animal in other_animals:
if other_animal in bloom:
print('{} is not in the bloom, but a false positive'.format(other_animal))
else:
print('{} is not in the bloom filter as expected'.format(other_animal))
if __name__ == '__main__':
main()
输出如下:
dog is in bloom filter as expected
cat is in bloom filter as expected
giraffe is in bloom filter as expected
fly is in bloom filter as expected
mosquito is in bloom filter as expected
horse is in bloom filter as expected
eagle is in bloom filter as expected
bird is in bloom filter as expected
bison is in bloom filter as expected
boar is in bloom filter as expected
butterfly is in bloom filter as expected
ant is in bloom filter as expected
anaconda is in bloom filter as expected
bear is in bloom filter as expected
chicken is in bloom filter as expected
dolphin is in bloom filter as expected
donkey is in bloom filter as expected
crow is in bloom filter as expected
crocodile is in bloom filter as expected
badger is not in the bloom filter as expected
cow is not in the bloom filter as expected
pig is not in the bloom filter as expected
sheep is not in the bloom, but a false positive
bee is not in the bloom filter as expected
wolf is not in the bloom filter as expected
fox is not in the bloom filter as expected
whale is not in the bloom filter as expected
shark is not in the bloom, but a false positive
fish is not in the bloom, but a false positive
turkey is not in the bloom filter as expected
duck is not in the bloom filter as expected
dove is not in the bloom filter as expected
deer is not in the bloom filter as expected
elephant is not in the bloom, but a false positive
frog is not in the bloom filter as expected
falcon is not in the bloom filter as expected
goat is not in the bloom filter as expected
gorilla is not in the bloom filter as expected
hawk is not in the bloom filter as expected
如你所见,上述输出中存在假阳性,但没有出现假阴性,这是预期的。
与这种布隆过滤器的实现不同,大多数在各种语言中可用的实现并不提供哈希函数参数。这是因为假阳性率在应用中比哈希函数更为重要,并且根据假阳性率,你总是可以调整要使用的哈希函数数量。通常,size 和 error_rate 是布隆过滤器的假阳性率。如果你在初始化布隆过滤器时减少 error_rate,它们会在后台调整哈希函数的数量。
假阳性
虽然布隆过滤器可以有信心地说“绝对不在”,但它们也会对某些项目说 possibly in。根据应用的不同,这可能是一个巨大的缺点,也可能相对还可以。如果偶尔出现假阳性是可以接受的,你应该考虑使用布隆过滤器来检查集合操作中的成员存在性。
还要注意,如果你任意降低假阳性率,你会增加哈希函数的数量,这将增加插入和成员存在性的延迟。在这一部分中还有一点,如果哈希函数彼此独立且能够较为均匀地分布输入空间,那么理论上的假阳性率是可以得到满足的。否则,布隆过滤器的假阳性率会比理论上的假阳性率更差,因为哈希函数之间存在相关性,哈希冲突发生的频率会比预期更高。
使用布隆过滤器时,要考虑假阳性的潜在影响。
确定性
如果你使用相同的大小和相同数量的哈希函数以及哈希函数,布隆过滤器在给出正面响应和负面响应时是确定性的。对于一个项目 x,如果它对该特定项目给出 probably in 的响应,那么 5 分钟后、1 小时后、1 天后和 1 周后它将给出相同的响应。我对这一点感到有些惊讶。它是“概率性的”,所以布隆过滤器的响应应该是某种随机的,对吧?其实不然。它的概率性在于你不能知道它会说哪个项目是 probably in。
否则,当它说
probably in时,它会一直说同样的话。
缺点
布隆过滤器并非完美无缺。
布隆过滤器的大小
布隆过滤器的大小需要根据你要插入的项的数量事先确定。如果你不知道或无法估计项的数量,这就不是很好。你可以设置一个任意大的大小,但那将浪费空间,而我们首先尝试优化的正是这个空间,因此选择布隆过滤器。可以通过创建一个动态调整的布隆过滤器来解决这个问题,但根据应用的不同,这可能并不总是可能。有一种变体称为 可扩展布隆过滤器,它根据不同的项数量动态调整大小。这可以缓解一些缺点。
在布隆过滤器中的构建和成员存在
使用布隆过滤器时,你不仅接受误报率,还愿意在速度方面有一点开销。与哈希映射相比,哈希项和构建布隆过滤器时确实存在开销。
不能给出你插入的项
布隆过滤器无法生成插入项的列表,你只能检查某项是否存在,但永远无法获取完整的项列表,因为哈希冲突和哈希函数。这正是布隆过滤器相较于其他数据结构的最大优势之一;它的空间效率也带来了这一劣势。
删除元素
从布隆过滤器中删除元素是不可能的,你不能撤销插入操作,因为不同项的哈希结果可能会索引到相同的位置。如果你想撤销插入操作,你要么需要对布隆过滤器中的每个索引进行插入计数,要么需要从头开始构建布隆过滤器,排除一个单一项。这两种方法都涉及开销且并不简单。根据应用的不同,可能需要尝试从头开始重建布隆过滤器,而不是从布隆过滤器中删除或移除项。
不同语言中的实现
在生产环境中,你不应自行推出布隆过滤器的实现。有两个原因:其一,选择和实现良好的哈希函数对分配错误率至关重要。其二,它需要经过实战考验,且在错误率和大小方面不应出现错误。每种语言都有开源实现,但根据我的经验,以下针对 node.js 和 Python 的实现非常好:
还有一个非常快速的实现(在成员存在性和将项目添加到布隆过滤器的速度上比上述 Python 库快 10 倍),pybloomfilter,但它运行在 Pypy 上,并且不支持 Python 3。
简介: Bugra Akyildiz 是 Hinge 应用的高级机器学习工程师。你可以在 Twitter 上找到他 @bugraa。
原文。经许可转载。
相关:
-
你会在泰坦尼克号中生存吗?Python 机器学习指南第一部分
-
数据科学入门 - Python
-
美国的下一个话题模型
更多相关内容
自然语言处理的温和介绍
原文:
www.kdnuggets.com/2022/06/gentle-introduction-natural-language-processing.html

图片由 Ryan Wallace 提供,来源于 Unsplash
介绍
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 工作
在数据处理、数据采集、数据排序甚至数据操作中,计算机需要从机器获取某些输入,并且机器将某些输出告知用户,这些都是以某种语言的形式存在的。这种语言对于人类和机器来说都是不同且难以理解的。为了编码输入并使机器更容易理解,反之亦然,涉及到一些被称为计算机编程的语言。所有这些都属于自然语言处理的广泛领域,通过它,编码语言被转换为二进制形式,以便机器可以理解,而二进制语言则被解码,使人类能够理解。(Nadkarni et al., 2011)自然语言处理被归类为 人工智能 的一个子领域。以下框图稍微演示了 NLP 如何与 AI 相关。

图 1. AI、ML、DL 和 NLP 之间的关系(简易表示)(自然语言处理:提升您的业务水平,2021 年 9 月)
与 NLP 相关的示例
在我们的日常生活中,当涉及到技术时,我们遇到了不同的自然语言处理应用实例。以下是一些与 NLP 相关的示例。
-
数据分析由统计分析技术人员使用,以便制作关于天气、城市犯罪、交通信号状况等的数据。简单来说,在数据输入中,它非常重要。
-
预测文本,当使用手机时,某些词语会自动弹出,这是因为用户更频繁地使用这些词语,还有一些其他算法也参与其中。这需要自然语言处理和人工智能。
-
邮件过滤器,是自然语言处理中的最基本功能。
-
搜索结果,谷歌搜索结果也利用自然语言处理根据用户历史和数据历史来优化搜索。
-
其他示例包括数字电话呼叫、智能助手和语言翻译。(赵等,2019)
自然语言处理中的数学
讨论自然语言处理中的数学时,数学本身是一个广阔的领域,有很多分支。对于一个希望继续在自然语言处理及其建模技术领域进行研究的人来说,他必须具备线性代数、微积分、概率和一些基本统计学知识。这里出现的主要问题是自然语言处理领域是否需要大量数学。这一问题的答案取决于你想要实现的目标。自然语言处理的一些分支需要大量数学,而其他分支只需要基本数学知识。(成为自然语言处理专家的学习路径 | 作者 Sara A. Metwalli | Towards Data Science,2021)
自然语言处理包含机器学习、深度学习和计算机视觉的部分。简单来说,当处理自然语言处理时,某些机器或系统可能记录了所有用户输入的数据。这可以通过一个简单的例子来解释。如前所述,我们手机中的自动纠错功能涉及自然语言处理。当你输入诸如“我住在”这样的词语时,你的手机的句子完成算法会根据你最近的活动显示“洛杉矶”。这与一些反向传播、线性代数和统计工具相关。反向传播在用户使用不同词汇时起作用。例如,当我们最初写“我住在”时,句子完成会显示纽约,在某些打字和写作后,系统知道用户写“洛杉矶”后,现在每次在系统中使用“在”时即使是在其他句子中也会显示“洛杉矶”。经过一段时间,当用户在“在”后不再使用“洛杉矶”时,系统已经训练到这种程度,知道在用户写“住在”时应该显示“洛杉矶”,否则使用其他在写作或聊天中更常用的词。这是自然语言处理中的反向传播的主要例子。简单来说,神经网络中权重的调整和误差的最小化完全是数学问题。(自然语言处理文本相似度,它是如何工作的及其背后的数学 | 作者 Jaskaran S. Puri | Towards Data Science,2018)

图 2. 反向传播的简单表示 (反向传播算法及其工作原理介绍 2020)
类似地,统计学已被应用于自然语言处理(NLP),以记录用户数据并制作用户使用哪些词汇的完整数据。例如,当用户开始对话时使用“Hello”。每次用户打开消息或 WhatsApp 时,开头都会出现 hello。这一切都得益于系统记录的最近数据,文本会根据用户采用的风格出现。这种对用户数据的统计分析还使用了概率分布。例如,通过适当的训练和错误修正,以及反向传播,系统经过良好训练,从而提出了令人兴奋的建议。概率和统计在 NLP 中的另一个例子是谷歌搜索历史或 YouTube 搜索历史。统计 NLP 的基本目标是获取具有某些未知概率分布的数据,并对其进行已知概率分布的推断。现在,借助于这些来自概率分布的结果,统计数据已被计算并优化,搜索结果也得到了改进,就像之前提到的谷歌搜索平台等一样。(什么是自然语言处理?, 2017)

图 3. 训练 NLP 系统所需的输入、输出和用户输入(Friedman et al., 2013)
参考文献
-
成为自然语言处理专家的学习路径 | 作者 Sara A. Metwalli | Towards Data Science. (n.d.). 取自 https://towardsdatascience.com/a-learning-path-to-becoming-a-natural-language-processing-expert-725dc67328c4
-
反向传播算法及其工作原理介绍 (n.d.). 取自 https://www.mygreatlearning.com/blog/backpropagation-algorithm/
-
Friedman, C., Rindflesch, T. C., & Corn, M. (2013). 自然语言处理:现状与重大进展的前景,由国家医学图书馆赞助的研讨会. 生物医学信息学杂志, 46(5), 765–773. https://doi.org/10.1016/J.JBI.2013.06.004
-
Nadkarni, P., … L. O.-M.-J. of the, & 2011, 未定义. (n.d.). 自然语言处理:介绍. Academic.Oup.Com. 取自 https://academic.oup.com/jamia/article-abstract/18/5/544/829676
-
自然语言处理:将您的业务提升到新水平 (n.d.). 取自 https://datacenterfrontier.com/natural-language-processing-how-this-technique-can-take-your-business-to-the-next-level/
-
NLP 文本相似性,它是如何工作的及其背后的数学 | Jaskaran S. Puri | 数据科学前沿。(无日期)。检索于 2022 年 1 月 26 日,来自 https://towardsdatascience.com/nlp-text-similarity-how-it-works-and-the-math-behind-it-a0fb90a05095
-
什么是自然语言处理?(无日期)。检索于 2022 年 1 月 26 日,来自 https://machinelearningmastery.com/natural-language-processing/
-
Zhao, W., Peng, H., Eger, S., … E. C. 预印本 arXiv, & 2019,未定义。(无日期)。面向可扩展和可靠的胶囊网络在挑战性 NLP 应用中的应用。Arxiv.Org。检索于 2022 年 1 月 26 日,来自 https://arxiv.org/abs/1906.02829
Neeraj Agarwal 是 Algoscale 的创始人,该公司提供数据工程、应用 AI、数据科学和产品工程等数据咨询服务。他在这一领域有超过 9 年的经验,帮助了从初创公司到《财富》100 强企业等各种组织摄取和存储大量原始数据,以便将其转化为可操作的洞见,从而更好地决策并加速业务价值。
更多相关内容
PyTorch 1.2 简介
原文:
www.kdnuggets.com/2019/09/gentle-introduction-pytorch-12.html
评论
由 Elvis Saravia,情感计算与 NLP 研究员

我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在的组织 IT
在我们之前的 PyTorch 笔记本中,我们学习了如何快速开始使用 PyTorch 1.2 和 Google Colab。在本教程中,我们将退一步,回顾使用 PyTorch 构建神经网络模型的一些基本组件。作为示例,我们将构建一个图像分类器,使用几个堆叠层,然后评估模型。
这将是一个简短的教程,避免使用行话和过于复杂的代码。也就是说,这可能是你可以用 PyTorch 构建的最基本的神经网络模型。
事实上,这么基础的内容对于那些刚开始学习 PyTorch 和机器学习的人来说是理想的。所以如果你有朋友或同事想要入门,我强烈建议你把他们推荐到这个教程作为起点。让我们开始吧!
开始使用
在开始代码之前,你需要安装最新版本的 PyTorch。我们使用 Google Colab 进行教程,因此我们将使用以下命令安装 PyTorch。你也可以在本博客文章的末尾找到一个 Colab 笔记本。
现在我们需要导入一些模块,这些模块将帮助我们获取构建神经网络模型所需的功能。主要的是torch和torchvision。它们包含了你开始使用 PyTorch 所需的大部分功能。然而,由于这是一个机器学习教程,我们还需要torch.nn、torch.nn.functional和torchvision.transforms,它们都包含了构建模型的实用函数。我们可能不会使用下面列出的所有模块,但这些是你在开始机器学习项目之前需要导入的典型模块。
在下面,我们检查 PyTorch 版本,以确保你使用的是本教程所用的正确版本。到本教程时,我们使用的是 PyTorch 1.2。
print(torch.__version__)
加载数据
让我们直接进入正题!与任何机器学习项目一样,你需要加载你的数据集。我们使用的是MNIST 数据集,它是机器学习领域中的“Hello World”数据集。
数据由一系列28 X 28大小的图像(包含手写数字)组成。我们将很快讨论这些图像,但我们的计划是将数据加载成32的批次,类似于下面的图示:

以下是我们在导入数据时执行的完整步骤:
-
我们将使用
transforms模块将数据导入并转换为张量。在机器学习的背景下,张量只是用于存储数据的高效数据结构。 -
我们将使用
DataLoader来构建便捷的数据加载器,这使得将数据高效地批量输入神经网络模型变得容易。稍后我们将讨论批次的问题,但现在,先把它们当作数据的子集。 -
如上所述,我们还将通过在数据加载器中设置
batch参数来创建数据批次。注意,在本教程中我们使用了32的批次,但如果你愿意,可以将其更改为64。
让我们检查一下trainset和testset对象包含的内容。
print(trainset)print(testset)## outputDataset MNIST
Number of datapoints: 60000
Root location: ./data
Split: Train
StandardTransform
Transform: Compose(ToTensor()) Dataset MNIST
Number of datapoints: 10000
Root location: ./data
Split: Test
StandardTransform Transform: Compose(ToTensor())
这是一个初学者教程,所以我会稍微拆解一下:
-
BATCH_SIZE是一个参数,表示我们将用于模型的批次大小。 -
transform包含你将应用于数据的所有转换代码。下面我会展示一个示例,演示它的作用,以便更好地理解它的使用。 -
trainset和testset包含实际的数据集对象。注意我使用train=True来指定这对应于训练数据集,我使用train=False来指定这是其余的数据集,我们称之为测试集。从上面打印的块中你可以看到,数据的划分是 85%(60000)/15%(10000),分别对应于训练集和测试集的样本部分。 -
trainloader是持有数据加载器对象的地方,它负责打乱数据并构建批次。
现在,让我们仔细看看transforms.Compose(...)函数,看看它的作用。我们将使用一个随机生成的图像来演示它的使用。让我们生成一张图像:
让我们渲染它:
输出:

好的,我们有了我们的图像样本,现在让我们对它应用一些虚拟转换。我们将把图像旋转45度。下面的转换处理了这一点:
输出:

请注意,你可以将任何转换放在 transforms.Compose(...) 中。你可以使用 PyTorch 提供的内置转换,也可以构建自己的转换并按需组合。事实上,你可以在函数中放入任意多的转换。让我们尝试另一种转换组合:rotate + vertical flip。
输出:

这很酷,对吧!继续尝试其他转换方法。在进一步探索我们的数据话题上,让我们更仔细地看看我们的图像数据集。
探索数据
作为一个从业者和研究人员,我总是花一点时间和精力探索和理解我的数据集。这很有趣,并且这是一个很好的做法,以确保在训练模型之前一切都井井有条。
让我们检查一下训练和测试数据集包含了什么。我将使用 matplotlib 库来打印出数据集中的一些图像。通过一点 numpy 代码,我可以将图像转换为合适的格式以打印出来。下面我打印出了一整批 32 张图像:
输出:

我们的批次维度如下:
输出:
Image batch dimensions: torch.Size([32, 1, 28, 28])
Image label dimensions: torch.Size([32])
模型
现在是时候构建用于执行图像分类任务的神经网络模型了。我们将保持简单,堆叠一个 dense 层、一个 dropout 层和一个 output 层来训练我们的模型。
让我们讨论一下模型:
-
首先,以下结构,涉及一个名为
MyModel的class,是用于在 PyTorch 中构建神经网络模型的标准代码: -
层在
def __init__()函数内定义。super(...).__init__()只是用来将各部分粘合在一起。对于我们的模型,我们堆叠了一个隐藏层(self.d1),接着是一个 dropout 层(self.dropout),然后是一个输出层(self.d2)。 -
nn.Linear(...)定义了密集层,它需要in和out维度,这些维度分别对应于该层输入特征和输出特征的大小。 -
nn.Dropout(...)用于定义一个 dropout 层。Dropout 是深度学习中的一种方法,帮助模型避免 overfitting。这意味着 dropout 作为一种正则化技术,帮助模型不在训练时看到的图像上过拟合。我们需要这样做,因为我们需要一个对未见示例——在我们这个案例中是测试数据集——有很好的泛化能力的模型。Dropout 随机将神经网络层的一些单元置为零,概率为p=0.2。更多关于 dropout 层的信息请参考 这里。 -
模型的入口点,即数据输入到神经网络模型的位置,放在
forward(...)函数下。通常,我们还会将训练过程中对数据进行的其他转换放在此函数内。 -
在
forward()函数中,我们对输入数据执行一系列计算:1) 我们首先将图像展平,将其从 2D (28 X 28) 转换为 1D (1 X 784); 2) 然后将这些 1D 图像的批次输入到第一个隐藏层; 3) 该隐藏层的输出应用了非线性激活函数 叫做ReLU。此时了解F.relu()的具体作用并不重要,但它的效果是允许神经网络架构在大数据集上更快、更有效地训练;4) 如上所述,dropout 还通过避免对训练数据过拟合来帮助模型更有效地训练;5) 然后我们将 dropout 层的输出输入到输出层(d2);6) 其结果接着传递到softmax 函数,它将输出转换或规范化为概率分布,有助于输出正确的预测值,这些值用于计算模型的准确率;7) 这将是模型的最终输出。
从视觉上讲,以下是我们刚刚构建的模型的图示。请记住,隐藏层比图示中显示的要大,但由于空间限制,图示应视为实际模型的近似。

正如我在之前的教程中所做的,我总是建议用一个批次测试模型,以确保输出的维度符合我们的期望。注意我们如何迭代数据加载器,它方便地存储了images和labels对。out包含模型的输出,这些输出是应用了softmax层的 logits,有助于预测。
输出:
batch size: torch.Size([32, 1, 28, 28])
torch.Size([32, 10])
我们可以清楚地看到,我们得到的每个批次有 10 个输出值与批次中的每个图像相关联;这些值用于检查模型的性能。
训练模型
现在我们准备好训练模型了,但在此之前,我们将设置一个损失函数,一个优化器,以及一个计算模型准确率的实用函数:
-
learning_rate是模型尝试优化其权重的速率,因此可以看作是模型的另一个参数。 -
num_epochs是训练步骤的数量……我们不需要训练这个模型太长时间,所以只用 5 个 epoch。 -
device确定我们将使用什么硬件来训练模型。如果存在gpu,则会使用它,否则默认为cpu。 -
model只是模型实例。 -
model.to(device)负责设置将用于训练模型的实际设备。 -
criterion只是用于计算模型在前向和反向训练过程中损失的度量标准。 -
optimizer是在反向传播步骤中用于修改权重的优化技术。注意,它需要learning_rate和模型参数,这些都是优化的一部分。稍后会详细介绍!
下面的实用函数有助于计算模型的准确性。目前,理解它是如何计算的并不重要,但基本上它比较了模型的输出(预测)与实际目标值(即数据集的标签),并试图计算正确预测的平均值。
训练模型
现在是训练模型的时候了。以下代码部分可以按以下步骤描述:
- 训练神经网络模型时的第一件事是定义训练循环,这通过以下方式实现:
for epoch in range(num_epochs):
...
-
我们定义了两个变量,
training_running_loss和train_acc,它们将帮助我们在模型训练不同批次时监控运行的准确性和损失。 -
model.train()明确表示我们准备好开始训练了。 -
注意,我们正在迭代dataloader,它方便地以图像-标签对的形式提供批次。
-
第二个
for循环意味着在每个训练步骤中,我们将迭代所有批次并在这些批次上训练模型。 -
我们通过
model(images)将图像输入模型,输出表示模型的预测。 -
预测结果与目标标签一起用于使用我们之前定义的损失函数计算损失。
-
在我们更新权重以进行下一轮训练之前,我们执行以下步骤:1) 我们使用优化器对象重置所有变量的梯度(
optimizer.zero_grad());2) 这是一个安全的步骤,它不会覆盖模型在训练过程中累积的梯度(这些梯度通过loss.backward()调用存储在缓冲区中);3)loss.backward()只是计算损失相对于模型参数的梯度;4)optimizer.step()然后确保模型参数得到适当更新;5) 最后,我们收集并累积损失和准确性,这将帮助我们判断模型是否有效地学习。
训练的输出:
Epoch: 0 | Loss: 1.6167 | Train Accuracy: 86.02
Epoch: 1 | Loss: 1.5299 | Train Accuracy: 93.26
Epoch: 2 | Loss: 1.5143 | Train Accuracy: 94.69
Epoch: 3 | Loss: 1.5059 | Train Accuracy: 95.46
Epoch: 4 | Loss: 1.5003 | Train Accuracy: 95.98
在所有训练步骤完成后,我们可以清楚地看到损失不断减少,而模型的训练准确性不断提高,这表明模型有效地学习了图像分类。
我们可以通过在测试数据集上计算准确性来验证这一点,以查看模型在图像分类任务上的表现如何。如下面所示,我们的基本神经网络模型在 MNIST 分类任务上表现非常好。
输出:
Test Accuracy: 96.32
最后总结
恭喜 ????!你已完成本教程。这是一个全面的教程,旨在提供神经网络和 PyTorch 的图像分类基础介绍。
本教程深受这篇TensorFlow 教程的启发。我们感谢相关参考的作者们的宝贵工作。
参考文献
???? Colab 笔记本
???? GitHub 仓库
简介:Elvis Saravia 是情感计算和自然语言处理领域的研究员和科学传播者。
原始文章。已获授权转载。
相关:
-
XLNet 在多个 NLP 任务上超越 BERT
-
适配器:一种紧凑且可扩展的 NLP 迁移学习方法
-
NLP 概述:现代深度学习技术在自然语言处理中的应用
相关主题
支持向量机的温柔介绍
原文:
www.kdnuggets.com/2023/07/gentle-introduction-support-vector-machines.html

图片由作者提供
支持向量机,通常称为 SVM,是一类简单但强大的机器学习算法,用于分类和回归任务。在本讨论中,我们将重点介绍支持向量机在分类中的应用。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
我们将从分类的基础知识和分隔类别的超平面开始。然后,我们将讨论最大间隔分类器,逐步构建到支持向量机及其在 scikit-learn 中的实现。
分类问题与分隔超平面
分类是一个监督学习问题,我们有标记的数据点,机器学习算法的目标是预测新数据点的标签。
为了简化,我们考虑一个二分类问题,其中有两个类别,即类别 A 和类别 B。我们需要找到一个超平面来分隔这两个类别。
从数学上讲,超平面是一个维度比环境空间少一个的子空间。也就是说,如果环境空间是直线,超平面就是一个点。如果环境空间是二维平面,则超平面是一个线,依此类推。
因此,当我们有一个分隔两个类别的超平面时,属于类别 A 的数据点位于超平面的一侧。而属于类别 B 的数据点则位于另一侧。
因此,在一维空间中,分隔超平面是一个点:

一维中的分隔超平面(一个点)| 图片由作者提供
在二维空间中,分隔类别 A 和类别 B 的超平面是一个线:

二维中的分隔超平面(一个线)| 图片由作者提供
在三维空间中,分隔超平面是一个平面:

三维中的分隔超平面(一个平面)| 图片由作者提供
类似地,在 N 维空间中,分隔超平面将是一个(N-1)维子空间。
如果你仔细观察,对于二维空间示例,以下每一个都是有效的超平面,可以分隔类别 A 和类别 B:

分隔超平面 | 图片作者
那么我们如何决定哪个超平面是最优的?引入最大边际分类器。
最大边际分类器
最优超平面是那个在最大化两个类别之间的边际的同时分隔这两个类别的超平面。这样功能的分类器称为最大边际分类器。

最大边际分类器 | 图片作者
硬边际和软边际
我们考虑了一个超级简化的例子,其中类别是完美可分的并且最大边际分类器是一个好的选择。
那么,如果你的数据点分布是这样的呢?这些类别仍然可以通过超平面完美分隔,而最大化边际的超平面将会是这样的:

最大边际分类器是否最优? | 图片作者
但你看到这个方法的问题了吗? 嗯,它仍然实现了类别分隔。然而,这是一种高变异性的模型,可能是尝试过于完美地拟合类别 A 的点。
不过注意,边际内没有任何误分类的数据点。这样的分类器被称为硬边际分类器。
不妨看看这个分类器。这样的分类器表现会更好吗?这是一个变异性更低的模型,它在对分类 A 和分类 B 的点进行分类时表现得相当好。

线性支持向量分类器 | 图片作者
注意到我们有一个在边际内被误分类的数据点。允许最小误分类的分类器是一种软边际分类器。
支持向量分类器
我们的软边际分类器是一个线性支持向量分类器。点可以通过一条直线(或线性方程)分隔开。如果你到目前为止一直在跟随,那么应该清楚支持向量是什么,以及为什么它们被称为支持向量。
每个数据点都是特征空间中的一个向量。最接近分隔超平面的数据点被称为支持向量,因为它们支持或辅助分类。
同样有趣的是,如果你移除一个或一组非支持向量的数据点,分隔超平面不会改变。但是,如果你移除一个或多个支持向量,超平面会改变。
在迄今为止的示例中,数据点是线性可分的。因此,我们可以拟合一个具有最小误差的软边际分类器。但如果数据点像这样分布呢?

非线性可分的数据 | 图片作者
在这个示例中,数据点不可线性可分。即使我们有一个允许误分类的软边际分类器,我们也无法找到一条(分隔超平面)能在这两个类别上取得良好表现的直线。
那我们现在该怎么办?
支持向量机与核技巧
这是我们将要做的总结:
-
问题:数据点在原始特征空间中不可线性分隔。
-
解决方案:将点投影到更高维空间,在该空间中它们是线性可分的。
但将点投影到更高维特征空间要求我们将数据点映射 从原始特征空间到更高维空间。
这种重新计算带来了不可忽视的开销,特别是当我们要投影到的空间比原始特征空间的维度高得多时。这里是核技巧发挥作用的地方。
从数学上讲,你可以用以下方程来表示支持向量分类器 [1]:

在这里, 是一个常量,
是一个常量, 表示我们对对应于支持点的索引集求和。
表示我们对对应于支持点的索引集求和。
 是点
是点  和
和 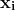 之间的内积。两个向量 a 和 b 之间的内积由以下公式给出:
之间的内积。两个向量 a 和 b 之间的内积由以下公式给出:

核函数 K(.) 使线性支持向量分类器能够推广到非线性情况。我们用核函数替换内积:

核函数处理非线性问题。它还允许在原始特征空间的数据点上执行计算,而无需在更高维空间中重新计算它们。
对于线性支持向量分类器,核函数只是内积,形式如下:

Scikit-Learn 中的支持向量机
现在我们理解了支持向量机的直觉原理,让我们使用 scikit-learn 库编写一个简单的示例。
-
svm 模块在 scikit-learn 库中包含了 Linear SVC、SVC 和 NuSVC 等类的实现。这些类可用于二分类和多分类问题。Scikit-learn 的扩展文档列出了 支持的核函数。
-
我们将使用 内置的葡萄酒数据集。这是一个分类问题,其中葡萄酒的特征用于预测输出标签,该标签是三类中的一个:0、1 或 2。数据集较小,大约有 178 条记录和 13 个特征。
-
在这里,我们将仅关注:
-
- 加载和预处理数据以及
-
将分类器适配到数据集
- 步骤 1 – 导入必要的库并加载数据集
- 首先,让我们加载 scikit-learn 数据集模块中可用的葡萄酒数据集:
from sklearn.datasets import load_wine
# Load the wine dataset
wine = load_wine()
X = wine.data
y = wine.target
- 步骤 2 – 将数据集拆分为训练集和测试集
- 我们将数据集拆分为训练集和测试集。在这里,我们使用 80:20 的拆分比例,其中 80% 的数据点用于训练集,20% 的数据点用于测试集:
from sklearn.model_selection import train_test_split
# Split the dataset into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=10)
- 步骤 3 – 预处理数据集
- 接下来,我们预处理数据集。我们使用
StandardScaler将数据点转换为均值为零和方差为一的分布:
# Data preprocessing
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
- 记得不要在测试数据集上使用
fit_transform,因为这会导致数据泄漏的问题。
- 步骤 4 – 实例化一个 SVM 分类器并将其适配到训练数据上
- 我们将使用
SVC作为示例。我们实例化了svm,一个 SVC 对象,并将其适配到训练数据上:
from sklearn.svm import SVC
# Create an SVM classifier
svm = SVC()
# Fit the SVM classifier to the training data
svm.fit(X_train_scaled, y_train)
- 步骤 5 – 预测测试样本的标签
- 要预测测试数据的类别标签,我们可以在
svm对象上调用predict方法:
# Predict the labels for the test set
y_pred = svm.predict(X_test_scaled)
- 步骤 6 – 评估模型的准确性
- 总结讨论,我们将只计算准确率。但我们也可以获得更详细的分类报告和混淆矩阵。
from sklearn.metrics import accuracy_score
# Calculate the accuracy of the model
accuracy = accuracy_score(y_test, y_pred)
print(f"{accuracy=:.2f}")
Output >>> accuracy=0.97
- 以下是完整的代码:
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# Load the wine dataset
wine = load_wine()
X = wine.data
y = wine.target
# Split the dataset into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=10)
# Data preprocessing
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Create an SVM classifier
svm = SVC()
# Fit the SVM classifier to the training data
svm.fit(X_train_scaled, y_train)
# Predict the labels for the test set
y_pred = svm.predict(X_test_scaled)
# Calculate the accuracy of the model
accuracy = accuracy_score(y_test, y_pred)
print(f"{accuracy=:.2f}")
- 我们有一个简单的支持向量分类器。你可以调整超参数以提高支持向量分类器的性能。常调的超参数包括正则化常数 C 和 gamma 值。
- 结论
- 希望你觉得这份介绍性支持向量机的指南有用。我们涵盖了足够的直觉和概念,以理解支持向量机的工作原理。如果你有兴趣深入了解,可以查看下面的参考资料。继续学习!
- 参考资料和学习资源
- [1] 支持向量机章节,《统计学习简介(ISLR)》
[关于核机器的章节,机器学习介绍]
[支持向量机,scikit-learn 文档]
Bala Priya C 是一位来自印度的开发者和技术写作者。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过撰写教程、操作指南、观点文章等方式,学习并与开发者社区分享她的知识。
更多相关话题
《最温和的 Tensorflow 入门 – 第二部分》
原文:
www.kdnuggets.com/2016/08/gentlest-introduction-tensorflow-part-2.html/2
训练变化。
随机、小批量、批量
在上述训练中,我们在每个时期喂入一个数据点。这被称为随机梯度下降。我们可以在每个时期喂入一批数据点,这被称为小批量梯度下降,甚至可以在每个时期喂入所有数据点,这被称为批量梯度下降。请参见下面的图形比较,并注意三张图之间的两个差异:
-
每个时期喂入 TF.Graph 的数据点数量(每个图的右上角)。
-
梯度下降优化器在调整 W、b 以降低成本时需要考虑的数据点数量(每个图的右下角)。

随机梯度下降

小批量梯度下降

批量梯度下降
每个时期使用的数据点数量有两个影响。使用更多的数据点:
-
计算资源(减法、平方和加法)用于计算成本和执行梯度下降的需求增加。
-
模型学习和泛化的速度增加。
随机、小批量、批量梯度下降的优缺点可以在下面的图表中总结:

随机、小批量和批量梯度下降的优缺点
要在随机/小批量/批量梯度下降之间切换,我们只需要在将数据点输入训练步骤 [D] 之前准备不同的批量大小,即使用下面的代码片段用于 [C]:
# * all_xs: All the feature values
# * all_ys: All the outcome values
# datapoint_size: Number of points/entries in all_xs/all_ys
# batch_size: Configure this to:
# 1: stochastic mode
# integer < datapoint_size: mini-batch mode
# datapoint_size: batch mode
# i: Current epoch number
if datapoint_size == batch_size:
# Batch mode so select all points starting from index 0
batch_start_idx = 0
elif datapoint_size < batch_size:
# Not possible
raise ValueError(“datapoint_size: %d, must be greater than
batch_size: %d” % (datapoint_size, batch_size))
else:
# stochastic/mini-batch mode: Select datapoints in batches
# from all possible datapoints
batch_start_idx = (i * batch_size) % (datapoint_size — batch_size)
batch_end_idx = batch_start_idx + batch_size
batch_xs = all_xs[batch_start_idx:batch_end_idx]
batch_ys = all_ys[batch_start_idx:batch_end_idx]
# Get batched datapoints into xs, ys, which is fed into
# 'train_step'
xs = np.array(batch_xs)
ys = np.array(batch_ys)
学习率变化
学习率是指我们希望梯度下降调整 W、b 时增减的幅度。使用较小的学习率,我们会缓慢而稳妥地接近最小成本,但使用较大的学习率,我们可以更快地达到最小成本,但存在“超调”的风险,从而无法找到最小值。
为了克服这个问题,许多机器学习从业者在初始阶段使用较大的学习率(假设初始成本离最小值很远),然后在每个时期后逐渐降低学习率。
TF 提供了两种方法,如此 StackOverflow 讨论 中精彩解释,但这里是总结。
使用梯度下降优化器变体。
TF 提供了多种梯度下降优化器,支持学习率变化,例如 tf.train.AdagradientOptimizer 和 tf.train.AdamOptimizer。
使用tf.placeholder来设置学习率
正如你之前学到的,如果我们声明一个tf.placeholder,在这种情况下用于学习率,并在tf.train.GradientDescentOptimizer中使用它,我们可以在每个训练 epoch 中向其提供不同的值,就像我们在每个 epoch 中向 x、y_(它们也是tf.placeholders)提供不同的数据点一样。
我们需要 2 个小修改:
# Modify [B] to make 'learn_rate' a 'tf.placeholder'
# and supply it to the 'learning_rate' parameter name of
# tf.train.GradientDescentOptimizer
learn_rate = tf.placeholder(tf.float32, shape=[])
train_step = tf.train.GradientDescentOptimizer(
learning_rate=learn_rate).minimize(cost)
# Modify [D] to include feed a 'learn_rate' value,
# which is the 'initial_learn_rate' divided by
# 'i' (current epoch number)
# NOTE: Oversimplified. For example only.
feed = { x: xs, y_: ys, learn_rate: initial_learn_rate/i }
sess.run(train_step, feed_dict=feed)
总结
我们展示了什么是机器学习的“训练”,以及如何仅通过模型和成本定义,循环进行训练步骤来使用 Tensorflow,这些步骤将数据点输入到梯度下降优化器中。我们还讨论了训练中的常见变体,即每个 epoch 中模型用于学习的数据点大小的变化,以及梯度下降优化器的学习率的变化。
接下来
-
设置 Tensor Board 以可视化 TF 执行,检测模型、成本函数或梯度下降中的问题
-
使用多个特征进行线性回归
资源
-
代码可以在 Github 上找到
-
关于此主题的幻灯片可在 SlideShare 上查看
-
视频可在 YouTube 上观看
简介: Soon Hin Khor,博士,致力于通过技术使世界更加关怀和负责任。ruby-tensorflow 的贡献者。东京 Tensorflow meetup 的共同组织者。
原文. 经许可转载。
相关内容:
-
TensorFlow 的优点、缺点和不足
-
Tensorflow 中的多任务学习:第一部分
-
理解深度学习的 7 个步骤
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织的 IT 需求
更多相关主题
数据科学家的地理编码
当数据科学家需要了解有关数据“位置”的所有信息时,他们通常会转向地理信息系统(GIS)。GIS 是一套复杂的技术和程序,服务于各种目的,但华盛顿大学提供了一个相当全面的定义,称“地理信息系统是一个复杂的相关或连接事物的排列,其目的是传达有关地球表面特征的知识”(Lawler et al)。GIS 涵盖了从获取到可视化处理空间数据的一系列技术,其中许多技术即使你不是 GIS 专家也是有价值的工具。本文提供了地理编码的全面概述,并通过 Python 演示了几个实际应用。具体而言,你将使用地址确定纽约市的一家比萨店的确切位置,并将其与附近公园的数据连接起来。尽管演示使用了 Python 代码,但核心概念可以应用于许多编程环境中,将地理编码集成到你的工作流程中。这些工具为将数据转换为空间数据提供了基础,并为更复杂的地理分析打开了大门。

我们的三大课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT 部门
什么是地理编码?
地理编码通常被定义为将地址数据转换为映射坐标。通常,这涉及到检测地址中的街道名称,将该街道与数据库中其实际世界对应物的边界匹配,然后估计在街道上放置地址的位置。以纽约百老汇的一个比萨店地址为例:2709 Broadway, New York, NY 10025。第一步是找到适合的路网形状文件。注意在这种情况下,地址的城市和州为“New York, NY”。幸运的是,纽约市在NYC Open Data页面(CSCL PUB)上发布了详细的道路信息。第二步,检查街道名称“Broadway”。你现在知道地址可能位于纽约市任何名为“Broadway”的街道上,因此你可以执行以下 Python 代码查询 NYC Open Data SODA API 中所有名为“Broadway”的街道。
import geopandas as gpd
import requests
from io import BytesIO
# Request the data from the SODA API
req = requests.get(
"https://data.cityofnewyork.us/resource/gdww-crzy.geojson?stname_lab=BROADWAY"
)
# Convert to a stream of bytes
reqstrm = BytesIO(req.content)
# Read the stream as a GeoDataFrame
ny_streets = gpd.read_file(reqstrm)
这个查询结果超过 700 个,但这并不意味着你必须检查 700 条街道才能找到你的比萨。通过数据可视化,你可以看到有 3 条主要的百老汇街和几条较小的街道。

这是因为每条街道被分割成与街区大致相对应的部分,从而允许更细致地查看数据。该过程的下一步是使用邮政编码和街道号码确定地址所在的具体部分。数据集中每个街道段包含街道两侧建筑的地址范围。同样,每个段还包含街道两侧的邮政编码。为了定位正确的段,以下代码应用过滤器,找到邮政编码与地址的邮政编码匹配且地址范围包含地址的街道号码的街道段。
# Address to be geocoded
address = "2709 Broadway, New York, NY 10025"
zipcode = address.split(" ")[-1]
street_num = address.split(" ")[0]
# Find street segments whose left side address ranges contain the street number
potentials = ny_streets.loc[ny_streets["l_low_hn"] < street_num]
potentials = potentials.loc[potentials["l_high_hn"] > street_num]
# Find street segments whose zipcode matches the address'
potentials = potentials.loc[potentials["l_zip"] == zipcode]
这将列表缩小到下面看到的一条街道段。

最终任务是确定地址在这条线上的位置。这是通过将街道号码放置在该段的地址范围内,规范化以确定地址应该在这条线上的位置,并将该常数应用于线的端点坐标以获得地址的坐标来完成的。以下代码概述了这一过程。
import numpy as np
from shapely.geometry import Point
# Calculate how far along the street to place the point
denom = (
potentials["l_high_hn"].astype(float) - potentials["l_low_hn"].astype(float)
).values[0]
normalized_street_num = (
float(street_num) - potentials["l_low_hn"].astype(float).values[0]
) / denom
# Define a point that far along the street
# Move the line to start at (0,0)
pizza = np.array(potentials["geometry"].values[0].coords[1]) - np.array(
potentials["geometry"].values[0].coords[0]
)
# Multiply by normalized street number to get coordinates on line
pizza = pizza * normalized_street_num
# Add starting segment to place line back on the map
pizza = pizza + np.array(potentials["geometry"].values[0].coords[0])
# Convert to geometry array for geopandas
pizza = gpd.GeoDataFrame(
{"address": [address], "geometry": [Point(pizza[0], pizza[1])]},
crs=ny_streets.crs,
geometry="geometry",
)
完成地址地理编码后,现在可以在地图上绘制这家比萨店的位置,以了解其位置。由于上述代码查看了街道段左侧的信息,因此实际位置将略微偏左于绘制的点,位于道路左侧的建筑物中。你终于知道了哪里可以吃到比萨饼。

这个过程涵盖了通常被称为地理编码的内容,但这不是该术语的唯一用法。你可能还会看到地理编码指的是将地标名称转化为坐标、邮政编码转化为坐标,或将坐标转化为 GIS 矢量的过程。你甚至可能会听到逆向地理编码(稍后会介绍)被称为地理编码。一个更宽松的地理编码定义是“在位置的近似自然语言描述和地理坐标之间的转换。”所以,每当你需要在这两种数据之间转换时,可以考虑地理编码作为解决方案。
作为重复进行地理编码的替代方法,许多 API 端点,如美国人口普查局地理编码器和谷歌地理编码 API,提供了免费的准确地理编码服务。一些付费选项,如Esri 的 ArcGIS、Geocodio和Smarty甚至为特定地址提供了屋顶级别的准确性,这意味着返回的坐标正好落在建筑物的屋顶上,而不是附近的街道上。以下部分将介绍如何使用这些服务,将地理编码融入你的数据处理流程,以美国人口普查局地理编码器为例。
如何进行地理编码
为了在地理编码时获得尽可能高的准确性,你应始终首先确保你的地址格式符合你选择的服务标准。不同服务之间会有些许差异,但常见格式是 USPS 格式的“PRIMARY# STREET, CITY, STATE, ZIP”,其中 STATE 是一个缩写代码,PRIMARY#是街道号码,所有套房号码、建筑号码和邮政信箱的提及都会被去除。
一旦你的地址格式化完成,你需要将其提交给 API 进行地理编码。以美国人口普查局地理编码器为例,你可以通过“一行地址处理”标签手动提交地址,或者使用提供的 REST API以编程方式提交地址。美国人口普查局地理编码器还允许你使用批量地理编码器对整个文件进行地理编码,并使用基准参数指定数据源。要对之前提到的披萨店进行地理编码,可以使用这个链接将地址传递给 REST API,这可以使用以下代码在 Python 中完成。
# Submit the address to the U.S. Census Bureau Geocoder REST API for processing
response = requests.get(
"https://geocoding.geo.census.gov/geocoder/locations/onelineaddress?address=2709+Broadway%2C+New+York%2C+NY+10025&benchmark=Public_AR_Current&format=json"
).json()
返回的数据是一个 JSON 文件,可以轻松解码为 Python 字典。它包含一个“tigerLineId”字段,可用于匹配最近街道的 shapefile,一个“side”字段,可用于确定地址位于街道的哪一侧,以及“fromAddress”和“toAddress”字段,包含街道段的地址范围。最重要的是,它包含一个“coordinates”字段,可以用于在地图上定位地址。以下代码从 JSON 文件中提取坐标,并处理成 GeoDataFrame,以备进行空间分析。
# Extract coordinates from the JSON file
coords = response["result"]["addressMatches"][0]["coordinates"]
# Convert coordinates to a Shapely Point
coords = Point(coords["x"], coords["y"])
# Extract matched address
matched_address = response["result"]["addressMatches"][0]["matchedAddress"]
# Create a GeoDataFrame containing the results
pizza_point = gpd.GeoDataFrame(
{"address": [matched_address], "geometry": coords},
crs=ny_streets.crs,
geometry="geometry",
)
可视化这个点显示它略微偏离了左侧的手动地理编码点。

如何进行反向地理编码
反向地理编码是将地理坐标与地理区域的自然语言描述匹配的过程。正确应用时,它是数据科学工具包中最强大的技术之一。反向地理编码的第一步是确定你的目标区域。这是包含你坐标数据的区域。一些常见的例子包括人口普查区、邮政编码和城市。第二步是确定这些区域中是否包含该点。使用常见区域时,美国人口普查地理编码器可以通过对 REST API 请求进行小幅修改来进行反向地理编码。确定哪个人口普查地理区域包含之前的比萨店的请求可以通过此链接获得。此查询的结果可以使用之前相同的方法处理。然而,创造性地定义区域以满足分析需求,并手动进行反向地理编码,打开了许多可能性。
要手动进行逆地理编码,你需要确定一个区域的位置和形状,然后判断该点是否在该区域的内部。确定一个点是否在多边形内部实际上是一个相当困难的问题,但可以使用射线投射算法,其中从点开始并无限延伸的射线如果与区域边界相交的次数为奇数,则点在区域内部,若为偶数则不在区域内部(Shimrat),来解决这个问题。在数学上,这实际上是乔丹曲线定理(Hosch)的直接应用。需要注意的是,如果你使用的是来自全球的数据,射线投射算法可能会失败,因为射线最终会绕到地球表面并变成一个圆圈。在这种情况下,你将需要找到区域和点的绕数(Weisstein)。如果绕数不为零,则点在区域内部。幸运的是,Python 的 geopandas 库提供了定义多边形区域内部以及测试点是否在其中所需的功能,而无需所有复杂的数学运算。
虽然手动地理编码对于许多应用可能过于复杂,但手动逆地理编码可以是你技能集中的一个实用补充,因为它允许你轻松地将点匹配到高度自定义的区域。例如,假设你想把你的披萨带到一个公园野餐。你可能希望知道披萨店是否在公园的短距离内。纽约市提供了作为Parks Properties 数据集(纽约市公园开放数据团队)一部分的公园形状文件,并且可以通过他们的 SODA API 使用以下代码访问。
# Pull NYC park shapefiles
parks = gpd.read_file(
BytesIO(
requests.get(
"https://data.cityofnewyork.us/resource/enfh-gkve.geojson?$limit=5000"
).content
)
)
# Limit to parks with green area for a picnic
parks = parks.loc[
parks["typecategory"].isin(
[
"Garden",
"Nature Area",
"Community Park",
"Neighborhood Park",
"Flagship Park",
]
)
]
这些公园可以被添加到可视化中,以查看哪些公园靠近披萨店。

显然,附近有一些选择,但使用形状文件和点来计算距离可能是困难且计算密集的。相反,可以应用逆地理编码。第一步,如上所述,是确定你要将点附加到的区域。在这种情况下,该区域是“距纽约市公园半英里”。第二步是计算点是否位于区域内部,这可以通过之前提到的方法进行数学计算,或通过应用 geopandas 中的“contains”函数来完成。以下代码用于在测试之前向公园的边界添加半英里缓冲区,以查看哪些公园的缓冲区域现在包含该点。
# Project the coordinates from latitude and longitude into meters for distance calculations
buffered_parks = parks.to_crs(epsg=2263)
pizza_point = pizza_point.to_crs(epsg=2263)
# Add a buffer to the regions extending the border by 1/2 mile = 2640 feet
buffered_parks = buffered_parks.buffer(2640)
# Find all parks whose buffered region contains the pizza parlor
pizza_parks = parks.loc[buffered_parks.contains(pizza_point["geometry"].values[0])]
这个缓冲区显示了附近的公园,这些公园在下图中以蓝色突出显示。

成功进行反向地理编码后,你了解到在比萨店半英里内有 8 个公园,你可以在这些公园里举行野餐。享受那一片比萨吧。

j4p4n 制作的比萨片
资源
-
Lawler, Josh 和 Schiess, Peter. ESRM 250: Introduction to Geographic Information Systems in Forest Resources. GIS 定义, 2009 年 2 月 12 日, 华盛顿大学, 西雅图. 课堂讲座.
courses.washington.edu/gis250/lessons/introduction_gis/definitions.html -
CSCL PUB. 纽约开放数据.
data.cityofnewyork.us/City-Government/road/svwp-sbcd -
美国普查局地理编码文档. 2022 年 8 月.
geocoding.geo.census.gov/geocoder/Geocoding_Services_API.pdf -
Shimrat, M., "算法 112: 点相对于多边形的位置" 1962, ACM 通讯 第 5 卷第 8 期, 1962 年 8 月.
dl.acm.org/doi/10.1145/368637.368653 -
Hosch, William L.. "Jordan curve theorem". Encyclopedia Britannica, 2018 年 4 月 13 日,
www.britannica.com/science/Jordan-curve-theorem -
Weisstein, Eric W. "Contour Winding Number." 来源于 MathWorld--Wolfram 网络资源.
mathworld.wolfram.com/ContourWindingNumber.html -
NYC Parks Open Data Team. 公园属性. 2023 年 4 月 14 日.
nycopendata.socrata.com/Recreation/Parks-Properties/enfh-gkve -
j4p4n, “Pizza Slice.” 来源于 OpenClipArt.
openclipart.org/detail/331718/pizza-slice
Evan Miller 是 Tech Impact 的数据科学研究员,他利用数据支持非营利组织和政府机构,以实现社会公益的使命。之前,Evan 在中密歇根大学使用机器学习训练自主车辆。
更多相关话题
Python 中的地理编码:完整指南
原文:
www.kdnuggets.com/2022/11/geocoding-python-complete-guide.html

照片由Andrew Stutesman在Unsplash上提供
介绍
在处理大数据集进行机器学习时,你是否遇到过看起来像这样的地址列?

图片由作者提供
位置数据可能非常混乱且难以处理。
编码地址很困难,因为它们的基数非常高。如果你尝试使用像独热编码这样的技术对这样的列进行编码,会导致高维度,并且你的机器学习模型可能表现不佳。
克服这个问题的最简单方法是地理编码这些列。
什么是地理编码?
地理编码是将地址转换为地理坐标的过程。这意味着你将把原始地址转换为纬度/经度对。
Python 中的地理编码
有许多不同的库可以帮助你用 Python 完成这项工作。最快的是Google Maps API,如果你需要在短时间内转换超过 1000 个地址,我推荐使用它。
然而,Google Maps API 并不是免费的。你需要为每 1000 个请求支付约$5。
Google Maps API 的一个免费替代方案是 OpenStreetMap API。然而,OpenStreetMap API 的速度较慢,且准确性稍差。
在这篇文章中,我将带你通过这两个 API 的地理编码过程。
方法 1:Google Maps API
首先使用 Google Maps API 将地址转换为纬度/经度对。你需要首先创建一个 Google Cloud 账户,并输入你的信用卡信息。
尽管这是一个付费服务,但 Google 在你第一次创建 Google Cloud 账户时会提供$200 的免费信用。这意味着在收费之前,你可以使用他们的地理编码 API 大约 40,000 次。只要你没有达到这个限制,你的账户将不会被收费。
首先,设置一个免费的账户在 Google Cloud 上。然后,一旦你设置了账户,你可以跟随这个教程获取你的 Google Maps API 密钥。
一旦你获得了 API 密钥,就可以开始编码了!
前提条件
我们将使用Zomato 餐馆 Kaggle数据集进行本教程。确保将数据集安装在你的路径中。然后,使用以下命令安装 googlemaps API 包:
pip install -U googlemaps
导入
运行以下代码行来导入你需要开始的库:
pip install -U googlemaps
读取数据集
现在,让我们读取数据集并检查数据框的前几行:
data = pd.read_csv('zomato.csv',encoding="ISO-8859-1")
df = data.copy()
df.head()

图片作者提供
这个数据框有 21 列和 9551 行。
我们只需要address列进行地理编码,所以我将删除所有其他列。然后,我将删除重复项,以便只保留唯一的地址:
df = df[['Address']]
df = df.drop_duplicates()
再次查看数据框的前几行,我们只能看到address列:

图片作者提供
很好!我们现在可以开始地理编码了。
地理编码
首先,我们需要用 Python 访问我们的 API 密钥。运行以下代码行来完成此操作:
gmaps_key = googlemaps.Client(key="your_API_key")
现在,让我们尝试首先进行一个地址的地理编码,并查看输出结果。
add_1 = df['Address'][0]
g = gmaps_key.geocode(add_1)
lat = g[0]["geometry"]["location"]["lat"]
long = g[0]["geometry"]["location"]["lng"]
print('Latitude: '+str(lat)+', Longitude: '+str(long))
上述代码的输出如下所示:

图片作者提供
如果你得到了上述输出,太好了!一切正常。
我们现在可以对整个数据框重复这个过程:
# geocode the entire dataframe:
def geocode(add):
g = gmaps_key.geocode(add)
lat = g[0]["geometry"]["location"]["lat"]
lng = g[0]["geometry"]["location"]["lng"]
return (lat, lng)
df['geocoded'] = df['Address'].apply(geocode)
让我们再次查看数据框的前几行,看看这是否有效:
df.head()

如果你的输出与上面的截图类似,恭喜你!你已经成功对整个数据框进行了地址地理编码。
方法 2:OpenStreetMap API
OpenStreetMap API 完全免费,但比 Google 地图 API 更慢且准确度较低。
这个 API 无法找到数据集中的许多地址,因此这次我们将使用locality列。
在我们开始教程之前,让我们看看address列和locality列之间的区别。运行以下代码行来完成此操作:
print('Address: '+data['Address'][0]+'\n\nLocality: '+data['Locality'][0])
你的输出将如下所示:

图片作者提供
address列比locality列更详细,它提供了餐厅的确切位置,包括楼层号。这可能是地址未被 OpenStreetMap API 识别的原因,但locality却被识别了。
让我们对第一个locality进行地理编码,并查看输出结果。
地理编码
运行以下代码行:
import url
import requests
data = data[['Locality']]
url = 'https://nominatim.openstreetmap.org/search/' + urllib.parse.quote(df['Locality'][0]) +'?format=json'
response = requests.get(url).json()
print('Latitude: '+response[0]['lat']+', Longitude: '+response[0]['lon'])
上述代码的输出与 Google Maps API 生成的结果非常相似:

图片作者提供
现在,让我们创建一个函数来查找整个数据框的坐标:
def geocode2(locality):
url = 'https://nominatim.openstreetmap.org/search/' + urllib.parse.quote(locality) +'?format=json'
response = requests.get(url).json()
if(len(response)!=0):
return(response[0]['lat'], response[0]['lon'])
else:
return('-1')
data['geocoded'] = data['Locality'].apply(geocode2)
很好!现在,让我们查看数据框的前几行:
data.head(15)
请注意,这个 API 无法为数据框中的许多地点生成坐标。
尽管这是 Google Maps API 的一个很好的免费替代品,但如果使用 OpenStreetMap 进行地理编码,你可能会丢失很多数据。
本教程就到这里!希望你能从中学到一些新知识,对处理地理空间数据有更好的理解。
祝你在数据科学之旅中好运,感谢你的阅读!
Natassha Selvaraj 是一位自学成才的数据科学家,热衷于写作。你可以通过LinkedIn与她联系。
原文。转载已获许可。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织进行 IT 支持
更多相关话题
使用 Python 进行地理绘图
评论
由 Ahmad Bin Shafiq, 机器学习学生。

我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
Plotly
Plotly 是一个用于在 Python 中创建交互式图表和仪表板的著名库。Plotly 还是一个 公司,允许我们托管在线和离线的数据可视化。
在本文中,我们将使用离线的 Plotly 来以不同的地理地图形式可视化数据。
安装 Plotly
pip install plotly
pip install cufflinks
在命令提示符中运行两个命令来安装 plotly 和 cufflinks 以及它们在本地机器上的所有包。
Choropleth 地图
Choropleth 地图是常用的主题地图,通过在预定的地理区域(即国家)上使用不同的阴影模式或符号来表示统计数据。它们擅长利用数据来轻松表示所需测量在一个区域的变化。
Choropleth 地图如何工作?
Choropleth 地图显示被划分的地理区域或地区,这些区域以颜色、阴影或图案的形式展示与数据变量相关的信息。这提供了一种可视化地理区域内值的方式,可以展示所显示位置的变化或模式。
使用 Python 绘制 Choropleth 地图
在这里,我们将使用一个 数据集 ,该数据集包含了 2014 年全球不同国家的电力消费数据。
好的,让我们开始吧。
导入库
import plotly.graph_objs as go
from plotly.offline import init_notebook_mode,iplot,plot
init_notebook_mode(connected=True)
import pandas as pd
在这里,init_notebook_mode(connected=True) 将 JavaScript 连接到我们的笔记本。
创建/解释我们的 DataFrame
df = pd.read_csv('2014_World_Power_Consumption')
df.info()

这里我们有 3 列,并且它们都有 219 个非空条目。
df.head()

将数据编译成字典
data = dict(
type = 'choropleth',
colorscale = 'Viridis',
locations = df['Country'],
locationmode = "country names",
z = df['Power Consumption KWH'],
text = df['Country'],
colorbar = {'title' : 'Power Consumption KWH'},
)
type = ’choropleth': 定义地图的类型,即此处为 choropleth。
colorscale = ‘Viridis': 显示一个颜色图(更多颜色刻度,请参见这里)。
locations = df['Country']: 添加所有国家的列表。
locationmode = 'country names’: 由于我们的数据集中包含国家名称,因此我们将位置模式设置为‘country names’。
z: 整数值列表,显示每个状态的功耗。
text = df['Country']: 当在地图上悬停每个状态元素时显示文本。在这种情况下,它是国家的名称。
colorbar = {‘title’ : ‘功耗 KWH’}: 一个字典,包含有关右侧边栏的信息。这里,colorbar 包含边栏的标题。
layout = dict(title = '2014 Power Consumption KWH',
geo = dict(projection = {'type':'mercator'})
)
layout**— 一个 Geo 对象,可用于控制绘制数据的基础地图的外观。
这是一个嵌套字典,包含有关我们的地图/图表应该如何显示的所有相关信息。
生成我们的图表/地图
choromap = go.Figure(data = [data],layout = layout)
iplot(choromap,validate=False)

太棒了!我们的“2014 年全球功耗”面积图已经生成。从上图中,我们可以看到每个国家在地图上的每个元素上悬停时显示其名称和功耗(以 kWh 为单位)。数据在某个特定区域越集中,地图上的颜色越深。这里‘中国’的功耗最大,因此其颜色最深。
密度图
密度映射只是显示某一特定区域内点或线可能集中位置的一种方式。
使用 Python 的密度图
在这里,我们将使用全球 数据集 ,包含地震及其震级。
好的,我们开始吧。
导入库
import plotly.express as px
import pandas as pd
创建/解释我们的数据框
df = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/earthquakes-23k.csv')
df.info()

这里我们有 4 列,所有列都有 23412 个非空条目。
df.head()

绘制我们的数据
fig = px.density_mapbox(df, lat='Latitude', lon='Longitude', z='Magnitude', radius=10,
center=dict(lat=0, lon=180), zoom=0,
mapbox_style="stamen-terrain")
fig.show()
lat='Latitude': 获取数据框中的纬度列。
lon='Longitude': 获取数据框中的经度列。
z: 整数值列表,显示地震的震级。
radius=10: 设置每个点的影响半径。
center=dict(lat=0, lon=180): 在字典中设置地图的中心点。
zoom=0: 设置地图缩放级别。
mapbox_style='stamen-terrain': 设置基础地图样式。这里,“stamen-terrain”是基础地图样式。
fig.show(): 显示地图。
地图

太好了!我们的“地震及其震级”密度图已生成,从上图中可以看到它覆盖了所有受到地震影响的区域,并且当我们悬停时还显示了每个区域的震级。
使用 plotly 进行地理绘图有时可能会有些挑战,因为数据格式多样,因此请参考这个 备忘单 以获取所有类型的 plotly 绘图语法。
相关:
更多相关主题
使用 Geemap 进行地理空间数据分析

作者插图
地理空间数据分析是一个处理、可视化和分析一种特殊类型数据的领域,这种数据称为地理空间数据。与普通数据相比,我们的表格数据中增加了一个列,即位置信息,如纬度和经度。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
数据主要分为两种类型:矢量数据和栅格数据。处理矢量数据时,你仍然拥有一个表格数据集,而栅格数据更类似于图像,例如卫星图像和航拍照片。
在这篇文章中,我将专注于 Google Earth Engine 提供的栅格数据,这是一种提供大量卫星影像数据的云计算平台。这种数据可以通过一个名为 Geemap 的救命 Python 包在你的 Jupyter Notebook 中轻松掌握。让我们开始吧!
什么是 Google Earth Engine?

作者截图。Google Earth Engine 的主页。
在开始使用 Python 库之前,我们需要了解 Google Earth Engine 的潜力。这个基于云的平台由 Google Cloud 平台提供支持,提供了用于学术、非营利和商业目的的公共和免费地理空间数据集。

作者截图。Earth Engine 数据目录概述。
这个平台的美在于它提供了一个多字节的栅格和矢量数据目录,这些数据存储在 Earth Engine 服务器上。你可以通过这个 链接 快速概览。此外,它提供了 API 以便于栅格数据集的分析。
什么是 Geemap?

作者插图。Geemap 库。
Geemap 是一个 Python 库,可以分析和可视化来自 Google Earth Engine 的大量地理空间数据。
在这个包之前,通过 JavaScript 和 Python API 已经可以进行计算请求,但 Python API 功能有限且缺乏文档。
为了填补这个空白,Geemap 被创建出来,允许用户通过少量代码访问 Google Earth Engine 的资源。Geemap 基于 earthengine-api、ipyleaflet 和 folium 构建。
要安装这个库,你只需输入以下命令:
pip install geemap
我建议你在 Google Colab 中尝试这个神奇的包,以了解它的全部潜力。查看教授 Dr. Qiusheng Wu 编写的 这本免费书,以便开始使用 Geemap 和 Google Earth Engine。
如何访问 Earth Engine?
首先,我们需要导入两个 Python 库,这些库将在教程中使用:
import ee
import geemap
除了 geemap,我们还导入了名为 ee 的 Earth Engine Python 客户端库。
这个 Python 库可用于 Earth Engine 的认证,但通过直接使用 Geemap 库会更快:
m = geemap.Map()
m
你需要点击这行代码返回的 URL,这将生成授权码。首先,选择云项目,然后点击“生成令牌”按钮。

作者截图。笔记本认证器。
然后,它会要求你选择账户。如果你正在使用 Google Colab,建议选择相同的账户。

作者截图。选择一个账户。
然后,点击“全选”旁边的复选框,按下“继续”按钮。简而言之,这一步允许笔记本客户端访问 Earth Engine 账户。

作者截图。允许笔记本客户端访问你的 Earth Engine 账户。
在此操作后,将生成认证代码,你可以将其粘贴到笔记本单元格中。

作者截图。复制认证码。
一旦输入验证码,你就可以创建并可视化这个交互式地图:
m = geemap.Map()
m

现在,你只是观察 ipyleaflet 上的基础地图,ipyleaflet 是一个 Python 包,能够在 Jupyter Notebook 中可视化交互式地图。
创建交互式地图
之前,我们已经看到了如何通过一行代码进行身份验证并可视化交互式地图。现在,我们可以通过指定中心的纬度和经度、缩放级别和高度来定制默认地图。我选择了罗马的坐标作为中心,以便集中关注欧洲地图。
m = geemap.Map(center=[41, 12], zoom=6, height=600)
m

如果我们想更改底图,有两种可能的方法。第一种方法是编写并运行以下代码行:
m.add_basemap("ROADMAP")
m

另外,你可以通过点击右侧的环形扳手图标手动更改底图。

此外,我们看到 Geemap 提供的底图列表:
basemaps = geemap.basemaps.keys()
for bm in basemaps:
print(bm)
这是输出:
OpenStreetMap
Esri.WorldStreetMap
Esri.WorldImagery
Esri.WorldTopoMap
FWS NWI Wetlands
FWS NWI Wetlands Raster
NLCD 2021 CONUS Land Cover
NLCD 2019 CONUS Land Cover
...
如你所见,有一长串底图,大多数是通过 OpenStreetMap、ESRI 和 USGS 提供的。
地球引擎数据类型
在展示 Geemap 的全部潜力之前,了解地球引擎中的两种主要数据类型是很重要的。有关更多细节,请查看Google Earth Engine 文档。

作者插图。矢量数据类型的示例:几何、特征和特征集合。
在处理矢量数据时,我们主要使用三种数据类型:
-
几何存储绘制矢量数据在地图上所需的坐标。地球引擎支持三种主要的几何类型:点、线段和多边形。
-
特征本质上是一行,结合了几何和非地理属性。它非常类似于 GeoPandas 的 GeoSeries 类。
-
FeatureCollection是一个包含一组特征的表格数据结构。FeatureCollection 和 GeoDataFrame 在概念上几乎是相同的。

作者截图。图像数据类型的示例。它显示了澳大利亚平滑数字高程模型(DEM-S)
在光栅数据的世界中,我们关注Image对象。Google Earth Engine 的图像由一个或多个波段组成,每个波段具有特定名称、估计的最小值和最大值,以及描述。
如果我们有一系列图像或时间序列,ImageCollection作为数据类型更为合适。

作者截图。 Copernicus CORINE 土地覆盖。
我们可视化了显示欧洲土地覆盖图的卫星影像。该数据集提供了 1986 年到 2018 年的变化。
首先,我们使用 ee.Image 加载图像,然后选择“landcover”波段。最后,通过将加载的数据集添加到地图上作为图层,使用 Map.addLayer 来可视化图像。
Map = geemap.Map()
dataset = ee.Image('COPERNICUS/CORINE/V20/100m/2012')
landCover = dataset.select('landcover')
Map.setCenter(16.436, 39.825, 6)
Map.addLayer(landCover, {}, 'Land Cover')
Map

作者截图。
同样,我们可以对加载和可视化显示欧洲土地覆盖地图的卫星影像做相同的操作。该数据集提供了 1986 年至 2018 年间的变化情况。

作者截图。 甲烷浓度的离线高分辨率影像。
要可视化 Earth Engine 的 ImageCollection,代码行类似,只需注意 ee.ImageCollection 的不同。
Map = geemap.Map()
collection = ee.ImageCollection('COPERNICUS/S5P/OFFL/L3_CH4').select('CH4_column_volume_mixing_ratio_dry_air').filterDate('2019-06-01', '2019-07-16')
band_viz = {
'min': 1750,
'max': 1900,
'palette': ['black', 'blue', 'purple', 'cyan', 'green', 'yellow', 'red']
}
Map.addLayer(collection.mean(), band_viz, 'S5P CH4')
Map.setCenter(0.0, 0.0, 2)
Map

作者截图。
很棒!从这张地图中,我们可以观察到甲烷作为温室效应的重要贡献者之一,如何在全球范围内分布。
最后的思考
这是一个入门指南,可以帮助你使用 Python 处理 Google Earth Engine 数据。Geemap 是最完整的 Python 库,用于可视化和分析此类数据。
如果你想深入了解这个包,可以查看我下面建议的资源。
代码可以在 这里 找到。希望你觉得这篇文章有用。祝你有美好的一天!
有用资源:
尤金妮亚·阿内洛**** 目前是意大利帕多瓦大学信息工程系的研究员。她的研究项目专注于结合异常检测的持续学习。
更多相关话题
如何获得数据科学家的认证
原文:
www.kdnuggets.com/2021/12/get-certified-data-science.html
comments

作者提供的图片。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
数据科学领域相比其他软件相关领域仍然较新,目前没有统一的标准来确定成为专业数据科学家需要掌握哪些技能。这时候,DataCamp认证可以帮助评估你的知识和技能。就像在计算机网络领域,Cisco认证是黄金标准一样,DataCamp 通过各种挑战来评估个人技能。
在证书挑战中,我是一名专业数据科学家,与多个公司合作进行各种项目。起初,我以为对我来说这很简单,但实际上却具有挑战性,我必须全力以赴才能通过所有阶段。认证挑战旨在筛选出 90%的候选人,并仅授予少数具备专业技能的个人。在本指南中,我们将详细学习每一步,并提供通过所有阶段的技巧和窍门。
在通过所有阶段后,你将收到如下所示的证书,一切都值得。

完成数据科学课程
首先,你需要在注册认证之前掌握所有技能。你需要学习 Python(最常用的语言)或 R(统计学家的语言)。
你还将学习:
-
数据管理: 数据摄取、处理、增强以及处理缺失值。
-
探索性分析: 特征工程、数据分析、可视化和数据洞察。
-
统计实验: 使用各种统计方法解决类似问题。
-
机器学习: 预测模型、机器学习工作流程、优化模型和实验。
-
面向生产环境的编码:可重用代码、单元测试、模块化以及采用行业标准。
-
沟通和报告:在报告或仪表板中展示数据,并向技术和非技术利益相关者传递关键信息。
你可以在 YouTube 上免费学习所有这些技能,但我强烈推荐你查看付费课程。

作者提供的图片 | 元素来自于 freepik。
我有Coursera、DataCamp、Udacity和Codecademy的经验,因此只能建议这些课程,但你总是可以寻找更好的在线课程。
定时评估
在你成功完成了 数据科学技能路径 后,前往 DataCamp 认证 部分并开始进行定时评估测试。共有三个定时评估测试,每个测试有 15 个问题。每个问题有时间限制,可能因问题复杂性而异,因此请不要在网上寻找答案,因为这会浪费时间,计分将为零。
这些问题将测试你的技能:
-
面向生产环境的编码
-
统计实验
-
使用 PostgreSQL 进行探索性分析
如果你考试失败,可以重新参加考试,有时即使你已经通过,也必须达到更高的分数才能进入下一阶段,这在某些情况下可能是第 90 百分位。要成功通过这一阶段,你需要全力以赴。
提示:如果你得分很低,请回过头检查所有错误答案。如果是愚蠢的错误,就尝试把它写在纸上,但如果你对问题毫无头绪,我建议你观看针对该问题的视频教程。这些问题不会重复,你可能会再次犯同样的错误。
编程挑战
在这个编码挑战中,没有时间限制,你可以完全自由地提出解决方案。目标是测试个人的编码技能和解决数据问题的能力。在我的案例中,我需要清理数据,添加额外的特征,并最终使用统计工具提出解决方案。这个挑战可以在 30 分钟内解决,但如果你卡住了,无法得到正确的结果,可能需要超过 30 分钟。
提示:
-
总是要读两遍问题陈述,并在开始编码之前给自己留出时间。
-
在编写任何一行代码之前,先制定计划。
-
不要过度思考。尽可能简单地尝试问题,因为没有技巧性问题。
-
如果你卡住了,休息一下,出去喝咖啡,甚至在测试期间也可以。
-
初次尝试未能得到答案也是可以的,因为这并不意味着你不够优秀。
你可以阅读我关于编码挑战的博客 这里 了解更多关于我的经验。
案例研究
在最终阶段,你必须通过 DataCamp 门户预订 24 小时测试的日期。之后,你将获得有关案例研究的详细信息以及专家如何评判该案例研究的方式。在展示日期前 24 小时,你将收到一封电子邮件,你有整整一天的时间来准备:技术报告和非技术性展示。这很简单明了,但你需要完成所有要求的任务,例如:
-
数据清洗
-
数据分析/可视化
-
机器学习模型
-
实验
-
报告
-
结果
-
非技术性展示
技术报告
技术报告通常基于 Jupyter notebook,DataCamp 将提供一个 工作空间 供你运行实验和开发技术报告。
成功通过这个阶段:
-
你需要练习数据分析和机器学习项目。
-
你需要熟练使用 Markdown 和 Python 代码。
-
你需要全面掌握各种可视化和机器学习工具。
-
最后,你需要有撰写技术报告的经验。
提示:尝试保持简单,并在 Jupyter notebook 中使用 Markdown 单元格解释每个部分。添加一些图片和有关问题陈述的背景故事。尝试实验所有机器学习算法,并更多地关注结果的解释。
大多数候选人在这个阶段失败,然后他们必须等待 4 周才能重新申请。
非技术性展示
对于这一部分,您需要使用 MS PowerPoint 或任何您感到舒适的软件创建演示文稿。请记住,您需要为非技术观众准备这份演示文稿,因此不要再有统计方程或机器学习结果。这是一个 Zoom 演讲,专家将根据各种属性给您评分。如果您花费超过12 分钟来覆盖所有主题,将会扣分。尽量复制粘贴可视化内容,减少文字。专注于结果并练习讲故事。
提示:* 计算您的演讲时间,并保持简短。不要添加过多文字。尽量用您的话解释案例研究。专注于关键发现和结果。根据您的发现向利益相关者提供商业解决方案。要自信并清晰地讲话。*
职业服务
演讲结束后,您将在四个工作日内收到关于您结果的电子邮件。如果您成功通过所有阶段,您将收到多封关于证书链接和个性化职业服务的电子邮件。
职业服务包括:
一切都是值得的,因为职业服务将帮助您在领域中提升,并与顶级公司匹配。我强烈建议候选人完成认证并充分利用个性化职业服务。
结论
在这篇博客中,我们涵盖了您获得认证所需的所有部分。首先,您需要通过实践项目或完成数据科学技能路径来获得所需技能。然后,开始在 DataCamp 上进行定时评估。之后,进行代码挑战和案例研究。就是这么简单,但并非所有人都能获得认证,因为候选人经常在课程中跳跃。您需要积累足够的经验和技能才能获得 DataCamp 认证。因此,开始根据我分享的提示工作,迅速启动您的数据科学家职业。

图像由作者提供 | 元素来自freepik。
相关:
更多相关话题
如何获得数据科学工作:一个极其具体的指南
原文:
www.kdnuggets.com/2017/03/get-data-science-job-guide.html
评论

1. 访问LinkedIn
-
向数据科学家发送二十个连接请求。
-
给一个连接发消息,告诉他们你在寻找数据科学职位。
-
分享一篇来自datatau.com的文章,这篇文章教会了你一些东西。
2. 访问GlassDoor
-
阅读三个数据科学家职位描述。记录你需要建立的技能。
-
申请数据科学家职位,无论你是否具备资格。
3. 建立技能
-
选择一个技能,并用它来创建一个小的演示或教程。不要花费超过十个小时。
-
将你的演示/教程发布到网上。将技能添加到你的 LinkedIn 个人资料中,并在项目部分添加链接。
4. 面试
-
只回答知道你名字的招聘人员。
-
参加你能参加的每一次面试。记录你需要建立的技能。
5. 拒绝报价
6. 回到第一步
最终你会遇到一个点,你会发现自己无法完成第五步。这个职位虽然不完全符合你的要求,但感觉非常合适,你无法放弃。那时你就完成了。
提示
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
每次公司不向你提供报价时,都会感到受伤。即使你打算拒绝他们,仍然会感觉像是胃部被重击。你会怀疑自己是否足够聪明、年轻、经验丰富或准备充分。这很正常。虽然很糟糕,但要接受这种失望。向你的男朋友倾诉,或者打电话给你的兄弟,或者去跳舞,或者喝一杯高杯苏格兰威士忌。不管你的处理方式如何,都要处理好,同时在脑海中重复“我足够好”。因为你确实足够好。然后回到第一步,再试一次。
这种方法是有效的。它是一个循环,终止条件是成功。或者用约翰·列侬的话来说:“一切都会好起来的。如果现在不好,那就不是结局。”
祝你好运!
你有任何想要添加的求职建议吗?在 LinkedIn 上联系我并发消息。我会汇总并分享出来。如果你希望保持匿名,请务必告知我。
原文。经授权转载
相关:
-
分析与数据科学专业人员的职业建议 –
-
想要一个数据科学职位?
-
如何获得你的第一份数据科学工作?
更多相关话题
如何在 GPT-4 时代成为数据科学家
原文:
www.kdnuggets.com/2023/04/get-hired-data-scientist-gpt4-era.html

图片来源:作者
科技世界以空前的速度发展,公司不断努力通过整合生成式 AI 或使用开源模型和数据集开发自己的 AI 来保持领先地位。作为寻求就业的数据科学家,获得多种工具和技能以在就业市场中保持竞争力是至关重要的。
在这篇博客中,我们将讨论成为 AI 数据科学家并被你喜欢的公司录用所需关注的核心主题。我们将重点学习统计学、核心数据科学概念、NLP、提示工程、数据科学作品集、面试准备以及 AIOps。通过掌握这些核心主题,你将能够成功成为 AI 数据科学家,并获得你梦想公司的工作。
统计学
即使你可以要求 GPT-4 解释结果,你仍需理解统计术语以得出结论或提出问题。在解释结果之后,你需要制定适合你公司的计划。GPT-4 在处理多个变动因素时难以给出正确答案,这正是我们统计分析知识发挥作用的地方。

照片来源:Kaboompics .com
核心数据科学概念
ChatGPT 和 GPT-4 在制定数据项目的可定制计划方面表现不佳。你需要编写大量后续提示以获取正确的行动计划。即使这样,你也需要在向经理提交之前仔细检查项目计划。所有这些后续提示都需要对数据核心概念有一定了解,如数据摄取、数据清理、数据处理、数据可视化、数据分析和数据建模。

图片来源:作者
即便如此,GPT-4 在调试、研究、提出最新 API 和添加专业代码等方面仍有许多不足。
了解更多关于 20 个初学者核心数据科学概念。
自然语言处理(NLP)
无论是文本生成图像还是文本生成文本的模型,都需要对自然语言处理有专业知识。没有这些知识,你无法对模型进行微调、提高结果,甚至提出自己的解决方案。随着 ChatGPT 的推出,NLP 和强化学习已成为热门职业。

图片来自Hugging Face
大型语言模型可用于文本分类、语言翻译、代码生成、问答、总结等。如果没有 NLP 知识,你将无法进行文本分析或创建特定任务的 AI 应用。
NLP 核心概念对于安全、理解模型架构和数据集也很重要。如果没有这些知识,你很难通过初步的面试阶段。
AI 提示工程
AI 提示工程正成为所有技术工作者越来越重要的技能。掌握这一技能可以让你编写快速且高效的代码,制定全面的项目计划,有效解决问题,快速适应新技术,并生成高质量的报告和文档。这种 AI 的潜在应用几乎是无限的。

作者提供的图片
AI 提示工程让你更好地与 AI 沟通,无论你是否相信。AI 不是来取代我们,而是来帮助我们在工作中。我们可以在 5 分钟内编写程序或报告。你需要做的唯一事情就是仔细检查结果。
查看 ChatGPT 数据科学备忘单,或通过查看学习 ChatGPT 的最佳免费资源了解提示工程。
数据科学作品集
从事作品集项目并展示你的作品集资料很重要。你需要在 GitHub 或 DagsHub、Kaggle 和 Huggingface 上拥有优质的数据科学项目。你甚至可以使用像我这样的模板创建自己的网站:Abid 的作品集,或查看我关于 7 个免费平台,帮助建立强大的数据科学作品集的博客。

作者提供的图片
在今天的数字时代,维护在 LinkedIn 上的强大在线存在变得至关重要。正如我通过 LinkedIn 和 GitHub 持续收到的工作邀请所证明的那样,积极参与在线讨论并不断完善你的作品集可以显著提高你被雇佣的机会。一旦你完成了项目,展示你的成果或创建简短教程,并在 Medium 和 KDnuggets 等平台上分享。不要忘记在各种社交媒体平台以及技术专注的 Discord 或 Slack 群组中推广你的项目。
面试准备
针对数据科学的多个面试环节,你需要为行为、情境、统计学、Python 代码、SQL、NLP、机器学习和数据分析问题做好准备。

图片来自作者
-
通过从事多样化的项目,你可以提高通过面试阶段的机会。查看完整的数据科学项目集合 – 第一部分 和 第二部分
-
复习每个主题的模拟面试。查看完整的数据科学面试集合 – 第一部分 和 第二部分。
-
使用备忘单复习遗忘的数据科学概念。查看完整的数据科学备忘单集合 – 第一部分 和 第二部分。
-
研究公司概况、产品类别和员工,以了解他们在寻找什么,并尝试相应地策划你的回答。
-
展示对最新技术的了解以及使用 AI 改善工作流程的能力。
AIOps
正如我之前提到的,许多公司正在寻找数据科学家和工程师,将 AI 集成到现有产品中或建立全新的产品。因此,心理上准备好回答与 AI 操作相关的问题至关重要。

图片来自作者
例如:
-
你会如何部署大型语言模型?
-
你知道如何构建、调试和运行数据管道吗?
-
你知道如何使用 docker / kubernetes 吗?
-
你有使用 Azure、GCP 或 AWS 的经验吗?
-
你会如何监控生产中的模型?
-
你会如何更新你的语言模型?
随着公司寻找具有 DevOps 或 MLOps 知识的数据科学家,这些问题变得越来越常见。你可以 通过这门免费课程学习 MLOps。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为饱受心理健康问题困扰的学生开发一款 AI 产品。
更多相关内容


 浙公网安备 33010602011771号
浙公网安备 33010602011771号