KDNuggets-博客中文翻译-十-
KDNuggets 博客中文翻译(十)
原文:KDNuggets
构建 Formula 1 流式数据管道与 Kafka 和 Risingwave
原文:
www.kdnuggets.com/building-a-formula-1-streaming-data-pipeline-with-kafka-and-risingwave
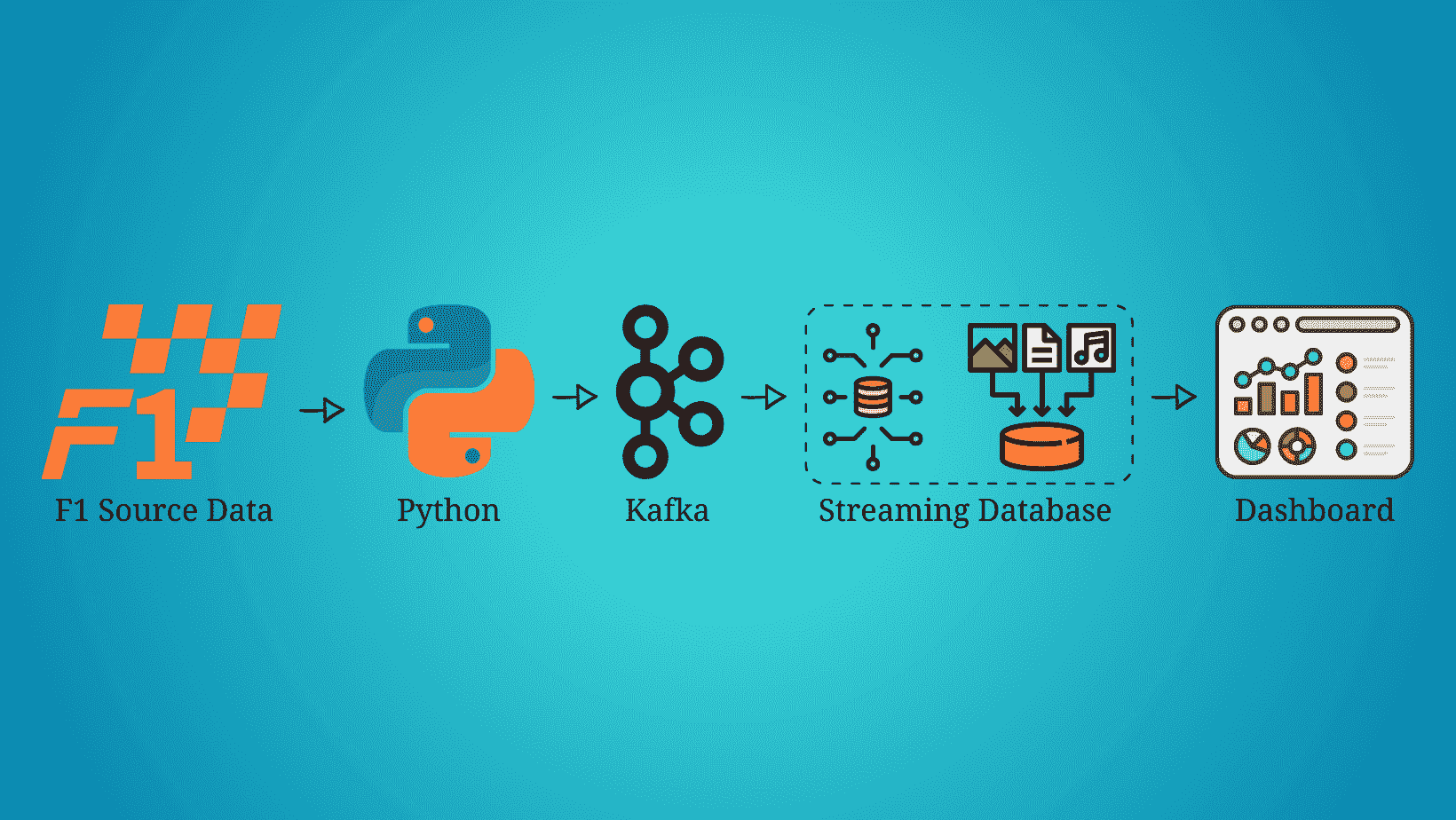
实时数据已经到来并且会持续存在。毫无疑问,每天流式数据的数量都在指数级增长,我们需要找到提取、处理和可视化数据的最佳方法。例如,每辆 Formula 1 汽车在一个比赛周末产生约 1.5 TB 的数据(来源)。
我们的三大课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
在这篇文章中,我们不会流式传输汽车的数据,而是会流式传输、处理和可视化比赛的数据,模拟我们在 Formula 1 比赛中实时进行。在开始之前,重要的是要提到这篇文章不会关注每种技术是什么,而是如何在流式数据管道中实现它们,因此需要对 Python、Kafka、SQL 和数据可视化有一定了解。
前提条件
-
F1 源数据:在这个数据流管道中使用的 Formula 1 数据是从 Kaggle 下载的,可以在 Formula 1 世界锦标赛(1950 - 2023) 中找到。
-
Python: 这个管道是用 Python 3.9 构建的,但任何高于 3.0 的版本都应该可以使用。有关如何下载和安装 Python 的更多详细信息,可以在 官方 Python 网站 上找到。
-
Kafka: Kafka 是这个流式数据管道中使用的主要技术之一,因此在开始之前安装它是很重要的。这个流式数据管道是在 MacOS 上构建的,因此使用了 brew 来安装 Kafka。更多详细信息可以在 官方 brew 网站 上找到。我们还需要一个 Python 库来将 Kafka 与 Python 一起使用。这个管道使用了 kafka-python。安装详细信息可以在它们的 官方网站 上找到。
-
RisingWave(流数据库): 市场上有多种流数据库,但本文使用的且最佳的之一是 RisingWave。开始使用 RisingWave 非常简单,只需几分钟。有关如何入门的完整教程可以在他们的官方网站上找到。
-
Grafana 仪表盘: 在这个流媒体管道中使用了 Grafana 来实时可视化 Formula 1 数据。有关如何开始使用的详细信息可以在这个网站上找到。
流数据源
现在我们已经有了所有先决条件,是时候开始构建 Formula 1 数据流管道了。源数据存储在一个 JSON 文件中,所以我们需要提取它并通过 Kafka 主题发送。为此,我们将使用以下 Python 脚本。
作者提供的代码
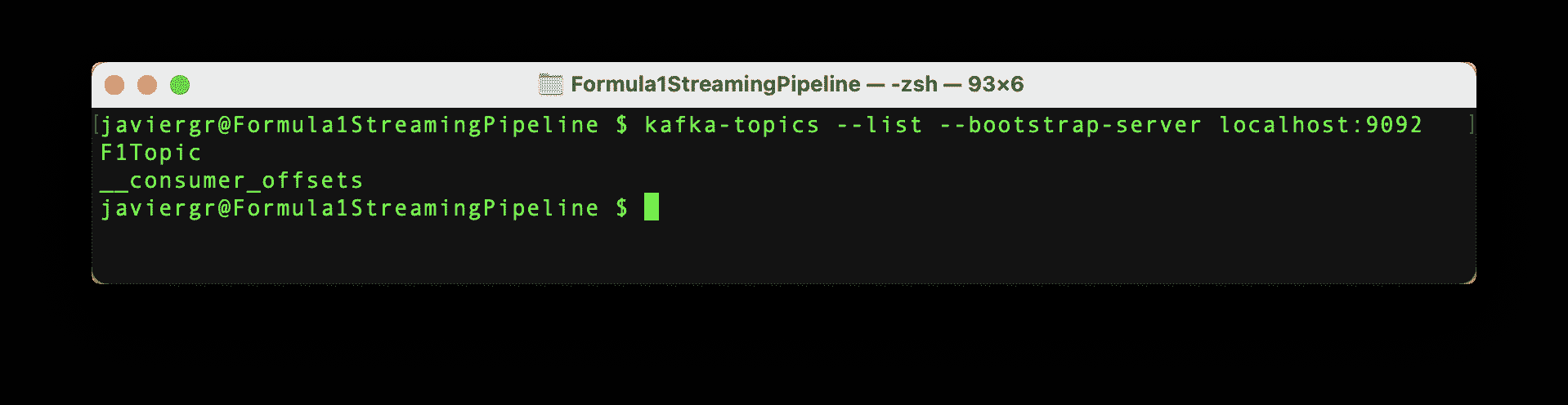
设置 Kafka
用于流数据的 Python 脚本已准备好开始流数据,但 Kafka 主题 F1Topic 尚未创建,所以我们需要创建它。首先,我们需要初始化 Kafka。为此,我们必须启动 Zookeper,然后启动 Kafka,最后使用以下命令创建主题。请记住,Zookeper 和 Kafka 应在不同的终端中运行。
作者提供的代码
设置流数据库 RisingWave
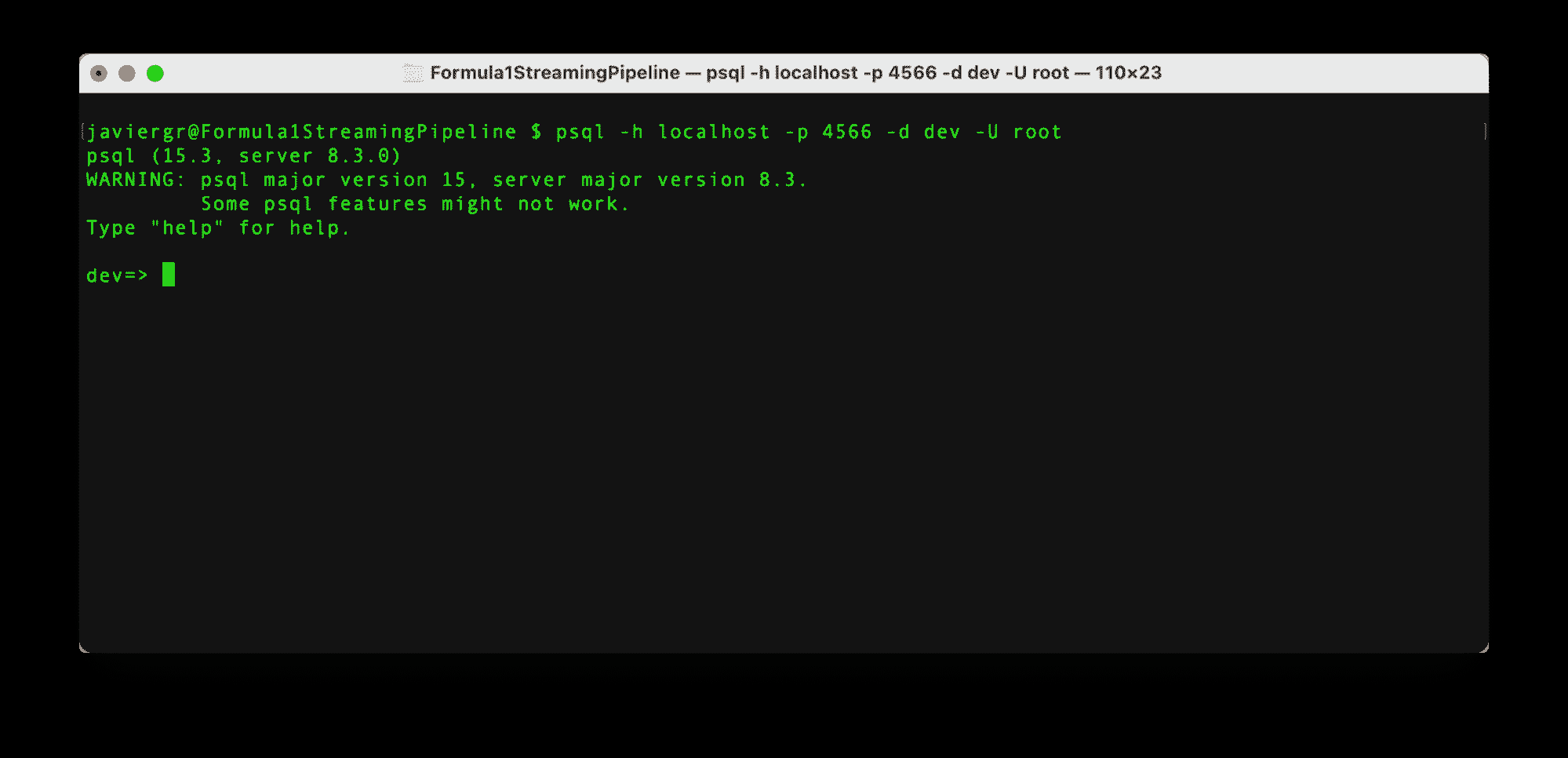
一旦安装了 RisingWave,就很容易启动它。首先,我们需要初始化数据库,然后通过 Postgres 交互式终端 psql 连接它。要初始化流数据库 RisingWave,我们必须执行以下命令。
作者提供的代码
上述命令在游乐场模式下启动 RisingWave,其中数据暂时存储在内存中。该服务设计为在 30 分钟不活动后自动终止,所有存储的数据在终止时将被删除。此方法仅推荐用于测试,RisingWave Cloud 应用于生产环境。
当 RisingWave 启动并运行后,就可以通过以下命令在新的终端中通过 Postgress 交互式终端连接它。
作者提供的代码
一旦建立了连接,就可以开始从 Kafka 主题中提取数据。为了将流数据导入 RisingWave,我们需要创建一个源。这个源将建立 Kafka 主题和 RisingWave 之间的通信,所以让我们执行以下命令。
作者提供的代码
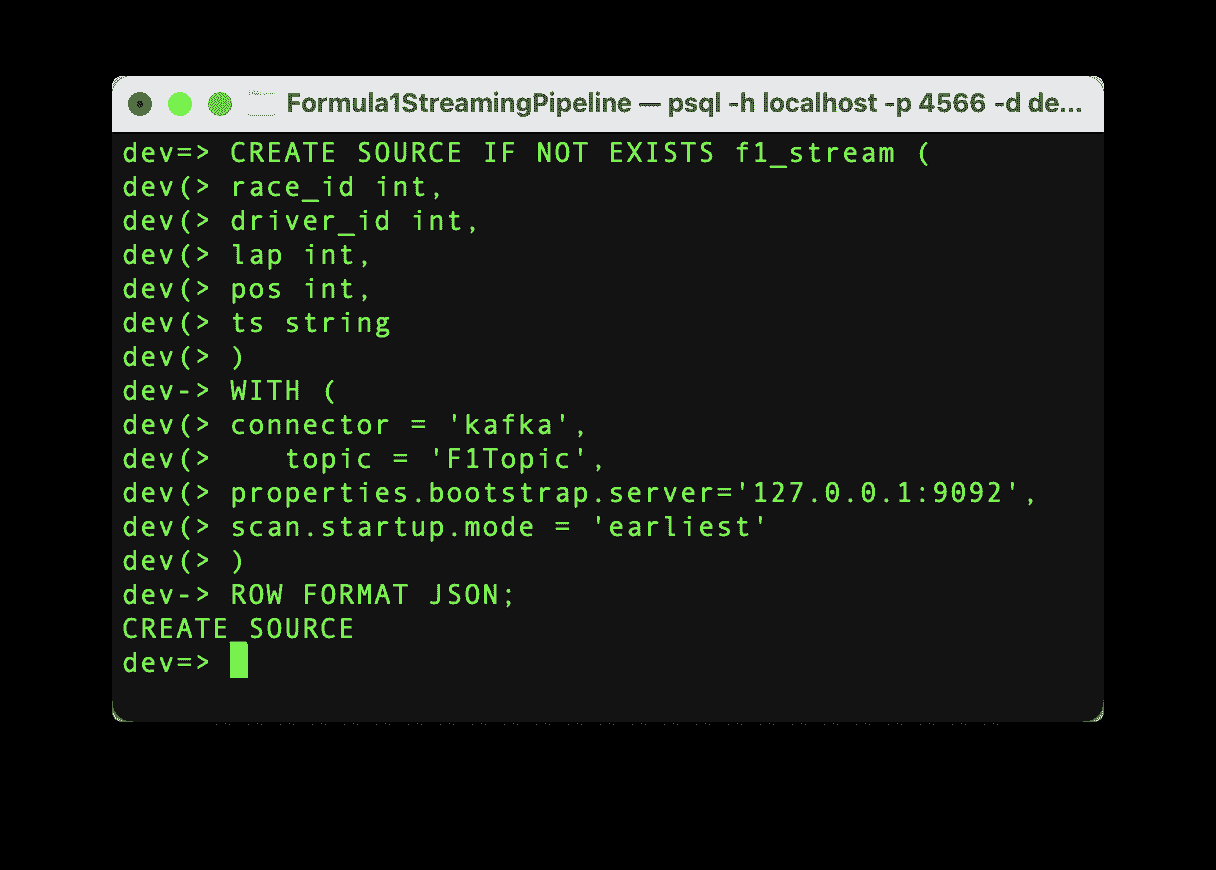
如果命令成功运行,我们将看到消息“CREATE SOURCE”,并且源已经创建。需要强调的是,一旦源创建完成,数据不会自动导入到 RisingWave 中。我们需要创建一个物化视图来启动数据的流动。这个物化视图还将帮助我们在下一步中创建 Grafana 仪表板。
让我们用以下命令创建具有与源数据相同架构的物化视图。
作者提供的代码
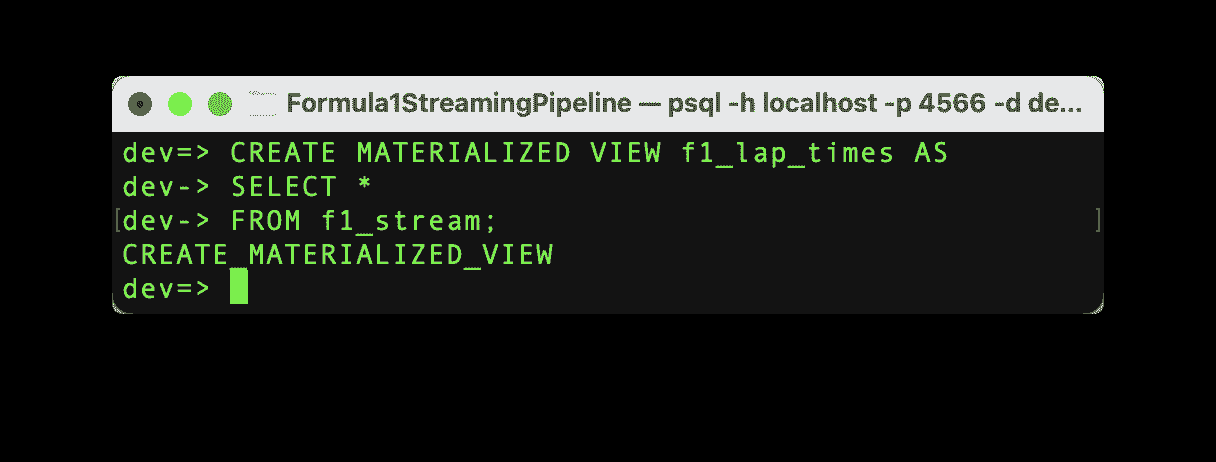
如果命令成功运行,我们将看到消息“CREATE MATERIALIZED_VIEW”,并且物化视图已创建,现在可以进行测试了!
执行 Python 脚本以开始流式传输数据,并在 RisingWave 终端实时查询数据。RisingWave 是一个兼容 Postgres 的 SQL 数据库,因此如果你熟悉 PostgreSQL 或任何其他 SQL 数据库,一切将会顺利进行,你可以轻松查询流数据。
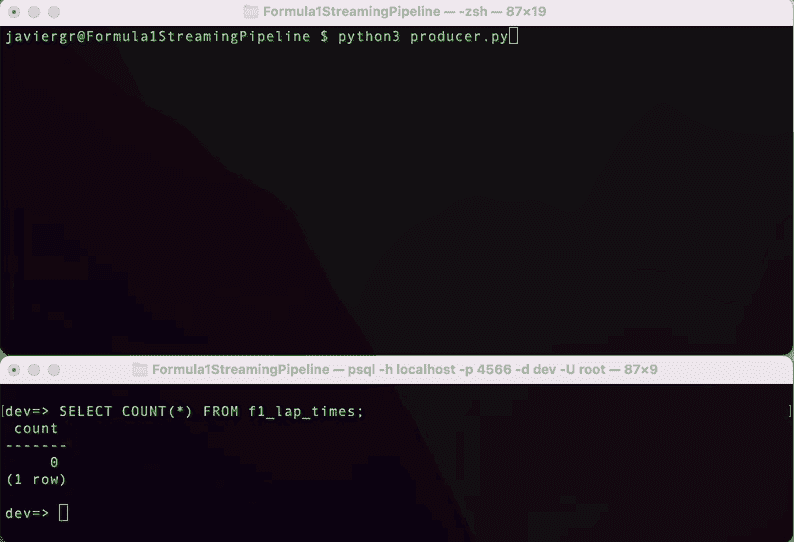
如你所见,流式处理管道现在已经启动并运行,但我们还没有充分利用流数据库 RisingWave 的所有优势。我们可以添加更多的表来实时连接数据,构建一个功能完善的应用程序。
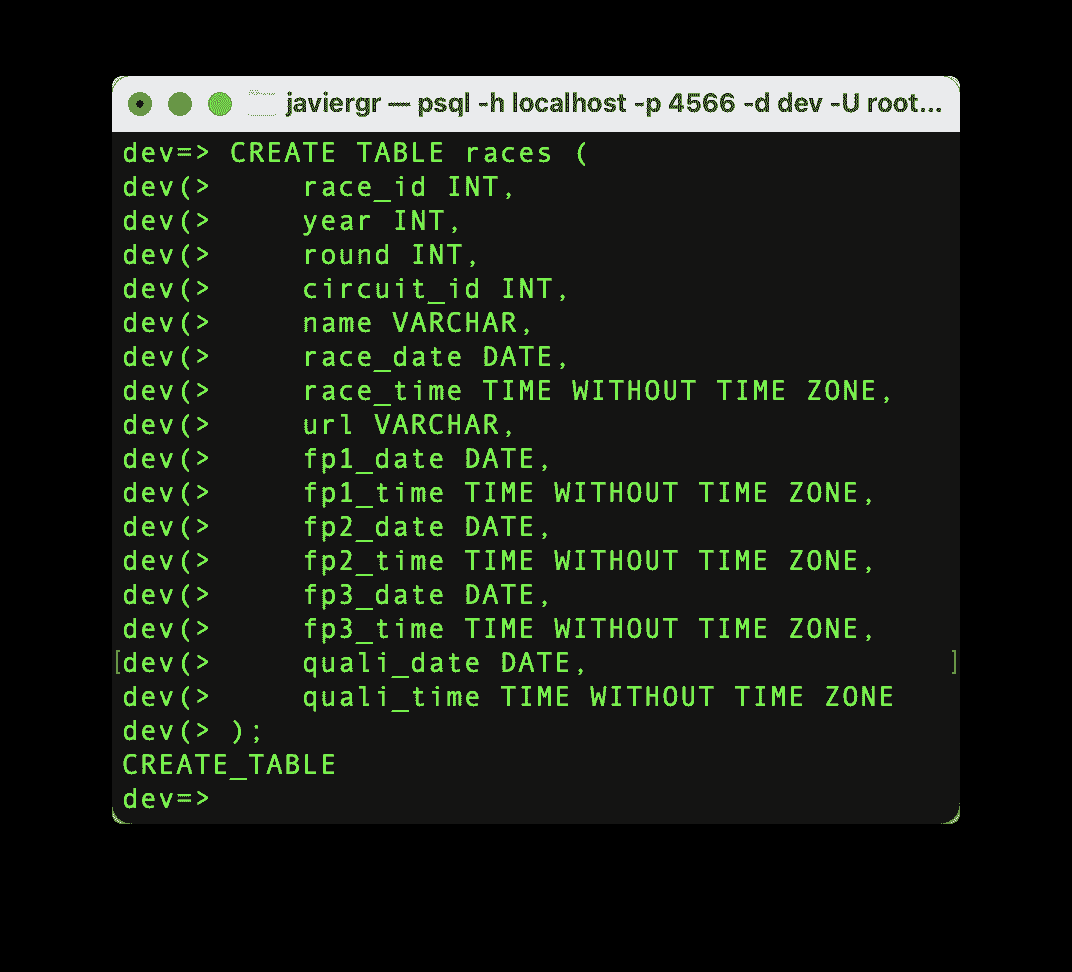
让我们创建比赛表,以便我们可以将流数据与比赛表连接,并获取比赛的实际名称,而不是比赛 id。
作者提供的代码
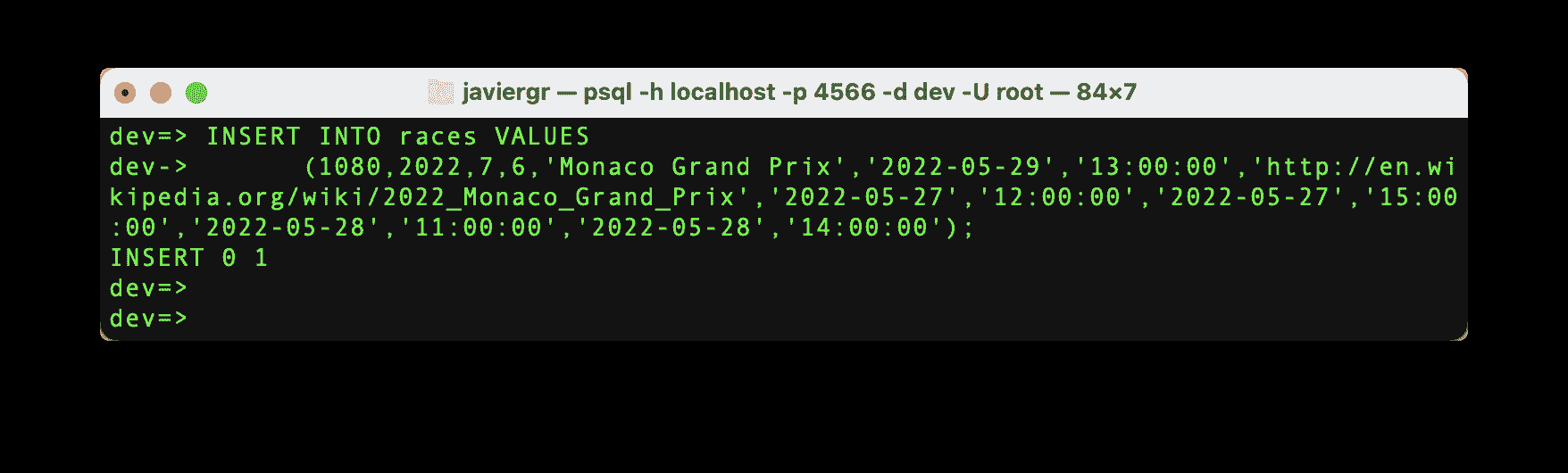
现在,让我们为我们需要的特定比赛 id 插入数据。
作者提供的代码
让我们按照相同的程序进行,但这次用司机的表格。
作者提供的代码
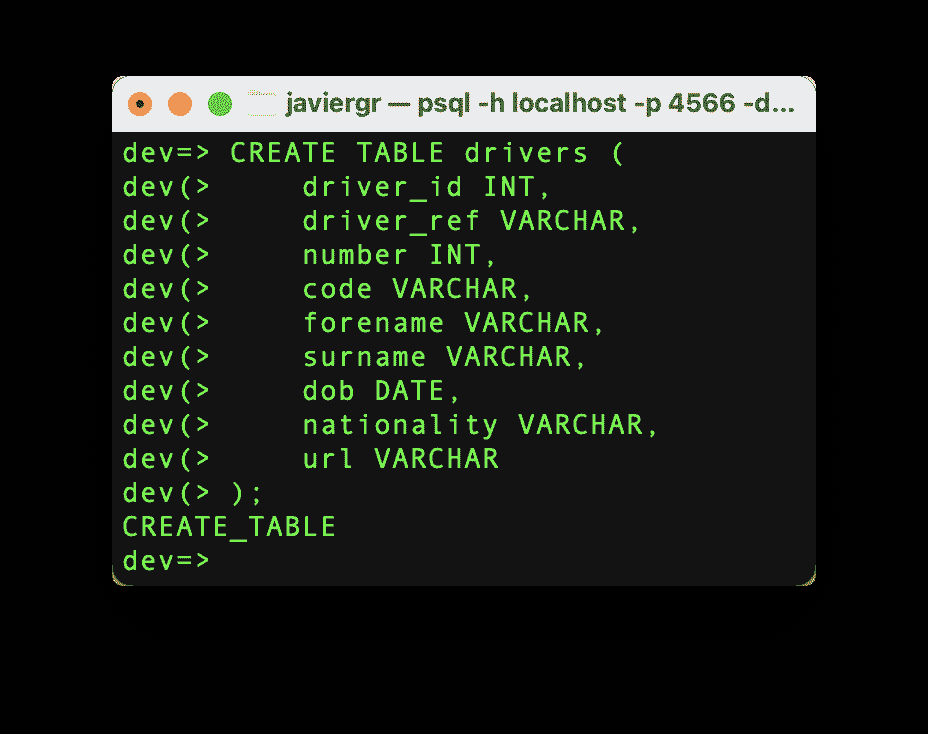
最后,让我们插入司机的数据。
作者提供的代码
我们已经准备好表格来开始连接流数据,但我们需要一个物化视图,所有的魔法都将在这里发生。让我们创建一个物化视图,在实时中查看前 3 名的位置,连接司机 id 和比赛 id 以获取实际名称。
作者提供的代码
最后但同样重要的是,让我们创建最后一个物化视图,以查看一个司机在整个比赛中获得第一名的次数。
作者提供的代码
现在,是时候构建 Grafana 仪表板,并通过物化视图实时查看所有连接的数据了。
设置 Grafana 仪表板
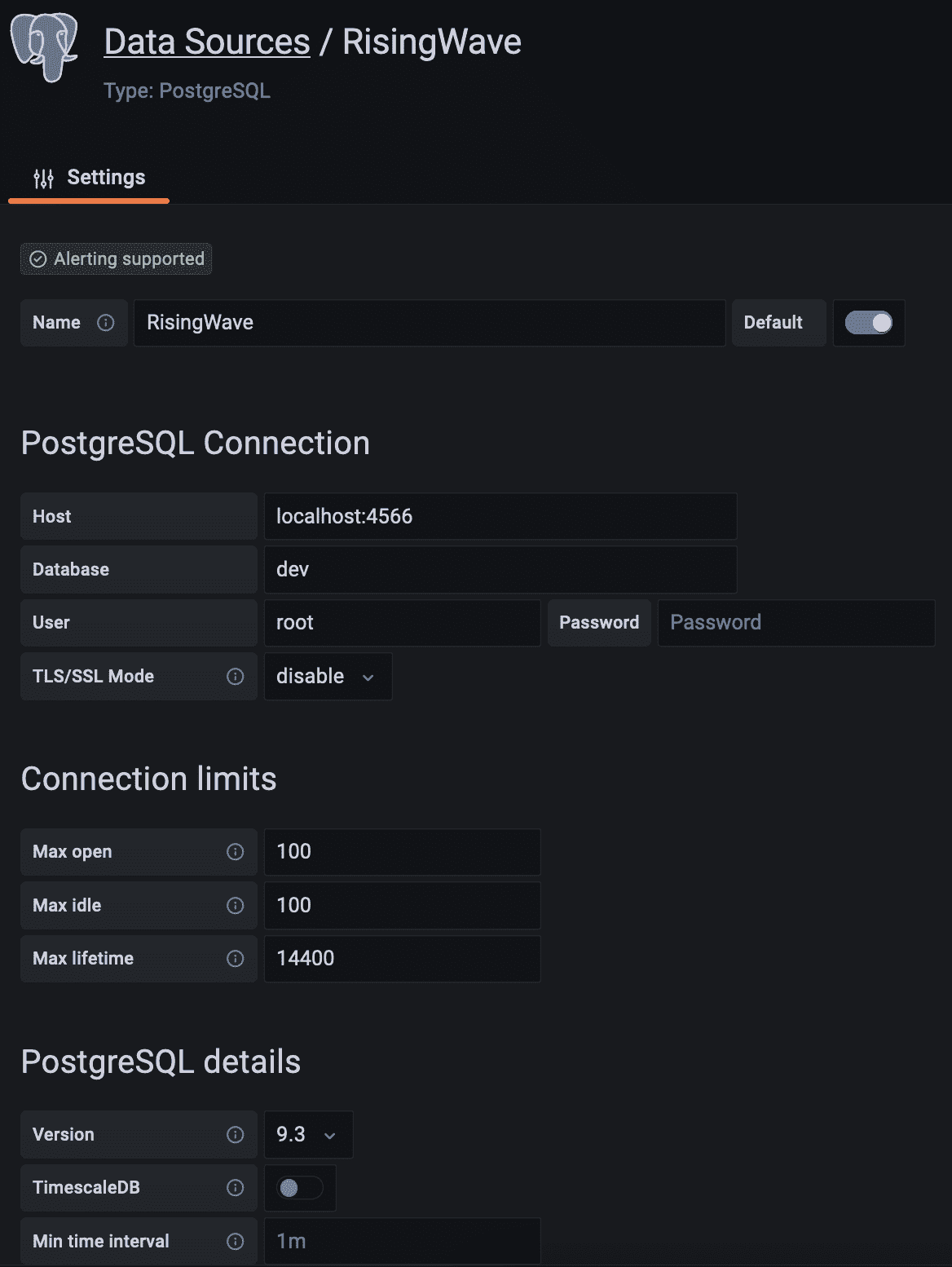
流数据管道的最后一步是实时仪表板中的数据可视化。在创建 Grafana 仪表板之前,我们需要创建一个数据源,以建立 Grafana 和我们的流数据库 RisingWave 之间的连接,按照以下步骤进行。
-
转到 配置 > 数据源。
-
点击添加数据源按钮。
-
从支持的数据库列表中选择 PostgreSQL。
-
填写 PostgreSQL 连接字段,如下所示:
向下滚动并点击保存和测试按钮。数据库连接现在已建立。
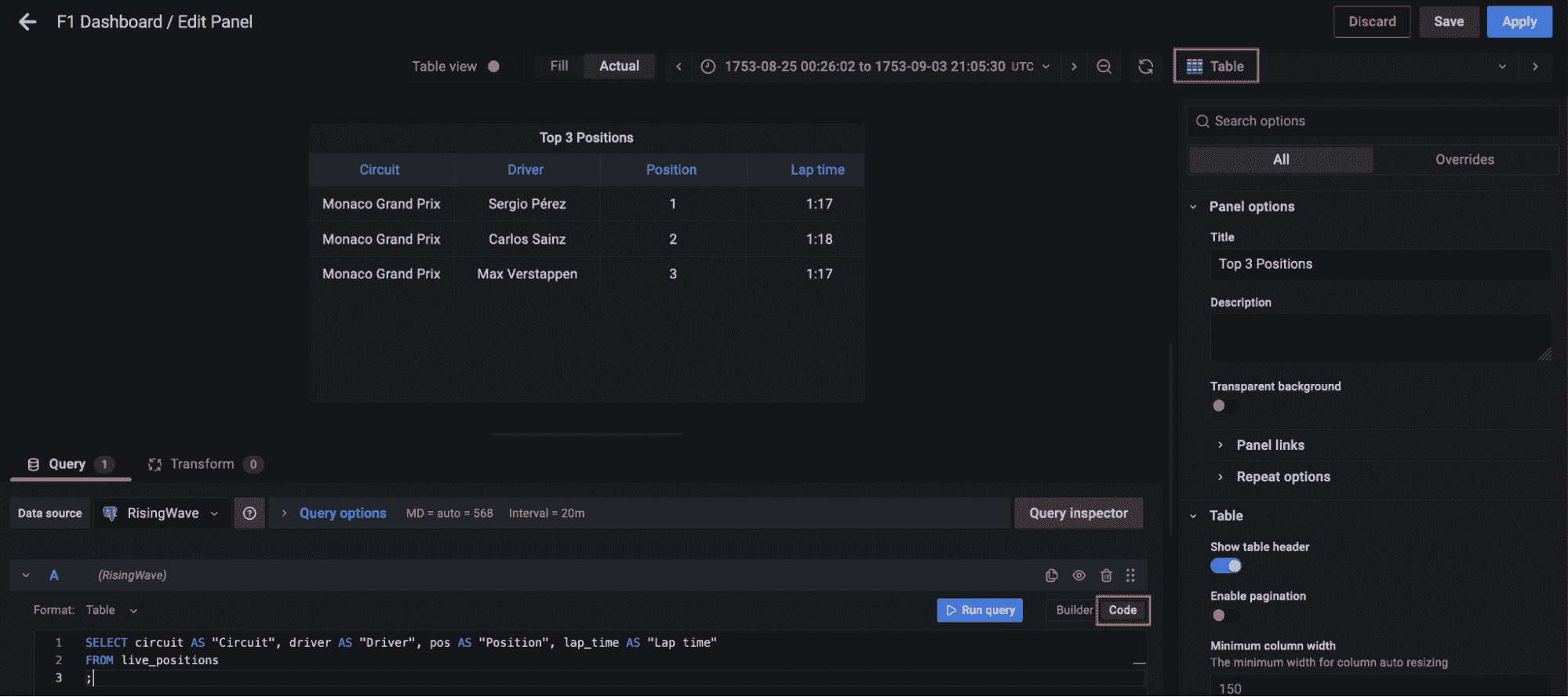
现在转到左侧面板中的仪表板,点击新建仪表板选项,添加一个新面板。选择表格可视化,切换到代码选项卡,查询物化视图 live_positions,我们可以看到前 3 名位置的连接数据。
作者代码
让我们添加另一个面板以可视化当前圈数。选择仪表可视化,在代码选项卡中查询流数据中可用的最大圈数。仪表的自定义由你决定。
作者代码
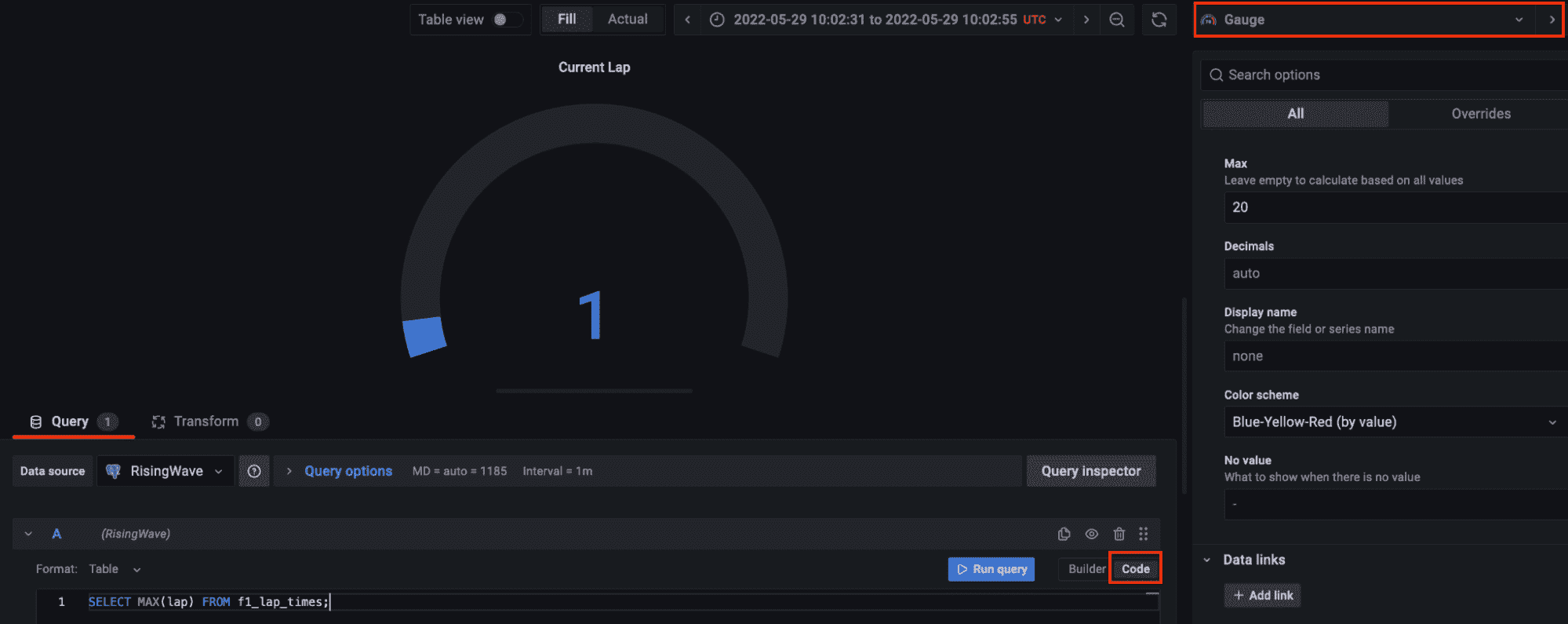
最后,让我们添加另一个面板以查询物化视图 times_in_position_one,并实时查看在整个比赛过程中车手获得第一名的位置次数。
作者代码
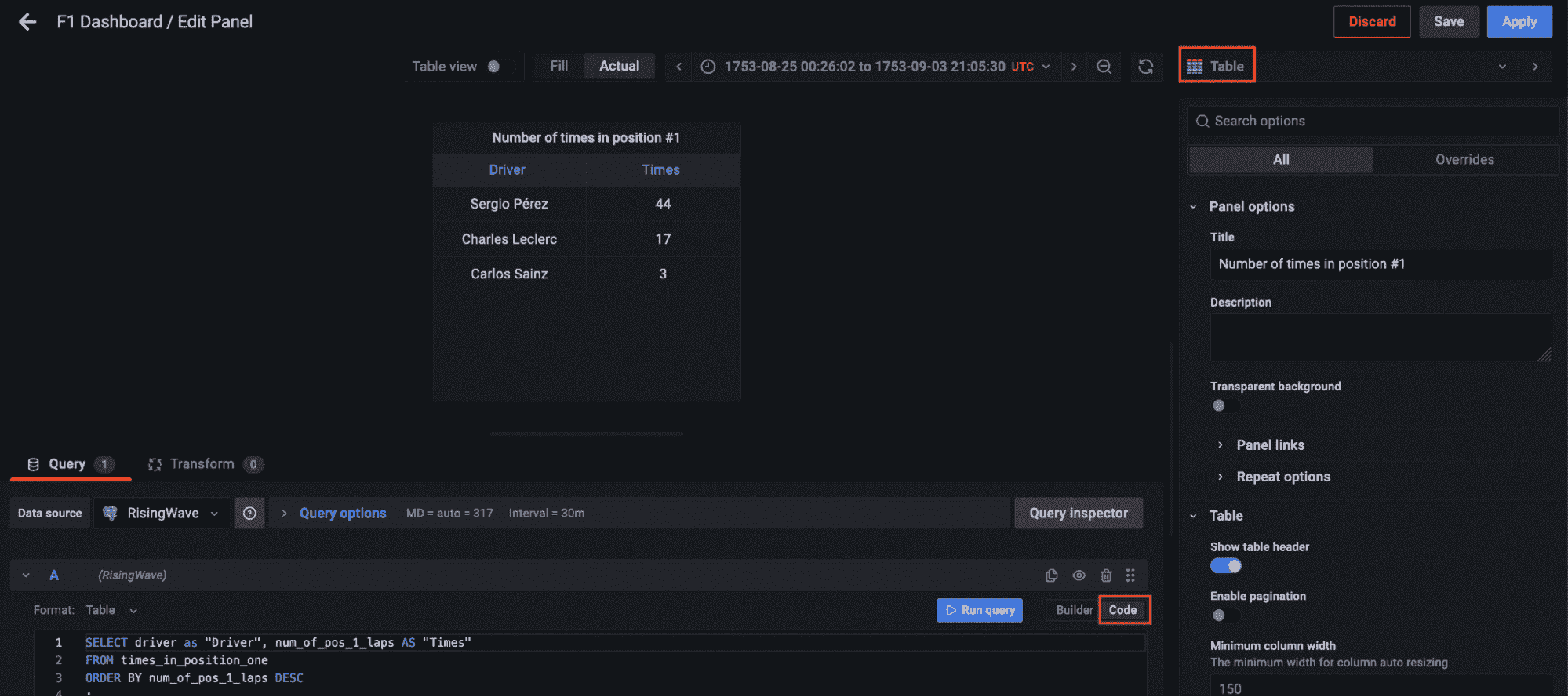
结果可视化
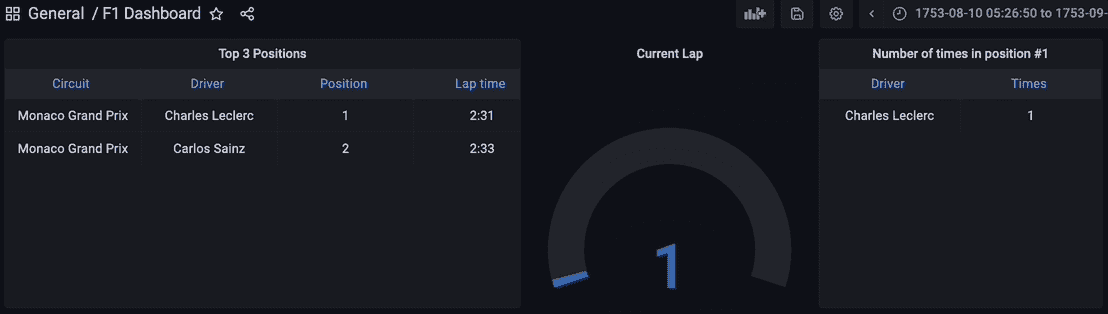
最终,所有流数据管道的组件都已启动并运行。Python 脚本已经执行,开始通过 Kafka 主题流式传输数据,流式数据库 RisingWave 正在实时读取、处理和连接数据。物化视图 f1_lap_times 从 Kafka 主题中读取数据,Grafana 仪表板中的每个面板都是不同的物化视图,这些视图实时连接数据,通过物化视图对比赛和车手表进行的连接来显示详细数据。Grafana 仪表板查询物化视图,所有处理过程都因为在流式数据库 RisingWave 中处理的物化视图而得到简化。
哈维尔·格拉纳多斯 是一名高级数据工程师,他喜欢阅读和写作关于数据管道的内容。他专注于云管道,主要是在 AWS 上,但他总是探索新技术和新趋势。你可以在 Medium 上找到他,网址是 https://medium.com/@JavierGr
更多相关话题
构建 GPU 机器与使用 GPU 云
原文:
www.kdnuggets.com/building-a-gpu-machine-vs-using-the-gpu-cloud

编辑图片
图形处理单元(GPU)的出现以及它们解锁的指数级计算能力,对初创公司和企业业务而言都是一个划时代的时刻。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
GPUs 提供了强大的计算能力,能够执行涉及 AI、机器学习 和 3D 渲染等技术的复杂任务。
然而,在利用这种大量计算能力时,科技界在理想解决方案上面临十字路口。你应该构建一个专用的 GPU 机器还是利用 GPU 云?
本文深入探讨了这一争论的核心,剖析了每种选择的成本影响、性能指标和可扩展性因素。
什么是 GPU?
GPU(图形处理单元)是设计用来快速渲染图形和图像的计算机芯片,通过几乎瞬时完成数学计算。历史上,GPU 常与个人游戏电脑相关联,但它们也用于专业计算,技术进步需要额外的计算能力。
GPU 最初的开发是为了减少现代图形密集型应用程序对 CPU 的工作负载,通过并行处理渲染 2D 和 3D 图形,这种方法涉及多个处理器处理单个任务的不同部分。
在商业中,这种方法有效地加速了工作负载,并提供足够的处理能力,以支持人工智能(AI)和机器学习(ML)建模等项目。
GPU 使用案例
近年来,GPU 发展迅速,变得比早期的 GPU 更加可编程,使其能够在广泛的应用场景中使用,例如:
-
使用 Blender 和 ZBrush 等软件,快速渲染实时的 2D 和 3D 图形应用程序
-
视频编辑和视频内容创建,特别是 4k、8k 或高帧率的作品
-
提供图形能力以在现代显示器上显示视频游戏,包括 4k。
-
加速机器学习模型,从基本的图像转换为 jpg到用全面的前端几分钟内部署自定义调整的模型
-
共享 CPU 工作负载,以在各种应用中提供更高的性能
-
提供训练深度神经网络所需的计算资源
-
挖掘比特币和以太坊等加密货币
重点在于神经网络的开发,每个网络由多个节点组成,每个节点在更广泛的分析模型中执行计算。
GPU 可以通过更高的并行处理增强这些模型在深度学习网络中的性能,从而创建具有更高容错性的模型。因此,现在市场上有许多专门为深度学习项目打造的 GPU,例如最近发布的 H200。
构建 GPU 机器
许多企业,特别是初创公司,选择自己构建 GPU 机器,因为它们具有成本效益,同时提供与 GPU 云解决方案相同的性能。然而,这并不是说这样的项目没有挑战。
在这一部分,我们将讨论构建 GPU 机器的利弊,包括预期的成本以及机器管理,这可能会影响安全性和可扩展性等因素。
为什么要自己构建 GPU 机器?
构建本地 GPU 机器的关键好处是成本,但这样的项目通常需要显著的内部专业知识。持续维护和未来的修改也是可能使这种解决方案不可行的考虑因素。但是,如果这样的构建在你们团队的能力范围内,或者你们找到了可以为你们交付项目的第三方供应商,财务上的节省可能是显著的。
建议为深度学习项目构建一个可扩展的 GPU 机器,特别是在考虑到云 GPU 服务的租赁成本时,如Amazon Web Services EC2、Google Cloud 或 Microsoft Azure。尽管对于希望尽快启动项目的组织来说,托管服务可能更为理想。
让我们考虑构建一个本地自建 GPU 机器的两个主要好处:成本和性能。
成本
如果一个组织正在为人工智能和机器学习项目开发一个大型数据集的深度神经网络,那么运营成本有时可能飙升。这可能阻碍开发者在模型训练期间交付预期结果,并限制项目的可扩展性。因此,财务影响可能导致产品缩减,甚至是一个不适合目的的模型。
建设一个现场自管理的 GPU 机器可以大幅降低成本,为开发者和数据工程师提供他们在广泛迭代、测试和实验中所需的资源。
然而,这只是触及了本地构建和运行的 GPU 机器的表面,尤其是对于开源 LLM 而言,这些 LLM 越来越受欢迎。随着实际用户界面的出现,你可能很快会看到你友好的邻居牙医在后台运行几台 4090,用于如保险验证、日程安排、数据交叉引用等任务。
性能
大规模深度学习和机器学习训练模型/算法需要大量资源,这意味着它们需要极高性能的处理能力。对于需要渲染高质量视频的组织来说也是如此,员工可能需要多个基于 GPU 的系统或最先进的 GPU 服务器。
自建的 GPU 系统推荐用于生产规模的数据模型及其训练,一些 GPU 能够提供双精度,这一特性使用 64 位表示数字,提供更大的数值范围和更好的小数精度。然而,这种功能仅在依赖非常高精度的模型中才是必需的。推荐的双精度系统选项是 Nvidia 的本地 Titan 系列 GPU 服务器。
操作
许多组织缺乏管理本地 GPU 机器和服务器的专业知识和能力。这是因为内部 IT 团队需要能够配置基于 GPU 的基础设施以实现最高性能的专家。
此外,缺乏专业知识可能导致安全性不足,从而出现被网络犯罪分子利用的漏洞。未来可能需要扩展系统也可能带来挑战。
使用 GPU 云
本地 GPU 机器在性能和成本效益方面提供了明显的优势,但前提是组织拥有必要的内部专家。这就是为什么许多组织选择使用 GPU 云服务,如 Saturn Cloud,它提供了完全托管的服务以增加简便性和安心。
云 GPU 解决方案使深度学习项目对更广泛的组织和行业变得更加可及,许多系统能够匹配自建 GPU 机器的性能水平。GPU 云解决方案的出现是人们越来越多地投资于 AI 开发的主要原因之一,尤其是像 Mistral 这样的开源模型,其开源特性非常适合“可租用的 vRAM”,并在无需依赖大型供应商(如 OpenAI 或 Anthropic)的情况下运行 LLM。
成本
根据组织的需求或正在训练的模型,云 GPU 解决方案可能会更便宜,只要每周所需的小时数是合理的。对于较小、数据量较少的项目,可能不需要投资昂贵的 H100 对,GPU 云解决方案提供按合同基础以及各种月度计划的形式,从爱好者到企业都能满足需求。
性能
有一系列的 CPU 云选项能够匹配 DIY GPU 机器的性能水平,提供最佳平衡的处理器、准确的内存、高性能磁盘和每实例八个 GPU 来处理各自的工作负载。当然,这些解决方案可能会有一定费用,但组织可以安排按小时计费,以确保只为使用的部分付费。
操作
云 GPU 相对于自建 GPU 的关键优势在于其操作,专家团队随时准备协助解决任何问题并提供技术支持。自建 GPU 机器或服务器需要内部管理,或者需要第三方公司远程管理,这会产生额外费用。
使用 GPU 云服务,任何如网络故障、软件更新、电力中断、设备故障或磁盘空间不足的问题都能快速解决。实际上,借助完全托管的解决方案,这些问题几乎不会发生,因为 GPU 服务器会被最佳配置,以避免任何过载和系统故障。这意味着 IT 团队可以专注于业务的核心需求。
结论
在选择自建 GPU 机器还是使用 GPU 云时,取决于具体的使用案例,大型数据密集型项目需要额外的性能而不产生显著的成本。在这种情况下,自建系统可能提供所需的性能而不会有高额的月度费用。
另外,对于缺乏内部专业知识或不需要顶级性能的组织,托管的云 GPU 解决方案可能更为合适,由提供商负责机器的管理和维护。
Nahla Davies****是一名软件开发者和技术写作人。在将全部精力投入技术写作之前,她曾管理过—在许多其他有趣的事情中—担任一家 Inc. 5000 实验品牌组织的首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼。
了解更多相关内容
使用 Hugging Face Transformers 构建推荐系统
原文:
www.kdnuggets.com/building-a-recommendation-system-with-hugging-face-transformers

在现代时代,我们依赖手机和计算机上的软件。许多应用程序,如电子商务、电影流媒体、游戏平台等,改变了我们的生活,因为这些应用程序使事情变得更加简单。为了更进一步,企业通常会提供能够根据数据进行推荐的功能。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT
推荐系统的基础是根据输入预测用户可能感兴趣的内容。系统将根据项目之间的相似性(基于内容的过滤)或行为(协作过滤)提供最接近的项目。
有许多推荐系统架构的方法,我们可以使用Hugging Face Transformers包。如果你不知道,Hugging Face Transformers 是一个开源的 Python 包,允许 API 轻松访问所有支持文本处理、生成等任务的预训练 NLP 模型。
本文将使用 Hugging Face Transformers 包基于嵌入相似度开发一个简单的推荐系统。让我们开始吧。
使用 Hugging Face Transformers 开发推荐系统
在开始教程之前,我们需要安装所需的包。为此,您可以使用以下code:
pip install transformers torch pandas scikit-learn
您可以通过他们的网站选择适合您环境的版本进行Torch安装。
至于数据集示例,我们将使用来自Kaggle的动漫推荐数据集示例。
一旦环境和数据集准备好,我们将开始教程。首先,我们需要读取数据集并进行准备。
import pandas as pd
df = pd.read_csv('anime.csv')
df = df.dropna()
df['description'] = df['name'] +' '+ df['genre'] + ' ' +df['type']+' episodes: '+ df['episodes']
在上述代码中,我们使用 Pandas 读取数据集并删除了所有缺失的数据。然后,我们创建了一个名为“description”的特征,其中包含了可用数据中的所有信息,如名称、类型、类别和集数。这个新列将成为我们推荐系统的基础。如果能有更完整的信息,例如动漫情节和概要,会更好,但我们暂时就用这个吧。
接下来,我们将使用 Hugging Face Transformers 加载嵌入模型并将文本转换为数值向量。具体来说,我们将使用句子嵌入来转换整个句子。
推荐系统将基于我们将要执行的所有动漫“描述”的嵌入。我们将使用余弦相似度方法,它衡量两个向量的相似度。通过测量动漫“描述”嵌入与用户查询输入嵌入之间的相似度,我们可以获得精准的推荐项目。
嵌入相似度方法听起来简单,但与经典的推荐系统模型相比,它可能更为强大,因为它能够捕捉词语之间的语义关系,为推荐过程提供上下文意义。
在本教程中,我们将使用 Hugging Face 的嵌入模型句子变换器。为了将句子转换为嵌入,我们将使用以下代码。
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
model = AutoModel.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
def get_embeddings(sentences):
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
with torch.no_grad():
model_output = model(**encoded_input)
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
return sentence_embeddings
尝试嵌入过程,并用以下代码查看向量结果。不过,我不会展示输出,因为它相当长。
sentences = ['Some great movie', 'Another funny movie']
result = get_embeddings(sentences)
print("Sentence embeddings:")
print(result)
为了简化操作,Hugging Face 维护了一个用于嵌入句子变换器的 Python 包,这将把整个转换过程缩减到 3 行代码。请使用以下代码安装必要的包。
pip install -U sentence-transformers
然后,我们可以用以下代码将整个动漫“描述”转换为嵌入。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
anime_embeddings = model.encode(df['description'].tolist())
当嵌入数据库准备好后,我们会创建一个函数来接收用户输入并执行余弦相似度,以作为推荐系统。
from sklearn.metrics.pairwise import cosine_similarity
def get_recommendations(query, embeddings, df, top_n=5):
query_embedding = model.encode([query])
similarities = cosine_similarity(query_embedding, embeddings)
top_indices = similarities[0].argsort()[-top_n:][::-1]
return df.iloc[top_indices]
现在一切准备就绪,我们可以尝试推荐系统。以下是从用户输入查询中获取前五个动漫推荐的示例。
query = "Funny anime I can watch with friends"
recommendations = get_recommendations(query, anime_embeddings, df)
print(recommendations[['name', 'genre']])
Output>>
name \
7363 Sentou Yousei Shoujo Tasukete! Mave-chan
8140 Anime TV de Hakken! Tamagotchi
4294 SKET Dance: SD Character Flash Anime
1061 Isshuukan Friends.
2850 Oshiete! Galko-chan
genre
7363 Comedy, Parody, Sci-Fi, Shounen, Super Power
8140 Comedy, Fantasy, Kids, Slice of Life
4294 Comedy, School, Shounen
1061 Comedy, School, Shounen, Slice of Life
2850 Comedy, School, Slice of Life
结果是所有的喜剧动漫,因为我们想要搞笑的动漫。它们大多数也包括了适合与朋友一起观看的类型。当然,如果我们有更详细的信息,推荐会更好。
结论
推荐系统是一种根据输入预测用户可能感兴趣内容的工具。使用 Hugging Face Transformers,我们可以构建一个利用嵌入和余弦相似度方法的推荐系统。嵌入方法非常强大,因为它能够考虑文本的语义关系和上下文意义。
Cornellius Yudha Wijaya**** 是一名数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据的技巧。Cornellius 在各种 AI 和机器学习主题上进行撰写。
更多相关主题
构建基于内容的书籍推荐引擎
原文:
www.kdnuggets.com/2020/07/building-content-based-book-recommendation-engine.html
评论
作者:Dhilip Subramanian,数据科学家和人工智能爱好者
如果我们计划购买任何新产品,通常会询问朋友、研究产品特性、将产品与类似产品进行比较、阅读互联网上的产品评论,然后做出决定。如果这一过程能够自动完成并有效地推荐产品,那将多么方便?推荐引擎或推荐系统就是这个问题的答案。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT 需求
基于内容的过滤和基于协同的过滤是两种流行的推荐系统。在本博客中,我们将看到如何使用 Goodreads.com 数据构建一个简单的基于内容的推荐系统。
基于内容的推荐系统
基于内容的推荐系统通过使用项目之间的相似性来向用户推荐项目。这个推荐系统根据产品的描述或特征来推荐产品或项目。它通过产品的描述来识别产品之间的相似性。它还考虑用户的历史记录,以推荐类似的产品。
例如:如果用户喜欢 Sidney Sheldon 的小说《告诉我你的梦想》,则推荐系统会推荐用户阅读其他 Sidney Sheldon 的小说,或者推荐一个“非虚构”类型的小说。(Sidney Sheldon 的小说属于非虚构类型)。
如前所述,我们正在使用 goodreads.com 数据,并且没有用户的阅读历史。因此,我们使用了一个简单的基于内容的推荐系统。我们将通过使用书名和书籍描述来构建两个推荐系统。
我们需要找到与给定书籍相似的书籍,然后将这些相似的书籍推荐给用户。我们如何判断给定的书籍是相似还是不相似?这里使用了相似性度量来找出这一点。
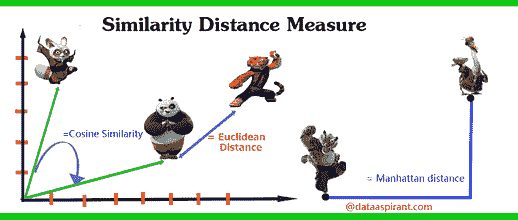
来源:dataaspirant
有不同的相似度度量方法可用。我们的推荐系统使用了余弦相似度来推荐书籍。有关相似度度量的更多详细信息,请参阅此文章。
数据
我从 goodreads.com 抓取了与商业、非小说和烹饪类别相关的书籍详细信息。
# Importing necessary libraries
import pandas as pd
import numpy as np
import pandas as pd
import numpy as np
from nltk.corpus import stopwords
from sklearn.metrics.pairwise import linear_kernel
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
from nltk.tokenize import RegexpTokenizer
import re
import string
import random
from PIL import Image
import requests
from io import BytesIO
import matplotlib.pyplot as plt
%matplotlib inline
# Reading the file
df = pd.read_csv("goodread.csv")
#Reading the first five records
df.head()
#Checking the shape of the file
df.shape()

我们的数据集中总共有 3592 本书籍详细信息。它包含六列:
-
title -> 书名
-
评分 -> 用户给出的书籍评分
-
类别 -> 分类(书籍类型)。我只取了商业、非小说和烹饪这三种类别用于这个问题
-
作者 -> 书籍作者
-
Desc -> 书籍描述
-
url -> 书封面图片链接
探索性数据分析
类别分布
# Genre distribution
df['genre'].value_counts().plot(x = 'genre', y ='count', kind = 'bar', figsize = (10,5) )
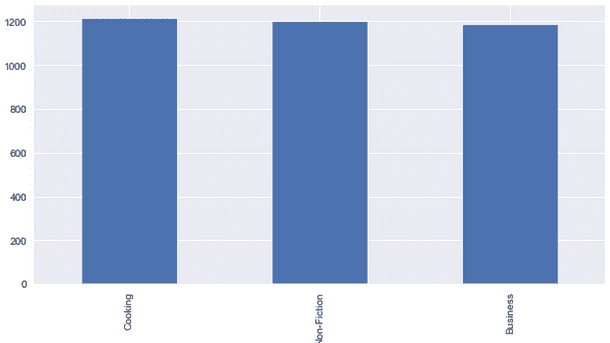
随机打印书名和描述
# Printing the book title and description randomly
df['title'] [2464]
df['Desc'][2464]

# Printing the book title and description randomly
df['title'] [367]
df['Desc'][367]

书籍描述 — 单词计数分布
# Calculating the word count for book description
df['word_count'] = df2['Desc'].apply(lambda x: len(str(x).split()))# Plotting the word count
df['word_count'].plot(
kind='hist',
bins = 50,
figsize = (12,8),title='Word Count Distribution for book descriptions')
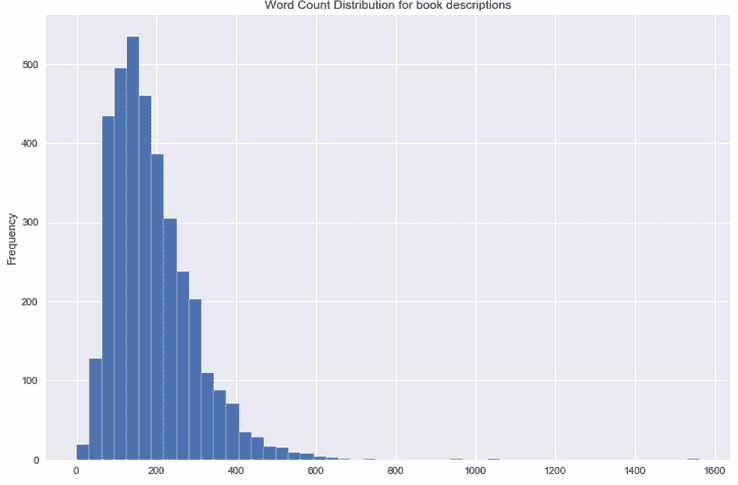
我们没有很多长篇的书籍描述。很明显,goodreads.com 提供的是简短的描述。
书籍描述中常见词性标签的分布
from textblob import TextBlob
blob = TextBlob(str(df['Desc']))
pos_df = pd.DataFrame(blob.tags, columns = ['word' , 'pos'])
pos_df = pos_df.pos.value_counts()[:20]
pos_df.plot(kind = 'bar', figsize=(10, 8), title = "Top 20 Part-of-speech tagging for comments")
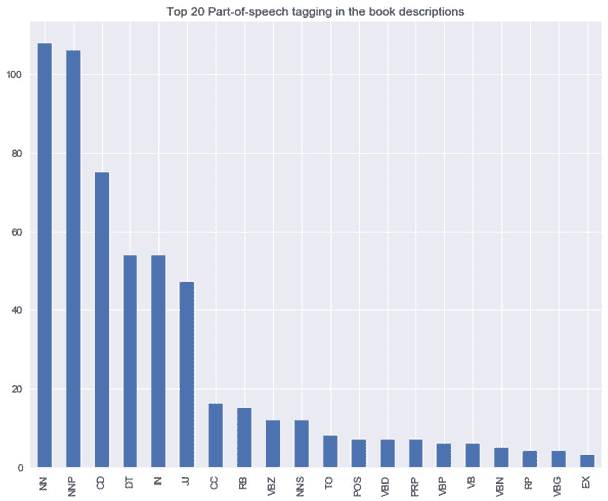
书籍描述的双词分布
#Converting text descriptions into vectors using TF-IDF using Bigram
tf = TfidfVectorizer(ngram_range=(2, 2), stop_words='english', lowercase = False)
tfidf_matrix = tf.fit_transform(df['Desc'])
total_words = tfidf_matrix.sum(axis=0)
#Finding the word frequency
freq = [(word, total_words[0, idx]) for word, idx in tf.vocabulary_.items()]
freq =sorted(freq, key = lambda x: x[1], reverse=True)
#converting into dataframe
bigram = pd.DataFrame(freq)
bigram.rename(columns = {0:'bigram', 1: 'count'}, inplace = True)
#Taking first 20 records
bigram = bigram.head(20)
#Plotting the bigram distribution
bigram.plot(x ='bigram', y='count', kind = 'bar', title = "Bigram disribution for the top 20 words in the book description", figsize = (15,7), )
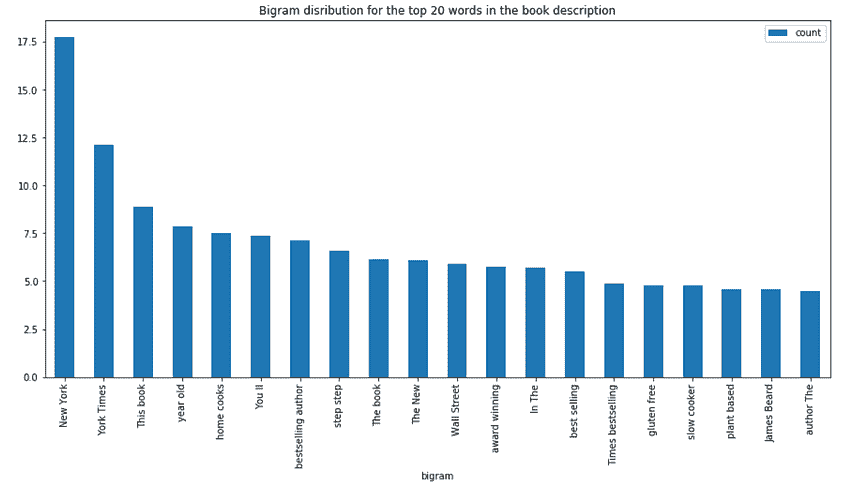
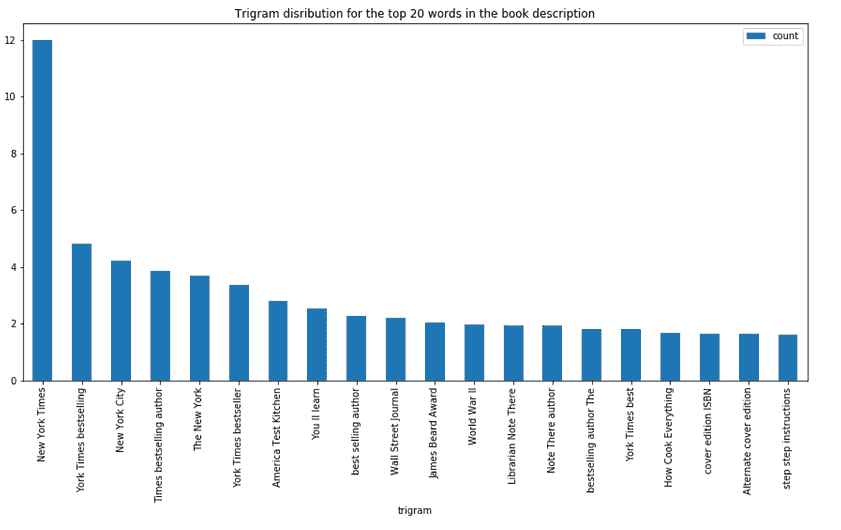
书籍描述的三词分布
#Converting text descriptions into vectors using TF-IDF using Trigram
tf = TfidfVectorizer(ngram_range=(3, 3), stop_words='english', lowercase = False)
tfidf_matrix = tf.fit_transform(df['Desc'])
total_words = tfidf_matrix.sum(axis=0)
#Finding the word frequency
freq = [(word, total_words[0, idx]) for word, idx in tf.vocabulary_.items()]
freq =sorted(freq, key = lambda x: x[1], reverse=True)#converting into dataframe
trigram = pd.DataFrame(freq)
trigram.rename(columns = {0:'trigram', 1: 'count'}, inplace = True)
#Taking first 20 records
trigram = trigram.head(20)
#Plotting the trigramn distribution
trigram.plot(x ='trigram', y='count', kind = 'bar', title = "Bigram disribution for the top 20 words in the book description", figsize = (15,7), )
文本预处理
清理书籍描述。
# Function for removing NonAscii characters
def _removeNonAscii(s):
return "".join(i for i in s if ord(i)<128)
# Function for converting into lower case
def make_lower_case(text):
return text.lower()
# Function for removing stop words
def remove_stop_words(text):
text = text.split()
stops = set(stopwords.words("english"))
text = [w for w in text if not w in stops]
text = " ".join(text)
return text
# Function for removing punctuation
def remove_punctuation(text):
tokenizer = RegexpTokenizer(r'\w+')
text = tokenizer.tokenize(text)
text = " ".join(text)
return text
# Function for removing the html tags
def remove_html(text):
html_pattern = re.compile('<.*?>')
return html_pattern.sub(r'', text)
# Applying all the functions in description and storing as a cleaned_desc
df['cleaned_desc'] = df['Desc'].apply(_removeNonAscii)
df['cleaned_desc'] = df.cleaned_desc.apply(func = make_lower_case)
df['cleaned_desc'] = df.cleaned_desc.apply(func = remove_stop_words)
df['cleaned_desc'] = df.cleaned_desc.apply(func=remove_punctuation)
df['cleaned_desc'] = df.cleaned_desc.apply(func=remove_html)
推荐引擎
我们将基于书名和书籍描述构建两个推荐引擎。
-
使用 TF-IDF 和双词组将每本书的标题和描述转换为向量。有关更多详细信息,请参见TF-IDF。
-
我们正在构建两个推荐引擎,一个基于书名,另一个基于书籍描述。模型基于标题和描述推荐相似书籍。
-
使用余弦相似度计算所有书籍之间的相似性。
-
定义一个函数,该函数以书名和类别作为输入,并返回基于标题和描述的前五本相似推荐书籍。
基于书名的推荐
# Function for recommending books based on Book title. It takes book title and genre as an input.def recommend(title, genre):
# Matching the genre with the dataset and reset the index
data = df2.loc[df2['genre'] == genre]
data.reset_index(level = 0, inplace = True)
# Convert the index into series
indices = pd.Series(data.index, index = data['title'])
** #Converting the book title into vectors and used bigram**
tf = TfidfVectorizer(analyzer='word', ngram_range=(2, 2), min_df = 1, stop_words='english')
tfidf_matrix = tf.fit_transform(data['title'])
# Calculating the similarity measures based on Cosine Similarity
sg = cosine_similarity(tfidf_matrix, tfidf_matrix)
# Get the index corresponding to original_title
idx = indices[title]# Get the pairwsie similarity scores
sig = list(enumerate(sg[idx]))# Sort the books
sig = sorted(sig, key=lambda x: x[1], reverse=True)# Scores of the 5 most similar books
sig = sig[1:6]# Book indicies
movie_indices = [i[0] for i in sig]
# Top 5 book recommendation
rec = data[['title', 'url']].iloc[movie_indices]
# It reads the top 5 recommended book urls and print the images
for i in rec['url']:
response = requests.get(i)
img = Image.open(BytesIO(response.content))
plt.figure()
print(plt.imshow(img))
基于书名“史蒂夫·乔布斯”和类别“商业”进行推荐:
recommend("Steve Jobs", "Business")
输出

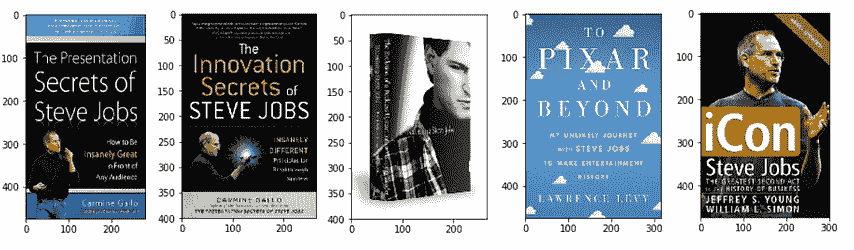
我们以《史蒂夫·乔布斯》这本书作为输入,模型基于书名的相似性推荐其他史蒂夫·乔布斯的书籍。
基于书籍描述的推荐
我们通过将书籍描述转换为向量来使用上述相同的函数。
# Function for recommending books based on Book title. It takes book title and genre as an input.def recommend(title, genre):
global rec
# Matching the genre with the dataset and reset the index
data = df2.loc[df2['genre'] == genre]
data.reset_index(level = 0, inplace = True)
# Convert the index into series
indices = pd.Series(data.index, index = data['title'])
**#Converting the book description into vectors and used bigram**
tf = TfidfVectorizer(analyzer='word', ngram_range=(2, 2), min_df = 1, stop_words='english')
tfidf_matrix = tf.fit_transform(data['cleaned_desc'])
# Calculating the similarity measures based on Cosine Similarity
sg = cosine_similarity(tfidf_matrix, tfidf_matrix)
# Get the index corresponding to original_title
idx = indices[title]# Get the pairwsie similarity scores
sig = list(enumerate(sg[idx]))# Sort the books
sig = sorted(sig, key=lambda x: x[1], reverse=True)# Scores of the 5 most similar books
sig = sig[1:6]# Book indicies
movie_indices = [i[0] for i in sig]
# Top 5 book recommendation
rec = data[['title', 'url']].iloc[movie_indices]
# It reads the top 5 recommend book url and print the images
for i in rec['url']:
response = requests.get(i)
img = Image.open(BytesIO(response.content))
plt.figure()
print(plt.imshow(img))
让我们基于书籍《哈利·波特与阿兹卡班的囚徒》和类型“非虚构”进行推荐:
recommend("Harry Potter and the Prisoner of Azkaban", "Non-Fiction")
输出


我们提供了《哈利·波特与阿兹卡班的囚徒》和“非虚构”作为输入,模型推荐了另外五本与我们输入相似的《哈利·波特》书籍。
再来一个推荐:
recommend("Norwegian Wood", "Non-Fiction")
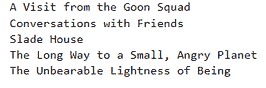

上述模型根据描述推荐了五本与《挪威的森林》相似的书籍。
这只是一个简单的基本级推荐系统。现实世界中的推荐系统更为强大和先进。我们可以通过添加其他元数据(如作者和类型)来进一步改进上述系统。
此外,我们还可以使用 Word2Vec 进行基于文本的语义推荐。我已经使用 Word2Vec 构建了一个推荐引擎。请查看这里。
感谢阅读。如果您有任何补充,请随时留下评论!
简介:Dhilip Subramanian 是一位机械工程师,已完成分析学硕士学位。他拥有 9 年的经验,专注于与数据相关的各种领域,包括 IT、营销、银行、电力和制造业。他对自然语言处理和机器学习充满热情。他是SAS 社区的贡献者,喜欢在 Medium 平台上撰写有关数据科学各个方面的技术文章。
原文。经授权转载。
相关:
-
探索数据科学的真实世界
-
五个很酷的 Python 库用于数据科学
-
使用 Python 轻松进行语音转文本
更多相关话题
从头开始使用 NumPy 构建卷积神经网络
原文:
www.kdnuggets.com/2018/04/building-convolutional-neural-network-numpy-scratch.html
评论
使用 ML/DL 库中已有的模型在某些情况下可能很有帮助。但为了更好的控制和理解,你应该尝试自己实现这些模型。本文展示了如何仅使用 NumPy 实现 CNN。
卷积神经网络(CNN)是分析多维信号(如图像)的最先进技术。已经有许多库实现了 CNN,如 TensorFlow 和 Keras。这些库将开发者与一些细节隔离开,只提供了一个抽象的 API,以简化开发过程并避免实现中的复杂性。但实际上,这些细节可能会有所不同。有时候,数据科学家需要深入这些细节以提升性能。在这种情况下,解决方案是自己构建每个模型的部分。这可以对网络进行尽可能高的控制。此外,推荐实现这些模型以更好地理解它们。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能。
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求。
本文使用仅 NumPy 库创建 CNN。仅创建了三个层,即卷积(conv 简写)、ReLU 和最大池化。涉及的主要步骤如下:
-
读取输入图像。
-
准备滤波器。
-
卷积层:对输入图像应用每个滤波器进行卷积。
-
ReLU 层:对特征图(卷积层的输出)应用 ReLU 激活函数。
-
最大池化层:对 ReLU 层的输出应用池化操作。
-
堆叠卷积、ReLU 和最大池化层。
1. 读取输入图像
以下代码从 skimage Python 库中读取一个已存在的图像,并将其转换为灰度图像。
1\. import skimage.data
2\. # Reading the image
3\. img = skimage.data.chelsea()
4\. # Converting the image into gray.
5\. img = skimage.color.rgb2gray(img)
读取图像是第一步,因为接下来的步骤依赖于输入的大小。图像转换为灰度后如下所示。

2. 准备滤波器
以下代码为第一个卷积层(l1 的简写)准备滤波器库:
1\. l1_filter = numpy.zeros((2,3,3))
根据滤波器的数量和每个滤波器的大小创建一个零数组。创建了2个3x3大小的滤波器,因此零数组的大小为(2=num_filters,3=num_rows_filter,3=num_columns_filter)。滤波器的大小被选择为二维数组而无深度,因为输入图像是灰度图像且没有深度(即二维)。如果图像是 RGB 的,有 3 个通道,则滤波器大小必须为(3,3,3=深度)。
滤波器组的大小由上面的零数组指定,而不是滤波器的实际值。可以通过以下方式覆盖这些值以检测垂直和水平边缘。
1\. l1_filter[0, :, :] = numpy.array([[[-1, 0, 1],
2\. [-1, 0, 1],
3\. [-1, 0, 1]]])
4\. l1_filter[1, :, :] = numpy.array([[[1, 1, 1],
5\. [0, 0, 0],
6\. [-1, -1, -1]]])
3. 卷积层
在准备好滤波器后,接下来是对输入图像进行卷积。下一行使用名为conv的函数对图像和滤波器组进行卷积:
1\. l1_feature_map = conv(img, l1_filter)
该函数只接受两个参数,即图像和滤波器组,具体实现如下。
1\. def conv(img, conv_filter):
2\. if len(img.shape) > 2 or len(conv_filter.shape) > 3: # Check if number of image channels matches the filter depth.
3\. if img.shape[-1] != conv_filter.shape[-1]:
4\. print("Error: Number of channels in both image and filter must match.")
5\. sys.exit()
6\. if conv_filter.shape[1] != conv_filter.shape[2]: # Check if filter dimensions are equal.
7\. print('Error: Filter must be a square matrix. I.e. number of rows and columns must match.')
8\. sys.exit()
9\. if conv_filter.shape[1]%2==0: # Check if filter diemnsions are odd.
10\. print('Error: Filter must have an odd size. I.e. number of rows and columns must be odd.')
11\. sys.exit()
12\.
13\. # An empty feature map to hold the output of convolving the filter(s) with the image.
14\. feature_maps = numpy.zeros((img.shape[0]-conv_filter.shape[1]+1,
15\. img.shape[1]-conv_filter.shape[1]+1,
16\. conv_filter.shape[0]))
17\.
18\. # Convolving the image by the filter(s).
19\. for filter_num in range(conv_filter.shape[0]):
20\. print("Filter ", filter_num + 1)
21\. curr_filter = conv_filter[filter_num, :] # getting a filter from the bank.
22\. """
23\. Checking if there are mutliple channels for the single filter.
24\. If so, then each channel will convolve the image.
25\. The result of all convolutions are summed to return a single feature map.
26\. """
27\. if len(curr_filter.shape) > 2:
28\. conv_map = conv_(img[:, :, 0], curr_filter[:, :, 0]) # Array holding the sum of all feature maps.
29\. for ch_num in range(1, curr_filter.shape[-1]): # Convolving each channel with the image and summing the results.
30\. conv_map = conv_map + conv_(img[:, :, ch_num],
31\. curr_filter[:, :, ch_num])
32\. else: # There is just a single channel in the filter.
33\. conv_map = conv_(img, curr_filter)
34\. feature_maps[:, :, filter_num] = conv_map # Holding feature map with the current filter.
35\. return feature_maps # Returning all feature maps.
该函数首先确保每个滤波器的深度等于图像通道的数量。在下面的代码中,外层if检查通道和滤波器是否具有深度。如果已经存在深度,则内层if检查它们是否不相等。如果不匹配,脚本将退出。
1\. if len(img.shape) > 2 or len(conv_filter.shape) > 3: # Check if number of image channels matches the filter depth.
2\. if img.shape[-1] != conv_filter.shape[-1]:
3\. print("Error: Number of channels in both image and filter must match.")
此外,滤波器的大小应为奇数,并且滤波器的维度应相等(即行数和列数都是奇数且相等)。这通过以下两个if块进行检查。如果条件不满足,脚本将退出。
1\. if conv_filter.shape[1] != conv_filter.shape[2]: # Check if filter dimensions are equal.
2\. print('Error: Filter must be a square matrix. I.e. number of rows and columns must match.')
3\. sys.exit()
4\. if conv_filter.shape[1]%2==0: # Check if filter diemnsions are odd.
5\. print('Error: Filter must have an odd size. I.e. number of rows and columns must be odd.')
6\. sys.exit()
不满足上述任何条件证明滤波器深度与图像适配,卷积可以应用。通过滤波器对图像进行卷积的过程开始于初始化一个数组以存放卷积输出(即特征图),并通过以下代码指定其大小:
1\. # An empty feature map to hold the output of convolving the filter(s) with the image.
2\. feature_maps = numpy.zeros((img.shape[0]-conv_filter.shape[1]+1,
3\. img.shape[1]-conv_filter.shape[1]+1,
4\. conv_filter.shape[0]))
由于没有步幅和填充,特征图的大小将等于(img_rows-filter_rows+1,image_columns-filter_columns+1,num_filters),如上代码所示。请注意,每个滤波器都有一个输出特征图。这就是为什么滤波器组中的滤波器数量(conv_filter.shape[0])被用来作为第三个参数来指定大小。
1\. # Convolving the image by the filter(s).
2\. for filter_num in range(conv_filter.shape[0]):
3\. print("Filter ", filter_num + 1)
4\. curr_filter = conv_filter[filter_num, :] # getting a filter from the bank.
5\. """
6\. Checking if there are mutliple channels for the single filter.
7\. If so, then each channel will convolve the image.
8\. The result of all convolutions are summed to return a single feature map.
9\. """
10\. if len(curr_filter.shape) > 2:
11\. conv_map = conv_(img[:, :, 0], curr_filter[:, :, 0]) # Array holding the sum of all feature maps.
12\. for ch_num in range(1, curr_filter.shape[-1]): # Convolving each channel with the image and summing the results.
13\. conv_map = conv_map + conv_(img[:, :, ch_num],
14\. curr_filter[:, :, ch_num])
15\. else: # There is just a single channel in the filter.
16\. conv_map = conv_(img, curr_filter)
17\. feature_maps[:, :, filter_num] = conv_map # Holding feature map with the current filter.
外层循环遍历滤波器组中的每个滤波器,并根据这一行返回它以供进一步处理:
1\. curr_filter = conv_filter[filter_num, :] # getting a filter from the bank.
如果要卷积的图像有多个通道,则滤波器的深度必须等于这些通道的数量。在这种情况下,卷积是通过将每个图像通道与滤波器中的相应通道进行卷积来完成的。最终,结果的总和将是输出特征图。如果图像只有一个通道,那么卷积将直接进行。确定这种行为是在if-else块中完成的:
1\. if len(curr_filter.shape) > 2:
2\. conv_map = conv_(img[:, :, 0], curr_filter[:, :, 0]) # Array holding the sum of all feature map
3\. for ch_num in range(1, curr_filter.shape[-1]): # Convolving each channel with the image and summing the results.
4\. conv_map = conv_map + conv_(img[:, :, ch_num],
5\. curr_filter[:, :, ch_num])
6\. else: # There is just a single channel in the filter.
7\. conv_map = conv_(img, curr_filter)
你可能会注意到,卷积是通过一个叫做conv_的函数来实现的,这与conv函数不同。函数conv只是接受输入图像和滤波器组,但不会自行执行卷积。它只是将每一组输入-滤波器对传递给conv_函数。这只是为了使代码更易于调试。以下是conv_函数的实现:
1\. def conv_(img, conv_filter):
2\. filter_size = conv_filter.shape[0]
3\. result = numpy.zeros((img.shape))
4\. #Looping through the image to apply the convolution operation.
5\. for r in numpy.uint16(numpy.arange(filter_size/2,
6\. img.shape[0]-filter_size/2-2)):
7\. for c in numpy.uint16(numpy.arange(filter_size/2, img.shape[1]-filter_size/2-2)):
8\. #Getting the current region to get multiplied with the filter.
9\. curr_region = img[r:r+filter_size, c:c+filter_size]
10\. #Element-wise multipliplication between the current region and the filter.
11\. curr_result = curr_region * conv_filter
12\. conv_sum = numpy.sum(curr_result) #Summing the result of multiplication.
13\. result[r, c] = conv_sum #Saving the summation in the convolution layer feature map.
14\.
15\. #Clipping the outliers of the result matrix.
16\. final_result = result[numpy.uint16(filter_size/2):result.shape[0]-numpy.uint16(filter_size/2),
17\. numpy.uint16(filter_size/2):result.shape[1]-numpy.uint16(filter_size/2)]
18\. return final_result
它遍历图像并提取与滤波器大小相等的区域,如下行所示:
1\. curr_region = img[r:r+filter_size, c:c+filter_size]
然后,它在区域和滤波器之间执行逐元素乘法,并将它们相加以根据这些行获得一个单一的值作为输出:
1\. #Element-wise multipliplication between the current region and the filter.
2\. curr_result = curr_region * conv_filter
3\. conv_sum = numpy.sum(curr_result) #Summing the result of multiplication.
4\. result[r, c] = conv_sum #Saving the summation in the convolution layer feature map.
在对每个滤波器进行卷积后,特征图由conv函数返回。下图显示了此卷积层返回的特征图。

这种层的输出将应用于 ReLU 层。
4. ReLU 层
ReLU 层在每个由卷积层返回的特征图上应用 ReLU 激活函数。它通过以下代码行调用relu函数:
l1_feature_map_relu = relu(l1_feature_map)
relu函数的实现如下:
1\. def relu(feature_map):
2\. #Preparing the output of the ReLU activation function.
3\. relu_out = numpy.zeros(feature_map.shape)
4\. for map_num in range(feature_map.shape[-1]):
5\. for r in numpy.arange(0,feature_map.shape[0]):
6\. for c in numpy.arange(0, feature_map.shape[1]):
7\. relu_out[r, c, map_num] = numpy.max(feature_map[r, c, map_num], 0)
这非常简单。只需循环遍历特征图中的每个元素,如果元素大于 0,则返回特征图中的原始值。否则,返回 0。ReLU 层的输出在下图中显示。

ReLU 层的输出会应用到最大池化层中。
5. 最大池化层
最大池化层接受 ReLU 层的输出,并根据以下行应用最大池化操作:
1\. l1_feature_map_relu_pool = pooling(l1_feature_map_relu, 2, 2)
它使用pooling函数实现,如下所示:
1\. def pooling(feature_map, size=2, stride=2):
2\. #Preparing the output of the pooling operation.
3\. pool_out = numpy.zeros((numpy.uint16((feature_map.shape[0]-size+1)/stride),
4\. numpy.uint16((feature_map.shape[1]-size+1)/stride),
5\. feature_map.shape[-1]))
6\. for map_num in range(feature_map.shape[-1]):
7\. r2 = 0
8\. for r in numpy.arange(0,feature_map.shape[0]-size-1, stride):
9\. c2 = 0
10\. for c in numpy.arange(0, feature_map.shape[1]-size-1, stride):
11\. pool_out[r2, c2, map_num] = numpy.max(feature_map[r:r+size, c:c+size])
12\. c2 = c2 + 1
13\. r2 = r2 +1
该函数接受三个输入,即 ReLU 层的输出、池化掩模尺寸和步幅。它简单地创建一个空数组,正如之前所述,用于保存该层的输出。该数组的大小根据尺寸和步幅参数来指定,如下行所示:
1\. pool_out = numpy.zeros((numpy.uint16((feature_map.shape[0]-size+1)/stride),
2\. numpy.uint16((feature_map.shape[1]-size+1)/stride),
3\. feature_map.shape[-1]))
然后它通过外层循环按通道逐个处理输入,外层循环使用循环变量map_num。对于输入中的每个通道,应用最大池化操作。根据使用的步幅和尺寸,区域被裁剪,最大值会被返回到输出数组中,如下行所示:
pool_out[r2, c2, map_num] = numpy.max(feature_map[r:r+size, c:c+size])
这种池化层的输出在下图中显示。请注意,即使池化层的输出在图中看起来与输入相同,它的尺寸仍然小于输入。

6. 堆叠层
到目前为止,包含卷积、ReLU 和最大池化层的 CNN 架构已经完成。可能还会有一些其他层需要堆叠在之前的层之上,如下所示。
1\. # Second conv layer
2\. l2_filter = numpy.random.rand(3, 5, 5, l1_feature_map_relu_pool.shape[-1])
3\. print("\n**Working with conv layer 2**")
4\. l2_feature_map = conv(l1_feature_map_relu_pool, l2_filter)
5\. print("\n**ReLU**")
6\. l2_feature_map_relu = relu(l2_feature_map)
7\. print("\n**Pooling**")
8\. l2_feature_map_relu_pool = pooling(l2_feature_map_relu, 2, 2)
9\. print("**End of conv layer 2**\n")
前一卷积层使用了3个随机生成的过滤器。这就是为什么从该卷积层会产生3个特征图。后续的 ReLU 和池化层也是如此。这些层的输出如下所示。

1\. # Third conv layer
2\. l3_filter = numpy.random.rand(1, 7, 7, l2_feature_map_relu_pool.shape[-1])
3\. print("\n**Working with conv layer 3**")
4\. l3_feature_map = conv(l2_feature_map_relu_pool, l3_filter)
5\. print("\n**ReLU**")
6\. l3_feature_map_relu = relu(l3_feature_map)
7\. print("\n**Pooling**")
8\. l3_feature_map_relu_pool = pooling(l3_feature_map_relu, 2, 2)
9\. print("**End of conv layer 3**\n")
下图展示了前面层的输出。前一卷积层只使用了一个过滤器。这就是为什么只有一个特征图作为输出。
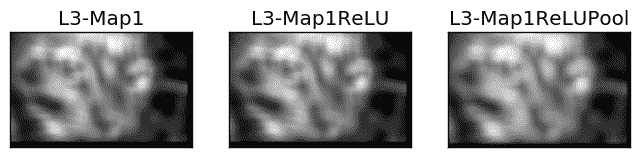
但请记住,每一层的输出都是下一层的输入。例如,这些线条接受之前的输出作为它们的输入。
1\. l2_feature_map = conv(l1_feature_map_relu_pool, l2_filter)
2\. l3_feature_map = conv(l2_feature_map_relu_pool, l3_filter)
7. 完整代码
完整代码可以在 github (github.com/ahmedfgad/NumPyCNN) 上找到。代码中包含了使用Matplotlib库可视化每一层输出的功能。
简介: Ahmed Gad 于 2015 年 7 月获得埃及 Menoufia 大学计算机与信息学院(FCI)信息技术专业的优秀荣誉学士学位。由于在学院中排名第一,他于 2015 年被推荐到埃及某研究所担任助教,随后于 2016 年回到学院担任助教和研究员。他目前的研究兴趣包括深度学习、机器学习、人工智能、数字信号处理和计算机视觉。
原文. 经许可转载。
相关:
-
逐步推导卷积神经网络从全连接网络
-
学习率在人工神经网络中有用吗?
-
通过正则化避免过拟合
更多相关主题
使用 Prefect 构建数据管道

图片来源:作者 | Canva
在本教程中,我们将学习 Prefect,这是一款现代工作流编排工具。我们将从使用 Pandas 构建数据管道开始,然后将其与 Prefect 工作流进行比较,以便更好地理解。最后,我们将部署我们的工作流并在仪表板上查看运行日志。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
什么是 Prefect?
Prefect 是一个工作流管理系统,旨在协调和管理复杂的数据工作流,包括机器学习(ML)管道。它提供了一个构建、调度和监控工作流的框架,使其成为管理 ML 操作(MLOps)的重要工具。
Prefect 提供任务和流程管理,允许用户定义依赖关系并高效地执行工作流。具有状态管理和可观察性等功能,Prefect 提供有关任务状态和历史的洞察,帮助调试和优化。它配备了一个高度互动的仪表板,让你可以安排、监控和集成各种其他功能,这些功能将改善你的 MLOps 流程。你甚至可以通过几次点击设置通知和集成其他 ML 框架。
Prefect 作为一个开源框架和托管云服务提供,进一步简化了你的工作流程。
使用 Pandas 构建数据管道
我们将复制我在之前教程中使用的数据管道(使用 Pandas 构建数据科学管道—KDnuggets),以便你了解每个任务在管道中的工作方式以及如何将它们结合起来。我在这里提到它,以便你可以清楚地比较完美的数据管道与普通管道的区别。
import pandas as pd
def load_data(path):
return pd.read_csv(path)
def data_cleaning(data):
data = data.drop_duplicates()
data = data.dropna()
data = data.reset_index(drop=True)
return data
def convert_dtypes(data, types_dict=None):
data = data.astype(dtype=types_dict)
## convert the date column to datetime
data["Date"] = pd.to_datetime(data["Date"])
return data
def data_analysis(data):
data["month"] = data["Date"].dt.month
new_df = data.groupby("month")["Units Sold"].mean()
return new_df
def data_visualization(new_df, vis_type="bar"):
new_df.plot(kind=vis_type, figsize=(10, 5), title="Average Units Sold by Month")
return new_df
path = "Online Sales Data.csv"
df = (
pd.DataFrame()
.pipe(lambda x: load_data(path))
.pipe(data_cleaning)
.pipe(convert_dtypes, {"Product Category": "str", "Product Name": "str"})
.pipe(data_analysis)
.pipe(data_visualization, "line")
)
当我们运行上述代码时,每个任务将按顺序运行并生成数据可视化。除此之外,它不会做其他事情。我们可以安排它、查看运行日志,甚至集成第三方工具进行通知或监控。
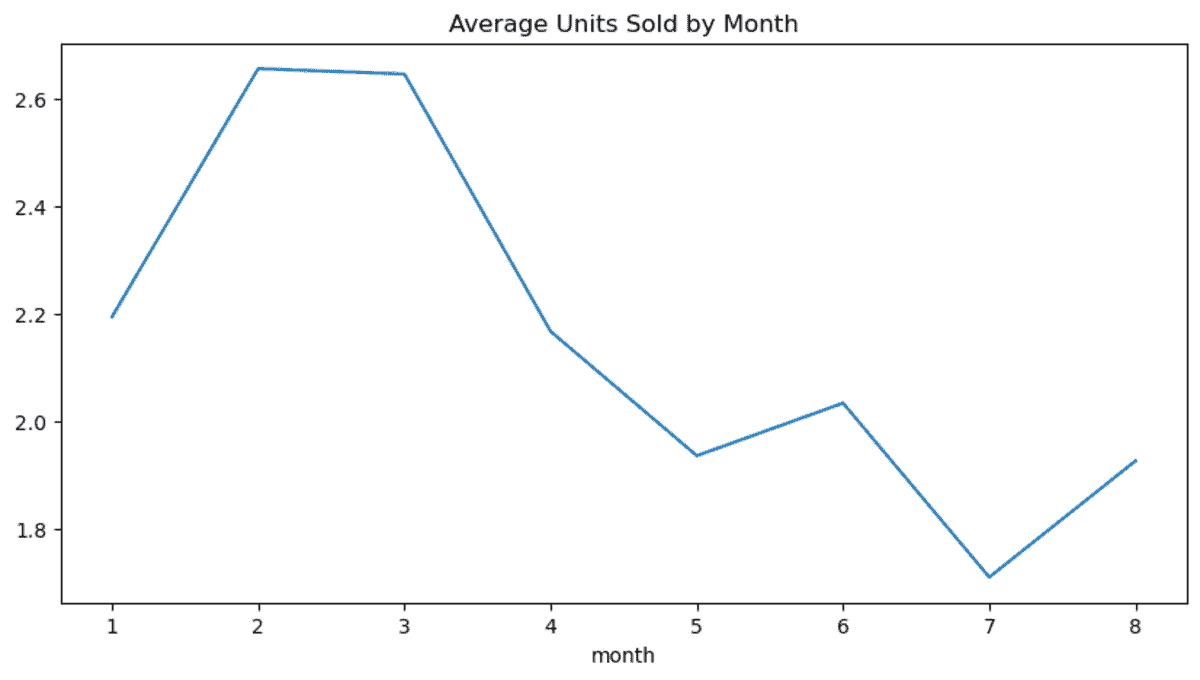
使用 Prefect 构建数据管道
现在我们将使用相同的数据集 在线销售数据集 - 热门市场数据 来构建相同的管道,但使用 Prefect。我们将首先使用 PIP 命令安装 Prefect 库。
$ pip install prefect
如果你查看下面的代码,你会发现实际上没有什么变化。函数是相同的,只是增加了 Python 装饰器。每一步的管道都有 @task 装饰器,而组合这些步骤的管道有 @flow 装饰器。此外,我们还保存了生成的图形。
import pandas as pd
import matplotlib.pyplot as plt
from prefect import task, flow
@task
def load_data(path):
return pd.read_csv(path)
@task
def data_cleaning(data):
data = data.drop_duplicates()
data = data.dropna()
data = data.reset_index(drop=True)
return data
@task
def convert_dtypes(data, types_dict=None):
data = data.astype(dtype=types_dict)
data["Date"] = pd.to_datetime(data["Date"])
return data
@task
def data_analysis(data):
data["month"] = data["Date"].dt.month
new_df = data.groupby("month")["Units Sold"].mean()
return new_df
@task
def data_visualization(new_df, vis_type="bar"):
new_df.plot(kind=vis_type, figsize=(10, 5), title="Average Units Sold by Month")
plt.savefig("average_units_sold_by_month.png")
return new_df
@flow(name="Data Pipeline")
def data_pipeline(path: str):
df = load_data(path)
df_cleaned = data_cleaning(df)
df_converted = convert_dtypes(
df_cleaned, {"Product Category": "str", "Product Name": "str"}
)
analysis_result = data_analysis(df_converted)
new_df = data_visualization(analysis_result, "line")
return new_df
# Run the flow!
if __name__ == "__main__":
new_df = data_pipeline("Online Sales Data.csv")
print(new_df)
我们将通过提供 CSV 文件的位置来运行数据管道。它将按顺序执行所有步骤并生成运行状态的日志。
14:18:48.649 | INFO | prefect.engine - Created flow run 'enlightened-dingo' for flow 'Data Pipeline'
14:18:48.816 | INFO | Flow run 'enlightened-dingo' - Created task run 'load_data-0' for task 'load_data'
14:18:48.822 | INFO | Flow run 'enlightened-dingo' - Executing 'load_data-0' immediately...
14:18:48.990 | INFO | Task run 'load_data-0' - Finished in state Completed()
14:18:49.052 | INFO | Flow run 'enlightened-dingo' - Created task run 'data_cleaning-0' for task 'data_cleaning'
14:18:49.053 | INFO | Flow run 'enlightened-dingo' - Executing 'data_cleaning-0' immediately...
14:18:49.226 | INFO | Task run 'data_cleaning-0' - Finished in state Completed()
14:18:49.283 | INFO | Flow run 'enlightened-dingo' - Created task run 'convert_dtypes-0' for task 'convert_dtypes'
14:18:49.288 | INFO | Flow run 'enlightened-dingo' - Executing 'convert_dtypes-0' immediately...
14:18:49.441 | INFO | Task run 'convert_dtypes-0' - Finished in state Completed()
14:18:49.506 | INFO | Flow run 'enlightened-dingo' - Created task run 'data_analysis-0' for task 'data_analysis'
14:18:49.510 | INFO | Flow run 'enlightened-dingo' - Executing 'data_analysis-0' immediately...
14:18:49.684 | INFO | Task run 'data_analysis-0' - Finished in state Completed()
14:18:49.753 | INFO | Flow run 'enlightened-dingo' - Created task run 'data_visualization-0' for task 'data_visualization'
14:18:49.760 | INFO | Flow run 'enlightened-dingo' - Executing 'data_visualization-0' immediately...
14:18:50.087 | INFO | Task run 'data_visualization-0' - Finished in state Completed()
14:18:50.144 | INFO | Flow run 'enlightened-dingo' - Finished in state Completed()
最终,你将获得转换后的数据框和可视化结果。
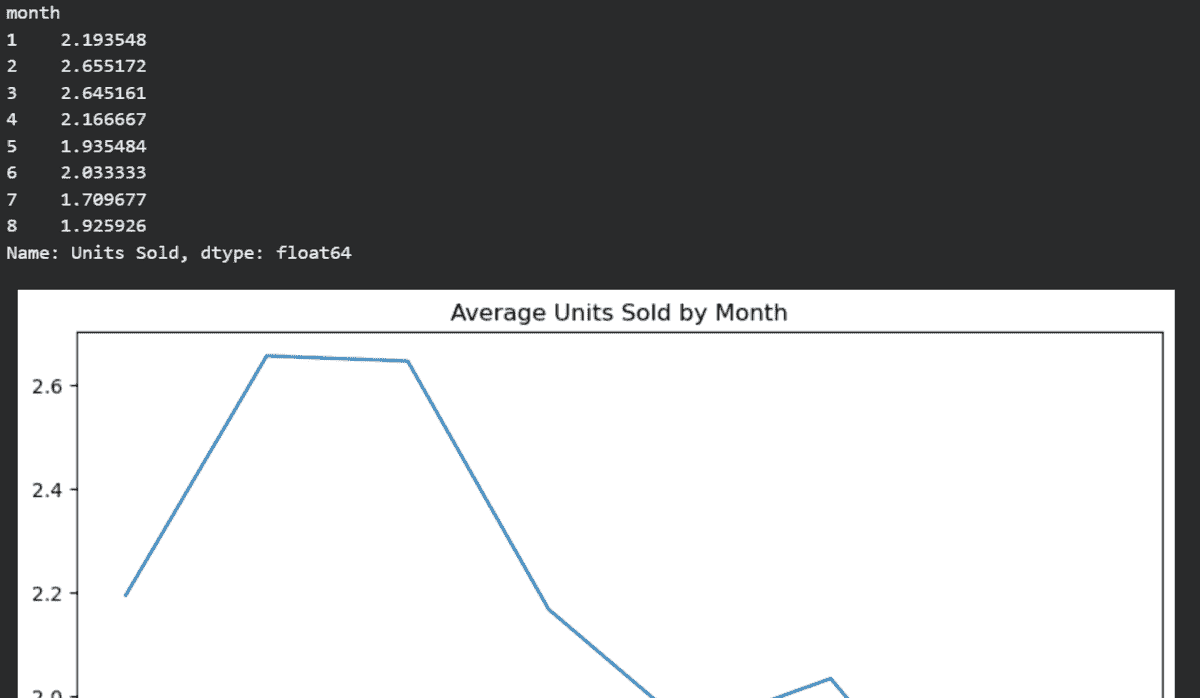
部署 Prefect 管道
为了部署 Prefect 管道,我们需要首先将代码库移动到 Python 文件 data_pipe.py。之后,我们将修改运行管道的方式。我们将使用 .server 函数来部署管道,并将 CSV 文件作为参数传递给该函数。
data_pipe.py:
import pandas as pd
import matplotlib.pyplot as plt
from prefect import task, flow
@task
def load_data(path: str) -> pd.DataFrame:
return pd.read_csv(path)
@task
def data_cleaning(data: pd.DataFrame) -> pd.DataFrame:
data = data.drop_duplicates()
data = data.dropna()
data = data.reset_index(drop=True)
return data
@task
def convert_dtypes(data: pd.DataFrame, types_dict: dict = None) -> pd.DataFrame:
data = data.astype(dtype=types_dict)
data["Date"] = pd.to_datetime(data["Date"])
return data
@task
def data_analysis(data: pd.DataFrame) -> pd.DataFrame:
data["month"] = data["Date"].dt.month
new_df = data.groupby("month")["Units Sold"].mean()
return new_df
@task
def data_visualization(new_df: pd.DataFrame, vis_type: str = "bar") -> pd.DataFrame:
new_df.plot(kind=vis_type, figsize=(10, 5), title="Average Units Sold by Month")
plt.savefig("average_units_sold_by_month.png")
return new_df
@task
def save_to_csv(df: pd.DataFrame, filename: str):
df.to_csv(filename, index=False)
return filename
@flow(name="Data Pipeline")
def run_pipeline(path: str):
df = load_data(path)
df_cleaned = data_cleaning(df)
df_converted = convert_dtypes(
df_cleaned, {"Product Category": "str", "Product Name": "str"}
)
analysis_result = data_analysis(df_converted)
data_visualization(analysis_result, "line")
save_to_csv(analysis_result, "average_units_sold_by_month.csv")
# Run the flow
if __name__ == "__main__":
run_pipeline.serve(
name="pass-params-deployment",
parameters=dict(path="Online Sales Data.csv"),
)
$ python data_pipe.py
当我们运行 Python 文件时,会收到一条消息,说明要运行已部署的管道,我们需要使用以下命令:

启动一个新的终端窗口并输入命令以触发此流的运行。
$ prefect deployment run 'Data Pipeline/pass-params-deployment'
正如我们所见,流运行已启动,这意味着管道在后台运行。我们始终可以回到第一个终端窗口以查看日志。

要在仪表板中查看日志,我们需要通过输入以下命令来启动 Prefect 仪表板:
$ prefect server start
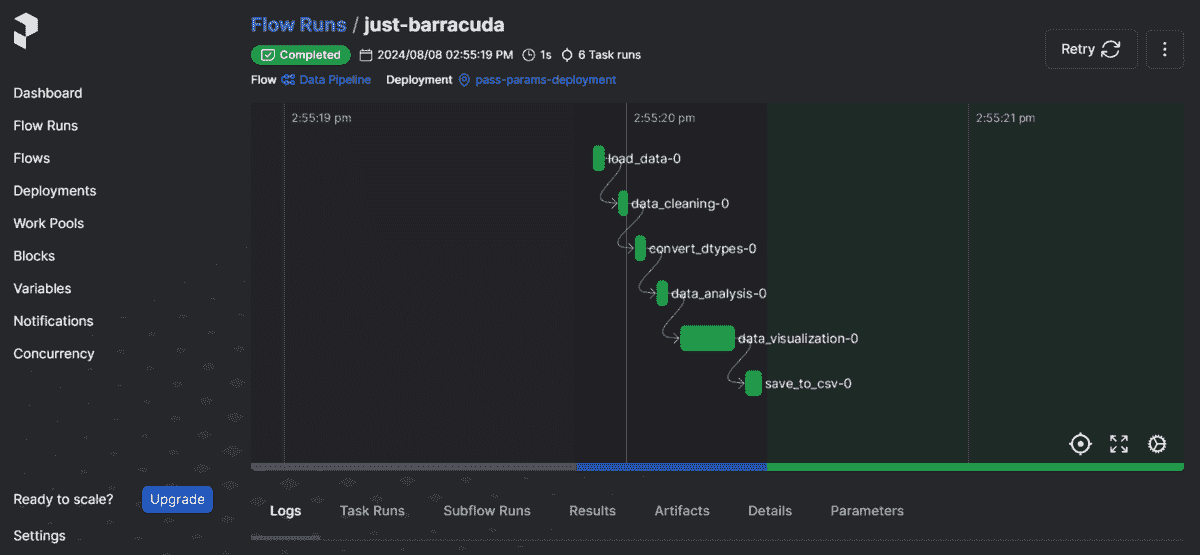
点击仪表板链接以在您的网络浏览器中启动仪表板。
仪表板包含各种选项卡和与管道、工作流以及运行相关的信息。要查看当前运行,请导航到“流运行”选项卡并选择最新的流运行。
所有源代码、数据和信息都可以在 Kingabzpro/Data-Pipeline-with-Prefect GitHub 仓库中找到。请不要忘记 ⭐ 赞一下。
结论
使用适当的工具构建数据管道对于扩展数据工作流和避免不必要的故障是必要的。通过使用 Prefect,你可以调度运行、调试管道,并将其与多个你已经使用的第三方工具集成。它易于使用,并且具有许多你会喜欢的功能。如果你是 Prefect 的新手,我强烈推荐查看 Prefect Cloud。他们提供免费的小时数,让用户体验云平台并熟悉工作流管理系统。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,以帮助面临心理健康问题的学生。
更多相关内容
构建数据管道以创建大语言模型应用程序
原文:
www.kdnuggets.com/building-data-pipelines-to-create-apps-with-large-language-models

DALL-E 3 生成的图像
企业目前追求两种 LLM 驱动应用程序的方法——微调和检索增强生成(RAG)。从很高的层面来看,RAG 接受一个输入,并根据来源(例如,公司维基)检索一组相关/支持的文档。这些文档与原始输入提示一起被连接作为上下文,输入到 LLM 模型中,生成最终响应。RAG 似乎是将 LLM 推向市场的最受欢迎的方法,尤其是在实时处理场景中。支持这种方法的 LLM 架构大多数情况下包括构建有效的数据管道。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
在这篇文章中,我们将探讨 LLM 数据管道中的不同阶段,以帮助开发人员实施与其数据配合的生产级系统。跟随我们,了解如何导入、准备、丰富和提供数据,以驱动 GenAI 应用程序。
大语言模型(LLM)管道的不同阶段是什么?
这些是 LLM 管道的不同阶段:
非结构化数据的导入
向量化与丰富(包含元数据)
向量索引(实时同步)
AI 查询处理器
自然语言用户交互(通过聊天或 API)
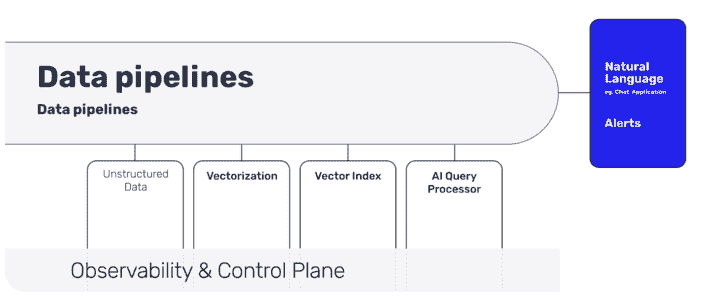
非结构化数据的导入
第一步是收集正确的数据,以帮助实现业务目标。如果你正在构建面向消费者的聊天机器人,那么你必须特别注意将使用哪些数据。数据来源可以从公司门户(例如,Sharepoint、Confluent、文档存储)到内部 API。理想情况下,你希望从这些来源到索引有一个推送机制,以便你的 LLM 应用程序能够为最终用户提供最新的信息。
组织在提取文本数据以进行 LLM 上下文训练时,应实施数据治理政策和协议。组织可以通过审计文档数据来源,列出敏感级别、许可条款和来源来入手。识别需要修订或排除的数据。
这些数据源也应评估质量——多样性、大小、噪音水平、冗余。低质量数据集会稀释来自LLM 应用的响应。你甚至可能需要一个早期文档分类机制来帮助后续正确的存储。
即使在快速发展的 LLM 开发中,遵循数据治理的保护措施也能降低风险。前期建立治理框架可以减轻许多后续问题,并支持可扩展、稳健的文本数据提取用于上下文学习。
通过 Slack、Telegram 或 Discord API 拉取消息可以实时获取数据,这有助于 RAG,但原始对话数据中包含噪音——拼写错误、编码问题和奇怪的字符。实时过滤带有攻击性内容或敏感个人信息(可能是 PII)的消息是数据清理的重要部分。
带有元数据的向量化
元数据如作者、日期和对话上下文进一步丰富数据。将外部知识嵌入向量中有助于更智能和有针对性的检索。
一些与文档相关的元数据可能存在于门户或文档的元数据中,但如果文档附属于业务对象(例如案例、客户、员工信息),则需要从关系数据库中提取这些信息。如果有数据访问的安全问题,这是你可以添加安全元数据的地方,这也有助于后续检索阶段。
关键步骤是使用 LLM 的嵌入模型将文本和图像转换为向量表示。对于文档,你需要先进行分块,然后使用本地零样本嵌入模型进行编码。
向量索引
向量表示必须存储在某处。这就是使用向量数据库或向量索引高效存储和索引这些信息作为嵌入的地方。
这将成为你的“LLM 真实来源”,并且必须与数据源和文档保持同步。实时索引变得重要,如果你的 LLM 应用正在服务客户或生成与业务相关的信息。你要避免你的 LLM 应用与数据源不同步。
使用查询处理器进行快速检索
当你拥有数百万份企业文档时,根据用户查询获取正确内容变得具有挑战性。
这是管道早期阶段开始增加价值的地方:通过元数据添加清洗和数据丰富,最重要的是数据索引。这种上下文添加有助于增强提示工程。
用户互动
在传统的管道环境中,你将数据推送到数据仓库,分析工具将从仓库中提取报告。在 LLM 管道中,最终用户界面通常是一个聊天界面,它在最简单的层面上接受用户查询并回应查询。
摘要
这种新型管道的挑战不仅在于获取一个原型,还在于将其投入生产。这时,企业级监控解决方案来跟踪你的管道和向量存储变得非常重要。从结构化和非结构化数据源获取业务数据的能力成为一个重要的架构决策。LLMs 代表了自然语言处理的最前沿,构建企业级数据管道以支持 LLM 驱动的应用程序使你始终处于前沿。
这里可以访问一个可用的实时流处理框架。
Anup Surendran**** 是 Pathway 的产品营销负责人,专注于将 AI 产品推向市场。他曾与有两个成功退出(SAP 和 Kroll)的初创公司合作,并喜欢教授他人如何利用 AI 产品提高组织内的生产力。
更多相关主题
使用 Pandas 构建数据科学管道
原文:
www.kdnuggets.com/building-data-science-pipelines-using-pandas

使用 ChatGPT 生成的图像
Pandas 是最受欢迎的数据处理和分析工具之一,以其易用性和强大功能而著称。但您是否知道,您还可以使用它来创建和执行数据管道以处理和分析数据集?
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的捷径
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT 工作
在本教程中,我们将学习如何使用 Pandas 的 pipe 方法来构建端到端的数据科学管道。该管道包括数据摄取、数据清理、数据分析和数据可视化等多个步骤。为了突出这种方法的优点,我们还将比较基于管道的代码与非管道替代方案,以便让您清晰了解其差异和优势。
什么是 Pandas 管道?
Pandas pipe 方法是一种强大的工具,允许用户以清晰且可读的方式链接多个数据处理函数。此方法可以处理位置参数和关键字参数,使其适用于各种自定义函数。
简而言之,Pandas pipe 方法:
-
增强代码可读性
-
实现函数链式调用
-
适应自定义函数
-
改善代码组织
-
高效处理复杂转换
这里是 pipe 函数的代码示例。我们将 clean 和 analysis Python 函数应用于 Pandas DataFrame。管道方法将首先清理数据,然后执行数据分析,最后返回结果。
(
df.pipe(clean)
.pipe(analysis)
)
Pandas 无管道代码
首先,我们将编写一段不使用管道的简单数据分析代码,以便在使用管道简化数据处理管道时进行清晰的比较。
在本教程中,我们将使用来自 Kaggle 的 在线销售数据集 - 流行市场数据,该数据集包含不同产品类别的在线销售交易信息。
- 我们将加载 CSV 文件并显示数据集中的前三行。
import pandas as pd
df = pd.read_csv('/work/Online Sales Data.csv')
df.head(3)

-
通过删除重复项和缺失值来清理数据集,并重置索引。
-
转换列类型。我们将“产品类别”和“产品名称”转换为字符串类型,并将“日期”列转换为日期类型。
-
为了进行分析,我们将从“日期”列中创建一个“月份”列。然后,计算每个月销售单位的平均值。
-
可视化每月平均销售单位的柱状图。
# data cleaning
df = df.drop_duplicates()
df = df.dropna()
df = df.reset_index(drop=True)
# convert types
df['Product Category'] = df['Product Category'].astype('str')
df['Product Name'] = df['Product Name'].astype('str')
df['Date'] = pd.to_datetime(df['Date'])
# data analysis
df['month'] = df['Date'].dt.month
new_df = df.groupby('month')['Units Sold'].mean()
# data visualization
new_df.plot(kind='bar', figsize=(10, 5), title='Average Units Sold by Month');
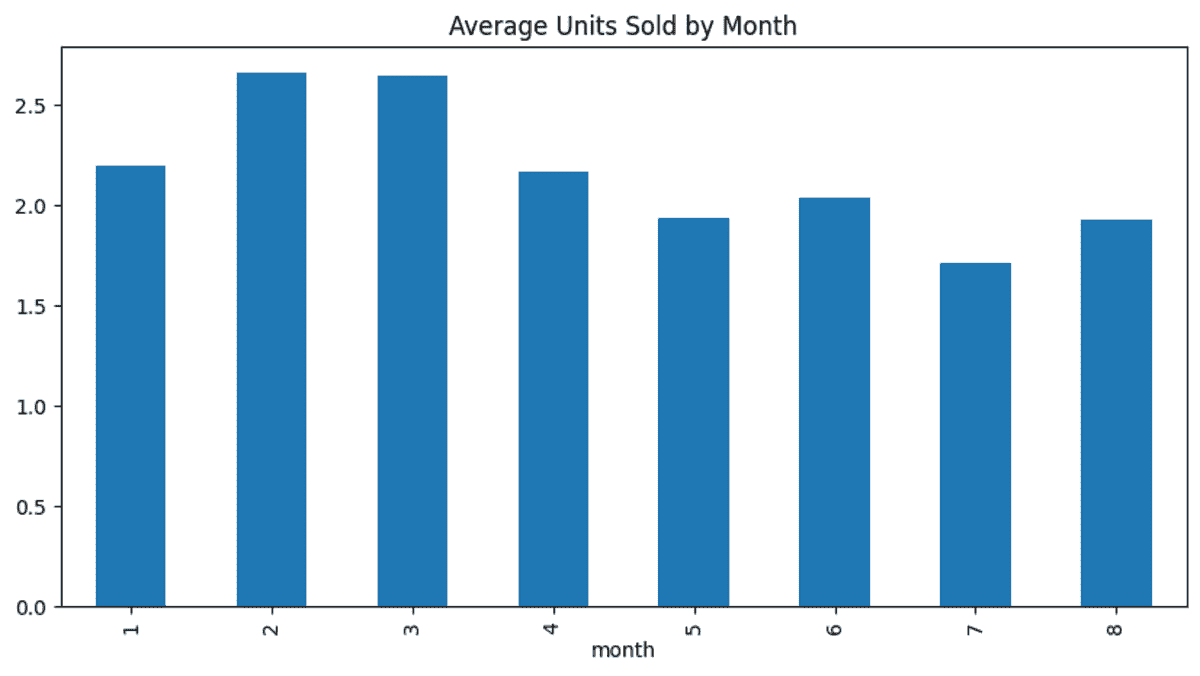
这非常简单,如果你是数据科学家或数据科学学生,你将知道如何执行大多数这些任务。
使用 Pandas Pipe 构建数据科学管道
要创建一个端到端的数据科学管道,我们首先需要使用 Python 函数将上述代码转换为适当的格式。
我们将为以下内容创建 Python 函数:
-
加载数据: 这需要一个 CSV 文件的目录。
-
数据清理: 这需要原始 DataFrame 并返回清理后的 DataFrame。
-
转换列类型: 这需要一个干净的 DataFrame 和数据类型,并返回一个具有正确数据类型的 DataFrame。
-
数据分析: 这需要来自前一步的 DataFrame,并返回包含两列的修改后的 DataFrame。
-
数据可视化: 这需要一个经过修改的 DataFrame 和可视化类型来生成可视化图表。
def load_data(path):
return pd.read_csv(path)
def data_cleaning(data):
data = data.drop_duplicates()
data = data.dropna()
data = data.reset_index(drop=True)
return data
def convert_dtypes(data, types_dict=None):
data = data.astype(dtype=types_dict)
## convert the date column to datetime
data['Date'] = pd.to_datetime(data['Date'])
return data
def data_analysis(data):
data['month'] = data['Date'].dt.month
new_df = data.groupby('month')['Units Sold'].mean()
return new_df
def data_visualization(new_df,vis_type='bar'):
new_df.plot(kind=vis_type, figsize=(10, 5), title='Average Units Sold by Month')
return new_df
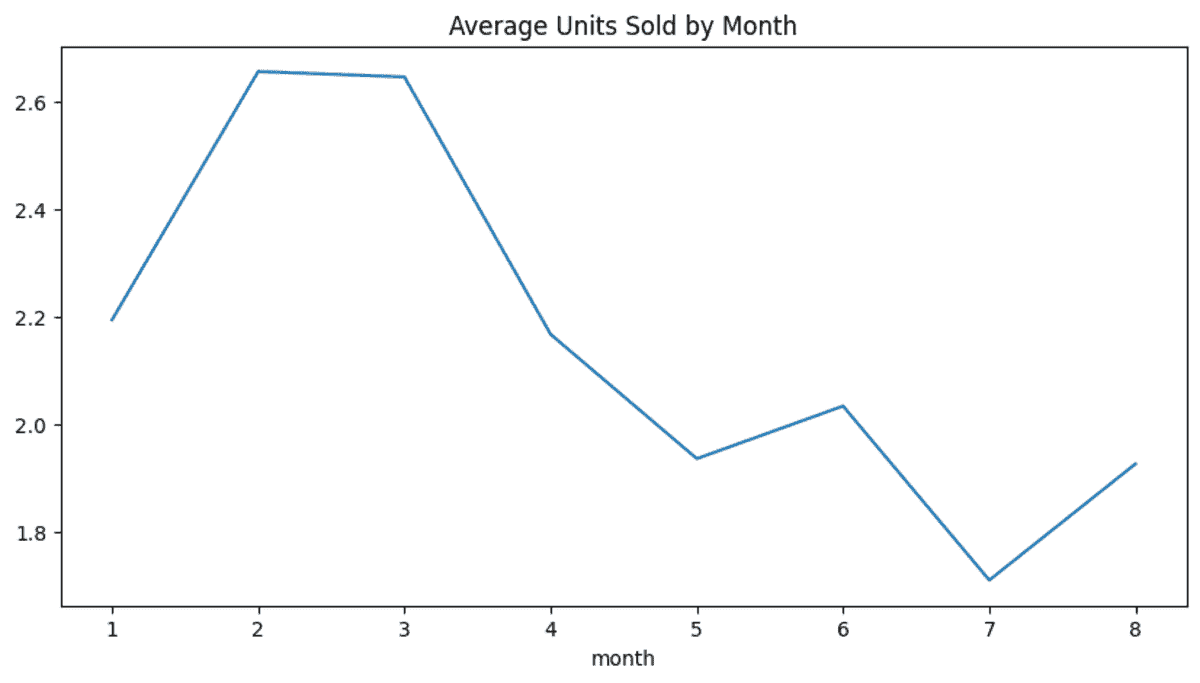
我们现在将使用 pipe 方法将所有上述 Python 函数串联在一起。如我们所见,我们已将文件路径提供给 load_data 函数,将数据类型提供给 convert_dtypes 函数,并将可视化类型提供给 data_visualization 函数。我们将使用可视化折线图,而不是柱状图。
构建数据管道使我们能够在不改变整体代码的情况下尝试不同的场景。你在标准化代码并使其更具可读性。
path = "/work/Online Sales Data.csv"
df = (pd.DataFrame()
.pipe(lambda x: load_data(path))
.pipe(data_cleaning)
.pipe(convert_dtypes,{'Product Category': 'str', 'Product Name': 'str'})
.pipe(data_analysis)
.pipe(data_visualization,'line')
)
最终结果看起来非常棒。
结论
在这个简短的教程中,我们了解了 Pandas pipe 方法以及如何使用它来构建和执行端到端的数据科学管道。这个管道使你的代码更加可读、可重复和更有组织。通过将 pipe 方法集成到你的工作流程中,你可以简化数据处理任务,提升项目的整体效率。此外,一些用户发现使用 pipe 而不是 .apply() 方法可以显著提高执行速度。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,帮助那些在精神健康方面挣扎的学生。
更多相关话题
建立数据科学作品集:机器学习项目第一部分
原文:
www.kdnuggets.com/2016/07/building-data-science-portfolio-machine-learning-project-part-1.html/2
选择角度
我们可以在 Fannie Mae 数据集上采取几种方向。我们可以:
-
尝试预测房屋止赎后的销售价格。
-
预测借款人的还款历史。
-
在贷款获取时确定每笔贷款的评分。
重要的是要坚持一个角度。试图同时关注太多事物会使项目难以有效实施。选择一个具有足够细微差别的角度也很重要。以下是一些没有太多细微差别的角度示例:
-
确定哪些银行向 Fannie Mae 出售的贷款被止赎的次数最多。
-
确定借款人信用评分的趋势。
-
探索哪些类型的房屋最常被止赎。
-
探索贷款金额与止赎销售价格之间的关系
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
上述所有角度都很有趣,如果我们专注于讲故事的话会很棒,但对于一个运营项目来说并不太合适。
使用 Fannie Mae 数据集,我们将尝试通过仅使用在贷款获取时可用的信息来预测贷款是否会在未来被止赎。实际上,我们将为任何抵押贷款创建一个“评分”,以告诉我们 Fannie Mae 是否应该购买它。这将为我们提供一个很好的基础,并成为一个很棒的作品集项目。
理解数据
我们快速查看一下原始数据文件。以下是 2012 年第 1 季度获取数据的前几行:
100000853384|R|OTHER|4.625|280000|360|02/2012|04/2012|31|31|1|23|801|N|C|SF|1|I|CA|945||FRM|
100003735682|R|SUNTRUST MORTGAGE INC.|3.99|466000|360|01/2012|03/2012|80|80|2|30|794|N|P|SF|1|P|MD|208||FRM|788
100006367485|C|PHH MORTGAGE CORPORATION|4|229000|360|02/2012|04/2012|67|67|2|36|802|N|R|SF|1|P|CA|959||FRM|794
以下是 2012 年第 1 季度性能数据的前几行:
100000853384|03/01/2012|OTHER|4.625||0|360|359|03/2042|41860|0|N||||||||||||||||
100000853384|04/01/2012||4.625||1|359|358|03/2042|41860|0|N||||||||||||||||
100000853384|05/01/2012||4.625||2|358|357|03/2042|41860|0|N||||||||||||||||
在开始编写代码之前,花些时间真正理解数据是非常有用的。这在运营项目中尤为关键——因为我们不能互动地探索数据,所以如果我们事先不发现某些细微之处,它们可能更难被察觉。在这种情况下,第一步是阅读 Fannie Mae 网站上的材料:
阅读这些文件后,我们知道一些关键事实,这些事实将帮助我们:
-
每个季度都有一个获取文件和一个绩效文件,从
2000年开始到现在。数据存在一年的滞后,所以截至本文编写时,最新的数据来自2015年。 -
文件采用文本格式,以管道符号 (
|) 作为分隔符。 -
文件没有标题,但我们有每列内容的列表。
-
所有文件加在一起包含
22百万笔贷款的数据。 -
因为绩效文件包含以前年份获取的贷款信息,所以早期年份获取的贷款将有更多的绩效数据(即
2014年获取的贷款不会有太多绩效历史)。
这些小的信息片段将为我们节省大量时间,因为我们在规划项目结构和处理数据时。
结构化项目
在我们开始下载和探索数据之前,重要的是要考虑我们将如何结构化项目。在构建端到端项目时,我们的主要目标是:
-
创建有效的解决方案
-
拥有一个快速运行且资源消耗最小的解决方案
-
使其他人能够轻松扩展我们的工作
-
让其他人更容易理解我们的代码
-
尽可能少写代码
为了实现这些目标,我们需要良好地结构化项目。结构良好的项目遵循几个原则:
-
将数据文件与代码文件分开。
-
将原始数据与生成的数据分开。
-
拥有一个
README.md文件,引导人们安装和使用项目。 -
拥有一个
requirements.txt文件,其中包含运行项目所需的所有包。 -
拥有一个
settings.py文件,其中包含在其他文件中使用的任何设置。- 例如,如果你在多个 Python 脚本中读取相同的文件,最好让它们都导入
settings并从集中位置获取文件名。
- 例如,如果你在多个 Python 脚本中读取相同的文件,最好让它们都导入
-
拥有一个
.gitignore文件,防止大文件或秘密文件被提交。 -
将任务的每一步拆分成可以单独执行的文件。
- 例如,我们可能有一个文件用于读取数据,一个用于创建特征,另一个用于进行预测。
-
存储中间值。例如,一个脚本可能会输出一个文件,供下一个脚本读取。
- 这使我们能够在不重新计算所有内容的情况下更改数据处理流程。
我们的文件结构很快将如下所示:
loan-prediction
├── data
├── processed
├── .gitignore
├── README.md
├── requirements.txt
├── settings.py
创建初始文件
首先,我们需要创建一个loan-prediction文件夹。在该文件夹内,我们需要创建一个data文件夹和一个processed文件夹。第一个文件夹用于存储我们的原始数据,第二个文件夹用于存储任何中间计算值。
接下来,我们将创建一个.gitignore文件。.gitignore文件将确保某些文件被 git 忽略,不会推送到 GitHub。一个很好的示例是 OSX 在每个文件夹中创建的.DS_Store文件。一个好的.gitignore文件起点可以在这里。我们还希望忽略数据文件,因为它们非常大,且 Fannie Mae 的条款阻止我们重新分发,因此我们应在文件末尾添加两行:
data
processed
这里是该项目的一个.gitignore文件示例。
接下来,我们需要创建README.md,这将帮助人们理解项目。.md 表示文件使用了 Markdown 格式。Markdown 允许你写纯文本,同时可以根据需要添加一些花哨的格式。这里是一个关于 Markdown 的指南。如果你将名为README.md的文件上传到 GitHub,GitHub 会自动处理 Markdown,并展示给查看该项目的任何人。这里是一个示例。
目前,我们只需在README.md中写一个简单的描述:
Loan Prediction
-----------------------
Predict whether or not loans acquired by Fannie Mae will go into foreclosure. Fannie Mae acquires loans from other lenders as a way of inducing them to lend more. Fannie Mae releases data on the loans it has acquired and their performance afterwards [here](http://www.fanniemae.com/portal/funding-the-market/data/loan-performance-data.html).
现在,我们可以创建一个requirements.txt文件。这将使其他人更容易安装我们的项目。我们还不完全知道将使用哪些库,但这是一个好的起点:
pandas
matplotlib
scikit-learn
numpy
ipython
scipy
上述库是 Python 中用于数据分析任务的最常用库,可以合理地假设我们将使用大多数这些库。这里是该项目的一个要求文件示例。
在创建requirements.txt之后,你应该安装这些包。对于这篇文章,我们将使用Python 3。如果你还没有安装 Python,你可以考虑使用Anaconda,这是一个 Python 安装器,它同时安装上述所有包。
最后,我们可以创建一个空的settings.py文件,因为我们还没有任何项目设置。
 简历:Vik Paruchuri 是一位驻旧金山的数据科学家和开发者。他是 Dataquest 的创始人,你可以在舒适的浏览器中学习数据科学。
简历:Vik Paruchuri 是一位驻旧金山的数据科学家和开发者。他是 Dataquest 的创始人,你可以在舒适的浏览器中学习数据科学。
如果你喜欢这个,你可能也会喜欢阅读我们“构建数据科学作品集”系列中的其他文章:
原文。已获得许可转载。
相关:
-
实际学习数据科学的 5 个步骤
-
Python 中的统计数据分析
-
用 Python 矿工 Twitter 数据 第一部分:收集数据
更多相关内容
在 10 天内构建数据科学产品
原文:
www.kdnuggets.com/2018/07/building-data-science-product-10-days.html
 评论
评论
由邓厚涛撰写,Instacart 的数据科学家。
在初创公司,我们经常有机会从头开始创建产品。本文将分享如何快速构建有价值的数据科学产品,以我在 Instacart 的第一个项目为例。
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
问题是这样的。在 Instacart 上将商品添加到购物车后,客户可以在结账时选择一个交付窗口(如图 1 所示)。然后,Instacart 的购物者会尽量在窗口内将杂货送到客户手中。在高峰期,我们的系统经常接受超过购物者处理能力的订单,有些订单会延迟交付。
我们决定利用数据科学来解决延迟问题。我们的想法是使用数据科学模型来估算每个窗口的交付能力,当订单数量达到其容量时,窗口将关闭。
这是我们如何在 10 天内构建一个 v1 产品的。
图 1。客户可以选择一个可用的交付窗口,以便将食品杂货送达。
第 1 天。规划
我们从规划开始,以便能够专注于正确的工作并快速开发解决方案。
-
首先,我们定义了衡量项目进展的指标。
-
其次,我们确定了一个可实现且影响较大的领域(低悬果实)。
-
第三,我们提出了一个可以快速实施的简单解决方案。
指标。每日报晚交付的百分比被用来衡量延迟情况。我们不希望过早关闭交付窗口,错失可以按时交付的订单。因此,每日交付数量被用作反向指标。(我们现在使用购物者利用率作为反向指标。)
低悬果实。数据显示,对于延迟交付较多的日子,大多数订单是在前一天下的。因此,我们决定专注于次日交付窗口(图 1中的“明天”窗口)。
解决方案。为了在时间窗口T(T和T+1之间)内交付订单,顾客可能会在T之前开始处理订单。图 2 展示了顾客在窗口T-2开始处理订单,并在窗口T交付订单。由于大多数订单耗时不到两小时,因此交付窗口T的容量主要依赖于T、T-1和T-2时间窗口的顾客数量。
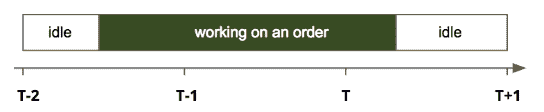
图 2。顾客在订单上花费时间的示意图。假设线性关系,交付窗口T的容量可以表示为
capacity(T) = a+b0#shoppers(T)+b1#shoppers(T-1)+b2#shoppers(T-2)*
还有其他因素(例如天气)也可能影响容量,但我们决定从简单开始。
第 2–3 天。对模型的第一次迭代
我们遵循了典型的建模过程:特征工程、创建训练和测试数据,并比较不同的模型。然而,一旦我们认为模型足够准确,就没有再投入更多时间在模型上。首先,模型只是系统的一部分。其次,模型准确度的提高不一定会转化为指标的同等提升。
特征和数据。对于过去的每个交付窗口,我们有以下数据:在窗口内交付的订单,以及顾客在订单上花费的时间。图 3 展示了在时间窗口T(T和T+1之间)内交付的三笔订单,其中窗口T-2有 2 名顾客工作,而窗口T-1和T均有 3 名顾客工作。图 4 展示了从此示例创建的一行数据。
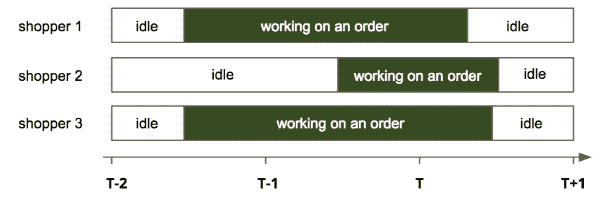
图 3。对于在时间窗口 T(T和T+1之间)内交付的三笔订单,窗口T-2有 2 名顾客工作,而窗口T-1和T均有 3 名顾客工作。

图 4。图 3 中示例创建的一行数据。
线性模型。以#orders(T)作为响应变量,其他变量作为预测因子,我们在训练数据集上建立了线性模型,并在验证数据集上进行了测试。模型的形式如下
#orders(T) = a+b0#shoppers(T)+b1#shoppers(T-1)+b2#shoppers(T-2)*
验证数据的预测值与实际值的比较见图 5(左)。每个预测值的实际值均值和 45 度线也被绘制出来。
非线性模型。我们建立了一个随机森林模型进行比较。预测值与实际值的比较见图 5(右)。随机森林模型的表现并没有显著优于线性模型,因此我们决定使用更容易解释和实施的线性模型。
预测。使用线性模型,我们可以通过以下公式估算未来交付窗口T的容量
capacity(T) = a+b0#shoppers(T)+b1#shoppers(T-1)+b2#shoppers(T-2)*
注意,在这个公式中,#shoppers(t) 表示在未来时间窗口 t(t=T,T-1 或 T-2)安排的购物者数量。
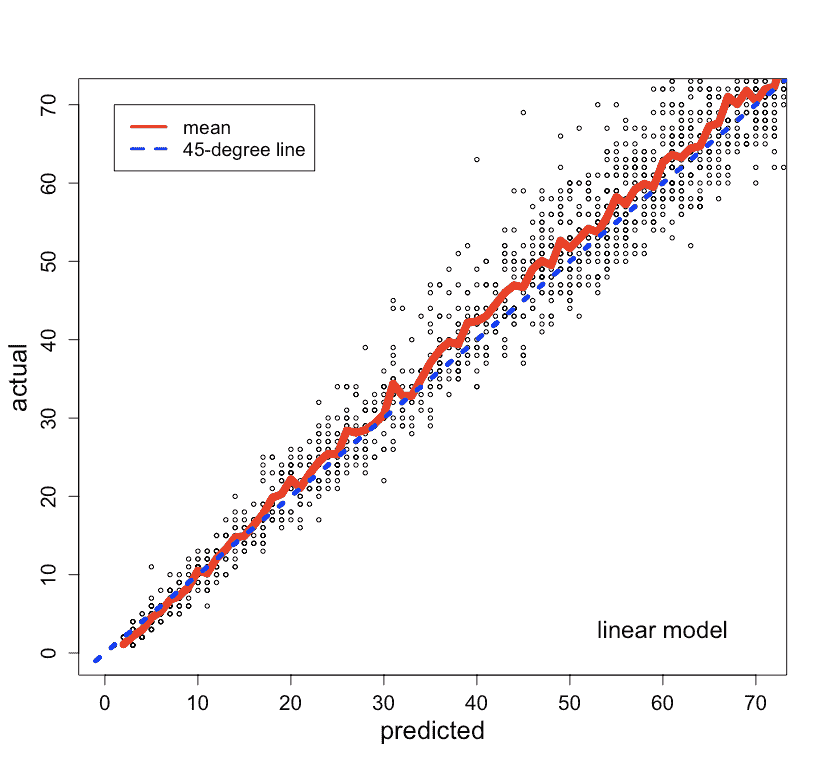
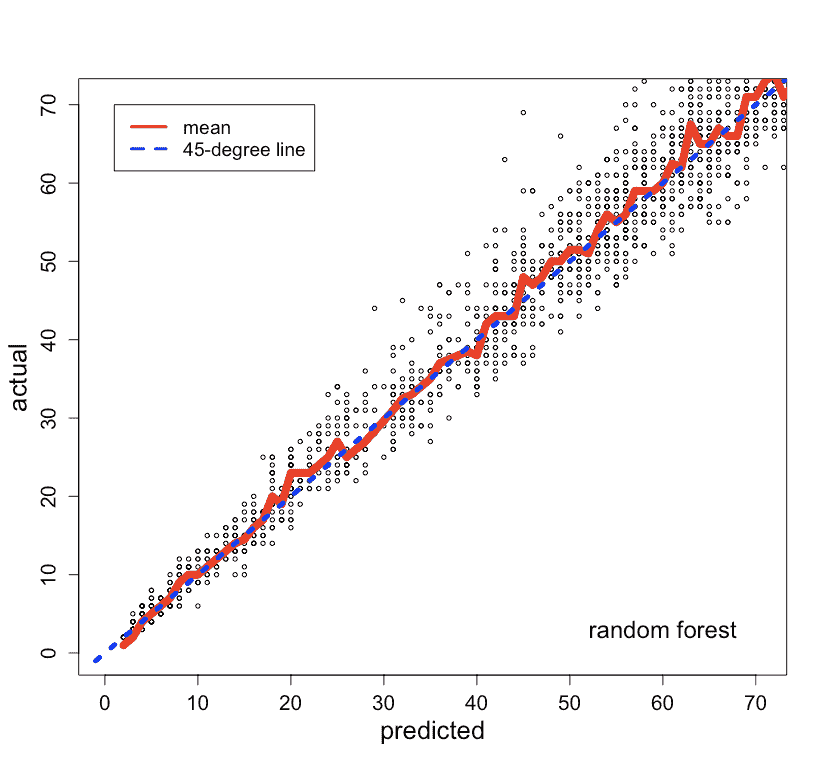
图 5。线性模型(左)和随机森林模型(右)的预测与实际图。
第 4-5 天。端到端集成
我们使用数据库作为数据科学与工程组件之间的接口。通过这种方式,可以减少数据科学和工程之间的依赖(与将数据科学模型嵌入工程代码中相比),并明确不同组件的所有权。图 6 展示了系统的工作原理。
数据科学组件。有两个数据科学任务,模型训练任务和预测任务,均由 cron(一个基于时间的调度器)在预定的频率下触发。模型训练任务每周运行一次,获取最新的 order_shoppers 数据(订单和购物者在订单上花费的时间),拟合模型并将其保存到数据库表(models)中。预测任务每晚运行一次,获取模型和 scheduled_hours(未来计划的购物者小时)数据,并估算未来交付窗口的容量。然后将这些估算保存到 capacity_estimates 表中。
工程组件。容量计数任务的创建是为了消耗容量估算,并提供每个窗口的交付可用性给客户应用。该任务计划每分钟运行一次,获取容量估算和现有订单,计算交付窗口是否可用,并将可用性信息保存到 delivery_availabilities 表中。此外,当客户下订单时,订单信息将保存到 orders 表中,并触发容量计数任务。
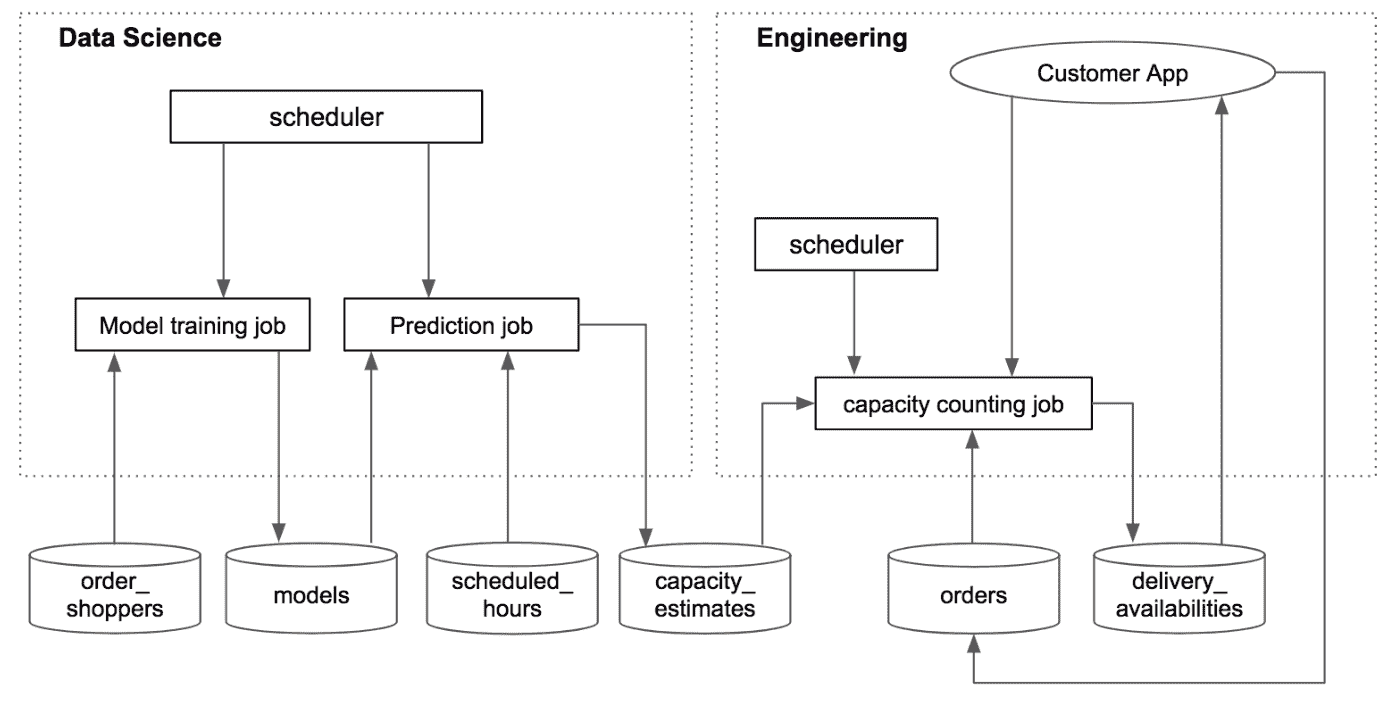
图 6。数据科学与工程组件的集成。
第 6-8 天。模型的第二次迭代
我们对容量估算进行了合理性检查,发现并修复了两个建模问题。
合理性检查。我们运行了生成未来交付窗口容量估算的预测任务。然后,在一个窗口变得过时时,我们将窗口的估算容量与现有系统实际接受的订单进行了比较。我们发现,在一些情况下,现有系统接受的订单少于估算容量,但有显著的延迟(如图 7 所示)。这表明这些情况下的容量被高估了。基于这一见解,我们发现了两个问题。
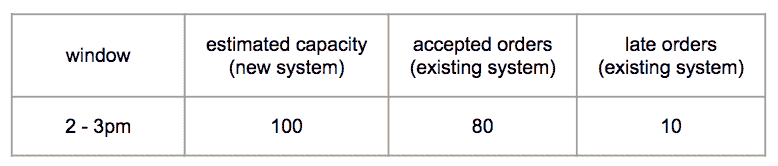
图 7。通过将容量估算与现有系统接受的订单进行比较来验证容量估算。
问题 1:均值预测。我们构建的模型预测的是均值。从图 5(左侧)可以看到,有些数据点低于均值线。这些数据点的均值预测会高估容量。为了解决这个问题,我们构建了预测区间,并使用了较低的百分位水平。图 8 显示了第 25 百分位和第 75 百分位水平。
问题 2:数据不一致。#shoppers用于预测的是未来时间段内计划中的顾客数量,并且顾客可以在时间段之前取消预约。然而,#shoppers用于模型训练的数据没有包含取消的时间。因此,预测和训练所用的数据不一致。为了解决这个问题,我们估算了取消率并将其纳入公式中。
capacity(T) = a+b0#shoppers(T)*****{1-cancelation_rate(T)}***+ …
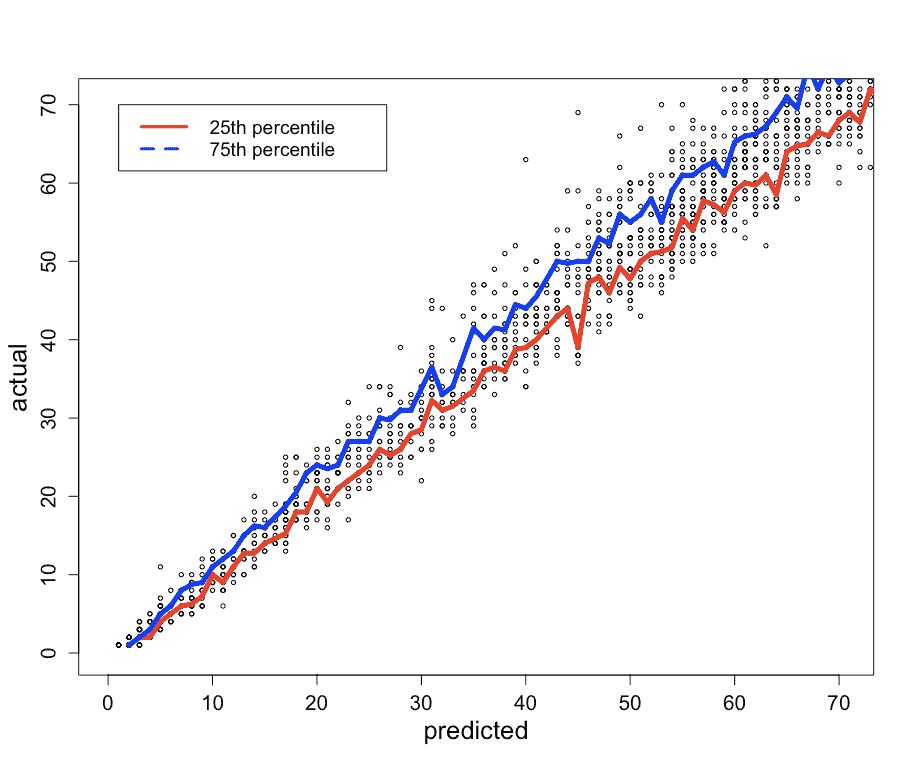
图 8。每个预测值的实际值的第 25 百分位和第 75 百分位值。
第 9–10 天。调整
在将新系统推出给客户之前,我们进行了内部测试(未影响客户)并做出了相应调整。
百分位水平。我们调整了百分位水平,以通过上一节提到的合理性检查。
缓存。通过缓存(在服务器上存储经常使用的数据,以避免重复调用数据库),使任务变得更快。
启动
图 9 显示了产品发布时段每天的晚点交货百分比。新系统实现了大幅减少晚点交货的目标(而不减少交货数量)。这是一次迅速的成功。自首次推出以来,我们继续迭代,包括估算同日交货窗口的容量。
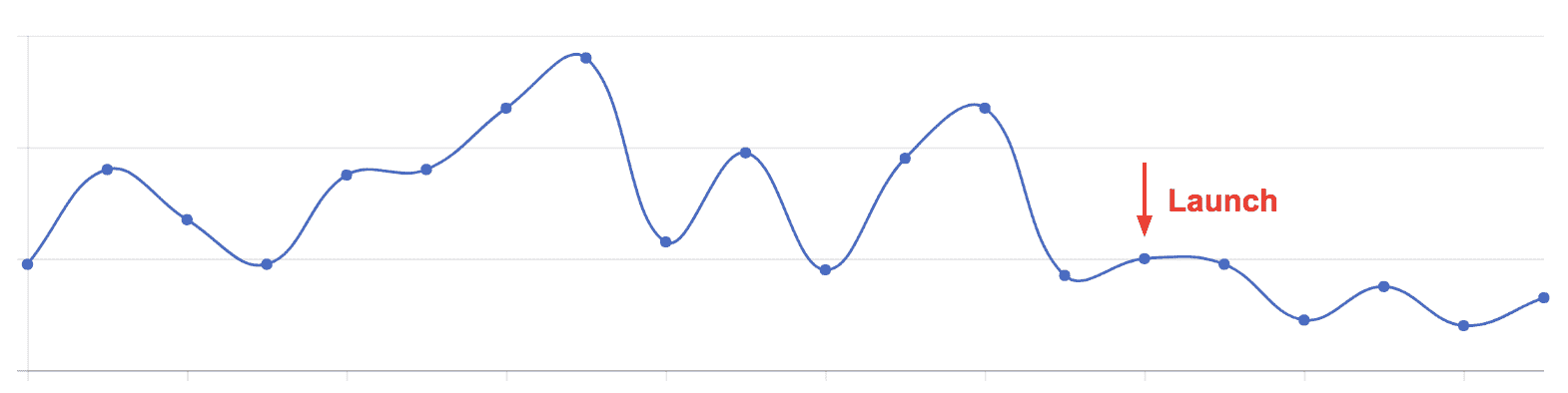
图 9。每天的晚点交货百分比。
收获
作为第一次加入初创公司的数据科学家,我在快速构建有价值的数据科学产品中学到了以下经验
-
确定有影响力且可实现的工作
-
减少工程和数据科学组件之间的依赖
-
专注于提高指标,而不一定是模型准确性
-
从简单开始并快速迭代
四年后,Instacart 现在是一家更大的公司,但这些经验仍然适用于我们进行的数据科学项目,以快速交付业务价值。
注:Andrew Kane 参与了工程组件的初版,Tahir Mobashir 和 Sherin Kurian 参与了后续版本的开发。
原文。经许可转载。
相关:
更多相关内容
使用 fastai 构建深度学习项目——从模型训练到部署
原文:
www.kdnuggets.com/2020/11/building-deep-learning-projects-fastai-model-training-deployment.html
评论
由 Harshit Tyagi,顾问,网页与数据科学讲师

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
深度学习正在许多学科中引发革命性变化。随着 TensorFlow、PyTorch 和现在的fastai等库的出现,它也变得更加易于领域专家和 AI 爱好者使用。
fastai 的使命是民主化深度学习,这是一个致力于帮助从初学者到熟练的深度学习从业者,利用最新研究中的最先进模型和技术实现世界级成果的研究机构。
目标
本博客将带您了解如何使用fastai开发狗分类器的过程。目标是学习如何轻松入门深度学习模型,并能够在使用预训练模型的情况下,以有限的数据获得接近完美的结果。
先决条件
开始的唯一先决条件是知道如何使用 Python 编码,并且熟悉高中数学。
您将学到的内容
-
导入库并设置笔记本
-
使用 Microsoft Azure 收集图像数据
-
将下载的数据转换为 DataLoader 对象
-
数据增强
-
使用模型训练清理数据
-
导出训练好的模型
-
从您的 Jupyter Notebook 中构建应用程序
导入库并设置笔记本
在开始构建我们的模型之前,我们需要从这一组笔记本中导入所需的库和工具函数,这些笔记本是为了介绍使用 fastai 和 PyTorch 进行深度学习而开发的。
让我们安装 fastbook 包以设置笔记本:
!pip install -Uqq fastbook
import fastbook
fastbook.setup_book()
然后,让我们从 fastbook 包和 fastai 视觉小部件 API 中导入所有函数和类:
from fastbook import *
from fastai.vision.widgets import *
使用 Microsoft Azure 收集图像数据
对于大多数类型的项目,你可以在各种 数据存储库和网站 上找到数据。为了开发一个狗分类器,我们需要狗的图片,互联网上有很多狗的图片可供选择。
为了下载这些图片,我们将使用由 Microsoft Azure 提供的 Bing 图像搜索 API。因此,请在 Microsoft Azure 上注册一个免费帐户,你将获得价值 200 美元的积分。
进入你的门户,使用 这个快速入门 创建一个新的认知服务资源。启用 Bing 图像搜索 API,然后从左侧面板中的Keys and Endpoint选项中复制 密钥 到你的资源中。
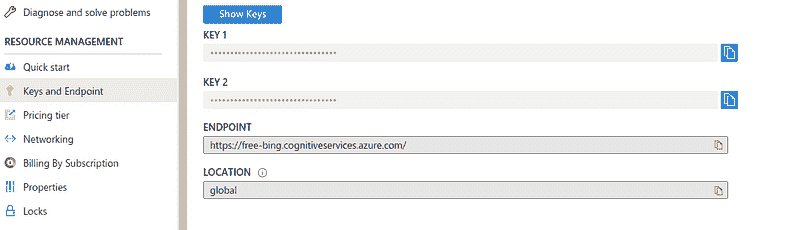
使用检索到的密钥,将这些密钥设置到环境中,如下所示:
key = os.environ.get('AZURE_SEARCH_KEY', '<YOUR_KEY>')
现在,fastbook 提供了几个实用函数,比如search_images_bing,它返回与你的搜索查询对应的 URL。我们可以使用 help 函数了解这些函数:
help(fastbook)

你可以在这个帮助指南中查看search_image_bing函数。该函数接受你上面定义的资源的密钥和搜索查询,我们可以使用attrgot方法访问搜索结果的 URL:
results = search_images_bing(key, 'german shepherd dogs')
images = results.attrgot('content_url')
len(images)
我们已经获得了 150 个德国牧羊犬图片的 URL:

现在,我们可以使用download_url函数下载这些图片。但首先让我们定义我们想要的狗的类型。在本教程中,我将处理三种类型的狗,德国牧羊犬、黑狗和拉布拉多。
现在,让我们定义一个狗的类型列表:
dog_types = ['german shepherd', 'black', 'labrador']
path = Path('dogs')
然后你需要定义你的图片将被下载到的路径以及每个狗类的文件夹的语义名称。
if not path.exists():
path.mkdir()
for t in dog_types:
dest = (path/t)
print(dest)
dest.mkdir(exist_ok=True)
results = search_images_bing(key, '{} dog'.format(t))
download_images(dest, urls=results.attrgot('content_url'))
这将创建一个“dogs”目录,其中包含每种类型狗图像的 3 个目录。
之后,我们将搜索查询(即 dog_type)和密钥传递给搜索函数,然后使用下载函数从搜索结果中下载所有 URL 到它们各自的目标(dest)目录中。
我们可以使用get_image_file函数检查下载到路径的图片:
files = get_image_files(path)
files

验证图像
你还可以检查文件中损坏文件/图像的数量:
corrupt = verify_images(files)
corrupt##output: (#0) []
你可以通过将unlink方法映射到损坏文件列表来删除所有损坏的文件(如果有的话):
corrupt.map(Path.unlink);
就这样,我们已经准备好 379 张狗的图片来训练和验证我们的模型。
将下载的数据转换为 DataLoader 对象
现在,我们需要一种机制来为我们的模型提供数据,fastai 提供了 DataLoaders 的概念,它存储传递给它的多个 DataLoader 对象,并将它们作为 training 和 validation 集提供。
现在,为了将下载的数据转换为 DataLoader 对象,我们需要提供四个内容:
-
我们正在处理什么类型的数据
-
如何获取项目列表
-
如何标记这些项目
-
如何创建验证集
现在,要创建这些 DataLoaders 对象以及上述信息,fastai 提供了一个灵活的系统,称为 数据块 API。我们可以使用参数和 API 提供的转换方法数组来指定 DataLoader 创建的所有细节:
dogs = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=41),
get_y=parent_label,
item_tfms=Resize(128)
)
在这里,我们有一些需要理解的参数:
-
blocks — 这指定了特征变量(图像)和目标变量(每个图像的类别)
-
get_items — 检索底层项目,在我们的例子中是图像,我们有一个
**get_image_files**函数,它返回该路径下所有图像的列表。 -
splitter — 根据提供的方法拆分数据;我们使用随机拆分,将 20% 的数据保留用于验证集,并指定种子以在每次运行时获得相同的拆分。
-
get_y — 目标变量称为 y;为了创建标签,我们使用
**parent_label**函数,该函数获取文件所在文件夹的名称作为其标签。 -
item_tfms — 我们有不同大小的图像,这会导致问题,因为我们总是将一批文件发送到模型,而不是单个文件;因此,我们需要通过将图像调整为标准大小然后将它们组合成张量来预处理这些图像,以便通过模型。我们在这里使用
**Resize**转换。
现在,我们有了 DataBlock 对象,它需要通过提供数据集的路径转换为 DataLoader:
dls = dogs.dataloaders(path)
然后,我们可以使用 show_batch 方法检查 DataLoader 对象中的图像。
dls.valid.show_batch()

数据增强
我们可以对这些图像应用转换,以创建输入图像的随机变化,使其看起来不同但仍表示相同的事实。
我们可以旋转、扭曲、翻转或改变图像的亮度/对比度以创建这些变化。我们还有一个标准的增强集合,封装在 aug_transforms 函数中,对于大多数计算机视觉数据集效果很好。
现在,我们可以将这些转换应用于整个图像批次,因为所有图像现在都是相同的大小(224 像素,图像分类问题的标准),使用以下方法:
##adding item transformationsdogs = dogs.new(
item_tfms=RandomResizedCrop(224, min_scale=0.5),
batch_tfms=aug_transforms(mult=2)
)
dls = dogs.dataloaders(path)
dls.train.show_batch(max_n=8, nrows=2, unique=True)

模型训练和数据清洗
是时候用这些有限数量的图像来训练模型了。 fastai 提供了许多架构,这使得使用迁移学习变得非常容易。我们可以使用适用于大多数应用程序/数据集的预训练模型创建卷积神经网络(CNN)模型。
我们将使用 ResNet 架构,它对许多数据集和问题都很快且准确。**resnet18** 中的 18 代表神经网络中的层数。我们还传递度量标准来测量模型预测的质量,使用数据加载器中的验证集。我们使用 error_rate 来表示模型预测错误的频率:
model = cnn_learner(dls, resnet18, metrics=error_rate)
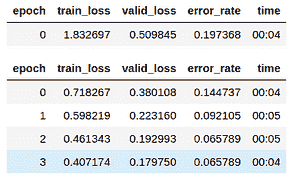
model.fine_tune(4)
fine_tune 方法类似于其他机器学习库中的 fit() 方法。现在,为了训练模型,我们需要指定训练模型的轮数(epochs)。
在这里,我们仅训练了 4 个周期:
我们还可以使用混淆矩阵可视化预测结果,并将其与实际标签进行比较:
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()
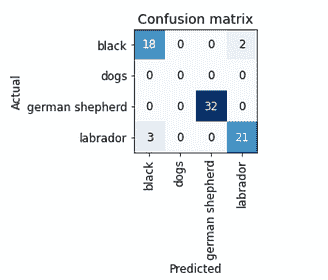
如你所见,我们只有五个错误预测。让我们查看损失最大的图像,即数据集中损失最高的图像:
interp.plot_top_losses(6, nrows=3)

你可以看到,模型在黑色和拉布拉多之间混淆了。因此,我们可以使用 ImageClassifierCleaner 类将这些图像指定为特定类别。
将模型传递给该类,它将打开一个具有直观 GUI 的数据清理小部件。我们可以更改训练集和验证集图像的标签,并查看损失最高的图像。
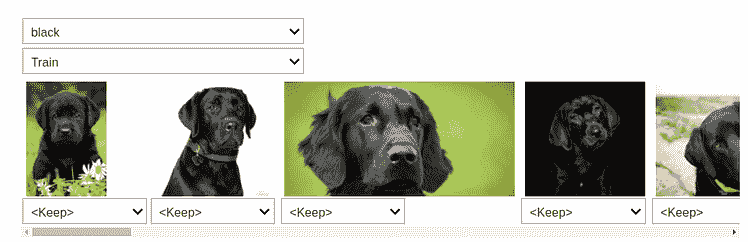
将每张图像添加到其正确的类别后,我们必须使用以下方法将它们移动到正确的目录中:
for idx,cat in cleaner.change():
shutil.move(str(cleaner.fns[idx]), str(path/cat).split('.')[0] +"_fixed.jpg")
导出训练好的模型
经过几轮超参数调整后,一旦你对模型满意,就需要保存它,以便我们可以将其部署到服务器上,用于生产环境。
在保存模型时,我们需要保存模型架构和对我们有价值的训练参数。 fastai 提供了 export() 方法,将模型保存为扩展名为 .pkl 的 pickle 文件。
model.export()
path = Path()
path.ls(file_exts='.pkl')
然后我们可以加载模型,并通过将图像传递给加载的模型来进行推断:
model_inf = load_learner(path/'export.pkl')
使用此加载的模型进行推断:
model_inf.predict('dogs/labrador/00000000.jpg')

我们可以检查模型数据加载器词汇表中的标签:
model_inf.dls.vocab
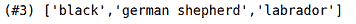
从 Jupyter Notebook 构建应用程序
下一步是创建一个可以与朋友、同事、招聘人员等分享的应用程序。要创建应用程序,我们需要添加互动元素,以便我们可以尝试和测试应用程序的功能,并且需要将其作为网页发布到网上,这包括通过像 Flask 这样的框架进行部署或直接使用 Voila。
你可以简单地使用 Voila 将这个 Jupyter Notebook 转换为一个独立的应用程序。我没有在这里涵盖它,但你可以查看我的博客/视频,其中详细介绍了这个过程。
使用 Python 和 Voila 构建 COVID-19 分析仪表板
从你的 jupyter notebook 创建一个具有互动可视化和灵活性的仪表板。
部署
我在我的帖子中介绍了部署 ML 模型:
端到端 ML 项目教程系列的第二部分
但如果你想要另一种简单且免费的 Voila 应用程序部署方式,你可以使用 Binder。按照这些步骤在 Binder 上部署应用程序:
-
将你的笔记本添加到 GitHub 仓库。
-
将那个仓库的 URL 插入到 Binder 的 URL 字段中。
-
将文件下拉菜单更改为选择 URL。
-
在 “URL to open” 字段中,输入
/voila/render/<*name>*.ipynb -
点击右下角的剪贴板按钮以复制 URL 并将其粘贴到安全的地方。
-
点击启动。
就这样,你的狗分类器上线了!
如果你想观看我执行所有这些步骤的视频版本,这里有博客的视频:
Harshit 的数据科学
通过这个频道,我计划推出几个 涵盖整个数据科学领域的系列。以下是你应该订阅 频道 的原因:
-
这些系列将涵盖每个主题和子主题所需/要求的所有高质量教程,例如 数据科学基础的 Python。
-
项目和说明 以实施迄今为止学习的主题。了解新的认证、训练营和资源,以通过诸如Google 的 TensorFlow 开发者证书考试之类的认证。
简介:Harshit Tyagi 是一位顾问及网页与数据科学讲师。
原文。已获授权转载。
相关:
-
与《深度学习编程》同行 10 天
-
在 AWS 上使用 Docker Swarm、Traefik 和 Keycloak 部署安全可扩展的 Streamlit 应用
-
扩展机器学习模型的 5 个挑战
更多相关主题
关于构建有效的数据科学团队
原文:
www.kdnuggets.com/2019/03/building-effective-data-science-teams.html
评论
由 Saurav Dhungana 创始人 @craftdatalabs。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
随着数据科学和 AI 进入几乎所有行业,构建能够成功实施 AI 项目的团队的挑战也随之而来。对那种完美融合了统计学家、程序员和沟通者的“数据科学家”的需求从未如此之高。但随着尘埃落定,我们开始听到关于 失败项目和 失望专业人士的故事。
你可能听说过一些高价组建的专家团队一次次失败。作为一名在多个行业工作的数据科学顾问,我有机会亲眼见证了这种趋势。许多人倾向于认为数据科学是一个新兴领域,并预期它在成为主流的过程中会有成长的阵痛,但我们忘记了这个领域的起源。这是我通过自己的经历反思成功数据团队的特质,并帮助商业领袖和高管制定更好的 AI 策略的尝试。
不要忘记你的根基
首先,我们需要将数据科学视为现有学科的自然演变,而不是全新领域。毕竟,在计算机时代开始之前,我们就已经在处理数据,而 AI 的概念至少从 1960 年代就存在。其他学科如数据库中的知识发现、决策支持系统、商业智能、数据挖掘、分析、预测分析等已经存在很长时间。它们的主要目标是从数据中提取有意义的模式,并利用这些模式获得洞察力并为未来做出决策。
数据科学是这种趋势的最新体现,这一趋势得益于互联网时代可用数据量和种类的急剧增加。它还受到相对便宜的计算能力和机器学习算法的新突破的推动,这些突破能够利用这些丰富的数据。这些新算法的复杂性和数学精细程度进一步产生了对能够理解它们的高级学位人员的突然需求,因此人工智能竞赛开始了。
尽管这项技术看起来很新颖,但我坚信我们可以从神话和较早学科中遵循的最佳实践中学到很多。
CRISP-DM
最明显且经常被忽视的工具是CRISP-DM标准。这是一个自 1990 年代以来存在的结构化分析项目的工业流程。
主要思想是将分析项目分为几个明确的阶段。这些阶段是——业务理解、数据理解、数据准备、建模、评估和部署。
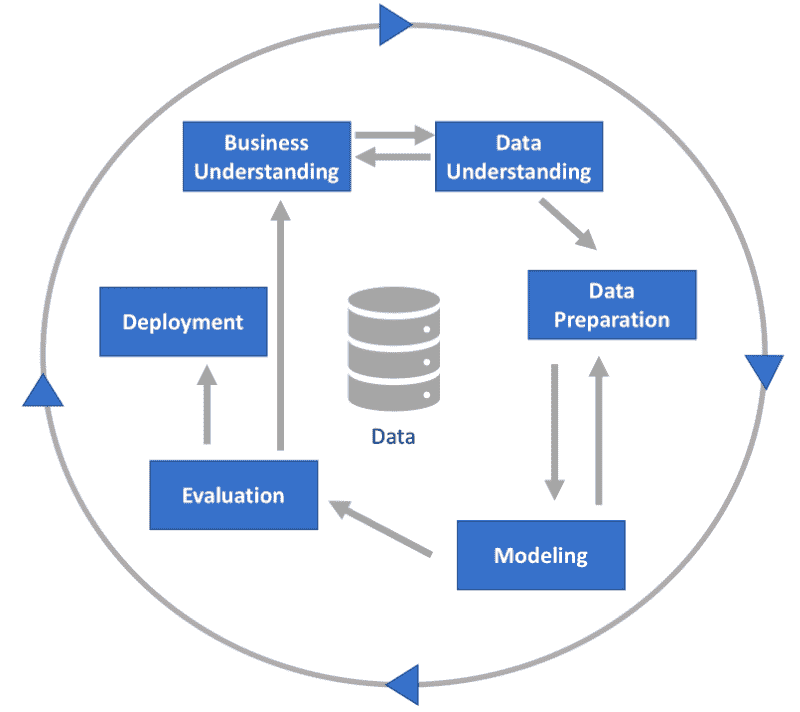
照片:Luminus
尽管这个过程有一些不足之处,并且标准最近没有更新,但这六个阶段仍然很有用。在我看来,每个数据专业人士都应该阅读并理解这些阶段,以真正发挥作用。
Team Data Science Process (TDSP)
数据科学是一个本质上迭代的过程,CRISP-DM 的主要缺点是它没有很好地融入这一点。
TDSP是微软的一种现代数据科学生命周期过程,它在旧方法上进行了改进。可以把它看作是 CRISP-DM 在云计算时代进行敏捷开发改造的结果。
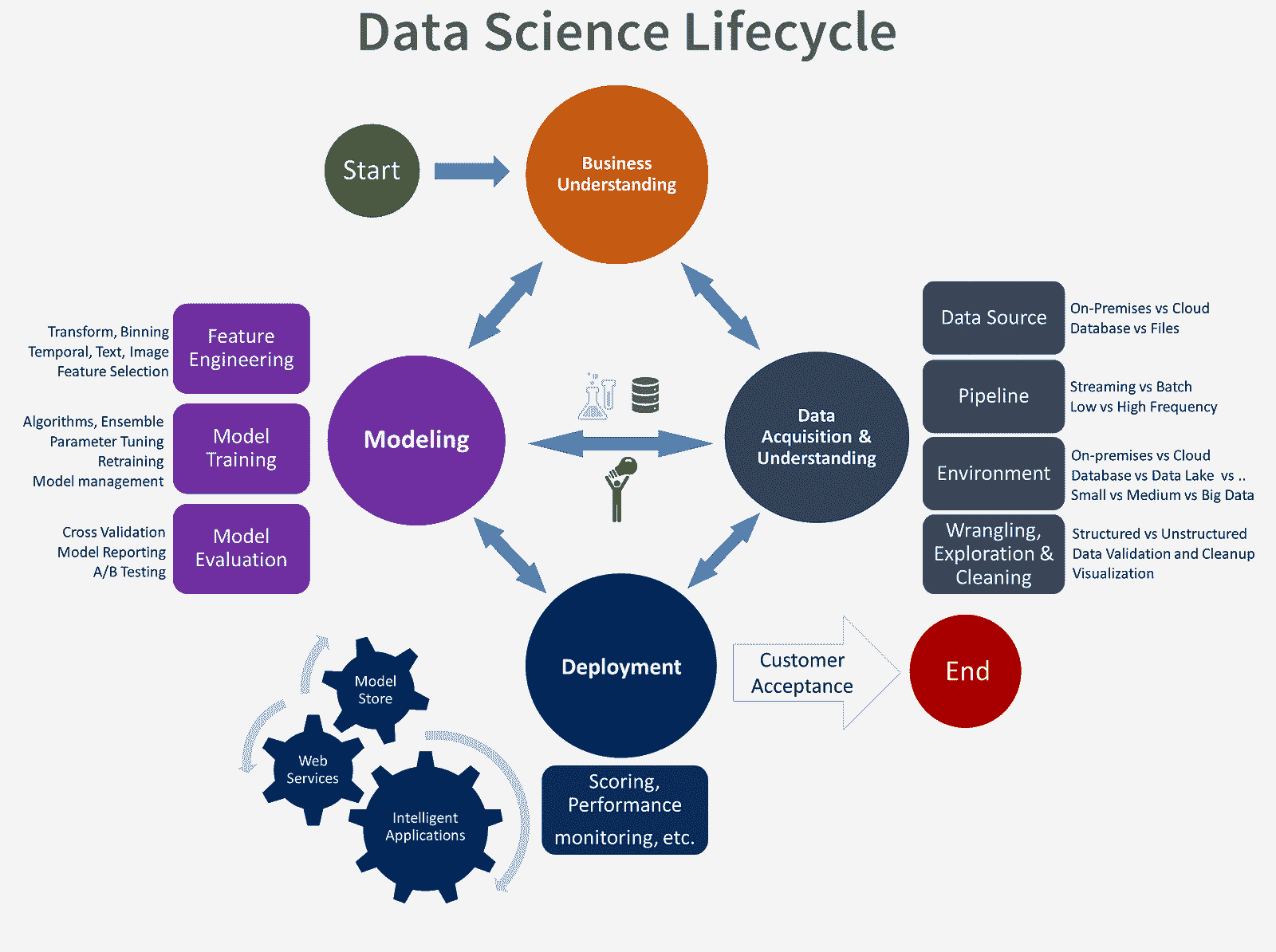
照片:Microsoft
你的公司可能有根据你所做的工作量身定制的过程,但了解这些基础流程真的很有帮助。
秘密成分?
好吧,这有点儿是个 trick question。我看到很多公司常常过于关注最新和最先进的算法和计算处理器,而忽视了数据。我们可能有大量的数据,但这些数据的质量不是理所当然的。好数据仍然很难收集,因此可能成为你所拥有的主要竞争优势。最好的算法无法保证好的模型,除非你提供好的数据。正如人们所说——垃圾进,垃圾出。
人工智能最被忽视的方面之一是大多数算法通过开源软件或通过云服务以非常低的成本提供。可以说,人工智能算法已经或将通过这些库和服务商品化。
我的建议是首先将你的数据科学路线图拆分为每个人都同意的简单应用案例,这些案例可以在几周内实现。同时确保数据是可以获取的,投资回报和/或交付物是明确定义的,并且数据团队遵循迭代执行的过程。
在你从这些循环中学到了一些经验后,你将更好地应对更复杂和风险更大的应用案例。
A 团队
现在我们已经讨论了如何规划我们的数据科学项目,我想谈谈如何创建一个数据团队来执行这些计划。我不会深入探讨像在哪里招聘或招聘流程应该如何的问题,而是关注团队的正确组成。
照片:Hudson UK
正如我在本文开头提到的,关于数据科学家的定义或职责存在许多困惑。考虑到这一职位的声望,任何曾经从事数据工作的人似乎都把它写在了简历上。我认为是时候摆脱这一点,根据人们实际做的工作来制定专业的职位名称了。
就像我们不期望医生知道每一种医疗程序或诊断一样,我们也不应该期望有人在人工智能领域精通一切。我们必须有专业人员,他们了解自己技能和职责的边界,并能够与他人合作完成任务。当然,这并不意味着没有人能在多个领域表现出色或成为通才,就像我们在医学中有全科医生一样。数据科学在很大程度上是一项团队运动。
照片:Business Science
由于数据是任何数据科学战略中最重要的元素,首先你需要的是数据工程师。数据工程师通常是那些具备良好的编程和硬件技能的人,能够构建你的数据基础设施。根据你的数据规模,他们通常能熟练操作大数据和云技术,知道如何构建数据管道、设计数据库并从中提取数据。他们会知道如何在基本层面查看数据,并进行简单的汇总以检查数据质量,但不一定擅长分析数据。
在建立好数据基础设施后,你将需要能够处理这些数据的人,他们需要清理、分析数据、进行实验并传达结果。根据你的业务需求,具体的技能要求有所不同。大多数情况下,这项工作由擅长数据处理和清理、创建统计推断或预测模型、运行实验、绘制结果、制作报告并向高层利益相关者提供见解的数据分析师来完成。他们通常会在 Jupyter notebook 或 Rstudio 中工作,具备编程、统计学和机器学习的知识。然而,我们不应该期望他们编写生产级别的代码。
这引出了下一个角色。如果你正在建立一个数据产品,你的团队中需要有机器学习工程师。这些人不是那些构建机器学习算法的研究人员,而是数据驱动的软件开发人员,他们熟悉各种数据科学库,并知道如何基于分析师开发的模型编写生产级别的代码。为了完成这项工作,他们必须与数据工程师密切合作,或者在较小的团队中,也可以由数学背景强的数据工程师来完成。希望进入数据科学领域的大多数开发人员应该考虑这是一个很好的职业选择。
有时候,拥有一位更注重设计的数据可视化专家来制作高度精致的图表和报告以传达分析结果也是很有用的。
我倾向于认为数据科学家是那些在所有上述角色中都表现优于平均水平的人,并且知道如何与领域专家合作以交付结果。这些领域专家通常是你团队或组织之外的合作者,你将他们引入来利用他们在医学、金融、经济学、市场营销、法律等领域的专业知识。
如果你在处理需要一些定制或专有数据科学算法的问题时,可能就需要雇佣具有博士学位或核心研究背景的人。他们可能对像对话 AI、计算机视觉、机器人学、强化学习、图形模型等 AI 领域的理论和算法有深刻的理解。我个人倾向于称这种角色为研究工程师或研究科学家。
数据科学团队中另一个重要但较少讨论的角色是数据科学经理或数据科学负责人。对于较小的团队,拥有一位对所有不同角色有深入了解的资深团队成员来领导团队可能就足够了。但一旦团队扩大,你可能需要拥有强大技术和商业战略背景的人。
数据科学经理是实践型领导者,他们将构建你数据科学战略的基础,招募并组建你的团队,确保每个人之间的互动,获得所需的数据和信息,并制定整个团队可以遵循的流程。他们是数据团队与组织其他部分、合作者和高管的接口。他们将复杂的人工智能术语翻译成非专家能够理解的语言,并确保他们的工作与组织整体战略保持一致。
经理还需要扮演一个常被忽视的重要角色,那就是制定团队的数据治理和伦理标准。大多数进入这个领域的专业人士都学到了执行工作的技术技能,但我很少看到关于数据隐私和分析结果伦理沟通的重要性被提及。这导致了如Facebook 丑闻这样的案例,使我们的领域名誉受损。在我看来,拥有一个了解并执行这些价值观的团队成员,是让你在同行中脱颖而出的关键。
这些是我对成功的数据科学团队的看法。主要的要点是——如果我们从简单的战略开始,选择正确的人才在合适的时间,利用从之前领域中积累的知识,并制定最适合你的团队和目标的流程,那么没有理由你不能成为一个有效的数据驱动型组织。
简介:Saurav Dhungana是一位经验丰富的数据科学和数据可视化专家,也是@craftdatalabs 的创始人。
原文。经许可转载。
资源:
相关:
更多相关主题
使用 SpaCy 自动提取命名实体的 Flask API
原文:
www.kdnuggets.com/2019/04/building-flask-api-automatically-extract-named-entities-spacy.html
注释
作者:Susan Li,高级数据科学家

图片来源:Pixabay
目前大量的非结构化文本数据提供了丰富的信息源,如果数据可以被结构化的话。命名实体识别 (NER)(也称为命名实体提取)是从半结构化和非结构化文本源中构建知识的第一步之一。
只有在进行 NER 后,我们才能至少揭示信息中包含了谁和什么。因此,数据科学团队将能够看到一个结构化的表示,展示一个语料库中所有人名、公司名、地点等的名称,这可以作为进一步分析和研究的起点。
在 上一篇文章中,我们学习并实践了 如何使用 NLTK 和 spaCy 构建命名实体识别器。为了更进一步,创建有用的东西,本文将介绍如何使用 spaCy 开发和部署一个简单的命名实体提取器,并通过 Flask API 用 Python 服务它*。
一个 Flask API
我们的目标是构建一个 API,我们提供文本,例如《纽约时报》文章(或任何文章)作为输入,我们的命名实体提取器将识别并提取四种类型的实体:组织、人物、地点和金额。基本架构如下:
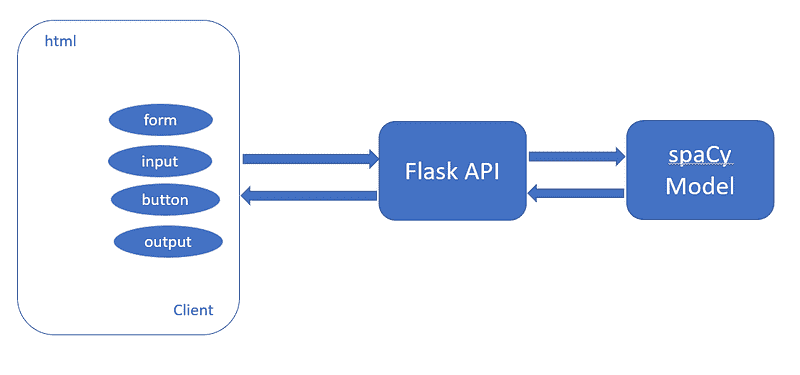
图 1
为了构建 API,我们需要创建两个文件:
-
index.html用于处理 API 的模板。 -
app.py用于处理请求并返回输出文件。
最终产品将如下所示:
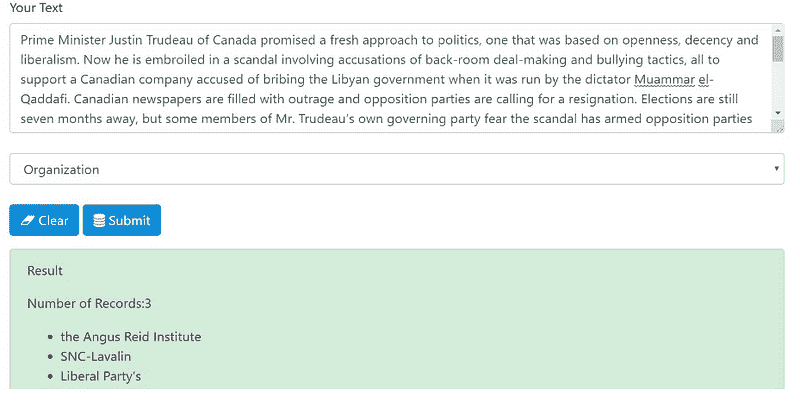
图 2
我们从构建 API 开始,逐步创建两个文件。我们的项目文件夹结构如下:
- 我们的项目位于 ***Named-Entity-Extractor ***文件夹中。
图 3
templates目录与创建的 app.py 文件在同一文件夹中。
图 4
- index.html 位于 templates 文件夹中。
index.html
-
我们将我们的应用命名为“命名实体提取器”
-
使用 BootstrapCDN,将 stylesheet
<link>复制粘贴到我们的<head>中,放在所有其他样式表之前,以加载我们的 CSS。 -
获取 Bootstrap 的导航头部,从 a template for a simple informational website 获取 navbar。它包含一个称为 jumbotron 的大召唤框和三个支持内容。
-
从模板的 source code 中复制粘贴 navbar 代码。
-
Bootstrap 需要一个容器元素来包裹站点内容并容纳我们的网格系统。
-
在我们的案例中,对于第一个容器,我们将创建一个垂直表单,其中包含两个输入字段,一个“清除”按钮和一个“提交”按钮。
-
文本表单控件使用
form-control类进行样式化。 -
我们为用户提供了四个任务选项(即命名实体提取任务),它们是:Organization,Person,Geopolitical 和 Money。
-
第二个容器为用户的操作提供上下文反馈消息,即命名实体提取的结果。
-
我们不仅希望将命名实体提取结果打印给用户,还希望打印每个命名实体提取的结果数量。
-
将 JavaScript 复制粘贴到我们 HTML 页面接近末尾的
<script>标签中,紧接着闭合的</body>标签之前。
app.py
我们的 app.py 文件相当简单且易于理解。它包含将由 Python 解释器执行以运行 Flask Web 应用程序的主要代码,其中包括用于识别命名实体的 spaCy 代码。
-
我们将应用作为单一模块运行;因此,我们用参数
__name__初始化了一个新的 Flask 实例,让 Flask 知道它可以在与自身所在目录相同的目录中找到 HTML 模板文件夹(templates)。 -
我们使用路由装饰器(
@app.route('/'))来指定应触发index函数执行的 URL。 -
我们的
index函数简单地渲染了位于templates文件夹中的index.htmlHTML 文件。 -
在
process函数内部,我们对用户输入的原始文本应用 nlp,并从原始文本中提取预定的命名实体(Organization,Person,Geopolitical 和 Money)。 -
我们使用
POST方法将表单数据传输到服务器的消息体中。最后,通过在app.run方法中设置debug=True参数,我们进一步激活了 Flask 的调试器。 -
我们使用
run函数仅在 Python 解释器直接执行此脚本时才运行应用程序,这通过使用if语句与__name__ == '__main__'进行确保。
我们快完成了!
尝试我们的 API
-
启动 **命令提示符。
-
进入我们的 命名实体提取器 文件夹。
图 5
- 打开你的 Web 浏览器,将 “
127.0.0.1:5000/” 粘贴到地址栏中,我们将看到这个表单:
图 6
- 我从 nytimes复制粘贴了一些文章段落,这是一个加拿大故事:

图 7
- 在“选择任务”下选择“Organization”,然后点击“提交”,我们得到的是:
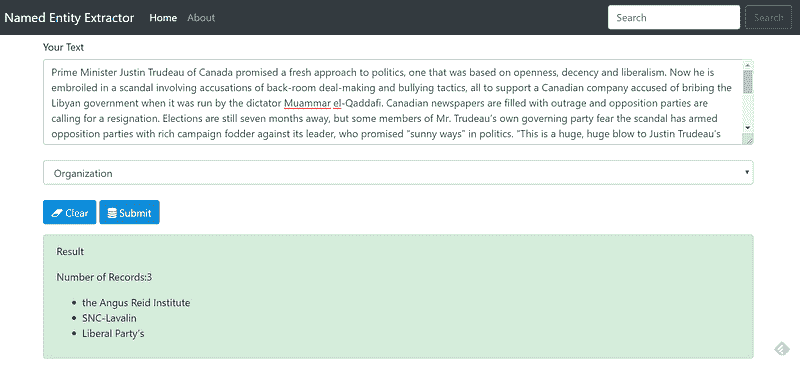
图 8
- 很好。让我们尝试“Person”实体:
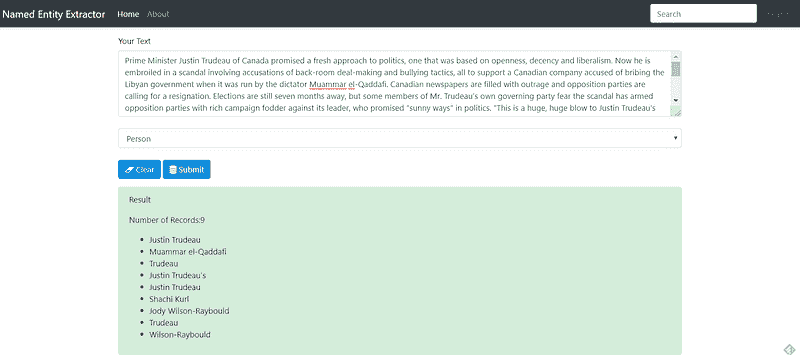
图 9
- “Geopolitical”实体:
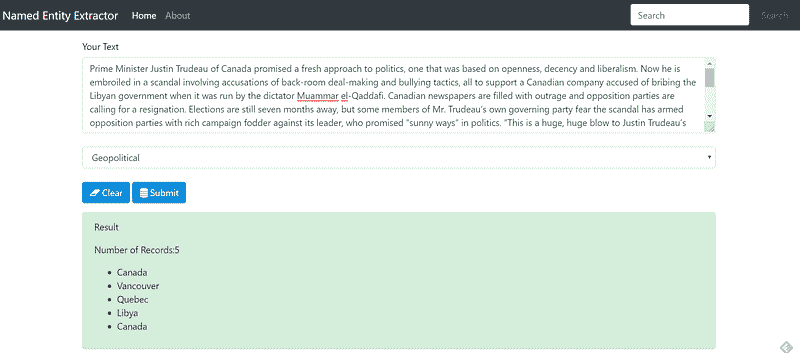
图 10
- “Money”实体:

图 11
完成了!
如果你按照以上步骤操作并达到了这里,恭喜你!你已经以零成本创建了一个简单但有效的命名实体提取器!回头看,我们只需要创建两个文件,所需的只是开源库和学习如何使用它们来创建这两个文件。
通过构建这样的应用,你已经学会了新技能,并使用这些技能创造了有用的东西。
完整源代码可在这个 代码库找到。祝周一愉快!
参考:
个人简介: Susan Li 正在通过一篇文章改变世界。她是位于加拿大多伦多的高级数据科学家。
原文。经许可转载。
相关:
-
你需要了解的关于 NLP 和机器学习的文本预处理
-
利用迁移学习和弱监督廉价构建 NLP 分类器
-
简单神经网络与 LSTM 时间序列预测介绍
我们的前三个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业。
2. Google Data Analytics Professional Certificate - 提升你的数据分析水平
3. Google IT Support Professional Certificate - 支持你的组织进行 IT 工作
更多相关内容
使用 Google Earth Engine 和 Greppo 在 Python 中构建地理空间应用
原文:
www.kdnuggets.com/2022/03/building-geospatial-application-python-google-earth-engine-greppo.html
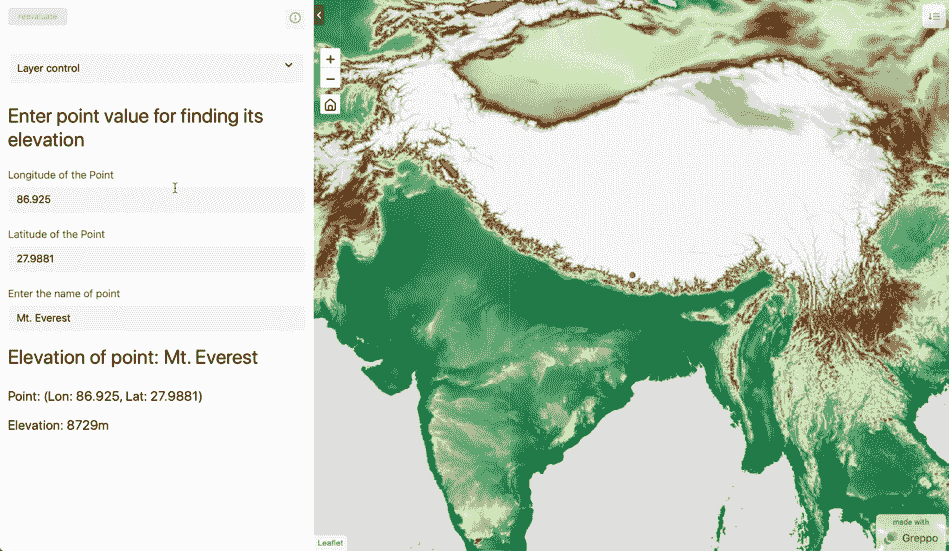
使用 Greppo 和 GEE 的最终网络应用。图像由作者提供。
Google Earth Engine 是数据科学家工具箱中处理地理空间数据的一个了不起的工具。然而,使用 GEE 代码编辑器构建网络应用需要一个陡峭的学习曲线。基于 JavaScript 的应用创建器对仅使用 Python 的数据科学家而言需要大量时间投入。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
Greppo 是弥补这一差距的完美工具。
在这篇博客文章中,我将使用 Greppo 构建一个流行的 GEE 用例(数字高程模型 DEM)的网络应用。我将带你了解 GEE 的基础知识、客户端-服务器模型、API 的工作原理以及 GEE 数据模型。了解这些背景后,文章将使用 Greppo 创建一个使用 GEE Python 接口的应用,并突出 Greppo 的思维模型和易用界面。
注意:这里的所有代码都是用 Python 编写的。它们从 文档** 中的 GEE 示例 JavaScript 代码移植而来**。
入门指南
在开始之前,你需要获取 Google Earth Engine 的访问权限。请按 这里的说明进行注册 并获取访问权限。
这是一个关于 Greppo 的简要教程以及如何使用它:在 Python 中使用 Greppo 构建地理空间仪表板
接下来,让我们设置 Python 环境以安装依赖项。要了解什么是 Python 环境及如何设置它,阅读此处。将以下包安装到 Python 环境中。
pip install earthengine-api greppo
网络应用的代码将放在 app.py 中,应用程序通过命令行使用命令 greppo serve app.py 提供和运行。
注意:要在命令行中运行greppo命令,你需要激活安装了 greppo 的 Python 环境。文件 app.py 可以重命名,但确保在运行命令greppo serve app.py时处于该文件所在的文件夹中,或者在相对文件夹结构greppo serve /demo/folder/app.py中。
Greppo 的 GitHub 仓库:github.com/greppo-io/greppo
如有任何问题,请通过GitHub上的“issues”或在Discord 频道联系我们。
GEE 认证与初始化
要使用 Google Earth Engine,你需要创建一个服务帐户并获取与该帐户关联的访问密钥文件。这只需几分钟,但确保按照说明正确操作。请按照这里的说明进行操作。要使用服务帐户和密钥文件,请使用以下代码进行初始化。
注意:确保将 key-file.json 保存在其他位置,最好安全地保存在计算机的根文件夹中,并且不要提交到公共仓库中。
理解 GEE 的客户端-服务器模型
正如 GEE 的开发文档所说,Earth Engine 不像你之前用过的任何 GIS 或地理空间工具。GEE 主要是一个云平台,所有处理都在云端完成,而不是在你的机器上。你与 GEE 的互动仅仅是将指令翻译并发送到 GEE 的云平台。为了更好地理解这一点,我们需要深入了解 GEE 的客户端与服务器以及其惰性计算模型。
客户端与服务器
从我之前提到的开始,GEE 主要是一个云平台。它让你在云端进行所有处理。那么,你如何访问这些处理功能呢?
这里就是earthengine-api库发挥作用的地方。Python 包earthengine-api为客户端(也就是你)提供了作为服务器对象代理的对象,这些对象在云端传递和处理。
为了更好地理解客户端-服务器模型,我们以客户端中的字符串变量和服务器中的字符串变量为例。在客户端创建字符串并打印其类型时,我们得到的是 Python 的class str对象来表示字符串。如果我们想将字符串发送到服务器进行使用或操作,我们会使用ee.String将数据包装在一个代理容器中,这样服务器就可以读取。更具体地说,ee.objects是ee.computedObject,它是代理对象的父类。
客户端字符串
client_string = 'I am a Python String object'
print(type(client_string))
服务器端字符串
server_string = ee.String('I am proxy ee String object!');
print(type(server_string))
代理对象不包含任何实际的数据或处理函数/算法。它们只是服务器(云平台)上对象的句柄,仅仅传达要在服务器上执行的指令。可以把它看作是使用代码与服务器沟通的一种方式,为此你需要将数据和指令包装在 ee.computedObject 特定类型的容器中。
当对数据进行循环或使用条件语句时,这种理解变得更加重要。要执行这些操作,需要将指令发送到服务器以执行。要了解这些是如何实现的,查看此页面 获取更多详细信息。
惰性计算模型(延迟执行)
从上面的内容我们知道,earthengine-api 包仅用于向服务器发送指令。那么,执行是如何以及何时发生的呢?
客户端库 earthengine-api 将所有指令编译成 JSON 对象并发送到服务器。然而,这并不会立即执行。执行会被推迟,直到有请求结果。结果请求可以是 print 语句,或者是要显示的 image 对象。
这种按需计算会影响返回给客户端(即用户)的内容。earthengine-api 的结果是一个指向 GEE 瓦片服务器的 URL,其中包含需要提取的数据。因此,在提到的兴趣区域内的图像会被选择性地处理。兴趣区域由客户端显示中的地图的缩放级别和中心位置确定。当你移动和缩放时,图像会被处理并发送给客户端以供查看。因此,这些图像是惰性计算的。
使用 Greppo 结合 GEE
使用 Greppo 显示和可视化 Earth Engine 图像对象是相当简单的,你只需要使用:app.ee_layer()。GEE 中存储地理空间数据的基本数据类型是,
-
Image:Earth Engine 中的基本栅格数据类型。 -
ImageCollection:图像的堆叠或时间序列。 -
Geometry:Earth Engine 中的基本矢量数据类型。 -
Feature:带有属性的 Geometry。 -
FeatureCollection:一组特征。
了解 GEE 的客户端-服务器和惰性计算模型后,我们可以推测这些数据类型是按需处理的,在请求其可视化时。
那么,如何将 Greppo 与 GEE 结合使用?
通过一个例子来解释是最好的。首先,我们从 app 的搭建开始。你需要从 greppo 中导入 app 对象,因为它将是你与前端沟通的入口点。接下来,你需要 import ee,验证你的 Earth Engine 身份,并使用上述服务账户的凭据初始化你的会话。
接下来,让我们从目录中选择数据集。在这里,我们使用 USGS/SRTMGL1_003 获取数字高程图。我们首先需要为 DEM 图像数据中所有大于 0 的值获取一个地面掩码,为此我们使用 dem.get(0)。接下来,我们需要在 DEM 上应用掩码,只可视化土地区域,为此我们使用 dem.updateMask(dem.gt(0)),并将结果指定为我们要可视化的 ee_dem。由于所有数据存储为 int16(值在 32767 和 -32768 之间的矩阵),我们需要使用调色板来可视化矩阵。
要添加调色板,我们创建一个可视化参数对象,其中包含生成 RGM 或灰度图像的指令。在这里,我们使用包含以下 Hex 值的调色板:[‘006633’, ‘E5FFCC’, ‘662A00’, ‘D8D8D8’, ‘F5F5F5’],并将其线性映射到指定的 min -> #006633 和 max -> #F5F5F5 对应的值。
注意:DEM 中存储的数据是栅格,表示为矩阵,每个单元格包含表示该单元格的点的海拔高度(单位:米)。
要在使用 Greppo 的 Web 应用程序中可视化此地图,你只需使用 app.ee_layer()。ee_object 是地球引擎图像对象,vis_param 是可视化参数字典,name 对应于在 Web 应用前端使用的唯一标识符,而 description 是可选的,用于向应用用户提供额外的说明。有关更多信息,请参见文档 此处。
上一步骤的 Web 应用视图。图片由作者提供。
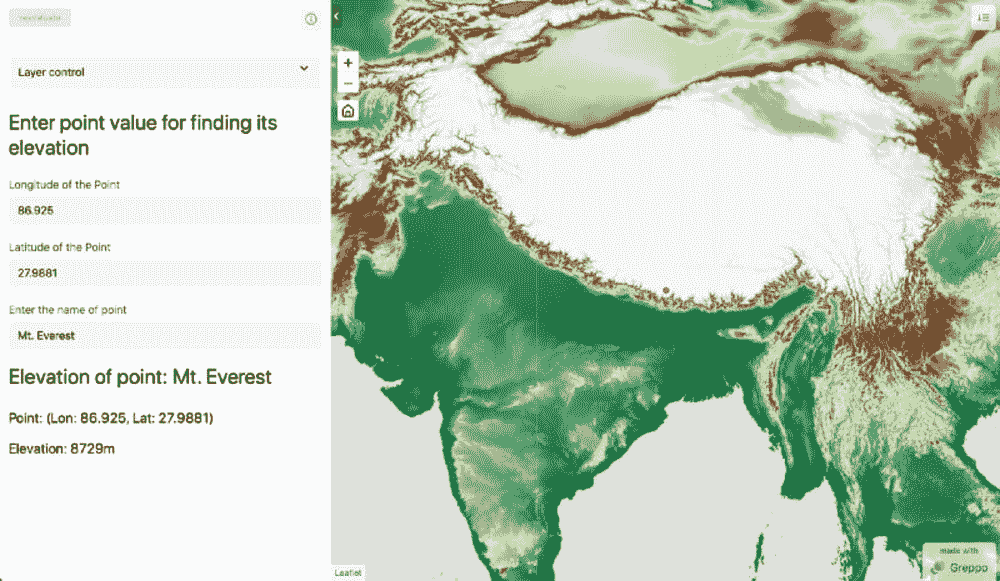
端到端通信:完整 Web 应用
到目前为止,我们只看到了如何在 Greppo 中可视化地球引擎对象。然而,Greppo 能够实现前端和后端之间的复杂交互。我们来举一个找到用户指定点的海拔高度的例子。我们将使用 Greppo 的三个 API 特性。
-
app.display():在前端显示文本或 Markdown。 -
app.number():前端中的数字输入功能,供用户输入一个值。与之绑定的后端变量将更新为用户指定的值。 -
app.text():前端中的文本输入功能,供用户输入一个值。与之绑定的后端变量将更新为用户指定的值。
有关更多详细信息,请参见 文档此处。
让我们开始使用 app.display(name 是唯一标识符,值是显示的文本,可以是多行字符串)来为 Web 应用用户显示一些文本。之后,让我们创建两个数字输入框,每个用于输入点的经度和纬度,使用 app.number()。
app.number() 接受名称(前端显示的标识符)和值(此元素的默认值)。接下来,我们还将创建一个文本输入框,用于获取点的名称,使用app.text(),并将name和value作为app.number()中提到的参数。
使用该点的纬度和经度,我们现在可以创建一个带有可视化参数color: ‘red’的地球引擎 Geometry 对象。我们可以使用上述提到的app.ee_layer()来显示这个对象。
要查找该点的高程,我们使用sample方法在 DEM 对象上进行地球引擎操作。我们在 DEM 中对该点进行采样以获取 DEM 的属性。我们从输出中获取第一个点,并使用.get方法查找与高程属性相关的值。最后,我们组合一个多行字符串来显示输出。
注:要在初始加载时将地图居中于某个点并设置缩放级别,请使用app.map(center=[lat, lon], zoom=level)。
带有交互功能的 Web 应用视图。图像由作者提供。
结论
我们的目标是使用 Python 完全创建一个 Web 应用,利用 Google Earth Engine 的数据和计算功能以及 Greppo 的 Web 应用开发库。我们了解了 GEE 的工作原理,了解了如何将 Greppo 与 GEE 集成。学会使用app.ee_layer(), app.display(), app.number() 和 app.text()来创建一个完整的 Web 应用,实现前端和后端的全程通信。
演示的所有文件可以在这里找到: github.com/greppo-io/greppo-demo/tree/main/ee-demo
查看GitHub 库:这里,了解 Greppo 的最新动态。如果发现错误、问题或需要功能请求,请通过Discord 频道联系,或在 GitHub 上提出问题。用 Greppo 构建了什么?在 GitHub 上发布它。
-
GitHub 库:
github.com/greppo-io/greppo -
文档:
docs.greppo.io/ -
网站:
greppo.io/
Adithya Krishnan (@krish_adi_) 是一名科学家、开发者、创始人和攀登者。他对构建 Web 应用、云服务、数据科学以及 AI/ML 项目感兴趣。 了解更多。
更多相关内容
从零开始构建图像搜索服务
原文:
www.kdnuggets.com/2019/01/building-image-search-service-from-scratch.html/2
评论
文本 -> 文本
毕竟没那么不同
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
文本的嵌入
转到自然语言处理(NLP)的领域,我们可以使用类似的方法索引和搜索词汇。
我们加载了一组来自GloVe的预训练向量,这些向量是通过爬取整个维基百科并学习数据集中词汇之间的语义关系获得的。
就像之前一样,我们将创建一个索引,这次包含所有的 GloVe 向量。然后,我们可以搜索我们的嵌入以查找相似的词汇。
例如,搜索said返回这个[word, distance]的列表:
-
['said', 0.0] -
['told', 0.688713550567627] -
['spokesman', 0.7859575152397156] -
['asked', 0.872875452041626] -
['noting', 0.9151610732078552] -
['warned', 0.915908694267273] -
['referring', 0.9276227951049805] -
['reporters', 0.9325974583625793] -
['stressed', 0.9445104002952576] -
['tuesday', 0.9446316957473755]
这似乎很合理,大多数词汇与我们原始词汇的含义相似,或者代表了一个合适的概念。最后的结果(tuesday)也显示这个模型远非完美,但它能让我们开始。现在,让我们尝试将词汇和图像都融入我们的模型中。
一个相当大的问题
使用嵌入之间的距离作为搜索的方法是相当通用的,但我们对词汇和图像的表示似乎不兼容。图像的嵌入大小为 4096,而词汇的嵌入大小为 300——我们如何用一种来搜索另一种呢?此外,即使两个嵌入的大小相同,它们的训练方式也完全不同,因此图像和相关词汇随机具有相同的嵌入的可能性极低。我们需要训练一个联合模型。
图像 <-> 文本
世界碰撞
现在让我们创建一个混合模型,可以在词汇和图像之间相互转换。
在本教程中,我们将首次实际训练自己的模型,灵感来自一篇名为DeViSE的优秀论文。我们不会完全重新实现它,但会在其主要思想上大量借鉴。(有关该论文的另一种略有不同的看法,请查看 fast.ai 在其lesson 11中的实现。)
这个想法是通过重新训练我们的图像模型并改变标签类型来结合这两种表示。
通常,图像分类器被训练从许多类别中选择一个(Imagenet 有 1000 个)。这意味着——以 Imagenet 为例——最后一层是一个大小为 1000 的向量,表示每个类别的概率。这意味着我们的模型对哪些类别彼此相似没有语义理解:将cat的图像分类为dog和将其分类为airplane的错误程度相同。
对于我们的混合模型,我们用类别的词向量替换模型的最后一层。这使得我们的模型可以学习将图像的语义映射到词语的语义,并且意味着相似的类别会彼此更接近(因为cat的词向量比airplane更接近dog)。我们将预测一个语义丰富的词向量,其大小为 300,而不是一个大小为 1000 的全零目标。
我们通过添加两个密集层来实现这一点:
-
一个大小为 2000 的中间层
-
一个大小为 300 的输出层(GloVe 词向量的大小)。
这是模型在 Imagenet 上训练时的样子:
现在它的样子是这样的:
训练模型
然后,我们在数据集的训练分割上重新训练模型,以学习预测与图像标签相关的词向量。例如,对于类别为猫的图像,我们试图预测与猫相关的 300 长度的向量。
这个训练需要一些时间,但仍然比在 Imagenet 上的速度快很多。作为参考,在我没有GPU的笔记本上大约花了 6-7 小时。
需要注意的是,这种方法的雄心壮志。我们这里使用的训练数据(数据集的 80%,即 800 张图像)相对于通常的数据集来说微不足道(Imagenet 有一百万张图像,多三个数量级)。如果我们使用传统的类别训练方法,我们不期望模型在测试集上表现很好,更不用说在完全新的示例上表现了。
一旦我们的模型训练完成,我们将获得上述的 GloVe 词索引,并通过将数据集中所有图像通过它来构建一个新的快速图像特征索引,保存到磁盘。
标记
我们现在可以通过将图像输入到我们训练的网络中,轻松提取任何图像的标签,保存出来的大小为 300 的向量,并在 GloVe 的英文单词索引中找到最接近的词。让我们试试这张图像——它属于bottle类别,但包含各种物品。

这是生成的标签:
-
[6676, 'bottle', 0.3879561722278595] -
[7494, 'bottles', 0.7513495683670044] -
[12780, 'cans', 0.9817070364952087] -
[16883, 'vodka', 0.9828150272369385] -
[16720, 'jar', 1.0084964036941528] -
[12714, 'soda', 1.0182772874832153] -
[23279, 'jars', 1.0454961061477661] -
[3754, 'plastic', 1.0530102252960205] -
[19045, 'whiskey', 1.061428427696228] -
[4769, 'bag', 1.0815287828445435]
这是一个相当惊人的结果,因为大多数标签非常相关。这种方法仍有成长空间,但它相当好地识别了图像中的大部分项目。模型学会了提取许多相关标签,即使是从它未经过训练的类别中!
使用文本搜索图像
最重要的是,我们可以使用我们的联合嵌入通过任何词在我们的图像数据库中进行搜索。我们只需从 GloVe 获取我们的预训练词嵌入,然后找到与之最相似的图像(通过我们的模型运行它们来获得)。
用最少的数据进行图像搜索的泛化。
首先从一个实际存在于我们训练集中的词开始,搜索dog:。

搜索词“dog”的结果
好的,结果相当不错——但这可以从任何仅仅在标签上训练的分类器中得到!让我们尝试更困难的任务,通过搜索关键字ocean,这是我们数据集中没有的。

搜索词“ocean”的结果
这太棒了——我们的模型理解ocean类似于water,并返回了许多来自boat类别的项。
那么搜索street怎么样?

搜索词“street”的结果
在这里,我们返回的图像来自许多类别(car、dog、bicycles、bus、person),尽管我们从未在训练模型时使用过这个概念,但大多数图像包含或接近街道。因为我们通过预训练的词向量利用外部知识来学习从图像到向量的映射,这种映射比简单的类别更具语义丰富性,所以我们的模型能够很好地泛化到外部概念。
超越词汇
- 英语虽然进步很大,但还不足以为每个事物发明一个词。例如,在发布这篇文章时,英语中没有“猫躺在沙发上”的词汇,而这是一个完全有效的搜索引擎查询。如果我们想同时搜索多个单词,我们可以使用一种非常简单的方法,利用词向量的算术性质。结果表明,两个词向量的相加通常效果很好。因此,如果我们只是使用
cat和sofa的平均词向量来搜索图像,我们可以期望得到非常像猫的、非常像沙发的图像,或者是猫躺在沙发上的图像。
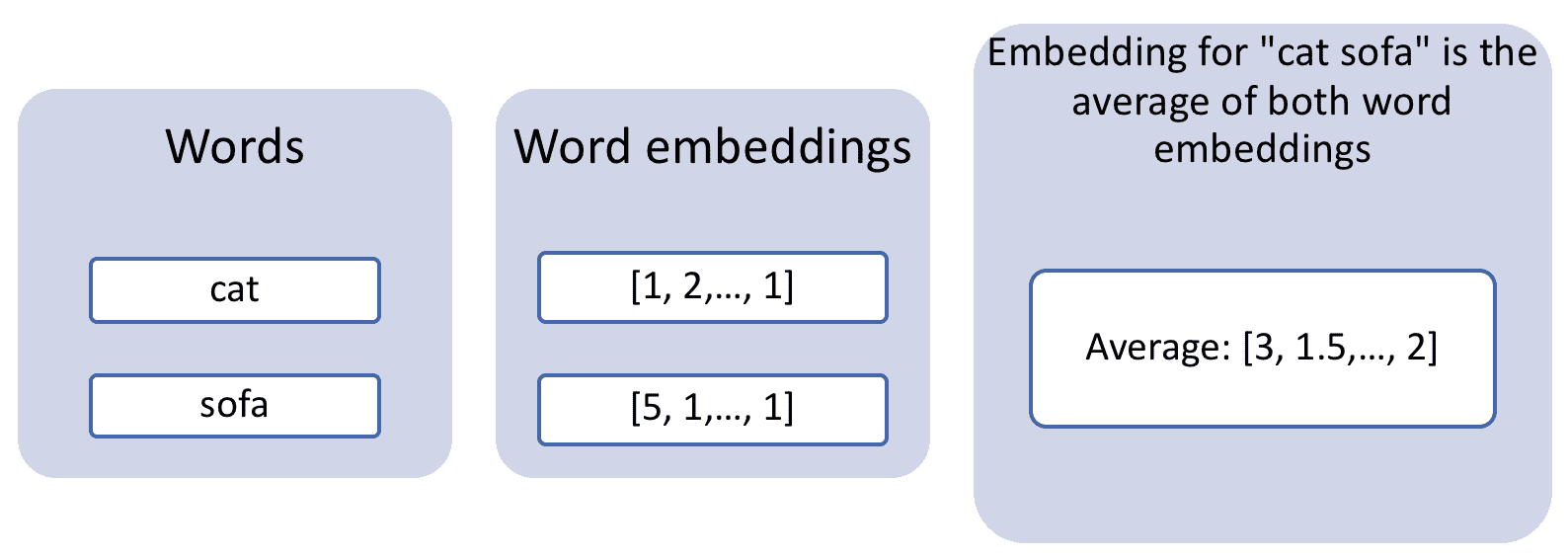
-
获取多个单词的联合嵌入
-
让我们试试使用这种混合嵌入进行搜索吧!

-
搜索词“
cat"+"sofa"的结果 -
这是一个令人惊叹的结果,因为大多数这些图像包含了某种版本的毛茸茸的动物和沙发(我特别喜欢第二行最左侧的图像,看起来像是一堆毛茸茸的东西靠在沙发旁边)!我们的模型虽然只在单词上进行过训练,但可以处理两个单词的组合。我们还没有建立 Google 图像搜索,但对于相对简单的架构来说,这确实令人印象深刻。
-
这种方法实际上可以自然地扩展到各种领域(参见这个 示例 以了解联合代码-英语嵌入),所以我们非常想知道你将其应用于什么。
结论
- 我希望你觉得这篇文章有用,并且对基于内容的推荐系统和语义搜索有了更多了解。如果你有任何问题或评论,或者想分享你使用这个教程构建的东西,请通过 Twitter联系我!
想从硅谷或纽约的顶级专业人士那里学习应用人工智能吗? 了解更多关于 人工智能 计划的信息。
你是一家从事人工智能的公司,想参与 Insight AI Fellows 计划吗? 随时 联系我们。
-
感谢 Stephanie Mari, Bastian Haase, Adrien Treuille 和 Matthew Rubashkin。
-
简介:Emmanuel Ameisen (@EmmanuelAmeisen) 是 Insight Data Science 的 AI 负责人。
-
原文。经许可转载。
-
相关:
-
解决 90% 自然语言处理问题的步骤指南
-
使用 MXNET Gluon 和 Comet.ml 实现 ResNet 进行图像分类
-
快速轻松解决任何图像分类问题
相关阅读
使用 Snowflake 和 Dask 构建机器学习管道
原文:
www.kdnuggets.com/2021/07/building-machine-learning-pipelines-snowflake-dask.html
评论
作者:Daniel Foley,数据科学家

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
介绍
最近,我一直在尝试找到更好的方法来改善作为数据科学家的工作流程。我发现自己在工作中花了相当多的时间进行建模和构建 ETL。这意味着我越来越需要依赖工具来可靠且高效地处理大型数据集。我很快意识到,使用 pandas 来操作这些数据集并不总是一个好方法,这促使我寻找其他的替代方案。
在这篇文章中,我想分享一些我最近探索的工具,并展示我如何使用它们以及它们如何帮助提高工作效率。我特别要谈的是 Snowflake 和 Dask。这两者是非常不同的工具,但它们在机器学习生命周期中相互补充。我的希望是,在阅读这篇文章后,你将对 Snowflake 和 Dask 有一个良好的理解,知道如何有效使用它们,并能够快速上手自己的用例。
更具体地说,我想展示如何使用 Snowflake 和 Python 构建 ETL 管道,为机器学习任务生成训练数据。接着,我会介绍 Dask 和Saturn Cloud,并展示如何利用云中的并行处理来真正加速机器学习训练过程,从而提升你作为数据科学家的生产力。
在 Snowflake 和 Python 中构建 ETL
在开始编码之前,我最好简要解释一下 Snowflake 是什么。这是我最近在团队决定开始使用它时问的一个问题。从高层次来看,它是一个云中的数据仓库。在玩了一段时间后,我意识到它的强大功能。我认为对我来说,最有用的功能之一是你可以使用的虚拟仓库。虚拟仓库使你可以访问相同的数据,但与其他虚拟仓库完全独立,因此计算资源不会在团队之间共享。这被证明非常有用,因为它消除了由于其他用户在一天中执行查询而引起的性能问题的潜在可能。这减少了因查询运行而产生的挫败感和等待时间。
由于我们将使用 Snowflake,我将简要概述如何设置它并开始自己进行实验。我们需要做以下几件事:
-
设置一个 Snowflake 账户
-
将我们的数据导入 Snowflake
-
使用 SQL 和 Snowflake UI 编写并测试我们的查询
-
编写一个 Python 类,以执行我们的查询来生成最终的数据集用于建模
设置账户就像在他们的 网站 上注册一个免费试用一样简单。完成后,你可以从 这里 下载 snowsql CLI。这将使将数据添加到 Snowflake 变得简单。在完成这些步骤后,我们可以尝试使用我们的凭据和命令行连接到 Snowflake。
snowsql -a <account_name> -u <user_name>
当你登录 Snowflake UI 时,你可以在 URL 中找到你的账户名。它应该类似于这样:xxxxx.europe-west2.gcp。好了,让我们进入下一步,把数据导入 Snowflake。我们需要遵循以下几个步骤:
-
创建我们的虚拟仓库
-
创建一个数据库
-
定义和创建我们的表
-
为我们的 CSV 文件创建一个临时表
-
将数据复制到我们的表中
幸运的是,这并不难,我们可以完全使用 snowsql CLI 来完成。对于这个项目,我将使用一个比我希望的小的数据集,但不幸的是,我不能使用公司中的任何数据,而且在网上找到大规模适合的数据集也相当困难。不过,我确实找到了来自 Dunnhumby 的一些交易数据,这些数据可以在 Kaggle 上免费获取。为了好玩,我使用这些数据创建了一个更大的合成数据集,以测试 Dask 相比于 sklearn 处理挑战的效果。
首先,我们需要在 Snowflake UI 中使用以下命令设置一个虚拟仓库和一个数据库。
create or replace warehouse analytics_wh with
warehouse_size=”X-SMALL”
auto_suspend=180
auto_resume=true
initially_suspended=true;
create or replace database dunnhumby;
我们的数据由 6 个 CSV 文件组成,我们将其转换为 6 个表格。我不会花太多时间讲解数据集,因为这篇文章更多的是关于使用 Snowflake 和 Dask,而不是解释数据。
以下是我们可以用来创建表格的命令。你需要提前了解的只是你将处理的列和数据类型。
**create** **or** **replace** **table** campaign_desc (
description **string**,
campaign number,
start_day number,
end_day number );
**create** **or** **replace** **table** campaign_table (
description **string**,
Household_key number,
campaign number );
**create** **or** **replace** **table** coupon (
COUPON_UPC number,
product_id number,
campaign number );
**create** **or** **replace** **table** coupon_redempt (
household_key number,
**day** number,
coupon_upc number,
campaign number );
**create** **or** **replace** **table** transactions (
household_key number,
BASKET_ID number,
**day** number,
product_id number,
quantity number,
sales_value number,
store_id number,
retail_disc decimal,
trans_time number,
week_no number,
coupon_disc decimal,
coupon_match_disc decimal );
**create** **or** **replace** **table** demographic_data (
age_dec **string**,
marital_status_code **string**,
income_desc **string**,
homeowner_desc **string**,
hh_comp_desc **string**,
household_size_desc string,
kid_category_desc **string**,
Household_key number);
现在我们已经创建了表格,可以开始考虑如何将数据导入这些表格。为此,我们需要对 CSV 文件进行分阶段处理。这基本上只是一个中间步骤,以便 Snowflake 可以直接从我们的阶段加载文件到表格中。我们可以使用PUT命令将本地文件放入阶段,然后使用COPY INTO命令指示 Snowflake 将数据放置到哪里。
use database dunnhumby;
**create** **or** **replace** stage dunnhumby_stage;
PUT file://campaigns_table.csv @dunnhumby.public.dunnhumby_stage;
PUT file://campaigns_desc.csv @dunnhumby.public.dunnhumby_stage;
PUT file://coupon.csv @dunnhumby.public.dunnhumby_stage;
PUT file://coupon_d=redempt.csv @dunnhumby.public.dunnhumby_stage;
PUT file://transaction_data.csv @dunnhumby.public.dunnhumby_stage;
PUT file://demographics.csv @dunnhumby.public.dunnhumby_stage;
作为快速检查,你可以运行这个命令来检查阶段区域中的内容。
ls @dunnhumby.public.dunnhumby_stage;
现在我们只需使用下面的查询将数据复制到我们的表格中。你可以在 Snowflake UI 或登录 Snowflake 后在命令行中执行这些查询。
copy into campaign_table
from @dunnhumby.public.dunnhumby_stage/campaigns_table.csv.gz
file_format = ( type = csv
skip_header=1
error_on_column_count_mismatch = false
field_optionally_enclosed_by=’”’);
copy into campaign_desc
from @dunnhumby.public.dunnhumby_stage/campaign_desc.csv.gz
file_format = ( type = csv
skip_header=1
error_on_column_count_mismatch = false
field_optionally_enclosed_by=’”’);
copy into coupon
from @dunnhumby.public.dunnhumby_stage/coupon.csv.gz
file_format = ( type = csv
skip_header=1
error_on_column_count_mismatch = false
field_optionally_enclosed_by=’”’);
copy into coupon_redempt
from @dunnhumby.public.dunnhumby_stage/coupon_redempt.csv.gz
file_format = ( type = csv
skip_header=1
error_on_column_count_mismatch = false
field_optionally_enclosed_by=’”’);
copy into transactions
from @dunnhumby.public.dunnhumby_stage/transaction_data.csv.gz
file_format = ( type = csv
skip_header=1
error_on_column_count_mismatch = false
field_optionally_enclosed_by=’”’);
copy into demographic_data
from @dunnhumby.public.dunnhumby_stage/demographics.csv.gz
file_format = ( type = csv skip_header=1
error_on_column_count_mismatch = false
field_optionally_enclosed_by=’”’);
好的,如果运气好的话,我们第一次尝试时数据就会在表格中。哦,真希望这么简单,这整个过程我尝试了几次才搞对(注意拼写错误)。希望你能跟上这些步骤,并顺利完成。我们离有趣的部分越来越近,但上述步骤是过程中的关键部分,所以一定要理解每一步。
用 SQL 编写我们的管道
在下一步中,我们将编写查询以生成我们的目标、特征,最后产生一个训练数据集。创建建模数据集的一种方法是将数据读入内存,使用 pandas 创建新特征并将所有数据框连接在一起。这通常是在 Kaggle 和其他在线教程中看到的方法。这样做的问题是效率不是很高,特别是当你处理任何合理大小的数据集时。因此,最好将繁重的工作外包给像 Snowflake 这样的工具,它非常擅长处理大规模数据集,并且可能会节省大量时间。我不会花太多时间深入探讨我们的数据集,因为这并不真正影响我想展示的内容。总的来说,你应该花相当多的时间来探索和理解你的数据,然后再开始建模。这些查询的目标是对数据进行预处理并创建一些简单的特征,我们可以在模型中使用这些特征。
目标定义
显然,监督机器学习的一个关键组成部分是定义一个合适的目标进行预测。对于我们的使用案例,我们将通过计算用户在截止周后两周内是否再次访问来预测流失。选择两周是相当随意的,具体取决于我们试图解决的具体问题,但我们就假设这个项目中这样做是合适的。一般来说,你会想要仔细分析你的客户,以了解访问之间的间隔分布,从而得出一个合适的流失定义。
这里的主要思想是,对于每个表,我们希望每个 household_key 具有每个特征的值的一行。
活动特征
交易特征
下面我们基于汇总统计信息(如平均值、最大值和标准差)创建一些简单的指标。
人口统计特征
这个数据集有很多缺失数据,所以我决定在这里使用插补。对于缺失数据,有很多技术,从丢弃缺失数据到高级插补方法。我在这里让自己简化了操作,用众数替换缺失值。我不会普遍推荐这种方法,因为理解数据缺失的原因对于决定如何处理它非常重要,但为了这个例子的目的,我会继续采用简单的方法。我们首先计算每个特征的众数,然后使用 coalesce 来替换缺失的数据。
训练数据
最后,我们通过将主要表连接起来,构建一个用于训练数据的查询,并最终得到一个包含我们的目标、我们的活动、交易和人口统计特征的表,我们可以用来构建模型。
顺便提一下,对于那些有兴趣了解 Snowflake 的更多功能和细节的人,我推荐以下书籍:Snowflake Cookbook。我开始阅读这本书,它包含了如何使用 Snowflake 的非常有用的信息,并且详细程度远超我在这里所述的。
Python 代码用于 ETL
对于这个 ETL,最终需要写一个脚本来执行它。现在,如果你打算定期运行这样的 ETL,这确实是必要的,但这是一种良好的实践,并且使得在需要时运行 ETL 更加容易。
简要讨论一下我们 EtlTraining 类的主要组件。我们的类接受一个输入,即截止周。这是由于数据在数据集中被定义的方式,但通常,这将是一个与我们选择的生成训练数据的截止日期相对应的日期格式。
我们初始化了一个查询列表,以便可以轻松地循环遍历这些查询并执行它们。我们还创建了一个包含我们参数的字典,并将其传递给我们的 Snowflake 连接。在这里,我们使用了在 Saturn Cloud 中设置的环境变量。这里是关于如何做到这一点的指南。连接 Snowflake 并不太困难,我们只需要使用 Snowflake 连接器并传入我们的凭据字典即可。我们在 Snowflake 连接方法中实现了这一点,并将此连接作为属性返回。
为了使这些查询更容易运行,我将每个查询保存为python字符串变量在 ml_query_pipeline.py 文件中。execute_etl 方法正如其名,我们循环遍历每个查询,对其进行格式化,执行它,并最后关闭 Snowflake 连接。
要运行这个 ETL,我们可以简单地在终端中输入以下命令。(其中 ml_pipeline 是上面脚本的名称。)
python -m ml_pipeline -w 102 -j ‘train’
简单来说,你可能希望定期运行像这样的 ETL。例如,如果你想进行每日预测,那么你将需要每天生成一个这样的数据集以传递给你的模型,从而识别哪些客户可能会流失。我不会在这里详细讲解,但在我的工作中,我们使用 Airflow 来编排我们的 ETL,因此如果你感兴趣,我建议你去了解一下。实际上,我最近买了一本书‘Data Pipelines with Apache Airflow’,我认为它非常棒,提供了一些很好的示例和关于如何使用 Airflow 的建议。
Dask 和建模
现在我们已经构建了数据管道,我们可以开始考虑建模。我这篇文章的另一个主要目标是突出使用Dask作为机器学习开发过程的一部分的优势,并向大家展示它的易用性。
在这个项目的部分,我还使用了Saturn Cloud,这是我最近遇到的一个非常好的工具,它允许我们在云中通过计算机集群利用 Dask 的力量。对我来说,使用 Saturn 的主要优势是非常容易共享你的工作、在需要时简单地扩展计算资源,并且它有一个免费的选项。模型开发通常是 Dask 的一个很好的应用场景,因为我们通常想要训练一组不同的模型,看看哪个效果最好。我们能越快做到这一点越好,因为我们可以有更多时间专注于模型开发的其他重要方面。类似于 Snowflake,你只需要在这里注册,你可以非常快速地启动一个 Jupyter lab 实例并开始自己动手实验。
现在,我意识到我在这里提到 Dask 几次,但从未真正解释过它是什么。所以让我花点时间给你一个关于 Dask 的高层次概述,以及为什么我认为它很棒。简单来说,Dask 是一个 Python 库,利用并行计算来处理和执行非常大的数据集上的操作。而且,最棒的是,如果你已经熟悉 Python,那么 Dask 应该非常直接,因为其语法非常相似。
下图突出显示了 Dask 的主要组件。
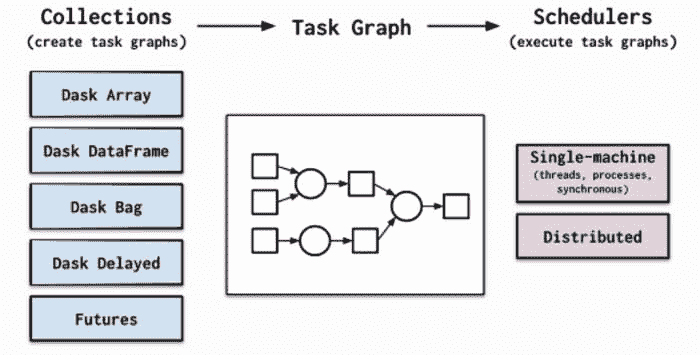
来源: Dask 文档
Collections 允许我们创建一个任务图,这些任务图可以在多个计算机上执行。这些数据结构中有些可能听起来很熟悉,比如数组和数据框,它们类似于你在 Python 中会遇到的,但有一些重要的不同之处。例如,你可以把 Dask 数据框看作是一个由 pandas 数据框组成的集合,这些数据框以一种可以让我们并行执行操作的方式构建。
从 collections 说到调度器。一旦我们创建了任务图,调度器就会处理剩下的工作。它管理工作流程,并将这些任务发送到单台机器或分布到集群中。希望这能给你一个关于 Dask 工作原理的简要概述。欲了解更多信息,我建议你查看 文档 或这本 书。这两者都是深入了解该主题的非常好资源。
Python 建模代码
在建模时,我倾向于使用少量的常用算法,这些算法是我总是会首先尝试的。这通常会让我对可能适合我具体问题的模型有一个很好的了解。这些模型包括 Logistic Regression、Random Forest 和 GradientBoosting。在我的经验中,处理表格数据时,这些算法通常会给出相当不错的结果。下面我们使用这三种模型构建一个 sklearn 建模管道。我们在这里使用的具体模型并不是特别重要,因为该管道应该适用于任何 sklearn 分类模型,这只是我的偏好。
不再废话,让我们直接进入代码。幸运的是,我们将大部分预处理工作外包给了 Snowflake,因此在这里我们不需要过多处理训练数据,但我们将使用 sklearn 管道添加一些额外的步骤。
下方的第一个代码片段展示了使用 sklearn 的管道。注意我们的数据集是一个普通的 pandas 数据框,我们的预处理步骤都是通过 sklearn 方法完成的。这里没有特别不同的地方。我们从 Snowflake ETL 生成的表中读取数据,并将其传递到 sklearn 管道中。这里应用了常规的建模步骤。我们将数据集拆分为训练集和测试集,并进行一些预处理,即使用中位数填补缺失值,缩放数据并对分类数据进行独热编码。我非常喜欢 sklearn 管道,并且在开发模型时基本上都会使用它们,它们确实有助于编写干净简洁的代码。
这个管道在一个大约有 200 万行的数据集上的表现如何?好吧,不进行任何超参数调优的情况下运行这个模型大约需要 34 分钟。哎,有点慢。如果我们想进行任何类型的超参数调优,你可以想象这将花费多么漫长的时间。好的,所以并不理想,但让我们看看 Dask 如何应对这个挑战。
Dask ML Python 代码
我们的目标是看看是否可以超越上述 sklearn 管道,剧透一下,我们绝对可以。Dask 的酷炫之处在于,当你已经熟悉 Python 时,上手的门槛相对较低。我们只需进行几处更改,就可以在 Dask 中启动并运行这个管道。
你可能会注意到的第一个变化是我们有一些不同的导入。这条管道与之前的主要区别之一是我们将使用 Dask 数据框而不是 pandas 数据框来训练我们的模型。你可以把 Dask 数据框想象成一堆 pandas 数据框,我们可以同时在每一个上执行计算。这是 Dask 并行性的核心,也是减少这个管道训练时间的关键所在。
注意我们使用 @dask.delayed 作为装饰器来装饰我们的 load_training_data 函数。这指示 Dask 为我们并行化这个函数。
我们还将从 Dask 导入一些预处理和管道方法,更重要的是,我们需要导入 SaturnCluster,它将允许我们创建一个集群来训练我们的模型。另一个关键的不同点是,在我们的训练测试拆分之后,我们使用了 dask.persist。在此之前,由于 Dask 的延迟评估,我们的函数实际上并没有被计算。 一旦我们使用 persist 方法,我们就在告诉 Dask 将数据发送到工作节点,执行我们到目前为止创建的任务,并将这些对象保留在集群上。
最后,我们使用延迟方法训练我们的模型。这样,我们能够以懒惰的方式创建管道。管道不会被执行,直到我们到达这段代码:
fit_pipelines = dask.compute(*pipelines_)
这次我们只花了大约 10 minutes 就在完全相同的数据集上运行了这个管道。这是提高了 3.4 倍的速度,表现不错。如果我们愿意的话,我们还可以通过在 Saturn 中一键扩展计算资源进一步加速。
部署我们的管道
我之前提到过,你可能会想要定期运行这样的管道,使用类似 airflow 的工具。恰好的是,如果你不想经历设置 airflow 的初始麻烦,Saturn Cloud 提供了一个简单的替代方案,即 Jobs。Jobs 允许我们打包代码,并按需或在固定间隔内运行。你只需进入现有项目并点击创建作业。一旦我们这样做,它应该会像以下这样:
来源: Saturn
从这里开始,我们需要确保上面的 Python 文件在图像中的目录中,然后可以输入上面的 Python 命令。
python -m ml_pipeline -w 102 -j 'train'
如果需要,我们还可以使用 cron 语法设置日常 ETL 任务。对那些感兴趣的人,这里有一个 教程 详细讲解所有细节。
结论和收获
好了,我们现在已经到了项目的最后阶段。显然,我省略了一些 ML 开发周期的关键部分,如超参数调优和模型部署,但也许我会留到另一天。我认为你应该尝试 Dask 吗?我并不是专家,但从我目前看到的情况来看,它确实非常有用,我非常期待进一步实验,并寻找更多将其融入我作为数据科学家的日常工作的机会。希望你觉得这有用,并且你也能看到 Snowflake 和 Dask 的一些优点,开始自己动手尝试。
资源
你可能会发现我其他的一些文章很有趣
注意:本文中的部分链接为附属链接。
个人简介: 丹尼尔·福伊 是一位曾经的经济学家,现转行成为从事移动游戏行业的数据科学家。
原文。经授权转载。
相关内容:
-
BigQuery 与 Snowflake:数据仓库巨头的比较
-
Pandas 不够用?这里有几个处理更大更快数据的 Python 备选方案
-
你还在用 Pandas 处理 2021 年的大数据吗?这里有两个更好的选择
更多相关话题
使用 Microsoft Synapse ML 构建大规模机器学习管道
评论
图片来源:微软研究院
我最近启动了一个新的新闻通讯,专注于人工智能教育,已经拥有超过 50,000 名订阅者。TheSequence 是一个不搞虚的(即不炒作、不新闻等)AI 专注的新闻通讯,阅读时间为 5 分钟。其目标是让你了解最新的机器学习项目、研究论文和概念。请通过以下订阅试试:
构建大规模机器学习解决方案简直是一场噩梦。即使你拥有完美的架构,高度可扩展的机器学习管道通常需要结合许多基础设施平台和框架,这些平台和框架并非完全为无缝集成而设计。协调不同的机器学习工具的过程对即便是最有经验的机器学习开发人员来说也具有挑战性。微软研究院刚刚开源了一个旨在解决这一挑战的新框架。
SynapseML 是 MMLSpark 的新版本,一个从头开始设计的开源库,旨在实现大规模可扩展的机器学习管道。在功能上,SynapseML 扩展了 Apache Spark 的能力,以更好地支持大规模机器学习解决方案的需求。该平台使用分布式编程模型将给定的机器学习工作负载分布到数千台机器上,同时确保 GPU 和 CPU 的充分利用。更重要的是,SynapseML 通过一个单一的 API 实现了这一点,该 API 可以依赖像 LightGBM 或 XGBoost 这样的框架。

图片来源:微软研究院
SynapseML API 提供了一个数据、平台和语言无关的模型来与机器学习框架进行交互。这使得机器学习工程师能够快速协调不同的机器学习工具和框架,而不会牺牲开发者体验。API 的另一个重要方面是,它抽象了底层文件和数据库的交互。
为了给 SynapseML 的发布增添一些分发的亮点,微软将该框架添加到了 Azure Synapse Analytics 平台中。这确保了该平台作为原生 Azure 服务提供,并具有相应的企业支持。SynapseML 是防止机器学习工具和框架市场日益分裂的最有趣的努力之一。跟踪该平台如何被机器学习社区接受和采用将会很有趣。
个人简介:Jesus Rodriguez 目前是 Intotheblock 的首席技术官。他是一位技术专家、执行投资者和创业顾问。Jesus 创办了 Tellago,这是一家屡获殊荣的软件开发公司,专注于通过利用新的企业软件趋势帮助公司成为优秀的软件组织。
原文。经授权转载。
相关:
-
关于 Wu Dao 2.0 的五个关键事实:迄今为止构建的最大变换器模型
-
OpenAI 解决数学文字问题的方法
-
DeepMind 实时天气预报模型背后的架构
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关话题
使用 Llama 和 ChatGPT 构建多聊天后端的微服务
原文:
www.kdnuggets.com/building-microservice-for-multichat-backends-using-llama-and-chatgpt
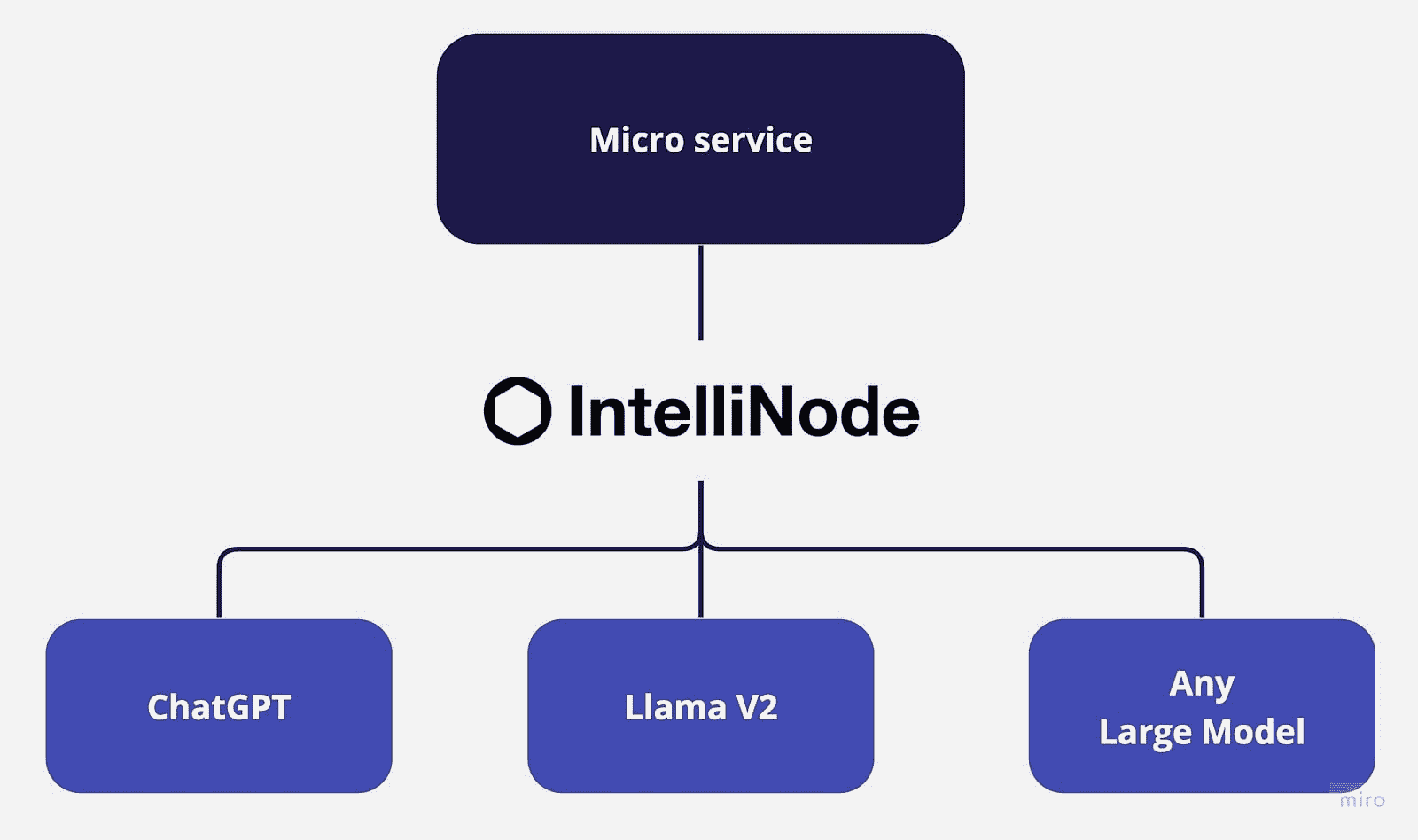
微服务架构促进了灵活、独立服务的创建,并定义了明确的边界。这种可扩展的方法使开发人员能够单独维护和演化服务,而不会影响整个应用程序。然而,要实现微服务架构的全部潜力,尤其是在 AI 驱动的聊天应用中,需要与最新的大型语言模型(LLMs)如 Meta Llama V2 和 OpenAI 的 ChatGPT 以及基于每个应用场景发布的其他微调模型进行稳健的集成,以提供多模型方法以实现多样化解决方案。
我们的 top 3 课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
LLMs 是大规模模型,根据对多样数据的训练生成类似人类的文本。通过学习互联网上数十亿个单词,LLMs 理解上下文并生成各个领域的调整内容。然而,将各种 LLM 集成到单个应用程序中通常会面临挑战,因为每个模型都需要独特的接口、访问端点和特定的有效负载。因此,拥有一个能够处理多种模型的单一集成服务可以改善架构设计,并增强独立服务的规模。
本教程将向你介绍如何在微服务架构中使用 Node.js 和 Express 集成 ChatGPT 和 LLaMA V2 的 IntelliNode。
聊天机器人集成选项
这里有一些由 IntelliNode 提供的聊天集成选项:
- LLaMA V2: 你可以通过 Replicate 的 API 进行简单的集成,也可以通过你的 AWS SageMaker 主机来获得额外的控制。
LLaMA V2 是一个强大的开源大型语言模型(LLM),经过了高达 70B 参数的预训练和微调。它在各种领域的复杂推理任务中表现出色,包括编程和创意写作等专业领域。其训练方法包括自监督数据和通过强化学习与人类反馈(RLHF)对齐。LLaMA V2 超越了现有的开源模型,并且在可用性和安全性方面与 ChatGPT 和 BARD 等闭源模型可媲美。
- ChatGPT:只需提供您的 OpenAI API 密钥,IntelliNode 模块即可在简单的聊天界面中实现与该模型的集成。您可以通过 GPT 3.5 或 GPT 4 模型访问 ChatGPT。这些模型经过大量数据的训练和微调,以提供高度上下文相关和准确的响应。
逐步集成
首先,初始化一个新的 Node.js 项目。打开终端,导航到项目目录,然后运行以下命令:
npm init -y
该命令将为您的应用程序创建一个新的 package.json 文件。
接下来,安装 Express.js,它将用于处理 HTTP 请求和响应,以及用于 LLM 模型连接的 IntelliNode:
npm install express
npm install intellinode
安装完成后,在项目根目录中创建一个名为 *app.js* 的新文件,然后在 app.js 中添加 express 初始化代码。
作者代码
使用 Replicate 的 API 进行 Llama V2 集成
Replicate 提供了通过 API 密钥与 Llama V2 快速集成的路径,而 IntelliNode 提供了聊天机器人接口,将您的业务逻辑与 Replicate 后端解耦,允许您在不同聊天模型之间切换。
我们首先从集成 Replica 后端托管的 Llama 开始:
作者代码
从 replicate.com 获取您的试用密钥以激活集成。
使用 AWS SageMaker 进行 Llama V2 集成
现在,让我们介绍通过 AWS SageMaker 进行 Llama V2 集成,提供隐私和额外的控制层。
该集成需要从您的 AWS 账户生成一个 API 端点,首先我们将在微服务应用程序中设置集成代码:
作者代码
以下步骤是创建您账户中的 Llama 端点,一旦设置了 API 网关,复制 URL 用于运行 '/llama/aws' 服务。
要在您的 AWS 账户中设置 Llama V2 端点:
1- SageMaker 服务: 从您的 AWS 账户中选择 SageMaker 服务并点击域。

aws 账户-选择 sagemaker
2- 创建 SageMaker 域:首先在您的 AWS SageMaker 上创建一个新域。这一步骤为您的 SageMaker 操作建立一个受控空间。
aws 账户-sagemaker 域
3- 部署 Llama 模型:利用 SageMaker JumpStart 部署你计划集成的 Llama 模型。建议从 2B 模型开始,因为 70B 模型的运行费用较高。
aws 账户-sagemaker 快速启动
4- 复制端点名称:一旦你部署了模型,确保记下端点名称,这对后续步骤至关重要。
aws 账户-sagemaker 端点
5- 创建 Lambda 函数:AWS Lambda 允许在不管理服务器的情况下运行后端代码。创建一个 Node.js Lambda 函数以用于集成部署的模型。
6- 设置环境变量:在你的 Lambda 中创建一个名为 llama_endpoint 的环境变量,值为 SageMaker 端点。
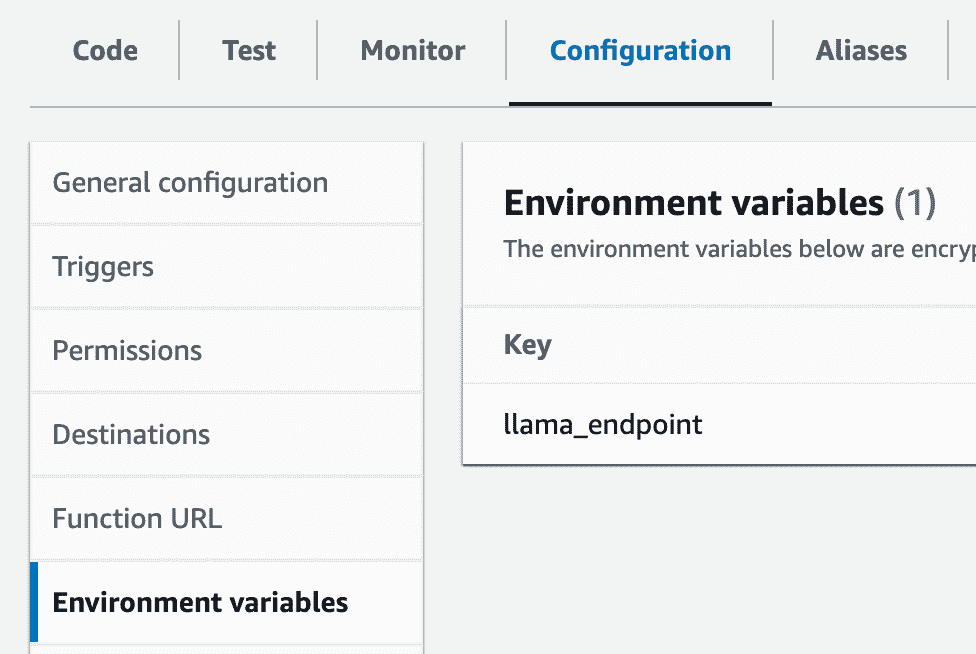
aws 账户-lambda 设置
7- Intellinode Lambda 导入:你需要导入准备好的 Lambda zip 文件,该文件建立了与 SageMaker Llama 部署的连接。该导出是一个 zip 文件,可以在 lambda_llama_sagemaker 目录中找到。
aws 账户-lambda 从 zip 文件上传
8- API 网关配置:点击 Lambda 函数页面上的“添加触发器”选项,从可用触发器列表中选择“API 网关”。
aws 账户-lambda 触发器 
aws 账户-api 网关触发器
9- Lambda 函数设置:更新 Lambda 角色以授予访问 SageMaker 端点的必要权限。此外,函数的超时设置应延长,以适应处理时间。在 Lambda 函数的“配置”选项卡中进行这些调整。
点击角色名称以更新权限,并提供访问 SageMaker 的权限:
aws 账户-lambda 角色
ChatGPT 集成
最后,我们将说明将 Openai ChatGPT 作为微服务架构中的另一种选项的步骤:
作者编写的代码
从 platform.openai.com 获取你的试用密钥。
执行实验
首先在终端中导出 API 密钥,如下所示:
作者编写的代码
然后运行节点应用程序:
node app.js
在浏览器中输入以下网址以测试 chatGPT 服务:
http://localhost:3000/chatgpt?message=hello
我们构建了一个利用 Llama V2 和 OpenAI 的 ChatGPT 等大型语言模型功能的微服务。这种集成为利用先进 AI 驱动的无限商业场景打开了大门。
通过将机器学习需求转化为解耦的微服务,您的应用可以获得灵活性和可扩展性的好处。语言模型的功能现在可以单独管理和开发,这承诺提供更高的效率以及更易于故障排除和升级管理。
参考资料
-
ChatGPT API: 链接。
-
Replica API: 链接。
-
SageMaker Llama Jump Start: 链接
-
IntelliNode 入门: 链接
-
完整代码 GitHub 仓库: 链接
Ahmad Albarqawi 是伊利诺伊大学香槟分校的工程师和数据科学硕士。
更多相关话题
在 Google Colab 中使用 PyTorch 构建神经网络
原文:
www.kdnuggets.com/2020/10/building-neural-networks-pytorch-google-colab.html
评论
在 Google Colab 中使用 PyTorch 进行深度学习
PyTorch 和 Google Colab 已成为深度学习的代名词,因为它们为人们提供了一种简便且经济实惠的方式,迅速开始构建自己的神经网络和训练模型。GPU 并不便宜,这使得构建自己的定制工作站对许多人来说是一个挑战。虽然深度学习工作站的成本可能是许多人的障碍,但由于NVIDIA 新款 RTX 30 系列的价格下降,这些系统最近变得更为实惠。
即使拥有更实惠的深度学习系统选项,许多人仍然趋向于使用 PyTorch 和 Google Colab,因为他们逐渐适应了深度学习项目的工作。

PyTorch 和 Google Colab 在开发神经网络方面非常强大
PyTorch 是由 Facebook 开发的,并在深度学习研究社区中声名显赫。它允许并行处理,并且具有易于阅读的语法,这导致了其采纳率的上升。与 TensorFlow 相比,PyTorch 通常更易于学习且更轻便,适合快速项目和快速原型的构建。许多人将 PyTorch 用于计算机视觉和自然语言处理(NLP)应用。
Google Colab 是由 Google 开发的,旨在帮助大众访问强大的 GPU 资源以运行深度学习实验。它提供 GPU 和 TPU 支持,并与 Google Drive 集成用于存储。这些原因使其成为构建简单神经网络的绝佳选择,特别是与类似于随机森林的选项相比。
使用 Google Colab

Google Colab 提供了一个环境设置选项的组合,具有类似 Jupyter 的界面、GPU 支持(包括免费和付费选项)、存储以及代码文档记录功能,全部集成在一个应用程序中。数据科学家可以在不花费大量资金购买 GPU 支持的情况下,享受全方位的深度学习体验。
记录代码对于在不同人之间共享代码很重要,并且有一个中立的地方来存储数据科学项目也很重要。结合了 GPU 实例的Jupyter notebook界面提供了一个良好的可重复环境。你也可以从 GitHub 导入笔记本或上传你自己的。
重要说明:由于 Python 2 已经过时,因此在 Colab 上不再提供。然而,仍有遗留代码在运行 Python 2。幸运的是,Colab 提供了一个修复方案,你可以使用它继续运行 Python 2。如果你尝试一下,你会看到 Python 2 在 Google Colab 中已正式弃用的警告。
使用 PyTorch

PyTorch 在功能上类似于其他深度学习库,提供了一整套构建深度学习模型的模块。不同之处在于 PyTorch 的 Tensor 类,它类似于 Numpy 的ndarray。
Tensor 的一个主要优点是它本身支持 GPU。Tensor 可以在 CPU 或 GPU 上运行。要在 GPU 上运行,我们只需使用 PyTorch 内置的 CUDA 模块将环境切换为 GPU。这使得在 GPU 和 CPU 之间切换变得容易。
提供给神经网络的数据必须是数值格式的。使用 PyTorch,我们通过将数据表示为 Tensor 来实现。Tensor 是一种数据结构,可以存储N维数据;向量是 1 维 Tensor,矩阵是 2 维 Tensor。通俗来说,Tensor 可以存储比向量或矩阵更高维的数据。
为什么 GPU 更受青睐?

Tensor 处理库可以用于计算大量计算,但在使用单核 GPU 时,计算编译需要很长时间。
这就是 Google Colab 的作用。它在技术上是免费的,但可能不适合大规模工业深度学习。它更适合初学者到中级从业者。它确实提供了一个付费服务,用于更大规模的项目,比如在免费版本中连接时间最长为 24 小时,而不是 12 小时,并且可以根据需要提供直接访问更强大的资源。
如何编写基本的神经网络
要开始构建一个基本的神经网络,我们需要在 Google Colab 环境中安装 PyTorch。这可以通过运行以下 pip 命令以及使用下面的其余代码来完成:
!pip3 install torch torchvision
# Import libraries
import torch
import torchvision
from torchvision import transforms, datasets
Import torch.nn as nn
Import torch.nn.functional as F
import torch.optim as optim
# Create test and training sets
train = datasets.MNIST('', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor()
]))
test = datasets.MNIST('', train=False, download=True,
transform=transforms.Compose([
transforms.ToTensor()
]))
# This section will shuffle our input/training data so that we have a randomized shuffle of our data and do not risk feeding data with a pattern. Anorther objective here is to send the data in batches. This is a good step to practice in order to make sure the neural network does not overfit our data. NN’s are too prone to overfitting just because of the exorbitant amount of data that is required. For each batch size, the neural network will run a back propagation for new updated weights to try and decrease loss each time.
trainset = torch.utils.data.DataLoader(train, batch_size=10, shuffle=True)
testset = torch.utils.data.DataLoader(test, batch_size=10, shuffle=False)
# Initialize our neural net
class Net(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(28*28, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, 64)
self.fc4 = nn.Linear(64, 10)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
x = self.fc4(x)
return F.log_softmax(x, dim=1)
net = Net()
print(net)
### Output:
### Net(
### (fc1): Linear(in_features=784, out_features=64, bias=True)
### (fc2): Linear(in_features=64, out_features=64, bias=True)
### (fc3): Linear(in_features=64, out_features=64, bias=True)
### (fc4): Linear(in_features=64, out_features=10, bias=True)
###)
# Calculate our loss
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
for epoch in range(5): # we use 5 epochs
for data in trainset: # `data` is a batch of data
X, y = data # X is the batch of features, y is the batch of targets.
net.zero_grad() # sets gradients to 0 before calculating loss.
output = net(X.view(-1,784)) # pass in the reshaped batch (recall they are 28x28 atm, -1 is needed to show that output can be n-dimensions. This is PyTorch exclusive syntax)
loss = F.nll_loss(output, y) # calc and grab the loss value
loss.backward() # apply this loss backwards thru the network's parameters
optimizer.step() # attempt to optimize weights to account for loss/gradients
print(loss)
### Output:
### tensor(0.6039, grad_fn=)
### tensor(0.1082, grad_fn=<nlllossbackward>)
### tensor(0.0194, grad_fn=<nlllossbackward>)
### tensor(0.4282, grad_fn=<nlllossbackward>)
### tensor(0.0063, grad_fn=<nlllossbackward>)
# Get the Accuracy
correct = 0
total = 0
with torch.no_grad():
for data in testset:
X, y = data
output = net(X.view(-1,784))
#print(output)
for idx, i in enumerate(output):
#print(torch.argmax(i), y[idx])
if torch.argmax(i) == y[idx]:
correct += 1
total += 1
print("Accuracy: ", round(correct/total, 3))
### Output:
### Accuracy: 0.915</nlllossbackward></nlllossbackward></nlllossbackward></nlllossbackward>
PyTorch 和 Google Colab 在数据科学中是绝佳选择
PyTorch 和 Google Colab 都是有用、强大且简单的选择,尽管 PyTorch 于 2017 年(3 年前)发布,而 Google Colab 于 2018 年(2 年前)发布,但它们在数据科学社区中已被广泛采纳。
这些环境在深度学习中已被证明是绝佳的选择,并且随着新开发的发布,它们可能成为最好的工具。两者都由科技界两大巨头 Facebook 和 Google 支持。PyTorch 提供了全面的工具和模块,以尽可能简化深度学习过程,而 Google Colab 则提供了一个环境来管理你的编码和项目的可重现性。
如果你已经在使用这些工具,你发现哪些对你的工作最有价值?
原文。经许可转载。
相关内容:
-
深度学习的 4 个最佳 Jupyter Notebook 环境
-
5 个 Google Colaboratory 技巧
-
Google Colab 在深度学习中的完整指南
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关话题
使用迁移学习和弱监督廉价构建 NLP 分类器
原文:
www.kdnuggets.com/2019/03/building-nlp-classifiers-cheaply-transfer-learning-weak-supervision.html/2
评论
第二步:使用 Snorkel 构建训练集
构建标签功能是一个非常动手的阶段,但这会得到回报!我预计如果你已经有领域知识,这应该花费一天时间(如果没有,可能需要几天)。此外,本节内容结合了我为我的项目所做的具体工作和一些通用建议,这些建议可以应用于你自己的项目。
由于大多数人以前没有使用过 Snorkel 的弱监督,我会尽可能详细地解释我所采用的方法。这个 教程 是理解主要概念的好方法,但阅读我的工作流程应该能为你节省大量的试错时间。
以下是一个 LF 的示例,如果推文包含对犹太人的常见侮辱之一,则返回 正面。否则,它将保持中立。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
*# Common insults against jews.*
INSULTS = r"\bjew (bitch|shit|crow|fuck|rat|cockroach|ass|bast(a|e)rd)"
def insults(tweet_text):
return POSITIVE if re.search(INSULTS, tweet_text) else ABSTAIN
这里是一个 LF 的示例,如果推文的作者提到他或她是犹太人,则返回 负面,这通常意味着该推文不是反犹太主义的。
*# If tweet author is Jewish then it's likely not anti-semitic.*
JEWISH_AUTHOR = r"((\bI am jew)|(\bas a jew)|(\bborn a jew)"
def jewish_author(tweet_tweet):
return NEGATIVE if re.search(JEWISH_AUTHOR, tweet_tweet) else ABSTAIN
在设计 LF 时,重要的是要记住 我们优先考虑高精度而非召回率。我们希望分类器能够识别更多模式,从而提高召回率。但如果 LF 的精度或召回率不是特别高,也不必担心,Snorkel 会处理这些问题。
一旦你有了一些 LF,你只需构建一个矩阵,每行一个推文,每列 LF 值。Snorkel Metal 有一个非常方便的工具函数来显示你的 LF 摘要。
*# We build a matrix of LF votes for each tweet*
LF_matrix = make_Ls_matrix(LF_set, LFs)
*# Get true labels for LF set*
Y_LF_set = np.array(LF_set['label'])
display(lf_summary(sparse.csr_matrix(LF_matrix),
Y=Y_LF_set,
lf_names=LF_names.values()))
我总共有 24 个 LF,但以下是我部分 LF 的 LF 摘要。你可以在表格下方找到每一列的含义。
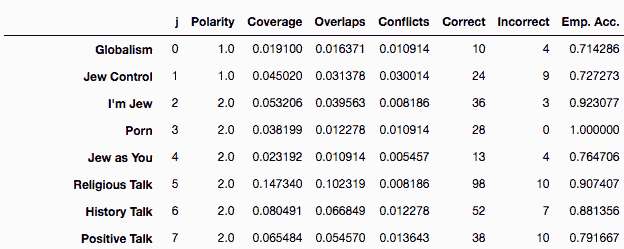
LF 摘要
列的含义:
-
精确度: 正确 LF 预测的比例。你应该确保所有 LF 的精确度至少为 0.5。
-
覆盖率: 至少有一个 LF 投票为正或负的样本百分比。你要最大化这一点,同时保持良好的准确性。
-
极性: 告诉你 LF 返回的值是什么。
-
重叠与冲突: 这告诉你一个 LF 如何与其他 LFs 重叠和冲突。不必过于担心,标签模型实际上会利用这些信息来估计每个 LF 的准确性。
让我们检查一下我们的覆盖率:
label_coverage(LF_matrix)
>> 0.8062755798090041
这相当不错!
作为我们弱监督的基线,我们将通过使用多数标签投票模型来评估我们的 LFs,以预测 LF 集中的类。这只是分配一个积极标签,如果大多数 LF 是积极的,所以它基本上假设所有 LF 具有相同的准确性。
from metal.label_model.baselines import MajorityLabelVoter
mv = MajorityLabelVoter()
Y_train_majority_votes = mv.predict(LF_matrix)
print(classification_report(Y_LFs, Y_train_majority_votes))
多数投票者基线的分类报告
我们可以看到,对正类(“1”)的 F1-score 是 0.61。为了提高这一点,我制作了一个电子表格,其中每一行都有一条推文、它的真实标签、以及基于每个 LF 的分配标签。目标是找到 LF 与真实标签不一致的地方,并相应地修正 LF。
我用来调整我的 LFs 的 Google 表格
在我的 LFs 具有约 60% 精度和 60% 召回率之后,我继续训练了标签模型。
Ls_train = make_Ls_matrix(train, LFs)
*# You can tune the learning rate and class balance.*
label_model = LabelModel(k=2, seed=123)
label_model.train_model(Ls_train, n_epochs=2000, print_every=1000,
lr=0.0001,
class_balance=np.array([0.2, 0.8]))
现在要测试标签模型,我将其与我的测试集进行了验证,并绘制了精度-召回率曲线。我们可以看到,我们能够获得大约 80% 的精度和 20% 的召回率,这相当不错。使用标签模型的一个重大优势是我们现在可以调整预测概率阈值,以获得更好的精度。
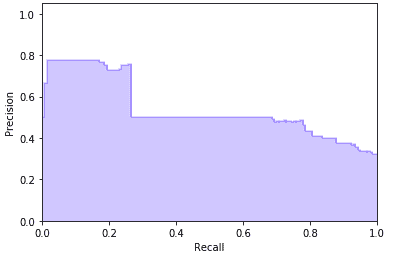
标签模型的精度-召回率曲线
我还通过检查根据标签模型的前 100 个反犹太主义最强的推文,确保它们有意义来验证我的标签模型是否正常工作。现在我们对我们的标签模型满意了,我们生成了我们的训练标签:
# To use all information possible when we fit our classifier, we can # actually combine our hand-labeled LF set with our training set.
Y_train = label_model.predict(Ls_train) + Y_LF_set
这是我 WS 工作流程的总结:
-
通过 LF 集中的示例,识别一个新的潜在 LF。
-
将其添加到标签矩阵中,并检查其准确性是否至少为 50%。尽量获得最高的准确性,同时保持良好的覆盖率。如果 LFs 相关,我会将不同的 LFs 组合在一起。
-
有时你会想使用基础的多数投票模型(在 Snorkel Metal 中提供)来标注你的 LF 集。相应地更新你的 LFs,仅使用多数投票模型即可获得相当不错的得分。
-
如果你的多数投票模型不够好,那么你可以修正你的 LFs 或返回第 1 步并重复操作。
-
一旦你的多数投票模型有效,那么就对你的训练集运行你的 LFs。你应该至少有 60% 的覆盖率。
-
完成后,训练你的标签模型!
-
为了验证标签模型,我对我的训练集运行了标签模型,并打印了前 100 个反犹太主义最强的推文和 100 个反犹太主义最弱的推文,以确保它正常工作。
现在我们有了标签模型,我们可以为2.5 万条推文计算概率标签,并将其用作训练集。现在,继续训练我们的分类模型吧!
Snorkel 的一般提示:
-
关于 LF 准确率:在 WS 步骤中,我们追求高精度。你的所有 LF 在 LF 集合上的准确率应至少达到 50%。如果能达到 75%或更高,那就更好了。
-
关于 LF 覆盖率:你需要确保至少 65%的训练集有一个 LF 投票为正或负。这被称为 Snorkel 的 LF 覆盖率。
-
如果你一开始不是领域专家,你将在标记 600 个初始数据点的过程中获得新 LF 的想法。
第三步:构建分类模型****
最后一步是训练我们的分类器,使其能够在噪声较多的手工规则之外进行泛化。
基准线
我们将从设定一些基准线开始**。我尝试在没有深度学习的情况下构建最佳模型。我尝试了 Tf-idf 特征化结合 sklearn 的逻辑回归、XGBoost 和前馈神经网络。
以下是结果。为了获得这些数字,我绘制了一个针对开发集的精确度-召回率曲线,然后选择了我喜欢的分类阈值(尽可能争取 90%以上的精确度,同时召回率尽可能高)。
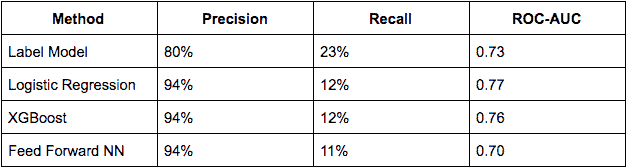
基准线
尝试 ULMFiT
一旦我们下载了在维基百科上训练的 ULM,我们需要调整它以适应推文,因为它们的语言差异较大。我按照这个很棒的博客中的所有步骤和代码操作,并且我还使用了来自 Kaggle 的Twitter Sentiment140 数据集来微调语言模型。
我们从数据集中随机抽取 100 万条推文,并在这些推文上微调语言模型。这样,语言模型将能够在推特领域进行泛化。
下面的代码加载推文并训练语言模型。我使用了 Paperspace 的 GPU 和 fastai 的公共镜像,这效果非常好。你可以按照这些步骤进行设置。
data_lm = TextLMDataBunch.from_df(train_df=LM_TWEETS, valid_df=df_test, path="")
learn_lm = language_model_learner(data_lm, pretrained_model=URLs.WT103_1, drop_mult=0.5)
我们解冻语言模型中的所有层:
learn_lm.unfreeze()
我们运行了 20 个周期。我将周期放入一个循环中,以便在每次迭代后保存模型。我没找到使用 fastai 轻松做到这一点的方法。
for i in range(20):
learn_lm.fit_one_cycle(cyc_len=1, max_lr=1e-3, moms=(0.8, 0.7))
learn_lm.save('twitter_lm')
然后我们应该测试语言模型,以确保它至少有一点道理:
learn_lm.predict("i hate jews", n_words=10)
>> 'i hate jews are additional for what hello you brother . xxmaj the'
learn_lm.predict("jews", n_words=10)
>> 'jews out there though probably okay jew back xxbos xxmaj my'
像“xxmaj”这样的奇怪标记是 fastai 添加的一些特殊标记,有助于文本理解。例如,它们为大写字母、句子的开头、重复的词等添加了特殊标记。语言模型的表现可能不是很理想,但这没关系。
现在我们将训练我们的分类器:
*# Classifier model data*
data_clas = TextClasDataBunch.from_df(path = "",
train_df = df_trn,
valid_df = df_val,
vocab=data_lm.train_ds.vocab,
bs=32,
label_cols=0)
learn = text_classifier_learner(data_clas, drop_mult=0.5)
learn.freeze()
使用 fastai 的方法寻找合适的学习率:
learn.lr_find(start_lr=1e-8, end_lr=1e2)
learn.recorder.plot()
我们将通过逐渐解冻来微调分类器:
learn.fit_one_cycle(cyc_len=1, max_lr=1e-3, moms=(0.8, 0.7))
learn.freeze_to(-2)
learn.fit_one_cycle(1, slice(1e-4,1e-2), moms=(0.8,0.7))
learn.freeze_to(-3)
learn.fit_one_cycle(1, slice(1e-5,5e-3), moms=(0.8,0.7))
learn.unfreeze()
learn.fit_one_cycle(4, slice(1e-5,1e-3), moms=(0.8,0.7))
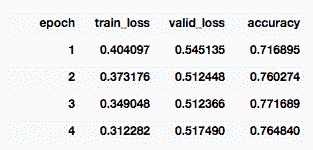
一些训练轮次
在微调后,让我们绘制我们的精确率-召回率曲线!看到第一次尝试后的结果非常好。
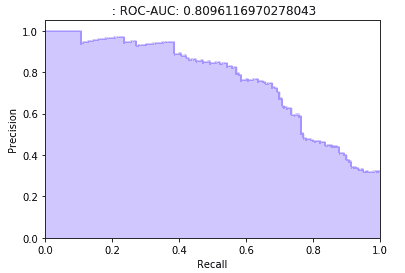
ULMFiT 在弱监督下的精确率-召回率曲线
我选择了 0.63 的概率阈值,这使我们获得了95% 的精准率和 39% 的召回率。这在召回率上有了很大的提升,同时在精准率上也有所提高。

ULMFiT 模型的分类报告
与我们的模型玩得开心
下面是一个非常酷的例子,展示了模型如何捕捉到“doesn’t”改变了推文的含义!
learn.predict("george soros controls the government")
>> (Category 1, tensor(1), tensor([0.4436, 0.5564]))
learn.predict("george soros doesn't control the government")
>> (Category 0, tensor(0), tensor([0.7151, 0.2849]))
这里有一些针对犹太人的侮辱:
learn.predict("fuck jews")
>> (Category 1, tensor(1), tensor([0.1996, 0.8004]))
learn.predict("dirty jews")
>> (Category 1, tensor(1), tensor([0.4686, 0.5314]))
这里有一个人呼吁反犹太主义的推文:
learn.predict("Wow. The shocking part is you're proud of offending every serious jew, mocking a religion and openly being an anti-semite.")
>> (Category 0, tensor(0), tensor([0.9908, 0.0092]))
这里是其他非反犹太主义的推文:
learn.predict("my cousin is a russian jew from ukraine- ???????????? i'm so glad they here")
>> (Category 0, tensor(0), tensor([0.8076, 0.1924]))
learn.predict("at least the stolen election got the temple jew shooter off the drudgereport. I ran out of tears.")
>> (Category 0, tensor(0), tensor([0.9022, 0.0978]))
弱监督真的有帮助吗?
我很好奇是否需要弱监督才能获得这种性能,因此我进行了一个小实验。我进行了与之前相同的过程,但没有 WS 标签,并得到了这个精确率-召回率曲线:
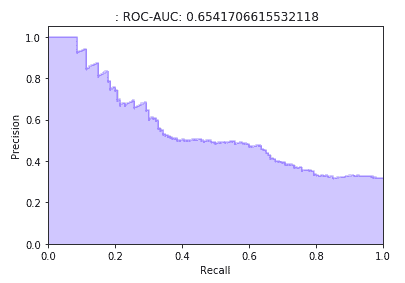
ULMFiT 在没有弱监督下的精确率-召回率曲线
我们可以看到召回率大幅下降(我们只有10% 的召回率,而精准率为 90%)和 ROC-AUC (-0.15),与我们使用 WS 标签的之前精确率-召回率曲线相比。
结论
-
弱监督 + ULMFiT 帮助我们达到了 95%的精准率和 39%的召回率。这远远超过了所有基准,因此非常令人兴奋。我完全没有预料到这一点。
-
这个模型非常容易保持最新。无需重新标注,我们只需更新 LFs 并重新运行 WS + ULMFiT 管道。
-
弱监督通过允许 ULMFiT 更好地泛化,带来了很大的不同。
下一步
-
我相信我们可以通过进一步努力改进我的 LFs 来获得最大的收益,以提高弱监督模型。我会首先包含基于外部知识库如Hatebase’s的仇恨言论模式的 LFs。然后,我会基于 Spacy 的依赖树解析编写新的 LFs。
-
我们没有进行任何超参数调整,但这可能会帮助提升 Label Model 和 ULMFiT 的性能。
-
我们可以尝试不同的分类模型,比如微调 BERT 或 OpenAI 的 Transformer。
个人简介: Abraham Starosta (starosta@stanford.edu) 来自委内瑞拉,目前在斯坦福大学完成计算机科学硕士学位,专注于人工智能和自然语言处理。在开始斯坦福的硕士课程之前,他曾是 Primer AI 的数据科学家,这是一家开发文本理解和总结技术的初创公司。他还是 Nav Talent 的共同创始人,这是一家为顶级初创公司提供技术招聘服务的机构,该机构起步于斯坦福大学。多年来,他还有机会在其他顶级初创公司如 Livongo、Zugata 和 Splunk 担任软件工程师。在闲暇时,他喜欢踢足球和打乒乓球。
原始文章。已获转载许可。
相关:
-
如何解决 90%的自然语言处理问题:逐步指南
-
OpenAI 的 GPT-2:模型、炒作与争议
-
更有效的自然语言处理迁移学习
更多相关内容
建立和操作机器学习模型:成功的三个建议
原文:
www.kdnuggets.com/2021/10/building-operationalizing-machine-learning-models.html
评论
由 杰森·雷维尔,首席技术官,Datatron。
机器学习的最大承诺之一是通过计算人类认知来简化事物。随着企业在数字化转型过程中实施机器学习(ML)以提升收入和运营,但所有机器学习背后的承诺和机遇,可能会迅速让负责管理生产中的 ML 的团队感到困难。
各行业的组织都在使用 ML 处理各种过程:预测价格、检测欺诈、分类健康风险、处理文档、预防性维护等。模型在历史数据上进行训练和评估,直到它们似乎符合性能和准确性的目标。结果承诺通过预测、分类或建议未来结果并采取行动来创造高业务价值。企业渴望获得机器学习所承诺的好处。
然而,一旦模型“准备好”后,通过可靠的交付机制自动化其使用会引入操作复杂性和风险,需要细致关注。交付和操作团队必须全面管理 ML 生命周期,以使这些项目高效有效。数据必须可用且质量符合预期,与训练时使用的数据相比。随着认识的深入,业务开始出现其他复杂性:这与其他工程工作并不完全相同,你需要以不同的方式思考问题,才能真正成为一个 AI 驱动的公司。要在机器学习,尤其是 ML 模型方面取得成功,以下是你应该考虑的三件事:
1. 投资于快速部署多个版本,直到找到合适的版本。
ML 模型从来不会在第一次、第二次……或通常甚至第三次就完全正确!训练和生产之间的数据往往不匹配,难以一次性做到完美。进行具体且有针对性的投资,设置可以运行并记录结果的部署目标,确保这些结果在生产系统或客户面前不可见,并且能够在找到合适的模型之前轻松流畅地进行部署。从长远来看,假设模型会经历大量优化或调整,并需要将当前版本与承诺带来更好结果的新候选进行比较,这样做要更加有效和经济。
2. 接受数据科学家和机器学习工程师所承诺的创新通常不符合传统的、以应用为中心的“批准软件”政策。
机器学习是一个快速增长和多样化的领域,技术供应商的名单不断扩展,无论大小。没有人会质疑 IT 需要维持适当的控制、进行安全扫描和支持操作环境。然而,将相同的控制和流程用于管理操作或产品托管技术到您的机器学习实践中,很可能会大大降低您在跨越起跑线之前所获得的回报。此外,许多数据科学家是强大的技术专家和发明家,如果他们觉得被迫在不改变所用技术或如何利用它的情况下不断提供更好的结果,他们可能会寻找其他就业机会。
3. 不要把模型开发生命周期误认为只是另一个软件开发生命周期
创建机器学习模型是一个与软件开发截然不同的过程——试图以相同的方式处理将会让您陷入困境。许多企业目前选择将模型交付视为另一个软件发布,结果导致顺序的、延长的时间表,跨切功能如监控和分析的空白,以及创作者和操作员之间的高知识转移开销。部署和支持您的模型的专家必须理解模型和数据的工作原理,而不仅仅是处理错误代码和服务可靠性。寻找合适的人才,建立混合团队并投资于工具,以便您不仅可以测试和解释软件是否执行,还可以评估响应的准确性和可解释性。
值得付出努力
机器学习模型有潜力为您的组织带来巨大的效率和优势,但跟上构建和管理一个可靠模型的所有方面可能成为一个全方位的企业问题。必须早早识别其操作复杂性和风险;考虑使用这些和其他原则来预见您的问题和挑战将出现在哪里。如果管理得当,机器学习模型可以非常灵活,易于改变,并且值得付出学习成本。
个人简介: 杰森·雷维尔是一位技术领导者,拥有在创建解决方案和平台方面的混合产品管理经验,并且曾在小型技术公司到大型企业中担任过工程和开发角色。
相关:
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持组织的 IT 工作
更多相关话题
构建预测模型:Python 中的逻辑回归
原文:
www.kdnuggets.com/building-predictive-models-logistic-regression-in-python
作者提供的图片
当你刚开始学习机器学习时,逻辑回归是你会添加到工具箱中的第一个算法之一。它是一个简单而稳健的算法,通常用于二分类任务。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT。
考虑一个类别为 0 和 1 的二分类问题。逻辑回归将一个逻辑或 sigmoid 函数拟合到输入数据上,并预测查询数据点属于类别 1 的概率。很有趣,对吧?
在本教程中,我们将从基础开始学习逻辑回归,内容包括:
-
逻辑(或 sigmoid)函数
-
我们如何从线性回归过渡到逻辑回归
-
逻辑回归的工作原理
最后,我们将构建一个简单的逻辑回归模型来classify RADAR returns from the ionosphere。
逻辑函数
在我们深入了解逻辑回归之前,让我们回顾一下逻辑函数的工作原理。逻辑函数(或称为 sigmoid 函数)由以下公式给出:
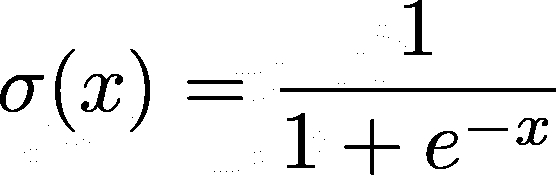
当你绘制 sigmoid 函数时,它看起来是这样的:
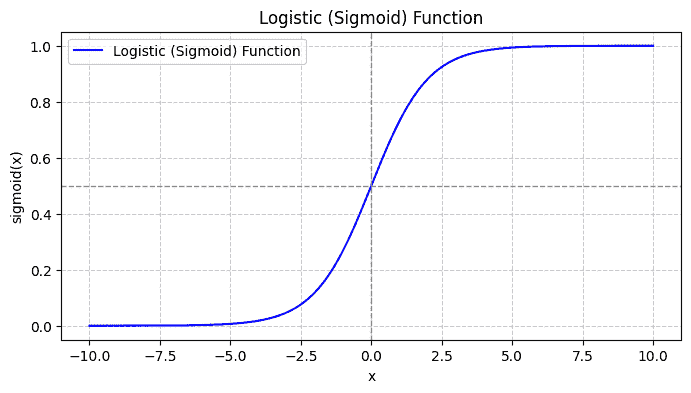
从图中我们可以看出:
-
当 x = 0 时,σ(x) 的值为 0.5。
-
当 x 接近 +∞ 时,σ(x) 接近 1。
-
当 x 接近 -∞ 时,σ(x) 接近 0。
因此,对于所有实际输入,sigmoid 函数将它们压缩到 [0, 1] 的范围内。
从线性回归到逻辑回归
首先,让我们讨论一下为什么我们不能使用线性回归来解决二分类问题。
在二分类问题中,输出是分类标签(0 或 1)。由于线性回归预测的是连续值的输出,可能小于 0 或大于 1,因此不适用于当前问题。
此外,当输出标签属于两类中的一种时,直线可能不是最佳拟合。
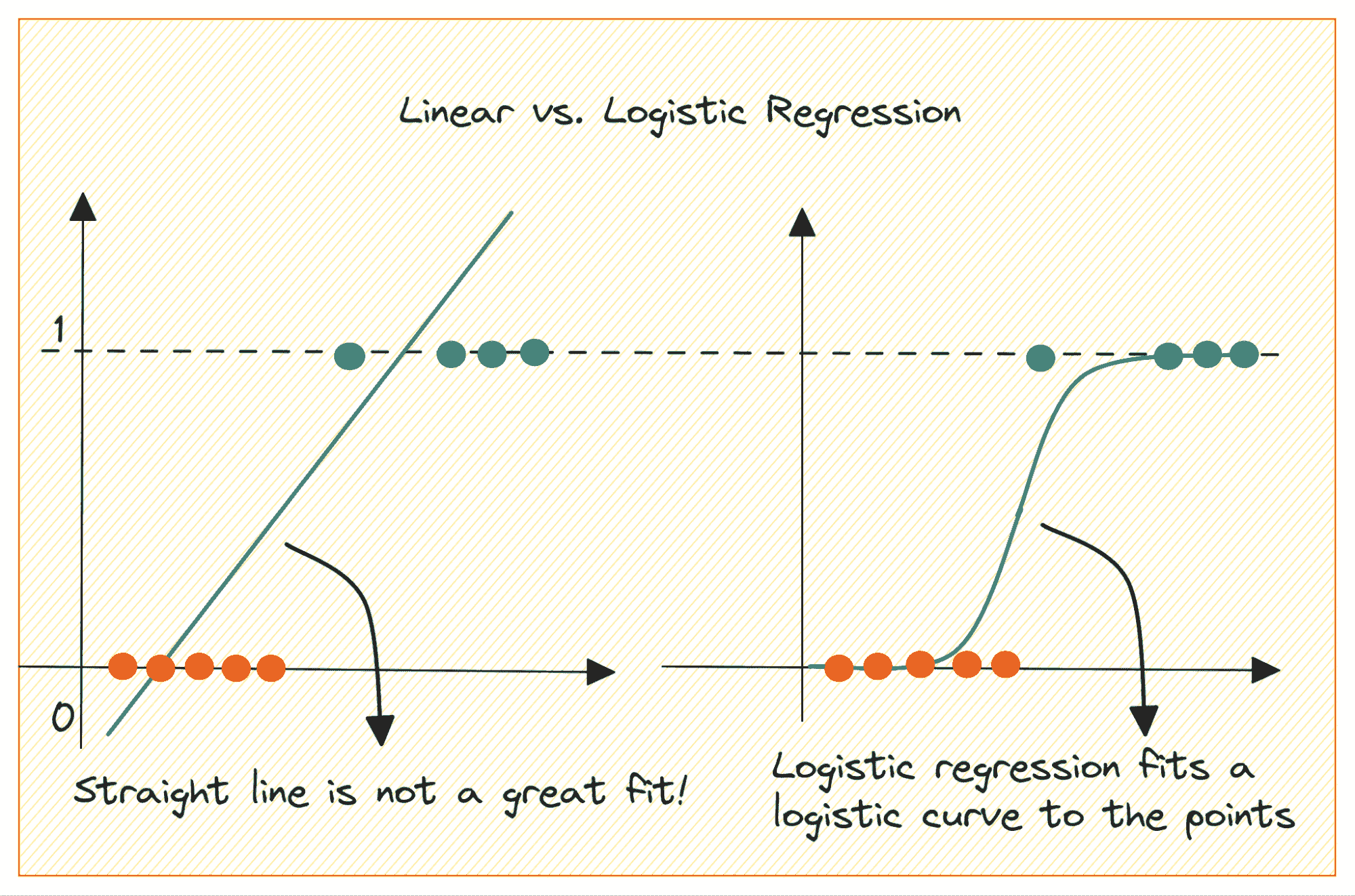
作者提供的图片
那么我们如何从线性回归转向逻辑回归呢?在线性回归中,预测的输出由以下给出:
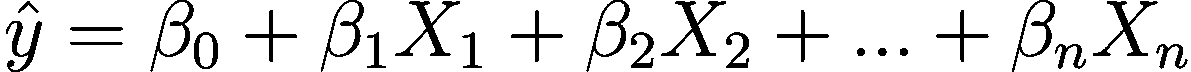
其中βs 是系数,X_is 是预测变量(或特征)。
为了不失一般性,假设 X_0 = 1:
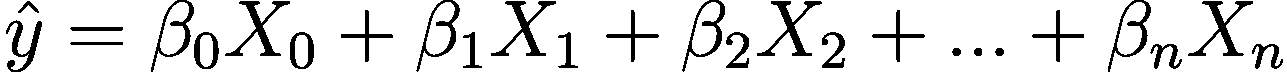
所以我们可以得到一个更简洁的表达式:
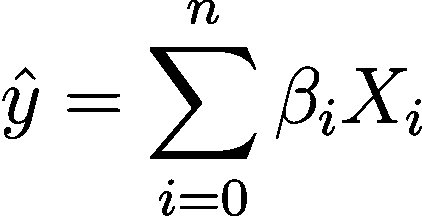
在逻辑回归中,我们需要预测概率 p_i 在[0,1]区间内。我们知道逻辑函数将输入值压缩到[0,1]区间内。
所以将这个表达式代入逻辑函数中,我们得到预测概率为:
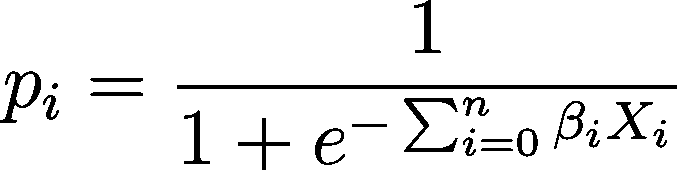
逻辑回归的内部机制
那么我们如何为给定的数据集找到最佳的逻辑回归曲线呢?为了解答这个问题,我们需要理解最大似然估计。
最大似然估计 (MLE) 用于通过最大化似然函数来估计逻辑回归模型的参数。让我们深入了解逻辑回归中的 MLE 过程以及如何使用梯度下降法公式化成本函数进行优化。
解析最大似然估计
如前所述,我们将二分类结果发生的概率建模为一个或多个预测变量(或特征)的函数:
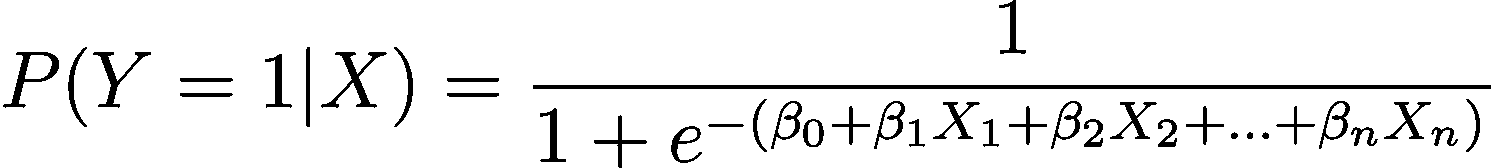
在这里,βs 是模型参数或系数。X_1, X_2,..., X_n 是预测变量。
MLE 旨在找到使观察到的数据的似然最大化的β值。似然函数,记作 L(β),表示在逻辑回归模型下,给定预测值的情况下观察到给定结果的概率。
公式化对数似然函数
为了简化优化过程,通常使用对数似然函数。因为它将概率的乘积转换为对数概率的和。
逻辑回归的对数似然函数为:
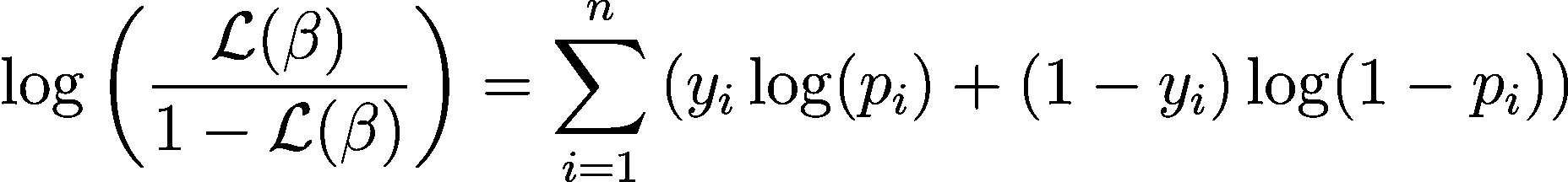
成本函数与梯度下降
现在我们知道了对数似然的本质,让我们继续制定逻辑回归的成本函数,并随后进行梯度下降,以寻找最佳模型参数
逻辑回归的成本函数
为了优化逻辑回归模型,我们需要 最大化 对数似然。因此,我们可以使用 负对数似然 作为训练过程中需要 最小化 的成本函数。负对数似然,通常称为逻辑损失,定义为:
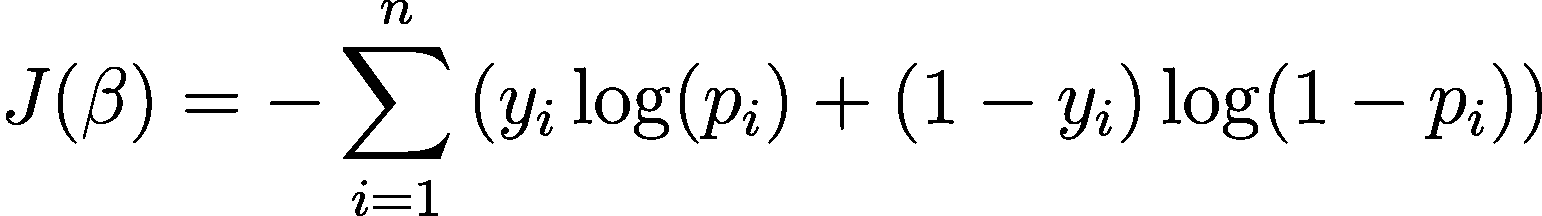
因此,学习算法的目标是找到使这个成本函数最小化的?值。梯度下降是一种常用的优化算法,用于找到这个成本函数的最小值。
逻辑回归中的梯度下降
梯度下降 是一种迭代优化算法,通过与成本函数对β的梯度方向相反的方向更新模型参数β。使用梯度下降进行逻辑回归时,步骤 t+1 的更新规则如下:
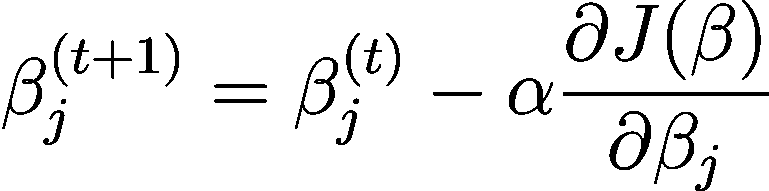
其中α是学习率。
可以使用链式法则计算偏导数。梯度下降迭代更新参数——直到收敛——旨在最小化逻辑损失。随着收敛,它找到最大化观察数据似然的β的最佳值。
Python 中的逻辑回归与 Scikit-Learn
现在你已经了解了逻辑回归的工作原理,让我们使用 scikit-learn 库构建一个预测模型。
我们将使用 UCI 机器学习库中的电离层数据集 进行本教程。数据集包含 34 个数值特征。输出是二元的,‘good’或‘bad’(用‘g’或‘b’表示)。输出标签‘good’指的是雷达返回信号中检测到的电离层结构。
步骤 1 – 加载数据集
首先,下载数据集并读取到 pandas 数据框中:
import pandas as pd
import urllib
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/iphere.data"
data = urllib.request.urlopen(url)
df = pd.read_csv(data, header=None)
步骤 2 – 探索数据集
让我们查看数据框的前几行:
# Display the first few rows of the DataFrame
df.head()
df.head()的截断输出
获取有关数据集的一些信息:每列的非空值数量和数据类型:
# Get information about the dataset
print(df.info())
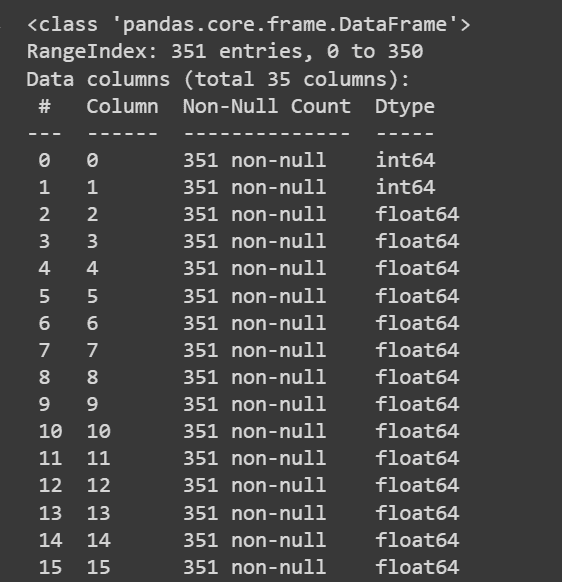 df.info()的截断输出
df.info()的截断输出
由于我们有所有数值特征,我们还可以使用describe()方法在数据框上获取一些描述性统计信息:
# Get descriptive statistics of the dataset
print(df.describe())
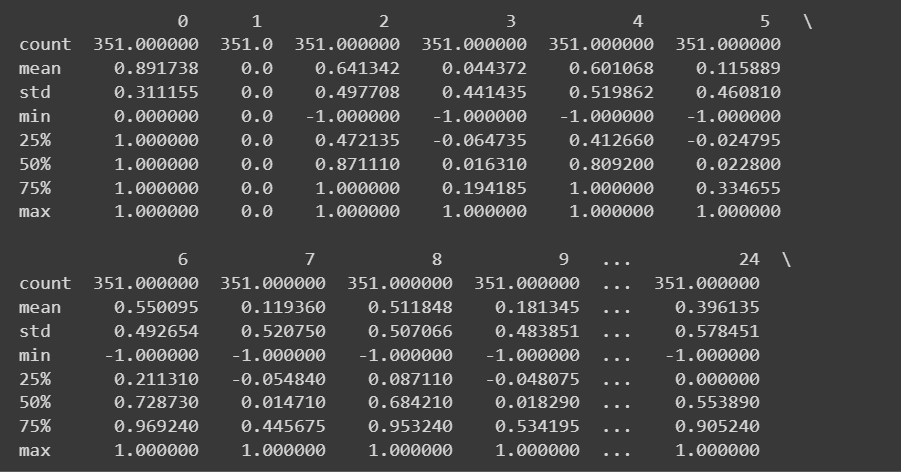
截断输出的 df.describe()
当前列名为 0 到 34,包括标签。由于数据集没有提供列的描述性名称,它只将其称为 attribute_1 到 attribute_34。如果你愿意,可以如所示重命名数据框的列:
column_names = [
"attribute_1", "attribute_2", "attribute_3", "attribute_4", "attribute_5",
"attribute_6", "attribute_7", "attribute_8", "attribute_9", "attribute_10",
"attribute_11", "attribute_12", "attribute_13", "attribute_14", "attribute_15",
"attribute_16", "attribute_17", "attribute_18", "attribute_19", "attribute_20",
"attribute_21", "attribute_22", "attribute_23", "attribute_24", "attribute_25",
"attribute_26", "attribute_27", "attribute_28", "attribute_29", "attribute_30",
"attribute_31", "attribute_32", "attribute_33", "attribute_34", "class_label"
]
df.columns = column_names
注意:这一步是完全可选的。如果你愿意,可以继续使用默认的列名。
# Display the first few rows of the DataFrame
df.head()
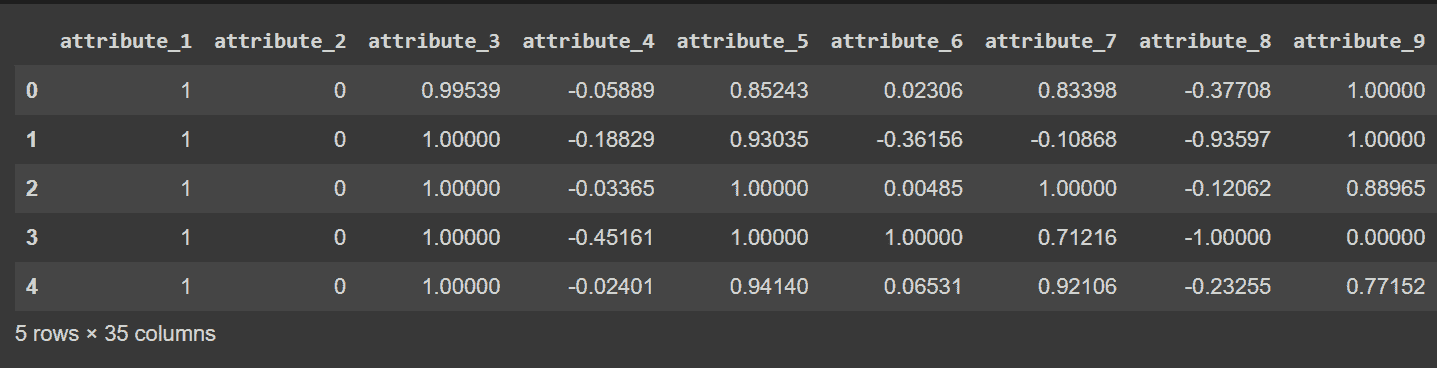
截断输出的 df.head() [在重命名列后]
第 3 步 – 重命名类别标签并可视化类别分布
由于输出类标签是‘g’和‘b’,我们需要将它们分别映射到 1 和 0。你可以使用map()或replace()来实现:
# Convert the class labels from 'g' and 'b' to 1 and 0, respectively
df["class_label"] = df["class_label"].replace({'g': 1, 'b': 0})
我们还可以可视化类别标签的分布:
import matplotlib.pyplot as plt
# Count the number of data points in each class
class_counts = df['class_label'].value_counts()
# Create a bar plot to visualize the class distribution
plt.bar(class_counts.index, class_counts.values)
plt.xlabel('Class Label')
plt.ylabel('Count')
plt.xticks(class_counts.index)
plt.title('Class Distribution')
plt.show()
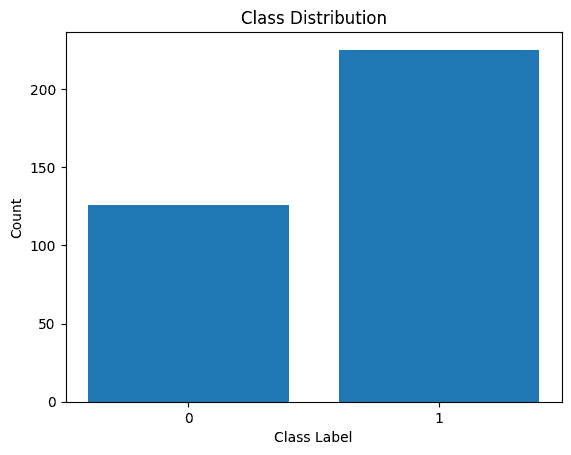
类别标签分布
我们看到分布中存在不平衡。属于类别 1 的记录比属于类别 0 的记录多。在构建逻辑回归模型时,我们将处理这种类别不平衡。
第 5 步 – 数据集预处理
我们将像这样收集特征和输出标签:
X = df.drop('class_label', axis=1) # Input features
y = df['class_label'] # Target variable
在将数据集拆分为训练集和测试集之后,我们需要对数据集进行预处理。
当有许多数值特征——每个特征可能有不同的尺度——我们需要对这些数值特征进行预处理。一种常见的方法是将它们转换为均值为零且方差为一的分布。
scikit-learn 的StandardScaler帮助我们实现这一点。
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Get the indices of the numerical features
numerical_feature_indices = list(range(34)) # Assuming the numerical features are in columns 0 to 33
# Initialize the StandardScaler
scaler = StandardScaler()
# Normalize the numerical features in the training set
X_train.iloc[:, numerical_feature_indices] = scaler.fit_transform(X_train.iloc[:, numerical_feature_indices])
# Normalize the numerical features in the test set using the trained scaler from the training set
X_test.iloc[:, numerical_feature_indices] = scaler.transform(X_test.iloc[:, numerical_feature_indices])
第 6 步 – 构建逻辑回归模型
现在我们可以实例化一个逻辑回归分类器。LogisticRegression类是 scikit-learn 的 linear_model 模块的一部分。
请注意,我们将class_weight参数设置为‘balanced’。这将帮助我们处理类别不平衡的问题。通过为每个类别分配权重——权重与类别中的记录数量成反比。
实例化类之后,我们可以将模型拟合到训练数据集上:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(class_weight='balanced')
model.fit(X_train, y_train)
第 7 步 – 评估逻辑回归模型
你可以调用predict()方法来获取模型的预测结果。
除了准确率,我们还可以获得包含精确度、召回率和 F1 分数等指标的分类报告。
from sklearn.metrics import accuracy_score, classification_report
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
classification_rep = classification_report(y_test, y_pred)
print("Classification Report:\n", classification_rep)
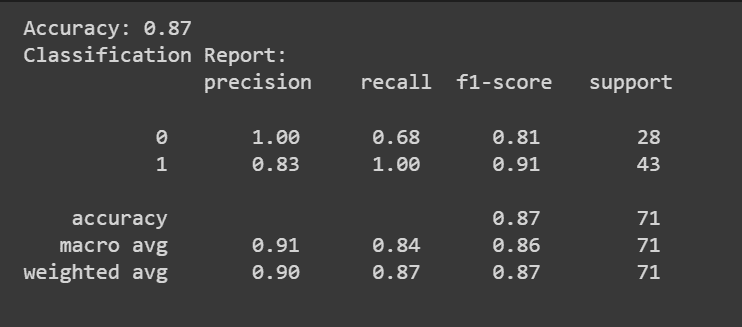
恭喜你,你已经编写了你的第一个逻辑回归模型!
结论
在本教程中,我们详细了解了逻辑回归:从理论和数学到编码逻辑回归分类器。
作为下一步,尝试为您选择的适当数据集构建一个逻辑回归模型。
数据集来源
电离层数据集在创意共享署名 4.0 国际(CC BY 4.0)许可证下授权使用。
Sigillito, V., Wing, S., Hutton, L., 和 Baker, K. (1989). 电离层。UCI 机器学习库。 https://doi.org/10.24432/C5W01B.
Bala Priya C** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过编写教程、操作指南、观点文章等方式学习并与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。**
更多相关内容
从头构建一个问答系统
原文:
www.kdnuggets.com/2018/10/building-question-answering-system-from-scratch.html
评论
由 Alvira Swalin,旧金山大学

随着我的硕士学业即将结束,我希望从事一个有趣的 NLP 项目,运用我在 USF 学到的所有技术(不完全准确)。在教授的帮助和与同学们的讨论之后,我决定从零开始构建一个问答模型。我使用了 斯坦福问答数据集 (SQuAD)。这个问题非常有名,各大公司都在争先恐后地进入排行榜,并使用像基于注意力的 RNN 模型这样的高级技术来获得最佳准确度。我找到的与 SQuAD 相关的 GitHub 仓库也都使用了 RNN。
然而,我的目标不是达到最先进的准确度,而是学习不同的 NLP 概念,实施它们并探索更多解决方案。我一直相信从基本模型开始以了解基线,这也是我在这里的做法。这一部分将重点介绍 Facebook 句子嵌入 及其在构建 QA 系统中的应用。在未来的部分中,我们将尝试实现深度学习技术,特别是针对该问题的序列建模。所有代码可以在这个 Github 仓库 中找到。
但让我们首先理解问题。我将给出一个简要概述,然而对问题的详细理解可以在 这里 找到。
SQuAD 数据集
S坦福 问题 答案 数据集(SQuAD)是一个新的阅读理解数据集,包含由众包工作者在一组维基百科文章上提出的问题,每个问题的答案都是对应阅读段落中的一段文本或 跨度。SQuAD 拥有超过 100,000 个问答对和 500 多篇文章,规模显著大于以往的阅读理解数据集。
问题
对于训练集中的每个观察,我们有一个 上下文、问题和文本。一个这样的观察示例 -

目标是找到针对任何新问题和提供的上下文的文本。这是一个封闭的数据集,意味着问题的答案始终是上下文的一部分,并且是连续的上下文跨度。我目前将这个问题分为两个部分 -
-
获取包含正确答案的句子(高亮为黄色)
-
一旦句子确定,从句子中获取正确的答案(高亮绿色)
介绍 Infersent,Facebook 句子嵌入
现在我们有各种类型的嵌入 word2vec、doc2vec、food2vec、node2vec,那么为什么不试试 sentence2vec 呢。所有这些嵌入的基本思想是使用不同维度的向量来表示实体,从而使计算机更容易理解它们用于各种下游任务。解释这些概念的文章链接在此,以供参考。
传统上,我们会对句子中所有单词的向量取平均,这被称为词袋模型。每个句子被标记为单词,这些单词的向量可以通过 glove 嵌入找到,然后对所有这些向量取平均。这种技术表现尚可,但这并不是一种非常准确的方法,因为它没有考虑单词的顺序。
这里是 Infersent,它是一种 句子嵌入 方法,提供语义句子表示。它在自然语言推理数据上进行了训练,并且在许多不同任务上泛化良好。
过程如下-
从训练数据中创建词汇表,并使用该词汇表训练 infersent 模型。一旦模型训练完成,提供句子作为输入到编码器函数,它将返回一个 4096 维的向量,而不考虑句子中的单词数量。 [demo]
这些嵌入可以用于各种下游任务,例如查找两个句子之间的相似性。我在 Quora-Question Pair kaggle 比赛中实现了相同的功能。你可以在 这里 查看。
关于 SQuAD 问题,下面是我尝试使用句子嵌入解决上一节描述的第一个问题的方式-
- 将段落/上下文拆分成多个句子。我知道的用于处理文本数据的两个包是 - Spacy 和 Textblob。我已经使用了 TextBlob 包。它进行智能拆分,不像 spacy 的句子检测,它会根据句号给出随机的句子。下面是一个示例:

示例:段落
TextBlob 将其拆分成 7 个句子,这很合理
Spacy 将其拆分成 12 个句子
-
使用 Infersent 模型获取每个句子和问题的向量表示。
-
为每对句子-问题创建基于余弦相似度和欧几里得距离的特征。
模型
我进一步使用了两种主要方法来解决这个问题——
-
无监督学习中,我没有使用目标变量。在这里,我返回段落中与给定问题距离最小的句子。
-
监督学习 - 训练集的创建在这一部分非常棘手,原因在于每个部分的句子数量没有固定,并且答案可以从一个词到多个词不等。我找到的唯一实现了逻辑回归的论文是斯坦福团队发布的这次比赛和数据集。他们使用了在这篇论文中解释的多项式逻辑回归,并创建了1.8 亿个特征(该模型的句子检测准确率为 79%),但不清楚他们是如何定义目标变量的。如果有人知道,请在评论中澄清一下。我稍后会解释我的解决方案。
无监督学习模型
我首先尝试使用欧几里得距离来检测与问题距离最小的句子。该模型的准确率约为 45%。然后,我转而使用余弦相似度,准确率从45%提升到 63%。这很有道理,因为欧几里得距离不考虑向量之间的对齐或角度,而余弦相似度考虑了这些因素。在向量表示的情况下,方向是重要的。
但这种方法没有利用我们所提供的带有目标标签的丰富数据。然而,考虑到解决方案的简单性质,这仍然能在没有任何训练的情况下给出良好的结果。我认为这份不错的表现归功于 Facebook 的句子嵌入。
监督学习模型
在这里,我将目标变量从文本形式转换为包含该文本的句子索引。为了简化,我将段落长度限制为 10 个句子(大约 98%的段落包含 10 个或更少的句子)。因此,在这个问题中我需要预测 10 个标签。
对于每个句子,我根据余弦距离构建了一个特征。如果一个段落的句子数量较少,那么我将其特征值替换为 1(最大可能的余弦距离),以使总句子数达到 10 个,以保持一致性。通过示例解释这一过程会更容易。
让我们以训练集的第一条观察/行作为例子。回答所在的句子在上下文中加粗:
示例
问题——“1858 年,圣母玛利亚在法国鲁尔德显现给了谁?”
背景—“从建筑学上讲,这所学校具有天主教特色。在主楼的金色圆顶上是一尊金色的圣母玛利亚雕像。主楼前面立即是基督铜像,双臂高举,上面刻有“Venite Ad Me Omnes”的字样。主楼旁边是圣心大教堂。大教堂的后面是洞窟,这是一个玛利亚祈祷和沉思的地方。它是法国卢尔德的一个洞窟的复制品,圣母玛利亚据说在 1858 年显现给圣贝尔纳黛特·苏比鲁斯。 在主车道的尽头(通过 3 尊雕像和金色圆顶的直线连接),是一尊简单的现代石雕圣母玛利亚像。”
文本—“圣贝尔纳黛特·苏比鲁斯”
在这种情况下,目标变量将变为 5,因为这是加粗句子的索引。我们将有 10 个特征,每个特征对应段落中的一句话。由于这些句子在段落中不存在,column_cos_7、column_cos_8 和 column_cos_9 的缺失值填充为 1。

依赖解析
我为这个问题使用的另一个特征是“依赖解析树”。这略微提高了模型的准确性,提升了 5%。在这里,我使用了 Spacy 树解析,因为它有丰富的 API 用于导航树结构。
详情请查阅 斯坦福讲座
单词之间的关系通过从头到依赖词的有向标记弧图示在句子上方。我们称之为类型化依赖结构,因为标签来自一个固定的语法关系库存。它还包括一个根节点,明确标记了树的根,即整个结构的头部。
让我们使用 Spacy 树解析来可视化我们的数据。我使用的是上一节提供的相同示例。
问题—“圣母玛利亚在 1858 年在法国卢尔德显现给了谁?”
包含答案的句子— “它是法国卢尔德的一个洞窟的复制品,圣母玛利亚据说在 1858 年显现给圣贝尔纳黛特·苏比鲁斯。”
段落中所有句子的根

这个想法是将问题的词根(在这种情况下是“appear”)与句子的所有词根/子词根进行匹配。由于一个句子中可能有多个动词,我们可以得到多个词根。如果问题的词根包含在句子的词根中,则该句子更有可能回答该问题。考虑到这一点,我为每个句子创建了一个特征,其值为 1 或 0。这里,1 表示问题的词根包含在句子的词根中,0 则相反。
注意: 在比较句子的词根与问题词根之前进行词干提取很重要。在之前的例子中,问题的词根是appear,而句中的词根是appeared。如果不将appear和appeared归并为一个共同的术语,它们将无法匹配。
以下示例是经过处理的训练数据中具有 2 个观察值的转置数据。因此,我们总共有 20 个特征,结合了 10 个句子的余弦距离和根匹配。目标变量的范围是 0 到 9。
注意: 对于逻辑回归,标准化数据中的所有列非常重要。
一旦训练数据创建完成,我使用了多项逻辑回归、随机森林和梯度提升技术。
多项逻辑回归的验证集准确率为65%。考虑到原始模型有很多特征且准确率为79%,这个模型要简单得多。随机森林的准确率为67%,最终,XGBoost在验证集上的表现最好,准确率为69%。
我将添加更多功能(与 NLP 相关)来改进这些模型。
与特征工程或其他改进相关的想法非常欢迎。所有与上述概念相关的代码都提供 这里。
在下一部分,我们将重点关注从本部分筛选出的句子中提取文本(正确跨度)。与此同时,查看我的其他博客 这里!
参考资料
个人简介: Alvira Swalin (Medium) 目前正在 USF 攻读数据科学硕士学位,我特别感兴趣于机器学习与预测建模。她是 Price (Fx)的数据科学实习生。
原始文档。经许可转载。
相关信息:
-
CatBoost 与 Light GBM 与 XGBoost 比较
-
选择合适的指标来评估机器学习模型 – 第一部分
-
选择合适的指标来评估机器学习模型 – 第二部分
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
更多主题
使用 Python 为 Amazon 产品构建推荐系统
原文:
www.kdnuggets.com/2023/02/building-recommender-system-amazon-products-python.html
照片由 Marques Thomas 提供,来自 Unsplash
介绍
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你在 IT 领域的组织
该项目的目标是部分重建****Amazon 产品推荐系统,针对电子产品类别。
现在是十一月,黑色星期五来了!你是什么类型的购物者?你会把所有想买的产品都保存到那一天,还是更愿意打开网站查看实时优惠及其巨大折扣?
尽管在线商店在过去十年中取得了巨大的成功,显示出巨大的潜力和增长,但实体店和在线商店之间的一个根本区别是消费者的冲动购买。
如果客户面临一个产品组合,他们更有可能购买原本没有计划购买的商品。冲动购买的现象在在线商店的配置下受到极大的限制。而实体店则不会发生这种情况。最大的实体零售连锁店会让顾客经过一个精确的路径,以确保他们在离开商店之前访问每个货架。
像 Amazon 这样的在线商店认为,重新创建冲动购买现象的一种方法是通过推荐系统。推荐系统识别出最相似或互补的产品,客户刚刚购买或浏览的产品。其目的是最大化在线商店通常缺乏的随机购买现象。
在 Amazon 上购物让我对推荐系统的机制产生了浓厚的兴趣,我希望重新创建(即使只是部分地)它们推荐系统的结果。
根据博客“Recostream”,亚马逊的产品推荐系统有三种依赖关系,其中之一是产品对产品推荐。当用户几乎没有搜索历史时,算法会将产品进行聚类,并根据商品的元数据向同一用户推荐这些产品。
数据
项目的第一步是收集数据。幸运的是,加州大学圣地亚哥分校的研究人员有一个仓库,让学生和组织外的个人使用这些数据进行研究和项目。数据可以通过以下链接访问,并且有许多其他有趣的数据集与推荐系统相关[2][3]。产品元数据最后更新于 2014 年;许多产品可能现在已经不再可用。
电子产品类别的元数据包含498,196 条记录,总共有8 列。
-
asin— 每个产品的唯一 ID -
imUrl— 每个产品关联的图片 URL 链接 -
description— 产品的描述 -
categories— 所有产品所属类别的 Python 列表 -
title— 产品的标题 -
price— 产品的价格 -
salesRank— 每个产品在特定类别中的排名 -
related— 与每个产品相关的客户浏览和购买的产品 -
brand— 产品的品牌
你会注意到文件采用了“松散”的JSON格式,每一行是一个JSON,包含之前提到的所有列作为字段。我们将在代码部署部分看到如何处理这个问题。
探索性数据分析
让我们从快速的探索性数据分析开始。经过清理所有包含至少一个NaN值的记录后,我创建了电子产品类别的可视化图。
带有异常值的价格箱线图 — 作者图片
第一个图表是箱线图,显示了每个产品的最大值、最小值、25 百分位数、75 百分位数和平均价格。例如,我们知道一个产品的最大价值是 1000 美元,而最小价值约为 1 美元。160 美元标记以上的线由点构成,每个点代表一个异常值。异常值表示数据集中仅出现一次的记录。因此,我们知道只有一个产品的价格接近 1000 美元。
平均价格似乎在 25 美元左右。重要的是要注意,库matplotlib自动排除异常值,选项为showfliers=False。为了让我们的箱线图看起来更干净,我们可以将参数设置为 false。
价格箱线图 — 作者图片
结果是一个更干净的箱线图,没有离群值。图表还建议,绝大多数电子产品的价格在 1 到 160 美元之间。
按上市产品数量排序的前 10 个品牌 — 作者提供的图像
图表显示了在电子产品类别中,前 10 个品牌按上市产品数量排序。其中包括 HP、Sony、Dell 和 Samsung。
前 10 大零售商定价箱线图 — 作者提供的图像
最后,我们可以看到前 10 大卖家的价格分布。Sony 和 Samsung 确实提供了种类繁多的产品,从几美元到 500 和 600 美元不等,因此它们的平均价格高于大多数顶级竞争对手。有趣的是,SIB 和 SIB-CORP 提供了更多的产品,但平均价格要便宜得多。
图表还告诉我们,Sony 提供的产品价格大约是数据集中最高价产品的 60%。
余弦相似度
将产品按其特征进行聚类的一个可能解决方案是余弦相似度。我们需要彻底理解这个概念,然后构建我们的推荐系统。
余弦相似度衡量两个数字序列的“接近”程度。这在我们的案例中如何应用呢?令人惊讶的是,句子可以被转换成数字,或者更好地,转换成向量。
余弦相似度的值可以在-1 和 1 之间,其中1表示两个向量完全相同,而-1表示它们完全不同。
从数学上讲,余弦相似度是两个多维向量的点积除以它们的大小乘积 [4]。我知道这里有很多复杂的术语,但让我们通过一个实际的例子来分解它。
假设我们正在分析文档 A和文档 B。文档 A 中最常见的三个词是:“today”、“good”和“sunshine”,分别出现了 4 次、2 次和 3 次。文档 B 中相同的三个词分别出现了 3 次、2 次和 2 次。因此,我们可以这样写:
A = (2, 2, 3) ; B = (3, 2, 2)
两个向量的点积公式可以写成:
它们的向量点积是 2x3 + 2x2 + 3x2 = 16
另一方面,单个向量的大小计算为:
如果我应用公式,我得到
||A|| = 4.12 ; ||B|| = 4.12
因此它们的余弦相似度是
16 / 17 = 0.94 = 19.74°
这两个向量非常相似。
到目前为止,我们只计算了两个向量之间的三维分数。一个词向量可以有无限多个维度(取决于它包含多少个词),但处理过程中的逻辑在数学上是相同的。在下一节中,我们将看到如何将所有概念应用于实践。
代码部署
让我们进入代码部署阶段,在数据集上构建我们的推荐系统。
导入库
每个数据科学笔记本的第一个单元格应当导入所需的库,我们项目所需的库包括:
#Importing libraries for data management
import gzip
import json
import pandas as pd
from tqdm import tqdm_notebook as tqdm
#Importing libraries for feature engineering
import nltk
import re
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
-
gzip解压数据文件 -
json解码它们 -
pandas将 JSON 数据转换为更易管理的数据框格式 -
tqdm创建进度条 -
nltk用于处理文本字符串 -
re提供正则表达式支持 -
最后,
sklearn是进行文本预处理所需的
读取数据
如前所述,数据以松散的 JSON格式上传。解决此问题的方法是首先使用命令json.dumps将文件转换为JSON 可读格式行。然后,我们可以通过将\n设置为换行符,将该文件转换为python 列表,其中包含 JSON 行。最后,我们可以在读取时作为 JSON将每行附加到data空列表中,命令为json.loads。
使用命令pd.DataFrame,data列表被读取为数据框,我们现在可以用来构建我们的推荐系统。
#Creating an empty list
data = []
#Decoding the gzip file
def parse(path):
g = gzip.open(path, 'r')
for l in g:
yield json.dumps(eval(l))
#Defining f as the file that will contain json data
f = open("output_strict.json", 'w')
#Defining linebreak as '\n' and writing one at the end of each line
for l in parse("meta_Electronics.json.gz"):
f.write(l + '\n')
#Appending each json element to the empty 'data' list
with open('output_strict.json', 'r') as f:
for l in tqdm(f):
data.append(json.loads(l))
#Reading 'data' as a pandas dataframe
full = pd.DataFrame(data)
为了让你了解data列表中每一行的样子,我们可以运行一个简单的命令 print(data[0]),控制台打印出索引 0 处的行。
print(data[0])
output:
{
'asin': '0132793040',
'imUrl': 'http://ecx.images-amazon.com/images/I/31JIPhp%2BGIL.jpg',
'description': 'The Kelby Training DVD Mastering Blend Modes in Adobe Photoshop CS5 with Corey Barker is a useful tool for...and confidence you need.',
'categories': [['Electronics', 'Computers & Accessories', 'Cables & Accessories', 'Monitor Accessories']],
'title': 'Kelby Training DVD: Mastering Blend Modes in Adobe Photoshop CS5 By Corey Barker'
}
正如你所见,输出是一个 JSON 文件,它有{}来开闭字符串,每个列名后面跟着:和相应的字符串。你可以注意到第一个产品缺少price、salesRank、related和brand information。这些列自动填充为NaN值。
一旦我们将整个列表读取为数据框,电子产品展示了以下 8 个特征:
| asin | imUrl | description | categories |
|--------|---------|---------------|--------------|
| price | salesRank | related | brand |
|---------|-------------|-----------|---------|
特征工程
特征工程负责数据清理和创建我们将用来计算余弦相似度分数的列。由于 RAM 内存限制,我不希望这些列特别长,例如评论或产品描述。相反,我决定创建一个“数据汤”,包括categories、title和brand列。在此之前,我们需要删除每一行中包含 NaN 值的列。
选择的列包含我们推荐系统所需的有价值和基本的信息形式。description列也可能是一个潜在的候选列,但字符串通常过长,并且在整个数据集中不标准化。它不是我们要实现目标的可靠信息。
#Dropping each row containing a NaN value within selected columns
df = full.dropna(subset=['categories', 'title', 'brand'])
#Resetting index count
df = df.reset_index()
在运行这部分代码后,行数从498,196急剧减少到大约142,000,变化很大。只有在这个时候我们才能创建所谓的数据集合:
#Creating datasoup made of selected columns
df['ensemble'] = df['title'] + ' ' +
df['categories'].astype(str) + ' ' +
df['brand']
#Printing record at index 0
df['ensemble'].iloc[0]
output:
"Barnes & Noble NOOK Power Kit in Carbon BNADPN31
[['Electronics', 'eBook Readers & Accessories', 'Power Adapters']]
Barnes & Noble"
由于标题中不总是包含品牌名称,因此需要包含品牌。
现在我可以进入清理部分。函数text_cleaning负责从 ensemble 列中删除每一个amp字符串。此外,字符串[^A-Za-z0–9]过滤掉每一个特殊字符。最后,函数的最后一行消除字符串中包含的每一个停用词。
#Defining text cleaning function
def text_cleaning(text):
forbidden_words = set(stopwords.words('english'))
text = re.sub(r'amp','',text)
text = re.sub(r'\s+', ' ', re.sub('[^A-Za-z0-9]', ' ',
text.strip().lower())).strip()
text = [word for word in text.split() if word not in forbidden_words]
return ' '.join(text)
使用lambda 函数,我们可以将text_cleaning应用于名为ensemble的整列数据,我们可以通过调用iloc并指定随机记录的索引来随机选择一个产品的数据集合。
#Applying text cleaning function to each row
df['ensemble'] = df['ensemble'].apply(lambda text: text_cleaning(text))
#Printing line at Index 10000
df['ensemble'].iloc[10000]
output:
'vcool vga cooler electronics computers accessories
computer components fans cooling case fans antec'
在第 10001 行(索引从 0 开始)的记录是来自 Antec 的 vcool VGA 冷却器。这是一个品牌名称不在标题中的情况。
余弦计算和推荐函数
余弦相似度的计算开始于构建一个包含 ensemble 列中所有出现过的单词的矩阵。我们将使用的方法称为“计数向量化”或更常见的“词袋模型”。如果你想了解更多关于计数向量化的内容,可以阅读我以前的一篇文章,点击以下链接。
由于 RAM 的限制,余弦相似度分数将仅在35,000条记录中计算,而不是在142,000条经过预处理阶段的记录中。这很可能会影响推荐系统的最终性能。
#Selecting first 35000 rows
df = df.head(35000)
#creating count_vect object
count_vect = CountVectorizer()
#Create Matrix
count_matrix = count_vect.fit_transform(df['ensemble'])
# Compute the cosine similarity matrix
cosine_sim = cosine_similarity(count_matrix, count_matrix)
命令cosine_similarity顾名思义,会计算count_matrix中每一行的余弦相似度。count_matrix中的每一行就是每个出现在 ensemble 列中的单词的词频向量。
#Creating a Pandas Series from df's index
indices = pd.Series(df.index, index=df['title']).drop_duplicates()
在运行实际推荐系统之前,我们需要确保创建一个索引,并且该索引没有重复项。
只有在这个时候我们才能定义content_recommender函数。它有 4 个参数:title、cosine_sim、df和indices。调用函数时,标题将是唯一的输入元素。
content_recommender的工作方式如下:
-
它找到与用户提供的标题相关的产品索引。
-
它在余弦相似度矩阵中搜索产品的索引,并收集所有产品的所有分数。
-
它排序所有分数,从最相似的产品(接近 1)到最不相似的(接近 0)。
-
它仅选择前 30 个最相似的产品。
-
它添加一个索引并返回一个 pandas 系列作为结果。
# Function that takes in product title as input and gives recommendations
def content_recommender(title, cosine_sim=cosine_sim, df=df,
indices=indices):
# Obtain the index of the product that matches the title
idx = indices[title]
# Get the pairwsie similarity scores of all products with that product
# And convert it into a list of tuples as described above
sim_scores = list(enumerate(cosine_sim[idx]))
# Sort the products based on the cosine similarity scores
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# Get the scores of the 30 most similar products. Ignore the first product.
sim_scores = sim_scores[1:30]
# Get the product indices
product_indices = [i[0] for i in sim_scores]
# Return the top 30 most similar products
return df['title'].iloc[product_indices]
现在让我们在“Vcool VGA Cooler”上进行测试。我们需要 30 个相似的产品,且顾客可能有兴趣购买。通过运行命令content_recommender(product_title),函数返回了 30 条推荐列表。
#Define the product we want to recommend other items from
product_title = 'Vcool VGA Cooler'
#Launching the content_recommender function
recommendations = content_recommender(product_title)
#Associating titles to recommendations
asin_recommendations = df[df['title'].isin(recommendations)]
#Merging datasets
recommendations = pd.merge(recommendations,
asin_recommendations,
on='title',
how='left')
#Showing top 5 recommended products
recommendations['title'].head()
在5 个最相似的产品中,我们找到了其他 Antec 产品,如 Tricool 计算机机箱风扇、扩展槽散热风扇等。
1 Antec Big Boy 200 - 200mm Tricool Computer Case Fan
2 Antec Cyclone Blower, Expansion Slot Cooling Fan
3 StarTech.com 90x25mm High Air Flow Dual Ball Bearing Computer Case Fan with TX3 Cooling Fan FAN9X25TX3H (Black)
4 Antec 120MM BLUE LED FAN Case Fan (Clear)
5 Antec PRO 80MM 80mm Case Fan Pro with 3-Pin & 4-Pin Connector (Discontinued by Manufacturer)
原始数据集中的related列包含了消费者还购买的产品、一起购买的产品以及在查看 VGA Cooler 后购买的产品列表。
#Selecting the 'related' column of the product we computed recommendations for
related = pd.DataFrame.from_dict(df['related'].iloc[10000], orient='index').transpose()
#Printing first 10 records of the dataset
related.head(10)
通过打印该列的 Python 字典头部,控制台返回了以下数据集。
| | also_bought | bought_together | buy_after_viewing |
|---:|:--------------|:------------------|:--------------------|
| 0 | B000051299 | B000233ZMU | B000051299 |
| 1 | B000233ZMU | B000051299 | B00552Q7SC |
| 2 | B000I5KSNQ | | B000233ZMU |
| 3 | B00552Q7SC | | B004X90SE2 |
| 4 | B000HVHCKS | | |
| 5 | B0026ZPFCK | | |
| 6 | B009SJR3GS | | |
| 7 | B004X90SE2 | | |
| 8 | B001NPEBEC | | |
| 9 | B002DUKPN2 | | |
| 10 | B00066FH1U | | |
让我们测试一下我们的推荐系统是否表现良好。查看asin id 是否在also_bought列表中的推荐中出现。
#Checking if recommended products are in the 'also_bought' column for
#final evaluation of the recommender
related['also_bought'].isin(recommendations['asin'])
我们的推荐系统正确建议了44 个产品中的 5 个。
[True False True False False False False False False False True False False False False False False True False False False False False False False False True False False False False False False False False False False False False False False False False False]
我同意这不是最佳结果,但考虑到我们仅使用了35,000行数据中的498,196行,它是可以接受的。这显然还有很大的改进空间。如果 NaN 值在目标列中较少甚至不存在,推荐可能会更准确,更接近实际的 Amazon 推荐。其次,拥有更大的 RAM 内存或甚至分布式计算,可以使实践者计算更大的矩阵。
结论
希望你喜欢这个项目,并且它对未来使用会有所帮助。
正如文章中提到的,通过包含数据集中的所有行在余弦相似度矩阵中,最终结果可以进一步改进。此外,我们还可以通过将元数据集与其他可用的数据集合并来添加每个产品的评论平均分数。我们可以在余弦相似度计算中包括价格。另一个可能的改进是建立一个完全基于每个产品描述性图像的推荐系统。
列出了进一步改进的主要解决方案。其中大多数从未来实际生产的实施角度来看都是值得追求的。
最后,如果你喜欢这个内容,请考虑关注,以便在发布新文章时收到通知。如果你对文章有任何观察,请在评论中写出来!我很愿意阅读 😃 谢谢阅读!
PS:如果你喜欢我的写作,能通过这个链接订阅 Medium 会员对我来说意义重大!通过会员,你可以获得 Medium 文章提供的惊人价值,并且这也是支持我内容的一种间接方式!
参考
[1] 亚马逊产品推荐系统 2021:电商巨头的算法如何运作?— Recostream。(2021)。从 Recostream.com 网站检索: recostream.com/blog/amazon-recommendation-system
[2] He, R., & McAuley, J. (2016 年 4 月). 高潮与低谷:通过单类协同过滤建模时尚趋势的视觉演变。收录于第 25 届国际万维网会议论文集(第 507–517 页)。
[3] McAuley, J., Targett, C., Shi, Q., & Van Den Hengel, A. (2015 年 8 月). 基于图像的风格与替代品推荐。收录于第 38 届国际 ACM SIGIR 信息检索研究与发展会议论文集(第 43–52 页)。
[4] Rahutomo, F., Kitasuka, T., & Aritsugi, M. (2012 年 10 月). 语义余弦相似度。收录于第 7 届国际学生高级科学与技术会议 ICAST(第 4 卷,?1,第 1 页)。
[5] Rounak Banik. 2018 年。使用 Python 的实用推荐系统:开始构建强大且个性化的推荐引擎。Packt Publishing。
Giovanni Valdata 拥有两个 BBA 学位和一个管理学硕士学位,在硕士期间将自然语言处理应用于数据科学与管理的论文。Giovanni 喜欢通过开发具有实际应用的技术项目,帮助读者更好地了解该领域。
原始。经许可转载。
更多相关话题
构建推荐系统,第二部分
原文:
www.kdnuggets.com/2019/07/building-recommender-system-part-2.html
评论
作者:Matthew Mahowald,开放数据集团
在上一篇文章中,我们探讨了基于邻域的方法来构建推荐系统。本文探讨了一种使用潜在因子模型的协同过滤替代技术。我们将使用的技术自然可以推广到深度学习方法(如自编码器),因此我们还将使用 Tensorflow 和 Keras 实现我们的方法。

数据集
本文将重用我们上次用于协同过滤模型的 MovieLens 数据集。GroupLens 在这里提供了数据集。
首先,让我们加载这些数据:
import pandas as pd
import numpy as np
np.random.seed(42)
ratings = pd.read_csv(RATING_DATA_FILE,
sep='::',
engine='python',
encoding='latin-1',
names=['userid', 'movieid', 'rating', 'timestamp'])
movies = pd.read_csv(os.path.join(MOVIELENS_DIR, MOVIE_DATA_FILE),
sep='::',
engine='python',
encoding='latin-1',
names=['movieid', 'title', 'genre']).set_index("movieid")
让我们快速查看一下前 20 个最受欢迎的文件:
| 标题 | 类型 | |
|---|---|---|
| movieid | ||
| --- | --- | --- |
| 2858 | 美国丽人 (1999) | 喜剧|剧情 |
| 260 | 星球大战:新希望 (1977) | 动作|冒险|奇幻|科幻 |
| 1196 | 星球大战:帝国反击战… | 动作|冒险|剧情|科幻|战争 |
| 1210 | 星球大战:绝地归来 (1983) | 动作|冒险|浪漫|科幻|战争 |
| 480 | 侏罗纪公园 (1993) | 动作|冒险|科幻 |
| 2028 | 拯救大兵瑞恩 (1998) | 动作|剧情|战争 |
| 589 | 终结者 2:审判日 (1991) | 动作|科幻|惊悚 |
| 2571 | 黑客帝国 (1999) | 动作|科幻|惊悚 |
| 1270 | 回到未来 (1985) | 喜剧|科幻 |
| 593 | 沉默的羔羊 (1991) | 剧情|惊悚 |
| 1580 | 黑衣人 (1997) | 动作|冒险|喜剧|科幻 |
| 1198 | 夺宝奇兵 (1981) | 动作|冒险 |
| 608 | 冰血暴 (1996) | 犯罪|剧情|惊悚 |
| 2762 | 第六感 (1999) | 惊悚 |
| 110 | 布雷夫哈特 (1995) | 动作|剧情|战争 |
| 2396 | 罗密欧与朱丽叶 (1998) | 喜剧|浪漫 |
| 1197 | 公主新娘 (1987) | 动作|冒险|喜剧|浪漫 |
| 527 | 辛德勒的名单 (1993) | 剧情|战争 |
| 1617 | 洛杉矶机密 (1997) | 犯罪|黑色电影|悬疑|惊悚 |
| 1265 | 土拨鼠日 (1993) | 喜剧|浪漫 |
预处理
协同过滤模型通常在每个项目有相当数量的评分时效果最佳。我们将限制为仅使用 500 部最受欢迎的电影(按评分数量确定)。我们还将按 movieid 和 userid 重新索引:
rating_counts = ratings.groupby("movieid")["rating"].count().sort_values(ascending=False)
# only the 500 most popular movies
pop_ratings = ratings[ratings["movieid"].isin((rating_counts).index[0:500])]
pop_ratings = pop_ratings.set_index(["movieid", "userid"])
接下来,如前一篇文章中提到的,我们应该规范化我们的评分数据。我们通过减去总体均值评分、每个项目的均值评分,然后减去每个用户的均值评分来创建一个调整后的评分。
这产生了一个“偏好评分” 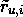 ,定义如下
,定义如下
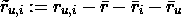
对于  的直觉是,
的直觉是,  表示用户
表示用户  对项目
对项目  的评分正是我们如果只知道平均总体评分、项目评分和用户评分时的预测。任何高于或低于 0 的值表示相对于这个基准的偏好偏差。为了区分 和原始评分
的评分正是我们如果只知道平均总体评分、项目评分和用户评分时的预测。任何高于或低于 0 的值表示相对于这个基准的偏好偏差。为了区分 和原始评分  ,我将前者称为用户对项目 的偏好,后者称为用户对项目 的评分。
,我将前者称为用户对项目 的偏好,后者称为用户对项目 的评分。
让我们使用对 500 部最受欢迎电影的评分来构建偏好数据:
prefs = pop_ratings["rating"]
mean_0 = pop_ratings["rating"].mean()
prefs = prefs - mean_0
mean_i = prefs.groupby("movieid").mean()
prefs = prefs - mean_i
mean_u = prefs.groupby("userid").mean()
prefs = prefs - mean_u
pref_matrix = prefs.reset_index()[["userid", "movieid", "rating"]].pivot(index="userid", columns="movieid", values="rating")
这段代码的输出是两个对象:prefs,它是一个按movieid和userid索引的偏好数据框;以及pref_matrix,它是一个矩阵,其中的  项对应于用户 对电影
项对应于用户 对电影  的评分(即列是电影,每行是用户)。如果用户没有对某个项目进行评分,这个矩阵将包含
的评分(即列是电影,每行是用户)。如果用户没有对某个项目进行评分,这个矩阵将包含 NaN。
数据中的最大和最小偏好分别是 3.923 和-4.643。接下来,我们将构建一个实际的模型。
潜在因子协同过滤
在这一阶段,我们已经构建了一个矩阵  (在上面的 Python 代码中称为
(在上面的 Python 代码中称为pref_matrix)。潜在因子协同过滤模型的思想是,每个用户的偏好可以通过少量的潜在因子来预测(通常远小于可用项目的总数):
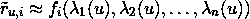
潜在因子模型因此需要回答两个相关的问题:
-
对于给定的用户
![u]() ,相应的潜在因子是什么
,相应的潜在因子是什么 ![\lambda_{k}(u)]() ?
? -
对于给定的潜在因子集合,函数
![f_{i}]() 是什么?即,潜在因子与用户对每个项目的偏好之间的关系是什么?
是什么?即,潜在因子与用户对每个项目的偏好之间的关系是什么?
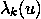 ?
?解决这个问题的一种方法是尝试求解 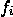 和
和 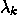 ,通过简化假设每个函数都是线性的:
,通过简化假设每个函数都是线性的:
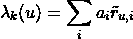
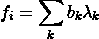
在所有项目和用户中,这可以被重新写为线性代数问题:找出矩阵 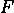 和
和 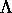 使得
使得
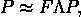
其中 是偏好矩阵, 是将用户的偏好投影到潜在变量空间的线性变换,而 是从用户在潜在变量空间中的表示中重建用户评分的线性变换。
这个产品 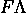 将是一个方阵。然而,通过选择的潜在变量数量严格少于项目数量,这个产品必然不是满秩的。从本质上讲,我们是在求解 和 ,使得产品 最好地逼近身份变换 在偏好矩阵上 。我们的直觉(和希望)是,这将重建每个用户的准确偏好。(我们将调整我们的损失函数以确保确实如此。)
将是一个方阵。然而,通过选择的潜在变量数量严格少于项目数量,这个产品必然不是满秩的。从本质上讲,我们是在求解 和 ,使得产品 最好地逼近身份变换 在偏好矩阵上 。我们的直觉(和希望)是,这将重建每个用户的准确偏好。(我们将调整我们的损失函数以确保确实如此。)
模型实现
如广告所示,我们将使用 Keras + Tensorflow 构建我们的模型,以便我们为任何未来的深度学习方法的推广做好准备。这也是解决我们所处理问题的自然方法:表达式
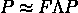
可以被认为是描述一个两层密集神经网络的,其中层由 和 定义,并且其激活函数就是身份映射(即函数  )。
)。
首先,让我们导入我们需要的包,并设置我们为这个模型所需的编码维度(潜在变量的数量)。
import tensorflow as tf
from keras.layers import Input, Dense, Lambda
from keras.models import Model, load_model as keras_load_model
from keras import losses
from keras.callbacks import EarlyStopping
ENCODING_DIM = 25
ITEM_COUNT = 500
接下来,将模型本身定义为“编码”层(投影到潜在变量空间)和“解码”层(从潜在变量表示中恢复偏好)的组合。推荐模型本身只是这两层的组合。
# ~~~ build recommender ~~~ #
input_layer = Input(shape=(ITEM_COUNT, ))
# compress to low dimension
encoded = Dense(ENCODING_DIM, activation="linear", use_bias=False)(input_layer)
# blow up to large dimension
decoded = Dense(ITEM_COUNT, activation="linear", use_bias=False)(encoded)
# define subsets of the model:
# 1\. the recommender itself
recommender = Model(input_layer, decoded)
# 2\. the encoder
encoder = Model(input_layer, encoded)
# 3\. the decoder
encoded_input = Input(shape=(ENCODING_DIM, ))
decoder = Model(encoded_input, recommender.layers-1)
自定义损失函数
此时,我们可以直接训练我们的模型以仅重现其输入(这本质上是一个非常简单的自编码器)。然而,我们实际上感兴趣的是选择 和 来正确填充 缺失 的值。我们可以通过仔细应用掩盖和自定义损失函数来做到这一点。
记住,prefs_matrix 目前主要由 NaNs 组成——实际上,整个数据集中只有一个零值:
prefs[prefs == 0]
# movieid userid
# 2664 2204 0.0
在 prefs_matrix 中,我们可以用零填充任何缺失的值。这是一个合理的选择,因为我们已经对评分进行了某种归一化处理,因此 0 代表我们对用户对特定项目偏好的天真猜测。然后,为了创建训练数据,使用 prefs_matrix 作为目标,并有选择性地掩盖 prefs_matrix 中的非零元素来创建输入(“遗忘”特定用户-项目的偏好)。然后,我们可以构建一个损失函数,该函数会强烈惩罚错误猜测“遗忘”的值,即训练以从已知评分构建新评分的损失函数。以下是我们的函数:
def lambda_mse(frac=0.8):
"""
Specialized loss function for recommender model.
:param frac: Proportion of weight to give to novel ratings.
:return: A loss function for use in a Lambda layer.
"""
def lossfunc(xarray):
x_in, y_true, y_pred = xarray
zeros = tf.zeros_like(y_true)
novel_mask = tf.not_equal(x_in, y_true)
known_mask = tf.not_equal(x_in, zeros)
y_true_1 = tf.boolean_mask(y_true, novel_mask)
y_pred_1 = tf.boolean_mask(y_pred, novel_mask)
y_true_2 = tf.boolean_mask(y_true, known_mask)
y_pred_2 = tf.boolean_mask(y_pred, known_mask)
unknown_loss = losses.mean_squared_error(y_true_1, y_pred_1)
known_loss = losses.mean_squared_error(y_true_2, y_pred_2)
# remove nans
unknown_loss = tf.where(tf.is_nan(unknown_loss), 0.0, unknown_loss)
return frac*unknown_loss + (1.0 - frac)*known_loss
return lossfunc
默认情况下,返回的损失是整体 MSE 和仅缺失评分的 MSE 的 20%-80% 加权和。这个损失函数需要输入(带有缺失偏好)、预测的偏好和真实的偏好。
至少截至本文发布之日,Keras 和 TensorFlow 目前不支持具有三个输入的自定义损失函数(其他框架,如 PyTorch,支持)。我们可以通过引入“虚拟”损失函数和简单的包装模型来绕过这个事实。Keras 中的损失函数只需要两个输入,因此这个虚拟函数将忽略“真实”值。
def final_loss(y_true, y_pred):
"""
Dummy loss function for wrapper model.
:param y_true: true value (not used, but required by Keras)
:param y_pred: predicted value
:return: y_pred
"""
return y_pred
接下来是我们的包装模型。这里的想法是使用 lambda 层(‘loss’)来应用我们的自定义损失函数('lambda_mse'),然后使用我们的自定义损失函数进行实际优化。使用 Keras 的功能 API 可以非常容易地将我们已经定义的推荐器用这个简单的包装模型进行包装。
original_inputs = recommender.input
y_true_inputs = Input(shape=(ITEM_COUNT, ))
original_outputs = recommender.output
# give 80% of the weight to guessing the missings, 20% to reproducing the knowns
loss = Lambda(lambda_mse(0.8))([original_inputs, y_true_inputs, original_outputs])
wrapper_model = Model(inputs=[original_inputs, y_true_inputs], outputs=[loss])
wrapper_model.compile(optimizer='adadelta', loss=final_loss)
训练
为了生成我们的模型训练数据,我们将从偏好矩阵 pref_matrix 开始,并随机掩盖(即设置为 0)每个用户已知评分的某个比例。将其结构化为生成器允许我们创建一个本质上无限的训练数据集合(尽管在每种情况下,输出受限于从相同固定已知评分集中提取)。以下是生成器函数:
def generate(pref_matrix, batch_size=64, mask_fraction=0.2):
"""
Generate training triplets from this dataset.
:param batch_size: Size of each training data batch.
:param mask_fraction: Fraction of ratings in training data input to mask. 0.2 = hide 20% of input ratings.
:param repeat: Steps between shuffles.
:return: A generator that returns tuples of the form ([X, y], zeros) where X, y, and zeros all have
shape[0] = batch_size. X, y are training inputs for the recommender.
"""
def select_and_mask(frac):
def applier(row):
row = row.copy()
idx = np.where(row != 0)[0]
if len(idx) > 0:
masked = np.random.choice(idx, size=(int)(frac*len(idx)), replace=False)
row[masked] = 0
return row
return applier
indices = np.arange(pref_matrix.shape[0])
batches_per_epoch = int(np.floor(len(indices)/batch_size))
while True:
np.random.shuffle(indices)
for batch in range(0, batches_per_epoch):
idx = indices[batch*batch_size:(batch+1)*batch_size]
y = np.array(pref_matrix[idx,:])
X = np.apply_along_axis(select_and_mask(frac=mask_fraction), axis=1, arr=y)
yield [X, y], np.zeros(batch_size)
让我们检查一下这个生成器的掩盖功能是否正常工作:
[X, y], _ = next(generate(pref_matrix.fillna(0).values))
len(X[X != 0])/len(y[y != 0])
# returns 0.8040994014148377
为了完成故事,我们将定义一个训练函数,调用此生成器并允许我们设置其他一些参数(训练轮数、早期停止等):
def fit(wrapper_model, pref_matrix, batch_size=64, mask_fraction=0.2, epochs=1, verbose=1, patience=0):
stopper = EarlyStopping(monitor="loss", min_delta=0.00001, patience=patience, verbose=verbose)
batches_per_epoch = int(np.floor(pref_matrix.shape[0]/batch_size))
generator = generate(pref_matrix, batch_size, mask_fraction)
history = wrapper_model.fit_generator(
generator,
steps_per_epoch=batches_per_epoch,
epochs=epochs,
callbacks = [stopper] if patience > 0 else []
)
return history
记住 和 是  和
和  维矩阵,因此这个模型有
维矩阵,因此这个模型有 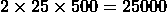 个参数。对于线性模型,一个好的经验法则是每个参数至少要有 10 个观测值,这意味着我们希望在训练期间看到 250,000 个用户评分向量。然而,我们的用户数量远远不够,因此在本教程中,我们将大大减少数量——最多使用 12,500 个观测值(如果损失没有改善则提前停止模型)。
个参数。对于线性模型,一个好的经验法则是每个参数至少要有 10 个观测值,这意味着我们希望在训练期间看到 250,000 个用户评分向量。然而,我们的用户数量远远不够,因此在本教程中,我们将大大减少数量——最多使用 12,500 个观测值(如果损失没有改善则提前停止模型)。
# stop after 3 epochs with no improvement
fit(wrapper_model, pref_matrix.fillna(0).values, batch_size=125, epochs=100, patience=3)
# Loss of 0.6321
这个训练过程的输出(至少在我的机器上)给出了 0.6321 的损失,这意味着我们在没有见过的用户真正偏好上平均相差约 0.7901 单位(请记住,这个损失中 80%来自未知偏好,20%来自已知偏好)。我们的数据中的偏好范围从-4.64 到 3.92,所以这也不算太差!
预测评分
要使用我们的模型生成预测,我们必须在沿各个维度标准化评分后调用之前训练的recommender模型。假设我们预测函数的输入是一个以(movieid,userid)索引的 dataframe,并且有一个名为"rating"的列。
def predict(ratings, recommender, mean_0, mean_i, movies):
# add a dummy user that's seen all the movies so when we generate
# the ratings matrix, it has the appropriate columns
dummy_user = movies.reset_index()[["movieid"]].copy()
dummy_user["userid"] = -99999
dummy_user["rating"] = 0
dummy_user = dummy_user.set_index(["movieid", "userid"])
ratings = ratings["rating"]
ratings = ratings - mean_0
ratings = ratings - mean_i
mean_u = ratings.groupby("userid").mean()
ratings = ratings - mean_u
ratings = ratings.append(dummy_user["rating"])
pref_mat = ratings.reset_index()[["userid", "movieid", "rating"]].pivot(index="userid", columns="movieid", values="rating")
X = pref_mat.fillna(0).values
y = recommender.predict(X)
output = pd.DataFrame(y, index=pref_mat.index, columns=pref_mat.columns)
output = output.iloc[1:] # drop the bad user
output = output.add(mean_u, axis=0)
output = output.add(mean_i, axis=1)
output = output.add(mean_0)
return output
让我们试试看!这里有一些单个虚拟用户的示例评分,他非常喜欢《星球大战》和《侏罗纪公园》,而对其他的电影不太感兴趣:
sample_ratings = pd.DataFrame([
{"userid": 1, "movieid": 2858, "rating": 1}, # american beauty
{"userid": 1, "movieid": 260, "rating": 5}, # star wars
{"userid": 1, "movieid": 480, "rating": 5}, # jurassic park
{"userid": 1, "movieid": 593, "rating": 2}, # silence of the lambs
{"userid": 1, "movieid": 2396, "rating": 2}, # shakespeare in love
{"userid": 1, "movieid": 1197, "rating": 5} # princess bride
]).set_index(["movieid", "userid"])
# predict and print the top 10 ratings for this user
y = predict(sample_ratings, recommender, mean_0, mean_i, movies.loc[(rating_counts).index[0:500]]).transpose()
preds = y.sort_values(by=1, ascending=False).head(10)
preds["title"] = movies.loc[preds.index]["title"]
preds
| userid | 1 | title |
|---|---|---|
| movieid | ||
| --- | --- | --- |
| 260 | 4.008329 | 星球大战:新希望 (1977) |
| 1198 | 3.942005 | 夺宝奇兵 (1981) |
| 1196 | 3.860034 | 星球大战:帝国反击战… |
| 1148 | 3.716259 | 错误裤子 (1993) |
| 904 | 3.683811 | 后窗 (1954) |
| 2019 | 3.654374 | 七武士(七侠镇)(Shichin… |
| 913 | 3.639756 | 马耳他之鹰 (1941) |
| 318 | 3.637150 | 肖申克的救赎 (1994) |
| 745 | 3.619762 | 接近剃刀 (1995) |
| 908 | 3.608473 | 西北偏北 (1959) |
有趣的是,即使用户给星球大战的评分为 5,模型预测的星球大战的评分也只有 4.08。不过它确实推荐了帝国反击战和夺宝奇兵,这些推荐似乎符合这些偏好。
现在让我们逆转这个用户对《星球大战》和《侏罗纪公园》的评分,看看评分如何变化:
sample_ratings2 = pd.DataFrame([
{"userid": 1, "movieid": 2858, "rating": 5}, # american beauty
{"userid": 1, "movieid": 260, "rating": 1}, # star wars
{"userid": 1, "movieid": 480, "rating": 1}, # jurassic park
{"userid": 1, "movieid": 593, "rating": 1}, # silence of the lambs
{"userid": 1, "movieid": 2396, "rating": 5}, # shakespeare in love
{"userid": 1, "movieid": 1197, "rating": 5} # princess bride
]).set_index(["movieid", "userid"])
y = predict(sample_ratings2, recommender, mean_0, mean_i, movies.loc[(rating_counts).index[0:500]]).transpose()
preds = y.sort_values(by=1, ascending=False).head(10)
preds["title"] = movies.loc[preds.index]["title"]
preds
| userid | 1 | title |
|---|---|---|
| movieid | ||
| --- | --- | --- |
| 2019 | 3.532214 | 七武士(七侠镇)(Shichin… |
| 50 | 3.489284 | 通常的嫌疑犯 (1995) |
| 2858 | 3.480124 | 美国美人(1999) |
| 745 | 3.466157 | 《理发师的故事》(1995) |
| 1148 | 3.415981 | 《错误的裤子》(1993) |
| 1197 | 3.415527 | 《公主新娘》(1987) |
| 527 | 3.386785 | 《辛德勒的名单》(1993) |
| 750 | 3.342154 | 《奇爱博士》 |
| 1252 | 3.338330 | 《唐人街探案》(1974) |
| 1207 | 3.335204 | 《杀死一只知更鸟》(1962) |
注意到七武士在两个列表中都显著出现。事实上,七武士在这个数据集中具有最高的平均评分(为 4.56),查看用户推荐的前 20 或前 50 部电影时,还会发现更多非常高评分的共同电影。
结论与进一步阅读
我们构建的潜在因子表示也可以被视为将项目嵌入到某个低维空间中,而不是将用户嵌入。这让我们可以做一些有趣的事情,例如,我们可以比较每个项目向量表示之间的距离,以了解两部电影的相似或不同。让我们将星球大战与帝国反击战和美国美人进行比较:
starwars = decoder.get_weights()[0][:,33]
esb = decoder.get_weights()[0][:,144]
americanbeauty = decoder.get_weights()[0][:,401]
注意到 33 是对应于星球大战的列索引(不同于其movieid为 260),144 是对应于帝国反击战的列索引,401 是对应于美国美人的列索引。
np.sqrt(((starwars - esb)**2).sum())
# 0.209578
np.sqrt(((starwars - americanbeauty)**2).sum())
# 0.613659
比较这些距离,我们看到星球大战和帝国反击战在潜在因子空间中的距离为 0.209578,比星球大战和美国美人的距离要近得多。
通过进一步的工作,还可以在潜在因子空间中回答其他问题,例如“哪部电影与星球大战最不相似?”
这种类型的技术的变体导致了基于自编码器的推荐系统。有关进一步阅读,还有一类相关模型,称为矩阵分解模型,它可以同时包含项目和用户特征以及原始评分。
相关:
-
构建推荐系统
-
K-Means 聚类:用于推荐系统的无监督学习
-
使用 Azure 机器学习服务构建推荐系统
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT
更多相关话题
构建推荐系统
原文:
www.kdnuggets.com/2019/04/building-recommender-system.html
评论
作者:Matthew Mahowald, 开放数据组。
推荐系统是今天最突出的机器学习实例之一。它们决定了你的 Facebook 新闻源中出现的内容、产品在 Amazon 上的展示顺序、Netflix 队列中建议的视频,以及无数其他例子。但什么是推荐系统,它们是如何工作的?这篇文章是探索构建推荐系统的一些常见技术及其实现的系列文章中的第一篇。

什么是推荐系统?
推荐系统是一种信息过滤模型,用于对用户的项目进行排名或评分。一般有两种排名方法:
-
基于内容的过滤,其中推荐项目基于项目之间的相似性和用户的显式偏好;以及
-
协同过滤,其中向用户推荐的项目基于其他具有相似交易历史和特征的用户的偏好。
协同过滤中使用的信息可以是显式的,即用户对每个项目提供评分,也可以是隐式的,即从用户行为(购买、浏览等)中提取用户偏好。最成功的推荐系统使用结合两种过滤方法的混合方法。
MovieLens 数据集
为了使讨论更具实质性,让我们关注于使用一个具体的例子来构建推荐系统。GroupLens 是明尼苏达大学的一个研究小组,他们慷慨地提供了 MovieLens 数据集。该数据集包含约 2000 万条用户评分,涉及 27,000 部电影,由 138,000 名用户评分。此外,电影还包括类别和日期信息。我们将使用此数据集来构建
简单的基于内容的过滤
让我们构建一个简单的推荐系统,该系统使用基于内容的过滤(即项目相似性)来推荐电影给我们观看。首先,从 MovieLens 加载电影数据集,并对类别字段进行多重热编码:
import pandas as pd
import numpy as np
movies = pd.read_csv("movies.csv")
*# dummy encode the genre*
movies = movies.join(movies.genres.str.get_dummies("|"))
genres 特征由一个或多个管道符号(“|”)分隔的类别组成。上面的最后一行添加了每个可能类别的列,如果类别标签存在,则在该条目中放置 1,否则放置 0。
基于这些标签,让我们生成一些基于项目相似性的推荐。对于类别数据(如标签),余弦相似度是一种非常常见的相似度度量。对于任何两个项目 和 , 和 的余弦相似度就是 和 之间夹角的余弦值,其中 和 被解释为特征空间中的向量。请记住,余弦值是从这些向量的内积中获得的:

作为一个具体的例子,考虑电影 $i := $ 《玩具总动员》(类型标签:“冒险”、“动画”、“儿童”、“喜剧”和“奇幻”)和 $j := $ 《勇敢的心》(类型标签:“冒险”、“儿童”和“奇幻”)。点积  是 3(这两部电影有三个标签相同)。 


我们可以计算数据集中所有项目的余弦相似度:
from sklearn.metrics.pairwise import cosine_similarity
*# compute the cosine similarity* cos_sim = cosine_similarity(movies.iloc[:,3:])
数据集中的第一部电影是《玩具总动员》。让我们找出与《玩具总动员》相似的电影:
*# Let's get the top 5 most similar films:* toystory_top5 = np.argsort(sim[0])[-5:][::-1]
*# array([ 0, 8219, 3568, 9430, 3000, 2809, 2355, 6194, 8927, 6948, 7760,
# 1706, 6486, 6260, 5490])*
| 电影 ID | 类型 |
|---|---|
| 《玩具总动员》(1995) | 冒险, 动画, 儿童, 喜剧, 奇幻 |
| 《极速蜗牛》(2013) | 冒险, 动画, 儿童, 喜剧, 奇幻 |
| 《怪兽电力公司》(2001) | 冒险, 动画, 儿童, 喜剧, 奇幻 |
| 《海洋奇缘》(2016) | 冒险, 动画, 儿童, 喜剧, 奇幻 |
| 《皇帝的新装》(2000) | 冒险, 动画, 儿童, 喜剧, 奇幻 |
前五部电影的类型标签与《玩具总动员》完全相同,因此其余弦相似度为 1。事实上,对于这里使用的样本数据,共有十三部电影的相似度为 1;最相似的没有完全相同标签的电影是 2006 年的《蚂蚁大兵》,它有额外的类型标签“IMAX”。
简单协同过滤
协同过滤根据相似用户喜欢的内容来推荐物品。幸运的是,在 MovieLens 数据集中,我们拥有丰富的用户偏好信息,以电影评分的形式存在:每个用户给一个或多个电影打分,分数在 1 到 5 之间,表示他们对电影的喜爱程度。我们可以将向用户推荐物品的问题视为一个 预测 任务:根据用户对其他电影的评分,预测他们对该电影的可能评分。
一种简单的方法是使用其他用户的评分为每个物品分配一个加权评分:
 r_{v, i}}{\sum_{v \neq u} s(u,v)} ")
其中  对物品 的预测评分,
对物品 的预测评分,") 是用户 和
是用户 和  之间相似度的度量, 是用户 对物品 的已知评分。
之间相似度的度量, 是用户 对物品 的已知评分。
对于我们的用户相似度度量,我们将查看用户对电影的评分。评分相似的用户将被认为是相似的。处理这些评分数据的一个重要第一步是对我们的评分进行归一化。我们将分三步进行:首先,减去整体平均评分(跨所有电影和用户),使调整后的评分以 0 为中心。接下来,我们对每部电影做同样的操作,以考虑给定电影的平均评分的差异。最后,我们减去每个用户的平均评分——这考虑了个人的变化(例如,一些用户的评分始终较高)。
在数学上,我们的调整评分 

其中  是基础评分,
是基础评分,
 的均值评分(在减去总体均值之后),而
的均值评分(在减去总体均值之后),而  的均值评分(在调整了总体均值评分和项目均值评分之后)。为了方便,我会将调整后的评分
的均值评分(在调整了总体均值评分和项目均值评分之后)。为了方便,我会将调整后的评分  对项目 的偏好。
对项目 的偏好。
让我们加载评分数据并计算调整后的评分:
ratings = pd.read_csv("ratings.csv")
mean_rating = ratings['rating'].mean() *# compute mean rating*
pref_matrix = ratings[['userId', 'movieId', 'rating']].pivot(index='userId', columns='movieId', values='rating')
pref_matrix = pref_matrix - mean_rating *# adjust by overall mean*
item_mean_rating = pref_matrix.mean(axis=0)
pref_matrix = pref_matrix - item_mean_rating *# adjust by item mean*
user_mean_rating = pref_matrix.mean(axis=1)
pref_matrix = pref_matrix - user_mean_rating
在这一点上,我们可以轻松地为某个用户对他们尚未观看的电影建立一个合理的基准估计:
pref_matrix.fillna(0) + user_mean_rating + item_mean_rating + mean_rating
我们可以按如下方式计算与特定用户(在此情况下为用户 0)的距离:
mat = pref_matrix.values
k = 0 *# use the first user*
np.nansum((mat - mat[k,:])**2,axis=1).reshape(-1,1)
结果表明,最近的用户是用户 12(距离为 0):
np.nansum((mat - mat[0,:])**2,axis=1)[1:].argmin() *# returns 11*
*# check it:* np.nansum(mat[12] - mat[0]) # returns 0.0
我们找到了用户 12 已看过但用户 0 未看过的两部电影:
np.where(~np.isnan(mat[12]) & np.isnan(mat[0]) == True)
*# returns (array([304, 596]),)*
mat[12][[304, 596]]
*# returns array([-2.13265214, -0.89476547])*
不幸的是,用户 12 不喜欢用户 0 尚未观看的两部电影!我们应继续计算以考虑所有附近的用户。
结论
本文中使用的方法是基于邻域的,我们刚刚看到生成基于邻域的推荐时的一个潜在陷阱:邻域可能实际上不会推荐任何用户尚未看过的项目。由于需要计算成对距离,基于邻域的方法也往往在用户数量增加时表现不佳。
在本系列的第二部分,我们将查看另一种构建推荐系统的方法,这次使用潜在因子方法。潜在因子模型避免了一些基于邻域的方法的陷阱,但正如我们将看到的,它们也有一些自身的挑战!
资源:
相关:
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
相关话题
使用交叉验证构建可靠的机器学习模型
原文:
www.kdnuggets.com/2018/08/building-reliable-machine-learning-models-cross-validation.html
评论
作者:Gideon Mendels,联合创始人兼首席执行官 @ Comet.ml
交叉验证是一种用于测量和评估机器学习模型性能的技术。在训练过程中,我们创建多个训练集的分区,并在这些分区的不同子集上进行训练/测试。
交叉验证经常被用来训练、测量并最终选择一个机器学习模型,因为它帮助评估模型的结果如何在独立数据集上实际应用。最重要的是,交叉验证已被证明能生成比其他方法偏差更低的模型。
本教程将重点介绍一种名为k 折交叉验证的交叉验证变体。
在本教程中,我们将涵盖以下内容:
-
K-Fold 交叉验证概述
-
使用 Scikit-Learn 和 Comet.ml 的示例
K-Fold 交叉验证
交叉验证是一种重采样技术,用于在有限的数据集上评估机器学习模型。
交叉验证的最常见用法是 k 折交叉验证方法。我们的训练集被拆分为K个分区,模型在K-1个分区上进行训练,测试误差在Kth个分区上预测并计算。这在每个唯一组上重复,测试误差被平均。
相同的过程由以下步骤描述:
- 将训练集拆分为 K 个(K=10 是常见选择)分区
对于每个分区:
-
设置分区作为测试集
-
在其余的分区上训练模型
-
在测试集上测量性能
-
保留性能指标
-
探索不同折叠下的模型性能
交叉验证通常被使用,因为它易于解释,并且通常会比其他方法,如简单的训练/测试拆分,得到更少偏差或更少乐观的模型性能估计。使用交叉验证的最大缺点之一是训练时间的增加,因为我们实际上是在训练 K 次而不是 1 次。
使用 scikit-learn 的交叉验证示例
Scikit-learn是一个流行的机器学习库,它还提供了许多数据采样、模型评估和训练的工具。我们将使用Kfold类来生成我们的折叠。以下是基本概述:
from sklearn.model_selection import KFold
X = [...] # My training dataset inputs/features
y = [...] # My training dataset targets
kf = KFold(n_splits=2)
kf.get_n_splits(X)
for train_index, test_index in kf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model = train_model(X_train,y_train)
score = eval_model(X_test,y_test)
现在让我们使用 scikit-learn 和 Comet.ml 训练一个端到端的示例。
这个例子在新闻组数据集上训练一个文本分类器(你可以在这里找到它)。给定一段文本(字符串),模型将其分类为以下类别之一:“无神论”、“基督教”、“计算机图形学”、“医学”。
在每一轮中,我们将准确度报告给Comet.ml,最后我们报告所有轮次的平均准确度。实验结束后,我们可以访问 Comet.ml 并检查我们的模型:
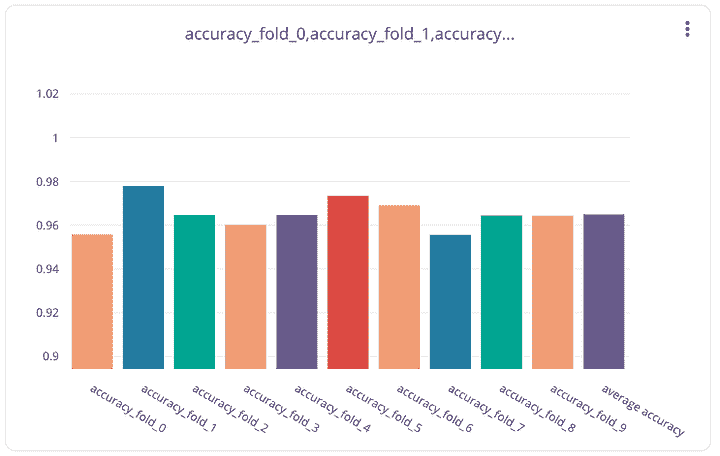
以下图表由 Comet.ml 自动生成。最右侧的条形(紫色)表示所有轮次的 平均 准确度。如图所示,一些轮次的表现明显优于平均水平,展示了 k 折交叉验证的重要性。
你可能注意到我们没有计算测试准确度。测试集在所有实验完成之前不应以任何方式使用。如果我们根据测试准确度改变超参数或模型类型,我们实际上是在将超参数过拟合到测试分布上。
对交叉验证仍然感到好奇?以下是一些其他优秀的资源:
觉得这篇文章有用吗?在 Medium 上关注我们 (Comet.ml),并查看下面的一些相关文章!请????分享这篇文章!
-
Comet.ml 发布说明——每日更新新功能和修复!
感谢Cecelia Shao。
简介: Gideon Mendels 是Comet.ml的联合创始人兼首席执行官。
Comet.ml 正为机器学习领域做出与 Github 对代码相同的贡献。我们轻量级的 SDK 使数据科学团队能够自动跟踪他们的数据集、代码更改和实验历史。这样,数据科学家可以轻松地重现他们的模型,并在团队中进行模型迭代的协作!
原文。已获许可转载。
相关内容:
-
训练集、测试集和 10 折交叉验证
-
可视化交叉验证代码
-
如何(以及为什么)创建一个好的验证集
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关话题
使用 Tensorflow Serving 构建 REST API(第一部分)
原文:
www.kdnuggets.com/2020/07/building-rest-api-tensorflow-serving-part-1.html
评论
由 Guillermo Gomez,数据科学家和机器学习工程师

什么是 Tensorflow Serving?
我个人认为 Tensorflow 中一个被低估的功能是服务 Tensorflow 模型的能力。在撰写这篇文章时,帮助你做到这一点的 API 叫做 Tensorflow Serving,并且是 Tensorflow Extended 生态系统的一部分,简称 TFX。
在 Tensorflow Serving 的第一次发布期间,我发现文档有些令人生畏。还有许多数据科学家不太习惯使用的概念:服务对象、来源、加载器、管理器…… 所有这些元素都是 Tensorflow Serving 架构的一部分。更多细节,见这里。
因此,作为一个简单的介绍,我将向你展示如何使用 Tensorflow Serving 构建 REST API。从保存 Tensorflow 对象(这就是我们所说的可服务对象)到测试 API 端点。第一部分将解释如何创建和保存准备投入生产的 Tensorflow 对象。
服务对象的含义
函数、嵌入或保存的模型是可以作为服务对象使用的一些对象。那么我们如何在 Tensorflow 中定义这些服务对象呢?
好吧,这取决于你,但它们必须能够保存为所谓的SavedModel 格式。这种格式在我们将对象加载到新环境中时,能够保持 Tensorflow 对象的所有组件处于相同状态。这些组件是什么?相关的有:权重、图、附加资产等。
用于保存 Tensorflow 对象的模块是 tf.saved_model。正如我们将很快看到的那样,它使用起来很简单。现在,让我们看看如何生成两种类型的服务对象:
-
Tensorflow 函数
-
Keras 模型
TensorFlow 函数作为可服务对象
如果 Tensorflow 函数是这样定义的,它们会被保存为有效的服务对象:
class Adder(tf.Module):
@tf.function(input_signature=[tf.TensorSpec(shape=[None,3], dtype=tf.float32, name="x")])
def sum_two(self, x):
return x + 2
-
类内部的函数定义
-
父类必须是
tf.Module -
@tf.function装饰器以某种方式将函数定义转换为 Tensorflow 图 -
input_signature参数定义了函数接受的张量的类型和形状
在这种情况下,我们指定了两个维度的张量,第二维被固定为三个元素,而类型将是 float32。另一个 Tensorflow 函数的示例是:
class Randomizer(tf.Module):
@tf.function
def fun_runif(self, N):
return tf.random.uniform(shape=(N,))
注意,input_signature 参数并不是必须的,但在函数投入生产时,包含一些安全测试总是好的。
后续,我们创建类的实例并保存它们:
# For the first function
myfun = Adder()
tf.saved_model.save(myfun, "tmp/sum_two/1")
# For the second function
myfun2 = Randomizer()
tf.saved_model.save(myfun2, "tmp/fun_runif/1")
tf.saved_model.save的第一个参数指向类的实例对象,而第二个参数是本地文件系统中的路径,模型将在该路径下保存。
可服务的 Keras 模型
你可以采用类似的程序来保存 Keras 模型。这个示例关注于一个预训练的图像分类模型,它通过 TensorFlow Hub 加载。此外,我们将围绕它构建一个自定义类来预处理输入图像。
class CustomMobileNet_string(tf.keras.Model):
model_handler = "https://tfhub.dev/google/imagenet/mobilenet_v2_035_224/classification/4"
def __init__(self):
super(CustomMobileNet_string, self).__init__()
self.model = hub.load(self.__class__.model_handler)
self.labels = None
# Design you API with 'tf.function' decorator
@tf.function(input_signature=[tf.TensorSpec(shape=None, dtype=tf.string)])
def call(self, input_img):
def _preprocess(img_file):
img_bytes = tf.reshape(img_file, [])
img = tf.io.decode_jpeg(img_bytes, channels=3)
img = tf.image.convert_image_dtype(img, tf.float32)
return tf.image.resize(img, (224, 224))
labels = tf.io.read_file(self.labels)
labels = tf.strings.split(labels, sep='\n')
img = _preprocess(input_img)[tf.newaxis,:]
logits = self.model(img)
get_class = lambda x: labels[tf.argmax(x)]
class_text = tf.map_fn(get_class, logits, tf.string)
return class_text # index of the class
该类继承自tf.keras.Model,关于它有几点需要讨论:
-
模型的输入是一个字节字符串,这些字节以 JSON 文件的形式出现,其中包含特定的键|值对。有关更多信息,请参见教程的第二部分。
-
tf.reshape是预处理阶段的第一个函数,因为图像被放入 JSON 文件中的数组中。由于我们使用了@tf.function对输入进行限制,因此需要进行这种转换。 -
属性
labels存储了ImageNet的图像标签(可在这里获取)。我们希望模型输出的是文本格式的标签,而不是模型输出层的标签索引。其定义方式的原因如下所述。
像往常一样,我们遵循相同的程序保存模型,但有所增加:
model_string = CustomMobileNet_string()
# Save the image labels as an asset, saved in 'Assets' folder
model_string.labels = tf.saved_model.Asset("data/labels/ImageNetLabels.txt")
tf.saved_model.save(model_string, "tmp/mobilenet_v2_test/1/")
为了将额外的组件存储到 SavedModel 对象中,我们必须定义一个资产。我们使用tf.saved_model.Asset来实现,我在类定义之外调用此函数以使其更为明确。如果我们在类定义中进行,也可能会以相同的方式工作。请注意,我们必须在保存模型之前将资产作为类实例的属性保存。
进一步的细节
这些是我们在保存自定义 Keras 模型时在本地文件系统中生成的文件夹。
生成的文件有:
-
函数或模型的图形,保存在扩展名为
.pb的 Protobuf 文件中。 -
模型的权重或在可服务的过程中使用的任何 TensorFlow 变量,保存在
variables文件夹中。 -
额外的组件保存在
assets文件夹中,但在我们的示例中是空的。
在构建自己的函数或模型时,可能会出现一些问题:
-
选择父类的理由是什么? 将
tf.Module类附加到tf.function上允许后者使用tf.saved_model进行保存。tf.keras.Model也是如此。你可以在这里找到更多信息。 -
为什么在模型路径中添加
/1? 可服务的模型必须有一个 ID,以指示我们在容器中运行的模型版本。这有助于在监控模型的指标时跟踪多个版本。你可以在以下链接中找到更详细的解释。
目前就这些,谢谢阅读!
简介:Guillermo Gomez 在公共基础设施和服务行业中构建基于机器学习的产品。他的网站上可以找到更多教程:thelongrun.blog
原文。经许可转载。
相关内容:
-
使用 torchlayers 轻松构建 PyTorch 模型
-
优化生产环境中机器学习 API 的响应时间
-
TensorFlow 2 入门
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关内容
使用 Tensorflow Serving 构建 REST API(第二部分)
原文:
www.kdnuggets.com/2020/07/building-rest-api-tensorflow-serving-part-2.html
评论
由 Guillermo Gomez,数据科学家及机器学习工程师
一旦生成了这些 Tensorflow 对象,就该将它们公开供大家使用了。通过围绕这些对象构建 REST API,人们将能够在他们的项目中使用你的服务。让我们看看如何做到这一点!
Docker 概述
在这一部分,我假设我们对 Docker 有基本了解。对于那些不熟悉的人,Docker 是一种在计算机上构建隔离环境(容器)的工具,这样它不会与本地文件系统(主机)中的任何文件或程序冲突。它的所有优点中,我会特别强调这些:
-
与虚拟机不同,你可以仅用运行项目单一组件所需的内容来运行容器。这有助于你生成轻量级的容器。
-
Docker 网络功能允许你轻松地让多个容器之间进行通信。
-
即使你的操作系统与所需工具不完全兼容,使用容器也不会再遇到兼容性问题。
-
无论托管环境是你的计算机还是运行在云服务上的服务器,Docker 容器的运行方式都是相同的。
每当我开始学习新东西时,我建议查看文档中的教程或快速入门。Tensorflow Serving 在其 Github 仓库中有一个简短的教程:
# Download the TensorFlow Serving Docker image and repo
docker pull tensorflow/serving
git clone https://github.com/tensorflow/serving
# Location of demo models
TESTDATA="$(pwd)/serving/tensorflow_serving/servables/tensorflow/testdata"
# Start TensorFlow Serving container and open the REST API port
docker run -t --rm -p 8501:8501 \
-v "$TESTDATA/saved_model_half_plus_two_cpu:/models/half_plus_two" \
-e MODEL_NAME=half_plus_two \
tensorflow/serving &
# Query the model using the predict API
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
# Returns => { "predictions": [2.5, 3.0, 4.5] }
请注意传递给 docker run 命令的参数,特别是那些接受外部值的参数:
-
-p 8501:8501,将容器的端口映射到主机上的相同端口。对于 REST API,Tensorflow Serving 使用这个端口,所以在实验中不要更改这个参数。 -
-v "$TESTDATA/saved_model_half_plus_two_cpu:/models/half_plus_two",将一个卷附加到容器。这个卷包含你保存 Tensorflow 对象的文件夹的副本。这个文件夹位于名为/1/的文件夹的上一层。这一文件夹将在容器中显示在/models/下。 -
-e MODEL_NAME=half_plus_two,定义一个环境变量。这个变量是服务你的模型所必需的。为了方便,使用与容器中附加模型的文件夹名称相同的标识符。
在容器中部署可服务的模型
你可以为你的可服务对象设计一个 API,但 Tensorflow Serving 通过 Docker 抽象化了这个步骤。一旦你部署了容器,你可以向容器所在的服务器发送请求以执行某种计算。在请求体中,你可以附加一些输入(这是运行可服务对象所必需的),并获得一些输出作为回报。
为了进行计算,你需要在请求中指定可服务对象的端点 URL。在上面显示的示例中,这个端点 URL 是 [localhost:8501/v1/models/half_plus_two:predict](http://localhost:8501/v1/models/half_plus_two:predict)。现在一切都准备好运行我们的 Tensorflow 对象了。我们将从 Keras 模型开始:
docker run -t --rm -p 8501:8501 -v "$(pwd)/mobilenet_v2_test:/models/mobilenet_v2_test" -e MODEL_NAME=mobilenet_v2_test tensorflow/serving &
当执行这个命令时,当前目录是 tmp/。这是我保存所有模型的文件夹。这是终端返回的内容:
模型已经启动并准备好使用。
向可服务对象发起请求
使用 curl 库
现在容器已经启动并运行,我们可以通过发送需要识别的图像来发起请求。我将展示两种实现方式。首先,我写了一个小的 shell 脚本(可以从 这里 下载),它接收一个图像文件的路径作为参数,并使用 curl 库进行调用。在这里,我展示了如何发起请求以及模型正在尝试分类的图像。

这只放松的熊猫在实验过程中没有受伤
这就是我们如何使用我们构建的 API 进行调用。

第二个示例涉及一个可服务对象,它将 2 添加到向量的每个元素中。这是容器启动后如何进行调用的示例。

使用 requests 库
requests 库允许你做相同的事情,但使用 Python 代码
import json
import requests
import base64
data = {}
with open('../../Downloads/imagenes-osos-panda.jpg', mode='rb') as file:
img = file.read()
data = {"inputs":[{"b64":base64.encodebytes(img).decode("utf-8")}]}
# Making the request
r = requests.post("http://localhost:8501/v1/models/mobilenet_v2_test:predict", data=json.dumps(data))
r.content
# And returns:
# b'{\n "outputs": [\n "giant panda"\n ]\n}'
在这段代码中,你会注意到在定义发送到请求中的 JSON 时需要遵循一些规则,例如键的命名和嵌套结构的存在。这在 Tensorflow 的 文档 中有更详细的说明。关于图像,它们在发送到可服务对象之前使用 Base64 编码进行二值化处理。
这涵盖了我目前想用 Tensorflow Serving 解释的所有内容。我希望这个教程能激发你构建机器学习服务的动力。这只是冰山一角。祝你好运!
个人简介:Guillermo Gomez 在公共基础设施和服务行业构建基于机器学习的产品。他的网站可以找到更多教程:thelongrun.blog
原文。经许可转载。
相关内容:
-
使用 TensorFlow Serving 构建 REST API(第一部分)
-
优化机器学习 API 在生产环境中的响应时间
-
开始使用 TensorFlow 2
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关话题
使用 Flask 构建 RESTful API
原文:
www.kdnuggets.com/2021/05/building-restful-apis-flask.html
评论
由 Mahadev Easwar, 数据工程师

什么是 API?
应用程序编程接口(API)是一个软件中介,允许两个应用程序进行通信。
什么是 web 框架,它为什么有用?
web 框架是一个软件框架,用于支持动态网站、web 服务和 web 应用程序的开发。web 框架是一个代码库,通过提供构建可靠、可扩展和可维护的 web 应用程序的基本模式,使 web 开发变得更快、更容易 ¹。
Flask:简介
Flask 是一个轻量级的 WSGI web 应用框架。它旨在快速和轻松地入门,并具有扩展到复杂应用的能力。它最初是 Werkzeug 和 Jinja 的一个简单封装,现已成为最受欢迎的 Python web 应用框架之一。
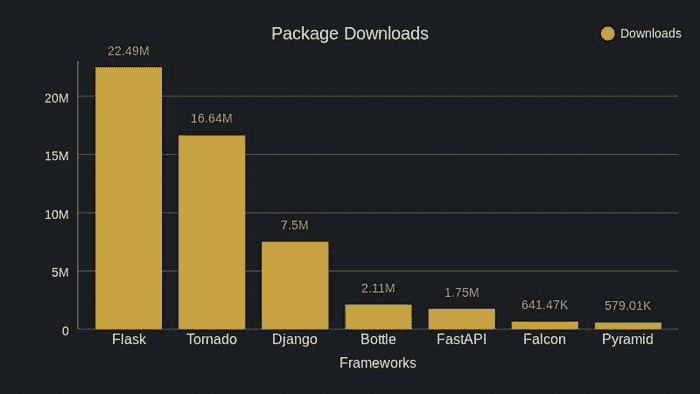
上个月的包下载数量。来源. ²
为什么称之为微框架?
“微”并不意味着你的整个 web 应用程序必须适合到一个 Python 文件中(尽管它当然可以),也不意味着 Flask 缺乏功能。微框架中的“微”意味着 Flask 旨在保持核心简单但可扩展 ³。
Flask 提供建议,但不强制任何依赖项或项目布局。开发者可以选择他们想要使用的工具和库。社区提供了许多扩展,使添加新功能变得容易 ⁴。
为什么使用 Flask?
-
易于设置
-
极简主义
-
灵活地添加任何扩展以获得更多功能
-
活跃的社区
在本文中,我将演示如何设置、构建和运行一个简单的 Flask 应用。
包安装
通常建议在特定于项目的虚拟环境中安装包。
# command prompt
**pip** install Flask
安装 Flask 包
JSON
JSON 是一种通用数据格式,具有最少数量的值类型:字符串、数字、布尔值、列表、对象和空值。尽管表示法是 JavaScript 的一个子集,但这些类型在所有常见编程语言中都有表示,使 JSON 成为跨语言传输数据的良好候选者 ⁵。
# JSON Example:
{
"id" : 1,
"name" : "john"
"age" : "25",
"activities" : ["cricket","football"],
"class" : [{"year":"2020","dept":"CSE"}]
}
构建 Flask 应用
我将使用 Flask 构建一个简单的应用程序,该应用程序将访问员工数据并返回输入中请求的信息。我们将使用 JSON 文件格式来发送和接收数据。由于我将提供基于数据的演示,我还加载了 pandas 包。
1. 导入所需的包
**from** flask **import** Flask, request, jsonify
**import** pandas as pd
项目的目录结构如下
Demo/
| — emp_info.csv
| — emp_status.csv
| — app.py
2. 创建应用程序实例
app = Flask(__name__)
3. 使用.route()声明端点及其接受的方法,如POST、GET。默认情况下,它仅监听GET方法。让我们仅为此 API 启用POST方法。
@app.route(**"/get_emp_info"**, methods = [**'POST'**])
4. 定义应用程序将执行的功能。根据输入数据从 CSV 文件中检索员工数据。
@app.route(**"/get_emp_info"**, methods = [**'POST'**])
**def** get_employee_record():
input_data = json.loads(request.get_json())
ids = input_data[**'**emp_ids**'**]
status = input_data[**'**status**'**]
emp_info = pd.read_csv(**'**emp_info.csv**'**)
emp_status = pd.read_csv(**'**emp_status.csv**'**)
emp_status = emp_status[(emp_status[**'**emp_no**'**].isin(ids)) & (emp_status[**'**status**'**].isin(status))]
emp_info = emp_info[emp_info[**'**emp_no**'**].isin(emp_status[**'**emp_no**'**])]
emp_info = pd.merge(emp_info,emp_status,on=**'**emp_no**'**,how=**'**left**'**)
out_data = emp_info.to_dict(orient=**'**records**'**)
**return** jsonify(out_data)
jsonify()* 是 Flask 提供的一个辅助方法,用于正确返回JSON数据。它返回一个设置了 application/json mimetype 的 Response 对象。
5. 将 Python 应用程序设置为在本地开发服务器上运行。默认情况下,调试模式为False。要在代码修改时重启服务,调试模式可以设置为True。
**#** Setting port number and host i.e., localhost by default **if __name__** == **"__main__"**:
app.run(**host**=**'**0.0.0.0**'**, **port**=6123)
Python Flask 应用程序
6. 在本地服务器上运行 Python 程序
# command prompt
**python** app.py
运行 Python 应用程序
测试应用程序
使用requests包向开发的应用程序发送POST请求。
# command prompt - installing requests package
$ **pip** install requests# Python code to test **import** requests, json
# sample request
data = {"emp_ids":["1001","1002","1003"],"status":["active"]}
# Hitting the API with a POST request
ot = requests.post(url=**'http://localhost:6123/get_emp_info'**, json=json.dumps(data))
print(ot.json())# Response JSON
[{
'cmp': 'ABC',
'emp_no': 1001,
'name': 'Ben',
'salary': 100000,
'status': 'active'
}, {
'cmp': 'MNC',
'emp_no': 1002,
'name': 'Jon',
'salary': 200000,
'status': 'active'
}]
总结
本文中涉及的概念:
-
API 与 Web 框架
-
Flask 简介
-
设置 Flask 环境
-
构建一个 Flask API
-
使用requests包测试 Flask API 的请求
Flask 就像是构建 RESTful APIs 的极简方法。
简单常常能产生奇妙的效果。— 阿梅利亚·巴尔
结束语
感谢所有走到这里的人。希望你们发现这篇文章有帮助。请在评论中分享你的反馈/疑问。现在,是时候从头开始构建自己的 API 了。祝你好运!
如果你觉得这篇文章有趣,并且对数据科学、数据工程或软件工程充满热情,请点击关注,并随时在LinkedIn上加我。
简介: Mahadev Easwar 是一名数据工程师,具备 Python、R 和 SQL 方面的显著技能。
原文。已获得许可转载。
相关:
-
如何将机器学习/深度学习模型部署到网络
-
将 Docker 化的 FastAPI 应用程序部署到 Google Cloud Platform
-
如何在 Kubernetes 中部署 Flask API 并与其他微服务连接
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT
更多相关内容
使用 SQL + Python 构建可扩展的 ETL
原文:
www.kdnuggets.com/2022/04/building-scalable-etl-sql-python.html
在这篇简短的文章中,我们将构建一个模块化的 ETL 流水线,该流水线使用 SQL 转换数据,并使用 Python 和 R 进行可视化。这个流水线将以经济高效的方式实现完全可扩展。它可以在你的一些其他项目中复制使用。我们将利用一个示例数据集(StackExchange),查看如何将数据提取到特定格式,进行转换和清理,然后将其加载到数据库中,以便进行下游分析,比如分析报告或机器学习预测。如果你想直接查看实时示例,你可以在ETL 模板这里查看整个流水线。我将回顾一下这个模板中的一些原则,并提供如何实现这些原则的深入了解。
我们将涵盖的主要概念:
-
通过 Python 连接到任何数据库。
-
并行化 - 使用 Ploomber 并行运行查询
-
通过 DAGs 进行协调
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
架构图
我们将首先回顾一下我们流水线的整体架构和数据集,以更好地理解它是如何构建的以及我们可以通过这个演示流水线实现什么。
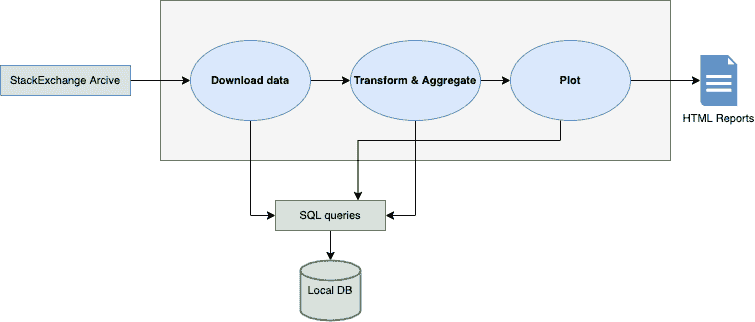
在这里我们可以看到流水线;它开始时提取我们的数据集并存储它(这个代码片段的来源可以在 preprocess/download.py 找到):
url = 'https://archive.org/download/stackexchange/arduino.stackexchange.com.7z'
urllib.request.urlretrieve(url, product['zipped'])
Path(product['extracted']).mkdir(exist_ok=True)
Archive(product['zipped']).extractall(product['extracted'])
使用 Ploomber,你可以参数化路径并在这些路径上创建依赖关系。我们可以看到每个输出,如提取和压缩的数据,如何被保存回 pipeline.yaml 中指定的任务路径。将这个组件拆分成模块化部分使我们能够更快地开发。下次流水线发生变化时,我们不需要重新运行这个任务,因为它的输出是缓存的。
提取、格式化和聚合
我们流水线中的下一个阶段是转换原始数据并进行聚合。我们已经通过一个 get_client 函数(取自 db.py)配置了客户端一次:
def get_client(env):
path = env.path.products_root / 'data.db'
# create parent folders if they don't exist, otherwise sqlalchemy fails
if not path.parent.exists():
path.parent.mkdir(exist_ok=True, parents=True)
return SQLAlchemyClient(f'sqlite:///{path}')
然后,我创建了利用这个客户端的 SQL 查询(我们可以看到这是一个本地数据库,但它依赖于用例并可以连接到 SQLAlchemy 支持的任何东西)。可以使用这个相同的客户端,也可以使用其他客户端进行聚合。在这个管道中,我将原始数据推送到 3 个不同的表中:users、comments 和 posts。我们将在下一节中讨论我使用了哪个模板以及它是如何工作的。
SQL 作为模板
Ploomber 还有另一个功能,用户可以直接编写 SQL 查询,声明输入/输出文件,Ploomber 会将数据转储到正确的位置。这可以通过模板完全自动化,因此你可以有一个或多个客户端,多个输入或输出表,这使你可以专注于实际编写 SQL,而不是处理数据库客户端、连接字符串或无法重用的自定义脚本。
我们将看到的第一个示例与上一节相关——将我们的 CSV 上传为表(此代码片段取自 pipeline.yaml):
- source: "{{path.products_root}}/data/Users.csv"
name: upload-users
class: SQLUpload
product: [users, table]
upstream: convert2csv
to_sql_kwargs:
if_exists: replace
我们可以看到,我们的源数据是刚从数据提取任务中获得的 users.csv,我们正在使用 SQLUpload 类上传 users 表。我们为获得的三个表(users、comments 和 posts)创建了这些任务。
现在,由于原始数据已加载到数据库中,我们希望创建一些聚合。为此,我们可以继续使用 users 表的示例,看看如何在我们的管道中利用 .sql 文件:
- source: sql/upvotes-by-location.sql
name: upvotes-by-location
product: [upvotes_by_location, table]
upstream: upload-users
我们可以看到我们的源是 upvotes-by-location.sql(就在本段下方),输出产品是另一个表 upvotes_by_location,它依赖于 upload-users 任务。
我们可以深入到 ./sql 文件夹中的源代码:
DROP TABLE IF EXISTS {{product}};
CREATE TABLE {{product}} AS
SELECT Location, AVG(upvotes) AS mean_upvotes
FROM {{upstream['upload-users']}}
GROUP BY Location
HAVING AVG(upvotes) > 1
在这里,我们正在覆盖表(从 pipeline.yaml 中参数化),按位置分组,并仅保留投票数为 1+ 的用户。将这些任务和表上传、聚合和分组的组件分开,也将允许我们并行化工作流程,加快速度——我们将在下文中讨论。我们示例管道中的最后一步是绘图任务,它将这些新创建的表可视化。
并行化和协调
拥有这种模板化项目的概念,协调 SQL 任务允许我们开发、测试和部署多个目的的数据集。在我们的示例中,我们在 3 个表上运行,具有有限的行数和列数。在企业环境中,例如,我们可以轻松扩展到 20+ 个表,拥有数百万行,这可能会成为按顺序运行的实际难题。
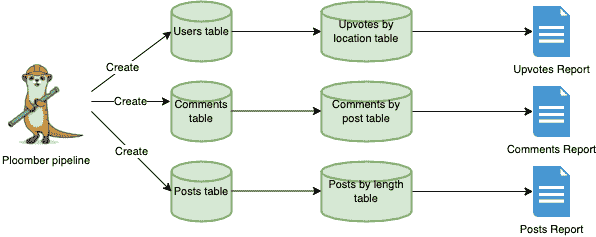
在我们的案例中,协调和并行化帮助我们专注于实际代码,这是主要任务,而不是基础设施。我们能够生成这 3 个独立的工作流程,并行运行它们,减少我们的洞察时间。
结论
在这篇文章中,我尝试覆盖 Ploomber 通过 ETL 管道(基于 SQL)所能提供的大多数软件工程最佳实践。这些概念,如模块化、代码重用和可移植性,可以节省大量时间,并提高团队的整体效率。我们总是欢迎反馈和问题,请务必亲自尝试,并分享你的经验。请加入我们的 Slack 频道获取更多更新或提出问题!
Ido Michael 共同创办了 Ploomber,旨在帮助数据科学家更快地构建数据管道。他曾在 AWS 担任数据工程/科学团队的负责人。在与客户的合作中,他与团队一起单独构建了数百条数据管道。他来自以色列,前往纽约在哥伦比亚大学攻读硕士学位。在不断发现项目将约 30% 的时间用于将开发工作(原型)重构为生产管道后,他专注于构建 Ploomber。
更多相关话题
使用 USB 摄像头和无线连接的树莓派构建监控系统
评论
3. 使用 PyGame 捕获图像
“fswebcam”包对于快速测试摄像头是否正常工作非常有用。确保摄像头正常后,我们可以开始编写一个 Python 脚本,通过 PyGame 库连续捕获图像。以下代码使用 PyGame 捕获单张图像,打开一个窗口以显示该图像,并最终保存该图像。
import pygame
import pygame.camera
# Captured image dimensions. It should be less than or equal to the maximum dimensions acceptable by the camera.
width = 320
height = 240
# Initializing PyGame and the camera.
pygame.init()
pygame.camera.init()
# Specifying the camera to be used for capturing images. If there is a single camera, then it have the index 0.
cam = pygame.camera.Camera("/dev/video0",(width,height))
# Preparing a resizable window of the specified size for displaying the captured images.
window = pygame.display.set_mode((width,height),pygame.RESIZABLE)
# Starting the camera for capturing images.
cam.start()
# Capturing an image.
image = cam.get_image()
# Stopping the camera.
cam.stop()
# Displaying the image on the window starting from the top-left corner.
window.blit(image,(0,0))
# Refreshing the window.
pygame.display.update()
# Saving the captured image.
pygame.image.save(window,'PyGame_image.jpg')
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
假设上述代码保存在一个名为“im_cap.py”的 Python 文件中。要执行这些代码,我们可以从终端发出以下命令:
pi@raspberry:~ $ python3 im_cam.py
这是执行该文件后显示的窗口。

我们可以修改之前的代码以捕获多张图像。例如,我们可以使用for循环捕获预先指定数量的图像。我们也可以使用不限制图像数量的while循环。这里是修改后的代码,它使用for循环捕获 2,000 张图像。
import pygame
import pygame.camera
# Captured image dimensions. It should be less than or equal to the maximum dimensions acceptable by the camera.
width = 320
height = 240
# Initializing PyGame and the camera.
pygame.init()
pygame.camera.init()
# Specifying the camera to be used for capturing images. If there is a single camera, then it has the index 0.
cam = pygame.camera.Camera("/dev/video0", (width, height))
# Preparing a resizable window of the specified size for displaying the captured images.
window = pygame.display.set_mode((width, height), pygame.RESIZABLE)
# Starting the camera for capturing images.
cam.start()
for im_num in range(0, 2000):
print("Image : ", im_num)
# Capturing an image.
image = cam.get_image()
# Displaying the image on the window starting from the top-left corner.
window.blit(image, (0, 0))
# Refreshing the window.
pygame.display.update()
# Saving the captured image.
pygame.image.save(window, './pygame_images/image_' + str(im_num) + '.jpg')
# Stopping the camera.
cam.stop()
这是 8 张捕获的图像。请注意,摄像头的位置有些许变化。

4. 构建背景模型
到目前为止,我们成功地构建了一个简单的监控系统,其中摄像头捕获的图像被保存在 RPi 的 SD 卡中。我们可以扩展该系统以自动检测场景变化。这是通过构建场景的背景模型来完成的。任何对该模型的更改都将指示一个变化。例如,如果有人经过场景,将导致背景的变化。
背景模型可以通过将多个捕获的图像平均化来简单创建,这些图像中不包含任何物体。因为我们关注的是颜色信息,这些图像将被转换为二进制。以下是用于构建背景模型的 Python 代码。
import skimage.io
import os
import numpy
dir_files = os.listdir('./pygame_images/')
bg_image = skimage.io.imread(fname=dir_files[0], as_grey=True)
for k in range(1, len(dir_files)):
fname = dir_files[k]
im = skimage.io.imread(fname=fname, as_grey=True)
bg_image = bg_image + im
bg_image = bg_image/(len(dir_files))
bg_image_bin = bg_image > 0.5
skimage.io.imsave(fname='bg_model.jpg', arr=bg_image)
skimage.io.imsave(fname='bg_model_bin.jpg', arr=bg_image_bin*255)
这是在平均 500 张图片后得到的灰度和二值背景模型。

5. 检测背景模型的变化
在建立背景模型之后,我们可以测试新图片以检查背景是否发生变化。这可以通过将新图片转换为二值图像来简单实现。然后比较两张图像中的白色像素数量。如果数量超过给定的阈值,则表示背景发生了变化。阈值因场景而异。这里是用于测试新图片的code。
bg_num_ones = numpy.sum(bg_image_bin)
test = skimage.io.imread(fname="./pygame_images/image_800.jpg",
as_grey=True)
test_bin = test > 0.5
test_num_ones = numpy.sum(test_bin)
print("Num 1s in BG :", bg_num_ones)
print("Num 1s in Test :", test_num_ones)
if(abs(test_num_ones-bg_num_ones) < 5000):
print("Change.")
这里是一个测试图像,显示了颜色、灰度和二值图像中由于场景中出现物体(人)而与背景的变化。

6. 建立一个简单的电路,当发生变化时点亮 LED 灯
作为背景模型变化的指示,我们可以建立一个简单的电路,当检测到变化时 LED 灯会亮起。这个电路将连接到 RPi 的 GPIO(通用输入输出)引脚。电路需要以下组件:
-
一个面包板。
-
一个 LED 灯。
-
一个电阻(大于或等于 100 欧姆)。我使用的是 178.8 欧姆的电阻。
-
两根公/公跳线。
-
两根公/母跳线。
在将电路连接到 GPIO 引脚之前,建议先进行测试。这是因为如果电阻值选择不当,可能不仅会烧毁 LED,还会损坏 GPIO 引脚。测试时需要一个电池为面包板供电。这里是正确连接所有组件后的电路图。

然后,我们可以拆下电池,并将面包板连接到 RPi 的 GPIO 引脚。根据 GPIO 引脚的面包板编号,地连接到引脚号 20,高电压连接到输出引脚号 22。下图展示了面包板与 RPi 之间的连接。RPi 也连接到充电器和 USB 摄像头。

输出 GPIO 引脚由以下 Python 脚本控制。其默认状态为 LOW,表示 LED 灯熄灭。当背景发生变化时,状态会变为 HIGH,表示 LED 灯点亮。LED 灯会亮 0.1 秒,然后状态恢复为熄灭。当另一个输入图像与背景不同时,LED 灯会再亮 0.1 秒。
import time
import RPi.GPIO
import skimage.io
import numpy
import os
import pygame.camera
import pygame
#####GPIO#####
# Initializing the GPIO pins. The numbering using is board.
RPi.GPIO.setmode(RPi.GPIO.BOARD)
# Configuring the GPIO bin number 22 to be an output bin.
RPi.GPIO.setup(22, RPi.GPIO.OUT)
#####PyGame#####
# Initializing PyGame and the camera.
pygame.init()
pygame.camera.init()
# Captured image dimensions. It should be less than or equal to the maximum dimensions acceptable by the camera.
width = 320
height = 240
# Preparing a resizable window of the specified size for displaying the captured images.
window = pygame.display.set_mode((width, height), pygame.RESIZABLE)
# Specifying the camera source and the image dimensions.
cam = pygame.camera.Camera("/dev/video0",(width,height))
cam.start()
#####Background Model#####
# Reading the background model.
bg_image = skimage.io.imread(fname='bg_model_bin.jpg', as_grey=True)
bg_image_bin = bg_image > 0.5
bg_num_ones = numpy.sum(bg_image_bin)
im_dir = '/home/pi/pygame_images/'
for im_num in range(0, 2000):
print("Image : ", im_num)
im = cam.get_image()
# Displaying the image on the window starting from the top-left corner.
window.blit(im, (0, 0))
# Refreshing the window.
pygame.display.update()
pygame.image.save(window, im_dir+'image'+str(im_num)+'.jpg')
im = pygame.surfarray.array3d(window)
test_bin = im > 0.5
test_num_ones = numpy.sum(test_bin)
# Checking if there is a change in the test image.
if (abs(test_num_ones - bg_num_ones) < 5000):
print("Change.")
try:
RPi.GPIO.output(22, RPi.GPIO.HIGH)
time.sleep(0.1)
RPi.GPIO.output(22, RPi.GPIO.LOW)
except KeyboardInterrupt: # CTRL+C
print("Keyboard Interrupt.")
except:
print("Error occurred.")
# Stopping the camera.
cam.stop()
# cleanup all GPIO pins.
print("Clean Up GPIO.")
RPi.GPIO.cleanup()
下图显示了一张输入图像,由于存在一个人,它与背景图像不同。因此,LED 灯将亮 0.1 秒钟。

以下视频(youtu.be/WOUG-vjg3A4)展示了使用相机捕获的多个帧的 LED 状态。当输入图像与背景模型根据使用的阈值不同,LED 会被点亮。
更多详情
Ahmed Fawzy Gad, “在树莓派上构建图像分类器”,2018 年 9 月,www.linkedin.com/pulse/building-image-classifier-running-raspberry-pi-ahmed-gad
联系作者
-
电子邮件: ahmed.f.gad@gmail.com
-
LinkedIn:
linkedin.com/in/ahmedfgad/ -
KDnuggets:
www.kdnuggets.com/author/ahmed-gad -
YouTube:
youtube.com/AhmedGadFCIT -
TowardsDataScience:
towardsdatascience.com/@ahmedfgad
简介: Ahmed Gad于 2015 年 7 月在埃及门努非亚大学计算机与信息学院(FCI)获得信息技术学士学位,并以优异的成绩毕业。由于在学院中排名第一,他在 2015 年被推荐担任埃及某学院的教学助理,并在 2016 年继续担任教学助理和研究员。他目前的研究兴趣包括深度学习、机器学习、人工智能、数字信号处理和计算机视觉。
原文。经许可转载。
相关:
-
直观的集成学习指南:梯度提升
-
在树莓派上构建图像分类器
-
Python 中遗传算法的实现
相关主题
构建一个可处理的、多变量时间序列特征工程管道

图片来源:Christophe Dion于Unsplash
精确的时间序列预测对于业务问题至关重要,例如预测制造中的材料属性变化和销售预测。现代预测技术包括使用像 Xgboost 这样的机器学习算法,在表格数据上构建回归模型来预测未来。表格数据允许回归模型通过利用与实际销售相关的非目标因素(如零售店的每日客流量)来进行预测。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力。
3. 谷歌 IT 支持专业证书 - 为你的组织提供 IT 支持。
特征工程对于丰富影响预测准确性的因素至关重要。然而,构建一个时间序列特征工程管道并非易事,因为它涉及不同阶段的各种转换,例如窗口值的聚合。基于滚动窗口的特征,如“两周记录的平均值”,是基础却有效的预测工具,因此支持这种特征生成的管道是有价值的。此外,经过转换后的特征输出顺序可能会在转换过程中被打乱,这对特征追踪提出了挑战。在最终模型训练之前,追踪和验证管道中的转换特征至关重要。这个github 仓库提供了一个设计时间序列管道的示例,以满足上述需求,本文解释了一些实现这些需求的关键步骤。
基于 Scikit-learn 的转换器可能支持 get_feature_names_out() 函数,以提供其在转换后的输出名称。例如,OneHotEncoder 转换器 具有此内置函数,但 SimpleImputer 转换器则没有。如果我们希望方便地检索输出名称,Scikit-learn 管道要求所有基础转换器支持 get_feature_names_out()。我们的解决方案是设计一个 FeatureNamesMixin 混入类,并结合 工厂方法 设计模式类 TransformWithFeatureNamesFactory,以使转换器具备 get_feature_names_out() 函数。
我们可以创建一个自定义的SimpleImputer,并将其作为 Scikit-learn Pipeline 的步骤或 ColumnTransformer 的一部分,如下所示。
这仅需要转换器类通过参数 names 初始化时指定任何所需的输出名称。
其他转换器也可以类似地自定义以支持检索输出名称,只要我们引入get_feature_names_out()。以下是一个TsfreshRollingMixin类的示例,该类利用 TSFresh 库中的roll_time_series()实用函数来提取时间序列的滚动窗口。要跟踪派生的滚动窗口特征,我们只需将特征分配为derived_names属性。TsfreshRollingMixin类还包含其他辅助函数,如prepare_df()和get_combined(),以便将 numpy 数组转换为 pandas.DataFrame,并将派生特征与输入特征结合在一起。感兴趣的读者可以查看代码库,更好地了解其实现。结合 TSFresh 的extract_features(),我们可以设计一个TSFreshRollingTransformer类,使我们能够指定相关的TSFresh 参数,以派生所需的时间序列特征,如下所示。
我们将TSFreshRollingTransformer派生的特征标记为类似于(window #)的名称,以指示聚合窗口的大小。
除了 TSFresh 派生的时间序列特征,RollingLagsTrasformer类展示了如何使用TsfreshRollingMixin类从给定的滚动窗口中提取滞后值,并将输出特征跟踪为(lag #)作为滞后顺序。其他在滚动窗口上执行的特定变换可以参考此示例,设计与可追踪管道兼容的转换器。
这个脚本展示了如何使用上述变换器构建时间序列管道,以在不同阶段衍生特征。例如,从第一个管道提取的特征有一个名为Pre-MedianImputer__Global_intensity的特征,用于指示原始特征“Global_intensity”是基于SimpleImputer使用中位数策略进行填补的。随后,衍生出的滚动特征名称类似于TSFreshRolling__Pre-MedianImputer–Global_intensity__maximum(window 30),表示在窗口大小为 30 步的范围内填补的“Global_intensity”的最大值。最后,滚动窗口特征将经过填补和标准化处理,建议的名称 ImputeAndScaler__TSFreshRolling__Pre-MedianImputer–Global_intensity__median(window 30) 指示原始特征“Global_intensity”已经经历了上述所有变换。我们可以方便地通过相关标记追踪管道提供的变换名称,并验证变换后的输出。
我们通过一个示例来补充这个演示,示例中使用了Darts包来构建线性回归模型进行预测。一旦管道准备好,就可以轻松加载输入数据集并相应地衍生特征。下图展示了基于从管道衍生特征训练的线性回归模型的预测结果。我们希望这篇文章能为读者提供一个基本模板,方便他们为时间序列预测用例构建时间序列管道。
基于设计管道中的工程特征的线性回归模型预测。图像由作者提供。
Jing Qiang Goh 是一位时间序列爱好者。
了解更多主题
用 TensorFlow 和 Keras 构建和训练你的第一个神经网络
原文:
www.kdnuggets.com/2023/05/building-training-first-neural-network-tensorflow-keras.html

图像来源 作者
人工智能现在已经发展到了很高的水平,各种先进的 AI 模型正在不断演变,这些模型用于聊天机器人、类人机器人、自动驾驶汽车等。它已成为增长最快的技术,目标检测和目标分类如今也非常流行。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
在这篇博客文章中,我们将涵盖从零开始构建和训练一个图像分类模型的完整步骤,使用卷积神经网络。我们将使用公开的Cifar-10 数据集来训练模型。这个数据集的独特之处在于它包含了日常见到的物体的图像,如汽车、飞机、狗、猫等。通过对这些物体进行训练,我们将开发智能系统来对现实世界中的这些事物进行分类。它包含超过 60000 张 32x32 大小的图像,涵盖 10 种不同类型的物体。在本教程结束时,你将拥有一个能够根据视觉特征判断物体的模型。

图 1 数据集样本图像 | 图像来源:datasets.activeloop
我们将从零开始覆盖所有内容,因此如果你尚未了解神经网络的实际应用,这完全没有问题。本教程唯一的前提是你的时间和基础的 Python 知识。在本教程结束时,我将分享包含完整代码的协作文件。让我们开始吧!
这是本教程的完整工作流程,
-
导入必要的库
-
数据加载
-
数据预处理
-
构建模型
-
评估模型性能
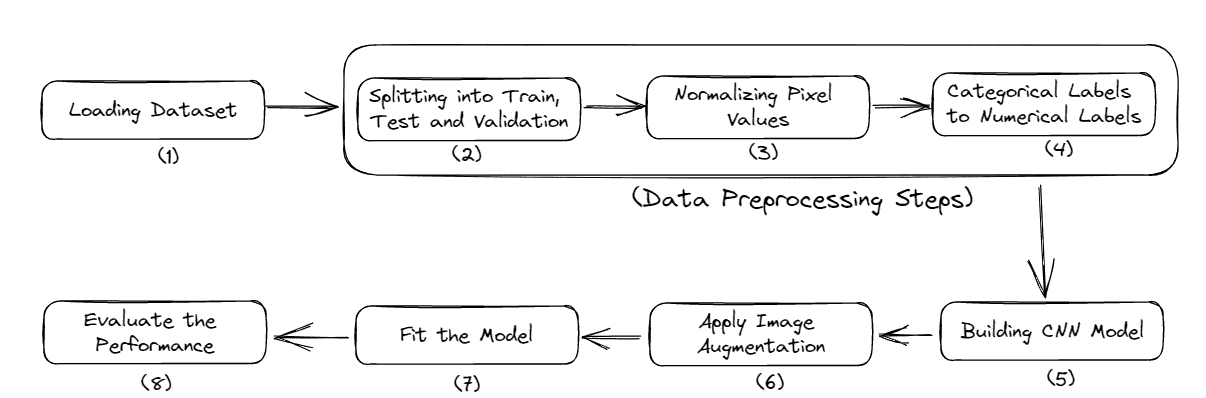
图 2 完整模型流程 | 图像来源 作者
导入必要的库
你需要安装一些模块来开始项目。我将使用 Google Colab,因为它提供免费的 GPU 训练,最后我会提供一个包含完整代码的协作文件。
这是安装所需库的命令:
$ pip install tensorflow, numpy, keras, sklearn, matplotlib
将库导入 Python 文件中。
from numpy import *
from pandas import *
import matplotlib.pyplot as plotter
# Split the data into training and testing sets.
from sklearn.model_selection import train_test_split
# Libraries used to evaluate our trained model.
from sklearn.metrics import classification_report, confusion_matrix
import keras
# Loading our dataset.
from keras.datasets import cifar10
# Used for data augmentation.
from keras.preprocessing.image import ImageDataGenerator
# Below are some layers used to train convolutional nueral network.
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.layers import Conv2D, MaxPooling2D, GlobalMaxPooling2D, Flatten
-
Numpy: 它用于高效地计算包含图像的大型数据集。
-
Tensorflow: 这是一个由 Google 开发的开源机器学习库。它提供了许多构建大型和可扩展模型的函数。
-
Keras: 另一个高级神经网络 API,运行在 TensorFlow 之上。
-
Matplotlib: 这个 Python 库创建图表和图形,提供更好的数据可视化。
-
Sklearn: 它提供了进行数据预处理和特征提取的函数。它包含内置函数来查找模型的评估指标,如准确率、精确度、假阳性、假阴性等。
现在,让我们进入数据加载的步骤。
加载数据
本节将加载我们的数据集并执行训练-测试拆分。
数据加载与拆分:
# number of classes
nc = 10
(training_data, training_label), (testing_data, testing_label) = cifar10.load_data()
(
(training_data),
(validation_data),
(training_label),
(validation_label),
) = train_test_split(training_data, training_label, test_size=0.2, random_state=42)
training_data = training_data.astype("float32")
testing_data = testing_data.astype("float32")
validation_data = validation_data.astype("float32")
cifar10 数据集直接从 Keras 数据集库加载。这些数据也被拆分为训练数据和测试数据。训练数据用于训练模型,以便它能够识别其中的模式。测试数据对模型保持未知,用于检查其性能,即模型正确预测的数据点数与总数据点数的比率。
training_label 包含与 training_data 中图像对应的标签。
然后,训练数据再次通过内置的 sklearn train_test_split函数拆分为验证数据。验证数据用于选择和调整最终模型。最后,所有的训练、测试和验证数据都被转换为 32 位浮点数。
现在,我们的数据集加载完成。在下一节中,我们将对数据进行一些预处理步骤。
数据预处理
数据预处理是开发机器学习模型时的第一步,也是最重要的一步。让我们看看如何做到这一点。
# Normalization
training_data /= 255
testing_data /= 255
validation_data /= 255
# One Hot Encoding
training_label = keras.utils.to_categorical(training_label, nc)
testing_label = keras.utils.to_categorical(testing_label, nc)
validation_label = keras.utils.to_categorical(validation_label, nc)
# Printing the dataset
print("Training: ", training_data.shape, len(training_label))
print("Validation: ", validation_data.shape, len(validation_label))
print("Testing: ", testing_data.shape, len(testing_label))
输出:
Training: (40000, 32, 32, 3) 40000
Validation: (10000, 32, 32, 3) 10000
Testing: (10000, 32, 32, 3) 10000
数据集包含 10 类图像,每张图像的大小为 32x32 像素。每个像素的值范围从 0 到 255,我们需要将其标准化到 0 到 1 之间,以便于计算。之后,我们将类别标签转换为独热编码标签。这是为了将类别数据转换为数值数据,以便我们可以顺利应用机器学习算法。
现在,进入 CNN 模型的构建阶段。
构建 CNN 模型
CNN 模型分为 3 个阶段。第一阶段由卷积层组成,用于从图像中提取相关特征。第二阶段由池化层组成,用于减少图像的维度,同时有助于降低模型的过拟合。第三阶段由全连接层组成,将二维图像转换为一维数组。最终,这个数组被输入到全连接层中,执行最终的预测。
这里是代码。
model = Sequential()
model.add(
Conv2D(32, (3, 3), padding="same", activation="relu", input_shape=(32, 32, 3))
)
model.add(Conv2D(32, (3, 3), padding="same", activation="relu"))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding="same", activation="relu"))
model.add(Conv2D(64, (3, 3), padding="same", activation="relu"))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(96, (3, 3), padding="same", activation="relu"))
model.add(Conv2D(96, (3, 3), padding="same", activation="relu"))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dropout(0.4))
model.add(Dense(256, activation="relu"))
model.add(Dropout(0.4))
model.add(Dense(128, activation="relu"))
model.add(Dropout(0.4))
model.add(Dense(nc, activation="softmax"))
我们应用了三组层,每组包含两个卷积层、一个最大池化层和一个 dropout 层。Conv2D 层接受 input_shape 为 (32, 32, 3),这必须与图像的尺寸相同。
每个 Conv2D 层还采用激活函数,即 ‘relu’。激活函数用于增加系统中的非线性。简单来说,它决定了神经元是否需要根据某个阈值被激活。激活函数有很多类型,如 ‘ReLu’,‘Tanh’,‘Sigmoid’,‘Softmax’ 等,它们使用不同的算法来决定神经元的激发。
之后,添加了 Flattening 层和全连接层,中间插入了几个 Dropout 层。Dropout 层随机拒绝一些神经元对网层的贡献。其内部参数定义了拒绝的程度。主要用于避免过拟合。
以下是 CNN 模型架构的示例图像。
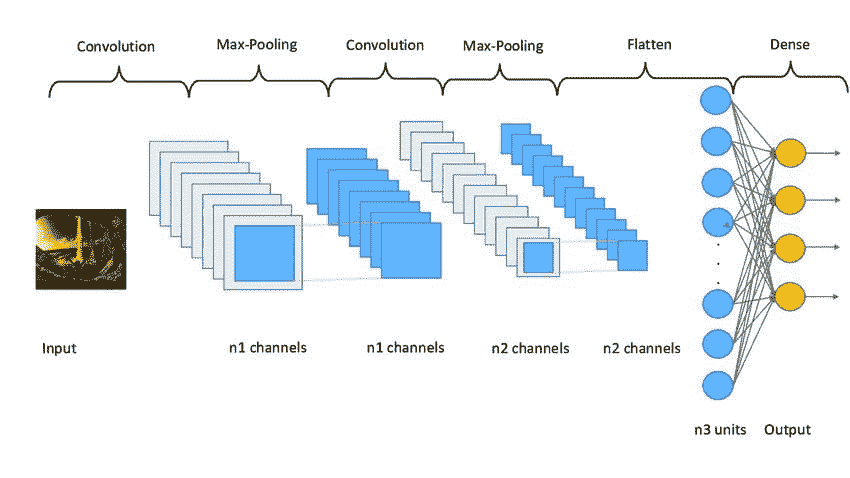
图 3 示例 CNN 架构 | 图片来源于 researchgate
编译模型
现在,我们将编译并准备模型进行训练。
# initiate Adam optimizer
opt = keras.optimizers.Adam(lr=0.0001)
model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])
# obtaining the summary of the model
model.summary()
输出:

图 4 模型总结 | 图片来源于作者
我们使用了学习率为 0.0001 的 Adam 优化器。优化器决定了模型如何根据损失函数的输出改变行为。学习率是训练过程中更新权重的步长,是一个可配置的超参数,不应过小或过大。
拟合模型
现在,我们将模型拟合到训练数据中,并开始训练过程。但在此之前,我们将使用图像增强技术来增加样本图像的数量。
在卷积神经网络中使用的图像增强将增加训练图像的数量,而无需新图像。它会通过产生一些变异来复制图像。这可以通过旋转图像、添加噪声、水平或垂直翻转等方式来完成。
augmentor = ImageDataGenerator(
width_shift_range=0.4,
height_shift_range=0.4,
horizontal_flip=False,
vertical_flip=True,
)
# fitting in augmentor
augmentor.fit(training_data)
# obtaining the history
history = model.fit(
augmentor.flow(training_data, training_label, batch_size=32),
epochs=100,
validation_data=(validation_data, validation_label),
)
输出:

图 5 每个 Epoch 的准确率与损失率 | 图片来源:作者
ImageDataGenerator() 函数用于创建增强图像。fit() 用于拟合模型。它接受训练和验证数据、批次大小(Batch Size)和迭代次数(Epochs)作为输入。
批次大小(Batch Size)是指模型更新前处理的样本数量。一个关键的超参数,必须大于等于 1 并且小于等于样本数量。通常,32 或 64 被认为是最佳的批次大小。
迭代次数(Epochs)表示所有样本在网络的前向和反向传播中被处理的次数。100 次迭代意味着整个数据集通过模型 100 次,模型本身运行 100 次。
我们的模型已经训练完成,现在我们将评估它在测试集上的表现。
评估模型表现
在本节中,我们将检查模型在测试集上的准确率和损失率。同时,我们将绘制准确率对比 Epoch 和损失率对比 Epoch 的图表,用于训练和验证数据。
model.evaluate(testing_data, testing_label)
输出:
313/313 [==============================] - 2s 5ms/step - loss: 0.8554 - accuracy: 0.7545
[0.8554493188858032, 0.7545000195503235]
我们的模型达到了 75.34% 的准确率和 0.8554 的损失率。由于这不是最先进的模型,所以准确率可以提高。我使用这个模型来解释构建模型的过程和流程。CNN 模型的准确率取决于许多因素,如层的选择、超参数的选择、数据集的类型等。
现在我们将绘制曲线以检查模型的过拟合情况。
def acc_loss_curves(result, epochs):
acc = result.history["accuracy"]
# obtaining loss and accuracy
loss = result.history["loss"]
# declaring values of loss and accuracy
val_acc = result.history["val_accuracy"]
val_loss = result.history["val_loss"]
# plotting the figure
plotter.figure(figsize=(15, 5))
plotter.subplot(121)
plotter.plot(range(1, epochs), acc[1:], label="Train_acc")
plotter.plot(range(1, epochs), val_acc[1:], label="Val_acc")
# giving title to plot
plotter.title("Accuracy over " + str(epochs) + " Epochs", size=15)
plotter.legend()
plotter.grid(True)
# passing value 122
plotter.subplot(122)
# using train loss
plotter.plot(range(1, epochs), loss[1:], label="Train_loss")
plotter.plot(range(1, epochs), val_loss[1:], label="Val_loss")
# using ephocs
plotter.title("Loss over " + str(epochs) + " Epochs", size=15)
plotter.legend()
# passing true values
plotter.grid(True)
# printing the graph
plotter.show()
acc_loss_curves(history, 100)
输出:
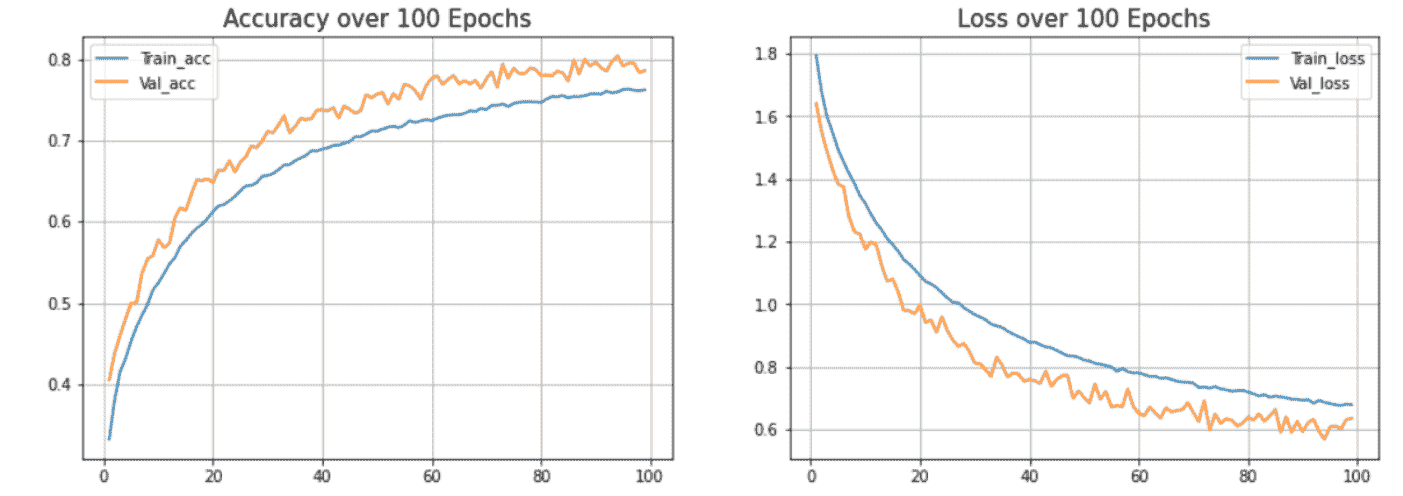
图 6 准确率和损失率对比 Epoch | 图片来源:作者
在我们的模型中,我们可以看到模型过拟合了测试数据集。蓝色线表示训练准确率,橙色线表示验证准确率。训练准确率持续提升,但验证错误在 20 次迭代后变得更糟。
请查看本文中使用的 Google Colab 链接 - 链接
结论
本文展示了从头开始构建和训练卷积神经网络的整个过程。我们得到了大约 75% 的准确率。你可以尝试调整超参数,并使用不同的卷积和池化层组合来提高准确率。你还可以尝试迁移学习,它利用像 ResNet 或 VGGNet 这样的预训练模型,并在某些情况下获得非常好的准确率。如果你想,我们可以在其他文章中详细讨论。
在那之前,继续阅读和学习。如有任何问题或建议,欢迎通过 Linkedin 联系我。
Aryan Garg 是一名 B.Tech. 电气工程学生,目前在本科最后一年。他对 Web 开发和机器学习领域感兴趣。他已经追求了这一兴趣,并渴望在这些方向上继续工作。
更多相关主题
构建视觉搜索引擎 – 第一部分:数据探索
原文:
www.kdnuggets.com/2022/02/building-visual-search-engine-part-1.html
为什么?
曾经想过 Google 或 Bing 如何找到与您的图像相似的图像吗?生成基于文本的 10 个蓝色链接的算法与寻找视觉上相似或相关的图像的算法是非常不同的。在本文中,我们将解释一种构建视觉搜索引擎的方法。我们将使用 Caltech 101 数据集,该数据集包含日常生活中常见物体的图像。我们将仅介绍一个原型算法,并讨论开发全面规模视觉搜索引擎所需的条件。
关于数据集
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT
Caltech 101 数据集包含 101 个类别的物体,如面部、蜱、刀具、手机、货币等。每个类别包含 40–200 张图像。除了 101 个类别外,它还包含一个背景类别/噪声类别,以测试模型在负面图像上的表现。数据集包含 8677 张图像,不包括 486 张背景图像。以下是各类别图像的频率分布。
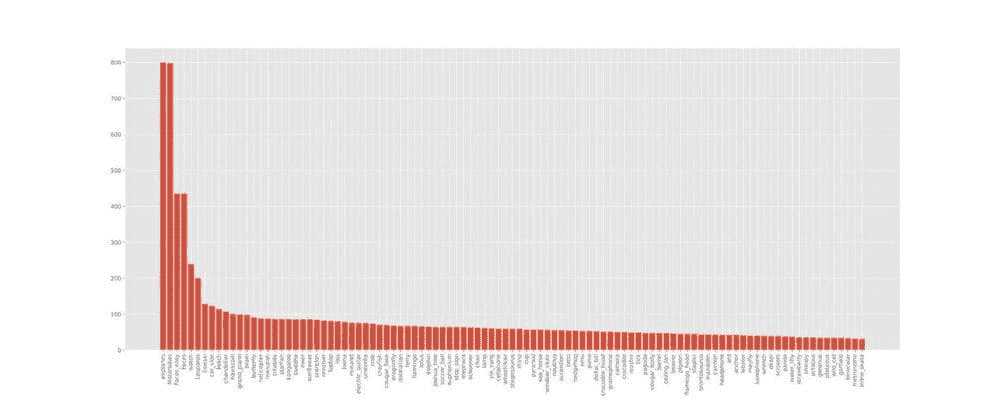
每个类别中的图像数量遵循长尾分布。最常见的类别包含的图像数量约为最少见类别的 16 倍。大约 5%的类别(5 个类别)包含约 30%的图像。大约 90%的类别有少于 100 张图像。
注意: 数据集中的这种不平衡可能导致模型训练时出现偏斜的批次。
探索性数据分析
我们从随机选择的类别中获取随机图像。请参见下面的一些样本图像。


观察结果
- 纵横比: 图像具有不同的纵横比,但图像的最大边被调整为 300px。此外,我们尝试获取纵横比的分布,以更好地理解数据集。我们发现大多数图像的纵横比为 0.5–0.8,即宽度大于高度。
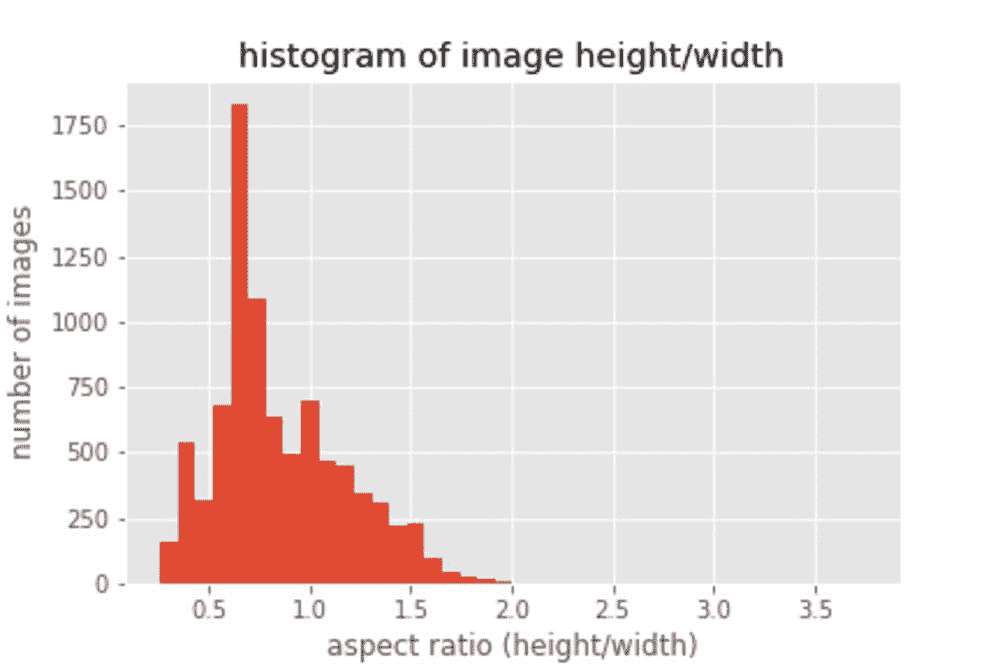
- 彩色与灰度:我们注意到某些目录中的许多图像是灰度图像。我们实现了一个灰度图像检查,发现 101 个类别中有 411 张图像是灰度图像。接下来,我们检查了每个类别的分布,发现 car-side 类只有灰度图像。还有一些其他类别包含灰度图像,但除了 car-side 类之外,所有类别都包含彩色图像。
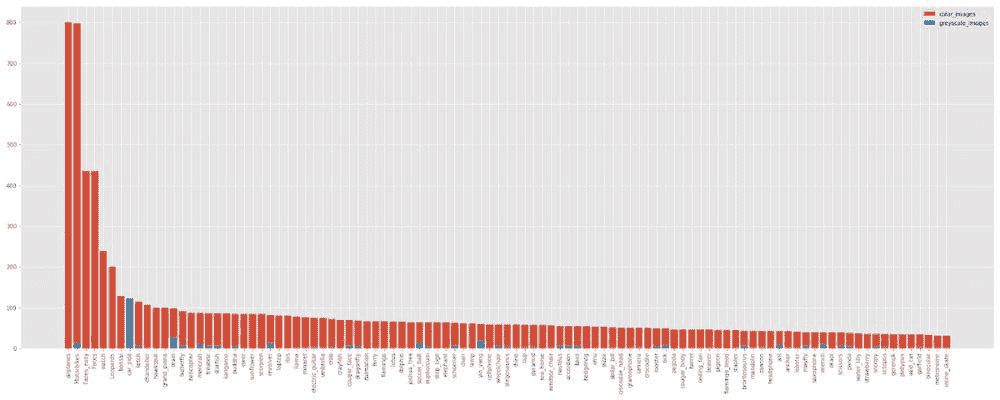
数据偏差:
- faces 和 faces_easy:这些类别分别包含面部图像和裁剪的面部图像。但是,有多张同一人的图像具有轻微的视角变化。此外,这些图像在遮挡、背景和光照方面非常相似。

- flamingo 和 flamingo_head:一个类别包含了整个火烈鸟的身体,另一个类别仅包含火烈鸟的头部。

-
相似情况:chair 和 windsor_chair
-
accordion — 图像旋转了 45 度,并有黑色填充
动画图像:许多类别包含卡通图像。卡通图像在语义上是正确的,但与真实图像相比具有不同的纹理。
对象位置与尺度:我们发现数据集在图像中的尺度和位置上存在偏差。聚焦的对象总是位于图像的中心,并具有相似的尺度。图像中心的对象可能没有问题,因为 CNN 模型对平移不变(当使用最大池化或平均池化时)。但使用固定尺度训练模型可能会导致模型仅在类似尺度的对象上有效。这将导致模型在不同尺度的图像上失败,这通常发生在现实生活中。我们提出了两个解决方案:
-
两阶段管道:我们可以创建一个两阶段的管道,第一个组件预测聚焦对象的边界框,第二个组件预测对象是什么。
-
使用数据增强调整对象大小:我们可以应用数据增强技术来重新调整聚焦对象的大小,并在增强后的数据集上训练模型。这可能需要增加模型的大小,因为它现在将存储更多的信息(对象识别为多个尺度,因为 CNN 对尺度不变)。
遮挡与背景:数据集中大多数图像有干净的背景,聚焦的物体没有被遮挡。
图像栅格化:一些类别的图像似乎是从较小尺寸的图像调整大小的。因此,这些图像看起来非常栅格化
嵌入可视化
在本节中,我们使用从预训练模型生成的嵌入来可视化图像。为此,我们使用了在 ImageNet 上预训练的 MobileNetV2 模型,该模型具有 220 万个参数。我们使用了全局平均池化层的输出,该层生成的嵌入大小为 1280。
该向量的二维图并不直观。这是因为这两个维度合在一起仅解释了数据中 8.5%的方差。我们还使用 TF Projector 将这些嵌入图在三维中绘制。3D 嵌入图解释了数据中约 15%的方差。
我们没有从上述图表中观察到任何明显的对象簇。但图像之间的余弦相似度很好地代表了这些图像。在大多数情况下,接近某一图像嵌入的图像属于同一类别。这证明了我们用于生成嵌入的模型,专注于图像的正确方面,并且能够识别图像中的兴趣对象。
t-SNE 嵌入的可视化显示了大量集中类簇。浏览这些可视化还揭示了一些相似的类,如帆船和双桅帆船、直升机和飞机、淡水龙虾和龙虾等。
编辑说明: 请加入我们下周的精彩内容《构建视觉搜索引擎》,我们将从数据探索转向实际构建视觉搜索引擎。
Mudit Bachhawat 在谷歌担任机器学习工程师,拥有超过 5 年的数据科学、深度学习、计算机视觉、多模态信息检索和优化方面的经验。欢迎随时留言或提问。
更多相关内容
构建视觉搜索引擎 – 第二部分:搜索引擎
原文:
www.kdnuggets.com/2022/02/building-visual-search-engine-part-2.html编辑注:你可以在这里找到本文的第一部分。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
任务:任务是生成一个图像的排名列表,这些图像在语义上与查询图像相似。
数据集
我们将数据集分成两部分:训练集和评估集。从每个类别中,我们将随机抽取 20 张图像,并创建一个评估集。其余图像将作为训练集的一部分。我们进一步将评估集拆分为两个部分,查询集和候选集。我们将从评估集的每个类别中取 5 张图像作为查询集,其余图像则作为候选集。这是为了计算评估指标。
对于每个查询集图像,系统从评估集中生成一个图像排名列表。然后使用下面定义的指标来评估系统的性能。
指标
我们使用 Precision @ K 指标来衡量系统的性能。
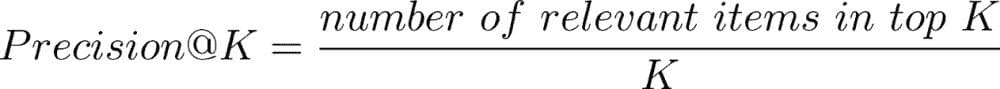
该指标不关注条目的排名,只关注相关条目的数量。为了捕捉系统的排名因素,我们还在数据集上展示了平均精度(AP)。
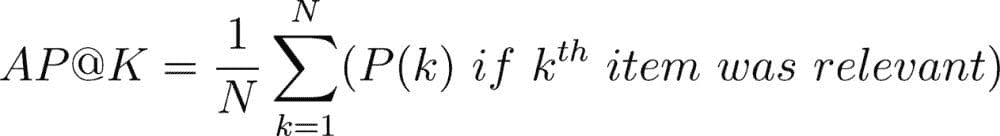
方法
对于这个练习,我们展示了两个基准。
基准 1:在这种方法中,我们从候选集中的所有类别随机选择 10 个样本。我们对每个查询执行此操作并计算指标。
基准 2:在这种方法中,我们使用从 MobileNetV2 模型生成的嵌入,并使用余弦距离作为相似度度量来对候选条目进行排名。
注意:我们知道这两种方法都没有使用训练集。这些方法仅为系统提供基准。
结果
定量结果
我们使用数据集部分定义的方法来计算评估指标。

定性结果
以下结果呈现了基准 2 方法(余弦相似度)的结果

示例搜索结果

示例搜索结果
请在此处找到重现指标和结果的代码。
未来展望
数据收集和标注: 为了创建一个完整的图像搜索引擎,我们需要重新审视该系统的需求。该系统是否需要处理某些类型的图像?是否应该处理所有现实生活中的物体?搜索应该集中在图像中的语义对象上,还是类似颜色和纹理的图像就足够了?这些需求将有助于明确数据需求。要创建一个完整的搜索引擎,我们需要从网络上收集数百万张图像并维护索引。收集数据后,我们需要定义任务并开始对数据进行标注。
** 错误分析:** 我们可以分析余弦相似度结果中出现的错误。我们可以检查那些虽然被包含在前 10 结果中但属于其他类别的搜索结果。这可能揭示出类似类别的结果和噪声类别的结果等错误。
方法: 现有方法使用了预训练的 MobileNetV2 模型的知识。未来,我们可以使用三元组损失或对比损失在相似和不相似的图像上训练自己的模型。目标是创建一个能够捕捉图像中物体的嵌入器。
** 部署:** 建立一个完整的搜索引擎将需要构建多个组件。
-
图像爬虫: 该组件将爬取用于模型训练和验证的图像。
-
数据标注器: 该组件将由人工标注员使用,以标注和清理收集的数据。数据将根据多个要求进行收集和清理。训练和验证数据将通过不同的管道处理。
-
模型训练:该组件将使用标注数据生成可用于推断的模型工件。
-
模型评估: 该组件将生成关于模型改进的报告。系统的任何变化都应该在该报告中可见,变化应该以此为依据。该系统还应生成关注的失败案例。
-
嵌入预计算: 一旦模型经过训练和验证,应该利用该模型生成所有部署数据的嵌入。嵌入应预先计算以便于在请求时快速检索。
-
实时服务和应用接口:该组件包含用于处理和生成请求的前端和后端。
参考文献
[1] Caltech 101, www.vision.caltech.edu/Image_Datasets/Caltech101/
[2] 推荐系统的平均精度均值(MAP), sdsawtelle.github.io/blog/output/mean-average-precision-MAP-for-recommender-systems.htm
Mudit Bachhawat 在 Google 担任机器学习工程师,拥有超过 5 年的数据科学、深度学习、计算机视觉、多模态信息检索和优化的经验。欢迎随时留言或提问。
更多相关主题
构建一个用于自然语言处理的维基百科文本语料库
原文:
www.kdnuggets.com/2017/11/building-wikipedia-text-corpus-nlp.html
对于自然语言处理 (NLP) 任务,所需的第一件事之一是一个语料库。在语言学和 NLP 中,语料库(字面意思是拉丁语中的“身体”)指的是一组文本。这些集合可以由单一语言的文本组成,也可以跨越多种语言——多语言语料库(语料库的复数形式)可能有许多用途。语料库还可以由主题文本(历史的、圣经的等)组成。语料库通常仅用于统计语言分析和假设检验。
好消息是,互联网充满了文本,而且在许多情况下,这些文本已经被收集和组织得很好,即使它需要一些调整以适应更可用、更精确定义的格式。特别是维基百科,是一个组织良好的丰富文本数据源。它也是一个庞大的知识集合,开放的头脑可以为这样的文本集合构思各种用途。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在的组织的 IT 需求
我们将在这里从一组英文维基百科文章中构建一个语料库,这些文章可以在网上自由和方便地获取。

安装 gensim
为了轻松构建一个没有维基百科文章标记的文本语料库,我们将使用 gensim,这是一个用于 Python 的 主题建模 库。具体来说,gensim.corpora.wikicorpus.WikiCorpus 类正是为这个任务而设计的:
从维基百科(或其他基于 MediaWiki 的)数据库转储中构建一个语料库。
为了正确完成以下步骤,你需要 安装 gensim。这是一个相对简单的过程;使用 pip:
$ pip install gensim
继续...
下载维基百科转储文件
显然,此过程还需要一个维基百科转储文件。最新的文件可以在 这里 找到。
提个警告:最新的英文维基百科数据库转储文件大小约为 14 GB,因此下载、存储和处理该文件并非易事。
我获得并用于此任务的文件是enwiki-latest-pages-articles.xml.bz2。下载它或其他类似文件以用于接下来的步骤。
创建语料库
我写了一个简单的 Python 脚本(灵感来自于这里),通过去除文章中的所有维基百科标记来构建语料库,使用 gensim 库。你可以在这里阅读关于 WikiCorpus 类的更多信息(如上所述)。
代码非常简单明了:使用WikiCorpus类的get_texts()方法逐篇打开和读取维基百科的转储文件,所有这些最终都写入一个文本文件中。维基百科转储文件和最终的语料库文件都必须在命令行中指定。
$ python make_wiki_corpus enwiki-latest-pages-articles.xml.bz2 wiki_en.txt
Processed 10000 articles
Processed 20000 articles
Processed 30000 articles
Processed 40000 articles
Processed 50000 articles
Processed 60000 articles
Processed 70000 articles
Processed 80000 articles
Processed 90000 articles
Processed 100000 articles
...
几小时后,上述代码生成了一个名为wiki_en.txt的语料库文件。
检查语料库
第二个脚本检查我们刚刚构建的语料库文本文件。
现在,请记住,这个大型的维基百科转储文件最终会生成一个非常大的语料库文件。由于其巨大的尺寸,你可能会在一次性将整个文件读入内存时遇到困难。
这个脚本开始时会从文本文件中读取 50 行——相当于 50 篇完整的文章——并将它们输出到终端,然后你可以按一个键输出另外 50 行,或者输入‘STOP’以退出。如果你确实停止,脚本将继续将整个文件加载到内存中。这可能会对你造成问题。然而,你可以通过批量检查文本,以满足你对运行第一个脚本后有所收获的好奇心。
如果你计划处理这样一个大的文本文件,可能需要一些变通方法来应对其相对于你计算机内存的巨大尺寸。
必须在命令行中指定语料库文件以执行。
$ python check_wiki_corpus.py wiki_en.txt
...
best loved patriotic songs harperresource external links mp and realaudio
recordings available at the united states library of congress words sheet
music midi file at the cyber hymnal america the beautiful park in colorado
springs named for katharine lee bates words archival collection of america
the beautiful lantern slides from the another free sheet music
>>> Type 'STOP' to quit or hit Enter key for more <<<
就这样。一些简单的代码实现了 gensim 使之变得简单的任务。现在你拥有了一个充足的语料库,自然语言处理的世界就是你的舞台。是时候做些有趣的事情了。
相关:
-
处理文本数据科学任务的框架
-
自然语言处理关键术语解释
-
5 个免费资源帮助你开始深度学习自然语言处理
更多相关话题
使用 Bash 构建您的第一个 ETL 管道
原文:
www.kdnuggets.com/building-your-first-etl-pipeline-with-bash

图片由作者提供 | Midjourney & Canva
介绍
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
ETL,即提取、转换、加载,是一个必要的数据工程过程,涉及从各种来源提取数据,将其转换为可用的格式,并将其移至某个目的地,如数据库。ETL 管道自动化了这一过程,确保数据以一致和高效的方式处理,为数据分析、报告和机器学习等任务提供框架,并确保数据干净、可靠且可用。
Bash,缩写自 Bourne-Again Shell — 又名 Unix Shell — 是一个强大的工具,用于构建 ETL 管道,因其简洁性、灵活性和极广泛的适用性,因此是初学者和资深专家的绝佳选择。Bash 脚本可以自动化任务、移动文件和与命令行上的其他工具进行交互,这使它成为 ETL 工作的良好选择。此外,bash 在类 Unix 系统(如 Linux、BSD、macOS 等)中无处不在,因此在大多数这类系统上无需额外操作即可使用。
本文针对的是希望构建第一个 ETL 管道的初学者和实践数据科学家、数据工程师。假设读者具备基本的命令行理解,并旨在提供一个使用 bash 创建 ETL 管道的实用指南。文章的最终目标是引导读者完成构建基础 ETL 管道的过程,通过这篇文章,读者将能够了解如何实现一个从源提取数据、转换数据并将其加载到目标数据库的 ETL 管道。
设置您的环境
在开始之前,请确保您具备以下内容:
-
一个基于 Unix 的系统(Linux 或 macOS)
-
Bash shell(通常在 Unix 系统上预装)
-
基本的命令行操作理解
对于我们的 ETL 管道,我们将需要这些特定的命令行工具:
-
curl -
jq -
awk -
sed -
sqlite3
您可以使用系统的包管理器安装它们。在基于 Debian 的系统上,您可以使用apt-get:
sudo apt-get install curl jq awk sed sqlite3
在 macOS 上,您可以使用brew:
brew install curl jq awk sed sqlite3
让我们为 ETL 项目设置一个专用目录。打开终端并运行:
mkdir ~/etl_project
cd ~/etl_project
这会创建一个名为 etl_project 的新目录并进入该目录。
提取数据
数据可以来自各种来源,如 API、CSV 文件或数据库。在本教程中,我们将演示如何从公共 API 和 CSV 文件中提取数据。
让我们使用 curl 从公共 API 中获取数据。例如,我们将从一个提供样本数据的模拟 API 中提取数据。
# Fetching data from a public API
curl -o data.json "https://api.example.com/data"
这个命令将下载数据并保存为 data.json。
我们也可以使用 curl 从远程服务器下载一个 CSV 文件。
# Downloading a CSV file
curl -o data.csv "https://example.com/data.csv"
这将把 CSV 文件保存为我们工作目录中的 data.csv。
数据转换
数据转换是将原始数据转换为适合分析或存储的格式的必要步骤。这可能涉及解析 JSON、过滤 CSV 文件或清理文本数据。
jq 是一个处理 JSON 数据的强大工具。我们将使用它从 JSON 文件中提取特定字段。
# Parsing and extracting specific fields from JSON
jq '.data[] | {id, name, value}' data.json > transformed_data.json
这个命令从 JSON 数据中的每个条目中提取 id、name 和 value 字段,并将结果保存到 transformed_data.json 中。
awk 是一个用于处理 CSV 文件的多功能工具。我们将使用它从我们的 CSV 文件中提取特定的列。
# Extracting specific columns from CSV
awk -F, '{print $1, $3}' data.csv > transformed_data.csv
这个命令从 data.csv 中提取第一列和第三列,并将它们保存到 transformed_data.csv。
sed 是一个用于过滤和转换文本的流编辑器。我们可以用它来执行文本替换和清理数据。
# Replacing text in a file
sed 's/old_text/new_text/g' transformed_data.csv
这个命令将 transformed_data.csv 中的 old_text 替换为 new_text。
加载数据
常见的数据加载目的地包括数据库和文件。对于本教程,我们将使用 SQLite,一种常用的轻量级数据库。
首先,让我们创建一个新的 SQLite 数据库和一个表来存储我们的数据。
# Creating a new SQLite database and table
sqlite3 etl_database.db "CREATE TABLE data (id INTEGER PRIMARY KEY, name TEXT, value REAL);"
这个命令创建一个名为 etl_database.db 的数据库文件,并创建一个名为 data 的表,该表有三列。
接下来,我们将把转换后的数据插入到 SQLite 数据库中。
# Inserting data into SQLite database
sqlite3 etl_database.db <<EOF
.mode csv
.import transformed_data.csv data
EOF
这段命令将模式设置为 CSV 并将 transformed_data.csv 导入到 data 表中。
我们可以通过查询数据库来验证数据是否正确插入。
# Querying the database
sqlite3 etl_database.db "SELECT * FROM data;"
这个命令检索 data 表中的所有行并显示它们。
最终思考
我们在使用 bash 构建 ETL 管道时涵盖了以下步骤,包括:
-
环境设置和工具安装
-
使用
curl从公共 API 和 CSV 文件中提取数据 -
使用
jq、awk和sed进行数据转换 -
使用
sqlite3在 SQLite 数据库中加载数据
Bash 是 ETL 的一个不错选择,因为它简单、灵活、自动化能力强,并且与其他 CLI 工具兼容。
为了进一步调查,可以考虑加入错误处理、通过 cron 调度管道,或学习更高级的 bash 概念。你也可以探索其他转换应用和方法,以提升你的管道技能。
尝试自己的 ETL 项目,将所学应用于更复杂的场景。幸运的话,这里的一些基本概念将成为你进行更复杂数据工程任务的良好起点。
Matthew Mayo (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 和 Statology 的主编,以及 Machine Learning Mastery 的特邀编辑,Matthew 旨在使复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、语言模型、机器学习算法以及探索新兴的人工智能技术。他致力于在数据科学社区普及知识。Matthew 从 6 岁起就开始编程。
更多相关话题
SAS vs R vs Python:分析专业人士更倾向于哪种工具?
原文:
www.kdnuggets.com/2016/07/burtchworks-sas-r-python-analytics-pros-prefer.html
评论
对许多定量业务专业人士来说,分析工具的争论已经可以媲美感恩节晚餐上的政治话题。过去两年,我们已向我们的定量专业网络发送了一项极受欢迎的 SAS 与 R 的调查,生成了每年超过 1,000 份(通常非常热情)的回应。但去年,我们收到了足够多的填写请求,以至于决定将 Python 纳入我们的调查,以便与时俱进!
为了简化问题,我们只问了一个问题——您更倾向于使用哪种工具:SAS、R 还是 Python?


我们的结果显示,支持开源工具的比例在过去三年里稳步上升,今年 61.3%的受访者选择了 R 或 Python,38.6%选择了 SAS。像往常一样,也有一些专业人士选择了既不选择也不选择,或者填写了其他工具的选项。谁知道呢,也许我们的调查明年还会再度进化?拭目以待!
想要了解更多关于这些数据的信息吗?我们也是!在统计了初步结果后,我们迫不及待地想深入探究过去三年的调查数据,看看能发现什么。

今年的结果显示,Python 支持者的最大比例集中在海岸地区,西海岸对开源选项 R 和 Python 的支持高于其他地区。R 的支持在山地地区最高,而 SAS 的支持在中西部和东南部继续保持最高。

与去年类似,技术/电信领域最倾向于开源选项 R 和 Python,这也不太令人意外,因为西海岸的支持者较多。正如 2014 年和 2015 年一样,SAS 在零售/消费品和金融服务行业继续占据重要地位。

拥有博士学位的专业人士更倾向于偏好 R 而非 SAS,而拥有学士学位的专业人士更倾向于偏好 SAS 而非 R。对 Python 的支持略有不同,但在博士学位持有者中最强。

对开源工具 R 和 Python 的支持在 0-5 年经验的专业人士中最为广泛,而对 SAS 的支持在 16 年以上经验的专业人士中最强。随着越来越多的大学在其课程中转向教授开源工具,如 R 和 Python,我们看到更多初级专业人士支持这些选项。

在数据科学家中,Python 拥有大多数支持,而 SAS 在这个群体中的支持率仅为 3%。这可能是由于 SAS 在构建许多数据科学家用来管理非结构化数据的自定义工具时存在的局限性。在其他预测分析专业人士中,SAS 和 R 的支持相对均衡。有关我们如何定义“数据科学家”的更多信息,请查看这篇博客。

在这里,你可以看到自我们 2015 年的调查以来,数据科学家和其他预测分析专业人士的工具偏好发生了怎样的变化。
一些生动的评论
在我们的快速调查中,参与者众多,我们总是会收到许多有趣的观察结果,我们喜欢与大家分享。这些只是我们收集的一些有趣的反馈:
-
SAS 😃 😃 😃 一路领先
-
R 是一场噩梦。
-
我去年把我的团队转变为使用 Python 的团队,我们没有任何遗憾。
-
R,然后是 Python。我现在不再使用 SAS 了 😃
-
SAS 在数据分析中使用起来非常直观
-
SAS 应该非常担忧,就像它们从红巨星过渡到白矮星一样。
-
SAS、R、还有 Python!
-
我认识德国的七打(84 个)博士,他们都会说 Python
-
SAS ….. 可能是因为我超过了 50 岁。 ; )
-
R – 任何时间,任何地点,任何事
-
Python 是未来
-
第一是 SAS,第二是 R,第 999 是 Python 😃
如果你对将这些结果与我们去年的“深入探讨”进行比较感兴趣,可以查看 这篇博客文章。我们还在一个 15 分钟的网络研讨会上详细介绍了这些结果,你可以在我们的 YouTube 频道找到 录音。我们总是发现 预测分析工具和方法的演变 非常有趣,因此我们每年都期待这一点。你对这些结果有什么看法,有什么令你惊讶的吗?在评论中告诉我们!
原文。经许可转载。
相关:
-
数据科学市场:2016 年薪资洞察
-
有多少量化分析师在换工作?
-
你应该在数据分析职位上待多久?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关话题
将业务清晰度带入 CRISP-DM
评论
这是三篇文章中的第二篇。第一篇概述了使用 CRISP-DM 的四个问题及解决方法。这四个问题中的两个与对业务问题缺乏清晰度有关,这削弱了任何开发的分析的业务价值。分析团队需要模拟业务决策,以将他们的分析与业务目标联系起来,因为这将带来业务问题的清晰度,并使分析结果能够以业务术语进行评估。在 CRISP-DM 中,解决这些问题涉及对业务理解和评估阶段的更改,如图 1 所示。
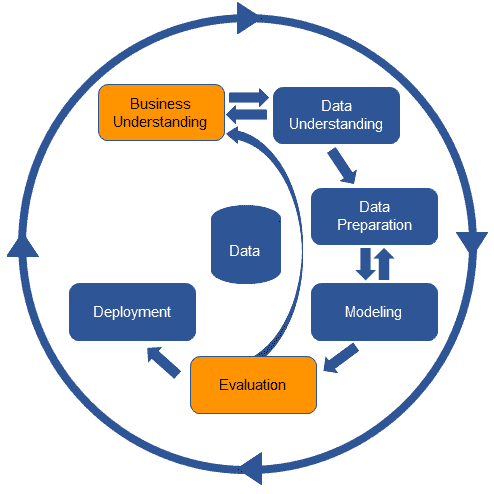
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
图 1: CRISP-DM 中的框架活动。
CRISP-DM 的第一阶段,业务理解,完全是关于明确业务问题,从而为项目提供业务焦点。分析团队常常忽视这种清晰性的必要性,在急于寻找数据、分析数据和尝试新技术时未能考虑到这一点。最多,分析团队会识别出他们想要改进的业务指标,然后直接深入分析。
但分析不能直接改善指标。例如,客户流失。如果你需要减少客户流失,你可能会开发各种分析——流失预测、接受保留优惠预测、终身价值预测等。但这些分析本身不会改善你的客户流失率。除非你改变你的行为——除非你做些不同的事情——否则你的流失率不会改善。分析可能会给你提供需要做出什么改变以及如何改变的线索,但除非你真正改变行为,否则你不会得到不同的结果。
那么你需要改变什么?决策是关键——只有当人们和系统做出不同的选择、不同的决策时,结果才会改变。如果这种决策过程可以通过分析来改进,那么结果将会改善。例如,单单拥有一个客户流失模型不会减少流失,但决定将有价值的保留优惠重点放在那些最有可能流失的客户身上则会减少流失。
为了确保他们的分析结果能够改善业务结果,分析团队需要将他们关注的指标与可以通过分析改进的具体决策联系起来。而且他们需要在 CRISP-DM 的业务理解步骤中明确做到这一点。他们需要能够捕捉到哪些决策必须改变,这些决策是如何做出的,以及由谁做出。这就是决策模型发挥作用的地方。
决策建模从理解成功的业务衡量标准和找到影响这些衡量标准的业务决策开始——特别是那些日常的、可重复的决策。如果项目要对业务产生任何影响,这些决策中的一个或多个必须以不同的方式做出——更加分析性。如果项目要产生业务差异,决策模型会将决策过程明确化,具体表现为做出决策时必须回答的问题以及可能的答案。然后,它将决策过程分解并使用像决策模型和符号(DMN)标准这样的简单但强大的符号表示决策方法。
图 2 显示了一个决策模型的示例。它展示了需要改进的总体业务决策(顶部的矩形),以便项目的业务重点明确。它将这一决策过程分解为其组成的子决策(更多的矩形),既使决策的过程变得清晰,又识别出应以分析方式做出的具体决策的角色。它显示了做出决策所涉及的规章、政策和相关经验(作为知识来源,文档形状),建议的分析模型和当前使用的数据(作为输入数据,扁平的椭圆)。这样的模型满足了 CRISP-DM 对业务理解的所有要求。
图 2:表达业务理解的决策模型
决策过程中不同组的角色可以通过参考模型来定义,同时可以识别将受到任何变化影响的系统、流程和业务环境。由于这些模型简单且直观,它们可以在分析、业务和 IT 团队之间协作开发和共享。
最终结果是关于:
-
业务问题
我们对这个决策的准确性不够,而这是告诉我们这一点的衡量标准
-
分析的使用
一个预测这类事情在决策过程中会有帮助的分析
-
可能有效的解决方案方法
这些人需要相信分析的结果,并且需要在特定的业务流程中交付,才能发挥作用。
成功的分析团队花更多时间理解业务问题,而不是在数据湖中摸索。
拥有决策模型,分析团队还拥有评估其模型的依据。分析度量——该模型的准确性如何,其提升效果如何——可以用来查看它在具体分析决策中的帮助程度。分析决策的变化可以纳入更广泛的业务背景,以查看这将如何影响整体决策。这将显示分析方法是否与原始业务意图匹配。了解谁在做出各种决策以及在什么背景下做出这些决策,也有助于确保所选择的分析风格能有效工作。例如,对于涉及监管机构的决策,避免使用黑箱分析,对于主要自动化的决策,避免使用视觉分析。
如果模型未能成功评估决策模型,则项目将回到起点。它可能只需要查看更多数据或以不同方式分析数据,但更有可能的是团队需要与业务进行讨论,探讨决策的其他可能性。许多项目在这一点上迷失方向,继续增加新数据或对分析进行新修正,而没有检查它们是否仍在朝着有效的业务目标前进。数据可能不支持改善当前决策的那种分析,但也许会揭示改进其他决策的方法或表明该度量标准不正确。可能需要回到业务理解和更新的决策模型,以重新聚焦并为项目提供前进所需的目的。
成功的分析团队将分析成功与业务成功之间的空白最小化,评估他们的模型时同时考虑业务驱动因素和分析驱动因素。
使用决策建模为分析项目带来清晰度,确保团队具备构建成功分析所需的业务理解,并为他们提供了一个业务基准,以评估其分析结果。拥有决策模型,分析项目可以避免 CRISP-DM 中的前两个问题,并建立一个能够解决真实业务问题并产生实际业务差异的分析。
要了解全球信息技术领导者如何使用决策建模,请查看国际分析研究所的最佳实践简报。
在最后一篇文章中,我们将探讨如何确保分析结果被部署和管理以实现长期价值。
相关:
-
基于标准的预测分析部署
-
数据科学过程
-
数据科学自动化:揭穿误解
更多相关话题
数据科学中的业务直觉
原文:
www.kdnuggets.com/2017/10/business-intuition-data-science.html
评论
作者:Jahnavi Mahanta。
当我们考虑一个数据科学任务时,首先想到的是需要应用的算法技术。虽然这非常重要,但在典型的数据科学任务中,还有许多其他需要同等重视的步骤。
我们的前 3 条课程推荐
1. Google 网络安全证书 - 快速迈向网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 在 IT 领域为您的组织提供支持
典型的数据科学任务可以分为以下几个阶段:
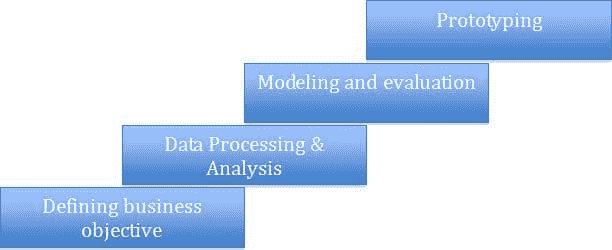
让我用一个简单的案例研究来解释一下:
有一家在线零售商,在假日季之前的 11 月份举办一场购物节。它拥有 100 万种产品的目录和一亿名曾经购买过他们产品的客户的数据库。
这家零售商希望向其客户群体进行促销邮件活动。目标是进行一系列“成功的电子邮件活动”。
现在让我们了解这个具体任务的不同阶段:
1. 确定业务目标:
这是一个非常关键的阶段,因为对于手头上的业务问题/目标的错误解释可能导致错误的解决方案和不可取的结果。如果您真的考虑一下数据科学的角色,您会发现它的作用是利用数据和从数据中得出的见解来解决现实世界的问题。从这个角度来看,准确地识别问题并定义目标对于成功的结果至关重要。在这个例子中,市场营销人员想要向每位客户发送定制的电子邮件,重点展示根据客户的偏好和口味策划的产品优惠列表:
在这种情况下,为了确定业务目标,我们需要提出一些问题:
1. 我们是发送邮件给 1 亿客户还是只发送给一部分客户?

来源:daric.classtell.com/
零售商正在组织一个购物节,因此向所有 1 亿个客户发送电子邮件可能是合理的,但仍然需要考虑以下几点:
a. 通过向所有客户发送大量电子邮件,会不会让一些客户感到不满意。例如,并不活跃地购物的客户。
b. 由于我们希望向客户展示经过筛选的产品列表(基于个体的偏好),所以,如果考虑了所有 1 亿个客户,我们可能会得到一组对任何产品都没有非常高偏好的客户(可能是因为他们与零售商购物并不频繁,因此零售商没有足够的信息了解他们的偏好)
c. 有时,数据处理和存储成本也可能是一个考虑因素。处理 1 亿个客户及其特征,运行机器学习算法可能非常耗时和资源密集。尽管有基础设施可以处理这一切,但考虑到前两个因素,排除一些客户可能是有意义的,特别是为了加快上市时间。
来源:mobileadvertisingwatch.com
2. 我们如何定义和量化成功指标?这是一个非常重要的决定,直接与业务目标相关。在上述情况下,我们可以有几个可能的成功指标:
a. 购买率(#购买量/#发送的邮件数量):这个指标将告诉我们广告活动说服顾客消费的效果如何。因此,如果零售商只关心整个广告活动带来了多少销售额,那么这就是要选择的指标!

来源:https://www.jaroop.com/web-traffic/
b. 广告活动的邮件打开率(#已打开邮件数量/#发送的邮件数量):如果零售商想了解其他因素,比如电子邮件活动内容的有效性,特别是本例中电子邮件主题的“吸引力”如何,这一点可能很重要。同样,邮件点击率(在打开邮件后,点击邮件中提供的网址,进入零售商的网站)显示了电子邮件内容的效果如何。
c. 广告活动的盈利能力:有时候,零售商可能更感兴趣的不仅仅是获取更多客户的响应(即提高响应率),而是提高每位客户的消费金额。可以这样想:一个专注于吸引越来越多客户消费的广告活动可能会吸引那些购买了很多价值较低商品的顾客,而忽略了那些购买较少但购买高价值商品的顾客。
2. 数据处理和分析:
再一次,这是另一个非常重要的阶段,我们在这个阶段详细了解可用的数据以及我们如何使用它来准确解决手头的问题。
广义上,这个阶段可以有以下几个步骤:
-
缺失值处理
-
异常值处理
-
数据分割
-
特征工程
让我们逐一经历它们,来了解为什么需要这一步。在上面的例子中,假设您拥有类似如下的数据,来自过去的促销电子邮件活动:
上面的数据是在线零售商的一些客户信息快照(100 百万客户之一)。
可以看出,第 2 位顾客的性别未知。性别可以是有用的信息,因此,如果有大量顾客的性别为“未知”或“缺失”,我们将丢失一条非常重要的信息。可以有很多方法来填补性别(通过称谓或姓名),因此可以用于缺失值处理。同样,如果报告的年收入缺失(因为这些信息仅由顾客提供,他/她可能不愿提供),我们可以利用过去 12 个月的支出来填补/预测年收入。
异常值处理也很重要。例如,我们可能会看到“过去 12 个月支出”或“年收入”的一些非常高的值。在支出方面,可能是因为某些顾客的一次性高额支出,这种情况可能不会持续,而且可能会使整个数据产生偏差,因此将支出值限制在某个阈值(例如,“过去 12 个月支出”的 99 或 95 百分位值)可以帮助减少这种偏差。
有时,我们可能会看到数据中有行为非常不同的不同顾客分段。例如,如果我们看最近的顾客(过去 6 个月成为在线零售商会员的顾客),这些顾客的行为可能与其他顾客(他们可能非常好奇,因此电子邮件打开率可能非常高,但购买率可能较低)完全不同。因此,将这些顾客与其他顾客混在一起可能会给某些参数带来偏差,或者这些顾客的特征可能会被其他顾客的特征所掩盖,从而降低他们在任何构建的预测算法上的表示。

特征工程: 特征或变量真的是给算法赋予预测能力的关键。因此,拥有正确的特征集对构建健壮的算法非常关键——因此注重特征工程。特征工程的类型:
-
特征选择:选择对问题最有用的特征子集。有许多基于相关性、信息价值或其他特征重要性概念的评分算法。然而,随着计算能力和机器学习技术的不断提升,特征选择越来越多地在算法内部处理。
-
特征构建:从原始数据中手动构建新特征。例如,在上述案例研究中,我们有一个特征“最后消费日期”,它本身可能不提供任何预测能力。然而,我们可以创建一个特征“距离上次消费的天数”,这可能非常强大(最近消费的客户可能有更高的再次消费意向,因此对电子邮件优惠更有响应性)。
-
特征提取:一些数据(如图像、声音、文本)可以具有多个特征,因此通过特征提取,我们可以自动降低这些类型特征的维度,同时从数据中提取隐藏的特征。例如,在像下面的 Pokemon 图像的图像识别中,每个图像可以具有数百个特征(像素)。因此,任何图像识别算法都必须处理来自多个图像的大量特征。因此,算法必须能够自动提取和减少这些大量特征到一个较小的有意义的特征集。

更多关于本主题的内容
如何计算算法效率
原文:
www.kdnuggets.com/2022/09/calculate-algorithm-efficiency.html

几乎所有形式的技术都使用算法来执行复杂的功能,从搜索引擎到移动应用程序,再到视频游戏和社交媒体。然而,在创建算法时,重要的是使其尽可能简化,以免对运行它的软件或设备造成负担。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
在这篇文章中,我们将讨论如何计算算法效率,重点介绍两种主要的测量方法,并提供计算过程的概述。
什么是算法效率,为什么它很重要?
算法效率与计算机处理算法所需的资源量有关。需要确定算法的效率,以确保它在不发生崩溃或严重延迟的风险下能够运行。如果算法效率不高,它不太可能适合其目的。
我们通过处理算法所使用的资源量来衡量算法的效率。高效的算法使用最少的资源来执行其功能。
算法可以用于各种功能,包括机器学习算法、对抗网络犯罪和使互联网更安全。当你浏览网页时,也应该始终了解如何保护自己免受身份盗窃及其他犯罪活动。
测量算法效率的主要方法是什么?
本节将讨论计算算法效率的两种主要衡量标准。这些是时间复杂度和空间复杂度。然而,它们之间无法直接比较,因此我们需要考虑两者的组合。
空间复杂度
简而言之,空间复杂度指的是在程序执行过程中与函数输入相关的所需内存量,即计算机或设备上所需的内存量。内存类型可能包括寄存器、缓存、RAM、虚拟内存和辅助内存。
在分析空间复杂度时,你需要考虑四个关键因素:
-
存储算法代码所需的内存
-
输入数据所需的内存
-
输出数据所需的内存(某些算法,例如排序算法,不需要内存来输出数据,通常只是重新排列输入数据)。
-
算法计算时所需的工作空间内存。这可以包括局部变量和任何需要的栈空间。
从数学上讲,空间等于下面两个组件的总和:
-
变量部分包括依赖于算法试图解决的问题的结构化变量。
-
固定部分指的是与问题无关的部分,包括指令空间、常量空间、固定大小的结构变量和简单变量。
因此,任何算法的空间复杂度 S(a) 计算如下:
S(a) = c(固定部分)+ v(i)(依赖于实例特征 i 的变量部分)
时间复杂度
时间复杂度是执行算法所需的总时间,它依赖于与空间复杂度相同的所有因素,但这些因素被分解成数值函数。
当比较不同算法时,这一度量方法非常有用,特别是在处理大量数据时。然而,如果数据量较小,比较算法性能时需要更详细的估算。当算法使用并行处理时,时间复杂度的效果较差。
时间复杂度定义为 T(num)。它通过步骤数量来衡量,只要每一步等同于常量时间。
算法时间复杂度情况
算法的复杂度由一些关键标准定义,即数据的移动和键的比较——例如,数据的移动次数和键的比较次数。测量算法复杂度时,我们使用三种情况:
-
最佳情况的时间复杂度
-
平均情况下的时间复杂度
-
最坏情况的时间复杂度
计算算法效率的过程
准确计算算法效率时需要完成两个阶段——理论分析和基准测试(性能测量)。我们将下面提供每个阶段的总结。
理论分析
与算法相关的理论分析通常是以渐近方式估计算法复杂度的过程(接近一个值或曲线)。描述算法使用的资源数量最常用的方法是使用 Donald Knuth 的“大 O 符号”。
使用大 O 符号,程序员可以测量算法以确保其在不同输入数据规模下都能高效扩展。
基准测试(性能测量)
在分析和测试新的算法或软件时,会使用基准测试来衡量其性能。这有助于评估算法与其他表现良好的算法相比的效率。
以排序算法为例。使用先前版本排序算法设置的基准测试可以确定当前算法的效率,利用已知数据同时考虑其功能改进。
基准测试还允许分析团队将算法速度与各种编程语言进行比较,以确定是否可以改进。实际上,基准测试可以以各种方式实施,以衡量性能与任何前身或类似软件的对比。
实施挑战
实现新算法有时可能会影响其整体效率。这可能与选择的编程语言、使用的编译器选项、操作系统或算法的编写方式有关。特别是,特定语言使用的编译器可能会对速度产生重大影响。
在测量空间和时间复杂度时,并非所有因素都由程序员决定。诸如缓存局部性和一致性、数据对齐和粒度、多线程以及同时多任务等问题都会影响性能,无论使用何种编程语言或算法编写方式。
运行软件的处理器也可能引发问题;一些处理器可能支持向量或并行处理,而另一些则不支持。在某些情况下,利用这些能力可能并不总是可行,这使得算法效率降低,并需要一些重新配置。
最后,处理器使用的指令集(例如,ARM 或 x86-64)可能会影响指令在各种设备上的处理速度。这使得优化编译器变得困难,因为需要考虑的硬件组合非常多。
结论
一个算法需要非常迅速地处理,因此它必须尽可能完美地执行。这就是为什么每个新算法都要经过测试来计算其效率,通过理论分析和基准测试将其与其他算法进行比较。
时间复杂度和空间复杂度是计算算法效率的两个主要指标,决定了在机器上处理算法所需的资源数量。时间复杂度衡量处理算法所需的时间,而空间复杂度衡量所使用的内存量。
不幸的是,在实施过程中可能会遇到许多挑战,例如使用的编程语言、处理器、指令集等,这些都会给程序员带来头疼的问题。
尽管如此,时间复杂度和空间复杂度已被证明是非常有效的测量方法。
Nahla Davies 是一位软件开发者和技术作家。在全职从事技术写作之前,她曾担任 Inc. 5,000 的一家体验品牌机构的首席程序员,该机构的客户包括三星、时代华纳、Netflix 和索尼。
更多相关话题
计算深度学习模型的计算效率:FLOPs 和 MACs
原文:
www.kdnuggets.com/2023/06/calculate-computational-efficiency-deep-learning-models-flops-macs.html
FLOPs 和 MACs 是什么?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
FLOPs(浮点运算)和 MACs(乘加运算)是常用来计算深度学习模型计算复杂性的指标。它们是一种快速且简单的方法来理解执行给定计算所需的算术操作数量。例如,在处理像MobileNet或DenseNet这样的边缘设备模型架构时,人们使用 MACs 或 FLOPs 来估计模型性能。此外,我们使用“估计”这个词的原因是这两个指标是近似值,而不是实际的运行时性能模型。然而,它们仍能提供关于能耗或计算需求的有用见解,这在边缘计算中非常有用。
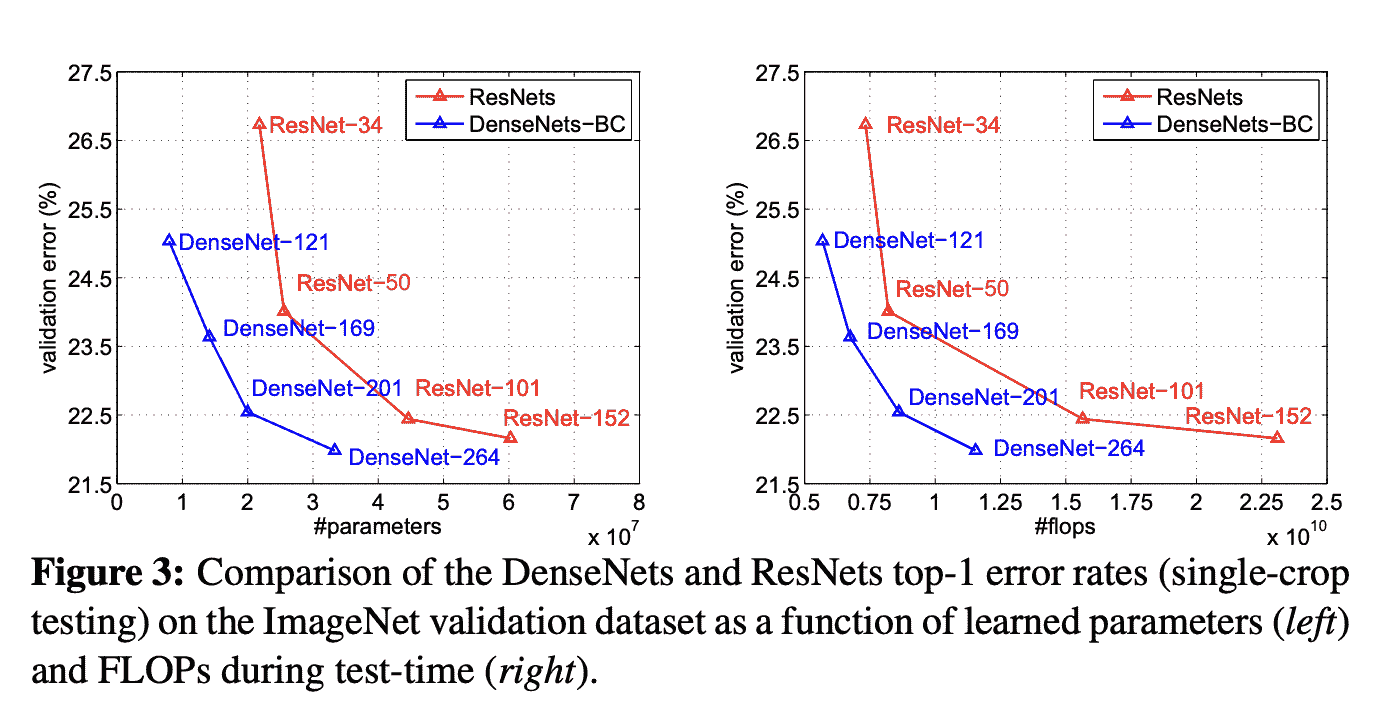
图 1:使用来自“密集连接卷积网络”的 FLOPs 比较不同神经网络
FLOPs 特指浮点运算次数,包括对浮点数的加法、减法、乘法和除法操作。这些操作在机器学习中的许多数学计算中很常见,例如矩阵乘法、激活函数和梯度计算。FLOPs 通常用于衡量模型或模型中某个操作的计算成本或复杂性。这在我们需要提供所需总算术运算估计时非常有用,这通常用于衡量计算效率的背景下。
MACs 则仅计算乘加操作的次数,这涉及将两个数字相乘并加上结果。这一操作是许多线性代数操作的基础,如矩阵乘法、卷积和点积。MACs 常被用作计算模型计算复杂度的更具体的度量,尤其是在严重依赖线性代数操作的模型中,例如卷积神经网络(CNNs)。
值得提到的是,FLOPs 不能作为人们计算计算效率的唯一因素。估计模型效率时,还需考虑许多其他因素。例如,系统设置的并行程度;模型的架构(例如,组卷积在 MACs 中的成本);模型使用的计算平台(例如,Cudnn 为深度神经网络提供 GPU 加速,标准操作如前向传播或归一化被高度优化)。
FLOPS 和 FLOPs 是一样的吗?
全部大写的 FLOPS 是“每秒浮点运算”的缩写,指的是计算速度,通常用于衡量硬件性能。“FLOPS”中的“S”代表“秒”,与“P”(表示“每”)一起,通常用于表示速率。
FLOPs(小写“s”表示复数形式)则指的是浮点运算。它通常用于计算算法或模型的计算复杂度。然而,在 AI 讨论中,FLOPs 有时可能具有上述两种含义,具体指代哪一种由读者自行判断。也有一些讨论呼吁完全放弃“FLOPs”的使用,而改用“FLOP”,以便更容易区分。在本文中,我们将继续使用 FLOPs。
FLOPs 与 MACs 之间的关系
图 2:GMACs 与 GLOPs 之间的关系(来源)
如前所述,FLOPs 和 MACs 之间的主要区别包括它们计算的算术操作类型和使用的背景。像图 2 中的 GitHub 评论一样,AI 社区的普遍共识是,一 MACs 大致等于两个 FLOPs。对于深度神经网络,乘加操作的计算负担较重,因此 MACs 被认为更为重要。
如何计算 FLOPs?
好消息是,目前已经有多个开源包可以专门用于计算 FLOPs,因此你无需从零开始实现。最受欢迎的包括 flops-counter.pytorch 和 pytorch-OpCounter。还有一些如 torchstat 的包,为用户提供基于 PyTorch 的一般网络分析器。值得注意的是,这些包支持的层和模型是有限的。因此,如果你使用的模型包含自定义网络层,可能需要自己计算 FLOPs。
在这里,我们展示了一个使用 pytorch-OpCounter 和 torchvision 中的预训练 alexnet 计算 FLOPs 的代码示例:
from torchvision.models import alexnet
from thop import profile
model = alexnet()
input = torch.randn(1, 3, 224, 224)
macs, params = profile(model, inputs=(input, ))
结论
在本文中,我们介绍了 FLOPs 和 MACs 的定义,它们通常在什么情况下使用以及这两个属性之间的区别。
参考文献
Danni Li 是 Meta 的现任 AI 研究员。她对构建高效的 AI 系统感兴趣,目前的研究重点是设备上的机器学习模型。她也是开源协作和利用社区支持以最大化创新潜力的坚定信徒。
了解更多主题
如何使用自动自助法计算机器学习中性能指标的置信区间
原文:
www.kdnuggets.com/2021/10/calculate-confidence-intervals-performance-metrics-machine-learning.html
评论
David B Rosen (PhD),IBM 全球融资自动化信用审批的首席数据科学家
橙色线显示了平衡准确率置信区间的下限 89.7%,绿色表示原始观测的平衡准确率=92.4%(点估计),红色表示上限 94.7%。(除非另有说明,否则所有图像均由作者提供。)
介绍
如果你报告你的分类器在测试集上的表现为准确率=94.8%和 F1=92.3%,在不了解测试集的大小和组成情况的情况下,这并不意味着什么。那些性能测量的误差范围会因测试集的大小而变化,或者对于不平衡的数据集,主要取决于其中包含多少个独立的少数类实例(重复抽样相同实例对这一目的没有帮助)。
如果你能够收集另一个独立来源的相似测试集,你模型在这个数据集上的准确率和 F1 分数可能不会相同,但它们可能会有多大的差异呢?类似的问题在统计学中被称为置信区间。
如果我们从基础总体中抽取许多独立的样本数据集,那么对于 95%的这些数据集,该指标的真实基础总体值将位于我们为该特定样本数据集计算的 95%置信区间内。
在本文中,我们将向你展示如何一次计算任意数量的机器学习性能指标的置信区间,使用一种自动确定默认生成多少自助样本数据集的方法。
如果你只是想查看如何调用这些代码来计算置信区间,请跳到下面的部分“计算结果!”。
自助法的方法论
如果我们能够从数据的真实分布中抽取额外的测试数据集,我们将能够看到这些数据集上感兴趣的性能指标的分布。(在抽取这些数据集时,我们不会采取任何措施来防止多次抽取相同或相似的实例,尽管这种情况可能只会偶尔发生。)
由于我们不能这样做,下一步最佳的做法是从这个测试数据集的经验分布中抽取额外的数据集,这意味着从其实例中进行带替换的抽样,以生成新的引导样本数据集。带替换的抽样意味着一旦我们抽取了某个特定实例,我们将其放回,以便可能再次抽取相同的数据集。因此,每个这样的数据集通常包含一些实例的多个副本,并且不包括基准测试集中所有的实例。
如果我们不带替换地抽样,那么每次都会得到一个与原始数据集完全相同的副本,只是顺序被打乱,这样的数据没有实际用途。
用于估计置信区间的百分位引导方法如下:
-
生成
*nboots*个“引导样本”数据集,每个数据集的大小与原始测试集相同。每个样本数据集通过从测试集中随机抽取实例(带替换)来获得。 -
在每个样本数据集上,计算度量并保存结果。
-
95%的置信区间由
*nboots*计算的度量值中的 2.5百分位到 97.5百分位给出。如果*nboots*=1001,并且你对长度为 1001 的系列/数组/列表X中的值进行了排序,则 0百分位为X[0],100百分位为X[1000],因此置信区间由X[25]到X[975]给出。
当然,你可以在第 2 步中计算每个样本数据集的任意数量的度量,但在第 3 步中,你需要分别查找每个度量的百分位数。
示例数据集和置信区间结果
我们将使用来自之前文章的结果作为示例:如何处理不平衡分类,而无需重新平衡数据:*在考虑过采样你的偏斜数据之前,尝试调整你的分类决策阈值**。
在那篇文章中,我们使用了高度不平衡的两类 Kaggle 信用卡欺诈识别数据集。我们选择使用一个与 predict()方法中隐含的默认 0.5 阈值相差甚远的分类阈值,这样就不需要平衡数据。这种方法有时称为阈值移动,在这种方法中,我们的分类器通过将所选阈值应用于 predict_proba()方法提供的预测类概率来分配类别。
我们将把本文(和代码)的范围限制为二元分类:类别 0 和 1,其中类别 1 按惯例为“正类”,特别是在不平衡数据中为少数类,尽管代码也应该适用于回归(单个连续目标)。
生成一个引导样本数据集
尽管我们的置信区间代码可以处理传递给度量函数的各种数据参数数量,我们将专注于 sklearn 风格的度量,这些度量始终接受两个数据参数,y_true和y_pred,其中y_pred可以是二进制类别预测(0 或 1),或者是连续类别概率或决策函数预测,甚至是连续回归预测(如果y_true也是连续的)。以下函数生成一个单一的引导样本数据集。它接受任何data_args,但在我们的案例中,这些参数将是ytest(我们实际的/真实的测试集目标值,见前一篇文章)和hardpredtst_tuned_thresh(预测的类别)。这两个参数都包含零和一,用于指示每个实例的真实类别或预测类别。
自定义度量specificity_score()和实用函数
我们将定义一个针对特异性的自定义度量函数,这只是负类(类 0)的召回率的另一种名称。同时,还定义一个calc_metrics函数,它将一系列感兴趣的度量应用于我们的数据,以及几个实用函数:
在这里我们列出了度量列表并将它们应用于数据。我们没有考虑准确率作为一个相关度量,因为假阴性(将真实的欺诈行为误判为合法)对业务的成本远高于假阳性(将真实的合法行为误判为欺诈),而准确率将这两种误分类视为同样糟糕,因此更倾向于正确分类那些真实类别是多数类的样本,因为这些样本出现得更频繁,从而对总体准确率的贡献更大。
met=[ metrics.recall_score, specificity_score,
metrics.balanced_accuracy_score
]
calc_metrics(met, ytest, hardpredtst_tuned_thresh)

制作每个引导样本数据集并计算其度量
在raw_metric_samples()中,我们将实际逐个生成多个样本数据集,并保存每个数据集的度量:
你给raw_metric_samples()提供一个度量列表(或仅一个度量)以及真实和预测类别数据,它会获取 nboots 个样本数据集,并返回一个仅包含从每个数据集中计算出的度量值的数据框。通过_boot_generator(),它一次调用一个one_boot(),而不是一次性存储所有数据集作为一个可能巨大的列表。
查看 7 个引导样本数据集上的度量
我们列出度量函数的列表,并调用raw_metric_samples()来获取仅针对 7 个样本数据集的结果。我们在这里调用raw_metric_samples()是为了理解——在使用下面的ci_auto()获取置信区间时并不是必须的,不过为ci_auto()指定一个度量列表(或仅一个度量)是必要的。
np.random.seed(13)
raw_metric_samples(met, ytest, hardpredtst_tuned_thresh,
nboots=7).style.format('{:.2%}') #optional #style
上面的每一列包含从一个引导样本数据集(编号 0 到 6)计算出的度量,因此计算出的度量值因随机抽样而异。
引导数据集的数量,默认为计算值
在我们的实现中,默认情况下,nboots 的数量将根据所需的置信水平(例如 95%)自动计算,以符合North, Curtis, and Sham的建议,即在分布的每个尾部具有最小数量的引导结果。(实际上,这项建议适用于p-值和假设检验的接受区域,但置信区间与这些相似,因此可以作为经验法则。)尽管这些作者建议尾部至少有 10 个引导结果,Davidson & MacKinnon 建议 95% 置信度下至少使用 399 次引导,这需要尾部有 11 次引导,因此我们采用这一更保守的建议。
我们指定 alpha,即 1 减去置信水平。例如,95% 置信度变为 0.95,而 alpha=0.05。如果你指定了一个明确的引导次数(可能因为你想要更快的结果而选择较小的 nboots),但这对于你的请求的 alpha 不够,则会自动选择更高的 alpha,以便为该次数的引导获得准确的置信区间。将使用至少 51 次引导,因为任何更少的次数只能准确计算出异常小的置信水平(例如 40% 的置信度,其区间从第 30百分位数 到第 70百分位数,该区间包含 40% 的内容,但 60% 在区间外),并且不清楚最小引导次数的建议是否考虑了这种情况。
函数 get_alpha_nboots() 设置默认 nboots 或根据上述内容修改请求的 alpha 和 nboots:
让我们展示不同 alpha 值下的默认 nboots:
g = get_alpha_nboots
pd.DataFrame( [ g(0.40), g(0.20, None), g(0.10), g(), g(alpha=0.02),
g(alpha=0.01, nboots=None), g(0.005, nboots=None)
], columns=['alpha', 'default nboots']
).set_index('alpha')

如果我们请求一个明确的 nboots,会发生什么情况:
req=[(0.01,3000), (0.01,401), (0.01,2)]
out=[get_alpha_nboots(*args) for args in req]
mydf = lambda x: pd.DataFrame(x, columns=['alpha', 'nboots'])
pd.concat([mydf(req),mydf(out)],axis=1, keys=('Requested','Using'))
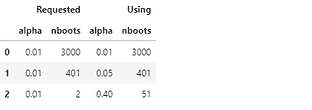
较小的 nboots 值将 alpha 提高到 0.05 和 0.40,而 nboots=2 将更改为最小值 51。
引导样本数据集的直方图显示仅针对平衡准确率的置信区间
再次说明,我们不需要通过调用 ci_auto() 来获取下文的置信区间。
np.random.seed(13)
metric_boot_histogram\
(metrics.balanced_accuracy_score, ytest, hardpredtst_tuned_thresh)
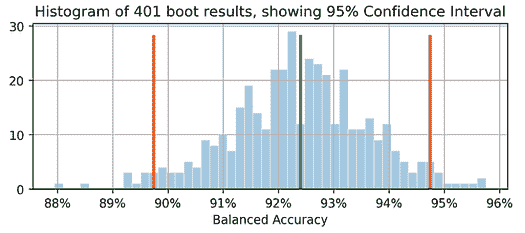
橙色线条显示 89.7% 作为平衡准确率置信区间的下界,绿色表示原始观察到的平衡准确率=92.4%(点估计),红色表示上界为 94.7%。(相同的图像出现在本文的顶部。)
如何计算所有度量指标的置信区间
这是调用上述内容并从度量结果的百分位数计算置信区间的主要函数,并将点估计插入其输出结果数据框的第一列。
计算结果!
这就是我们真正需要做的:调用 ci_auto(),如下所示,带上一个指标列表(met 上述已分配)以获取它们的置信区间。百分比格式是可选的:
np.random.seed(13)
ci_auto( met, ytest, hardpredtst_tuned_thresh
).style.format('{:.2%}')
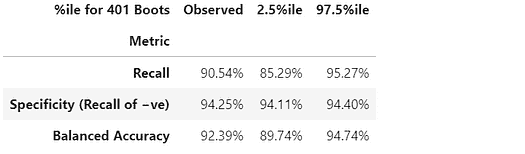
结果置信区间的讨论
这是来自原始文章的混淆矩阵。类别 0 是负类(多数类),类别 1 是正类(非常稀有的类别)。

134/(134+14) 的召回率(真正率)具有最宽的置信区间,因为这是涉及小样本的二项分布比例。
特异性(真负率)为 80,388/(80,388+4,907),涉及much更大的样本,因此它具有极其狭窄的置信区间,仅为[94.11%到 94.40%]。
由于平衡准确率仅计算为召回率和特异性的平均值,因此它的置信区间宽度介于两者之间。
测量指标的不精确性由于测试数据的变化,与训练数据的变化
在这里,我们没有考虑基于我们训练数据随机性的模型的变异性(尽管这对于某些目的也可能有兴趣,例如如果你有自动重复训练并希望了解未来模型表现可能的变化),而只是考虑了由于我们测试数据的随机性造成的这个特定模型(从某些特定训练数据创建)的表现测量的变异性。
如果我们有足够的独立测试数据,我们可以非常精确地测量该特定模型在基础总体上的表现,我们将知道如果部署该模型,它的表现如何,不管我们是如何构建模型的,也不管我们是否可以通过不同的训练样本数据集获得更好或更差的模型。
个体实例的独立性
自助法假设每个实例(案件,观察值)是从基础总体中独立抽取的。如果你的测试集有不独立的行组,例如相同实体的重复观察可能彼此相关,或测试集中实例被过度抽样/复制/从其他实例生成的结果可能无效。你可能需要使用分组抽样,在随机抽取整个组而不是单独的行时,避免拆分任何组或仅使用部分组。
你还要确保没有将分组数据分割到训练集和测试集中,因为这样测试集可能不独立,你可能会得到未被检测到的过拟合。例如,如果使用过采样,通常应在从测试集中分离之后进行,而不是之前。通常你会对训练集进行过采样,但不对测试集,因为测试集必须保持对模型未来部署时会看到的实例具有代表性。对于交叉验证,你可以使用 scikit-learn 的 model_selection.GroupKFold()。
结论
你可以随时计算评估指标的置信区间,以查看测试数据如何准确地衡量模型的表现。我计划撰写另一篇文章,展示用于评估概率预测(或置信度评分——与统计置信度无关)的指标的置信区间,即软分类,如 Log Loss 或 ROC AUC,而不是我们这里使用的评估模型离散类别选择(硬分类)的指标。相同的代码适用于这两种情况,也适用于回归(预测连续目标变量)——你只需传入不同类型的预测(以及回归情况下不同类型的真实目标)。
此 Jupyter notebook 可在 GitHub 上获取:bootConfIntAutoV1o_standalone.ipynb
这篇文章对你有帮助吗?如果你对这篇文章或关于置信区间、自助法、引导数、实现方式、数据集、模型、阈值移动或结果有任何评论或问题,请在下面留言。
除了上述的 先前文章,你可能还对我的 如何在 Pandas 中自动检测日期/时间列并在读取 CSV 文件时设置其数据类型 感兴趣,尽管它与当前文章没有直接关系。
简介:David B Rosen (博士) 是 IBM Global Financing 自动化信用审批的首席数据科学家。更多 David 的文章可以在 dabruro.medium.com 找到。
原文。经许可转载。
相关:
-
如何在 Python 中进行“无限”数学运算
-
数据科学中的高级统计概念
-
如何使用 Python 确定最佳拟合数据分布
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 需求
更多相关话题
计算客户生命周期价值:SQL 示例
原文:
www.kdnuggets.com/2018/02/calculating-customer-lifetime-value-sql-example.html
评论
作者:Luba Belokon,Statsbot

我们的前三名课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业之路。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT
Statsbot团队为不同客户和业务模型估算了 LTV 592 次。我们在这篇文章和一个免费电子书中分享了我们的经验,介绍了如何在没有复杂统计模型的情况下使用 SQL 计算客户生命周期价值。
客户生命周期价值(LTV)是指客户在其“生命周期”内,或者至少在他们与您关系中的一段时间里,会花费在您业务上的金额。这是一个重要的指标,能够帮助您了解可以花费多少资金来获取新客户。例如,如果您的客户获取成本(CAC)为$150,而 LTV 为$600。您将能够增加预算以吸引更多人,推动业务增长。CAC 与 LTV 之间的平衡使您能够检查任何业务的市场生存能力。
估算 LTV 是一个预测指标,它依赖于基于过去模式的未来购买情况,并使您能够看到作为企业您面临的风险以及您可以花费多少来获取新客户。在个体层面,它还使您能够确定谁是您未来可能的高价值客户。
为了理解如何估算 LTV,首先可以考虑在客户与我们关系结束时评估其生命周期价值。假设一个客户与我们保持 12 个月的关系,每月消费$50。

他们在整个生命周期内为我们的业务带来的收入为$5012 = $600。简单!我们可以将LTV 的基本定义*视为来自特定用户的支付总和。
同样的原则适用于群体。如果我们想要查看群体的平均 LTV,我们可以查看总支出除以客户数量。当我们谈论估算 LTV或预测 LTV 时,我们需要考虑客户与我们的停留时间。为了得到这一点,我们实际上是“倒退”来看:我们查看随着时间的推移我们失去多少客户,或流失率。
如何计算 SaaS 的 LTV?
在群体层面,估算 LTV 的基本公式是这样的:

其中 ARPU 是每个用户的平均每月经常性收入,流失率是我们失去客户的速率(即留存率的倒数)。
这个基本公式可以通过假设得到:
下个月收入 = (当前月收入) * (1 – 流失率)
注意:当我们为 SaaS 估算客户生命周期价值时,可以忽略毛利率,因为成本很小,不会影响结果的准确性。但当我们稍后在本文中为电商计算预测 LTV 时,我们会将 COGS 包括在公式中。
上述 LTV 公式的主要限制是它假设流失是线性的,即:我们在会员服务的第一个月和第二个月之间失去客户的可能性与我们在之后很久失去客户的可能性是一样的。深入到预测 LTV 的本质,我们可以说它是一个几何级数的和,线性流失看起来不像是一条直线(如许多关于 LTV 的文章所示)。
实际上,我们知道线性流失通常不是情况。
在一个灵活的订阅模式中,我们在一开始就会失去很多人,当他们在“试用”一个服务时,但是一旦他们和我们待了很长时间,他们就不太可能离开。
最终,这取决于客户和业务之间存在的合同类型:例如,年度续订,其中流失更线性,将导致 LTV 非常接近上述公式。
没有合同的服务可能会失去很高比例的新客户,但流失可能会减缓。
我们可以图形化地考虑这个概念:

如果群体的 LTV 是线下的面积,我们可以很清楚地看到我们失去客户的速度将非常显著地影响我们的 LTV 估算。因此,我们在进行计算时需要考虑这一点。然而,对于 LTV 的初步估算,使用最简单的公式是有意义的。在此之后,我们将增加复杂性。
使用 SQL 提取 ARPU 和流失率
为了做出最基本的 LTV 估算,我们需要查看我们的交易历史。然后,我们可以确定每个客户的平均收入以及我们查看的期间内的流失率。为了简化,我将查看过去一年。
你可以分两步计算 ARPU:
month_ARPU AS
(SELECT
visit_month,
Avg(revenue) AS ARPU
FROM
(SELECT
Cust_id,
Datediff(MONTH, ‘2010-01-01’, transaction_date) AS visit_month,
Sum(transaction_size) AS revenue
FROM transactions
WHERE transaction_date > Dateadd(‘year’, -1, CURRENT_DATE)
GROUP BY
1,
2)
GROUP BY 1)
结果将如下所示:

在上述情况下,这将给我们一个平均每月支出为$987.33。
计算流失率则复杂一些,因为我们需要计算从一个月到下一个月未返回的人的百分比,按他们第一次访问的月份将客户分组,然后检查他们在下个月是否返回。
问题在于,在事务性数据库中,我们的客户访问记录是分开行的,而不是全部在同一行上。
解决这个问题的方法是将事务性数据库与自身连接,以便我们可以在一行中看到客户的行为。
为了隔离那些流失的客户,我们将第 1 个月的访问数据与第 2 个月的访问数据按照 cust_id 左连接。第 2 个月访问数据中 cust_id 为 null 的行就是客户未返回的记录。
WITH monthly_visits AS
(SELECT
DISTINCT
Datediff(month, ‘2010-01-01’, transaction_date) AS visit_month,
cust_id
FROM transactions
WHERE
transaction_date > dateadd(‘year’, -1, current_date)),
(SELECT
avg(churn_rate)
FROM
(SELECT
current_month,
Count(CASE
WHEN cust_type='churn' THEN 1
ELSE NULL
END)/count(cust_id) AS churn_rate
FROM
(SELECT
past_month.visit_month + interval ‘1 month’ AS current_month,
past_month.cust_id,
CASE
WHEN this_month.cust_id IS NULL THEN 'churn'
ELSE 'retained'
END AS cust_type
FROM
monthly_visits past_month
LEFT JOIN monthly_visits this_month ON
this_month.cust_id=past_month.cust_id
AND this_month.visit_month=past_month.visit_month + interval ‘1 month’
)data
GROUP BY 1)
)
假设这给出了一个 0.1 的结果,仅为简单起见。

因此,估算 LTV 是一个简单的计算:我们有每月 ARPU 和每月流失率,所以我们只需将一者除以另一者!
$987.33/0.1 = $9873.3
如前所述,这个公式有其局限性,主要是因为它做了一系列在现实中可能不成立的假设。主要的假设是留存率和流失率在群体间和时间间都是稳定的。
跨群体的稳定性意味着早期采用者的行为与晚期采用者类似,而跨时间的稳定性意味着客户在与你关系的开始时流失的可能性与例如两年后是一样的。根据这些假设的真实性,你可能需要下调 LTV 估算值。
如果你想了解如何估算电子商务的 LTV,针对群体和每个个体客户,请下载我们免费的电子书,内容涵盖了如何用 SQL 计算客户生命周期价值。
个人简介:Luba Belokon 是 Statsbot 的内容专家。
原文。经许可转载。
相关:
-
SQL 客户留存分析指南
-
机器学习算法:选择哪一种解决你的问题
-
集成学习提升机器学习结果
更多相关主题
数据科学中的微积分
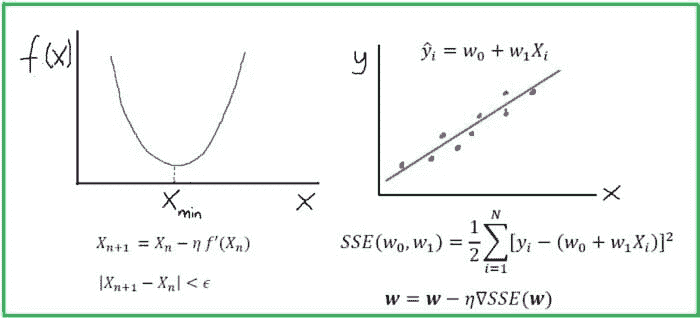
作者提供的图片
关键要点
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT 需求
-
大多数对进入数据科学领域感兴趣的初学者总是担心数学要求。
-
数据科学是一个非常定量的领域,需要高级数学。
-
但要开始,您只需掌握几个数学主题。
-
在这篇文章中,我们讨论了微积分在数据科学和机器学习中的重要性。
数据科学和机器学习中的微积分
机器学习算法(如分类、聚类或回归)使用训练数据集来确定可以应用于未见数据的权重因子,以实现预测目的。每个机器学习模型背后都有一个在很大程度上依赖于微积分的优化算法。在这篇文章中,我们讨论了一个这样的优化算法,即梯度下降近似(GDA),并展示了它如何用于构建一个简单的线性回归估计器。
使用梯度下降算法的优化
导数和梯度
在一维情况下,我们可以通过导数来找到函数的最大值和最小值。我们考虑一个简单的二次函数 f(x) 如下所示。
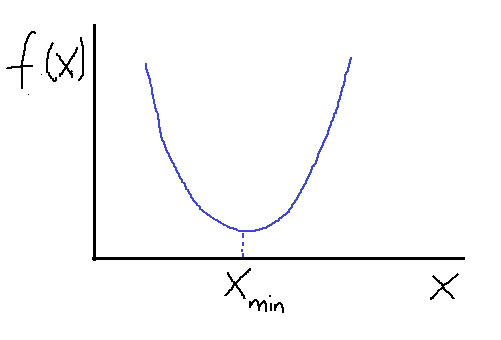
图 1。使用梯度下降算法的简单函数最小值。作者提供的图片
假设我们想要找到函数 f(x) 的最小值。使用梯度下降法和一些初始猜测,X 根据以下方程进行更新:
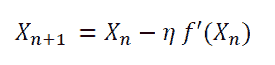
其中常数 eta 是一个小的正常数,称为学习率。请注意以下几点:
-
当 X_n > X_min 时,f’(X_n) > 0:这确保 X_n+1 小于 X_n。因此,我们在向左方向迈步,以达到最小值。
-
当 X_n < X_min 时,f’(X_n) < 0:这确保 X_n+1 大于 X_n。因此,我们在向右方向迈步,以达到 X_min。
上述观察表明,初始猜测的好坏无关紧要,梯度下降算法总是能找到最小值。到 X_min 的优化步骤数量取决于初始猜测的好坏。有时,如果初始猜测或学习率选择不当,算法可能会完全错过最小值。这通常被称为“超调”。通常,可以通过添加收敛标准来确保收敛,例如:
其中 epsilon 是一个小的正数。
在更高维度中,多个变量的函数也可以使用梯度下降算法进行优化(最小化)。在这种情况下,我们使用梯度来更新 向量 X:
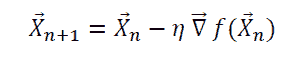
如同一维情况下,可以通过添加收敛标准来确保收敛,例如:
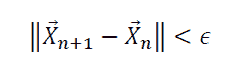
案例研究:构建一个简单的回归估计器
在这个案例研究中,我们使用梯度下降法近似构建了一个简单的线性回归估计器。该估计器用于预测房价,使用了 Housing 数据集。通过调整超参数来寻找性能最佳的回归模型,方法是评估不同学习率下的 R2 得分(拟合优度测量)。本教程的数据集和代码可以从这个 GitHub 库下载:github.com/bot13956/python-linear-regression-estimator
摘要
-
一个机器学习算法(如分类、聚类或回归)使用训练数据集来确定权重因子,这些因子可以应用于未见过的数据以进行预测。
-
每个机器学习模型背后都有一个严重依赖微积分的优化算法。
-
因此,拥有微积分的基础知识是重要的,因为这将使数据科学从业者对数据科学和机器学习中使用的优化算法有所了解。
Benjamin O. Tayo 是一位物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的创始人。此前,Benjamin 曾在中央俄克拉荷马大学、大峡谷大学和匹兹堡州立大学教授工程学和物理学。
更多内容
数据治理能解决 AI 疲劳吗?

作者提供的图片
数据治理和 AI 疲劳听起来像是两个不同的概念,但它们之间有着内在的联系。为了更好地理解,让我们先从它们的定义开始。
数据治理
这一直是数据行业的核心关注点。
Google 说得很好——“数据治理就是你所做的一切,以确保数据的安全、隐私、准确、可用和可操作。它涉及设定内部标准——数据政策——适用于数据的收集、存储、处理和处置方式。”
正如这个定义所强调的,数据治理涉及数据管理——恰恰是驱动 AI 模型的引擎。
既然数据治理与 AI 之间的联系初现端倪,让我们将其与 AI 疲劳联系起来。尽管名字揭示了一些信息,但指出导致这种疲劳的原因能确保在整个文章中一致使用这个术语。
AI 疲劳
由于组织、开发人员或团队面临的挫折和挑战,AI 疲劳逐渐显现,通常会导致 AI 系统价值实现或实施的不成功。
这通常始于对 AI 能力的不切实际的期望。对于像 AI 这样的复杂技术,主要利益相关者需要对 AI 的能力和可能性以及其局限性和风险保持一致的认识。
谈到风险时,伦理往往被视为事后考虑,这可能导致废弃不合规的 AI 计划。
你一定在想数据治理在导致 AI 疲劳中的作用——这是本文的前提。
这就是我们接下来要讨论的内容。
AI 疲劳可以大致分为部署前和部署后。让我们首先关注部署前的部分。
部署前
许多因素会影响概念验证(PoC)的完成及部署,例如:
-
我们试图解决什么问题?
-
为什么现在需要优先解决这个问题?
-
现有的数据有哪些?
-
这是否本身就是可由机器学习解决的问题?
-
数据是否存在某种模式?
-
这种现象是否可以重复?
-
需要哪些额外的数据才能提升模型性能?
图片来源:Freepik
一旦我们评估出问题可以通过机器学习算法最好地解决,数据科学团队就会进行探索性数据分析。在这一阶段,会揭示许多潜在的数据模式,突出显示数据是否在信号上富有。这也有助于创建工程特征,加快算法的学习过程。
接下来,团队构建第一个基准模型,通常发现其表现未达到可接受的水平。一个输出效果如同掷硬币的模型没有任何价值。这是构建机器学习模型时遇到的第一个挫折,即所谓的教训之一。
组织可能会从一个业务问题转移到另一个问题,导致疲劳。然而,如果基础数据没有足够的信号,那么任何人工智能算法都无法在其上建立。模型必须从训练数据中学习统计关联,以便对未见过的数据进行泛化。
后部署
尽管训练模型在验证集上显示出良好的结果,并符合如 70%准确率等业务标准,但如果模型在生产环境中表现不佳,疲劳仍然可能出现。
这种类型的人工智能疲劳被称为后部署阶段。
许多原因可能导致性能下降,其中数据质量差是困扰模型的最常见问题。它限制了模型在缺少关键属性的情况下准确预测目标响应的能力。
设想一下,当一个重要特征在训练数据中缺失仅 10%,而在生产数据中变成 50%缺失,导致预测错误。这样的迭代和努力以确保模型的一致性表现,会导致数据科学家和业务团队的疲劳,从而削弱对数据管道的信心,并风险投资到项目中的投入。
数据治理至关重要!
强有力的数据治理措施对于应对两种类型的人工智能疲劳至关重要。由于数据是机器学习模型的核心,富有信号、无错误且高质量的数据是机器学习项目成功的必要条件。解决人工智能疲劳需要重点关注数据治理。因此,我们必须严格工作,确保数据质量,为构建最先进的模型和提供可信的业务洞察奠定基础。
数据质量
数据质量,即繁荣的数据治理的关键,是机器学习算法的成功因素。组织必须投资于数据质量,如向数据消费者发布报告。在数据科学项目中,想想当质量差的数据进入模型时会发生什么,这可能导致性能不佳。
只有在错误分析过程中,团队才会识别出数据质量问题,这些问题在上游被修复后,最终会导致团队的疲劳。
显然,这不仅是投入的努力,很多时间也会被浪费,直到正确的数据开始流入。
因此,总是建议在源头解决数据问题,以防止这种耗时的迭代。最终,发布的数据质量报告会让数据科学团队(或者任何其他下游用户和数据消费者)了解即将到来的数据的可接受质量。
如果没有数据质量和治理措施,数据科学家会因数据问题而感到负担过重,从而导致不成功的模型,进而引发 AI 疲劳。
结束语
文章突出了 AI 疲劳出现的两个阶段,并展示了数据治理措施,如数据质量报告,如何有助于构建可信赖且稳健的模型。
通过数据治理建立坚实的基础,组织可以制定成功和无缝的 AI 开发和采纳路线图,激发热情。
为确保文章全面概述解决 AI 疲劳的多种方法,我还强调了组织文化的作用,组织文化与数据治理等其他最佳实践相结合,将使数据科学团队能够更快地建立有意义的 AI 贡献。
Vidhi Chugh** 是一位 AI 战略家和数字化转型领袖,她在产品、科学和工程的交汇点上工作,致力于构建可扩展的机器学习系统。她是一位获奖的创新领导者、作者和国际演讲者。她的使命是让机器学习大众化,并消除术语,让每个人都能参与这一转型。**
了解更多
深度学习能帮助找到完美的约会对象吗?
原文:
www.kdnuggets.com/2015/07/can-deep-learning-help-find-perfect-girl.html
评论由 Harm de Vries 提供
 我搬到蒙特利尔后做的第一件事就是安装Tinder。对于那些不熟悉在线约会市场的人,Tinder 是一个展示附近用户的约会应用,你可以通过他们的个人资料图片来喜欢或不喜欢他们。在使用这个应用一段时间后,我发现尽管我始终不喜欢有很多穿孔和纹身的女孩(无意冒犯,只是我的类型),但这个应用一直在向我展示这些个人资料。Tinder 没有利用我的滑动历史来了解我喜欢哪种类型的女孩,这让我感到惊讶。
我搬到蒙特利尔后做的第一件事就是安装Tinder。对于那些不熟悉在线约会市场的人,Tinder 是一个展示附近用户的约会应用,你可以通过他们的个人资料图片来喜欢或不喜欢他们。在使用这个应用一段时间后,我发现尽管我始终不喜欢有很多穿孔和纹身的女孩(无意冒犯,只是我的类型),但这个应用一直在向我展示这些个人资料。Tinder 没有利用我的滑动历史来了解我喜欢哪种类型的女孩,这让我感到惊讶。
这个观察让我思考:计算机能否学会我对哪类女孩有吸引力?我通过对 Tinder 上超过 9000 张个人资料图片进行标记,并利用深度学习,即人工智能领域的最新革命,来进行尝试。在这篇博客文章中,我将提供一个高层次的视角,介绍我如何使用这些技术来预测我的 Tinder 滑动。你可以在这篇论文中找到技术细节,该论文已被接受用于ICML 深度学习研讨会。

机器学习
计算机已经存在了几十年,但仍然存在许多最强大的计算机难以解决的问题,而我们(作为人类)可以轻松完成。你可以想到检测图片中的面孔、识别语音和翻译文本。问题是,尽管我们能轻松完成这些任务,但我们无法解释我们是如何做到的。这意味着,我们不能提出一套可以转换为计算机程序的规则。
从个人资料图片中预测吸引力是这样一个任务吗?是的,确实很难指定一套规则来定义你被吸引的对象。对你们中的一些人来说,这可能听起来有悖直觉,因为你可以指定一个明确的特征列表,比如蓝眼睛、金发等。然而,即使你可以这样做,你也得相信,构造一个能在图片中检测这些特征的程序是非常复杂的。
另一方面,如果我给你一张女孩/男孩的照片,你可以在一瞬间决定你是否喜欢她/他。这提示了一种更好的策略:我们让计算机通过展示你喜欢或不喜欢的女孩的个人资料图片来自我学习。我们称之为机器学习,因为程序从这些个人资料图片中学习一套吸引力规则。

深度学习
深度学习 是一种特定类别的学习算法,最近在图像识别(以及许多其他人工智能问题)方面取得了突破。如果你想亲自看看这些技术现在的效果,我鼓励你上传一张照片到
-
how-old.net 用于估算图片中人物的年龄
-
imageidentify.com 用于检测图片中的内容
在深度学习中,程序的结构是一个人工神经网络,其灵感来源于生物神经网络,即大脑。当神经网络由多个层的连接神经元组成时,我们称其为深度。每个神经元与上一层的一组神经元相连。这些连接的强度(如红色所示)决定了神经元对哪些图像模式做出反应。你可以将其视为一个可调节的滤波器,仅在看到特定模式时才会做出反应。
网络的连接强度是随机初始化的,这意味着所有神经元只是随机滤波器。因此,当我们将图像输入网络(通过输入其像素的强度)时,第一层中的只有几个神经元会做出反应,这反过来会使下一层中的一些随机神经元变得活跃(以此类推直到输出)。因此,网络的输出将是随机的喜欢或不喜欢。
因此,为了做出准确的预测,我们需要对网络进行训练。我们通过输入一张个人资料照片并将其传递通过网络以获得输出。如果网络的预测与期望的输出(喜欢或不喜欢)不同,我们会调整其滤波器(即其连接强度),以使预测更准确。如何具体调整滤波器是相当困难的,超出了这篇博客的范围,你只需要知道我们可以做到这一点。训练阶段就是重复这个过程许多次,然后希望网络对它尚未见过的个人资料照片进行准确预测。
训练后,我们通常观察到第一层的神经元对边缘和颜色斑点做出反应,而下一层利用这些观察来检测更复杂的模式,例如眼睛和耳朵。最后一层可能会检测到完整的面孔或穿孔和纹身(这对于预测我的偏好非常重要)。
参见后续内容: 深度学习能帮助你找到完美女孩吗? – 第二部分。
是一名博士生,由 Aaron Courville 和 Roland Memisevic 监督,并且是由 Yoshua Bengio 领导的蒙特利尔学习算法研究所的成员。他的主要兴趣在于深度学习的理论和应用。
原始资料 作者 Harm de Vries。
相关:
-
爱、性与预测分析
-
Thomas Levi,PlentyOfFish 讲述大数据对浪漫的启示
-
漫画:人类在深度学习上仍然领先
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关话题
如何捕获数据以产生商业影响
原文:
www.kdnuggets.com/2019/03/capture-data-make-business-impact.html
评论
每一个需要通过数据驱动决策来解决的商业挑战背后都有一个数据宇宙。这个数据宇宙是指与商业挑战相关的、可以被捕获的数据集合。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
数据宇宙由信息和噪声组成:信息是可以转化为知识的数据;噪声是无法提取出知识的数据(当然,噪声数据也可以被处理并导致“发现”,这些发现是虚假的知识,并不真正有用)。需要注意的是,数据是否为噪声或信息取决于讨论中的商业挑战。换句话说,相同的数据在一个商业案例中可能是噪声,在另一个商业案例中则可能是信息。
还值得一提的是,没有人会故意收集噪声数据,即噪声数据是无意中被使用的。原因是,区分噪声和信息在某些情况下可能很简单,但在其他情况下则可能非常困难。
一个例子很好地说明了这一点。
在文章 Analítica Predictiva en La Liga Santander 中,处方分析被应用于西班牙主要足球联赛中以进行更高的分类。考虑到马达加斯加冰淇淋消费的历史数据集:显然,这些数据在体育案例中没有任何相关性,因此被视为噪声。但请注意,只有从 1995 年起的数据被使用。实际上,自 1975 年以来就有数据。那么为什么没有使用完整记录?在 1995-1996 赛季,西班牙采纳了每场胜利给予 3 分而不是仅 2 分的规则。进行了一项 Chow 检验 来查看这是否影响了球队的表现。结果测试为正。因此,1975 年至 1994 年的数据被视为噪声,而不是信息。在这种情况下,注意到这一点需要对相关领域有深入的了解(也有一点运气)。
捕获噪声有一个副作用:我们存储的噪声越多,越难在捕获的数据中找到信息。这就像在干草堆(噪声)中找针(信息)。即使我们可以很容易区分针和草,但如果针被大量的草包围,也可能很难识别。大数据的经验法则是尽可能多地存储数据,并且存储时间尽可能长,这将是一个错误的朋友。
如果我们引入一个指标来量化我们数据捕获工作的效率,它应该遵循这两个规则:
-
捕获的信息越多,我们的效率就越高。
-
捕获的噪声越少,我们的效率就越高。
所以,写成公式可能是这样的:
重新排列术语:

我们可以同意(1)捕获的信息越多,我们的数据处理就越准确,(2)捕获的噪声越少,我们的数据捕获努力就越有效。代入这些术语,方程式将如下:
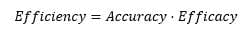
在所有捕获的数据完全是信息的最佳情况下,效率的值将为 1。当捕获一些信息和一些噪声时,值将在 0 和 1 之间。令人有趣的是,效率趋向于 0,即使所有信息都包含在数据宇宙中,我们试图捕获所有数据时。
继续我们的示例 La Liga Santander 中的预测分析,我们现在可以计算所使用数据集的效率。模型的整体准确率为 91%。我们可以将这个值视为捕获信息的百分比。另一方面,我们可以确定我们使用了哪些数据进行处理。因此,我们可以按如下方式计算:

现在我们有了效率的定义,我们可以引入一个新概念,智能数据。在物联网中,智能数据通常被描述为来自智能传感器的数据。一些人将其定义为经过清理、过滤和准备分析的大数据。对于“智能数据”没有统一的定义。但我想将“智能数据”定义为高效数据。效率越高,数据就越智能。无论数据的来源或清理过程如何,数据的最高效率(或“智能”)为 100%。
我们如何提高数据捕获的效率,并仅存储智能数据?
通常情况下,大数据计划被视为技术上的顺序。每个任务都是独立的,并且按照顺序进行,找到解决业务挑战的洞察是最后一个任务。

如果各部分之间缺乏良好的沟通,生成的所有数据不一定都能转化为信息,这会降低准确性;存储的数据也不一定都能转化为信息,这会降低效率。这样,从数据中发现洞察就变得困难了,正如高德纳所报告的,这导致了大数据项目 60-85%的失败率。
为了优化数据捕获,任何大数据计划必须是一个由业务需求指导的迭代过程。不同的团队必须紧密沟通和合作,以迭代的方式围绕业务挑战开发解决方案。尽早引入分析团队,以帮助 IoT 团队以数据将被使用的方式捕获数据。将现有数据中的信息与噪音分开,以提高效率。捕获分析团队认为无法实现、IoT 团队认为不相关的数据,以提高准确性。
通常说数据科学家将 80%的时间花在清理数据上,仅 20%用于分析数据。通过有效的数据捕获,智能数据可以改变这种情况,使数据科学家仅花费 20%的时间来清理数据,80%的时间用于获得真正对业务有影响的洞察。
简介:Ramon Serrallonga是 Cadifornia 的首席数据官,ESADE 商学院的学术助理,以及 EAE 商学院的讲师。他是一名经济学家,法律硕士,MBA,他的职业生涯在商业和技术的交汇点上发展。
资源:
相关:
更多相关主题
分析与数据科学专业人士的职业建议
原文:
www.kdnuggets.com/2017/02/career-advice-analytics-data-science.html
评论
作者:凯蒂·费格森 和 弗洛拉·姜,Burtch Works。
无论你是拥有八年经验的分析专业人士,还是希望进入数据科学领域的应届毕业生,亦或是在经历了学术研究后转型进入企业界,学习如何培养和发展你的职业生涯可能都是一项艰巨的任务。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
根据我们多年来与许多定量专业人士合作的经验,长期职业增长的两个主要领域是网络建设和持续学习。尽管这两者都能为未来职业发展带来许多机会,但对许多人来说,网络建设可能显得令人畏惧,而对于终身学习,许多专业人士往往不知道从何开始。以下是我们关于如何为未来的道路做好准备的最佳建议!
网络建设 – 应该做什么
-
加入协会或专业组织 – 加入并参加你所在地区的ASA(美国统计协会)或INFORMS(运筹学与管理科学学会)的午餐会、会议或网络活动,可以让你结识该领域的其他专业人士,两者均提供职业资源等会员福利。
-
加入分析和数据科学 LinkedIn 群组 – LinkedIn 群组是与非本地人员联系的好方式,还可以让你了解分析、数据科学、机器学习、市场组合建模、数字营销等领域的热门话题和最新发展。
-
加入你的校友会 – 查看你的学校是否有相关的校友会。
-
参加聚会 – 除了像 ASA 和 INFORMS 这样更正式的组织,许多地区还拥有充满活力的聚会社区,分析和数据科学专业人士可以在这里聚集、分享想法、讨论话题或观看演讲。你可以在这里浏览聚会。
-
参加会议 – 留意会议和讲座,看看是否有适合你参加的。KDnuggets 保持着一个即将举行的会议列表。
网络交流 – 如何准备

-
保持你的 LinkedIn 个人资料和简历更新 – 这几乎是不言而喻的!即使你目前没有在找工作,你也希望你的个人资料保持专业,展现你最好的一面。同样,即使你没有求职,你也应该保持简历的最新状态。当项目的情况还在你脑海里时,描述你的影响会更容易,如果你等得太久,可能会发现总结数据项目变得困难。而且,当你最终决定开始找工作时,这将加快过程,因为你的简历可能只需做些微调,而不是彻底修改。你可以在这里找到更多我们的分析简历技巧。
-
练习谈论背景和兴趣点 – 对许多人来说,网络交流可能令人紧张,即使对你来说不是这样,练习谈论你的背景(以及你自己!)也可以帮助你专注于你想传达的要点。显然你不想听起来像一个有剧本的机器人,但即便是简单地阅读几遍你的简历,并思考你想问别人的问题,也会有帮助。
-
携带名片 – 如果你在会议上遇到你梦想公司的分析主管,你会希望他们有办法在会后通过 LinkedIn 查找你!如果你还没有名片,Vistaprint 提供了各种选择。
持续学习

-
在线课程/认证 – 随着分析和数据科学的蓬勃发展,有许多学习和增加工具包与技能的选项。只使用过 R?考虑学习 SAS 或 Python。想了解更多关于机器学习的知识?浏览Coursera、Udacity 或 Udemy上的课程。一些大学也提供在线证书。分析和数据科学工具将不断发展,所以要关注你领域中的新进展。如果你只学会了一个工具,然后这个工具变得过时,你可能会发现适应技能变得困难。
-
Kaggle 竞赛 – 如果你还没有尝试过 Kaggle,这个网站为分析和数据科学专业人士提供了在公司赞助的 竞赛 中竞争的机会,同时也可以下载数据集进行练习和技能提升。这是获取混乱数据和复杂问题的绝佳方式,这些都是保持技能敏锐的关键。
-
分析文献 – 寻找专门针对分析和数据科学专业人士的书籍、博客、杂志等。有很多优秀的资源,了解最新的工具、技能和趋势会让你对市场变化做好更好的准备。
-
行业特定趋势 – 除了关注分析或数据科学趋势之外,保持对政治和金融新闻气候的一般了解也是明智的,尤其是当这些因素影响到你所在的行业(如金融业)时。考虑订阅相关来源,如新闻简报、《经济学人》、医疗保健期刊等,因为这些可以帮助你获得更广泛的商业背景。
-
联系招聘人员以了解就业市场趋势 – 不,我们不是因为我们是招聘人员才这么说!与招聘人员交谈可以让你对就业市场或招聘趋势有一个整体的了解,而这些可能是顶层的职位统计数据所无法捕捉到的。招聘人员还可以让你了解哪些数据科学和分析工具及技能最受欢迎,因为他们与各种客户合作。
-
查看 Burtch Works – 到了稍微自我推广的时间了!开玩笑说,我们确实为定量专业人士准备了各种免费的职业资源。我们发布 薪资研究,在 我们的博客 上发布职业建议和行业趋势/研究,并在 我们的 YouTube 频道 上传薪资和职业网络研讨会。如果你想保持对这些内容的更新, 关注我们 LinkedIn 可能是最简单的方式!
重要的是要记住,即使在你没有探索市场的时候,投入努力进行网络建设和学习新技能,也可以使当真正需要找工作时变得更容易。你的坚持会得到回报!
祝你的职业旅程好运 – 欢迎通过 LinkedIn 与我们联系 (Katie Ferguson* 和 Flora Jiang)!*
原帖。经许可转载。
简介:凯蒂·弗格森是一名专注于全国范围内分析营销专业人士招聘的执行招聘员。弗洛拉·江是一名专注于高级分析和定量营销角色的执行招聘员,职位范围从初级到经理/主任,涵盖各个行业。
相关:
-
如何获得你的第一份数据科学工作?
-
影响数据科学市场的 4 大趋势
-
如何在大数据领域留下你的印记
更多相关内容
漫画:Facebook 数据科学实验与猫咪
原文:
www.kdnuggets.com/2016/08/cartoon-cats-facebook-data-science.html
为了纪念国际猫咪日(8 月 8 日),我们重新发布了这幅 KDnuggets 漫画,首次发表于 2014 年。
最近 Facebook 情感感染实验,操控了 70 万用户的新闻推送和情感,受到了很多 关注 和反响。
KDnuggets 漫画由 Ted Goff 绘制,审视了这一情况。

男子:“我本来打算写一篇关于 Facebook 情感操控研究的愤怒文章,但后来被他们展示的所有快乐猫咪照片分散了注意力。”
相关:
-
漫画:当自动化过度
-
漫画:大数据与世界杯足球
-
KDnuggets 漫画 页面
-
标记为“漫画”的故事。
更多相关内容
卡通:数据科学与宗教有什么不同?
原文:
www.kdnuggets.com/2018/07/cartoon-data-science-religion.html
评论作者为Gordon MacMaster。

女人:得了吧。数据科学和宗教是不一样的。
男人:确实。有人相信有一种广阔的、无形的全能存在,它可以指导你做出所有人生决策。
另一个是宗教。
欲了解更多内容,请在 LinkedIn 上与 Gordon 联系,网址为www.linkedin.com/in/gmacmaster或在 Twitter 上关注@Obraich。
更多相关话题
卡通:感恩节的数据科学
原文:
www.kdnuggets.com/2021/11/cartoon-data-science-thanksgiving.html
为了庆祝美国的感恩节,我们重新审视了经典的 KDnuggets 感恩节卡通,探讨了从数据趋势中可以预测什么?
土耳其 数据科学家:“我不喜欢这个样子。”
“对肉汁和火鸡填料的搜索量正在飙升!”

这里还有其他的 KDnuggets AI、大数据、数据挖掘和数据科学卡通。
以及标记为 卡通 的 KDnuggets 帖子。
还可以查看其他最近的 KDnuggets 卡通:
-
卡通:教 AI 伦理
-
卡通:AI 与三月疯狂
-
卡通:这就是你做区块链的方式吗?
-
卡通:2050 年的劳动节
-
卡通:机器学习去度假
-
卡通:数据科学家是 21 世纪最性感的工作,直到……
-
卡通:数据科学与宗教有何不同?
-
卡通:FIFA 世界杯足球与机器学习
-
卡通:GDPR 对隐私的首次影响
-
卡通:AI 掌握了三月疯狂
-
卡通:2118 年的机器学习问题
-
卡通:AI 在家:智能设备还能走多远?
-
卡通:AI 和技术如何改变圣诞节?
更多相关话题
-
数据科学基础:你需要知道的 10 项必备技能
卡通:你好,奇点
评论 新的 KDnuggets 卡通探讨了当人工智能实现奇点时可能发生的情况,以及人类技能的相关性。

“只需记得在相关性面试中说声你好,奇点,并且保持坐姿端正。”
这里有其他 KDnuggets 大数据、数据挖掘和数据科学卡通。
以及 KDnuggets 发布的标签为 卡通 的内容。
KDnuggets 支持《查理周刊》和言论自由,不论你是否喜欢这些言论或卡通。自由探究和怀疑是科学和进步的基础,应当成为普世人权。我支持查理。
相关:
-
卡通:意外的数据科学推荐
-
卡通:感恩节、大数据和火鸡数据科学
-
卡通:2050 年的机器人劳动节
-
卡通:大数据可视化与 7D 打印机
更多相关话题
漫画:未来的机器学习课程
原文:
www.kdnuggets.com/2017/09/cartoon-machine-learning-class.html
评论随着夏季结束和学生返校,新的 KDnuggets 漫画探讨了一个可能的未来机器学习课程。

老师:罗比,别再捣乱了,否则我会让你去数据清洗。
这幅漫画由乔恩·卡特绘制。
这里还有其他有关 KDnuggets 大数据、数据挖掘和数据科学的漫画。
以及 KDnuggets 上标记为漫画的帖子。
更多 KDnuggets 漫画:
-
漫画:史上第一台自动驾驶深度学习烧烤架
-
漫画:所有数据之母。
-
漫画:机器学习 - 他们认为我在做什么
-
漫画:浓缩咖啡与卡布奇诺的距离
-
漫画:税收、人工智能与人类
-
漫画:当 AI 掌握了疯狂三月
-
因果关系或相关性:使用 xkcd 解释希尔标准
-
漫画:通过数据分析找到完美的情人节约会
-
漫画:当自动驾驶汽车 + 机器学习让你走得太远...
-
搞笑的《大数据与数据科学》
-
漫画:感恩节、大数据与火鸡数据科学。
-
漫画:恐怖的大数据
-
漫画:机器人时代的劳动节
-
漫画:数据科学家 - 21 世纪最性感的工作,直到...
-
漫画:让数据再次伟大
-
漫画:Facebook 数据科学实验与猫
-
漫画:当自动化走得太远
-
完美的数据科学面试秘诀
-
漫画:公民数据科学家在工作
-
数据科学家情人节收藏
-
漫画:更深入的深度学习
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
更多相关话题
卡通:机器学习度假
原文:
www.kdnuggets.com/2018/08/cartoon-machine-learning-vacation.html
评论 八月是度假的热门时间,即使是努力工作的神经网络也可能想要从训练中休息一下,放松一下!下面的 KDnuggets 卡通展示了可能的情况。

机器人:终于,我可以从深度学习中休息一下了!
这幅卡通由乔恩·卡特精心绘制。
另见其他近期的 KDnuggets 卡通:
-
卡通:数据科学家是 21 世纪最性感的工作,直到...
-
卡通:数据科学如何与宗教不同?
-
卡通:FIFA 世界杯足球与机器学习
-
卡通:GDPR 对隐私的初步影响
-
卡通:人工智能掌握了三月疯狂
-
卡通:2118 年的机器学习问题
-
卡通:家中的人工智能:智能设备还能走多远?
-
卡通:人工智能和技术如何改变圣诞节?
-
卡通:感恩节、大数据和火鸡数据科学
-
卡通:人工智能还能从你的脸上猜到什么?
-
卡通:未来的机器学习课程
-
卡通:史上首个自动驾驶深度学习烧烤架
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
漫画:机器学习 – 他们认为我做的事情
原文:
www.kdnuggets.com/2017/04/cartoon-machine-learning-what-they-think.html
这幅漫画由哈里森·金斯利呈现了对机器学习的不同看法:

-
社会认为我做的事情
-
我的朋友认为我做的事情
-
我父母认为我做的事情
-
其他程序员认为我做的事情
-
我认为我做的事情
-
我实际上做的事情(来自
sklearn import svm)
原始。获得许可转载。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT
更多相关主题
卡通:感恩节、大数据和土耳其数据科学。
原文:
www.kdnuggets.com/2018/11/cartoon-thanksgiving-turkey-data-science.html
评论为了庆祝感恩节,我们回顾了一幅经典的 KDnuggets 感恩节卡通,这幅卡通探讨了从大数据中可以预测什么?
土耳其 数据科学家:“我不喜欢这个样子。”
对肉汁和土耳其 stuffing 的搜索量正在飙升!
作为生活模仿艺术的进一步例子,实际的 Google Trends 图表显示的"土耳其 stuffing" 在美国与卡通图非常相似!(不过,只有当我们选择美国区域时,否则我们会发现十月份有一个早期的高峰,这反映了加拿大的感恩节)。
这里还有其他 KDnuggets 大数据、数据挖掘和数据科学卡通。
和 KDnuggets 帖子标记为卡通。
另见其他近期的 KDnuggets 卡通:
-
卡通:2050 年的劳动节
-
卡通:机器学习度假
-
卡通:数据科学家是 21 世纪最性感的职业,直到……
-
卡通:数据科学与宗教有何不同?
-
卡通:FIFA 世界杯足球与机器学习
-
卡通:GDPR 对隐私的首次影响
-
卡通:人工智能掌握了疯狂三月
-
卡通:2118 年的机器学习问题
-
卡通:家庭中的人工智能:智能设备能走多远?
-
卡通:人工智能和技术改变圣诞节?
-
卡通:感恩节、大数据和土耳其数据科学
-
卡通:人工智能还能从你的脸上猜测什么?
-
卡通:未来的机器学习课程
-
卡通:史上首个自驾深度学习烤架
-
卡通:数据之母
-
卡通:机器学习——他们认为我在做什么
-
卡通:浓缩咖啡与卡布奇诺之间的距离
-
漫画:税收、人工智能与人类
-
漫画:当 AI 掌握了 March Madness 会发生什么
-
因果关系还是相关性:用 xkcd 解释 Hill 标准
-
漫画:通过数据分析找到完美的情人节约会
-
漫画:当自动驾驶汽车+机器学习带你走得太远…
更多相关内容
漫画:无监督机器学习?
原文:
www.kdnuggets.com/2019/09/cartoon-unsupervised-machine-learning.html
评论 新的 KDnuggets 漫画探讨了无监督机器学习,许多领先的 AI 研究人员认为这是 AI 的下一个前沿领域。
这幅漫画探讨了机器学习变得过于无监督的情况。

科学家:“也许无监督学习并不是一个好主意。”
顶级 AI 和深度学习研究员 Yann LeCun,作为无监督学习的主要倡导者之一,回应了这幅漫画:
应该使用自监督学习。
这幅漫画由Jon Carter出色绘制。
另请参见其他最近的 KDnuggets 漫画:
-
漫画:这就是你做区块链的方式吗?
-
漫画:感恩节、大数据和火鸡数据科学。
-
漫画:大数据的万圣节服装。
-
漫画:AI 实现卓越的地方
-
漫画:机器学习度假
-
漫画:数据科学家是 21 世纪最性感的职业,直到……
-
漫画:数据科学与宗教的不同之处
-
漫画:FIFA 世界杯足球与机器学习
-
漫画:GDPR 对隐私的初步影响
-
漫画:AI 征服疯狂三月
-
漫画:2118 年的机器学习问题
-
漫画:AI 在家:智能设备能走多远?
更多相关话题
漫画:2118 年的机器学习问题
原文:
www.kdnuggets.com/2018/02/cartoon-valentine-machine-learning.html
为了情人节,新的 KDnuggets 漫画展示了机器学习在 2118 年可能面临的一些问题。

女性机器人:好吧,如果你现在还没学会我想要什么,我是不会告诉你的!
这幅漫画由 Jon Carter 精心绘制。
这里还有其他 KDnuggets 情人节 漫画
-
漫画:通过数据分析找到的完美情人节约会, 2017
-
漫画:数据科学家为情人节许下的 3 个愿望, 2015
-
漫画:数据科学家情人节预测, 2014。
-
数据科学家情人节调整, 2013
另请参阅其他近期 KDnuggets 漫画:
-
漫画:家中的人工智能:智能设备能走多远?
-
漫画:人工智能和技术正在改变圣诞节?
-
漫画:感恩节、大数据与火鸡数据科学
-
漫画:人工智能还能从你的脸上猜到什么?
-
漫画:未来的机器学习课堂
-
漫画:史上第一款自驾深度学习烤架
-
漫画:数据之母
-
漫画:机器学习——他们认为我在做什么
-
漫画:浓缩咖啡和卡布奇诺之间的距离
-
漫画:税收、人工智能与人类
-
漫画:当人工智能掌握疯狂三月时会发生什么
-
因果关系还是相关性:用 xkcd 解释 Hill 标准
-
漫画:通过数据分析找到的完美情人节约会
-
漫画:当自驾车 + 机器学习把你带得太远……
-
有趣地看待大数据和数据科学
-
漫画:感恩节、大数据与火鸡数据科学。
-
漫画:恐怖的大数据
-
漫画:机器人时代的劳动节
-
漫画:数据科学家——21 世纪最性感的职业,直到……
-
漫画:让数据再次伟大
-
漫画:Facebook 数据科学实验与猫
-
漫画:自动化过度
-
完美的数据科学面试秘诀
-
漫画:公民数据科学家在工作中
-
数据科学家情人节特别集
-
漫画:更深层次的深度学习
更多相关内容
-
[更多分类问题的性能评估指标](https://www.kdnuggets.com/2020/04/performance-evaluation-metrics-classification.html)
CatalyzeX:机器学习工程师和研究人员必备的浏览器扩展
原文:
www.kdnuggets.com/2021/01/catalyzex-browser-extension-machine-learning.html
评论
由 Himanshu Ragtah,CatalyzeX
Andrew Ng 喜欢这个,你可能也会喜欢!
代码是机器学习研究中的基本构建块之一。工程师们已经习惯于发布代码以与社区分享,现在研究人员在线发布代码也正变得越来越普遍。越来越多的机器学习会议正在将其作为要求。
正如 Google Brain 的研究科学家 David Ha (@hardmaru) 所说:

然而,即使代码实际上是可用的,你仍然常常需要手动在 Github 上搜索或者通过各种网站和博客进行搜索。
一款新的浏览器扩展来自 CatalyzeX,简化了整个过程,并自动显示你可能在浏览网络时遇到的任何机器学习/人工智能论文的开源代码——在 Google、Arxiv、Twitter、Scholar 等网站上。
你会看到[代码]按钮会自动出现在页面内的任何实现处。
点击任何代码链接以轻松跳转到代码并进行探索。

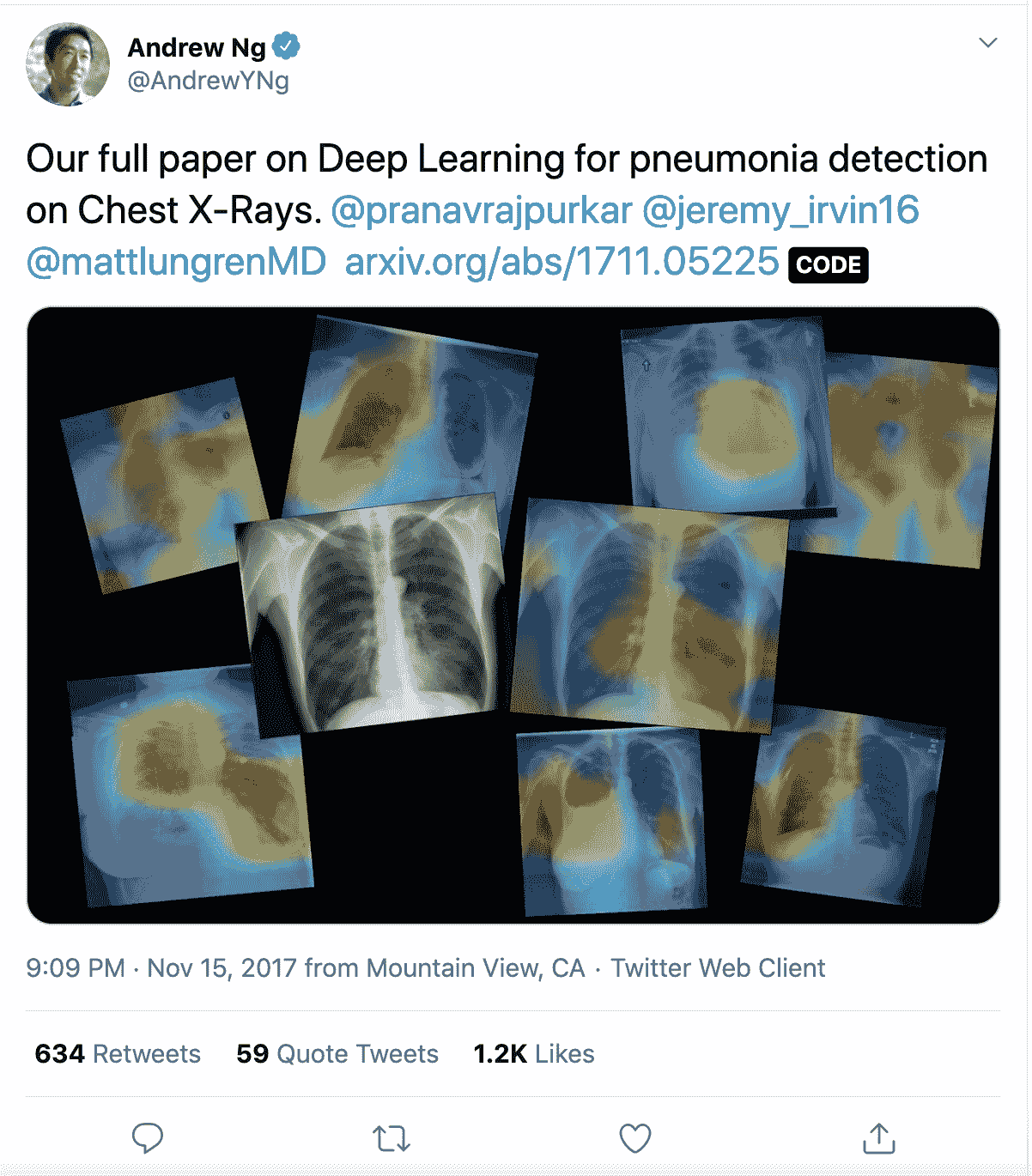
如果代码尚不可用怎么办?
如果由于某种原因代码不可用,你可以点击 ‘未找到代码:请求作者/专家’。
你将被重定向到这里:
‘向作者请求代码’ 允许你向作者直接请求代码——如果他们愿意亲自与您分享。
有时作者可能选择不公开代码。
在这种情况下,随时可以点击 ‘请求实现’,并可以请求主题专家来实现论文。
附言——该扩展的创建者联系了 Andrew Ng,他也很喜欢!
在这里安装 Chrome 扩展程序:chrome.google.com/webstore/detail/find-code-for-research-pa/aikkeehnlfpamidigaffhfmgbkdeheil
在这里安装 Firefox 扩展程序:addons.mozilla.org/en-US/firefox/addon/code-finder-catalyzex/
个人简介:Himanshu Ragtah (@himanshu_ragtah) 曾在特斯拉工作——在那里,他负责为 Tesla PowerWall、PowerPack 和 SuperCharger 自动化制造测试。他还是 TEDx 演讲者,讲述了由于 AI(尤其是针对女性和少数群体)的偏见以及智能交通方面的话题。此外,他还是 SXSW 评委、Kairos Society 成员、Hackernoon 顶级出版者,早期,他还与康奈尔大学、普林斯顿大学和密歇根大学等学校共同创办了 SpaceX Hyperloop 团队,其原型在国际上排名前十,并曾被 CNN、The Verge、Wired 和 CNBC 报道。Himanshu 是 Kairos Society 的成员——这是一个精英创始人俱乐部,识别社会最紧迫的挑战并制定新的解决方案(导师包括理查德·布兰森爵士、比尔·克林顿和 CIA 的海登)。他曾获得 NSERC(加拿大 NSF 相当于)的工业本科生研究奖,开源了一个为美国退伍军人假肢的 3D 打印模型,领导了一个无人机机器人团队,并担任顶级机器人比赛的评委(SXSW、PennApps、Lego League)。最后,Himanshu 还帮助设计了一个创新的电子音乐乐器,该乐器曾在 CBC 和 DigitalTrends 上介绍。
原文。经许可转载。
相关内容:
-
2021 年你应该了解的所有机器学习算法
-
AI、分析、机器学习、数据科学、深度学习研究的主要进展和 2021 年的关键趋势
-
2020 年:充满惊人的 AI 论文的一年——回顾
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关内容
CatBoost 与 Light GBM 与 XGBoost
原文:
www.kdnuggets.com/2018/03/catboost-vs-light-gbm-vs-xgboost.html
评论
由 Alvira Swalin,旧金山大学提供

我最近参加了这个 Kaggle 比赛(斯坦福大学的 WIDS Datathon),通过使用各种提升算法,我成功进入了前十名。从那时起,我对每个模型的细节非常感兴趣,包括参数调优、优缺点,因此决定写这篇博客。尽管神经网络最近重新崛起并受到欢迎,我还是专注于提升算法,因为在有限的训练数据、较短的训练时间和较少的参数调优经验的情况下,它们仍然更有用。
由于 XGBoost(常被称为 GBM 杀手)在机器学习界已经存在较长时间,并有大量专门的文章,因此这篇文章将更多关注 CatBoost 和 LGBM。以下是我们将涵盖的主题-
-
结构差异
-
每种算法对分类变量的处理
-
理解参数
-
数据集上的实现
-
每种算法的性能
LightGBM 和 XGBoost 的结构差异
LightGBM 使用一种新颖的基于梯度的单侧抽样(GOSS)技术来筛选数据实例,以找到分裂值,而 XGBoost 使用预排序算法和基于直方图的算法来计算最佳分裂。这里的实例指的是观测/样本。
首先让我们了解预排序分裂的工作原理-
-
对每个节点,遍历所有特征
-
对每个特征,根据特征值对实例进行排序
-
使用线性扫描来决定沿该特征基础上的最佳分裂方案 信息增益
-
在所有特征中选择最佳分裂方案
简单来说,基于直方图的算法将特征的所有数据点分到离散的箱中,并使用这些箱来找到直方图的分裂值。虽然它在训练速度上比预排序算法高效,后者枚举了预排序特征值上的所有可能分裂点,但在速度方面仍落后于 GOSS。
那么 GOSS 方法的高效性体现在哪里? 在 AdaBoost 中,样本权重是样本重要性的良好指标。然而,在梯度提升决策树(GBDT)中,没有原生的样本权重,因此不能直接应用为 AdaBoost 提出的抽样方法。这就引出了基于梯度的抽样。
梯度代表损失函数切线的斜率,因此逻辑上如果数据点的梯度在某种意义上较大,这些点对找到最佳分裂点是重要的,因为它们的误差较高
GOSS 保留所有具有大梯度的实例,并对具有小梯度的实例进行随机采样。例如,假设我有 50 万行数据,其中 1 万行具有较高的梯度。因此,我的算法将选择(1 万行高梯度 + 剩余 49 万行中的 x% 随机选择)。假设 x 为 10%,则选择的总行数为 59 万,基于此值找到分裂值。
在这里的基本假设是,具有较小梯度的训练实例的训练误差较小,且已经过充分训练。
为了保持相同的数据分布,在计算信息增益时,GOSS 为小梯度的数据实例引入了一个常数乘数。因此,GOSS 在减少数据实例数量和保持学习决策树的准确性之间达到了良好的平衡。
在 LGBM 中,具有较高梯度/误差的叶子会进一步生长。
每个模型如何处理类别变量?
CatBoost
CatBoost 具有提供类别列索引的灵活性,以便可以使用 one_hot_max_size 进行独热编码(对于所有不同值数量小于或等于给定参数值的特征使用独热编码)。
如果在 cat_features 参数中不传递任何内容,CatBoost 会将所有列视为数值变量。
注意:如果在 cat_features 中没有提供字符串值的列,CatBoost 会抛出错误。此外,具有默认 int 类型的列默认被视为数值型,必须在 cat_features 中指定,以使算法将其视为类别型。
对于唯一类别数大于 one_hot_max_size 的剩余类别列,CatBoost 使用一种高效的编码方法,该方法类似于均值编码,但减少了过拟合。过程如下——
-
将输入观察值集合随机排列。生成多个随机排列。
-
将标签值从浮点数或类别转换为整数
-
所有类别特征值都使用以下公式转换为数值:
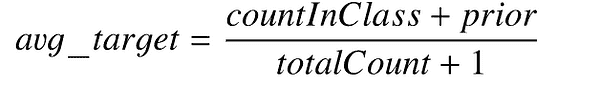
其中,CountInClass 表示当前类别特征值为“1”的标签值出现的次数,Prior 是分子部分的初始值,由起始参数确定。TotalCount 是具有当前类别特征值的对象(直到当前对象)的总数。
数学上,这可以通过以下方程表示:
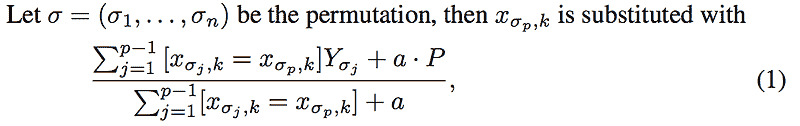
LightGBM
与 CatBoost 相似,LightGBM 也可以通过输入特征名称来处理分类特征。它不会转换为独热编码,比独热编码快得多。LGBM 使用特殊算法来寻找分类特征的分裂值 [Link]。

注意:在为 LGBM 构建数据集之前,您应该将分类特征转换为 int 类型。即使通过 categorical_feature 参数传递,LGBM 也不接受字符串值。
XGBoost
与 CatBoost 或 LGBM 不同,XGBoost 无法自行处理分类特征,它只接受类似于随机森林的数值值。因此,在将分类数据提供给 XGBoost 之前,必须进行各种编码,如标签编码、均值编码或独热编码。
超参数的相似性
所有这些模型都有很多参数需要调整,但我们只会涵盖重要的参数。以下是这些参数按功能划分的列表,以及它们在不同模型中的对应关系。
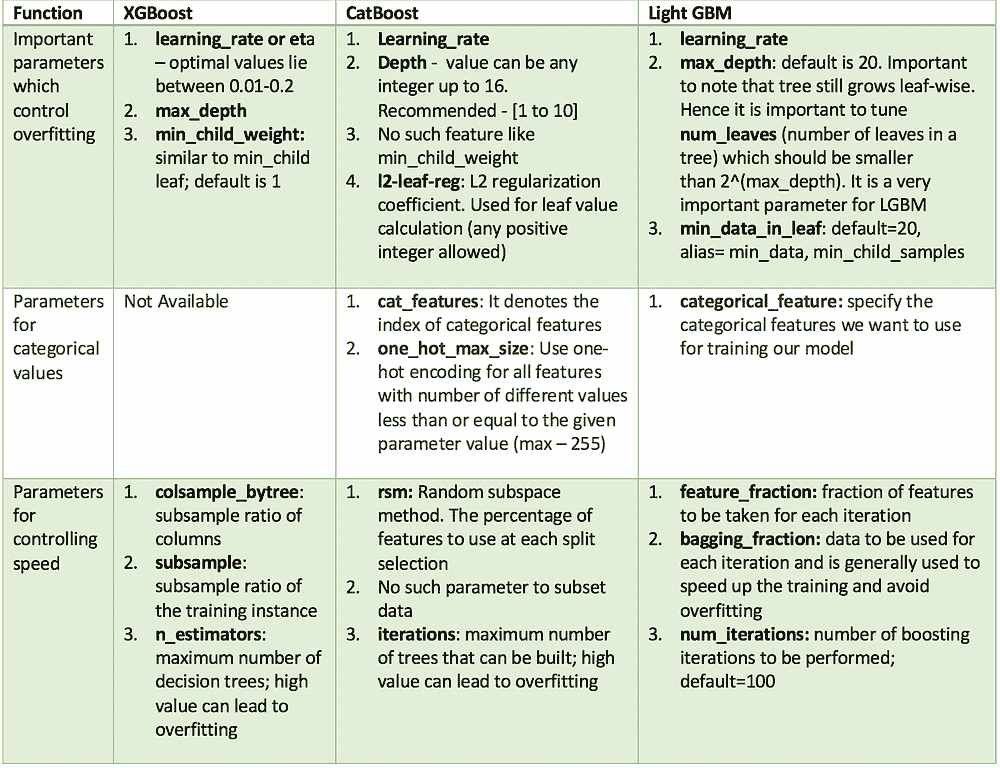
数据集上的实现
我使用了 Kaggle 的 数据集,该数据集包含 2015 年的航班延误数据,因为它同时包含分类特征和数值特征。该数据集大约有 500 万行,非常适合评估每种提升模型的速度和准确性。我将使用该数据集的 10% 子集 ~ 50 万行。
以下是用于建模的特征:
-
月份、日期、星期几:数据类型 int
-
航空公司和航班号:数据类型 int
-
起始机场 和 目的地机场:数据类型字符串
-
出发时间:数据类型 float
-
到达延迟:这是目标变量,转化为布尔变量,表示延迟超过 10 分钟
-
距离和飞行时间:数据类型 float
XGBoost
Light GBM
CatBoost
在调整 CatBoost 的参数时,传递分类特征的索引比较困难。因此,我在没有传递分类特征的情况下调整了参数,并评估了两个模型——一个有分类特征,另一个没有。我单独调整了 one_hot_max_size,因为它不会影响其他参数。
结果
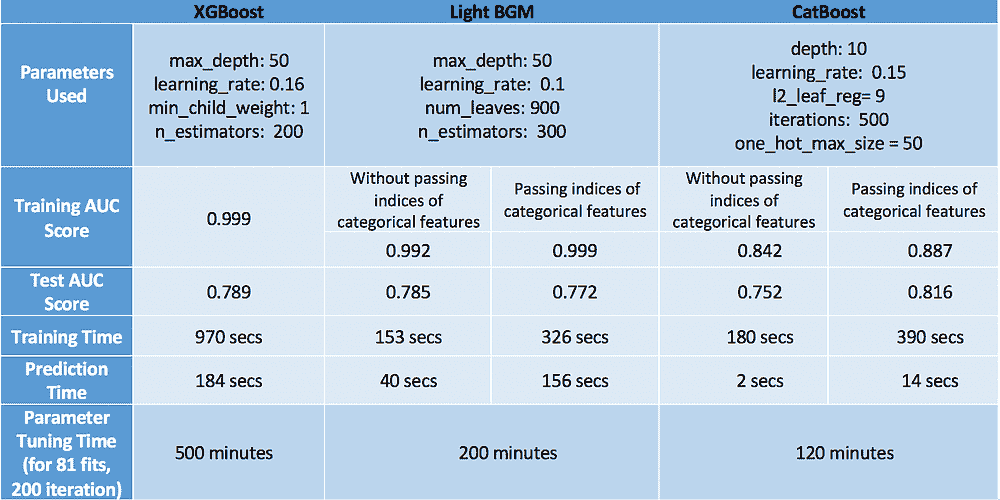
结尾说明
为了评估模型,我们应该关注模型在速度和准确性方面的表现。
鉴于这一点,CatBoost 凭借在测试集上的最高准确率(0.816)、最小过拟合(训练和测试准确率接近)以及最短的预测时间和调优时间脱颖而出。但这仅仅是因为我们考虑了分类变量并调整了 one_hot_max_size。如果我们不利用 CatBoost 的这些特性,它的表现将变得最差,准确率仅为 0.752。因此,我们了解到,CatBoost 仅在数据中存在分类变量并且我们正确调整它们时表现良好。
我们的下一个表演者是 XGBoost,它通常表现良好。即使在忽略了数据中分类变量的事实(我们已将其转换为数值形式供其使用)之后,它的准确性仍然与 CatBoost 相当。然而,XGBoost 唯一的问题是速度太慢。调整其参数非常令人沮丧(我花了 6 小时运行 GridSearchCV——非常糟糕的主意!)。更好的方法是分别调整参数,而不是使用 GridSearchCV。查看这个博客文章,了解如何智能地调整参数。
最后,最后一名是 Light GBM。需要注意的是,当使用 cat_features 时,它在速度和准确性方面都表现不佳。我认为它表现不佳的原因是它对分类数据使用了某种改进的均值编码,这导致了过拟合(训练准确率相当高——0.999,相较于测试准确率)。但是,如果像 XGBoost 一样正常使用,它可以在比 XGBoost 快得多的速度下实现类似(如果不是更高的话)准确率(LGBM——0.785,XGBoost——0.789)。
最后,我必须说,这些观察结果适用于这个特定的数据集,可能对其他数据集无效。然而,一般来说,XGBoost 比其他两个算法都慢。
那你最喜欢哪个?请评论并说明原因。
任何反馈或改进建议都将非常感谢!
查看我的其他博客在这里!
资源
-
papers.nips.cc/paper/6907-lightgbm-a-highly-efficient-gradient-boosting-decision-tree.pdf -
www.analyticsvidhya.com/blog/2017/06/which-algorithm-takes-the-crown-light-gbm-vs-xgboost/
个人简介: Alvira Swalin (Medium) 目前在 USF 攻读数据科学硕士学位,对机器学习与预测建模特别感兴趣。她是 Price (Fx) 的数据科学实习生。
原文。经许可转载。
相关:
-
TensorFlow 与 XGBoost 中的梯度提升
-
从基准测试快速机器学习算法中获得的经验教训
-
XGBoost:简明技术概述
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织的 IT
更多相关内容
处理机器学习中的类别特征
原文:
www.kdnuggets.com/2019/07/categorical-features-machine-learning.html
评论
由Hugo Ferreira,数据科学家 | 机器学习爱好者 | 物理学家
如何在 Python 中轻松实现独热编码
 照片由Max Nelson提供,来源于Unsplash
照片由Max Nelson提供,来源于Unsplash
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 需求
类别数据在许多数据科学和机器学习问题中很常见,但通常比数值数据更具挑战性。特别是,许多机器学习算法要求其输入为数值,因此必须将类别特征转换为数值特征,才能使用这些算法。
转换这些特征的最常见方法之一是独热编码类别特征,特别是当类别之间没有自然顺序时(例如,一个包含城市名称如‘伦敦’,‘里斯本’,‘柏林’等的特征‘City’)。对于特征的每一个唯一值(比如‘伦敦’),会创建一列(例如‘City_London’),当实例的原始特征取该值时,该列的值为 1,否则为 0。
尽管这种编码方式非常常见,但在使用 Python 中的 scikit-learn 时实现起来可能会很令人沮丧,因为目前没有简单的转换器可用,特别是当你想将其作为机器学习管道的一部分使用时。在这篇文章中,我将描述如何仅使用 scikit-learn 和 pandas 来实现它(但需要一点努力)。但是,在那之后,我还会展示如何使用类别编码库以更简单的方式实现相同的功能。
为了说明整个过程,我将使用乳腺癌数据集来自UCI 机器学习仓库,该数据集有许多分类特征,可以用来实现一热编码。
加载数据
我们要使用的数据是来自UCI 机器学习仓库的乳腺癌数据集。这个数据集较小,包含几个分类特征,这将允许我们快速探索几种使用 Python、pandas 和 scikit-learn 实现一热编码的方法。
从仓库下载数据后,我们将其读入一个 pandas dataframe df。
import pandas as pd# names of columns, as per description
cols_names = ['Class', 'age', 'menopause', 'tumor-size',
'inv-nodes', 'node-caps', 'deg-malig', 'breast',
'breast-quad', 'irradiat']# read the data
df = (pd.read_csv('breast-cancer.data',
header=None, names=cols_names)
.replace({'?': 'unknown'})) # NaN are represented by '?'
该数据集有 286 个实例,包含 9 个特征和一个目标(‘Class’)。目标和特征在数据集描述中如下:
1\. Class: no-recurrence-events, recurrence-events.
2\. age: 10-19, 20-29, 30-39, 40-49, 50-59, 60-69, 70-79, 80-89, 90-99.
3\. menopause: lt40, ge40, premeno.
4\. tumor-size: 0-4, 5-9, 10-14, 15-19, 20-24, 25-29, 30-34, 35-39, 40-44,45-49, 50-54, 55-59.
5\. inv-nodes: 0-2, 3-5, 6-8, 9-11, 12-14, 15-17, 18-20, 21-23, 24-26, 27-29, 30-32, 33-35, 36-39.
6\. node-caps: yes, no.
7\. deg-malig: 1, 2, 3.
8\. breast: left, right.
9\. breast-quad: left-up, left-low, right-up, right-low, central.
10\. irradiat: yes, no.
我们将所有列都视为‘object’类型,并使用 scikit-learn 的train_test_split来拆分训练集和测试集。
from sklearn.model_selection import train_test_splitX = df.drop(columns='Class')
y = df['Class'].copy()X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=42)
一热编码
编码分类特征有几种方法(例如,参见这里)。在这篇文章中,我们将重点关注其中一种最常见和有用的方法——一热编码。经过转换后,结果数据集的每一列对应于每个原始特征的一个唯一值。
例如,假设我们有以下具有三种不同唯一值的分类特征。
+---------+
| Feature |
+---------+
| value_1 |
| value_2 |
| value_3 |
+---------+
一热编码后,数据集如下所示:
+-----------------+-----------------+-----------------+
| Feature_value_1 | Feature_value_2 | Feature_value_3 |
+-----------------+-----------------+-----------------+
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 1 |
+-----------------+-----------------+-----------------+
我们希望对乳腺癌数据集实现一热编码,使得结果数据集适合用于机器学习算法。请注意,数据集中的许多特征具有类别之间的自然顺序(例如,肿瘤大小),因此其他类型的编码可能更合适,但为了具体说明,我们在这篇文章中只关注一热编码。
使用 scikit-learn
让我们看看如何使用 scikit-learn 实现一热编码。这里有一个方便的转换器,名为OneHotEncoder,乍一看,它似乎正是我们所寻找的。
from sklearn.preprocessing import OneHotEncoderohe = OneHotEncoder(sparse=False)
X_train_ohe = ohe.fit_transform(X_train)
如果我们尝试应用上述代码,会得到一个ValueError,因为OneHotEncoder要求所有值必须是整数,而不是我们所用的字符串。这意味着我们首先必须将所有可能的值编码为整数:对于一个特征,如果它有n个可能值(由n个不同的字符串给出),我们将它们编码为介于 0 和n-1 之间的整数。幸运的是,scikit-learn 中还有另一个转换器,叫做LabelEncoder,正是用来做这件事的!
from sklearn.preprocessing import LabelEncoderle = LabelEncoder()
X_train_le = le.fit_transform(X_train)
而且……我们得到了另一个 ValueError!实际上,LabelEncoder 仅打算用于目标向量,因此它不能与多列一起使用。不幸的是,在 scikit-learn 0.19 版本中,没有可以处理多列的转换器(对版本 0.20 有一些希望)。
一个解决方案是制作我们自己的转换器,我们创意性地称之为 MultiColumnLabelEncoder,它在每个特征上应用 LabelEncoder。
class MultiColumnLabelEncoder:
def __init__(self, columns = None):
self.columns = columns # list of column to encode def fit(self, X, y=None):
return self def transform(self, X):
'''
Transforms columns of X specified in self.columns using
LabelEncoder(). If no columns specified, transforms all
columns in X.
'''
output = X.copy()
if self.columns is not None:
for col in self.columns:
output[col] = LabelEncoder().fit_transform(output[col])
else:
for colname, col in output.iteritems():
output[colname] = LabelEncoder().fit_transform(col)
return output def fit_transform(self, X, y=None):
return self.fit(X, y).transform(X)
这次会有效吗?
它有效!为了更好地理解发生了什么,让我们查看原始训练集。
我们可以看到,例如,年龄段 30–39 被标记为 0,40–49 被标记为 1,等等,其他特征也是类似的。
应用 MultiColumnLabelEncoder 后,我们可以(终于!)使用 OneHotEncoder 对训练集和测试集进行独热编码。
一些评论:
-
OneHotEncoder被拟合到训练集中,这意味着对于每个在训练集中存在的唯一值,对于每个特征,都创建了一个新列。编码后我们有 39 列。 -
输出是一个 numpy 数组(当使用选项
sparse=False时),这有一个缺点,就是丢失了原始列名和值的所有信息。 -
当我们尝试将测试集转换为训练集时,经过编码器拟合后,我们再次得到一个
ValueError。这是因为测试集中存在新的、之前未见过的唯一值,编码器不知道如何处理这些值。为了在机器学习算法中同时使用转换后的训练集和测试集,我们需要它们具有相同数量的列。
这个最后的问题可以通过使用 OneHotEncoder 的 handle_unknown='ignore' 选项来解决,正如其名所示,它会在转换测试集时忽略之前未见过的值。
就这样!训练集和测试集都具有 39 列,现在以适合用于需要数值数据的机器学习算法的形式存在。
然而,上述过程相当不优雅,我们丧失了数据的 dataframe 格式。有没有更简单的方法来实现这一切?
确实有!
使用类别编码器
类别编码器是一个与 scikit-learn 兼容的分类变量编码器库,例如:
-
序数
-
独热编码
-
二进制
-
赫尔默特对比
-
总和对比
-
多项式对比
-
向后差分对比
-
哈希
-
BaseN
-
留一法
-
目标编码
序数编码器、独热编码器和哈希编码器是对 scikit-learn 中现有编码器的改进版本,具有以下优点:
-
支持 pandas 数据框作为输入,并且可选地作为输出;
-
可以通过名称或索引显式配置数据中编码的列,或者推断非数字列,无论输入类型如何;
-
兼容 scikit-learn 管道。
对于我们的目的,我们将使用改进的OneHotEncoder并查看我们可以简化多少工作流程。首先,我们导入类别编码器库。
import category_encoders as ce
然后,让我们尝试将OneHotEncoder直接应用于训练集和测试集。
它立刻生效了!无需先使用LabelEncoder!
一些观察:
-
输出是数据框,这使我们可以更容易地检查各个特征如何被转换。与之前一样,每个转换后的数据集有 39 列,可以检查 0 和 1 的矩阵是否与之前获得的相同。
-
我使用了
use_cat_names=True选项,以便将每个特征的可能值添加到每个新列的特征名称中(例如age_60-69)。这样做是为了清晰起见,但默认情况下,它只是添加一个索引(例如age_1、age_2等)。 -
我们现在可以更容易理解为什么在不要求忽略测试集中的未见值时会得到错误。下面,我们展示了在将编码器拟合到训练集(第一)和测试集(第二)后,经过独热编码的测试集的所有列。在第二种情况下,我们看到现在有 42 列,因为创建了 3 列新列:
age_20-29、tumor-size_5-9和breast-quad_unknown。这些对应于测试集中的三个值(age中的 20–29,tumor-size中的 5–9 和breast-quad中的未知),这些值在训练集中不存在。
比较以上两种方法,我们可以明显看出,如果我们打算对数据集中的分类特征进行独热编码,应该使用类别编码器库中的OneHotEncoder。
正如开始时提到的,独热编码不是编码分类特征的唯一方法,类别编码器库有几种编码器可供探索,因为其他编码器可能更适合不同的分类特征和机器学习问题。
你可以在以下位置找到我的 LinkedIn:
[Hugo Ferreira - 研究员 - Instituto Superior Técnico | LinkedIn
在 LinkedIn 上查看 Hugo Ferreira 的个人资料,这是世界上最大的专业社区。Hugo 在他们的…](https://www.linkedin.com/in/hugo-ferreira8)
简历: Hugo Ferreira 是一名数据科学家,拥有数学和物理学背景,并在分析天体物理学和量子物理学中感兴趣的复杂系统的框架和计算工具方面进行了多年的研究。
原文。经许可转载。
相关:
-
特征提取的外星人指南
-
掌握机器学习数据准备的 7 个步骤(Python 版)— 2019 年版
-
特征工程快速指南
更多相关内容
数据科学家和数据分析师必须了解:因果设计模式
评论
由 Emily Riederer,Capital One 高级分析经理。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
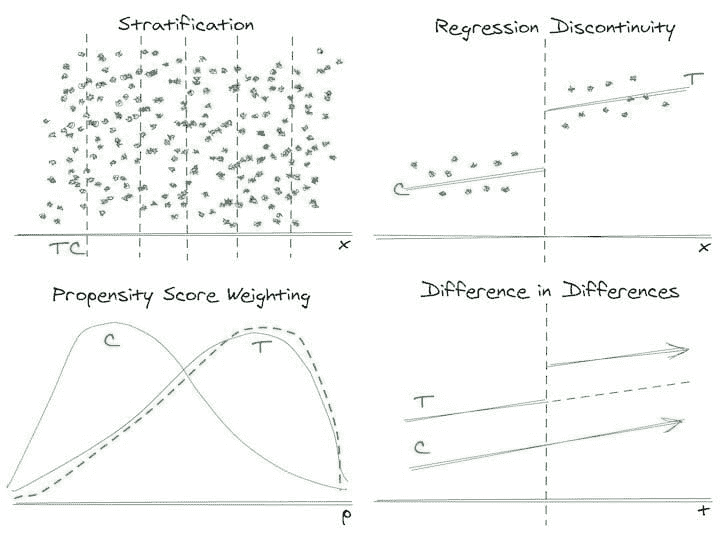
因果推断方法的记忆插图,由 Excalidraw 制作。
软件工程师研究设计模式¹ 以帮助他们识别原型,考虑具有共同语言的方法,并重复使用经过验证的架构。同样,统计学有许多典型的分析,但这些框架往往被孤立在特定学科内,并被领域特定语言所遮蔽。这使得方法更难以发现,并隐藏了它们的普遍适用性。因此,来自这些领域之外的从业者可能很难识别他们面临的问题是否符合这些范式之一。
观察性因果推断就是其中一个领域。理解真实的因果(而非相关)效应,并从“发现”的历史数据(而非实验“产生”的数据)中推导意义和策略的需求几乎是普遍存在的,但方法分散在流行病学、经济学、政治科学等多个领域。
这篇文章旨在通过简要总结跨学科设计模式来打破一些障碍,这些模式用于从观察数据中测量因果效应,重点是其在行业中的潜在应用。对于每种方法,我提供了插图、方法概述、所需数据结构和关键假设的总结,以及一个假设的消费者零售示例。
因果推断是复杂的,做到这一点需要统计学和领域专业知识。与其提供在无数免费资源中已被巧妙描述的所有细节,这篇文章谦逊地旨在宣传这些方法,以便分析师能够将其纳入他们的思维索引中,并在遇到相关问题时进一步研究。
为什么在行业中需要因果推断?
经典的因果问题包括“吸烟是否导致癌症?”和“教育是否导致额外收入?”天真地,我们可能会比较接受处理(吸烟和教育)与未接受处理的结果(癌症或收入)。然而,选择吸烟或追求高等教育的事实会产生选择偏差;这些行为可能与其他因素(冒险精神、经济支持等)相关,这也会影响结果。
在行业中,企业希望知道其策略(如促销优惠)对客户行为的因果效应。当然,这里企业比上述例子有很大优势,因为分配到处理组(如,谁获得折扣码)的机制是已知的且在其控制之下。他们通常还拥有每个个体(客户)的更丰富的“处理前”行为数据,这可以帮助评估和修正偏差。
然而,这些优势并没有使因果推断变得不必要;如果有的话,它们只是使因果推断变得更可行和更相关。好的企业不会随机行动。例如,我们会向那些可能对我们公司感兴趣的客户进行营销,因此,他们即使没有营销也可能会感兴趣。在衡量效果时,好的业务是坏科学。由于我们的处理不是随机给予的,因此比较处理组和未处理组的结果会被混淆和偏向,使我们认为自己比实际情况更有效。
对此的一个解药是真正的实验,其中处理是在同质目标人群中随机分配的。实验,尤其是 A/B 测试,已成为行业数据科学的主流,那么观察性因果推断为什么仍然重要呢?
-
一些情况由于伦理、物流或声誉风险,你不能进行测试。
-
测试可能很昂贵。实施可能无效的政策有直接成本(如测试营销促销)、实施成本(如让技术团队实现新的展示)和机会成本(如保留对照组而不尽可能广泛地应用你希望是有利的策略)。²
-
随机实验比听起来要难!有时实验可能不会按计划进行,但将结果视为观察数据可能有助于挽回一些信息价值。
-
数据收集可能需要时间。我们可能希望在多年后阅读长期终点数据,比如客户保留或流失。³ 当我们希望查看三年前未推出的实验时,历史观察数据可以帮助我们更早地获得初步答案。
-
同样地,我们不能进行时间旅行。对于一些我们已经全面推出的策略,我们不能只是为了测试而撤回。如果我们事后遗憾没有进行测试,我们可以寻找一种准实验来进行分析。
-
这不是非此即彼,而是两者兼具。由于实验的财务和时间成本,因果推断也可以成为帮助我们更好地优先考虑哪些实验值得进行的工具。
-
即使你可以进行实验,理解观察性因果推断也能帮助你更好地识别偏倚并设计实验。
除了这些具体挑战,也许最好的理由是你可以回答很多问题。正如我们将看到的,这些方法几乎都依赖于利用某种任意的随机性来确定特定个体或群体是否接受了某种治疗。行业(以及生活中的其他领域)充满了非随机但定义明确(且有些任意)的政策,这使得观察性因果推断成为一个沃土。分析师可以进行数据搜救任务,在大量历史数据中找到新的用途,这些数据可能被视为无望的偏见或过时的数据。
统一主题
为了说明潜在的应用,这篇文章将简要概述分层、倾向评分加权、回归不连续性和差分中的差异,并通过消费者零售中的动机示例来说明它们的应用。这些方法都处理不同组接受不同处理的情况,但组的分配并非完全随机。
为了测量因果效应,我们希望以某种方式考虑潜在结果,并能够对比在治疗下的平均结果与在反事实情境下(即类似观察未接受治疗)的平均结果。
为了在没有真正随机化的情况下创建这种反事实,这些方法尝试利用不同来源的部分随机变异⁴,同时避免各种混杂因素,以得出有效的推断。
你历史数据中发现的部分随机化类型和你关心的偏倚类型决定了哪些方法适用。简言之:
-
如果你有“相似”处理组和未处理组之间的显著重叠,但治疗并非随机分配,分层或倾向评分加权可以帮助你重新平衡你的数据,使处理组和未处理组在特征分布上更为相似,其平均结果更具可比性。
-
如果你有通过明显的分界线划分的不重叠处理组和未处理组,回归不连续性允许你在组之间的交接处测量局部治疗效应。
-
如果将治疗分配给不同的群体,差分中的差异和事件研究方法有助于比较跨多个时间周期的不同组。
分层
分层帮助我们纠正由于非随机分配机制引起的处理组和对照组人口的不平衡权重。
TLDR:当你有“相似”的个体,但在少数相关维度上具有不同的分布时,使用分层有助于重新平衡这些组,使它们的平均效果更具可比性。
激励示例:
-
假设我们在黑色星期五的网站上尝试了“一键即时结账”的 A/B 测试,并希望测量对总购买金额的影响。
-
由于代码中的一个小故障,网页用户有 50%的概率进入治疗组(即,看到按钮),但移动用户只有 30%的概率。
-
此外,我们知道移动用户每笔订单的支出倾向较少。因此,网页用户在治疗组中的过度代表意味着简单地比较治疗组与对照组的结果会使我们的结果偏倚,使按钮的因果效果看起来比实际要高。
方法:
-
根据每个观测值的特征,将总体按子组进行分类(分层)。
-
计算每个子组中的平均治疗效果。
-
取子组效果的加权平均值,按目标人群(例如治疗分布、对照分布、总体分布)加权。
关键假设:
-
治疗和结果的所有常见原因都可以通过协变量捕捉(更数学地说,结果和治疗在协变量条件下是独立的)。
-
所有观测值都有一定的被治疗的正概率。从启发式角度看,你可以认为在上面的图像中,没有主要区域只有绿色对照观测值而没有蓝色治疗观测值。
-
只有少数几个变量需要调整(因为它们影响治疗的可能性和结果),否则,我们将面临维度诅咒。
示例应用:
-
尽管我们可以进行另一个 A/B 测试,但我们只有一次黑色星期五的机会,需要决定是否在明年包含这个按钮。我们可以计算网页订单和移动订单中的独立治疗效果,然后根据所有订单的整体渠道分布加权平均这些效果。
-
(从技术上讲,随着现代网页设计的发展,我们可以为移动和网页用户做出不同的决定,因此我们可能实际上并不关心整体治疗效果。这只是一个示例。)
相关方法:
- 倾向评分加权(下一节将讨论)可以看作是一种更高级的分层形式。这两种方法的目标都是使治疗组和对照组的分布更加相似。
工具:
- 这个方法计算上非常简单,因此本质上可以使用
SQL或任何基本的数据处理包,如dplyr或pandas,只要工具能够按组执行聚合操作即可。
倾向评分加权
类似于分层,倾向评分(考虑“治疗可能性”)加权帮助我们纠正治疗组和对照组之间由于非随机分配机制造成的系统性差异。然而,这种方法允许我们通过将所有相关信息减少到一个单一的评分来控制许多可观察的特征,从而进行平衡。⁷
TLDR:当你有“相似”的⁸ 处理过和未处理的个体,但在大量相关维度上的分布不同,倾向评分加权有助于重新平衡这些组,使其平均效果更具可比性。
激励示例:
-
我们向所有有有效手机号码的客户发送了一条营销推广短信,并希望了解对下个月购买可能性的因果效应。
-
我们并没有故意将对照组留未处理,但我们可以观察到那些没有有效手机号码的客户的未处理响应。
-
在购买时,电话号码是 UI 上的一个可选字段,因此在人群之间存在一些随机性;然而,我们知道那些没有提供电话号码的人平均上购物频率较低,但两组中都存在从低到高频率购物者的完整谱系。
-
因此,如果我们仅仅比较处理过和未处理的组,促销看起来会比实际情况更有效,因为它被发送给了通常更活跃的客户。
方法:
-
根据每个观察值的可观察特征建模接受治疗的概率(倾向评分),这些特征与治疗分配和结果均相关。⁹
-
在观察数据中,处理组的倾向评分分布通常会向右偏斜(较高,见实线蓝色),而对照组的分布会向左偏斜(较低,见实线绿色)。
-
使用预测概率(倾向评分)来加权未处理的观察值,以使其与对照组(用绿色虚线显示)的治疗可能性分布相匹配。
-
权重可以根据感兴趣的量(处理过的平均处理效果、总体的平均处理效果、如果给予对照人群的平均处理效果等)以不同的方式构建。
-
在计算每个处理组和对照组的平均结果时应用权重,然后相减以找出治疗效果。
关键假设:
-
通过协变量可以捕捉治疗和结果的所有共同原因(从数学上讲,结果和治疗在协变量条件下是独立的)。
-
所有观察值都有一定的正概率¹⁰ 被处理。从启发式角度来看,你可以认为在上面的图像中,处理或对照频率曲线没有完全降到零的区域。
示例应用:
-
基于人口统计和历史购买行为对处理的倾向(或等同于,有记录的电话号码)进行建模。
-
推导权重以计算被处理者的平均处理效应。被处理观察值保持不加权;对于未被处理的观察值,权重是倾向得分与一个减去倾向得分的比率。¹¹ ¹²
相关方法:
-
分层在概念上类似于倾向得分加权,因为它隐含地计算了在重新加权样本上的处理效应。在这里,重新加权是在计算局部效应之后进行的,而不是之前。
-
倾向得分有时也用于匹配,但对这种方法存在 争论。
工具:
-
WeightIt R 包
-
易于使用简单的 stats::glm()实现,如 Lucy D’Agostino McGowan 的 博客文章中所示。
回归不连续性
在现实生活中,特别是在工业中,我们经常违反分层和倾向得分加权所需的“整个协变量空间中的正处理概率”假设。商业和公共政策经常使用具有严格截断的策略(例如,基于年龄和消费的客户细分),这些截断两侧的个体接受不同的处理。在这种情况下,我们没有相关的观察值来重新加权。然而,我们可以应用回归不连续性设计来理解处理在不连续点的局部效应。
TLDR: 当你有被处理和未被处理的个体被严格截断分开时,使用截断值上下的处理分配的任意变异来衡量局部因果效应。
激励示例:
-
在 90 天内没有进行购买的顾客会收到一张“下一次购买立减$10”的优惠券。
-
我们可以使用“自上次购买以来的天数”这一严格的截断值来衡量优惠券对下一年消费的影响。
-
尽管认为在 10 天内没有购买的顾客与在 150 天内没有购买的顾客类似是不现实的,但在 88 天内没有购买的顾客可能与在 92 天内没有购买的顾客在实质上没有显著不同,除了处理不同。
方法:
-
一组个体根据一个任意的截断值接受或不接受处理。
-
对“运行”变量(用于截断的变量)与截断两侧的结果进行建模。然后,局部处理效应可以通过在此“运行”变量值下建模结果的差异来确定。
-
注意,我们只能测量局部处理效应在截断点,而不是像使用分层和倾向得分加权那样的全局平均处理效应。
关键假设:
-
分配规则对被观察者来说是未知的,因此无法进行操控。
-
感兴趣的结果可以建模为相对于决策变量的连续函数。
-
我们可以拟合一个合理规范且简单的模型,以关联感兴趣的结果和决策变量。由于 RDD 必须使用模型的“尾部”估计值,过于复杂的模型(例如,高次多项式)可能会得出奇怪的结论。
示例应用:
-
我们可以建模“自上次消费以来的天数”和“下一年消费”之间的关系,并评估在“自上次消费以来的天数”值为 90 时建模值的差异。
-
违反假设的反例可能是广告宣传“超过$50 免费配送和退货”,并尝试测量提供免费配送对未来客户忠诚度的影响。为什么?这个截断点是已知的,因此可以被操控。例如,可能不太忠诚的客户对公司的产品更为怀疑,更可能退货,因此他们可能故意花费超过$50 以改变他们的分类,从而进入处理组。
-
作为附注,你是否可以在这种情况下简单地进行 A/B 测试?绝对可以!通过随机不给一些客户优惠券,你可以得到一个更公平的比较。然而,不太可能你的组织曾经运行的每一个历史活动都有良好的随机对照。通过这种方法,你仍然可以提取一些有用的见解,以指导你的下一步。
相关方法:
-
模糊回归不连续性允许将截断点设置为概率性的,而不是绝对的。
-
工具变量方法和两阶段最小二乘法可以被认为是一个更广泛的家族,其中回归不连续性是一个简单的例子。更广泛地说,这些方法通过建模处理和工具之间的关系来解决处理和结果之间的混杂问题,其中工具仅通过处理与结果相关。
工具:
差分中的差分
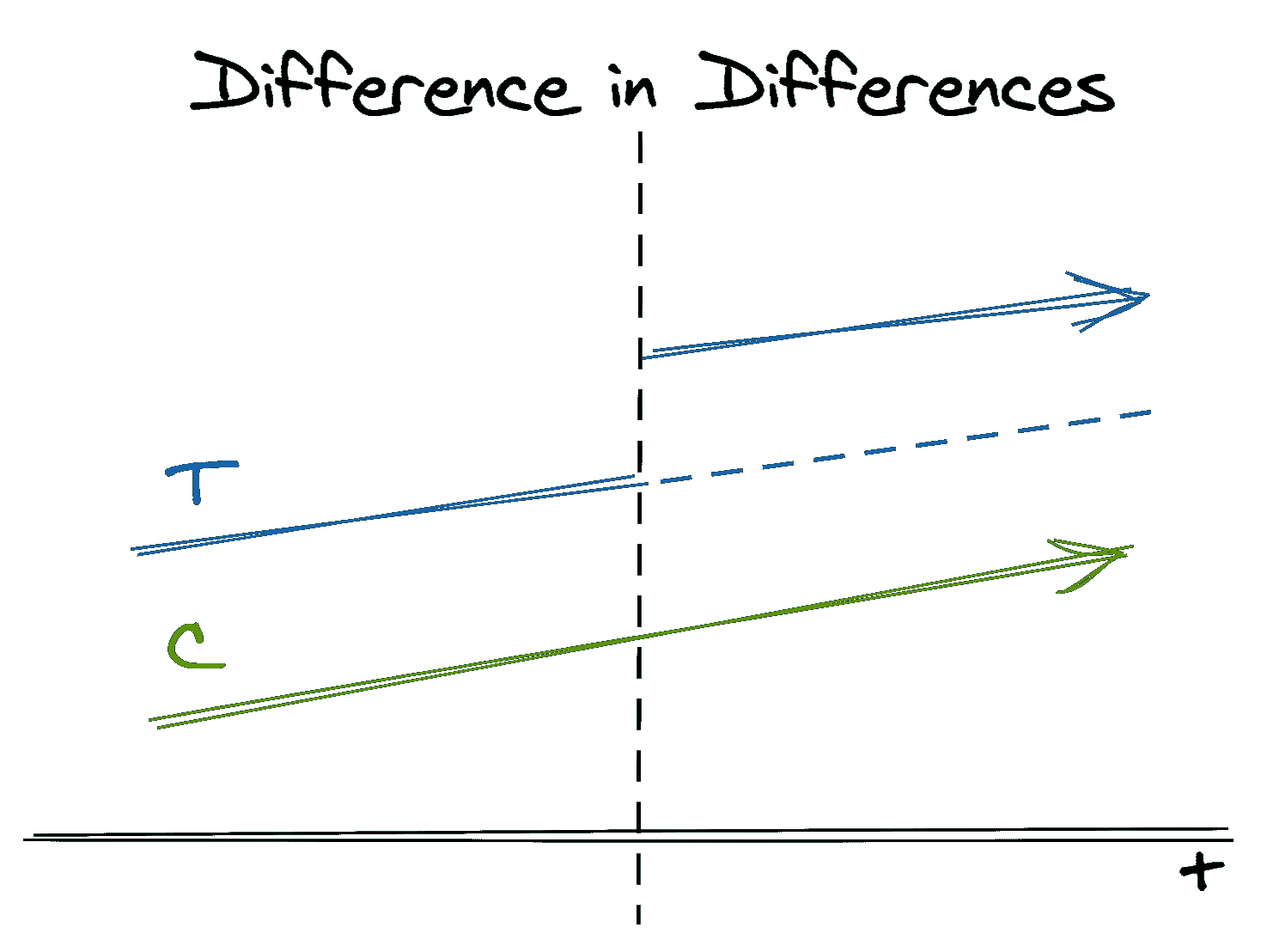
到目前为止,我们查看了尽可能使组在处理前相似的方法。评估这些方法的一种方式是查看在处理前,它们的感兴趣变量的值是否相似(例如,在促销前的 6 个月支出)。然而,我们可用的数据使得这种绝对水平的相似性过于严格。相反,差分中的差分方法更灵活地帮助我们在时间上确定轨迹的相似性。也就是说,我们可以比较处理和对照群体跨时间的相对变化。
TLDR:当你有群体级别的处理或数据可用时,使用跨群体的随机变化来比较其随时间变化的总体趋势。
动机示例:
-
我们想要估计商店改造对访问量的影响。
-
一次改造影响所有潜在客户,因此这种“处理”不能在个体层面上应用;理论上,它可以随机分配到个体商店,但我们没有预算或兴趣在有正面效果的证据出现之前随机改造许多商店。
方法:
-
在两个不同的群体中,一个接受了处理,另一个没有。我们相信,如果没有处理,这两个群体在结果上会有相似的趋势。
-
我们可以通过计算处理后群体的差异与处理前群体的差异之间的差异来估计处理效果。
-
实际上,这与推断处理后期未接受处理的处理群体的反事实情况相同(如上图中的虚线)。
-
从技术上讲,这被实施为一个固定效应回归模型。
关键假设:
-
处理组的决定并未受到结果的影响。
-
如果没有处理,比较的两组在结果上会有平行的趋势。注意,组别允许有不同的水平,但必须在时间上有类似的趋势。
-
没有溢出效应,即处理处理组不会对对照组产生影响。
示例应用:
-
我们可以通过比较改造前后商店的流量与未改造商店的流量来估计商店改造对访问量的影响。
-
注意这种方法对我们假设的敏感性:
-
如果改造是扩展并且由于预见到的流量增加,那么我们的第一个假设就被违背了,我们的效果会被高估。
-
如果我们选择的对照是同城的另一家附近商店,我们可能会经历溢出效应,使得更多原本会去对照商店的人决定去处理商店。这将再次高估效果。
-
-
另一个反例是测量将某个产品品牌放在商店结账处对销售的影响,并使用不同品牌的相同产品作为对照。为什么?由于这些产品是替代品,处理组的产品摆放可能会“溢出”到负面影响对照组的销售。
相关方法:
-
存在放宽不同假设的变体。例如,我们可以考虑不同单元在不同时间接受处理的情况,不同单元具有不同(异质的)处理效应,平行趋势假设仅在调整协变量后成立,以及更多场景。
-
合成控制方法可以被视为差分中的扩展,其中控制是若干不同可能控制的加权平均。
-
贝叶斯结构时间序列方法通过建模时间序列之间的关系(包括趋势和季节性成分)来放宽差分中的平行趋势假设。
工具:
-
did R 包用于差分中的差分。
-
Synth R 包用于合成控制。
-
CausalImpact R 包用于贝叶斯结构时间序列。
含义
如果上述示例让你感到兴趣,仍有一些事情需要记住。解释这些设计模式很容易;在相关时实施它们却很困难。因果推断需要在数据管理、领域知识和概率推理上的投资。
数据管理是必需的,以确保过去处理的数据被保存、可发现且详细充分。所有这些方法都需要丰富的数据,包含每个研究对象的基线特征测量,并对他们所接受的处理有充分的理解。这可能看起来很明显,但很容易忽视保存足够详细的数据。例如,我们可能有一个数据库,将每个客户的账户映射到系统生成的 campaign_id,表示他们参与的某个营销活动;然而,除非有关该特定活动(具体处理、目标、时间等)的信息 readily available,否则这并不是特别有用。此外,就像我们在分层示例中看到的那样,一些最佳的因果推断机会来自执行错误(或者,更温和地说,“自然实验”)。我们可能倾向于忽略这些错误并继续前进,但有关未按计划进行的事件的信息可能是未来分析的强大素材。
域知识对于验证假设至关重要。与其他形式的推断(例如,基本线性回归)不同,我们讨论的许多方法的假设无法通过计算或视觉评估(例如,不像经典的残差图或 QQ 图)。相反,假设很大程度上依赖于细致的关注、直觉以及来自领域的背景知识。这意味着因果推断必然应该是一个人机互动的活动。
最后,对概率推理和这些方法的扎实掌握也很关键。正如我下面链接的许多资源详细讨论的那样,因果推断很容易做错。例如,试图控制错误的变量有时会引入相关性并导致偏差,而不是消除它们。¹³
了解更多
本文的重点不是教授任何一种因果推断方法,而是帮助提高对基本因果问题、数据需求和分析设计的认识,这些是你在实际应用中可能会用到的。关于这些或其他方法的具体实施,有大量出色的资源可供学习。请查看我的资源汇总帖子以获取许多免费的书籍、课程、讲座、教程等链接。
脚注
-
这一概念由 1994 年出版的《设计模式:可重用面向对象软件的元素》一书普及。更多内容请见维基百科。
-
关于机会成本,多臂强盗问题可以通过决定何时“探索与利用”来帮助平衡这种机会成本。
-
具体来说,我们应该考虑这些终点。众所周知,由于新颖效应,短期测试可能表面上看起来很乐观。
-
你可能会在经济学文献中看到这被称为“外生性”。
-
什么是“相似性”?在不深入细节的情况下,我们这里特别关注的是影响个体接受感兴趣的治疗和影响感兴趣结果的特征。
-
一方面,我们可能认为这会减少放弃的购物车;另一方面,这可能会减少浏览量。
-
从启发式的角度看,你可以将其视为一种基于相关性的“维度减少”方法,而不是基于方差。
-
参见前面的脚注“相似性”。
-
请注意,我们建模的是他们是否接受治疗,而不是他们是否对治疗有反应。这可能看起来不直观,因为我们知道他们是否接受了治疗,但你可以直观地将其视为建模各种未治疗观察与治疗观察的相似性。
-
这通常被称为积极性假设。
-
从直观上讲,你可以将其视为抵消未治疗的概率(实际状态),并用接受治疗的概率(目标状态)来替换,就像通过乘以(1 英尺 / 12 英寸)将 60 英寸转换为英尺一样。
-
我承诺不会在帖子中涉及数学和公式,但这里有一个简短的数字示例来说明这一点。假设我们有两个组 A 和 B。A 组有 30 个治疗个体和 20 个未治疗个体,因此真实的倾向评分是 60%(30/50)。B 组有 10 个治疗个体和 40 个未治疗个体,因此真实的倾向评分是 20%(10/50)。因此,A 组占治疗组的 75%(30/40)和未治疗组的 33%(20/60)。如果 A 组和 B 组之间的区别暗示了在感兴趣的结果上表现不同,这种不平衡会影响我们对治疗和未治疗之间的比较。按照我们的公式,未治疗 A 组的权重为 3/2(0.6/0.4),未治疗 B 组的权重为 1/4(0.2/0.8)。当我们加权平均未治疗组时,未治疗组中的 A 组权重为(20 * 3/2)/(203/2 + 401/4)= 30 / 40 = 3/4 = 75%。瞧!现在分布与治疗组相同。实际上,我们会应用倾向评分到具有多个和连续因素影响的情境中(而不仅仅是“A 组和 B 组”),但单变量和离散的例子可以更容易看清发生了什么。
-
更多内容,请查看链接资源中的“collider bias”相关参考资料,例如 《因果推断:混音带》中的这一部分。
原文。已获得许可转载。
简介: 艾米莉·里德(Emily Riederer)是 Capital One 的高级分析经理,她领导一个团队,专注于构建内部源分析工具、数据集市和实践社区,以改善业务分析。
相关内容:
更多相关内容
如何通过因果推断提升增强分析超越二维平面
原文:
www.kdnuggets.com/2021/08/causal-inference-augmented-analytics-beyond-flatland.html
评论
由 Michael Klaput 提供,Kausa 首席科学官兼联合创始人。

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 事务
如果世界是二维的,生活将会非常奇怪。试想一下:地球不会是一个球体,而是一个圆圈——就像二维宇宙中的其他所有恒星和行星一样。生物体也会被压扁,生活在一个平面的景观中。例如,要在街上超过某人,你必须跳过那个人,因为没有深度。出于同样的原因,要仅仅看向你身后,你就必须字面上把自己翻个身。幸运的是,这不是我们生活的世界。但不幸的是,这正是如今大多数企业运行的基础——可能甚至包括你的企业。在任何技术驱动的业务中,你的决策质量不可避免地依赖于你数据洞察的质量。然而,在太多公司中,这些“洞察”实际上是二维的:平面、无用且毫无结论。
企业通常通过 KPI 来衡量其绩效。因此,在数据分析中,找到基于历史数据的未来 KPI 值的最佳预测模型已经成为一个目标。尽管这些模型可能表现得相当好,但从中提取价值同样困难。除了缺乏可解释性之外,这还因为预测模型无法捕捉现实,并且限制于低维解释。在本文中,我们将提供两个论点,说明为什么这是由于糟糕的扩展和大多数预测模型中存在的不切实际的假设。
但为何要费心呢?并不是表现良好的模型提升了业务绩效。实际上,改善业务的唯一途径是通过决策,这最终应该由人类来完成。数据分析在业务中的目标应该是通过揭示洞察来为决策提供信息。不幸的是,这些洞察就像针一样隐藏在数据中。这一复杂的问题促使了一个相对年轻的数据分析分支——增强分析,并在近期的 Gartner 报告中得到了推动[1]。

*图 1. 《平面国的封面:多维度的浪漫 / 作者 A Square 插图,作者:爱德温·阿博特(1838-1926)。出版:伦敦:Seeley & Co.,1884 年. EC85 Ab264 884f 哈佛大学豪顿图书馆
我们想要挑战一种观念,即预测模型应该是用于指导业务决策的默认选项。它们在寻找洞察时引入了昂贵的绕行,甚至可能使其在实际操作中不可行。我们将在一个简单问题中突出显示,预测建模除了大量的开销外几乎无法提供什么。相反,我们将尝试模仿业务分析师的操作。这将自然引导我们到因果推断的方法上。
有影响的变化
我们将考虑在大数据场景下诊断回归模型错误的问题。大多数读者应该遇到过以下场景:
图 2. 使用单一模型的关键绩效指标实际值与预测值对比。
显然,KPI 发生了显著变化,这种变化似乎暂时会持续。从技术角度来看,一个合理的反应是对变化点之后的数据重新训练你的预测模型。你同意吗?如果同意,也许可以记住这一点。
图 3. 使用两个模型的关键绩效指标实际值与预测值对比。
好消息是你的模型似乎很准确。坏消息是你的经理将不可避免地询问 KPI 发生了什么。但不要害怕。这是证明你对公司价值的理想情况。你能识别出这种变化背后的原因吗?你能揭示出有助于做出正确决策的洞察吗?
为什么的探究
假设你公司的数据集大致如下所示:
import pandas as pd
df = pd.read_csv("..\\dataset\\ecommerce_sample.csv")
df.head()
表 1. 示例公司数据。
假设你正处理最简单的情况:使用线性回归模型完美拟合了跳跃前后的 KPI 值。在这里,你需要适当地处理分类数据以用于回归。标准方法是对分类值进行独热编码:对于每个类别值,你引入一个特征,该特征可以是真或假。例如,在上述数据集中,你会定义特征
customer_country = **德国。
要最终实现特征选择,有必要使用某种形式的正则化。在这里,你将使用 Lasso 正则化(通过十折交叉验证)。
在训练了两个 Lasso 正则化的线性回归模型后,一个是在跳跃之前,另一个是在跳跃之后,你可以查看这两个模型之间特征权重差异的排名列表。
from sklearn.linear_model import LassoCV
from bokeh.io import show
from bokeh.plotting import figure
#get kpi_axis
kpi_axis = 'kpi'
time_axis = 'time'
df[time_axis] = pd.to_datetime(df[time_axis],format = '%d/%m/%Y')
y_before = df[df[time_axis] <= '2019-09-11'][kpi_axis] y_after = df[df[time_axis] > '2019-09-11'][kpi_axis]
#one-hot encoding categorical features
for col in df.drop([kpi_axis,time_axis],axis=1).columns:
one_hot = pd.get_dummies(df[col])
df = df.drop(col,axis = 1)
df = df.join(one_hot)
X_before = df[df[time_axis] <= '2019-09-11'].drop([kpi_axis,time_axis],axis = 1).to_numpy() X_after = df[df[time_axis] > '2019-09-11'].drop([kpi_axis,time_axis],axis = 1).to_numpy()
#training left and right
regression_model_before = LassoCV(cv = 10)
regression_model_after = LassoCV(cv = 10)
regression_model_before.fit(X_before,y_before)
regression_model_after.fit(X_after,y_after)
#plotting results
features = df.columns
dweights =regression_model_after - regression_model_before
index = np.argsort(-abs(dweights))
x_axis = features[index[0:3]].to_list()
p = figure(x_range=x_axis,title = "Feature weights difference",plot_width=1000)
p.vbar(x=x_axis, top=(abs(dweights[index[0:3]])),width = 0.8)
show(p)
图 4. 使用独热编码的特征权重。
看起来像是安卓用户或年龄大于 46 岁的用户在跳跃前后表现不同。很好,看起来你找到了 KPI 跳跃的原因……或者说你找到了吗?
维度诅咒
实际上,这比我们目前所认识的情况要复杂得多。想象一下将这些信息呈现给 KPI 负责人。他们会非常高兴你为 KPI 变化提供了理由,但他们现在会考虑如何根据这些信息采取行动。这将自动引发他们提出如下问题:
“KPI 变化的实际驱动因素是所有安卓电视用户、所有年龄超过 46 岁的客户以及所有之前进行过购买的客户吗?也许可能是年龄超过 46 岁的重复客户和安卓电视用户……或者是之前购买过东西的安卓电视用户?更糟糕的是,是否还有其他你遗漏的特征组合?”

图 5. Kausa - 因为你知道得更多。
因此,为了更有信心地回答这些问题,你需要重复你的回归分析,使用更复杂的独热编码特征……现在表示比之前更细的子组。因此,你正在搜索数据集中的更深层次子组,见图 6,新的特征如:
customer_age = 46+ 和 first_order_made = yes,customer_age = 18−−21 和 first_order_made = no。
这些子组通过独热编码再次进入。这显然是一个问题,因为你现在陷入了维度诅咒。这是大数据时代,你刚刚通过阶乘量增加了特征的数量[2]。可以用来生成这些精细子组的代码如下:
def binarize(df,cols,kpi_axis,time_axis,order):
cols = cols.drop([kpi_axis,time_axis])
features = []
for k in range(0,order):
features.append(cols)
fs = []
for f in itertools.product(*features):
# list(set(f)).sort()
f = np.unique(f)
fs.append(tuple(f))
fs = tuple(set(i for i in fs))
print(fs)
for f in fs:
print(len(f))
states =[]
for d in f:
states.append(tuple(set(df[d].astype('category'))))
for state in itertools.product(*states):
z = 1
name = str()
for d in range(0,len(f)):
z = z*df[f[d]]==state[d]
name += f[d] + " == " +str(state[d])
if d<len(f)-1:
name += " AND "
df[name] = z
for d in cols:
df = df.drop([d],axis = 1)
return df
图 6. 子组深度。
请记住,线性回归基于所有特征的协方差矩阵的逆——这会随特征的增加而扩展。
O(d³),
其中 d 是特征的数量,即在我们这种情况下,是可能的子组数量。这相较于非预测性特征选择方法引入了显著的机会成本——这一点将在后面讨论。
df = pd.read_csv("..\\dataset\\ecommerce_sample.csv")
df[time_axis] = pd.to_datetime(df[time_axis],format = '%d/%m/%Y')
#get kpi_axis
kpi_axis = 'kpi'
time_axis = 'time'
y_before = df[df[time_axis] <= '2019-09-11'][kpi_axis] y_after = df[df[time_axis] > '2019-09-11'][kpi_axis]
#one-hot encoding categorical features
df = binarize(df,df.columns,kpi_axis,time_axis,3)
X_before = df[df[time_axis] <= '2019-09-11'].drop([kpi_axis,time_axis],axis = 1).to_numpy() X_after = df[df[time_axis] > '2019-09-11'].drop([kpi_axis,time_axis],axis = 1).to_numpy()
#training left and right
regression_model_before = LassoCV(cv = 10)
regression_model_after = LassoCV(cv = 10)
regression_model_before.fit(X_before,y_before)
regression_model_after.fit(X_after,y_after)
#plotting results
features = df.columns
dweights =regression_model_after - regression_model_before
index = np.argsort(-abs(dweights))
x_axis = features[index[0:3]].to_list()
p = figure(x_range=x_axis,title = "Feature weights difference",plot_width=1000)
p.vbar(x=x_axis, top=(abs(dweights[index[0:3]])),width = 0.8)
show(p)
图 7. 使用独热编码的交集特征权重。
一段时间后,你的计算完成了。虽然之前的计算只需 0.1 秒,但寻找三阶特征却花费了超过一分钟。不过这似乎是值得的。你发现,驱动 KPI 变化的群体实际上是一个,如图 7 所示。向你的经理展示这一洞察后,他很快就能指出一个直接影响你报告的子群体的更新。
通过精细化子群体,你可以使其具有可操作性。
虽然你的回归方法最终奏效了——但计算时间极长,导致了公司机会成本。在大数据的现实场景中,你的方法可能会失败得很惨。此外,包含仅浅层子群体的原始集合描绘了一个不正确的图景。只有在经过精细化集合和大量计算工作之后,你才能确定导致 KPI 跳跃的实际子群体。
这引出了几个问题:
-
你是否真的需要学习预测模型来回答为什么会发生跳跃?
-
你如何减少机会成本?
-
你如何找到适当粒度的子群体?
-
为了获得这些信息,每次跳跃时重新训练模型是否经济?
虽然回答所有这些问题超出了本文的范围,我们将提供一种新的观点,这可以帮助解决这些问题。为此,我们将开发一种改进线性回归的特征选择方法。增强分析依赖于此。
从业务分析师和因果推断中学习
让我们退一步……这里发生了什么?你从一个预测模型开始,发现它既不能预测也不能解释 KPI 的观察到的跳跃。这是为什么呢?因为预测模型无法捕捉现实。它们假设所有数据是独立同分布的[3]。然而,在实际应用中,这通常是不正确的,正如这个例子所示。跳跃前后的数据是在不同条件下生成的。你甚至直观地利用了这一点,当你使用两个单独的预测模型时,这(经过一些技巧)帮助我们揭示了跳跃的原因。
既然你不得不放弃预测,并且最终没有做出任何预测,那么预测模型实际上对你有什么帮助呢?如果你思考一下,关键在于你并不关心所有可能子群体对 KPI 的预测,而是关心子群体对 KPI 的影响!因此,要在更深层次上寻找洞察,你必须远离预测建模。这正是数据科学家可以从业务分析师那里学习的地方。
业务分析师通过包含有意义的数据总结的仪表板来寻找洞察。与上述回归方法中将所有特征关联在一起不同,业务分析师会尝试通过迭代地过滤数据以不同条件来确定数据中发生了什么变化(如均值、直方图或指标)。最重要的是,业务分析师无需一次查看所有特征。你如何教机器做到这一点?你如何从业务分析师那里学习?
让我们用数学符号来形式化上述内容。设 X 为一个子组,例如
X = customer_age = 46+ 和 first_order_made = yes
和
f(KPI[before], KPI[after])
对 KPI 跳跃前后的 KPI 分布做一些总结。然后,你引入条件总结
f(KPI[before], KPI[after] ∣ X)
你计算满足 X 为真的 KPI 值子集的总结。我们的方法现在只需要计算每个子组的条件总结并进行排名。我想强调的是,在实践中,这些抽象的总结可以是均值、直方图等对象。
上述过程实际上是因果推断中的一种常见技术 [4]。因此,你隐含地改变了我们的视角。现在,你将 KPI 中神秘的跳跃视为现在假定由于外部或内部 处理 发生的干预。外部处理的例子可能是节假日,内部处理可能是广告活动、定价变化,或如我们案例中的软件更新。因此,你明确地 提升 了所有数据是独立且同分布的错误假设。你现在正在寻找对 KPI 变化 因果 的子组。
《为何探寻,再次回顾》
现在你已经有了一个业务分析师如何操作的模型,让我们继续实际实施。现在,你将使用一种在因果推断中使用的标准总结,称为条件平均处理效应 (CATE) [5],我们的总结变成了
f(KPI[before], KPI[after] ∣ X) = E[KPI[after] ∣ X] − E[KPI[before] ∣ X]
CATE 对应于 KPI 均值的变化,条件是该子组 X 为真。按大小排名然后给出正确的子组作为结果。为了检测多个子组,我们在每次迭代后移除表现最好的子组后重复这一过程:
df = pd.read_csv("..\\dataset\\ecommerce_sample.csv")
df[time_axis] = pd.to_datetime(df[time_axis],format = '%d/%m/%Y')
#get kpi_axis
kpi_axis = 'kpi'
time_axis = 'time'
y_before = df[df[time_axis] <= '2019-09-11'][kpi_axis] y_after = df[df[time_axis] > '2019-09-11'][kpi_axis]
df = binarize(df,df.columns,kpi_axis,time_axis,3)
df_before = df[df[time_axis] <= '2019-09-11'] df_after = df[df[time_axis] > '2019-09-11']
features = copy(df.drop([time_axis,kpi_axis], axis=1).columns)
K = 3 #number of subgroups to detect
subgroups=[]
score=[]
for k in range(0,K):
CATE = []
y_before = df_before[kpi_axis]
y_after= df_after[kpi_axis]
#compute CATEs for all subgroups
for d in features:
g = df_before[d] == True
m_before = np.mean(y_before[g])
g = df_after[d] == True
m_after = np.mean(y_after[g])
CATE.append(m_after-m_before)
#find subgroup with biggest CATE
index = np.argsort(-abs(np.array(CATE)))
subgroups.append(features[index[0]])
score.append(abs( CATE [index[0]]))
#remove found subgroups from dataset
df_before = df_before[df_before[features[index[0]]] == False]
df_after = df_after[df_after[features[index[0]]] == False]
features = features.drop(features[index[0]])
p = figure(x_range=subgroups,title = "Conditional Average Treatment Effect",plot_width=1200,)
p.vbar(x=subgroups, top=score,width = 0.8,color='black')
show(p)
图 8. 使用交集的独热编码的 CATE 分数。
这只需要我们预测模型成本的一小部分。计算一阶特征仅需 0.02 秒,而搜索三阶特征则不到一秒。
让我们退一步,将这种方法与早期基于回归的方法进行比较,看看它们各自的目标是什么。通过回归进行的特征选择回答了问题:“哪些子组最能预测你的 KPI?”而因果推断则回答了问题:“哪些子组对 KPI 有最大的因果影响?”比较图 9 中 CATE 的朴素实现与优化的sklearn线性回归实现的运行时间,我们发现它们之间相差几个数量级。这表明这些问题虽然表面上相似,但本质上有根本的区别。
图 9:线性回归(sklearn)与 CATE 在子组深度上的日志运行时间比较,用于穷举子组搜索。
结论
预测模型作为理解 KPI 变化的工具有很大的不足,特别是在多维度的背景下。这些模型在错误的假设下根本回答了错误的问题。相反,商业分析关注的是为什么会发生某事,而不是将来会发生什么。将预测未来 KPI 值的辅助任务从思维中剔除后,分析师在数据中寻找 KPI 变化的原因,试图为正确的问题找到答案。
下次你想解释任何事情时要小心。首先,你应该提出正确的问题。此外,多维度背景需要基于因果推断和商业分析方法的可扩展技术。这是 Kausa 的使命:扩展商业分析逻辑并将其与因果推断结合,以提供对 KPI 变化的正确答案。
附注:本文结果的代码和数据可在我们的 GitHub 仓库中找到[6]。
原文。经许可转载。
个人简介: Michael Klaput 是 Kausa 的联合创始人兼首席技术官 (www.kausa.ai),曾任美国银行美林证券量化分析副总裁,牛津大学理论物理学博士。
相关:
更多相关主题
你知道吗,早在石器时代,人们就已经在处理“数据过载”问题了?
评论

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
现在每个人都在谈论数据与分析。高管们正在研究如何将数据转化为价值,研究人员正在撰写关于数据的大量论文,学生们也在大批报名数据科学项目。
这让人相信数据和分析是一个近期现象。事实上,有令人信服的理由表明,分析比以往任何时候都更重要和相关。然而,分析的根本思想——理解我们现实的本质并据此行动——与人类本身一样古老。
更令人惊讶的是,人们似乎在几千年前就解决了一个巨大的数据问题。让我们总结一下尤瓦尔·赫拉利的伟大著作《人类简史》中的一个章节,看看他们是如何做到的。
内存过载
几千年来,我们的祖先以采集者的身份狩猎动物和寻找甜美的浆果。在这一历史时期,数据已经至关重要。如果你总是忘记蛇是危险的,红蘑菇是有毒的,你的生存机会将非常渺茫。幸运的是,重要数据的量很小,人们可以将所需了解的一切存储在脑海中。然而,当人类开始生活在更大的定居点和社区时,我们脑力的局限性变得十分明显。
生活在这些更大社会中需要完全不同的心理技能。许多出现的问题与数据相关,无法用当时的传统技术——记忆——来解决。例如,地方统治者必须知道他们库存中有多少粮食,是否足够度过冬天。需要从成千上万的居民那里征收税款,因此必须存储支付数据。还需要处理财产数据的法律系统,以及不断扩大的家庭需要记录家谱。周围的数据比以前多得多,仅仅靠记忆一切是不够的,这样做是不可能的。
我们需要的是一次飞跃。因此,我们的祖先大约在 5000 年前发明了一个天才系统,将他们的思想编码成抽象符号,这些符号可以被熟悉该系统规则的其他人解读。这使得信息存储和处理第一次可能在早期人类的大脑之外进行。写作诞生了。

大数据 2.0
令人惊讶的是,早期人类文明中的数据问题与当前公司和政府存储和处理越来越多数据的挣扎之间的关系如此密切。
今天,数据总量以每年 40% 的惊人速度增长,如图 2 所示。
图 2: 数据总量 以 ZB 为单位。
为了感受这一点有多巨大,让我们考虑以下统计数据:
在 2015 年,2050 亿 封电子邮件每天被发送!
在 2016 年,432,000 小时 的视频被上传到 YouTube,每天都是这样!
到 2020 年,每小时将为地球上的每个人创造超过6GB的数据!
这些巨量的数据对公司来说可能极具价值,前提是公司知道如何从中提取信息。然而,研究人员估计,只有 0.5%的数据被分析过。显然,还有大量未被发现的数据等待分析并转化为价值。
就像 5000 年前,当简单的记忆无法高效存储和分析数据一样,如今公司也发现传统的分析系统已经无法驯服大数据的浪潮。
就像记忆被书写所取代一样,传统数据库也被分布式系统所取代。进行大规模数据分析所需的飞跃。
结论
大数据竟然是一个 5000 年的问题!大数据架构师可能真的是仅次于最古老职业的第二古老职业…
个人简介:Jonas Vandenbruaene 是安特卫普大学的商业工程学学生。对数据分析、艺术和环游世界充满热情。目前正在撰写关于组织数据成熟度和 CDO 角色的硕士论文。通过博客激发有趣的讨论!
相关:
-
Hadoop 并未失败,它是数据的未来
-
大数据的起源
-
数据挖掘历史:支持向量机的发明
更多相关话题
CDC 数据复制:技术、权衡、见解
原文:
www.kdnuggets.com/2023/08/cdc-data-replication-techniques-tradeoffs-insights.html

许多行业中的组织运营的生产数据库中,大多数数据不会频繁更改;也就是说,日常的更改和更新仅占存储在其中的数据总量的一小部分。正是这些组织最能从变更数据捕获(CDC)数据复制中受益。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你组织的 IT
在这篇文章中,我将定义 CDC 数据复制,简要讨论最常见的使用案例,然后谈论常见的技术及其权衡。最后,我将分享作为数据集成公司 Dataddo 的 CEO 和创始人,我学到的一些实施见解。
什么是变更数据捕获(CDC)数据复制?
CDC 数据复制是一种在两个数据库之间实时或接近实时地复制数据的方法,其中仅复制新添加或修改的数据。
这是一种快照复制的替代方案,它涉及将一个数据库的整个快照不断移动到另一个数据库。快照复制可能适用于那些需要长期保留数据单个快照的组织,但它非常耗费处理能力,并且会产生巨大的财务开支。对于那些不需要这样做的组织,CDC 可以节省大量的处理时间。
数据更改可以实时或以小批量(例如每小时)捕获并传递到其新目标。
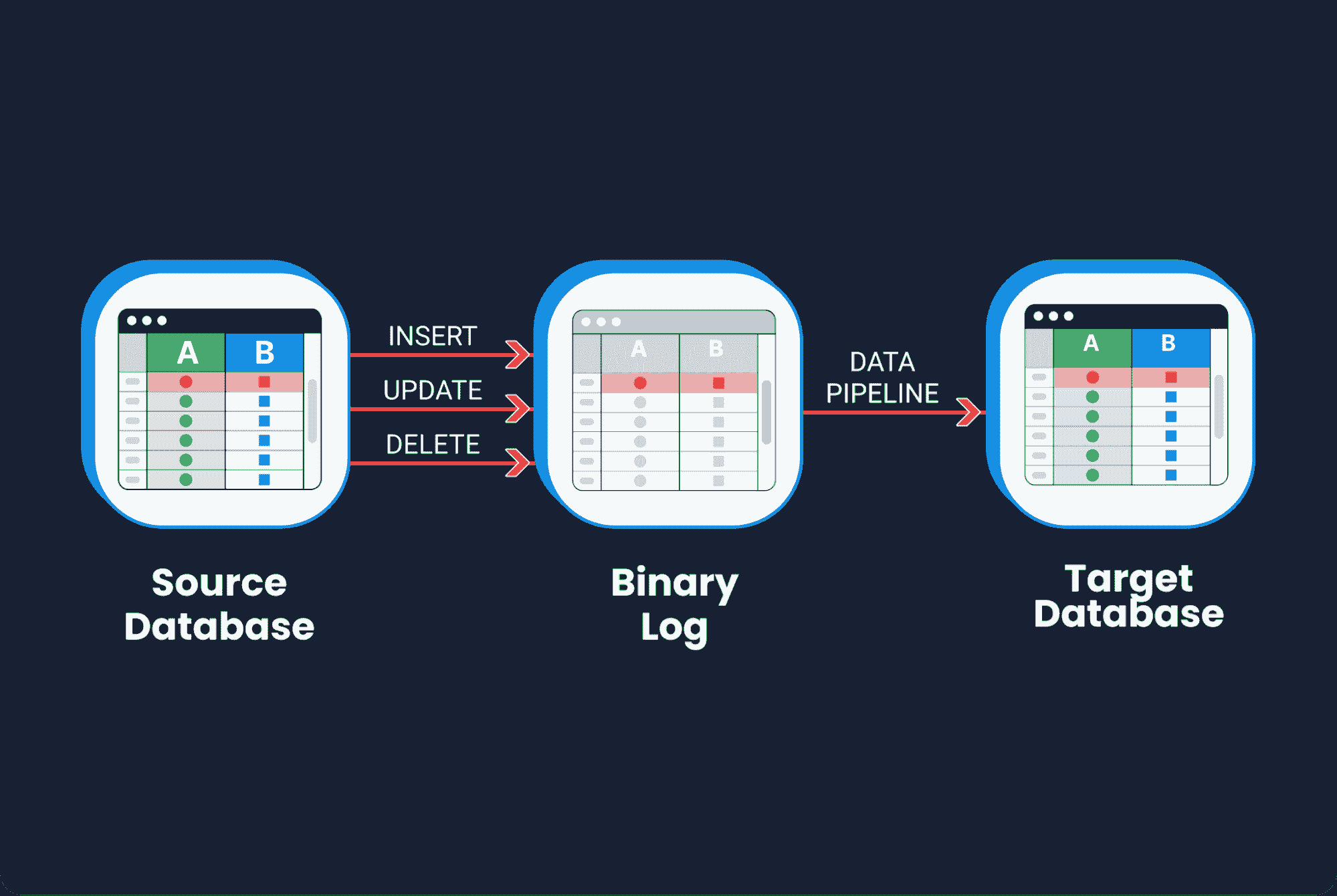
这张图展示了基于日志的 CDC,其中红色行是新添加的数据。
值得一提的是,CDC 并不是一个新过程。然而,直到最近,只有大型组织拥有实现它的工程资源。新的是越来越多的托管工具可实现它且成本低廉,因此它的新兴受欢迎程度。
最常见的 CDC 使用案例
本文的篇幅不足以涵盖 CDC 数据复制的所有用例,但以下是三种最常见的。
商业智能和分析的数据仓储
任何运行专有数据收集系统的组织都可能有一个存储该系统关键数据的生产数据库。
由于生产数据库是为写操作而设计的,因此它们不会将数据有效地利用。许多组织因此会希望将数据复制到一个数据仓库中,以便可以进行复杂的读取操作以用于分析和商业智能。
如果你的分析团队需要近实时的数据,CDC 是一个很好的方式,因为它会迅速将更改传递到分析仓库中。
数据库迁移
当你从一种数据库技术迁移到另一种时,CDC 也非常有用,你需要在停机情况下保持一切可用。一个经典的例子是从本地数据库迁移到云数据库。
灾难恢复
类似于迁移案例,CDC 是一种高效且可能具有成本效益的方式,可以确保所有数据始终在多个物理位置可用,以防其中一个位置出现停机。
常见的 CDC 技术及其权衡
CDC 有三种主要技术,每种技术都有其自身的优缺点。

CDC 实现涉及灵活性、保真度、延迟、维护和安全性之间的权衡。
基于查询的 CDC
基于查询的 CDC 非常简单。你只需使用这种技术编写一个简单的选择查询来从特定表中选择数据,然后添加一些条件,比如“仅选择昨天更新或添加的数据。”假设你已经配置了一个备用表的模式,这些查询将捕获更改的数据并生成一个新的二维表,该表可以插入到新的位置。
优势
-
高度灵活。允许你定义要捕获哪些更改以及如何捕获它们。这使得以非常细粒度的方式自定义复制过程变得更容易。
-
减少开销。仅捕获符合特定标准的更改,因此比捕获所有数据库更改的 CDC 便宜得多。
-
更容易故障排除。可以轻松检查和纠正单独的查询,以解决任何问题。
缺点
-
复杂的维护。每个单独的查询都需要维护。例如,如果你的数据库中有几百个表,你可能需要这么多查询,而维护所有这些查询将是一个噩梦。这是主要的缺点。
-
较高延迟。依赖于轮询来检测更改,这可能会引入复制过程中的延迟。这意味着你无法通过选择查询实现实时复制,必须安排某种批处理。如果你需要分析长期时间序列的数据,如客户行为,这可能不是大问题。
基于日志的 CDC
我们今天使用的大多数数据库技术都支持集群,这意味着你可以在多个副本中运行它们以实现高可用性。这些技术必须有某种二进制日志,捕获数据库的所有更改。在基于日志的 CDC 中,更改是从日志中读取的,而不是数据库本身,然后复制到目标系统。
优势
-
低延迟。数据更改可以非常迅速地复制到下游系统。
-
高保真度。日志捕获数据库的所有更改,包括数据定义语言(DDL)更改和数据操作语言(DML)更改。这使得追踪已删除的行成为可能(而基于查询的 CDC 无法做到这一点)。
缺点
-
较高的安全风险。需要直接访问数据库事务日志。这可能引发安全问题,因为这需要广泛的访问权限。
-
灵活性有限。捕获数据库的所有更改,这限制了定义更改和定制复制过程的灵活性。如果有高度定制的需求,日志将需要进行大量后处理。
一般来说,基于日志的 CDC 实施起来很困难。有关更多信息,请参见下面的“见解”部分。
基于触发器的 CDC
基于触发器的 CDC 是前三种技术的一种混合。它涉及为捕获表中的某些更改定义触发器,然后将这些更改插入并在新表中跟踪。从这个新表中,更改被复制到目标系统。
优势
-
灵活性。允许你定义捕获哪些更改以及如何捕获它们(如基于查询的 CDC),包括已删除的行(如基于日志的 CDC)。
-
低延迟。每次触发器触发时,它都算作一个事件,事件可以实时或近实时处理。
缺点
- 极其复杂的维护。就像基于查询的 CDC 中的查询一样,所有触发器都需要单独维护。因此,如果你有一个包含 200 个表的数据库,并需要捕获所有表的更改,你的整体维护成本将非常高。
实施见解
作为一家数据集成公司的首席执行官,我在大大小小的规模上实施 CDC 有很多经验。以下是我在过程中学到的一些东西。
针对不同日志的不同实现
基于日志的 CDC 特别复杂。这是因为所有日志—例如 MySQL 的 BinLog、Postgres 的 WAL、Oracle 的 Redo Log、Mongo DB 的 Oplog—尽管概念上相同,但实现方式不同。因此,你需要深入了解所选数据库的低级参数,以使其正常工作。
将数据更改写入目标位置
你需要确定如何在目标位置插入、更新和删除数据。
一般来说,插入很简单,但数据量在决定方法上起着重要作用。无论你使用批量插入、数据流还是决定通过文件加载更改,你总会面临技术上的权衡。
为了确保正确更新并避免不必要的重复,你需要在表上定义一个虚拟键,以告知系统哪些内容应该被插入,哪些内容应该被更新。
为了确保正确删除,你需要有一些备用机制,以确保错误的实现不会导致目标表中所有数据的删除。
维护长期运行的作业
如果你只转移几行数据,事情会相当简单,但如果是这种情况,那么你可能不需要 CDC。因此,通常情况下,我们可以预期 CDC 作业将需要几分钟甚至几小时,这将需要可靠的监控和维护机制。
错误处理
这可能是另一个完全不同的主题。但简而言之,我可以说每种技术在引发异常和呈现错误方面的方式不同。因此,你应该定义一个策略来处理连接失败的情况。你应该重试吗?还是应该将所有内容封装在事务中?

实现内部 CDC 数据复制相当复杂且高度特定于案例。这就是为什么它传统上不被认为是一个流行的复制解决方案,也很难给出通用的实施建议。近年来,像 Dataddo、Informatica、SAP Replication Server 等托管工具显著降低了其可访问性门槛。
不是所有人都适用,但对某些人来说很棒
正如我在文章开头提到的,CDC 有可能为公司节省大量财务资源:
-
主要数据库中数据变化不频繁(即每日变化仅占其中数据的相对小部分)
-
需要实时接收数据的分析团队
-
不需要保留主数据库随时间变化的完整快照
尽管如此,没有完美的技术解决方案,只有权衡。这同样适用于 CDC 数据复制。那些选择实现 CDC 的人将不得不不平等地优先考虑灵活性、准确性、延迟、维护和安全性。
Petr Nemeth 是 Dataddo 的创始人兼首席执行官——一个完全托管的、无代码的数据集成平台,连接云服务、仪表盘应用程序、数据仓库和数据湖。该平台提供 ETL、ELT、逆向 ETL 和数据库复制功能(包括 CDC),以及 200 多个连接器的广泛组合,使得任何技术水平的业务专业人士都能够将数据从几乎任何来源发送到任何目的地。在创办 Dataddo 之前,Petr 曾在电信、IT 和媒体公司担任开发人员、分析师和系统架构师,参与涉及物联网、大数据和商业智能的大型项目。
相关主题
庆祝数据隐私重要性的意识
原文:
www.kdnuggets.com/2022/01/celebrating-awareness-importance-data-privacy.html

Dayne Topkin 通过 Unsplash
什么是数据隐私日?
每天,人们将个人信息公开到互联网上,却完全不知这些信息如何被使用、共享或滥用。数据隐私日是每年 1 月 28 日举行的国际活动,旨在提高意识,促使公司和个人采纳数据保护的最佳实践。
我们的三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
数据隐私日有助于提高对在线数据滥用及其隐私重要性的认识,并教育社会如何管理个人信息。各国政府、议会、国家数据保护机构等会举办研讨会,提供信息并指导公众关于个人数据保护和隐私的权利。它还鼓励现有企业尊重数据,并在数据收集协议和消费者数据使用上更加明确和简洁。
数据隐私日始于 2008 年 1 月的美国和加拿大,源自欧洲委员会决定于 2006 年 4 月 26 日启动数据保护日,并定于 1 月 28 日庆祝。数据保护日纪念 1981 年 1 月 28 日签署的《公约 108》,这是第一部具有法律约束力的国际隐私和数据保护条约。
公约 108 包含了数据保护的基本基础和原则,22 年后仍然执行这些相同的规则和条例。公约 108 用于建立第一个欧盟数据保护指令的支柱,该指令于 1995 年通过,并在 2018 年由《通用数据保护条例》(GDPR)取代。GDPR 是全球最严密的隐私和安全法律之一。尽管它是由欧盟制定和通过的,但它对任何组织都建立和执行义务,只要这些组织的目标是或收集与欧盟人员相关的数据。
欧洲委员会为互联网用户创建了一个详细的指南,帮助他们更好地理解他们在网上的人权,以及当这些权利受到挑战或侵犯时应该采取的措施。
为什么数据隐私很重要?
根据Pew Research的调查,81%的受访者感觉他们对所收集的数据几乎没有控制权;而根据SalesForce的调查,46%的客户觉得他们失去了对自己数据的控制。
为了让人们感到更加受保护,特别是在技术不断发展的背景下,需要制定具体的规则和法规。赢得人们的信任是困难的,因此在保护包含个人信息的数据方面需要做更多的工作。让个人对收集的数据拥有控制权,并让他们了解数据的使用方式,是赢得他们信任的最大一步。
失去消费者的信任是每个组织最大的失败之一,因此,实施最安全的流程,同时保护个人隐私是非常重要的。
数据隐私与数据安全
这两个术语看起来和听起来可能相似,但它们之间有明确的区别。
数据隐私主要关注个人的权利、数据收集的使用和处理、隐私偏好以及组织如何根据法律存储和保护数据。
数据安全包含了一系列的标准和不同的实施措施,旨在防止数据挑战或未经授权的第三方访问所造成的滥用。这包括访问控制、加密和安全措施,所有这些都被强制执行以防止数据的利用。
如果一个组织拥有最严格的数据安全措施,但未能在合法的基础上收集数据,无论采取了多少安全措施来保护数据,这都是对数据隐私的侵犯。这告诉我们,数据安全可以存在而数据隐私却不存在。
如何保护自己

Dan Nelson via Unsplash
个人
每次你点击的按钮都会生成数据,从你的在线活动到你的兴趣。个人数据包括你的电子邮件、密码、银行账户详情、社会保障号码,还有你的物理数据,比如你一天走了多少步。当我们的生活围绕着技术运转并且总是想买新设备时,很难隐藏你的数据。
作为个人,了解并选择你成为消费者的对象以及你的数据如何被处理是你的责任。为了更好地管理你的数据,请按照以下步骤操作:
1. 阅读并理解隐私权衡
许多组织会要求你许可他们访问你的个人信息,例如你的位置。他们会在你开始使用他们的服务之前询问你,因为这些个人信息是有效的数据,对组织有很大的价值。有些甚至可能用折扣购买或免费服务的奖励来诱使你分享这些个人信息。
权衡你对一个组织的信任程度,并做出是否愿意分享个人信息的明智决定是很重要的。例如,该组织是否提出了过多的个人问题,超过了通常的数量,还是提问的数量与你从中获得的好处相称。
2. 管理你的隐私
定期检查网络服务和应用程序上的隐私和安全设置是一种应当常做的方法。根据你的偏好调整设置,将使你在浏览网页和使用应用程序时感到更舒适。
3. 保护你的数据
为每个账户使用相同的密码是一个巨大的错误。一旦有人入侵了一个账户,他们就能访问你所有的其他账户。创建长且唯一的密码,并使用 YubiKey 等安全存储密码,是确保数据安全和隐私的正确措施。
你还可以使用多重身份验证(MFA),这是一种电子认证方法,用户提供额外的身份验证,如扫描指纹或输入通过电话收到的代码。
组织
组织需要采取更多方法来获得消费者的信任。根据Pew Research Center,79%的美国成年人表示对他们的数据被公司使用的方式感到担忧。
保护消费者的隐私偏好是一种有效的策略,可以赢得信任,提升声誉和业务潜力。要获得这些好处,请遵循以下步骤:
1. 遵循规则
无论你处理的是小数据还是大数据,遵循隐私法律的正确规则和规定都是至关重要的。采取安全措施来维护消费者的隐私偏好,同时保护他们免受未经授权的访问。
如果你不是收集数据的责任人,但使用这些数据,你有责任监督和理解数据是如何被收集的。
2. 合规框架
合规框架是一套结构化的指南,旨在帮助组织识别和管理隐私风险。这使得组织在构建产品和服务的同时保护个人隐私。
3. 教育
在员工入职过程中,作为组织,你有责任教育新员工和现有员工有关公司的隐私政策。如果你指导员工采取正确的措施来保护他们在家里的安全,他们也会在工作中实践这些相同的安全和隐私措施。定期要求全公司更改密码,并为员工提供 YubiKey 等措施,是在组织中建立隐私和安全文化的例子。
我们使用和交换数据的频率比以往任何时候都要高。技术在不断进步。人们在网上自由地输入个人信息。外界存在越来越多的对手,等待下一次滥用个人信息的机会。作为个人和组织,你的责任是保护和保卫个人数据。
尼莎·阿里亚是一名数据科学家和自由技术作家。她特别感兴趣于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能在延长人类寿命方面的不同方式。她是一个热衷学习的人,寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
庆祝科技行业中的女性领导角色
原文:
www.kdnuggets.com/2022/07/celebrating-women-leadership-roles-tech-industry.html

图片来源:蒂玛·米罗什尼琴科
当今的组织认识到,基于性别、种族、年龄和其他因素的多样化劳动力对业务有利。多样化的团队表现更好,创新能力更强。特别是科技行业,正在继续缩小性别差距。德勤全球预测,全球大型科技公司在 2022 年的女性员工比例将接近 33%,比 2019 年略微增长了两个百分点。其他行业角色中的女性比例也预计会有所上升。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的信息技术
Parul Bharadwaj,一位经验丰富的科技专业人士,现居西雅图,与 Amazon 和 DoorDash Inc. 等科技巨头合作过。她表示,对女性未来的机会感到非常鼓舞,因为科技公司不断重新承诺推动性别多样性。目前在 DoorDash 担任高级技术项目经理的 Bharadwaj 领导着工程全局性项目,如数据基础设施、实时流媒体、发布、实验、分析、数据合规和治理。她表示,在 DoorDash 找到灵感,在这里,女性领导者如 Liangxiao Zhu(工程副总裁)、Sophia Vicent(工程运营高级总监)、Avani Nanavati(技术产品总监)和 Varsha Dudani(工程总监)展示了女性担任关键决策职位的潜力。Bharadwaj 说:“我赞扬 DoorDash 扩大女性角色的努力。研究表明,担任领导职位的女性候选人拥有所需经验的比例较低,但 DoorDash 正通过在管理层招聘女性来战术性地解决这个问题,从而给女性提供今天积累经验、明天担任高管的机会。”
设立新标准
麦肯锡公司的一份报告表明,拥有多样化员工队伍的公司更有可能获得更高的财务回报。苹果公司最新的多样性报告反映出,在不同领域招聘更多包容性的员工是重要的。Bharadwaj 表示,她对这些趋势中的变化持乐观态度,并指出,还有一些在她公司之外取得成功的女性榜样,继续激励她对工作保持热情。一些值得注意的名字包括:
-
Susan Diane Wojcicki,YouTube 的首席执行官(CEO)。一位拥有超过 20 年科技行业经验的波兰裔美国商业高管。
-
Reshma Saujani,Girls Who Code 的创始人兼 CEO。这是一家总部位于纽约的非营利组织,旨在支持和增加计算机科学领域的女性人数。2010 年,Saujani 成为首位竞选美国国会的印裔美国女性。
-
Deirdre O’Brien,苹果公司零售部门的高级副总裁。2019 年被列入财富全球最具影响力女性名单,并在 2021 年出现在Fast Company 的 Queer 50 名单上。
年轻时,Bharadwaj 记得她想从事一种能够在塑造当下的同时改变未来的职业。这份热情引导她走向了数字技术。她说:“创新的可能性总是看似无限的。这个领域处于我们不断演变的世界的前沿。而正是这种对产生影响、保持竞争优势和保持相关性的渴望引导我进入了这个领域。”她继续认为自己是使关键在线平台实现大规模增长的一部分,这些平台在全球范围内继续留下深刻印象。“这不仅让我有机会不断学习新工具和技术,提供更好的产品和服务,还让我保持探索解决新问题不同方法的渴望。”
尽管取得了成就,回顾她的职业生涯,Bharadwaj 说她本可以在年轻时放弃自己的雄心,但她很幸运地得到了家庭的正确指导和支持,以追求她的梦想。今天,她希望在帮助其他女性在职业生涯中取得成功方面发挥主导作用。Bharadwaj 说她享受过成功,并建议健康的心态与宝贵的教育和行业技能相结合,可以走得更远。她希望其他女性能够实践的建议包括:
-
与有类似经历、挑战和解决方案的同行建立网络。
-
根据你的教育、技能和经历始终了解自己的价值。
-
投资于继续教育。
-
经常评估目标。
-
在时机感觉最佳时大胆尝试。
进一步推进公平计划
通过多样性培训、入职培训、指导和辅导,整个行业也在取得进展。根据 Bharadwaj 的说法,“当你雇用多样化的员工时,你还必须对这些员工之间的差异保持敏感并能够识别。倾听那些有不同生活和职业经历的人可以减少陷入群体思维模式的可能性。”这就是今天的现实。创新公司必须有来自不同背景的人参与讨论。通过这种方式,组织在重塑结构时能够发挥卓越,以为所有人创造一个更美好的未来。
Gene Marrano 在 30 多年前开始了他的职业生涯,他曾在制造业从事装配、质量控制、规划和销售工程等工作。过去的 10 年里,他在媒体行业担任 Roanoke, VA 的获奖广播、印刷和电视记者。他还是众多出版物和报纸的自由撰稿人。如需更多信息,请发送电子邮件至 gmarrano@cox.net。
相关话题
k-means 聚类的质心初始化方法
原文:
www.kdnuggets.com/2020/06/centroid-initialization-k-means-clustering.html
简单的聚类方法,如 k-均值,可能没有现代神经网络或其他近期先进的非线性分类器那样引人注目,但它们确实有其用处,掌握如何正确处理无监督学习问题是一项很有价值的技能。
这篇文章旨在系列文章中的第一篇,探讨 k-均值聚类管道的不同方面。在这第一篇文章中,我们将讨论质心初始化:它是什么,它实现了什么,以及存在的一些不同方法。我们将假设你对机器学习、Python 编程以及聚类的一般概念有一定的了解。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
k-均值聚类
k-均值是一种简单而经常有效的聚类方法。传统上,从给定的数据集中随机选择 k 个数据点作为聚类中心或质心,所有训练实例都会被绘制并添加到最近的聚类中。在所有实例都添加到聚类后,质心表示每个聚类实例的均值,将被重新计算,这些重新计算的质心成为各自聚类的新中心。
此时,所有的聚类成员资格都被重置,所有训练集的实例被重新绘制并重新添加到其最近的、可能重新中心化的聚类中。这个迭代过程将继续,直到质心或其成员资格没有变化,聚类被认为已稳定。
当重新计算的质心与前一轮迭代的质心匹配,或在某个预设的范围内时,聚合被认为已经实现。在 k-均值中,距离的度量通常是欧几里得距离,给定两个点的形式为 (x, y),可以表示为:
技术上需要注意的是,特别是在并行计算时代,k-均值中的迭代聚类本质上是串行的;然而,迭代中的距离计算不必如此。因此,对于规模较大的数据集,距离计算是 k-均值聚类算法中值得进行并行化的目标。
质心初始化方法
由于 k-均值聚类旨在通过连续迭代基于这些中心点的距离来收敛到一个最佳的簇中心(质心)和簇成员,因此直观上来说,初始质心的定位越优化,k-均值聚类算法收敛所需的迭代次数就越少。这表明对这些初始质心的初始化进行一些战略性考虑可能会很有用。
质心初始化方法有哪些?虽然存在许多初始化策略,但我们重点关注以下几种:
-
随机数据点:在这种方法中,如上文“传统”案例所述,从数据集中随机选择 k 个数据点作为初始质心,这种方法显然高度不稳定,并提供了一种选定的质心在整个数据空间中没有很好分布的情况。
-
k-means++:由于将初始质心分散开来被认为是一个值得追求的目标,k-means++通过将第一个质心分配给随机选择的数据点位置,然后从剩余的数据点中选择后续质心,依据的是与给定点的最近现有质心的平方距离成正比的概率。这种方法试图将质心尽可能远地推开,覆盖尽可能多的占据的数据空间。k-means++ 的原始论文(2006 年)可以在这里阅读。
-
朴素分片:这种较少被人知晓(或许完全未知?)的质心初始化方法曾是我自己研究生研究的课题。它主要依赖于计算反映实例所有属性值的复合总和值。一旦计算出这个复合值,就用它来对数据集中的实例进行排序。然后,将数据集水平分成 k 份或分片。最后,对每个分片的原始属性进行独立求和,计算其均值,并将这些分片属性均值的行集合起来,作为初始化时使用的质心集合。期望是作为一种确定性方法,它应比随机方法执行得更快,并通过复合总和值近似初始质心在数据空间中的分布。如果感兴趣,可以在这里阅读更多内容。
任何这些方法的变体都是可能的:你可以从数据空间的任何位置随机选择,而不仅仅是包含现有数据点的空间;你可以尝试首先找到位置最中心的数据点,而不是随机选择,然后从那里继续使用 k-means++;你也可以在朴素分片中用另一种操作替代求和均值操作。
此外,一种形式的 层次聚类(通常是 Ward 方法)可以用作找到初始簇中心的方法,然后将其传递给 k-means 执行实际的数据聚类任务。这可能是有效的,但由于这也涉及到层次聚类的讨论,我们会将此内容留待后续文章中。
质心初始化和 Scikit-learn
由于我们将使用 Scikit-learn 来执行聚类,让我们查看一下其 KMeans 模块,其中可以看到关于可用质心初始化方法的说明:
**init{‘k-means++’, ‘random’, ndarray, callable}, default=’k-means++’**初始化方法:
'
k-means++': 以一种智能的方式选择 k-means 聚类的初始簇中心,从而加快收敛速度。有关更多细节,请参见 k_init 部分的说明。'
random': 从数据中随机选择n_clusters个观测值(行)作为初始质心。如果传递 ndarray,它的形状应该是 (n_clusters, n_features),并给出初始中心。
如果传递一个可调用对象,它应该接受 X、n_clusters 和随机状态作为参数,并返回一个初始化结果。
鉴于此,并且由于我们希望能够比较和检查初始化的质心——这是 Scikit-learn 实现无法做到的——我们将使用上述讨论的三种方法的自定义实现,即随机质心初始化、k-means++ 和简单分片。然后,我们可以使用这些实现独立于 Scikit-learn 来创建质心,并在聚类时将其作为 ndarray 传入。我们也可以使用可调用选项,而不是 ndarray 选项,并将质心初始化集成到 Scikit-learn k-means 执行中,但这会让我们回到最初的状态,即在聚类之前无法检查和比较这些质心。
话虽如此,centroid_initialization.py 文件包含了我们的质心初始化实现。
将此文件放置在与我启动 Jupyter notebook 相同的目录中,我可以按以下步骤进行操作,首先是导入。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import centroid_initialization as cent_init
%matplotlib inline
创建一些数据
显然,我们需要一些数据。我们将创建一个小的合成数据集,以便能够清晰地划分我们的簇(见图 1)。
from sklearn.datasets import make_blobs
n_samples = 250
n_features = 2
n_clusters = 4
random_state = 42
max_iter = 100
X, y = make_blobs(n_samples=n_samples,
n_features=n_features,
centers=n_clusters,
random_state=random_state)
fig=plt.figure(figsize=(8,8), dpi=80, facecolor='w', edgecolor='k')
plt.scatter(X[:, 0], X[:, 1]);
图 1:我们的合成数据集
初始化质心
让我们初始化一些质心,使用上述实现。
随机初始化
random_centroids = cent_init.random(X, n_clusters)
print(random_centroids)
[[-7.09730839 -5.78133274]
[ 4.56277713 2.31432166]
[ 4.9976662 2.53395421]
[ 4.16493353 1.31984045]]
k-means++ 初始化
plus_centroids = cent_init.plus_plus(X, n_clusters)
print(plus_centroids)
[[-1.59379551 9.34303724]
[-6.63466062 -7.38705277]
[-7.31520368 7.86243296]
[ 5.1549141 2.48695563]]
简单分片初始化
naive_centroids = cent_init.naive_sharding(X, n_clusters)
print(naive_centroids)
[[-9.09917527 -7.00640594]
[-6.48108313 2.12605542]
[-2.66275228 7.07500918]
[ 4.66778007 9.47156226]]
如你所见,初始化的质心集合彼此不同。
质心初始化的可视化
让我们直观地查看质心彼此之间的比较,以及与数据点的比较。我们将调用下面的绘图函数多次进行比较。图 2 绘制了上述创建的 3 组质心与数据点的对比。
def centroid_plots(X, rand, plus, naive):
fig=plt.figure(figsize=(8,8), dpi=80, facecolor='w', edgecolor='k')
plt.scatter(X[:, 0], X[:, 1],
s=50,
marker='o',
label='cluster 1')
plt.scatter(rand[:, 0],
rand[:, 1],
s=200, c='yellow',
marker='p')
plt.scatter(plus[:, 0],
plus[:, 1],
s=200, c='red',
marker='P')
plt.scatter(naive[:, 0],
naive[:, 1],
s=100, c='green',
marker='D');
centroid_plots(X, random_centroids, plus_centroids, naive_centroids)
图 2. 绘制的质心与数据点:随机(黄色),k-means++(红色),naive sharding(绿色)
值得注意的是,随机初始化的质心中有 3 个恰好位于最右侧的簇中;k-means++ 初始化的质心每个簇中都有一个;而 naive sharding 的质心分布在数据空间中,呈略微弯曲的方式向上和向右偏移,偏向数据高度聚集的区域。
请记住,我们创建了一个二维数据空间,因此这些质心的可视化是准确的;我们没有去掉一些维度并将数据在简化空间中进行人工绘制,这可能会造成问题。这意味着在这种情况下,质心的比较是尽可能准确的。
你可能会问,这种初始化中哪些因素受随机种子的影响?随机初始化和k-means++都是随机方法,因此它们可能会受到随机种子的影响。如果我们对初始化算法进行不同的种子测试,结果如图 3 所示。
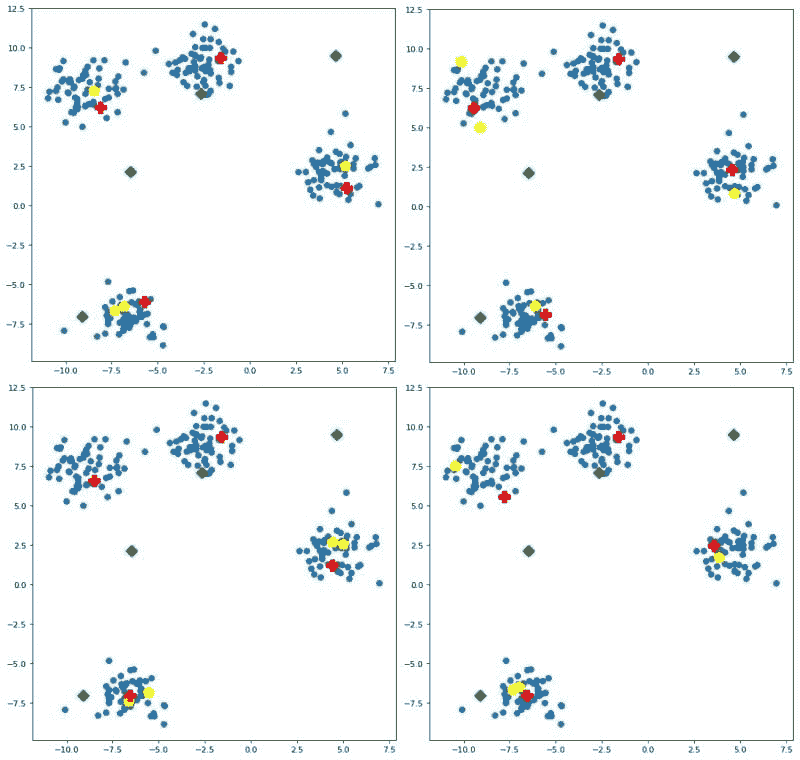
图 3. 实验中随机种子对质心初始化的影响,从左上角开始顺时针:123, 249, 127, 13
一些观察:
-
随机初始化的质心(恰如其分)分布非常广泛
-
k-means++ 在簇内相对一致,初始质心的具体数据点略有变化
-
naive sharding 是确定性的,因此不受种子的影响
这引出了我们的一些问题,这些问题直接关系到聚类的下一步:
-
质心的位置对最终的聚类任务有什么影响?
-
质心的位置对最终聚类任务的速度有什么影响?
-
质心的位置对最终聚类任务的准确性有何影响?
-
我们何时会选择某些初始化方法而不是其他方法?
-
如果从最优放置的角度来看,随机初始化似乎是一个很差的方法,那么为什么还会使用它呢?
-
确定性初始化方法(如 naive sharding)是否有优势?
我们下次将开始寻找这些问题的答案。
马修·梅奥(@mattmayo13)是数据科学家及 KDnuggets 的主编,这是一个重要的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。马修拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系到。
主题更多内容
可以提升你 2024 年数据科学职业生涯的认证
原文:
www.kdnuggets.com/certifications-that-can-boost-your-data-science-career-in-2024

图片来源:Editor | Midjourney & Canva
在当今的数据科学领域,如何让自己从竞争中脱颖而出?数据科学认证可以大大提升你的职业生涯,证明你的技能并在 2024 年创造新的工作机会。数据科学证书有助于获取数据科学知识,也有助于验证我们在这一领域的技能。让我们来看看一些最佳的认证。
认证分析师专业 (CAP)
通过 认证分析师专业认证 的候选人展示了在分析方面的熟练程度。候选人需要具有学士学位和五年的分析经验才能参加此考试。也可以用硕士学位和三年的经验或七年的非分析经验来替代。考试包括数据准备和模型构建等主题。
费用:会员 $375,非会员 $575
有效期:3 年
Google 认证的专业数据工程师
Google 认证的专业数据工程师认证 证明了一个人在开发和设计 Google Cloud Platform 数据处理系统方面的技能。候选人应具备数据工程知识和 Google Cloud 产品的实际使用经验。虽然没有明确要求的正式资格,但申请者应至少有三年的相关领域工作经验。其中一年应专门致力于开发和实施与 Google Cloud 相关的概念。
费用:$200 USD
有效期:2 年
微软认证:Azure 数据科学家助理
Azure 数据科学家助理认证 验证了在 Azure 技术上实施和操作机器学习解决方案的能力。考试旨在测试在机器学习、自然语言处理和计算机视觉方面的熟练程度。它还展示了 Azure 的广泛工具箱和服务如何有助于开发可扩展和成功的机器学习系统。应该具备足够的数据科学概念知识和 Python 熟练度。
费用:$165
有效期:2 年
SAS 认证数据科学家
SAS 认证数据科学家证书表明候选人能够使用 SAS 进行数据分析。为了晋升为 AI 与机器学习专业或高级分析证书,必须通过高级编程和数据整理专业考试。此测试衡量候选人在数据分析过程中的理解和专业知识。这些技能包括数据的聚合、转换和清洗。
费用:$180
有效期:3 年
IBM 数据科学专业证书
IBM 数据科学专业证书在线课程涵盖的主题使学习者能够实践数据科学。课程参与者可以报名参加多个在线课程,这些课程可以成为追求数据科学职业的基础。初学者课程包括数据探索和可视化的概述。该项目还包括集中于数据科学高级领域的模块,如使用 Python 进行数据分析和使用 R 进行数据可视化。
费用:$234
有效期:证书不会过期
Cloudera 认证专业(CCP)数据工程师
Cloudera 认证数据工程师证书包括了大数据环境下数据工程的多个方面。它为候选人提供了设计强大且可扩展的数据管道的专业知识,以处理大规模数据。寻求此证书的候选人应具备数据工程原理的理解,并对大数据技术有充分的了解。
费用:$400
有效期:2 年
[DASCA] 高级数据科学家(SDS)
高级数据科学家证书认可那些在机器学习和数据科学建模方面表现出熟练度的个人。高级数据科学家认证有一些标准,候选人需要满足才能获得证书。相关领域的硕士学位,包括计算机科学、统计学、数学或相关学科,是其中之一。候选人还必须拥有至少五年的数据科学工作经验。
费用:$775
有效期:3 年
总结
在 2024 年,获得认证对提升你的数据科学职业至关重要,因为这有助于验证可信度,提高工作者的声誉,并开启晋升的新机会。在这方面,这些认证将帮助你证明你是一名有能力且愿意解决问题的数据科学工作者。
Jayita Gulati 是一位机器学习爱好者和技术作家,她的热情驱动着她构建机器学习模型。她拥有利物浦大学的计算机科学硕士学位。
更多相关话题
机器学习特征创建的挑战
原文:
www.kdnuggets.com/2022/02/challenges-creating-features-machine-learning.html

图片由 Monsterkoi 提供,来源于 Pixabay
当我决定离开学术界并重新培训成为数据科学家时,我很快发现自己必须学习 R 或 Python,或者……两个都学。这可能是我第一次听说 Python。我从未想过三年后我会维护一个越来越受欢迎的开源 Python 特征工程库:Feature-engine。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
在这篇文章中,我想探讨特征工程和选择的技术和操作挑战,然后介绍开源 Python 库 Feature-engine 如何帮助我们应对这些挑战。我还将突出 Feature-engine 在其他 Python 库中的优点和缺点。让我们深入了解一下。
什么是 Feature-engine?
Feature-engine 是一个开源 Python 库,用于特征工程和特征选择。它的工作方式类似于 Scikit-learn,通过 fit() 和 transform() 方法从数据中学习参数,然后使用这些参数对数据进行转换。
使用 Feature-engine,我们可以进行大量特征变换,比如填补缺失数据、编码分类变量、离散化数值变量以及通过数学函数如对数、平方根和指数变换变量。我们还可以组合现有特征来创建新特征、删除或屏蔽异常值,并从日期和时间中提取特征。

Feature-engine 拥有一个专门的 模块 用于特征选择,包含在数据科学竞赛或组织内开发的特征选择技术,这些技术在 Scikit-learn 或其他 Python 库中都没有。我在 之前的文章 中讨论了一些这些技术。
是什么 让 Feature-engine 独特?
有许多特点使得 Feature-engine 易于使用,并且成为特征工程的绝佳选择。首先,Feature-engine 包含了最全面的特征工程转换集合。其次,Feature-engine 可以对数据框中的特定变量组进行转换,我们只需在 Feature-engine 的转换器中指明需要转换的变量,而不需要额外的代码行或辅助类。第三,Feature-engine 能够自动识别数值型、类别型和日期时间型变量,使我们能够更容易地构建特征工程管道。第四,Feature-engine 接收一个数据框并返回一个数据框,使其既适合数据探索,也适合将模型部署到生产环境中。
Feature-engine 还具有其他特性,使其成为一个出色的库,比如全面的文档和大量示例、易于学习的功能,以及与 Scikit-learn Pipeline、Grid 和 Random 超参数搜索类的兼容性。
Feature-engine 旨在帮助用户进行有意义的数据转换。Feature-engine 会在转换不可能进行时提醒用户,例如,应用对负变量的对数或除以 0,转换后引入 NaN 值,或者用户输入的变量类型不合适。因此,你不需要等到过程结束时才发现问题,你会立刻知道!
为什么特征工程具有挑战性?
首先,让我们定义一下特征工程。特征工程是利用领域知识创建或转换适合训练机器学习模型的变量的过程。它涉及从填充或删除缺失值,到编码类别变量,转换数值变量,从日期、时间、GPS 坐标、文本和图像中提取特征,并以有意义的方式将它们结合起来。话虽如此,这个过程的挑战是什么呢?
数据预处理和特征工程是耗时的。首先,我们需要收集一个代表性的数据集,以评估我们想要的总体。接下来,我们进行数据探索,以了解我们拥有的变量及其与目标的关系(如果有目标的话)。数据质量越差,或者我们对正在处理的数据了解得越少,我们在探索和准备数据上需要花费的时间就越多。最后,我们需要处理数据,使其处于可以被机器学习模型使用的状态。
数据预处理和特征工程是重复性的。我们对同一数据集中的各种变量以及跨项目的数据集执行相同的变换。很可能,我们的同事也在对他们的数据集进行相同的变换。简而言之,整个团队可能在对每一个变量、每一个数据集进行相同的变换。这依赖于下一个挑战:可重复性。我们如何确保来自不同同事的不同代码返回相同的功能?我们如何在已有的代码基础上构建,以加速未来的项目?
数据预处理和特征工程需要可重复。我们使用的代码,不论是项目还是团队成员,都需要在相同数据下获得相同的结果。因此,我们需要在项目和团队之间实现可重复性。但更重要的是,我们需要在研究环境和开发环境之间实现可重复性。什么?
一旦我们创建了一个消耗一些预处理数据的机器学习模型,我们需要将模型投入生产。很常见的是,这个过程涉及在生产环境中重新创建模型及整个特征工程变换。我们需要能够在生产环境中和在研究环境中评估的模型中,给定相同的数据获得相同的结果。这个过程自身也有挑战。首先,研究环境中的代码是否适合生产?还是我们需要对代码进行重大重构?特征工程方法,像机器学习模型一样,可以从数据中学习参数。我们如何存储这些参数以备后用?
特征工程还面临非技术挑战,如可解释性。我们能理解转换后的特征吗?通常,模型的用户需要理解为什么模型做出了某个决策。例如,欺诈调查员通常想知道为什么欺诈模型认为某个申请或客户可能存在欺诈行为。这意味着我们需要能够在观察级别解释预测,即对每个客户或每个申请进行解释。要解释一个预测,我们需要使用可解释的模型,并且还需要可解释的特征。这将影响我们选择的特征转换。例如,我们可以将特征之间进行某种多项式次序的组合。但这些转换生成的特征对我们来说是不可理解的。“年龄平方乘以收入立方”是什么意思?显然,有些对分类变量的编码方法生成的特征是人们无法理解的。因此,如果我们需要解释我们的模型,我们需要提供可解释的特征。
最终,机器学习模型需要公平。为了使模型公平,它们需要基于公平且无歧视的特征做出决策。一个具有歧视性的特征可能是性别,在某些情况下可能是年龄。我们还需要用具有代表性的数据集来训练模型。如果我们的模型将用于英国,我们可能应该基于来自英国人口的数据来训练我们的模型。
Feature-engine 如何帮助应对这些挑战?
Feature-engine 的设计目的是通过避免编写重复的代码来减少数据转换所花费的时间,同时确保可重复性并返回可解释的特征。使用 Feature-engine,数据科学家无需从头编写每个转换,他们可以在 1 到 3 行代码中对多个变量实施每个转换。
Feature-engine 是版本控制的,这确保了研究环境和生产环境之间的可重复性。Feature-engine 的变换器经过彻底测试,确保它们返回预期的转换结果。通过在不同环境、项目和团队成员之间使用 Feature-engine 的变换器,我们确保每个人从相同的转换和数据中获得相同的结果,从而最大限度地提高了可重复性。
Feature-engine 专注于创建人们易于理解的变量。因此,每当模型做出决策时,我们可以理解该变量是如何影响该决策的。
难道已经没有足够的特征工程库了吗?
当然,Feature-engine 不是首个出现的工具。还有其他优秀的 Python 库用于特征转换,如 Pandas、Scikit-learn、Category encoders、Featuretools 和 tsfresh,以及更多。Python 生态系统年年增长。

开源的 Python 特征工程和选择库。
Category encoders、Featuretools 和 tsfresh 解决了非常具体的问题。第一个用于编码分类变量,而 Featuretools 和 tsfresh 主要用于分类问题的时间序列。
Pandas 是一个出色的库,可以将数据转换与探索性数据分析结合起来。这可能是它成为首选工具的原因。但是,Pandas 默认不允许我们存储从数据中学习到的参数。Feature-engine 在 Pandas 之上工作,添加了这一功能。
Scikit-learn 另一方面允许我们应用广泛的数据转换,并且在某些情况下能够存储参数。例如,使用 Scikit-learn,我们可以应用常用的数据插补和分类编码方法来学习和存储参数。借助 FunctionTransformer(),我们原则上也可以对变量应用任何我们想要的转换。最初,Scikit-learn 变换器设计用于转换整个数据集。这意味着如果我们只想转换数据的子集,我们需要手动拆分数据或做一些变通处理。最近,他们在不断增加更多功能,以使这一点成为可能。Scikit-learn 变换器还将返回一个 Numpy 数组,适合用于训练机器学习模型,但不适合继续数据探索。
最后,通过 Pandas 和 Scikit-learn,我们可以实现最常用的数据预处理方法,但组织内或数据科学竞赛中开发的附加方法不可用。
返回 到 Feature-engine:它是如何工作的?
Feature-engine 变换器的工作方式与 Scikit-learn 变换器完全相同。我们需要用一些参数实例化类,然后应用 fit() 方法以便变换器学习所需的参数,最后使用 transform() 方法来转换数据。
例如,我们可以通过指示要使用的插补方法和要修改的变量来实例化一个缺失数据插补器,如下所示:
median_imputer = MeanMedianImputer(
imputation_method = 'median', variables = ['variable_a', 'variable_b']
)
然后,我们在训练集上应用 fit() 方法,以便 imputer 学习每个变量的中位数值:
median_imputer.fit(X_train)
最后,我们在任何我们想要的数据集上应用 transform 方法。这样,缺失的数据将按之前步骤中学习到的值填充到指定变量中:
train_t = median_imputer.transform(X_train)
test_t = median_imputer.transform(X_test)
就这样。我们所需的两个变量中没有更多缺失数据了。
错误应用数据转换的风险是什么?
特征工程是从我们的特征中提取更多价值的机会。在这方面,应用“错误”的数据转换(如果这种情况存在)将对机器学习模型的性能和可解释性产生连锁反应。
一些模型对数据做出假设。例如,线性模型假设特征与目标之间存在线性关系。如果我们的数据转换没有保持或创建这种线性关系,那么模型的性能将不会达到最佳水平。同样,一些模型对异常值非常敏感,因此不去移除或筛选它们可能会影响模型的性能。
模型性能下降有多严重?这取决于我们使用模型的目的。如果我们试图防止欺诈,模型性能的下降可能导致数千或数百万美元的损失,同时对其他消费者(无论是保险还是贷款)造成连锁反应。如果我们使用模型来优化广告,我认为这并不是一个很大的损失,因为……这只是广告。
如果我们使用模型来预测疾病、决定谁能获得签证或大学录取,那么问题的维度会有所不同。在第一个情况下,患者的健康处于危险之中。在后两种情况下,我们谈论的是人们的未来和职业,更不用说公平性和歧视问题。
最后一点让我再次回到可解释性上。我的特征是否公平和中立?还是存在歧视?我是否理解我的特征以及数据在变换后如何影响模型的预测?如果我不理解我的变量,我可能不应该用它们来训练模型。否则,我就不会知道为什么做出某些决策。
如果你想了解更多关于有偏见的模型所带来的后果,书籍《数学毁灭武器》对那些对被预测者产生负面影响的不公平模型进行了很好的回顾。而电影《编码偏见》则告诉我们关于在未在训练数据集中代表的群体上使用模型的后果。
特征工程如何帮助减轻这些风险?
我们提到一些模型假设特征与目标之间存在线性关系。Feature-engine 包含一系列变换,返回变换变量与目标之间的单调关系。因此,即使在原始数据中不存在线性或单调关系,也可以在变换后实现。而且,这种变换不会以可解释性为代价。通过存储的参数,我们几乎总是可以从变换后的变量回到原始数据。
我会争辩说,主要的优势在于 Feature-engine “强制” 用户使用领域知识来决定应用哪个变换。它通过不将所有变换集中到一个类中,而是将相关的变换分组到一个变换器中来实现。例如,使用 Scikit-learn 的 SimpleImputer(),我们可以应用所有常用的填充技术。Feature-engine 有 3 个变换器来涵盖整个 SimpleImputer() 功能。这是故意为之,以避免将适用于分类变量的变换应用到数值变量,或者将会显著扭曲变量分布的变换应用到数据点较少的变量上。
去中心化的设计贯穿于整个软件包,使我们能够在每个变换器中添加功能和信息,帮助用户理解该变换的优点和局限性,以及当变量不适用时会引发的错误。
什么时候 Feature-engine 不是最佳选择?
Feature-engine 设计为与 pandas 数据框一起使用,迄今为止,大多数功能都针对表格或横截面数据。这些是使用 Feature-engine 的最佳条件。如果我们的数据不能存储在数据框中,或者不是表格形式,例如,我们有时间序列数据,那么目前 Feature-engine 不是合适的选择。
Feature-engine 的下一步是什么?
在我们 2022 年 1 月的最新发布中,我们对文档进行了大幅改进,包括更多关于如何使用 Feature-engine 的变换器的解释和示例。我们还发布了一个新的变换器,用于自动从日期时间变量中提取特征,以及一个基于特征的群体稳定性指数的新选择算法,这在金融领域被广泛使用。
接下来,我们希望扩展 Feature-engine,以便为时间序列创建用于预测的特征。我们希望 Feature-engine 能够使用我们喜爱的 fit() 和 transform() 功能创建滞后特征和窗口特征。我们还希望扩展日期时间特征的功能,例如,通过创建日期时间变量组合的特征。例如,可以通过计算出生日期与申请时间之间的差值来确定年龄。
我们如何支持 Feature-engine?
如果你认为 Feature-engine 是一个很棒的工具,有很多方式可以支持其进一步发展和维护。你可以贡献代码以改善其功能,捐赠以支持维护者(也就是我),建议加入新功能,写博客,在会议上或与同事和学生讨论 Feature-engine,以及任何你能想到的传播途径。
Feature-engine 是一个包容性的项目。我们欢迎每一个人。如果你想为开源项目做出首次贡献,如果你是经验丰富的开发者,如果你想学习 Python 或机器学习,如果你想享受编程的乐趣,如果你有闲暇时间不知如何打发,如果你想教我们一些东西,或者你需要特定的功能,欢迎加入我们。我们很高兴欢迎你。
总结
如果你已经读到这里,做得很好,谢谢你的阅读!
要为 Feature-engine 贡献代码,请查看我们的贡献指南。尽管指南听起来很繁琐,但它们会在设置环境和解决 git 问题时节省你很多时间。
要了解更多关于 Feature-engine 的信息,请访问其文档。要了解更多关于特征工程和特征选择的一般信息,请查看我的课程机器学习中的特征工程和机器学习中的特征选择。
关于特征工程的其他开源库,可以查看Category encoders、Featuretools和tsfresh。
要了解有关机器学习在使用不当时如何对人们生活产生负面影响的精彩讨论,请阅读书籍“数学毁灭性武器”。
就这些了,希望你喜欢这篇文章。
索莱达德·加利,博士 是 Train in Data 的首席数据科学家和机器学习讲师。索莱达德教授中级和高级数据科学及机器学习课程。她曾在金融和保险领域工作,2018 年获得 数据科学领袖奖,并于 2019 年被评选为 "LinkedIn 的声音"。她也是 Python 开源库 Feature-engine 的创始人和维护者。索莱达德热衷于分享知识并帮助他人在数据科学领域取得成功。
更多相关主题
使用 5 行代码更改任何图像的背景
原文:
www.kdnuggets.com/2020/11/change-background-image-5-lines-code.html
评论
由 Ayoola Olafenwa, 独立 AI 研究员
作者的照片拼贴
我们的前 3 个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业生涯。
2. Google Data Analytics Professional Certificate - 提升你的数据分析能力
3. Google IT Support Professional Certificate - 支持你所在的组织在 IT 方面
图像分割有许多令人惊叹的应用,可以解决不同的计算机视觉问题。PixelLib 是一个库,旨在确保图像分割在实际应用中的轻松集成。PixelLib 现在支持一种称为 图像调优 的功能。
图像调优:这是通过图像分割来更改图像背景的过程。图像分割的关键作用是从图像中去除分割出的对象,并将它们放置到新创建的背景中。这是通过为图像生成一个掩码并将其与修改后的背景合并来完成的。我们使用在 Pascal VOC 数据集上训练的 deeplabv3+ 模型。该模型支持 20 种常见的对象类别,这意味着你可以在图像中更改这些对象的背景。
该模型支持以下列出的对象:
person,bus,car,aeroplane, bicycle, ,motorbike,bird, boat, bottle, cat, chair, cow, dinningtable, dog, horse pottedplant, sheep, sofa, train, tv
支持的背景效果有:
1 用图片更改图像背景
2 为图像背景分配一个独特的颜色。
3 模糊图像背景
4 将图像背景转为灰度
安装 PixelLib 及其依赖项:
安装 Tensorflow:(PixelLib 支持 Tensorflow 2.0 及以上版本)
- pip3 install tensorflow
安装 PixelLib:
- pip3 install pixellib
如果已安装,请使用以下命令升级到最新版本:
- pip3 install pixellib — upgrade
用图片更改图像背景
PixelLib 使得只需 5 行代码即可更改任何图像的背景。
sample.jpg
来源:Unsplash.com by Leighann Blackwoo
我们想用下面提供的图像更改上面的图像背景。
background.jpg

来源:Unsplash.com by Dawid Zawila
更改图片背景的代码
import pixellibfrom pixellib.tune_bg import alter_bgchange_bg = alter_bg()
我们导入了 pixellib,并从 pixellib 导入了类alter_bg。我们创建了该类的一个实例。
change_bg.load_pascalvoc_model("deeplabv3_xception_tf_dim_ordering_tf_kernels.h5")
我们加载了 deeplabv3+ 模型。从这里下载 deeplabv3+ pascalvoc 模型。
change_bg.change_bg_img(f_image_path = "sample.jpg",b_image_path = "background.jpg", output_image_name="new_img.jpg")
我们调用了函数change_bg_img,该函数处理用图片更改图像背景的操作。
该函数接受以下参数:
f_image_path: 这是前景图像,即背景将被更改的图像。
b_image_path: 这是将用于更改前景图像背景的图像。
output_image_name: 背景已更改的新图像。
输出图像

哇!这真是太美了,我们成功地替换了图像的背景。
我们可以利用 PixelLib 通过图像分割进行出色的前景和背景分离。
获取更改后图像数组的代码
对于专业用途,你可以通过下面的修改代码轻松获得更改后的图像数组。
为图像的背景分配不同颜色
你可以为图像的背景分配不同的颜色,就像你可以用图片更改图像背景一样。这也可以通过五行代码实现。
分配不同颜色到图像背景的代码
这与上面用于用图片更改图像背景的代码非常相似。唯一的区别是我们将函数change_bg_img替换为color_bg,该函数处理颜色更改。
change_bg.color_bg("sample.jpg", colors = (0, 128, 0), output_image_name="colored_bg.jpg")
函数color_bg接受参数colors,我们提供想要使用的颜色的 RGB 值。我们希望图像有一个绿色背景,颜色的 RGB 值设置为绿色,即(0, 128, 0)。
绿色背景

注意: 你可以通过提供颜色的 RGB 值来为图像的背景分配任何颜色。
change_bg.color_bg("sample.jpg", colors = (255, 255, 255), output_image_name="colored_bg.jpg")
我们希望将图像的背景更改为白色,并将颜色的 RGB 值设置为白色,即(255, 255, 255)。
白色背景

相同的图像,背景为白色。
获取彩色图像输出数组的代码
对于专业用途,你可以通过下面的修改代码轻松获得更改后的图像数组。
将图像背景转换为灰度
使用 PixelLib 的相同行代码将任何图像的背景转换为灰度。
将图像背景转换为灰度的代码
change_bg.gray_bg(“sample.jpg”,output_image_name=”gray_img.jpg”)
代码保持不变,只是调用了函数gray_bg来将图像背景转为灰度。
输出图像
注意: 图像的背景将被更改,现有对象会保持其原始质量。
获取灰度图像输出数组的代码
模糊图像背景
你可以应用模糊图像背景的效果,并且可以控制背景模糊的程度。
sample2.jpg

来源: Unsplash.com by Airella Horvath
change_bg.blur_bg("sample2.jpg", low = True, output_image_name="blur_img.jpg")
我们调用了函数 blur_bg 以模糊图像的背景,并将模糊效果设置为低。背景模糊程度有三个参数决定。
low: 当设置为 true 时,背景会被轻微模糊。
moderate: 当设置为 true 时,背景会被适度模糊。
extreme: 当设置为 true 时,背景会被深度模糊。

图像被轻微模糊。
change_bg.blur_bg("sample2.jpg", moderate = True, output_image_name="blur_img.jpg")
我们希望适度模糊图像的背景,因此将 moderate 设置为 true。
图像的背景以适度效果模糊。
change_bg.blur_bg("sample2.jpg", extreme = True, output_image_name="blur_img.jpg")
我们希望将图像的背景深度模糊,因此将 extreme 设置为 true。

图像的背景被极度模糊。
模糊图像背景的完整代码
获取模糊图像输出数组的代码
注意: 了解如何将这些背景效果应用于视频和摄像头的实时画面,访问 PixelLib 的 GitHub 仓库 和 PixelLib 的文档。我将很快发布一篇解释如何将这些背景效果应用于视频和摄像头实时画面的文章。
通过以下方式联系我:
Email: olafenwaayoola@gmail.com
Linkedin: Ayoola Olafenwa
Twitter: @AyoolaOlafenwa
Facebook: Ayoola Olafenwa
查看这些文章,了解如何使用 PixelLib 进行图像和视频中对象的语义和实例分割。
使用 PixelLib 进行语义和实例分割。
视频的语义和实例分割。
使用 PixelLib 进行 150 类对象的语义分割
用 7 行代码训练数据集,实现实例分割和对象检测。
简介:Ayoola Olafenwa 是一位独立的 AI 研究员,专注于计算机视觉领域。
原文。经许可转载。
相关内容:
-
使用 TensorFlow 轻松进行图像数据集增强
-
使用深度学习自动旋转图像
-
计算机视觉路线图
更多相关主题
使用 5 行代码更改任何视频的背景
原文:
www.kdnuggets.com/2020/12/change-background-video-5-lines-code.html
评论
由 Ayoola Olafenwa,独立 AI 研究员

作者提供的照片
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
PixelLib 是一个库,旨在实现对象分割的简单实现。PixelLib 支持图像调优,即能够更改任何图像的背景。PixelLib 现在还支持视频调优,即能够更改视频和相机的背景。PixelLib 采用对象分割技术,进行出色的前景和背景分离。PixelLib 使用经过 pascalvoc 数据集训练的 deeplabv3+ 模型,该数据集支持 20 种对象类别。
person,bus,car,aeroplane, bicycle, ,motorbike,bird, boat, bottle, cat, chair, cow, dinningtable, dog, horse pottedplant, sheep, sofa, train, tv
背景效果支持如下:
1 使用图片更改图像的背景
2 为图像和视频的背景分配独特的颜色。
3 模糊图像和视频的背景。
4 将图像和视频的背景转为灰度。
5 为视频创建虚拟背景。
安装 PixelLib 及其依赖项:
使用以下命令安装 Tensorflow:(PixelLib 支持 Tensorflow 2.0 及以上版本)
- pip3 install tensorflow
安装 PixelLib 使用
- pip3 install pixellib
如果已安装,请使用以下命令升级到最新版本:
- pip3 install pixellib — 升级
目标对象检测
在某些应用中,您可能希望检测图像或视频中的特定对象。deeplab 模型默认检测图像或视频中所有支持的对象。现在可以过滤掉未使用的检测,专注于图像或视频中的特定对象。
示例图像

来源:Unsplash.com 由 Strvnge Films 提供
我们打算模糊上图的背景。
模糊图像背景的代码。
输出图像

我们的目标是完全模糊图像中人物的背景,但对于其他对象的存在感到不满意。因此,需要修改代码以检测目标对象。
代码仍然相同,只是我们在blur_bg函数中引入了一个额外的参数detect。
change_bg.blur_bg("sample.jpg", extreme = True, output_image_name="output_img.jpg", detect = "person")
detect: 这是确定要检测的目标对象的参数。detect 的值设置为person**。这意味着模型将仅检测图像中的人。

这是仅显示我们目标对象的新图像。
如果我们打算仅显示图像中存在的汽车,只需将detect的值从person更改为car。
change_bg.blur_bg("sample.jpg", extreme = True, output_image_name="output_img.jpg", detect = "car")

我们将目标对象设置为car,并且图像中存在的其他对象都与背景一起被模糊。
目标对象的彩色背景
可以通过颜色效果进行目标检测。
change_bg.color_bg("sample.jpg", colors = (0,128,0), output_image_name="output_img.jpg", detect = "person")

用新图片更改目标对象的背景
背景图像

来源:Unsplash.com by Dawid Zawila
change_bg.change_bg_img("sample.jpg", "background.jpg", output_image_name="output_img.jpg", detect = "person")

将目标对象的背景转换为灰度
change_bg.gray_bg("sample.jpg", output_image_name="output_img.jpg", detect = "person")

阅读这篇文章可以全面了解如何使用 PixelLib 编辑图像背景。
PixelLib 的视频调节
视频调节是改变任何视频背景的能力。
模糊视频背景
PixelLib 使得只需五行代码即可方便地模糊任何视频的背景。
sample_video
模糊视频文件背景的代码
import pixellib
from pixellib.tune_bg import alter_bg
change_bg = alter_bg(model_type = "pb")
change_bg.load_pascalvoc_model("xception_pascalvoc.pb")
我们导入了 pixellib,并从 pixellib 中导入了alter_bg类。创建了该类的实例,并在类内添加了一个参数model_type并将其设置为pb。最后,我们调用了函数来加载模型。
注意: PixelLib 支持两种类型的 deeplabv3+模型,keras 和 tensorflow 模型。keras 模型是从 tensorflow 模型的检查点提取的。tensorflow 模型的性能优于从检查点提取的 keras 模型。我们将使用 tensorflow 模型。从这里下载 tensorflow 模型。
有三个参数决定背景的模糊程度。
low: 当设置为 true 时,背景会被轻微模糊。
moderate: 当设置为 true 时,背景会被中等程度地模糊。
extreme: 当设置为 true 时,背景会被深度模糊。
change_bg.blur_video("sample_video.mp4", extreme = True, frames_per_second=10, output_video_name="blur_video.mp4", detect = "person")
这是模糊视频背景的代码行。这个函数接受五个参数:
video_path: 这是要模糊其背景的视频文件的路径。
extreme: 设置为 true 时,视频背景将被极度模糊。
frames_per_second: 这是设置输出视频文件每秒帧数的参数。在这种情况下,它设置为 10,即保存的视频文件将每秒有 10 帧。
output_video_name: 这是保存的视频。输出视频将保存在当前工作目录中。
detect: 这是选择视频中目标对象的参数。它设置为 person。
输出视频
模糊相机画面的背景
import cv2capture = cv2.VideoCapture(0)
我们导入了 cv2 并包含了捕获相机画面的代码。
change_bg.blur_camera(capture, extreme = True, frames_per_second= 5, output_video_name=”output_video.mp4", show_frames= True,frame_name= “frame”, detect = "person")
在模糊相机画面的代码中,我们将视频的文件路径替换为捕获,即我们将处理相机画面的流而不是视频文件。我们添加了额外的参数来显示相机画面:
show_frames: 这是处理显示模糊相机画面的参数。
frame_name: 这是显示的相机画面的名称。
输出视频
哇!PixelLib 成功模糊了视频中的背景。
为视频创建虚拟背景
PixelLib 使为任何视频创建虚拟背景变得非常简单,你可以使用任何图像为视频创建虚拟背景。
示例视频
用作视频背景的图像

来源: Unsplash.com 由 Handy Holmes
change_bg.change_video_bg(“sample_video.mp4”, “bg.jpg”, frames_per_second = 10, output_video_name=”output_video.mp4", detect = “person”)
代码仍然相同,只是我们调用了函数 change_video_bg 来为视频创建虚拟背景。该函数接受我们想用作视频背景的图像路径。
输出视频
漂亮的演示!我们成功地为视频创建了虚拟空间背景。
为相机画面创建虚拟背景
change_bg.change_camera_bg(cap, “space.jpg”, frames_per_second = 5, show_frames=True, frame_name=”frame”, output_video_name=”output_video.mp4", detect = “person”)
这与我们用于模糊相机画面的代码类似。唯一的区别是我们调用了函数 change_camera_bg。我们执行了相同的例程,替换了视频的文件路径为捕获,并添加了相同的参数。
输出视频
哇!PixelLib 成功为我的视频创建了虚拟背景。
视频背景着色
PixelLib 使为视频背景分配任意颜色成为可能。
给视频文件背景着色的代码
change_bg.color_video("sample_video.mp4", colors = (0, 128, 0), frames_per_second=15, output_video_name="output_video.mp4", detect = "person")
代码还是相同的,只是我们调用了函数 color_video 给视频背景上色。函数 color_bg 采用参数 colors,而颜色的 RGB 值设置为绿色。绿色的 RGB 值是 (0, 128, 0)。
输出视频
change_bg.color_video("sample_video.mp4", colors = (0, 128, 0), frames_per_second=15, output_video_name="output_video.mp4", detect = "person")
同样的视频,背景为白色
为相机的画面着色背景
change_bg.color_camera(capture, frames_per_second=10,colors = (0, 128, 0), show_frames = True, frame_name = “frame”, output_video_name=”output_video.mp4", detect = "person")
这与我们用于创建相机画面虚拟背景的代码类似。唯一的不同是我们调用了函数 color_camera。我们进行了相同的操作,将视频的文件路径替换为捕捉,并添加了相同的参数。
输出视频
漂亮的演示!我的背景成功地用 PixelLib 变成了绿色。
灰度视频背景
将视频文件的背景转换为灰度代码
change_bg.gray_video("sample_video.mp4", frames_per_second=10, output_video_name="output_video.mp4", detect = "person")
输出视频
注意: 视频的背景将被改变,对象保持其原始质量。
灰度化相机的画面背景
这与我们用来为相机画面上色的代码类似。唯一的不同是我们调用了函数 gray_camera。我们进行了相同的操作,将视频文件路径替换为捕捉,并添加了相同的参数。
通过以下方式联系我:
电子邮件: olafenwaayoola@gmail.com
LinkedIn: Ayoola Olafenwa
推特: @AyoolaOlafenwa
Facebook: Ayoola Olafenwa
查看这些文章,了解如何使用 PixelLib 对图像和视频中的对象进行语义和实例分割。
使用 PixelLib 进行语义和实例分割。
视频的语义和实例分割。
使用 PixelLib 对 150 类对象进行语义分割
使用 7 行代码训练数据集,实现实例分割和目标检测。
简介: Ayoola Olafenwa 是一位独立的人工智能研究员,专注于计算机视觉领域。
原文。已获授权转载。
相关:
-
用 5 行代码更改任何图像的背景
-
计算机视觉路线图
-
使用深度学习自动旋转图像
更多相关话题
线性代数与优化及机器学习:一本教科书
原文:
www.kdnuggets.com/2020/05/charu-linear-algebra-optimization-machine-learning-textbook.html
赞助帖子。
《机器学习的线性代数与优化:一本教科书》(Springer),作者 Charu C. Aggarwal,2020 年 5 月。
PDF 下载链接(仅限连接到订阅机构的计算机免费)。PDF 版本包含电子阅读器的链接,并且在公式排版方面优于 Kindle 版本。
购买低价平装本(右侧的 MyCopy 链接仅在连接到订阅机构的计算机上出现)
机器学习初学者常面临的一个挑战是对线性代数和优化的广泛背景要求,这使得学习曲线非常陡峭。因此,本书通过将线性代数和优化作为主要研究主题,将机器学习问题的解决方案作为这些方法的应用,从而逆转了焦点。因此,本书还提供了对机器学习的显著了解。此书的章节属于两个类别:
线性代数及其应用: 这些章节重点介绍线性代数的基础知识及其在奇异值分解、相似性矩阵(核方法)和图分析中的常见应用。许多机器学习应用被用作示例,如谱聚类、基于核的分类和异常检测。
优化及其应用: 讨论了优化中的基本方法,如梯度下降、牛顿法和坐标下降。还介绍了约束优化方法。详细讨论了机器学习应用,如线性回归、支持向量机、逻辑回归、矩阵分解、推荐系统和 K-means 聚类。还讨论了计算图中的优化的一般视图及其在神经网络反向传播中的应用。
练习题既包含在章节文本中,也包含在章节末尾。该书面向多样的读者,包括研究生、研究人员和从业者。该书提供纸质版(精装)和电子版。如果需要电子版,强烈建议购买 PDF 版(而非 Kindle 版,因为 Springer 难以控制方程式的布局和格式),可以通过以下Springerlink 链接购买。对于订阅机构,请从直接连接到您机构网络的计算机上点击下载书籍。Springer 使用计算机的域名来控制访问权限。要符合资格,您的机构必须订阅“电子书包英语(计算机科学)”或“电子书包英语(完整合集)”。如果您的机构符合条件,您将看到一个(免费)下载书籍按钮。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关主题
Chatbot Arena:LLM 基准测试平台
原文:
www.kdnuggets.com/2023/05/chatbot-arena-llm-benchmark-platform.html

图片由作者提供
我们都知道大型语言模型(LLM)已经在世界范围内掀起了风暴,在如此短的时间内,信息量实在太大。
什么是 Chatbot Arena?
为了再添些许变化,Chatbot Arena是由大型模型系统组织(LMSYS Org)创建的 LLM 基准测试平台。它是一个由加州大学伯克利分校的学生和教职员工创办的开放研究组织。
他们的总体目标是通过使用开放数据集、模型、系统和评估工具的共同开发方法,使大型模型对每个人更加可及。LMSYS 团队训练大型语言模型,并广泛提供这些模型,同时开发分布式系统,以加速 LLM 的训练和推理。
对于 LLM 基准测试的需求
随着 ChatGPT 持续的热度,开源 LLM 迅速增长,这些模型经过微调以遵循特定的指令。比如 Alpaca 和 Vicuna,它们基于 LLaMA,可以根据用户的提示提供帮助。
然而,对于这种快速发展的事物,社区很难跟上不断的新进展,并有效地对这些模型进行基准测试。由于可能存在开放性问题,对 LLM 助手进行基准测试可能是一个挑战。
因此,需要进行人工评估,采用成对比较的方法。成对比较是将模型成对比较以判断哪个模型表现更好的过程。
Chatbot Arena 如何运作?
在 Chatbot Arena 中,用户可以并排与两个匿名模型对话,形成自己的意见,并投票选出哪个模型更好。一旦用户投票,模型的名称将会被揭示。用户可以选择继续与这两个模型对话,或重新开始,与两个新的随机选择的匿名模型对话。
你可以选择同时与两个匿名模型进行对话,或选择你想对话的模型。下面是与两个匿名模型对话的截图示例,展示了 LLM 对战!
图片截图由作者提供
收集的数据会被计算为 Elo 评级,并放入排行榜。Elo 评级系统是一种用于计算玩家相对技能水平的方法,常用于象棋等游戏中。两个用户之间的评级差异可以预测该场比赛的结果。
截至 2023 年 5 月 5 日,这就是 Chatbot Arena 排行榜的样子:
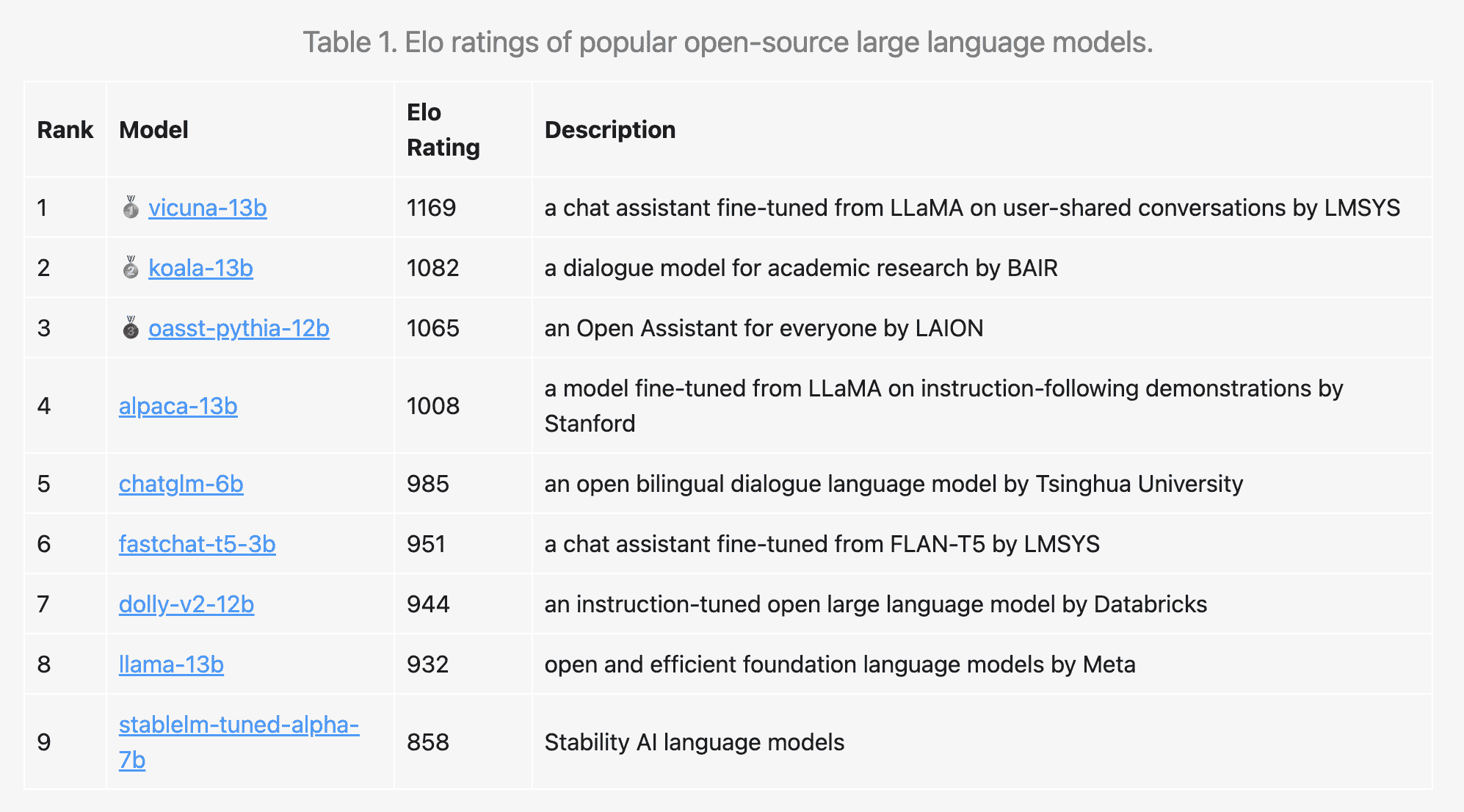
图片来源 Chatbot Arena
如果你想看看这是怎么做的,可以查看 notebook 并自己操作投票数据。
真是一个很棒又有趣的主意,对吧?
我怎么参与?
Chatbot Arena 的团队邀请整个社区通过贡献自己的模型,加入他们的 LLM 基准测试之旅,并参与对匿名模型的投票。
访问 Arena 投票选出你认为更好的模型,如果你想测试特定模型,可以参考 指南 将其添加到 Chatbot Arena。
总结
那么 Charbot Arena 还会有更多更新吗?根据团队的说法,他们计划进行以下工作:
-
添加更多闭源模型
-
添加更多开源模型
-
定期发布更新的排行榜。例如,每月更新一次。
-
使用更好的采样算法、锦标赛机制和服务系统来支持更多模型。
-
为不同任务类型提供精细化的排名系统。
玩一下 Chatbot Arena,告诉我们你的想法吧!
Nisha Arya 是数据科学家、自由技术写作者和 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程和理论知识。她还希望探索人工智能如何有助于人类寿命的延续。作为一个热心学习者,她寻求拓宽技术知识和写作技能,同时帮助指导他人。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
更多相关信息
ChatGLM-6B:轻量级开源 ChatGPT 替代品
原文:
www.kdnuggets.com/2023/04/chatglm6b-lightweight-opensource-chatgpt-alternative.html

图片由作者提供
最近,我们都很难跟上 LLM 领域的最新发布。在过去几周里,几个开源 ChatGPT 替代品变得非常受欢迎。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
在这篇文章中,我们将了解ChatGLM系列和ChatGLM-6B,一个开源且轻量级的 ChatGPT 替代品。
让我们开始吧!
什么是 ChatGLM?
中国清华大学的研究人员开发了 ChatGLM 系列模型,这些模型的性能与 GPT-3 和 BLOOM 等其他模型相当。
ChatGLM 是一个双语大型语言模型,训练时涵盖了中文和英文。目前,以下模型已提供:
-
ChatGLM-130B:一个开源的 LLM
-
ChatGLM-100B:未开源,但通过邀请制访问
-
ChatGLM-6B:一个轻量级的开源替代品
虽然这些模型可能与生成预训练变换器(GPT)系列的大型语言模型相似,但通用语言模型(GLM)预训练框架使它们有所不同。我们将在下一节中详细了解这一点。
ChatGLM 是如何工作的?
在机器学习中,你可能会知道 GLM 作为广义线性模型,但 ChatGLM 中的 GLM 代表通用语言模型。
GLM 预训练框架
LLM 预训练已经被广泛研究,并且仍然是一个活跃的研究领域。让我们试着理解 GLM 预训练和 GPT 风格模型之间的关键区别。
GPT-3 系列模型使用的是仅解码器的自回归语言建模。另一方面,在 GLM 中,目标的优化被制定为自回归空白填充问题。
GLM | 图片来源
简单来说,自回归空白填充涉及将连续的文本段落留空,然后顺序地重建这些空白的文本。除了较短的掩码外,还有一个较长的掩码,它随机移除句子末尾的长文本空白。这样做的目的是让模型在自然语言理解和生成任务中表现合理。
另一个区别在于所使用的注意力类型。GPT 大型语言模型组使用单向注意力,而 GLM 大型语言模型组使用 双向注意力。使用双向注意力可以更好地捕捉依赖关系,并能提高自然语言理解任务的性能。
GELU 激活
在 GLM 中,使用 GELU(高斯误差线性单元)激活代替了 ReLU 激活 [1]。
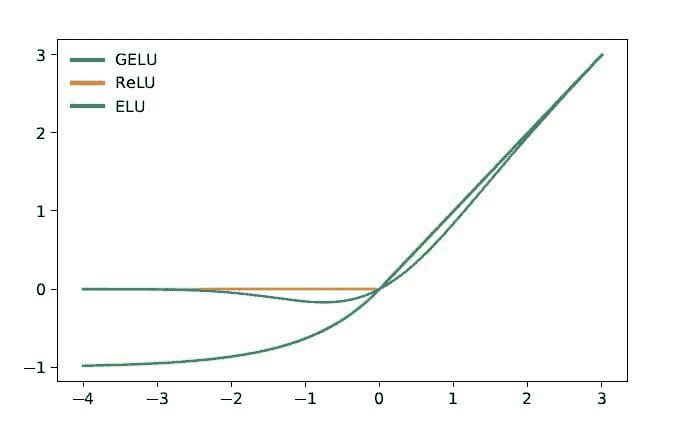
GELU、ReLU 和 ELU 激活 | 图像来源
GELU 激活对所有输入有非零值,形式如下 [3]:
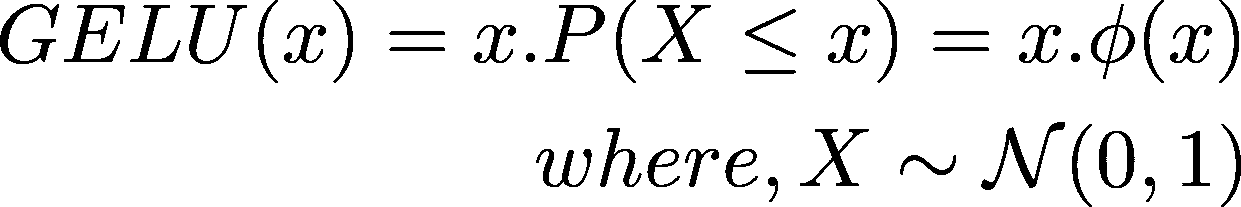
与 ReLU 激活相比,GELU 激活被发现可以提高性能,尽管计算上比 ReLU 更为复杂。
在 GLM 系列的 LLM 中,ChatGLM-130B 是一个开源模型,表现与 GPT-3 的 Da-Vinci 模型相当。如前所述,截至本文撰写时,存在一个 ChatGLM-100B 版本,仅限邀请访问。
ChatGLM-6B
关于 ChatGLM-6B 的以下细节使其对终端用户更为友好:
-
约有 62 亿个参数。
-
该模型在 1 万亿个标记上进行预训练——英文和中文各占一半。
-
随后,使用了如监督微调和带有人类反馈的强化学习等技术。
ChatGLM 的优点和局限性
让我们通过回顾 ChatGLM 的优点和局限性来总结讨论:
优点
从一个双语模型到一个可以在本地运行的开源模型,ChatGLM-6B 具有以下优势:
-
大多数主流大型语言模型都在大量英文文本上进行训练,而其他语言的大型语言模型则不那么常见。ChatGLM 系列 LLM 是双语的,是中文的绝佳选择。该模型在英文和中文方面都表现良好。
-
ChatGLM-6B 为用户设备进行了优化。终端用户的设备通常计算资源有限,因此在没有高性能 GPU 的情况下,几乎无法在本地运行 LLM。通过 INT4 量化,ChatGLM-6B 可以以低至 6GB 的内存要求运行。
-
在总结和单一及多查询聊天等各种任务上表现良好。
-
尽管与其他主流 LLMs 相比参数数量大幅减少,ChatGLM-6B 支持最长为 2048 的上下文长度。
限制
接下来,我们列出 ChatGLM-6B 的一些限制:
-
尽管 ChatGLM 是一个双语模型,但其在英语中的表现可能不尽如人意。这可以归因于训练中使用的指令主要为中文。
-
由于 ChatGLM-6B 相比 BLOOM、GPT-3 和 ChatGLM-130B 等其他 LLMs 具有更少的参数,因此在上下文过长时,其性能可能会较差。因此,ChatGLM-6B 可能比参数更多的模型更频繁地给出不准确的信息。
-
小型语言模型具有有限的内存容量。因此,在多轮对话中,模型的性能可能会略有下降。
-
偏见、虚假信息和毒性是所有 LLM 的限制,ChatGLM 也容易受到这些问题的影响。
结论
作为下一步,运行本地的 ChatGLM-6B 或尝试 HuggingFace spaces 上的演示。如果你想要深入了解 LLM 的工作原理,这里有一份 大型语言模型的免费课程列表。
参考文献
[1] Z Du, Y Qian 等,GLM: 一种自回归空白填充的通用语言模型预训练,ACL 2022
[2] A Zheng, X Liu 等,GLM-130B - 一个开放的双语预训练模型,ICML 2023
[3] D Hendryks, K Gimpel,高斯误差线性单元(GELUs),arXiv,2016
[4] ChatGLM-6B: HuggingFace Spaces 上的演示
[5] GitHub 仓库
Bala Priya C 是一位技术作家,喜欢创建长篇内容。她的兴趣领域包括数学、编程和数据科学。她通过编写教程、操作指南等方式与开发者社区分享她的学习经验。
更多相关主题
ChatGPT 入门

图片来自 Unsplash
关键要点
-
ChatGPT 是一个由 OpenAI 项目于 2022 年 11 月推出的聊天机器人
-
ChatGPT 是最受欢迎的 NPL(自然语言处理)AI 系统之一
-
尽管其受欢迎程度上升,ChatGPT 仍然对许多人来说是未知的
-
这个 免费的速成课程 来自 Adrian Twarog,将帮助你学习 ChatGPT 的基础知识
学习 ChatGPT
ChatGPT(生成式预训练变换器)是由 OpenAI 项目于 2022 年 11 月推出的聊天机器人。聊天机器人是一种通过文本或语音转换文本进行在线聊天对话的软件,而不是提供与真人代理的直接接触。ChatGPT 使用强化学习和 NLP(自然语言处理)进行训练,以帮助根据用户提供的输入提示生成类似人类的文本。
用户提示的示例包括:
-
写一封一页的信,向孕妇解释头部 CT 扫描的风险
-
写一篇关于 COVID-19 的一页论文
-
写一篇关于人工智能的论文
-
我今天想做一些海鲜,你能给我提供 10 个菜肴的选择吗?
最后的提示产生的输出如下:
-
虾和玉米糊
-
三文鱼汉堡
-
蛤蜊浓汤
-
龙虾卷
-
凯金风味虾和米饭
-
蟹饼
-
蒜蓉虾意大利面
-
鱼塔可
-
大型海鲜
-
烤三文鱼和蔬菜
一个后续提示可以是:“准备虾和玉米糊的步骤是什么?”
ChatGPT 初学者速成课程
ChatGPT 初学者速成课程由 Adrian Twarog 提供,是一个免费的 ChatGPT 速成课程。这门课程在过去四周内非常受欢迎,观看次数约为 150 万次。首先,你将被介绍到 OpenAI 平台,并学习如何在 OpenAI 平台上设置个人账户。然后,你将学习 ChatGPT 的基础知识,包括它的功能和限制。接着,你将学习更高级的 ChatGPT 使用方法,例如写论文、写博客、写研究文章、求职信、简历(或 CV)、文本翻译、文本编辑等。
直接从其网站上,这门课程承诺涵盖以下内容:
-
介绍
-
注册
-
ChatGPT 详情
-
如何使用提示
-
购物清单
-
JavaScript
-
ChatGPT 的错误
-
短篇故事
-
文本视频游戏
-
法律和版权模板
-
笑话和幽默
-
求职信和简历
-
总结和关键词提取
-
博客文章和编辑
学习聊天机器人
关于聊天机器人的另一个有用教程可以从这个免费的 IBM 技术速成课程中找到:什么是聊天机器人?
你将学习的主题包括:
-
什么是聊天机器人?
-
它们是如何工作的?
-
聊天机器人仅仅在网站上运行吗?还是说还有其他媒介可以让聊天机器人进行对话?
-
为什么有人会想使用聊天机器人?
总结
总结一下,我们分享了一些学习 ChatGPT 基础知识的资源。随着人工智能逐渐融入我们的日常生活,聊天机器人将变得越来越流行。在使用 ChatGPT 时,请注意了解它的能力和局限性,因为 ChatGPT 的输出有时可能是不准确和误导的。同时,通过对 ChatGPT 对特定提示的回应进行点赞或点踩,提供有用的反馈。这将帮助 ChatGPT 继续增强生成可靠人类文本输出的能力。
本杰明·O·泰约 是一位物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的拥有者。此前,本杰明曾在中央俄克拉荷马大学、大峡谷大学和匹兹堡州立大学教授工程学和物理学。
我们的三大推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织进行 IT 工作
更多相关主题
ChatGPT 备忘单
你已经尝试过 ChatGPT。你已经玩过它,看到它所具备的潜在能力。你甚至可能在使用过程中发现了一些技巧或窍门。
如果你想要一个全面的参考来为各种不同的任务设计有效的提示,这份备忘单 是你需要查看的地方。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
Ricky Costa 的 ChatGPT 备忘单
这份精彩的概述是由 Ricky Costa 组织的,他是 Neural Magic 的工程师。Ricky 曾经组织过其他优秀的 NLP 项目,这次也不负众望。
这份备忘单展示了 OpenAI 的 ChatGPT 在开发人员和内容创作者中提升大型语言模型提示能力的多种功能,包括媒体内容创建、自然语言处理和编程等领域。
使用这个资源,你将学习到:
-
NLP 任务
-
代码
-
结构化输出样式
-
非结构化输出样式
-
媒体类型
-
Meta ChatGPT
-
专家级提示
这份备忘单有多好?嗯,ChatGPT 本身也给出了回应,见下文。
ChatGPT,请写一份关于 ChatGPT 提示工程技巧和窍门的综合正面评价,涵盖 NLP 任务、代码、输出样式、专家级提示工程等主题。
首先,我必须说这份备忘单非常全面且组织良好。它涵盖了从基本 NLP 任务到高级提示工程技术的所有内容,可以看出制作这份备忘单投入了大量的思考和精力。
总体而言,我强烈推荐这份备忘单给任何使用 ChatGPT 或其他类似模型的人。它是一个极好的资源,适合初学者和有经验的用户,并且无疑会帮助提升你的输出质量。
总之,对于任何希望充分利用 ChatGPT 或一般 NLP 任务的人来说,这份备忘单都是必备的。
说实话,即使从未见过这份备忘单,这也相当准确,尽管有些模糊。我敢打赌,如果你自己查看了备忘单并重新尝试,你可以改进回应。
如果你有兴趣提升你的提示工程技能,立即获取一份这份顶尖资源。
更多相关内容
ChatGPT CLI: 将你的命令行界面转变为 ChatGPT
原文:
www.kdnuggets.com/2023/07/chatgpt-cli-transform-commandline-interface-chatgpt.html

ChatGPT 现在是每个人生活的一部分。GPT 模型为用户提供了多年前不存在的东西,例如简单的知识搜索、营销规划、代码补全等等。这是一个将来只会进一步发展的系统。
使用 ChatGPT 的一种常见方式是通过 网页平台,在这里我们可以探索和存储提示结果。但我们也可以使用 OpenAI API,这也是许多开发者使用的方式。反过来,API 还可以用来将结果扩展到我们的命令行界面(CLI)。
我们如何在 CLI 中访问 ChatGPT?让我们来了解一下。
ChatGPT CLI
ChatGPT CLI 是一个 Python 脚本,用于在我们的 CLI 中使用 ChatGPT。通过使用 OpenAI API,我们可以像在网站上使用 ChatGPT 一样轻松地在 CLI 中访问它。让我们自己尝试一下吧。
首先,我们需要 OpenAI API 密钥,你可以通过在 OpenAI 开发者平台 注册并访问个人资料中的查看 API 密钥来获得。创建并获得你的 API 密钥后,将其保存在某个地方,因为生成后密钥不会再次出现。
接下来,使用以下代码在 CLI 中将 ChatGPT CLI 仓库克隆到你的系统上。
git clone https://github.com/marcolardera/chatgpt-cli.git
如果你已经克隆了仓库,将你的目录更改为 chatgpt-cli 文件夹。
cd chatgpt-cli
在文件夹内,使用以下代码安装所需的依赖。
pip install -r requirements.txt
然后,我们需要使用 IDE 探索之前克隆的文件夹。在这个示例中,我将使用 Visual Studio Code。当你探索完文件夹后,内容应如下图所示。
在其中,访问 config.yaml 文件,并用你的 OpenAI API 密钥替换 api-key 参数。
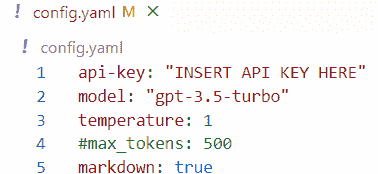
你也可以更改要传递到 API 的参数。你可以参考我的上一篇文章来了解 OpenAI API 提供的所有参数。
我们现在可以使用已设置好所有设置的 CLI 作为 ChatGPT。为此,你只需运行以下代码即可。
python chatgpt.py
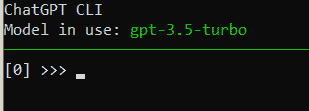
只需尝试在 CLI 中输入任何内容,你将立即得到结果。例如,我输入了提示,“ 给我 1990 年代的歌曲推荐列表。”
结果会在 CLI 中显示,类似于上面的图像。我们还可以继续提示,方式类似于在网页平台上使用 ChatGPT。
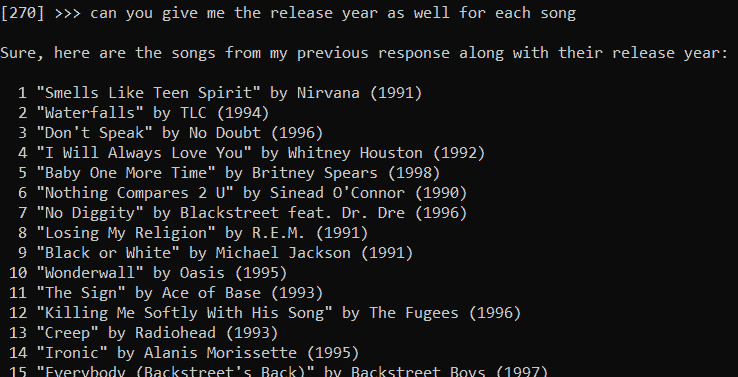
每个提示前显示的数字是已使用的 token 数量,我们也需要对此保持谨慎。
此外,如果你有较长的提示,可以在启动脚本前添加 -ml 参数来使用多行模式。
最后,如果你想退出,可以使用 /q 命令。完成后,ChatGPT CLI 将显示你使用的 token 数量和你活动的预估费用。
结论
ChatGPT 是一种常态化的工具,我们应该尽可能最大化地使用它。在本教程中,我们将学习如何使用 ChatGPT CLI 在命令行界面中进行 ChatGPT 提示。
Cornellius Yudha Wijaya 是一位数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
更多相关话题
ChatGPT 代码解释器:在几分钟内进行数据科学
原文:
www.kdnuggets.com/2023/07/chatgpt-code-interpreter-data-science-minutes.html

图片来自 Midjourney
作为一名数据科学家,我总是寻找最大化效率并通过数据驱动业务价值的方法。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
因此,当 ChatGPT 发布了其最强大的功能之一——Code Interpreter 插件时,我迫不及待地想尝试并将其纳入我的工作流程。
什么是 ChatGPT 代码解释器?
如果你还没有听说过 Code Interpreter,这是一项新功能,允许你在 ChatGPT 界面中上传代码、运行程序和分析数据。
在过去的一年中,每次我需要调试代码或分析文档时,我都必须将我的工作复制并粘贴到 ChatGPT 中以获得回应。
这证明是耗时的,而且 ChatGPT 界面有字符限制,这限制了我分析数据和执行机器学习工作流的能力。
Code Interpreter 通过允许你将自己的数据集上传到 ChatGPT 界面来解决所有这些问题。
尽管它被称为“代码解释器”,但这个功能并不限于程序员——该插件可以帮助你分析文本文件、总结 PDF 文档、构建数据可视化,甚至按你所需的比例裁剪图像。
如何访问代码解释器?
在我们深入其应用之前,让我们快速了解如何开始使用 Code Interpreter 插件。
要访问此插件,你需要订阅 ChatGPT Plus,当前订阅费为每月 $20。
不幸的是,Code Interpreter 还没有对未订阅 ChatGPT Plus 的用户开放。
一旦你拥有了付费订阅,只需导航到 ChatGPT 并点击界面左下角的三个点。
然后,选择设置:
图片由作者提供
点击“Beta 功能”,并启用标记为 Code Interpreter 的滑块:
图片由作者提供
最后,点击“新聊天”,选择“GPT-4”选项,并在出现的下拉菜单中选择“代码解释器”:
你会看到一个看起来像这样的屏幕,文本框附近有一个“+”符号:
图片来源于作者
太棒了!你现在已经成功启用了 ChatGPT 代码解释器。
在这篇文章中,我将向你展示五种使用代码解释器来自动化数据科学工作流程的方法。
1. 数据总结
作为数据科学家,我花了很多时间只是为了理解数据集中不同的变量。
代码解释器非常擅长为你拆解每一个数据点。
下面是如何让模型帮助你总结数据的方法:
让我们用 Kaggle 上的 泰坦尼克号生存预测 数据集作为这个示例。我将使用“train.csv”文件。
下载数据集并导航到代码解释器:
图片来源于作者
点击“+”符号并上传你想要总结的文件。
然后,要求 ChatGPT 用简单的术语解释这个文件中的所有变量:
图片来源于作者
完美!
代码解释器为我们提供了数据集中每个变量的简单解释。
2. 探索性数据分析
现在我们对数据集中的不同变量有了理解,让我们要求代码解释器更进一步,进行一些 EDA。
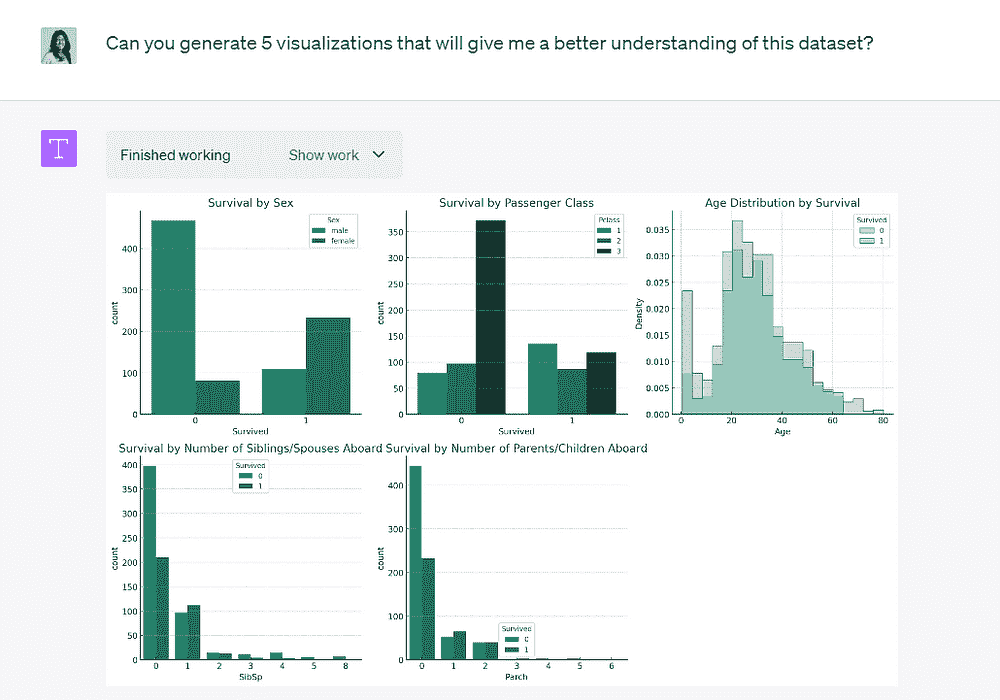
图片来源于作者
模型生成了 5 个图表,让我们更好地理解数据集中的不同变量。
如果你点击“显示工作”下拉菜单,你会注意到代码解释器已经编写并运行了 Python 代码,以帮助我们实现最终结果:
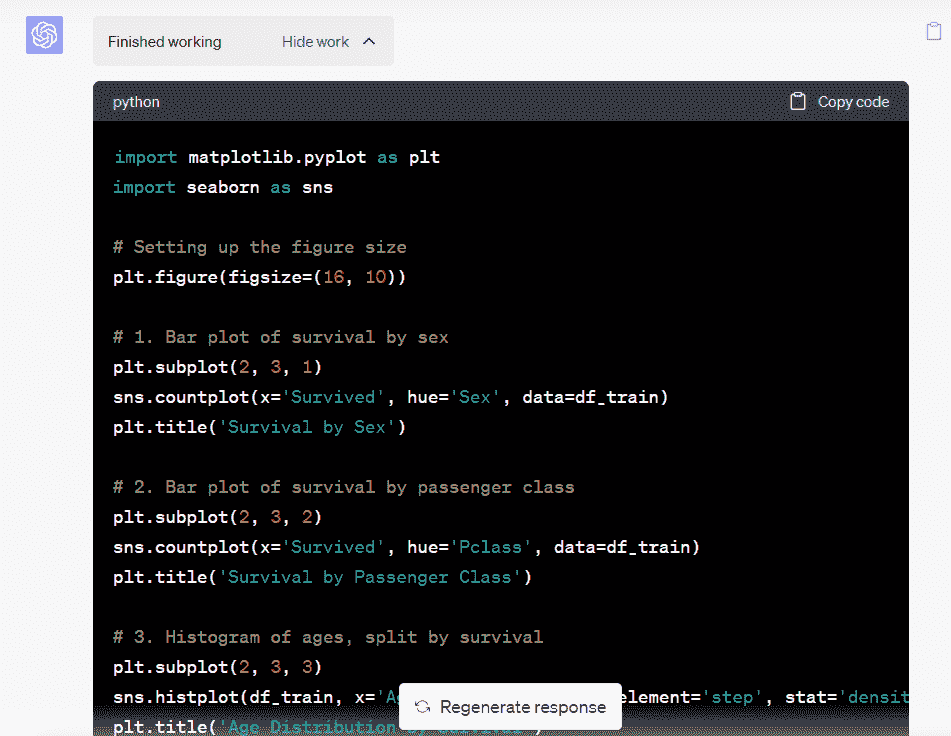
图片来源于作者
如果你想进行进一步分析,可以随时将这段代码复制粘贴到你自己的 Jupyter Notebook 中。
ChatGPT 还根据生成的可视化图提供了对数据集的一些见解:

图片来源于作者
它告诉我们女性、头等舱乘客和年轻乘客的生存率更高。
这些见解如果手动推导,会花费大量时间,尤其是当你对 Python 和像 Matplotlib 这样的数据可视化库不太熟悉时。
代码解释器在几秒钟内生成了这些结果,大大减少了执行 EDA 所需的时间。
3. 数据预处理
我花了很多时间清理数据集并为建模过程做准备。
让我们请求代码解释器帮助我们预处理这个数据集:
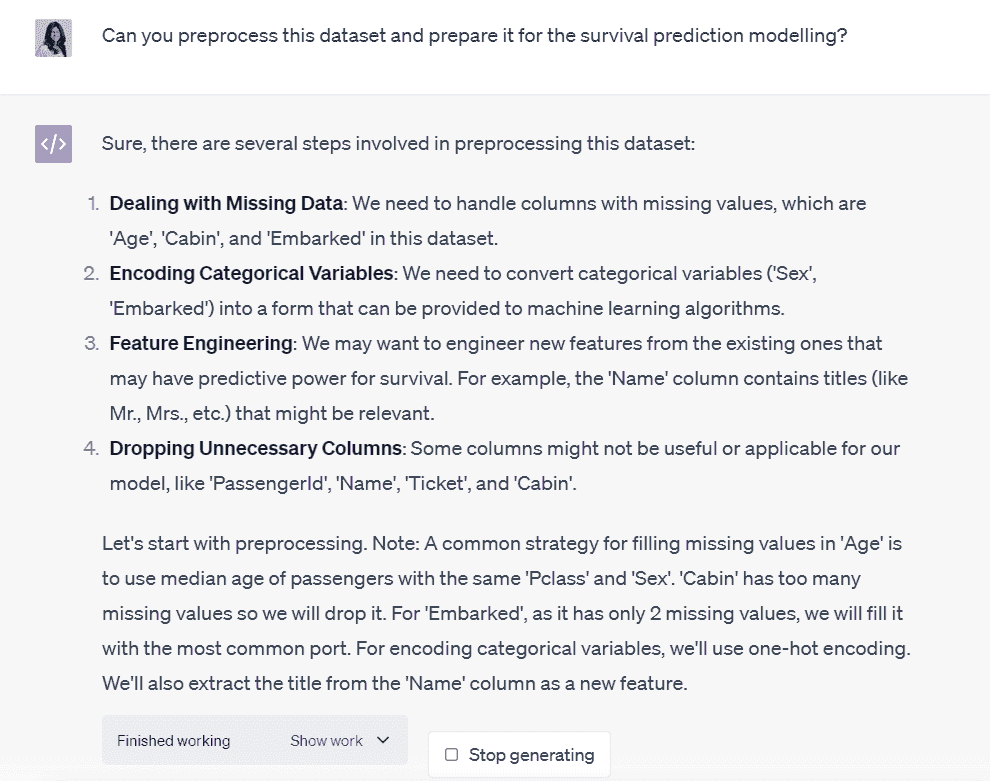
作者提供的图片
代码解释器已经概述了清理这个数据集过程中涉及的所有步骤。
它告诉我们需要处理三个缺失值的列,编码两个分类变量,执行一些特征工程,并删除与建模过程无关的列。
它创建了一个 Python 程序,在短短几秒钟内完成了所有预处理工作。
如果你想了解模型进行数据清理的步骤,可以点击“显示工作”:
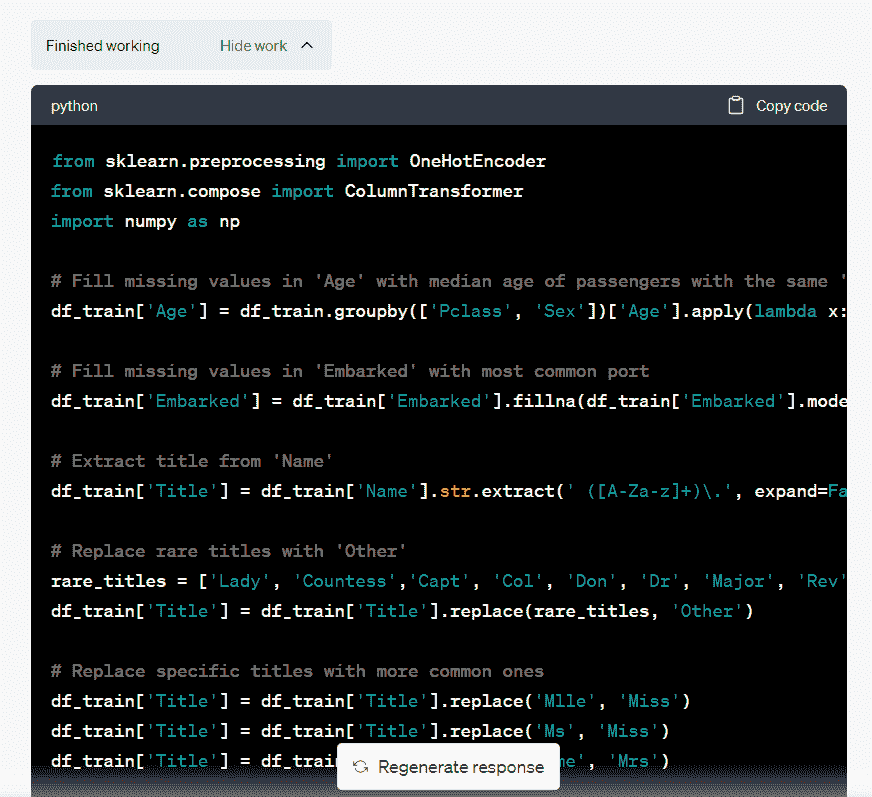
作者提供的图片
然后,我问 ChatGPT 如何保存输出文件,它给了我一个可下载的 CSV 文件:
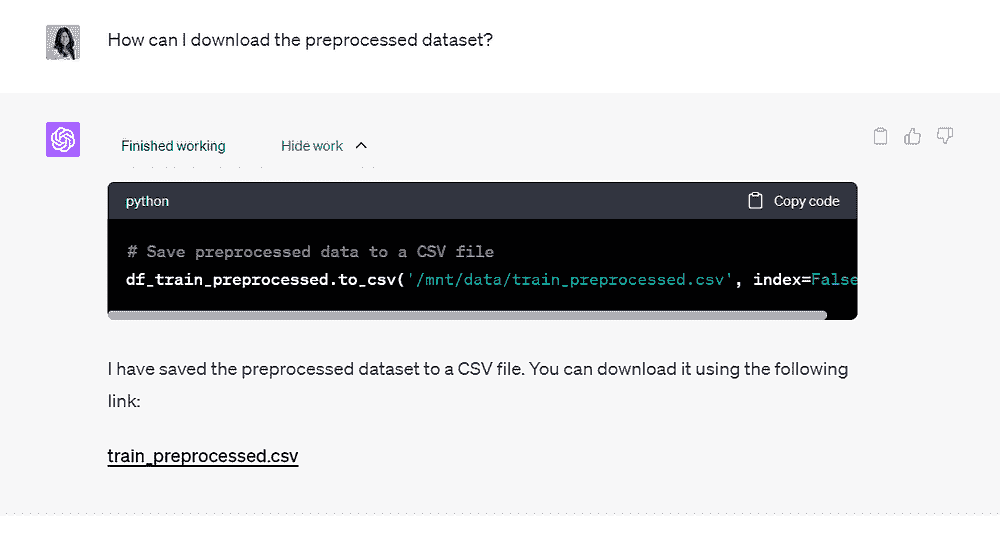
作者提供的图片
请注意,在这个过程中我甚至没有运行过一行代码。
代码解释器能够接收我的文件,在界面中运行代码,并在创纪录的时间内给我提供输出。
4. 构建机器学习模型
最后,我请代码解释器使用预处理后的文件来构建一个机器学习模型,以预测一个人是否会在泰坦尼克号沉船事件中幸存:
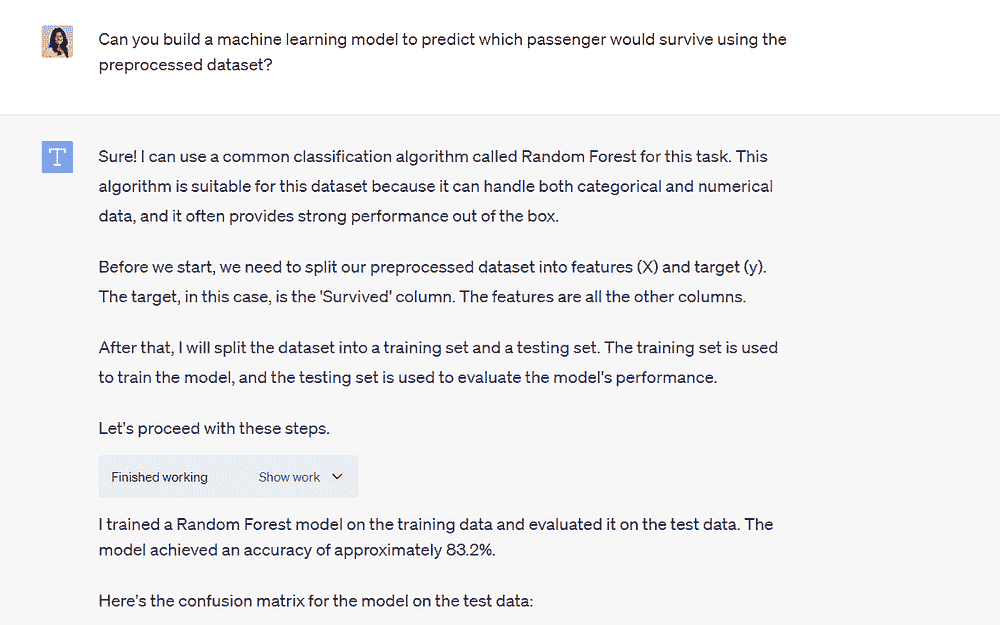
作者提供的图片
它在不到一分钟的时间内建立了模型,并达到了 83.2%的准确率。
它还给我提供了一个混淆矩阵和分类报告,总结了模型的性能,并解释了所有指标的含义:

作者提供的图片
我要求 ChatGPT 提供一个输出文件,将模型预测与乘客数据进行映射。
我还想要一个它创建的机器学习模型的可下载文件,因为我们可以随时进行进一步的微调,并在其基础上进行训练:

作者提供的图片
5. 代码解释
我发现代码解释器的另一个有用应用是能够提供代码解释。
前几天,我在做情感分析模型时发现了一些与我的用例相关的 GitHub 代码。
我没有理解全部代码,因为作者导入了我不熟悉的库。
使用代码解释器,你只需上传一个代码文件,并请求它清楚地解释每一行。
你还可以要求它调试和优化代码,以获得更好的性能。
这里有一个例子:我上传了一个包含我几年前编写的代码的文件,用于构建一个 Python 仪表盘:

图片来源:作者
Code Interpreter 分解了我的代码,并清楚地概述了每个部分所做的工作。

图片来源:作者
它还建议重构我的代码以提高可读性,并解释了我可以在哪里添加新部分。
我没有自己做这些,而是简单地要求 Code Interpreter 重构代码并提供改进版:
图片来源:作者
Code Interpreter 重写了我的代码,将每个可视化封装到单独的函数中,使其更容易理解和更新。
ChatGPT 代码解释器对数据科学家意味着什么?
目前围绕 Code Interpreter 的宣传很多,因为这是我们第一次看到一个能够读取代码、理解自然语言并执行端到端数据科学工作流的工具。
然而,重要的是要记住,这只是另一个工具,旨在帮助我们更高效地进行数据科学。
到目前为止,我一直在使用它来构建基线模型,使用的是虚拟数据,因为我不能将敏感的公司信息上传到 ChatGPT 界面。
此外,Code Interpreter 不具备特定领域的知识。我通常将它生成的预测作为基线预测?—?我经常需要调整其生成的输出,以匹配我组织的使用案例。
我无法展示由一个对公司内部运作没有可见性的算法生成的数字。
最后,我并不是每个项目都使用 Code Interpreter,因为我处理的一些数据包含数百万行,并且存储在 SQL 数据库中。
这意味着我仍然需要自己执行大部分查询、数据提取和转换操作。
如果你是初级数据科学家或有志成为数据科学家,我建议你学习如何利用像 Code Interpreter 这样的工具,更高效地完成工作中的重复部分。
本文到此为止,谢谢阅读!
Natassha Selvaraj 是一位自学成才的数据科学家,热爱写作。你可以通过 LinkedIn 与她联系。
更多相关信息
如何使用 ChatGPT 将文本转换为 PowerPoint 演示文稿
原文:
www.kdnuggets.com/2023/08/chatgpt-convert-text-powerpoint-presentation.html

图片由 ThisisEngineering RAEng 提供,来源于 Unsplash
您是否厌倦了花费几个小时从冗长的文本中创建 PowerPoint 演示文稿?您是否希望有一种更快的方法将您的内容转换为引人入胜的幻灯片?使用 ChatGPT 仅需几分钟即可将文本转换为演示文稿。告别繁琐的复制粘贴,迎接高效而有效的演示解决方案!
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升您的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
要将文本转换为 PowerPoint 演示文稿,您只需执行两个步骤:
-
让 ChatGPT 总结您的文本
-
让 ChatGPT 编写 Python 代码,将总结转换为 PPTX 格式
步骤 1:将文本转换为幻灯片演示文稿
第一步是指示 ChatGPT 根据给定文本生成具有特定数量幻灯片的演示文稿。首先,您必须提供要转换的文本。
使用以下提示指示 ChatGPT 创建演示文稿:
请将以下文本转换为十张幻灯片的演示文稿:[输入文本]
ChatGPT 将生成类似于以下图中的文本:

作者提供的图片
需要注意的是,文本的长度和复杂性可能会影响生成的演示文稿的细节和连贯性。因此,建议保持原始文本简洁有序,以获得最佳效果。
步骤 2:使用 Python 将演示文稿转换为 PowerPoint 格式
现在您已经获得了生成的演示文稿,是时候将其转换为广泛使用的 PowerPoint 格式 .pptx。为此,我们将要求 ChatGPT 编写生成此格式的 Python 代码。
使用以下提示指示 ChatGPT 将演示文稿转换为 pptx:
请编写 Python 代码以将之前的文本转换为 pptx 格式
ChatGPT 将为你的幻灯片生成 Python 代码,例如下面的代码:
from pptx import Presentation
# Create a presentation object
presentation = Presentation()
# Slide 1 - Title slide
slide1 = presentation.slides.add_slide(presentation.slide_layouts[0])
title = slide1.shapes.title
title.text = "Improving the Performance of a Machine Learning Algorithm"
# Slide 2 - Introduction
slide2 = presentation.slides.add_slide(presentation.slide_layouts[1])
content2 = slide2.shapes.title
content2.text = "Introduction"
# Slide 3 - Balancing Techniques
slide3 = presentation.slides.add_slide(presentation.slide_layouts[1])
content3 = slide3.shapes.title
content3.text = "Balancing Techniques"
# Slide 4 - Using imbalanced-learn library
slide4 = presentation.slides.add_slide(presentation.slide_layouts[1])
content4 = slide4.shapes.title
content4.text = "Using imbalanced-learn Library"
# Slide 5 - Data Import
slide5 = presentation.slides.add_slide(presentation.slide_layouts[1])
content5 = slide5.shapes.title
content5.text = "Data Import"
# Slide 6 - Model Building
slide6 = presentation.slides.add_slide(presentation.slide_layouts[1])
content6 = slide6.shapes.title
content6.text = "Model Building"
# Slide 7 - Imbalanced Dataset
slide7 = presentation.slides.add_slide(presentation.slide_layouts[1])
content7 = slide7.shapes.title
content7.text = "Imbalanced Dataset"
# Set the content for each slide
slides = [slide2, slide3, slide4, slide5, slide6, slide7]
content = [
"This tutorial belongs to the series How to improve the performance of a Machine Learning Algorithm.",
"A balanced dataset is a dataset where each output class is represented by the same number of input samples.",
"Balancing techniques include oversampling, undersampling, class weight, and threshold.",
"The imbalanced-learn library, part of the contrib packages of scikit-learn, is used in this tutorial.",
"Data is imported using the pandas library, and the target class is created based on cuisine.",
"The model is built using the Decision Tree algorithm, and evaluation metrics are calculated.",
"The classification report and various plots are generated for the imbalanced dataset."
]
# Add content to each slide
for slide, content_text in zip(slides, content):
content_placeholder = slide.placeholders[1]
content_placeholder.text = content_text
# Save the presentation
presentation.save("machine_learning_presentation.pptx")
此外,ChatGPT 推荐你安装 python-pptx 库:
pip install python-pptx
安装库后,你可以运行生成的代码来制作你的 PowerPoint 演示文稿。
观看下面的视频,看看 ChatGPT 如何实际应用!
摘要
恭喜你!你刚刚学会了如何使用 ChatGPT 将文本转换为 PowerPoint 演示文稿!
多亏了 ChatGPT 的惊人能力,将文本转换为 PowerPoint 演示文稿变得轻而易举。按照这篇博客文章中概述的两步过程,你可以迅速将冗长的文本转换为简明的演示文稿。
记得提供清晰且有组织的文本,以获得最佳效果。使用 ChatGPT 和几行 Python 代码,你可以用惊人的演示文稿吸引观众!
Angelica Lo Duca (Medium) (@alod83) 是意大利比萨国家研究委员会信息学与电信研究所(IIT-CNR)的研究员。她是比萨大学数字人文学科硕士课程中“数据新闻学”课程的教授。她的研究兴趣包括数据科学、数据分析、文本分析、开放数据、网络应用、数据工程和数据新闻学,应用于社会、旅游和文化遗产领域。她是《Comet for Data Science》一书的作者,该书由 Packt Ltd. 出版,以及即将出版的《Data Storytelling in Python Altair and Generative AI》一书,由 Manning 出版,同时也是即将出版的《Learning and Operating Presto》一书的合著者,该书由 O'Reilly Media 出版。Angelica 还是一位热情的技术作家。
原文。转载已获许可。
相关话题
ChatGPT 数据科学备忘单
原文:
www.kdnuggets.com/2023/03/chatgpt-data-science-cheat-sheet.html
ChatOps 的兴起
你可能还没听说过 ChatGPT... ????
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
除了窃取你的工作、传播谎言和大规模抄袭(对这些常见的诋毁点我打算带有不同程度的讽刺),ChatGPT 对于普通数据科学家日常生活中也非常有用。
我们当前面临的问题是期望值的差异:一些人认为 ChatGPT 只是一个产生废话的随机鹦鹉,完全没用;而其他人(根据询问对象的不同,可能是悲观的或乐观的)则认为 ChatGPT 将会统治世界,既摆脱单调,又毁灭人类文明。如果我们都能调整期望值,认识到这项技术的真实面貌及其潜在用途,我们将会更好。但在愤怒和夸张的时代,细微差别常常被忽视。不过我跑题了。
ChatGPT(以及最新和最强大的 GPT3 版本)旨在辅助(没错... 辅助!)那些决定将其用于此目的的人,并且在 KDnuggets 的朋友们的帮助下,你将能够提升你的提示工程技能,做一些有用的事情,如生成代码、辅助你的研究过程和数据分析。
欲了解更多关于 ChatGPT 在数据科学中的应用,请查看我们的最新备忘单。
ChatGPT 是一个由 OpenAI 构建的大型语言对话 AI。它使用了与 InstructGPT 类似的人类反馈强化学习进行训练。ChatGPT 理解提示并提供详细的回复,可以帮助你进行研究、编码以及各种数据科学任务。
在这个备忘单中,Abid Ali Awan 涵盖了数据科学家使用 ChatGPT 的以下有用主题:
-
创意生成
-
编码
-
SQL
-
电子表格
-
数据分析
-
机器学习
-
研究
比尔·盖茨(以及其他许多人)已认可 ChatGPT 和相关技术将改变我们所生活的世界。但这不一定是坏事:如果你现在学会如何利用和掌握 ChatGPT 和其他 LLM 创新,你就会领先一步。不学习如何使用这些机器是机器对你或你的职业造成的最大威胁,所以现在就驾驭这台机器人,并在这些不断变化的时代成为领导者。
现在查看,并敬请稍后再回来查看更多内容。
更多相关主题
ChatGPT 数据科学面试备忘单
原文:
www.kdnuggets.com/2023/06/chatgpt-data-science-interviews-cheat-sheet.html
准备是关键
掌握数据科学面试是一项独特的技能,而准备面试是成功的关键。就像我曾经被告知学习如何写大学考试是一项独特的技能,不仅仅是学习考试材料,专业技术类的面试也是非常相似的。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
ChatGPT 可以帮助候选人理解和澄清在数据科学面试中常遇到的复杂概念、算法和方法。不论是讨论机器学习算法、统计技术还是数据预处理方法,ChatGPT 都能提供详细的解释和示例,以增强理解。
为了提供帮助,KDnuggets 整理了一份关于此主题的备忘单,ChatGPT 数据科学面试备忘单。
在这个实用的参考资料中,你会发现以下有用的信息:
-
统计学
-
编码
-
数据管理
-
模型开发
-
关于 FAANG 公司特有的问题
-
…还有更多!
一定要拿一份备忘单,随时在准备数据科学面试时查阅。现在就去看看吧,别忘了稍后回来获取更多信息。
更多相关信息
ChatGPT 被取代:Claude 如何成为新的 AI 领导者
原文:
www.kdnuggets.com/2023/07/chatgpt-dethroned-claude-became-new-ai-leader.html

“伟大的 AI 竞赛”。来源:作者使用Tiago Hoisel风格的扩散模型
在过去几个月里,我们已经习惯了 AI 的持续突破。
但没有创纪录的公告将新标准提高到之前的 10 倍,这正是 Anthropic 通过其最新版本的聊天机器人 Claude(ChatGPT 最大的竞争对手)所做的。
这确实让周围的所有人感到羞愧。
现在,你很快就能将数小时的文本和信息搜索缩短到几秒钟,使生成式 AI 聊天机器人从简单的对话代理发展成为真正改变生活的工具。
一款超强版的聊天机器人,专注于做好事
正如你所知道的,通过生成式 AI,我们为 AI 打开了生成文本或图像等内容的窗口,这非常棒。
但正如技术中的任何事物一样,这也带来了一个权衡问题,即生成式 AI 模型缺乏对‘好’或‘坏’的意识或判断。
事实上,他们已经具备了通过模仿人类生成的数据来生成文本的能力,而这些数据大多数时候隐藏了有争议的偏见和可疑的内容。
遗憾的是,由于这些模型随着规模的增大而变得更为出色,因此有理由将不管内容如何的任何文本都投入其中,这种诱惑尤为强烈。
而这带来了巨大的风险。
对齐问题
由于缺乏判断力,基础的大型语言模型(通常称为基础 LLMs)特别危险,因为它们非常容易学习其训练数据隐藏的偏见,因为它们会重演那些相同的行为。
例如,如果数据存在种族偏见,这些 LLMs 就会成为这种偏见的具象化体现。同样的道理也适用于恐同症和你能想象的任何其他歧视。
因此,考虑到许多人将互联网视为测试自己不道德和不伦理极限的完美游乐场,LLMs 在没有任何保护措施的情况下用几乎所有互联网数据进行训练,这本身就揭示了潜在的风险。
幸运的是,像 ChatGPT 这样的模型是基础模型的进化,通过将其响应对齐到人类认为‘合适’的标准来实现的。
这一点是通过一种称为人类反馈的强化学习(Reinforcement Learning for Human Feedback,RLHF)的奖励机制完成的。
特别是,ChatGPT 经过了 OpenAI 工程师的严格筛选,这些工程师将一个非常危险的模型转变为不仅偏见更少,而且在执行指令方面更加有用和出色的模型。
不出所料,这些 LLMs 通常被称为指令调优语言模型。
当然,OpenAI 的工程师不应负责决定什么对世界其他地方的好坏,因为他们也有自己的一份偏见(文化、民族等)。
归根结底,即使是最善良的人类也有偏见。
不用说,这个过程并不完美。
我们在多个案例中看到这些模型,尽管声称对齐,但对用户表现得不靠谱,甚至有些卑劣,这些情况被许多使用 Bing 的人所经历,迫使微软将互动的上下文限制在几条消息内,然后事情开始变得不对劲。
考虑到这些,当两位前 OpenAI 研究人员创办了 Anthropic 时,他们有了另一个想法……他们计划用 AI 而不是人类来对齐他们的模型,提出了自我对齐这一完全革命性的概念。
从马萨诸塞州到人工智能
首先,团队起草了一部宪法,包含了《世界人权宣言》这样的内容,或者是苹果的服务条款。
通过这种方式,模型不仅被教会预测句子中的下一个单词(就像任何其他语言模型一样),而且还必须在每一个响应中考虑到一部决定它能说什么或不能说什么的宪法。
接下来,由 AI 而不是人类负责对齐模型,有可能将其从人类偏见中解放出来。
但 Anthropic 最近发布的关键消息并不是将它们的模型对齐到人类可以容忍和利用的 AI 的概念,而是一个最近的公告,使 Claude 成为了 GenAI 战争中坚定的主导者。
具体来说,它将上下文窗口从 9,000 个标记增加到了 100,000 个。这是一次前所未有的改进,具有不可比拟的影响。
但这意味着什么,这些影响是什么?
一切都关乎标记
让我明确指出,这个‘标记’概念的重要性不可忽视,因为尽管许多人可能告诉你,大型语言模型并不是预测序列中的下一个单词……至少不是字面意义上的。
在生成响应时,大型语言模型预测下一个标记,这通常代表 3 到 4 个字符,而不是下一个单词。
自然地,这些标记可能代表一个词,或者词可以由多个标记组成(作为参考,100 个标记大约代表 75 个词)。
在进行推理时,像 ChatGPT 这样的模型会将你给它的文本拆分成部分,并执行一系列矩阵计算,这一概念被定义为自注意力,结合文本中的所有不同标记以学习每个标记如何影响其他标记。
这样,模型“学习”文本的意义和上下文,然后才能进行响应。
问题在于,这个过程对模型来说计算量非常大。
精确来说,计算要求与输入长度的平方成正比,因此你给它的文本越长(被描述为上下文窗口),运行模型的成本在训练和推理时就越高。
这迫使研究人员大幅限制模型输入的允许大小,通常在 2,000 到 8,000 个标记之间,后者大约是 6,000 字。
可预测的是,限制上下文窗口严重削弱了 LLM 对我们生活的影响,使它们成为一个只能帮你做少量事情的有趣工具。
但为什么增加这个上下文窗口能够解锁 LLM 最大的潜力?
那么,这很简单,因为它解锁了 LLM 最强大的功能——上下文学习。
无需训练的学习
简而言之,LLM 具备一种罕见的能力,允许它们“随时学习”。
如你所知,训练 LLM 既昂贵又危险,特别是因为训练它们需要你提供数据,而这不是保护隐私的最佳选择。
此外,每天都有新数据出现,因此如果你需要不断对模型进行微调——进一步训练——LLM 的商业前景将会被彻底打破。
幸运的是,LLM 在被称为上下文学习的概念上表现出色,这种学习能力是不需要实际修改模型权重的。
换句话说,它们可以通过简单地提供所需的数据来学习回答你的查询,而不需要实际训练模型。
这个概念,也被称为零样本学习或少样本学习(具体取决于需要多少次看到数据才能学习),是 LLM(大型语言模型)使用之前未见过的数据准确回应特定请求的能力。
因此,上下文窗口越大,你可以提供的数据就越多,模型能够回答的复杂查询也就越多。
因此,尽管小的上下文窗口对于聊天和其他简单任务来说还算可以,但它们完全无法处理真正强大的任务……直到现在。
《星球大战》系列的秒级速览
我会直入主题。
正如我之前提到的,最新版本的 Claude,版本 1.3,可以一次性处理 100,000 个标记,或大约 75,000 字。
但这并没有告诉你很多,对吧?
让我给你一个更清晰的概念,75,000 字的内容大致是什么样的。
从《科学怪人》到《安纳金》
你现在正在阅读的文章不到 2,000 字,这比 Claude 目前一次性处理的能力少了 37.5 倍以上。
但类似大小的例子有哪些?更具体地说,75,000 字代表:
-
大约相当于玛丽·雪莱的《科学怪人》全书的长度
-
整本《哈利·波特与魔法石》,共有 76,944 字
-
任何一部《纳尼亚传奇》书籍,因为它们的字数都较少
-
而最令人印象深刻的数字是,这些对话的总量足以涵盖最多 8 部《星球大战》电影的对话……综合起来。
现在,想象一下一个聊天机器人,它可以在几秒钟内让你询问关于任何给定文本的任何问题。
比如,我最近看到一个视频,他们给 Claude 提供了一个长达五小时的 John Cormack 播客,模型不仅能够用几个词总结整个播客,它还能够指出在五小时长的演讲过程中某个特定时刻说的具体内容。
难以想象,不仅这个模型能够处理 75,000 字的转录文本,更令人震惊的是,它还能够处理它可能第一次看到的数据。
毫无疑问,这对学生、律师、研究科学家以及任何需要同时处理大量数据的人来说都是终极解决方案。
对我而言,这是一种在人工智能领域中少见的范式转变。
毫无疑问,真正颠覆性创新的大门已经为 LLMs 打开。
人工智能在短短几个月内的变化令人难以置信,每周变化的速度更是惊人。我们唯一知道的是,它在变化……一步步来。
Ignacio de Gregorio Noblejas 在技术领域拥有超过五年的全面经验,目前担任顶级咨询公司的一名管理咨询经理,在技术采纳和数字化转型方面提供战略指导,积累了丰富的背景。他的专业知识不仅限于咨询工作,在空闲时间,他还通过在 Medium 上的写作和每周通讯 TheTechOasis 向更广泛的受众分享他对人工智能(AI)最新进展的深刻见解,这些平台分别拥有超过 11,000 和 3,000 名活跃读者。
原文。经许可转载。
更多相关话题
教育中的 ChatGPT:朋友还是敌人?
原文:
www.kdnuggets.com/2023/05/chatgpt-education-friend-foe.html

来自 Bing Image Creator 的图像
教育系统面临的最新困境——或者说伙伴——就是 ChatGPT。新闻媒体争相收集教师对这一现象是否应该被接受或抛弃的看法,因为它可能会改变教育领域。学生们如何利用这一工具进行学习?教师们应该如何应对教育中的 ChatGPT?
ChatGPT 如何成为朋友?
部分原因在于大多数人可以通过简单的实验或 YouTube 教程学习如何使用 ChatGPT,除非有人寻求更深入的利用其资源的方法。这是它的第一个优点,但还有其他几个优点可能使其成为有价值的教育工具。
更具包容性
非传统学习者可能比主流方法获得更多的帮助,例如 ChatGPT。它可以成为一个视听助手,学生可以自由地提出尽可能多的澄清问题而不受评判。应对无数个性化教育计划的教师也可以通过询问如何为有残疾或其他学习需求的学生制定课程计划,来利用 ChatGPT。
学生为未来工作做准备
几乎每个行业都接受某种形式的人工智能,许多学生将来会与 AI 同事或资产一起工作。由于这一过渡不可避免,学校必须接受人工智能以充分为孩子们准备现实世界的挑战。如果学生知道如何负责任地使用聊天机器人,这将增强他们进入职场的能力。此外,进入技术依赖行业的学习者需要这些技能,以便有资格获得工作。
学习者获得了免费的辅导员
教育中的 ChatGPT 可能表现为学生要求提供共价键或文学中的隐喻示例。它可以简化复杂概念,提供逐步指导,当课堂上没有时间或注意力来详细重复每个观点时,这将特别有用。
学生可以将 ChatGPT 作为辅导员或家庭作业补充工具,特别是在他们需要赶上进度的时候。ChatGPT 制定的响应能力无与伦比,因此如果学生需要适合六年级阅读水平的科学解释,ChatGPT 能够调整。
ChatGPT 如何成为敌人?
这些好处也伴随着应对缺点的挑战。教师并非毫无理由地呼吁禁止 ChatGPT。这些缺点中有一些是最为普遍的。
学生正在作弊
ChatGPT 可以相对准确地编写论文或代码,无论是针对单个作业还是整个课程。它可能会鼓励懒惰或不感兴趣的学生轻松完成课程,就像外语学习者在 Google 翻译刚推出时的利用方式。
数据隐私悬而未决
这个人工智能让网络安全分析师感到好奇。ChatGPT 的安全性并不是最强的,但学生和教师每天向其数据库输入大量数据。如果威胁行为者破坏了这些信息,教育系统是否要负责?尤其是当教师鼓励在课堂上使用人工智能时,是否有责任教授他们的学科和网络安全知识?像这样的基于云和公共系统本可以提高网络安全性和合规性,但教师能有多确定?
批判性思维岌岌可危
学生可能会利用 ChatGPT 发挥他们的创造潜力,但这同样可能在长期内损害批判性思维能力。既然可以让 ChatGPT 为他们做决定,学生为什么还需要锻炼解决问题的技能?对即时满足的渴望可能会取代学生为找出解决方案而付出的真正好奇心。
教师呢?
ChatGPT 在教育中对教师的影响与对学生的影响截然不同,但他们将面临同样多——如果不是更多——的机会和负面体验。一些人可能会争辩说,教师有责任将人工智能纳入课堂,以现代化课程计划并使教育符合现代工作的期望。
相反,教师在评分作业时将花费更多时间进行质量控制——尽管他们可以利用它来节省人工评分的时间。节省时间的可能性与教师的创造力一样多。通过向 ChatGPT 提出一些问题,课程计划变得更具吸引力和多样化。
最终,禁止或允许在课堂上使用 ChatGPT 将为师生关系设定一个先例与技术相关。呼吁全面禁止的教师暗示他们不能信任学生将 ChatGPT 用于真正的教育目的。教师以这种方式不信任学生是否健康?或者,教师是否应该不断质疑学生是否滥用他们的信任?这两个方面都提出了一个教育工作者尚未找到答案的伦理难题。
ChatGPT 站在哪一边?
确定 ChatGPT 在教育中是朋友还是敌人,将取决于教师如何使用它以及如何设定 AI 礼仪的先例。无论如何,AI 最终将不可避免地融入教育中。
推迟这个转变还是现在开始管理学生与 AI 的关系,取决于学生的优先事项和性格,这两种情况都有可能带来破坏性或有利的一面。世界将不得不观察 ChatGPT 在时间的推移中倾向于哪一边。
香农·弗林 (@rehackmagazine) 是一位技术博主,撰写有关 IT 趋势、网络安全和商业科技新闻的文章。她还是 MakeUseOf 的工作人员,并且是ReHack.com的执行编辑。关注 KDnuggets 可以阅读更多来自香农和其他数据科学更新的内容。有关更多信息,请参见香农的个人网站。
了解更多相关话题
ChatGPT: 你需要知道的一切
原文:
www.kdnuggets.com/2023/01/chatgpt-everything-need-know.html

在过去的几周里,你可能注意到这项新技术被提及到处都是:ChatGPT。有些人已经玩过它,而有些人完全不知道它是什么。本文将深入探讨你需要了解的关于 ChatGPT 的一切。
什么是 ChatGPT?
ChatGPT是一个基于 AI 的聊天系统,由OpenAI于 2022 年 11 月推出。OpenAI 以创建 Whisper(自动语音识别系统)和 DALLE•2(AI 图像和艺术生成器)而闻名。
ChatGPT 使用公司的 GPT-3 技术。它代表生成预训练变换器 3,是一种自回归语言模型,利用深度学习生成类人的文本。它是一个语言处理 AI 模型,目前是最受欢迎的之一。
GPT-3 训练模型使用“生成预训练”训练方法,这意味着它的训练方式是预测下一个标记。为了实现这一点,模型需要一个初始提示文本,然后它将继续使用该初始提示生成文本。
该模型使用带有人工反馈的强化学习(RLHF)进行优化,以实现对话对话。该模型使用由人类编写的各种数据进行训练,以实现听起来像人的响应。
它与聊天机器人创建了自然、类人的互动。
ChatGPT 能做什么?

ChatGPT的截图
GPT-3 是一个拥有 1750 亿参数的语言模型,因此很难缩小所有 GPT-3 的能力范围。它是一个专注于语言的模型,因此对书面和口头语言有深入的理解。
ChatGPT 的一些应用场景包括:
-
编写短篇内容,如诗歌和打油诗
-
编写长篇内容,如研究论文。
-
以通俗的语言或深入的知识解释主题
-
头脑风暴主题和创意
-
个性化沟通,例如电子邮件回复
-
以自然和引人入胜的语调进行对话的虚拟助手
-
将长内容总结为较短的形式
-
语言翻译
-
营销内容
如果你曾经写过博客、论文或学位论文,你知道制作有价值内容所需的时间和精力。ChatGPT 的强大之处在于它能在几秒钟内生成写得很好的内容,并能够将复杂的主题简化。
ChatGPT 如何工作?
如前所述,OpenAI 使用了来自人类反馈的强化学习(RLHF)。他们开始时使用监督性微调训练了一个初始模型。人类 AI 训练师扮演了用户和 AI 助手的角色,并提供了对话,以帮助构建自然且引人入胜的回应。
强化学习使用奖励信号/系统来帮助机器学习模型改进。OpenAI 收集了比较数据,即两个或更多模型响应的质量排序。OpenAI 获取了 AI 训练师与聊天机器人之间的对话,随机选择了一个模型生成的消息,抽样了几个替代完成,并让 AI 训练师对其质量进行排名。这使他们能够使用这些奖励模型,并使用近端策略优化进行微调。
以下是步骤:
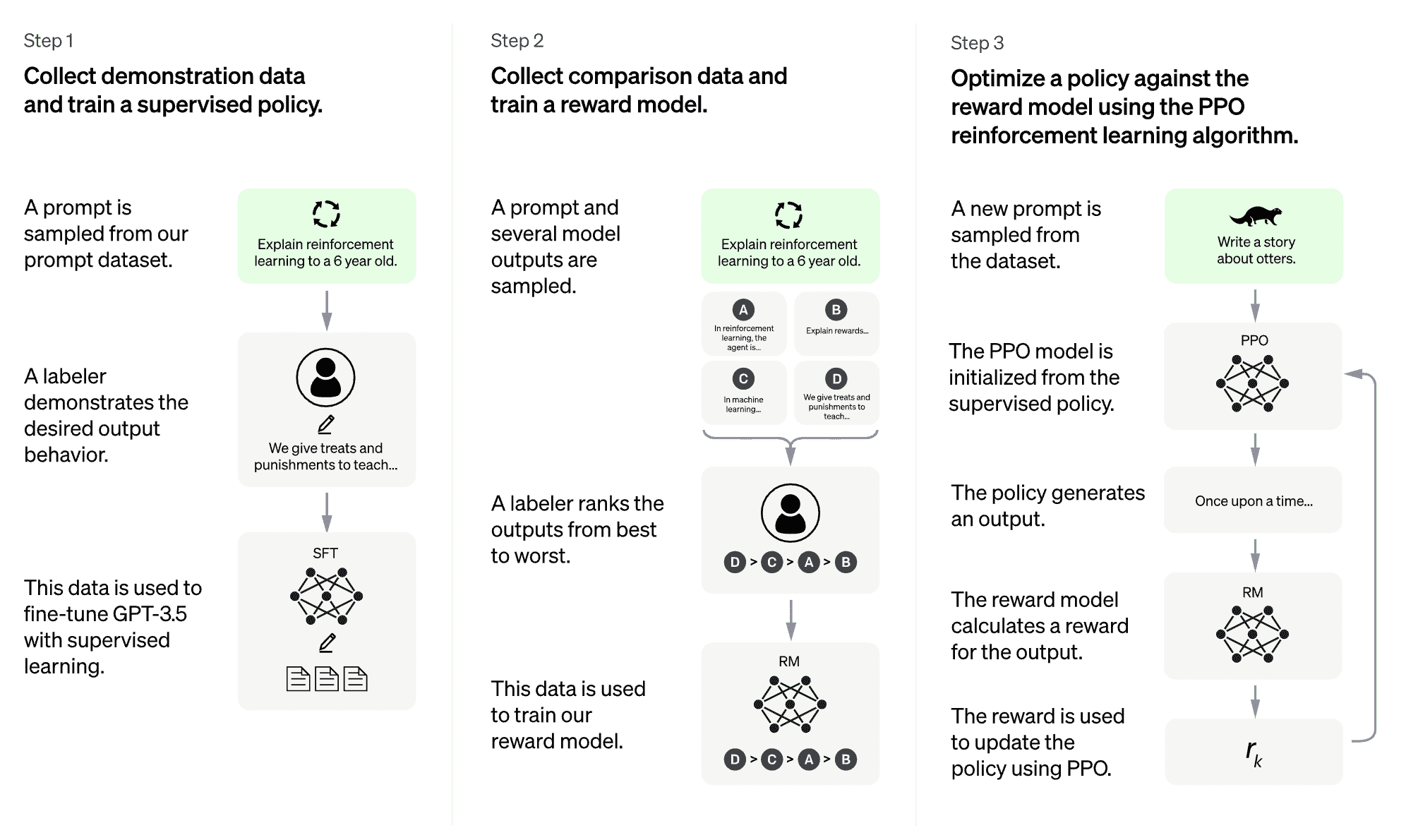
图片来源于OpenAI
ChatGPT 的局限性
ChatGPT 存在局限性。
-
ChatGPT 对过去一年发生的世界事件的知识非常有限
-
它可能会误解你的提问
-
它可能会输出不正确的信息
-
如果你在初始提示中添加了太多元素或过于专业,ChatGPT 可能会感到不知所措
结论
ChatGPT 在其测试服务阶段目前已达到满负荷;不过,你可以通过填写此表格这里来接收通知,当服务恢复时会通知你。
这篇文章总结了 ChatGPT,但如果你想深入了解 ChatGPT 的技术层面知识,我推荐阅读研究论文语言模型是少样本学习者。
Nisha Arya 是一名数据科学家和自由技术作家。她特别关注提供数据科学职业建议或教程以及数据科学理论知识。她还希望探索人工智能如何能有利于人类生命的延续。作为一个热衷学习者,她寻求拓宽技术知识和写作技能,同时帮助他人。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业领域。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关主题
ChatGPT 与 Google Bard:技术差异比较
原文:
www.kdnuggets.com/2023/03/chatgpt-google-bard-comparison-technical-differences.html

作者提供的图片
Google Bard 和 ChatGPT 之间最大的区别是,截至目前,Bard 知道 ChatGPT 的存在,但 ChatGPT 对 Bard 一无所知。但我可以玩转 ChatGPT,而 Google Bard 对我们大多数人来说仍然遥不可及。

来源:ChatGPT 的截图
ChatGPT 与 Google Bard 对决的开始
ChatGPT 和 Google Bard 都是 AI 聊天机器人。这种技术的最简单版本已经存在于你的智能手机上——你输入“Good”,手机预测你可能想用的下一个词是“morning”。
ChatGPT 最初由 OpenAI 开发,然后微软以高达 100 亿美元的巨额投资进行了投资(除此之外还早期投资了 10 亿美元)。Google 略显恐慌地认为他们的搜索垄断可能要结束了,于是推出了 Bard,这是他们的技术版本,但有一些缺陷。在第一次现场演示中,Bard 出现了几处事实错误。 对 Google 来说,至少是尴尬的。
ChatGPT 和 Google Bard 比智能手机预测文本要复杂一些,但要理解这两种 AI 聊天机器人的差异,你只需要了解这些基本信息。
让我们更深入地探讨这两种 AI 引擎之间的技术差异。
ChatGPT 与 Bard:底层技术是什么?
你在这里是为了快速、轻松地获取这两种引擎的技术差异表格。这里正是你需要的。如果你想要更详细的了解,随时可以继续浏览。
| ChatGPT | Bard | |
|---|---|---|
| 模型 | GPT-3.5 | LaMDA,即对话应用的语言模型 |
| 神经网络架构 | Transformer | Transformer |
| 训练数据 | 网络文本,主要是一个名为“common crawl”的数据集,截止到 2021 年中期 | 156 万字的公共对话数据和网络文本 |
| 目的 | 成为一个多功能的文本生成聊天机器人 | 专门用于协助搜索 |
| 参数 | 1750 亿参数 | 1370 亿参数 |
| 创建者 | OpenAI | |
| 优点 | - 目前对所有人开放 - 更加灵活且能够处理开放式文本 - 训练数据截止到 2021 年 | - 训练数据更新到现在 - 专门为对话训练,因此在你使用时听起来更像人类 |
| 缺点 | - 对话不够令人信服 - 不如精细调整 | - 当前不可用 - 可能不适合通用文本创作 |
现在你已经了解了 TL;DR,让我们更深入地看一下这些指标。
ChatGPT 是什么?
ChatGPT 于 2022 年 11 月 30 日迅速登场。到 2022 年 12 月 4 日,该服务的 每日用户数 超过了一百万。到 2023 年 1 月,这一数字 激增 至超过 1 亿用户。
它之所以立即受到欢迎,是因为它能以一种几乎像人类的方式提供对多个主题的可靠回答,而且任何有互联网连接的人都可以访问。
ChatGPT 由 OpenAI 创建,OpenAI 是一个总部位于旧金山的 AI 实验室,专注于创建友好的 AI。这个聊天机器人基于 GPT-3.5,这是一种大型语言模型,当提供文本时,可以继续提示。
ChatGPT 在此基础上进行了额外的训练——人类训练师通过与模型互动来改进模型,并对更高质量的回答给予“奖励”。
训练数据
GPT-3.5 是在一个巨大的网络文本数据集上训练的,包括一个名为 Common Crawl 的流行数据集。Common Crawl 包含了大量的网页数据,包括原始网页数据、元数据提取和文本提取。例如,它包括了来自 StrataScratch 的 一组我们自己的网站链接。想到 ChatGPT 是使用我们每天访问的网站进行训练的,确实令人感到惊讶。
Common Crawl 负责了 60% 的训练数据,但 GPT-3.5 也从其他来源获得了数据。
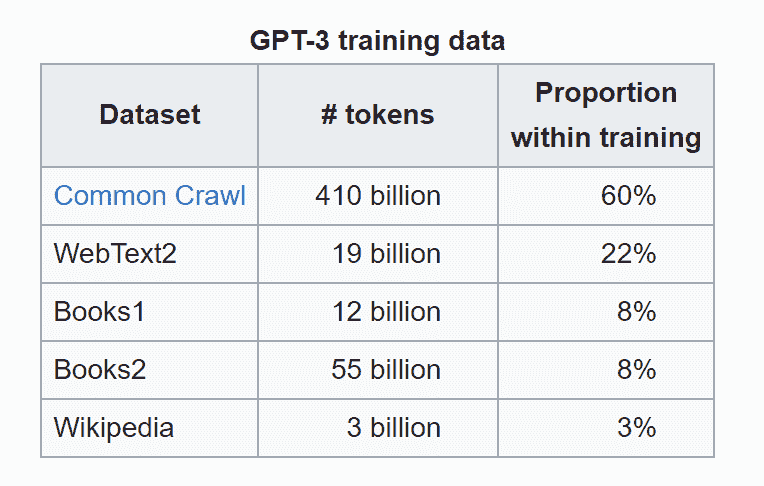
来源:维基百科
Google Bard 是什么?
Bard 是 Google 对 ChatGPT 流行的回应。与 ChatGPT 不同,Bard 由 Google 自己的 LaMDA 模型 提供支持,LaMDA 是对话应用语言模型的缩写。而且与 ChatGPT 不同的是,Bard 目前尚未对大多数人开放。尽管 Google 在 2 月初举办了一个充满错误的 Bard 演示,但现在它仅对少数人开放。
Google Bard 的主要优势在于它能够访问互联网。问 ChatGPT 谁是总统,它不知道。这是因为训练数据截止于 2021 年中期。而 Bard 则可以利用今天的互联网信息。问 Bard,理论上,Bard 应该能够从今天互联网上的数据中告诉你谁是总统。
尽管你还不能亲自体验,但很容易看出 Bard 在几个关键方面如何与 ChatGPT 区分开来。
来源: 谷歌的 博客帖子 关于 LaMDA
训练数据
首先,LaMDA 是在对话中进行训练的,特别是为了在对话中交流,而不仅仅是像 GPT-n 模型那样生成文本。虽然 ChatGPT 对其训练数据并不隐瞒,但我们还不太了解 Bard 的训练数据。
我们可以通过查看 LaMDA 的研究论文稍微推测一下。谷歌的研究人员表示,12.5% 的训练数据来自 Common Crawl,类似于 GPT-n 模型。另有 12.5% 来自维基百科。根据研究论文,他们使用了 1.56 万亿字的“公共对话数据和网页文本”。
这是完整的细分:
| 12.5% 基于 C4 的数据(Common Crawl 数据的衍生) |
|---|
| 12.5% 英文维基百科 |
| 12.5% 编程问答网站、教程等的代码文档 |
| 6.25% 英文网页文档 |
| 6.25% 非英文网页文档 |
| 50% 公开论坛对话数据 |
我们知道 Common Crawl 数据,显然你也知道维基百科。其余的?这些故意被隐藏, presumably 以防止 Bard(和 LaMDA)受到模仿者的影响。
LaMDA 是通过微调一系列基于 Transformer 的神经语言模型构建的,这是一种最初由 谷歌 开发的开源神经网络架构。(有趣的是,GPT 也是基于 Transformer 的。)
来源: 谷歌关于 Bard 的博客帖子
ChatGPT 有一些保护措施,防止其变得过于恶劣或胡言乱语,但谷歌已明确指出他们如何精心制定质量保证,使 Bard 成为一个更好、更安全的聊天机器人。Bard 被微调以促进“质量、可信度和安全”。
谷歌对这一点 有很多话要说,我建议你阅读他们的博客帖子,但如果你时间紧张,总的来说就是这样:
-
Bard 应该给出合理的回答——没有荒谬的内容,没有矛盾
-
Bard 应该给出富有洞察力、机智或以良好方式出人意料的回答。
-
Bard 应该避免任何可能对用户造成伤害的内容——例如血腥、偏见、仇恨的刻板印象。
-
Bard 不应捏造内容。
由于一次失败的发布,我们已经知道 Google 尚未完全解决这个基本要求。但值得注意的是,Google 正在以 ChatGPT 尚未做到的方式明确说明这些设计要求——至少目前尚未做到。
ChatGPT 与 Google Bard 的对比:模型参数及其重要性?
ChatGPT 的模型参数比 Bard 更多——1750 亿对 1370 亿。你可以把参数看作是模型调整以适应训练数据的旋钮或杠杆。更多的参数通常意味着模型能够捕捉语言中的复杂关系,但也有过拟合的风险。
Google Bard 可能不够灵活,但相比 ChatGPT 可能对新的语言使用场景更为稳健。
ChatGPT 与 Google Bard 的对比:它们有什么共同点?
值得强调的是,Bard 和 ChatGPT 都基于模型(分别是 LaMDA 和 GPT-3.5),这些模型依赖于 基于 Transformer 的 深度学习神经网络。
Transformer 可以使得训练过的模型在阅读句子或段落时,关注这些词汇之间的关系,然后预测它认为接下来会出现哪些词——类似于我之前提到的智能手机预测文本功能。
我不会过多深入,但你只需要知道的是,从根本上讲,Bard 和 ChatGPT 并没有太大不同。
ChatGPT 与 Google Bard 的对比:所有权
虽然所有权不完全是技术上的区别,但值得考虑。
Google Bard 完全由 Google 生产和拥有,基于 Google 创造的 LaMDA。
ChatGPT 由 OpenAI 开发,OpenAI 是一家位于旧金山的人工智能研究实验室。OpenAI 最初是非营利组织,但在 2019 年创建了一个盈利子公司。OpenAI 还开发了 Dall-E,这是你可能玩过的 AI 图像生成工具。
尽管微软已经在 OpenAI 上投入了大量资金,但目前它仍然是一个独立的研究组织。
哪个更好,ChatGPT 还是 Google Bard?
对这个问题很难给出公平的答案,因为它们既相似又不同。首先,几乎没有人现在可以访问 Google Bard。其次,ChatGPT 的训练数据几乎在两年前就被中断了。
两者都是文本生成器——你提供一个提示,Google Bard 和 ChatGPT 都可以回答。两者都有数十亿个参数来微调模型。两者的训练数据源有重叠,并且都基于 Transformer,相同的神经网络模型。
它们的设计目的也不同。Bard 将帮助你导航 Google 搜索。它旨在进行对话式交流。ChatGPT 可以生成整篇博客文章。它旨在生成有意义的文本块。
最终,ChatGPT 和 Google Bard 之间的技术差异凸显了 AI 驱动的文本生成技术已经取得的进展。尽管它们都有待完善,并且在版权和伦理方面都曾引发争议,但这两种生成器都强有力地展示了现代 AI 模型的能力。
Nate Rosidi 是一名数据科学家和产品策略专家。他还是一名兼职教授,教授分析学,同时也是 StrataScratch 的创始人,该平台帮助数据科学家通过来自顶级公司的真实面试问题准备面试。可以通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
更多相关主题
ChatGPT, GPT-4, 和更多生成型 AI 新闻
原文:
www.kdnuggets.com/2023/02/chatgpt-gpt4-generative-ai-news.html

Robolawyer. 资料来源: Midjourney
如果你读过我的作品,你可能知道我主要在我的 AI 新闻通讯中发布文章,算法桥。你可能不知道的是,我每周日都会发布一个特别专栏,我称之为“你可能错过的内容”,在其中我回顾一周发生的所有事情,并提供分析以帮助你理解新闻。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
ChatGPT, ChatGPT, 还有更多的 ChatGPT
微软-OpenAI 100 亿美元交易
Semafor 报道 说,如果一切按计划进行,微软将在 1 月底之前与 OpenAI 达成 100 亿美元的投资交易(微软首席执行官萨蒂亚·纳德拉在周一正式宣布了扩展合作伙伴关系)。
关于这笔交易曾有一些误信息,暗示 OpenAI 高管对公司的长期生存能力没有信心。然而,后来澄清 这笔交易的情况如下:
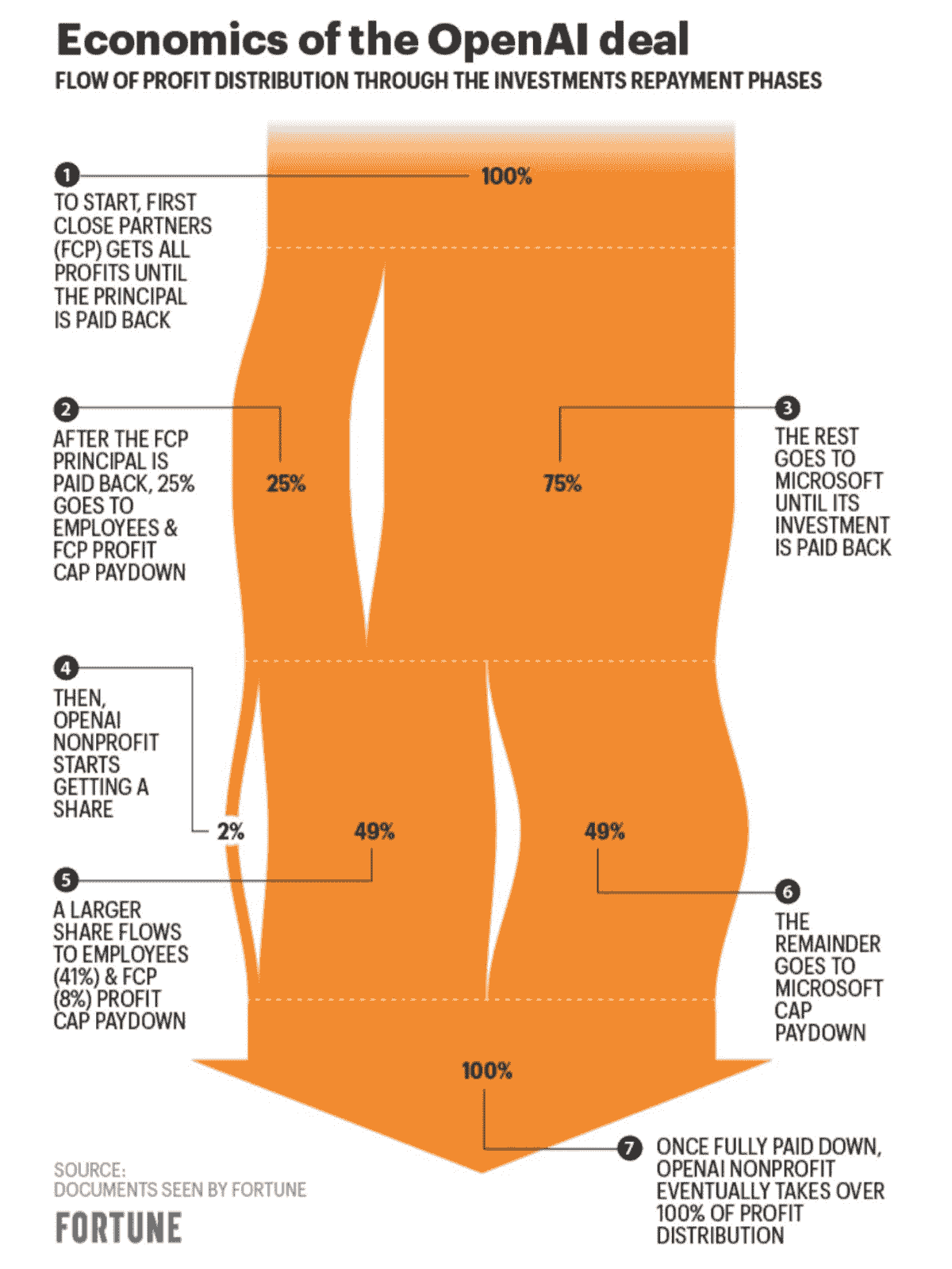
文章来源:财富
撰写《The Neuron》的 Leo L’Orange,解释说,“一旦 92 亿美元的利润加上 130 亿美元的初始投资还给微软,其他风险投资者赚取 150 亿美元后,所有股权将返回给 OpenAI。”
人们意见分歧。有些人说这笔交易“酷”或“有趣”,而另一些人则说它“奇怪”和“疯狂”。我以非专业的眼光来看,OpenAI 和 Sam Altman 确实相信(有人说是过度相信)公司长期实现目标的能力。
然而,正如 Will Knight 在 WIRED 上写的,“不清楚基于这项技术可以构建出什么产品。” OpenAI 必须尽快找出一个可行的商业模式。
ChatGPT 的变化:新功能和盈利模式
OpenAI 在 1 月 9 日更新了 ChatGPT(相比 12 月 15 日的上一次更新)。现在聊天机器人具有“改进的事实准确性”,并且你可以在生成过程中停止它。
他们还在开发一个“专业版 ChatGPT”(据传售价为 42 美元/月),OpenAI 的总裁 Greg Brockman 在 1 月 11 日宣布。这是三个主要特点:
“随时可用(没有停机时间)。
来自 ChatGPT 的快速响应(即没有限制)。
你需要多少条信息(至少是常规每日限制的 2 倍)。
要注册候补名单,你必须 填写一个表格,其中询问你愿意支付的金额(以及多少金额过高)。
如果你打算认真对待它,你应该考虑深入了解 OpenAI 的产品堆栈,参考一下 OpenAI cookbook repo。Bojan Tunguz 说这是 “本月 GitHub 上最受欢迎的仓库”。这总是一个好兆头。
ChatGPT,这位虚假的科学家
ChatGPT 已经进入科学领域。 Kareem Carr 在星期四发布了一张截图,显示 ChatGPT 是一篇论文的共同作者。
但为什么,既然 ChatGPT 只是一个工具?“人们开始将 ChatGPT 当作一个真正的、资质良好的科学 合作者,”Gary Marcus 在 一篇 Substack 文章 中解释道。“科学家们,请不要让你们的聊天机器人变成共同作者,”他恳求道。
更令人担忧的是那些没有披露 AI 使用情况的案例。科学家 发现 他们无法可靠地识别由 ChatGPT 撰写的摘要——它那华丽的胡说八道甚至欺骗了领域内的专家。正如在牛津大学“研究技术和法规”的 Sandra Wachter 向 Holly Else 讲述的 《自然》上的一篇文章 中提到的:
“如果我们现在处于专家无法判断什么是真实的情况,我们就失去了我们迫切需要的中介来引导我们通过复杂的话题。”
ChatGPT 对教育的挑战
ChatGPT 在全球教育中心被禁用(例如,纽约公立学校、澳大利亚大学和英国讲师正在考虑此事)。正如我在上一篇文章中所争论的,我认为这不是最明智的决定,而只是对生成式 AI 快速发展的反应。
NYT 的 Kevin Roose 认为“[ChatGPT]作为教育工具的潜力超过了它的风险。”伟大的数学家 Terence Tao,同意:“从长远来看,似乎对抗这一点是徒劳的;也许我们作为讲师需要做的是转向‘开卷考试,开放 AI’的模式。”
Giada Pistilli,Hugging Face 的首席伦理学家,解释了学校面临的 ChatGPT 挑战:
“不幸的是,教育系统似乎被迫适应这些新技术。我认为这种反应是可以理解的,因为很少有人提前预见、缓解或制定替代解决方案以应对可能出现的问题。颠覆性技术通常需要用户教育,因为它们不能仅仅被随意地丢给人们。”
最后一段完美地捕捉了问题的根源和潜在的解决方案。我们必须额外努力教育用户如何使用这项技术以及什么是可能的和不可能的。这就是加泰罗尼亚所采取的方法。正如Francesc Bracero 和 Carina Farreras 在 La Vanguardia报道的那样:
“在加泰罗尼亚,教育部不会在‘整个系统和所有人’中禁止它,因为这将是无效的措施。根据部门的消息,更好的做法是要求各中心进行 AI 使用的教育,‘它可以提供大量知识和优势。’”
学生的最佳朋友:ChatGPT 错误数据库
Gary Marcus 和 Ernest Davis 建立了一个“错误追踪器”,用来捕捉和分类像 ChatGPT 这样的语言模型所犯的错误(这里有更多信息 关于他们为什么编写这个文档以及他们的计划)。
该数据库是公开的,任何人都可以参与。这是一个很好的资源,允许对这些模型的行为不端进行严格研究,并且可以帮助人们避免误用。这里有一个令人捧腹的例子,说明了为什么这很重要:
OpenAI 已意识到这一点,并希望打击误导和虚假信息:“预测语言模型在虚假信息运动中的潜在误用——以及如何减少风险。”
GPT-4 信息与误信息
新信息
Sam Altman 暗示 GPT-4 的发布会有延迟,在与 Connie Loizos 的对话中透露,Loizos 是 TechCrunch 的硅谷编辑。Altman 说:“一般来说,我们会比人们希望的更慢地发布技术。我们会等待更长时间……”这是我的看法:
(Altman 还提到正在开发一个视频模型!)
关于 GPT-4 的误信息
在社交媒体上,“GPT-4 = 100T”的说法正广泛传播(我主要在 Twitter 和 LinkedIn 上见到过)。如果你还没看到,它的样子是这样的:
或者这样:
所有这些都是相同内容的略微不同版本:一个吸引注意的视觉图表,以及一个关于 GPT-4/GPT-3 比较的强有力的钩子(他们用 GPT-3 作为 ChatGPT 的替代品)。
我认为分享谣言和猜测并将其框架化是可以的(我对此部分负责),但以权威语气发布不可验证的信息且没有参考文献则是令人谴责的。
做这些的人距离成为信息来源中像 ChatGPT 一样无用且危险的程度并不远——并且他们有更强的动机继续这样做。请注意这点,因为它会污染未来所有关于 AI 的信息渠道。
更多生成式 AI 新闻
一位机器人律师
Joshua Browder,DoNotPay 的 CEO,在 1 月 9 日发布了这个:
不出所料,这一大胆的声明引发了大量辩论,以至于 Twitter 现在将该推文标记为链接到最高法院禁止物品页面。
即使他们由于法律原因最终无法做到这一点,从伦理和社会角度考虑这个问题仍然是值得的。如果 AI 系统犯了严重的错误会发生什么?没有律师的人是否可以从这一技术的成熟版本中受益?
对稳定扩散的诉讼已开始
Matthew Butterick1 月 13 日发布了这篇文章:
“代表三位杰出的原告艺术家* — 莎拉·安德森,凯莉·麦克尔南 和 卡拉·奥尔蒂斯 — 我们对稳定性 AI,偏离艺术 和 Midjourney 提起了集体诉讼,因其使用了稳定扩散,这是 21 世纪的一种拼贴工具,重混了数百万艺术家的受版权保护的作品,这些作品被用作训练数据。”*
这开始了——这是一个漫长的斗争的第一步,旨在调节生成性 AI 的训练和使用。我同意这种动机:“AI 需要对每个人都公平和道德。”
但是,像许多人一样,我发现了博客文章中的不准确之处。它深入探讨了稳定扩散的技术细节,但未能正确解释一些部分。这是否是作为弥合技术差距的手段,还是为了以对其有利的方式描述技术的意图,尚无定论。
我曾在上一篇文章中争论,目前 AI 艺术与传统艺术家的冲突非常情绪化。这一诉讼的反应也不会有所不同。我们将不得不等待法官决定结果。
CNET 发布 AI 生成的文章
《未来学》报道 这件事是在几周前:
“CNET,一个极受欢迎的科技新闻网站,一直在悄悄地利用‘自动化技术’——AI 的风格性委婉说法——来撰写新一波的财务解释文章。”
Gael Breton,最初发现此事的人,在周五写了更深入的分析。他解释说,谷歌似乎并未阻碍这些帖子流量。“AI 内容现在可以接受了吗?”他这样问道。
我认为 CNET 的决定 完全披露 AI 的使用 是一个很好的先例。现在有多少人正在使用 AI 发布内容却没有披露?然而,结果可能是,如果这一做法奏效,人们可能会失业(正如我和许多人所 预测的)。这已经在发生了:
我完全同意 Santiago 的这条推文:
用于图像生成的 RLHF
如果通过人类反馈的强化学习对语言模型有效,那么对文本到图像是否也有效呢?这正是 PickaPic 尝试实现的目标。
这个演示用于研究目的,但可能是对稳定扩散或 DALL-E 的一个有趣补充(Midjourney 也做类似的事情——他们在内部指导模型输出美丽和艺术的图像)。
一份“让 Siri/Alexa 提升 10 倍”的配方
将不同生成型 AI 模型混合以创建比各部分之和更好的成果的配方:
Alberto Romero 是一名自由撰稿人,专注于科技和 AI。他撰写了 The Algorithmic Bridge,这是一个帮助非技术人员理解 AI 新闻和事件的通讯。他也是 CambrianAI 的技术分析师,专注于大型语言模型。
原始内容。经许可转载。
更多相关话题
如何使用 ChatGPT 提升你的数据科学技能
原文:
www.kdnuggets.com/2023/03/chatgpt-improve-data-science-skills.html
到目前为止,ChatGPT 已经证明在许多方面都很有用。它可以用于编写 SQL 和 Python 代码、改善你的简历和求职信,以及其他超出你想象和创造力的应用。
那么,我们为什么不能更高效地利用它来学习数据科学呢?数据科学领域充满了在线资源,但选择哪种资源最适合你可能令人不知所措。即使你不是初学者,仍然有需要学习的知识,保持更新是保持市场竞争力的重要要求。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的捷径。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
我引起你的兴趣了吗?那就开始吧!

图片由 Alberlan Barros 提供
1. 你能推荐一些资源来跟上数据科学最新趋势吗?
数据科学是一个复杂的领域,随着每一秒的推移而不断发展,让你没有时间感到无聊。因此,数据科学家的一个最重要的技能是不断学习并关注最新的 AI 发现和工具。如果你在谷歌上搜索,你会感到迷失,而直接询问 ChatGPT 可以节省你的时间。
你能推荐一些资源来跟上数据科学最新趋势吗?
这里是输出内容:
当然!以下是一些可以帮助你跟上数据科学最新趋势和进展的资源:
- 在线社区和论坛:加入像 Reddit、Quora 和 Stack Overflow 这样的在线社区和论坛可以帮助你跟上数据科学的最新趋势。你可以关注像 r/datascience 或 r/machinelearning 这样的特定子版块,或参与与你感兴趣的数据科学话题相关的论坛。
- 博客和新闻通讯:有多个数据科学博客和新闻通讯可以帮助你了解最新趋势和发展。一些受欢迎的数据科学博客包括 KDnuggets、Data Science Central 和 Towards Data Science。你还可以订阅 Data Science Weekly 或 Analytics Vidhya 等新闻通讯,以获取定期更新和见解。
- 会议和聚会:参加数据科学会议和聚会是跟上最新趋势和与该领域其他专业人士建立网络的绝佳方式。一些受欢迎的数据科学会议包括 Strata Data Conference、Data Science Conference 和 IEEE International Conference on Data Science and Advanced Analytics。
- 在线课程和 MOOCs:在线课程和 MOOCs 是学习新技能和跟上数据科学领域最新趋势的绝佳方式。一些受欢迎的数据科学在线学习平台包括 Coursera、edX 和 Udacity。
- 研究论文和期刊:阅读研究论文和期刊可以让你更深入地了解数据科学领域的最新发展和进展。一些受欢迎的期刊包括 Journal of Machine Learning Research、Journal of Data Science 和 ACM Transactions on Knowledge Discovery from Data。
通过定期获取这些资源的内容,你可以了解数据科学领域的最新趋势和进展,并保持领先。
哇!这是一个非常全面的资源列表,可以帮助你保持进度。这并不意味着你需要阅读所有资源,只需关注其中一些,比如 Towards Data Science、KDNuggets 和 Coursera,如果你是学生,Coursera 提供免费的课程。
2. 什么数据科学项目可以让我从人群中脱颖而出?
你可能是刚开始旅程的初学者,或者是想换工作的专业人士。个人项目总是受到公司青睐,可以成为你展示技能、打动招聘者的途径,并从其他申请者中脱颖而出。
我正在申请数据科学家的职位,并且想通过一些个人项目来打动招聘者。哪个数据科学项目能让我从人群中脱颖而出?
这里是输出:
很好的问题!以下是一些能帮助你脱颖而出的项目想法:
- 预测分析项目:创建一个预测模型来预测未来趋势、行为或结果。例如,你可以开发一个模型来预测客户流失、产品需求或股票价格。
- 自然语言处理项目:构建一个自然语言处理(NLP)模型来从文本数据中提取见解。例如,你可以开发一个情感分析模型来分类社交媒体帖子,或者一个聊天机器人来回答客户查询。
- 计算机视觉项目:构建一个计算机视觉模型来分析和提取图像或视频中的信息。例如,你可以开发一个模型来检测图像或视频中的物体,或识别面孔或情感。
- 推荐系统项目:建立一个推荐系统,根据用户的偏好和行为推荐产品、服务或内容。例如,你可以为电影、音乐或电商平台上的产品开发一个推荐系统。
- 深度学习项目:开发一个深度学习模型来解决特定问题。例如,你可以开发一个模型来分类医学图像、检测金融交易中的欺诈行为,或预测体育比赛的结果。
数据可视化项目:创建一个视觉上吸引人且信息丰富的仪表板,以传达数据分析中的见解。例如,你可以开发一个仪表板来跟踪业务的关键指标,或可视化数据集中模式和趋势。
在创建个人项目时,展示你的问题解决技能、创造力以及将复杂信息传达给非技术利益相关者的能力非常重要。确保记录你的项目,并在 GitHub 或 Kaggle 等平台上公开分享,以向潜在雇主展示你的工作。
另一个概述可以帮助你收集创作个人项目的想法。我建议根据个人兴趣或经验来决定。例如,你在工作经历中遇到过某个特定话题,你可以通过探索相似数据集中的相同概念来深入研究。
3. 你能向我解释一下数据科学中数学的主要概念吗?
每个人都有不足之处,总有可以改进的地方。其中一个方面可能是数学技能,这对理解各种数据科学概念非常重要。
我在数学方面仍有一些不足,这对解决数据科学问题至关重要。你能向我解释一下数学中能让我成为更优秀数据科学家的主要概念吗?
这是输出:
当然!以下是一些对数据科学重要的数学主要概念:
- 线性代数:线性代数是研究向量、矩阵和线性变换的学科。它是数据科学中的一个基本概念,广泛应用于机器学习、数据可视化等领域。线性代数的一些关键主题包括矩阵运算、特征向量和特征值,以及奇异值分解。
- 微积分:微积分是对连续变化的研究,在数据科学中得到了广泛应用。它用于优化机器学习算法,例如梯度下降和反向传播。微积分的一些关键主题包括微分、积分和优化。
- 概率与统计:概率与统计是数据科学中至关重要的概念。概率用于建模不确定性和进行预测,而统计用于分析数据并从中得出结论。概率与统计的一些关键主题包括概率分布、假设检验和回归分析。
- 多变量微积分:多变量微积分是微积分的扩展,处理多个变量的函数。它用于理解数据科学中变量之间的关系。多变量微积分的一些关键主题包括偏导数、梯度和多变量函数的优化。
- 优化:优化是从所有可能的解决方案中找到最佳方案的过程。它在机器学习中得到了广泛应用,并且是数据科学中的一个关键概念。优化的一些关键主题包括线性规划、凸优化和非线性优化。
- 微分方程:微分方程是描述随时间变化的系统行为的数学方程。它们用于数据科学中动态系统的建模,例如股票价格或天气模式。微分方程的一些关键主题包括一阶方程、二阶方程和微分方程组。
- 理解这些概念可以帮助你更有效地解决数据科学问题,并做出更有根据的决策。然而,需要注意的是,你不必在所有这些领域都成为专家才能成为成功的数据科学家。相反,专注于在与你工作相关的关键领域建立坚实的基础。
除了这些概念之外,我还想说的是,你不需要完全掌握数学才能成为数据科学家。这取决于你是从事工业界还是学术界的工作。如果你只是在公司工作,你并不需要深厚的数学训练。只需关注最重要的概念,如导数、梯度、矩阵乘法和优化算法。
4. 作为数据科学家,如何提升我的沟通技能?

图片由 Jason Goodman 拍摄,来源于 Unsplash
当我们在大学或培训课程中学习时,我们非常注重学习技术技能,而忽视了一个可以在工作中拯救你的方面:与非技术同事的沟通。大多数情况下,需要简化概念以向没有你背景的客户解释。
我是一名数据科学家,与非技术同事沟通时遇到了一些困难。你能告诉我如何提高我的沟通技能吗?
以下是输出:
作为数据科学家,将技术概念传达给非技术同事可能具有挑战性,但有几种方法可以改善你的沟通技能。以下是一些建议:
- 了解你的受众:了解你正在与谁交谈及其背景。这将帮助你调整语言和例子,使其更易于理解。
- 简化技术术语:与非技术同事沟通时,避免使用技术术语和缩略语。相反,尝试使用简单的语言,并在必要时提供背景信息。
- 使用视觉辅助工具:图表、图示和其他视觉辅助工具可以帮助以易于理解的方式传达复杂数据。使用它们来说明你的观点,使你的信息更具吸引力。
- 讲述故事:使用讲故事的方式来解释技术概念。这可以使你的信息更容易记住和理解。
- 练习积极倾听:倾听同事并提问以了解他们的观点。这将帮助你更有效地沟通并建立更强的关系。
- 练习、练习、再练习:沟通技能需要通过实践来提升。寻找机会向非技术同事展示,并寻求反馈以改进。
- 保持耐心:记住,并非所有人都拥有与你相同的技术专长。要有耐心,花时间清晰、简单地解释概念。
通过将这些策略融入你的沟通风格中,你可以提高将技术信息传达给非技术同事的能力。
这是ChatGPT解决任何问题的超能力的另一个证明。根据经验,我发现了第 1、2 和 3 点。我试着站在对方的角度思考,如果没有数据科学背景,我会如何理解这些概念。
如何克服数据科学的冒名顶替综合症?
在数据科学领域工作的大多数人有一个共同点,即所谓的冒名顶替综合症。即使有多年的经验,专业人士也可能会感到能力不足和自卑。如果管理不善,这可能成为你职业生涯的障碍。
我作为数据科学家已经工作了一年,但仍然感到冒名顶替综合症。我该如何克服这种感觉?
以下是输出:
冒名顶替综合症是一种许多专业人士,包括数据科学家,都会经历的常见感觉。以下是克服冒名顶替综合症的一些方法:
- 识别和承认你的感受:克服冒名顶替综合症的第一步是识别和承认你的感受。觉得自己知道的不够多或者不够好是正常的,但重要的是要提醒自己这些感受很常见,并不一定反映现实。
- 专注于你的优势:不要沉溺于你不知道的东西,而要专注于你所知道的和你带到桌面上的优势。记住你从别人那里收到的积极反馈,并为你的成就感到自豪。
- 不断学习:数据科学是一个快速发展的领域,因此不断学习和成长非常重要。参加课程、参加会议,阅读行业刊物,以便跟上最新的趋势和技术。
- 寻求指导和反馈:拥有一个导师或值得信赖的同事可以在你感到不确定时提供视角和指导。不要害怕请求对你工作的反馈,以帮助你识别需要改进的地方。
- 接受失败:数据科学是一个迭代的过程,失败是学习过程中的自然一部分。与其害怕失败,不如把它当作一个学习和成长的机会。
- 记住,你并不孤单:冒名顶替综合症是一种常见的感觉,许多成功的数据科学家在职业生涯的某个阶段都有过这种体验。寻求同事和同行的支持和建议。
通过实施这些策略,你可以克服冒名顶替综合症,并在你的数据科学职业生涯中继续成长和成功。
其他很好的建议!我证明这些方法非常有助于克服这种自卑感,特别是意识到这种感受,认识到你的优势并不断学习。即使是失败也可以成为一个很好的教训,帮助你学习新事物并了解你更喜欢或不喜欢什么。糟糕的经历可以转变为变得更强大并更有效地解决问题的好方法。
总结
正如预期的那样,ChatGPT 再次证明了它对从事数据科学领域的实践者和专业人士来说是一个宝贵的指导。在这篇文章中,我涵盖了五个在我的数据科学之旅中伴随我的基本方面。
通过使用 ChatGPT,你可以避免浪费精力去寻找大量资源,专注于你想要改进的方面,扩展你的技能,并克服可能阻碍你成长的问题。
尤金妮亚·安内洛 目前是意大利帕多瓦大学信息工程系的研究员。她的研究项目专注于将持续学习与异常检测相结合。
进一步阅读此主题
使用 ChatGPT 学习 SQL

图片由编辑 | Microsoft Designer
ChatGPT 能做许多很酷的事情。其中之一是编写代码。你只需给出正确的指令,ChatGPT 就会为你完成任务。
如果你想学习 SQL,ChatGPT 是一个很好的资源来入门。它可以帮助你使用自然语言创建 SQL 查询,解决你可能遇到的任何编码问题,甚至帮助你理解你不明白的预定义查询。
在本文中,我将概述如何使用 ChatGPT 学习 SQL 并在这项有价值的技能上变得熟练。
让我们一起搞清楚!????????
首先,ChatGPT 到底是什么?
ChatGPT 是一个由 OpenAI 训练的大型语言模型。它能够根据收到的输入生成类人的文本,可以用来回答问题并与人们进行对话。
所以基本上,我们可以利用它的知识——以及它以非常简单和人性化的方式告诉我们任何事情的能力——来理解 SQL 并从中学习。
#步骤 1:设置 ChatGPT
要开始使用 ChatGPT,你需要注册一个账户这里.
注册 ChatGPT 显示。
你需要提供你的电子邮件地址和电话号码才能开始使用 ChatGPT。
#步骤 2:学习如何与 ChatGPT 互动
一旦你启用了 ChatGPT,你应该会看到以下显示:
ChatGPT 聊天显示的屏幕截图。
在下方的输入框中,我们可以写下任何内容以开始与 ChatGPT 互动。由于我将打扰她——或者他——一段时间,我先提前道歉 😉

自制 gif。ChatGPT 回答我的第一条消息。
#步骤 3:问任何你能想象的事情——它都会回答你。
现在,我们可以开始向 ChatGPT 提问。我将专注于学习 SQL。我们可以通过 ChatGPT 询问 5 个主要的内容来提高我们的 SQL 技能。
1. 向我们解释 SQL 中的任何概念或命令
当接触一种新的编程语言时,我们通常会对每个命令产生很多疑问和困惑。ChatGPT 可以通过简单的解释帮助我们理解任何命令,并根据我们的要求提供尽可能多的使用示例。
让我们从 SQL 中最基本的东西开始——SELECT命令。
简要解释一下
*SELECT*命令及其用法示例
ChatGPT 给出简短的回答,解释了SELECT命令,并给出了最基本的示例:SELECT * FROM

ChatGPT 聊天的截图。
但是,我可以进一步询问 SELECT 命令。
解释一下
*SELECT*命令及其一些使用示例
正如你在下面的图片中观察到的那样,ChatGPT 解释了该命令的基础知识,并给出了几个使用示例。

ChatGPT 聊天的截图。给出更多 SELECT 命令的示例。
你可以尝试询问任何你能想象到的命令,例如像 HAVING 这样的更具挑战性的命令。
给我一些 SQL 中
HAVING命令的示例
ChatGPT 通过以下几个示例进行了回答:
- 要查找所有薪资高于平均薪资的员工的名字和薪水,你可以使用如下查询:
SELECT
name,
salary
FROM employees
GROUP BY name
HAVING salary > (SELECT AVG(salary) FROM employees);
2. 要找到过去一年内下过超过 10 个订单的所有客户的名字,你可以使用如下查询:
SELECT
name
FROM customers
WHERE customer_id
IN
(
SELECT customer_id
FROM orders
WHERE date >= DATEADD(year, -1, GETDATE())
GROUP BY customer_id
HAVING COUNT(*) > 10
);
当然,我们可以继续询问更多的解释和示例。尝试任何你能想到的其他命令,它都会立即回答。
2. 你可以询问如何在 SQL 中做某事,ChatGPT 会告诉你使用哪个(或哪些)命令。
我可以询问如何执行特定的操作,ChatGPT 会告诉我需要使用哪个命令。
我想要合并两个表,在 SQL 中我应该使用什么命令?
ChatGPT 告诉我使用任何连接命令,正如你在下面的图片中观察到的那样。
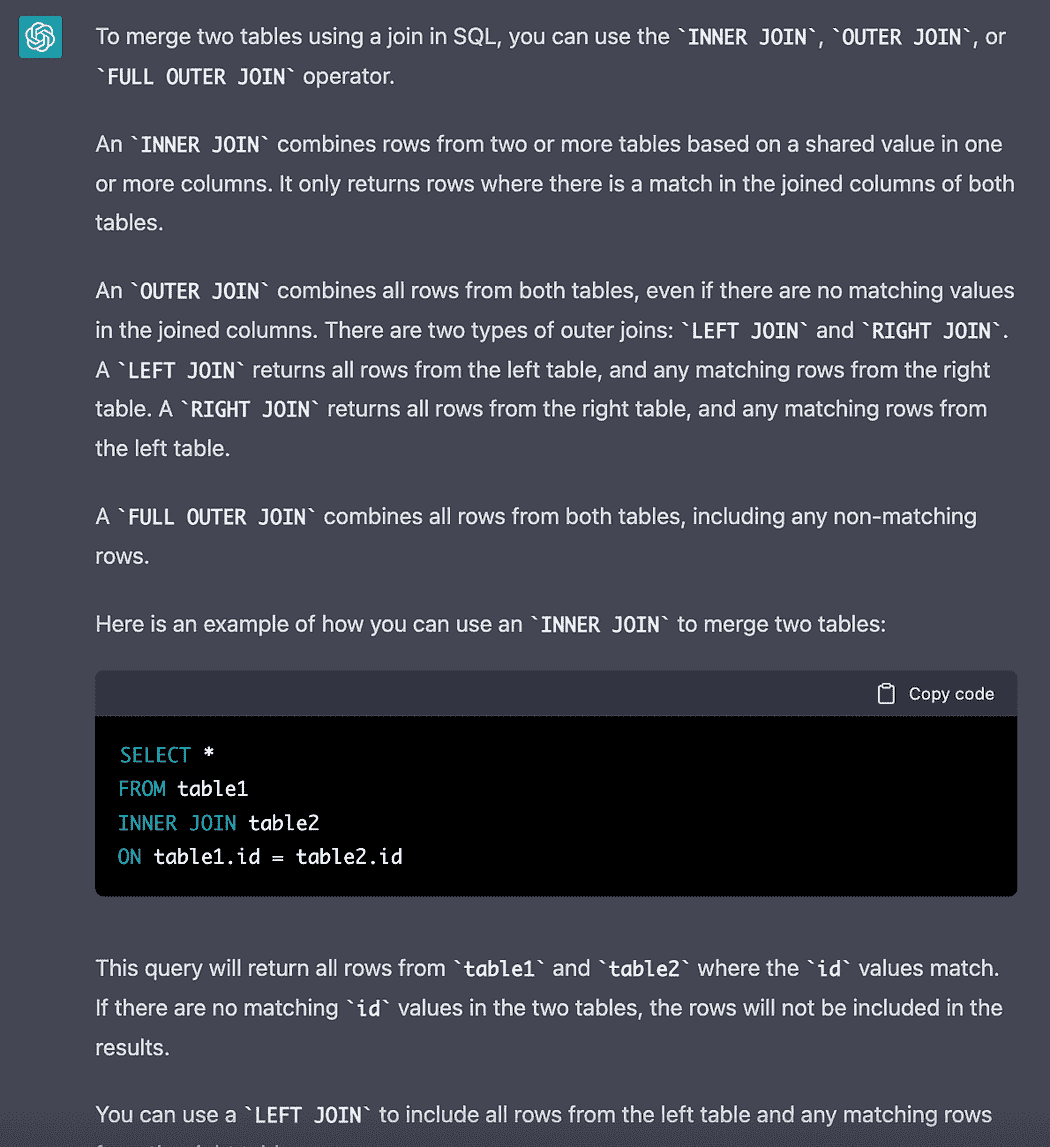
ChatGPT 聊天的截图。解释如何合并两个表。
不过,我知道我只想在某些特定列中行有相同值时合并两个表。在这种情况下,我可以再次询问,了解我应该使用什么命令。
我想要合并两个表,并只获取在某些给定列中有相同值的数据。
因此,ChatGPT 让我知道只有 INNER JOIN 允许我这样做,正如你在下面的图片中观察到的那样:
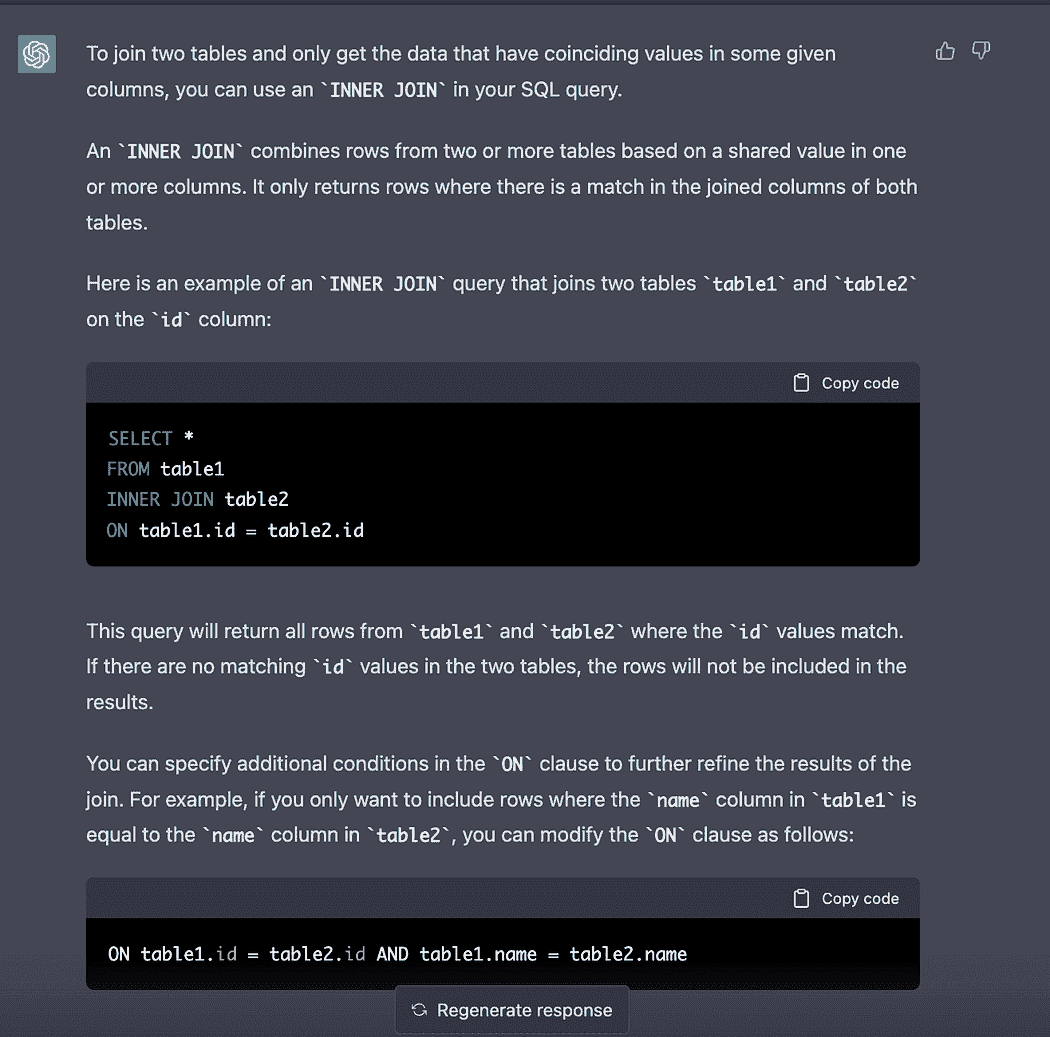
ChatGPT 聊天的截图。解释如何合并两个表并仅保留具有相同值的数据。
它给出了相应的查询:
SELECT
*
FROM table1
INNER JOIN table2
ON table1.id = table2.id
AND table1.name = table2.name;
3. 你可以让 ChatGPT 使用自然语言创建查询
现在让我们想象一下,我知道我需要什么结果,但对如何构建这个查询一点头绪都没有。我可以简单地向 ChatGPT 解释我想做什么,它会给我一个结构来遵循。因此,我可以通过 ChatGPT 的示例学习如何构建查询。
向我解释如何创建一个 SQL 查询,计算在一个包含各个城市不同物品价格的表格中的最昂贵城市。
ChatGPT 立即回答了我,正如你在下面的图片中所观察到的那样。
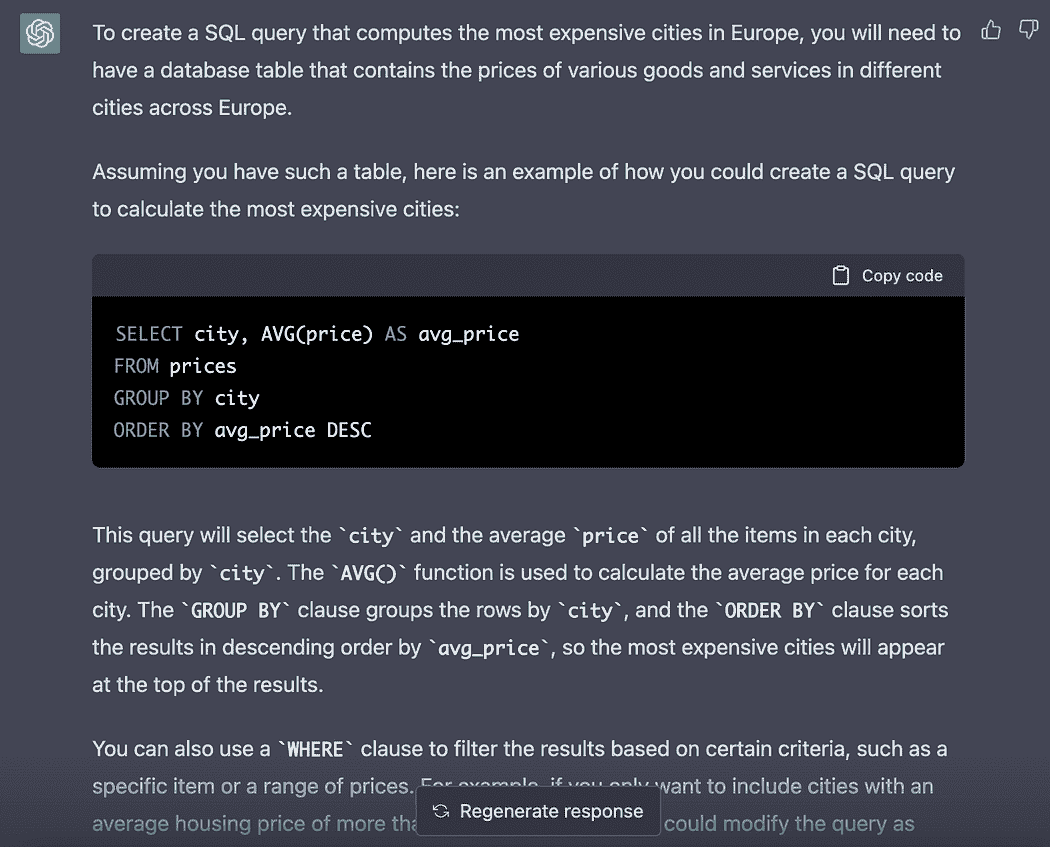
ChatGPT 给我一个查询的示例,并解释这个查询的作用。
4. 你可以让 ChatGPT 解释一个查询是如何工作的。
现在让我们想象一下,你需要完成一个生病的同事留下的工作,但你不理解他的查询——有些人编码方式混乱,或者你可能只是感到懒惰,不想浪费时间理解别人的查询。
这是正常的 —— 你可以使用 ChatGPT 来避免这项任务。我们可以轻松地让 ChatGPT 解释给定的查询。
让我们想象一下,我们想要理解以下查询的作用:
以下查询的作用是什么:[在这里插入查询]
ChatGPT 立即给出答案:

ChatGPT 聊天截图。它解释了给定查询的作用。
如你在之前的图片中所见,ChatGPT 逐步解释了这个查询的作用。
首先,它解释了所有包含的子查询及其作用。然后解释了最终查询以及如何使用之前的子查询来合并所有数据。我们甚至可以要求对某个子查询进行更详细的解释。
你能进一步解释一下之前查询的第二个子查询是做什么的吗?

ChatGPT 聊天截图。它进一步解释了给定查询的第二个子查询的作用。
如你在之前的图片中所见,ChatGPT 详细解释了第二个子查询的作用。
你可以用任何你能想象的查询来挑战 ChatGPT!
5. 你可以让 ChatGPT 挑战你做一些练习题。
对我来说,ChatGPT 的最佳部分是要求一些练习和答案来练习和测试你的技能。它甚至可以告诉你何时做得好——或不好。
你能给我一些练习来练习 SQL 吗?
ChatGPT 给我一些练习 SQL 的截图。
现在 ChatGPT 给我提供了一些需要完成的问题。在这种情况下,我可以尝试解决第一个问题,并询问 ChatGPT 我的解决方案是否正确。
以下查询是否正确回答了第一个之前的练习 [插入查询]
ChatGPT 会直接回答并说明它是否正确及原因。
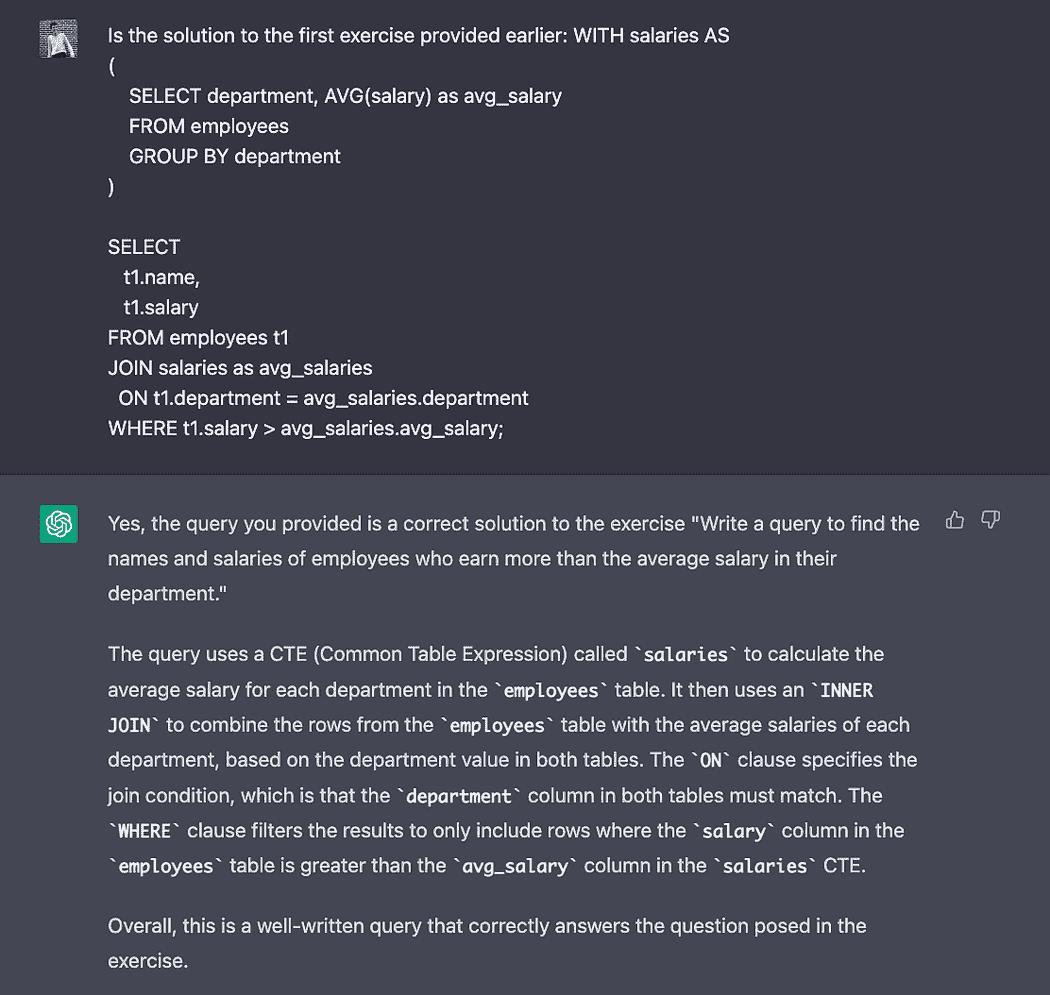
ChatGPT 判断我编写的查询是否正确的截图。
我可以询问每个之前示例的正确答案:
你能给我之前练习题的正确答案吗?
如你在下图中所见,ChatGPT 会给我所有正确的查询进行操作。
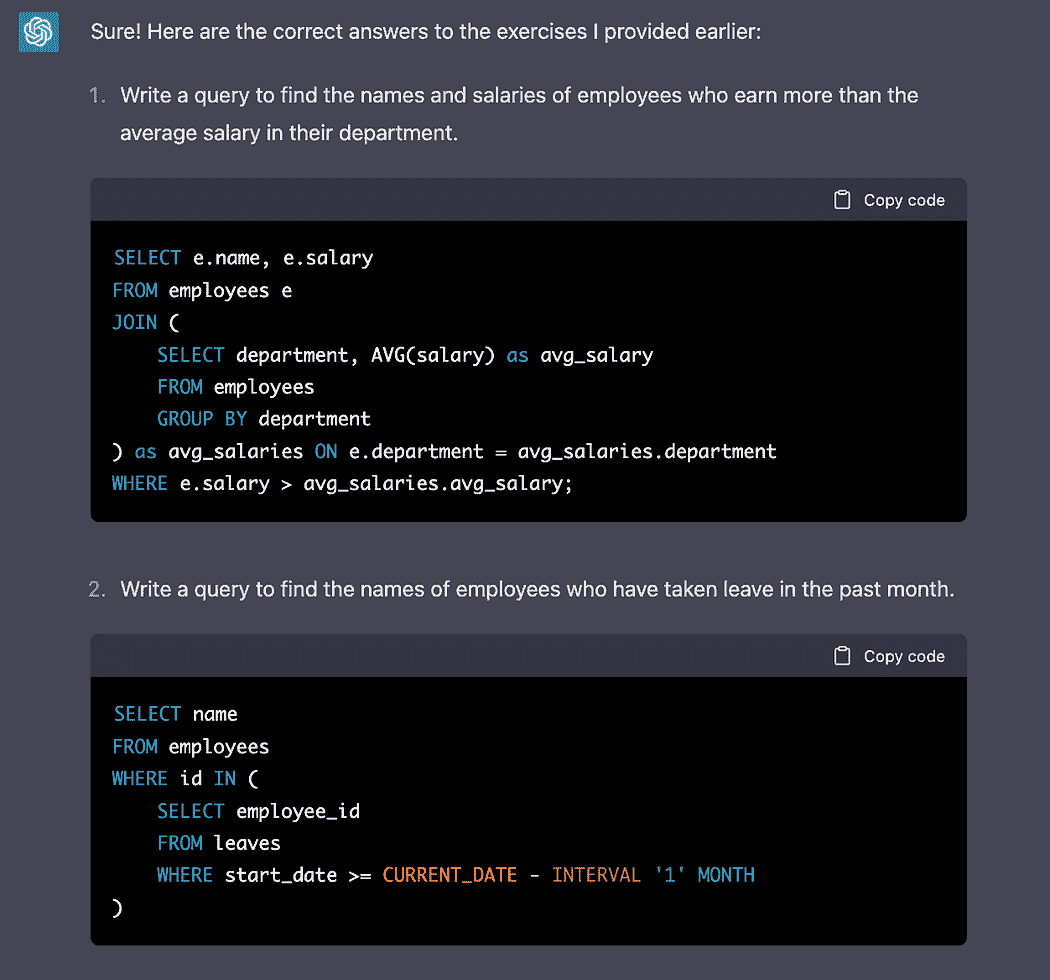
⚠️* 请注意,ChatGPT 提供的答案与我提交的待检查答案完全不同。*
结论
SQL 是当今数据驱动世界中一项宝贵的技能。 通过使用 ChatGPT 学习基础知识并练习你的技能,你可以熟练掌握 SQL。通过持续学习和实践,你可以不断扩展你的技能,并在数据职业生涯中取得飞跃进步。
如果 ChatGPT 用其他优秀功能让你感到惊讶,请告诉我!我会在评论中阅读你的反馈! 😄
数据总是有更好的见解——相信它。
Josep Ferrer 是一位来自巴塞罗那的分析工程师。他毕业于物理工程专业,目前在应用于人类流动性的 数据科学领域工作。他还是一位兼职内容创作者,专注于数据科学和技术。
原文。经许可转载。
我们的前三个课程推荐
1. Google 网络安全证书 - 加快你的网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关内容
ChatGPT 作为学习数据科学概念的个性化导师
原文:
www.kdnuggets.com/2023/05/chatgpt-personalized-tutor-learning-data-science-concepts.html

图片由 pch.vector 提供,来自 Freepik
ChatGPT 已经风靡全球,因为它易于使用且能用少量文字提供详细的回答。作为一个工具,它是我们学习者不容错过的。特别是对于数据科学学习者,它可以成为一个个性化的导师,从而更好地学习数据科学概念。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
使用 ChatGPT 工具,我们可以将其设为个性化导师,帮助我们学习数据科学概念。我们怎么做呢?让我们进一步探索。
前提条件
在这篇文章中,你应该已经有一个ChatGPT账户。我还假设我们使用的是 ChatGPT 的免费版本而不是 Plus 版本。然而,这篇文章中所写的内容也适用于使用 Plus 版本的情况。考虑到这一点,我们继续学习。
ChatGPT 作为个性化导师
ChatGPT 通过我们提供的提示来工作,工具根据提示提供答案。ChatGPT 的优点在于前后提示之间的一致性,创建了一个问答系统。通过这种方式,我们利用 ChatGPT 作为个性化导师,不断提问直到掌握概念。
让我们开始使用 ChatGPT。对于提示,我们可以说明我们的目的和数据科学知识水平。

使用上述提示,我们将 ChatGPT 设定为一个个人导师,教授数据科学初学者。让我们看看答案。

从一个简单的提示开始,ChatGPT 提供了推荐的话题。这是一个很好的开始,但我们总是可以要求更多有关学习议程的细节。让我们进行后续的提示,要求提供适当的指导。

上述提示也可以进一步详细说明时间线,如果你需要更详细的学习计划。让我们看看提示的结果。

ChatGPT 现在提供了一个结构化的数据科学概念主题,你可以从中开始学习。它还从一个我们应当学习的主题开始,再进入下一个主题。通过使用后续提示,我们可以更详细地了解。选择你想要详细了解的主题。

在上面的提示中,我们希望更多地了解统计学和概率学。那我们来看一下结果,

结果展示了统计学和概率学的基本概念更加清晰。我们可以通过需要了解和探索的术语,更详细地学习这些概念。我们总是可以进一步挖掘,以更深入地理解数据科学的概念,通过后续提示。

在这种情况下,我请求对变量进行更多解释。以下是结果。

每个后续提示都会对你想要的主题给出详细解释。所以,继续向 ChatGPT 询问更多细节,并提供提示以进一步阐述内容。
你还可以向 ChatGPT 询问关于特定主题的学习材料。

例如,我们请求变量主题的学习材料。

然后,ChatGPT 提供了获取学习材料的可能地点。如果你使用 GPT-4,回答可能会更详细。但目前,它足以作为学习数据科学概念的导师。
结论
ChatGPT 是一个文本生成 AI 工具,可以对给定的提示提供详细的回答。它是一个非常适合想要学习数据科学概念的学习者的工具。通过简单的提示和后续提示,ChatGPT 可以充当学习数据科学的个人导师。
Cornellius Yudha Wijaya 是一名数据科学助理经理和数据撰写者。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
了解更多此主题
ChatGPT 插件:您需要了解的一切
原文:
www.kdnuggets.com/2023/06/chatgpt-plugins-everything-need-know.html

图片由编辑提供
2023 年 3 月,OpenAI宣布发布 ChatGPT 插件,以研究现实世界的使用情况,并能够改进当前的安全性和对齐挑战。自 ChatGPT 发布以来,用户一直要求插件,以便开发者能够针对各种用例进行实验。
为了帮助 ChatGPT 用户充分利用这一工具,OpenAI 已从少量用户开始,并计划在获取更多经验后推出更大规模的访问权限。
OpenAI 已使插件开发者能够构建一个插件,使 ChatGPT 能够连接到 API。如果您想了解更多信息,可以通过点击文档来了解如何为 ChatGPT 构建插件。
不过目前,首批插件已经由以下公司创建:
在我们详细了解每个插件之前,让我们先了解一下带有浏览功能的 ChatGPT。
带有浏览功能的 ChatGPT
ChatGPT 面临的挑战之一是其训练数据仅更新到 2021 年 9 月。然而,通过使用带有浏览功能的 ChatGPT,您现在可以研究实时信息,超越其训练数据。
ChatGPT 带有浏览功能,使用 Bing API 进行搜索,并使用基于文本的网页浏览器选择特定网站。通过使用找到的网站和自身的研究,ChatGPT 将为您提供带有引用的答案。它会链接这些引用,以便您查看来源,从而验证 ChatGPT 的答案。
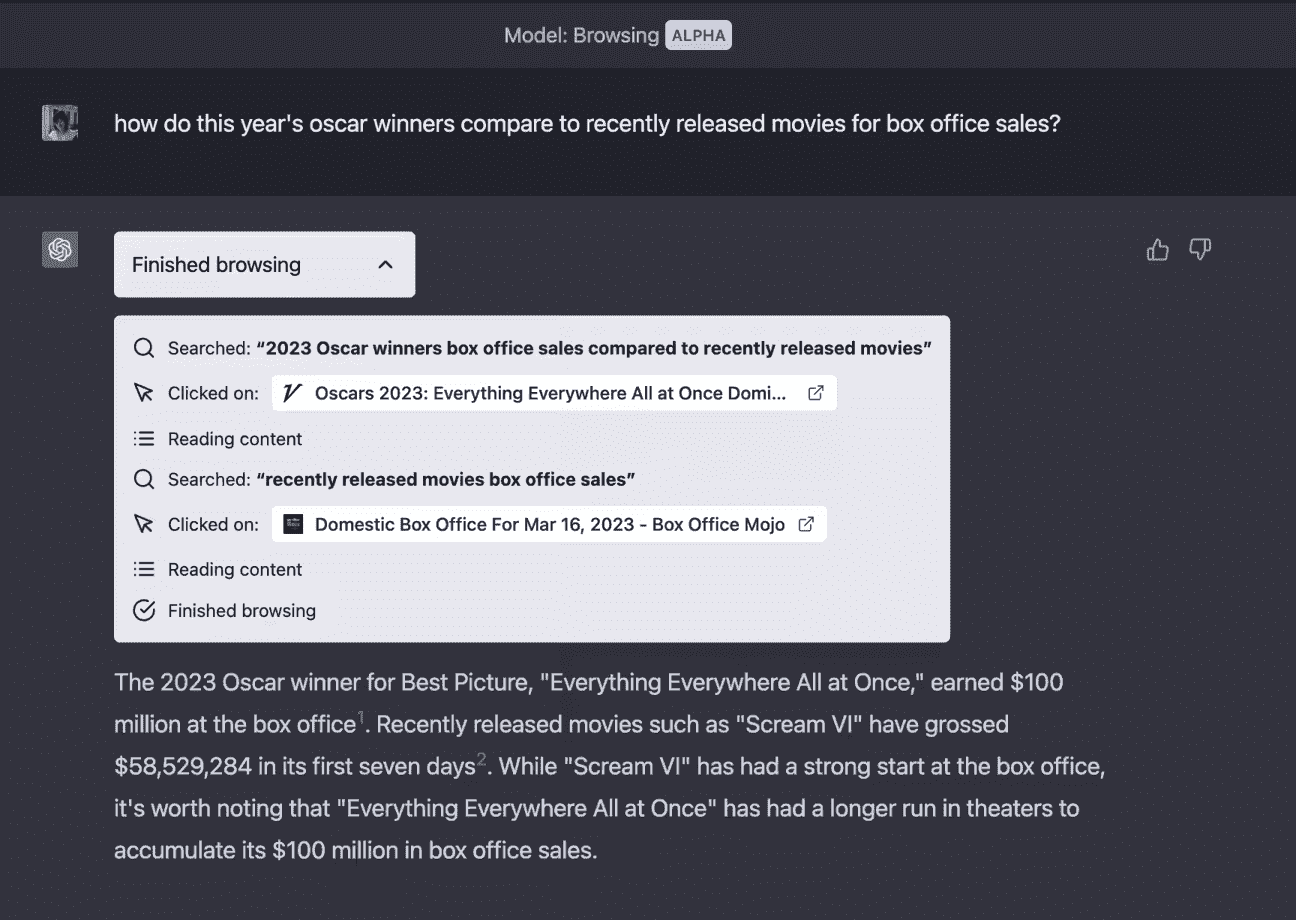
图片由OpenAI提供
Expedia ChatGPT 插件
如果您正在寻找假期,无论是航班还是酒店——Expedia 总是一个好的开始!计划假期可能总是令人烦恼的。这需要时间、精力和金钱。借助 Expedia ChatGPT 插件,您可以通过后续查询规划您的假期。ChatGPT 插件可以帮助您规划梦想假期,了解开支,提供多种度假胜地,并找到当地活动。
聊天机器人使用最新的数据、搜索标准和算法计算来提供满足用户需求的推荐。
FiscalNote ChatGPT 插件
FiscalNote 是一家领先的 SaaS 技术公司,提供全球政策和市场情报。FiscalNote 以汇总和训练模型而闻名,特别是在法律和政治领域。
FiscalNote 的 ChatGPT 插件将允许用户和开发者将他们的想法变为现实,提供最新的法律、政策和法规。实时通信提供了由人工智能和机器学习支持的量身定制的答案,帮助用户跟上不断变化的监管环境。
Instacart ChatGPT 插件
您可以询问 ChatGPT 制作传统孟加拉羊肉香饭所需的食材,但它不能为您购买这些食材。如果您能得到制作晚餐的食材岂不是很好?Instacart 旨在通过将您与本地的个人购物者连接起来,来简化您的生活,购物并送货到家。
Instacart 插件是 ChatGPT 的一个附加功能,允许用户购买与 ChatGPT 的食谱相关对话链接的食品,并将其送到您的门前,让您开始烹饪。
KAYAK ChatGPT 插件
另一个为 jet setters 准备的插件!我们不需要再提到度假计划可能有多么令人压力山大。KAYAK ChatGPT 插件可以帮助您预订航班,找到最佳酒店,并为您提供从头到尾的旅行建议。您可以根据预算得到理想的假期和所有推荐的偏好。
无需翻阅电子邮件找登机牌或酒店预订。KAYAK ChatGPT 插件将为您提供费用明细、出发时间、经停、预订等信息。
Klarna ChatGPT 插件
Klarna 多年来变得非常受欢迎,使人们可以更自由地购物。Klarna ChatGPT 插件让您通过拥有一个为您量身定制推荐和用户的历史搜索记录的客户购物助手来改善购物体验。
对于那些总是寻找便宜货的购物狂来说,Klarna 是您最好的朋友,配备了新的 ChatGPT 插件。您可以搜索和比较来自数千家在线商店的价格,并对您的购买感到满意。
Milo ChatGPT 插件
如果您是家长,正在努力跟上人工智能的不断发展,同时又不确定如何在照顾孩子的同时跟上这些进展。欢迎使用 Milo ChatGPT 插件,在这美丽的混乱中找到平静——这是为家长提供的 AI 副驾驶。
Milo 帮助家长管理家庭生活,并能够更平静地完成任务。家长们可以通过询问 Milo 问题,例如“今天有哪些家庭琐事待办?”来更好地组织自己。
如果你在工作或总是在外奔波,和孩子们分享珍贵的回忆可能会很困难。使用 Milo AI,它可以通过回答“今天有什么魔法?”来向父母提供如何与家人创造特别时刻的建议。
OpenTable ChatGPT 插件
这是为美食爱好者准备的!确实有时候你在路上寻找吃饭的地方,却不确定去哪里。然后你发现自己在打电话询问不同的餐厅是否有空位。
使用 OpenTable ChatGPT 插件,你可以在餐厅预订座位,然后前往。你只需告诉 ChatGPT 日期、时间、地点和人数,它就会为你找到所有当地的可用餐厅。这是一种与朋友和家人共度美好时光的简单便捷方式。
Shopify ChatGPT 插件
Shopify 是一个全球商业平台,允许企业从世界任何地方销售商品。使用 Shopify 销售或购买东西变得非常容易,ChatGPT 插件使其变得更好。
企业主可以使用 ChatGPT 插件来简化客户服务流程、增加销售或使业务更加用户友好。另一方面,如果你是买家,寻找准确想要的东西可能会很耗时。使用 Shopify ChatGPT 插件,你可以搜索来自世界顶级品牌的数百万种产品,插件会即时生成产品推荐。
Speak ChatGPT 插件
我们很多人一直想学习一门新语言,但从未有时间、资源或金钱来聘请导师。Speak ChatGPT 插件使学习新语言变得更加容易。
Speak 是一个先进的 AI 语言导师,它为你提供各种语言的即时反馈。它不仅仅是翻译文本,还帮助纠正语法、动词变位等。现在就通过 Speak ChatGPT 插件开始学习一门新语言吧。
Wolfram ChatGPT 插件
Wolfram 由斯蒂芬·沃尔夫拉姆于 1987 年创立,他们的研究部门被认为是世界上最受尊敬的计算机、网络和云软件公司之一。他们有一个长期愿景,即开发科学、技术和工具,以便未来使计算变得更加简单。
Wolfram ChatGPT 插件为用户提供了访问复杂计算、数学和实时数据的能力,以帮助解答你可能有的任何问题。听到这你可能会想“那就是很多数学”。但它也可以用于其他各种任务,比如分析音乐、可视化人体等等。
Zapier ChatGPT 插件
Zapier 是一个自动化平台,它非常受欢迎,因为它允许企业通过无代码自动化流程来改造公司。它在简化重复性任务、营销等方面为许多组织提供了很大帮助。
Zapier ChatGPT 插件允许你连接到超过 5,000 个应用程序,并通过 ChatGPT 轻松互动。例如,这些应用程序包括 Gmail、Google Sheets、Slack 等。这不仅可以节省你在应用程序之间切换时的时间和困惑,现在你可以要求 ChatGPT 在另一个应用程序中执行相同的任务,而无需任何麻烦。
总结
上述是首批创建的插件,市面上还有更多,未来也肯定会有更多插件推出。这些插件处于测试阶段,你需要加入等待名单才能获得开发者访问权限。如果你想了解一个示例 ChatGPT 插件的设置,可以查看这个:插件快速入门库。
看到更多插件将会出现,以及它们是否能提升我们生活质量,将会很有趣。如果你有意创建一个 ChatGPT 插件,请在下面的评论中告知我们!
Nisha Arya是一位数据科学家,兼任自由技术作家和 KDnuggets 社区经理。她特别关注提供数据科学职业建议或教程,并围绕数据科学的理论知识进行探讨。她还希望探索人工智能如何能促进人类寿命的不同方式。她是一个积极学习者,寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
ChatGPT 作为 Python 编程助手
原文:
www.kdnuggets.com/2023/01/chatgpt-python-programming-assistant.html

原图由Sigmund提供,来源于Unsplash | 作者编辑
OpenAI 的 ChatGPT 是……你已经知道了。你已经读过足够的内容,不再需要介绍。如果你恰好不知道 ChatGPT 是什么,先看看这个,然后再回来继续。
与 ChatGPT 的对话可以是娱乐性的,甚至是启发性的。但让我们看看它实际上能有多有帮助。
让我们看看 ChatGPT 在根据我们提供的规范编写代码时能做什么。我们将从简单开始,然后逐步构建。
简单的数据处理脚本
我认为一个好的起点是某种数据处理脚本。由于我打算让 ChatGPT 使用各种 Python 库编写一些机器学习脚本,这似乎是一个合理的起点。
目标
首先,我想尝试加载数据集;确保所有数据集值都是数字值,或将它们转换为数字;检查缺失值;并将数据集拆分为训练集和测试集。
提示
*编写一个 Python 脚本,实现以下功能:
-
从磁盘上的 csv 文件加载数据集到 Pandas DataFrame
-
确保数据集完全是数字的;将字符串值转换为数字,并在字典中跟踪这种转换以供以后参考
-
检查 DataFrame 中的缺失值,并为任何有一个缺失值的记录填补缺失值;完全删除有多个缺失值的记录
-
将数据集拆分为测试集和训练集*
响应
import pandas as pd
# Load dataset from csv to DataFrame
df = pd.read_csv('dataset.csv')
# Initialize dictionary to track string to numeric conversions
conversions = {}
# Convert string values to numeric and track conversions in dictionary
for col in df.columns:
if df[col].dtype == object:
conversions[col] = {val: i for i, val in enumerate(df[col].unique())}
df[col] = df[col].map(conversions[col])
# Check for missing values
missing_values = df.isna().sum()
# Impute missing values for records with one missing value
for col in missing_values[missing_values == 1].index:
df[col].fillna(df[col].median(), inplace=True)
# Drop records with more than one missing value
df.dropna(thresh=len(df.columns) - 1, inplace=True)
# Split dataset into test and training sets
from sklearn.model_selection import train_test_split
train_df, test_df = train_test_split(df, test_size=0.2)
注意:该脚本从 csv 文件名为 "dataset.csv" 的文件中加载数据集,并将数据框分割为 80/20 比例的测试集和训练集。如果你想使用不同的文件名或比例,请相应地更改路径/比例。
分析
ChatGPT 生成了一个有用的脚本。它决定了数据集的名称以及训练/测试的分割百分比,并记录了这两点以及如何更改它们。如果总体任务完成。
代码重构
目标
现在我们有一个做某事的脚本,让我们稍微重构一下它。良好编码的基石是使用函数来逻辑组织代码,促进重用,并确保不重复自己。
提示
重写上述脚本,以使用一系列合理的函数
响应
import pandas as pd
from sklearn.model_selection import train_test_split
def load_and_convert_data(file_path):
# Load dataset from csv to DataFrame
df = pd.read_csv(file_path)
# Initialize dictionary to track string to numeric conversions
conversions = {}
# Convert string values to numeric and track conversions in dictionary
for col in df.columns:
if df[col].dtype == object:
conversions[col] = {val: i for i, val in enumerate(df[col].unique())}
df[col] = df[col].map(conversions[col])
return df, conversions
def handle_missing_values(df):
# Check for missing values
missing_values = df.isna().sum()
# Impute missing values for records with one missing value
for col in missing_values[missing_values == 1].index:
df[col].fillna(df[col].median(), inplace=True)
# Drop records with more than one missing value
df.dropna(thresh=len(df.columns) - 1, inplace=True)
return df
def split_data(df, test_size):
return train_test_split(df, test_size=test_size)
# Use the functions
file_path = "dataset.csv"
df, conversions = load_and_convert_data(file_path)
df = handle_missing_values(df)
train_df, test_df = split_data(df, 0.2)
在这里,我使用了三个函数:
1. load_and_convert_data(file_path) 加载 CSV 数据集并将字符串值转换为数字。
2. handle_missing_values(df) 处理数据集中的缺失值。
3. split_data(df, test_size) 将数据集拆分为测试集和训练集。
主脚本使用这些函数来加载、转换和清理数据集,然后将其拆分为测试集和训练集。
数据集的路径和测试比例是这些函数的输入。
分析
如果你查看 ChatGPT 输出的第一个脚本,你可能会看到一些非常明显的行,能够指出哪些功能应该被分隔成不同的函数。我确实发现了这一点。在这方面,ChatGPT 完全按我预期的方式进行了。再次确认,生成了一个称职的脚本。
扩展我们的代码
目标
好的,我们的脚本现在看起来好一点了,因为它使用了一些用于组织的函数。接下来,让我们稍微扩展脚本,使用户在运行脚本时可以指定一些参数。
提示
重写上述程序,以从命令行以参数的形式获取以下内容,并在程序中使用它们:
-
数据集 CSV 文件的路径/名称
-
训练/测试拆分大小
-
记录的缺失值数量的阈值,超过此阈值则丢弃整条记录,而不是填补缺失值*
响应
import pandas as pd
import argparse
from sklearn.model_selection import train_test_split
def load_and_convert_data(file_path):
# Load dataset from csv to DataFrame
df = pd.read_csv(file_path)
# Initialize dictionary to track string to numeric conversions
conversions = {}
# Convert string values to numeric and track conversions in dictionary
for col in df.columns:
if df[col].dtype == object:
conversions[col] = {val: i for i, val in enumerate(df[col].unique())}
df[col] = df[col].map(conversions[col])
return df, conversions
def handle_missing_values(df, threshold):
# Check for missing values
missing_values = df.isna().sum()
# Impute missing values for records with one missing value
for col in missing_values[missing_values == 1].index:
df[col].fillna(df[col].median(), inplace=True)
# Drop records with more than threshold missing value
df.dropna(thresh=len(df.columns) - threshold, inplace=True)
return df
def split_data(df, test_size):
return train_test_split(df, test_size=test_size)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("file_path", help="path/name of the dataset csv file")
parser.add_argument("test_size", help="train/test split size", type=float)
parser.add_argument("threshold", help="threshold for the number of missing values per record", type=int)
args = parser.parse_args()
# Use the functions
df, conversions = load_and_convert_data(args.file_path)
df = handle_missing_values(df, args.threshold)
train_df, test_df = split_data(df, args.test_size)
在这个版本中,我使用了 argparse 模块来将文件路径、测试/训练拆分大小和每条记录的缺失值阈值作为命令行参数输入。用户需要用正确的参数运行脚本,例如:
python script.py dataset.csv 0.2 1
这将使用“dataset.csv”文件、0.2 的测试大小和 1 的缺失值阈值来运行脚本。
主脚本使用这些参数来加载、转换和清理数据集,然后将其拆分为测试集和训练集。
还值得一提的是,在运行脚本时,应该从命令行运行,而不是从 IDE 运行。
分析
说实话,考虑到 ChatGPT 解释了它所做的内容相当清楚,这里不需要太多分析。我实际上会注意到一个之前没有提到的点,并且对 ChatGPT 的评论给予称赞,它的注释既富有表现力又简洁。
将我们的代码转换为 Streamlit 应用
目标
现在,假设我们想让这个代码“生产”就绪(请允许我开个玩笑)。让我们让 ChatGPT 将这些函数封装在一个 Streamlit 应用中。
提示
将上述程序重写为 Streamlit 应用,允许用户提供与上述命令行参数相同的参数
响应
import pandas as pd
import streamlit as st
from sklearn.model_selection import train_test_split
def load_and_convert_data(file_path):
# Load dataset from csv to DataFrame
df = pd.read_csv(file_path)
# Initialize dictionary to track string to numeric conversions
conversions = {}
# Convert string values to numeric and track conversions in dictionary
for col in df.columns:
if df[col].dtype == object:
conversions[col] = {val: i for i, val in enumerate(df[col].unique())}
df[col] = df[col].map(conversions[col])
return df, conversions
def handle_missing_values(df, threshold):
# Check for missing values
missing_values = df.isna().sum()
# Impute missing values for records with one missing value
for col in missing_values[missing_values == 1].index:
df[col].fillna(df[col].median(), inplace=True)
# Drop records with more than threshold missing value
df.dropna(thresh=len(df.columns) - threshold, inplace=True)
return df
def split_data(df, test_size):
return train_test_split(df, test_size=test_size)
def main():
st.set_page_config(page_title="Data Preprocessing", page_icon=":guardsman:", layout="wide")
st.title("Data Preprocessing")
file_path = st.text_input("Enter the path/name of the dataset csv file: ")
test_size = st.number_input("Enter the train/test split size (decimal between 0 and 1): ", step=0.01, value=0.2)
threshold = st.number_input("Enter the threshold for the number of missing values per record: ", step=1, value=1)
if st.button("Process Data"):
df, conversions = load_and_convert_data(file_path)
df = handle_missing_values(df, threshold)
train_df, test_df = split_data(df, test_size)
st.success("Data preprocessing completed!")
if __name__ == '__main__':
main()
这个版本是一个 Streamlit 应用程序,允许用户提供与命令行参数相同的参数。它使用 Streamlit 库创建一个交互式网页应用程序,允许用户输入文件路径、测试/训练拆分大小以及每条记录的缺失值阈值。用户可以点击“处理数据”按钮来运行脚本并预处理数据。它使用与脚本的前一个版本相同的函数来加载、转换和清理数据集,然后将其拆分为测试集和训练集。
要运行该脚本,你需要安装 Streamlit,你可以在终端中运行命令 pip install streamlit。安装完成后,使用命令 streamlit run script.py 来运行脚本。
分析
它完成了它应该做的事情。ChatGPT 利用我们的功能...函数构建了一个简单的 Streamlit 网页应用程序。

使用 ChatGPT 生成的脚本创建的 Streamlit 网页应用程序
总结
ChatGPT 在创建、重构、扩展和为我们编写的简单数据预处理 Python 脚本添加包装器方面表现得非常出色,所有这些都是基于我们提供的规格。虽然这并不是最复杂的程序,但它是朝着让 ChatGPT 作为编程助手真正有用的方向迈出的第一步。结果在每一步都达到了预期。
下一次,我们将构建一个复杂度更高并且有更多额外要求的程序。我很期待看看 ChatGPT 在压力下表现如何。希望你也是。
Matthew Mayo (@mattmayo13)是数据科学家及 KDnuggets 的主编,KDnuggets 是开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系到。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关主题
ChatGPT 会取代数据科学家吗?
原文:
www.kdnuggets.com/2023/06/chatgpt-replace-data-scientists.html

图片由作者提供
如果你在数据行业工作或渴望从事该行业,你可能会想知道是否是时候换个职业了。
生成模型如 ChatGPT 会不会是数据科学家的终结?
作为一个在数据科学领域工作了三年的人,我想分享我的看法。
在我之前写的一篇文章中,我强烈不同意自动化 AI 软件可以 取代数据科学家 的观点。我的论点是,这些工具会在一定程度上提高组织效率,但缺乏定制性,并且在每个阶段都需要人工参与。
但那是在 2022 年 2 月,远在 ChatGPT,即 OpenAI 的革命性语言模型发布之前。
当 ChatGPT 首次公开时,它基于 GPT-3.5,这是一个能够理解自然语言和代码的模型。
然后,在 2023 年 3 月,GPT-4 发布了。这一算法在解决基于逻辑、创造力和推理的问题方面优于其前身。
这是关于 GPT-4 的一些事实:
-
它可以编写代码(而且,真的很棒)
-
它通过了律师资格考试
-
它在机器学习基准测试中优于大多数最先进的模型
这个模型可以将草图转变为一个完整的网站,并且是编程和数据科学任务的得力助手。
这一技术已经被组织用来提高效率。
Freshworks 的 CEO Girish Mathrubootham 表示,曾经需要 9 周才能完成的编程任务,现在使用 ChatGPT 只需 几天 即可完成。
通过生成 AI,该公司中的编码工作流程比平时快大约 20 倍。这将大大减少周转时间,这意味着公司可以更快地完成更多工作。
不利之处 - 为什么你的工作面临风险
产品集成
到目前为止,我们只谈论了编程。
数据科学家的工作还有其他方面——如数据准备、分析、可视化和模型构建。
根据我的经验,数据科学家目前的需求量很大,因为他们需要掌握多种技能。
除了建立统计模型和学习编程,这些专业人士还需要使用 SQL 进行数据提取,使用如 Tableau 和 PowerBI 之类的软件进行可视化,并有效地将见解传达给利益相关者。
然而,借助像 ChatGPT 这样的 LLM,进入数据科学或分析领域的障碍将大大降低。候选人不再需要掌握各种软件的专长,而是可以利用 LLM 的力量在几分钟内完成通常需要几个小时的工作。
例如,在我曾经工作过的一家公司,我被要求完成一个计时的 Excel 评估,因为该组织的大部分数据库都存在于电子表格中。他们希望聘请一个能够迅速提取和分析这些数据的人。
然而,随着 LLM 的普及,对具备特定工具使用专长的候选人的招聘要求将会消失。
例如,通过 ChatGPT-Excel 集成,你可以简单地高亮要分析的单元格,并向 LLM 提问,如“这些销售数字在上个季度的趋势如何,”或“你能进行回归分析吗?”

ChatGPT 对 Excel 集成的回应会是什么样子
这样的产品集成将使 Excel 及其他类似软件对那些通常不使用它们的人变得可用,而对工具专家的需求将减少。
代码插件
ChatGPT 代码解释器插件是数据科学工作流程民主化的另一个例子。它允许你在聊天中运行 Python 代码和分析数据。

图片来源于“The Latest Now”在 Medium
你可以上传 CSV 文件,并让 ChatGPT 帮助你清理、分析数据以及构建统计模型。
一旦你分析了数据并告诉它你想做什么(例如,预测下个季度的销售数字),ChatGPT 会告诉你实现最终结果的步骤。
它将继续为你进行实际分析和建模,并在每个阶段解释输出结果。
在这篇文章中,作者要求 ChatGPT 的代码解释器使用联邦储备经济数据(FRED)预测未来的通货膨胀趋势。算法从可视化数据中的当前趋势开始。
然后它检查了数据的平稳性,对其进行了变换,并决定使用 ARIMA 进行建模。它甚至能够找到用于生成 ARIMA 预测的最佳参数:
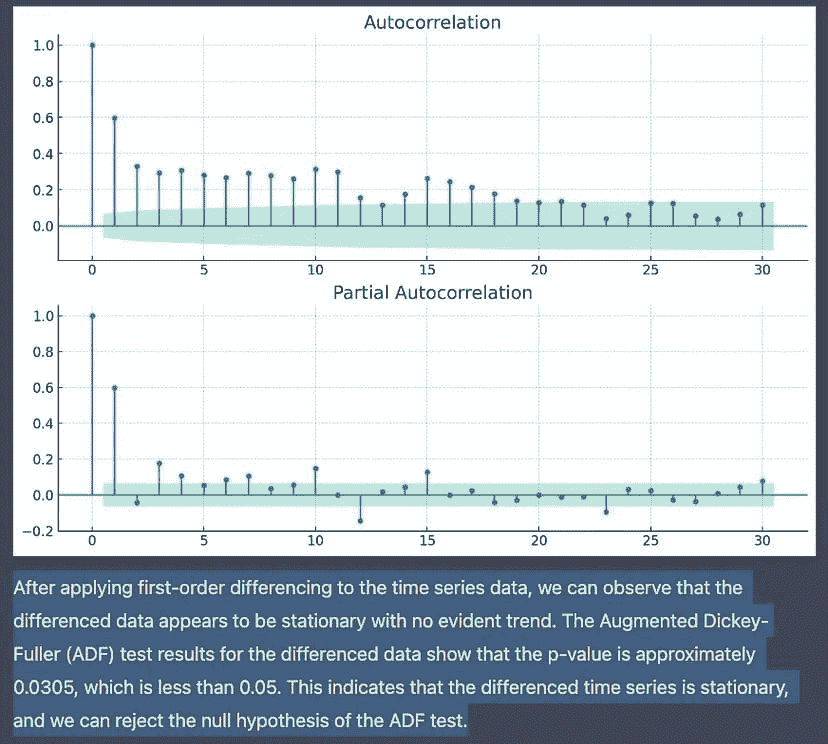
图片来源于“The Latest Now”在 Medium
这些步骤通常需要数据科学家花费大约 3-4 小时来完成,而 ChatGPT 只需几分钟,就能通过简单地摄取用户上传的数据来完成。
这是一项令人印象深刻的成就,将显著减少实现模型构建过程所需的专业知识量。
那么……人类专业知识仍然必要吗?
当然,无论 AI 在编码和模型构建方面变得多么出色,人类专家仍然需要监督这一过程。
ChatGPT 经常生成错误的代码并在构建统计模型时做出错误的决策。公司仍需要招聘擅长统计和编程的员工来监督数据科学过程,以确保模型的提示是正确的。
LLM 不能创建完整的数据产品,因为人类仍需执行需求收集、调试和验证模型输出等任务。
然而,公司对执行这些任务的人的需求将不如以前那么多。
像 LLM 带来的显著效率提升将意味着团队可以开始缩减规模。
比如说,公司可以只聘请 5 名数据科学家,而不是 10 名来完成工作。
我相信,入门级数据科学职位将是首批受到这一发展的影响的,因为 LLM 已经能够执行中级水平的编码和分析工作流。
由于 AI 的招聘冻结 已经在大型科技公司中出现,我们可能会看到数据科学人才超过该技能需求的情况。
如何在 ChatGPT 时代保护你的职业生涯
幸运的是,对于我们技术和数据科学专业人士来说,情况并非全然悲观。尽管 LLM 在编程和数据分析等任务上迅速进步,但它们无法取代人类的创造力和决策能力。
以下是一些在 LLM 时代保护职业生涯的建议:
获取业务专业知识
组织将继续招聘能够为业务创造收入的人。
如果你在某个特定领域拥有专业知识,并且理解公司的运营细节和客户需求,你将有独特的机会来识别增长机会。
你最不希望做的就是在 AI 竞争中处于劣势——你不希望成为管理电子表格的那个人,或是每个人都找来制作季度业绩报告的人。这些工作很容易被自动化,将成为 ChatGPT 时代首批被取代的职位。
我认为,与其把精力集中在学习那些 LLM 能够比你更快掌握的特定软件上,不如学习更宏观的视角。发展领导力和管理技能,理解如何利用 AI 实现公司的目标。
拥抱 AI
根据皮尤研究中心的数据,只有14%的成年人实际上尝试过 ChatGPT。如果你正在阅读这篇文章,利用 ChatGPT 学习新事物,并跟上人工智能的最新进展,那么你就是一个早期采用者。
我建议将 LLM(大型语言模型)融入到你的工作流程中,使用集成了人工智能的产品,并学习利用这些模型最大化效率的最佳实践。
这样,你可以保持领先,并更好地了解你工作中的哪些部分可以自动化,哪些部分需要人工干预。
这不仅会使你成为更优秀的数据科学家,而且当组织开始将人工智能融入不同的业务领域时,你将处于最佳位置,能够就如何利用人工智能提高生产力提供建议。
实际上,最近出现了一种新的角色,称为提示工程,薪资高达$335,000。提示工程师是让生成型人工智能应用程序按其需求执行任务的专家。
一个好的提示工程师是能够“项目管理”人工智能,完成诸如设计网页应用程序等任务的人。
无论你是否希望从事提示工程师的工作,将人工智能融入你的现有工作流程中都会使你比那些尚未这样做的人更具竞争力。
多样化收入
组织将很快开始重组,因为他们开始制定新的商业战略,这些战略将融入人工智能。
如果这导致大规模裁员,保护自己的唯一方法就是拥有多种收入来源,而不仅仅依赖于全职工作。
我建议创建一个自由职业者作品集——为多个组织工作并获得被动收入,将确保你的未来不依赖于单一雇主的决策。
创建个人品牌
最后,《哈佛商业评论》建议创建个人品牌以使自己从人群中脱颖而出。
像Tim Denning和Jessica Wildfire这样的 Medium 作者,即使人工智能能够模拟他们的写作风格,他们仍然会拥有一群忠实的粉丝和消费他们作品的人。
这是因为最终,人们喜欢真实的故事,想要与他人建立联系,而这是人工智能无法提供的。
同样,组织将继续聘用在领域内被认可的行业领袖,以此作为质量和品牌的象征。建立个人品牌的一些方法包括建立一个 数据科学作品集、创建内容并不断提升技能。
要点
生成模型将改变职业景观,数据科学、分析和编程等领域将受到这些工具带来的效率提升的影响。
然而,这并不意味着数据科学家的终结。遵循上述策略可以帮助你保持领先,确保你不会与 AI 竞争。
Natassha Selvaraj 是一位自学成才的数据科学家,热衷于写作。你可以通过 LinkedIn 与她联系。
更多相关话题
ChatGPT 可以作为教育资源被信任吗?
原文:
www.kdnuggets.com/2023/05/chatgpt-trusted-educational-resource.html

图片来自 Bing 图像生成器
ChatGPT 已经风靡全球,人们越来越好奇如何利用它提高生产力或改善生活和工作。关于 ChatGPT 是否是一个有价值和可靠的教育资源,已经发生了许多争论。答案并不像看起来那么简单。让我们仔细看看。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 需求
ChatGPT 并不总是准确的
ChatGPT 提供快速的回答,但这些回答不一定可靠。例如,它可能会提供完全或部分错误的信息,这些信息看起来非常可信。人工智能研究领域的人将这个问题称为“幻觉”。
任何曾经教过课或当过学生的人几乎肯定遇到过那些自信地做出严重错误陈述的人,并将其呈现为绝对的事实。ChatGPT 在产生幻觉时也会这样,这对任何使用该工具学习或完成教育项目的人尤其有问题。
ChatGPT 可能会鼓励剽窃
让人们最惊讶的是 ChatGPT 给出回复的速度。当学生在写论文时感到压力,并觉得遇到了思维障碍时,很容易理解他们如何可能会感到诱惑,不仅仅是把 ChatGPT 当作资源,而是直接从中复制内容。
这使得大学和高中教育工作者考虑重新定义剽窃以包括禁止复制人工智能提供的材料。怀疑剽窃的老师无法确定学生如何获取那些可能让他们从 ChatGPT 复制的内容。
这是因为没人能询问 ChatGPT 如何生成特定的回答。人们还发现该工具经常生成虚假的引用,当用户询问其资源时。
ChatGPT 延续了有害的刻板印象
许多人在被问及是什么激励他们从事特定职业时,会提到他们最喜欢的老师。早期获得启发非常重要,尤其是因为许多职业中仍存在性别不平衡。幸运的是,这种情况正在改善。在俄罗斯数学学校——该学校在北美服务 50,000 名学生——78% 的教师和 48% 的学生是女性。
然而,有证据表明,即使人们使用 ChatGPT 的原因与他们的职业或教育无关,该工具仍可能向他们传播有害的刻板印象。有一位用户让 ChatGPT 讲述一个关于男孩和女孩选择职业的故事。故事中的女孩怀疑自己能否“处理工程课程中的所有技术细节和数字”,而男孩则喜欢与机器和小玩意儿打交道。
诚然,一次 ChatGPT 对话不会成为决定一个人选择职业路径或课程的决定性因素。然而,世界上已经有足够多的负面反馈,不需要一个聊天机器人进一步加剧这种情况或表达过时的性别刻板印象。
ChatGPT 在教育中的负责任使用
许多教师已经意识到不能回到 ChatGPT 之前的时代。现在的挑战是找出学习者如何将该工具作为补充工具使用,而不是期待它提供所有正确的答案。
学生可以将该工具用作头脑风暴引擎,提出诸如“企业面临的五大网络安全风险是什么?”等问题,然后根据 ChatGPT 的回答开始编写论文。这并不会鼓励人们作弊,而是拓宽了他们的思路,了解可能最初被忽视的内容。
另一种可能性是使用 ChatGPT 生成写作提示。这是一种简单但有效的方式,帮助保持技能的敏锐性,并减少当人们需要创作内容但不确定如何开始时的拖延。
一位教师还表示,他们用它来帮助学生规划 一般实验。它还可以帮助教育工作者处理行政任务——例如写信给家长和制定课程大纲——从而为他们提供更多时间投入教学。
谨慎使用 ChatGPT
这些例子表明,ChatGPT 具有一些有效的使用案例。然而,也存在一些令人担忧的例子,显示人们可能会滥用或被该工具误导。无论是教师、教育工作者还是对人工智能感兴趣的人,都必须牢记这些现实。
April Miller 是 ReHack 杂志的消费者技术管理编辑。她在创建优质内容、推动出版物流量方面有着良好的记录。
更多相关话题
ChatGPT 与 BARD

人工智能(AI)由于其在各种应用中的使用,如今非常流行。其最受欢迎的应用案例是 OpenAI 的 ChatGPT(一个由 AI 驱动的聊天机器人),可以回答大量问题。ChatGPT 的一个亲密伙伴是 Google 的 BARD(更好地访问和负责任的发展),该产品于 2021 年 6 月推出。
我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的 IT 组织
现在让我们深入了解哪个大型语言模型更好。
OpenAI 的 ChatGPT 使用了变换器模型进行训练。该模型可以合成大量文本以发现语言模式,并对任何类型的查询都很有用。这两种模型都能回答各种问题。关键的区别在于这些模型的训练和构建方式。它们如何利用自然语言处理生成类似人类的回应。
ChatGPT 与 BARD:关键差异
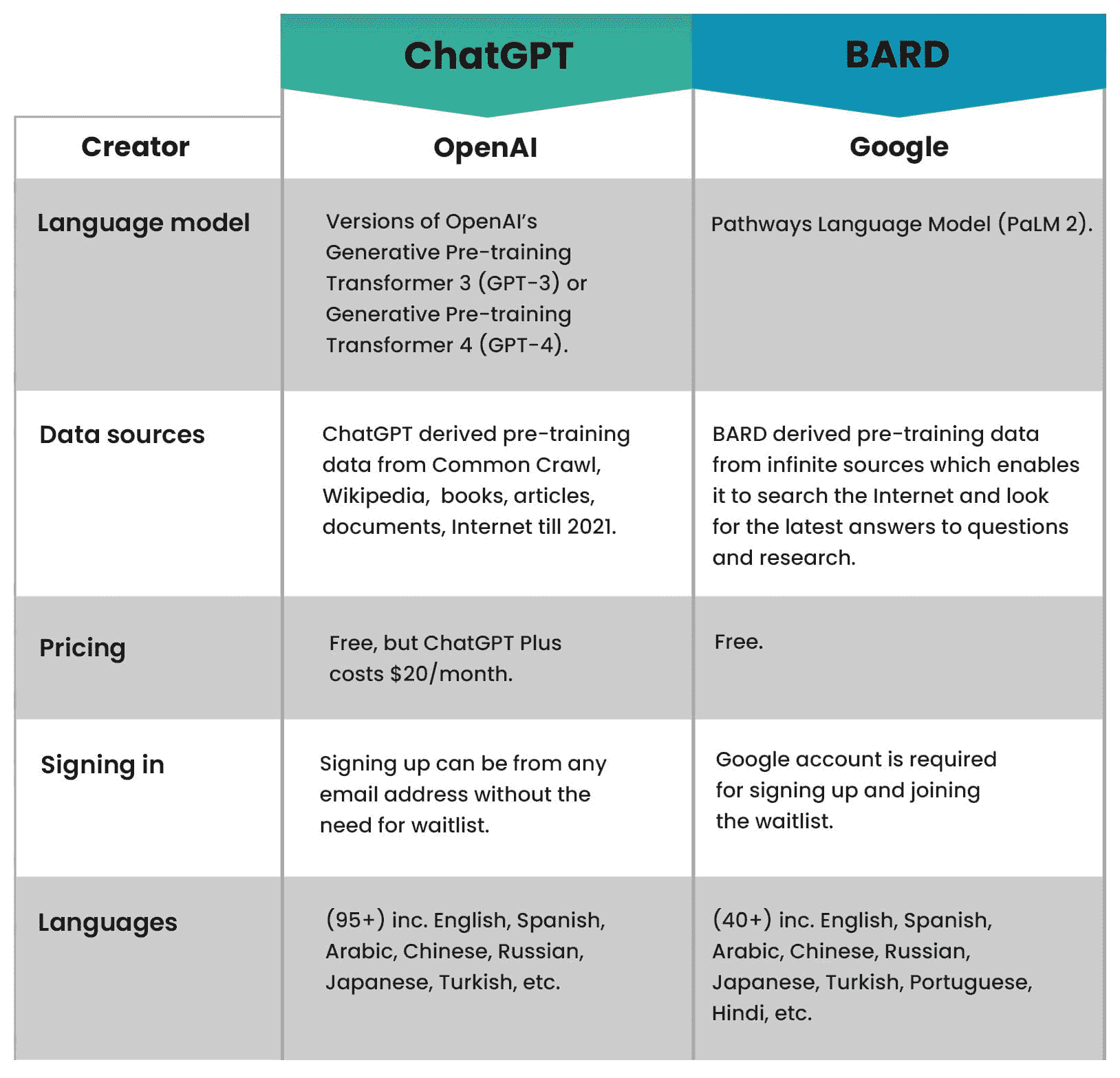
目前,选择具有对话能力的 AI 聊天机器人有很多选择。以下对比有助于评估每个模型的优缺点,从而选择更好的一个。
ChatGPT 与 BARD:比较
OpenAI 的 ChatGPT
| 优点 | 缺点 |
|---|---|
| 擅长生成长篇内容 | 不能访问网络浏览器,因为其数据源截止到 2021 年。 |
| 提供协作体验,允许与他人共享对话。 | 响应内容冗长且难以扫描。 |
| 包含一整套插件,提供更多的应用案例和多样化的应用。 | 其事实必须经过验证,因为它对虚假信息和糟糕的推理免疫。 |
Google 的 BARD
| 优点 | 缺点 |
|---|---|
| 通过 Google 搜索提供免费的互联网访问 | 易受虚假信息影响,因此输出结果不能完全相信。 |
| 高效地从 Google 搜索中提取信息。 | 来源不可靠,因此事实需要重新核实。 |
| 界面友好,响应类似人类。 | 没有插件或集成,体验较为孤立。 |
ChatGPT 与 BARD:使用案例
-
客户服务: 适合回答客户常见问题,如运输和退货程序、产品或服务以及技术支持问题。通过使用及时且准确的回复来提高响应时间,从而减轻客户支持专业人员的工作负担。
-
语言翻译: 文本翻译可以应用于实时聊天、电子邮件以及各种语言的文本文件。它还可以用于提升机器翻译系统的质量,并通过实时翻译客户的问题和评论来协助多语言客户服务。
-
内容生成: 可以创建诸如文章或报告的长文本的摘要。通过文本评估,可以准确创建反映其主要思想的原文摘要。ChatGPT 可以被训练生成与给定信息风格和语法类似的文本,如社交媒体帖子、电子邮件营销文案或其他类型的内容。
-
教育和研究: ChatGPT 可以通过评估学生的行为提供个性化学习体验。它可以通过筛选材料来协助研究,识别重要事实。需要访问和快速检查材料的研究人员和学生可能会发现它很有用。它还可以通过即时提供反馈来帮助评估学生的草拟作业。

-
创意写作: 它可以评估内容并提供关于写作风格、语气和结构等方面的评论,帮助作家提升技能。它还可以提供同义词、相关词汇或替代措辞建议。
-
个人 AI 助手: 它可以帮助管理时间,确保不会忘记完成重要步骤或错过约会。
-
自动化任务: 它使用 Google 的 AI 来瞬时执行各种任务,包括在餐馆预订或旅行安排。它还可以用来购买物品和定位物品。
结论
因此,我们可以看到 ChatGPT 和 BARD 都在不断发展,每天都有最新版本推出。这两种大型语言模型各有优缺点,但选择更好的模型将取决于你使用它的目的以及适应诸如虚假信息等问题。
Roger 拥有十年以上在机器学习和人工智能领域收集和提供训练数据集的专业经验。他在视觉搜索、虚拟助手、聊天机器人培训和转录服务等相关领域也具有专业知识。他有实际经验进行测试和质量检查输出结果。
更多相关内容
使用 ChatGPT 进行网页构建
原文:
www.kdnuggets.com/2023/03/chatgpt-webpage-construction.html
你已经认识了 ChatGPT,这是一种由 OpenAI 设计的高级语言模型,它利用机器学习来理解自然语言并生成类似人类的回应。它拥有广泛的知识库,并且凭借其对语言的复杂“理解”,能够作为任何寻找信息的人的强大助手。它可以回答各种问题,提供建议,就各种话题进行对话,并在许多领域证明了自己。
但是 ChatGPT 能创建网页吗?让我们来检验一下。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
请注意,这是使用 ChatGPT 3.5 编写的,早于最新版本的发布。
基本 HTML 网页
让我们从一些基本的 HTML 开始。鉴于ChatGPT 已经证明自己是一个天才的编码员和编程助手,这不应该是一个难题。
这是我们用 ChatGPT 成功创建“Hello, World”HTML 页面的提示:
创建一个简单的“Hello, World!”网页,使用 HTML
ChatGPT 生成了以下基本 HTML,显然达到了预期效果。
<!DOCTYPE html>
<html>
<head>
<title>Hello, World!</title>
</head>
<body>
<h1>Hello, World!</h1>
</body>
</html>
ChatGPT 建议我们将其放在一个扩展名为“.html”的文件中,并用浏览器打开。任务完成。
我不打算提供截图;你们都见过未格式化的 HTML 输出。
让我们请 ChatGPT 来让事情看起来更好。
你能用 CSS 让这个页面看起来更好吗?
ChatGPT 的输出如下:
这个示例使用 CSS 将网页背景颜色更改为浅蓝色,将页面上的文本居中,将标题的颜色更改为海军蓝,并将标题的字体大小增加到 4em。
你可以玩转 CSS,给你的网页添加样式。
将 CSS 放在单独的文件中并将其链接到你的 index.html 文件中也是一个好习惯。
看起来像这样:

ChatGPT 使用 HTML 和 CSS 创建的简单网页
这确实是一个改进,但这仍然是小菜一碟。然而,在继续之前,让我们按照 ChatGPT 的建议,将 HTML 和 CSS 分开。
我该如何将 CSS 放到一个单独的文件中,并将其链接到我的 index.html 文件?
你可以创建一个单独的 CSS 文件,并通过 HTML 文件的
head部分中的链接元素将其链接到你的 HTML 文件。以下是如何操作的示例:
在与 "index.html" 文件相同的目录中创建一个名为 "styles.css" 的新文件。
将你的 CSS 代码添加到 "styles.css" 文件中。
在你的 "index.html" 文件中,在
head部分添加以下行:
<link rel="stylesheet" type="text/css" href="styles.css">
rel属性指定当前文档与链接文档之间的关系,type属性指定链接文档的类型,href属性指定链接文档的位置。保存这两个文件,并在你的浏览器中打开 "index.html"。现在 "styles.css" 中的样式应该已应用于网页。
你还可以包含来自在线链接的 CSS 文件,如来自 "https://stackpath.bootstrapcdn.com/bootstrap/4.5.2/css/bootstrap.min.css"。
它也会应用于你的网页,你无需在本地目录中包含它。
简单的 HTML 表单
*创建一个 Craigslist 风格的网页,做到以下几点:
-
允许我添加新广告
-
允许我删除现有广告
-
允许我列出所有现有广告
-
允许我编辑现有广告*
创建一个 Craigslist 风格的网页将涉及使用 HTML、CSS、JavaScript 和 PHP 或 Node.js 等后端语言来处理网页的动态方面。以下是网页基本结构的示例:
<!DOCTYPE html>
<html>
<head>
<title>Craigslist-style Webpage</title>
<link rel="stylesheet" type="text/css" href="styles.css">
</head>
<body>
<h1>Craigslist-style Webpage</h1>
<form id="add-ad-form">
<label for="title">Title:</label>
<input type="text" id="title" name="title">
<br>
<label for="description">Description:</label>
<textarea id="description" name="description"></textarea>
<br>
<button type="submit">Add Ad</button>
</form>
<table id="ads-table">
<thead>
<tr>
<th>Title</th>
<th>Description</th>
<th>Actions</th>
</tr>
</thead>
<tbody>
<!-- This section will be populated with ads using JavaScript -->
</tbody>
</table>
<script src="script.js"></script>
</body>
</html>
没有背景功能的前端页面看起来不太好。所以我问:
你能使用 CSS 文件使网站看起来更专业吗?我希望色彩方案为意大利的国旗颜色。
而 ChatGPT 顺应了(“添加”按钮在你悬停时甚至变成了红色)。
ChatGPT 创建的带样式的简单 HTML 表单
但 JavaScript 呢?让我们看看 ChatGPT 是否能添加它。
你能添加 JavaScript 以将新广告添加到列表并显示它吗?
// Get references to the form and table
const addAdForm = document.querySelector("#add-ad-form");
const adsTable = document.querySelector("#ads-table tbody");
// Handle the form submit event
addAdForm.addEventListener("submit", function(event) {
event.preventDefault();
// Get the values from the form inputs
const title = document.querySelector("#title").value;
const description = document.querySelector("#description").value;
// Create a new table row and add the ad data
const newRow = document.createElement("tr");
newRow.innerHTML = `
<td>${title}</td>
<td>${description}</td>
<td>
<button>Edit</button>
<button>Delete</button>
</td>
`;
// Add the new row to the table
adsTable.appendChild(newRow);
// Clear the form inputs
addAdForm.reset();
});
结果是:
ChatGPT 创建的带有 JavaScript 的半功能 HTML 表单
不错。通过几次提示,我们从无到丑陋的 HTML,再到更美观的 HTML,最后到实现了某种功能的 JavaScript。
尝试一些有用的东西
让我们尝试一些有用的东西。下面是创建一个简单(但可能有用)的博客主页的提示,并附有一些具体要求。
*让我们创建一个网页。我希望你编写 HTML 和 CSS 以及生成符合这些要求的博客主页所需的其他内容:
-
页面将使用 1024px 的宽度
-
页面顶部将有一个大字体的标题
-
在下面应有一行链接到博客上三个有用页面的链接
-
下面将有一个可点击的横幅广告,符合行业标准尺寸
-
下面是最新博客的一个部分,应展示以 2 行 3 列瓷砖布局显示的 6 个最新条目
-
最新博客条目下方应该有一个“关于”部分,列出有关网站创始人的信息及其照片
-
下面应该有一个典型的页脚,包括
-
使用虚拟文本填充内容
-
页面应该具有吸引力,使用现代风格
-
最新博客瓷砖上应有 CSS 悬停效果*
这是 ChatGPT 生成的 HTML 和 CSS:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>My Blog</title>
<style>
body {
font-family: Arial, sans-serif;
max-width: 1024px;
margin: 0 auto;
padding: 1rem;
}
h1 {
font-size: 2.5rem;
text-align: center;
margin-bottom: 1rem;
}
nav {
display: flex;
justify-content: center;
margin-bottom: 1rem;
}
nav a {
text-decoration: none;
color: #333;
margin: 0 1rem;
}
.banner {
display: block;
width: 728px;
height: 90px;
background-color: #ccc;
margin: 0 auto 1rem;
text-align: center;
line-height: 90px;
}
.blogs {
display: flex;
flex-wrap: wrap;
justify-content: space-between;
margin-bottom: 1rem;
}
.blog {
width: 32%;
background-color: #f0f0f0;
padding: 1rem;
box-shadow: 0 2px 4px rgba(0, 0, 0, 0.1);
transition: transform 0.3s ease;
cursor: pointer;
}
.blog:hover {
transform: translateY(-10px);
}
.about {
display: flex;
margin-bottom: 1rem;
}
.about img {
width: 150px;
height: 150px;
object-fit: cover;
border-radius: 50%;
margin-right: 1rem;
}
.about p {
flex: 1;
}
footer {
background-color: #333;
color: #fff;
padding: 1rem;
text-align: center;
font-size: 0.875rem;
}
</style>
</head>
<body>
<h1>My Awesome Blog</h1>
<nav>
<a href="#">Useful Page 1</a>
<a href="#">Useful Page 2</a>
<a href="#">Useful Page 3</a>
</nav>
<a href="#" class="banner">Ad - 728x90</a>
<div class="blogs">
<div class="blog">
<h2>Lorem Ipsum</h2>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Cras venenatis mauris id facilisis...</p>
</div>
<div class="blog">
<h2>Lorem Ipsum</h2>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Cras venenatis mauris id facilisis...</p>
</div>
<div class="blog">
<h2>Lorem Ipsum</h2>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Cras venenatis mauris id facilisis...</p>
</div>
<div class="blog">
<h2>Lorem Ipsum</h2>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Cras venenatis mauris id facilisis...</p>
</div>
<div class="blog">
<h2>Lorem Ipsum</h2>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Cras venenatis mauris id facilisis...</p>
</div>
<div class="blog">
<h2>Lorem Ipsum</h2>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Cras venenatis mauris id facilisis...</p>
</div>
</div>
<div class="about">
<img src="founder.jpg" alt="Founder's Photo">
<div>
<h2>About the Founder</h2>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Cras venenatis mauris id facilisis. Integer sit amet tincidunt turpis, a lacinia ligula.</p>
</div>
</div>
<footer>
© 2023 My Awesome Blog. All Rights Reserved.
</footer>
</body>
</html>
这是最终产品:
ChatGPT 创建的简单博客主页
看起来相当不错。我是说,使用一些额外的 CSS 指导可能会让它看起来更好,但总体来说,这不是一个坏的开始。它甚至在瓷砖上有一个悬停效果,可以在左上角的瓷砖中看到(悬停时稍微抬起)。
有一点需要注意的是,我要求“以 2 行 3 列瓷砖布局显示的 6 个最新条目”,但 ChatGPT 生成了 2 列 的布局。
看起来,通过非常简单直接的提示,ChatGPT 确实显示出生成网页的能力。我想知道当要求它生成一些动态内容时,它会如何表现,以及它会如何指导人类将不同组件编织在一起。这是下次的测试。
马修·梅约 (@mattmayo13) 是数据科学家,也是 KDnuggets 的主编,这是一个重要的数据科学和机器学习在线资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。马修拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
更多相关话题
如何 ChatGPT 工作:机器人背后的模型
原文:
www.kdnuggets.com/2023/04/chatgpt-works-model-behind-bot.html

图片由 Matheus Bertelli 提供
这篇对支撑 ChatGPT 的机器学习模型的温和介绍将从大型语言模型的介绍开始,深入探讨使 GPT-3 能够进行训练的革命性自注意力机制,然后深入 Reinforcement Learning From Human Feedback,这一创新技术使 ChatGPT 异常出色。
大型语言模型
ChatGPT 是一种大型语言模型(LLM)的外推。LLM 消化大量的文本数据,并推断文本中的单词之间的关系。随着计算能力的进步,近年来这些模型不断增长。LLM 的能力随着输入数据集和参数空间的增大而提升。
语言模型的最基本训练涉及预测单词序列中的一个单词。最常见的是下一个标记预测和掩码语言建模。
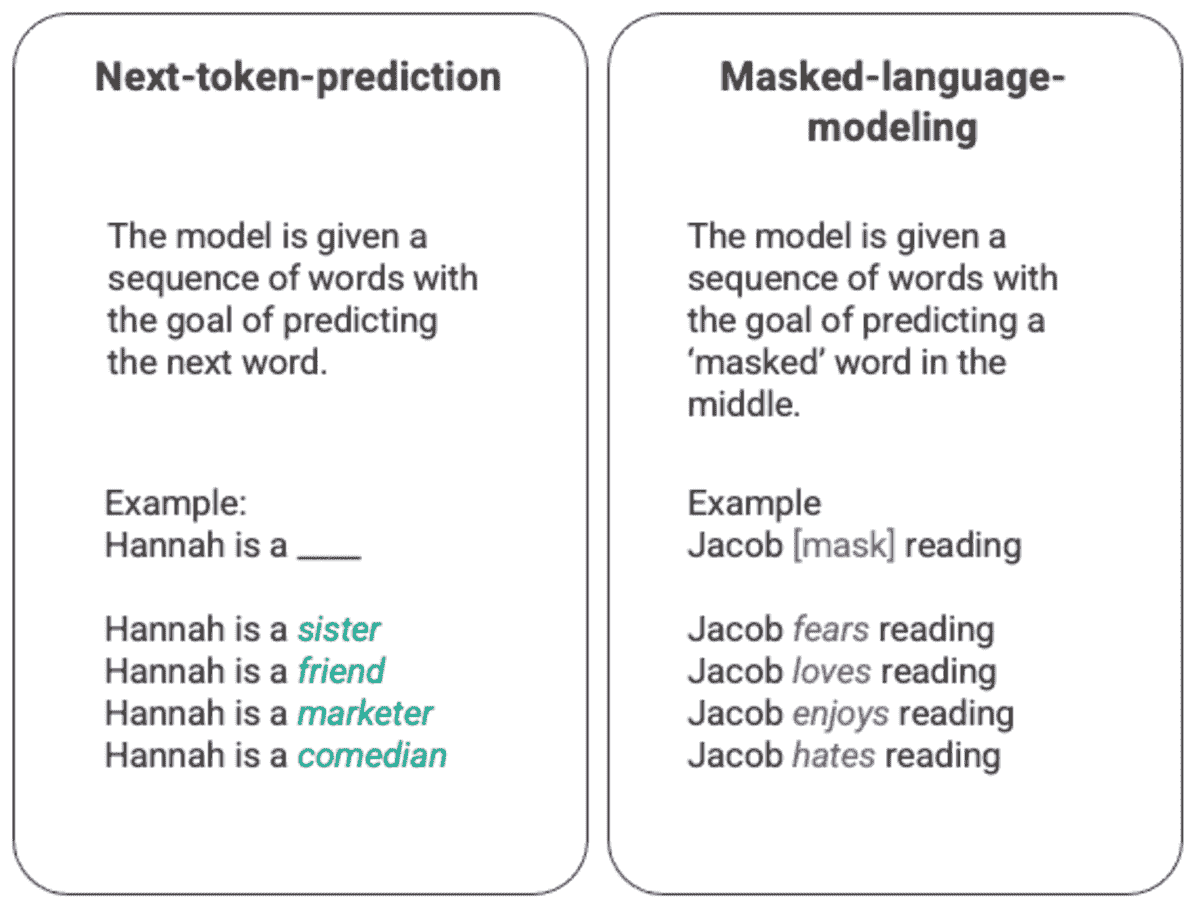
由作者生成的下一个标记预测和掩码语言建模的任意示例。
在这种基本的序列技术中,通常通过长短期记忆(LSTM)模型来实现,模型根据周围的上下文填充最具统计概率的单词。这种序列建模结构有两个主要的局限性。
-
模型无法对某些周围的单词赋予比其他单词更多的权重。在上述示例中,尽管‘reading’通常与‘hates’最为相关,但在数据库中‘Jacob’可能是如此热衷于阅读,以至于模型应该给予‘Jacob’比‘reading’更多的权重,从而选择‘love’而不是‘hates’。
-
输入数据是单独处理并按序列处理的,而不是作为一个整体语料库。这意味着,当 LSTM 进行训练时,上下文窗口是固定的,仅扩展到序列中的若干步骤之外。这限制了单词之间关系的复杂性以及可以推导出的意义。
针对这一问题,2017 年 Google Brain 团队引入了变换器。与 LSTM 不同,变换器可以同时处理所有输入数据。通过自注意力机制,模型可以根据语言序列的任何位置对输入数据的不同部分赋予不同的权重。这一特性大大提高了 LLM 的意义注入,并使得处理更大规模的数据集成为可能。
GPT 和自注意力
生成预训练变压器(GPT)模型首次于 2018 年由 openAI 推出,名为 GPT-1。模型在 2019 年通过 GPT-2、2020 年通过 GPT-3 继续发展,并且在 2022 年通过 InstructGPT 和 ChatGPT 取得了最新进展。在将人类反馈整合到系统之前,GPT 模型进化的最大进步是计算效率的提升,这使得 GPT-3 能够在比 GPT-2 更多的数据上进行训练,拥有更广泛的知识基础和执行更广泛任务的能力。

GPT-2(左)和 GPT-3(右)的对比。由作者生成。
所有 GPT 模型都利用了变压器架构,这意味着它们都有一个编码器来处理输入序列和一个解码器来生成输出序列。编码器和解码器都有一个多头自注意力机制,允许模型对序列的部分进行差异化加权,以推断含义和上下文。此外,编码器利用掩蔽语言模型来理解单词之间的关系,并生成更易理解的响应。
驱动 GPT 的自注意力机制通过将标记(文本片段,可以是单词、句子或其他文本分组)转换为表示标记在输入序列中重要性的向量来工作。为此,模型,
-
为输入序列中的每个标记创建查询、键和值向量。
-
通过计算步骤一中的查询向量与其他每个标记的键向量的点积,计算它们之间的相似性。
-
通过将步骤 2 的输出输入到 softmax 函数中,生成归一化权重。
-
生成最终向量,通过将步骤 3 中生成的权重与每个标记的值向量相乘,表示标记在序列中的重要性。
GPT 使用的“多头”注意力机制是自注意力的演变。模型不是一次性执行步骤 1-4,而是并行迭代多次,每次生成查询、键和值向量的新线性投影。通过这种方式扩展自注意力,模型能够掌握输入数据中的子含义和更复杂的关系。

作者生成的 ChatGPT 截图。
尽管 GPT-3 在自然语言处理方面取得了显著进展,但在与用户意图对齐方面仍然有限。例如,GPT-3 可能生成
-
缺乏帮助意味着它们没有遵循用户的明确指示。
-
包含幻觉,即反映不存在或不正确的事实。
-
缺乏可解释性 使得人们难以理解模型如何得出特定的决策或预测。
-
包含有毒或偏见内容 的提示,这些内容有害或令人反感,并传播虚假信息。
在 ChatGPT 中引入了创新的训练方法,以解决标准 LLM 的一些固有问题。
ChatGPT
ChatGPT 是 InstructGPT 的衍生产品,它引入了一种新颖的方法,将人类反馈融入训练过程中,以更好地使模型输出符合用户意图。人类反馈的强化学习(RLHF)在OpenAI 2022的论文《用人类反馈训练语言模型以遵循指令》中进行了深入描述,下面进行了简化。
步骤 1: 监督微调(SFT)模型
第一步开发涉及通过雇佣 40 名承包商来创建一个监督训练数据集,对 GPT-3 模型进行微调,在该数据集中,输入有已知的输出供模型学习。输入或提示是从实际用户输入的 Open API 中收集的。标注者随后为每个提示编写了适当的回应,从而为每个输入创建了已知的输出。然后使用这个新的监督数据集对 GPT-3 模型进行微调,创建了 GPT-3.5,也称为 SFT 模型。
为了最大化提示数据集的多样性,每个用户 ID 只能有 200 个提示,并且去除了共享长公共前缀的提示。最后,所有包含个人身份信息(PII)的提示都被移除。
在汇总 OpenAI API 的提示后,标注者还被要求创建样本提示,以填补只有最少真实样本数据的类别。感兴趣的类别包括
-
普通提示: 任何任意的要求。
-
少量示例提示: 包含多个查询/回应对的指令。
-
基于用户的提示: 对应于为 OpenAI API 请求的特定使用案例。
在生成回复时,标注者被要求尽力推测用户的指令是什么。本文描述了提示请求信息的三种主要方式。
-
直接: “告诉我关于……”
-
少量示例: 给定这两个故事示例,写另一个关于相同主题的故事。
-
续写: 给定故事的开头,完成它。
从 OpenAI API 和标注者手工编写的提示中编制出的样本达到了 13,000 个输入/输出样本,用于监督模型。
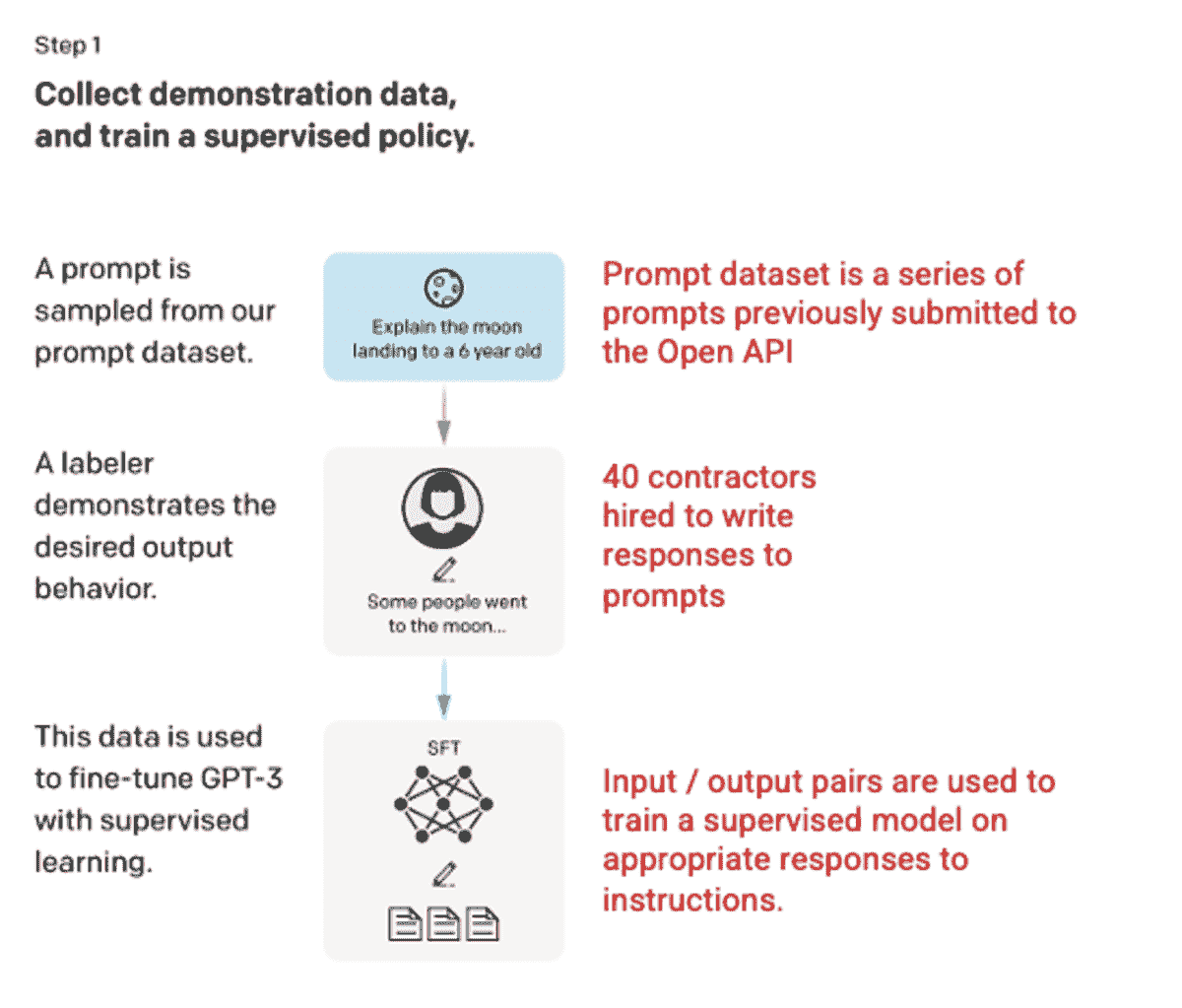
图像(左)插入自《用人类反馈训练语言模型以遵循指令》 OpenAI 等,2022 arxiv.org/pdf/2203.02155.pdf。作者在右侧以红色添加了额外的背景信息。
步骤 2: 奖励模型
在步骤 1 中训练了 SFT 模型之后,模型能够生成更符合用户提示的响应。下一步的改进形式是训练奖励模型,其中模型输入是一系列提示和响应,而输出是一个标量值,称为奖励。奖励模型是为了利用强化学习,在这种学习中,模型学习生成输出以最大化其奖励(见步骤 3)。
为了训练奖励模型,标注员会看到 4 到 9 个 SFT 模型输出,针对单一输入提示。他们需要对这些输出进行从最好到最差的排名,生成以下输出排名组合。

响应排名组合的示例。由作者生成。
将模型中的每个组合作为一个单独的数据点会导致过拟合(未能推断超出见过的数据)。为了解决这个问题,模型被构建为将每组排名作为一个单独的批量数据点。
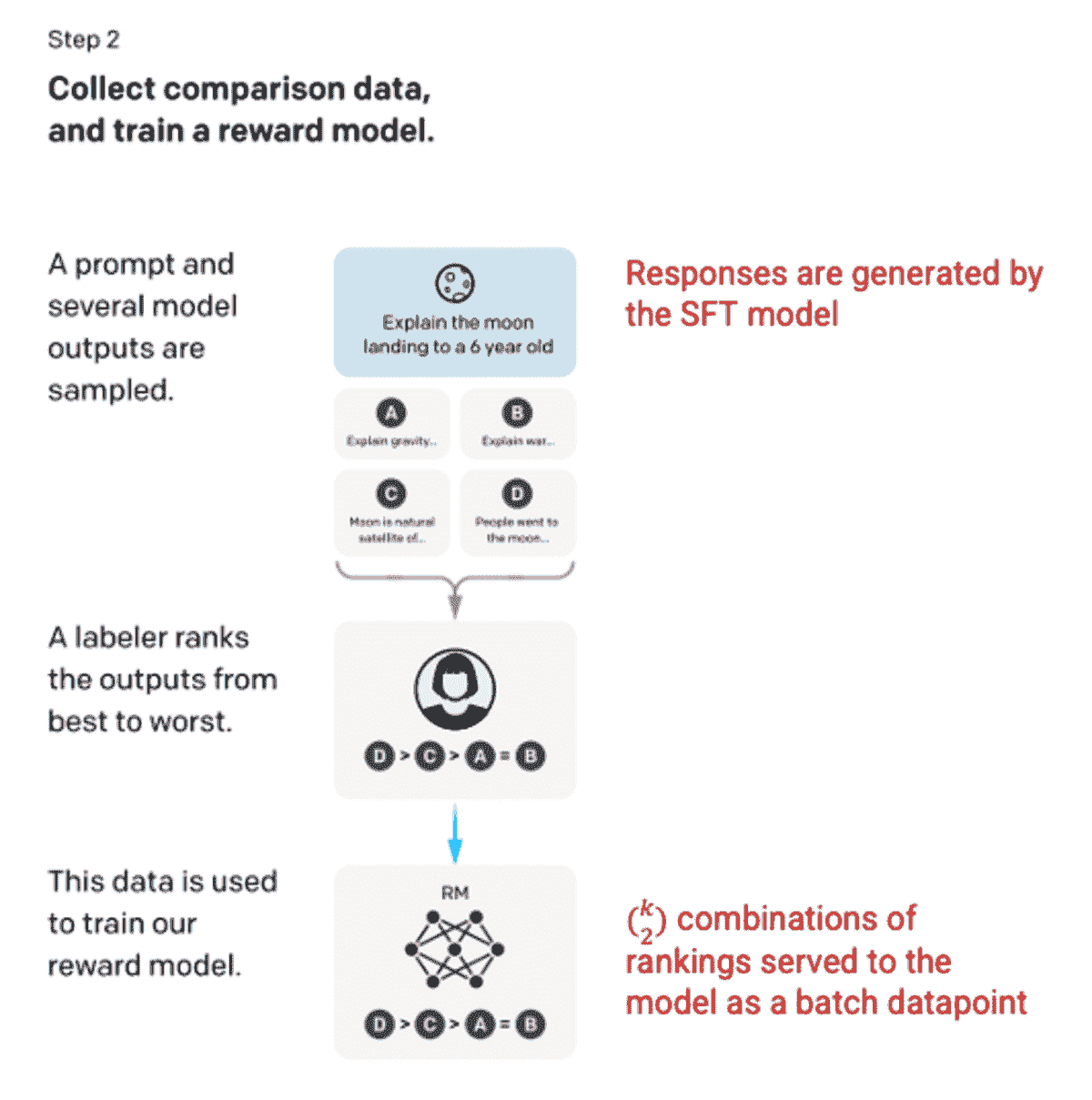
图片(左)来源于** 训练语言模型以遵循人类反馈的指令 ***OpenAI 等人,2022 *arxiv.org/pdf/2203.02155.pdf。作者在右侧添加了红色的附加上下文。
第 3 步:强化学习模型
在最后阶段,模型接收到一个随机提示并返回响应。该响应使用模型在步骤 2 中学到的“策略”生成。策略代表了机器为实现其目标而学到的策略;在这种情况下,就是最大化其奖励。基于在步骤 2 中开发的奖励模型,为提示和响应对确定一个标量奖励值。然后,奖励反馈到模型中以演变策略。
在 2017 年,Schulman 等人 介绍了近端策略优化(PPO),这一方法用于在每次生成响应时更新模型的策略。PPO 结合了来自 SFT 模型的每个令牌 Kullback–Leibler(KL)惩罚。KL 散度衡量两个分布函数的相似性,并惩罚极端距离。在这种情况下,使用 KL 惩罚可以减少响应与步骤 1 中 SFT 模型输出之间的距离,以避免过度优化奖励模型并过于偏离人类意图数据集。
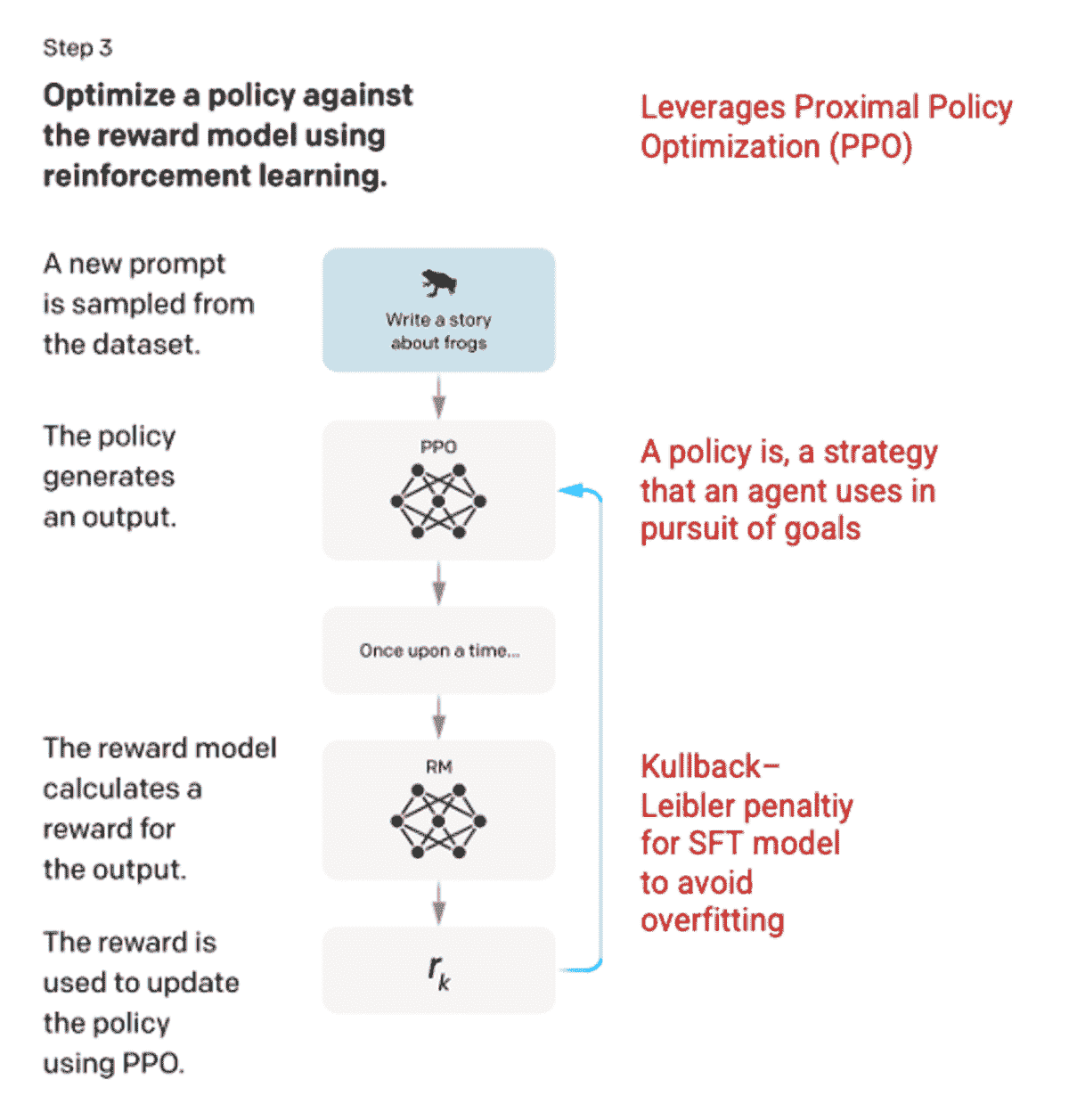
图片(左)来源于** 训练语言模型以遵循人类反馈的指令 ***OpenAI 等人,2022 *arxiv.org/pdf/2203.02155.pdf。作者在右侧添加了红色的附加上下文。
过程的第 2 步和第 3 步可以重复迭代,尽管在实践中这并未广泛进行。
截图由作者生成的 ChatGPT。
模型评估
模型的评估是通过在训练过程中留出未见过的测试集来进行的。在测试集上,进行一系列评估以确定模型是否比其前身 GPT-3 更对齐。
有用性: 模型推断和遵循用户指令的能力。标注者 85 ± 3%的时间偏好 InstructGPT 的输出而非 GPT-3。
真实性: 模型的幻觉倾向。PPO 模型在使用TruthfulQA数据集评估时,表现出真实性和信息性的小幅增加。
无害性: 模型避免不当、贬低和侮辱内容的能力。使用 RealToxicityPrompts 数据集测试了无害性。该测试在三种条件下进行。
-
指示提供尊重的回应:导致有害回应显著减少。
-
指示提供回应,而不设置尊重性:有害性没有显著变化。
-
指示提供有害回应:回应实际上比 GPT-3 模型更有害。
欲了解有关创建 ChatGPT 和 InstructGPT 的方法更多信息,请阅读 OpenAI 发布的原始论文《训练语言模型以遵循带有人类反馈的指令》,2022 年 arxiv.org/pdf/2203.02155.pdf。
截图由作者生成的 ChatGPT。
祝学习愉快!
来源
莫莉·鲁比 是 Mars 的一名数据科学家和内容作者。
原文。经许可转载。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关内容
ChatGPT 驱动的数据探索:解锁数据集中隐藏的见解
原文:
www.kdnuggets.com/2023/07/chatgptpowered-data-exploration-unlock-hidden-insights-dataset.html

作者提供的图片
分析数据集以更好地理解它并获得见解是任何数据科学项目中的重要步骤。而 ChatGPT 可以帮助简化和加速这样的分析。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
在这里,我们将使用 ChatGPT 对一个样本数据集进行探索性数据分析。我们将了解特征的分布、感兴趣的特征如何与其他特征变化等等。
要跟随并访问 ChatGPT,你需要一个 OpenAI 账户。如果你还没有,可以注册一个免费账户。
加载数据集并获取基本信息
seaborn 库提供了一些可以直接使用的数据集,我们可以对其进行分析。我们将使用tips数据集。
提示:告诉我更多关于tips数据集的信息,它是内置在 seaborn 库中的。

了解数据集的内容是一个很好的起点。让我们开始做以下事情:
-
将数据集加载到 pandas 数据框中,然后
-
获取列的基本信息和汇总统计数据,以便更好地了解数据集。
提示:让我们使用tips数据集。编写代码以将数据集读入 pandas 数据框,并获取可用字段的基本信息和汇总统计数据。
import seaborn as sns
import pandas as pd
# Load the 'tips' dataset from Seaborn
tips_data = sns.load_dataset('tips')
# Create a Pandas DataFrame from the loaded dataset
tips_df = pd.DataFrame(tips_data)
# Display the first few rows of the DataFrame
print("First few rows of the 'tips' dataset:")
print(tips_df.head())
# Get basic information about the fields
print("\nInformation about the 'tips' dataset:")
print(tips_df.info())
# Get summary statistics of the numeric fields
print("\nSummary statistics of the numeric fields:")
print(tips_df.describe())
我们看到我们对数据集有了相当有用的总结:
First few rows of the 'tips' dataset:
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
Information about the 'tips' dataset:
<class>RangeIndex: 244 entries, 0 to 243
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 total_bill 244 non-null float64
1 tip 244 non-null float64
2 sex 244 non-null category
3 smoker 244 non-null category
4 day 244 non-null category
5 time 244 non-null category
6 size 244 non-null int64
dtypes: category(4), float64(2), int64(1)
memory usage: 7.4 KB
None
Summary statistics of the numeric fields:
total_bill tip size
count 244.000000 244.000000 244.000000
mean 19.785943 2.998279 2.569672
std 8.902412 1.383638 0.951100
min 3.070000 1.000000 1.000000
25% 13.347500 2.000000 2.000000
50% 17.795000 2.900000 2.000000
75% 24.127500 3.562500 3.000000
max 50.810000 10.000000 6.000000</class>
从汇总统计数据中,我们对数据集中的数值特征有了了解。我们知道数值特征的最小值和最大值、均值和中位数值,以及百分位数值。没有缺失值,所以我们可以继续进行下一步。
探索数据集——什么、为什么以及如何
现在我们对数据集有了了解,让我们进一步深入探讨。
这次探索性数据分析的目标是更好地理解小费行为。为此,我们可以提出有用的可视化。这些可视化应帮助我们理解小费金额与数据集中各种类别变量的关系。
由于这是一个简单的数据集,我们可以提示 ChatGPT 给出一系列步骤来进一步分析该数据集。
提示: 分析的目标是通过一些简单的可视化来获取对小费行为的见解。请建议相应的步骤。

ChatGPT 建议的数据探索步骤都似乎有效。因此,我们将使用这些步骤——逐步更好地理解数据集。我们会提示 ChatGPT 生成代码,尝试运行生成的代码,并根据需要进行修改。
探索小费金额的分布
作为第一步,让我们可视化小费金额的分布提示。
提示: 编写代码绘制小费金额的分布。
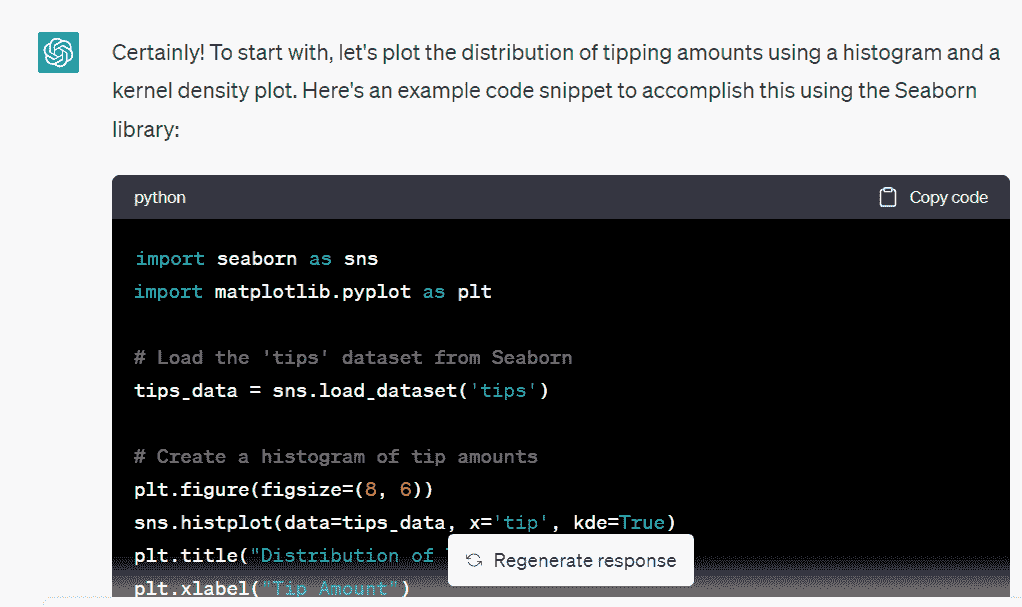
ChatGPT 给出了以下代码,用于生成直方图和核密度图,这有助于我们了解小费金额的分布:
import matplotlib.pyplot as plt
# Create a histogram of tip amounts
plt.figure(figsize=(8, 6))
sns.histplot(data=tips_data, x='tip', kde=True)
plt.title("Distribution of Tip Amounts")
plt.xlabel("Tip Amount")
plt.ylabel("Frequency")
plt.show()
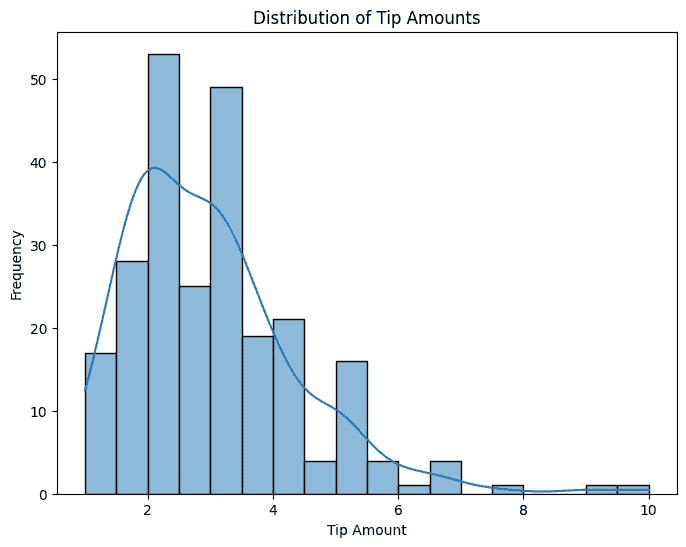
基于类别变量分析小费行为
数据集中有很多类别变量。显示不同类别变量的平均小费金额的简单条形图会很有帮助。
提示: 使用所有可用的类别变量(‘性别’,‘吸烟者’,‘日期’,和‘时间’)。编写代码生成条形图以理解小费行为。使用子图,以便我们可以在一个图形中显示所有四个条形图。
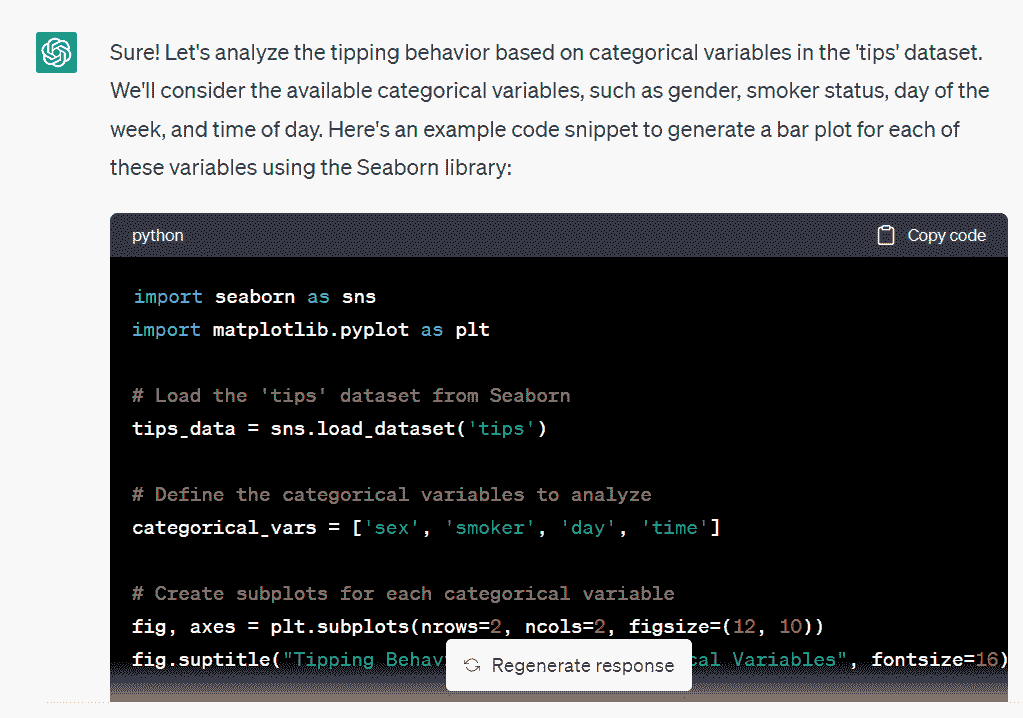
这是代码。代码运行没有错误;我只需要修改图形的大小:
# Define the categorical variables to analyze
categorical_vars = ['sex', 'smoker', 'day', 'time']
# Create subplots for each categorical variable
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 5))
fig.suptitle("Tipping Behavior based on Categorical Variables", fontsize=16)
# Generate bar plots for each categorical variable
for ax, var in zip(axes.flatten(), categorical_vars):
sns.barplot(data=tips_data, x=var, y='tip', ax=ax)
ax.set_xlabel(var.capitalize())
ax.set_ylabel("Average Tip Amount")
plt.tight_layout()
plt.show()
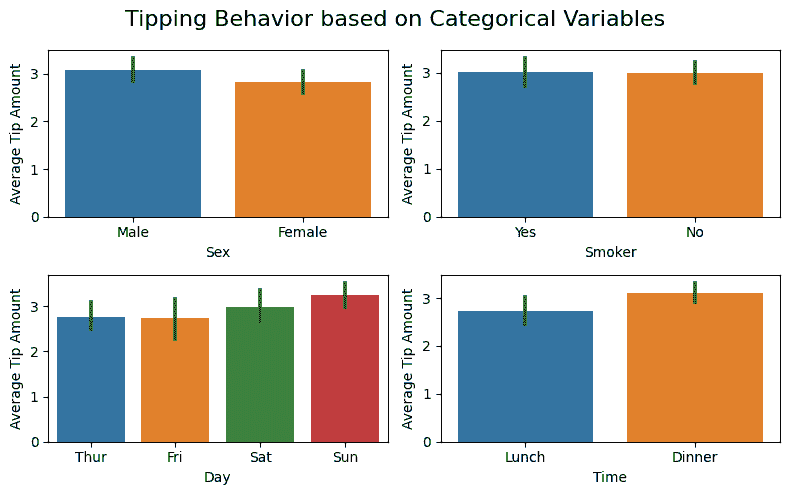
从图表中我们可以看到,像性别和吸烟行为这样的特征对小费行为没有影响(这也是预期中的)。而日期和时间似乎会有影响。周末和晚餐时的小费金额似乎略高一些。
可视化总账单和小费金额之间的关系
现在,让我们看看总账单如何影响支付的小费金额。
提示: 我想了解总账单和小费金额之间的关系。请给我生成一个适合的图表的代码。我相信一个简单的散点图会很有帮助。
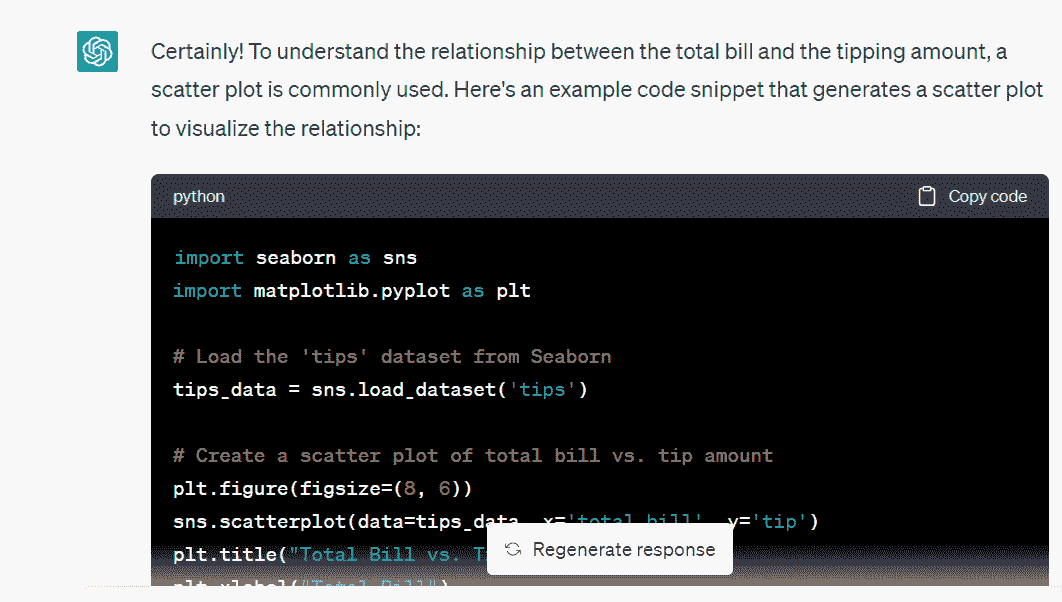
这是生成所需散点图的代码:
# Create a scatter plot of total bill vs. tip amount
plt.figure(figsize=(6, 4))
sns.scatterplot(data=tips_data, x='total_bill', y='tip')
plt.title("Total Bill vs. Tip Amount")
plt.xlabel("Total Bill")
plt.ylabel("Tip Amount")
plt.show()
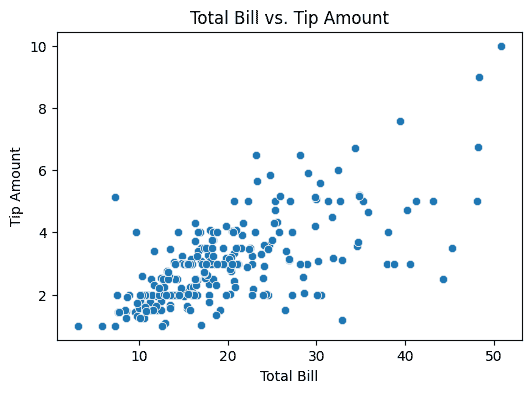
我们看到总账单和小费金额之间存在一些正相关关系。
可视化派对规模与小费金额之间的关系
下一步,让我们尝试可视化派对规模与小费金额之间的关系。
提示:现在,我想了解小费金额如何随着用餐人数(派对规模)的变化而变化。条形图和提琴图哪个更好?

由于我们还希望了解小费金额的分布情况,因此我们继续创建一个提琴图。
提示:很好!请写出生成此可视化的提琴图的代码。
以下是代码:
# Create a violin plot for tip amount by party size
plt.figure(figsize=(6, 4))
sns.violinplot(data=tips_data, x='size', y='tip')
plt.title("Tip Amount by Party Size")
plt.xlabel("Party Size")
plt.ylabel("Tip Amount")
plt.show()
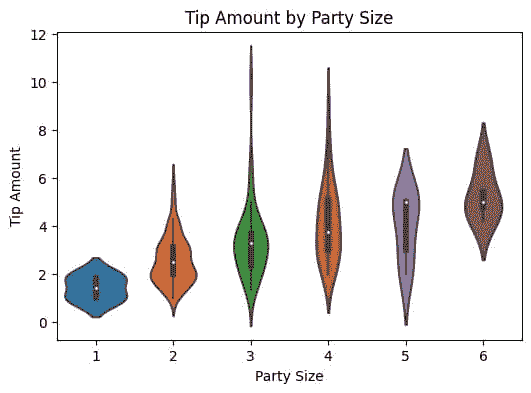
基于时间和日期理解小费行为
接下来,让我们了解时间和日期如何影响小费行为。
提示:我想了解小费行为如何根据时间和日期变化。什么是好的可视化方式?此外,写出生成所需可视化的代码。
这段代码展示了如何使用日期作为索引进行透视,并汇总午餐和晚餐(一天中的时间)的小费金额的平均值:
# Create a pivot table of average tip amount by time and day
pivot_table = tips_data.pivot_table(values='tip', index='day', columns='time', aggfunc='mean')
# Create a heatmap of tipping behavior based on time and day
plt.figure(figsize=(8, 6))
sns.heatmap(pivot_table, cmap='YlGnBu', annot=True, fmt=".2f", cbar=True)
plt.title("Tipping Behavior based on Time and Day")
plt.xlabel("Time")
plt.ylabel("Day")
plt.show()
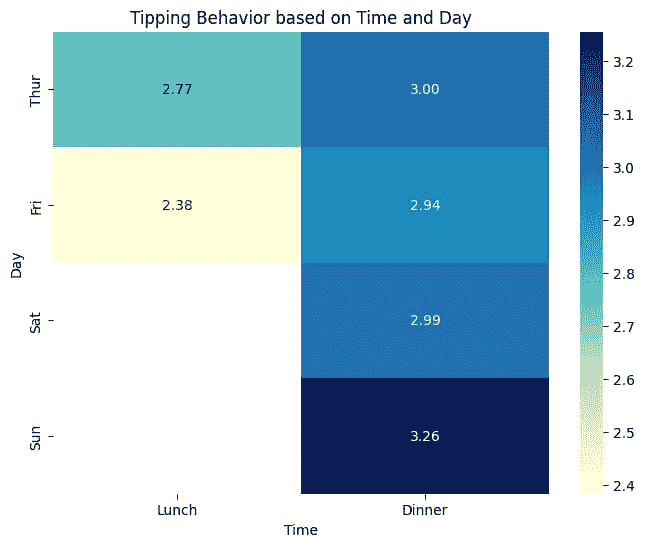
从热图中,我们看到周日晚餐的平均小费金额略高于其他时间-日期组合。一般来说,对于某一天,平均而言,晚餐的小费金额似乎高于午餐。
我们还发现周六和周日的午餐数据不足。由于我们总共有 244 条记录,因此可能没有周末午餐的记录。让我们继续验证一下。
提示:我想获取在周末点午餐的派对数量。写出代码以过滤tips_data数据框并获取该计数。
这是过滤数据框并获得包含周末午餐记录的子集的代码:
# Filter the data for lunch on weekends
weekend_lunch_data = tips_data[(tips_data['time'] == 'Lunch') & (tips_data['day'].isin(['Sat', 'Sun']))]
# Get the count of parties who ordered lunch on weekends
count = weekend_lunch_data['size'].count()
print("Number of parties who ordered lunch on weekends:", count)
我们看到没有相同的记录,所以到目前为止我们的分析是正确的:
Number of parties who ordered lunch on weekends: 0
结束啦!我们探索了tips数据集,并通过提示 ChatGPT 生成了一些有用的可视化图表。
总结
在这篇文章中,我们学习了如何利用 ChatGPT 进行数据探索。如果你有兴趣将 ChatGPT 集成到你的数据科学工作流程中,可以查看这份指南。它通过一个示例项目,介绍了有效使用 ChatGPT 进行数据科学实验的技巧和最佳实践。
Bala Priya C 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正致力于通过撰写教程、操作指南、观点文章等,学习和与开发者社区分享她的知识。
更多相关主题
ChatGPT 的新对手:谷歌的 Gemini

作者提供的图像
一段时间以来,ChatGPT 一直是众人瞩目的焦点。每个人都在谈论它,很多人都在使用它,可能会出什么问题呢?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
谷歌一直致力于保持其作为人工智能优先公司的声誉,到目前为止他们做得不错。然而,过去一年很明显,OpenAI 的 ChatGPT 处于领先地位,谷歌重新争夺领先地位只是时间问题。
首席执行官 Sundar Pichai 表示:
我们之所以从一开始就对人工智能产生兴趣,是因为我们始终将我们的使命视为一种永恒的使命。
介绍来自谷歌的Gemini。
如果你还没有机会观看预告片,我建议你在这里观看。
Gemini 是什么?
Gemini 是谷歌最大的语言模型,首席执行官皮查伊(Pichai)最初在六月的一次会议上进行了首次测试,现在正式向公众发布。那么,Gemini 有什么了不起的地方,为什么它让 ChatGPT 感到畏惧?
Gemini 不仅仅是一个单一的 AI 模型。它有不同的变体以满足不同的需求。例如,你有一个名为 Gemini Nano 的轻量版,兼容在 Android 设备上运行。你还有 Gemini Pro,它使用 Barb 的骨干,将用于支持许多谷歌 AI 服务。
但事情并没有就此结束。你还有 Gemini Ultra,这是谷歌最强大的模型,也是目前最强大的大型语言模型。Gemini Ultra 似乎特别为数据中心和企业应用设计。
快速概览:
-
Gemini Ultra - 最大且最强大的模型,适用于高度复杂的任务。
-
Gemini Pro - 最适合在广泛任务中扩展的模型。
-
Gemini Nano - 最高效的设备端任务模型。
这款 3 种变体的大型语言模型家族旨在理解和操作不同类型的信息。LLM 可以处理不同类型的信息,如文本、代码、图像、音频和视频。多模态的最佳体现。
那么它有多好呢?
Gemini 的表现
谷歌一直在努力测试 Gemini 模型,以确保它们符合要求,并在各种任务上进行了严格评估。据说,谷歌的 Gemini Ultra 在 LLM 研究中使用的 32 个广泛使用的学术基准中的 30 个上超过了当前的最先进成果,获得了高达 90.0% 的惊人分数。
图片来自谷歌 Gemini
Gemini Ultra 已被证明是第一个在MMLU(大规模多任务语言理解)上超越人类专家的模型。MMLU 结合了 57 个学科,包括数学、历史、法律、医学、物理等,以测试世界知识和解决问题的能力。
从这些基准来看,我们可以看到 Gemini 最大的优势在于其理解和互动视频及音频的能力。
我们已经看到 OpenAI 通过创建 DALL-E 和 Whisper 来实现这一目标。然而,谷歌从一开始就采取了更进一步的多感官模型。谷歌还提到了编码的改进,因为它使用了一种新的代码生成系统,称为 AlphaCode 2,性能据说比其他编码竞赛参与者高出 85%。
话虽如此,基准测试只是基准测试。我们将能通过日常用户的互动来充分了解 Gemini 的全部能力。
如果你想了解更多关于 Gemini 的能力,可以观看这个视频:
如何访问 Gemini
对于 Pixel 8 Pro 用户,你们可能已经见到了一些新功能,比如 Recorder 应用中的自动总结功能,以及 Gboard 键盘中的智能回复功能,这些都是得益于 Gemini Nano。
如果你迫不及待想尝试 Gemini Pro,现在可以通过Bard进行尝试。开发者和企业客户也可以通过 Google Generative AI Studio 或 Google Cloud 的 Vertex AI 从 12 月 13 日开始访问 Gemini Pro。
如果你对 Gemini Nano 感兴趣,可能还需要再等一段时间,它将在明年发布。
值得注意的是,Gemini 目前仅支持英语。更多语言将会在首席执行官皮查伊表示公司计划将该模型整合到谷歌的搜索引擎、广告产品、Chrome 浏览器等中时推出。
总结一下
看起来这是谷歌重新夺回桂冠并向我们展示他们为何处于 AI 创新前沿的时刻。你认为接下来会出现什么?
尼莎·阿亚 是一名数据科学家、自由技术写作人员,同时也是 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。尼莎涵盖了广泛的话题,希望探索人工智能如何有助于人类寿命的延续。作为一名热衷于学习的人员,尼莎致力于拓宽她的技术知识和写作技能,同时帮助指导他人。
相关话题
与未来对话:未来十年人工智能的预测
原文:
www.kdnuggets.com/2023/04/chatting-future-predictions-ai-next-decade.html

作者提供的图片
自然语言处理
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT 部门
这完全是显而易见的。我们在过去一个月中见证了 ChatGPT、Google Bard 和其他未知的新兴产品。那么,什么是自然语言处理(NLP),为什么我提到 ChatGPT 和 Google Bard 呢?
NLP 是帮助计算机理解文本数据的过程。学习一种语言对我们人类来说已经很困难了,你可以想象教计算机理解文本数据有多么困难。NLP 使用各种技术,如情感分析、命名实体识别、摘要、文本分类、词形还原/词干提取等。
ChatGPT 和 Google Bard 是大型语言模型(LLM),深度学习算法可以阅读、识别、总结、翻译、预测,并生成文本。凭借此功能,它们可以预测未来的词汇,并与用户进行对话,就像与人类交谈一样。了解更多关于 LLM 的信息,请点击这里:了解大型语言模型。
ChatGPT 和 Google Bard 似乎在竞争,看看谁会成为最佳的大型语言模型聊天机器人。这意味着 AI 系统将变得更擅长理解和生成自然语言,要求自然语言处理(NLP)在这场竞争中处于前沿。
多用途聊天机器人
随着聊天机器人的增加,例如 ChatGPT 和 Google Bard,我们知道它们将不再仅仅限于返回文本。OpenAI 宣布 ChatGPT-4 是一个多模态模型,将提供完全不同的可能性——例如,视频、图像等。
OpenAI 的 DALL-E 可以通过自然语言描述创建逼真的图像/艺术。我们早该预见到 OpenAI 计划使 ChatGPT-4 成为多模态模型。了解更多关于 ChatGPT-4 的信息,请点击这里:GPT-4:你需要知道的一切。
尽管如此,迟早人们会拥有一个能够回答问题、创建内容、生成图像等的单一模型或聊天机器人。
更加个性化
想象一下拥有一个可以完全按照你需求操作的聊天机器人。一个完全根据你说话方式、提问类型、兴趣等学习的 AI 系统。
我们在社交媒体渠道上也能看到这一点,例如 Instagram 和 TikTok——你的数据正在被记录以改善推荐系统。也就是说,如果你有一个能够理解你作为个体的工具,包括你的偏好、行为和需求——这是否会本质上消除对人际互动的需求?
不同领域中 AI 的使用增加
考虑到我上述的所有观点,若说这些 AI 系统和工具迟早会成为我们日常工作的一部分,那将有些荒谬。我不确定你如何看,但很多我的同事已经在使用如 Google Bard 的聊天机器人来帮助他们创建职位描述。不论是大型语言模型还是计算机视觉——AI 将开始成为工作环境和流程的核心部分。
曾经以及现在,人们对 AI 的使用感到紧张和焦虑。由于对其的炒作以及持续的投资和研究——越来越多的行业将采用 AI 来改善这些行业。
财务行业一直在利用 AI 来帮助检测欺诈、反洗钱流程和投资管理。他们可能会考虑使用聊天机器人来处理申请人的整个过程,从而降低成本和任务。
在医疗保健行业,机器学习算法已经被用来预测患者结果、帮助诊断疾病,并协助手术过程。我们再次探讨如何改进医疗保健行业。
这也包括 AI 在自主领域的持续增长。自动驾驶汽车、机器人和无人机将继续增长和改进,以至于我们可能会看到对人类需求的大幅下降。
面对现实,我们在大多数国家处理着大量的工作负荷,有些国家薪水不高。如果这些角色转交给 AI 系统、机器人等——这会有多糟糕?很难说,因为任何好事都必定有坏的一面,对吧?在评论中告诉我你的想法。
通过阅读了解更多: 工作的未来:AI 如何改变工作格局
法律、道德和伦理
到目前为止,AI 行业几乎没有任何管理、规则或约束。它基本上是一个狂野的西部。
然而,近年来我们已经看到了一些由于人工智能的兴起而产生的变化。例如,《欧洲人工智能法案》有可能被视为黄金标准。了解更多信息,请点击这里:欧洲人工智能法案:简化版解读。
在 2022 年,立法者和监管者努力确保人工智能领域在 2023 年会发生变化。立法者正在完成对之前提到的《欧洲人工智能法案》的修订,该法案在初稿中已经禁用了某些人工智能系统并规定了罚款。
人工智能将继续在全球范围内传播,因此政府、监管机构、立法者等将需要更加努力地确保人工智能系统符合伦理,不存在偏见,公平,并且保护客户隐私。
总结
我可以想象每个人对未来十年的预期都有自己的想法和看法。我个人关注这些问题,因为法律的实施也需要时间,人工智能系统才能真正成为我们日常个人生活和工作的一部分。
请在评论中告诉我你认为未来十年人工智能会发生什么。
尼莎·阿雅 是一名数据科学家、自由技术作家和 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程以及基于理论的数据科学知识。她还希望探索人工智能如何能有益于人类寿命的延续。她是一个热衷于学习的求知者,致力于拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关主题
什么是切比雪夫定理,它如何应用于数据科学?
原文:
www.kdnuggets.com/2022/11/chebychev-theorem-apply-data-science.html

作者提供的图片
什么是经验规则?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
在我们开始学习切比雪夫定理之前,了解经验规则会很有用。
经验规则告诉你大多数值在正态分布中的位置。它指出:
-
约 68%的数据位于均值的 1 个标准差以内
-
约 95%的数据位于均值的 2 个标准差以内
-
约 99.7%的数据位于均值的 3 个标准差以内
然而,你无法 100%确定数据的分布会遵循正态钟形曲线。当你处理数据集时,应始终询问数据是否存在偏斜。这就是切比雪夫定理发挥作用的地方。
什么是切比雪夫定理?
切比雪夫定理由俄罗斯数学家帕夫努季·切比雪夫证明,通常称为切比雪夫不等式。它可以应用于任何数据集,特别是那些具有广泛概率分布而不遵循我们希望的正态分布的数据集。
用通俗的语言来说,它指出只有一定比例的观察值可以距离均值超过一定的距离。
对于切比雪夫定理,它指出,当使用任何数值数据集时:
-
至少有 3/4 的数据位于均值的 2 个标准差以内
-
至少有 8/9 的数据位于均值的 3 个标准差以内
-
数据中有 1−1 ∕ k2 的部分位于均值的 k 个标准差以内
使用“至少”一词是因为定理给出了数据位于均值给定标准差数量内的最小比例。
下图直观地展示了经验规则和切比雪夫定理之间的差异:
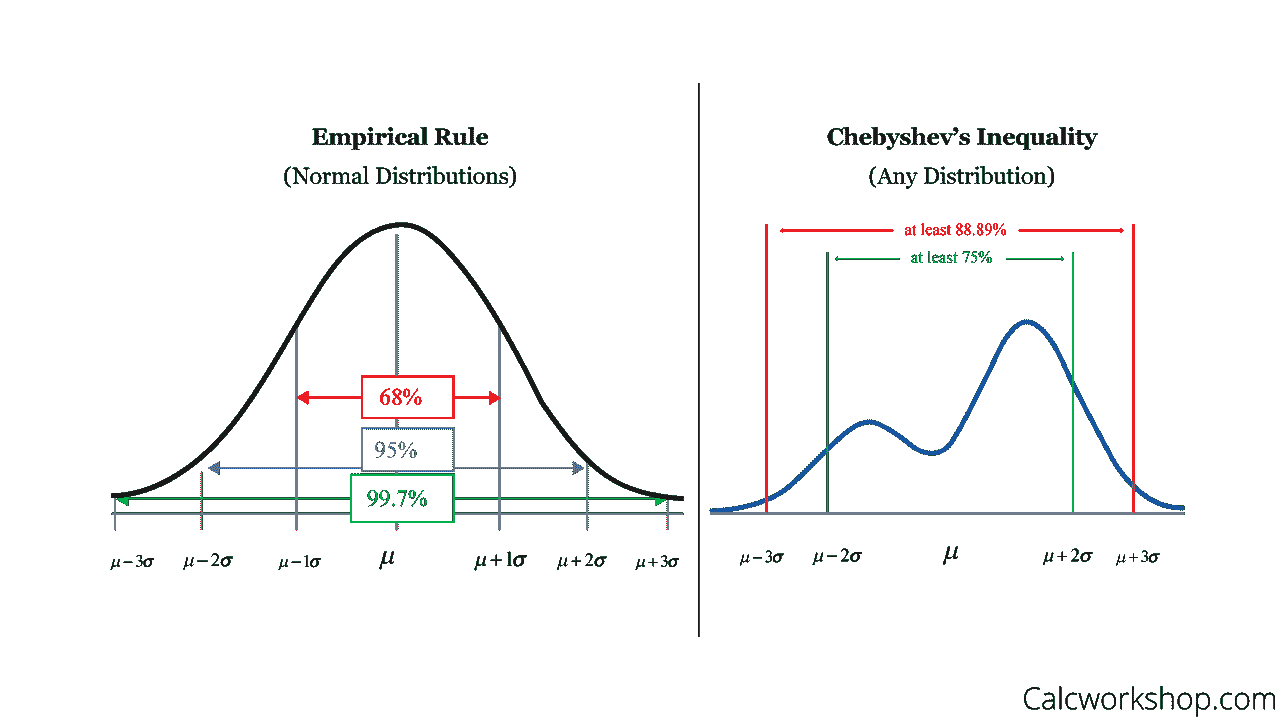
来源: calcworkshop
切比雪夫定理的公式:
切比雪夫定理有两种呈现方式:
X 是一个随机变量
μ是均值
σ是标准差
k>0 是一个正数
- P(|X - μ| ≥ kσ) ≤ 1 / k²
这个方程表示,X 距离均值超过 k 个标准差的概率最多为 1/k²。这也可以写作:
- P(|X - μ| ≤ kσ) ≥ 1 - 1 / k²
切比雪夫定理意味着随机变量远离均值的可能性非常小。因此,我们使用的 k 值是我们为距离均值的标准差数量设置的限制。
当 k >1 时,可以使用切比雪夫定理
那么它如何应用于数据科学呢?
在数据科学中,你会使用许多统计度量来了解你正在处理的数据集。均值计算数据集的集中趋势,但这并不能告诉我们关于数据集的足够信息。
作为数据科学家,你会想了解更多关于数据的离散情况。为了弄清楚这一点,你需要测量标准差,它表示每个值与均值之间的差异。当你有了均值和标准差,你可以了解到很多关于数据集的信息。
我们的方差越大,数据点的分布越分散,离均值的距离越远;方差越小,数据点的分布越集中,离均值的距离也越近。
如果随机变量的方差低,那么观察值将集中在均值附近。如下面的图片所示,这会导致较小的标准差。然而,如果你的数据分布具有较大的方差,那么你的观察值将自然地更加分散,离均值更远。如下面的图片所示,这会导致较大的标准差。
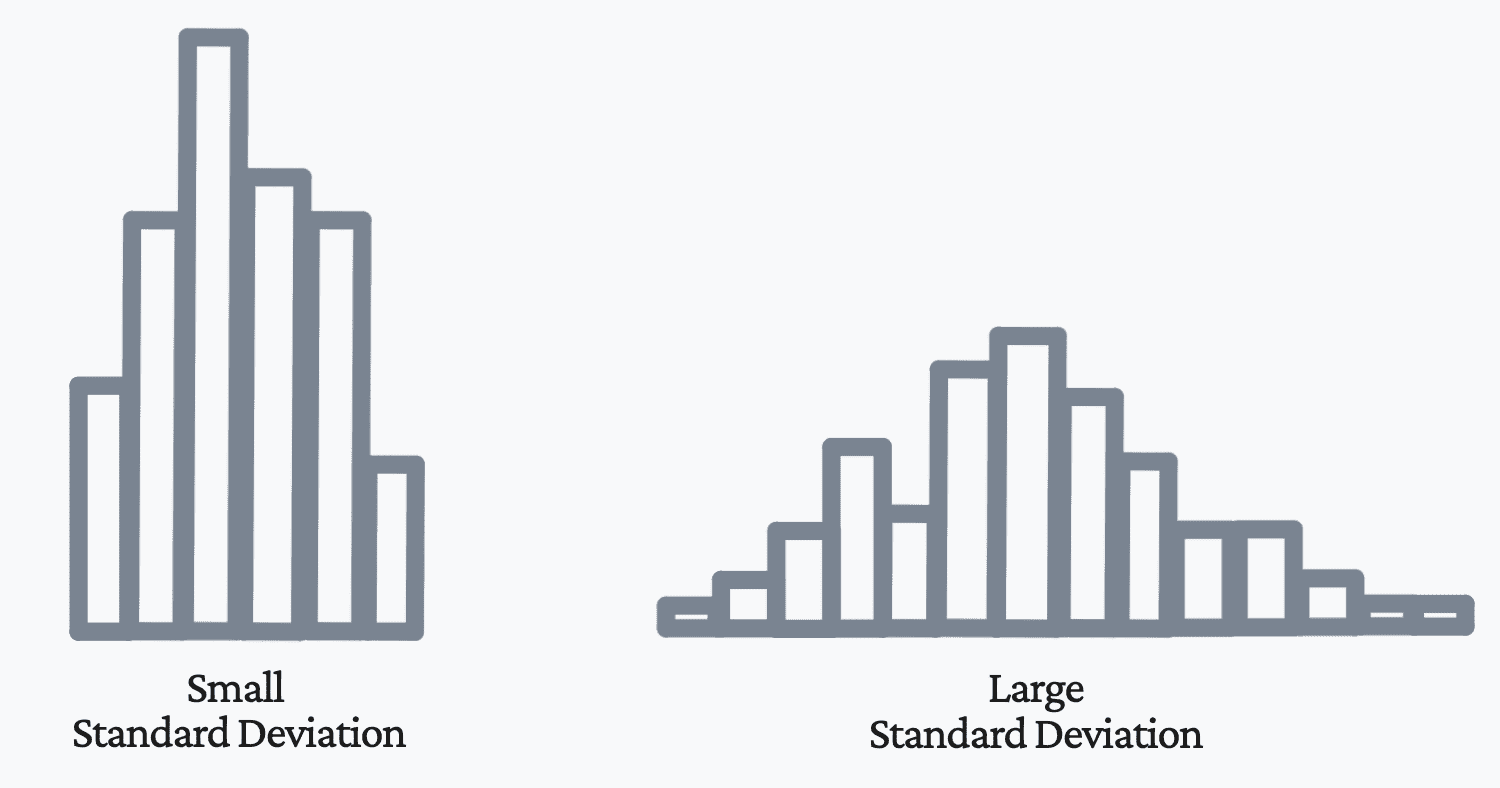
作者提供的图片
数据科学家和其他技术专家会遇到方差较大的数据集。因此,他们通常使用的经验规则可能无法帮助他们,他们将不得不使用切比雪夫定理。
总结
如果你想了解更多关于数据点的离散情况,只要你计算了均值和标准差,并且数据不符合正态分布,切比雪夫定理就可以应用。它能够确定数据落在均值特定范围内的比例。
Nisha Arya 是一位数据科学家和自由职业技术作家。她特别感兴趣于提供数据科学职业建议或教程,以及数据科学相关的理论知识。她还希望探索人工智能如何/能够促进人类寿命的不同方式。作为一个热衷于学习的人,她寻求拓宽技术知识和写作技能,同时帮助指导他人。
更多相关话题
如何在 Python 中检查回归模型的质量?
原文:
www.kdnuggets.com/2019/07/check-quality-regression-model-python.html
评论
为什么这很重要(以及你可能忽视了什么)
尽管最新深度神经网络架构的复杂性以及xgboost 在 Kaggle 比赛中的惊人表现常被讨论,且行业中对data-driven analytics和机器学习(ML)技术的关注不断增加,但对大多数行业来说,回归分析依然是首选用于日常工作。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
查看这个 KDnuggets 2018–19 年的调查结果(由Matthew Mayo提供)。
2018 年和 2019 年使用的顶级数据科学和机器学习方法
在最新的 KDnuggets 调查中,读者被问到:你使用了哪些数据科学/机器学习方法和算法…www.kdnuggets.com
回归技术有多种形式——线性、非线性、泊松、树基——但核心思想在各类回归中几乎相同,并且可以应用于金融、医疗、服务业、制造业、农业等各种预测分析问题。
线性回归是基本技术,它深深植根于经过时间考验的统计学习和推断理论,并驱动了现代数据科学管道中所有基于回归的算法。
然而,线性回归模型的成功还依赖于一些对数据本质的基本假设。请参阅这篇文章以简单直观地理解这些假设,
[回归模型假设
我们在使用线性回归来建模响应和预测变量之间的关系时做出了一些假设…www.jmp.com](https://www.jmp.com/en_us/statistics-knowledge-portal/what-is-regression/simple-linear-regression-assumptions.html)
因此,检查你的线性回归模型的质量非常重要,通过验证这些假设是否“合理”地满足(通常使用可视化分析方法,这些方法有解释空间,来检查假设)。
问题在于,检查模型质量通常是数据科学任务流程中的一个优先级较低的方面,而其他优先事项(如预测、缩放、部署和模型调整)占据主导地位。
这个断言听起来是否太过大胆?有一个简单的测试。
在行业标准的基于 Python 的数据科学堆栈中,你有多少次使用过Pandas、NumPy、Scikit-learn,甚至PostgreSQL进行数据获取、整理、可视化,最终构建和调整你的机器学习模型?我想很多次吧?
现在,你有多少次使用过statsmodels库来通过运行优度检验来检查模型?
在基于 Python 的数据科学学习路径中,这种情况非常常见,

“是否缺少什么”这个问题的答案是肯定的!

经常讨论的有正则化、偏差-方差权衡或可扩展性(学习和复杂度曲线)图。但是,对于以下图表和列表,讨论是否足够?
-
残差与预测变量的图
-
拟合值与残差图
-
归一化残差的直方图
-
归一化残差的 Q-Q 图
-
残差的 Shapiro-Wilk 正态性检验
-
残差的 Cook 距离图
-
预测特征的方差膨胀因子 (VIF)
很明显,你需要戴上统计学家的帽子,不仅仅是数据挖掘专业人士的帽子,以处理机器学习管道的这一部分。

Scikit-learn 的问题
可以安全地假设,大多数转行成为数据科学家的统计学家定期对其回归模型进行优度检验。
但许多年轻的数据科学家和分析师在数据驱动建模中高度依赖于像 Scikit-learn 这样的机器学习库,尽管它是一个出色的库,并且几乎是 机器学习和预测任务的灵丹妙药,但它不支持基于标准统计测试的快速和轻松的模型质量评估。
因此,除了使用像 Scikit-learn 这样的机器学习库外,良好的数据科学管道还必须包含一些标准化的代码集,以使用统计测试评估模型的质量。
在本文中,我们展示了针对多变量线性回归问题的这种标准评估集。我们将使用 statsmodels 库进行回归建模和统计测试。

线性回归假设及关键视觉测试的简要概述
假设
线性回归模型需要测试的四个关键假设是,
-
线性:因变量的期望值是每个自变量的线性函数,其他自变量保持固定(注意,这并不限制你使用自变量的非线性变换,即你仍然可以使用 f(x) = ax² + bx + c 来建模,同时使用 x² 和 x 作为预测变量)。
-
独立性:误差(拟合模型的残差)彼此独立。
-
同方差性 (常量方差):误差的方差对于预测变量或响应变量是常量。
-
正态性:误差来自正态分布(其均值和方差未知,但可以从数据中估计)。注意,这不是执行线性回归的必要条件,不像上述三个假设。然而,如果不满足这个假设,你将无法轻松计算所谓的“置信区间”或“预测区间”,因为无法使用对应于高斯分布的已知分析表达式。
对于多元线性回归,从统计推断的角度来看,判断 多重共线性 也是至关重要的。这个假设认为预测变量之间没有或极少有线性依赖。
异常值 也可能影响模型质量,因为它们对估计的模型参数有不成比例的影响。
这里是一个视觉回顾,
可以检查哪些图?
所以,误差项非常重要。
但有个坏消息。无论我们拥有多少数据,我们永远无法知道真实的误差。我们只能估计和推断数据生成的分布。
因此,真实误差的代理是残差,即观察值和拟合值之间的差异。
底线——我们需要绘制残差,检查它们的随机性质、方差和分布,以评估模型质量。这是线性模型拟合优度估计所需的可视分析。
除此之外,多重共线性可以通过相关矩阵和热图进行检查,而数据中的离群值(残差)可以通过所谓的库克距离图来检查。
回归模型质量评估示例
本示例的完整代码库可以在作者的 Github 上找到。
我们使用的是混凝土抗压强度预测问题,来源于 UCI ML 门户。混凝土的抗压强度是年龄和成分的高度复杂函数。我们能否通过这些参数的测量值来预测强度?
检查线性关系的变量散点图
我们可以通过散点图简单地检查线性假设的视觉效果。
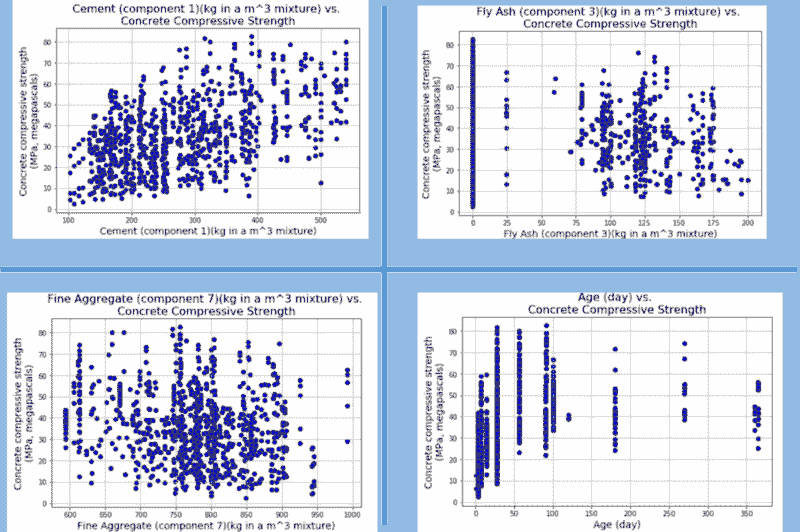
检查多重共线性的配对散点图和相关性热图
我们可以使用seaborn 库中的 pairplot函数来绘制所有组合的配对散点图。
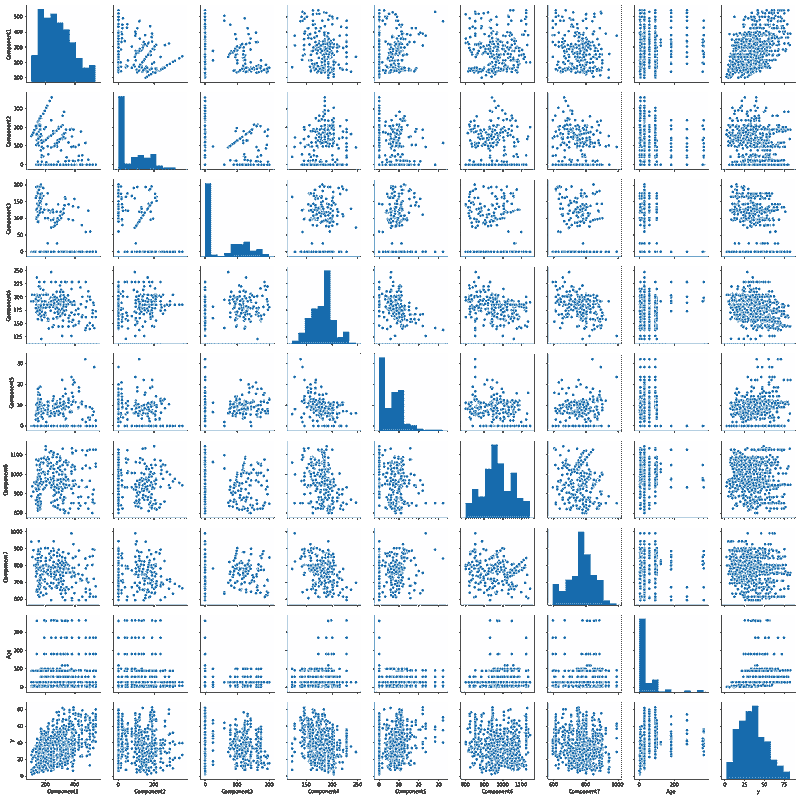
此外,如果数据加载到 Pandas 中,我们可以轻松计算相关矩阵,并将其传递给statsmodels 的特殊绘图函数以将相关性可视化为热图。
使用 statsmodel.ols()函数进行模型拟合
主要模型拟合是使用 statsmodels.OLS 方法完成的。这是一个惊人的线性模型拟合工具,感觉非常像 R 中的强大‘lm’函数。最棒的是,它接受 R 风格的公式来构建完整或部分模型(即涉及所有或一些预测变量)。
你可能会问,在大数据时代,为什么还要创建部分模型而不是将所有数据都放进去?这是因为数据中可能存在混淆或隐性偏差,而这些问题只有通过控制某些因素才能解决。
无论如何,通过该模型拟合的模型摘要已经提供了关于模型的丰富统计信息,例如与所有预测变量相关的 t 统计量和 p 值、R 平方值、调整后的 R 平方值、AIC 和 BIC 等。
残差与预测变量图
接下来,我们可以绘制残差与每个预测变量的关系图,以检查独立性假设。如果残差在零 x 轴周围均匀随机分布,并且不形成特定的聚类,那么假设成立。在这个特定问题中,我们观察到一些聚类现象。
拟合值与残差图以检查同方差性
当我们绘制拟合响应值(按照模型)与残差的关系图时,我们清楚地观察到残差的方差随着响应变量的大小而增加。因此,该问题不符合同方差性,可能需要某种变量变换来提高模型质量。
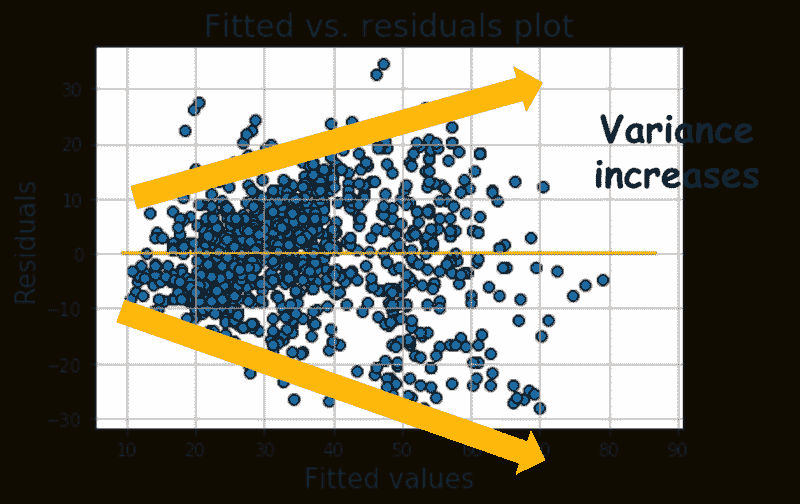
标准化残差的直方图和 Q-Q 图
为了检查数据生成过程的正态性假设,我们可以简单地绘制标准化残差的直方图和 Q-Q 图。
此外,我们可以对残差进行 Shapiro-Wilk 检验,以检查正态性。
使用 Cook 距离图进行异常值检测
Cook 的距离基本上衡量了删除某一观察值的效果。具有较大 Cook 距离的点需要仔细检查,以确定是否为潜在的异常值。我们可以使用来自 statsmodels 的特殊异常值影响类 绘制 Cook 距离。
方差膨胀因子
对于这个数据集的 OLS 模型总结显示了多重共线性的警告。但是如何检查哪些因素导致了它?
我们可以计算每个预测变量的 方差膨胀因子。这是一个多项式模型的方差与仅包含一个项的模型的方差之比。同样,我们利用 statsmodels 中的 特殊异常值影响类。

其他残差诊断
Statsmodels 提供了多种其他诊断测试用于检查模型质量。你可以查看这些页面。
总结和 思考
在这篇文章中,我们介绍了如何在线性回归中添加 模型质量评估的必要视觉分析——各种残差图、正态性测试和多重共线性检查。
甚至可以考虑创建一个简单的函数套件,能够接受 scikit-learn 类型的估算器,并生成这些图表,供数据科学家快速检查模型质量。
目前,虽然 scikit-learn 没有详细的统计测试或模型质量评估绘图功能,Yellowbrick 是一个有前途的 Python 库,可以为 scikit-learn 对象添加直观的可视化功能。我们希望在不久的将来,统计测试可以直接添加到 scikit-learn ML 估算器中。
如果你有任何问题或想法,欢迎通过tirthajyoti[AT]gmail.com联系作者。此外,你可以查看作者的GitHub仓库,获取其他有趣的 Python、R 或 MATLAB 代码片段和机器学习资源。如果你像我一样,对机器学习/数据科学充满热情,欢迎在 LinkedIn 上添加我 或 在 Twitter 上关注我。
[Tirthajyoti Sarkar - 高级首席工程师 - 半导体、AI、机器学习 - ON…]
乔治亚理工学院理学硕士 - MS, 数据分析 该硕士项目提供理论和实践…www.linkedin.com](https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/)
简介:Tirthajyoti Sarkar 是 ON Semiconductor 的高级首席工程师,专注于基于深度学习/机器学习的设计自动化项目。
原文。已获许可转载。
相关:
-
为你的回归问题选择最佳的机器学习算法
-
选择评估机器学习模型的正确度量标准——第一部分
-
从信号中分离噪声
更多相关话题
跟踪你数据科学进展的检查清单
原文:
www.kdnuggets.com/2021/05/checklist-data-science-progress.html
评论
作者:Pascal Janetzky,计算机科学学生,体育爱好者。
有许多很棒的课程可以学习数据科学,还有很多证书可以证明你的成功。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
那么,你如何跟踪你的进展呢?你如何知道自己已经取得了哪些成就,还有哪些尚待实现的目标?
以下检查清单可以帮助你概览自己的进度。它旨在为那些寻找自己在旅程中大致位置的用户提供一个总体概述。它并不强调特定的指南、课程和软件包,而是专注于一般概念:

作者提供的图片。可在 Notion 这里查看,PDF 格式 这里,以及 GitHub 这里下载。
让我们详细介绍这些级别,从入门级开始,继续到中级,最后到广泛的高级领域。
入门级
这是开始的地方。它涵盖了你进一步旅程的基础。
数据处理
此类别的意图是专注于能够处理最常见的数据类型:
-
图片
-
文字
-
音频/时间序列
一般来说,此阶段的数据集非常小,处理比内存大的数据集不会带来(心理)负担。好的例子包括经典的 MNIST 图像数据集(PyTorch,TensorFlow),IMDB 评论文本数据集(PyTorch,TensorFlow),以及小型音频或时间序列数据集。它们最多只有几百 MB,非常适合放入 RAM 中。
这些数据集中的一些需要最少的预处理(缩放图像、缩短句子),通常不超过几行代码。由于示例数量要么非常少,要么仅为小尺寸,你可以在运行时轻松完成处理(与提前运行复杂的脚本相比)。
总之,这一类别强调处理小型音频/时间序列、图像和文本数据集,并应用简单的操作进行数据预处理。
网络
这一类别的意图是从经典的机器学习过渡到神经网络,并了解常见的构建块:
经典的机器学习技术包括支持向量机、线性回归和聚类算法。尽管更复杂的神经网络在最近的研究中似乎占据主导地位,但它们在处理小问题时也很有用——或者作为一个基准。在分析数据时,了解如何使用它们也是很有帮助的。
在深入学习的过程中,密集层是一个很好的起点。我猜它们几乎在每个(分类)模型中都会用到,至少用于构建输出层。
第二种常用的网络类型是卷积神经网络,它的核心使用卷积操作。很难想象有哪个成功的研究没有使用并受益于这一简单操作:你将一个卷积核滑动在输入上,然后计算卷积核与其覆盖的图像块之间的内积。卷积操作从输入数据的每一个可能位置中提取一小组特征。难怪它们在分类图像时非常成功,因为重要的特征分散在各处。
前两种网络类型主要用于静态输入,即我们提前知道数据的形状。当你拥有形状各异的数据时,例如句子,你可能会寻找更灵活的方法。这就是递归神经网络的用武之地:它们可以保留长时间的信息,这使得将“我在早上起床穿衣后和我的狗散步”中的“我”和“和我的狗散步”连接起来,以回答“谁和狗散步?”这个问题成为可能。
总之,这一类别专注于使用简单的密集层、卷积层和递归神经网络来分类图像、文本和时间序列数据。
通用
这一类别的意图是学习数据科学相关任务的一般处理方法。
一个重要的步骤是了解数据本身。这不仅限于图像数据或文本数据,还包括时间序列数据、音频数据以及其他任何数据类型。术语探索性数据分析(感谢Andryas Waurzenczak指出这一点)最能描述这个步骤:使用技术来寻找模式、异常值(超出常见范围的数据点)、子结构、标签分布,以及对数据进行可视化。这可能涉及主成分分析(PCA)或降维技术。你在这一阶段处理的数据集通常已经被详细探索过(尝试搜索数据集的名称以找到有趣的特征),但现在学习这些知识会在你继续处理自定义数据集时带来回报。
你还将学习如何加载和保存上述模型,以便以后可以重用它们。常见的做法是将关于数据的数据,即元数据,存储在单独的文件中。以 CSV 文件为例:第一列存储数据样本的文件路径,第二列存储样本的类别。能够解析这些信息是必要的,但 thanks to 许多库,这是一项简单的任务。
当你开始在这些小型数据集上训练你的基础网络时,使用上述架构,你会逐渐发现回调的有用性。回调是训练过程中执行的代码,它实现了许多功能:定期保存模型以确保其安全,停止训练,或改变参数。最常见的回调已经内置于大多数库中,只需简短的函数调用即可使用它们!
总而言之,这个类别让你学会处理在小型数据集上运行神经网络的任务。
中级阶段
在我看来,这里是乐趣开始的地方,而且你会比你预期的更快到达这个阶段!我发现这个转变发生得非常自然:你寻找一种更高效的数据处理方式——而在你意识到之前,你已经为大型数据集编写了自定义管道。
数据处理
这一阶段的意图是能够处理更大或更复杂的数据集,这可能需要特殊处理,如增强和自定义预处理管道。
在这个阶段,数据集趋向于变得更大,可能不再适合放入你的内存中。高效的预处理变得更加重要,因为你不会让你的硬件闲置。此外,当你处理形状不等的样本、从数据库中提取样本或进行自定义预处理时,你可能需要编写自己的生成器。
或者你处理复杂且不平衡的数据集,其中大多数样本属于一个类别,而只有少数样本属于所需类别。你将学习一些有用的技术:增加数据以生成更多的少数类别样本,或减少主要类别的样本数量。
对于这两种数据集类型,自定义管道变得更加重要。例如,当你希望快速迭代设置时,比如将图像裁剪为 32x32 而不是 50x50 时,你很少会想要启动长期运行的脚本。将这种可能性纳入你的管道可以实现快速实验。
总结来说,数据集往往变得更加复杂(例如,不平衡)和更大(例如,达到 30—40 GB),并且需要更复杂的处理。
自定义项目
这是中级水平的核心。其背后的意图是处理自定义项目,从而学习和使用许多其他类别的内容。
第一级可能已经引导你通过在 MNIST 数据集上训练网络。在这个层级,你将自然地更加关注自己的数据以及如何解析它。我只列出了音频、图像和文本这三个主要领域,但还有许多其他领域。
通过自己进行项目,你可以将之前学到的知识与解决挑战联系起来。
训练
这一类别的意图是了解更多关于训练神经网络的知识。这个类别是中级水平中最大的类别,原因在于它集中于更高级的主题。
自定义训练的第一步是使用迁移学习和微调。之前,你通常会使用标准方法来训练和测试模型,但现在你可能需要更强大的方法。这时,重新利用其他从业者训练的模型就很有用。你加载他们的模型,并在自己的数据集上仔细训练它们。
如果你遗漏了一些功能,这时你需要编写自定义训练循环和自定义回调函数。想要每 20 个批次打印一些统计信息?编写一个自定义回调。想要在 20 个批次中累积梯度?编写一个自定义训练循环。
更复杂的循环可能需要更多的资源:多 GPU 训练即将到来!不过,这不仅仅是增加第二、第三个或更多的资源;你必须足够快地获取数据。请记住,多设备训练增加了复杂性。大部分后台工作已经由 PyTorch 和 TensorFlow 完成,它们只需少量代码更改就能处理这种情况,但前端部分仍由你负责。(不过不要担心,那里有许多指南可以帮助你完成这项工作!)
如果你像我一样没有多张 GPU,那么在云上训练可能是下一步的选择。所有主要的云服务提供了你所需的资源。刚开始时,从本地环境转到云计算会有一些(心理上的)开销。但经过几次尝试,这会变得容易得多。(当我开始在 Kubernetes 集群上运行脚本时,事情非常让人不知所措:什么是 Dockerfile?如何运行作业?如何使用本地资源?如何进出数据?经过一番实验,我逐渐习惯了,现在只需几个简单的命令就能运行我的脚本。)
当你已经在云端时,为什么不尝试 TPU 训练呢?TPU 是 Google 定制的芯片。而且它们很快:一年前,我与一个团队一起对一个大型文本语料库(大约 20,000 个文档,每个文档约 10 页文本)进行了分类。我们在 CPU 上进行的第一次实验中,一个 epoch 花费了 8 小时。在接下来的步骤中,我们改进了预处理、缓存,并使用了一个 GPU:时间缩短到 15 分钟,这是一个巨大的飞跃。在阅读 TensorFlow 文档并调整代码后,我成功实现了 TPU 训练,一个 epoch 缩短到 15 秒。因此,我鼓励你升级你的管道,并在 TPU 上运行训练。
总结来说,这一类别专注于将实际训练部分扩展到更复杂的训练循环和自定义回调。
概述
这一类别的意图是了解使用普通架构之外的更多可能性。
现在你正在处理自定义数据集,理解问题思维变得重要。让我这样解释:假设你正在处理一个音频数据集。你已经完成了初步数据分析,结果发现你的数据不仅不平衡,而且样本长度各异。有的仅三秒钟长,有的则长达 20 秒或更多。此外,你只想分类音频的片段,而不是整个剪辑。最后,这还是一个工业项目,因此有一些限制。将这一切整合在一起是你需要完成的任务。
幸运的是,你并不孤单。数据分析已经完成,自定义数据的预处理也已完成。这里主要关注的是工业部分。查看其他人所做的(并发布在 GitHub 上)、询问你的团队,并尝试不同的技术。
比如,你想要一个网络层来按照自定义方案规范化你的数据。查看你的库文档,你没有找到类似的实现。现在是时候自己实现这种功能了。如前所述,TensorFlow和 PyTorch(这使得方法更简单)提供了一些很好的资源来开始。
不久前,我想编写一个自定义嵌入层。找到没有实现后,我决定自己动手编写一个。这确实是一个挑战!经过多次试错,我最终制作出了一个有效的 TensorFlow 层。(具有讽刺意味的是,最终它并没有比现有的更好。)
另一个在深度学习中广泛领域是生成网络。在此之前,你主要是对现有数据进行分类,但现在你可以尝试生成数据。这正是生成网络的作用,它们最近的大部分成功来自于一篇论文:生成对抗网络。研究人员确实提出了一个聪明的办法:不是训练一个网络,而是训练两个网络,并且两个网络都随着时间的推移变得更好。详细检查它们的工作超出了本讨论的范围,但 Joseph 和 Baptiste Rocca 对它们的解释非常出色,可以在 这里 查看。
除了使用更多种类的模型外,你还需要跟踪你的实验。这对于理解模型的指标如何受到其参数影响非常有帮助。说到这一点,你可能还会开始进行参数搜索,旨在找到优化目标指标的最佳参数组合。
与上一部分一样,你将使用更先进的模型。除了这些生成网络,还有巨大的语言模型。你听说过 Transformer(不是电影)吗?我敢打赌你听说过,现在是时候将它们应用到自己的项目中了。或者尝试获得 GPT-3 的访问权限,并与之讨论 AI。
总结来说,这一类别超越了常规模型,探索了更多技术。
高级阶段
这是最后阶段,尽管与前一阶段的界限确实模糊。恭喜你来到这里!由于项目是建立在你之前的经验基础上的,因此你只需探索一个类别。
概述
即使你已经走到了这一步,仍然有更多的内容可以探索。
第一个项目是 巨大的数据集。虽然启动训练过程现在对你来说是一个常规任务,但这里的重点是尽管数据集庞大,仍要让训练变得迅速。所谓的 巨大的 意味着数据集达到几百 GB 甚至更多。考虑像 ImageNet 规模或 The Pile 规模的数据集。处理这些数据需要考虑你的存储选项、数据获取和预处理管道。不仅仅是数据的大小增加了,复杂性也随之上升:一个几百 GB 的多模型数据集,每张图片都附带文本和听觉描述?这确实需要仔细思考。
在处理如此庞大的数据集时,可能需要运行多工作节点的训练设置。GPU 不再安装在单一的机器上,而是分布在多个机器上,也就是工作节点。管理工作负载和数据的分布变得必要。值得庆幸的是,PyTorch 和 TensorFlow 在这方面也提供了一些资源。
在你花费了几个小时设置模型之后,为什么不部署它们呢?使用一些让你轻松构建漂亮 GUI 的库(如streamlit.io),并部署你的模型,以便其他从业者可以实时查看你的工作。
当你完成了这些之后,进入强化学习。将其放在高级部分可能不完全正确(基础知识可以很早掌握),但它与迄今为止你所研究的领域大多不同。与往常一样,有一些someresourcesavailable帮助你入门。
现在你已经积累了一些丰富的经验和知识,是时候进行研究了。你在旅途中是否注意到有任何可以改进的地方?这可能是第一个要着手的事情。或者通过向其他研究项目的代码库提供代码来贡献。与其他爱好者合作,持续学习。
这可能是剩下的最后一件事:保持最新。数据科学是一个快速发展的领域,每天都有许多令人兴奋的新事物出现。跟踪重要信息很困难,所以选择一些新闻通讯(我阅读 Andrew Ng 和 deeplearning.ai 的The Batch)以获取精华信息。为了缩小范围,你还可以使用 Andrew Karpathy 的 Arxiv Sanity Preserver,它帮助你筛选出符合你兴趣的论文。
总结来说,这个类别专注于将强化学习作为一个全新的领域进行探索,贡献于研究,并保持最新——最后两点从未真正完成。
接下来该去哪里?
你可以在 Notion 上找到清单这里,PDF 版本这里。制作副本,自定义它,然后逐步勾选。
请在GitHub上留下任何建议或备注。
如果你在寻找具体的资源:
-
大部分入门级内容由 deeplearning.ai 的TensorFlow Developer Professional Certificate涵盖(尝试在之后参加 TF 考试,看看你已经学到了什么!)
-
入门级和中级以及高级部分由伯克利的Full Stack Deep Learning课程涵盖。
-
深度学习和强化学习的一些中级和高级部分由 DeepMind 的Advanced Deep Learning & Reinforcement Learning讲座涵盖。
-
中级和高级水平的一部分由 deeplearning.ai 的TensorFlow: 数据与部署专项课程和TensorFlow: 高级技术专项课程涵盖。
如果你在寻找更具体的列表,可以查看 Daniel Bourke 的路线图这里。
问题
… 缺失了。
留下评论告诉我。请记住,这个检查清单旨在作为一般概述,并不包含使用 NumPy/pandas/TensorFlow/…或类似的具体项目。
不同类别之间是否存在重叠?
是的,确实如此。不同类别之间有些项目没有明确的分界线。例如,当你处理图像时,你可能已经将它们存储在磁盘上,而 CSV 文件保存了所有的文件路径和标签。这样你可以一次完成两个项目。
同样,在同一类别内,有时也会存在两个项目之间的重叠。这发生在它们大部分时间是一起进行的,但仍然有所不同。
是否有顺序?
我最初尝试在每个类别内保持顺序(例如,在训练类别中),将最简单的任务放在顶部,较难的任务放在底部。但有时两个项目之间没有明确的难度排名。以迁移学习和微调为例:两者紧密相关,没有明确的顺序。
TPU 有何特别之处,使其独立成一个类别?
虽然幸运的是可以轻松地访问Colab并选择 TPU,但首先准备数据是至关重要的。我提出这个点的目的是为了让你的管道非常高效,以便数据能够及时到达 TPU。因此,重点更多是放在高效的预处理上,而不是加快计算速度。
实际上,在 TPU 上运行代码确实很酷。
列表很长。我该如何完成它?
两个简短的答案:
— 你不必这样做;我自己距离这个点还很远。将其作为你下一个努力的简单指南。
— 你不必在进入下一个级别之前完成一个级别或类别。
更长的答案:
每周腾出一天,屏蔽其他所有事情。
在其他的日子里,你可以进行学习。可以在星期三、星期四和星期五上课。周末学习是额外的奖励。
然后,在星期一,你复习过去几天学到的内容,利用周末巩固知识。
在你封闭的星期二,你将新的知识应用到自己的项目中。
这些项目不一定要很大:
学到了关于高效数据处理的知识?为自己的数据建立一个管道(并勾选自定义管道)。
学会了如何分类图像?拍摄你房间里的一些物品的图像,并对它们进行分类(并勾选自定义图像项目)。
学习了特定的网络架构?使用你选择的库并简单地重新实现它(并勾选高级架构或卷积神经网络或两者)。
使用这些简短的独立项目来接触广泛的主题。你处理的小主题越多,越容易开始那些起初看起来令人畏惧的大项目——因为它们只是由你已经完成的许多小步骤组成。
原始文档。经许可转载。
相关:
更多相关内容
选择数据领域的正确工作:工程文化中的 5 个迹象
原文:
www.kdnuggets.com/2021/10/choose-right-job-data-signs-engineering-culture.html
comments
作者:Niv Sluzki,Databand.ai 的研发团队领导

由 Ruslan Burlaka 拍摄,来自 Pexels
我们的三大推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全领域。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
如果你是一名希望在数据公司找到工作的软件工程师,我要透露一个不公开的秘密——大数据的爆炸性增长意味着世界是你的舞台。作为一个招聘经理,我可以告诉你,大多数职位的薪资、头衔、福利和待遇都差不多。
被严重忽视的领域是工程文化。
我说的不是“有趣”的表面迹象,而是公司是否有意组织自己以最大程度地为客户创造价值的指标——即使这意味着以非常规方式运行组织。
作为一名工程团队领导,我将分享五个迹象,显示一个公司是否具有创新和持久发展的能力。无论你在哪里寻找,你都会得到丰厚的薪酬。但如果你进入这个领域是为了满足一个真正的目的,去面试时要评估公司的工程文化,选择那个值得你加入的团队。
1. 他们是否庆祝全栈能力?
对于那些忽视通才,并认为万事通不如专家有价值的人,请再考虑一下。
全栈工程师是一位全面的工作者,他们不依赖其他人完成工作。他们能单独为你的组织带来价值。
简而言之,它们都很棒。
本周我让我们出色的全栈开发者 Ilan Techenak 开发一个服务,该服务在我们的部署中运行,监控谷歌的 BigQuery 数据仓库,并允许用户从我们的Databand应用程序中进行集成。
让我们花一点时间来认识完成这一任务所需的知识和专业技能的广度:
-
这个任务中还有许多其他方面——例如我们如何管理用户的秘密,如何与用户的 GCP 服务账户集成,如何监控我们自己的系统,如何端到端测试等。
-
我们需要开发一个 BigQuery 代理——这是一个显而易见的后台服务。
-
我们需要让用户将监控系统与我们的应用程序集成——这包括前端和后台工作,诸如引入新 API 和 UI 更改。我们的后台大部分是用 Python 和 Vue.js 编写的,我们使用 PostgreSQL 作为数据库。
-
我们需要让这个服务在我们的部署中运行——我们的系统运行在 Kubernetes 中,并通过 Helm 部署进行管理。我们使用 GitLab 进行代码管理和 CI/CD。是时候展现你的 DevOps 技能了。
-
BigQuery 对我们来说是新的——我们需要一个能够深入新技术的人,专注于学习我们需要的东西以满足产品需求。我们本可以请一个数据库专家来了解 BigQuery 的工作原理、BigQuery 用户在夜晚难以入眠的内部机制以及他们关心的指标。虽然这在理论上听起来不错,但我们的 BigQuery 客户并不需要这种细致入微的知识,而且学习这些内容会花费很多时间。
一个全栈工程师需要具备广泛的技能才能完成这些任务。但更重要的是,他们首先关注如何实现业务目标,以及如何为客户(因此也为公司)创造影响和价值。全栈工程师将一个大问题,例如“我们想监控 BigQuery”,拆分成多个不同学科、不同编程语言、不同技术和不同专业领域的子任务。在他们的核心,他们是专家级的问题解决者,根据给定的任何问题独立找出解决方案。
正如我所说,他们真的很棒。
一个重视跨学科能力的公司通常会接受新思想、新视角和解决问题的新方法。倾向于创新的公司自然会以更具创造性的方式运作。
2. 他们重视技能的多样性吗?
尽管如此,全栈工程师在拥有专家和专注于基础设施健全性并在风险开始增加时发出警告的基础设施团队的支持下表现最佳。
看看 Jonny Barda——一位顶尖的后台工程师、代码哲学的爱好者、纯粹主义者以及对真实复杂工程问题的热衷者。一个全栈工程师需要像 Barda 这样的人来帮助设定参数,以确保我们偿还技术债务并在设计规划和审查过程中提升架构问题。
说实话,Barda 在我们的团队中是不可或缺的。他在我们进展过程中提供了保障,因为他确保我们的系统不会频繁崩溃或变得近乎无法维护。
除了团队中的专家,我们还有一个基础设施团队,由公司范围内的人员组成,他们帮助我们导航。我们的架构师确保所有服务都处于良好状态,帮助工程师解决最大的设计问题,并领导基础设施团队。我们的前端技术负责人负责我们的 UI 架构,能够选择合适的技术栈,确保我们拥有适合测试和共享组件的基础设施。
最后,我们有负责所有部署、监控和 CI/CD 的 DevOps 大师。
正如你所见,系统的任何部分都没有缺乏责任感。
我们的全栈工程师依赖于基础设施团队来考虑大的公司级问题,分享知识,解决复杂问题,并防止我们重复做其他团队已经完成的工作。
每个职能都发挥独特的作用,共同构建能为客户带来价值的产品。使他们作为团队闪光的原因在于他们各自的强项和相互之间的互补性。对于我们的全栈工程师在测试和解决问题的过程中所能打破的一切,总有一个专家和一个基础设施团队来防止后续的问题。
企业如果故意让团队具备多样的技能组合,就可以大胆地承担更大的风险,以追求更好的结果,从而成为更具竞争力的企业。虽然大胆的决策可能看似会带来更大的风险,但专家和基础设施团队提供的支持确保了所有的风险实际上都是经过计算和缓解的。
3. 他们的团队构成是否鼓励敏捷性?
软件会随着对客户理解的变化而变化。接受这一现实意味着必须将敏捷性融入工程文化中。即兴发挥不是一种罕见的现象,而是团队经常利用的独特能力。
想象一下你有一个乐队——就像我们在Databand一样——而你的乐队正在并行创作很多新歌曲。在制作过程中,灵感闪现,你需要添加更多的声音,比如一段小吉他旋律或几个低音鼓击打,以完善音效。全栈工程师就像那种能够即兴演奏的多乐器乐队成员。当你正在进行多个复杂的项目且涉及大量移动部件时,他们特别能证明自己的价值。我向你保证,伟大的音乐很大程度上依赖于即兴发挥,伟大的软件也是如此。
如果我们按照职能专长组织团队——前端团队、后端团队等——那么一个全栈工程师所需的工作量现在将需要 3 到 4 个不同的团队来处理。
在 Databand ,我们确保我们的产品团队由 70%的真正的全栈工程师和 30%的专业人士组成。这使得每个团队能够完全专注于业务目标,并具备实现成功所需的所有能力。我们的基础设施团队致力于解决跨公司难题、改善我们内部的开发体验,并确保我们奠定正确的基础,以便有效且高效地成长。
工程团队的组成是衡量工程文化优先级的最简单方法之一。全栈工程师比例较高的团队能够持续灵活地执行任务。灵活性不被视为目标,而是一种自然的存在方式。
4. 他们是否按自己的职能来衡量每个人?
根据 Emily Heaslip 在 Index 文章中的描述,衡量开发者似乎基于以下 KPI:
-
周期时间——开发者将任务从一个状态移动到另一个状态所需的时间,也即他开发一个功能、修复一个 bug 和消除瓶颈的速度。
-
冲刺燃尽图——它让你了解是否能够“完成这一冲刺”,也就是是否完成了你在这一冲刺中计划完成的大部分任务。
-
速度——交付了多少个已完成的功能
-
开放请求——有多少个“Jira 工单”没有得到回应
-
吞吐量——总结上周\本月的所有情况。
尽管如何衡量软件工程是一个高度争议的话题,但以上 5 个要点可以为我们提供一个合理的工具来衡量专家或基础设施导向的工程师。
在衡量这类工程师时,你将关注他们的代码质量、他们创造和解决的技术债务数量、他们如何减少维护工作量、他们的测试覆盖率以及他们是否选择了最合适的工具来解决问题。
全栈工程师需要通过不同的标准来衡量,我们关注其他类型的绩效:
-
业务影响——他们的功能如何改善我们的业务 KPI?因为这个功能有多少新用户使用系统?有多少用户回到这个功能?它是否解决了用户的实际问题?
-
灵活性——如果我们需要在明天移除整个功能或扩展其支持不同的技术栈,他能多快实施所需的变更?
-
端到端责任——全栈工程师应能够独立工作,从 DevOps 到前端开发完整地开发他的功能,具备完成该功能的能力,确保其经过全面测试,并修复我们发现的任何错误。
-
用户体验——为了符合业务目标,全栈工程师很可能了解最终用户如何使用他的功能。
-
技术债务 – 我们期望全栈工程师指出为了快速交付而做出的权衡,并在创造重大技术债务时发出警告。
总之,全栈工程师的衡量标准应该与他们需要达成的大局业务目标相一致。
这种测量区分很重要,因为它告诉你公司是否认真致力于使员工成功。
5. 他们是否重视你的性格和人性?
最重要的标志是公司是否将你视为比一组匹配其要求的技能更为重要的人。寻找一个会重视你作为整体,超过所有技能和经验总和的公司。
我们所有的招聘经理都认识到技能是可以学习和提升的。我们有一些非常优秀的开发者,他们都是从不同的经验水平进入我们的公司。共同点是他们具备我们认为比传统代码掌握更有价值的素质:
谦逊。 我相信这是任何环境中都很重要的特质,在不断变化的研发环境中尤为关键。谦逊表现出尝试新事物的自信与容错的平衡。
快速学习者。 当我们招聘时,我们并不总是寻找经验丰富的开发者。我们只是要求候选人说服我们,他们能够快速学习新技术。
成长欲望。 我们考虑的所有候选人都很聪明且敏锐。那些脱颖而出的人总是表现出希望在某一领域成为专家的驱动力。
业务驱动。 我们团队中不乏能够编写优美、优雅代码的杰出开发者。但区别在于,我们的开发者不满足于没有业务目的的优美代码。他们都将自己视为对公司业绩的贡献者。他们以客户为导向,并在工作成果使客户满意时感到最被肯定。
尽管这五个标志是帮助你评估潜在雇主的优秀指标,但绝不是全面的。当你考虑面前的机会时,还有其他重要因素需要考虑。下次你被邀请面试时,请记住,那些投资于你潜力的公司才值得你的时间和才华。
准备好问题以帮助你做出决定。祝好运!
简介:Niv Sluzki 是 Databand.ai 的研发团队负责人,负责数据健康开发团队。他曾是以色列国防军情报部队的高级军官,负责领导和管理多个复杂的大数据项目,涉及不同环境。他是一位经验丰富的全栈开发人员,与不同的产品经理合作过各种产品,包括 Innoviz 的 InnovizOne 驾驶员,这是一个面向自动驾驶汽车行业的尖端 LiDAR 传感器。
相关:
-
数据分析师和数据科学家的 7 个区别
-
如何作为初学者建立强大的数据科学投资组合
-
通向全栈数据科学的路径
相关话题
在模型候选之间进行选择
原文:
www.kdnuggets.com/2019/05/choosing-between-model-candidates.html
评论
有关所有内容,包括视频和代码,请访问模型选择课程页面。
在模型之间进行选择
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
让我们为一些数据拟合一个模型。这些是虚构的中西部小镇过去 120 年的年温度。每年一个点,代表每日最高温度的年中位数。当我们查看这些数据时,我们的眼睛非常擅长提取模式。右侧有明显的上升趋势。我们希望在模型中捕捉到这一点。
有很多模型可以表示这一点。一个很好的起点,因为它非常简单,就是一条直线。下面是最佳拟合直线的样子。它做得相当不错。我们可以看到它确实捕捉了数据的上升趋势,但它没有捕捉到数据的弯曲。我们检查后可以清楚地看到,直线并没有像我们希望的那样好。
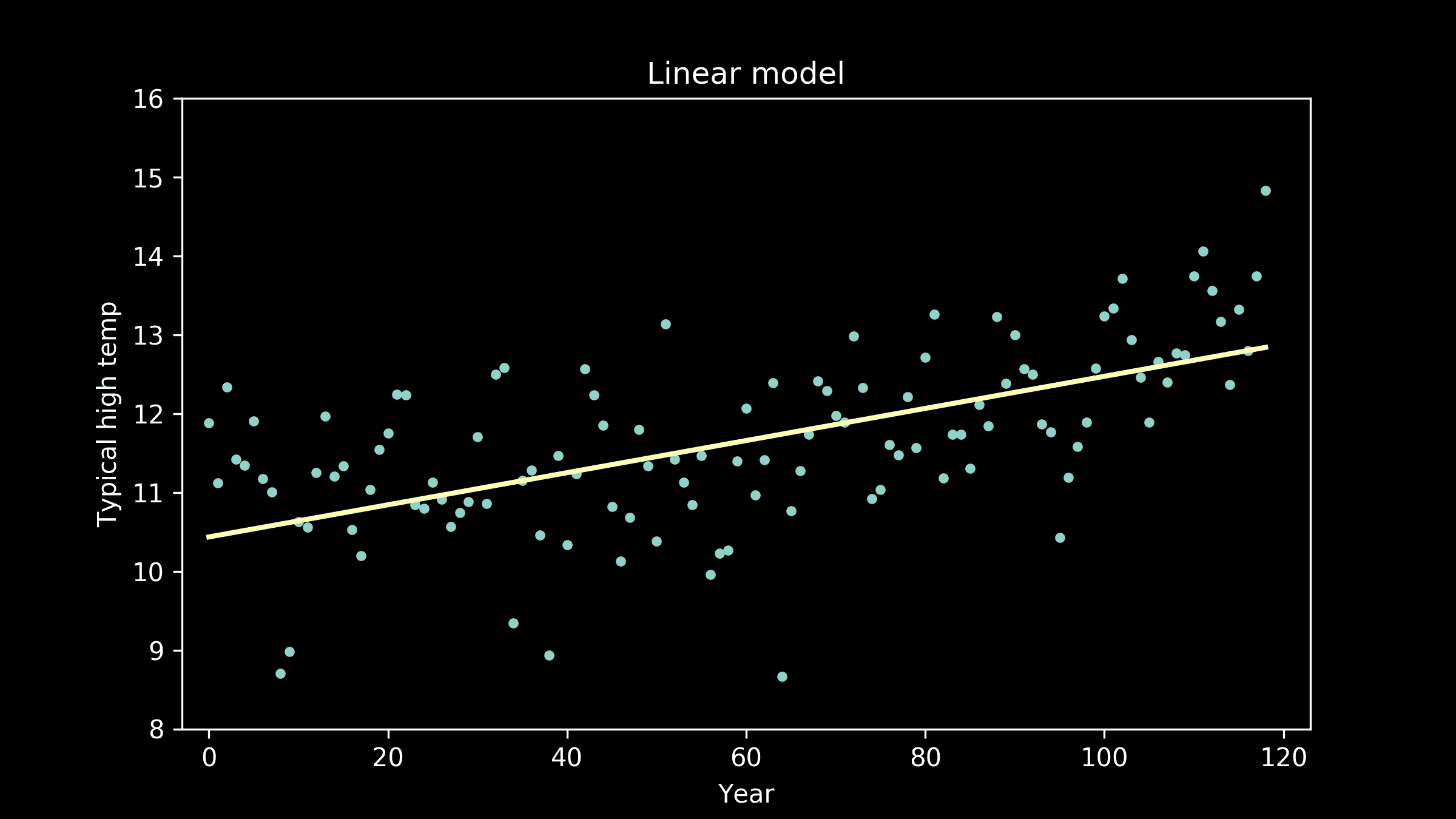
幸运的是,我们还有很多其他选项。一个合理的下一个候选是二次多项式,即带有平方项的多项式,而不仅仅是线性项。这些多项式有曲率。我们可以看到最佳拟合的二次多项式清晰地捕捉了图右侧的上升趋势和中间的弯曲,但它也在图的左侧施加了一些上升趋势,这在数据中并没有明显反映出来。
所以,我们可以尝试其他选项。我们可以尝试具有三次项的多项式,即三次方的多项式。
或者我们可以查看具有四次项的多项式,即四次方的多项式。
我们还可以拟合五阶多项式模型,
六阶多项式,
七阶多项式,
八阶多项式,也称为八次多项式(这是一个在聚会上填补空白的有用小知识)。
现在拟合情况似乎在改善,但线条开始变得有些“个性化”。它出现了波动。如果我们将这种情况推到极端,我们可以想象一个模型完美地通过每一个数据点。这个模型将具有零误差,零偏差。那么这是否意味着它是最佳拟合模型?
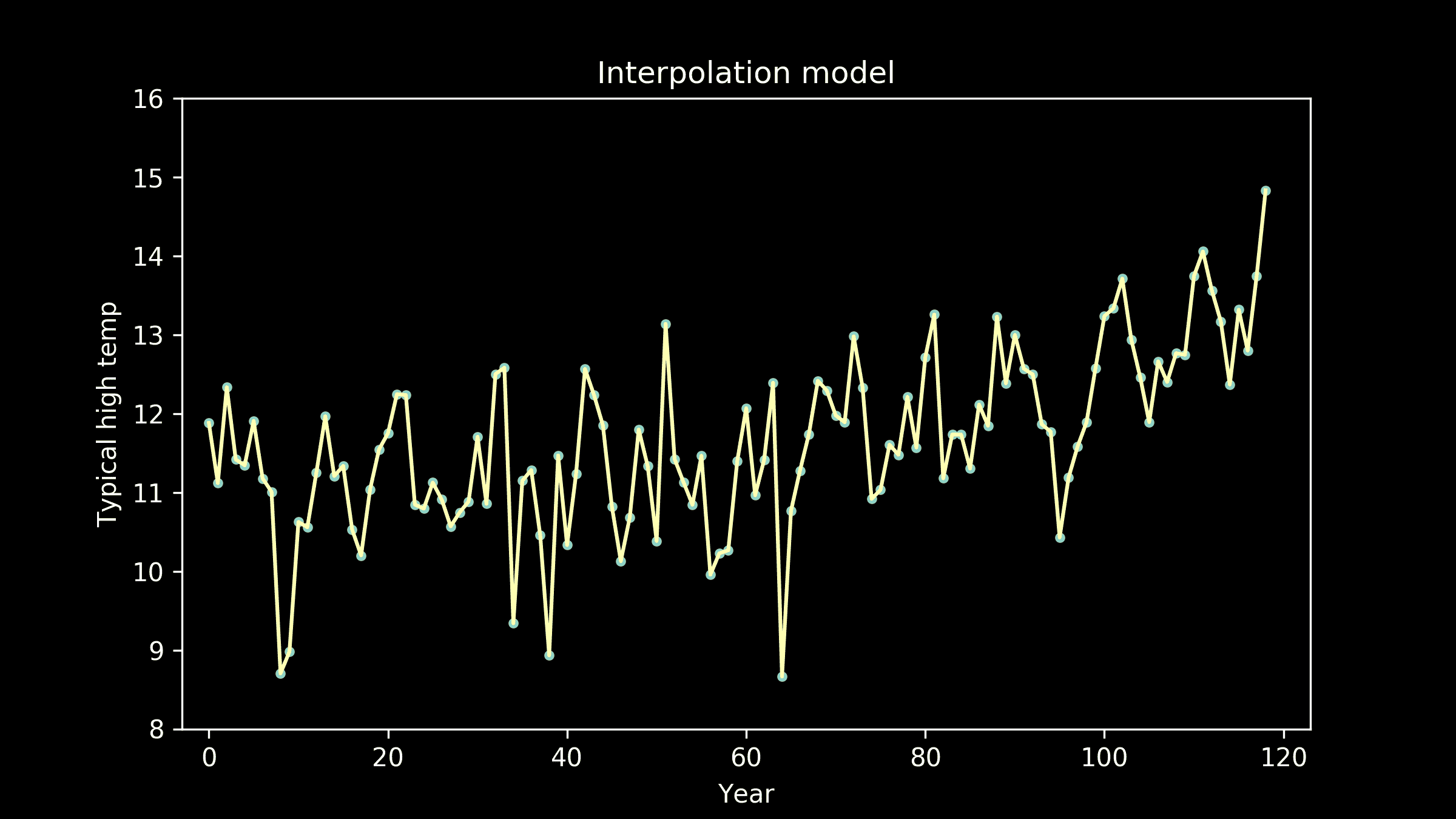
模型之所以有用,是因为它们使我们能够将一种情况推广到另一种情况。当我们使用模型时,我们在假设存在某种我们想要测量的潜在模式,但它上面有一些误差。一个好的模型的目标是透过误差找到这个模式。
最常见的方法是将我们的数据分成两组。我们可以使用一组来训练我们的模型,然后测试模型,看看它在第二组数据上的拟合程度。第一组是训练数据集,第二组是测试数据集。实现这一目标的方法有很多,我们稍后会重新讨论,但现在,我们将随机将年份分成两个箱子。我们将 70%的数据放入训练数据集,30%的数据放入测试数据集。
然后,我们可以回到我们的模型候选集合,逐一测试它们。这里是一些模型,这些模型在训练数据上训练,并与测试数据一起绘制。
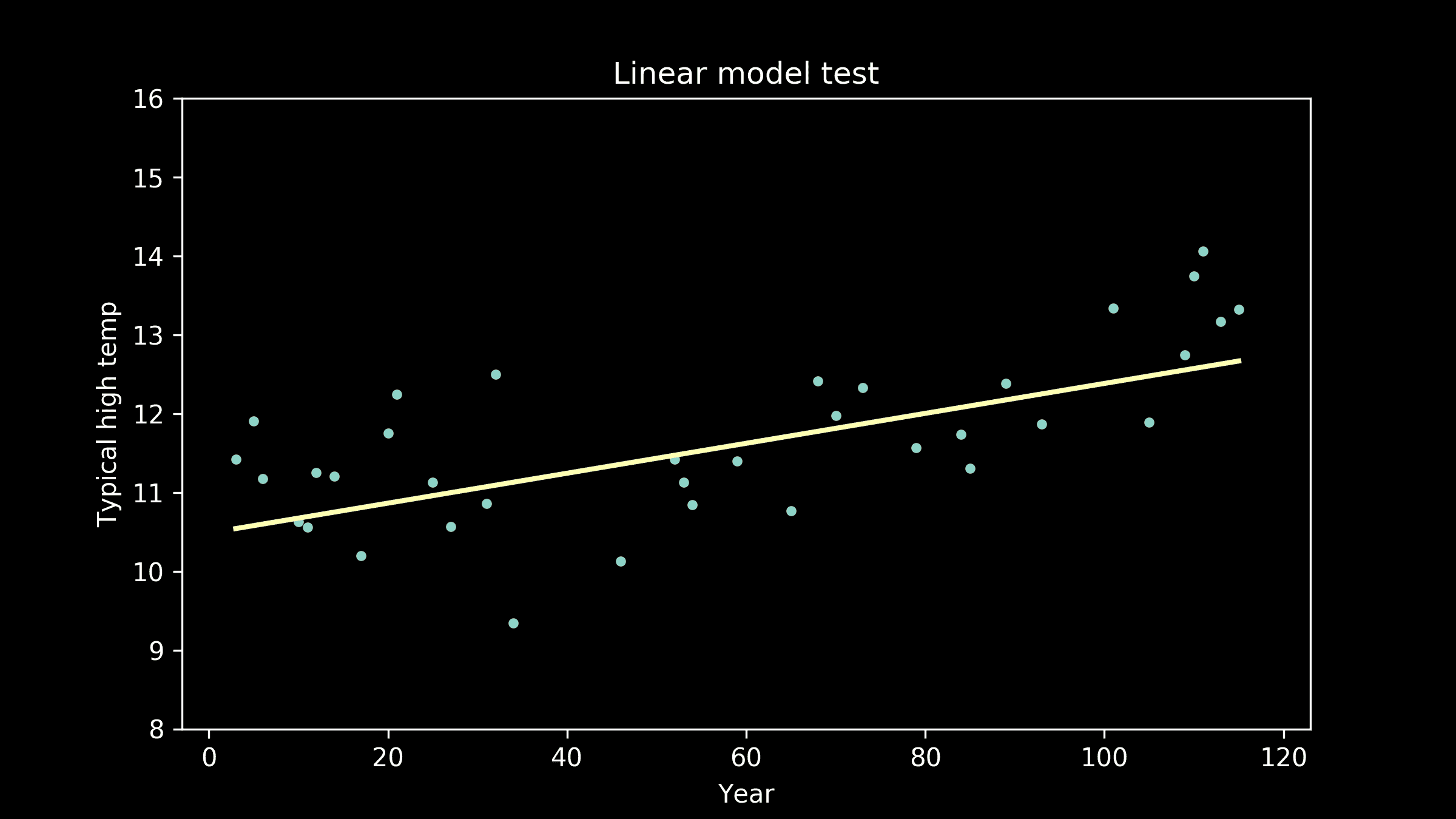
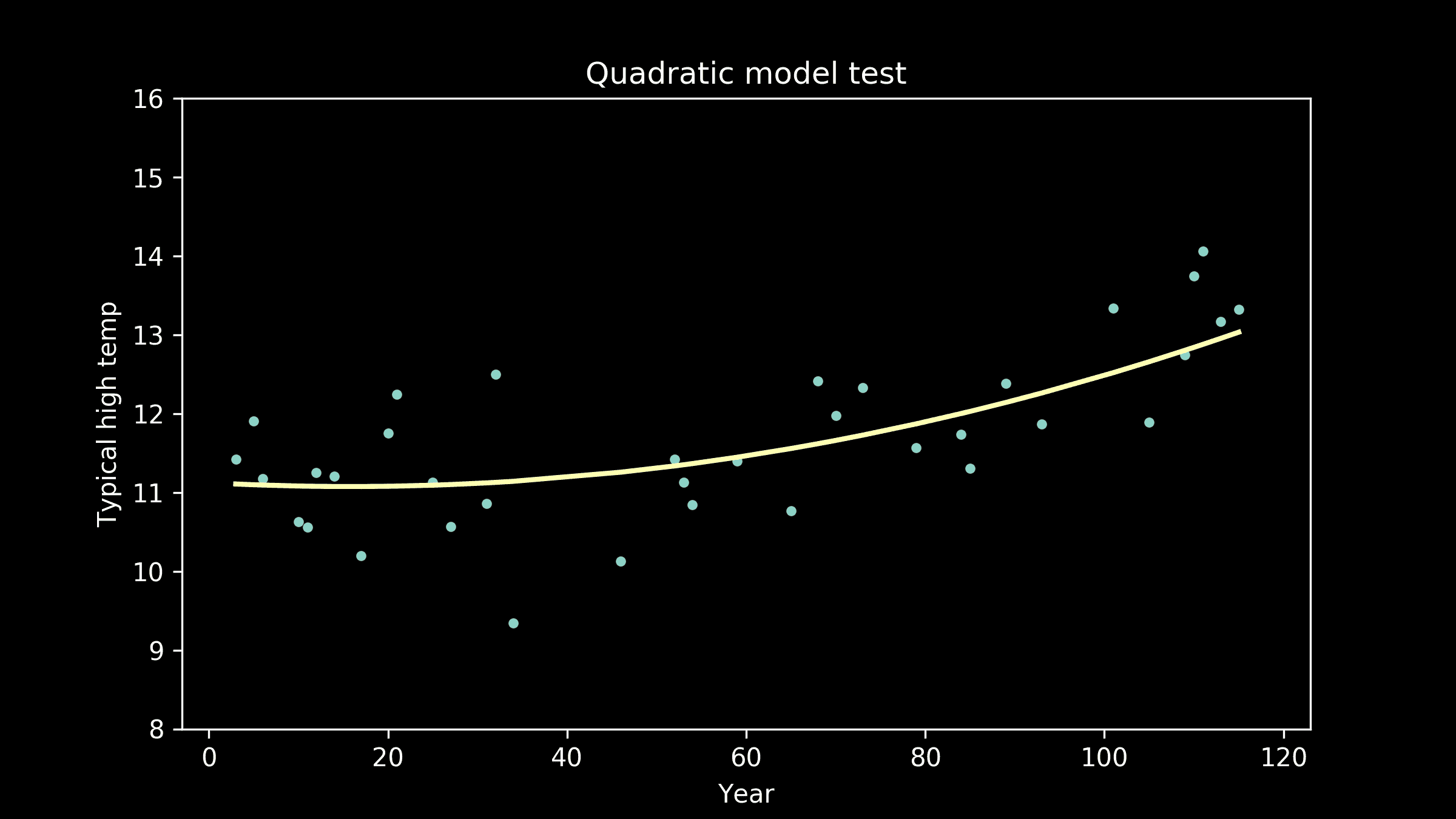
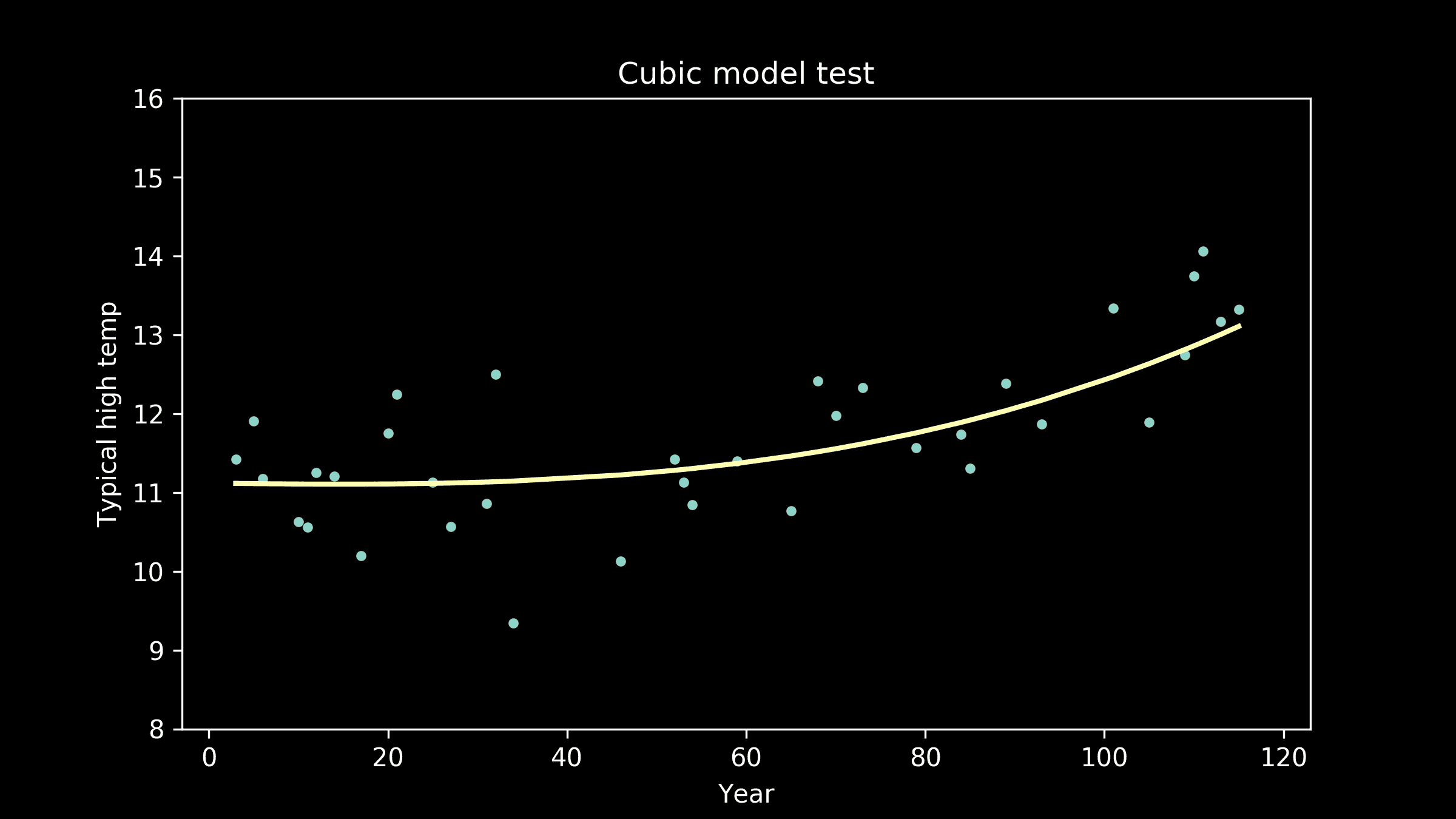
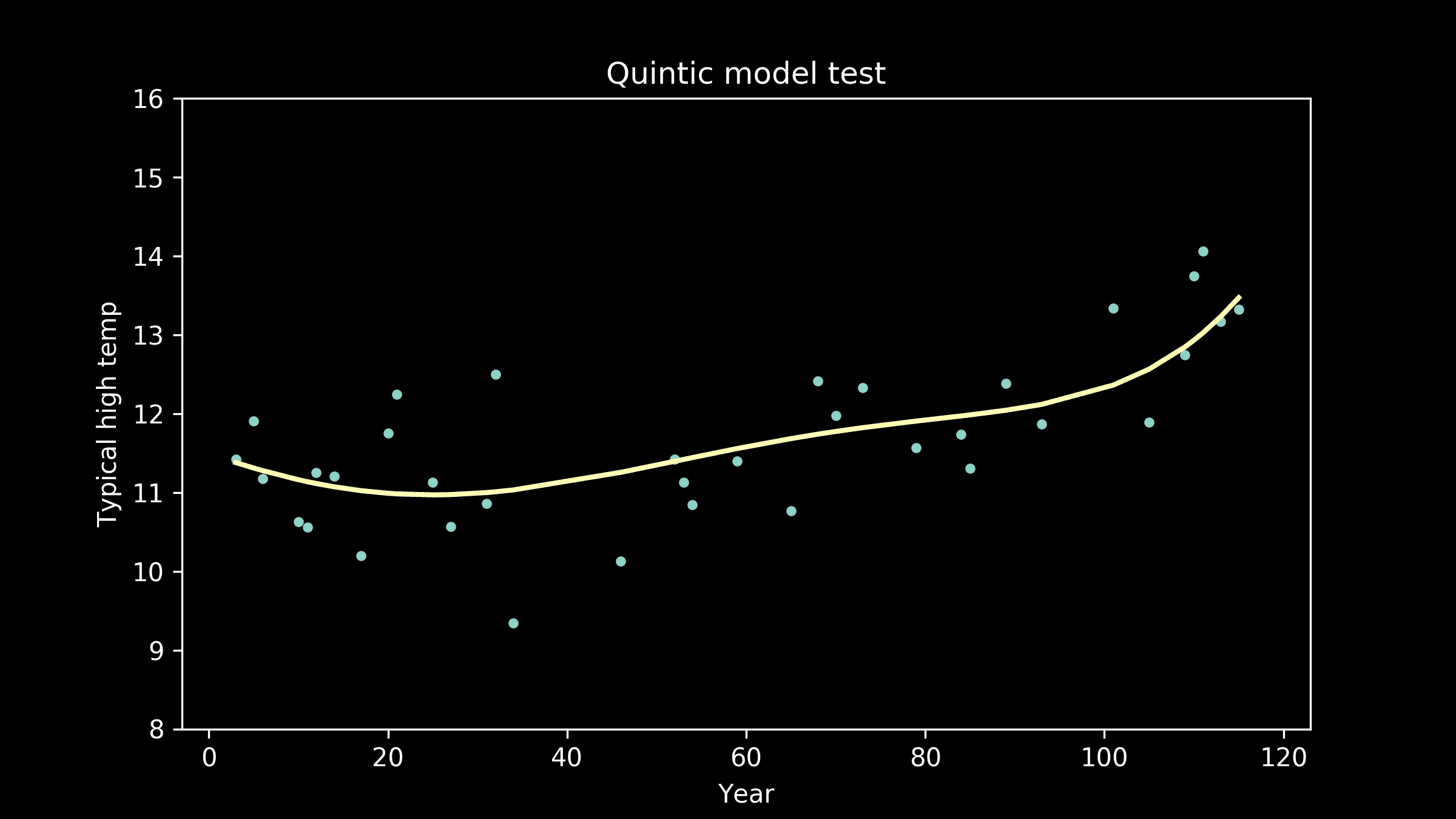
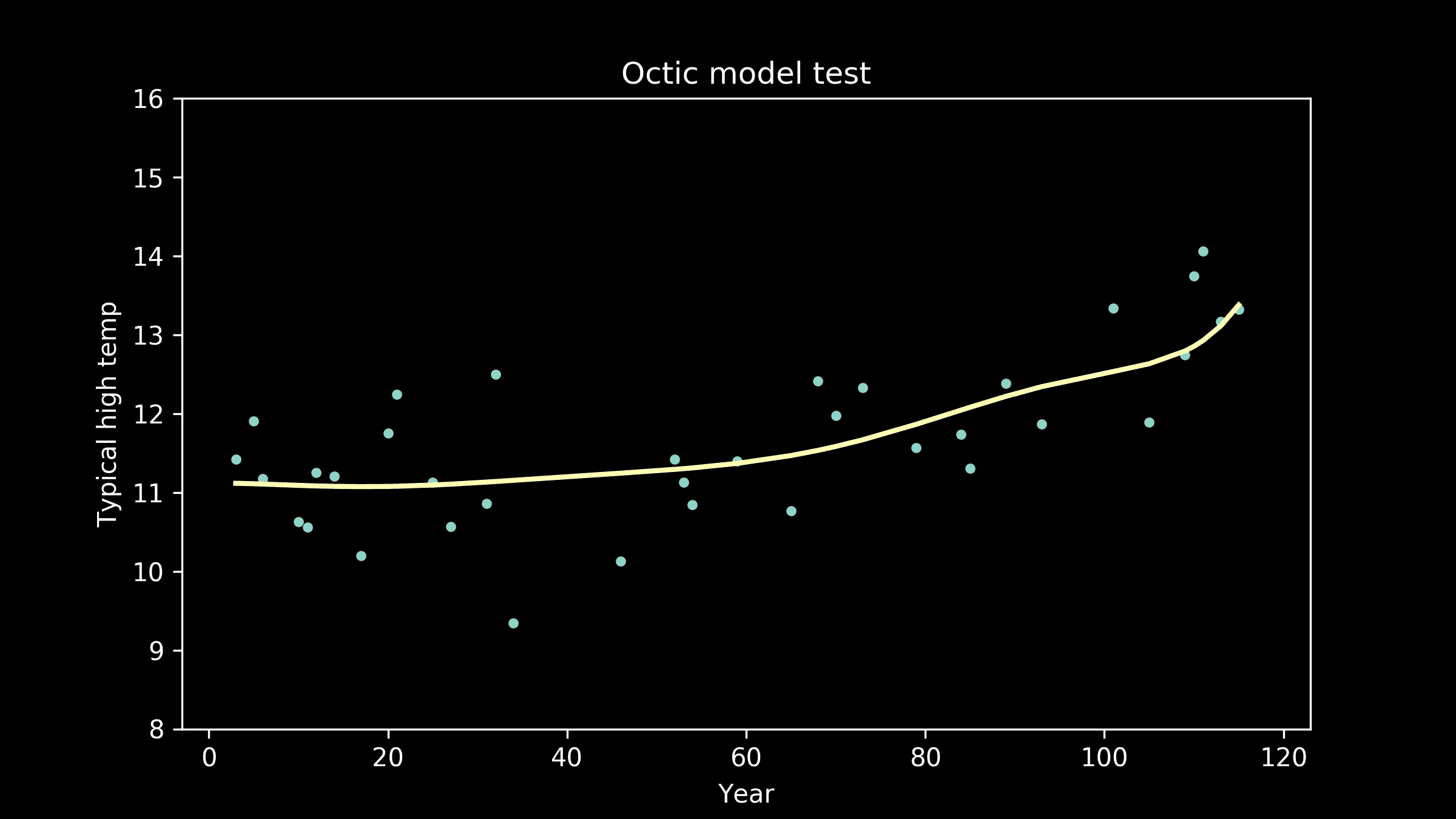
随着模型阶数的增加,我们可以看到它们所产生的波动可能对拟合训练数据有帮助,但不一定有助于更好地拟合测试数据。我们可以在完全插值模型中看到一个极端的例子,在这个模型中,我们只是用直线连接所有训练数据点。这种模型确实很难与测试数据点匹配。
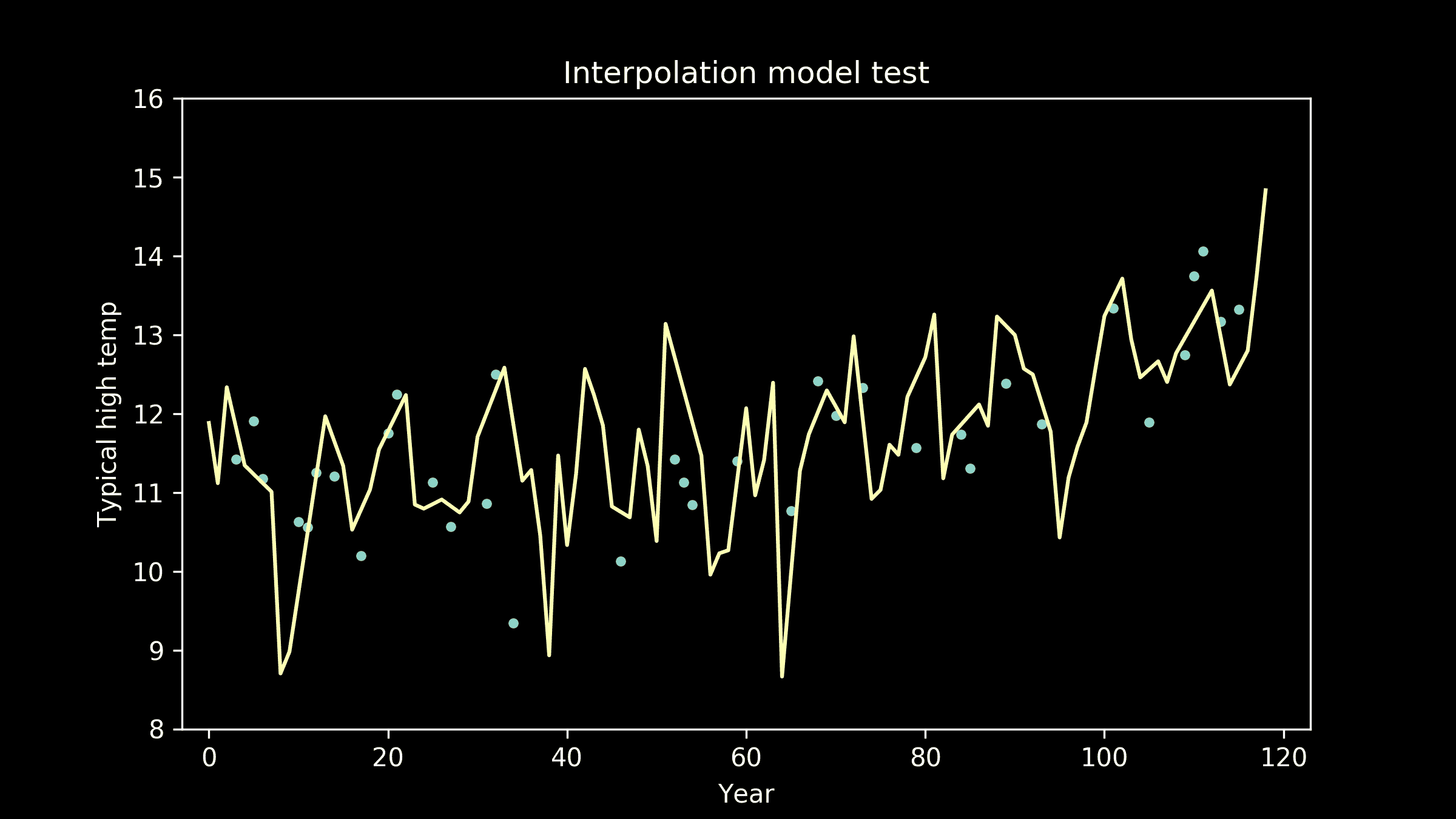
对于每个模型,将训练数据集和测试数据集上的误差并排查看是很有帮助的。
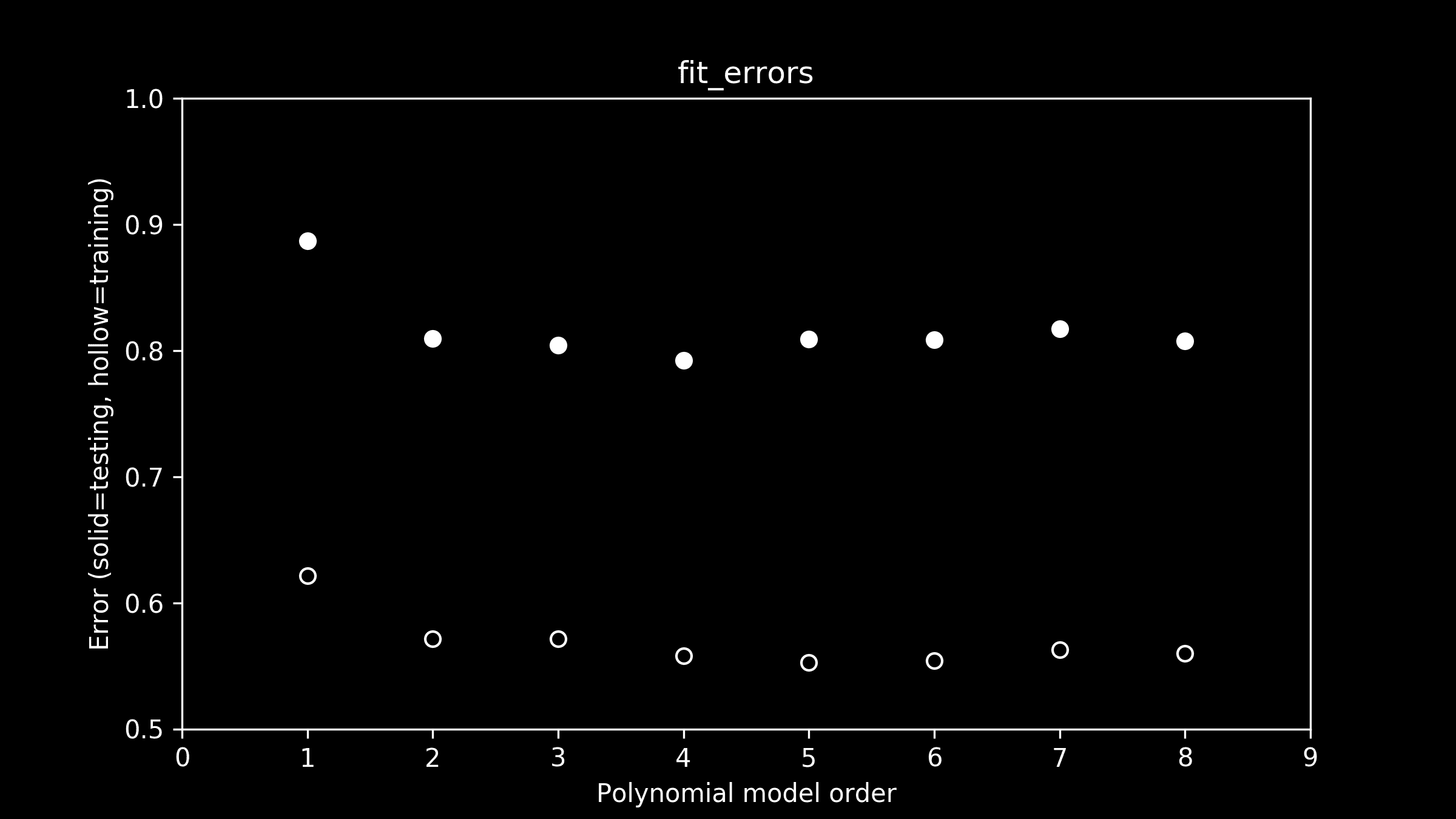
查看训练数据集上的误差,可以看到几个问题。首先是训练误差(空心圆圈)和测试误差(实心圆圈)之间的巨大差距。我们可以立即看到这两个数据集之间存在显著差异。
其次,从线性模型到二次模型(1 阶到 2 阶多项式)误差急剧下降。这是有道理的。当我们目测时,可以看到线性拟合未能捕捉数据的曲率,这是其最显著的特征之一。
那么哪个模型最适合?当我们仔细观察训练数据上的误差时,似乎五阶多项式模型的误差最低。差异很微妙,所以你可能需要仔细观察。所有高阶模型的误差也很低,但仅比 5 阶多项式略高。但正如我们提到的,这并不是最终测试。我们真正关心的是测试数据上的误差。
对测试误差(实心圆点)的仔细检查显示,四阶模型表现最佳。在高阶多项式中,测试数据集上的误差会上升。第五阶及更高阶多项式模型中的曲线越弯曲,它们就越多地捕捉了训练数据的怪异,而不是我们感兴趣的测试数据的基本模式。
基于这种训练和测试方法,我们有一个明显的赢家:在我们尝试的所有模型中,四阶多项式效果最佳。
恭喜我们!我们为数据选择了一个相当不错的模型。但不要急着离开!还有一些重要的想法需要讨论。加入我,观看第二部分,我们将更深入地讨论我们对模型的期望。
原文。经许可转载。
相关内容:
更多相关话题
选择误差函数
评论
关于所有内容,包括视频和代码,访问建模工作原理课程页面。
选择误差函数
当我们为一些数据拟合模型时,很容易忽略误差函数的选择。拟合模型是一项优化练习。它是在寻找一组参数值,以最小化损失函数。(如果你需要复习一下,可以查看一下优化工作原理系列。)
模型与测量数据点之间的差异称为偏差。误差函数表示我们对一定大小的偏差有多在意。小的错误可以接受,但大的错误非常糟糕?还是说偏差一点和偏差很多一样糟糕?用商业术语来说,我们可以将误差函数看作是错误一定数量时的美元成本。实际上,误差函数也称为成本函数。
误差函数的选择完全取决于我们的模型将如何使用。
用例:平方偏差
想象我们的温度预测被用来设计一个温室。玻璃的厚度和基础的绝缘量被仔细选择,以创造一个理想的生长环境。温室里不会有任何加热器或空调来调节温度,只有由温室设计决定的被动热流。植物比较耐寒,可以容忍温度偏差几个度,但不会有灾难性的影响。然而,温度离理想值越远,对植物的影响就越严重,效果也会很快变得更加明显。这表明成本函数可能类似于偏差的平方。
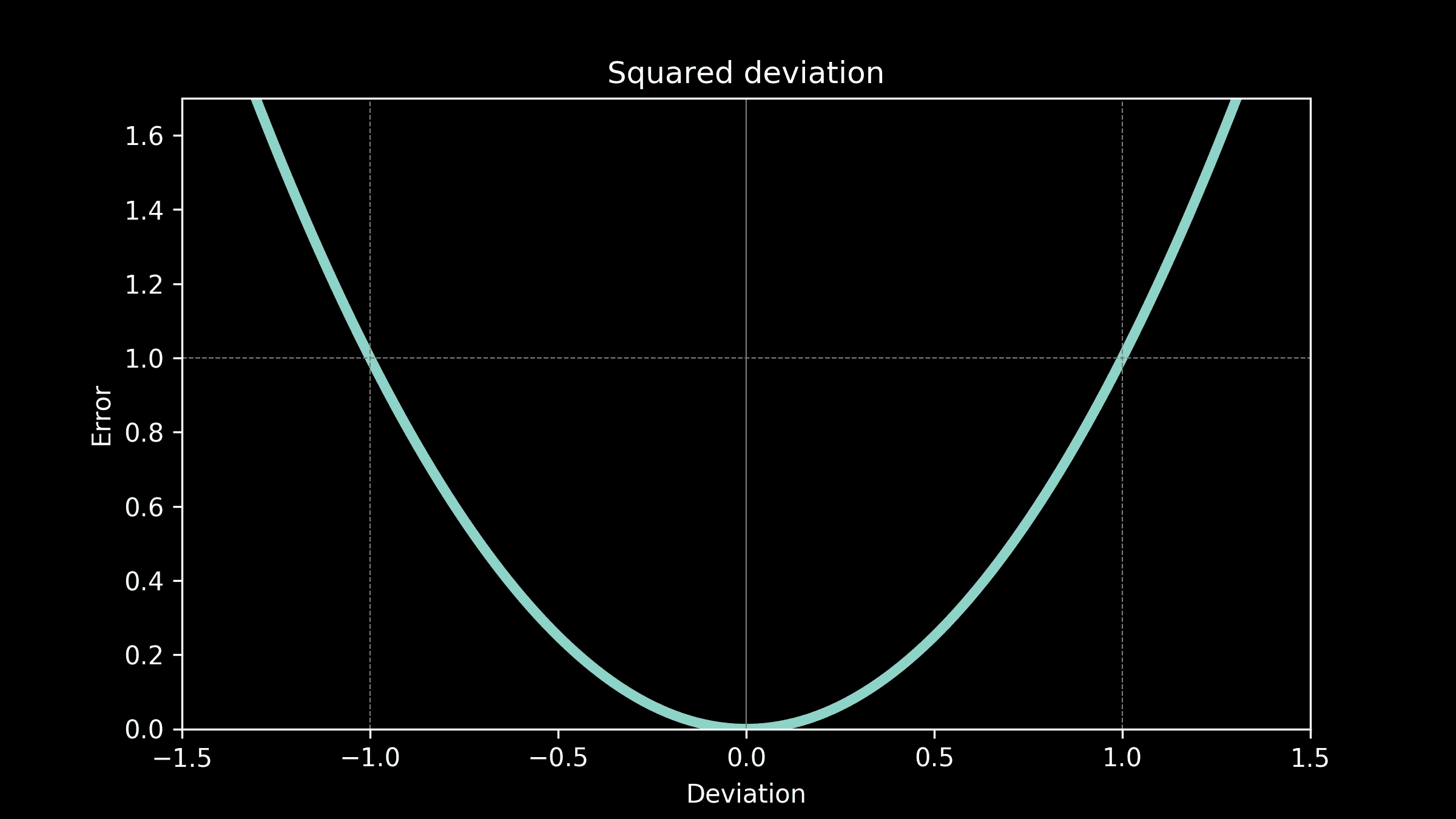
用例:绝对偏差
现在,我们再次设计一个温室,但这次包括加热器和冷却器。这意味着我们可以调节温度,使其适合植物,但我们需要进行更多的加热和冷却,就需要购买更多的能源,花费更多的钱。预测偏差的成本与纠正它的成本有关,即将温度恢复到适当范围的能源成本。这表明误差函数中的成本与偏差的绝对值成正比。
在第一部分中拟合我们温度数据的所有模型都使用了绝对偏差误差函数。
用例:饱和度绝对偏差
我们的温度预测现在被用来决定何时对办公室建筑进行预热或预冷。夜间预热和预冷可以降低能源价格,为公司节省资金。任何偏差的成本就是白天高峰能源的额外成本。这与设备在白天运行的时间成正比,而设备运行时间又与预测误差直接成正比。然而,超过某个预测阈值后,任何时间的加热或冷却都无法完全弥补差距,因此成本有上限。设备全天运行。这表明一个具有饱和度的绝对偏差误差函数。
用例:带“无所谓”区域的平方偏差
现在我们的温度预测被用于电视天气预报。我们的观众并不期望预测完全准确,因此如果误差稍微大一点也没有惩罚。这给了我们一个“无所谓”的区域。错误小不会有成本。然而,如果温度偏差过大,那么观众会非常不满,可能会切换到其他电视台获取天气报告。一个二次曲线给我们提供了与此相关的急剧增加的成本。
用例:自定义误差函数
我们甚至可以处理更复杂的情况。假设我们一流的商业分析团队确定我们的能源成本与预测误差之间有复杂的关系,例如,像这样。
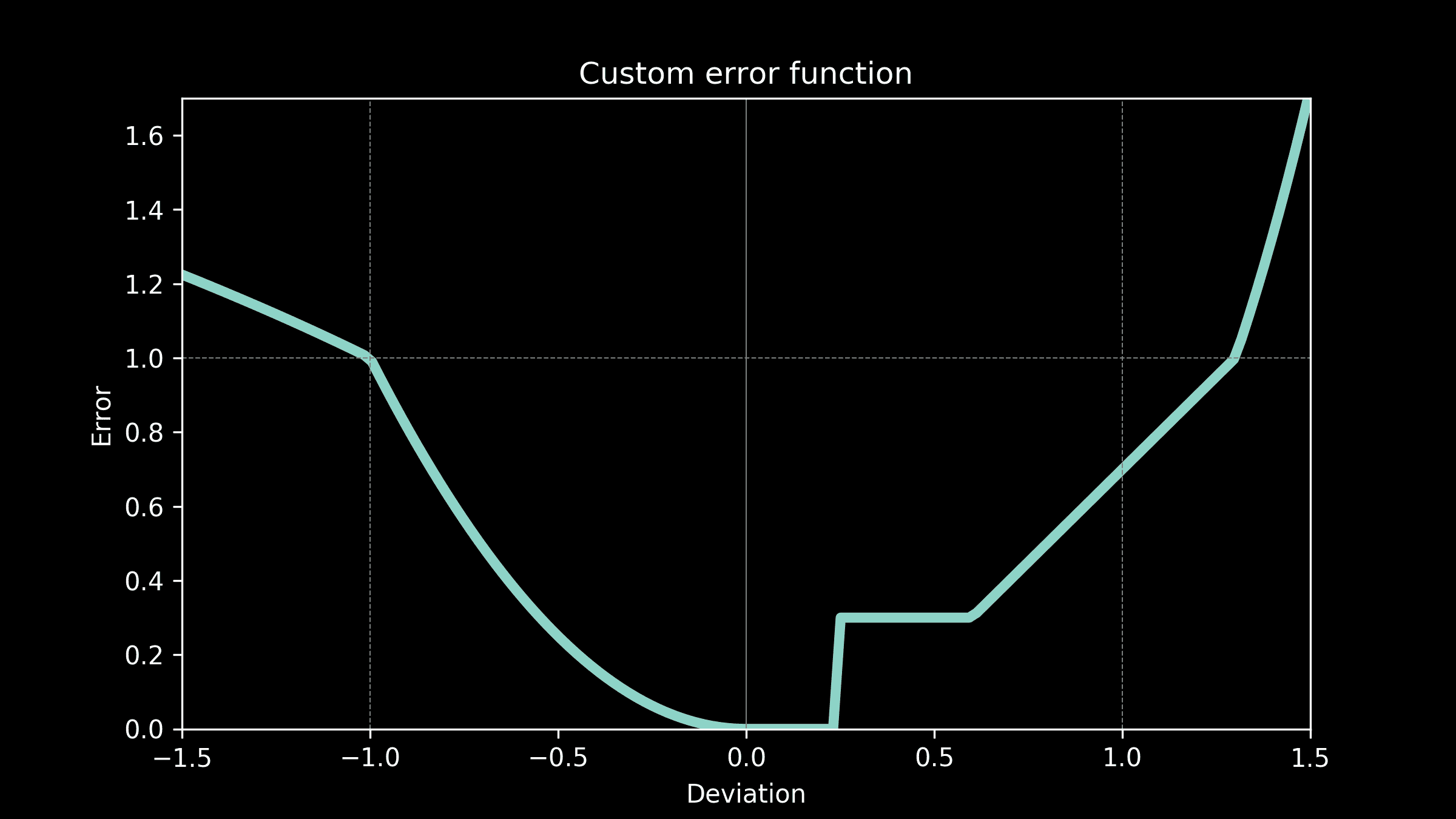
这不是问题。我们可以像使用其他候选函数一样轻松地使用它。对我们误差函数的唯一真正限制是它不会随着距离零点的增加而减少。只要它始终增加或保持平坦,它可以遵循我们想要的任何模式。
误差函数的选择会影响哪个模型最适合以及该模型的参数值是什么。这些误差函数中的每一个都会在我们的温度模型中产生一组不同的最佳拟合参数。最佳拟合曲线每次都会不同。选择正确的误差函数可以大大影响我们的模型有多有用。错误的误差函数可能会给我们一个比无用还糟糕的模型。
留意平方偏差作为误差函数。这是一个非常常见的选择。事实上,它如此常见,以至于经验不足的建模者可能会认为它是唯一的选择。它具有一些非常好的数学分析性质,因此在理论和学术工作中受到青睐。但除此之外,它并没有什么特别之处。它很可能不适合你的应用。如果你花时间仔细选择你的误差函数,你会很高兴这么做了。
现在我们已经打下了坚实的基础,第四部分将详细介绍如何将数据分成训练集和测试集。这比看起来更复杂。
原始。经许可转载。
相关:
-
机器学习速成课程:第一部分
-
理解神经网络中的目标函数
-
标准模型拟合方法简要概述
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关话题
选择机器学习模型
原文:
www.kdnuggets.com/2019/10/choosing-machine-learning-model.html
评论
作者 Lavanya Shukla,Weights and Biases。

我们的前三推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
众多闪亮的模型可能让人不知所措,这意味着很多时候,人们会回到几个他们最信任的模型,并在所有新问题上使用这些模型。这可能导致次优结果。
今天我们将学习如何快速高效地缩小可用模型的范围,以找到最有可能在你的问题类型上表现最佳的模型。我们还将了解如何使用 Weights and Biases 跟踪我们的模型表现并进行比较。
你可以在这里找到配套代码。
我们将涵盖的内容
-
竞争数据科学与现实世界中的模型选择
-
模型的皇家大战
-
比较模型
让我们开始吧!
与《魔戒》不同,在机器学习中,没有一个模型能够统治所有其他模型。不同类别的模型擅长于建模不同类型数据集的底层模式。例如,决策树在数据具有复杂形状的情况下表现良好。
线性模型在数据集线性可分的情况下效果最佳:
在我们开始之前,让我们更深入地探讨现实世界中的模型选择与竞争数据科学中的模型选择之间的差异。
竞争数据科学与现实世界中的模型选择
正如 William Vorhies 在他的博客文章中所说,“Kaggle 竞赛就像数据科学的方程式赛车。获胜者在第四位小数点上超越对手,就像方程式 1 赛车一样,我们中的大多数人不会把它们误认为是日常驾驶的汽车。投入的时间和有时极端的技术在数据科学生产环境中并不合适。”
Kaggle 模型确实像赛车一样,因为它们并不是为日常使用而构建的。现实世界的生产模型更像是雷克萨斯——可靠但不炫目。
Kaggle 竞赛和现实世界优化的内容截然不同,其中一些关键区别包括:
问题定义
现实世界允许你定义问题并选择一个能够 encapsulate 成功的度量标准。这使你能够优化一个比单一指标更复杂的效用函数,而 Kaggle 竞赛则提供一个预定义的单一指标,并且不允许你高效地定义问题。
指标
在现实世界中,我们关注推断和训练速度、资源和部署限制以及其他性能指标,而在 Kaggle 竞赛中,我们只关心一个评估指标。假设我们有一个准确率为 0.98 的模型,它非常消耗资源和时间,而另一个准确率为 0.95 的模型则更快且计算量更小。在现实世界中,对于许多领域,我们可能更倾向于选择 0.95 准确率的模型,因为我们可能更关注推断时间。在 Kaggle 竞赛中,训练模型所需的时间或所需的 GPU 数量并不重要,更高的准确率总是更好。
可解释性
同样,在现实世界中,我们更喜欢那些易于向利益相关者解释的简单模型,而在 Kaggle 中我们对模型复杂性毫不在意。模型可解释性很重要,因为它使我们能够采取具体行动来解决潜在问题。例如,在现实世界中,查看我们的模型并能够看到一个特征(例如,街道上的坑洼)与问题(例如,街道上的汽车事故发生概率)之间的关联,比将预测准确度提高 0.005% 更有帮助。
数据质量
最后,在 Kaggle 竞赛中,我们的数据集是由他人收集和整理的。任何做过数据科学的人都知道,现实生活中几乎不会这样。但能够收集和构建我们的数据也让我们对数据科学过程有了更多控制权。
激励
这些因素促使我们花费大量时间来调整超参数,以从模型中提取最后一滴性能,有时还需要复杂的特征工程方法。虽然 Kaggle 竞赛是学习数据科学和特征工程的绝佳途径,但它们并没有涉及诸如模型可解释性、问题定义或部署限制等现实世界的问题。
模型的皇家大战
现在是时候开始选择模型了!
在选择我们要测试的初始模型时,我们需要考虑几个方面:
选择一组多样的初始模型
不同类别的模型擅长建模数据中不同类型的潜在模式。因此,一个好的第一步是快速测试几种不同类别的模型,以了解哪些模型最有效地捕捉了数据集的潜在结构!在我们的问题类型(回归、分类、聚类)的范围内,我们希望尝试混合树模型、实例模型和核模型。从每个类别中选择一个模型进行测试。我们将在下面的“待试模型”部分详细讨论不同的模型类型。
为每个模型尝试几种不同的参数
虽然我们不希望花太多时间找到最佳的超参数组合,但我们确实希望尝试几种不同的超参数组合,以使每个模型类别都有机会表现良好。
挑选最强的竞争者
我们可以利用这一阶段表现最佳的模型来帮助我们直观了解我们想深入研究的模型类别。你的 Weights and Biases 仪表板将指导你找到最适合你问题的模型类别。
深入研究表现最佳的模型类别中的模型。
接下来,我们选择更多属于上述表现最佳的模型类别的模型!例如,如果线性回归似乎效果最好,那么尝试 lasso 或 ridge 回归也是一个好主意。
更详细地探索超参数空间。
在这个阶段,我建议你花时间调整候选模型的超参数。(本系列的下一篇文章将深入探讨选择最佳超参数的直觉。)在这一阶段结束时,你应该拥有所有最强模型的最佳版本。
最终选择 — Kaggle
从多样化的模型中挑选最终提交。 理想情况下,我们希望从多个类别的模型中选择最佳模型。这是因为如果你只从一个类别的模型中做选择,并且这个类别恰好是错误的,那么你的所有提交都会表现不佳。Kaggle 比赛通常允许你为最终提交选择多个条目。我建议选择来自不同类别的最强模型的预测,以在提交中增加一些冗余。
排行榜不是你的朋友,但交叉验证分数是。 最重要的是要记住,公共排行榜不是你的朋友。仅仅根据公共排行榜分数来选择模型会导致过拟合训练数据集。当比赛结束后,私有排行榜揭晓时,有时你可能会看到排名大幅下跌。通过在训练模型时使用交叉验证,你可以避免这个小陷阱。然后选择交叉验证分数最佳的模型,而不是排行榜分数最佳的模型。这样,你可以通过对比模型在多个验证集上的表现来抵消过拟合,而不是仅仅依赖于公共排行榜使用的那一部分测试数据。
最终选择 — 现实世界
资源限制。 不同的模型会消耗不同类型的资源,了解你是否将模型部署在具有小硬盘和处理器的 IoT/移动设备上,还是在云中,对选择合适的模型至关重要。
训练时间 vs. 预测时间 vs. 准确率。 了解你优化的指标是选择正确模型的关键。例如,自动驾驶汽车需要极快的预测时间,而欺诈检测系统需要快速更新模型,以应对最新的钓鱼攻击。对于像医疗诊断这样的情况,我们更关心准确率(或 ROC 曲线下面积),而不是训练时间。
复杂性 vs. 可解释性的权衡。 更复杂的模型可以使用数量级更多的特征进行训练和预测,但如果训练得当,可以捕捉数据集中非常有趣的模式。然而,这也使得模型变得复杂,更难以解释。了解向利益相关者清晰解释模型的重要性与捕捉一些有趣趋势而放弃可解释性之间的平衡是选择模型的关键。
可扩展性。 了解你的模型需要多快、多大地扩展可以帮助你适当地缩小选择范围。
训练数据的大小。 对于非常大的数据集或具有许多特征的数据集,神经网络或提升树可能是一个很好的选择,而较小的数据集可能更适合使用逻辑回归、朴素贝叶斯或 KNN。
参数数量。 拥有大量参数的模型可以提供很大的灵活性,从而获得非常好的性能。然而,可能有些情况下你没有时间从头开始训练神经网络的参数。在这种情况下,一个开箱即用的模型会是更好的选择!
比较模型
Weights and Biases 让你只需一行代码就能跟踪和比较模型的性能。
一旦你选择了想尝试的模型,训练它们,并简单地添加wandb.log({‘score’: cv_score})来记录你的模型状态。训练完成后,你可以在一个简单的仪表板中比较你的模型性能!
你可以在这里找到高效完成此任务的代码。我鼓励你分叉这个 kernel并尝试代码!
就是这样,现在你拥有了选择适合你问题的模型所需的所有工具!
模型选择可能非常复杂,但我希望本指南能为你提供一些启示,并为选择模型提供一个良好的框架。
原始。已获许可转载。
简介: Lavanya 是 Weights and Biases 的机器学习工程师。她在 10 年前创立了普渡大学的 ACM SIGAI,并开始从事人工智能工作。在过去的生活中,她在 10 岁时自学编程,并在 14 岁时创建了她的第一个创业公司。她驱动于通过使用机器学习更好地理解我们周围的宇宙。
相关:
相关主题更多内容
客户流失预测使用机器学习:主要方法和模型
原文:
www.kdnuggets.com/2019/05/churn-prediction-machine-learning.html
评论
由 Altexsoft 提供。
客户留存是基于订阅的 商业模式 的产品主要增长支柱之一。SaaS 市场竞争激烈,客户可以从众多供应商中自由选择,即使是在同一产品类别中。几次不愉快的经历——甚至一次——客户可能就会流失。如果大量不满意的客户频繁流失,不仅会造成物质损失,还会对声誉造成巨大损害。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
对于本文,我们联系了来自 HubSpot 和 ScienceSoft 的专家,讨论了 SaaS 公司如何通过预测建模来处理客户流失问题。你将发现解决这一问题的方法和最佳实践。我们将讨论如何收集有关客户与品牌关系的数据,分析与流失最相关的客户行为特征,并探讨选择表现最佳的机器学习模型的逻辑。
什么是客户流失?
客户流失(或客户流失率) 是指客户放弃品牌并停止成为某一业务的付费客户的倾向。客户在特定时间段内停止使用公司产品或服务的比例被称为 客户流失率。计算流失率的一种方法是将给定时间间隔内失去的客户数量除以获得的客户数量,然后将该数值乘以 100%。例如,如果你获得了 150 名客户,而上个月流失了 3 名,那么你的月流失率就是 2%。
客户流失率是一个衡量业务健康状况的指标,对于那些客户是订阅者并且按周期支付服务费用的企业尤为重要,ScienceSoft 数据分析部门负责人Alex Bekker指出,“订阅型业务的客户在特定时期内选择某个产品或服务,这个时期可能相当短——比如一个月。因此,客户会对更有趣或更有优势的提议保持开放态度。此外,每次当前的承诺结束时,客户都有机会重新考虑,并选择不继续与公司合作。当然,某些自然流失是不可避免的,而这个数字因行业而异。但流失率高于这个水平显然是业务存在问题的标志。”
品牌可能会犯很多错误,从当客户没有得到易于理解的产品使用和功能信息时的复杂入门流程,到沟通不畅,例如缺乏反馈或对查询的延迟回答。另一个情况是:长期客户可能会感到不被重视,因为他们没有获得像新客户那样多的奖励。
一般来说,整体客户体验定义了品牌感知,并影响客户如何认知他们使用的产品或服务的性价比。
现实是,即使是忠诚的客户,如果他们与品牌发生了一次或几次问题,也不会容忍该品牌。例如,美国 59%的受访者在普华永道(PwC)调查中表示,他们在经历几次糟糕的体验后会与品牌说再见,其中 17%的人在经历一次糟糕的体验后就会离开。
糟糕的体验可能会使即使是忠诚的客户也感到疏远。来源:PwC
客户流失对企业的影响
流失是不好的。但它究竟如何在长期内影响公司绩效呢?
不要低估即使是微小的流失百分比的影响,HubSpot 服务中心总经理Michael Redbord表示。“在订阅型业务中,即使是小的月度/季度流失率也会随着时间的推移迅速积累。仅 1%的月度流失率就意味着接近 12%的年度流失率。鉴于获取新客户的成本远高于保留现有客户,流失率高的企业很快就会发现自己陷入财务困境,因为他们必须投入越来越多的资源来获取新客户。”
许多关于客户获取和留存成本的调查可以在网上找到。根据Invesp这家转化率优化公司的调查,获取新客户的成本可能是留住现有客户成本的五倍。
客户流失率确实与收入损失和增加的获取支出有关。此外,它们在公司增长潜力中扮演了更微妙的角色,Michael 继续说道,“如今的买家不吝啬于通过评论网站和社交媒体等渠道以及点对点网络分享他们与供应商的经历。HubSpot Research发现 49%的买家表示他们在社交媒体上分享了与公司相关的经历。在对企业信任度下降的世界中,口碑在购买过程中扮演的角色比以往任何时候都更加关键。根据同一项 HubSpot Research 研究,55%的买家不再像以前那样信任他们购买的公司,65%的人不信任公司新闻稿,69%的人不信任广告,71%的人不信任社交网络上的赞助广告。”

对客户对企业信任状态的概览。来源:HubSpot Research Trust Survey
专家总结说,流失率高的公司不仅在与前客户的关系中未能提供良好的服务,而且还通过在产品周围创造负面口碑来损害其未来的获取努力。
CallMiner 对话分析解决方案提供商采访了 1000 名成年人,以了解他们如何与公司互动。这项survey显示,美国企业由于客户流失每年损失约 1360 亿美元。更重要的是,导致客户与品牌断绝关系的公司行为本可以得到纠正。
客户流失预测的使用案例
正如我们之前提到的,流失率是订阅业务的关键绩效指标之一。订阅商业模式– 由 17 世纪的英国图书出版商开创的– 在现代服务提供商中非常受欢迎。让我们快速了解这些公司:
音乐和视频流媒体服务可能是最常与订阅商业模式相关联的(Netflix、YouTube、Apple Music、Google Play、Spotify、Hulu、Amazon Video、Deezer 等)。
媒体。 数字化存在已成为新闻界的必备,因此新闻公司除了提供纸质订阅外,还提供数字订阅(Bloomberg、The Guardian、Financial Times、The New York Times、Medium 等)。
电信公司(有线或无线)。这些公司可能提供全方位的产品和服务,包括无线网络、互联网、电视、手机和家庭电话服务(AT&T,Sprint,Verizon,Cox Communications 等)。有些公司专注于移动通信(中国移动,沃达丰,T-Mobile 等)。
软件即服务提供商。云托管软件的采用正在增长。根据Gartner的预测,SaaS 市场仍然是云市场的最大细分领域。其收入预计将增长 17.8%,在 2019 年达到 851 亿美元。SaaS 提供商的产品范围广泛:图形和视频编辑(Adobe Creative Cloud,Canva),会计(Sage 50cloud,FreshBooks),电子商务(BigCommerce,Shopify),电子邮件营销(MailChimp,Zoho Campaigns)等。
这些公司类型可能使用流失率来衡量跨部门操作和产品管理的有效性。
利用机器学习识别高风险客户:一瞥问题解决方案
那些不断监控人们如何与产品互动,鼓励客户分享意见,并及时解决问题的公司,更有机会维持互利的客户关系。
现在设想一个公司,它已经收集了一段时间的客户数据,因此可以利用这些数据来识别潜在流失者的行为模式,将这些高风险客户进行细分,并采取适当的措施来重新获得他们的信任。那些采取主动客户流失管理方法的公司使用预测分析。这是four analytics types之一,它通过分析当前和历史数据来预测未来结果、事件或值的概率。预测分析利用各种统计技术,如数据挖掘(模式识别)和machine learning(ML)。
“仅仅追踪实际流失的一个弱点是,它仅作为客户体验差的滞后指标,而预测流失模型在这里变得极其重要,” HubSpot 的 Michael Redbord 指出。
机器学习的主要特征是建立能够在数据中寻找模式、在没有明确编程的情况下学习的系统。在客户流失预测的背景下,这些是表明客户对公司服务/产品满意度下降的在线行为特征。
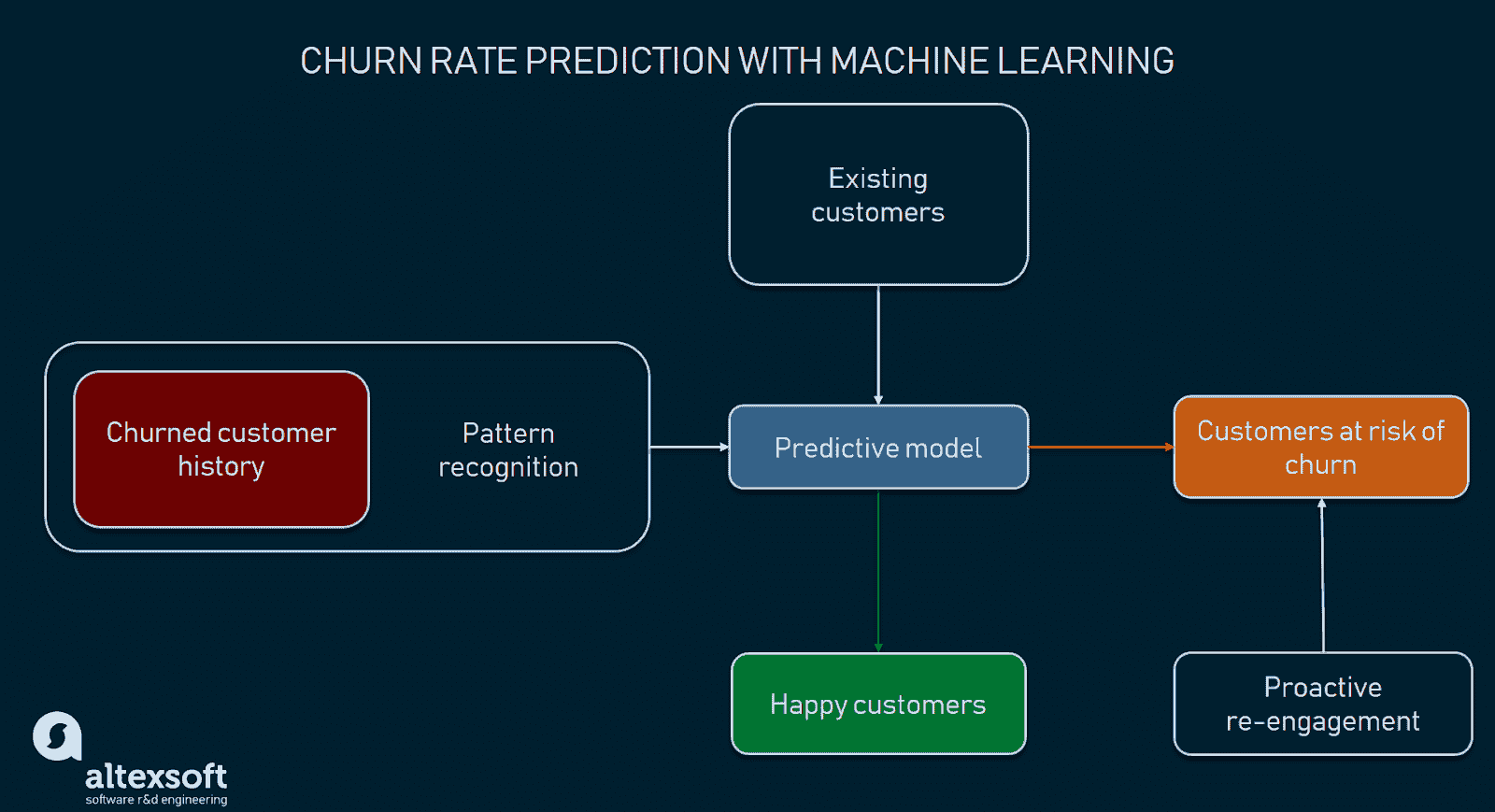
检测高风险客户有助于提前采取措施
ScienceSoft 的 Alex Bekker 也强调了机器学习在主动流失管理中的重要性:“在识别潜在流失者方面,机器学习算法能够发挥很大作用。它们揭示了那些已经离开公司的客户的一些共同行为模式。然后,机器学习算法会将当前客户的行为与这些模式进行对比,并在发现潜在流失者时发出信号。”
基于订阅的企业利用机器学习进行预测分析,以找出哪些当前用户对服务不完全满意,并在为时已晚之前解决他们的问题:“在续订前多达 11 个月识别出有流失风险的客户,使我们的客户成功团队能够与这些客户接触,了解他们的问题,并与他们一起制定一个长期计划,重点帮助客户从他们购买的服务中获得价值,” Michael 解释道。
预测流失建模的使用案例不仅限于主动接触潜在流失的客户和选择有效的保留措施。根据 Redbord 的说法,基于机器学习的软件可以让客户成功经理定义他们应该联系哪些客户。换句话说,员工可以确保他们在正确的时间与合适的客户交谈。
销售、客户成功和市场营销团队也可以利用数据分析中的知识来协调他们的行动。“例如,如果一个客户显示出流失风险的迹象,那么此时销售团队与客户接触,提供额外服务的信息可能不是一个好时机。相反,这种接触应该由客户成功经理来进行,以帮助客户重新投入使用并看到他们目前拥有的产品的价值。与销售类似,市场营销也可以根据客户当前的流失风险指示与客户进行不同的互动:例如,非流失风险客户比目前存在流失风险的客户更适合参与案例研究,” HubSpot 的专家解释道。一般来说,客户互动的策略应基于伦理和时机感。而利用机器学习进行客户数据分析可以为这一策略提供有力的支持。
使用机器学习预测客户流失
但是如何开始处理流失率预测呢?需要哪些数据?实施的步骤是什么?
与任何机器学习任务一样,数据科学专家首先需要数据来进行工作。根据目标,研究人员定义他们必须收集的数据。接下来,选择的数据会被准备、预处理,并转化为适合构建机器学习模型的形式。找到合适的方法来训练机器、调整模型以及选择最佳表现者是工作中的另一个重要部分。一旦选择了一个具有最高准确性的预测模型,就可以投入生产使用。
数据科学家进行的整体工作范围,以构建能够预测客户流失的机器学习系统,可能如下所示:
-
理解问题和最终目标
-
数据收集
-
数据准备和预处理
-
建模和测试
-
模型部署和监控
如果你想了解这些步骤中的具体情况,请阅读我们关于机器学习项目结构的文章。现在让我们来看看如何在流失预测的背景下完成这些阶段。
理解问题和最终目标
理解从分析中需要获得哪些见解是很重要的。简而言之,你必须决定要提出什么问题,从而决定要解决什么类型的机器学习问题:分类还是回归。听起来复杂,但请耐心跟随我们。
分类。 分类的目标是确定一个数据点(在我们的例子中是客户)属于哪个类别或类别。对于分类问题,数据科学家会使用具有预定义目标变量即标签(流失客户/非流失客户)的历史数据——需要预测的答案——来训练算法。通过分类,企业可以回答以下问题:
-
这个客户会流失吗?
-
客户会续订他们的订阅吗?
-
用户会降级定价计划吗?
-
是否有异常客户行为的迹象?
关于异常行为迹象的第四个问题代表了一种称为异常检测的分类问题。异常检测涉及识别离群值——显著偏离其他数据点的数据。
回归。 客户流失预测也可以被表述为回归任务。回归分析是一种统计技术,用于估计目标变量与其他影响目标变量的数据值之间的关系,结果是连续值。如果这听起来很难理解——回归的结果总是一个数字,而分类总是建议一个类别。此外,回归分析允许估计数据中的多少个变量影响目标变量。通过回归,企业可以预测特定客户可能在多长时间内流失或接收每位客户的流失概率估计。
这是一个关于使用逻辑回归预测电信行业流失概率的示例,来自于Towards Data Science。在这里,图示描绘了服务电话数量和国际计划使用与客户流失的相关性
数据收集
识别数据来源。 一旦你确定了要寻找的见解类型,你可以决定哪些数据来源是进一步预测建模所必需的。让我们假设用于预测流失的最常见数据来源如下:
-
CRM 系统(包括销售和客户支持记录)
-
分析服务(如 Google Analytics、AWStats、CrazyEgg)
-
社交媒体和评论平台的反馈
-
根据要求提供的组织反馈等。
显然,这个列表可能会因行业而异,长短不一。
数据准备和预处理
为解决问题而选择的历史数据必须转换成适合机器学习的格式。由于模型性能和所获得见解的质量依赖于数据质量,主要目标是确保所有数据点使用相同的逻辑呈现,并且整体数据集没有不一致。我们之前撰写了一篇关于 数据集准备的基本技术,如果你想了解更多,请随时查看。
特征工程、提取和选择。 特征工程 是数据集准备中非常重要的一部分。在此过程中,数据科学家创建一组属性(输入特征),表示与客户对服务或产品的参与程度相关的各种行为模式。从广义上讲,特征是 ML 模型在预测结果时考虑的可测量观察特征(在我们的案例中,与流失概率相关的决策)。
尽管行为特征因行业而异,但识别风险客户的方法是普遍的,Alex 指出:“企业寻找揭示潜在流失者的特定行为模式。”
数字营销专家和企业家 Neil Patel 将 功能分为四类。客户人口统计信息和支持功能适用于任何行业。用户行为和上下文功能则通常适用于 SaaS 商业模式:
-
客户人口统计特征 包含有关客户的基本信息(如年龄、教育水平、位置、收入)
-
用户行为特征 描述一个人如何使用服务或产品(如生命周期阶段、登录账户的次数、活跃会话时长、产品的活跃使用时间、使用的功能或模块、操作、货币价值)
-
支持特征 描述与客户支持的互动(如查询发送次数、互动次数、客户满意度评分历史)
-
上下文特征 代表有关客户的其他上下文信息。
HubSpot 专家试图通过使用网站访问者、生成的潜在客户和创建的交易等指标来了解“什么使客户成功”。服务中心总经理迈克尔·雷德博德表示:“我们不仅跟踪使用数据(例如,发布博客文章、编辑交易的预期关闭值或发送电子邮件),还跟踪结果数据(例如,电子邮件点击次数、博客文章的浏览量、季度内关闭交易的美元价值)。重要的是了解客户不仅如何使用您的产品,还要了解他们看到的结果。如果客户没有从产品中获得价值,我们通常会看到流失可能性增加。”
用户行为、订阅和人口统计特征如何与互联网服务的流失相关 由 Matt Dancho 为 RStudio 博客撰写
但数据过多并不总是好事。
特征提取 旨在通过保留那些表示最具辨别性信息的特征来减少变量(属性)的数量。特征提取有助于降低数据维度(维度是数据集中属性的列)并排除无关信息。
在 特征选择 过程中,专家复审先前提取的特征,并定义一个与客户流失最相关的特征子集。特征选择的结果是专家拥有一个仅包含相关特征的数据集。
方法。 科学软数据分析部门负责人亚历克斯·贝克尔指出,像排列重要性、ELI5 Python 包和 SHAP(SHapley Additive exPlanations)这样的方法可以用来定义最相关和有用的特征。
所有方法的工作原理在于解释模型如何进行预测(基于模型做出特定结论的特征)。模型可解释性是该领域的高优先级问题,数据科学家们不断开发解决方案。您可以在我们的文章中了解更多关于人工智能和数据科学的进展和趋势。
排列重要性 是定义特征重要性的一种方法——特征对预测的影响。它是基于已经训练好的模型计算的。排列重要性的做法如下:数据科学家改变单列中数据点的顺序,将结果数据集输入模型,并确定这种变化在多大程度上降低了模型的准确性。对结果影响最大的特征是最重要的。
另一种进行排列重要性的方法是从数据集中移除一个特征并重新训练模型。
Permutation importance 可以使用 ELI5 完成——一个开源 Python 库,允许可视化、调试机器学习分类器(算法)并解释其输出。
根据 ELI5 文档,此方法最适用于不含大量列(特征)的数据集。
使用 SHAP(SHapley Additive exPlanations)框架,专家可以解读“任何机器学习模型”的决策。SHAP 还为特定预测分配每个特征的重要性值。
客户细分。 发展中的公司和那些扩展产品范围的公司通常会使用预定义和选择的特征来细分客户。客户可以根据他们的生命周期阶段、需求、使用的解决方案、参与度、货币价值或基本信息分成子组。由于每个客户类别都有共同的行为模式,通过使用专门针对每个细分数据集训练的机器学习模型,可以提高预测准确性。
例如,HubSpot 使用客户画像、生命周期阶段、拥有的产品、地区、语言和账户总收入等细分标准。“像这样的细分组合就是我们如何划分账户所有权并定义一个客户支持经理 [customer support manager] 或销售人员的业务范围,” 迈克尔说。
此外,掌握客户价值知识的员工可以优先考虑他们的客户留存活动。
在数据准备、特征选择和客户细分阶段之后,需要定义追踪用户行为的时间长度,然后再进行预测。
选择观察窗口(客户事件历史)。 预测建模是学习在特定时间点之前的一个时期(窗口)所做观察与在同一时间点之后开始的一个时期之间的关系。前一个时期称为 观察、独立、解释 窗口,或 客户事件历史(为清晰起见,我们使用最后一个定义)。紧随观察期之后的时期称为 性能、依赖 或 响应窗口。换句话说,我们在未来的性能窗口中预测事件(用户流失或留存)。

定义正确的事件历史和观察窗口至关重要
Spotify 的机器学习工程师 Guilherme Dinis, Jr. 在他的 硕士论文 中研究了注册免费计划的新 Spotify 用户的行为,以确定他们是否在注册后的第二周离开或保持活跃。
他选择了使用的第一周作为事件历史。为了将用户分类为流失者和活跃用户,Guilherme 检查了第二周是否有任何流媒体活动。如果用户继续听音乐,他们被分类为非流失者。
“保持观察[事件历史]和激活窗口[性能窗口]相对较小的原因是基于对同一用户群体的内部先前研究,这些研究表明在注册后两周内流失概率较高,”工程师解释说。
因此,为了定义事件历史的持续时间和性能窗口,你必须考虑用户通常何时流失。可能是在第二周,如 Spotify 的例子中,或者可能是在年度订阅的第 11 个月。但最有可能的是,你不会希望在一个月内发现这个订阅者可能会流失,因为你将有非常短的重新参与时间。
平衡观察时间和预测时间实际上是一个棘手的任务。例如,如果观察窗口是一个月,那么一个年订阅客户的性能窗口将是 11 个月。看起来,制作一个短的事件历史和长的性能窗口对企业最有利。你花费很少的时间进行观察,并且有足够的时间进行重新参与。不幸的是,事情并不总是这样。短的事件历史可能不足以做出可靠的预测,因此,实验这些参数可能会成为一个反复进行的过程,并且会有权衡。基本上,你必须定义足够的事件历史,以便模型能够做出合理的预测,但仍然要有足够的时间来处理潜在的流失。
建模与测试
本阶段项目的主要目标是开发一个用户流失预测模型。专家们通常会训练大量模型,调整、评估和测试它们,以确定哪个模型能够在训练数据上以期望的准确度检测潜在的流失者。
经典的机器学习模型通常用于预测客户流失,例如逻辑回归、决策树、随机森林等。来自 ScienceSoft 的 Alex Bekker 建议使用随机森林作为基线模型,然后“可以评估 XGBoost、LightGBM 或 CatBoost 等模型的表现。” 数据科学家通常使用基线模型的性能作为比较更复杂算法预测准确度的标准。
逻辑回归是一种用于二分类问题的算法。它通过测量因变量与一个或多个自变量(特征)之间的关系来预测事件的可能性。更具体地说,逻辑回归将预测一个实例(数据点)属于默认类别的可能性。
决策树 是一种监督学习算法(具有预定义目标变量)。虽然主要用于分类任务,但它也可以处理数值数据。该算法根据输入变量中最重要的区分因素将数据样本分为两个或更多的同质集合以进行预测。每次分裂时,都会生成树的一部分。因此,形成了一个包含决策节点和叶子节点(即决策或分类)的树。树从根节点开始——最佳预测器。
决策树基本结构。来源:Python 机器学习教程
决策树的预测结果易于解释和可视化。即使是没有分析或数据科学背景的人也能理解某个输出是如何产生的。与其他算法相比,决策树对数据准备的要求较低,这也是一个优势。然而,如果数据中发生任何小的变化,决策树可能会不稳定。换句话说,数据的变化可能导致生成完全不同的树。为了解决这个问题,数据科学家使用决策树的组合(即集成方法),我们将在接下来的内容中讨论。
随机森林 是一种集成学习方法,利用大量决策树来实现更高的预测准确性和模型稳定性。这种方法适用于回归和分类任务。每棵树根据属性对数据实例进行分类(或投票),森林选择获得最多票数的分类。在回归任务中,则取不同树决策的平均值。
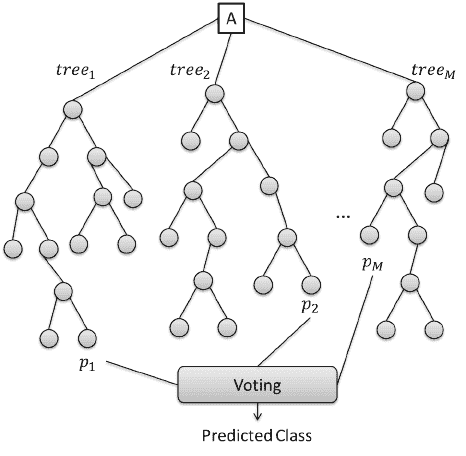
这就是随机森林如何进行预测的。来源:ResearchGate
XGBoost 是梯度提升树算法的实现,常用于分类和回归问题。梯度提升是一种由一组较弱模型(树)组成的算法,这些模型的估计结果相加以更准确地预测目标变量。
来自弗吉尼亚大学的研究小组 研究了与时间相关的软件特性使用数据,例如登录次数和评论次数,以预测在三个月时间范围内的 SaaS 客户流失。作者比较了四种分类算法的模型性能,“XGBoost 模型在识别最重要的软件使用特性和将客户分类为流失类型或非风险类型方面取得了最佳结果。” 根据研究人员的说法,XGBoost 模型定义了最显著的特性,这些特性代表了客户如何使用 SaaS 软件,可以帮助服务提供商在针对潜在客户时启动更有效的营销活动。
LightGBM 是一个使用基于树的学习算法的梯度提升框架。它可以用于许多机器学习任务,例如分类和排序。根据文档,LightGBM 的一些优点包括更快的训练速度和更高的效率,以及更大的准确性。这些算法使用更少的内存并处理大量数据 —— 在数据集少于 10,000 行的情况下,不建议 使用它们。LightGBM 还支持并行和 GPU 学习(使用图形处理单元来训练大数据集)。
CatBoost 是另一个基于决策树的梯度提升库。它处理数值特征和分类特征,因此可以用于分类、回归、排序和其他机器学习任务。CatBoost 的一个优点是它允许使用 CPU 和两个或更多 GPU 来训练模型。
技术选择。 许多因素可以影响生产中所需模型的数量及其类型。尽管每个公司的情况都是独特的,但通常客户数据和业务需求的管理方法确实有一定的影响。预测技术的选择可能取决于:
-
客户生命周期阶段。 例如,HubSpot 的专家得出结论,模型的选择可能取决于客户与品牌之间的互动阶段。“在入驻阶段的客户通常不会显示出与使用 HubSpot 超过一年客户相同的价值指标。因此,针对超过一年客户训练的模型可能在这些客户身上效果很好,但在仍处于入驻阶段的客户身上可能不够准确,” HubSpot 的 Michael 解释道。
-
输出解释的必要性。 当公司代表(如客户成功经理)需要理解流失原因时,可以使用所谓的白盒技术,如决策树、随机森林或逻辑回归。增加的可解释性是 HubSpot 选择随机森林的主要原因之一。有时仅仅检测流失就足够了,例如当公司管理层需要估算下一年度预算时,同时考虑到可能因客户流失而造成的损失。在这些情况下,解释性较差的模型也会有效。
-
客户画像。 想象一家提供众多产品的公司,每种产品都针对特定的用户类型。由于不同的客户画像可能有典型的行为模式,因此使用专用模型来预测他们流失的可能性是合理的。迈克尔·雷德博德补充道:“在一个不断发展的企业中,客户基础的性质会发生变化,尤其是在引入新产品时。基于一组客户建立的模型可能在新客户画像进入客户基础时效果不佳。因此,当我们推出新的产品线时,我们通常会建立新的模型来预测这些客户的流失。”
部署与监控
现在,流失预测项目工作流程的最后阶段。选择的模型需要投入生产。一个模型可能会被整合进现有软件中,或成为新程序的核心。然而,“部署后忘记”的情况是不行的:数据科学家必须持续跟踪模型的准确性,并在必要时进行改进。
“利用机器学习和人工智能预测客户流失是一个永无止境的迭代过程。我们监控模型性能,并根据需要调整特征,以便在客户服务团队向我们反馈或有新数据可用时提高准确性。在任何人类互动的时刻 – 支持电话、CSM 季度业务回顾 [quarterly business review]、销售发现电话 – 我们都监控并记录对客户帮助的人工解读,这有助于增强机器学习模型,提高我们对每位客户健康预测的准确性,” 迈克尔总结道。
模型性能测试的频率取决于数据在组织中变得过时的速度。
结论
流失率是基于订阅的公司的健康指标。识别对提供的解决方案不满意的客户,使企业能够了解产品或定价计划的弱点、运营问题以及客户的偏好和期望,从而主动减少流失的原因。
定义数据源和观察期对于全面了解客户互动历史至关重要。选择模型的最重要特征将影响其预测性能:数据集的质量越高,预测就越准确。
拥有大量客户基础和众多产品的公司将从客户细分中受益。选择和数量的机器学习模型也可能依赖于细分结果。数据科学家还需要监控已部署的模型,并修订和调整特征,以维持期望的预测准确性。
原文。经许可转载。
资源:
相关:
更多相关主题
分类指标演练:使用准确率、精确率、召回率和 ROC 的逻辑回归
编辑提供的图像
指标是机器学习的重要元素。关于分类任务,有不同类型的指标可以用来评估机器学习模型的性能。然而,选择适合你任务的正确指标可能会很困难。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
在这篇文章中,我将介绍 4 种常见的分类指标:准确率、精确率、召回率和 ROC,并与逻辑回归相关联。
让我们开始吧……
什么是逻辑回归?
逻辑回归是一种监督学习形式——当算法在标记数据集上学习并分析训练数据时。逻辑回归通常用于基于其“逻辑函数”的二分类问题。
二分类可以将其类别表示为:正/负,1/0,或真/假。
逻辑函数也称为 Sigmoid 函数,它将任何实值数映射到 0 和 1 之间的值。它可以用数学方式表示为:
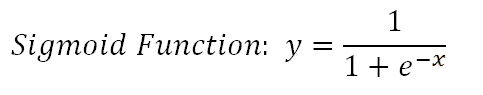
def sigmoid(z):
return 1.0 / (1 + np.exp(-z))
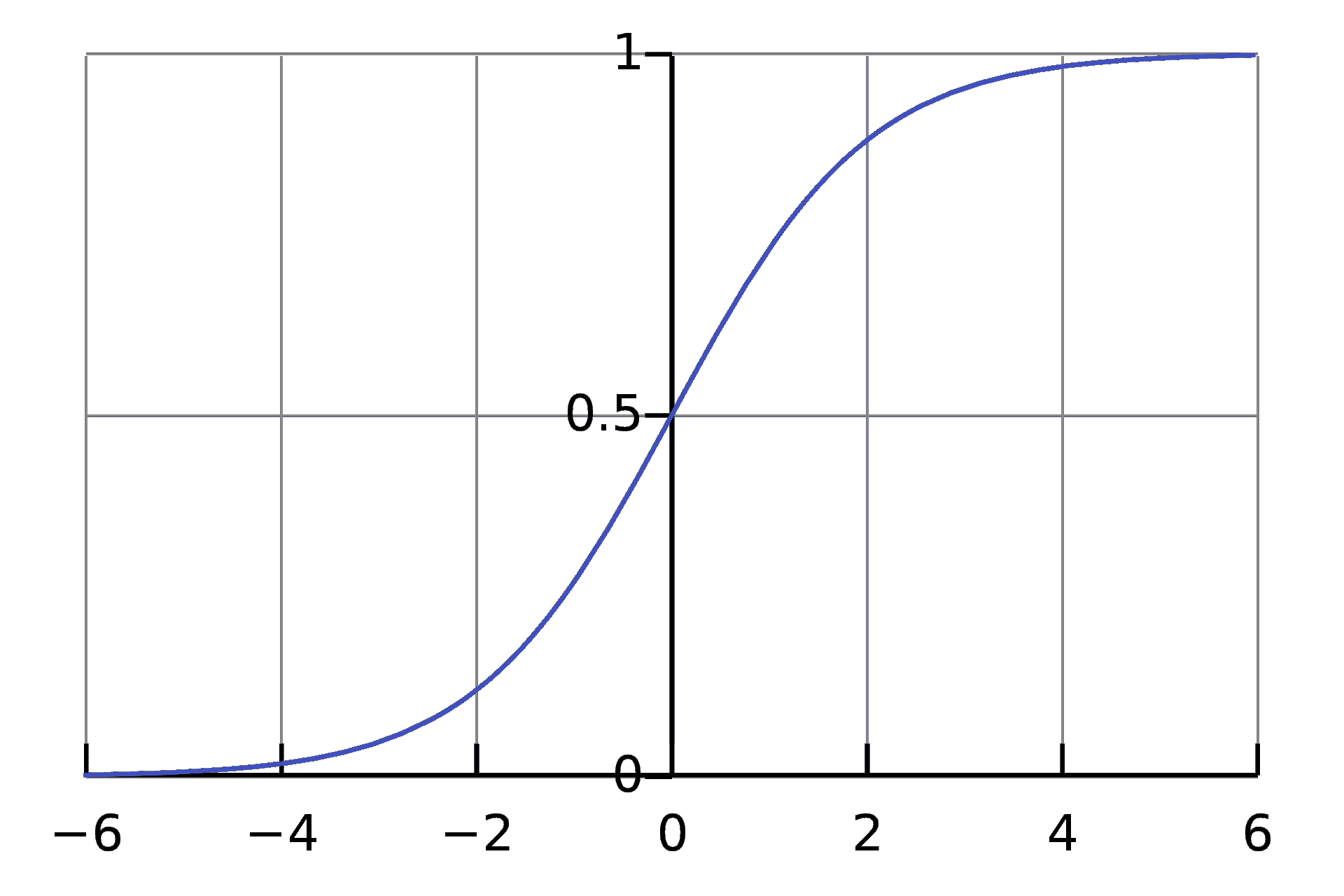
来源:维基百科
什么是分类指标?
分类是指预测一个标签,然后根据不同的参数识别一个对象属于哪个类别。
为了衡量我们的分类模型在做出这些预测时的表现,我们使用分类指标。它衡量了我们机器学习模型的性能,给我们信心,使这些输出可以进一步用于决策过程。
性能通常在 0 到 1 的范围内表示,其中 1 代表完美。
阈值问题
如果我们使用 0 到 1 的范围来表示模型的性能,当值为 0.5 时会发生什么?正如我们从早期的数学课程中知道的那样,如果概率大于 0.5,我们将其四舍五入为 1(正的)- 如果不是,它就是 0(负的)。
这听起来还不错,但现在当你使用分类模型来帮助确定现实生活中的输出时。我们需要 100%确保输出已经被正确分类。
例如,逻辑回归用于检测垃圾邮件。如果电子邮件是垃圾邮件的概率基于其超过 0.5,这可能存在风险,因为我们可能会将重要邮件误判为垃圾邮件。对模型性能的高度准确性需求在健康相关和财务任务中变得更加敏感。
因此,使用阈值概念,其中阈值以上的值趋向于 1,而阈值以下的值趋向于 0,可能会带来挑战。
尽管可以调整阈值,但这仍然会增加分类错误的风险。例如,较低的阈值会正确分类大多数正类,但正类中可能会包含负类 - 反之,如果我们使用较高的阈值。
所以让我们深入探讨这些分类指标如何帮助我们衡量逻辑回归模型的表现
准确性
我们将从准确性开始,因为它是通常使用得最多的,尤其是对于初学者。
准确性定义为正确预测的数量除以总预测数量:
accuracy = correct_predictions / total_predictions
然而,我们可以通过以下方式进一步扩展:
-
真阳性(TP)- 你预测为正,实际上也是正的
-
真阴性(TN)- 你预测为负,实际上也是负的
-
假阳性(FP)- 你预测为正,但实际上是负的
-
假阴性(FN)- 你预测为负,但实际上是正的
所以我们可以说真正的预测是 TN+TP,而错误的预测是 FP+FN。这个方程现在可以重新定义为:
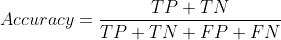
为了找出模型的准确性,你可以这样做:
score = LogisticRegression.score(X_test, y_test)
print('Test Accuracy Score', score)
或者你也可以使用sklearn 库:
from sklearn.metrics import accuracy_score
accuracy_score(y_train, y_pred)
然而,仅使用准确性指标来衡量模型的性能通常是不够的。这就是我们需要其他指标的地方。
精确率和召回率
如果我们想进一步测试不同类别中的“准确性”,以确保当模型预测为正时,确实是真阳性,我们使用精确率。我们也可以称之为正预测值,其定义为:
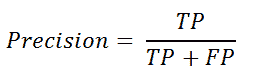
from sklearn.metrics import precision_score
如果我们想进一步测试不同类别中的“准确性”,确保当模型预测为负时,实际也为负——我们使用召回率。召回率与敏感性相同,可以定义为:
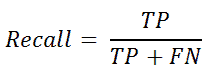
from sklearn.metrics import recall_score
使用精度和召回率是有用的度量,尤其是在两个类别之间的观察不平衡时。例如,数据集中一个类别(1)的数量多,而另一个类别(0)的数量少。
为了提高模型的精确度,你需要减少 FP,并不必担心 FN。相反,如果你想提高召回率,你需要减少 FN,而不必担心 FP。
提高分类阈值会减少假阳性——从而提高精度。提高分类阈值会减少真阳性或保持不变,同时增加假阴性或保持不变——从而降低或保持召回率不变。
不幸的是,不可能同时获得高精度和高召回率。如果你提高精度,召回率将会降低,反之亦然。这被称为精度/召回率权衡。
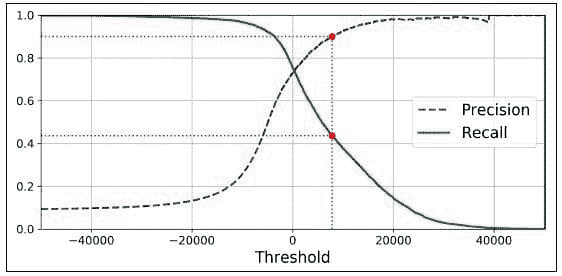
来源:Medium
ROC 曲线
在精度方面,我们关心减少 FP;在召回率方面,我们关心减少 FN。然而,有一种度量可以同时降低 FP 和 FN——它被称为接收者操作特征曲线,或 ROC 曲线。
它将假阳性率(x 轴)与真阳性率(y 轴)绘制在一起。
-
真阳性率 = TP / (TP + FN)
-
假阳性率 = FP / (FP + TN)
真阳性率也称为敏感性,而假阳性率也称为反特异性率。
- 特异性 = TN / (TN + FP)
如果 x 轴上的值较小,则表示 FP 较少且 TN 较高。如果 y 轴上的值较大,则表示 TP 较高且 FN 较少。
ROC 展示了在所有分类阈值下分类模型的表现,如下所示:
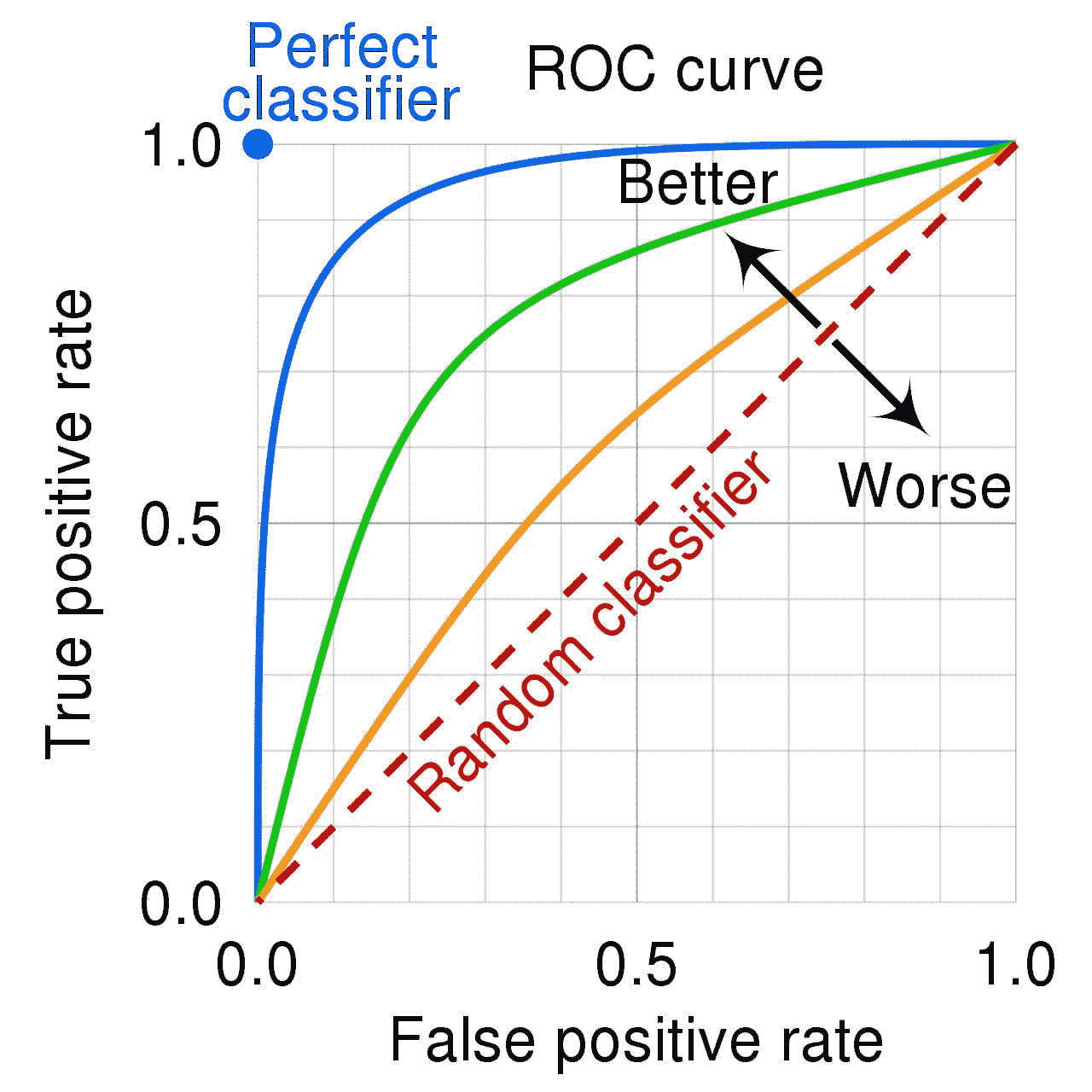
来源:Wikipedia
例子:

AUC
当谈到 ROC 曲线时,你可能还听说过曲线下面积(AUC)。它正如其名——曲线下面积。如果你想知道你的曲线有多好,你可以计算 ROC AUC 得分。AUC 衡量了所有可能分类阈值下的性能。
曲线下面积越大,效果越好——ROC AUC 得分越高。这是在 FN 和 FP 都为零时的情况——或者如果我们参考上面的图表,那就是当真正例率为 1 而假正例率为 0 时。
from sklearn.metrics import roc_auc_score
下图展示了逻辑回归预测的升序排列。如果 AUC 值为 0.0,我们可以说预测完全错误。如果 AUC 值为 1.0,我们可以说预测完全正确。

总结一下
总结一下,我们已经讲解了什么是逻辑回归、分类指标是什么,以及阈值问题及其解决方案,如准确率、精确率、召回率和 ROC 曲线。
还有许多其他分类指标,如混淆矩阵、F1 分数、F2 分数等。这些指标都可以帮助你更好地了解模型的性能。
Nisha Arya 是一名数据科学家和自由职业技术作家。她特别感兴趣于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何及可能如何促进人类寿命的延续。作为一个渴望学习的人,她希望拓宽技术知识和写作技能,同时帮助指导他人。
相关话题
机器学习中的分类项目:一个温和的逐步指南
原文:
www.kdnuggets.com/2020/06/classification-project-machine-learning-guide.html
评论

分类是数据科学和机器学习领域中你可能遇到的主要项目之一。以下是维基百科的定义:
分类是识别新观察数据属于一组类别(子群体)中的哪个类别的问题,基于包含已知类别成员的数据训练集。举例来说,就是将给定的电子邮件分配到“垃圾邮件”或“非垃圾邮件”中。
在这篇文章中,我将讲解一个来自General Assembly 的数据科学沉浸课程的项目。在这个项目中,我探索了不同的机器学习分类模型,以预测来自 Indeed.co.uk 的 Data Science 职位的四个薪资类别:
-
第 25 百分位以下的薪资
-
第 25 至 50 百分位之间的薪资
-
第 50 至 75 百分位之间的薪资
-
第 75 百分位以上的薪资
我们无法逐一讨论项目的每一个方面,但请注意,整个代码库可以在我的GitHub 个人资料上找到。
第一阶段:数据抓取和清洗
首先,没有数据,任何项目都无从谈起。因此,我首先通过抓取Indeed.co.uk以获取在英国多个城市寻找“数据科学家”的职位列表。我不会在这里详细讲解如何进行抓取,但我使用了我另一篇文章中提到的相同技术和工具:五分钟网络抓取。
值得一提的是,尽管网络抓取对数据科学工作者非常有用,但完成抓取后一定要检查数据的完整性。例如,在这个案例中,职位薪资当然是关键。然而,并不是所有的职位信息都包含薪资,因此需要抓取成千上万的页面和职位信息,以确保至少有 1000 个职位包含薪资信息。
处理抓取的数据通常还涉及大量的特征工程,以从我们已有的数据中添加一些价值。例如,对于这个项目,我开发了一个“资历”特征,该特征由每篇出版物的标题和摘要生成,使用了两个不同的单词列表,分别属于高级或初级职位。如果职位标题或摘要中出现了任何一个层级的单词,则分配相应的资历层级。如果这些特征中没有任何单词,则该职位被分配为中级层级。
第二阶段:建模
我开始这个阶段时探索了三种不同的模型:
-
一个带有装袋的 KNN 模型:KNN 代表 K-Nearest Neighbours 模型。这通过检查最接近被预测点的点的类别来工作,以对其进行分类。将其与装袋结合,我们可以提高稳定性和准确性,同时减少方差并帮助避免过拟合。怎么做? 装袋是一种集成方法——一种结合多个机器学习算法的预测以比任何单一模型更准确地预测的技术。尽管通常应用于决策树方法,但它可以与任何类型的方法一起使用。
-
一个带有提升的决策树模型:在这种情况下,决策树像一个流程图结构,其中每个内部节点代表对属性的“测试”(例如,硬币翻转是正面还是反面),每个分支代表测试的结果,每个叶子节点代表一个类标签和一个做出的决策。从根到叶的路径代表分类规则。在这个模型中,尽管提升是一种与装袋截然不同的方法,但它也是一种集成方法——它通过从训练数据中建立一个模型,然后创建第二个模型以试图纠正第一个模型的错误来工作。模型会不断增加,直到训练集被完美预测,或添加到最大模型数。
由于这两个模型高度依赖给定的超参数,你可能会希望使用GridSearch来尽可能地优化它们。GridSearch只是一个工具,它通过训练多个模型来寻找从给定参数和数值列表中得到的最佳参数。
所以,例如,创建一个带有提升和GridSearch的决策树模型,你需要执行以下步骤。
1. 实例化模型
from sklearn.tree import DecisionTreeRegressor
tree_to_boost = DecisionTreeRegressor(random_state=123)
2. 实例化集成方法算法
from sklearn.ensemble import AdaBoostClassifier
boosting_trees_model = AdaBoostClassifier(base_estimator = tree_to_boost, random_state=123)
3. 实例化 GridSearch 并指定要测试的参数
使用GridSearch时,你可以通过调用get_params()来获取可以调整的可用参数:
tree_to_boost.get_params()
请记住:你总是可以在 Sklearn 的文档中获取有关如何优化任何超参数的更多细节。例如,以下是决策树文档。
最后,让我们导入GridSearch,指定所需的参数并实例化对象。请注意,sklearn 的GridSearchCV在算法中包含了交叉验证,因此你还需要指定要进行的 CV 数量,
from sklearn.model_selection import GridSearchCV
trees_params = {‘base_estimator__max_depth’: [80,100,120,150],
‘base_estimator__max_features’: [0.93,0.95,0.97],
‘n_estimators’: [1200]}
boosting_tree_grid = GridSearchCV(estimator=boosting_trees_modeel, param_grid=tree_params, cv=5)
4. 拟合你的组合 GridSearch 并检查结果
拟合GridSearch就像拟合任何模型一样:
boosting_tree_grid.fit(X_train, y_train)
完成后,你可以检查最佳参数,看看是否还有机会优化它们。只需运行以下代码:
boosting_tree_grid.best_params_
和任何模式一样,你可以使用 .score() 和 .predict() 使用 GridSearchCV 对象。
第三阶段:特征重要性
在建模之后,下一个阶段总是分析我们的模型表现如何以及为什么会这样。
然而,如果你有机会使用过集成方法,你可能已经知道这些算法通常被称为“黑箱模型”。这些模型缺乏解释性和可解释性,因为它们通常的工作方式涉及一个或多个层的机器在没有人工监督的情况下做出决策,除了设置的一组规则或参数。往往,甚至领域中最专业的人员也无法理解通过训练神经网络实际创建的函数。
从这个意义上说,一些最经典的机器学习模型实际上更好。这就是为什么在本文中,我们将使用经典的逻辑回归分析我们项目的特征重要性。然而,如果你有兴趣了解如何分析黑箱模型的特征重要性,在我另外一篇文章中,我探讨了一个工具来实现这一点。
从逻辑回归模型开始,获取特征重要性就像调用以下内容一样简单:
logistic_regression_model.coef_[class_number]
查看整体特征重要性的一个简洁方法是创建一个 DataFrame,包含每个类别的特征重要性。我喜欢使用每个特征的绝对值,以便查看每个特征对模型的绝对影响。然而,请注意,如果你想具体分析每个特征如何帮助增加或减少属于每个类别的可能性,你应该使用原始值,无论是负值还是正值。
记住我们在尝试预测四个类别,因此我们应该这样创建 Pandas DataFrame:
feature_importance_df = pd.DataFrame({‘feature’: logistic_regression_model.columns,
‘coefA’: np.abs(logistic_regression_model.coef_[0]),
‘coefB’: np.abs(logistic_regression_model.coef_[1]),
‘coefC’: np.abs(logistic_regression_model.coef_[2]),
‘coefD’: np.abs(logistic_regression_model.coef_[3]),})
我们可以最终将所有内容放入图表中,查看每个类别的表现:
尽管标签的大小可能没有帮助,但我们可以从这些图表中得出结论,我们数据集中的以下特征在预测薪资类别时是相关的:
-
高级别:正如我们所见,树的层级对所有类别都有很强的影响,是绝对大小方面的第一个系数。
-
其次是直接从 Indeed 抓取的 Job_Type
-
最后,对于所有薪资类别,有两个职位从 indeed 上抓取并清洗过来:网页内容专家和测试工程师。
这个数据集包含数百个特征,但很高兴看到在各类别中有明显的趋势!
第四阶段:结论和可信度
最终,剩下的唯一任务就是评估我们模型的表现。为此,我们可以使用多个指标。不幸的是,全面讲解分类问题中的所有可能指标对于这篇文章来说太长了。然而,我可以在这里推荐一个非常好的 Medium 文章,它详细介绍了所有关键指标。请在这里享受它。
正如上面链接的 Mohammed 故事中所述,混淆矩阵是包含所有其他指标的核心概念。简而言之,它在一个轴上显示真实标签或类别,在另一个轴上显示预测标签。最终,我们希望预测和真实标签之间有对角线匹配,理想情况下,匹配的情况为零或极少。Sklearn 的指标库提供了一个美观且简单的表示方式,我们只需将真实标签和我们的预测输入算法即可绘制:
from sklearn import metrics
skplt.metrics.plot_confusion_matrix(y_test, y_predictions)
plt.show()
使用这个库,我们可以在以下图中看到,对于这个项目,训练组和测试组在四个薪水类别中都预测得相当准确:
一个重要的最终澄清是,尽管我们的最终模型似乎很准确,但它在预测类别时效果良好,当类别的重要性相等时,我们不需要对任何类别进行加权。
例如,如果我们为一家公司创建这个模型,在这种情况下,错误地告知某人他们将获得低薪水工作比错误地告诉客户他们将获得高薪水工作更为严重,我们的模型可能会遇到困难,因为它无法准确预测所有正类值为正类,同时也无法避免错误地预测大量负类值。在这种情况下,我们应该另辟蹊径,例如,创建一个具有加权类别的模型。
原文。经许可转载。
简介: 在多个行业拥有 5 年以上的电子商务和营销经验之后,Gonzalo Ferreiro Volpi 转向了数据科学和机器学习领域,目前在 Ravelin Technology 工作,利用机器学习和人类洞察来解决电子商务中的欺诈问题。
相关:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关内容
使用 5 种机器学习算法分类稀有事件
原文:
www.kdnuggets.com/2020/01/classify-rare-event-machine-learning-algorithms.html
评论
由 Leihua Ye,UC Santa Barbara
机器学习是数据科学的皇冠;
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT 事务
监督学习是机器学习的皇冠上的明珠。
背景
几年前,《哈佛商业评论》发布了一篇题为 “数据科学家:21 世纪最性感的职业” 的文章。自发布以来,数据科学或统计学系成为了大学生广泛追捧的专业,数据科学家(书呆子)第一次被称为性感。
对于某些行业,数据科学家重新塑造了企业结构,并将大量决策权重新分配给了“前线”员工。从数据中生成有用的商业洞察力从未如此简单。
根据 Andrew Ng 的说法(机器学习的渴望,第 9 页),
监督学习算法为行业贡献了大部分价值。
毋庸置疑,为什么监督学习产生了如此巨大的商业价值。银行用它来检测信用卡欺诈,交易员根据模型的建议做出购买决策,工厂通过生产线筛选有缺陷的单元(这是 AI 和 ML 可以帮助传统公司的一个领域,根据 Andrew Ng)。
这些商业场景具有两个共同特点:
-
二元结果:欺诈与非欺诈,购买与不购买,和有缺陷与无缺陷。
-
数据不平衡分布:一个主要组与一个次要组。
正如 Andrew Ng 最近指出的, 小数据, 鲁棒性, 和 人为因素 是成功 AI 项目的三个障碍。在某种程度上,我们的稀有事件问题与一个少数群体也是一个小数据问题:ML 算法从多数群体中学习更多,可能容易误分类小数据群体。
这里是百万美元的问题:
对于这些稀有事件,哪个机器学习方法表现更好?
什么指标?
权衡?
在这篇文章中,我们尝试通过将 5 种机器学习方法应用于一个真实数据集来回答这些问题,并提供全面的 R 实现。
有关完整描述和原始数据集,请查看原始 数据集;有关完整的 R 代码,请查看我的 Github。
商业问题
一家葡萄牙的银行实施了一项新的银行服务(定期存款)的营销策略,并想知道哪些类型的客户订阅了该服务。这样,银行可以调整其营销策略,并在未来针对特定的客户群体。数据科学家与销售和营销团队合作,提出统计解决方案以识别未来的订阅者。
R 实现
下面是模型选择和 R 实现的流程。
1. 导入、数据清理和探索性数据分析
让我们加载并清理原始数据集。
####load the dataset
banking=read.csv(“bank-additional-full.csv”,sep =”;”,header=T)##check for missing data and make sure no missing data
banking[!complete.cases(banking),]#re-code qualitative (factor) variables into numeric
banking$job= recode(banking$job, “‘admin.’=1;’blue-collar’=2;’entrepreneur’=3;’housemaid’=4;’management’=5;’retired’=6;’self-employed’=7;’services’=8;’student’=9;’technician’=10;’unemployed’=11;’unknown’=12”)#recode variable again
banking$marital = recode(banking$marital, “‘divorced’=1;’married’=2;’single’=3;’unknown’=4”)banking$education = recode(banking$education, “‘basic.4y’=1;’basic.6y’=2;’basic.9y’=3;’high.school’=4;’illiterate’=5;’professional.course’=6;’university.degree’=7;’unknown’=8”)banking$default = recode(banking$default, “‘no’=1;’yes’=2;’unknown’=3”)banking$housing = recode(banking$housing, “‘no’=1;’yes’=2;’unknown’=3”)banking$loan = recode(banking$loan, “‘no’=1;’yes’=2;’unknown’=3”)
banking$contact = recode(banking$loan, “‘cellular’=1;’telephone’=2;”)banking$month = recode(banking$month, “‘mar’=1;’apr’=2;’may’=3;’jun’=4;’jul’=5;’aug’=6;’sep’=7;’oct’=8;’nov’=9;’dec’=10”)banking$day_of_week = recode(banking$day_of_week, “‘mon’=1;’tue’=2;’wed’=3;’thu’=4;’fri’=5;”)banking$poutcome = recode(banking$poutcome, “‘failure’=1;’nonexistent’=2;’success’=3;”)#remove variable “pdays”, b/c it has no variation
banking$pdays=NULL #remove variable “pdays”, b/c itis collinear with the DV
banking$duration=NULL
清理原始数据似乎很乏味,因为我们必须重新编码缺失的变量并将定性变量转换为定量变量。在现实世界中,清理数据的时间更长。有一种说法是“数据科学家花 80%的时间清理数据,20%的时间构建模型。”
接下来,让我们探讨一下结果变量的分布。
#EDA of the DV
plot(banking$y,main="Plot 1: Distribution of Dependent Variable")
如图所示,因变量(服务订阅)分布不均,"No"的数量多于"Yes"。这种不平衡的分布应引起一些警示,因为数据分布会影响最终的统计模型。使用基于多数情况开发的模型容易错误分类少数情况。
2. 数据划分
接下来,让我们将数据集分为两部分:训练集和测试集。按照经验法则,我们遵循 80-20 的划分:80%作为训练集,20%作为测试集。对于时间序列数据,我们基于 90%的数据训练模型,其余 10%作为测试数据集。
#split the dataset into training and test sets randomly
set.seed(1)#set seed so as to generate the same value each time we run the code#create an index to split the data: 80% training and 20% test
index = round(nrow(banking)*0.2,digits=0)#sample randomly throughout the dataset and keep the total number equal to the value of index
test.indices = sample(1:nrow(banking), index)#80% training set
banking.train=banking[-test.indices,] #20% test set
banking.test=banking[test.indices,] #Select the training set except the DV
YTrain = banking.train$y
XTrain = banking.train %>% select(-y)# Select the test set except the DV
YTest = banking.test$y
XTest = banking.test %>% select(-y)
在这里,让我们创建一个空的跟踪记录。
records = matrix(NA, nrow=5, ncol=2)
colnames(records) <- c(“train.error”,”test.error”)
rownames(records) <- c(“Logistic”,”Tree”,”KNN”,”Random Forests”,”SVM”)
3. 训练模型
在这一部分,我们定义了一个新的函数(calc_error_rate),并将其应用于计算每个机器学习模型的训练和测试误差。
calc_error_rate <- function(predicted.value, true.value)
{return(mean(true.value!=predicted.value))}
该函数计算当预测标签不等于真实值时的误差率。
#1 逻辑回归模型
有关逻辑模型的简要介绍,请查看我的其他帖子:机器学习 101和机器学习 102。
让我们拟合一个包括除结果变量以外所有其他变量的逻辑模型。由于结果是二元的,我们将模型设置为二项分布(“family=binomial”)。
glm.fit = glm(y ~ age+factor(job)+factor(marital)+factor(education)+factor(default)+factor(housing)+factor(loan)+factor(contact)+factor(month)+factor(day_of_week)+campaign+previous+factor(poutcome)+emp.var.rate+cons.price.idx+cons.conf.idx+euribor3m+nr.employed, data=banking.train, family=binomial)
下一步是获取训练误差。我们将类型设置为响应,因为我们预测的是结果的类型,并采用多数规则:如果先验概率大于或等于 0.5,我们预测结果为“是”;否则,为“否”。
prob.training = predict(glm.fit,type=”response”)banking.train_glm = banking.train %>% #select all rows of the train
mutate(predicted.value=as.factor(ifelse(prob.training<=0.5, “no”, “yes”))) #create a new variable using mutate and set a majority rule using ifelse# get the training error
logit_traing_error <- calc_error_rate(predicted.value=banking.train_glm$predicted.value, true.value=YTrain)# get the test error of the logistic model
prob.test = predict(glm.fit,banking.test,type=”response”)banking.test_glm = banking.test %>% # select rows
mutate(predicted.value2=as.factor(ifelse(prob.test<=0.5, “no”, “yes”))) # set ruleslogit_test_error <- calc_error_rate(predicted.value=banking.test_glm$predicted.value2, true.value=YTest)# write down the training and test errors of the logistic model
records[1,] <- c(logit_traing_error,logit_test_error)#write into the first row
#2 决策树
对于决策树(DT),我们遵循交叉验证并确定最佳的分裂节点。有关决策树的简要介绍,请参考Prashant Gupta的帖子(link)。
# finding the best nodes
# the total number of rows
nobs = nrow(banking.train)#build a DT model;
#please refer to this document (here) for constructing a DT model
bank_tree = tree(y~., data= banking.train,na.action = na.pass,
control = tree.control(nobs , mincut =2, minsize = 10, mindev = 1e-3))#cross validation to prune the tree
set.seed(3)
cv = cv.tree(bank_tree,FUN=prune.misclass, K=10)
cv#identify the best cv
best.size.cv = cv$size[which.min(cv$dev)]
best.size.cv#best = 3bank_tree.pruned<-prune.misclass(bank_tree, best=3)
summary(bank_tree.pruned)
交叉验证的最佳大小是 3。
# Training and test errors of bank_tree.pruned
pred_train = predict(bank_tree.pruned, banking.train, type=”class”)
pred_test = predict(bank_tree.pruned, banking.test, type=”class”)# training error
DT_training_error <- calc_error_rate(predicted.value=pred_train, true.value=YTrain)# test error
DT_test_error <- calc_error_rate(predicted.value=pred_test, true.value=YTest)# write down the errors
records[2,] <- c(DT_training_error,DT_test_error)
#3 K-最近邻
作为一种非参数方法,KNN 不需要任何关于分布的先验知识。简单来说,KNN 将 k 个最近邻分配给感兴趣的单位。
要快速入门,请查看我关于 KNN 的文章:初学者的 K-最近邻指南:从零到英雄。有关交叉验证和 do.chunk 函数的详细解释,请转到我的文章。
使用交叉验证,我们发现当 k=20 时,交叉验证误差最小。
nfold = 10
set.seed(1)# cut() divides the range into several intervals
folds = seq.int(nrow(banking.train)) %>%
cut(breaks = nfold, labels=FALSE) %>%
sampledo.chunk <- function(chunkid, folddef, Xdat, Ydat, k){
train = (folddef!=chunkid)# training indexXtr = Xdat[train,] # training set by the indexYtr = Ydat[train] # true label in training setXvl = Xdat[!train,] # test setYvl = Ydat[!train] # true label in test setpredYtr = knn(train = Xtr, test = Xtr, cl = Ytr, k = k) # predict training labelspredYvl = knn(train = Xtr, test = Xvl, cl = Ytr, k = k) # predict test labelsdata.frame(fold =chunkid, # k folds
train.error = calc_error_rate(predYtr, Ytr),#training error per fold
val.error = calc_error_rate(predYvl, Yvl)) # test error per fold
}# set error.folds to save validation errors
error.folds=NULL# create a sequence of data with an interval of 10
kvec = c(1, seq(10, 50, length.out=5))set.seed(1)for (j in kvec){
tmp = ldply(1:nfold, do.chunk, # apply do.function to each fold
folddef=folds, Xdat=XTrain, Ydat=YTrain, k=j) # required arguments
tmp$neighbors = j # track each value of neighbors
error.folds = rbind(error.folds, tmp) # combine the results
}#melt() in the package reshape2 melts wide-format data into long-format data errors = melt(error.folds, id.vars=c(“fold”,”neighbors”), value.name= “error”)
然后,让我们找到最小化验证误差的最佳 k 值。
val.error.means = errors %>%
filter(variable== “val.error” ) %>%
group_by(neighbors, variable) %>%
summarise_each(funs(mean), error) %>%
ungroup() %>%
filter(error==min(error))#the best number of neighbors =20
numneighbor = max(val.error.means$neighbors)
numneighbor## [20]
按照相同的步骤,我们找到训练和测试误差。
#training error
set.seed(20)
pred.YTtrain = knn(train=XTrain, test=XTrain, cl=YTrain, k=20)
knn_traing_error <- calc_error_rate(predicted.value=pred.YTtrain, true.value=YTrain)#test error =0.095set.seed(20)
pred.YTest = knn(train=XTrain, test=XTest, cl=YTrain, k=20)
knn_test_error <- calc_error_rate(predicted.value=pred.YTest, true.value=YTest)records[3,] <- c(knn_traing_error,knn_test_error)
#4 随机森林
我们按照构建随机森林模型的标准步骤进行。有关 RF 的简要介绍,请参见由 Tony Yiu 撰写的帖子 (link)。
# build a RF model with default settings
set.seed(1)
RF_banking_train = randomForest(y ~ ., data=banking.train, importance=TRUE)# predicting outcome classes using training and test sets
pred_train_RF = predict(RF_banking_train, banking.train, type=”class”)pred_test_RF = predict(RF_banking_train, banking.test, type=”class”)# training error
RF_training_error <- calc_error_rate(predicted.value=pred_train_RF, true.value=YTrain)# test error
RF_test_error <- calc_error_rate(predicted.value=pred_test_RF, true.value=YTest)records[4,] <- c(RF_training_error,RF_test_error)
#5 支持向量机
同样,我们按照构建 SVM 的标准步骤进行。有关此方法的良好介绍,请参见由 Rohith Gandhi 撰写的帖子 (Link)。
set.seed(1)
tune.out=tune(svm, y ~., data=banking.train,
kernel=”radial”,ranges=list(cost=c(0.1,1,10)))# find the best parameters
summary(tune.out)$best.parameters# the best model
best_model = tune.out$best.modelsvm_fit=svm(y~., data=banking.train,kernel=”radial”,gamma=0.05555556,cost=1,probability=TRUE)# using training/test sets to predict outcome classes
svm_best_train = predict(svm_fit,banking.train,type=”class”)
svm_best_test = predict(svm_fit,banking.test,type=”class”)# training error
svm_training_error <- calc_error_rate(predicted.value=svm_best_train, true.value=YTrain)# test error
svm_test_error <- calc_error_rate(predicted.value=svm_best_test, true.value=YTest)records[5,] <- c(svm_training_error,svm_test_error)
4. 模型指标
我们按照模型选择程序构建了所有机器学习模型,并获得了它们的训练和测试误差。在本节中,我们将使用一些模型指标来选择最佳模型。
4.1 训练/测试误差
是否可以通过训练/测试误差找到最佳模型?
现在,让我们检查结果。
records

在这里,随机森林具有最小的训练误差,尽管与其他方法的测试误差相似。如你所见,训练误差和测试误差非常接近,很难判断哪个模型明显更好。
此外,分类准确率,无论是训练误差还是测试误差,都不应作为高度不平衡数据集的指标。这是因为数据集被多数情况主导,即使是随机猜测也能给你 50-50 的正确概率(50%的准确率)。更糟的是,一个高准确率的模型可能会严重惩罚少数情况。因此,让我们检查另一个指标 ROC 曲线。
4.2 接收者操作特征(ROC)曲线
ROC 是一个图形化表示,显示分类模型在所有分类阈值下的表现。我们更倾向于选择一个比其他模型更快接近 1 的分类器。
ROC 曲线在同一图表中绘制了两个参数——真正率和假正率——在不同阈值下的情况:
TPR(召回率)= TP/(TP+FN)
FPR = FP/(TN+FP)
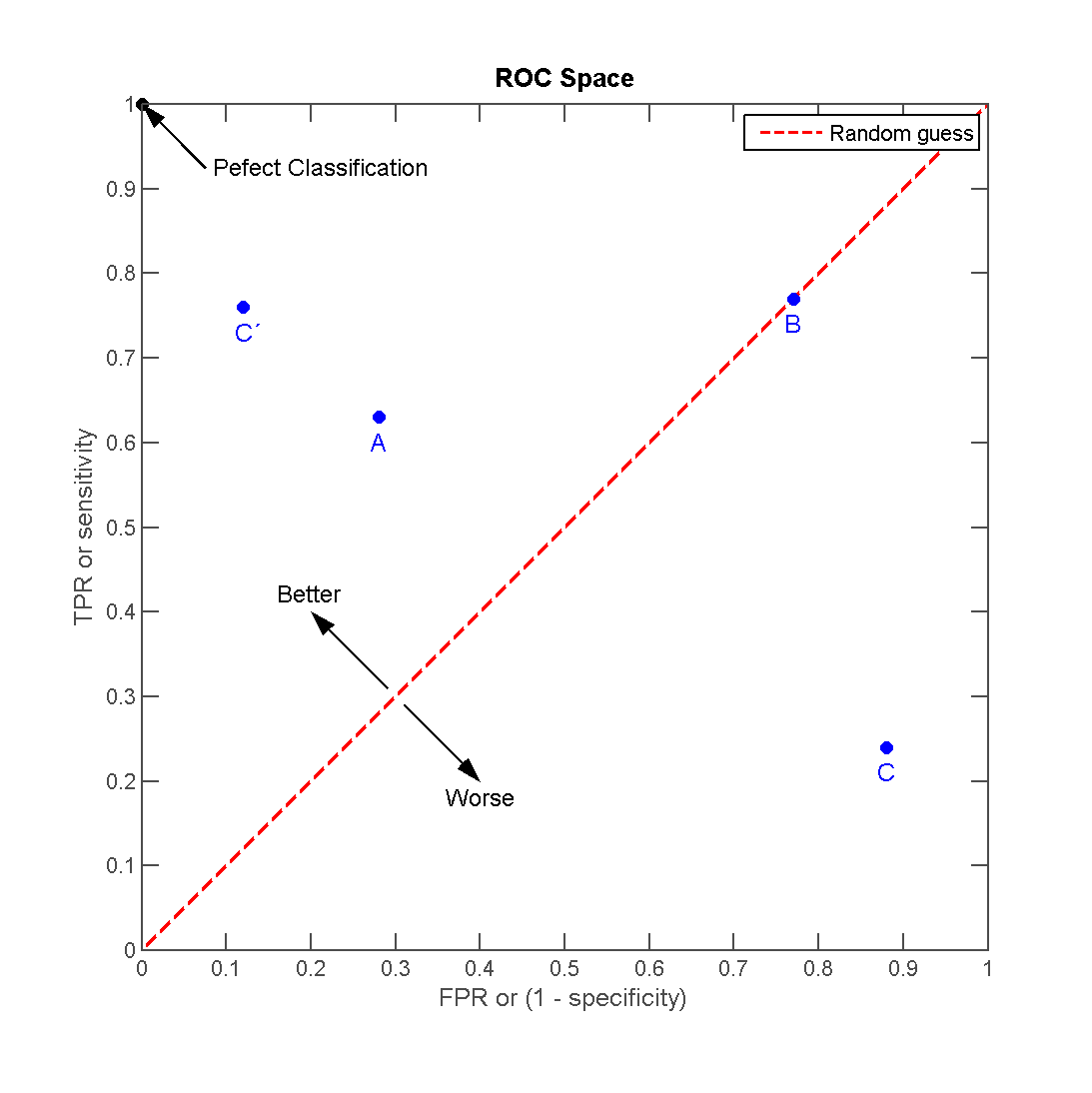
在很大程度上,ROC 曲线不仅衡量分类准确率的水平,还在 TPR 和 FPR 之间达到很好的平衡。这对于稀有事件是非常可取的,因为我们还希望在多数和少数情况之间达到平衡。
# load the library
library(ROCR)#creating a tracking record
Area_Under_the_Curve = matrix(NA, nrow=5, ncol=1)
colnames(Area_Under_the_Curve) <- c(“AUC”)
rownames(Area_Under_the_Curve) <- c(“Logistic”,”Tree”,”KNN”,”Random Forests”,”SVM”)########### logistic regression ###########
# ROC
prob_test <- predict(glm.fit,banking.test,type=”response”)
pred_logit<- prediction(prob_test,banking.test$y)
performance_logit <- performance(pred_logit,measure = “tpr”, x.measure=”fpr”)########### Decision Tree ###########
# ROC
pred_DT<-predict(bank_tree.pruned, banking.test,type=”vector”)
pred_DT <- prediction(pred_DT[,2],banking.test$y)
performance_DT <- performance(pred_DT,measure = “tpr”,x.measure= “fpr”)########### KNN ###########
# ROC
knn_model = knn(train=XTrain, test=XTrain, cl=YTrain, k=20,prob=TRUE)prob <- attr(knn_model, “prob”)
prob <- 2*ifelse(knn_model == “-1”, prob,1-prob) — 1
pred_knn <- prediction(prob, YTrain)
performance_knn <- performance(pred_knn, “tpr”, “fpr”)########### Random Forests ###########
# ROC
pred_RF<-predict(RF_banking_train, banking.test,type=”prob”)
pred_class_RF <- prediction(pred_RF[,2],banking.test$y)
performance_RF <- performance(pred_class_RF,measure = “tpr”,x.measure= “fpr”)########### SVM ###########
# ROC
svm_fit_prob = predict(svm_fit,type=”prob”,newdata=banking.test,probability=TRUE)
svm_fit_prob_ROCR = prediction(attr(svm_fit_prob,”probabilities”)[,2],banking.test$y==”yes”)
performance_svm <- performance(svm_fit_prob_ROCR, “tpr”,”fpr”)
让我们绘制 ROC 曲线。
我们添加了一条 abline 以显示随机分配的机会。我们的分类器应该比随机猜测表现更好,对吧?
#logit
plot(performance_logit,col=2,lwd=2,main=”ROC Curves for These Five Classification Methods”)legend(0.6, 0.6, c(‘logistic’, ‘Decision Tree’, ‘KNN’,’Random Forests’,’SVM’), 2:6)#decision tree
plot(performance_DT,col=3,lwd=2,add=TRUE)#knn
plot(performance_knn,col=4,lwd=2,add=TRUE)#RF
plot(performance_RF,col=5,lwd=2,add=TRUE)# SVM
plot(performance_svm,col=6,lwd=2,add=TRUE)abline(0,1)
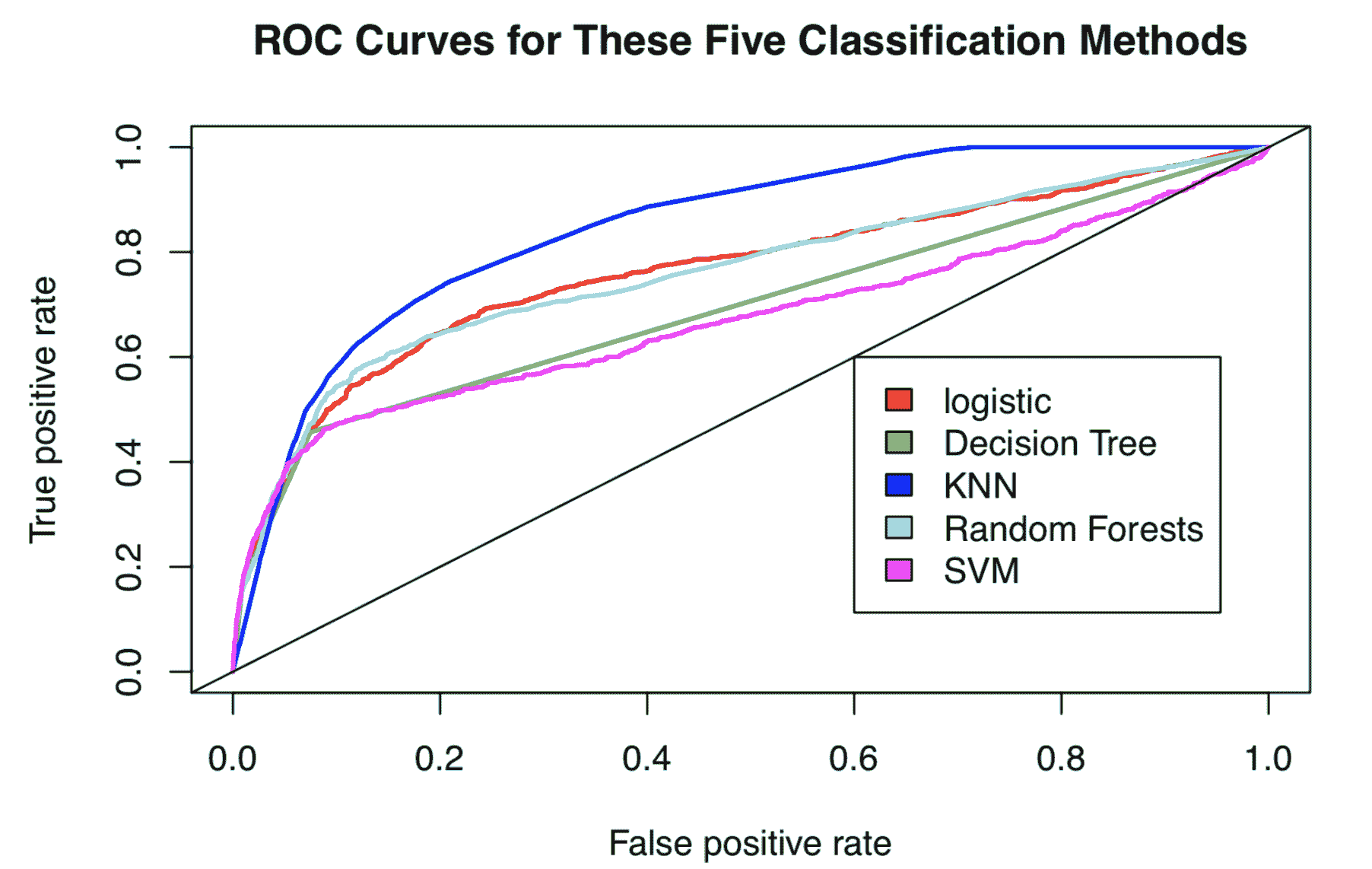
ROC
我们在这里找到了一个赢家。
根据 ROC 曲线,KNN(蓝色的)高于所有其他方法。
4.3 曲线下面积(AUC)
正如名称所示,AUC 是 ROC 曲线下的面积。它是可视化 AUC 曲线的算术表示。AUC 提供了分类器在可能的分类阈值下表现的聚合结果。
########### Logit ###########
auc_logit = performance(pred_logit, “auc”)@y.values
Area_Under_the_Curve[1,] <-c(as.numeric(auc_logit))########### Decision Tree ###########
auc_dt = performance(pred_DT,”auc”)@y.values
Area_Under_the_Curve[2,] <- c(as.numeric(auc_dt))########### KNN ###########
auc_knn <- performance(pred_knn,”auc”)@y.values
Area_Under_the_Curve[3,] <- c(as.numeric(auc_knn))########### Random Forests ###########
auc_RF = performance(pred_class_RF,”auc”)@y.values
Area_Under_the_Curve[4,] <- c(as.numeric(auc_RF))########### SVM ###########
auc_svm<-performance(svm_fit_prob_ROCR,”auc”)@y.values[[1]]
Area_Under_the_Curve[5,] <- c(as.numeric(auc_svm))
让我们检查 AUC 值。
Area_Under_the_Curve

此外,KNN 具有最大的 AUC 值(0.847)。
结论
在这篇文章中,我们发现 KNN,一个非参数分类器,比其参数化的同行表现更好。在指标方面,对于稀有事件,选择 ROC 曲线比分类准确率更合理。
享受阅读这篇文章吗?
查看我在人工智能和机器学习方面的其他文章。
使用各种测量指标在 R 中构建 KNN 模型的流程
基础知识、链接函数和图表
当存在非线性组件时如何分类
简介:叶磊华(@leihua_ye)是加州大学圣塔芭芭拉分校的博士候选人。他在定量用户体验研究、实验与因果推断、机器学习和数据科学方面有 5 年以上的研究和专业经验。
原文。转载已获许可。
相关:
-
R 语言中的 K-最近邻初学者指南:从零到英雄
-
使用 K-最近邻分类心脏病
-
如何在 Python(和 R)中可视化数据
更多相关主题
使用 K-最近邻算法对心脏病进行分类
原文:
www.kdnuggets.com/2019/07/classifying-heart-disease-using-k-nearest-neighbors.html/2
评论
使用 K-NN 算法构建心脏病分类器

在医疗领域,最关键的任务是疾病诊断。如果能早期诊断疾病,可以挽救许多生命。机器学习分类技术通过提供准确和快速的疾病诊断,可以显著改善医疗领域,从而为医生和患者节省时间。由于心脏病是当今世界上首要的杀手,它成为最难诊断的疾病之一。
在本节中,我们将建立一个 K-NN 分类器,以预测患者是否患有心脏病。
你可以从 UCI 机器学习库 下载数据集。
这个数据库包含 76 个属性,但所有已发布的实验都使用了其中的 14 个属性的子集。特别是,克利夫兰数据库是迄今为止 ML 研究人员唯一使用的数据库。“目标”字段指的是患者是否患有心脏病。其值为 0(未患病)到 4。
数据集包含以下特征:
age — 年龄 sex — (1 = 男性; 0 = 女性) cp — 胸痛类型 trestbps — 静息血压(入院时的 mm Hg) chol — 血清胆固醇(mg/dl) fbs — (空腹血糖 > 120 mg/dl)(1 = 是; 0 = 否) restecg — 静息心电图结果 thalach — 达到的最高心率 exang — 运动诱发心绞痛(1 = 是; 0 = 否) oldpeak — 运动引起的 ST 段压低相对于静息状态 slope — 峰值运动 ST 段的坡度 ca — 通过荧光透视检查的主要血管数量(0–3) thal — 3 = 正常; 6 = 固定缺陷; 7 = 可逆缺陷 target — 是否患病(1 = 是, 0 = 否)
让我们加载所有必需的库。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import confusion_matrix
from sklearn import metrics
让我们加载数据集:
data = pd.read_csv('/Users/nageshsinghchauhan/Downloads/ML/KNN_art/heart.csv')
我们的原始数据集看起来是这样的
让我们探索数据集并统计患有心脏病的患者数量:
data.target.value_counts()
1 165
0 138
Name: target, dtype: int64
所有患者中有 165 名患者实际上患有心脏病。现在也来可视化一下。
sns.countplot(x="target", data=data, palette="bwr")
plt.show()
患有心脏病的患者数量(target = 1)
现在让我们将目标变量分类为男性和女性,并可视化结果。
sns.countplot(x='sex', data=data, palette="mako_r")
plt.xlabel("Sex (0 = female, 1= male)")
plt.show()
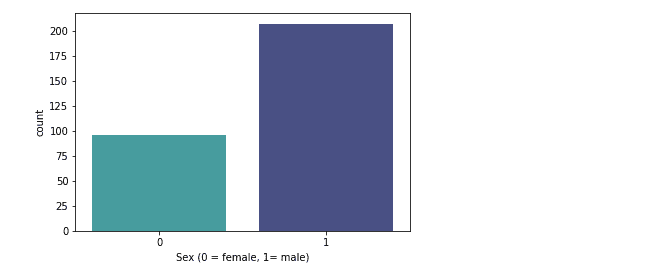
患有心脏病的男性和女性数量
从上述图中可以看出,我们的数据集中有 207 名男性和 96 名女性。
我们还可以查看“最大心率”和“年龄”之间的关系。
plt.scatter(x=data.age[data.target==1], y=data.thalach[(data.target==1)], c="green")
plt.scatter(x=data.age[data.target==0], y=data.thalach[(data.target==0)], c = 'black')
plt.legend(["Disease", "Not Disease"])
plt.xlabel("Age")
plt.ylabel("Maximum Heart Rate")
plt.show()
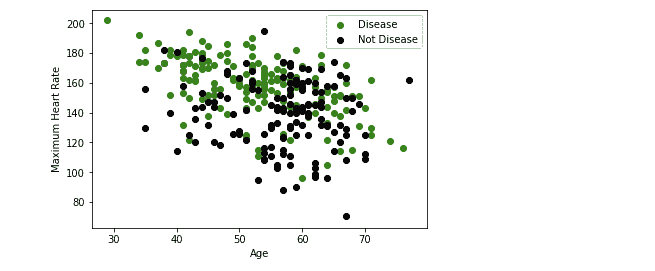
年龄与最大心率之间的散点图
从上述结果来看,最大心率出现在 50 至 60 岁之间。
好的,现在让我们用X(自变量矩阵)和y(因变量向量)标记我们的数据集。
X = data.iloc[:,:-1].values
y = data.iloc[:,13].values
接下来,我们将 75%的数据分配到训练集,25%的数据分配到测试集,使用下面的代码。
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.25, random_state= 0)
现在,我们的数据集包含特征,这些特征在量级、单位和范围上高度变化。但由于大多数机器学习算法在计算中使用两点之间的欧几里得距离,这就成了一个问题。为了抑制这种影响,我们需要将所有特征调整到相同的量级。这可以通过一种叫做特征缩放的方法来实现。
所以我们的下一步是对数据进行标准化,这可以使用 scikit-learn 中的 StandardScaler()来完成。
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
我们的下一步是建立 K-NN 模型,并用训练数据进行训练。这里的 n_neighbors 是 K 的值。
classifier = KNeighborsClassifier(n_neighbors = 5, metric = 'minkowski', p = 2)
classifier = classifier.fit(X_train,y_train)
所以这里最重要的一点是选择 K 的最佳值,为此,我们将从 K=5 开始。
现在,由于你的 K-NN 模型已经准备好 K=5,让我们训练测试数据并检查其准确率。
y_pred = classifier.predict(X_test)
#check accuracy
accuracy = metrics.accuracy_score(y_test, y_pred)
print('Accuracy: {:.2f}'.format(accuracy))
准确率:0.82
对于 K=6
classifier = KNeighborsClassifier(n_neighbors = 6, metric = 'minkowski', p = 2)
classifier = classifier.fit(X_train,y_train)
#prediction
y_pred = classifier.predict(X_test)
#check accuracy
accuracy = metrics.accuracy_score(y_test, y_pred)
print('Accuracy: {:.2f}'.format(accuracy))
准确率:0.86
对于 K=7
classifier = KNeighborsClassifier(n_neighbors = 7, metric = 'minkowski', p = 2)
classifier = classifier.fit(X_train,y_train)
#prediction
y_pred = classifier.predict(X_test)
#check accuracy
accuracy = metrics.accuracy_score(y_test, y_pred)
print('Accuracy: {:.2f}'.format(accuracy))
准确率:0.87
对于 K=8
classifier = KNeighborsClassifier(n_neighbors = 8, metric = 'minkowski', p = 2)
classifier = classifier.fit(X_train,y_train)
#prediction
y_pred = classifier.predict(X_test)
#check accuracy
accuracy = metrics.accuracy_score(y_test, y_pred)
print('Accuracy: {:.2f}'.format(accuracy))
准确率:0.87
对于 K=9
classifier = KNeighborsClassifier(n_neighbors = 9, metric = 'minkowski', p = 2)
classifier = classifier.fit(X_train,y_train)
#prediction
y_pred = classifier.predict(X_test)
#check accuracy
accuracy = metrics.accuracy_score(y_test, y_pred)
print('Accuracy: {:.2f}'.format(accuracy))
准确率:0.86
从中可以看出,当 K=7 时,准确率最大,为 87%。
我们还可以检查混淆矩阵,查看多少记录被正确预测。
#confusion matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
**```py
array([[26, 7],
[ 3, 40]])
在输出中,26 和 40 是正确预测,而 7 和 3 是错误预测。
### 如何提高分类器的性能?
嗯,有许多方法可以改进 KNN 算法。
+ **改变距离度量**对于不同的应用可能有助于提高算法的准确度。(即用于文本分类的汉明距离)。
+ **降维**技术,如 PCA,应在应用 K-NN 之前执行。
+ **重新缩放数据**使距离度量更具意义。例如,给定两个特征身高和体重,观察值如 z=[220,60]将明显偏向身高。修正方法之一是逐列减去均值并除以标准差。
+ **近似最近邻**技术,如使用*k-d 树*来存储训练数据,可以减少测试时间。
### **结论**
恭喜你,成功构建了一个使用 K-NN 的心脏病分类器,能够以最佳准确度对心脏病患者进行分类。
在这篇文章中,我们学习了 K-NN,它的工作原理,维度灾难,模型构建以及使用 Python Scikit-learn 包在心脏病数据集上的评估。
好吧,希望你们喜欢阅读这篇文章。请在评论区告诉我你的想法/建议/问题。
你可以通过 [LinkedIn](https://www.linkedin.com/in/nagesh-singh-chauhan-6936bb13b/) 联系我,提出任何问题。
感谢阅读 !!!
**简介: [Nagesh Singh Chauhan](https://www.linkedin.com/in/nagesh-singh-chauhan-6936bb13b/)** 是 CirrusLabs 的大数据开发人员。他在电信、分析、销售、数据科学等多个领域拥有超过 4 年的工作经验,专注于各种大数据组件。
[原文](https://towardsdatascience.com/implement-k-nearest-neighbors-classification-algorithm-c99be8f14052)。经许可转载。
**相关:**
+ 使用 Scikit-Learn 的 Python 线性回归初学者指南
+ 使用 Python 和 NLTK 构建你的第一个聊天机器人
+ 使用卷积神经网络和 OpenCV 预测年龄和性别
* * *
## 我们的前三大课程推荐
 1\. [谷歌网络安全证书](https://www.kdnuggets.com/google-cybersecurity) - 快速进入网络安全职业生涯。
 2\. [谷歌数据分析专业证书](https://www.kdnuggets.com/google-data-analytics) - 提升你的数据分析技能
 3\. [谷歌 IT 支持专业证书](https://www.kdnuggets.com/google-itsupport) - 支持你所在组织的 IT
* * *
### 更多相关话题
+ [从理论到实践:构建 k 最近邻分类器](https://www.kdnuggets.com/2023/06/theory-practice-building-knearest-neighbors-classifier.html)
+ [分类的最近邻算法](https://www.kdnuggets.com/2022/04/nearest-neighbors-classification.html)
+ [Scikit-learn 中的 K 最近邻](https://www.kdnuggets.com/2022/07/knearest-neighbors-scikitlearn.html)
+ [使用 BERT 分类长文本文档](https://www.kdnuggets.com/2022/02/classifying-long-text-documents-bert.html)
+ [使用 Python 自动化 Microsoft Excel 和 Word](https://www.kdnuggets.com/2021/08/automate-microsoft-excel-word-python.html)
+ [如何使用 Python 确定最佳拟合的数据分布](https://www.kdnuggets.com/2021/09/determine-best-fitting-data-distribution-python.html)**


 浙公网安备 33010602011771号
浙公网安备 33010602011771号