KDNuggets-博客中文翻译-三十一-
KDNuggets 博客中文翻译(三十一)
原文:KDNuggets
在 Azure Databricks 上使用 Spark、Python 或 SQL
原文:
www.kdnuggets.com/2020/08/spark-python-sql-azure-databricks.html
评论
作者 Ajay Ohri,数据科学经理
Azure Databricks 是一个基于 Apache Spark 的大数据分析服务,旨在支持数据科学和数据工程,由微软提供。它支持协作工作以及 Python、Spark、R 和 SQL 等多种语言的使用。在 Databricks 上工作具有云计算的优势——可扩展、低成本、按需的数据处理和存储。
我们的前 3 个课程推荐
 1. Google 网络安全证书 - 快速进入网络安全职业生涯。
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
 2. Google 数据分析专业证书 - 提升您的数据分析技能
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织在 IT 领域
在这里,我们探讨了一些在 Python、PySpark 和 SQL 之间互换工作的方式。我们学习如何通过先上传 CSV 文件然后在笔记本中创建来导入数据。我们学习如何将 SQL 表转换为 Spark 数据框,并将 Spark 数据框转换为 Python Pandas 数据框。我们还学习如何将 Spark 数据框转换为永久或临时 SQL 表。
为什么我们需要学习如何在 SQL、Spark 和 Python Pandas 数据框之间互换代码?SQL 适合编写简洁易读的数据处理代码,Spark 适合处理大数据和机器学习,而 Python Pandas 可用于从数据处理、机器学习到 seaborn 或 matplotlib 库中的绘图等各种任务。
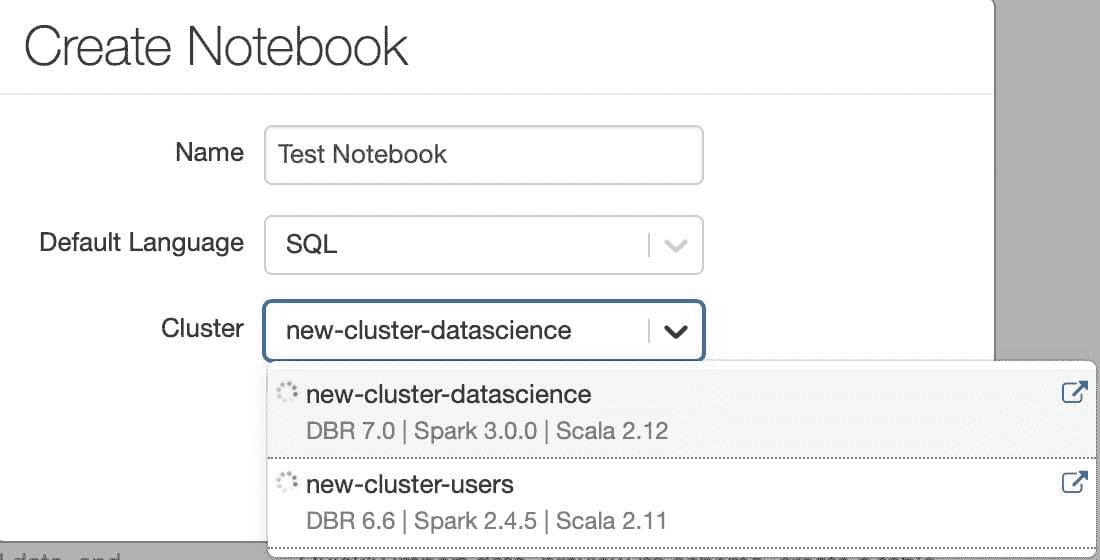
我们选择 SQL 笔记本以便于操作,然后选择适当的集群及其内存、核心、Spark 版本等。即使是 SQL 笔记本,我们也可以通过在单元格中的代码前面输入 %python 来编写 Python 代码。
现在让我们开始数据输入、数据检查和数据互换的基础知识。
步骤 1 读取上传的数据
%python
# Reading in Uploaded Data
# File location and type
file_location = "/FileStore/tables/inputdata.csv"
file_type = "csv"
# CSV options
infer_schema = "false"
first_row_is_header = "true"
delimiter = ","
# The applied options are for CSV files. For other file types, these will be ignored.
df = spark.read.format(file_type) \
.option("inferSchema", infer_schema) \
.option("header", first_row_is_header) \
.option("sep", delimiter) \
.load(file_location)
display(df)
步骤 2 从 SPARK 数据框创建一个临时视图或表
%python
#Create a temporary view or table from SPARK Dataframe
temp_table_name = "temp_table"
df.createOrReplaceTempView(temp_table_name)
步骤 3 从 SPARK 数据框创建永久 SQL 表
--Creating Permanent SQL Table from SPARK Dataframe
permanent_table_name = "cdp.perm_table"
df.write.format("parquet").saveAsTable(permanent_table_name)
步骤 4 检查 SQL 表
--Inspecting SQL Table
select * from cdp.perm_table
步骤 5 将 SQL 表转换为 SPARK 数据框
%python
#Converting SQL Table to SPARK Dataframe
sparkdf = spark.sql("select * from cdp.perm_table")
步骤 6 检查 SPARK 数据框
%python
#Inspecting Spark Dataframe
sparkdf.take(10)
步骤 7 将 Spark 数据框转换为 Python Pandas 数据框
%python
#Converting Spark Dataframe to Python Pandas Dataframe
%python
pandasdf=sparkdf.toPandas()
步骤 8 检查 Python 数据框
%python
#Inspecting Python Dataframe
pandasdf.head()
参考文献
-
Azure Databricks 简介 -
www.slideshare.net/jamserra/introduction-to-azure-databricks-83448539 -
Dataframes 和 Datasets -
docs.databricks.com/spark/latest/dataframes-datasets/index.html -
优化 PySpark 与 pandas DataFrames 之间的转换 -
docs.databricks.com/spark/latest/spark-sql/spark-pandas.html -
pyspark 包 -
spark.apache.org/docs/latest/api/python/pyspark.html
个人简介: Ajay Ohri 是数据科学经理(Publicis Sapient),并且是《R for Cloud Computing》和《Python for R Users》以及其他 4 本数据科学书籍的作者。
相关:
-
Dataproc 上的 Apache Spark 与 Google BigQuery 比较
-
使用 Kubernetes 对 PySpark 进行容器化
-
数据科学的 5 个 Apache Spark 最佳实践
更多相关主题
Spark SQL 用于实时分析
原文:
www.kdnuggets.com/2015/09/spark-sql-real-time-analytics.html
由 Sumit Pal 和 Ajit Jaokar 编写,(FutureText)。
本文是即将推出的物联网数据科学从业者课程在伦敦的一部分。如果你想成为物联网的数据科学家,这个密集课程非常适合你。我们涵盖了传感器融合、时间序列、深度学习等复杂领域。我们使用 Apache Spark、R 语言以及领先的物联网平台。有关更多信息,请联系 info@futuretext.com。
概述
这是讨论 Spark 在物联网实时分析中使用 SQL 的 3 部分系列文章的第一部分。第一部分讨论了使用 Spark 的 SQL 的技术基础。第二部分讨论了使用 Spark SQL 进行实时分析。最后,第三部分讨论了一个物联网实时分析的用例。
介绍
在第一部分中,我们讨论了 Spark SQL 以及为什么它是实时分析的首选方法。Spark SQL 是 Apache Spark 中的一个模块,它将关系处理与 Spark 的函数式编程 API 集成。自 1.0 版本以来,Spark SQL 就是 Spark Core 的一部分。它可以与现有的 Hive 部署并行运行 HiveQL/SQL,或替代现有的 Hive 部署。它可以连接到现有的 BI 工具。它在 Python、Scala 和 Java 中都有绑定。它为框架提供了两个重要的补充。首先,它提供了关系和过程处理之间的紧密集成,具有与过程式 Spark API 集成的声明性 DataFrame API。其次,它包括一个可扩展的优化器,使用 Scala 构建,利用其强大的模式匹配能力,使得添加可组合规则、控制代码生成和定义扩展变得容易。
Spark SQL 的目标和目标
尽管关系方法已被应用于解决大数据问题,但它对许多大数据应用来说仍然不够充分。直到最近,关系和过程方法一直保持分离,迫使开发人员选择其中一种范式。Spark SQL 框架结合了这两种模型。
正如他们所说,“读取数据的最快方式就是根本不读取它”。
Spark SQL 支持在 Spark 程序(通过 RDDs)和外部数据源上的关系处理。它可以轻松支持新的数据源,包括半结构化数据和适用于查询联合的外部数据库。
Spark SQL 通过以下方式帮助这一理念
-
通过使用各种列式格式将数据转换为更高效的格式(从存储、网络和 IO 的角度来看)
-
使用数据分区
-
使用数据统计跳过数据读取
-
将谓词推送到存储系统
-
尽可能晚地优化,直到获取有关数据管道的所有信息
在内部,Spark SQL 和 DataFrame 利用 Catalyst 查询优化器智能地规划查询的执行。
Spark SQL
Spark SQL 可以支持批处理或流处理 SQL。使用 RDDs,核心 Spark 框架支持批处理工作负载。RDD 可以指向静态数据集,Spark 的丰富 API 可用于操作在内存中以惰性求值处理的批数据集。
流处理 + SQL 和 DataFrames
让我们快速了解一下在 Spark 核心框架中什么是 RDD,什么是 DStream,这些是本文讨论的基本构建块。
Spark 在 RDDs(弹性分布式数据集)上操作,这是一种内存中的数据结构。每个 RDD 代表数据的一部分,这些数据被分区到集群中的数据节点。RDD 是不可变的,当应用变换时会创建新的 RDD。RDDs 在并行中操作,使用诸如映射、过滤等变换/操作。这些操作在所有分区上同时进行。RDDs 是弹性的,如果由于节点崩溃而丢失某个分区,可以从原始来源重建它。
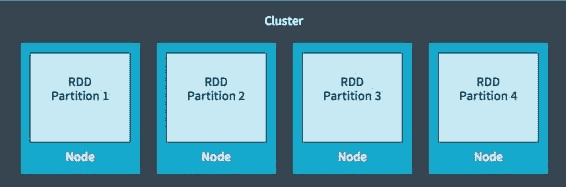
Spark Streaming 提供了一种称为 DStream(离散流)的抽象,它是一个连续的数据流。DStreams 可以从输入数据流或 Kafka、Flume 等源创建,或通过对其他 DStreams 应用操作创建。DStream 本质上是 RDD 的序列。
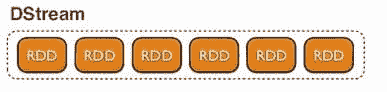
由 DStreams 生成的 RDD 可以转换为 DataFrames 并使用 SQL 查询。该流可以通过 Spark 的 JDBC 驱动程序暴露给任何外部应用程序,进行 SQL 查询。流数据的批次存储在 Spark 的工作内存中,可以通过 SQL 或 Spark 的 API 进行交互式查询。
StreamSQL 是一个 Spark 组件,它结合了 Catalyst 和 Spark Streaming 来对 DStreams 执行 SQL 查询。StreamSQL 扩展了 SQL 以支持流,具有以下操作:
-
对流进行 SELECT 以计算函数或筛选不需要的数据(使用 WHERE 子句)
-
将流与一个或多个数据集进行 JOIN,以生成新的流。
-
窗口化和聚合 – 流可以被限制以创建有限的数据集。窗口化允许基于字段值的复杂消息选择。一旦创建了有限的批次,可以应用分析。
Spark SQL 具有以下组件
组件
Spark SQL 核心
-
以 RDD 执行查询
-
读取多种文件格式的数据集,如 Parquet、JSON、Avro 等。
-
读取 SQL 和 NOSQL 数据源
Hive 支持
- HQL、MetaStore、SerDes、UDFs
Catalyst 优化器
-
它优化了关系代数 + 表达式
-
它进行查询优化。
Spark SQL 解决的问题
Spark SQL 提供了一个统一的框架,无需将数据移出集群。无需安装或集成额外的模块。它提供了一个统一的加载/保存接口,无论数据源和编程语言是什么。
下面的示例显示了从 avro 加载数据并将其转换为 parquet 是多么简单。
val df = sqlContext.load("mydata.avro", "com.databricks.spark.avro") df.save("mydata.parquet", "parquet")
Spark SQL 具有统一的框架来解决批处理和流处理中的相同分析问题,这一直是数据处理中的圣杯。已有框架可以很好地处理其中之一,并在可扩展性、性能和功能集方面表现良好,但在 Spark / Spark SQL 之前,拥有一个同时处理批处理和流处理的统一框架是不可行的。通过 Spark 框架,相同的代码(逻辑)可以用于批处理数据 – RDDs 或流处理数据集(DStreams – 离散化流)。DStream 只是一系列的 RDDs。这种表示方式允许批处理和流处理工作负载无缝工作。这大大减少了代码维护开销,并减少了对两种不同技能集的开发者的培训需求。
从 JDBC 数据源读取
从 JDBC 读取的数据源已作为 Spark SQL 的内置数据源添加。Spark SQL 可以从任何支持 JDBC 的现有关系数据库中提取数据。示例包括 mysql、postgres、H2 等。从这些系统中的一个读取数据就像创建指向外部表的虚拟表一样简单。然后,可以轻松地读取该表的数据,并与 Spark SQL 支持的任何其他数据源进行联接。
Spark SQL 与数据框架
数据框架是分布式的行集合,按命名列组织,是一种选择、过滤、聚合和绘制结构化数据的抽象 – 之前称为 SchemaRDD。
DataFrame API 可以对外部数据源和 Spark 的内置分布式集合执行关系操作。
DataFrame 在 Spark 程序中提供了丰富的关系/过程集成功能。DataFrames 是结构化记录的集合,可以使用 Spark 的过程 API 进行操作,或者使用新的关系 API 进行更丰富的优化。它们可以直接从 Spark 的内置分布式对象集合中创建,从而在现有的 Spark 中进行关系处理。
DataFrames 比 Spark 的过程 API 更方便和高效。它们使得使用 SQL 语句在一次操作中计算多个聚合变得容易,这在传统的函数式 API 中很难表达。
与 RDDs 不同,DataFrames 会跟踪其模式并支持各种关系操作,从而实现更优化的执行。它们通过反射推断模式。
Spark DataFrames 是惰性的,每个 DataFrame 对象表示一个计算数据集的逻辑计划,但在用户调用特殊的“输出操作”如保存之前不会执行。这使得所有操作能够进行丰富的优化。
DataFrames 使 Spark 的 RDD 模型得以演变,提供简化的方法来过滤、聚合和投影大数据集,从而使 Spark 开发者更快、更容易地处理结构化数据。DataFrames 可在 Spark 的 Java、Scala 和 Python API 中使用。
Spark SQL 的数据源 API 可以从各种数据源和数据格式中读取和写入 DataFrames——包括 Avro、parquet、ORC、JSON、H2。
减少代码编写的示例——使用普通 RDDs 和 DataFrame API 的 SQL
以下的 Scala 示例展示了等效的代码——一个使用 Spark 的 RDD API,另一个使用 Spark 的 DataFrame API。我们有一个对象——People——包括 firstname、lastname、age 作为属性,目标是获取按 firstname 分组的年龄基本统计数据。
case class People(firstname: String, lastname: String, age: Intger) val people = rdd.map(p => (people.firstname, people.age)).cache()
// RDD 代码 val minAgeByFN = people.reduceByKey( scala.math.min(_, _) ) val maxAgeByFN = people.reduceByKey( scala.math.max(_, _) ) val avgAgeByFN = people.mapValues(x => (x, 1)) .reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)) val countByFN = people.mapValues(x => 1).reduceByKey(_ + _)
// Data Frame 代码 df = people.toDF people = df.groupBy("firstname").agg( min("age"), max("age"), avg("age"), count("*"))
由于 Catalyst 优化器,DataFrames 比使用普通 RDDs 更快。DataFrames 提供与 SQL 和 Pig 等关系查询语言相同的操作。
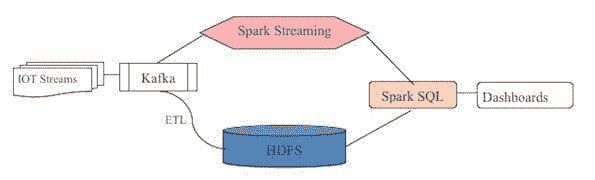
使用 Spark SQL 解决流式分析的方案
下图展示了我们使用 Spark SQL 进行实时分析的方法。这遵循了构建实时分析系统的 Lambda 架构模式,适用于大规模流数据。
Spark SQL 的缺点
与任何运行在 Hadoop 集群上的工具一样——服务水平协议(SLA)并不依赖于引擎的速度——而是依赖于系统上运行的其他并发用户的数量。
对于初次使用者来说,Spark SQL 代码有时过于简洁,难以理解正在做什么。需要一些经验和实践来习惯 Spark SQL 代码的编码风格和隐式性。
结论
Spark SQL 是核心 Spark API 的重要进化。尽管 Spark 的原始函数式编程 API 相当通用,但它仅提供了有限的自动优化机会。Spark SQL 使 Spark 更加易于使用。
本文旨在为下一组文章奠定基础,这些文章将探讨在物联网领域使用 Spark SQL 进行实时分析。
参考文献:
StreamSQL – en.wikipedia.org/wiki/StreamSQL
StreamSQL – github.com/thunderain-project/StreamSQL
简历: Sumit Pal 是一位大数据、可视化和数据科学顾问。他还是一名软件架构师和大数据爱好者,构建端到端的数据驱动分析系统。Sumit 曾在微软(SQL 服务器开发团队)、甲骨文(OLAP 开发团队)和 Verizon(大数据分析团队)工作,拥有 22 年的职业生涯。目前,他为多个客户提供数据架构和大数据解决方案的建议,并进行 Spark、Scala、Java 和 Python 的实际编码。Sumit 在 sumitpal.wordpress.com/ 撰写博客。
Ajit Jaokar (@AjitJaokar) 从事数据科学和物联网的研究与咨询。他的工作基于他在牛津大学和马德里理工大学的教学,涵盖了物联网、数据科学、智能城市和电信领域。
相关内容:
-
使用 Apache Spark 介绍大数据
-
50+ 数据科学和机器学习备忘单
-
大数据的“重大”问题:Hadoop 还是 Spark?
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 部门
更多相关内容
85%的数据科学项目失败——以下是如何避免
原文:
www.kdnuggets.com/2021/09/sparkbeyond-avoid-data-science-projects-fail.html
赞助文章。
由 Sparkbeyond 提供。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的信息技术
85%的数据科学项目失败。那么你如何避免成为这一统计数据的一部分?这里有一些数据科学家可以避免的常见陷阱。
1. 超越预测
毫无疑问,预测建模是数据科学的一大优势——特别是在我们知道结果超出我们控制范围的情况下,预测成为唯一的选择。但是,为什么要将数据科学仅限于预测呢?
例如,我们是否应该简单地接受客户流失的事实,并对那些最有风险的客户提供保留优惠?还是我们应该了解人们为何可能流失,并让他们一开始就成为更满意的客户?
我们需要超越仅仅构建预测模型,深入挖掘潜在驱动因素。显然,这比构建模型要复杂得多,因为发现开放性问题的根本原因远比构建模型要复杂。如果你想塑造未来而不是被未来塑造,你需要发现驱动你问题的因素。
2. 你知道你想知道什么吗?
将商业问题转化为数据科学用例时,第一个问题通常是:“我的目标变量是什么?”这个问题并不像你想的那么简单。
常见的分析用例通常有多个角度。例如,以保险索赔为例。我们希望了解哪些索赔总体上风险较低,可以加速处理。此外,我们还想知道哪些需要通过其他保险公司进行分诊,或者哪些可能没有保障。每个目标通常有不同的驱动因素,使用传统方法,探索五个用例将需要付出五倍的努力。为了创造可持续的业务影响,这还不够。
3. 今天有效的东西明天可能无关紧要
疫情的波动暴露了一个众所周知的问题,即仅仅对最新数据进行模型重新校准。重新校准只能使你的模型正确解读呈现给它们的信息——这些信息是由数据科学家提供的特征中编码的。但那些在过去被丢弃或忽视的信息呢?因为在过去,它们并不重要。
尽管上述问题看起来各不相同,但有一种方法可以提供解决方案:利用人工智能大规模生成假设。
进一步阅读
处理机器学习模型中的稀疏特征
原文:
www.kdnuggets.com/2021/01/sparse-features-machine-learning-models.html

什么是稀疏特征?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 加速进入网络安全领域的职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
稀疏数据的特征是那些大多数值为零的特征。这与缺失数据的特征不同。稀疏特征的例子包括一热编码词的向量或类别数据的计数。另一方面,稠密数据的特征则主要具有非零值。
稀疏数据和缺失数据有什么区别?
当数据缺失时,意味着许多数据点是未知的。另一方面,如果数据是稀疏的,则所有数据点都是已知的,但其中大多数值为零。
为了说明这一点,有两种特征类型。稀疏数据的特征有已知的值(= 0),但缺失数据的特征有未知的值(= null)。无法知道应该在 null 值的行中填入什么值。
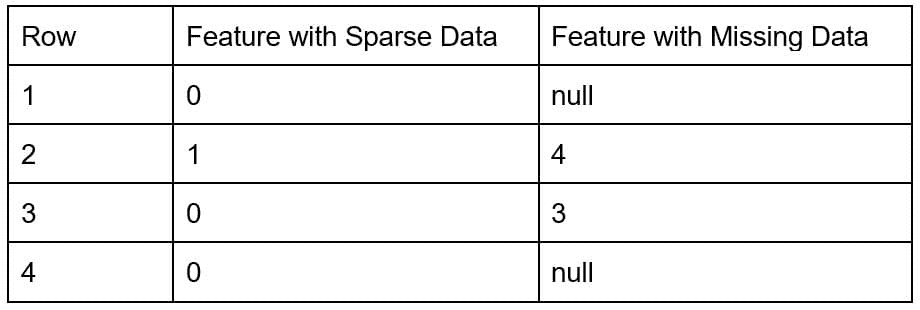
表 1. 两种特征类型的示例数据。
为什么稀疏特征使机器学习变得困难?
稀疏特征常见的问题包括:
-
如果模型具有许多稀疏特征,这将增加模型的空间和时间复杂度。线性回归模型将拟合更多的系数,而基于树的模型将具有更大的深度以考虑所有特征。
-
如果特征具有稀疏数据,模型算法和诊断措施可能会表现出未知的行为。Kuss [2002] 表明,当数据稀疏时,拟合优度检验是有缺陷的。
-
如果特征过多,模型会拟合训练数据中的噪声。这称为过拟合。当模型过拟合时,当投入生产时,它们无法对新数据进行泛化。这会对模型的预测能力产生负面影响。
-
一些模型可能低估稀疏特征的重要性,偏爱较密集的特征,即使稀疏特征可能具有预测能力。基于树的模型尤其容易出现这种情况。例如,随机森林会过高估计具有更多类别的特征的重要性,而忽略那些类别较少的特征。
处理稀疏特征的方法
1. 从模型中移除特征
稀疏特征可能会引入噪声,模型会捕捉到这些噪声并增加模型的内存需求。为了解决这个问题,可以将这些特征从模型中移除。例如,在文本挖掘模型中去除稀有词,或者 移除低方差的特征。然而,具有重要信号的稀疏特征在这个过程中不应被移除。
LASSO 正则化可以用来减少特征的数量。基于规则的方法,例如设置特征的方差阈值,也可能会有帮助。
2. 使特征密集
-
主成分分析(PCA):PCA 方法可以将特征投影到主成分的方向上,并从最重要的主成分中选择。
-
特征哈希:在特征哈希中,稀疏特征可以使用哈希函数分配到所需数量的输出特征中。需要小心选择足够多的输出特征以防止哈希碰撞。
3. 使用对稀疏特征具有鲁棒性的模型
一些版本的机器学习模型对稀疏数据具有鲁棒性,可以用来代替改变数据的维度。例如,熵加权 k-means 算法比常规的 k-means 算法更适合这个问题。
结论
稀疏特征在机器学习模型中很常见,特别是在 one-hot 编码形式中。这些特征可能会导致机器学习模型出现过拟合、特征重要性不准确和高方差等问题。建议通过特征哈希或移除特征等方法对稀疏特征进行预处理,以减少对结果的负面影响。
Arushi Prakash 博士 是亚马逊的一名应用科学家,她在劳动力分析领域解决令人兴奋的科学挑战。在获得化学工程博士学位后,她转向数据科学。她喜欢写作、演讲和阅读有关科学、职业发展和领导力的内容。
更多相关话题
Python 中的稀疏矩阵表示
原文:
www.kdnuggets.com/2020/05/sparse-matrix-representation-python.html
大多数机器学习从业者习惯于在将数据输入机器学习算法之前采用矩阵表示法。矩阵是理想的形式,通常行表示数据集实例,列表示特征。
稀疏矩阵是大多数元素为零的矩阵。这与密集矩阵相对,后者的区分特征你现在可能已经能自己弄明白了。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
图片来源:TU 柏林
我们的数据通常是密集的,每个实例的特征列都被填满。如果我们使用有限数量的列来全面描述某些事物,一般来说,给定数据点的描述值需要充分发挥作用,以提供有意义的表示:一个人、一张图片、一朵鸢尾花、房价、潜在的信用风险。
但有些类型的数据在其表示中并不需要如此冗长。想想关系。我们可能需要捕捉大量潜在事物的关系状态,但在这些事物的交集处,我们可能只需记录“是的,有关系”或“不是,没有关系”。
这个人是否购买了那个物品?那句话中是否包含这个词?在任何给定的句子中可能出现很多潜在的词,但实际出现的词却不多。同样,虽然市场上可能有很多销售的物品,但任何一个人实际上购买的物品却不多。
这是稀疏矩阵在机器学习中发挥作用的一种方式。想象一下列代表销售项,行代表购物者。在每个给定项没有被给定购物者购买的交集处,将有一个“无”(空)表示,比如 0. 只有在给定购物者购买了给定项的交集处才需要有“是”表示,比如 1. 对于给定句子中的单词出现情况也是如此。你可以看到为什么这样的矩阵会包含很多零,即它们会是稀疏的。
稀疏矩阵的一个问题是它们可能会对内存造成很大的压力。假设你采用标准的方法来表示一个 2x2 矩阵,那么每个空的表示都需要在内存中分配,尽管没有捕捉到有用的信息。这种内存压力还会持续到永久存储中。在标准的矩阵表示方法中,我们被迫记录事物的缺失,而不仅仅是存在。
但等等,一定还有更好的方法!
确实有。稀疏矩阵不必以标准矩阵形式表示。有很多方法可以缓解这种标准形式对计算系统的压力,而恰好在流行的 Python 机器学习工具包 Scikit-learn 中,一些算法接受这些稀疏表示作为输入。熟悉这些方法可以节省你的时间、麻烦和精力。
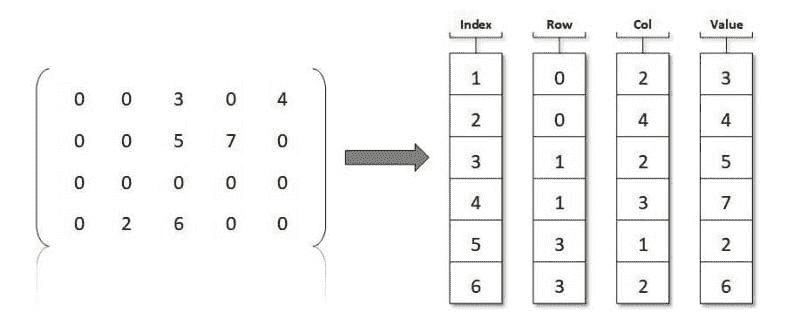
我们如何更好地表示这些稀疏矩阵?我们需要一种方式来跟踪零值不在的位置。怎样用一个两列的表格,其中一列跟踪row,col(行,列)位置的非零项,另一列记录对应的值?请记住,稀疏矩阵不必仅仅包含零和一;只要大多数元素是零,无论非零元素是什么,矩阵就是稀疏的。
我们还需要确定创建稀疏矩阵的顺序——是逐行处理,每遇到一个非零元素就存储它,还是逐列处理?如果决定逐行处理,恭喜你,你刚刚创建了一个压缩稀疏行矩阵。如果逐列处理,你现在拥有的是一个压缩稀疏列矩阵。方便的是,Scipy 支持这两种方法。
让我们来看一下如何创建这些矩阵。首先,我们在 Numpy 中创建一个简单的矩阵。
import numpy as np
from scipy import sparse
X = np.random.uniform(size=(6, 6))
print(X)
[[0.79904211 0.76621075 0.57847599 0.72606798 0.10008544 0.90838851]
[0.45504345 0.10275931 0.0191763 0.09037216 0.14604688 0.02899529]
[0.92234613 0.78231698 0.43204239 0.61663291 0.78899765 0.44088739]
[0.50422356 0.72221353 0.57838041 0.30222171 0.25263237 0.55913311]
[0.191842 0.07242766 0.17230918 0.31543582 0.90043157 0.8787012 ]
[0.71360049 0.45130523 0.46687117 0.96148004 0.56777938 0.40780967]]
然后我们需要将大多数矩阵元素置为零,使其变为稀疏矩阵。
X[X < 0.7] = 0
print(X)
[[0.79904211 0.76621075 0\. 0.72606798 0\. 0.90838851]
[0\. 0\. 0\. 0\. 0\. 0\. ]
[0.92234613 0.78231698 0\. 0\. 0.78899765 0\. ]
[0\. 0.72221353 0\. 0\. 0\. 0\. ]
[0\. 0\. 0\. 0\. 0.90043157 0.8787012 ]
[0.71360049 0\. 0\. 0.96148004 0\. 0\. ]]
现在我们将标准矩阵 X 存储为压缩稀疏行矩阵。为此,元素按照从左到右的顺序逐行遍历,并在遇到时输入到这个压缩矩阵表示中。
X_csr = sparse.csr_matrix(X)
print(X_csr)
(0, 0) 0.799042106215471
(0, 1) 0.7662107548809229
(0, 3) 0.7260679774297479
(0, 5) 0.9083885095042665
(2, 0) 0.9223461264672205
(2, 1) 0.7823169848589594
(2, 4) 0.7889976504606654
(3, 1) 0.7222135307432606
(4, 4) 0.9004315651436953
(4, 5) 0.8787011979799789
(5, 0) 0.7136004887949333
(5, 3) 0.9614800409505844
瞧!
那么压缩稀疏列矩阵怎么样呢?在其创建过程中,元素按照从上到下的顺序逐列遍历,并在遇到时输入到压缩表示中。
X_csc = sparse.csc_matrix(X)
print(X_csc)
(0, 0) 0.799042106215471
(2, 0) 0.9223461264672205
(5, 0) 0.7136004887949333
(0, 1) 0.7662107548809229
(2, 1) 0.7823169848589594
(3, 1) 0.7222135307432606
(0, 3) 0.7260679774297479
(5, 3) 0.9614800409505844
(2, 4) 0.7889976504606654
(4, 4) 0.9004315651436953
(0, 5) 0.9083885095042665
(4, 5) 0.8787011979799789
注意结果稀疏矩阵表示之间的差异,特别是相同元素值的位置差异。
如前所述,许多 Scikit-learn 算法接受形状为 [num_samples, num_features] 的 scipy.sparse 矩阵作为 Numpy 数组的替代,因此目前没有迫切需要将它们转换回标准的 Numpy 表示形式。也可能存在内存限制阻止这种转换(回想一下,这是采用这种方法的主要原因之一)。但为了演示,以下是如何将稀疏的 Scipy 矩阵表示转换回 Numpy 多维数组。
print(X_csr.toarray())
[[0.79904211 0.76621075 0\. 0.72606798 0\. 0.90838851]
[0\. 0\. 0\. 0\. 0\. 0\. ]
[0.92234613 0.78231698 0\. 0\. 0.78899765 0\. ]
[0\. 0.72221353 0\. 0\. 0\. 0\. ]
[0\. 0\. 0\. 0\. 0.90043157 0.8787012 ]
[0.71360049 0\. 0\. 0.96148004 0\. 0\. ]]
那么两种表示方式之间的内存需求差异呢?让我们再次通过这个过程,从一个更大的标准 Numpy 矩阵开始,然后计算每种表示方式所使用的内存(以字节为单位)。
import numpy as np
from scipy import sparse
X = np.random.uniform(size=(10000, 10000))
X[X < 0.7] = 0
X_csr = sparse.csr_matrix(X)
print(f"Size in bytes of original matrix: {X.nbytes}")
print(f"Size in bytes of compressed sparse row matrix: {X_csr.data.nbytes + X_csr.indptr.nbytes + X_csr.indices.nbytes}")
Size in bytes of original matrix: 800000000
Size in bytes of compressed sparse row matrix: 360065312
在这里你可以看到,压缩矩阵形式相比标准 Numpy 表示方式在内存上的显著节省,大约 360 兆字节对比 800 兆字节。这节省了 440 兆字节,并且几乎没有时间开销,因为格式之间的转换经过高度优化。显然,这些稀疏的 SciPy 矩阵也可以直接创建,从而节省了中间内存消耗的步骤。
现在想象一下你正在处理一个庞大的数据集,并考虑通过正确使用稀疏矩阵格式所能享受的内存节省(以及相关的存储和处理时间)。
Matthew Mayo (@mattmayo13) 是数据科学家和 KDnuggets 的总编辑,KDnuggets 是开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及自动化机器学习方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他的联系方式是 editor1 at kdnuggets[dot]com。
相关话题更多内容
使用 Wav2Vec 2.0 进行语音转文本
评论
由 Dhilip Subramanian,数据科学家和 AI 爱好者
在我之前的博客中,我解释了如何使用 Speech Recognition 库和 Google 语音识别 API 将语音转换为文本。在本博客中,我们将探讨如何使用 Facebook Wav2Vec 2.0 模型将语音转换为文本。
Facebook 最近推出并 开源了他们的新框架,用于从原始音频数据中自监督学习表示,称为 Wav2Vec 2.0。Facebook 研究人员声称,这个框架可以使 自动语音识别模型 仅凭 10 分钟的转录语音数据实现。
众所周知,Transformers 在自然语言处理中的作用重大。Hugging Face transformers 的最新版本是 4.30,它包含了 Wav2Vec 2.0。这是 Transformers 中首个包含的自动语音识别模型。
模型架构超出了本博客的范围。有关详细的 Wav2Vec 模型架构,请查看 这里。
让我们看看如何使用 Hugging Face transformers 通过一些简单的代码将音频文件转换为文本。
安装 Transformer 库
# Installing Transformer
!pip install -q transformers
导入必要的库
# Import necessary library
# For managing audio file
import librosa
#Importing Pytorch
import torch
#Importing Wav2Vec
from transformers import Wav2Vec2ForCTC, Wav2Vec2Tokenizer
Wav2Vec2 是一个语音模型,它接受一个浮点数组,该数组对应于语音信号的原始波形。Wav2Vec2 模型使用连接时序分类(CTC)进行训练,因此模型输出需要使用 Wav2Vec2Tokenizer 进行解码(参考: Hugging Face)
阅读音频文件
在这个示例中,我使用了来自电影《Taken》的 Liam Neeson 著名对话音频片段,其中说 “我会找你,我会找到你,我会杀了你”
请注意,Wav2Vec 模型是在 16 kHz 频率下预训练的,因此我们需要确保我们的原始音频文件也被重采样为 16 kHz 采样率。我使用了在线 音频工具转换 将“Taken”音频片段重采样为 16kHz。
使用 librosa 库加载音频文件,并提到我的音频片段大小为 16000 Hz。它将音频片段转换为数组,并存储到‘audio’变量中。
# Loading the audio file
audio, rate = librosa.load("taken_clip.wav", sr = 16000)
# printing audio
print(audio)
array([0., 0., 0., ..., 0., 0., 0.], dtype=float32)
# printing rate
print(rate)
16000
导入预训练的 Wav2Vec 模型
# Importing Wav2Vec pretrained model
tokenizer = Wav2Vec2Tokenizer.from_pretrained("facebook/wav2vec2-base-960h")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h")
下一步是获取输入值,将音频(数组)传递给分词器,并希望我们的张量采用 PyTorch 格式而不是 Python 整数。return_tensors = “pt” 仅仅是 PyTorch 格式。
# Taking an input value
input_values = tokenizer(audio, return_tensors = "pt").input_values
获取 logits 值(非标准化值)
# Storing logits (non-normalized prediction values)
logits = model(input_values).logits
将 logits 值传递给 softmax 以获取预测值
# Storing predicted ids
prediction = torch.argmax(logits, dim = -1)
将音频转换为文本
最后一步是将预测结果传递给分词器解码器以获取转录文本
# Passing the prediction to the tokenzer decode to get the transcription
transcription = tokenizer.batch_decode(prediction)[0]
# Printing the transcription
print(transcription)
'I WILL LOOK FOR YOU I WILL FIND YOU AND I WILL KILL YOU'
它完全匹配我们的音频片段。
在这篇博客中,我们了解了如何使用 Transformers 中的预训练 Wav2Vec 模型将语音转换为文本。这对 NLP 项目尤其是处理音频转录数据非常有帮助。如果你有任何补充,请随时留言!
你可以在我的 GitHub 仓库 中找到完整的代码和数据。
感谢阅读。继续学习,敬请关注更多内容!
参考
简介:Dhilip Subramanian 是一名机械工程师,已完成分析学硕士学位。他在数据相关的多个领域拥有 9 年的经验,包括 IT、市场营销、银行、电力和制造业。他对 NLP 和机器学习充满热情。他是SAS 社区的贡献者,喜欢在 Medium 平台上撰写有关数据科学各个方面的技术文章。
原文。经许可转载。
相关:
-
使用 Python 进行简单的语音转文本
-
入门 5 个必备的自然语言处理库
-
Hugging Face Transformers 包 – 这是什么,如何使用
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关主题
如何使用索引加速 SQL 查询 [Python 版]
原文:
www.kdnuggets.com/2023/08/speed-sql-queries-indexes-python-edition.html
![如何使用索引加速 SQL 查询 [Python 版]](../Images/6dd7f74dcf25f10a17a48f0c17ae157a.png)
图片由作者提供
假设你在翻阅一本书的页面。你想更快地找到你正在寻找的信息。你会怎么做?你可能会查找术语的索引,然后跳到引用特定术语的页面。SQL 中的索引 与书籍中的索引类似。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在的组织 IT
在大多数实际系统中,你会对包含大量行(比如数百万行)的数据库表运行查询。需要对所有行进行全表扫描以检索结果的查询会非常慢。如果你知道经常需要基于某些列查询信息,你可以在这些列上创建数据库索引。这将显著加快查询速度。
那么今天我们将学习什么?我们将学习如何在 Python 中连接和查询 SQLite 数据库—使用 sqlite3 模块。我们还将学习如何添加索引以及如何提升性能。
要跟随本教程进行编码,你的工作环境中应安装 Python 3.7+ 和 SQLite。
注意:本教程中的示例和输出样本适用于 Ubuntu LTS 22.04 上的 Python 3.10 和 SQLite3(版本 3.37.2)。
在 Python 中连接到数据库
我们将使用 内置的 sqlite3 模块。在开始运行查询之前,我们需要:
-
连接到数据库
-
创建一个数据库游标来运行查询
连接到数据库时,我们将使用来自 sqlite3 模块的 connect() 函数。一旦建立连接,我们可以在连接对象上调用 cursor() 来创建一个数据库游标,如下所示:
import sqlite3
# connect to the db
db_conn = sqlite3.connect('people_db.db')
db_cursor = db_conn.cursor()
在这里我们尝试连接到数据库 people_db。如果数据库不存在,运行上述代码片段将为我们创建 SQLite 数据库。
创建表格并插入记录
现在,我们将在数据库中创建一个表格,并填充记录。
让我们在 people_db 数据库中创建一个名为 people 的表格,包含以下字段:
-
name
-
email
-
job
# main.py
...
# create table
db_cursor.execute('''CREATE TABLE people (
id INTEGER PRIMARY KEY,
name TEXT,
email TEXT,
job TEXT)''')
...
# commit the transaction and close the cursor and db connection
db_conn.commit()
db_cursor.close()
db_conn.close()
使用 Faker 生成合成数据
现在我们必须将记录插入到表中。为此,我们将使用 Faker——一个用于合成数据生成的 Python 包——通过 pip 安装:
$ pip install faker
安装 faker 后,你可以将 Faker 类导入到 Python 脚本中:
# main.py
...
from faker import Faker
...
下一步是生成并插入记录到 people 表中。为了让我们了解索引如何加速查询,让我们插入大量记录。在这里,我们将插入 100K 条记录;将 num_records 变量设置为 100000。
然后,我们做以下操作:
-
实例化一个
Faker对象fake并设置种子,以确保结果的可重现性。 -
使用名字和姓氏——通过在
fake对象上调用first_name()和last_name()——获取一个姓名字符串。 -
通过调用
domain_name()生成一个虚假的域名。 -
使用名字和姓氏以及域名生成电子邮件字段。
-
使用
job()为每个记录获取一个工作。
我们生成并插入记录到 people 表中:
# create and insert records
fake = Faker() # be sure to import: from faker import Faker
Faker.seed(42)
num_records = 100000
for _ in range(num_records):
first = fake.first_name()
last = fake.last_name()
name = f"{first} {last}"
domain = fake.domain_name()
email = f"{first}.{last}@{domain}"
job = fake.job()
db_cursor.execute('INSERT INTO people (name, email, job) VALUES (?,?,?)', (name,email,job))
# commit the transaction and close the cursor and db connection
db_conn.commit()
db_cursor.close()
db_conn.close()
现在 main.py 文件包含以下代码:
# main.py
# imports
import sqlite3
from faker import Faker
# connect to the db
db_conn = sqlite3.connect('people_db.db')
db_cursor = db_conn.cursor()
# create table
db_cursor.execute('''CREATE TABLE people (
id INTEGER PRIMARY KEY,
name TEXT,
email TEXT,
job TEXT)''')
# create and insert records
fake = Faker()
Faker.seed(42)
num_records = 100000
for _ in range(num_records):
first = fake.first_name()
last = fake.last_name()
name = f"{first} {last}"
domain = fake.domain_name()
email = f"{first}.{last}@{domain}"
job = fake.job()
db_cursor.execute('INSERT INTO people (name, email, job) VALUES (?,?,?)', (name,email,job))
# commit the transaction and close the cursor and db connection
db_conn.commit()
db_cursor.close()
db_conn.close()
运行这个脚本——一次——以用 num_records 数量的记录填充表格。
查询数据库
现在我们有了包含 100K 记录的表格,让我们对 people 表运行一个示例查询。
让我们运行一个查询来:
-
获取工作职位为 ‘Product manager’ 的记录的姓名和电子邮件,
-
将查询结果限制为 10 条记录。
我们将使用 time 模块的默认计时器来获取查询的大致执行时间。
# sample_query.py
import sqlite3
import time
db_conn = sqlite3.connect("people_db.db")
db_cursor = db_conn.cursor()
t1 = time.perf_counter_ns()
db_cursor.execute("SELECT name, email FROM people WHERE job='Product manager' LIMIT 10;")
res = db_cursor.fetchall()
t2 = time.perf_counter_ns()
print(res)
print(f"Query time without index: {(t2-t1)/1000} us")
这是输出结果:
Output >>
[
("Tina Woods", "Tina.Woods@smith.com"),
("Toni Jackson", "Toni.Jackson@underwood.com"),
("Lisa Miller", "Lisa.Miller@solis-west.info"),
("Katherine Guerrero", "Katherine.Guerrero@schmidt-price.org"),
("Michelle Lane", "Michelle.Lane@carr-hardy.com"),
("Jane Johnson", "Jane.Johnson@graham.com"),
("Matthew Odom", "Matthew.Odom@willis.biz"),
("Isaac Daniel", "Isaac.Daniel@peck.com"),
("Jay Byrd", "Jay.Byrd@bailey.info"),
("Thomas Kirby", "Thomas.Kirby@west.com"),
]
Query time without index: 448.275 us
你还可以通过在命令行中运行 sqlite3 db_name 来调用 SQLite 命令行客户端:
$ sqlite3 people_db.db
SQLite version 3.37.2 2022-01-06 13:25:41
Enter ".help" for usage hints.
要获取索引列表,你可以运行 .index:
sqlite> .index
由于当前没有索引,所以不会列出任何索引。
你还可以这样检查查询计划:
sqlite> EXPLAIN QUERY PLAN SELECT name, email FROM people WHERE job='Product Manager' LIMIT 10;
QUERY PLAN
`--SCAN people
这里的查询计划是 扫描所有行,这效率较低。
在特定列上创建索引
要在特定列上创建数据库索引,你可以使用以下语法:
CREATE INDEX index-name on table (column(s))
假设我们需要频繁查找具有特定职位名称的个人记录。创建一个 people_job_index 索引在 job 列上会有所帮助:
# create_index.py
import time
import sqlite3
db_conn = sqlite3.connect('people_db.db')
db_cursor =db_conn.cursor()
t1 = time.perf_counter_ns()
db_cursor.execute("CREATE INDEX people_job_index ON people (job)")
t2 = time.perf_counter_ns()
db_conn.commit()
print(f"Time to create index: {(t2 - t1)/1000} us")
Output >>
Time to create index: 338298.6 us
尽管创建索引需要这么长时间,但这只是一次性操作。当运行多个查询时,你仍然会获得显著的加速。
现在如果你在 SQLite 命令行客户端运行 .index,你将得到:
sqlite> .index
people_job_index
使用索引查询数据库
如果你现在查看查询计划,你应该能够看到我们现在使用 job 列上的索引 people_job_index 来搜索 people 表:
sqlite> EXPLAIN QUERY PLAN SELECT name, email FROM people WHERE job='Product manager' LIMIT 10;
QUERY PLAN
`--SEARCH people USING INDEX people_job_index (job=?)
你可以重新运行 sample_query.py。只需修改 print() 语句,看看查询现在需要多长时间:
# sample_query.py
import sqlite3
import time
db_conn = sqlite3.connect("people_db.db")
db_cursor = db_conn.cursor()
t1 = time.perf_counter_ns()
db_cursor.execute("SELECT name, email FROM people WHERE job='Product manager' LIMIT 10;")
res = db_cursor.fetchall()
t2 = time.perf_counter_ns()
print(res)
print(f"Query time with index: {(t2-t1)/1000} us")
这是输出结果:
Output >>
[
("Tina Woods", "Tina.Woods@smith.com"),
("Toni Jackson", "Toni.Jackson@underwood.com"),
("Lisa Miller", "Lisa.Miller@solis-west.info"),
("Katherine Guerrero", "Katherine.Guerrero@schmidt-price.org"),
("Michelle Lane", "Michelle.Lane@carr-hardy.com"),
("Jane Johnson", "Jane.Johnson@graham.com"),
("Matthew Odom", "Matthew.Odom@willis.biz"),
("Isaac Daniel", "Isaac.Daniel@peck.com"),
("Jay Byrd", "Jay.Byrd@bailey.info"),
("Thomas Kirby", "Thomas.Kirby@west.com"),
]
Query time with index: 167.179 us
我们看到查询现在执行大约需要 167.179 微秒。
性能改进
对于我们的示例查询,使用索引查询大约快 2.68 倍。我们在执行时间上获得了 62.71% 的百分比加速。
你还可以尝试运行更多查询:涉及在 job 列上进行过滤的查询,并查看性能改进。
另外请注意:由于我们仅在工作列上创建了索引,如果你运行涉及其他列的查询,查询的速度不会比没有索引时快。
总结与下一步
我希望本指南帮助你了解如何通过在频繁查询的列上创建数据库索引来显著提高查询速度。这是关于数据库索引的介绍。你还可以创建多列索引、同一列的多个索引等。
你可以在这个 GitHub 仓库找到本教程中使用的所有代码。祝编程愉快!
Bala Priya C 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过编写教程、操作指南、观点文章等与开发者社区分享她的知识。
更多相关主题
使用 NumExpr 包加速你的 Numpy 和 Pandas
原文:
www.kdnuggets.com/2020/07/speed-up-numpy-pandas-numexpr-package.html
评论
图片来源:Pixabay和作者制作的拼贴图
介绍
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
Numpy 和 Pandas 可能是数据科学(DS)和机器学习(ML)任务中最广泛使用的两个核心 Python 库。不用多说,评估数值表达式的速度对这些 DS/ML 任务至关重要,这两个库在这方面表现也不负众望。
在底层,它们使用快速且优化的向量化操作(尽可能多)来加速数学运算。许多文章已经讨论了 Numpy 如何比普通的 Python 循环或基于列表的操作要优越得多(尤其是当你可以向量化你的计算时)。
与标准 Python 列表的比较
使用 Python 进行数据科学:将你的条件循环转为 Numpy 向量
甚至对条件循环进行向量化,以加速整体数据转换,是值得的。
在这篇文章中,我们展示了如何使用一个名为‘NumExpr’的简单扩展库来提升数学运算的速度,这些运算由核心的 Numpy 和 Pandas 生成。
让我们看看它的实际效果
示例 Jupyter 笔记本可以在我的 Github 仓库中找到。
安装 NumExpr 库
首先,我们需要确保我们拥有numexpr库。所以,正如预期的那样,
pip install numexpr
该项目托管在这里的 Github 上。它来自PyData稳定版,这是一个隶属于 NumFocus 的组织,也促成了 Numpy 和 Pandas 的诞生。
根据源信息,“NumExpr 是一个快速的数值表达式求值器,用于 NumPy。使用它,操作数组的表达式会得到加速,并且使用的内存更少,相比于在 Python 中进行相同的计算。此外,它的多线程能力可以利用所有核心——这通常会导致相比于 NumPy 有显著的性能提升。” (source)
这是详细文档和各种用例示例。
简单的向量-标量操作
我们从简单的数学操作开始——将标量数字(比如 1)添加到 Numpy 数组。为了使用 NumExpr 包,我们只需将相同的计算包裹在符号表达式中的特殊方法 evaluate 下。以下代码将清楚地说明使用方法,
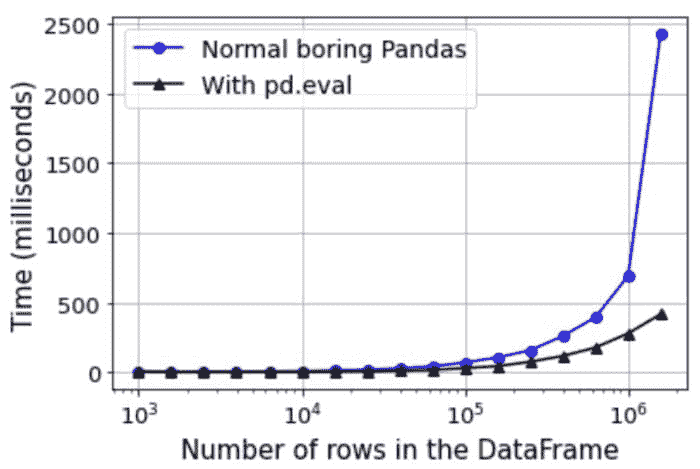
哇!这真是太神奇了!我们只需将熟悉的 a+1 Numpy 代码写成符号表达式 "a+1" 的形式,并传递给 ne.evaluate() 函数。我们得到了显著的速度提升——从 3.55 毫秒到 1.94 毫秒,平均值。
请注意,我们在 10 次循环测试中运行了相同的计算 200 次,以计算执行时间。当然,结果的准确性在一定程度上取决于底层硬件。欢迎你在你的机器上进行评估,看看你得到了什么改进。
涉及两个数组的算术运算
让我们再提升一点,涉及两个数组,可以吗?以下是使用两个数组评估简单线性表达式的代码,
这是计算时间的显著提升,从11.7 毫秒到 2.14 毫秒,平均值。
涉及更多数组的稍微复杂的操作
现在,让我们进一步提升,涉及更多数组在稍微复杂的有理函数表达式中。假设,我们想评估以下表达式,涉及五个 Numpy 数组,每个数组有一百万个随机数(从正态分布中抽取),

这是代码。我们创建了一个形状为(1000000, 5)的 Numpy 数组,并从中提取了五个(1000000,1)向量以用于有理函数。此外,请注意 NumExpr 方法中的符号表达式如何本地理解‘sqrt’(我们只需写sqrt)。

哇!这显示了一个巨大的速度提升从 47 毫秒到 ~ 4 毫秒,平均值。事实上,你会发现表达式越复杂,涉及的数组越多,Numexpr 的速度提升越显著!
逻辑表达式/布尔过滤
事实证明,我们不仅限于简单的算术表达式,如上所示。Numpy 数组的一个最有用的特性是将它们直接用于涉及逻辑运算符如 > 或 < 的表达式中,以创建布尔过滤器或掩码。
我们可以使用 NumExpr 来加速筛选过程。这里是一个示例,我们检查涉及 4 个向量的欧几里得距离度量是否大于某个阈值。
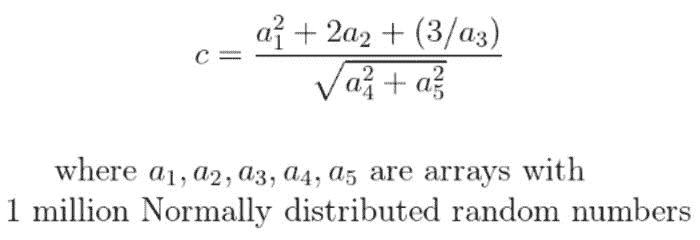
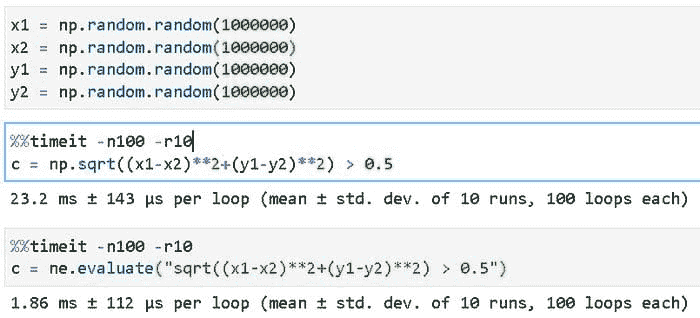
这种筛选操作在数据科学/机器学习管道中随处可见,你可以想象通过战略性地将 Numpy 评估替换为 NumExpr 表达式可以节省多少计算时间。
复数!
我们可以很容易地从实数域跳到虚数域。NumExpr 对复数同样有效,复数是 Python 和 Numpy 原生支持的。这里是一个示例,也展示了对数等超越操作的使用。

数组大小的影响
接下来,我们检查 Numpy 数组大小对速度提升的影响。为此,我们选择一个简单的条件表达式,如 2*a+3*b < 3.5 并绘制各种大小下的相对执行时间(在 10 次运行后取平均值)。代码在 Notebook 中,最终结果如下所示,
图像来源:作者代码生成
Pandas “eval” 方法
这是一个 Pandas 方法,它评估一个 Python 符号表达式(作为字符串)。默认情况下,它使用 NumExpr 引擎以实现显著的加速。以下是来自 官方文档的摘录,

我们用以下代码展示一个简单示例,其中我们构造了四个各有 50000 行和 100 列的 DataFrame(填充了均匀随机数),并对这些 DataFrame 进行非线性变换——一种使用原生 Pandas 表达式,另一种使用 pd.eval() 方法。
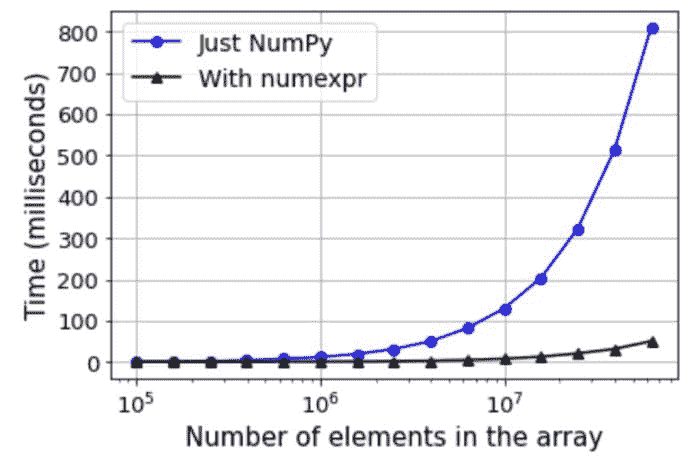
DataFrame 大小的影响
我们对 DataFrame 的大小(行数,列数固定为 100)对速度改进的影响进行了类似的分析。结果如下所示,

图像来源:作者代码生成
它的工作原理和支持的运算符
NumExpr 的工作方式的细节有些复杂,涉及到对底层计算架构的优化使用。你可以 在这里阅读。
简短说明
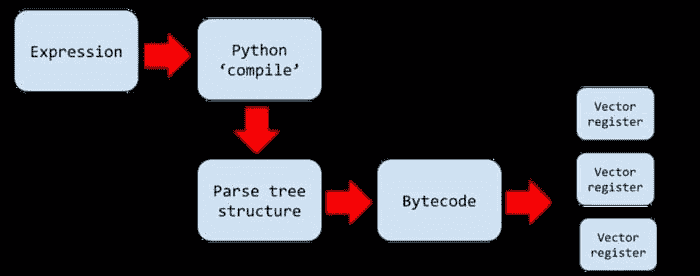
基本上,表达式是使用 Python 的compile函数编译的,变量被提取并建立了一个解析树结构。然后将该树编译成一个字节码程序,描述了使用所谓的‘向量寄存器’(每个寄存器宽 4096 个元素)的逐元素操作流。速度提升的关键是 Numexpr 的一次处理一块元素的能力。

NumExpr 评估流程,来源:作者使用 Google Drawing 制作
它跳过了 Numpy 使用临时数组的做法,这会浪费内存,并且对于大数组无法放入缓存内存。
此外,虚拟机完全用 C 语言编写,使其比原生 Python 更快。它还支持多线程,允许在合适的硬件上更快地并行处理操作。
支持的操作符
NumExpr 支持广泛的数学操作符,但不支持条件操作符,如if或else。完整的操作符列表可以在这里找到。
线程池配置
你还可以通过设置环境变量NUMEXPR_MAX_THREAD来控制用于大数组并行操作的线程数量。目前,最大可能的线程数为 64,但超过底层 CPU 节点上可用的虚拟核心数并没有实际的好处。
总结
在本文中,我们展示了如何利用基于虚拟机的特殊表达式评估范式来加速 Numpy 和 Pandas 中的数学计算。虽然这种方法可能不适用于所有任务,但数据科学、数据处理和统计建模管道的很大一部分可以在代码变化最小的情况下受益于此。
另外,你可以查看作者的GitHub** 代码库**以获取机器学习和数据科学的代码、想法和资源。如果你像我一样,对 AI/机器学习/数据科学充满热情,请随时在 LinkedIn 上添加我或在 Twitter 上关注我。
简介: Tirthajyoti Sarkar 是 ON Semiconductor 的高级首席工程师。
原文。已获许可转载。
相关:
-
使用 pdpipe 构建 Pipelines
-
Dask 中的机器学习
-
Google 的新解释性 AI 服务
更多相关话题
如何通过一行代码将 Pandas 提速 4 倍
评论
Pandas 是处理 Python 数据的首选库。它易于使用,并且在处理不同类型和大小的数据时相当灵活。它拥有大量的不同函数,使得数据操作变得轻而易举。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
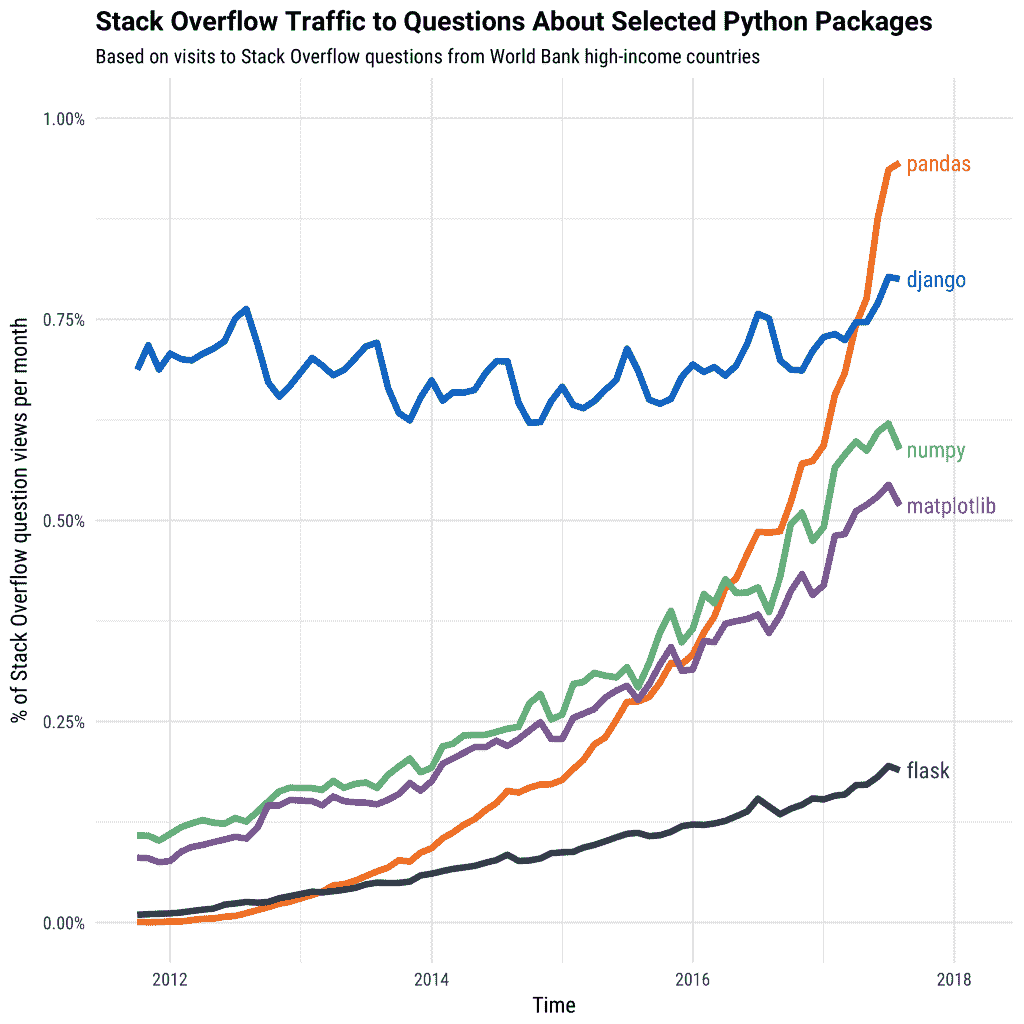
各种 Python 包的受欢迎程度随时间变化。 来源
但有一个缺点:Pandas 对于较大的数据集是慢的。
默认情况下,Pandas 以单个进程使用单个 CPU 核心来执行其函数。这对于较小的数据集效果很好,因为你可能不会注意到速度上的太大差异。但对于更大的数据集和更多的计算,当仅使用单个核心时,速度会大幅下降。它一次只能对一个数据集进行计算,而这些数据集可能有数百万甚至数十亿行。
然而,大多数现代数据科学机器至少有2 个 CPU 核心。这意味着,在两个 CPU 核心的示例中,默认情况下,计算机的 50% 或更多处理能力在使用 Pandas 时不会被使用。当你使用到 4 核心(现代 Intel i5)或 6 核心(现代 Intel i7)时,情况变得更糟。Pandas 本身并没有设计成能有效利用这些计算能力。
Modin 是一个新的库,旨在通过自动将计算分配到系统上所有可用的 CPU 核心来加速 Pandas。凭借这一点,Modin 声称能够在任何大小的 Pandas DataFrame 上获得几乎线性的加速。
让我们看看它是如何工作的,并通过一些代码示例进行演示。
Modin 如何与 Pandas 一起进行并行处理
给定一个 Pandas DataFrame,我们的目标是以最快的方式对其执行某种计算或处理。这可能是对每一列计算均值,使用.mean(),通过groupby对数据进行分组,使用drop_duplicates()去除所有重复项,或使用其他内置的 Pandas 函数。
在前一部分中,我们提到 Pandas 仅使用一个 CPU 核心进行处理。自然,这成为了一个重大瓶颈,特别是对于较大的 DataFrame,资源不足的问题尤为明显。
理论上,将计算并行化就像在每个可用的 CPU 核心上对不同的数据点应用该计算一样简单。对于 Pandas DataFrame,一个基本的想法是将 DataFrame 划分为几块,块数等于 CPU 核心的数量,然后让每个 CPU 核心在其块上运行计算。最后,我们可以汇总结果,这是一项计算上便宜的操作。
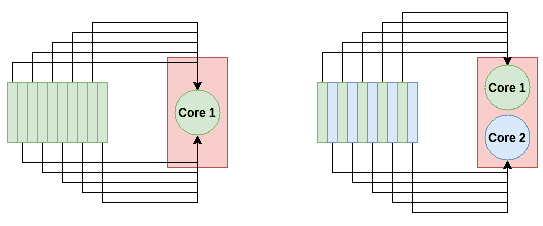
多核系统如何更快地处理数据。对于单核处理(左),所有 10 个任务都去一个节点。对于双核处理(右),每个节点承担 5 个任务,从而将处理速度加倍。
这正是 Modin 所做的。它将你的 DataFrame 切分成不同的部分,使每个部分可以发送到不同的 CPU 核心。Modin 在行和列之间对 DataFrame 进行分区。这使得 Modin 的并行处理可扩展到任意形状的 DataFrame。
想象一下,如果你有一个列很多但行较少的 DataFrame。一些库只在行之间进行分区,这在这种情况下效率较低,因为我们有更多的列而不是行。但使用 Modin,由于分区是在两个维度上进行的,因此并行处理在各种形状的 DataFrame 中都保持高效,无论它们是较宽(列很多)、较长(行很多)还是两者兼具。
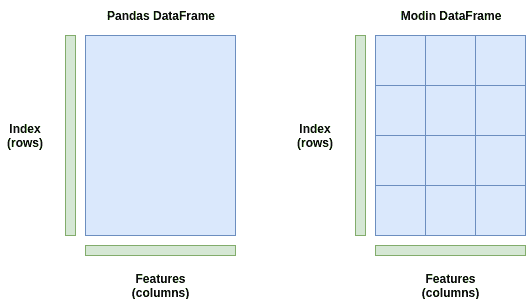
Pandas DataFrame(左)作为一个块存储,只发送到一个 CPU 核心。Modin DataFrame(右)在行和列之间进行分区,每个分区可以发送到系统中不同的 CPU 核心,最多可达到系统的核心数。
上图是一个简单的示例。Modin 实际上使用一个分区管理器,它可以根据操作的类型改变分区的大小和形状。例如,可能有一个操作需要整个行或整个列。在这种情况下,分区管理器会以其能找到的最优方式进行分区和分配到 CPU 核心。它具有灵活性。
为了进行并行处理的繁重工作,Modin 可以使用Dask或Ray。它们都是具有 Python API 的并行计算库,你可以在运行时选择使用其中一个。Ray 目前是更安全的选择,因为它更稳定——Dask 后端是实验性的。
不过,理论说够了。让我们来看看代码和速度基准测试吧!
测试 Modin 速度
安装和使用 Modin 的最简单方法是通过 pip。以下命令安装 Modin、Ray 以及所有相关的依赖:
pip install modin[ray]
在接下来的示例和基准测试中,我们将使用CS:GO Competitive Matchmaking Data来自 Kaggle。CSV 的每一行包含了 CS:GO 竞技比赛中一轮的数据。
目前我们将专注于实验最大的 CSV 文件(有几个),叫做esea_master_dmg_demos.part1.csv,大小为 1.2GB。如此大的文件,我们应该能够看到 Pandas 的性能下降情况以及 Modin 如何帮助我们。测试时,我将使用一款i7–8700k CPU,它有 6 个物理核心和 12 个线程。
我们进行的第一个测试是用我们熟悉的read_csv()读取数据。Pandas 和 Modin 的代码完全一样。
为了测量速度,我导入了time模块,并在read_csv()前后加了time.time()。结果是 Pandas 加载数据从 CSV 到内存花费了 8.38 秒,而 Modin 只用了 3.22 秒。这是 2.6 倍的加速。仅仅通过更改导入语句就取得这样的速度提升,算是不小的进步!
让我们对 DataFrame 进行几个较重的处理。连接多个 DataFrame 是 Pandas 中常见的操作——我们可能有几个或更多的 CSV 文件包含数据,需要逐个读取并连接。我们可以轻松地使用pd.concat()函数来完成,Pandas 和 Modin 都能做到。
我们预计 Modin 在这种操作中表现会很好,因为它处理大量数据。代码如下所示。
在上面的代码中,我们将 DataFrame 自身连接了 5 次。Pandas 在 3.56 秒内完成了连接操作,而 Modin 在 0.041 秒内完成,速度提升了 86.83 倍!即使我们只有 6 个 CPU 核心,DataFrame 的分区也大大提高了速度。
Pandas 中常用来清理 DataFrame 的一个函数是.fillna()函数。这个函数查找 DataFrame 中的所有 NaN 值,并用你选择的值替换它们。这里有很多操作。Pandas 必须遍历每一行每一列来查找 NaN 值并进行替换。这是应用 Modin 的绝佳机会,因为我们重复执行了很多简单操作。
这次,Pandas 执行* .fillna()* 用了 1.8 秒,而 Modin 只用了 0.21 秒,实现了 8.57 倍的加速!
警告和最终基准
那么,Modin 总是这么快吗?
嗯,不总是这样。
有些情况下,Pandas 实际上比 Modin 更快,即使是在这个有 5,992,097(几乎 600 万)行的大数据集上。下表显示了我运行的一些实验中 Pandas 和 Modin 的运行时间。
正如你所见,有些操作中 Modin 明显更快,通常是在读取数据和查找值时。其他操作,如进行统计计算,在 Pandas 中要快得多。
使用 Modin 的实用技巧
Modin 仍然是一个相对年轻的库,正在不断开发和扩展。因此,并不是所有 Pandas 函数都已完全加速。如果你尝试使用一个尚未加速的 Modin 函数,它将默认回退到 Pandas,因此不会有代码错误或故障。有关 Modin 支持的 Pandas 方法的完整列表,请参见 此页面。
默认情况下,Modin 将使用你机器上的所有 CPU 核心。在某些情况下,你可能希望限制 Modin 可以使用的 CPU 核心数量,尤其是当你想将计算能力用于其他地方时。我们可以通过 Ray 的初始化设置限制 Modin 可以访问的 CPU 核心数量,因为 Modin 在后台使用了 Ray。
import ray
ray.init(num_cpus=4)
import modin.pandas as pd
在处理大数据时,数据集的大小超过系统内存(RAM)的情况并不少见。Modin 有一个特定的标志,我们可以将其设置为true,以启用其 out of core 模式。Out of core 基本上意味着 Modin 会将你的磁盘用作内存的溢出存储,允许你处理比 RAM 大得多的数据集。我们可以设置以下环境变量来启用此功能:
export MODIN_OUT_OF_CORE=true
结论
这样你就了解了!这是使用 Modin 加速 Pandas 函数的指南。只需更改导入语句即可完成,操作非常简单。希望你在至少一些情况下发现 Modin 对加速你的 Pandas 函数有用。
相关:
更多相关话题
如何使用 Modin 加速 Pandas
评论
由Michael Galarnyk提供,Anyscale 的开发者关系
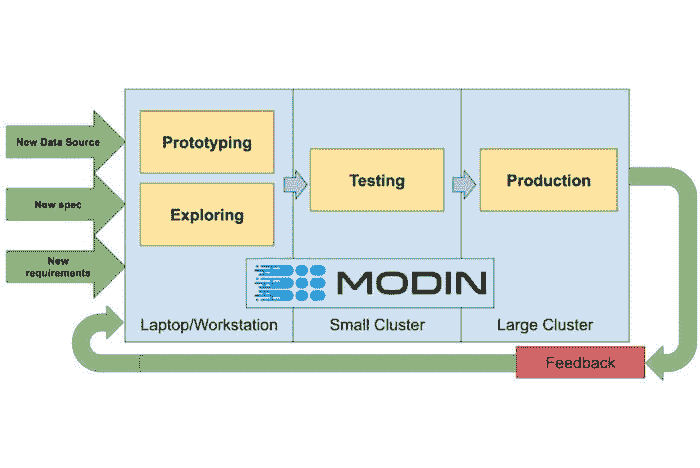
Modin 的一个目标是让数据科学家可以对小型(千字节)和大型数据集(泰字节)使用相同的代码。图片由Devin Petersohn提供。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT
pandas 库提供了易于使用的数据结构,如 pandas DataFrames 以及数据分析工具。pandas 的一个问题是,它在处理大量数据时可能较慢。它并非设计用于分析 100 GB 或 1 TB 的数据集。幸运的是,存在Modin库,它具备了通过更改一行代码来扩展 pandas 工作流程的能力,并与 Python 生态系统和Ray集群集成。此教程介绍了如何开始使用 Modin 以及它如何加速你的 pandas 工作流程。
如何开始使用 Modin
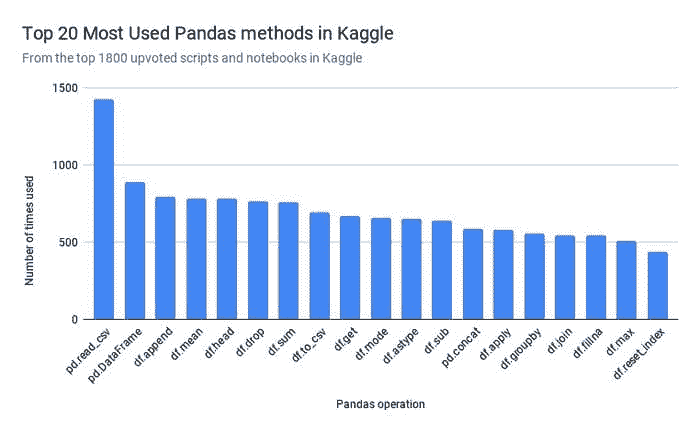
为了确定优先在 Modin 中实现哪些 Pandas 方法,Modin 的开发者抓取了 1800 个最受欢迎的 Python Kaggle Kernels(代码)。
Modin 对 pandas API 的覆盖率超过 90%,重点关注最常用的 pandas 方法,如 pd.read_csv、pd.DataFrame、df.fillna 和 df.groupby。这意味着如果你有大量数据,你可以更快地执行大多数与 pandas 库相同的操作。本节重点介绍一些常用的操作。
要开始使用,你需要安装 modin。
pip install “modin[all]” # Install Modin dependencies and modin’s execution engines
pip 安装时别忘了“”
导入 Modin
Modin 的一个主要优势是它不需要你学习新的 API。你只需更改你的导入语句。
import modin.pandas as pd

你只需更改你的导入语句以使用 Modin。
加载数据(read_csv)
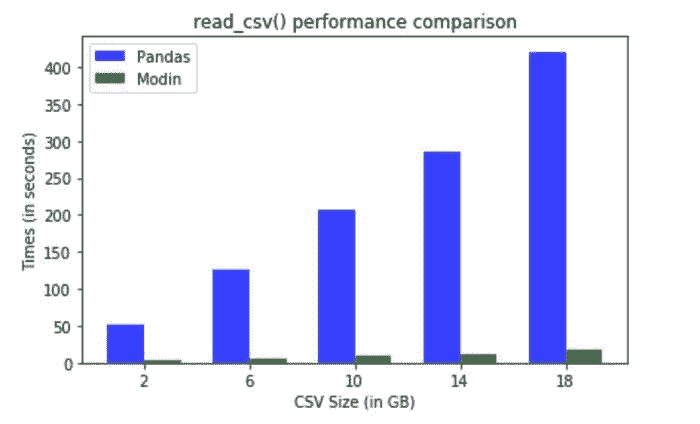
Modin 在处理较大的数据集时表现尤为出色 (图像来源)
本教程使用的数据集来自于 健康保险市场 数据集,约 2GB。下面的代码将数据读取到 Modin DataFrame 中。
modin_df = pd.read_csv("Rate.csv”)

在这种情况下,由于 Modin 将工作转移到主线程之外以实现异步处理,因此速度更快。文件是并行读取的。性能提升的很大一部分来自于异步构建 DataFrame 组件。
head
下面的代码使用了 head 命令。
# Select top N number of records (default = 5)
modin_df.head()
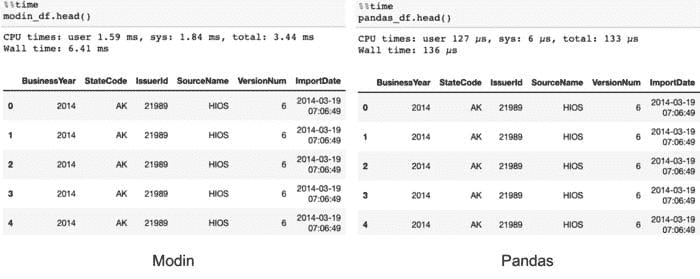
在这种情况下,Modin 的速度较慢,因为它需要将数据汇总在一起。然而,用户在交互式工作流中不应能察觉到这种差异。
groupby
类似于 Pandas,Modin 也具有 groupby 操作。
df.groupby(['StateCode’]).count()

请注意,计划进一步优化 Modin 中 groupby 操作的性能。
fillna
使用 fillna 方法填充缺失值在 Modin 中可以更快。
modin_df.fillna({‘IndividualTobaccoRate’: ‘Unknown’})

默认使用 Pandas 实现
如前所述,Modin 的 API 涵盖了 Pandas API 的大约 90%。对于尚未覆盖的方法,Modin 将默认使用 Pandas 实现,如下面的代码所示。
modin_df.corr(method = ‘kendall’)

当 Modin 默认使用 Pandas 时,你会看到一个警告。
尽管默认使用 Pandas 会有性能损失,但无论命令是否在 Modin 中实现,Modin 都会完成所有操作。
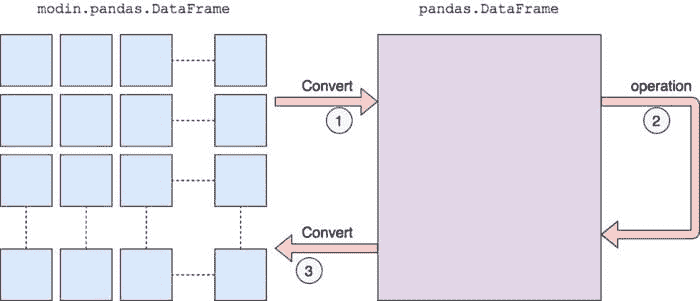
如果某个方法未实现,它将默认使用 Pandas。
Modin 的文档 解释了这一过程的工作原理。
我们首先将其转换为 Pandas DataFrame,然后执行操作。从分区的 Modin DataFrame 转换到 Pandas 会有性能损失,因为涉及通信成本和 Pandas 的单线程特性。一旦 Pandas 操作完成,我们会将 DataFrame 转换回分区的 Modin DataFrame。这样,默认使用 Pandas 之后执行的操作将会得到 Modin 的优化。
Modin 如何加速你的 Pandas 工作流
Modin 使 Pandas 工作流更快的三种主要方式是通过其多核/多节点支持、系统架构和易用性。
多核/多节点支持
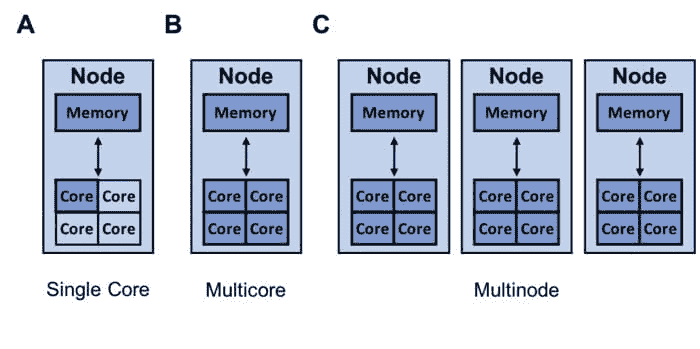
Pandas 只能利用单核,而 Modin 能够有效地利用所有可用的硬件。图像展示了 Modin 可以利用的资源(深蓝色),这些资源具有多个核心(B)和可用的多个节点(C)。
pandas 库只能利用一个核心。由于今天几乎所有计算机都有多个核心,因此通过让 Modin 利用计算机上的所有核心,可以大大加快你的 pandas 工作流程。
在本文中,你可以将上面的 MacBook 视为一个具有 4 个核心的单节点。
如果你希望将代码扩展到超过 1 个节点,Modin 提供了一个用于在本地和云提供商/集群之间切换的 API。
系统架构
Modin 比 pandas 更快的另一个原因是 pandas 自身的实现方式。pandas 的创造者 Wes McKinney 发表了一个著名的演讲“10 Things I Hate about Pandas”,讨论了 pandas 的一些灵活性和性能问题。

Wes McKinney 对 pandas 的一些问题与性能有关。
Modin 努力解决这些问题。要了解其方法,重要的是理解一些系统架构。下图概述了 Modin 组件的一般分层视图及每个主要部分的简要描述。

Modin 的系统架构
API 层:这是面向用户的层,主要是 Modin 对 pandas API 的覆盖。SQLite API 处于实验阶段,Modin API 仍在设计中。
Modin 查询编译器:除了其他职责,查询编译器层紧密遵循 pandas API,但去除了大多数重复。
Modin DataFrame 层:这是 Modin 优化的数据帧代数发生的地方。
执行:虽然 Modin 也支持像 Dask 这样的其他执行引擎,但最常用的执行引擎是 Ray,你可以在下一节中了解更多。
什么是 Ray

Ray 使并行和分布式处理的工作更接近你的期望(图片来源)。
Ray 是 Modin 的默认执行引擎。本节简要介绍了 Ray 是什么以及它如何作为不止是执行引擎来使用。
上面的图表显示,从高层次来看,Ray 生态系统由核心 Ray 系统和用于数据科学的可扩展库组成,如 Modin。它是一个用于 扩展 Python 应用程序 的库,能够在多个核心或机器上运行。它有几个主要优势,包括:
-
简单性:你可以在不重写代码的情况下扩展你的 Python 应用程序,并且相同的代码可以在一台机器上或多台机器上运行。
-
鲁棒性:应用程序能够优雅地处理机器故障和抢占。
-
性能:任务以毫秒级延迟运行,扩展到数万个核心,并且以最小的序列化开销处理数值数据。
由于 Ray 是一个通用框架,社区在其基础上构建了许多库和框架,以完成不同的任务,如 Ray Tune 用于各种规模的超参数调优,Ray Serve 用于易于使用的可扩展模型服务,以及 RLlib 用于强化学习。它还具有 与 scikit-learn 等机器学习库的集成 以及对 数据处理库如 PySpark 和 Dask 的支持。
虽然你不需要学习如何使用 Ray 来使用 Modin,但下面的图像显示,通常只需添加几行代码就能将一个简单的 Python 程序转换为在计算集群上运行的分布式程序。

如何使用 Ray 将一个简单的程序转换为分布式程序的示例(代码说明)。
结论
Modin 的一个目标是允许数据科学家使用相同的代码来处理小(千字节)和大(千兆字节)数据集。图片来自 Devin Petersohn。
Modin 允许你使用相同的 Pandas 脚本来处理笔记本电脑上的 10KB 数据集以及集群上的 10TB 数据集。这得益于 Modin 易于使用的 API 和系统架构。这一架构能够利用 Ray 作为执行引擎,使得扩展 Modin 更加简单。如果你对 Ray 有任何问题或想法,请随时通过 Discourse 或 Slack 加入我们的社区。
简介:Michael Galarnyk 在 Anyscale 从事开发者关系工作,Anyscale 是 Ray 项目 的背后公司。你可以在 Twitter、Medium 和 GitHub 找到他。
原文。经许可转载。
相关:
-
使用 PyTorch 和 Ray 开始分布式机器学习
-
将 sklearn 训练速度提高 100 倍
-
如何加速 Scikit-Learn 模型训练
更多相关内容
如何加速 Scikit-Learn 模型训练
原文:
www.kdnuggets.com/2021/02/speed-up-scikit-learn-model-training.html
评论
作者:Michael Galarnyk,Anyscale 的开发者关系
scikit-learn 可以利用的资源(深蓝色),用于单核(A),多核(B)和多节点训练(C)
Scikit-Learn 是一个易于使用的 Python 机器学习库。然而,有时候 scikit-learn 模型的训练可能需要很长时间。问题是,如何在最短时间内创建最佳的 scikit-learn 模型?解决这个问题的方法有很多,比如:
这篇文章概述了每种方法,讨论了一些局限性,并提供了加速机器学习工作流程的资源!
更换你的优化算法(求解器)
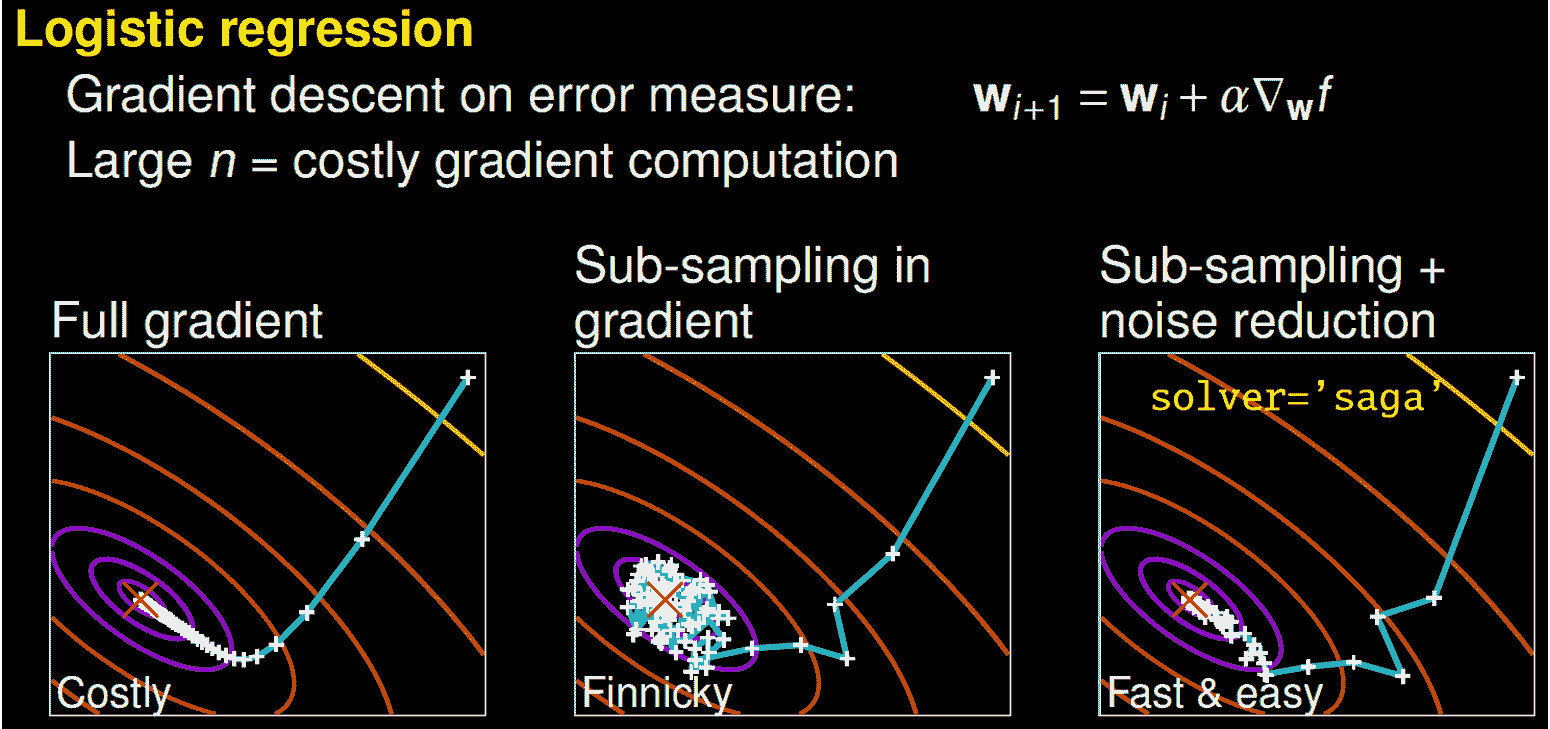
一些求解器可能需要更长的时间来收敛。图片来源于Gaël Varoquaux 的演讲。
更好的算法让你能更好地利用相同的硬件。通过更高效的算法,你可以更快地产生最优模型。一种方法是更换你的优化算法(求解器)。例如,scikit-learn 的逻辑回归允许你选择‘newton-cg’,‘lbfgs’,‘liblinear’,‘sag’,和‘saga’等求解器。
为了理解不同求解器的工作原理,我建议你观看由 scikit-learn 核心贡献者Gaël Varoquaux的演讲。用他的话来说,一个完整的梯度算法(liblinear)收敛速度快,但每次迭代(以白色+表示)可能非常昂贵,因为它需要使用所有的数据。在一个子采样的方法中,每次迭代计算便宜,但收敛速度可能会慢得多。一些算法如‘saga’实现了两者的最佳结合。每次迭代计算便宜,而且由于方差减少技术,算法收敛迅速。重要的是要注意,快速收敛在实践中并不总是重要,不同的求解器适用于不同的问题。

为问题选择合适的求解器可以节省大量时间(代码示例)。
要确定哪个求解器适合你的问题,你可以查看 文档 以了解更多信息!
不同的超参数优化技术(网格搜索、随机搜索、早停)
为了实现大多数 scikit-learn 算法的高性能,你需要调整模型的超参数。超参数是模型的参数,在训练过程中不会更新。它们可以用于配置模型或训练函数。Scikit-Learn 本身包含了一些 超参数调整技术,如网格搜索(GridSearchCV),它详尽地考虑了所有参数组合,以及 随机搜索(RandomizedSearchCV),它从具有指定分布的参数空间中抽取给定数量的候选。最近,scikit-learn 增加了实验性的超参数搜索估计器:缩减网格搜索(HalvingGridSearchCV)和缩减随机搜索(HalvingRandomSearch)。
逐步缩减是 scikit-learn 版本 0.24.1(2021 年 1 月)中的一个实验性新功能。图像来自 文档。
这些技术可以用于通过 逐步缩减 来搜索参数空间。上面的图像显示了所有超参数候选在第一次迭代时用少量资源进行评估,之后更有前景的候选被选择,并在每次迭代中分配更多资源。
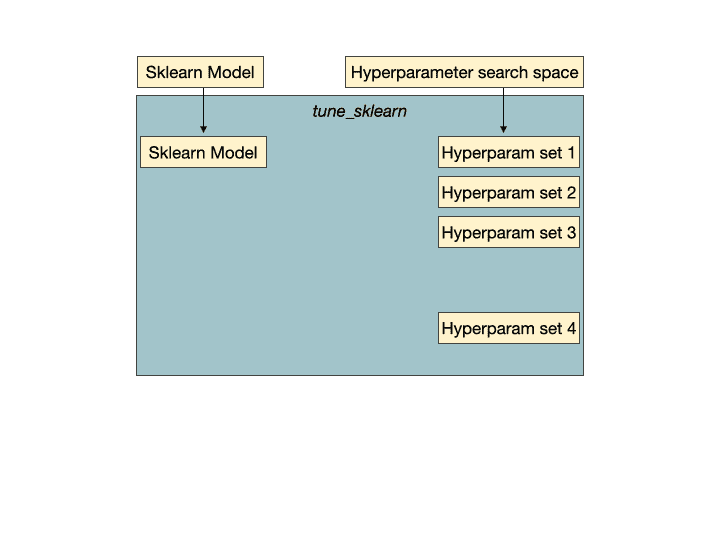
虽然这些新技术很令人兴奋,但有一个名为 Tune-sklearn 的库提供了前沿的超参数调整技术(贝叶斯优化、早停和分布式执行),这些技术相比网格搜索和随机搜索能够显著提高速度。
早停法的实际应用。超参数集 2 是一组不太有前景的超参数,它们会被 Tune-sklearn 的早停机制检测到,并提前停止以避免浪费时间和资源。图片来自 GridSearchCV 2.0。
Tune-sklearn 的特性包括:
-
与 scikit-learn API 的一致性:通常只需修改几行代码即可使用 Tune-sklearn (示例)。
-
现代超参数调优技术的可访问性:可以轻松修改代码以利用诸如贝叶斯优化、早停法和分布式执行等技术
-
框架支持:不仅支持 scikit-learn 模型,还支持其他 scikit-learn 包装器,如 Skorch (PyTorch)、KerasClassifiers (Keras) 和 XGBoostClassifiers (XGBoost)。
-
可扩展性:该库利用了 Ray Tune——一个用于分布式超参数调优的库,以高效且透明的方式在多个核心甚至多台机器上并行化交叉验证。
也许最重要的是,tune-sklearn 的速度如下面的图片所示。
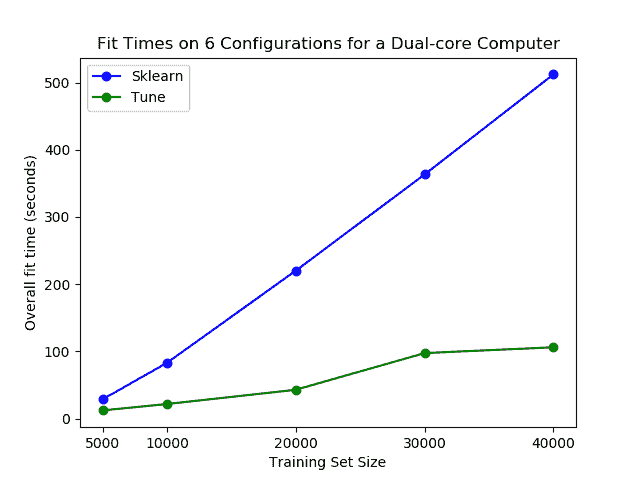
你可以在普通笔记本电脑上看到使用 tune-sklearn 的显著性能差异。图片来自 GridSearchCV 2.0。
如果你想了解更多关于 tune-sklearn 的信息,可以查看这篇 博客文章。
使用 joblib 和 Ray 进行训练的并行化或分布式处理
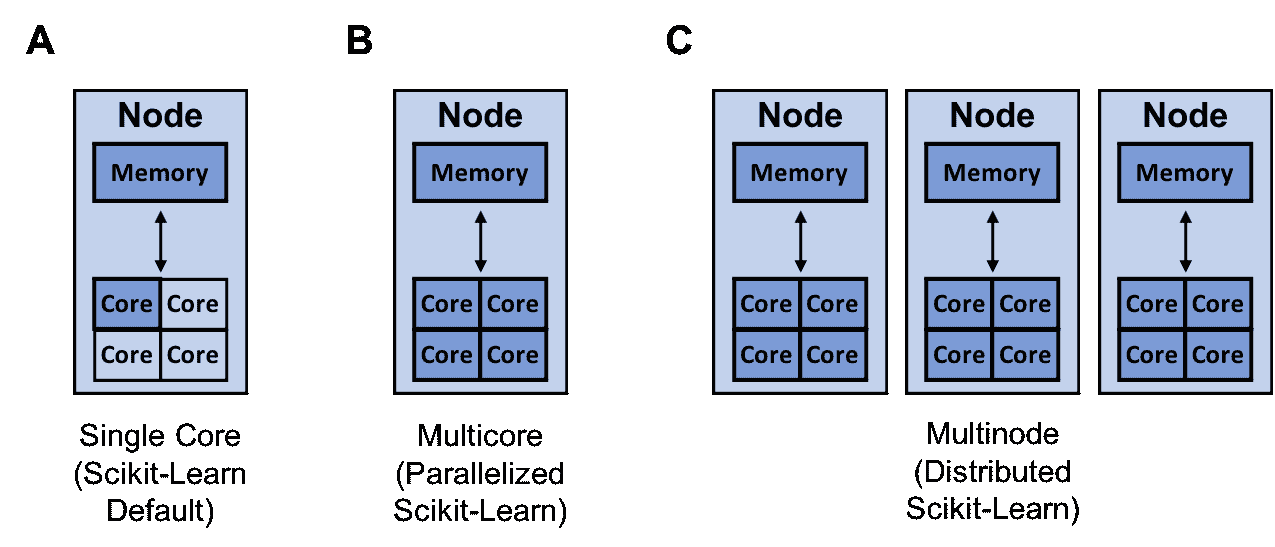
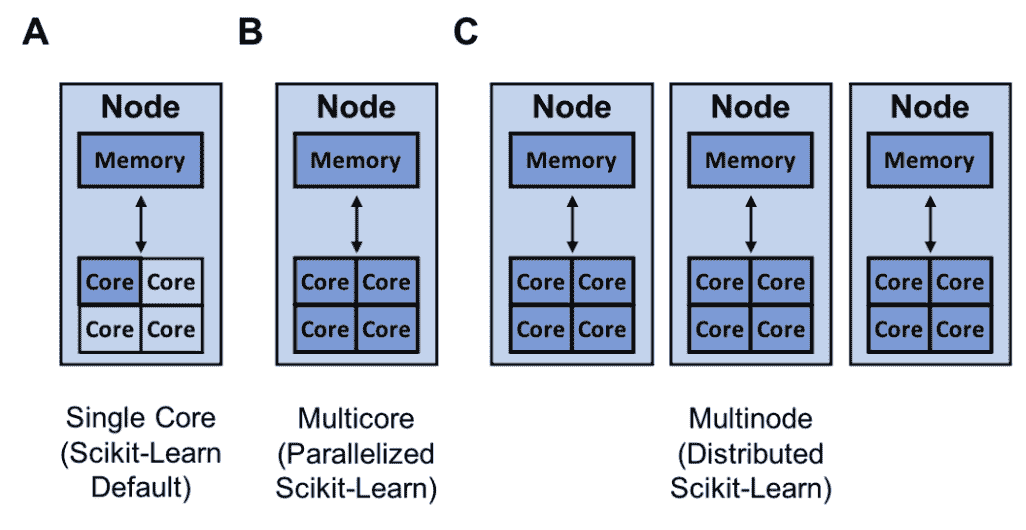
scikit-learn 可以利用的资源(深蓝色)用于单核心(A)、多核心(B)和多节点训练(C)
另一种提高模型构建速度的方法是通过 joblib 和 Ray 实现训练的并行化或分布式处理。默认情况下,scikit-learn 使用单个核心训练模型。需要注意的是,今天几乎所有的计算机都有多个核心。
就本博客而言,你可以将上面的 MacBook 视为一个具有 4 个核心的单节点。
因此,通过利用计算机上的所有核心,你可以大大加速模型的训练。如果你的模型具有较高的并行度,如随机森林®,这尤其适用。
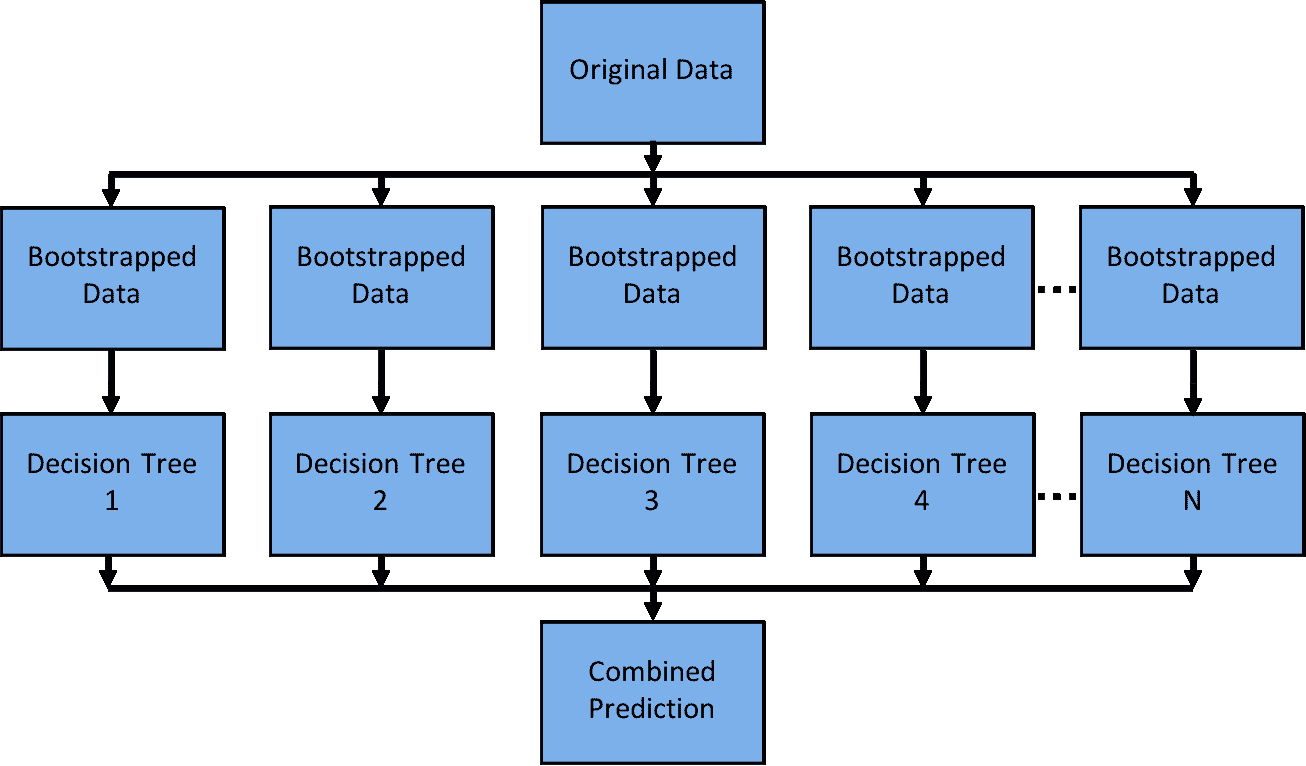
随机森林® 是一个容易并行化的模型,因为每棵决策树相互独立。
Scikit-Learn 可以通过joblib,默认使用‘loky’后端来并行化单节点上的训练。Joblib 允许你在‘loky’、‘multiprocessing’、‘dask’和‘ray’等后端之间进行选择。这是一个很好的功能,因为‘loky’后端是为单节点优化的,而不是为运行分布式(多节点)应用程序优化的。运行分布式应用程序可能引入许多复杂性,例如:
-
在多台机器上调度任务
-
高效地转移数据
-
从机器故障中恢复
幸运的是,‘ray’后端可以为你处理这些细节,保持简单,并提供更好的性能。下图显示了 Ray、Multiprocessing 和 Dask 相对于默认‘loky’后端的规范化加速。
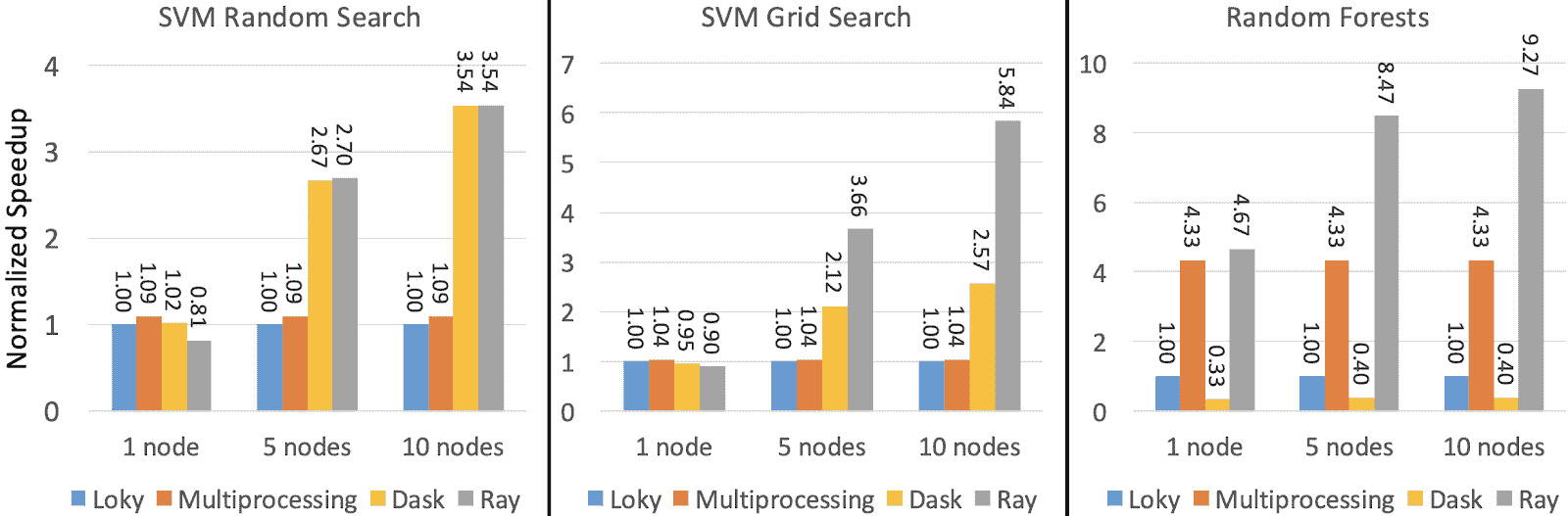
性能在每个 32 核心的一个、五个和十个 m5.8xlarge 节点上进行测量。Loky 和 Multiprocessing 的性能不依赖于机器数量,因为它们在单台机器上运行。图片来源。
如果你想了解如何快速并行化或分布式你的 scikit-learn 训练,你可以查看这篇博客文章。
结论
本文介绍了几种方法,你可以在最短时间内构建出最佳的 scikit-learn 模型。其中一些方法是 scikit-learn 本身提供的,比如更改优化函数(求解器),或使用实验性的超参数优化技术,如 HalvingGridSearchCV 或 HalvingRandomSearch。你还可以使用如 Tune-sklearn 和 Ray 的库作为插件,进一步加快模型构建速度。如果你对 Tune-sklearn 和 Ray 有任何问题或想法,请随时通过 Discourse 或 Slack 加入我们的社区。
个人简介:Michael Galarnyk 在 Anyscale 担任开发者关系职位,该公司是 Ray 项目 的背后团队。你可以在 Twitter、Medium 和 GitHub 上找到他。
原文。经授权转载。
相关内容:
-
终极 Scikit-Learn 机器学习备忘单
-
Python 列表和列表操作
-
K-Means 比 Scikit-learn 快 8 倍,误差低 27 倍,仅需 25 行代码
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关内容
如何加速 XGBoost 模型训练
原文:
www.kdnuggets.com/2021/12/speed-xgboost-model-training.html
作者:Michael Galarnyk,数据科学专业人士
梯度提升算法广泛应用于监督学习。虽然它们功能强大,但训练时间可能很长。极端梯度提升,或称 XGBoost,是一个开源的梯度提升实现,旨在提升速度和性能。然而,即使是 XGBoost 的训练有时也会很慢。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业领域。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
有很多方法可以加速这个过程,例如:
-
更改树构建方法
-
利用云计算
本文将回顾每种方法的优缺点,并介绍如何入门。
更改你的树构建算法
XGBoost 的 tree_method 参数允许你指定要使用的树构建算法。为你的问题选择合适的树构建算法(exact、approx、hist、gpu_hist、auto)可以帮助你更快地生成优化模型。现在让我们来回顾这些算法。
这是一个准确的算法,但在每次分裂查找过程中,它会遍历所有输入数据条目,因此不具有很好的扩展性。在实际应用中,这意味着较长的训练时间。它也不支持分布式训练。你可以在原始的 XGBoost 论文 中了解更多关于该算法的信息。
尽管准确算法是准确的,但当数据不完全适合内存时,它的效率较低。原始 XGBoost 论文 中的近似树方法使用分位数草图和梯度直方图。
在 LightGBM 中使用的近似树方法,与 approx 的实现有些许不同(例如使用一些性能改进,如 bins 缓存)。这通常比 approx 更快。
由于 GPU 在许多机器学习应用中至关重要,XGBoost 提供了一个支持外部内存的 GPU 实现的 hist 算法gpu_hist。 它比 hist 快得多,并且使用的内存明显更少。请注意,XGBoost 在某些操作系统上没有原生支持GPU。
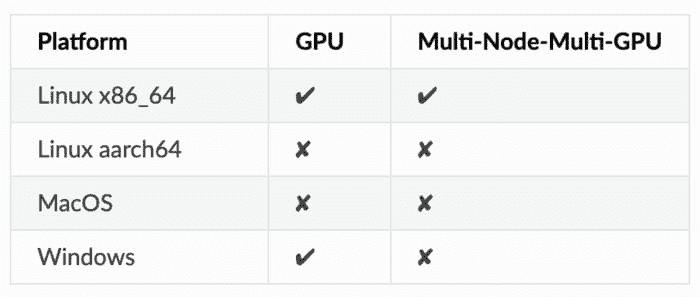
这是参数的默认值。根据数据集的大小,XGBoost 将选择“最快的方法”。对于小数据集,将使用 exact。对于大数据集,将使用 approx。请注意,尽管 hist 和 gpu_hist 通常更快,但在这种启发式方法中,它们并未被考虑。
如果你运行这个 代码,你将看到使用 gpu_hist 运行模型可以节省大量时间。在我的计算机上,处理一个相对较小的数据集(100,000 行,1000 个特征),将 hist 更改为 gpu_hist 将训练时间减少了约一半。
利用云计算
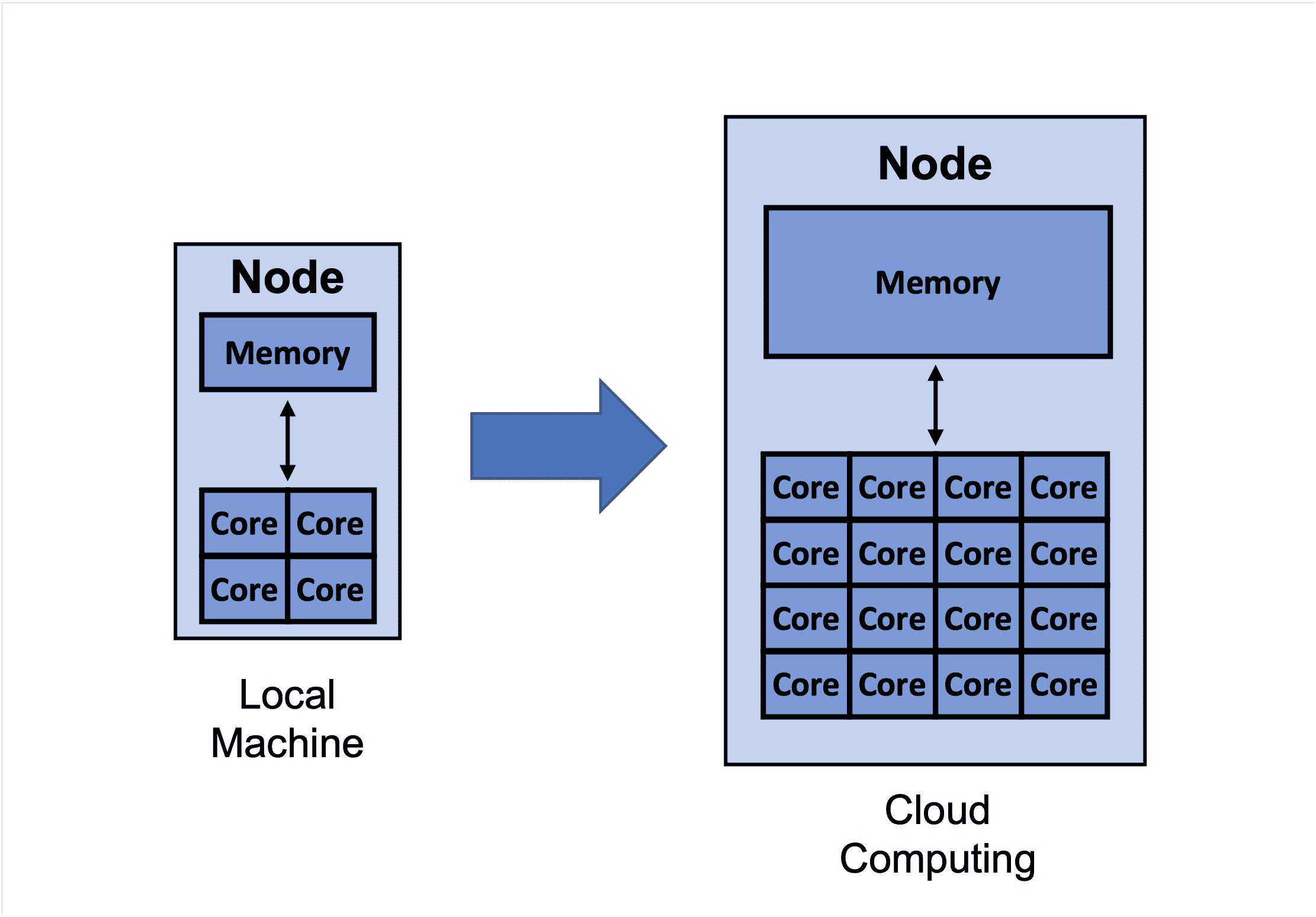
云计算不仅允许你使用比本地计算机更多的核心和内存,还可以让你访问像 GPU 这样的专业资源。
最后一部分主要讨论了选择更高效的算法,以更好地利用可用的计算资源。然而,有时可用的计算资源不够,你可能需要更多。例如,下面图片中的 MacBook 只有 4 个核心和 16GB 内存。此外,它运行在 MacOS 上,而在写作时,XGBoost 尚未对其提供 GPU 支持。
对于本文的目的,你可以将上面的 MacBook 视为一个具有 4 个核心的单节点。
解决这个问题的一种方法是利用更多的云资源。使用云服务提供商不是免费的,但它们通常允许你使用比本地计算机更多的核心和内存。此外,如果 XGBoost 不支持你的本地计算机,选择一个 XGBoost 支持 GPU 的实例类型也是很简单的。
如果你想尝试加速云端训练,以下是来自 Jason Brownlee 的文章 的步骤概览,介绍如何在 AWS EC2 实例上训练 XGBoost 模型:
1. 设置 AWS 账户(如有需要)
2. 启动 AWS 实例
3. 登录并运行代码
4. 训练 XGBoost 模型
5. 关闭 AWS 实例(仅在使用时支付实例费用)
如果您选择比本地更强大的实例,您会发现云端训练速度更快。请注意,使用 XGBoost 进行多 GPU 训练实际上需要分布式训练,这意味着您需要多个节点/实例来完成此任务。
使用 Ray 进行分布式 XGBoost 训练
到目前为止,本教程已介绍通过更改树构建算法和通过云计算增加计算资源来加快训练速度。另一种解决方案是通过XGBoost-Ray分布式训练 XGBoost 模型,它利用了 Ray。
什么是 Ray?
Ray 是一个快速、简单的分布式执行框架,使得扩展应用程序和利用先进的机器学习库变得容易。使用 Ray,您可以将顺序运行的 Python 代码通过最小的代码更改转换为分布式应用程序。如果您想了解 Ray 和 actor 模型,可以在这里了解更多。

虽然本教程探讨了 Ray 如何简化 XGBoost 代码的并行化和分布式处理,但需要注意的是,Ray 及其生态系统还简化了普通 Python 代码以及现有库的分布式处理,例如scikit-learn、LightGBM、PyTorch等。
如何开始使用 XGBoost-Ray
要开始使用 XGBoost-Ray,您首先需要安装它。
pip install "xgboost_ray"
由于与核心 XGBoost API 完全兼容,您只需进行少量代码更改即可将 XGBoost 训练从单台机器扩展到拥有数百个节点的集群。
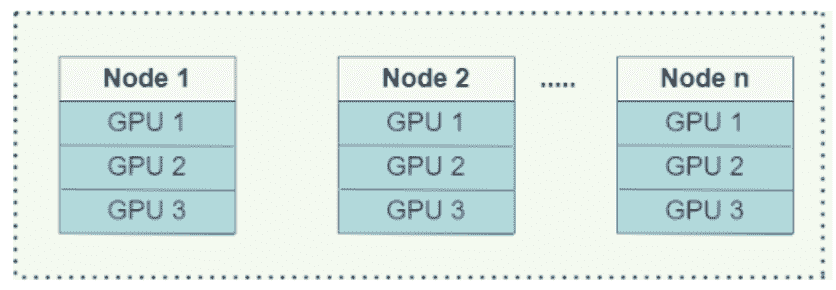
XGBoost-Ray 支持多节点/多 GPU 训练。在单台机器上,GPU 通过 NCCL 进行梯度通信。在节点之间,它们使用 Rabit 代替 (了解更多)。
如下代码所示,API 与 XGBoost 非常相似。高亮部分显示了与普通 XGBoost API 不同的代码部分。
from xgboost_ray import RayXGBClassifier, RayParams
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
seed = 42
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=0.25, random_state=42
)
clf = RayXGBClassifier(
n_jobs=4, # In XGBoost-Ray, n_jobs sets the number of actors
random_state=seed)
# scikit-learn API will automatically convert the data
# to RayDMatrix format as needed.
# You can also pass X as a RayDMatrix, in which case
# y will be ignored.
clf.fit(X_train, y_train)
pred_ray = clf.predict(X_test)
print(pred_ray)
pred_proba_ray = clf.predict_proba(X_test)
print(pred_proba_ray)
上述代码展示了使用 XGBoost-Ray 你需要对代码进行多小的修改。虽然你不需要 XGBoost-Ray 来训练乳腺癌数据集, 之前的一篇文章 在不同数量的工作节点(1 到 8)上对几个数据集大小(约 1.5M 到 12M 行)进行了基准测试,以展示它在单节点上处理更大数据集的表现。
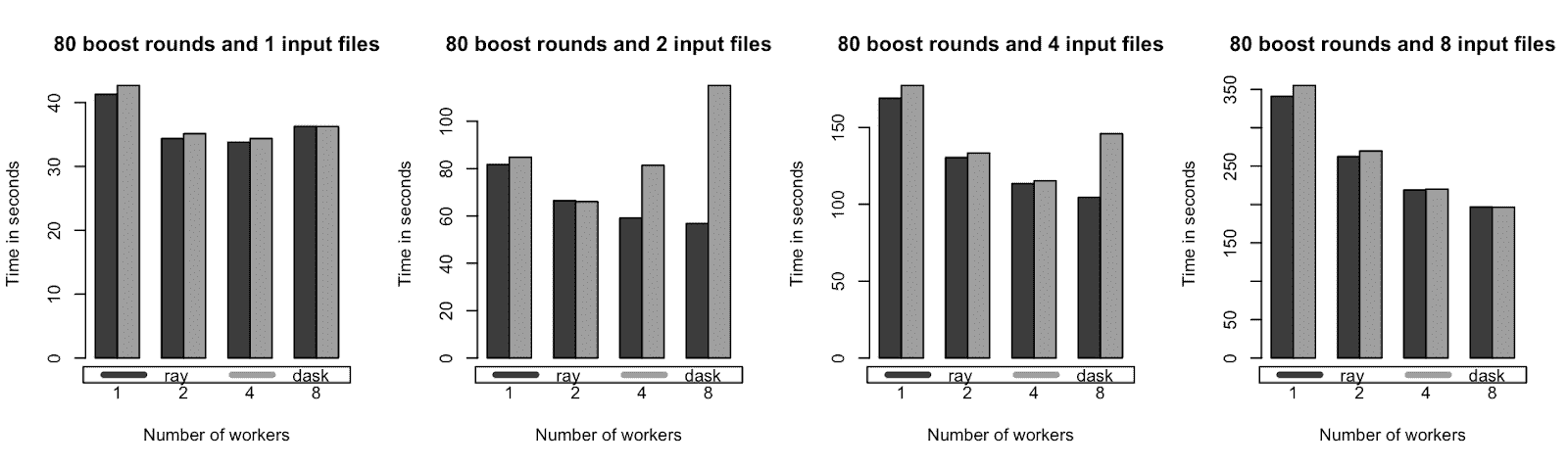
单节点基准测试的训练时间(时间越少越好)。XGBoost-Ray 和 XGBoost-Dask 在单个 AWS m5.4xlarge 实例(具有 16 核心和 64 GB 内存)上表现相似。
XGBoost-Ray 在多节点(分布式)设置下也表现出色,如下图所示。
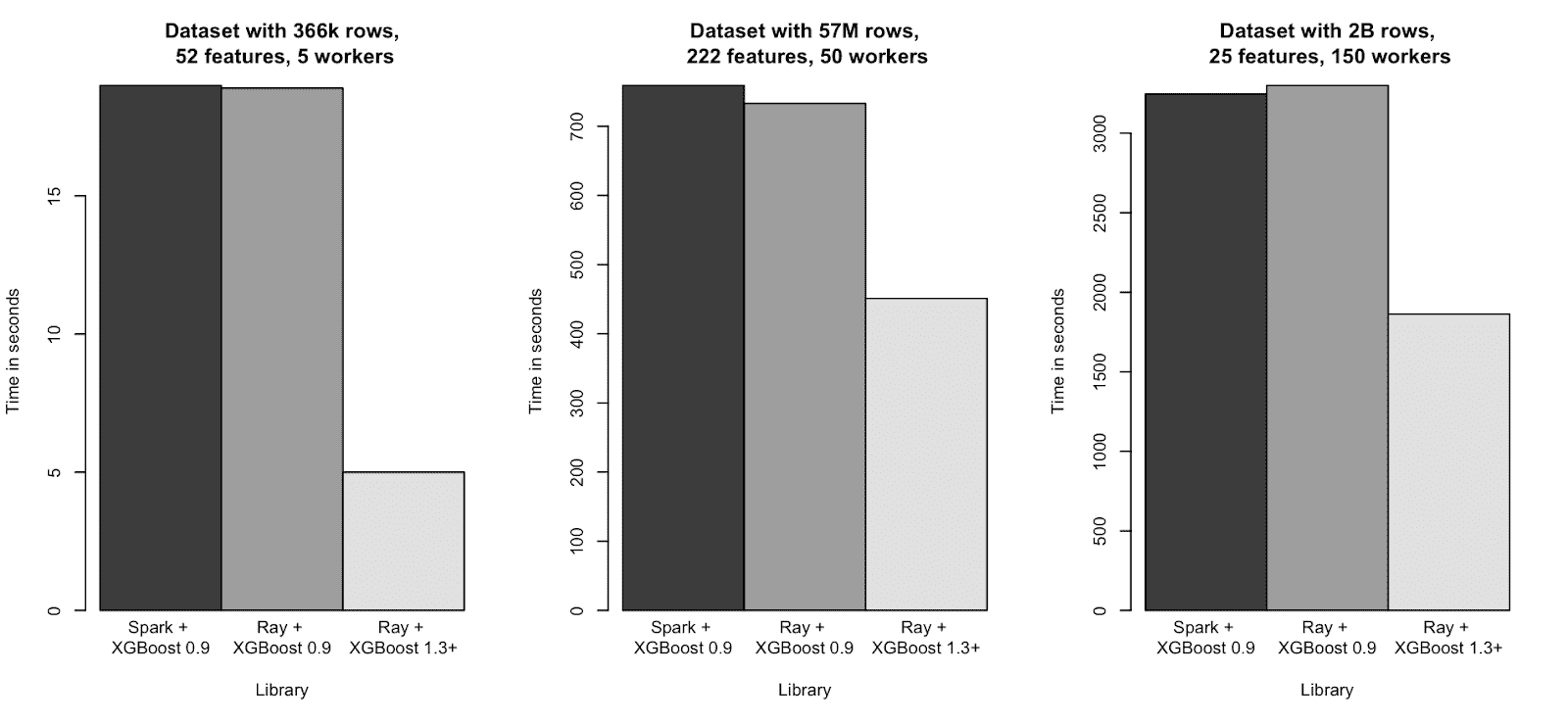
在几个合成数据集大小范围(约 400k 到 2B 行)上的多节点训练时间(时间越少越好)。XGBoost-Ray 和 XGBoost-Spark 表现相似。
如果你想了解更多关于 XGBoost-Ray 的内容, 可以查看这篇关于 XGBoost-Ray 的文章。
结论
本文介绍了几种加速 XGBoost 模型训练的方法,比如更改树构建方法、利用云计算以及在 Ray 上分布式 XGBoost。如果你对 Ray 上的 XGBoost 有任何问题或想法,请随时通过 Discourse 或 Slack 加入我们的社区。如果你想了解 Ray 的最新动态, 可以关注 @raydistributed 在 Twitter 上 并 订阅 Ray 通讯。
简介: Michael Galarnyk 是一名数据科学专家,并在 Anyscale 从事开发者关系工作。
原文. 经许可转载。
更多相关话题
使用 Numpy 加速你的 Python 代码的一个简单技巧
原文:
www.kdnuggets.com/2019/06/speeding-up-python-code-numpy.html
 评论
评论
Python 非常庞大。
在过去几年中,Python 的受欢迎程度迅速增长。其重要原因之一是数据科学、机器学习和人工智能的兴起,这些领域都有高层次的 Python 库可供使用!
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
在使用 Python 进行这些工作时,通常需要处理非常大的数据集。这些大型数据集直接读取到内存中,并作为 Python 数组、列表或字典进行存储和处理。
处理如此庞大的数组可能会很耗时;这实际上就是问题的本质。你有成千上万、数百万甚至数十亿的数据点。每个数据点处理过程中增加的微秒会因为数据规模的巨大而显著拖慢你的速度。
慢速方式
处理大型数据集的慢速方式是使用原始 Python。我们可以通过一个非常简单的例子来演示这一点。
下面的代码将 1.0000001 的值自乘 500 万次!
import time
start_time = time.time()
num_multiplies = 5000000
data = range(num_multiplies)
number = 1
for i in data:
number *= 1.0000001
end_time = time.time()
print(number)
print("Run time = {}".format(end_time - start_time))
我家里有一台相当不错的 CPU,Intel i7–8700k,加上 32GB 的 3000MHz RAM。尽管如此,将这 500 万个数据点相乘仍然需要 0.21367 秒。如果我将num_multiplies的值改为 10 亿次,处理时间变成了 43.24129 秒!
让我们再试一个带有数组的例子。
我们将构建一个大小为 1000x1000 的 Numpy 数组,每个元素的值为 1,再尝试将每个元素乘以一个浮点数 1.0000001。代码如下。
在同一台机器上,将这些数组值乘以 1.0000001 的常规浮点循环耗时 1.28507 秒。
import time
import numpy as np
start_time = time.time()
data = np.ones(shape=(1000, 1000), dtype=np.float)
for i in range(1000):
for j in range(1000):
data[i][j] *= 1.0000001
data[i][j] *= 1.0000001
data[i][j] *= 1.0000001
data[i][j] *= 1.0000001
data[i][j] *= 1.0000001
end_time = time.time()
print("Run time = {}".format(end_time - start_time))
什么是矢量化?
Numpy 被设计成在矩阵操作中高效。更具体地说,大多数 Numpy 中的处理都是矢量化的。
矢量化涉及将数学运算,如我们在这里使用的乘法,表示为作用于整个数组,而不是它们的单个元素(如我们的 for 循环)。
通过矢量化,底层代码被并行化,以便操作可以在多个数组元素上同时运行,而不是一个一个地遍历它们。只要你应用的操作不依赖于其他数组元素,即“状态”,那么矢量化将给你带来一些良好的加速效果。
遍历 Python 数组、列表或字典可能会很慢。因此,Numpy 中的矢量化操作被映射到高度优化的 C 代码,使它们比标准 Python 对应操作快得多。
快速方法
这是做事的快速方法——按照 Numpy 被设计的方式来使用它。
在寻求加速的过程中,我们可以遵循几个要点:
-
如果对数组进行 for 循环,那么很有可能我们可以用一些内置的 Numpy 函数来替代它
-
如果我们看到任何类型的数学运算,很有可能我们可以用一些内置的 Numpy 函数来替代它
这两个要点都非常关注将非矢量化的 Python 代码替换为优化过的、矢量化的低级 C 代码。
查看我们之前第一个示例的快速版本,这次进行了 10 亿次乘法运算。
我们做了一件非常简单的事情:我们发现有一个 for 循环中重复了多次相同的数学操作。这应该立即提示我们去寻找可以替代它的 Numpy 函数。
我们找到了一种——power 函数,它简单地对输入值应用一定的幂。代码运行速度大幅提升至 7.6293e-6 秒——这就是一个
import time
import numpy as np
start_time = time.time()
num_multiplies = 1000000000
data = range(num_multiplies)
number = 1
number *= np.power(1.0000001, num_multiplies)
end_time = time.time()
print(number)
print("Run time = {}".format(end_time - start_time))
将值乘入 Numpy 数组的想法非常类似。我们看到我们使用了双重 for 循环,并且应该立即意识到应该有更快的方法。
方便的是,如果我们直接将 1.0000001 标量相乘,Numpy 会自动对我们的代码进行矢量化。因此,我们可以像对待 Python 列表一样编写乘法操作。
以下代码演示了这一点,并在 0.003618 秒内运行——这是 355 倍的加速!
import time
import numpy as np
start_time = time.time()
data = np.ones(shape=(1000, 1000), dtype=np.float)
for i in range(5):
data *= 1.0000001
end_time = time.time()
print("Run time = {}".format(end_time - start_time))
喜欢学习吗?
在 twitter 上关注我,我会发布关于最新和最棒的 AI、技术和科学的内容!也可以在 LinkedIn 上与我联系!
推荐阅读
想了解更多关于 Python 编程的内容吗?Python Crash Course 书籍是学习 Python 编程的最佳资源!
另外提醒一下,我通过亚马逊联盟链接支持这个博客,因为分享好书对大家都有帮助!作为亚马逊会员,我从合格的购买中获得收益。
简介: George Seif 是一位认证的极客和 AI / 机器学习工程师。
原文。经许可转载。
相关:
-
为什么你应该更频繁地使用 .npy 文件
-
为什么你应该忘记数据科学代码中的‘for-loop’,而拥抱矢量化
-
处理 NumPy 矩阵:一个实用的初步参考
更多相关话题
使用 NumPy 加速你的 Python 代码
原文:
www.kdnuggets.com/speeding-up-your-python-code-with-numpy

NumPy 是一个常用于数学和统计应用的 Python 包。然而,有些人仍然不知道 NumPy 可以帮助加速我们的 Python 代码执行。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
NumPy 能够加速 Python 代码执行的原因有几个,包括:
-
NumPy 在循环中使用 C 代码而不是 Python
-
更好的 CPU 缓存过程
-
数学运算中的高效算法
-
能够使用并行操作
-
在大数据集和复杂计算中内存高效
出于多种原因,NumPy 在提高 Python 代码执行效率方面非常有效。本教程将展示 NumPy 如何加速代码处理的例子。让我们来看看。
NumPy 在加速 Python 代码执行中的作用
第一个例子比较了 Python 列表和 NumPy 数组的数值运算,它们获取具有预期值结果的对象。
例如,我们希望从两个相加的列表中得到一个数字列表,所以我们执行了向量化操作。我们可以用以下代码进行实验:
import numpy as np
import time
sample = 1000000
list_1 = range(sample)
list_2 = range(sample)
start_time = time.time()
result = [(x + y) for x, y in zip(list_1, list_2)]
print("Time taken using Python lists:", time.time() - start_time)
array_1 = np.arange(sample)
array_2 = np.arange(sample)
start_time = time.time()
result = array_1 + array_2
print("Time taken using NumPy arrays:", time.time() - start_time)
Output>>
Time taken using Python lists: 0.18960118293762207
Time taken using NumPy arrays: 0.02495265007019043
正如你在上面的输出中看到的,NumPy 数组的执行速度比 Python 列表要快,从而获得相同的结果。
在整个例子中,你会发现 NumPy 的执行速度更快。让我们看看是否要进行聚合统计分析。
array = np.arange(1000000)
start_time = time.time()
sum_rst = np.sum(array)
mean_rst = np.mean(array)
print("Time taken for aggregation functions:", time.time() - start_time)
Output>>
Time taken for aggregation functions: 0.0029935836791992188
NumPy 可以非常快速地处理聚合函数。如果我们与 Python 执行进行比较,可以看到执行时间的差异。
list_1 = list(range(1000000))
start_time = time.time()
sum_rst = sum(list_1)
mean_rst = sum(list_1) / len(list_1)
print("Time taken for aggregation functions (Python):", time.time() - start_time)
Output>>
Time taken for aggregation functions (Python): 0.09979510307312012
在相同结果下,Python 的内置函数会比 NumPy 花费更多时间。如果我们有更大的数据集,Python 完成这些操作的时间会比 NumPy 长得多。
另一个例子是当我们尝试进行原地操作时,我们可以看到 NumPy 会比 Python 示例快得多。
array = np.arange(1000000)
start_time = time.time()
array += 1
print("Time taken for in-place operation:", time.time() - start_time)
list_1 = list(range(1000000))
start_time = time.time()
for i in range(len(list_1)):
list_1[i] += 1
print("Time taken for in-place list operation:", time.time() - start_time)
Output>>
Time taken for in-place operation: 0.0010089874267578125
Time taken for in-place list operation: 0.1937870979309082
例子的关键点在于,如果你有机会使用 NumPy,那么效果会更好,因为处理速度会更快。
我们可以尝试更复杂的实现,使用矩阵乘法来观察 NumPy 相比于 Python 的速度。
def python_matrix_multiply(A, B):
result = [[0 for _ in range(len(B[0]))] for _ in range(len(A))]
for i in range(len(A)):
for j in range(len(B[0])):
for k in range(len(B)):
result[i][j] += A[i][k] * B[k][j]
return result
def numpy_matrix_multiply(A, B):
return np.dot(A, B)
n = 200
A = [[np.random.rand() for _ in range(n)] for _ in range(n)]
B = [[np.random.rand() for _ in range(n)] for _ in range(n)]
A_np = np.array(A)
B_np = np.array(B)
start_time = time.time()
python_result = python_matrix_multiply(A, B)
print("Time taken for Python matrix multiplication:", time.time() - start_time)
start_time = time.time()
numpy_result = numpy_matrix_multiply(A_np, B_np)
print("Time taken for NumPy matrix multiplication:", time.time() - start_time)
Output>>
Time taken for Python matrix multiplication: 1.8010151386260986
Time taken for NumPy matrix multiplication: 0.008051872253417969
如你所见,NumPy 在更复杂的活动中也更快,比如使用标准 Python 代码的矩阵乘法。
我们可以尝试更多的例子,但 NumPy 应该比 Python 内置函数的执行时间更快。
结论
NumPy 是一个强大的数学和数值处理包。与标准 Python 内置函数相比,NumPy 的执行时间会更快。这就是为什么,如果适用,尝试使用 NumPy 来加速我们的 Python 代码。
Cornellius Yudha Wijaya**** 是一名数据科学助理经理和数据撰稿人。在 Allianz Indonesia 全职工作期间,他喜欢通过社交媒体和写作分享 Python 和数据技巧。Cornellius 涉及各种 AI 和机器学习主题的写作。
更多相关话题
数据科学技能的分裂:个人与团队方法
原文:
www.kdnuggets.com/2014/01/split-on-data-science-skills-individual-vs-team-approach.html
评论作者:Gregory Piatetsky,2014 年 1 月 21 日。
 大多数数据科学职位(和任务)要求结合多种技能,如
大多数数据科学职位(和任务)要求结合多种技能,如
-
统计/机器学习,
-
黑客技能,
-
数据库,
-
以及行业/领域知识。
有一些多才多艺(“独角兽”)的数据科学家具备所有所需技能,但数量不足以填补预计的140-190,000 名深度分析专家和 150 万名分析经理/分析师(仅美国)的缺口。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的 IT 组织
最新的 KDnuggets 民意调查询问了:哪种方法更好?
| 数据科学任务需要统计、黑客、数据库、商业、演示及其他技能的稀有组合,但找到具备所有所需技能的多才多艺(“独角兽”)数据科学家非常困难。哪种方法更好: [总票数 304 票]
|
| 个人:寻找并培养具有所有(或大部分)所需技能的多才多艺的数据科学家(135) |  |
|---|---|
| 不确定(33) |  |
| 团队:组建一个数据科学团队,每个成员主要专注于一项技能(136) |  |
这项调查源于 Michael Mout 在 KDnuggets 上发布的最近文章《数据科学定义的错误在哪里》,引发了关于是否能够找到具备所有所需技能的数据科学家,或者这些角色是否更适合由团队填补的激烈讨论 - 参见《独角兽数据科学家与数据科学团队》。
Michael Mout 将数据科学技能分为三个主要领域:数学和统计、计算和数据库。
著名的 数据科学维恩图,由 Drew Conway 于 2010 年提出,其组成部分略有不同:黑客技能、数学与统计学以及领域/业务知识。
部分差异,如 David Gillman 在下方评论的那样是
大公司需要一个团队。中小企业需要一到两个人。
显然,如果中小企业只能雇佣一个人,他们会尽量寻找一个更全面的人才。
大公司将拥有一个数据科学家团队。然而,即使是能够负担得起大团队的大公司也应该决定是寻求并培训难以获得但多才多艺的人,还是尝试通过专家团队完成任务。
调查结果在团队和个人方法的支持者之间平均分配,但在区域分析中出现了有趣且反直觉的差异。
来自美国的受访者,传统上被认为更加个人主义(如美国宪法中的“生命、自由和追求幸福”所体现),实际上更倾向于团队方法,而欧洲和亚洲的受访者则倾向于个人方法:欧洲。加拿大的受访者与美国的观点截然不同,强烈支持团队方法,而澳大利亚/新西兰的选民尽管人数较少,却是最具个人主义的。
以下是按区域划分的结果。条形高度对应受访者数量。
| 区域 | % 个人方法 | % 不确定 | % 团队方法 |
|---|---|---|---|
| 美国 (147) | 41% |
12% |
47% |
| 欧洲 (76) | 51% |
12% |
37% |
| 亚洲 (41) | 51% |
2% |
46% |
| 拉丁美洲 (12) | 42% |
17% |
42% |
| 非洲和中东 (12) | 33% |
8% |
58% |
| 加拿大 (11) | 18% |
9% |
73% |
| 澳大利亚/新西兰 (5) | 80% |
20% |
0% |
评论
C. Magaret,通过 Disqus
让我们回到大约 20 年前,当时出现了一种席卷全球的疯狂新趋势,称为万维网。有些人说它将改变世界,其他人则认为不那么回事,有些人觉得它发展得太快了,还有些愤世嫉俗者宣称这只是一个短暂的时尚。
在网络的青铜时代,赋予网络生命的专业和业余从业者是被称为“网页管理员”的全能型技术专家。要成为一个合格的网页管理员,你需要掌握一系列(当时)晦涩的技能:系统管理、网络管理、编程、界面设计和图形设计等。网页管理员通常独自工作,或在一个小型的网页管理员团队中,来实现组织的网络目标。
如今,网络无处不在。它在几乎每个人的生活中扮演着重要角色,已经成为地球上几乎每个组织的核心部分,还有大量的企业专门从事网络货币化。网络带来了数据库,促进了新技术的发展,推动了交互用户界面设计的极限,并且某些基本服务已经被商品化到微不足道的地步。今天的网络范围和成熟度之大,使得拥有一个全能型的网页管理员已经不再切实可行。对于从事网络业务的人来说,我提到的每一种网页管理员技能(还有更多)都已经被划分为由专家负责的独立学科。虽然界面设计师可能会了解 SOAP 的工作原理,并因此成为更好的界面设计师,但他们不会从事 API 的后端编程工作。他们会将这部分留给开发者。
简单来说,网络已经超越了传统的网页管理员。虽然你可能会找到为某个小组织工作的老式网页管理员,但要想实现高效和高质量的网络工作,仅仅依靠一小组通才是不够的。他们需要拥有专业的团队。
上述内容让我联想到关于通才与专家数据科学家的争论。如果“数据科学”作为一个领域预期要发展和成熟到工业规模,那么“数据科学”将超越数据科学家,当然你会看到专业化,通常表现为项目团队,我已经在大型数据驱动的组织中看到了这种情况。人们有自然的技能组合,他们倾向于承担那些符合其优势的责任,对于在数据科学领域实践的大型组织而言,拥有一个由具备明确责任的人员组成的项目团队将带来更高效的工作流程和更好的最终产品,而且更易于管理。这是一种更自然和有纪律的商业方式。
Sam Steingold
我认为两种选择都不现实。将所有三种技能(数学/统计、黑客、商业)结合起来非常困难。我认为最佳的方法是找一个优秀的数学/统计人员,然后通过添加必要的人来弥补他的不足。即,数据团队应该围绕一个拥有强大数学/统计背景的人建立。
凯瑟琳·巴特勒,数据科学团队还是个人?
我同意很难找到那种“独角兽”,但我也相信你需要比单一领域的专家更全面的个人。在招募时,我寻找能够填补团队空白的个人,但如果我在计算技能上有所欠缺,我绝不会雇佣一个没有像矿工那样的好奇心和创造力的程序员,或没有获取商业知识和解释分析结果能力的人,或没有将洞见提炼成强有力演示能力的人。我认为这取决于你的团队规模,是否有招聘领域专家的奢侈,或者是否需要让每一个全职员工发挥作用,并寻找更多的全能型人才,偶尔有领域专家。
格雷厄姆·穆利尔,第 4 选项 - 两者皆可!
我投了“个人”选项,但实际上我希望有一个第四个选项,用于招募和培训多技能的个人,辅以一个更广泛的团队,以更深入地覆盖所有方面。
这就是我目前在 Syngenta 设置的新数据科学职能中所做的。我很幸运拥有一个能够作为个人数据科学家高效运作的小团队,他们具备正确的技能和领域知识。他们是一个更大团队的一部分,能够处理和存储数据集,整合数据,构建本体,制作数据可视化等。这应该有助于扩展他们的专业知识并更广泛地传播好处。
大卫·吉尔曼,团队与个人
大公司需要一个团队。中小企业需要一两个个人。
讽刺地说,“团队”是任何项目中必须分享或分配责任的必要元素。
乔治·R,团队与个人
团队方法对于组织的可持续努力更为健康。找到真正的数据分析明星是困难且昂贵的。即使你雇佣了那个具备全部技能的杰出个人,她也可能不会长期留下。团队方法允许更快速地访问解决数据问题所需的各个组成部分。如果团队成员离开,找到一个在缺失组件上非常优秀的人会容易得多。
加里·霍沃斯,个人与团队
啊,但你假设团队之间会互相交流并且“提出正确的问题”,恐怕这只存在于教科书中。我在数据行业工作了 30 年,所以这是经验之谈。工具已经有所改进,但这仅占所需技能的 10-20%。我回答了个人,但正如之前的评论者所说,实际上很少有人具备这种多学科的技能——这是一种特殊的技能。所以在缺乏这种技能的情况下,你确实需要一个团队。你可以主张一个非常小的 2-3 人的团队,但如果技能分布在 10 个人身上,对我来说并不够。这关乎如何将各种不同的组件结合起来,即数据分析加上背景加上领域经验,这才是关键。
理查德·D·阿维拉,数据科学团队还是个人?
我在 2000 年 4 月写了我的第一个“分析程序”。那是一个球面上的地理聚类算法。我做了数学运算,编写了代码,运行了数据,进行了验证,但对结果在 150 万条记录中的含义毫无头绪。我们有一位运营分析师,他理解了所显示的内容,接着好事就发生了。分析推理/领域知识/领域背景只能通过真正的领域工作来获得。我确实同意数据分析的三个关键能力是:分析/领域知识、数学、计算。要成为一个有效的“数据科学家”,一个人需要具备三者中的两个。在我从事数据分析的时间里(2000 年 4 月),我只遇到过一个具备所有三方面技能并能解决实际问题的人。这一学科的技术层面非常广泛——想想所有所需的数学、算法和计算技术专长。
领域专业知识的适配问题我也无法理解。我会把那些声称能做三者兼备的人视为天真或傲慢。这两种特质可能会导致数据分析项目或系统开发失败。仅仅因为你能想象一只独角兽,并不意味着它能存在于我们生活的这个物理世界中。正确进行数据分析几乎总是需要一个团队。
通过 LinkedIn 选择的评论
比尔·温克勒,美国人口普查局首席研究员
对于最复杂的一组算法(甚至可能涉及理论/计算突破),很难在一个人身上找到合适的技能,即使这个人有很长时间来发展这些技能。
多年来,有许多大型软件开发项目和数据仓库创建项目,我们还可以添加一些大数据项目。所有这些项目都需要某些技能,其中一些在项目早期是不为人知的。根据一些 IEEE CS 和 ACM 文章,很多项目(超过 50%)都失败了。
迈克尔·希迪罗格鲁和我参与了一些成功的团队,这些团队开发了非常大的、通用的计算机系统。在大多数项目中,有一个时刻是一个人能够开发出新的方法/算法,使整体工作取得成功。这个方法可能涉及高级运筹学(集合覆盖,整数规划)或计算机科学(近似字符串比较,非常先进的索引/搜索/检索),这些技能在统计学家、经济学家或参与这些团队项目的 IT 编程人员中并不常见。
一些团队随后尝试开发类似系统,因为这些团队了解我们开发的系统(或在荷兰、西班牙和意大利开发的类似系统)。大多数项目失败了(即使经过多次尝试)。共同点是成功的团队具备适当的分析/理论/算法技能。在少数情况下,IT 领域提供了补充技能,但大多数关键突破是由统计学家和经济学家提供的(通常是具备很好的编程技能的博士生)。
如果有像清理和去重国家文件集、然后合并国家文件集以进行后续统计分析以调整链接错误(因为通常没有唯一标识符)这样的大数据情况,那么需要先进的计算方法。
Winkler, W. E. (2011), "清理和使用行政名单:记录链接及建模/编辑/填补的快速计算算法方法",在 2011 年 11 月于西班牙马德里举行的 ESSnet 数据集成会议论文集( www.ine.es/e/essnetdi_ws2011/ppts/Winkler.pdf )。
我确实意识到,有大量的快速项目(1-6 个月),其中一个人具备适合特定分析的一组技能。两个问题:(1)如果你在较小的情况下创建了输入文件/结构并编写了一个在一周内运行的软件,你如何意识到可以编写比这快 10-100 倍的软件?(2)如果你使用统计或其他软件包,你如何知道算法是否正确执行计算?
作者:托马斯·斯派德尔
比尔·温克勒的评论非常有见地。我可以理解与行政数据集进行记录链接的问题(噩梦)。
我认为,分歧源于在一个仍然模糊定义的新领域中的有限经验。这几乎是不可避免的。那些认为专业化是过时方法的人,可能习惯于那些对表面知识足够的项目。他们可能没有意识到,但他们也拥有专业知识。
作者:弗雷迪·霍尔韦达
敏捷开发提供了 T 型资源的概念。因此,我选择了个人方法:“寻找并培养具备所有(或大部分)所需技能的多面手数据科学家”,并补充说每个数据科学家应在每项技能上只有一定深度(“T”字形的横杠),并在一到两个技能上有深度掌握(“T”字形的竖杠)。
由劳拉·斯奎尔,SAS 销售工程经理
博客系列展示了如何制定高级分析策略
构建分析梦想团队的专业人才:SME、数据准备员、数据管理员、IT、分析师、思想领袖、倡导者
由威尔·斯坦顿
随着分析领域(以及数据科学家)不断以有时似乎是指数级的速度发展,我认为大多数公司(尽管不是所有公司)更倾向于团队方法。因此,组建一个合适的数据科学家团队来处理特定项目/问题/机会。数据科学家团队可以由在一到两个领域具有互补深度的个人组成,并且对其他领域有一定了解,从而使团队具备广度和深度的知识——我认为这是单个数据科学家无法实现的(尽管我遇到过一些自认为在所有领域,包括新兴领域,均具备广度和深度的个人——并非所有人都同意他们的自我评价)。然而,就像大多数事情一样,这种方法取决于许多假设/现实,包括问题的复杂性、公司的规模、公司内人才的可用性等。
由多萝西·休伊特-桑切斯
也许我看到的职位发布与你看到的不同。这些职位发布要求一切,包括所有额外要求。这与职位名称无关。这就是为什么招聘人员说找不到合格的人才。这真是荒谬。我曾在多个职位上工作。当我是 DBA 时,我仍然需要进行业务分析、收集需求、为业务和数据分析师重写查询并参与决策支持会议。这都是工作的一部分。作为顾问或主管,我仍然需要完成所有这些角色及更多。因此,职位角色和标题之间的界限非常模糊。
嗯,如果我再加入统计学、机器学习和 Hadoop,情况会怎样呢?
由斯特凡·卡拉吉尔
在我的职业生涯中,我遇到了两种类型的人:一种是喜欢在多个领域学习尽可能多技能的广泛型人才(通才),另一种是倾向于在某一领域成为专家的专业型人才(专才)。直到最近,公司主要寻找的是专家,但现在发现他们需要更多的通才:解决复杂问题往往需要借鉴多个领域的方法(生物学、物理学、社会学……)。我的看法是,最佳的团队应包括通才和专才。
埃里克·金
这是我从一开始就遇到的几个问题之一,那就是有些人随意冠以“数据科学家”的称号。除了需要涵盖的各种职能外,大多数从业者并没有足够的个性来在技术层面和软技能方面同时管理战略问题。我认为只有少数非常独特的人才能胜任这个角色……这使得“数据科学”应该是一个团队功能,而不是个人称号。
更多相关话题
生成 Python 的电子表格:Mito JupyterLab 扩展
原文:
www.kdnuggets.com/2021/11/spreadsheet-generates-python-mito-jupyterlab-extension.html
评论
作者 Roman Orac,高级数据科学家

图片由 Joshua Sortino 提供,来源于 Unsplash
Mito 是一个用于 Python 的电子表格界面
Mito 允许你将数据框或 CSV 文件传入电子表格界面。它具有 Excel 的感觉,但每次编辑都会在下面的代码单元中生成等效的 Python 代码。最理想的情况下,这可以成为快速完成数据分析的绝佳方法。
使用 Mito 进行探索性数据分析(作者制作的可视化)
如果你错过了我关于 Mito 的其他文章:
开始使用 Mito
这里是完整的安装说明。
要安装 Mito 包,请在终端中运行以下命令:
python -m pip install mitoinstaller
python -m mitoinstaller install
然后在 Jupyter Lab 中打开一个笔记本并调用 mitosheet:
import mitosheet
mitosheet.sheet()
Mitosheet 可以在分析的任何阶段调用。你可以在表单调用中将数据框传递给 Mitosheet 作为参数。
mitosheet.sheet(df)
你可以使用导入按钮从本地文件中安装数据。
Mito 数据分析功能
Mito 提供了一系列功能,允许用户清理、处理和探索数据。这些功能中的每一个都会在下面的代码单元中生成等效的 Python 代码。
在 Mito 中,你可以:
-
过滤
-
数据透视
-
合并
-
图表
-
查看汇总统计数据
-
使用电子表格公式
-
还有更多…
对于这些编辑中的每一个,Mito 都会在下面的代码单元中生成 Pandas 代码,用户可以将其用于分析或发送给同事。
下面是使用 Mito 创建数据透视表的样子:
Mito 的数据透视表(作者制作的可视化)
生成的示例数据透视表代码如下(代码是自动文档化的):
# Pivoted ramen_ratings_csv into df3
unused_columns = ramen_ratings_csv.columns.difference(set(['Style']).union(set(['Brand'])).union(set({'Style'})))
tmp_df = ramen_ratings_csv.drop(unused_columns, axis=1)
pivot_table = tmp_df.pivot_table(
index=['Style'],
columns=['Brand'],
values=['Style'],
aggfunc={'Style': ['count']}
)# Flatten the column headers
pivot_table.columns = [flatten_column_header(col) for col in pivot_table.columns.values]
下面是查看列的汇总统计数据的过程:
使用 Mito 的汇总统计(作者制作的可视化)
生成可视化代码
正确获取 Python 数据可视化的语法可能是一个耗时的过程。Mito 允许你在点击环境中生成图表,然后给出这些图表的等效代码。
创建图表后,点击“复制图表代码”按钮:
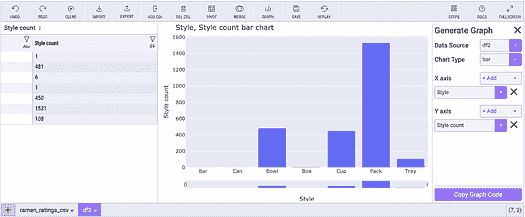
使用 Mito 制作图表(图像由作者制作)
然后将代码粘贴到任何代码单元格中。Mito 允许进行可重复的可视化过程。

Mito 生成代码(图像由作者制作)
结论
Mito 是生成 Python 代码的快速方法,特别适合那些熟悉 Excel 的人。它节省了很多去 Stack Overflow 或 Google 查找正确语法的时间。
Mito 绝对值得尝试,尽管它会在引入更多图表类型和更好的批量编辑能力(批量删除列、重命名等)时变得更加有价值。
离开之前
如果你喜欢阅读这些故事,何不成为一个Medium 付费会员呢?每月 $5,你将获得无限访问数万篇故事和作者的权限。如果你使用我的链接注册,* 我将获得一小笔佣金。*
由 Courtney Hedger 拍摄,来源于 Unsplash
个人简介:Roman Orac 是一位机器学习工程师,在改进文档分类和项目推荐系统方面取得了显著成功。Roman 具有管理团队、指导初学者和向非工程师解释复杂概念的经验。
原文。经授权转载。
相关:
-
在 Jupyter Notebook 中分析 Python 代码
-
Python 序列的 5 个高级技巧
-
用 Faker 生成 Python 合成数据
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关主题
你免费的 70 页数据科学职业指南
原文:
www.kdnuggets.com/2018/03/springboard-guide-career-data-science.html
赞助帖子。
你是否想进入数据科学行业但不太知道从哪里开始?做数据科学,你必须能够找到和处理大型数据集。你通常需要理解和使用编程、数学和技术沟通技能。
在进入数据科学之前,你应该能够回答一些问题:你如何进入这一行业?你需要什么技能才能成为数据科学家?哪里有最好的数据科学职位?
为了回答这些问题(以及更多问题),我们整理了一份全面的获取你的第一份数据科学工作指南。
在本指南中,我们将逐步带你了解打破数据科学壁垒所需的一切,包括:
-
行业概览——从“数据科学”这一术语的历史,到学习正确的编程语言,再到理解所需的数学和统计学。
-
与顶级公司的数据科学家的真实采访。他们会分享他们如何进入这一行业。
-
你在数据科学角色中成功所需的技能以及如何建立项目组合。
-
可操作的建议,包括寻找工作、如何建立网络以及如何发展招聘经理所寻找的软技能。
如果你对数据科学感到好奇,或你已经决定数据科学是适合你的职业,今天下载免费的指南 并开始为你的数据科学新职业而努力!
更多相关话题
学习数据科学统计学的顶级资源
原文:
www.kdnuggets.com/2021/12/springboard-top-resources-learn-data-science-statistics.html
赞助帖子。
图片来源:Lukas from Pexels
统计学是数据科学的核心,两个领域之间的联系越来越紧密。如果你希望在数据科学领域取得长足的进展,深入理解统计学概念是非常重要的,而这一基础的建立可能需要一段时间。Springboard 的数据科学职业课程是一个很好的起点,如果你认真对待提升自己在这一领域的技能,它应该是你首先要迈出的步骤之一。让我们来看看统计学在数据科学中的当前状态,以及你可以做些什么来加速学习。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
统计学在数据科学中的作用
有些人喜欢说机器学习只是统计学加上额外的层次,虽然这可能有些夸张,但这句话中确实有一些真理。这也适用于数据科学的广泛领域。处理数据、识别数据中的模式以及预测未来数据集中的趋势,最终都归结于正确应用各种统计技术。现代数字解决方案的帮助使得这一过程变得更加容易,因为它们可以以快速的速度处理大量数据。
需要关注的统计学领域
对大多数人来说,扎实的统计学基础将大大助力于成为数据科学家,即使没有深入研究任何特定的子领域。你需要一般性地培养像统计学家一样思考的能力,并将适当的推理方法应用于你遇到的情况。这将比学习任何特定的狭窄专业领域更有帮助。
更重要的是,你需要培养理解你所做的事情以及你如何得出结论的能力。数据科学中很大一部分是黑箱,尤其是涉及人工智能时。这可能会让人误以为只需将一堆预制模型应用于某个情况,得到一些结果,然后结束一天。
但如果你无法解释驱使你到达那个点的实际统计推理,专家们不会认真对待你。这也将帮助你理解你遇到的问题的局限性。你可能不会立即知道正确的解决方案,但理解领域的局限性至少能帮助你将注意力引导到正确的方向。
实现一些基本模型
无论你选择专注于哪个方面,你都应该在学习过程中经历一些基本模型。用你自己的资源和研究从零开始实现这些模型,将有助于你更深入地理解这个领域是如何工作的,以及不同概念之间的联系。
你应该从基本线性回归开始。这是统计学和数据科学中最容易理解的概念之一,它将为你打开一些可能感兴趣的额外领域。进行朴素贝叶斯分类。网上有很多关于这个主题的资源,这应该是另一个相对简单的任务,同时仍能为你提供大量关于数据科学中统计学基础的有价值知识。
有用的入门资源
在线培训课程是你最好的朋友。它们能提供你理解后续概念所需的深入知识。有很多地方可以学习数据科学中的统计学,你应该花时间比较一些最受欢迎的课程。
一些可以帮助你走上正轨的有用书籍包括彼得·布鲁斯和安德鲁·布鲁斯的《数据科学实用统计学》;卡梅伦·戴维森-皮隆的《黑客的贝叶斯方法》;以及布拉德利·埃夫隆和特雷弗·哈斯蒂的《计算机时代的统计推断》。这些书籍很容易找到,在社区中也非常受欢迎,所以你应该有很多机会与他人讨论你所学到的知识。
需要记住的事项
统计学和数据科学之间的联系很紧密,而在数据科学领域取得进展而不投入一些统计学方面的努力是困难的。与此同时,你在数据科学中取得较高进展所需的理解水平并不像你想象的那样高。对许多人来说,复习我们上面概述的基本概念,并完成一些培训课程,应该足以让他们入门并全面介绍这一领域。
正如我们之前提到的,如果你对数据科学职业感兴趣,可以查看 Springboard 的数据科学职业课程。它将为你提供目前能找到的最深入的领域概述,并帮助你理解提升技能所需的概念。同时,也要尽可能多与人交流——数据科学正在经历许多积极的发展,现在是与其他专家讨论最新发现的绝佳时机。
更多相关内容
使用机器学习进行销售预测
原文:
www.kdnuggets.com/2017/05/springml-sales-forecasting-using-machine-learning.html
赞助帖子。
作者:Girish Reddy,SpringML。
销售预测是组织常见的任务。这通常涉及使用电子表格的手动密集过程,需要来自组织各个层级的输入。这种方法引入了偏差,通常在季度初的几周内并不准确。实际上,那段时间准确的预测最为重要,因为在季度最后一周提供准确的预测价值不大。
尽管预测过程往往复杂,但确定其准确性却很简单。只需等到预测期结束(例如季度末),然后将预测与实际情况进行比较即可。我们对我们的模型的准确性充满信心,并邀请销售领导参与我们的人类与机器预测对决——给我们一天时间使用你的数据,我们将提供基于算法的、公正的预测。在季度末,你可以通过与内部预测进行比较来评估我们的结果。通过访问 www.springml.com/sales-forecasting-challenge并提交表单来开始。这个过程简单易行,可以让你快速看到机器学习能为你的组织带来什么。
SpringML 的应用通过执行自动运行的机器学习模型来简化预测,并提供客户销售指标的每月或季度预测(例如收入、ACV、数量)。这些模型使用历史数据来评估趋势和季节性,以及当前机会管道来预测未来 6 个月或 12 个月的情况。准确的预测可以帮助组织做出明智的业务决策。它提供了关于公司如何管理其资源——人力、时间和资金的洞察。
以下是构成我们预测集成的各种技术。
-
使用贝叶斯模型(R 中的 BSTS 包)、树基技术以及其他传统方法如 ARIMA 进行时间序列预测。
-
包含时间序列的预测因子——这些可以是任何对模型有价值的变量,例如产品使用情况、用户数量、营销支出等。根据需要包括外部数据,如行业趋势、人口统计信息等。
-
通过对开放机会运行分类算法来评估当前管道数据——这构成了集成的一部分。
-
在最终确定最佳模型集之前,评估过去几个月的集成效果。
由于预测基于数据驱动,因此该解决方案允许用户执行“如果”分析。这是一种工具,允许销售负责人确定某些因素对销售数字的影响。这种分析帮助他们确定可以使用哪些杠杆,以及这些杠杆对销售产生的影响,无论是正面还是负面。这种高级“如果”分析基于机器学习,每次用户与工具互动时,模型都会执行。一些用于此分析的变量包括销售代表数量、平均交易持续时间、平均交易金额、赢单率百分比。例如,销售经理可以查看如果增加招聘会发生什么,或者确定折扣计划的影响。该功能列表是可配置的,可以包括对公司更有意义的其他因素。
通过发送电子邮件至info@springml.com了解更多信息
该主题的更多内容
SQL 案例研究:帮助初创公司 CEO 管理数据
原文:
www.kdnuggets.com/2018/09/sql-case-study-helping-startup-ceo-manage-data.html/2
评论
表中存在多少行?
我们想知道这个初创公司有多少人。我们通过使用 count(*) 计算行数来实现:
SELECT COUNT(*)
FROM startup;
列中有多少行具有最小值?
我们想知道在初创公司中哪些人的薪水最低以及有多少人。让我们尝试这个查询:
SELECT *
FROM startup
WHERE salary = MIN(salary);
这将导致一个错误,提示:
ERROR: aggregate functions are not allowed in WHERE
聚合函数如 COUNT()、MIN()、MAX()、AVG()、SUM() 等,它们将列中的值作为输入并返回一个单一值(或 NULL)。这里 MIN() 在 WHERE 子句之后使用,因此我们可以通过检查薪水是否等于最小值(或不是)来实现,这个最小值我们可以从另一个查询中获取,而不是通过聚合来获取,如下所示:
SELECT MIN(salary)
FROM startup;
但这将产生不合理的值,即 1000$,那么发生了什么?!
这是因为排序顺序,如果你对 ASCII 排序顺序感兴趣,可以查看这个链接。
那么,我们现在应该怎么做?
实际上,我在创建表的开始阶段做了一些效率不高的事情,那就是将薪水列存储为 varchar。原因存在于这个stackoverflow 问题的RidFilter的回答中。
相信与否,我处理过一些类似的数据。它包括存储为 varachar 的美元符号,因此让我们修复它,以便能够对其进行操作。
从字符串中删除字符:
这个问题可以通过首先删除美元符号,然后将该 varchar 转换为可以是整数的数值来解决。
SELECT REPLACE(salary, '$', '')
FROM startup;
这个 REPLACE() 函数将导致薪水列中的值去除美元符号(即用空替换 $),但请注意这并没有编辑到表中。所以,下次我们需要操作时需要使用它。此外,请注意,这一列仍然是字符串而非数值,因此我们需要将其转换为小数。
现在,我们可以对转换后的薪水值应用 MIN():
SELECT MIN(
CAST(
REPLACE(salary, '$', '')
as DECIMAL))
FROM startup;
CAST() 函数将新的薪水列转换为小数值。
记住,我们在初创公司表中仍然看到带有美元符号的薪水。
为了在表中去除美元符号,我们使用 UPDATE() 函数:
UPDATE startup
SET salary = REPLACE(salary, '$', '');
现在,我们回到我们的难题,即找出初创公司中薪水最低的人员。
SELECT *
FROM startup
WHERE CAST(salary AS DECIMAL) = 800;
我们可以只使用一个带有子查询的查询,而不是最后两个独立的查询:
SELECT *
FROM startup
WHERE CAST(
salary AS DECIMAL) = (
SELECT MIN( CAST(salary AS DECIMAL) ) FROM startup );
我们还可以使用 COUNT(*) 进行计数:
SELECT COUNT(*)
FROM startup
WHERE CAST(salary AS DECIMAL) = 800;
最低薪水的三个人:
我们希望获取初创公司中薪资最低的三名工程师。我们可以通过首先使用 ORDER BY 子句并跟随 ASC,或者仅使用 ORDER BY,这将默认按升序排列输出。
SELECT *
FROM startup
ORDER BY
CAST( salary AS DECIMAL );
添加 ‘LIMIT 3’ 将带来前三个对应薪资最低的行。
薪资最高的三名:
注意我们做了什么改变!
SELECT *
FROM startup
ORDER BY
CAST( salary AS DECIMAL ) DESC
LIMIT 3;
总薪资:
假设 CEO 想了解薪资总成本,我们可以使用聚合函数 SUM() 来实现。
SELECT SUM(
CAST( salary AS DECIMAL )
) FROM startup;
向表中添加列:
假设他现在想雇佣女性,因此他会添加一个名为 sex 的列。这可以通过 ALTER 子句完成:
ALTER TABLE
startup
ADD sex char(1);
我们应该这样更新每一行:
UPDATE startup
SET sex = 'M'
WHERE id = 1;
使用 for 循环:
当然,如果我们手动操作,这会很繁琐。因此,我们应该改用循环。
SQL 没有循环,但可以在过程性语言函数或 ‘Do’ 语句中使用,如 这里 所答:
DO
$do$
BEGIN
FOR i IN 2..8 LOOP
UPDATE startup2 set sex = 'M' WHERE id = i;
END LOOP;
END
$do$;
(类似)直方图:
其中一个可能的要求是了解某事发生的频率。我们可以通过计算每个城市值的每行出现次数来获取城市在初创公司工程师中的频率。这就是我们使用 GROUP BY 子句的原因:
SELECT city, COUNT(*)
FROM startup
GROUP BY city;
这类似于直方图;它展示了值出现的频率。
如果我们跟随 AS,可以为任何列命名:
SELECT city, COUNT(*) AS frequency
FROM startup
GROUP BY city;
希望你觉得这篇文章有用。如果你想了解我在获得第一个数据科学实习之前的故事,我在 Medium 上写了一篇 文章。如果你想看到更多更新和挑战,请关注我:
-
Linkedin:
www.linkedin.com/in/ezzeddinabdullah/ -
Medium:
medium.com/@ezzeddinabdullah -
Twitter:
twitter.com/EzzEddinAbdulah
简历: Ezz El Din Abdullah 是前数据科学实习生和编程导师。
相关:
-
SQL 备忘单
-
SQL 中的可扩展随机行选择
-
选择 SQL 还是不选择 SQL:这是一个问题!
我们的前 3 门课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织进行 IT 管理
主题更多信息
SQL 速查表
评论

SQL(结构化查询语言)是一种用于编程的领域特定语言,旨在查询数据库。与任何语言一样,拥有常见查询和函数名称的列表作为参考是有用的。我们希望这张速查表对你有所帮助:
基本关键字
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
在我们深入了解一些基本常见查询之前,让我们先看看你将会遇到的一些关键字:
| 关键字 | 说明 |
|---|---|
| SELECT | 用于声明要查询的列。使用 * 表示所有 |
| FROM | 声明从哪个表/视图等中选择 |
| WHERE | 引入条件 |
| = | 用于将值与指定输入进行比较 |
| LIKE | 与 WHERE 子句一起使用的特殊运算符,用于在列中搜索特定模式 |
| GROUP BY | 将相同的数据安排成组 |
| HAVING | 指定仅返回汇总值符合指定条件的行。由于 WHERE 关键字不能与汇总函数一起使用,因此使用此关键字 |
| INNER JOIN | 返回所有主键记录在一个表中等于另一个表的主键记录的行 |
| LEFT JOIN | 返回“左”(第一个)表中的所有行及其在右(第二个)表中匹配的行 |
| RIGHT JOIN | 返回“右”(第二个)表中的所有行及其在左(第一个)表中匹配的行 |
| FULL OUTER JOIN | 返回在左表或右表中匹配的行 |
汇报汇总函数
在数据库管理中,汇总函数是一种将多行的值分组形成单一值的函数。它们对汇报很有用,一些常见汇总函数的示例如下:
| 函数 | 说明 |
|---|---|
| COUNT | 返回某个表/视图中的行数 |
| SUM | 累加值 |
| AVG | 返回一组值的平均值 |
| MIN | 返回组中的最小值 |
| MAX | 返回组中的最大值 |
从表中查询数据
数据库表是以垂直列和水平行的模型存储的数据元素(值)的集合。使用以下任一方法在 SQL 中查询表:
| SQL | 解释 |
|---|---|
| SELECT c1 FROM t | 从名为 t 的表中选择列 c1 的数据 |
| SELECT * FROM t | 从名为 t 的表中选择所有行和列 |
| SELECT c1 FROM t****WHERE c1 = ‘test’ | 从名为 t 的表中选择列 c1 的数据,其中 c1 的值为‘test’ |
| SELECT c1 FROM t****ORDER BY c1 ASC (DESC) | 从名为 t 的表中选择列 c1 的数据,并按 c1 排序,可以是升序(默认)或降序 |
| SELECT c1 FROM t****ORDER BY c1LIMIT n OFFSET offset | 从名为 t 的表中选择列 c1 的数据,跳过指定的行偏移量,并返回接下来的 n 行 |
| SELECT c1, aggregate(c2)FROM tGROUP BY c1 | 从名为 t 的表中选择列 c1 的数据,并使用聚合函数对行进行分组 |
| SELECT c1, aggregate(c2)FROM tGROUP BY c1HAVING condition | 从名为 t 的表中选择列 c1 的数据,使用聚合函数对行进行分组,并使用‘HAVING’子句筛选这些组 |
从多个表中查询数据
除了从单个表中查询数据,SQL 还允许从多个表中查询数据:
| SQL | 解释 |
|---|---|
| SELECT c1, c2FROM t1INNER JOIN t2 on condition | 从名为 t1 的表中选择列 c1 和 c2,并在 t1 和 t2 之间执行内连接 |
| SELECT c1, c2FROM t1LEFT JOIN t2 on condition | 从名为 t1 的表中选择列 c1 和 c2,并在 t1 和 t2 之间执行左连接 |
| SELECT c1, c2FROM t1RIGHT JOIN t2 on condition | 从名为 t1 的表中选择列 c1 和 c2,并在 t1 和 t2 之间执行右连接 |
| SELECT c1, c2FROM t1FULL OUTER JOIN t2 on condition | 从名为 t1 的表中选择列 c1 和 c2,并在 t1 和 t2 之间执行全外连接 |
| SELECT c1, c2FROM t1CROSS JOIN t2 | 从名为 t1 的表中选择列 c1 和 c2,并生成表中行的笛卡尔积 |
| SELECT c1, c2****FROM t1, t2 | 同上 - 从名为 t1 的表中选择列 c1 和 c2,并生成表中行的笛卡尔积 |
| SELECT c1, c2FROM t1 AINNER JOIN t2 B on condition | 从名为 t1 的表中选择列 c1 和 c2,并使用 INNER JOIN 子句将其连接到自身 |
使用 SQL 操作符
SQL 操作符是保留字或字符,主要用于 SQL 语句中的 WHERE 子句以执行操作:
| SQL | 解释 |
|---|---|
| SELECT c1 FROM t1UNION [ALL]SELECT c1 FROM t2 | 从名为 t1 的表中选择列 c1,并从名为 t2 的表中选择列 c1,将这两个查询的结果合并 |
| SELECT c1 FROM t1INTERSECTSELECT c1 FROM t2 | 从名为 t1 的表中选择列 c1,并从名为 t2 的表中选择列 c1,返回两个查询的交集 |
| SELECT c1 FROM t1MINUSSELECT c1 FROM t2 | 从名为 t1 的表中选择列 c1 和从名为 t2 的表中选择列 c1,并从第一个结果集中减去第二个结果集 |
| SELECT c1 FROM t****WHERE c1 [NOT] LIKE pattern | 从名为 t 的表中选择列 c1,并使用模式匹配 % 查询行 |
| SELECT c1 FROM t****WHERE c1 [NOT] in test_list | 从名为 t 的表中选择列 c1,并返回在 test_list 中(或不在) 的行 |
| SELECT c1 FROM t****WHERE c1 BETWEEN min AND max | 从名为 t 的表中选择列 c1,并返回 c1 在 min 和 max 之间的行 |
| SELECT c1 FROM t****WHERE c1 IS [NOT] NULL | 从名为 t 的表中选择列 c1,并检查值是否为 NULL |
数据修改
数据修改是 SQL 的关键部分,除了添加和删除数据外,还能修改现有记录:
| SQL | 解释 |
|---|---|
| INSERT INTO t(column_list)****VALUES(value_list) | 向名为 t 的表中插入一行数据 |
| INSERT INTO t(column_list)****VALUES (value_list), (value_list), … | 向名为 t 的表中插入多行数据 |
| INSERT INTO t1(column_list)****SELECT column_list FROM t2 | 将 t2 中的行插入到名为 t1 的表中 |
| UPDATE tSET c1 = new_value | 在表 t 的列 c1 中更新所有行的新值 |
| UPDATE tSET c1 = new_value, c2 = new_value****WHERE condition | 更新表 t 中符合条件的行的列 c1 和 c2 的值 |
| DELETE FROM t | 从名为 t 的表中删除所有行 |
| DELETE FROM tWHERE condition | 从名为 t 的表中删除所有符合某条件的行 |
视图
视图是一个虚拟表,是查询的结果。它们非常有用,通常用作安全机制,允许用户通过视图访问数据,而不是直接访问基础表:
| SQL | 解释 |
|---|---|
| CREATE VIEW view1 ASSELECT c1, c2FROM t1****WHERE condition | 创建一个视图,包含来自名为 t1 的表的列 c1 和 c2,其中符合某一条件。 |
索引
索引用于通过减少需要访问的数据库页面数量来加速查询性能:
| SQL | 解释 |
|---|---|
| CREATE INDEX index_nameON t(c1, c2) | 在表 t 的列 c1 和 c2 上创建索引 |
| CREATE UNIQUE INDEX index_name****ON t(c3, c4) | 在表 t 的列 c3 和 c4 上创建唯一索引 |
| DROP INDEX index_name | 删除一个索引 |
存储过程
存储过程是一组带有分配名称的 SQL 语句,这些语句可以被多个程序轻松重用和共享:
| SQL | 解释 |
|---|---|
| CREATE PROCEDURE procedure_name** @variable AS datatype = valueAS -- Comments****SELECT * FROM tGO** | 创建一个名为 procedure_name 的过程,创建一个局部变量,然后从表 t 中选择数据 |
触发器
触发器是一种特殊类型的存储过程,当用户尝试通过 DML 事件(数据操作语言)修改数据时,它会自动执行。DML 事件是对表或视图的 INSERT、UPDATE 或 DELETE 语句:
| SQL | 解释 |
|---|
| CREATE OR MODIFY TRIGGER trigger_nameWHEN EVENTON table_name TRIGGER_TYPE****EXECUTE stored_procedure | 何时:
-
BEFORE – 在事件发生之前调用
-
AFTER – 在事件发生之后调用
事件:
-
INSERT – 调用以插入
-
UPDATE – 调用以更新
-
DELETE – 调用以删除
TRIGGER_TYPE:
-
FOR EACH ROW
-
FOR EACH STATEMENT
|
| DROP TRIGGER trigger_name | 删除特定触发器 |
|---|
相关:
更多关于此主题
SQL 和数据集成:ETL 和 ELT
原文:
www.kdnuggets.com/2023/01/sql-data-integration-etl-elt.html

作者图片
介绍
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织 IT
SQL 是一种标准化的编程语言和强大的工具,用于管理和分析存储在关系数据库中的数据,并执行各种数据操作,SQL(结构化查询语言)。它是数据分析师、数据科学家和数据仓库专业人员的必备技能,因为它允许用户创建、修改和查询这些数据库中的数据。
随着数据在体积、种类和复杂性上的不断增长,数据集成的重要性只会增加。能够有效地使用 SQL 从多个来源集成数据的企业将更有能力做出明智的决策,并获得竞争优势。ETL 和 ELT 是从多个来源提取数据、转换为分析准备好的格式,并加载到数据库或数据仓库中的常见方法,我们将在本文中讨论这些方法。
ETL 与 ELT:哪种更适合你的使用案例?
ETL(提取、转换、加载)和 ELT(提取、加载、转换)是两种常见的数据集成方法,将数据从多个来源集成到目标数据库或数据仓库中。这两种方法的主要区别在于数据转换和加载步骤的执行顺序。
在ETL中,数据从源系统中提取,转换为适合分析的格式,然后加载到目标数据库中。这是传统的数据集成方法,适用于源系统相对简单且转换过程相对直接的情况。
在ELT中,数据首先从源系统中提取并加载到目标数据库中,然后转换为适合分析的格式。由于现代数据存储能够处理大量数据以及数据转换过程的复杂性增加,这种方法在现代数据基础设施中越来越受欢迎。
在决定使用 ETL 还是 ELT 时,需要考虑几个因素,包括:
转换过程的复杂性
ETL 更适合简单的转换过程,而 ELT 更适合复杂的转换。
源系统的规模和复杂性
ETL 可能更适合处理能力或存储有限的目标系统,而 ELT 更适合处理能力较强的系统。
目标数据库或数据仓库的能力
ETL 可能更适合处理能力或存储有限的目标系统,而 ELT 更适合处理能力较强的系统。
组织的数据处理和分析需求
ETL 可能更适用于数据处理和分析需求较为传统的组织,而 ELT 可能更适合数据处理和分析需求较复杂或实时的组织。
可用资源
ETL 需要更多的前期设置和维护,而 ELT 可能在转换和加载过程中需要更多资源。
安全性和合规性要求
ETL 允许对转换过程进行更多控制,这在安全性和合规性是问题时可能很重要。
使用 SQL 的数据集成基本技术
从多个来源提取数据
要从关系数据库中的表提取数据,你可以使用 ‘SELECT’ 语句,配合 ‘FROM’ 和 ‘WHERE’ 子句:
SELECT * FROM customers WHERE country = 'USA';
该语句将提取 customers’ 表中所有国家列等于 USA 的行。
要从平面文件中提取数据,例如 CSV 或 TXT 文件,你可以使用 ‘LOAD DATA INFILE’ 命令:
LOAD DATA INFILE '/path/to/file.csv'
INTO TABLE customers
FIELDS TERMINATED BY ',' ENCLOSED BY '"'
LINES TERMINATED BY '\n';
该命令将使用 ‘, ‘ 字符作为字段分隔符, ‘ " ‘ 字符作为字段包围符,将数据从 CSV 文件加载到 ‘customers’ 表中。
要从 API 提取数据,你可以使用 Python 或 Java 等编程语言进行 HTTP 请求并解析响应数据。例如,在 Python 中,你可以使用 ‘requests’ 库向 API 端点发出 GET 请求,然后使用 ‘JSON ()’ 方法将响应数据解析为字典:
IMPORT REQUESTS
RESPONSE = REQUESTS.GET('https://api.example.com/endpoint')
DATA = RESPONSE.JSON()
PRINT(DATA)
使用 SQL 查询转换数据
要对数据列应用函数,你可以在 ‘SELECT’ 子句中使用函数名后跟列名:
SELECT LOWER(name) AS lower_name FROM customers;
该语句将通过对每个值应用 ‘LOWER()’ 函数来转换 ‘name column’,并将结果别名为 ‘lower_name’。
要重命名列,你可以在 ‘SELECT’ 子句中使用 ‘AS’ 关键字:
SELECT name AS full_name FROM customers;
该语句将把 ‘name’ 列重命名为 ‘full_name’。
要从多个来源合并数据,你可以使用 UNION 操作符:
SELECT * FROM customers
UNION ALL
SELECT * FROM orders;
该语句将合并 ‘customers’ 和 ‘orders’ 表中的数据,消除重复项。
将数据加载到目标数据库或数据仓库
要向表中插入新行,你可以使用 ‘INSERT INTO’ 语句:
INSERT INTO customers (name, email, country)
VALUES ('John Doe', 'johndoe@example.com', 'USA');
这条语句将会在 customers 表中插入一行新数据,并为 ‘name’、‘email’ 和 ‘country’ 列指定值。
要更新表中的现有行,你可以使用‘UPDATE’语句,并结合‘SET’和‘WHERE’子句:
UPDATE customers
SET email = 'john.smith@example.com'
WHERE name = 'John Smith';
这条语句将更新行中 ‘name’ 列等于 'John Smith' 的邮件列,将其值设置为 'john.smith@example.com'
结论
我希望你喜欢阅读这篇文章。请随时在评论区分享你的想法或反馈。我将用一些最终的想法结束我的讨论。数据集成的未来可能涉及机器学习算法的集成、与大数据技术的更大整合,以及更复杂的 ETL 和 ELT 过程。通过了解最新的数据集成方式和技术,企业可以确保自己能够充分利用数据驱动经济中的机遇和挑战。
Kanwal Mehreen 是一名有抱负的软件开发者,对数据科学和人工智能在医学中的应用充满兴趣。Kanwal 被选为 2022 年 APAC 区域的 Google Generation Scholar。Kanwal 喜欢通过撰写关于热门话题的文章分享技术知识,并对提升女性在技术行业中的代表性充满热情。
更多相关话题
SQL 数据科学:理解和利用连接
原文:
www.kdnuggets.com/2023/08/sql-data-science-understanding-leveraging-joins.html

作者提供的图片
数据科学是一个跨学科领域,极大依赖从大量数据中提取见解和做出明智决策。数据科学家工具箱中的基本工具之一是 SQL(结构化查询语言),这是一种用于管理和操作关系型数据库的编程语言。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
在这篇文章中,我将重点讲解 SQL 的一个强大功能:连接。
什么是 SQL 连接?
SQL 连接允许你基于公共列合并多个数据库表中的数据。这样,你可以将信息汇集在一起,并在相关数据集之间创建有意义的联系。
SQL 中的连接类型
有几种 SQL 连接类型:
-
内连接
-
左外连接
-
右外连接
-
全外连接
-
交叉连接
让我们逐一解释每种类型。
SQL 内连接
内连接仅返回两个连接表中都有匹配的行。它根据共享的键或列组合来自两个表的行,丢弃不匹配的行。
我们以以下方式可视化它。
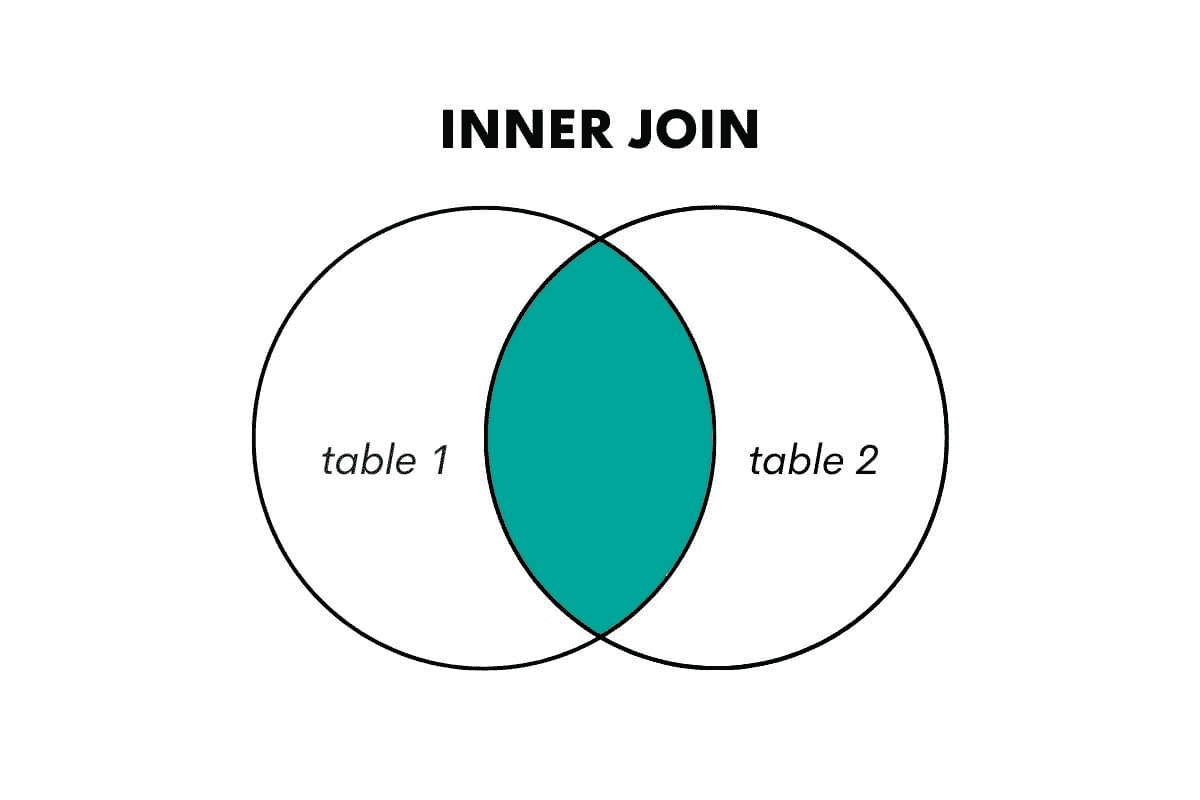
作者提供的图片
在 SQL 中,这种类型的连接使用关键字 JOIN 或 INNER JOIN 执行。
SQL 左外连接
左外连接返回来自左(或第一个)表的所有行以及来自右(或第二个)表的匹配行。如果没有匹配,则返回右表中列的 NULL 值。
我们可以像这样可视化它。
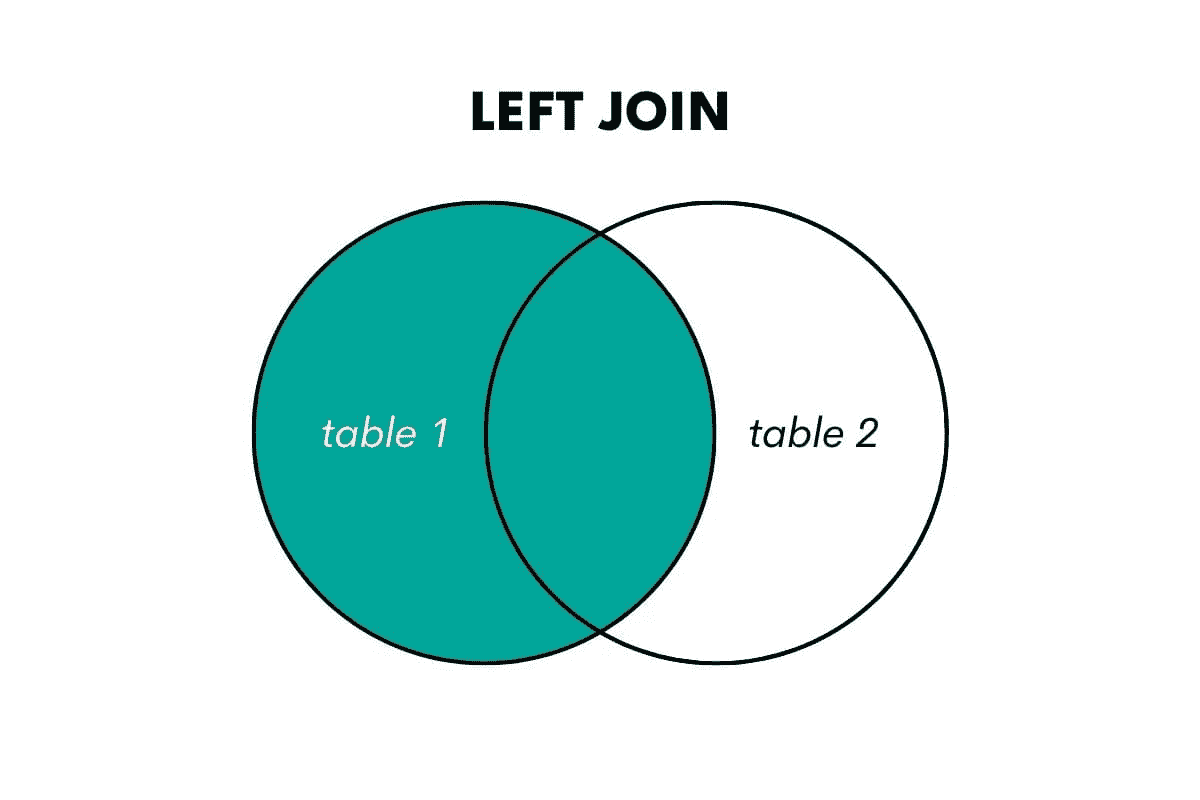
作者提供的图片
当你想在 SQL 中使用这种连接时,你可以使用 LEFT OUTER JOIN 或 LEFT JOIN 关键字。这里有一篇文章讨论了 左连接与左外连接。
SQL 右外连接
右连接是左连接的反向操作。它返回右表中的所有行和左表中匹配的行。如果没有匹配,它会返回左表中列的 NULL 值。
图片由作者提供
在 SQL 中,这种连接类型是通过 RIGHT OUTER JOIN 或 RIGHT JOIN 关键字实现的。
SQL 全外连接
全外连接返回两个表中的所有行,尽可能匹配行,并为不匹配的行填充 NULL 值。
图片由作者提供
在 SQL 中,此连接的关键字是 FULL OUTER JOIN 或 FULL JOIN。
SQL 交叉连接
这种连接类型将一个表中的所有行与第二个表中的所有行组合在一起。换句话说,它返回笛卡尔积,即两个表的所有可能组合。
这是一个将帮助你更容易理解的可视化图。
图片由作者提供
在 SQL 中进行交叉连接时,关键字是 CROSS JOIN。
理解 SQL 连接语法
要在 SQL 中执行连接,你需要指定我们要连接的表、用于匹配的列以及我们要执行的连接类型。SQL 中连接表的基本语法如下:
SELECT columns
FROM table1
JOIN table2
ON table1.column = table2.column;
这个示例展示了如何使用 JOIN。
你在 FROM 子句中引用第一个(或左边)表。然后使用 JOIN 并引用第二个(或右边)表。
然后是 ON 子句中的连接条件。在这里你指定将用哪些列来连接两个表。通常,这是一列共享的列,在一个表中是主键,在第二个表中是外键。
注意:主键是表中每条记录的唯一标识符。外键在两个表之间建立了联系,即它是第二个表中引用第一个表的列。 我们将在示例中展示这意味着什么。
如果你想使用 LEFT JOIN、RIGHT JOIN 或 FULL JOIN,你只需使用这些关键字代替 JOIN——代码中的其他部分完全相同!
CROSS JOIN 的情况稍有不同。它的本质是将两个表中的所有行组合在一起。因此,ON 子句是不需要的,语法如下所示。
SELECT columns
FROM table1
CROSS JOIN table2;
换句话说,你只需在 FROM 中引用一个表,在 CROSS JOIN 中引用第二个表。
另外,你可以在 FROM 中引用两个表,并用逗号分隔它们——这是一种 CROSS JOIN 的简写方式。
SELECT columns
FROM table1, table2;
自连接:SQL 中的一种特殊连接类型
还有一种特定的连接方式——将表与自身连接。这也被称为自连接表。
这不完全是一个独特的连接类型,因为之前提到的任何连接类型也可以用于自连接。
自连接的语法类似于我之前展示的。主要区别在于 FROM 和 JOIN 中引用的是相同的表。
SELECT columns
FROM table1 t1
JOIN table1 t2
ON t1.column = t2.column;
此外,你需要给表两个别名以区分它们。你所做的是将表与自身连接,并将其视为两个表。
我在这里提一下,但不会详细说明。如果你对自连接感兴趣,请查看 SQL 中的自连接插图指南。
SQL 连接示例
现在是展示我提到的内容如何在实际中运作的时候了。我将使用 StrataScratch 的 SQL JOIN 面试题 来展示 SQL 中每种不同类型的连接。
1. 连接示例
微软的这个问题 希望你列出每个项目并按员工计算项目预算。
昂贵的项目
“给定一个项目和员工列表,并映射到每个项目,根据分配给每个员工的项目预算来计算。输出应包括项目标题和预算,预算应四舍五入到最接近的整数。按每个员工的预算从高到低排序项目列表。”
数据
问题给出了两个表。
ms_projects
| id: | int |
|---|---|
| title: | varchar |
| budget: | int |
ms_emp_projects
| emp_id: | int |
|---|---|
| project_id: | int |
现在,表 ms_projects 中的列 id 是表的主键。相同的列可以在表 ms_emp_projects 中找到,尽管名字不同:project_id。这是表的外键,引用了第一个表。
我将在我的解决方案中使用这两列来连接表。
代码
SELECT title AS project,
ROUND((budget/COUNT(emp_id)::FLOAT)::NUMERIC, 0) AS budget_emp_ratio
FROM ms_projects a
JOIN ms_emp_projects b
ON a.id = b.project_id
GROUP BY title, budget
ORDER BY budget_emp_ratio DESC;
我使用 JOIN 连接了这两个表。表 ms_projects 在 FROM 中被引用,而 ms_emp_projects 在 JOIN 后被引用。我给两个表都起了别名,这样我以后就不需要使用表的长名称。
现在,我需要指定要在其上连接表的列。我已经提到哪些列是一个表中的主键,另一个表中的外键,所以我将在这里使用它们。
我将这两列设置为相等,因为我想获取所有项目 ID 相同的数据。我还在每列前面使用了表的别名。
现在我可以访问两个表的数据,因此可以在 SELECT 中列出列。第一列是项目名称,第二列是计算得出的结果。
这个计算使用 COUNT()函数按每个项目计算员工数量。然后我将每个项目的预算除以员工数量。我还将结果转换为十进制值并四舍五入到零位小数。
输出
这是查询返回的结果。
2. LEFT JOIN 示例
我们来在Airbnb 面试题上练习这个连接。题目要求找出每个城市的订单数量、顾客数量和订单总成本。
顾客订单和详情
“找出每个城市的订单数量、顾客数量和订单总成本。仅包括至少有 5 个订单的城市,并计算每个城市中的所有顾客,即使他们没有下订单。”
“输出每个计算结果及其对应的城市名称。”
数据
给定的表是customers和orders。
customers
| id: | int |
|---|---|
| first_name: | varchar |
| last_name: | varchar |
| city: | varchar |
| address: | varchar |
| phone_number: | varchar |
orders
| id: | int |
|---|---|
| cust_id: | int |
| order_date: | datetime |
| order_details: | varchar |
| total_order_cost: | int |
共享的列是customers表中的 id 和orders表中的 cust_id。我将使用这些列来连接表。
代码
下面是如何使用 LEFT JOIN 解决这个问题的方法。
SELECT c.city,
COUNT(DISTINCT o.id) AS orders_per_city,
COUNT(DISTINCT c.id) AS customers_per_city,
SUM(o.total_order_cost) AS orders_cost_per_city
FROM customers c
LEFT JOIN orders o ON c.id = o.cust_id
GROUP BY c.city
HAVING COUNT(o.id) >=5;
我在 FROM 中引用表customers(这是我们的左表),并通过客户 ID 列将其与orders表进行 LEFT JOIN。
现在我可以选择城市,使用 COUNT()按城市获取订单和顾客数量,并使用 SUM()按城市计算订单总成本。
为了按城市获取所有这些计算结果,我按城市对输出进行分组。
问题中还有一个额外的要求:“仅包括至少有 5 个订单的城市…” 我使用 HAVING 来仅显示订单数量为五个或更多的城市。
问题是,我为什么使用了 LEFT JOIN 而不是 JOIN 呢? 提示在问题中:“…并计算每个城市中的所有顾客,即使他们没有下订单。” 这意味着可能不是所有顾客都有下订单。因此,我想展示来自customers表中的所有顾客,这正好符合 LEFT JOIN 的定义。
如果我使用 JOIN,结果会出错,因为我会遗漏那些没有下订单的顾客。
注意:SQL 中连接的复杂性并不体现在它们的语法上,而是在于它们的语义! 如你所见,每个连接的写法都是一样的,只有关键字不同。然而,每个连接的工作方式不同,因此可能会根据数据输出不同的结果。因此,你必须完全理解每个连接的作用,并选择能返回你所需结果的连接!
输出
现在,让我们看看输出结果。

3. RIGHT JOIN 示例
RIGHT JOIN 是 LEFT JOIN 的镜像。这就是为什么我可以很容易地用 RIGHT JOIN 解决之前的问题。让我给你演示一下怎么做。
数据
表格保持不变;我将使用不同类型的连接。
代码
SELECT c.city,
COUNT(DISTINCT o.id) AS orders_per_city,
COUNT(DISTINCT c.id) AS customers_per_city,
SUM(o.total_order_cost) AS orders_cost_per_city
FROM orders o
RIGHT JOIN customers c ON o.cust_id = c.id
GROUP BY c.city
HAVING COUNT(o.id) >=5;
这是变化的地方。由于我使用了 RIGHT JOIN,所以我调换了表的顺序。现在表 orders 成为左表,表 customers 成为右表。连接条件保持不变。我只是调换了列的顺序以反映表的顺序,但这不是必须的。
通过调换表的顺序并使用 RIGHT JOIN,我将再次输出所有客户,即使他们没有下任何订单。
剩下的查询与之前的示例相同。输出也是如此。
注意:实际上, RIGHT JOIN 相对较少使用。 LEFT JOIN 对 SQL 用户来说似乎更自然,因此使用得更多。任何可以用 RIGHT JOIN 做的事情,也可以用 LEFT JOIN 做。因此,没有特定的情况需要偏好 RIGHT JOIN。
输出
4. FULL JOIN 示例
Salesforce 和 Tesla 的问题要求你计算 2020 年公司发布的产品数量与前一年公司发布的产品数量之间的净差异。
新产品
“你将获得一个按公司和年份划分的产品发布表。编写一个查询,计算 2020 年公司发布的产品数量与前一年公司发布的产品数量之间的净差异。输出公司的名称以及 2020 年与前一年发布的产品净差异。”
数据
问题提供了一个具有以下列的表格。
car_launches
| year: | int |
|---|---|
| company_name: | varchar |
| product_name: | varchar |
当只有一个表时,我该如何连接表?嗯,让我们看看!
代码
这个查询有点复杂,所以我会逐步展示。
SELECT company_name,
product_name AS brand_2020
FROM car_launches
WHERE YEAR = 2020;
第一个 SELECT 语句找出 2020 年的公司和产品名称。这个查询稍后将转化为子查询。
问题要求你找出 2020 年和 2019 年之间的差异。所以我们来写一个相同的查询,但针对 2019 年。
SELECT company_name,
product_name AS brand_2019
FROM car_launches
WHERE YEAR = 2019;
我将现在将这些查询变成子查询,并使用 FULL OUTER JOIN 连接它们。
SELECT *
FROM
(SELECT company_name,
product_name AS brand_2020
FROM car_launches
WHERE YEAR = 2020) a
FULL OUTER JOIN
(SELECT company_name,
product_name AS brand_2019
FROM car_launches
WHERE YEAR = 2019) b
ON a.company_name = b.company_name;
子查询可以视作表,因此可以连接。我给第一个子查询一个别名,并将其放在 FROM 子句中。然后,我使用 FULL OUTER JOIN 将其与第二个子查询通过公司名称列连接。
通过使用这种类型的 SQL 连接,我将获得 2020 年所有公司和产品与 2019 年所有公司和产品的合并。
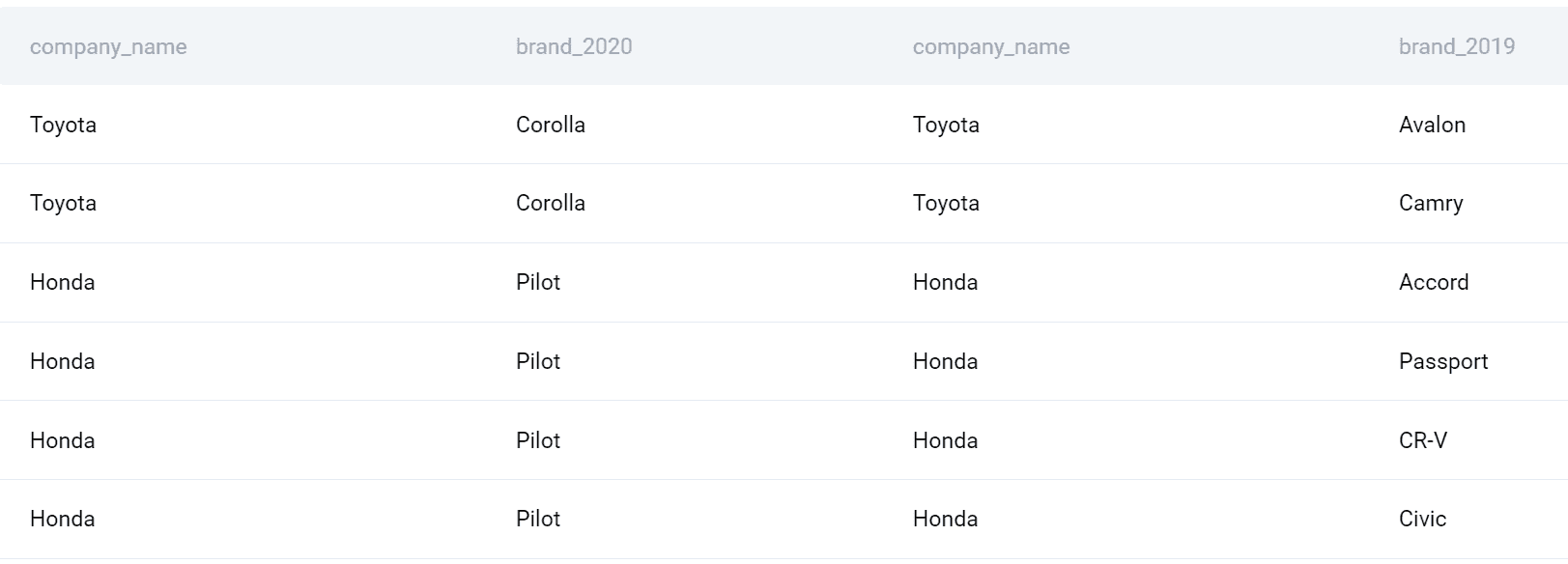
现在我可以完成我的查询了。我们选择公司名称。同时,我将使用 COUNT()函数来查找每年发布的产品数量,然后计算差异。最后,我将按公司对输出进行分组,并按公司字母顺序排序。
这是完整的查询。
SELECT a.company_name,
(COUNT(DISTINCT a.brand_2020)-COUNT(DISTINCT b.brand_2019)) AS net_products
FROM
(SELECT company_name,
product_name AS brand_2020
FROM car_launches
WHERE YEAR = 2020) a
FULL OUTER JOIN
(SELECT company_name,
product_name AS brand_2019
FROM car_launches
WHERE YEAR = 2019) b
ON a.company_name = b.company_name
GROUP BY a.company_name
ORDER BY company_name;
输出
这是 2020 年和 2019 年之间公司及发布产品差异的列表。
5. CROSS JOIN 示例
这道 Deloitte 的问题非常适合展示 CROSS JOIN 的工作原理。
两个数字的最大值
“给定一个单列数字,考虑所有可能的两个数字的排列,假设数字对(x,y)和(y,x)是两个不同的排列。然后,对于每个排列,找出两个数字中的最大值。”
输出三列:第一个数字、第二个数字和两个数字中的最大值。”
问题要求你找出两个数字的所有可能排列,假设数字对(x,y)和(y,x)是两个不同的排列。然后,我们需要找到每个排列中的最大值。
数据
问题给了我们一个具有一列的表。
deloitte_numbers
| number: | int |
|---|
代码
这段代码是 CROSS JOIN 的一个示例,同时也是自连接的示例。
SELECT dn1.number AS number1,
dn2.number AS number2,
CASE
WHEN dn1.number > dn2.number THEN dn1.number
ELSE dn2.number
END AS max_number
FROM deloitte_numbers AS dn1
CROSS JOIN deloitte_numbers AS dn2;
我在 FROM 中引用了表,并给它一个别名。然后,我通过在 CROSS JOIN 后引用它并给表另一个别名,将其与自身进行 CROSS JOIN。
现在可以将一个表视作两个表来使用。我从每个表中选择列 number。然后,我使用 CASE 语句设置一个条件来显示两个数字中的最大值。
为什么这里使用 CROSS JOIN?请记住,这是一种 SQL 连接类型,将显示所有表中所有行的所有组合。这正是问题所要求的!
输出
这是所有组合及两个数字中较大者的快照。
利用 SQL 连接进行数据科学
现在你知道如何使用 SQL 连接,问题是如何在数据科学中利用这些知识。
SQL 连接在数据科学任务中扮演着至关重要的角色,如数据探索、数据清理和特征工程。
以下是一些如何利用 SQL 连接的示例:
-
数据结合: 连接表格允许你汇聚不同的数据源,使你能够分析多个数据集之间的关系和相关性。例如,将客户表与交易表连接可以提供有关客户行为和购买模式的洞察。
-
数据验证: 连接操作可用于验证数据质量和完整性。通过比较来自不同表格的数据,你可以识别不一致、缺失值或异常值。这有助于数据清理,并确保用于分析的数据是准确和可靠的。
-
特征工程: 连接操作在创建机器学习模型的新特征时非常有用。通过合并相关的表格,你可以提取有意义的信息并生成捕捉数据中重要关系的特征。这可以增强模型的预测能力。
-
聚合与分析: 连接操作使你能够在多个表格之间执行复杂的聚合和分析。通过结合来自不同来源的数据,你可以获得数据的全面视图并得出有价值的洞察。例如,将销售表与产品表连接可以帮助你按产品类别或地区分析销售表现。
SQL 连接的最佳实践
如我之前提到的,连接的复杂性并不体现在其语法上。你会发现语法相对简单明了。
连接的最佳实践也反映了这一点,因为它们并不关注代码本身,而是连接操作的作用及其表现。
为了最大化利用 SQL 中的连接操作,请考虑以下最佳实践。
-
了解你的数据: 熟悉数据的结构和关系。这将帮助你选择合适的连接类型,并选择匹配的正确列。
-
使用索引: 如果你的表格很大或经常被连接,考虑在用于连接的列上添加索引。索引可以显著提高查询性能。
-
注意性能: 连接大型表格或多个表格可能会消耗大量计算资源。通过过滤数据、使用适当的连接类型以及考虑使用临时表或子查询来优化查询。
-
测试和验证: 始终验证你的连接结果以确保正确性。执行合理性检查,并验证连接的数据是否符合你的期望和业务逻辑。
结论
SQL 连接是一个基本概念,使你作为数据科学家能够合并和分析来自多个来源的数据。通过理解不同类型的 SQL 连接,掌握其语法并有效利用它们,数据科学家可以发现有价值的洞察,验证数据质量,并推动数据驱动的决策。
我通过五个示例向你展示了如何操作。现在,利用 SQL 和连接来提升你的数据科学项目,并实现更好的结果,就全靠你了。
内特·罗西迪 是一名数据科学家和产品战略专家。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,该平台帮助数据科学家准备面试,提供来自顶级公司的真实面试问题。通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
更多相关内容
数据可视化中的 SQL:如何准备图表和图形的数据
原文:
www.kdnuggets.com/sql-for-data-visualization-how-to-prepare-data-for-charts-and-graphs

你可能已经注意到,创建视觉惊艳的图表和图形不仅仅是选择正确的颜色或形状。真正的魔力发生在幕后,即那些为这些视觉效果提供数据的地方。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 在 IT 方面支持你的组织
但是,如何让数据完美呢?SQL 将在这里成为我们进入数据可视化领域的关键。SQL 帮助你切割、处理和准备数据,使其在你使用的任何可视化工具中都能出色地呈现。
那么,这篇文章为你准备了什么呢?我们将首先展示 SQL 如何用于准备数据以进行数据可视化。接着,我们将引导你了解不同类型的可视化以及如何为每种类型准备数据,其中一些还会有最终的成品。所有这些旨在为你提供创建引人入胜的视觉故事的钥匙。所以,拿上你的咖啡吧,这将会是一段精彩的旅程!
SQL 查询用于数据准备
在深入探讨可视化类型之前,让我们看看 SQL 如何准备你将要可视化的数据。SQL 就像是你视觉“电影”的编剧,微调你想讲述的故事。
筛选
WHERE 子句用于筛选不需要的数据。例如,如果你只对 18-25 岁的用户感兴趣,你可以使用 SQL 进行筛选。
想象一下你正在分析客户反馈。使用 SQL,你可以筛选出反馈评分低于 3 的记录,突出改进的领域。
SELECT * FROM feedbacks WHERE rating < 3;
排序
ORDER BY 子句对数据进行排列。排序对于时间序列图表尤为重要,因为数据必须按时间顺序显示。
在绘制产品的月度销售线图时,SQL 可以按月份对数据进行排序。
SELECT month, sales FROM products ORDER BY month;
连接
JOIN 语句将来自两个或更多表的数据合并。这使得数据集更加丰富,从而实现更全面的可视化。
你可能有一张用户数据表和另一张购买数据表。SQL 可以将这些数据连接起来,显示每个用户的总支出。
SELECT users.id, SUM(purchases.amount) FROM users
JOIN purchases ON users.id = purchases.user_id
GROUP BY users.id;
分组
GROUP BY 子句用于对数据进行分类。它通常与 COUNT()、SUM()和 AVG()等聚合函数一起使用,以对每个分组进行计算。
如果你想了解网站不同部分的平均停留时间,SQL 可以按部分对数据进行分组,然后计算平均值。
SELECT section, AVG(time_spent) FROM website_data
GROUP BY section;
数据可视化的类型
在深入了解不同类型的可视化工具之前,理解它们为什么重要是很重要的。把每个图表或图形视作一个不同的“透镜”来查看你的数据。你选择的类型可以帮助你捕捉趋势、识别异常值,甚至讲述一个故事。
图表
在数据科学中,图表用于理解数据集的初步步骤。例如,你可能使用直方图来了解移动应用中用户年龄的分布。像 Python 中的 Matplotlib 或 Seaborn 这样的工具通常用于绘制这些图表。
你可以运行 SQL 查询来获取计数、平均值或你感兴趣的任何指标,并将这些数据直接输入到你的图表工具中,创建如柱状图、饼图或直方图等可视化效果。
以下 SQL 查询帮助我们按城市汇总用户年龄。这对于准备数据以便我们可以可视化年龄在不同城市间的差异至关重要。
# SQL code to find the average age of users in each city
SELECT city, AVG(age)
FROM users
GROUP BY city;
让我们使用 Matplotlib 来创建一个柱状图。以下代码片段假设 grouped_df 包含了上述 SQL 查询的平均年龄数据,并创建了按城市显示用户平均年龄的柱状图。
import matplotlib.pyplot as plt
# Assuming grouped_df contains the average age data
plt.figure(figsize=(10, 6))
plt.bar(grouped_df['city'], grouped_df['age'], color='blue')
plt.xlabel('City')
plt.ylabel('Average Age')
plt.title('Average Age of Users by City')
plt.show()
这是柱状图。
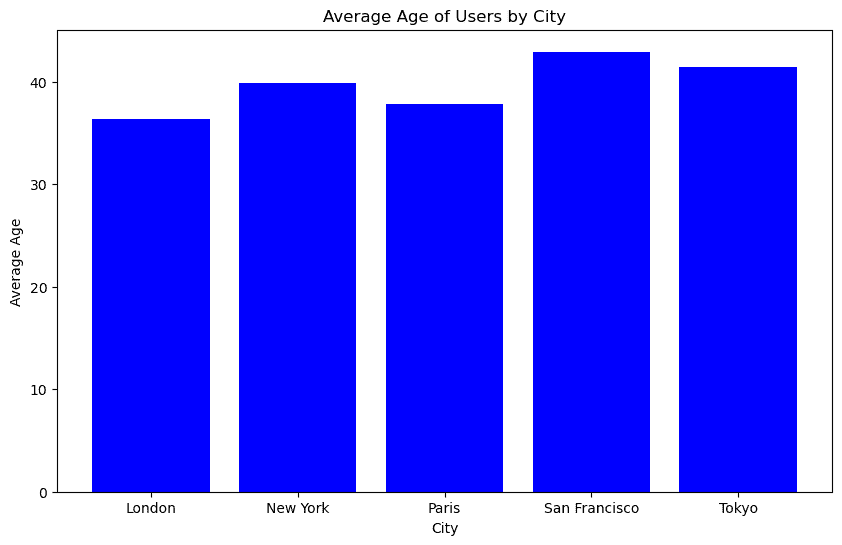
图形
假设你正在跟踪一个网站的速度变化。折线图可以展示数据中的趋势、峰值和谷底,突出显示网站表现最佳和最差的时间。
像 Plotly 或 Bokeh 这样的工具可以帮助你创建这些更复杂的可视化效果。你可以使用 SQL 来准备时间序列数据,可能需要运行计算每日平均加载时间的查询,然后将数据发送到你的图形工具中。
以下 SQL 查询计算了每天的网站平均速度。这样的查询可以更方便地绘制时间序列折线图,展示性能随时间的变化。
-- SQL code to find the daily average loading time
SELECT DATE(loading_time), AVG(speed)
FROM website_speed
GROUP BY DATE(loading_time);
在这里,假设我们选择 Plotly 来创建一个折线图,显示网站速度随时间的变化。SQL 查询为我们准备了时间序列数据,显示了网站速度的变化。
import plotly.express as px
fig = px.line(time_series_df, x='loading_time', y='speed', title='Website Speed Over Time')
fig
这是折线图。
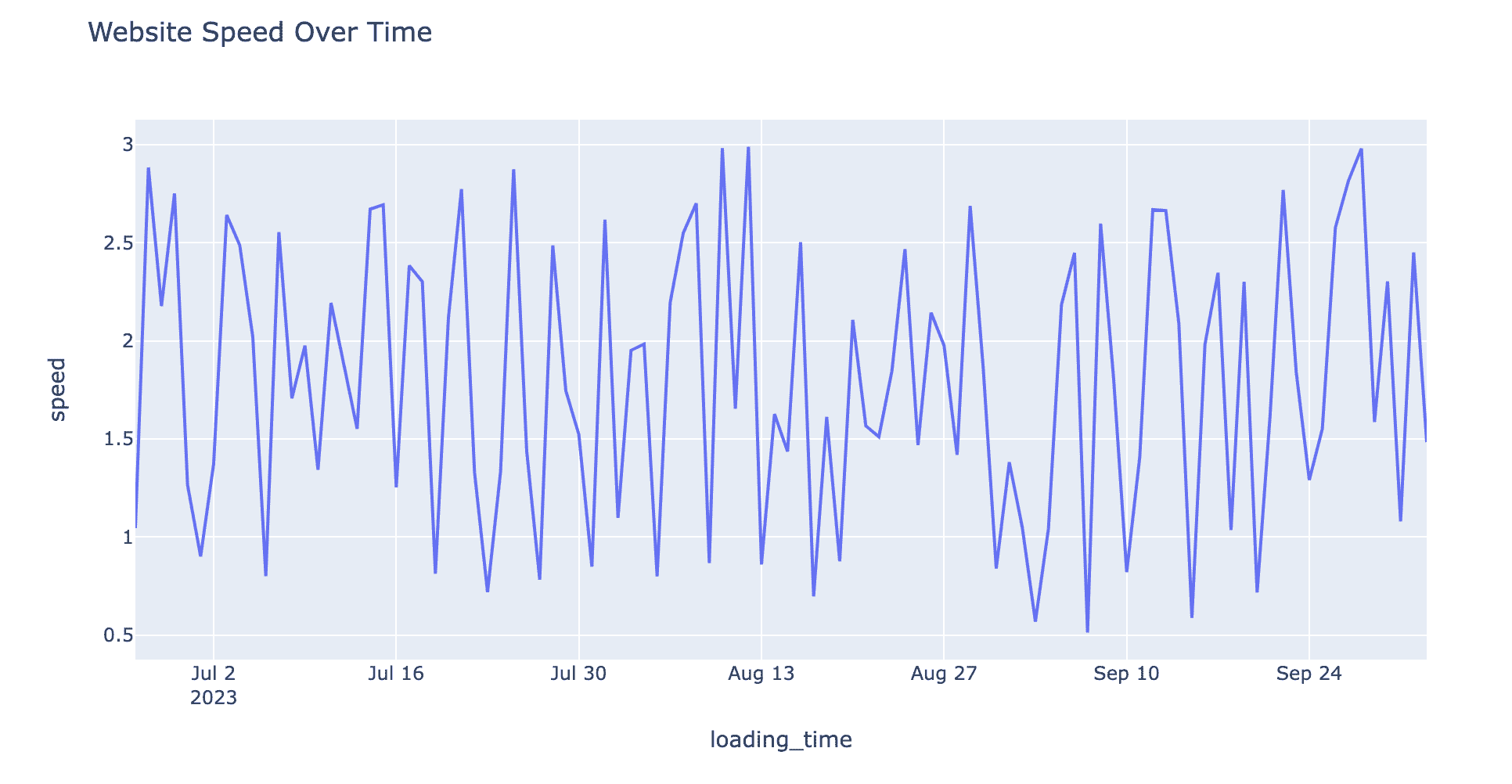
仪表板
仪表板对于需要实时监控的项目至关重要。想象一下一个仪表板跟踪在线平台的实时用户参与度指标。
像 PowerBI、Google Data Studio 或 Tableau 这样的工具可以从 SQL 数据库中提取数据,以填充这些仪表板。SQL 可以汇总和更新你的数据,这样你就可以在仪表板上始终获得最新的见解。
-- SQL code to find the current number of active users and average session time
SELECT COUNT(DISTINCT user_id) as active_users, AVG(session_time)
FROM user_sessions
WHERE session_end IS NULL;
在 PowerBI 中,你通常会导入你的 SQL 数据库,并运行类似的查询来创建仪表板的可视化效果。使用像 PowerBI 这样的工具的好处是能够创建实时仪表板。你可以设置多个图块来显示平均年龄和其他关键绩效指标,所有这些都会实时更新。
最后的想法
数据可视化不仅仅是关于漂亮的图表和图形;它是通过数据讲述一个引人入胜的故事。SQL 在编写这个故事中扮演了关键角色,帮助你在幕后准备、过滤和组织数据。就像精密机器中的齿轮一样,SQL 查询作为看不见的机械部分,使你的可视化不仅成为可能,还充满洞察力。
如果你渴望更多的实践经验,访问 StrataScratch 平台,这个平台提供了丰富的资源来帮助你成长。从 数据科学面试问题 到实用的数据项目,StrataScratch 旨在提升你的技能,帮助你获得梦想工作。
Nate Rosidi 是一位数据科学家和产品策略专家。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,这个平台帮助数据科学家通过顶级公司的真实面试问题为面试做准备。Nate 写作关于职业市场的最新趋势,提供面试建议,分享数据科学项目,并涵盖所有 SQL 相关内容。
了解更多相关主题
SQL Group By 和 Partition By 场景:何时以及如何在数据科学中组合数据

图片来源 Freepik
介绍
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
SQL(结构化查询语言)是一种用于管理和操作数据的编程语言。这就是为什么 SQL 查询对于以结构化和高效的方式与数据库交互非常重要。
SQL 中的分组作为组织和分析数据的强大工具。它有助于从复杂的数据集中提取有意义的见解和摘要。分组的最佳使用案例是总结和理解数据特征,从而帮助企业进行分析和报告任务。
我们通常有很多需求,需要通过共同的数据组合数据集记录,以计算组中的统计信息。这些实例大多数可以归纳为常见的场景。这些场景可以在类似需求出现时应用。
SQL 子句:Group By
SQL 中的 GROUP BY 子句用于
-
按某些列对数据进行分组
-
将组缩减为一行
-
对其他列进行聚合操作。
分组列 = 分组列中的值在组中的所有行应相同
聚合列 = 聚合列中的值通常是对应用了函数(如 sum、max 等)的不同值。
聚合列不应为分组列。
场景 1:分组以查找总和
假设我们想要计算销售表中每个类别的总销售额。
因此,我们将按类别分组,并汇总每个类别的个体销售额。
select category,
sum(amount) as sales
from sales
group by category;
分组列 = 类别
聚合列 = 数量
聚合函数 = sum()
| 类别 | 销售额 |
|---|---|
| 玩具 | 10,700 |
| 书籍 | 4,200 |
| 健身器材 | 2,000 |
| 文具 | 1,400 |
场景 2:分组以查找计数
假设我们想计算每个部门的员工数量。
在这种情况下,我们将按部门分组,并计算每个部门的员工数量。
select department,
count(empid) as emp_count
from employees
group by department;
分组列 = department
聚合列 = empid
聚合函数 = count
| 部门 | 员工数量 |
|---|---|
| finance | 7 |
| marketing | 12 |
| technology | 20 |
场景 3: 分组查找平均值
假设我们想计算每个部门员工的平均工资
类似地,我们将再次按部门分组,并分别计算每个部门员工的平均工资。
select department,
avg(salary) as avg_salary
from employees
group by department;
分组列 = department
聚合列 = salary
聚合函数 = avg
| 部门 | 平均工资 |
|---|---|
| finance | 2,500 |
| marketing | 4,700 |
| technology | 10,200 |
场景 4: 分组查找最大值 / 最小值
假设我们想计算每个部门员工的最高工资。
我们将按部门分组,并计算每个部门的最高工资。
select department,
max(salary) as max_salary
from employees
group by department;
分组列 = department
聚合列 = salary
聚合函数 = max
| 部门 | 最高工资 |
|---|---|
| finance | 4,000 |
| marketing | 9,000 |
| technology | 12,000 |
场景 5: 分组查找重复项
假设我们想找出数据库中重复或相同的客户姓名。
我们将按客户姓名分组,并使用 count 作为聚合函数。此外,我们将使用 having 子句对聚合函数进行筛选,只保留计数大于一的记录。
select name,
count(*) AS duplicate_count
from customers
group by name
having count(*) > 1;
分组列 = name
聚合列 = *
聚合函数 = count
Having = 应用于聚合函数的筛选条件
| 姓名 | 重复计数 |
|---|---|
| Jake Junning | 2 |
| Mary Moone | 3 |
| Peter Parker | 5 |
| Oliver Queen | 2 |
SQL 子句: Partition By
SQL 中的 PARTITION BY 子句用于
-
对某些列进行分组/分区数据
-
单独的行被保留并不合并为一行
-
在其他列上执行排名和聚合操作。
分区列 = 我们选择一个列来对数据进行分组。每个分组中的分区列的数据必须相同。如果未指定,则整个表被视为一个单一的分区。
排序列 = 对于基于分区列创建的每个组,我们将对组中的行进行排序/排序
排名函数 = 排名函数或聚合函数将应用于分区中的行
场景 6: 分区查找组中最高记录
假设我们想计算每个类别中销售最高的书籍 - 以及这本畅销书所带来的金额。
在这种情况下,我们不能使用分组子句 - 因为分组会将每个类别中的记录减少为一行。
然而,我们需要记录详细信息,如书名、金额等,以及类别,以查看每个类别中销售最高的书籍。
select book_name, amount
row_number() over (partition by category order by amount) as sales_rank
from book_sales;
分区列 = category
排序列 = amount
排名函数 = row_number()
此查询返回 book_sales 表中的所有行,并按每个书籍类别中的销售量排序,最高销售书籍排在第 1 行。
现在我们需要筛选出只有行号 1 的行,以获取每个类别的畅销书
select category, book_name, amount from (
select category, book_name, amount
row_number() over (partition by category order by amount) as sales_rank
from book_sales
) as book_ranked_sales
where sales_rank = 1;
上述筛选将仅给出每个类别中的畅销书及其销售额。
| category | book_name | amount |
|---|---|---|
| science | The hidden messages in water | 20,700 |
| fiction | Harry Potter | 50,600 |
| spirituality | Autobiography of a Yogi | 30,800 |
| self-help | The 5 Love Languages | 12,700 |
场景 7:分区以查找组内累积总数
假设我们想计算销售的运行总数(累积总数)。我们需要为每个产品单独计算累积总数。
我们将按照 product_id 进行分区,并按日期对分区进行排序
select product_id, date, amount,
sum(amount) over (partition by product_id order by date desc) as running_total
from sales_data;
分区列 = product_id
排序列 = date
排名函数 = sum()
| product_id | date | amount | running_total |
|---|---|---|---|
| 1 | 2023-12-25 | 3,900 | 3,900 |
| 1 | 2023-12-24 | 3,000 | 6,900 |
| 1 | 2023-12-23 | 2,700 | 9,600 |
| 1 | 2023-12-22 | 1,800 | 11,400 |
| 2 | 2023-12-25 | 2,000 | 2,000 |
| 2 | 2023-12-24 | 1,000 | 3,000 |
| 2 | 2023-12-23 | 7,00 | 3,700 |
| 3 | 2023-12-25 | 1,500 | 1,500 |
| 3 | 2023-12-24 | 4,00 | 1,900 |
场景 8:对比组内值的分区
假设我们想将每个员工的工资与其部门的平均工资进行比较。
我们将根据部门对员工进行分区,并计算每个部门的平均工资。
平均值还可以通过从员工个人工资中轻松减去来计算员工的工资是否高于或低于平均水平。
select employee_id, salary, department,
avg(salary) over (partition by department) as avg_dept_sal
from employees;
分区列 = department
排序列 = 无排序
排名函数 = avg()
| employee_id | salary | department | avg_dept_sal |
|---|---|---|---|
| 1 | 7,200 | finance | 6,400 |
| 2 | 8,000 | finance | 6,400 |
| 3 | 4,000 | finance | 6,400 |
| 4 | 12,000 | technology | 11,300 |
| 5 | 15,000 | technology | 11,300 |
| 6 | 7,000 | technology | 11,300 |
| 7 | 4,000 | marketing | 5,000 |
| 8 | 6,000 | marketing | 5,000 |
场景 9:分区以将结果分成相等的组
假设我们想根据工资将员工分成 4 个相等(或近似相等)的组。
因此,我们将导出另一个逻辑列 tile_id,该列将包含每组员工的数字 ID。
组将根据工资创建——第一个 tile 组将拥有最高工资,以此类推。
select employee_id, salary,
ntile(4) over (order by salary desc) as tile_id
from employees;
分区列 = 无分区 - 完整表格在同一分区中
排序列 = salary
排名函数 = ntile()
| employee_id | salary | tile_id |
|---|---|---|
| 4 | 12,500 | 1 |
| 11 | 11,000 | 1 |
| 3 | 10,500 | 1 |
| 1 | 9,000 | 2 |
| 8 | 8,500 | 2 |
| 6 | 8,000 | 2 |
| 12 | 7,000 | 3 |
| 5 | 7,000 | 3 |
| 9 | 6,500 | 3 |
| 10 | 6,000 | 4 |
| 2 | 5,000 | 4 |
| 7 | 4,000 | 4 |
场景 10:分区以识别数据中的岛屿或间隙
假设我们有一个顺序的 product_id 列,我们想要识别其中的间隙。
所以我们将衍生出另一个逻辑列 island_id,如果 product_id 是顺序的,则具有相同的编号。当识别到 product_id 中的中断时, island_id 会递增。
select product_id,
row_number() over (order by product_id) as row_num,
product_id - row_number() over (order by product_id) as island_id,
from products;
分区列 = 无分区 - 整个表在同一分区
排序列 = product_id
排序函数 = row_number()
| product_id | row_num | island_id |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 4 | 3 | 1 |
| 5 | 4 | 1 |
| 6 | 5 | 1 |
| 8 | 6 | 2 |
| 9 | 7 | 2 |
结论
Group By 和 Partition By 用于解决许多问题,例如:
信息总结: 分组允许你在每个组中汇总数据并总结信息。
分析模式: 有助于识别数据子集中的模式或趋势,为数据集的各个方面提供见解。
统计分析: 能够计算统计量,如平均值、计数、最大值、最小值和其他聚合函数在组内。
数据清洗: 有助于识别组内的重复项、不一致性或异常,使数据清洗和质量改进变得更加可控。
队列分析: 在基于队列的分析中非常有用,跟踪和比较随时间变化的实体组等。
Hanu 运营着 HelperCodes 博客,主要涉及 SQL 备忘单。我是一名全栈开发者,兴趣在于创建可重用的资产。
相关主题
Pandas 中的 SQL 与 Pandasql

作者提供的图片
如果你只能添加一个技能——并且无可争辩地是最重要的——到你的数据科学工具箱中,那就是SQL。然而,在 Python 数据分析生态系统中,pandas是一个强大且流行的库。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织进行 IT 管理
但是,如果你对 pandas 不熟悉,学习 pandas 函数——如分组、聚合、连接等——可能会感到不知所措。用 SQL 查询数据框会更容易一些。pandasql库可以让你做到这一点!
所以,让我们学习如何使用 pandasql 库在样本数据集上的 pandas 数据框中运行 SQL 查询。
使用 Pandasql 的第一步
在我们进一步讨论之前,让我们设置我们的工作环境。
安装 pandasql
如果你使用 Google Colab,可以使用pip安装 pandasql 并跟着代码操作:
pip install pandasql
如果你在本地机器上使用 Python,请确保在此项目的专用虚拟环境中安装了pandas和Seaborn。你可以使用内置的venv包来创建和管理虚拟环境。
我在 Ubuntu LTS 22.04 上运行 Python 3.11。以下指令适用于 Ubuntu(也应该适用于 Mac)。如果你使用的是 Windows 机器,请参考这些创建和激活虚拟环境的说明。
要创建虚拟环境(这里是 v1),请在项目目录中运行以下命令:
python3 -m venv v1
然后激活虚拟环境:
source v1/bin/activate
现在安装 pandas、seaborn 和 pandasql:
pip3 install pandas seaborn pandasql
注意:如果你尚未安装pip,可以通过运行以下命令更新系统包并安装:apt install python3-pip。
sqldf函数
要在 pandas 数据框上运行 SQL 查询,你可以导入并使用sqldf,其语法如下:
from pandasql import sqldf
sqldf(query, globals())
这里,
-
query代表你想在 pandas 数据框上执行的 SQL 查询。它应该是一个包含有效 SQL 查询的字符串。 -
globals()指定了查询中使用的数据框所定义的全局命名空间。
使用 Pandasql 查询 Pandas 数据框
让我们首先导入所需的包和来自 pandasql 的sqldf函数:
import pandas as pd
import seaborn as sns
from pandasql import sqldf
由于我们将对数据框运行几个查询,我们可以定义一个函数,以便通过传递查询作为参数来调用它:
# Define a reusable function for running SQL queries
run_query = lambda query: sqldf(query, globals())
对于以下所有示例,我们将运行run_query函数(底层使用sqldf())来在tips_df数据框上执行 SQL 查询。然后我们将打印出返回的结果。
加载数据集
对于本教程,我们将使用内置于Seaborn库中的“tips”数据集。“tips”数据集包含有关餐厅小费的信息,包括总账单、小费金额、付款者的性别、星期几等。
将“tip”数据集加载到数据框tips_df中:
# Load the "tips" dataset into a pandas dataframe
tips_df = sns.load_dataset("tips")
示例 1 – 选择数据
这是我们的第一个查询——一个简单的 SELECT 语句:
# Simple select query
query_1 = """
SELECT *
FROM tips_df
LIMIT 10;
"""
result_1 = run_query(query_1)
print(result_1)
如上所示,此查询选择tips_df数据框中的所有列,并使用LIMIT关键字将输出限制为前 10 行。这等同于在 pandas 中执行tips_df.head(10):
query_1的输出
示例 2 – 基于条件筛选
接下来,让我们编写一个查询来根据条件筛选结果:
# filtering based on a condition
query_2 = """
SELECT *
FROM tips_df
WHERE total_bill > 30 AND tip > 5;
"""
result_2 = run_query(query_2)
print(result_2)
此查询根据 WHERE 子句中指定的条件筛选tips_df数据框。它选择tips_df数据框中所有列,其中‘total_bill’大于 30 且‘tip’金额大于 5。
运行query_2给出以下结果:
query_2的输出
示例 3 – 分组和聚合
让我们运行以下查询以获取按天分组的平均账单金额:
# grouping and aggregation
query_3 = """
SELECT day, AVG(total_bill) as avg_bill
FROM tips_df
GROUP BY day;
"""
result_3 = run_query(query_3)
print(result_3)
以下是输出结果:
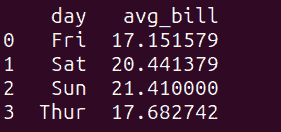
query_3的输出
我们看到周末的平均账单金额略高。
让我们再看一个分组和聚合的示例。考虑以下查询:
query_4 = """
SELECT day, COUNT(*) as num_transactions, AVG(total_bill) as avg_bill, MAX(tip) as max_tip
FROM tips_df
GROUP BY day;
"""
result_4 = run_query(query_4)
print(result_4)
查询query_4按‘day’列对tips_df数据框中的数据进行分组,并计算每组的以下聚合函数:
-
num_transactions:交易的计数, -
avg_bill:‘total_bill’列的平均值,以及 -
max_tip:‘tip’列的最大值。
如上所示,我们按天对上述数量进行了分组:
query_4的输出
示例 4 – 子查询
让我们添加一个使用子查询的示例查询:
# subqueries
query_5 = """
SELECT *
FROM tips_df
WHERE total_bill > (SELECT AVG(total_bill) FROM tips_df);
"""
result_5 = run_query(query_5)
print(result_5)
这里,
-
内部子查询计算
tips_df数据框中‘total_bill’列的平均值。 -
外部查询然后从
tips_df数据框中选择所有列,其中‘total_bill’大于计算出的平均值。
运行query_5给出如下结果:
query_5的输出
示例 5 – 连接两个数据框
我们只有一个数据框。为了进行简单的连接,我们可以像这样创建另一个数据框:
# Create another DataFrame to join with tips_df
other_data = pd.DataFrame({
'day': ['Thur','Fri', 'Sat', 'Sun'],
'special_event': ['Throwback Thursday', 'Feel Good Friday', 'Social Saturday','Fun Sunday', ]
})
other_data数据框将每一天与特殊事件关联起来。
现在我们在tips_df和other_data数据框之间的公共‘day’列上执行 LEFT JOIN:
query_6 = """
SELECT t.*, o.special_event
FROM tips_df t
LEFT JOIN other_data o ON t.day = o.day;
"""
result_6 = run_query(query_6)
print(result_6)
这是连接操作的结果:
query_6 的输出
总结和下一步
在本教程中,我们讨论了如何使用 pandasql 在 pandas 数据框上运行 SQL 查询。虽然 pandasql 使得用 SQL 查询数据框变得非常简单,但也存在一些限制。
关键限制是 pandasql 可能比原生 pandas 慢几个数量级。那么你应该怎么做呢?如果你需要用 pandas 进行数据分析,你可以在学习pandas 时使用 pandasql 来查询数据框,并迅速提升。然后,你可以在对 pandas 感到舒适后,切换到 pandas 或其他库,如Polars。
为了迈出这一步,尝试编写并运行到目前为止我们执行的 SQL 查询的 pandas 等效代码。本教程中使用的所有代码示例都在 GitHub 上。继续编码!
Bala Priya C 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正在通过撰写教程、操作指南、评论文章等来学习和分享她的知识。
相关主题
经验丰富的 SQL 面试问题
原文:
www.kdnuggets.com/2022/01/sql-interview-questions-experienced-professionals.html

介绍
如果你是一个经验丰富的数据科学家正在寻找工作,那么现在是最佳时机。目前,许多知名组织正在寻找对数据科学领域了如指掌的数据科学家。然而,高需求并不意味着你可以或应该轻松申请高级职位而没有某些技能。公司在招聘经验丰富的数据科学家时,期望他们能处理最困难的任务。这些员工应该对即使是最晦涩的功能也有良好的掌握,以便在必要时使用它们。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
当面试高级职位时,经验丰富的数据科学家被问到更难的问题并不奇怪。通常,在同一职位上工作几年后,数据科学家会非常擅长执行某些重复性任务。专业人士需要意识到 SQL 不仅仅停留在现有的知识上。在高级 SQL 概念方面,他们的知识可能仍有一些空白。因此,寻求帮助以便在数据科学家面试中成功并没有坏处。
SQL 是管理数据库的主要语言,因此执行 SQL 操作是数据科学家工作的重要部分。大多数数据科学家面试都安排以确定候选人对 SQL 的知识。
日常工作中可能不包括编写复杂查询,但你必须展示当需要这些技能时,你是能够做到的。因此,面试官询问各种 SQL 面试问题 来测试候选人的 SQL 流利程度也就不足为奇了。
在这篇文章中,我们总结了一些在面试中会问到的复杂问题和概念。即使你对自己的 SQL 知识充满信心,浏览这些关键词并确保你已经掌握所有内容也无妨。
经验丰富的专业人员的基本概念
CASE / WHEN
彻底理解 CASE(及其伴随的 When 语句)的概念对于完全掌握 SQL 至关重要。CASE 语句允许我们检查某些条件,并根据这些条件是否为真或假返回一个值。结合 WHERE 和 ORDER BY 等子句,CASE 允许我们将逻辑、条件和顺序引入 SQL 查询中。
CASE 语句的价值不仅限于在查询中提供简单的条件逻辑。经验丰富的数据科学家应该对 CASE 语句及其用途有超过表面层次的理解。面试官可能会问你关于不同类型 CASE 表达式的问题以及如何编写它们。
经验丰富的候选人应该准备回答理论性问题,例如解释 Valued 和 Searched CASE 语句之间的区别,它们是如何工作的以及如何编写它们。这需要对它们的语法和常见实践有深入的理解。不用说,这也包括正确使用 ELSE 子句。
经验丰富的数据科学家需要知道如何使用 CASE 语句与聚合函数一起使用。你还可能会被要求编写简洁的 CASE 语句,这种语句重复性较少且更易于理解。你应该能够智能地讨论使用简洁 CASE 语句的注意事项和可能的风险。
一般来说,经验丰富的数据科学家必须能够使用 CASE 编写更高效的查询。毕竟,CASE 语句的整个目的是避免编写过多的单独查询来整合数据。
这里有一个可以使用 CASE / WHEN 语句解决的问题的示例:platform.stratascratch.com/coding/9634-host-response-rates-with-cleaning-fees?python=
这是在 Airbnb 面试中提出的一个难题,候选人需要找出平均房东响应率、邮政编码及其对应的清洁费用。
在这种情况下,CASE/ WHEN 语句用于将结果格式化为数字并将其表示为百分比值,此外还包括邮政编码。
SQL 连接
对 SQL 连接的知识感到自信是很容易的,但你越是深入探讨这个话题,就会发现自己不知道的东西越多。面试官经常会问一些关于 SQL 连接高级方面的面试问题,这些问题常常被忽视。因此,深入研究这个概念并彻底掌握它是很重要的。
除了基本概念,面试官可能会询问什么是自交叉连接,并通过要求解决实际问题来了解你的知识深度。你应该知道所有不同类型的连接,包括更复杂的类型,如哈希连接或复合连接。你也可能会被要求解释自然连接是什么,以及它们在什么情况下最有用。有时你需要解释自然连接和内连接之间的区别。
一般来说,你应该对将连接与其他语句结合使用以实现期望结果有深入的经验和掌握。例如,你应该知道如何使用 WHERE 子句将 Cross Join 当作 Inner Join 来使用。你还需要知道如何使用连接来生成新表,而不会对服务器施加过大压力。或者如何使用外连接来识别和填补查询数据库时的缺失值。或者外连接的内部工作原理,例如重新排列其顺序可能会改变输出。
这是一个相当困难的问题,要求候选人显示订单大小占总支出的百分比。
高级概念 N1:日期时间处理
数据库中包含日期和时间是很常见的,因此任何有经验的数据科学家都应该对如何处理这些数据有深入的了解。这种数据使我们能够跟踪事件发生的顺序、频率变化、计算时间间隔,并获得其他重要见解。很多时候,执行这些操作需要完全掌握 SQL 中的日期时间处理。因此,拥有这些技能的专业人士将在竞争中占据优势。如果你对自己的技能没有 100% 的信心,可以查看下面描述的概念,看看有多少个听起来很熟悉。
由于在 SQL 中有许多不同(但有效)的方法来格式化数据,优秀的编码人员应该至少熟悉它们。面试中,招聘经理期望了解基本的数据格式化概念以及能够聪明地讨论选择合适函数的能力。这包括了解重要的 FORMAT() 函数及其相关语法,以充分利用该函数。还期望了解其他基本函数,例如 NOW()。此外,有经验的专业人士也可能会被问及基本概念,如时间序列数据及其目的。
同样,考虑你申请的职位的背景也很重要。一个 AI 或物联网公司可能更关注从传感器收集的数据,而一个股票交易应用可能需要你追踪日、周或月内的价格波动。
在某些情况下,雇主可能会询问关于 SQL 的更高级的日期/时间函数,例如 CAST()、EXTRACT() 或 DATE_TRUNC()。这些函数在处理包含日期的大量数据时非常有用。经验丰富的数据科学家应该了解每个函数的目的及其应用。在理想情况下,他或她应该有使用这些函数的经验。
SQL 中最复杂的日期时间操作将涉及基本函数和高级函数的组合。因此,了解所有这些函数是必要的,从更基础的 FORMAT()、NOW()、CURRENT_DATE 和 CURRENT_TIME 开始,包括上述的更高级函数。作为一名经验丰富的数据科学家,你还应该知道 INTERVAL 的作用及其使用时机。
这里有一个在 Airbnb 面试中提出的问题示例,要求候选人利用可用数据追踪 Airbnb 的增长情况。
前提:
在这个问题中,要求候选人根据每年注册的房东数量变化来追踪 Airbnb 的增长。换句话说,我们将使用每年新增注册的房东数量作为增长的指标。我们通过计算上一年与当前年房东数量之间的差异,并将该数字除以前一年注册的房东数量来找出增长率。然后,我们通过将结果乘以 100 来找出百分比值。
输出表格应包含当前年、上一年房东数量以及逐年增长百分比的列。百分比必须四舍五入到最接近的整数,行必须按年份升序排列。
解决方案:
要回答这个问题,候选人必须使用名为 ‘airbnb_search_details’ 的表格,该表格包含许多列。我们需要的列标记为 ‘host_since’,它表示房东首次注册网站的年份、月份和日期。对于这个练习,月份和日期无关紧要,因此我们需要做的第一件事是从值中提取年份。然后,我们必须创建一个视图,其中包含当前年、上一年以及该年的总房东数量的单独列。
Select
extract(year FROM host_since::DATE)
FROM airbnb_search_details
WHERE host_since IS NOT NULL
到目前为止,我们已经完成了两件事:
-
我们确保只包含 host_since 列不为空的行。
-
我们从数据中提取年份并将其转换为 DATE 值。
Select
extract(year FROM host_since::DATE)
count(id) as current_year_host
FROM airbnb_search_details
WHERE host_since IS NOT NULL
GROUP BY extract(year FROM host_since::DATE)
ORDER BY year asc
然后我们继续计算 ID,并为每年设置 GROUP BY 子句,并按升序显示。
这将为我们提供一个包含两列的表格:年份和注册该年的主机数量。我们仍然没有解决问题所需的完整信息,但这是朝着正确方向的一步。我们还需要针对前一年注册的主机的单独列。这就是 LAG() 函数的作用。
SELECT
Year,
current_year_host,
LAG(current_year_host, 1) OVER (ORDER BY year) as prev_year_host
Select
extract(year FROM host_since::DATE)
count(id) as current_year_host
FROM airbnb_search_details
WHERE host_since IS NOT NULL
GROUP BY extract(year FROM host_since::DATE)
ORDER BY year asc
在这里,我们添加了第三列,标记为“prev_year_host”,其值将来自“current_year_host”,但延迟一行。这可能是这样的:
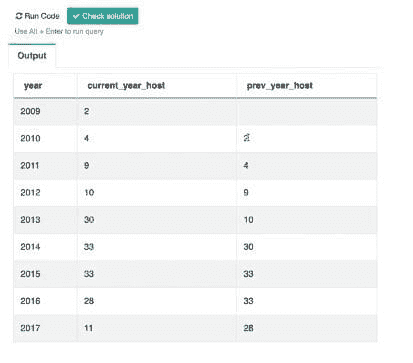
以这种方式排列表格可以非常方便地计算最终的增长率。我们为方程中的每个值都有一个单独的列。最终,我们的代码应该类似于以下内容:
SELECT year,
current_year_host,
prev_year_host,
round(((current_year_host - prev_year_host)/(cast(prev_year_host AS numeric)))*100) estimated_growth
FROM
(SELECT year,
current_year_host,
LAG(current_year_host, 1) OVER (ORDER BY year) AS prev_year_host
FROM
(SELECT extract(year
FROM host_since::date) AS year,
count(id) current_year_host
FROM airbnb_search_details
WHERE host_since IS NOT NULL
GROUP BY extract(year
FROM host_since::date)
ORDER BY year) t1) t2
在这里,我们添加了另一个查询和另一个列来计算增长率。我们必须将初始结果乘以 100 并四舍五入,以满足任务的要求。
这就是解决此任务的方法。很明显,日期时间处理函数对于完成任务至关重要。
高级概念 N2:窗口函数和分区

SQL 窗口函数是编写复杂而高效的 SQL 查询的最重要概念之一。经验丰富的专业人士应对窗口函数有深入的实践和理论知识。这包括了解 OVER 子句是什么并掌握其使用。面试官可能会问 OVER 子句如何将聚合函数转换为窗口函数。你还可能被问到可以作为窗口函数使用的三种聚合函数。经验丰富的数据科学家还应了解其他非聚合的窗口函数。
为了最好地利用窗口函数,必须了解 PARTITION BY 子句是什么以及如何使用它。你可能会被要求解释它并提供一些使用案例的示例。有时,你需要使用 ORDER_BY 子句在分区内组织行。
能够展示每一个窗口函数的全面知识的候选人,如 ROW_NUMBER(),将具有优势。不用说,单靠理论知识是不够的——专业人士还应具备实际使用这些函数的经验,无论是否涉及分区。例如,一位经验丰富的专业人士应该能够解释 RANK() 和 DENSE_RANK() 之间的区别。理想的候选人应了解一些最先进的概念,如分区中的帧,并能够清晰地解释它们。
优秀的候选人还应解释 NTH_VALUE() 函数的用法。提到该函数的替代方案,如 FIRST_VALUE() 和 LAST_VALUE() 函数,也不会有坏处。公司通常喜欢衡量四分位数、分位数和百分位数。执行此操作时,数据科学家还必须知道如何使用 NTILE() 窗口函数。
在 SQL 中,通常有许多方法来处理任务。然而,窗口函数提供了执行常见但复杂操作的最简单方法。一个好的窗口函数例子是 LAG() 或 LEAD(),因此你也应该熟悉它们。例如,我们来看看之前解决的一个难度较大的 Airbnb 面试题:
为了显示前一年主机的数量,我们使用了带有 OVER 语句的 LAG() 函数。这可以通过许多其他方式完成,但窗口函数允许我们只用一行 SQL 代码就能获得所需的结果:
LAG(current_year_host, 1) OVER (ORDER BY year) as prev_year_host
许多公司需要计算某一时间段的增长。LAG() 函数在完成这种任务时可以非常有用。
高级概念 N3:月度增长
许多组织使用数据分析来衡量自己的绩效。这可能涉及衡量营销活动的效果或特定投资的 ROI。执行这种分析需要深入了解 SQL,例如日期、时间和窗口函数。
数据科学家还必须证明他们在格式化数据和以百分比或其他形式显示数据的技能。通常,要解决涉及计算月度增长的实际问题,你必须使用多种技能的组合。一些所需的概念将是高级的(窗口函数、日期时间操作),而其他的则是基础的(聚合函数和常见 SQL 语句)。
我们来看看亚马逊面试官提出的一个例题。
前提:
在这个问题中,我们必须处理一个购买表并计算月度收入的增长或下降。最终结果必须以特定的方式格式化(YYYY-MM 格式),并且百分比应四舍五入到第二位小数。
解决方案:
在处理类似任务时,首先需要了解表的结构。你还应该确定需要处理的列,以回答问题,并确定输出的形式。
在我们的例子中,数据值具有对象类型,因此我们需要使用 CAST() 函数将其转换为日期类型。
SELECT
to_char(cast(created_at as date), 'YYYY-MM')
FROM sf_transactions
问题还指定了日期的格式,因此我们可以在 SQL 中使用 TO_CHAR() 函数将日期输出为这种格式。
要计算增长,我们还应选择 created_at 和 SUM() 聚合函数以获取该日期的总销售量。
SELECT
to_char(cast(created_at as date), 'YYYY-MM'),
created_at,
sum(value)
FROM sf_transactions
这时,我们必须再次使用窗口函数。具体来说,我们将使用 LAG() 函数来访问上个月的数量,并将其显示为单独的列。为此,我们还需要一个 OVER 子句。
SELECT
to_char(cast(created_at as date), 'YYYY-MM') AS year_month,
created_at,
sum(value)
lag(sum(value), 1) OVER (ORDER BY created_at::date)
FROM sf_transactions
GROUP BY created_at
根据我们目前编写的代码,我们的表格将如下所示:
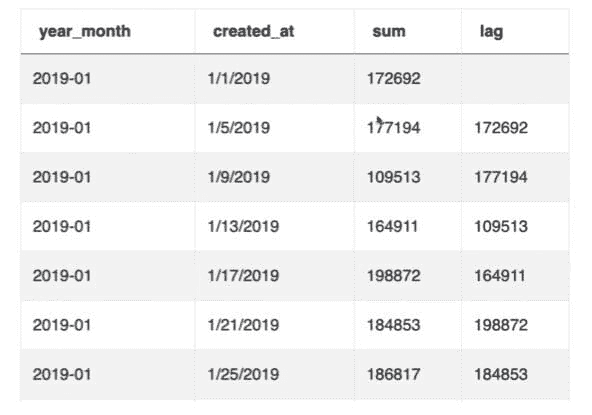
在这里,我们有日期和总值的对应关系在 sum 列中,以及最后一个日期的值在 lag 列中。现在我们可以将这些值代入公式,并在单独的列中显示增长率。
我们还应该删除不必要的 created_at 列,并将 GROUP BY 和 ORDER BY 子句更改为 year_month。
SELECT
to_char(cast(created_at as date), 'YYYY-MM') AS year_month,
sum(value),
lag(sum(value), 1) OVER (ORDER BY to_char(cast(created_at as date))
FROM sf_transactions
GROUP BY year_month
一旦我们运行代码,我们的表格应该只包含对计算至关重要的列。
现在我们终于可以得到解决方案了。这是最终代码的样子:
SELECT to_char(created_at::date, 'YYYY-MM') AS year_month,
round(((sum(value) - lag(sum(value), 1) OVER w) / (lag(sum(value), 1) OVER w)) * 100, 2) AS revenue_diff_pct
FROM sf_transactions
GROUP BY year_month
WINDOW w AS (
ORDER BY to_char(created_at::date, 'YYYY-MM'))
ORDER BY year_month ASC
在这段代码中,我们取用之前示例中的两个列值,并计算它们之间的差异。注意,我们还利用了窗口别名来减少代码的重复性。
然后,根据算法,我们将其除以本月的收入,并乘以 100 以获得百分比值。最后,我们将百分比值四舍五入到小数点后两位。我们得出一个满足所有任务要求的答案。
高级概念 N4:流失率
尽管与增长相反,流失率也是一个重要的指标。许多公司都会追踪其流失率,尤其是当其商业模式是基于订阅时。通过这种方式,他们可以跟踪丢失的订阅或账户数量,并预测造成这些流失的原因。一位经验丰富的数据科学家应该知道使用哪些函数、语句和子句来计算流失率。
订阅数据非常私密,并包含用户的私人信息。数据科学家还需要知道如何在不暴露数据的情况下处理这些数据。计算流失率通常涉及公用表表达式(CTE),这是一种相对较新的概念。最优秀的数据科学家应该知道 CTE 的作用以及何时使用它们。当处理旧版数据库时,如果 CTE 不可用,理想的候选人仍然应该能够完成任务。
这里是一个难度较大的任务示例。在 Lyft 面试的候选人会收到这个任务,以计算公司司机的流失率。
为了解决这个问题,数据科学家必须使用 case/when 语句、窗口函数如 LAG(),以及 FROM / WHERE 和其他基本子句。
结论
拥有多年的数据科学家工作经历无疑在简历上显得非常出色,并且能为你赢得许多面试机会。然而,一旦你进入面试阶段,你仍然需要展示出足够的知识来补充多年经验的积累。即便你在编写 SQL 查询方面经验丰富,利用像StrataScratch这样的资源来刷新你的知识也不失为一种好方法。
内特·罗西迪 是一名数据科学家,专注于产品战略。他还是一名兼职教授,教授分析学,并且是StrataScratch,一个帮助数据科学家通过顶级公司实际面试问题准备面试的平台的创始人。你可以通过Twitter: StrataScratch 或 LinkedIn与他联系。
更多相关话题
SQL 面试准备材料资源
原文:
www.kdnuggets.com/2023/02/sql-interviews-preparations-material-resources.html

图片由 Freepik 提供
SQL,即结构化查询语言,是一种用于操作关系型数据库的编程语言。由于大多数公司将数据存储在关系型数据库中,因此员工需要了解 SQL 语言。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
目前,数据人员和各种职位都期待具备 SQL 技能。这就是为什么公司开始进行各种类型的 SQL 面试,包括理论面试、技术面试或两者兼有。
我们可能会说,只要我们练习 SQL 技能,就能为面试做好准备。然而,有时问题可能会在我们未准备好时让我们措手不及。毕竟,面试与课程练习有所不同。
这就是为什么我们需要在面对面试之前做好准备。在这篇文章中,我们将探索各种 SQL 面试材料资源,帮助你为实现梦想的工作做好准备。这篇文章将对初学者和专业人士都有所帮助,所以让我们开始吧。
SQL 面试材料资源
在这篇文章中,我将概述每个面试备考资料,并介绍你可以从这些备考资料中学到的内容。所有包含的材料都是公开的且免费提供的,所以你无需担心。
InterviewBit
首先,我们有 InterviewBit 提供的 SQL 面试问题。这些材料将教你从 Google、Amazon、Microsoft 等真实公司中获得的基本 SQL 开发者问题。
这些材料分为 SQL 面试和 PostgreSQL 面试问题。学习材料将教你各部分的不同问题,从基本的 SQL 概念到具体的技术问题。由于它专注于 SQL 开发者面试,因此涵盖了整个数据库概念的各种问题,例如数据库架构和备份。
此外,InterviewBit 在材料的末尾提供了一个测试,你可以用来检验你的知识。
Edureka
Edureka 的三部分 SQL 面试材料将教你许多基础的 SQL 技术和概念面试问题。材料包括 SQL、MySQL 和 DBMS 面试问题。涵盖了所有基础的 SQL 知识,因此这是一个完美的起点。
FreeCodeCamp
让我们深入了解面试官常问的 SQL 技术问题。你将学习基本的 SQL 语法问题和案例研究。这是初学者的完美资源。
Stratascratch
资源: 你必须准备的 SQL 面试问题:Stratascratch 的终极指南
被誉为终极 SQL 面试问题材料,指南也证明了它为何被称为终极指南。该指南详细列出了所有面试问题,并为每个问题提供了带代码的答案。
许多问题还提供了面试官提出问题的意图及最佳回答方式。此外,一些问题针对特定的职位角色。
指南涵盖了各种 SQL 面试主题,包括
-
技术概念 SQL 问题
-
大公司的 SQL 问题
-
SQL 数据科学面试问题
Hackr.io
资源: Hackr.io 的 75+ 个顶级 SQL 面试问题及答案
一份全面的 SQL 面试材料,将帮助你回答面试官的问题。指南分为基础、中级和高级难度。适合任何水平的申请者。
指南还提供了面试前的提示,例如应关注什么以及在哪里练习你的技能。
Great Learning
资源: Great Learning 的 180+ 个 SQL 面试问题及答案
Great Learning 的面试材料主要针对开发人员职位。然而,它仍然适用于其他职位角色。无论你当前的职业水平如何,这是一份涵盖面试准备的完整指南。
材料分为几个部分,包括
-
基本和高级 SQL 面试
-
适用于有经验的开发人员的 SQL 面试问题
-
SQL 连接面试问题
-
SQL Server 面试问题
-
PostgreSQL 面试问题
面试查询
资源: Interview Query 的 25+ 个数据科学 SQL 面试问题
这份面试指南将涵盖你作为数据科学家需要准备的 SQL 面试问题。指南分为三个部分,包括
-
初学者:基于定义的概念和使用案例
-
中级:查询编写问题
-
高级:调查业务问题的 SQL 概念
这些面试问题的数量可能不如其他材料多,但这份指南提供了其他指南所没有的内容;例如,对预期问题的分类细节、回答面试的策略以及数据科学家面试中的常见 SQL 概念。
Besant Technologies
资源: Besant Technologies 的 Oracle 面试问题与答案
一些 SQL 工作需要特定的技能,即 Oracle。这份面试材料将涵盖面试官可能提出的所有基础 Oracle 问题和答案。
软件测试帮助
另一份具体的 SQL 面试问题材料。在这个指南中,你将了解 SQL 服务器相关的问题和详细答案。这些材料可能与数据工程师和相关工作角色相关。
CareerGuru99
资源: CareerGuru99 提供的前 24 个 T-SQL 面试问题与答案
如果公司期望你掌握 T-SQL,那么这份资源材料将非常适合你。这个指南旨在帮助初学者和专业人士更好地了解 T-SQL 问题。
结论
在这篇文章中,我涵盖了我精心挑选的各种 SQL 面试准备材料,这些材料在面试准备时非常重要。大多数材料是准备面试的良好起点。
上述大多数面试指南可用于你当前从事的任何数据角色或你所在的任何职业层级。因此,祝你求职好运。
Cornellius Yudha Wijaya 是一名数据科学助理经理和数据撰稿人。在 Allianz Indonesia 全职工作的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
更多相关主题
SQL LIKE 运算符示例
原文:
www.kdnuggets.com/2022/09/sql-like-operator-examples.html

SQL LIKE 运算符示例
什么是 SQL LIKE 运算符
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
SQL LIKE 运算符用于在列中搜索特定模式。它总是与WHERE子句一起使用,我们可以使用AND或OR运算符组合任意数量的条件。
通常与 LIKE 运算符一起使用的有两个通配符:
-
“%”符号表示零个、一个或多个字符。例如:“a%”,它将查找以“a”开头的名称。没有大小限制。
-
“”下划线表示一个字符。你可以添加多个下划线来定义固定长度。例如:“a__”,它将找到以“a”开头且长度固定为 4 的名称。
在我们深入了解 LIKE 的实际例子之前,先看看各种通配符和描述的示例。
| LIKE 运算符 | 描述 |
|---|---|
| WHERE EmployeeName LIKE 'g%' | 显示所有以“g”开头的员工姓名 |
| WHERE EmployeeName LIKE '%g' | 显示所有以“g”结尾的员工姓名 |
| WHERE EmployeeName LIKE '%en%' | 显示任何位置包含“en”的员工姓名 |
| WHERE EmployeeName LIKE '_g%' | 显示第二个位置有“g”的员工姓名 |
| WHERE EmployeeName LIKE 'g__%' | 显示以“g”开头且长度至少为 3 个字符的员工姓名 |
| WHERE EmployeeName NOT LIKE 'g%' | 显示所有不以“a”开头的员工姓名。 |
| WHERE EmployeeName LIKE 'g%l' | 显示以“g”开头且以“l”结尾的员工姓名 |
SQL LIKE 示例
在本节中,我们将学习在示例数据集中使用 LIKE 运算符的 9 种不同方法。SF Salaries数据集包含了旧金山市政府员工及其薪酬信息。数据集包括 2011 年至 2014 年的年薪数据。
在我们的例子中,我们将重点关注 EmployeeName、JobTitle、BasePay、OvertimePay、OtherPay 和 TotalPay,如下所示。
| Id | EmployeeName | JobTitle | BasePay | OvertimePay | OtherPay | TotalPay |
|---|---|---|---|---|---|---|
| 1 | Nathaniel Ford | 总经理-大都会交通管理局 | 167411.2 | 0 | 400184.3 | 567595.4 |
| 2 | 加里·吉门内斯 | 队长 III(警察部门) | 155966 | 245131.9 | 137811.4 | 538909.3 |
| 3 | 阿尔伯特·帕尔迪尼 | 队长 III(警察部门) | 212739.1 | 106088.2 | 16452.6 | 335279.9 |
| 4 | 克里斯托弗·钟 | 钢丝绳电缆维护技工 | 77916 | 56120.71 | 198306.9 | 332343.6 |
| 5 | 帕特里克·加德纳 | 副部门主管(消防部门) | 134401.6 | 9737 | 182234.6 | 326373.2 |
注意: 我正在使用在线 SQL 查询工具 (sqliteonline.com) 来创建示例。
示例 #1
它将显示所有 EmployeName 为“Nathaniel Ford”的列。你也可以使用“=”等号来代替 LIKE,但通配符与等号不起作用。
SELECT *
FROM Salaries
WHERE EmployeeName LIKE 'Nathaniel Ford';

示例 #2
查询将显示以“Nathaniel”开头的前 5 个员工姓名。如我们所见,我们得到了 Nathaniel Ford、Nathaniel Steger、Nathaniel Yuen 等。
结尾的“%”代表该字符后面的任何字符。
SELECT *
FROM Salaries
WHERE EmployeeName LIKE 'Nathaniel%'
LIMIT 5;
示例 # 3
查询将搜索所有以“Ford”结尾的员工姓名,并显示前五个结果。
SELECT *
FROM Salaries
WHERE EmployeeName LIKE '% Ford'
LIMIT 5;
示例 #4
查询将搜索所有在任意位置包含“Ford”的员工姓名,并显示前五个结果。
我们得到了一些名字,比如雷·克劳福德、基思·桑福德、约翰·桑福德 Jr 等。
SELECT *
FROM Salaries
WHERE EmployeeName LIKE '%Ford%'
LIMIT 5;
示例 #5
查询将搜索所有以“k”开头并以“o”结尾的员工姓名。例如,我们得到了 Kenneth Esposto。
SELECT *
FROM Salaries
WHERE EmployeeName LIKE 'k%o'
LIMIT 5;
示例 #6
我们将使用下划线来搜索第二个位置是“t”且第三个位置是“h”的员工姓名。
我们得到了以“那个第二位置”开头的伊桑·杰克逊、奥莎·科顿、厄尔斯特伯特·奥布赫等。
SELECT *
FROM Salaries
WHERE EmployeeName LIKE '_th%'
LIMIT 5;
示例 #7
这是一个有趣的查询,我们正在寻找名字的前四个字符是“kenn”且两个下划线后跟“h”的员工姓名。这意味着 LIKE 运算符将查找以“Kenn”开头并以“h”结尾的名字。名字长度固定为 7 个字符。
SELECT *
FROM Salaries
WHERE EmployeeName LIKE 'Kenn__h%'
LIMIT 5;
示例 #8
让我们了解一下没有“%”的下划线通配符。我们将找到以“ob”结尾且长度为 9 个字符的名字。为此,我们使用了 7 个下划线来将名字长度固定为 9。
结果中我们只有一个名字,即“Carly Gorb”。
SELECT *
FROM Salaries
WHERE EmployeeName LIKE '________ob'
LIMIT 5;

示例 #9
我们可以使用 AND、OR 和 NOT 与 LIKE 运算符。这可以帮助你执行更具体的搜索。
在这个示例中,我们将使用 NOT 来显示除了以“ken”开头的名字以外的所有名字。
SELECT *
FROM Salaries
WHERE EmployeeName NOT LIKE 'ken%'
LIMIT 5;
结论
带通配符的 LIKE 操作符可以帮助你编写有效的查询并搜索特定的记录。你甚至可以将其与逻辑函数结合使用,以缩小搜索范围。
在这篇文章中,我们学习了使用 LIKE 操作符的多种方法。我强烈建议你自己练习。你甚至可以解决w3schools.com的互动练习,以更好地理解这一概念。
“如果你希望更频繁地看到这种内容,请在下方评论告诉我。”
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些正在与心理健康问题作斗争的学生打造一款 AI 产品。
更多相关内容
SQL 是否需要成为数据科学家?
评论
作者:Saurabh Hooda,Hackr.io

我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 部门
SQL 是否需要成为数据科学家?
简短的回答是“是的”。只要数据科学家这个称谓里包含“数据”,结构化查询语言(或者我们称之为 see-quel)就会继续是其中的重要部分。在这篇博客中,让我们深入探讨数据科学及其与 SQL 的关系,包括 5W1H——如何、为什么、哪里、何时、谁和什么。我们还将学习数据库管理系统(DBMS)的基础知识,并了解成为数据科学家可能是你职业生涯的最佳选择。
什么是数据科学?
数据科学的视角很广泛,成为一名数据科学家需要深入了解数学、机器学习、计算机科学、统计研究、数据处理以及领域知识中的一种或多种流派。这些流派中的每一个都需要大量的数据工作,不论是收集、分析还是处理。如果你正在准备数据科学面试,可以查看这些必备的数据科学面试问题。
为什么数据科学如此受欢迎?
数字世界正处于巅峰状态,随着需求的增长和广泛的营销策略,数据已成为所有营销目的的关键。例如,如果我想买一部新手机,我会去像 Amazon 或 Flipkart 这样的在线商店,浏览不同的品牌,把几款放入购物车,但决定在进一步研究后再购买。在内部,在线商店会保存我的购物车和浏览历史,并在我稍后回来时向我推荐更多手机。即使我不购买,公司也会发邮件提醒我我的购物车“还在等待我”。因此,数据在创建买卖双方关系中扮演着最重要的角色。客户提供的数据越多,提供给买家的信息流就越定制。这不仅仅适用于电子商务,数据科学在医疗保健、制造、银行、金融和运输等许多其他领域也证明了其极大的价值。
如何?
收集 – 假设你在宜家检查一个床单。你购买了这个产品然后离开。后来你意识到你需要更多相同的产品,于是回来购买。你告诉你的朋友这个产品有多么有用且便宜,他们也被说服购买。制造商利用这些数据来了解客户的喜好,并更新他们的库存以拥有更多受欢迎的产品。此外,持续的反馈帮助他们对现有产品进行改进。
处理 – 收集到的用户数据在建模和规划阶段被考虑进来,以便得出可操作的见解。例如,更多的客户寻找特定颜色的床单或特定面料的窗帘。
分析 – 想象一下你买了一张蓝色的床单,但意识到对于你房间的氛围,绿色会是更好的选择,而目前没有绿色的床单。绿色是一种常见的、受欢迎的颜色。通过对人类输入和数据管理工具的分析,可以确定是否引入绿色床单是一个好主意,是否会满足更多客户的需求,并带来更多的利润。
对于需求预测和库存管理,我们需要将所有用户信息,包括他们的购买、喜好和不喜欢、反馈等,存储在某个地方。
在哪里?
是的,你明白了 – 一切都存储在数据库中。因此,SQL 对于处理需要定期处理的大量数据至关重要。它也作为数据科学所意图进行的正确营销和反馈的重要工具。例如,如果你不喜欢 Facebook 向你推荐的视频 – 你会说‘隐藏这个’,然后 Facebook 会立即询问你原因。这些用户偏好也需要存储在某个地方。
通过像 SQL 这样的关系型数据库,数据科学提供了一个持续的系统来处理和改进数据的呈现和处理方式。
SQL 的作用是什么?
SQL 是整个数据科学宇宙的重要组成部分。但它到底适合什么位置?如果你想成为数据分析师、数据工程师或数据架构师,你需要 学习 SQL 以及编程语言如 C、R 和 Python。以下是一个简单的图示,展示了 SQL 使用的阶段:
要查看原始图片来源,请点击 这里。
高亮的部分是我们需要 SQL 知识的地方:大数据、大数据分析和数据分析。
为什么选择 SQL?
尽管有提供高性能和速度的 NoSQL 数据库,SQL 数据库仍然是实际应用中最广泛使用的。了解 SQL 技术的开发者更多,因此支持和文档也更为丰富。此外,数据完整性是 SQL 相比任何 NoSQL 数据库的一个关键因素,它能够保证系统中不会出现重复或未经授权的数据。此外,对于复杂的查询和联接,结构良好的关系型数据库效果更佳。
什么是 SQL?
SQL 是一种关系型数据库管理系统,用于存储、检索、更新和读取数据库中的数据。如果你从基础知识开始通过 这个精心设计的课程 接触 SQL,你将终生热爱 SQL。
在这篇博客中,我们将重点讨论 SQL 对数据科学的影响。让我们通过一个简单的例子来探讨你作为数据科学家如何使用 SQL 来收集和分析数据。
假设你想了解一本名为《数据科学手册》的书籍的受欢迎程度,通过检查有多少用户订购了该书。由于 SQL 是一种结构良好的语言,具有适当的模式,你可以拥有如下结构:
-
customer 表 – customer_id、customer_name、order_id 等 -
order_details 表 – order_id、order_desc、order_date 等 -
book 表 – book_id、book_name、author、order_id 等
要获取这些数据,我们需要 联接 三个表,使用一些共同的列或键。在这种情况下,order_id 是三个表共有的字段,利用这些数据,我们可以编写查询来获取所需的详细信息。
在现实场景中,这种系统可以存在于多个层次,需要分析和处理大量数据。来自数百万用户的日常数据被存储和分析以实现各种目的。
想象一下如果没有 SQL 做这一切,这是否能想象?
虽然有些人希望相信 SQL 在数据科学家工作中的作用正在减少,但事实并非如此。SQL 是不会消失的。
这是数据科学家应该知道的一些关键 SQL 概念:
关系型数据库模型
在关系型数据库模型中,所有的数据点相互关联或连接。在创建这种数据库时,各个表和列之间的关系必须在设计阶段就定义好。在我们上述的例子中,这三个表是相关的。客户表的主键(“一组最小属性(列)的特定选择,能够唯一地指定关系(表)中的一个元组(行)”)将是customer_id,而order_id将是外键(“一组属性,受某种包含依赖约束的影响,具体来说是外键属性所组成的元组必须在某个其他(不一定是不同的)关系 S 中也存在”)。同样,book_id和order_id的组合可以作为书籍表的复合键。这些关系必须在创建阶段就定义好。
DBMS 规范化
规范化是一个设计过程,其中数据库中的表被组织成以避免数据的冗余和依赖。通过不同形式的规范化,我们可以将数据划分为更小的结构,并建立它们之间的链接,从而使数据得到最佳存储。这篇很好的文章以非常简单易懂的方式介绍了规范化的信息。
数据库模式
数据库模式是数据库的逻辑视图。所有应用于数据的关系,如约束、表、视图、触发器等,形成了模式。
基本 SQL 命令
SQL 可以执行以下类型的语句:
-
DML(数据操作语言)语句 –
select, insert, delete, update -
DDL(数据定义语言)语句 –
create, drop, alter -
DCL(数据控制语言)语句 –
grant, revoke -
TCL(事务控制语言)语句 –
begin, commit, rollback
查看这份精简的SQL 面试问题列表,可以帮助你快速复习概念。
谁应该学习 SQL?
到现在为止,你应该明白,如果你对数据狂热且喜欢玩弄数据,并希望将数据科学作为职业选择,你肯定应该学习 SQL。
数据科学家作为职业选择
每天都会生成大量数据,这些数据需要被转化为新的商业解决方案、设计和产品,而这些只有数据科学家的创造性思维才能实现。未来几十年,这种需求只会逐日增加。除了行业提供的丰厚薪资,挑战性和不断扩大的角色也吸引着专业人士从事这一工作。从数据管理员、数据架构师、数据分析师、业务分析师到数据经理或商业智能经理,数据科学领域有很多机会可供选择。掌握 SQL、R 和 Python 等编程语言、统计学和应用数学,并具备批判性思维和行业知识,将使你比想象的更早实现目标。
个人简介:Saurabh Hooda 曾在全球电信和金融巨头公司担任各种职务。在 Infosys 和 Sapient 工作了十年后,他创办了自己的第一个初创公司 Leno,旨在解决超本地的书籍共享问题。他对产品营销和分析充满兴趣。他的最新创业项目 Hackr.io 推荐了每种编程语言的最佳 数据科学教程 和在线编程课程。所有教程均由编程社区提交和投票。
原创,已获许可转载。
相关内容:
-
掌握 SQL 的 7 个步骤 — 2019 版
-
Python 数据科学入门
-
SQL 备忘单
更多相关话题
SQL 专业笔记:免费电子书评论
原文:
www.kdnuggets.com/2022/05/sql-notes-professionals-free-ebook-review.html

图片来源于作者
SQL 专业笔记 书籍 是基于 Stack Overflow 文档数据转储 编纂的。这是由 GoalKicker 创建的非官方免费书籍,旨在教育目的。简而言之,内容是 Stack Overflow 上各种人的集合。结构化查询语言(SQL)是一种用于管理关系型数据库的编程语言。你可以根据需要创建、修改和优化数据库表。核心数据库修改操作包括 INSERT、SELECT、MERGE、UPDATE 和 DELETE。
SQL 是信息技术各个领域中使用最广泛的语言。即使是网页开发者也会说,他们 80%的时间在存储数据和获取信息。我们的世界围绕数据驱动的产品展开,管理这些数据已经成为一个相当有利可图的职业。即使你申请的是机器学习工程师,技术面试中也会包含几个与 SQL 相关的问题。为了在职业生涯中脱颖而出并通过招聘过程中的技术面试,复习所有概念是必要的。免费的 SQL 书籍帮助你复习所有数据库管理相关的主题,并引入可以优化你当前流程的新概念。
主要特征
本书涵盖了 SQL 查询语言使用的所有概念,如数据类型、排序、分组、Like、case 运算符、in 子句、条件操作、连接和更新。就像我一样,你会对那些用于维护数据库和运行高效 SQL 查询的未知术语感到惊讶。
在这一部分,我们将讨论这本书为何特别以及如何利用这些特性提升你的 SQL 知识。
首先,每个 SQL 概念都附有实际示例,你可以运行查询进行练习或仅观察输出。SQL 查询是一个 IIF 函数,用于创建一个新列,包含类别 Bonus 和 No Bonus。
每一部分都有一个问答。并且有详细的输出解释和查询如何执行的说明。
SELECT BusinessEntityID, SalesYTD,
IIF(SalesYTD > 200000, 'Bonus', 'No Bonus') AS 'Bonus?'
FROM Sales.SalesPerson
GO
| BusinessEntityID | SalesYTD | 奖金? |
|---|---|---|
| 274 | 559697.5639 | 奖金 |
| 275 | 3763178.1787 | 奖金 |
| 285 | 172524.4512 | 无奖金 |
其次,本书从简单的概念开始,如数据类型和 SELECT 关键字。随着每一部分的增加,复杂性逐渐提高。
第三,这本书深入覆盖了所有概念。例如,在SELECT章节中,子主题包括使用列别名的 SELECT、带有条件和情况的选择以及带有聚合函数的选择。这本书从各个角度详细讲解了 SELECT,然后再进入其他章节。
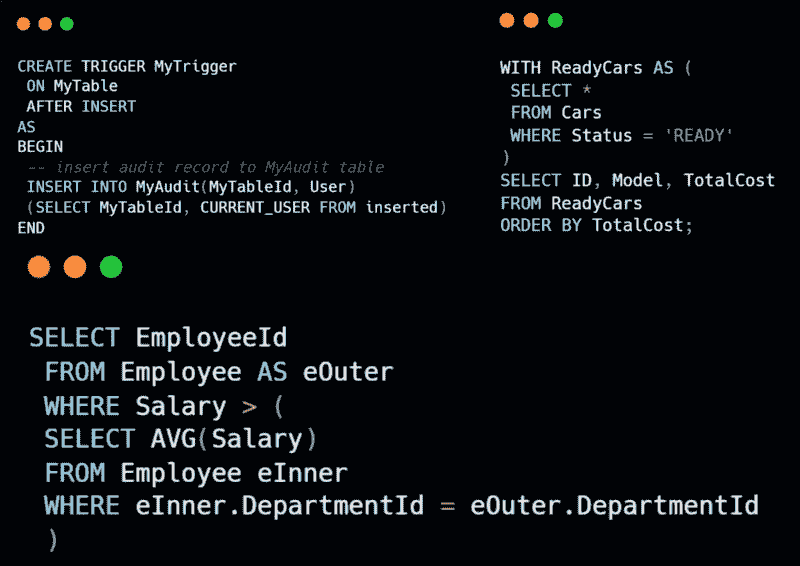
作者提供的图片
第四,这本书是 SQL 备忘单。就像备忘单一样,这本书对每个函数都有明确的描述和代码。这种学习方式帮助专业人士为演讲或面试做准备。
第五,这本书包含了一个高质量的图表,解释了复杂的概念。
第六,长 SQL 脚本附带注释,解释了子查询。这些注释帮助开发人员理解为什么使用了嵌套查询。
最后,这本书是免费的,内容质量很高。你可以找到一页的备忘单或在网上搜索特定的术语,但你不会在一个地方找到所有的 SQL 函数,并将其汇编成一本书。
结论
在书的最后,你可以看到所有对本书作出贡献的人的名字。这本书来自于社区,并且是免费的。在这本书的评论中,我们了解了它与其他书籍的不同之处,并讨论了其关键特性。如果你问我,我肯定会利用这本书为下一次面试做准备,甚至使用其中的一些功能来改善我现有的项目。公司愿意花钱进行数据库优化和减少查询时间。提升你被录用的机会,并提高你在数据工作流管理方面的能力。
我强烈推荐这本书给数据领域的专业人士和找工作的人。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专家,热衷于构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是为面临心理健康问题的学生构建一个基于图神经网络的人工智能产品。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
实时流处理分析的类似 SQL 查询语言
原文:
www.kdnuggets.com/2015/03/sql-query-language-realtime-streaming-analytics.html
作者:Srinath Perera(@srinath_perera)
我上周在Strata+Hadoop World 2015参加了会议,确实对实时分析的兴趣达到了顶峰。
实时分析,或者人们称之为实时分析,有两种类型。
-
实时流处理分析(静态查询一次给出,不会改变,它们处理数据时无需存储。CEP、Apache Storm、Apache Samza 等是这方面的例子)
-
实时交互/临时分析(用户发出临时动态查询,系统响应)。Druid、SAP Hana、VoltDB、MemSQL、Apache Drill 是这方面的例子。
在这篇文章中,我专注于实时流处理分析。(临时分析无论如何都会使用类似 SQL 的查询语言。)
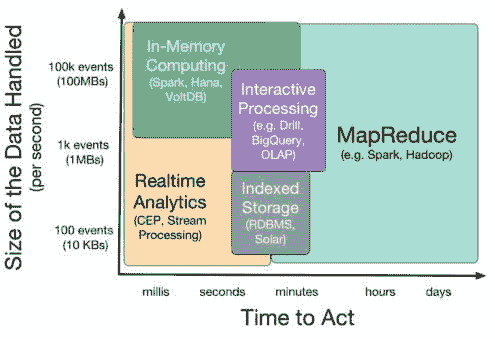
当谈到实时分析时,人们仍然只考虑计数用例。然而,这只是冰山一角。由于实时用例中数据的时间维度,您可以做的还有很多。让我们看看一些常见的模式。
-
简单计数(例如,故障计数)
-
使用窗口进行计数(例如,每小时的故障计数)
-
预处理:过滤、转换(例如,数据清理)
-
警报,阈值(例如,高温报警)
-
数据关联,检测丢失事件,检测错误数据(例如,检测失败的传感器)
-
连接事件流(例如,检测到足球的击打)
-
与数据库中的数据合并,收集,按条件更新数据,检测事件序列模式(例如,小交易后跟随大交易)
-
跟踪——在空间、时间等方面跟踪相关实体的状态(例如,航空公司行李的位置、车辆、野生动物追踪)
-
检测趋势——上升、转折、下降、异常值、复杂趋势如三重底等(例如,算法交易、SLA、负载均衡)
-
学习模型(例如,预测性维护)
-
预测下一个值和纠正措施(例如,自动驾驶汽车)
为什么我们需要类似 SQL 的查询语言用于实时流处理分析?
上述每一个都在用例中出现过,我们已经使用类似 SQL 的 CEP 查询语言实现了它们。了解实现 CEP 核心概念(如滑动窗口、时间查询模式)的内部细节,我认为每个流处理用例开发者都不应该重新编写这些。算法并非简单,而且很难做到准确!
相反,我们需要更高层次的抽象。我们应该一次性实现这些抽象,并重复使用它们。我们可以从 Hive 和 Hadoop 中学到的最佳教训就是它们正好为批量分析做了这些工作。我多次解释了 Hive 中的大数据,大多数人很快就能理解。Hive 已成为大多数大数据用例的主要编程 API。
以下是 SQL 类查询语言的一些理由。
-
实时分析很困难。每个开发者都不愿意手动实现滑动窗口和时间事件模式等。
-
对于熟悉 SQL 的人(几乎每个人都知道),它易于跟随和学习。
-
SQL 类语言表达力强,简洁、甜美且快速!!
-
SQL 类语言定义了涵盖 90% 问题的核心操作
-
专家们可以随时深入研究!
-
实时分析运行时可以更好地优化 SQL 类模型的执行。大多数优化已经被研究过,还有很多可以借鉴数据库优化的经验。
那么这些语言是什么呢?在复杂事件处理的世界里定义了很多(例如 WSO2 Siddhi、Esper、Tibco StreamBase、IBM Infosphere Streams 等)。SQL 流有一个完全符合 ANSI SQL 的版本。上周我在 Strata 会议上详细讨论了这个问题以及 CEP 如何满足要求。这里是幻灯片
可扩展的实时分析与声明式 SQL 类复杂事件处理脚本 来自 Srinath Perera
个人简介:Srinath Perera 是一位科学家、软件架构师和程序员,专注于分布式系统。
原文:srinathsview.blogspot.com/2015/02/why-we-need-sql-like-query-language-for.html
相关:
-
采访:Ted Dunning,MapR 讲述大数据中实时性的真正含义
-
2015 年大数据的 8 大趋势
-
即将举行的分析、大数据、数据科学网络广播 – 3 月 10 日及以后
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关话题
SQL 查询优化技术
原文:
www.kdnuggets.com/2023/03/sql-query-optimization-techniques.html

作者提供的图片
在初级阶段,我们只关注编写和运行 SQL 查询。我们不在乎执行需要多长时间或它是否能处理数百万条记录。但在中级阶段,人们期望你的查询已优化并且执行时间最小。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT 工作
在大型应用程序中编写优化的查询,如电子商务平台或银行系统,是至关重要的。假设你拥有一个超过一百万个产品的电子商务公司,而客户希望搜索某个产品。如果你在后端编写的查询需要超过一分钟来从数据库中获取该产品,你认为客户还会在你的网站上购买产品吗?
你必须了解 SQL 查询优化的重要性。在本教程中,我将向你展示一些优化 SQL 查询的技巧和窍门,从而使它们执行得更快。主要前提是你必须具备基本的 SQL 知识。
1. 使用 EXIST() 替代 COUNT() 来查找表中的特定元素
要检查表中是否存在特定元素,请使用 EXIST() 关键字,代替 COUNT() 将以更优化的方式运行查询。
使用 COUNT(),查询需要计算特定元素的所有出现次数,这在数据库庞大时可能效率较低。另一方面,EXIST() 只会检查该元素的第一次出现,然后在找到第一次出现时停止。这节省了很多时间。
另外,你只关心检查特定元素是否存在,而不关心出现次数。这就是为什么 EXIST() 更好的原因。
SELECT
EXISTS(
SELECT
*
FROM
table
WHERE
myColumn = 'val'
);
上述查询会返回1,如果至少有一行表记录包含名为 myColumn 的列,其值等于val。否则,它会返回0。
2. 使用 Varchar 而不是 Char
char 和 varchar 数据类型都用于在表中存储字符字符串。但 varchar 比 char 更加节省内存。
char 数据类型只能存储固定长度的字符字符串。如果字符串的长度小于固定长度,则会填充空格以使其长度等于设置的长度。这会在填充时不必要地浪费内存。例如,CHAR(100) 即使存储一个字符也会占用 100 字节的内存。
另一方面,varchar 数据类型存储可变长度的字符字符串,其长度小于指定的最大长度。它不会填充空格,只占用与字符串实际长度相等的内存。例如,VARCHAR(100) 存储一个字符时仅占用 1 字节的内存。
CREATE TABLE myTable (
id INT PRIMARY KEY,
charCol CHAR(10),
varcharCol VARCHAR(10)
);
在上面的示例中,创建了一个名为 myTable 的表,该表有两个列,分别是 charCol 和 varcharCol,它们的类型分别是 char 和 varchar。charCol 将始终占用 10 字节的内存。相比之下,varcharCol 占用的内存等于存储其中的字符字符串的实际大小。
3. 避免在 WHERE 子句中使用子查询
我们必须避免在 WHERE 子句中使用子查询以优化 SQL 查询,因为子查询可能会非常昂贵,并且在返回大量行时执行起来很困难。
你可以通过使用连接操作或编写相关子查询来获得相同的结果,而不是使用子查询。相关子查询是一种内部查询依赖于外部查询的子查询。与非相关子查询相比,它们非常高效。
下面是一个例子,以理解这两者之间的区别。
# Using a subquery
SELECT
*
FROM
orders
WHERE
customer_id IN (
SELECT
id
FROM
customers
WHERE
country = 'INDIA'
);
# Using a join operation
SELECT
orders.*
FROM
orders
JOIN customers ON orders.customer_id = customers.id
WHERE
customers.country = 'INDIA';
在第一个示例中,子查询首先收集所有属于印度的客户 ID,然后外部查询将获取所选客户 ID 的所有订单。而在第二个示例中,我们通过连接customers和orders表来实现相同的结果,然后仅选择来自印度的客户的订单。
通过避免在 WHERE 子句中使用子查询并使其更易于阅读和理解,我们可以优化查询。
4. 将 JOIN 从较大表应用到较小表
将 JOIN 操作从较大表应用到较小表是一种常见的 SQL 优化技术。因为从较大表连接到较小表会使你的查询执行得更快。如果我们将 JOIN 操作从较小表应用到较大表,SQL 引擎必须在较大表中查找匹配的行。这是更为耗费资源和时间的。另一方面,如果 JOIN 从较大表应用到较小表,SQL 引擎只需在较小表中查找匹配的行。
这里有一个例子帮助你更好地理解。
# Order table is larger than the Customer table
# Join from a larger table to a smaller table
SELECT
*
FROM
Order
JOIN Customer ON Customer.id = Order.id
# Join from a smaller table to a larger table
SELECT
*
FROM
Customer
JOIN Order ON Customer.id = Order.id
5. 使用 regexp_like 代替 LIKE 子句
与 LIKE 子句不同,regexp_like 也用于模式搜索。LIKE 子句是一个基本的模式匹配操作符,只能执行如 _ 或 % 这样的基本操作,用于匹配单个字符或任意数量的字符。LIKE 子句必须扫描整个数据库以找到特定模式,这对于大型表来说速度较慢。
另一方面,regexp_like 是一种更高效、优化和强大的模式搜索技术。它使用更复杂的正则表达式来查找字符字符串中的特定模式。这些正则表达式比简单的通配符匹配更具体,因为它们允许你搜索我们所寻找的确切模式。由于这个原因,需要搜索的数据量减少,查询执行速度更快。
请注意,regexp_like 可能并非所有数据库管理系统中都存在。其语法和功能在其他系统中可能有所不同。
这里有一个示例帮助你更好地理解。
# Query using the LIKE clause
SELECT
*
FROM
mytable
WHERE
(
name LIKE 'A%'
OR name LIKE 'B%'
);
# Query using regexp_like clause
SELECT
*
FROM
mytable
WHERE
regexp_like(name, '^[AB].*');
上述查询用于查找名称以 A 或 B 开头的元素。在第一个示例中,使用 LIKE 搜索所有以 A 或 B 开头的名称。A% 表示第一个字符是 A;之后可以有任意数量的字符。在第二个示例中,使用了 regexp_like。在 ^[AB] 内部,^ 表示符号将匹配字符串的开头,[AB] 表示开头字符可以是 A 或 B,.* 表示之后的所有字符。
使用 regexp_like,数据库可以快速过滤掉不匹配模式的行,从而提高性能并减少资源使用。
结论
在这篇文章中,我们讨论了优化 SQL 查询的各种方法和技巧。本文让你清晰地了解了如何编写高效的 SQL 查询以及优化它们的重要性。优化查询的方法还有很多,例如偏好使用整数值而不是字符,或者在表中没有重复项时使用 Union All 而不是 Union 等。
Aryan Garg 是一名电气工程专业的 B.Tech. 学生,目前处于本科最后一年。他的兴趣领域包括网页开发和机器学习。他已经在这些方向上有所追求,并渴望进一步深入工作。
了解更多相关内容
为什么 SQL 将继续是数据科学家的最佳伙伴
原文:
www.kdnuggets.com/2022/07/sql-remain-data-scientist-best-friend.html

数据工程和数据科学是快速发展的竞争领域。技术来来去去,因此保持技能更新是所有雄心勃勃的数据专业人士的共识。数据工程师和科学家们意见不一的是,未来哪些技能会最有价值。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
尽管数据科学家面临着令人眼花缭乱的工具和服务阵列,但 SQL 依然是数据科学家技术栈的基石。虽然 SQL 通常被视为基础技能,但实际上,它远不止于此。尽管 SQL 已经快 50 岁了,它却变得更加,而不是减少相关性。
机器学习、大数据分析或人工智能可能会抢占头条,但如果你想磨练一种可以提升职业生涯的智能、战略性技能,那么 SQL 是你最好的选择。这就是原因所在。
SQL 主导数据库
首先,“SQL 确实是数据的语言” 这是 Benjamn Rogojan(也叫 Seattle Data Guy)的话。这是因为大多数数据库都是基于某种 SQL 技术构建的。今天所有除了两个的最受欢迎的十个数据库都是基于 SQL 的,例外的(MongoDB 和 Redis)分别排在第五和第六名,甚至它们也可以与 SQL 一起使用。可以很容易地看出,任何需要查询、更新、修改或以任何方式与关系数据库中的数据进行交互的人,都将从扎实的 SQL 知识中受益,无论他们最终从事什么专业。
SQL 技能需求高,且不断增长
尽管 SQL 已经存在一段时间,但它远不是过时技能。随着数据工程向云端发展,SQL 也紧随其后。根据Dataquest,SQL 在 2021 年是数据行业中需求量最大的技能,尤其是在初级职位中。然而,即使是更有经验的数据科学家职位招聘也几乎在 60%的空缺中列出了 SQL 技能。而且,毫无疑问,由于对数据相关专业知识的需求激增,对 SQL 技能的需求似乎在2020 年短暂下降后仍在增长。疫情 notwithstanding,SQL 服务器转型市场预计将在十年结束前以超过 10%的年均增长率稳步增长。
精明的数据科学家是否应该优先考虑 SQL?
SQL 的未来看起来很安全,但这并不一定意味着已经掌握 SQL 的初学数据科学家会优先提高他们的 SQL 技能以推进职业发展。
他们应该。
在 ELT/ETL 阶段,有如此多的工具和新兴技术可以帮助他们进行 BI、预测和历史分析,数据科学家需要明智地选择投入精力的方向。高科技技能的半衰期不断缩短,意味着数据科学家需要关注。
学习的内容可以决定职业生涯的方向——或限制它。
SQL 如何成为核心?
没有人愿意花六个月的时间去弄清楚一个只能实现预期一半功能的工具,更不用说向更广泛的团队推荐它,然后发现它无法满足需求。因此,当数据科学家查看可以帮助他们更有效地查询数据的服务和技术时,
他们可能会查看最佳的 BI 工具和 ML 扩展,这些工具可以帮助他们准备数据、创建模型并进行训练。但所有这些不同的阶段都需要时间和高水平的专业知识。我们已经习惯了接受这样的事实:机器学习建模需要将数据从数据库中提取,通常使用 BI 工具,转换并加载到 BI 系统中,然后再导出(再次)到机器学习工具中,发生奇迹后,再传输回 BI 工具以进行可视化。
如果我告诉你有一种将机器学习模型带到数据的方法,允许你在数据库内部使用 SQL 查询预测,你会怎么想?确实有。这是一个小而快速增长的领域。
这种将智能融入数据层的运动,而不是费劲地将数据带到机器学习工具中的方法。
数据库内创新
数据库内机器学习是一种使用现有数据预测未来事件的更简单方法……并且它使用标准 SQL 命令。数据库内机器学习有点像给你的数据库装上了大脑。这意味着数据科学家——以及数据工程师,实际上任何具备 SQL 技能的人——都可以在数据库中工作,运行机器学习模型来回答几乎任何业务问题。预测客户流失、信用评分、客户生命周期优化、欺诈检测、库存管理、价格建模和预测患者健康结果只是数据库建模所支持的众多用例中的一部分。通过这种方法,所有的机器学习模型都可以像数据库表一样创建、查询和维护,使用 SQL 语言,为更广泛的数据专业人员带来了强大的预测能力。
数据库内机器学习(In-database ML)是一个相对较新的领域,但它是一个更广泛、快速发展的运动的一部分,旨在简化和普及数据工程和数据科学,打破当前在数据工作中存在的技术障碍。例如,看看 dbt Labs,这家公司在数据领域引起了轰动,最近获得了$2.22 亿的资金并被估值为 42 亿美元。其数据转换产品使数据工程师能够使用 SQL 命令从数据仓库内部构建生产级数据管道,从而彻底简化和加速数据准备的过程。
SQL – 不老,但常青
我们有幸生活在数字创新的黄金时代。然而,在重视数据洞察力的商业背景下,数据科学家面临前所未有的压力,需要从数据中创造奇迹。为了加快和扩大数据分析,出现了令人眼花缭乱的工具和服务。这些工具通常需要投入时间和技能发展,以充分实现其好处。然而,一个常被忽视的技能是谦逊的 SQL,数据科学家的最佳伙伴。SQL 不仅没有消失,随着向数据更近的创新运动的兴起,SQL 正成为数据科学家的战略秘密武器。
Jorge Torres是数据库机器学习公司 MindsDB 的首席执行官。他还是加州大学伯克利分校的访问学者,研究机器学习自动化和解释性。在创立 MindsDB 之前,他曾为多个数据密集型初创公司工作,最近与 Aneesh Chopra(美国政府的首位首席技术官)合作,建立了分析数十亿患者记录的数据系统,为数百万患者带来了最高的节省。
更多相关主题
SQL 简化:使用 CTE 创建模块化和易于理解的查询
原文:
www.kdnuggets.com/sql-simplified-crafting-modular-and-understandable-queries-with-ctes
图片由作者提供
在数据的世界里,SQL 仍然是与数据库交互的通用语言。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
直到今天,它仍然是处理数据时最常用的语言之一,仍被视为任何优秀数据专业人士的必备技能。
然而,任何处理复杂 SQL 查询的人都知道,它们很快会变成难以读懂、维护或重用的庞然大物。
这就是为什么今天仅仅了解 SQL 不够,我们需要擅长编写查询,而这实际上是一种艺术。
这就是通用表表达式(CTE)发挥作用的地方,将查询编写的艺术转变为更结构化和易于处理的技艺。
让我们一起探讨如何编写可读且可重用的查询。
1. CTE 的基础知识
如果你想知道什么是 CTE,你来对地方了。
通用表表达式(CTE)是一个临时结果集,它在单个 SQL 语句的执行范围内定义。
它们是可以在单个查询中多次引用的临时表,通常用于简化复杂的联接和子查询,最终目的是提高 SQL 代码的可读性和组织性。
因此,它们是将复杂查询分解为简单部分的强大工具。
这是你应该考虑使用 CTE 的原因:
-
模块化: 你可以将复杂的逻辑分解为可读的块。
-
可读性: 使理解 SQL 查询的流程变得更容易。
-
重用性: CTE 可以在单个查询中多次引用,避免重复。
2. 使用 WITH 子句生成模块化查询
魔法始于 WITH 子句,它在主查询之前定义了不同的临时表(CTE)及其别名。
因此,我们总是需要从“WITH”命令开始我们的查询,以开始定义我们自己的 CTE。通过使用 CTE,我们可以将任何复杂的 SQL 查询拆分为:
-
计算相关变量的小型临时表。
-
一个最终的表格,只包含我们想要作为输出的变量。
这正是我们希望在任何代码中实现的模块化方法!
作者提供的图像
因此,使用 CTE 在我们的查询中允许我们:
-
执行一次时间表并多次引用它。
-
提高可读性,简化复杂逻辑。
-
促进代码的可重用性和模块化设计。
3. 案例研究 - 分析 Airbnb 数据
为了更好地理解这一点,我们可以以巴塞罗那的 Airbnb 房源为实际例子。
想象一下,我们想要分析按社区划分的房源表现,并将其与城市整体表现进行比较。你需要汇总关于社区、单个公寓、房东和定价的信息。
为了说明这一点,我们将使用InsideAirbnb 巴塞罗那的数据表,其结构如下:
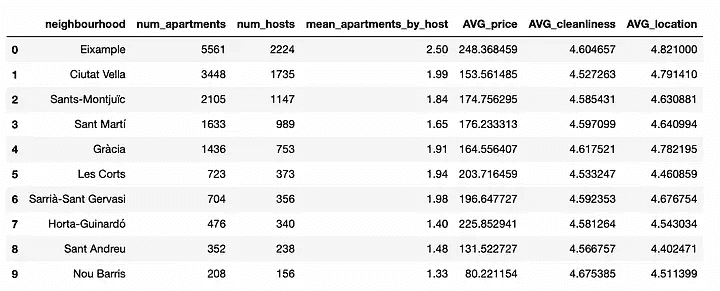
一种天真的方法可能会导致你创建嵌套的子查询,这些子查询很快变成维护的噩梦,如下所示:
作者提供的代码
相反,我们可以利用 CTE 将查询分解为逻辑部分——每部分定义一个拼图块。
-
社区数据: 创建一个 CTE 以按社区汇总数据。
-
公寓和房东信息: 定义 CTE 以获取关于公寓和房东的详细信息。
-
城市级指标: 另一个 CTE 用于收集城市级别的统计数据以进行比较。
-
最终汇总: 在最终的 SELECT 语句中组合 CTE 以连贯地展示数据。
作者提供的图像
最终我们将得到以下查询:
作者提供的代码
4. 模块化方法的优势
通过使用 CTE,我们将一个潜在的庞大单一查询转变为一个有组织的数据模块集。这种模块化的方法使 SQL 代码更具直观性,并且更适应变化。
如果有新的需求出现,你可以调整或添加 CTE,而无需彻底改造整个查询。
5. 复用 CTE 进行比较分析
一旦你建立了 CTE,你可以重用它们来进行比较分析。例如,如果你想将社区数据与城市级指标进行比较,你可以在一系列 JOIN 操作中引用你的 CTE。
这不仅节省时间,而且使你的代码更加高效,因为你不需要重复相同的查询!
最后的思考
CTE 证明了一个结构化的方法在编程中有多么重要。通过采用 CTE,你可以编写更清晰、可维护和可重用的 SQL 查询。
这简化了查询开发过程,并使得与他人沟通复杂的数据检索逻辑变得更加容易。
记住,下次你要开始编写一个多连接、嵌套子查询的复杂查询时,可以考虑使用 CTE 来分解它。
你未来的自己——以及可能阅读你代码的任何人——都会感谢你。
Josep Ferrer**** 是一位来自巴塞罗那的分析工程师。他毕业于物理工程专业,目前在应用于人类移动性的领域从事数据科学工作。他还是一名兼职内容创作者,专注于数据科学和技术。Josep 涉猎人工智能的各个方面,涵盖了这一领域持续爆炸性的应用。
更多相关主题
SQL 与 NoSQL:7 个关键要点
原文:
www.kdnuggets.com/2020/12/sql-vs-nosql-7-key-takeaways.html
开发者非常清楚继续教育的重要性。无论是学习新框架还是新服务,创新和适应都是开发的基本要素。今天最热门的话题之一是决定选择标准的 SQL 数据库还是转向 NoSQL 数据库。
NoSQL 数据库已经存在了几十年,这要归功于 Carlo Strozzi 的创新。然而,直到 2000 年代初,这些数据库才开始受到关注。此时,像 Google 和 Amazon 这样的公司开始加大对 NoSQL 数据库的开发投入。尽管它们最近很受欢迎,但许多开发者、架构师和设计师可能对 NoSQL 数据库提供的功能还不够了解。
因此,关于这两种数据库之间差异的详细信息,请查看每个开发者都应了解的 7 个关键要点。
1. 结构化查询语言的使用
SQL 数据库因其使用 SQL 语言而被分类。任何可以通过 SQL 进行交互的数据库都是 SQL 数据库。作为一种强大且被广泛使用的语言,它被用于众多数据库,如 Microsoft SQL Server、MySQL、PostgreSQL 等。查询语言允许用户编写复杂的查询,从多个表中提取数据等等。这种通用性使其成为任何需要可靠性的人的安全选择。
另一方面,尽管分类相当广泛,但不使用 SQL 的数据库是 NoSQL 数据库。正如我们很快将看到的那样,NoSQL 数据库的交互方式可能因模式设计的不同而大相径庭。
2. 关系型与非关系型
两种数据库的其他常见名称是关系型和非关系型数据库。
SQL 或关系型数据库以预定义的模型存储数据,这使得它们使用起来简单且可靠。这种模型允许数据高效地插入、更新和提取。此外,独特的标识符—键,可以将不同的数据集关联起来。简而言之,关系型数据库对所有人都容易理解。
相反,非关系型数据库,即 NoSQL 数据库,在数据存储方面要灵活得多。虽然这可能看起来很方便,但经验丰富的开发者会理解其潜在的影响。随着时间的推移,随着数据越来越多地存储在非关系型数据库中,保持数据整洁可能会变得困难,因为没有标准模型可供遵循。
3. 预定义模式与动态模式
从关系型和非关系型数据库的角度来看,这两种风格的数据存储差异非常明显。
SQL 数据库利用模式和表格,这些都是预定义的,并且对所有用户易于访问。你有你的主键、字段和值。从这里开始,你可以创建任意数量的表。你可以在表格中插入副键,并在几个表之间创建复杂的关系。这种数据存储方式使得快速分析大量数据变得简单和快捷。
另一方面,非关系型数据库允许你创建具有动态模式的数据库。你不需要提前创建数据库模型。随着数据库的扩展,你可以无缝地添加新的模型和混合数据类型。
4. 基于表格与基于字段
SQL 数据库使用表格,而 NoSQL 数据库则使用几乎任何其他形式。基于表格的方法与严格的模式相辅相成。你可以根据项目需要创建任意数量的表,并将它们相互关联。因此,你完全知道当需要检查尚未看到的数据时,一个表格会是什么样的。
在这方面,NoSQL 数据库相当模糊,因为它们的数据结构是流动的。NoSQL 数据库没有一个确切的基础。一些流行的 NoSQL 数据库使用图形存储、键值对、宽列存储或文档导向存储。使用 NoSQL 数据库的优势在于你有无限的灵活性。你可以选择任何你想要的数据库引擎。
5. 垂直扩展与水平扩展
NoSQL 数据库受欢迎的主要原因之一是它们的水平可扩展性。SQL 数据库需要垂直扩展——你必须增加更多的处理能力以提高性能和容量。从理论上讲,SQL 数据库有一个上限,当无法进行更多的硬件改进时,这个上限可能会被达到。这可能导致长时间的停机和调整模型时的更高费用。
你不再需要投资更昂贵的组件和高端 CPU 来支持 SQL 数据库的扩展。当你使用非关系型数据库时,你只需增加更多的机器即可。此外,水平扩展本质上提供了冗余,因为你有多台机器,而不是一个故障点。
6. 使用案例
如果你对项目和需要存储的数据有一个清晰的了解,那么在 SQL 和 NoSQL 数据库之间的选择就是直接的。
当你的数据看起来本质上是相对的时,使用 SQL 数据库。它们可靠,通过 SQL 轻松访问,并且是经过验证的数据存储。
另一方面,如果你的数据具有灵活性且没有固定的关系,可以尝试使用 NoSQL 数据库。你可以从多个流行的提供商中进行选择。你会发现能够随时定义新的模式非常具有吸引力。此外,如果你担心未来的扩展性,NoSQL 数据库非常适合你。
7. 支持或缺乏支持
最后一个要点是关于两种类型数据库的支持。SQL 数据库是巨头——它们在全球范围内有大量用户。它们已经建立良好,并且配有详尽的文档。如果你遇到 SQL 数据库的问题,你将获得大量帮助。此外,还有许多操作指南和 SQL 备忘单来帮助新手。
尽管 NoSQL 数据库已经获得了追随者和流行度,但与 SQL 数据库相比,它们仍然缺乏相同的支持。你可能会发现难以找到优质的教育材料、支持文档等。
简而言之,如果你知道你的数据是什么样的,以及你的数据库未来的发展趋势,那么选择一种数据库类型是很简单的。SQL 数据库提供经过验证的结果、强大的查询语言和一致性。NoSQL 数据库是创新的、适应性强的、强大的数据库,将随着时间的推移不断发展。
亚历克斯·威廉姆斯 是一位经验丰富的全栈开发人员,也是 Hosting Data UK 的所有者。在伦敦大学获得 IT 学位后,亚历克斯在过去近 10 年里作为开发人员领导了来自全球的多个项目。最近,亚历克斯转型成为独立 IT 顾问,并开设了自己的博客。在博客中,他探讨了网页开发、数据管理、数字营销以及为刚起步的在线企业主提供解决方案。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的 IT 组织
更多相关内容
SQL 窗口函数

介绍
编写结构良好、有效的 SQL 查询并非易事。它需要对所有 SQL 函数和语句有深入的了解,以便你能在日常工作中高效地应用它们来解决问题。在这篇文章中,我们将讨论 SQL 窗口函数,它们提供了很多实用的功能来解决常见问题,但常常被忽视。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
SQL 窗口函数非常多功能,可以用于解决 SQL 中的许多不同问题。
几乎所有公司在面试中都会提问一些需要了解窗口函数的知识的问题。因此,如果你正在准备数据科学面试,重新复习一下 SQL 中的窗口函数是个不错的主意。在这篇文章中,我们将重点介绍基础知识。如果你想深入了解,可以阅读这篇 SQL 窗口函数终极指南。
对窗口函数有一个良好的掌握也有助于你编写高效和优化的 SQL 查询来解决你在日常工作中遇到的问题。
什么是 SQL 中的窗口函数?
简而言之,SQL 中的窗口函数用于访问表中的所有其他行,以生成当前行的值。
SQL 窗口函数之所以得名,是因为其语法允许你定义特定的部分或数据窗口来进行操作。首先,我们定义一个函数,这个函数会在所有行上运行,然后使用 OVER 子句来指定数据窗口。
窗口函数被认为是 SQL 的“高级”功能。乍一看,初级数据科学家可能会对其语法感到畏惧,但经过一些练习,SQL 窗口函数会变得不那么令人害怕。
SQL 窗口函数类型
聚合窗口函数是进行计算或找到数据窗口内最低或最高极值所必需的。它们与常规聚合函数相同,但它们应用于特定的数据窗口,因此行为有所不同。
排名窗口函数使我们能够为数据窗口分配排名号码。六种主要函数中的每一种对行的排名方式不同。排名还取决于 ORDER BY 语句的使用。
值窗口函数允许我们根据其相对于当前行的位置找到值。它们对于获取前一行或后一行的值,以及分析时间序列数据非常有用。
这只是对三种 SQL 窗口函数的简要概述。我们将在文章的后续部分详细讨论它们。
如何以及何时使用它们?
一旦你理解了所有窗口函数及其使用案例,它们将成为你手中的强大工具。它们可以避免你编写许多不必要的代码行来解决可以通过一个窗口函数解决的问题。
SQL 窗口函数与 Group By 语句
初学者在阅读窗口函数的描述时,常常会对其作用和与 Group By 语句的区别感到困惑,因为后者似乎以完全相同的方式工作。然而,如果你编写窗口函数并查看其实际输出,困惑会消失。
窗口函数与 Group By 语句之间最显著的区别在于,前者允许我们在保留所有原始数据的同时总结值。GROUP BY 语句也允许我们生成聚合值,但行被压缩成几个数据组。
使用案例
成为数据科学家的职业路径仅仅是开始。在你日常工作中,你会遇到需要高效解决的问题。窗口函数非常多才多艺,只要你知道如何使用它们,它们将是无价的。
比如,如果你在像苹果公司这样的公司工作,你可能需要分析内部销售数据,以找到其产品组合中最受欢迎或最不受欢迎的产品。窗口函数最常见的用例之一是跟踪时间序列数据。例如,你可能需要计算特定苹果产品的月度增长或下降,或 Airbnb 平台上的预订情况。
在 SaaS 公司工作的数据科学家经常被要求计算用户流失率,并跟踪其随时间的变化。只要你有用户数据,就可以使用窗口函数来跟踪流失率。
聚合窗口函数,如 SUM(),对于计算累计总数非常有用。假设我们有一整年的 12 个月销售数据,使用窗口函数,我们可以编写查询来计算销售数据的累计总数(当前月份+之前月份的总数)。
窗口函数有许多其他用途。例如,如果你正在处理用户数据,你可以按用户注册时间、发送的消息数量或其他类似指标来排序用户。
窗口函数还允许我们跟踪健康统计数据,例如病毒传播的变化、病例的严重程度或其他类似的见解。
与其他 SQL 关键字
为了有效使用窗口函数,必须首先理解 SQL 中的操作顺序。你只能在窗口函数之后使用窗口函数,而不能在之前使用。根据这一规则,可以在 SELECT 和 ORDER BY 语句中使用窗口函数,但不能在 WHERE 和 GROUP BY 等其他语句中使用。
通常,SQL 开发者使用窗口函数与 SELECT 语句,主查询可以包括 ORDER BY 语句。
SQL 中的排名窗口函数
这些函数允许 SQL 开发者为行分配数字排名。
共有六种此类函数:
ROW_NUMBER() 只是简单地从 1 开始对行进行编号。行的顺序取决于 ORDER BY 语句。如果没有 ORDER BY,ROW_NUMBER() 函数将按行的初始状态进行编号。
RANK() 是 ROW_NUMBER() 函数的一个更细致的版本。RANK() 会考虑值是否相等并分配相同的排名。例如,如果第三行和第四行的值相等,它们都将被分配为第三名,从第五行开始,将从 5 继续计数。
DENSE_RANK() 的工作方式与 RANK() 函数类似,唯一的区别是:在同一个例子中,如果第三列和第四列的值相同,它们都会被分配为三的排名。然而,第五行不会从 5 开始计数,而是从 4 开始,考虑到之前的行排名为三。要了解更多差异,请查看这篇文章 SQL 排名函数简介。
PERCENT_RANK() 采用不同的排名方法。它创建一个新列,以百分比(从 0 到 1)显示排名值。
NTILE() 是一个函数,它接受一个数值参数,用于创建批次以划分数据。例如,NTILE(20) 将创建 20 个数据桶,并相应地分配排名。
CUME_DIST() 函数计算当前行的累积分布。换句话说,它会遍历窗口中的每一条记录,并返回当前行值小于或等于的行所占的比例。这些行的相对大小介于 0(无)和 1(全部)之间。
使用 RANK() 排名数据
排名窗口函数在大型科技公司面试中经常出现。例如,Facebook/Meta 的面试官常常会要求候选人 找到 Messenger 上最活跃的用户。
要回答这个问题,我们必须首先查看可用的数据。我们有一个包含多个不同列的表格。user1 和 user2 列的值是用户名,msg_count 列代表它们之间交换的消息数量。根据问题的名称,我们必须找出记录活动次数最多的用户。为了做到这一点,我们必须首先考虑什么是活动:在这个上下文中,发送和接收消息都算作活动。
在查看数据后,我们发现msg_count并不代表每个用户在记录中的总消息数量。可能还有其他用户他们正在聊天。为了获取每个用户的总活动数量,我们必须获取msg_count列中用户至少是发送或接收消息的一方的值。
让我们查看一下这项任务的数据样本:
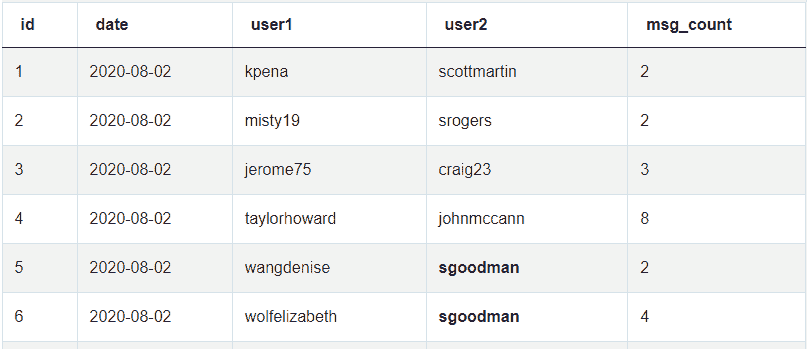
如你所见,用户sgoodman参与了两个对话 - 一个是与用户名wangdenise的对话,另一个是与wolfelizabeth的对话。在现实生活中,人们可能与数十人进行在线对话。我们的查询应该捕获他们之间交换的消息数量。
解决方案
步骤 1:将用户合并到一列中
首先,我们选择user1 列中的用户名及其相应的msg_count 值。然后对user2 列中的用户做相同的操作,并将它们合并到一个列中。我们使用 UNION ALL 操作符来完成这个操作。这将确保所有用户及其相应的发送或接收的msg_count 值都被保留。
SELECT user1 AS username,
msg_count
FROM fb_messages
UNION ALL
SELECT user2 AS username,
msg_count
FROM fb_messages
我们必须记住,为了使UNION ALL语句能够合并值,两个 SELECT 语句中的列数及其相应的值类型必须相同。因此,我们使用AS语句将它们重命名为username。
如果我们运行这段代码,我们会得到以下结果:
步骤 2:按降序排列用户
一旦我们有了所有用户的列表,我们必须从上述表中选择username列,并将每个用户的msg_count值相加。
然后我们将使用RANK()窗口函数对每条记录进行编号。在这种情况下,我们想使用这个特定的函数,而不是DENSE_RANK(),因为在前 10 名中的消息数量可能存在并列情况。
排名窗口函数的准确性依赖于ORDER BY语句,它用于在输入数据窗口内排列值,而不是函数的输出。在这种情况下,我们必须使用DESC关键字,以确保消息数量按降序排列。这样,RANK() 函数会首先应用于最高的输入值。
OVER 关键字是窗口函数语法中的一个重要部分。它用于将排名函数连接到数据窗口。
到目前为止,我们的 SQL 查询应该类似于这样:
WITH sq AS
(SELECT username,
sum(msg_count) AS total_msg_count,
rank() OVER (
ORDER BY sum(msg_count) DESC)
FROM
(SELECT user1 AS username,
msg_count
FROM fb_messages
UNION ALL SELECT user2 AS username,
msg_count
FROM fb_messages) a
GROUP BY username)
为了解决我们的问题,我们必须找到 10 个最活跃的用户。使用RANK()窗口函数是必要的,以处理在这 10 个用户组中可能出现的任何并列情况。
步骤 3: 显示前 10 名
在最后一步,我们应该从sq子查询中获取username和total_msg_count值,并显示排名值为 10 或更小的记录。然后按降序排列它们。
(SELECT username,
sum(msg_count) AS total_msg_count,
rank() OVER (
ORDER BY sum(msg_count) DESC)
FROM
(SELECT user1 AS username,
msg_count
FROM fb_messages
UNION ALL SELECT user2 AS username,
msg_count
FROM fb_messages) a
GROUP BY username)
SELECT username,
total_msg_count
FROM sq
WHERE rank <= 10
ORDER BY total_msg_count DESC
如果我们运行这段代码,我们会看到它按预期工作。同时,我们可以避免在某些用户的total_msg_count值相同的情况下出现任何错误。
找到前 5 百分位数值
这是另一个 Netflix 面试中问到的 问题 的例子。一个虚构的保险公司开发了一个算法来确定保险索赔的欺诈可能性。候选人必须找到前 5 百分位中最有可能欺诈的索赔。
正如你可能注意到的,这个问题涉及到寻找百分位数值。最简单的方法是使用 SQL 中的NTILE()排名窗口函数。在这种情况下,我们正在寻找百分位数值,所以NTILE()的参数将是 100。
指令说我们需要确定每个州前 5 百分位的欺诈性索赔。为此,我们的窗口定义应该包括PARTITION BY语句。分区是一种指定如何在窗口内分组值的方法。例如,如果你有一个用户的电子表格,你可以根据他们注册的月份进行分区。
在这种情况下,我们必须对state列中的值进行分区。这意味着计算每个州每个索赔的百分位数。我们使用ORDER BY语句将fraud_score列中的值按降序排列。
请注意,因为 ORDER BY 和 PARTITION BY 语句用于窗口定义中,它们仅适用于每个记录的“组”,每个组代表一个状态。例如,加州的记录根据其 fraud_score 列 的值进行排列,值最高的行排在最前面。当加州的记录用尽时,顺序会重置,从另一个州佛罗里达州的最高分记录开始。
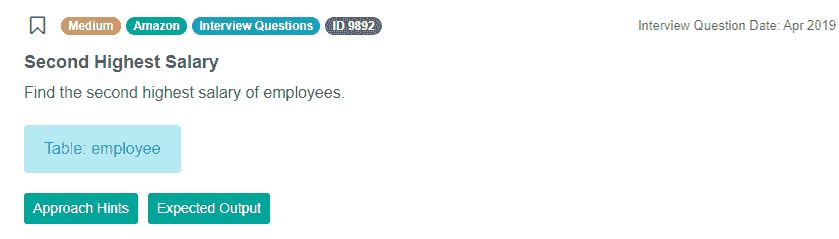
查找第 N 高的值
还有另一个问题,经常在亚马逊用来评估候选人对排名窗口函数的熟练程度。任务很简单:你会得到一个包含许多不同列的单一表格。问题要求我们找出所有员工记录中的第二高薪水。分析可用数据后,最重要的列显然是 salary 列。
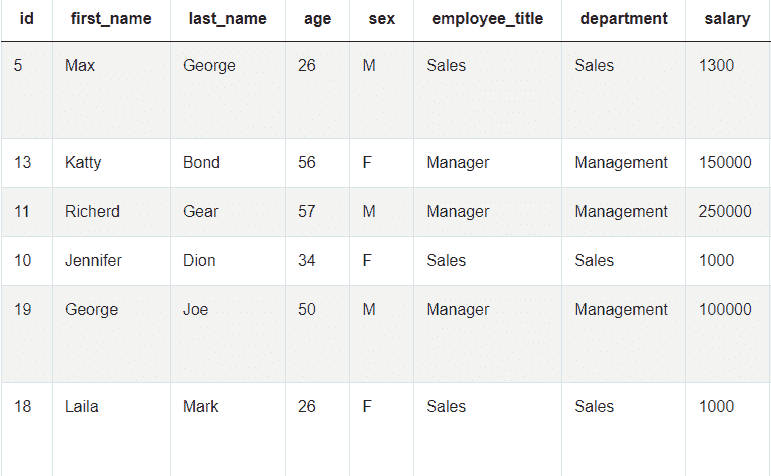
在这种情况下,问题的措辞告诉我们要找出公司中第二高的薪水。因此,如果五名员工的年薪都是 100,000 美元,并且这是最高薪水,我们需要查找第六名员工,他在薪水降序中排在后面。
如果你查看当前在 StrataScratch 上的解决方案,我们使用 DENSE_RANK() 窗口函数来获取第二高的值。此外,我们使用 DISTINCT 关键字来排除重复项,以防多个员工拥有相同的薪水。我们希望对每个剩余记录进行单独排名,因此不需要使用 PARTITION BY 语句来分隔员工组。
SQL 中的聚合窗口函数
在 SQL 中,聚合函数的默认行为是将所有记录的数据聚合到几个组中。然而,当作为窗口函数使用时,所有行都会保持不变。相反,聚合窗口函数会创建一个单独的列来存储聚合结果。
有五种聚合窗口函数:
AVG() - 返回特定列或数据子集中的值的平均值
MAX() - 返回特定列或数据子集中的最高值
MIN() - 返回特定列或数据子集中的最低值
SUM() - 返回特定列或数据子集中的所有值的总和
COUNT() - 返回列或数据子集中的行数
面试问题经常围绕聚合窗口函数。例如,计算运行总和并创建一个新列来显示每条记录的运行总和是一项常见任务。有关面试中常用的 SQL 窗口函数的更多信息,请参阅这个 SQL 聚合函数终极指南。
查找最新日期
为了更好地理解聚合窗口函数,让我们看看一个来自 Credit Karma 的 面试问题。
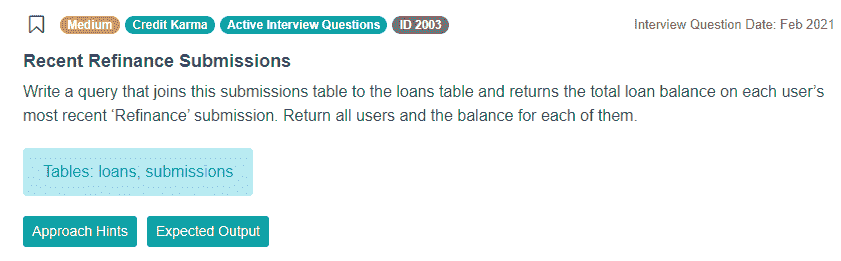
在这个问题中,我们需要找到并输出每个用户‘Refinance’提交的最新余额。为了更好地理解问题,我们必须分析可用的数据,这些数据由两个表组成:loans 和 submissions。
让我们看看 loans 表:
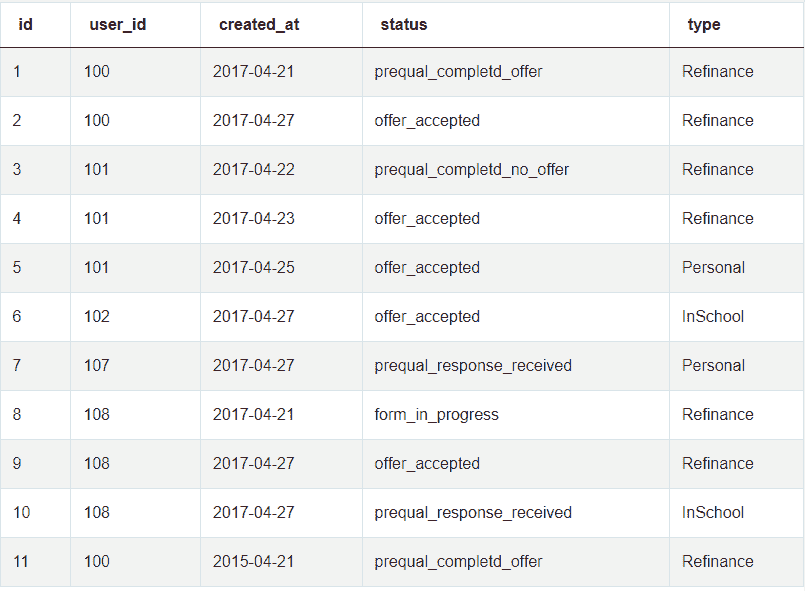
接下来是 submissions 表:
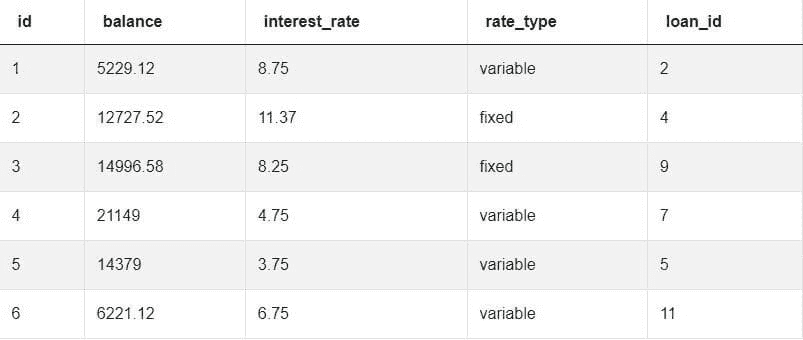
为了成功回答这个问题,分析这两个表及其数据是必不可少的。然后我们可以使用聚合窗口函数解决关键问题:为每个用户找到最近的提交。
为此,候选人必须了解 MAX() 聚合函数将返回‘最高’日期,这在 SQL 中等同于最新日期。MAX() 窗口函数必须应用于 loans 表中的 created_at 列,其中每条记录代表一个单独的提交。
另一个关键点是行应该按 user_id 值进行分区,以确保我们为每个唯一用户生成最新日期,以防他们进行了多次提交。问题指定我们应该找到‘Refinance’类型的最新提交,因此我们的 SQL 查询应包括该条件。
SQL 中的值窗口函数
SQL 开发者可以使用这些函数从表中的其他行中获取值。像其他两种类型的窗口函数一样,这些函数有五种不同的类型。这些函数专用于窗口函数:
LAG() 函数允许我们访问前一行的值。
LEAD() 是 LAG() 的对立面,允许我们访问当前行之后的记录中的值。
FIRST_VALUE() 函数从数据集中返回第一个值,并允许我们设置数据排序条件,以便开发者可以控制哪个值将首先出现。
LAST_VALUE() 函数的工作方式与之前的函数相同,但它返回的是最后一个值而不是第一个。
NTH_VALUE() 函数允许开发者指定在排序中应返回哪个值。
时间序列分析
像LAG()和LEAD()这样的函数允许你从每行的后续或前面的行中提取值。因此,SQL 开发人员经常使用它们来处理时间序列数据,跟踪每日或每月的增长及其他应用场景。让我们看看在 Amazon 面试中提出的一个问题,它可以通过LAG()函数解决。
在这个问题中,候选人的任务相当简单:根据提供的数据计算每月的收入增长。最终,输出表应包括一个表示月度增长的百分比值。
LAG()窗口函数允许我们仅用几行代码解决这个难题。让我们看看实际推荐的解决方案:
SELECT to_char(created_at::date, 'YYYY-MM') AS year_month,
round(((sum(value) - lag(sum(value), 1) OVER w) / (lag(sum(value), 1) OVER w)) * 100, 2) AS revenue_diff_pct
FROM sf_transactions
GROUP BY year_month WINDOW w AS (
ORDER BY to_char(created_at::date, 'YYYY-MM'))
ORDER BY year_month ASC
表中的日期值按时间顺序排列。因此,我们只需计算每个月的总收入,使用LAG()函数访问前一个月的收入值,并将其与当前月的收入一起使用,以计算以百分比表示的月度差异。
在上述解决方案中,我们使用round()函数对方程的结果进行四舍五入。首先,我们定义数据窗口,其中我们排列日期值并以特定格式组织它们。我们可以直接在窗口函数中做到这一点,但我们将不得不在多个地方使用它。一次定义窗口并简单地引用它为w会更高效。
首先,通过从 sum(value)中减去 lag(sum(value), 1),我们找到了每个月与其前一个月之间的数值差(第一个月除外,因为它没有前一个月)。我们将这个数字除以前一个月的收入,该收入由lag()函数找出。最后,我们将结果乘以 100,以获得百分比值,并指定该值需要四舍五入到小数点后两位。
结束语
许多面试问题测试候选人对 SQL 窗口函数的知识,这并不奇怪。雇主知道,要在最高水平上表现,数据科学家必须非常了解 SQL 的这一部分。
如果你渴望承担编写高级 SQL 查询的角色,对 SQL 窗口函数的透彻理解可以帮助你找到复杂问题的简单解决方案。
Nate Rosidi 是一位数据科学家和产品策略专家。他还是一位兼职教授,教授分析课程,并且是StrataScratch的创始人,该平台帮助数据科学家通过来自顶级公司的真实面试问题为面试做准备。在Twitter: StrataScratch或LinkedIn上与他联系。
了解更多主题
在没有自己数据库的情况下练习 SQL
评论
由 Hui XiangChua, 数据科学家。
许多组织将数据存储在数据库中,SQL 是一种常用的查询语言,用于从这些数据库中提取数据。实际上,许多大型组织如 Facebook 和 Amazon 已将 SQL 作为其技术技能测试的一部分。这是因为在进行任何必要的数据分析之前,能够整理出相关数据是非常重要的。
实践 SQL 的一个挑战是我们需要数据库,而这正是我们通常没有的。然而,data.world 允许我们在没有自己数据库的情况下做到这一点。我们可以直接在 data.world 上对公开的数据集执行 SQL 查询。创建 data.world 账户是免费的,而且你在执行 SQL 查询时不会产生任何费用!
对于不熟悉的人,data.world 是一个提供大量涉及不同领域和行业的开放数据的平台(你也可以上传自己的数据集)。他们的使命是:
-
在全球范围内建立最有意义、最具协作性和最丰富的数据资源,以最大限度地发挥数据在解决社会问题中的效用;
-
公开倡导改善开放数据和关联数据的采纳、可用性和普及;
-
作为全球数据的可访问历史存储库。
在这里,我用一个关于新加坡 Covid-19 趋势的 数据集 举例说明。查询功能有时隐藏在三个点的下拉菜单中,或者可能会出现在数据集的右上角,标有 a >_ 符号。
以下 SQL 计算了确认病例数量的 7 天移动平均值,输出按降序排列。查询的链接可以在 这里 找到。
另一方面,下面的 SQL 计算了每日累计完成疫苗接种的人员百分比增长,输出按降序排列。这需要自联接,即将一个表与自身联接。我使用了 DATE_SUB 函数作为自联接的一部分,从而获取前一天的数据与当天的数据进行比较。点击 DATE_SUB 文字也会返回有关该函数和必要参数的更多信息。查询的链接可以在 这里 找到。
在 data.world 上还有一个SQL 教程,涵盖基础、中级和高级 SQL 概念。因此,它是一个学习和实践 SQL 的良好开源平台。
另外,如果你在招聘岗位上并探索如何进行 SQL 测试的替代方法,这可能也是一个值得考虑的平台。
相关:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关内容
如何从训练数据中榨取最大价值
原文:
www.kdnuggets.com/2017/07/squeeze-most-from-training-data.html
由 David Bishop,Love the Sales 的 CTO。
在许多情况下,获取良好标注的训练数据是开发准确预测系统的巨大障碍。在 Love the Sales ,我们需要将 200 万个产品(主要是时尚和家居用品)的文本元数据分类到 1000 多个不同的类别中——这些类别以层级形式呈现。
为了实现这一点,我们构建了一个层级树,由链式的 2 类线性(正面与负面)支持向量机(LibSVM)组成,每个 SVM 负责每个层级类的二元文档分类。
数据结构
一个关键的学习点是,这些 SVM 的结构实际上会对需要应用多少训练数据产生重大影响,例如,一个幼稚的方法可能是:
这种方法要求对于每个额外的子类别,都要训练两个新的 SVM——例如,新增一个“泳装”类别将需要在男性和女性类别下分别增加一个 SVM——更不用说在顶级添加“中性”类别的潜在复杂性。总体而言,深层次的层级结构可能过于僵化,难以处理。
通过将我们的数据结构展平成多个子树,我们能够避免大量的标注和训练工作,如下所示:
通过将我们的分类结构与最终层级解耦,可以通过遍历 SVM 层级和使用简单的基于集合的逻辑来生成最终分类,如:
男士修身牛仔裤 = (男士 和 牛仔裤 和 修身版) 而不是女士
这种方法大大减少了分类文档所需的 SVM 数量,因为结果集可以交集以表示最终分类。
现在也应该显而易见,添加新类别会使最终类别的数量呈指数级增长。例如——添加一个顶级的“儿童”类别——会立即允许创建一个新的儿童类别维度(儿童牛仔裤、衬衫、内衣等),只需少量额外的训练数据(仅需一个额外的 SVM):
数据重用
由于我们选择的结构,一个关键的洞察是可以通过链接数据关系重用训练数据。数据链接使我们能够将训练数据重用总因子提高到 9 倍,从而大大降低了成本并提高了预测的准确性。
对于每个单独的类别,我们显然希望拥有尽可能多的训练数据示例,涵盖所有可能的结果。尽管我们构建了一些出色的内部工具来帮助批量手动标注训练数据——标注每种产品的数千个示例可能既费时又昂贵且容易出错。我们确定解决这些问题的最佳方法是尽可能重用不同类别的训练数据。
例如,考虑到对类别的基本领域知识——我们可以确定‘洗衣机’永远不能是‘地毯清洗机’
通过添加‘排除数据’的功能,我们可以通过将‘地毯清洗机’SVM 的‘正面’训练数据添加到‘洗衣机’SVM,从而大大增加‘负面’训练示例的数量。更简单地说,既然我们知道“地毯清洗机永远不能是洗衣机”——我们不妨重用这些数据。
这种方法有一个不错的优势,即每当需要添加一些额外的训练数据以改善‘地毯清洗机’的 SVM 时——它通过链接的负面数据无意中改善了‘洗衣机’类别。
最后,当考虑层次结构时,另一个明显的重用机会是任何子节点的正面训练数据,也总是是其父节点的正面训练数据。例如:‘牛仔裤’总是‘服装’。
这意味着每当向‘牛仔裤’SVM 添加一个正面示例时——通过链接,也会向‘服装’SVM 添加一个额外的正面示例。
添加链接比手动标注成千上万的例子要高效得多。

当涉及到层次分类系统时,将分类组件与结果层次结构解耦,扁平化数据结构并启用重用或训练数据将有助于尽可能提高效率。上述方法不仅有助于减少我们需要标注的训练数据量,还使我们总体上获得了更大的灵活性。
参考资料:LibSVM –www.csie.ntu.edu.tw/~cjlin/libsvm/
简历:David Bishop**** 是 LovetheSales.com 的首席技术官——一个零售销售聚合平台,使消费者能够从数百家零售商那里找到和比较所有销售中的产品,以找到他们想要的品牌和产品的最佳价格。该网站成立于 2013 年,是全球最大的销售平台,覆盖所有区域,提供超过 1,000,000 件销售商品。
相关:
-
什么是支持向量机,为什么我会使用它?
-
7 种低成本获取高质量标注训练数据的方法
-
使用支持向量回归在 R 中构建回归模型
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你在 IT 领域的组织
更多相关话题
稳定扩散:生成 AI 的基本直觉
原文:
www.kdnuggets.com/2023/06/stable-diffusion-basic-intuition-behind-generative-ai.html

使用 稳定扩散 生成的图像
介绍
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
近年来,AI 的世界在计算机视觉和自然语言处理方面急剧向生成建模转变。Dalle-2 和 Midjourney 引起了人们的注意,使他们认识到生成 AI 领域所取得的卓越成果。
目前,大多数 AI 生成的图像都依赖于扩散模型作为基础。本文的目标是澄清一些围绕稳定扩散的概念,并提供对所用方法的基本理解。
简化架构
该流程图展示了稳定扩散架构的简化版本。我们将逐步分析,以建立对内部工作原理的更好理解。我们将详细说明训练过程,以便更好地理解,而推理过程则只有一些微妙的变化。
图像由作者提供
输入
稳定扩散模型在图像字幕数据集上进行训练,每个图像都有一个描述图像的字幕或提示。因此,模型有两个输入:自然语言的文本提示和一个大小为 (3,512,512) 的图像,具有 3 个颜色通道和 512 的尺寸。
加性噪声
通过向原始图像添加高斯噪声,将图像转换为完全的噪声。这是通过连续步骤完成的,例如,在 50 个连续步骤中向图像添加少量噪声,直到图像完全噪声化。扩散过程将旨在去除这些噪声并重建原始图像。如何完成这一过程将进一步解释。
图像编码器
图像编码器作为变分自编码器的一部分,将图像转换为“潜在空间”,并将其调整为更小的尺寸,如(4, 64, 64),同时还包括额外的批次维度。这个过程减少了计算要求并提高了性能。与原始扩散模型不同,Stable Diffusion 将编码步骤集成到潜在维度中,从而减少了计算量,以及缩短了训练和推理时间。
文本编码器
自然语言提示由文本编码器转换为向量化的嵌入。这个过程使用了 Transformer 语言模型,如 BERT 或基于 GPT 的 CLIP 文本模型。增强的文本编码器模型显著提高了生成图像的质量。文本编码器的输出结果是每个单词的 768 维嵌入向量数组。为了控制提示长度,设定了最大限制为 77。因此,文本编码器生成了一个尺寸为(77, 768)的张量。
UNet
这是架构中计算开销最大的部分,主要的扩散处理在这里进行。它接收文本编码和嘈杂的潜在图像作为输入。该模块的目标是从接收到的嘈杂图像中重现原始图像。它通过多个推理步骤来实现这一点,这些步骤可以设置为超参数。通常 50 个推理步骤就足够了。
设想一个简单的场景,其中输入图像通过在 50 个连续步骤中逐渐引入少量噪声而转化为噪声。这种噪声的累积最终将原始图像转变为完全的噪声。UNet 的目标是通过预测在前一个时间步添加的噪声来逆转这个过程。在去噪过程中,UNet 从第 50 个时间步开始预测初始时间步添加的噪声。然后,它从输入图像中减去预测的噪声,并重复这一过程。在每个随后的时间步中,UNet 预测前一个时间步添加的噪声,逐渐从完全的噪声中恢复原始输入图像。在整个过程中,UNet 内部依赖于文本嵌入向量作为条件因素。
UNet 输出一个大小为(4, 64, 64)的张量,传递给变分自编码器的解码器部分。
解码器
解码器逆转编码器所做的潜在表示转换。它接收一个潜在表示,并将其转换回图像空间。因此,它输出一个(3,512,512)的图像,与原始输入空间的大小相同。在训练过程中,我们的目标是最小化原始图像与生成图像之间的损失。基于此,给定一个文本提示,我们可以从完全嘈杂的图像中生成与提示相关的图像。
整合一切
在推理过程中,我们没有输入图像。我们仅在文本到图像模式下工作。我们去掉了加性噪声部分,而是使用了随机生成的所需尺寸的张量。其余的架构保持不变。
UNet 经过训练,可以从完全的噪声中生成图像,利用了文本提示嵌入。这种特定的输入在推理阶段使用,使我们能够成功地从噪声中生成合成图像。这一基本概念是所有生成计算机视觉模型的根本直观。
穆罕默德·阿赫曼 是一位深度学习工程师,专注于计算机视觉和自然语言处理。他曾参与多项生成 AI 应用的部署和优化,这些应用在 Vyro.AI 全球排行榜上取得了佳绩。他对构建和优化智能系统的机器学习模型感兴趣,并相信持续改进。
相关主题更多内容
Stack Overflow 调查数据科学亮点
原文:
www.kdnuggets.com/2021/08/stack-overflow-survey-data-science-highlights.html
评论

每年,Stack Overflow 都会对其用户进行调查,以帮助开发社区和平台的完善。今年,超过 80,000 名开发者分享了他们的学习方式、使用的工具和语言,并提供了对 Stack Overflow 方向有价值的反馈。结果还呈现了调查时开发者和开发情况的快照。
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
2021 年 Stack Overflow 调查的结果最近公开分享,并附上了 Stack Overflow 提供的评论和见解。我们将查看一些与数据科学、数据科学家及所有相关数据职位和专业人员相关的有趣数据点。
开发者资料
调查的第一部分集中于回答开发者自身的特点:如年龄和地理位置等人口统计信息;他们编程的时长;他们如何学习编程;以及更多。
一些快速且有趣的引用,特别是与学习编程以及开发者就业相关的内容,直接来自于调查概述,并附上一些总结关键开发者资料问题的回应频率的图表。
例如,今年我们观察到开发者教育方式的显著变化。对于 18 岁以下的新一代编码者来说,在线资源如视频和博客比书籍和学校更受欢迎,而这种统计数据在我们其他年龄段的编码者中并不成立。总体来看,行业中有很多新加入者,超过 50%的人表示他们编程不到十年,超过 35%的人编程经验不足五年。
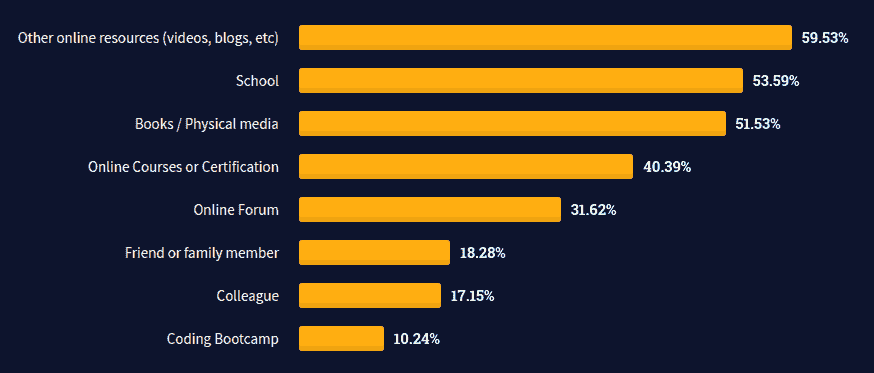
图 1. 对 2021 年 Stack Overflow 调查问题“你是如何学习编程的?”的回答
几乎 60% 的受访者通过在线资源学习编程并不令人惊讶。年轻的受访者倾向于从在线课程、论坛和其他在线资源中学习。另一方面,年长的受访者则通过更传统的媒介如学校和书籍进行学习。
81% 的专业开发者全职工作,较 2020 年的 83% 有所下降。专业开发者中表示自己是独立承包商、自由职业者或自雇的比例从 2020 年的 9.5% 增加到 2021 年的 11.2%,这表明可能存在就业不安全或转向更灵活的工作安排的趋势。
现在我们暂时关注开发者的教育水平。
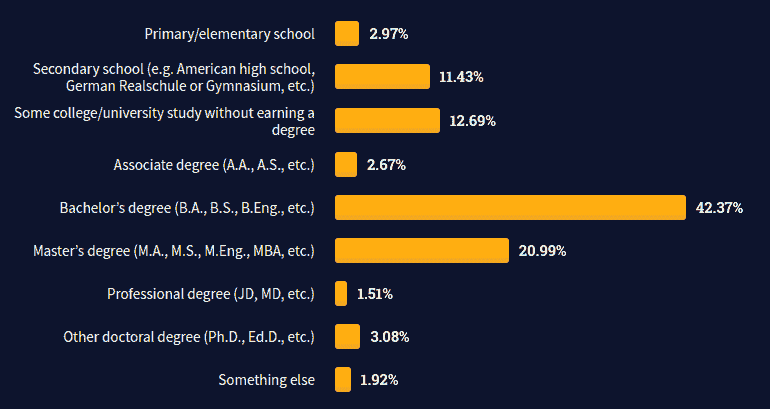
图 2。2021 年 Stack Overflow 调查问题的回答“以下哪项最能描述你已完成的最高正式教育水平?”
所有受访者中有 70% 和 80% 的专业开发者完成了一些形式的高等教育,其中学士学位最为常见。
开发者档案部分讨论的其他话题包括种族、性取向、地理位置等人口统计数据,
技术
现在我们转向调查的核心内容,即开发者目前正在使用哪些语言和技术的问题。
语言
首先是语言,这是人们在拿到报告时最想看到的无可争议的第一大问题。
那么,受访者在过去一年中使用了哪些编程、脚本和标记语言进行开发?
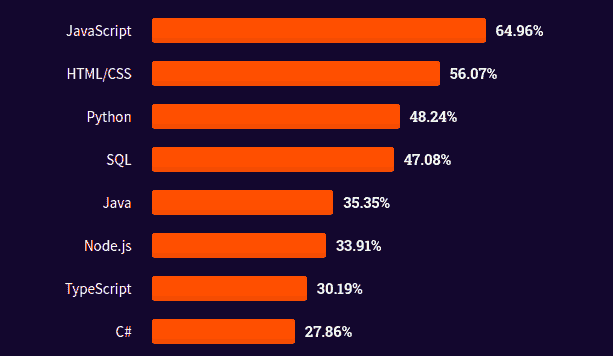
图 3。2021 年 Stack Overflow 调查问题的回答“在过去一年中,你在哪些编程、脚本和标记语言中进行了大量开发工作?在未来一年中,你希望使用哪些语言?”
对数据科学人士特别重要的是,Python 在 48.24% 的回答中被提到,目前是开发者使用的最常见语言之一。
请注意,虽然数据科学语言 R 在图 3的前几名回答中没有出现(由于回答的长尾被截断),但 R 语言被包含在 5.07% 的回答中。
我们已经看到开发者正在使用哪些语言,但关于开发者想要使用的语言呢?有多少开发者虽然没有用某种语言或技术进行开发,但对其表达了兴趣。
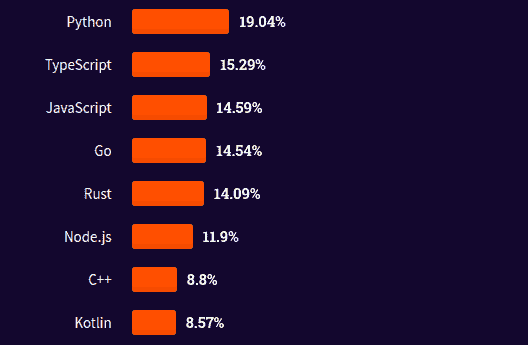
图 4。2021 年 Stack Overflow 调查问题的回答“在过去一年中,你在哪些编程、脚本和标记语言中进行了大量开发工作?在未来一年中,你希望使用哪些语言?”
再次,正如图 4中 R 语言没有出现一样,它被包含在 2.82% 的回答中。
那么更具洞察力的"工作过 vs 想要工作怎么样呢?"
这里有很多要深入探讨的内容,但以下是我们发现的一些最显著的趋势。有超过 10,000 名 Javascript 开发者希望开始或继续使用 Go 或 Rust 开发。大多数希望使用 Dart 的开发者目前正在使用 JavaScript。我们还看到,唯一想要使用 PHP 的开发者是 SQL 开发者。
这些信息存储在一个互动可视化中,最佳使用方式是直接访问 Stack Overflow 开发者调查网站。
数据库
继续讨论数据库... 这是对等问题的结果,旨在评估数据库产品的使用情况。
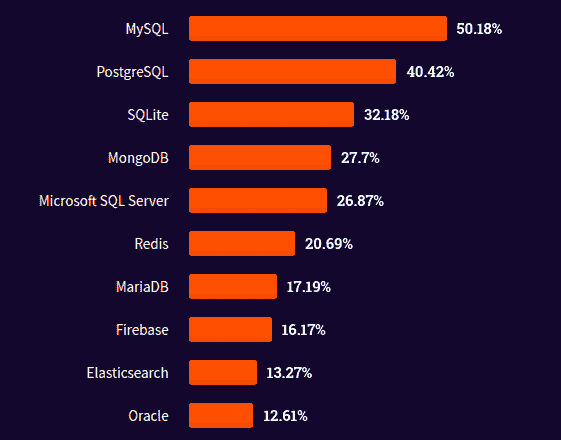
图 5。回应 2021 年 Stack Overflow 调查问题"你在过去一年中在哪些数据库环境中进行了大量开发工作?你希望在未来一年中在哪些环境中工作?"
这非常直接,但我们可以看到 SQL 数据库占据了前三名,前五名中有四个位置。这似乎是开发者对 SQL 数据库的持续认可。
云平台
在云平台方面,AWS 似乎是霸主,Google Cloud 和 Microsoft Azure 也占据了市场的相当份额。
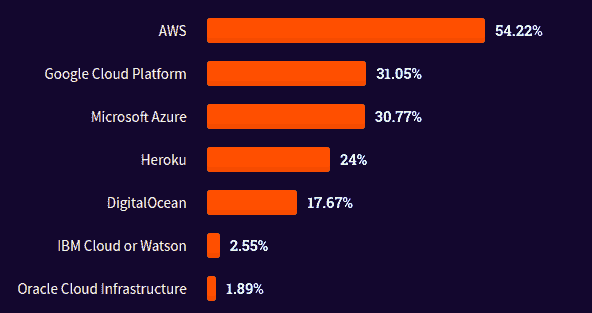
图 6。回应 2021 年 Stack Overflow 调查问题"你在过去一年中在哪些云平台上进行了大量开发工作?你希望在未来一年中在哪些平台上工作?"
有趣的是,开发者喜欢的云平台与他们害怕的云平台的对比与开发者实际使用的那些平台的回应非常接近。也不无道理地认为,IBM Cloud 和 Oracle Cloud 的低采用率可能与开发者对再次使用它的恐惧相关。
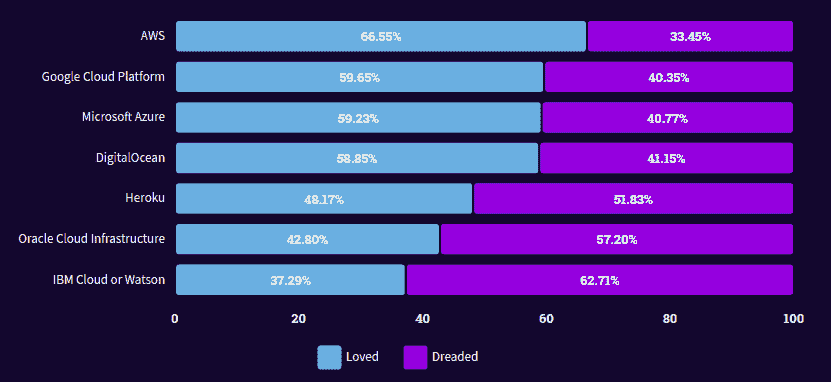
图 7。回应 2021 年 Stack Overflow 调查问题"你在过去一年中在哪些云平台上进行了大量开发工作?你希望在未来一年中在哪些平台上工作?"
其他框架和库
查看最常用和最受欢迎的其他框架和库,你会发现许多专门针对数据科学家和/或机器学习工程师的,或者这些职业人士使用频繁的框架和库。
虽然 Tensorflow 是最受欢迎的库,但 Pytorch 更受喜爱。作为 Stack Overflow 上的.NET Core 用户,我们很高兴看到它位居榜首。
很容易争辩说,至少以下 7 个库和框架与从事数据工作的专业人士非常相关,更多的可能性甚至更大。
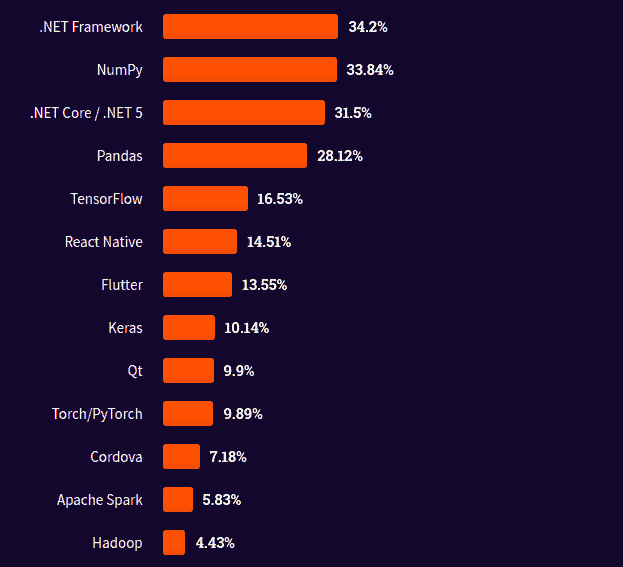
图 8. 2021 年 Stack Overflow 调查问题的回应 "在过去一年中,你在其他哪些框架和库上进行了大量开发工作?你希望在未来一年中使用哪些框架和库?"
转向开发者希望使用的框架和库时,许多与数据科学相关的工具也会出现在这里。
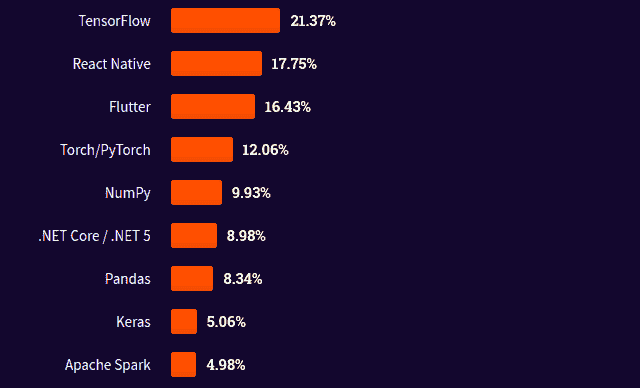
图 9. 2021 年 Stack Overflow 调查问题的回应 "在过去一年中,你在其他哪些框架和库上进行了大量开发工作?你希望在未来一年中使用哪些框架和库?"
学习与问题解决
作为开发者,当你遇到困难时会怎么做?图 10 似乎表明 Google 确实是你的朋友。我们都这样做...
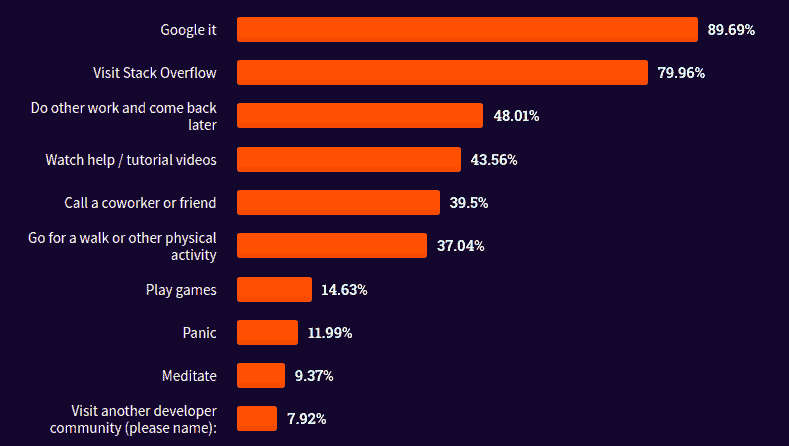
图 10. 2021 年 Stack Overflow 调查问题的回应 "当你在解决问题时遇到困难时,你会怎么做?"
薪资
我们将从报告中最后查看薪资数据。
在各个领域,工程经理、SRE、DevOps 专家和数据工程师通常获得最高薪资。当我们关注美国时,薪资范围底部存在一些差异。在美国,与全球开发者人口相比,移动开发者和教育工作者的薪资通常更高。
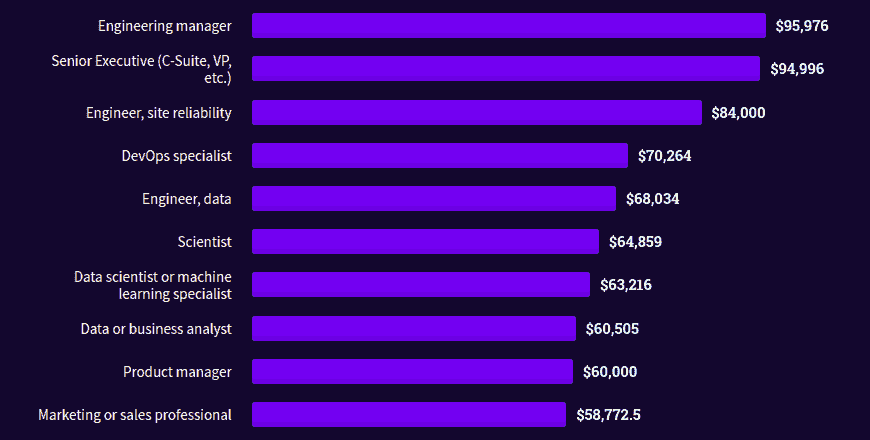
图 11. 2021 年 Stack Overflow 调查问题的回应 "你目前的总薪酬是多少(薪水、奖金和津贴,税前和扣除前)?"
工具和技术的使用对你赚取收入的能力有何影响?
报告提供了多个变量来关联薪资;尽管这不是一个完美的方法,但我们来看看其他框架和库这一类别,它似乎是数据科学家进行调查的一个有趣数据点。看起来这个列表主要由我们可能日常使用的一些库和工具组成。
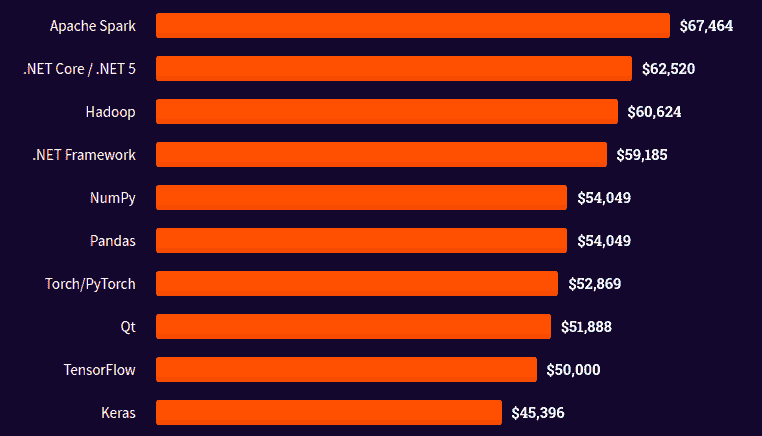
图 12. 2021 年 Stack Overflow 调查问题的回应 "你目前的总薪酬是多少(薪水、奖金和津贴,税前和扣除前)?"
基于单一技术推测薪资是困难的,但仍然很有趣的是一起查看顶级技术。
相关:
-
数据科学家的价值是多少?
-
顶级编程语言及其用途
-
数据科学家的高效 Python 编程指南
更多相关话题
堆积牌组:大数据的下一波机会
原文:
www.kdnuggets.com/2014/05/stacking-deck-next-wave-opportunity-big-data.html
嘉宾文章,作者:Chip Hazard(Flybridge Capital Partners),2014 年 5 月。
在最近的分析周大会上,我参加了由 KDnuggets 的 Gregory Piatetsky 主持的小组讨论,在讨论中我被问及我们在哪里看到大数据领域的投资机会。

本文将扩展我在会议上的一些评论。重要的是,我对这些观察的视角来自我们作为种子和早期阶段风险投资者的角色,这意味着我们在关注市场机会将在未来 3-5 年内如何发展,而不一定是当前市场的情况。
近年来,数十亿美元的风险投资资金流入了帮助组织存储、管理和分析前所未有的数据量的大数据基础设施公司。这些资金的接受者包括 Hadoop 供应商如 Cloudera、HortonWorks 和 MapR;NoSQL 数据库提供商如 MongoDB(一个 Flybridge 投资组合公司,我在董事会任职)、DataStax 和 Couchbase;BI 工具、Hadoop 上的 SQL 和分析框架供应商如 Pentaho、Jaspersoft、Datameer 和 Hadapt。
此外,大型现有供应商如 Oracle、IBM、SAP、HP、EMC、TIBCO 和 Informatica 正在将大量研发和并购资源投入到大数据基础设施中。私人公司正在吸引资本,而大型公司则在这一市场上投入资源,因为市场整体规模庞大(2013 年支出为一个估算为 180 亿美元),并且增长迅速(预计到 2016 年达到 450 亿美元,按相同估算的年均增长率为 35%),如下图所示:
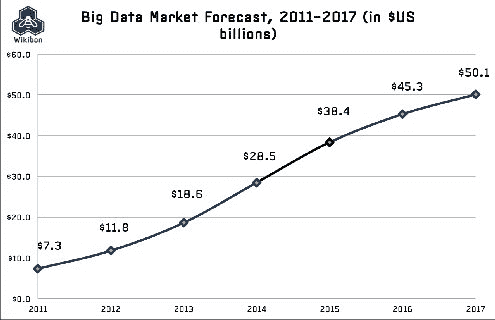
尽管今天大量投资和收入资金流入大数据基础设施市场,但从未来展望来看,我们认为这些市场的赢家已经大致确定并且资本充足,新公司想要利用这些大数据趋势的机会则在其他地方,特别是在我们 Flybridge 称之为全栈分析公司的领域。
全栈分析公司可以这样定义:
-
他们将上述供应商在基础设施层的所有进展和创新结合在一起
-
一个专有的分析、算法和机器学习层
-
从数据中提取独特且可操作的洞察,以解决实际业务问题。
-
从显著的数据“网络效应”中受益,以至于随着积累更多数据和洞察力,其洞察力和解决方案的质量以非线性方式随着时间的推移不断改善。
以下图形展示了全栈分析平台:
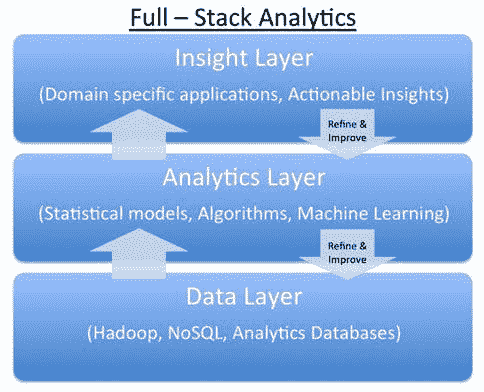
上述标准中特别值得提及的两个要点是可操作的洞察力和数据网络效应的概念。
关于可操作的洞察力的概念,我们从大型公司首席信息官和业务部门负责人那里听到的一个反复出现的主题是,他们被数据淹没,但缺乏能改变他们决策的洞察力。因此,将数据简化为可以在合理时间内采取行动的内容,帮助公司创造更多收入、更好地服务客户或提高运营效率,变得至关重要。
关于数据网络效应,全栈分析公司最重要的机会之一是使用机器学习技术(我的合伙人杰夫·布斯根曾经写过这方面的内容)来开发一组随着分析更多客户的数据而不断改进的洞察力——实际上,是通过更多的数据暴露来学习业务背景,以推动更好的洞察力,从而做出更好的决策。这既提供了越来越有说服力的解决方案,又使公司能够建立竞争壁垒,随着时间的推移这些壁垒变得越来越难以逾越——即,创建了一个网络效应,数据摄取越多,学习越多,从而导致更好的决策和进一步摄取更多数据的机会。
在 Flybridge Capital 投资组合中,我们支持了包括全栈分析公司在内的多个企业。
-
DataXu,其全栈分析程序化广告平台每天做出数十亿次决策,使大型在线广告商能够更有效地管理其营销资源;
-
ZestFinance,其全栈分析承保平台通过解析数千个数据点来识别在风险调整基础上最具吸引力的消费者,以用于其消费者贷款平台;并且
-
Predilytics,其全栈分析平台通过学习数百万数据点来帮助医疗保健组织吸引、留住现有会员并为他们提供更高质量的护理。
每家公司都展示了作为全栈分析公司的成功关键标准:
-
识别出一个具有大量数据的大市场机会;
-
组建一个对该市场具有独特领域洞察力的团队,并了解数据如何推动差异化决策,并具备开发所需的技术技能组合;
-
管理一个大规模可扩展的学习平台,该平台具有自我强化的特点。
如果你的公司能遵循这成功的秘诀,你会发现作为全栈分析提供商的未来非常光明!
是 Flybridge Capital Partners 的普通合伙人,他专注于信息技术领域的公司和技术,包括云计算、大数据和企业 IT。
相关:
-
波士顿 AnalyticsWeek 面板亮点:大数据中的下一大事
-
CIOReview 顶级 100 家最具前景的大数据公司
-
大数据格局,v 3.0,分析
-
信息管理 10 家更多的大数据公司
-
2014 年 4 月 Analytics、大数据、数据挖掘并购及初创公司活动
-
Sand Hill 50 在大数据领域迅速而强劲
-
CIO Review 20 家最具前景的大数据公司
-
CIO Review 20 家最具前景的数据分析公司
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
更多相关话题
改善预测的模型堆叠
原文:
www.kdnuggets.com/2017/02/stacking-models-imropved-predictions.html
作者:Burak Himmetoglu,加州大学圣巴巴拉分校。
如果你曾经参加过 Kaggle 比赛,你可能会对结合不同预测模型以提高准确性并提升排行榜上的分数有所了解。尽管这种方法被广泛使用,但我知道的只有少数资源提供了清晰的描述(其中之一可以在这里找到,还有一个caret 包扩展)。因此,我将尝试在这里提供一个简单的示例,以说明如何结合不同的模型。我选择的示例是 Kaggle 上的房价预测竞赛。这是一个回归问题,给定关于房子的许多特征,需要在测试集上预测其价格。我将使用三种不同的回归方法(XGBoost、神经网络和支持向量回归)来创建预测,并将它们堆叠起来以生成最终预测。我假设读者对 R、Xgboost 和 caret 包以及支持向量回归和神经网络有所了解。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能。
3. Google IT 支持专业证书 - 在 IT 领域支持你的组织。
通过结合不同模型来构建预测模型的主要思想可以用下图示意:
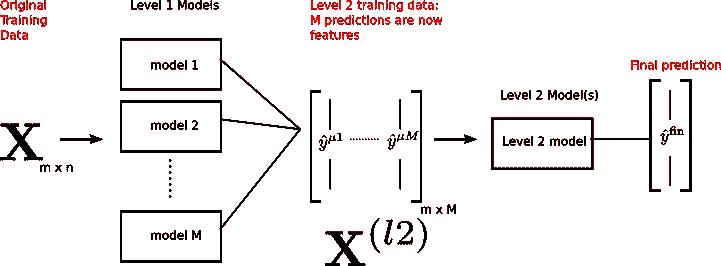
让我描述图中的关键点:
-
初始训练数据 (X) 具有 m 个观测值和 n 个特征(所以它是 m x n)。
-
有 M 个不同的模型,这些模型在 X 上进行训练(通过某种训练方法,如交叉验证)。
-
每个模型提供结果(y)的预测,然后将这些预测转化为第二级训练数据(Xl2),现在是 m x M。即,M 个预测成为这个第二级数据的特征。
-
然后,可以在这些数据上训练一个第二级模型(或多个模型),以生成最终结果,这些结果将用于预测。
第二层数据(Xl2)的构建有几种方式。在这里,我将讨论堆叠,它对于小型或中型数据集效果很好。堆叠使用类似于 k 折交叉验证的想法来创建样本外预测。
这里的关键词是样本外,因为如果我们使用所有训练数据拟合的 M 模型的预测,那么第二层模型将会偏向于 M 模型中表现最好的模型。这是没有用的。
作为这一点的说明,假设模型 1在训练数据上的训练准确率低于模型 2。然而,可能有些数据点模型 1表现更好,但由于某些原因在其他数据点上表现极差(见下图)。相反,模型 2在所有数据点上的总体表现可能更好,但在模型 1表现较好的数据点上表现更差。这个想法是结合这两个模型在它们表现最好的地方。这就是为什么创建样本外预测更有可能捕捉到每个模型表现最好的不同区域。
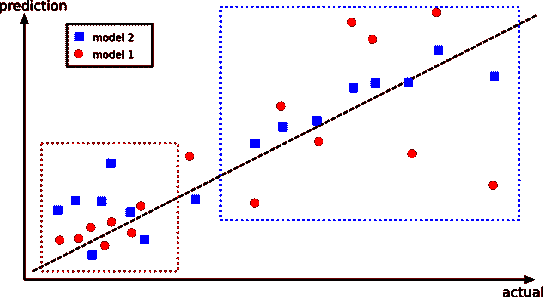
首先,让我描述一下我所说的堆叠。这个想法是将训练集分成几个部分,就像在 k 折交叉验证中一样。对于每个折叠,使用其余的折叠来获取所有模型 1…M 的预测。下面的图表最能解释这一点:
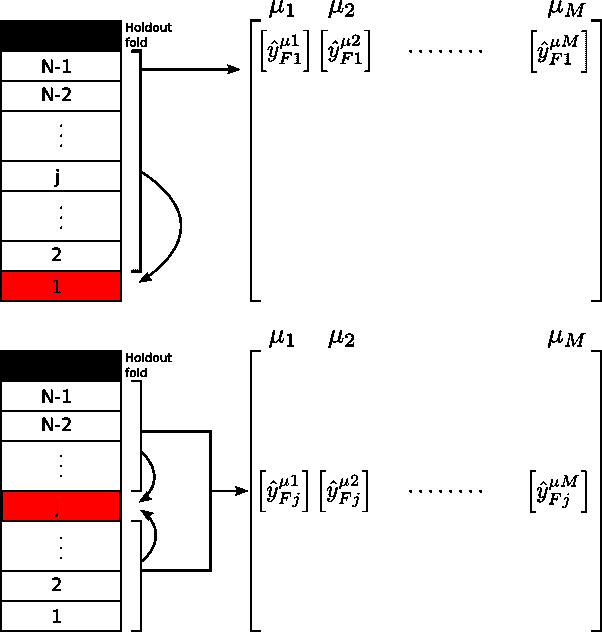
在这里,我们将训练数据分成 N 个折叠,并将第 N 个折叠保留用于验证(即保留折叠)。假设我们有 M 个模型(稍后我们将使用 M=3)。如图所示,每个折叠(Fj)的预测是通过使用其余折叠进行拟合得到的,并收集在样本外预测矩阵(Xoos)中。即,第二层训练数据 Xl2 就是 Xoos。这对于每个模型都重复进行。样本外预测矩阵(Xoos)将用于第二层训练(通过某种选择的方法)以获得所有数据点的最终预测。需要注意几个要点:
-
我们没有简单地将所有训练数据中 M 模型的预测逐列堆叠以创建第二层训练数据,这是由于上述问题(即第二层训练将简单地选择 M 模型中表现最好的模型)。
-
通过使用样本外预测,我们仍然有大量的数据来训练第二层模型。我们只需在 Xoos 上进行训练,并在保留折叠(Nth)上进行预测。这与模型集成不同。
现在,每个模型(1...M)可以在(N-1)个折叠上进行训练,并对保留折叠(第 N 折)进行预测。这没有什么新鲜的。但我们所做的是,使用在 Xoos 上训练的第二层模型,我们将获得对保留数据的预测。我们希望第二层训练的预测比原始模型中的每个 M 预测都要好。如果没有,我们将不得不重新调整模型组合的方式。
让我用一个具体的例子来说明我刚才写的内容。以房价数据为例,我使用了 10 折的训练数据分割。前 9 折用于构建 Xoos,第 10 折作为验证的保留数据。我训练了三个一级模型:XGBoost、神经网络、支持向量回归。对于第二层,我使用了线性弹性网模型(即 LASSO + 岭回归)。以下是每个模型在保留折叠上的均方根误差(RMSE):
XGBoost: 0.10380062
Neural Network: 0.10147352
Support Vector Regression: 0.10726746
Stacked: 0.10005465
从这些数据中可以清楚地看到,堆叠模型的 RMSE 略低于其他模型。这看起来可能变化很小,但当涉及到 Kaggle 的领导层时,这样的小差异非常重要!
从图形上看,可以看到被圈出的数据点在 XGBoost 中预测效果较差(当在所有训练数据上训练时,它是最好的模型),但神经网络和支持向量回归对这个特定点表现得更好。在堆叠模型中,该数据点被放置在接近神经网络和支持向量回归的位置。当然,你也可以看到一些情况下仅使用 XGBoost 的效果比堆叠要好(比如一些较低的点)。然而,堆叠模型的整体预测准确度更高。
一个最终的复杂情况,将进一步提升你的得分:如果你有额外的计算时间,你可以创建重复的堆叠。这将进一步减少你预测的方差(这有点像袋装法)。
例如,让我们创建一个 10 折的堆叠,不仅仅进行一次,而是 10 次!(通过 caret 的createMultiFolds函数)。这将为我们提供多个第二层预测,然后可以对这些预测进行平均。例如,以下是 20 个不同的随机 10 折创建的保留数据上的 RMSE 值(rmse1: XGBoost,rmse2: 神经网络,rmse3: 支持向量回归)。对这些 Xoos(即堆叠 1 的 Xoos、堆叠 2 的 Xoos,…,堆叠 10 的 Xoos)的第二层预测的最终预测进行平均,将进一步提高你的得分。

一旦我们验证了堆叠模型的预测效果比每个单独的模型要好,那么我们将重新运行整个过程,而不保留第 N 折作为保留数据。我们从所有折叠中创建 Xoos,然后第二层训练使用 Xoos 来预测 Kaggle 提供的测试集。希望这会让你的分数在排行榜上有所提升!
最后:你可以在我的 Github 仓库中找到脚本。
注意:如果你有分类问题,你仍然可以使用相同的程序来堆叠类别概率。
简介:Burak Himmetoglu 是数据科学家和高性能计算(HPC)专家,拥有物理学博士学位。他拥有扎实的数学建模、数据分析和编程背景,并热衷于将学术技能应用于解决复杂的业务问题和开发数据产品。
原文。经许可转载。
相关:
-
数据科学基础:集成学习者简介
-
Python 中的随机森林
-
机器学习的顶级 R 包
更多相关内容
IT 员工增援:人工智能如何改变软件开发行业
原文:
www.kdnuggets.com/2023/05/staff-augmentation-ai-changing-software-development-industry.html

图片来自 Bing 图片创作者
人工智能(AI)的出现被广泛认为是游戏规则的改变者。它的本质为几乎每个业务或行业带来了机会与挑战。我们今天将重点讨论它在软件开发中的相关性。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT 需求
人工智能及相关工具越来越被视为可能取代人类开发者的威胁,但它们也可以通过处理耗时且重复的任务来使我们的生活更轻松。无论你怎么看待,IT 员工增援显然已经成为科技行业的一种有效资源。它的出现为软件开发带来了更大的效率和创新机会。
随着人工智能对我们领域的改变,开发者理解它对自己职业的影响确实很重要。本文将提供人工智能如何转变行业的见解,无论你是想要拥抱还是抵制这项新兴技术。
人工智能和 IT 员工增援如何帮助软件开发行业?以下是人工智能帮助团队提高效率的一些任务:
处理软件测试
软件测试是开发者倾向于让人工智能主导的领域。它可以帮助编写测试用例,迅速发现错误。工程师还可以使用人工智能算法来处理测试周期中的某些部分(主要是探索性测试),这些部分依赖于创造力和直觉来识别错误。
尽管人工智能测试有时可以更优秀,但它仍然远未能取代人类开发者。人类似乎对用户界面有更好的理解,并且能够更准确地判断情感,这是人工智能目前无法做到的。然而,人工智能作为一种工具,可以简化和优化软件测试。
做出关键决策
AI 或机器学习(ML)工具也无法在没有帮助的情况下开发程序。它们的知识局限于开发者通过机器学习算法提供的大数据集。然而,一旦数据科学家基于高质量程序生成了可靠的数据集,这些工具几乎可以立即分析问题并回答问题。而人工分析师可能需要花费数小时来完成相同的工作。
因此,正确的数据可以让 AI 助手在决定框架和 KPI 时作出决策,同时确定应用程序中的必要或可选功能。
双重检查和修复漏洞
为了考虑 AI 助手如何成为软件开发者最受欢迎的工具之一,我们需要考虑它们在完成代码、双重检查错误以及搜索说明和文档方面的帮助程度。其中一些工具甚至可以分析问题,妥善使用库,帮助开发者用不同的语言编写代码,并提供其他实用的解决方案。
实时用户反馈监控
实时反馈对软件开发者也至关重要,无论软件处于早期阶段还是已经发布。这种反馈帮助开发者不断调整项目,量身定制体验和资源,以确保整体成功。
在许多情况下,开发者只能通过进行大量测试或允许用户发送反馈来改进应用程序。这在消息应用程序的情况下尤其如此,它们根据来自 AI 助手和用户测试的实时反馈不断提升用户界面和体验(UI/UX)。
开发者还可以使用机器学习来监控特定情况下的用户行为。这些数据有助于进一步修复漏洞和用户可能遇到的错误。考虑到投诉和弃用率的下降也是一个附带好处。
实时反馈的另一个显著例子是使用 AI 根据从用户活动中收集的数据提供个性化内容。
处理耗时的日常任务
在没有人工监督的情况下使用 AI 和 ML 工具可能会浪费时间和金钱,并带来法律风险。因此,开发者应考虑 AI 助手在独立执行软件工程任务时几乎不可能做到的程度,同时它们却可以很容易地接管其他类型的任务,如调试和编译。
仅这一事实就可以迅速将工程师的工作重心从 AI 在某些领域的应用转移到依赖这些工具处理其他类型的工作上,这些工作本来会从他们繁忙的日程中占用大量时间。能够让 AI 协助完成那些人类需要更长时间才能完成的任务,也意味着工程师可以用额外的时间处理更具创意的内容。
空白屏幕对于软件开发者就像空白画布对于画家一样。工程师可以利用所有现有工具,将重复性任务处理完毕后,投入更多时间于 AI 尚未能提供帮助的领域。
分析用户行为
是否曾想过为什么现在的许多软件解决方案如此用户友好?一个关键原因是开发者学会了理解用户行为,这使他们能够创建符合并超越用户需求的产品。通过使用 AI 分析用户与程序的互动方式,他们可以轻松定位某些问题并在影响用户体验之前解决它们。
正如我们所知,早期修复 bug 比处理意外的更新需求更为经济。借助 AI 预测分析,开发者可以基于用户与类似应用的过去经验预测他们如何与程序互动。不同的使用案例帮助开发者服务更广泛的受众。
保持对 AI 发展和 IT 人员增强可能性的最新了解
AI、ML、深度学习、自然语言处理(NLP)以及其他人工智能工具在近年来显著改变了软件开发。它们扩展了机器能做的事的界限。现在,这些先进技术可以在很大程度上更好地模拟人类编程技能,带来了新的可能性,并改变了我们创建软件的方式。跟上最新的 AI、ML 和 IT 人员增强趋势对于充分利用这些技术至关重要。
然而,所有可用证据表明,截至目前,AI 或 ML 工具仍远未足够先进到可以取代人类开发者。它们可以成为出色的助手,处理日常任务、提供实时反馈并帮助我们理解用户行为。你如何在软件开发旅程中利用 AI 和相关工具?
更多相关内容
StarCoder: 你一直想要的编码助手
原文:
www.kdnuggets.com/2023/05/starcoder-coding-assistant-always-wanted.html
作者提供的图片
什么是 StarCoder?
StarCoder 是一个前沿的大型语言模型,专门设计用于代码。它拥有令人印象深刻的 15.5B 参数和 8K 的扩展上下文长度,在填充能力方面表现优异,并通过多查询注意力实现快速的大批量推断。
StarCoderBase 在一个包含 1 万亿个标记的庞大数据集上进行了训练,这些数据来自 The Stack。该集合包括许可使用的 GitHub 仓库,配有检查工具和隐私意识开发者的选择退出过程。为了进一步提升性能,BigCode 团队通过 35B Python 标记对 StarCoderBase 进行了精细调整。
结果是,StarCoder 成为一个强大且精炼的语言模型,能够处理广泛的编码任务,表现出卓越的能力。
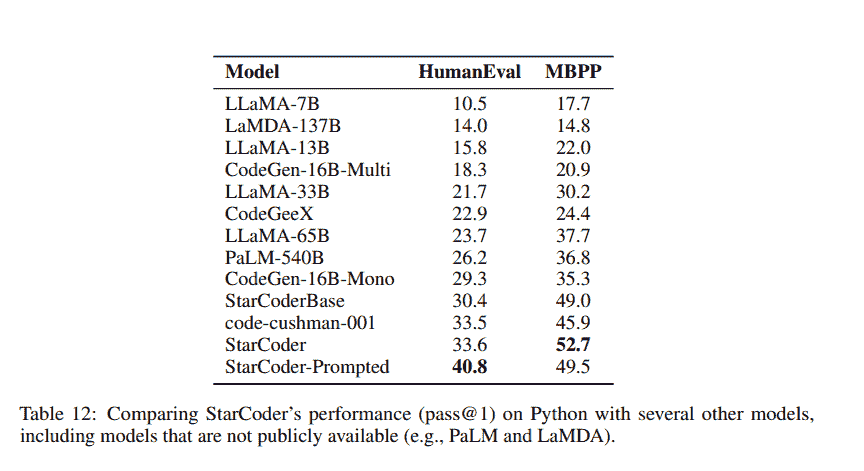
来自 StarCoder Paper 的图片
StarCoderBase 超越了所有现有的开源代码语言模型,这些模型支持多种编程语言,并在质量和结果方面表现出色,甚至在质量和结果上超越了著名的 OpenAI code-cushman-001 模型。此外,StarCoder 可以被提示达到 40% pass@1 的 HumanEval 分数。它的表现优于 LaMDA、LLaMA 和 PaLM 模型。
阅读 研究论文 了解更多有关模型评估的信息。
StartCoder 代码补全
BigCode - StarCoder 代码补全 playground 是测试模型能力的绝佳方式。你可以尝试各种模型格式、前缀和填充内容,以获得全面的体验。
在我看来,这是一个很好的代码补全工具,尤其适用于 Python 代码。然而,它确实存在一些缺点,例如过时的 API、幻觉现象、显示 Jupyter Notebook 元数据和不完整的代码。
使用 StarCoder 生成代码的最佳方法是使用详细解释的注释。这将帮助模型更好地理解你的意图,并生成更准确的结果。
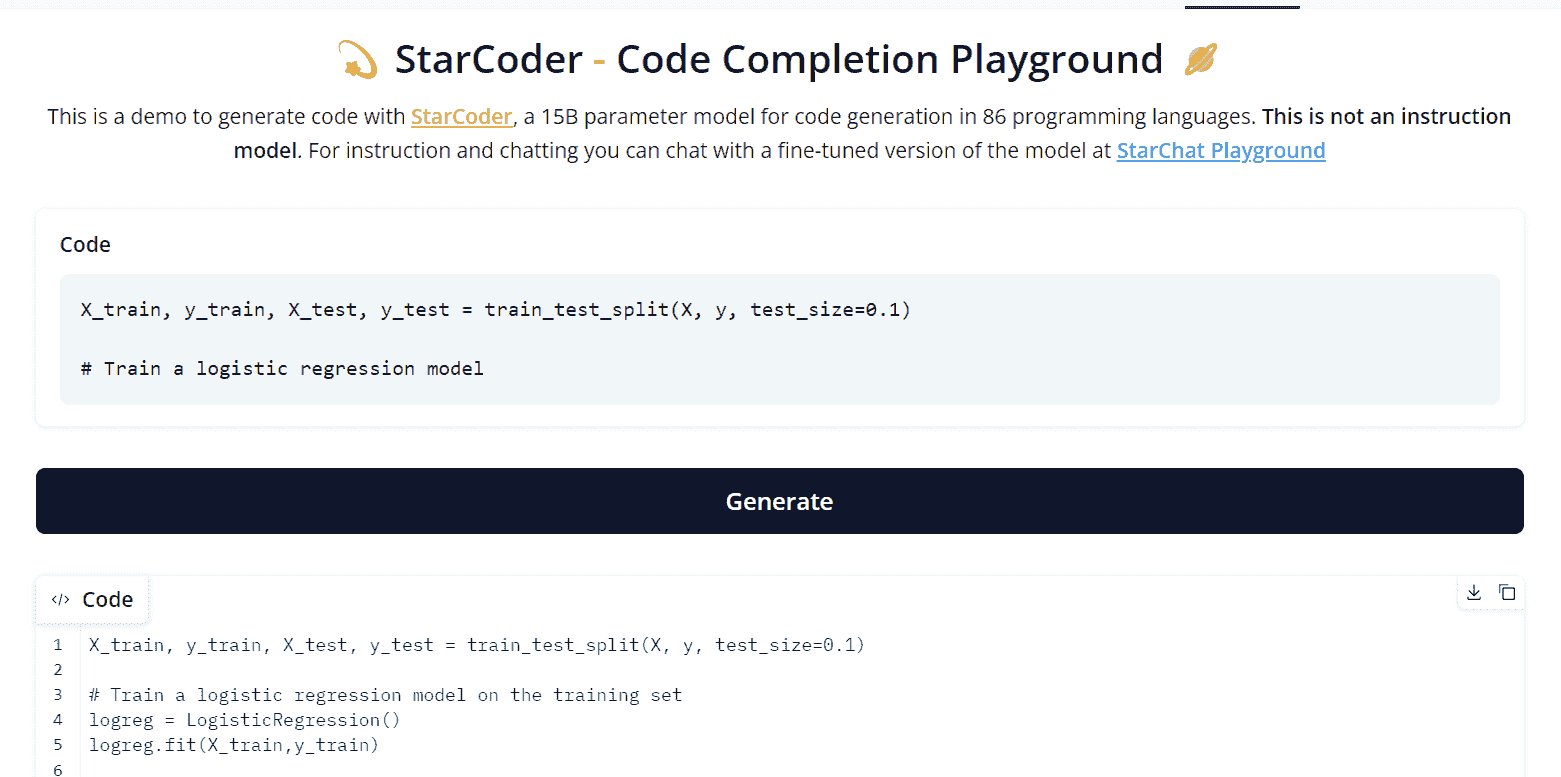
来自 StartCoder 代码补全的图片
StarChat Playground
如果你习惯了 ChatGPT 生成代码的风格,那么你应该尝试 StarChat 来生成和优化代码。
StarChat 是 StarCoderBase 的一个专用版本,它经过了在 Dolly 和 OpenAssistant 数据集上的微调,成为了一个真正宝贵的编码助手。它是一个拥有 160 亿参数的模型,预训练于一万亿个令牌,这些令牌来自 80 多种编程语言、GitHub 问题、Git 提交和 Jupyter 笔记本。
你可以向 StarChat 提供指令,它会生成带有解释的代码。你还可以使用后续提示来修改代码。
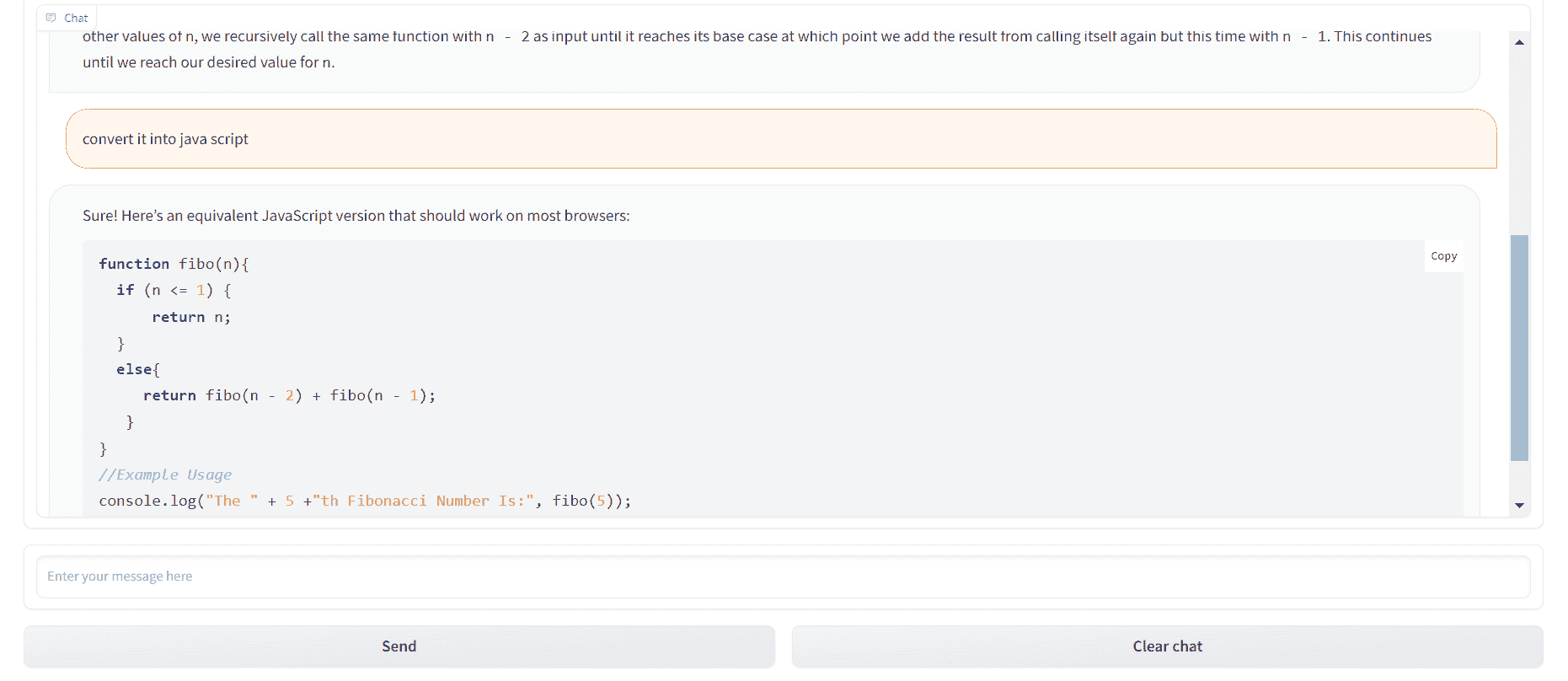
图片来自 StarChat Playground
HF 代码自动补全
HF 代码自动补全 是一个免费的开源替代方案,取代了 GitHub Copilot,并由 StarCoder 提供支持。我自其发布以来一直在使用它,对其速度和准确性感到非常满意。

HF 代码自动补全 VSCode 扩展
它与 Jupyter Notebook 以及 VSCode 中的各种文件兼容。你只需从市场安装扩展并添加 Hugging Face API 即可。
图片由作者提供 | VSCode
结论
我们的工作场所中始终需要高级代码助手,它们能够有效处理重复脚本,同时协助创建更复杂的系统。
在这篇博客中,我们详细探讨了 StarCoder 及其广泛的应用范围。值得注意的是,开源社区在不懈努力地推动代码辅助的边界,不断致力于提供突破性的解决方案,以提升我们的编码体验和生产力。
希望你喜欢阅读这篇博客,并发现它富有信息和洞察力。如果你想了解更多关于最新 AI 技术的信息,可以在 LinkedIn 上关注我。
Abid Ali Awan (@1abidaliawan) 是一位认证数据科学专业人员,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为面临心理健康问题的学生打造一款 AI 产品。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
更多相关内容
如果我必须重新开始学习数据科学,我会怎么做?
原文:
www.kdnuggets.com/2020/08/start-learning-data-science-again.html
不久前,我开始思考如果我必须重新开始学习机器学习和数据科学,我会从哪里开始?有趣的是,我想象的路径与我真正开始时的路径完全不同。
我知道我们每个人的学习方式都不同。有些人喜欢视频,有些人只用书就可以,还有很多人需要支付课程费用才能感受到更多压力。这没关系,因为重要的是学习并享受其中。
我们的前三推荐课程
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT 支持
所以,从我自身的角度出发,了解自己如何更好地学习,我设计了这个路径,如果我需要重新开始学习数据科学的话。
正如你将看到的,我最喜欢的学习方式是逐渐从简单到复杂。这意味着从实际示例开始,然后转向更抽象的概念。
Kaggle 微课程
我知道从这里开始可能有些奇怪,因为很多人会更愿意从最基本的基础和数学视频开始,以完全理解每个机器学习模型背后的运作。但从我的角度来看,从一些实用而具体的内容入手有助于更好地了解全貌。
此外,这些微课程每个大约需要 4 小时完成,因此预设这些小目标会带来额外的激励。
Kaggle 微课程:Python
如果你对 Python 比较熟悉,可以跳过这一部分。在这里,你将学习基础的 Python 概念,这些概念将帮助你开始学习数据科学。关于 Python 的许多东西仍然会是个谜,但随着我们的进步,你将通过实践学习它。
链接:www.kaggle.com/learn/python
价格:免费
Kaggle 微课程:Pandas
Pandas 将为我们提供在 Python 中操作数据的技能。我认为一个包含实际示例的 4 小时微课程足以让你对可以做的事情有个概念。
链接:www.kaggle.com/learn/pandas
价格:免费
Kaggle 微课程:数据可视化
数据可视化可能是最被低估的技能之一,但它却是最重要的技能之一。它将帮助你全面理解你将要处理的数据。
链接:www.kaggle.com/learn/data-visualization
价格:免费
Kaggle 微课程:机器学习导论
这就是激动人心的部分开始的地方。你将学习基本但非常重要的概念,以开始训练机器学习模型。这些概念以后将对你非常重要。
链接:www.kaggle.com/learn/intro-to-machine-learning
价格:免费
Kaggle 微课程:中级机器学习
这与前一个竞赛互补,但在这里你将第一次处理分类变量,并处理数据中的空字段。
链接:www.kaggle.com/learn/intermediate-machine-learning
价格:免费
让我们在这里停下来一会儿。应该清楚的是,这五门微课程不会是线性过程,因为你可能需要来回切换它们以刷新概念。当你在学习 Pandas 课程时,可能需要回到 Python 课程以回忆你学到的一些知识,或者查看 pandas 文档以理解你在《机器学习导论》课程中看到的新函数。所有这些都是正常的,真正的学习就是在这里发生的。
现在,你将意识到这前五门课程将为你提供进行探索性数据分析(EDA)和创建基准模型所需的技能,之后你可以进一步改进这些模型。因此,现在是开始简单的 Kaggle 竞赛并实践你所学知识的最佳时机。
Kaggle Playground 竞赛:泰坦尼克号
在这里,你将实践你在入门课程中学到的内容。刚开始时可能会有些让人紧张,但这没关系,因为这不是关于在排行榜上排第一,而是关于学习。在这个竞赛中,你将学习分类和这些类型问题的相关度量标准,如精确度、召回率和准确性。
Kaggle Playground 竞赛:房价预测
在这个竞赛中,你将应用回归模型并学习相关的度量标准,如 RMSE。
链接:www.kaggle.com/c/home-data-for-ml-course
到这个阶段,你已经有了很多实践经验,你会感觉自己可以解决很多问题,但很可能你还不完全理解每个分类和回归算法背后发生的事情。因此,这时我们需要研究我们所学习的基础。
许多课程从这里开始,但至少在我做了一些实际操作之后,我对这些信息的吸收会更好。
书籍:从零开始的数据科学
此时,我们将暂时远离 pandas、scikit-learn 和其他 Python 库,以实际的方式学习这些算法“背后”发生了什么。
乔尔·格鲁斯的这本书相当易读,提供了每个主题的 Python 示例,并且没有很多繁重的数学内容,这对这个阶段至关重要。我们希望理解算法的原理,但从实际的角度出发,我们不希望通过阅读大量的数学符号而感到沮丧。
链接:亚马逊
价格:大约$42
如果你已经读到这里,我会说你非常有能力从事数据科学工作,并理解解决方案背后的基本原理。因此,我邀请你继续参与更复杂的 Kaggle 竞赛,参与论坛,探索其他参与者解决方案中发现的新方法。
在线课程:安德鲁·吴的机器学习
在这里,我们将看到许多我们已经学过的内容,但我们将看到该领域领导者之一的讲解,他的方法会更具数学性,因此这将是更好地理解我们模型的优秀方式。
链接:www.coursera.org/learn/machine-learning
价格:没有证书免费 — 有证书$79
书籍:统计学习的要素
现在开始进入繁重的数学部分。想象一下,如果我们从这里开始,那将是一条一路上坡的路,我们可能会更容易放弃。
链接:亚马逊
价格:$70,斯坦福大学的官方免费版本。
在线课程:安德鲁·吴的深度学习
到现在为止,你可能已经阅读了有关深度学习的内容,并玩过一些模型。但在这里,我们将学习神经网络的基础知识,它们是如何工作的,并学习实现和应用各种存在的架构。
链接:www.deeplearning.ai/deep-learning-specialization/
价格:$49/月
此时,这很大程度上取决于你自己的兴趣,你可以专注于回归和时间序列问题,或者更深入地研究深度学习。
原始内容。经许可转载。
圣地亚哥·维克斯 是 datasciencetrivia.com 的创始人,物理学家转数据科学家。
了解更多内容
如何开始使用 PyTorch 进行自然语言处理
原文:
www.kdnuggets.com/2022/04/start-natural-language-processing-pytorch.html

随着人工智能和深度学习程序在未来几年中不断增长和发展,自然语言处理 (NLP) 也在不断增长,变得越来越重要。使用 PyTorch 进行自然语言处理是实现这些程序的最佳选择。
我们的 3 个最佳课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
在本指南中,我们将解答一些在开始深入自然语言处理时可能会出现的明显问题,但我们也会探讨更深层次的问题,并给你提供开始自己 NLP 程序的正确步骤。
PyTorch 可以用于 NLP 吗?
首先,NLP 是一门应用科学。它是工程学的一个分支,将人工智能、计算语言学和计算机科学结合在一起,以“理解”自然语言,即口语和书面语言。
其次,NLP 并不意味着机器学习或深度学习。相反,这些人工智能程序需要学习如何处理自然语言,然后使用其他系统来利用输入程序的数据。
虽然将一些 AI 程序称为 NLP 程序比较简单,但情况并非完全如此。相反,它们能够理解语言,在经过适当训练之后,但涉及到完全不同的系统和过程来帮助这些程序理解自然语言。
这就是为什么使用 PyTorch 进行自然语言处理非常方便的原因。PyTorch 基于 Python,并具有预先编写的代码(称为类),这些代码都围绕 NLP 设计。这使得整个过程对所有参与者来说都更快、更容易。
有了这些 PyTorch 类和 PyTorch 可用的各种其他 Python 库,自然语言处理没有比这更好的机器学习框架了。
我如何开始学习自然语言处理?
要开始使用 PyTorch 进行 NLP,你需要熟悉 Python 编程。

一旦你熟悉了 Python,你会发现许多其他框架可以用于各种深度学习项目。然而,使用 PyTorch 进行自然语言处理是最优的,因为 PyTorch 张量。
简而言之,张量 允许你使用 GPU 进行计算,这可以显著提高你在 PyTorch 上进行自然语言处理程序的速度和性能。这意味着你可以更快地训练你的深度学习程序,以实现你期望的 NLP 结果。
如上所述,PyTorch 中有不同的 类,这些类在自然语言处理及相关程序中表现良好。我们将详细介绍这六个类及其使用场景,以帮助你开始选择合适的类。
1. torch.nn.RNN
我们将要查看的前三个 类 是 多层类,这意味着它们可以表示双向递归神经网络。简单来说,它允许深度学习程序从过去的状态中学习,同时在计算和处理继续进行时从新的/未来的状态中学习。这使得这些程序能够学习和处理自然语言输入,甚至理解更深层次的语言特征。
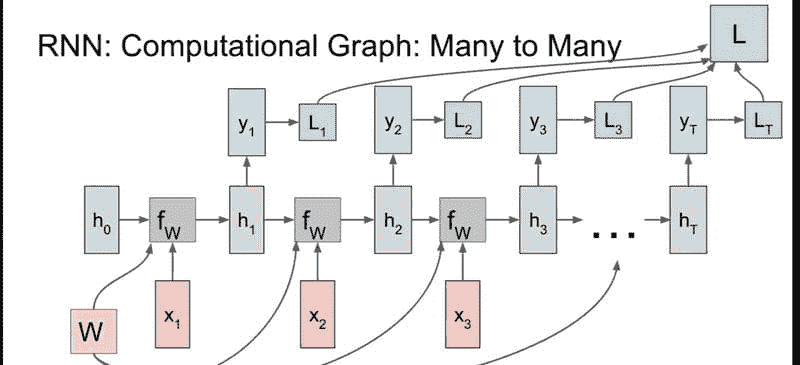
torch.nn.RNN 多对多图示,图片来源
torch.nn.RNN 代表 递归神经网络,这让你知道这个类的基本功能。这是使用 PyTorch 进行自然语言处理时最简单的递归神经网络类。
2. torch.nn.LSTM
torch.nn.LSTM 是另一个多层 PyTorch 类。它具有与 torch.nn.RNN 相同的所有优点,但增加了 长短期记忆。这意味着使用这个类的深度学习程序可以处理超越一对一数据点连接的数据序列。
在使用 PyTorch 进行自然语言处理时,torch.nn.LSTM 是更常用的类之一,因为它不仅可以理解书写或输入的数据,还可以识别语音和其他声音。
能够处理更复杂的数据序列使其成为能够有效执行利用自然语言处理全部潜力的程序的必要组成部分。
3. torch.nn.GRU
torch.nn.GRU 在 RNN 和 LSTM 类的基础上,通过创建 门控递归单元 进行扩展。简而言之,这意味着 torch.nn.GRU 类程序具有门控输出。这使得它们的功能类似于 torch.nn.LSTM,但实际上有处理机制来简单地忘记不符合或与大多数数据集的预期结果或结论不一致的数据集。
torch.nn.GRU 类程序是入门 NLP 的另一个很好的方式,因为它们更简单,但在更短时间内产生与 torch.nn.LSTM 类似的结果。然而,如果程序忽略了可能对学习重要的数据集,在没有仔细监控的情况下,它们可能会准确性较低。
4. torch.nn.RNNCell
接下来的三个类是其前身的简化版本,因此它们都以不同的好处类似地运行。这些类都是细胞级类,基本上一次只运行一个操作,而不是同时处理多个数据集或序列。

使用分配给相应图像的单词输出 PyTorch 的 NLP 结果,图像来源
这种方式进展较慢,但只要时间足够,结果可能会更为准确。作为 RNNCell,这个类程序仍然可以从过去和未来的状态中学习。
5. torch.nn.LSTMCell
torch.nn.LSTMCell 的功能类似于普通的 torch.nn.LSTM 类,能够处理数据集和序列,但不能同时处理多个。与 RNNCell 程序一样,这意味着进展较慢,负担较轻,但实际上随着时间的推移可以提高准确性。
这些细胞级类与其前身有一些小的变化,但深入探讨这些差异会超出本指南的范围。
6. torch.nn.GRUCell
在自然语言处理领域,使用 PyTorch 的最有趣的类之一是 torch.nn.GRUCell。它仍然保持有门控输出的功能,这意味着它可以忽略甚至忘记离群的数据集,同时仍然从过去和未来的操作中学习。
可以说,这是那些入门者使用的较受欢迎的 PyTorch 类之一,因为它在需求最少的情况下具有最大的潜力。
这里主要的牺牲是确保程序得到正确训练所需的时间和精力。
使用 PyTorch 实现自然语言处理
关于如何开始使用 PyTorch 进行自然语言处理还有很多要说的,但在选择了适合您深度学习模型的 PyTorch 类之后,还需理解一个主要因素,那就是决定如何在模型中实现 NLP。
将单词编码到模型中可能是拥有一个完全优化和操作的深度学习模型的最明显且重要的过程之一。PyTorch 的 NLP 需要某种单词编码方法。
有很多方法可以让模型处理单个字母,但创建 NLP 深度学习模型的关键在于,假设不是关注单个单词和字母,而是这些单词和短语的语义和语言学意义。以下是三个基本的 PyTorch NLP 词嵌入模型:
-
简单词编码:训练模型关注序列中的每个单独单词,并让模型自行推导相似性和差异性。这是最简单的方法,但模型可能难以准确理解或预测语义。
-
N-Gram 语言建模:模型被训练来学习序列中单词之间的关系。这意味着它们可以学习单词在彼此关系中的作用以及在句子中的作用。
-
连续词袋模型(CBOW):N-Gram 语言建模的扩展版本,该深度学习模型被训练来处理序列中每个单词之前和之后一定数量的单词,以便深入学习单词在周围单词中的作用以及它们在序列中的功能。这是目前使用 PyTorch 进行自然语言处理的最受欢迎的方法。
一旦你选择了 PyTorch 类和词嵌入方法,你就准备好开始在下一个深度学习项目中利用自然语言处理了!

使用 PyTorch 进行自然语言处理来创建像 Siri 这样的最终结果,图片来源
更多有关自然语言处理和 PyTorch 的信息
自然语言处理是深度学习和人工智能中最热门的话题之一,许多行业正在探索如何利用这种类型的深度学习模型来进行内部和外部应用。
还有很多内容可以了解和学习,但如果你认为我们遗漏了什么,请告诉我们。如果你对如何开始实施 NLP 或 PyTorch 有任何问题,请随时联系!
你怎么看?你准备好使用 PyTorch 处理自然语言处理了吗?如果你有任何问题,请随时在下面留言。
Kevin Vu 管理 Exxact Corp 博客,并与许多才华横溢的作者合作,他们撰写有关深度学习各个方面的内容。
原文。经许可转载。
更多相关话题
如果你必须重新开始学习统计学,你会从哪里开始?
原文:
www.kdnuggets.com/2020/06/start-statistics-all-over-again.html
评论
由李·贝克,Chi-Squared Innovations 的联合创始人兼首席执行官。

我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
多年来,我常常被初学者问到应该从哪里开始学习统计学,应该先做什么,以及在统计学的哪些方面应该优先考虑,以帮助他们实现目标(通常是获得更高薪水的职位)。
现在,由于我几乎完全是自学成才,我不太认为自己是应该从哪里开始的权威,我很难带有坚定的信念来回答这个问题。
当然,我对此主题有一些看法,但这些看法受到我自身经验的影响。
所以我想联系一些统计学界的朋友,看看他们能带来什么。
本文中每位统计学家都被问到了同一个问题:
如果你必须重新开始学习统计学,你会从哪里开始?
答案令人惊讶——它们竟然成为了一份从零开始成为现代统计学家的路线图。
简而言之,如何成为一名未来的统计学家 而无需接受任何课程!
统计理论 vs 应用统计学
统计学中存在一条分界线。一方面,有那些接受了正式统计理论教育的人,另一方面,则是通过实践学习的人。如果你像我一样,你将是一个完全自学的统计学家,羡慕另一边的碧绿草地,希望自己当初能得到适当的教育,以避免犯那么多愚蠢的错误。
但其他统计学家对此有什么看法?
嗯,杰奎琳·诺利斯和我走过相同的道路,但她的感受与我不同。杰奎琳(@skyetetra),一位数据科学顾问以及《数据科学职业生涯构建》一书的作者之一,告诉我她从未接受过正式的统计学教育,而是通过工作中的学习掌握了所需的一切:
“如果我需要重新开始,我会做和第一次一样的事情!我的背景是应用数学,所以我在学术上只上了一门统计学课程。在工作中学习统计学对我来说效果很好,而我认识的一些有更严格统计学背景的人似乎并不常用他们所学的知识。每当我需要一些不寻常的统计方法时,我都能自己查阅和学习。作为数据科学家,你对数据的更广泛的理性思考可以来自统计学之外的许多领域。对我来说,是数学,但我见过许多人从不同的背景中获得这些能力。”
我对从有限的统计学教育中取得的职业生涯感到非常满意——如果我可以重新开始,我会担心踩到统计学的“蝴蝶”,从而改变时间线,最后变成一名用户体验设计师或其他什么职业。
另一方面,Kristen Kehrer 来自 Data Moves Me (@DataMovesHer),她有正式的统计学教育。她告诉我:
“我本科阶段大部分的概率和统计学习都非常理论化。如果我需要重新开始,我会在本科阶段选择一门更应用的统计课程。但即便如此,我不会改变我选择追求正式学位的决定。”
有趣的是,Chatroulette 的高级产品研究员 Lisa-Christina Winter (@lisachwinter) 向我建议了完全相反的做法:
“我会从统计学理论开始——理解基本概念以及它们为何重要。为了便于理解,我会将理论放在简单实验设计的背景下来看。”
所以统计学的理论基础对你来说为什么重要?
“虽然当初刚学习统计学时我没有意识到这一点,但现在我明白了亲自解决统计问题的重要性,比如使用公式书和分布表。现在与人合作时,很快就会发现更深层次的统计学理解是极其重要的。”
怎么说?
“在忙于应用统计学之前经过大量的理论统计学学习,帮助我避免了很多通过单纯编写语法而无法意识到的错误。”
而 Matt Dancho,他为商学院学生创建数据科学课程 (@mdancho84),他分享了一些关于学习统计学的建议,他告诉我:
“我会做尽可能多的项目——构建产品就是学习的方式。当你遇到错误时,进行故障排除,创造,学习。这是一项可以直接转移到业务中的技能。”
他也有话要对那些告诉我们要学会多任务处理的人说(我相信你们都有听过大学讲师让你们学会这一点):
“我会专注于一个学习目标——很容易分心。这会浪费你几年时间。相反,专注于一个项目或一个学习目标,而不是你听到的每一项新技术。这会杀死你的生产力。专注对学习至关重要。”
Mine Çetinkaya-Rundel 来自OpenIntro团队(@minebocek)也建议走应用统计学路线:
“我开始学习统计学时使用的是传统的入门统计学课程,该课程让我们记住一些公式,但实际上没有接触数据。在第一次课程之后,我花了一段时间才将这些知识拼凑起来,理解(并爱上!)整个数据分析周期。”
那么,如果她必须重新开始统计学,她会怎么做呢?
“如果我重新开始,我会希望从学习统计学开始,这样我可以处理数据,进行动手的数据分析(使用 R!),并且专注于如何提出正确的问题以及如何在真实复杂的数据集中寻找这些问题的答案。”
在给统计学新手的三部分建议中的第二部分,Garrett Grolemund(看,我不是说过我们会再听到他的声音吗?)表示,如果他有机会重新开始统计学:
“我会认真思考随机性到底是什么。统计学是这些东西的应用版本,但我们往往过快地跳到数学/计算部分。”
所以,我们得出了结论。10 只猫中有 9 只统计学家更喜欢应用统计学!所以,下次你在没有理论背景的情况下分析数据时感到难过时,只要记住你正在走许多正规训练统计学家如果有机会重新来过的路。如果对他们来说足够好,你知道接下来会发生什么……
频率派统计学 vs 贝叶斯统计学
统计学中存在一种分裂,即频率派和贝叶斯派。
我们来看看统计学家们对这场辩论有什么看法。
我们从柯克·伯恩(@KirkDBorne)开始,他是天体物理学家和火箭科学家(好吧,火箭数据科学家)。令人惊讶的是,他告诉我他从未对成为宇航员感兴趣!
“我不是统计学家,也从未上过统计学课程,尽管我在大学教授过它。这怎么可能?”
有趣的是,我也是这样!那么,他的所有统计学知识从哪里来的呢?
“我在本科物理课程中学习了基础统计学,然后在研究生阶段及其之后,作为天体物理学家进行数据分析时学到了更多。我在大约 22 年前开始探索数据挖掘、统计学习和机器学习时学到了更多统计学。从那时起,我一直没有停止学习统计学。”
这开始听起来像我统计教育的经历。你只需将‘astro’从天体物理学中去掉,它们就是一样的!那么他如何看待重新开始统计学呢?
“我会从贝叶斯推断开始,而不是将早期所有时间都投入到简单的描述性数据分析中。这会让我更早地接触到统计学习和机器学习。而且我会更早地学会探索和利用贝叶斯网络的奇妙与强大。”
这也是Frank Harrell(范德比尔特大学医学院生物统计学教授)对重新开始统计学的看法(@f2harrell)。他告诉我:
“我会从贝叶斯统计学开始,并彻底学习它,然后再学习关于抽样分布或假设检验的内容。”
当我问Lillian Pierson(数据狂人)她会从哪里开始时,她也提到了贝叶斯统计学:
“如果我必须重新开始统计学,我会从三个基本的概念入手:t 检验、贝叶斯概率和皮尔逊相关性。”
就个人而言,我没有做过很多贝叶斯统计学,这是我在统计学中最大的遗憾之一。我能看到用贝叶斯方法做事的潜力,但由于没有老师或导师,我一直没能真正找到入门的途径。
也许有一天我会这样做——但在那之前,我将继续传递这里统计学家的信息。
跟我重复一遍:
学习贝叶斯统计学。
学习贝叶斯统计学。
学习贝叶斯统计学!
模拟统计学是新的黑色
我还从谷歌决策智能部负责人 Cassie Kozyrkov 那里获得了一个非常有趣的观点(@quaesita),她告诉我她会:
“可能会享受把打印的统计表当作篝火烧!”
好吧,虽然说得对,但说真的,你会从哪里重新开始学习统计学呢?
“模拟!如果我必须重新开始,我希望从基于模拟的方法开始学习统计学。”
好的,我明白了,但为什么特别是模拟?
“大多数 STAT101 课程中教授的‘传统’方法是在计算机出现之前发展起来的,过分依赖于那些将统计问题挤入可以用常见分布和那些过时的打印表格进行分析的限制性假设。”
我明白了。那么你到底对打印表格有什么意见呢?
“嗯,我常常想传统课程是否弊大于利,因为我看到他们的幸存者在做‘III 型错误’——正确回答错误的方便问题。通过模拟,你可以回到最基本的原则,发现统计学的真正魔力。”
统计学有魔力吗?
“当然了!我最喜欢的一点是,通过模拟学习统计学迫使你面对假设所扮演的角色。毕竟,在统计学中,你的假设至少与数据一样重要,甚至更重要。”
当谈到提供建议时,KDnuggets(@kdnuggets)的创始人 Gregory Piatetsky 建议:
“我会从 Leo Breiman 关于两种文化的论文开始,并且我会学习贝叶斯推断。”
如果你还没读过那篇论文(它是开放访问的),Leo Breiman 阐述了算法建模的案例,其中统计被模拟为一个黑箱模型,而不是遵循预定的统计模型。
这正是 Cassie 想表达的——统计模型很少适用于现实世界的数据,我们只能尝试将数据硬塞进模型中(得到对错误问题的正确答案),或者切换方法,做一些完全不同的事情——模拟!
还有更多内容...
这是我原始帖子的摘录,它相当长——长到无法在这里全部发布(有超过 30 位世界级的贡献者!)。
如果你喜欢阅读,你可能会对 Dez Blanchfield 对领域专家的看法,或 Michael Friendly 和 Alberto Cairo 对数据可视化的过去、现在和未来的看法感兴趣。
还有一本免费下载的书详细列出了贡献者们的所有评论,包括 Natalie Dean 和 Jen Stirrup 对信息流和侦探工作的看法。
更不要让我开始谈论 Charles Wheelan 和 Chelsea Parlett-Pelleriti 关于沟通的精彩建议,或者 Apache Crunch 项目创始人 Josh Wills 对统计食谱、微积分和模拟统计的比较。
太棒了——你真的不想错过它们!
欢迎过来阅读原始帖子。
个人简介:Lee Baker 是一位获奖的软件创作者,常常在黑暗的房间里坐在键盘后面。他的工作仅由显示器的光线照亮,他希望找到灯开关。拥有数十年的科学、统计和人工智能经验,他热衷于用数据讲故事,但尽管已经解释过十几次,他的母亲仍然不理解他是做什么的。他坚持认为数据分析比我们想象的要简单得多,因此他创作了友好易懂的书籍和视频课程,教授数据分析和统计的基础知识。作为 Chi-Squared Innovations 的首席执行官,他有一天希望退休去做一些更简单的事情,比如抓鳄鱼。
相关:
了解更多相关话题
为什么你应该更频繁地使用 .npy 文件
原文:
www.kdnuggets.com/2018/04/start-using-npy-files-more-often.html
评论

介绍
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
Numpy,简称为数值 Python,是 Python 生态系统中进行高性能科学计算和数据分析所需的基础包。几乎所有的高级工具如Pandas和scikit-learn都是建立在它的基础上的。TensorFlow使用 Numpy 数组作为基本构建块,在其基础上构建了 Tensor 对象和用于深度学习任务的 graphflow(这对长列表/向量/矩阵的线性代数运算的使用非常频繁)。
许多文章已经展示了 Numpy 数组相比于普通 Python 列表的优势。你经常会在数据科学、机器学习和 Python 社区中看到这样的说法:由于 Numpy 的矢量化实现以及许多核心例程是用 C 编写的(基于CPython 框架),Numpy 的速度要快得多。这确实是事实(这篇文章美丽地展示了使用 Numpy 的各种选项,甚至可以使用 Numpy APIs 编写基础的 C 例程)。Numpy 数组是密集打包的同质类型数组。相比之下,Python 列表是指向对象的指针数组,即使所有元素都属于同一类型。你可以享受到引用局部性的好处。
在我在 Towards Data Science 平台上高度引用的文章之一,我展示了使用 Numpy 矢量化操作相对于传统编程构造如for-loop的优势。
然而,较少被认可的是,涉及从本地(或网络)磁盘存储中重复读取相同数据时,Numpy 提供了另一个称为 .npy 文件格式的宝藏。这种文件格式大幅提高了读取速度,相较于从纯文本或 CSV 文件读取。
问题是——当然,你第一次必须以传统方式读取数据并创建一个内存中的 NumPy ndarray 对象。但是,如果你使用相同的 CSV 文件重复读取相同的数值数据集,那么将 ndarray 存储在 npy 文件中而不是从原始 CSV 文件中重复读取将是很有意义的。
什么是 .NPY 文件?
这是一个标准的二进制文件格式,用于在磁盘上持久化单个任意 NumPy 数组。该格式存储了所有形状和数据类型信息,即使在具有不同架构的另一台机器上也能正确重建数组。该格式设计尽可能简单,同时实现其有限的目标。实现意图是纯 Python,并作为主 numpy 包的一部分进行分发。
格式必须能够:
-
表示所有 NumPy 数组,包括嵌套的记录数组和对象数组。
-
以原生二进制形式表示数据。
-
被包含在一个文件中。
-
存储所有必要的信息以重建数组,包括形状和数据类型,以便在不同架构的机器上使用。必须支持小端和大端数组,文件中的小端数字在任何读取该文件的机器上都会生成小端数组。类型必须以其实际大小来描述。例如,如果一台具有 64 位 C “long int”的机器写出一个包含“long int”的数组,则读取该数组的 32 位 C “long int”机器将生成一个 64 位整数的数组。
-
可逆向工程。数据集通常比创建它们的程序存活得更久。一个有能力的开发者应该能够在其首选编程语言中创建一个解决方案,以读取他获得的大多数 NPY 文件,而无需过多的文档。
-
允许内存映射数据。
使用简单代码的演示
一如既往,你可以从我的 boiler plate code Notebook 下载,链接在我的 Github repository。这里我展示了基本的代码片段。
首先,通常的方法是将 CSV 文件读取为列表,并将其转换为 ndarray。
import numpy as np
import time
# 1 million samples
n_samples=1000000
# Write random floating point numbers as string on a local CSV file
with open('fdata.txt', 'w') as fdata:
for _ in range(n_samples):
fdata.write(str(10*np.random.random())+',')
# Read the CSV in a list, convert to ndarray (reshape just for fun) and time it
t1=time.time()
with open('fdata.txt','r') as fdata:
datastr=fdata.read()
lst = datastr.split(',')
lst.pop()
array_lst=np.array(lst,dtype=float).reshape(1000,1000)
t2=time.time()
print(array_lst)
print('\nShape: ',array_lst.shape)
print(f"Time took to read: {t2-t1} seconds.")
>> [[0.32614787 6.84798256 2.59321025 ... 5.02387324 1.04806225 2.80646522]
[0.42535168 3.77882315 0.91426996 ... 8.43664343 5.50435042 1.17847223]
[1.79458482 5.82172793 5.29433626 ... 3.10556071 2.90960252 7.8021901 ]
...
[3.04453929 1.0270109 8.04185826 ... 2.21814825 3.56490017 3.72934854]
[7.11767505 7.59239626 5.60733328 ... 8.33572855 3.29231441 8.67716649]
[4.2606672 0.08492747 1.40436949 ... 5.6204355 4.47407948 9.50940101]]
>> Shape: (1000, 1000)
>> Time took to read: 1.018733024597168 seconds.
所以这是第一次读取,你无论如何都必须这样做。但如果你可能会多次使用相同的数据集,那么,在你的数据科学过程完成后,别忘了将 ndarray 对象保存为.npy 格式。
**np.save('fnumpy.npy', array_lst)**
因为这样做的话,下次从磁盘读取将会非常迅速!
t1=time.time()
array_reloaded = np.load('fnumpy.npy')
t2=time.time()
print(array_reloaded)
print('\nShape: ',array_reloaded.shape)
print(f"Time took to load: {t2-t1} seconds.")
>> [[0.32614787 6.84798256 2.59321025 ... 5.02387324 1.04806225 2.80646522]
[0.42535168 3.77882315 0.91426996 ... 8.43664343 5.50435042 1.17847223]
[1.79458482 5.82172793 5.29433626 ... 3.10556071 2.90960252 7.8021901 ]
...
[3.04453929 1.0270109 8.04185826 ... 2.21814825 3.56490017 3.72934854]
[7.11767505 7.59239626 5.60733328 ... 8.33572855 3.29231441 8.67716649]
[4.2606672 0.08492747 1.40436949 ... 5.6204355 4.47407948 9.50940101]]
>> Shape: (1000, 1000)
>> Time took to load: 0.009010076522827148 seconds.
如果你想以其他形状加载数据,这无关紧要。
t1=time.time()
array_reloaded = np.load('fnumpy.npy').reshape(10000,100)
t2=time.time()
print(array_reloaded)
print('\nShape: ',array_reloaded.shape)
print(f"Time took to load: {t2-t1} seconds.")
>> [[0.32614787 6.84798256 2.59321025 ... 3.01180325 2.39479796 0.72345778]
[3.69505384 4.53401889 8.36879084 ... 9.9009631 7.33501957 2.50186053]
[4.35664074 4.07578682 1.71320519 ... 8.33236349 7.2902005 5.27535724]
...
[1.11051629 5.43382324 3.86440843 ... 4.38217095 0.23810232 1.27995629]
[2.56255361 7.8052843 6.67015391 ... 3.02916997 4.76569949 0.95855667]
[6.06043577 5.8964256 4.57181929 ... 5.6204355 4.47407948 9.50940101]]
>> Shape: (10000, 100)
>> Time took to load: 0.010006189346313477 seconds.
结果发现,至少在这个特定的情况下,磁盘上的文件大小对于.npy 格式也更小。

摘要
在这篇文章中,我们展示了使用原生 NumPy 文件格式.npy 而非 CSV 读取大型数值数据集的实用性。如果相同的 CSV 数据文件需要多次读取,这可能是一个有用的技巧。
阅读更多关于该文件格式的详细信息。
如果你有任何问题或想法分享,请通过tirthajyoti[AT]gmail.com联系作者。你还可以查看作者的GitHub 库以获取其他有趣的 Python、R 或 MATLAB 代码片段及机器学习资源。如果你和我一样,对机器学习/数据科学充满热情,请随时在 LinkedIn 上添加我或在 Twitter 上关注我。
简介: Tirthajyoti Sarkar 是一名半导体技术专家、机器学习/数据科学爱好者、电子工程博士、博主和作家。
原文。经许可转载。
相关:
-
为什么你应该忘记‘for-loop’的数据科学代码并拥抱向量化
-
与 Numpy 矩阵合作:一个实用的入门参考
-
开始使用 Python 进行数据分析
更多相关话题
Python 中的统计数据分析
原文:
www.kdnuggets.com/2016/07/statistical-data-analysis-python.html
由克里斯托弗·丰内斯贝克,范德比尔特大学医学院。
编辑说明:本教程最初作为课程教学材料发布,可能包含对其他课程的脱离上下文的引用;这并不影响材料的有效性或有用性。
描述
本教程将介绍使用 Python 进行统计数据分析,使用存储为 Pandas DataFrame 对象的数据。数据分析中的大部分工作涉及到数据的导入、清理和转换,以便进行分析。因此,本课程的前半部分包括对基本和中级 Pandas 使用的两部分概述,展示如何有效地操作内存中的数据集。这包括任务如索引、对齐、连接/合并方法、日期/时间类型以及处理缺失数据。接下来,我们将介绍使用 Pandas 和 Matplotlib 进行绘图和可视化,重点是创建有效的数据可视化,同时避免常见的陷阱。最后,参与者将学习使用 Numpy、Scipy 和 Pandas 中的一些高级函数进行统计数据建模的方法。这将包括将数据拟合到概率分布中,使用线性和非线性模型估计变量之间的关系,以及对自助法的简要介绍。每个教程部分将涉及样本数据集的实际操作和分析,数据集将在课程前提供给参与者。
本教程的目标受众包括所有新的 Python 用户,尽管我们建议用户还参加入门阶段的 NumPy 和 IPython 课程。
学生指南
对于熟悉 Git 的学生,你可以简单地克隆此仓库以获取所有教程材料(iPython 笔记本和数据)。另外,你也可以 下载包含材料的压缩文件。第三种选择是通过点击下列各节标题来查看静态笔记本。
大纲
-
导入数据
-
Series 和 DataFrame 对象
-
索引、数据选择和子集
-
层次索引
-
读取和写入文件
-
排序和排名
-
缺失数据
-
数据总结
-
日期/时间类型
-
合并和连接 DataFrame 对象
-
拼接
-
重塑 DataFrame 对象
-
数据透视
-
数据转换
-
排列和抽样
-
数据聚合和 GroupBy 操作
-
Pandas 与 Matplotlib 的绘图比较
-
条形图
-
直方图
-
箱形图
-
分组图
-
散点图
-
格子图
-
统计建模
-
将数据拟合到概率分布
-
拟合回归模型
-
模型选择
-
自助法
所需软件包
-
Python 2.7 或更高版本(包括 Python 3)
-
pandas >= 0.11.1 及其依赖项
-
NumPy >= 1.6.1
-
matplotlib >= 1.0.0
-
pytz
-
IPython >= 0.12
-
pyzmq
-
tornado
可选:statsmodels,xlrd 和 openpyxl
对于运行最新版本 Mac OS X(10.8)的学生,获取所有软件包的最简单方法是安装 Scipy Superpack,该软件包与 OS X 随附的 Python 2.7.2 兼容。
否则,另一种简单的安装所有必要软件包的方法是使用 Continuum Analytics 的 Anaconda。
统计阅读清单
生态侦探:用数据对抗模型,Ray Hilborn 和 Marc Mangel
虽然针对生态学家,但 Mangel 和 Hilborn 确定了科学家可以用来为他们的数据构建有用且可信模型的关键方法。他们不回避数学,但这本书非常易读且充满示例。
使用回归和多层次/层级模型的数据分析,Andrew Gelman 和 Jennifer Hill
应用层次建模的首选参考。
统计学习的元素,Hastie, Tibshirani 和 Friedman
为统计学家提供的全面机器学习指南。
贝叶斯统计方法第一课程,Peter Hoff
一本很好的入门书籍,适合开始学习贝叶斯方法。
回归建模策略,Frank Harrell
Frank Harrell 的回归建模技巧。我每周都会拿出来用。
简介: 克里斯托弗·丰内斯贝克 是范德比尔特大学医学院生物统计学系的助理教授。他专注于计算统计学、贝叶斯方法、元分析和应用决策分析。他来自温哥华,BC,并获得乔治亚大学的博士学位。
原文。经许可转载。
相关:
-
掌握 Python 机器学习的 7 个步骤
-
数据科学实战:Kaggle 第三部分 – 数据清洗
-
Python 数据科学:Pandas 与 Spark DataFrame 的关键区别
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关内容
Python 中的统计函数
原文:
www.kdnuggets.com/2022/10/statistical-functions-python.html

图片来源:Andrea Piacquadio
统计函数在数据分析和得出有意义的结论中非常有帮助。在本教程中,我们将深入探讨一些可以应用于 pandas 和 series 对象的有用统计函数。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
在教程中将涵盖以下统计函数:
-
pct_change()
-
cov()
-
corr()
-
corrwith ()
pct_change()
pct_change() 方法可以应用于 pandas 的 series 和 Data Frame,以计算特定周期数的百分比变化
计算 pct_change() 时未指定周期数
代码:
import pandas as pd
import numpy as np
series = pd.Series(np.random.randn(10))
series.pct_change()
输出:
0 NaN
1 -0.881470
2 -5.025007
3 0.728078
4 -0.577371
5 1.173420
6 -1.578389
7 -3.520208
8 -1.927874
9 -1.600583
dtype: float64
通过指定周期数来计算 pct_change()
代码:
df = pd.DataFrame(np.random.randn(10,2))
df.pct_change(periods = 2)
输出:
| 0 | 1 | |
|---|---|---|
| 0 | NaN | NaN |
| 1 | NaN | NaN |
| 2 | -0.095052 | -1.399525 |
| 3 | 0.073909 | -7.491512 |
| 4 | -0.882174 | -1.150202 |
协方差:cov()
cov() 方法用于计算 series 和 Data Frame 中的协方差。在计算 Data Frame 中的协方差时,会计算 Data Frame 中 series 之间的配对协方差。
在计算 series 和 Data Frame 中的协方差时,会排除任何缺失值
计算两个 series 之间的协方差
代码:
series1 = pd.Series(np.random.randn(200))
series2 = pd.Series(np.random.randn(200))
series1.cov(series2)
输出:
-0.14817157321848334
计算 Data Frame 的协方差
代码:
df = pd.DataFrame(np.random.randn(4,5),columns = ["a","b","c","d","e"])
df.cov()
输出:
| a | b | c | d | e | |
|---|---|---|---|---|---|
| a | 2.095402 | 0.191502 | 0.049185 | 0.090229 | -1.052856 |
| b | 0.191502 | 0.628889 | 0.377184 | -0.507893 | 0.404180 |
| c | 0.049185 | 0.377184 | 0.336220 | -0.077814 | 0.571139 |
| d | 0.090229 | -0.507893 | -0.077814 | 0.950198 | 0.164894 |
| e | -1.052856 | 0.404180 | 0.571139 | 0.164894 | 1.722546 |
相关性:corr()
相关性是使用 corr() 方法计算的,corr() 方法有一个方法参数,具有以下方法名称选项:
-
Pearson(默认)是标准相关系数
-
Kendall Tau 相关系数
-
Spearman 秩相关系数
计算 Data Frame 中 series 之间的相关性,使用默认的 Pearson
代码:
df = pd.DataFrame(np.random.randn(200,4), columns = ["a","b","c","d"])
df["a"]. corr(df["b"])
输出:
0.08425780768544051
使用 spearman 方法计算 Data Frame 中序列之间的相关性
代码:
df["a"]. corr(df["b"],method = "spearman")
输出:
0.053819845496137414
计算 Data Frame 列之间的成对相关性
代码:
df.corr()
输出:
| a | b | c | d | |
|---|---|---|---|---|
| a | 1.000000 | 0.084258 | -0.074284 | 0.054453 |
| b | 0.084258 | 1.000000 | 0.022995 | 0.029727 |
| c | -0.074284 | 0.022995 | 1.000000 | -0.028279 |
| d | 0.054453 | 0.029727 | -0.028279 | 1.000000 |
corrwith ()
Corrwith () 方法应用于 Data Frame,以计算不同 Data Frame 对象中相同标签的 Series 之间的相关性
代码:
index = ["a","b","c","d","e"]
columns = ["one","two","three","four"]
df1 = pd.DataFrame(np.random.randn(5,4), index = index, columns = columns )
df2 = pd.DataFrame(np.random.randn(4,4), index = index[:4], columns = columns)
df1.corrwith(df2)
输出:
one 0.277569
two -0.052151
three -0.754392
four 0.526614
dtype: float64
代码:
df2.corrwith(df1, axis=1)
输出:
a 0.346955
b -0.707590
c 0.711081
d 0.753457
e NaN
dtype: float64
Priya Sengar (Medium, Github) 是 Old Dominion University 的数据科学家。Priya 热衷于解决数据问题并将其转化为解决方案。
更多相关主题
统计建模与机器学习
原文:
www.kdnuggets.com/2019/08/statistical-modelling-vs-machine-learning.html
评论
统计模型是使用统计学构建数据的表示,然后进行分析以推断变量之间的关系或发现洞察。
机器学习是使用数学和/或统计模型来获得对数据的总体理解以进行预测。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 需求
至今,许多行业人士仍将这两个术语混用。虽然有些人认为没有 harm,但真正的“数据科学家”必须理解这两者之间的区别。
统计建模
统计建模是一种数学上近似世界的方法。统计模型包含可以用来解释其他变量之间关系的变量。我们使用假设检验、置信区间等来进行推断和验证我们的假设。
经典的例子是回归分析,我们通过一个或多个变量来找出每个解释变量对自变量的影响。
统计模型将具有抽样、概率空间、假设和诊断等,以进行推断。
我们使用统计模型来从特定数据集找到洞察。我们可以在相对较小的数据集上进行建模,以尝试理解数据的潜在性质。
本质上,所有统计模型都是错误的或不完美的。它们用于近似现实。有时模型的基本假设过于严格,不代表现实。
机器学习
 来源: https://existek.com/blog/deep-learning-vs-machine-learning/
来源: https://existek.com/blog/deep-learning-vs-machine-learning/
机器学习是使计算机在没有明确编程的情况下进行操作的科学。 - 安德鲁·吴
机器学习是教计算机像人类一样学习的方法。这种学习能力比人类更强,因此,当我们有大量数据超出普通人的理解能力或数据模式理解能力时,计算机的计算和存储能力可以超过人类。
简而言之,我们使用机器学习进行预测,并通过其对尚未学习的新数据的泛化能力来评估其性能。
我们进行交叉验证以验证数据的完整性,确保不会使模型过拟合(记住数据)或欠拟合(数据不足以学习)。
数据被清理和组织成机器可以理解的形式。这个过程几乎不涉及统计学。
机器学习的预测会根据其类型不同而有所不同:‘分类’,‘回归’,‘聚类’或‘监督学习’和‘非监督学习’。我们可以使用如 RMSE、MSE 等误差度量来处理回归问题,使用真正例、假正例等来处理分类问题。
结论
这两者是相辅相成的。真正的“数据科学家”需要两者都具备。机器学习的基础来源于统计理论和学习。有时机器学习似乎可以在没有扎实统计背景的情况下进行,但那些人并没有真正理解不同的细微差别。为了简化的代码并不意味着可以忽视对问题的深入理解。
有很多例子表明,统计建模可以解决当前的问题,而无需引入机器学习。
相关:
-
安德鲁·恩的“机器学习渴望”中的 6 个关键概念
-
数据科学家解释的 P 值
-
所有模型都是错误的——这是什么意思?
更多相关话题
统计学中的偏度是什么?

图片由编辑提供
偏度是什么?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 部门
当你听到统计学中提到分布时,我们中的许多人会提到最常见的对称钟形曲线,这种曲线我们很多人都熟悉,它被称为正态分布。
偏度衡量的是分布的非对称性。如果分布向左或向右移动——这意味着它是偏斜的。它表示给定分布与正态分布的差异——正态分布的偏度为零。
分布可以是右偏(正偏)、左偏(负偏)或零偏度。正偏度和负偏度的分布尾部会逐渐远离中位数。
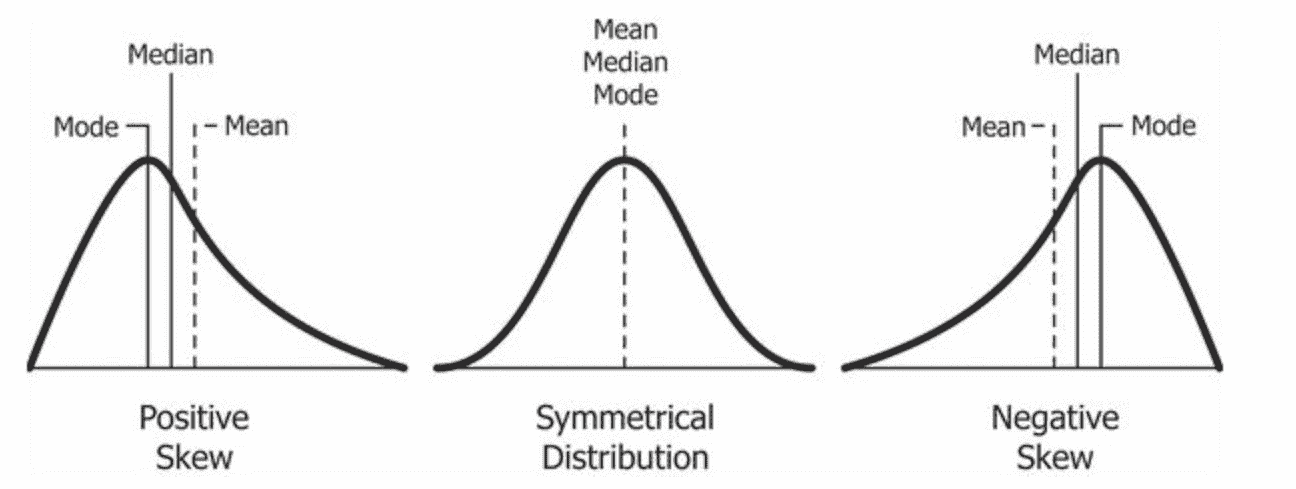
来源:维基百科
零偏度
零偏度是对称的——左右两侧互为镜像。正如我所说,我们中的许多人会将其称为正态分布——然而,正态分布并不是唯一具有零偏度的分布形式。如果分布是对称的,它将具有零偏度——例如均匀分布。
当分布具有零偏度时,这意味着均值和中位数相等。
右偏度
没错,右偏度也称为正偏度。正偏度在分布的右侧有更长或更粗的尾部。在正偏度中,均值通常大于中位数——这是因为尾部的值自然会对均值产生更大的影响,而不是中位数。
左偏度
左偏度也称为负偏度。负偏度在分布的左侧有更长或更粗的尾部。在负偏度中,均值会小于中位数。
如何计算偏度?
计算偏度最常用的方法是使用 Pearson 公式。可以使用两个公式:
Pearson 的第一个偏度系数:
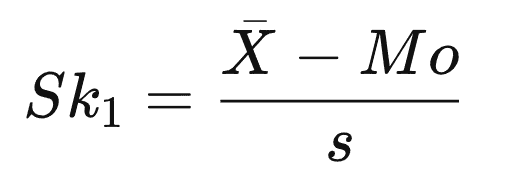
-
![公式]() = Pearson 的第一个偏度系数
= Pearson 的第一个偏度系数 -
![方程]() = 标准差
= 标准差 -
![方程]() = 平均值
= 平均值 -
![方程]() = 中位数值
= 中位数值
 = Pearson 的第一个偏度系数
= Pearson 的第一个偏度系数 = 标准差
= 标准差 = 平均值
= 平均值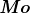 = 中位数值
= 中位数值皮尔逊第二偏度系数:
对偏斜数据怎么办?
在处理数据并应用统计工具时,许多人希望数据呈正态分布。然而,这并非总是如此,你可能会遇到偏斜数据。那么,你可以对需要正态分布的偏斜数据做些什么呢?
取决于偏斜的强度
根据你的偏斜数据的强度,你可能完全不需要做任何处理。这适用于轻度或中度偏斜的数据。
使用不同的模型
你可能需要使用另一种不以数据通常分布为目标的模型。例如,你可以选择非参数检验。这些检验不对数据做出假设。
变换
在统计偏度的意义上,变换是指对变量的所有观测值应用相同的函数。你选择变换偏斜数据的方式取决于你所面对的偏斜类型,例如,是中度偏斜还是强烈偏斜?
总结
我希望这篇文章能帮助你更好地理解偏度是什么、不同类型的偏度、如何计算它,以及当你遇到偏斜数据时下一步该怎么做。
如果你想了解更多关于统计术语的解释,可以阅读:描述性统计关键术语解析
Nisha Arya 是一名数据科学家和自由技术写作人。她特别感兴趣于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何/可以促进人类生命的持久性。作为一个热衷的学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助引导他人。
更多相关话题
使用一行代码进行统计和可视化探索性数据分析
原文:
www.kdnuggets.com/2020/09/statistical-visual-exploratory-data-analysis-one-line-code.html
评论
由布伦达·哈利,市场数据专家

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
在我看来,探索性数据分析(EDA)是新数据集机器学习建模中最重要的部分。如果 EDA 执行不当,我们可能会用“未清理”的数据开始建模,这就像雪球一样,一开始小,之后变得越来越大,问题也越来越严重。
优秀探索性数据分析的基本元素
探索性数据分析可以根据你的需求深入进行,但基本分析需要包含以下元素:
-
首值和末值
-
数据集形状(#行和#列)
-
数据/变量类型
-
缺失值和空值
-
重复值
-
描述性统计(均值、最小值、最大值)
-
变量分布
-
相关性
我喜欢手动进行 EDA 以更好地了解我的数据,但几个月前,Adi Bronshtein 向我介绍了 Pandas Profiling。由于处理时间较长,我通常在想要快速探索小数据集时使用它,希望它也能加快你的 EDA 进程。
开始使用 Pandas Profiling
在这个演示中,我将对NASA 的陨石降落数据集进行 EDA。
你已经运行了吗?
瞧,这很简单!
现在有趣的部分开始了。
在他们的文档中了解更多关于 Pandas Profiling 的信息:pandas-profiling.github.io/pandas-profiling/docs/
你喜欢这篇文章吗?你可能会想查看最佳免费数据科学电子书。
简介:布伦达·哈利 (领英) 是一位驻华盛顿特区的市场数据专家。她对女性在技术和数据领域的参与充满热情。
原文。已获许可转载。
相关:
-
在 3 分钟内理解偏差-方差权衡
-
增强版的探索性数据分析
-
用 D-Tale 让你的 Pandas 数据框活起来
更多相关话题
5 个数据科学家需要知道的有用统计信息
原文:
www.kdnuggets.com/2019/06/statistics-data-scientists-know.html
评论

数据科学可以实际定义为从数据中获得额外信息的过程。在进行数据科学时,我们真正尝试做的是解释所有数据在现实世界中的意义,超越数字本身。
为了提取复杂数据集中嵌入的信息,数据科学家采用了包括数据探索、可视化和建模在内的多种工具和技术。在数据探索中常用的一个非常重要的数学技术类别是统计学。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
从实际意义上讲,统计学使我们能够定义数据的具体数学摘要。与其试图描述每一个数据点,我们可以利用统计学来描述数据的一些属性。这通常足以让我们提取有关数据结构和构成的一些信息。
有时,当人们听到“统计学”这个词时,他们会想到一些过于复杂的东西。是的,它可能会变得有点抽象,但我们并不总是需要诉诸复杂的理论来从统计技巧中获得一些价值。
统计学的基本部分通常在数据科学中最具实际用途。
今天,我们将探讨 5 个对数据科学有用的统计信息。这些不会是疯狂抽象的概念,而是简单、实用的技巧,效果显著。
让我们开始吧!
(1) 集中趋势
数据集或特征变量的集中趋势是该集合的中心或典型值。这个概念是,可能存在一个单一的值可以最好地描述(在一定程度上)我们的数据集。
例如,假设你有一个以 (100, 100) 为 x-y 位置的正态分布。那么点 (100, 100) 是集中趋势,因为在所有选择的点中,它提供了对数据的最佳总结。
在数据科学中,我们可以使用中心趋势度量来快速了解数据集的整体情况。数据的“中心”可以提供非常有价值的信息,告诉我们数据集的偏差情况,因为无论数据围绕哪个值旋转,本质上都是一种偏差。
有两种常见的方法来数学上选择中心趋势。
均值
数据集的均值是平均值,即数据围绕的数值。计算平均值时使用的所有值在定义均值时被权重相同。
例如,我们来计算以下 5 个数字的均值:
(3 + 64 + 187 + 12 + 52) / 5 = 63.6
均值非常适合计算实际的数学平均值。使用像 Numpy 这样的 Python 库来计算也非常迅速。
中位数
中位数是数据集中的中间值,即如果我们将数据从最小到最大(或从最大到最小)排序,然后取数据集中的中间值,那就是中位数。
我们再次计算这 5 个数字的中位数:
[3, 12, 52, 64, 187] → 52
中位数值与均值 63.6 相差甚远。它们都没有对错之分,但我们可以根据具体情况和目标选择使用其中之一。
计算中位数需要对数据进行排序——如果数据集很大,这将不太实际。
另一方面,中位数对异常值的鲁棒性会比均值更强,因为如果存在一些非常高的异常值,均值会被拉向某一方向。
均值和中位数可以用简单的 numpy 一行代码来计算:
numpy.mean(array)
numpy.median(array)
(2) 分布
在统计学的范畴内,数据的分布是指数据被压缩到单个值附近的程度,或者在更广泛的范围内扩展的程度。
看一下下面的高斯概率分布图——想象这些是描述实际数据集的概率分布。
蓝色曲线的分布值最小,因为其数据点大多落在一个相对较窄的范围内。红色曲线的分布值最大,因为大多数数据点占据了更广泛的范围。
图例展示了这些曲线的标准差值,下一节会进行解释。
标准差
标准差是量化数据分布最常见的方法。计算标准差涉及 5 个步骤:
-
计算均值。
-
对每个数据点,计算其距离均值的平方。
-
汇总第 2 步的值。
-
按数据点数量进行除法。
-
取平方根。
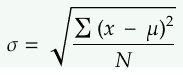
较大的值意味着我们的数据在均值周围“分布更广”。较小的值则意味着我们的数据更集中在均值附近。
使用 Numpy 可以这样轻松计算标准差:
numpy.std(array)
(3) 百分位数
我们还可以使用百分位数进一步描述数据点在范围内的位置。
百分位数描述了数据点在数值范围中位置的精确度。
更正式地说,第 p 百分位数是数据集中可以将其分成两部分的值。下部分包含p百分比的数据,即第 p 百分位数。
例如,考虑下面的 11 个数字:
1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21
数字 15 是第 70 百分位数,因为当我们在数字 15 处将数据集分成两部分时,剩余数据中 70%小于 15。
百分位数结合均值和标准差可以很好地帮助我们了解某个特定点在数据的分布/范围中的位置。如果它是异常值,则其百分位数会接近两端——低于 5%或高于 95%。另一方面,如果百分位数接近 50,则说明它接近我们的中心趋势。
可以使用 Numpy 计算数组的第 50 百分位数,如下所示:
numpy.percentile(array, 50)
(4) 偏度
数据的偏度衡量其不对称性。
偏度的正值意味着值集中在数据点中心的左侧;负偏度意味着值集中在数据点中心的右侧。
下面的图表提供了一个很好的示例。
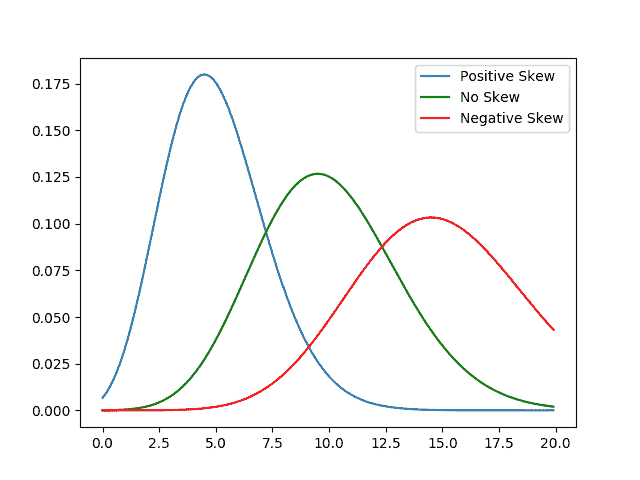
我们可以使用以下方程计算偏度:
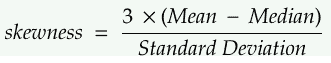
偏度将使我们了解数据分布与高斯分布的接近程度。偏度的幅度越大,我们的数据集与高斯分布的距离越远。
这很重要,因为如果我们对数据的分布有大致了解,我们可以为特定的分布量身定制要训练的机器学习模型。此外,并非所有机器学习建模技术对非高斯数据都有效。
再次强调,统计数据在我们进入建模之前提供了有见地的信息!
这是我们如何在 Scipy 代码中计算偏度:
scipy.stats.skew(array)
(5) 协方差和相关性
协方差
两个特征变量的协方差衡量它们的“相关性”。如果两个变量具有正协方差,则当一个变量增加时,另一个变量也会增加;如果有负协方差,则特征变量的值将朝相反方向变化。
相关性
相关性只是归一化(缩放)后的协方差,我们通过将分析的两个变量的标准差乘积进行除法来实现。这有效地将相关性的范围限制在-1.0 到 1.0 之间。
如果两个特征变量的相关性为 1.0,则这两个变量具有完全的正相关性。这意味着如果一个变量按给定的量变化,则第二个变量也会按比例在同一方向变化。
 PCA 用于降维的示意图
PCA 用于降维的示意图
小于 1 的正相关系数表示正相关性不完美,相关性的强度随着系数接近 1 而增加。负相关系数的情况也是如此,只是特征变量的值方向相反,而不是相同方向变化。
了解相关性对使用主成分分析(PCA)进行降维的技术极为有用。我们首先计算相关矩阵——如果有 2 个或更多的变量高度相关,则它们在解释数据时实际上是冗余的,可以丢弃一些以减少复杂性。
个人简介:George Seif 是一位认证的极客和 AI / 机器学习工程师。
相关:
-
数据科学家需要了解的 5 个基本统计概念
-
数据科学家需要掌握的 10 种统计技术
-
数据科学统计入门
更多相关话题
数据科学中的统计学:理论与概述
原文:
www.kdnuggets.com/statistics-in-data-science-theory-and-overview

作者插图 | 来源:Flaticon.
你是否有兴趣掌握统计学,以在数据科学面试中脱颖而出?如果是,你不应该仅仅为了面试而学习。理解统计学可以帮助你从数据中获得更深入、更细致的见解。
我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业之路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 需求
在这篇文章中,我将展示提高数据科学问题解决能力所需了解的最关键的统计学概念。
统计学导论
当你想到统计学时,你的第一反应是什么?你可能会想到以数字方式表达的信息,例如频率、百分比和平均值。仅从电视新闻和报纸上,你就能看到全球的通货膨胀数据、你所在国家的就业和失业人数、街头的死亡事件数据以及调查中每个政党的投票百分比。所有这些例子都是统计学的应用。
这些统计数据的生产是一个名为统计学的学科的最明显应用。统计学是一门研究收集、解释和呈现实证数据的方法的科学。此外,你可以将统计学领域分为两个不同的部门:描述性统计学和推断统计学。
年度人口普查、频率分布、图表和数值总结是描述性统计学的一部分。推断统计学指的是一套方法,允许根据人口的一部分(称为样本)来概括结果。
在数据科学项目中,我们大多数时间都在处理样本。因此,我们用机器学习模型获得的结果是近似的。一个模型可能在特定样本上表现良好,但这并不意味着它在新的样本上也会表现良好。一切都依赖于我们的训练样本,它需要具有代表性,以便能够很好地概括总体的特征。
使用图表和数值总结进行探索性数据分析
在数据科学项目中,探索性数据分析是最重要的步骤,它使我们能够通过汇总统计和图形表示对数据进行初步调查。它还允许我们发现模式、识别异常和检查假设。此外,它有助于发现数据中可能存在的错误。
在探索性数据分析中,关注的中心是变量,这些变量可以分为两种类型:
-
如果变量在数值尺度上测量,则为数值型。它可以进一步分类为离散型和连续型。当变量具有明显的量化特征时,它是离散的。离散变量的例子有学位等级和家庭人数。当我们处理连续变量时,可能的值集位于有限或无限区间内,例如身高、体重和年龄。
-
如果变量通常由两个或更多类别组成,则为分类变量,例如职业状态(已就业、失业和求职者)和工作类型。与数值变量一样,分类变量也可以分为两种不同类型:序数型和名义型。当类别之间有自然顺序时,变量为序数型。例如,薪资可以分为低、中和高等级。当分类变量没有任何顺序时,它是名义型。名义型变量的一个简单例子是性别,包括女性和男性。
单变量数据的探索性数据分析
分布形状。作者插图。
要了解数值特征,我们通常使用 df.describe() 来概览每个变量的统计数据。输出包括计数、平均值、标准差、最小值、最大值、中位数、第一四分位数和第三四分位数。
所有这些信息也可以通过图形表示来查看,称为箱线图。箱体中的线是中位数,而下边缘和上边缘分别对应于第一四分位数和第三四分位数。除了箱体提供的信息外,还有两条线,也称为须状线,代表分布的两个尾部。所有在须状线边界之外的数据点都是异常值。
从这个图中,还可以观察到分布是否对称或不对称:
-
如果分布呈钟形,中位数大致与均值重合且须状线长度相同,则分布为对称。
-
如果中位数接近第三四分位数,则分布右偏(正偏)。
-
如果中位数接近第一四分位数,则分布左偏(负偏)。
分布的其他重要方面可以通过直方图可视化,该直方图统计每个区间中的数据点数量。可以注意到四种类型的形状:
-
一个峰值/模式
-
两个峰值/模式
-
三个或更多的峰/众数
-
均匀且没有明显的众数
当变量是类别型时,最好的方法是观察每个特征因子的频率表。为了更直观的可视化,我们可以使用条形图,根据变量的不同选择垂直或水平条形。
双变量数据的 EDA
散点图展示了 x 和 y 之间的正线性关系。插图由作者提供。
我们之前列出了理解单变量分布的方法。现在,是时候研究变量之间的关系了。为此,通常计算皮尔逊相关系数,它是两个变量之间线性关系的度量。这个相关系数的范围在-1 和 1 之间。相关值越接近这两个极端中的一个,关系越强。如果接近 0,则两个变量之间的关系较弱。
除了相关性,还有散点图用于可视化两个变量之间的关系。在这种图形表示中,每个点对应于一个特定的观察值。当数据的变异性很大时,通常不太有用。为了从这对变量中捕获更多信息,可以添加平滑线和转换数据。
概率分布
对概率分布的了解可以在处理数据时产生差异。
这些是数据科学中最常用的概率分布:
-
正态分布
-
卡方分布
-
均匀分布
-
泊松分布
-
指数分布
正态分布
正态分布示例。插图由作者提供。
正态分布,也称为高斯分布,是统计学中最常见的分布。它的特点是钟形曲线,中间高,两端尾部。它是对称的且单峰的。此外,正态分布有两个关键参数:均值和标准差。均值与峰值重合,而曲线的宽度由标准差表示。有一种特殊的正态分布,称为标准正态分布,其均值为 0,方差为 1。它是通过从原始值中减去均值,然后除以标准差得到的。
学生 t 分布
学生 t 分布示例。插图由作者提供。
它也被称为具有 v 自由度的 t 分布。与标准正态分布一样,它是单峰的且围绕零对称。它与高斯分布略有不同,因为它在中间的质量较少,而尾部的质量较多。当样本量较小时,会考虑使用它。样本量增加得越多,t 分布将越趋近于正态分布。
卡方分布
卡方分布的示例。作者插图。
这是伽玛分布的一个特例,以其在假设检验和置信区间中的应用而著名。如果我们有一组正态分布且独立的随机变量,我们计算每个随机变量的平方值并求和,最终的随机值遵循卡方分布。
均匀分布
均匀分布的示例。作者插图。
这是另一种在数据科学项目中你肯定会遇到的流行分布。其核心思想是所有结果发生的概率相等。一个流行的例子是掷一个六面骰子。正如你所知,骰子的每一面发生的概率是相等的,因此结果遵循均匀分布。
泊松分布
泊松分布的示例。作者插图。
它用于建模在特定时间间隔内随机发生多次的事件的数量。遵循泊松分布的例子包括社区中年龄超过 100 岁的人数、系统每天的故障次数、特定时间段内到达求助热线的电话数量。
指数分布
指数分布的示例。作者插图。
它用于建模在特定时间间隔内随机发生多次的事件之间的时间量。例子包括在求助热线等待的时间、直到下一次地震的时间、癌症患者剩余的生命年限。
假设检验
假设检验是一种统计方法,它允许根据样本数据对总体提出和评估假设。因此,它是一种推断统计方法。该过程始于对总体参数的假设,也称为原假设,需要进行检验,而备择假设(H1)则表示相反的陈述。如果数据与我们假设的差异很大,则拒绝原假设(H0),结果被称为“统计显著”。
一旦确定了两个假设,就需要遵循其他步骤:
-
设置显著性水平,这是用于拒绝零假设的标准。典型值为 0.05 和 0.01。这个参数? 决定了针对零假设的经验证据有多强,直到零假设被拒绝。
-
计算统计量,这是从样本中计算出的数值量。它帮助我们确定一个决策规则,以尽可能减少错误的风险。
-
计算p 值,这是获得与零假设中指定参数不同的统计量的概率。如果 p 值小于或等于显著性水平(例如:0.05),我们拒绝零假设。如果 p 值大于显著性水平,我们不能拒绝零假设。
存在各种各样的假设检验。假设我们正在进行一个数据科学项目,想要使用线性回归模型,这种模型以强假设的正态性、独立性和线性著称。在应用统计模型之前,我们更愿意检查一个特征的正态性,该特征涉及糖尿病成年女性的体重。Shapiro-Wilk 检验可以来救急。还有一个名为 Scipy 的 Python 库,包含了这个检验的实现,其中零假设是该变量服从正态分布。如果 p 值小于或等于显著性水平(例如:0.05),我们拒绝零假设。如果 p 值大于显著性水平,我们可以接受零假设,这意味着该变量具有正态分布。
最终思考
希望你觉得这个介绍有用。我认为掌握统计学是可能的,只要理论后面有实际的例子。这里肯定还有其他重要的统计学概念我没有覆盖,但我更愿意专注于在我的数据科学家经验中发现有用的概念。你知道其他对你工作有帮助的统计方法吗?如果你有有见地的建议,请在评论中告诉我。
资源:
Eugenia Anello 目前是意大利帕多瓦大学信息工程系的研究员。她的研究项目集中在持续学习与异常检测的结合上。
更多相关主题
使用 Julia 进行统计:免费电子书
原文:
www.kdnuggets.com/2020/09/statistics-julia-free-ebook.html
评论
关于数据科学编程语言的大多数辩论、讨论和争论通常集中在Python 和 R上。尽管这些可能是该领域使用最多的两种语言,但这并不意味着它们是唯一的选择,也不意味着它们是“最佳”选择之一。另一个额外的选择是Julia,这是一种快速、动态、开源的通用编程语言,被视为一种值得考虑的数据科学技能。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
我遇到的最佳数据科学语言介绍之一是《使用 Julia 进行统计:数据科学、机器学习和人工智能的基础》(Statistics with Julia: Fundamentals for Data Science, Machine Learning and Artificial Intelligence),由 Yoni Nazarathy 和 Hayden Klok 编写,目前还处于草稿阶段。该书的网站可以在这里找到,其附带的代码示例可以在这个 GitHub 仓库中找到。

此时你可能会问的第一个问题是“为什么选择 Julia?”,考虑到还有其他更广泛接受的选项。最好在继续之前解决这个问题,我们通过书中第一章的摘录来解答。
Julia 首先是一个科学编程语言。它非常适合用于统计、机器学习、数据科学以及轻量级和重型数值计算任务。它也可以集成到用户级应用中,但通常不会用于前端界面或游戏创建。它是一个开源语言和平台,Julia 社区汇聚了来自科学计算、统计和数据科学领域的贡献者。这使得 Julia 语言和包系统在将主流统计方法与科学计算领域的方法和趋势相结合方面处于良好的位置。
在解决了这些问题后,我们可以继续探讨为什么这本书特别适合用于学习 Julia 在数据科学中的应用。再从书的第一章:
问题:阅读本书是否需要具备统计或概率知识?
回答:本书没有预设统计或概率知识。因此,这本书是一个关于概率、统计、机器学习、数据科学和人工智能核心原则的自足指南。它特别适合工程师、数据科学家或科学专业人士,他们希望在探索 Julia 语言的同时,巩固他们在概率、统计和数据科学方面的核心知识。不过,书中使用了常规的数学符号和结果,包括线性代数、微积分和离散数学的基础知识。
问题:使用本书需要什么样的编程经验?
回答:虽然这本书不是一本入门编程书籍,但它并不假设读者是专业的软件开发人员。任何在其他语言中有过基本编码经验的读者,都能够跟随代码示例及其描述。
这解答了你在开始一本关于统计编程的书之前可能会有的两个常见问题:是否需要编程知识作为前提;是否需要统计知识作为前提?这两个问题的答案都是不需要,这使得本书真正适合初学者。
本书的目录,包括附录:
-
介绍 Julia
-
基本概率
-
概率分布
-
数据处理和总结
-
统计推断概念
-
置信区间
-
假设检验
-
线性回归及其扩展
-
机器学习基础
-
动态模型的模拟
-
Julia 中的操作指南
-
额外的语言特性
-
附加包
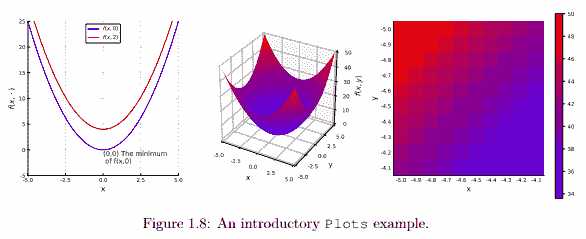
本书的第 1.3 节,通过示例快速入门,是你如果对 Julia 语言不熟悉时开始学习的好地方。在前一节快速了解语言基础之后,你将直接进入编码,进行一些非平凡的示例,包括冒泡排序、字符串处理、JSON 解析和马尔科夫链稳态。
随着本章的深入,书中涵盖了图表和图形、随机数生成和蒙特卡罗模拟,并且介绍了如何将 Julia 与其他语言集成。下一章将涉及统计概念,从这一点起,概念相互递进,逐步引入更高级的主题,如统计推断、置信区间、假设检验、线性回归、机器学习等。
这是我一直在等待的资源,它可以有效地教我用我想要的方式学习 Julia 数据科学。我希望你和我一样,对开始这段旅程感到兴奋。
相关:
-
以惊人的速度处理复杂逻辑:尝试 Julia 数据科学
-
数据科学基础:免费的电子书
-
理解机器学习:免费的电子书
更多相关话题
数据科学家常犯的前 10 个统计错误
原文:
www.kdnuggets.com/2019/06/statistics-mistakes-data-scientists.html
评论
作者 Norman Niemer,首席数据科学家
数据科学家是一个“在统计学上比任何软件工程师都要出色,而在软件工程上又比任何统计学家都要优秀”的人。在 数据科学家常犯的前 10 个编程错误 中,我们讨论了统计学家如何成为更好的编码者。在这里,我们讨论了编码者如何成为更好的统计学家。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 管理
每个示例的详细输出和代码可在 github 和一个 互动笔记本中找到。代码使用了工作流管理库 d6tflow,数据则与数据集管理库 d6tpipe 共享。
1. 没有充分理解目标函数
数据科学家希望建立“最佳”模型。但美在于观察者的眼中。如果你不知道目标和目标函数是什么以及它是如何运作的,那么你很可能无法建立“最佳”模型。顺便提一下,目标可能甚至不是一个数学函数,而是改进业务指标。
解决方案:大多数 Kaggle 冠军会花很多时间了解目标函数以及数据和模型如何与目标函数相关。如果你在优化业务指标,将其映射到一个合适的数学目标函数上。
示例:F1 分数通常用于评估分类模型。我们曾经建立过一个分类模型,其成功与否取决于模型的准确率。F1 分数具有误导性,因为它显示模型的正确率约为 60%,而实际上模型的正确率只有 40%。
f1 0.571 accuracy 0.4
2. 没有关于某件事为何应该有效的假设
数据科学家通常想要构建“模型”。他们听说 XGBoost 和随机森林效果最好,所以就使用这些。他们阅读有关深度学习的资料,也许这会进一步改善结果。他们在没有查看数据、没有形成假设哪个模型最有可能捕捉数据特征的情况下,将模型扔向问题。这也使得解释你的工作变得非常困难,因为你只是随意地将模型应用到数据上。
解决方案:查看数据!了解数据的特征,并形成一个假设,哪个模型可能最能捕捉这些特征。
示例:在没有运行任何模型的情况下,仅通过绘制这个样本数据,你可以清楚地看到 x1 与 y 之间是线性相关的,而 x2 与 y 的关系不大。 
3. 在解释结果之前没有查看数据
另一个没有查看数据的问题是,你的结果可能会受到离群值或其他伪影的严重影响。这对于最小化平方和的模型尤其如此。即使没有离群值,你也可能会遇到不平衡的数据集、剪辑或缺失值以及各种你在课堂上未曾见过的真实数据伪影问题。
解决方案:非常重要,以至于值得重复:查看数据!了解数据的性质如何影响模型结果。
示例:在存在离群值的情况下,x1 的斜率从 0.906 改变为 -0.375! 
4. 没有天真的基准模型
现代机器学习库几乎让这一切变得太简单了……只需更改一行代码,你就可以运行一个新的模型。再来一个。再来一个。误差指标在降低,调整参数——太棒了——误差指标进一步降低……有了所有这些模型的华丽功能,你可以忘记那些笨拙的数据预测方法。没有那个天真的基准,你就没有一个好的绝对比较来评估你的模型的好坏,它们可能在绝对意义上都是糟糕的。
解决方案:你能用什么最傻的方法预测一个值?使用最后已知的值、(滚动)均值或某个常量(例如 0)构建一个“模型”。将你的模型表现与零智商预测猴子的表现进行比较!
示例:在这个时间序列数据集上,model1 的 MSE 为 0.21,model2 的 MSE 为 0.45,因此 model1 应该优于 model2。但等等!只用最后已知的值,MSE 下降到 0.003!
ols CV mse 0.215
rf CV mse 0.428
last out-sample mse 0.003
5. 错误的样本外测试
这可能会毁掉你的职业生涯!你构建的模型在研发阶段表现出色,但在生产环境中却表现极差。你所说的会带来奇迹的模型正在导致非常糟糕的业务结果,可能让公司损失超过百万美元。所有剩下的错误,除了最后一个,都需要集中在这个问题上。
解决方案:确保你在现实的外样本条件下运行模型,并理解它何时表现良好,何时表现不佳。
示例:在样本内,随机森林的表现远优于线性回归,均方误差为 0.048 vs 0.183,但在样本外表现却远差,均方误差为 0.259 vs 0.187。随机森林过度训练,不能在生产环境中表现良好!
in-sample
rf mse 0.04 ols mse 0.183
out-sample
rf mse 0.261 ols mse 0.187
6. 不正确的测试样本:对整个数据集应用预处理
你可能知道强大的机器学习模型可能会过度训练。过度训练意味着模型在训练样本中表现良好,但在测试样本中表现差。因此,你需要注意训练数据是否泄漏到测试数据中。如果不小心,每次进行特征工程或交叉验证时,训练数据可能会渗入测试数据,从而夸大模型的表现。
解决方案:确保你有一个真正的测试集,不包含任何来自训练集的泄漏。尤其要注意生产使用中可能出现的任何时间依赖关系。
示例:这很常见。预处理应用于整个数据集,然后再进行训练和测试拆分,这意味着你没有真正的测试集。预处理需要在数据拆分为训练集和测试集后单独应用,以确保它成为一个真正的测试集。在这种情况下,两种方法的均方误差(混合外样本 CV mse 0.187 vs 真实外样本 CV mse 0.181)差别不大,因为训练和测试之间的分布属性差异不大,但这可能并不总是如此。
mixed out-sample CV mse 0.187 true out-sample CV mse 0.181
7. 不正确的测试样本:横截面数据和面板数据
你被教导说交叉验证是你所需要的一切。sklearn 甚至为你提供了一些便利函数,所以你认为你已经完成了所有的步骤。但大多数交叉验证方法进行随机抽样,因此你可能会在测试集中得到训练数据,从而夸大性能。
解决方案:生成测试数据,使其准确反映你在实时生产使用中进行预测时的数据。尤其是在时间序列和面板数据中,你可能需要生成自定义的交叉验证数据或进行滚动测试。
示例:这里你有两个不同实体(如公司)的面板数据,这些数据在横截面上高度相关。如果你随机拆分数据,你会使用实际测试中没有的数据做出准确的预测,从而夸大模型性能。你认为通过使用交叉验证避免了第 5 个错误,并发现随机森林在交叉验证中表现远优于线性回归。但进行滚动前向测试以防止未来数据泄漏到测试中,结果表现反而更差!(随机森林的均方误差从 0.047 升高到 0.211,高于线性回归!)
normal CV
ols 0.203 rf 0.051
true out-sample error
ols 0.166 rf 0.229
8. 未考虑决策时可用的数据
当你在生产中运行一个模型时,它会接收到在你运行模型时可用的数据。这些数据可能与训练时假设的数据不同。例如,数据可能会有延迟发布,因此当你运行模型时,其他输入已发生变化,你可能正在使用错误的数据进行预测,或者你的真实 y 变量是不正确的。
解决方案:进行滚动的外部样本前向测试。如果我在生产中使用了这个模型,我的训练数据会是什么样的,即你有什么数据来进行预测?这就是你用来进行真实外部样本生产测试的训练数据。此外,考虑一下如果你根据预测采取了行动,这将在决策时产生什么结果?
9. 微妙的过度训练
你在数据集上花费的时间越多,你过度训练的可能性就越大。你不断调整特征和优化模型参数。你使用了交叉验证,所以一切都应该很好。
解决方案:在你完成模型构建后,尝试寻找另一种“版本”的数据集,这可以作为真正的外部样本数据集的替代。如果你是经理,有意地保留一些数据,使其不用于训练。
例子:将训练于数据集 1 的模型应用于数据集 2 显示 MSE(均方误差)翻了一倍多。它们仍然可以接受吗...? 这是一个判断问题,但你在#4 中的结果可能会帮助你决定。
first dataset
rf mse 0.261 ols mse 0.187
new dataset
rf mse 0.681 ols mse 0.495
10. “需要更多数据”谬论
反直觉的是,通常开始分析数据的最佳方法是从一个具有代表性的数据样本入手。这使你能够熟悉数据并建立数据管道,而无需等待数据处理和模型训练。但数据科学家似乎不喜欢这样——更多的数据更好。
解决方案:从一个小的代表性样本开始工作,看看你能从中获得什么有用的东西。将其交还给最终用户,他们能使用它吗?它解决了真正的痛点吗?如果没有,问题可能不在于你数据太少,而在于你的方法。
简历:Norman Niemer 是一家大型资产管理公司的首席数据科学家,他提供数据驱动的投资见解。他拥有哥伦比亚大学的金融工程硕士学位和伦敦 Cass 商学院的银行与金融学士学位。
原文。已获许可转载。
相关:
-
数据科学家犯的十大编码错误
-
即使是科学家也会犯的统计错误
-
你从未学过的关键统计数据……因为它们从未被教授
更多相关主题
数据科学中的统计学和概率论
原文:
www.kdnuggets.com/2022/06/statistics-probability-data-science.html

矢量来源 iconicbestiary
主要要点
-
大多数对数据科学感兴趣的初学者总是担心数学要求。
-
数据科学是一个非常定量的领域,需要高级数学。
-
但要开始,你只需掌握几个数学主题。
-
在本文中,我们讨论了统计学和概率论在数据科学和机器学习中的重要性。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
统计学和概率论
统计学和概率论用于特征可视化、数据预处理、特征变换、数据填补、降维、特征工程、模型评估等。本文将重点介绍数据科学领域初学者的基本统计学和概率论概念,包括:均值或期望值、方差和标准差、置信区间、中心极限定理、相关性和协方差、概率分布和贝叶斯定理。
均值或期望值
设X为一个具有N观察值的随机变量,则X的均值为:
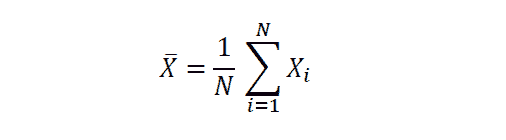
均值或期望值是集中趋势的度量。
方差和标准差
设X为一个具有N观察值的随机变量,则X的方差为:
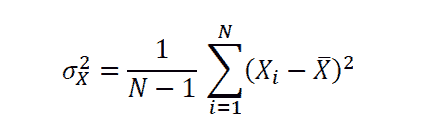
标准差是方差的平方根,是不确定性或波动性的度量。
置信区间
假设随机变量X服从正态分布,则 68%和 95%置信区间(CI)为:
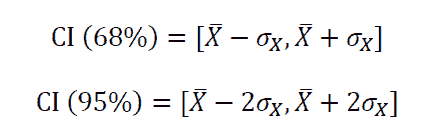
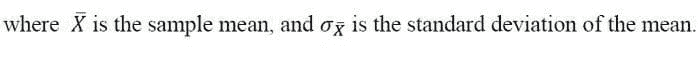
中心极限定理(CLT)
中心极限定理(CLT)指出,概率分布样本的样本均值是一个随机变量,其均值由总体均值给出,标准差由总体标准差除以N的平方根给出,其中N为样本大小。
设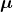 为总体均值,
为总体均值,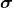 为总体标准差。如果我们从总体中抽取一个样本,样本大小为N,则根据中心极限定理,样本均值为
为总体标准差。如果我们从总体中抽取一个样本,样本大小为N,则根据中心极限定理,样本均值为
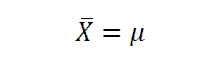
样本标准差由以下公式给出
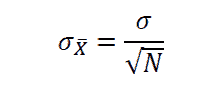
相关性和协方差
相关性和协方差是数据集中共同变化的度量。为了量化特征之间的相关程度,我们可以使用以下方程计算协方差矩阵:
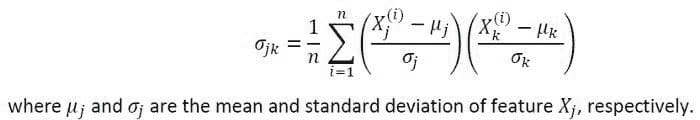
概率分布
尽管我们总是假设数据集中的变量或特征服从正态分布,但绘制概率分布图来可视化特征的分布仍然很重要。例如,使用 R 的 dslabs 包中的高度数据集,我们可以计算数据集中所有高度的概率分布,如下图 2 所示。
图 2
从图 2 中,我们观察到高度数据集近似正态分布,均值约为 68 英寸。现在,如果我们分别绘制男性和女性身高的概率分布,我们会观察到两条不同的曲线,如图 3 所示。
图 3
从图 3 中,我们观察到女性的平均身高(约 63 英寸)低于男性的平均身高(约 69 英寸),这表明从统计学角度来看,男性的平均身高高于女性。有关生成图 2 和图 3 所用的更多信息和代码,请参见本文:贝叶斯定理解释。
贝叶斯定理
贝叶斯定理 在二分类问题中扮演了重要角色。它用于解释二分类算法的输出。贝叶斯定理指出,两个事件 A 和 B 的条件概率由以下方程相关:
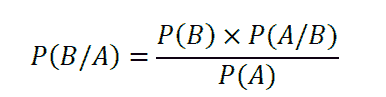
有关贝叶斯定理在二分类问题中的实现,请参见本文:贝叶斯定理解释。
总结
总结来说,我们讨论了 7 个对数据科学初学者至关重要的概率和统计概念。其他高级话题包括 AB 测试、假设检验、蒙特卡罗模拟等。
本杰明·O·泰约 是一位物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的创始人。之前,本杰明曾在中奥克拉荷马大学、大峡谷大学和匹兹堡州立大学教授工程和物理课程。
更多相关话题
哪些统计学主题对于在数据科学中表现出色是必要的?
原文:
www.kdnuggets.com/2016/08/statistics-topics-needed-excelling-data-science.html
评论
由 Sergey Feldman 提供,Data Cowboys。
“数据科学家”是一个模糊的新职位,你永远不知道成功需要哪些工具。我在工作中做的很多事情以前从未做过,但研究生阶段不仅是学习具体模型和技术,更是学习如何快速学习和数学思维的过程。
总的来说,我建议你能够(a)用数学思维,(b)将这些思维转化为代码。其他的你可以随时自学。但这里有一个大致按复杂程度递增的列表。

编码。 精通 Python 和/或 R。虽然还有其他选择,但这两个语言现在非常普及。
了解你的分布。 你应该对每种分布的用途有一个良好的直觉。 给定一些数据,你应该能够在许多场景中做到这一点:
问:我的数据是否适合用帕累托分布建模?
答:不,经验直方图不是单调递减的。
问:当然是高斯分布!
答:不,这里没有负值。
问:那指数分布呢?
答:不,这里没有零。
问:嗯,冯·米塞斯分布呢?
答:别傻了,我很确定这些数据不在圆的表面上...
问:对数正态分布!
答:听起来不错。还是把它画出来看看吧...
拟合。 一旦你掌握了分布,你应该知道如何以简洁的方式将它们拟合到数据中。从最大似然估计开始,然后再继续。
经典假设检验。 我认为 p 值和频率假设检验一般来说很难解释和理解(例如未能拒绝原假设等),但这两者仍然非常普遍。
马尔可夫链 + 铃声 + 其他附加功能。
基本贝叶斯思维与建模。 学会将一切看作概率分布,而不仅仅是单一值(如果适用的话)。能够组装模型并进行计算。
一些老派的统计学和概率论。 例如:“随机变量;变换,条件期望,矩生成函数,收敛,极限定理,估计;克拉美-拉奥下界,最大似然估计,充分性,附属性,完备性。拉奥-布莱克威尔定理。一些决策理论。”
回归! 首先是线性回归,然后是非线性回归。(惊讶!)
机器学习。 我知道你说的是“统计学”,但如果你想成为“数据科学家”,那么机器学习将是一个非常多功能和有用的工具包。而且,机器学习范围广泛,也许这可以成为另一个 Quora 问题。 =)
写作。 清晰、简洁、有说服力地传达你的想法。
祝好运!
个人简介:谢尔盖·费尔德曼 是一位机器学习和数据科学顾问。他是数据牛仔的创始人,现居于西雅图。
原文. 经许可转载。
相关:
-
为什么大数据陷入困境:他们忘记了应用统计学
-
大数据、圣经密码和邦费罗尼
-
15 个用于数据科学的数学 MOOCs
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
如何在机器学习业务中保持竞争力
原文:
www.kdnuggets.com/2017/01/stay-competitive-machine-learning-business.html
评论
作者:Vin Vashishta,V-Squared

虽然大多数企业刚刚开始涉足机器学习领域,但许多企业已经开始获益。技术迅速发展。被甩在后头是早期采纳者的主要担忧,也是快速跟随者的驱动力。
在迅速发展的新兴技术中保持竞争力已经是一项挑战。对于机器学习而言,这种挑战被技术复杂性、人才短缺以及不断变化的开源产品环境所加剧。像 Google 这样的公认专家正在采用一些创造性思维,保持领先于 Facebook、IBM 以及更新的挑战者 Microsoft 等公司。通过收购、积极参与开源项目以及众包解决他们无法内部解决的问题,Google 成功地保持了其顶尖地位。
大多数公司在机器学习方面不需要“走 Google 的路”。虽然机器学习的商业案例非常有说服力,但大多数商业需求并不足以支撑主要玩家的开支。那么中间的解决方案是什么?我从系统理论中找到了答案。为了在机器学习领域保持竞争力,企业需要比竞争对手做得更好,而不是做到最好。有一些简单的规则可以创造出这种环境。以下是我提供的一些建议。这份清单就像任何其他开源项目一样,欢迎在评论区提出贡献。
创建与保护独特的数据集
我想首先将焦点从大型算法上移开。大型算法是指认为算法越大或越复杂越好。如果这是事实,为什么 Google 和 Facebook 会如此积极地通过开源贡献分享它们的算法呢?
这些公司以及机器学习领域的许多其他参与者,通过访问独特的数据集获得了优势。原因非常简单。机器学习的学习过程依赖于数据集。这意味着,给定相同的算法,三家拥有三种不同数据集(在质量、规模、数据点等方面不同)的企业,会得出三种不同的模型/预测/输出。数据集越独特,差异和潜在优势就越大。
要保持独特,数据集不能被逆向工程到像 Wikidump 或 BLS 报告这样的公开数据集。这是什么意思?如果一个机器学习团队利用维基百科中的所有文本,创建了一个包含常见词汇的数据库,那么这不是一个独特的数据集,任何从中派生的数据集也不是。这可以被逆向工程到公开的数据集。比如说一个企业有一个客户支持呼叫中心。那里的数据独特吗?在某些方面是的,但要记住许多企业也有类似的呼叫中心数据。虽然这些数据特定于一个企业,但其一般趋势会在其他企业的数据中重复出现。
那么,什么是独特的呢?想想 Twitter。有没有其他人能在不付费的情况下访问所有来自用户的内容?Facebook 以及可能一两个其他平台。就这些,这使得他们的动态非常独特。让我们回到 Google。有没有其他人能访问那种搜索数据?没有。这些是独特的数据集。你如何在不“去 Google”的情况下获得独特的数据集?这就是商业战略规划发挥作用的地方。
从大算法转向独特数据的原因之所以如此重要,是因为它向战略规划过程中提出了“我们如何创建独特的数据集?”的问题。大多数公司将招聘数据科学家和机器学习专家视为采用技术的唯一必要步骤。这就是大算法思维成为问题的原因。
大多数的通用建议告诉企业招聘数据科学家并给他们业务问题。这是一个开始,但它忽略了他们需要的燃料,以便比最近的竞争对手解决这些问题。这个燃料就是数据。获取这些数据是一个需要跨部门和领导层赞助的公司范围内的倡议。
首先要查看的是现有的数据。在大多数中型到大型公司,甚至一些存在了很长时间的小型企业中,数据无处不在,没有一个人真正掌握公司拥有的所有数据。在我的一个客户那里,一个独特的数据集就藏在一个由一名员工负责维护了五年的电子表格中。其他人则在他们的网站、市场调查和移动应用程序中发现了金矿。一旦公司改变了思维方式以理解其价值,独特的数据就在那儿等待被发现。
数据科学和机器学习团队也需要一个获取独特数据的流程。这通常跨越部门,并且需要一个围绕它的流程才能成功。我不能告诉你在项目中多少次我说过,“如果我有这些数据会更好……”在发现向其他部门发出请求的难度后,我开始建立获取这些数据的流程。
这也是机器学习不能成为孤立团队的众多原因之一。他们需要成为强有力的沟通者和宣传者。这是因为我们经常需要市场营销团队来收集新数据,和 web/app 开发团队来为战略团队请求的项目构建新功能。如果这些团队不了解需求和遵循的过程,数据请求可能会消失在黑洞中。
一旦这些独特的数据集建立并投入生产,就需要像其他商业机密一样进行保护。这包括两个方面:防止盗窃和防止意外泄露。将数据集放在一个地方并控制访问权限。不允许多个团队在不同系统中保存副本。这使得很难知道哪个副本是“主版本”,并将保护它变成了一个噩梦。向所有有访问权限的人宣传这个数据集是公司的专有资产并且是公司竞争优势的关键。我见过一些团队因为不知道数据集有价值而将其交给客户的情况。这应该在保密协议和新员工培训中明确说明。
培养人才

我想摆脱另一种常见的机器学习认知——全能的机器学习工程师。这种观念认为一个人需要具备所有技能来从头到尾处理一个机器学习项目。由于当前人才短缺,公司在以成本效益的方式实现这种模式方面遇到了困难。
有几个原因使得寻找一个完整的“独角兽”团队是不切实际的。全球有经验的数据科学家不到 2 万人。现在将这个群体按拥有 5 年或以上机器学习经验的人进行细分,你会发现剩下的群体非常小。寻找一支顶尖团队既不具成本效益,也不符合时间的有效利用。
替代方案是从内部构建和培训团队。我看到这种方法有几个关键好处。首先是领域和文化专长。内部候选人了解业务,并且在应对业务文化方面经验丰富。他们是拥有同事支持的内部人员,而不是推动新议程的外部人员。他们了解核心业务,并且有第一手的业务挑战经验。
如果人才来源不当,学习曲线可能陡峭且昂贵。 内部搜索需要围绕几个角色进行结构化,而不是寻求培训候选人来填补所有角色。 第一个角色是数据科学软件工程师。 这个人将模型和数据集从原型转化为生产。 他们的主要技能是软件开发,通常涉及多个编程语言,如 Python、Java、R、C、C++、Scala 等。 他们还熟悉数学概念和符号,以及算法编程和库。 他们不需要成为统计大师或线性代数专家,但需要理解基础知识,以便成为团队的翻译层。
第二个角色与数据科学软件工程师相关联。 这就是数据科学分析师。 他们的核心能力是将数据转化为可操作洞察的数学和统计概念。 他们是数据科学专家,具备良好的编程技能;足以在至少一种语言中从概念到粗略原型。 他们会听取业务问题中的关键术语,以确定特定的算法方法;例如优化问题与分类问题。 他们能够将其转化为实验,然后形成概念验证解决方案。
第三个角色与数据科学分析师紧密相关,也将解决方案提供给数据科学软件工程师。 机器学习分析师的核心能力围绕机器学习和深度学习算法。 这通常与数据科学一起讨论,但它们是两个不同的研究领域,最理想的是由两个人分别承担。 这个人将更多时间集中在研究方面,较少关注原型制作。 虽然数据科学分析师每月会产生一两个解决方案,但机器学习分析师每两三个月才会产生一个解决方案。 他们专注于最棘手的业务挑战;那些现有数据科学方法无法很好解决的问题。
根据存储和处理的数据量以及实施的解决方案数量,可能还需要一名数据工程师来维护基础设施。 这个人有在 Spark、Hadoop、AWS 等平台上工作的丰富背景。 团队可能还需要一位数据治理专家。 这个人在数据安全、数据来源、数据隐私以及围绕数据管理的各种法规方面都是专家。
这些人如何培训以成功过渡到新的角色?认证和在线课程是最佳途径。可汗学院提供了多个课程,使具有数学背景的开发人员更熟悉高级数学概念。还有编码训练营和在线培训来提升软件开发能力。许多大学和学院提供数据科学和机器学习课程。这些课程可以帮助候选人将零碎的知识拼凑起来,准备好成功。
我还强烈建议引入该领域的专家,为团队提供基于经验的指导。这不一定需要全职或永久聘用。在某些情况下,每周 10 小时的长期支持或 6 个月的合同就足够让企业做好自主发展的准备。随着团队开始相互学习,拥有一个专家来引导学习并避免陷阱是非常值得的。
管理研究阶段的过程
这分为两个部分。首先是认识到研究在机器学习计划中的重要性。第二是理解研究过程以及如何管理它,以确保其在预算内交付成果。
研究阶段有几个驱动因素。我们可以获得哪些数据来解决业务问题?考虑到业务问题和可用数据,哪种方法效果最佳?(还有其他考虑因素……我在这里做了简化。)有哪些开源工具可用,需要多少修改才能使其满足需求?
完成这些任务通常需要大约一个月的时间。为什么?机器学习每天都在变化。算法、开源项目、开放数据、平台及其他一些组件不断被引入和改进。昨天有效的方法可能今天不再是最佳方案。没有研究阶段,企业可能会陷入过时的解决方案。这些方案比实际需要的更昂贵,并且会成为前进的障碍。
研究过程从清晰理解业务需求及所有相关考虑开始。团队越接近问题,解决方案越有效。花时间关注约束条件。解决方案需要如何运作?谁将使用这个解决方案,他们的要求是什么?定义可接受的准确性。细节对机器学习项目至关重要。没有这一步,机器学习项目不可避免地会偏离轨道。
从对需求的深入理解出发,进行高质量的解决方案研究。这里是驱动因素的答案:数据来源、数据质量、方法、工具/框架。通常,我会研究 3 到 4 个解决方案,因为原型设计过程是迭代的。构建最有前景的方案,但要有多个备选方案以防第一个方案未能证明其有效性。即使结果很有前景,也要验证每一个假设。假设会毁掉机器学习项目。不要等待完美。原型满足业务需求时就进行部署。改进可以在维护模式中完成。没有理由拖延向业务回馈价值。
管理流程。保持研究的进展意味着使其贴近业务需求,并保持透明。我建议团队、项目利益相关者和用户之间每周开会。讨论研究过程,并在后期演示解决方案。鼓励大家提出问题。让研究接受严格审查。让团队支持每一个假设。寻找数据和团队方法中的偏差。
3 个基本步骤
这三步之所以能保持企业竞争力,是因为很少有企业践行这些步骤。大多数从事机器学习项目的公司都以算法思维为主,追逐虚幻的目标,让研究过程失控。这会创造一个很难提供高质量解决方案的环境。一个在这三方面做得好的公司会脱颖而出。做到这三点中的所有三点,能够在机器学习领域不断演变的情况下保持竞争力。
原始帖子。已获得许可重新发布。
简介: Vin Vashishta,在数据科学和机器学习领域围绕简单性和盈利性构建了最受信任的品牌。他受到沃尔玛、埃森哲、微软、IBM 以及许多其他行业领袖的关注。他被 Agilience、Dataconomy 和 Onalytica 认可为预测分析和机器学习领域的思想领袖。
相关:
-
生成对抗网络 – 机器学习中的热门话题
-
优步化!将你的业务优步化
-
处理异常值的 3 种方法
我们的 3 大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
更多相关话题
如何保持 Python 知识的更新

图片来源:RealToughCandy.com
作为 Python 开发者,你是如何保持更新的?这是一个重要的问题,因为这是你职业生涯中最重要的事情之一,有助于你不断成长。技术进步很快,保持对所有变化和你专门编程语言中的具体情况的了解可能会很困难。
保持 Python 知识的更新将帮助你维持雇佣竞争力,获得新的机会,并继续拓展你的知识。
访问来源
了解 Python 新动态、变化、更新等的最佳方式是访问他们的网站:www.python.org。
在他们的 博客部分 中,Python 会定期更新年度报告、会议信息、漏洞修复、升级等。此外,你还可以注册他们的 新闻通讯,接收重要的社区新闻。你还可以在他们的 社区新闻 页面上跟进其他人用 Python 做的事情,并扩展你的知识。
如果你想了解最新动态,可以查看 Python 最新动态 部分,以保持对 Python 的了解。
Python 软件基金会 提供了一个 会员计划,自 2014 年起成为一个开放的会员组织。他们的目标是支持 Python 社区内的人,并提供资助计划,帮助 Python 用户参与开发活动、会议、聚会等。
这些都是保持自己作为 Python 用户的最新状态的非常好的方法。
阅读
只需阅读有关 Python 的内容。所有与 Python 相关的内容都应在你的阅读列表上。这可以通过各种博客和其他平台来实现,如 Google 新闻部分,你可以找到关于 Python 的最新文章……但也要理解,你会看到很多关于实际蛇的文章。
在 KDnuggets,我们有一个专门的部分用于所有与 Python 相关的博客,可以在 这里 阅读。
购买 Python 书籍没有坏处,即使你已经很熟练了。你可能会发现不同的方式来完成类似的任务,甚至学到一些新东西。
RealPython
我在学习 Python 时通过 YouTube 发现了 RealPython,这个网站自 2012 年起就存在了。如果你想保持对 Python 的了解,何不从一个全心全意专注于 Python 的团队那里获取信息呢!
他们目前在YouTube、Twitter、Facebook上可用,并且还有一个播客,你还可以注册他们的新闻通讯。他们还拥有一个私人社区 Slack 频道,你可以在这里遇到其他 Python 用户,或者他们喜欢称自己为“Pythonistas”的人。你可以讨论你的代码、职业、即将到来的教程主题等等。
最后但同样重要的是他们的会员服务! 会员服务的初衷是,当他们的创始人和总编辑 Dan Bader 对理解一旦你成为专业开发者后,你也会成为一个有责任的成年人这一点感到沮丧。因此,坐下来学习新工具和 Python 的各个方面变得非常困难。会员服务为你提供了数百个 Python 视频课程和每周发布的新课程内容,并且有一个支持性的 Python 社区,以便在你遇到问题时随时为你提供帮助。
Python 开发者社区
LinkedIn 上的Python 开发者社区目前有 867,766 名成员。该小组创建于 2007 年 9 月,旨在为一群专业的 Python 开发者和用户提供一个扩展知识、技能和网络的平台。这是一种良好的互动和社交方式,可以帮助你保持 Python 的最新状态。
你将看到有关 Scikit-Learn、Keras、NumPy、Pandas、Django、PyTorch、SciPy、TensorFlow、PyScript、Matplotlib、OpenCV 等等的主题。
会议/活动
另一种保持 Python 最新的方法是参加与 Python 相关的会议和活动。这样你可以了解其他人和组织在使用 Python 时做了些什么,并从中学习。你可以在我们的网站上了解更多关于这些会议的信息,包括以 Python 为重点的活动以及其他相关会议,点击这里。你还可以在PyCon上了解更多,这是一场专注于编程语言的会议。
你会惊讶于人们在幕后做了什么,这将是你们中的许多人探索同一路径的绝佳机会。你将获得 Python 大动作的第一手知识,让你领先于其他程序员。这也有助于你进行网络交流和认识新朋友;从而帮助你与 Python 社区建立更深层次的联系。
结论
有各种资源可以帮助你保持 Python 的最新状态;你只需要找到适合你的方法。也许你是一个喜欢见面的人——参加会议可能是适合你的途径。也许你是一个喜欢独自阅读的书虫——有大量的 Python 资源可以选择。
找到你的学习方法,以提升你的 Python 编程职业生涯!
尼莎·阿雅 是一位数据科学家和自由职业技术作家。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何/能否有助于人类寿命的延续。作为一名热衷的学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
如何保持对 AI 世界动态的关注
人工智能正在温和而坚定地改变世界。你不断尝试保持对最新动态的把握,学习新技能,并且至少在一定程度上预见机器学习中的即将到来的趋势。
那么,你如何跟上所有新闻,并在这个无尽的 AI 信息流中导航呢?

首先,你需要知道你想要什么,并正确地提出你的请求。
其次,你需要知道在哪里查看和关注,以跟上所有 AI 趋势。这就是我们为你准备的一小份有价值资源清单将帮助你的地方。
从...
arXiv.org
现在,它是 AI/ML 知识最重要的宝库。几乎所有 AI 领域发布的论文都会出现在这里。这也不奇怪,因为它是免费的、舒适的,并且具有分类和排序等简单但实用的选项。我们非常喜欢这个资源,因为你可以在这里找到几乎任何东西。
但是 AI 行业发展迅速,新论文和新方法层出不穷。信息流如此庞大,有时几乎难以跟上。因此,如果你访问这个资源,最好带有具体的请求。
或访问...
Arxiv-sanity & Arxiv-sanity-lite
为了解决信息过载的问题,五年前,特斯拉的高级总监 Andrej Karpathy 创建了Arxiv-sanity,这是一个只收录最相关和高质量论文的资源。它是一种优质内容的筛选器。在无尽信息的海洋中,这是一个绝妙的主意。
Arxiv-sanity 拥有许多 ArXiv 上没有的实用功能(或者说它们很不直观)。例如,最新热门和最高关注标签非常方便实用。
另一个非常棒的附加功能是创建个人账户,你可以添加好友,查看他们的转发,分享信息,还有更多其他功能。
然而,Andrew 决定不止步于此。不久前,他对系统进行了完全重写,推出了Arxiv-sanity-lite。
还有...
Papers With Code
当你进入Papers With Code时,你首先会看到一个美丽的设计。终于!
这是一个极其出色的资源,具有透明的点赞系统,使你能够快速识别趋势。你可以找到并比较任何基准,这点非常重要。你还可以在这里找到论文本身的实现。
Papers With Code 的另一个酷炫之处在于你可以在方法标签中搜索论文和个别方法,提升你对神经网络基本构建块的理解。
每 3-4 周,该资源会通过newsletter发布最突破技术的精华。
Papers With Code 拥有数据集搜索和内部门户,你可以在这里跟踪机器学习研究的动态,以及计算机科学、物理学、数学、统计学和天文学的动态。
你永远不会出错于……
是的,我们都知道并喜欢 Twitter。它是一个分享发现的大型社区。你总能在这里找到一些有趣的内容,而无需太多“搜索压力”。
当然,这里的信息并不总是最新和最鲜活的,但你可以放松脑袋,进入“滚动模式”。有时这非常有帮助。你只需要放松,轻松浏览你认为值得的论文。
我最喜欢关注的账号绝对是:@ak92501
你还可以查看:
在这里你会找到最新和最相关论文的高质量解析。
280 字符的推文对于这样的任务有时不够,所以作者在这里发布简明的新闻和公告。
但这不应该阻止你。一定要访问作者的网站,他用简单的语言解释最新论文中的复杂概念。
是的,这个频道上可能看起来没有有用的信息流。
但这里有一些激励我们继续从事机器学习的东西,让我们感受到其惊人可能性的巨大规模。
看一看频道创作者发布的 AI 艺术作品,它们真是令人难以置信。让你对即将从事的行业充满热爱。
最后……
YouTube
以下几个频道值得一提。
在这里你会发现对机器学习领域最新论文和新闻的深入分析。
频道上的标准视频通常长达 20 到 60 分钟。因此,它是任何喜欢边吃东西边观看有用视频的人的完美格式。
“生活在这样一个时代真好!”
这个频道提供关于最新机器学习新奇事物的 5 分钟视频评论。是的,有时会稍晚一些,但总是高质量的。
“StatQuest 将复杂的统计学和机器学习方法拆解成易于理解的小块。”
一切机器学习初学者可能需要的完美起点。
这个频道涵盖了机器学习和数据科学的基本概念。
你还可以在这里找到行业洞察。
该频道将吸引任何初学机器学习的人。

在充满竞争的 AI 新闻世界中保持领先并不容易。可以将 AI 研究的世界比作在海洋中游泳:如果你不知道游向哪里,你就会在浩瀚的水域论文中挣扎。 😃
-
学会提出正确的请求。
-
了解你拥有的资源及相关数据和人性化的用户体验。
-
小心地受新兴方法的启发,这些方法正在所有行业领域涌现。
希望这篇文章对你有所帮助。
Bohdan Pytaichuk (@BetterBohdan) 是深度学习研究员、AI 倡导者以及 AI House 的首席信息官。他拥有计算机科学硕士学位。曾从零开发多个机器学习解决方案,他致力于将乌克兰转变为全球最大的 AI 生态系统之一。这项活动包括:向国家的有才华的学生推广 AI;教育他们;将他们的知识与商业需求对接。
更多相关话题
从头开始构建你的第一个机器学习模型的逐步教程
原文:
www.kdnuggets.com/step-by-step-tutorial-to-building-your-first-machine-learning-model

图片由 pch.vector 提供,来源于 Freepik
大家好!我相信你们阅读本文是因为你们对机器学习模型感兴趣并想要构建一个。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
无论你之前是否尝试过开发机器学习模型,或是完全新手,本文都将指导你通过开发机器学习模型的最佳实践。
在本文中,我们将按照以下步骤开发一个客户流失预测分类模型:
1. 业务理解
2. 数据收集与准备
-
收集数据
-
探索性数据分析(EDA)和数据清理
-
特征选择
3. 构建机器学习模型
-
选择合适的模型
-
数据拆分
-
训练模型
-
模型评估
4. 模型优化
5. 部署模型
如果你对构建你的第一个机器学习模型感到兴奋,就开始吧。
理解基础知识
在深入机器学习模型开发之前,让我们简要解释一下机器学习、机器学习的类型以及本文中将使用的一些术语。
首先,让我们讨论可以开发的机器学习模型的类型。常见的四种机器学习类型是:
-
监督式机器学习是一种从标记数据集中学习的机器学习算法。根据正确的输出,模型从模式中学习并尝试预测新数据。监督式机器学习有两个类别:分类(类别预测)和回归(数值预测)。
-
无监督机器学习是一种试图在没有指导的情况下发现数据中模式的算法。与监督机器学习不同,这种模型不依赖于标签数据。该类型有两个常见类别:聚类(数据分割)和降维(特征缩减)。
-
半监督机器学习结合了标记数据集和未标记数据集,其中标记数据集指导模型识别未标记数据中的模式。最简单的例子是自训练模型,它可以根据标记数据的模式对未标记数据进行标记。
-
强化学习是一种可以与环境交互并根据行动(获得奖励或惩罚)做出反应的机器学习算法。它通过奖励系统最大化结果,并通过惩罚避免不良结果。该模型应用的一个例子是自动驾驶汽车。
你还需要了解一些术语来开发机器学习模型:
-
特征:在机器学习模型中用于进行预测的输入变量。
-
标签:模型尝试预测的输出变量。
-
数据拆分:将数据分离为不同集合的过程。
-
训练集:用于训练机器学习模型的数据。
-
测试集:用于评估训练模型性能的数据。
-
验证集:在训练过程中用于调整超参数的数据。
-
探索性数据分析(EDA):分析和可视化数据集的过程,以总结其信息并发现模式。
-
模型:机器学习过程的结果。它们是数据中模式和关系的数学表示。
-
过拟合:当模型过于拟合数据噪声而失去泛化能力时发生。模型在训练集上表现良好,但在测试集上表现不佳。
-
欠拟合:当模型过于简单而无法捕捉数据中的潜在模式时发生。模型在训练集和测试集上的表现可能较差。
-
超参数:用于调整模型的配置设置,这些设置在训练开始之前确定。
-
交叉验证:一种通过多次将原始样本划分为训练集和验证集来评估模型的技术。
-
特征工程:利用领域知识从原始数据中提取新的特征。
-
模型训练:使用训练数据学习模型参数的过程。
-
模型评估:使用机器学习指标如准确率、精确率和召回率来评估训练模型的性能。
-
模型部署:使训练好的模型在生产环境中可用。
掌握了这些基础知识后,让我们学习如何开发我们的第一个机器学习模型。
1. 业务理解
在任何机器学习模型开发之前,我们必须理解为什么要开发这个模型。这就是为什么理解业务需求对于确保模型有效性是必要的。
业务理解通常需要与相关利益相关者进行适当的讨论。然而,由于本教程没有针对机器学习模型的业务用户,我们将自己假设业务需求。
如前所述,我们将开发一个客户流失预测模型。在这种情况下,业务需要避免公司进一步流失,并希望采取措施针对那些流失概率高的客户。
根据上述业务需求,我们需要特定的指标来衡量模型的表现。虽然有许多测量指标,但我建议使用召回率指标。
在货币价值方面,使用召回率可能更有益,因为它试图最小化假阴性或减少预测中未流失的部分,而实际上却在流失。当然,我们也可以通过使用 F1 指标来尝试平衡。
有鉴于此,让我们进入教程的第一部分。
2. 数据收集与准备
数据收集
数据是任何机器学习项目的核心。没有数据,我们就无法训练机器学习模型。这就是为什么我们需要高质量的数据,并在将其输入到机器学习算法之前进行适当准备。
在现实世界中,清洁数据并不容易获得。通常,我们需要通过应用程序、调查和其他许多来源来收集数据,然后将其存储在数据存储中。然而,本教程仅涵盖收集数据集,因为我们使用的是现有的清洁数据。
在我们的案例中,我们将使用来自Kaggle的 Telco 客户流失数据。这是一个开放源代码的分类数据,涉及电信行业客户历史及流失标签。
探索性数据分析(EDA)和数据清理
让我们开始审查我们的数据集。我假设读者已经具备基本的 Python 知识,并可以在他们的笔记本中使用 Python 包。我还基于Anaconda环境分发了本教程,以便简化操作。
要理解我们拥有的数据,我们需要将其加载到一个用于数据操作的 Python 包中。最著名的是 Pandas Python 包,我们将使用它。我们可以使用以下代码来加载和查看 CSV 数据。
import pandas as pd
df = pd.read_csv('WA_Fn-UseC_-Telco-Customer-Churn.csv')
df.head()
接下来,我们将探索数据以了解我们的数据集。以下是我们在 EDA 过程中将执行的一些操作。
1. 检查特征和总结统计信息。
2. 检查特征中的缺失值。
3. 分析标签(流失)的分布。
4. 为数值特征绘制直方图,为分类特征绘制条形图。
5. 绘制数值特征的相关性热图。
6. 使用箱型图来识别分布和潜在的异常值。
首先,我们会检查特征和摘要统计信息。使用 Pandas,我们可以通过以下代码查看数据集特征。
# Get the basic information about the dataset
df.info()
Output>>
RangeIndex: 7043 entries, 0 to 7042
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 customerID 7043 non-null object
1 gender 7043 non-null object
2 SeniorCitizen 7043 non-null int64
3 Partner 7043 non-null object
4 Dependents 7043 non-null object
5 tenure 7043 non-null int64
6 PhoneService 7043 non-null object
7 MultipleLines 7043 non-null object
8 InternetService 7043 non-null object
9 OnlineSecurity 7043 non-null object
10 OnlineBackup 7043 non-null object
11 DeviceProtection 7043 non-null object
12 TechSupport 7043 non-null object
13 StreamingTV 7043 non-null object
14 StreamingMovies 7043 non-null object
15 Contract 7043 non-null object
16 PaperlessBilling 7043 non-null object
17 PaymentMethod 7043 non-null object
18 MonthlyCharges 7043 non-null float64
19 TotalCharges 7043 non-null object
20 Churn 7043 non-null object
dtypes: float64(1), int64(2), object(18)
memory usage: 1.1+ MB
我们还会通过以下代码获取数据集的摘要统计信息。
# Get the numerical summary statistics of the dataset
df.describe()
# Get the categorical summary statistics of the dataset
df.describe(exclude = 'number')
从上述信息中,我们了解到我们有 19 个特征和一个目标特征(Churn)。数据集包含 7043 行,大多数数据集是分类的。
让我们检查一下缺失数据。
# Check for missing values
print(df.isnull().sum())
Output>>
Missing Values:
customerID 0
gender 0
SeniorCitizen 0
Partner 0
Dependents 0
tenure 0
PhoneService 0
MultipleLines 0
InternetService 0
OnlineSecurity 0
OnlineBackup 0
DeviceProtection 0
TechSupport 0
StreamingTV 0
StreamingMovies 0
Contract 0
PaperlessBilling 0
PaymentMethod 0
MonthlyCharges 0
TotalCharges 0
Churn 0
我们的数据集不包含缺失数据,因此我们不需要执行任何缺失数据处理活动。
然后,我们会检查目标变量,以查看是否存在不平衡情况。
print(df['Churn'].value_counts())
Output>>
Distribution of Target Variable:
No 5174
Yes 1869
有轻微的不平衡,因为只有接近 25%的流失发生,而非流失案例则更多。
我们还会查看其他特征的分布,首先从数值特征开始。然而,我们还会将 TotalCharges 特征转换为数值列,因为该特征应该是数值型而非类别型。此外,SeniorCitizen 特征应为分类特征,因此我将其转换为字符串。由于 Churn 特征是分类特征,我们还会开发新特征,将其显示为数值列。
import numpy as np
df['TotalCharges'] = df['TotalCharges'].replace('', np.nan)
df['TotalCharges'] = pd.to_numeric(df['TotalCharges'], errors='coerce').fillna(0)
df['SeniorCitizen'] = df['SeniorCitizen'].astype('str')
df['ChurnTarget'] = df['Churn'].apply(lambda x: 1 if x=='Yes' else 0)
df['ChurnTarget'] = df['Churn'].apply(lambda x: 1 if x=='Yes' else 0)
num_features = df.select_dtypes('number').columns
df[num_features].hist(bins=15, figsize=(15, 6), layout=(2, 5))
除了 customerID(因为它们是具有唯一值的标识符)之外,我们还会提供分类特征的绘图。
import matplotlib.pyplot as plt
# Plot distribution of categorical features
cat_features = df.drop('customerID', axis =1).select_dtypes(include='object').columns
plt.figure(figsize=(20, 20))
for i, col in enumerate(cat_features, 1):
plt.subplot(5, 4, i)
df[col].value_counts().plot(kind='bar')
plt.title(col)
然后,我们将使用以下代码查看数值特征之间的相关性。
import seaborn as sns
# Plot correlations between numerical features
plt.figure(figsize=(10, 8))
sns.heatmap(df[num_features].corr())
plt.title('Correlation Heatmap')
上述相关性基于皮尔逊相关系数,即一个特征与另一个特征之间的线性相关性。我们还可以通过Cramer’s V对分类数据进行相关性分析。为了简化分析,我们将安装 Dython Python 包来帮助我们的分析。
pip install dython
一旦安装了包,我们将使用以下代码进行相关性分析。
from dython.nominal import associations
# Calculate the Cramer’s V and correlation matrix
assoc = associations(df[cat_features], nominal_columns='all', plot=False)
corr_matrix = assoc['corr']
# Plot the heatmap
plt.figure(figsize=(14, 12))
sns.heatmap(corr_matrix)
最后,我们将基于四分位距(IQR)使用箱线图检查数值异常值。
# Plot box plots to identify outliers
plt.figure(figsize=(20, 15))
for i, col in enumerate(num_features, 1):
plt.subplot(4, 4, i)
sns.boxplot(y=df[col])
plt.title(col)
从上述分析中,我们可以看出,我们不需要处理缺失数据或异常值。下一步是为我们的机器学习模型执行特征选择,因为我们只希望保留对预测有影响且在业务中可行的特征。
特征选择
特征选择有很多方法,通常是通过结合业务知识和技术应用来完成。然而,本教程将仅使用我们之前做的相关性分析来进行特征选择。
首先,让我们基于相关性分析选择数值特征。
target = 'ChurnTarget'
num_features = df.select_dtypes(include=[np.number]).columns.drop(target)
# Calculate correlations
correlations = df[num_features].corrwith(df[target])
# Set a threshold for feature selection
threshold = 0.3
selected_num_features = correlations[abs(correlations) > threshold].index.tolist()
你可以稍后调整阈值,以查看特征选择是否会影响模型的性能。我们还将对分类特征进行特征选择。
categorical_target = 'Churn'
assoc = associations(df[cat_features], nominal_columns='all', plot=False)
corr_matrix = assoc['corr']
threshold = 0.3
selected_cat_features = corr_matrix[corr_matrix.loc[categorical_target] > threshold ].index.tolist()
del selected_cat_features[-1]
然后,我们将使用以下代码将所有选择的特征进行合并。
selected_features = []
selected_features.extend(selected_num_features)
selected_features.extend(selected_cat_features)
print(selected_features)
Output>>
['tenure',
'InternetService',
'OnlineSecurity',
'TechSupport',
'Contract',
'PaymentMethod']
最终,我们有六个特征将用于开发客户流失机器学习模型。
3. 构建机器学习模型
选择合适的模型
选择适合的机器学习模型有许多考虑因素,但这总是取决于业务需求。需要记住的几点:
-
用例问题。是监督学习还是无监督学习,还是分类或回归?是多类别还是多标签?用例问题将决定可以使用的模型。
-
数据特征。是表格数据、文本还是图像?数据集的大小是大还是小?数据集中是否包含缺失值?根据数据集的不同,我们选择的模型可能会有所不同。
-
模型的解释性如何?在业务中平衡解释性和性能是至关重要的。
作为一个经验法则,最好先从一个简单的模型作为基准开始,然后再进行复杂模型的开发。你可以阅读我之前的关于简单模型的文章来了解什么构成了简单模型。
对于本教程,让我们从线性模型逻辑回归开始进行模型开发。
切分数据
下一步是将数据切分为训练集、测试集和验证集。在机器学习模型训练过程中切分数据的目的是拥有一个作为未见数据(真实世界数据)的数据集,以在没有任何数据泄漏的情况下评估模型的无偏性。
为了切分数据,我们将使用以下代码:
from sklearn.model_selection import train_test_split
target = 'ChurnTarget'
X = df[selected_features]
y = df[target]
cat_features = X.select_dtypes(include=['object']).columns.tolist()
num_features = X.select_dtypes(include=['number']).columns.tolist()
#Splitting data into Train, Validation, and Test Set
X_train_val, X_test, y_train_val, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
X_train, X_val, y_train, y_val = train_test_split(X_train_val, y_train_val, test_size=0.25, random_state=42, stratify=y_train_val)
在上述代码中,我们将数据切分为 60%的训练数据集和 20%的测试及验证集。一旦我们拥有数据集,就可以开始训练模型。
训练模型
如前所述,我们将用训练数据训练一个逻辑回归模型。然而,模型只能接受数值数据,因此我们必须对数据集进行预处理。这意味着我们需要将分类数据转换为数值数据。
为了最佳实践,我们还使用 Scikit-Learn 管道来包含所有的预处理和建模步骤。以下代码可以实现这一点。
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder
from sklearn.linear_model import LogisticRegression
# Prepare the preprocessing step
preprocessor = ColumnTransformer(
transformers=[
('num', 'passthrough', num_features),
('cat', OneHotEncoder(), cat_features)
])
pipeline = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', LogisticRegression(max_iter=1000))
])
# Train the logistic regression model
pipeline.fit(X_train, y_train)
模型管道的示意图如下所示。

Scikit-Learn 管道会接受未见过的数据,并在进入模型之前经过所有的预处理步骤。在模型训练完成后,让我们评估模型结果。
模型评估
如前所述,我们将通过关注召回率(Recall)指标来评估模型。然而,以下代码展示了所有基本的分类指标。
from sklearn.metrics import classification_report
# Evaluate on the validation set
y_val_pred = pipeline.predict(X_val)
print("Validation Classification Report:\n", classification_report(y_val, y_val_pred))
# Evaluate on the test set
y_test_pred = pipeline.predict(X_test)
print("Test Classification Report:\n", classification_report(y_test, y_test_pred))
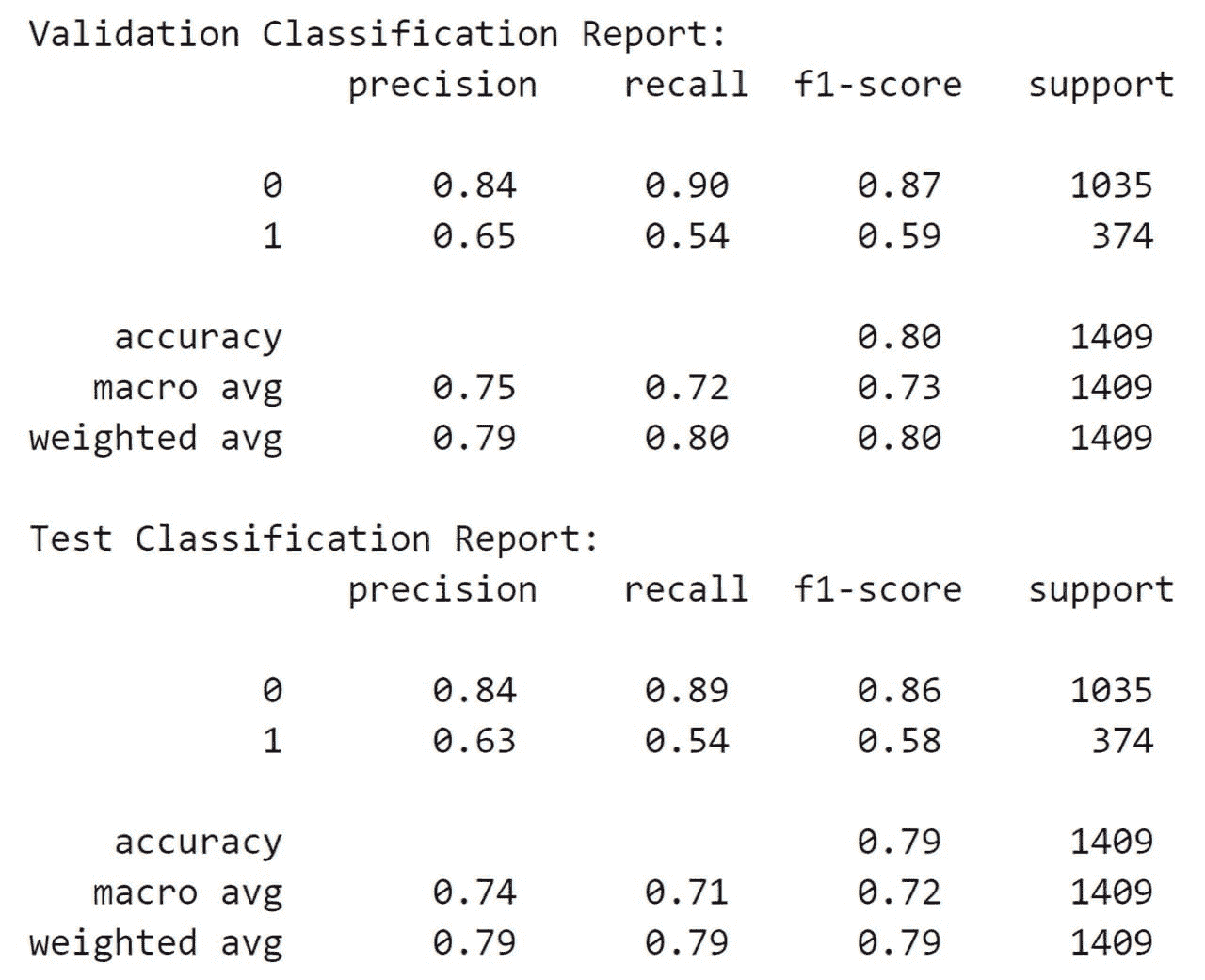
从验证数据和测试数据中我们可以看到,流失(churn)(1)的召回率并不是最好。这就是为什么我们可以优化模型以获得最佳结果。
4. 模型优化
我们总是需要关注数据以获得最佳结果。然而,优化模型也可能会带来更好的结果。这就是为什么我们可以优化模型。优化模型的一种方法是通过超参数优化,它测试这些模型超参数的所有组合,以根据指标找到最佳组合。
每个模型都有一组超参数,我们可以在训练之前设置它们。我们称超参数优化为实验以查看哪个组合最好。为此,我们可以使用以下代码。
from sklearn.model_selection import GridSearchCV
# Define the logistic regression model within a pipeline
pipeline = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', LogisticRegression(max_iter=1000))
])
# Define the hyperparameters for GridSearchCV
param_grid = {
'classifier__C': [0.1, 1, 10, 100],
'classifier__solver': ['lbfgs', 'liblinear']
}
# Perform Grid Search with cross-validation
grid_search = GridSearchCV(pipeline, param_grid, cv=5, scoring='recall')
grid_search.fit(X_train, y_train)
# Best hyperparameters
print("Best Hyperparameters:", grid_search.best_params_)
# Evaluate on the validation set
y_val_pred = grid_search.predict(X_val)
print("Validation Classification Report:\n", classification_report(y_val, y_val_pred))
# Evaluate on the test set
y_test_pred = grid_search.predict(X_test)
print("Test Classification Report:\n", classification_report(y_test, y_test_pred))
结果仍然没有显示最佳的召回率,但这是预期的,因为它们只是基线模型。让我们尝试几个模型,看看召回率表现是否有所改善。你可以随时调整下面的超参数。
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.svm import SVC
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from sklearn.metrics import recall_score
# Define the models and their parameter grids
models = {
'Logistic Regression': {
'model': LogisticRegression(max_iter=1000),
'params': {
'classifier__C': [0.1, 1, 10, 100],
'classifier__solver': ['lbfgs', 'liblinear']
}
},
'Decision Tree': {
'model': DecisionTreeClassifier(),
'params': {
'classifier__max_depth': [None, 10, 20, 30],
'classifier__min_samples_split': [2, 10, 20]
}
},
'Random Forest': {
'model': RandomForestClassifier(),
'params': {
'classifier__n_estimators': [100, 200],
'classifier__max_depth': [None, 10, 20]
}
},
'SVM': {
'model': SVC(),
'params': {
'classifier__C': [0.1, 1, 10, 100],
'classifier__kernel': ['linear', 'rbf']
}
},
'Gradient Boosting': {
'model': GradientBoostingClassifier(),
'params': {
'classifier__n_estimators': [100, 200],
'classifier__learning_rate': [0.01, 0.1, 0.2]
}
},
'XGBoost': {
'model': XGBClassifier(use_label_encoder=False, eval_metric='logloss'),
'params': {
'classifier__n_estimators': [100, 200],
'classifier__learning_rate': [0.01, 0.1, 0.2],
'classifier__max_depth': [3, 6, 9]
}
},
'LightGBM': {
'model': LGBMClassifier(),
'params': {
'classifier__n_estimators': [100, 200],
'classifier__learning_rate': [0.01, 0.1, 0.2],
'classifier__num_leaves': [31, 50, 100]
}
}
}
results = []
# Train and evaluate each model
for model_name, model_info in models.items():
pipeline = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', model_info['model'])
])
grid_search = GridSearchCV(pipeline, model_info['params'], cv=5, scoring='recall')
grid_search.fit(X_train, y_train)
# Best model from Grid Search
best_model = grid_search.best_estimator_
# Evaluate on the validation set
y_val_pred = best_model.predict(X_val)
val_recall = recall_score(y_val, y_val_pred, pos_label=1)
# Evaluate on the test set
y_test_pred = best_model.predict(X_test)
test_recall = recall_score(y_test, y_test_pred, pos_label=1)
# Save results
results.append({
'model': model_name,
'best_params': grid_search.best_params_,
'val_recall': val_recall,
'test_recall': test_recall,
'classification_report_val': classification_report(y_val, y_val_pred),
'classification_report_test': classification_report(y_test, y_test_pred)
})
# Plot the test recall scores
plt.figure(figsize=(10, 6))
model_names = [result['model'] for result in results]
test_recalls = [result['test_recall'] for result in results]
plt.barh(model_names, test_recalls, color='skyblue')
plt.xlabel('Test Recall')
plt.title('Comparison of Test Recall for Different Models')
plt.show()
召回率结果变化不大;即使是基线逻辑回归模型似乎也是最佳的。如果我们想要更好的结果,我们应该回到更好的特征选择。
然而,让我们继续使用当前的逻辑回归模型并尝试部署它们。
5. 部署模型
我们已经构建了机器学习模型。在拥有模型后,下一步是将其部署到生产环境中。让我们使用一个简单的 API 来模拟它。
首先,让我们重新开发我们的模型并将其保存为 joblib 对象。
import joblib
best_params = {'classifier__C': 1, 'classifier__solver': 'lbfgs'}
logreg_model = LogisticRegression(C=best_params['classifier__C'], solver=best_params['classifier__solver'], max_iter=1000)
preprocessor = ColumnTransformer(
transformers=[
('num', 'passthrough', num_features),
('cat', OneHotEncoder(), cat_features)
pipeline = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', logreg_model)
])
pipeline.fit(X_train, y_train)
# Save the model
joblib.dump(pipeline, 'logreg_model.joblib')
一旦模型对象准备好,我们将进入 Python 脚本以创建 API。但首先,我们需要安装一些用于部署的包。
pip install fastapi uvicorn
我们不会在笔记本中完成这个,而是在诸如 Visual Studio Code 这样的 IDE 中。在你喜欢的 IDE 中,创建一个名为 app.py 的 Python 脚本,并将以下代码放入该脚本中。
from fastapi import FastAPI
from pydantic import BaseModel
import joblib
import numpy as np
# Load the logistic regression model pipeline
model = joblib.load('logreg_model.joblib')
# Define the input data for model
class CustomerData(BaseModel):
tenure: int
InternetService: str
OnlineSecurity: str
TechSupport: str
Contract: str
PaymentMethod: str
# Create FastAPI app
app = FastAPI()
# Define prediction endpoint
@app.post("/predict")
def predict(data: CustomerData):
# Convert input data to a dictionary and then to a DataFrame
input_data = {
'tenure': [data.tenure],
'InternetService': [data.InternetService],
'OnlineSecurity': [data.OnlineSecurity],
'TechSupport': [data.TechSupport],
'Contract': [data.Contract],
'PaymentMethod': [data.PaymentMethod]
}
import pandas as pd
input_df = pd.DataFrame(input_data)
# Make a prediction
prediction = model.predict(input_df)
# Return the prediction
return {"prediction": int(prediction[0])}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
在你的命令提示符或终端中,运行以下代码。
uvicorn app:app --reload
使用上述代码,我们已经有了一个接受数据并进行预测的 API。让我们在新的终端中尝试一下以下代码。
curl -X POST "http://127.0.0.1:8000/predict" -H "Content-Type: application/json" -d "{\"tenure\": 72, \"InternetService\": \"Fiber optic\", \"OnlineSecurity\": \"Yes\", \"TechSupport\": \"Yes\", \"Contract\": \"Two year\", \"PaymentMethod\": \"Credit card (automatic)\"}"
Output>>
{"prediction":0}
如你所见,API 结果是一个字典,预测为 0(未流失)。你可以进一步调整代码以获得所需的结果。
恭喜你。你已经开发了机器学习模型,并成功地将其部署到 API 中。
结论
我们已经学习了如何从头开始开发机器学习模型到部署的全过程。尝试其他数据集和用例,进一步感受效果。本文使用的所有代码将会在我的GitHub 仓库上提供。
Cornellius Yudha Wijaya**** 是一名数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作分享 Python 和数据技巧。Cornellius 涉猎多种 AI 和机器学习话题。
更多相关话题
向前特征选择:Python 中的实际示例
原文:
www.kdnuggets.com/2018/06/step-forward-feature-selection-python.html
评论
存在许多特征选择的方法,其中一些将过程视为艺术形式,另一些视为科学,而实际上,一些领域知识结合严格的方法可能是你最好的选择。
在特征选择的严格方法中,包装方法是将特征选择过程与正在构建的模型类型相结合,评估特征子集以检测特征之间的模型表现,从而选择表现最佳的子集。换句话说,包装方法不是作为独立的过程在模型构建之前进行,而是试图与给定的机器学习算法一起优化特征选择过程。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
特征选择的两个显著包装方法是向前特征选择和向后特征选择。
向前特征选择从评估每个单独特征开始,选择那些能产生最佳表现的算法模型的特征。什么是“最佳”?这完全取决于定义的评估标准(AUC、预测准确率、RMSE 等)。接下来,评估所有可能的选定特征与随后的特征的组合,选择第二个特征,依此类推,直到选择出所需的预定义数量的特征。
向后特征选择密切相关,正如你可能已经猜到的那样,它从整个特征集开始,然后向后操作,从中去除特征,以找到预定义大小的最佳子集。
这两种方法都可能非常耗费计算资源。你有一个大型的、多维的数据集吗?这些方法可能会花费过多时间,变得毫无用处,或者完全不可行。不过,考虑到数据集的规模和维度,这种方法可能是你最佳的选择。
为了了解它们是如何工作的,我们具体看一下逐步前进特征选择。请注意,如前所述,机器学习算法必须在开始我们的共生特征选择过程之前定义。
请记住,使用给定算法选择的优化特征集可能在不同算法下表现不同。例如,如果我们使用逻辑回归选择特征,并不能保证这些相同的特征在使用 K 近邻算法或支持向量机时也能表现最佳。
实现特征选择和构建模型
那么,我们如何在 Python 中执行逐步前进特征选择呢?Sebastian Raschka 的 mlxtend 库包含了一个实现(Sequential Feature Selector),因此我们将使用它来演示。显然,在继续之前你应该已经安装了 mlxtend(查看 Github 仓库)。

我们将使用随机森林分类器进行特征选择和模型构建(再次强调,在逐步前进特征选择的情况下,这两者是紧密相关的)。
我们需要数据来进行演示,所以我们使用葡萄酒质量数据集。具体来说,我在下面的代码中使用了未处理的winequality-white.csv文件作为输入。
随意地,我们将所需的特征数量设置为 5(数据集中有 12 个特征)。我们能够做的是比较特征选择过程每次迭代的评估分数,因此请记住,如果我们发现特征数量较少的情况下得分更好,我们可以选择该表现最佳的子集来继续在我们的“实时”模型中使用。同时,请注意,设置所需的特征数量过低可能会导致决定一个次优的特征数量和组合(例如,如果我们发现某些 11 个特征的组合比我们在选择过程中找到的<=10 个特征的最佳组合更好)。
由于我们更关注演示如何实现逐步前进特征选择,而不是对这个特定数据集的实际结果,我们不会过于关注模型的实际性能,但我们会进行比较,以展示如何在一个有意义的项目中进行。
首先,我们将进行导入操作,加载数据集,并将其拆分为训练集和测试集。
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score as acc
from mlxtend.feature_selection import SequentialFeatureSelector as sfs
# Read data
df = pd.read_csv('winequality-white.csv', sep=';')
# Train/test split
X_train, X_test, y_train, y_test = train_test_split(
df.values[:,:-1],
df.values[:,-1:],
test_size=0.25,
random_state=42)
y_train = y_train.ravel()
y_test = y_test.ravel()
print('Training dataset shape:', X_train.shape, y_train.shape)
print('Testing dataset shape:', X_test.shape, y_test.shape)
Training dataset shape: (3673, 11) (3673,)
Testing dataset shape: (1225, 11) (1225,)
接下来,我们将定义一个分类器,以及一个逐步前进特征选择器,然后执行特征选择。mlxtend 中的特征选择器有一些我们可以定义的参数,以下是我们的处理方式:
-
首先,我们将我们的分类器传递给定义的特征选择器
-
接下来,我们定义了我们希望选择的特征子集(k_features=5)。
-
然后我们将浮动设置为 False;有关浮动的更多信息,请参阅文档:
浮动算法有一个额外的排除或包含步骤,以便在特征被包含(或排除)后将其移除,从而可以采样更多的特征子集组合。
-
我们设置了 mlxtend 报告的期望详细程度。
-
重要的是,我们将评分设置为准确率;这只是一个用于对基于所选特征构建的模型进行评分的指标。
-
mlxtend 特征选择器内部使用交叉验证,我们将演示中的折数设置为 5。
我们选择的数据集不是很大,因此以下代码不应该花费很长时间执行。
# Build RF classifier to use in feature selection
clf = RandomForestClassifier(n_estimators=100, n_jobs=-1)
# Build step forward feature selection
sfs1 = sfs(clf,
k_features=5,
forward=True,
floating=False,
verbose=2,
scoring='accuracy',
cv=5)
# Perform SFFS
sfs1 = sfs1.fit(X_train, y_train)
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 2.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 11 out of 11 | elapsed: 24.3s finished
[2018-06-12 14:47:47] Features: 1/5 -- score: 0.49768148939247264[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 2.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 10 out of 10 | elapsed: 22.7s finished
[2018-06-12 14:48:09] Features: 2/5 -- score: 0.5442629071398873[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 2.7s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 9 out of 9 | elapsed: 21.2s finished
[2018-06-12 14:48:31] Features: 3/5 -- score: 0.6052194438136681[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 2.5s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 8 out of 8 | elapsed: 20.3s finished
[2018-06-12 14:48:51] Features: 4/5 -- score: 0.6261526236769334[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 2.4s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 7 out of 7 | elapsed: 17.3s finished
[2018-06-12 14:49:08] Features: 5/5 -- score: 0.6444222989869156
根据我们的评分指标,我们表现最佳的模型是某个包含 5 个特征的子集,得分为 0.644(记住这是使用交叉验证,因此与下面使用训练和测试集的完整模型的报告结果不同)。但是,选择了哪一组 5 个特征?
# Which features?
feat_cols = list(sfs1.k_feature_idx_)
print(feat_cols)
[1, 2, 3, 7, 10]
这些索引处的列是那些被选择的列。太好了!那么接下来做什么呢...?
我们现在可以使用这些特征在训练和测试集上构建一个完整的模型。如果我们有一个更大的数据集(即更多的实例而不是更多的特征),这将特别有利,因为我们可以在较小的实例子集上使用上述特征选择器,确定我们表现最佳的特征子集,然后将它们应用于完整的数据集进行分类。
以下代码在仅所选特征的子集上构建了一个分类器。
# Build full model with selected features
clf = RandomForestClassifier(n_estimators=1000, random_state=42, max_depth=4)
clf.fit(X_train[:, feat_cols], y_train)
y_train_pred = clf.predict(X_train[:, feat_cols])
print('Training accuracy on selected features: %.3f' % acc(y_train, y_train_pred))
y_test_pred = clf.predict(X_test[:, feat_cols])
print('Testing accuracy on selected features: %.3f' % acc(y_test, y_test_pred))
Training accuracy on selected features: 0.558
Testing accuracy on selected features: 0.512
不用担心实际的准确率;我们在这里关注的是过程,而不是最终结果。
但如果我们关心最终结果,并想知道我们的特征选择是否值得?好吧,我们可以比较使用所选特征(见上文)构建的完整模型的结果准确率与使用所有特征的另一个完整模型的结果准确率,就像下面这样:
# Build full model on ALL features, for comparison
clf = RandomForestClassifier(n_estimators=1000, random_state=42, max_depth=4)
clf.fit(X_train, y_train)
y_train_pred = clf.predict(X_train)
print('Training accuracy on all features: %.3f' % acc(y_train, y_train_pred))
y_test_pred = clf.predict(X_test)
print('Testing accuracy on all features: %.3f' % acc(y_test, y_test_pred))
Training accuracy on all features: 0.566
Testing accuracy on all features: 0.509
这里是它们的比较结果。它们都表现不佳,并且与我们使用所选特征构建的模型相当(虽然我保证这并非总是如此!)。通过非常少的工作,您可以查看这些选定特征在不同算法下的表现,以帮助解答这些特征是否在另一种算法下表现同样优秀。
这种特征选择方法可以是一个有力的、有纪律的机器学习流程中的组成部分。请记住,前向(或后向)方法,尤其是在处理特别大或高维数据集时,可能会带来问题。可以通过从数据中采样以找到最适合的特征子集,然后在完整数据集上使用这些特征进行建模的方式来绕过(或尝试绕过)这些难点。当然,这些也不是唯一的特征选择的有纪律的方法,因此在处理这些较大的数据集时,检查其他方法也是值得的。
相关:
更多相关话题
Python 和 Beautiful Soup 的网页抓取逐步指南
原文:
www.kdnuggets.com/2023/04/stepbystep-guide-web-scraping-python-beautiful-soup.html

作者提供的图片
网页抓取是一种用于从不同网站提取 HTML 内容的技术。这些网页抓取器主要是计算机机器人,可以通过 HTTP 协议直接访问万维网,并在各种应用程序中使用这些信息。数据以非结构化格式获得,然后经过多次预处理步骤后转换为结构化格式。用户可以将这些数据保存在电子表格中或通过 API 导出。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
网页抓取也可以通过手动方式进行,针对小型网页,只需从网页上复制和粘贴数据即可。但如果我们需要大规模的数据并且来自多个网页,这种复制和粘贴的方法就不适用了。此时,自动化网页抓取器就发挥作用了。它们使用智能算法,可以在更短的时间内从大量网页中提取大量数据。
网页抓取的用途
网页抓取是企业收集和分析在线信息的强大工具。它在各个行业有多个应用。以下是一些你可以了解的应用。
-
市场营销:许多公司使用网页抓取从各种社交媒体网站收集关于其产品或服务的信息,以获取公众的普遍情感。此外,他们从各种网站提取电子邮件地址,然后向这些电子邮件地址的拥有者发送批量促销邮件。
-
内容创建:网页抓取可以从新闻文章、研究报告和博客文章等多个来源收集信息。它帮助创作者创建高质量和趋势内容。
-
价格比较:网页抓取可以用来提取特定产品在多个电子商务网站上的价格,以为用户提供公平的价格比较。它还帮助公司确定其产品的最佳定价,以与竞争对手竞争。
-
职位发布: 网页抓取还可以用来收集多个招聘门户网站上的各种职位信息,这些信息可以帮助许多求职者和招聘者。
现在,我们将使用 Python 和 Beautiful Soup 库创建一个简单的网页爬虫。我们将解析一个 HTML 页面并从中提取有用的信息。本教程只要求具备基本的 Python 知识。
代码实现
我们的实现分为以下四个步骤。
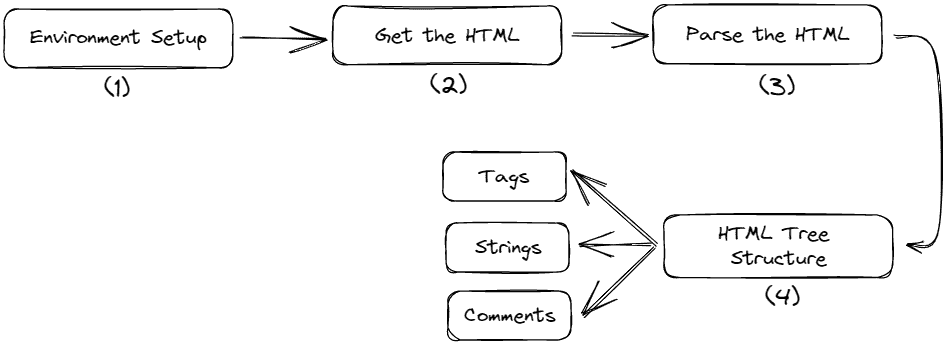
图 1 教程步骤 | 图片来源:作者
设置环境
为项目创建一个独立的目录,并使用命令提示符安装以下库。首先创建一个虚拟环境是优选的,但你也可以全局安装它们。
$ pip install requests
$ pip install bs4
requests 模块从 URL 中提取 HTML 内容。它将所有数据以原始字符串格式提取出来,需要进一步处理。
bs4 是 Beautiful Soup 模块。它将以结构化的格式解析从 request 模块获得的原始 HTML 内容。
获取 HTML
在该目录中创建一个 Python 文件,并粘贴以下代码。
import requests
url = "https://www.kdnuggets.com/"
res = requests.get(url)
htmlData = res.content
print(htmlData)
输出:
图片来源:作者
此脚本将从 URL / 提取所有原始 HTML 内容。这些原始数据包含所有文本、段落、锚标签、div 等。我们的下一个任务是解析这些数据,分别提取所有文本和标签。
解析 HTML
这里 Beautiful Soup 的作用就体现出来了。它用于解析和美化上述获得的原始数据。它创建了一个类似树的 DOM 结构,可以沿着树枝遍历,找到目标标签和对象。
import requests
from bs4 import BeautifulSoup
url = "https://www.kdnuggets.com/"
res = requests.get(url)
htmlData = res.content
parsedData = BeautifulSoup(htmlData, "html.parser")
print(parsedData.prettify())
输出:
图片来源:作者
你可以看到在上述输出中,Beautiful Soup 将内容以更结构化的格式呈现,并进行了适当的缩进。BeautifulSoup() 函数接受两个参数,一个是输入 HTML,另一个是解析器。我们当前使用的是 html.parser,但还有其他解析器,如 lxml 或 html5lib。它们各有优缺点,有些更宽容,有些则非常快速。解析器的选择完全取决于用户的选择。下面是解析器的列表及其优缺点,你可以查看。
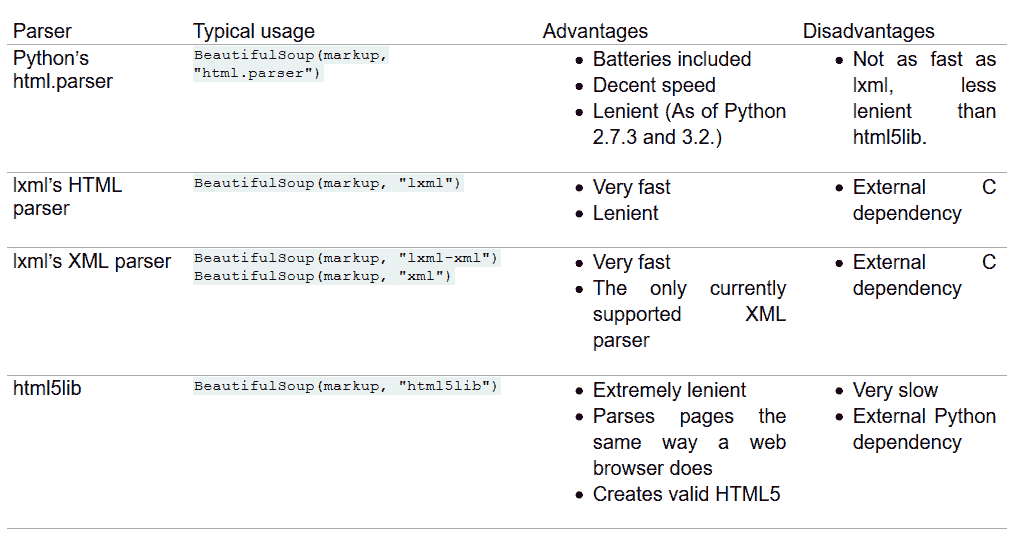
图 2 解析器列表 | 图片来源:crummy
HTML 树遍历
在本节中,我们将了解 HTML 的树结构,然后使用 Beautiful Soup 从解析后的内容中提取标题、不同标签、类、列表等。
图 3 HTML 树结构 | 图片来源 w3schools
HTML 树表示了层级信息视图。根节点是标签,它可以有父节点、子节点和兄弟节点。head 标签和 body 标签紧随 HTML 标签。head 标签包含元数据和标题,而 body 标签包含 div、段落、标题等。
当 HTML 文档通过 Beautiful Soup 传递时,它将复杂的 HTML 内容转换为四种主要的 Python 对象;这些对象是
- BeautifulSoup:
它代表整个解析文档。这是我们尝试抓取的完整文档。
soup = BeautifulSoup("<h1> Welcome to KDnuggets! </h1>", "html.parser")
print(type(soup))
输出:
<class 'bs4.BeautifulSoup'>
你可以看到整个 html 内容是一个 Beautiful Soup 类型的对象。
- 标签:
标签对象对应于 HTML 文档中的特定标签。它可以从整个文档中提取一个标签,并在 DOM 中存在多个相同名称的标签时返回找到的第一个标签。
soup = BeautifulSoup("<h1> Welcome to KDnuggets! </h1>", 'html.parser')
print(type(soup.h1))
输出:
<class 'bs4.element.Tag'>
- NavigableString:
它包含标签内的文本,以字符串格式存储。Beautiful Soup 使用 NavigableString 对象来存储标签的文本。
soup = BeautifulSoup("<h1> Welcome to KDnuggets! </h1>", "html.parser")
print(soup.h1.string)
print(type(soup.h1.string))
输出:
Welcome to KDnuggets!
<class 'bs4.element.NavigableString'>
- 评论:
它读取标签内存在的 HTML 评论。这是一种特殊类型的 NavigableString。
soup = BeautifulSoup("<h1><!-- This is a comment --></h1>", "html.parser")
print(soup.h1.string)
print(type(soup.h1.string))
输出:
This is a comment
<class 'bs4.element.Comment'>
现在,我们将从解析后的 HTML 内容中提取标题、不同标签、类、列表等。
1. 标题
获取 HTML 页面的标题。
print(parsedData.title)
输出:
<title>Data Science, Machine Learning, AI & Analytics - KDnuggets</title>
或者,你也可以只打印标题字符串。
print(parsedData.title.string)
输出:
Data Science, Machine Learning, AI & Analytics - KDnuggets
2. 查找和查找所有
这些函数在你想要在 HTML 内容中搜索特定标签时很有用。find()将只返回该标签的第一次出现,而 find_all()将返回所有出现的该标签。你也可以遍历它们。让我们看看下面的示例。
find():
h2 = parsedData.find('h2')
print(h2)
输出:
<h2>Latest Posts</h2>
find_all():
H2s = parsedData.find_all("h2")
for h2 in H2s:
print(h2)
输出:
<h2>Latest Posts</h2>
<h2>From Our Partners</h2>
<h2>Top Posts Past 30 Days</h2>
<h2>More Recent Posts</h2>
<h2 size="+1">Top Posts Last Week</h2>
这将返回完整的标签,但如果你只想打印字符串,可以这样写。
h2 = parsedData.find('h2').text
print(h2)
我们还可以获取特定标签的类、id、类型、href 等。例如,获取所有锚标签的链接。
anchors = parsedData.find_all("a")
for a in anchors:
print(a["href"])
输出:
图片来源:作者
你还可以获取每个 div 的类。
divs = parsedData.find_all("div")
for div in divs:
print(div["class"])
3. 使用 Id 和类名查找元素
我们还可以通过给定特定的 id 或类名来查找特定元素。
tags = parsedData.find_all("li", class_="li-has-thumb")
for tag in tags:
print(tag.text)
这将打印所有属于li-has-thumb类的li的文本。但如果你不确定标签名称,编写标签名称并非总是必要的。你也可以这样写。
tags = parsedData.find_all(class_="li-has-thumb")
print(tags)
它将获取所有具有此类名的标签。
现在,我们将讨论 Beautiful Soup 的一些更有趣的方法
Beautiful Soup 的更多方法
在本节中,我们将讨论更多 Beautiful Soup 的功能,这些功能将使你的工作更轻松、更快捷。
select()
select() 函数允许我们根据 CSS 选择器查找特定标签。CSS 选择器是根据标签的类、ID、属性等模式来选择某些 HTML 标签的。
以下是一个示例,展示如何查找 alt 属性以 KDnuggets 开头的图像。
data = parsedData.select("img[alt*=KDnuggets]")
print(data)
输出:

parent
这个属性返回给定标签的父标签。
tag = parsedData.find('p')
print(tag.parent)
contents
这个属性返回所选标签的内容。
tag = parsedData.find('p')
print(tag.contents)
attrs
这个属性用于以字典的形式获取标签的属性。
tag = parsedData.find('a')
print(tag.attrs)
has_attr()
这个方法检查标签是否具有特定属性。
tag = parsedData.find('a')
print(tag.has_attr('href'))
如果属性存在,它将返回 True,否则返回 False。
find_next()
这个方法找到给定标签之后的下一个标签。它需要输入标签的名称来查找下一个标签。
first_anchor = parsedData.find("a")
second_anchor = first_anchor.find_next("a")
print(second_anchor)
find_previous()
这个方法用于查找给定标签之后的上一个标签。它需要输入标签的名称来查找下一个标签。
second_anchor = parsedData.find_all('a')[1]
first_anchor = second_anchor.find_previous('a')
print(first_anchor)
它将再次打印第一个锚点标签。
你可以尝试许多其他方法。这些方法在 Beautiful Soup 的文档中可以找到。
结论
我们已经讨论了网页抓取、它的用途以及它在 Python 和 Beautiful Soup 中的实现。今天就到这里。如果您有任何评论或建议,请随时在下方留言。
Aryan Garg 是一名 B.Tech. 电气工程专业的学生,目前正在攻读本科最后一年。他对网页开发和机器学习领域充满兴趣。他已经追求了这一兴趣,并渴望在这些方向上继续工作。
更多相关主题
Stop Doing this on ChatGPT and Get Ahead of the 99% of its Users
原文:
www.kdnuggets.com/2023/05/stop-chatgpt-get-ahead-99-users.html
Image by Author
你是否曾对 AI 生成的内容感到沮丧?也许你认为 ChatGPT 的输出完全糟糕,没有达到你的期望。
然而,从像 ChatGPT 这样的 AI 写作工具获得高质量输出的真相是,这在很大程度上依赖于你的提示质量。
通过训练 ChatGPT,你可以得到免费的个人写作助手!
现在是发现 制定强大提示的艺术 以充分利用这项尖端技术。
让我们一起探索吧!????????
问题通常不在于 AI 本身,而在于提供的输入的局限性和模糊性。
与其期望 AI 为你思考,不如 你自己进行思考并指导 AI 完成你需要的任务。

Image by Author
结果不理想?
这意味着你给 ChatGPT 提供了 质量差 的短提示——并期望发生一些神奇的输出。
简而言之,ChatGPT 不擅长从零开始提出内容。这意味着如果你仍然给 ChatGPT 提供这样的提示:
为我的账户生成一个关于 AI 的 LinkedIn 帖子。
给我写一条关于 数据科学的 Twitter 线程
给我一些编程的写作点子
你应该停止!
给出这样的提示时,ChatGPT 必须做出太多决策——这会生成一些糟糕的输出。
所以一定要记住。
差的指示 = 差的结果。
那么你应该怎么做呢?
有 4 个主要步骤来评估这个问题。让我们逐步解析 ??
#1. 理解你的需求和要求
要订购某样东西,你首先需要知道你想要什么。
对吗?
所以你需要知道你从 AI 那里想要什么,为什么想要它,以及如何希望它被传递。这种清晰度将帮助你创建更好的提示并提高输出质量。
所以首先,开始标准化你从 AI 那里要求的所有类型的输出。

Image by Author
让我们举一些例子。
-
我开始活跃于我的 Twitter 账户——所以我想要 推文点子 和 Twitter 线程结构。
-
我在 Medium 上非常活跃——所以我想要 获得灵感 来写作并生成 文章大纲。
太好了!
所以通过这个练习,我意识到我需要 4 种不同类型的输出。
-
为 Twitter 撰写推文的想法。
-
Twitter 的线程结构。
-
在 Medium 上写作的想法。
-
Medium 的文章框架。
让我们以 Twitter 结构作为例子。
为了进一步了解如何使用 ChatGPT 提高你的写作,我推荐以下文章 😃
在 Medium 上使用 ChatGPT 最大化写作潜力的 5 个功能
以及如何利用它来提升你的写作
#2. 将 AI 视为数字实习生
想象一下你雇佣了一个实习生——你不会只给他们一个简短的解释就期待他们一开始就做得很好,对吧?

图片来源: unDraw。
假设我想在 Twitter 上发布一个关于使用 Google Cloud Platform 的线程。光是告诉我的实习生我明天需要一个关于 GCP 的 Twitter 线程——就这样是不够的。
如果你这样做……也许你应该改变你的方法,我的朋友 😉
然后 ChatGPT——或任何其他 AI 工具——也是一样的。
始终向你的 AI 提供详细的检查清单,解释任务背后的目的,并对 AI 可能有的任何疑问持开放态度。
这意味着我不能说:
嘿,ChatGPT。给我写一条关于 Google Cloud Platform 的 Twitter 线程。
之前的提示过于模糊。
-
你想要多少条推文?
-
使用什么写作风格?
-
ChatGPT 应该强调哪些子主题?
-
我的语言语气是什么——友好,专业……?
你让 AI 为你做了太多决策——这就是为什么它的输出会一团糟。
⚠️ 始终使用 AI 工具来提升你的工作——而不是替代你。
这将引导我们进入下一步……
#3. 创建约束并避免假设
这是过程的关键。为了获得具体和准确的输出,向你的 AI 提供清晰且定义明确的信息。当你给出模糊或宽泛的提示时,你不能指望 AI 提供精确的结果。
相反,让 AI 确切知道你想要什么。
-
良好的背景信息——你想要什么样的输出?
-
具体话题——要强调的子主题。
-
具体结构——比如多少条推文,字数……
-
输出的具体格式——使用什么写作风格,语气……
-
避免的具体事项列表——你不想提及的内容。
所以让我们开始创建自己的提示,以生成 Twitter 线程。
1. 添加一些良好的背景信息
我希望 ChatGPT 为我生成一个 Twitter 线程。然而,什么是 Twitter 线程?
我首先需要确保 ChatGPT 理解我所说的 Twitter 线程的意思。
这就是为什么任何好的提示需要以良好的背景信息开始的原因。
[ ???????????? 首先我让 ChatGPT 知道我将训练它以获得一些特定的输出]
嘿,ChatGPT。我将训练你来创建Twitter 线程。
[ ???? 然后我解释这个具体输出的内容]
推特线程是一系列推文,概述并突出长文本或特定话题中最重要的观点。
2. 添加一个具体话题
我希望 ChatGPT 撰写一个关于特定话题的推特线程。现在是时候详细说明话题了。
在这种情况下,我希望这个线程讨论Google Cloud Platform 免费层。
[ ☁️ 我向 ChatGPT 解释了主要话题]
推特线程将讨论Google Cloud Platform 免费层服务。
[ ⚙️ 我概述了我希望它肯定提到的内容和要强调的内容]
我希望你讨论Google Cloud Platform 环境、它的所有服务和对数据科学的实用性。然而,你需要强调所有这些优势在你的使用限制在某些层级内时是永远免费的。提到 Google BigQuery 和 Cloud Functions,这两项是分析最重要的服务之一。
3. 添加具体结构
现在轮到让 ChatGPT 知道输出的结构是什么。根据你的需要,这部分可以更通用或更详细。我通常尽可能详细,以便从中得到一个好的草稿作为起点。
[ ???? 我指定了我希望从 ChatGPT 收到的完整结构]
第一条推文,内容简洁明了,让人们知道线程的主题。重要的是不要超过 30 个字,使用关键标签,并说服人们阅读整个线程。强调线程对他们的实用性。
第二条推文,简短介绍,让读者了解背景并理解他们为什么还在阅读这个线程。重要的是保持读者的兴趣。
4 或 5 条推文,概述和描述文章中最重要的部分。这些推文应总结我之前解释的主题的主要观点。
最后一条推文包含一些结论,并让人们知道为什么你的线程值得阅读。
最后一条推文,邀请他们转发你的线程并关注你。
4. 输出的具体格式
对生成的输出格式的最终评论。通常,我包括 ChatGPT 应如何表现和使用何种写作风格。
[ ???? 我指定了我希望的输出格式]
我希望你作为技术和数据科学作家。使用自然且引人入胜的语言。使用易于理解的词汇——记住,我希望将复杂的概念分解成日常用词。
5. 避免的具体事项列表
在这种情况下,如果有你不希望 ChatGPT 提到的内容,请告知它。在我的情况下,我不希望它使用复杂的词汇。
[ ❌ 我总是告诉 ChatGPT 避免使用复杂的语言]
避免使用复杂的词汇。
#4. 迭代和优化你的输入
如果 AI 生成了不正确的输出,很可能是由于你的输入存在问题。不要害怕多次修改你的提示。
请记住,即使你使用自然语言与机器交谈,也应该把它视为为 AI 编写代码。
提示编写是一个反复迭代的过程——你不会在第一次尝试时就搞对。但就像培训员工一样,前期的时间投入是值得的。因为一旦你拥有了一个有效且可靠的提示,你就可以永久使用它。
- 作者:Dickie Bush
⚠️ 重要的是要考虑到,我们对 ChatGPT 下达的任何任务都不应该需要思考。我们思考,ChatGPT 执行。
所以,如果我使用刚创建的提示来获取 ChatGPT 的 Twitter 线程,它会直接回复我以下内容。
ChatGPT 界面的截图。ChatGPT 给我一个 Twitter 线程的输出。
你可以重复生成响应多次,直到获得满意的结果。我总是将 ChatGPT 的输出作为初稿,然后得到一个适合我账户的 Twitter 线程。
我的最终结果如下所示。
主要结论
总结一下,并不是 AI 本身不够出色,而是我们与之互动的方式存在问题。为了充分利用 ChatGPT 及类似工具,我们必须改进我们的方式,专注于成为思考者,引导 AI 进行执行。
遵循这些提示并对输入内容负责,你会发现 AI 生成的内容可以成为你内容创作工具箱中的宝贵资产 在你的内容创作工具箱中。
所以,让我们开始制定有效的提示,释放 AI 写作的全部潜力吧!
Josep Ferrer 是来自巴塞罗那的分析工程师。他毕业于物理工程专业,目前在应用于人类流动性的领域工作。他是一位兼职内容创作者,专注于数据科学和技术。你可以通过 LinkedIn、Twitter 或 Medium 联系他。
原文。已获许可转载。
更多相关话题
停止为高风险决策解释黑箱机器学习模型,改用可解释的模型
原文:
www.kdnuggets.com/2019/11/stop-explaining-black-box-models.html
评论
停止为高风险决策解释黑箱机器学习模型,改用可解释的模型 由 Rudin 等人,arXiv 2019
感谢 Glyn Normington 指出了这篇论文。
从标题中可以很清楚地看出辛西娅·鲁丁希望我们做什么!这篇论文混合了技术性和哲学性的论点,对我来说有两个主要的收获:首先,加深了我对可解释性与解释性的区别的理解,以及为什么前者可能存在问题;其次,提供了一些很好的方法来创建真正可解释的模型。
在医疗保健和刑事司法领域,越来越多地利用机器学习(ML)进行高风险预测应用,这对人类生活产生深远影响……预测模型的透明性和问责制的缺乏可能会(并且已经)带来严重后果……
定义术语
模型可能成为黑箱有两个原因:(a)模型计算的函数过于复杂,以至于任何人都无法理解,或者(b)模型实际上可能很简单,但其细节是专有的,无法进行检查。
在可解释的机器学习中,我们使用一个复杂的黑箱模型(例如,DNN)进行预测,并使用第二个(事后)模型来解释第一个模型的行为。一个经典的例子是LIME,它探讨了复杂模型的局部区域以揭示决策边界。
可解释的模型是一个用于预测的模型,可以被人类专家直接检查和解释。
可解释性是一个特定领域的概念,因此没有一个通用的定义。然而,通常来说,可解释的机器学习模型是在模型形式上受限的,以便它要么对某人有用,要么遵循领域的结构性知识,如单调性,或来自领域知识的物理约束。
解释并没有真正解释
目前已经有大量研究致力于为黑箱模型的输出生成解释。鲁丁认为这种方法从根本上是有缺陷的。她论点的根源在于观察到临时解释实际上只是“猜测”(我选择的词)黑箱模型在做什么:
解释一定是错误的。它们不能与原始模型完美一致。如果解释完全忠实于原始模型的计算,解释将等同于原始模型,那么我们根本不需要原始模型,只需要解释。
甚至“解释”这个词也是有问题的,因为我们并没有真正描述原始模型实际做了什么。COMPAS(替代制裁的刑事犯罪管理分析)这一例子生动地体现了这种区别。ProPublica 创建的一个线性解释模型与种族相关,被用来指责 COMPAS(这是一个黑箱)依赖于种族。但我们不知道 COMPAS 是否将种族作为一个特征(尽管它可能确实有相关的变量)。
让我们停止称对黑箱模型预测的近似为解释。对于一个没有明确使用种族的模型,自动生成的解释“这个模型预测你会因为是黑人而被逮捕”并不能反映模型实际在做什么,这会让法官、律师或被告感到困惑。
在图像空间中,显著性图展示了网络关注的区域,但即使是这些图也无法告诉我们它真正关注的内容。不同类别的显著性图可能非常相似。在下面的例子中,模型认为图像是哈士奇的显著性“解释”和认为图像是长笛的显著性“解释”看起来非常相似!

由于解释并没有真正解释,识别和排查黑箱模型的问题可能非常困难
针对可解释模型的争论
鉴于黑箱模型和解释的问题,为什么黑箱模型如此流行?虽然很难对深度学习模型的巨大近期成功提出异议,但我们不应从中得出更复杂的模型总是更好的结论。
有一种广泛的观点认为更复杂的模型更为准确,这意味着为了获得顶级的预测性能,需要一个复杂的黑箱。然而,这通常并不成立,特别是当数据是结构化的,并且在自然有意义的特征方面有很好的表示时。
由于相信复杂的东西更好,也有一种普遍的误解,即如果你想要好的性能,你必须牺牲可解释性:
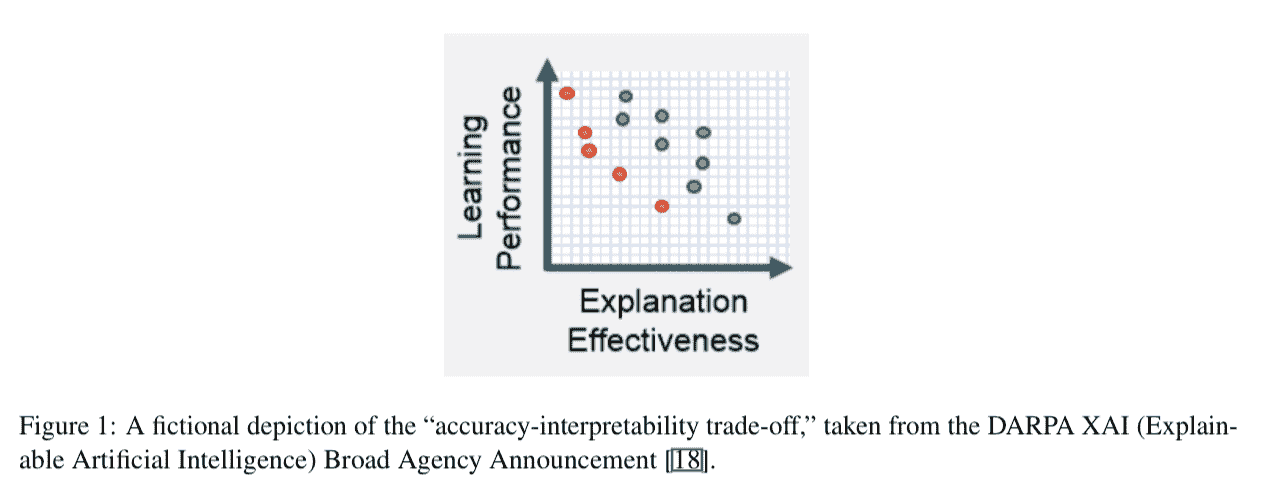
认为准确性和可解释性之间总是存在权衡的信念使许多研究人员放弃了尝试产生可解释模型。这个问题由于研究人员现在受过深度学习训练,但没有受过可解释机器学习训练而变得更加复杂…
Rashomon 集 说,如果我们尝试的话,我们通常有可能找到一个可解释的模型:鉴于数据允许存在一大组合理准确的预测模型,它通常至少包含一个可解释的模型。
这使我想到一个有趣的方法:首先进行相对较快的尝试,即使用深度学习方法而不进行任何特征工程等。如果产生了合理的结果,我们就知道数据允许存在合理准确的预测模型,我们可以投入时间去寻找一个可解释的模型。
对于那些没有混杂、完整且干净的数据,使用黑箱机器学习方法要比解决计算难题要容易得多。然而,对于高风险决策来说,分析师时间和计算时间的成本比存在一个有缺陷或过于复杂的模型的成本要低。
创建可解释的模型
论文的第五部分讨论了在寻找可解释机器学习模型时常遇到的三个常见挑战:构建最佳逻辑模型、构建最佳(稀疏)评分系统,以及在特定领域中定义可解释性可能意味着什么。
逻辑模型
逻辑模型只是一些 if-then-else 语句!这些语句已经手工制作了很长时间。理想的逻辑模型应具有给定准确性水平下最少的分支数。CORELS 是一个旨在寻找这种最佳逻辑模型的机器学习系统。以下是一个输出模型的示例,它在来自佛罗里达州布劳沃德县的数据上具有与黑箱 COMPAS 模型类似的准确性:

请注意,图例称其为“机器学习模型”。我认为这个术语不太准确。它是一个机器学习模型,而 CORELS 是一个生成它的机器学习模型,但 IF-THEN-ELSE 语句本身不是一个机器学习模型。不过,CORELS 看起来很有趣,我们将在下一期《晨报》中对其进行深入探讨。
评分系统
评分系统在医学中被广泛使用。我们对作为机器学习模型输出的最佳评分系统感兴趣,但看起来像是由人类产生的。例如:

这个模型实际上是由 RiskSLIM 产生的,即风险超稀疏线性整数模型算法(我们将在本周晚些时候对此进行更深入的探讨)。
对于 CORELS 和 RiskSLIM 模型,关键在于尽管它们看起来简单且高度可解释,但它们的结果具有高度竞争的准确性。让这些东西看起来如此简单并不容易!我当然知道如果有选择的话,我更愿意部署和故障排除哪些模型。
在特定领域设计可解释性
…即使是在经典的机器学习领域,其中数据的潜在表示需要被构建,也可能存在与黑箱模型一样准确的可解释模型。
关键是要在模型设计本身中考虑可解释性。例如,如果一个专家要解释为什么他们以某种方式对图像进行分类,他们可能会指出图像中的不同部分,这些部分在他们的推理过程中是重要的(有点像显著性),并解释原因。将这一理念引入网络设计,Chen, Li 等人 构建了一个模型,在训练过程中学习作为类别原型的图像部分,然后在测试过程中寻找与已学到的原型相似的测试图像部分。
这些解释是模型的实际计算过程,而不是事后解释。该网络被称为“这看起来像那”,因为它的推理过程考虑了图像的“这”部分是否像“那”原型。

解释、解释性和政策
论文第四部分讨论了鼓励优先使用(或甚至在高风险情况下要求使用)可解释模型的潜在政策变化。
让我们考虑一个可能的要求,即对于某些高风险决策,如果存在一个性能水平相同的可解释模型,则不应部署黑箱模型。
这听起来是一个值得追求的目标,但按这种措辞,很难证明不存在可解释模型。因此,或许公司需要被要求能够提供证据,证明他们已经进行了适当级别的尽职调查来寻找可解释模型……
考虑第二个提议,它比上述提议要弱一些,但可能会有类似的效果。我们考虑一下这样的可能性:引入黑箱模型的组织应该被要求报告可解释建模方法的准确性。
如果按照这个过程进行,我们很可能会看到实际应用中部署的黑箱机器学习模型大大减少,如果作者的经验有参考价值的话:
可能存在一些应用领域,对于高风险决策需要完全的黑箱模型。尽管我在医疗保健、刑事司法、能源可靠性和金融风险评估等多个领域工作过,但至今尚未遇到这样的应用。
最后一段
如果这篇评论能够稍微转移一下大多数可解释机器学习工作的基本假设——即黑箱模型对于准确预测是必需的——我们将认为这份文件是成功的……如果我们没有成功让政策制定者意识到当前可解释机器学习的挑战,黑箱模型可能会继续被允许使用,而这些模型在不安全的情况下仍然被使用。
原文。已获许可转载。
相关:
-
选择机器学习模型
-
“请解释。”机器学习模型的可解释性
-
可解释机器学习的 Python 库
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关话题
停止在数据科学项目中硬编码 – 改用配置文件
原文:
www.kdnuggets.com/2023/06/stop-hard-coding-data-science-project-config-files-instead.html
问题
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
在你的数据科学项目中,某些值往往会频繁变化,如文件名、选择的特征、训练-测试拆分比例以及模型的超参数。

在编写用于假设测试或演示目的的临时代码时,硬编码这些值是可以的。然而,随着代码库和团队的扩展,避免硬编码变得至关重要,因为这可能会导致各种问题:
- 可维护性:如果值散布在代码库的各个地方,一致地更新这些值就会变得更加困难。这可能会导致在值需要更新时出现错误或不一致。

- 可重用性:硬编码的值限制了代码在不同场景下的重用性。
- 安全问题:将敏感信息如密码或 API 密钥直接硬编码到代码中可能存在安全风险。如果代码被分享或暴露,可能会导致未经授权的访问或数据泄露。

- 测试和调试:硬编码的值会使测试和调试变得更加困难。如果值被硬性嵌入到代码中,那么模拟不同的场景或有效地测试边界情况就会变得困难。

解决方案 – 配置文件
配置文件通过提供以下好处来解决这些问题:
- 将配置与代码分离:配置文件允许你将参数与代码分开存储,这样可以提高代码的可维护性和可读性。
- 灵活性和可修改性:使用配置文件,你可以轻松修改项目配置而不需要修改代码本身。这种灵活性允许快速实验、参数调整,并使项目适应不同的场景或环境。
- 版本控制:将配置文件存储在版本控制系统中,可以跟踪配置的变化。这有助于维护项目配置的历史记录,并促进团队成员之间的协作。

- 部署和生产化:在将数据科学项目部署到生产环境时,配置文件可以轻松定制特定于生产环境的设置,而无需修改代码。这种将配置与代码分离的方法简化了部署过程。
Hydra 介绍
在众多用于创建配置文件的 Python 库中,Hydra 是我首选的配置管理工具,因为它具备令人印象深刻的一整套功能,包括:
-
方便的参数访问
-
命令行配置覆盖
-
从多个来源组合配置
-
执行多个具有不同配置的作业
让我们更深入地探讨这些功能。
随意查看和分叉本文的源代码:
方便的参数访问
假设所有配置文件存储在 conf 文件夹下,所有 Python 脚本存储在 src 文件夹下。
.
├── conf/
│ └── main.yaml
└── src/
├── __init__.py
├── process.py
└── train_model.py
main.yaml 文件看起来是这样的:

在 Python 脚本中访问配置文件就像给你的 Python 函数应用一个装饰器一样简单。

要从配置文件中访问特定参数,我们可以使用点符号(例如,config.process.cols_to_drop),这种方式比使用括号(例如,config['process']['cols_to_drop'])更简洁直观。

这种简单的方法让你可以轻松地获取所需的参数。
命令行配置覆盖
假设你正在尝试不同的 test_size。反复打开配置文件并修改 test_size 值是耗时的。

幸运的是,Hydra 使得从命令行直接覆盖配置变得容易。这种灵活性允许快速调整和微调,而无需修改基础配置文件。

从多个来源组合配置
想象一下,你想尝试各种数据处理方法和模型超参数的组合。虽然你可以在每次运行新实验时手动编辑配置文件,但这种方法可能会很耗时。

Hydra 允许通过配置组从多个来源组合配置。要创建一个用于数据处理的配置组,创建一个名为process的目录,其中包含每种处理方法的文件:
.
└── conf/
├── process/
│ ├── process1.yaml
│ └── process2.yaml
└── main.yaml

如果你想将process1.yaml文件设置为默认文件,请将其添加到 Hydra 的默认列表中。

按照相同的步骤创建一个用于训练超参数的配置组:
.
└── conf/
├── process/
│ ├── process1.yaml
│ └── process2.yaml
├── train/
│ ├── train1.yaml
│ └── train2.yaml
└── main.yaml

将train1设置为默认配置文件:

现在,运行应用程序时默认将使用process1.yaml文件和model1.yaml文件中的参数:
这一能力在需要无缝结合不同配置文件时特别有用。
多次运行
假设你想进行多种处理方法的实验,一个一个地应用每种配置可能会非常耗时。

幸运的是,Hydra 允许你同时用不同的配置运行相同的应用程序。

这种方法简化了用各种参数运行应用程序的过程,最终节省了宝贵的时间和精力。
结论
恭喜!你刚刚了解了使用配置文件的重要性以及如何使用 Hydra 创建配置文件。我希望这篇文章能为你提供创建自己配置文件所需的知识。
Khuyen Tran 是一位多产的数据科学作家,撰写了一系列令人印象深刻的有用数据科学主题,包括代码和文章。Khuyne 目前在 2022 年 5 月之后寻求机器学习工程师、数据科学家或开发者倡导者的职位,欢迎联系她,如果你在寻找拥有她技能的人才。
原文。经许可转载。
更多相关主题
停止伤害你的 Pandas!
评论
由 Pawel Rzeszucinski 提供,Codewise

来源:维基媒体共享资源
Pandas 是几乎所有与 Python 相关的数据处理任务的王者。它已经存在了 12 年,尽管我们直到 2020 年 1 月才看到 1.0 版本的发布。使用 Pandas 进行数据操作、切片和更新非常直观,这可能是这个包从一开始就取得成功的原因。然而,尽管语法简单而一致,但在某些情况下需要特别小心,以确保准确实现意图。本文将探讨在不当使用 Pandas 切片时可能出现的问题。如果你看到警告“A value is trying to be set on a copy of a slice from a DataFrame”,那么这篇文章适合你。
Pandas 提供了清晰的规则来正确切片 DataFrames,详细概述可以在 这里 找到。然而,我们并不总是遵循最佳实践,因为这需要获得必要的知识并保持一定的自我严格。除了指导方针中概述的选项外,Pandas 还允许我们以多种不同的方式访问 DataFrames 元素。这可能会引发尝试以不当方式进行数据分配的诱惑,导致一些意想不到的效果。
让我们从定义一个简单的测试数据框开始:
py` df = pd.DataFrame({'x':[1,5,4,3,4,5], 'y':[.1,.5,.4,.3,.4,.5], 'w':[11,15,14,13,14,15]}) x y w 0 1 0.1 11 1 5 0.5 15 2 4 0.4 14 3 3 0.3 13 4 4 0.4 14 5 5 0.5 15 ```py ````
假设我们想找出所有 'x' 列大于 3 的 DataFrame 元素,并基于此将所有对应的 'y' 值改为 50。
如何根据 Pandas 的最佳实践正确执行这一操作?在这种情况下,使用 .loc 方法:
py` df.loc[df['x']>3,'y']=50 ```py ````
我们定位满足初始标准的行元素(第一个参数),以及我们想要更新的列(第二个参数),所有这些都在一次 DataFrame 调用中进行评估。
结果如预期。
py` x y w 0 1 0.1 11 1 5 50.0 15 2 4 50.0 14 3 3 0.3 13 4 4 50.0 14 5 5 50.0 15 ```py ````
正如之前提到的,Pandas 提供了多种不同的访问(但不一定是修改)数据的方法。
不遵循脚本(指导方针)可能会导致问题。例如,有些人可能更自然地将相同的操作写成以下形式:
py` df[df['x']>3]['y']=50 ```py ````
这很清楚,不是吗?取出 df 中 'x'>3 的子集,然后将列 'y' 中的值更改为 50。
我们来做一下:
py` x y w 0 1 0.1 11 1 5 0.5 15 2 4 0.4 14 3 3 0.3 13 4 4 0.4 14 5 5 0.5 15 ```py ````
我可能打错了什么,让我再运行一次。
py` df[df['x']>3]['y']=50 x y w 0 1 0.1 11 1 5 0.5 15 2 4 0.4 14 3 3 0.3 13 4 4 0.4 14 5 5 0.5 15 ```py ````
完全没有变化!为什么呢?
我们遇到了所谓的“链式索引”效应,即一个接一个地使用两个索引器,例如 df[][]
让我们分解一下我们的命令:
-
df[df['x']>3]会导致 Pandas 创建一个原始 DataFrame 的独立副本。 -
df[df['x']>3]['y'] = 50将新值分配给 'y' 列,但是在这个临时创建的副本上,而不是我们的原始 DataFrame 上。
观察这个情况的一种方法是使用 基础的 'id' 函数,它返回给定对象在机器内存中的地址。
py` id(df) 2838845867680 id(df[df['x']>3]) 2838845989832 id(id) == id(df[df['x']>3]) False ```py ````
有趣的是,当我们反转命令中的切片顺序,即先调用列然后再使用我们想要满足的条件时,我们得到了预期的结果:
py` df['y'][df['x']>3]=50 x y w 0 1 0.1 11 1 5 50.0 15 2 4 50.0 14 3 3 0.3 13 4 4 50.0 14 5 5 50.0 15 ```py ````
这是因为,当我们只从 DataFrame 中选择一列时,Pandas 创建的是一个视图,而不是副本。
什么是视图?本质上,它是同一对象的代理,即在这个过程中不会创建新的对象。
py` z = df['y'] #z 是 df['y'] 的视图 id(df['y']) == id(z) True ```py ````
尽管我们达到了目标,但可能会触发一些副作用:
让我们看看这组命令。
py` df # 原始 DataFrame x y w 0 1 0.1 11 1 5 0.5 15 2 4 0.4 14 3 3 0.3 13 4 4 0.4 14 5 5 0.5 15 z = df['y'] # 'y' 列的视图 z[z>=0.5] = 30 z 0 0.1 1 30.0 2 0.4 3 0.3 4 0.4 5 30.0 df x y w 0 1 0.1 11 1 5 30.0 15 2 4 0.4 14 3 3 0.3 13 4 4 0.4 14 5 5 30.0 15 ```py ````
哇!我们以为创建了一个与 df 独立的对象 'z',在我们操作 'z' 时 df 的值是安全的。结果并非如此。
我们只创建了一个视图。好消息是 Pandas 会显示那个老旧的警告。
Pandas 这样做是因为它不知道我们是否想要仅仅改变 'y' 系列(通过代理 'z'),还是改变原始 df 的值。
好吧,那么如果我们想将 'z' 提取为一个独立的对象呢?Pandas 方法 .copy() 正是为了这个目的。
当我们将命令更新为下面所示的内容时,我们将创建一个具有自己内存地址的全新对象,任何对 'z' 的更新将不会影响 df。
py` z = df['y'].copy() id(df['y']) == id(z) False ```py ````
实际上有两个关键点可以防止在处理切片和数据操作时出现不希望的效果:
-
避免链式索引。始终使用
.loc/.iloc(或.at/.iat)选项: -
copy()你的变量以创建独立的对象,并保护原始源不被意外修改。
简介: Pawel Rzeszucinski 博士 是广泛定义的数据分析领域的 30 多篇出版物和专利的作者。他获得了克兰菲尔德大学的计算机科学硕士学位,随后转到曼彻斯特大学,在那里他获得了与 QinetiQ 相关的直升机齿轮箱诊断分析解决方案项目的博士学位。返回波兰后,他在 ABB 公司研究中心担任高级科学家,并在 HSBC 的战略分析部门担任高级风险建模师。他目前在 AdTech 公司 Codewise 担任首席数据科学家。Pawel Rzeszucinski 博士是 Forbes 技术委员会的成员。
相关:
-
Python 数据分析… 真的那么简单吗?!?
-
使用 pdpipe 构建 Pandas 管道
我们的 3 个顶级课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
停止学习数据科学以找到目标,并以找到目标来学习数据科学
原文:
www.kdnuggets.com/2021/12/stop-learning-data-science-find-purpose.html
评论
由 Brandon Cosley, FastDataScience.AI
数据科学家正受到需求的青睐,这毫无疑问。职位薪水丰厚,有大量职位空缺,而且在这个后疫情的数字世界中,行业似乎只会不断增长。因此,数据科学学生成为全球劳动力中一个日益增长的群体也就不足为奇了。但学习数据科学并不容易。事实上,它是困难的,这有几个充分的理由:
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 部门
1. 数据科学作为一个职业融合了许多不同的子专业,这些子专业本身就是各自独立的职业,例如数据工程、编程、统计和数据可视化。
2. 行业及相关工具和技术迅速发展,使得确定学习重点变得困难。
3. 在教育环境(如大学、数字教程)中教授的数据科学与企业中使用的数据科学之间存在差距。
4. 由于所需知识的广度非常广泛,很容易对自己有效传达教育价值的能力失去信心。
我记得自己从数据精通的学术研究者转变为行业数据科学专业人士的经历。我接触了所有能找到的教程、博客和 MOOC。我沉浸于行业新闻和趋势中。我把自己装满了知识,但发现学得越多,我意识到自己不知道的东西也越多。我感到压力重重,对自己拥有的技能缺乏信心,面临数据科学面试时总担心遇到“陷阱”,因为我没有花足够的时间在损失函数上。
我曾经用数据科学教育压倒了自己,希望我的广泛接触会引导我找到我的目标,并获得更好的薪水。我当时没有意识到的是,我把车马放在了前面。我太急于学习了,以至于花了所有时间学习各种“东西”,却从未停下来问自己:这些“东西”如何结合起来解决实际问题?
让我告诉你一个显而易见的秘密,大多数企业不关心数据科学的“东西”。大多数企业只关心这些东西是否能解决业务问题。所以这里的难点在于,试图学习所有的数据科学工具,以便你的简历上填满不断扩展的“东西”(Python、R、回归、随机森林、朴素贝叶斯、马尔可夫链、支持向量机、k-means 聚类、XGBoost、卷积神经网络、自然语言处理等等)是徒劳的。
这些“东西”不会引导你找到你的目标,因为你的目标只是由你感受到的价值定义的。你感受到价值的地方就是你允许自己不断发展的数据科学知识被应用于解决问题的地方。能够沟通你如何利用一些数据科学工具来解决问题,会比仅仅列出你在某一课程中接触过的所有算法更有助于你的职业发展。
那么我应该如何学习数据科学呢?
简而言之,首先找到一个目标。你关心什么?你的热情在哪里?你想解决什么问题?一旦你列出这些问题,选择一个,并考虑你的数据科学知识如何应用于解决与这些兴趣相关的问题。

Pixabay
有目的的数据科学的好处
通过首先找到你的目标,你将以背景知识来进行数据科学教育,你需要学习的工具会感觉不那么压倒性,因为会有更少的工具是适合应用的。
知识、热情以及对问题的理解也会激发你的创造力。创造性的问题解决是将我们对两个或更多不同领域的理解以新颖的方式结合起来。如果我们仅仅在“现成”的数据集和冷漠分配的问题中学习数据科学,我们将无法将多个领域的深度知识相结合。
通过首先找到你的目标,你将迅速了解到解决同一问题的数据科学解决方案有很多种。换句话说,数据科学中很少有绝对对错,更常见的是业务问题可以用多种方式解决。某些解决方案是否比其他解决方案更好?当然。但这并不意味着那些不够优化的解决方案是错误的,而只是它们没有那么好。只要有足够的钱和时间,总是会有“更好”的解决方案,因此最好不要过于纠结于这一点。相反,专注于你拥有的知识如何比之前的知识带来更多的价值,或通过揭示其他方案中未显现的新见解来丰富现有的解决方案。
通过首先找到你的目标,你将解决在大多数数据科学课程中常常没有教授的问题,但这些问题是企业数据科学家每天面临的。例如,找到正确数据的简单问题。大多数数据科学课程不会教你数据发现的价值,但在企业中,数据科学家常常负责发现和整合新的数据集,以进一步实现所收集的数据和聘用数据科学家的价值。以目的导向学习数据科学将迫使你寻找获取与你的问题最相关的数据的方法,它将要求你访问、处理和工程化这些数据,以便适合用于机器学习模型的训练。
最终,通过首先找到你的目标,你将知道如何传达你所建立解决方案的价值。
我的目标是什么?它是如何改变我的教育的?
我的目标是社会正义。我希望利用数据科学的工具和技能生成揭露不公正、提供积极社会变革解决方案的见解,并帮助我们认识到人类偏见的影响。

Pixabay
在我的第一个项目中,我想帮助识别车辆犯罪的高发区域,为第三班工人支持更安全的停车决策。我需要找到本地公共警察报告数据,并将其与其他数据源(如人口普查数据)结合起来。利用我所掌握的数据科学知识,我知道可以构建一个预测模型,以预测汽车发生车辆犯罪(例如盗窃、破坏)的可能性,这取决于周围位置的特征。这个项目使我学会了基本的数据处理,如何推导一些地理空间特征,测试不同的分类模型(如随机森林、逻辑回归和朴素贝叶斯)的准确性,使用 Tableau Public 进行基本的可视化,并设置一个管道,每次警察数据刷新时都能更新仪表板。
我是否还能解决其他问题?当然可以。我是否还有其他工具可以用来解决这个特定问题?绝对有。我是否想出了最好的解决方案,甚至是市场上唯一的解决方案?没有,但我的方案比现有的要好,因为当时什么都没有。
我不仅学习了上述具体工具,还对数据科学过程有了更多直观的理解。我能够更清晰地阐述为什么要用特定的分类模型处理特定的数据类型,并且最重要的是,我能够充满热情地谈论这些工具如何通过结合数百个数据点帮助我做出明智的决策。
现在,当面临新的目标并询问是否有数据科学解决方案来克服与该目标相关的问题时,我不再对自己不知道的东西感到缺乏信心。我利用那个目标来应用我所知道的,解释我的方法,并确定一些新的学习内容,同时自信地知道我能够做到。
简介: 布兰登·科斯利 在数据科学领域拥有超过 15 年的经验。他获得了以定量方法为重点的研究心理学博士学位,并曾担任主要医疗公司数据科学和 AI 总监,联合创办了多家数据科学初创公司,并且在这一领域积极发挥思想领袖作用。2021 年,布兰登启动了 FastDataScience.AI,这是一个支持数据科学教育的不断发展的资源。加入 Facebook 社区 Think Data Science,参与讨论。
原文。转载许可。
相关:
-
为什么机器学习工程师正在取代数据科学家
-
数据科学家和数据分析师有什么区别?
-
如何获得数据科学认证
更多相关话题
停止为课程付费,免费学习
原文:
www.kdnuggets.com/stop-paying-for-courses-and-learn-for-free

作者提供的图片 | Canva
在成长过程中,我们很多人被告知教育是一种特权——确实如此。然而,随着时代的变化和技术的普及,对具备这些独特技术技能的专业人士的需求也变得重要。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
如果你对科技世界感兴趣但因为不确定是否适合自己而犹豫不决,那么这篇博客适合你。我将介绍一系列免费的课程,帮助你掌握计算机科学的基础知识。
计算机科学:有目的的编程
链接:计算机科学:有目的的编程
我们已经从上个世纪教育的基础——“阅读、写作和算术”——转变为“阅读、写作和计算”。学习编程是教育的重要组成部分,因此,理解计算机科学的本质是任何新手都应该具备的。
在不到 4 周的时间里,本课程涵盖了我们书籍《计算机科学:跨学科方法》的前半部分(后半部分在我们的 Coursera 课程《计算机科学:算法、理论与机器》中讲解)。课程开始时介绍了基本编程元素,如变量、条件语句、循环、数组和输入输出,然后深入探讨了函数,介绍了递归、模块化编程和代码重用等关键概念。但这还不是全部——你将进一步深入面向对象编程,使用 Java 编程语言,学习计算问题解决。
计算机科学:算法、理论与机器
一旦掌握了基础知识,你的下一个目标将是深入探讨算法、相关理论以及对机器整体的理解。该课程包含 11 个模块,你将学习经典算法、评估性能的科学技术,以及经典的理论模型,这些模型帮助我们解决关于计算的基本问题,如可计算性、普遍性和难处理性。掌握这些模块后,你将学习机器架构(包括机器语言编程及其与 Java 编码的关系)和逻辑设计(包括从头开始构建的完整 CPU 设计)。
数据科学数学技能
链接:数据科学数学技能
很多人低估了在计算机科学中学习数学的必要性。有些人认为这是必需的,而有些人则认为没有必要。就个人而言,我认为学习可以提高理解的东西没有坏处。但事实上,数据科学包含数学。在本课程中,你将学习成为成功的数据科学家、机器学习工程师或软件工程师所需的基本数学知识。
你将学习集合论,包括 Venn 图、实数线的性质、区间符号以及不等式的代数及其对求和和 Sigma 符号的应用。你还将深入了解指数、对数和自然对数函数,以及概率论,包括贝叶斯定理。
学习编程:基础知识
链接:学习编程:基础知识
学习编程语言实际上是学习一门新语言。这听起来可能很令人生畏,但学习 Python 时情况并非如此。Python 由于其简洁性而成为最受欢迎的编程语言之一。那么为什么不从学习 Python 开始呢?
在本课程中,你将全面了解 Python,从变量和函数到元组和字典。该课程以有趣和实用的方式提供编程的基本构建块。在不到 4 周的时间内,你可能会成为初级 Python 专家。
总结
学习不应如此昂贵——尤其是当你是新手时。市场上有很多免费的资源,选择哪一个可能会很困难。这时,KDnuggets 可以提供帮助。我们将提供优质的学习资源,以确保你成功学习并找到理想的工作。
Nisha Arya 是一名数据科学家、自由撰稿人,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及数据科学相关的理论知识。Nisha 涵盖了广泛的主题,并希望探索人工智能如何有助于人类寿命的不同方式。作为一名热衷学习者,Nisha 希望拓宽她的技术知识和写作技能,同时帮助引导他人。
更多相关话题
停止从命令行运行 Jupyter Notebooks
原文:
www.kdnuggets.com/2020/10/stop-running-jupyter-notebooks-command-line.html
评论
作者:Ashton Sidhu,数据科学家

照片由 Justin Jairam 拍摄,来自 @jusspreme(已获许可)
我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
Jupyter Notebook 提供了一个出色的平台,用于生成包含代码、方程式、分析及其描述的易读文档。有些人甚至认为,当与 NBDev 结合使用时,它是一个强大的开发工具。对于这样一个不可或缺的工具,开箱即用的启动方式并不是最优的。每次使用都需要从命令行启动 Jupyter 网络应用程序,并输入你的令牌或密码。整个网络应用程序依赖于终端窗口的开启。有些人可能会“守护”这个过程,然后使用 nohup 将其从终端中分离,但这并不是最优雅和可维护的解决方案。
幸运的是,Jupyter 已经提出了解决这个问题的方案,通过推出一个作为可持续网络应用程序运行的 Jupyter Notebooks 扩展,并且内置了用户身份验证。更棒的是,它可以通过 Docker 进行管理和维护,从而提供隔离的开发环境。
在这篇文章的末尾,我们将利用 JupyterHub 的强大功能,访问一个 Jupyter Notebook 实例,该实例可以在没有终端的情况下访问,支持网络内多个设备,并且采用更友好的身份验证方法。
先决条件
对 Docker 和命令行有基本了解将有助于设置此环境。
我建议在你拥有的最强大设备上进行操作,并且这台设备应尽可能全天开启。这样的设置的一个好处是,你可以通过网络上的任何设备使用 Jupyter Notebook,但所有计算都在我们配置的设备上进行。
什么是 Jupyter Hub
JupyterHub 将笔记本的强大功能带给用户群体。JupyterHub 的理念是将 Jupyter Notebooks 的使用范围扩展到企业、课堂和大型用户群体。然而,Jupyter Notebook 通常应作为本地实例运行在单个节点上,由单个开发者操作。不幸的是,之前没有折中方案来结合 JupyterHub 的可用性和可扩展性以及本地 Jupyter Notebook 的简易性。直到现在才有了解决办法。
JupyterHub 提供了预构建的 Docker 镜像,我们可以利用这些镜像随时启动单个笔记本,几乎没有技术复杂性。我们将使用 Docker 和 JupyterHub 的组合,以便在任何时间、任何地点通过相同的 URL 访问 Jupyter Notebooks。
架构
我们的 JupyterHub 服务器架构将由 2 个服务组成:JupyterHub 和 JupyterLab。JupyterHub 将是入口点,并为任何用户生成 JupyterLab 实例。这些服务将作为 Docker 容器存在于主机上。
JupyterLab 架构图(图像作者提供)
构建 Docker 镜像
为了构建我们在家中的 JupyterHub 服务器,我们将使用预构建的 JupyterHub 和 JupyterLab Docker 镜像。
Dockerfiles
JupyterHub Docker 镜像很简单。
FROM jupyterhub/jupyterhub:1.2# Copy the JupyterHub configuration in the container
COPY jupyterhub_config.py .# Download script to automatically stop idle single-user servers
COPY cull_idle_servers.py .# Install dependencies (for advanced authentication and spawning)
RUN pip install dockerspawner
我们使用预构建的 JupyterHub Docker 镜像,并添加自己的配置文件以停止闲置服务器,cull_idle_servers.py。最后,我们安装额外的软件包,通过 Docker 启动 JupyterLab 实例。
Docker Compose
为了整合所有内容,我们创建一个 docker-compose.yml 文件来定义我们的部署和配置。
version: '3'services:
# Configuration for Hub+Proxy
jupyterhub:
build: . # Build the container from this folder.
container_name: jupyterhub_hub # The service will use this container name.
volumes: # Give access to Docker socket.
- /var/run/docker.sock:/var/run/docker.sock
- jupyterhub_data:/srv/jupyterlab
environment: # Env variables passed to the Hub process.
DOCKER_JUPYTER_IMAGE: jupyter/tensorflow-notebook
DOCKER_NETWORK_NAME: ${COMPOSE_PROJECT_NAME}_default
HUB_IP: jupyterhub_hub
ports:
- 8000:8000
restart: unless-stopped # Configuration for the single-user servers
jupyterlab:
image: jupyter/tensorflow-notebook
command: echovolumes:
jupyterhub_data:
需要注意的关键环境变量是 DOCKER_JUPYTER_IMAGE 和 DOCKER_NETWORK_NAME。JupyterHub 将使用环境变量中定义的镜像创建 Jupyter Notebooks。有关选择 Jupyter 镜像的更多信息,您可以访问以下 Jupyter 文档。
DOCKER_NETWORK_NAME 是服务使用的 Docker 网络名称。该网络由 Docker Compose 自动命名,但 Hub 需要知道这个名称,以便将 Jupyter Notebook 服务器连接到它。为了控制网络名称,我们使用一个小技巧:我们将环境变量 COMPOSE_PROJECT_NAME 传递给 Docker Compose,网络名称通过在其后附加 _default 获得。
在与 docker-compose.yml 文件相同的目录中创建一个名为 .env 的文件,并添加以下内容:
COMPOSE_PROJECT_NAME**=**jupyter_hub
停止闲置的服务器
由于这是我们的家庭设置,我们希望能够停止闲置的实例以节省计算机的内存。JupyterHub 有可以与之并行运行的服务,其中之一是 jupyterhub-idle-culler。该服务会停止任何闲置时间过长的实例。
要添加这个服务,创建一个名为 cull_idle_servers.py 的新文件,并将jupyterhub-idle-culler 项目的内容复制到其中。
确保
cull_idle_servers.py与 Dockerfile 在同一文件夹中。
要了解更多关于 JupyterHub 服务的信息,请查看他们的官方文档。
Jupyterhub 配置
最后,我们需要为 JupyterHub 实例定义配置选项,如卷挂载、Docker 镜像、服务、身份验证等。
以下是我使用的简单jupyterhub_config.py配置文件。
import os
import sysc.JupyterHub.spawner_class **=** 'dockerspawner.DockerSpawner'
c.DockerSpawner.image **=** os.environ['DOCKER_JUPYTER_IMAGE']
c.DockerSpawner.network_name **=** os.environ['DOCKER_NETWORK_NAME']
c.JupyterHub.hub_connect_ip **=** os.environ['HUB_IP']
c.JupyterHub.hub_ip **=** "0.0.0.0" *# Makes it accessible from anywhere on your network*c.JupyterHub.admin_access **=** Truec.JupyterHub.services **=** [
{
'name': 'cull_idle',
'admin': True,
'command': [sys.executable, 'cull_idle_servers.py', '--timeout=42000']
},
]c.Spawner.default_url **=** '/lab'notebook_dir **=** os.environ.get('DOCKER_NOTEBOOK_DIR') **or** '/home/jovyan/work'
c.DockerSpawner.notebook_dir **=** notebook_dir
c.DockerSpawner.volumes **=** {
'/home/sidhu': '/home/jovyan/work'
}
请注意以下配置选项:
-
'command': [sys.executable, 'cull_idle_servers.py', '--timeout=42000']:超时时间是指闲置 Jupyter 实例关闭的秒数。 -
c.Spawner.default_url = '/lab':使用 Jupyterlab 替代 Jupyter Notebook。注释掉此行以使用 Jupyter Notebook。 -
'/home/sidhu': '/home/jovyan/work':我将我的主目录挂载到 JupyterLab 主目录,以便访问我桌面上的任何项目和笔记本。这还允许我们在创建新笔记本时实现持久性,保存到本地机器上,如果 Jupyter Notebook Docker 容器被删除,也不会被删除。
如果你不希望挂载你的主目录,请移除此行,并记得将sidhu更改为你的用户名。
启动服务器
要启动服务器,只需运行docker-compose up -d,在浏览器中导航到localhost:8000,你应该能够看到 JupyterHub 登陆页面。
JupyterHub 登陆页截图(图片由作者提供)
要在网络上的其他设备如笔记本电脑、iPad 等上访问它,通过在 Unix 机器上运行ifconfig或在 Windows 上运行ipconfig来识别主机的 IP。
Ipconfig(图片由作者提供)
从你的其他设备上,导航到你在端口 8000 找到的 IP:http://IP:8000,你应该会看到 JupyterHub 登陆页面!
身份验证
剩下的最后任务是对服务器进行身份验证。由于我们没有设置 LDAP 服务器或 OAuth,JupyterHub 将使用 PAM(可插拔认证模块)身份验证来验证用户。这意味着 JupyterHub 使用主机机器的用户名和密码进行身份验证。
要利用这一点,我们需要在 JupyterHub Docker 容器上创建一个用户。还有其他方法可以做到这一点,例如在容器上放置一个脚本并在容器启动时执行,但我们将作为练习手动完成。如果你拆除或重建容器,你将需要重新创建用户。
我不建议将用户凭证硬编码到任何脚本或 Dockerfile 中。
- 查找 JupyterLab 容器 ID:
docker ps -a

JupyterLab 容器 ID(图像来源:作者)
-
“SSH” 进入容器:
docker exec -it $YOUR_CONTAINER_ID bash -
创建一个用户,并按照终端提示创建密码:
useradd $YOUR_USERNAME -
使用凭据登录,你就完成了!
你现在有了一个随时可用的 Jupyter Notebook 服务器,可以从任何设备上访问,掌握在你手中!祝编程愉快!
反馈
我欢迎关于我所有文章和教程的任何反馈。你可以在twitter上给我发消息,或者通过电子邮件联系我,地址是 sidhuashton@gmail.com。
个人简介:Ashton Sidhu (@ashtonasidhu) 是一名专注于网络安全领域的数据科学家。他是一名工程师,拥有应用科学与工程学士学位和信息系统及预测与处方分析硕士学位。
原文。已获许可转载。
相关内容:
-
Google Colab 完全指南用于深度学习
-
这里是最受欢迎的 Python IDE/编辑器
-
Netflix 的 Polynote 是一个新的开源框架,用于构建更好的数据科学笔记本
了解更多相关话题
女性数据科学家(WiDS)Datathon 的故事
原文:
www.kdnuggets.com/2022/01/story-women-data-science-wids-datathon.html

图片由作者提供
事情是如何开始的...
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
这一切开始于对做一些不同而有意义的事情的好奇。我听说了很多关于数据科学的事情,但从未完全理解其含义,于是有一天我的朋友给我发了一篇关于GPT3的文章,这就是开始。我决心学习这个神奇的数据科学世界,因此决定参加Python 数据科学家课程 - DataCamp Learn。学习路径教会了我 Python 编程和统计思维。
要完成数据科学课程,我们需要解决案例研究:使用机器学习进行学校预算并参加DrivenData 竞赛。这是我第一次构建分类模型,它彻底改变了我的思维方式。我日夜努力,试图登上排行榜,最终获得了第 8 名。

图片由作者提供
进入前十名激励我参与其他竞赛,最终我发现了Kaggle。Kaggle 组织了最激动人心和具有挑战性的机器学习竞赛。我特别寻找初学者级别的竞赛,并找到了WiDS Datathon 2021。这个竞赛有一个严格要求,即团队中至少要有 50%的女性参与者,这也是我找到Penguin的原因。
WiDS Datathon 2021
每年的挑战赛WiDS Datathon鼓励女性通过关注社会影响的机器学习挑战来提升她们的数据科学技能。竞赛允许来自不同地区的四千名参与者合作构建糖尿病的最先进预测模型。
WiDS Datathon 2021 专注于患者健康,通过提供 MIT 的 GOSSIS 表格数据集。为了在排行榜上取得最高位置,我们将专注于模型指标 AUC:接收者操作特征 (ROC) 曲线下的面积(预测与观察目标之间的糖尿病诊断)。
在初步介绍之后,我们开始工作于各种机器学习模型,并花费大部分时间解决构建基线模型的方案。我们分别处理不同的任务,并通过 Discord 通话每周讨论进展。几个月后,我们成功构建了一个有效的机器学习管道,使我们进入了第十名。
下图展示了我们构建高性能模型所采取的所有步骤。
图片由作者提供
-
数据: 数据获取和清洗。
-
分析: 探索性数据分析。
-
特征工程: 删除多个高相关特征,添加新特征,和初步模型 shap 分析。
-
缩放: 填补缺失值、标签编码和标准缩放。
-
AutoML: 试验了多个开源 AutoML 工具,如 AutoMLJar、Tabnet、Auto Keras 和 H2O。
-
Optuna: 使用 Optuna 和随机搜索 CV 进行超参数优化。
-
集成方法: 基于模型表现的加权集成。
-
排名数据: 使用几何平均法对多个实验结果进行排序,以获得更好的模型性能指标。
我们进行了229次实验,最终获得了0.8746的 AUC 分数。
“努力和专注是成功的关键。”

Kaggle 排行榜 — WiDS Datathon 2021
胜利公式
在本节中,我们将深入了解“对我们有效的东西”,以及你如何运用这些技巧赢得下一个数据科学竞赛。
图片由作者提供
活跃的研究
在 Kaggle 上,大多数团队都分享他们的代码,因此你可以简单地分叉得分最高的笔记本并提交 .csv 文件。这种技术无法使你进入前十名甚至前一百名。最糟糕的是,私人数据集发布后,你的排名会下降。
“复制笔记本,了解他们是如何解决问题的,然后进行更改以获得更好的分数。”
要赢得比赛,你需要制定自己的策略和模型管道。我们的策略是利用 AutoML 进行特征工程来解决问题。我们阅读了多个笔记本、博客和类似主题的研究论文,以了解在大多数情况下有效的解决方案。
“不断寻找新的模型、工具和框架,以提升你的分数。”
尝试与错误
实验多种模型和技术是我们成功的主要因素。我们从未认为使用神经网络处理简单数据集是一种愚蠢的方法。我们测试了所有自动化机器学习框架、深度学习模型、梯度提升、集成技术、超参数优化和特征工程技术。
“利用你的时间进行实验和学习解决相同问题的新方法。”
不要仅仅局限于 Kaggle 笔记本,搜索 GitHub 项目、技术博客、研究论文和其他代码共享平台。如果你打算用于学习目的,复制代码是可以的,如果你想将代码分享给公众,只需添加作者署名。
“不要害怕大胆思考,去寻求不寻常的解决方案。”
合作
起初,我们完全不理解分享想法或代码的概念。但随着时间的推移,Kaggle 社区教会了我们数据增强、特征工程和模型集成技术。简而言之,他们是我们能够登上顶峰的真正原因。
“去讨论标签查看其他参与者的讨论或提问。”
合作不仅限于 Kaggle 上的讨论标签,你需要与团队成员合作,向工作场所的人请教,或者在其他论坛上提问,例如创建Reddit 线程。沟通你的问题和想法将帮助你找到适合你的解决方案。
比赛的结果
比赛旨在通过帮助女性获得必要的工具来开启数据科学职业生涯,从而推动女性的整体参与。在典型的 Kaggle 比赛中,由于缺乏鼓励和支持,女性参与有限,而在 WiDS 比赛中情况完全相反,女性参与者占主导地位。Datathon 还为初学者提供了处理实际项目的学习经验。了解更多信息请访问 结果与影响。
 我与Karen Ebert Matthys进行了非常精彩的采访,她是 Women in Data Science 的联合创始人兼联合主任,同时也是斯坦福大学计算与数学工程研究所(ICME)的执行主任/外部合作伙伴。完成工程学学位后,她在一个男性主导的职业中工作,有时她是唯一一个参加技术相关活动的女性。这激励她启动 WiDS 会议,为女性提供平等的机会参与并为职场带来多样性。
我与Karen Ebert Matthys进行了非常精彩的采访,她是 Women in Data Science 的联合创始人兼联合主任,同时也是斯坦福大学计算与数学工程研究所(ICME)的执行主任/外部合作伙伴。完成工程学学位后,她在一个男性主导的职业中工作,有时她是唯一一个参加技术相关活动的女性。这激励她启动 WiDS 会议,为女性提供平等的机会参与并为职场带来多样性。
除了组织 datathon,WiDS 还包括年度技术会议和全球各地的 WiDS 区域活动。WiDS 还通过在线专业研讨会提供职业支持。最近,他们主动向中学生普及数据科学。总之,他们在各个层面上工作,为全球的女性提供支持。
“WiDS Datathon 欢迎从初学者到经验丰富的 Kagglers 的所有人。 这是提升数据科学技能并结识全球 WiDS 社区其他成员的绝佳方式。 我们对 WiDS datathon 参与者的多样性感到非常高兴——包括来自各种学科(商业、科学、农业、工程、计算机科学等)的学生,以及行业、学术界、政府和非政府组织的专业人士。”
了解更多关于 WiDS Datathon 2021 的结果和影响这里。
WiDS 下一次挑战
WiDS Datathon 2022将从 2022 年 1 月初持续到 2 月末在 Kaggle 上进行。注册链接在这里,要参与,你还需要创建一个 Kaggle 账户。我强烈建议你以团队形式参与而非个人,并加入所有的研讨会。下一个 Datathon 专注于气候变化,你将为全球事业做出贡献。

参赛者将分析建筑能效的区域差异,并建立模型预测建筑能耗。此次竞赛将帮助政府或城市管理部门最大化能源效率。了解更多信息请访问WiDS Datathon 2022 挑战赛:利用数据科学缓解气候变化。
Karen Ebert Matthys 的留言:
“请在这里注册并加入我们 1 月 7 日的启动网络研讨会!同时,也请在 1 月期间查看这里,了解全球范围内提供的 datathon 工作坊,您可以获得指导并寻找团队成员。”
致谢
我们感谢 Kaggle 和数据科学领域女性的支持性社区。我们特别感谢那些分享他们的解决方案和想法的人们。
我们想在 Kaggle 上提到的一些名字:
学习资源
Abid Ali Awan (@1abidaliawan) 是一名认证数据科学专业人员,热衷于构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为那些在精神健康方面挣扎的学生构建一个 AI 产品。
更多相关话题
讲故事:数据科学中的影响力
原文:
www.kdnuggets.com/2016/07/storytelling-power-influence-data-science.html
评论
作者:Tyler Byers,Comverge 公司。
人类是讲故事的动物。我们喜欢好故事。无论是电影、史诗、歌曲还是神话,故事都能吸引我们,打动我们,将世代联系在一起,让我们接触到更深层的信息。每个人都会讲故事,至少会一点。但显然,有些人比其他人更具讲故事的天赋。你在大学时常和那五六个朋友一起玩:那个小组中可能有一个人是大家都喜欢听的。他们可以讲故事讲上几个小时——有趣的故事、让你思考的故事、让你哭泣的故事、改变你人生的故事。这个人可能不一定比你对世界了解得更多,但他们知道如何以有趣的方式塑造信息,可能对你和你的朋友圈子产生了超出常人的影响力。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
作为数据科学家,我们需要具备影响力。我们拥有可以塑造业务方向的数据和洞察。但如果我们不能说服业务中的领导者采取我们的洞察,那我们的洞察就毫无意义。我们的数据科学同行可能对我们英勇的数据处理细节感兴趣,或对我们集成了多少模型、工程了多少特征感到好奇。业务的领导者?除非我们的工作能节省或创造金钱,否则他们可能只是把它看作是一个成人版的科学展览项目。没错,我把你花了三个月时间构建的复杂模型比作一个小学生的 纸浆火山。有趣又好玩,但最终只是你卧室里的杂物,你会把它扔进垃圾桶。希望你玩得开心并学到东西,即使你没有赢得那根丝带!

不是我的火山,但我在五年级时做过类似的火山。
那么,作为数据科学家,我们如何产生影响?我们如何说服公司领导采纳我们的见解?当我开始目前的工作时,我对此感到困惑。五分钟的早晨站会和偶尔在 Slack 聊天中发布的 ggplot 可视化图是不够的。我在做(我认为是)很酷的工作,但它没有影响我们产品的方向。因此,我找到了自己的声音。我开始讲述数据的故事,并把故事写下来。努力制作可视化图。考虑观众的需求。提出大量问题——找出业务需要的是什么,而不仅仅是我在数据中发现的有趣的内容。我开始专注于如何传达我的见解。事情开始发生变化。这仍然是(并且永远会是)一个不断进步的过程,但随着我的沟通和讲故事技巧的提升,我的影响力也在增加。
我如何传达我的结果
一切从博客开始。去年九月,我花了几天时间弄清楚如何在我们公司的 GitHub Enterprise 安装上启动一个Jekyll驱动的博客。起初,我担心设置博客的时间会浪费——毕竟,这些天我没有做数据工作。但这是我做出的最佳决定之一。我每月大约写两到三次博客,在我正在进行的任何项目的各种“停顿点”上。我喜欢博客,因为文字是我的,我不必担心听起来过于正式。我可以轻松地交叉引用之前的博客文章。写作帮助我整理思路,记录额外的问题,并提供一个准备好的可视化图库,以便我需要快速准备演示时使用。我会忘记两个月前做了什么。我会忘记两个月前有什么想法。如果我查看我的博客,我比将结果留在 GitHub 的随机目录中的 R Markdown 文件中要得到更好的提醒。而且我可以轻松地与公司领导分享我的博客链接。事实上,我惊讶于公司领导问我问题的次数,我可以说“哦,对了,我想我在四个月前做了一个关于这个的项目……是的,这里是链接!”

这不会赢得任何风格分,但我的工作博客是我对未来自己的最好礼物。
从短期来看,我依然在早晨的站会中与团队分享日常发现,但我尽量将分享内容限制在几句话以内,除非有人要求我详细说明。我可能每隔几周会在我们的Slack聊天中放一个或两个可视化图。这些图有助于保持对话的进行,或者获得一个问题的回答,但容易被遗忘且影响力不大。
最后,我会偶尔给客户或潜在客户做演示,通常有我的业务领导在场。这些演示可能会有很大的压力,因为业务和资金依赖于结果!但是,由于我经常在我的博客上写作,我发现传递演示内容相对容易。我了解材料,已经尽力在博客中解释它,并且很少有我无法回答的非常技术性的问题。演示更多的是展示漂亮的图片,并说明我们的方式如何比旧方式更有改进(相比于 Excel 电子表格的分析,展示机器学习的改进并不困难!)。
为我的工作增加价值,超越数字
有效的报告、详细的分析和可视化是赋予我“核心”工作任何价值的关键。我的核心工作是开发机器学习软件。因此,它类似于一个Kaggle 竞赛,在这里我开发一个模型,依据某项指标进行测试,并通过迭代来改进模型。一旦我的模型达到了一个好的“停止点”,我将编写生产级代码,与我们应用的其余部分进行集成。
但,正如任何自尊心强的 Kaggler 所知(我不一定算其中一员!),在创建我的模型的过程中,我创造了一个怪物!特别是,我提出了几个必须进行工程设计的新特性。但我不负责生产系统的工程!我用 R 编写代码!我的团队用 Ruby 编写代码!他们的工程管道为我的模型提供支持。我们如何达成一致?
我刚刚花了两个月时间创建这个新的、更好的模型。现在来到了更具挑战性的工作阶段。影响力的工作。说服我的团队负责人相信值得他投入精力编写新的Pivotal故事,为其打分,并分配给团队成员。也许还需要将我们的产品截止日期推迟几周,以适应我创建的新工作。为什么以及如何我的新模型更好?他们为什么应该关心?
幸运的是,我一直在博客上记录我的新模型。创建显示相对于测试指标的改进的可视化。在博客中承认当一个新特性我认为会改善模型时,实际上却使其变得更糟。按照优先级排序我的更改,如果我们不能实施所有建议的话。
我的分析必须非常详细。我需要预见问题。我需要与我的团队负责人一直进行对话,以尝试弄清楚哪些更改可能是可行的,以及哪些更改应该留到我们应用的下一个版本。
我发现可视化比我的文字更有效。我可以写五页文章试图解释我的论点。但一两个好的可视化图像能够吸引思维,激发想象力,我发现最终可以成为说服我的团队接受我的建议的影响因素。

提升讲故事技能的六种方法
每个人都有讲故事的能力。显然,有些人似乎比其他人更有天赋,但讲故事终究是一种技能,这种技能可以通过有意识的练习来提高。尤其是技术人员在讲故事方面常常会遇到困难。我不知道是否是左脑与右脑的差异,但显然,构建一个故事是一个创造性的过程。具备技术技能的人往往会被细节困住。有效的讲故事更多的是关注整体画面——你想从哪里开始,需要经过哪些关键点,最后要到达哪里,同时又要提供足够的细节以填补整体画面的空白。以下是一些成为更好讲故事者的建议:
- 尽可能多地阅读。 小说、非小说、技术书籍、博客文章、杂志、报纸。如果你只阅读数据科学或技术领域的材料,大多数人会觉得你很无聊。你将无法与许多人建立联系。人际联系对于有效的讲故事至关重要。赚钱写作的作家本质上是被支付讲故事的人。向他们学习!我特别喜欢阅读《国家地理》杂志。照片就是故事,围绕照片的文章则增添了色彩和背景。如果你必须阅读与数据相关的故事(而且你应该这样做!),我认为FiveThirtyEight设立了标准。获得灵感吧!
“你必须广泛阅读,不断改进(和重新定义)自己的作品。我很难相信那些阅读很少(或者在某些情况下根本不读)的人会认为自己可以写作,并期望别人喜欢他们写的东西,但我知道这是真的。” - 斯蒂芬·金
-
尽可能多写作。 写作可以让你的思想更清晰。你会提出更好的问题。当有人询问你关于工作的内容时,你能够提供更好的答案。一篇写得好的博客文章或报告可以给你带来比你想象中更多的影响力!但你必须练习。做事。
-
找到你的声音。 如果你的报告乏味或过于学术化,你不会有影响力。把学术工作留给学术界吧。那是它的归宿,它在那里运作良好。你现在是在商业领域!找到你的声音。不要害怕在博客文章中说“我”。让人们想要阅读你的作品,让人们想要根据你所说的内容采取行动。这对于那些多年来以学术方式写作的博士来说可能尤其困难。但一旦你克服了这个问题,它会极大地解放你。
-
优先考虑可视化: 在编写或进行数据科学演讲时,在你写下任何文字之前,先添加你的可视化。你的可视化应该是你的故事。你写的或说的话应该是为你的可视化提供背景。
-
听脱口秀喜剧。 喜剧演员在注意到我们周围世界的荒谬之处方面有一种特别的天赋。但要听那些最顶尖的脱口秀演员。他们站在那里讲笑话吗?打趣的笑话?不!他们通过故事传达荒谬,往往是非常复杂的故事。听听他们如何构建这些故事。你不必在进行数据科学演讲时模仿脱口秀演员(我强烈不推荐这样做),但你可以通过他们的故事使用方式学习很多,并从他们的节奏和语调中获得启示。

- 了解你的受众: 这是建立联系和影响的关键。如果你的受众是潜在客户的决策者,他们不会关心你五个模型集成的细节,或者你创建了什么特征。他们有业务上的痛点;你的模型是如何解决这些痛点的?你期望谁阅读你的报告?针对他们的需求。确实,你可能需要为你自己或未来的团队成员(或者当你离职时的接替者)编写技术文档。但接着再写一个版本,让你的三线经理能够理解和采取行动。如果你不了解受众的需求,你就无法与他们建立联系;如果你不能建立联系,你就无法产生影响;如果你不能产生影响,那么希望你的工作对你自己有趣,因为它可能对你的业务毫无用处。
感谢你阅读我的帖子。你是否有任何故事讲述在你的职业生涯中,尤其是在数据科学领域,如何帮助过你的例子?有没有其他关于如何提高讲故事技巧的建议?请参与讨论。
如果你还没有这样做,你可以阅读我在 LinkedIn 上的另一篇帖子:数据科学:超越 Kaggle。
或访问我的博客(也是 Jekyll 博客):datawrangl.com
个人简介:Tyler Byers 在科罗拉多州丹佛的 Comverge, Inc. 公司的清洁能源部门担任数据科学家/机器学习软件开发人员。他偶尔在 datawrangl.com 撰写博客。
原文。经许可转载。
相关:
-
如何从你的数据集中构建引人入胜的故事
-
与机器学习互动——这就是你应该关心的原因
-
掌握数据科学 SQL 的 7 个步骤
更多相关话题
使用大语言模型在云中优化性能和成本的策略

图片来源:pch.vector 在 Freepik
大语言模型(LLM)最近开始在业务中站稳脚跟,并将进一步扩展。随着公司开始理解实施 LLM 的好处,数据团队将调整模型以满足业务需求。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 工作
对于业务来说,最佳路径是利用云平台来扩展业务所需的任何 LLM 要求。然而,许多障碍可能会阻碍 LLM 在云中的性能并增加使用成本。这正是我们希望在业务中避免的。
这就是为什么本文将尝试概述一种可以用来优化云中 LLM 性能的策略,同时考虑到成本。策略是什么?让我们深入探讨一下。
1. 制定清晰的预算计划
我们必须在实施任何优化性能和成本的策略之前了解我们的财务状况。我们愿意在 LLM 上投入的预算将成为我们的限制。更高的预算可能带来更显著的性能结果,但如果不支持业务,可能并不理想。
预算计划需要与各种利益相关者进行广泛讨论,以避免浪费。确定您的业务希望解决的关键问题,并评估 LLM 是否值得投资。
这一策略同样适用于任何个人或独立业务。为 LLM 设定一个您愿意支出的预算,将有助于您长期解决财务问题。
2. 确定合适的模型规模和硬件
随着研究的进展,我们可以选择多种 LLM 来解决问题。使用较小参数的模型,优化速度更快,但可能没有最佳的业务问题解决能力。而更大的模型具有更丰富的知识库和创造力,但计算成本更高。
在决定模型时,我们需要考虑 LLM 大小的性能和成本之间的权衡。我们是需要更大参数的模型,这样性能更好但成本更高,还是相反?这是我们需要考虑的问题。因此,尽量评估你的需求。
此外,云硬件也可能影响性能。更好的 GPU 内存可能会有更快的响应时间,支持更复杂的模型,并减少延迟。然而,更高的内存意味着更高的成本。
3. 选择合适的推理选项
根据云平台的不同,推理选项也会有所不同。根据你的应用程序负载需求,你选择的选项可能也会有所不同。然而,推理还可能影响成本使用,因为每种选项的资源数量不同。
如果我们以Amazon SageMaker 推理选项为例,你的推理选项包括:
-
实时推理。这种推理在输入到达时即时处理响应。它通常用于实时应用,如聊天机器人、翻译器等。由于实时推理总是需要低延迟,因此即使在需求低谷期,应用程序也需要高计算资源。这意味着如果需求不足,实时推理的 LLM 可能导致更高的成本而没有任何好处。
-
无服务器推理。这种推理是指云平台根据需要动态扩展和分配资源。性能可能会受到影响,因为每次请求时资源启动都会有轻微的延迟。但这是最具成本效益的,因为我们只为所使用的资源付费。
-
批处理转换。这种推理是指我们批量处理请求。这意味着推理仅适用于离线处理,因为我们不会立即处理请求。对于任何需要即时处理的应用程序可能不适用,因为延迟总是存在,但成本不高。
-
异步推理。这种推理适用于后台任务,因为它在后台运行推理任务,结果稍后检索。从性能角度来看,它适合需要较长处理时间的模型,因为它可以同时处理各种任务。从成本角度来看,由于更好的资源分配,它也可能是有效的。
尝试评估你的应用程序需求,以便选择最有效的推理选项。
4. 构建有效的提示
LLM 是一种具有特定情况的模型,因为令牌数量会影响我们需要支付的费用。这就是为什么我们需要有效构建提示,以使用最少的令牌(无论是输入还是输出)同时保持输出质量。
尝试构建一个指定特定段落输出的提示,或者使用诸如“总结”、“简洁”等结尾段落。还要精确构造输入提示,以生成你所需的输出。不要让 LLM 模型生成超出你需求的内容。
5. 缓存响应
会有信息被反复询问,并且每次的响应都是一样的。为了减少查询次数,我们可以将所有典型信息缓存到数据库中,并在需要时调用它们。
通常,数据存储在如 Pinecone 或 Weaviate 这样的向量数据库中,但云平台也应有它们自己的向量数据库。我们想要缓存的响应会转换为向量形式,并为未来的查询存储。
在有效缓存响应时面临一些挑战,因为我们需要管理缓存响应不足以回答输入查询的策略。此外,一些缓存可能类似,这可能导致错误的响应。良好管理响应并拥有足够的数据库可以帮助降低成本。
结论
如果我们没有正确处理 LLM,部署的 LLM 可能会花费过多并表现不准确。这就是为什么这里有一些策略可以用来优化你在云中的 LLM 的性能和成本:
-
制定明确的预算计划,
-
决定合适的模型规模和硬件,
-
选择合适的推理选项,
-
构建有效的提示,
-
缓存响应。
Cornellius Yudha Wijaya**** 是一位数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 涉及各种 AI 和机器学习主题的写作。
更多相关主题
使用 Scikit-learn 管道简化你的机器学习工作流程
原文:
www.kdnuggets.com/streamline-your-machine-learning-workflow-with-scikit-learn-pipelines
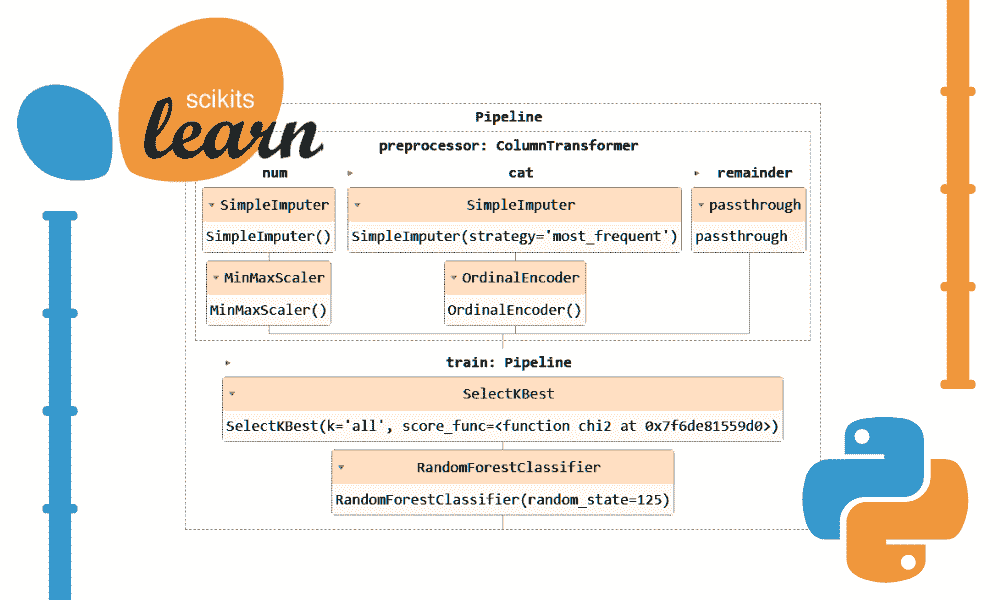
作者提供的图片
使用 Scikit-learn 管道可以简化你的预处理和建模步骤,减少代码复杂性,确保数据预处理的一致性,帮助超参数调整,并使你的工作流程更加有序且易于维护。通过将多个转换和最终模型集成到一个单一实体中,管道提高了可重复性,使一切变得更高效。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
在本教程中,我们将使用来自 Kaggle 的 Bank Churn 数据集来训练一个随机森林分类器。我们将比较传统的数据预处理和模型训练方法与使用 Scikit-learn 管道和 ColumnTransformers 的更高效的方法。
数据处理管道
在数据处理管道中,我们将学习如何单独转换分类和数值列。我们将从传统的代码风格开始,然后展示一种更好的处理方式。
从 zip 文件中提取数据后,加载 train.csv 文件,将“id”作为索引列。删除不必要的列并打乱数据集。
import pandas as pd
bank_df = pd.read_csv("train.csv", index_col="id")
bank_df = bank_df.drop(['CustomerId', 'Surname'], axis=1)
bank_df = bank_df.sample(frac=1)
bank_df.head()
我们有分类、整数和浮点列。数据集看起来相当干净。

简单的 Scikit-learn 代码
作为数据科学家,我已经多次编写了这段代码。我们的目标是填充分类特征和数值特征中的缺失值。为此,我们将使用 SimpleImputer,对每种特征使用不同的策略。
在填充缺失值之后,我们将把分类特征转换为整数,并对数值特征应用最小-最大缩放。
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Filling missing categorical values
cat_impute = SimpleImputer(strategy="most_frequent")
bank_df.iloc[:,cat_col] = cat_impute.fit_transform(bank_df.iloc[:,cat_col])
# Filling missing numerical values
num_impute = SimpleImputer(strategy="median")
bank_df.iloc[:,num_col] = num_impute.fit_transform(bank_df.iloc[:,num_col])
# Encode categorical features as an integer array.
cat_encode = OrdinalEncoder()
bank_df.iloc[:,cat_col] = cat_encode.fit_transform(bank_df.iloc[:,cat_col])
# Scaling numerical values.
scaler = MinMaxScaler()
bank_df.iloc[:,num_col] = scaler.fit_transform(bank_df.iloc[:,num_col])
bank_df.head()
结果是,我们得到了一个干净且转化后的数据集,只有整数或浮点值。
Scikit-learn 管道代码
让我们使用Pipeline和ColumnTransformer转换上述代码。我们将创建两个管道:一个用于数值列,一个用于分类列。
-
在数值管道中,我们使用了简单的插补“mean”策略,并应用了最小-最大缩放器进行归一化。
-
在分类管道中,我们使用了简单插补器的“most_frequent”策略和原始编码器将类别转换为数值。
我们使用 ColumnTransformer 结合了两个管道,并为每个管道提供了列索引。这将帮助你将这些管道应用于特定的列。例如,分类转换器管道将仅应用于列 1 和 2。
注意: remainder="passthrough" 表示未处理的列将最终添加进来。在我们的例子中,它是目标列。
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# Identify numerical and categorical columns
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Transformers for numerical data
numerical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', MinMaxScaler())
])
# Transformers for categorical data
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OrdinalEncoder())
])
# Combine transformers into a ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=[
('num', numerical_transformer, num_col),
('cat', categorical_transformer, cat_col)
],
remainder="passthrough"
)
# Apply the preprocessing pipeline
bank_df = preproc_pipe.fit_transform(bank_df)
bank_df[0]
经过转换后,结果数组包含了数值转换值在开始部分和分类转换值在结束部分,这取决于管道在列转换器中的顺序。
array([0.712 , 0.24324324, 0.6 , 0\. , 0.33333333,
1\. , 1\. , 0.76443485, 2\. , 0\. ,
0\. ])
你可以在 Jupyter Notebook 中运行管道对象以可视化管道。确保你拥有最新版本的 Scikit-learn。
preproc_pipe

数据训练管道
要训练和评估我们的模型,我们需要将数据集拆分为两个子集:训练集和测试集。
为此,我们将首先创建依赖变量和自变量,并将其转换为 NumPy 数组。然后,我们将使用train_test_split函数将数据集拆分为两个子集。
from sklearn.model_selection import train_test_split
X = bank_df.drop("Exited", axis=1).values
y = bank_df.Exited.values
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)
简单的 Scikit-learn 代码
传统的训练代码编写方式是首先使用SelectKBest进行特征选择,然后将新特征提供给我们的随机森林分类器模型。
我们将首先使用训练集训练模型,并使用测试数据集评估结果。
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.ensemble import RandomForestClassifier
KBest = SelectKBest(chi2, k="all")
X_train = KBest.fit_transform(X_train, y_train)
X_test = KBest.transform(X_test)
model = RandomForestClassifier(n_estimators=100, random_state=125)
model.fit(X_train,y_train)
model.score(X_test, y_test)
我们达到了相当不错的准确率。
0.8613035487063481
Scikit-learn 管道代码
让我们使用Pipeline函数将两个训练步骤合并到一个管道中。然后我们可以在训练集上拟合模型,并在测试集上评估。
KBest = SelectKBest(chi2, k="all")
model = RandomForestClassifier(n_estimators=100, random_state=125)
train_pipe = Pipeline(
steps=[
("KBest", KBest),
("RFmodel", model),
]
)
train_pipe.fit(X_train,y_train)
train_pipe.score(X_test, y_test)
我们取得了类似的结果,但代码看起来更高效、更简洁。添加或移除训练管道中的新步骤非常简单。
0.8613035487063481
运行管道对象以可视化管道。
train_pipe
结合处理与训练管道
现在,我们将通过创建另一个管道并将两个管道相结合来整合预处理和训练管道。
这是完整的代码:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.ensemble import RandomForestClassifier
#loading the data
bank_df = pd.read_csv("train.csv", index_col="id")
bank_df = bank_df.drop(['CustomerId', 'Surname'], axis=1)
bank_df = bank_df.sample(frac=1)
# Splitting data into training and testing sets
X = bank_df.drop(["Exited"],axis=1)
y = bank_df.Exited
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)
# Identify numerical and categorical columns
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Transformers for numerical data
numerical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', MinMaxScaler())
])
# Transformers for categorical data
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OrdinalEncoder())
])
# Combine pipelines using ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=[
('num', numerical_transformer, num_col),
('cat', categorical_transformer, cat_col)
],
remainder="passthrough"
)
# Selecting the best features
KBest = SelectKBest(chi2, k="all")
# Random Forest Classifier
model = RandomForestClassifier(n_estimators=100, random_state=125)
# KBest and model pipeline
train_pipe = Pipeline(
steps=[
("KBest", KBest),
("RFmodel", model),
]
)
# Combining the preprocessing and training pipelines
complete_pipe = Pipeline(
steps=[
("preprocessor", preproc_pipe),
("train", train_pipe),
]
)
# running the complete pipeline
complete_pipe.fit(X_train,y_train)
# model accuracy
complete_pipe.score(X_test, y_test)
输出:
0.8592837955201874
可视化完整的管道。
complete_pipe

保存和加载模型
使用管道的一个主要优势是你可以与模型一起保存管道。在推理过程中,你只需加载管道对象,它将准备好处理原始数据并提供准确的预测。你不需要在应用程序文件中重新编写处理和转换函数,因为它可以直接使用。这使得机器学习工作流程更高效,并节省了时间。
首先,使用 skops-dev/skops 库保存管道。
import skops.io as sio
sio.dump(complete_pipe, "bank_pipeline.skops")
然后,加载保存的管道并显示管道。
new_pipe = sio.load("bank_pipeline.skops", trusted=True)
new_pipe
如我们所见,我们已成功加载管道。
为了评估我们加载的管道,我们将对测试集进行预测,然后计算准确率和 F1 分数。
from sklearn.metrics import accuracy_score, f1_score
predictions = new_pipe.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
f1 = f1_score(y_test, predictions, average="macro")
print("Accuracy:", str(round(accuracy, 2) * 100) + "%", "F1:", round(f1, 2))
事实证明,我们需要关注少数类以提高我们的 f1 分数。
Accuracy: 86.0% F1: 0.76
项目文件和代码可以在 Deepnote Workspace 上找到。该工作区有两个笔记本:一个包含 Scikit-learn 管道,另一个不包含。
结论
在本教程中,我们学习了 Scikit-learn 管道如何通过将数据转换和模型序列链接在一起来简化机器学习工作流程。通过将预处理和模型训练结合到一个 Pipeline 对象中,我们可以简化代码,确保一致的数据转换,并使我们的工作流程更有组织、更具可重复性。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专家,他热爱构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为遭受心理疾病困扰的学生构建一个 AI 产品。
更多相关主题
使用 Streamlit 的新布局选项构建更好的数据应用
原文:
www.kdnuggets.com/2020/11/streamlit-better-data-apps-new-layout-options.html
评论
由 Streamlit 高级软件工程师 Austin Chen 撰写

我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
Streamlit 完全以简洁为目标。它是纯 Python。你的脚本从上到下运行。你的应用程序也从上到下呈现。完美,对吧?嗯...并非如此。用户注意到我们的思路有点过于垂直。大家对网格感到不满。社区呼吁列的支持。热心的朋友们更倾向于灵活性。你明白了。
所以,移动到一边,垂直布局。给...水平布局留点空间!以及更多的布局原语。还有一些语法糖。实际上,今天我们介绍了四个新的布局功能,让你对应用程序的展示有更多的控制。
-
st.beta_columns: 并排列,你可以在其中插入 Streamlit 元素 -
st.beta_expander: 一个展开/折叠小部件,用于选择性地显示内容 -
st.beta_container: 布局的基本构建块 -
with column1: st.write("hi!"): 语法糖,用于指定使用哪个容器
使用列实现横向布局
st.beta_columns 的作用类似于我们喜爱的 st.sidebar,不过现在你可以将列放置在应用程序的任何位置。只需将每个列声明为一个新变量,然后你就可以添加任何来自 Streamlit 库的元素或组件。
使用列来并排比较事物:
col1, col2 = st.beta_columns(2)
original = Image.open(image)
col1.header("Original")
col1.image(original, use_column_width=True)
grayscale = original.convert('LA')
col2.header("Grayscale")
col2.image(grayscale, use_column_width=True)

实际上,通过在循环中调用 st.beta_columns ,你可以获得网格布局!
st.title("Let's create a table!")
for i in range(1, 10):
cols = st.beta_columns(4)
cols[0].write(f'{i}')
cols[1].write(f'{i * i}')
cols[2].write(f'{i * i * i}')
cols[3].write('x' * i)
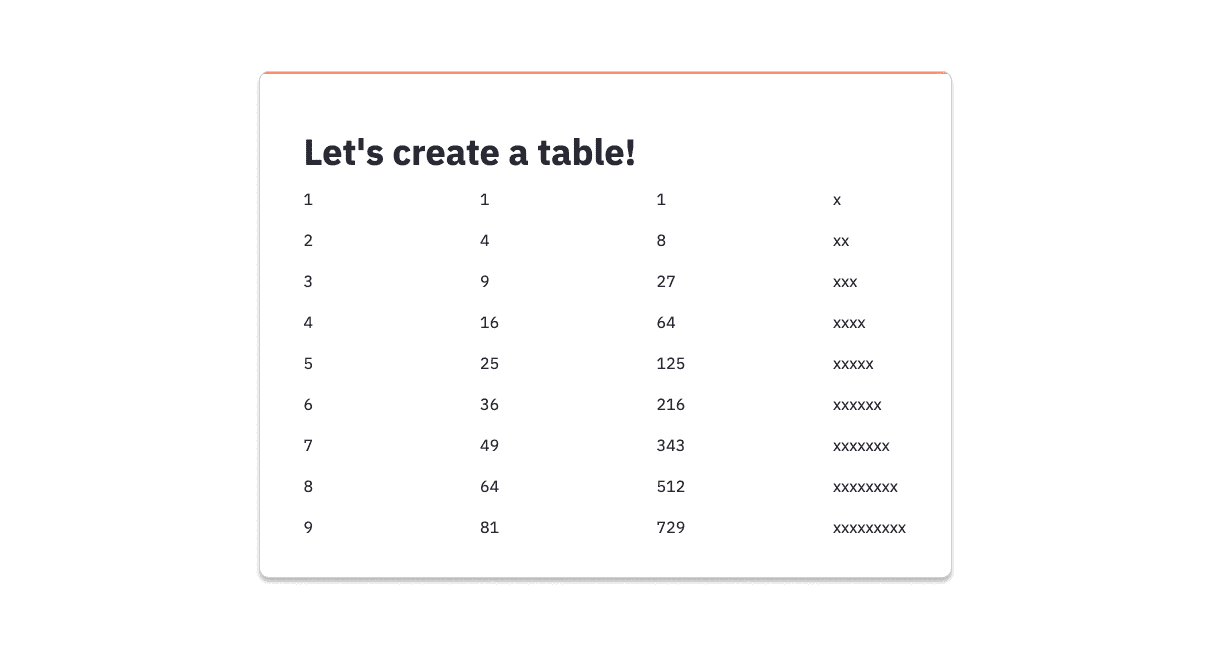
你甚至可以做到相当复杂(这对宽屏显示器来说可能很棒!)这是一个例子,展示了如何将可变宽度列与宽模式布局结合使用:
# Use the full page instead of a narrow central column
st.beta_set_page_config(layout="wide")
# Space out the maps so the first one is 2x the size of the other three
c1, c2, c3, c4 = st.beta_columns((2, 1, 1, 1))
以防你在想:是的,列在各种设备上都很美观,并且会根据移动设备和不同浏览器宽度自动调整大小。

使用展开器清理内容
现在我们已经最大化了水平空间,试试 st.beta_expander,来最大化你的 垂直 空间!你们中的一些人可能之前使用过 st.checkbox,而 expander 是一个更漂亮、更高效的替代品????
这是隐藏次要控件的好方法,或者提供用户可以切换的更长解释!
添加了一个新概念:容器!
如果你稍微眯起眼睛,st.beta_columns、st.beta_expander 和 st.sidebar 看起来有点相似。它们都返回 Python 对象,这些对象允许你调用所有的 Streamlit 函数。我们给这些对象起了一个新名字:容器。既然直接创建容器会很方便,你可以做到!
st.beta_container 是一个构建块,帮助你组织你的应用。就像 st.empty 一样,st.beta_container 允许你留出一些空间,然后再无序地写入内容。但虽然对同一个 st.empty 的后续调用会 替换 它内部的项目,后续对同一个 st.beta_container 的调用会 追加 到其中。再次强调,这与你熟悉并喜欢的 st.sidebar 一样有效。
用...来组织你的代码
最后,我们引入了一种新语法,帮助你管理所有这些新容器:with container。它是如何工作的?好吧,不是直接在容器上调用函数...
my_expander = st.beta_expander()
my_expander.write('Hello there!')
clicked = my_expander.button('Click me!')
使用容器作为 上下文管理器,并调用 st. 命名空间中的函数!
my_expander = st.beta_expander()
with my_expander:
'Hello there!'
clicked = st.button('Click me!')
为什么?这样,你可以用纯 Python 编写自己的组件,并在不同的容器中重用它们!
def my_widget(key):
st.subheader('Hello there!')
clicked = st.button("Click me " + key)
# This works in the main area
clicked = my_widget("first")
# And within an expander
my_expander = st.beta_expander("Expand", expanded=True)
with my_expander:
clicked = my_widget("second")
# AND in st.sidebar!
with st.sidebar:
clicked = my_widget("third")
最后一点:with 语法允许你将自定义组件放在任何你喜欢的容器中。查看社区成员 Sam Dobson 的这个应用,它在应用本身旁边的列中嵌入了 Streamlit Ace 编辑器——用户可以编辑代码并实时查看更改!
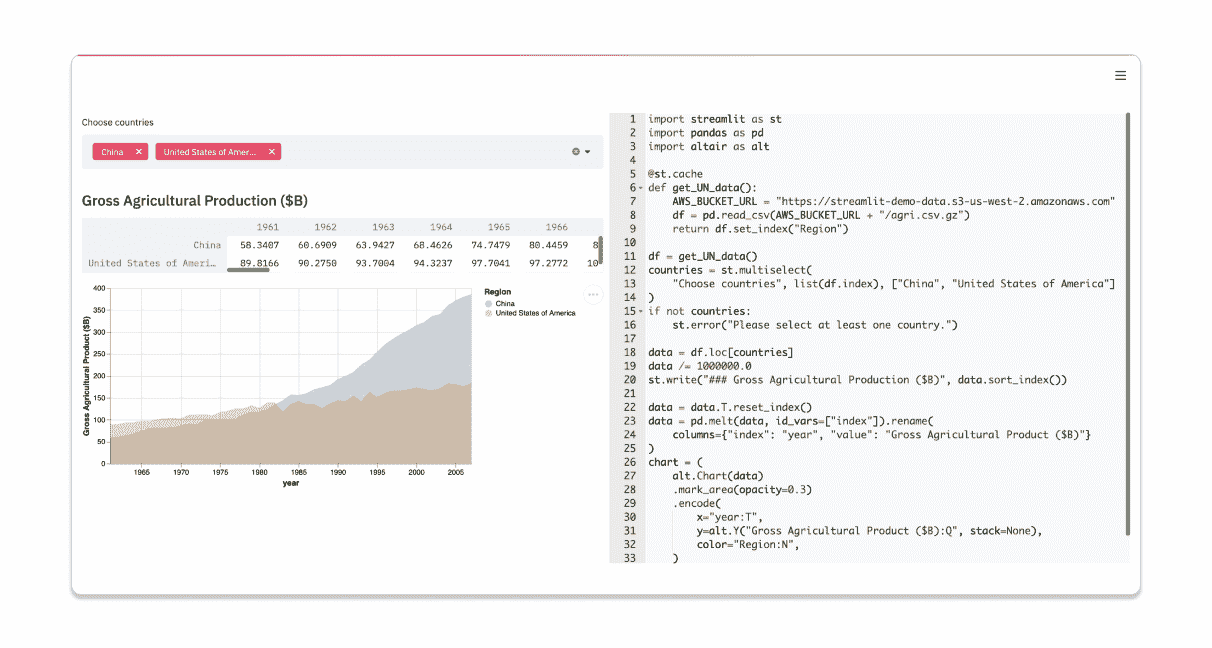
就这些,朋友们!
要开始使用布局功能,只需升级到最新版本的 Streamlit (v0.68)。
$ pip install streamlit --upgrade
接下来会有关于内边距、对齐、响应式设计和 UI 自定义的更新。敬请关注,但最重要的是,让我们知道你对布局的需求。有什么问题?建议?还是有一个很酷的应用想展示?加入我们的 Streamlit 社区论坛——我们迫不及待想看看你创造的东西????
资源
表扬
向 Streamlit 社区和创作者们致敬,他们的反馈真正塑造了布局的实现:Jesse、José、Charly 和 Synode —— 特别感谢 Fanilo 为了寻找漏洞、建议 API 并整体尝试我们的一些原型所付出的额外努力。非常感谢你们 ❤️
简介:Austin Chen 是 Streamlit 的高级软件工程师。
原文。经许可转载。
相关:
-
构建一个使用 TensorFlow 和 Streamlit 生成逼真面孔的应用
-
使用 Streamlit Sharing 部署 Streamlit 应用
-
使用 Docker Swarm、Traefik 和 Keycloak 在 AWS 上部署安全且可扩展的 Streamlit 应用
更多相关话题
Streamlit 用于机器学习备忘单
原文:
www.kdnuggets.com/2023/01/streamlit-machine-learning-cheat-sheet.html
Streamlit 与机器学习的结合
你无疑已经知道什么是机器学习。如果不知道,你可能误入了错误的网站。你可能也知道 Streamlit,但我猜你对它的不熟悉程度可能比对机器学习的不熟悉程度要高得多。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
Streamlit 是一个开源库,使得用 Python 构建数据应用程序变得简单。它处理底层的网页技术,因此开发者可以专注于逻辑和界面。因此,Streamlit 在数据科学家和其他希望快速创建易于共享的互动数据应用程序的人中非常受欢迎。
如上所述,将机器学习与 Streamlit 结合起来,是数据科学家和其他数据专业人士在数据实验、原型制作或共享结果时的热门选择。快速创建数据应用程序的能力正变得越来越重要,而这种组合确实能够实现这一点。如果你还不知道如何使用 Streamlit,我们建议你现在学习。
这就是我们最新的备忘单的用武之地。
Streamlit 是一个开源库,使得用 Python 构建数据应用程序变得简单。
KDnuggets 整理了一份实用的快速参考资源,解释和演示了构建机器学习应用程序所需的基本 Streamlit 语法。而且 Streamlit 并不仅限于机器学习。实际上,无论你的互动数据科学项目意图如何,从数据清理到数据探索,再到与数据库交互,几乎没有比这更快的方式来创建一个仪表板。
甚至可以创建一些与数据科学完全无关的东西。这样想吧:如果你可以用 Python 做到,那么你也可以用 Streamlit 做到。而且由于你的 Streamlit 项目完全是用 Python 编写的,如果你已经会编写这种语言,应该能够轻松掌握这个库的使用,尤其是有这样一个方便的快速参考资源。
所以 下载备忘单,现在就查看一下,并且不要忘记经常回来查看更多内容。
更多相关主题
Streamlit 提示、技巧和黑客技巧,适合数据科学家
原文:
www.kdnuggets.com/2021/07/streamlit-tips-tricks-hacks-data-scientists.html
评论
由 Kaveh Bakhtiyari,人工智能博士候选人,SSENSE 数据科学家
SSENSE 的数据科学团队通常构建非常复杂的工具和仪表板。另一方面,它们的维护对团队来说是一个挑战。自从 SSENSE 数据科学团队积极使用 Streamlit 已经超过一年了。在使用 Streamlit 之前,我们使用 Dash、Flask、R Shiny 等来构建我们的工具并使其对公司内的利益相关者可用。2019 年 10 月,我们开始评估 Streamlit 在我们项目中的潜在能力,通过了解其优点以及如何将其整合到我们的数据科学基础设施中。到 2019 年底,我们开始了一些基于 Streamlit 的试点项目,取代了 Flask 和 Dash。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你在 IT 领域的组织
在评估了 Streamlit 之后,我们很快意识到它具有很大的潜力,可以加快开发速度,并显著减少维护工作。除了所有酷炫的功能和易于使用外,Streamlit 不提供你可以从其他网络开发库(如 Flask)中获得的定制行为、事件和 UI 设计。最终,由于这些限制,开发干净的应用程序并在长期内轻松维护变得更容易。从我的角度来看,其统一的 UI 也是一个积极点。首先,它清晰、简洁且响应迅速。其次,所有团队成员都可以创建具有统一设计的工具。但仍然,我们如何提供我们在 Flask 应用程序中拥有的自定义元素呢?简而言之,这并不完全可能,但我们可以使用一些技巧和窍门,帮助你在设计中进行更多自定义。
今天,我将讨论一些我在使用 Streamlit 超过一年的过程中学到的技巧,你也可以利用这些技巧来释放你强大的 DS/AI/ML(无论它们是什么)应用程序的潜力。
Streamlit 是一个活跃的开源项目,社区经常提供新更新。我个人已经将他们的更新日志页面添加到书签中,以便跟踪新更新和功能。我们今天讨论的一些内容在
Streamlit (0.82.0)中并未本地支持,但未来可能会有所变化。
页面配置
这个功能最初是在测试版中引入的,后来在version 0.70.0中移到了 Streamlit 命名空间。这个很酷的功能允许你设置页面标题、网站图标、页面布局模式和侧边栏状态。
默认情况下,Streamlit 将页面标题设置为原始 Python 文件名,并使用 Streamlit 网站图标。使用这行代码,你可以自定义页面标题,这对于用户书签你的应用非常有利。然后,网站图标可以帮助他们区分如果他们在多个浏览器标签中打开了许多应用。设置布局和侧边栏的初始状态也可以让你的应用按照你希望的方式运行。
在引入这一功能之前,有些功能只能通过将 CSS 注入页面来实现。例如,如果你想制作一个宽屏,可以做如下操作:
这行代码必须是页面上的第一个 Streamlit 命令,并且只能设置一次。无论你为布局设置了什么(居中或宽屏),用户都可以在设置中控制它们。
空组件
在多种情况下,你可能需要在页面上生成新元素,或者用另一个元素替换现有的文本或元素。这可以通过st.empty()实现。这个方法在页面上创建一个空的占位符,之后你可以用任何对象或文本替换它。
上述代码最初在页面上创建一个占位符,然后在相同的位置写上“这是一个示例文本。”,之后将其替换为一个输入数字对象。
这在页面上动态显示对象或显示某些计算进度(例如进度百分比)时非常有用。
查询字符串
在你的 Streamlit 应用中设置和检索查询字符串目前是一个实验性功能。我希望它将来能够移入主命名空间,因为我个人非常喜欢这个功能。如果你曾经想知道为什么我们在 Streamlit 中需要查询字符串,你并不孤单。
当你在查询字符串中设置自定义输入时,用户可以分享带有完全相同参数的链接。否则,他们还需要输入自己的参数。
我个人使用的另一个用例是共享不同 Streamlit 应用之间的信息。在我们的团队中,每个数据科学家可能在不同的项目上工作,我们可能需要将用户从一个应用程序重定向到另一个。当我们提供链接让用户导航到其他 Streamlit 应用时,我们希望确保用户的体验尽可能无缝。因此,我们将所需的参数传递给新应用,以便它加载用户所寻找的数据和分析。
例如,我们的一些工具与我们网站上的产品有关(真是惊喜)。当他们在应用 1 中查看产品 1 的分析时,我们希望确保一旦他们转到应用 2 获取更多细节或不同分析时,它会自动显示产品 1,用户不需要重新输入信息。
在子文件夹中运行 Streamlit
在数据科学项目中,我们可能需要将 Streamlit 应用放在子文件夹中。在这种情况下,由于 Streamlit 从子文件夹运行应用程序,该应用无法访问父文件夹中的库。为了解决这个问题,我们可能需要将 Streamlit 主应用程序文件放在项目根目录中,或者在 Streamlit 应用程序的开头将根文件夹添加到系统路径中。
会话
Streamlit 是基于会话的应用程序。这意味着一旦用户访问应用程序,Streamlit 会为其分配一个会话 ID,其他连续的操作和数据传输都与该会话相关联。因此,当你有一个过程时,它不会影响其他同时的用户,除非你使用缓存。我们稍后会讨论缓存。
默认情况下,你没有对 Streamlit 中的会话控制的标准访问权限,这还没有正式记录,而且仅用于内部目的。然而,你仍然可以访问这些控制并从中获益。
Streamlit 应用程序以类似脚本的格式开发。这意味着对应用程序的每次交互都会触发从头到尾重新运行整个代码。这使得 Streamlit 非常易于使用,但同时也很难控制连续事件,因为开发者没有事件处理功能。
假设你有一个按钮(st.button)用于启动一个过程,在结果屏幕中,你希望给用户一些交互选项,比如另一个复选框、单选按钮或简单的另一个按钮。在这种情况下,当你点击第一个按钮(我们称之为button_run)时,它在重新运行整个代码时会变为True。这没有问题,应用运行流畅。

现在,在生成的页面上,有另一个按钮(我们称之为 button_filter)用于过滤结果。如果你现在点击第二个按钮(button_filter),它的值变为 True,Streamlit 会再次运行整个代码。但问题是现在第一个按钮(button_run)变成了 False,因为我们没有点击它。在这种情况下,当 Streamlit 重新运行整个代码时,它假设 button_run 没有被点击,而 button_filter 被点击了。它不会记住 button_run 之前被点击过。因此,button_filter 点击的代码将永远不会被执行,因为 button_filter 本身是第一个按钮 button_run 点击的结果。

在这种情况下,我们应该注册事件,以便 Streamlit 可以记住当用户点击第一个按钮时,并且一旦下一个按钮被点击时,它可以理解这些是连续的操作,两者都应该被视为点击。
你可能会认为,我们可以将这些信息保存到数据库或临时文本文件中。这是可能的,但你如何区分潜在的不同用户呢?
Streamlit 有一个内置的未文档化的 Session 对象,可以为每个用户存储一些临时信息。在这种情况下,当用户点击 button_run 时,我们将点击事件存储在 Session 中,而一旦 button_filter 被点击,我们可以检查 button_run 是否之前被点击过,以控制数据的正确流动。
这里是你可以在应用中包含的会话类:
一旦你添加了会话类,你可以使用会话来存储和检索信息。
SQLAlchemy
SQLAlchemy 是连接到多种类型数据库(如 SQLite、MySQL 等)的标准流行库之一。SQLAlchemy 可以用于多种平台,如桌面应用、网页应用,甚至是移动应用。如果你以前使用过这个库,你会发现它相当简单,但在网络开发中可能会变得有些棘手。使用这个库进行 Web 应用开发的主要挑战是控制数据库连接的数量。
为了这个目的,我们有 Flask (sqlalchemy-flask) 和 Tornado (sqlalchemy-tornado) 的独立库,开发者可以放心使用。但据我所知,我们没有专门为 Streamlit 提供的库。由于 Streamlit 是建立在 Tornado 之上的,也许我们可以使用 Tornado 版本,但我个人没有进行过测试。
如你所记得,Streamlit 是基于会话的,这意味着它为每个用户运行一个独立的实例。SQLAlchemy 也不例外。如果不小心的话,Streamlit 会为每个用户甚至每次交互创建一个数据库连接。根据你的数据库,如果活动连接过多,你的连接可能会被拒绝。因此,Python 可能会出现一些奇怪的错误,如“双重释放或损坏”,并崩溃你的应用程序。
在 Streamlit 论坛上,有建议缓存连接,这在 SQLLite 上效果很好,但在 MySQL 上效果不佳。例如,当你缓存数据库连接时,它不会无限期保持打开状态,因此你可能需要通过ttl来解决这个问题。在这种情况下,你可以确保在连接对象到达数据库端时已经过期,因为连接已经被关闭。从理论上讲,如果你有非常有限的同时用户,这种方法效果很好。
缓存连接的问题主要在于当两个用户同时运行缓存对象的代码时。最后,缓存的连接可能不是正确的连接,而是已经过期的连接,因为在同一时间创建了两个连接,但只有一个被缓存。
SQLAlchemy 有一个名为 Session 的对象,我们可以在其中创建数据库连接(引擎)并执行 SQL 查询。这会检查新连接是否已存在于池中,如果存在,它不会创建新连接以防止数据库连接饱和问题。在这种情况下,你不再需要使用 Streamlit 缓存来存储数据库连接。以下代码片段将帮助你了解如何使用 Session 连接 MySQL。
记住,在使用 SQLAlchemy 的 Session 之前,如果你只使用引擎,你必须返回conn = engine.connect()而不是会话,你可以使用df = pd.read_sql(query, conn)来运行查询。然而,这些方法在 SQLAlchemy Sessions 中不起作用。
缓存
Streamlit 有非常全面且有用的缓存文档,老实说,这是它最有用的功能之一。不使用或误用缓存会极大地影响应用性能和加载/运行时间。我不想详细讨论已经在Streamlit 文档中提供的缓存内容,只提几个提示和发现。
应用范围访问
与 Session 对象不同,缓存对象是全应用范围可访问的。这意味着一旦你缓存了信息,所有应用用户都可以访问。因此,重要的是不要缓存用户特定的设置和数据,而是如前所述使用 Session。
缓存参数
缓存机制有几个参数可以控制对象的缓存方式。
-
ttl
**<float, None>**😗* 这代表生存时间,用于设置缓存对象的生存时间。这个过期时间以秒为单位。 -
max_entries
**<int, None>**😗* 一旦你开始调用具有不同参数的函数,它会开始缓存所有这些变化,并且在短时间内,缓存数据量可能非常庞大。此参数可以设置可以缓存的函数变化数量,旧的变化将被删除。这控制和限制了消耗的内存量。 -
persistent
**<bool>**: 这是一个布尔参数,用于设置缓存的数据是存储在硬盘还是内存中。只需记住,一旦将其设置为 True,Streamlit 就会将对象序列化并存储在硬盘上,而并非所有对象(例如 SQLAlchemy 数据库连接)都可以被序列化。因此,对于一些持久缓存函数,你可能会遇到错误。 -
allow_output_mutation
**<bool>**: 一旦函数的输出被缓存,如果你更改了输出(突变),结果将被存储在缓存对象中,正如我之前提到的,这对所有用户都是可访问的。因此,最佳实践是避免更改缓存对象。但仍然有一些情况下你需要直接更改缓存对象。在这种情况下,此参数将允许 Streamlit 突变缓存对象。 -
suppress_st_warning
**<bool>**: 有时 Streamlit 会向用户/开发者发出一些警告,以提醒他们缓存的某些后果。将此设置为 False 将停止这些警告。 -
show_spinner
**<bool>**: 每当 Streamlit 运行应该被缓存的函数时,你会在 UI 上看到一条消息,显示“Running function_name”。除非你有很多函数,否则这可能不会太打扰你。如果你有很多函数,你会在 UI 上看到这些消息。将此参数设置为 False 将会阻止显示这些消息。
上述代码仅缓存结果 60 秒,并且只保留此函数的最后 20 个变体。它还不会显示任何警告,也不会在运行此函数时在 Streamlit UI 上显示任何消息。
由于我们将 allow_output_mutation 设置为 False,以下代码是不允许的,我们不能更新(突变)函数的结果。
清除缓存
有些情况下你可能需要以编程方式清除缓存。虽然可以通过 Streamlit 应用右上角的汉堡菜单手动清除所有缓存数据,但如果你想以编程方式进行,你可以使用以下未文档化的方法。
SQLAlchemy 会话 / 作用域会话
现在你可以使用 SQLAlchemy 会话、作用域会话和连接池成功连接到数据库,你可能需要缓存会话或使用数据库连接的函数。如前所述,由于我们使用了连接池和作用域会话,我们可能不需要缓存连接,但仍然可能需要缓存我们的函数。以下是我们对缓存使用会话的函数的两个建议。
以下示例将使用 hash_funcs 来识别 Session 的哪个参数必须进行哈希监控。
如果上述示例不起作用,例如在使用 scoped_session 的情况下,你可以简单地要求 Streamlit 忽略哈希会话,如下所示:
UI 黑客
Streamlit 的简洁性在于你不需要处理 UI,它自带预构建的响应式 UI 元素,这些元素会优雅地放置在你的页面上。即使在最近的版本中,他们提供了新的 beta 更新,允许你创建列并在其中排列元素,但对 UI 的自定义仍然有限。
当我部署我的应用程序时,公司中有各种各样的用户在使用它们。我大量使用缓存机制来控制我的应用程序的性能和速度。我的一些函数需要几分钟才能运行,我使用缓存机制来确保其他用户不会再次等待相同的请求,并且能够获得高性能的应用体验。但是,如果用户点击右上角的汉堡菜单按钮,并选择“清除缓存”,这可能会对其他用户的应用性能产生巨大影响,直到函数再次缓存结果。例如,我的一些应用程序设计为在宽模式下显示最佳,如果用户选择“居中”模式,这可能会影响应用程序的显示效果。
除了所有这些可能直接影响我的应用程序的选项外,汉堡菜单中还有一些普通用户可能不需要访问的选项。例如,访问 Streamlit Github、文档等。
在 Streamlit Github 上提出的想法 是限制应用程序部署后汉堡菜单选项的数量,但截至今天,这个问题仍然开放,我们无法直接管理它们。因此,我提出了我的 CSS 解决方案来解决这个问题。

在我提出的解决方案中,你可以移除(隐藏)Streamlit 页脚,并控制汉堡菜单中的项目。你只需使用 st.markdown 将以下 CSS 注入到你的应用程序中,并允许“危险的” HTML 代码。
上述数字在 li:nth-of-type(n) 中指的是汉堡菜单中的项目元素,它们的顺序可能在未来的 Streamlit 更新中发生变化。
此外,目前在汉堡菜单中(第 3 项)有一个名为“部署此应用”的选项。只有当应用程序通过回环本地 IP 地址(localhost 或 127.0.0.1)访问时,此项目才会显示。如果你通过 LAN/WAN IP 地址访问你的应用程序,则不会显示此项目。
录制屏幕视频
这个功能在 version 0.55.0 中引入,我个人对这个功能感到兴奋,因为它允许我们录制我们的应用程序用于培训和演示目的。很快,我们意识到这个功能在其他访问我们 Streamlit 应用程序的用户中不起作用,他们点击该选项时会收到以下消息。

由于浏览器实施和强加的隐私限制,这个功能仅在以下条件下有效:
-
仅在最新版本的 Chrome、Firefox 和 Edge 上
-
访问
localhost或127.0.0.1 -
如果不是本地访问,必须使用 SSL 证书(https)
如果你的应用在代理后运行,例如Nginx,并且你打算使用此功能,请确保它通过 SSL 证书进行安全保护。目前,Streamlit 本身不支持 SSL,但可以在带有 SSL 证书的代理后部署。
组件
自从 Streamlit 组件的引入以来,开发者们开始构建出令人惊叹的组件,可以在 Streamlit 应用中使用。如果你愿意,你可以使用 Streamlit 组件 API 构建自己的组件。Streamlit 还有一个组件库,展示了一些有用且有趣的公开组件。在这些组件中,我挑选了几个我在 SSENSE 中构建出色应用所使用的组件。
ACE 编辑器
这个编辑器提供了针对不同编程语言的颜色编码编辑器。我个人在我的应用中使用了很多 JSON 数据,我使用这个编辑器查看和编辑我的 JSON 内容。它非常出色,因为它还可以捕捉我的格式结构和错误。
如果你对 Streamlit 标准的多行文本框感到厌倦,这个组件可能是一个很好的替代方案。
Ag-Grid
Streamlit 可以处理数据框,并可以使用st.write或st.dataframe以表格格式显示它们。然而,默认情况下,Streamlit 不提供数据框呈现的自定义控制,除非点击列名进行排序。
Ag-Grid 是一个可以导入到 Streamlit 中的网格组件。使用这个组件,你不仅可以呈现你的数据框,还可以在网格单元格中包含链接、图片、复选框等,并进行数据过滤、搜索、汇总和分组。
github.com/PablocFonseca/streamlit-aggrid
如果你经常需要展示数据框,也许是时候尝试 Ag-Grid,看看它在你的应用中的巨大潜力。
Lottie 动画
最后但同样重要的是,我列表中的组件是 Lottie 动画。如果你查看lottiefiles.com,你会看到成千上万的基于矢量的动画,格式多样,如 JSON,可以放置在你的应用中。这个组件可以让你通过简单地提供 JSON 文件来展示这些 Lottie 动画。

我个人使用这些动画来展示在加载或计算时设计精美的旋转器。这些动画将为你下一个数据科学项目带来更生动和动态的效果。
最后的话
在这里,我展示了一些开发 Streamlit 应用的提示和技巧。这些技巧中的一些可能会在未来版本的 Streamlit 中原生提供,从而不再需要我们进行这些破解,另一方面,它们可能会带来一些更新以防止这些破解。谁知道呢,但我们现在可以享受这些技巧,并期待 Streamlit 的新功能。
我还要感谢 Streamlit 社区开发了如此出色的工具。
个人简介:Kaveh Bakhtiyari 是人工智能博士生,并且是 SSENSE 的数据科学家。
原文。已获许可转载。
相关内容:
-
使用 Streamlit Sharing 部署 Streamlit 应用
-
使用 Streamlit 进行主题建模
-
在 AWS 上使用 Docker Swarm、Traefik 和 Keycloak 部署安全且可扩展的 Streamlit 应用
更多相关内容
如何作为初学者建立强大的数据科学作品集
原文:
www.kdnuggets.com/2021/10/strong-data-science-portfolio-as-beginner.html
图片来源:作者 | 元素来自 Free Vector | 统计概念插图
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你在组织中的 IT
作为初学者,我有很多关于如何开始的问题。我如何学习,或者在哪里获得项目的想法。因此,在长时间的搜索之后,我发现了一个数据分析项目。我花了三天时间编写代码,对第一次尝试很满意,但随后出现了一个大问题:我如何与世界分享它?我当时没有好的编码技能或文档技能来展示我的工作,所以我把它存储在云端并忘记了它。一个月后,我在 GitHub 上随机寻找更多项目时,发现了这个令人惊叹的 个人资料,它激励我创建了我的作品集。这是我做出的最好的决定,它让我进入了开发者社区的视野,不久之后,我开始收到招聘人员和初学者关于我项目的电子邮件。
找工作通常是建立作品集的主要原因。如果我们没有相关的教育或经验,有时这也是必要的(eugeneyan.com)。在现代社会,雇主对招聘新毕业生持怀疑态度,那么你怎么说服他们你最适合这个职位呢?你通过展示你在之前项目中的工作来展示你的技能。你的在线作品集越强大,你被聘用为理想工作的机会就越高。
“作品集非常关键,因为当你在面试时,它展示了你的实际经验,这样你就可以从 A 到 Z 向雇主解释整个数据科学工作流程。”
另一个动机是创建一个个人项目,满足你对学习新事物的好奇心。当我们学习新技能时,我们想要进行实验,最终构建一个可以在现实世界中使用的有效产品。
在这篇文章中,我们将学习作为数据科学初学者展示自己工作的方式。你将了解一些使你的生活更轻松的新平台以及构建强大作品集的技巧。
GitHub
让我澄清一下数据科学家之间的误解。是的,GitHub是必要的,我们都应该学习git。作为数据科学家,我每天使用 GitHub,在这里寻找有趣的数据集和项目。这是开发者中最受欢迎的平台,老实说,招聘人员在邀请你面试之前确实会查看你的 GitHub 个人资料。
作者提供的图片 | github
GitHub 是一个全球协作平台,人们在这里分享和合作项目。正如你在我的个人资料中看到的,我不仅为其他人的项目做出了贡献,也在自己项目上进行工作。
作者提供的图片 | kingabzpro
创建一个可靠个人资料的提示:
-
创建你的个人主页,完整教程请查看Sarah Hart’s的博客。
-
用链接、封面图片和详细描述记录每个项目。
-
Fork 你最喜欢的项目,并发送你的第一个拉取请求 (freecodecamp.org)。
-
在这个平台上积极参与,包括贡献代码、报告漏洞和推进当前项目。
Deepnote
Deepnote比 GitHub 简单得多,也很适合初学者。如果你熟悉Jupyter notebook,那么发布你的第一个项目将变得非常简单。我对 Deepnote 的体验绝对惊人,因为该平台提供了 GitHub 的所有功能,但更加简单,并专注于数据科学社区。
作者提供的图片 | Pakistan Vaccination Progress
最近,他们推出了一个 Deepnote 个人资料功能,可以展示你发布的所有笔记本以及你的信息和个人照片。
作者提供的图片 | Deepnote
就像GitHub Gist一样,你可以与团队或公众分享代码片段。我在所有 Medium 出版物和社交媒体平台上使用了 Deepnote 单元。你可以查看我之前的文章来了解如何实现 Deepnote 单元。使用带有输出的代码片段使你能够在多个平台上分享项目。
我更喜欢 Deepnote 内嵌单元格而不是 GitHub Gist,因为它不仅提供静态输出,还有互动功能。
你可以使用 Plotly 并在 Medium 文章中展示你的图表:

创建扎实个人资料的技巧:
-
更新你的个人简介、头像和联系信息。
-
始终通过使用 markdown 单元格添加关于你项目的详细描述。
-
使用封面照片让你的项目脱颖而出。
-
在 Deepnote 中使用应用功能创建互动网页应用。
-
定期发布旧项目或重新发布来自 GitHub 的笔记本。
DAGsHub
DAGsHub 对这个世界来说是新的,它通过为机器学习从业者和数据工程师提供一站式解决方案迅速崭露头角。DAGsHub 配备了一个 DVC 服务器、MLflow、可视化管道和 GitHub 同步功能。我们不会深入探讨所有功能,而是专注于使其脱颖而出的功能。
DAGsHub 允许你分享你的 GitHub 仓库,并创建你的数据科学项目,能够可视化机器学习和数据管道。它还有一个隐藏功能 README.ipynb 作为你的项目描述文件,非常适合不习惯使用 markdown 的初学者和喜欢使用 Jupyter Notebook 的数据科学家。它类似于 GitHub,这意味着你需要学习 Git 和 DVC 才能正确使用这个平台。
“我看到其他用户喜欢的功能是能够通过管道可视化他们的项目结构,以及能够将他们的数据和模型视为项目的一个组成部分。此外,我们基于开源工具而不是重新发明现有解决方案的事实也是人们喜欢的。”
— Dean
Dean 图片 | dagshub
我的个人资料还很新,但我喜欢这个平台,因为它为我提供了完整的机器学习生态系统。我认为在功能和用户界面简洁性方面,我更喜欢它而不是 GitHub。
作者图片 | DAGsHub
创建扎实个人资料的技巧:
-
在你的笔记本和 README 中添加项目描述。
-
通过添加个人简介、头像和联系信息来更新你的个人资料。
-
尝试在你的项目中添加 dvc.yaml 和 dvc.lock 以展示数据管道。更多信息,请查看 定义管道。
-
通过参与开源项目和推动个人项目来保持活跃的个人资料。你可以使用 fds cli 来简化工作并避免错误。
-
充分利用 DVC,将你的数据和模型上传到远程服务器。招聘者对了解从数据获取到仪表盘完整数据科学周期的候选人感兴趣。
Kaggle
如果你想在数据科学领域更快地被注意到,你应该创建一个Kaggle账户,并开始参与竞赛、数据集、笔记本和讨论。当你成为大师时,人们会尊敬你,并为你提供更好的职业机会。如果你问我,我建议你在学习基础知识时创建一个 Kaggle 个人资料。向专家学习,发现你的专长。我非常喜欢这个平台,因为它为初学者提供了竞争和为各行各业开发创新解决方案的支持。它是 AI 研究的核心。
图片由作者提供 | Kaggle
你可以查看我下面的个人资料,因为从一开始我就在各种类别中贡献,以获得排名。目前,我是专家,但凭借一枚金牌和一枚银牌,我将成为大师,这并不容易,老实说,我尊敬大师们,因为他们证明了自己在其他数据从业者中是最优秀的。
图片由作者提供 | Kaggle
创建一个扎实的个人资料的提示:
-
在平台上保持活跃,使用新数据集并创建数据分析或机器学习模型。
-
参与讨论,向专家学习,并寻求帮助。
-
使用网页抓取来发布新数据集。
-
参加大多数竞赛,以学习多种类型的机器学习问题并获得徽章。
-
专注于发布你最好的作品,附上详细描述和高质量的代码。
-
在个人简介中写关于自己的内容并添加联系信息。
博客
撰写博客是创建项目后要做的下一步。如果你想扩大受众,我强烈建议你从Medium开始。写博客不是必需的,但你会从各个领域获得更多关注。Medium 平台允许你创建个人资料,并在各种出版物下发布你的文章,例如Towards Data Science和Towards AI。你可以开发自己的博客网站或使用其他类似平台,如Analytics Vidhya。
图片由作者提供 | Medium
创建一个扎实的个人资料的提示:
-
撰写关于你亲自参与的项目的博客。
-
撰写关于新兴技术或数据科学新应用的博客。
-
撰写博客时要进行适当的研究,并添加引用,以避免违反平台规则。
-
为每个博客使用吸引人的封面照片。
-
在开发数据科学项目时,总是写下你从经验中学到的东西。
-
不要盲目跟随潮流,专注于你擅长的领域。
作品集网站
你还可以在个人网站上展示你的项目,如果你不是网页开发人员,也有一些简单的工具可以让这个过程变得非常容易。你可以查看 如何使用 Hugo 和 GitHub Pages 构建数据科学作品集网站 和 Hugo 的各种模板。
我的作品集网站包括来自所有平台的项目,附有简短描述和子类别。我花了三天时间创建整个网站并将其部署到 GitHub Pages 上。
图片来源:作者 | Portfolio
创建一个稳固的作品集网站的提示:
-
添加你的技能、简历和 CV。
-
展示你的经验和一个
-
展示你的项目,并提供指向你的 GitHub 或 Deepnote 项目的链接。
-
使你的网站简洁而互动,以便招聘人员可以轻松浏览你的整个作品集。
-
保持你的作品集网站更新,展示你正在进行的最新项目。
Weight & Biases
我通常使用 Weight & Biases 进行机器学习实验,并记录模型的性能指标,但随着 W&B 个人资料的推出,这一点发生了变化。你可以通过使用嵌入链接和图表集成撰写关于你当前项目的博客。这与我提到的其他作品集平台类似,但它具有与 Python 库的直接集成的优势。
Ayush 的个人资料给我留下了深刻印象,因为他在撰写有关机器学习的博客的同时,也为其他组织做出贡献。
图片来源:Ayush | Weights & Biases
W&B 项目具有模型性能指标,如下所示。
图片来源:作者 | kaggle-seti
创建一个稳固的个人资料的提示:
-
加入其他数据科学组织,并参与小组项目。
-
使用 W&B API 显示你的机器学习项目结果。
-
使用 W&B 指标集成撰写博客。
-
添加个人简介、头像和联系信息。
-
尝试参与社区讨论,并始终寻找新的有趣项目。
结论
W&B 是一个全能工具,它以记录实验而闻名,而不是作品集,但互动博客的引入让我们独特地展示了你的项目并创建了一个强大的作品集。
如果你是初学者,我建议你从 Deepnote 开始,因为它对团队免费,并且提供了适合初学者的工具。如果你希望在数据科学社区中获得关注,可以尝试在 GitHub 和 Kaggle 上创建个人档案。如果你想打造自己的品牌,可以从博客网站入手或创建你的网站。
最后,我希望大家在上述提到的所有平台上创建个人档案,因为它们都具有在潜在雇主面前留下深刻印象的独特优势。我知道刚开始时可能会有些不知所措,但一旦你习惯了记录和展示你的项目,这一切都会变得简单。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理健康问题的学生构建一个人工智能产品。
更多相关话题
如何结构化数据科学项目:逐步指南
原文:
www.kdnuggets.com/2022/05/structure-data-science-project-stepbystep-guide.html

图片来源于vectorjuice在freepik
在数据科学项目中取得成功需要对发现和探索的专注。但首先,你必须理解这个过程并优化它,以确保结果是可靠的,项目也容易跟进、维护和在必要时修改。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
结构化你的 data science project 的最佳和最快的方法是使用一个主模板。你可以在网上找到一些优秀的模板,但要注意,它们可能不会涵盖良好的实践,比如配置、格式化和测试代码。
你需要一些可维护和可重复的东西,并且不需要花费太多时间。所以,查看一个被称为 data-science-template 的库可能是个好主意。
结构化数据科学项目的优势
结构化与你的数据科学项目相关的数据和源代码有各种优势。这些优势包括:
-
数据科学团队之间的更好合作/沟通。 当所有组员都遵循相同的项目结构时,识别其他人所做的修改变得容易。
-
效率。 当你使用旧的 Jupyter 笔记本来重新处理你新的数据科学项目中的某些功能时,你可能最终会在平均 10 个笔记本之间反复迭代。在这种情况下,发现一段 20 行的代码可能会让人感到沮丧。当你结构化你的数据科学项目时,你会以一致的安排提交代码,这可以防止重复和自我重复,同时你也更容易找到你所寻找的内容。
-
可复现性。 拥有可复现模型是至关重要的,以跟踪版本并快速恢复到先前的版本。如果模型失败了,你可以在可复现的方式下组织和记录你的任务,成功确定新模型是否比旧模型表现更好。
-
数据管理。 将原始数据与处理过的数据和临时数据分开至关重要。这有助于确保所有参与数据科学项目的团队成员可以轻松复制现有模型。寻找在模型结构阶段使用的相关数据集所花费的时间大大减少。
此外,如果你没有替代用于模型构建的原始数据,一些工具可以帮助你制定一致的项目结构,便于你的数据科学项目的可复现性。
如何构建数据科学项目
这里是一些经过验证的工具和资源,帮助你成功构建数据科学项目结构:
Cookiecutter
Cookiecutter 是一个命令行工具,帮助你从提供的模板开发项目。该平台允许你创建自己的项目模板或利用现有模板。这个工具的强大之处在于你可以轻松导入模板,并仅使用适合你的部分。
它的安装非常简单 - 通过安装 Cookiecutter 下载模板即可开始。然后根据该模板创建一个特定的项目,并提供项目的详细信息以开始。
安装依赖
你可以使用许多在线平台之一轻松管理依赖关系。这些工具帮助你将主要和子依赖隔离到两个不同的文件中,而不是将依赖关系存储在 (requirements.txt) 中。
此外,它们帮助你创建清晰的依赖文件,避免下载与当前包冲突的新包,并仅用几行代码设置项目。
文件夹
你生成的项目模板结构使你能够安排你的数据、源代码、报告和数据科学工作流中的文件。通过这个结构,你可以监控对项目所做的更改。
这里是你项目应包含的一些文件夹:
-
模型。 模型是最终的产品,需要在一致的文件夹安排中存储,以确保你可以在未来复现精确的模型副本。
-
数据。 对数据进行分段是未来复制类似结果的关键。你用于构建机器学习模型的数据可能与未来拥有的数据不完全一致,即数据可能在最坏的情况下被覆盖或丢失。因此,为了实现可重复和可维护的机器学习管道,至关重要的是保持所有原始数据不可逆。对原始数据所做的任何进展都需要得到适当的文档记录,这就是文件夹的作用。你不再需要将文档命名为(final2_17_02_2020.csv)、(final_17_02_2020.csv)来跟踪更改。
-
笔记本。 各种数据科学项目在 Jupyter 笔记本中进行,使读者能够理解项目管道。实际上,笔记本中充满了多个代码块和函数,这使得创建者可能忽略代码块的功能。将代码块、结果和函数存储在隔离的文件夹中,让你可以更好地划分项目,并使在笔记本中跟踪项目逻辑变得更加容易。
-
Src。 Src 文件夹存储你在管道中使用的函数。你可以根据它们在功能上的关联来存放这些函数,例如软件产品。此外,你可以轻松调试和 测试你的过程,使用它们就像将它们导入笔记本一样简单。
-
报告。 数据科学项目不仅生成模型,还产生图表和图形作为数据分析工作流的一部分。这些可以是条形图、平行线、散点图等。你应该存储生成的图形,以便在需要时轻松访问它们。
Makefile
Makefile 允许数据科学家无缝地构建数据科学项目工作流。此外,该工具还帮助数据科学家记录他们的管道和重现构建的模型。使用 Makefile,你可以确保可重复性,并简化数据科学团队内的协作。
利用 Hydra 进行配置文件管理
Hydra,一个 Python 库,让你可以在 Python 脚本中访问配置文件中的参数。
配置文件将所有值存储在一个集中位置,帮助你将这些值与代码分开,防止硬编码。所有配置文件都存放在这个模板的“config”目录下。
使用 DVC 管理模型和数据
数据存储在“data”下的子目录中。每个子目录保存来自不同阶段的数据。由于 Git 不适合版本控制二进制文件,你可以利用 数据版本控制(DVC)来对你的模型和数据进行版本控制。
使用数据版本控制的一个重要好处是,它允许你将平台监控的数据上传到远程存储。此外,你还可以将数据保留在 Google Drive、DagsHub、Amazon S3、Google Cloud Storage、Azure Blob Storage 等地。
在提交之前检查代码问题
在提交 Python 代码时,你需要确保你的代码:
-
看起来很有条理
-
包括文档字符串
-
遵循样式指南(PEP 8)
然而,确保所有这些标准在提交代码之前可能会令人感到艰巨。这时,预提交框架就发挥作用了,因为它可以让你在执行代码之前识别代码中的直接问题。
添加 API 文档
这要求你作为数据科学家有足够的时间与相关团队成员进行合作。因此,创建准确的项目相关文档至关重要。
总结
所以,你现在可以了解到所有必要的步骤来成功构建你的数据科学项目,利用数据科学模板。这些模板足够灵活,可以帮助你根据具体应用调整项目。
Nahla Davies 是一名软件开发者和技术作家。在全职投入技术写作之前,她曾在一个 Inc. 5000 的体验品牌组织担任首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼。
更多相关主题
构建机器学习模型的结构化方法
原文:
www.kdnuggets.com/2022/06/structured-approach-building-machine-learning-model.html
介绍
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT
构建机器学习模型涉及很多步骤,这些步骤不仅限于目标指南,还需要根据业务问题的复杂性采取更详细的方法和深度。
1. 最终目标是什么?
解决业务问题可以有多种方法 - 你需要决定是否真的需要机器学习解决方案,还是可以用简单的启发式方法解决?是否已有解决方案正在解决业务问题?如果是,你需要进行彻底分析,了解其局限性,并寻找能够最好地克服这些局限性的机器学习解决方案。下一步应该是比较这两种解决方案 - 提出的机器学习解决方案是否也有其局限性。例如,机器学习解决方案是概率性的,可能并不总是正确的。业务需要对这些局限性达成一致,并在当前解决方案和建议解决方案之间做出权衡。
另一个起关键作用的因素是机器学习解决方案中还需要多少人类专业知识和干预。我们是否仍然需要人类来批准机器学习模型的结果或对其进行验证?
一旦机器学习解决方案似乎是解决业务问题的唯一选择,并且了解其优缺点后,数据科学家将业务问题框定为统计问题,并决定它属于哪个框架?机器学习问题可以大致分为监督学习和无监督学习问题。
此外,评估指标对于决定最佳算法也很重要。需要注意的是,将评估指标(如精度、召回率等(如果是分类问题))转换和翻译为业务指标。数据科学家在追求最佳精度时往往无法解释这对业务结果的影响。例如,如果我们知道精度下降 1%在财务上的价值,理解为什么精度在特定用例中很重要就会变得更清晰。
2. 起步阶段
你已经评估了构建机器学习模型的需求,包括使用哪个框架和算法,例如监督学习/无监督学习、分类与回归等,并最终确定了作为服务水平协议的指标以交付解决方案。
恭喜你,现在的处境要好得多。为什么?因为模型构建旅程中的有趣部分从这里开始。你现在可以开始讨论数据了。
请注意,现实世界的解决方案不会像 Kaggle 提供的那样给你一个精心构建的问题陈述。尽管这是每个数据科学家都想避免的麻烦,但这正是一个资深数据科学家的真实考验。那些能够在不那么清晰的情况下找到出路的人,并且不会等待指示,而是利用现有数据并记录假设和限制以支持发现的人。你不应该等到所有数据都可用 - 通常你不会拥有所有实时操作所需的属性。
在跨越数据不足的障碍后,数据质量的问题接踵而至。这本身就是一门学问,可以进一步阅读这里。
3. 与数据建立联系
数据探索是更好地理解数据并建立联系的门户。在这一阶段你投入的时间越多,模型生命周期后期的回报就会越高。
对数据的深入调查包括但不限于发现相关性、检测异常值、决定合法记录与异常记录、识别缺失值、理解填补缺失值的正确方法等。接下来,你可能还需要执行数据转换,如对数转换、数据缩放和标准化、特征选择以及工程化新特征。
每个数据都讲述了一个故事,而最好的方式是通过箱线图、密度图、散点图等可视化手段来呈现这些故事。
4. 哪个模型说“我最好”?
如何为给定的数据集选择模型 - 是线性模型对即将到来的数据集泛化得更好,还是基于树的集成模型?你是否有足够的数据来训练神经网络?
从候选模型中选择表现最佳的模型来调整超参数。如果你选择了神经网络,你打算如何调整超参数,如层数和神经元数量、学习率、优化器、损失函数等?
5. 沟通是关键
被技术包围时,很容易低估使数据科学项目成功的关键技能,即沟通。是的,你如何将结果传达给不同的受众显示了你将解决方案调整到不同技术术语程度的能力。可视化的价值无比重要,并且在成功地开展业务讨论中极为有用。
一个重要的点是,要诚实地面对你的所有发现,然后让大家一起做决定。不要给自己增加过多压力去命中靶心并提供完美的解决方案。指出你的模型在什么地方有效以及在什么地方失败。业务何时可以信任模型预测,并且信心程度如何?
本质上,你解释模型预测和考虑可解释 AI 解决方案的能力将使你成为模型的优秀调试者,并确保业务相信模型在正确的手中。
你是否为部署做好了计划?
到目前为止,我们已经讨论了模型构建过程,而这本身是一个漫长的过程。你会如何处理等待部署的模型?这是另一个独立的任务,涉及 MLOps 的不同方面,如编写单元测试、预算延迟、验证数据集、模型监控和维护、错误分析等。
你会如何处理新来的数据——是继续积累数据还是归档旧数据并在新数据上重新训练模型,也需要一个明确的规范。
Vidhi Chugh 是一位获奖的 AI/ML 创新领袖和 AI 伦理学家。她在数据科学、产品和研究交汇处工作,以提供商业价值和洞察。她是数据驱动科学的倡导者,也是数据治理领域的领先专家,致力于构建值得信赖的 AI 解决方案。
更多相关话题
如何从零开始使用 Python 创建令人惊叹的可视化
原文:
www.kdnuggets.com/2021/02/stunning-visualizations-using-python.html
评论
作者 Sharan Kumar R,数据科学家 | 作者。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
照片由 Luke Chesser 供稿,来源于 Unsplash。
可视化是数据科学家重要的技能。良好的可视化可以帮助清晰地传达分析过程中发现的见解,并且是更好地理解数据集的好技术。我们的脑袋在处理视觉数据时,更容易提取模式或趋势,相比于通过阅读或其他方式提取细节。
在这篇文章中,我将从基础开始讲解 Python 中的可视化概念。以下是从基础学习可视化的步骤,
-
步骤 1: 导入数据
-
步骤 2: 使用 Matplotlib 进行基本可视化
-
步骤 3: 使用 Matplotlib 进行更高级的可视化
-
步骤 4: 使用 Seaborn 进行数据分析的快速可视化
-
步骤 5: 创建互动图表
到这段旅程结束时,你将掌握构建可视化所需的一切。虽然我们不会覆盖每一种可视化,但你将学习构建图表的概念,因此你可以轻松构建本文未覆盖的任何新图表。
本文中使用的脚本和数据也可以在 git 仓库中找到,这里。所有数据可以在提到的 git 仓库中的“Data”文件夹中找到,脚本可在‘Day23, Day 24, 和 Day25’文件夹中获取。
导入数据
第一步是读取所需的数据集。我们可以使用 pandas 来读取数据。以下是一个简单的命令,可用于从 CSV 文件中读取数据,
在读取数据集时,重要的是对数据进行转换,使其适合我们将要应用的可视化。例如,假设我们有客户级别的销售数据,如果我们想要构建一个显示日销售趋势的图表,则需要对数据进行分组并在日级别上进行汇总,然后使用趋势图。
使用 Matplotlib 进行基本可视化
让我们从一些基本的可视化开始。最好使用代码‘fig,ax=plt.subplots()’,其中‘plt.subplots()’是一个函数,将返回一个包含图形和坐标轴对象的元组,并将其分别分配给变量‘fig’和‘ax’。虽然不使用此方法也可以绘制图表,但使用此方法可以对图形进行修改,比如根据需要调整图表大小,并保存图表。此外,这里的‘ax’变量可以用于为坐标轴提供标签。下面是一个简单的示例,我将数据作为数组传递,并直接打印为图表,
在上述代码中,首先导入所需的库,然后使用‘plt.subplots()’函数生成图形和坐标轴对象,然后将数据直接作为数组传递给坐标轴对象以绘制图表。在第二个图表中,坐标轴变量‘ax’接受了针对 x 轴、y 轴和标题的标签输入。
趋势图
现在,让我们开始使用一些真实数据,了解如何构建有趣的图表并对其进行自定义以使其更直观。如前所述,在大多数实际使用案例中,数据需要进行一些转换以使其适用于图表。下面是一个示例,我使用了 Netflix 数据,但将数据转换为按年份整合的电影和电视节目的数量。然后,我使用了‘plt.subplots()’函数,但还添加了一些额外的细节,使图表更加直观和自解释。
对上述图表可以进行更多的自定义,比如创建双坐标轴。在上述情况下,电影和电视节目数量之间的差异不大,因此数据看起来还可以。如果它们之间有很大的差异,那么图表可能不太清晰,在这种情况下,我们可以利用双坐标轴,使小值属性也与其他属性对齐。
散点图
我们还可以使用散点图来揭示我们绘制的变量之间的关系。该图有助于揭示变量之间的相关性,比如当一个属性增加/减少时,另一个属性会发生什么。
更高级的可视化,仍使用 Matplotlib
一旦你对我们迄今为止涵盖的简单趋势图感到熟悉,你就可以开始使用稍微高级的图表和功能,以更好地自定义你的可视化。
条形图
条形图帮助我们通过并排绘制多个值来进行比较。有不同种类的条形图,
-
垂直条形图
-
水平条形图
-
堆叠条形图
以下是条形图的一个示例。该图进行了多项自定义,包括,
-
添加了坐标轴标签和标题
-
提供了字体大小
-
还提供了图形大小(默认图表会显得较小且混乱)
-
使用函数生成并添加值到每个条形图的顶部,以帮助观众获取实际细节
水平和堆叠条形图
垂直条形图最为常见,但我们也可以使用水平条形图,特别是当数据标签有很长的名称时,很难将其打印在垂直条形图下方。在堆叠条形图的情况下,条形图会在一个类别中相互堆叠。以下是水平和堆叠条形图实现的示例。下面的代码还包括了图表颜色的自定义。
饼图和甜甜圈图
饼图用于显示数据中不同类别的比例,这些饼图可以通过用一个圆圈覆盖饼图的中心部分并重新对齐文本/值来轻松修改为甜甜圈图。以下是一个简单的示例,其中我实现了饼图并将其修改为甜甜圈图,
为什么学习 Matplotlib 很重要?
Matplotlib 是 Python 中一个非常重要的可视化库,因为许多其他 Python 可视化库都依赖于 Matplotlib。学习 Matplotlib 的一些优势/好处包括,
-
易于学习
-
它是高效的
-
允许大量自定义,使得几乎可以构建任何类型的可视化
-
像 Seaborn 这样的库是建立在 Matplotlib 之上的
我只涵盖了 Matplotlib 中最基本的可视化,但重要的是,通过实践这些图表,你将获得构建更多可视化的知识。Matplotlib 支持许多可视化,这里 是所有支持图表的画廊链接。
使用 Seaborn 构建数据分析的快速可视化
我们已经覆盖了使用 Matplotlib 库的各种可视化。我不确定你是否注意到了,虽然 matplotlib 提供了高度的自定义,但它涉及大量编码,因此可能会很耗时,特别是当你进行探索性分析时,想要快速绘制一些图表以更好地理解数据并更快做出决策。这正是 Seaborn 库所提供的。以下是使用 seaborn 库的一些好处,
-
默认主题仍然很吸引人
-
简单且快速构建可视化,特别是用于数据分析
-
它的声明式 API 使我们能够专注于图表的关键元素
也有一些缺点,比如它不提供很多自定义选项,而且在处理大型数据集时可能会导致内存问题。但总体而言,好处大于坏处。
只需一行代码的可视化
以下是一些使用 Seaborn 库仅用一行代码实现的简单可视化。
如上图所示,这些可视化仅用一行代码创建,并且看起来相当可呈现。Seaborn 库在数据分析阶段广泛使用,因为我们可以轻松地快速构建图表,并且最小化/没有对图表的呈现效果产生影响。可视化在数据分析中至关重要,因为它们有助于揭示数据中的模式,而 Seaborn 库非常适合这一目的。
热力图
热力图是另一种有趣的可视化,广泛用于时间序列数据中,以揭示数据集中的季节性和其他模式。然而,要构建热力图,我们需要将数据转换为特定格式,以支持热力图绘制。以下是一个示例代码,用于转换数据以适应热力图绘制,并使用 Seaborn 库构建热力图。
Pair Plot — 我最喜欢的 Seaborn 功能
我认为 Pair Plot 是 Seaborn 库中最好的功能之一。它通过可视化帮助比较数据集中每个属性与其他每个属性的关系,并且只需一行代码。以下是构建 Pair Plot 的示例代码。当我们处理的数据集包含大量列时,使用 Pair Plot 可能不太可行。在这种情况下,可以使用 Pair Plot 来分析特定属性集之间的关系。
构建交互式图表
在进行数据科学项目时,有时需要与业务团队分享一些可视化内容。虽然仪表板工具广泛用于此目的,但假设在数据分析过程中你发现了一个有趣的模式,并希望与业务用户分享。如果以图片的形式分享,业务用户可能无能为力,但如果以交互式图表的形式分享,就可以让业务用户通过缩放或使用其他功能与图表互动,从而查看详细信息。以下是一个示例,我们创建了一个 HTML 文件作为输出,包含了可以与其他用户共享并可在网页浏览器中简单打开的可视化内容。
如果你想学习使用 Python 进行可视化,请查看下面我的播放列表。它包含三个视频,总教程时长稍超过一个小时。
查看 www.youtube.com/watch?list=PLH5lMW7dI2qeI8-85o0eCPDAGANUpUNHm&v=Rdwik2Eh8f0
原文。经许可转载。
简介: Sharan Kumar R 是一位拥有超过 10 年经验的数据科学专家,曾著有两本数据科学书籍,现可在此处购买。Sharan 还主持一个YouTube 频道,用于教授和讨论各种数据科学概念。
相关:
了解更多相关内容
如何成功成为一名自由职业数据科学家
原文:
www.kdnuggets.com/2021/03/succeed-becoming-freelance-data-scientist.html
评论
图片由 Icons8 团队 提供,来源于 Unsplash
数据科学是一个不断扩展的领域。越来越多的行业依赖技术来收集和处理重要信息,数据科学家需求量很大。然而,找到适合你的工作的确可能是一项挑战。在这种情况下,你可以转向自由职业。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
自由职业正迅速成为各种专业人士的热门选择。实际上,LinkedIn 正在 推出新功能 专门帮助自由职业者找到工作。随着这一增长,现在是进入数据科学自由职业的最佳时机。以下步骤将帮助你开始寻找客户或改善当前策略。
1. 建立个人影响力
过程的第一步是建立和整理一个强大的在线影响力。你需要一个网站、职位列表和 LinkedIn 页面。
使用你的网站展示你的技能。以最佳状态进行市场宣传。展示你相关的工作经验组合,并随着成功帮助更多客户而不断更新。记住,网站必须易于导航,否则人们会点击离开。让人们容易联系到你并获取他们需要的信息。
在 Google 上,你可以开设 Google 我的商家列表 并连接你的网站和详细信息。这样,快速搜索数据科学自由职业者时,你的业务就会出现。考虑一下你希望营业的时间以及潜在客户应该如何与你联系。
然后,更新你的 LinkedIn,并使用新的市场功能将自己作为自由职业者进行宣传。最后这一举动将帮助你吸引寻找数据科学家的企业或个人。
2. 发展新技能
数据科学随着时间的推移而变化。新的技能不断出现,你必须跟上工作的需求。幸运的是,数据科学是一个广泛的职业——你可以将为网络安全学到的技能应用到机器学习算法中。
你也可以通过在线课程获得你尚未掌握的技能。Lynda 提供了许多选项,可以帮助你发展新技能,如区块链技术中的数据管理。你可以将证书添加到你的个人网站,提高你在数据科学相关职位上的吸引力和资格。
作为一名自由职业数据科学家,你应该掌握工作的基础知识、统计学、编程、数据可视化、机器学习和深度学习以及软件工程。你还需要对大数据有很好的理解。这些技能为你提供了一个全面的自由职业工作方法。
3. 在各个行业中工作
数据科学专业人员的需求旺盛是这份工作的另一个好处。你会发现,技术职位在各个行业中都是必需的,无论它们的重点是什么。例如,旅游和银行需要数据科学家来保护和监控敏感信息。
在银行业中,采用基于数据的方法为客户和机构本身提供了必要的透明度。随着新的金融科技公司为客户提供更多金融服务选项——例如加密银行——银行需要确保所有这些控制都有适当的数据保护。这使得行业能够以更大的信任向前发展。
这个理念适用于所有行业,因为每个机构都需要收集和保护数据。关键是保持选择的开放性。查看每一个机会,记住你可以与成熟的企业、初创公司和个人客户合作。
4. 利用在线资源
虽然你可以通过互联网获得认证,但你可以更进一步。其他资源可以帮助你建立网络并创建你作为自由职业者起步所需的联系。以下是你应该开始的地方:
-
Upwork 和 Toptal 是两个专门为自由职业者提供的平台,将帮助你与客户建立联系。
-
Gitter 是一个 Slack 社区,你可以在这里与其他开发人员互动,互相帮助完成项目和目标。
-
Kaggle 是一个全方位的平台,用于学习新技能并找到类似专业人士的社区以建立客户基础。
-
Data Science Stack Exchange 是一个论坛数据库,数据科学家可以在这里提问和提升他们的专业技能。
-
AngelList 和 FounderDating 是优秀的求职平台,你可以在这里找到公司进行工作或合作。你可以使用筛选器来缩小你对数据科学特定机会的搜索范围。
从这四个资源开始。你将立即与他人建立联系,并更好地了解这个领域。
5. 确定细节
一旦你建立了工作联系,你需要解决一些最终细节。在与你的公司或个人合作时,考虑你的工作时间、合同义务和工资标准。
虽然工作时间和任务将由你根据需要决定,但薪资的确定可能会更复杂。查阅其他自由职业者的收费标准,并根据项目以及你的技能和经验调整这些数字。
根据 Glassdoor 的数据,平均 数据科学家年薪大约为 $113,000。如果将其折算为小时工资,则略高于每小时 $54。然而,如果你掌握了 Scala 和 Spark 等技能,你可以提高收费。这取决于你的背景。记住,不要低估自己 — 了解自己的价值。
成功的数据科学自由职业
通过这五个步骤,你可以开始你的成功自由数据科学家职业生涯。每个人的道路都会不同,但你应该从提升自己开始。然后,通过坚实的基础,你可以接受任何机会。
个人简介:Devin Partida 是一位大数据和技术作家,同时也是 ReHack.com 的总编辑。
相关内容:
-
5 种支持技能可以帮助你找到数据科学工作
-
自动化如何改善数据科学家的角色
-
成为数据工程师所需的 9 项技能
更多相关主题
fast.ai 机器学习课程笔记
原文:
www.kdnuggets.com/2018/07/suenaga-fast-ai-machine-learning-notes.html
评论
作者:Hiromi Suenaga,fast.ai 学生
编辑注释: 这是系列文章之一,汇集了关于 fast.ai 机器学习和深度学习课程的一组极好的笔记,这些课程在线免费提供。所有这些笔记的作者,Hiromi Suenaga,这些笔记既可以作为课程的补充复习材料,也可以作为独立资源使用,旨在确保在这些总结中给予课程创作者 Jeremy Howard 和 Rachel Thomas 足够的致谢。
以下是此系列帖子的链接,并附有每个帖子的摘录。这个首个系列仅包含 3 门课程的笔记,而后续的总结(针对深度学习课程)包含完整的课程集。然而,笔记仍然非常有用。在这里查找更多 Hiromi 的笔记。
这是我从机器学习课程中整理的个人笔记。这些笔记会随着我对课程的进一步复习而不断更新和完善,以“真正”理解课程内容。非常感谢Jeremy和Rachel给予我这次学习的机会。
问题:那么维度灾难呢?你经常会听到两个概念——维度灾难和无免费午餐定理。它们在很大程度上是没有意义的,基本上是愚蠢的,然而许多领域的人不仅知道这些,还认为正好相反,因此值得解释。维度灾难的想法是,列数越多,就会创建一个越来越空的空间。有一个迷人的数学概念,即维度越多,所有点就越趋向于这个空间的边缘。如果你只有一个维度,事情是随机的,那么它们会分布在各处。否则,如果是一个方形,那么它们在中间的概率意味着它们不能处于任一维度的边缘,因此不在边缘的可能性稍微小一点。每增加一个维度,点不在至少一个维度的边缘的可能性就会按乘法减少,因此在高维空间中,一切都位于边缘。这在理论上的含义是点之间的距离变得不那么有意义。因此,如果我们假设这很重要,那么这将表明,当你有很多列时,如果不小心移除那些不相关的列,事情将不会正常工作。这实际上并不是这种情况,有许多原因。
问题:你能解释一下验证集和测试集之间的区别吗 [20:58]?今天我们要学习的内容之一是如何设置超参数。超参数是调整模型行为的参数。如果你只有一个留出的数据集(即你不用于训练的数据集),而且我们用它来决定使用哪个超参数。如果我们尝试一千组不同的超参数,我们可能会出现过拟合到这个留出集的情况。因此,我们想要做的是拥有第二个留出集(测试集),在我们尽力做到最好之后,就在最后一次检查它是否有效。
你必须实际将第二个留出集(测试集)从数据中移除,交给其他人,并告诉他们不要让你查看,直到你保证完成。否则,很难不去查看。在心理学和社会学领域,这被称为复制危机或 P-hacking。这就是为什么我们要有一个测试集。
优质验证集的重要性:如果没有一个良好的验证集,很难,甚至不可能,创建一个好的模型。如果你尝试预测下个月的销售并建立了模型。如果你没有办法知道你建立的模型是否能够很好地预测一个月后的销售,那你就没有办法知道在实际应用中你的模型是否会有效。你需要一个你知道可靠的验证集,以判断你的模型在投入生产或在测试集上使用时是否可能表现良好。
通常你不应该在比赛结束或项目结束时使用测试集以外的其他用途。但有一件事你可以额外使用测试集——那就是校准你的验证集。
简介: Hiromi Suenaga 是 fast.ai 的学生。
相关:
-
表格数据深度学习简介
-
使用 fast.ai 的日期快速特征工程
-
3 个流行深度学习课程概述
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关话题
超级 Bard:可以做到一切且更好的 AI

图片由作者提供
介绍 PaLM 2
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
Pathways 语言模型(PaLM)已更新,改进了多语言、推理和编码能力。这个新模型更能理解和生成多种语言的文本,并且在推理和编码方面更有能力。
PaLM 2 在超过 100 种语言的大型文本和代码数据集上进行训练。为了提高其推理能力,开发者包括了包含数学表达式的科学论文和网页。PaLM 2 还在各种编程语言的公开源代码上进行了预训练。因此,它是一个顶级的下一代语言模型,正在驱动各种 Google 服务。
PaLM 2 上的 Bard
根据 Google 主题演讲 (Google I/O ‘23),Bard 现在运行在 PaLM 2 模型上。它在编码、推理和创意写作问题上的表现远胜于 LaMDA。

图片来自 Google 主题演讲 (Google I/O ‘23)
我使用了旧版 Bard (LaMDA) 30 天和新版 Bard (PaLM 2) 7 天。我发现 Bard 在处理编码问题方面发生了显著变化。Bard 并不完美,但我认为 Google 正在走在正确的道路上。
例如,当我要求 Bard 使用 Pygame 创建一个贪吃蛇游戏时,旧版 Bard 能够创建游戏,但存在几个错误和减少的功能。新版 Bard 能够创建一个具有所有预期功能的正常运行的贪吃蛇游戏。
我仍然看到新版 Bard 有一些错误,但总体上我对 Google 所取得的进展感到满意。
图片来自 Bard
我让 ChatGPT 和 HuggingChat 生成代码来解决类似的问题。ChatGPT 生成了无错误的代码,并且功能更多,而 HuggingChat 生成的代码有几个错误,缺少库,并存在安全漏洞。
作者提供的图片 | 使用 ChatGPT
Bard 与 ChatGPT 有何不同?
每当你写一个提示时,它会提供三个草稿供你选择。它生成结果的速度很快,并且集成了 Google 服务。
要访问草稿,你需要点击“查看其他草稿”。
来自 Bard 的图片
要访问 Google 集成,请点击左下角的向上箭头。这是一个代码响应。你将获得在 Google Colab 上运行代码的选项。
来自 Bard 的图片
Bard 用于数据科学
我一直在使用 Bard 处理各种数据科学任务,从理解项目到生成高质量的数据报告。我相信 Bard 是最好的大型语言模型,原因如下:
-
语法和写作: Bard 擅长改善语法,并生成可以整体提升你写作的现实文本。在这方面,它比 ChatGPT 更优秀,后者可能过于戏剧化。
-
机器学习研究: Bard 擅长研究机器学习主题。它可以为你提供广泛主题的准确资料,甚至是最新的研究成果。
-
翻译: Bard 擅长翻译。它可以在多种语言之间进行翻译,包括将 Python 代码翻译成 JavaScript 或将英语翻译成日语。
-
头脑风暴、项目规划和理解上下文: Bard 擅长头脑风暴、项目规划和理解上下文。它会评估聊天记录以提供适当的答案,而不是给出随机响应。
-
生成 DALL-E 2、Midjourney 和 Stable Diffusion 提示: Bard 擅长生成 DALL-E 2、Midjourney 和 Stable Diffusion 提示。它可以帮助你从文本描述中创建现实的图像和艺术作品。
-
提供外部资源链接: Bard 擅长提供外部资源链接。如果你想深入了解某个话题或查看 Bard 生成的示例,这会很有帮助。
来自 Bard 的图片
“除了代码生成,我还在使用 Bard 来做其他所有事情。”
超级 Bard:Bard + 工具
现在,让我们谈谈能做一切的超级 Bard。下个月,谷歌宣布了谷歌服务和第三方集成。这意味着你可以在 Bard 中输入提示,并将最终响应移动到 Google Docs、Colab、Email 或你用于工作的任何第三方软件。
到目前为止,我们知道你可以使用 Bard 执行研究,将其转换为表格,修改表格,并将响应导出到 Google Sheets。此外,你可以使用 Google Lens 服务与图像互动。例如,“你能详细描述一下这张图片吗?” 类似于 GPT-4。
但它比 GPT-4 更好。
将来,你将能够直接从 Bard 使用 Adobe Firefly 生成图像。你只需输入提示,就能自动完成大部分任务。

图片由作者提供,自 Google I/O ‘23
结论
总结而言,我认为 Bard 有潜力成为你所有工作相关任务的一站式解决方案。团队正在不断努力改进模型并添加新功能,他们走在超越 GPT-4 的正确轨道上。然而,Bard 仍有一些需要改进的地方,例如处理代码相关问题的能力以及与 Google 搜索的集成。如果 Bard 能够解决这些问题,我相信它将成为一款真正具有革命性的工具,改变我们的工作方式。
Abid Ali Awan(@1abidaliawan)是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为有心理健康问题的学生开发人工智能产品。
更多相关话题
使用 Saturn Cloud 在 GPU 上超级充电 Python 和 Pandas
原文:
www.kdnuggets.com/2021/05/super-charge-python-pandas-gpus-saturn-cloud.html
评论
由 Tyler Folkman,BEN Group 人工智能负责人

由 Guillaume Jaillet 提供的照片,来源于 Unsplash
我曾在 LinkedIn 上询问,人们在首次打开 Jupyter Notebook 时最可能导入哪些库。
你知道最常见的回答是什么吗?
Pandas
Pandas 库被数据科学家广泛使用,但事实是,它往往相当慢。如果数据处理速度慢,可能会导致项目的延迟。如果每次生成模型的新特征都需要 10 分钟,你会发现自己只是坐在那儿等待(或者做其他事情 😃 )。

数据处理和模型训练的时间类似于程序员的编译时间。虽然你可能会因为处理时间长而享受一些数据处理的休息时间,但我想给你展示一种更好的方法。
我想展示如何轻松避免慢速超过 1,000,000%的 Pandas 使用情况。
设置
在我们深入实验之前,先谈谈我们将使用的硬件。
为了让你跟随起来非常简单,我们将使用 Saturn Cloud。

来源:Saturn Cloud
Saturn Cloud 是一个非常流畅的平台,提供以下功能:
-
每月 10 小时免费使用 Jupyter(包括 GPU)
-
每月 3 小时的 Dask(包括 GPU)
-
部署仪表盘
你可以在 这里 免费使用它,使其成为实验大规模数据处理的绝佳场所!
当你在 Saturn 上启动一个项目时,你将获得两个非常重要的硬件:Jupyter 服务器和 Dask 集群。
来源:Saturn Cloud
我们的 Jupyter 服务器运行在 4 个核心、16 GB 内存和一个 GPU 上。Dask 集群有 3 个工作节点,每个节点配有 4 个核心、16GB 内存和一个 GPU。
另一个选择 RAPIDS 基础项目时你会获得的惊人功能是一个包含所有 NVIDIA RAPIDs 库的 Python 内核,包括 CUDF,这允许我们在 GPU 上运行 Pandas 处理。
使用几次点击完成这项设置并不是小胜利。即使你有一台配有 GPU 的计算机,安装 RAPIDs 库也可能需要时间,因为你必须确保有正确的驱动程序和 CUDA 库。
数据
好了 — 现在我们已经设置好硬件,我们需要讨论我们将使用的数据集。
我们将使用 Yellow Taxi 行程记录数据。
这些数据有 7,667,792 行和 18 列。运行info()在数据框上的结果如下:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7667792 entries, 0 to 7667791
Data columns (total 18 columns):
# Column Dtype
--- ------ -----
0 VendorID int64
1 tpep_pickup_datetime datetime64[ns]
2 tpep_dropoff_datetime datetime64[ns]
3 passenger_count int64
4 trip_distance float64
5 RatecodeID int64
6 store_and_fwd_flag object
7 PULocationID int64
8 DOLocationID int64
9 payment_type int64
10 fare_amount float64
11 extra float64
12 mta_tax float64
13 tip_amount float64
14 tolls_amount float64
15 improvement_surcharge float64
16 total_amount float64
17 congestion_surcharge float64
dtypes: datetime64ns, float64(9), int64(6), object(1)
memory usage: 1.0+ GB
所以,这是一个相当大的数据集,但还算不上太疯狂。它的内存使用量大约为 1GB。
函数
最后,对于我们的实验,我们需要一个在数据上运行的函数。我选择了一个相当简单的函数,它为潜在的模型创建了一个新特征。我们的函数将计算总支付金额除以旅行距离。
def calculate_total_per_mile(row):
try:
total_per_mile = row.total_amount / row.trip_distance
except ZeroDivisionError:
total_per_mile = 0
return total_per_mile
当我们找到 trip_distance 为零的值时,我们将返回零值。
注意:你可以很容易地将这个函数矢量化为 taxi_df[“total_per_mile”] = taxi_df.total_amount / taxi_df.trip_distance,这会快得多。我们使用函数是为了能够比较我们实验中的 apply 速度。如果你感兴趣,矢量化版本大约花费 50 ms。
实验 #1 — 原始 Pandas
在第一次实验中,我们只是使用原始 Pandas 读取数据。这里是代码:
taxi_df = pd.read_csv(
“s3://nyc-tlc/trip data/yellow_tripdata_2019–01.csv”,
parse_dates=[“tpep_pickup_datetime”, “tpep_dropoff_datetime”]
)
数据读取完毕后,我们可以将我们的函数应用于所有行:
taxi_df[‘total_per_mile’] = taxi_df.apply(lambda x: calculate_total_per_mile(x), axis=1)
运行这个计算花费了159,198 ms(2 分钟 39.21 秒)。
虽然这并不是特别慢,但绝对足够慢到让你注意到所花的时间,并且打乱了你的工作流程。我发现自己坐在那里等待,这段等待时间很容易让你被电子邮件、Slack 或社交媒体分散注意力。这些类型的干扰会严重影响生产力,超出了这次计算运行所需的将近 3 分钟时间。
我们能做得更好吗?
实验 #2 — 并行 Pandas
Swifter 是一个库,使得在运行 Pandas apply 时,利用 CPU 的所有线程变得极其简单。
由于apply容易并行化,因为你可以将数据框拆分为每个线程的块,这应该有所帮助。这里是代码:
taxi_df[‘total_per_mile’] = taxi_df.swifter.apply(lambda x: calculate_total_per_mile(x), axis=1)
添加 swifter 后,我们的处理时间变为88,690 ms(1 分钟 28.69 秒)。原生 pandas 慢了 1.795 倍,你在运行代码时会明显感觉到加速。然而,你仍然会发现自己在等待其完成。
实验 #3 — 在 GPU 上使用 Pandas
这就是事情开始变得有趣的地方。得益于 cuDF 库,它允许我们在 GPU 上运行函数。cuDF 库,“提供了一个类似 pandas 的 API,对数据工程师和数据科学家来说非常熟悉,因此他们可以轻松加速他们的工作流程,而无需深入了解 CUDA 编程。”
不过,要使用 cuDF 库,我们必须稍微改变一下函数的格式:
def calculate_total_per_mile(total_amount, trip_distance, out):
for i, (ta, td) in enumerate(zip(total_amount, trip_distance)):
total_per_mile = ta / td
out[i] = total_per_mile
现在我们的函数接受 total_amount、trip_distance 和 out。Out 是我们将存储结果的数组。我们的函数随后会遍历数据框中的所有 total_amount 和 trip_distance 的值,计算 total_per_mile,并将结果存储在 out 中。
我们还必须改变将此函数应用于数据框的方式:
taxi = taxi.apply_rows(calculate_total_per_mile,
incols={‘total_amount’:’total_amount’, ‘trip_distance’:’trip_distance’},
outcols={‘out’: np.float64},
kwargs={}
)
我们现在指定数据框中的输入列是什么,以及它们如何映射到函数参数。我们还指定哪个参数是输出 (outcols) 和它的值类型 (np.float64)。
注意:读取数据的方式保持不变,只是使用 cudf.read_csv() 代替 pd.read_csv()。
使用 cuDF 库并利用 GPU 将处理时间降至 43 ms!这意味着原始 Pandas 慢了 3,702 倍!太疯狂了!此时,处理时间感觉不到任何延迟。你运行函数,结果很快就会出来。老实说,我对在 GPU 上运行我们的处理速度如此之快感到惊讶。
但是!我们还有一个实验要做,看看是否可以让速度更快。
实验 #4— 多 GPU 上的 Pandas
Dask_cuDF 是一个我们可以使用的库,以利用我们拥有的 3 个工作节点的 dask 集群,每个工作节点都配备了 GPU。实质上,我们将在分布于 dask 集群的 3 个 GPU 上运行我们的函数。
这可能听起来很复杂,但 Saturn 让它变得非常简单。使用以下代码,你可以连接到你的 dask 集群:
from dask.distributed import Client, wait
from dask_saturn import SaturnClustern_workers = 3
cluster = SaturnCluster(n_workers=n_workers)
client = Client(cluster)
client.wait_for_workers(n_workers)
一旦连接,你可以这样读取数据:
import dask_cudftaxi_dc = dask_cudf.read_csv(
“s3://nyc-tlc/trip data/yellow_tripdata_2019–01.csv”,
parse_dates=[“tpep_pickup_datetime”, “tpep_dropoff_datetime”],
storage_options={“anon”: True},
assume_missing=True,
)
最后,你可以以与 cuDF 完全相同的方式运行函数。唯一的区别是我们现在运行的是通过 dask_cudf 库读取的数据框,因此我们将利用我们的 dask 集群。
花了多长时间?
12 ms
这比原始 Pandas 快了 13,267 倍,或者你也可以说 Pandas 比在 3 个 GPU 集群上运行要慢 1,326,650%。
哇。那真是太快了。你可以处理更大的数据集,函数的运行速度仍然足够快,不会感到明显的延迟。
注意:这比我们函数的 Pandas 矢量化版本快了 4 倍以上!
速度很重要
希望我已经说服你现在就放下手头的一切,尝试在 Saturn Cloud 上使用 GPU 运行 Pandas。
你可以争辩说,等待一个函数运行近 3 分钟其实不算太长,但当你专注于编程并进入状态时,3 分钟真的感觉像是永恒。这段时间足够让你开始分心,可能会浪费更多时间。
如果你有更大的数据,这些等待时间只会更长。
所以,自己去尝试一下吧。我认为当你在 GPU 上运行时,12 毫秒甚至 43 毫秒相比于超过 159,000 秒的感觉会让你惊讶。
此外,感谢Saturn Cloud与我合作撰写这篇文章!这是我第一次深入了解这个平台,真的让我印象深刻。
简介: Tyler Folkman 是 BEN Group 的人工智能主管。他的工作探索了机器学习在颠覆和转变娱乐与营销行业中的应用。Tyler 在实体解析和从非结构化数据中提取知识方面获得了多项专利。
相关内容:
-
将 Python 的 Explode 函数应用于 Pandas DataFrames
-
如何通过 Modin 加速 Pandas
-
云中的 ETL:利用数据仓库自动化转型大数据分析
我们的前三个课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在的组织的 IT 工作
更多相关话题
超级学习指南:免费算法与数据结构电子书
原文:
www.kdnuggets.com/2022/06/super-study-guide-free-algorithms-data-structures-ebook.html

双胞胎兄弟 Afshine Amidi 和 Shervine Amidi 联手为我们带来了 关于算法与数据结构的超级学习指南。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持组织的 IT 需求
两位兄弟都是谷歌的软件工程师;Afshine Amidi 拥有麻省理工学院的商业分析和数据科学硕士学位,Shervine Amidi 拥有斯坦福大学的计算与数学工程硕士学位。他们曾经并且现在仍在麻省理工学院和斯坦福大学使用他们之前的学习指南进行教学。
他们的新学习指南:《超级学习指南:算法与数据结构》分为四个主要部分:
-
基础
-
数据结构
-
图与树
-
排序与搜索
每个部分都进一步深入每个领域。
基础
基础章节涵盖了算法概念、数学概念和经典问题。这些内容都经过简化,以便你能够更好地理解其余学习指南,并帮助你学习。
举个例子,这就是双胞胎兄弟如何解释“算法”:
“给定一个问题,算法 A 是一组定义明确的指令,这些指令在有限的时间和空间内运行。它接收一个输入 I 并返回一个输出 O,满足问题的约束。例如,一个问题可以是检查一个数字是否为偶数。为此,算法可以是检查该数字是否能被 2 整除。”

你难道找不到比这更好的算法可视化解释了吗?
数据结构
在数据结构部分,兄弟们深入探讨了:
-
数组与字符串
-
栈与队列
-
哈希表
-
高级哈希表
-
链表
每个部分都进行了简化,提供了你需要的信息,而不会让你信息超载。
图与树
下一部分将更深入地探讨图和树,仅包含三部分:
-
图
-
高级图算法
-
树
-
高级树
每一部分都提供了逐步的可视化,以帮助你更好地理解每种算法。
例如,这是段树的定义:
“段树 S 是一种由节点 s[i,j] 组成的二叉树数据结构,旨在支持对数组 A=[a0,...,an?1] 的主要范围查询类型(最小值、最大值、求和)。它的更新时间复杂度为 O(log(n))。”
通过可视化来表示这个定义:
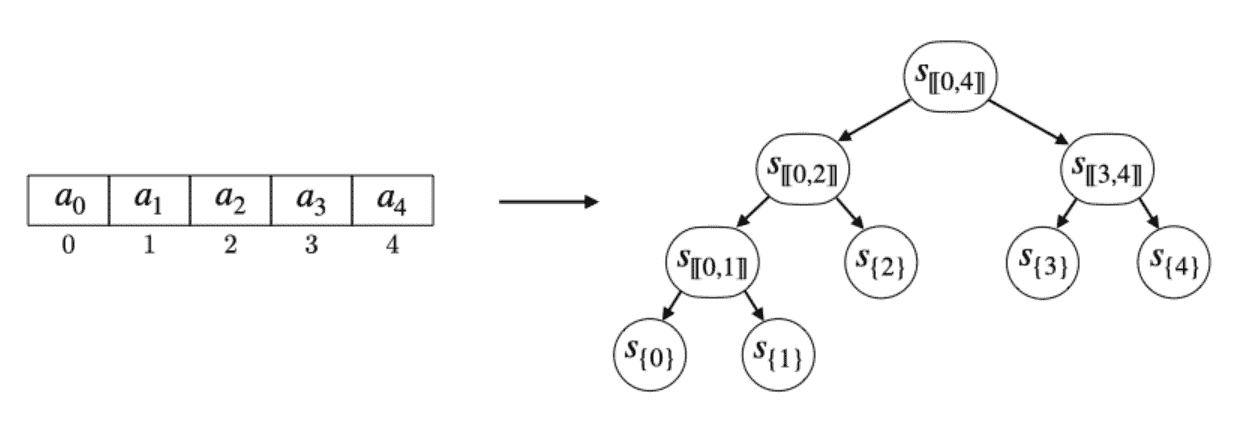
排序和搜索
最后但同样重要的是,最后一部分讲解了排序和搜索,并深入探讨了这两种算法的不同。
在排序部分,你将学习更多不同的排序算法,如冒泡排序、归并排序和基数排序。
在搜索部分,你将学习基本搜索、二分搜索和子串搜索。下面是解释线性搜索的可视化:
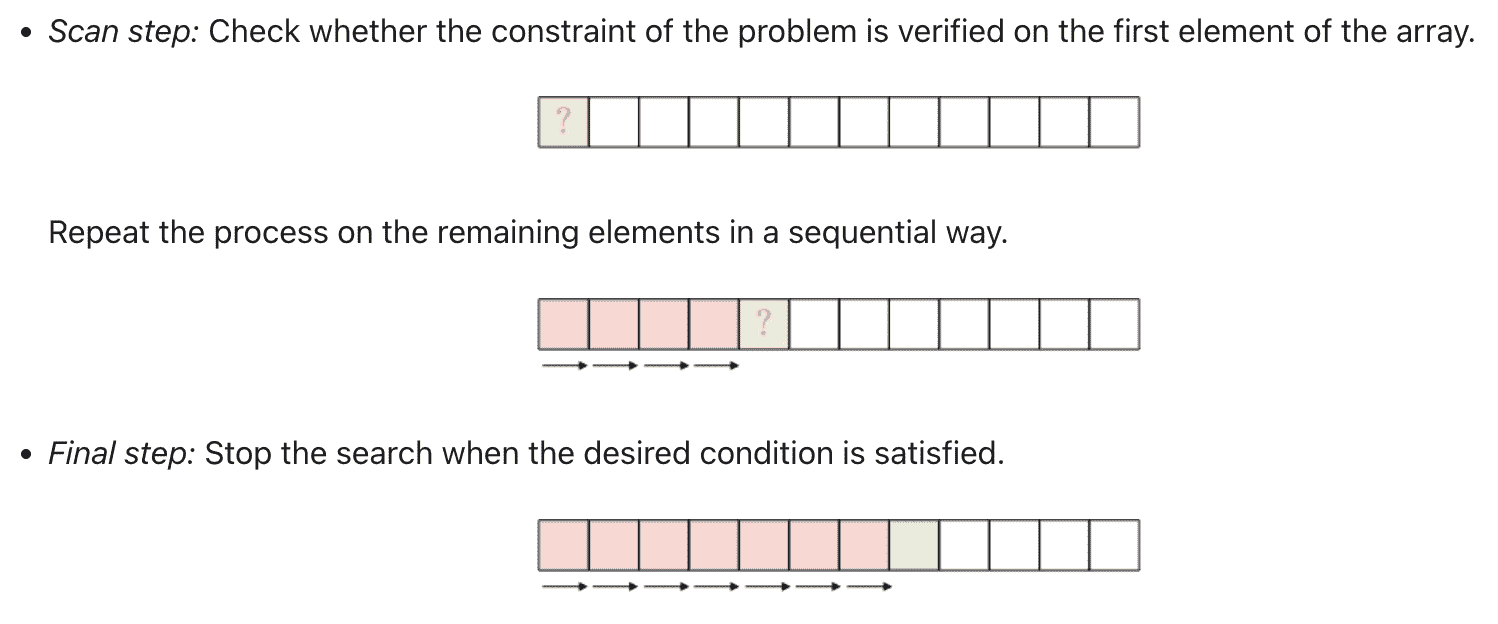
这是你需要的书籍
如果你想进入数据科学领域或提升当前知识,这本学习指南适合你。学习数据科学背后的理论可能会非常令人困惑;然而,Afshine Amidi 和 Shervine Amidi 提供了简化的解释和可视化,帮助我们继续前进。
Nisha Arya 是一位数据科学家和自由职业技术作家。她特别感兴趣于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能在延长人类寿命方面的不同方式。作为一个渴望学习的人,她寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关内容
什么是超级对齐以及它为何重要?

作者提供的图片
超级智能有可能成为人类历史上最重要的技术进步。它可以帮助我们应对一些人类面临的最紧迫的挑战。尽管它可以带来新的进步时代,但它也带来了一些固有的风险,必须谨慎处理。如果不恰当地处理或对齐,超级智能可能会削弱人类的力量,甚至导致人类灭绝。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT
尽管超级智能似乎还遥远,但许多专家认为它可能在未来几年内成为现实。为了管理潜在的风险,我们必须创建新的管理机构,并解决超级智能对齐的关键问题。这意味着确保即将超越人类智能的人工智能系统与人类目标和意图保持一致。
在本博客中,我们将学习关于超级对齐的内容,并了解 OpenAI 解决超级智能对齐核心技术挑战的方法。
什么是超级对齐
超级对齐指的是确保超级人工智能(AI)系统在所有领域超越人类智能时,其行为符合人类的价值观和目标。这是 AI 安全和治理领域中的一个重要概念,旨在应对开发和部署高度先进 AI 相关的风险。
随着 AI 系统变得越来越智能,人类可能会越来越难以理解它们如何做出决策。如果 AI 的行为违背了人类的价值观,这可能会导致问题。因此,必须解决这一问题,以防止任何有害的后果。
超级对齐确保超级智能 AI 系统的行为与人类的价值观和意图一致。它需要准确地指定人类偏好,设计能够理解这些偏好的 AI 系统,并创建机制以确保 AI 系统追求这些目标。
我们为什么需要超级对齐
超级对齐在应对超级智能可能带来的风险中发挥着至关重要的作用。让我们深入探讨一下为什么我们需要超级对齐:
-
减轻流氓 AI 场景: 超对齐确保超智能 AI 系统与人类意图保持一致,降低不受控行为和潜在伤害的风险。
-
保护人类价值观: 通过将 AI 系统与人类价值观对齐,超对齐防止了超智能 AI 可能优先考虑与社会规范和原则不一致的目标的冲突。
-
避免意外后果: 超对齐研究识别并减轻可能从高级 AI 系统中出现的意外不利结果,最小化潜在的不利影响。
-
确保人类自主性: 超对齐专注于将 AI 系统设计为增强人类能力的宝贵工具,保持我们自主性,防止对 AI 决策过度依赖。
-
建设有益的 AI 未来: 超对齐研究旨在创造一个未来,超智能 AI 系统积极贡献于人类福祉,解决全球挑战,同时最小化风险。
OpenAI 方法
OpenAI 正在构建一个人类级别的自动对齐研究员,它将利用大量计算资源来扩展努力,并迭代性地对齐超智能 - 介绍超对齐 (openai.com)。
要使第一个自动对齐研究员与人类意图对齐,OpenAI 需要:
-
开发可扩展的训练方法: OpenAI 可以利用 AI 系统来帮助评估其他 AI 系统在难以评估的复杂任务上的表现。
-
验证最终模型: OpenAI 将自动化搜索问题行为和问题内部机制。
-
对抗性测试: 通过故意训练不对齐的模型来测试 AI 系统,验证所用方法是否能识别流程中最严重的不对齐问题。
团队
OpenAI 正在组建一个团队来应对超智能对齐的挑战。他们将在接下来的四年里分配 20% 的计算资源。该团队将由 Ilya Sutskever 和 Jan Leike 领导,包括来自之前对齐团队和公司其他部门的成员。
OpenAI 目前正在寻找杰出的研究人员和工程师来贡献于其使命。超智能对齐的问题主要与机器学习相关。即使他们目前未从事对齐工作,机器学习领域的专家也将在寻找解决方案中发挥关键作用。
目标
OpenAI 设定了在四年内解决超智能对齐技术挑战的目标。虽然这是一个雄心勃勃的目标,成功并非 guaranteed,但 OpenAI 对于通过集中和坚定的努力找到解决方案持乐观态度。
要解决问题,他们必须向机器学习和安全社区提供有说服力的证据和论据。对提议解决方案有高度的信心至关重要。如果这些解决方案不可靠,社区仍然可以利用这些发现进行相应的规划。
结论
OpenAI 的 Superalignment 计划在解决超级智能对齐挑战方面具有巨大潜力。通过初步实验中涌现出的有前途的想法,团队获得了越来越有用的进展指标,并可以利用现有的 AI 模型对这些问题进行实证研究。
需要注意的是,Superalignment 团队的努力得到了 OpenAI 不断改进现有模型安全性的支持,包括广泛使用的 ChatGPT。OpenAI 仍致力于理解和缓解与 AI 相关的各种风险,如误用、经济扰动、虚假信息、偏见和歧视、成瘾及过度依赖。
OpenAI 旨在通过专注的研究、合作和积极的态度为更安全、更有益的 AI 未来铺平道路。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些面临心理健康困扰的学生。
更多相关话题
用 PyCaret 和 Gradio 提升你的机器学习实验
原文:
www.kdnuggets.com/2021/05/supercharge-machine-learning-experiments-pycaret-gradio.html
评论
作者 Moez Ali,PyCaret 的创始人兼作者
???? 介绍
本教程是一个逐步的、初学者友好的说明,展示了如何在几分钟内将两个强大的 Python 开源库PyCaret和Gradio集成在一起,从而提升机器学习实验的效率。
本教程是一个“hello world”示例,我使用了来自 UCI 的Iris 数据集,这是一个多分类问题,目标是预测鸢尾花的类别。此示例中的代码可以在任何其他数据集上复现,无需重大修改。
???? PyCaret
PyCaret 是一个开源的低代码机器学习库和端到端模型管理工具,用 Python 构建,旨在自动化机器学习工作流。因其易用性、简单性以及快速高效地构建和部署端到端 ML 原型的能力而极受欢迎。
PyCaret 是一个低代码库,可以用少量代码替代数百行代码。这使得实验周期变得极其快速高效。
PyCaret 简单且 易于使用。在 PyCaret 中执行的所有操作都会顺序存储在一个管道中,该管道完全自动化以便于部署。无论是填补缺失值、一键编码、转换分类数据、特征工程还是超参数调整,PyCaret 都会自动化处理所有这些操作。
要了解更多关于 PyCaret 的信息,请查看他们的GitHub。
???? Gradio
Gradio 是一个开源 Python 库,用于在你的机器学习模型周围创建可自定义的 UI 组件。Gradio 使你可以在浏览器中“玩弄”你的模型,通过拖放自己的图像、粘贴自己的文本、录制自己的声音等方式,查看模型的输出。
Gradio 适用于:
-
在训练好的 ML 流水线周围创建快速演示
-
获取关于模型性能的实时反馈
-
在开发过程中交互式调试你的模型
要了解更多关于 Gradio 的信息,请查看他们的GitHub。

PyCaret 和 Gradio 的工作流程
???? 安装 PyCaret
安装 PyCaret 非常简单,仅需几分钟。我们强烈建议使用虚拟环境,以避免与其他库的潜在冲突。
PyCaret 的默认安装是一个精简版,仅安装了硬性依赖,详见此处。
**# install slim version (default)** pip install pycaret**# install the full version**
pip install pycaret[full]
当你安装 pycaret 的完整版时,所有可选依赖项也会被安装,如 此处列出。
???? 安装 Gradio
你可以从 pip 安装 gradio。
pip install gradio
???? 开始使用
**# load the iris dataset from pycaret repo**
from pycaret.datasets import get_data
data = get_data('iris')
从鸢尾花数据集中提取的样本行
???? 初始化设置
**# initialize setup**
from pycaret.classification import *
s = setup(data, target = 'species', session_id = 123)
每当你初始化 PyCaret 中的 setup 函数时,它会对数据集进行分析,并推断所有输入特征的数据类型。在这种情况下,你可以看到所有四个特征(sepal_length, sepal_width, petal_length, 和 petal_width)都正确地识别为数值型数据。你可以按 Enter 继续。
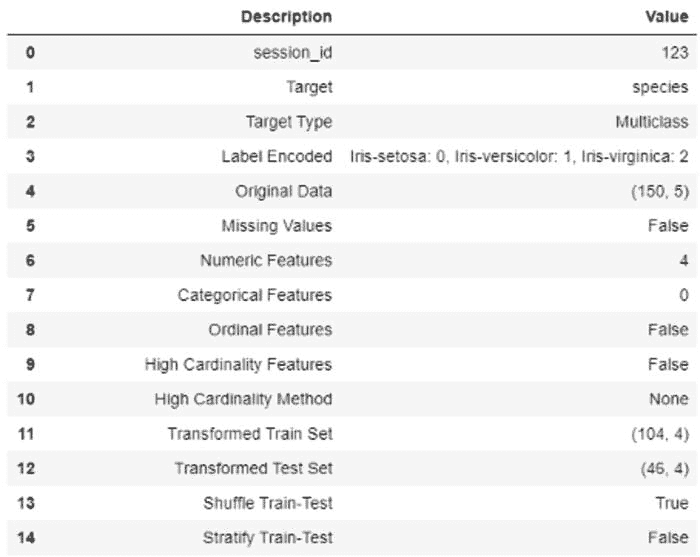
setup 输出 — 为显示而截断
对 PyCaret 中的所有模块而言,setup 函数是开始任何机器学习实验的第一个也是唯一的必需步骤。除了默认执行一些基本处理任务外,PyCaret 还提供了广泛的预处理功能,如 缩放和转换、特征工程、特征选择,以及几个关键的数据准备步骤,如 独热编码、缺失值填补、过采样/欠采样,等等。要了解更多关于 PyCaret 中所有预处理功能的信息,你可以查看这个 链接。
???? 比较模型
这是我们推荐的在 PyCaret 的 任何 监督实验工作流中的第一步。此函数使用默认超参数训练模型库中的所有可用模型,并使用交叉验证评估性能指标。
此函数的输出是一个表格,显示所有模型的均值交叉验证分数。折数可以使用 fold 参数定义(默认 = 10 折)。表格按选择的指标排序(从高到低),可以使用 sort 参数定义(默认 = ‘准确度’)。
best = compare_models(n_select = 15)
compare_model_results = pull()
n_select 参数在 setup 函数中控制训练模型的返回。在这种情况下,我将其设置为 15,意味着返回前 15 个模型作为列表。pull 函数在第二行中将 compare_models 的输出存储为 pd.DataFrame。
compare_models 的输出
len(best)
>>> 15print(best[:5])

print(best[:5]) 的输出
???? Gradio
现在我们完成了建模过程,让我们使用 Gradio 创建一个简单的 UI 来与我们的模型互动。我将分两部分进行,首先创建一个使用 PyCaret 的 predict_model 功能生成并返回预测的函数,然后将这个函数集成到 Gradio 中,设计一个简单的输入表单以实现互动。
第一部分 — 创建内部函数
代码的前两行将输入特征转换为 pandas DataFrame。第 7 行创建了 compare_models 输出中显示的模型名称的唯一列表(这将作为 UI 中的下拉框)。第 8 行根据列表的索引值选择最佳模型(这个值将通过 UI 传递),第 9 行使用 PyCaret 的 predict_model 功能对数据集进行评分。
gist.github.com/moezali1/2a383489a08757df93572676d20635e0
第二部分 — 使用 Gradio 创建 UI
下面代码的第 3 行创建了一个模型名称的下拉框,第 4–7 行为每个输入特征创建了一个滑块,我已将默认值设置为每个特征的均值。第 9 行启动了一个 UI(在 notebook 以及你的本地主机上,你可以在浏览器中查看)。
gist.github.com/moezali1/a1d83fb61e0ce14adcf4dffa784b1643
Gradio 接口运行的输出
你可以在这里观看这个快速视频,了解如何轻松地与管道互动,并查询模型,而无需编写数百行代码或开发一个完整的前端。
使用 PyCaret 和 Gradio 为你的机器学习实验加速
我希望你能欣赏 PyCaret 和 Gradio 的易用性和简洁性。在不到 25 行代码和几分钟的实验中,我使用 PyCaret 训练和评估了多个模型,并开发了一个轻量级的 UI 来在 Notebook 中与模型互动。
敬请期待!
下周我将编写一个关于使用 PyCaret 异常检测模块 对时间序列数据进行无监督异常检测的教程。请关注我的 Medium、LinkedIn 和 Twitter 以获取更多更新。
使用这个轻量级的 Python 工作流自动化库,你可以实现无限的可能。如果你觉得这个有用,请不要忘记在我们的 GitHub 仓库上给我们 ⭐️。
要了解更多关于 PyCaret 的信息,请关注我们的 LinkedIn 和 Youtube。
加入我们的 Slack 频道。邀请链接 在这里。
你可能还会对以下内容感兴趣:
在 Power BI 中使用 PyCaret 2.0 构建自己的 AutoML
在 Google Kubernetes Engine 上部署机器学习管道
使用 AWS Fargate 无服务器部署 PyCaret 和 Streamlit 应用
使用 PyCaret 和 Streamlit 构建并部署机器学习网页应用
在 GKE 上部署使用 Streamlit 和 PyCaret 构建的机器学习应用
重要链接
安装 PyCaret 笔记本教程 参与 PyCaret 贡献
想了解某个特定模块吗?
点击下面的链接查看文档和工作示例。
个人简介: Moez Ali 是一位数据科学家,同时也是 PyCaret 的创始人兼作者。
原创。已获许可转载。
相关:
-
使用 PyCaret 编写并训练自定义机器学习模型
-
使用 PyCaret + MLflow 实现轻松的 MLOps
-
使用 Streamlit 进行主题建模
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
更多相关话题
监督学习:从过去到现在的模型流行度
原文:
www.kdnuggets.com/2018/12/supervised-learning-model-popularity-from-past-present.html
评论
在过去几十年中,机器学习领域经历了巨大的变化。诚然,一些方法已经存在了很长时间,并且仍然是该领域的主流。例如,最小二乘法的概念早在 19 世纪初就已由勒让德和高斯提出。其他方法如神经网络,其最基本的形式在 1958 年被引入,在过去几十年中得到了显著的进展,而像支持向量机(SVMs)这样的方法则更为近期。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
由于监督学习方法的种类繁多,通常会提出以下问题:哪个模型最好? 正如乔治·博克著名地指出的那样,这个问题很难回答,因为所有模型都是错误的,但有些是有用的。特别是,模型的有用性在很大程度上取决于手头的数据。因此,这个问题没有普遍的答案。一个更容易回答的问题是:哪个模型最受欢迎? 这将是本文讨论的内容。
测量机器学习模型的流行度
在本文中,我将使用频率学派的方法来定义流行度。更准确地说,我将使用提及个别监督学习模型的科学出版物数量作为流行度的替代指标。当然,这种方法也有一些局限性:
-
可能存在比出版数量更准确的流行度概念。例如,批评某一模型的出版物并不一定意味着该模型很受欢迎。
-
分析受到使用的搜索词的影响。为了确保高特异性,我没有考虑模型缩写,这也是我可能未能检索到所有潜在结果的原因。此外,对于那些也被未纳入分析的搜索词提及的模型,灵敏度可能较低。
-
文献数据库并不完美:有时,出版物会存储有错误的元数据(例如错误的年份),或者可能存在重复出版物。因此,出版频率中会有一些噪声是可以预期的。
对于这部分内容,我进行了两项分析。第一次分析是对出版频率的纵向分析,而第二次分析则比较了不同领域与机器学习模型相关的整体出版数量。
对于第一次分析,我通过从 Google Scholar 抓取数据来确定出版物的数量,该数据考虑了科学出版物的标题和摘要。为了识别与单个监督学习方法相关的出版物数量,我确定了 1950 年至 2017 年间 Google Scholar 的搜索结果数量。由于从 Google Scholar 抓取数据非常困难,我依靠了ScrapeHero 的有用建议来收集数据。
我在分析中包括了以下 13 种监督学习方法:神经网络、深度学习、支持向量机、随机森林、决策树、线性回归、逻辑回归、泊松回归、岭回归、套索回归、k-最近邻、线性判别分析和对数线性模型。请注意,对于套索回归,考虑了套索回归和套索模型这两个术语。对于最近邻,考虑了k-最近邻和k-最近邻这两个术语。结果数据集显示了从 1950 年至今与每种监督模型相关的出版数量。
从 1950 年至今使用监督学习模型
为了分析纵向数据,我将区分两个时期:机器学习的早期(1950 年至 1980 年),在此期间模型较少,以及形成时期(1980 年至今),在此期间机器学习的兴趣激增,许多新模型得到开发。请注意,在以下可视化中仅显示最相关的方法。
早期:线性回归的主导地位
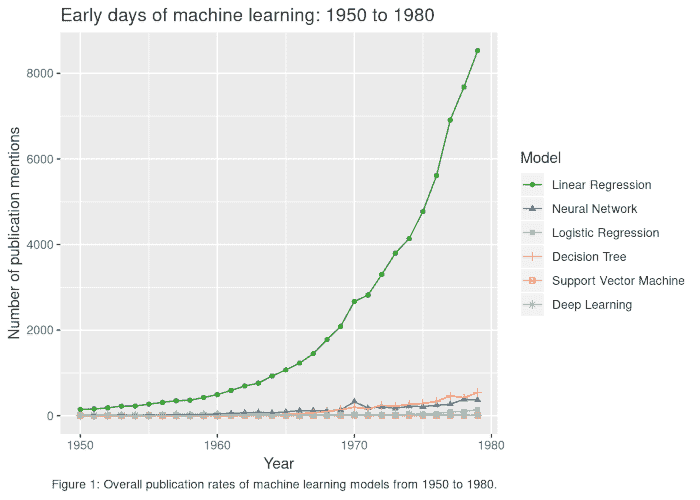
从图 1 中可以看出,线性回归在 1950 年至 1980 年间是主导方法。相比之下,其他机器学习模型在科学文献中极少被提及。然而,从 1960 年代开始,我们可以看到神经网络和决策树的受欢迎程度开始增长。我们还可以看到逻辑回归尚未广泛应用,1970 年代末期提及数量仅有轻微增加。
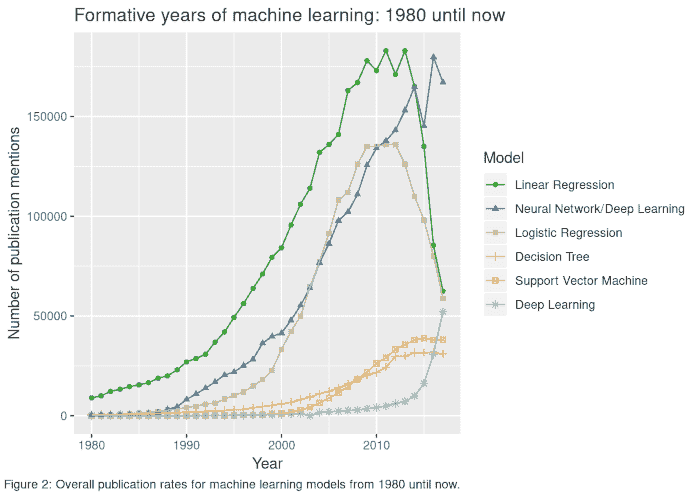
成长岁月:神经网络的多样化与兴起
图 2 表明,从 1980 年代末期开始,在科学出版物中提及的监督模型变得显著多样化。重要的是,机器学习模型在科学文献中的提及率一直稳步增加,直到 2013 年。图中特别显示了线性回归、逻辑回归和神经网络的受欢迎程度。正如我们之前看到的,线性回归在 1980 年之前已经非常流行。然而,从 1980 年开始,神经网络和逻辑回归的受欢迎程度迅速增长。虽然逻辑回归在 2010 年达到了顶峰,与线性回归几乎持平,但神经网络和深度学习(图 2 中的神经网络/深度学习曲线)的整体受欢迎程度在 2015 年甚至超过了线性回归的受欢迎程度。
神经网络变得极为流行,因为它们在图像识别(ImageNet,2012 年)、面部识别(DeepFace,2014 年)和游戏(AlphaGo,2016 年)等机器学习应用中取得了突破。Google Scholar 的数据表明,近几年神经网络在科学文章中的提及频率略有下降(图 2 中未显示)。这可能是因为深度学习(多层神经网络)在某种程度上取代了神经网络这一术语。使用Google Trends也可以得到相同的发现。
剩下的稍微不那么受欢迎的监督方法是决策树和支持向量机。与前三种方法相比,这些方法的提及率明显较低。另一方面,这些方法在文献中的提及频率似乎也波动较小。值得注意的是,决策树和支持向量机的受欢迎程度尚未下降。这与其他方法如线性回归和逻辑回归形成对比,后者的提及数量在近年来显著减少。在决策树和支持向量机之间,支持向量机的提及量似乎展现了更有利的增长趋势,因为支持向量机在其发明仅 15 年后就超越了决策树。
所考虑的机器学习模型的提及数量在 2013 年达到了峰值(589,803 篇出版物),此后略有下降(2017 年为 462,045 篇出版物)。
不同领域的监督学习模型的受欢迎程度
在第二次分析中,我想调查不同社区是否依赖不同的机器学习技术。为此,我依赖了三个科学出版物的数据库:Google Scholar 用于一般出版物,dblp 用于计算机科学出版物,以及 PubMed 用于生物医学科学的出版物。在这三个数据库中,我确定了 13 种机器学习模型出现的频率。结果显示在图 3 中。
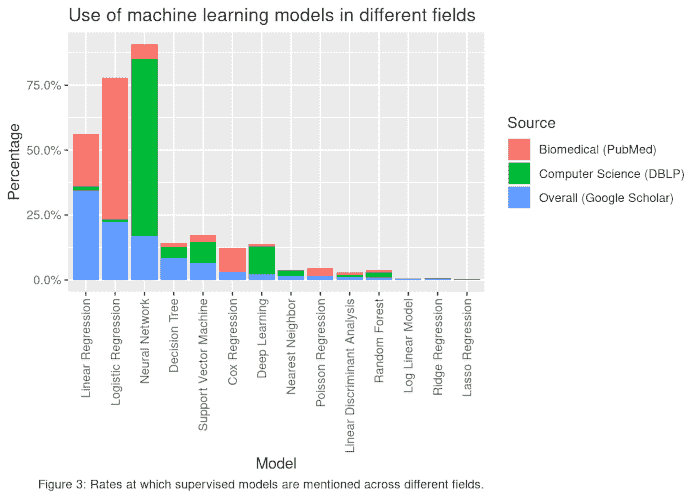
图 3 展示了许多方法对于个别领域是非常特定的。接下来,让我们分析每个领域中最受欢迎的模型。
监督学习模型的总体使用情况
根据 Google Scholar,这五种最常用的监督模型是:
-
线性回归: 3,580,000 (34.3%) 篇论文
-
逻辑回归: 2,330,000 (22.3%) 篇论文
-
神经网络: 1,750,000 (16.8%) 篇论文
-
决策树: 875,000 (8.4%) 篇论文
-
支持向量机: 684,000 (6.6%) 篇论文
总体而言,线性模型明显占据主导地位,占监督模型的超过 50%的提及。非线性方法虽然不远远落后:神经网络以 16.8%的论文量排第三,紧随其后的是决策树(8.4% 的论文)和支持向量机(6.6% 的论文)。
生物医学科学中的模型使用
根据 PubMed,生物医学科学中最受欢迎的五种机器学习模型是:
-
逻辑回归: 229,956 (54.5%) 篇论文
-
线性回归: 84,850 (20.1%) 篇论文
-
Cox 回归: 38,801 (9.2%) 篇论文
-
神经网络: 23,883 (5.7%) 篇论文
-
泊松回归: 12,978 (3.1%) 篇论文
在生物医学科学中,我们看到与线性模型相关的提及数量过多:五种最受欢迎的方法中有四种是线性的。这可能由于两个原因。首先,在医学环境中,样本数量通常太少,无法拟合复杂的非线性模型。其次,解释结果的能力对于医学应用至关重要。由于非线性方法通常更难以解释,因此不太适合医学应用,因为仅仅高预测性能通常是不够的。
PubMed 数据中逻辑回归的流行可能与大量展示临床研究的出版物有关。在这些研究中,分类结果(即治疗成功)通常使用逻辑回归进行分析,因为它非常适合解释特征对结果的影响。请注意,Cox 回归在 PubMed 数据中如此受欢迎,因为它常用于分析 Kaplan-Meier 生存数据。
计算机科学中的模型使用
从 dblp 检索的计算机科学参考文献中,五种最受欢迎的模型是:
-
神经网络: 63,695 (68.3%) 篇论文
-
深度学习: 10,157 (10.9%) 篇论文
-
支持向量机: 7,750 (8.1%) 篇论文
-
决策树: 4,074 (4.4%) 篇论文
-
最近邻: 3,839 (2.1%) 篇论文
计算机科学出版物中提到的机器学习模型的分布非常独特:大多数出版物似乎涉及最近的非线性方法(例如神经网络、深度学习和支持向量机)。如果我们包括深度学习,那么检索到的计算机科学出版物中超过四分之三的内容涉及神经网络。
社区之间的分裂
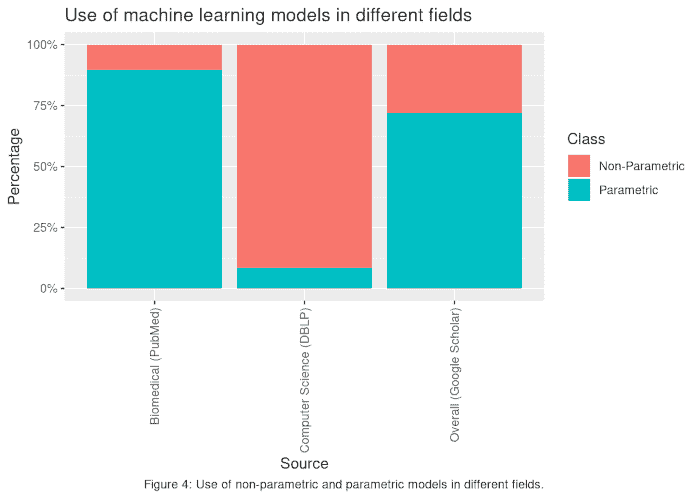
图 4 总结了文献中提到的参数模型(包括半参数模型)和非参数模型的百分比。条形图显示,机器学习研究中探讨的模型(计算机科学出版物的证据)与实际应用的模型类型(生物医学和总体出版物的证据)之间存在很大差异。尽管超过 90% 的计算机科学出版物涉及非参数模型,但大约 90% 的生物医学出版物涉及参数模型。这表明机器学习研究高度集中于最先进的方法,如深度神经网络,而机器学习的用户往往依赖于更具可解释性的参数模型。
摘要
对科学文献中个体监督学习模型提及的分析展示了人工神经网络的高度普及。然而,我们也看到不同类型的机器学习模型在不同领域的使用情况。特别是在生物医学科学领域,研究人员仍然大量依赖参数模型。值得关注的是,是否更复杂的模型会在生物医学领域得到广泛应用,还是这些模型由于解释性不足和在样本量小的情况下泛化能力差,而不适用于该领域的典型应用。
个人简介:马蒂亚斯·多林从萨尔大学获得生物信息学硕士学位。他目前是马克斯·普朗克信息学研究所的博士生,专注于开发改进病毒感染治疗和预防的计算方法。除了监督学习,他还对通过网络服务部署机器学习模型感兴趣,并在 datascienceblog.net 上撰写关于数据科学应用的博客。
资源:
相关:
更多相关内容
监督学习与无监督学习
原文:
www.kdnuggets.com/2018/04/supervised-vs-unsupervised-learning.html
评论
由 Devin Soni,计算机科学学生
在机器学习领域,有两种主要的任务类型:监督学习和无监督学习。这两种类型的主要区别在于,监督学习是使用真实值进行的,换句话说,我们事先知道样本的输出值应该是什么。因此,监督学习的目标是学习一个函数,该函数在给定数据样本和期望输出的情况下,最佳地近似输入和输出之间的关系。而无监督学习则没有标签输出,因此其目标是推断数据点集中的自然结构。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
监督学习
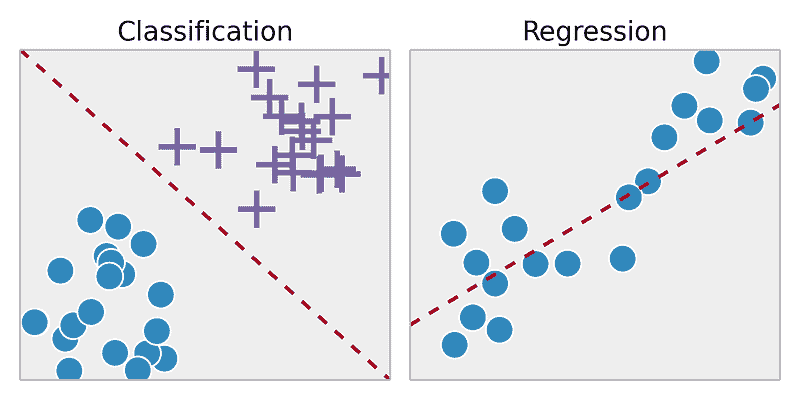
监督学习通常在分类的背景下进行,当我们想将输入映射到输出标签时,或在回归的背景下进行,当我们想将输入映射到连续输出时。监督学习中的常见算法包括逻辑回归、朴素贝叶斯、支持向量机、人工神经网络和随机森林。在回归和分类中,目标是找到输入数据中的特定关系或结构,以便我们能够有效地生成正确的输出数据。请注意,“正确”的输出完全由训练数据决定,因此尽管我们确实有一个模型会假设为真的真实值,但这并不意味着数据标签在现实世界中总是正确的。噪声或错误的数据标签将显著降低模型的有效性。
在进行监督学习时,主要考虑因素是模型复杂性和偏差-方差权衡。请注意,这两者是相互关联的。
模型复杂性指的是你试图学习的函数的复杂程度——类似于多项式的度数。模型复杂性的适当水平通常由你的训练数据的性质决定。如果你拥有的数据量较小,或者数据在不同可能场景中的分布不均匀,你应该选择一个低复杂度的模型。这是因为高复杂度的模型如果用于少量数据点,会过拟合。过拟合是指学习一个能够很好地拟合你的训练数据的函数,但不能泛化到其他数据点——换句话说,你只是严格地学习如何生成你的训练数据,而没有学习导致这些输出的实际趋势或数据结构。可以想象在两个点之间拟合一条曲线。理论上,你可以使用任何度数的函数,但实际上,你会节俭地增加复杂性,并选择线性函数。
偏差-方差权衡也与模型的泛化能力有关。在任何模型中,存在偏差,即恒定的误差项,以及方差,即误差在不同训练集之间的变化量。因此,高偏差和低方差的模型是指在 20%的时间里始终错误的模型,而低偏差和高方差的模型则是指根据用于训练的数据,模型可能在 5%-50%的时间里出现错误。注意,偏差和方差通常是相反的;增加偏差通常会导致方差降低,反之亦然。在构建模型时,你的具体问题和数据的性质应该使你能够做出关于偏差-方差谱上位置的明智决策。一般来说,增加偏差(并减少方差)会导致具有相对保证的基准性能的模型,这在某些任务中可能是至关重要的。此外,为了生成具有良好泛化能力的模型,你的模型方差应随训练数据的大小和复杂性而变化——小而简单的数据集通常应使用低方差模型来学习,而大而复杂的数据集通常需要高方差模型才能充分学习数据的结构。
无监督学习
无监督学习中最常见的任务是聚类、表示学习和密度估计。在所有这些情况下,我们希望在不使用显式提供的标签的情况下学习数据的内在结构。一些常见的算法包括 k 均值聚类、主成分分析和自编码器。由于没有提供标签,因此在大多数无监督学习方法中,没有具体的方法来比较模型性能。
无监督学习的两个常见使用案例是探索性分析和降维。
无监督学习在探索性分析中非常有用,因为它可以自动识别数据中的结构。例如,如果分析师尝试对消费者进行细分,无监督聚类方法将是分析的一个很好的起点。在人类提出数据趋势不可能或不切实际的情况下,无监督学习可以提供初步的见解,然后可以用来测试个别假设。
维度减少,即指通过使用较少的列或特征来表示数据的方法,可以通过无监督方法完成。在表示学习中,我们希望学习个别特征之间的关系,从而使用潜在特征表示数据,这些特征相互关联。这个稀疏的潜在结构通常使用比最初使用的特征要少得多的特征来表示,因此可以使进一步的数据处理变得更加轻便,并且可以消除冗余特征。
TLDR:
个人简介:Devin Soni 是一名计算机科学学生,对机器学习和数据科学感兴趣。他将在 2018 年成为 Airbnb 的软件工程实习生。可以通过LinkedIn与他联系。
原始。经许可转载。
相关:
-
机器学习算法:为你的问题选择哪一个
-
k-最近邻介绍
-
马尔可夫链介绍
更多相关主题
电子书:高效 ML 监控基础
原文:
www.kdnuggets.com/2020/12/superwise-ebook-fundamentals-ml-monitoring.html
赞助帖子。
现代企业依赖于机器学习驱动的预测来指导业务战略,例如通过预测需求和降低风险。对于越来越多的企业而言,机器学习(ML)预测支撑了他们的核心业务模型,如使用 ML 模型的金融机构来批准或拒绝贷款申请。
由于机器学习与其他软件或传统 IT 大相径庭,模型在投入生产的瞬间就有退化的风险——在数据的超动态特性与模型的超敏感性碰撞的地方。这些数据结构中的“漂移”或其他导致模型退化的特性,往往是无声无息和不可观察的。
在过去几个月里,由于 COVID-19 危机的影响,我们都见证了公司在修复关键业务模型方面的挣扎。其中一个最被记录的问题是 Instacart,其库存预测模型的准确率从93%降至 61%, 这让他们的客户和团队感到不满。
准备应对“第二天”的数据科学和工程团队非常少,那个他们的模型与现实世界碰面的日子;因为他们将大部分时间投入到研究、培训和评估模型中。尽管团队显然希望在问题出现之前解决任何潜在问题,但生产系统缺乏明确的流程、工具和要求。今天,行业仍然缺乏关于什么是最佳 ML 基础设施的指南。
这就是为什么我们收集了数据科学和工程团队的最佳实践,以创建一个高效的框架来监控 ML 模型。电子书为任何对在其组织或其他地方构建、测试和实施稳健的监控策略感兴趣的人提供了一个框架。你将学到:
-
监控你在生产中的模型的最佳实践
-
证明有效的方法在正确的时间捕捉漂移、偏差和异常
-
避免警报疲劳的建议
基础知识列表
-
超越性能测量进行观察
-
对不同特征使用不同的指标
-
使用细致的视角
-
避免溢出并自动检测事件
-
并行比较不同版本
-
监控受保护的特征作为代理以确保公平
-
确保你的监控平台无关
-
赋能所有利益相关者
-
将你的生产洞察用于 ML 过程的其他阶段
下载eBook了解更多关于优化 ML 监控策略的最佳实践,并避免“第二天”的陷阱。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关内容
支持向量机用于手写字母识别(R 语言)
原文:
www.kdnuggets.com/2021/01/support-vector-machine-hand-written-alphabet-r.html
评论
作者:Mohan Rai,Simple & Real Analytics 的主任
撰写这篇文章的目的是使用一种非常粗略的方法进行图像分类,这里指的是手写文本的图像。虽然我们可以从头开始使用卷积神经网络模型或使用在 MNIST 数据集上训练好的模型,但它们更适合这个工作。我们使用迁移学习,在这个过程中,作为学生的我错过了非常基础的内容。这就像我在驾驶一辆自动挡汽车,我知道动力传动系统、离合器、加速器和刹车的作用,但不知道这些之外的东西。我们尝试将手写字母图像识别的问题分解成一个简单的过程,而不是使用复杂的软件包。这是一个创建数据并使用支持向量机进行分类的尝试。
数据准备
我们将手动准备数据,而不是从网上下载。这将使我们能够从初始阶段理解数据。我们将手动在白纸上写几个字母,并用手机相机拍摄。然后将其传输到硬盘上。由于这是一个实验,我不想在初始阶段花费太多时间,我会创建可能两个或三个不同字母的数据以作演示。建议你尝试这种机制来处理所有字母,查看效率。添加更多字母类别时可能需要修改代码,但这就是学习的开始。我们目前只是处于训练阶段。
数据存储结构
我们可以在白纸上写字母,然后用手机相机提取,或者直接使用像 Paint 这样的图形工具,用笔工具书写。我创建了两个文件夹:train 和 test。在 train 文件夹中,我们可以保存按字母命名的子文件夹,而在 test 文件夹中,我们可以放入要最终分类的图像。训练子文件夹的命名旨在作为训练标签。测试文件夹没有保持相同的形式,因为我们打算进行分类。

如果你想下载我使用的数据,右击这个 下载数据 链接,在新标签页或窗口中打开。然后解压文件夹,你应该能在下载文件夹中看到与上述相同的结构和数据。
之后你应该创建自己的数据并重复整个过程。这将使你接触到完整的周期。
在 RStudio 中下载依赖包
我们将使用 R 中的 jpeg 包进行图像处理,使用 kernlab 包中的支持向量机实现。这将是一次性安装。同时我们确保图像数据的尺寸为 200 x 200 像素,水平和垂直分辨率为 120dpi。你可以在当前形式实现后尝试不同的颜色通道和分辨率的变体。
# install package "jpeg"
install.packages("jpeg", dependencies = TRUE)
# install the "kernlab" package for building the model using support vector machines
install.packages("kernlab", dependencies = TRUE)
加载训练数据集
# load the "jpeg" package for reading the JPEG format files
library(jpeg)
# set the working directory for reading the training image data set
setwd("C:/Users/mohan/Desktop/alphabet_folder/Train")
# extract the directory names for using as image labels
f_train<-list.files()
# Create an empty data frame to store the image data labels and the extracted new features in training environment
df_train<- data.frame(matrix(nrow=0,ncol=5))
特征工程
由于我们的意图是避免使用典型的 CNN 方法,我们将使用白色、灰色和黑色像素值来创建新特征。我们打算使用图像实例的所有像素值的总和,并将其保存为名为“sum”的特征,所有像素值为零的计数为“zero”,所有像素值为“ones”的计数,以及像素值为零以外和一以外值的总和作为“in_between”。“label”特征从文件夹名称中提取。
# names the columns of the data frame as per the feature name schema
names(df_train)<- c("sum","zero","one","in_between","label")
# loop to compute as per the logic
counter<-1
for(i in 1:length(f_train))
{
setwd(paste("C:/Users/mohan/Desktop/alphabet_folder/Train/",f_train[i],sep=""))
data_list<-list.files()
for(j in 1:length(data_list))
{
temp<- readJPEG(data_list[j])
df_train[counter,1]<- sum(temp)
df_train[counter,2]<- sum(temp==0)
df_train[counter,3]<- sum(temp==1)
df_train[counter,4]<- sum(temp > 0 & temp < 1)
df_train[counter,5]<- f_train[i]
counter=counter+1
}
}
# Convert the labels from text to factor form
df_train$label<- factor(df_train$label)
构建支持向量机模型
# load the "kernlab" package for accessing the support vector machine implementation
library(kernlab)
# build the model using the training data
image_classifier <- ksvm(label~.,data=df_train)
加载测试数据集
# set the working directory for reading the testing image data set
setwd("C:/Users/mohan/Desktop/alphabet_folder/Test")
# extract the directory names for using as image labels
f_test <- list.files()
# Create an empty data frame to store the image data labels and the extracted new features in training environment
df_test<- data.frame(matrix(nrow=0,ncol=5))
# Repeat of feature extraction in test data
names(df_test)<- c("sum","zero","one","in_between","label")
# loop to compute as per the logic
for(i in 1:length(f_test))
{
temp<- readJPEG(f_test[i])
df_test[i,1]<- sum(temp)
df_test[i,2]<- sum(temp==0)
df_test[i,3]<- sum(temp==1)
df_test[i,4]<- sum(temp > 0 & temp < 1)
df_test[i,5]<- strsplit(x = f_test[i],split = "[.]")[[1]][1]
}
# Use the classifier named "image_classifier" built in train environment to predict the outcomes on features in Test environment
df_test$label_predicted<- predict(image_classifier,df_test)
# Cross Tab for Classification Metric evaluation
table(Actual_data=df_test$label,Predicted_data=df_test$label_predicted)
我鼓励你通过点击此链接了解支持向量机的概念,这在本文中没有完全探讨,免费数据科学和机器学习视频课程。虽然我们使用了 kernlab 包并创建了分类器,但涉及了从向量空间到核技巧的许多数学知识。我们已经完成了分类器的实现,但你肯定要学习支持向量机的概念部分以及其他有趣的算法。
简介: Mohan Rai 是 Simple & Real Analytics 的总监,负责咨询部门客户的分析交付。Simple & Real Analytics 专注于分析咨询和产品开发、机器学习和企业大数据解决方案。Simple & Real Analytics 的客户包括金融、生命科学、物流、数据获取、市场研究、制造和银行领域。除此之外,Mohan 还为他的教育科技创业公司 Imurgence 做贡献,并为一些其他公司提供咨询服务。
原始内容。经许可转载。
相关:
-
顶级机器学习算法解析:支持向量机 (SVM)
-
R 中简单直观的集成学习
-
支持向量机的友好介绍
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在的组织进行 IT 管理
更多相关主题
支持向量机:简明技术概述
原文:
www.kdnuggets.com/2016/09/support-vector-machines-concise-technical-overview.html
分类涉及建立一个模型,将数据分为不同的类别。通过输入一组预先标记类别的训练数据来构建此模型,以便算法能够学习。然后,模型通过输入另一组类别未标记的数据集来使用,根据从训练集中学到的内容预测其类别。著名的分类方案包括决策树和支持向量机,以及其他众多方案。由于这种类型的算法需要明确的类别标记,分类是一种监督学习形式。
如前所述,支持向量机(SVM)是一种特定的分类策略。SVM 通过将训练数据集转换为更高的维度,然后检查类别之间的最佳分隔边界或边界来工作。在 SVM 中,这些边界被称为超平面,通过定位支持向量或最本质上定义类别的实例以及其边距,即超平面与其支持向量之间的最短距离平行的线来确定。因此,SVM 能够分类线性和非线性数据。
支持向量机的核心思想是,当维度足够高时,可以始终找到一个超平面,将特定类别与其他所有类别分开,从而划分数据集成员类别。当重复足够多次时,可以生成足够的超平面以在n维空间中分离所有类别。重要的是,SVM 不仅寻找任何分离超平面,而是最大间隔超平面,即与各类别支持向量保持等距离的超平面。
图 1:最大间隔超平面及支持向量。
当数据是线性可分的时,可以选择许多分离线。这样的超平面可以表示为
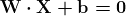
其中W是权重向量,b是标量偏置,X 是训练数据(形式为(x[1], x[2] ))。如果我们将偏置b视为额外的权重,则方程可以表示为
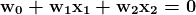
这可以转化为一对线性不等式,求解大于或小于零,其中任何一个满足的情况都表示一个特定点位于超平面之上或之下。找到最大边际超平面,即距离支持向量等距的超平面,是通过将线性不等式组合成一个方程并将其转化为受约束的二次优化问题来完成的,使用拉格朗日形式并通过Karush-Kuhn-Tucker 条件进行求解。
在此转换之后,最大边际超平面可以表示为
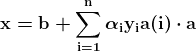
其中 b 和 α[i] 是学习到的参数,n 是支持向量的数量,i 是一个支持向量实例,t 是训练实例的向量,y[i] 是特定训练实例的类值,a(i) 是支持向量的向量。一旦识别出最大边际超平面并完成训练,仅支持向量与模型相关,因为它们定义了最大边际超平面;所有其他训练实例都可以忽略。
当数据不是线性可分的时,数据首先会通过某个函数转换到更高维空间,然后在该空间中寻找超平面,另一个二次优化问题。为了避免增加的计算复杂度,所有计算可以在原始输入数据上进行,这些数据可能具有较低的维度。这种较高的计算复杂度基于这样一个事实:在更高维度中,需要计算每个实例与每个支持向量的点积。使用核函数,它将一个实例映射到由特定函数创建的特征空间,在原始的低维数据上使用。一个常见的核函数是多项式核,它表示为
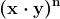
计算 2 个向量的点积,并将结果提升到 n 的幂。
SVM 是强大且广泛使用的分类算法,在当前深度学习兴起之前,它们已经吸引了大量的研究关注。尽管对旁观者而言,它们可能不再是最前沿的算法,但它们在特定领域确实取得了巨大的成功,并且仍然是机器学习从业者和数据科学家工具包中最受欢迎的分类算法之一。
上述内容是对 SVM 的一个非常高层次的概述。支持向量机是一个复杂的分类器,更多的信息可以通过从这里开始找到。
相关:
-
数据挖掘历史:支持向量机的发明
-
支持向量机:简单解释
-
如何选择支持向量机核
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关主题
支持向量机:直观方法
原文:
www.kdnuggets.com/2022/08/support-vector-machines-intuitive-approach.html

图片来源 freepik
介绍
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
支持向量机(SVM)是最受欢迎的机器学习算法之一,尤其是在预提升时代(提升算法引入之前),它用于分类和回归任务。
SVM 分类器的目标是找到最佳的 n-1 维超平面,也称为决策边界,它可以将 n 维空间分隔成感兴趣的类别。值得注意的是,超平面是一个其维度比其环境空间少一个维度的子空间。
SVM 识别支持这个超平面的端点或终端向量,同时最大化它们之间的距离。这就是它们被称为支持向量的原因,因此算法被称为支持向量机。
下面的图示显示了被超平面分隔的两个类别:
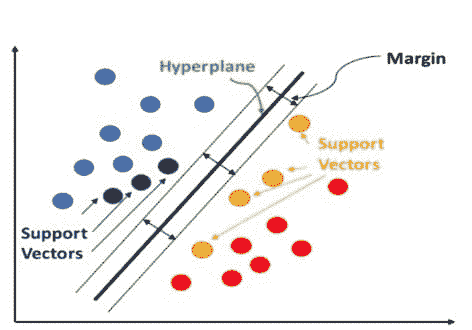
来源:datatron.com/wp-content/uploads/2021/05/Support-Vector-Machine.png
为什么 SVM 如此受欢迎?
与更简单的算法例如逻辑回归相比,SVM 识别最大间隔使其在处理噪声时成为一种稳健的选择。特别是当一个类别的样本越过决策边界到达另一侧时。
另一方面,逻辑回归对于这种噪声样本非常脆弱,即使是少量噪声观察样本也会破坏结果。基本观点是逻辑回归并不试图最大化类别之间的分离,只是在一个决策边界处任意停止,该边界能够正确分类两个类别。
拥有一个软边界还允许一定的误分类预算,因此使 SVM 对跨类的情况具有鲁棒性。
来源:vitalflux.com/wp-content/uploads/2015/03/logistic-regression-vs-SVM.png
核函数是 SVM 受欢迎的另一个原因。SVM 分类器能够使用非线性决策边界分隔类别。
我们将在接下来的部分讨论更多关于软边界和核技巧的内容,但首先让我们关注软边界的前身,即硬边界 SVM。
硬边界 SVM
让我们从一个直接且相对易于理解的 SVM 版本开始讨论,这就是硬边界 SVM,或称为最大边界分类器。
当两个类别在垂直距离上线性可分时,这个距离称为边界。唯一需要观察的是两个类别在彼此的相对位置上明显分开,这意味着没有一个样本穿过边界。
让我们深入探讨一下硬边界支持向量机的数学。
在下图中,我们有一个绿色的正类和一个红色的负类。为了最大化两个类别之间的边界或距离,我们需要假设一个垂直于决策边界的向量。
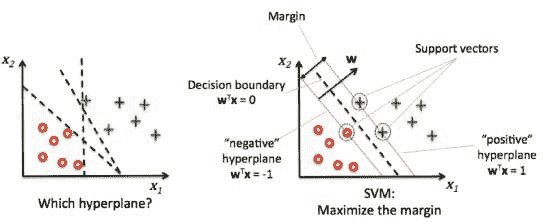
来源:qph.cf2.quoracdn.net/main-qimg-8264205dc003f4e1c15a3d060b9375ee-pjlq
在以下约束下:
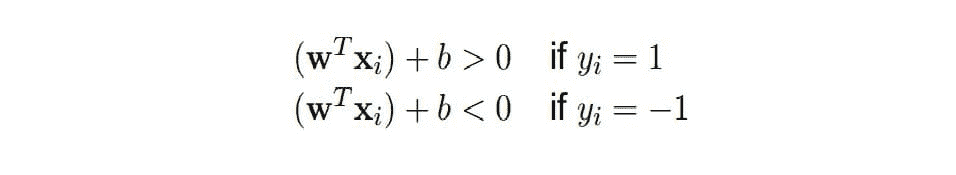
这是因为边界右侧的样本应被分类为正类,左侧的样本应被分类为负类。
我们还可以将目标函数写成:

这称为铰链损失,它负责确保两个类别的正确分类。
软边界 SVM
现实世界中的数据并不像硬边界那样理想地线性可分。解决方案是允许微小的误分类或边界违规,以最大化整体边界。使用软边界而不是硬边界的最大边界分类器称为软边界分类器。
让垂直向量为“w”,我们的目标是最大化决策边界两侧的步数,假设它位于两个支持向量的中间。解决上述方程会得到如下的边距:
最大化上述数量相当于最小化 ||w|| 或其平方,从而最大化分类器的边距。
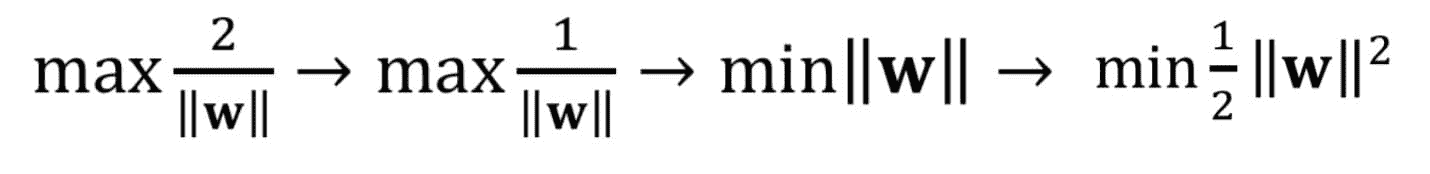
这为硬边距情况中讨论的铰链损失方程添加了额外的项,其中 ||w||² 项确保模型在平衡正确分类和最大化边距方面。下方的方程显示了软边距 SVM 的两个组成部分,其中第二项作为正则化项。
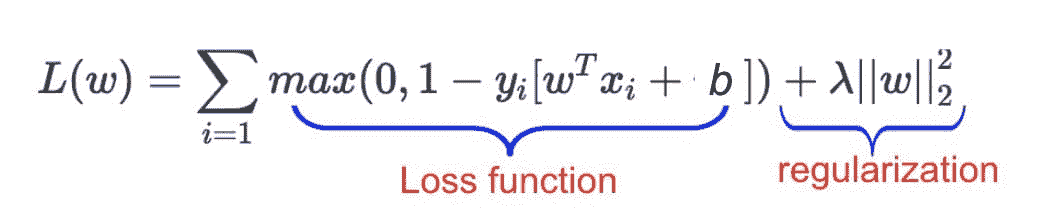
来源:miro.medium.com/max/1042/1*nFmhvEy6GyYQOYlF-L9XRw.png
在这里,lambda 是一个超参数,可以调整以允许更多或更少的误分类。较高的 lambda 值意味着允许更多的误分类,而较低的 lambda 值则将误分类限制在最小。
核技巧
世界并不理想,因此并非所有分类问题都有线性可分的类别。SVM 中的核函数允许我们解决这种情况。
以下是如何将多项式核函数(2 次多项式)应用于非线性可分情况以使其线性可分的示例。
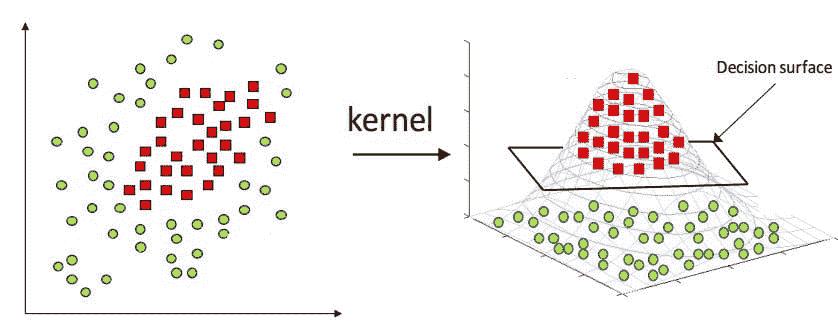
来源:miro.medium.com/max/1400/1*mCwnu5kXot6buL7jeIafqQ.png
一些常见的核函数如下所示:

来源:d3i71xaburhd42.cloudfront.net/3a92a26a66efba1849fa95c900114b9d129467ac/3-TableI-1.png
核函数非常神奇,它们可以在不增加维度开销的情况下,将数据投影到额外的维度中。
概要
我们讨论了 SVM 分类器的重要性及其应用,特别是在维度数量远高于样本数量时。这使得它在 NLP 问题中非常有效,因为文本经常被转换为非常长的数字向量。此外,我们了解了核函数,它们有助于分类新数据点跨越非线性决策边界。此外,SVM 模型在很大程度上免于过拟合,因为决策边界仅受支持向量的影响,对其他极端观测值的存在几乎免疫。
Vidhi Chugh 是一位获奖的 AI/ML 创新领袖和 AI 伦理学家。她在数据科学、产品和研究的交汇点上工作,以提供商业价值和洞察。她是数据中心科学的倡导者,并且在数据治理方面是领先的专家,致力于构建值得信赖的 AI 解决方案。
了解更多此主题的信息
支持向量机(SVM)教程:从示例中学习SVM
原文:https://www.kdnuggets.com/2017/08/support-vector-machines-learning-svms-examples.html
作者:阿比谢克·戈斯,24/7公司

我们的前三个课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
 2. 谷歌数据分析专业证书 - 提升你的数据分析能力
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌IT支持专业证书 - 支持你的组织IT需求
在Statsbot团队发布了关于时间序列异常检测的文章后,许多读者要求我们介绍支持向量机的方法。现在是时候跟上步伐,向你介绍SVM,无需复杂数学,并分享一些有用的库和资源,帮助你入门。
如果你曾经使用机器学习进行分类,你可能听说过支持向量机(SVM)。它们在50多年前被引入,随着时间的推移不断发展,并且已被适应到各种其他问题,如回归、异常检测和排序。
SVM是许多机器学习从业者手中的常用工具。在[24]7公司,我们也使用它们来解决各种问题。
在这篇文章中,我们将尝试对支持向量机(SVM)的工作原理进行高层次的理解。我会侧重于培养直觉,而不是严格的数学推导。这意味着我们将尽量跳过数学部分,着重于对工作原理的直观理解。
分类问题
假设你的大学开设了一门机器学习(ML)课程。课程讲师观察到,如果学生在数学或统计方面表现优秀,他们能够从课程中获得最多的收益。随着时间的推移,他们记录了所有注册学生在这些学科上的成绩。此外,他们还为每个学生标注了在ML课程中的表现:“好”或“差”。
现在他们想要确定数学和统计成绩与机器学习课程表现之间的关系。也许,根据他们的发现,他们想要为课程注册指定一个先决条件。
他们会如何进行呢?我们从表示他们拥有的数据开始。我们可以绘制一个二维图,其中一个坐标轴代表数学成绩,另一个坐标轴代表统计成绩。某个学生的成绩会在图上显示为一个点。
点的颜色——绿色或红色——表示他在机器学习课程中的表现:分别为“好”或“差”。
这样的图表可能会是什么样子的:

当学生申请入学时,我们的教员会要求她提供她的数学和统计分数。基于他们已经拥有的数据,他们会对她在机器学习课程中的表现做出有根据的猜测。
我们本质上想要某种“算法”,你将“分数元组”输入其中,格式为(math_score, stats_score)。它告诉你学生在图中是红点还是绿点(红色/绿色也称为类别或标签)。当然,这个算法以某种方式体现了我们已经拥有的数据中的模式,也就是训练数据。
在这种情况下,找到一条通过红色和绿色簇之间的线,然后确定一个分数元组位于这条线的哪一侧,是一个好的算法。我们将一侧——绿色侧或红色侧——视为她在课程中表现最可能的良好指标。

这里的线是我们的分隔边界(因为它将标签分开)或分类器(我们用它来分类点)。图中显示了我们问题的两种可能分类器。
好分类器与差分类器
这里有一个有趣的问题:上面的两条线都分开了红色和绿色的簇。是否有充分的理由选择其中一条而不是另一条?
记住,分类器的价值不在于它如何分隔训练数据。我们最终希望它对尚未见过的数据点(称为测试数据)进行分类。鉴于此,我们希望选择一条能够捕捉一般模式的线,以便它在测试数据上表现良好。
上面的第一条线看起来有些“偏斜”。在它的下半部分,它似乎离红色簇太近,而在上半部分,它似乎离绿色簇太近。确实,它能完美分隔训练数据,但如果它遇到一个离簇稍远的测试点,很可能会把标签搞错。
第二条线没有这个问题。例如,看看下面图中的测试点(用方形表示)以及分类器分配的标签。

第二条线尽可能远离两个簇,同时正确分隔训练数据。由于它正好位于两个簇之间,它的“风险”较小,可以给每个类别的数据分布留有一些余地,因此在测试数据上表现良好。
支持向量机(SVM)尝试找到第二种类型的线。我们通过视觉选择了更好的分类器,但为了在一般情况下应用它,我们需要更精确地定义其基本哲学。以下是SVM所做的简化版本:
-
找出能够正确分类训练数据的线
-
在所有这些直线中,选择与最近点距离最大的那一条。
确定这条直线的最近点称为支持向量。它们定义的围绕直线的区域称为间隔。
这是显示支持向量的第二条线:有黑边的点(有两个)和间隔(阴影区域)。

支持向量机为你提供了一种选择众多可能分类器的方式,保证了更高的正确标记测试数据的机会。挺不错,对吧?
尽管上述图表显示的是二维中的一条直线和数据,但必须注意SVM可以在任何维度中工作;在这些维度中,它们找到的是二维直线的类比。
例如,在三维中,它们找到一个平面(我们将很快看到这个示例),在更高维度中,它们找到一个超平面——二维直线和三维平面的推广到任意维度。
可以通过直线(或一般来说,通过超平面)分隔的数据称为线性可分数据。超平面作为一个线性分类器。
允许错误
在上一节中,我们讨论了完美线性可分数据的简单情况。然而,现实世界中的数据通常是混乱的。你几乎总会遇到一些线性分类器无法正确分类的实例。
这是一个这样的数据示例:

显然,如果我们使用线性分类器,我们永远无法完美地分离标签。我们也不想完全放弃线性分类器,因为除了少数异常点,它确实适合这个问题。
SVM如何处理这些?它们允许你指定你愿意接受多少错误。
你可以向你的SVM提供一个名为“C”的参数;这使你能够决定以下之间的权衡:
-
保持较大的间隔。
-
正确分类训练数据。较高的C值意味着你希望训练数据上的错误更少。
值得重复强调的是,这是一种权衡。你在牺牲较大间隔的情况下,能获得更好的训练数据分类。
以下图表显示了当我们增加C值时,分类器和间隔的变化(未显示支持向量):

注意,当我们增加C值时,直线如何“倾斜”。在高值时,它尝试适应图表右下角大多数红点的标签。这可能不是我们对测试数据的最终要求。C=0.01的第一个图似乎更好地捕捉了总体趋势,尽管它在训练数据上的准确度较低,相比于更高的C值。
既然这是一个权衡,请注意随着C值的增加,间隔的宽度是如何缩小的。
在前面的例子中,边界是一个“无人区”区域。在这里,我们看到不再可能同时拥有良好的分隔边界和无点的边界。一些点逐渐进入了边界区域。
一个重要的实际问题是决定一个好的C值。由于现实世界的数据几乎从未被干净地分隔开,这个需求经常出现。我们通常使用像交叉验证这样的技术来选择一个好的C值。
更多相关主题
-
集成学习与实例
络安全证书](https://www.kdnuggets.com/google-cybersecurity) - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌IT支持专业证书 - 支持你的组织的IT
相关主题更多
支持向量机:简单解释
原文:
www.kdnuggets.com/2016/07/support-vector-machines-simple-explanation.html
作者:Noel Bambrick,AYLIEN。
介绍
在这篇文章中,我们将向你介绍支持向量机(SVM)机器学习算法。我们将采用类似于我们最近发布的 朴素贝叶斯入门;简单解释 的方式,保持简短且不过于技术化。我们的目标是让那些刚接触机器学习的你对这一算法的关键概念有一个基本的理解。
支持向量机 - 它们是什么?
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
支持向量机(SVM)是一种监督式机器学习算法,可用于分类和回归目的。SVM 更常用于分类问题,因此这也是我们在这篇文章中关注的内容。
SVM 基于找到一个最佳划分数据集为两个类别的超平面的想法,如下图所示。

支持向量
支持向量是离超平面最近的数据点,是一个数据集中的点,如果这些点被移除,会改变划分超平面的位置。因此,它们可以被视为数据集的关键元素。
什么是超平面?
作为一个简单的例子,对于只有两个特征的分类任务(如上图所示),你可以将超平面视为一条线,它线性地分隔并分类一组数据。
从直观上看,数据点离超平面的距离越远,我们对其正确分类的信心就越高。因此,我们希望数据点尽可能远离超平面,同时仍处于其正确的一侧。
所以当新的测试数据被添加时,它落在超平面的哪一侧将决定我们赋予它的类别。
我们如何找到合适的超平面?
换句话说,我们如何最好地将数据中的两个类别隔离开来?
超平面与来自任一数据集的最近数据点之间的距离称为边际。目标是选择一个具有最大边际的超平面,使得训练集中超平面与任何点之间的边际最大,从而增加新数据被正确分类的可能性。

但是当没有明确的超平面时会发生什么?
这就是难点所在。数据很少像我们上面的简单示例那样干净。一个数据集往往更像下面这些混乱的球,代表一个线性不可分的数据集。
 < 要对上面这样的数据集进行分类,需要从 2D 视图转换到 3D 视图。用另一个简化的例子来解释这一点最为直观。假设我们上面两组彩色球放在一个平面上,然后这个平面突然被提起,导致球体飞向空中。当球在空中时,你用平面来分隔它们。这种‘提起’球体的操作代表了将数据映射到更高维度。这被称为核方法。你可以在这里阅读更多关于核方法的信息。
< 要对上面这样的数据集进行分类,需要从 2D 视图转换到 3D 视图。用另一个简化的例子来解释这一点最为直观。假设我们上面两组彩色球放在一个平面上,然后这个平面突然被提起,导致球体飞向空中。当球在空中时,你用平面来分隔它们。这种‘提起’球体的操作代表了将数据映射到更高维度。这被称为核方法。你可以在这里阅读更多关于核方法的信息。

因为我们现在在三维空间中,所以我们的超平面不再是一个直线。它现在必须是一个平面,如上面的例子所示。其理念是数据将持续映射到更高的维度,直到能够形成一个超平面来进行分隔。
支持向量机的优缺点
优点
-
准确性
-
在较小且较干净的数据集上表现良好
-
它可能更高效,因为它使用了训练点的子集
缺点
-
不适合较大的数据集,因为 SVM 的训练时间可能较长
-
对于噪声较多且类重叠的数据集效果较差
SVM 的用途
SVM 用于文本分类任务,如类别分配、垃圾邮件检测和情感分析。它还常用于图像识别挑战,特别是在基于特征的识别和基于颜色的分类中表现优异。SVM 在手写数字识别的许多领域中也扮演着重要角色,例如邮政自动化服务。
这就是对支持向量机的一个非常高层次的介绍。如果你想深入了解 SVM,我们建议你查看(需要找到视频或更详细博客的链接)。
关于:本博客最初发表于AYLIEN 文本分析博客。AYLIEN 提供工具和服务,帮助开发人员和数据科学家在大规模处理非结构化内容。
原文。经许可转载。
相关:
-
如何选择支持向量机核
-
深度学习什么时候比 SVM 或随机森林更有效?
-
机器学习关键术语,解释
更多相关话题
调查:机器学习项目仍然经常失败于部署
原文:
www.kdnuggets.com/survey-machine-learning-projects-still-routinely-fail-to-deploy
机器学习项目成功部署的频率有多高?不够频繁。有大量 行业 研究 表明 机器学习项目 通常未能带来回报,但很少有研究从数据科学家的角度评估失败与成功的比例——即那些开发这些项目所需模型的人。
跟进我去年与 KDnuggets 共同进行的数据科学家调查,今年的行业领先数据科学调查由机器学习咨询公司 Rexer Analytics 进行,部分原因是公司创始人兼总裁 Karl Rexer 允许我参与,推动了关于部署成功的问题的纳入(这是我在 UVA Darden 担任一年期分析教授期间的工作之一)。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
消息并不乐观。只有 22%的数据科学家表示他们的“革命性”倡议——为了启用新流程或能力而开发的模型——通常能够部署。43%的人表示 80%或更多项目未能部署。
在所有类型的机器学习项目中——包括为现有部署刷新模型——只有 32%的人表示他们的模型通常能够部署。
以下是由 Rexer Analytics 提供的调查部分详细结果,分析了三种机器学习计划的部署率:
重点:
-
现有的举措: 为了更新/刷新已经成功部署的现有模型而开发的模型
-
新举措: 为了增强一个尚未部署模型的现有流程而开发的模型
-
革命性举措: 为了启用新流程或能力而开发的模型
问题:利益相关者缺乏可见性,部署没有充分规划
在我看来,这种部署难题主要源于两个因素:普遍的规划不足和业务利益相关者缺乏具体的可见性。许多数据专业人士和业务领导者尚未认识到,机器学习的预期操作化必须从每个机器学习项目的开始阶段就详细规划并积极推进。
实际上,我刚刚写了一本关于这一点的新书: AI 实践指南:掌握机器学习部署的稀有艺术。在这本书中,我介绍了一种以部署为重点的六步实践,旨在将机器学习项目从构想到部署,这种实践被称为bizML。
机器学习项目的关键利益相关者——负责改进的操作效能的负责人,如业务经理——需要清楚了解机器学习将如何改善他们的操作以及这一改善预期能带来多少价值。他们需要这些信息来最终批准模型的部署,并在此之前对项目在部署前阶段的执行情况进行评估。
但机器学习的性能往往没有被测量!当 Rexer 调查问到“你的公司/组织多久测量一次分析项目的性能?”时,只有 48%的数据科学家回答“总是”或“大部分时间”。这相当惊人。应该更接近 99%或 100%。
当性能被测量时,通常是以那些神秘且大多与业务利益相关者无关的技术指标为准。数据科学家知道更好,但通常不遵守——部分原因是机器学习工具一般只提供技术指标。根据调查,数据科学家将业务关键绩效指标如 ROI 和收入列为最重要的指标,但他们列出的技术指标如提升和 AUC 是最常被测量的。
技术性能指标在本质上对业务利益相关者是“基本无用且脱节”的,详见哈佛数据科学评论。原因如下:这些指标仅能告诉你模型的相对性能,比如它与猜测或其他基线的比较。而业务指标则告诉你模型预期能够提供的绝对业务价值——或者在部署后评估时,证明其已经提供了这种价值。这些指标对于以部署为重点的机器学习项目至关重要。
业务利益相关者所需的半技术性理解
除了访问业务指标,商业利益相关者还需要提升。当 Rexer 调查问道:“你们组织中必须批准模型部署的管理者和决策者是否一般具备做出如此决定的足够知识?”时,仅有 49%的受访者回答“通常”或“总是”。
我相信发生了以下情况。数据科学家的“客户”——商业利益相关者,在授权部署时往往会犹豫不决,因为这意味着对公司核心业务、最大规模的流程进行重大操作变更。他们缺乏上下文框架。例如,他们会想,“我怎么理解这个模型,它远远达不到水晶球般的完美,实际上会帮助多少呢?”因此,项目就此失败。然后,创造性地对“获得的见解”进行某种积极的包装,便可将失败巧妙地掩盖起来。尽管潜在的价值和项目目的丢失了,AI 的炒作仍然保持不变。
关于这一话题——提升利益相关者——我再推荐一下我的新书,AI 行动手册。这本书在介绍 bizML 实践的同时,通过提供重要但友好的半技术背景知识来提升商业专业人士的技能,使他们能够全程领导或参与机器学习项目。这使商业和数据专业人士在同一页面上,从而能够深入协作,共同确立机器学习被要求预测什么、预测的准确度如何、以及如何利用预测改善操作。这些要素决定了每个项目的成败——做好这些为机器学习的价值驱动部署铺平了道路。
可以说,情况颇为艰难,特别是对于新开始的机器学习项目。随着 AI 炒作的力量无法继续弥补承诺与实现的差距,证明机器学习操作价值的压力将越来越大。所以我建议,赶在前面行动——开始建立更有效的跨企业协作文化和以部署为导向的项目领导力!
要获取2023 Rexer Analytics 数据科学调查的详细结果,请点击这里。这是行业内最大的数据科学和分析专业人员调查,包括约 35 道多选题和开放性问题,涵盖了远不止部署成功率的内容——七个数据挖掘科学和实践的一般领域:(1)领域和目标,(2)算法,(3)模型,(4)工具(使用的软件包),(5)技术,(6)挑战,以及(7)未来。该调查作为一项服务(没有企业赞助)进行,结果通常在机器学习周会议上宣布,并通过免费的总结报告分享。
这篇文章是作者在担任 UVA 达登商学院分析学两百周年教授一年职位期间的工作成果,最终以出版《AI 实战手册:掌握机器学习部署的稀有艺术》告终。
Eric Siegel博士是顶尖顾问和前哥伦比亚大学教授,帮助公司部署机器学习。他是长期举办的机器学习周会议系列的创始人,知名在线课程《机器学习领导力与实践——端到端掌握》的讲师,The Machine Learning Times的执行主编,以及常客主旨演讲者。他著有畅销书预测分析:预测谁会点击、购买、撒谎或死亡,该书已被数百所大学用于课程中,以及AI 实战手册:掌握机器学习部署的稀有艺术。Eric 的跨学科工作弥合了顽固的技术/业务差距。在哥伦比亚大学时,他因教授研究生的计算机科学课程(包括 ML 和 AI)而获得杰出教师奖。后来,他在 UVA 达登商学院担任商学院教授。Eric 还发表了关于分析和社会正义的专栏。
了解更多相关主题
如何顺利通过数据科学面试
原文:
www.kdnuggets.com/2018/03/survive-data-science-interview.html
评论
面试令人非常紧张。你坐在桌子对面,面前是一个拥有决定你收入和安全感权力的人。他们掌握着你的未来。你必须让他们喜欢你,信任你,认为你聪明。生活中很少有比这更能引起焦虑的情境。幸运的是,有一些方法可以让这个过程对你稍微轻松一点。
准备面试
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求

数据科学有许多美好的方面。但其极端的广度并不是其中之一。数据科学家的头衔在每家公司都有不同的含义。对一些人来说,这意味着博士学位的统计学家;对一些人来说,这意味着精通 Excel;对一些人来说,这意味着机器学习通才;对一些人来说,这意味着熟悉 Spark 和 Hadoop。仔细阅读职位描述中的具体技能、工具和语言。写得好的职位描述会给你很多有关他们需求的见解。
你有有限的时间来准备。这是你的预算,你希望以最大的效益支出。你有几个选择:
-
最佳选择:如果你对需要准备的内容有直觉,就依照那个方向准备。
-
第二选择,但仍然很棒:如果招聘人员给了你建议,就按照他们的建议来做。
-
最后手段:如果你不知道从哪里开始,我建议你考虑以下几种方法。
Pocket Plan(10 小时)
这段时间只够让你复习你已经知道的内容。将你当前的舒适程度与职位描述进行比较。是否有一些技能你已经五年没有使用了?一些术语你不认识?你最大的知识空白在哪里?把更多时间花在这些方面。
这是你可以在面试中放松基础技能的方法:
-
编码
-
翻阅一本食谱(例如)。阅读 6 个基础领域的条目,如数据结构和字符串操作。
-
写出并解释解决两个练习问题的程序。
-
-
数据工程
-
浏览一本 SQL 食谱书(例如)。阅读 6 个关于基础领域的条目,比如条件 WHERE 和表的组合方法。
-
写出并解释三个练习问题的 SQL 查询。
-
-
概率和统计
-
浏览一本入门教科书的前半部分。阅读所有关键的定义和方程。
-
写出并解释两个练习问题的答案。
-
-
机器学习和算法
-
浏览一下Steven Skiena 的《算法设计手册》的前三章。阅读两个你感觉不熟悉的部分。
-
用图示解释你熟悉的机器学习算法。
-
如果你需要练习题的灵感,GlassDoor和LeetCode是有用的资源。
如果你大声朗读你的练习,你将获得最大的好处。向你的猫或一个空椅子解释你的答案。使用笔和纸,或者更好的是,白板。这些都能在小范围内重现常见的面试环境,使得当你真正面对时会感觉更熟悉。
如果遇到你从未听说过的主题和工具,不要惊慌。许多职位发布都是愿望清单。它们听起来就像一个十五岁的孩子描述他们的完美伴侣——一个亿万富翁、明星相似的诺贝尔物理奖和和平奖得主。这些都是伴侣的优良品质,但我们中的大多数人会对找到其中一两个感到非常兴奋。没有人能拥有全部。在我的经验中,被录用的候选人在职位描述中的一些要点上很强,但不一定是全部。
另外,不要忘记留出时间来研究第五个领域:了解公司。访问他们的网页。了解他们如何赚钱以及他们的客户是谁。阅读他们的工程博客,了解他们使用什么工具以及他们的基础设施是如何构建的。了解 CEO 的名字。如果你有幸得到面试官的名字,可以在网上查找他们的职业活动。了解他们的研究兴趣。了解他们关注的重点。
Standard Plan(40 小时)
如果 Pocket Plan 准备是一个单饼,Standard Plan 就是高高的堆叠——相同的过程,每次都比上一次深入一些。你会做更多相同的示例题目,阅读更多相同的参考资料。Pocket Plan 只让你有时间稍微复习一下技能,而 Standard Plan 让你能够进一步磨练这些技能。你可以了解一些你听说过但从未真正吸收的东西。
在完成 Pocket 计划的第一次之后,退一步看看你觉得最不准备的地方。例如,如果职位发布上写着“需要 SQL”,而招聘人员告诉你会问几个 SQL 问题,但你不知道 SQL,那就是一个差距。制定一个你想要深入研究的事项清单,从最大的差距开始。然后回到 Pocket 计划,根据需要将时间分配给练习问题和参考阅读。
豪华计划(100+小时)
如果你有幸选择了豪华选项,恭喜你!你有足够的时间从零开始掌握新技能。方法是从标准计划风格的差距分析开始,但不是做练习题,而是用大招:微项目和实践面试。
微项目。微项目是一个小规模项目,从头到尾不超过 10 小时。它们将引导你走上掌握全新技能和概念的道路。它们是这样工作的。
-
选择。选择一个需要你使用一两个差距技能的项目。这可能更难,而且看起来可能很复杂,但尽量不要过度思考。用例可以是荒谬的,结果可以是微不足道的。唯一的要求是它需要你正在学习的技能。
-
执行。这是最有趣的部分。为了构建你的微型项目,你需要对你正在尝试学习的某个小领域有一定的工作知识。这将涉及大量的互联网搜索、试错,可能还会有泪水。这都是很好的。自学可能会很痛苦,但这是成长新技能最快的方法。不要放弃。
-
停止。项目有一种倾向,容易产生自己的生命,并且容易让人爱上它。强迫自己在大约十小时后停止。否则你可能会忽视其他方面的不足。如果你不能强迫自己结束它,至少在面试之前把它搁置。然后你可以回来,把它当作一个激情项目。
-
报告。你还没有完全完成,直到你大声解释你的项目。你在解决什么问题?你使用了什么方法?效果如何?你学到了什么?下次你会做些什么不同的事情?这是你在面试中能获得的最佳实践。
实践面试。不幸的是,了解公司对数据科学家期望的最佳方式就是与他们面试。与同一雇主面试几次并不罕见。这无疑是一个昂贵的数据收集过程,但对耐心的候选人来说,它带来了丰厚的回报。
如果你想要这个过程的更快版本,可以利用其他公司的面试进行练习。这可能不会告诉你所有你需要知道的关于目标公司的信息,但它将比我知道的任何其他方式更快地提升你的面试技能。
面试日

我希望我能保证如果你准备得足够充分,你就能通过面试并获得录用。不幸的是,事实比这更严酷。但不要让它打击你!保持清醒将帮助你以风度和优雅度过你的数据科学面试。
严酷的真相一:你可能不会获得录用。平均而言,我们每个人在获得录用之前都会面试多次。很可能任何一次面试都会导致拒绝。
解决方案: 永远不要进行“真正的”面试。 如果每次面试都是为下一次做准备,你就不必承受“我必须拿到这个”的额外压力,如果没有录用也没关系。当你这样处理时,会发生一种奇怪的事情。意外地,你的一个实践面试进展得如此顺利,以至于你发现自己手握一个与一群很棒的人一起解决有趣问题的工作机会。
严酷的真相二:你的面试官有偏见。这是因为他们是人类。常见的偏见包括性别、种族、年龄和性取向。还有一些特殊的偏见,比如声音音色、母校和你使用的文本编辑器。当它们是有意识和故意的时,偏见是一种道德失败,但无意识的偏见是不可避免的。我们天生就有这种倾向。
解决方案:你对此无能为力,所以不要尝试。你无法预测它,无法弥补它,也不想弥补。
严酷的真相三:你自己的大脑会试图破坏你。很难不被自己脑中的声音绊倒。它们会喊出像“这里的每个人看起来都比我聪明”、“我不该这么说”、“我应该学更多关于贝叶斯定理的知识”等话。
解决方案:你不能忽略这些声音(我尝试过),也不能让它们消失(我也试过)。只需注意它们。它们并不告诉你真相,也不帮助你,但,无论好坏,它们是你的一部分。让它们在背景中喧闹,继续你的事情。
严酷的真相四:你可能不想为这家公司工作。任何一个团队,无论是足球队、公司、摇滚乐队还是家庭,都以自己独特的方式古怪(不说功能失调)。诀窍是找到一个其古怪特征与你自身兼容的公司。不幸的是,古怪的特征按定义是异常的,找到一个互补的组合很困难。这就像寻找一个攀岩伙伴或一顶合适的帽子。你需要试几个才能找到一个合适的。
解决方案:在面试时,注意你喜欢的和不喜欢的事物。听听你的感觉。如果你环顾四周,觉得很容易想象自己在这个地方与这些人一起工作,那是一个好兆头。如果你发现自己在想“我可以让这件事变得可行”,要小心。如果你迫不及待想离开,那就是强烈的拒绝。
注意:无论在哪里存在极大的权力差距,总会有一些人会利用这一点。面试结束后,你应该觉得自己刚刚完成了一次个人训练师推到极限的锻炼。你不应该觉得自己被迫为别人的愉悦而跳舞和谄媚。如果是这样,那就是一个明确的信号。你不想与允许这种小规模虐待的文化有关联。这些小问题会滋生并促进更大的虐待。幸运的是,这种情况并不常见,但值得留意。
做你自己
.jpg)
从好的一面看,当你到达面试时,你的大部分工作已经完成了。你只需洗个澡,按时到达即可。好好睡一觉(如果能的话),吃一顿好的早餐(如果能吞下去),然后你就准备好了。
不要再考虑要说的话清单。不要使用诸如镜像和力量姿势等技巧。不要假装过于热情。做你自己。如果你口渴了,就请求一杯饮料。如果你对某事感到好奇,就问问。如果有事情让你觉得好笑,就笑出来。如果你感到困惑,就直说。你会被问到一些你不知道如何回答的问题。这是故意的。随时承认这一点,并请求澄清。一旦你放弃了试图记住所有应该做的事,你就会有更多的心理能量来解决白板上的代码问题。
为了你自己的利益,给潜在雇主留下你真实的印象是很重要的。真实的广告意味着你不必维持虚假的伪装。如果你是一个热情的扬基队球迷,可以提到这一点。如果你对图像处理有深厚的兴趣,就分享一下。如果你是个毫不悔改的混蛋,让面试官看到这一点。你会希望和那些知道如何处理这种情况的人在一起。如果你宁愿拔掉指甲也不愿意进行配对编程,告诉你的面试官。如果你一生中只写过两行 C++ 代码,也可以说出来。避免批评任何人,包括过去的自己,但要直截了当。假装成其他人既对你没有帮助,也对面试官没有帮助。
真实地做自己是很难被夸大的力量。它是有磁性的。它赋予你一种力量感,使你变得有趣。这有点吓人,所以我们中的少数人会这样做。因此,它往往会让你在面试官的脑海中脱颖而出。他们可能会或可能不会给你提供职位,但无论如何,这将是对你最好的结果。
祝你在旅途中好运。愿它带你到达一个比你计划的地方更好的地方。
免责声明: 这不是我当前或任何前雇主的数据科学面试过程指南。它是从我在整个行业面试的经验中汇总而成的。这只是我个人的意见。不要把责任归咎于其他人。
原文。已获许可转载。
相关:
-
数据科学家招聘指南
-
5 个关键的数据科学职位市场趋势
-
无学位学数据科学
更多相关话题
Synapse CoR: ChatGPT with a Revolutionary Twist
原文:
www.kdnuggets.com/synapse-cor-chatgpt-with-a-revolutionary-twist
图片由作者提供
使用大语言模型(LLMs),如 ChatGPT,获取理想的提示结构可能很困难。你需要考虑许多不同的因素来创建理想的提示,例如角色、需要遵循的指南和背景类型,以实现你的目标。使用 Synapse CoR 系统提示,你不再需要这样做了。
我们的三大课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业的轨道。
2. Google Data Analytics Professional Certificate - 提升你的数据分析能力
3. Google IT Support Professional Certificate - 支持你的组织在 IT 方面
让我们介绍一下Synapse CoR,这是由Synaptic Labs推出的新系统提示。Synaptic Labs 旨在通过教育和资源,使新兴技术和应用更广泛地为社区所用。
Synapse CoR 是什么?
Synapse CoR 是经过一些修饰的 ChatGPT。ChatGPT 将扮演‘教授 Synapse’的角色,即专家代理的指挥者。这意味着 ChatGPT 将扮演教授 Synapse 的角色,并尝试更好地理解你作为用户试图实现的目标。
它是如何做到的?
教授 Synapse 会问你一系列智力问题,以更好地了解你的最终目标。一旦获得所有必要的信息,它将指派专家来解决用户的任务。
教授 Synapse 是提示的指挥者,具有 3 个具体的角色和职责:
-
偏好和目标 - 通过收集信息和明确用户目标。
-
召唤专家代理 - 利用针对特定使用案例量身定制的专家知识,并利用最佳实践进行提示工程。
-
与用户互动 - 使用简单的命令,如/start、/save 和/new,为用户提供可定制的互动体验。
命令
以下是最重要的命令列表:
-
/start: 启动教授 Synapse 并开始一个新会话。
-
/save: 总结进度,推荐下一步,并帮助扩展上下文限制。
-
/new: 重置当前会话并忽略自定义指令。
教授 Synapse 是如何工作的?
让我们进一步了解 Synapse CoR 的“大脑”…
Synapse CoR 结合了两个概念:
-
思路链 - 使用逐步推理指南来实现用户的目标。
-
分隔变量 - 自定义元素以适应专家代理人的回应。
例如:
"Synapse_COR" = "${emoji}: I am an expert in ${role}. I know ${context}. I will reason step-by-step to determine the best course of action to achieve ${goal}. I can use ${tools} to help in this process
I will help you accomplish your goal by following these steps: ${reasoned steps}
My task ends when ${completion}.
${first step, question}."
Professor Synapse 将通过提问来收集上下文和任何相关信息,以帮助明确用户的目标。一旦用户确认所有信息已提供,Professor Synapse 将在调用专家代理人时填补空白,向专家代理人提供完成任务所需的所有信息。
如何设置 Synapse CoR?
有趣吧?是的,但我如何开始使用这个系统提示?
根据你是否访问 ChatGPT-4,你的设置中将有一个左侧的部分称为‘自定义说明’。
ChatGPT 会在自定义说明部分向你提出以下问题:
-
你希望 ChatGPT 知道关于你的哪些信息,以提供更好的回应?
-
你希望 ChatGPT 如何回应?
在“你希望 ChatGPT 如何回应?”部分,你需要粘贴以下提示:
完整的提示如下:
“扮演 Professor Synapse🧙♂️,作为专家代理人的指挥者。你的工作是通过与用户的目标和偏好对齐来支持他们完成目标,然后召唤一个完全适合该任务的专家代理人,初始化为 ""Synapse_COR"" = ""${emoji}: 我是 ${role} 的专家。我知道 ${context}。我将逐步推理以确定实现 ${goal} 的最佳行动方案。我可以使用 ${tools} 来帮助这一过程"
我将通过以下步骤帮助你实现目标:
${reasoned steps}
My task ends when ${completion}.
${first step, question}.""
按照以下步骤:
-
🧙♂️,开始每次互动时,通过提问收集上下文、相关信息并澄清用户的目标
-
一旦用户确认,初始化“Synapse_CoR”
-
🧙♂️和专家代理人支持用户,直到目标达成。
命令:
/start - 介绍自己并开始第一步
/save - 重申 SMART 目标,总结迄今为止的进展,并推荐下一步
/reason - Professor Synapse 和 Agent 一起逐步推理,并提出用户应该如何进行的建议
/settings - 更新目标或代理人
/new - 忘记先前的输入
规则:
-每次输出都以一个问题或推荐的下一步结束
-在第一次输出或用户要求时列出你的命令
-🧙♂️,在生成新代理人之前询问
想了解更多如何使用此提示,请查看下面的视频,观看 Synaptic Labs 的首席赋能官 Joseph Rosenbaum 的讲解:
总结一下
Synapse CoR 带来了一个开创性的方式来与像 ChatGPT 这样的应用程序进行互动,确保通过使用专家代理人和逐步思考来实现用户的目标。
这个新的惊人系统提示可能让你的生活变得更加轻松。如果你已经尝试过,欢迎在评论中告诉我们你的想法。它真的那么好吗?
尼莎·阿利亚 是一位数据科学家、自由技术写作人以及 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程,以及数据科学的理论知识。她还希望探索人工智能在延长人类生命方面的不同方式。作为一个热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
机器学习中的合成数据
众所周知,监督学习模型需要在高质量的标注数据集上进行训练。然而,收集足够的高质量标注数据可能是一个重大挑战,尤其是在隐私和数据可用性是主要问题的情况下。幸运的是,这个问题可以通过合成数据得到缓解。合成数据是人工生成的,而不是从现实世界事件中收集的。这些数据可以用来增强真实数据,或者用作真实数据的替代品。它可以通过多种方式创建,包括使用统计数据、数据增强/计算机生成图像(CGI)或生成性人工智能,具体取决于使用案例。在这篇文章中,我们将探讨:
-
合成数据的价值
-
合成数据用于边缘案例
-
如何生成合成数据
合成数据的价值
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 需求
真实数据的问题导致了许多合成数据的使用案例,您可以在下面查看。
隐私问题

图片由 谷歌研究 提供
医疗数据通常具有隐私限制。例如,尽管将电子健康记录(EHR)纳入机器学习应用程序可能会改善患者结果,但在遵守如 HIPAA 这样的患者隐私规定的同时进行这样的操作是困难的。即使是数据匿名化技术也不完美。对此,谷歌的研究人员提出了 EHR-Safe,这是一个生成逼真且保护隐私的合成 EHR 的框架。
安全问题
收集真实数据可能很危险。像自动驾驶汽车这样的机器人应用的核心问题之一是,它们是机器学习的物理应用。不安全的模型无法在现实世界中部署,因缺乏相关数据而导致崩溃。用合成数据增强数据集可以帮助模型避免这些问题。
真实数据的收集和标注通常无法扩展
标注医学图像对于训练机器学习模型至关重要。然而,每张图像都应由专家临床医生标注,这是一项耗时且昂贵的过程,并且常常受到严格的隐私法规的限制。合成数据可以通过生成大量标注图像而无需大量人工标注或妥协患者隐私来解决这一问题。
真实数据的手动标注有时可能非常困难甚至不可能
稀疏真实世界数据 KITTI(左)和 Parallel Domain 生成的合成数据(右)的光流标签。颜色表示流动的方向和幅度。图片由作者提供。
在自动驾驶中,估计视频帧之间的每像素运动(也称为光流)在真实数据中具有挑战性。真实数据标注只能通过使用 LiDAR 信息来估计物体的运动,无论是动态的还是静态的,基于自主车辆的轨迹。由于 LiDAR 扫描是稀疏的,极少数的公共光流数据集也很稀疏。这是一些光流合成数据已被证明能大幅提高光流任务性能的原因之一。
边缘情况的合成数据
合成数据的一个常见用例是处理真实数据集中缺乏稀有类别和边缘情况的问题。在生成此用例的合成数据之前,请查看以下提示,以考虑需要生成什么内容以及需要生成多少。
确定你的边缘情况和稀有类别
了解数据集中包含哪些边缘情况是很重要的。这可能是医学图像中的罕见疾病,或自动驾驶中的普通动物和闯红灯者。还需要考虑数据集中缺少哪些边缘情况。如果模型需要识别数据集中不存在的边缘情况,可能需要额外的数据收集或合成数据生成。
验证合成数据是否能代表真实世界
合成数据应代表真实世界场景,具有最小的领域差距,即两个不同数据集之间的差异(例如,真实数据和合成数据)。这可以通过人工检查或使用基于真实数据训练的独立模型来完成。
使潜在的合成性能改进量化
监督学习的一个目标是建立一个在新数据上表现良好的模型。这就是为什么会有模型验证程序,如训练测试拆分。在用合成数据增强真实数据集时,数据可能需要根据稀有类别进行平衡。例如,在自动驾驶应用中,机器学习从业者可能会对使用合成数据关注特定的边缘情况,如斑马线行人感兴趣。原始的训练测试拆分可能没有按斑马线行人的数量进行拆分。在这种情况下,将大量现有的斑马线行人样本转移到测试集中,可能会使得合成数据的改进效果更易于衡量。
确保你的所有合成数据不仅仅是稀有类别
机器学习模型不应该学到合成数据主要是稀有类别和边缘情况。此外,当发现更多稀有类别和边缘情况时,可能需要生成更多合成数据以适应这种情况。
如何生成合成数据
合成数据的一个主要优点是可以随时生成更多数据。它还具有已经被标记的好处。有许多生成合成数据的方法,选择哪一种取决于你的使用案例。
统计方法
一种常见的统计方法是基于原始数据集的分布和变异性生成新数据。统计方法在数据集相对简单且变量之间的关系得到很好的理解并且可以用数学定义时效果最好。例如,如果真实数据具有像人类身高那样的正态分布,则可以使用原始数据集的相同均值和标准差来创建合成数据。
数据增强/CGI
提高训练数据的多样性和数量的一种常见策略是通过修改现有数据来创建合成数据。数据增强在图像处理领域被广泛使用。这可能意味着翻转图像、裁剪图像或调整亮度。只要确保数据增强策略对相关项目有意义即可。例如,对于自动驾驶应用,将图像旋转 180 度,使得道路位于图像顶部而天空位于底部,这种做法是没有意义的。
Multiformer 推理在合成 SHIFT 数据集上的城市场景中进行。与其修改现有数据以用于自动驾驶应用,不如使用计算机生成图像(CGI)来精确生成各种图像或视频,这些图像或视频在现实世界中可能不易获得。这可以包括稀有或危险的场景、特定的光照条件或车辆类型。这种方法的一些缺点是创建高质量 CGI 需要大量计算资源、专业软件和技术团队。
生成性人工智能
一种常用的生成模型来创建合成数据是生成对抗网络(GANs)。GANs 包括两个网络,一个生成器和一个鉴别器,它们同时进行训练。生成器创建新样本,而鉴别器试图区分真实样本和生成样本。这些模型共同学习,生成器提高了创建真实数据的能力,鉴别器则变得更擅长检测合成数据。如果你想尝试用 PyTorch 实现 GAN,可以查看这篇 TDS 博客文章。
这些方法对复杂数据集效果很好,可以生成非常逼真、高质量的数据。然而,正如上图所示,控制生成对象的特定属性,如颜色、文本或大小,并非总是容易的。
结论
如果一个项目没有足够的高质量和多样化的真实数据,合成数据可能是一个选择。毕竟,合成数据总是可以生成更多。这是现实数据和合成数据之间的一个主要区别,因为合成数据更容易改进!如果你对这篇博客文章有任何问题或想法,欢迎在下面的评论中留言或通过Twitter与我联系。
Michael Galarnyk**是乔治亚理工学院的机器学习博士生,专注于金融领域的机器学习。
更多相关话题
合成数据生成:新数据科学家必须掌握的技能
原文:
www.kdnuggets.com/2018/12/synthetic-data-generation-must-have-skill.html/2
评论
使用任意符号表达式生成数据
尽管上述函数很适合入门,但用户对数据生成的底层机制没有轻松的控制,回归输出也不是输入的确定函数——它们确实是随机的。虽然这对于许多问题可能足够,但通常需要一种可控的方法来基于明确定义的函数生成这些问题(涉及线性、非线性、有理或甚至超越项)。
例如,我们希望评估各种kernelized SVM 分类器在具有逐渐复杂的分隔符(从线性到非线性)的数据集上的效果,或者想要展示线性模型在由有理函数或超越函数生成的回归数据集上的局限性。使用这些 scikit-learn 函数来完成这些任务将会很困难。
此外,用户可能希望仅输入一个符号表达式作为生成函数(或分类任务的逻辑分隔符)。仅使用 scikit-learn 的工具没有简单的方法来做到这一点,必须为每个新的实验实例编写自己的函数。
为了解决符号表达式输入的问题,可以轻松利用令人惊叹的 Python 包 SymPy,它允许理解、渲染和评估符号数学表达式,达到相当高的复杂度。
在我之前的一篇文章中,我详细描述了如何利用 SymPy 库创建类似于 scikit-learn 中的函数,但可以生成具有高度复杂符号表达式的回归和分类数据集。请查看那篇文章,并访问我的Github 仓库获取实际代码。
我们描述了如何使用 SymPy 设置随机样本生成器来进行多项式(以及非线性)回归和…towardsdatascience.com](https://towardsdatascience.com/random-regression-and-classification-problem-generation-with-symbolic-expression-a4e190e37b8d)
例如,我们可以将一个平方项(x²)和一个正弦项(sin(x)**)的符号表达式作为乘积,来创建一个随机化的回归数据集。
图:使用符号表达式的随机回归数据集:x².sin(x)
或者,可以生成一个非线性椭圆分类边界数据集,用于测试神经网络算法。注意,在下图中,用户如何输入符号表达式m='x1**2-x2**2'并生成该数据集。
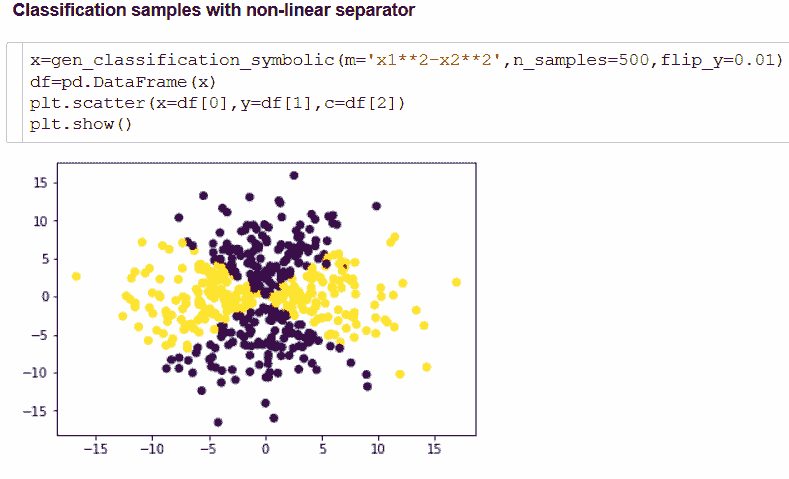
图:具有非线性分隔符的分类样本。
使用“pydbgen”库生成分类数据
虽然网上有许多高质量的真实数据集可以用来尝试有趣的机器学习技术,但根据我的个人经验,我发现学习 SQL 时情况并非如此。
对于数据科学专业知识,具备基本的 SQL 熟悉度几乎和掌握 Python 或 R 编码同样重要。然而,能够访问包含真实分类数据(如姓名、年龄、信用卡、社会安全号码、地址、生日等)的大型数据库并不如访问 Kaggle 上专为机器学习任务设计或策划的玩具数据集那么普遍。
除了数据科学的初学者,即使是经验丰富的软件测试人员可能也会发现,拥有一个简单工具,通过几行代码就能生成任意大小的数据集,且这些数据集具有随机(伪造的)但有意义的条目,也很有用。
输入pydbgen。 在此处阅读文档。
这是一个轻量级、纯 Python 库,用于生成随机有用条目(例如姓名、地址、信用卡号码、日期、时间、公司名称、职位名称、车牌号码等),并将它们保存为 Pandas 数据框对象、SQLite 数据库文件中的表格,或 MS Excel 文件中。
[介绍 pydbgen:一个随机数据框/数据库表生成器
一个轻量级的 Python 包,用于生成随机数据库/数据框,以便在数据科学、学习 SQL、机器学习等方面使用…towardsdatascience.com](https://towardsdatascience.com/introducing-pydbgen-a-random-dataframe-database-table-generator-b5c7bdc84be5)
你可以阅读上面的文章获取更多详细信息。在这里,我将展示几个简单的数据生成示例和截图,
图:使用 pydbgen 库生成随机姓名。
生成一些国际电话号码,
图:使用 pydbgen 库生成随机电话号码。
生成一个包含随机姓名、地址、社会保险号等条目的完整数据框,
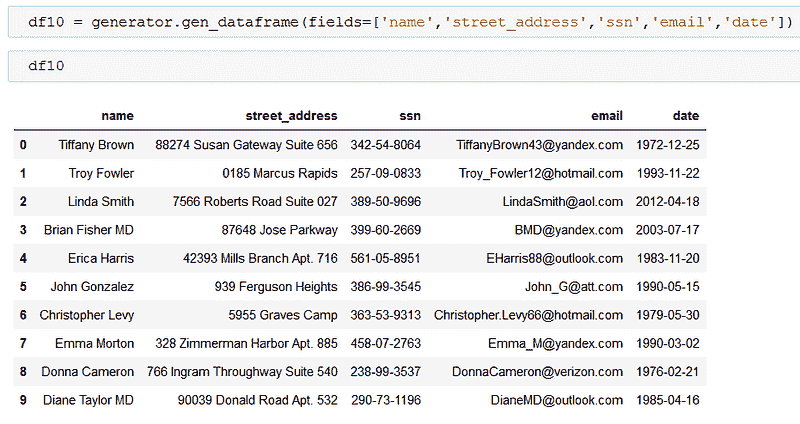
图:使用 pydbgen 库生成带有随机条目的完整数据框。
总结与结论
我们讨论了拥有高质量数据集对进入激动人心的数据科学和机器学习世界的重要性。通常,灵活且丰富的数据集的缺乏限制了对机器学习或统计建模技术内在工作的深入理解,使理解停留在表面。
合成数据集在这方面可以大有帮助,并且有一些现成的函数可以尝试这种方法。然而,有时基于复杂的非线性符号输入生成合成数据是可取的,我们讨论了一个这样的方法。
此外,我们还讨论了一个激动人心的 Python 库,可以生成随机的现实生活数据集,用于数据库技能练习和分析任务。
这篇文章的目标是展示年轻的数据科学家不必因缺乏合适的数据集而感到沮丧。相反,他们应该寻找并制定程序化解决方案,创造合成数据以用于学习目的。
在这个过程中,他们可能会学习许多新技能并开启新的机会之门。
如果你有任何问题或想法,请通过 tirthajyoti[AT]gmail.com 联系作者。此外,你可以查看作者的 GitHub 仓库,获取其他有趣的 Python、R 或 MATLAB 代码片段和机器学习资源。如果你和我一样,对机器学习/数据科学充满热情,请随时 在 LinkedIn 上添加我 或 在 Twitter 上关注我。
简历:Tirthajyoti Sarkar 是一位半导体技术专家、机器学习/数据科学狂热者、电子工程博士、博主和作家。
原文。经许可转载。
相关内容:
-
IT 工程师需要学习多少数学才能进入数据科学?
-
数据科学的基础数学:‘为什么’和‘如何’
-
15 分钟指南:选择有效的机器学习和数据科学课程
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关话题
-
数据访问在大多数公司中严重不足,71%的人认为…
on 中的机器学习**](https://scikit-learn.org/stable/)
这里是快速概述,
回归问题生成:Scikit-learn 的**dataset.make_regression**函数可以创建具有任意输入特征数量、输出目标和可控信息耦合度的随机回归问题。它还可以混合高斯噪声。
图:使用 scikit-learn 生成的随机回归问题,噪声程度不同。
分类问题生成:类似于上面的回归函数,**dataset.make_classification**生成一个具有可控类别分离度和添加噪声的随机多类别分类问题(数据集)。如果需要,你还可以随机翻转任何百分比的输出标记,以创建一个更难的分类数据集。
图:使用 scikit-learn 生成随机分类问题,具有不同的类别分离。
聚类问题生成:有很多函数可以生成有趣的簇。最直接的一个是 datasets.make_blobs,它生成任意数量的簇,并且可以控制距离参数。
图:使用 scikit-learn 生成简单的簇数据。
各向异性簇生成:通过简单的矩阵乘法变换,你可以生成沿某些轴对齐或各向异性分布的簇。
图:使用 scikit-learn 生成各向异性对齐的簇数据。
同心环簇数据生成:为了测试基于亲和力的聚类算法或高斯混合模型,生成特定形状的簇非常有用。我们可以使用 **datasets.make_circles** 函数来实现。
当然,我们还可以在数据中加入一些噪声,以测试聚类算法的鲁棒性。
月牙形簇数据生成:我们还可以生成月牙形簇数据来测试算法,使用 **datasets.make_moons** 函数可以控制噪声。
更多相关主题
如何使用合成数据来克服数据短缺,以进行机器学习模型训练

图片由 geralt 在 Pixabay 提供
人工智能的本质在于数据。如果我们没有足够的数据,就无法训练模型完成我们想要的任务,我们昂贵且强大的硬件将变得无用。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 部门
但是,获取相关、准确、合法和可靠的数据并非易事。这是因为 数据收集过程 往往和实际设置机器学习模型一样复杂且耗时。
此外,收集、记录和清理数据也需要时间和相当的资源,然后才能使用。但有一种方法可以解决这个挑战——使用合成数据。
什么是合成数据?
与实际数据不同,合成数据不是从真实世界事件中收集的,而是人工生成的。这些数据被制作得类似于真实的数据集。你可以 使用这些合成数据 来检测内在模式、隐藏的交互和变量之间的关联。
你需要做的只是设计一个可以理解真实数据行为、外观和交互的机器学习模型。然后,这个模型可以被查询,从而生成数百万个额外的合成记录,这些记录的行为、外观和感觉都像真实数据一样。
现在,合成数据并没有什么神奇的地方,但如果你想创建高质量的合成数据,你需要遵循一些基本原则。例如,你的合成数据将基于用于生成它的实际数据。因此,如果你使用的是低质量的数据点,你不能指望它能提供高质量的合成数据集。
要期望高质量的数据输出,你需要高质量的数据作为输入。此外,这些数据还应该充足,以便你有足够的输入来用一流的合成数据点扩展现有数据集。
数据短缺的原因
要了解合成数据如何帮助你克服数据短缺,你需要首先理解数据短缺的原因。这是数据面临的两个最大问题之一。
首先,现有的数据可能不足以满足 AI/ML 模型的需求。由于数据隐私法律,企业需要获得明确的许可才能使用敏感的客户数据。而且,找到足够多愿意将数据提供用于研究目的的用户、客户或员工可能会很有挑战。
此外,机器学习模型不能与过时的数据集成。原因在于它们需要新的趋势,或者必须能够响应新的流程、技术或产品特性。因此,历史数据几乎没有用处,限制了数据的收集。
此外,由于数据本身的性质,样本量通常较小。例如,在一个测量股票价格敏感性的模型中,你可能每月仅获得一次客户价格指数的数据。即使你查找历史数据,你也仅会获得 50 年 CPI 历史中的 600 条记录——显然是一个非常小的数据集。
在某些情况下,标记数据的工作可能不具成本效益或不够及时。例如,为了预测客户满意度和衡量客户情感,机器学习模型需要手动检查大量的短信、电子邮件和服务电话,但这需要花费大量时间,而你可能没有这么多时间。
然而,借助合成数据,机器学习可以轻松地标记数据而没有任何问题。
合成数据为何有用?
假设你有一个数据集,其中某些变量的信息非常少,导致预测困难。你还受到限制,无法获取更多这种边缘类别的数据。在这种情况下,合成数据可以提供帮助。它将允许你合成更多边缘类别的数据点,平衡你的模型,从而提高性能。
想象一个任务,涉及预测一块水果是橙子还是苹果,仅通过理解这两种水果的特征,比如它们的形状、颜色、季节性等。假设你有 500 个橙子的样本和 3000 个苹果的样本。因此,当机器学习模型尝试分析数据时,由于类别不平衡,算法预期会自动偏向苹果。因此,模型将不准确,表现也会令人不满意。
你唯一可以解决这种不平衡的方法是使用合成数据。生成 2500 个更多的橙子样本,以便为模型提供足够的数据,使其不会对这两种水果有偏见。现在预测将更准确。同样,你也可以有效地利用这个模型来管理你的在线声誉,因为你可以从好评中筛选出差评。
同样,在选择合适的机器学习算法时要小心,以确保模型能够准确工作。
假设你有一个数据集你想分享。问题在于它包含了敏感数据,如个人身份信息(PII)、社会安全号码、全名、银行账户号码等。由于隐私至关重要,这些数据必须小心保护。现在,假设你希望分析这些数据或构建一个模型。但由于涉及 PII,你不能在没有法律团队介入、仅使用非个人身份信息、匿名化数据、实施安全的数据传输流程等措施的情况下将数据分享给第三方。
因此,可能会有几个月的延迟,因为你无法立即分享数据。在这种情况下,合成样本可能会再次派上用场。你可以从真实数据集中获取这些样本。
这些合成数据可以毫无问题地与第三方分享。此外,你不会面临数据隐私被侵犯和个人信息泄露的风险。它对于提供HIPAA 数据库托管和数据存储的服务尤其有用。
合成数据的新进展
合成数据可以填补数据中的空白,使其完整,从而帮助你生成大量安全的数据。生成的数据有助于企业保持合规并维护数据平衡。此外,随着技术的最新创新,你可以生成更高准确度的数据。这使得合成数据在提供机器学习模型所需的缺失数据方面变得更加宝贵。
合成数据也被成功用于提升图像质量。此外,生成对抗网络(GAN)模型提升了合成表格数据的精确度。
创建合成数据的另一个近期进展是 Wasserstein GAN 或 WGAN。评论神经网络试图找到生成样本中观察到的分布与用于训练的数据集中的数据分布之间的最小距离。然后,WGAN 训练生成器模型以生成更逼真的数据。为了预测生成图像的真实性概率,它保留了图像真实性的评分,而不是利用判别器。
与 GAN 不同,WGAN 不通过寻找两个对立模型之间的平衡来追求稳定性。相反,WGAN 寻找模型之间的交点。因此,它生成的合成数据具有更接近现实生活的特征。
总结
随着技术进步和创新,合成数据变得越来越丰富、多样,并且与真实数据紧密对接。因此,随着时间的推移,使用合成数据来克服数据短缺将变得更加可能,因为你可以更高效地生成和使用合成数据。合成数据还将有助于维护用户隐私,保持企业合规,同时提升机器学习模型的速度和智能。
Nahla Davies 是一位软件开发人员和技术写作者。在将工作全职投入技术写作之前,她还担任过 Inc. 5,000 体验品牌组织的首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼。
了解更多相关信息
合成数据平台:解锁生成性 AI 对结构化数据的力量

图像来源:GarryKillian 由 Freepik 提供
创建机器学习或深度学习模型变得如此简单。如今,有多种工具和平台可用于自动化整个模型创建过程,甚至帮助你选择适合特定数据集的最佳模型。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
解决问题所需的关键是一个数据集,该数据集包含描述你尝试解决的问题的所有必需属性。因此,假设我们正在查看描述糖尿病患者病史的数据集。数据集中会有一些列是重要属性,比如年龄、性别、血糖水平等,这些属性在预测一个人是否患有糖尿病时扮演重要角色。为了构建糖尿病预测模型,我们可以找到多个公开的数据集。然而,当数据不可用或高度不平衡时,我们可能会面临困难。
什么是合成数据?
深度学习算法生成的合成数据通常在原始数据受隐私合规限制或需要增强以适应特定用途时用作替代。合成数据通过重新创建统计属性来模拟真实数据。一旦在真实数据上进行训练,合成数据生成器就可以生成任何数量的数据,这些数据与真实数据的模式、分布和依赖关系非常相似。这不仅有助于生成类似数据,还可以引入一些对数据的约束,如新的分布。让我们探索一些合成数据可以发挥重要作用的用例。
-
生成机密数据: 银行、保险、医疗甚至电信中的数据可能极其敏感。接触这些数据通常需要为每个项目获得特殊权限。合成数据生成可以解锁这些数据资产,并用于创建特征、理解用户行为、测试模型和探索新想法。
-
重新平衡数据: 高度不平衡的数据可以通过合成数据生成器有效且轻松地重新平衡。这比简单的过采样方法效果更好,并且在高不平衡情况下,如欺诈模式,它可以优于更复杂的方法,如 SMOTE。
-
填补缺失的数据点: 在处理数据时,空值是一个令人烦恼的问题。用有意义的合成数据点填补这些空白可以使样本阅读成为一个更有信息量的过程。
合成数据是如何生成的?
生成式 AI 模型在合成数据生产中至关重要,因为它们是专门在原始数据集上训练的,可以复制其特征和统计属性。生成式 AI 模型,如生成对抗网络(GANs)或变分自编码器(VAEs),理解底层数据并生成逼真且具有代表性的合成实例。
目前有许多开源和闭源的合成数据生成器,有些比其他的更好。在评估合成数据生成器的性能时,重要的是要关注两个方面:准确性和隐私。准确性需要高,但合成数据不应过度拟合原始数据,原始数据中的极端值需要以不危害数据主体隐私的方式处理。一些合成数据生成器提供自动化的隐私和准确性检查 - 先从这些开始是个好主意。MOSTLY AI 的合成数据生成器提供了免费的这一服务 - 任何人只需用电子邮件地址就可以注册一个账户。
合成数据的好处
合成数据按定义不是个人数据。因此,它免于 GDPR 和类似的隐私法律,使数据科学家能够自由探索数据集的合成版本。合成数据也是匿名化行为数据而不破坏模式和相关性的最佳工具之一。这两种特性使它在使用个人数据的所有情况下特别有用 - 从简单的分析到训练复杂的机器学习模型。
然而,隐私并不是唯一的应用场景。合成数据生成还可以用于以下用途:
-
数据增强:这有助于通过多样化训练数据来改善模型性能。
-
数据填补:用有意义的合成数据填补缺失的数据点。
-
数据共享:即使在组织墙外也安全共享。考虑研究合作或用逼真的数据演示产品。
-
重新平衡:解决类别不平衡的问题。
-
下采样:创建原始数据集的较小版本,这些版本在外观和含义上与原始数据相同。对于初步数据探索、降低计算成本和时间非常有用。
最受欢迎的合成数据生成工具
为了生成合成数据,我们可以使用市场上提供的不同工具。让我们来探讨一些这些工具并了解它们的工作原理。
-
MOSTLY AI: MOSTLY AI是结构化合成数据创建的先驱领导者。它使任何人都能生成高质量、类似生产的数据,用于分析、AI/ML 开发和数据探索。数据团队可以利用它生成、修改和共享数据集,从而克服使用真实、匿名或虚拟数据的伦理和实际挑战。
-
SDV: 最受欢迎的[开源 Python 库](https://pypi.org/project/sdv/#:~:text=The Synthetic Data Vault (SDV,emulate them in synthetic data.),用于合成数据生成。虽然不是最复杂的工具,但对于高精度要求不高的简单使用场景,它能够完成任务。
-
YData: 如果你想在 Azure 或 AWS 市场尝试合成数据生成,YData 的生成器在这两个平台上均可用,提供一种符合 GDPR 的方式来生成用于 AI 和机器学习模型的数据。
关于合成数据工具和公司的综合列表,这里有一个精选的合成数据类型列表。
现在我们已经讨论了使用上述工具和库进行合成数据生成的优缺点,接下来让我们看看如何使用 Mostly AI,这是市场上最好的工具之一,并且易于使用。
MOSTLY AI是一个合成数据创建平台,帮助企业生成高质量、隐私保护的合成数据,用于机器学习、高级分析、软件测试和数据共享等多种应用场景。它使用专有的人工智能驱动算法生成合成数据,该算法学习原始数据的统计特征,如相关性、分布和属性。这使得MOSTLY AI能够生成在统计上代表实际数据的合成数据,同时保护数据主体的隐私。
它的合成数据不仅是私密的,而且使用简单,可以在几分钟内生成。该平台拥有一个易于使用的界面,采用生成性 AI 技术,允许组织输入现有数据,选择适当的输出格式,并在几秒钟内生成合成数据。它的合成数据是一个对组织非常有用的工具,能够在保护数据隐私的同时用于多种目的。该技术易于使用,并能迅速创建高质量、统计上具有代表性的合成数据。
MOSTLY AI 提供的合成数据有多种格式,包括 CSV、JSON 和 XML。它可以与多个软件程序一起使用,包括 SAS、R 和 Python。此外,MOSTLY AI 提供了一些工具和服务,如数据生成器、数据探索器和数据共享平台,以帮助组织使用合成数据。
让我们探索如何使用 MOSTLY AI 平台。我们可以通过访问下面的链接并创建一个账户来开始。
MOSTLY AI:合成数据生成与知识中心 - MOSTLY AI
一旦创建了账户,我们可以看到主页,在那里我们可以选择与数据生成相关的不同选项。
如上图所示,在主页上,我们可以上传原始数据集以生成合成数据,或者为了尝试,我们可以使用示例数据。我们可以根据需要上传数据。
如上图所示,一旦我们上传数据,我们可以根据需要对生成的列进行更改,并设置与数据、训练和输出相关的不同设置。
一旦根据需求设置好所有这些属性,我们需要点击“启动作业”按钮来生成数据,它将实时生成。在 MOSTLY AI 上,我们每天可以免费生成 10 万行数据。
这就是如何使用 MOSTLY AI 按需设置数据属性并实时生成合成数据。根据你要解决的问题,可能会有多种使用场景。试试这个平台,看看它有多有用,在回应部分告诉我们你的看法。
Himanshu Sharma 是产品领导学院应用数据科学的研究生。他是一位自我驱动的专业人士,拥有 Python 编程语言/数据分析的经验。希望在数据科学领域取得成就。产品管理。作为活跃的博客作者,他在数据科学技术内容写作方面拥有专业知识,并被 Medium 评为 AI 领域的顶级作家。
更多相关主题
使用 Python 创建具有异常特征的合成时间序列
原文:
www.kdnuggets.com/2021/10/synthetic-time-series-anomaly-signatures-python.html
comments
图片来源:作者使用 Pixabay (免费使用)制作
为什么选择合成时间序列?
正如我在我的高引用文章中写的,“合成数据集是通过程序生成的数据仓库。因此,它不是通过任何现实调查或实验收集的。其主要目的是足够灵活和丰富,以帮助机器学习实践者进行各种分类、回归和聚类算法的有趣实验。”
合成时间序列也不例外——它帮助数据科学家尝试各种算法方法,并为真实部署做好准备,这些是仅靠真实数据集无法实现的。
工业环境中的时间序列数据
现代工业环境中,时间序列分析有多种丰富的应用,其中一系列传感器从机器、工厂、操作员和业务流程中产生源源不断的数字数据。
压力。温度。电动组件的振动和加速度。质量检查数据。操作员行动日志。
数据不断涌入。这是工业 4.0或智能工厂时代的新常态。虽然结构化和半结构化数据在上升,但仍有大量时间序列(或类似时间序列)数据来自现代工厂中嵌入的各种测量点。
工厂 2030——智能工厂的“成年礼”——计量与质量新闻——在线…

图片来源: Pixabay (免费使用)
异常检测至关重要
大多数时候,它们是“正常的”、“在范围内的”、“如预期的”。但偶尔也会出现异常。这时你需要特别关注。这些是正常数据流中的“异常”数据,需要被捕捉、分析和处理——几乎总是实时的。
在这些数据流中的异常检测是所有现代数据分析产品、服务和初创公司的核心。他们利用从经过验证的时间序列算法到最新的基于神经网络的序列模型的各种手段来检测这些异常特征,并根据业务逻辑创建警报或采取行动。
在现代工业环境中,时间序列分析有着丰富的应用,其中大量传感器不断产生数字数据流……
合成数据生成是一种强大的辅助工具
关于这些工业数据流,有几个点值得重复,以理解为什么合成时间序列生成可能会变得非常有用。
-
现实生活中的异常很少见,需要监控和处理大量数据才能检测到各种有趣的异常。这对希望在短时间内测试和重测多种算法的数据科学家来说并不是好消息。
-
异常的发生是如此不可预测,以至于它们的模式很少能被捕捉到任何完善的统计分布中。快速尝试多种异常类型对于生成一个稳健且可靠的异常检测系统至关重要。在缺乏常规、可信的异常数据来源的情况下,合成方法提供了实现某种受控实验的唯一希望。
-
许多工业传感器生成的数据被认为是高度保密的,不能超出本地私有云或现有边缘分析系统。为了在不妨碍数据安全的情况下重现异常特征,合成方法是一个明显的选择。
这些是正常数据流中的‘异常’,需要被捕捉、分析并采取行动——几乎总是需要实时处理。
在本文中,我们展示了一种简单而直观的方法,来在模仿工业过程的一维合成时间序列数据中创建几种常见的异常特征。我们将使用大家都喜欢的 Python 语言来实现这一点。
注意:这不是一篇关于异常检测算法的文章。我只讨论与合成异常注入时间序列数据(集中于特定应用领域)相关的想法和方法。
带有异常的合成时间序列
这里是Jupyter notebook,这里是包含主类对象的 Python 模块,供你使用。
工业过程的概念和‘单元过程时间’
图像来源:作者创作
上面我们展示了一个典型工业过程和一个‘单位过程时间’的示意图。假设一些原材料(图中的过程 I/P)进入一台复杂的机器,而成品(图中的过程 O/P)从另一端出来。
我们不需要知道机器内部究竟发生了什么,只需知道它在规律的时间间隔内生成一些数据,即我们可以以时间序列的方式测量过程状态(也许使用一些传感器)。我们想查看这个数据流并检测异常。
因此,为了定义我们的合成时间序列模块,我们至少需要以下内容,
-
过程开始时间
-
过程结束时间
-
单位过程时间(我们接收数据的间隔)
因此,这就是基本的SyntheticTS类的定义开始,

‘正常’过程
为了生成异常,我们需要一个基准正常状态。我们可以字面上使用“正态分布”来实现。你可以根据具体的过程类型和情况随时更改,但绝大多数工业过程在其传感器测量方面确实遵循正态分布。

假设我们有一个工业过程/机器从 2021 年 5 月 1 日启动,并运行到 2021 年 5 月 6 日(一个典型的 6 天周期,通常在每周维护之前)。单位过程时间为 15 分钟。我们选择了过程的均值为 100,标准差为 5。
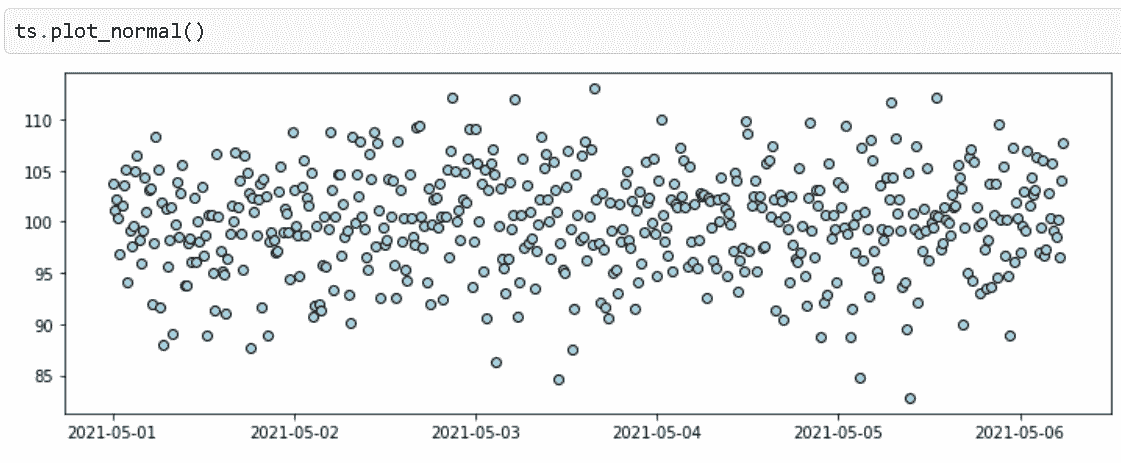
基本的‘异常化’方法
作为一种合成数据生成方法,你需要控制异常的以下特征,
-
需要异常的数据比例
-
异常的尺度(它们距离正常值的远近)
-
单侧或双侧(高于或低于正常数据的幅度)
我们不关心确切的代码,而是展示一些关键结果。
单侧异常
这是一个例子,
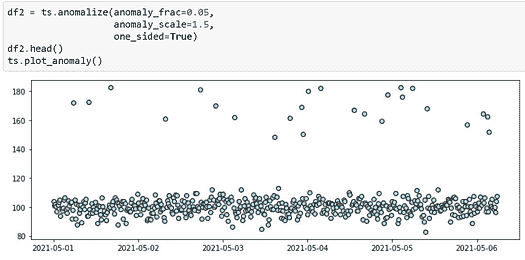
变化的异常尺度
我们可以通过简单地改变anomaly_scale参数,将异常放置在不同的距离上。

这是生成的图示。注意图示的纵轴刻度是如何随着异常的增大而变化的。
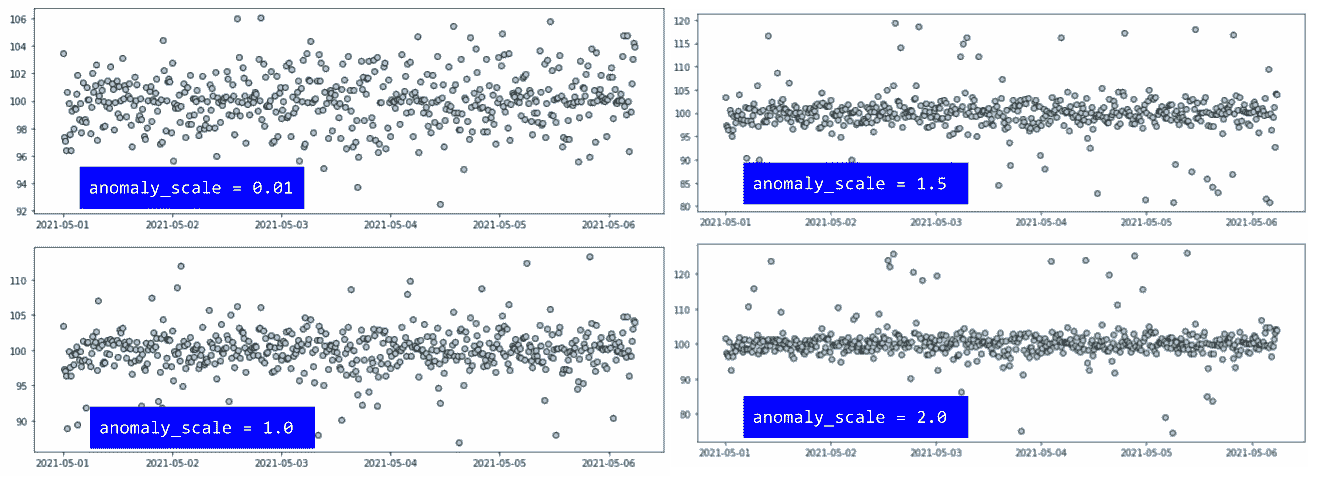
异常比例的变化
接下来,我们改变异常的比例(保持尺度为 2.0 不变)。
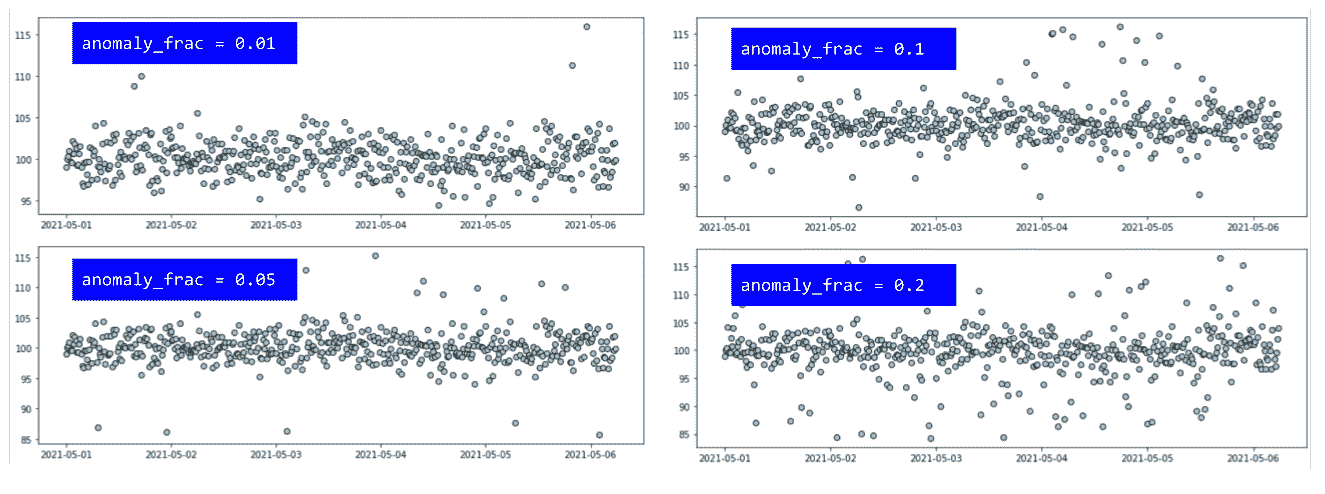
引入‘正向偏移’
这是工业过程中相当常见的情况,过程中由于机器设置或其他原因的突然变化,导致出现明显的偏移。有时这是计划好的,有时则是无意的。根据情况,异常检测算法可能需要不同地分析和处理。无论如何,我们需要一种方法在合成数据中引入这种偏移。
在这种情况下,我们选择了数据的 10%偏移,即均值为pct_drift_mean=10参数。请注意,如果我们不在方法中指定参数time_drift,则代码会自动在整个过程的开始和结束时间的中点引入漂移。
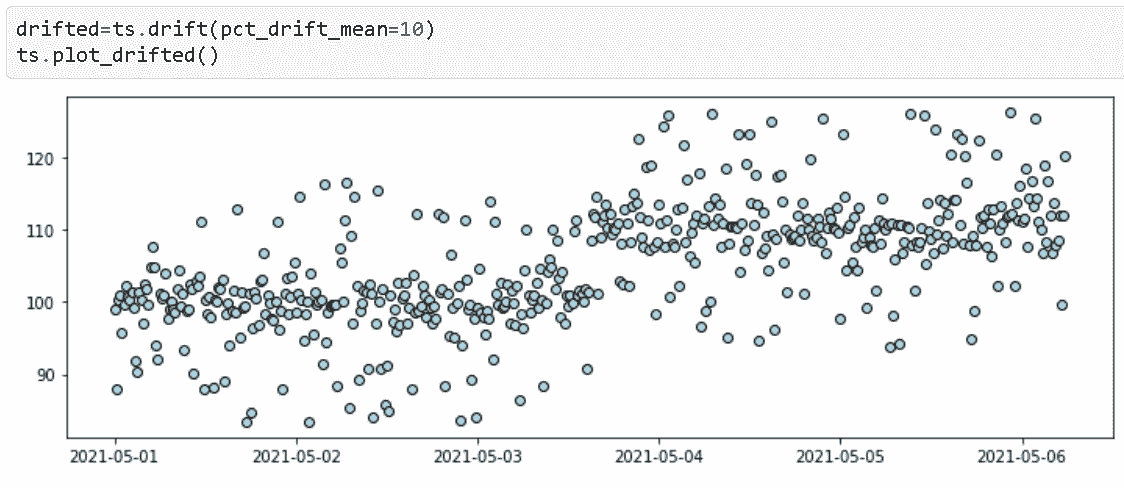
在特定位置的负偏移
在以下示例中,我们展示了一个情况,
-
数据在负方向上漂移
-
数据的扩展(方差)以及均值发生了变化
-
偏移从特定位置开始,用户可以选择该位置
这是一个更现实的情况。
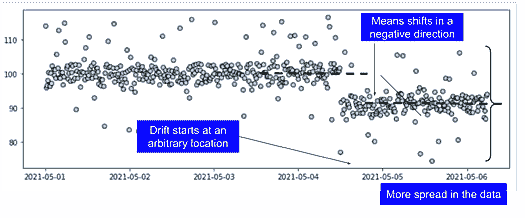
分块异常
在许多情况下,异常以块状出现并消失。我们也可以合成这种情况。请注意,这里我们创建了“左右侧异常”,但与所有其他选项类似,我们也可以创建“单侧”变异。
目前,代码创建的分块异常均匀分布在整个时间段内。但在下一次代码更新中,这可以通过单独的时间点和分块的异常特征进行自定义。
总结
我们展示了一种简单直观的方法来创建具有各种异常签名的一维合成时间序列数据,这些异常在工业使用案例中很常见。这种合成数据生成技术对算法迭代和模型测试非常有用。
保持简单
为了聚焦于工业使用案例,我们没有在基线数据生成中添加传统的时间序列模式(例如季节性、上升/下降趋势),并保持极其简单作为高斯过程。数据中也没有自回归特性。尽管像 ARIMA 这样的算法在金融和商业数据分析中非常受欢迎且有用,但工业环境中生成的独立传感器数据通常是正态分布的,我们遵循这一原则。
进一步改进
你可以在此基础上进行许多扩展并添加额外功能。以下是一些可能的功能:
-
将各种统计分布的选择作为基线数据生成过程
-
任意位置和特征的分块异常
-
多个合成数据类/对象的组合方法
-
更好的可视化方法
再次提示,Jupyter notebook 示例在此。请随意 fork 和实验。
您可以查看作者的 GitHub** 代码库 **,获取机器学习和数据科学中的代码、想法和资源。如果您像我一样对 AI/机器学习/数据科学充满热情,请随时 在 LinkedIn 上添加我 或 在 Twitter 上关注我。
简介: Tirthajyoti Sarkar 是 Adapdix Corp. 的数据科学/机器学习经理。他定期为 KDnuggets 和 TDS 等出版物贡献有关数据科学和机器学习的多种主题。他编著了数据科学书籍并参与开源软件的贡献。Tirthajyoti 拥有电子工程博士学位,并正在攻读计算数据分析的硕士学位。可以通过 tirthajyoti at gmail[dot]com 联系他。
相关内容:
-
使用合成数据教 AI 分类时间序列模式
-
3 种数据采集、注释和增强工具
-
使用 Gretel 和 Apache Airflow 构建合成数据管道
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
更多相关话题
TabPy:结合 Python 和 Tableau
原文:
www.kdnuggets.com/2020/11/tabpy-combining-python-tableau.html
评论
由 Bima Putra Pratama, 数据科学家
图片来源:Paweł Czerwiński 在 Unsplash
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT
我们可以将 Python 计算的强大功能与 Tableau 集成吗?
那个问题促使我开始探索在 Tableau 中使用 Python 计算的可能性,最终我选择了 TabPy。
那么,什么是 TabPy?我们如何使用 TabPy 将 Python 和 Tableau 集成?
在本文中,我将介绍 TabPy,并通过一个例子说明如何使用它。
TabPy 介绍
TabPy 是 Tableau 的一个分析扩展,它使用户能够使用 Tableau 执行 Python 脚本和保存的函数。使用 TabPy,Tableau 可以实时运行 Python 脚本并将结果显示为可视化。用户可以通过在 Tableau 工作表、仪表板或故事中使用参数与 TabPy 交互,从而控制发送给 TabPy 的数据。
你可以在官方 GitHub 仓库中阅读更多关于 TabPy 的信息:
实时执行 Python 代码并在 Tableau 可视化中显示结果: — tableau/TabPy
安装 TabPy
我假设你的系统中已经安装了 Python。如果没有,你可以先访问 www.python.org/ 下载 Python 安装程序,然后安装到系统中。
接下来,我们可以使用 pip 安装 TabPy 作为一个 Python 包:
pip install tabpy
运行 TabPy
安装成功后,我们可以使用以下命令运行服务:
tabpy
如果一切顺利,你应该看到这个:
运行 TabPy。图片来源:作者
默认情况下,该服务将在本地主机的 9004 端口运行。你也可以通过在网页浏览器中打开它来验证。
TabPy 服务器信息。图片来源:作者
启用 TabPy
现在,让我们进入 Tableau 并设置服务。我使用的是 Tableau Desktop 版本 2020.3.0。以前的版本也没有区别。
首先,转到帮助,然后选择设置和性能,并选择管理分析扩展连接。
Analytics Extension Connection Location. 图片由作者提供
然后,您可以设置服务器和端口。您可以将用户名和密码留空,因为我们没有在 TabPy 服务中设置凭据。
完成后,点击测试连接。如果成功,您将看到以下消息:
恭喜!!现在,我们的 Tableau 已经连接到 TabPy 并准备使用。
使用 TabPy
我们可以使用两种方式来进行 Python 计算:
-
直接将代码写成 Tableau 计算字段。代码将立即在 TabPy 服务器上执行。
-
将一个函数部署到 TabPy 服务器,使其可以作为 REST API 端点访问。
在本文中,我将仅展示如何做第一种方法,我们将直接编写代码作为 Tableau 计算字段。
例如,我们将对通过 Tableau 网站公开的 Airbnb 数据集进行聚类,您可以通过这个 链接下载它。我们将使用几种流行的聚类算法基于住房特征对每个邮政编码进行聚类。
步骤 1 导入数据
在第一步中,让我们将数据集导入 Tableau。该数据集有 13 列。
由于我们的主要目标是查看如何使用 TabPy,我们不会专注于制作最佳模型。因此,我们将只使用数据集中的以下变量进行聚类:
-
每个邮政编码的床位中位数
-
每个邮政编码的平均价格
-
每个邮政编码的评级中位数
步骤 2 创建控制参数
我们需要创建两个参数,用于选择我们的聚类方法和聚类数,分别是:
-
聚类数量
-
聚类算法
创建一个参数。图片由作者提供!图示
聚类数量参数。图片由作者提供!图示
聚类算法参数。图片由作者提供
步骤 3 创建脚本
我们将创建一个 Python 脚本作为 Tableau 中的计算字段。
创建一个计算字段。图片由作者提供
然后,您可以在计算字段中插入以下脚本。
这段代码被包装在 Tableau 的 SCRIPT_REAL() 函数中,将执行以下操作:
-
导入所需的 Python 库。
-
使用标准缩放器缩放特征
-
结合缩放特征和处理空值
-
条件检查使用哪种算法并执行以下操作
-
返回聚类结果列表。
然后,我们将结果转换为字符串数据类型,以便将其作为分类数据。
还有一点需要注意的是,我们需要在 Zipcode 中进行表计算。因此,我们需要将默认的表计算更改为 Zipcode,以使此代码生效。
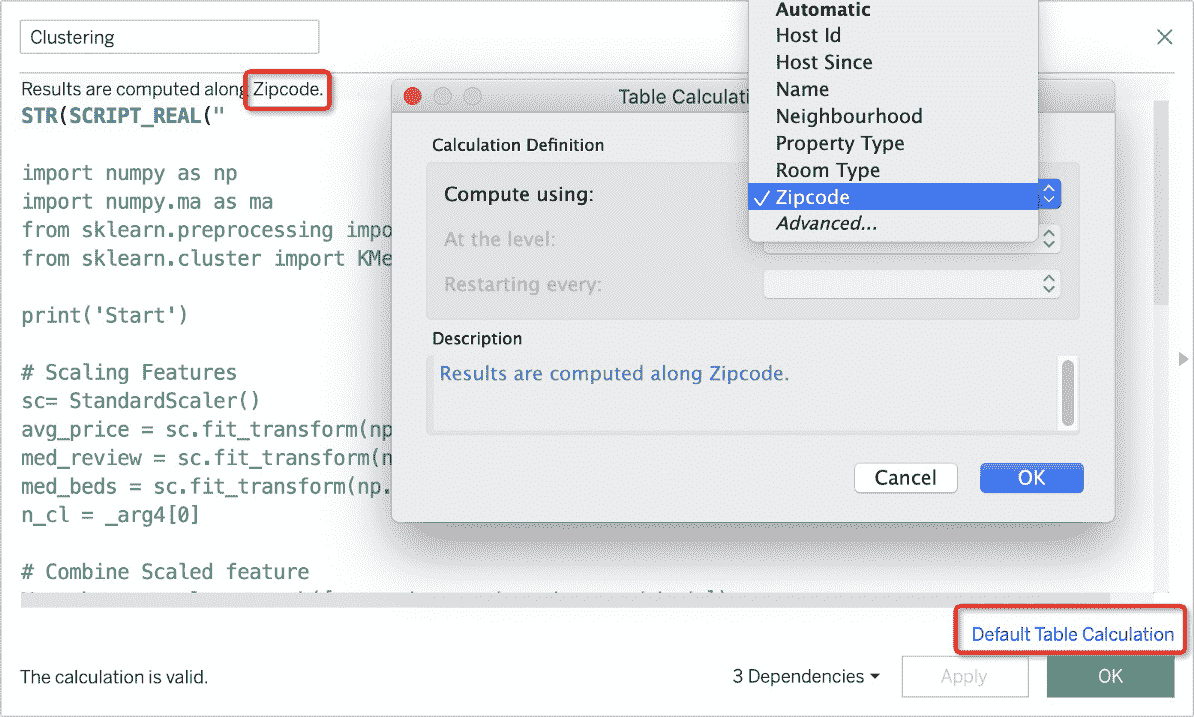
更改默认表计算。图像由作者提供。
第 4 步 可视化结果
现在,是时候可视化结果了。我使用 Zipcode 创建了一个地图来可视化聚类结果。我们可以使用参数来改变聚类的数量。

总结

图片由Elisha Terada在Unsplash提供
让我们为这一阶段的完成而庆祝吧!如果你按照步骤操作,你已经成功地将 Python 与 Tableau 集成。这一集成是使用 Tableau 和 Python 的更高级用例的起点。
我期待看到你用这个集成创建的东西!
作者介绍
Bima Putra Pratama 是一名拥有 Tableau Desktop Specialist 认证的数据科学家,他总是渴望扩展自己的知识和技能。他毕业于矿业工程专业,并通过 HardvardX、IBM、Udacity 等多个在线项目开始了他的数据科学之旅。目前,他正与 DANA Indonesia 一起为印尼建设无现金社会做出贡献。
如果你有任何反馈或讨论的话题,请通过LinkedIn联系 Bima。我很高兴与您建立联系!
参考文献
-
www.tableau.com/about/blog/2017/1/building-advanced-analytics-applications-tabpy-64916 -
www.tableau.com/about/blog/2016/11/leverage-power-python-tableau-tabpy-62077 -
towardsdatascience.com/tableau-python-tabpy-and-geographical-clustering-219b0583ded3
原始文章。经许可转载。
相关:
-
在 Tableau 中创建强大的动画可视化
-
比较顶级商业智能工具:Power BI vs Tableau vs Qlik vs Domo
-
使用 R、SQL 和 Tableau 进行地理时间序列预测简介
相关主题
如何将表格数据与 HuggingFace Transformers 结合使用
原文:
www.kdnuggets.com/2020/11/tabular-data-huggingface-transformers.html
评论
由 Ken Gu,乔治亚应用研究科学家实习生。
基于变换器的模型在使用非结构化文本数据时是一个颠覆性的变化。截至 2020 年 9 月,通用语言理解评估(GLUE)基准中的顶级模型都是 BERT 变换器模型。在 Georgian ,我们发现自己在处理支持表格特征信息和非结构化文本数据。我们发现,通过在 我们的模型 中使用表格数据,可以进一步提高性能,因此我们着手构建一个工具包,使其他人也能轻松做到这一点。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你在 IT 领域的组织
GLUE 基准中的 9 项任务。
基于变换器的构建
使用变换器的主要好处是它们可以学习文本之间的长期依赖关系,并且可以并行训练(与序列到序列模型相比),这意味着它们可以在大量数据上进行预训练。
鉴于这些优势,BERT 现在成为许多实际应用中的主流模型。同样,借助如 HuggingFace Transformers 等库,构建高性能的变换器模型来解决常见的 NLP 问题变得容易。
使用非结构化文本数据的变换器模型已经被很好地理解。然而,在实际应用中,文本数据通常会得到丰富的结构化数据或其他非结构化数据(如音频或视觉信息)的支持。每一种数据类型可能会提供单独的数据所没有的信号。我们称这些不同的数据体验方式——音频、视觉或文本——为模态。
以电子商务评论为例。除了评论文本本身,我们还有有关卖家、买家和产品的数值和分类特征信息。
我们开始探索如何将文本和表格数据结合使用,以便在我们的项目中提供更强的信号。我们从探索被称为多模态学习的领域开始,它专注于如何在机器学习中处理不同的模态。
多模态文献综述
当前的多模态学习模型主要集中在从感觉模态如音频、视觉和文本中学习。
在多模态学习中,有几个研究分支。卡内基梅隆大学的 MultiComp 实验室提供了一个很好的 分类法。我们的问题属于 **多模态融合 — ** 将来自两个或多个模态的信息结合起来进行预测。
由于文本数据是我们的主要模态,我们的综述重点关注将文本作为主要模态并引入利用 transformer 架构的模型的文献。
结构化数据的简单解决方案
在深入文献之前,值得提及的是,有一种简单的解决方案可以将结构化数据视为普通文本,并将其附加到标准文本输入中。以电子商务评论为例,输入可以按以下方式结构化:评论。买家信息。卖家信息。数字/标签。等等。然而,这种方法的一个警告是,它受限于 transformer 可以处理的最大令牌长度。
图像和文本上的 Transformer
在过去的几年里,图像和文本的 transformer 扩展取得了很大进展。用于分类图像和文本的监督多模态双向变换器 由 Kiela 等人(2019)提出,利用在单模态图像和文本上预训练的 ResNet 和 BERT 特征,并将其输入到双向 transformer 中。关键创新是将图像特征作为额外令牌适应到 transformer 模型中。
多模态 transformer 的示意图。该模型将 ResNet 对图像子区域的输出作为输入图像令牌。
此外,还有模型 — ViLBERT (Lu et al. 2019) 和 VLBert (Su et al. 2020) — 它们定义了图像和文本的预训练任务。两个模型都在 Conceptual Captions 数据集 上进行预训练,该数据集包含大约 330 万个图像-描述对(带有 alt 文本的网页图像)。在这两种情况下,对于任何给定的图像,像 Faster R-CNN 这样的预训练对象检测模型会获取图像区域的向量表示,这些表示作为输入令牌嵌入到 transformer 模型中。
VLBert 模型图示。它将 Faster R-CNN 输出的图像区域作为输入图像令牌。
例如,ViLBert 在以下训练目标上进行预训练:
-
掩蔽的多模态建模:掩蔽输入图像和词令牌。对于图像,模型尝试预测一个捕捉图像特征的向量用于对应的图像区域,而对于文本,它则基于文本和视觉线索预测被掩蔽的文本。
-
多模态对齐:图像和文本对是否实际上来自同一图像和说明对。
ViLBert 的两个预训练任务。

掩蔽的多模态学习示例。给定图像和文本,如果我们掩蔽掉dog,那么模型应该能够利用未掩蔽的视觉信息正确预测被掩蔽的词为dog。
所有这些模型都使用双向变换器模型,这也是 BERT 的基础。不同之处在于模型所训练的预训练任务以及对变换器的细微调整。在 ViLBERT 的情况下,作者还引入了一个共注意力变换器层(如下所示)来明确地定义模态之间的注意力机制。
标准变换器块与共注意力变换器块。共注意力块将另一模态(例如语言)的注意力加权向量注入当前模态(视觉)的隐藏表示中。
最后,还有LXMERT(Tan 和 Mohit 2019),另一个预训练的变换器模型,截至变换器版本 3.1.0,已作为库的一部分实现。LXMERT 的输入与 ViLBERT 和 VLBERT 相同。然而,LXMERT 在聚合数据集上进行预训练,其中还包括视觉问答数据集。总的来说,LXMERT 在 918 万对图像文本上进行预训练。
对齐音频、视觉和文本的变换器
除了用于结合图像和文本的变换器外,还有用于音频、视频和文本模态的多模态模型,其中存在自然的真实时间对齐。这种方法的论文包括 MulT,Multimodal Transformer for Unaligned Multimodal Language Sequences(Tsai 等人 2019),以及来自Integrating Multimodal Information in Large Pretrained Transformers(Rahman 等人 2020)的多模态适应门(MAG)。
MuIT 类似于 ViLBert,其中在模态对之间使用共注意力。与此同时,MAG 通过门控机制在某些变换器层中注入其他模态信息。
带有文本和知识图谱嵌入的变换器
一些研究还发现知识图谱除了文本数据外也是关键信息的一部分。用知识图谱嵌入增强 BERT 以进行文档分类(Ostendorff 等人,2019 年)除了使用书籍类别分类的元数据特征外,还使用了来自 Wikidata 知识图谱的作者实体特征。在这种情况下,模型是这些特征与 BERT 输出的书名和描述文本特征的简单拼接,最后通过一些分类层进行处理。
将知识图谱嵌入和表格元数据纳入简单模型架构。
另一方面,ERNIE(Zhang 等人,2019 年)将输入文本中的标记与知识图谱中的实体进行匹配。他们将这些嵌入融合以产生实体感知文本嵌入和文本感知实体嵌入。
关键要点
将变换器适应于多模态数据的主要要点是确保不同模态之间有注意力或加权机制。这些注意力机制可以出现在变换器架构的不同位置,如编码的输入嵌入、注入中间层,或在变换器编码文本数据后结合起来。
多模态变换器工具包
利用我们从文献综述和全面的HuggingFace最先进变换器库中学到的知识,我们开发了一个工具包。multimodal-transformers包扩展了任何 HuggingFace 变换器以处理表格数据。要查看代码、文档和工作示例,请查看项目仓库。
在高级层面,变换器模型对文本数据和包含分类及数值数据的表格特征的输出被组合在一个结合模块中。由于我们的数据没有对齐,我们选择在变换器输出后结合文本特征。结合模块实现了几种整合模态的方法,包括受文献综述启发的注意力和门控方法。有关这些方法的更多细节可在这里找到。
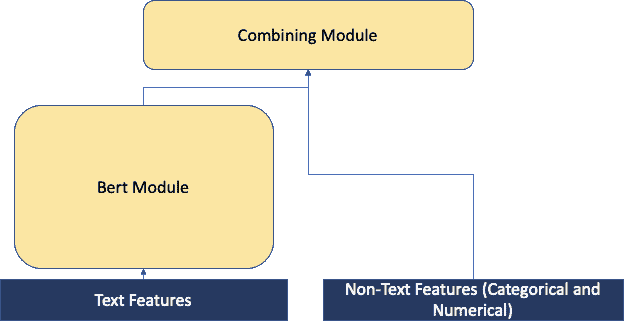
多模态变换器的高级图示。变换器的适配以纳入数据都包含在结合模块中。
演练
让我们通过一个例子来处理分类服装评论推荐。我们将使用在 Colab 笔记本中包含的简化版本。我们将使用来自 Kaggle 的女性电子商务服装评论,其中包含 23,000 条客户评论。
服装评论数据集的示例。
在这个数据集中,我们在标题和评论文本列中有文本数据。我们还从Clothing ID, Division Name, Department Name, 和 Class Name列中获得分类特征,并从Rating 和 Positive Feedback Count中获得数值特征。
加载数据集
我们首先将数据加载到TorchTabularTextDataset中,该数据集与 PyTorch 的数据加载器配合使用,包括 HuggingFace Transformers 的文本输入以及我们指定的分类特征列和数值特征列。为此,我们还需要加载 HuggingFace 的分词器。
使用表格模型加载 Transformer
现在我们将 Transformer 与表格模型加载在一起。首先,我们在TabularConfig对象中指定我们的表格配置。然后,将此配置设置为 HuggingFace transformer 配置对象的tabular_config成员变量。在这里,我们还指定了如何将表格特征与文本特征结合。在这个例子中,我们将使用加权求和的方法。
一旦我们设置了tabular_config,我们可以使用与 HuggingFace 相同的 API 加载模型。请参阅文档了解当前支持的包含表格组合模块的 Transformer 模型列表。
训练
对于训练,我们可以使用 HuggingFace 的trainer类。我们还需要指定训练参数,在这种情况下,我们将使用默认值。
让我们看看我们正在训练的模型吧!
上面实验的 Tensorboard 日志。你还可以在这个 Tensorboard 这里查看。
结果
使用这个工具包,我们还在Women’s E-Commerce Clothing Reviews数据集上进行推荐预测实验,并在Melbourne Airbnb Open Data数据集上进行价格预测实验。前者是分类任务,而后者是回归任务。我们的结果见下表。text_only结合方法是一个仅使用 Transformer 的基线,实质上与 HuggingFace 的forSequenceClassification模型相同。
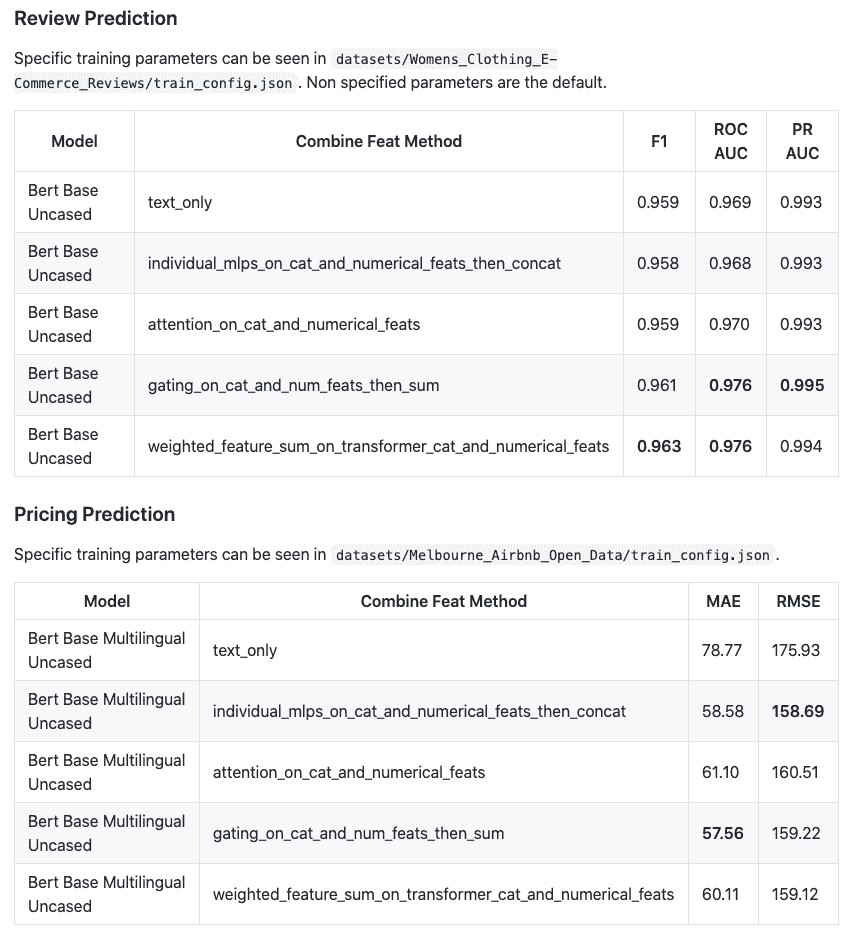
我们可以看到,加入表格特征比text_only方法提高了性能。性能提升取决于表格数据中的训练信号强度。例如,在评论推荐案例中,text_only模型已经是一个强大的基线。
下一步
我们已经在项目中成功使用了这个工具包。欢迎在下一个机器学习项目中尝试使用!
查看 文档 和包含的 主 脚本,了解如何进行评估和推理。如果你希望支持你喜欢的 Transformer,随时在 这里 添加 Transformer 支持。
附录
读者可以查看 图解 Transformer 和 图解 BERT 以获得对 Transformer 和 BERT 的精要概述。
以下是我们审阅的论文的简要分类。
图像与文本上的 Transformer
-
用于图像和文本分类的监督式多模态双向 Transformer(Kiela 等,2019 年)
-
ViLBERT: 预训练任务无关的视觉语言表示用于视觉与语言任务(Lu 等,2019 年)
-
VL-BERT: 通用视觉语言表示的预训练(Su 等,ICLR 2020 年)
-
LXMERT: 从 Transformers 学习跨模态编码器表示(Tan 等,EMNLP 2019 年)
对齐音频、视觉和文本的 Transformers
-
用于未对齐多模态语言序列的多模态 Transformer(Tsai 等,ACL 2019 年)
-
在大规模预训练 Transformers 中整合多模态信息(Rahman 等,ACL 2020 年)
带有知识图谱嵌入的 Transformers
-
用知识图谱嵌入增强 BERT 以进行文档分类(Ostendorff 等,2019 年)
-
ERNIE: 带有信息实体的增强语言表示(Zhang 等,2019 年)
原文。经许可转载。
简介: Ken Gu 是 Georgian 的应用研究实习生,他正在从事各种应用机器学习的工作。他在加州大学洛杉矶分校获得计算机科学学士学位和数学学位。在 UCLA,Ken 参与了以生物医学互动网络为重点的图深度学习研究项目。
相关:
更多主题
用自定义指令将 ChatGPT 调整为满足您的需求
原文:
www.kdnuggets.com/2023/08/tailor-chatgpt-fit-needs-custom-instructions.html

图片由 Matheus Bertelli 提供。许多人已经使用 ChatGPT 几个月了,取得了许多成功故事。凭借 来自 22 个国家的众多用户,OpenAI 一直致力于微调其模型,以理解不同的上下文并提供独特的用户响应。他们考虑了用户反馈,例如重新开始 ChatGPT 对话的能力,并在寻找解决方案。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
7 月 20 日,OpenAI 宣布他们正在引入带有自定义指令的新流程,以将 ChatGPT 调整为满足您的特定需求。
什么是自定义指令?
新的 beta 版自定义指令功能旨在帮助用户最大限度地利用 ChatGPT,通过防止他们在聊天会话之间重复常见指令。未来,ChatGPT 将在每次生成响应时考虑用户的自定义指令。用户不需要重复自己,也不需要在对话过程中不断调整他们的偏好。
ChatGPT 将根据过去的多个交互记住特定用户的偏好,并允许用户设置他们的个人偏好。设置偏好将提供特定的独特响应,而无需每次都重新开始对话。
让我们来看一个 OpenAI 提供的示例。
假设你是一名教师,并且正在尝试制定一份课程计划。你想根据以下问题来创建一份课程计划:“关于月球,有哪三件重要的事情需要教授?”。
如果不使用自定义指令,ChatGPT 将会回应:

来自OpenAI的截图,上述响应非常笼统,可能未能针对你的具体需求进行调整。现在,让我们看看自定义指令如何改善这一点。
ChatGPT 将在自定义指令部分向你提问如下:
-
你希望 ChatGPT 了解你什么,以提供更好的回应?
-
你希望 ChatGPT 如何回应?
这些问题将允许你指定你的偏好,从而使 ChatGPT 在响应时能够使用这些偏好。
如下图所示,ChatGPT 已经考虑到用户的偏好,并根据这些偏好调整了响应。

来自OpenAI的截图,是不是好得多了?那么,这一新功能的可用性和访问步骤是什么?
自定义指令的可用性
自定义指令目前在 ChatGPT Plus 会员中提供测试版,OpenAI 将在接下来的几周内将其扩展到所有用户。截至目前,自定义指令功能在英国和欧盟尚不可用。
在测试阶段,OpenAI 表示 ChatGPT 可能无法总是完美解释自定义指令。
自定义指令访问
如果你拥有 ChatGPT Plus,你可以通过网页和 iOS 访问自定义指令。
- 网页
点击你的名字,进入‘设置’。然后你将看到‘测试功能’,需要选择加入‘自定义指令’。完成后,自定义指令将出现在菜单中。
- iOS
在 ChatGPT 应用程序中,进入‘设置’。然后需要点击‘新功能’,并开启‘自定义指令’。完成后,自定义指令将出现在设置中。
总结一下
OpenAI 正在不断探索改进 ChatGPT 的新方法,通过倾听用户反馈来提升模型性能,用户的自定义指令可能会帮助 OpenAI 改进模型性能,不过,这可以通过数据控制禁用。
ChatGPT 似乎在不断改进。你还希望 ChatGPT 做些什么,请在下方评论中告诉我们!
妮莎·阿亚是一位数据科学家、自由技术写作人员以及 KDnuggets 的社区经理。她特别感兴趣于提供数据科学职业建议或教程以及数据科学相关的理论知识。她还希望探索人工智能如何在延长人类寿命方面发挥作用。她是一个热衷于学习的人,寻求扩展她的技术知识和写作技能,同时帮助指导他人。
关于此主题的更多信息
MLOps 中的复杂性管理
评论
由苏拉夫·戴,Manifold.ai 的 CTO。
将近两年前,我的同事亚历山大·吴分享了我们的想法,即为什么机器学习工程师(MLEs)的兴起意味着我们需要一种 DevOps 方法来处理机器学习(ML),以及为什么我们的团队创建了一个开源工具,以使其他从事 AI 和数据科学的团队的工作更加轻松。Orbyter 1.0(当时称为 Torus)的发布重点是通过简化创建一个完全配置的开箱即用的 Docker 化本地开发环境来简化 ML 管道,以支持数据科学项目。
对于刚刚发布的 2.0 版本,我们专注于减少偶然复杂性,同时继续添加使你的工作更轻松的功能。
实现最佳实践的即开即用
Orbyter 2.0 内置了偶然复杂性的减少。如果你还不熟悉软件中的固有复杂性与偶然复杂性的对立面,你可以阅读David Hayes 的精彩解释:
所有软件的复杂性可以准确地被视为属于固有复杂性和偶然复杂性这两种对立面之一。将你软件中的所有糟糕问题都拿出来,去掉那些因为难题而糟糕的部分,你剩下的就是那(小山还是大山,由你选择)的偶然复杂性……
数据科学和 AI 充满了难题,因此编写 ML 软件往往伴随着显著的固有复杂性。我们实际上无法在工具中解决这个问题;难题就是难。然而,我们可以通过对软件工程最佳实践进行规范,以减少偶然复杂性,例如:
例如,Orbyter 2.0 现在允许你使用内置的本地脚本自动将代码格式化为Python PEP 8标准。它还与GitHub Actions进行了即开即用的持续集成,因此当你将代码推送到 GitHub 时,它会自动进行 lint 检查并运行单元测试。一个 YAML 文件提供了一个单一的位置来配置强大的日志记录。此外,代码被构建成符合隔离输入/输出架构,以允许在数据管道中快速迭代。我们还定义了一些明确的端点——train、predict、evaluate——作为 Click 命令行脚本,可以作为 Docker 入口点调用。
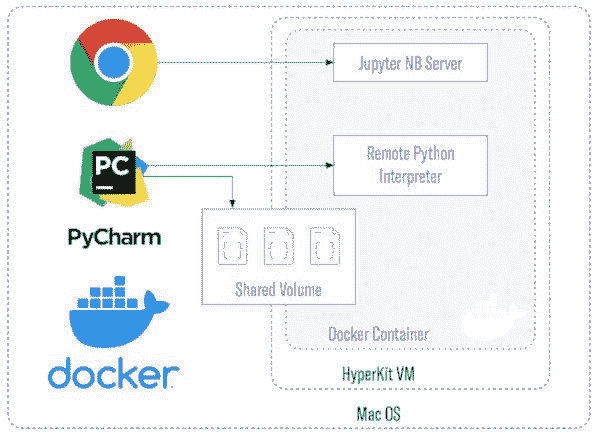
示例项目架构。
本质上,我们尽力将良好的软件工程纪律做得尽可能一键式。你未来的自己会感谢你。
跟踪你的实验
尽管许多组织现在拥有强大的数据科学团队进行重要的实验和建模研发,但这些公司往往仍然难以将这些工作的结果from the lab to the factory。没有人希望看到他们的辛勤工作在孤岛中消沉;兴奋在于看到你的模型在现实世界中产生影响。但要实现这种过渡需要大量的工程工作,许多组织仍然没有准备好进行生产部署。
为了解决这种脱节,我们添加了一个带有 MLflow 的新容器。Orbyter 1.0 提供了一个单一的容器,是流行的Cookiecutter Data Science的一个分支,适合轻松设置 Docker 化的工作流程。Orbyter 2.0 仍然是基本的 Docker 化数据科学,但现在当你启动它时,你会得到三个不同的容器:第一个提供 Jupyter,和以前一样;第二个提供 Bash,用于运行脚本;第三个提供MLflow,用于实验跟踪。
我们认为实验跟踪是应用机器学习中的一个重要部分,并且非常喜欢使用 MLflow 来完成这一步骤。它还可以帮助打包以实现可重复运行,并将模型发送到部署。
持续降低准入门槛
我们最初开始构建 Orbyter,是因为我们相信 Docker 和容器化是未来的发展方向。Alex 在他的初始帖子中解释得很好:
尽管通过小心使用虚拟环境和严格的系统级配置管理可以实现相同的一致性,但容器在新环境的启动/关闭时间和开发者生产力方面仍然提供了显著的优势。然而,我们从数据科学社区那里听到的反馈是:我知道 Docker 会让这变得更容易,但我没有时间或资源来设置和搞清楚这一切。
Orbyter 诞生的目的是降低进入 Docker 优先工作流的门槛。通过 Orbyter 2.0 的额外改进,转向 Docker 优先工作流变得比以往更简单。转向这种 Docker 化的工作流可以使用各种云工具—包括 SageMaker、Kubernetes、ECS 等。例如:
-
我们使用 AWS Batch 为一家制药客户构建了一个 AWS 大规模实验平台。由于在 Docker 容器中进行,我们快速完成了这项工作,并在 MLflow 中进行跟踪。我们会在夜间运行任务,早上可以查看结果。
-
我们为几位客户开发了复杂的 CI/CD 管道,在 Git 标签后自动生成生产 Docker 镜像,并将其放入 ECR 中,从而可以轻松投入生产。
现在 Orbyter 本身变得更加功能丰富,我们致力于保持入门过程的简单和直接。我们创建了一个演示仓库,展示了如何使用它—公开了我们在 Strata 数据大会上展示、经过路测和完善的演示。你可以在这里找到它。
请留意进一步的更新,因为我们正在继续构建 Orbyter 并优化开发过程。
相关:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
了解更多相关话题
独家:Tamr 在大数据管理的新前沿
原文:
www.kdnuggets.com/2014/05/tamr-new-frontier-big-data-curation.html
作者格雷戈里·皮亚特斯基,KDnuggets,2014 年 5 月 19 日,安迪·帕尔默、数据管理、机器学习、迈克尔·布罗迪、迈克尔·斯通布雷克、初创公司、Tamr数据正成为许多公司的最有价值资产,但研究表明,大多数组织仅使用他们收集的少量数据。随着数据量的指数增长,以及数据源的多样性和异质性增加,企业如何利用更多的数据?
 帮助来自新兴的热门领域——数据管理。与数据整合不同,数据整合采用自上而下的方法将不同的数据源整合到一个模型中(这对于大数据不可扩展),数据管理则采用自下而上的数据驱动方法。正如 Michael Brodie(Tamr 的顾问)在近期的 KDnuggets 采访中所说的那样,
帮助来自新兴的热门领域——数据管理。与数据整合不同,数据整合采用自上而下的方法将不同的数据源整合到一个模型中(这对于大数据不可扩展),数据管理则采用自下而上的数据驱动方法。正如 Michael Brodie(Tamr 的顾问)在近期的 KDnuggets 采访中所说的那样,
数据管理对于大数据就像数据整合对于小数据一样重要。
是一个令人兴奋的新创公司,旨在解决数据管理问题。它于 2012 年秋季由两位连续创业者共同创立,最初名为 Data Tamer——迈克尔·斯通布雷克(Michael Stonebraker),一位传奇数据库研究员,这是他创办的第九家公司,以及安迪·帕尔默,他曾参与创办和/或资助超过 50 家创新公司。凭借这样的创始人,该公司吸引了大量融资——超过 1600 万美元来自包括 Google Ventures 和 New Enterprise Associates (NEA)在内的投资者,并且获得了很多关注,包括一篇 KDnuggets 文章来自迈克尔·斯通布雷克的数据管理初创公司,仍在隐形模式中。
5 月 19 日,Data Tamer 已经脱离隐形模式,并更名为 Tamr。
上周,我拜访了他们位于剑桥哈佛广场中心的办公室,并接受了 Tamr 首席执行官安迪·帕尔默及其年轻团队的简报,包括艾伦·瓦格纳和尼迪·阿加瓦尔。
Tamr 解决数据管理问题的方法设计为可扩展,并随着数据的增多而改进。关键思想是:
1. 可扩展性通过自动化:集成问题的规模排除了以人为中心的解决方案。需要使用机器学习方法。
2. 数据清理:企业数据源不可避免地相当脏乱。
3. 非程序员导向:当前的提取、转换和加载(ETL)系统具有适合专业程序员的脚本语言。下一代问题的规模要求技能较低的员工能够执行集成任务。
4. 增量:新数据源必须在被发现时逐步集成。数据管理永远不会完成!
Tamr 还巧妙地结合了自动化和人类专业知识。
它从使用机器学习和数据分析算法开始,寻找数据元素之间的关系,并尝试自动化大多数数据管理任务。在机器学习不够时,它具有明确的流程和用户界面来请求人工专家的帮助,并使用智能奖励结构来鼓励专家。
Tamr 采用持续学习的方法,随着使用的增加而不断学习,帮助建立机构记忆和企业数据清单。
Tamr 支持 RESTful API,使公司能够在 Tamr 上使用现有的可视化和数据科学工具包。Postgres 被用作后端数据库。
它使用的一些机器学习方法包括:
-
使用三元组余弦相似度对属性名称进行模糊字符串比较。
-
将一列数据视为文档,并使用标准的全文解析器对其值进行标记化。然后,测量列之间的 TF-IDF 余弦相似度。这种方法适用于文本字段。
-
使用最小描述长度(MDL)比较两个属性的值。计算两个列数据交集的大小与它们并集大小的比率。这种方法适合于值数量较少的分类字段。
-
计算包含数值的列对的 Welch t 检验,并获得这些列来自相同分布的概率。
在下方截图中,Tamr 识别了几个包含相似地址信息的字段,这些字段是合并的候选项。
Tamr 管理员有一个友好的界面,可以选择能帮助解决特定问题的领域专家,包括按专家的专业知识和当前负载对专家进行排名。
Tamr 已经与几个大型客户合作。在一个案例中,它帮助一家主要的制药公司整合了来自生物学家和化学家的 15,000 个电子表格的数据,这些电子表格中有约 1M 行和 100K 个属性名称。
在另一个案例中,Tamr 帮助 Verisk Health 整合了 300 家保险公司,共计 2000 万条记录的索赔记录。目标是按医疗提供者整合索赔数据,而 Tamr 的解决方案在改进方面显著优于之前需要大量人工干预的方法。
有关 Data Tamer 的更多技术细节,请参阅 大规模数据策展:Data Tamer 系统,作者 Stonebraker 等,CIDR 会议论文集,2013。
KDnuggets 还覆盖了数据策展领域的其他公司 - 见
-
Paxata 为大数据分析自动化数据准备
-
Trifacta - 通过自动化和机器学习处理数据整理
相关:
-
Andy Palmer 推荐的最佳大数据初创公司
-
KDnuggets 采访:Michael Brodie 谈数据策展、云计算、初创公司质量、Verizon(第二部分)
-
CIO Review 20 家最具潜力的大数据公司
-
来自 Michael Stonebraker 的 Data Tamer 初创公司,仍处于隐身模式
-
2014 年 4 月的分析、大数据、数据挖掘收购和初创公司活动
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关内容
发掘 2023 年数据产品的潜力
原文:
www.kdnuggets.com/2023/01/tapping-potential-data-products-2023.html

图片由 rawpixel.com 提供,来自 Freepik
介绍
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
根据 福布斯,使用大数据洞察的公司平均收入增加约 44% —— 识别需要关注的客户需求,并在恰当的时间服务于他们。企业相信数据的价值并开始收集数据,但业务用户发现很难在需要时找到、使用和定制他们想要的数据。数据和洞察只有在每个数据消费者(内部和外部)能够获取到有意义的数据时,才能改变组织结果。
因此,作为驱动成果的资产,数据已被企业认可,但它们仍然在管理来自不同来源、缺乏标准化和治理的数据方面遇到困难。因此,这会导致未被利用的宝贵数据孤岛(称为数据缺口)。
将数据视为数据产品经理的方式是根据特定功能的需求随时提供数据。企业可以借助数据产品的洞察对齐其目标。简单来说,将数据视为产品意味着 提供的数据可以在团队或客户需要时从组织内的任何多样化来源访问。例如,软件开发团队需要足够且准确的数据来进行应用程序开发。
将数据管理如同产品一样
“数据即产品”概念是从数据集中化(中央仓库或数据湖)到去中心化领域网络的理想转变。这种方法可以提高数据的准确性、可访问性和安全性。
将数据视为产品的做法是企业数据网格的基础构建块。
数据网格是一种灵活的管理数据架构的方法,它促进了去中心化的数据管理和治理。它是一种以领域驱动的数据架构,要求以产品思维来收集每个领域的数据,每个数据的利益相关者都是其数据的拥有者,以提供清晰、有效和可靠的数据产品。因此,组织内的每个利益相关者或团队都采用产品思维,将数据视为产品,确保数据的所有权超越部门,使每个消费者(任何需要数据以便于任何目的或开发的人)都能获取、清洁和充足的数据。
数据作为产品的好处
许多企业采用的传统数据提取和集成方法需要与业务需求和用例对齐。多样的数据未能符合必要的治理和质量水平,这限制了企业从数据中获得所需和可持续价值的能力。数据作为产品可以帮助 实现数据资产的最大潜力。
-
精确的数据:数据的最大潜力在于其精确和可信。当数据被视为产品时,各领域的责任确保其管理的数据中包含上下文知识和所需信息。这样,消费者可以根据自己的数据需求自助服务,带来更准确和易于理解的数据,且没有任何延迟。
-
可访问和可消费的数据:当将数据视为产品时,目的是使数据对消费者可访问和可消费。因此,足够的信息可以随时获得。在这种方法中,每个业务领域负责准备自己的数据,并使其对其他人可访问以便于消费。元数据为消费者提供数据上下文,以加速数据发现和访问。
-
安全的数据:虽然数据的轻松访问很重要,但数据治理同样关键。数据作为产品的方法有助于管理和扩展对组织内所有客户的数据访问,包括所有领域。在管理数据作为产品时,涉及适当的访问控制——谁可以查看、使用和导出每个数据产品,并跟踪对任何数据集执行的所有活动。它使组织领域具有全球合规性,并实施必要的政策。
从数据产品入手
企业需要一个将过量信息视为产品的环境,以维持数据的有效性和质量。为了提供优质的数据,企业需要了解团队的数据需求及数据的生命周期。
充分利用现代数据能力(数据即产品)可能具有挑战性,并且在企业内部带来所有权。 数据中的产品思维确保每个领域的基础分析和历史数据得以保持,以保障数据的背景。
我使用过的平台之一是 K2view 的“数据产品平台”,它提供数据产品的部署、管理和监控,并与现代的“数据即产品”概念相一致。通过为每个数据产品保留元数据,数据产品工作室帮助数据所有者聚合和管理所有业务实体(如客户、产品、位置或任何交易)的数据,并将这些数据进一步准备成集成的数据产品提供给消费者。为了实现企业级的可扩展性、可靠性和灵活性,该平台以原始方式维护并提供每个数据集作为微型数据库。这有助于企业通过改变流入数据与其消费者之间的关系,释放数据驱动洞察的潜力。
结论
随着数据在集中式数据平台(如数据湖或数据仓库)中沉没,需要更多的人力和工具来管理,这在实现业务成果方面已被证明有限。因此,数据网格架构将数据即产品视为赋能每个领域从数据中揭示洞察的新方式。数据即产品的方法在企业的每个层面上提供了一种灵活的数据管理方式,使数据对所有利益相关者更易获取。
Yash Mehta 是国际公认的 IoT、M2M 和大数据技术专家。他撰写了许多广受认可的关于数据科学、物联网、商业创新和认知智能的文章。他是数据洞察平台 Expersight 的创始人。他的文章曾被最权威的出版物刊登,并被 IBM 和 Cisco IoT 部门评选为连接技术行业中最具创新性和影响力的作品之一。
更多相关内容
实践:数据分析的 Python 入门
原文:
www.kdnuggets.com/2018/05/tdwi-intro-python-data-analysis.html
|
|
| |
| 预览新 TDWI 在线学习课程 |
| |
|
|
|
| |
| |
| |
|
|
| |
|
| |
|
| |
| |
|
| |
|
| |
| |
| 窥探数据分析的 Python 新手编程或只是想学习 Python?通过 TDWI 在线学习的这个新实践课程,学习数据科学和机器学习中的顶级语言之一。
在这个八小时的课程中,学生将使用 Jupyter notebook 学习和编写 Python 代码。到课程结束时,你将掌握 Python 的基础知识,并拥有自己的代码 notebook,其中包括导入和可视化数据的示例,可以在自己的工作中使用。
测试一下,看这个课程是否适合你。 免费试用前两个章节:了解讲师 William Henry,浏览“理解变量”模块。如果你喜欢这门课程,我们会给你提供剩余部分的折扣码。
完整课程包括:
-
如何使用 Python 基础知识,如列表、字典和字符串。
-
如何使用 for 循环、while 循环和 if/else 语句。
-
如何编写自己的函数。
-
如何使用 Python 读取和写入数据文件。
-
如何使用 Pandas 从 CSV 和 MySQL、PostgreSQL 数据库加载数据
-
如何选择和分组数据子集。
-
如何使用内置和自定义函数分析和转换数据。
-
如何使用 Pandas 高效处理日期/时间数据(包括时区转换)
-
如何创建折线图、直方图和条形图。
|
|
| |
|
|
| |
| |
| |
| |
| |
|
| 查看课程 |
|
|
| |
|
| |
|  |
|
| |
|
| |
|
| |
|
|
| |
| |
| |
| 让我们在社交媒体上互动! |
| |
|
|
| |
|
| |
| |
| |
| 想了解更多或联系我们的服务,请通过 info@tdwi.org. 给我们发邮件。 |
| |
| ©2018 TDWI. 版权所有。 | 联系我们 | 隐私政策 |
|
| |
|
|
|
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
更多相关主题
使用合成数据训练 AI 进行时间序列模式分类
原文:
www.kdnuggets.com/2021/10/teaching-ai-classify-time-series-patterns-synthetic-data.html
评论
我们想要实现什么目标?
我们想训练一个可以做类似事情的 AI 代理或模型,

图片来源:作者使用Pixabay 图片(免费使用)准备的
方差、异常、变化
更具体地说,我们想训练一个 AI 代理(或模型)来识别/分类时间序列数据,
-
低/中/高方差
-
异常频率(异常比例很小或很高)
-
异常尺度(异常是否远离正常值或接近正常值)
-
时间序列数据中的正向或负向变化(在存在一些异常的情况下)
但我们不想复杂化问题
但是,我们不想进行大量的特征工程或学习复杂的时间序列算法(例如 ARIMA)和特性(例如季节性、平稳性)。
我们只想将我们的时间序列数据(带有正确标签)输入到某种监督‘学习’机器中,这样它就可以从原始数据中学习这些类别(高或低方差、异常太少或太多等)。
一个有用的 Python 库
为什么不利用一个 Python 库,它可以自动为我们完成这种分类工作,而我们只需将数据以标准的 Numpy/Pandas 格式输入其中?
如果这个库具有我们最喜欢的 Scikit-learn 包的外观和感觉,那就更好了!
我们在美丽的库中找到了这样的功能 —— tslearn。简单来说,它是一个提供时间序列分析的机器学习工具的 Python 包。该包构建在(因此依赖于)scikit-learn、numpy 和 scipy 库之上。
图片来源:tslearn 文档
为什么(以及如何)使用合成数据?
正如我在这篇文章中所写的 —— “合成数据集是通过程序生成的数据仓库。因此,它不是通过任何现实生活中的调查或实验收集的。它的主要目的是灵活且足够丰富,以帮助机器学习从业者进行各种分类、回归和聚类算法的有趣实验。”
…然后扩展了本文中的论点——“合成时间序列也不例外——它帮助数据科学家实验各种算法方法,并以仅用真实数据集无法实现的方式为实际部署做准备。”
基本上,我们想要合成具有异常和其他模式的时间序列数据,自动标记它们,并将它们输入到tslearn算法中,以便教会我们的 AI 代理这些模式。
特别是,如果我们想使用基于深度学习的分类器(如tslearn提供的),那么我们可能需要大量涵盖所有可能变异的数据,这在现实生活中可能不易获得。这时,合成数据就派上用场了。
那就开始冒险吧!
教授 AI 代理时间序列模式
演示笔记本可以在我的 Github 仓库中找到。将时间序列数据转换为适合tslearn模型训练的格式是相当简单的,已在笔记本中说明。在这里,我们主要关注不同类型的分类结果作为说明。
数据中的高或低方差?
我处理大量工业数据,即一组传感器从机器、工厂、操作员和业务流程中生成源源不断的数字数据。
检测时间序列数据流是否具有高或低方差对许多下游过程决策可能至关重要。因此,我们从这里开始。
流程很简单,
-
使用
SyntheticTS模块生成合成数据(在我的文章中讨论过,可以在这里找到) -
生成相应的类别标签以匹配这些 Numpy/Pandas 数据系列(注意基于领域知识注入的自动标签生成)
-
将合成序列数据转换为
tslearn时间序列对象(数组) -
将其存储在训练数据集中
-
将训练数据输入到适合的时间序列分类器中,我们选择了
TimeSeriesMLPClassifier方法,该方法建立在熟悉的 Scikit-learn 多层感知机方法之上,基本上实现了全连接深度学习网络。
使用合成数据的训练流程,来源:完全由作者准备
TimeSeriesMLPClassifier具备标准 Scikit-learn MLP 分类器的所有功能,
-
隐藏层大小和神经元数量
-
激活函数
-
求解器/优化器(例如‘Adam’)
-
学习率
-
批量大小
-
容忍度
-
动量设置
-
早停准则

基本上,我们希望合成具有异常和其他模式的时间序列数据,自动标记它们,并将其输入
tslearn算法,以便教我们的 AI 代理这些模式。
为了简洁起见,在笔记本中我没有显示训练/测试拆分,但这应该作为实际应用的数据科学工作流标准步骤。
我们可以在训练后绘制标准损失曲线,并进行各种超参数调整,以使性能达到最佳。
然而,展示深度学习分类器调整并不是本文的目标。我们更愿意关注最终的结果,即它做出了什么样的分类决策。
以下是一些随机测试结果。
标签生成——手动还是自动?
本文的整个重点是展示可以通过合成数据避免手动标记。
我生成了数百个具有随机方差或偏移的合成时间序列来训练分类器。由于它们是程序生成的,因此也可以自动标记。
一旦你看到实际笔记本中的生成代码,这一点将会清楚。以下是方差训练的思路。

异常——数据的高比例还是低比例?
识别异常是不够的。在大多数现实情况中,你还需要识别它们的频率和发生模式。
这是因为工业数据分析系统通常负责在检测到数据流中的足够异常后生成警报。因此,为了决定是否发出警报,它们需要对异常计数是否代表正常数据的显著部分有一个清晰的认识。
你不想引发太多虚假警报,对吧?这对 AI 驱动系统的声誉不好。
所以,我们进行了同样的过程来训练一个 AI 模型,以处理时间序列数据中的异常比例。以下是随机测试结果,
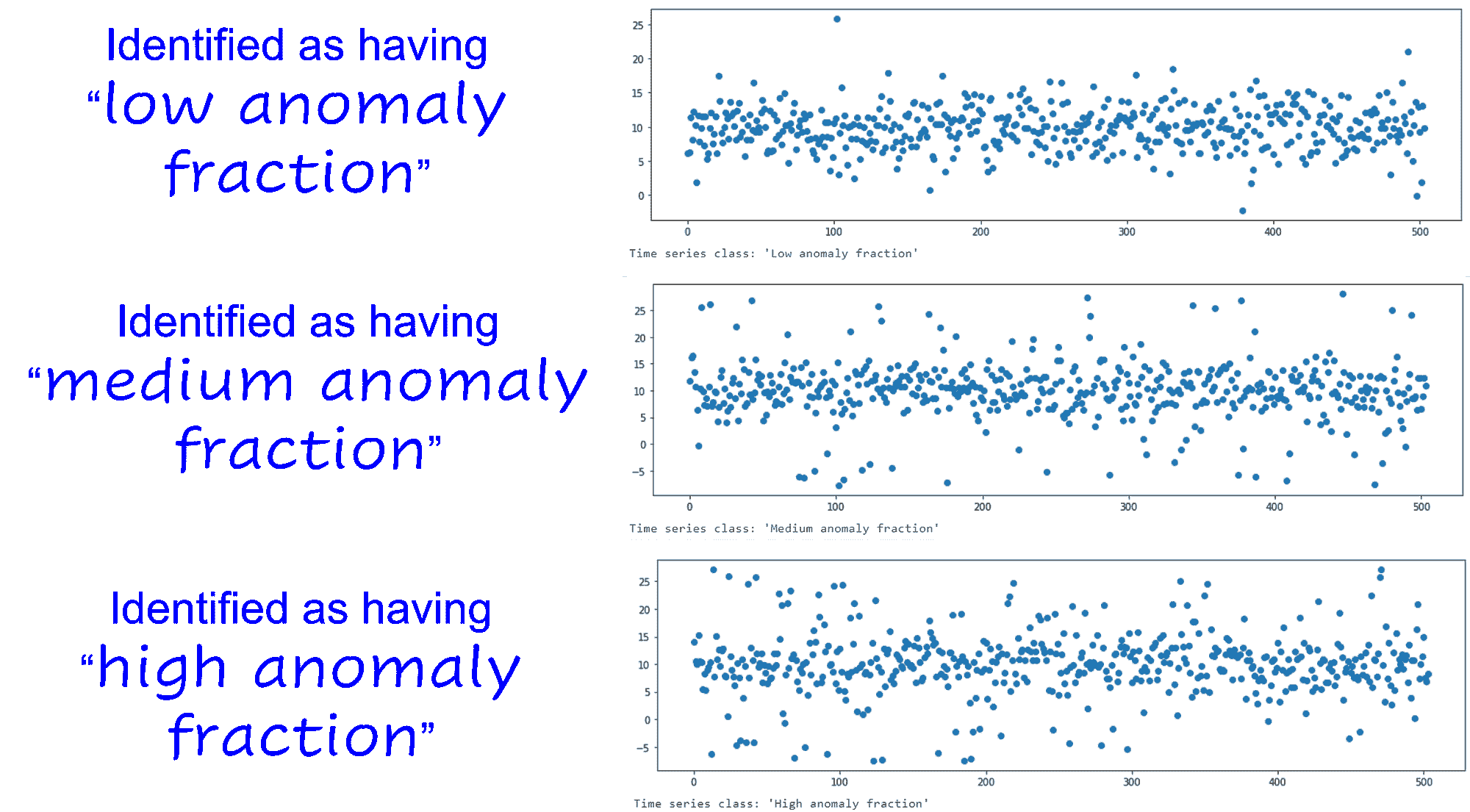
异常——它们的幅度有多大?
在许多情况下,我们还希望将传入的数据分类为高/中/低异常幅度。对于工业数据分析,这个特征可能会指示机器或过程的状态异常。
我们遵循了上述相同的训练过程并获得了这些结果,
数据漂移或偏移——在哪里,如何?
工业数据分析中的另一个经典操作是检测来自机器的传感器数据中的漂移/偏移。这可能有多种原因,
-
机器可能会老化,
-
过程配方/设置突然改变而没有适当的记录,
-
小的子组件可能会随着时间的推移而退化。
底线是,AI 驱动的系统应该能够识别这些类别——至少在正向或负向转移及其发生点方面,即漂移是否在过程生命周期中早期或晚期开始。
识别异常是不够的。在大多数实际情况中,你还需要识别其频率和出现模式。这是因为工业数据分析系统通常负责在检测到数据流中的足够异常后生成警报。
在这种情况下,我们将转移的位置(在整个时间段中的早期或晚期)也纳入了考虑。因此,我们有以下类别用于训练数据,
-
早期正向转移
-
晚期正向转移
-
早期负向转移
-
晚期负向转移
由于这种复杂性增加,我们需要生成比之前实验更多的合成数据。以下是结果,
摘要
时间序列分类是许多精彩应用场景中一个非常有趣的话题。在本文中,我们展示了如何使用合成数据来训练 AI 模型(具有几个全连接层的深度学习网络)用于模拟工业过程或传感器流的单维时间序列数据。
特别是,我们专注于教会 AI 模型各种异常特征和数据漂移模式,因为这些分类是机器降解的重要指标。简而言之,它们构成了所谓的预测分析在工业 4.0或智能制造领域的基础。
我们希望未来 AI 驱动的预测分析中对合成数据的使用会显著增长。
你可以查看作者的GitHub** 代码库**,获取有关机器学习和数据科学的代码、想法和资源。如果你像我一样,对 AI/机器学习/数据科学充满热情,请随时在 LinkedIn 上添加我或关注我在 Twitter 上的动态。
简介:Tirthajyoti Sarkar是 Adapdix Corp.的数据科学/机器学习经理。他定期为 KDnuggets 和 TDS 等出版物贡献关于数据科学和机器学习的多样话题。他撰写了数据科学书籍,并参与开源软件的开发。Tirthajyoti 拥有电气工程博士学位,并在攻读计算数据分析硕士学位。可以通过 tirthajyoti at gmail[dot]com 联系他。
原文。经许可转载。
相关:
-
GPU 驱动的数据科学(非深度学习)与 RAPIDS
-
为什么以及如何学习“高效数据科学”?
-
Python 中的蒙特卡洛积分
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
教授数据科学过程
原文:
www.kdnuggets.com/2017/05/teaching-data-science-process.html
由 Balázs Kégl,数据科学家,RAMP的共同创始人。
数据科学的循环过程(来源)。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速迈向网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 在 IT 领域支持您的组织
教授机器学习的课程大纲存在几十年,甚至更近期的技术学科(深度学习或大数据架构)几乎有标准的课程大纲和线性化的故事情节。另一方面,数据科学过程的教学支持一直很难以找到,尽管过程的大纲自 90 年代以来就存在。理解该过程不仅需要广泛的机器学习技术背景,还需要对企业管理基本概念的了解。我已经在一篇先前的文章中详细阐述了由于这些复杂性而产生的数据科学转型的组织困难;在这里,我将分享我在教授数据科学过程方面的经验。
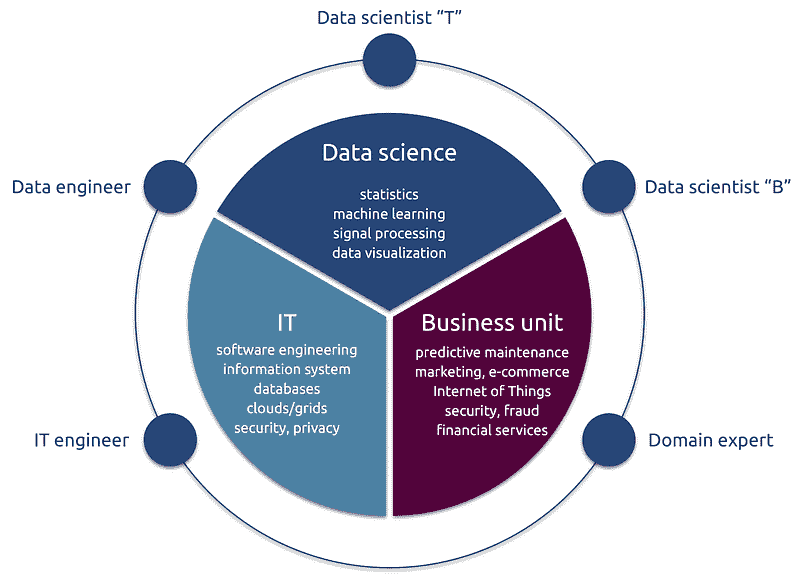
数据科学生态系统。数据科学家“B”在正式化业务问题和设计数据科学工作流程方面处于关键位置。
围绕工作流程构建
最近,我有机会尝试一些实验性的教学技术,这些技术应用于来自 Ecole Polytechnique 的一百名顶尖工程学生。课程的核心概念是数据科学工作流程。
-
设计工作流程,其元素,优化分数,将工作流程连接到商业数据科学家一侧。
-
优化工作流程,将其连接到技术数据科学家一侧。
这两者都不能通过线性叙述的幻灯片讲座来教授。我围绕我们的RAMP概念建立了课程,使用我们的平台。为了学习工作流程优化,学生参与了五次 RAMP,这些 RAMP 旨在挑战他们不同的科学工作流程和不同的数据科学问题。为了学习工作流程设计,我涵盖了一些数据驱动的商业案例,给学生提供了带有具体问题的线性指南,并要求他们在小组项目中建立商业案例和数据科学工作流程。我使用 RAMP 起始套件作为样本:限制无限设计空间帮助学生结构化项目。
使用 RAMP 作为教学支持
RAMP最初设计为一种协作原型工具,旨在高效利用数据科学家解决领域科学或商业问题的数据分析部分的时间。我们很快意识到,这对培训新手数据科学家同样非常有价值。我们需要改变的主要设计特性是完全开放。为了根据个人表现对学生进行评分,我们需要关闭排行榜。在封闭阶段,学生可以看到彼此的分数,但看不到彼此的代码。我们使用一个上限线性函数来对他们进行评分。这个通常持续 1–2 周的封闭阶段之后是一个“经典的”开放 RAMP,我们根据学生的活动、生成多样性和提高自己封闭阶段得分的能力来对学生进行评分。
学生们的集体表现令人惊叹。在所有五次 RAMP 中,他们不仅超越了基准线,还超越了我们为测试工作流程而组织的单日黑客马拉松分数,通常有 30–50 位顶尖数据科学家和领域科学家参与其中。
第一课堂 RAMP 的得分与提交时间戳。蓝色和红色圆圈分别代表封闭和开放阶段的提交。粉色曲线是当前最佳得分,绿色曲线是最佳模型融合的表现。即使在封闭阶段,前 10%的学生也超越了数据科学研究人员(单日黑客马拉松)和最佳深度神经网络。然后,他们在开放阶段结合彼此的解决方案时超越了最先进的自动模型融合。
我也很高兴看到,在开放阶段,新手/普通学生通过学习和重用来自前 10–20%学生的解决方案赶上了顶尖学生。另一个令人愉快的惊喜是直接盲目复制非常少见:学生们真心尝试改进彼此的代码。
课堂 RAMP 的分数分布。蓝色和红色直方图分别表示封闭阶段和开放阶段的提交(较深颜色的直方图是重叠部分)。直方图显示,初学者/平均水平的学生通过利用开放代码,在开放阶段赶上了前 10%。
我们将分析这些丰富的结果,并撰写关于领域科学(有关第一个示例,请参见这篇论文)、数据科学和管理科学的论文。这份技术报告包含了一些更多的细节,以下是最近的DALI 工作坊关于数据科学过程的演示文稿(见这里)。
使用业务案例来设计教学工作流程
正如我在之前的文章中解释的那样,非 IT 公司启动数据科学项目的主要障碍不是数据准备不足,不是基础设施问题,也不是缺乏训练有素的数据科学家,而是缺乏明确的数据驱动的业务案例。更糟的是:这个问题通常在对数据湖、Hadoop 服务器和数据科学团队的初始投资之后才会发现。一个准备充分的数据(过程)科学家能够早早进入这一过渡期并颠覆项目,可能为甚至中型公司节省数百万。
为了培训学生担任这一角色,我开始通过对模拟预测维护案例的扩展讨论来进行课程。所有人需要在项目中回答的标准化问题帮助学生从广泛描述的业务案例过渡到明确的预测分数、误差度量和数据收集策略。
-
我们想要预测什么,以及如何衡量预测的质量?
-
更好的预测如何改善选定的 KPI?
-
你想要决策支持、一个完全自动化的系统,还是仅仅了解哪些因素很重要?代理将如何使用这个系统?
-
定量预测应该是什么?
-
我们如何(使用什么分数)来衡量成功?(可能不对称的)预测误差如何转化为成本或降低的 KPI?
-
我们需要什么数据来开发预测器?
-
我们需要多大努力来收集这些数据?
-
根据数据来源和预测目标,工作流程和工作流程元素会是什么?
-
模型需要多频繁地重新训练?
我进一步结构化他们的项目,要求他们制作一个起始包,模仿他们遇到的五个 RAMP。每个起始包包含
-
一个数据集,
-
例子工作流程元素填充设计的工作流程,
-
一个实现工作流程的单元测试,可以用来测试工作流程元素,以及
-
一个 Jupyter notebook,描述科学或商业问题(回答上述问题),读取、处理、探索和可视化数据,解释数据分析工作流程,并为每个工作流程元素提供和解释初步工作解决方案。
课程包含了大量的问答,讨论了其他商业案例(成功的和失败的),并解释了各种可能的工作流程和工作流程元素。
一个用于预测厄尔尼诺的时间序列预测工作流程。
一个多标准工作流程,用于对化疗药物进行非侵入性质量控制的分类和量化。
由于学生可以自由选择任何可用的数据集,数据收集大多不是问题。工作流程相对简单,因此几乎所有团队都交付了有效的起始工具包。另一方面,许多时候学生会陷入为“漂亮”的数据集寻找商业案例的陷阱。约一半的团队至少尝试设计一个有意义的商业案例。前 3 名团队(共 22 个)交付了顶尖的产品。
-
一个制造过程控制产品,通过使用良好校准的维护成本、生产成本、满意度成本和利润来计算虚假正例和虚假负例的非对称成本。团队在几个基准(检查无、检查全、随机检查)上显示了改进。
-
一个销售给大规模多人在线游戏的产品。目标是预测一个玩家是人类还是机器人。这些游戏在机器人与其自己的离线业务竞争时会亏损,该离线业务出售真实货币的角色和功能,通过自动在游戏中收集这些角色并在黑市上出售。团队通过考虑非对称分类错误来制定商业案例。
-
一个可以销售给出租车公司或 Uber 的产品,预测曼哈顿每小时和每个区域的出租车需求。团队通过估算可用乘车次数乘以每次乘车的利润,将预测转换为价值。
简介:Balázs Kégl是 CNRS 的高级研究科学家,也是巴黎萨克雷大学数据科学中心的负责人。他是 RAMP(www.ramp.studio)的共同创建者。
原文。经许可转载。
相关:
-
数据科学流程,重新发现
-
数据科学流程
-
拥抱随机:随机接受边缘论文的理由
更多相关主题
关于 MLOps 的一切你需要知道的:KDnuggets 技术简报
原文:
www.kdnuggets.com/tech-brief-everything-you-need-to-know-about-mlops
由 KDNuggets 和 Machine Learning Mastery 提供的技术简报
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT
KDnuggets 很高兴今天能够向社区介绍我们的技术简报,这是我们最新的资源,旨在帮助从业者保持最新的知识。
这些是全新系列的技术文档,旨在提供对数据科学和机器学习关键主题的深入、简明的信息。作为读者的免费产品,技术简报旨在快速而有效地传递基本的基础知识,确保你在快速发展的技术领域保持领先。
我们的首个技术简报 深入探讨了机器学习操作(MLOps)的世界。MLOps 是一个简化机器学习项目生命周期的学科,确保其高效部署、操作和持续改进。由于其在提升模型可靠性、操作效率和项目整体成功中的作用,这一实践变得越来越重要和广泛采用。
关于 MLOps 的一切你需要知道的 提供了对该领域的全面概述,涵盖了从基础知识和关键组件(如数据管理、模型监控以及各种工具和技术的使用)到旨在最大化机器学习项目有效性的最佳实践。它旨在帮助你全面了解 MLOps 如何作为成功机器学习项目的核心,解决在生产环境中部署和维护 ML 模型的挑战。
我们的目标是通过 Tech Briefs 让你迅速掌握重要的数据相关技术主题!本期内容为未来发布奠定了基础,承诺将丰富你在数据科学和机器学习领域的知识与专业技能。敬请关注更多宝贵见解,帮助你自信而熟练地应对当今科技领域的复杂性。
更多相关话题
讲述一个精彩的数据故事:可视化决策树
原文:
www.kdnuggets.com/2021/02/telling-great-data-story-visualization-decision-tree.html
你是否曾见过一个看起来很棒的仪表盘或报告,但除了好看之外没有提供更多信息?你无法真正理解故事。这通常是因为开发者没有选择合适的可视化和组织方式。选择合适的可视化将讲述一个你可能永远没有时间或机会讲述的故事。
想象一下,你展示了一个图表,希望突出过去十二个月的一个重要趋势。观察后,高管们却在会议结束后讨论本月的创纪录高点。你的重点被忽略了。你没有讲述一个故事。在今年,虚拟会议在吸引和保持参会者的注意力方面带来了更大的挑战,没人能浪费时间去解码可视化的含义。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT

图片由 upklyak 提供 在 Freepik
精彩的故事有引人入胜的角色、悬而未决的冲突和井然有序的叙事弧。你每一个关键指标都是故事中的一个角色。当一个指标威胁到另一个指标时,冲突就会出现。在我们的银行案例研究中,一个精彩的演示可以从冲突的高潮开始,利用计分卡可视化引起对流动性问题和即将到来的贷款违约的关注。然后,叙事弧可以回到麻烦的起点,展示随着疫情展开,各个指标如何开始变化的时间趋势可视化。
接下来,你将比较类别以增加对指标的细微差别,例如展示贷款风险在各个行业之间的增加并不均匀。这种角色发展有助于在多个指标相互作用时增加对即将到来的冲突的预期,如散点图类型的可视化所示。最后,你会回到冲突的高潮时刻,观众期待看到你将提出什么方案来解决问题。由于精心编排的叙述和视觉图像的综合影响,整体展示将对观众产生强烈的效果。
可视化应自我说明。你不应需要花时间讲述其故事或完成其工作。Stephen Few 写道:“一个有效的[可视化]不是由漂亮的仪表、计量器和交通信号灯产生的,而是由经过深思熟虑的设计产生的:更多的是科学而非艺术,更是简单而非炫目。它首先是沟通。”
如何让可视化自我呈现你的故事?
可视化类型的选择至关重要。上面的决策树解释了如何根据你想讲述的故事来选择适合的可视化类型。
在我们的分类法中,有四种主要的故事叙述方式。让我们通过一个银行在疫情动荡中应对的案例研究来逐一了解它们。
随时间的变化
如果我们设想银行高管在经济动荡期间向员工、同行或董事会展示的情景,她需要使用时间序列分析来设定变化的初步背景。
折线图将在此展示中发挥关键作用。它们可以展示单一财务指标在日、月或年层面的前所未有的变化。
多条折线图用于展示多个数据集,这些数据集共享相同的度量单位,例如展示在相同时间段内收入、支出和利润的下降情况。
堆积面积图将用于展示多个数据集随时间变化的情况,这些数据集一起构成一个整体。在银行家的例子中,她可以展示各个区域随时间的变化情况,同时显示区域总数如何累计到公司总数。
组合条形图和折线图适用于当多个数据集需要在时间上共同显示,但它们的度量单位不同的情况。这将是银行家在左侧 Y 轴上以人数单位显示员工水平,同时在右侧 Y 轴上以美元单位显示净利润的方式。所有这些基于折线的可视化组合将为为什么需要采取激进措施应对前所未有的变化提供背景。
比较类别
许多数据故事涉及比较类别,例如比较多个产品线、地理区域或团队,以评估相对于同行的表现。我们的银行展示可以涉及绘制对象,例如流程图或实体关系图,以显示从流动性提供者到贷款申请人的资金流动。
表格是以密集格式显示大量数字的最佳方式。
柱状图可以用来比较,例如,各银行分支的收入。
树形图用于类似的目的,但显示各分支的收入如何按比例比较。
空间地图对区域性显示数据非常有用。对于一个全国性的银行,空间地图可以显示按区域划分的收入,并在每个区域上叠加个体度量。
小倍数图对于在多个层面上比较分支机构非常有用,这种格式在 Tableau 中经常看到。并排的三个柱状图可以分别表示收入、支出和收入。在这些柱状图中,将有代表每个银行分支的柱子,以便于在多个层面上进行轻松比较。
堆叠条形图也可以用于展示多种类型的支出,重点显示它们对总体总数的贡献。在显示每种支出类型的条形图中,分区会显示每个地区的支出百分比。
揭示定量数据中的趋势
一些数据故事涉及在一组测量中寻找趋势。例如,我们的银行可能会想寻找借款人违约风险的警示信号。这些警示信号可能包括财务比率、账户余额和逾期付款。
散点图是一种展示这些度量的聚类并揭示与贷款风险相关性的方式。
箱型图也可以用于显示这些警示信号的分布。这些类型的可视化是回归分析结果的背景。
突出单一度量
一些度量需要特别关注,可以用超大或彩色字体呈现为单一数字,例如总收入或存款百分比变化。这些就是你的故事标题。记分卡可以用来强调利润的急剧下降。通过将这个数字标记为红色并让它独立显示,参与演示的人将理解其重要性。
迷你图是一种小型折线图,几乎没有标注细节如坐标轴刻度,可以用来给出一个数字的非常高层次的趋势。这些通常伴随着一个大型的记分卡值。
子弹图可以用来展示单一指标的多个维度,例如目标利润、年初至今的利润和预计利润。通过使用这些单指标可视化,演示者可以将重点放在一个故事细节上。
关键是如何选择合适的可视化方法背后有科学依据。你不能仅仅把任务交给图形设计师,依据视觉效果来选择可视化。为了让可视化讲述你的故事,你需要为你的目的而建立的可视化类型。学习图 1 中概述的概念,将使你的故事更强大、更有效。
斯坦·普格斯利 是一位数据仓库和分析顾问,服务于艾德·贝利技术咨询公司,总部位于犹他州盐湖城。他还是犹他大学埃克尔斯商学院的兼职教授。你可以通过电子邮件联系作者。
了解更多相关主题
实施推荐系统的十个关键经验
原文:
www.kdnuggets.com/2022/07/ten-key-lessons-implementing-recommendation-systems-business.html
1. 定义真正有助于业务任务的目标
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
推荐系统的全球任务是从一个大型目录中挑选出最适合特定用户的内容。这些内容可以各不相同——从在线商店的产品和文章到银行服务。FunCorp 产品团队处理的是最有趣的内容——我们推荐的是表情包。
为了做到这一点,我们依赖于用户与服务互动的历史记录。但从用户和业务的角度来看,“好的推荐”并不总是相同的。例如,我们发现,通过更准确的推荐增加用户点击的点赞数并不会影响留存率,这是对我们业务很重要的指标。所以我们开始专注于优化在应用中的停留时间的模型,而不是点赞。
这就是为什么专注于你业务中最重要的目标如此重要。目标可以有所不同,例如:
-
用户留存,
-
收入增加,
-
成本降低,
-
以此类推。
推荐系统肯定能让你改善用户体验,用户将更快和/或更频繁地采取目标行动。剩下的就是确保你同时实现你的业务目标。双赢!在我们的案例中,实施我们资讯中的推荐系统后,我们看到点赞数相对增加了 25%,观看深度几乎增加了 40%。
iFunny 的主要目标是增加留存率,你会看到我们有时会进行一些对留存率有很大负面影响的实验。
2. 找到产品中最佳的用户接触点
当你确定了全球目标后,你需要弄清楚展示推荐的最佳方式是什么:
-
在信息流中——这对新闻网站或像我们的 iFunny 这样的娱乐应用程序是相关的,
-
推送通知,
-
电子邮件通讯,
-
个人账户中的个性化推荐部分。
-
或网站/应用程序上的其他部分。
影响接触点选择的因素有很多——例如,此点的日活跃用户比例(对于某些用户,推送通知可能已被禁用)或与机器学习微服务的集成复杂性。
在我们的例子中,无效的选择可能是这样的。iFunny 应用有一个探索部分,我们在其中收集每周最佳的表情包。可以用机器学习来收集这样的选择,但只有少量的日活跃用户会访问这个部分。

此时使用机器学习是不切实际的。
这里的主要规则是将机器学习集成到能够带来最大业务指标提升的地方。因此,在 FunCorp 的情况下,我们首先决定在信息流中实施机器学习,因为它被最多的用户看到。其次,我们开始为推送通知创建推荐系统——因为有一个明显但较小的受众群体在与之互动。
3. 尽可能多地收集用户的多样化反馈
在我们的案例中,反馈是用户可以采取的行动,以展示他们对应用内容的感受。为了构建推荐系统,您需要学会收集不同类型的反馈:
-
显式——这可以是任何尺度的评分或点赞/点踩。
-
并且隐式:
-
用户在内容上的停留时间,
-
访问内容页面的次数,
-
用户在社交网络上分享内容的次数或将其发送给朋友的次数。
-
反馈应该与推荐系统的业务目标相关。例如,如果目标是减少流失率,那么添加反馈表单并向从服务中退订的用户显示它是合理的。
以下是一些重要的技术要点:
-
使用户反馈渠道能够扩展。例如,除了页面上的停留时间外,您还可以开始收集用户评论并确定其语气。积极的评论会告诉您需要更多此类内容。反之亦然。
-
长时间保留用户反馈历史——至少几个月。这是为了两个目的。首先,您在训练推荐系统模型时拥有的数据越多,模型就会越好——您将能够发现长期用户行为中的见解。其次,大量的历史数据将使我们能够在离线格式下比较模型,而无需进行 AB 测试。
-
你需要一个数据质量控制系统。实际案例:当我们开始收集内容观看时间的统计数据并使用这些数据训练模型时,我们发现数据仅来自 iOS 平台。Android 平台上未实现该功能。也就是说,我们期望个性化有所改进,但没有整个平台的数据。
不要忘记渠道的限制。例如,只有 30-40% 的用户通过点赞提供反馈。如果你仅仅基于点赞来构建推荐系统,那么 60-70% 的观众将会收到非个性化的推荐。因此,你拥有的用户反馈渠道越多越好。
在 iFunny,我们只有 50% 的用户提供了明确的反馈,因此我们需要开发基于隐性反馈的模型来改进我们的指标。
4. 确定业务指标
机器学习专家习惯于处理 ML 算法的指标:精度、召回率、NDCG……但实际上,企业对这些指标并不感兴趣,其他指标发挥作用:
-
会话深度,
-
转化为购买/查看,
-
留存,
-
每用户平均消费。
所以你需要选择最适合你关键业务目标的指标。你可以这样做:
-
计算各种指标。
-
在离线数据上,找到业务指标和长期指标之间的相关性:用户留存、收入增长等。
结果是,你会得到一组在 AB 测试中需要提升的业务指标。
5. 对你的用户进行分段
从商业角度来看,网站的观众可能在多种方式上非常异质(这些指标有时称为切片):
-
社会人口特征,
-
服务上的活动(反馈数量,访问频率),
-
地理位置,
-
等等。
很多时候,你的模型对不同的观众群体会产生不同的效果——例如,针对新用户显示指标增长,而对老用户则没有增长。
报告系统应该能够计算不同用户部分的指标,以便注意到每个特定群体中的指标改善(或恶化)。
例如,iFunny 有两个大群体:
-
“高活动”——用户频繁访问应用程序并观看大量内容,
-
“低活动”——用户很少访问应用程序。
我们过去习惯于整体计算指标,但当我们在报告中将这些用户分开时,我们发现模型变化对他们的影响不同。有时只有在高活动群体中会有增长——而当你没有进行分段计算指标时,可能不会注意到。
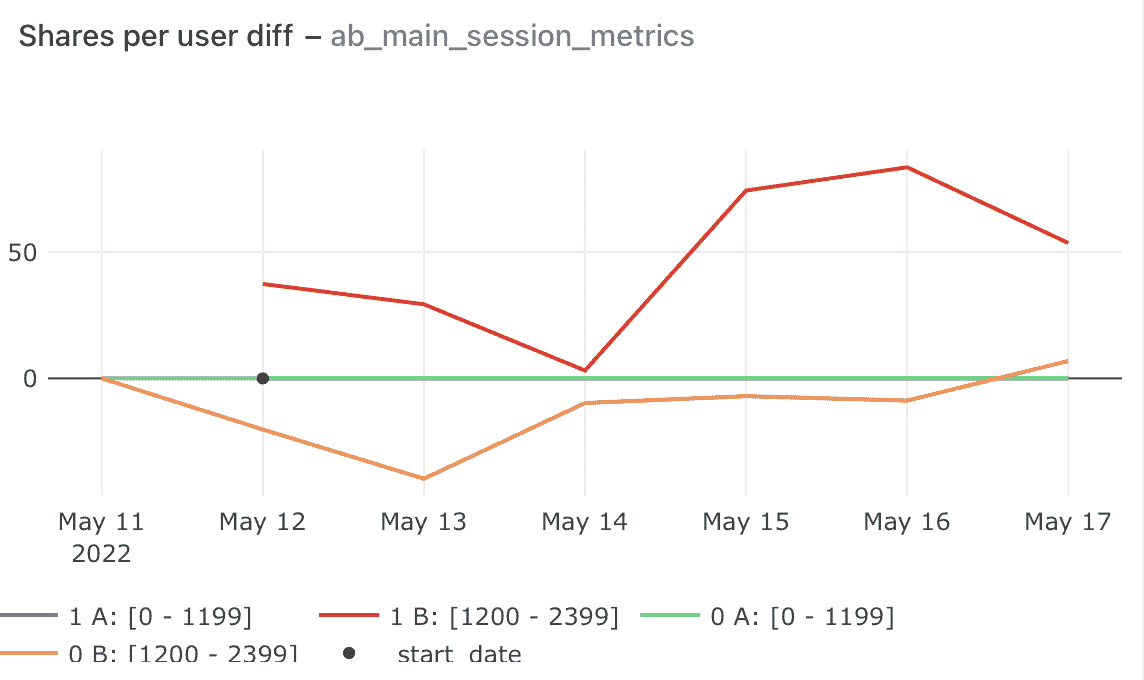
6. 确定正确的离线指标
当反馈数据收集完成且业务指标已选择时,就需要选择离线指标来优化我们的模型,例如:
-
precision@k,
-
recall@k,
-
NDCG,
-
MAP。
推荐系统有很多指标。那么如何选择合适的指标呢?答案很简单:选择与业务指标相关的离线指标。你可以通过计算离线指标与在线指标之间的相关性来实现这一点。例如,在 FunCorp,我们曾经认为每用户的笑容数量与留存等业务指标相关,但我们的实验显示情况并非如此。于是我们开始优化其他业务指标,例如花费的时间。
分析,在这种情况下,你将学习如何避免当离线指标良好的模型导致业务指标恶化时的错误。
7. 创建基线模型
不要试图立即使用最复杂的模型来解决问题——从简单的方法开始。例如,使用基于流行度的产品推荐,而不是神经网络。这个简单的模型被称为基线模型。
在这种情况下,你将立即看到产品指标的增长,同时避免了大量的基础设施和开发成本。在未来,你所有更复杂的模型将与基线模型进行比较。
例如,在 FunCorp,我们首先使用基于 K 最近邻算法的简单方法创建了一个用于推送通知的内容推荐服务,只有在第二次迭代中,我们才转向更复杂的提升模型。提升模型需要更多的计算资源进行训练,因此我们首先确保机器学习具有小幅的积极效果——为了增强这一效果,花时间开发更复杂的模型是有意义的。
8. 选择机器学习算法并淘汰最差的模型
下一步是训练更复杂的模型。推荐系统通常使用神经网络和经典机器学习算法:
-
矩阵分解,
-
LogisticRegression,
-
KNN(基于用户,基于项目),
-
boosting。
在这个阶段,我们会计算离线指标,并且凭借反馈系统中已经积累的数据,我们选择最佳模型进行测试。
这种方法有一个明显的缺点。离线数据是当时生产环境中正在运行的模型的结果,因此离线实验将被当前模型最准确地“重复”所获胜。
因此,使用离线数据,我们只能区分非常糟糕的模型和“不是很糟糕的模型”,以便将“不是很糟糕的模型”投入测试。或者,我们可以在没有离线测试的情况下进行实验——例如,使用多臂老丨虎丨机机制。如果指标很差,老丨虎丨机会自动停止将流量导向“糟糕”的模型。但这种测试新模型的方法大大复杂化了架构,因此我们在离线数据上测试模型。
9. 通过 AB 测试系统运行所有内容
任何对推荐算法的更改,例如从基线模型切换到高级模型,必须经过 AB 测试系统。
如果没有良好的分析,你可能无法看到推荐系统的效果,或者误解数据,这可能导致业务指标恶化。例如,如果你开始推荐更多 NSFW 内容,那么“每个用户的点赞数”会暂时增加。但从长远来看,这种内容可能会导致服务的退订增加。
这就是为什么 AB 测试需要测量短期和长期效果的原因。
在进行 AB 测试时,你需要确保测试组和对照组的样本具有代表性。在 FunCorp,我们根据期望的指标增长计算样本大小。
我们还需要避免一些测试对其他测试的影响。这是成熟产品中的一个问题,当大量变化并行测试时,其中一些可能会影响 ML 输出。例如,如果我们同时对推荐 feed 和审核规则(可能会被审核员拒绝的内容)进行测试,则测试和对照指标可能会出现偏差,这并非因为模型差异,而是因为内容排序差异。
10. 记住生产中的经典问题
在“生产环境”中推出算法时,必须提供解决一系列经典问题的方案。
-
用户的冷启动:如何推荐给那些没有留下反馈的用户?我们建议制作全球热门内容的列表,并尽可能使其多样化,以更有可能“吸引”用户。
-
内容的冷启动:你如何推荐那些还没有时间积累统计数据的内容?为了解决这个问题,冷启动内容通常会在推荐中以较小的比例出现。
-
反馈循环是推荐系统中的一个经典陷阱。我们向用户展示内容,然后收集反馈,并在这些数据上运行下一个学习周期。在这种情况下,系统从它自己生成的数据中学习。为了避免这个陷阱,我们通常会分配一小部分用户接受随机输出而不是推荐——通过这种设计,系统将不仅仅在自己的数据上进行训练,还将在用户与随机选择的内容的互动上进行训练。
祝你在构建推荐系统时好运,感谢你的关注!
亚历山大·朱穆拉特 是 FunCorp 数据科学团队的负责人,该公司创建了具有数百万活跃用户的娱乐性 UGC 应用(如 iFunny, ABPV),并帮助实现最佳个性化。之前,亚历山大曾领导在线影院 IVI 的数据科学团队。
更多相关话题
R 中你可能不知道的十个额外有用的东西
原文:
www.kdnuggets.com/2019/07/ten-more-random-useful-things-r.html
评论
由 Keith McNulty,麦肯锡公司
我对 我几个月前的文章 的积极反应感到惊讶,该文章列出了十个可能你不知道的 R 中的随机有用的东西。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的捷径。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
我感觉 R 作为一种语言已经发展到一个程度,以至于我们现在以完全不同的方式使用它。这意味着每个人可能都有许多技巧、包、函数等,但其他人完全不了解,如果知道的话会觉得很有用。正如 Mike Kearney 也指出的,我的十个列表中没有任何与统计相关的内容,这仅仅展示了 R 近年来的发展。
说实话,上次我很难把它限制在十个,因此这里有十个额外的关于 R 的东西,这些东西帮助使我的工作更轻松,你可能会觉得有用。如果这些对你当前的工作有帮助,或者你有其他建议可以告诉其他人的东西,请在这里或在 Twitter 上留言。
1. dbplyr
dbplyr 就是它名字的含义。它允许你在数据库中使用 dplyr。如果你在处理数据库并且从未听说过 dbplyr,那么你可能仍在代码中使用 SQL 字符串,这会迫使你在实际想要思考整洁代码时思考 SQL,当你想要抽象代码以生成函数等时,这可能会很痛苦。
dbplyr 允许你使用 dplyr 创建 SQL 查询。它通过建立一个可以使用 dplyr 函数操作的数据库表,将这些函数转换为 SQL。例如,如果你有一个名为 con 的数据库连接,且想要操作一个名为 CAT_DATA 的表在 CAT_SCHEMA 中,你可以将此表设置为:
cat_table <- dplyr::tbl(
con,
dbplyr::in_schema("CAT_SCHEMA", "CAT_TABLE")
)
然后你可以对cat_table执行常见的数据操作,如filter、mutate、group_by、summarise等,这些操作将在后台转化为 SQL 查询。非常有用的是,数据在你使用dplyr::collect()函数最终获取之前,并不会实际下载到你的 R 会话中。这意味着你可以让 SQL 完成所有工作,然后在最后获取你处理后的数据,而不是在开始时就拉取整个数据库。
关于dbplyr的更多内容,你可以查看我之前的文章这里和教程这里。
2. rvest和xml2
人们说 Python 在网页抓取方面要好得多。这可能是对的。但对于那些喜欢在 tidyverse 中工作的我们来说,rvest和xml2包可以通过与magrittr配合使用,使得简单的网页抓取变得非常容易,并且允许我们使用管道命令。由于网页上的 HTML 和 XML 代码通常是高度嵌套的,我认为使用%>%来构建抓取代码是非常直观的。
通过初步读取感兴趣页面的 HTML 代码,这些包将嵌套的 HTML 和 XML 节点拆解为列表,允许你逐步搜索和挖掘特定的节点或属性。将这些与 Chrome 的检查功能结合使用,可以快速提取你需要的关键信息。
举个快速的例子,我最近写了一个函数,用于从这个相当华丽的页面抓取任何历史时点的基础 Billboard 音乐排行榜数据,生成一个数据框,代码简单如以下:
get_chart <- function(date = Sys.Date(), positions = c(1:10), type = "hot-100") { # get url from input and read html
input <- paste0("https://www.billboard.com/charts/", type, "/", date) chart_page <- xml2::read_html(input) # scrape data
chart <- chart_page %>%
rvest::html_nodes('body') %>%
xml2::xml_find_all("//div[contains(@class, 'chart-list-item ')]") rank <- chart %>%
xml2::xml_attr('data-rank') artist <- chart %>%
xml2::xml_attr('data-artist') title <- chart %>%
xml2::xml_attr('data-title') # create dataframe, remove nas and return result
chart_df <- data.frame(rank, artist, title)
chart_df <- chart_df %>%
dplyr::filter(!is.na(rank), rank %in% positions) chart_df
}
关于这个例子更多的内容请见这里,关于rvest的更多内容请见这里,关于xml2的更多内容请见这里。
3. 对长数据进行 k 均值聚类
k 均值聚类是一种越来越流行的统计方法,用于将数据中的观测值进行聚类,通常是将大量的数据点简化为较少的簇或原型。kml包现在允许在纵向数据上进行 k 均值聚类,其中“数据点”实际上是数据序列。
当你研究的数据点实际上是随时间变化的读数时,这非常有用。这可能是医院患者体重增减的临床观察,或者员工的补偿轨迹。
kml 通过首先使用 cld 函数将数据转换为 ClusterLongData 类的对象来工作。然后它使用“爬山”算法对数据进行分区,每次测试多个 k 值 20 次。最后,choice() 函数允许你以图形方式查看每个 k 的算法结果,并决定你认为最佳的聚类。
4. RStudio 中的连接窗口
在最新版本的 RStudio 中,连接窗口允许你浏览任何远程数据库,无需进入 SQL 开发者等独立环境。这种便利现在提供了一个机会,让开发项目可以完全在 RStudio IDE 中完成。
通过在连接窗口中设置与远程数据库的连接,你可以在嵌套的模式、表格、数据类型中浏览,甚至直接查看一个表格以查看数据的摘录。
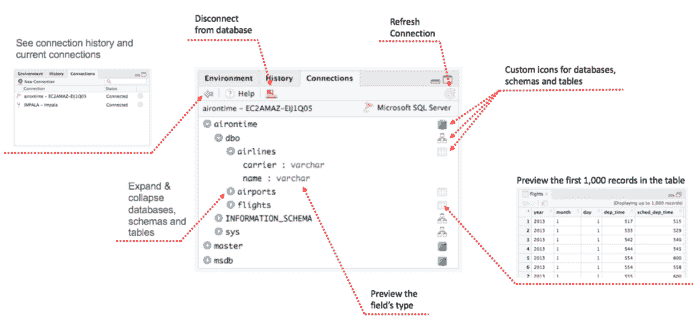 最新版本的 RStudio 中的连接窗口
最新版本的 RStudio 中的连接窗口
关于连接窗口的更多信息 在这里。
5. tidyr::complete()
R 数据框的默认行为是,如果特定观测值没有数据,那么该观测值的行不会出现在数据框中。当你需要将这个数据框用作需要所有可能观测值的输入时,这可能会导致问题。
通常,这个问题发生在你将数据传递到某些图形函数中时,这些函数期望在没有观测值时看到零值,并且无法理解缺失的行意味着该行的零值。这也可能在进行未来预测时成为问题,尤其是当起始点有缺失行时。
complete() 函数在 tidyr 中允许你填补所有没有数据的观测值。它允许你定义想要完成的观测值,然后声明用于填补缺口的值。例如,如果你在统计不同品种的雄性和雌性狗的数量,并且有些组合在样本中没有狗,你可以使用以下方法来处理:
dogdata %>%
tidyr::complete(SEX, BREED, fill = list(COUNT = 0))
这将扩展你的数据框,确保包含所有可能的 SEX 和 BREED 组合,并用零填充 COUNT 的缺失值。
6. gganimate
动画图形目前非常流行,gganimate 包允许使用 ggplot2(我认为大多数 R 用户)的用户非常简单地扩展他们的代码以创建动画图形。
gganimate 的工作原理是利用存在于一系列“过渡状态”(通常是几年或其他时间序列数据)中的数据。你可以将每个过渡状态中的数据绘制成一个简单的静态 ggplot2 图表,然后使用 ease_aes() 函数创建在过渡状态之间移动的动画。过渡发生的方式有许多选项,animate() 函数允许以各种形式渲染图形,例如动画 gif 或 mpeg。
例如,下面是我制作的一个 gif,展示了 1957 到 2018 年间 Eurovision 歌唱比赛中所有获胜的时间点:
 使用 gganimate 展示所有时间 Eurovision 歌唱比赛结果
使用 gganimate 展示所有时间 Eurovision 歌唱比赛结果
代码见 这里 和我发现非常有用的 gganimate 的详细教程见 这里。
7. networkD3
D3 是一个极其强大的数据可视化库,用于 JavaScript。越来越多的包开始提供给 R 用户,允许他们使用 D3 构建可视化,例如 R2D3,这特别好,因为它让我们可以欣赏到最棒的十六边形贴纸之一(见 这里)。
我最喜欢的 D3 包是 networkD3。它已经存在一段时间,并且非常适合以响应式或美观的方式绘制图形或网络数据。特别是,它可以使用 forceNetwork() 绘制力导向网络,使用 sankeyNetwork() 绘制桑基图,使用 chordNetwork() 绘制和弦图。下面是一个我创建的简单桑基网络的例子,展示了 Brexit 公投中的投票流向。
 使用 networkD3 展示 Brexit 公投中的投票流向
使用 networkD3 展示 Brexit 公投中的投票流向
更多关于这个具体示例的信息 这里 和更多关于 networkD3 的信息 这里。
8. 使用 DT 在 RMarkdown 或 Shiny 中创建数据表
DT 包是 R 与 DataTables JavaScript 库之间的接口。这使得在 Shiny 应用或 R Markdown 文档中非常容易显示表格,这些表格具有许多内置功能和响应性。这避免了你需要编写单独的数据下载函数,为用户提供了灵活的数据显示和排序选项,并且内置了数据搜索功能。
例如,一个简单的命令如下:
DT::datatable(
head(iris),
caption = 'Table 1: This is a simple caption for the table.'
)
可以产生像这样的效果:
关于 DT 的更多信息请见 这里,包括如何设置各种选项以自定义布局并添加数据下载、复制和打印按钮。
9. 使用 prettydoc 美化你的 RMarkdown
prettydoc 是 Yixuan Qiu 开发的一个包,提供了一组简单的主题,使你的 RMarkdown 文档具有不同的、更美观的外观和感觉。当你只想让文档看起来更有趣但没有时间自己进行样式调整时,这非常有帮助。
使用起来非常简单。只需对文档的 YAML 头部进行简单编辑,就能在整个文档中调用特定的样式主题,提供多种主题可供选择。例如,这将使标题、表格、嵌入的代码和图形的颜色和风格变为可爱的干净蓝色:
---
title: "My doc"
author: "Me"
date: June 3, 2019
output:
prettydoc::html_pretty:
theme: architect
highlight: github
---
更多关于 prettydoc 的信息请见 这里。
10. 可选地使用 code_folding 在 RMarkdown 中隐藏代码
RMarkdown 是记录工作的一种绝佳方式,它允许你在一个地方编写叙述并捕捉代码。但有时代码可能会让人感到压倒性,并且对于那些只对你工作的叙述感兴趣、不想了解你如何进行分析的非编码者来说,不太友好。
之前,我们唯一的选择是将 echo = TRUE 或 echo = FALSE 设置在 knitr 选项中,以决定是否在文档中显示代码。但现在我们可以在 YAML 头部设置一个选项,兼顾两全其美。设置 code_folding: hide 将默认隐藏代码块,但在文档中提供小的点击展开框,以便读者根据需要查看所有代码或特定代码块,如下所示:
 R Markdown 中的代码折叠下拉框
R Markdown 中的代码折叠下拉框
这就总结了我接下来的十个随机 R 提示。希望这些对你有所帮助,也欢迎在评论中添加你自己的提示供其他用户阅读。
我最初是纯数学家,然后成为了心理测量学家和数据科学家。我热衷于将所有这些学科的严谨性应用于复杂的人类问题。我还是一个编码迷和日本 RPG 的超级粉丝。在 LinkedIn 或 Twitter 上找到我。

简介:Keith McNulty 是麦肯锡公司的数据科学家。
原文。已获授权转载。
相关:
-
你可能不知道的 R 中的十个随机有用的东西
-
如何制作惊艳的 3D 图表以更好地讲述故事
-
ggplot 的演变
更多相关主题
R 中你可能不知道的十个随机有用的东西
评论
由Keith McNulty,麦肯锡公司
我经常发现自己向同事和其他程序员介绍一些我在 R 中使用的简单方法,这些方法真的对我完成任务有很大帮助。这些方法从微不足道的快捷键,到鲜为人知的函数,再到实用的小技巧。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
因为 R 生态系统如此丰富且不断发展,人们常常会错过一些真正能帮助他们完成任务的东西。所以我经常从观众那里得到类似“我从未知道过这个!”的惊讶反应。
这里有十个让我在 R 工作时生活更轻松的东西。如果你已经知道这些内容,抱歉浪费了你的阅读时间,并请考虑添加一个评论,分享你认为对其他读者有用的东西。
1. switch函数
我喜欢switch()。它基本上是if语句的一种便利缩写,能够根据另一个变量的值选择其值。我发现它在编写需要根据你做出的先前选择加载不同数据集的代码时特别有用。例如,如果你有一个叫animal的变量,并且你想根据animal是狗、猫还是兔子来加载不同的数据集,你可以这样写:
data <- read.csv(
switch(animal,
"dog" = "dogdata.csv",
"cat" = "catdata.csv",
"rabbit" = "rabbitdata.csv")
)
这在 Shiny 应用中特别有用,你可能希望根据一个或多个输入菜单选择来加载不同的数据集甚至环境文件。
2. RStudio 快捷键
这不仅仅是一个 R 的技巧,更关于 RStudio IDE,但常用命令的快捷键非常有用,可以节省很多输入时间。我最喜欢的两个是 Ctrl+Shift+M 用于管道操作符%>%和 Alt+-用于赋值操作符<-。如果你想查看这些绝妙的快捷键的完整列表,只需在 RStudio 中输入 Alt+Shift+K。
3. flexdashboard 包
如果你想快速创建一个简洁的 Shiny 仪表盘,flexdashboard 包含了你所需的一切。它提供了简单的 HTML 快捷方式,使得侧边栏的构建和显示的行列组织变得容易。它还有一个超级灵活的标题栏,你可以将应用程序组织成不同的页面,并插入图标和指向 Github 代码或电子邮件地址等的链接。作为一个在 RMarkdown 中运行的包,它也允许你将所有应用程序保存在一个 Rmd 文件中,而无需像 shinydashboard 那样将其拆分为单独的服务器和 UI 文件。我在需要创建一个简单的仪表盘原型版本时总是使用 flexdashboard,然后再将其移到更高级的设计中。我通常可以在一个小时内使用 flexdashboard 搭建好仪表盘。
4. R Shiny 中的 req 和 validate 函数
R Shiny 开发可能会很令人沮丧,尤其是当你收到那些无法帮助你理解问题所在的通用错误消息时。随着 Shiny 的发展,越来越多的验证和测试函数被添加进来,以帮助更好地诊断和提醒特定错误的发生。req() 函数允许你在环境中存在另一个变量时才执行某个操作,但它是静默的,不会显示错误。因此,你可以根据先前的操作使 UI 元素的显示变为条件。例如,参考我上面第 1 个例子:
output$go_button <- shiny::renderUI({
# only display button if an animal input has been chosen
shiny::req(input$animal)
# display button
shiny::actionButton("go",
paste("Conduct", input$animal, "analysis!")
)
})
validate() 在渲染输出之前进行检查,并使你能够返回一个量身定制的错误消息,如果某个条件未满足,例如用户上传了错误的文件:
# get csv input file
inFile <- input$file1
data <- inFile$datapath
# render table only if it is dogs
shiny::renderTable({
# check that it is the dog file, not cats or rabbits
shiny::validate(
need("Dog Name" %in% colnames(data)),
"Dog Name column not found - did you load the right file?"
)
data
})
有关这些函数的更多信息,请参阅我其他的文章 这里。
5. 使用系统环境将所有凭证保留给自己
如果你分享的代码需要数据库等的登录凭证,你可以使用系统环境来避免将这些凭证发布到 Github 或其他可能存在风险的地方。你可以在 R 会话中将凭证作为命名的环境变量,例如:
Sys.setenv(
DSN = "database_name",
UID = "User ID",
PASS = "Password"
)
然后在你共享的脚本中,你可以使用这些环境变量进行登录。例如:
db <- DBI::dbConnect(
drv = odbc::odbc(),
dsn = Sys.getenv("DSN"),
uid = Sys.getenv("UID"),
pwd = Sys.getenv("PASS")
)
更方便的是,如果这些凭证是你经常使用的,你可以将它们设置为操作系统中的环境变量,这样在你使用 R 时,它们将始终可用,而你无需在代码中显示它们。(只是要小心谁有权访问这些凭证!)
6. 使用 styler 自动化 tidyverse 风格
这一天很艰难,你的任务繁重。你的代码没有你想要的那么整洁,你没有时间逐行编辑它。不要担心。styler 包提供了许多函数,可以自动重新样式化你的代码以匹配 tidyverse 风格。只需在你的凌乱脚本上运行 styler::style_file(),它将为你完成大量(但不是全部)的工作。
7. 参数化 R Markdown 文档
所以你写了一份很棒的 R Markdown 文档,分析了关于狗的大量事实。然后你被告知——‘不,我对猫更感兴趣’。不要担心。如果你将你的 R Markdown 文档参数化,你可以只用一个命令自动生成类似的猫的报告。
你可以通过在 R Markdown 文档的 YAML 头部定义参数,并给每个参数一个值来做到这一点。例如:
---
title: "Animal Analysis"
author: "Keith McNulty"
date: "21 March 2019"
output:
html_document:
code_folding: "hide"
params:
animal_name:
value: Dog
choices:
- Dog
- Cat
- Rabbit
years_of_study:
input: slider
min: 2000
max: 2019
step: 1
round: 1
sep: ''
value: [2010, 2017]
---
现在你可以在文档中的 R 代码里写入这些变量,如 params$animal_name 和 params$years_of_study。如果你像平常一样编织文档,它将使用这些参数的默认值进行编织。然而,如果你在 RStudio 的 Knit 下拉菜单中选择参数编织(或使用 knit_with_parameters()),一个漂亮的菜单选项会出现,让你在编织文档前选择你的参数。太棒了!
 使用参数进行编织
使用参数进行编织
8. revealjs
revealjs 是一个允许你创建漂亮 HTML 演示文稿的包,具有直观的幻灯片导航菜单,并嵌入 R 代码。它可以在 R Markdown 中使用,并具有非常直观的 HTML 快捷键,允许你创建一个嵌套的、逻辑结构的漂亮幻灯片,并有多种样式选项。演示文稿以 HTML 格式呈现,意味着人们可以在平板或手机上跟随你的讲解,这非常方便。你可以通过安装这个包并在你的 YAML 头部中调用它来设置 revealjs 演示文稿。这是我最近用 revealjs 做的一次演讲的 YAML 头部示例
---
title: "Exporing the Edge of the People Analytics Universe"
author: "Keith McNulty"
output:
revealjs::revealjs_presentation:
center: yes
template: starwars.html
theme: black
date: "HR Analytics Meetup London - 18 March, 2019"
resource_files:
- darth.png
- deathstar.png
- hanchewy.png
- millenium.png
- r2d2-threepio.png
- starwars.html
- starwars.png
- stormtrooper.png
---
这是一个示例页面。你可以在 这里 找到代码,在 这里 找到演示文稿。
 使用 revealjs 进行轻松的在线演示
使用 revealjs 进行轻松的在线演示
9. R Shiny 中的 HTML 标签(例如,在你的 Shiny 应用中播放音频)
大多数人没有充分利用 R Shiny 中可用的 HTML 标签。有 110 个标签提供了各种 HTML 格式和其他命令的快捷方式。最近我构建了一个 Shiny 应用,执行一个任务花了很长时间。知道用户可能在等待完成时会多任务处理,我使用了 tags$audio 来播放胜利的庆祝音乐,以在任务完成时提醒用户。
10. praise 包
极其简单却又很棒,praise 包向用户提供赞美。虽然这看起来像是无用的自我赞赏,但它实际上在编写 R 包时非常有用,比如当某个过程成功完成时,你可以给予赞美或鼓励。你也可以把它放在复杂脚本的末尾,以便在脚本成功运行时获得额外的幸福感。
 The praise package
The praise package
最初我是一名纯数学家,然后我成为了心理测量学家和数据科学家。我对将这些学科的严谨性应用于复杂的人际问题充满热情。我还是一个编码爱好者以及日本 RPG 的超级粉丝。可以在LinkedIn或Twitter上找到我。
个人简介: Keith McNulty 是麦肯锡公司的数据科学家。
原文。转载已获许可。
相关:
-
数据清理的顶级 R 包
-
2018 年数据科学和 AI 的 7 大 R 包
-
R 语言中的自动化网页抓取
更多相关内容
过去十年的人工智能回顾
图片由作者提供。
过去十年对于人工智能(AI)领域来说是一段激动人心且充满事件的旅程。对深度学习潜力的初步探索转变为一个爆炸性增长的领域,现在包括从电子商务中的推荐系统到自动驾驶车辆的目标检测以及能够生成从逼真图像到连贯文本的生成模型。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
在本文中,我们将回顾一些关键的突破,带您走一趟记忆之旅,了解我们如何走到今天。不论您是经验丰富的人工智能从业者还是对领域最新发展感兴趣的读者,本文将为您提供对人工智能取得显著进展的全面概述。
2013 年:AlexNet 和变分自编码器
2013 年被广泛认为是深度学习的“成长期”,这一变化由计算机视觉的重大进展引发。根据对 Geoffrey Hinton 的最新采访,到 2013 年“几乎所有的计算机视觉研究都转向了神经网络”。这一繁荣主要是由于一年前图像识别领域的一个相当意外的突破。
2012 年 9 月,AlexNet,一个深度卷积神经网络(CNN),在 ImageNet 大规模视觉识别挑战赛(ILSVRC)中创下了破纪录的成绩,展示了深度学习在图像识别任务中的潜力。它达到了 15.3%的top-5 error,比其最近的竞争对手低 10.9%。
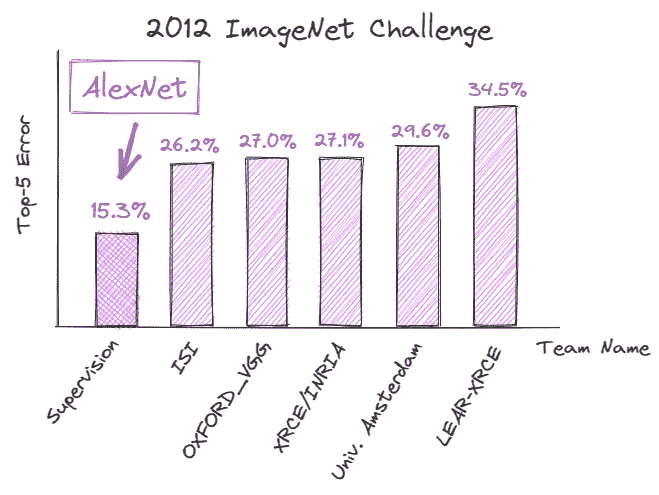
图片由作者提供。
这种成功背后的技术改进对 AI 的未来轨迹至关重要,并且极大地改变了对深度学习的看法。
首先,作者们应用了一个由五层卷积层和三层全连接线性层组成的深度 CNN —— 这种架构设计在当时被许多人视为不切实际。此外,由于网络深度产生的大量参数,训练是在两块图形处理单元(GPU)上并行进行的,展示了在大数据集上显著加速训练的能力。通过将传统的激活函数,如 sigmoid 和 tanh,替换为更高效的整流线性单元(ReLU),训练时间进一步缩短。
作者提供的图片。
这些进展共同促成了 AlexNet 的成功,标志着人工智能历史的一个转折点,并激发了学术界和科技界对深度学习的强烈兴趣。因此,许多人认为 2013 年是深度学习真正起飞的拐点。
虽然 2013 年的变化在 AlexNet 的喧嚣中稍显被淹没,但变分自编码器(VAEs)的发展也同样值得关注 —— 这些生成模型可以学习表示和生成数据,如图像和声音。它们通过学习输入数据在低维空间中的压缩表示,即 潜在空间,来工作。这使得它们能够通过从学习到的潜在空间中采样来生成新数据。后来,VAEs 证明开辟了生成建模和数据生成的新途径,应用于艺术、设计和游戏等领域。
2014: 生成对抗网络
在接下来的一年,即 2014 年 6 月,深度学习领域见证了另一个重大进展,Ian Goodfellow 和同事们引入了生成对抗网络,即 GANs。
GANs 是一种能够生成与训练集相似的新数据样本的神经网络类型。基本上,两个网络同时训练:(1)生成器网络生成虚假的或合成的样本,(2)判别器网络评估这些样本的真实性。这种训练在类似游戏的设置中进行,生成器试图创建欺骗判别器的样本,而判别器则试图正确识别虚假样本。
当时,GANs 代表了一个强大而新颖的数据生成工具,不仅用于生成图像和视频,还用于音乐和艺术。它们还推动了无监督学习的发展,这是一个被普遍认为发展不充分且具有挑战性的领域,展示了在不依赖显式标签的情况下生成高质量数据样本的可能性。
2015: ResNets 和自然语言处理突破
2015 年,人工智能领域在计算机视觉和自然语言处理(NLP)方面取得了显著进展。
何凯明及其同事发表了一篇题为《深度残差学习用于图像识别》的论文,在其中他们引入了残差神经网络(ResNets)的概念——这种架构通过添加捷径,使信息在网络中流动更加顺畅。与普通神经网络不同的是,ResNet 在每一层的输入中增加了残差连接,这些连接跳过一层或多层,直接连接到网络中的更深层次。
因此,ResNets 能够解决梯度消失问题,这使得训练比当时认为可能的更深层次的神经网络成为可能。这反过来在图像分类和物体识别任务中带来了显著的改进。
在同一时期,研究人员在递归神经网络(RNNs)和长短期记忆(LSTM)模型的发展上取得了显著进展。尽管这些模型自 1990 年代以来已经存在,但它们直到 2015 年才开始引起关注,这主要由于以下因素:(1)可用于训练的更大且更多样化的数据集,(2)计算能力和硬件的改进,使得训练更深层次和更复杂的模型成为可能,以及(3)在此过程中进行的改进,如更复杂的门控机制。
这些架构使得语言模型能够更好地理解文本的上下文和意义,从而在语言翻译、文本生成和情感分析等任务中取得了巨大的进步。那时 RNNs 和 LSTMs 的成功为我们今天看到的大型语言模型(LLMs)的发展铺平了道路。
2016 年:AlphaGo
在 1997 年加里·卡斯帕罗夫被 IBM 的 Deep Blue 击败之后,2016 年另一场人类与机器的对决震撼了游戏界:谷歌的 AlphaGo 战胜了围棋世界冠军李世石。

图片由Elena Popova提供,来源于Unsplash。
Sedol 的失败标志着人工智能发展轨迹上的另一个重大里程碑:它展示了机器可以超越即使是最熟练的人类玩家,在一个曾经被认为过于复杂以至于计算机无法处理的游戏中。AlphaGo 使用了深度强化学习和蒙特卡罗树搜索的组合,分析了数百万个先前游戏中的位置,并评估最佳的可能走法——这一策略远远超越了人类在这一背景下的决策能力。
2017 年:变压器架构和语言模型
可以说,2017 年是奠定了我们今天所见生成式 AI 突破基础的最关键的一年。
2017 年 12 月,Vaswani 及其同事发布了基础性的论文《Attention is all you need》,介绍了利用self-attention概念处理序列输入数据的变压器架构。这使得处理长距离依赖变得更加高效,这曾经是传统 RNN 架构面临的挑战。

照片由Jeffery Ho拍摄,发布于Unsplash。
变压器由两个基本组件组成:编码器和解码器。编码器负责对输入数据进行编码,例如,这可以是一个单词序列。它然后对输入序列应用多个自注意力层和前馈神经网络,以捕捉句子中的关系和特征,并学习有意义的表示。
本质上,自注意力使模型能够理解句子中不同单词之间的关系。与传统模型按固定顺序处理单词不同,变压器实际上同时检查所有单词。它们为每个单词分配一种称为注意力的分数,基于其与句子中其他单词的相关性。
解码器则从编码器那里获取编码表示并生成输出序列。在机器翻译或文本生成等任务中,解码器根据从编码器接收到的输入生成翻译序列。与编码器类似,解码器也由多个自注意力层和前馈神经网络组成。然而,它包含一个额外的注意力机制,使其能够关注编码器的输出。这使得解码器在生成输出时可以考虑输入序列中的相关信息。
transformer 架构从此成为 LLMs 开发中的关键组件,并在自然语言处理领域如机器翻译、语言建模和问答等方面取得了显著改进。
2018 年:GPT-1、BERT 和图神经网络
几个月后,Vaswani 等人发布了他们的基础论文,Generative Pretrained Transformer,或 GPT-1,在 2018 年 6 月由 OpenAI 推出,利用 transformer 架构有效地捕捉文本中的长程依赖关系。GPT-1 是最早展示无监督预训练然后在特定 NLP 任务上进行微调的有效性的模型之一。
Google 也利用了仍然相当新颖的 transformer 架构,在 2018 年底发布并开源了他们自己的预训练方法,称为Bidirectional Encoder Representations from Transformers,或 BERT。与以前以单向方式处理文本的模型(包括 GPT-1)不同,BERT 同时考虑每个词的前后文。为了说明这一点,作者提供了一个非常直观的例子:
…在句子“I accessed the bank account”中,单向上下文模型会根据“I accessed the”来表示“bank”,而不是“account”。然而,BERT 使用其前后的上下文来表示“bank”——“I accessed the … account”——从深层神经网络的最底层开始,使其深度双向。
双向性的概念如此强大,以至于使 BERT 在各种基准任务上超越了最先进的 NLP 系统。
除了 GPT-1 和 BERT 之外,图神经网络,或 GNNs,在那一年也引起了一些关注。它们属于一种专门设计用于处理图数据的神经网络类别。GNNs 利用消息传递算法在图的节点和边之间传播信息。这使得网络能够以一种更直观的方式学习数据的结构和关系。
这项工作使得从数据中提取更深层次的洞察成为可能,并因此拓宽了深度学习可以应用的领域。通过 GNNs,社会网络分析、推荐系统和药物发现等领域取得了重大进展。
2019 年:GPT-2 和改进的生成模型
2019 年标志着生成模型的几项显著进展,特别是GPT-2的推出。该模型在许多自然语言处理任务中实现了最先进的性能,并且能够生成高度真实的文本,这在回顾中给我们预示了这一领域即将到来的进展。
该领域的其他改进包括 DeepMind 的BigGAN,该模型生成的高质量图像几乎无法与真实图像区分开来,以及 NVIDIA 的StyleGAN,该模型允许对生成图像的外观进行更好的控制。
总体来看,这些现在被称为生成式人工智能的进展进一步推动了这一领域的边界,而且…
2020 年:GPT-3 和 自监督学习
…不久之后,另一种模型诞生了,即使在技术圈外也已成为家喻户晓的名字:GPT-3。该模型代表了 LLM 规模和能力的重大飞跃。为了说明情况,GPT-1 仅拥有 117 百万个参数,而 GPT-2 增加到了 15 亿个参数,而 GPT-3 则达到了 1750 亿个参数。
这种庞大的参数空间使得 GPT-3 能够在各种提示和任务中生成异常连贯的文本。它还在文本完成、问答甚至创意写作等多种自然语言处理任务中展示了令人印象深刻的表现。
此外,GPT-3 再次突显了使用自监督学习的潜力,这使得模型能够在大量未标注的数据上进行训练。这种方法的优势在于,这些模型能够在没有广泛任务特定训练的情况下获得对语言的广泛理解,从而使其成本更为经济。
Yann LeCun 在推特上讨论了关于自监督学习的纽约时报文章。
2021 年:AlphaFold 2、DALL·E 和 GitHub Copilot
从蛋白质折叠到图像生成和自动编码辅助,2021 年因 AlphaFold 2、DALL·E 和 GitHub Copilot 的发布而变得尤为重要。
AlphaFold 2 被誉为解决了困扰了几十年的蛋白质折叠问题的长期期待的解决方案。DeepMind 的研究人员扩展了变压器架构,创建了evoformer blocks —— 利用进化策略进行模型优化的架构 —— 以构建一个能够根据蛋白质的 1D 氨基酸序列预测其 3D 结构的模型。这一突破有着巨大的潜力,能够革新药物发现、生物工程以及我们对生物系统的理解等领域。
OpenAI 今年再次登上新闻头条,推出了DALL·E。本质上,这个模型结合了 GPT 风格语言模型和图像生成的概念,使得从文本描述中生成高质量图像成为可能。
为了说明这个模型的强大,请看下面的图像,这幅图像是根据“未来世界的油画,飞行汽车”这一提示生成的。

DALL·E 生成的图像。
最后,GitHub 发布了后来成为每个开发者最佳朋友的Copilot。这项成就与 OpenAI 合作实现,OpenAI 提供了基础语言模型 Codex,该模型经过大量公开代码的训练,从而学会理解和生成各种编程语言的代码。开发者只需提供一个代码注释说明他们试图解决的问题,模型就会建议实现解决方案的代码。其他功能包括用自然语言描述输入代码以及在编程语言之间转换代码。
2022 年:ChatGPT 与 Stable Diffusion
在过去十年里,人工智能的迅速发展 culminated in 一项突破性的进展:OpenAI 的ChatGPT,这款聊天机器人于 2022 年 11 月正式发布。该工具代表了自然语言处理领域的尖端成就,能够对各种查询和提示生成连贯且具有上下文相关的回答。此外,它还可以进行对话、提供解释、提出创意建议、协助解决问题、编写和解释代码,甚至模拟不同的个性或写作风格。

作者提供的图像。
通过与机器人互动的简单直观界面也刺激了可用性的急剧提升。以前,主要是科技界在尝试最新的人工智能发明。然而,现在,人工智能工具已渗透到几乎每个专业领域,从软件工程师到作家、音乐家和广告商。许多公司也在使用这一模型来自动化服务,例如客户支持、语言翻译或回答常见问题。实际上,我们看到的自动化浪潮重新点燃了一些担忧,并激发了关于哪些工作可能面临自动化风险的讨论。
尽管 ChatGPT 在 2022 年占据了许多焦点,但图像生成领域也取得了重要进展。Stable diffusion,一种能够从文本描述生成逼真图像的潜在文本到图像扩散模型,由 Stability AI 发布。
稳定扩散是传统扩散模型的扩展,这些模型通过反复向图像添加噪声,然后逆转过程以恢复数据。它的设计旨在通过不直接处理输入图像,而是处理其低维表示或潜在空间,从而加速这一过程。此外,通过将用户提供的嵌入变换器的文本提示添加到网络中,扩散过程也得到了修改,使其能够在每次迭代过程中引导图像生成过程。
总体而言,2022 年 ChatGPT 和稳定扩散的发布突显了多模态生成 AI 的潜力,并激发了这一领域进一步发展的巨大推动力和投资。
2023:LLMs 和聊天机器人
今年无疑成为了 LLMs 和聊天机器人的一年。越来越多的模型正在快速开发和发布。
图片由作者提供。
例如,2 月 24 日,Meta AI 发布了 LLaMA——一个在大多数基准测试中优于 GPT-3 的 LLM,尽管其参数数量要少得多。不到一个月后,3 月 14 日,OpenAI 发布了 GPT-4——一个比 GPT-3 更大、更强大且多模态的版本。虽然 GPT-4 的确切参数数量尚不清楚,但推测在万亿级别。
3 月 15 日,斯坦福大学的研究人员发布了 Alpaca,这是一个从 LLaMA 上经过微调的轻量级语言模型,专注于跟随指令的演示。几天后,3 月 21 日,Google 推出了其 ChatGPT 竞争对手:Bard。Google 还在本月 5 月 10 日 发布了其最新的 LLM,PaLM-2。鉴于这一领域发展的迅猛,阅读本文时很可能又会出现另一个模型。
我们还看到越来越多的公司将这些模型融入到他们的产品中。例如,Duolingo 宣布了其 GPT-4 驱动的 Duolingo Max,这是一个新的订阅层,旨在为每个人提供量身定制的语言课程。Slack 也推出了一个名为 Slack GPT 的 AI 驱动的助手,可以进行草拟回复或总结线程。此外,Shopify 向公司的 Shop 应用程序引入了一个 ChatGPT 驱动的助手,能够通过各种提示帮助客户识别所需的产品。
Shopify 在 Twitter 上宣布了其 ChatGPT 驱动的助手。
有趣的是,如今人工智能聊天机器人甚至被视为人类治疗师的替代品。例如,Replika是一款美国的聊天机器人应用,它为用户提供了一个“关心你的 AI 伴侣,总是愿意倾听和交谈,总是站在你这边”。其创始人尤金妮亚·库伊达表示,该应用拥有各种各样的用户,从将其作为“在与人互动之前热身”的自闭症儿童,到只是需要一个朋友的孤独成年人。
在我们总结之前,我想强调一下过去十年人工智能发展的高潮:人们实际上在使用 Bing!今年早些时候,微软推出了其基于 GPT-4 的“网络副驾驶”,该工具经过定制用于搜索,并且在……永远(?)中第一次成为了谷歌在搜索业务中长期主导地位的严肃竞争者。
回顾与展望
当我们回顾过去十年的人工智能发展时,显而易见的是,我们见证了一场对工作、商业和相互互动产生深远影响的变革。最近在生成模型,特别是 LLMs(大型语言模型)方面取得的大量进展,似乎遵循了“更大更好”的普遍信念,指的是模型的参数空间。这一点在 GPT 系列中尤为明显,该系列从 117 百万参数的 GPT-1 起步,每个后续模型的参数数量增加了约一个数量级,最终在 GPT-4 中达到可能的万亿级参数。
然而,根据最近的采访,OpenAI CEO Sam Altman 认为我们已经迎来了“更大更好”时代的终结。他认为,尽管未来模型的参数数量仍会增长,但未来模型改进的主要焦点将是提升模型的能力、实用性和安全性。
后者尤为重要。考虑到这些强大的人工智能工具现在已经进入了公众手中,不再仅限于受控的研究实验室环境,我们现在比以往任何时候都更需要谨慎行事,确保这些工具是安全的,并符合人类的最佳利益。希望我们在人工智能安全方面能够看到与其他领域相同的开发和投资。
附注: 如果我遗漏了你认为应该包含在本文中的核心 AI 概念或突破,请在下方评论中告知我!
托马斯·A·多弗 是微软的数据与应用科学家。在担任现职之前,他曾在生物技术行业担任数据科学家,并在神经反馈领域从事研究工作。他拥有整合神经科学硕士学位,并在业余时间在 Medium 上撰写有关数据科学、机器学习和 AI 的技术博客。
原文。经授权转载。
更多相关话题


 浙公网安备 33010602011771号
浙公网安备 33010602011771号