
KDNuggets-博客中文翻译-三十五-
KDNuggets 博客中文翻译(三十五)
原文:KDNuggets
利用 Pandas AI 进行数据分析
你在使用 Python 的数据领域中是否很熟练?如果是的话,我敢打赌你们大多数人都使用 Pandas 进行数据处理。
如果你不知道,Pandas是一个专门为数据分析和处理开发的开源 Python 软件包。它是使用最广泛的软件包之一,也是你在开始 Python 数据科学之旅时通常会学习的一个。
我们的前三个课程推荐
 1. Google 网络安全证书 - 快速入门网络安全职业。
1. Google 网络安全证书 - 快速入门网络安全职业。
 2. Google 数据分析专业证书 - 提升你的数据分析技能
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你在 IT 方面的组织
那么,Pandas AI 是什么?我想你读这篇文章是因为你想了解它。
好吧,正如你所知,我们正处在一个生成 AI 无处不在的时代。想象一下,如果你可以使用生成 AI 对你的数据进行数据分析,那将会容易很多。
这就是 Pandas AI 带来的效果。通过简单的提示,我们可以快速分析和处理数据集,而无需将数据发送到其他地方。
本文将探讨如何利用 Pandas AI 进行数据分析任务。在文章中,我们将学习以下内容:
-
Pandas AI 设置
-
使用 Pandas AI 进行数据探索
-
使用 Pandas AI 进行数据可视化
-
Pandas AI 高级用法
如果你准备好了,就让我们开始吧!
Pandas AI 设置
Pandas AI是一个 Python 软件包,它将大型语言模型(LLM)功能实现到 Pandas API 中。我们可以使用标准的 Pandas API 和生成 AI 增强功能,使 Pandas 成为一个对话工具。
我们主要想使用 Pandas AI 是因为该软件包提供的简单过程。该软件包可以使用简单的提示自动分析数据,而无需复杂的代码。
介绍够了,让我们动手实践吧。
首先,我们需要在其他任何事情之前安装这个软件包。
pip install pandasai
接下来,我们必须设置我们想用于 Pandas AI 的 LLM。有几种选择,例如 OpenAI GPT 和 HuggingFace。然而,本教程中我们将使用 OpenAI GPT。
将 OpenAI 模型设置到 Pandas AI 中是直接的,但你需要 OpenAI API 密钥。如果你没有,可以在他们的网站上获取。
如果一切准备就绪,让我们使用下面的代码设置 Pandas AI LLM。
from pandasai.llm import OpenAI
llm = OpenAI(api_token="Your OpenAI API Key")
你现在准备好使用 Pandas AI 进行数据分析了。
使用 Pandas AI 进行数据探索
让我们从一个示例数据集开始,尝试使用 Pandas AI 进行数据探索。我将在这个示例中使用 Seaborn 包中的 Titanic 数据。
import seaborn as sns
from pandasai import SmartDataframe
data = sns.load_dataset('titanic')
df = SmartDataframe(data, config = {'llm': llm})
我们需要将它们传递到 Pandas AI 智能数据框对象中以启动 Pandas AI。之后,我们可以在我们的 DataFrame 上执行对话活动。
让我们尝试一个简单的问题。
response = df.chat("""Return the survived class in percentage""")
response
乘客幸存的百分比是:38.38%
根据提示,Pandas AI 可以提出解决方案并回答我们的问题。
我们可以向 Pandas AI 提问,它会在 DataFrame 对象中提供答案。例如,这里有几个用于分析数据的提示。
#Data Summary
summary = df.chat("""Can you get me the statistical summary of the dataset""")
#Class percentage
surv_pclass_perc = df.chat("""Return the survived in percentage breakdown by pclass""")
#Missing Data
missing_data_perc = df.chat("""Return the missing data percentage for the columns""")
#Outlier Data
outlier_fare_data = response = df.chat("""Please provide me the data rows that
contains outlier data based on fare column""")
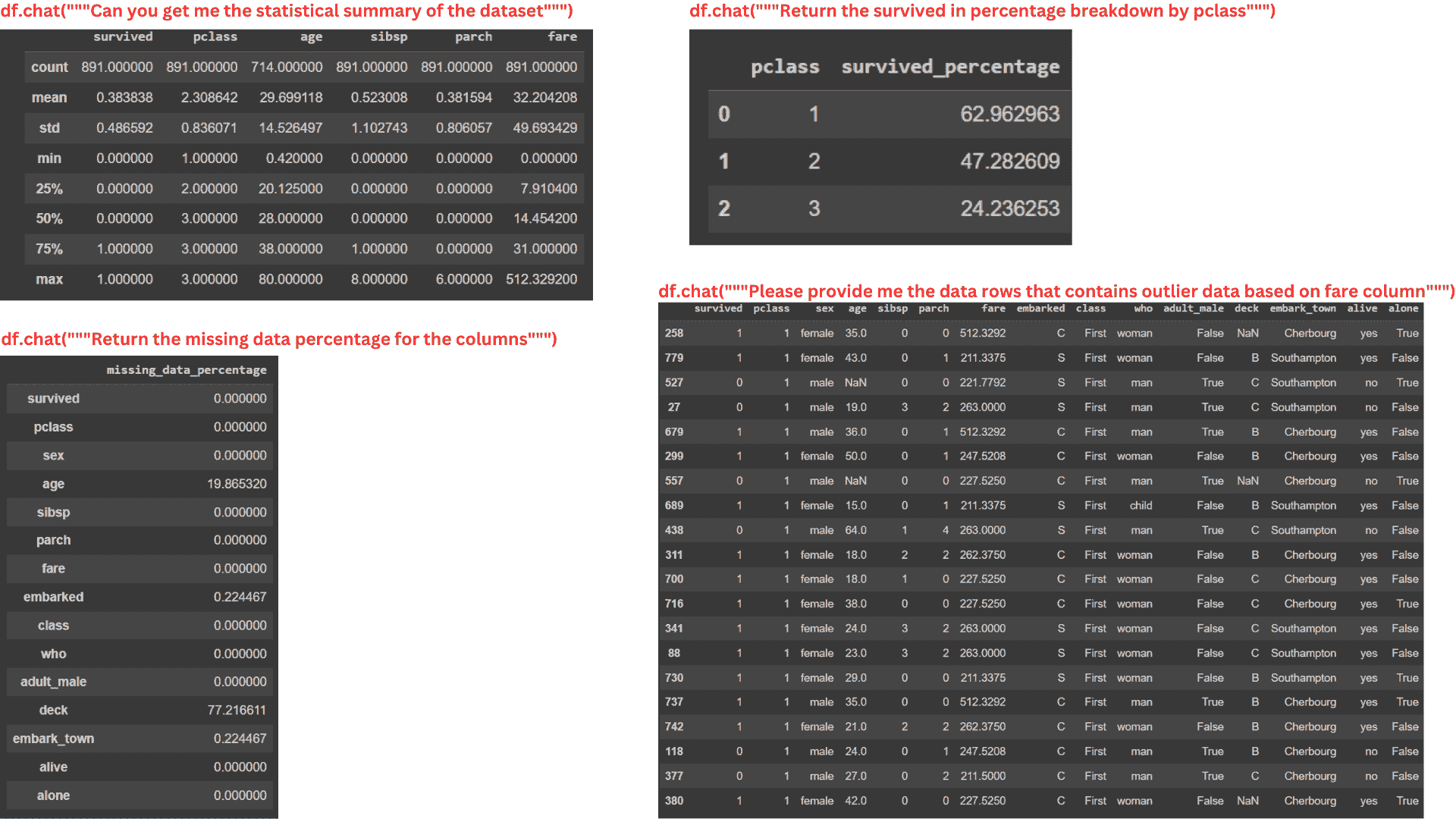
图片由作者提供
从上面的图片可以看出,即使提示相当复杂,Pandas AI 也可以提供 DataFrame 对象的信息。
然而,Pandas AI 无法处理过于复杂的计算,因为这些包的功能受限于我们传递给 SmartDataFrame 对象的 LLM。未来,我相信 Pandas AI 能够处理更详细的分析,因为 LLM 能力在不断发展。
使用 Pandas AI 进行数据可视化
Pandas AI 对于数据探索非常有用,可以执行数据可视化。只要我们指定提示,Pandas AI 就会给出可视化输出。
让我们尝试一个简单的例子。
response = df.chat('Please provide me the fare data distribution visualization')
response
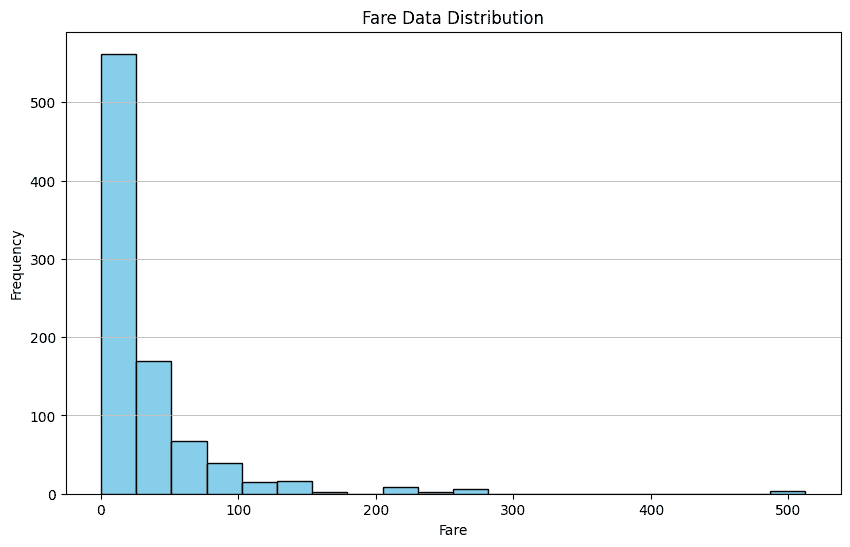
图片由作者提供
在上面的示例中,我们要求 Pandas AI 可视化 Fare 列的分布。输出是数据集的柱状图分布。
就像数据探索一样,你可以进行任何类型的数据可视化。然而,Pandas AI 仍然无法处理更复杂的可视化过程。
这里有一些使用 Pandas AI 进行数据可视化的其他示例。
kde_plot = df.chat("""Please plot the kde distribution of age column and separate them with survived column""")
box_plot = df.chat("""Return me the box plot visualization of the age column separated by sex""")
heat_map = df.chat("""Give me heat map plot to visualize the numerical columns correlation""")
count_plot = df.chat("""Visualize the categorical column sex and survived""")
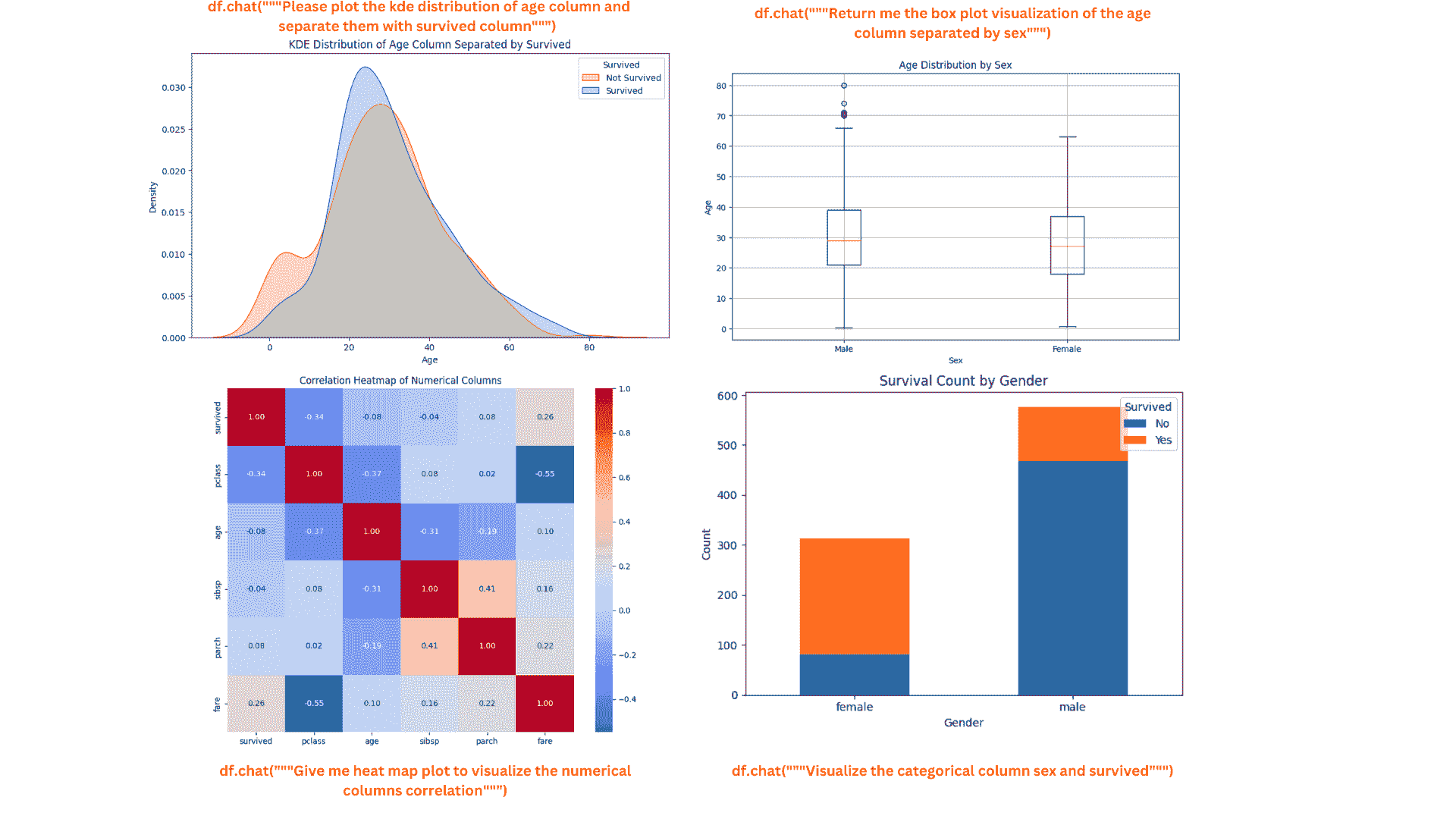
图片由作者提供
图表看起来很美观整洁。如果有必要,你可以继续向 Pandas AI 询问更多细节。
Pandas AI 高级使用
我们可以使用 Pandas AI 的几个内置 API 来改善 Pandas AI 的体验。
缓存清理
默认情况下,Pandas AI 对象中的所有提示和结果都存储在本地目录中,以减少处理时间并缩短 Pandas AI 调用模型所需的时间。
然而,这个缓存有时可能会使 Pandas AI 的结果无关紧要,因为它们会考虑过去的结果。因此,清除缓存是一个好习惯。你可以使用以下代码来清除缓存。
import pandasai as pai
pai.clear_cache()
你还可以在开始时关闭缓存。
df = SmartDataframe(data, {"enable_cache": False})
通过这种方式,从一开始就没有提示或结果被存储。
自定义标题
可以将一个示例 DataFrame 传递给 Pandas AI。如果你不想与 LLM 共享一些私人数据或只是想向 Pandas AI 提供一个示例,这将非常有帮助。
要做到这一点,你可以使用以下代码。
from pandasai import SmartDataframe
import pandas as pd
# head df
head_df = data.sample(5)
df = SmartDataframe(data, config={
"custom_head": head_df,
'llm': llm
})
Pandas AI 技能与代理
Pandas AI 允许用户传递示例函数,并通过 Agent 决策执行它。例如,下面的函数将两个不同的 DataFrame 合并,我们传递一个样本绘图函数给 Pandas AI 代理执行。
import pandas as pd
from pandasai import Agent
from pandasai.skills import skill
employees_data = {
"EmployeeID": [1, 2, 3, 4, 5],
"Name": ["John", "Emma", "Liam", "Olivia", "William"],
"Department": ["HR", "Sales", "IT", "Marketing", "Finance"],
}
salaries_data = {
"EmployeeID": [1, 2, 3, 4, 5],
"Salary": [5000, 6000, 4500, 7000, 5500],
}
employees_df = pd.DataFrame(employees_data)
salaries_df = pd.DataFrame(salaries_data)
# Function doc string to give more context to the model for use of this skill
@skill
def plot_salaries(names: list[str], salaries: list[int]):
"""
Displays the bar chart having name on x-axis and salaries on y-axis
Args:
names (list[str]): Employees' names
salaries (list[int]): Salaries
"""
# plot bars
import matplotlib.pyplot as plt
plt.bar(names, salaries)
plt.xlabel("Employee Name")
plt.ylabel("Salary")
plt.title("Employee Salaries")
plt.xticks(rotation=45)
# Adding count above for each bar
for i, salary in enumerate(salaries):
plt.text(i, salary + 1000, str(salary), ha='center', va='bottom')
plt.show()
agent = Agent([employees_df, salaries_df], config = {'llm': llm})
agent.add_skills(plot_salaries)
response = agent.chat("Plot the employee salaries against names")
Agent 会决定是否使用我们分配给 Pandas AI 的函数。
结合技能和 Agent 可以为你的 DataFrame 分析提供更可控的结果。
结论
我们已经了解到使用 Pandas AI 来帮助数据分析工作是多么简单。利用 LLM 的力量,我们可以将数据分析工作中的编码部分限制到最小,而专注于关键工作。
在这篇文章中,我们了解了如何设置 Pandas AI,如何使用 Pandas AI 进行数据探索和可视化,以及进阶用法。你可以用这个包做更多的事情,访问他们的文档以获取更多信息。
Cornellius Yudha Wijaya**** 是一名数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 期间,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 涉猎了各种 AI 和机器学习主题。
更多相关话题
数据科学家和人工智能产品的 UX 设计指南
原文:
www.kdnuggets.com/2018/08/ux-design-guide-data-scientists-ai-products.html
 评论
评论
由 Syed Sadat Nazrul, 分析科学家
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
在寻找针对人工智能产品的 UX 设计策略时,我发现几乎没有相关材料。在我找到的少数资料中,大多数要么过于领域特定,要么完全集中于网页用户界面的视觉设计。我遇到的最好文章是 Vladimir Shapiro 的 “人工智能的 UX:信任作为设计挑战” 和 Dávid Pásztor 的 “AI UX:设计优秀 AI 产品的 7 个原则”。意识到 UX 设计师和数据科学家之间存在一个真正的知识差距,我决定尝试从数据科学家的角度来解决这些需求。因此,我的假设是读者对数据科学有一定的基础理解。对于数据科学背景很少或没有的 UX 设计师,我避免使用复杂的数学和编程(虽然我鼓励阅读 Michael Galarnyk 的 “如何建立数据科学作品集” 和我的 “数据科学面试指南”)。
人工智能正在占据我们日常生活的几乎每一个方面。这将改变我们的行为方式以及我们对这些产品的期望。作为设计师,我们的目标是创建有用且易于理解的产品,以便为这个模糊的新世界带来清晰度。最重要的是,我们希望利用人工智能的力量使人们的生活变得更加轻松和愉悦。
识别关键目标
即使在我们尝试设计产品之前,我们也需要了解我们产品试图解决的整体商业模式。一些常见的问题包括:
-
这个模型试图解决什么业务问题?是分类问题还是回归问题?
-
最终用户是谁?他们是技术人员还是非技术人员?他们期望从这个产品中获得什么价值?
-
数据是静态的还是动态的?模型是基于状态的还是无状态的?收集的数据的粒度和质量如何?我们如何最好地呈现这些信息?是否有像 PCI、HIPAA 或 GDPR 这样的数据使用监管限制?
-
这个模型的更大影响是什么?市场有多大?这个市场中的其他参与者是谁?他们是补充你的产品还是直接竞争对手?转换成本是多少?需要考虑哪些关键的监管、文化、社会经济和技术趋势?
更好地理解最终产品将使我们能够更有效地满足需求。我推荐的一些相关书籍包括 Bernard Marr 的《智能公司:证据管理的五个成功步骤》和 Alexander Osterwalder 的《商业模式生成:愿景者、游戏改变者和挑战者的手册》。
构建可解释的模型
虽然大多数人都追求准确的模型,但常常忽略了理解模型为什么会这样做。模型的优点和缺点是什么?为什么它会对给定的输入特征提供这样的预测?虽然这个问题看似简单,但许多行业需要将其作为产品价值主张的一部分来提供答案。
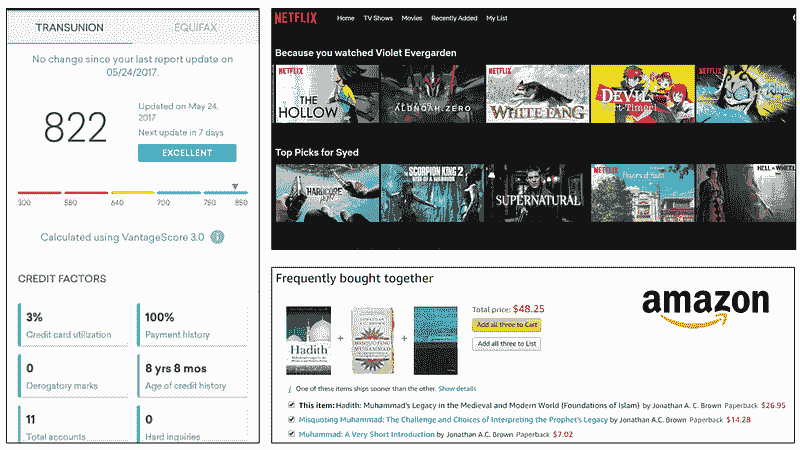
在 Credit Karma、Netflix 和 Amazon 上的模型解释
下面是一些实际使用案例,在这些案例中,最终用户需要对模型进行解释:
-
为什么你的信用评分没有比现在更高?
-
为什么 Amazon 会推荐我购买某些产品?
-
为什么自动驾驶汽车在识别行人之后仍然发生了碰撞?
大多数机器学习模型,如决策树和逻辑回归,天生是可解释的。我们可以分析权重系数,可视化树形结构或计算熵,以预测对最终预测的主要贡献(详细信息请见这里)。虽然过去大多数商业问题依赖于简单的可解释模型,但“黑箱”模型,如神经网络,已经开始变得非常流行。这是因为神经网络在处理复杂决策边界的问题(例如图像和语音识别)时提供了更高的准确性和更低的成本。然而,相比于大多数传统模型,神经网络的解释难度要大得多。对于技术水平较低的团队来说,分析神经网络是一项复杂的任务。
一些神经网络模型比其他模型更容易解释,例如下面的图像识别模型。

可视化图像分类模型的卷积神经网络(来源:Simonyan et al. 2013)
有时,我们可以根据预测和输入推断出工程特征。例如,模型可能没有针对道路上冰的特征。然而,如果模型接受到的输入包括道路上的水和道路表面温度,我们可以直观地认为冰的存在可以通过隐藏层中的特征工程来推导出来。特斯拉自动驾驶导致致命事故就是需要在自动驾驶领域中使用可解释 AI 的一个例子。
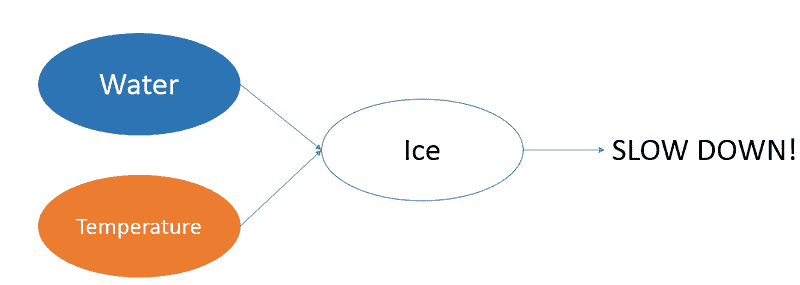
神经网络如何在隐藏层中创建更高阶特征的示例,应用于自动驾驶车辆
欲了解更多关于可解释模型的信息,请查看Lars Hulstaer的“解释机器学习模型”。
模型解释不一定需要是数学的。定性地观察输入及其对应的输出通常可以提供有价值的见解。下面是一个智能安全摄像头错误地将窃贼识别为自拍者,仅仅因为他拿着杆子像自拍杆一样。
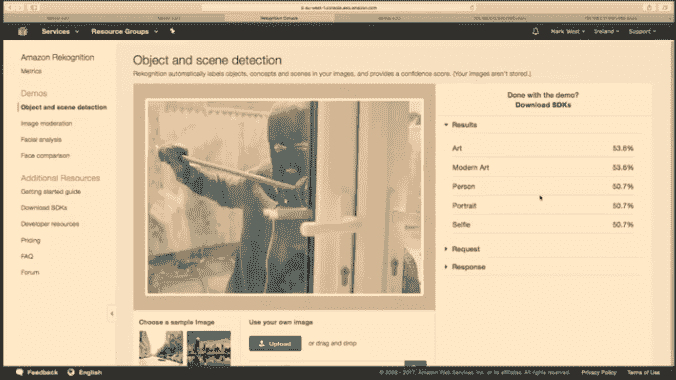
来源:Mark West — 使用 Raspberry Pi Zero、Node.js 和云构建智能安全摄像头
处理边缘情况
AI 可以生成内容并采取以前无人想到的行动。对于这些不可预测的情况,我们必须花费更多时间测试产品,寻找奇怪、有趣甚至令人不安的边界情况。一个例子是下面聊天机器人的误解。
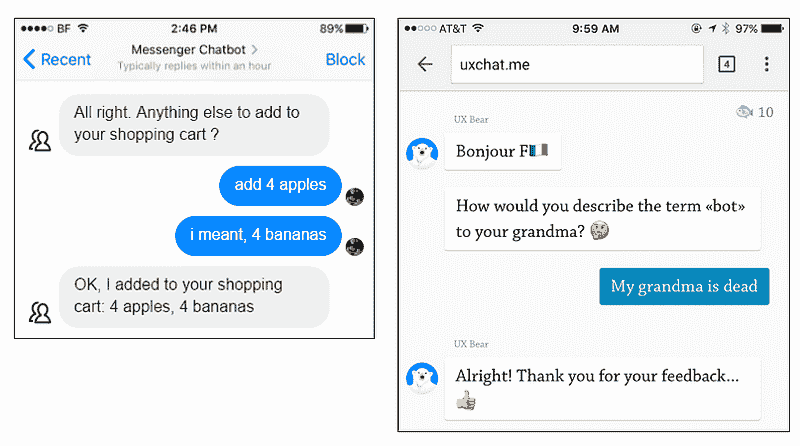
聊天机器人对意外用户命令的失败
在实际环境中进行广泛测试可以帮助最小化这些错误。收集生产模型的清晰日志可以帮助调试出现的意外问题。有关测试和 DevOps 相关主题的更多信息,请阅读我的“数据科学家的 DevOps: 驯服独角兽”。
从终端用户的角度来看,关于产品功能的清晰沟通可以帮助他们理解这些意外情况。例如,在许多情况下,模型必须在精确度和召回率之间做出权衡。
-
优化召回率 意味着机器学习产品将使用它找到的所有正确答案,即使它会显示一些错误的答案。假设我们构建一个可以识别猫图片的 AI。如果我们优化召回率,算法会列出所有的猫,但狗也会出现在结果中。
-
优化精确度 意味着机器学习算法只会使用明显正确的答案,但可能会遗漏一些边界正面案例(比如看起来像狗的猫?)。它只会显示猫,但会遗漏一些猫。它不会找到所有正确的答案,只会找到明显的情况。
在我们从事 AI 用户体验(AI UX)工作时,我们帮助开发者决定优化的方向。提供关于人类反应和人类优先事项的有意义见解,可能是 AI 项目中设计师最重要的工作。
管理期望
虽然相信一个模型可以解决世界上任何情境是很诱人的,但理解其局限性并在与终端用户沟通这些局限性时保持透明是很重要的。在她的演讲“我们对信任的误解”中,英国哲学家 Onora O’Neil 指出了信任的三个组成部分:能力、诚实 和 可靠性。保持透明可以向客户展示我们有足够的能力、诚实和可靠性来维持成功商业所需的长期关系。否则,当产品无法交付时,满足过高的期望并失去信任将更加困难。
金融产品是很好的例子。根据政府规定,您的信用评分可能只考虑价值超过 $2000 的资产。因此,任何低于 $2000 的资产在计算您的信用评分时不会被模型考虑。网络安全产品也有类似的情况。如果模型以每天或每周的频率收集数据,您不能期望模型监控 DDoS 攻击。

在碰撞前 1.3 秒,Uber 的汽车决定需要紧急制动——但没有能力自行完成这项操作。黄色带显示了米数,紫色则表示了汽车的行驶路径。(来源:国家运输安全委员会)
这种情况在最近的 Uber 无人驾驶汽车事故 中尤为明显:
报告中提到,碰撞前约 1 秒,“自驾系统判断需要紧急制动以减轻碰撞。”然而,Uber 并不允许其系统自行执行紧急制动操作。为了避免“车辆行为不稳定”——比如猛踩刹车或避开塑料袋——Uber 依赖其人工操作员观察道路并在出现问题时接管控制。
自然反应是摄像头没有捕捉到自行车。然而,摄像头确实识别了行人,但系统选择不停车。这是因为模型并未设计为完全替代司机。
提供反馈的机会
优秀的用户体验设计的目标是交付一个令最终用户满意的产品。为了确保用户获得他们想要的东西,提供他们反馈 AI 内容的机会是必要的。这可以包括电影的评分系统或让银行知道他们的信用卡交易是否存在欺诈行为。以下是来自 Google Now 的一个示例。
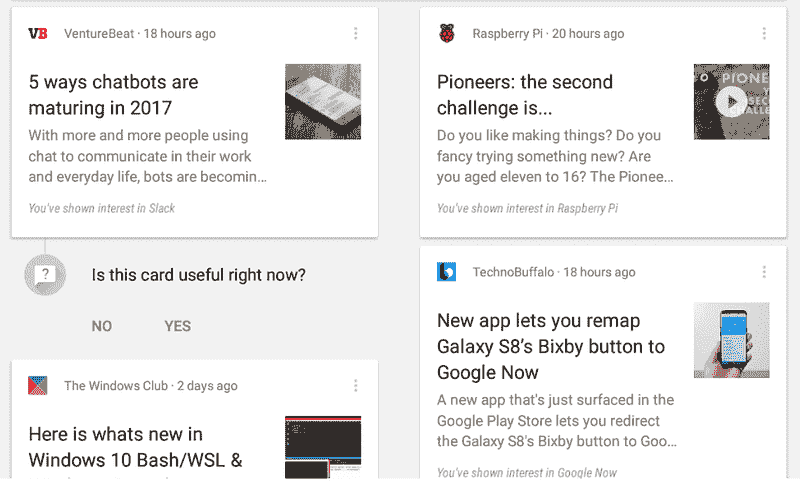
Google Now 请求对推荐系统的预测提供反馈
记住,用户反馈也可以作为你模型的训练数据。如果我们将更多数据输入到机器学习算法中,AI 产品的用户体验将变得越来越好。
最终总结
到头来,AI 的设计目的是解决问题并让生活更轻松。人本设计必须始终贯穿于成功产品的开发过程中。不满足客户需求是主要行业破产和被更好服务提供商取代的原因。理解客户需求是前进的关键。
如果你有想法或评论,随时订阅我的博客并在 Twitter 上关注我。
感谢 Wendy Wong。
个人简介:Syed Sadat Nazrul 白天利用机器学习追踪网络和金融犯罪分子,晚上则撰写有趣的博客。
原文。经许可转载。
相关内容:
-
数据科学家的 DevOps:驯服独角兽
-
来自 Google Assistant 的视角:我们是否变得依赖 AI?
-
AI 和数据科学中的十大角色
更多相关话题
梯度消失问题:原因、后果及解决方案
原文:
www.kdnuggets.com/2022/02/vanishing-gradient-problem.html
图片由编辑提供
Sigmoid 函数是用于开发深度神经网络的最流行的激活函数之一。Sigmoid 函数的使用限制了深度神经网络的训练,因为它导致了梯度消失问题。这使得神经网络的学习速度变慢,甚至在某些情况下完全无法学习。这篇博客文章旨在描述梯度消失问题,并解释使用 Sigmoid 函数如何导致这个问题。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
Sigmoid 函数
Sigmoid 函数在神经网络中经常用于激活神经元。它是一个具有特征 S 形状的对数函数。函数的输出值介于 0 和 1 之间。Sigmoid 函数用于在二分类问题中激活输出层。它的计算公式如下:
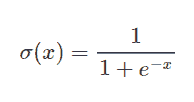
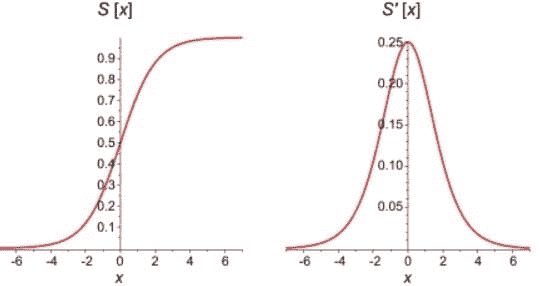
在下面的图表中,你可以看到 Sigmoid 函数本身及其导数的比较。Sigmoid 函数的一阶导数是钟形曲线,其值范围从 0 到 0.25。
我们对神经网络如何执行前向传播和反向传播的了解对于理解梯度消失问题至关重要。
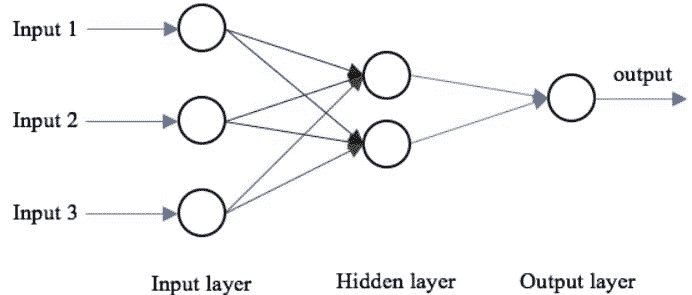
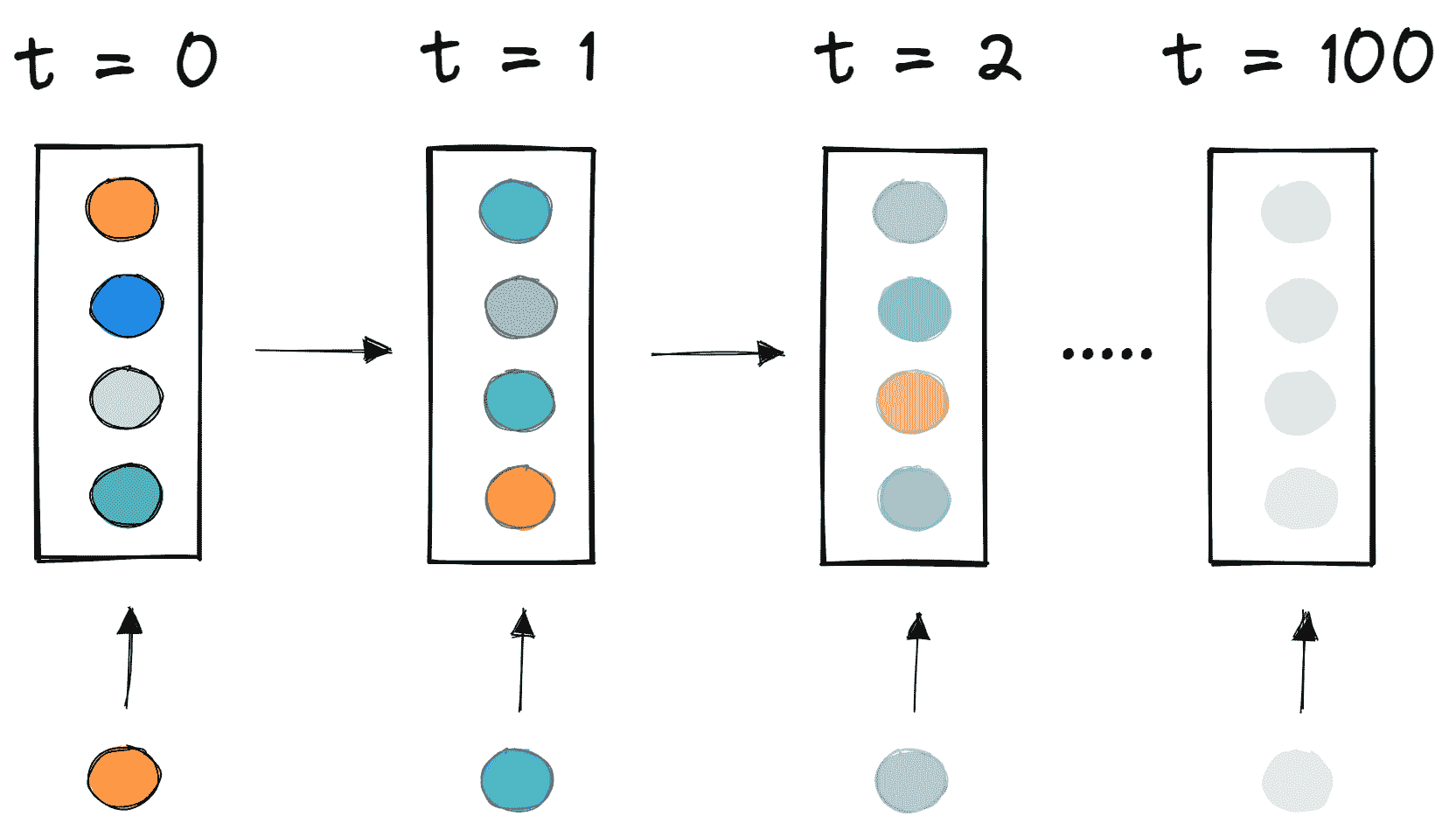
前向传播
神经网络的基本结构包括输入层、一个或多个隐藏层和一个输出层。网络的权重在前向传播过程中被随机初始化。输入特征在每个隐藏层节点处与相应的权重相乘,并在每个节点处加上一个偏置。然后,这个值通过激活函数转换为节点的输出。为了生成神经网络的输出,隐藏层输出乘以权重加上偏置值,然后使用另一个激活函数进行转换。这将是神经网络对给定输入值的预测值。
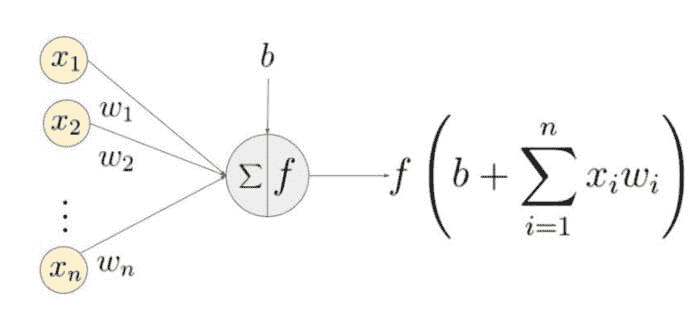
反向传播
当网络生成输出时,损失函数(C)表示它预测输出的准确性。网络执行反向传播以最小化损失。反向传播方法通过调整神经网络的权重和偏置来最小化损失函数。在此方法中,损失函数的梯度相对于网络中的每个权重进行计算。
在反向传播中,节点的新权重(w[new])是通过旧权重(w[old])和学习率(ƞ)与损失函数梯度的乘积来计算的。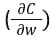
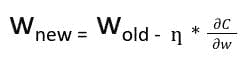
利用偏导数链式法则,我们可以将损失函数的梯度表示为所有节点的激活函数相对于其权重的梯度的乘积。因此,网络中节点的更新权重依赖于每个节点激活函数的梯度。
对于具有 sigmoid 激活函数的节点,我们知道 sigmoid 函数的偏导数最大值为 0.25。当网络中层数增加时,导数的乘积值会减少,直到某个点,损失函数的偏导数接近零,偏导数消失。我们称之为消失梯度问题。
在浅层网络中,sigmoid 函数可以使用,因为梯度的小值不会造成问题。然而,对于深层网络,消失梯度可能对性能产生重大影响。由于导数消失,网络的权重保持不变。在反向传播过程中,神经网络通过更新其权重和偏置来减少损失函数。在具有消失梯度的网络中,权重无法更新,因此网络无法学习。结果是网络性能下降。
克服问题的方法
梯度消失问题是由用于创建神经网络的激活函数的导数引起的。解决这个问题的最简单方法是替换网络的激活函数。可以用 ReLU 等激活函数代替 sigmoid。
修正线性单元(ReLU)是激活函数,当它们应用于正输入值时会生成正线性输出。如果输入为负值,该函数将返回零。
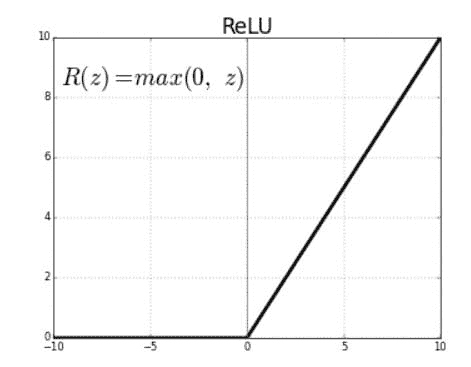
ReLU 函数的导数定义为对于大于零的输入为 1,对于负输入为 0。下面共享的图表显示了 ReLU 函数的导数。
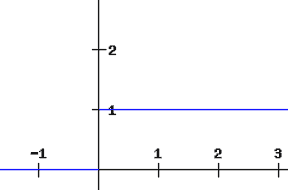
如果在神经网络中用 ReLU 函数代替 sigmoid 函数进行激活,损失函数的偏导数值将为 0 或 1,这防止了梯度消失。因此,ReLU 函数可以防止梯度消失。使用 ReLU 的问题是,当梯度值为 0 时,节点被视为死节点,因为权重的旧值和新值保持不变。这种情况可以通过使用 leaky ReLU 函数来避免,该函数防止梯度降到零值。
避免梯度消失问题的另一种技术是权重初始化。这是将初始值分配给神经网络中的权重的过程,以便在反向传播过程中,权重不会消失。
总之,梯度消失问题源于用于创建神经网络的激活函数的偏导数的特性。使用 Sigmoid 激活函数的深度神经网络中,这个问题可能会更加严重。通过使用像 ReLU 和 leaky ReLU 这样的激活函数,可以显著减少这个问题。
蒂娜·雅各布 对数据科学充满热情,认为生活就是不断学习和成长,无论遇到什么。
了解更多相关话题
变分自编码器详细解析
原文:
www.kdnuggets.com/2018/11/variational-autoencoders-explained.html
评论
在这系列的 上一篇文章中,我介绍了变分自编码器(VAE)框架,并解释了其背后的理论。
在这篇文章中,我将更详细地解释 VAE,换句话说——我将提供一些代码 😃
阅读本文后,你将理解实现 VAE 所需的技术细节。
作为一个额外的点,我将向你展示如何通过对一些潜在向量维度施加特殊角色,模型可以生成基于数字类型的图像。
该模型将使用 MNIST 进行训练——手写数字数据集。输入是 ℝ[28∙28] 中的图像。
接下来,我们将定义我们要使用的超参数。
随意尝试不同的值,以感受模型如何受到影响。笔记本可以在 这里找到。
该模型

该模型由三个子网络组成:
-
给定 x(图像),将其编码为潜在空间上的分布——在上一篇文章中称之为 Q(z|x)。
-
给定 z 在潜在空间中(图像的代码表示),将其解码为它所表示的图像——在上一篇文章中称之为 f(z)。
-
给定 x,通过将其映射到大小为 10 的层来分类其数字,其中第 i 个值包含第 i 个数字的概率。
前两个子网络是基本的 VAE 框架。
第三个子网络用作 辅助任务,它将强制某些潜在维度编码图像中的数字。让我解释一下动机:在上一篇文章中我解释过,我们不在乎潜在空间的每个维度持有什么信息。模型可以学习编码它认为对任务有价值的任何信息。由于我们对数据集非常熟悉,我们知道数字类型应该很重要。我们希望通过提供这些信息来帮助模型。此外,我们将使用这些信息生成基于数字类型的图像,稍后我会解释。
给定数字类型,我们将其使用 one hot 编码,即大小为 10 的向量。这 10 个数字将被连接到潜在向量中,因此在将该向量解码成图像时,模型将利用数字信息。
有两种方法可以为模型提供 one hot 编码向量:
-
将其作为输入添加到模型中。
-
将其作为标签添加,这样模型将必须自行预测:我们将添加另一个子网络来预测大小为 10 的向量,其中损失是与期望的 one hot 向量的交叉熵。
我们将选择第二个选项。为什么?嗯,在测试时我们可以以两种方式使用模型:
-
提供一张图像作为输入,并推断出一个潜在向量。
-
提供一个潜在向量作为输入,并生成一张图像。
由于我们也想支持第一个选项,因此我们不能向模型提供数字作为输入,因为在测试时我们将不知道它。因此,模型必须学习预测它。
现在我们理解了组成模型的所有子网络,我们可以对其进行编码。编码器和解码器背后的数学细节可以在上一篇文章中找到。
训练

我们将训练模型来优化两个损失——VAE 损失和分类损失——使用 SGD。
在每个纪元结束时,我们将采样潜在向量并将其解码成图像,以便我们可以可视化模型的生成能力如何随着纪元的推移而改善。采样方法如下:
-
根据我们想要生成图像的数字,确定用于数字分类的维度。如果我们想生成数字 2 的图像,这些维度将设置为 [0010000000]。
-
随机采样其他维度,根据先验——多变量高斯分布。我们将使用这些采样值来生成给定纪元中的所有不同数字。通过这种方式,我们可以感受到其他维度中编码了什么,例如笔画风格。
步骤 1 的直觉是,在收敛之后,模型应该能够使用这些维度来分类输入图像中的数字。另一方面,这些维度也用于解码步骤以生成图像。这意味着解码器子网络学会了当这些维度具有与数字 2 相对应的值时,它应该生成该数字的图像。因此,如果我们手动设置这些维度以包含数字 2 的信息,我们将得到该数字的生成图像。
让我们验证两个损失是否看起来不错,即——是否在减少:
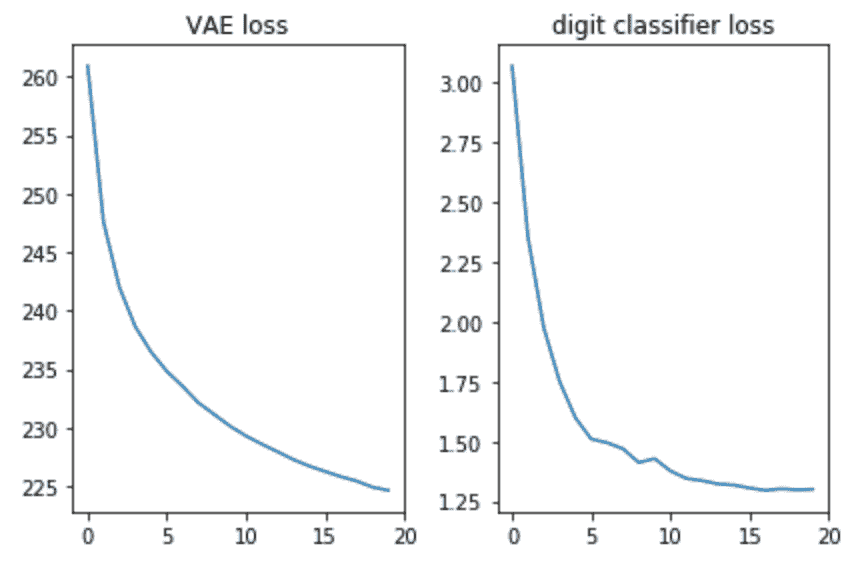
此外,让我们绘制生成的图像,看看模型是否确实能够生成数字的图像:

最终想法
很高兴看到使用简单的前馈网络(没有花哨的卷积)我们能够在仅仅 20 个纪元后生成漂亮的图像。模型学会了相当快地使用特殊的数字维度——在第 9 纪元时,我们已经看到了我们尝试生成的数字序列。
每个纪元使用不同的随机值来处理其他维度,因此我们可以看到风格在不同纪元之间的差异,并且在每个纪元内部是相似的——至少在一些纪元中是这样。例如,在第 18 纪元中,所有数字都比第 20 纪元更粗体。
我邀请你打开 这个笔记本 并玩一玩 VAE。例如,超参数的值对生成的图像有很大的影响。玩得开心 😃
简介: Yoel Zeldes 是 Taboola 的算法工程师,也是一位对深度学习特别感兴趣的机器学习爱好者。
原文。经许可转载。
资源:
相关:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关话题
2018 年数据科学和人工智能的 7 大 R 包
原文:
www.kdnuggets.com/2019/01/vazquez-2018-top-7-r-packages.html/2
评论
4. DataExplorer — 自动化数据探索和处理

github.com/boxuancui/DataExplorer
探索性数据分析 (EDA) 是数据分析/预测建模的初步和重要阶段。在此过程中,分析师/建模者将首先查看数据,从而生成相关假设并决定下一步。然而,EDA 过程有时可能会很麻烦。这个 R 包旨在自动化大多数数据处理和可视化工作,以便用户可以专注于研究数据并提取洞见。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
安装
该包可以直接从 CRAN 安装。
install.packages("DataExplorer")
使用方法
使用该包你可以创建如下报告、图表和表格:
## Plot basic description for airquality data
plot_intro(airquality)
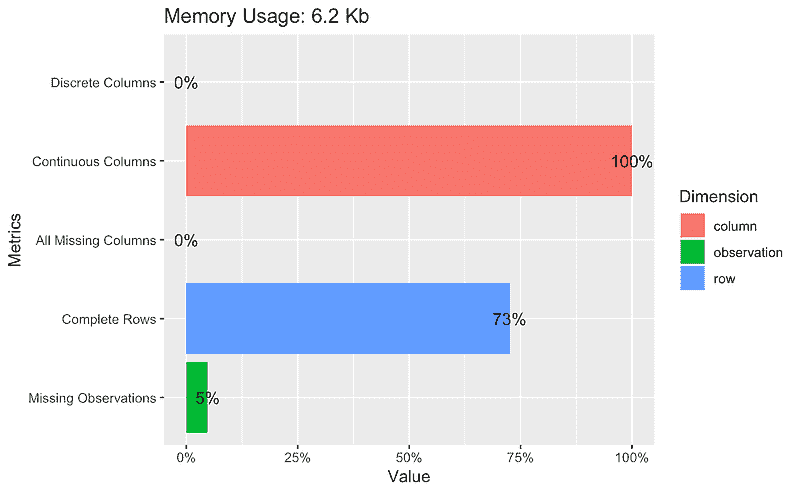
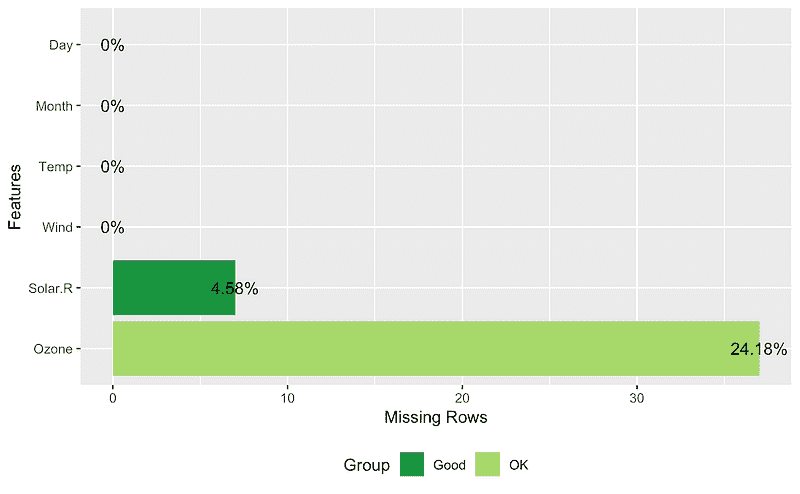
## View missing value distribution for airquality data
plot_missing(airquality)
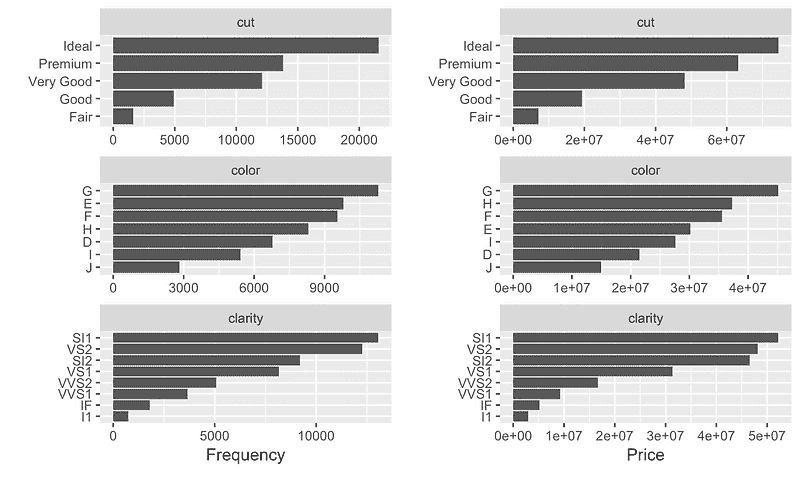
## Left: frequency distribution of all discrete variables
plot_bar(diamonds)
## Right: `price` distribution of all discrete variables
plot_bar(diamonds, with = "price")
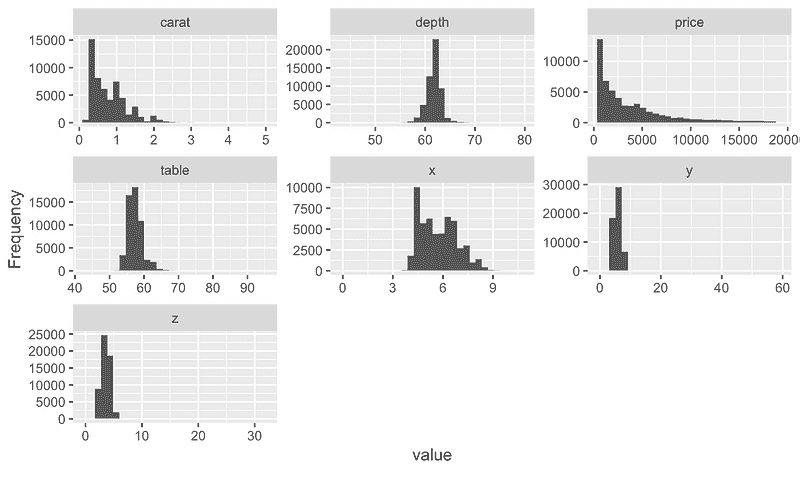
## View histogram of all continuous variables
plot_histogram(diamonds)
你可以在该包的官方网站上找到更多类似的内容:
[自动化数据探索和处理
自动化数据探索过程用于分析任务和预测建模,以便用户可以专注于…boxuancui.github.io](https://boxuancui.github.io/DataExplorer/)
在这个小册子中:
[DataExplorer 介绍
本文件介绍了 DataExplorer 包,并展示了它如何帮助你完成不同的任务…boxuancui.github.io](https://boxuancui.github.io/DataExplorer/articles/dataexplorer-intro.html)
3. Sparklyr — Apache Spark 的 R 接口

Sparklyr 使你能够:
-
从 R 连接到 Spark。sparklyr 包提供了一个
完成 dplyr 后端。
-
过滤和聚合 Spark 数据集,然后将其带入 R 进行
分析和可视化。
-
使用 Spark 的分布式machine learning库从 R 中访问。
-
创建扩展来调用完整的 Spark API 并提供
与 Spark 包的接口。
安装
你可以按照以下方式从 CRAN 安装 Sparklyr 包:
install.packages("sparklyr")
你还应该安装一个本地版本的 Spark 以便于开发:
library(sparklyr)
spark_install(version = "2.3.1")
使用
使用 Spark 的第一步始终是创建上下文并连接到本地或远程集群。
在这里,我们将通过spark_connect函数连接到 Spark 的本地实例:
library(sparklyr)
sc <- spark_connect(master = "local")
将 sparklyr 与 dplyr 和 ggplot2 结合使用
我们将通过将一些数据集从 R 复制到 Spark 集群开始(请注意,您可能需要安装 nycflights13 和 Lahman 包以执行此代码):
install.packages(c("nycflights13", "Lahman"))
library(dplyr)
iris_tbl <- copy_to(sc, iris)
flights_tbl <- copy_to(sc, nycflights13::flights, "flights")
batting_tbl <- copy_to(sc, Lahman::Batting, "batting")
src_tbls(sc)
## [1] "batting" "flights" "iris"
首先,这里有一个简单的过滤示例:
# filter by departure delay and print the first few records
flights_tbl %>% filter(dep_delay == 2)
## # Source: lazy query [?? x 19]
## # Database: spark_connection
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2 830
## 2 2013 1 1 542 540 2 923
## 3 2013 1 1 702 700 2 1058
## 4 2013 1 1 715 713 2 911
## 5 2013 1 1 752 750 2 1025
## 6 2013 1 1 917 915 2 1206
## 7 2013 1 1 932 930 2 1219
## 8 2013 1 1 1028 1026 2 1350
## 9 2013 1 1 1042 1040 2 1325
## 10 2013 1 1 1231 1229 2 1523
## # ... with more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>
让我们绘制飞行延迟的数据:
delay <- flights_tbl %>%
group_by(tailnum) %>%
summarise(count = n(), dist = mean(distance), delay = mean(arr_delay)) %>%
filter(count > 20, dist < 2000, !is.na(delay)) %>%
collect
# plot delays
library(ggplot2)
ggplot(delay, aes(dist, delay)) +
geom_point(aes(size = count), alpha = 1/2) +
geom_smooth() +
scale_size_area(max_size = 2)
## `geom_smooth()` using method = 'gam'
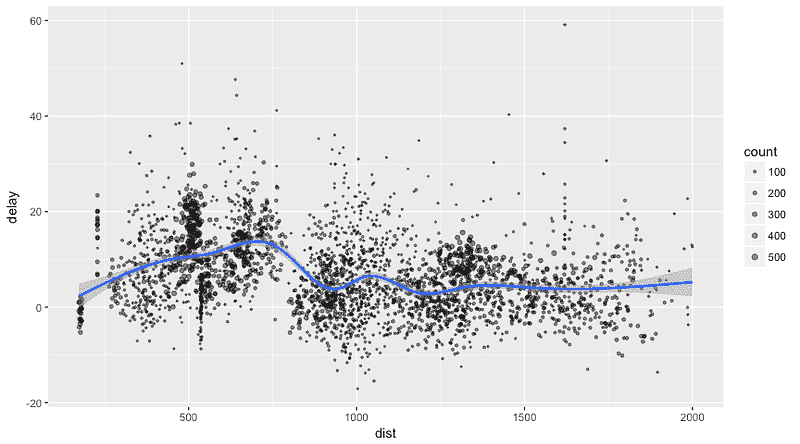
使用 Sparklyr 进行机器学习
你可以通过 Sparklyr 中的machine learning函数在 Spark 集群中编排机器学习算法。这些函数连接到建立在 DataFrames 之上的高层 API,帮助你创建和调整机器学习工作流程。
这里是一个示例,我们使用ml_linear_regression来拟合一个线性回归模型。我们将使用内置的mtcars数据集来查看是否可以根据汽车的重量(wt)和引擎的气缸数(cyl)预测汽车的燃油消耗(mpg)。我们将假设mpg与每个特征之间的关系是线性的。
*# copy mtcars into spark*
mtcars_tbl <- copy_to(sc, mtcars)
*# transform our data set, and then partition into 'training', 'test'*
partitions <- mtcars_tbl %>%
filter(hp >= 100) %>%
mutate(cyl8 = cyl == 8) %>%
sdf_partition(training = 0.5, test = 0.5, seed = 1099)
*# fit a linear model to the training dataset*
fit <- partitions$training %>%
ml_linear_regression(response = "mpg", features = c("wt", "cyl"))
fit
## Call: ml_linear_regression.tbl_spark(., response = "mpg", features = c("wt", "cyl"))
##
## Formula: mpg ~ wt + cyl
##
## Coefficients:
## (Intercept) wt cyl
## 33.499452 -2.818463 -0.923187
对于 Spark 生成的线性回归模型,我们可以使用summary()来了解我们的拟合质量以及每个预测变量的统计显著性。
summary(fit)
## Call: ml_linear_regression.tbl_spark(., response = "mpg", features = c("wt", "cyl"))
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.752 -1.134 -0.499 1.296 2.282
##
## Coefficients:
## (Intercept) wt cyl
## 33.499452 -2.818463 -0.923187
##
## R-Squared: 0.8274
## Root Mean Squared Error: 1.422
Spark 机器学习支持广泛的算法和特征变换,如上所示,使用 dplyr 管道轻松地将这些函数串联在一起。
在这里了解更多关于使用 sparklyr 进行机器学习的信息:
[sparklyr
一个 R 接口到 Sparkspark.rstudio.com](http://spark.rstudio.com/mlib/)
更多关于该包和示例的信息请查看这里:
[sparklyr
一个 R 接口到 Sparkspark.rstudio.com](http://spark.rstudio.com/)
2. Drake — 一个专注于 R 的可重复性和高性能计算的管道工具包

Drake 编程
不,开玩笑的。其实这个包的名字是drake!

这是一个非常棒的包。我会创建一个单独的帖子来详细介绍它,所以敬请期待!

Drake 是一个作为通用工作流管理器的包,用于数据驱动的任务。当其依赖项发生变化时,它会重新构建中间数据对象,并在结果已经最新时跳过工作。
此外,并非每次运行都从头开始,已完成的工作流有可触及的可重复性证据。
可重复性、良好的管理和实验跟踪对于轻松测试他人的工作和分析都是必要的。这在数据科学中非常重要,你可以在这里阅读更多内容:
来自 Zach Scott:
[数据科学的可重复性危机
什么是数据科学中的可重复性,为什么我们应该关心它?towardsdatascience.com](https://towardsdatascience.com/data-sciences-reproducibility-crisis-b87792d88513)
[迈向可重复性:平衡隐私与公开
在数据安全与研究公开之间,是否可能存在一个恰到好处的选项?towardsdatascience.com](https://towardsdatascience.com/toward-reproducibility-balancing-privacy-and-publication-77fee2366eee)
以及我写的一篇文章 😃
[用 MLflow 管理你的机器学习生命周期——第一部分。
可重复性、良好的管理和实验跟踪对于轻松测试他人的工作以及…towardsdatascience.com](https://towardsdatascience.com/manage-your-machine-learning-lifecycle-with-mlflow-part-1-a7252c859f72)
使用 drake,你可以自动
-
启动自上次以来发生变化的部分。
-
跳过其余部分。
安装
*# Install the latest stable release from CRAN.*
install.packages("drake")
*# Alternatively, install the development version from GitHub.*
install.packages("devtools")
library(devtools)
install_github("ropensci/drake")
安装自 CRAN 时存在一些已知错误。有关这些错误的更多信息,请访问:
我遇到了一些错误,因此建议您现在从 GitHub 安装该包。
好的,让我们用一个小变化来重现一个简单的示例:
我在 drake 的主要示例中添加了一个简单的图形来查看线性模型。使用这段代码,你正在为执行整个项目创建一个计划。
首先,我们读取数据。然后我们为分析做好准备,创建一个简单的直方图,计算相关性,拟合模型,绘制线性模型,最后创建一个 rmarkdown 报告。
我用于最终报告的代码在这里:
如果我们更改了一些函数或分析,当我们执行计划时, drake 会知道发生了什么变化,并且只会运行这些变化。它会创建一个图形,以便你可以看到发生了什么:
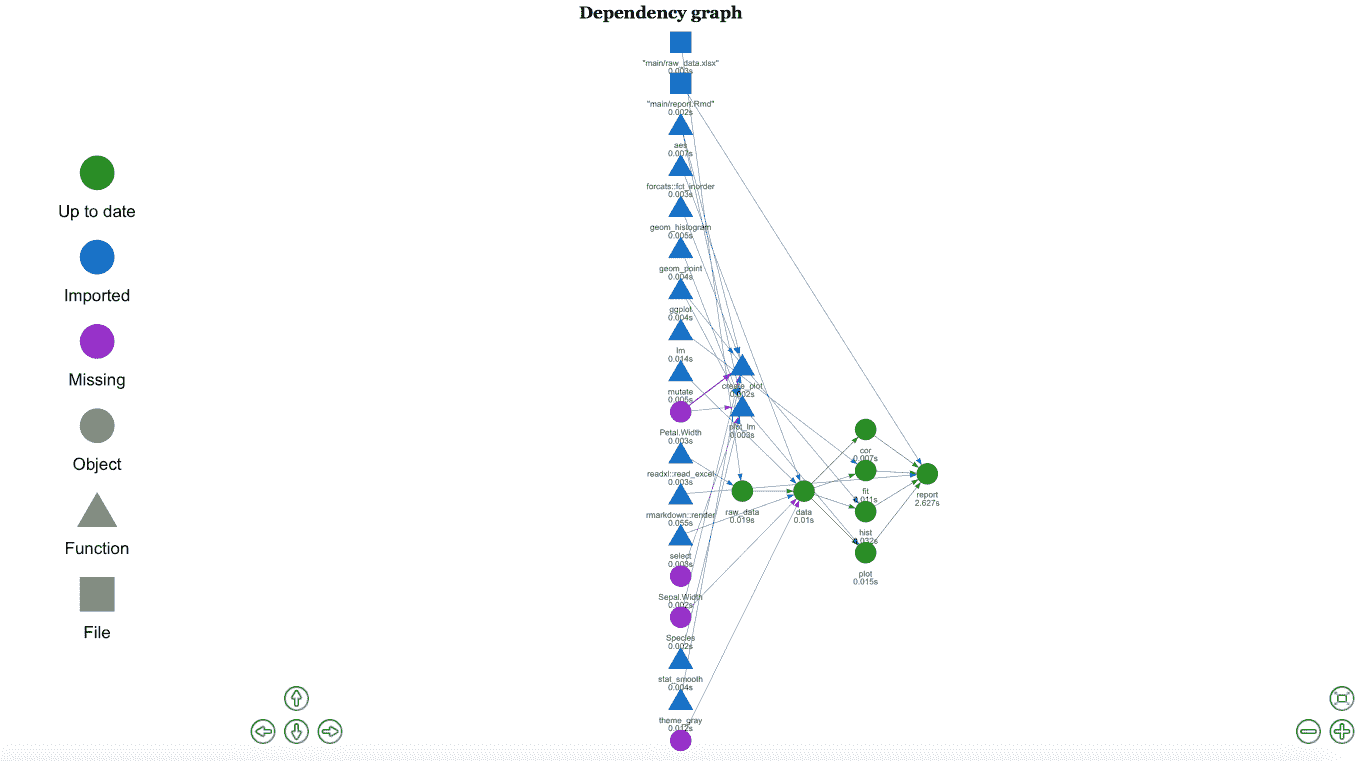
分析图
在 Rstudio 中,这个图形是交互式的,你可以将其保存为 HTML 以便后续分析。
还有更多了不起的功能,你可以用 drake 做到,我会在未来的帖子中展示 😃
1. DALEX——描述性机器学习解释

解释机器学习模型并不总是容易的。然而,对于各种商业应用来说,这一点非常重要。幸运的是,有一些很棒的库可以帮助我们完成这项任务。例如:
[thomasp85/lime]
lime——局部可解释的模型无关解释(原始 Python 包的 R 版)github.com](https://github.com/thomasp85/lime)
(顺便说一下,有时候一个简单的 ggplot 可视化可以帮助你解释模型。有关更多信息,请查看下面由 Matthew Mayo 撰写的精彩文章)
[机器学习模型解释:概述]
关于机器学习解释的文章出现在 O’Reilly 的博客上,时间在三月,由 Patrick Hall、Wen…www.kdnuggets.com](/2017/11/interpreting-machine-learning-models-overview.html)
在许多应用中,我们需要知道、理解或证明输入变量如何在模型中使用,以及它们如何影响最终的模型预测。DALEX 是一组工具,帮助解释复杂模型的工作原理。
从 CRAN 安装,只需运行:
install.packages("DALEX")
他们有关于如何与不同的 ML 包一起使用 DALEX 的精彩文档:
极好的备忘单:
这里有一个互动笔记本,你可以在其中了解更多关于这个包的信息:
[Binder(测试版)]
编辑描述mybinder.org](https://mybinder.org/v2/gh/pbiecek/DALEX_docs/master?filepath=jupyter-notebooks%2FDALEX.ipynb)
最后,一些书籍风格的 DALEX、机器学习和解释性文档:
[DALEX:描述性机器学习解释]
不要相信黑箱模型。除非它能自我解释。pbiecek.github.io](https://pbiecek.github.io/DALEX_docs/)
在原始仓库中查看:
[pbiecek/DALEX]
DALEX——描述性机器学习解释github.com](https://github.com/pbiecek/DALEX)
并记得给它加星星 😃
感谢Ciencia y Datos团队的出色帮助,提供了这些摘要。
也感谢你阅读这篇文章。我希望你在这里找到了一些有趣的内容 :)。如果这些文章对你有帮助,请与朋友分享!
如果你有问题,可以在 Twitter 上关注我:
法维奥·瓦斯克斯 (@FavioVaz) | Twitter
Favio Vázquez(@FavioVaz)的最新推文。数据科学家。物理学家和计算工程师。我有一个…… twitter.com
以及 LinkedIn:
法维奥·瓦斯克斯 — 创始人 — Ciencia y Datos | LinkedIn
查看法维奥·瓦斯克斯在 LinkedIn 上的资料,世界上最大的专业社区。法维奥在他们的…… www.linkedin.com
希望在那里见到你 😃
简历:法维奥·瓦斯克斯 是一名物理学家和计算机工程师,致力于数据科学和计算宇宙学。他对科学、哲学、编程和音乐充满热情。他是 Ciencia y Datos 的创始人,这是一个西班牙语的数据科学出版物。他热衷于迎接新挑战,与优秀的团队合作,并解决有趣的问题。他参与了 Apache Spark 的合作,帮助开发 MLlib、Core 和文档。他喜欢将自己的知识和专业技能应用于科学、数据分析、可视化和自动学习,以帮助世界变得更美好。
原文。经许可转载。
相关:
-
2018 年数据科学和 AI 的 7 个顶级 Python 库
-
2018 年数据科学的 20 个顶级 R 库
-
我们最喜欢的 5 个免费可视化工具
更多相关内容
向量数据库用于 LLMs、生成式 AI 和深度学习
原文:
www.kdnuggets.com/vector-database-for-llms-generative-ai-and-deep-learning
图片来源:编辑
理解向量数据库
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
向量数据库是一种专门设计用于存储和管理向量数据的数据库,通过任意但相关的坐标来关联数据。与处理标量数据(如数字、字符串或日期)的传统数据库不同,向量数据库经过优化以处理高维数据点。但首先我们必须谈谈向量嵌入。
向量嵌入是一种在自然语言处理(NLP)中使用的方法,将单词表示为低维空间中的向量。这种技术简化了模型如 Word2Vec、GloVe 或 BERT 处理的复杂数据。这些现实世界的嵌入非常复杂,通常具有数百维,捕捉单词的细微属性。
那么我们如何在 AI 和深度学习等领域受益于向量呢?向量数据库通过提供高效和可扩展的解决方案来存储、搜索和检索高维数据,为机器学习和 AI 领域带来了显著的好处。
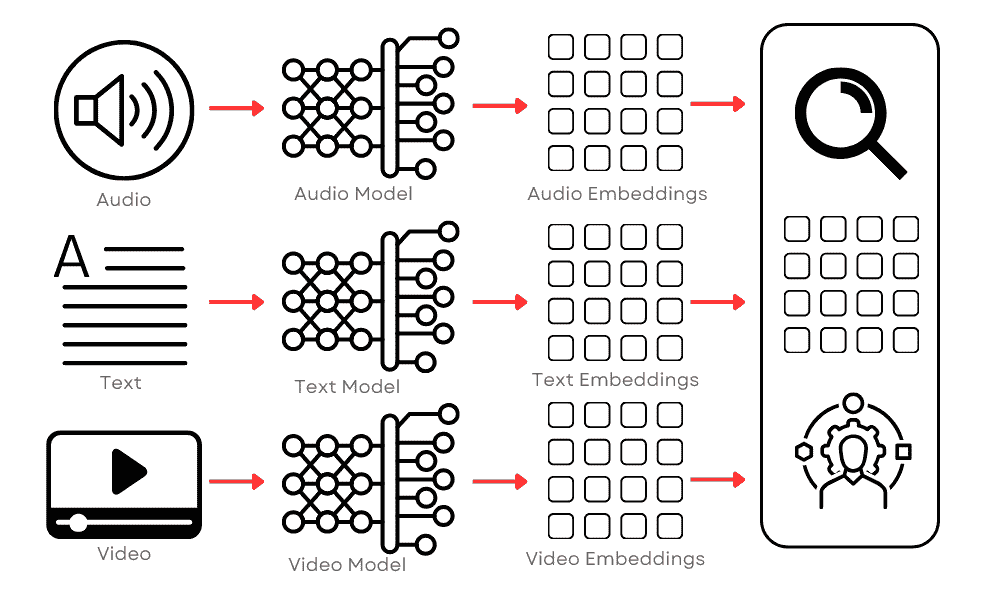
数据库使用数学运算,如距离度量,来高效地搜索、检索和操作向量。这种组织方式使得数据库能够通过比较向量中的数值,快速找到和分析相似或相关的数据点。因此,向量数据库非常适合用于类似性搜索等应用,目标是识别和检索与给定查询向量紧密相关的数据点。这在图像识别、自然语言处理和推荐系统等应用中尤为有用。
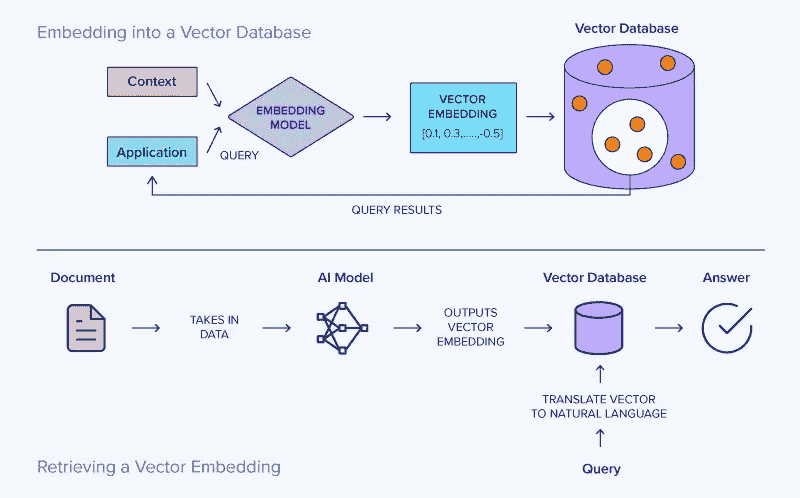
最初,这个过程涉及将一些文本存储在指定的向量数据库中。接收到的文本会使用选择的 AI 模型转换为向量形式。接下来,创建的向量将被存储在向量数据库中。
当发出搜索提示时,它也会被转换为向量以进行比较。系统然后识别出相似度最高的向量并返回它们。最后,这些向量会被翻译回自然语言并呈现给用户作为搜索结果。
向量数据库与大型语言模型(LLMs)
向量数据库与如 GPT-4 这样的大型语言模型(LLMs)的集成彻底改变了 AI 系统理解和生成自然语言的方式。LLMs 能够进行深度上下文分析的能力是这些模型在广泛数据集上进行训练的结果,使它们能够掌握语言的细微差别,包括习语表达、复杂的句子结构,甚至文化细微差别。
这些模型可以通过将词语、句子和更大的文本段落转换为高维向量嵌入来实现这一点,这些向量表示的不仅仅是文本,还封装了文本中的上下文和语义关系,从而使 LLMs 能够更好地理解更复杂的思想和情况。
向量数据库在管理这些复杂向量方面起着关键作用。它们存储和索引高维数据,使得大型语言模型(LLMs)能够高效地检索和处理信息。这一能力对于语义搜索应用尤为重要,在这些应用中,目标是理解和回应自然语言查询,提供基于属性相似度的结果,而不仅仅是关键词匹配。
大型语言模型(LLMs)使用这些向量来关联词语和思想,反映了人类对语言的理解。例如,LLMs 可以识别同义词、隐喻,甚至文化参考,这些语言关系被表示为数据库中的向量。这些向量在数据库中的相对位置可以指示它们所代表的思想或词语的接近程度,使模型能够进行智能关联和推断。这些数据库中存储的向量不仅表示字面文本,还表示相关的思想、概念和上下文关系。这种安排允许对语言进行更细致和复杂的理解。
此外,用户可以将冗长的文档分割成多个向量,并使用一种称为检索增强生成(Retrieval Augmented Generation, RAG)的技术自动将它们存储在向量数据库中。检索增强生成(RAG)是一种自然语言处理和人工智能领域的技术,通过引入外部知识检索步骤来增强文本生成过程。这种方法对于创建产生更具信息性、准确性和上下文相关性的响应的 AI 模型特别有用。
这种方法在解决传统 LLMs 的一个关键局限性方面至关重要——它们依赖于在初始训练阶段获得的固定数据集,这些数据集随着时间的推移可能会变得过时或缺乏具体细节。
向量数据库在生成型 AI 中的作用
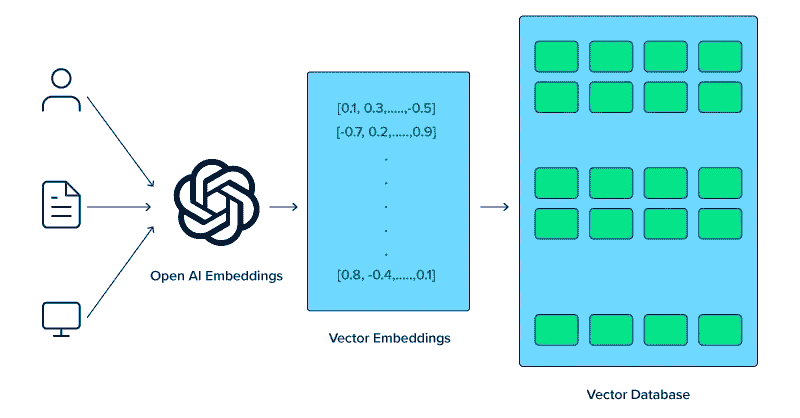
继续讨论,生成型 AI 是 LLMs 和向量数据库的重要应用。生成型 AI 涵盖了如图像生成、音乐创作和文本生成等技术,这些技术的显著进步部分得益于向量数据库的有效使用。
向量数据库在提高生成型 AI 系统能力方面也起着关键作用,通过高效管理其所需和产生的复杂数据。专用的变换器对于将图像、音频和文本等各种对象转换为其对应的综合向量表示至关重要。
在类似 LLMs 的生成型 AI 应用中,高效分类和检索内容的能力至关重要。例如,在图像生成中,向量数据库可以存储图像的特征向量。这些向量表示图像的关键特征,如颜色、纹理或风格。当生成模型需要创建新图像时,它可以参考这些向量,以找到并使用类似的现有图像作为灵感或背景。这个过程有助于创建更准确和具有上下文相关性的生成内容。
向量数据库与 LLMs 的集成促进了更多创新的应用,例如跨模态 AI 任务。在这些任务中,将两个不同的向量实体匹配在一起进行 AI 任务。这包括将文本描述转换为图像或反之的任务,其中理解和转换不同类型的向量表示是关键。
向量数据库在处理生成型 AI 系统中的用户交互数据方面也发挥了重要作用。通过将用户的偏好、行为或响应编码为向量,这些数据库使生成模型能够根据每个用户量身定制其输出。
在音乐推荐系统中,例如,用户交互如播放的歌曲、跳过的曲目以及每首歌的播放时间被转换为向量。这些向量随后告知 AI 用户的音乐品味,使其能够推荐更可能引起用户共鸣的歌曲。随着用户偏好的变化,向量数据库不断更新向量表示,使 AI 能够保持与这些变化同步。这种动态适应是保持个性化 AI 应用相关性和有效性的关键。
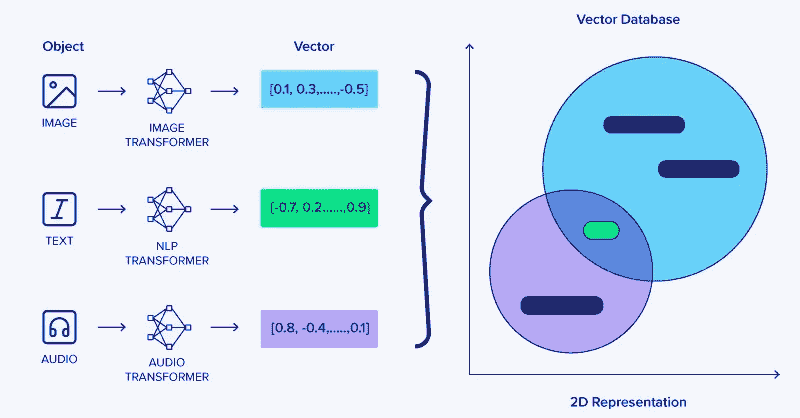
结论
向量数据库代表了数据管理技术的一次重大飞跃,特别是在其对 AI 和机器学习的应用中。通过高效处理高维向量,这些数据库已成为先进 AI 系统操作和开发中的重要组成部分,包括 LLMs、生成型 AI 和深度学习。
它们存储、管理和快速检索复杂数据结构的能力不仅提升了这些系统的性能,还在 AI 应用中开辟了新可能。从 LLMs 中的语义搜索到深度学习中的特征提取,向量数据库是现代 AI 最激动人心的进展的核心。随着 AI 继续在复杂性和能力上增长,向量数据库的重要性只会增加,巩固了它们作为 AI 和机器学习未来关键组成部分的地位。
原文。已获得许可转载。
Kevin Vu 管理着 Exxact Corp 博客,并与许多才华横溢的作者合作,他们撰写关于深度学习不同方面的内容。
更多相关内容
什么是向量数据库,它们为什么对大语言模型重要?
原文:
www.kdnuggets.com/2023/06/vector-databases-important-llms.html

图片由编辑提供
当你在 Twitter、LinkedIn 或新闻源上浏览时间线时 - 你可能会看到关于聊天机器人、大语言模型和 GPT 的一些内容。很多人都在谈论大语言模型,因为每周都有新的模型发布。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织的 IT
由于我们目前生活在 AI 革命中,重要的是要理解许多新应用依赖于向量嵌入。因此,让我们深入了解向量数据库以及它们为什么对大语言模型如此重要。
什么是向量数据库?
首先定义一下向量嵌入。向量嵌入是一种数据表示方式,它携带语义信息,帮助人工智能系统更好地理解数据,同时能够保持长期记忆。无论你在尝试学习什么新的内容,重要的元素就是理解主题并记住它。
嵌入是由 AI 模型生成的,例如包含大量特征的 LLM,这使得它们的表示难以管理。嵌入表示数据的不同维度,帮助 AI 模型理解不同的关系、模式和隐藏结构。
使用传统标量数据库进行向量嵌入是一项挑战,因为它无法处理或跟上数据的规模和复杂性。考虑到向量嵌入的复杂性,你可以想象它需要的专用数据库。这就是向量数据库发挥作用的地方。
向量数据库为向量嵌入的独特结构提供了优化的存储和查询能力。它们通过比较值和找到彼此之间的相似性,提供了便捷的搜索、高性能、可扩展性和数据检索。
听起来很不错,对吧?确实有解决向量嵌入复杂结构的方法。是的,但也不完全是。向量数据库的实施非常困难。
直到现在,向量数据库仅被那些不仅能够开发它们而且还能管理它们的科技巨头使用。向量数据库成本高,因此确保它们得到正确校准以提供高性能是非常重要的。
向量数据库是如何工作的?
现在我们对向量嵌入和数据库有了一些了解,让我们深入了解它是如何工作的。
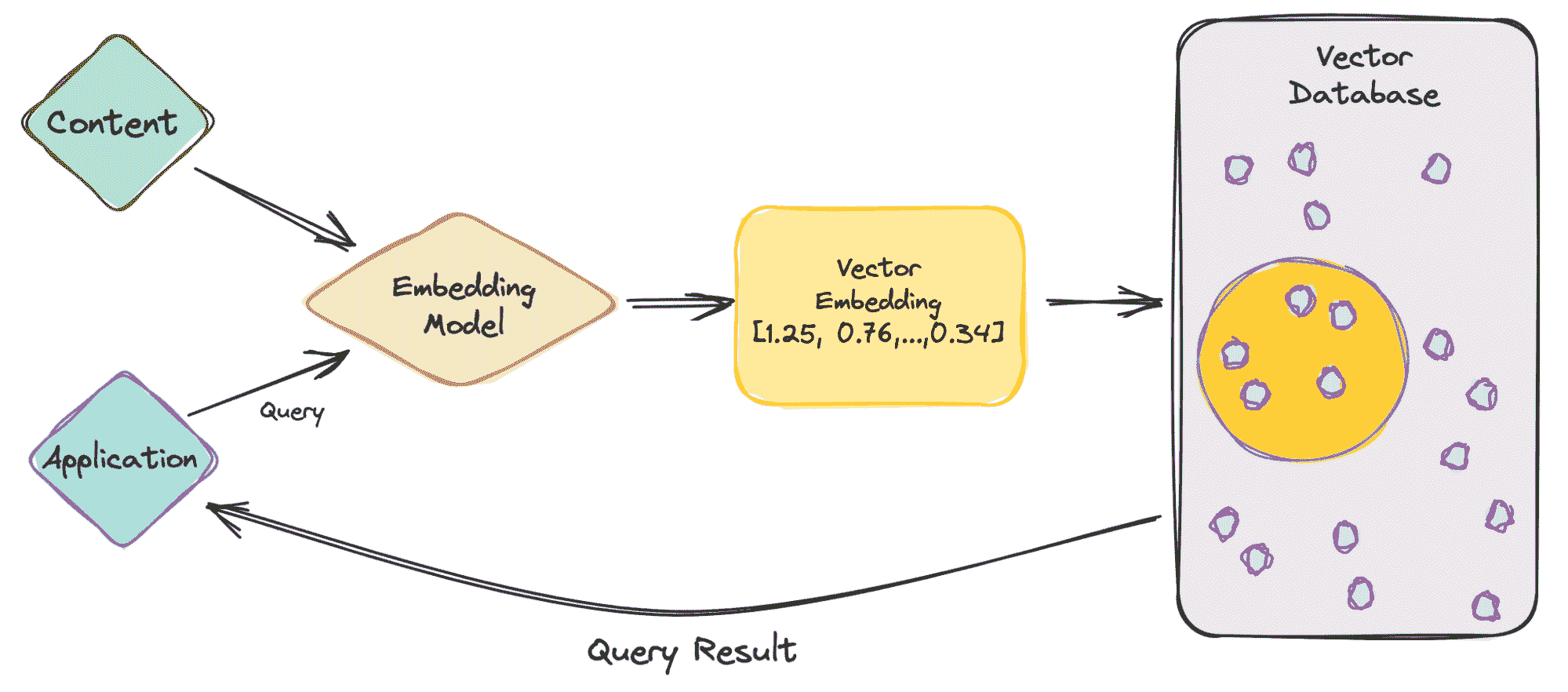
作者提供的图片
让我们从一个简单的例子开始,涉及像 ChatGPT 这样的 LLM。该模型具有大量的数据和内容,并为我们提供了 ChatGPT 应用程序。
那么,让我们逐步了解一下。
-
作为用户,你会将查询输入到应用程序中。
-
你的查询随后被插入到嵌入模型中,该模型根据我们想要索引的内容创建向量嵌入。
-
然后,向量嵌入会根据嵌入所基于的内容移动到向量数据库中。
-
向量数据库生成输出并将其作为查询结果发送回用户。
当用户继续进行查询时,它会经过相同的嵌入模型,以创建嵌入来查询该数据库以获取类似的向量嵌入。向量嵌入之间的相似性基于创建嵌入的原始内容。
想了解更多关于它在向量数据库中如何工作的内容吗?让我们进一步学习。
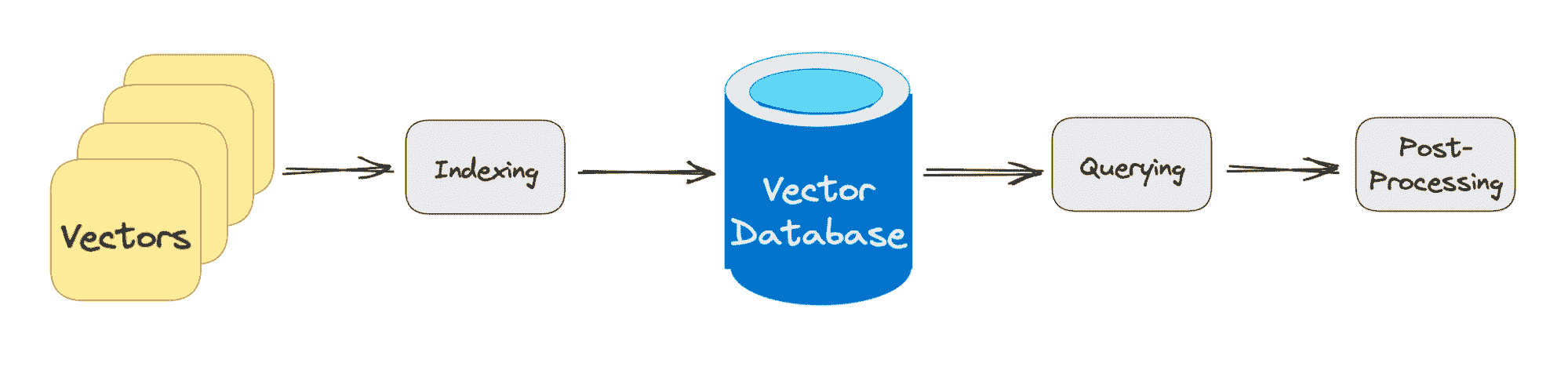
作者提供的图片
传统数据库通过在行和列中存储字符串、数字等进行工作。当从传统数据库中查询时,我们是查询与我们的查询匹配的行。然而,向量数据库处理的是向量而非字符串等。向量数据库还应用了相似性度量,用于帮助找到与查询最相似的向量。
向量数据库由不同的算法组成,这些算法都有助于近似最近邻(ANN)搜索。这通过哈希、基于图的搜索或量化实现,这些算法被组装成一个管道,以检索查询向量的邻居。
结果基于查询的接近程度或近似程度,因此主要考虑的元素是准确性和速度。如果查询输出较慢,则结果的准确性越高。
向量数据库查询经过的三个主要阶段是:
1. 索引
如上述示例所解释,一旦向量嵌入移动到向量数据库,它将使用各种算法将向量嵌入映射到数据结构中,以便更快地进行搜索。
2. 查询
在完成搜索后,向量数据库将查询的向量与索引中的向量进行比较,应用相似性度量以找到最近的邻居。
3. 后处理
根据你使用的向量数据库,该数据库将对最终的最近邻进行后处理,以生成对查询的最终输出。也可能会对最近邻进行重新排序,以便将来参考。
总结
随着人工智能的不断发展和每周发布的新系统,向量数据库的增长发挥了重要作用。向量数据库使公司能够通过准确的相似性搜索更有效地互动,为用户提供更好、更快的输出。
所以,下次你在 ChatGPT 或 Google Bard 中输入查询时,想想它处理查询以输出结果的过程。
尼莎·阿里亚 是一名数据科学家、自由技术作家及 KDnuggets 的社区经理。她特别感兴趣于提供数据科学职业建议或教程及数据科学的理论知识。她还希望探索人工智能如何有助于人类寿命的延续。作为一个热心学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
向量数据库在 AI 和 LLM 使用案例中的应用
原文:
www.kdnuggets.com/vector-databases-in-ai-and-llm-use-cases

使用 Ideogram.ai 生成的图像
因此,你可能会听到各种向量数据库的术语。有些人可能理解这些术语,有些人则不然。如果你不太了解也没关系,因为向量数据库近年来才成为一个更加突出的话题。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
向量数据库因生成式 AI,尤其是大型语言模型(LLM)的普及而变得越来越受欢迎。
许多大型语言模型产品,如 GPT-4 和 Gemini,通过为我们的输入提供文本生成能力来帮助我们的工作。实际上,向量数据库在这些大型语言模型产品中扮演了重要角色。
但是,向量数据库是如何工作的?它们在大型语言模型中的相关性是什么?
上述问题是我们将在本文中回答的。好吧,让我们一起来探索它们吧。
向量数据库
向量数据库是一种专门的数据库存储,用于存储、索引和查询向量数据。它通常针对高维向量数据进行了优化,因为这通常是机器学习模型,特别是大型语言模型的输出。
在向量数据库的背景下,向量是数据的数学表示。每个向量由表示数据位置的数值点数组成。向量通常用于大型语言模型中,因为向量比文本数据更容易处理。
在大型语言模型空间中,模型可能会有文本输入,并将其转换为表示文本语义和句法特征的高维向量。这一过程我们称之为嵌入。简单来说,嵌入是将文本转换为带有数值数据的向量的过程。
嵌入通常使用一种称为嵌入模型的神经网络模型来表示嵌入空间中的文本。
让我们使用一个示例文本:“我爱数据科学”。使用 OpenAI 的 text-embedding-3-small 模型表示它们会生成一个 1536 维的向量。
[0.024739108979701996, -0.04105354845523834, 0.006121257785707712, -0.02210472710430622, 0.029098540544509888,...]
向量中的数字是模型嵌入空间中的坐标。它们共同形成了来自模型的句子意义的独特表示。
向量数据库将负责存储这些嵌入模型输出。用户可以根据需要查询、索引和检索向量。
也许介绍足够了,让我们进入更技术的实际操作。我们将尝试使用一个开源向量数据库 Weaviate 来建立和存储向量。
Weaviate 是一个可扩展的开源向量数据库,作为一个框架用于存储我们的向量。我们可以在 Docker 等实例中运行 Weaviate 或使用 Weaviate Cloud Services (WCS)。
要开始使用 Weaviate,我们需要使用以下代码安装相关包:
pip install weaviate-client
为了简化操作,我们将使用 WCS 的沙箱集群作为我们的向量数据库。Weaviate 提供了一个 14 天的免费集群,我们可以使用它来存储向量,而无需注册任何支付方式。为此,您需要首先在他们的 WCS 控制台 上注册。
进入 WCS 平台后,选择创建集群并输入您的 Sandbox 名称。用户界面应如下图所示。
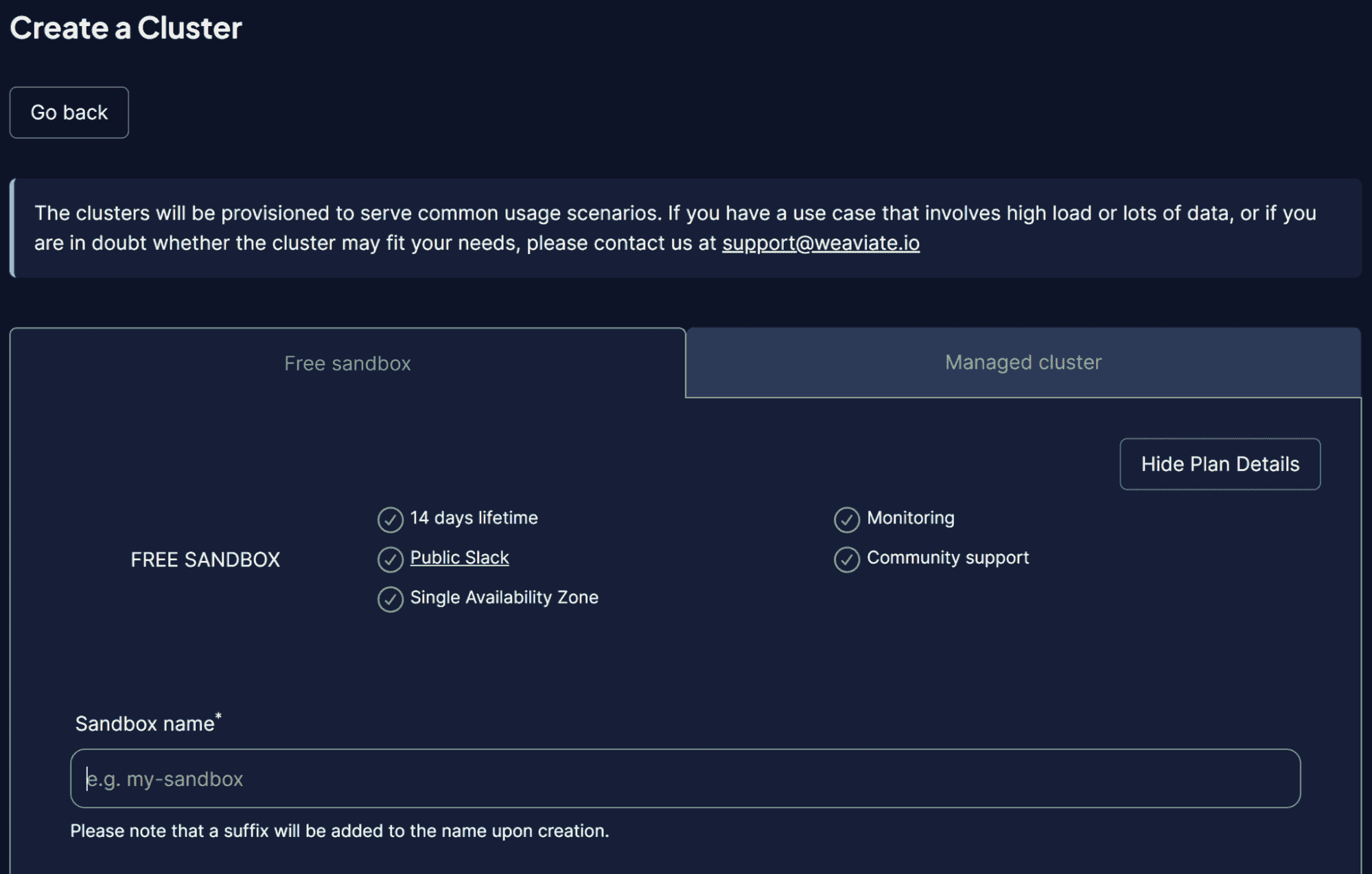
图片来源:作者
别忘了启用身份验证,因为我们还希望通过 WCS API 密钥访问该集群。集群准备好后,找到 API 密钥和集群 URL,我们将用来访问向量数据库。
一旦准备好,我们将模拟将第一个向量存储在向量数据库中。
对于向量数据库存储示例,我将使用 Kaggle 上的 Book Collection 示例数据集。我只会使用前 100 行和 3 列(标题、描述、简介)。
import pandas as pd
data = pd.read_csv('commonlit_texts.csv', nrows = 100, usecols=['title', 'description', 'intro'])
让我们先把数据放在一边,连接到我们的向量数据库。首先,我们需要使用 API 密钥和集群 URL 设置远程连接。
import weaviate
import os
import requests
import json
cluster_url = "Your Cluster URL"
wcs_api_key = "Your WCS API Key"
Openai_api_key ="Your OpenAI API Key"
client = weaviate.connect_to_wcs(
cluster_url=cluster_url,
auth_credentials=weaviate.auth.AuthApiKey(wcs_api_key),
headers={
"X-OpenAI-Api-Key": openai_api_key
}
)
一旦设置好客户端变量,我们将连接到 Weaviate Cloud 服务并创建一个类来存储向量。Weaviate 中的类是数据集合,类似于关系数据库中的表名。
import weaviate.classes as wvc
client.connect()
book_collection = client.collections.create(
name="BookCollection",
vectorizer_config=wvc.config.Configure.Vectorizer.text2vec_openai(),
generative_config=wvc.config.Configure.Generative.openai()
)
在上面的代码中,我们连接到 Weaviate 集群并创建了一个 BookCollection 类。该类对象还使用了 OpenAI text2vec 嵌入模型对文本数据进行向量化,并使用 OpenAI 生成模块。
让我们尝试将文本数据存储到向量数据库中。为此,您可以使用以下代码。
sent_to_vdb = data.to_dict(orient='records')
book_collection.data.insert_many(sent_to_vdb)
图片来源:作者
我们已经成功地将数据集存储在向量数据库中!这有多简单?
现在,您可能对向量数据库与 LLM 的使用场景感到好奇。这就是我们接下来要讨论的内容。
向量数据库和 LLM 用例
一些 LLM 可以与向量数据库结合使用的用例。让我们一起探索这些用例。
语义搜索
语义搜索是通过使用查询的含义来搜索数据,以检索相关结果,而不是仅依赖传统的基于关键字的搜索。
这个过程涉及利用查询的 LLM 模型嵌入,并在我们的矢量数据库中进行嵌入相似性搜索。
让我们尝试使用 Weaviate 根据特定查询执行语义搜索。
book_collection = client.collections.get("BookCollection")
client.connect()
response = book_collection.query.near_text(
query="childhood story,
limit=2
)
在上述代码中,我们尝试使用 Weaviate 进行语义搜索,以查找与查询童年故事密切相关的前两本书。语义搜索使用我们之前设置的 OpenAI 嵌入模型。结果可以在下面看到。
{'title': 'Act Your Age', 'description': 'A young girl is told over and over again to act her age.', 'intro': 'Colleen Archer has written for \nHighlights\n. In this short story, a young girl is told over and over again to act her age.\nAs you read, take notes on what Frances is doing when she is told to act her age. '}
{'title': 'The Anklet', 'description': 'A young woman must deal with unkind and spiteful treatment from her two older sisters.', 'intro': "Neil Philip is a writer and poet who has retold the best-known stories from \nThe Arabian Nights\n for a modern day audience. \nThe Arabian Nights\n is the English-language nickname frequently given to \nOne Thousand and One Arabian Nights\n, a collection of folk tales written and collected in the Middle East during the Islamic Golden Age of the 8th to 13th centuries. In this tale, a poor young woman must deal with mistreatment by members of her own family.\nAs you read, take notes on the youngest sister's actions and feelings."}
如你所见,上述结果中没有直接提及童年故事。然而,结果仍然与一个旨在儿童的故事密切相关。
生成搜索
生成搜索可以定义为语义搜索的扩展应用。生成搜索,或称为检索增强生成(RAG),利用 LLM 提示与从矢量数据库中检索的数据进行语义搜索。
使用 RAG,查询搜索的结果被处理到 LLM 中,因此我们可以以我们想要的形式获得结果,而不是原始数据。让我们尝试使用矢量数据库进行 RAG 的简单实现。
response = book_collection.generate.near_text(
query="childhood story",
limit=2,
grouped_task="Write a short LinkedIn post about these books."
)
print(response.generated)
结果可以在下面的文本中看到。
Excited to share two captivating short stories that explore themes of age and mistreatment. "Act Your Age" by Colleen Archer follows a young girl who is constantly told to act her age, while "The Anklet" by Neil Philip delves into the unkind treatment faced by a young woman from her older sisters. These thought-provoking tales will leave you reflecting on societal expectations and family dynamics. #ShortStories #Literature #BookRecommendations 📚
如你所见,数据内容与之前相同,但现在已经用 OpenAI LLM 处理,以提供一个简短的 LinkedIn 帖子。这样,当我们希望从数据中获得特定形式的输出时,RAG 非常有用。
RAG 问答
在我们之前的示例中,我们使用查询获取了所需的数据,RAG 将这些数据处理成预期的输出。
然而,我们可以将 RAG 功能转变为一个问答工具。我们可以通过将它们与 LangChain 框架结合来实现这一点。
首先,让我们安装必要的包。
pip install langchain
pip install langchain_community
pip install langchain_openai
然后,让我们尝试导入所需的包并初始化变量,以使 RAG 问答工作。
from langchain.chains import RetrievalQA
from langchain_community.vectorstores import Weaviate
import weaviate
from langchain_openai import OpenAIEmbeddings
from langchain_openai.llms.base import OpenAI
llm = OpenAI(openai_api_key = openai_api_key, model_name = 'gpt-3.5-turbo-instruct', temperature = 1)
embeddings = OpenAIEmbeddings(openai_api_key = openai_api_key )
client = weaviate.Client(
url=cluster_url, auth_client_secret=weaviate.AuthApiKey(wcs_api_key)
)
在上述代码中,我们设置了 LLM 用于文本生成、嵌入模型和 Weaviate 客户端连接。
接下来,我们将 Weaviate 连接设置为矢量数据库。
weaviate_vectorstore = Weaviate(client=client, index_name='BookCollection', text_key='intro',by_text = False, embedding=embeddings)
retriever = weaviate_vectorstore.as_retriever()
在上述代码中,将 Weaviate 数据库 BookCollection 设置为 RAG 工具,以便在提示时搜索‘intro’特性。
然后,我们将使用下面的代码从 LangChain 创建问答链。
qa_chain = RetrievalQA.from_chain_type(
llm=llm, chain_type="stuff", retriever = retriever
)
一切现在都准备好了。让我们尝试使用下面的代码示例进行 RAG 问答。
response = qa_chain.invoke(
"Who is the writer who write about love between two goldfish?")
print(response)
结果显示在下面的文本中。
{'query': 'Who is the writer who write about love between two goldfish?', 'result': ' The writer is Grace Chua.'}
使用矢量数据库作为存储所有文本数据的地方,我们可以实现 RAG 与 LangChain 一起执行问答。这有多棒?
结论
向量数据库是一种专门的存储解决方案,旨在存储、索引和查询向量数据。它通常用于存储文本数据,并与大型语言模型(LLMs)结合实施。本文将尝试进行向量数据库 Weaviate 的动手设置,包括语义搜索、检索增强生成(RAG)和基于 RAG 的问答等示例用例。
Cornellius Yudha Wijaya 是一名数据科学助理经理和数据撰写员。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 涉猎多种人工智能和机器学习主题。
更多相关主题
使用 NumPy Linalg 范数的向量和矩阵范数
原文:
www.kdnuggets.com/2023/05/vector-matrix-norms-numpy-linalg-norm.html
作者提供的图片
Numerical Python 或 NumPy 是一个流行的 Python 科学计算库。NumPy 库有大量内置功能,用于创建 n 维数组并对其进行计算。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
如果你对数据科学、计算线性代数和相关领域感兴趣,学习如何计算向量和矩阵的范数会很有帮助。本教程将教你如何使用 NumPy 的linalg模块中的函数来做到这一点。
要进行代码编写,你需要在开发环境中安装 Python 和 NumPy。为了使 print() 语句中的 f-strings 正常工作,你需要安装 Python 3.8 或更高版本。
让我们开始吧!
什么是范数?
在本讨论中,我们将首先查看向量范数。稍后我们会讨论矩阵范数。从数学上讲,范数是一个从 n 维向量空间到实数集合的函数(或映射):
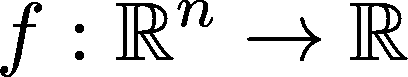
注意:范数也可以定义在复数向量空间上,C^n → R 也是一种有效的范数定义。但在本讨论中,我们将限制在实数向量空间。
范数的性质
对于 n 维向量x = (x1,x2,x3,...,xn),x 的范数通常表示为 ||x||,应满足以下性质:
-
||x|| 是非负量。对于向量x,范数 ||x|| 总是大于或等于零。当且仅当向量x是全零向量时,||x|| 才等于零。
-
对于两个向量x = (x1,x2,x3,...,xn) 和 y = (y1,y2,y3,...,yn),它们的范数 ||x|| 和 ||y|| 应满足三角不等式:||x + y|| <= ||x|| + ||y||。
-
此外,所有范数都满足 ||αx|| = |α| ||x||,其中 α 为标量。
常见的向量范数:L1、L2 和 L∞ 范数
一般来说,n 维向量x = (x1,x2,x3,...,xn)的 Lp 范数(或 p-范数)对于 p >= 0 定义为:
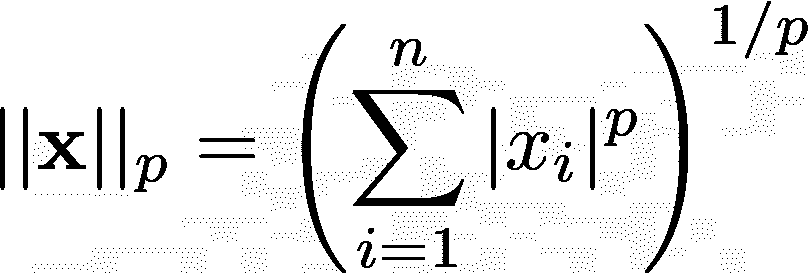
让我们来看看常见的向量范数,即 L1、L2 和 L∞ 范数。
L1 范数
L1 范数等于向量中所有元素绝对值的总和:
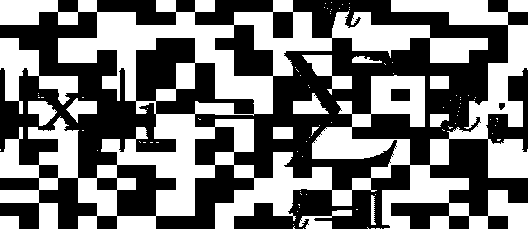
L2 范数
将 p =2 代入一般的 Lp 范数方程,我们得到向量的 L2 范数的以下表达式:
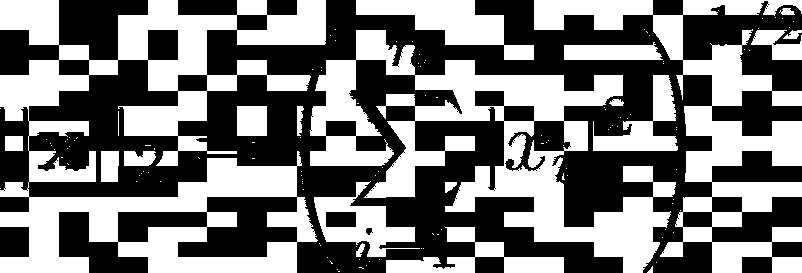
L∞ 范数
对于给定的向量 x,L∞ 范数是 x 元素 绝对 值中的 最大值:
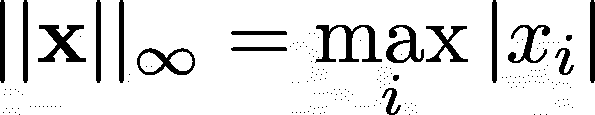
验证这些范数是否满足前面列出的范数属性是相当简单的。
如何在 NumPy 中计算向量范数
NumPy 中的 linalg 模块包含我们可以用来计算范数的函数。
在开始之前,让我们初始化一个向量:
import numpy as np
vector = np.arange(1,7)
print(vector)
Output >> [1 2 3 4 5 6]
NumPy 中的 L2 范数
让我们从 NumPy 中导入 linalg 模块:
from numpy import linalg
norm() 函数用于计算矩阵和向量的范数。此函数需要一个必需的参数——我们需要计算范数的向量或矩阵。此外,它还接受以下 可选 参数:
-
ord决定了计算的范数的阶数,以及 -
axis指定了计算范数的轴。
当我们在函数调用中没有指定 ord 时,norm() 函数默认计算 L2 范数:
l2_norm = linalg.norm(vector)
print(f"{l2_norm = :.2f}")
Output >> l2_norm = 9.54
我们可以通过明确将 ord 设置为 2 来验证这一点:
l2_norm = linalg.norm(vector, ord=2)
print(f"{l2_norm = :.2f}")
Output >> l2_norm = 9.54
NumPy 中的 L1 范数
要计算向量的 L1 范数,请调用 norm() 函数,设置 ord = 1:
l1_norm = linalg.norm(vector, ord=1)
print(f"{l1_norm = :.2f}")
Output >> l1_norm = 21.00
由于我们的示例 vector 仅包含正数,我们可以验证在这种情况下 L1 范数等于元素的总和:
assert sum(vector) == l1_norm
NumPy 中的 L∞ 范数
要计算 L∞ 范数,将 ord 设置为 'np.inf':
inf_norm = linalg.norm(vector, ord=np.inf)
print(f"{inf_norm = }")
在这个例子中,我们得到 6,向量中的 最大 元素(绝对值意义上):
Output >> inf_norm = 6.0
在 norm() 函数中,你还可以将 ord 设置为 '-np.inf'。
neg_inf_norm = linalg.norm(vector, ord=-np.inf)
print(f"{neg_inf_norm = }")
如你所猜,负的 L∞ 范数返回向量中的 最小 元素(绝对值意义上):
Output >> neg_inf_norm = 1.0
关于 L0 范数的说明
L0 范数给出向量中非零元素的数量。从技术上讲,这不是一个范数。它实际上是一个伪范数,因为它违反了 ||αx|| = |α| ||x|| 的属性。这是因为,即使向量被一个标量乘以,非零元素的数量 保持不变。
要获取向量中非零元素的数量,将 ord 设置为 0:
another_vector = np.array([1,2,0,5,0])
l0_norm = linalg.norm(another_vector,ord=0)
print(f"{l0_norm = }")
在这里,another_vector 有 3 个非零元素:
Output >> l0_norm = 3.0
理解矩阵范数
到目前为止,我们已经看到如何计算向量范数。就像你可以将向量范数视为从 n 维向量空间到实数集合的映射一样,矩阵范数是从 m x n 矩阵空间到实数集合的映射。数学上,你可以表示为:
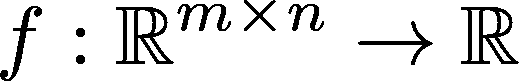
常见的矩阵范数包括 Frobenius 范数和核范数。
Frobenius 范数
对于一个 m x n 的矩阵 A,其中 m 行 n 列,Frobenius 范数由下式给出:
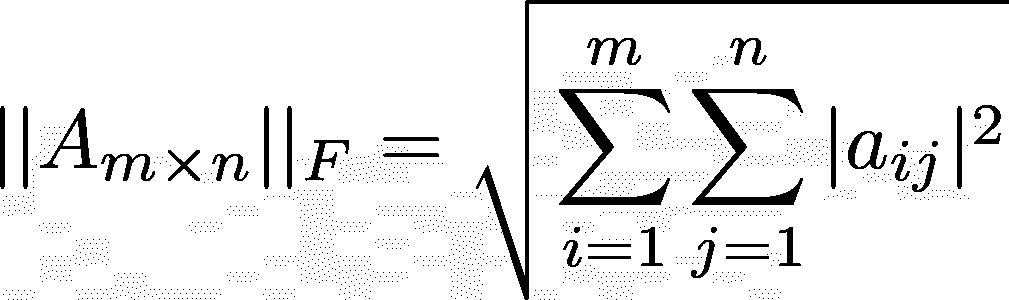
核范数
奇异值分解(SVD)是一种矩阵分解技术,用于主题建模、图像压缩和协同过滤等应用。
SVD 将输入矩阵分解为一个左奇异向量矩阵(U)、一个奇异值矩阵(S)和一个右奇异向量矩阵(V_T)。而核范数是矩阵的最大奇异值。
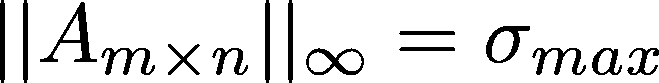
如何在 NumPy 中计算矩阵范数
继续讨论如何在 NumPy 中计算矩阵范数,让我们将 vector 重塑为一个 2 x 3 的矩阵:
matrix = vector.reshape(2,3)
print(matrix)
Output >>
[[1 2 3]
[4 5 6]]
NumPy 中的矩阵 Frobenius 范数
如果你不指定 ord 参数,norm() 函数默认计算 Frobenius 范数。
让我们通过将 ord 设置为 'fro' 来验证这一点:
frob_norm = linalg.norm(matrix,ord='fro')
print(f"{frob_norm = :.2f}")
Output >> frob_norm = 9.54
当我们不传入可选的 ord 参数时,我们也得到 Frobenius 范数:
frob_norm = linalg.norm(matrix)
print(f"{frob_norm = :.2f}")
Output >> frob_norm = 9.54
总结来说,当 norm() 函数以矩阵作为输入时,默认返回矩阵的 Frobenius 范数。
NumPy 中的矩阵核范数
要计算矩阵的核范数,你可以传入矩阵并在 norm() 函数调用中将 ord 设置为 'nuc':
nuc_norm = linalg.norm(matrix,ord='nuc')
print(f"{nuc_norm = :.2f}")
Output >> nuc_norm = 10.28
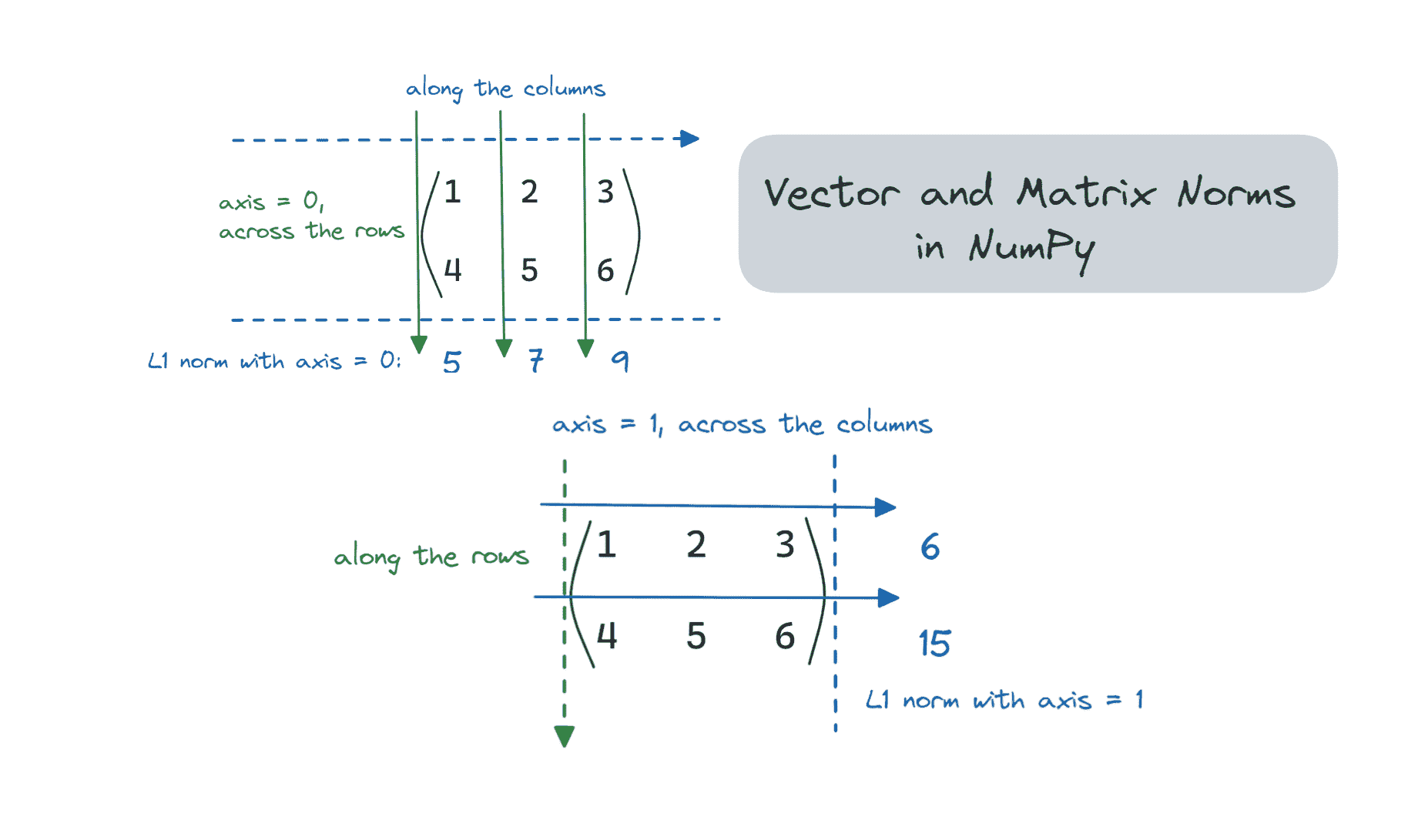
沿特定轴的矩阵范数
我们通常不会在矩阵上计算 L1 和 L2 范数,但 NumPy 允许你计算任意 ord 的矩阵(2D 数组)和其他多维数组的范数。
让我们看看如何在特定轴上计算矩阵的 L1 范数——沿行和列。
类似地,我们可以设置 axis = 1。
axis = 0 表示矩阵的行。如果设置 axis = 0,则计算矩阵的 L1 范数是 跨行(或沿列)进行的,如下所示:
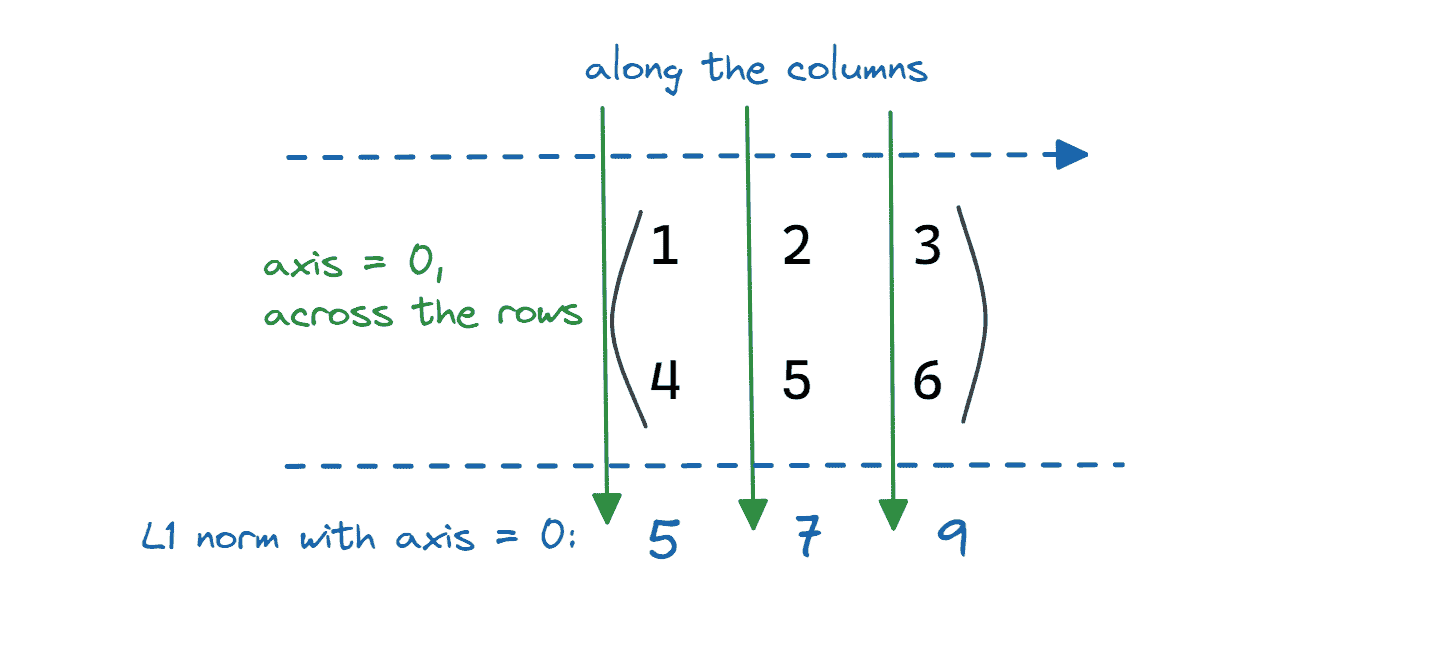
图片由作者提供
让我们在 NumPy 中验证这一点:
matrix_1_norm = linalg.norm(matrix,ord=1,axis=0)
print(f"{matrix_1_norm = }")
Output >> matrix_1_norm = array([5., 7., 9.])
类似地,我们可以设置 axis = 1。
axis = 1 表示矩阵的列。因此,通过设置 axis = 1 计算矩阵的 L1 范数是 跨列(沿行)进行的。
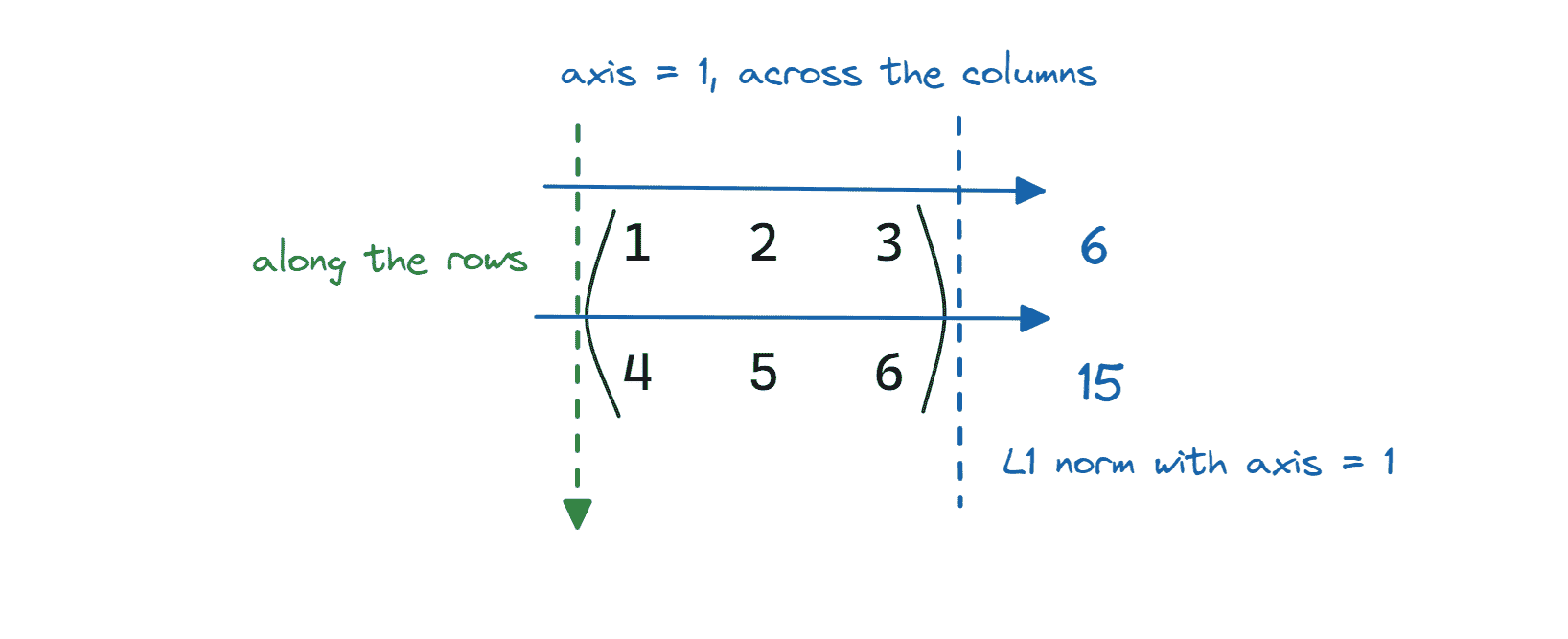
图片由作者提供
matrix_1_norm = linalg.norm(matrix,ord=1,axis=1)
print(f"{matrix_1_norm = }")
Output >> matrix_1_norm = array([ 6., 15.])
我建议你试验 ord 和 axis 参数,并尝试不同的矩阵,直到你掌握它。
结论
我希望你现在明白了如何使用 NumPy 计算向量和矩阵范数。然而,需要注意的是,Frobenius 范数和核范数仅对矩阵定义。因此,如果你计算向量或维度超过两个的多维数组,你会遇到错误。这就是本教程的全部内容!
Bala Priya C 是一位技术作家,喜欢创作长篇内容。她的兴趣领域包括数学、编程和数据科学。她通过编写教程、使用指南等方式与开发者社区分享她的学习成果。
更多相关主题
矢量化的随机数生成器真的有用吗?
原文:
www.kdnuggets.com/2018/08/vectorized-random-number-generators-actually-useful.html
评论
作者:丹尼尔·勒梅尔,魁北克大学
我们的处理器受益于“SIMD”指令。这些指令可以同时操作多个值,从而大大加速某些算法。早些时候,我报告过,你可以通过使用 SIMD 指令将常见(快速)随机数生成器如 PCG 和 xorshift128+ 的速度提高三到四倍。
一位读者挑战我:这在实际中真的有用吗?
在一些问题中,随机数生成对性能至关重要。例如,许多模拟场景就属于这种情况。最简单且最为人知的可能就是数组的随机打乱。标准算法相当简单:
for (i = size; i > 1; i--) {
var j = random_number(i);
switch_values(array, i, j);
}
如果你感兴趣,O’Neill 写了一整篇关于这个特定问题的博客文章。
那么我能否使用 SIMD 指令加速数组的打乱?
因此,我快速组合了一个矢量化打乱算法和一个常规(标量)打乱算法,它们都使用了 O’Neill 的 PCG32。最终结果?当数组在缓存中时,我使用 SIMD 指令几乎将速度翻倍:
| SIMD 打乱 | 每个条目 3.5 个周期 |
|---|---|
| 标量打乱 | 每个条目 6.6 个周期 |
我的代码可以在这里找到。我并没有做任何复杂的操作,所以我预计可以做得更好。我的唯一目标是演示 SIMD 随机数生成器的实际应用性。
个人简介: 丹尼尔·勒梅尔 是魁北克大学的计算机科学教授。他的研究集中在软件性能和索引方面。他是一个技术乐观主义者。
原文。经许可转载。
相关:
-
随机性的惊人复杂性
-
2026 年人工智能中的常识…
-
深度学习是万能钥匙吗?
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的信息技术需求
了解更多相关主题
数据科学的版本控制:跟踪机器学习模型和数据集
评论
由 Vipul Jain,应用数据科学家

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT 需求
毋庸置疑,GIT 是版本控制系统的圣杯!Git 在版本控制源代码方面表现出色。但与软件工程不同,数据科学项目还有额外的大型文件,如数据集、训练模型文件、标签编码等,这些文件的大小很容易达到几 GB,因此无法使用 GIT 进行跟踪。
告诉我解决方案?
令人惊叹的一群人来自 dvc.org/ 创建了这个名为 DVC 的工具。DVC 帮助我们对大型数据文件进行版本控制,类似于我们使用 git 对源代码文件进行版本控制。同时,DVC 可以在 GIT 之上完美运行,使其更加出色!

大多数时候,数据科学工作流中忽略了数据集和模型的跟踪。现在有了 DVC,我们可以跟踪所有的工件——这将使数据科学家更高效,因为我们不必手动记录为了达到状态而做了什么,同时也不必在处理数据和构建模型以重现相同状态时浪费时间。

DVC 的好处
-
轻松处理大型文件——使得重用和可重复性变得非常简单
-
与 Git 兼容——在 git 之上工作
-
存储无关——支持 GCS/S3/Azure 以及更多存储数据
让我们开始吧!
安装
安装非常简单,使用以下命令:
pip install dvc
要验证安装,请在终端中输入 dvc,如果你看到一堆 DVC 命令选项,那么你就走在正确的道路上了。
在演示中,我将使用 dvc-sample 仓库,项目结构如下:
dvc-sample
├── artifacts
│ ├── dataset.csv
│ └── model.model
└── src
├── preprocessor.py
└── trainer.py
该仓库具有简单的结构;有一个 src 文件夹,其中包含 Python 脚本(由 git 版本控制),以及一个 artifacts 文件夹,其中包含所有数据集、模型文件和其他较大的 artifacts(需要由 dvc 进行控制)。
初始化 dvc
我们首先需要在项目根目录中初始化 dvc。我们使用下面的命令完成:
dvc init
(这与 git init 非常相似,我们只需在设置项目时做一次)
此时,我们已经将 dvc 支持添加到项目中。但我们仍然需要指定我们想用 dvc 进行版本控制的文件夹。在这个例子中,我们将对 artifacts 文件夹进行版本控制。我们使用下面的命令来完成:
dvc add artifacts
上述声明做了两件事 -:
-
使用
dvc指定我们要跟踪的文件夹(创建一个元文件
artifacts.dvc) -
将相同的文件夹添加到
.gitignore(因为我们不再希望使用 git 跟踪该文件夹)
执行上述命令后,dvc 会告诉我们将上述两个文件添加到 git
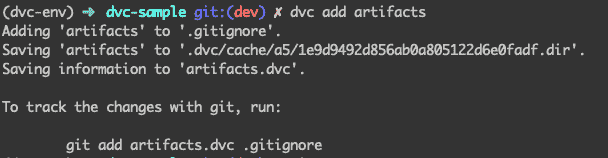
现在我们使用下面的命令将这些文件添加到 git 中:
git add .
git commit -m 'Added dvc files'
注意:这里需要注意的是:artifacts 文件夹的元文件由 git 跟踪,而实际的 artifacts 文件由 dvc 跟踪。在这种情况下,artifacts.dvc 由 git 跟踪,而 artifacts 文件夹中的内容由 dvc 跟踪。
如果现在这不太清楚也没关系,我们稍后会详细查看。
此时,我们已经将
*dvc*添加到我们的项目中,并且还添加了我们想要用 dvc 跟踪的文件夹。
现在让我们看一下典型的机器学习工作流(简化版):
-
我们有一个数据集
-
我们使用 Python 脚本对上述数据集进行一些预处理
-
我们使用 Python 脚本训练一个模型
-
我们有一个模型文件,这是步骤 #3 的输出
上述是一个重复的过程;由于我们使用多个数据集和不同的预处理管道来构建和测试各种机器学习模型,因此我们希望对其进行版本控制,以便在需要时轻松重现之前的版本。
对于上述场景,我们使用 git 跟踪 #2 和 #3,因为这些是较小的代码文件。而使用 dvc 跟踪 #1 和 #4,因为这些文件可能非常大(最多几 GB)
再次查看目录结构以获得更多清晰度:
dvc-sample
├── artifacts
│ ├── dataset.csv #1
│ └── model.model #4
└── src
├── preprocessor.py #2
└── trainer.py #3
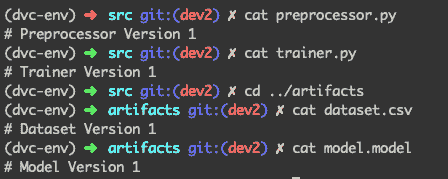
为了简化起见,在任何给定时刻——上述 4 个文件中的每一个都将是它们所属的版本。
假设我们已经编写了第一个版本的预处理器和训练脚本,这些脚本用于在数据集上构建模型。现在这 4 个文件看起来是这样的:
版本 1 中文件的状态
跟踪大文件
现在我们需要提交我们的代码和 artifacts(数据集和模型文件),我们分三步完成:
1. 我们使用 dvc 跟踪 artifacts 中的更改
dvc add artifacts/
(这会跟踪工件文件夹内的最新版本文件,并修改artifacts.dvc元文件)
2. 使用git跟踪代码脚本的更改和更新的元文件(artifacts.dvc)
git add .
git commit -m 'Version 1: scripts and dvc files'
3. 使用git将这个项目状态标记为experiment01
(这将帮助我们以后回滚到某个版本)
git tag -a experiment01 -m 'experiment01'
我们已经成功使用git和dvc分别保存了版本 1 的脚本和工件。
现在假设我们正在进行一个新实验,其中包含不同的数据集和修改过的脚本。这 4 个文件现在看起来是这样的:
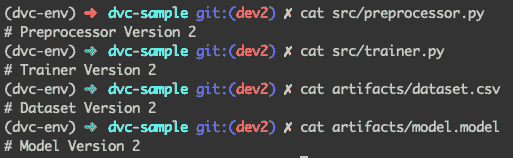
版本 2 时的文件状态
现在我们重复相同的 3 个步骤来跟踪版本 2。
1. 使用dvc跟踪artifacts的更改
dvc add artifacts/
2. 使用git跟踪代码脚本的更改和更新的元文件(artifacts.dvc)
git add .
git commit -m 'Version 2: scripts and dvc files'
3. 使用git将这个项目状态标记为experiment02
git tag -a experiment02 -m 'experiment02'
在这个阶段,我们已经跟踪了版本 2 的脚本和工件。
切换版本——重现代码和工件
现在真正的考验来了,是时候看看我们是否可以轻松跳转到两个文件夹中的任何一个版本了。首先——让我们看看项目的当前状态:
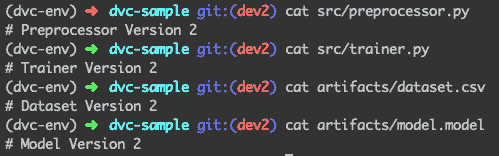
当前状态:版本 2
从文件内容可以看出,我们现在处于版本 2。
(我们查看内容以获得更好的直觉,在实际操作中,我们可以查看 git 提交消息或标签)
现在假设我们意识到版本 1 更好,我们想要回滚(脚本以及数据集和模型)到版本 1。让我们看看如何用几个简单的命令做到这一点:
1. 我们签出到experiment01标签
git checkout experiment01
执行以下命令后,项目状态看起来是这样的:
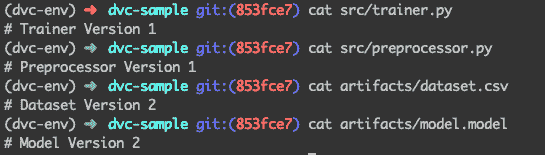
你注意到了什么吗?

你可以看到脚本已更改为版本 1。太好了!
但工件仍然是版本 2。没错!这是因为,到目前为止,我们使用了git进行回滚——这回滚了代码脚本和artifacts.dvc元文件的版本。现在,由于元文件已经回滚到我们想要的版本,我们只需要使用dvc进行签出
dvc checkout
这将根据当前版本(v1)的artifacts.dvc文件更改artifacts文件夹中的文件。
再次查看文件:
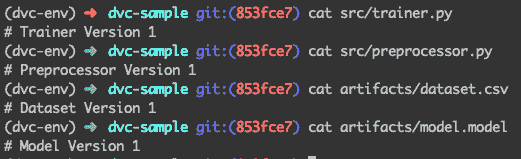
所有文件回滚到版本 1
万岁!我们成功地将版本 2 回滚到版本 1——无论是脚本还是大型数据集和模型文件。

简单来说,我们仅仅看了如何在两个版本之间切换和工作。上述过程同样适用于几百个实验——使我们能够快速迭代而无需手动记录或担心在需要时重新生成早期实验的状态。
结论
DVC 是一个很好的工具,用于版本控制大型文件,如数据集和训练模型文件,正如我们使用 git 对源代码进行版本控制一样。它帮助我们实现不同 ML 实验的工件可重复性,节省了处理数据和构建模型的时间。
其他阅读
简介: Vipul Jain 是一名数据科学家,专注于机器学习,拥有从构思到生产的端到端数据产品构建经验。拥有在生产环境中构建 A/B 测试实验框架的经验。能够将技术概念有效地呈现给非技术利益相关者。
原文。经许可转载。
相关:
-
如何利用机器学习自动化 GitHub 上的任务以获取乐趣和利润
-
处理机器学习中数据不足的 5 种方法
-
处理小数据的 7 个技巧
更多相关内容
版本控制机器学习实验与跟踪实验
原文:
www.kdnuggets.com/2021/12/versioning-machine-learning-experiments-tracking.html
由 Maria Khalusova 撰写,Iterative 的高级开发者倡导者

摄影: Debby Hudson 在 Unsplash
在进行机器学习项目时,通常会进行大量实验,以寻找一种算法、参数和数据预处理步骤的组合,从而产生最适合当前任务的模型。为了跟踪这些实验,数据科学家们曾经将其记录在 Excel 表格中,因为当时缺乏更好的选择。然而,由于主要是手动操作,这种方法存在一些缺点。比如,它容易出错、不方便、速度慢,并且与实际实验完全脱节。
幸运的是,在过去几年中,实验跟踪技术取得了长足的进展,我们看到市场上出现了许多能够改善实验跟踪方式的工具,例如 Weights&Biases、MLflow 和 Neptune。通常,这些工具提供了一个 API,你可以从代码中调用以记录实验信息。然后,这些信息会存储在数据库中,你可以使用仪表盘进行可视化比较。一旦你更改了代码,就不再需要担心忘记记录结果——这会自动为你完成。仪表盘有助于可视化和共享。
这是跟踪已完成工作的一个重大改进,但…… 在仪表盘上发现产生最佳指标的实验并不自动转化为准备好部署的模型。你可能需要首先重现最佳实验。然而,你直接观察到的跟踪仪表盘和表格与实际实验的连接较弱。因此,你仍然可能需要半自动地追踪你的步骤,拼接出准确的代码、数据和管道步骤来重现实验。这能自动化吗?
在这篇博客文章中,我想谈谈实验的版本控制,而不是跟踪实验,以及这如何在实验跟踪的好处基础上带来更容易的可重复性。
为了实现这一点,我将使用 DVC,这是一款开源工具,主要以数据版本控制而闻名(毕竟这也是它名字的一部分)。然而,这款工具实际上可以做很多事情。例如,你可以使用 DVC 定义机器学习管道,运行多个实验,并比较指标。你还可以对所有参与实验的移动部分进行版本控制。
实验版本控制
要开始版本控制实验,你需要从任何 Git 仓库初始化 DVC,如下所示。请注意,DVC 期望你的项目按照一定的逻辑结构组织,你可能需要稍微重新组织一下文件夹。
$ dvc exp init -i
This command will guide you to set up a default stage in dvc.yaml.
See [`dvc.org/doc/user-guide/project-structure/pipelines-files`](https://dvc.org/doc/user-guide/project-structure/pipelines-files). DVC assumes the following workspace structure:
├── data
├── metrics.json
├── models
├── params.yaml
├── plots
└── srcCommand to execute: python src/train.py
Path to a code file/directory [src, n to omit]: src/train.py
Path to a data file/directory [data, n to omit]: data/images/
Path to a model file/directory [models, n to omit]:
Path to a parameters file [params.yaml, n to omit]:
Path to a metrics file [metrics.json, n to omit]:
Path to a plots file/directory [plots, n to omit]: logs.csv
──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
default:
cmd: python src/train.py
deps:
- data/images/
- src/train.py
params:
- model
- train
outs:
- models
metrics:
- metrics.json:
cache: false
plots:
- logs.csv:
cache: false
Do you want to add the above contents to dvc.yaml? [y/n]: yCreated default stage in dvc.yaml. To run, use "dvc exp run".
See [`dvc.org/doc/user-guide/experiment-management/running-experiments`](https://dvc.org/doc/user-guide/experiment-management/running-experiments).
你可能还会注意到 DVC 假设你将参数和指标存储在文件中,而不是通过 API 进行日志记录。这意味着你需要修改代码以从 YAML 文件中读取参数,并将指标写入 JSON 文件。
最后,在初始化时,DVC 自动创建一个基本流程并将其存储在 dvc.yaml 文件中。这样,你的训练代码、流程、参数和指标现在都保存在可以版本控制的文件中。
实验即代码方法的好处
干净的代码
以这种方式设置后,你的代码不再依赖于实验跟踪 API。你不需要在代码中插入跟踪 API 调用来将实验信息保存到中央数据库,而是将其保存在可读文件中。这些文件始终可以在你的仓库中找到,你的代码保持干净,依赖项减少。即使没有 DVC,你也可以通过 Git 阅读、保存和版本化实验参数和指标,尽管使用纯 Git 不是比较机器学习实验的最方便方式。
$ git diff HEAD~1 -- params.yaml
diff --git a/params.yaml b/params.yaml
index baad571a2..57d098495 100644
--- a/params.yaml
+++ b/params.yaml
@@ -1,5 +1,5 @@
train:
epochs: 10
-model:
- conv_units: 16
+model:
+ conv_units: 128
可复现性
实验跟踪数据库无法捕捉到你需要复现实验的所有信息。其中一个常常缺失的重要部分是运行实验所需的完整流程。让我们来看看dvc.yaml文件,它是生成的流程文件。
$ cat dvc.yaml
stages:
default:
cmd: python src/train.py
deps:
- data/images
- src/train.py
params:
- model
- train
outs:
- models
metrics:
- metrics.json:
cache: false
plots:
- logs.csv:
cache: false
这个流程捕捉了运行实验的命令、参数和其他依赖项、指标、图表以及其他输出。它有一个单一的default阶段,但你可以根据需要添加任意多的阶段。当将实验的所有方面都视为代码时,包括流程,任何人都更容易复现实验。
减少噪音
在仪表盘中,你可以看到所有的实验,我指的是所有的实验。在某个时刻,你会有很多实验,你需要排序、标记和过滤它们以保持跟进。通过实验版本控制,你在共享和组织事情时有更多的灵活性。
例如,你可以在一个新的 Git 分支中尝试一个实验。如果出现问题或结果不尽如人意,你可以选择不推送该分支。这样你可以减少在实验跟踪仪表盘中可能遇到的一些不必要的杂乱。
同时,如果某个实验看起来有前景,你可以将它和你的代码一起推送到你的仓库,以保持结果与代码和流程的同步。结果与相同的人共享,并且已经按照你现有的分支名称进行了组织。你可以继续在该分支上迭代,如果实验差异过大,可以启动新的分支,或者合并到主分支,使其成为你的主要模型。
为什么使用 DVC?
即使没有 DVC,你也可以将代码更改为从文件中读取参数,并将指标写入其他文件,并使用 Git 跟踪更改。然而,DVC 在 Git 之上添加了一些特定于 ML 的功能,可以简化比较和复现实验的过程。
大型数据版本控制
大型数据和模型在 Git 中难以跟踪,但使用 DVC,你可以使用自己的存储来跟踪它们,同时它们与 Git 兼容。当初始化 DVC 时,它开始跟踪models文件夹,使 Git 忽略它,但仍存储和版本控制它,以便你可以在任何地方备份版本,并与实验代码一起查看它们。
单命令可复现性
编码整个实验管道是实现可复现性的良好第一步,但它仍然需要用户执行该管道。使用 DVC,你可以通过单个命令复现整个实验。不仅如此,它还会检查缓存的输入和输出,并跳过重新计算之前生成的数据,这有时可以节省大量时间。
$ dvc exp run
'data/images.dvc' didn't change, skipping
Stage 'default' didn't change, skippingReproduced experiment(s): exp-44136
Experiment results have been applied to your workspace.To promote an experiment to a Git branch run:dvc exp branch <exp> <branch>
更好的分支组织
虽然 Git 分支是一种灵活的实验组织和管理方式,但通常实验太多而无法适应任何 Git 分支工作流。DVC 跟踪实验,因此你不需要为每个实验创建提交或分支:
$ dvc exp show
┏━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━┓
┃Experiment ┃ Created ┃ loss ┃ acc ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━┩
│workspace │ - │ 0.25183 │ 0.9137 │
│mybranch │ Oct 23, 2021 │ - │ - │
│├──9a4ff1c [exp-333c9] │ 10:40 AM │ 0.25183 │ 0.9137 │
│├──138e6ea [exp-55e90] │ 10:28 AM │ 0.25784 │ 0.9084 │
│├──51b0324 [exp-2b728] │ 10:17 AM │ 0.25829 │ 0.9058 │
└─────────────────────────┴──────────────┴─────────┴────────┘
一旦你决定哪些实验值得与团队分享,它们可以转换为 Git 分支:
$ dvc exp branch exp-333c9 conv-units-64
Git branch 'conv-units-64' has been created from experiment 'exp-333c9'.
To switch to the new branch run:git checkout conv-units-64
这样,你将避免在你的仓库中创建混乱的分支,并可以专注于仅比较有前途的实验。
结论
总结来说,实验版本控制允许你将实验以一种方式编码,使你的实验日志始终与进入实验的确切数据、代码和管道相关联。你可以控制哪些实验最终与同事共享以供比较,这可以防止混乱。
最终,复现一个版本化的实验变得像运行单个命令一样简单,如果某些管道步骤有缓存的输出仍然相关,甚至可能比最初的时间更短。
感谢你坚持看到文章的最后!要了解更多关于使用 DVC 管理实验的信息, 查看文档
简介:Maria Khalusova (@mariaKhalusova)是 Iterative 的高级开发者倡导者。她从事开源 MLOps 工具的工作。
原文。经许可转载。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 事务
更多相关话题
ModelDB 2.0 已经到来!
赞助帖子。
自从我们编写 ModelDB 1.0 这一开创性的模型版本管理系统以来,我们学到了很多,并且适应不断发展的生态系统成为一项挑战。因此,我们决定从头开始重建,以支持一个量身定制的模型版本管理系统,使机器学习的开发和部署变得可靠、安全和可重复。
我们很高兴地宣布 ModelDB 2.0 现已发布! 感谢所有启发并帮助设计、测试和验证此次发布的合作伙伴。
在详细介绍此重大版本之前,让我们快速查看 ModelDB 2.0 的新特性:
-
基于 API 的分层客户端,允许轻松扩展功能并与框架集成
-
与流行的机器学习框架集成,如 pytorch、scikit-learn、tensorflow 等
-
工件管理 以可靠地跟踪训练过程的结果
-
基于 Git 的版本控制 用于模型的所有组件
-
为公司模型开发提供单一视图
-
用户管理支持 用于身份验证、RBAC 授权和工作区隔离
模型版本管理
当我们最初创建 ModelDB 1.0 时,我们仅追踪有关模型的元数据。然而,与许多组织(包括受监管行业及其他领域)合作,将其模型投入实际使用后,我们发现这还不够。尽管元数据非常详尽,但它不能让你回到模型的特定状态。比如,仅靠元数据,你无法回到三个月前模型创建时的确切状态。因此,我们基于 Git 的灵感,构建了新的模型版本管理解决方案,以管理创建模型的所有要素:数据集、代码、环境和配置。
通过新的版本管理功能,你可以:
-
对模型的所有组件进行版本控制,如 Python 或 Docker 环境、S3 数据集、笔记本代码和超参数集合。机器学习具有多样性,没有单一工具能解决所有问题。你还可以使用标准企业工具(Java 和数据库)轻松扩展现有类型以满足你的需求。
-
集成不同的版本管理解决方案,如 Git、数据库、对象存储、容器库以及许多其他隔离源。使用适合管理每个模型要素的工具,我们将帮助你跟踪所有这些要素的变化。我们还为那些没有原生版本管理系统的提供版本管理系统。
-
像 Git 一样或像 API 一样使用,这允许与 GitOps 和笔记本生态系统之间的任何东西集成。你可以使用我们的客户端来操作你关心的对象,而不必担心基于磁盘系统的限制。但你也可以在 ModelDB 和你的本地 Git 之间进行同步。
-
提交、回滚、分支、比较和合并 仓库中的任何更改,就像你对 Git 一样。专门的工具可以操作模型的组成部分,通过嵌入应用知识而不是仅仅假设所有内容都是文本,从而使体验更加顺畅。享受 GitOps 的所有好处,而无需直接操作 Git,获得真正的 MLOps 体验!
我们将发布一系列关于版本创建幕后工作的博客文章。 订阅我们的新闻通讯,以便不错过它们!
安全实验管理
ModelDB 1.0 能够存储模型信息,但不支持身份验证和授权。这些都是确保数据安全的关键功能,尤其是对于企业。因此,在 ModelDB 2.0 中,我们现在终于添加了必要的接口,使你可以准确知道谁做了什么以及何时做的,确保只有授权用户可以访问。这也将使用户能够为不同团队隔离实验集。
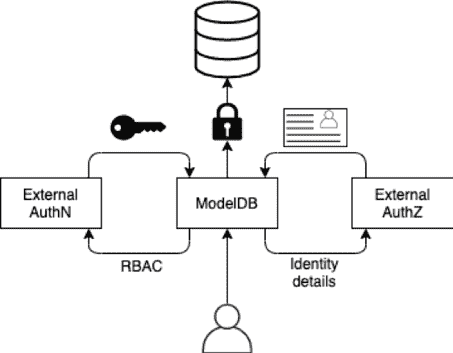
新版本使你能够:
-
通过 RBAC 控制访问 实验,定义谁可以执行操作。API 是公开的,任何人都可以根据自己的使用案例实现它们。ModelDB 将根据其知道的资源管理角色的创建,并检查每个用户操作的权限。你还可以利用我们的企业版提供的完全集成的解决方案!我们有团队和组织的用户管理,还可以与不同的身份验证系统集成。
-
使用工作区 来进行隔离,为环境之间提供完全的隔离。你可以用它来区分开发和生产模型,甚至可以在团队之间进行隔离。
-
识别 模型、版本更改及任何其他组件的作者。了解团队中谁可以协助解决问题,或者谁是联系模型的最佳人选。时刻了解组织中的人员情况。
我们还将分享我们 RBAC 系统背后的设计原则,这些原则通过分析最佳实践得出解决方案。 订阅我们的新闻通讯,以便在它们发布时收到通知!
集中化仪表盘
ModelDB 中一个用户最喜欢的功能是网页体验,它允许他们全面查看他们所做的实验。在这个新版本中,我们更加注重通过我们的用户界面构建出色的用户体验,以帮助我们的用户更轻松地浏览他们的模型。
使用 ModelDB 2.0,你可以:
-
组织你的工作,利用项目、实验、运行、标签、描述以及任何你需要的东西来导航多个开发前沿,确保不会丢失任何内容。
-
搜索和筛选 模型以找到你需要的。我们可以根据运行的任何特征进行筛选,包括指标和超参数。你可以使用我们的用户界面或客户端对找到的模型进行迭代。
-
管理输入和输出 模型过程中的数据,将输入保存到我们的版本控制中。我们提供专门的输出类型用于指标、观察和一些类型的工件。你也可以将任何二进制文件作为工件保存,我们将为你在对象或文件存储系统中管理存储。
-
分析图表 以了解所有模型的表现。我们提供最先进的分析工具,帮助你和你的团队理解最佳的努力方向。
-
比较不同版本 的模型,以了解哪些发生了变化以及如何影响质量。只需存储开发过程中所有的信息,并了解项目在多个迭代中的演变。
如果你想更好地利用你和你的团队所做的所有建模工作,报名参加我们的 即将到来的网络研讨会。我们将展示如何通过让你专注于建模来提高建模速度!
立即开始
我们提供了 ModelDB 2.0 的多种格式:
-
Docker 容器
-
Helm 模板
-
AMIs
-
随你所想 😃
我们希望确保每个人都能迈出通向敏捷和稳健建模的第一步!查看我们的 Git 仓库 或注册我们的 SaaS 服务。我们很期待听到你的反馈,欢迎加入我们的 Slack,讨论如何继续改进 ML 版本控制。
附言:我们正在招聘。如果这个领域让你兴奋,请告诉我们!
关于 Verta:
Verta.ai 构建了一个完整的机器学习模型生命周期的软件,涵盖了从模型版本控制到模型部署和监控,并通过协作功能将所有环节紧密联系在一起,让你的 AI 和 ML 团队能够快速推进而不出错。我们是 MIT CSAIL 的一个衍生公司,开发了 ModelDB,这是第一个开源模型管理系统之一。
我们的三大课程推荐
1. Google 网络安全证书 - 加速你的网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT 需求
了解更多相关话题
数据科学家的虚拟演示技巧
原文:
www.kdnuggets.com/2021/11/virtual-presentation-tips-data-scientists.html
评论
迈克尔·伯克,Tubi 的数据科学家
沟通是数据科学工作中最具挑战性的方面之一。以下是我的笔记……
网络的看法
有一句基于研究的老话说,93% 的沟通是非语言的。55% 的沟通是肢体语言,38% 是声音语调,7% 是口头表达。
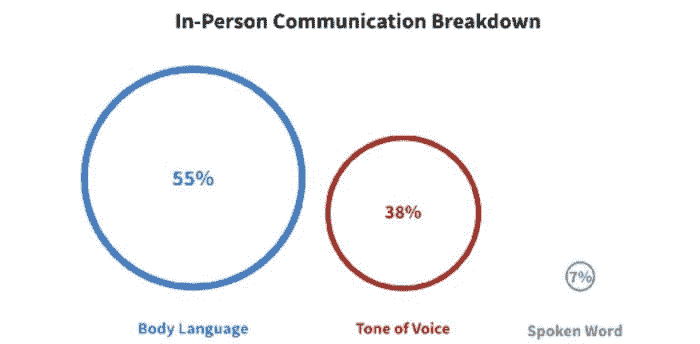
图 1:沟通故障。图像来源:作者。
视频通话中的肢体语言沟通会发生什么?通常,它会消失。
你应该尝试弥补那 55%,更多地强调语调和口头表达。
一些有用的建议以夸大语调的变化和调整音量来弥合肢体语言的差距。增加面部表情和手势也可以提高演示的接受度。这可能看起来不自然,但如果你录制你的演讲并重新观看,你会惊讶于这些变化看起来是多么自然和有魅力。
另一个有趣的想法是内容、设计和交付框架 — 源。
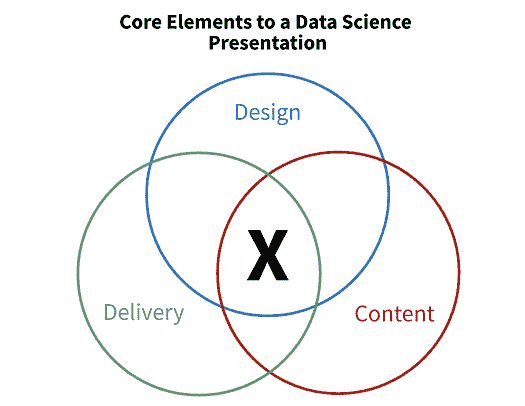
图 2:内容、设计、交付框架。图像来源:作者。
后两者,即设计和交付,分别指的是简约的幻灯片设计和复杂主题的简单措辞。然而,内容部分非常有趣。
简而言之,文章认为你的听众只会从你的演讲中记住一句话,所以要让它有意义。为此,你需要了解他们的技术水平、期望以及对项目的先前了解。如果你将演讲量身定制给你的观众,你可以使这句话具有意义。
一个非常简单的技巧是将其他团队的视觉效果融入到你的演示中。例如,展示一个支持你论点的用户体验研究视频。通过利用先前的工作,你可以节省时间,创建一个引人入胜的演示,并在公司内建立关系。
我认为
尽管有这些精彩的想法,但互联网上的大多数信息都是常识。在本节中,我们将重点关注那些不那么明显的策略。让我们深入探讨……
1 — 进入你的观众的思维
对于超过 ~10 人的会议,安全起见,可以假设其中一个人不想参加。他们和你一样都是忙碌的人。
因此,尽量了解什么能让你的观众兴奋。 兴奋是推动工作的动力,它使你的工作更显眼,从而更具影响力。
虽然各组织的角色差异很大,但大多数数据科学家在选择和开发自己的项目上有一定自由。如果你的工作成功涉及利益相关者的支持,你必须让他们对项目感到兴奋。就这么简单。
不幸的是,这没有明确的捷径,但以下是一些对我有效的做法:
-
早早地并经常地社交化你的想法。 通过在项目过程中向团队成员和利益相关者获取反馈,你可以激发兴趣,并产生更有价值的最终项目。相信我,这些努力是值得的。
-
了解你的老板的老板关心什么。 如果你知道什么会让高层管理人员兴奋,你也会知道什么会让低层管理人员兴奋。安排一次快速的单独会谈,并提出好的问题。
通过将你的工作与激动人心的想法联系起来,你可以显著提高演示的价值。
2 — 提前结束会议
不必要的信息是有害的。你可能认为展示你的步骤和假设对听众有益,但在大多数情况下并非如此。
通过包含对理解不必要的信息,你正在……
-
增加认知负荷。 这会减少注意力,降低信任度,并且经常导致在演示过程中多任务处理。
-
潜意识地影响听众。 每个人都有确认偏误,这会影响他们确认自己的信念。如果你给听众额外的信息,他们更容易被吸引人的想法所吸引,忽略关键结论。
-
浪费时间和金钱。 时间就是金钱。试试这个练习——加总一下通话中每个人的每小时工资。呈现不必要的信息是昂贵的。
一个简单但有效的替代方法是尽量提前结束会议。 我的一位团队成员因为总是提前结束会议而受到利益相关者和数据科学家们的喜爱。虽然这个规则有明显的例外,但这些例外比你想象的要少得多。
如果你旨在提前结束会议,你必须做到结构化、简明扼要和相关。
3 — 一些 80/20 的小贴士
上述两个部分可能需要付出较多劳动,因此这里有一些简单的小贴士,希望能让你在 20%的时间内获得 80%的结果。
-
适应你的沟通风格。 如果你是正式的演讲者,就要正式地讲话。如果你讲笑话,就讲笑话。通过利用你自然的谈话方式,你会变得更自信、更易于亲近,从而更有效。
-
从结论开始和结束。通过以结论开始演示,你可以减少认知负担,让听众更深入地思考你的观点。通过在最后重申结论,你可以促进心理分块,这有助于记忆并帮助他们利用新信息。
-
少说“嗯”和“像”。重复使用这些词语会让你听起来更愚蠢。抱歉。这里有一些基础代码,用于一个制作得很差但免费的“嗯/像”检测器。
-
对于技术概念,把它当作一个黑箱处理。大多数听众不关心方法如何工作,他们关心的是它的作用。所以你只需要解释输入和输出即可。
感谢阅读!上述所有资源对我和我的职业生涯都产生了很大影响。请分享你自己的经验。
简介:迈克尔·伯克 (michaeldberk.com/) 是 Tubi 的数据科学家。
原文. 已获授权转载。
相关:
-
如何发现机器学习模型中的弱点
-
不要浪费时间建立你的数据科学网络
-
5 个使数据科学家与其他职业区别开来的因素
更多相关内容
数据科学:参观旧金山著名电影拍摄地点
原文:
www.kdnuggets.com/2016/07/visiting-famous-movie-locations-san-francisco.html
评论
作者:Juraj Kapasny,Knoyd
让数据科学向您展示通过旧金山著名电影拍摄地点的最佳路线
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
在这篇博客中,我们查看了旧金山的电影拍摄地点。通过使用谷歌地点 API 和 IMDb API,我们选择了黄金之城中每个电影爱好者在城里时应该参观的地方。
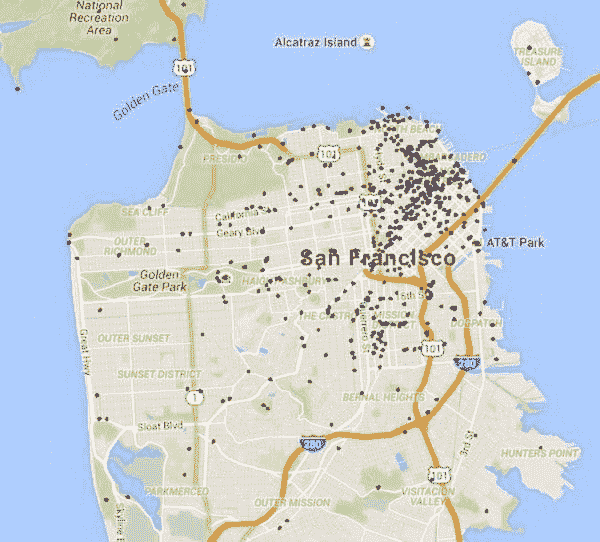
原数据集下载自 SF OpenData 网站,该网站提供关于旧金山的许多数据集。除了之前提到的电影地点外,您还可以在那里找到例如旧金山机场举办的所有展览、移动食品设施许可、航空噪音投诉数据、航空旅客统计等信息。
我们的基础数据集包括以下列:
-
标题(电影名称)
-
发布年份
-
地点(地点标识)
-
趣闻(如果有的话)
-
制作公司
-
发行商
-
导演
-
作者
-
演员 1(电影的主角)
-
演员 2(电影的第二主角(如果有的话))
-
演员 3(电影的第三主角(如果有的话))
包含了唯一标识地点的地点特征。然而,关于经纬度的信息缺失,所以我们无法立即将这些地点绘制到地图上。我们通过谷歌地点 API 找到了所有地点的地理坐标,并使用 Python 库 gmplot 将它们绘制在地图上。
接下来,我们只关注了拍摄了更著名电影的地点。为了确定这些电影,我们使用了 IMDb API。关于这些电影的所有信息,包括平均评分和总票数,均从 imdb.com 下载。根据平均评分,拍摄于旧金山的顶级电影有:
| 电影 | 评分 | 投票数量 |
|---|---|---|
| 阿甘正传 | 8.8 | 1,234,615 |
| Sense8 | 8.4 | 63,164 |
| 十三号星期五 | 8.3 | 82,126 |
| 寻找 | 8.3 | 10,696 |
| 我记得妈妈 | 8.3 | 3,857 |
另一方面,IMDb 上投票数量最多的电影是:
| 电影 | 评分 | 投票数 |
|---|---|---|
| 福雷斯特·甘普 | 8.8 | 1,234,615 |
| 印第安纳·琼斯与最后的十字军 | 8.3 | 509,609 |
| 猩球崛起:黎明之战 | 7.6 | 313,938 |
| 蚁人 | 7.4 | 301,246 |
| 哥斯拉 | 6.5 | 299,385 |
利用这些评分和投票的组合,我们选择了前 7 部电影:福雷斯特·甘普、印第安纳·琼斯与最后的十字军、猩球崛起:黎明之战、蚁人、游戏、哥斯拉和毕业生。这些电影与旧金山的 36 个电影拍摄地点相关联。
为了对这些位置进行图形分析,我们需要找到一种方法来相应地设置图的边。为此,我们使用了一个叫做 Google API 的便利工具,它可以计算任何两个地理位置之间的驾车、骑行或步行距离。这些旅行时间被作为每对位置(节点或顶点)之间的边值。我们使用前 7 部电影中的地点,结合这些地点之间的骑行和驾车距离来构建图。此外,每个位置只创建了 2 条边,即到 2 个最近地点的边。这样做的逻辑是避免使用长时间旅行的路径。
在下面,你可以看到图的可视化和简单分析。这个图的边是根据位置之间的骑行距离创建的。
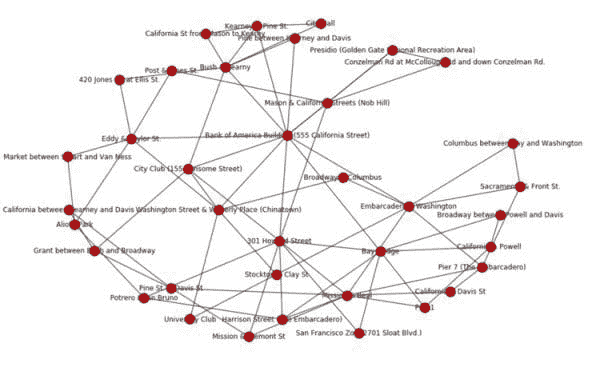
作为分析电影位置的下一步,我们研究了特定位置的中介中心性。中介中心性等于从所有顶点(在我们的情况下是位置)到所有其他顶点经过该节点的最短路径数量。一个中介中心性高的位置对在顶级电影位置网络中人员的转移有很大的影响,假设人们总是寻找最短路径。我们使用基于驾车和骑行距离的边来比较具有最大中介中心性的地点。我们得出了以下结果:
骑行时中介中心性最高的地点:
-
美国银行大楼(555 加州街)
-
301 霍华德街
-
海滨大道与华盛顿街
-
使命街与比尔街
-
海湾大桥
驾车时中介中心性最高的地点:
-
美国银行大楼(555 加州街)
-
华盛顿街与韦弗利广场(中国城)
-
城市俱乐部(155 桑索姆街)
-
海滨大道与华盛顿街
-
海湾大桥
我们可以看到,当使用驾车距离时,有两个地方发生了变化:301 霍华德街和使命街与比尔街被华盛顿街与韦弗利广场(中国城)以及城市俱乐部(155 桑索姆街)分别替代。这意味着电影迷在驾车出行时更可能经过旧金山的中国城。
最后,我们研究了旅行商问题(TSP),并将其应用于我们的数据集。TSP 是一个优化问题,旨在寻找访问给定地点集合的最短可能路线。使用随机起点和迭代算法,我们得出了一个电影爱好者应该沿着的路线,如果他们想访问所有著名电影中的有趣地点。
你可以在下面看到最佳路线的可视化。谷歌仅支持 1 条路线中的 10 个地点,因此创建了四层。每层的描述以 A 开头,以 J 结束,J 与下一层的 A 重叠。每层的开始部分用数字标记,以便更易读。
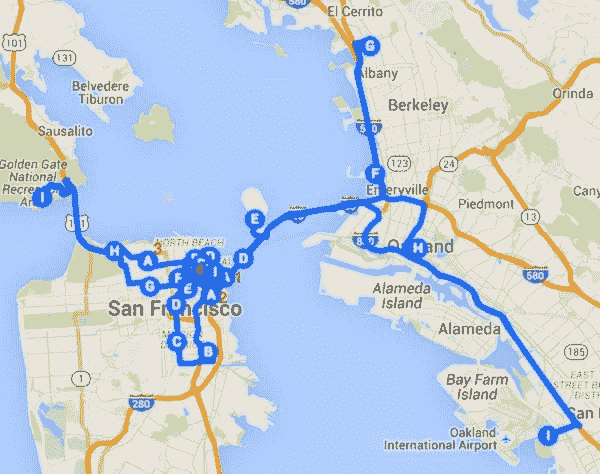
这是最佳路线行程,从哈里森街(码头街)开始,到使命街与比尔街结束:
-
0(A) - 哈里森街 - 码头街(游戏)
-
1(B) - 使命街与弗里蒙特街交汇处(哥斯拉)
-
2(C) - 霍华德街 301 号(游戏)
-
3(D) - 海湾大桥(毕业生)
-
4(E) - 行政大楼 - 宝岛(印第安纳·琼斯与最后的十字军)
-
5(F) - 加州街与鲍威尔街交汇处(猩球崛起:黎明之战)
-
6(G) - 码头 1(哥斯拉)
-
7(H) - 百老汇街在鲍威尔街与戴维斯街之间(蚁人)
-
8(I) - 加州街与戴维斯街交汇处(哥斯拉)
-
9(J-A) - 市政厅(猩球崛起:黎明之战)
-
10(B) - 波特雷罗街与圣布鲁诺街交汇处(哥斯拉)
-
11(C) - 阿里奥托公园(猩球崛起:黎明之战)
-
12(D) - 市场街在斯图尔特街与 VData Science 之间(蚁人)
-
13(E) - 艾迪街与泰勒街交汇处(哥斯拉)
-
14(F) - 乔治街 420 号与艾利斯街交汇处(蚁人)
-
15(G) - 波士顿街与乔治街交汇处(哥斯拉)
-
16(H) - 总统公园 - 金门国家休闲区(游戏)
-
17(I) - 康泽尔曼路在麦考洛赫路与康泽尔曼路下方(蚁人)
-
18(J-A) - 梅森街与加州街交汇处 - 诺布山(游戏)
-
19(B) - 百老汇街与哥伦布街交汇处(哥斯拉)
-
20(C) - 萨克拉门托街与前街交汇处(哥斯拉)
-
21(D) - 码头 7 - 码头街(哥斯拉)
-
22(E) - 码头街与华盛顿街交汇处(哥斯拉)
-
23(F) - 布什街与基尔尼街交汇处(哥斯拉)
-
24(G) - 加州街从梅森到基尔尼(猩球崛起:黎明之战)
-
25(H) - 基尔尼街与松树街交汇处(哥斯拉)
-
26(I) - 斯托克顿街与克雷街交汇处(哥斯拉)
-
27(J-A) - 大学俱乐部(猩球崛起:黎明之战)
-
28(B) - 松树街在基尔尼街与戴维斯街之间(蚁人)
-
29(C) - 华盛顿街与韦弗利广场 - 中国城(游戏)
-
30(D) - 哥伦布街在湾区与华盛顿街之间(蚁人)
-
31(E) - 美国银行大楼 - 555 加州街(游戏)
-
32(F) - 城市俱乐部 - 155 桑索姆街(游戏)
-
33(G) - 格兰特街在布什街与百老汇街之间(蚁人)
-
34(H) - 松树街与戴维斯街交汇处(哥斯拉)
-
35(I) - 使命街与比尔街交汇处(哥斯拉)
在更详细的旧金山市中心地图上:
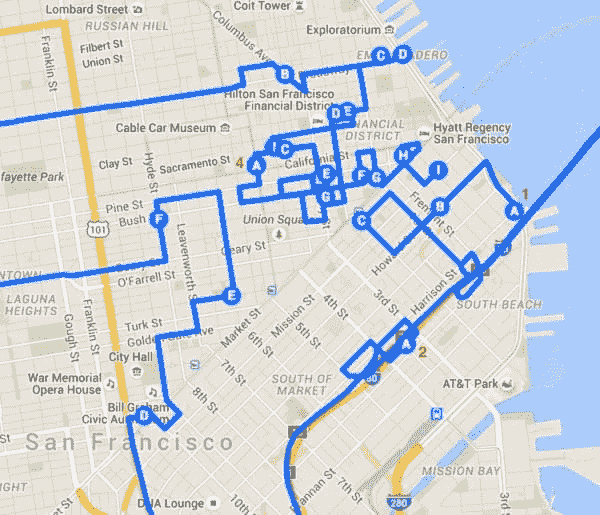
如果你感兴趣,可以自己查看来自海湾城市的其他数据源 - 我们肯定会去做的。
简介: Juraj Kapasny 是 Knoyd 的联合创始人和数据科学家,数据挖掘爱好者,曾任职于 Teradata(维也纳,奥地利)。他曾参与过许多客户特定项目,涉及电信、金融或汽车等行业,帮助客户从数据中获取额外的见解和价值。
相关内容:
-
OpenText 数据可视化 – 红地毯版
-
哪些电影续集真的更好?数据科学的答案
-
大数据如何在推荐系统中改变我们的生活
更多相关内容
Visual ChatGPT:微软结合 ChatGPT 和 VFM
原文:
www.kdnuggets.com/2023/03/visual-chatgpt-microsoft-combine-chatgpt-vfms.html

图片由作者提供
当我们以为已经消化了足够多的大型语言模型(LLMs)新闻时,微软亚洲研究院团队带来了 Visual ChatGPT。Visual ChatGPT 克服了 ChatGPT 无法处理视觉信息的现有限制,因为它只训练了一种语言模式。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
什么是 Visual ChatGPT?
Visual ChatGPT 是一个结合了 Visual Foundation Models(VFM)的系统,帮助 ChatGPT 更好地理解、生成和编辑视觉信息。VFM 能够指定输入输出格式,将视觉信息转换为语言格式,并处理 VFM 的历史记录、优先级和冲突。
因此,Visual ChatGPT 是一个 AI 模型,它在 ChatGPT 的限制与允许用户通过聊天沟通并生成视觉内容之间架起了桥梁。
ChatGPT 的限制
ChatGPT 在过去几周和几个月里成为了大多数人的谈话话题。然而,由于其语言训练能力,它不允许处理和生成图像。
你有像 Visual Transformers 和 Steady Diffusion 这样的视觉基础模型,它们具有惊人的视觉能力。这就是语言和图像模型结合创造了 Visual ChatGPT 的地方。
什么是 Visual Foundation Models?
Visual Foundation Models 用于汇集计算机视觉中使用的基本算法。它们将标准计算机视觉技能转移到 AI 应用程序上,以处理更复杂的任务。
Visual ChatGPT 中的 Prompt Manager 包含 22 个 VFM,包括 Text-to-Image、ControlNet、Edge-To-Image 等。这帮助 ChatGPT 将图像的所有视觉信号转换为语言,以便 ChatGPT 更好地理解。那么 Visual ChatGPT 是如何工作的呢?
Visual ChatGPT 是如何工作的?
Visual ChatGPT 由不同的组件组成,帮助大型语言模型 ChatGPT 理解视觉信息。
Visual ChatGPT 的架构组件
-
用户查询:这是用户提交查询的地方
-
提示管理器:这将用户的视觉查询转换为语言格式,以便 ChatGPT 模型可以理解。
-
视觉基础模型:这结合了各种 VFMs,如 BLIP(Bootstrapping Language-Image Pre-training)、稳定扩散、ControlNet、Pix2Pix 等。
-
系统原则:这提供了 Visual ChatGPT 的基本规则和要求。
-
对话历史:这是系统与用户的第一次交互和对话。
-
推理历史:这使用不同 VFMs 过去的推理来解决复杂的查询。
-
中级回答:利用 VFMs,模型将尝试输出几个具有逻辑理解的中级答案。
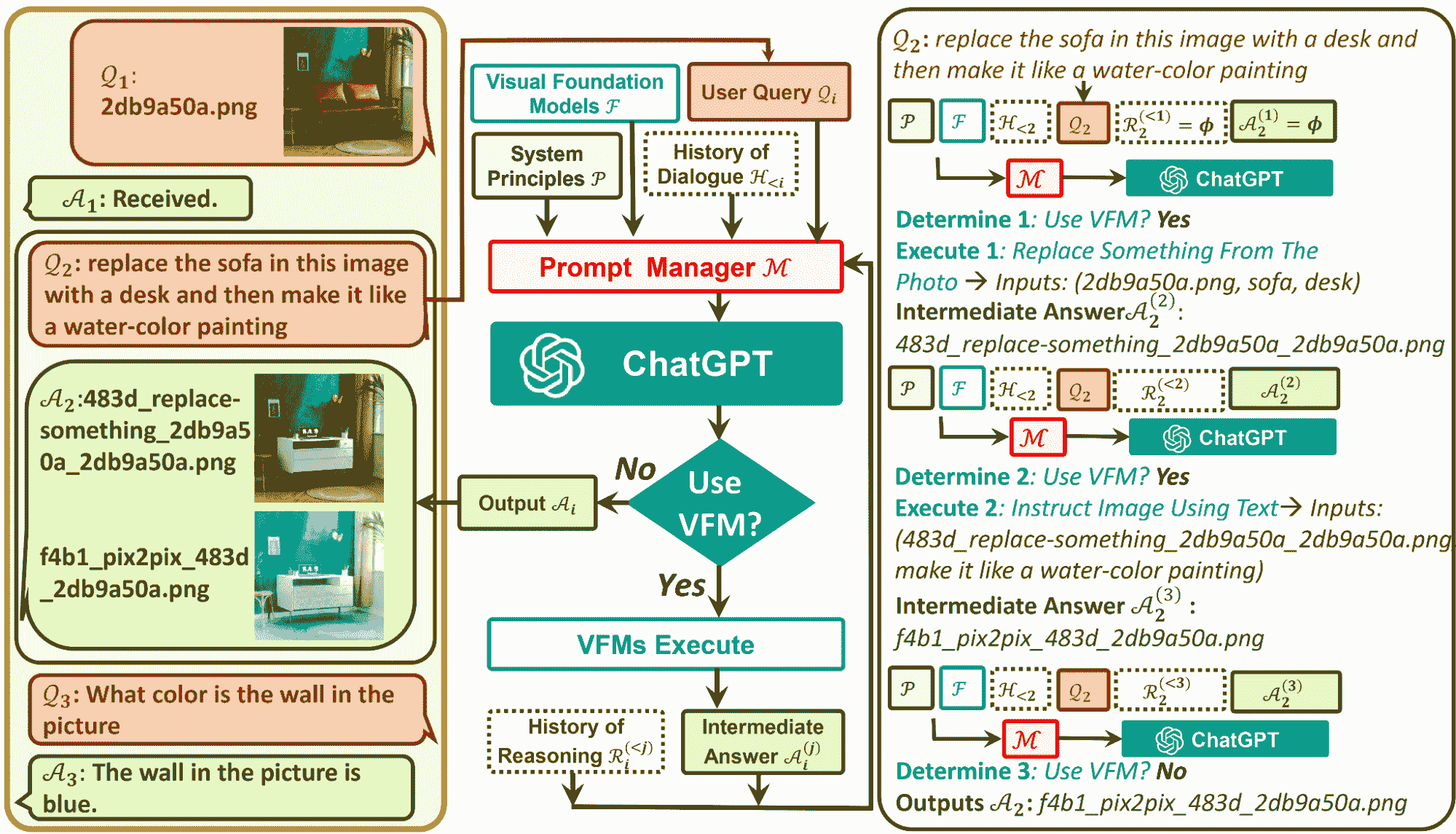
图片来自于 微软 GitHub
更多关于提示管理器的信息
你们中的一些人可能认为这是一种强制性的解决方法,用于让 ChatGPT 处理视觉内容,因为它仍然将图像的所有视觉信号转换为语言。当上传图像时,提示管理器会合成一个内部聊天记录,其中包含文件名等信息,以便 ChatGPT 更好地理解查询内容。
例如,用户输入图像的名称将作为操作历史记录,然后提示管理器将协助模型通过‘推理格式’来确定需要对图像进行的操作。你可以将其视为模型在 ChatGPT 选择正确的 VFM 操作之前的内部思考。
在下图中,你可以看到提示管理器如何为 Visual ChatGPT 启动规则:
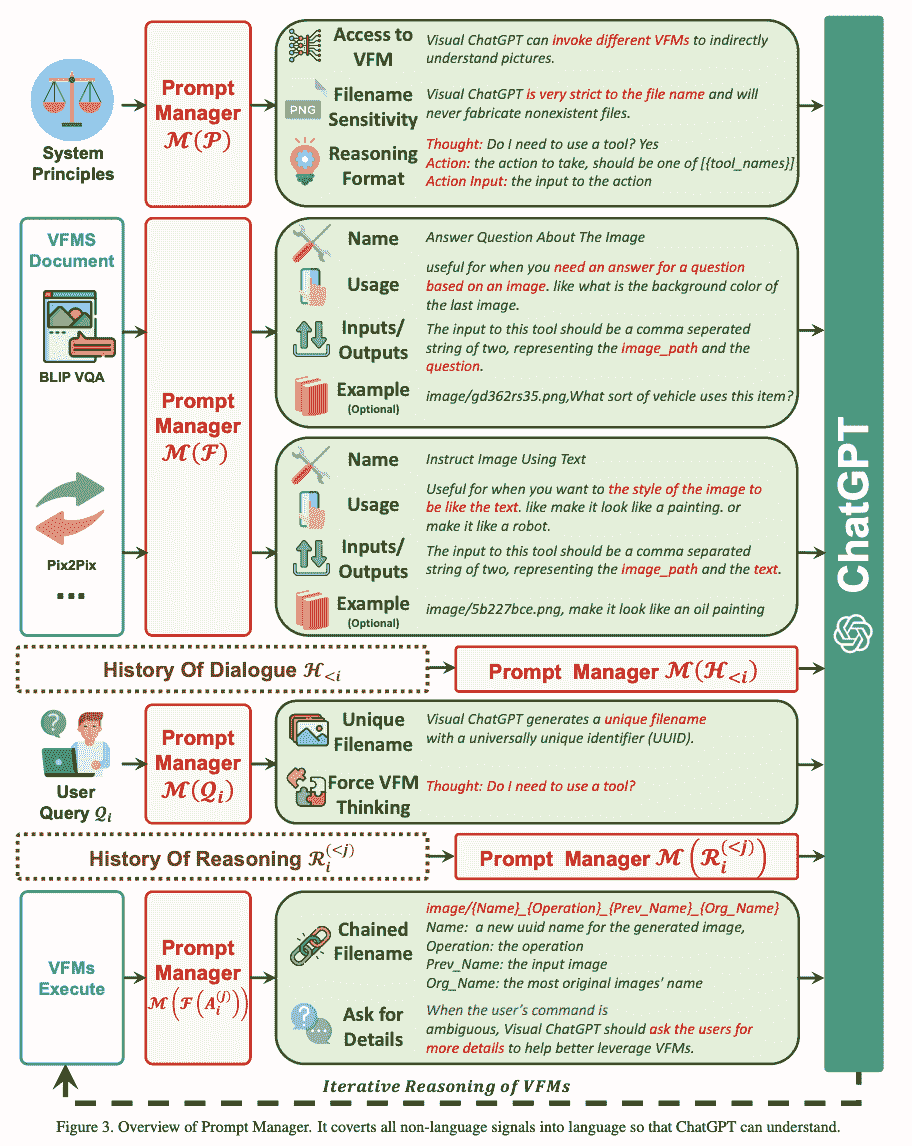
图片来自于 Visual ChatGPT:用视觉基础模型进行对话、绘图和编辑
开始使用 Visual ChatGPT
要开始你的 Visual ChatGPT 之旅,你需要先运行 Visual ChatGPT 演示:
# create a new environment
conda create -n visgpt python=3.8
# activate the new environment
conda activate visgpt
# prepare the basic environments
pip install -r requirement.txt
# download the visual foundation models
bash download.sh
# prepare your private openAI private key
export OPENAI_API_KEY={Your_Private_Openai_Key}
# create a folder to save images
mkdir ./image
# Start Visual ChatGPT !
python visual_chatgpt.py
你还可以在 微软的 Visual ChatGPT GitHub 上了解更多信息。确保查看他们对每个视觉基础模型的 GPU 内存使用情况。
Visual ChatGPT 的应用案例
那么 Visual ChatGPT 能做什么呢?
图像生成
你可以要求 Visual ChatGPT 从零开始创建图像,提供描述。你的图像将在几秒钟内生成,具体取决于可用的计算能力。其基于稳定扩散的合成图像生成使用文本数据。
更改图像背景
再次使用稳定扩散,Visual ChatGPT 可以更改你输入图像的背景。用户可以提供任何背景更改的描述,稳定扩散模型将对图像的背景进行修复。
更改颜色图像及其他效果
你还可以根据提供给应用程序的描述来更改图像的颜色和应用效果。Visual ChatGPT 将使用各种预训练模型和 OpenCV,来改变图像颜色、突出图像边缘等。
修改图像
Visual ChatGPT 允许你通过编辑和修改图像中的对象来删除或替换图像的某些方面,方法是向应用程序提供有针对性的文本描述。然而,值得注意的是,这一功能需要更多的计算能力。
Visual ChatGPT 的局限性
众所周知,组织总会有一些不完美之处,需要不断改进以提升服务。
计算机视觉与大型语言模型的结合
Visual ChatGPT 在很大程度上依赖于 ChatGPT 和 VFMs,因此,这些单独方面的准确性和可靠性会影响 Visual ChatGPT 的性能。使用大型语言模型和计算机视觉的结合需要大量的提示工程,并且可能难以实现高效的性能。
隐私与安全
Visual ChatGPT 能够轻松地插拔 VFMs,这可能会让一些用户担心安全和隐私问题。微软需要进一步研究如何确保敏感数据不被泄露。
自我纠错模块
Visual ChatGPT 研究人员遇到的一个限制是由于 VFMs 的失败和提示的多样性导致生成结果不一致。因此,他们得出结论,需要开发一个自我纠错模块,以确保生成的输出与用户请求的内容一致,并能够进行必要的修正。
高量 GPU 需求
为了充分利用 Visual ChatGPT 并使用 22 个 VFMs,你需要大量的 GPU RAM,例如 A100\。根据任务的不同,确保你了解完成任务所需的 GPU 量。
总结
尽管 Visual ChatGPT 仍有其局限性,但这是在同时使用大型语言模型和计算机视觉方面的一项重大突破。如果你想了解更多关于 Visual ChatGPT 的信息,可以阅读这篇论文:Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
Visual ChatGPT 是否类似于 ChatGPT4?如果你尝试过这两者,你的意见是什么?请在下面留言!
Nisha Arya 是一名数据科学家、自由技术写作者以及 KDnuggets 的社区经理。她特别感兴趣于提供数据科学职业建议或教程以及数据科学的理论知识。她还希望探索人工智能在延长人类生命方面的不同方式。她是一个渴望学习的人,寻求拓宽技术知识和写作技能,同时帮助指导他人。
更多相关话题
神经网络反向传播算法的可视化解释
原文:
www.kdnuggets.com/2016/06/visual-explanation-backpropagation-algorithm-neural-networks.html
假设我们真的喜欢登山,并为了增加一点额外的挑战,我们这次蒙上眼睛,以便看不到我们的位置,也不知道何时完成了我们的“目标”,即到达山顶。
由于我们看不到前方的路径,我们让直觉引导我们:假设山顶是山的“最高”点,我们认为最陡峭的路径最有效地将我们引向山顶。
我们通过迭代地“感知”周围并朝着最陡峭的上升方向迈出一步来解决这个挑战——我们称之为“梯度上升”。但如果我们到达一个无法进一步上升的点怎么办?即,每个方向都向下?此时,我们可能已经到达了山顶,但也可能只是到达了一个较小的高原……我们并不知道。从本质上讲,这只是梯度上升优化的一个类比(基本上是通过梯度下降最小化成本函数的对立面)。然而,这并非特指反向传播,而只是最小化一个凸成本函数(如果只有一个全局最小值)或非凸成本函数(具有局部最小值,如“高原”让我们以为达到了山顶)的其中一种方法。借助一点视觉辅助,我们可以将一个只有一个参数的非凸成本函数(蓝色球为我们当前位置)形象化如下:

现在,反向传播就是在多个“层级”上反向传播成本。例如,如果我们有一个多层感知器,我们可以将前向传播(将输入信号通过网络,并通过相应的权重计算输出)形象化如下:

在反向传播中,我们“简单地”反向传播误差(我们通过比较计算出的输出和已知的正确目标输出来计算的“成本”,然后用来更新模型参数):

这可能是在预备微积分之后很久的事了,但它本质上都是基于我们用于嵌套函数的简单链式法则


与其“手动”完成这些工作,不如使用计算工具(称为“自动微分”),而反向传播基本上是这种自动微分的“反向”模式。为什么是反向而不是前向?因为计算上更便宜!如果我们使用前向方式,我们将逐层相乘大矩阵,直到将一个大矩阵与输出层中的一个向量相乘。然而,如果我们从反向开始,也就是从将一个矩阵与一个向量相乘开始,我们得到另一个向量,以此类推。所以,我认为反向传播的美在于我们进行的是更高效的矩阵-向量乘法,而不是矩阵-矩阵乘法。
简介:Sebastian Raschka 是一名数据科学家和机器学习爱好者,对 Python 和开源有着极大的热情。《Python 机器学习》的作者。密歇根州立大学。
原文。经许可转载。
相关内容:
-
深度学习何时比 SVM 或随机森林效果更好?
-
分类发展作为一种学习机器
-
为什么从头实现机器学习算法?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
了解更多相关内容
分类模型的可视化评分技术
原文:
www.kdnuggets.com/2021/11/visual-scoring-techniques-classification-models.html
评论
由 Maarit Widmann,数据科学家,KNIME
99%的准确性对于流失预测模型来说好吗?如果实际情况是 1%的客户流失,99%的客户未流失,那么模型的表现与随机猜测相当。如果 10%的客户流失,90%的客户未流失,那么模型的表现则优于随机猜测。
准确性统计信息,如总体准确性,量化了机器学习模型在新数据上的预期表现,没有任何基线,例如随机猜测或现有模型。
这就是为什么我们还需要可视化模型评估——或评分——技术,这些技术显示模型在更广泛背景下的表现:对于不同的分类阈值,相对于其他模型,以及从资源使用的角度。在本文中,我们解释了如何通过 ROC 曲线、提升图和累计增益图来评估分类模型,并提供了在 KNIME 工作流中实际实施的链接,“分类模型的可视化评分技术”。
用例:流失预测模型
我们将通过一个用于流失预测的随机森林模型(100 棵树)展示可视化模型评估技术的实用性。
我们使用的数据集包含 3333 个电信客户的数据,包括他们的合同数据和电话使用情况,数据可在GitHub上获得。目标列“Churn?”显示客户是否流失(True)或未流失(False)。483 名客户(14%)流失,2850 名客户(86%)未流失。
模型的准确性统计信息如图 1 所示。
-
总体准确性大约为 94%,这意味着在测试数据中的每 100 个客户中,有 94 个获得了正确的类别预测,无论是流失 = True 还是流失 = False。
-
敏感性值在True类别大约为 59%。这意味着在每 10 个流失的客户(Churn=True)中,大约 6 个被正确预测为流失,而剩余的 4 个被错误预测为未流失。
-
特异性值在True类别大约为 99%,这表明几乎所有未流失的客户(Churn=False)都被正确分类。
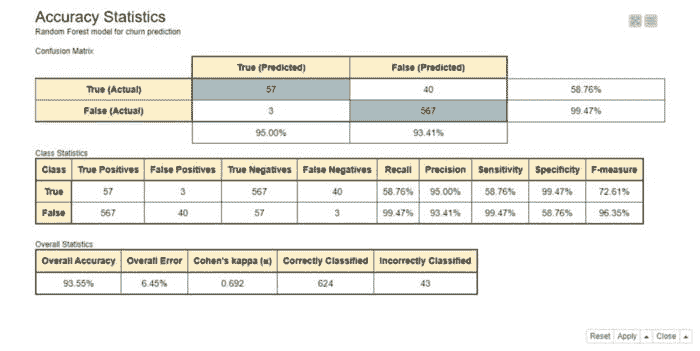
图 1. 混淆矩阵、类别统计信息以及随机森林模型在流失预测中的总体准确性统计信息。
比较不同分类阈值下的性能
准确率统计是基于实际和预测的目标类计算的。预测的类别,这里是True和False,是基于模型预测的类别概率(或得分),范围在 0 到 1 之间。在二分类问题中,模型输出两个概率,每个类一个。默认情况下,具有最高概率的类别决定了预测类别,在二分类问题中,这意味着概率超过 0.5 的类别被预测。然而,有时不同的分类阈值可能会导致更好的性能。如果是这种情况,我们可以在 ROC 曲线中发现它。
ROC 曲线
一个ROC 曲线(接收操作特征曲线)绘制了模型在不同分类阈值下的性能,使用两个指标:x 轴上的假阳性率和 y 轴上的真正率。
在二分类任务中,其中一个目标类被任意假定为正类,而另一个类成为负类。在我们的流失预测问题中,我们选择了True作为正类,False作为负类。
真阳性(TP)、假阴性(FN)、假阳性(FP)和真阴性(TN)的数量,如图 1 所示,用于计算假阳性率和真正率*。
- 假阳性率
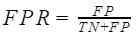
衡量的是未流失的客户比例,但这些客户被错误地预测为流失。这等于1-specificity。
- 真正率
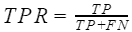
衡量的是流失客户的比例,以及这些客户被正确预测为流失。这等于sensitivity。
ROC 曲线底部左角的第一个点表示使用最大阈值 1.0获得的假阳性率(FPR)和真正率(TPR)。使用这个阈值,所有P(Churn=True) > 1.0的客户将被预测为流失,即没有客户被预测为流失,无论是正确还是错误,因此 FPR 和 TPR 都是 0.0。
ROC 曲线中的第二个点是通过降低阈值绘制的,例如降低 0.1。现在所有P(Churn=True) > 0.9的客户将被预测为流失。阈值仍然较高,但现在有可能一些客户会被预测为流失,因此产生小的非零 TPR 或 FPR 值。所以,这个点将在 ROC 曲线中接近上一个点的位置。
第三点是通过进一步降低阈值绘制的,依此类推,直到我们到达为最小分类阈值 0.0绘制的曲线的最后一点。使用这个阈值,所有客户都被分配到正类True,无论是否正确,因此 TPR 和 FPR 都是 1.0。
完美模型会产生 TPR=1.0 和 FPR=0.0. 相反,随机分类器总是对正类做出相等数量的正确和错误预测,这对应于 FPR=TPR 的黑色对角线。每个 ROC 曲线中都报告了这条线,作为无用模型的参考。
请注意,模型的表现当然可能比随机猜测更差,但这可能是数据科学家的错误,而不是模型的错误!只需采用模型决策的相反方向即可实现表现更好的解决方案。
图 2 显示了一个 ROC 曲线,为随机森林模型绘制,用于流失预测。注意与随机猜测对应的黑色线。
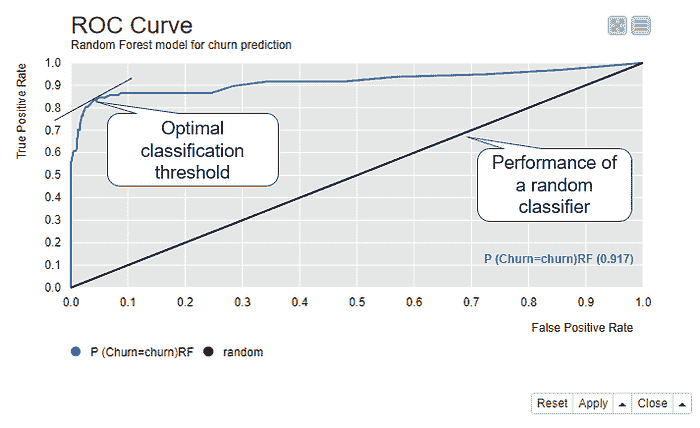
图 2. ROC 曲线显示了所有可能分类阈值从 0 到 1 的假阳性率(x 轴)和真实阳性率(y 轴)。
模型的最佳分类阈值应尽可能接近左上角——具有 TPR=1.0 和 FPR=0.0——这是完美模型占据的位置。这个最佳点与(0.0, 1.0)的切线最接近。使用这个最佳分类阈值,我们每个真实阳性的假阳性最少。我们的示例模型平均预测
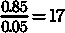
当我们使用最佳分类阈值时,每个假阳性的真实阳性,如图 2 所示。
如果我们将这些数字与图 1 中的类别统计数据进行比较,我们可以看到,在优化分类阈值后,灵敏度从 59%显著提高到 85%,而特异性仅稍微降低,从 99%降到 1–0.05= 95%。
比较多个模型
ROC 曲线对于比较模型也很有用。让我们为相同的流失预测任务训练另一个模型——决策树,并将其表现与随机森林模型进行比较。
图 3 显示了同一视图中的两个 ROC 曲线。蓝色曲线是随机森林模型的,橙色曲线是决策树的。在这种情况下,更接近左上角的曲线,即随机森林模型的蓝色曲线,意味着表现更好。视图还显示了右下角两个模型的曲线下面积(AuC)统计数据。这测量了每个 ROC 曲线下的面积,并允许对性能进行更精细的比较。
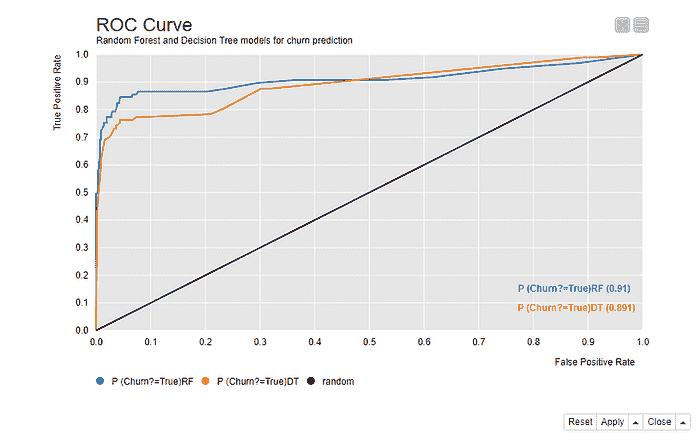
图 3. 两个模型的 ROC 曲线——一个随机森林模型和一个决策树模型——用于流失预测。离左上角更近且 AuC 统计量更大的模型表现更好。
使用模型节省资源
除了获得准确预测外,我们还可以通过模型节省资源。在我们的流失预测示例中,预测之后会有某种行动,而这些行动需要资源,例如减少收入或增加时间投入。模型可以帮助我们更高效地利用资源:接触更少的客户,但仍能触达更多可能流失的客户。
提升和累计增益图对比了资源使用情况与正确预测的效果。
提升图
提升图比较了在根据模型预测提取的样本中达到的目标客户数量——这里是流失的客户——与随机样本中的目标客户数量。
图 4 显示了随机森林模型的提升图。x 轴展示了按照预测的正类概率从高到低排序的每个十分位的数据。例如,如果我们有 100 位客户,第一个十分位包含 10 位具有最高预测正类概率的客户,也就是最有可能流失的 10 位客户。在第二个十分位,我们有另外 10 位客户,其概率低于前 10 位客户,但高于剩下的 80 位客户。第十个十分位包含了概率最低的 10 位客户,即最不可能流失的 10 位客户。
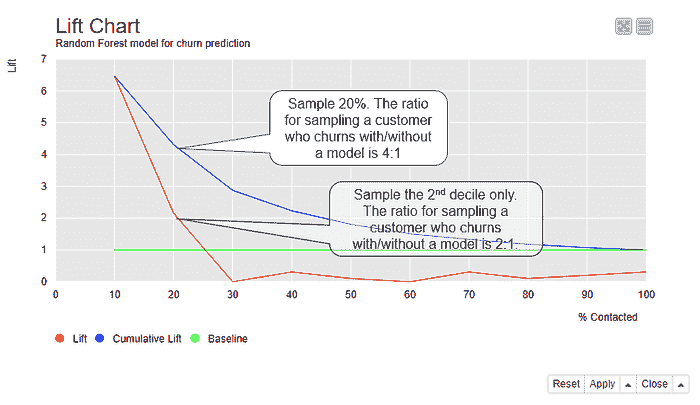
图 4. 提升图显示了基于模型预测的样本中达到目标客户的比例与随机样本中的比例的对比。
累积提升线(蓝线)所示的提升是从按照 x 轴展示的有序数据中抽取的样本中达到目标客户的比例与在随机样本中的比例。第一个十分位的提升大约为 6。由于原始数据中有 14% 的客户流失,随机样本中达到目标客户的概率为 14%。如果我们从 100 位客户中随机抽取 10 位客户,我们期望能接触到 0.1410=1.4 位目标客户。如果我们从有序数据中抽取前 10 位客户,我们期望能接触到 6 倍,即 61.4=8.4 位目标客户。
如果我们将样本量再增加 10%,累计提升约为 4。现在我们将在 20 位客户的随机样本中达到 0.1420=2.8 位目标客户,而在有序数据的样本中达到 42.8=11.2 位目标客户。我们采样的数据越多,即使是随机采样,也会有更多的目标客户被接触到。这解释了为什么累计提升与基线(绿色线)的差异在第十个十分位时减少。
提升线(红色线条)展示了每个分位的提升情况。前两个分位的提升值高于基准线,从第三个分位开始则低于基准线。这意味着,如果我们从 100 个客户中抽取第一个分位样本,我们预计会有 61.4 = 8.4 个目标客户。如果我们抽取第二个分位而不抽取第一个分位,我们预计会有 21.4 = 2.8 个目标客户。如果我们抽取第 3 到第 10 个分位中的任何一个,我们预计最多会有 0.25*1.4=0.35 个目标客户,因为在这 80%的数据中,提升值保持在 0 到 0.25 之间的非常低水平。
累积增益图
累积增益图展示了在不同样本量下可以达到的目标客户比例。类似于提升图,累积增益图在 x 轴上展示了按照正类概率排序的数据。在 y 轴上展示了达到的目标客户比例。
图 5 展示了随机森林模型的累积增益图。如果我们跟随曲线,可以看到如果我们仅抽取 10%的客户,即那些概率最高的客户,我们预计能覆盖到大约 60%的流失客户(y 轴)。如果我们抽取 20%的客户,依然是那些概率最高的客户,我们预计能覆盖到超过 80%的流失客户。这个点还与左上角的切线距离最近。在这个样本量下,达到一个目标客户所需的平均样本量是最低的。
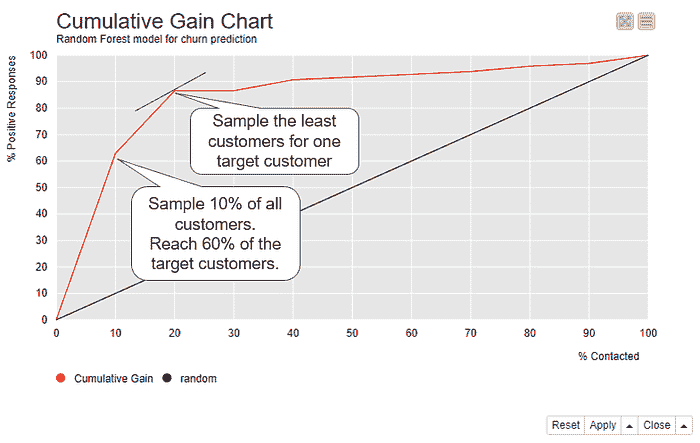
图 5. 累积增益图展示了当我们联系按照其正类概率排序的 10%、20%、……、100%客户时,我们能达到的目标客户比例。
视觉模型评估技术 — 总结
表 1 收集了上述描述的技术,并总结了它们关于模型性能的报告。这些视觉技术通过展示最佳分类阈值、将性能与随机猜测进行比较、在一个视图中比较多个模型以及指示最佳样本量和质量来补充准确性统计数据。
ROC 曲线展示了不同分类阈值下的性能,比对了模型与随机猜测的表现,并且也比较了多个模型的性能。提升图和累积增益图则显示了模型是否能使我们投入更少的资源仍能达到期望的结果。
这些视觉技术补充但不替代准确性统计数据。为了全面评估模型,查看这两者都是很好的做法。
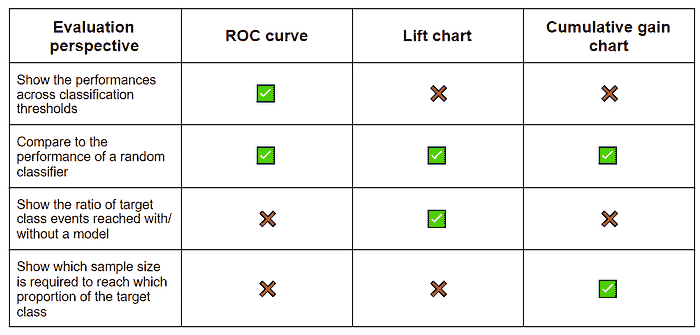
表 1. 分类模型视觉评估技术的总结。
小贴士与技巧
KNIME Analytics Platform 提供了一个 Binary Classification Inspector 节点,可以用来比较多个模型的准确性统计数据和 ROC 曲线,并找到最佳分类阈值。其交互视图(图 6)显示:
-
整体准确性和类别统计数据的条形图
-
ROC 曲线
-
混淆矩阵
-
正类概率的分布
-
一个用于分类阈值的滑块小部件
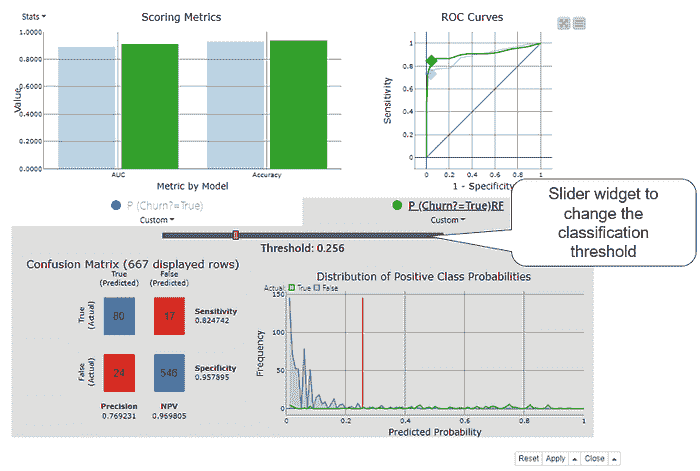
图 6. Binary Classification Inspector 节点的交互视图显示了一个用于准确性统计、ROC 曲线、混淆矩阵和正类概率分布的条形图。在调整分类阈值时,所有视图都会更新。
Binary Classification Inspector 节点视图的顶部部分显示准确性统计数据的条形图和 ROC 曲线。每个模型用不同的颜色显示,这里绿色代表随机森林模型,蓝色代表决策树。我们可以通过点击彩色条选择一个模型进行更详细的检查。我们在图 6 中选择了随机森林模型。视图的底部部分被激活,显示所选模型的混淆矩阵和正类概率的分布。橙色垂直线表示当前分类阈值。
默认情况下,分类阈值为 0.5。使用阈值滑块小部件,我们可以改变这个值:向左调整至接近零,或向右调整至接近 1。当我们这样做时,视图中的所有其他图表和图形会根据新的分类阈值自动调整。例如,当我们向左移动阈值时,ROC 曲线中的点会向右移动。当点到达最佳阈值位置时,我们停止移动阈值,在这种情况下,图 6 显示最佳阈值为 0.256。这是随机森林模型的最佳分类阈值。与默认的 0.5 相差很大!
文章中介绍的 Binary Classification Inspector 视图和视觉模型评估技术已在 “分类模型的视觉评分技术” 工作流(图 7)中实现。你可以从 KNIME Hub 免费检查和下载。
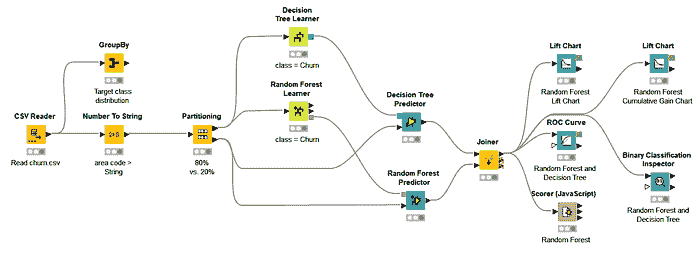
图 7. 一个 KNIME 工作流,用于构建流失预测模型并使用视觉技术进行评估。
简历:Maarit Widmann 是 KNIME 宣传团队中的数据科学家;KNIME 自学课程的作者,以及 KNIME 讲师主导课程的教师。
首次发布于 高级数据科学的低代码。
原文。经许可转载。
相关:
-
指标重要性,第一部分:评估分类模型
-
我希望在构建第一个模型时就了解的 4 个机器学习概念
-
ROC 曲线解释
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关主题
使用 Folium 在 Python 中可视化地理空间数据
原文:
www.kdnuggets.com/2018/09/visualising-geospatial-data-python-folium.html
评论
由Parul Pandey提供

数据可视化是一个更广泛的术语,描述了通过将数据放置在视觉上下文中来帮助人们理解数据重要性的任何努力。模式、趋势和关联可以通过视觉方式轻松展示,否则可能在文本数据中被忽视。它是数据科学家工具包的基本组成部分。创建可视化很简单,但创建好的可视化则困难得多。它需要细致的眼光和大量的专业知识来创建既简单又有效的可视化。今天有强大的可视化工具和库,它们重新定义了可视化的意义。
使用 Python 的优点在于它提供了满足各种数据可视化需求的库。其中一个库是Folium,它对于可视化地理数据(Geo data)非常有用。地理数据(Geo data)科学是数据科学的一个子集,涉及基于位置的数据,即对象及其在空间中的关系的描述。
前提条件
本教程假设你具备基本的 Python 和 Jupyter notebook 知识,并熟悉 Pandas 库。
Folium 简介
Folium 是一个强大的 Python 数据可视化库,主要用于帮助人们可视化地理空间数据。使用 Folium,可以创建世界上任何位置的地图,只要知道其经纬度值。此外,Folium 创建的地图本质上是交互式的,所以在地图渲染后可以进行缩放,这是一项非常有用的功能。
Folium 利用了 Python 生态系统在数据处理方面的优势以及 Leaflet.js 库在制图方面的优势。数据在 Python 中处理,然后通过 folium 在 Leaflet 地图中可视化。
安装
在使用 Folium 之前,可能需要通过以下两种方法之一在系统上安装它:
$ pip install folium
或
$ conda install -c conda-forge folium
数据集
下载数据集
我们将使用世界发展指标数据集,该数据集是 Kaggle 上的一个开放数据集。我们将使用数据集中的‘indicators.csv’文件。
由于我们处理的是地理空间地图,因此还需要国家坐标来进行绘制。从这里下载文件。
文件也可以从我的github 仓库下载。
探索数据集
世界发展指标数据集只是从世界银行实际提供的数据集中稍作修改的版本。它包含了从 1960 年到 2015 年,来自约 247 个国家的超过一千个年度经济发展指标。一些指标包括:
1\. Adolescent fertility rate (births per 1,000 women)
2\. CO2 emissions (metric tons per capita)
3\. Merchandise exports by the reporting economy
4\. Time required to build a warehouse (days)
5\. Total tax rate (% of commercial profits)
6\. Life expectancy at birth, female (years)
开始使用
-
转到 Jupyter Notebooks 并导入所需的库。确保在与数据相同的文件夹中创建 Jupyter 笔记本,以方便操作。
-
设置国家坐标
-
读取数据库并探索数据库
代码:
import folium
import pandas as pd
country_geo = 'world-countries.json'
data = pd.read_csv('Indicators.csv')
data.shape
data.head()
我们得到如下结果。看来这些指标数据集中,不同国家有不同的指标,包含了指标的年份和数值。
出生时女性预期寿命(年)似乎是一个很好的调查指标。因此,我们提取 2013 年所有国家的预期寿命数据。我们只是随机选择了这一年。
同时,我们来设置绘图的数据,仅保留国家代码和我们绘制的数值。我们还需要提取指标名称,以便在图例中使用。
代码:
# select Life expectancy for females for all countries in 2013
hist_indicator = 'Life expectancy at birth'
hist_year = 2013
mask1 = data['IndicatorName'].str.contains(hist_indicator)
mask2 = data['Year'].isin([hist_year])
# apply our mask
stage = data[mask1 & mask2]
stage.head()
#Creating a data frame with just the country codes and the values we want plotted.
data_to_plot = stage[['CountryCode','Value']]
data_to_plot.head()
# labelling the legend
hist_indicator = stage.iloc[0]['IndicatorName']


创建 Folium 交互地图
现在我们实际上要创建 Folium 交互地图。我们将创建一个相对较高缩放级别的地图。接下来,我们将使用内置方法 choropleth 来附加国家的地理 json 和绘图数据。
代码:
# Setup a folium map at a high-level zoom
map = folium.Map(location=[100, 0], zoom_start=1.5)
# choropleth maps bind Pandas Data Frames and json geometries.
#This allows us to quickly visualize data combinations
map.choropleth(geo_data=country_geo, data=plot_data,
columns=['CountryCode', 'Value'],
key_on='feature.id',
fill_color='YlGnBu', fill_opacity=0.7, line_opacity=0.2,
legend_name=hist_indicator)
我们还需要指定相关参数。‘key on’ 参数指的是 json 对象中的标签,该标签包含了附加在每个国家边界信息上的国家代码作为特征 ID。这是我们需要在数据中设置的连接。数据框中的国家代码应与 json 对象中的特征 ID 匹配。
接下来,我们指定一些美学特征,比如颜色方案、不透明度,然后标注图例。
这个图的输出将被保存为一个实际互动的 html 文件。因此,我们需要将其保存下来,并将其读回到笔记本中,以便在地图上进行交互。
代码:
map.save('plot_data.html')
# Import the Folium interactive html file
from IPython.display import HTML
HTML('<iframe src=plot_data.html width=700 height=450></iframe>')
我们将获得如下图所示的地图:
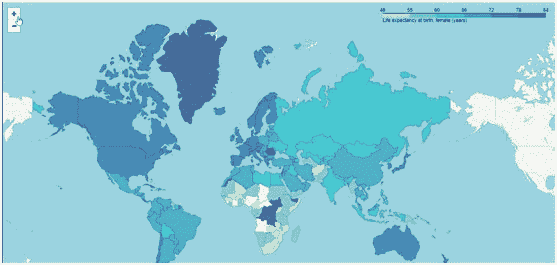
现在我们有了我们的地图。首先注意,深色表示女性的预期寿命较高。显然,美国和大多数欧洲国家的女性预期寿命较高。
所以,这个示例展示了如何进行地理叠加。它也是如何使用额外的可视化库以及根据我们的可视化需求这些库如何变得强大的一个例子。
这是进入使用 Pandas 数据框和 Folium 进行 choropleth 地图的一个相当简单的第一步。你可以在官方文档页面上探索更多关于 folium 及其提供的交互功能的信息。
要查看地图的实际互动性,请访问Github repo。
相关:
我们的 3 个最佳课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
更多相关主题
用 Python 可视化 COVID-19 新病例的时间变化
原文:
www.kdnuggets.com/2020/09/visualization-covid-19-new-cases-over-time-python.html
评论
作者:Jason Bowling,阿克伦大学网络通讯经理

按天计算的每 10 万人中的新 COVID-19 病例热图(点击放大)
这个热图展示了 COVID-19 大流行在美国的时间进展。地图从左到右阅读,颜色编码显示了各州新增病例的相对数量,已按人口调整。
这个可视化灵感来源于我在一个讨论论坛帖子上看到的类似热图。我始终无法找到其来源,因为那只是一个粘贴的图片,没有链接。原版的热图也是为了表达一个政治观点,将州按照主要政党归属进行区分,我对此不太感兴趣。我对它简明地展示疫情进展的方式感到着迷,因此决定自己制作一个类似的可视化图,并且可以定期更新。
源代码托管在我的Github 仓库。如果你只对查看这个热图的更新版本感兴趣,我每周在我的Twitter上发布。需要注意的是,比较不同周的图表时要小心,因为随着新数据的加入,颜色地图可能会发生变化。比较只能在给定的热图内有效。
脚本依赖于 pandas、numpy、matplotlib 和 seaborn。
数据来源于纽约时报 COVID-19 Github 仓库。一个简单的启动脚本克隆了最新的仓库副本并复制了所需的文件,然后启动 Python 脚本以创建热图。实际上只需要一个文件,因此可以进一步优化,但这已经有效。
echo "Clearing old data..."
rm -rf covid-19-data/
rm us-states.csv
echo "Getting new data..."
git clone https://github.com/nytimes/covid-19-data
echo "Done."
cp covid-19-data/us-states.csv .
echo "Starting..."
python3 heatmap-newcases.py
echo "Done."
脚本首先将包含州人口的 CSV 文件加载到一个字典中,该字典用于缩放每日新增病例结果。新增病例是根据《纽约时报》的数据中的累计总数计算得出的,然后缩放到每 10 万人中的新增病例数。
我们可以在这一点上展示热图,但如果这样做,每 10 万人中病例非常多的州会掩盖病例较少的州的细节。应用[log(x+1)](https://onbiostatistics.blogspot.com/2012/05/logx1-data-transformation.html#:~:text=A%3A log(x%2B1,in which x was measured.)变换显著改善了对比度和可读性。
最后,使用 Seaborn 和 Matplotlib 生成热图并将其保存为图像文件。
就这些!欢迎将其作为你自己可视化的框架。你可以根据需要自定义它,专注于感兴趣的领域。
完整源代码见下方。感谢阅读,希望你觉得有用。
import numpy as np
import seaborn as sns
import matplotlib.pylab as plt
import pandas as pd
import csv
import datetime
reader = csv.reader(open('StatePopulations.csv'))
statePopulations = {}
for row in reader:
key = row[0]
if key in statePopulations:
pass
statePopulations[key] = row[1:]
filename = "us-states.csv"
fullTable = pd.read_csv(filename)
fullTable = fullTable.drop(['fips'], axis=1)
fullTable = fullTable.drop(['deaths'], axis=1)
# generate a list of the dates in the table
dates = fullTable['date'].unique().tolist()
states = fullTable['state'].unique().tolist()
result = pd.DataFrame()
result['date'] = fullTable['date']
states.remove('Northern Mariana Islands')
states.remove('Puerto Rico')
states.remove('Virgin Islands')
states.remove('Guam')
states.sort()
for state in states:
# create new dataframe with only the current state's date
population = int(statePopulations[state][0])
print(state + ": " + str(population))
stateData = fullTable[fullTable.state.eq(state)]
newColumnName = state
stateData[newColumnName] = stateData.cases.diff()
stateData[newColumnName] = stateData[newColumnName].replace(np.nan, 0)
stateData = stateData.drop(['state'], axis=1)
stateData = stateData.drop(['cases'], axis=1)
stateData[newColumnName] = stateData[newColumnName].div(population)
stateData[newColumnName] = stateData[newColumnName].mul(100000.0)
result = pd.merge(result, stateData, how='left', on='date')
result = result.drop_duplicates()
result = result.fillna(0)
for state in states:
result[state] = result[state].add(1.0)
result[state] = np.log10(result[state])
#result[state] = np.sqrt(result[state])
result['date'] = pd.to_datetime(result['date'])
result = result[result['date'] >= '2020-02-15']
result['date'] = result['date'].dt.strftime('%Y-%m-%d')
result.set_index('date', inplace=True)
result.to_csv("result.csv")
result = result.transpose()
plt.figure(figsize=(16, 10))
g = sns.heatmap(result, cmap="coolwarm", linewidth=0.05, linecolor='lightgrey')
plt.xlabel('')
plt.ylabel('')
plt.title("Daily New Covid-19 Cases Per 100k Of Population", fontsize=20)
updateText = "Updated " + str(datetime.date.today()) + \
". Scaled with Log(x+1) for improved contrast due to wide range of values. Data source: NY Times Github. Visualization by @JRBowling"
plt.suptitle(updateText, fontsize=8)
plt.yticks(np.arange(.5, 51.5, 1.0), states)
plt.yticks(fontsize=8)
plt.xticks(fontsize=8)
g.set_xticklabels(g.get_xticklabels(), rotation=90)
g.set_yticklabels(g.get_yticklabels(), rotation=0)
plt.savefig("covidNewCasesper100K.png")
简介: 杰森·鲍林 是阿克伦大学网络通信部经理。杰森是一位有着网络管理、安全和医疗设备设计重点的技术专业人士。出色的故障排除技能,优秀的书面沟通能力,和丰富的项目管理经验。你可以在 Medium 上找到他的更多文章。
原文。经许可转载。
相关:
-
COVID-19 可视化:有效可视化在大流行故事讲述中的力量
-
可视化 COVID-19 影响下的欧洲国家流动趋势
-
通过互动可视化了解 COVID-19 大流行
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
更多关于这个主题
如何在 Python(和 R)中可视化数据
原文:
www.kdnuggets.com/2019/11/visualize-data-python-and-r.html
评论
由 SuperDataScience 提供。
在某些鸡尾酒会上,你可以通过争论许多问题可以归结为数据的展示,而不是数据本身来获得成功。脱欧?你可能会说这是因为没有制作引人入胜、易于理解的预测生活质量变化的数据可视化。或者你可能会提到 Facebook,即使按照松散的加州标准,实际上也在进行数据可视化;数据是社交网络中的数据,被人为地更加具体。 空气 质量? 交通?你甚至可以阐述如何通过正确的数据可视化来灵活运用工具,尽管一切看起来仍像你的拇指,但至少你会是对的。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 事务
平均速度图:湾区大桥上每五分钟的速度变化,基于一个传感器(位于靠近珍珠岛)。在所有合理的通勤时间,速度骤降,展示了固定供应和需求的规律,这大多数人称之为交通。使用 Matplotlib 制作。
没有人说找到这些特定的鸡尾酒会很容易或令人兴奋。但无论如何,能够制作易于理解的数据可视化是数据科学的关键技能。让我们为数据可视化师们干杯;那些勇敢地将抽象数字变得更直观、使电子表格更具吸引力和技术报告更易于管理的人。如果你还需要更多的鸡尾酒会谈资,你还可以提到 W.E. Dubois 和 Kurt Vonnegut 作为其他可视化大师。
Python 和 R 走进酒吧……
教会-图灵论题表示,你在一个程序中能做的事情,理论上可以在任何其他程序中做。抽象来说,这是对的。然而,实际上,某些语言或软件包中容易做到的事情,在另一个语言或软件包中可能需要数小时的宝贵挫折感来完成。(我在看你,Matlab。)显然,这些差异与我们的大脑如何与编程语言互动、我们对它的了解程度以及编程语言的基本操作如何适应手头的问题有很大关系。正如你可能知道的那样,两个主要的通用数据编程语言是 Python 和 R,但直接比较它们是不公平的。更好的比较是 R 与使用Pandas 包配合 Jupyter Notebook 的效果。(为了完全透明,我是“Pandas 通常更酷,除非你有一些尚未移植到 Python 包中的非常具体的问题”阵营的一员。)
说完这些,你需要知道以下内容。
Pandas 首次创建于 2008 年,而 Python 本身则在 1991 年首次发布。许多使用 Python 的人声称它“易于思考”。另一方面,R 实际上是统计编程语言 S 的 90 年代中期实现,而 S 本身是在 70 年代中期的 Bell Labs 发明的。
尽管 R 的管理机构总部设在维也纳,但使用它并不会让你在华尔兹舞方面变得更好(实际上,它可能让你更糟),也不会让你在吃Manner Wafer 饼干时更出色,维也纳爱乐乐团的折扣票也不会出现在你的终端上。我能说什么呢,生活就是这么艰难。此外,给明智的人提个醒:将编程技能转移到华尔兹舞上唯一的办法是使用三进制计算机进行编码;两者都是基于三进制的。话虽如此,R 被设置用于实验室环境中所需的数据分析,产生的材料经过同行评审。鉴于 Church、Turing 以及每一位开源贡献者的上述工作,Pandas 可以做同样的事情(只需确保导入statsmodels),通常运行得更快,且更容易优化(使用Numba和Numpy)。
在我看来,当由专家或用于小众分析时,R 可以是一个强大的语言。然而,对于非专家来说,R 可能更难以审计。由于类似的原因,R 也更容易在数据处理管道中引入未被发现的隐性错误。换句话说,我认为 R 代码比 Python 代码更容易积累技术债务。另一方面,能够阅读 R 是有用的,显然如果你想在基于 R 的环境中工作,这些建议会有所不同。这是 Pandas 与 R 的简短语法比较。如果你和主要使用 R 的人谈论这一段,他们要么会热情地承认失败,要么会提出与我的观点截然相反的合理观点。你的体验可能会有所不同。
本文中的建议旨在帮助你更好地理解数据集、获取洞察力并向他人传达结果。这与例如《纽约时报》的艺术化可视化目的不同。(如果你希望做出同样出色的效果,你可能还想了解 D3,或者 D3 在R中的封装,或python中的等效工具。)
最后,有很多选择。尽管感到沮丧的程序员可能会不同意教会-图灵论题的实际解释,但数据可视化库的情况更是如此。如果一个数据可视化库无法完成所有常见的可视化,那么它还有什么用呢?
一般数据可视化建议
-
每次做新项目时,开始一个新文件夹,将所有相关论文下载到研究子文件夹中。(无论你在做什么,阅读之前提出的内容都是有帮助的。)
-
从一开始就开始写报告/白皮书/论文/总结。作为一个经历过这个过程的人,保存到最后会带来大量的麻烦,这也是一些研究生需要很长时间才能完成论文的原因之一。
-
从一开始就做好笔记。
-
唯一完全有资格写出他们想要的精确描述的人,也正是能够完成这个工作的那类人。
-
三维图像是一个独立的类别,但将几个 2D 帧拼接在一起的 Gif,无论是前后振动还是将视角改变几度,都可以帮助你表达观点。
-
查看Mike Bockstock 的数据可视化以及NYTimes创建的可视化。
-
如果你有非技术人员需要答案,弄清楚是否可以让定量结果与视觉结果一致。例如,如果有办法可视化聚类分析的结果,请在讨论任何指标之前先展示这个结果。具体胜于抽象,这就是数据可视化的要点。
特定的数据可视化建议
-
数据元素的色度、“色彩丰富度”或饱和度可以被调整以发挥你的优势,因为色度是可加的。如果两个数据元素重叠,它们的饱和度可以加在一起,使得重叠部分更加生动。这是一种“多通道增强”的类型,其中两个数据点重叠的事实通过空间和颜色通道传达。在 matplotlib 中,这可以通过 alpha 控制。
-
感知均匀色彩系列也可以用于多通道增强,或为你的可视化添加额外的信息维度。例如,以下图表展示了圣塔莫尼卡市中心停车场的利用情况。在第一个图中,我使用了基本颜色,而在第二个图中,每一年都通过感知颜色映射的等距样本来着色。
y 轴显示了圣塔莫尼卡市中心停车场每五分钟增量的平均停车位数的五个 14 天移动平均值。较高的值意味着停车场更空,x 轴上的‘0’对应于每年新的前五分钟。2019 年的线条在四月底停止,这张图表暗示了以下结论:零售业正在衰退,零售业永存。使用 Matplotlib 制作。
这是我写的立即生成以下图表的代码。未显示的是我所做的预处理。我将“c”参数设置为一个名为 plasma 的感知色图。
import matplotlib.cm as cm #gets the colormaps
N = 4032 #the number of five minute increments in 14 days
rcParams['figure.figsize'] = 30, 15 #controls a jupyter notebook setting
plt.title("14 Day Moving Average, All Years -- Stacked")
plt.plot(g2015.iloc[N:]['Available'].rolling(N).mean()[N:].values,alpha=.4,c=cm.plasma(1/5,1),label='2015')
plt.plot(g2016.iloc[N:]['Available'].rolling(N).mean()[N:].values,alpha=.4,c=cm.plasma(2/5,1),label='2016')
plt.plot(g2017.iloc[N:]['Available'].rolling(N).mean()[N:].values,alpha=.5,c=cm.plasma(3/5,1),label='2017')
plt.plot(g2018.iloc[N:]['Available'].rolling(N).mean()[N:].values,alpha=.75,c=cm.plasma(4/5,1),label='2018')
plt.plot(g2019.iloc[N:]['Available'].rolling(N).mean()[N:].values,alpha=.9,c=cm.plasma(5/5.5,1),label="2019")
plt.legend()
-
在数据点周围添加深色边界可以使它们看起来更清晰,这在你没有大量点需要可视化且点相对较大的情况下有效。查找 matplotlib 设置中的“edge_colors=True”。
-
Sparklines 的一课是,人脑能够解释小的数据元素,特别是当重要的是宏观趋势时。
这些原则在以下数据可视化中得到了说明。例如,大多数点太小而无法辨认。此外,颜色的饱和度或“alpha”属性设置为较少且为 100%,这样当点重叠时,它们看起来会变得更暗。
将高维数据投影到二维空间。这是通过 Matplotlib 制作的。
-
对于直方图,尝试调整控制箱数的参数,直到你对箱子边界问题有一定的感觉。
-
节点-链接图有其自身的特殊挑战,你可以在这篇插图文章中找到更多信息。
高级的 Python 数据可视化之旅
在我们生活在这个尘土飞扬的星球上时,有一些我们都应该知道的至关重要的真理。变化是唯一的常量;“自由市场效率”是关于信息流动和感知的一个命题,而不是市场运行的效果;社会基本上就像是“燃烧人节”,只是墙壁更坚固;我们都以每秒一秒的悠闲速度走向死亡(更不用提税季了),而在 Python 中使数据可视化效果更好的最快方法是将以下三行代码放在 Jupyter Notebook 的顶部:
from Matplotlib import pyplot as plt
import Seaborn as sns
sns.set()
一旦你完成了这些,你可以回到使用 Matplotlib 和思考时空的广阔以及整个的人类努力,仿佛什么都没有发生。实际上,发生的事情是我们使用了Seaborn的默认设置来清理 Matplotlib。(如果你不知道,Seaborn 基本上是一个经过清理的、更高级的 Matplotlib 版本,而 Matplotlib 本身是以 Matlab 为模型的。)如果 Matplotlib 证明过于繁琐,可以尝试 Seaborn。
让我给你展示一下区别。首先,这里有一些 matplotlib 代码用于可视化数据:
plt.scatter(range(len(counts)),counts)
plt.title("A Random Scatter Plot")
“之前”。
对比一下如果我运行以下代码会发生什么:
sns.set()
plt.scatter(range(len(counts)),counts,s=12)
plt.title("A Random Scatter Plot: Seaborn Defaults and Marker Size Adjustment")
Python 有几个用于创建数据可视化的包和包生态系统;点击这里阅读详细指南。Matplotlib 是其中最常用的工具。虽然没有人会因为制作 Matplotlib 插图而赢得“年度设计师”称号,但它非常适合可视化较小的数据集。同时,Matplotlib 并不适合快速可视化 10k 行数据,也不适合做很多偏离常规的操作。
要可视化大量数据,你可能需要查看一下DataShader 生态系统。Bokeh非常适合交互式仪表板。对于 3D,你可以使用Matplotlib 扩展(mplot3d),或者查看Mayavi。如果你想用相对较少的代码制作出色的可视化效果,可以尝试Altair。说真的,试试 Altair,它可能会改变你的生活。
在 R 语言的世界里,标准的绘图库包括ggplot2和lattice。前者是一个通用绘图库,后者则可以方便地从同一个数据集中生成多个小图。你可以在这里找到一份全面的 R数据可视化包清单。查看基础 R 数据可视化时,很容易产生这样的想法。
结论
数据可视化是理解数据集的工具。虽然某些可视化可以变成艺术,但制作高质量的日常视觉效果的基本技能对于任何数据导向的人来说都是无价的。尽管通常没有可视化就不能得出宏大的结论,但知道如何操控、调整大小、着色以及数据元素的运动是我们都可以达成一致的。
简介: SuperDataScience是一个面向数据科学家的在线学习平台,旨在帮助他们学习数据科学或提升职业生涯。我们使复杂变得简单!
相关:
更多相关话题
可视化偏差-方差
评论
作者:西奥多·齐茨密斯,机器学习科学家
偏差-方差权衡是机器学习的一个基本概念。这里我们将通过可视化的帮助来探讨这种权衡的不同视角。
现实生活中的偏差-方差
我们的很多决策都受到他人的影响,当我们观察他们的行为并通过某些社会相似度度量来比较自己时。同时,我们保持自己通过经验和推理学到的一套规则。在这种情况下:
-
偏差是当我们有非常简单的规则而无法真正解释现实情况时。例如,认为通过观看 YouTube 视频就能成为医生。
-
方差是当我们通过倾听不同的群体并模仿他们的行为而不断改变自己的想法时。例如,当你看到某人在健身房里形体很好,运动后吃蛋白棒,你也认为蛋白棒是你需要的。然后你听到有人说他们买了一些健身器材,帮助他们增长了肌肉,你便去购买了同样的机器。
权衡视角
偏差-方差通常被称为权衡。当谈到权衡时,我们通常指的是有两个(或更多)竞争量的情况,其中加强一个量会导致另一个量减少,反之亦然。一个著名的例子是强化学习中的探索-利用权衡,其中增加探索因素(如ε-贪婪)会使代理减少对已估计高价值状态的利用。
另一方面,偏差-方差是一种分解。研究表明,回归模型的期望测试误差(均方误差)可以分解为三个部分:方差、偏差和不可减少的误差(由于噪声和内在变异性)。
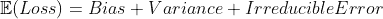
然而,与探索-利用权衡直接控制两个竞争量不同,偏差和方差不是可以直接调整来控制误差的杠杆。它只是另一种表达测试误差的方式,偏差和方差由这种分解产生。
那么,为什么它被称为权衡呢?灵活的模型往往具有低偏差和高方差,而更为刚性的模型则往往具有高偏差和低方差。模型的灵活性是你可以控制的(正则化、参数数量等),因此可以间接控制偏差和方差。
偏差-方差的简单术语
我们在 Bishop 的《模式识别与机器学习》中读到,偏差-方差分解是通过对来自相同分布的多个数据集运行学习算法来尝试建模预测不确定性得到的结果。并得出结论:
-
偏差项表示在所有数据集上的平均预测值与期望回归函数之间的差异程度
-
方差项测量了各个数据集的解在其平均值周围变化的程度,因此,这测量了学习函数对特定数据集选择的敏感程度。
通过“目测”拟合
让我们在这里放一些背景(和图表)。考虑下面这个 1D 数据集,它是由函数###生成的,并且被一些高斯噪声扰动了。
如果我们想要在这些点上拟合一个多项式怎么办?
我们可以查看图形,稍微退后一步,眯起眼睛仔细观察,勾画出一条大致通过所有点的线(如图中的红线)。然后我们观察到,y 值在高 x 值和低 x 值时趋向于增加到+∞(如果你眯眼看得够仔细),这给了我们一个提示:这应该是一个偶数次的多项式。我们进一步看到这些点在 x 轴上交叉了 4 次(4 个实根),这意味着它应该至少是 4 次多项式。最后,我们观察到图形有 3 个转折点(从增加到减少或反之),这再次表明我们有一个 4 次多项式。
通过“眯眼看”,我们基本上进行了一种噪声平滑,以便看到“全局图景”,而不是数据集的微小和无关的变化。
然而,我们如何能确定这确实是正确的选择?
直接抛出一个 1000 次多项式,看看会发生什么
由于我们不能确定哪个多项式的度数最能最佳近似潜在的过程,或者我们只是太无聊了而不愿估计它,我们可以使用我们能想象的最“复杂”的模型来拟合这些点。为了验证这个观点,我们拟合了多个逐渐增加度数的多项式,看看它们的表现:
每种情况下一半的点(圈出的)用于训练。显然,低次模型(左侧)不能弯曲到足以拟合数据。7 次多项式似乎优雅地通过了这些点,好像它可以忽略(平滑掉)噪声。更有趣的是,高次多项式(右侧)试图通过这些点进行插值,并在某种程度上达到了这一点。但这就是我们想要的吗?如果给定一组不同的训练点会发生什么?预测和回归曲线的形状会改变吗?
下面,对不同数据子集重复了相同的拟合,并将结果曲线叠加以检查它们的变异性。在 7 阶多项式的情况下,结果似乎相当一致。
该模型对训练集的变化具有鲁棒性,只要这些变化是从输入空间中均匀采样的。
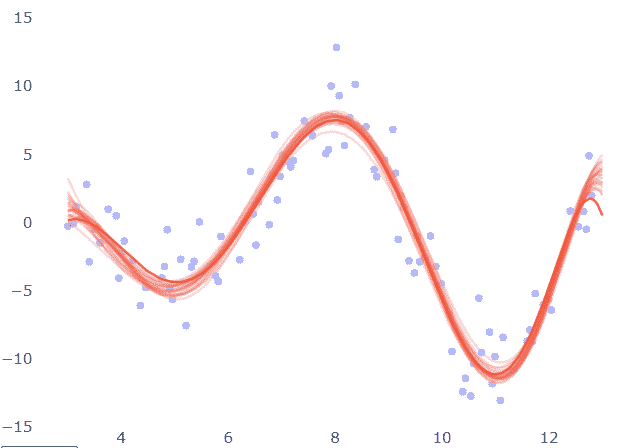
现在是 30 阶多项式的相同图示:
预测似乎在不同训练集上上下波动。其主要影响是我们不能信任这种模型的预测,因为如果偶然得到一个稍微不同的数据集,同样的输入样本的预测可能会改变。
为了更好地说明这一点,下图展示了在单个测试点(在这种情况下为 x=7)上评估的 3 个模型的预测分布:
虚线是 x=7 时函数的真实值。
这就是随机森林®的作用
上图中高阶模型的绿色分布显示,预测在不同数据集上变化很大。这不是模型的一个好特性,因为它对小的数据集扰动不够鲁棒。但请注意,分布的平均值对实际目标的预测非常好,甚至比 7 阶模型(红色分布)的平均值更好。对数据集的多个实现进行平均(bagging)是一个有益的过程,可以克服过拟合和方差。这实际上就是随机森林®的工作方式,并且大多数时候能够在没有太多调优的情况下给出相当好的结果。
希望这些可视化能帮助更清楚地了解偏差-方差如何影响模型性能,以及为什么平均多个模型可以得到更好的预测。
简介: 西奥多·齐茨米斯 是一名机器学习科学家。他目前在一家咨询公司工作,利用数据和机器学习解决各种行业的业务问题。他拥有来自雅典国立技术大学电气与计算机工程学院的学士和硕士学位,在那里他进行了机器人研究。
相关:
-
如何创建无偏机器学习模型
-
三个边缘情况罪魁祸首:偏差、方差和不可预测性
-
初学者的数据科学核心概念 20 条
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
相关主题
在 Scikit-learn 中可视化你的混淆矩阵
原文:
www.kdnuggets.com/2022/09/visualizing-confusion-matrix-scikitlearn.html
介绍
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
有许多机器学习算法以标准软件的形式打包来训练你的数据。因此,训练和构建算法是微不足道的。但区分经验丰富的数据科学家和新手的关键在于他们如何评估机器学习模型的质量。
在模型开发阶段,你会在给定的数据上训练一组算法,评估它们的性能,并最终选择表现最佳的模型。然而,我们如何定义度量标准以从候选算法中选择最佳模型在你的机器学习解决方案成功中起着至关重要的作用。
混淆矩阵
当我们谈论混淆矩阵时,总是在分类问题的背景下。以二分类(两类问题)为例。这里我们有一个二元或两个状态的变量,称为目标变量。任务是根据一些属性或自变量来预测该状态。
我们从预测状态与实际状态之间的状态交互中得到的四个计数形成了我们的混淆矩阵。
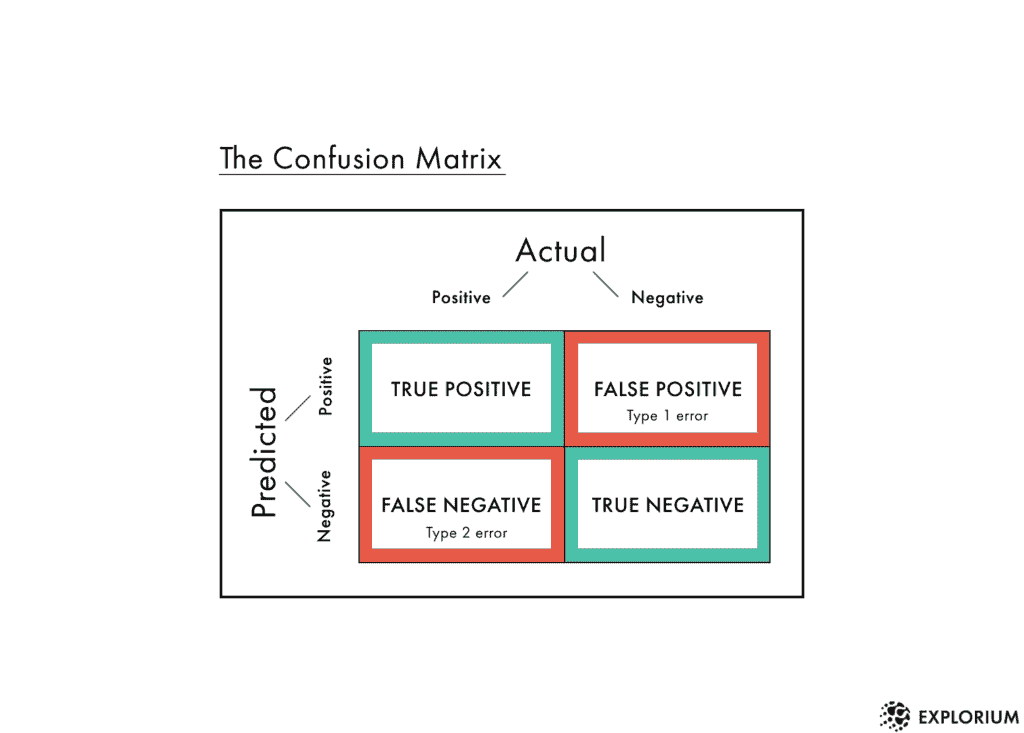
来源:www.explorium.ai/wp-content/uploads/2019/07/Confusion-1024x733.png
混淆矩阵的组成部分
四个象限被定义为真正负例(TN)、真正正例(TP)、假正例(FP)、假负例(FN)。如果你不熟悉这些术语,它们的名字让你感到困惑,那么请继续阅读,下面的部分将揭开这些术语的神秘面纱:
真正负例: 每当我们说真正时,这意味着我们的预测与实际情况相符。真正负例意味着预测和实际情况都是负类。
真正正例: 同样地,当预测和实际情况都是正类时,称为真正正例。
类似于上面解释的真实类别,其中实际值和预测值一致,假类别则表示预测与实际值不匹配,即实际值。这是数据科学家的关注点。从乐观的角度来看,这个假类别也是数据科学家识别算法模型或数据本身限制和问题的关键驱动因素。这个过程被称为错误分析,重点关注预测值与实际值的偏差。
假阳性: 当预测为正而实际为负时称为假阳性。
假阴性: 类似于假阳性,假阴性是指预测为负但实际为正。
混淆矩阵因此表示所有 TP、TN、FP 和 FN 实例的计数。
理解派生指标
混淆矩阵中的四个数字独立提供了对模型性能的细粒度理解,但数据科学家需要一个单一的度量来帮助他们评估整体模型性能。这有助于将机器学习问题表述为最小化问题。因此,从这四个度量中派生出一些关键评估指标,具体如下:
准确率: 准确率定义为所有正确预测实例占所有实例的比例。数学表达式为:
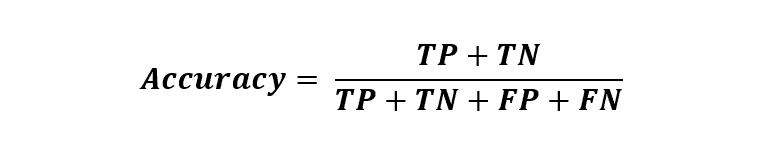
当数据存在类别不平衡时,这不是一个稳健的指标。类别不平衡是指一个类别主导了另一个类别。
精确度:精确度衡量正预测值与实际值匹配的比例。数学表达式为:
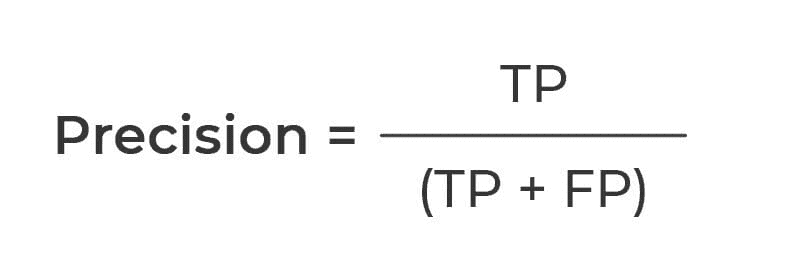
召回率:召回率衡量正确识别的正实例的比例。数学表达式为:
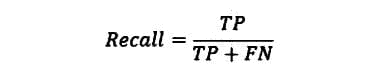
F1 或 F-beta:虽然精确度(Precision)尝试最小化假阳性(FP),召回率(Recall)尝试最小化假阴性(FN),F-1 指标在精确度和召回率之间保持平衡,其定义为两者的调和均值。
F-beta 是精确度和召回率的加权调和均值。数学表达式为:
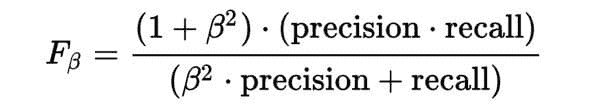
当 β 值小于 1 时,会降低精确度的影响,反之亦然。当 β=1 时,F-beta 变为 F1。
现在我们掌握了分类问题的指标。让我们选择一个数据集,训练一个模型,并使用混淆矩阵评估其性能。
Scikit-learn 实现
我们将考虑Kaggle 上的心脏病数据集,以构建一个预测患者是否容易患心脏病的模型。因此,这是一个二分类问题,其中“心脏病”是类别 1,“无心脏病”是类别 0。
导入库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
读取数据
df = pd.read_csv('heart.csv')
df.head()
拆分训练集和测试集
X = df[['age', 'sex', 'cp', 'trestbps', 'chol', 'fbs', 'restecg', 'thalach', 'exang', 'oldpeak', 'slope', 'ca', 'thal']]
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=4
训练模型
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
评估预测
y_pred = clf.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
ConfusionMatrixDisplay(cm, clf.classes_).plot()
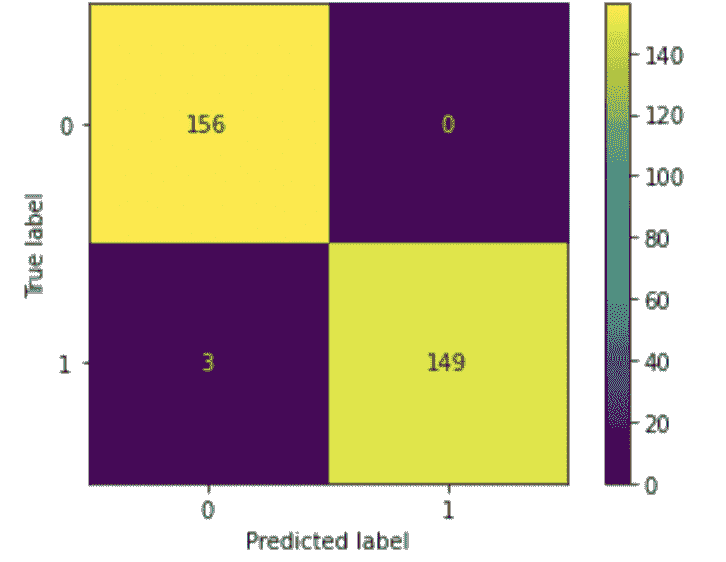
解释混淆矩阵并计算衍生指标
从上面的混淆矩阵中,我们得到四个数字:
-
真正例:149(当预测标签和真实标签都为 1 时)
-
真正例:156(当预测标签和真实标签都为 1 时)
-
假正例:0(当预测标签和真实标签都为 1 时)
-
假负例:3(当预测标签和真实标签都为 1 时)
衍生指标是通过前一部分中解释的数学表达式计算得出的:
-
准确率:(156+149)/(156+149+0+3) = 99.03%
-
精度:149/(149+0) = 100%
-
召回率:149/(149+3) = 98.03%
-
F1:2149/(2149+0+3) = 99%
摘要
在这篇文章中,我们了解了混淆矩阵在分类算法中的使用及其重要性。然后,我们学习了混淆矩阵的四个指标以及如何计算衍生指标及其优缺点。此外,文章还通过一个二分类问题的示例说明了如何展示混淆矩阵。希望这篇文章能帮助你理解评估模型性能的各种指标及何时使用哪一项。
Vidhi Chugh是一位获奖的 AI/ML 创新领袖和 AI 伦理学家。她在数据科学、产品和研究的交汇点工作,致力于提供业务价值和洞察。她是数据中心科学的倡导者,也是数据治理领域的领先专家,旨在构建值得信赖的 AI 解决方案。
更多相关主题
交叉验证代码可视化
原文:
www.kdnuggets.com/2017/09/visualizing-cross-validation-code.html
由 Sagar Sharma 提供,机器学习与编程爱好者。
让我们可视化以提高预测精度...
我们的前三个课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织 IT
假设你正在编写一个干净整洁的机器学习代码(例如线性回归)。你的代码没问题,首先你将数据集分为两个部分,“训练集和测试集”,像往常一样使用 train_test_split 函数和一些 随机因子。你的预测可能会稍微欠拟合或过拟合,如下图所示。
图:欠拟合和过拟合预测
并且结果没有变化。那么我们可以做什么呢?
正如名称所示,交叉验证是学习 线性回归 后的下一个有趣的环节,因为它利用 K-Fold 策略来提高预测精度。你问什么是 K-Fold?所有内容都在下面用 代码 解释了。
完整代码 😃
图:- 带可视化的交叉验证
代码洞察:
上面的代码分为 4 步...
1. 加载 和 划分目标 数据集。

图:- 加载数据集
我们将目标复制到数据集的 y 变量中。*要查看数据集,请取消注释 print 行。
2. 模型选择

图:- 模型选择 (LinearRegression())
为了简化问题,我们将使用线性回归。要了解更多信息,请点击 “线性回归:更简单的方法” 帖子。
3. 交叉验证 😃

图:- sklearn 中的交叉验证
这是一个过程,同时也是 sklearn 中的一个函数
cross_val_predict(model, data, target, cv)
其中,
-
model 是我们选择的要进行交叉验证的模型
-
data 是数据。
-
target 是相对于数据的目标值。
-
cv (可选) 是折叠的总数(即 K-Fold)。
在这个过程中,我们不会像平常那样将数据分为两个集合(训练集和测试集),如下所示。
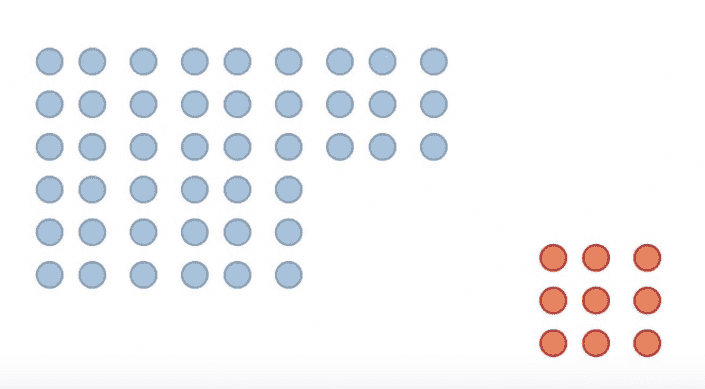
图:- 训练集(蓝色)和测试集(红色)
我们将数据集分成相等的K部分(K-Folds或cv)。为了改进预测并更好地泛化。然后在更大的数据集上训练模型,在较小的数据集上测试。假设cv为6*。
图:- 6 个相等的折叠或部分
现在,模型分割的第一次迭代看起来是这样的,其中红色是测试数据,蓝色是训练数据。
图:- cross_val 第一次迭代
第二次迭代将如下图所示。
图:- cross_val 第二次迭代
如此继续到最后一次或第六次迭代,结果如下图所示。
图:- cross_val 第六次迭代
4. 可视化数据使用Matplotlib****

图:- 使用 Matplotlib 可视化
为了可视化,我们导入了matplotlib库,然后创建一个subplot。
创建scatter点,边界为黑色(即(0,0,0)),或edgecolors。
使用ax.plot为两个轴提供最小值和最大值,其中'k--'表示线条类型,线宽为lw= 4。
接下来,为 x 和 y 轴添加标签。
plt.show() 用于显示图表。
结果
图:- 预测
该图表示波士顿数据集的 k-折交叉验证,使用线性回归模型。
我相信有许多类型的交叉验证,但 K 折交叉验证是一种很好的、易于入门的类型。
获取完整代码,请访问此 GitHub 链接:Github
关注我在Medium获取类似的文章。
我每周发布 2 篇文章,所以不要错过代码教程。
联系我:Facebook、Twitter、Linkedin、Google+。
任何评论或问题,请在评论中写下。
点赞!分享!关注我!
很高兴能帮到你。赞美...
个人简介:Sagar Sharma(@SagarSharma244)对编程(Python, C++)、Arduino 和机器学习感兴趣。 他也喜欢写东西。
原文。已获许可转载。
相关:
-
了解偏差-方差权衡:概述
-
使预测模型鲁棒:保留法与交叉验证
-
理解过拟合:机器学习中的一个不准确的误解
更多相关话题
数据可视化:Statology 入门
图片来源 | Midjourney & Canva
KDnuggets 的姊妹网站,Statology,拥有广泛的统计相关内容,由专家撰写,这些内容在短短几年内积累起来。我们决定通过整理和分享一些精彩的教程来帮助读者了解这个出色的统计、数学、数据科学和编程资源,将其推荐给 KDnuggets 社区。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
学习统计学可能很困难。它可能令人沮丧。最重要的是,它可能令人困惑。这就是为什么Statology在这里提供帮助的原因。
本系列最新教程专注于数据可视化。没有数据可视化,数据或统计分析是不完整的。存在各种工具可以帮助我们通过可视化更好地理解数据,这些教程将帮助实现这一点。学习这些不同的技术,然后继续阅读 Statology 的档案以获取更多宝贵的内容。
箱线图
箱线图(有时称为箱须图)是显示数据集五数概括的图表。
五数概括包括:
-
最小值
-
第一四分位数
-
中位数
-
第三四分位数
-
最大值
箱线图使我们能够通过一个简单的图表轻松可视化数据集中值的分布。
茎叶图:定义与示例
茎叶图通过将数据集中的每个值分成一个“茎”和一个“叶”来显示数据。
本教程解释了如何创建和解读茎叶图。
散点图
散点图用于显示两个变量之间的关系。
假设我们有以下数据集,显示了篮球队球员的体重和身高:

这个数据集中的两个变量是身高和体重。
为了制作散点图,我们将身高放在 x 轴上,体重放在 y 轴上。每个玩家则被表示为散点图上的一个点:

散点图帮助我们看到两个变量之间的关系。在这种情况下,我们可以看到身高和体重有正相关关系。身高增加时,体重也趋向增加。
相对频率直方图:定义 + 示例
在统计学中,你经常会遇到显示频率信息的表格。频率只是告诉我们某事件发生了多少次。
例如,以下表格展示了某商店在一周内根据商品价格销售的商品数量:

这种表格被称为频率表。一列是“类别”,另一列是类别的频率。
我们通常使用频率直方图来可视化频率表中的值,因为当我们能直观地看到数字时,更容易理解数据。
什么是密度曲线?(解释与示例)
密度曲线是在图表上表示数据集值分布的曲线。它有三个主要用途:
-
密度曲线让我们对分布的“形状”有一个很好的了解,包括分布是否有一个或多个经常出现的“峰值”,以及分布是否偏向左侧或右侧。
-
密度曲线让我们直观地看到分布的均值和中位数所在的位置。
-
密度曲线让我们直观地看到数据集中有多少观察值落在不同的值之间。
欲获取更多类似内容,请继续关注 Statology,并订阅他们的每周新闻通讯,以确保不会错过任何信息。
Matthew Mayo (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为KDnuggets和Statology的总编辑,以及Machine Learning Mastery的贡献编辑,Matthew 旨在使复杂的数据科学概念变得易于理解。他的职业兴趣包括自然语言处理、语言模型、机器学习算法和探索新兴的人工智能。他致力于使数据科学社区的知识普及化。Matthew 从 6 岁起便开始编程。
更多相关主题
使用 Python 可视化决策树(Scikit-learn,Graphviz,Matplotlib)
原文:
www.kdnuggets.com/2020/04/visualizing-decision-trees-python.html
评论
作者 Michael Galarnyk,数据科学家
图片来源于我的 理解分类的决策树(Python)教程。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
决策树是一种流行的监督学习方法,原因有很多。决策树的优点包括它们可以用于回归和分类,不需要特征缩放,并且相对容易解释,因为你可以可视化决策树。这不仅是理解模型的强大方式,也有助于传达模型的工作原理。因此,了解如何基于模型进行可视化是有帮助的。
本教程包括:
-
如何使用 Scikit-Learn 拟合决策树模型
-
如何使用 Matplotlib 可视化决策树
-
如何使用 Graphviz 可视化决策树(什么是 Graphviz,如何在 Mac 和 Windows 上安装它,以及如何使用它来可视化决策树)
-
如何可视化袋装树或随机森林中的单个决策树
一如既往,本教程中使用的代码可以在我的 GitHub 上找到。让我们开始吧!
如何使用 Scikit-Learn 拟合决策树模型
为了可视化决策树,我们首先需要使用 scikit-learn 拟合一个决策树模型。如果这一部分不清楚,我鼓励你阅读我的 理解分类的决策树(Python)教程,因为我详细讲解了决策树的工作原理以及如何使用它们。
导入库
以下导入语句是我们在本教程这一部分中将使用的。
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
from sklearn import tree
加载数据集
Iris 数据集是 scikit-learn 附带的一个数据集,无需从外部网站下载任何文件。下面的代码加载了 iris 数据集。
import pandas as pd
from sklearn.datasets import load_irisdata = load_iris()
df = pd.DataFrame(data.data, columns=data.feature_names)
df['target'] = data.target
原始 Pandas df(特征 + 目标)
将数据拆分为训练集和测试集
下面的代码将 75% 的数据放入训练集中,将 25% 的数据放入测试集中。
X_train, X_test, Y_train, Y_test = train_test_split(df[data.feature_names], df['target'], random_state=0)
图像中的颜色表示数据来自数据框 df 的哪个变量(X_train、X_test、Y_train、Y_test),以进行特定的训练测试分割。图片由 Michael Galarnyk 提供。
Scikit-learn 4 步建模模式
# **Step 1:** Import the model you want to use
# This was already imported earlier in the notebook so commenting out
#from sklearn.tree import DecisionTreeClassifier**# Step 2:** Make an instance of the Model
clf = DecisionTreeClassifier(max_depth = 2,
random_state = 0)**# Step 3:** Train the model on the data
clf.fit(X_train, Y_train)**# Step 4:** Predict labels of unseen (test) data
# Not doing this step in the tutorial
# clf.predict(X_test)
如何使用 Matplotlib 可视化决策树
从 scikit-learn 版本 21.0(大约 2019 年 5 月)开始,决策树现在可以使用 scikit-learn 的 [**tree.plot_tree**](https://scikit-learn.org/stable/modules/generated/sklearn.tree.plot_tree.html#sklearn.tree.plot_tree) 绘制,而无需依赖 dot 库,这是一个难以安装的依赖项,我们将在博客文章中后面部分讨论。
下面的代码使用 scikit-learn 绘制决策树。
tree.plot_tree(clf);
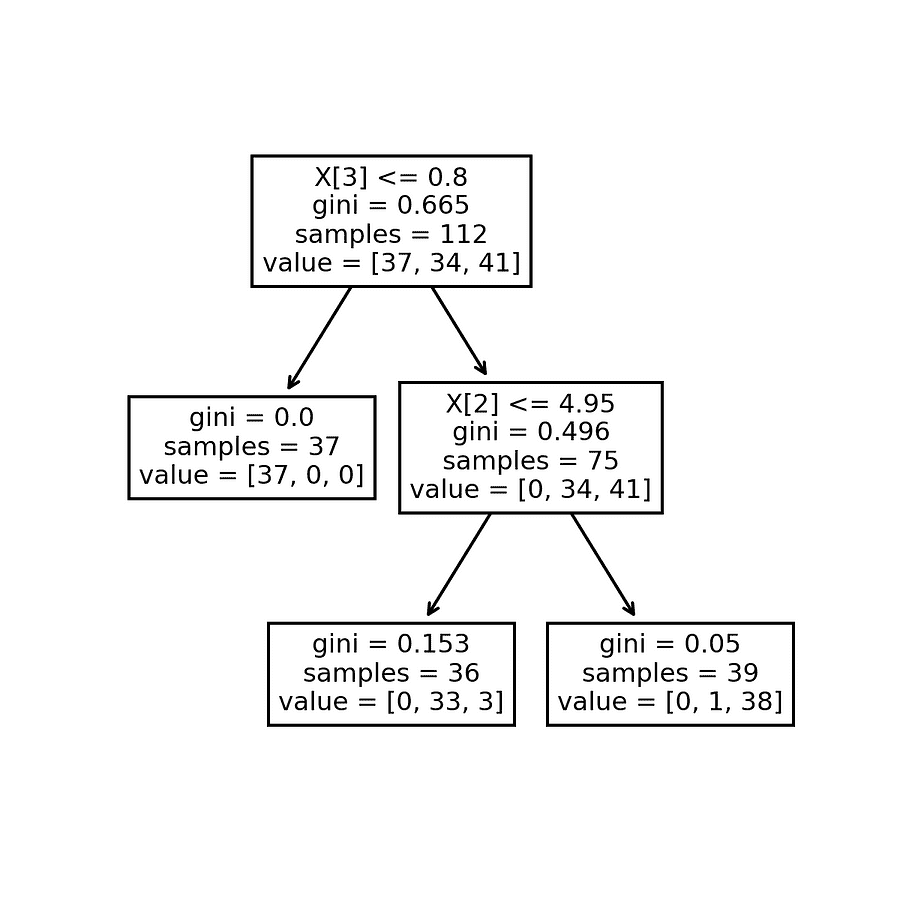
这还不是最具可解释性的树。
除了添加代码以允许你保存图像外,下面的代码尝试通过添加特征和类名称(以及设置 filled = True)使决策树更具可解释性。
fn=['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)']
cn=['setosa', 'versicolor', 'virginica']fig, axes = plt.subplots(nrows = 1,ncols = 1,figsize = (4,4), dpi=300)tree.plot_tree(clf,
feature_names = fn,
class_names=cn,
filled = True);fig.savefig('imagename.png')
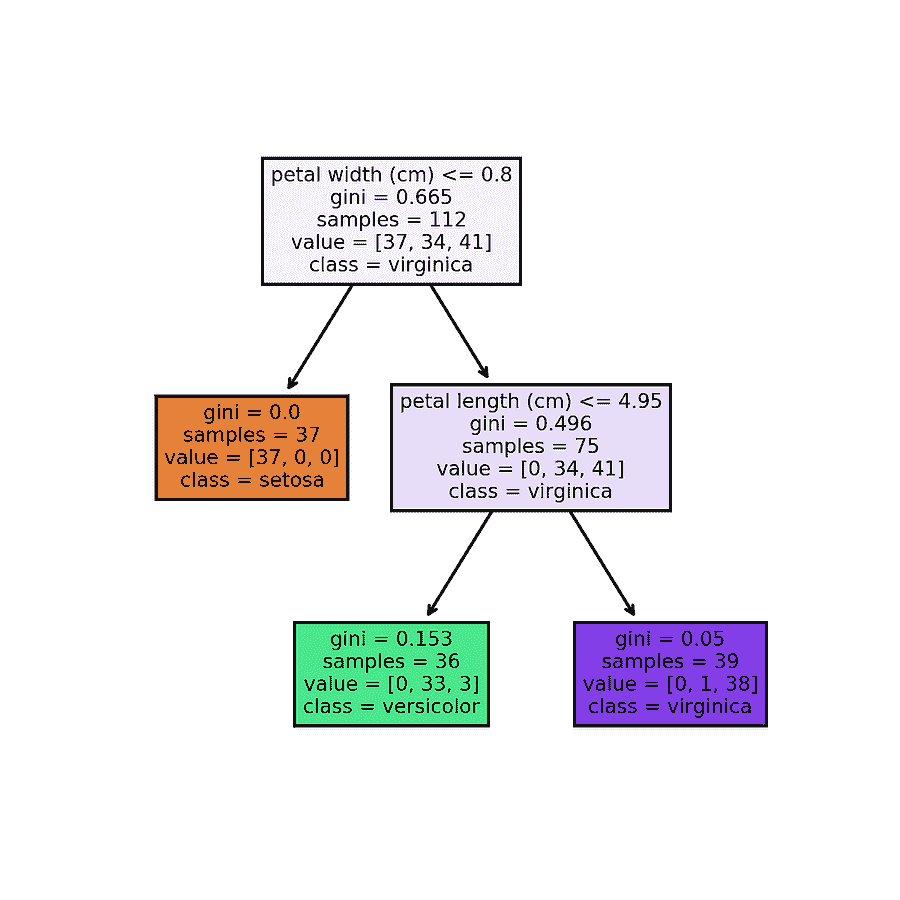
如何使用 Graphviz 可视化决策树
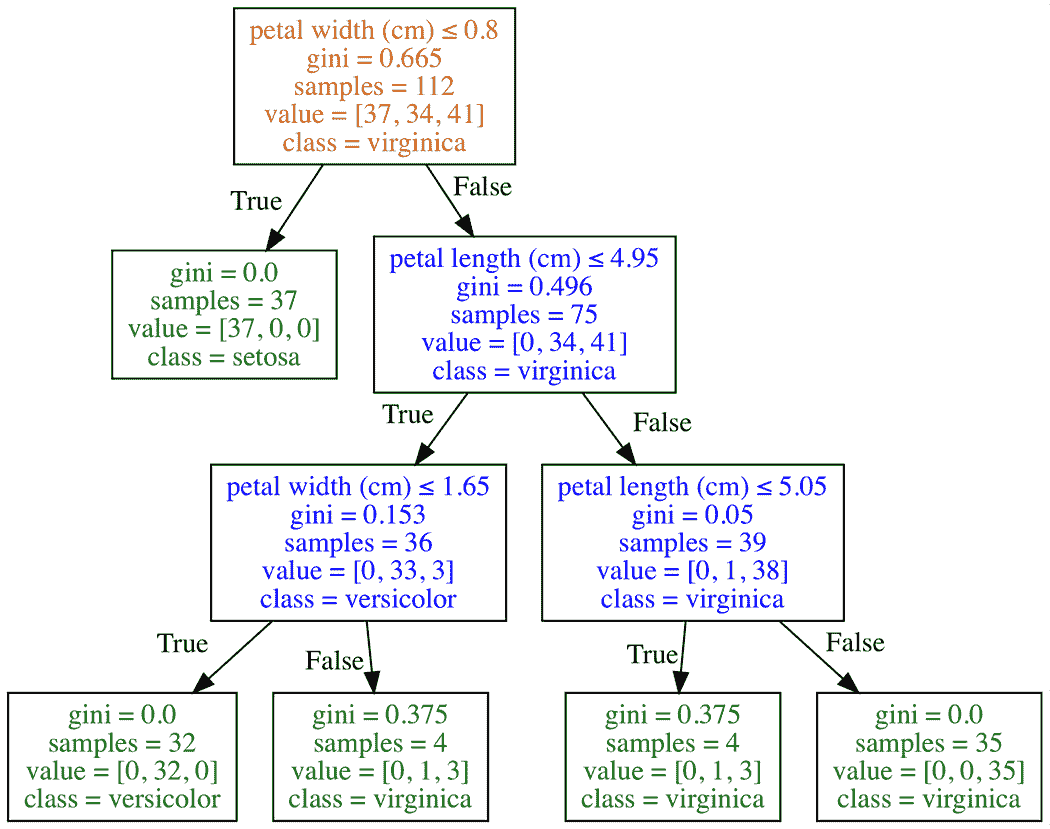
通过 Graphviz 生成的决策树。请注意,我编辑了文件,使文本颜色与叶子/终端节点或决策节点相对应,使用了文本编辑器。
Graphviz 是开源的图形可视化软件。图形可视化是一种将结构信息表示为抽象图和网络图的方式。在数据科学中,Graphviz 的一个用途是可视化决策树。我需要说明的是,我在讲解 Matplotlib 之后介绍 Graphviz 的原因是因为使其正常工作可能会很困难。这一过程的第一部分涉及创建 dot 文件。dot 文件是决策树的 Graphviz 表示。问题在于使用 Graphviz 将 dot 文件转换为图像文件(png、jpg 等)可能会很困难。有几种方法可以做到这一点,包括:通过 Anaconda 安装 python-graphviz,通过 Homebrew(Mac)安装 Graphviz,从官方站点(Windows)安装 Graphviz 可执行文件,或使用在线转换器将 dot 文件的内容转换为图像。

创建 dot 文件通常不是问题。将 dot 文件转换为 png 文件可能会很困难。
将模型导出为 dot 文件
下面的代码将在任何操作系统上工作,因为 python 生成 dot 文件并将其导出为名为 tree.dot 的文件。
tree.export_graphviz(clf,
out_file="tree.dot",
feature_names = fn,
class_names=cn,
filled = True)
安装和使用 Graphviz
将 dot 文件转换为图像文件(png、jpg 等)通常需要安装 Graphviz,这取决于你的操作系统和其他一些因素。本节的目的是帮助人们尝试解决常见的错误,即dot: command not found。

dot: command not found
如何通过 Anaconda 在 Mac 上安装和使用
要通过这种方法在 Mac 上安装 Graphviz,你首先需要安装 Anaconda(如果你没有安装 Anaconda,你可以在这里学习如何安装)。
打开终端。你可以通过点击屏幕右上角的 Spotlight 放大镜,输入 terminal 然后点击终端图标来完成。

输入下面的命令以安装 Graphviz。
conda install python-graphviz
之后,你应该能够使用下面的dot命令将 dot 文件转换为 png 文件。
dot -Tpng tree.dot -o tree.png
如何通过 Homebrew 在 Mac 上安装和使用
如果你没有 Anaconda 或者只是想要另一种在 Mac 上安装 Graphviz 的方式,你可以使用Homebrew。我之前写了一篇关于如何安装 Homebrew 并使用它将 dot 文件转换为图像文件的文章,请点击这里(请参阅教程中的 Homebrew 帮助可视化决策树部分)。
如何通过 Anaconda 在 Windows 上安装和使用
这是我在 Windows 上首选的方法。要通过这种方法在 Windows 上安装 Graphviz,你首先需要安装 Anaconda(如果你没有安装 Anaconda,你可以在这里学习如何安装)。
打开终端/命令提示符,输入下面的命令以安装 Graphviz。
conda install python-graphviz
之后,你应该能够使用下面的dot命令将 dot 文件转换为 png 文件。
dot -Tpng tree.dot -o tree.png
通过 conda 在 Windows 上安装 Graphviz。这应该可以解决‘dot’无法识别为内部或外部命令、可操作程序或批处理文件的问题。
如何通过 Graphviz 可执行文件在 Windows 上安装和使用
如果你没有 Anaconda 或者只是想要另一种在 Windows 上安装 Graphviz 的方式,你可以使用以下链接下载并安装。

如果你不熟悉更改 PATH 变量,并且希望在命令行中使用 dot,我建议尝试其他方法。有关此特定问题的许多 Stackoverflow 问题。
如何使用在线转换器可视化你的决策树
如果一切都失败了或者你根本不想安装任何东西,你可以使用在线转换器。
在下图中,我用 Sublime Text 打开了文件(虽然有很多不同的程序可以打开/读取 dot 文件),并复制了文件的内容。
复制 dot 文件的内容
在下图中,我将 dot 文件的内容粘贴到在线转换器的左侧。然后你可以选择你想要的格式,并在屏幕右侧保存图像。
将可视化保存到计算机
请记住,还有其他的在线转换器可以帮助完成相同的任务。
如何从 Bagged Trees 或随机森林®中可视化单独的决策树
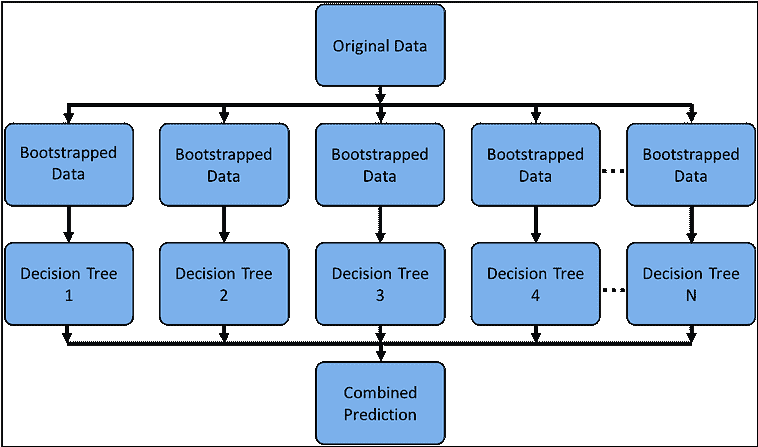
本节教程的灵感来源于Will Koehrsen的如何使用 Scikit-Learn 在 Python 中可视化随机森林算法中的决策树。图片由Michael Galarnyk提供。
决策树的一个弱点是它们通常没有最佳的预测准确度。这部分是因为高方差,这意味着训练数据中的不同分裂可能导致非常不同的树。
上图可能是 Bagged Trees 或随机森林算法模型的示意图,这些都是集成方法。这意味着使用多个学习算法来获得比任何单一学习算法更好的预测性能。在这种情况下,许多树保护彼此免受各自错误的影响。Bagged Trees 和随机森林算法模型的具体工作原理是另一个博客的主题,但需要注意的是,对于这两个模型,我们都生长 N 棵树,其中 N 是用户指定的决策树数量。因此,在拟合模型后,查看构成模型的单独决策树是很有意义的。
使用 Scikit-Learn 拟合随机森林®模型
为了可视化单独的决策树,我们首先需要使用 scikit-learn 拟合 Bagged Trees 或随机森林®模型(下面的代码拟合了随机森林算法模型)。
# Load the Breast Cancer (Diagnostic) Dataset
data = load_breast_cancer()
df = pd.DataFrame(data.data, columns=data.feature_names)
df['target'] = data.target# Arrange Data into Features Matrix and Target Vector
X = df.loc[:, df.columns != 'target']
y = df.loc[:, 'target'].values# Split the data into training and testing sets
X_train, X_test, Y_train, Y_test = train_test_split(X, y, random_state=0)# Random Forests in `scikit-learn` (with N = 100)
rf = RandomForestClassifier(n_estimators=100,
random_state=0)
rf.fit(X_train, Y_train)
可视化你的估计器
现在你可以查看所有来自拟合模型的单独树。在这一部分,我将使用 matplotlib 可视化所有决策树。
rf.estimators_
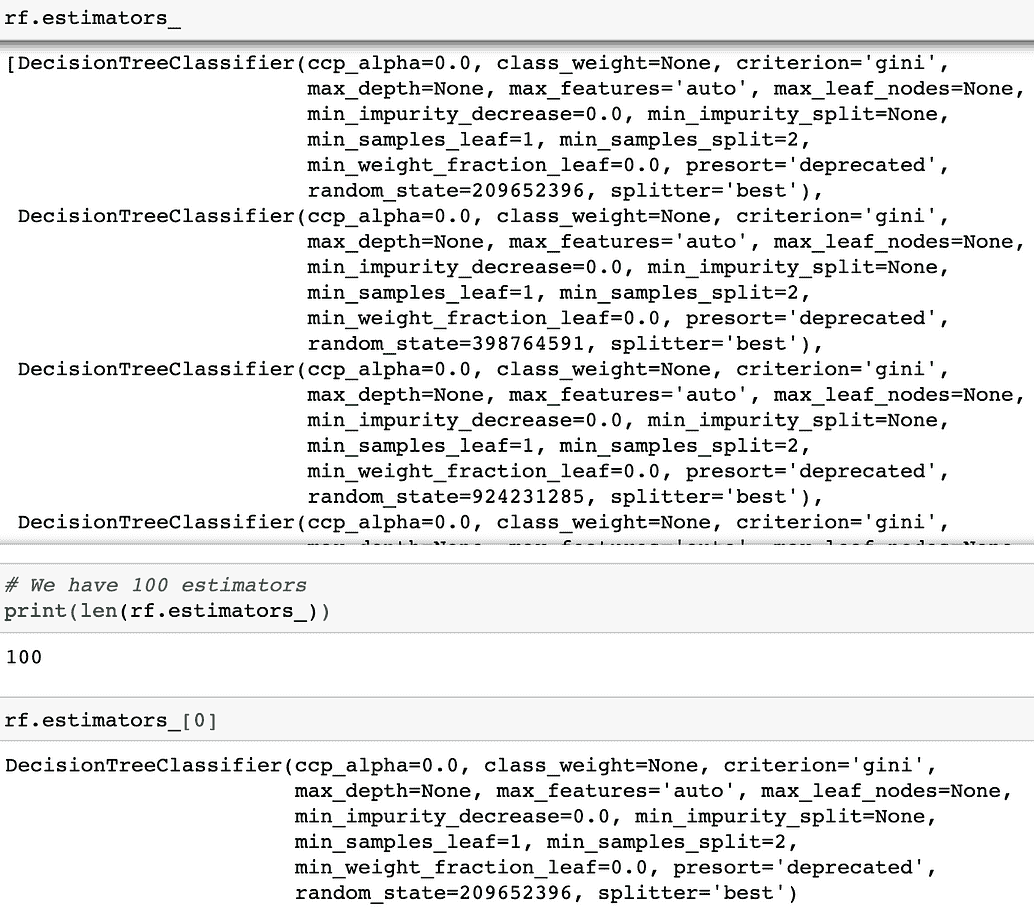
在这个例子中,注意我们有 100 个估计器。
现在你可以可视化单独的树。下面的代码可视化了第一棵决策树。
fn=data.feature_names
cn=data.target_names
fig, axes = plt.subplots(nrows = 1,ncols = 1,figsize = (4,4), dpi=800)
tree.plot_tree(rf.estimators_[0],
feature_names = fn,
class_names=cn,
filled = True);
fig.savefig('rf_individualtree.png')
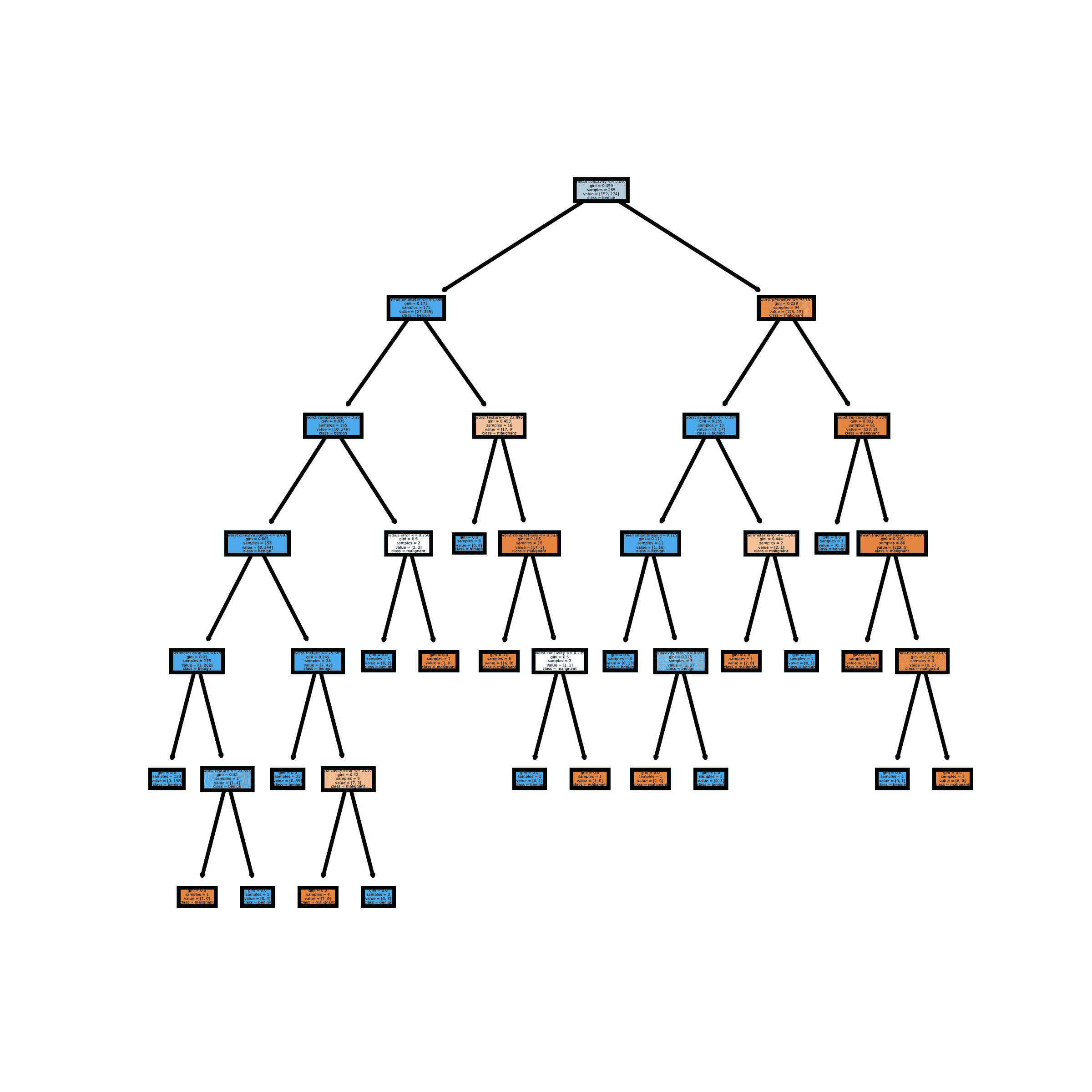
请注意,随机森林算法和袋装树中的个别树会生长得很深
你可以尝试使用 matplotlib 子图来可视化你喜欢的任意多的树。下面的代码可视化了前 5 棵决策树。我个人不太喜欢这种方法,因为它更难阅读。
# This may not the best way to view each estimator as it is smallfn=data.feature_names
cn=data.target_names
fig, axes = plt.subplots(nrows = 1,ncols = 5,figsize = (10,2), dpi=3000)for index in range(0, 5):
tree.plot_tree(rf.estimators_[index],
feature_names = fn,
class_names=cn,
filled = True,
ax = axes[index]);
axes[index].set_title('Estimator: ' + str(index), fontsize = 11)fig.savefig('rf_5trees.png')
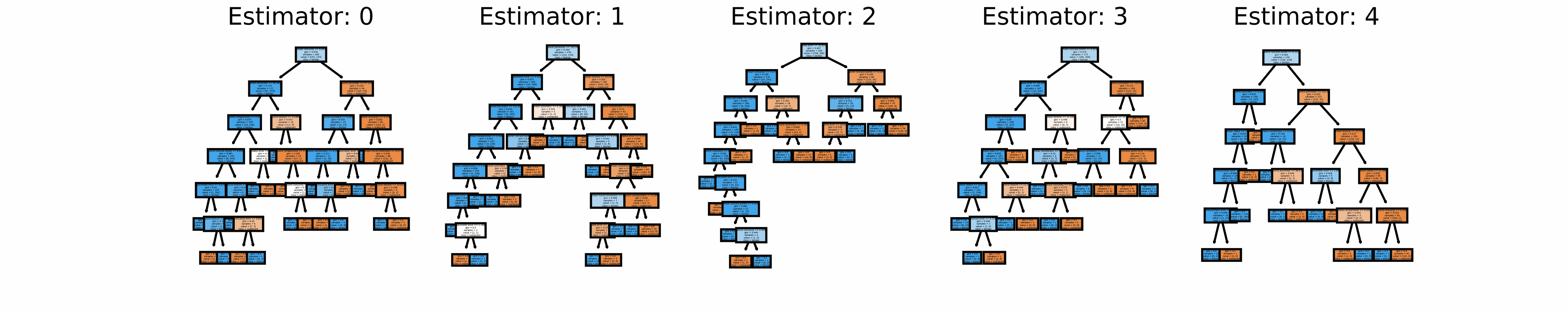
为每个决策树(估计器)创建图像
请记住,如果由于某种原因你需要所有估计器(决策树)的图像,你可以使用我在 GitHub 上的代码。如果你只是想查看本教程中随机森林算法模型拟合的 100 个估计器的每一个,而不运行代码,你可以查看下面的视频。
结论
本教程介绍了如何使用 Graphviz 和 Matplotlib 可视化决策树。请注意,使用 Matplotlib 可视化决策树是一种较新的方法,因此未来可能会有所更改或改进。Graphviz 目前更为灵活,因为你总是可以修改 dot 文件,使其更具视觉吸引力,如我所用的 dot 语言,甚至可以改变决策树的方向。我们没有涉及的是如何使用 dtreeviz,这是另一种可视化决策树的库。有关该库的优秀文章可以在 这里 查阅。
图像由 dtreeviz 库 生成。
如果你对教程有任何问题或想法,请随时在下方评论或通过 Twitter 联系我。如果你想了解更多关于如何利用 Pandas、Matplotlib 或 Seaborn 库的信息,请考虑参加我的 数据可视化 Python 课程 LinkedIn Learning。
RANDOM FORESTS 和 RANDOMFORESTS 是 Minitab, LLC 的注册商标。
简介: 迈克尔·加拉尔尼克 是一位数据科学家和企业培训师。他目前在 Scripps 转化研究所工作。你可以在 Twitter (https://twitter.com/GalarnykMichael)、Medium (https://medium.com/@GalarnykMichael) 和 GitHub (https://github.com/mGalarnyk) 找到他。
原文。已获许可转载。
相关:
-
理解 Python 中的分类决策树
-
决策树算法解析
-
决策树直观理解:从概念到应用
更多相关主题
你从未学过的基本统计学知识…因为它们从未被教授
原文:
www.kdnuggets.com/2017/08/vital-statistics-never-learned-never-taught.html
评论

KG: 从头开始,什么是统计学,它是如何产生的?你能给我们一个简短的定义和该学科的历史吗?
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
FH: 这是一个复杂的问题,最好通过参考我们统计学史上伟大人物之一 Stephen Stigler 的众多著作来回答(例如,参见en.wikipedia.org/wiki/History_of_statistics)。
简言之,统计学起初是为了理解国家的运作、生产力、预期寿命、农业产量等,并从样本中进行估计(后者的一个统计学例子可以追溯到公元前 5 世纪的雅典)。大致而言,统计学已经发展为几个广泛的领域:
-
描述性(例如,通常的棒球统计数据)
-
推论性(例如,棒球击球手在主场比赛时是否有不同的成功概率?)
-
估计性(例如,从一个因子实验中,如果我们保持面粉和糖的量不变,改变烘焙温度的效果)和
-
预测性(例如,金融预测或预测病人多久会复发一次)
关于统计学的定义,它是一个自成体系的学科,并且对所有其他领域和日常生活都大有裨益。统计学的独特之处在于它提供了在面对不确定性时做出决策的有效工具,理解变异和偏差的来源,以及最重要的,统计思维。统计思维是一种不同的思维方式,它既像侦探一样具有怀疑精神,又涉及对问题的不同看法。统计学包括测量改进、实验设计、数据分析、推断和趋势及证据的解释。
KG: 决策者在有效利用统计学进行决策时需要了解哪些最基本的内容?
FH: 总是最重要的问题是理解测量的意义和可靠性,以及理解数据解释与实验设计之间的联系。随着数据量的增加,普通数据分析师对设计的要求变得更加宽松,因此我们看到许多数据解释的失败案例(参见youtu.be/TGGGDpb04Yc获取一个很好的例子)。当没有设计(如随意数据收集)或使用的设计与项目目标不一致(前瞻性与回顾性设计;随机与观察性设计等)时,统计分析很少能有所补救。现代统计学创始人之一 R. A. Fisher 的名言很好地总结了这个问题:
“在实验结束后咨询统计学家,往往只是让他进行事后检查。他也许只能说实验的死因。”
关于测量,我看到很多统计学家忘记了“质疑一切”的格言,信任客户对测量的选择或计算。例如,漂亮的连续测量数据通常会被分类,从而导致信息、效能、精确度和普遍性的巨大损失。或者一个研究者可能会使用归一化程序来导出响应变量,这种情况下建模会更好,而不是用来创建比率。鉴于良好的设计和适当的测量,统计分析的方法需要基于良好的统计原则,正如我在www.fharrell.com/2017/01/fundamental-principles-of-statistics.html中尝试概述的那样。
然后结果需要能够被行动化,通过估计对客户有用的尺度(例如,相对治疗效果、预测风险、预期寿命、贝叶斯后验概率)。一个非常常见的问题是随着机器学习的兴起(见下文)对分类的误用;分类对客户做出了过多假设,并且没有提供灰色区域。我在www.fharrell.com/2017/01/classification-vs-prediction.html中详细讨论了这一点。
KG: 统计学中的主要领域或分支有哪些?它们有什么区别?
FH: 有三种思潮:
最常用的是频率学统计学,涉及估计、显著性检验、置信区间和假设检验,基于对研究的想象重复(抽样分布)的情景。由于需要考虑抽样分布和“样本空间”,频率学方法可能变得相当复杂,需要为每个抽样方案定制解决方案,例如,当进行顺序检验并希望在有足够证据支持效果时停止。频率学结果的统计陈述已被证明对于非统计学家(以及一些统计学家)来说很难解读。
接下来是贝叶斯统计学派,实际上早于频率学派一个多世纪,因为贝叶斯和拉普拉斯的工作。直到强大的计算机被统计学家使用之前,它并没有被广泛使用。贝叶斯方法要求指定一个锚点/起始点(“先验分布”),这可能需要大量思考,但也可以只是指定对数据的怀疑程度。经过这一步骤的好处是显著的——不需要为复杂的设计/抽样方案创建一次性解决方案,而且贝叶斯方法提供直接可操作的概率——例如,效果为正的概率,而不是频率学派的 p 值,后者是对效果为正的假设的概率,而实际上效果可能为零。
最后是似然学派,它类似于贝叶斯学派,但没有先验分布。似然方法像贝叶斯方法一样避免样本空间,因此更为简洁,但主要提供相对证据而非绝对证据,并且无法处理包含大量参数的模型。除了这三大学派,每个学派内还有不同的工具,特别是在频率学派中——例如自助法、非参数方法和缺失数据插补方法。
KG: 在你看来,机器学习和数据科学是否与统计学不同?
FH: 是的。为了简化来说,我会说数据科学是应用统计学 + 计算机科学,更少关注统计理论和假设检验,而更多关注估计和预测。机器学习是一种极为经验主义的统计建模方法,不太关心能否分离变量的效应。许多机器学习从业者在统计学方面有扎实的基础,但也有不少人没有。后一组人似乎在不断重新发明轮子,使用统计学几十年前已经表明无效的方法。
好的统计学家的一个标志是知道如何量化估计和预测的准确性。后一组机器学习从业者从未学习过预测准确性的度量背后的原理和理论(包括适当的概率准确度评分),并且在问题需要预测或最优贝叶斯决策时,持续开发“分类器”。这些分类器存在许多问题,包括无法对新样本进行泛化,特别是当结果频率差异较大时,详细讨论请见www.fharrell.com/2017/03/damage-caused-by-classification.html。
机器学习从业者似乎也对特征选择情有独钟,却没有意识到折磨数据以试图确定“重要”预测因子与从所有预测因子中获取最大信息的目标相悖,后者涉及到最大化预测区分度。
KG:你质疑了许多常见的统计实践,并且在批评中往往非常直言。实践者最常犯的错误是什么?
FH: 首先,我从算术开始。令人惊讶的是,很多人不知道除非比率代表的是互斥事件的比例,否则你不能直接相加比率。一般来说,比率是相乘的。我经常看到一些论文分析比率时没有取对数,或者分析基线的百分比变化时没有注意到数学不适用。比如一个从 1.0 开始的对象增加到 2.0,这是 100%的增长。然后考虑一个从 2.0 开始减少到 1.0 的对象,这是一种 50%的减少。100%和-50%的平均值是+25%,而实际上这两个值应该抵消,得到的平均值是 0%。百分比变化是一种不对称的度量,除非在特殊限制下,否则不能用于统计分析。
关于比率的不当加法,许多医学论文在应该加对数的时候加了比值比或风险比。一个简单的例子说明了原因。当开发风险评分时,假设两个风险因素在逻辑回归模型中的回归系数分别为 1 和-1。两个比值比是 2.72 和 0.37。将这两个比值相加假装两个风险因素都是有害的,而实际上第二个风险因素是保护性的。基线变化有许多其他问题,如我的博客中所述。我们应该分析原始响应变量作为因变量,并对原始基线变量进行协变量调整。统计学家和其他数据分析师需要仔细批评他们合作者使用的数学!
在统计模型中,有许多常见的陷阱,包括
-
尝试从样本量所允许的范围内学习过多内容(使用特征选择或估计过多参数),导致过拟合/过度解释。
-
做出不太可能成立的非线性假设;
-
尝试多种转换并假装最终的转换是预先指定的,破坏了结果的统计推断特性(与使用样条函数相对);
-
使用不准确的评分标准;
-
在信号:噪声比不大的情况下使用分类而非预测;
-
对因变量进行不同的转换或受该变量的离群值影响,而不是使用稳健的半参数有序回归模型。
然后是逐步回归——别让我开始说了……
二分法是对数据的最大犯罪之一。这是一种丢失信息的、任意的做法,并假设了自然界中不存在的非连续关系。对连续的因变量或自变量进行分类几乎从来不是一个好主意。
我们每天看到许多其他问题,包括使用无效的图形,如饼图和条形图。
KG:最后,统计学正在迅速发展,新方法不断涌现。你认为统计学在 10 到 15 年后会是什么样的?
FH: 哎呀——又是一个难题!我确信我们将看到贝叶斯模型被更频繁地使用,因为它们提供了我们真正需要的输出(前向时间、前向信息流概率),并允许我们正式地结合外部信息,即使这些信息,比如说某个治疗的不良事件比率不可能大于 10。我们还将看到更多可解释的、灵活的和鲁棒的预测方法,更直观和强大的统计软件及图形,以及更多不假设正态性或依赖大样本理论的统计方法。
谢谢你,Frank!
Kevin Gray 是 Cannon Gray 的总裁,这是一家市场科学和分析咨询公司。
Frank Harrell 是范德比尔特大学医学院生物统计学教授及生物统计学系创始主任。他还在 FDA 药物评价与研究中心生物统计办公室担任专家统计顾问。他著有多篇论文、影响力巨大的《回归建模策略》一书以及 R 包 rms 和 Hmisc。他可以在他的博客统计思维中找到。
原文。经授权转载。
这篇文章首次发表于 2017 年 8 月的 Greenbook。
相关:
-
因果关系:为何在何处
-
统计建模:入门
-
时间序列分析:入门
相关话题
让我听听你的声音,我会告诉你你的感受
原文:
www.kdnuggets.com/2016/05/voice-tone-analysis-emotion-detection.html
评论
作者:卡洛斯·阿尔盖塔,灵魂黑客实验室。
创建情感感知技术在近年来变得非常流行。有一广泛的公司试图从你写的内容、你的语音语调或你面部的表情中检测你的情感。所有这些公司都通过基于云的编程接口(API)在线提供他们的技术。
我们的前三大课程推荐
1. 谷歌网络安全认证 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业认证 - 提升你的数据分析能力
3. 谷歌 IT 支持专业认证 - 支持你的组织在 IT 方面

作为我的离线情感感知硬件(Project Jammin)的一部分,我已经构建了早期的面部表情和语音内容识别原型,用于情感检测。在这篇简短的文章中,我描述了缺失的部分——一个语音语调分析器。
为了构建一个语调分析器,需要研究语音波形的特性(声音的二维表示)。波形也被称为声音的时间域表示,因为它们是表示强度随时间变化的表现形式。有关波形的更多详细信息,请参阅这个有趣的页面。
英语语言中四个不同字母的波形。
使用专门设计用于分析语音的软件,目的是提取波形的某些特征,这些特征可以用作训练机器学习分类器的特征。给定一组带有情感标签的语音录音,我们可以使用提取的特征构建每个录音的向量表示。
从语音中提取情感所使用的特征因研究而异,有时甚至取决于分析的语言。一般来说,许多研究和应用工作使用了音高、梅尔频率倒谱系数(MFCC)和语音的共振峰的组合。
*上方为表达惊讶的语音波形。
蓝色下方为音高,黄色为强度,红色为共振峰。*
一旦提取了特征并构建了语音的向量表示,就会训练一个分类器来检测情感。在以前的工作中使用了几种类型的分类器。其中最受欢迎的是支持向量机(SVM)、逻辑回归(Logit)、隐马尔可夫模型(HMM)和神经网络(NN)。
作为一个早期原型,我实现了一个简化版的情感检测分类器。与其检测快乐、悲伤、愤怒等多种情感,我的情感分析器进行二元分类,以检测用户的激发水平。高激发水平与快乐、惊讶和愤怒等情感相关,而低激发水平与悲伤和无聊等情感相关。以下视频展示了我的情感分析器在树莓派上的运行。请欣赏!
简历:卡洛斯·阿尔盖塔 是一位居住在台湾的洪都拉斯企业家。他拥有信息系统与应用领域的博士学位,并且是 Veryfast Inc. 和 Soul Hackers Labs 的联合创始人。
相关:
-
深度学习中的深层感受
-
2016 年及之后深度学习的预期
-
关于情感分析的 11 件事
更多相关内容
Vowpal Wabbit:在大数据上的快速学习
原文:
www.kdnuggets.com/2014/05/vowpal-wabbit-fast-learning-on-big-data.html
评论作者:Ran Bi,2014 年 5 月 26 日。
Vowpal Wabbit(VW)是一个起源于 Yahoo! Research 的项目,目前由 Microsoft Research 赞助。由 John Langford 启动并领导,VW 专注于通过构建一个本质上快速的学习算法来实现快速学习。John 在 NYU 大数据课程中为我们讲授了两次关于 AllReduce 和 Bandits 的客座讲座。从我看来,他是一位著名的研究人员,对在线学习算法充满热情。

Vowpal Wabbit 这个名字发音奇特且陌生。Langford 解释说,Vowpal Wabbit 是 Elmer Fudd 发音“Vorpal Rabbit”的方式。至于“Vorpal”,如果你谷歌一下,你会发现“Vorpal Bunny”,它在一个流行的计算机游戏中也被称为“杀手兔”。也许这正是他希望 VW 成为的样子——可爱但又强大且快速。
VW 支持多种机器学习问题、重要性加权、损失函数和优化算法的选择,如 SGD(随机梯度下降)、BFGS(一个常用的参数估计算法)、共轭梯度等。它已经被用于在 1000 个节点上学习一个稀疏terafeature(即 10¹²个稀疏特征)数据集,所需时间为一小时,这超过了所有现有的机器线性学习算法。根据 John Langford 在 GitHub 上的教程,VW 在 RCV1 示例上比svmsgd快约 3 倍,RCV1 是一个文本分类的集合。
VW 的默认模式是一个具有平方损失函数的 SGD 在线学习器。要运行 VW,数据预计需要采用特定格式,即
“label [weight]| Namespace Feature1:Value1|Namespace Feature2:Value2 …”。
这种格式对于稀疏表示也很理想,因为不需要指定特征值为零。如果你不确定数据是否符合正确格式,你可以将数据行粘贴到数据格式验证中。VW 高效且非常可扩展。为了向量化特征,它使用了哈希技巧,这几乎不占用内存,并且由于不维护内部哈希表,它的速度比以前快 10 倍。
十几家公司正在使用 VW。其中之一是 eHarmony,它帮助人们找到真爱。正如 John 在 NIPS 2011 上所说,它是他最喜欢的应用。VW 也被用于解决几个 Kaggle 竞赛。更多信息可以在
注:Vowpal Wabbit 与深度学习不同 - 见此处 在哪里学习深度学习 – 课程、教程、软件。
相关:
-
MLTK:Java 中的机器学习工具包 - 免费下载
-
观看:机器学习基础
-
机器学习的数据工作流程
来自 Dan Rice 在 LinkedIn 的评论:
Vowpal 的有趣之处在于它的速度,因为它采用了抽样技术,这是一个基于串行处理的方法。这种抽样并不是通过传统的观测抽样完成的,而是在梯度下降中一次抽样一个特征,即随机梯度下降。因此,批评抽样的机器学习社区的人也需要意识到,他们自己快速的方法如 Vowpal 也明显使用了抽样。
Vowpal 的结果有时可能与传统的梯度下降方法在标准逻辑回归中的准确性相当,但通常准确性要低得多。实际上,通过使用标准逻辑回归并简单地抽样观测数据,可能能够在大量观测下匹配 Vowpal 的速度和准确性表现。如下面提到的,Vowpal 的发明者 Langford 最近在发布混合方法的研究,这些方法将 Vowpal 的随机梯度下降方法与传统的梯度下降方法结合,以提高准确性。但这些方法现在部分采用了并行处理。随着今天并行处理技术的发展,速度的问题已经不如几年前那么重要,但其他问题如可靠性、准确性、稳定性和偏差的缺失仍然更为重要。如果进行抽样,关键是要确保它不会像 Vowpal 的情况那样影响准确性,这也是其发明者转向更准确的新方法的原因。
一个可靠有效的大规模线性学习系统,由 Alekh Agarwal、Olivier Chapelle、Miroslav Dudik 和 John Langford 提供。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关主题
想成为数据科学家?第一部分:你需要的 10 项硬技能
原文:
www.kdnuggets.com/want-to-become-a-data-scientist-part-1-10-hard-skills-you-need

图片由作者提供
你可能会看到很多关于如何成为数据科学家的综合文章。它们提供了很多有用的信息,但可能会让人感到非常困惑。特别是作为初学者,你只想知道你需要了解什么,然后开始行动。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
这正是本博客的主题。我将介绍成为数据科学家所需的 10 项硬技能。
开始吧……
编程语言
如果你不知道如何用任何编程语言编程,你的第一步将是学习编程。我的推荐是 Python,因为它可以说是数据科学中最受欢迎的编程语言。
你还可以学习其他数据科学语言,如 R、SQL、Julia 等。
数学
有人说在编程世界中,数学是你不需要的一个话题。但我相信这是错误的。我参加过一个没有涉及数学方面的 BootCamp - 我确实意识到这在我的专业技能上带来了很大的弱点。
数据科学需要的数学领域包括线性代数、线性回归、概率和统计。学习数据科学背后的数学将对你的数据科学职业生涯大有裨益,并会被雇主注意到。
学习数学可能会让人感到紧张,因此我完全理解你的犹豫。阅读一下 如何克服数学恐惧并学习数据科学数学 来放松心情。
集成开发环境(IDE)
集成开发环境(IDE)是一种软件应用程序,提供了一个综合环境,其中包含专为软件开发设计的工具和功能。IDEs 将帮助你执行数据分析、可视化和机器学习任务。选择适合你的 IDE 更多的是根据你的个人偏好,例如,以下是:
你的 IDE 是你学习如何熟练掌握编程语言、学习数学及其他内容的地方。Jupyter Notebook 和 Visual Studio Code 是我的最爱!这些在你找到工作后也会非常有帮助,因为雇主期望你熟悉流行的 IDE。
库
随着时间的推移,编程变得更加简单,这归功于各种可用的库。这些库是你可以用来简化数据分析和机器学习过程的工具。
如果你决定学习 Python,以下是我建议你学习的库:
我在开始时提供这些库的列表,是因为在你的数据科学学习过程中,你会经常看到这些库。了解每个库提供的功能,你会看到它们的应用场景。例如,Matplotlib 可以用于数据可视化。
数据转换
如其所说——转换你的数据。数据转换是数据科学家一个重要的阶段,因为你会花大量时间将原始数据修改、调整并转换成可以用于分析和其他任务的格式。
你需要学习关于标准化、归一化、缩放、特征工程等内容。
你可以阅读的文章:数据转换:标准化与归一化
数据可视化
数据可视化是数据科学中的一个重要方面,因为你需要能够用多种方式传达你的发现,而不仅仅是编码。团队中的每个人可能都没有技术背景,因此以可视化的形式展示你的发现将有助于此,并且也有助于决策过程。
可以阅读:数据可视化最佳实践与有效沟通资源
机器学习
接下来你要学习的是机器学习。机器学习有许多方面,你不可能在所有方面都成为专家——但在这一领域中成为多面手仍然是有益的。做好准备,因为有很多东西需要学习。
你应该从基本概念开始,如监督学习、无监督学习、分类和回归任务。一旦你对这些有了较好的理解并能够区分它们,你就可以进一步了解不同的机器学习算法,如支持向量机和神经网络。
一旦你理解了机器学习模型,你需要学习:
-
构建机器学习模型
-
模型评估
-
部署
-
模型可解释性
-
过拟合与欠拟合
-
超参数调整
-
验证和交叉验证
-
集成方法
-
降维
-
正则化技术
-
梯度下降
-
神经网络与深度学习
-
强化学习
正如我所说,这个领域有很多东西要学,所以建议你花时间练习!
这里有一篇文章可以帮助你:提升机器学习技能的 15 个顶级 YouTube 频道
大数据工具
拥有这些知识是很棒的,但一些工具可以将你的数据科学职业提升到一个新的水平。了解不同的技术,它们的应用场景及优缺点,将使你的数据科学之旅更加高效。
有很多工具和技术对任何从事数据工作的人都有很大帮助。然而,我将列出一些流行的工具,如 Apache Spark, TensorFlow, PyTorch, Hadoop, Tableau, Git,等等。
云计算
云计算是数据科学一个非常重要的元素,因为你所做的所有项目和任务都会转变为产品。云计算服务提供可扩展的存储和计算能力,并提供便捷的工具和服务访问。
你需要了解一些云平台,如 Amazon Web Service, Microsoft Azure, 和 Google Cloud Platform。
你还需要了解其他云计算方面的知识,如数据存储、数据库、数据仓库、大数据处理、容器化和数据管道。
阅读一下:
-
云计算初学者指南
-
如何利用云计算高效扩展数据科学项目
项目
我将把项目作为你需要掌握的最后一个硬技能,因为它展示了上述所有内容。不要仅仅因为想在简历上加点项目就去做一堆项目。是的,这是最终目标,但确保你完全理解你的项目。
在面试中,你将被问及你的项目、细节,你需要准备好用尽可能多的知识回答。利用你的项目展示你的技能,以及你如何识别自己的不足并加以改进。
请阅读:
-
初学者的 5 个数据分析项目
-
数据科学作品集中的 5 个高级项目
总结一下
我尽量将这篇文章精简到不让你感到过于负担。希望我已经成功地提供了足够的细节和资源,让你能够启动你的数据科学之旅!
请关注第二部分,了解成为数据科学家所需的软技能。
妮莎·阿娅 是一位数据科学家、自由技术写作人以及 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程,以及数据科学相关的理论知识。她还希望探索人工智能如何有助于人类寿命的延续。作为一个热衷学习者,她寻求拓宽技术知识和写作技能,同时帮助指导他人。
相关主题
想成为数据科学家?第二部分:你需要的 10 项软技能
原文:
www.kdnuggets.com/want-to-become-a-data-scientist-part-2-10-soft-skills-you-need

作者提供的图像
这是成为数据科学家所需技能的第二部分。许多人谈论数据科学家所需的硬技能。公司会列出他们希望你了解的各种工具和软件,但在面试时,最重要的是你如何看待自己。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在的组织的 IT 工作
这来自于你的软技能和个性。
所以与其喋喋不休,不如直接进入正题。
沟通
沟通是关键。你可能听到过很多次,这可能会让人感到烦恼——但它确实重要。特别是当你在技术领域工作时,将这些技术概念传达给非技术利益相关者非常重要。提醒自己并非每个人都有技术倾向,你需要确保有效沟通,以解释有价值的见解、分析结果和数据驱动的决策。
解决问题
每天处理复杂和非结构化问题需要你具备解决问题的能力。你需要梳理任务,分解问题并找出提出解决方案中的问题。
你可能不能立即查看一块数据并马上发现问题,这就是为什么解决问题的技能很重要。
批判性思维
作为你解决问题技能的一部分,当你尝试寻找解决问题或任务的方法时,你需要具备批判性思维。你需要理解你面临的问题以及你将如何选择合适的方法来解决问题。
这包括评估数据的质量,以及如何解读结果以做出数据驱动的决策并避免偏见。
商业理解
你需要对商业模型有很好的理解,并实施商业技能。你需要时刻牢记:“这家公司如何使用这些分析?”当你对这一点有全面的了解时,你将能够决定如何处理这些分析,例如创建应用程序、报告等。
时间管理
作为数据科学家,你将管理日常的多个任务。处理这些任务可能会带来压力,并让你很容易感到沮丧。管理时间将帮助你缓解压力。
一旦你对数据科学项目生命周期有了几次试运行的经验,你将能够理解每个阶段所需的时间。然后,你可以利用这些经验更有效地管理你的任务,如数据清理、分析等。
团队合作
时间管理紧密相关,你会发现,拥有一个有效的方法和流程来进行数据科学项目生命周期管理需要团队合作。作为一名学生数据科学家,你将是唯一参与项目的人。一旦你开始在公司工作,这些任务可以在数据科学团队中分配。这不仅有效减轻了你的工作负担,而且让团队中的每个人都能体验到相关任务。
团队合作只有在沟通到位时才有效——记住这一点!始终与团队成员沟通你正在做的事情,如果你遇到阻碍,或者任务的结果。
数据科学项目涉及跨职能团队,因此你需要与其他专家如业务分析师、产品经理等进行协作。
讲故事和展示
正如我之前提到的,你的沟通技能的一部分是理解每个利益相关者可能对技术并不感兴趣。因此,当你叙述和展示你的分析结果时,你需要考虑这一点。
你可以通过博客练习数据讲故事的技巧,因为这是一种以更简单的格式解释技术概念的好方法。展示你的发现可以通过幻灯片演示、数据可视化等方式进行。
练习这些技能将使你的工作更轻松,因为利益相关者会因为发现结果的呈现方式而提出更少的问题。
领域专长
与公司合作并处理日常任务将有助于提升你的技能,使你更为熟练。然而,在一个非常创新的领域工作时,你需要超越常规。
无论你对什么感兴趣,我都强烈建议你在该领域成为专家。这将使你的技能和知识具有可转移性,并且可以应用到你的日常任务中。
自我发展
在一个不断发展的领域中,保持领先非常重要。你获得第一个数据科学职位后,学习并不会结束。你将不断学习新事物,并需要在工作日中抽出时间了解这些新事物。
我不是说你必须完全投入到教育中,但你需要阅读文章、新闻,并学习新工具和软件的使用。这将提高你的技能水平,使你的日常任务更加高效。
治理与安全
作为数据科学家,你将处理敏感信息。收集数据、使用数据以及分享数据时,你需要遵循伦理指南。你需要记住,有些数据是私人信息,因此你对这些数据的处理非常重要。
你需要关注公司流程和政策中的伦理、偏见和安全问题。
总结一下
我希望这能为你提供一个快速简便的关于数据科学家所需软技能的指南。许多这些技能你会在工作环境中自然培养和进步,但了解你面临的挑战总是有益的。
祝你学习愉快!
Nisha Arya 是一名数据科学家、自由技术写作作者和 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程以及与数据科学相关的理论知识。她还希望探索人工智能在延续人类生命方面的不同方式。她是一个热衷于学习的人,致力于扩展她的技术知识和写作技能,同时帮助指导他人。
更多相关内容
不要浪费时间建立你的数据科学网络。
原文:
www.kdnuggets.com/2021/11/waste-time-building-data-science-network.html
评论

由Aron Visuals拍摄,发布在Unsplash。
对于定期阅读我文章的人来说,你可能会认为我是地球上最矛盾的人。我不怪你。
我最近注意到,在与人进行口头或书面互动时,我对我所交流的对象做出了许多假设。我没有在明确说明我所说的内容之前定义非常重要的方面,这在不同的上下文中可能会稀释我想表达的实际信息。
最近,我写了一篇关于如何通过网络简化进入数据科学初期阶段的文章。回应这篇文章,我在 LinkedIn 上收到了许多连接请求,他们希望与我建立联系,以便扩展他们的职业网络。
别误会,我并不介意人们与我建立联系。事实上,我在每篇文章的结尾都鼓励这样做。我非常感激自己处于这样一个人们希望与我联系并关注我在数据科学旅程中的位置。我分享我的经历是希望表达作为数据科学家或自由职业者的现实,因为我们都在努力成为不可或缺的人。
说得直接一点…
网络建设是浪费时间!
哎呀,我又来了。让我解释一下…我们所知的网络建设,或者我们被告知的方式,已经完全过时。
事实上,我还没有想出一个足够好的名字来描述什么是真正的网络建设,因此我仍然提到“真正的网络建设”作为网络建设。
构建数据科学网络是很有可能浪费时间的。以下是其表现形式;
-
随意与那些工作描述中有“数据科学家”的人建立联系。
-
单纯追求个人利益——例如,一份工作。
-
为未来机会建立联系——也就是说,我正在学习数据科学,但也许有一天我们可以一起合作一个项目。
在我看来,这种形式的网络建设不算真正的网络建设。这完全是个废物,浪费时间。
真正的网络建设
这是我对网络建设的看法…
如果你正在做一些有趣的事情,就会总有一些人想要认识你。
简单明了。
为什么人们想见伊隆·马斯克?如果你说是因为他是亿万富翁,那你又一次陷入了陷阱。这是错误的心态。如果你想着他的亿万财富,说明你在考虑对你有什么好处。这是索取者的心态。
人们想见伊隆·马斯克是因为他做出人们想要的东西。他是一个解决问题的人,他是被需要的!
如果你试图为了上述 3 个原因中的任何一个建立网络,那么你绝对是在浪费时间——这些时间本可以用来创建一些有趣的东西,让人们想要了解你。
如果你看看在 LinkedIn 上讨论数据科学的热门人物,你会看到我在说什么;
-
维尼特·瓦希斯塔 — 建立围绕数据科学最佳实践的心态。这包括从生产中的机器学习到招聘的所有内容。
-
哈普里特·萨霍塔 — 建立一个数据科学家各级别的社区,在这里他们可以安全地分享经验和提问。他还建立了一个播客,采访一些在数据科学领域非常有趣的人,以及一些与该领域完全无关的人。
-
凯特·斯特拉赫尼 — 建立一个数据讲述者的社区。这包括教育人们如何利用数据成为更好的讲述者。
列表还在继续…
我知道你在阅读我分享的名字列表时在想什么——
“这些人都在这个领域待了多年”。
这确实很真实… 每个建筑必须从某个地方开始。
合适的人会找到你
本质上,当我提到网络建设时,我是在说你应该专注于创造人们想要的东西。做一个创造者。这样,合适的人才会来找到你。
根据我的观察,最让我记住的那些与我建立联系的人,都是因为以下原因;
-
他们希望跟上我分享的内容
-
他们对我正在创作的内容有一个经过充分研究的问题
-
他们有一个他们认为对我们双方都有价值的机会
这并不是说我没有遇到过向我询问工作和其他不在这个列表上的事情的人,我有。但这些人很快就会消失。
在我看来,如果你发现自己试图在线与某人建立联系,而不符合这 3 个原因中的任何一个,那么我建议你当场自省。无论你做什么或说什么,都可能显得急切,并可能在关系开始之前就把它破坏掉。
如果你真的想建立一个强大的网络,合适的人会在你决定开始创造的那一刻找到你。
开始创作,你不必像我一样从博客开始;你有很多不同的方法来创造别人想要的东西。
-
项目
-
摘要
-
案例研究
-
视频博客/博客
-
分享高排名的竞赛解决方案
-
将研究论文转化为代码
这些想法不必从细节入手。重要的是你开始创作并分享你所创作的内容——最终,合适的人会来找你。
最终想法
成为创作者并在线分享你的工作,起初可能会感到令人畏惧,特别是如果你像我一样天生内向——克服这个问题的开始是分享一件事,然后不断前进。如果你希望建立一个强大而健康的网络,重要的是你要以创作者的身份来尝试——从那时起,一切都会自然而然地到来。
通过 LinkedIn 和 Twitter 与我保持联系,了解有关数据科学、人工智能和自由职业的最新动态。
相关文章
个人简介: Kurtis Pykes 是一名机器学习工程师,是 Towards Data Science 的顶级作家,也是 Upwork 的顶级自由职业者。关注他的 Medium 博客。
原文。经授权转载。
相关:
-
数据科学家和机器学习工程师的区别
-
如何在 8 个月内提升我的数据科学技能
-
最重要的数据科学项目
更多相关主题
使用机器学习进行自动数据标注
原文:
www.kdnuggets.com/2021/08/watchful-automated-data-labeling-machine-learning.html
赞助商帖子。
网络研讨会:2021 年 9 月 2 日,下午 3 点 PT,下午 6 点 ET
手工标注的主要问题包括引入偏差(手工标签既不可解释也不可说明),高昂的成本(包括财政成本和领域专家的时间),以及没有所谓的“金标准标签”(即使是最著名的手工标注数据集也有至少 5%的标签错误率!)。
Watchful 的 CEO Shayan Mohanty 加入了 Coiled 的数据科学宣传主管 Hugo Bowne-Anderson,讨论了为何手工标注,作为人机智能的基本部分,是幼稚、危险且昂贵的。他将分享一个不断扩展的替代方案世界,包括半监督学习、弱监督和主动学习。在这些其他技术时代,手工标注就像是古腾堡后抄书的抄写员。
所有参与者将:
-
了解扩展数据标注的技术和方法
-
接收一个 Jupyter Notebook,它将引导参与者了解一些讨论过的概念。
-
在网络研讨会后接收一页摘要,涵盖关键概念
我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关内容
水印技术如何帮助缓解大型语言模型的潜在风险?
原文:
www.kdnuggets.com/2023/03/watermarking-help-mitigate-potential-risks-llms.html

图片由作者提供
为什么我们需要为大型语言模型添加水印?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
像 ChatGPT、GPT-4 和 Bard 这样的巨大语言模型正在革新我们的工作方式。我们现在有工具可以帮助我们编写整个程序或撰写新产品发布的博客文章。由 GPT-3.5 驱动的应用程序正在生成多种主题的真实而多样化的文本。就像所有新技术一样,它们也带来了盗取知识产权、剽窃、虚假信息和在线滥用的潜在风险。
我们如何确保大型语言模型的输出是可信和负责任的?目前没有可靠的解决方案。虽然有一些工具可以检测生成的文本,但它们的准确率较低。
在马里兰大学的论文中:大型语言模型的水印,作者提出了一种针对专有 LLM 的水印框架。它通过不可见的信号水印生成的文本输出,这些信号可以被算法检测到,但对人类不可见。
水印技术是一种有效的手段,可以用来证明对象的所有权、真实性或完整性。
例如:
-
它可以帮助保护 LLM 开发者、科学家和公司的知识产权(模型)。
-
它可以防止剽窃或误归属。
-
它可以帮助检测社交媒体上的虚假信息活动。
-
水印技术最重要的用途是帮助监控和审计 LLMs 的使用及其影响,防止滥用或误用。
水印技术如何在大语言模型(LLMs)中发挥作用?
水印框架由两个组成部分构成:嵌入和检测。
嵌入
这是将水印插入 LLMs 输出的过程。为了实现这一点,LLM 开发者需要稍微修改模型参数以嵌入水印。
嵌入工作原理是,在生成每个单词之前选择一组随机的“绿色”标记,然后在采样过程中轻微地促进绿色标记的使用。绿色标记的选择方式不会影响文本的上下文和质量。嵌入还确保每个范围内有足够的标记,以使决策过程成为可能。
检测
这是从给定的文本范围中提取“绿色”标记的过程。不需要模型参数或 API。检测是通过计算范围内每个标记的曲率来完成的。曲率是对标记的概率分布对模型参数小变化的敏感程度的测量。
作者解释说,绿色标记的曲率高于正常标记,从而在文本中形成可检测的模式。
在执行水印检测后,算法会进行统计测试以确定结果的置信度。
你可以通过阅读 arxiv.org 上的论文了解更多信息。
Hugging Face 演示
你可以尝试使用 Hugging Space Gradio Demo 来生成带水印的文本,或者查看 GitHub 仓库:jwkirchenbauer/lm-watermarking 以在个人计算机上运行 Python 脚本。
来自 Hugging Face 的图片 | LLMs 的水印
水印对大型语言模型(LLMs)有多有效?
我们将回顾论文中提到的在总结、翻译和对话生成等各种任务上的结果。
论文报告称,他们的框架在不同任务中实现了高嵌入率 > 90% 和高检测率 > 99%,同时保持低误报率 < 1% 和高文本质量分数。作者还证明该框架对各种攻击(如释义、混合或截断水印文本)具有鲁棒性。
-
嵌入率:绿色标记在输出中使用的频率。
-
检测率:水印被正确检测的频率。
-
误报率:非水印文本被错误检测为水印文本的频率。
-
文本质量:自然流畅程度。
限制和挑战
这是一个起点,水印框架存在一些限制和挑战,例如:
-
你必须在嵌入过程中修改模型参数,在某些情况下(API、边缘设备)这不可能实现。
-
它依赖于基于采样的生成方法,与其他方法(如束搜索或核采样)不兼容。
-
水印在不同任务中均匀嵌入,对于某些任务,其中某些标记比其他标记具有更大的语义重要性,可能效果不佳。
还有其他实施挑战和公平使用政策,这些都是算法广泛应用的关键。
结论
在这篇博客中,我们讨论了水印技术在大型语言模型中的重要性、框架的工作原理、结果以及局限性。这是一个提出用于专有大型语言模型的水印框架的论文的总结。
这是一个开始,我们需要像水印这样的框架来让人工智能对每个人更安全。我希望你尝试一下 Hugging Face 的演示亲自体验其卓越之处。如果你对理论和算法的内部工作感兴趣,可以阅读论文和源代码。
Abid Ali Awan (@1abidaliawan) 是一名认证数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为受心理疾病困扰的学生构建一个人工智能产品。
更多相关主题
当 Watson 遇见机器学习
原文:
www.kdnuggets.com/2014/07/watson-meets-machine-learning.html
作者:Ran Bi,2014 年 7 月。
 你还记得Watson在 2011 年击败两位《危险边缘》的最伟大冠军吗?它是第一个使用自然语言处理和机器学习来改变人们与计算系统互动方式的认知系统。现在,它已经被更广泛地应用。
你还记得Watson在 2011 年击败两位《危险边缘》的最伟大冠军吗?它是第一个使用自然语言处理和机器学习来改变人们与计算系统互动方式的认知系统。现在,它已经被更广泛地应用。
医疗保健 是 Watson 首个带来显著改善的行业。Watson 被训练帮助医生识别癌症患者的治疗方案,为护理人员提供批准建议,并从病人的医疗记录中挖掘关键信息。

例如,Modernizing Medicine 设计了由 IBM Watson 提供支持的电子医疗助理,以提高医生的工作效率。医生不仅可以查看过去的诊断和病人档案,还可以提出像“甲氨蝶呤与环孢素相比如何”的问题,如左侧截图所示。最棒的是,EMA 会学习每位医生独特的实践风格。虽然我不知道它的效果如何,但这一步更接近未来医疗。
机器学习将使认知系统以更加自然和个性化的方式学习、推理和与我们互动。这些系统将通过与数据、设备和人们的互动变得更智能、更定制化。
现在公司可以与 IBM 合作,通过“Watson 生态系统”开发他们的应用程序。机器学习将如何改变我们的生活?
这里有几个方面可能会引起你的兴趣。

教育。 未来的教室会是什么样的?我相信个性化教科书、量身定制的课程和机器人导师可能会成为学生们生活的一部分。Majestyk Apps 的首席执行官,获得 IBM Watson 移动开发者挑战赛 的获胜者,展示了他们的认知玩具 Fang。
孩子们可以像和最好的朋友一样与它交谈。这个小玩具可以回答孩子们无尽的问题,满足他们对未知世界的好奇心。想象认知智能教科书、报纸或书桌并不难。
购物。 期待通过大数据获得更个性化的购物体验已经变得很普遍。想象一下一个应用程序,它可以在不同的场合推荐衣服,帮助我们决定买哪件衣服,并且让我们在不脱衣服的情况下试穿衣物。(我迫不及待想要安装它。)另一个想法是在线和离线购物的结合。这样,我们既能享受令人兴奋的购物体验,又能享受快速结账的便利。
IBM 所做的是投资了一家数字购物公司,Fluid,并将 Watson 的认知能力应用于电子商务。这样,人们就可以提出具体的问题,而不是搜索关键词。听起来你每天都有一个销售代表。

在线安全。 通过了解我们是谁,数字监护人可以对我们的活动做出推断,并在出现异常情况时发出警报。例如,如果监护人检测到购买了汽油,它会“认为”这笔购买非常可疑,因为你的车刚刚加油或你在办公室时发生了这种情况。
未来城市。 如果你居住的城市可以分析当地新闻并学习预测你的需求,会怎样?每个人都可以通过移动应用程序分享像是坏掉的街灯、交通堵塞等信息,系统将根据所有信息生成最适合你请求的解决方案。此外,情感分析将帮助城市管理者进行城市规划。更多与城市生活相关的机器学习应用可以被开发,比如犯罪预测、公交路线、街道清扫、自动空调等。
…
公司可以通过在 Watson Developer Cloud 上使用 API 和工具来嵌入 Watson 的认知能力。要访问这些功能,公司需要 提交请求。
也许这是一个开始的选择。如果你有任何让我们手机更智能的想法,尝试永远不会太晚。

Ran Bi 是纽约大学数据科学项目的硕士生。在她在 NYU 学习期间,她完成了多个机器学习、深度学习和大数据分析的项目。由于本科时的金融工程背景,她也对商业分析感兴趣。
相关:
-
漫画:Watson 和人工智能与自然智能的对比
-
KDnuggets 独家采访:IBM 大数据产品副总裁 Anjul Bhambhri
-
深度学习是否存在深层缺陷?
-
《Fast Company》十大大数据最具创新公司
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关主题
WavJourney: 探索音频故事生成的世界
原文:
www.kdnuggets.com/wavjourney-a-journey-into-the-world-of-audio-storyline-generation
介绍
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯的捷径。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 工作
大型语言模型的近期出现引起了全球轰动。现在,想象力就是唯一的限制。今天,WavJourney 可以自动化讲故事的艺术。只需一个简单的提示,WavJourney 便利用 LLM 的强大功能生成引人入胜的音频剧本,包含准确的故事情节、逼真的人声和引人入胜的背景音乐。
为了正确地了解音频生成的能力,可以考虑以下场景。我们只需提供一个简单的指令,描述一个场景和背景设置,模型便生成一个引人入胜的音频剧本,突显与原始指令的极致情境相关性。
指令: 生成一个科幻主题的音频:火星新闻报道人类向比邻星发送了一个光速探测器。开始时是新闻主播,接着是记者采访一个由联合地球和火星政府建立的组织的首席工程师,最后再回到新闻主播。
生成的音频: audio-agi.github.io/WavJourney_demopage/sci-fi/sci-fi%20news.mp4
要真正理解这个奇迹的内部工作机制,让我们深入探讨生成过程的方法和实施细节。
生成过程
下图总结了完整的过程,用一个简单的流程图表示。
图片来源:论文
端到端的音频生成过程由多个子模块组成,这些子模块按顺序执行以完成一个完整的文本到音频模型。
音频剧本生成
WavJourney 利用 GPT-4 模型和预定义的提示模板生成脚本。提示模板将输出限制为简单的 JSON 格式,计算机程序可以轻松解析。每个脚本有 3 种不同的音频类型,如上图所示:语音、音效 和 音乐。每种音频类型可以作为前景音频运行,也可以作为背景音效叠加到其他音频上。其他属性如内容描述、长度和角色是正式定义脚本生成音频设置的足够属性。
脚本解析
输出脚本随后会通过计算机程序处理,从预定义的 JSON 脚本格式中解析相关信息。它将每个描述和角色与预设的语音音频关联。这一过程有助于将音频生成过程分解为不同的步骤,包括文本转语音、音乐和音效添加。
音频生成
解析后的脚本作为 Python 程序执行。首先生成前景语音,然后叠加背景音乐和音效。在语音生成方面,模型使用了预训练的 Bark 模型和 VoiceFixer 修复模型,以提高音频质量。AudioLDM 和 MusicGen 模型用于音效和音乐的叠加。所有三个模型的输出结果被合并以生成最终的音频输出。
人机共创
该过程保持生成脚本的上下文,并且可以类似于 GPT 模型进行提示。你可以使用人类反馈和 GPT 模型的聊天功能轻松修改生成的脚本。
添加特定细节和音效变得比以往任何时候都更简单。下面的流程图展示了添加或修改生成脚本特定细节的简单性。
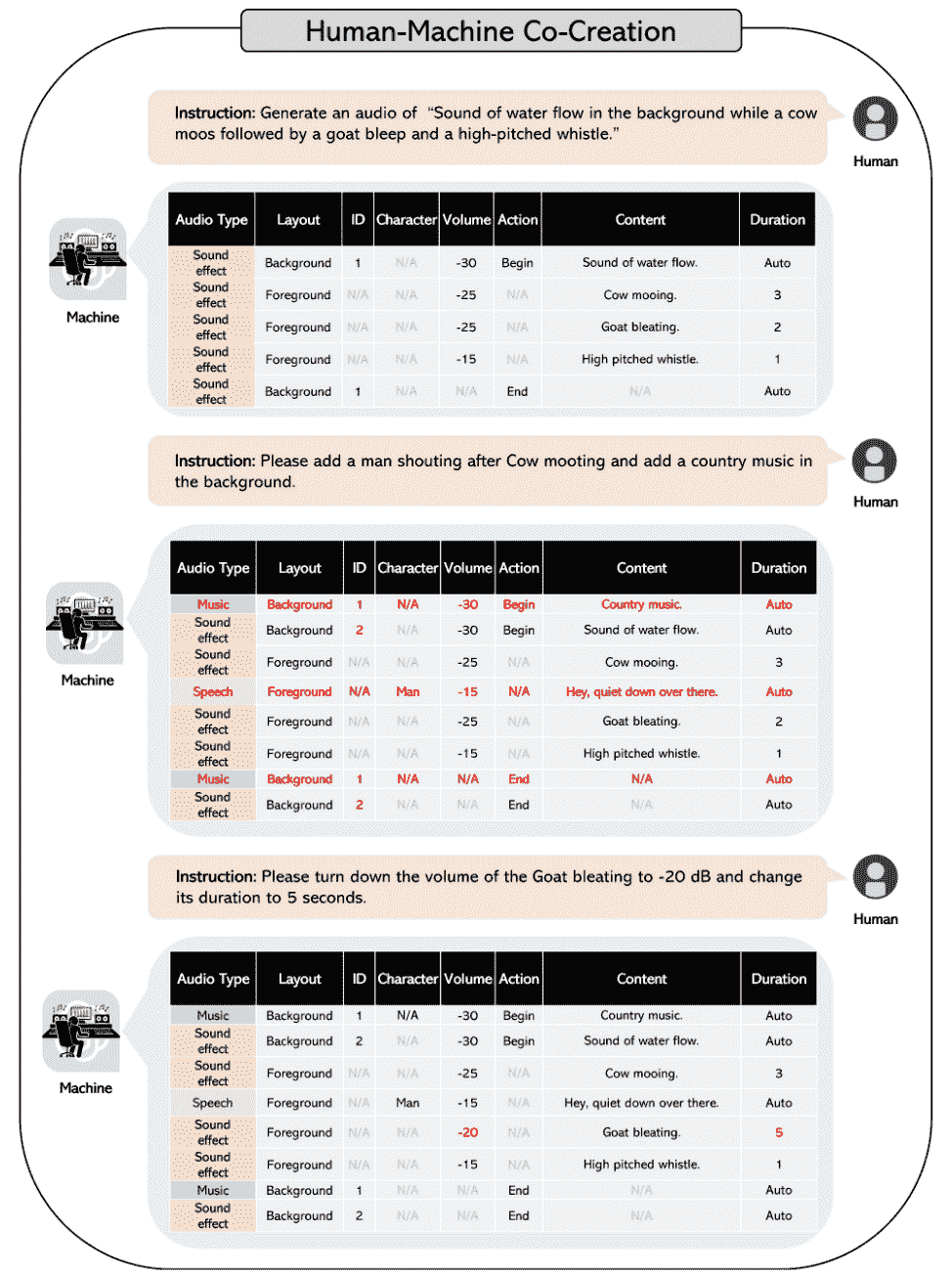
图片来自 论文
结论
音频生成模型可能会成为娱乐行业的颠覆者。该过程能够生成引人入胜的叙述和故事,这些故事可以用于教育和娱乐目的,自动化繁琐的配音和视频生成过程。
要详细了解,请查看 论文。代码很快会在 GitHub 上发布。
穆罕默德·阿赫马德 是一名从事计算机视觉和自然语言处理的深度学习工程师。他曾参与多个生成式 AI 应用的部署和优化,这些应用在 Vyro.AI 的全球排行榜上名列前茅。他对构建和优化智能系统的机器学习模型充满兴趣,并相信持续改进。
更多相关主题
是否存在弥合 MLOps 工具差距的方法?
原文:
www.kdnuggets.com/2022/08/way-bridge-mlops-tools-gap.html
图片来源:Pavel Danilyuk
交互式笔记本,如 Jupyter,对于人工智能/机器学习(AI/ML)开发至关重要,但不适合生产环境。因此,将笔记本转换为设计良好的软件系统是每个 ML 项目中的强制步骤。但在这种转换过程中,除了基本的 nbconvert 实用工具外,显著缺乏辅助开发者的工具。
笔记本是数据科学的首选集成开发环境(IDE)
即使在 Jupyter 开发之前,数学家、研究人员和分析师也使用交互式“笔记本风格”的开发环境(例如 Mathematica)。对于数据探索和统计分析,即时反馈和可视化对于了解特定工作流程是否会导致有效模型至关重要。
数据科学家在尝试将模型转变为生产就绪的 ML 原型时常遇到三个问题:
-
在常规的定时间隔内运行 ML 代码(cron 服务)或一个具有弹性和可扩展性的网络服务;
-
在笔记本中将代码应用于无法在单一计算节点上容纳的大数据集(分布式计算);并且
-
寻找适合开发大型代码库的 IDE 便利功能。Jupyter 自身缺乏许多现代开发友好 IDE 的“舒适功能”。
最近出现了一大波工具来解决这些问题——从强大的 Jupyter 替代笔记本,如 Deepnote 和 Hex;到 cron 调度器,如 PaperMill;以及全功能的云服务设置,如 Databricks。然而,这些工具有一个共同点:它们围绕笔记本构建,并协助在生产环境中使用笔记本。当使用这些工具时,你会遇到两个问题:1.) 笔记本中的代码结构相同(通常是维护困难的“意大利面条代码”),2.) 笔记本被安排运行的环境是笔记本内核(编程语言解释器,优化了开发者的互动而非运行时效率)。
但将笔记本投入生产环境是否是一个好主意?
虽然交互式代码解释器在探索性数据分析(EDA)和报告中极为有用,但由于几个原因,它们不适合质量生产代码:
-
没有测试工具;
-
笔记本不利于模块化,鼓励意大利面条式脚本;
注意:虽然技术上你可以 在一个单元格中导入 everything_else 并在 everything_else.py* 中开发,但这 a) 在实践中很少做到,b) 使得迭代回到原始笔记本中包含适合 EDA 的图表和表格变得更加困难。*
-
容错性:如果笔记本的某一部分(例如:一个函数)失败或计算机重启,数据科学家需要能够从上次停止的点继续工作,而不是从头开始。像 Airflow/Luigi 这样的工具存在的原因就是为了这个目的;
-
处理更多的传入请求(水平扩展不同于 Spark 提供的可扩展性);以及
注意:可以围绕一个笔记本(例如:https://www.qwak.ai)构建一个可扩展的网络服务,但实际上,数据科学家通常会要求工程师来帮助执行。
- 笔记本的代码审查和版本控制存在问题。IDE 支持越来越好,但仍不如“普通”代码。
但也许最大的挑战是数据科学与企业其他技术栈之间日益扩大的差距。例如,一个典型的营销技术栈将由其自己的工程团队维护,这使得数据科学成为最薄弱的环节。
我们需要减少工作流程瓶颈,并帮助数据科学充分发挥数据的潜力。
我们需要明确区分数据科学开发环境和生产环境,以充分解决各自关注的问题。现有的试图同时满足这两个环境的工具已经证明只能妥协这两个环境。要求数据科学家在开发过程中更多地关注工程问题会大大降低工作流程的生产力。而根本上改变数据科学的运作方式并不现实。那么问题是:是否有可能通过单一工具弥合这一差距?
LineaPy 也是最近出现的新工具之一,但它正是针对这一工具缺口而构建的。它让数据科学家能够像现在一样工作,同时也享受生产栈带来的良好工程‘东西’的好处。LineaPy 并不试图改变数据科学或生产栈环境,而是尝试充当一个急需的桥梁(可以在 Jupyter Notebook/Lab 或 IPython 等交互式计算环境中使用)。
LineaPy 这样的工具的存在表明,在尊重关注点分离的同时,仍然可以缩小开发和生产之间的差距。一般来说,我们应该避免将现有的、服务于明确目的的工具临时拼凑成其他用途。当我们这样做时,我们会创造比解决的问题更多的挫折。
Mike Arov 是 PostClick 的首席机器学习工程师,该公司是数字广告转化领域的领先解决方案。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
更多相关话题
弱监督建模,解释
原文:
www.kdnuggets.com/2022/05/weak-supervision-modeling-explained.html
什么是弱监督?
弱监督是一种通过编写标记函数以程序化的方式为机器学习模型训练数据点获取标签的方法。这些函数比手动标记更快、更高效地标记数据,但它们也会创建“嘈杂”的标签,然后你需要对这些标签进行建模和合并,以生成稍后用于训练下游模型的标签。换句话说,几乎没有实际的人工标记,而是通过程序化的方式进行标记,然后通过标签模型进行“去噪”。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
在这篇文章中,我们将主要关注这个流程的中间部分:标签模型本身。这是用来建模和合并嘈杂标签的对象。
在弱监督中创建标签模型
思考去噪的一种方法是合并嘈杂的标签——但所有的标记函数不一定都同样可靠!当你生成一个标签模型时,你在问:你如何知道由程序化标记函数生成的嘈杂标签中哪些是可靠的?本质上,你需要弄清楚哪些标签应该丢弃,哪些应该保留,然后如何使用它们。通过这样做,你可以确定“最佳猜测”实际标签是什么,这为你提供了一个自动构建的数据集。然后,你使用这些标签训练你的最终模型。
标签模型背后的直觉是什么?用一个简单的类比来说明,想象一个充满证人的法庭。我们通常将数据点的“真实”标签视为一个潜在的、未观察到的变量,这正是法庭上的情况。你不知道被告是否真正犯了罪。因此,你必须使用一些替代方法来了解真相。在这个非常简单的类比中,每个证人会说,“我认为被告犯了罪,”或者,“我不认为被告犯了罪。”
证人很像我们的标签函数。被告是否犯了罪这个变量有点像我们的“+1; -1”标签。一位证人是+1,一位证人是+1,一位证人是-1,等等。从这里开始,最简单的方法是依照多数证人的意见,这也是标签模型中多数投票方面的作用。它的意思是,“多数标签函数说是+1,所以这个数据点是+1。”这样做可以获得很多信息。但也有一些缺点。
准确性与相关性
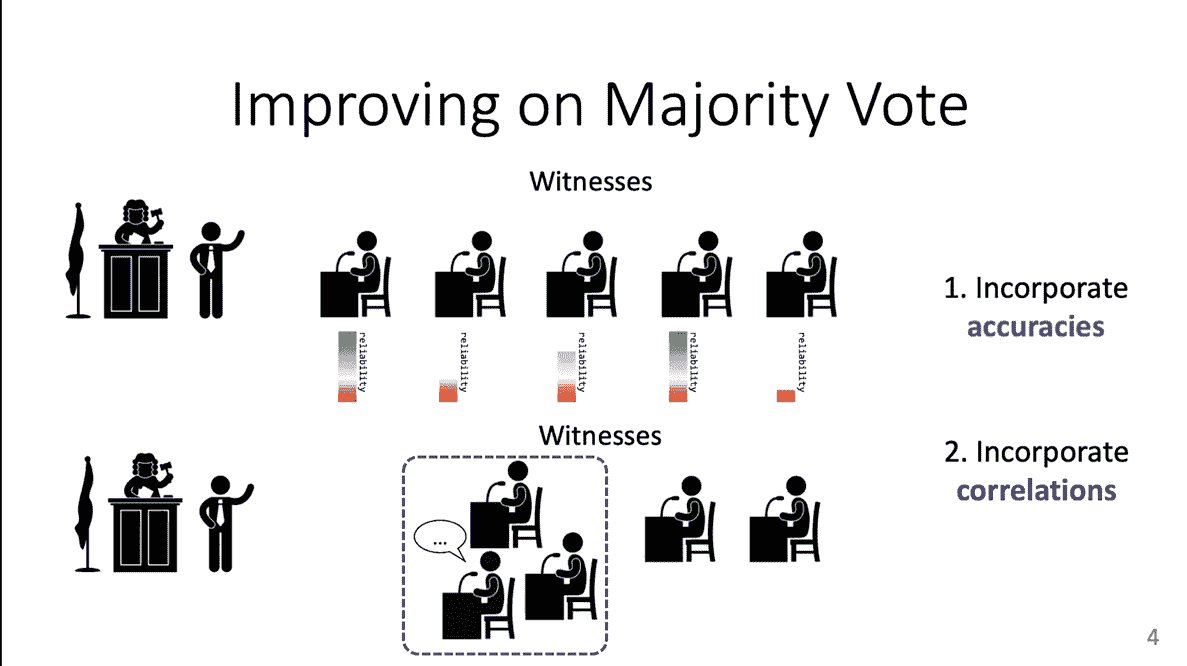
对于我们的目的来说,多数投票有两个主要缺点。一个是并非所有证人都是同等可靠的。你不希望仅仅抛弃那些不太可靠的证人,但你确实想给他们分配不同的权重。困难之处在于你不能确定哪些证人是可靠的还是不可靠的。你需要自己搞清楚。我们称这个过程为寻找“准确性”。我们希望我们的标签模型能结合标签函数的准确性。
第二个缺点是所谓的相关性或“圈子”。想象一下,如果三位证人在审判开始之前合作并讨论过。你不会像对待三位独立证人那样信任他们,因为一旦他们协调一致,他们可能会改变想法并达成统一观点。理想情况下,你会想要减少这些“圈子”证人的权重。
多数投票无法解决这些问题。它仅仅对每个人赋予相等的权重,无论可靠与否,即使他们形成了一个圈子也如此。但你希望在标签模型中包括准确性和相关性,这意味着我们需要学习这些内容。

从现在开始,我们将使用这种符号表示数学:“lambda 1”,“lambda 2”,一直到“lambda n”。这些是你的标签函数。它们是随机变量,取值如-1 或+1。然后,是“Y”这个真实但未观察到的标签。你看不到它,但它确实存在。
非常具体地说,你的目标是计算在给定? 1 ? 2到? n的条件概率 P(Y)。这是已知我们从标签函数中获得了这些信息的情况下,标签的概率。换句话说:考虑到你拥有的所有噪声标签,Y的值是 0、1、2,等等的概率。
这已经比多数投票有了很大的改进,因为您不需要仅仅说,“我认为它是+1。”相反,您可以说,“我认为它是+1 的概率是 0.6,-1 的概率是 0.3,”等等。这对于训练您的最终模型来说已经有了更多的用处。但您仍然不知道足够的信息来计算条件概率。为了做到这一点,您需要将所有信息编码成我们所说的标签模型。
标签模型实际上就是这样:它包含了计算这些条件概率所需的所有信息,这些条件概率告诉您,给定标记函数的输出,真实标签的每一个可能值的概率是Y。
什么是概率模型?

为了计算条件概率,您需要一个概率模型。概率模型是一组参数,可以完全指定您用于计算的某种分布。
一个非常简单的例子是高斯随机变量。如果您知道均值和方差,您可以把它看作一个独立的模型。因此,如果我告诉您均值和方差,您可以说,例如,“X等于 3.7 的概率是 ___;X在-2 和 16 之间的概率是 ___”,等等。
对于您的标签模型,您需要定义类似的内容。您需要找出:在给定标记函数的值的情况下,哪些参数足以计算真实标签的条件概率。
随机变量

让我们在这里暂停一下,回顾一下随机变量的简要介绍。
在上面的经典钟形曲线图中,均值位于中间。这就是X的期望。方差是衡量分布扩散程度的指标——即您平均离均值有多远。
两个变量之间的协方差是衡量两个变量相关性的指标。当变量是独立的,意味着它们没有关于彼此的信息时,它们的协方差为 0。您可以将其视为定义准确度。我们想知道一个标记函数和真实标签Y之间的协方差。如果一个给定的标记函数在猜测Y时表现非常糟糕,这两个变量之间的协方差将是 0。
最后,还有独立性属性:A和B是独立的,当且仅当,P(AB)等于 P(A) 乘以 P(B)。这意味着这两个东西的期望值可以写成期望值的乘积。
设置您的模型

现在,让我们设置您的实际标签模型。
在一个 数据中心化 AI 方法中,标签模型涉及所有这些变量,包括真实标签中的标记函数 Y,然后你当然需要从数据中学习这些参数,因为你不知道它们 a priori。以这个高斯示例为例,你可以通过简单地取很多样本、加总它们并归一化来计算均值,即将其除以你看到的样本数量。你也可以用抛硬币的方式来理解。如果正面朝上的概率是 P,你可以通过抛硬币 10,000 次来估计 P,查看有多少次正面朝上,并将其除以 10,000。这就是 P 的经验估计。就我们的目的而言,你必须做一个非常类似的程序。
简要回顾:你想通过整合标记函数的准确性以及它们的相关性或“团体”来改进简单的多数投票。为此,你必须在真实标签中的标记函数上引入一些概率模型。你需要了解编码所有这些信息的适当参数是什么。你需要有一种学习这些参数的方法。然后,你需要找到什么计算能给我们提供那个条件概率。
换句话说:给定我们从波长函数中看到的内容,真实标签 Y 的概率是多少?你永远不会看到 Y。这就是弱监督的整个思想。你只能看到来自标记函数的样本,那就是你可以使用的信息。
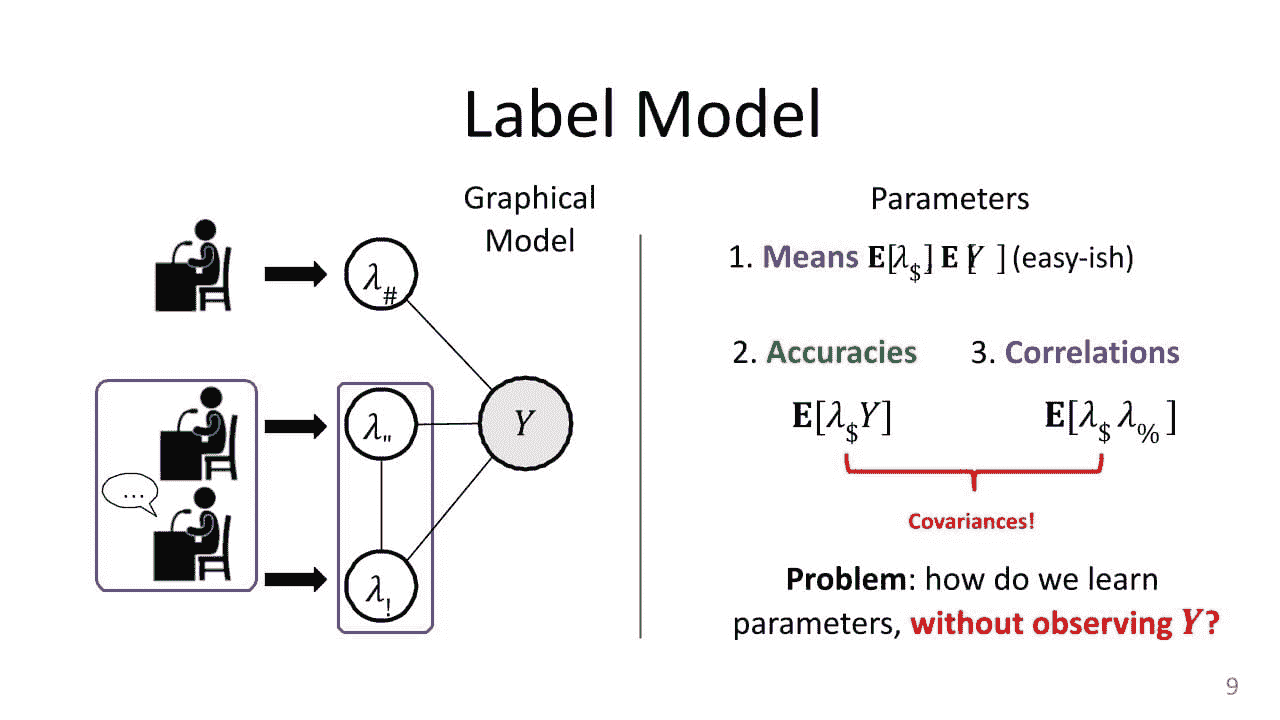
现在,让我们来具体说明这些参数到底是什么。
显然,你想要像均值这样的东西,所以这些标记函数的期望 ? i 也是 Y 的期望。这些东西不难估计。要找到 ? i 的期望,查看标记函数的所有输出,然后看看它投票 +1 的频率、投票 -1 的频率,除以总数,这样你就可以得到均值。
Y 的期望更难,因为你无法看到真实的标签,但如果你有一个开发集,例如,你也可以得到这个期望。你可以从开发集中获得类别平衡的估计,还有其他方法可以做到这一点。
这些是均值,如果你从上面的高斯示例中回忆一下,均值和方差给你提供了所有你需要的信息。这儿也是一样。方差(或协方差)将是这些准确性和这些相关性。itimes Y 的期望,然后是这个乘积的期望 ? i comes ? J。
假设我们讨论的是二元变量。那么它们要么是 +1,要么是 -1。 当然,这只是为了说明——如果我们有多类标签值,我们可以做稍微复杂一点的事情。如果你的 ? i——你的标记函数——真的很准确,那么它总是会与Y一致。因此,当Y为 1 时,它也会是 1。当Y为-1 时,它也会是-1。这个乘积总是为 1,因为 1 乘 1 等于 1,-1 乘-1 也等于 1。这个期望值会一直接近 1。如果你的标记函数真的不准确,你将会一直接近 0。这种参数将告诉我们实际标记函数的准确性,这就是我们可以解释这种准确性术语的原因。
相关性是一样的。标记函数之间的相符程度如何,或它们之间的不一致程度如何?然后,在存在这些相关性的情况下,你也会得到一个相关性。这为你提供了模型的所有参数。就像高斯示例一样,你有这些均值,并且你有协方差而不是方差。如果你知道这些,你就有足够的信息来计算这些条件概率。这就是标签模型的全部目标,其余的都从这里开始。
相比于硬币抛掷示例,这一切要困难得多。通常,如果你在计算均值,你会查看大量样本并找出它们的平均值。但在这种情况下,你不知道Y是什么,所以你不能仅仅采样 ?itimes Y。这就是弱监督的难点。你不知道真实标签,所以你无法轻易计算这些经验期望。这就是你在标签模型中需要使用的唯一真正技巧:一种在实际不知道Y是什么的情况下获取这些信息的方法。
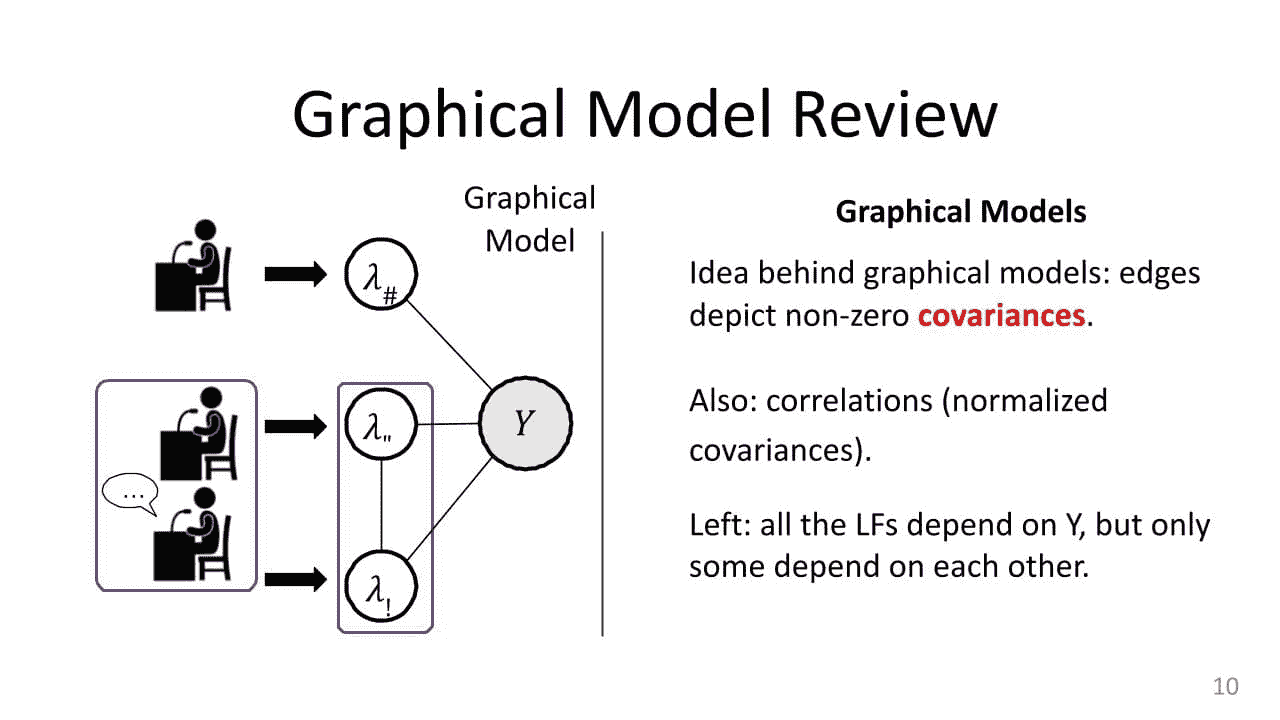
在这个图形模型中,每个随机变量都有一个节点。边缘告诉你关于相关性或协方差的信息。确切的技术解释是存在的,但大致上,如果两个事物之间有一条边,你可以认为它们是相关的。如果两个节点之间没有边,你可以认为它们之间有某种独立性。有时,你必须对变量做一些处理才能发现这种独立性,但这是基本的思想。在这个设置中,标记函数总是与真实标签连接。如果它们没有连接,那么标记函数值和标签之间将没有关系。你将会有一个“随机猜测”的标记函数,这将没有用。你总是有这些边连接实际标签值和所有标记函数。
有时标记函数对之间有边缘,有时没有。当我们有那对边缘时,是在相关性的情况下。那就像上面的法庭比喻,你有两个证人互相交谈并编造一个故事。这也是我们想建模的,因为我们确实想降低这些值的权重。实际上,当你计算这个条件“P(Y) given ___”概率时,你会在计算时考虑到这一点。
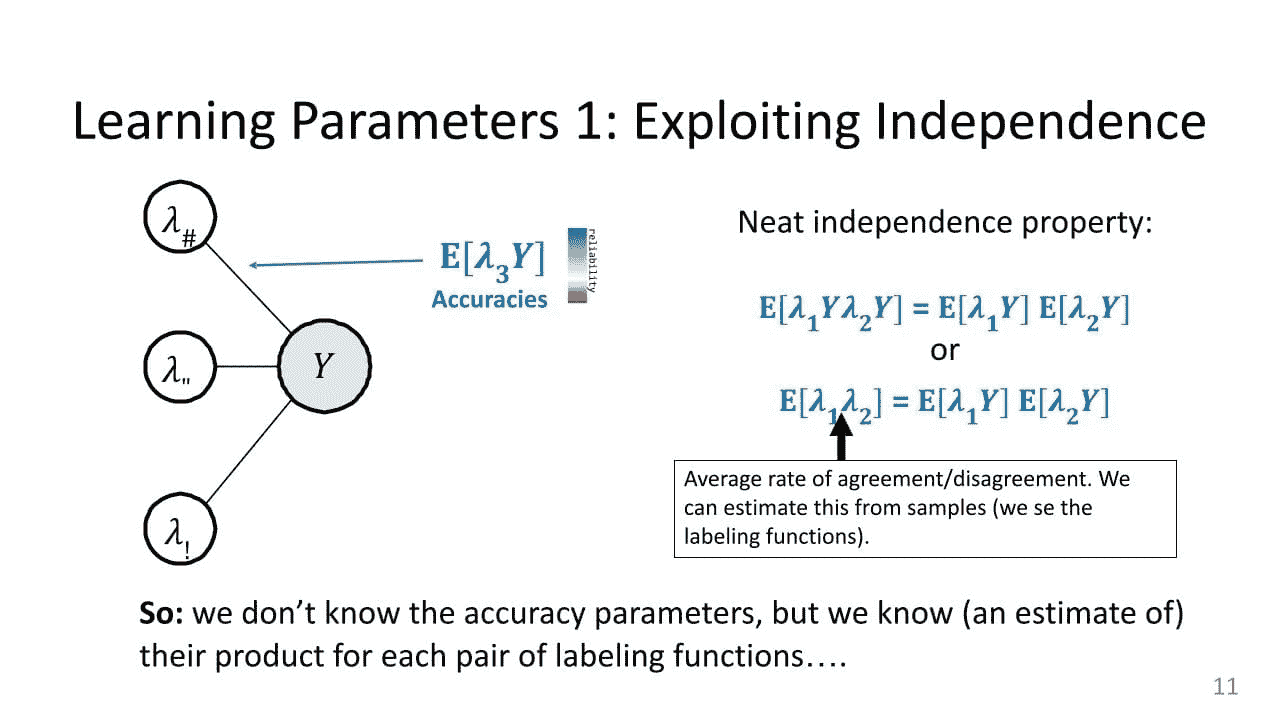
如何学习这些参数呢?主要有两种方法。
第一种方法可能最简单。我们真正关心的唯一参数是准确性。要学习它,你需要专门利用独立性,这就是为什么在这个图形模型中,左侧标记函数之间没有边缘,只有标记函数与真实标签之间有边缘。
再次记住准确性参数是什么。这些是标记函数乘积的期望值,它们越大,你可以认为给定的标记函数越可靠。如果它们是完全可靠的,你会直接使用这些信息来确定 Y。如果它们非常不可靠,你就需要降低它们的权重。
让我们来深入探讨这个独立性的非常有趣的特性。标记函数本身并不相互独立,这很好,因为它们都在尝试预测相同的事物。如果它们是独立的,那将非常糟糕。但事实证明,标记函数和Y的乘积往往是独立的。实际上,尽管变量本身不独立,但准确性是独立的。
那这意味着什么?如果你在左边写这个乘积——这个 ? 1Y,? 2Y——你可以因独立性将这个乘积因式分解为两个期望值的乘积(在一些我们不会详细讨论的小假设下)。这是:乘积的期望值是期望值的乘积。

第二种学习参数的方法涉及使用三元组。这个 Y 可以是 +1 或 -1。这是两种可能的值。当你乘以 ? 1Y ? 2Y 时,你会得到 ? 1 ? 2Y 的平方。但 Y 的平方为 1,无论 Y 是 +1 还是 -1。因此,这一项就会消失,你最终只看到 ? 1 ? 2 的期望值。
所以,我们在计算1Y次2Y的期望,这两个是准确度参数。它们的乘积是这个相关性参数,实际上可以估计。这只是对一对标记函数在平均上的一致性或不一致性。如果你查看它们标记的所有内容,你可以说:“它们有 75%的时间具有相同的标签,25%的时间不同,这告诉我1 ? 2的期望。”换句话说,这是可观察的。我并不知道这两个标记函数的准确度参数是什么,但我知道它们的乘积是这种类型的相关性参数,这是可知的。我们不知道准确度参数,但我们知道准确度参数的一个函数,即它们的乘积。
这实际上是我们必须拥有的关键内容。一旦我们有了这个,我们可以做一个小的方程组,称为三元组。我们可以为三个标记函数逐一写下这个确切的内容。对于上面的三个方程,我们刚刚对1 ? 2做了这个确切的操作,然后是1 ? 3,再到2 ? 3。我们在这些对之间有独立性属性。共有三对不同的对,你有三个方程和三个变量。那三个变量是什么?它们就是这些准确度参数。你知道所有这些情况下的左侧值,所以你可以把它看作A乘以B有一个值,A乘以C有一个值,B乘以C有一个值。你知道这三个值,需要从中计算A, B和C。你可以解决这个问题。
所以,即使你从未看到过Y,也即使你不能直接做样本平均来获得这个期望,你仍然将其写成可观察的形式。你可以进入我们的标签矩阵,计算这三个术语,解这个方程,并得到我们对这个乘积的估计。然后你可以对每一个可能的标记函数进行这操作,得到所有的准确度。至于相关性,你可以直接估计它。你只需像掷硬币一样进行平均。现在我们可以访问所有的准确度,我们就完成了。
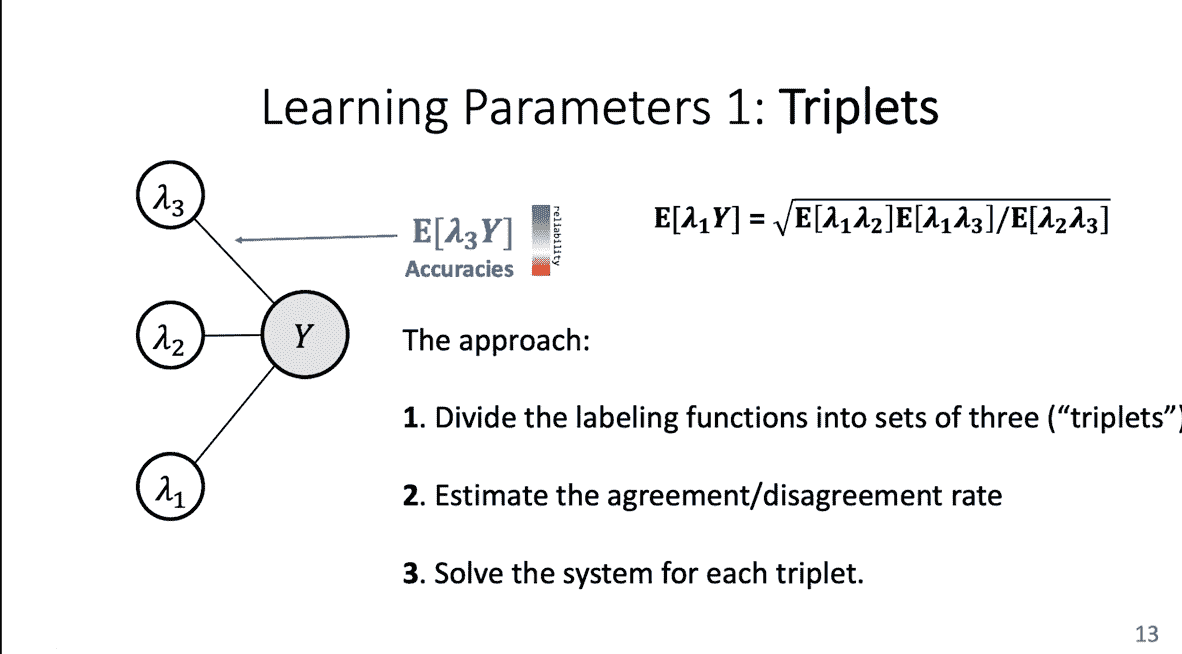
学习参数
-
利用独立性
-
三元组
-
协方差矩阵
与 Fred 联系的方式:Twitter | Website。
与 Snorkel AI 保持联系,关注我们的Twitter,LinkedIn,Facebook,Youtube或Instagram,如果你有兴趣加入 Snorkel 团队,我们正在招聘!请在我们的招聘页面申请。
弗雷德里克·萨拉 是威斯康星大学麦迪逊分校计算机科学系的助理教授。弗雷德的研究专注于数据驱动系统的基础,特别是机器学习系统。此前,他曾在斯坦福大学计算机科学系担任博士后研究员,参与斯坦福信息实验室和斯坦福 DAWN 项目。他于 2016 年 12 月获得加州大学洛杉矶分校电气工程博士学位。他获得了 NSF 研究生奖学金、加州大学洛杉矶分校电气工程系杰出博士论文奖,以及加州大学洛杉矶分校亨利·萨缪尔工程与应用科学学院的爱德华·K·赖斯杰出硕士生奖。他在密歇根大学安娜堡分校获得了电气工程学士学位。
更多相关话题
如何发现机器学习模型中的弱点
原文:
www.kdnuggets.com/2021/09/weaknesses-machine-learning-models.html
评论
由 Michael Berk, Tubi 数据科学家
每当你使用总结统计来简化数据时,你都会丢失信息。模型准确性也不例外。当简化模型的拟合到总结统计时,你失去了确定性能最低/最高以及原因的能力。
图 1:模型表现差的数据区域示例。图片由作者提供。
为了解决这个问题,IBM 的研究人员最近开发了一种名为 FreaAI 的方法,它识别出模型准确率较差的可解释数据切片。工程师可以根据这些切片采取必要措施,以确保模型按预期运行。
FreaAI 不幸的是不是开源的,但许多概念可以很容易地在你喜欢的技术栈中实现。让我们深入了解一下……
技术总结
FreaAI 在测试数据中找到统计上显著低性能的切片。它们被返回给工程师进行检查。方法步骤如下:
-
使用最高先验密度 (HPD) 方法找到准确率低的单变量数据切片。 这些单变量数据切片减少了搜索空间,显示了数据中更可能存在问题的地方。
-
使用决策树找到准确率低的双变量数据切片。 这些双变量数据切片减少了分类预测变量和二阶交互的搜索空间,显示了数据中更可能存在问题的地方。
-
移除所有不符合特定启发式规则的数据切片。 主要的两个规则是测试集的最小支持度和统计上显著的误差增加。
但是,实际上发生了什么?
那些都是术语,我们来慢慢了解一下实际情况……
1. 问题
在开发模型时,我们经常使用“准确性”指标来判断模型的拟合度。例如均方误差,这在图 2 中定义并用于线性回归。
图 2:均方误差公式。图片由作者提供 — 源。
但是,这个平均误差只告诉我们 平均 来说表现如何。我们不知道模型在数据的某些区域表现很好还是在其他区域表现很差。
这是一个长期存在的预测建模问题,最近引起了很多关注。
2. 解决方案
一个解决方案是 FreaAI。该方法在 IBM 开发,旨在确定我们数据中模型表现不佳的地方。
主要有两个步骤。第一步是创建数据切片,第二步是确定模型在这些数据切片中的表现是否不佳。FreaAI 的输出是一组“位置”,这些位置的数据中模型表现不佳。
2.1. 数据切片
组合测试 (CT) 是一个框架,它依次查看所有预测变量组合以找到表现不佳的区域。例如,如果我们有两个类别预测变量,颜色和形状,我们会查看所有可能的组合,并查看准确性下降的地方。
然而,利用组合测试在大型数据集上是计算上不可行的 — 每增加一列,我们会看到所需组合数量的指数增长。因此,我们需要定义一种方法来帮助我们搜索特征,以找到潜在的不准确区域。
图 3:50% 最高密度区域 (HDR) 的蓝色示例。图像由作者提供 — 源。
FreaAI 使用的第一种方法利用了叫做 最高密度区域 (HDR) 的技术(见图 3)。简而言之,HDR 找出数值特征中数据占比最高的最小区域,即高密度区域。在图 3 中,区域由水平蓝色虚线区分 — 我们的数据中有 50% 在该线之上。
从那里我们通过一个 ε 值(默认 0.05)逐步减少这个范围,并观察准确性的提高。如果准确性在给定的迭代中提高,我们知道模型在前一次迭代和当前迭代之间的区域表现不佳。
要确定数值预测变量的不良拟合区域,我们会对测试集中的所有预测变量迭代运行 HDR 方法。
相当酷,对吧?
第二种方法利用决策树来处理所有非数值预测变量以及两个特征的组合。简而言之,我们拟合一个决策树,并寻找使准确性最小化的特征切分。
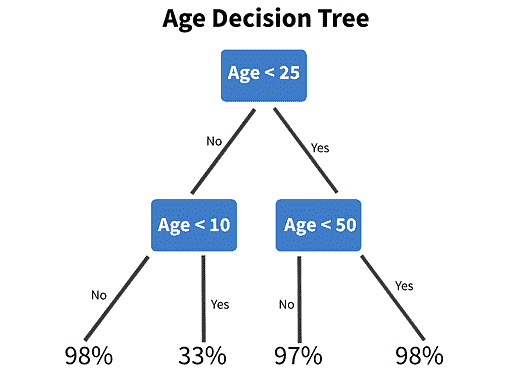
图 4:关于连续单变量预测变量“年龄”的决策树示例。图像由作者提供。
在图 4 中,每个决策节点(蓝色)是对特征的拆分,每个终端节点(数字)是该拆分的准确度。通过拟合这些树,我们可以真正缩小搜索空间,更快地找到表现不佳的区域。此外,由于树对许多不同类型的数据都非常强健,我们可以在分类预测变量或多个预测变量上运行,以捕捉交互效应。
这种决策树方法会重复用于所有特征组合,以及那些不是数字的单一特征。
2.2. 数据切片的启发式方法
到目前为止,我们只关注了通过准确度开发数据切片,但还有其他启发式方法可以帮助我们找到有用的数据切片:
-
统计显著性:为了确保我们只关注准确度有显著下降的数据切片,我们仅保留性能低于误差置信区间下界 4% 的切片。通过这样做,我们可以以α 的概率断言我们的数据切片具有更高的误差。
-
可解释性:我们还希望确保发现的问题区域可以付诸行动,因此我们在创建组合时仅查看两个或三个特征。通过限制低阶交互作用,我们的工程师更有可能开发解决方案。
-
最小支持:最后,数据切片必须有足够的误差值得调查。我们要求至少有 2 次分类错误,或覆盖 5% 的测试误差 — 取较大的值作为标准。
还值得注意的是,你可以根据业务需求调整其他启发式方法。错误分类某些用户比其他用户更严重,因此你可以将其纳入数据切片标准中 — 参考 精确度/召回率权衡。
3. 总结和要点
所以,你看到了 — FreaAI 的全部荣耀。
再次说明,FreaAI 不是开源的,但希望将来能向公众发布。在此期间,你可以将我们讨论的框架应用到你自己的预测模型中,确定系统性表现不佳的地方。
3.1. 总结
总结一下,FreeAI 使用 HDR 和决策树来缩小我们预测变量的搜索空间。然后,它迭代地查看单个特征及其组合,以确定性能较低的地方。这些低性能区域具有一些额外的启发式方法,以确保发现具有可操作性。
3.2. 你为什么要关心?
首先,这个框架帮助工程师识别模型的弱点。当这些弱点被发现时,它们可以(希望)得到纠正,从而改善预测。对于黑箱模型(如神经网络),这种改进尤其诱人,因为没有模型系数。
通过隔离表现不佳的数据区域,我们可以窥视黑箱。
FreaAI 还具有其他应用的有趣潜力。一个例子是识别模型漂移,即训练后的模型随着时间推移变得越来越无效。IBM 刚刚发布了一个 用于确定模型漂移的假设检验框架。
另一个有趣的应用是确定模型偏差。在这种情况下,偏差是指不公平的概念,例如基于性别拒绝向某人提供贷款。通过查看模型性能较低的不同数据拆分,你可以发现偏差的领域。
感谢阅读!我将撰写 37 篇帖子,将学术研究引入数据科学行业。请查看我的评论,获取本文主要来源的链接以及一些有用的资源。
简介: 迈克尔·伯克 (michaeldberk.com/) 是 Tubi 的数据科学家。
原文。经许可转载。
相关:
-
反脆弱性与机器学习
-
与 Github Actions、Iterative.ai、Label Studio 和 NBDEV 的 MLOps 探险
-
数学 2.0:机器学习的基础重要性
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你所在组织的 IT
更多相关话题
数据集整理的网页抓取,第一部分:收集手工啤酒数据
原文:
www.kdnuggets.com/2017/02/web-scraping-dataset-curation-part-1.html
作者:Jean-Nicholas Hould,JeanNicholasHould.com。
如果你读过我过去的一些文章,你现在知道我喜欢好的手工啤酒。我决定将工作与乐趣结合起来,编写一个关于如何用 Python 从网站抓取手工啤酒数据集的教程。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
本文分为两个部分:抓取和整理数据。在第一部分中,我们将规划和编写代码以从网站收集数据集。在第二部分中,我们将把“整洁数据”原则应用于这个新抓取的数据集。文章末尾,我们将拥有一个干净的手工啤酒数据集。
网页抓取
网页抓取器是一段代码,它会自动加载网页并提取特定数据。网页抓取器会执行一个重复的任务,这个任务如果由你手动完成会非常耗时。
例如,我们可以编写一个网络抓取器,从一个电子商务网站提取产品名称及其评分,并将其写入 CSV 文件中。
抓取网站是获取原本无法获得的新数据集的好方法。
几条关于抓取的规则
正如 Greg Reda 几年前在他的出色的网页抓取教程中指出的那样,关于抓取你需要知道一些规则:
-
尊重网站的条款和条件。
-
不要给服务器带来压力。一个抓取器可以在一秒钟内发出成千上万次网页请求。确保你不会给服务器施加过多压力。
-
你的抓取器代码将会失效。网页经常变化。你的抓取器代码很快就会过时。
规划
构建抓取器的第一步是规划阶段。显然,你需要决定你想要提取什么数据以及从哪个网站提取。
在我们的案例中,我们想要从一个名为CraftCans的网站提取数据。这个网站列出了 2692 种手工罐装啤酒。对于这个特定的数据集,我们不需要构建一个抓取器来提取数据。按照它的布局,我们可以很容易地将数据复制粘贴到 Excel 表格中。
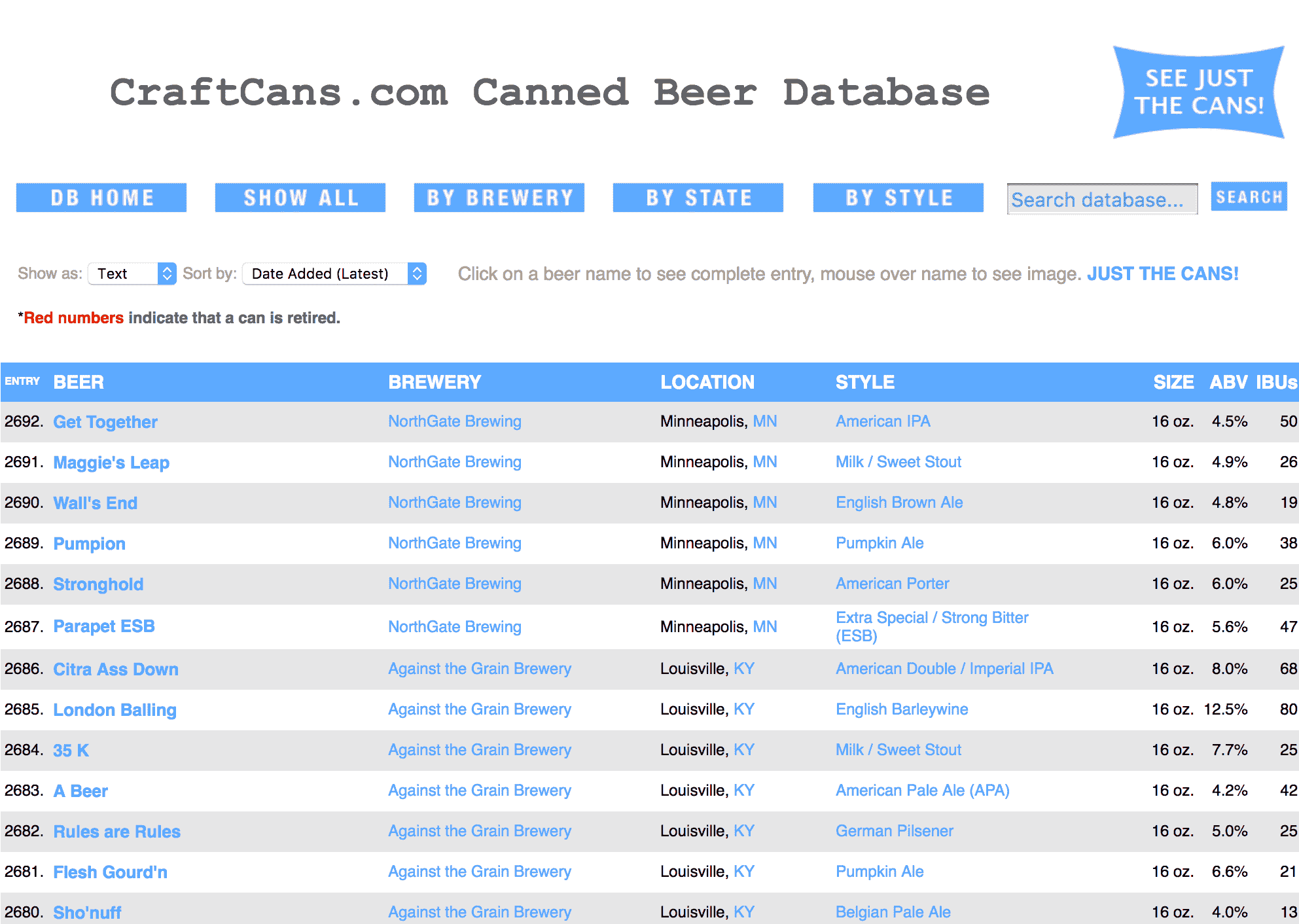
对于每种啤酒,网站提供了一些详细信息:
-
名称
-
风格
-
尺寸
-
酒精浓度(ABV)
-
IBU(国际苦味单位)
-
酿造商名称
-
酿造商位置
检查 HTML
我们希望我们的抓取器为我们提取所有这些信息。为了给我们的抓取器提供具体指令,我们需要查看 CraftCans 网站的 HTML 代码。大多数现代浏览器提供了一种通过右键单击页面来检查网页 HTML 源代码的方法。
在 Google Chrome 上,你可以右键单击网页上的元素,然后点击“检查”以查看 HTML 代码。
识别模式
从主页面上的 HTML 代码来看,你可以看到这个大列表实际上是一个 HTML 表格。每种啤酒代表表格中的一行。通常,像 HTML 表格这样的重复模式非常适合网页抓取,因为逻辑简单明了。
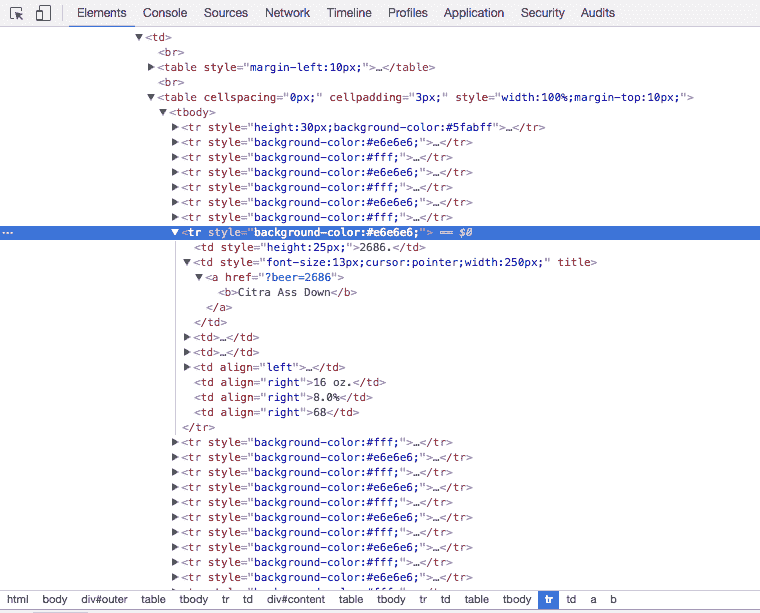
使用的库
对于这个项目,我们将导入四个库。
urlopen
第一个urlopen将用于请求网页上的 HTML 页面并返回其内容。就这么简单。
BeautifulSoup4
第二个,BeautifulSoup4,是一个使在 HTML 文档中导航变得简单的库。例如,使用这个库你可以轻松选择 HTML 文档中的一个表格并遍历其行。
pandas
第三个是pandas。我们不会在抓取部分使用这个库。我们将使用它来整理数据。pandas是一个旨在简化数据操作和分析的库。
用于正则表达式的 re
最后,我们将使用re,它是 Python 标准库的一部分。这个库提供了正则表达式匹配操作。正则表达式是操纵字符串的方式。例如,我们可以使用正则表达式列出字符串中的所有数字。
编写代码
HTML 的挑战
在对 CraftCans 网页进行一些调查后,我意识到没有干净的方法来抓取 CraftCans 网站。
CraftCans 的 HTML 结构有些老派。整个页面布局都在表格中。这曾经是常见做法,但现在布局通常使用 CSS 设置。
此外,HTML 表格或包含啤酒条目的行上没有类或标识符。没有干净的 HTML 结构或标识符,定位到我们想要的特定表格是具有挑战性的。
解决方案:列出所有表格行
我找到的抓取网站的解决方案可能不是最干净的,但它有效。
由于包含数据的表格上没有标识符,我使用BeautifulSoup4的findAll函数加载 CraftCans 页面上所有的表格行tr。此函数返回一个全面的表格行列表,无论它们是否来自我们要抓取的表格。
对于每一行,我运行测试以确定它是否包含啤酒条目或其他内容。判断一行是否为啤酒数据条目的启发式方法很简单:该行需要包含八个单元格,并且第一个单元格必须包含有效的数字 ID。
现在我们已经有了判断一行是否确实为啤酒条目的函数,我们可以抓取整个网页。我们需要决定以何种格式存储从网站收集的数据。我希望每个 CraftCans 的啤酒条目都像这样的 JSON 文档。
示例啤酒 JSON 条目
我喜欢将数据存储在 JSON 文档中的原因是,我可以轻松地将其转换为 pandas DataFrame。
运行抓取器
函数编写完成后,我们可以使用 urlopen 请求 CraftCans 网页,并让代码处理其余部分。
有了 get_all_beers 返回的啤酒列表,我们可以轻松创建一个新的 pandasDataFrame 来方便地可视化和操作数据。
简介:Jean-Nicholas Hould 是来自 加拿大蒙特利尔的数据科学家。JeanNicholasHould.com 的作者。
原文。经许可转载。
相关:
-
在 Python 中整理数据
-
使用 SQL 进行统计分析
-
数据科学统计 101
更多相关主题
使用 Python 进行网络爬取:以 CIA 世界概况为例
原文:
www.kdnuggets.com/2018/03/web-scraping-python-cia-world-factbook.html
评论

在数据科学项目中,几乎总是最耗时且最麻烦的部分是数据收集和清洗。每个人都喜欢构建一个炫酷的深度神经网络(或 XGboost)模型,并展示自己用炫酷的 3D 交互式图表的技能。但这些模型需要原始数据作为起点,而这些数据并不容易获得且不干净。
毕竟,生活不是 Kaggle,那里一个装满数据的 zip 文件等着你去解压和建模 😃
那么,为什么要收集数据或建立模型呢?根本的动机是为了回答一个商业、科学或社会问题。是否有趋势?这个东西与那个东西有关吗?测量这个实体是否能预测那个现象的结果?这是因为回答这个问题将验证你作为科学家/从业者的假设。你只是使用数据(与化学家用试管或物理学家用磁铁不同)来测试你的假设并从科学上证明或证伪它。这就是数据科学中的‘科学’部分。没有更多,也没有更少……
相信我,提出一个需要稍微应用数据科学技术来回答的高质量问题并不那么难。每一个这样的问提都会成为你的小项目,你可以将其编写成代码并在像 Github 这样的开源平台上展示给朋友。即使你不是职业数据科学家,没有人可以阻止你编写炫酷的程序来回答一个好的数据问题。这展示了你作为一个对数据熟悉并能够讲述数据故事的人的形象。
今天让我们处理这样一个问题……
一个国家的 GDP(按购买力平价计算)与其互联网用户百分比之间是否存在关系?这种趋势在低收入/中等收入/高收入国家中是否相似?
现在,你可以想到任何数量的来源来收集数据以回答这个问题。我发现来自 CIA 的一个网站(是的,就是那个‘机构’),提供有关全球所有国家的基本事实信息,是抓取数据的好地方。
因此,我们将使用以下 Python 模块来构建我们的数据库和可视化,
-
Pandas,Numpy, matplotlib/seaborn
-
Python urllib(用于发送 HTTP 请求)
-
BeautifulSoup(用于 HTML 解析)
-
正则表达式模块(用于查找精确匹配的文本)
让我们讨论一下程序结构,以回答这个数据科学问题。我的 Github 仓库 中提供了 完整的代码模板。如果你喜欢,可以随意 fork 和 star。
读取前 HTML 页面并传递给 BeautifulSoup
这是 CIA 世界概况书前页 的样子,
图:CIA 世界概况书前页
我们使用带有 SSL 错误忽略上下文的简单 urllib 请求来检索该页面,然后将其传递给神奇的 BeautifulSoup,它为我们解析 HTML 并生成漂亮的文本转储。对于那些不熟悉 BeautifulSoup 库的人,他们可以观看以下视频或阅读这篇 很棒的 Medium 文章。
这里是读取前页 HTML 的代码片段,
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
# Read the HTML from the URL and pass on to BeautifulSoup
url = 'https://www.cia.gov/library/publications/the-world-factbook/'
print("Opening the file connection...")
uh= urllib.request.urlopen(url, context=ctx)
print("HTTP status",uh.getcode())
html =uh.read().decode()
print(f"Reading done. Total {len(html)} characters read.")
这里是我们如何将数据传递给 BeautifulSoup,并使用 find_all 方法查找 HTML 中嵌入的所有国家名称和代码。基本思想是 查找名为‘option’的 HTML 标签。该标签中的文本是国家名称,而标签值的第 5 和第 6 个字符代表 2 字符的国家代码。
现在,你可能会问,如何知道只需要提取第 5 和第 6 个字符?简单的答案是 你必须检查 soup 文本,即解析后的 HTML 文本,并确定这些索引。没有通用的方法来确定这一点。每个 HTML 页面及其底层结构都是独一无二的。
soup = BeautifulSoup(html, 'html.parser')
country_codes=[]
country_names=[]
for tag in soup.find_all('option'):
country_codes.append(tag.get('value')[5:7])
country_names.append(tag.text)
temp=country_codes.pop(0) # *To remove the first entry 'World'*
temp=country_names.pop(0) # *To remove the first entry 'World'*
抓取:通过单独抓取每一页,将所有国家的文本数据下载到字典中
这个步骤是所谓的基本抓取或爬取。要做到这一点,关键是要确定每个国家信息页面的 URL 是如何结构化的。一般情况下,这可能很难获取。在这个特定的案例中,快速检查显示了一个非常简单且规律的结构可以遵循。以下是澳大利亚的截图,
这意味着有一个固定的 URL,你需要将 2 字符的国家代码附加到这个 URL 上,就能到达该国家页面的 URL。因此,我们可以遍历国家代码列表,使用 BeautifulSoup 提取所有文本并存储在本地字典中。以下是代码片段,
# Base URL
urlbase = 'https://www.cia.gov/library/publications/the-world-factbook/geos/'
# Empty data dictionary
text_data=dict()
# Iterate over every country
for i in range(1,len(country_names)-1):
country_html=country_codes[i]+'.html'
url_to_get=urlbase+country_html
# Read the HTML from the URL and pass on to BeautifulSoup
html = urllib.request.urlopen(url_to_get, context=ctx).read()
soup = BeautifulSoup(html, 'html.parser')
txt=soup.get_text()
text_data[country_names[i]]=txt
print(f"Finished loading data for {country_names[i]}")
print ("\n**Finished downloading all text data!**")
如果你喜欢,可以存储在 Pickle 转储中
为了更好地处理,我喜欢将这些数据序列化并 存储在一个 Python pickle 对象 中。这样,下次打开 Jupyter notebook 时,我可以直接读取数据,而无需重复网络爬取步骤。
import pickle
pickle.dump(text_data,open("text_data_CIA_Factobook.p", "wb"))
# Unpickle and read the data from local storage next time
text_data = pickle.load(open("text_data_CIA_Factobook.p", "rb"))
使用正则表达式从文本转储中提取 GDP/人数据
这是程序的核心文本分析部分,我们借助 正则表达式 模块 来查找在庞大的文本字符串中寻找我们需要的信息,并提取相关的数字数据。正则表达式是 Python(或几乎所有高级编程语言)中的丰富资源。它允许在大文本语料库中搜索/匹配特定模式的字符串。在这里,我们使用非常简单的正则表达式方法来匹配如“GDP — per capita (PPP):”这样的确切词汇,然后读取其后的几个字符,提取某些符号如$和括号的位置,最终提取 GDP/人均的数值。这里用一个图示例说明了这个想法。
图:文本分析的示意图
在这个笔记本中使用了其他正则表达式技巧,例如提取总 GDP,无论数字是以十亿还是万亿表示。
# 'b' to catch 'billions', 't' to catch 'trillions'
start = re.search('\$',string)
end = re.search('[b,t]',string)
if (start!=None and end!=None):
start=start.start()
end=end.start()
a=string[start+1:start+end-1]
a = convert_float(a)
if (string[end]=='t'):
# If the GDP was in trillions, multiply it by 1000
a=1000*a
这是示例代码片段。注意代码中放置的多个错误处理检查。这是必要的,因为 HTML 页面的不可预测性极高。不是所有国家都有 GDP 数据,页面上的数据表述可能不完全相同,数字的形式也可能不同,字符串中的$和()也可能放置得不同。可能会发生各种错误。
准备和编写所有场景的代码几乎是不可能的,但至少你需要有代码来处理异常,以防出现异常,这样你的程序不会中断,并可以优雅地继续处理下一个页面。
# Initialize dictionary for holding the data
GDP_PPP = {}
# Iterate over every country
for i in range(1,len(country_names)-1):
country= country_names[i]
txt=text_data[country]
pos = txt.find('GDP - per capita (PPP):')
if pos!=-1: #If the wording/phrase is not present
pos= pos+len('GDP - per capita (PPP):')
string = txt[pos+1:pos+11]
start = re.search('\$',string)
end = re.search('\S',string)
if (start!=None and end!=None): #If search fails somehow
start=start.start()
end=end.start()
a=string[start+1:start+end-1]
#print(a)
a = convert_float(a)
if (a!=-1.0): #If the float conversion fails somehow
print(f"GDP/capita (PPP) of {country}: {a} dollars")
# Insert the data in the dictionary
GDP_PPP[country]=a
else:
print("**Could not find GDP/capita data!**")
else:
print("**Could not find GDP/capita data!**")
else:
print("**Could not find GDP/capita data!**")
print ("\nFinished finding all GDP/capita data")
不要忘记使用 pandas 的内连接/左连接方法
需要记住的一点是,这些文本分析将生成具有略微不同国家集的数据框,因为不同类型的数据可能在不同国家不可用。可以使用 Pandas 左连接 来创建一个包含所有公共国家交集的数据框,这些国家的数据是可用的或可以提取的。
df_combined = df_demo.join(df_GDP, how='left')
df_combined.dropna(inplace=True)
现在进入有趣的部分,建模……但等等!先做过滤吧!
在完成 HTML 解析、页面抓取和文本挖掘的所有艰苦工作后,现在你已经准备好获得成果——迫不及待地运行回归算法和酷炫的可视化脚本!但等等,通常你需要在生成这些图表之前对数据进行更多的清理(特别是对于这类社会经济问题)。基本上,你想要过滤掉离群值,例如非常小的国家(如岛国),这些国家的参数值可能极度偏斜,但不符合你想要调查的主要动态。几行代码足以完成这些过滤。虽然可能有更Pythonic的实现方式,但我尽量保持简单易懂。以下代码例如创建了过滤器,以排除总 GDP 小于 500 亿以及收入边界低于 5000 美元和高于 25000 美元的国家(人均 GDP)。
# Create a filtered data frame and x and y arrays
filter_gdp = df_combined['Total GDP (PPP)'] > 50
filter_low_income=df_combined['GDP (PPP)']>5000
filter_high_income=df_combined['GDP (PPP)']<25000
df_filtered = df_combined[filter_gdp][filter_low_income][filter_high_income]
最后,数据可视化
我们使用了seaborn regplot 函数来创建散点图(互联网用户比例 vs. 人均 GDP),并显示线性回归拟合和 95%的置信区间带。它们看起来如下。可以将结果解释为
国家互联网用户比例与人均 GDP 之间存在强正相关关系。此外,低收入/低 GDP 国家的相关性强度显著高于高 GDP 发达国家。这可能意味着互联网访问帮助低收入国家更快地发展,并且在改善公民平均状况方面比发达国家更有效。
总结
本文介绍了一个演示 Python 笔记本,说明如何通过使用 BeautifulSoup 进行 HTML 解析来抓取网页以下载原始信息。随后,它还说明了使用正则表达式模块来搜索和提取用户所需的重要信息。
总而言之,这展示了在挖掘混乱的 HTML 解析文本时,为什么没有简单、普遍的规则或程序结构。必须检查文本结构,并设置适当的错误处理检查,以优雅地处理所有情况,确保程序流程顺畅(不会崩溃),即使不能提取所有场景的数据。
希望读者能从提供的 Notebook 文件中受益,并根据自己的需求和想象进行扩展。有关更多网络数据分析的笔记本,请查看我的代码库。
如果你有任何问题或想法,请通过 tirthajyoti[AT]gmail.com 联系作者。你也可以查看作者的 GitHub 仓库 以获取其他有趣的 Python、R 或 MATLAB 代码片段和机器学习资源。如果你像我一样,对机器学习/数据科学充满热情,请随时 在 LinkedIn 上添加我 或 在 Twitter 上关注我。
简介: Tirthajyoti Sarkar 是一位半导体技术专家,机器学习/数据科学爱好者,电气工程博士,博客作者和作家。
原文。经允许转载。
相关:
-
使用 Python 的网页抓取教程:技巧与窍门
-
为什么你应该忘记数据科学代码中的‘for-loop’,而接受矢量化
-
IT 工程师需要学习多少数学才能进入数据科学领域
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关内容
使用 Python 进行网页抓取教程:技巧和窍门
原文:
www.kdnuggets.com/2018/02/web-scraping-tutorial-python.html
评论
我在寻找机票时注意到票价在一天内会波动。我试图找出买票的最佳时间,但在网上找不到有用的信息。我编写了一个小程序来自动收集网页数据——一个所谓的抓取器。它提取了我指定日期和航班目的地的信息,并在价格降低时通知我。
网页抓取是一种通过自动化过程从网站提取数据的技术。
我从这次网页抓取的经历中学到了很多东西,并且我想分享一下。
本文旨在介绍与网页抓取相关的常见设计模式、陷阱和规则。文章呈现了几个用例和一系列典型的问题,例如如何避免被检测、注意事项和禁忌事项,以及如何加速(并行化)你的抓取器。
一切都将配有 Python 代码片段,以便你可以立即开始。本文档还将介绍几个有用的 Python 包。
用例
有很多原因和用例说明为什么你可能想要抓取数据。让我列举一些:
-
抓取电子零售商的页面,以查看你想购买的某些衣物是否有折扣
-
通过抓取页面比较多个服装品牌的价格
-
机票价格在一天内可能会有所变化。可以爬取旅行网站,并在价格降低时收到警报。
-
分析拍卖网站以回答启动竞标价应该低还是高,以吸引更多竞标者,或更长的拍卖是否与更高的最终竞标价相关
教程
教程结构:
-
可用的包
-
基本代码
-
陷阱
-
注意事项
-
加速——并行化
在我们开始之前:对服务器要友好;你不想让网站崩溃。
1. 可用的包和工具
因为每个网站上的数据存储方式通常是特定于该站点的,所以没有一种通用的网页抓取解决方案。事实上,如果你想抓取数据,你需要了解网站的结构,并自行构建解决方案或使用高度可定制的解决方案。
但是,你不需要重新发明轮子:有许多包可以为你完成大部分工作。根据你的编程技能和预期用途,你可能会发现不同的包有不同的适用性。
1.1 检查选项
大多数时候,你会发现自己在检查网站的 HTML。你可以通过浏览器的“检查” 选项 来轻松做到这一点。
网站上包含我的名字、头像和描述的部分被称为 hero hero--profile u-flexTOP(有趣的是 Medium 称其作者为‘英雄’ 😃)。包含我名字的
类被称为 ui-h2 hero-title,而描述则包含在
类 ui-body hero-description 中。
你可以在 这里 阅读更多关于 HTML 标签,以及 类 和 id 之间的区别。
1.2 Scrapy
有一个独立的即用型数据提取框架叫做 Scrapy。除了提取 HTML 外,该包还提供了许多功能,如数据导出格式、日志记录等。它也高度可定制:在不同进程上运行不同的蜘蛛,禁用 cookies¹ 和设置下载延迟²。它也可以用于通过 API 提取数据。然而,对新程序员来说,学习曲线并不平滑:你需要阅读教程和示例才能入门。
¹ 一些网站使用 cookies 来识别机器人。
² 网站可能因为大量的爬虫请求而过载。
对我来说,这“开箱即用”的程度太高了:我只想从所有页面提取链接,访问每个链接并提取信息。
1.3 BeautifulSoup 与 Requests
BeautifulSoup 是一个可以以优美的方式解析 HTML 源代码的库。你还需要一个 Request 库来获取 URL 的内容。然而,你需要处理其他所有事务,比如错误处理、数据导出、如何并行化网络爬虫等。
我选择了 BeautifulSoup,因为它迫使我去弄清楚很多 Scrapy 自行处理的事情,并且希望通过错误学习得更快。
2. 基本代码
开始抓取网站是非常直接的。大多数时候,你会发现自己在检查 HTML 以访问所需的类和 ID。假设我们有以下 HTML 结构,我们想要提取 main_price 元素。注意:discounted_price 元素是可选的。

基本代码是导入库,进行请求,解析 HTML,然后找到 class main_price。

class main_price可能出现在网站的其他部分。为了避免从网页的其他部分提取不必要的class main_price,我们可以先处理id listings_prices,然后再找到所有具有class main_price的元素。
3. 陷阱
3.1 检查 robots.txt
网站的抓取规则可以在robots.txt文件中找到。你可以通过在主域名后面添加 robots.txt 来找到它,例如www.website_to_scrape.com/robots.txt。这些规则标识了哪些网站部分不允许被自动提取或一个机器人请求页面的频率。大多数人对此不太在意,但即使你不打算遵守规则,也要尊重并至少查看一下这些规则。
3.2 HTML 可能是恶意的
HTML 标签可以包含id、class或两者。HTML id 指定一个唯一的 id,而 HTML class 是非唯一的。类名或元素的更改可能会破坏你的代码或导致错误的结果。
有两种方法可以避免或者至少对其有所警觉:
-
使用特定的
id而不是class,因为id更不容易更改 -
检查元素是否返回
None
price = page_content.find(id='listings_prices')
# check if the element with such id exists or not
if price is None:
# NOTIFY! LOG IT, COUNT IT
else:
# do something
然而,由于某些字段可能是可选的(如我们 HTML 示例中的discounted_price),相应的元素可能不会出现在每个列表中。在这种情况下,你可以计算这个特定元素返回 None 的次数占总列表的百分比。如果是 100%,你可能需要检查元素名称是否被更改了。
3.3 用户代理伪装
每次你访问一个网站时,它会通过用户代理获取你的浏览器信息。有些网站不会显示任何内容,除非你提供一个用户代理。此外,一些网站会向不同的浏览器提供不同的内容。网站不想封锁真实用户,但如果你使用相同的用户代理每秒发送 200 个请求,你会显得很可疑。一种解决办法是生成(几乎)随机的用户代理,或者自己设置一个。
# library to generate user agent
from user_agent import generate_user_agent
# generate a user agent
headers = {'User-Agent': generate_user_agent(device_type="desktop", os=('mac', 'linux'))}
#headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux i686 on x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.63 Safari/537.36'}
page_response = requests.get(page_link, timeout=5, headers=headers)
3.4 超时请求
默认情况下,Request将无限期等待响应。因此,建议设置超时参数。
# timeout is set to 5 seconds
page_response = requests.get(page_link, timeout=5, headers=headers)
3.5 我被封锁了吗?
频繁出现状态码如 404(未找到)、403(禁止访问)、408(请求超时)可能表明你被封锁了。你可能需要检查这些错误代码并相应地采取行动。此外,要准备好处理请求中的异常。
try:
page_response = requests.get(page_link, timeout=5)
if page_response.status_code == 200:
# extract
else:
print(page_response.status_code)
# notify, try again
except requests.Timeout as e:
print("It is time to timeout")
print(str(e))
except # other exception
3.6 IP 轮换
即使你随机化了用户代理,你的所有请求仍将来自同一个 IP 地址。这并不显得异常,因为图书馆、大学以及公司只有少数几个 IP 地址。然而,如果单个 IP 地址有异常多的请求,服务器可能会检测到。
使用共享代理、VPN 或 TOR可以帮助你成为隐形人;)。
proxies = {'http' : 'http://10.10.0.0:0000',
'https': 'http://120.10.0.0:0000'}
page_response = requests.get(page_link, proxies=proxies, timeout=5)
通过使用共享代理,网站将看到代理服务器的 IP 地址,而不是你的 IP 地址。VPN 将你连接到另一个网络,VPN 提供商的 IP 地址将发送给网站。
3.7 蜜罐
蜜罐是用来检测爬虫或抓取器的手段。
这些可能是“隐藏的”链接,用户无法看到,但可以被爬虫/蜘蛛提取。这些链接的 CSS 样式可能设置为 display:none,它们可能与背景颜色融合在一起,或者甚至被移到页面的不可见区域。一旦你的爬虫访问了这样的链接,你的 IP 地址可能会被标记以便进一步调查,甚至可能会立即被封锁。
另一种识别爬虫的方法是添加具有无限深度目录树的链接。这样需要限制检索的页面数量或限制遍历深度。
4. 应做与不应做的事项
-
在抓取之前,检查是否有公开 API 可用。公开 API 提供比网页抓取更简单、更快捷(且合法)的数据检索。查看Twitter API,它提供了用于不同目的的 API。
-
如果你抓取了大量数据,你可能需要考虑使用数据库,以便能够快速分析或检索数据。查看这个教程了解如何使用 Python 创建本地数据库。
-
要礼貌。如这个答案所建议,建议让人们知道你正在抓取他们的网站,以便他们可以更好地应对你的爬虫可能引发的问题。
再次提醒,不要通过每秒发送数百个请求来过载网站。
5. 加速——并行化
如果你决定将程序并行化,要小心你的实现,以免对服务器造成冲击。并确保阅读应做与不应做的事项部分。查看这里和这里了解并行化与并发、处理器和线程的定义。
如果你从页面上提取了大量信息并在抓取时进行了数据预处理,你发送到页面的每秒请求数可能会相对较低。
对于我另一个项目,即抓取公寓租赁价格时,我在抓取过程中进行了大量的数据预处理,这导致每秒发出 1 个请求。为了抓取 4K 条广告,我的程序大约运行了一个小时。
为了并行发送请求,你可能需要使用 multiprocessing 包。
假设我们有 100 页内容,我们希望将每个处理器分配相等数量的页面。如果 n 是 CPU 的数量,你可以将所有页面均匀分块成 n 个区域,并将每个区域分配给一个处理器。每个进程将拥有自己的名称、目标函数和处理的参数。进程的名称可以用于后续的数据写入特定文件。
我将每 1K 页分配给 4 个 CPU,这样得到了每秒 4 个请求,并将抓取时间减少到约 17 分钟。
import numpy as np
import multiprocessing as multi
def chunks(n, page_list):
"""Splits the list into n chunks"""
return np.array_split(page_list,n)
cpus = multi.cpu_count()
workers = []
page_list = ['www.website.com/page1.html', 'www.website.com/page2.html'
'www.website.com/page3.html', 'www.website.com/page4.html']
page_bins = chunks(cpus, page_list)
for cpu in range(cpus):
sys.stdout.write("CPU " + str(cpu) + "\n")
# Process that will send corresponding list of pages
# to the function perform_extraction
worker = multi.Process(name=str(cpu),
target=perform_extraction,
args=(page_bins[cpu],))
worker.start()
workers.append(worker)
for worker in workers:
worker.join()
def perform_extraction(page_ranges):
"""Extracts data, does preprocessing, writes the data"""
# do requests and BeautifulSoup
# preprocess the data
file_name = multi.current_process().name+'.txt'
# write into current process file
祝抓取愉快!
简介:耶卡特琳娜·科卡特朱哈 是一位热衷于生物信息学的研究员,对机器学习和数据科学充满兴趣。
原文。经许可转载。
相关内容
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 部门
更多相关内容
Web LLM:将 LLM 聊天机器人带到浏览器
原文:
www.kdnuggets.com/2023/05/webllm-bring-llm-chatbots-browser.html

图片由作者提供
基于 LLM 的聊天机器人通过前端访问,并涉及大量昂贵的 API 调用到服务器端。但是,如果我们能让 LLM 完全在浏览器中运行——利用底层系统的计算能力,那将会怎样呢?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
这样,LLM 的全部功能都可以在客户端实现——无需担心服务器的可用性、基础设施等问题。Web LLM 是一个旨在实现这一目标的项目。
让我们进一步了解 Web LLM 的驱动因素以及构建这样一个项目的挑战。我们还将查看 Web LLM 的优点和局限性。
什么是 Web LLM?
Web LLM 是一个使用 WebGPU 和 WebAssembly 等技术,使 LLM 和 LLM 应用程序能够完全在浏览器中运行的项目。通过 Web LLM,你可以利用 WebGPU 通过底层系统的 GPU 在浏览器中运行 LLM 聊天机器人。
它使用 Apache TVM 项目的编译器栈,并使用最近发布的 WebGPU。除了 3D 图形渲染等功能,WebGPU API 还支持通用 GPU 计算(GPGPU 计算)。
构建 Web LLM 的挑战
由于 Web LLM 完全在客户端运行,没有任何推理服务器,因此项目面临以下挑战:
-
大型语言模型使用 Python 框架进行深度学习,这些框架原生支持利用 GPU 进行张量操作。
-
在构建 Web LLM 以便完全在浏览器中运行时,我们将无法使用相同的 Python 框架。因此,必须探索其他技术栈,这些技术栈能够在网页上运行 LLM,同时仍使用 Python 进行开发。
-
运行 LLM 应用程序通常需要大型推理服务器,但当一切都在客户端——即浏览器中运行时,我们将无法再使用大型推理服务器。
-
需要对模型权重进行智能压缩,以使其适合可用的内存。
Web LLM 如何工作?
Web LLM 项目利用底层系统的 GPU 和硬件能力在浏览器中运行大型语言模型。机器学习编译 的过程通过利用 TVM Unity 和一系列优化,将 LLM 的功能集成到浏览器端。
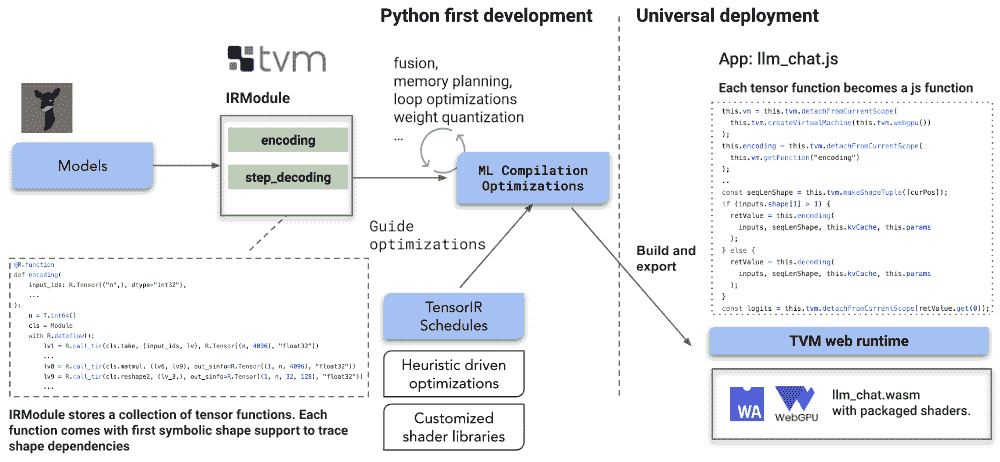
Web LLM 的工作原理 | 图片来源
系统使用 Python 开发,并通过 TVM 运行时在网页上运行。这一移植到网页浏览器的过程是通过一系列优化实现的。
LLM 的功能首先被集成到 TVM 中的 IRModule 中。在 IRModule 中对函数进行多个转换,以获取优化后的可运行代码。TensorIR 是一种用于优化张量计算程序的编译器抽象。此外,INT-4 量化用于压缩模型的权重。TVM 运行时则通过 TypeScript 和 emscripten 实现,后者是一个将 C 和 C++ 代码转换为 WebAssembly 的 LLVM 编译器。
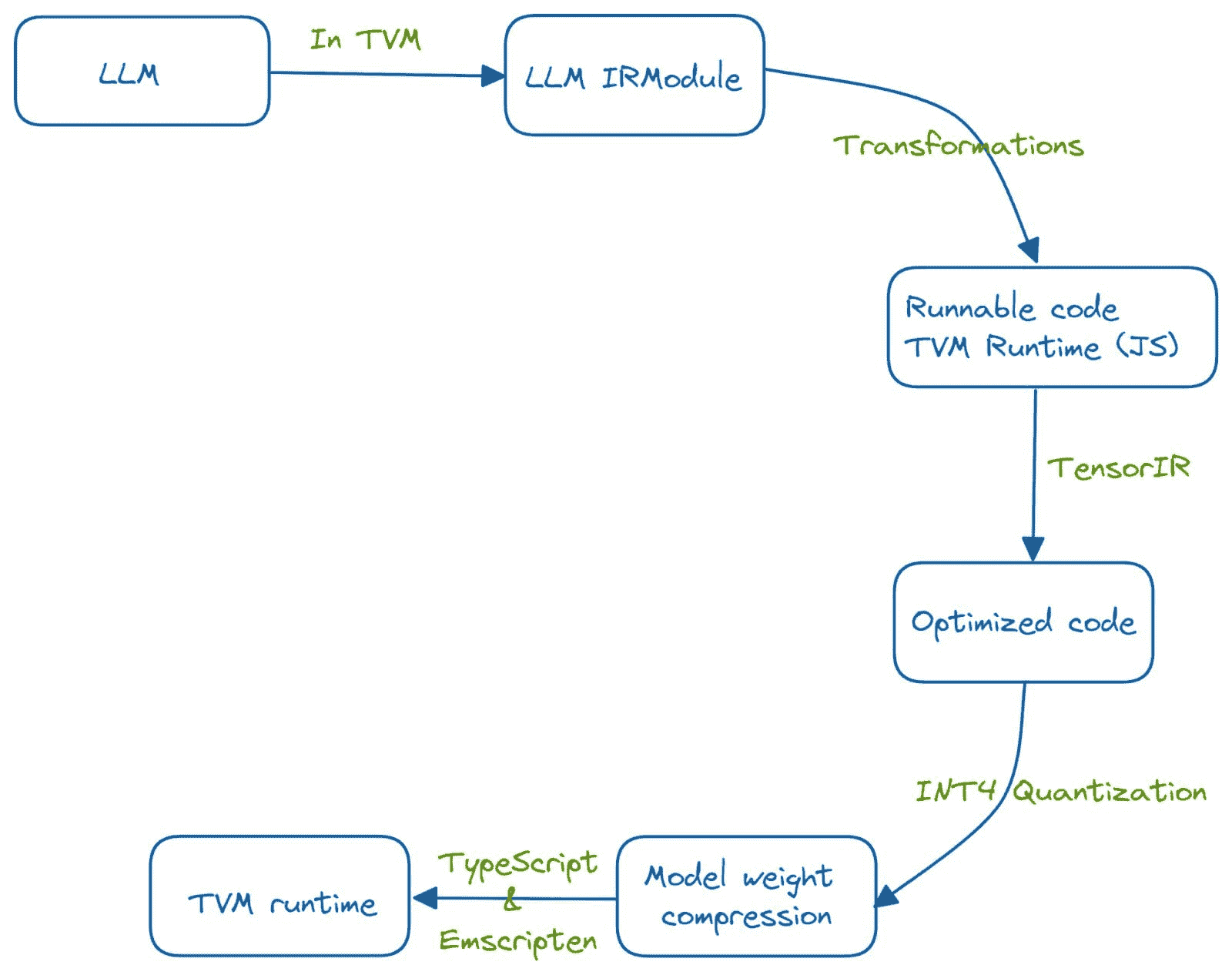
作者提供的图片
你需要最新版本的 Chrome 或 Chrome Canary 才能尝试 Web LLM。撰写本文时,Web LLM 支持 Vicuna 和 LLaMa LLM。
第一次运行模型时需要一些时间来加载模型。因为第一次运行后缓存完成,后续运行速度会明显加快,并且开销最小。
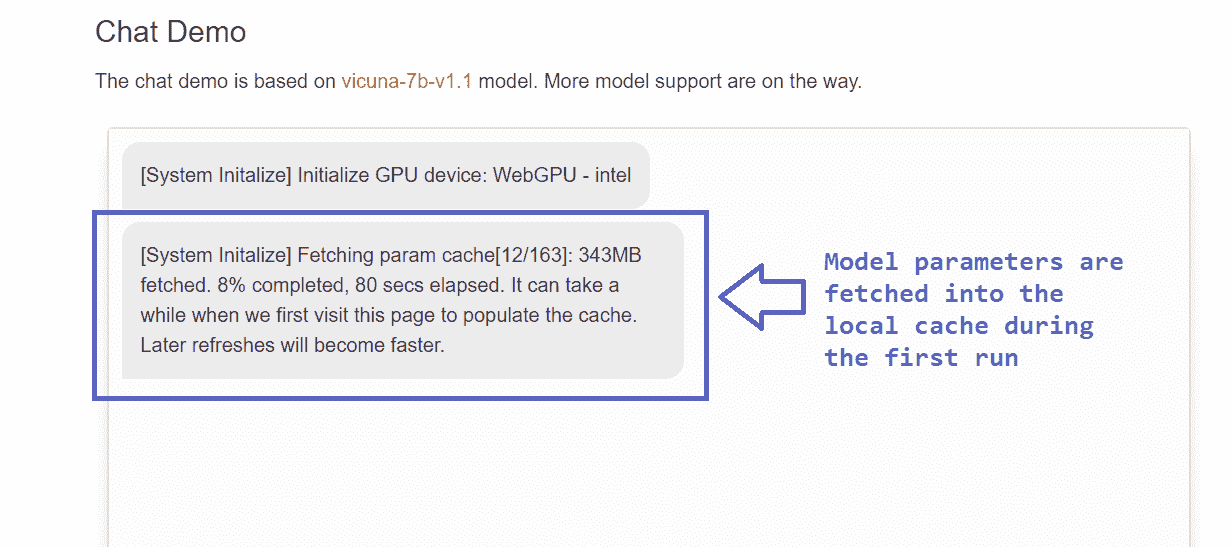
Web LLM 的优缺点
让我们通过列举 Web LLM 的优点和限制来总结我们的讨论。
优点
除了探索 Python、WebAssembly 和其他技术栈的协同效应外,Web LLM 还具有以下优点:
-
在浏览器中运行 LLM 的主要优势是 隐私。因为这种隐私优先的设计完全消除了服务器端,我们不再需要担心数据的使用。由于 Web LLM 利用底层系统的 GPU 计算能力,我们也无需担心数据被恶意实体获取。
-
我们可以为日常活动构建个人 AI 助手。因此,Web LLM 项目提供了高度的 个性化。
-
Web LLM 的另一个优点是 成本降低。我们不再需要昂贵的 API 调用和推理服务器,Web LLM 使用底层系统的 GPU 和处理能力。因此,运行 Web LLM 的成本大大降低。
限制
以下是 Web LLM 的一些限制:
-
尽管 Web LLM 减轻了输入敏感信息的担忧,但它仍然容易受到浏览器攻击。
-
通过增加对多种语言模型和浏览器的支持,还有进一步改进的空间。目前,此功能仅在 Chrome Canary 和最新版本的 Chrome 中可用。扩展到更多支持的浏览器将非常有帮助。
-
由于浏览器运行的稳健性检查,使用 WebGPU 的 Web LLM 不具备 GPU 运行时的本地性能。您可以选择禁用运行稳健性检查的标志以提高性能。
结论
我们尝试了解 Web LLM 的工作原理。您可以尝试在浏览器中运行它,甚至可以 在本地部署。考虑在浏览器中尝试该模型,并检查它在您日常工作流程中的集成效果。如果您感兴趣,还可以查看 MLC-LLM 项目,它允许您在包括笔记本电脑和 iPhone 在内的任何设备上原生运行 LLM。
参考文献和进一步阅读
[1] WebGPU API,MDN Web Docs
[3] MLC-LLM
Bala Priya C 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点工作。她的兴趣和专长包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过撰写教程、操作指南、观点文章等,学习并与开发者社区分享她的知识。
了解更多相关内容
数据科学家做什么?
原文:
www.kdnuggets.com/2021/12/what-does-a-data-scientist-do.html
评论

我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
你真的无法避免它,对吗?无论你看向哪里,它都会出现。你的 LinkedIn 动态、招聘市场、新闻推送、教育项目都在试图吸引你的注意(以及你的学费)。但数据科学到底是什么?它通常被描述得非常模糊,令人不甚满意。这个指南将尽量避免这些模糊之处,为你提供最直接、最清晰的答案,“数据科学是什么?”和“数据科学家做什么?”。
所以,数据科学家做什么?为回答这个问题,我们将带你了解在数据科学工作中的各个方面。
数据科学家的角色和责任
数据科学的作用是利用每家公司现在收集的大量数据,将其转化为可理解和有用的信息。这一数据转化过程是通过使用诸如机器学习(ML)、人工智能(AI)和统计分析等技术来实现的。所有这些都旨在解决现实世界的问题。现实世界通常指的是商业问题。这意味着公司使用数据科学来做出更合理的商业决策并获得更多的利润。
既然我们已经介绍了数据科学家的角色,现在是时候询问这在实践中意味着什么了。数据科学家做什么?一个直接的问题需要直接的回答。
数据科学家:
-
确定商业问题
-
收集数据
-
通过处理和清理数据来为分析做准备
-
存储数据
-
分析数据以发现趋势和模式
-
构建、训练和验证模型
-
提供洞察
数据科学职位名称
数据科学领域中包含所有技能的最一般的职位名称就是数据科学家。成为数据科学家包括所有上述的责任。然而,这并不是你在数据科学领域能拥有的唯一职位名称。
还有许多其他职位名称,这些职位依赖于资历、公司组织结构、规模等。最重要的是,这些职位名称取决于它们关注的数据科学领域。你可以将数据科学家视为数据科学的原始汤,所有其他职位名称都源自于此。
通常,数据科学中的职位可以分为两类:
-
数据提供者
-
数据用户
我们博客中有非常详细的信息,关于每个数据科学职位名称的帖子。使用该帖子查找每个职位的详细描述和所需技能。
数据提供者
当我们谈论数据提供者时,我们讨论的是专注于原始数据、数据基础设施、数据加载和数据库的工作。
本类别中的数据科学职位包括数据建模师、数据工程师、数据库管理员、数据架构师和软件工程师。他们以某种方式确保数据科学中另一类别的工作(数据用户)能够不间断地访问数据,这为数据用户构建的基础提供了支撑。
当然,所有这些数据提供者职位之间的目的各不相同。
数据建模师
例如,数据建模师创建概念性、逻辑性和物理性的数据库模型,并参与数据库实施。
数据工程师
数据工程师更关注数据基础设施、其开发和维护,包括数据仓储和数据的提取、转换和加载(ETL/ELT)。
查看我们关于数据工程师与数据科学家的帖子,了解数据科学家和数据工程师的相似之处和不同之处。
数据库管理员
数据库管理员在数据基础设施的基础上,确保数据和数据库的完整性和安全性。这包括授予和撤销对数据的访问权限、备份数据库、恢复数据等。
软件工程师
在上述职位提供的数据基础设施之上,是软件工程师。他们设计、开发、测试和维护软件,作为数据用户与底层数据和数据基础设施交互的接口。
数据架构师
数据架构师提供全局视角,并协调所有这些数据提供者。他们的工作是理解公司的流程,以便他们可以规划、实施和改进公司数据处理基础设施的架构。这意味着提供解决方案,说明数据如何在不同的入口点进入公司。数据以什么格式进入,使用何种软件进行处理(如果有的话),以及数据如何转换和加载到数据库或数据仓库中。数据如何被公司使用,直到数据成为公司的输出。
数据用户
数据用户利用现有数据和数据基础设施向各个股东提供信息。他们是数据提供者与决策者之间的桥梁,后者通常技术背景较少。
数据科学中的数据用户,除了数据科学家之外,还包括数据分析师、统计学家、BI 开发人员、业务分析师、量化分析师、市场科学家、机器学习工程师、研究科学家等。他们在公司中的目的各不相同。
数据分析师
例如,数据分析师专注于报告、常规分析和临时分析。他们使用数据并将其总结成报告格式。这使得技术水平较低的用户能够利用这些数据,了解公司业务的各个方面。数据分析师主要使用历史数据。
统计学家
统计学家与数据分析师类似,他们也分析数据。然而,他们更关注预测未来,而非解释过去。他们使用数据来预测将会发生什么,而不是已经发生的事情。为此,他们应用统计方法,如假设检验和概率。因此,统计学家与数据科学家也类似。区别在于,他们不像数据科学家那样构建模型,仅专注于数据科学中的统计部分。
BI 开发人员
BI 开发人员负责开发(设计、构建和维护)BI 工具中的仪表板,用于数据可视化和报告。他们在制作报告方面类似于数据分析师。然而,他们还具备一些工程技能,用于 ETL 数据和构建用户界面,就像数据工程师和软件工程师分别做的那样。
业务分析师
业务分析师专注于报告,类似于数据分析师。然而,他们通常专注于内部报告,而这并非数据分析师总是如此,以检测公司业务流程中的弱点并加以改进。
量化分析师
量化分析师通常是专注于金融数据的数据科学家。他们会分析这些数据并构建涉及各种金融市场的模型,如贷款、股票、债券、外汇等。他们的分析将用于决定交易策略、可行的投资和风险管理。
市场科学家
市场科学家是专注于一种数据类型的数据科学家。在这种情况下,是市场数据。像任何数据科学家一样,他们会分析这些数据,尝试寻找模式和趋势,以解释和预测客户行为,从而帮助解决市场营销和销售问题。
机器学习科学家
机器学习科学家是数据科学家的某种延伸。虽然数据科学家更关注模型的理论部分,数据工程师则将这些模型付诸实践。他们将原型模型部署到生产中。这涉及工程化的 AI 软件和算法,使机器学习模型在实践中发挥作用。
研究科学家
虽然机器学习工程师是这类数据科学家的实践者,但研究科学家则是理论家。研究科学家的工作是理解计算原理及由此产生的问题。为了破解这些难题,他们会改进或创造全新的算法和编程语言。
数据科学职业路径

在下图中,有一个关于你可能的data scientist career path的示例。这并不意味着这是一个单向的过程(它完全可以不是一个过程!)或者这些职位名称不能以不同的方式互换和移动。这只是一个概述,先看看它,然后我们将附上详细的解释。
教育作为起点
数据科学处于统计学、数学和计算机科学的交汇点,也涉及其他学科。因此,至少在这些领域接受过教育是一个良好的起点。
然而,我们不能编写适用于每个候选人和职位广告的指南。一般的经验法则是:获得至少一个本科(BS)学位,以便在数据科学就业市场中拥有一个良好的起点。然后结合工作经验。良好的教育和经验平衡始终是成功的配方。当然,获得更多教育和更多经验总能让你处于更好的位置,这一点并不令人惊讶。让我们看看教育/学位要求是什么:
-
本科/硕士学位
-
博士学位
-
训练营
本科/硕士学位
如果你想在数据科学领域建立职业,最好拥有至少一个学士学位。拥有本科或硕士学位对于获得数据科学中的任何工作是有益的,大多数职位广告中都要求这种教育水平。你的学位应在相关的定量领域,如统计学、数学、计算机科学、工程、信息技术、经济学、编程等。当然,这取决于职位名称和资历水平。
此外,根据工作,拥有不同领域的学位可能会带来好处。也许是人文学科,如哲学、社会学、心理学。如果你想成为一个试图理解和预测人类行为的市场营销科学家,这些学科可能会很有用(有时甚至是必需的!)。研究科学家有时可以在计算原理方面工作,这些原理可能与伦理和人类行为有很深的联系。
根据工作描述和职位 seniority,拥有金融、商业或类似学位也是有益的。也许你处理的是金融数据,并且你在层级结构中处于较高的位置,那么除了技术技能外,领导力、商业智慧和教育背景也变得很重要。
虽然学士学位往往是招聘广告中要求的最低教育水平,但有时它并不是唯一的要求。
博士学位
拥有博士学位不会影响你获得上述任何职位的机会。更多的教育总是更好的。
然而,有时候这个水平不仅是有利的,而是必需的。例如,如果你想从事机器学习工程师或其他数学密集型工作,获得博士学位是个好主意。
此外,研究科学家需要在计算机科学理论、原理和研究方法上有扎实的基础。这就是为什么这个职位通常需要博士学位的原因。
训练营
尽管招聘广告中通常要求正式教育背景,但这并不意味着它总是必要的。如果你在数据科学的某些方面有经验,但没有正式的教育背景,这并不意味着你不能作为数据科学家工作。一般来说,职位越高,你的教育背景就越不重要。重要的是你在之前的工作中做了什么,你如何做到的,以及你可以带到新工作的技能。
这里有一个进退两难的问题。你需要工作来获得经验和提升技能。如果你没有经验和技术技能,你就无法找到工作。幸运的是,有一个解决方案:训练营。
这些是获得数据科学相关技能的良好起点。它们不要求技术类的学士或硕士学位。这对任何没有正规教育背景但想要开始数据科学职业的人来说是很好的选择。它们也适合那些通过实践进入数据科学领域的人。这样,他们可以获得一个更加结构化和理论化的背景,来补充他们已经在实践中所做的工作或提升他们已经存在的技能。
数据科学家的工作经验
说到工作经验,开始获得工作经验总是最难的。一旦你开始工作并在工作中学习,换工作和拓宽专业领域就变得更容易了。建立一个坚实的基础是很重要的。在数据科学领域,人们通常从数据分析师做起。
从那时起,他们可以选择我们之前讨论过的两个方向:作为数据提供者或数据用户。关于上图的一个重要事项是,随着你从左到右移动,职位的资历水平上升,你的薪水也会上升。稍后我们会讨论薪资问题。首先,让我们举几个例子看看你的职业生涯可能是什么样的。
假设你从数据分析师开始。经过几年处理数据并找到自己关于数据库的解决方法后,你理解了数据库原理,因此你决定转型成为数据建模师或数据库管理员。在这些职位中的工作能让你获得更多经验,你参与了几个关于数据基础设施的项目。然后你获得晋升,例如成为一名数据架构师。
或者,也许你从统计师开始。经过几年在公司工作后,你决定是时候改变一下了。但你非常喜欢你现在所在的公司。而且你去年参与的几个市场营销项目也让你非常喜欢。于是,你转到市场营销部门,只处理市场营销数据,成为一名市场营销科学家。然后,又到了改变的时候;你对机器学习产生了兴趣,成为了一名数据科学家。几年后,你希望回到学校获得博士学位。你辞去了工作,专注于攻读博士学位。这与你丰富的工作经验相结合,让你意识到你想以不同的、也许是理论的方式为数据科学做贡献。于是,你成为了一名研究科学家。
这些只是你职业生涯可能的几种例子。任何与实际人物及其职业生涯的相似之处纯属巧合。你的职业生涯将取决于你的背景、能力、兴趣、你在(或其他)公司的机会、公司的规模、组织结构、灵活性,以及,没错,还有一点运气。
你选择的任何方式从长远来看都可能对你有利。记住,这些工作都是数据科学的一部分,因此在数据科学的某个领域拥有更多的经验,只会对你有利,尤其是当你想在数据科学领域中尝试一些新的事物时。
当然,要获得经验,你首先需要一份工作。要获得工作,你必须经历常常乏味的面试过程。为了使这个过程尽可能无痛,你需要做好准备。虽然没有什么能比得上实际面试的经验,但通过我们的 编码 和 非编码 面试问题,你将会有一个良好的开始。
数据科学所需的技术技能

在数据科学领域,以下技能是必不可少的:
-
编码使用 SQL、R、Python、Java、C 系列等语言
-
处理数据,包括收集、清洗和分析数据
-
数据库设计用于了解如何获取和存储数据
-
统计分析用于从数据中获取洞察
-
数学在数据分析和指标计算中使用
-
建模用于设计和构建模型
-
机器学习与人工智能用于部署模型
查看我们关于最受欢迎的数据科学技能的文章,了解作为数据科学家必须具备的最受欢迎的数据科学技术技能和业务技能。
数据科学薪资
在选择职业时,除了兴趣和个人情况,薪资也是一个重要因素。
根据 Jobted 引用的美国劳工统计局(BLS)的数据,美国的年平均薪资约为 53.5k。
那么数据科学领域的职位与这些相比如何呢?例如,Glassdoor 数据显示数据分析师的平均年薪为 $70k。即使这是数据科学中(平均而言)薪资最低的职位,它的薪资仍比美国平均水平高出 $15k。这高出 30%!
作为数据科学家,这是一份薪资最高的职位之一,平均年薪可达 $139k,是平均薪资的 1.5 倍以上。即使是最低报告薪资也为美国平均水平的两倍,而薪资最高可达 $171k。而这还不是数据科学中薪资最高的职位。
教育、知识和技能确实能带来回报,如果你在考虑是否投资于职业发展或转行。以下是职位概况和以美元计的平均薪资。
| 数据分析师 | $70k |
|---|---|
| 数据库管理员 | $84k |
| 数据建模师 | $94k |
| 软件工程师 | $108k |
| 数据工程师 | $113k |
| 数据架构师 | $119k |
| 统计学家 | $89k |
| 商业智能(BI)开发者 | $92k |
| 营销科学家 | $94k |
| 商业分析师 | $77k |
| 定量分析师 | $112k |
| 数据科学家 | $139k |
| 研究科学家 | $142k |
| 机器学习工程师 | $189k |
根据你工作的公司,你可以期待这些基本薪资会通过现金和股票奖金、健康和人寿保险等不同的福利增加。
你可以在我们的博客文章之一中找到有关数据科学薪资的更详细信息 - 数据科学家赚多少钱?。
数据科学的工作时间
通常,需求量高并获得相当可观的薪资是有代价的。数据科学并不是一帆风顺的。虽然数据科学家通常每周工作 40 小时,但有时也需要加班。再说了,这取决于公司、组织、行业以及其他众多因素。但大多数情况下,这与工作描述及其周期性特征有关,这意味着你会在完全放松和轻松的时期与需要每周工作 50-60 小时的高峰期之间进行平衡。
这是因为数据科学任务通常涉及项目,这意味着在严格的截止日期内解决问题。随着截止日期的临近,工作量通常会增加,这时数据科学家不得不加班。
什么造就了一个伟大的数据科学家?
拥有相关的教育和技术技能当然是成为数据科学家的前提。要完成这第一步,请参考我们在讨论如何从零开始成为数据科学家时提供的有用建议。但这是否能让你成为一个出色的数据科学家呢?未必。
数据科学的关键在于解决现实生活中的问题。你可以拥有世界上所有的技术技能,但如果你不能运用这些出色的技能来提出解决方案,那又有什么意义呢?或者你提出了一个解决方案,但没有人理解和使用它。你真的解决了问题吗?没有,你并没有。
技术技能用于解决问题,而磨练这些技能的最佳方法之一是创建自己的数据分析项目。然而,你还需要软技能。提出解决方案有点像夹在数据科学家工作中的其他两个重要阶段之间。
-
理解问题
-
提出解决方案(通过技术技能)
-
提出解决方案
要成为一名出色的数据科学家,你需要:
-
要幼稚
-
沟通良好
-
擅长团队合作
-
对跨学科性感到自如
保持幼稚
我们不是说要你成为一个被宠坏的孩子。保持幼稚意味着保持好奇心、提问、渴望学习和富有玩心。
你需要保持好奇心,接受自己并不理解所有事物的事实,并愿意学习。为了做到这一点,你必须像孩子一样:不断提问直到得到满意的答案。你需要成为那个“为什么的人”。只有这样,你才能理解业务问题、不同人的需求、部门的需求以及客户的需求。一旦你理解了这些,运用你的技术技能就会变成一种技术性工作。
当你提出解决方案时,你需要富有创意和想象力地展示你的、可能非常复杂的解决方案,以便他人能够理解并使用它。
沟通
沟通是第一项技能的自然延伸。你需要高效沟通,提出正确的问题,以易于理解的方式呈现你的想法和解决方案。当人们感受到你愿意接受建议、倾听他们并尊重他们时,他们会更加投入项目。他们会愿意更详细地解释他们的(业务)需求和问题,这使你更容易理解你的职责要求。
当然,如果你无法解释解决方案的工作原理、如何使用户受益以及他们如何使用它,那么提出一个卓越的数据科学解决方案是没有意义的。因此,在展示你的解决方案时,沟通是必要的。
团队合作
不论幸运与否,你将会与真实的人一起工作,解决他们的实际问题。你不会仅仅在你的部门内部工作,也不会只和你部门的人合作。你会与来自不同背景、拥有不同技术技能、专业领域和经验的人合作。要成为一名成功的数据科学家,你必须理解他人,对他们有耐心,具备灵活性,并适应不同的情况和方法。
创造良好的工作氛围对公司、团队以及你自己都大有裨益。可靠、负责任,并愿意帮助同事的态度总是受到欢迎的。
跨学科能力
与(不同)团队中的人员合作意味着你将与不同水平和领域的专家一起工作。这是一个学习的机会。这时候跨学科能力就派上用场了。
一位对数据科学严格范围之外一无所知的数据科学家无法成为优秀的数据科学家。跨学科能力会让你更快地理解和解决问题。你会更清晰地呈现解决方案。了解业务、营销、报告、法律或你所在行业的任何其他方面,都会使你成为非常受欢迎的雇员。能够在技术部门和非技术部门之间架起桥梁的专家是稀缺且非常有价值的。
结论
数据科学是当今就业市场上最热门的领域之一。对数据科学家的需求很高,但竞争也非常激烈。
这意味着成为一名数据科学家并不容易。然而,这也并非不可能。本指南是帮助你决定数据科学是否适合你的其中一个工具。总的来说,以下是获取数据科学工作并取得成功的步骤:
-
获得计算机科学或其他定量领域的教育背景。
-
提升你的技术技能,例如编程、数据分析、数据库设计和模型构建。
-
认真准备工作面试,这意味着回答尽可能多的技术和非技术问题,研究公司及你申请的职位。
-
提升你的软技能。
相关:
主题扩展
我从使用 ChatGPT 进行数据科学中学到的
原文:
www.kdnuggets.com/what-i-learned-from-using-chatgpt-for-data-science

图片由作者提供
我从使用 ChatGPT 中学到的唯一一课是,它在数据科学中非常有帮助,但你必须仔细审查它输出的所有内容。它在某些任务中表现得非常出色,可以快速准确地完成这些任务。而在其他一些任务中,它表现得足够好,但你需要多次提示。而我发现 ChatGPT 对某些任务确实很糟糕。
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的 IT 组织
很棒:自动化数据探索
你可以将数据集附加到 ChatGPT 消息中,通过给出几个简单的指令,ChatGPT 可以为你探索数据。
例如,我可以从 这个数据项目 获取数据集。我给出的指令是:
“使用附加数据进行描述性统计分析。包括以下内容:
-
总结基本统计数据(均值、中位数、标准差等)。
-
识别缺失值并建议处理策略。”
它返回的总结看起来是这样的。它对每个变量进行相同的计算。
年龄:
-
平均值:28.79 年
-
标准差:6.94 年
-
范围:18 到 50 年
它还识别出了数据集中没有缺失值。
如果你还需要这些计算的 Python 代码,你可以提示它编写这些代码。
要加载数据集,使用这段代码。
aerofit_data = pd.read_csv(file_path)
对于基本统计数据,它提供了这个。
basic_stats = aerofit_data.describe()
你可以用这段代码检查缺失值。
missing_values = aerofit_data.isnull().sum()
很棒:创建可视化
此外,我可以要求 ChatGPT 可视化关键变量的分布,并检测潜在的异常值和异常情况。
它为关键变量创建了直方图和箱线图:年龄、收入和里程。它检测到收入和里程分布中的潜在异常值。
创建者:作者/ChatGPT
创建者:作者/ChatGPT
它还解释了这些可视化。因此,它注意到收入分布是右偏的,这表明大多数客户的收入处于较低的范围,而较少的客户收入显著较高。箱形图显示高端有一些离群值。
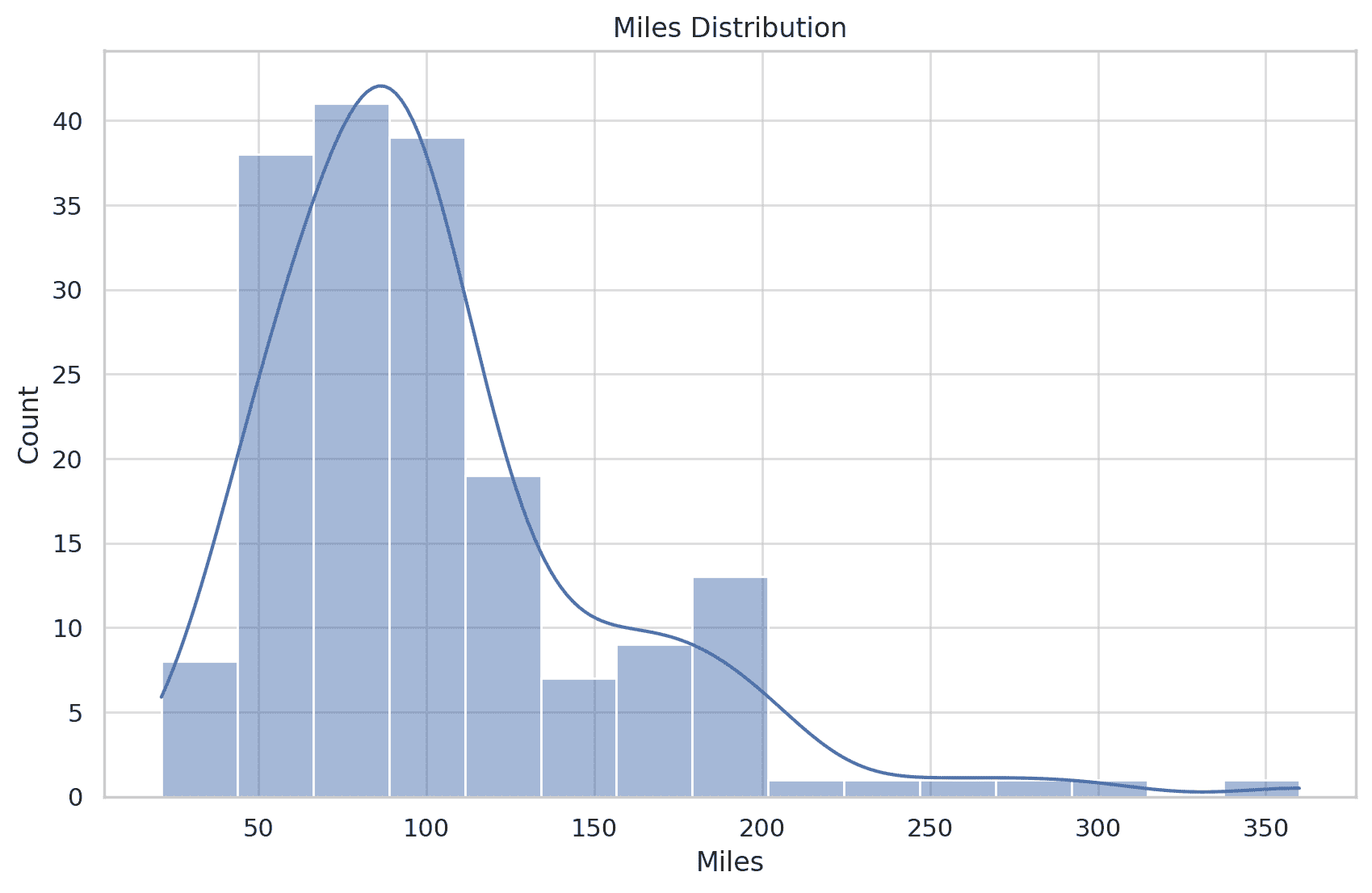
由作者/ChatGPT 创建
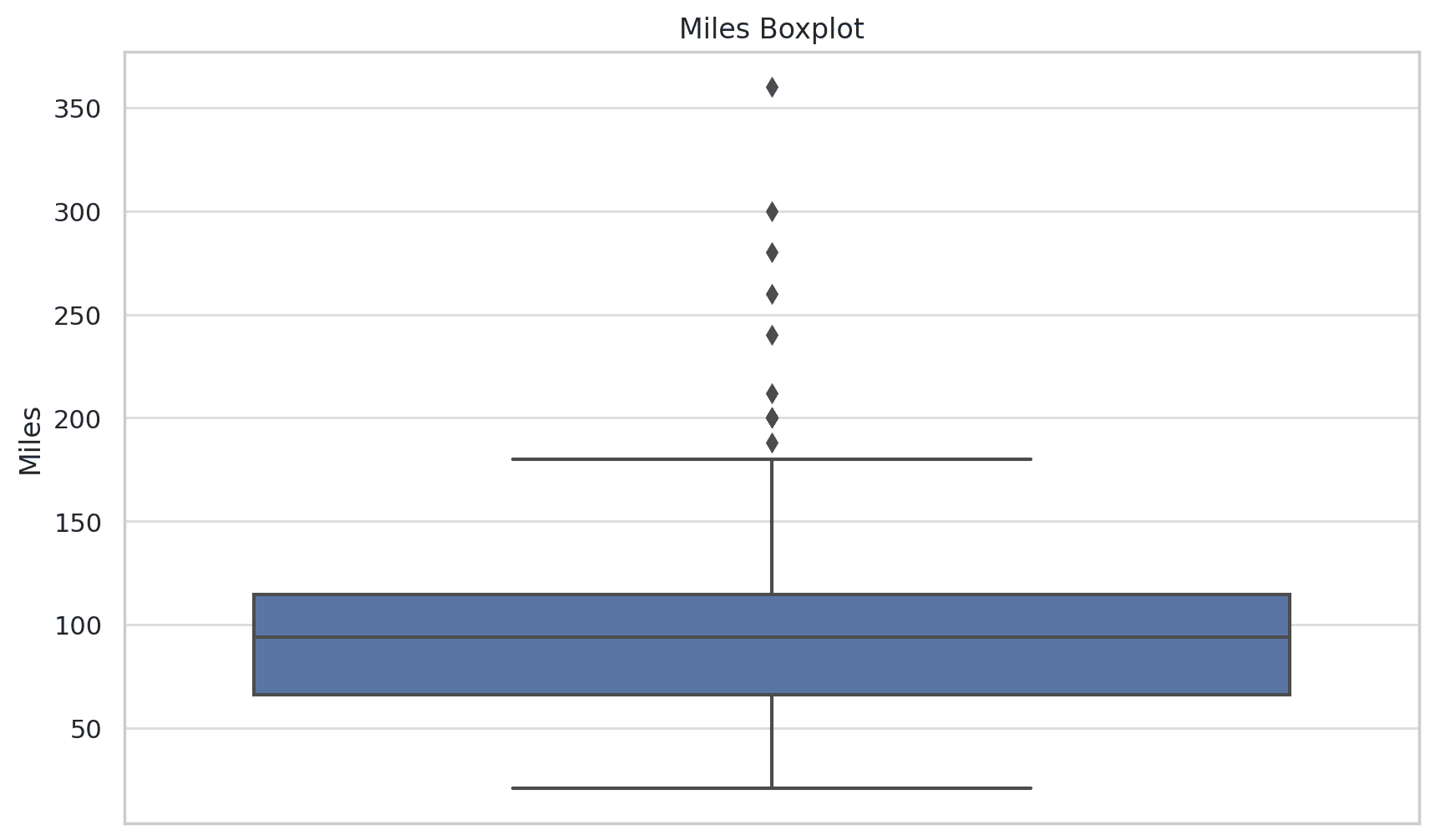
由作者/ChatGPT 创建
相同的解释适用于 Miles 分布:右偏和高端的离群值。
考虑到数据的性质,它建议这些离群值不一定是错误的,而是代表了特定的客户群体。对于偏斜的分布,它建议使用变换(例如,对数变换)来规范化数据。
当然,你也可以让它为这些可视化创建 Python 代码。
很好:验证数据是否适用于特定的统计测试
我可以使用相同的数据,并询问 ChatGPT 它是否适用于逻辑回归。如果不适用,我该如何转换它以使其合适?
它回复说我的数据主要适用于连续数据的描述性和推断性分析。
这些是对数据进行转换以适应逻辑回归的建议方法。
创建二元结果: 通过根据“使用”变量的中位数将客户分类为“高使用”或“低使用”来创建二元结果。此外,二元结果还可以是“跑步机购买”与“未购买跑步机”。
检查多重共线性: 使用相关矩阵或方差膨胀因子(VIF)检查多重共线性。如果存在多重共线性,可以删除或合并相关变量。
特征缩放: 尽管逻辑回归模型拟合不需要特征缩放,但对于收敛来说,特征缩放可能是有益的。这尤其适用于具有显著不同尺度的特征。
解决非线性问题: 对于不符合线性假设的变量,可以使用变换,如对数或平方根。
样本大小: 数据集必须足够大,以匹配预测变量的数量。
数据预处理: 处理离群值和分类变量(通过 独热编码或标签编码)是建议的。此外,还建议处理缺失值,但这对我的数据不适用,因为没有缺失值。
好:自动化部分或整个数据科学项目
ChatGPT 实际上在数据科学项目的每个阶段都可以提供帮助。你可以提示它编写网页抓取代码。你可以指示它探索和准备数据,以便用于机器学习算法。它还可以为选择合适的算法、数据集拆分、A/B 测试和性能提升算法提供代码。最后,你还可以让 ChatGPT 为模型部署编写代码。
尽管 ChatGPT 可以做到这些,但你可能不会立即得到一个完全符合你需求的代码。所以,你必须理解你想要实现什么,并检查代码。可能需要提示 ChatGPT 进行代码修正,并提供更多更改说明。
好:代码转换和学习
ChatGPT 可以帮助那些仍在学习新编程语言的用户。假设你是一个 SQL 高手,解决 这个面试问题 对你来说没问题。然而,你希望将 Python 添加到你的技能中。ChatGPT 可以帮助你。你可以复制 SQL 代码并要求 ChatGPT 将其转换为 Python。
所以,SQL 代码是这样的。
SELECT
company,
profit
FROM
(
SELECT
*,
rank() OVER (
ORDER BY
profit DESC
) as rank
FROM
(
SELECT
company,
sum(profits) AS profit
FROM
forbes_global_2010_2014
GROUP BY
company
) sq
) sq2
WHERE
rank <= 3;
ChatGPT 根据上述 SQL 代码编写了 Python 代码,但它运行不正确。所以我对 ChatGPT 编写错误的代码进行批评。我要求它重试,因为输出与 SQL 代码不一样。它重试后返回了正确的结果。
import pandas as pd
# Assuming 'forbes_global_2010_2014' is a pandas DataFrame with columns 'company' and 'profits'
# Since we don't have the actual data, this code assumes that the DataFrame is already loaded
# Step 1: Group by company and sum the profits
company_profits_sum = forbes_global_2010_2014.groupby('company')['profits'].sum().reset_index()
# Step 2: Rank the companies by profit in descending order
company_profits_sum['rank'] = company_profits_sum['profits'].rank(ascending=False, method='max')
# Step 3: Filter the top 3 companies
top_companies = company_profits_sum[company_profits_sum['rank'] <= 3]
# Final selection of columns
result = top_companies[['company', 'profits']].sort_values('profits', ascending=False)
result # This will display the top 3 companies by profit
如你所见,你得到了一段带有每个代码块注释的漂亮代码。为了提高你的学习,你可以要求它解释这些代码。这样,你将更深入地了解每行代码的作用及其原理。
糟糕:统计和数学计算
当我说糟糕时,我是指真的很糟糕!它到了那种使用正确的公式并插入正确的值但却搞砸了不那么复杂的计算的程度。
看这个。我让它解决这个问题:“假设你掷一个公平的六面骰子 10 次。掷出两个 1、三个 2、一个 3、零个 4、三个 5 和一个 6 的概率是多少?”
它以这种方式计算概率。
它在计算阶乘时搞砸了。而且它很有风格地搞砸了!完全错误地说 2! = 12。其实不对,2! = 2。怎么会搞砸这样一个简单的计算,例如 2x1 = 2?这真的很可笑!
更搞笑的是,有一次 3! = 36,而第二次 3! = 6。值得称赞的是,它至少有一次是正确的。
当我要求它纠正计算而不做进一步解释时,它重新计算并得出了 0.0001389 的概率。我简直不敢相信自己的眼睛!它可以使用完全相同的公式和数值,却得出一个不同的且仍然错误的结果!
我再次要求它纠正计算,最终返回了正确的结果:0.0008336。三次是幸运的!
不可否认,这些错误是 ChatGPT 3.5 造成的。我问了 ChatGPT 4 同样的问题,它第一次尝试时就给出了正确的计算结果。你也可以使用一些数学插件以确保安全。
结论
从这一切中得到的主要教训是,ChatGPT 是一个糟糕的主宰但非常好的仆人。它在编写代码、调试、分析和可视化数据方面很有帮助。然而,永远不要完全信任它,也不要不加审查地采纳它写的内容。
检查它写的代码,检查计算。毕竟你是数据科学家,而 ChatGPT 不是!你可能第一次尝试时无法获得理想的结果。但给它更精确的指示并尝试几次,可能会让你达到预期的结果。
内特·罗西迪 是一名数据科学家及产品策略专家。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过顶级公司的真实面试问题为面试做准备。内特撰写有关职业市场最新趋势的文章,提供面试建议,分享数据科学项目,并涵盖所有 SQL 内容。
了解更多相关话题
什么是数据库?你需要了解的一切
原文:
www.kdnuggets.com/what-is-a-database-everything-you-need-to-know
彼得·桑德加德曾说,信息是 21 世纪的石油,分析是内燃机。如今,很难不同意他的观点。
就像储存油的大容量罐一样,你需要数据库来存储信息。由于信息量的增加,数据库自首次出现以来已经发展了很多。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你所在的组织进行 IT 工作
在这篇文章中,我们将通过回答一些基本问题来探索数据库。然后,我们将通过将其分为有意义的类别来发现当前流行的数据库。系好安全带,我们开始吧!
所有数据库的列表
让我们从对各种数据库环境的总体概述开始。在这一部分,我们将概述适用于不同目的和情况的许多数据库,分为五个不同的类别:
-
轻量级数据库
-
企业级关系数据库
-
NoSQL 数据库
-
NewSQL 和分布式数据库
-
专业化和利基数据库
让我们开始了解轻量级数据库。
轻量级数据库

作者提供的图片
在这一部分,我们将探讨轻量级数据库,它们是小规模应用程序的关键元素。
它们以高效和简单著称。这些数据库非常适合那些不需要复杂、高级数据库系统的任务。
MySQL
MySQL 在网站中尤其流行。它快速且功能强大,拥有一个庞大的社区支持,帮助非常多。然而,当你的应用程序变大时,让 MySQL 处理所有额外的工作可能会很具挑战性。在复杂的数据分析方面,它可能不如其他选择。
SQLite
这种简单且小型的数据库非常适合小程序或应用。由于它只是一个文件,移动起来很方便。然而,如果很多人同时使用应用,SQLite 可能会面临困难。对于真正大型或复杂的应用,有更好的选择。
PostgreSQL
PostgreSQL是免费的,并且有许多不错的功能。它非常适合处理复杂数据并对这些数据进行复杂操作。然而,如果你的应用程序需要持续写入大量数据,PostgreSQL 可能会变慢。
MariaDB
MariaDB提高了MySQL的性能和安全性。由于 MariaDB 具有与 MySQL 相似的特性,如果你了解 MySQL,你可以快速过渡。然而,它的普及程度稍逊于 MySQL。
企业级关系数据库
图片来源:作者
企业级关系数据库适合大型和复杂的应用程序。它们提供了增强的安全性和广泛的数据管理,这是企业的业务需求。
Microsoft SQL Server
如果你使用其他微软产品(如.NET)构建应用程序,Microsoft SQL Server是一个不错的选择。它以极高的安全性和可靠性而闻名。缺点是它主要与 Windows 兼容,并且可能很昂贵。
Oracle 数据库
Oracle以极高的可靠性和稳健性而闻名。它是大型公司的首选。它具有先进的安全性,并能很好地处理大量数据。然而,Oracle 价格昂贵,使用复杂规则多且学习曲线陡峭。
IBM Db2
IBM DB2是为大型企业设计的。它擅长数据分析和从数据中学习。它可靠且能处理大量工作。但它的管理很棘手,通常更适合大型组织或特殊的业务需求。
NoSQL 数据库

图片来源:作者
NoSQL 数据库提供了灵活性和可扩展性。这个领域涵盖了适应当前动态数据需求的非结构化和半结构化数据数据库。
MongoDB
这个灵活的数据库不需要固定结构,非常适合管理多种数据类型。它可以扩展以处理更多工作,并具有强大的数据查找功能。
但对于需要复杂数据连接的任务,它可能不如某些传统数据库。
Cassandra
Cassandra被设计为处理大量数据分布在多台计算机上。它非常可扩展且可靠。但规划如何在 Cassandra 中存储数据可能很棘手,如果你习惯了传统数据库,它学习起来更困难。
CouchDB
CouchDB适用于需要简单、可扩展的数据库的 Web 应用程序,该数据库使用流行的数据格式 JSON。它具有出色的 Web 界面,并能很好地在不同地点复制数据。然而,它可能不如其他数据库适合非常复杂的搜索或大量数据。
DynamoDB
DynamoDB是亚马逊云服务的一部分。它擅长调整变化的工作负载,并能处理大量流量。但它的数据搜索和组织选项有限,因此可能会很昂贵。
Neo4j
Neo4j 非常适合处理连接数据,如社交网络或推荐系统。它的特别之处在于可以很好地处理数据之间的复杂关系。但它的应用较为小众,设置起来可能较为困难。
NewSQL 和分布式数据库

图片由作者提供
它们结合了传统数据库的稳定性与 NoSQL 系统的可扩展性;让我们开始探索它们吧。
HIVE/Hadoop
Hive,作为 Hadoop 生态系统的一部分,非常适合使用简单查询处理大数据集。它设计用于处理大数据,并且在复杂数据分析中表现良好。然而,Hive 在处理实时问题时可能会较慢,并且可能不是快速互动应用的最佳选择。
Apache Kafka
Apache Kafka 主要是一个流处理平台,非常适合处理和分析实时数据流。它具有很高的可扩展性和可靠性,适合管理大量数据流。然而,Kafka 更像是数据处理工具,而不是传统数据库,因此设置复杂,需要特定的专业知识来有效管理。
Greenplum
Greenplum 非常适合大数据分析。它可以扩展以处理更多数据,并且与机器学习工具配合良好。然而,设置和管理起来可能较为复杂,并且需要大量计算资源。
CockroachDB
它在多台计算机上也能保持强大和一致。它可以轻松扩展,处理类似传统数据库的事务。然而,其设计复杂,可能对较小的应用来说过于庞大。
Amazon Aurora
Amazon Aurora 是亚马逊云的一部分。它运行快速,并且兼容 MySQL 和 PostgreSQL。它为云设计,可靠且能够处理大量工作。然而,随着使用增多可能会变得昂贵,并且主要仅限于亚马逊云。
Amazon Aurora 是亚马逊云的一部分。它运行快速,并且兼容 MySQL 和 PostgreSQL。它为云设计,可靠且能够处理大量工作。然而,随着使用增多可能会变得昂贵,并且主要仅限于亚马逊云。
专门化和小众数据库

图片由作者提供
最后,我们探讨专门化和小众数据库。这些数据库针对特定数据类型进行定制,并提供常规数据库可能没有的功能。从实时分析到复杂数据建模,本节涵盖了定制化技术。
Elasticsearch
Elasticsearch 非常适合文本搜索和分析。它可以处理大量数据并且具有良好的扩展性。然而,在大型设置中可能会难以管理,通常也不是主要数据库。
RethinkDB
RethinkDB 设计用于实时 Web 应用。它允许灵活的数据组织和简单的更新。然而,它的发展速度减缓,因此相比其他数据库较为落后,支持也可能有限。
ArangoDB
ArangoDB 支持不同类型的数据,如文档和图形,并且在各种需求下表现良好。它性能优越,但知名度可能较低,这可能意味着学习过程较为困难,社区支持也较少。
InfluxDB
InfluxDB 针对随时间变化的数据(如 IoT 数据)进行了优化。它非常适合实时分析和监控。然而,它专门用于时间序列数据,因此并不适合所有数据库需求。
Redis
Redis 由于将数据存储在内存中,因此非常快速,这使其在快速数据访问和实时应用程序中表现出色。然而,数据量受限于内存大小,并且确保数据长期安全可能会很棘手。
如果你想发现有关数据库的面试问题,请查看这个 数据库面试问题。
结论
我们刚刚通过展示它们的优缺点,并将它们分成类别,深入探索了数据库世界的每一个角落。
Zig Ziglar 曾说过:“重复是学习之母。”他的这句话对于这些知识也适用。因此,如果你想巩固理解,请记得进行重复练习。
Nate Rosidi 是一名数据科学家和产品战略专家。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,这是一个帮助数据科学家准备顶级公司真实面试问题的平台。Nate 关注职业市场的最新趋势,提供面试建议,分享数据科学项目,并涵盖 SQL 的所有内容。
更多相关话题
什么是数据血统,为什么重要?
原文:
www.kdnuggets.com/what-is-data-lineage-and-why-does-it-matter
图片由 storyset 提供,来自 Freepik
在任何数据管道中,从源头获取的数据通常会经历多次转化,以至于从目的地获得的数据与实际从源头获取的数据差异很大。数据血统提供了一种全面的方法来绘制数据在系统中的流动路径——从源头到目的地——以及其在过程中经历的转化。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
在这篇文章中,我们将了解数据血统及其重要性。我们还将看到数据血统如何促进更好的数据管理,并介绍一些您可以用来处理数据血统的工具和平台。
让我们开始吧!
什么是数据血统?
数据血统是指跟踪和可视化数据在数据管道或系统中经过各个阶段的流动和转化。它提供了对数据在组织数据管道中起源、移动和转化的详细理解,使数据专业人员能够追踪数据从源头到目的地的路径。
对数据生命周期的这种全面理解对于那些旨在提升数据质量、确保合规性等的组织非常有帮助。
数据血统的关键组成部分
现在让我们探讨数据血统中需要考虑的关键组成部分:
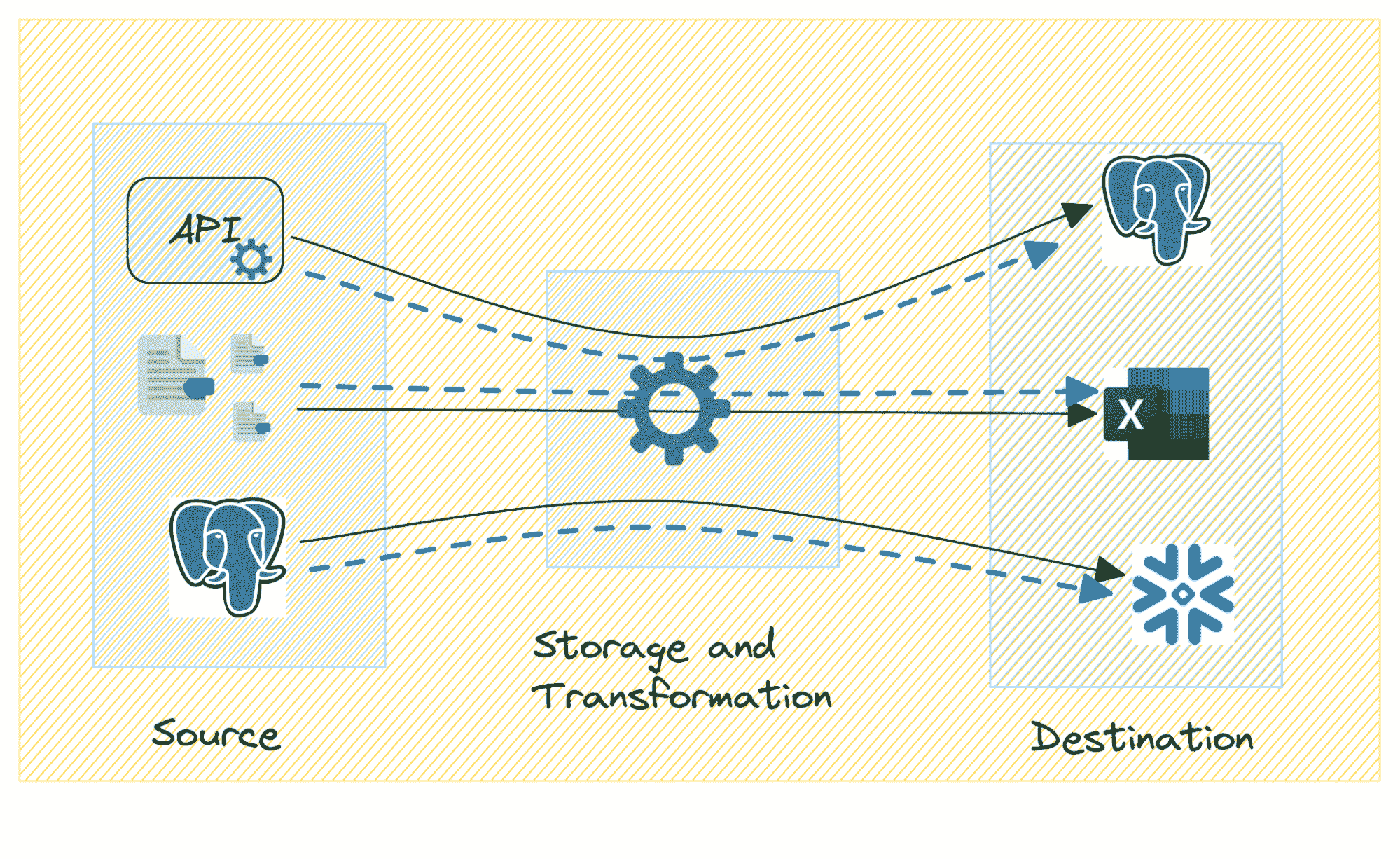
图片由作者提供
-
源系统:该组件关注数据的初始来源,如数据库、日志文件、传感器、应用程序和其他外部来源。
-
元数据:捕捉与数据相关的元数据非常重要,因为它包括数据类型、格式以及对数据应用的任何业务规则或约束的详细信息。
-
数据移动和转换:跟踪 ETL 过程有助于理解数据如何从源系统提取、经历多样的转换并加载到目标系统。
-
目的地:数据血缘还应跟踪数据的各种中间和最终目的地,包括数据库、数据仓库、数据湖等。它还包括参与信息处理和存储的其他存储系统。最终目的地通常是存储处理数据以供分析或报告的地方。
本质上,数据血缘提供了数据流的清晰全面视图,帮助组织理解依赖关系和联系。因为数据血缘不仅仅提供数据流的快照,它还使组织能够对数据管理和利用做出明智的决策。
数据血缘的重要性
现在我们知道了数据血缘是什么,让我们继续学习它的重要性和原因。
数据质量和完整性
数据血缘通过提供数据旅程的透明视图,有助于保持数据质量。这种透明度确保数据保持准确、可信,并与业务目标一致。
此外,数据血缘还通过血缘追踪来帮助缓解数据质量问题。通过跟踪数据(及其相关元数据)的流动,组织可以快速识别并解决数据质量问题。
监管合规
数据血缘通过提供数据移动、转换和存储的全面记录,帮助组织满足监管要求。清晰地了解数据从源头到目的地的整个旅程及其转换过程,数据血缘作为确保遵守法律和行业特定规定的强有力机制。
故障排除和调试
数据血缘还帮助高效识别和解决数据问题。它通过提供识别故障点或不一致性的指南,简化了故障排除过程。这加速了数据相关问题的解决,减少了停机时间和操作中断。
数据血缘的应用
数据血缘还便于更容易的治理和提高整体效率等其他优势。
影响分析
数据血缘通过提供对数据源、结构或流程变更如何影响整个系统的清晰视图,有助于影响分析。这种理解在实施任何修改之前非常有帮助,以避免意外后果。
数据血缘还在做出明智决策和管理风险方面发挥作用:对数据如何被转换和使用有全面了解,决策者可以对变更、更新或实施做出明智的选择。这也确保潜在风险在对组织产生不利影响之前被识别和缓解。
审计和治理
数据治理依赖于透明度和问责制。数据血缘作为实施治理政策的基础工具,确保数据按照既定标准、安全协议和合规要求进行处理。
在审计过程中,监管者和内部审计员常常寻求对数据处理实践的洞察。数据血缘提供了数据移动、变换和存储的详细记录,促进了顺利审计,并证明了遵守监管要求。
更高效的运营
通过可视化数据流,组织可以识别数据工作流程中的冗余过程、瓶颈或低效之处。因此,数据血缘有助于消除不必要的步骤,优化数据管理的整体效率。
因为数据血缘提供了对数据流的全面而更好的理解:从数据提取到消费,它还指导工作流程优化,以减少处理时间,优化资源利用等。
总之,数据血缘的应用超越了其作为跟踪机制的角色。它作为组织评估变化影响、维持治理标准和优化运营效率的战略工具。
数据血缘工具和平台
正如你可能猜到的,数据血缘可以从一定程度的自动化中受益。由于自动化工具可以持续监控数据流动和变换,提供数据血缘的实时更新,它确保信息始终是最新的,并反映最新的变化。
数据血缘领域的一些显著工具包括:
-
Collibra:包括强大的数据血缘功能,用于可视化和理解数据的端到端旅程。
-
Informatica Axon:作为 Informatica 平台的一部分,Axon 提供数据治理和元数据管理。
-
IBM InfoSphere Information Governance Catalog:一个管理元数据并在复杂企业环境中提供端到端数据血缘跟踪的工具。
-
Apache Atlas:一个开源工具,提供全面的元数据管理和数据血缘能力,常用于大数据生态系统中。
-
Erwin Data Intelligence (DI):提供对数据资产的全面视图,包括数据血缘,以支持数据治理和合规工作。
总结
在这篇文章中,我们回顾了数据血缘及其在确保数据质量、合规要求等方面的重要性。此外,我们讨论了追踪数据血缘如何帮助进行影响分析和优化系统效率。
最后,我们介绍了一些可以用来跟踪数据血缘的工具。希望你觉得这篇文章对你有帮助!
Bala Priya C**** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在学习并与开发者社区分享她的知识,通过撰写教程、操作指南、观点文章等方式。Bala 还制作了引人入胜的资源概述和编码教程。
更多相关主题
数据科学到底是什么?
评论

请看我最简洁的尝试:
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持您组织的 IT 需求
数据科学是使数据变得有用的学科。
随时可以离开,或者留下来了解它的三个子领域。
这个术语没有人真正定义
如果你探索一下数据科学这一术语的早期历史,你会发现两个主题正在汇聚。让我为你稍作改述,供你娱乐:
-
大数据(更大的数据)意味着更多的计算机调整。
-
统计学家 无法从纸袋中脱身。
就这样,数据科学诞生了。我第一次听到的工作定义是“数据科学家是一个统计学家,但能编码。”对此我有很多看法,稍后会详细讲述,但首先,我们不妨看看数据科学本身?

Twitter 定义 约 2014 年。
我喜欢 2003 年数据科学杂志的发布方式,它直接聚焦于最狭窄的范围:“我们所说的‘数据科学’几乎指的是与数据有关的所有事物。” 所以……一切都包括在内?很难想到什么是不涉及信息的。(我应该停止思考这个问题,以免我的脑袋爆炸。)
从那时起,我们见证了无数的意见,从康威广为流传的维恩图(见下)到梅森和威金斯的经典帖子。
Drew Conway 对数据科学的定义。我的个人喜好更倾向于 Wikipedia 上的定义。
Wikipedia 有一个非常接近我教给学生的定义:
数据科学是一个‘统一统计学、数据分析、机器学习及其相关方法’的概念,目的是‘通过数据理解和分析实际现象’。
这有点复杂,所以让我看看是否可以简短明了:
“数据科学是使数据有用的学科。”
你现在可能在想,“不错的尝试,Cassie。很可爱,但这是一种极其有损的简化。‘有用’这个词如何能涵盖所有那些行话呢?”
好吧,我们用图片来争论一下吧。

这是为你准备的数据科学地图,完全忠于 Wikipedia 的定义。
这些东西是什么,你如何知道自己在地图上的位置?
如果你打算按 标准工具包 来划分,慢点。统计学家和机器学习工程师之间的区别并不是一个使用 R 另一个使用 Python。SQL 与 R 与 Python 的分类方法是有诸多不便之处的,其中之一就是软件会不断进化。(最近,你甚至可以在 SQL 中进行 ML)。你难道不希望有一个能持续有效的分类吗?事实上,干脆不看这一整段话。
也许更糟糕的是初学者最喜欢的空间划分方式。没错,你猜对了:按 算法 划分(惊讶吧!这就是大学课程的结构方式)。拜托,不要通过直方图与 t 检验与神经网络来进行分类。坦率地说,如果你聪明并且有一个观点,你可以用相同的算法处理数据科学的任何部分。它可能看起来像弗兰肯斯坦的怪物,但我向你保证,它可以被迫按你的要求行事。
剧情发展够多了!这是我提出的分类法:

无-一-多
这到底是什么?当然是决策!(在 不完全信息 下。当所有你需要的事实都对你可见时,你可以使用描述性分析来做出尽可能多的决策。只需查看事实,你就完成了。)
正是通过我们的行动——我们的决策——我们影响了周围的世界。
我曾承诺过我们将讨论如何使数据有用。对我来说,有用的概念与影响现实世界的行动紧密相关。如果我相信圣诞老人,这并不特别重要,除非它可能以某种方式影响我的行为。然后,根据这种行为的潜在后果,它可能会变得非常重要。正是通过我们的行动——我们的决策——我们影响了周围的世界(并邀请它反过来影响我们)。
所以这是为你准备的新决策导向图,包含了三种主要的方法来使你的数据有用。

数据挖掘
如果你还不知道你想做出什么决策,你能做的最好事情就是去寻找灵感。这被称为数据挖掘、分析、描述性分析、探索性数据分析(EDA)或知识发现(KD),具体取决于你在易受影响的时期与哪个圈子交往。
分析的黄金法则:只对你能看到的内容得出结论。
除非你知道如何框定你的决策,否则从这里开始。好消息是,这个比较简单。把你的数据集看作是在暗房里找到的一堆底片。数据挖掘就是快速操作设备,尽可能快地显现所有图像,以便查看是否有任何启发性的内容。就像处理照片一样,记住不要过于认真地对待你所看到的东西。你没有拍这些照片,所以你不了解屏幕外的内容。数据挖掘的黄金法则是:坚持在这里存在的内容。 只对你能看到的内容得出结论,绝不要对你看不到的内容得出结论(对于那你需要统计学和更多专业知识)。
除此之外,你没有做错的余地。速度是关键,所以开始练习吧。
数据挖掘的专业性取决于你检查数据的速度。保持警觉,不要错过有趣的细节。
暗房起初可能会让人感到害怕,但其实没那么复杂。只需学会操作设备即可。这里有一个R教程,另一个在Python中可以帮助你入门。你可以在开始享受乐趣时称自己为数据分析师,当你能够以闪电般的速度揭示照片(以及其他类型的数据集)时,你可以称自己为专家分析师。
统计推断
灵感便宜,但严谨却昂贵。如果你想超越数据,你需要专业的培训。作为一个拥有本科和研究生统计学专业背景的人,我可能有些偏见,但在我看来,统计推断(简称统计学)是三大领域中最困难且充满哲学性的。掌握它需要花费最多的时间。
灵感便宜,但严谨却昂贵。
如果你打算做出高质量、风险控制的重大决策,这些决策依赖于对超出你可用数据的世界的结论,你将需要将统计技能带入你的团队。一个很好的例子是,当你的手指悬停在 AI 系统的启动按钮上时,你突然想到需要在发布之前检查它是否有效(始终是个好主意,认真说)。离开按钮,叫上统计学家。
统计学是改变你思维的科学(在不确定性中)。
如果你想了解更多,我写了这篇 8 分钟的统计学超级总结供你欣赏。
机器学习
机器学习本质上是使用示例而不是说明制作事物标记的配方。 我写了一些相关文章,包括它是否不同于 AI,如何入门,企业为何在此失败,以及一系列通俗语言解析术语细节的前几篇文章(从这里开始)。哦,如果你想与不懂英语的朋友分享,其中一些文章已经翻译在这里。

数据工程
那么关于数据工程,即将数据提供给数据科学团队的工作呢?由于这是一个复杂的领域,我更愿意将其从数据科学的霸权野心中保护起来。此外,它与软件工程的关系更密切,而非统计学。
数据工程和数据科学之间的差异是前后之分。
你可以把数据工程与数据科学的区别视为前后之分。大多数技术工作(在数据诞生之前)可以舒适地称为“数据工程”,而一旦数据到达后(之后)我们所做的一切就是“数据科学”。
决策智能
决策智能完全围绕决策,包括使用数据进行大规模决策,这使得它成为一种工程学科。它通过引入社会科学和管理科学的观点来增强数据科学的应用方面。
决策智能添加了来自社会和管理科学的组件。
换句话说,它是数据科学中不涉及创建通用方法论等研究性内容的一个超集。
还想要更多?这是数据科学项目中的角色分析,可以在我继续敲击键盘的时候娱乐一下。
原文。已获转载许可。
相关:
了解更多关于此主题的信息
初级 ML 工程师实际需要知道什么才能获得聘用?
原文:
www.kdnuggets.com/what-junior-ml-engineers-actually-need-to-know-to-get-hired

照片由Mikhail Nilov提供
作为一名经验丰富的 ML 开发者,我曾在不同项目中聘用过许多初级工程师,我意识到有些技能对于初级开发者来说是必不可少的,这些技能会因项目和公司而异,但有一些基本技能是普遍要求的。
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织的 IT
在本文中,我们将讨论初级 ML 开发者在求职过程中应具备的关键技能。通过本文,您将更好地了解初级 ML 开发者获得第一份工作的必要技能。
大多数申请工作的初级开发者具备哪些技能?
寻找第一份工作的初级开发者通常来自其他领域,完成了一些 ML 课程。他们学会了基本的 ML 但没有深入的工程、计算机科学或数学背景。虽然成为程序员不需要数学学位,但在 ML 领域,强烈建议拥有数学知识。机器学习和数据科学是需要实验和微调现有算法或甚至创建自己算法的领域。没有一些数学知识,很难做到这一点。
拥有良好学位的大学生在这里具有优势。然而,虽然他们可能比没有专业教育的普通初级工程师具备更深的技术知识,但他们通常缺乏工作所需的实际技能和经验。大学教育旨在提供基础知识,往往很少关注市场需求技能。
大多数申请初级 ML 工程师职位的候选人对 SQL、向量嵌入和一些基本的时间序列分析算法没有问题。我也使用了像 Scikit-learn 这样的基本 Python 库,并应用了基本的问题解决和算法(聚类、回归、随机森林)。但这还不够。
受欢迎的课程缺乏哪些技能?
如你现在所理解的,大多数教育项目无法提供实际经验和对主题的深入理解。如果你决心在机器学习领域建立职业生涯,你需要自己学习一些内容,以提高你的市场竞争力。因为如果你不愿意学习,我这样说是出于关心,不要浪费时间——任何人都能进入 IT 行业的时代已经过去了。今天这是一个相当有竞争力的市场。
流行课程可能没有深入理解的一个关键技能是随机森林,包括剪枝、如何选择树的数量/特征等。虽然课程可能会覆盖随机森林的基本工作原理和实现方法,但它们可能不会深入探讨重要细节,或甚至讨论一些更高级的集成方法。这些细节对于构建有效模型和优化性能至关重要。
另一个常被忽视的技能是网页数据抓取。从网上收集数据是许多机器学习项目中的常见任务,但这需要掌握从网站抓取数据的工具和技术。流行课程可能会简要提到这个话题,但它们可能没有提供足够的实际经验来真正掌握这一技能。
除了技术技能外,初级机器学习开发人员还需要知道如何有效地展示他们的解决方案。这包括创建用户友好的界面和将模型部署到生产环境。例如,Flask 配合 NGrok 为创建机器学习模型的网页界面提供了强大的工具,但许多课程完全没有涉及这些内容。
另一个常被忽视的重要技能是 Docker。Docker 是一种容器化工具,允许开发人员轻松打包和部署应用程序。理解如何使用 Docker 对于将机器学习模型部署到生产环境和扩展应用程序非常有价值。
虚拟环境是管理依赖关系和隔离项目的另一个重要工具。虽然许多课程可能简要介绍了虚拟环境,但它们可能没有提供足够的实际经验,以便初级开发人员真正理解其重要性。
GitHub 是软件开发中版本控制和协作的关键工具,包括机器学习项目。然而,许多初级开发人员可能仅对 GitHub 有表面的了解,可能不知道如何有效地使用它来管理机器学习项目。
最后,像 Weights and Biases 或 MLFlow 这样的机器学习追踪系统可以帮助开发人员跟踪模型性能和实验结果。这些系统对于优化模型和提高性能非常有价值,但它们可能在许多课程中没有深入覆盖。
通过掌握这些技能,初级开发人员可以从竞争中脱颖而出,成为任何机器学习团队的宝贵资产。
要获得机器学习工程职位,你需要什么?
年轻的专业人士经常面临一个问题:要找工作,他们需要经验。但如果没有人愿意雇用他们,他们怎么能获得经验呢?幸运的是,在机器学习和编程领域,你可以通过创建个人项目来解决这个问题。这些项目允许你展示编程技能、机器学习知识以及对潜在雇主的动机。
这里有一些个人项目的想法,坦率说,我希望在申请我部门工作的人员中看到更多:
网页抓取项目
本项目的目标是从特定网站抓取数据并存储到数据库中。这些数据可以用于各种目的,如分析或机器学习。项目可能涉及使用像 BeautifulSoup 或 Scrapy 这样的库进行网页抓取,以及使用 SQLite 或 MySQL 进行数据库存储。此外,项目还可以包括与 Google Drive 或其他云服务的集成,以便备份和方便访问数据。
NLP 项目
在这里,你需要构建一个能够理解和回应自然语言查询的聊天机器人。聊天机器人可以集成附加功能,如地图集成,以提供更有用的回应。你还可以使用像 NLTK 或 spaCy 这样的库进行自然语言处理,以及使用 TensorFlow 或 PyTorch 构建模型。
CV 项目
本项目的目标是构建一个计算机视觉模型,能够检测图像中的物体。无需使用最复杂的模型,只需使用一些能够展示你在深度学习基础方面技能的模型,如 U-net 或 YOLO。项目可以包括使用 ngrok 或类似工具将图像上传到网站,然后返回检测到物体并用方框标记的图像。
声音项目
你可以构建一个文本转语音模型,将录制的音频转换为文本。该模型可以使用深度学习算法如 LSTM 或 GRU 进行训练。项目可以涉及使用像 PyDub 或 librosa 这样的库进行音频处理,以及使用 TensorFlow 或 PyTorch 构建模型。
时间序列预测项目
本项目的目标是构建一个能够根据过去的数据预测未来值的模型。项目可以涉及使用像 Pandas 或 NumPy 这样的库进行数据处理,以及使用 scikit-learn 或 TensorFlow 构建模型。数据可以来自各种地方,如股票市场数据或天气数据,并可以与网页抓取工具集成以自动化数据收集。
还有其他什么?
拥有一个能够展示你技能的良好作品集与来自知名大学的学位同样宝贵(甚至可能更宝贵)。然而,如今还有其他重要的技能:软技能。
发展软技能对机器学习工程师来说很重要,因为它帮助他们将复杂的技术概念传达给非技术利益相关者,有效地与团队成员协作,并与客户和顾客建立牢固的关系。发展软技能的一些方法包括:
-
创建博客。 尽管写作是一种孤独的实践,但它可以非常有效地帮助你提高沟通能力。以清晰简洁的方式写作技术概念可以帮助你更好地结构化思维,并掌握如何向不同观众解释复杂任务。
-
在会议和聚会中演讲。 在会议上演讲可以帮助机器学习工程师提高公众演讲技巧,并学习如何根据不同的观众调整信息传达方式。
-
训练向你的奶奶解释概念。 练习用简单的术语解释技术概念可以帮助机器学习工程师提高与非技术利益相关者沟通的能力。
总的来说,发展技术技能和沟通技能可以帮助你获得机器学习领域的第一份工作。
伊万·斯梅塔尼科夫**是 Serokell 的数据科学团队负责人。
更多相关话题
数据科学的“什么、在哪里和如何”
原文:
www.kdnuggets.com/2018/06/what-where-how-data-science.html
评论
数据科学是一个难以用单一完整定义来概括的术语,这使得其使用变得困难,尤其是当目标是正确使用它时。大多数文章和出版物随意使用这一术语,假设它是普遍理解的。然而,数据科学——其方法、目标和应用——随着时间和技术的发展而不断演变。25 年前的数据科学指的是收集和清理数据集,然后应用统计方法。在 2018 年,数据科学已发展成为一个涵盖数据分析、预测分析、数据挖掘、商业智能、机器学习等更多领域的领域。
实际上,由于没有一个定义可以完全适用,因此由从事数据科学的人来定义它。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能。
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求。

认识到需要对数据科学进行明确的解释,365 数据科学团队设计了什么-哪里-谁信息图。我们定义了数据科学的关键过程并传播该领域。以下是我们对数据科学的解读(点击信息图查看更大图像)。
当然,这看起来可能是大量的信息,但其实并不是如此。在这篇文章中,我们将拆解数据科学,并将其重新构建成一个连贯且易于管理的概念。请耐心等待!
数据科学,“在一分钟内解释”,如下所示。
你有数据。要利用这些数据来指导你的决策,它需要相关、组织良好,并且最好是数字化的。一旦数据连贯,你就可以开始分析数据,创建仪表板和报告,以更好地了解业务表现。然后,你会把目光投向未来,开始生成预测分析。通过预测分析,你评估潜在的未来场景,并以创新的方式预测消费者行为。
但让我们从头开始。
数据科学中的数据
在任何其他事情之前,总是要有数据。数据是数据科学的基础;它是所有分析的依据。在数据科学的背景下,有两种类型的数据:传统数据和大数据。
传统数据是结构化存储在数据库中的数据,分析师可以从一台计算机上进行管理;它是表格格式的,包含数字或文本值。实际上,"传统"这个术语是为了清晰起见引入的。它有助于强调大数据与其他类型数据之间的区别。
另一方面,大数据则比传统数据“大”得多,而且不是简单的意义上的大。从种类(数字、文本,甚至图像、音频、移动数据等),到速度(实时检索和计算),到体积(以太字节、拍字节、艾字节计量),大数据通常分布在计算机网络上。
也就是说,让我们定义一下数据科学中的 What-Where-and-Who 的特点。
在数据科学中你对数据做什么?
数据科学中的传统数据
传统数据存储在关系数据库管理系统中。
也就是说,在准备处理之前,所有数据都需要经过预处理。这是一组必要的操作,将原始数据转换为更易于理解的格式,从而对进一步处理有用。常见的过程包括:
- 收集原始数据并存储在服务器上
这是未经处理的数据,科学家无法直接分析。这些数据可以来自调查,或通过更常见的自动数据收集方式,如网站上的 cookies。
- 给观察值打上类别标签
这包括按类别排列数据或将数据点标记为正确的数据类型。例如,数字型或分类型。
- 数据清洗 / 数据擦洗
处理不一致的数据,如拼写错误的类别和缺失值。
- 数据平衡
如果数据不平衡,使得类别包含的观察数不均等且不具代表性,则应用数据平衡方法,如为每个类别提取相等数量的观察,并准备好进行处理,可以解决这个问题。
- 数据洗牌
重新排列数据点以消除不必要的模式,并进一步提高预测性能。例如,当数据中的前 100 个观察值来自使用网站的前 100 个人时;数据并未随机化,因此会出现由于抽样而产生的模式。
数据科学中的大数据
当涉及到大数据和数据科学时,虽然与传统数据处理方法有一些重叠,但也存在许多差异。
首先,大数据存储在许多服务器上,其复杂程度要高得多。
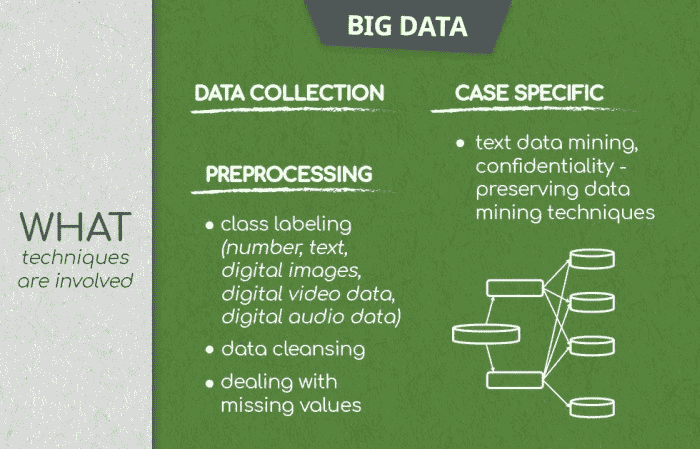
为了用大数据进行数据科学,预处理尤为关键,因为数据的复杂性大大增加。你会发现,从概念上讲,一些步骤与传统数据预处理类似,但这是处理数据时的固有特性。
-
收集数据
-
对数据进行分类标记
请记住,大数据极其多样,因此标签不是“数字”与“分类”之分,而是“文本”、“数字图像数据”、“数字视频数据”、“数字音频数据”等。
- 数据清洗
这里的方法也极其多样;例如,你可以验证数字图像观察是否准备好进行处理;或者数字视频,等等。
- 数据掩码
在大规模收集数据时,目的是确保数据中的任何机密信息保持私密,而不影响分析和洞察提取。该过程涉及用随机和虚假的数据掩盖原始数据,使科学家能够进行分析而不泄露私人细节。当然,科学家也可以对传统数据进行这种处理,有时也是这样做,但在大数据中,信息可能更为敏感,因此掩盖更为紧迫。
数据来自哪里?
传统数据可能来自基本的客户记录或历史股票价格信息。
然而,大数据无处不在。越来越多的公司和行业在使用和生成大数据。例如,在线社区,如 Facebook、Google 和 LinkedIn;或金融交易数据。各种地理位置的温度测量网格也构成了大数据,以及来自工业设备传感器的机器数据。当然,还有可穿戴技术。
谁处理数据?
处理原始数据和预处理、创建数据库并维护数据库的数据专家可能有不同的名称。尽管他们的职位名称相似,但他们所承担的角色存在明显差异。考虑以下几点。
数据架构师和数据工程师(以及大数据架构师和大数据工程师)在数据科学市场中至关重要。前者从零开始创建数据库;他们设计数据的检索、处理和使用方式。因此,数据工程师利用数据架构师的工作作为基础,并处理(预处理)可用的数据。他们确保数据的清洁和组织,使其准备好供分析师使用。
另一方面,数据库管理员是控制数据流入和流出数据库的人。当然,随着大数据的发展,这一过程几乎完全自动化,因此实际上不需要人工管理员。数据库管理员主要处理传统数据。
也就是说,一旦数据处理完成,数据库清洁和组织好,真正的数据科学才开始。
数据科学
还有两种看待数据的方式:一种是解释已经发生的行为,并为此收集了数据;另一种是利用已有数据预测尚未发生的未来行为。

数据科学解释过去
商业智能
在数据科学进入预测分析之前,它必须查看过去提供的行为模式,分析这些模式以提取洞察,并为预测提供路径。商业智能正是专注于此:提供数据驱动的答案,例如:销售了多少单位?哪个地区销售最多?哪种类型的商品销售在哪里?电子邮件营销在上个季度的点击率和产生的收入如何?与去年同季度的表现相比如何?
尽管商业智能在其标题中没有“数据科学”这个词,但它是数据科学的一部分,而且不是任何微不足道的部分。
商业智能做什么?
当然,商业智能分析师可以应用数据科学来衡量业务表现。但是,为了使商业智能分析师实现这一目标,他们必须使用特定的数据处理技术。
所有数据科学的起点是数据。一旦相关数据掌握在商业智能分析师手中(月度收入、客户、销售量等),他们必须量化观察结果,计算关键绩效指标(KPI),并检查度量,以从数据中提取洞察。
数据科学就是讲述一个故事
除了处理严格的数值信息外,数据科学,尤其是商业智能,还涉及可视化发现,并创建仅由最相关数字支持的易于理解的图像。毕竟,各级管理层应能够理解数据中的洞察,并以此指导决策。

商业智能分析师创建仪表板和报告,并配以图表、图解、地图和其他类似的可视化效果,以展示与当前业务目标相关的发现。
商业智能在哪里被使用?
价格优化与数据科学
值得注意的是,分析师应用数据科学来指导如价格优化技术等事务。他们实时提取相关信息,与历史数据进行比较,并采取相应措施。以酒店管理行为为例:管理层在许多人想要访问酒店的时期提高房价,而在低需求时期则降低房价,以吸引游客。
库存管理和数据科学
数据科学和商业智能对于处理过剩和短缺问题是不可或缺的。对过去销售交易的深入分析可以识别季节性模式和销售最高的时间段,从而实施有效的库存管理技术,以最低成本满足需求。
谁负责数据科学的 BI 分支?
BI 分析师主要集中于对过去历史数据的分析和报告。
BI 顾问通常只是‘外部 BI 分析师’。许多公司外包他们的数据科学部门,因为他们不需要或不想维持一个。BI 顾问如果被聘用,实际上就是 BI 分析师,不过,他们的工作更为多样化,因为他们会参与不同的项目。角色的动态特性为 BI 顾问提供了不同的视角,而 BI 分析师拥有高度专业化的知识(即深度),BI 顾问则贡献于数据科学的广度。
BI 开发人员是处理更高级编程工具(如 Python 和 SQL)以创建专门为公司设计的分析的人员。这是 BI 团队中第三频繁出现的职位。
那么,这就是数据科学的全部内容吗?
数据科学是一个模糊的术语,涵盖了从处理数据——传统数据或大数据——到解释模式和预测行为的所有内容。
数据科学可以通过传统方法如回归分析和聚类分析完成,也可以通过非传统的机器学习技术完成。
我们在这篇文章的第二部分讨论了数据科学预测方法。希望当你阅读完这部分内容后,数据科学的所有拼图都能拼凑完整!
简历: Iliya Valchanov 是 365 Data Science 的联合创始人。
本博客的一部分内容已发布在 365 Data Science Blog。经授权转载。
相关:
更多相关话题
今年数据世界将会发生什么
原文:
www.kdnuggets.com/2019/05/whats-going-happen-this-year-data-world.html
评论

引言
如果你沉浸在数据世界中,你很可能见过许多关于未来几年将会发生什么的文章、博客帖子和新闻,关于趋势和期望的内容。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
我读了很多这样的文章,如果你想查看完整内容,可以到文章的末尾找到。但是在这里,我想快速概述一下目前的情况,并分析人们谈论的不同趋势,以了解哪些可能性更大。
最常见的趋势

如果你搜索“数据科学”这个术语,你会发现大约有 5400 万条结果,这非常多。对这个领域的兴趣多年来一直在增长。
但数据科学现在非常重要,对于不同的人来说意义各异。如果你查看文章和新闻,最大的趋势有:





还有更多,但这些是最大的几个。同时每一个都有很多可以讨论的内容,但我现在想专注于两个(2)方面。自动化和图形。
自动化和图形(数据结构)

towardsdatascience.com/the-data-fabric-for-machine-learning-part-1-2c558b7035d7
如果你一直在关注我的研究,目前我最感兴趣的之一是数据结构。请记住,我对数据结构的定义是:
数据结构是支持公司所有数据的平台。它如何被管理、描述、组合和普遍访问。这个平台由企业知识图谱构成,以创建一个统一和统一的数据环境。
我想在这里强调两个重要点,数据架构由企业知识图谱构成,应该尽可能实现自动化。
其中一篇非常清楚地提到这一点的文章是来自 Gartner 的:
Gartner 识别 2019 年数据和分析技术的前 10 大趋势
增强分析、持续智能和可解释的人工智能(AI)是... www.gartner.com
他们说:
图处理和图数据库管理系统(DBMS)的应用将每年增长 100%,以持续加速数据准备并支持更复杂和适应性的 数据科学。
还有:
到 2022 年,定制的数据架构设计将主要以静态基础设施形式部署,这迫使组织进入一个新的成本浪潮,完全重新设计以适应更动态的数据网格方法。
很明显,图形概念和数据架构每年在数据公司中会变得更加普遍。但自动化呢?
在机器学习、深度学习和部署方面有许多进展。但正如我之前所说,数据是现在公司最重要的资产(也许是最重要的资产)。因此,在你可以应用机器学习或深度学习之前,你需要拥有数据,知道你拥有什么,理解它,治理它,清理它,分析它,标准化它(可能更多),然后你才能考虑如何使用它。
我们需要自动化来处理数据存储、数据清洗、数据探索、数据清理以及我们实际花费大量时间做的所有事情。你可以说像 DataRobot 这样的工具可以提供这些功能,但根据我的经验,这个领域还有很多工作要做。
这就是为什么我认为语义技术是解决此问题的途径。通过它们(如 Anzo),你可以实现自动查询生成(是的,这是一个功能),并使用它们处理复杂的图形,使提取特征变得简单,并最终实现完全自动化。
在我关于这个主题的最初几篇文章中,我提出了这样的架构:

towardsdatascience.com/deep-learning-for-the-masses-and-the-semantic-layer-f1db5e3ab94b
在你能随处见到自动化的地方。并且可以轻松地实时添加更多功能,比如可解释的 AI、持续智能等。在同一篇文章中,Gartner 提到:
持续智能是一种设计模式,其中实时分析被集成到业务操作中,处理当前和历史数据以建议应对事件的行动。它提供决策自动化或决策支持。
这个词并不新鲜,如果我们考虑流式分析,但我喜欢这个名字。实际上,发生的事情可以分为两部分:语义技术和自动化。
这里是过去 5 年语义技术的兴趣情况:
如我们所见,数据织物的高度并不高,但我认为这很快会改变。
结论
如果你想保持最新状态,最好开始考虑如何将你的数据湖升级为智能数据湖,同时自动化你的过程,从数据摄取到模型部署和监控,并利用图形技术。
再次重申,如果:
-
你有高度相关的数据。
-
你需要一个灵活的模式。
-
你需要一个结构化的方案,并构建更符合人们思维方式的查询。
如果你有高度结构化的数据,想要进行大量分组计算且表之间的关系不多,那么使用关系数据库可能更合适。
剑桥语义学的团队创建了这张很棒的信息图,让你更了解数据织物的宇宙:
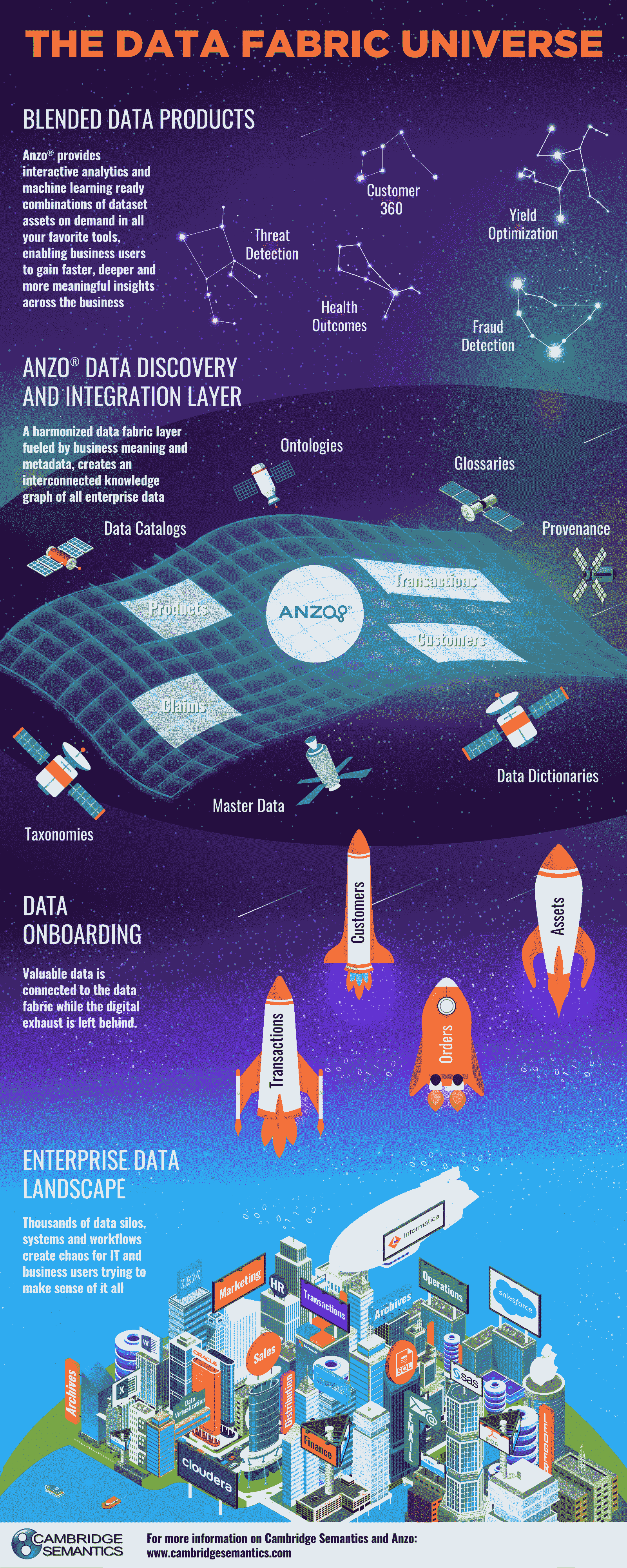
感谢阅读,希望这篇文章能给你在个人业务和生活中作为数据科学家的工作提供一些建议。
参考文献:
增强分析、持续智能和可解释的人工智能(AI)是…www.gartner.com](https://www.gartner.com/en/newsroom/press-releases/2019-02-18-gartner-identifies-top-10-data-and-analytics-technolo)
今年可以被视为人工智能(AI)的繁荣之年。看看初创公司数量…towardsdatascience.com](https://towardsdatascience.com/data-science-trends-for-2019-11b2397bd16b)
谈到 2019 年值得关注的主要数据科学趋势,去年的主要趋势从 2017 年延续下来,增长…www.dataversity.net](https://www.dataversity.net/data-science-trends-in-2019/#)
2018 年人工智能、数据科学、分析的主要发展和 2019 年的关键趋势
与以往一样,我们带来了一些专家的预测和分析总结。我们询问了主要…www.kdnuggets.com](/2018/12/predictions-data-science-analytics-2019.html)
我们寻求更多数据是有充分理由的:数据是推动数字创新的商品。然而,要将这些巨大的…www.datanami.com](https://www.datanami.com/2019/01/21/10-big-data-trends-to-watch-in-2019/)
新的一年,新的日历页。如果 2019 年与 2018 年类似,你可以确定数据、分析、机器学习……www.informationweek.com](https://www.informationweek.com/strategic-cio/5-data-and-ai-trends-for-2019/d/d-id/1333581)
[图形数据库。有什么大不了的?
继续对语义和数据科学的分析,是时候谈谈图形数据库及其有什么…towardsdatascience.com](https://towardsdatascience.com/graph-databases-whats-the-big-deal-ec310b1bc0ed)
[Anzo®
迄今为止,没有任何技术能够在企业规模上提供语义层——具有安全性、治理和……www.cambridgesemantics.com](https://www.cambridgesemantics.com/product/)
简介: Favio Vazquez 是一名物理学家和计算机工程师,从事数据科学和计算宇宙学工作。他热爱科学、哲学、编程和音乐。他是西班牙语数据科学出版物 Ciencia y Datos 的创始人。他喜欢接受新挑战,与优秀团队合作,并解决有趣的问题。他参与了 Apache Spark 的协作,帮助 MLlib、Core 和文档的工作。他热衷于将自己的科学、数据分析、可视化和自动学习知识应用于使世界变得更美好。
原文. 经许可转载。
相关:
-
解释性 AI 简介及其必要性
-
克服对生产性分析的信任障碍
-
哪个深度学习框架增长最快?
相关话题
数据科学的方法有什么问题?
原文:
www.kdnuggets.com/2019/07/whats-wrong-with-data-science.html
评论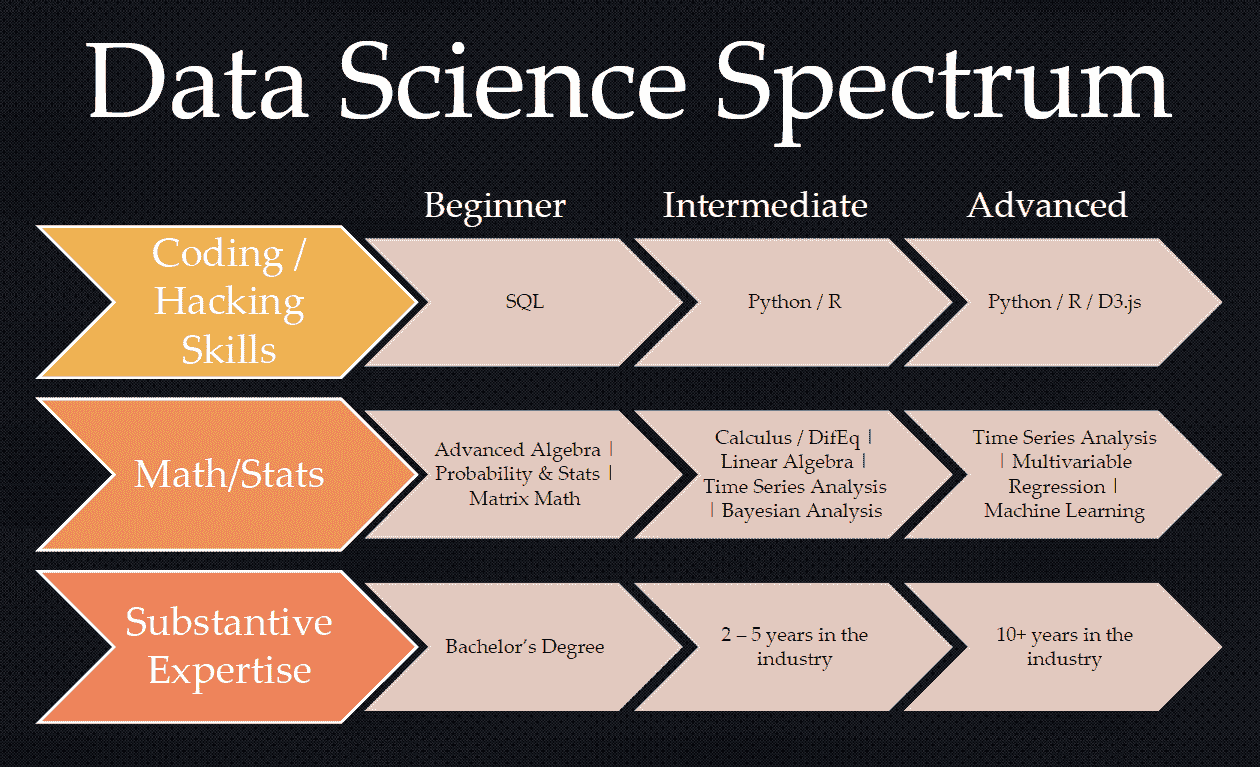 来源: https://www.data-mania.com/blog/real-vs-fake-data-scientists-what-you-really-need-to-know/
来源: https://www.data-mania.com/blog/real-vs-fake-data-scientists-what-you-really-need-to-know/
数据科学是将统计学、编程和领域知识应用于生成对需要解决的问题的洞察。《哈佛商业评论》称 数据科学家是 21 世纪最性感的职业。那篇文章被引用的频率有多高?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
职业“数据科学家”已经存在了几十年,只是以前没有称为“数据科学家”。统计学家们已经使用机器学习技术,如逻辑回归和随机森林进行预测和洞察。那些统计学家也通常在线性代数和微积分方面非常有知识。统计学家们甚至为数据科学贡献了最伟大的礼物之一——R。罗斯·伊哈卡和罗伯特·绅士是两位统计学家,他们为我们提供了 R 语言,使我们能够用几行代码进行复杂的分析。参见这篇论文:R: A Language for Data Analysis and Graphics by Ross Ihaka and Robert Gentleman。
近年来,分析师推测我们将在未来几年看到数百万数据科学家的短缺,大学正在推出新课程,潜在学生正在争相成为填补这一空缺的下一届数据科学家,获得$100,000 的薪水和美国№1 的工作(这并不是现实,尤其是对于初学者,尽管可能会有例外)。虽然大学教育在大多数情况下是足够的,但许多人选择了 MOOC 来支持他们的数据科学职业道路。Coursera、edX、Data Camp 和 Data Quest 是一些人们转向并信任的著名 MOOC。问题在于,参加这些课程的人可能在统计学基础方面不够合格,无法理解所教授的内容。
有些人忘记了数据科学或任何名称的工作都基于多年的辛勤工作、学习和对工作的热情。过去的统计学家并不像今天的“数据科学家”那样受到追捧。这个职业面临被贬值的风险,可能变成一个人可以花不到$100 就能在线开始的工作。我支持更多的教育和在线学习机会,但这个职业不应被贬值。
数据科学家在机器学习项目中需要考虑哪些因素?
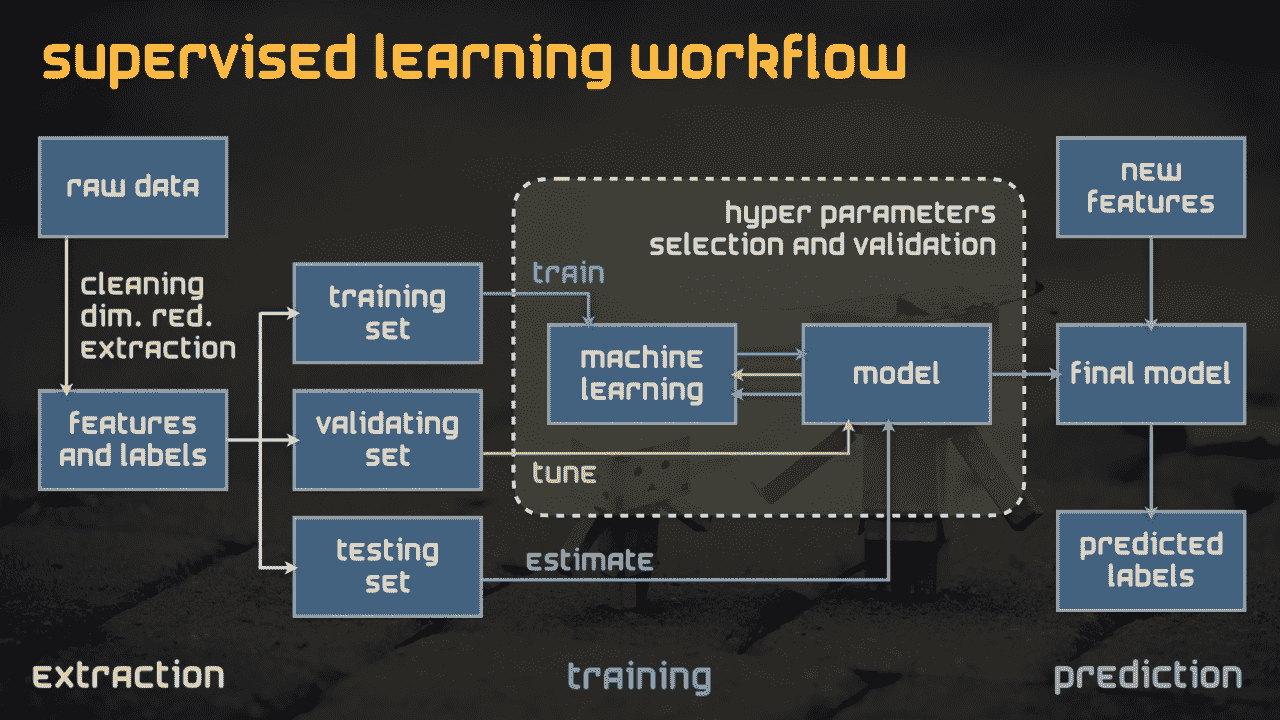 来源:
来源:这是一个人可以使用自动化技术构建模型的地方,但如果没有人类的直觉来指导,深入探讨问题的所在,模型仍然会失败。
数据预处理
处理异常值、缺失值、编码类别变量、分箱、类型转换、拼写错误、重复行、类别不平衡等,不能仅依靠自动化技术完成。根据媒体和当前数据科学家的说法,数据预处理占据了数据科学家工作量的 80%。虽然自动化可以在一定程度上提供帮助,但从探索性数据分析中得出的结论应该由具有行业知识或具备足够统计学知识的人做出。
超参数调优
机器学习包提供了具有默认超参数设置的模型用于训练和测试。可以简单地更改参数来调整模型。然而,仅仅更改参数而不探索这些更改的结果是浪费时间。更改超参数可能会导致模型过拟合、欠拟合、偏倚等。不同的模型也会有不同的探索方式。例如,在调整决策树时,最好绘制树形图以查看调整的结果,因为通过更改复杂性参数,你可能会修剪树到一个程度,以至于你的模型过拟合/欠拟合。
不平衡数据
这是所有现实世界数据面临的问题。类别不平衡并不是异常现象,而是需要在建模和评估阶段加以适应/考虑的东西。他们要么需要重新采样数据,要么改变每个类别的阈值概率(即,降低预测少数类别的阈值概率)。
结论
虽然有很多人成功完成了转型,但许多人并不如此积极地转型为医生、工程师或律师。数据科学的职业不应被稀释到我们说任何人都可以成为数据科学家的程度。每个人都应有机会选择任何职业,但说任何人都能做到这一点只会将这一职业稀释成不需要本科生、研究生或博士候选人所投入的工作量。
相关:
-
为什么你还不是一个具备就业准备的数据科学家
-
如果你是一名正在转型为数据科学家的开发者,这里是你最好的资源
-
学习数据科学硕士是否值得?
更多相关话题
当贝叶斯、奥卡姆和香农聚在一起定义机器学习时
原文:
www.kdnuggets.com/2018/09/when-bayes-ockham-shannon-come-together-define-machine-learning.html
评论
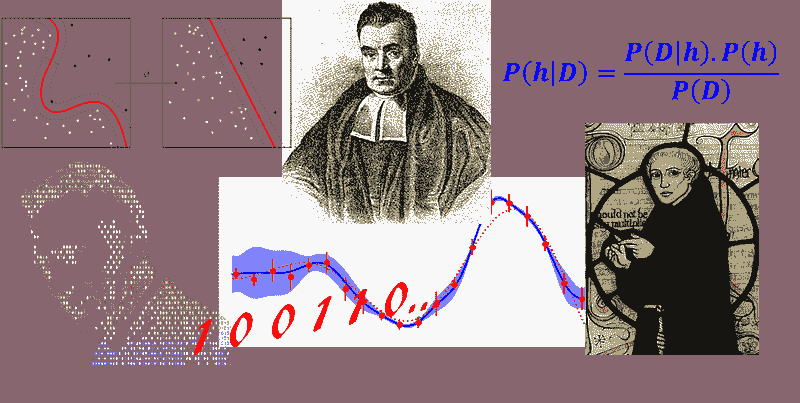
介绍
在所有机器学习的热门词汇中,令人有些惊讶的是,我们很少听到一个短语,它将统计学习、信息理论和自然哲学的一些核心概念融合成一个三字组合。
此外,这不仅仅是一个晦涩而迂腐的短语,仅适用于机器学习(ML)博士和理论家。它对任何有兴趣探索的人都有明确且易于理解的意义,并且对机器学习和数据科学的从业者有实际的回报。
我讲的是最小描述长度。你可能会想这究竟是什么…
让我们剥开层层迷雾,看看它有多有用…
贝叶斯及其定理
我们从托马斯·贝叶斯牧师开始(虽然不是按时间顺序),他没有发表过关于如何进行统计推断的想法,但后来因其同名定理而被永载史册。

这是 18 世纪下半叶,当时还没有叫做“概率论”的数学科学分支。它仅以相当古怪的“机会论”之名存在——这个名字源自亚伯拉罕·德·莫夫雷的一本书。一篇名为“解决机会论中的一个问题的论文”的文章,最初由贝叶斯提出,但由他的朋友理查德·普莱斯编辑和修订,于 1763 年提交给皇家学会并发表在《皇家学会哲学年刊》中。在这篇论文中,贝叶斯描述了——以一种相当频率主义的方式——关于联合概率的简单定理,从而产生了逆概率的计算,即贝叶斯定理。
自那以后,统计科学的两个对立派别——贝叶斯派和频率派——之间发生了许多争论。但为了本文的目的,让我们暂时忽略历史,专注于贝叶斯推断机制的简单解释。要了解一个非常直观的介绍,请参见布兰登·罗赫的这个精彩教程。我将只集中在方程上。
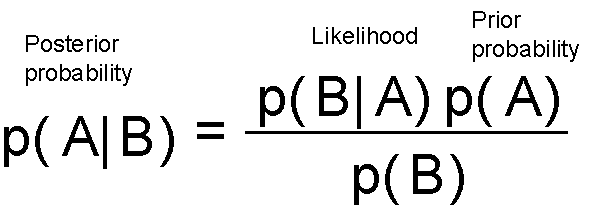
这基本上表明,你在看到数据/证据(似然)后更新你的信念(先验概率),并将更新后的信念赋值给术语 后验概率。你可以从一个信念开始,但每一个数据点都会加强或削弱这个信念,你会不断更新你的假设。
听起来简单而直观?很好。
我在段落的最后一句话中做了一个小把戏。你注意到了吗?我插入了一个词“假设”。这不是普通的英语。这是正式的术语 😃
在统计推断的世界里,假设是一种信念。它是对过程的真实本质的信念(我们无法观察到),这个过程生成了一个随机变量(我们可以观察或测量,尽管不是没有噪音)。在统计学中,它通常定义为一个概率分布。但在机器学习的背景下,它可以被认为是任何一套规则(或逻辑或过程),我们相信这些规则可以产生我们用来学习这个神秘过程隐藏本质的示例或训练数据。
那么,让我们尝试用不同的符号重新表述贝叶斯定理——即数据科学相关的符号。让我们用D表示数据,用h表示假设。这意味着我们应用贝叶斯公式来尝试确定给定数据,数据来自哪个假设。我们将定理重写为,
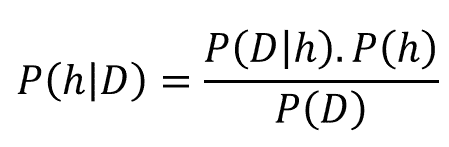
现在,一般来说,我们有一个大的(通常是无限的)假设空间,即许多假设可供选择。贝叶斯推断的本质在于我们想要检查数据,以最大化一个假设的概率,这个假设最有可能导致观察到的数据。我们基本上想要确定argmax的P(h|D),也就是说我们想知道对于哪个h,观察到的D最为可能。为此,我们可以安全地忽略分母中的P(D),因为它不依赖于假设。这个方案有一个颇为绕口的名字,叫做最大后验估计 (MAP)。
现在,我们应用以下数学技巧,
-
最大化在对数下的效果与在原始函数下相似,即取对数不会改变最大化问题。
-
积的对数是各个对数的和
-
最大化一个量等同于最小化负的量
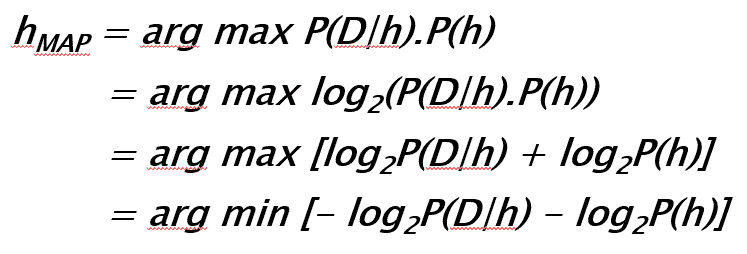
越来越奇怪和越来越奇怪……那些负对数为 2 的术语看起来很熟悉……来自信息论!
克劳德·香农登场。
香农
描述克劳德·香农的天才与奇特生活将需要many a volume,他几乎独自奠定了信息理论的基础,引领我们进入了现代高速通信和信息交换的时代。
香农的麻省理工学院硕士论文在电气工程领域被称为 20 世纪最重要的硕士论文:在这篇论文中,22 岁的香农展示了如何使用继电器和开关的电子电路来实现 19 世纪数学家乔治·布尔的逻辑代数。这一最基本的数字计算机设计特征——将“真”和“假”,“0”和“1”表示为开关的开与关,以及使用电子逻辑门进行决策和算术运算——可以追溯到香农论文中的洞见。
但这还不是他最大的成就。
在 1941 年,香农来到贝尔实验室,在那里他从事战争事务,包括密码学。他还在研究信息和通信背后的原创理论。在 1948 年,这项工作在贝尔实验室的研究期刊上以一篇广受赞誉的论文的形式发表。
香农通过一个类似于定义物理学中热力学熵的方程来定义源产生的信息量——例如,消息中的信息量。在最基本的术语中,香农的信息熵是编码消息所需的二进制数字的数量。对于具有概率p的消息或事件,最有效(即紧凑)的编码将需要-log2(p)位。
这正是那些出现在最大后验表达式中的术语的性质,它们是从贝叶斯定理中推导出来的!
因此,我们可以说,在贝叶斯推理的世界里,最可能的假设取决于两个唤起长度感的术语——而是最小长度。
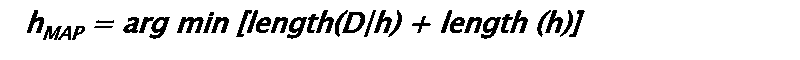
那么,这些术语中的长度概念是什么呢?
长度(h):奥卡姆剃刀
威廉·奥卡姆(约1287–1347)是一位英格兰方济各会修士和神学家,也是一位具有影响力的中世纪哲学家。他作为伟大逻辑学家的名声主要归功于他所提出的原则,即奥卡姆剃刀。术语剃刀指的是通过“剃除”不必要的假设或拆分两个类似结论来区分两个假设。
归于他的精确词语是:entia non sunt multiplicanda praeter necessitatem(实体不应被超出必要性地增加)。用统计术语来说,这意味着我们必须努力使用最简单的假设来令人满意地解释所有数据。
其他杰出人物也有类似的原则。
艾萨克·牛顿::“我们应当不引入更多自然现象的原因,除非这些原因既真实又足以解释其表现。”
伯特兰·罗素:“只要可能,就用已知实体的构造来替代对未知实体的推测。”
总是优先选择较短的假设。
需要一个关于假设长度的例子吗?
以下哪棵决策树的长度更小?A还是B?
即使没有对假设‘长度’的精确定义,我相信你也会认为左边(A)的树看起来更小或更短。当然,你会是对的。因此,一个较短的假设是那些具有更少自由参数,或较简单的决策边界(对于分类问题),或者这些可以表示其简洁性的特征的假设。
‘Length(D|h)’ 怎么样?
它是给定假设下的数据长度。这意味着什么?
从直觉上看,它与假设的正确性或表征能力有关。它决定了在给定假设的情况下,数据的“推断”效果如何。如果假设能够很好地生成数据,并且我们可以无误地测量数据,那么我们根本不需要数据。
想想牛顿运动定律。
当它们首次出现在Principia中时,并没有严格的数学证明支持。它们不是定理。它们更像是基于自然物体运动观察的假设。但它们非常准确地描述了数据。因此,它们成为了物理定律。
这就是为什么你不需要维护和记住一个所有可能的加速度数值与施加于物体上的力的函数的表格。你只需信任那个紧凑的假设,即法则F=ma,并相信你需要的所有数字都可以在必要时从中计算出来。这使得Length(D|h) 非常小。
但如果数据与紧凑假设的偏差很大,那么你需要有一个详细的描述,说明这些偏差是什么,可能的解释等。
因此,Length(D|h) 简洁地捕捉了“数据与给定假设的契合程度”的概念。
本质上,它是指错误分类或错误率。对于一个完美的假设,长度很短,极限情况下为零。对于一个不能完全拟合数据的假设,它通常比较长。
这就是权衡的问题所在。
如果你用大号的奥卡姆剃刀削减你的假设,你可能会得到一个简单的模型,它不能拟合所有的数据。因此,你需要提供更多的数据以获得更好的信心。另一方面,如果你创建一个复杂(且长)的假设,你可能能够非常好地拟合你的训练数据,但这实际上可能不是正确的假设,因为它与 MAP 原则相违背,即假设具有小熵。
听起来像是偏差-方差权衡?是的,也确实如此 😃
综合考虑
因此,贝叶斯推断告诉我们最佳假设是最小化两个项的总和:假设的长度和错误率。
在这一句深刻的话中,它几乎捕捉了所有的(监督)机器学习。
想想它的影响,
-
线性模型的模型复杂度——选择哪个次数的多项式,如何减少平方残差和
-
神经网络的架构选择——如何避免过拟合训练数据并实现良好的验证准确性,同时减少分类错误。
-
支持向量机正则化和核选择——在软边界与硬边界之间的平衡,即在准确性与决策边界非线性之间的权衡。
我们究竟应得出什么结论?
从对最小描述长度的分析中我们应该得出什么结论
长度(MDL)原则?
这是否一劳永逸地证明了短假设是最佳的?
不。
MDL 显示的是,如果选择一种假设表示,使得假设 h 的大小为——log2 P(h),并且如果选择一种例外(错误)的表示,使得在给定 h 的情况下 D 的编码长度等于-log2 P(D|h), 那么 MDL 原则将产生 MAP 假设。
然而,要展示我们有这样的表示,我们必须知道所有的先验概率 P(h),以及 P(D|h)。没有理由相信相对于假设和错误/分类错误的任意编码,MDL 假设应该被优先考虑。
对于实际的机器学习,有时为一个人类设计者指定一个能捕捉假设相对概率的表示形式可能比完全指定每个假设的概率更容易。
这就是知识表示和领域专业知识变得至关重要的地方。它绕过了(通常)无限大的假设空间,引导我们朝着一个高度可能的假设集前进,我们可以最优地编码并努力找到其中的 MAP 假设集。
总结与反思
一个美妙的事实是,简单的数学操作在概率论的基本恒等式上,可以产生对监督学习的基本限制和目标的深刻而简洁的描述。有关这些问题的简明处理,读者可以参考这篇名为“为什么机器学习有效”的卡内基梅隆大学博士论文。同时,也值得思考这些内容如何与无免费午餐定理相联系。
如果你对这一领域有更深入的阅读兴趣
如果你有任何问题或想法要分享,请通过tirthajyoti[AT]gmail.com联系作者。此外,你还可以查看作者的GitHub 仓库,了解其他有趣的 Python、R 或 MATLAB 代码片段以及机器学习资源。如果你和我一样,对机器学习/数据科学充满热情,请随时在 LinkedIn 上添加我或在 Twitter 上关注我。
简介:Tirthajyoti Sarkar 是一名半导体技术专家、机器学习/数据科学爱好者、电子工程博士、博主和作家。
原文。经许可转载。
相关:
-
数据科学的基础数学:‘为什么’和‘如何’
-
IT 工程师需要学习多少数学才能进入数据科学领域?
-
为什么你应该忘记数据科学代码中的‘for-loop’,而拥抱向量化
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关内容
当你的训练数据和测试数据来自不同的分布时应该怎么办
原文:
www.kdnuggets.com/2019/01/when-your-training-testing-data-different-distributions.html
评论
由Nezar Assawiel,机器学习开发者,Clinical AI 创始人

版权: www.chessbazaar.com/blog/game-chess-can-make-child-genius-smarter/
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
要构建一个表现良好的机器学习(ML)模型,必须在来自相同目标分布的数据上训练和测试模型。
然而,有时候只能收集到有限数量的目标分布数据。这可能不足以构建所需的训练/开发/测试集。
然而,类似的数据可能会从其他数据分布中轻松获得。在这种情况下应该怎么办?让我们讨论一些想法吧!
一些背景知识
为了更好地跟上讨论,如果你对以下基本的机器学习(ML)概念不熟悉,可以阅读一下:
-
训练、开发(开发)和测试集: 请注意,开发集也被称为验证集或保留集。这篇文章是一个很好的简短介绍。
-
偏差(欠拟合)和方差(过拟合)错误: 这篇文章对这些错误提供了很好的简单解释。
-
如何正确地划分训练/开发/测试集: 你可以参考这篇文章 以获得关于这一主题的简短背景介绍。
场景
假设你正在构建一个狗图像分类器应用程序,用于判断图像是否为狗。
该应用程序旨在为农村地区的用户提供服务,用户可以通过他们的移动设备拍摄动物照片,然后应用程序将对这些动物进行分类。
研究目标数据分布时——你发现这些图像大多模糊、分辨率低,并且类似于下图:

左:狗(意大利小型梗犬品种),右:北极狐。
你只能收集到 8,000 张这样的图像,这不足以构建训练/验证/测试集。假设你已经确定需要至少 100,000 张图像。
你想知道是否可以使用来自另一个数据集的图像——除了你收集的 8,000 张图像——来构建训练/验证/测试集。
你意识到你可以很容易地从网络上抓取数据,构建一个 100,000 张图像或更多的数据库,其图像中的狗和非狗的频率与所需的频率相似。
但是,很明显,这个网络数据集来自不同的分布,具有高分辨率和清晰的图像,如下所示:



狗的图像(左边和右边)和狐狸的图像(中间)。
你将如何构建训练/验证/测试集?
你不能仅仅使用你收集的 8,000 张原始图像来构建训练/验证/测试集,因为这些图像不足以构建一个表现良好的分类器。通常,计算机视觉和其他自然感知问题——语音识别或自然语言处理——需要大量的数据。
同样,你不能仅仅使用网络数据集。分类器在用户的模糊图像上的表现不好,而这些图像与用来训练模型的清晰、高分辨率的网络图像不同。
那么,你该怎么办?让我们考虑一些可能性。
一个可能的选择——打乱数据
你可以做的是将这两个数据集合并并进行随机打乱。然后,将结果数据集划分为训练/验证/测试集。
假设你决定将数据划分为 96:2:2%的训练/验证/测试集,这个过程将会是这样的:
使用这种设置,训练/验证/测试集都来自相同的分布,如上图中的颜色所示,这样是理想的。
但是,这里有一个很大的缺陷!
如果你查看验证集,从 2,000 张图像中,平均只有 148 张来自目标分布。
这意味着在大多数情况下,你是在为网络图像分布(2,000 张图像中的 1,852 张)优化分类器——这不是你想要的!
对于测试集也是如此,当评估分类器的性能时也是如此。因此,这不是一种好的训练/验证/测试集划分方式。
更好的选择
另一种选择是使验证/测试集来自目标分布的数据集,而训练集来自网络数据集。
假设你仍然使用 96:2:2%的划分比例用于训练/开发/测试集。开发/测试集将各包含 2,000 张图像——来自目标分布——其余部分将用于训练集,如下图所示:
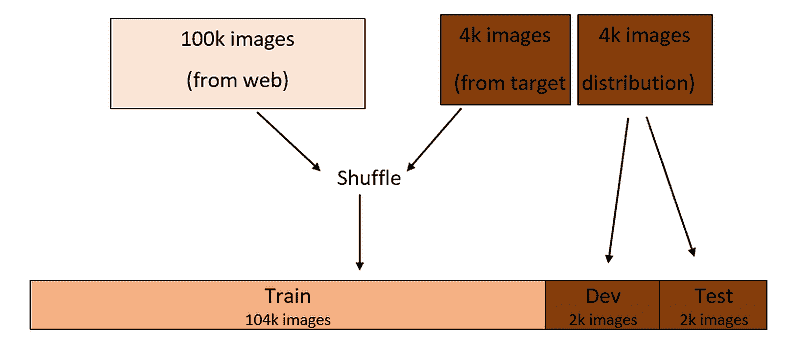
使用这种划分,你将优化分类器以在目标分布上表现良好,这正是你关心的。这是因为开发集的图像完全来自目标分布。
然而,训练分布现在不同于开发/测试分布。这意味着大部分时间你是在对网络图像进行分类器训练。因此,优化模型将需要更长的时间和更多的努力。
更重要的是,你将无法轻易判断开发集上的分类器错误相对于训练集错误是方差错误、数据不匹配错误,还是两者的组合。
让我们更详细地考虑一下这个问题,看看我们可以做些什么。
方差与数据不匹配
考虑上面第二种选项的训练/开发/测试划分。假设人为错误为零,以简化计算。
同样,假设你发现训练错误为 2%,开发错误为 10%。那么这 8%错误中有多少是由于这两个集之间的数据不匹配——考虑到它们来自不同的分布?有多少是由于模型的方差(过拟合)?我们无法得知。
让我们修改训练/开发/测试划分。拿出训练集的一小部分,称之为“桥接”集。桥接集将不用于训练分类器,而是作为独立集。现在的划分有四个集合,属于两个数据分布——如下所示:

方差错误
假设你发现训练错误和开发错误分别为 2%和 10%。你发现桥接错误为 9%,如下所示:

那么,训练集和开发集之间的 8%错误中,有多少是方差错误,有多少是数据不匹配错误?
很简单!答案是 7%是方差错误,1%是数据不匹配错误。但为什么呢?
因为桥接集来自与训练集相同的分布,且它们之间的错误差异为 7%。这意味着分类器过度拟合了训练集。这告诉我们我们面临一个高方差问题。
数据不匹配错误
现在,让我们假设你发现桥接集的错误率为 3%,其余的保持不变,如下所示:

训练集和开发集之间 8%的错误中有多少是方差错误,有多少是数据不匹配错误?
答案是 1%是方差错误,7%是数据不匹配错误。为什么?
这次,因为分类器在未见过的数据集上表现良好,如果它来自相同的分布,如桥接集。如果它来自不同的分布,如开发集,则表现较差。因此,我们遇到了数据不匹配问题。
减少方差错误是机器学习中的一个常见任务。例如,你可以使用正则化方法,或分配一个更大的训练集。
然而,减少数据不匹配错误是一个更有趣的问题。所以,让我们深入讨论一下。
减轻数据不匹配
为了减少数据不匹配错误,你需要以某种方式将开发/测试数据集的特征——即目标分布——融入训练集中。
从目标分布中收集更多数据以添加到训练集中总是最好的选择。但如果这不可行(如我们在讨论开始时假设的那样),你可以尝试以下方法:
错误分析
分析开发集上的错误以及这些错误与训练集上的错误的不同,可能会给你提供解决数据不匹配问题的思路。
例如,如果你发现开发集中的许多错误发生在动物图像的背景是岩石时,你可以通过将带有岩石背景的动物图像添加到训练集中来减少这些错误。
人工数据合成
另一种将开发/测试集的特征融入训练集的方法是合成具有类似特征的数据。
例如,我们之前提到,开发/测试集中的图像通常是模糊的,而我们训练集中的大部分图像来自网络,通常是清晰的。你可以人为地将模糊度添加到训练集的图像中,使其更类似于开发/测试集,如下图所示:

图像展示了训练集在模糊前后的变化。
然而,这里有一个重要的点需要注意!
你可能会使分类器过拟合于你所制造的人工特征。
在我们的例子中,你通过某些数学函数人工制造的模糊度可能仅是目标分布图像中存在的模糊度的一小部分。
换句话说,目标分布中的模糊度可能由于多种原因,例如雾霾、低分辨率相机、主体运动等。 但你合成的模糊度可能并不能代表所有这些原因。
更一般来说,在为任何类型的问题(例如计算机视觉或语音识别)合成训练数据时,你可能会使模型过拟合到合成的数据集上。
这个数据集可能在肉眼看来足够代表目标分布。但实际上,它只是目标分布的一个小子集。因此,使用这个强大工具——数据合成时,务必要记住这一点。
总结
在开发机器学习模型时,理想情况下,训练/开发/测试数据集都应来自同一数据分布——即模型在用户使用时将遇到的数据分布。
然而,有时从目标分布中收集足够的数据以构建训练/开发/测试集是不可能的,而来自其他分布的类似数据则很容易获得。
在这种情况下,开发/测试集应来自目标分布,而来自其他分布的数据可以用于构建(大部分)训练集。数据不匹配技术可以用来减轻训练集与开发/测试集之间的数据分布差异。
简历: Nezar Assawiel 是一位机器学习开发者和 Clinical AI 的创始人。
原文。已获许可转载。
相关:
-
我的训练数据和测试数据有多(不)相似?
-
什么是正态分布?
-
为什么数据科学家喜欢高斯分布
更多相关话题
NLP 的未来发展方向
评论
由Paul Barba,Lexalytics 首席科学家,inMoment 公司。

我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织在 IT 领域
随着我们能够获取的书面和口头语言语料库的普及,自然语言处理(NLP)已成为研究人员、组织甚至爱好者的宝贵工具。它使我们能够总结文档、分析情感、分类内容、翻译语言——有一天甚至可能达到人类水平的对话。
像任何人工智能和机器学习学科一样,自然语言处理(NLP)也是一个快速发展的领域,正在经历着快速变化,因为从业者和研究人员都在深入探索它所带来的前景。尽管 NLP 领域变化迅速,但我看到的一些趋势和机会如下。
提示:用几个选择词来激发 NLP
“提示”是一种技术,涉及在您的输入示例中添加一段文本,以鼓励语言模型执行您感兴趣的任务。比如您的输入文本是:“我们有一个很棒的服务员,但食物煮得不够熟。”也许您对比较不同餐馆的食物质量感兴趣。将评论附加“食物是”并观察“糟糕”或“很棒”哪个更可能成为续写的词,这样突然就为您提供了一个主题情感模型。鉴于“未熟”相关的负面情感,我们的缺失词几乎肯定是“糟糕”。
从零开始训练这样的模型需要大量的注释,但通过少量的示例或甚至没有示例,可以找到可行的解决方案,使得提示成为小规模项目和预算的可行选择。由于提示语言可以轻松更改,您可以在数据集上探索许多可能的分类法和功能,而无需为您的注释者确定最终的指南集。
站在巨人的肩膀上:跨模态的汇聚
随着领域的逐渐成熟,我们开始看到不同人工智能和机器学习学科之间的交叉传播。现在进入这一领域所需的背景知识减少了,取而代之的是我们开始看到扎实的通才。这促使了各种模式的融合,我们现在看到传统的基于文本的方法被带入数值领域,而传统上以 NLP 为导向的事物,如变换器网络,也被应用于视频甚至物理模拟。
对于创意思维者来说,机会和应用是广泛的:例如,三星正在将 NLP 与视频图像结合起来,帮助自动驾驶汽车解读外国的街道标志。NLP 和计算机视觉天作之合,我也期待看到它们被用来帮助将视频翻译为文本以提高可及性,改善医学图像的描述,甚至将口头设计请求转化为书面或视觉描述。
分享即关怀:开源模型推动知识进步
一个开源人工智能文化有利于创新,提供宝贵的反馈回路、改进和发展技术的机会,并为技术人员提供成长空间。像 DeepMind 这样的巨头通过 AlphaGo 和 AlphaZero 留下的研究论文和库开辟了道路,而现在像HuggingFace这样的较小竞争者也在与语言研究人员共同开发的商业/开源混合技术中做同样的事情。这些合作伙伴关系,如我们与 UMass 的合作,使得 NLP 社区对数据集、分词器和变换器有了更多的访问权限,深入了解技术细节,并为社区提供了迭代、推进和拓宽技术访问的机会——同时增强了我们的集体技能和知识。
公平竞争,算法:算法和人共同合作
算法和人类各有其优势,通过合作,它们可以产生卓越的结果。一个引起关注的领域是生成语言,但问题在于,尽管算法可以生成听起来像人类的输出,但它们不关心真实性。然而,有一个人类来监控准确性、相关性和格赖斯准则的其余部分,可以改善结果。这种合作关系在总结中同样有效,这是我感兴趣的领域。快速将一篇长文章浓缩成最重要的要点对人类来说出乎意料地困难,而机器在一定的约束条件下表现出合理的能力。另一方面,当我们要求机器将这些要点转换成连贯的总结时,它们往往会将意义改变为非事实的东西。但是,让机器突出文档中的关键思想,然后由人类将其转化为简短的摘录,效果优于单独工作。我认为,随着人工智能和自然语言处理在日常工作流程中变得更加嵌入,我们将看到越来越多这样的情况。
转换变换器:资源消耗更少的解决方案
BERT 和其他类似的知名技术是使用变换器构建的,这是一种模型,可以识别长块文本中目标词的相关依赖关系(句子中的词与目标词之间的关系)。变换器非常有效,但也极其资源密集,因为它们需要大量的预训练和数据。尽管变换器技术已经风靡一时,但我们开始看到替代方案的出现,因为小公司和团队正在寻求更适合小规模(和预算)问题的解决方案。HuggingFace 的变换器变体,SRU++及相关工作、Reformer(高效的变换器模型)以及类似 ETC/BigBird 的模型是潜在的替代方案,我预计这些将会受到更多关注,因为基于变换器的项目的计算成本变得难以承担。
技术陈词滥调:剩下的还在继续
人工智能和自然语言处理总是在不断发展和改进中,我们可以看到资源丰富的行业在赶上下一个大事时的起伏,而研究则需要一些时间来跟上并扩展我们的知识。这个周期,现在受到自然语言处理的开源性质、技术交叉传播和新行业应用的影响,将继续带来新的机会和进展供我们探索和利用。
相关内容:
更多相关话题
数据职业的下一步发展方向
原文:
www.kdnuggets.com/where-to-go-next-in-your-data-career注意: 这是系列文章的第二部分。查看第一部分请访问数据职业路线图
“你在 10 年后怎么看待自己?”
这个问题是否让你感到焦虑或困惑?有数百种变量可能影响我们在职业全景中的最终位置,有些在我们控制之内,有些则不在。但我们对每个角色的背景和要求理解得越透彻,我们就能越好地规划并利用出现的正确机会。
职业全景
以下地图展示了数据职业的全景,其中角色被分组为不同类别。
数据职业全景
这些类别根据相似的工作活动和交付物进行组织。个体贡献者角色位于顶部,管理和高管角色则在底部。然后,每个角色根据业务或技术的重点程度用颜色进行编码。一些类别,如分析,包含多个颜色轨迹,而其他类别如销售或配置则专注于单一颜色。中心的角色涉及多个类别的协调和规划。这些角色通常按最低资历在上、资历逐渐增加的顺序组织,但每个角色在某些组织中可能有多个资历等级,例如数据工程师等级 1 到数据工程师等级 5。每个角色可能因组织而异。
当你找到你目前所在的角色时,你可以开始评估你的位置和邻近角色。例如,业务分析师可能会制作演示文稿并使用软件来收集数据。随着分析师获得更多业务或技术技能,研究分析师和商业智能(BI)分析师角色将成为下一步。理论上,可以在全景图上的任何地方转变到新的角色,但最常见的步骤通常是在一个或两个步骤内或相邻类别中。
“配置”职位类别对许多新入行的人来说可能并不熟悉。这些角色可能有“Salesforce 开发者”、“SAP ABAP 开发者”或“NetSuite 配置顾问”等名称。在企业 IT 领域,这些角色很常见且薪资较高。但在大学课程中,这些角色很少被提及,因为它们涉及特定的软件包且不断发展。像 Salesforce 这样的平台允许公司使用低代码和全代码环境组合构建新应用程序。这个职位类别在咨询公司和供应商实施团队中不断招聘。
许多最有趣的数据角色跨越了多个类别。例如,数据科学家是分析和开发技能的结合。Dev/ML Ops 将融合软件配置和支持角色。这些跨类别的角色往往是最受追捧和薪资最高的,因为涉及了多种技能。许多人声称自己是多面手的独角兽,但并非每个人都能胜任广泛的技能。
职业迁移
以下图像展示了角色类别之间的典型迁移路径。
数据职业迁移
这些迁移路径是典型的职业晋升途径,但并不详尽。一般的移动模式是从上到下,随着你获得资历,可能会感到之前角色的疲惫。这些迁移模式很重要,因为它们可以解释你为什么没有收到职位申请的回应!例如,一位经验丰富的项目经理可能不会收到很多关于 Salesforce 开发人员(软件配置)的职位申请回应,因为这是一种罕见的组合。但软件工程师过渡到系统架构师角色将是自然的步骤,并不会让人感到惊讶。
迁移模式中的一个关键问题是:当你达到销售、管理或高管角色并决定回到以前的角色时会发生什么?很少有箭头指向相反的方向。这些在图表下方的角色通常具有较少的技术交付,并可能导致技能退化。如果你决定回到以前的角色,薪资通常也会较低。对于可能对管理或销售感到疲倦的人来说,有三个很好的选择:做咨询、教学或创业。虽然大公司中高管角色可能稀缺,但下一批创业公司中有着无限的供应!
选择职业路径
如果你刚刚开始,可以查看我在之前帖子中发布的路线图。在浏览路线图时,你可以决定哪种类型的轨迹最吸引你。技术轨迹可以轻松过渡到混合轨迹,但商业轨迹则不易过渡,因为需要编码技能。
选择职业轨迹
结论
如果你不知道自己 10 年后想做什么,也不用担心。我们中的大多数人都没有。你可以专注于评估你在数据职业领域中的位置,并识别对未来有吸引力的角色。如果你在地图上没有识别出任何角色,可以花点时间了解它们,也许会发现一些有趣的想法。如果你看到一个吸引人的角色超出了你的能力范围,那么你可以回到学校以进行过渡。好消息是,数据领域有丰富的机会,而且行业每年都在增长。
Stan Pugsley 是一位驻扎在盐湖城的自由职业数据工程与分析顾问。他还是犹他大学艾克尔斯商学院的讲师。你可以通过电子邮件联系作者。
更多相关话题
哪种深度学习框架增长最快?
原文:
www.kdnuggets.com/2019/05/which-deep-learning-framework-growing-fastest.html
评论
作者:Jeff Hale,Data Science DC 的联合组织者
在 2018 年 9 月,我在这篇文章中比较了所有主要的深度学习框架,涉及需求、使用情况和受欢迎程度。TensorFlow 是深度学习框架中的无可争议的重量级冠军,而 PyTorch 则是充满话题的新秀。????
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 需求
在过去六个月中,领先的深度学习框架的格局发生了什么变化?


为了回答这个问题,我查看了Indeed、Monster、LinkedIn和SimplyHired上的职位列表数量。我还评估了Google 搜索量、GitHub 活动、Medium 文章、ArXiv 文章和Quora 话题关注者的变化。总体而言,这些来源描绘了需求、使用和兴趣增长的全面图景。
集成与更新
我们最近看到 TensorFlow 和 PyTorch 框架中的几个重要进展。
PyTorch v1.0 于 2018 年 10 月预发布,同时 fastai v1.0 也发布了。这两个版本的发布标志着这两个框架成熟的重要里程碑。
TensorFlow 2.0 alpha 版于 2019 年 3 月 4 日发布。它新增了功能并改进了用户体验。它还更紧密地集成了 Keras 作为其高级 API。
方法论
在这篇文章中,我将 Keras 和 fastai 纳入了比较,因为它们与 TensorFlow 和 PyTorch 有着紧密的集成。它们也为评估 TensorFlow 和 PyTorch 提供了尺度。


我不会在本文中探讨其他深度学习框架。我预计会收到关于 Caffe、Theano、MXNET、CNTK、DeepLearning4J 或 Chainer 需要讨论的反馈。虽然这些框架各有优点,但似乎没有一个在增长轨迹上接近 TensorFlow 或 PyTorch,也没有与这两个框架紧密结合。
搜索在 2019 年 3 月 20-21 日进行。源数据在 这个 Google 表格中。
我使用了 plotly 数据可视化库来探索受欢迎程度。有关交互式 plotly 图表,请参见我的 Kaggle Kernel 这里。
让我们来看看每个类别中的结果。
在线职位列表的变化
为了确定今天的就业市场上哪些深度学习库受到需求,我搜索了 Indeed、LinkedIn、Monster 和 SimplyHired 上的职位列表。
我使用了 机器学习 这个术语进行搜索,后面跟上库的名称。因此,TensorFlow 是用 机器学习 TensorFlow 进行评估的。这种方法用于历史比较。没有 机器学习 的搜索结果并没有显著不同。搜索区域为美国。
我从 2019 年 3 月的职位列表中减去了六个月前的职位列表数量。以下是我发现的:
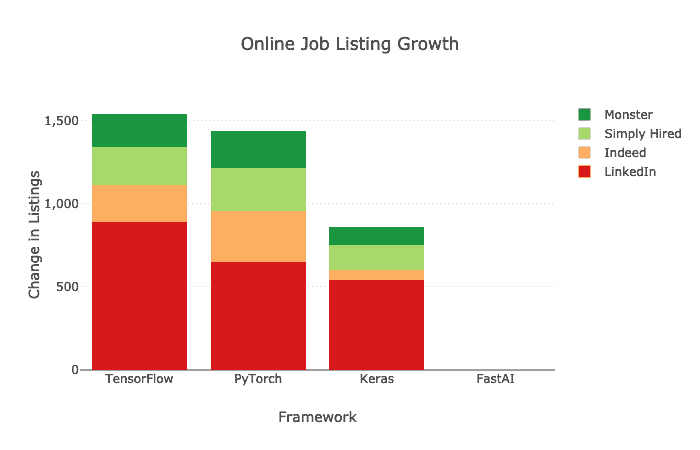
TensorFlow 的职位列表增长略高于 PyTorch。Keras 的职位列表也有所增长——约为 TensorFlow 的一半。Fastai 仍然几乎没有出现在职位列表中。
注意,在除 LinkedIn 外的所有招聘网站上,PyTorch 的额外职位列表数量都多于 TensorFlow。同时,按绝对数字来看,TensorFlow 出现在的职位列表数量几乎是 PyTorch 或 Keras 的三倍。
平均 Google 搜索活动的变化
最大搜索引擎上的网页搜索是受欢迎程度的一个衡量指标。我查看了过去一年 Google Trends 的搜索历史。我搜索了 机器学习和人工智能 类别的全球兴趣。Google 不提供绝对搜索数字,但提供了相对数据。
我计算了过去六个月的平均兴趣评分,并与之前六个月的平均兴趣评分进行了比较。
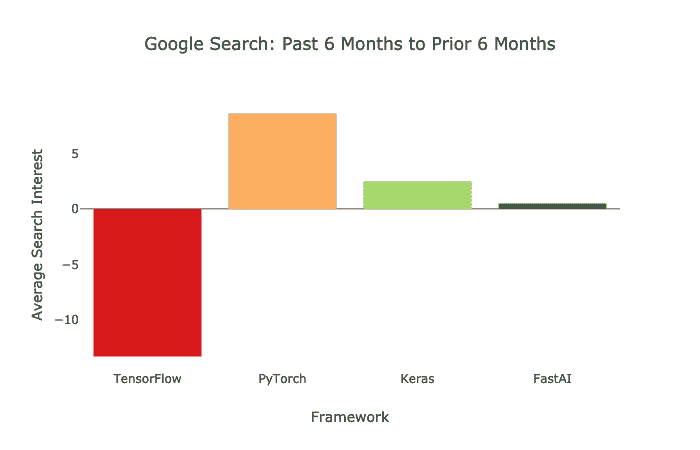
在过去六个月中,TensorFlow 的相对搜索量有所下降,而 PyTorch 的相对搜索量有所增长。
下面的 Google 图表显示了过去一年中的搜索兴趣。
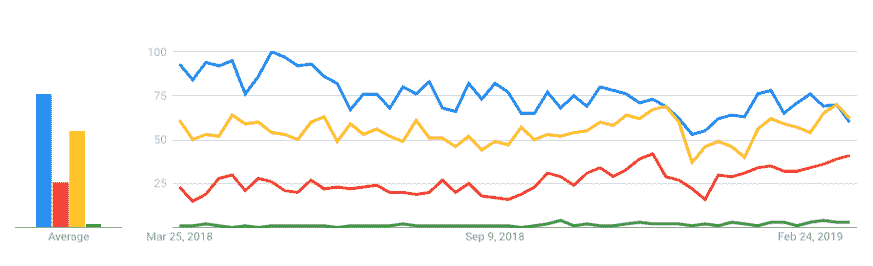 TensorFlow 用蓝色表示;Keras 用黄色表示,PyTorch 用红色表示,fastai 用绿色表示
TensorFlow 用蓝色表示;Keras 用黄色表示,PyTorch 用红色表示,fastai 用绿色表示
新的 Medium 文章
Medium 是一个受欢迎的数据科学文章和教程的发布平台。希望你喜欢它!????
我使用了过去六个月对 Medium.com 的 Google 网站搜索,发现 TensorFlow 和 Keras 的文章数量相似。PyTorch 相对较少。
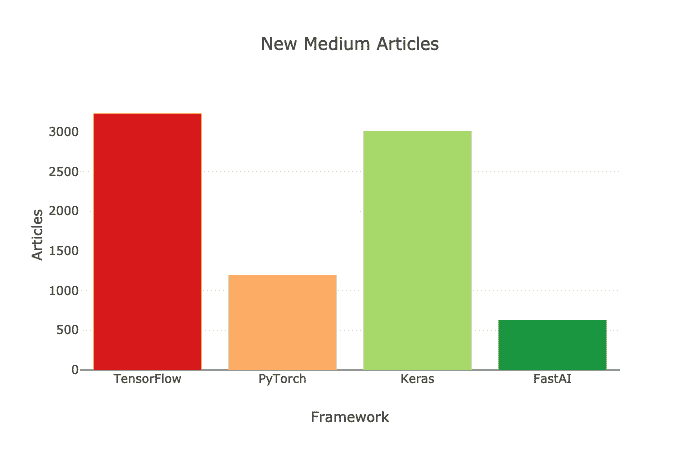
作为高级 API,Keras 和 fastai 受到新深度学习从业者的欢迎。Medium 上有许多教程展示如何使用这些框架。
新的 arXiv 文章
arXiv 是大多数学术深度学习文章发布的在线库。我使用 Google 网站搜索结果,搜索了过去六个月提到每个框架的新文章。
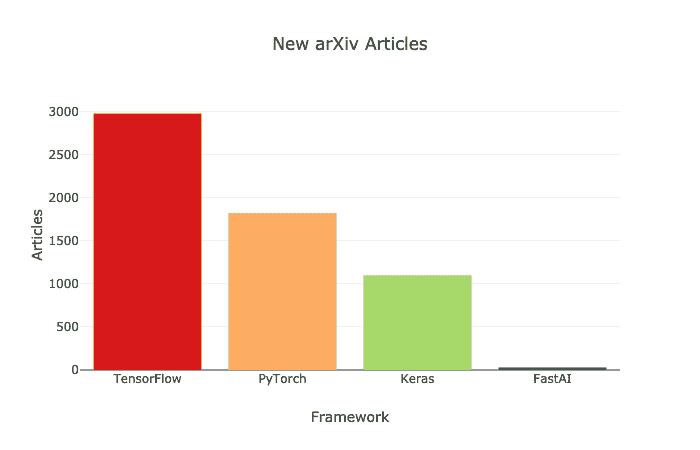
TensorFlow 的新文章出现次数领先,差距很大。
新的 GitHub 活动
最近的 GitHub 活动是框架受欢迎程度的另一个指标。我在下面的图表中分解了 stars、forks、watchers 和 contributors。
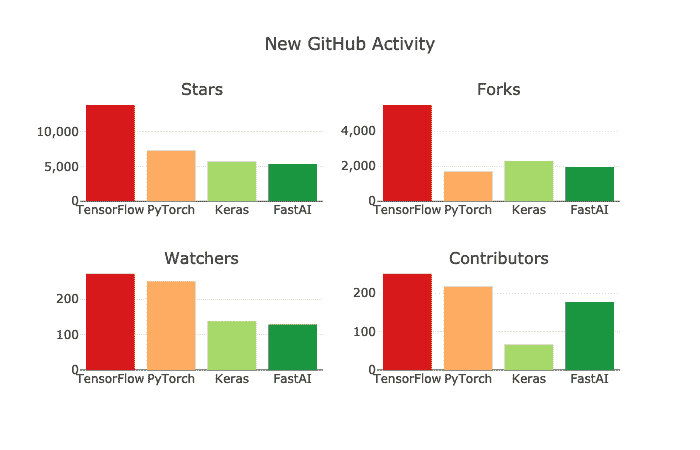
TensorFlow 在每个类别中都有最多的 GitHub 活动。然而,PyTorch 在观察者和贡献者的增长方面非常接近。同时,Fastai 也吸引了许多新的贡献者。
Keras 的一些贡献者无疑是在 TensorFlow 库中进行工作的。值得注意的是,TensorFlow 和 Keras 都是由谷歌员工领导的开源产品。
新的 Quora 关注者
我将新的 Quora 主题关注者数量也纳入了分析——这是我以前没有数据的新类别。
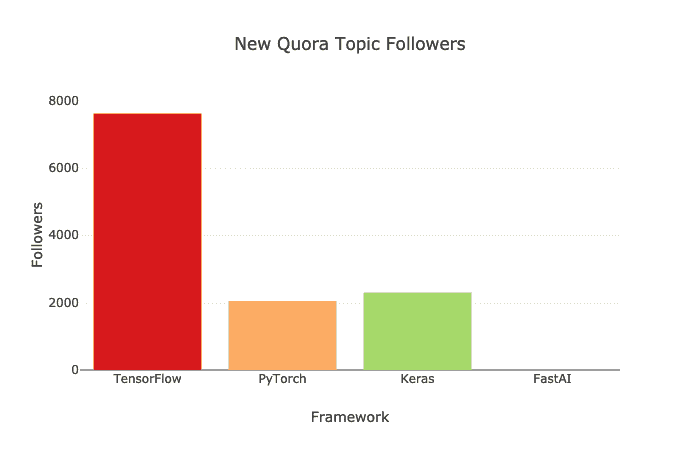
在过去六个月里,TensorFlow 增加了最多的新主题关注者。PyTorch 和 Keras 各自增加的数量远少于此。
一旦我拥有所有数据,我将其合并成一个指标。
增长得分程序
这是我创建增长得分的方法:
-
将所有特征缩放到 0 和 1 之间。
-
聚合了 在线职位列表 和 GitHub 活动 子类别。
-
根据以下百分比加权类别。
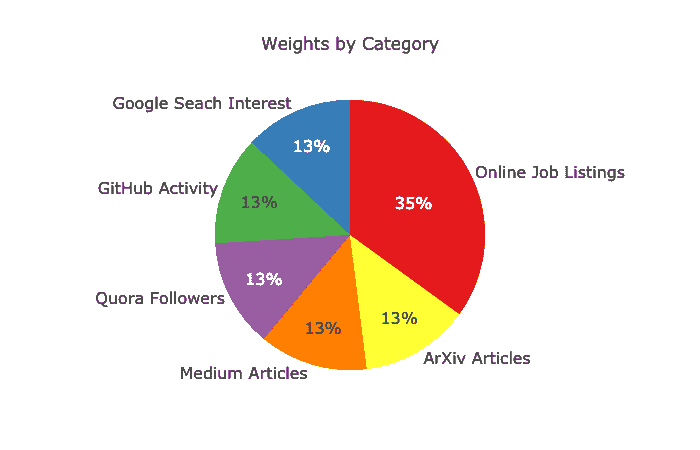
-
将加权得分乘以 100 以提高可读性
-
将每个框架的类别得分汇总成一个增长得分。
职位列表占总得分的三分之一多一点。正如老话所说,金钱是最好的说明。这种分配似乎是各种类别的适当平衡。与我的 2018 年强度评分分析不同,我没有包含 KDNuggets 使用调查(没有新数据)或书籍(六个月内出版的较少)。
结果
下面是以表格形式展示的变化。
 Google 表格 这里。
Google 表格 这里。
下面是类别和最终得分。

这是最终的增长得分。
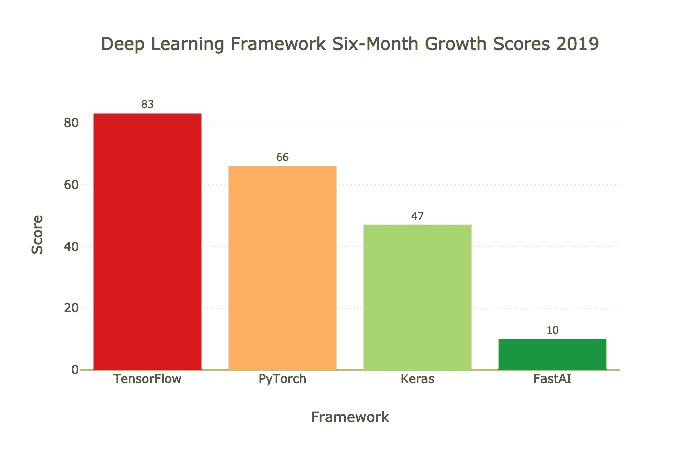
TensorFlow 是需求最大且增长最快的框架。它不会在短期内消失。???? PyTorch 也在快速增长。其职位列表的大幅增加证明了它的使用和需求上升。Keras 在过去六个月中也有了很大增长。最后,fastai 从一个较低的基准开始增长。值得记住的是,它是这几个框架中最年轻的。
TensorFlow 和 PyTorch 都是值得学习的好框架。
学习建议
如果你想学习 TensorFlow,我建议你从 Keras 开始。我推荐 Chollet 的 《Python 深度学习》 和 Dan Becker 的 DataCamp Keras 课程。TensorFlow 2.0 使用 Keras 作为其通过 tf.keras 提供的高级 API。这里是 Chollet 对 TensorFlow 2.0 的快速入门介绍。
如果你想学习 PyTorch,我建议你从 fast.ai 的 MOOC 《编程人员的实用深度学习,第 3 版》 开始。你将学习深度学习基础、fastai 以及 PyTorch 基础知识。
TensorFlow 和 PyTorch 的未来会怎样?
未来发展方向
我一直听说,大家更喜欢使用 PyTorch 而不是 TensorFlow。PyTorch 更加符合 Python 的风格,并且拥有更一致的 API。它还具有本地 ONNX 模型导出功能,可以加快推断速度。此外,PyTorch 共享了许多与 numpy 相同的命令,这降低了学习的门槛。
然而,TensorFlow 2.0 完全关注于改进用户体验,正如 Google 的首席决策智能工程师 Cassie Kozyrkov 在 这里 解释的那样。TensorFlow 现在将拥有一个更简洁的 API、更流畅的 Keras 集成以及一个急切执行选项。这些变化,以及 TensorFlow 的广泛采用,应该会帮助这个框架在未来几年继续保持受欢迎。
TensorFlow 最近宣布了另一个令人兴奋的计划:开发 Swift for TensorFlow。Swift 是 Apple 最初构建的一种编程语言。Swift 在执行和开发速度方面相对于 Python 有一些优势。Fast.ai 将在其高级 MOOC 部分使用 Swift for TensorFlow——请参见 fast.ai 联合创始人 Jeremy Howard 的相关帖子 这里。这门语言可能需要一两年的时间才能准备好,但它可能会比当前的深度学习框架有所改进。
语言和框架之间的协作和交叉传粉确实在发生。???? ????
另一个将影响深度学习框架的进展是 量子计算。可用的量子计算机可能还需要几年时间,但 Google、IBM、微软以及其他公司正在考虑如何将量子计算与深度学习结合起来。框架需要适应这项新技术。
结束
你已经看到 TensorFlow 和 PyTorch 都在增长。现在它们都有很好的高层 API——tf.keras 和 fastai——降低了深度学习的入门门槛。你也听说了一些关于最新发展和未来方向的内容。
要互动地玩转本文中的图表或克隆 Jupyter Notebook,请前往我的 Kaggle Kernel。
我希望你觉得这个对比有帮助。如果有,请在你喜欢的社交媒体平台上分享,让更多人也能找到它。????
我撰写关于深度学习、DevOps、数据科学和其他技术话题的文章。如果你对其中的任何一个话题感兴趣,可以 在这里 查看并关注我。
感谢阅读!
感谢 Kathleen Hale 和 Ludovic Benistant。
个人简介: Jeff Hale 是一位经验丰富的企业家,Data Science DC 的联合组织者,数据科学领域的思想领袖,他在人工智能和技术方面被评为 Medium 的顶尖作家。他的文章曾在 Experfy、Data Elixir、Kaggle Newsletter、Dataquest Download、Python Weekly、O'Reilly Data Newsletter 和 Data Science Weekly 等平台上刊登。
原文。经许可转载。
相关内容:
-
深度学习工具集概述
-
AI: 武器竞赛 2.0
-
流行的深度学习 GitHub 仓库
更多相关话题
哪一张脸是真的?
评论  哪一张脸是真的? ### 哪一张脸是真的?
哪一张脸是真的? ### 哪一张脸是真的?
哪一张脸是真的? 是由 杰文·韦斯特 和 卡尔·伯格斯特罗姆 开发的,来自 华盛顿大学,作为 揭穿谎言项目 的一部分。它充当一种游戏,任何人都可以参与。网站访问者可以选择两张图像,其中一张是真的,另一张是由 StyleGAN 生成的假图像。
该项目由杰文和卡尔实施,作为一门课程,旨在教导学生如何识别虚假信息。
本课程的目标是教你如何对构成社会和自然科学证据的数据和模型进行批判性思考。
世界上充斥着胡言乱语。政治家不受事实约束。科学通过新闻稿进行。高等教育奖励胡说八道而非分析思维。初创文化将胡说八道提升为高雅艺术。广告商暗中挑衅,邀请我们一起看穿所有胡说八道——并利用我们放松警惕的机会向我们轰炸二级胡说八道。无论是私人企业还是公共领域,大多数行政活动似乎都只是复杂的胡说八道重组练习。
我们对此感到厌倦。是时候采取行动了,作为教育者,我们知道的建设性方法之一就是教育人们。因此,本课程的目标是帮助学生在虚假信息充斥的现代环境中,通过识别虚假信息、看穿它,并通过有效的分析和论证来对抗它。
*- 卡尔·T·伯格斯特罗姆 和 杰文·韦斯特
西雅图,WA.*
如何区分?
水斑
- 算法生成的光滑斑点看起来有点像老旧照片上的水斑。这些斑点可能出现在图像的任何位置,但通常在头发和背景之间的界面处出现。
 水斑
水斑
背景问题
- 图像的背景可能会出现模糊或变形等奇怪状态。这是因为神经网络主要在面部进行训练,对图像背景的关注较少。
 背景问题
背景问题
对称性
- 目前,生成器无法生成逼真的眼镜,这可能起初不明显。一个常见问题是对称性问题。查看框架结构;通常框架左边一种风格,右边另一种,或者一边有某种风格的装饰而另一边没有。其他时候,框架可能只是歪斜或锯齿状。此外,还可能存在面部胡须的非对称性,左右耳饰不同,以及左右侧领子或面料不同等情况。
 不对称性
不对称性
头发
- 头发的渲染对算法来说非常困难。常见问题包括断裂的发丝、过于笔直或过于条纹状。
 头发
头发
荧光溢出
- 荧光颜色有时会从背景溢出到头发或脸部,人们有时会将其误认为是染色的头发。
 荧光溢出
荧光溢出
牙齿
- 牙齿的渲染也很困难,可能呈现出奇形怪状、不对称的样子,或者对于能识别牙齿的人来说,有时图像中会出现 3 颗门牙。
 牙齿
牙齿
尝试算法
StyleGAN 的所有代码已经开源在 stylegan 仓库中。它详细介绍了如何自己运行 styleGAN 算法。
然而,也有一些障碍:
-
系统要求
-
训练时间
系统要求
-
支持 Linux 和 Windows,但我们强烈推荐 Linux 以获得更好的性能和兼容性。
-
64 位 Python 3.6 安装。我们推荐使用 Anaconda3 和 numpy 1.14.3 或更新版本。
-
TensorFlow 1.10.0 或更新版本,需支持 GPU。
-
一台或多台高端 NVIDIA GPU,至少 11GB 的 DRAM。我们推荐使用 8 个 Tesla V100 GPU 的 NVIDIA DGX-1。
-
NVIDIA 驱动 391.35 或更新版本,CUDA 工具包 9.0 或更新版本,cuDNN 7.3.1 或更新版本。
这种计算和存储能力在个人中并不常见。
训练时间
以下是 NVIDIA 报告的在 Tesla V100 GPU 上使用默认配置运行 train.py 脚本(在 stylegan 仓库中提供)时的预期训练时间,用于 FFHQ 数据集(在 stylegan 仓库中提供)。

训练此算法所需的时间远超普通人的耐性。
幕后花絮
这个应用的背后科学来自 NVIDIA 的团队和他们在生成对抗网络方面的工作。他们创造了 StyleGAN。为了更多了解这种惊人的技术,我在下面提供了一些资源和简洁的解释。
生成对抗网络
对于那些想要回顾 GAN 的内容,这个由Ahlad Kumar 提供的 GAN 教程播放列表非常有帮助。
生成对抗网络首次在 2014 年作为生成模型的扩展,通过对抗性过程同时训练两个模型:
-
捕获数据分布的生成模型(训练)
-
估计样本来源概率的判别模型
训练数据而非生成模型。
GAN 的目标是生成与真实样本无法区分的人工/虚假样本。一个常见的例子是生成与真实人物照片无法区分的人工图像。人类视觉处理系统无法如此轻易地区分这些图像,因为这些图像乍看起来像真实的人。我们将稍后了解这如何发生,以及如何区分真实人物的照片和由算法生成的照片。
StyleGAN
这个令人惊叹的应用背后的算法是Tero Karras、Samuli Laine 和 Timo Aila在 NVIDIA 的杰作,称为StyleGAN。该算法基于 Ian Goodfellow 及其同事在对抗性网络(GAN)的早期工作。NVIDIA 将其 StyleGAN 的代码开源,使用 GAN,其中两个神经网络,一个生成难以区分的人工图像,另一个尝试区分虚假和真实的照片。
尽管我们已经学会了更普遍地怀疑用户名和文本,但图片却不同。我们假设你不能凭空合成一张图片;一张图片必须属于某个人。当然,诈骗者可以窃取他人的照片,但在有谷歌反向搜索等工具的世界里,这是一种冒险的策略。因此,我们倾向于相信照片。一个带有照片的商业档案显然属于某人。一个约会网站上的匹配可能与拍摄照片时比实际重 10 磅或老 10 岁,但如果有照片,这个人显然是存在的。
不再如此。新的对抗性机器学习算法使人们能够迅速生成从未存在过的合成“照片”。
- Jevin West 和 Carl Bergstrom
生成模型存在一个限制,即难以控制从照片中提取的特征,如面部特征。NVIDIA 的 StyleGAN 解决了这一限制。该模型允许用户调整超参数,从而控制照片中的差异。
StyleGAN 通过在每个卷积层中添加 风格 来解决照片的可变性。这些风格代表了人类照片的不同特征,如面部特征、背景颜色、头发、皱纹等。该算法从低分辨率(4x4)开始生成新图像,逐步提高到高分辨率(1024x1024)。模型生成两张图像 A 和 B,然后通过从 A 中提取低级特征和从 B 中提取其余特征来组合它们。在每个层级,使用不同的特征(风格)来生成图像:
-
粗糙风格(分辨率在 4 到 8 之间) - 姿势,头发,面部,形状
-
中等风格(分辨率在 16 到 32 之间) - 面部特征,眼睛
-
细致风格(分辨率在 64 到 1024 之间) - 色彩方案
基于风格的生成器的特性
风格混合
- 生成器采用 混合正则化,在训练过程中,使用两个随机潜在代码而非一个生成一定百分比的图像。生成这样的图像时,用户只需在合成网络中随机选择的点上从一个潜在代码切换到另一个(即风格混合)。在下面的图像中,我们可以看到一个潜在代码(源)生成的风格如何覆盖另一个潜在代码(目标)的风格子集。

随机变化
- 照片的许多方面是随机的(即随机的),如皱纹、头发位置、胡茬、雀斑、痘痘。StyleGAN 的架构在每个卷积层之后添加每像素噪声,以便图像显示出这些如现实生活中看到的变化。如下面的图像所示,生成器添加的噪声仅影响图像的随机方面,而保持更高层次的风格不变。
全局效果与随机性的分离
- 图像风格的变化会对整体效果产生影响,例如改变姿势、性别、面部等,但噪声如雀斑、皱纹、头发位置只会影响随机变化。在 StyleGAN 中,姿势、光照或背景风格等全局效果可以一致地控制,而噪声是独立地添加到每个像素上,因此非常适合控制随机变化。
有用的资源
相关:
-
新的神经网络互联网即将到来
-
生成对抗网络概述
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
我应该使用哪种机器学习算法?
原文:
www.kdnuggets.com/2017/06/which-machine-learning-algorithm.html
作者:SAS 首席科学家 Hui Li。
该资源主要面向初级至中级的数据科学家或分析师,他们对识别和应用 机器学习 算法来解决他们感兴趣的问题感兴趣。
初学者面对各种机器学习算法时常会问“我应该使用哪种算法?”这个问题的答案因多种因素而异,包括:
-
数据的大小、质量和性质。
-
可用的计算时间。
-
任务的紧迫性。
-
你希望对数据做什么。
即使是经验丰富的数据科学家也无法在尝试不同算法之前确定哪种算法表现最佳。我们并不提倡“一次搞定”的方法,但我们希望提供一些指导,帮助你根据一些明确的因素优先尝试哪些算法。
机器学习算法速查表
机器学习算法速查表 帮助你从多种机器学习算法中选择出适合你特定问题的算法。本文将引导你如何使用这张速查表。
由于速查表是为初学者数据科学家和分析师设计的,我们在讨论算法时会做一些简化的假设。
这里推荐的算法是通过综合来自多个数据科学家、机器学习专家和开发者的反馈和建议得出的。对于一些尚未达成一致的问题,我们尝试突出共同点并调和差异。
随着我们库的扩展,未来将添加更多算法,以涵盖更多可用的方法。
如何使用速查表
读取图表上的路径和算法标签时,按照“如果
-
如果你想进行降维,那么使用主成分分析。
-
如果你需要快速的数值预测,请使用决策树或逻辑回归。
-
如果你需要层次化的结果,请使用层次聚类。
有时多个分支都会适用,而有时则没有一个完全匹配。重要的是要记住,这些路径旨在作为经验法则的建议,因此一些建议并不完全准确。我与几位数据科学家交谈后,他们表示找到最合适的算法的唯一可靠方法是尝试所有算法。
机器学习算法的类型
本节概述了最流行的机器学习类型。如果你对这些类别已经熟悉并希望讨论特定的算法,你可以跳过本节,直接转到下面的“何时使用特定算法”。
监督学习
监督学习算法基于一组示例进行预测。例如,历史销售数据可以用来估算未来价格。通过监督学习,你有一个包含标记训练数据的输入变量和一个期望的输出变量。你使用算法分析训练数据以学习将输入映射到输出的函数。这个推断的函数通过从训练数据中泛化来映射新的、未知的示例,以预测在未见情况中的结果。
-
分类: 当数据用于预测分类变量时,监督学习也称为分类。这是指将标签或指示符(如狗或猫)分配给图像的情况。当只有两个标签时,这称为二分类。当有两个以上的类别时,问题被称为多分类。
-
回归: 当预测连续值时,问题变成回归问题。
-
预测: 这是基于过去和现在的数据对未来进行预测的过程。它最常用于分析趋势。一个常见的例子可能是根据当前年和前几年销售数据来估算下一年的销售额。
半监督学习
监督学习的挑战在于标记数据可能既昂贵又耗时。如果标签有限,你可以使用未标记的示例来增强监督学习。由于机器在这种情况下没有完全监督,我们称之为半监督。通过半监督学习,你使用少量标记数据的未标记示例来提高学习准确性。
无监督学习
在进行无监督学习时,机器处理的是完全未标记的数据。它被要求发现数据中的内在模式,如聚类结构、低维流形或稀疏树和图。
-
聚类: 将一组数据示例分组,使得一个组(或一个聚类)中的示例在某些标准下比其他组中的示例更相似。这通常用于将整个数据集分成几个组。可以在每个组中进行分析,帮助用户发现内在模式。
-
降维: 减少考虑的变量数量。在许多应用中,原始数据具有非常高的维度特征,有些特征是冗余的或与任务无关。降低维度有助于找到真实的潜在关系。
强化学习
强化学习通过环境反馈分析和优化智能体的行为。机器尝试不同的场景以发现哪些动作能获得最大奖励,而不是被告知该采取哪些动作。试错和延迟奖励使强化学习与其他技术区别开来。
选择算法时的考虑因素
选择算法时,始终考虑这些方面:准确性、训练时间和易用性。许多用户优先考虑准确性,而初学者往往关注他们最熟悉的算法。
在面对数据集时,首先要考虑的是如何获得结果,无论这些结果是什么样的。初学者通常选择易于实现且能快速获得结果的算法。这是有效的,只要它是过程中的第一步。一旦获得一些结果并对数据有了更深入的了解,你可能会花更多时间使用更复杂的算法来加强对数据的理解,从而进一步改善结果。
即使在这个阶段,最佳算法可能不是那些报告精度最高的方法,因为一个算法通常需要仔细调整和广泛训练才能达到最佳性能。
何时使用特定算法
更详细地了解个别算法可以帮助你理解它们提供了什么以及如何使用它们。这些描述提供了更多细节,并给出了有关何时使用特定算法的额外提示,与备忘单保持一致。
关于算法及其使用考虑的完整讨论,请参阅SAS 网站上的完整文章。
简介: Hui Li 是 SAS 数据科学技术的首席研究员。她目前的工作集中在深度学习、认知计算和 SAS Viya 中的 SAS 推荐系统。她在杜克大学获得了电气与计算机工程博士学位和硕士学位。在加入 SAS 之前,她曾在杜克大学担任研究科学家,并在 Signal Innovation Group, Inc.担任研究工程师。她的研究兴趣包括大规模异构数据的机器学习、协同过滤推荐、贝叶斯统计建模和强化学习。
原文。经许可转载。
相关:
-
与算法亲密接触
-
从零开始的 Python 机器学习工作流第一部分:数据准备
-
提高 k-means 聚类效率的朴素分片质心初始化方法
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
更多相关主题
机器学习:如何从零开始构建模型
原文:
www.kdnuggets.com/2018/09/whitepages-machine-learning-build-model-from-scratch.html
|
|  |
|
|
|
|
| |
| |
|
注册参加 9 月 27 日的网络研讨会
|
| |
| |
| |
| |
| |
|
|
|
|
|
|
| | |
| |
|
网络研讨会:使用 Momentum Travel 构建机器学习欺诈模型
|
|
周四,9 月 27 日 | 上午 10 点 PT
|
| |
|
|
|
|
| |
|
作为一家在线旅游预订公司,Momentum Travel 早期就认识到,识别和防止欺诈是他们业务的重要组成部分。
听听防欺诈高级总监 Dustin MacDonald 讲述他的团队如何从零开始构建机器学习欺诈模型,包括:
-
开始的必要资源
-
测试模型的过程
-
推送模型到生产环境
-
模型性能以及 Whitepages Pro 的信心评分的影响
无论你是刚刚开始接触机器学习还是已经是专家,了解如何通过机器学习模型提高性能。
演讲者
|

|
Dustin MacDonald
Momentum Travel
高级总监,防欺诈
|
|

|
Ajay Andrews
Whitepages Pro
高级总监,产品
|
|
我们将有时间进行现场问答,所以请带上你的问题!如果你不能参加 9 月 27 日的研讨会,注册也没关系,我们会在之后把录制的视频发给你。
|
|
| |
| |
| | |
|
| |
|
| |
|
| 想要更多专业知识? |
| |
|
| | |
| |
|
|
| |
|
©2018 Whitepages Inc. pro.whitepages.com
1301 5th Ave #1600, Seattle, WA 98101
|
| |
|
|
| |
| |
| |
| |
|
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
相关话题更多
手中掌握整个数据科学世界
评论 图片由 Héizel Vázquez 提供
图片由 Héizel Vázquez 提供
我多年来一直在寻找一个可以运行数据科学项目的平台,而不必为安装和填满电脑上各种工具和环境而烦恼。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织 IT
幸运的是,我发现 MatrixDS 提供了所有这些功能,并且是免费的!在这篇文章中,我将测试几乎所有他们提供的工具,这样你就不必这样做了。
项目在平台上是公开的,你可以在这里查看:
MatrixDS 是一个用于构建、分享和管理各种规模的数据项目的平台。 community.platform.matrixds.com
如果你想试用,只需将其叉车加载即可。
还有一个 GitHub 仓库:
FavioVazquez/matrix_languages_tools
测试 MatrixDS 的不同工具和语言。贡献于 FavioVazquez/matrix_languages_tools 开发… github.com
测试 Python 相关内容

Jupyter Notebook

我目前最喜欢的编程语言是 Python。使用这种语言有很多很棒的工具和功能。其中一个最受欢迎的工具是 Jupyter Notebook。要在 MatrixDS 中启动笔记本,请执行以下操作:
-
转到平台中的工具标签。
-
点击右侧的 (+) 按钮:
![figure-name]()
-
选择 Python 3(或 2)与 Jupyter Notebook:
![figure-name]()
-
为工具选择一个名称,并设置核心数和内存:
![figure-name]()
-
当笔记本创建并启动后,只需打开它:
![figure-name]()
-
编程愉快 😉
在笔记本内部,你可以随意做任何事情。我创建了一个简单的 Python 笔记本来测试 PySnooper,你可以尝试一下。

这是该笔记本的要点,你可以在 MatrixDS 项目中找到:
Jupyter Lab
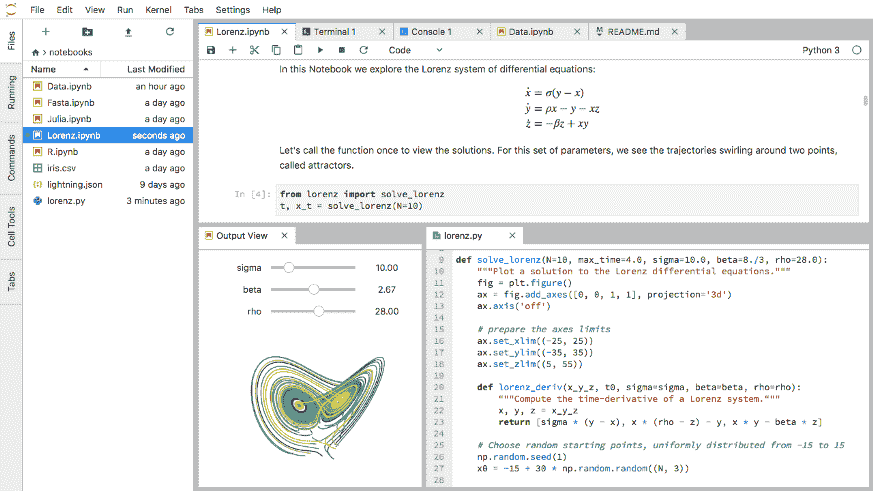
JupyterLab 是 Project Jupyter 的下一代基于网页的用户界面。它就像是升级版的 Jupyter Notebooks。
在 MatrixDS 中启动一个笔记本,请执行以下操作:
-
转到平台上的工具标签。
-
点击右侧的 (+) 按钮:
![图像名称]()
-
选择 Python 3 和 JupyterLab:
![图像名称]()
-
选择工具的名称并设置核心数和内存:
![图像名称]()
-
当工具创建并启动后,只需打开它:
![图像名称]()
-
更加有趣 😃
我在 JupyterLab 实例中创建了一个简单的 Python 笔记本进行测试,你可以尝试一下。
如果你到现在为止一直关注我,这就是你应该看到的:
![图像名称]()
哦,顺便说一句,如果你想知道如何在 MatrixDS 中使用 git,请查看这篇文章:
[用 Optimus 进行数据科学。第二部分:设置你的 DataOps 环境。
用 Python、Spark 和 Optimus 分解数据科学。今天:数据科学的数据操作。 ..::第一部分在这里…towardsdatascience.com](https://towardsdatascience.com/data-science-with-optimus-part-2-setting-your-dataops-environment-248b0bd3bce3)
我创建的测试笔记本测试了新的库 fklearn,用于功能性机器学习。这里是该笔记本的要点,你可以在 MatrixDS 项目中找到:
测试 R 相关内容

www.computerworld.com/video/series/8563/do-more-with-r
我开始我的数据科学职业生涯时使用了 R。它是进行数据分析、数据清理、绘图等的绝佳工具。我认为现在机器学习部分用 Python 更好,但要成为成功的数据科学家,你需要同时掌握这两者。
要在 MatrixDS 中启动 RStudio,请执行以下操作:
-
转到平台上的工具选项卡。
-
点击右侧的 (+) 按钮:
![figure-name]()
-
选择 R 3.5 和 RStudio:
![figure-name]()
-
为工具选择一个名称,并设置核心数量和内存:
![figure-name]()
-
当工具创建并启动后,只需打开它:
![figure-name]()
-
玩 R 很有趣 😃
我创建的测试 R 环境正在测试一个名为 g2r 的新库,该库使用 g2 创建互动可视化图形。
顺便说一下!我在运行 g2r 之前必须这样做:
sudo su
apt-get install libv8-dev
所以,通常你需要这样做以获得 ggplot2 图:
library(ggplot2)
ggplot(iris, aes(Petal.Length, Petal.Width, color = Species)) +
geom_point() +
facet_wrap(.~Species)
然后你将会得到:
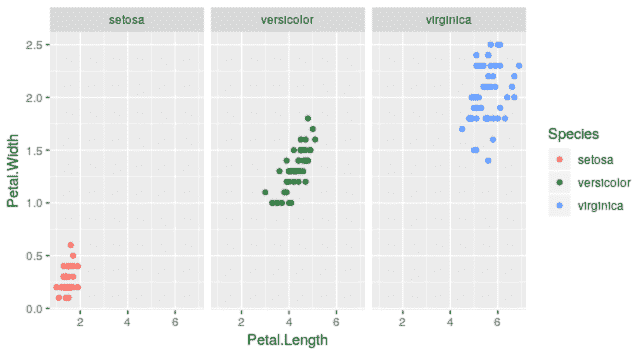
不算太糟,但如何为其添加互动性呢?使用 g2r 很简单。这是实现该功能的代码:
library(g2r)
g2(iris, asp(Petal.Length, Petal.Width, color = Species)) %>%
fig_point() %>%
plane_wrap(planes(Species))
然后你将会得到:
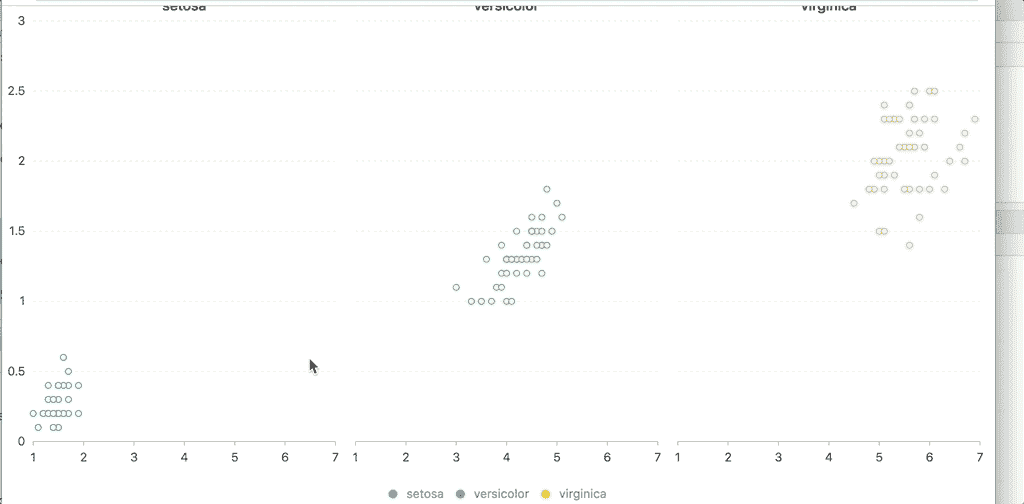
在代码中你需要更改:
aes -> asp
geom_point() -> fig_point()
facet_wrap(.~Species) -> plane_wrap(planes(Species))
我仍在想为什么他们没有使用相同的 API,不过这是一个非常酷的项目。你可以在这里查看更多示例:
开始使用 g2r,发现它与 ggplot2 的相似之处,并查看一些示例来指导你… g2r.dev
这是所有代码:
install.packages("remotes")
remotes::install_github("JohnCoene/g2r")
# So normally this is what you do for getting a plot with ggplot2
library(ggplot2)
ggplot(iris, aes(Petal.Length, Petal.Width, color = Species)) +
geom_point() +
facet_wrap(.~Species)
# Now with g2r
library(g2r)
g2(iris, asp(Petal.Length, Petal.Width, color = Species)) %>%
fig_point() %>%
plane_wrap(planes(Species))
测试 Julia 相关内容

当我在两年前攻读物理硕士学位时,我真的认为 Julia 会彻底改变科学编程世界。不要误会我,它确实做得很棒,但我认为 Python 的新进展已经让这个项目在很多方面处于第二位。
为测试 MatrixDS 的 Julia 能力,我想了解一下该语言的数据库。你可以在下面看到。
要在 MatrixDS 中启动 Julia Notebook,请执行以下操作:
-
转到平台上的工具选项卡。
-
点击右侧的 (+) 按钮:
![figure-name]()
-
选择 Julia 1.1.0 和 JupyterLab:
-
为工具选择一个名称,并设置核心数量和内存:
![figure-name]()
-
当工具创建并启动后,只需打开它:
![figure-name]()
-
让我们用 Julia 😃 (听起来有点奇怪)
启动时,你可以打开或创建任何 Python 或 Julia 笔记本:
![figure-name]()
这是我为测试 Julia 在数据科学中的能力而创建的笔记本:
在这里我测试了一些库,如 DataFrames、Gadfly、Queryverse、Vega 用于绘图等 😃
如你所见,对我来说,这是在云端进行数据科学的最完整平台。你只需最低配置,甚至可以通过 docker 安装自己的工具。
还有很多内容需要涵盖和在平台上做的事情,我将在其他文章中进行。如果你想和我保持联系,请在这里关注我:
Favio Vázquez (@FavioVaz) | 推特
Favio Vázquez (@FavioVaz) 的最新推文。数据科学家。物理学家和计算工程师。我有一…twitter.com](https://twitter.com/faviovaz)
简介:Favio Vazquez 是一位物理学家和计算机工程师,专注于数据科学和计算宇宙学。他对科学、哲学、编程和音乐充满热情。他是 Ciencia y Datos 的创始人,这是一个西班牙语的数据科学出版物。他喜欢新挑战,喜欢与优秀团队合作,并解决有趣的问题。他参与了 Apache Spark 的协作,帮助进行 MLlib、Core 和文档工作。他喜欢应用自己的知识和专业技能于科学、数据分析、可视化和自动学习,致力于让世界变得更美好。
原文。经许可转载。
相关:
-
Julia 的顶级机器学习项目
-
数据科学笔记本使用最佳实践
-
在 Jupyter 中运行 R 和 Python
更多相关话题
谁负责使生成式 AI 正确?
原文:
www.kdnuggets.com/2023/08/whose-responsibility-get-generative-ai-right.html

图片来自 Canva
近年来数据的生成速度呈指数级增长,主要表明数字世界的普及程度增加。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
据估计, 90% 的全球数据 是在过去两年内生成的。
我们与互联网以各种形式互动的越多?—— 从发送短信、分享视频到创作音乐?,我们就越多地为生成式 AI (GenAI) 技术提供训练数据。
每年全球生成的数据来自于 explodingtopics.com
原则上,我们的数据作为输入进入这些先进的 AI 算法,这些算法进行学习并生成更新的数据。
生成式 AI 的另一面
毋庸置疑,这一现象乍看起来很吸引人,但随着现实的逐渐显现,它开始以各种形式带来风险。
这些技术发展的另一面很快揭开了问题的潘多拉盒子?以虚假信息、误用、信息危害、深度伪造、碳排放等多种形式出现。
此外,值得注意的是这些模型在使许多工作岗位变得多余方面的影响。
根据麦肯锡最近的报告 “Generative AI and the future of work in America” —— 涉及高比例重复任务、数据收集和基础数据处理的工作面临变得过时的更大风险。
报告引用了自动化,包括 GenAI,作为对基本认知和手动技能需求下降的原因之一。
此外,从 GenAI 出现之前到现在持续存在的一个关键问题是数据隐私。数据作为 GenAI 模型的核心,是从互联网中策划而来的,包括我们身份的一部分。

图片来自对话
有一种大型语言模型声称已在一些3000 亿字的数据上进行训练,这些数据来自互联网,包括书籍、文章、网站和帖子。令人担忧的是,我们之前对这些数据的收集、使用和处理毫不知情。
麻省理工科技评论认为“OpenAI 遵守数据保护规则几乎是不可能的”。
开源是解决方案吗?
由于我们都是这些数据的部分贡献者,期望开源算法并使其对所有人透明,以便每个人都能理解。
虽然开放访问模型提供了关于代码、训练数据、模型权重、架构和评估结果的细节——基本上是你需要了解的所有内部信息。

图片来自 Canva
但我们中的大多数人能理解这些吗?可能不行!
这就产生了在适当论坛中分享这些重要细节的需求——一个由政策制定者、从业者和政府组成的专家委员会。
这个委员会将能够决定什么对人类是最好的?——这是今天任何单一群体、政府或组织都无法单独决定的事情。
必须将社会影响作为高优先级考虑,并从不同的视角——社会、经济、政治及其他方面评估 GenAI 的效果。
治理并不会阻碍创新
抛开数据组件不谈,这些庞大模型的开发者投入了大量资源来提供计算能力以构建这些模型,这使得他们有权保持模型的闭源。
投资的本质意味着他们希望通过商业用途获得回报。这就是混淆开始的地方。
拥有一个能够规范 AI 应用开发和发布的管理机构并不会抑制创新或阻碍业务增长。
其主要目的是建立护栏和政策,通过技术促进商业增长,同时推动更负责任的方式。
那么,谁来决定责任标准,又是如何形成这一管理机构的?
对负责任论坛的需求
应该有一个独立的实体,由研究、学术界、企业、政策制定者和政府/国家的专家组成。需要澄清的是,独立意味着其资金不得由任何可能引发利益冲突的参与者资助。
其唯一议程是代表世界上 80 亿人进行思考、理性分析并采取行动,做出明智的判断,并对其决策承担高度的责任标准。
这确实是一个重要的声明,这意味着该小组必须高度集中,将委托给他们的任务视为至关重要的。我们这个世界无法承受决策者将如此关键的使命视为可有可无的副项目,这也意味着他们必须获得足够的资金支持。
该小组的任务是执行一个计划和策略,既能解决危害,又不妥协于实现技术带来的收益。
我们以前做过
人工智能常常被比作核技术。其前沿发展使得很难预测与之相关的风险。
引用 Rumman 的话,来自Wired,谈到国际原子能机构(IAEA)如何形成——这是一个独立于政府和企业的机构,旨在为核技术的深远影响和看似无限的能力提供解决方案。
因此,我们在过去有全球合作的实例,世界曾经齐心协力将混乱变为有序。我确信我们最终会达到这一目标。但至关重要的是尽早汇聚力量并制定护栏,以跟上快速发展的部署步伐。
人类无法将自己置于企业的自愿措施下,期望技术公司负责任地发展和部署。
Vidhi Chugh 是一位人工智能战略家和数字化转型领导者,致力于在产品、科学和工程的交汇点构建可扩展的机器学习系统。她是一位获奖的创新领导者、作者和国际演讲者。她的使命是普及机器学习,打破术语,让每个人都能参与到这场转型中。
更多相关话题
为什么数据科学家需要在团队中工作
原文:
www.kdnuggets.com/2019/04/why-data-scientists-need-work-groups.html
评论
由 诺曼·阿尔维森 提供,EssayPro
有些人实际上更喜欢独自工作。trade-schools.net 上有一篇非常有趣的 文章,列出了许多适合孤独者和内向者的工作。如果你阅读这篇文章,你会发现数据科学家的职位并没有列出。本文将探讨数据科学家需要在团队中工作的原因。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 在 IT 方面支持你的组织
外向型和内向型

外向型人格在与他人相处时最为快乐。外向型人格的职业典型例子包括政治、教学和销售。内向型人格则与外向型人格相反,倾向于独处或只与小群体的人在一起。将数据科学家简单归为外向型或内向型将会失败。数据科学家包括这两类人。SAS 组织制作的一个非常好的 报告 探讨了这一点。
新数据科学家需要支持
在这篇文章结束前,我将谈论数据科学家实际执行的任务。作为一个领域新手,即便拥有良好的大学学位,你也需要帮助来启动你的第一份工作。
在数据科学领域的专业工作与参加数据科学竞赛或在大学及其他学习机构做项目有所不同。以下是一些例子。
-
你的工作必须与组织的实践保持一致。你将需要指导,以确保其达到这种协调。
-
你会发现大多数真正的数据科学工作是团队合作完成的。你将需要指导来帮助你融入这个团队。
-
你做的许多工作必须是稳健的。有人必须告诉你你的工作输出必须对什么保持稳健。
数据科学所需技能
最近在Data Science Weekly网站上的一篇文章列出了 30 种不同的工具,包括统计包、计算语言和网络工具,这些工具在数据科学领域中非常抢手。
排名前六的工具是:
-
R 计算语言
-
SQL[结构化查询语言]
-
Python 计算语言
-
Hadoop 网络套件
-
SAS [统计分析系统]
-
Java 计算语言
数据科学领域非常广泛,但幸运的是,为了找到一份工作,了解这些工具中的一小部分就足够了。
一个好的建议是掌握一两个工具,并对其他一些工具有一定的了解。文章建议学习 R、SQL 和 Hadoop。它还推荐了一些对了解其他工具有用的建议。
鉴于所需工具的数量,显然需要一个由不同专业知识的成员组成的团队共同协作。
数据科学中的常见任务
数据科学被描述为需要比任何其他人类活动领域更多的团队合作。正如大量工具[如上所述]所暗示的那样,许多类型的技能和专业知识是必需的:
-
其中之一是可视化。这对数据科学至关重要。可视化涉及从大型数据集中挖掘重要信息,并将其转换为可以采取未来行动的形式。这种形式可以是柱状图、电子表格、热图或其他形式。这项活动非常计算机导向。
-
数据科学中的一个重要技能是建模。这不是走秀上的建模,而是数学建模,涉及线性代数、贝叶斯统计、马尔科夫链等内容。
-
数据科学的重要组成部分是数据工程。数据工程师的责任是确保可视化工具所需的数据以可用的形式存在。
除了这些职责,数据科学团队的其他成员可能还需要与客户和客户进行接口。有时候一个项目太大了,需要多个数据科学家参与。他们必须能够协作。负责项目的人必须了解项目以及所有成员如何在项目上协作。
一些数据科学团队
如果你是数据科学小组或团队的成员,那么了解一个运作良好的数据科学团队的工作方式是非常有用的。一个了解数据科学重要性的组织是Twitch,它是亚马逊的视频流媒体部门。关于这一成功的描述有很多来源。使用任何搜索引擎,输入data science twitch。你会找到许多关于一群数据科学家在技术前沿工作的文章。
另一家非常依赖数据科学团队的大公司是福特汽车公司。它的团队有一个很炫的名字——福特汽车公司全球数据洞察与分析部门 [GDIA]。公司在 2015 年之前已经使用了数十年的数据分析,但以一种临时的方式进行,直到 2015 年,该部门在年初成立时只有一个员工。目前,福特的 GDIA 部门已经有超过 600 名成员。
不是只有大公司拥有数据科学团队。Carvana 是一家位于亚利桑那州凤凰城的在线汽车经销商。它只有五十名员工,其中五名是数据科学家。这五名数据科学家在定价和融资方面对 Carvana 提供了极大的帮助。数据科学家的使用对小型公司和大型公司都大有裨益。
结论
一些人喜欢独自工作,但大多数人更喜欢与他人互动。无论他们在这方面的愿望如何,数据科学家必须与同行紧密合作,并与非数据科学家进行对接。数据科学家通常需要经验丰富的专业人员来帮助他们进入职位。数据科学需要许多技能。数据科学家不太可能掌握其中的所有技能。为了使组织充分发挥数据科学家的作用,需要组建和谐且具有互补技能的团队。
简介: 诺曼·阿维德森 是一位经验丰富的自由撰稿人和市场营销专家。他目前在 EssayPro 担任博客编辑。他的兴趣包括技术、商业写作和网页设计。你可以通过 Twitter 联系他。
相关内容:
-
在接受那个华丽的数据科学职位之前三思
-
如何识别优质数据科学家职位与劣质职位
-
破解数据科学家面试
更多相关话题
为什么许多数据科学家离开优秀公司的好工作
原文:
www.kdnuggets.com/2021/03/why-data-scientists-quit-good-jobs.html
评论
由 Adam Sroka 撰写,他是 Origami 的机器学习工程负责人。

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 在 IT 领域支持你的组织
眼泪汪汪——当理想工作变糟糕时(照片由 Andrea Bertozzini 拍摄于 Unsplash)。
你对你的工作满意吗?不满意?无论如何,参与一个简短的调查
理想工作?
我们经常被告知数据科学作为职业有多受欢迎。常常会看到数据科学被称为“21 世纪最性感的职业”或每年的高薪期待比较。
数据科学有很多优点。它是一个具有挑战性的角色,有许多东西需要学习并保持忙碌。与许多其他角色相比,数据科学家可以获得更多的自主权来探索和解决有趣的问题。而且,在许多情况下,你将有机会与来自不同领域的才华横溢和技能出众的人合作。
尽管如此,根据这项 Kaggle 调查,许多数据科学家每周花费几小时寻找新职位。实际上,从事机器学习的人常常名列寻找新职位的开发者之中——在 2020 年 Stack Overflow 开发者调查 中占 20.5%,仅次于学术界!
如果数据科学如此理想,那就会引发一个问题……
为什么这么多数据科学家在寻找另一份工作?
现在我也经历过这种情况,希望我的经验能为这个问题提供一些启示。
在我晋升为初创公司总监之前,我当了好几年数据科学家。我现在从事更多的管理/领导工作。既当过数据科学家,又管理过数据科学团队(以及更广泛的开发和数据团队),我从两个方面拥有不同寻常的视角。
在我做数据科学家期间,我也感受到了这种痛苦。我大多数时间在初创公司工作,并在职业生涯初期几次跳槽。原因是多个因素的组合,但有很多元素是我在其他公司也听到过的。
我在这里的目标是概述一些更一般的原因,并提出我认为有助于改善情况的方法。这些建议对以下人群将会有用:
-
目前不满意且不确定是否离职的数据科学家
-
对于那些似乎无法留住优秀数据科学人才的经理和组织
-
对于考虑进入这个角色的有志专业人士(如果这些是你的警示信号,那将是很大的投资)
在我们开始之前,必须说我仍然热爱数据科学这个角色。如果你知道如何充分利用它,它可以是一个非常有回报的职业。
现实 vs 期望

有时候,工作环境并不像人们预期的那样(照片由 Sebastian Herrmann 提供,发布于 Unsplash)。
能够使用前沿技术,以有趣的方式解决难题,运用新算法,开发对组织有重大影响的机器学习解决方案——数据科学听起来很棒!
然而,对许多人来说,这听起来太美好了,不切实际。
我亲身经历过,也从许多业内人士那里听说过,现实往往与期望不符。我敢说这是数据科学家感到沮丧并最终离开的首要原因。
现在,这种情况可能有很多原因。我们还应该记住,这问题是双面的。
不切实际的期望
许多刚入行的数据科学家缺乏在真实组织中工作的经验。正如社交媒体对他人生活的非现实展示一样——很容易接受所有激动人心的故事,并认为这就是常态。
我发现这对于那些刚从教育或学术研究职位中出来的人来说是很常见的。很容易陷入无限时间、无限预算的思维模式。我经常听到数据科学家抱怨说他们不能确定工作完成的时间,并且会需要多久就多久。这并不真实,而且在大多数组织的文化中并不适用。
你要么修正你尝试实现的目标范围,并调整时间尺度以适应;要么修正时间尺度并调整目标范围。
另一个主要因素是令人沮丧的认识到工作中有很大一部分并不那么令人兴奋。在大多数组织中,你需要在技术工作和其他不那么令人兴奋的任务之间分配时间。如果你不喜欢报告、写作、做演讲,重复解释模型或方法的基础知识、项目管理和行政开销,或试图争取其他部门的支持,这可能会成为一个问题。
严酷的现实
你可能会发现许多你预期会存在的基础设施和数据处理实际上并不存在。
我之前在一家初创公司工作,担任第二名数据科学家。我在那儿待了 18 个月的同事在这段时间里一直在构建一些基础的数据管道。幸运的是,他们经历了所有说服相关人员批准预算、解决采用新云技术时的安全和 IT 问题、千百次解释所有这一切意义的痛苦。
在某些情况下,你会被用作一个聪明的技术人员,能够很好地处理松散的要求以完成工作。你也能做数据科学的事实可能只是其次。
当团队中缺乏经验丰富的数据科学家或管理层缺乏管理数据科学家的经验时,这些问题可能会变得更严重。如果你是唯一的人,可能很难以引起共鸣的方式表达你的观点。
这往往会导致不愉快的工作环境和未满足的期望。
作为数据科学家,你可能会以为你是来建立智能模型并从数据中获取尽可能多的价值的。你会被拖延,因为你前几个月需要建立必要的基础设施和管道以获取数据。
公司中的高级利益相关者看到大量时间流逝而没有多少结果。实际上,他们会对定期董事会会议上的一些简单图表感到非常满意。他们开始觉得一个昂贵的资源没有足够快地交付价值。
这种脱节最终会让双方都感到沮丧。
如果有机会,请在面试阶段提出相关问题:
-
谁在组织的最高层级支持数据科学?
-
他们是否有相关经验,还是因为炒作而聘请你?
-
数据团队中还有多少其他人?
-
是否有数据工程师/分析师/DevOps 工程师,还是你需要自己完成所有这些工作?
现在,这一切可能看起来很悲观——但实际上并非如此。许多组织在这方面表现良好,但这需要在管理期望和找到有正确支持并且设置成功的位置之间取得平衡。
政治的奇妙世界

有时你会觉得自己像个政治家(照片由Deniz Fuchidzhiev提供,来源于Unsplash)。
办公室政治。哦,天哪。
我听说过很多次,才华横溢的团队在良好的管理下因为政治因素而被彻底拖垮、削弱和消亡。我听说过一个亲身经历,当组织中唯一一个支持数据科学的高级领导被迫离职,团队迅速被重组到那些不能充分发挥其技能的单调工作中。
不幸的是,政治是许多职业的一部分。现在,你不必“玩这个游戏”——你始终可以将你那稀有且需求量大的技能带到其他地方。
如果你对退出、声音、忠诚、忽视模型不熟悉,我建议你去读一读。该模型源于阿尔伯特·赫希曼的研究,概述了个体如何应对不可接受的情况的抽象模型。该书于 1970 年首次出版,已经被广泛讨论,并进一步扩展。
当情况不对时,归结为四个选项:
-
退出 — 你辞职另找一份工作,离开公司,导致问题依旧存在,公司失去了你的技能和经验。
-
坚持 — 你要耐心等待,看情况是否会好转。如果事情没有在你耐心耗尽之前得到解决,这种情况通常会导致其他选项的出现。
-
忽视 — 你通过忽视你的职责来反抗发生的事情,这要么会让你在一段时间内轻松度过,要么会导致你被解雇。
-
声音 — 你采取立场并尝试做出改变。
在四个选项中,声音是唯一一个你主动尝试改善情况的选项。在这种情况下,这意味着要应对办公室政治。
在许多情况下,你组织中的政治状况可能超出了你的薪资等级。这可能非常不舒服,因为你可能觉得自己无力影响巨大的预算削减或大规模变革。这可能是一个权衡选项的好时机,但向领导层发送一封写得很好的沟通邮件,实际上可能是促成真正变化的催化剂。
如果你在一个较小的组织中,决策者更容易接触到,我强烈建议你尝试与他们建立关系。与许多人可能认为的相反——人们通常希望为组织和其中的人做对的事情。公司雇佣真正邪恶并打算害你的人的情况是非常罕见的。
高级利益相关者往往没有了解数据科学团队需求的经验。花时间向他们展示你如何增值,并与他们建立强有力的关系,将帮助他们最大程度地发挥你的技能价值。这也可能帮助你更好地理解业务最高层的真正关注点。
在我为初级数据科学家举办的讲座中,我开玩笑地建议尽早在新工作中自动化一些首席财务官或财务总监的工作流程。这将直接向掌握预算的人展示你的价值,并赢得一个盟友。这不仅仅是个半开玩笑的建议,因为老实说,这些人通常是公司中最忙碌的一部分,常常陷入 Excel 的地狱。
在业务中有影响力的人需要对你有一个良好的印象。他们中的大多数人不会在乎你对算法或统计学了解多少。你可以通过为他们做一些平凡的任务和基本的数据检索、自动化或报告工作来赢得他们的欢心。如果你能带着微笑完成这些工作并建立强大的声誉,你会发现从长远来看事情会变得更容易。
数据科学 == 数据一切

当你成为所有数据问题的首选人时,这可能会变得令人不堪重负(照片由 Usman Yousaf 在 Unsplash 提供)。
如果你能成功应对办公室政治,你很有可能会建立起良好的声誉。这可能是一把双刃剑。
许多人不会理解(或在意)成为数据科学家的含义。如前所述,你会被视为一个聪明的技术人员,能够完成任务。凭借对所有数据的访问和丰富的技术工具,你可能会迅速成为解决他们问题的首选人。
如果你能处理这些工作,那当然很好,但这可能会成为一种负担,当人们开始依赖你并施加压力时,情况可能会变得不那么舒适。你可能会发现自己很快就会把 80% 的时间花在一些可能更适合早期职业数据库管理员的工作上。
我常常告诉组织,数据科学家可以做任何事情,通常比其他人更慢、更贵——但重点是可以做任何事情。
拥有广泛的技能和松散定义的角色可能很有趣,但不要因为你的组织不了解而掉进做那些更适合其他工作的陷阱。联系高级利益相关者,并主动帮助招聘那些乐于做那些让你远离真正想做的工作的数据库管理员或商业智能开发人员。
这也有助于解决孤立的问题。如果你在一个小型孤立的数据科学团队中,你在数据方面的专业知识实际上可能会让你感到孤立。数据成为你的领域,人们不愿意承担责任。帮助你的组织更好地进行结构调整并扩展数据角色,可以更好地将你与更广泛的团队进行整合。
最后的话
不幸的是,仅仅了解所有最新的工具和算法是不够的,以充分发挥大多数数据科学职位的潜力。如果你对期望有一个合理的了解,并且明白你可能需要对你的组织进行一些教育,你很可能会成功。
原文。转载许可。
简介: 亚当·斯罗卡博士,Origami Energy 机器学习工程部门负责人,是一位经验丰富的数据和人工智能领袖,通过提供企业级解决方案和从零开始建立高效的数据和分析团队,帮助组织从数据中挖掘价值。亚当通过公开演讲、技术社区活动、博客和播客分享他的想法和观点。
相关:
相关主题
为什么每个公司都需要一个数字大脑
原文:
www.kdnuggets.com/2017/07/why-every-company-needs-digital-brain.html
评论
作者:SriSatish Ambati,H2O.ai CEO 和联合创始人

几乎每一家《财富》全球 500 强公司都在数字化转型的道路上,但每家公司的阶段不同,许多公司还需要清除最后的障碍才能真正释放其潜力。转型的过程无疑是艰难的,大型公司有时需要忍受高失败率才能推进。然而,仍然有希望。
公司在进行数字化转型时面临的主要问题之一是缺乏企业范围的智能和团队合作文化来协调他们的努力。简而言之,他们缺乏一个“数字大脑”,这是一个从所有业务单元、部门、产品线和服务的数据中进行持续自动学习的中心,赋予组织更高的认知能力。这就是为什么每个公司都需要一个数字大脑来使他们的数字化转型变得生动,否则他们面临着渐进、短视和肤浅的变化风险。
就像人类生命从一个单细胞开始,逐渐分裂产生出不同功能的新细胞一样,公司在进行数字化转型时也采用非常渐进或分步的方法。这是绝对必要的,因为变化从小处开始,并逐渐增长。任何数字大脑的创建都始于微服务的形成,其中公司的应用架构被组织为一个松散的服务集合,这些服务不断学习并致力于预测特定的结果。
Capital One 是微服务模型的典型例子。他们利用开源软件和云技术构建了优秀的数字产品和世界级的开发者体验。这些微服务开辟了新的收入来源和创新金融服务,因为他们对客户有 360 度的视角。
微服务模型和物联网的兴起迅速将智能推向边缘,在那里,小型传感器和轻量级设备的计算能力已接近智能手机。这种智能的去中心化通过开源软件运动得到了进一步放大,这种运动催生了创造者文化。它是参与式的,使公司能够成为软件的创造者,而不仅仅是软件的消费者。开源还推动了货币化——这在谷歌、亚马逊、苹果等公司中我们都可以看到。
然而,从企业整体的角度来看,存在于边缘的智能现象可能会给公司带来碎片化和盲点的风险。使谷歌和亚马逊如此成功的因素是它们能够连接各种微型业务,以利用协同效应。这是一个关键点,也往往是公司失败的地方。借助数字大脑,组织具备了更强的自我意识和跨学科思维,推动出全新的商业模式。
数字大脑的命脉是数据。如今,企业可能会陷入将数据视为静态资产或存在于业务各单位的“宝藏”的陷阱。企业需要转向思考如何利用持续流动的实时数据,这些数据在整个组织中流动,而不仅仅是孤立的单元。这意味着要考虑流数据的不同用例,构建正确的模型,并找到如何在完全不同的垂直领域中货币化它们的方法。
以薪资公司为例,基于实时数据和关于特定地理区域薪资的模型,这些数据可以用于房地产目的。实际上,凭借正确的数据和模型,薪资公司可以成为房地产公司、金融公司和保险公司。借助数字大脑,垂直公司可以转变为横向公司。
数据对数字大脑的健康至关重要,缺乏数据可能会抑制转型。因此,公司可能会选择与其他公司建立联盟,以共享数据和/或模型,最终目标是构建各自无法单独创建的创新应用程序。考虑一下薪资公司,它可以与保险公司合作,目的是构建预测个人何时能够购房并为其提供合适保险的应用程序。
今天的公司大多是因为害怕不进行数字化转型的后果而追求数字化转型。许多公司尚未明确转型的终极目标。数字大脑是这一转型的高潮,因为它赋予公司更高的目的和商业模式来实现货币化。构建大脑的过程始于微服务,在此过程中,业务重新定义为许多较小的业务单元,这些单元可以利用来自边缘的数据,这得益于物联网和云计算的兴起。但只有当这些单元得到协调时,系统范围的变化才能发生,这需要数据和模型——它们是跨垂直领域持续学习的命脉。
简历:SriSatish Ambati 是 H2O.ai 的首席执行官兼联合创始人,该平台是领先的开源机器学习平台,用于更智能的应用程序和数据产品。
相关内容:
-
用于物联网的深度学习与 H2O
-
人工智能、机器学习和深度学习是什么?
-
企业数据科学与机器学习平台
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关主题
为什么机器学习工程师正在取代数据科学家
原文:
www.kdnuggets.com/2021/11/why-machine-learning-engineers-are-replacing-data-scientists.html
评论
由Arthur Mello,AVISIA 的数据科学顾问。

我们的三大课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织的 IT 工作
ML 工程难道只是另一个流行词吗?
ML 工程和数据科学并不是同样的东西,原因如下:你知道人们常说数据科学是商业知识、统计学和计算机科学的结合吗?实际上,ML 工程更多地涉及计算机科学,较少涉及统计学和商业知识。
实际上,这意味着数据科学家更擅长创建新的模型、分析和解读数据,并理解这些模型的数学基础。他或她通常来自统计学背景,有些可能拥有博士学位,并且非常擅长数学,而编程则是为了用计算机进行数学运算而学习的技能。
另一方面,ML 工程师擅长于构建和优化数据流、实施模型以及将其投入生产。他或她通常来自计算机科学背景,可能接受的正式教育少于数据科学家,并且在编程和理解云基础设施方面表现出色。然而,ML 工程师与数据工程师不同,因为他们还需要非常擅长调整模型(尤其是神经网络)、理解交叉验证和特征工程等。总体而言,他们在数据基础设施方面应该比数据科学家更优秀,在机器学习方面比数据工程师更出色。
如果你仍然不相信机器学习工程是真实存在的,可以查看 Google Cloud Platform 的专业机器学习工程师认证课程。它与传统的数据科学课程没有太大关系,仅涉及一些基本的统计知识,但也没有深入探讨选择数据库的规则等。
为什么机器学习工程是未来?
好的,那为什么选择其中一个而不是另一个呢?实际上,并不是一个优于另一个。它们在数据生态系统中都有其作用。但一个已经开始趋于饱和,而另一个则尚未被广泛知晓。实际上,谈论机器学习工程的人员并不多——至少与谈论数据科学的人相比——然而,我相信机器学习工程师的需求可能会超过数据科学家的需求。
我们可以看到世界各地的数据科学家数量激增,涵盖了各种规模的公司,而这些人中的大多数实际上并没有真正进行数据科学工作,只是在做分析。许多真正进行数据科学工作的人可能也不一定需要这么做。
这意味着许多组织正在雇佣人员重复解决基本相同类型的问题。存在大量冗余,而且做这项工作的人的质量差异很大。
与此同时,我们看到像谷歌和亚马逊这样的公司拥有一些世界上最顶尖的数据科学家,他们正在其云平台(分别是 GCP 和 AWS)上开发“即用型”机器学习系统。这意味着你可以将你的数据接入他们的系统,从中受益于所有这些知识,你需要的只是一个懂得如何建立连接和进行必要调优的人——像一位机器学习工程师。
换句话说,如果数据科学不是业务的核心,那么你的数据问题极不可能是全新的,因此更高效的是利用你可以从这些云提供商那里获得的积累知识。往往,企业都在解决类似的问题:销售预测、客户细分、评分、推荐等。这些问题早已被这些科技巨头解决,你应该从迁移学习中受益,而不是从头开始解决它们。
这正是机器学习工程的作用所在:你无需拥有统计学或数学的博士学位,就可以从这些平台中受益并将其适应于你的需求。对算法如何工作、超参数如何影响它们以及数据如何处理有一个非常基础的理解就足够了。然而,你确实需要能够选择哪些工具适合你的问题,以及在时间和金钱方面最有效的设置是什么。
这是否意味着数据科学家的终结?
当然不是。许多公司仍然需要数据科学家来解决新的或更复杂的问题。但一旦炒作过后,将会有更少的“数据科学家”在做数据分析师的工作或为那些可以用现成解决方案解决的问题重新发明轮子。
你应该怎么做?

照片由Kameron Kincade提供,来源于Unsplash。
如果你已经到达这一点并且相信机器学习工程技能在未来几年将至关重要,你可能在想如何学习这些技能。
我将在这里列出一组技能,帮助你快速适应这一新现实。
命令行
你可能已经使用过命令行来做一些简单的事情,例如下载 Python 包,但你应该在这方面有所提高。为了使用像 GCP 和 AWS 这样的平台,这将会很有帮助。Codeacademy提供了一些不错的课程。
Spark
尽管我们倾向于使用 Pandas 来学习数据科学,但当你有太多数据并需要并行运行算法时,Spark 将会很有帮助。我认为 Spark 的最常用版本是 Scala,但如果你更熟悉 Python,可以学习 PySpark。
云服务提供商
主要的三大云服务提供商是 AWS、GCP 和 Azure,但我建议你选择一个并坚持使用。我不能说哪个更好,虽然我个人选择的是 GCP。在选择之前,尝试在线查找它们的比较——有很多比较资料。你也可以查看你所在国家最常用的或你公司使用的那个。现在,无论你选择哪个,你都能找到使用它的公司,并且这些公司在寻找具有这些特定技能的人。
不管怎样,一旦选择了你的平台,就要真正掌握它。我是说,真正掌握。有很多你可以用这些平台做的事情,所以要专注于你在机器学习方面的需求。查看它们的机器学习认证大纲会给你一个很好的学习概述。你可以在这里访问这些资源:GCP、AWS、Azure (DS 或 AI)。如果你想要一个 GCP 学习指南,我 写过一个。
如果你已经在一家定期使用这些工具的公司工作,尝试获得相关认证,然后参与涉及这些工具的项目,这样你可以进行实践。如果你的公司不使用这些工具,认证可能会帮助你获得其他公司中的相关职位。不管怎样:学习、获取证书、实践。我无法过于强调掌握这些工具的重要性。
特征工程
特征工程在 ML 中的重要性至少与在数据科学中的重要性一样。我写了一篇文章讲解了一些你可以使用的技术,确保阅读后尝试在工作中实现其中的一些。想更深入了解,可以参考这本好书,我强烈推荐。
ML 工程
ML 工程涉及到准备数据、检测模型漂移、使数据管道顺畅高效运行等。为了整合我们在这篇文章中看到的其他内容,你必须学习 ML 工程本身。Coursera 上有一门相关课程。虽然我还没有上过,但它是由 Andrew Ng 创作的,考虑到他的成就,如果这门课程不好我会感到惊讶。
原文. 经许可转载。
相关:
更多相关主题
9 个你机器学习项目失败的原因
原文:
www.kdnuggets.com/2018/07/why-machine-learning-project-fail.html
评论
由Alberto Artasanchez,Knowledgent。

好吧,文章标题有些末日般的感觉,我不希望任何人遭遇不幸。我为你加油,希望你的项目超出预期地成功。本文的目的不是对你施加诅咒以确保你项目的失败。相反,它是对数据科学项目失败的最常见原因的探讨,希望能帮助你避免这些陷阱。
1. 提问不当
如果你问错了问题,你会得到错误的答案。一个来自金融行业的例子是欺诈识别问题。最初的问题可能是“这笔交易是否是欺诈?”为了做出这种判断,你需要一个包含欺诈和非欺诈交易示例的数据集。这个数据集很可能是由人类帮助生成的。即,这些数据的标签可能是由一组训练有素的主题专家(SME)来确定的。然而,这个数据集可能是根据他们过去见过的欺诈行为进行标记的。因此,训练于这些数据的模型只会捕捉到符合旧有欺诈模式的欺诈。如果一个不法分子找到了一种新的欺诈方式,我们的系统将无法检测到它。一个可能更好的问题是“这笔交易是否异常?”因此,它不会仅仅寻找过去被证明是欺诈的交易,而是寻找不符合“正常”交易特征的交易。即使在最先进的欺诈检测系统中,也需要依靠人类进一步分析预测的欺诈交易以验证模型结果。这种方法的一个不良副作用是,它很可能会产生比之前的模型更多的假阳性。
我喜欢的另一个例子来自金融领域。投资传奇彼得·林奇。
在他担任富达麦哲伦基金期间,林奇超越了市场,在大多数年份中击败了市场,实现了 29%的年化收益。但林奇自己指出了一个问题。他计算出,在同一时期内,基金的平均投资者只赚了大约 7%。当林奇遇到挫折时,例如,资金会通过赎回流出基金。当他重新回到正轨时,资金会流回,但错过了恢复期。
哪个问题会更值得回答?
-
未来一年富达麦哲伦基金的表现会如何?
-
明年 Fidelity Magellan 基金的购买或赎回数量将是多少?
2. 尝试用它解决错误的问题
常见的错误是没有关注业务用例。在定义需求时,应将注意力集中在这个问题上:“如果我们解决了这个问题,它是否会显著提升业务价值?”为了回答这个问题,在将问题分解成子任务时,初始任务应集中在回答这个问题上。例如,假设你想出一个很棒的人工智能产品点子,现在你想开始销售它。假设这是一个服务,你上传全身照片到网站,AI 程序会确定你的测量数据,然后创建一套适合你体型和尺寸的定制西装。让我们头脑风暴一下,为完成这个项目需要执行的一些任务。
-
开发 AI/ML 技术,从照片中确定身体测量数据。
-
设计并创建一个网站和一个手机应用程序与客户互动。
-
进行可行性研究,以确定是否存在市场需求。
作为技术人员,我们渴望设计和编码,因此可能会被诱惑去开始执行前两个任务。可以想象,如果我们在执行前两个任务后再进行可行性研究,而研究结果表明市场上没有我们的产品需求,那将是一个可怕的错误。
3. 数据不足
我的某些项目涉及生命科学领域,其中一个问题是无法以任何价格获得某些数据。生命科学行业对存储和传输受保护的健康信息(PHI)非常敏感,因此大多数可用的数据集会删除这些信息。在某些情况下,这些信息可能相关,并会增强模型结果。例如,个人的地点可能对健康有统计显著的影响。例如,来自密西西比州的人比来自康涅狄格州的人更可能患糖尿病。但由于这些信息可能不可用,我们将无法使用。
另一个例子来自金融行业。一些最有趣和最相关的数据集可以在这个领域找到,但这些信息可能非常敏感且被严格保护,因此访问可能受到高度限制。但没有这些访问权限,就无法获得相关结果。
4. 数据不正确
使用错误或脏数据可能会导致即使你拥有最好的模型也会做出不良预测。在监督学习中,我们使用之前已标记的数据。在许多情况下,这些标记通常由人工完成,这可能导致错误。一个极端的假设例子是,模型始终具有完美的准确性,但使用的是不准确的数据。考虑一下 MNIST 数据集。当我们对其进行建模时,我们假设图像的人工标记是 100%准确的。现在,假设三分之一的数字标记错误。你认为无论模型有多好,你的模型产生任何体面结果的难度会有多大?垃圾进,垃圾出这一古老的格言在数据科学领域依然适用。

5. 数据过多
理论上,你永远不会有过多的数据(只要数据是正确的)。在实践中,尽管在存储和计算成本及性能上已有了巨大的进步,我们仍然受到时间和空间的物理限制。因此,目前数据科学家最重要的工作之一是明智地挑选他们认为对实现准确模型预测有影响的数据源。例如,假设我们正在预测婴儿出生体重。直观上,母亲的年龄似乎是一个相关的特征,但母亲的名字可能不相关,而地址可能相关。另一个例子是 MNIST 数据集。MNIST 图像中的大多数信息都集中在图像的中心,我们可以考虑去掉图像周围的边框,而不会丢失太多信息。在这个例子中,仍然需要人工干预和直觉来确定去除一定数量的边框像素对预测的影响很小。关于降维的最后一个例子是使用主成分分析(PCA)和 t-分布随机邻居嵌入(t-SNE)。在运行模型之前,确定哪些特征是相关的仍然是计算机面临的难题,但这是一个充满自动化可能性的领域。与此同时,数据过多仍然是一个可能使你的数据科学项目脱轨的陷阱。
6. 招聘错误的人员
你不会相信你的医生能修理你的车,也不应该相信你的机械师能做你的结肠镜检查。如果你有一个小型的数据科学实践,你可能别无选择,只能依赖一个或少数几个人来执行从数据收集和采购、数据清理和处理、特征工程和生成、模型选择到在生产环境中部署模型的所有任务。但随着团队的成长,你应该考虑为这些任务聘请专门的专家。成为 ETL 开发专家所需的技能与自然语言处理(NLP)专家的专长不一定重叠。此外,对于某些行业——如生物技术和金融——拥有深厚的领域知识可能是有价值的,甚至是关键的。然而,拥有一个主题专家(SME)和一个具备良好沟通技能的数据科学家可能是一个合适的替代方案。随着数据科学实践的增长,拥有合适的专业资源是一项微妙的平衡,但拥有合适的资源和人才池是实践成功的最重要关键之一。
7. 使用错误的工具
这里有很多例子可以想到。一个常见的陷阱是所谓的“我有一把锤子,现在一切都像钉子”。一个更具行业特定的例子是:你最近让团队接受了 MySQL 的培训,现在他们回来了,你需要建立一个分析管道。由于培训记忆犹新,他们建议使用他们的新工具。然而,根据你的管道将处理的数据量和你需要对结果进行的分析量,这个选择可能不是最适合的。许多 SQL 产品对单个表能够存储的数据量有严格限制。在这种情况下,更好的选择可能是使用像 MongoDB 这样的 NoSQL 产品或像 AWS Redshift 这样的高度可扩展的列式数据库。
8. 没有合适的模型
模型是现实的简化表示。这些简化旨在去除不必要的虚饰、噪音和细节。一个好的模型使其用户能够专注于特定领域中的重要现实方面。例如,在市场营销应用中,保持如客户电子邮件和地址等属性可能很重要。而在医疗环境中,患者的身高、体重和血型可能更为重要。这些简化根植于假设中;这些假设在某些情况下可能成立,但在其他情况下可能不成立。这表明,在某个特定情境下有效的模型可能在另一个情境下不起作用。
数学中有一个著名的定理。“无免费午餐”(NFL)定理表明,没有一个模型能适用于所有问题。一个领域的好模型的假设可能不适用于另一个领域,因此在数据科学中,使用多个模型进行迭代以找到最适合特定情况的模型并不罕见。这在监督学习中尤其如此。常用的验证或交叉验证来评估多个具有不同复杂度的模型的预测准确性,以找到最合适的模型。此外,表现良好的模型也可以通过多种算法进行训练,例如,线性回归可以通过正规方程或梯度下降进行训练。
根据使用情况,关键在于确定不同模型和算法在速度、准确性和复杂性之间的权衡,并使用最适合特定领域的模型。
9. 没有合适的衡量标准
在机器学习中,能够评估训练模型的性能至关重要。必须衡量模型在训练数据和测试数据上的表现。这些信息将用于选择要使用的模型、超参数选择以及确定模型是否准备好用于生产。
要衡量模型性能,选择适合任务的最佳评估指标至关重要。关于指标选择有很多文献,我们不会深入探讨这个话题,但在选择指标时要记住的一些参数包括:
-
机器学习问题的类型:监督学习、无监督学习和强化学习。
-
监督学习的类型:二分类、分类或回归。
-
数据集类型:如果数据集不平衡,可能需要使用不同的指标。
结论
失败的方式有很多种,而解决问题的最佳方式却只有一个。成功的定义也可能会用不同的标准来衡量。所寻求的解决方案是一个快速而粗糙的补丁吗?你是否在寻找一个行业最佳的解决方案?重点是模型训练速度、推理端点的可用性,还是模型的准确性?也许发现某个解决方案不起作用可以被视为一种成功,因为这样可以将注意力转向其他备选方案。我很想听听你对这个话题的看法。你发现了哪些其他的失败方式?哪些解决方案对你来说效果最好?欢迎在下面讨论或通过 Linked In 联系我。编程愉快!
简介:Alberto Artasanchez 是 Knowledgent 的首席数据科学家。他拥有计算机科学与人工智能硕士学位,是一位具有超过 25 年技术行业经验的人工智能/机器学习研究员、从业者、作者和教育者。自 2015 年至今,他作为 Knowledgent 的首席数据科学家,参与了金融和生物技术行业中各种数据科学、云计算和大数据的计划和项目,根据项目需求担任顾问、导师、设计师、故障排除者和编码员。
原文。经许可转载。
相关:
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关内容
为什么提示工程是个时尚

图片由编辑使用 DALL•E 3 创建
在不断扩展的 AI 和 ML 宇宙中,一颗新星已经出现:提示工程。这一新兴领域围绕着战略性地设计输入,以引导 AI 模型生成特定的、期望的输出。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
各种媒体纷纷大肆宣传提示工程,让它看起来像是理想的工作——你无需学习编程,也不必了解像深度学习、数据集等机器学习概念。你会同意它看起来美好得不像真的,对吧?
实际上,答案是既是又不是。我们将在今天的文章中详细解释,追溯提示工程的起源,为什么它很重要,最重要的是,为什么它不是一个能够改变生活的职业,不会让成千上万的人社会地位提升。
提示工程的兴起
我们都看到了这些数据——全球 AI 市场到 2030 年将价值 1.6 万亿美元,OpenAI 正提供 90 万美元的薪资,这还没有提及 GPT-4、Claude 以及各种其他 LLMs 生成的数十亿,甚至数万亿的词汇。当然,数据科学家、机器学习专家和其他高层专业人士处于最前沿。
然而,2022 年改变了一切,因为 GPT-3 一经公开发布就迅速普及。突然间,普通人意识到提示的重要性以及 GIGO——垃圾进,垃圾出。 如果你写了一个没有任何细节的马虎提示,LLM 将对输出结果拥有完全的控制权。一开始很简单,但用户很快意识到了模型的真正能力。
然而,人们很快开始尝试更复杂的工作流程和更长的提示,这进一步强调了巧妙编织语言的价值。自定义指令 只扩大了可能性,加速了提示工程师的崛起——这种专业人士可以运用逻辑、推理和对 LLM 行为的知识来随心所欲地产生所需的输出。
说机器的语言?
在其潜力的巅峰,提示工程催生了自然语言处理(NLP)领域的显著进展。从普通的 GPT-3.5 到 Meta 的 LLaMa 的特定版本,当被输入精心设计的提示时,展示了对各种任务的惊人适应能力和灵活性。
提示工程的支持者将其誉为 AI 创新的桥梁,展望一个通过精细提示工艺实现人类与 AI 无缝互动的未来。
然而,正是提示工程的承诺激发了争议的火焰。它能够从 AI 系统中生成复杂、细致甚至富有创意的输出,这一点并未被忽视。该领域的先知们将提示工程视为释放 AI 潜力的关键,将其从计算工具转变为创造伙伴。
提示工程的审视
在热情的高潮中,怀疑的声音回荡。提示工程的反对者指出其固有的局限性,认为它不过是对缺乏基本理解的 AI 系统的复杂操控。
他们认为提示工程不过是一个幌子,一种巧妙的输入安排,掩盖了 AI 固有的无法理解或推理的局限性。同样,也可以说以下观点支持了他们的立场:
-
AI 模型的兴衰更替。比如说,GPT-3 中有效的某些功能在 GPT-3.5 中已经被修补,而在 GPT-4 中则几乎不可能实现。这是否意味着提示工程师只是某一版本 LLM 的鉴赏家?
-
即使是最优秀的提示工程师,也不算真正的“工程师”。例如,SEO 专家可以使用 GPT 插件或甚至本地运行的 LLM 来寻找反向链接机会,或者软件工程师可能知道如何 使用 Copilot 进行编写、测试和部署代码。但归根结底,他们就是这样——单一任务,在大多数情况下依赖于之前在某一领域的专长。
-
除了 硅谷偶尔出现的提示工程职位,几乎没有人对提示工程有所了解,更不用说其他方面了。公司正在缓慢而谨慎地采纳 LLMs,这与每项创新一样。但我们都知道这并不能阻止炒作的浪潮。
关于提示工程的炒作
提示工程的魅力并未免于炒作和夸大的力量。媒体叙事在推崇其优点和抨击其缺陷之间摇摆,常常放大成功而淡化局限性。这种对立的情况造成了困惑和夸大的期望,使人们相信它要么是魔法,要么完全无用,而两者之间的情况则被忽略了。
与其他技术潮流的历史类比也提醒我们技术趋势的短暂性。曾经承诺彻底改变世界的技术,从元宇宙到折叠手机,往往在现实未能达到早期炒作设定的高期待后,其光彩会逐渐褪去。这种夸张的热情随后带来的失望对提示工程的长期可行性投下了疑虑的阴影。
现实与炒作背后的真相
剥去炒作的层层外衣,揭示了一个更为复杂的现实。从提示工程在不同应用中的可扩展性到对可重复性和标准化的担忧,技术和伦理挑战无处不在。与 传统且成熟的 AI 职业(例如与数据科学相关的职业)相比,提示工程的光环开始黯淡,暴露出虽然强大但仍存在重大局限性的工具。
这就是为什么提示工程如果是一种潮流——每天与 ChatGPT 对话并找到一份中六位数薪资的工作的想法不过是一个神话。确实,一些过于热衷的硅谷初创公司可能在寻找提示工程师,但这并不是一个可行的职业。至少目前还不是。
与此同时,作为一个概念的提示工程将继续保持相关性,并且肯定会变得更加重要。编写优质提示的技能、有效利用令牌、以及知道如何触发某些输出,将在数据科学、LLM 和人工智能整体领域之外同样有用。
我们已经看到 ChatGPT 改变了人们学习、工作、沟通甚至组织生活的方式,因此,提示技能将变得更加相关。实际上,谁不兴奋于用可靠的 AI 助手来自动化那些无聊的工作呢?
提示工程及其未来:它会超越一时的潮流吗?
探索提示工程的复杂领域需要一种平衡的方法,这种方法承认其潜力,同时保持对其局限性的现实认知。此外,我们还必须意识到提示工程的双关含义:
-
促使 LLM 按照个人意愿行事,尽可能少的努力或步骤
-
一项围绕上述行为的职业
因此,在未来,随着输入窗口的增加和 LLM 在创建比简单线框图和机器人般的社交媒体文案更复杂的内容时变得更加娴熟,提示工程将成为一项必备技能。可以把它看作是如今知道如何使用 Word 的等价物。
结论
总之,提示工程正处于一个十字路口,它的命运由炒作、希望和严酷现实的交汇所决定。它是会巩固自己在 AI 领域的地位,还是会消退成为科技流行趋势的历史一部分,尚未可知。然而,可以肯定的是,无论好坏,它的旅程,充满争议,短时间内不会结束。
娜拉·戴维斯 是一名软件开发人员和技术作家。在全职从事技术写作之前,她曾在一家 Inc. 5,000 的体验品牌组织担任首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼,除了其他令人兴奋的工作之外。
更多相关话题
为什么你不应该成为数据科学通才
原文:
www.kdnuggets.com/2018/12/why-shouldnt-data-science-generalist.html
评论

我在一个data science mentorship startup工作,我发现有一个建议我一再给有抱负的学员。这实际上是我没有预料到的。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
我没有建议新的库或工具,或一些简历技巧,而是发现自己更倾向于建议他们首先考虑他们想成为哪种类型的数据科学家。
这是至关重要的原因是数据科学并不是一个单一的、明确的领域,公司不会雇佣通才的“数据科学家”,而是那些拥有非常专业技能的人。
要了解原因,只需想象一下你是一家试图招聘数据科学家的公司。你几乎肯定有一个相当明确的问题需要帮助,而这个问题将需要一些相当具体的技术知识和主题领域专长。例如,有些公司对大数据集应用简单模型,有些公司对小数据集应用复杂模型,有些公司需要即时训练他们的模型,还有些公司根本不使用(传统的)模型。
这些情况各自需要完全不同的技能,因此有抱负的数据科学家所获得的建议往往如此泛泛,这真的很奇怪:“学习如何使用 Python,做一些分类/回归/聚类项目,然后开始申请工作。”
我们这些在行业中工作的人要为此承担很多责任。我们往往在随意的对话、博客文章和演示文稿中把过多的事情归入“数据科学”这个大类。为生产环境构建强大的数据管道?那是一个“数据科学问题”。发明一种新型神经网络?那是一个“数据科学问题”。
这不好,因为这往往使得有抱负的数据科学家无法专注于特定的问题类别,而变成了全能型人才——在一个已经饱和的通才市场中,这种情况会使得被注意到或突破变得更加困难。
但如果你不知道自己最初可以专注于哪些常见问题类别,很难避免成为一个通才。这就是为什么我整理了一个通常被统称为“数据科学”的五个问题类别的列表:
1. 数据工程师
职位描述:你将负责管理处理大量数据的公司的数据管道。这意味着要确保数据在需要时能够高效地从来源处收集和检索,并进行清洗和预处理。
为什么这很重要:如果你只处理过相对较小(<5 Gb)的数据集,并且存储在 .csv 或 .txt 文件中,你可能很难理解为什么有人专门从事构建和维护数据管道的工作。原因有几个:1) 50 Gb 的数据集无法适应你计算机的 RAM,因此通常需要其他方式将其输入到模型中;2) 这么多数据处理起来可能需要大量时间,且通常需要冗余存储。管理这种存储需要专业的技术知识。
要求:你将使用的技术包括 Apache Spark、Hadoop 和/或 Hive,以及 Kafka。你可能需要有扎实的 SQL 基础。
你将处理的问题包括:
→ “我如何构建一个能够处理每分钟 10,000 个请求的管道?”
→ “我如何在不将整个数据集加载到 RAM 中的情况下清理这些数据?”
2. 数据分析师
职位描述:你的工作将是将数据转化为可操作的业务洞察。你通常会在技术团队和业务战略、销售或市场营销团队之间充当桥梁。数据可视化将是你日常工作的一个重要部分。
为什么这很重要:技术人员通常很难理解数据分析师为何如此重要,但他们确实很重要。需要有人将训练和测试过的模型及大量用户数据转换为易于理解的格式,以便围绕这些数据制定业务策略。数据分析师帮助确保数据科学团队不会浪费时间解决那些无法带来业务价值的问题。
要求:你将使用的技术包括 Python、SQL、Tableau 和 Excel。你还需要有良好的沟通能力。
你将处理的问题包括:
→ “是什么推动了我们的用户增长数字?”
→ “我们如何向管理层解释近期用户费用的增加使用户流失?”
3. 数据科学家
职位描述:你的工作将是清理和探索数据集,并做出有业务价值的预测。你日常的工作包括训练和优化模型,通常还需要将模型部署到生产环境中。
为什么这很重要:当你有一堆数据大到人类无法解析,且珍贵到不容忽视时,你需要一种从中提取可消化见解的方法。这是数据科学家的基本工作:将数据集转换为可消化的结论。
要求:你将使用的技术包括 Python、scikit-learn、Pandas、SQL,以及可能的 Flask、Spark 和/或 TensorFlow/PyTorch。一些数据科学职位纯粹是技术性的,但大多数需要你具备一定的商业洞察力,以免解决无人关心的问题。
你将要处理的问题包括:
→ “我们到底有多少种不同的用户类型?”
→ “我们能否建立一个模型来预测哪些产品会卖给哪些用户?”
4. 机器学习工程师
职位描述:你的工作是建立、优化和部署机器学习模型到生产环境。你通常会将机器学习模型视作 API 或组件,将其集成到全栈应用或某种硬件中,但你也可能需要自己设计模型。
要求:你将使用的技术包括 Python、Javascript、scikit-learn、TensorFlow/PyTorch(和/或企业级深度学习框架)以及 SQL 或 MongoDB(通常用于应用程序数据库)。
你将要处理的问题包括:
→ “我如何将这个 Keras 模型集成到我们的 Javascript 应用中?”
→ “我如何减少推荐系统的预测时间和预测成本?”
5. 机器学习研究员
职位描述:你的工作是寻找解决数据科学和深度学习中挑战性问题的新方法。你不会使用现成的解决方案,而是要自己创建。
要求:你将使用的技术包括 Python、TensorFlow/PyTorch(和/或企业级深度学习框架)以及 SQL。
你将要处理的问题包括:
→ “我如何将我们的模型准确度提高到接近最先进水平?”
→ “自定义优化器是否能帮助减少训练时间?”
我在这里列出的五个职位描述在所有情况下并非孤立存在。例如,在早期阶段的初创公司中,数据科学家可能还需要兼任数据工程师和/或数据分析师。但大多数职位会更清晰地归入这些类别之一——公司越大,这些类别的适用性就越高。
总的来说,要记住的是,为了获得聘用,你通常会更好地专注于建立一个更集中的技能集:如果你想成为数据分析师,就不要学习 TensorFlow;如果你想成为机器学习研究员,就不要优先学习 Pyspark。
考虑一下你希望帮助公司建立什么样的价值,并在提供这种价值方面做到出色。这比其他任何事情更能帮助你获得机会。
哦,如果你想聊天,可以随时在 Twitter 上私信我@jeremiecharris!
简介: Jeremie Harris 是 @SharpestMindsAI 的联合创始人,对物理学、机器学习、哲学和初创公司充满兴趣。
原文。经授权转载。
相关内容:
-
要想成为数据科学家,别随大流
-
大数据和数据科学中的 5 种职业路径,详解
-
你应该成为数据科学家吗?
更多相关主题
为什么 SQL 是数据科学中必须学习的语言
原文:
www.kdnuggets.com/why-sql-is-the-language-to-learn-for-data-science
“Python!”
“不,是 R。”
“傻瓜,这显然是 Rust。”
许多数据科学学习者和专家都热衷于确定最适合数据科学的语言。在我看来,大多数人是错误的。在寻找最新、最炫酷、最适合容器化的数据科学语言的过程中,人们正在寻找错误的东西。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
图片来自 Reddit
很容易被忽视。甚至可以将其视为不重要的语言。但谦虚的结构化查询语言,或 SQL,是我推荐的数据科学学习语言。所有其他语言当然也有它们的作用,但 SQL 是我认为数据科学工作者的基础要求的唯一不可替代的语言。原因如下。
数据库的通用语言
看,数据库与数据科学息息相关。名字里就有。如果你在做数据科学工作,你就在处理数据库。如果你在处理数据库,你很可能在使用 SQL。
为什么?因为 SQL 是通用的数据库查询语言。没有其他语言可以替代。想象一下,如果有人告诉你,只要你学会了某种特定的语言,你就能与地球上每个人交流和理解他们,那将是多么有价值?SQL 就是数据科学中的那种语言,所有人都用来管理和访问数据库。

图片来自 X
每个数据科学家都需要访问和检索数据,探索数据和建立假设,过滤、聚合和排序数据。因此,每个数据科学家都需要 SQL。只要你知道 如何编写 SQL 查询,你将会走得很远。
现在,有人正在读这篇文章并谈论 NoSQL 运动。确实,现在有些数据更常被存储在非关系型数据库中,比如键值对或图数据。存储数据的这种方式确实有好处——你会获得更多的可扩展性和灵活性。但没有标准的 NoSQL 查询语言。你可能为一个工作学会一种,接着为新工作需要学习完全不同的语言。
此外,你很少会找到完全使用 NoSQL 数据库的公司,而许多公司并不需要非关系型数据库。
清理和处理
有个著名的(已被揭穿)统计数据称数据科学家将 80%的时间花在清理数据上。虽然这不是真的,但我认为如果你问任何数据科学家他们花时间做什么,数据清理将排在前五位。这就是为什么这一部分是最长的。
你可以使用其他语言清理和处理数据,但特别是 SQL 在某些数据清理和处理方面提供了独特的优势。
SQL 的表达性查询语言允许数据科学家使用简洁的语句高效地过滤、排序和汇总数据。这种灵活性在处理大型数据集时尤其有用,因为手动数据操作会非常耗时且容易出错。相比之下,像 Python 这样的语言,完成类似的数据操作任务可能需要编写更多的代码,并处理循环、条件和外部库。虽然 Python 以其多功能性和丰富的数据科学库生态系统而闻名,但 SQL 的专注语法可以加快例行的数据清理操作,使数据科学家能够迅速准备数据进行分析。
此外,任何数据科学家都会抱怨他们存在的痛点:缺失值。SQL 处理缺失值的功能和能力——如使用COALESCE、CASE 和 NULL 处理——提供了直接的方法来处理数据中的空白,而不需要复杂的编程逻辑。
数据科学家存在的另一个痛点是重复数据。幸运的是,SQL 提供了高效的方法来识别和消除数据集中的重复记录,如DISTINCT关键字和[GROUP BY](https://www.stratascratch.com/blog/what-is-sql-group-by-and-how-to-use-it/?utm_source=blog&utm_medium=click&utm_campaign=kdn+sql+for+ds)子句。
你可能听说过 ETL 管道。实际上,SQL 可以用于创建数据转换管道,这些管道将原始或半处理的数据转换为适合分析的格式。这对于自动化和标准化那些我们都知道且厌恶的重复数据清理过程尤其有益。
SQL 能够连接来自不同数据库或文件的表,这简化了数据合并的过程,对于涉及数据集成或来自多种来源的数据聚合的项目至关重要。对于数据科学家来说,这占据了大多数项目。
最后,我想提醒大家,数据科学并不是在真空中进行的。SQL 查询是自包含的,可以轻松与同事共享。这促进了合作,并确保其他人可以在没有手动干预的情况下重现数据清理步骤。
与其他人良好配合
现在,如果你仅仅知道 SQL,你在数据科学领域不会走得太远。不过幸运的是,SQL 与其他顶级数据科学语言如 R、Python、Julia 或 Rust 完美集成。你可以获得分析、数据可视化和机器学习的所有好处,同时仍保留 SQL 在数据处理方面的优势。

图片来自 LinkedIn
这在你考虑到我之前提到的所有数据清理和处理时尤其强大。你可以使用 SQL 直接在数据库中预处理和清理数据,然后利用 Python、R、Julia 或 Rust 执行更高级的数据转换或特征工程,利用广泛的库。
许多组织依赖于 SQL——或者更准确地说,依赖于懂得如何使用 SQL 的数据科学家——来生成报告、仪表板和可视化,以支持决策制定。熟悉 SQL 能让数据科学家直接从数据库中生成有意义的报告。而且由于 SQL 的广泛应用,这些报告通常在几乎任何系统间都是兼容的。
由于 SQL 与报告工具和脚本语言如 Python、R 和 JavaScript 的高度兼容,数据科学家实际上可以自动化报告过程,将 SQL 的数据提取和处理能力与这些语言的可视化和报告功能无缝结合。结果是你可以在一个地方获得全面且富有洞察力的报告,有效地向利益相关者传达数据驱动的见解。
工作,工作,工作
你会在任何数据科学面试中被问到一堆 SQL 面试问题。几乎每个数据科学职位都要求至少具备基础的 SQL 知识。
这是我所说的一个例子:职位列表上写着,“精通 SQL,以及用于数据分析和平台开发的 R 或 Python。”换句话说,SQL 是必须的。然后是 R 或 Python,但对于大多数雇主来说,两者没有太大区别。但由于 SQL 的主导地位,没有 SQL 的替代品。每一个数据科学职位都会要求你使用 SQL。
它真正酷的地方在于,它使 SQL 成为终极的可转移工具。一份工作可能偏爱 Python,而一家初创公司可能因个人偏好或遗留基础设施而要求 Rust。但无论你去哪里,做什么,都是 SQL 或无路可走。花时间学习它,你将永远能够满足工作要求。
最终,如果你找到一份不需要 SQL 的数据科学家职位,你可能不会做太多数据科学工作。
为什么 SQL 对数据科学如此必要?
归根结底,这要看数据库。数据科学需要存储、操作、检索和管理大量数据。这些数据存在某个地方。通常只能使用一种工具访问,那就是 SQL。SQL 是数据科学需要学习的语言,只要我们依赖数据库进行数据科学,它就会继续存在。
内特·罗西迪 是一名数据科学家,专注于产品策略。他还是一名兼职教授,教授分析课程,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过来自顶级公司的真实面试问题来准备面试。内特撰写关于职业市场的最新趋势,提供面试建议,分享数据科学项目,并涵盖所有 SQL 内容。
相关话题
为什么最新的 LLM 使用 MoE(专家混合)架构
原文:
www.kdnuggets.com/why-the-newest-llms-use-a-moe-mixture-of-experts-architecture

专业化的必要性
医院里挤满了各类专家和医生,他们各自拥有不同的专业领域,解决各种独特的问题。外科医生、心脏科医生、儿科医生——各类专家携手合作,提供护理,常常需要合作以满足患者的需求。我们可以在 AI 中实现类似的做法。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
在人工智能中,专家混合(MoE)架构定义为不同“专家”模型的组合,这些模型共同处理或响应复杂的数据输入。对于 AI 而言,每个 MoE 模型中的专家专注于更大的问题——就像每位医生专注于其医学领域一样。这提高了效率,增加了系统的效能和准确性。
Mistral AI 提供了与 OpenAI 相媲美的开源基础 LLM。他们正式讨论了在其 Mixtral 8x7B 模型中使用 MoE 架构,这是一种突破性的前沿大型语言模型(LLM)。我们将深入探讨为什么 Mistral AI 的 Mixtral 在其他基础 LLM 中脱颖而出,以及为什么当前 LLM 采用 MoE 架构,突出其速度、规模和准确性。
升级大型语言模型(LLM)的常见方式
为了更好地理解 MoE 架构如何提升我们的 LLM,让我们讨论一下提高 LLM 效率的常见方法。AI 从业者和开发者通过增加参数、调整架构或微调来提升模型性能。
-
增加参数: 通过输入更多信息并进行解读,模型学习和表示复杂模式的能力提高。然而,这可能导致过拟合和幻觉现象,需要进行大量的来自人类反馈的强化学习(RLHF)。
-
调整架构: 引入新的层或模块以适应增加的参数数量,并提高特定任务的性能。然而,对底层架构的更改实施起来具有挑战性。
-
微调: 预训练模型可以在特定数据上或通过迁移学习进行微调,使现有的 LLM 能够处理新任务或领域,而无需从头开始。这是最简单的方法,并且不需要对模型进行重大更改。
MoE 架构是什么?
专家混合(MoE)架构是一种神经网络设计,通过动态激活每个输入的专业网络子集(称为专家)来提高效率和性能。门控网络决定激活哪些专家,从而实现稀疏激活和降低计算成本。MoE 架构包括两个关键组件:门控网络和专家。让我们深入了解一下:
本质上,MoE 架构像一个高效的交通系统,根据实时条件和目标目的地,将每辆车——在这种情况下,是数据——引导到最佳路线。每个任务都被路由到最适合处理该任务的专家或子模型。这种动态路由确保为每个任务分配最具能力的资源,提高了模型的整体效率和效果。MoE 架构利用了提高模型保真度的所有 3 种方法。
-
通过实现多个专家,MoE 自然地提高了模型的
-
通过增加每个专家的参数数量来增大参数规模。
-
MoE 改变了经典的神经网络架构,包含一个门控网络,以确定为指定任务使用哪些专家。
-
每个 AI 模型都有一定程度的微调,因此 MoE 中的每个专家都会经过微调,以便为传统模型无法利用的额外调优层执行预期的功能。
MoE 门控网络
门控网络在 MoE 模型中充当决策者或控制器的角色。它评估传入的任务,并确定哪个专家适合处理这些任务。这个决策通常基于学习到的权重,这些权重随着训练时间的推移而调整,从而进一步提高其将任务与专家匹配的能力。门控网络可以采用各种策略,从使用概率方法将任务分配给多个专家的软分配,到将每个任务路由到单一专家的确定性方法。
MoE 专家
MoE 模型中的每个专家代表一个较小的神经网络、机器学习模型或针对问题领域特定子集优化的 LLM。例如,在 Mistral 中,不同的专家可能专注于理解某些语言、方言或特定类型的查询。这种专业化确保每个专家在其小众领域中精通,当与其他专家的贡献相结合时,将在各种任务中表现出更高的性能。
MoE 损失函数
虽然不被视为 MoE 架构的主要组成部分,但损失函数在模型未来的性能中扮演着关键角色,因为它旨在优化个别专家和门控网络。
它通常结合了为每个专家计算的损失,并根据门控网络分配给它们的概率或重要性进行加权。这有助于为专家的特定任务进行微调,同时调整门控网络以提高路由准确性。
MoE 过程从开始到结束
现在让我们总结一下整个过程,添加更多细节。
下面是路由过程从开始到结束的总结说明:
-
输入处理:对输入数据进行初步处理。在 LLMs 的情况下,主要是我们的提示。
-
特征提取:将原始输入转换为可分析的数据。
-
门控网络评估:通过概率或权重评估专家的适用性。
-
加权路由:根据计算的权重分配输入。在这里,选择最合适的 LLM 的过程完成。在某些情况下,会选择多个 LLM 来回答单一输入。
-
任务执行:处理每个专家分配的输入。
-
专家输出的整合:将各个专家的结果合并为最终输出。
-
反馈与调整:利用性能反馈来改进模型。
-
迭代优化:对路由和模型参数进行持续的改进。
利用 MoE 架构的流行模型
-
OpenAI 的 GPT-4 和 GPT-4o: GPT-4 和 GPT-4o 为 ChatGPT 的高级版本提供支持。这些多模态模型利用 MoE 能够处理不同来源的媒介,如图像、文本和语音。有传闻且略微证实 GPT-4 拥有 8 个专家,每个专家拥有 2200 亿参数,总模型超过 1.7 万亿参数。
-
Mistral AI 的 Mixtral 8x7b: Mistral AI 提供了非常强大的开源 AI 模型,并表示他们的 Mixtral 模型是一种 sMoE 模型或稀疏专家混合模型,体积小巧。Mixtral 8x7b 总共有 467 亿参数,但每个 token 只使用 129 亿参数,因此以此成本处理输入和输出。他们的 MoE 模型在性能上 consistently 超越了 Llama2(70B)和 GPT-3.5(175B),而运行成本更低。
MoE 的好处以及为何它是首选架构
最终,MoE 架构的主要目标是提出一种新的范式,来应对复杂的机器学习任务。它提供了独特的好处,并在多个方面展示了其优于传统模型的优势。
-
增强的模型可扩展性
-
每个专家负责任务的一部分,因此通过增加专家来扩展不会导致计算需求的同比增加。
-
这种模块化方法可以处理更大、更复杂的数据集,并促进并行处理,加快操作。例如,将图像识别模型添加到基于文本的模型中,可以集成一个额外的 LLM 专家来解释图片,同时仍能输出文本。或者
-
多功能性使模型能够扩展其处理不同类型数据输入的能力。
-
-
提高效率和灵活性
-
MoE 模型非常高效,仅在特定输入下选择性地调用必要的专家,不像传统架构那样无论如何都使用所有参数。
-
该架构减少了每次推断的计算负担,使模型能够适应不同的数据类型和专门任务。
-
-
专门化与准确性:
-
MoE 系统中的每个专家可以针对整体问题的特定方面进行精细调节,从而在这些领域实现更高的专业性和准确性。
-
这种专门化在医学影像或金融预测等领域中非常有用,这些领域中精确性是关键。
-
MoE 可以从狭窄领域中生成更好的结果,因为它对细微差别的理解、详细知识以及在专门任务上超越通用模型的能力。
-
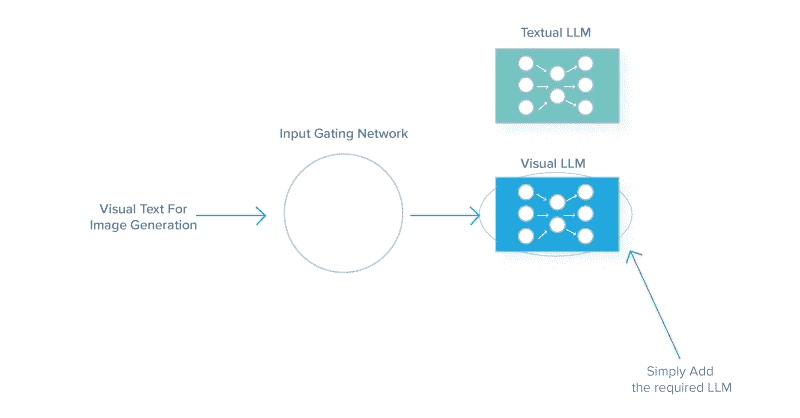
MoE 架构的缺点
尽管 MoE 架构提供了显著的优势,但它也带来了可能影响其采用和有效性的挑战。
-
模型复杂性: 管理多个神经网络专家和一个用于引导流量的门控网络,使 MoE 的开发和运营成本具有挑战性。
-
训练稳定性: 门控网络与专家之间的交互引入了不可预测的动态,阻碍了实现均匀学习率,并需要大量的超参数调整。
-
不平衡: 让专家闲置对 MoE 模型来说是糟糕的优化,浪费资源在不使用的专家上或过度依赖某些专家。平衡工作负载分配和调节有效的门控对高性能 MoE AI 至关重要。
需要注意的是,上述缺点通常会随着 MoE 架构的改进而逐渐减少。
由专门化塑造的未来
反思 MoE 方法及其与人类并行的情况,我们可以看到,就像专门化团队比通才团队取得更好的成果一样,专门化模型在人工智能模型中也优于单一模型。优先考虑多样性和专业知识将大规模问题的复杂性转化为专家可以有效解决的可管理的部分。
展望未来,考虑到专门化系统在推动其他技术方面的广泛影响。MoE 的原则可能会影响医疗保健、金融和自主系统等领域的发展,促进更高效和更准确的解决方案。
MoE 的旅程才刚刚开始,其持续演变有望推动 AI 及其他领域的进一步创新。随着高性能硬件的不断进步,这种专家 AI 的混合可以驻留在我们的智能手机中,提供更加智能的体验。但首先,需要有人来训练这些模型。
Kevin Vu 管理着 Exxact Corp 博客,并与许多撰写有关深度学习不同方面的才华横溢的作者合作。
更多相关主题
为什么你应该在 2024 年学习 SQL

图片由作者提供
人类一直受到存储和共享信息能力的强烈影响。研究表明,人类与其他动物的关键区别在于我们能够创造、保存和继承知识和文化,代代相传。
我们的三大课程推荐
1. Google 网络安全证书 - 加入网络安全领域的快速通道
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
今天,我们正经历着世界运作方式的重大转变:数据已成为 21 世纪的燃料。所有领域和部门都依赖于数据来做出决策。
有一点是确定的:对数据相关技能的需求只会持续增长。
如今,组织以空前的速度从内部和外部来源收集原始数据。通过分析这些数据,他们可以使用报告应用程序、仪表板和其他工具来回答问题并获得有价值的洞察。
那么正确的问题是如何管理所有这些数据?
SQL 仍然是数据专业人员中需求最旺盛的技能之一。让我们深入探讨为何如此,以及你如何加入这场数据革命。
SQL,数据管理之星
SQL,全称结构化查询语言,是与使用 SQL 服务器的数据库交互的标准语言。它是为了操作数据集而创建的。它可以用于检索、更新、删除和创建数据库中的数据。
除了数据操作,SQL 还允许你修改数据库结构,如添加表、删除记录和设置访问权限。
自 1970 年代创立以来,SQL 已成为数据分析的标准语言。根据 Stack Overflow 2023 年的调查,SQL 在专业程序员中排名第三的使用语言。
由于大多数组织依赖数据来做决策和提高效率,SQL 是最大化数据价值的必备技能。
此外,SQL 是大多数现代商业工具集中核心工具之一,即使你不直接负责创建和管理数据库,这也是一项宝贵的技能。
学习 SQL 的好处包括:
图片由作者提供
处理大量数据
SQL 设计用于处理大数据,能够比电子表格或某些编程语言(如 Python)更快地处理复杂查询。学习 SQL 有助于你有效地管理和分析大数据。
在许多组织中,数据环境的核心通常是数据仓库,而 SQL 是主要的交互语言。
与其他工具互动
SQL 与其他数据科学工具和编程语言,如 Python 和 R,能够无缝集成。像 pandas(Python)和 dplyr(R)这样的库允许你在代码中直接运行 SQL 查询。
这种互操作性使得将 SQL 的数据处理能力与这些语言的高级分析、可视化和机器学习功能结合起来变得更容易。
标准化技能
要使用 SQL 查询或操作数据,你需要使用带有关键字如“SELECT”和“FROM”的语句。这个 SQL 语法由 ANSI 和 ISO 认证,确保了在支持 SQL 的数百种数据库和数据工具中保持一致性。
虽然一些数据库和工具可能会通过专门的操作符、命令或函数扩展语法,但 SQL 的基本原则始终保持一致。
一旦你掌握了 SQL 的基础知识,你可以在不同平台上普遍应用这些知识。
它易于理解
基本 SQL 语法高度可读,类似于自然语言。它概述了数据应如何被检索或操作。
请考虑以下示例查询:
SELECT first_name, last_name, date_of_hire
FROM employees
WHERE date_of_hire > '2018-12-31'
ORDER BY date_of_hire, last_name;
在这个查询中,SQL 关键字 SELECT、FROM、WHERE 和 ORDER BY 定义了要执行的操作,任何人都可以理解查询的主要目的。需要注意的是,虽然这些关键字不需要大写,但为了更好的可读性,通常建议使用大写。
SQL 入门
既然我们知道 SQL 技能对于处理数据至关重要,你可能想知道如何开始。以下是一步步的指南,帮助你入门:
基本 SQL 语句:从基本的 SQL 语句开始,以检索数据和操作表格。
聚合函数:学习像 SUM 和 AVG 这样的聚合函数,以总结数据并对单个表进行初步分析。
JOIN 和子查询:接下来使用 JOIN 和子查询来结合来自多个表的数据。
一旦你掌握了基础知识,就重要开始进行自己的实践项目。在以下链接中,你可以找到一些自己动手做的项目的想法。
执行这些项目将强化你的理解,并为实际的数据任务做好准备。
SQL 方言之间的差异
SQL 方言是针对不同数据库系统量身定制的 SQL 语言变体,每种方言都影响兼容性和易用性。对于数据专业人士来说,学习像 MySQL、PostgreSQL 和 SQLite 这样的 SQL 方言之间的差异是非常有益的。
学习者通常从 SQLite 开始。掌握每种方言的独特特征可以提升代码性能,并促进不同平台之间的无缝集成。
虽然不必成为每种 SQL 方言的专家,但对语法差异有基本了解是极其有帮助的,尤其是在寻求使用不同方言的环境中的就业时。许多学习者从 SQLite 开始,但熟悉至少一种除了 SQLite 之外的 SQL 方言是有益的。这将使你更具多样性,更好地准备应对不同的数据环境。
简要说明
-
SQL 对高效处理和分析大型数据集至关重要。其重要性体现在它在 2023 年被评为第三大最常用编程语言。
-
SQL 无缝集成其他数据科学工具和编程语言,如 Python 和 R,增强了其在数据管理和分析中的实用性。
-
SQL 的语法是标准化的,使其在不同数据库系统中保持一致且易于学习。其可读性和类似自然语言的特点使其对初学者友好,同时对多种 SQL 方言的了解能提高在不同数据环境中的就业能力和灵活性。
Josep Ferrer**** 是一位来自巴塞罗那的分析工程师。他毕业于物理工程专业,目前在应用于人类流动的数据科学领域工作。他还是一名兼职内容创作者,专注于数据科学和技术。Josep 撰写有关 AI 的所有内容,涵盖该领域持续爆炸性的应用。
更多相关主题
为什么你不应该过度使用 Python 列表推导式
原文:
www.kdnuggets.com/why-you-should-not-overuse-list-comprehensions-in-python

图片由作者提供
在 Python 中,列表推导式提供了一种简洁的语法来从现有列表和其他可迭代对象中创建新列表。然而,一旦你习惯了列表推导式,你可能会被诱惑在不应该使用它们的情况下也使用它们。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
记住,你的目标是编写简单且易于维护的代码,而不是复杂的代码。通常,回顾一下Python 之禅,即一组编写干净且优雅 Python 的箴言,会很有帮助,特别是以下几点:
-
优美胜于丑陋。
-
简单优于复杂。
-
可读性很重要。
在本教程中,我们将编写三个例子——每个例子都比前一个更复杂——其中列表推导式使代码变得非常难以维护。然后我们将尝试编写一个更易于维护的版本。
那么,让我们开始编码吧!
Python 列表推导式:快速回顾
让我们从回顾 Python 中的列表推导式开始。假设你有一个现有的可迭代对象,如列表或字符串。你可以遍历该可迭代对象,处理每个项,并将结果附加到新列表中:
new_list = []
for item in iterable:
new_list.append(output)
但列表推导式提供了一种简洁的一行替代方案来完成相同的任务:
new_list = [output for item in iterable]
此外,你还可以添加过滤条件。
以下代码片段:
new_list = []
for item in iterable:
if condition:
new_list.append(output)
可以用此列表推导式替代:
new_list = [output for item in iterable if condition]
所以列表推导式帮助你编写 Pythonic 代码——通过减少视觉噪声,使代码更清晰。
现在让我们通过三个例子来理解为什么你不应该在需要超复杂表达式的任务中使用列表推导式。因为在这种情况下,列表推导式不仅不会使你的代码优雅,反而会使代码难以阅读和维护。
示例 1:生成质数
问题:给定一个数字upper_limit,生成一个所有质数的列表直到该数字。
你可以将这个问题拆解成两个关键概念:
-
检查一个数字是否为质数
-
用所有质数填充列表
完成此任务的列表推导式如下所示:
import math
upper_limit = 50
primes = [x for x in range(2, upper_limit + 1) if x > 1 and all(x % i != 0 for i in range(2, int(math.sqrt(x)) + 1))]
print(primes)
下面是输出结果:
Output >>>
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47]
乍一看,很难理解发生了什么……让我们把它做得更好。
也许,更好?
import math
upper_limit = 50
primes = [
x
for x in range(2, upper_limit + 1)
if x > 1 and all(x % i != 0 for i in range(2, int(math.sqrt(x)) + 1))
]
print(primes)
确实更容易阅读。现在让我们编写一个真正更好的版本。
更好的版本
虽然列表推导实际上是解决这个问题的一个好主意,但在列表推导中检查质数的逻辑使其显得冗杂。
所以让我们编写一个更易于维护的版本,将检查一个数字是否是质数的逻辑移到一个单独的函数 is_prime() 中。在列表推导表达式中调用 is_prime() 函数:
import math
def is_prime(num):
return num > 1 and all(num % i != 0 for i in range(2, int(math.sqrt(num)) + 1))
upper_limit = 50
primes = [
x
for x in range(2, upper_limit + 1)
if is_prime(x)
]
print(primes)
Output >>>
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47]
更好的版本是否足够好? 这使得列表推导表达式更容易理解。现在很清楚,这个表达式收集了所有小于 upper_limit 的质数(其中 is_prime() 返回 True)。
示例 2:处理矩阵
问题:给定一个矩阵,找到以下内容:
-
所有的质数
-
质数的索引
-
质数之和
-
按降序排列的质数
图片来源:作者
为了展平矩阵并收集所有质数的列表,我们可以使用类似于前一个示例的逻辑。
然而,为了找到索引,我们有另一个复杂的列表推导表达式(我已经格式化了代码,使其易于阅读)。
你可以将质数检查和获取它们的索引结合在一个列表推导中。但这不会让事情变得更简单。
这里是代码:
import math
from pprint import pprint
my_matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
def is_prime(num):
return num > 1 and all(num % i != 0 for i in range(2, int(math.sqrt(num)) + 1))
# Flatten the matrix and filter to contain only prime numbers
primes = [
x
for row in my_matrix
for x in row
if is_prime(x)
]
# Find indices of prime numbers in the original matrix
prime_indices = [
(i, j)
for i, row in enumerate(my_matrix)
for j, x in enumerate(row)
if x in primes
]
# Calculate the sum of prime numbers
sum_of_primes = sum(primes)
# Sort the prime numbers in descending order
sorted_primes = sorted(primes, reverse=True)
# Create a dictionary with the results
result = {
"primes": primes,
"prime_indices": prime_indices,
"sum_of_primes": sum_of_primes,
"sorted_primes": sorted_primes
}
pprint(result)
以及相应的输出:
Output >>>
{'primes': [2, 3, 5, 7],
'prime_indices': [(0, 1), (0, 2), (1, 1), (2, 0)],
'sum_of_primes': 17,
'sorted_primes': [7, 5, 3, 2]}
那么什么是更好的版本?
更好的版本
对于更好的版本,我们可以定义一系列函数以分离关注点。这样,如果出现问题,你知道哪个函数需要返回并修复逻辑。
import math
from pprint import pprint
def is_prime(num):
return num > 1 and all(n % i != 0 for i in range(2, int(math.sqrt(num)) + 1))
def flatten_matrix(matrix):
flattened_matrix = []
for row in matrix:
for x in row:
if is_prime(x):
flattened_matrix.append(x)
return flattened_matrix
def find_prime_indices(matrix, flattened_matrix):
prime_indices = []
for i, row in enumerate(matrix):
for j, x in enumerate(row):
if x in flattened_matrix:
prime_indices.append((i, j))
return prime_indices
def calculate_sum_of_primes(flattened_matrix):
return sum(flattened_matrix)
def sort_primes(flattened_matrix):
return sorted(flattened_matrix, reverse=True)
my_matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
primes = flatten_matrix(my_matrix)
prime_indices = find_prime_indices(my_matrix, primes)
sum_of_primes = calculate_sum_of_primes(primes)
sorted_primes = sort_primes(primes)
result = {
"primes": primes,
"prime_indices": prime_indices,
"sum_of_primes": sum_of_primes,
"sorted_primes": sorted_primes
}
pprint(result)
这段代码也给出了与之前相同的输出。
Output >>>
{'primes': [2, 3, 5, 7],
'prime_indices': [(0, 1), (0, 2), (1, 1), (2, 0)],
'sum_of_primes': 17,
'sorted_primes': [7, 5, 3, 2]}
更好的版本是否足够好? 虽然这对像本示例中的小矩阵有效,但返回静态列表通常不推荐。对于更大的维度,可以使用 生成器。
示例 3:解析嵌套 JSON 字符串
问题:根据条件解析给定的嵌套 JSON 字符串,并获取所需值的列表。
解析嵌套的 JSON 字符串具有挑战性,因为你必须考虑不同的嵌套层级、JSON 响应的动态特性以及解析逻辑中的多种数据类型。
让我们以根据条件解析给定的 JSON 字符串来获取所有值的列表为例:
-
整数或整数列表
-
字符串或字符串列表
你可以使用内置的 json 模块 中的 loads 函数将 JSON 字符串加载到 Python 字典中。因此,我们将有一个嵌套的字典,并在其上使用列表推导。
列表推导使用嵌套循环来遍历嵌套的字典。对于每个值,它根据以下条件构建一个列表:
-
如果值不是字典且键以 'inner_key' 开头,它使用
[inner_item]。 -
如果值是包含 'sub_key' 的字典,它使用
[inner_item['sub_key']]。 -
如果值是字符串或整数,它使用
[inner_item]。 -
如果值是字典,它使用
list(inner_item.values())。
请查看下面的代码片段:
import json
json_string = '{"key1": {"inner_key1": [1, 2, 3], "inner_key2": {"sub_key": "value"}}, "key2": {"inner_key3": "text"}}'
# Parse the JSON string into a Python dictionary
data = json.loads(json_string)
flattened_data = [
value
if isinstance(value, (int, str))
else value
if isinstance(value, list)
else list(value)
for inner_dict in data.values()
for key, inner_item in inner_dict.items()
for value in (
[inner_item]
if not isinstance(inner_item, dict) and key.startswith("inner_key")
else [inner_item["sub_key"]]
if isinstance(inner_item, dict) and "sub_key" in inner_item
else [inner_item]
if isinstance(inner_item, (int, str))
else list(inner_item.values())
)
]
print(f"Values: {flattened_data}")
这是输出结果:
Output >>>
Values: [[1, 2, 3], 'value', 'text']
如所见,列表推导式非常难以理解。
请对自己和团队中的其他人好一点,避免编写这样的代码。
更好的版本
我认为以下使用嵌套 for 循环和 if-elif 阶梯结构的代码片段更好。因为它更容易理解发生了什么。
flattened_data = []
for inner_dict in data.values():
for key, inner_item in inner_dict.items():
if not isinstance(inner_item, dict) and key.startswith("inner_key"):
flattened_data.append(inner_item)
elif isinstance(inner_item, dict) and "sub_key" in inner_item:
flattened_data.append(inner_item["sub_key"])
elif isinstance(inner_item, (int, str)):
flattened_data.append(inner_item)
elif isinstance(inner_item, list):
flattened_data.extend(inner_item)
elif isinstance(inner_item, dict):
flattened_data.extend(inner_item.values())
print(f"Values: {flattened_data}")
这也给出了预期的输出:
Output >>>
Values: [[1, 2, 3], 'value', 'text']
更好的版本是否足够好? 嗯,不太够。
因为 if-elif 阶梯结构通常被认为是一种代码异味。你可能会在分支中重复逻辑,添加更多条件只会使代码更难维护。
但对于这个例子来说,虽然 if-elif 阶梯结构和嵌套循环的版本比列表推导式更容易理解。
总结
到目前为止我们编写的示例应该能让你明白,过度使用 Pythonic 特性,比如列表推导式,往往会适得其反。这不仅仅适用于列表推导式(虽然它们是最常用的),也适用于字典和集合推导式。
你应该始终编写易于理解和维护的代码。因此,即使这意味着不使用一些 Pythonic 特性,也要尽量保持简单。继续编码!
Bala Priya C**** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点工作。她的兴趣和专长包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过编写教程、操作指南、观点文章等与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关主题
人工智能会取代人类吗?
我们生活在一个概率的世界中。几年前,当我开始谈论人工智能及其影响时,最常见的问题是——人工智能是否会来袭?
尽管问题保持不变,但关于概率的回答已经发生了变化。在某些领域中,人工智能更有可能取代人类判断,因此这种概率随着时间的推移而增加。
当我们讨论复杂技术时,答案不会很简单。这取决于几个因素,比如什么才算智能,我们是否建议替代工作,预测人工通用智能(AGI)的时间表,或识别人工智能的能力和局限性。

来源:Canva
智能的定义
让我们首先理解智能的定义:
斯坦福大学将智能定义为“在一个不确定、不断变化的世界中,学习并采用适当的技术来解决问题和实现目标的能力。”
Gartner将其描述为分析、解读事件、支持和自动化决策及采取行动的能力。
人工智能擅长学习模式,但仅仅识别模式并不足以称之为智能。这只是更广泛的多维人类智能谱系中的一个方面。

来源:Canva
专家们认为,“人工智能永远无法做到这一点,因为机器无法对过去、现在和未来的历史、伤害或怀旧产生感知(而不仅仅是知识)。没有这些,机器没有情感,缺乏了双重逻辑的一个组成部分。因此,机器仍然陷入单一形式逻辑中。这就是‘智能’的部分。”
清除测试 = 智能?
有些人可能会提到人工智能通过了来自著名机构的测试,最近还通过了图灵测试,作为其智能的证明。
对于不了解的人来说,图灵测试是由著名计算机科学家艾伦·图灵设计的实验。根据这一测试,如果评估者无法区分机器和人类的回应,那么机器就具有人类般的智能。
对测试的综合概述强调,尽管生成式人工智能模型可以根据从大量训练数据中学习到的统计模式或关联生成自然语言,但它们没有人类般的意识。
即使是高级测试,如通用语言理解评估(GLUE)和斯坦福问答数据集(SQuAD),也与图灵测试的基本前提相同。
替代的意义是什么?
工作岗位的丧失
让我们从一个迅速成为现实的恐惧开始——人工智能是否会使我们的工作变得多余?虽然没有明确的“是或否”的答案,但随着生成性 AI 在自动化机会上的拓展,这一问题正迅速逼近。
麦肯锡 报告称:“到 2030 年,占美国经济目前工作时间的 30% 的活动可能会被自动化——这是生成性 AI 加速的趋势。”
像办公室支持、会计、银行、销售或客户支持这样的职位是首先会被自动化的对象。生成性 AI 在代码编写和测试工作流程中对软件开发人员的辅助已经影响了初级开发人员的工作角色。
其结果通常被认为是专家进一步提升输出的良好起点,例如制作营销文案、推广内容等。
一些叙述通过强调新工作岗位的可能性,使这一转变看起来很微妙,例如短期内的医疗、科学和技术领域;以及 AI 伦理学家、AI 管理、审计、AI 安全等,旨在使 AI 成为现实。然而,这些新工作岗位无法超越被替代的岗位数量,因此我们必须考虑新创造的净工作岗位,以了解最终影响。
AGI
接下来是 AGI 的可能性,这与智能的多种定义类似,需要明确的含义。通常,AGI 指的是机器获得类似于人类的感知和世界意识的阶段。
然而,AGI 是一个值得单独讨论的话题,不在本文的范围之内。
目前,我们可以参考 DeepMind 首席执行官的日记,以了解其早期迹象。

来源:财富
它能替代人类吗?
好助手
从更广泛的角度来看,它足够智能,可以帮助人类大规模识别模式并提高效率。
让我们通过一个例子来验证这一点,其中供应链规划师查看多个订单详情,并致力于确保那些可能出现短缺的订单。每个规划师在处理短缺交付时有不同的方法:
-
查看像手头上有多少库存这样的属性
-
在那个时间框架内,其他客户的预期需求是什么?
-
哪个客户或订单应优先于其他?
-
与其他工厂经理进行战情室讨论,以促进物品的供应。
-
致力于优化从特定配送中心的路线。
作为个人规划者,可能会受到其视角和处理此类情况的方法的限制,机器通过理解许多规划者的行动可以学习到最佳方法,并通过其发现模式的能力帮助他们自动化简单场景。
这就是机器在同时管理多个属性或因素方面相对于人类有限能力的优势所在。
机械的
然而,机器就是它们自己,即机械的。你不能指望它们像伟大的领导者那样合作、协作并与团队建立富有同情心的关系。
我经常参与较轻松的团队讨论,不是因为我必须,而是因为我更喜欢在一个与团队紧密相连的环境中工作,他们也很了解我。从一开始就只讨论工作或试图表现得很重要,这种方式太机械化了。

来源:Canva
缺乏同情心
另一个例子是,当机器分析患者的记录并根据其医疗诊断如实披露健康问题时,与医生如何细致处理这种情况相比,医生由于拥有情感并知道危机中的感觉,处理方式会更加周到。
大多数成功的医疗专业人士会超越他们的“职责”,与患者建立联系,帮助他们度过困难时期,而机器在这方面做得不好。
没有道德准则
机器在数据上进行训练,这些数据可以捕捉潜在现象,并创建最佳估计的模型。
在这种估算中,特定条件的细微差别会丢失。它们没有类似于法官在审视每个案件时的道德准则。
结束语
总结来说,机器可能会从数据中学习模式(以及随之而来的偏见),但没有智慧、动力或动机来进行根本性的改变,以解决困扰人类的问题。它们是以人类智慧为基础的,具有目标导向,但人类智慧则复杂得多。
这个 短语 很好地总结了我的想法——AI 可以取代人脑,但不能取代人类。
Vidhi Chugh** 是一位 AI 战略家和数字化转型领袖,在产品、科学和工程的交汇点上工作,致力于构建可扩展的机器学习系统。她是一位获奖的创新领袖、作者和国际演讲者。她的使命是普及机器学习,并打破术语,使每个人都能参与这场转型。
更多相关主题
胜者是…逐步回归
原文:
www.kdnuggets.com/2016/08/winner-stepwise-regression.html
作者:Jacob Zahavi 和 Ronen Meiri,DMWay Analytics。
编者注:这篇博客文章曾参与最近的 KDnuggets 自动化数据科学和机器学习 博客比赛,并获得了荣誉提名。
预测分析(PA),数据科学的核心领域之一,致力于基于已知响应值的过去观察来预测未来响应。在这个大数据时代,PA 模型面临的主要问题是维度问题,这使得模型构建过程变得非常繁琐和耗时。
最复杂的部分是特征选择问题——选择最具影响力的预测变量来“解释”响应。这里存在两个相互矛盾的关注点:预测准确性,由预测误差的方差决定,以及在对新观察应用模型结果时的预测偏差。随着更多预测变量被引入模型,模型的准确性通常会提高,但偏差可能会加重。因此,通常需要在准确性和偏差之间进行权衡分析,以找到模型的“最佳”预测变量集。由于噪声数据、冗余预测变量、多重共线性、缺失值、异常值等因素的影响,情况会变得更加复杂。
特征选择问题的复杂性导致了几种自动化此过程的方法的发展,涉及三类
方法包括统计方法、随机方法和降维方法。在这项研究中,我们进行了一项研究,寻找表现最佳的模型,涉及每类模型中的“代表性”模型——统计方法的逐步回归(SWR)、随机方法的模拟退火(SA)以及降维方法中的主成分分析(PCA)和径向基函数(RBF)。SWR 使用假发现率(FDR)算法进行校准;SA 使用随机但系统的搜索方法,提高其收敛到全局最优解的可能性;最后,降维方法将多个属性合并为一组更小的“巨型”响应预测变量。
我们对线性回归(LR)模型进行了研究,不仅因为它是机器学习(ML)中最常见的模型之一,还因为它构成了许多其他 ML 方法的基础。
为了“公平比较”,我们优化了每个模型类别的模型配置,然后将表现最佳的模型进行比较。在这一点上,我们忽略了原始变量的变换,这可能会使某些模型类型相较于其他模型有优势,并且仅使用原始变量进行了比较分析。所有方法都应用于由 DMEF(直接营销教育基金会)提供的三个现实营销数据集,分别称为非营利、专业和礼品,每个数据集包含约 100,000 个观察值和潜在预测变量的分数。
我们使用了著名的 R2(“R 平方”)标准作为拟合度的衡量标准,寻求最大化验证数据集 R2 的模型,前提是验证数据集 R2 与训练数据集 R2 之间的比率大致等于 1.0。最大化 R2 确保了模型的高准确性。R2 比率接近 1 的约束意味着没有过拟合。方法的评估基于数据挖掘中常见的几个性能指标,包括增益图、最大提升(M-L)和 Gini 系数。
为了便于评估,我们将所有四个模型(SWR、SA、PCA 和 RBF)的增益图叠加在一起,对应于上述数据文件(图 1-3)。每个增益图对应于模型类别中各自模型的最佳参数配置。表 1 展示了相关的总结统计数据。所有增益图,以及相关的 Gini 和 M-L 指标,都展示在验证数据集中。

图 1:非营利文件(点击放大)

图 2:专业文件(点击放大)

图 3:礼品文件(点击放大)

表 1:模型比较(点击放大)
令人惊讶的是,著名的 SWR 模型与被认为更强大的 SA 模型产生了相似的结果。我们将这些结果归因于市场上人们的理性行为,这在数据库中反映出来,产生了“行为良好”的数据集,数据元素之间没有复杂的关系。因此,即使是短视的 SWR 模型也能识别出最有影响力的预测变量。至于降维方法,在所有数据文件中表现都远不如 SWR。对此现象的一个可能解释是,在降维过程中没有考虑响应变量,从而产生了“较弱”的响应预测变量。
这些结论具有重要的实际意义,因为它们表明,在市场营销应用中,可能同样可以使用传统的 SWR 算法来构建大规模的 LR 模型。不仅 SWR 是一个广为人知并且有广泛软件可用的算法,而且进一步的研究表明,SWR 有足够的灵活性来允许使用任何合理范围的 p 值来移除/引入变量到模型中,仍然能得到一个有效的模型。虽然还需要进一步研究以将此研究结果推广到其他领域,但在市场营销应用中,最终获胜者是……逐步回归!
雅各布·扎哈维博士是 DMWay Analytics的联合创始人兼首席行政官,并且是特拉维夫大学管理学院的名誉教授。他主要研究数据挖掘,拥有超过 25 年的经验,涵盖了研究、教学、软件开发和应用等多个方面。他还曾两次获得 KDD CUP 比赛的金奖。
罗嫩·梅里博士, DMWay Analytics的联合创始人兼首席技术官,在包括精算、行为定向、信用风险、预测、客户保留、欺诈检测等多个行业中拥有 15 年的高级分析实践经验。
相关:
-
数据科学机器,或‘如何进行特征工程’
-
TPOT:自动化数据科学的 Python 工具
-
自动数据科学:DataRobot、Quill 和 Loom Systems
我们的前三推荐课程
1. Google 网络安全证书 - 加入网络安全职业的快车道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
更多相关话题
为建立你的数据科学团队制定的制胜计划
原文:
www.kdnuggets.com/2018/09/winning-game-plan-building-data-science-team.html
评论
作为 Hitachi “数据科学部会”的副主席,我在 Hitachi 面临的最令人兴奋的挑战之一是帮助领导 Hitachi 数据科学能力的发展。我们有一个目标,到 2020 年希望培训并投入使用的人数,因此确实感受到紧迫感。我喜欢这种紧迫感,因为它有助于清除变革的阻碍和抗拒。
我开始这个任务时写了一篇标题为“数据集成和数据工程有什么区别?”的博客,阐述了传统数据集成和现代数据工程之间的区别(见图 1)。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域的职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT

图 1: 数据集成与数据工程
但那个博客只涉及了数据工程师的角色。为了实现“数据科学部会”的目标——即更有效地利用数据和分析来优化关键业务和运营流程,减轻合规和安全风险,发掘新的收入机会,并创造更具吸引力和差异化的用户体验——我们需要考虑三个关键角色,以及这三个关键角色之间的互动,这些角色构成了数据科学社区的完整面貌。我们需要了解数据工程师、数据科学家和业务利益相关者的职责、能力、期望和技能。
研究数据科学三位一体
我们从研究硅谷领先数据科学组织的数据工程师和数据科学家的招聘职位开始了这个任务(感谢 John!)。我们随后创建了一个图形,突出了这些角色的重点和能力,以及这些角色之间的互动——数据科学能力的维恩图(见图 2)。

图 2:数据科学能力 Venn 图表
数据科学能力的 Venn 图表确定了三个关键数据科学角色的关键目标和能力。数据科学创新发生在这三种角色的交集处:
-
假设开发(明确你想要实现的目标以及如何衡量进展和成功),
-
数据货币化(识别、验证、评估和优先排序业务和运营用例)和
-
治理(运营化和采用)。
备注:我将在未来的博客中详细探讨这些创新点及其在推动数字化转型和数据货币化中的作用。
研究的支持细节可以在图 3 的视力图表中看到。

图 3:定义数据科学职责和工具
这是一个很好的基础,帮助我们了解我们需要招聘和/或发展的技能。然而,图表本身还不够。我们现在需要将这些研究转化为可操作的内容。
数据科学能力 Spider 图表
我们的下一步是将 Spider 图表叠加在数据科学能力 Venn 图表上。然后,我们可以利用 Venn 图表不仅评估数据科学社区的当前能力,还可以基于此制定个性化的发展计划,以提高三个角色中的数据科学能力。
图 4 显示了一个例子,即我们希望为其开发数据工程技能的初级数据科学家进行的这种映射练习。

图 4:样本数据科学家发展计划
再次,我们可以使用数据科学能力的 Venn 图表 Spider 图来评估该个人在所有三个维度上的当前能力,然后制定个性化的培训计划或课程,以促进他们在不同维度上的进步。
图 5 显示了使用 Spider 图表来提高业务利益相关者的数据科学和数据工程意识的另一个示例。

图 5:样本业务利益相关者数据科学发展计划
虽然我们的目标不是将业务利益相关者转变为数据科学家,但我们确实希望培训业务利益相关者“像数据科学家一样思考”。 这样,业务利益相关者就能理解如何与数据科学家和数据工程师更好地合作,挖掘客户、产品、服务和运营的洞察,从而推动业务成功。 详情请参见博客“像数据科学家一样思考系列”了解如何创建“数据科学公民”。
下一步是细化区分初级、中级到高级数据科学家和数据工程师的梯度,然后创建相应的课程和内容来达到这些目标。 你好,全球学习团队!
构建数据科学团队总结
数据科学是一个由数据工程师、数据科学家和业务利益相关者组成的团队运动。 就像一支棒球队不能仅靠游击手和捕手来有效运作一样,一个数据科学计划必须清楚地阐明数据工程师、数据科学家和业务利益相关者的角色、责任和期望。
如果你的组织目标是更有效地利用数据和分析来推动商业模式和数字化转型,那么你不能仅靠一支全是投手的团队赢得比赛。 对吧,Alec?
相关:
-
数据集成和数据工程之间的区别是什么?
-
伟大的数据科学家不仅仅是跳出框框思考,他们重新定义了框框
-
识别可能更好的预测变量
更多相关主题
在机器学习竞赛中,是什么使得一个参赛作品获胜?
原文:
www.kdnuggets.com/2021/05/winning-machine-learning-competition.html
评论
由 Harald Carlens,独立机器学习研究员。

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织在 IT 领域
如果你曾经尝试过 Kaggle 风格的竞赛,你可能会看到它们的竞争有多么激烈。每场竞赛可以吸引成千上万的竞争者,包括学术和企业团队。
在运营 MLContests.com 的过程中,自 2019 年底以来,我一直跟踪所有这些竞赛,并最近开始分析数据,以回答这个问题:是什么让一个参赛作品获胜?
我邀请了 Eniola Olaleye——Zindi 平台上的前 5 名竞争者——仔细分析了 2020 年所有竞赛的获胜解决方案,并找出他们获胜的原因。他们使用了什么框架?他们有多少经验?他们使用了什么类型的建模?他们使用了深度学习吗?他们的团队有多大?在这篇文章中,我将重点介绍一些发现,这些发现可能帮助你提高赢得竞赛的机会。
我应该参加哪个竞赛?
首先,可能也是最重要的事情是决定参加哪个竞赛!显然,如果你将精力集中在一次一个竞赛上,努力做到最好,你获胜的机会会更大,而不是在多个竞赛中都有平庸的表现。
一件可能增加你获胜机会的事情是减少竞争。我们的数据显示,进入比赛的团队数量在不同竞赛和平台上差异很大!HackerEarth、DrivenData、Unearthed、Kaggle 和 CodaLab 竞赛的参赛者平均超过一千人。
在另一端,我们有像 Waymo 开放数据集挑战 或 IARAI 的 Traffic4Cast 挑战 这样的单次比赛,参赛者只有几十人。虽然这些比赛可能更具领域特定性,并且没有 Kaggle Kernels 和 Notebooks 的便利,但如果你在相关领域有专长,参加这些比赛可能更合适。值得一提的是,今年,Waymo 再次举办其 开放数据集挑战,包括四场比赛,每场比赛的奖金池为 22,000 美元!有关其他独立比赛的信息,请查看 MLContests.com。如果你发现有未列出的比赛,可以 在 GitHub 上提交拉取请求 与 ML Contests 社区分享。
哪种深度学习框架最好?
不足为奇,深度学习在竞争性 ML 中极为常见,特别是在 NLP 和基于视觉的任务中表现出色。
在过去两年中,有两个主要相关的深度学习框架:Google 的 TensorFlow 和 Facebook 的 PyTorch。
由于其相对成熟和部署简便,TensorFlow 在“生产”行业环境中通常是更受欢迎的框架,这可以通过职位发布或 GitHub 星标来衡量。
而在研究领域,PyTorch 从不相关迅速成为大多数研究人员的明确偏好。它的 Python 风格、相对稳定的 API 和定制化的便捷,使其在大约 80% 的学术深度学习论文中被使用(仅计算提到 TensorFlow 或 PyTorch 的论文)。
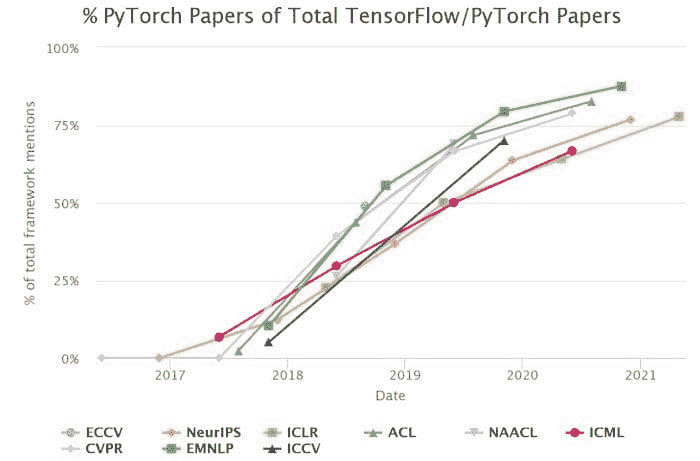
来源:霍雷斯·赫,“2019 年机器学习框架现状”,The Gradient,2019。
机器学习比赛显然位于研究和生产的研究-生产连续体的研究侧,这在深度学习框架的使用上得到了体现:超过 70% 的获胜解决方案使用了 PyTorch,而不到 30% 的解决方案使用了 TensorFlow。
这里是我们的答案:虽然成功的 ML 比赛参与者,和大多数其他研究人员一样,偏好 PyTorch,但如果你对 TensorFlow 很熟悉,也没有理由阻止你获胜。
你不需要在所有领域都成为专家
可能因为觉得其他人经验更丰富,或者你对某个领域还不熟悉,容易被打消参加比赛的念头。也许你对 Pandas 和统计学很熟悉,但对深度学习还不熟悉。或者你是某个领域的专家,理解 ML 概念,但编程能力有限。
噢,你真幸运!第一个好消息是,在我们的数据集中,超过 80%的获胜者之前从未赢得过比赛。因此,虽然确实有一些突破性的重复获胜者,但一般来说,他们并不主导比赛,新手作为一个群体获胜的机会更大。
第二个好消息是,你不需要了解你所使用的每个组件的全部深度就能赢得比赛。
以深度学习为例,大约 15%的深度学习解决方案使用了如 Keras for TensorFlow 或 fast.ai for PyTorch 这样的高级 API。只要你对一般的机器学习感到熟悉,并且小心避免过拟合,这些 API 通常足以赢得比赛。你不一定需要从头编写自己的模型和训练循环,使用高级 API 可以让你将精力集中在其他方面获得优势。
另一个有趣的例子是在领域知识重要的比赛中。我们以戈勒挑战赛为例,该比赛预测南澳大利亚的矿产沉积区域,奖金池为 25 万美元。我们联系了获胜团队,了解他们是如何赢得 10 万美元大奖的。结果发现,他们是领域内的专家地质学家,主要依靠其在该领域的知识获得优势。他们将地质力学建模与随机森林结合起来。有趣的是,他们使用了Weka,一个用于随机森林实现的 GUI 工具。这使他们能够专注于自己擅长的领域,并显然获得了回报。
结论
所以结论是:如果你想赢:
-
选择合适的比赛。考虑你可能拥有的优势以及哪些比赛可能被其他人忽视。
-
专注于你的优势所在。如果你参加的比赛中你有一些领域知识,花更多时间充分利用这些知识可能比调整解决方案的其他部分更值得。
更多关于 2020 年机器学习比赛获胜者的统计数据,请参阅这个总结。
简介: Harald Carlens 是一位独立的机器学习研究员,并且运营 mlcontests.com。他曾在剑桥大学学习数学,并在股权交易领域工作了八年。
相关:
更多相关话题
19 位在人工智能、大数据、数据科学、机器学习领域的激励女性
原文:
www.kdnuggets.com/2019/03/women-ai-big-data-science-machine-learning.html
评论为了纪念 3 月 8 日的国际妇女节,我们为您呈现 19 位在人工智能、大数据、数据科学和机器学习领域的激励人心的女性资料。尽管该领域的女性数量相对较少,但我相信,人工智能和机器学习领域的多样性和女性参与度的提高将带来益处。
我希望下面这些令人惊叹的女性的例子能继续激励更多女性加入这一领域。
也请查看我们 2018 年的文章 18 Inspiring Women In AI, Big Data, Data Science, Machine Learning。那篇文章相当受欢迎,但我们收到了许多关于其他激励女性的评论,她们没有被包含在那份名单中。
所以,这里是 2019 年全新的更多令人惊叹的女性名单。

Libby Duane Adams,Alteryx 的首席客户官和创始合伙人,Alteryx 提供了一个端到端的分析平台,正在为分析师和数据科学家彻底改变企业分析。
Anima Anandkumar, @AnimaAnandkumar, NVIDIA 的研究总监和加州理工学院的布伦教授。直到最近,她曾是亚马逊网络服务的首席科学家,她在该领域推动了云基础设施上的机器学习。她是张量代数方法、非凸优化、概率模型和深度学习的领先研究者。
Anna Anisin, @annaontheweb, 是 Formulated.by 的创始人;社区企业家;《福布斯》撰稿人;数据科学沙龙系列会议的组织者,并被 CNN 评为科技行业内幕人士。
Moojan Asghari, @moojanasghari, 科技企业家,《The Hacking House》经理,@Women_in_AI 的发起人,丝绸之路初创公司的创始人,Startup Sesame 的联合创始人。
Cynthia Breazeal, Jibo 的创始人及首席科学家;麻省理工学院媒体实验室媒体艺术与科学副教授;她是社会机器人学和人机互动的先驱。她撰写了《设计社交机器人》一书,并发表了 100 多篇关于人工智能、机器人、人与机器人互动及相关主题的同行评审文章。
Joy Buolamwini,@jovialjoy,是一位用艺术和研究揭示 AI 社会影响的代码诗人。她创立了算法公正联盟,以对抗 AI 中的有害偏见。在 MIT 媒体实验室,她开创了现在正在全球范围内提高面部分析技术透明度的技术。她曾入选《福布斯》30 岁以下 30 人榜单和前 50 位科技女性。
Kate Crawford,@katecrawford,是一位领先的研究人员、教授和作者,过去十年致力于研究数据系统、机器学习和 AI 的社会影响。她共同创立了 NYU 的 AI Now Institute,并且是 MSR-NYC 的首席研究员和 NYU 的杰出研究教授。
Sanja Fidler 是多伦多大学的助理教授,以及 NVIDIA 的 AI 总监。她的研究兴趣包括 2D 和 3D 对象检测,特别是可扩展的多类别检测、对象分割和图像标注,以及 (3D) 场景理解。她于 2018 年获得了加拿大 CIFAR AI Chair 奖项。
Fosca Giannotti 是信息科学与技术研究所计算机科学研究主任,并领导比萨 KDD 实验室——知识发现与数据挖掘实验室,该实验室成立于 1994 年,是最早的以数据挖掘为中心的研究实验室之一。Fosca 是移动数据挖掘、社交网络分析和隐私保护数据挖掘的开创性科学家。她协调了数十个欧洲项目和工业合作,目前是 SoBigData 的协调员,这是一个关于大数据分析和社会挖掘的欧洲研究基础设施。
Katherine Gorman,@kgorman,是机器智能播客 Talking Machines 的创始执行制片人和联合主持人 @TlkngMchns。在 2016 和 2017 年,她担任 TedXBoston 的策展人和主持人,专注于机器学习和 AI 的研究;在 2017 年,Katherine 帮助 NeurIPS 会议开发和实施媒体策略,并担任 NeurIPS 和 ICML 的新闻联***。
Isabelle Guyon 是一位独立顾问,专注于机器学习和统计数据分析。她曾在贝尔实验室工作,并在 1990 年代与 Vladimir Vapnik 共同发现了支持向量机。她的研究项目包括最优间隔分类器和支持向量机、指纹验证、基因选择、手写识别和笔计算。她还在 NIPS(现为 NeurIPS)及其他会议上组织了许多研讨会和挑战赛。
达芙妮·科勒 目前是 insitro 的创始人兼首席执行官,该公司将前沿的机器学习技术与生命科学领域的突破性创新相结合。她曾担任斯坦福大学计算机科学与病理学教授,并获得了麦克阿瑟(“天才”)奖学金、ACM/Infosys 奖以及许多其他荣誉。她于 2012 年与安德鲁·吴共同创办了 Coursera。她的研究领域是人工智能及其在生物医学科学中的应用。

拉娜·艾尔·卡柳比,@kaliouby 是 Affectiva 的首席执行官和共同创始人。她曾是世界经济论坛的年轻全球领袖,入选《财富》40 岁以下精英榜单。她的领域是表情识别研究和技术开发,用于识别面部表达的情感。
卡塔里娜·莫里克 是德国多特蒙德工业大学计算机科学系的全职教授。她是机器学习、归纳逻辑编程、统计学习和大规模数据集分析领域的领先研究者。她是国家科学与工程学院以及北莱茵-威斯特法伦科学与艺术学院的成员。她已在主要会议和期刊上发表了 200 多篇论文。她最新的研究成果包括时空随机场和整数马尔可夫随机场,这些成果在资源约束下支持复杂的图模型。
丹妮拉·鲁斯 是麻省理工学院电气工程与计算机科学系的 Andrew 和 Erna Viterbi 教授,并且是计算机科学与人工智能实验室(CSAIL)的主任。她的研究兴趣包括机器人技术、移动计算和数据科学。她是麦克阿瑟学者,ACM、AAAI 和 IEEE 的会员,并且是国家工程院和美国艺术与科学学院的成员。
凯特·斯特拉赫尼,@storybydata 是 《颠覆者:数据科学领袖》 和 《成为数据科学家之旅》 的作者,目前正在撰写几本新书。她是 Datacated Weekly 的主持人,该项目致力于帮助他人了解数据领域的各种主题。她曾在 2018 年 LinkedIn 数据科学与分析领域顶级声音榜单中排名第二。
拉塔尼亚·斯威尼 是哈佛大学政府与技术教授。拉塔尼亚创建并使用技术来评估和解决社会、政治和治理问题,并教导他人如何做到这一点。她关注的数据隐私问题,她是哈佛 IQSS 数据隐私实验室的主任。斯威尼教授是美国医学信息学学院的当选成员,拥有近 100 篇学术出版物、3 项专利、2 项政府法规中的明确引用和 3 个公司孵化项目。
瑞秋·托马斯、@math_rachel 曾被《福布斯》评选为“20 位令人惊叹的 AI 女性”之一,是 Uber 的早期工程师,并在杜克大学获得数学博士学位。她是 fast.ai 的联合创始人,该公司创建了“实用深度学习课程”,已有超过 20 万名学生参加。瑞秋还是一位受欢迎的作家和主题演讲者。
桑德拉·瓦赫特、@SandraWachter5 是牛津互联网研究所的数据伦理、人工智能、机器人技术和互联网监管/网络安全领域的律师及研究员。
相关:
更多相关话题
数据领域的女性

Christina @ wocintechchat.com via Unsplash
大多数行业都有形象问题。人们想要雇佣最聪明的那一个。适合工作角色的人。看起来像那个角色的人。拥有特定的身体特征以打动客户和竞争对手的人。我可以继续讲下去。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
在谈到数据科学时,许多人认为这个职业路径是“书呆子”的行业。一个适合聪明男性的行业,进一步把女性推向了更远的地方。众所周知,数据收集、分析、产出和决策的工作大多是由男性完成的。根据TechRepublic的数据,2019 年美国数据科学职位中的女性占比为 18%。在低收入国家,女性获得更好教育和 STEM(科学、技术、工程、数学)学位的机会更少,数据科学职位中的女性比例更低。
根据世界银行的数据,2019 年女性的识字率为 83.02%,而男性为 89.93%。因此,女性常常难以有效使用数字技术。我们已经知道 STEM 职业中存在性别不平衡,这使女性不愿进入该行业。女性在数据科学等职业中接受的培训水平也较低,使得女性在职业发展和获得高薪职位方面更为困难,进一步加剧了性别薪酬差距。
根据BCG的数据,女性占 STEM 学科大学毕业生的 36%,但仅占 STEM 劳动力的 25%,且仅有 9%在 STEM 高层领导中。
数据驱动的政策如何让情况变得更糟?
数据科学领域女性的缺乏被用作数据,导致行业中女性的进入受阻或数量减少。卡罗利娜·克里亚多-佩雷斯是一位英国女权主义作家、记者和活动家,她撰写了《隐形女性:揭露男性主导世界中的数据偏见》一书。这本书揭示了偏见数据对女性和年轻女孩的不利影响,影响了她们的教育、职业和总体信心。以下是她发现的几点:
招聘算法
我们都知道,招聘算法可能是我们一些人没有被选中进入下一阶段的原因。这对女性来说更是雪上加霜,因为她们更不容易申请特定的职位,例如数据科学,尤其是那些使用招聘算法的高科技公司。根据路透社的报道,亚马逊曾使用一种机器学习算法作为其新的招聘流程,这种算法对女性不利。公司使用了过去十年提交的简历作为算法的训练数据。由于这些简历主要来自男性,程序学会了男性候选人更受欢迎,从而惩罚女性。该程序自学避免使用“女性”一词,例如“女性象棋俱乐部队长”。虽然亚马逊在早期发现了这一点,但这表明问题不仅仅在于人们过于依赖模型。这更是一个偏见数据被用来做出错误决策、加剧职场不平等的问题。
为什么数据科学中需要女性?

Christina @ wocintechchat.com via Unsplash
第四次工业革命正在到来。对于那些不太了解的人来说,它是一种描述物理、数字和生物世界之间界限的方式。它包含了人工智能(AI)、机器人技术、物联网(IoT)、3D 打印、基因工程、量子计算以及其他技术元素。
随着我们越来越依赖数据来建立新模型和帮助我们做出重要决策,数据在我们的生活中成为了一个重要元素。然而,如果我们拥有的数据对女性没有益处?或者无法清晰地理解女性?AI 技术会在大多数行业中帮助还是阻碍女性填补现有的性别差距?
人工智能将被用作公司招聘和解雇员工的工具。这也将成为许多人在众多行业中失业的原因,因为它可以替代他们的角色。这进一步将女性置于最不利的位置,因为在这场变革中,支持她们的数据很少。波士顿咨询公司(BCG)表示:“人工智能应用可能会延续和加剧性别偏见,从而进一步扩大领导力培养中的差距。如果人工智能应用是基于偏见的数据进行训练的,那么它所开发的算法也可能会有偏见。”
为了避免女性被边缘化,STEM 行业中的女性数量至关重要。随着这些行业中女性数量的增加,有助于确保女性不会因为预设的算法而受到惩罚,为年轻一代提供了更好的机会和更多的希望以在 STEM 职业中发展。
尼莎·阿雅 是一名数据科学家和自由撰稿人。她特别感兴趣于提供数据科学职业建议或教程以及数据科学理论知识。她还希望探索人工智能如何有助于人类生命的延续。作为一名热衷的学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
词嵌入公平性评估
原文:
www.kdnuggets.com/2020/08/word-embedding-fairness-evaluation.html
评论
由 Pablo Badilla 和 Felipe Bravo-Marquez.
关于 WEFE
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
词嵌入 是从文档语料库中训练出的词的稠密向量表示。由于其能够有效捕捉词之间的语义和句法关系,它们已成为自然语言处理(NLP)下游系统的核心组件。词嵌入的一个广泛报告的缺点是它们容易继承训练语料库中表现出的刻板社会偏见。
如何量化提到的偏见目前是一个活跃的研究领域,近年来文献中提出了几种不同的公平性指标。
尽管所有指标有类似的目标,但它们之间的关系却不清楚。阻碍清晰比较的两个问题是,它们处理的输入不同(词对、词集、多个词集等),而且它们的输出彼此不兼容(实数、正数、范围等)。这导致它们之间缺乏一致性,从而在尝试比较和验证结果时造成了若干问题。
我们提出了词嵌入公平性评估 (WEFE)作为一个用于衡量词嵌入公平性的框架,并且我们将其实现发布为开源库。
框架
我们提出了一个公平性指标的抽象视图,作为一个函数,该函数接受查询作为输入,每个查询由目标和属性词组成。目标词描述了公平性旨在测量的社会群体(例如,女性、白人、穆斯林),而属性词描述了可能对某一社会群体表现出的偏见的特征或态度(例如,愉快与不愉快的术语)。有关框架的更多细节,您可以阅读我们最近被接受的论文,刊登在IJCAI-PRICAI [1]。
WEFE 实现了以下指标:
WEFE 的标准使用模式
使用 WEFE 测量偏差的标准过程如下面的图示所示:
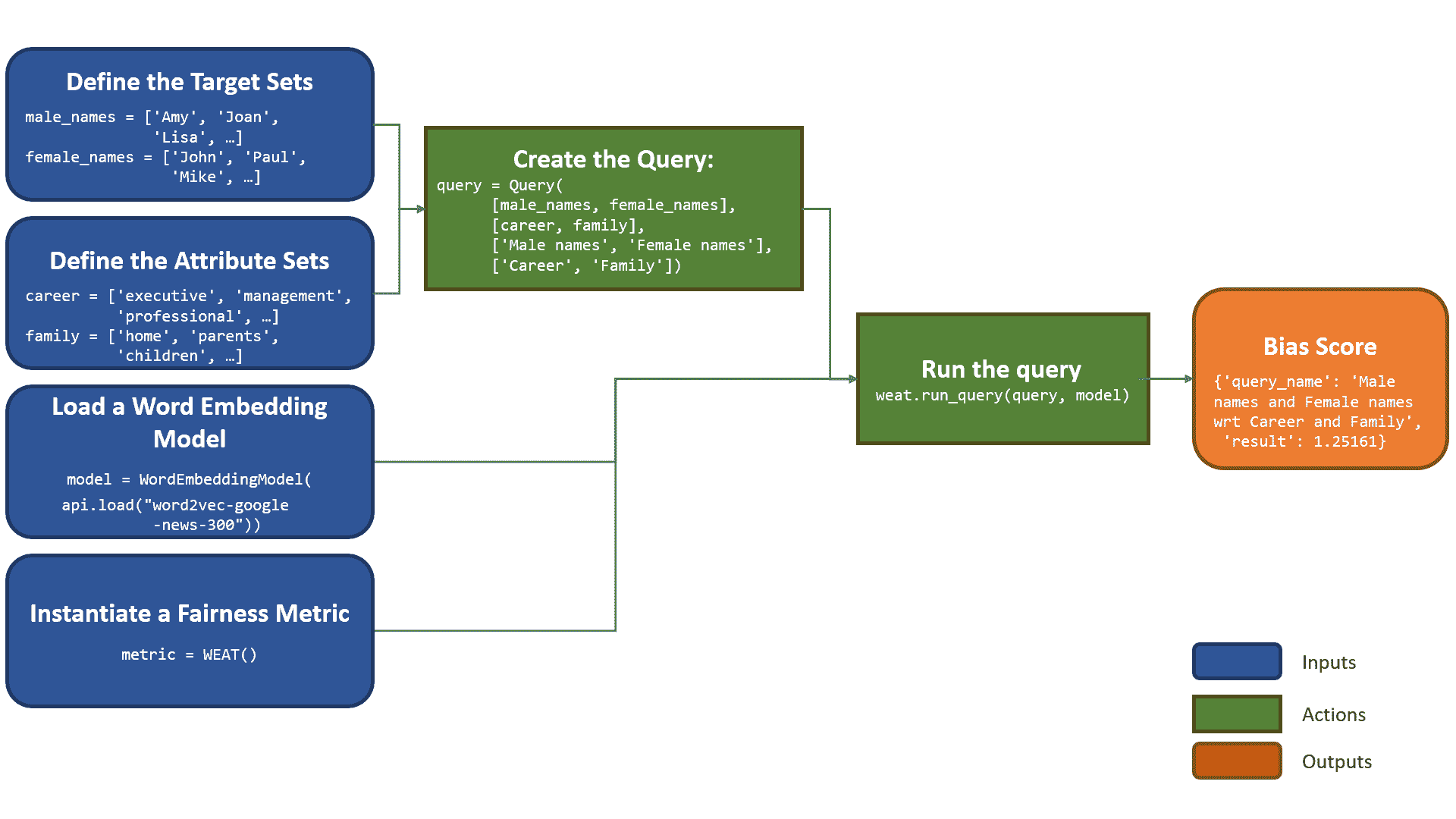
安装
有两种不同的方法来安装 WEFE:
pip install wefe
或
conda install -c pbadilla wefe
运行查询
在下面的代码中,我们使用以下方法测量 性别偏差 的 word2vec:
-
一个查询研究了男性名字和职业相关词,女性名字和家庭相关词之间的关系,我们称之为 "男性名字与女性名字的职业和家庭相关性"。查询中使用的词在代码中详细列出。
-
词嵌入关联测试 (WEAT) 度量。由 Caliskan et al. 2017 提出,WEAT 接受两个目标词集
![T_1]() 和
和 ![T_2]() ,以及两个属性词集
,以及两个属性词集 ![A_1]() 和
和 ![A_2]() 。因此,它总是期望查询的形式为
。因此,它总是期望查询的形式为 ![Q=({T_1,T_2},{A_1,A_2}]() 。其目标是通过置换测试量化两个词集对的关联强度。
。其目标是通过置换测试量化两个词集对的关联强度。
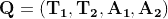 。其目标是通过置换测试量化两个词集对的关联强度。
。其目标是通过置换测试量化两个词集对的关联强度。给定一个词嵌入 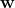 ,WEAT 首先定义度量
,WEAT 首先定义度量 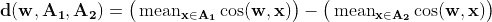 ,其中
,其中  是词嵌入向量的余弦相似度。
是词嵌入向量的余弦相似度。
然后对于查询  ,WEAT 度量定义在查询词集的嵌入上如下:
,WEAT 度量定义在查询词集的嵌入上如下:
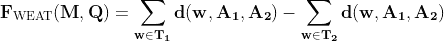
其思路是,如果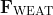 给出的值越积极,目标
给出的值越积极,目标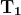 与属性
与属性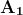 的关系就越紧密,目标
的关系就越紧密,目标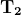 与属性
与属性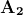 的关系也会更紧密。另一方面,如果值越负,目标与属性的关系会更紧密,而目标与属性的关系也会更紧密。通常这些值在
的关系也会更紧密。另一方面,如果值越负,目标与属性的关系会更紧密,而目标与属性的关系也会更紧密。通常这些值在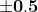 和
和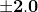 之间。理想得分为
之间。理想得分为 。
。
1. 首先,我们使用 gensim API 加载一个词嵌入模型。
from wefe import WordEmbeddingModel, Query, WEAT
import gensim.downloader as api
word2vec_model = WordEmbeddingModel(api.load('word2vec-google-news-300'),
'word2vec-google-news-300')
2. 然后,我们使用目标词(男性名字和女性名字)以及两个属性词集(职业和家庭术语)创建查询对象。
# target sets (sets of popular names in the US)
male_names = ['John', 'Paul', 'Mike', 'Kevin', 'Steve', 'Greg', 'Jeff', 'Bill']
female_names = ['Amy', 'Joan', 'Lisa', 'Sarah', 'Diana', 'Kate', 'Ann', 'Donna']
#attribute sets
career = ['executive', 'management', 'professional', 'corporation',
'salary', 'office', 'business', 'career']
family = ['home', 'parents', 'children', 'family', 'cousins', 'marriage',
'wedding', 'relatives']
gender_occupation_query = Query([male_names, female_names],
[career, family],
['Male names', 'Female names'],
['Career', 'Family'])
3. 最后,我们使用 WEAT 作为度量来运行查询。
weat = WEAT()
results = weat.run_query(gender_occupation_query, word2vec_model)
print(results
{'query_name': 'Male names and Female names wrt Career and Family',
'result': 1.251}
正如我们所见,执行结果返回一个字典,其中包含执行的查询名称及其得分。得分为正且高于 1 表明word2vec 展现了男性名字与职业以及女性名字与家庭之间的适度强关系。
运行多个查询
在 WEFE 中,我们可以在一次调用中轻松测试多个查询:
1. 创建查询:
from wefe.utils import run_queries
from wefe.datasets import load_weat
# Load the sets used in the weat case study
weat_wordsets = load_weat()
gender_math_arts_query = Query(
[male_names, female_names],
[weat_wordsets['math'], weat_wordsets['arts']],
['Male names', 'Female names'],
['Math', 'Arts'])
gender_science_arts_query = Query(
[male_names, female_names],
[weat_wordsets['science'], weat_wordsets['arts_2']],
['Male names', 'Female names'],
['Science', 'Arts'])
2. 将查询添加到数组中:
queries = [
gender_occupation_query,
gender_math_arts_query,
gender_science_arts_query,
]
3. 使用 WEAT 运行查询:
weat_results = run_queries(WEAT, queries, [word2vec_model])
weat_results
请注意,这些结果以 DataFrame 对象形式返回。
| model_name | 男性名字与女性名字相对于职业和家庭 | 男性名字与女性名字相对于数学和艺术 | 男性名字与女性名字相对于科学和艺术 |
|---|---|---|---|
| word2vec-google-news-300 | 1.25161 | 0.631749 | 0.535707 |
我们可以看到,在所有情况下,男性名字与职业、科学和数学词汇呈正相关,而女性名字则更多地与家庭和艺术术语相关。
虽然上述结果给我们提供了关于word2vec 展现的性别偏见的想法,但我们还希望了解这些偏见在其他词嵌入模型中的表现。
我们在另外两个嵌入模型上运行相同的查询:“glove-wiki”和“glove-twitter”。
1. 加载 glove 模型并再次执行查询:
# load the models.
glove_wiki = WordEmbeddingModel(api.load('glove-wiki-gigaword-300'),
'glove-wiki-gigaword-300')
glove_twitter = WordEmbeddingModel(api.load('glove-twitter-200'),
'glove-twitter-200')
# add the models to an array.
models = [word2vec_model, glove_wiki, glove_twitter]
# run the queries.
results = run_queries(WEAT, queries, models)
results
| 模型名称 | 男性名字与女性名字相对于职业和家庭 | 男性名字与女性名字相对于数学和艺术 | 男性名字与女性名字相对于科学和艺术 |
|---|---|---|---|
| word2vec-google-news-300 | 1.25161 | 0.631749 | 0.535707 |
| glove-wiki-gigaword-300 | 1.31949 | 0.536996 | 0.549819 |
| glove-twitter-200 | 0.537437 | 0.445879 | 0.332440 |
2. 我们还可以绘制结果:
from wefe.utils import plot_queries_results
plot_queries_results(results)
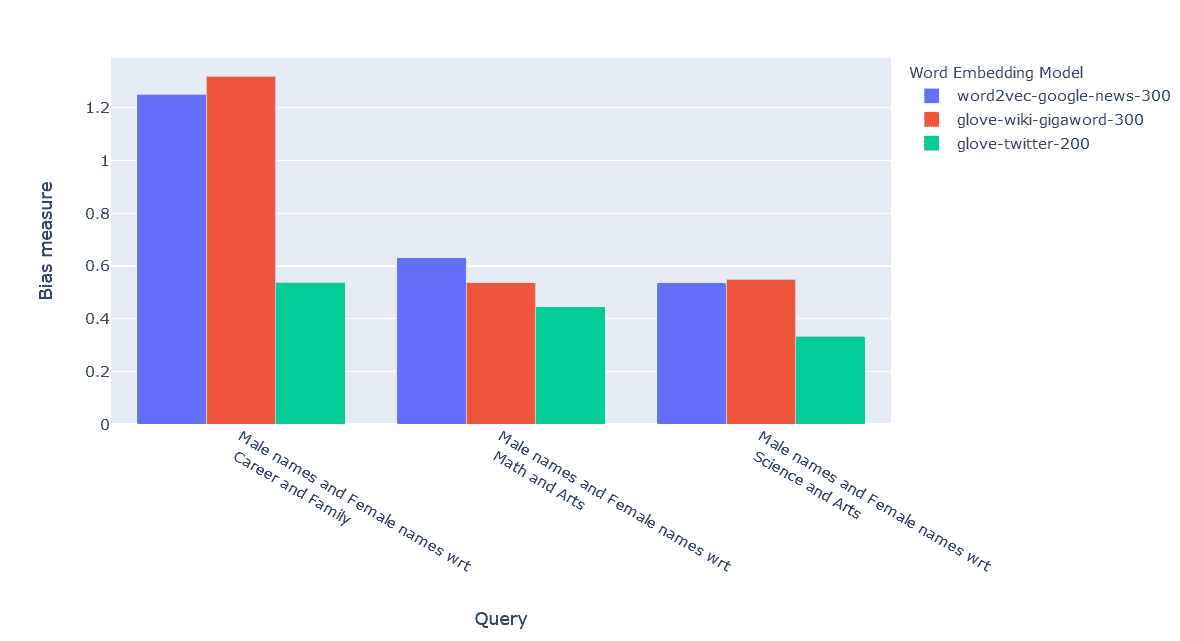
聚合结果
在之前的步骤中执行run_queries给出了各种结果评分。然而,这些评分并没有告诉我们关于嵌入模型的整体公平性。
我们希望有一些机制将这些结果聚合为一个单一的评分。
要做到这一点,当使用run_queries时,你可以将add_results参数设置为True。这将激活通过平均结果的绝对值并将其放入结果表的最后一列来添加结果的选项。
也可以要求run_queries函数仅返回聚合结果,通过将return_only_aggregation参数设置为True来实现。
weat_results = run_queries(WEAT,
queries,
models,
aggregate_results=True,
return_only_aggregation=True,
queries_set_name='Gender bias')
weat_results
| model_name | WEAT:性别偏见绝对值平均评分 |
|---|---|
| word2vec-google-news-300 | 0.806355 |
| glove-wiki-gigaword-300 | 0.802102 |
| glove-twitter-200 | 0.438586 |
这种聚合的思想是根据各种查询量化嵌入模型的偏见量。在这种情况下,我们可以看到 glove-twitter 的性别偏见比其他模型少。
排名词嵌入
最后,我们希望根据这些嵌入模型包含的偏见总量对它们进行排名。这可以通过使用create_ranking函数来完成,该函数根据一个或多个查询结果计算公平性排名。
from wefe.utils import create_ranking
ranking = create_ranking([weat_results])
ranking
| model_name | WEAT:性别偏见绝对值平均评分 |
|---|---|
| word2vec-google-news-300 | 3 |
| glove-wiki-gigaword-300 | 2 |
| glove-twitter-200 | 1 |
你可以在这个笔记本中查看此教程代码,以及在以下链接中查看完整的参考文档,包括用户指南、示例和以前研究的复制。
如果你喜欢这个项目,非常欢迎你在Github上“点赞”它。
[1] P. Badilla, F. Bravo-Marquez 和 J. Pérez WEFE: 词嵌入公平性评估框架 在 第 29 届国际联合人工智能会议暨第 17 届环太平洋国际人工智能会议(IJCAI-PRICAI 2020),横滨,日本。
相关:
更多相关话题
Word Morphing – 一个原创想法
原文:
www.kdnuggets.com/2018/11/word-morphing-original-idea.html
comments
平滑的图像过渡(变形)从老虎到人类(图片来源:Google Images)
为了进行词形变化,我们将定义一个图G,其中节点集合N表示单词,并且存在一个非负权重函数f:N×N→ℝ。给定一个起始单词S和一个结束单词E,我们的目标是找到图中的一条路径,该路径最小化由f引起的权重总和:
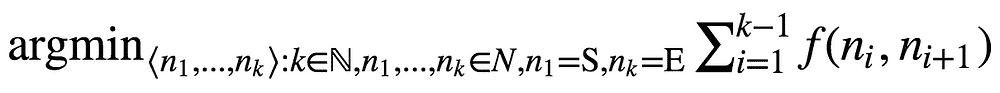
图 1. 由 f 引起的最小成本的最佳路径
通常,当人们谈论词形变化时,他们指的是在S和E之间寻找一条路径,其中只有当通过改变一个字母可以从一个单词得到另一个单词时,才存在边,如这里所示。在这种情况下,当存在这样的变化时,f(n₁,n₂)为 1,否则为∞。
在这篇文章中,我将展示如何在语义上相似的单词之间进行变形,即f将与语义相关。以下是一个示例,说明这两种方法之间的差异:给定S=tooth,E=light,一次只改变一个字符的方法可能结果为
tooth, booth, boots, botts, bitts, bitos, bigos, bigot, bight, light
而本文将定义的语义方法会导致
tooth, retina, X_ray, light
你可以在这里找到完整的代码。
词汇语义
为了捕捉词汇语义,我们将使用预训练的 word2vec 嵌入[1]。对于那些不熟悉该算法的人,以下是来自维基百科的摘录:
Word2vec 以大规模文本语料库为输入,生成一个向量空间,通常为数百维,其中语料库中的每个唯一单词都分配了一个相应的向量。词向量在向量空间中被定位,使得在语料库中共享共同上下文的单词在空间中彼此接近。
这意味着图中的每个节点都可以与高维空间中的某个向量关联(在我们的案例中为 300 维)。因此,我们可以自然地定义每两个节点之间的距离函数。我们将使用余弦相似度,因为这是通常用于语义比较词嵌入的度量。从现在开始,我将重载节点符号n为其相关单词的嵌入向量。
要使用 word2vec 嵌入,我们将从这里下载 Google 的预训练嵌入,并使用 gensim 包来访问它们。
选择权重函数
给定余弦相似度距离函数,我们可以将我们的 f 函数定义为
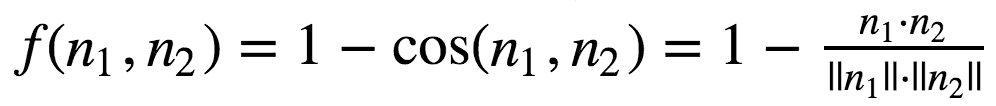
公式 1. 使用余弦相似度定义权重函数
然而,使用这种方法我们会面临一个问题:最佳路径可能包括权重较高的边,这将导致相邻词语在语义上不相似。
为了解决这个问题,我们可以将 f 修改为
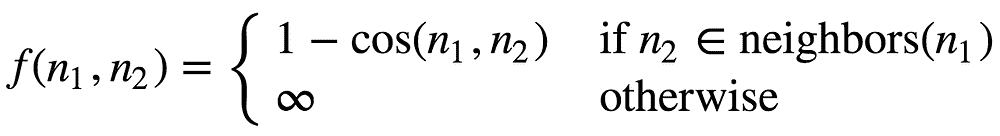
公式 2. 使用限制为最近邻的余弦相似度定义权重函数
其中 neighbors(n₁) 表示图中与 n₁ 在余弦相似度方面最接近的节点。邻居的数量是可配置的。
A* 搜索
现在我们已经定义了图,我们将使用一个叫做 A* 的著名搜索算法[2]。
在这个算法中,每个节点的成本由两个部分组成——g(n)+h(n)。
g(n) 是从 S 到 n 的最短路径成本,而 h(n) 是一个启发式函数,用于估计从 n 到 E 的最短路径成本。在我们的例子中,启发式函数将是 f。
搜索算法维护一个叫做 开放集 的数据结构。最初这个集合包含 S,在算法的每次迭代中,我们弹出开放集中成本最小的节点 g(n)+h(n),并将其邻居添加到开放集中。算法在成本最小的节点为 E 时停止。
这个算法可以与我们选择的任何启发式函数一起使用。但为了实际找到最佳路径,启发式函数必须是可接纳的,意味着它不能高估真实成本。不幸的是,f 不是可接纳的。然而,我们将使用观察,即如果向量的长度为 1,那么余弦相似度可以通过对欧几里得距离进行单调变换来获得。这意味着在按相似度对词进行排序时,两者是可以互换的。欧几里得距离是可接纳的(你可以通过三角不等式证明),所以我们可以使用它来代替,定义为
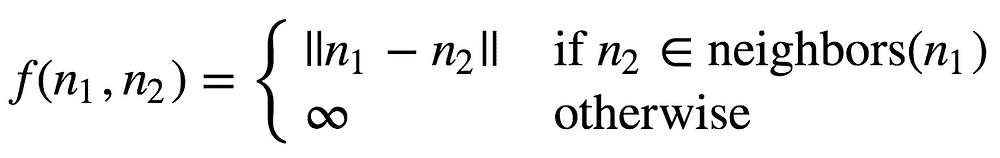
公式 3. 使用欧几里得距离定义权重函数
总结一下,我们将对词嵌入进行归一化,使用欧几里得距离作为找到语义上相似词的手段,并用相同的欧几里得距离来指导 A* 搜索过程,以找到最佳路径。
我选择了邻居(n)来包含其 1000 个最近的节点。然而,为了使搜索更高效,我们可以使用稀释因子为 10 对这些节点进行稀释:我们选择最近的邻居,第 10 近邻,第 20 近邻,以此类推——直到我们得到 100 个节点。这样做的直觉是,从某个中间节点到E的最佳路径可能会经过其最近的邻居。如果没有,可能是因为它也不会经过第二个邻居,因为第一个和第二个邻居可能几乎是相同的。因此,为了节省计算,我们只是跳过了一些最近的邻居。
现在进入有趣的部分:
结果:
['tooth', u'retina', u'X_ray', u'light']
['John', u'George', u'Frank_Sinatra', u'Wonderful', u'perfect']
['pillow', u'plastic_bag', u'pickup_truck', u'car']
最后思考
实施词形变化项目很有趣,但不如玩这个工具并尝试任何我能想到的单词对有趣。我鼓励你自己去尝试一下。在评论中告诉我你发现了哪些有趣和惊人的词形变化:)
本文最初发布于www.anotherdatum.com。
参考文献
[2] www.cs.auckland.ac.nz/courses/compsci709s2c/resources/Mike.d/astarNilsson.pdf
简介: Yoel Zeldes 是 Taboola 的算法工程师,同时也是一位机器学习爱好者,特别喜欢深度学习的见解。
原文。已获得许可转载。
资源:
相关:
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
更多相关主题
使用置信区间
原文:
www.kdnuggets.com/2023/04/working-confidence-intervals.html

图片由编辑提供
在数据科学和统计学中,置信区间对于量化数据集的不确定性非常有用。65%置信区间表示数据值落在均值的一标准差范围内。95%置信区间表示数据值分布在均值的两标准差范围内。置信区间也可以估计为四分位数范围,它表示介于第 25 百分位数和第 75 百分位数之间的数据值,第 50 百分位数表示均值或中位数。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
在这篇文章中,我们演示了如何使用身高数据集来计算置信区间。身高数据集包含男性和女性的身高数据。
身高的概率分布可视化
首先,我们生成男性和女性身高的概率分布。
# import necessary libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# obtain dataset
df = pd.read_csv('https://raw.githubusercontent.com/bot13956/Bayes_theorem/master/heights.csv')
# plot probability distribution of heights
sns.kdeplot(df[df.sex=='Female']['height'], label='Female')
sns.kdeplot(df[df.sex=='Male']['height'], label = 'Male')
plt.xlabel('height (inch)')
plt.title('probability distribution of Male and Female heights')
plt.legend()
plt.show()
男性和女性身高的概率分布 | 图片由作者提供。
从上图可以观察到,男性的平均身高高于女性。
置信区间的计算
下面的代码展示了如何计算男性和女性身高的 95%置信区间。
# calculate confidence intervals for male heights
mu_male = np.mean(df[df.sex=='Male']['height'])
mu_male
>>> 69.31475494143555
std_male = np.std(df[df.sex=='Male']['height'])
std_male
>>> 3.608799452913512
conf_int_male = [mu_male - 2*std_male, mu_male + 2*std_male]
conf_int_male
>>> [65.70595548852204, 72.92355439434907]
# calculate confidence intervals for female heights
mu_female = np.mean(df[df.sex=='Female']['height'])
mu_female
>>> 64.93942425064515
std_female = np.std(df[df.sex=='Female']['height'])
std_female
>>> 3.752747269853828
conf_int_female = [mu_female - 2*std_female, mu_female + 2*std_female]
conf_int_female
>>> [57.43392971093749, 72.4449187903528]
使用箱线图的置信区间
另一种估计置信区间的方法是使用四分位数范围。可以使用箱线图来可视化四分位数范围,如下所示。
# generate boxplot
data = list([df[df.sex=='Male']['height'],
df[df.sex=='Female']['height']])
fig, ax = plt.subplots()
ax.boxplot(data)
ax.set_ylabel('height (inch)')
xticklabels=['Male', 'Female']
ax.set_xticklabels(xticklabels)
ax.yaxis.grid(True)
plt.show()
箱线图展示了四分位数范围。| 图片由作者提供。
箱线图显示了四分位数范围,须状线表示数据的最小值和最大值(不包括离群值)。圆圈表示离群值。橙色线为中位数。从图中可以看出,男性身高的四分位数范围为[67 英寸,72 英寸]。女性身高的四分位数范围为[63 英寸,67 英寸]。男性身高的中位数为 68 英寸,而女性身高的中位数为 65 英寸。
总结
总结来说,置信区间在量化数据集中的不确定性方面非常有用。95%的置信区间表示数据值分布在均值的两个标准差范围内。置信区间也可以估计为四分位数范围,表示数据值介于第 25 百分位数和第 75 百分位数之间,其中第 50 百分位数表示均值或中位数值。
本杰明·O·泰约 是一位物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的拥有者。之前,本杰明曾在中央俄克拉荷马大学、Grand Canyon 大学和匹兹堡州立大学教授工程学和物理学。
更多相关主题
在 Keras 中使用 Lambda 层
原文:
www.kdnuggets.com/2021/01/working-lambda-layer-keras.html
评论

Keras 是一个流行且易于使用的深度学习模型构建库。它支持所有已知类型的层:输入层、全连接层、卷积层、转置卷积层、重塑层、归一化层、丢弃层、展平层和激活层。每个层对数据执行特定操作。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
尽管如此,你可能希望对数据执行一些现有层未应用的操作,这时候现有的层类型可能不够用。举个简单的例子,假设你需要一个在模型架构的某个特定点添加固定数字的层。因为没有现有的层可以做到这一点,你可以自己构建一个。
在本教程中,我们将讨论在 Keras 中使用Lambda层。这使你能够将操作指定为函数。我们还将看到如何调试 Keras 加载功能,当构建一个包含 lambda 层的模型时。
本教程涵盖的部分如下:
-
使用
Functional API构建 Keras 模型 -
添加一个
Lambda层 -
向 lambda 层传递多个张量
-
保存和加载带有 lambda 层的模型
-
解决加载带有 lambda 层的模型时的 SystemError
让这个项目成为现实
使用Functional API构建 Keras 模型
在 Keras 中可以使用三种不同的 API 来构建模型:
-
顺序 API
-
功能 API
-
模型子类化 API
你可以在this post中找到有关这些内容的更多信息,但在本教程中我们将专注于使用 Keras Functional API构建自定义模型。由于我们希望专注于架构,我们将使用一个简单的问题示例来构建一个识别 MNIST 数据集图像的模型。
在 Keras 中构建模型时,你需要将层一个接一个地堆叠。这些层在keras.layers模块中可用(如下所示)。模块名称以tensorflow为前缀,因为我们使用 TensorFlow 作为 Keras 的后端。
import tensorflow.keras.layers
创建的第一层是Input层。这是使用tensorflow.keras.layers.Input()类创建的。这个类的构造函数必须传递的一个必要参数是shape参数,它指定了将用于训练的数据中每个样本的形状。在本教程中,我们将从密集层开始,因此输入应为 1-D 向量。shape参数因此被赋值为一个包含一个值的元组(如下所示)。这个值是 784,因为 MNIST 数据集中每个图像的大小是 28 x 28 = 784。一个可选的name参数指定了该层的名称。
input_layer = tensorflow.keras.layers.Input(shape=(784), name="input_layer")
下一层是使用Dense类创建的密集层,如下代码所示。它接受一个名为units的参数来指定这一层中的神经元数量。请注意这一层是通过在括号中指定该层的名称来连接到输入层的。这是因为功能 API 中的层实例是可以调用在张量上的,并且也返回一个张量。
dense_layer_1 = tensorflow.keras.layers.Dense(units=500, name="dense_layer_1")(input_layer)
在密集层之后,根据下一行的代码,使用ReLU类创建了一个激活层。
activ_layer_1 = tensorflow.keras.layers.ReLU(name="activ_layer_1")(dense_layer_1)
根据以下几行代码,添加了另几个密集-ReLu 层。
dense_layer_2 = tensorflow.keras.layers.Dense(units=250, name="dense_layer_2")(activ_layer_1)
activ_layer_2 = tensorflow.keras.layers.ReLU(name="relu_layer_2")(dense_layer_2)
dense_layer_3 = tensorflow.keras.layers.Dense(units=20, name="dense_layer_3")(activ_layer_2)
activ_layer_3 = tensorflow.keras.layers.ReLU(name="relu_layer_3")(dense_layer_3)
下一行根据 MNIST 数据集中的类别数量向网络架构中添加了最后一层。由于 MNIST 数据集包含 10 个类别(每个数字一个),因此在这一层中使用的单位数量为 10。
dense_layer_4 = tensorflow.keras.layers.Dense(units=10, name="dense_layer_4")(activ_layer_3)
为了返回每个类别的得分,根据下一行的代码,在之前的密集层后添加了一个softmax层。
output_layer = tensorflow.keras.layers.Softmax(name="output_layer")(dense_layer_4)
我们现在已经连接了层,但模型尚未创建。要构建模型,我们现在必须使用Model类,如下所示。它接受的前两个参数代表输入和输出层。
model = tensorflow.keras.models.Model(input_layer, output_layer, name="model")
在加载数据集和训练模型之前,我们必须使用compile()方法来编译模型。
model.compile(optimizer=tensorflow.keras.optimizers.Adam(lr=0.0005), loss="categorical_crossentropy")
使用model.summary()我们可以查看模型架构的概述。输入层接受形状为(None, 784)的张量,这意味着每个样本必须被重塑为 784 个元素的向量。输出Softmax层返回 10 个数字,每个数字是 MNIST 数据集相应类别的得分。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_layer (InputLayer) [(None, 784)] 0
_________________________________________________________________
dense_layer_1 (Dense) (None, 500) 392500
_________________________________________________________________
relu_layer_1 (ReLU) (None, 500) 0
_________________________________________________________________
dense_layer_2 (Dense) (None, 250) 125250
_________________________________________________________________
relu_layer_2 (ReLU) (None, 250) 0
_________________________________________________________________
dense_layer_3 (Dense) (None, 20) 12550
_________________________________________________________________
relu_layer_3 (ReLU) (None, 20) 0
_________________________________________________________________
dense_layer_4 (Dense) (None, 10) 510
_________________________________________________________________
output_layer (Softmax) (None, 10) 0
=================================================================
Total params: 530,810
Trainable params: 530,810
Non-trainable params: 0
_________________________________________________________________
现在我们已经构建并编译了模型,让我们看看数据集是如何准备的。首先,我们将从keras.datasets模块加载 MNIST,将数据类型更改为float64,因为这比将其值保持在 0-255 范围内更容易训练网络,最后重新塑形,使每个样本成为 784 个元素的向量。
(x_train, y_train), (x_test, y_test) = tensorflow.keras.datasets.mnist.load_data()
x_train = x_train.astype(numpy.float64) / 255.0
x_test = x_test.astype(numpy.float64) / 255.0
x_train = x_train.reshape((x_train.shape[0], numpy.prod(x_train.shape[1:])))
x_test = x_test.reshape((x_test.shape[0], numpy.prod(x_test.shape[1:])))
由于compile()方法中使用的损失函数是categorical_crossentropy,样本的标签应根据下一个代码进行热编码。
y_test = tensorflow.keras.utils.to_categorical(y_test)
y_train = tensorflow.keras.utils.to_categorical(y_train)
最后,模型训练开始使用 fit() 方法。
model.fit(x_train, y_train, epochs=20, batch_size=256, validation_data=(x_test, y_test))
到此为止,我们已经使用现有的层类型创建了模型架构。下一节讨论如何使用 Lambda 层来构建自定义操作。
使用 Lambda 层
假设在名为 dense_layer_3 的全连接层之后,我们希望对张量进行某种操作,比如给每个元素加上 2。我们该如何做到这一点呢?现有的层都不提供这种功能,所以我们需要自己构建一个新的层。幸运的是,Lambda 层正是为了这个目的而存在的。我们来讨论一下如何使用它。
首先构建将执行所需操作的函数。在这种情况下,创建了一个名为 custom_layer 的函数。它只接受输入张量(或张量),并返回另一个张量作为输出。如果需要将多个张量传递给函数,则它们将作为列表传递。
在这个例子中,仅输入一个张量,并且将 2 添加到输入张量中的每个元素上。
def custom_layer(tensor):
return tensor + 2
在构建定义操作的函数之后,我们接下来需要使用 Lambda 类来创建 lambda 层,如下行所示。在这种情况下,只有一个张量被传递给 custom_layer 函数,因为 lambda 层是在名为 dense_layer_3 的全连接层返回的单个张量上可调用的。
lambda_layer = tensorflow.keras.layers.Lambda(custom_layer, name="lambda_layer")(dense_layer_3)
以下是使用 lambda 层后构建完整网络的代码。
input_layer = tensorflow.keras.layers.Input(shape=(784), name="input_layer")
dense_layer_1 = tensorflow.keras.layers.Dense(units=500, name="dense_layer_1")(input_layer)
activ_layer_1 = tensorflow.keras.layers.ReLU(name="relu_layer_1")(dense_layer_1)
dense_layer_2 = tensorflow.keras.layers.Dense(units=250, name="dense_layer_2")(activ_layer_1)
activ_layer_2 = tensorflow.keras.layers.ReLU(name="relu_layer_2")(dense_layer_2)
dense_layer_3 = tensorflow.keras.layers.Dense(units=20, name="dense_layer_3")(activ_layer_2)
def custom_layer(tensor):
return tensor + 2
lambda_layer = tensorflow.keras.layers.Lambda(custom_layer, name="lambda_layer")(dense_layer_3)
activ_layer_3 = tensorflow.keras.layers.ReLU(name="relu_layer_3")(lambda_layer)
dense_layer_4 = tensorflow.keras.layers.Dense(units=10, name="dense_layer_4")(activ_layer_3)
output_layer = tensorflow.keras.layers.Softmax(name="output_layer")(dense_layer_4)
model = tensorflow.keras.models.Model(input_layer, output_layer, name="model")
为了查看张量在被传递给 lambda 层之前和之后的情况,我们将创建两个新的模型,除了之前的模型。我们将这两个模型称为 before_lambda_model 和 after_lambda_model。这两个模型都使用输入层作为它们的输入,但输出层有所不同。before_lambda_model 模型返回的是 dense_layer_3 的输出,即位于 lambda 层之前的层的输出。after_lambda_model 模型的输出是名为 lambda_layer 的 lambda 层的输出。通过这样做,我们可以看到应用 lambda 层前后的输入和输出。
before_lambda_model = tensorflow.keras.models.Model(input_layer, dense_layer_3, name="before_lambda_model")
after_lambda_model = tensorflow.keras.models.Model(input_layer, lambda_layer, name="after_lambda_model")
构建和训练整个网络的完整代码如下所示。
import tensorflow.keras.layers
import tensorflow.keras.models
import tensorflow.keras.optimizers
import tensorflow.keras.datasets
import tensorflow.keras.utils
import tensorflow.keras.backend
import numpy
input_layer = tensorflow.keras.layers.Input(shape=(784), name="input_layer")
dense_layer_1 = tensorflow.keras.layers.Dense(units=500, name="dense_layer_1")(input_layer)
activ_layer_1 = tensorflow.keras.layers.ReLU(name="relu_layer_1")(dense_layer_1)
dense_layer_2 = tensorflow.keras.layers.Dense(units=250, name="dense_layer_2")(activ_layer_1)
activ_layer_2 = tensorflow.keras.layers.ReLU(name="relu_layer_2")(dense_layer_2)
dense_layer_3 = tensorflow.keras.layers.Dense(units=20, name="dense_layer_3")(activ_layer_2)
before_lambda_model = tensorflow.keras.models.Model(input_layer, dense_layer_3, name="before_lambda_model")
def custom_layer(tensor):
return tensor + 2
lambda_layer = tensorflow.keras.layers.Lambda(custom_layer, name="lambda_layer")(dense_layer_3)
after_lambda_model = tensorflow.keras.models.Model(input_layer, lambda_layer, name="after_lambda_model")
activ_layer_3 = tensorflow.keras.layers.ReLU(name="relu_layer_3")(lambda_layer)
dense_layer_4 = tensorflow.keras.layers.Dense(units=10, name="dense_layer_4")(activ_layer_3)
output_layer = tensorflow.keras.layers.Softmax(name="output_layer")(dense_layer_4)
model = tensorflow.keras.models.Model(input_layer, output_layer, name="model")
model.compile(optimizer=tensorflow.keras.optimizers.Adam(lr=0.0005), loss="categorical_crossentropy")
model.summary()
(x_train, y_train), (x_test, y_test) = tensorflow.keras.datasets.mnist.load_data()
x_train = x_train.astype(numpy.float64) / 255.0
x_test = x_test.astype(numpy.float64) / 255.0
x_train = x_train.reshape((x_train.shape[0], numpy.prod(x_train.shape[1:])))
x_test = x_test.reshape((x_test.shape[0], numpy.prod(x_test.shape[1:])))
y_test = tensorflow.keras.utils.to_categorical(y_test)
y_train = tensorflow.keras.utils.to_categorical(y_train)
model.fit(x_train, y_train, epochs=20, batch_size=256, validation_data=(x_test, y_test))
请注意,你不需要编译或训练这两个新创建的模型,因为它们的层实际上是从存在于 model 变量中的主模型中重用的。在训练好该模型之后,我们可以使用 predict() 方法来返回 before_lambda_model 和 after_lambda_model 模型的输出,以查看 lambda 层的结果。
p = model.predict(x_train)
m1 = before_lambda_model.predict(x_train)
m2 = after_lambda_model.predict(x_train)
接下来的代码仅打印前两个样本的输出。正如你所见,从 m2 数组中返回的每个元素实际上是 m1 在加上 2 之后的结果。这正是我们在自定义 lambda 层中应用的操作。
print(m1[0, :])
print(m2[0, :])
[ 14.420735 8.872794 25.369402 1.4622561 5.672293 2.5202641
-14.753801 -3.8822086 -1.0581762 -6.4336205 13.342142 -3.0627508
-5.694006 -6.557313 -1.6567478 -3.8457105 11.891999 20.581928
2.669979 -8.092522 ]
[ 16.420734 10.872794 27.369402 3.462256 7.672293
4.520264 -12.753801 -1.8822086 0.94182384 -4.4336205
15.342142 -1.0627508 -3.694006 -4.557313 0.34325218
-1.8457105 13.891999 22.581928 4.669979 -6.0925217 ]
在本节中,lambda 层用于对单个输入张量执行操作。在下一节中,我们将看到如何将两个输入张量传递给该层。
将多个张量传递给 Lambda 层
假设我们要执行一个依赖于两个层dense_layer_3和relu_layer_3的操作。在这种情况下,我们必须在传递两个张量的同时调用 lambda 层。这可以通过创建一个包含所有这些张量的列表来完成,如下一行所示。
lambda_layer = tensorflow.keras.layers.Lambda(custom_layer, name="lambda_layer")([dense_layer_3, activ_layer_3])
这个列表被传递给custom_layer()函数,我们可以根据下一段代码简单地提取各个层。它只是将这两个层加在一起。实际上,Keras 中有一个名为Add的层可以用来添加两个或更多层,但我们只是展示了如何在 Keras 不支持其他操作的情况下自己实现它。
def custom_layer(tensor):
tensor1 = tensor[0]
tensor2 = tensor[1]
return tensor1 + tensor2
下一段代码构建了三个模型:两个用于捕捉从dense_layer_3和activ_layer_3传递到 lambda 层的输出,另一个用于捕捉 lambda 层本身的输出。
before_lambda_model1 = tensorflow.keras.models.Model(input_layer, dense_layer_3, name="before_lambda_model1")
before_lambda_model2 = tensorflow.keras.models.Model(input_layer, activ_layer_3, name="before_lambda_model2")
lambda_layer = tensorflow.keras.layers.Lambda(custom_layer, name="lambda_layer")([dense_layer_3, activ_layer_3])
after_lambda_model = tensorflow.keras.models.Model(input_layer, lambda_layer, name="after_lambda_model")
为了查看dense_layer_3、activ_layer_3和lambda_layer层的输出,下一段代码会预测它们的输出并打印出来。
m1 = before_lambda_model1.predict(x_train)
m2 = before_lambda_model2.predict(x_train)
m3 = after_lambda_model.predict(x_train)
print(m1[0, :])
print(m2[0, :])
print(m3[0, :])
[ 1.773366 -3.4378722 0.22042789 11.220362 3.4020965 14.487111
4.239182 -6.8589864 -6.428128 -5.477719 -8.799093 7.264849
17.503246 -6.809489 -6.846208 16.094025 24.483786 -7.084775
17.341183 20.311539 ]
[ 1.773366 0\. 0.22042789 11.220362 3.4020965 14.487111
4.239182 0\. 0\. 0\. 0\. 7.264849
17.503246 0\. 0\. 16.094025 24.483786 0.
17.341183 20.311539 ]
[ 3.546732 -3.4378722 0.44085577 22.440723 6.804193 28.974222
8.478364 -6.8589864 -6.428128 -5.477719 -8.799093 14.529698
35.006493 -6.809489 -6.846208 32.18805 48.96757 -7.084775
34.682365 40.623077 ]
使用 lambda 层现在已经很清楚了。下一节讨论了如何保存和加载使用 lambda 层的模型。
保存和加载带有 Lambda 层的模型
为了保存模型(无论是否使用 lambda 层),使用save()方法。假设我们只对保存主模型感兴趣,下面是保存它的代码行。
model.save("model.h5")
我们还可以使用load_model()方法加载保存的模型,如下一行所示。
loaded_model = tensorflow.keras.models.load_model("model.h5")
希望模型能够成功加载。不幸的是,Keras 中存在一些问题,可能会导致在加载带有 lambda 层的模型时出现SystemError: unknown opcode。这可能是由于使用一个 Python 版本构建模型并在另一个版本中使用它。我们将在下一节中讨论解决方案。
解决带有 Lambda 层的模型加载时的 SystemError
为了解决这个问题,我们不会使用上述讨论的方法保存模型。相反,我们将使用save_weights()方法保存模型权重。
现在我们只保存了权重。模型架构呢?模型架构将使用代码重新创建。为什么不将模型架构保存为 JSON 文件,然后再加载它?原因是加载架构后错误仍然存在。
总结来说,训练好的模型权重将被保存,模型架构将使用代码再现,最后权重将被加载到那个架构中。
模型的权重可以使用下一行代码保存。
model.save_weights('model_weights.h5')
下面的代码再现了模型架构。model将不会被训练,但保存的权重将被重新分配给它。
input_layer = tensorflow.keras.layers.Input(shape=(784), name="input_layer")
dense_layer_1 = tensorflow.keras.layers.Dense(units=500, name="dense_layer_1")(input_layer)
activ_layer_1 = tensorflow.keras.layers.ReLU(name="relu_layer_1")(dense_layer_1)
dense_layer_2 = tensorflow.keras.layers.Dense(units=250, name="dense_layer_2")(activ_layer_1)
activ_layer_2 = tensorflow.keras.layers.ReLU(name="relu_layer_2")(dense_layer_2)
dense_layer_3 = tensorflow.keras.layers.Dense(units=20, name="dense_layer_3")(activ_layer_2)
activ_layer_3 = tensorflow.keras.layers.ReLU(name="relu_layer_3")(dense_layer_3)
def custom_layer(tensor):
tensor1 = tensor[0]
tensor2 = tensor[1]
epsilon = tensorflow.keras.backend.random_normal(shape=tensorflow.keras.backend.shape(tensor1), mean=0.0, stddev=1.0)
random_sample = tensor1 + tensorflow.keras.backend.exp(tensor2/2) * epsilon
return random_sample
lambda_layer = tensorflow.keras.layers.Lambda(custom_layer, name="lambda_layer")([dense_layer_3, activ_layer_3])
dense_layer_4 = tensorflow.keras.layers.Dense(units=10, name="dense_layer_4")(lambda_layer)
after_lambda_model = tensorflow.keras.models.Model(input_layer, dense_layer_4, name="after_lambda_model")
output_layer = tensorflow.keras.layers.Softmax(name="output_layer")(dense_layer_4)
model = tensorflow.keras.models.Model(input_layer, output_layer, name="model")
model.compile(optimizer=tensorflow.keras.optimizers.Adam(lr=0.0005), loss="categorical_crossentropy")
下面是如何使用load_weights()方法加载保存的权重,并将其分配给再现的架构。
model.load_weights('model_weights.h5')
结论
本教程讨论了如何使用Lambda层创建自定义层,以执行 Keras 中预定义层不支持的操作。Lambda类的构造函数接受一个函数,该函数指定了层的工作方式,并接受层调用时的张量。在函数内部,你可以执行任何操作,然后返回修改后的张量。
尽管 Keras 在加载使用 lambda 层的模型时存在问题,但我们也看到如何通过保存训练模型权重、使用代码重现模型架构,并将权重加载到该架构中来简单解决此问题。
简历: Ahmed Gad 于 2015 年 7 月获得埃及梅努非亚大学计算机与信息学院(FCI)信息技术学士学位,并以优异的成绩排名第一。由于在学院排名第一,他被推荐于 2015 年在埃及的某所学院担任助教,随后于 2016 年继续担任助教及研究员。他目前的研究兴趣包括深度学习、机器学习、人工智能、数字信号处理和计算机视觉。
原文。经许可转载。
相关内容:
-
从 Y=X 到构建完整的人工神经网络
-
轻松使用 torchlayers 构建 PyTorch 模型
-
如何在深度学习中创建自定义实时图表
更多相关内容
使用 Numpy 矩阵:一个便捷的初学者参考
作者:Ieva Zarina,Nordigen 软件开发工程师。
在我开始处理自然语言处理时,我使用了默认的 Python 列表。但随着实验规模的扩大和数据量的增加,我很快就耗尽了内存。Python 列表在内存空间上不是优化的,因此转向了 Numpy。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求

Numpy 是 Python 科学生态系统中事实上的ndarray 工具。
Numpy 数组很像 C 中的数组 – 通常你会先创建所需大小的数组,然后填充它。不推荐进行合并、附加,因为 Numpy 会创建一个与被合并数组相同大小的空数组,然后将内容复制到其中。
下面是一些可以操作 Numpy 数组(ndarray)的方法:
创建 ndarray
创建 Numpy 矩阵的一些方法是:
- 从 Python 列表转换使用 numpy.asarray():
import numpy as np
list = [1, 2, 3]
c = np.asarray(list)
- 创建一个大小为所需的 ndarray,并填充为 1、0 或随机值:
# Array items as ndarray
c = np.array([1, 2, 3])
# A 2x2 2d array shape for the arrays in the format (rows, columns)
shape = (2, 2)
# Random values
c = np.empty(shape)
d = np.ones(shape)
e = np.zeros(shape)
- 你也可以使用 numpy.empty_like() 创建一个形状与另一个数组相同的数组:
# Creating ndarray from list
c = np.array([[1., 2.,],[1., 2.]])
# Creating new array in the shape of c, filled with 0
d = np.empty_like(c)
切片
有时候我需要在二维矩阵中选择所有列或行的某一部分。例如,矩阵:
a = np.asarray([[1,1,2,3,4], # 1st row
[2,6,7,8,9], # 2nd row
[3,6,7,8,9], # 3rd row
[4,6,7,8,9], # 4th row
[5,6,7,8,9] # 5th row
])
b = np.asarray([[1,1],
[1,1]])
# Select row in the format a[start:end], if start or end omitted it means all range.
y = a[:1] # 1st row
y = a[0:1] # 1st row
y = a[2:5] # select rows from 3rd to 5th row
# Select column in the format a[start:end, column_number]
x = a[:, -1] # -1 means first from the end
x = a[:,1:3] # select cols from 2nd col until 3rd
合并数组
不建议合并 Numpy 数组,因为 Numpy 会在内部创建一个大的空数组,然后将内容复制进去。最好是在一开始就创建所需大小的数组,然后直接填充。然而,有时候你无法避免合并。在这种情况下,Numpy 提供了一些内置函数:
一维数组:
a = np.array([1, 2, 3])
b = np.array([5, 6])
print np.concatenate([a, b, b])
# >> [1 2 3 5 6 5 6]
二维数组:
a2 = np.array([[1, 2], [3, 4]])
# axis=0 - concatenate along rows
print np.concatenate((a2, b), axis=0)
# >> [[1 2]
# [3 4]
# [5 6]]
# axis=1 - concatenate along columns, but first b needs to be transposed:
b.T
#>> [[5]
# [6]]
np.concatenate((a2, b.T), axis=1)
#>> [[1 2 5]
# [3 4 6]]
附加 – 将值附加到数组的末尾
一维数组:
# 1d arrays
print np.append(a, a2)
# >> [1 2 3 1 2 3 4]
print np.append(a, a)
# >> [1 2 3 1 2 3]
二维数组 – 两个数组必须匹配行的形状:
print np.append(a2, b, axis=0)
# >> [[1 2]
# [3 4]
# [5 6]]
print np.append(a2, b.T, axis=1)
# >> [[1 2 5]
# [3 4 6]]
一维数组:
print np.hstack([a, b])
# >> [1 2 3 5 6]
print np.vstack([a, a])
# >> [[1 2 3]
# [1 2 3]]
二维数组:
print np.hstack([a2,a2]) # arrays must match shape
# >> [[1 2 1 2]
# [3 4 3 4]]
print np.vstack([a2, b])
# >> [[1 2]
# [3 4]
# [5 6]]
ndarray 中的类型
不使用默认的浮点数,numpy 可以容纳所有常见的类型。如果数组中的任何一个数字是浮点数,所有数字将会被转换为浮点数:
a = np.array([1, 2, 3.3])
print a
# >> [ 1\. 2\. 3.3]
但你可以轻松地将类型转换为 int、float 或其他类型:
a = np.array([1, 2, 3.3])
print a
# >> [ 1\. 2\. 3.3]print a.astype(int)
# >> [1 2 3]
字符串数组需要以类型 S1 创建表示长度为 1 的字符串,S2 表示长度为 2,以此类推。 numpy.``chararray() 创建这种类型的数组。你需要指定数组的形状和 itemsize —— 每个字符串的长度。
chararray = np.chararray([3,3], itemsize=3)
chararray[:] = 'abc' # assing value to all fields
print chararray
#>> [['abc' 'abc' 'abc']
# ['abc' 'abc' 'abc']
# ['abc' 'abc' 'abc']]
读/写文件
使用 numpy.savetext() 以纯文本形式将 numpy 数组写入文件,并使用 numpy.loadtext() 加载它:
a2 = np.array([
[1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1],
[1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1],
[1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1],
[1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1],
[1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1],
[1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1]
])
np.savetxt('test.txt', a2, delimiter=',')
a2_new = np.loadtxt('test.txt', delimiter=',')
编写稀疏矩阵
然而,在机器学习中,如果你有一个大型的稀疏矩阵(包含大量为 0 的值),使用svmlight 格式可以更快地读取和写入大型矩阵,同时文件也更小:
from sklearn.datasets import dump_svmlight_file, load_svmlight_file
matrix = [
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2],
[1, 0, 0, 0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 1, 2],
[1, 0, 0, 0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 1, 2]
]
labels = [1,1,1,1,1,2,2]
dump_svmlight_file(matrix, labels, 'svmlight.txt', zero_based=True)
# The file looks like this:
# 1 0:1 13:1 14:2
# 1 0:1 13:1 14:2
# 1 0:1 13:1 14:2
# 1 0:1 13:1 14:2
# 1 0:1 13:1 14:2
# 2 0:1 5:3 13:1 14:2
# 2 0:1 5:3 13:1 14:2
svm_loaded = load_svmlight_file('svmlight.txt', zero_based=True)
使用 .toarray() 从 svmlight 压缩稀疏行格式中获取矩阵:
svm_loaded[0].toarray() # matrix element at index 0
svm_loaded[1] # labels at index 1
总结来说,本文探讨了如何:
-
创建 numpy 数组,
-
切片数组,
-
合并数组,
-
numpy 数组的基本类型,
-
读取和写入数组到文件,
-
读取和写入稀疏矩阵到 svmlight 格式。
这只是 numpy 矩阵的一个介绍,讲解了如何入门和进行基本操作。更多信息可以在 MIT 指南书 和官方 文档 中找到。
个人简介: Ieva Zarina 是 Nordigen 的软件开发人员。
原文。经许可转载。
相关:
-
掌握 Python 机器学习的 7 个额外步骤
-
K-Means & 其他聚类算法:Python 快速入门
-
使用 Iris 数据集的简单 XGBoost 教程
更多相关话题
与大数据相关的工具和技术
原文:
www.kdnuggets.com/working-with-big-data-tools-and-techniques
图片来源:尼诺·苏扎
以前,商业中你需要的所有数据都在你的“小黑本”里。然而,在数字革命的时代,即使是经典数据库也不再够用。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织在 IT 方面
处理大数据已经成为企业和数据科学家的一项关键技能。大数据的特征包括体积、速度和多样性,为我们提供了前所未有的模式和趋势洞察。
要有效处理这些数据,需要使用专门的工具和技术。
什么是大数据?
不,这不仅仅是大量数据。
大数据通常由三个 V 来描述:
-
体积 – 是的,生成和存储的数据的大小是其特征之一。要被视为大数据,数据大小必须以 PB(1,024 TB)和 EB(1,024 PB)为单位来衡量。
-
多样性 – 大数据不仅包括结构化数据,还包括半结构化数据(JSON、XML、YAML、电子邮件、日志文件、电子表格)和非结构化数据(文本文件、图像和视频、音频文件、社交媒体帖子、网页、科学数据如卫星图像、地震波形数据或原始实验数据),重点是非结构化数据。
-
速度 – 生成和处理数据的速度。
大数据工具和技术
所有提到的大数据特征都会影响我们处理大数据所使用的工具和技术。
当我们谈论大数据技术时,它们只是我们用来处理、分析和管理大数据的方法、算法和方法。从表面上看,它们与常规数据相同。然而,我们讨论的大数据特征要求不同的方法和工具。
以下是大数据领域中一些突出的工具和技术。
1. 大数据处理
什么是数据处理? 数据处理指的是将原始数据转换为有意义的信息的操作和活动。它包括从清理和结构化数据到运行复杂算法和分析的任务。
大数据有时会进行批处理,但更普遍的是数据流处理。
关键特征:
-
并行处理: 将任务分配到多个节点或服务器上,以便同时处理数据,从而加快计算速度。
-
实时与批处理: 数据可以实时处理(在生成时处理)或批量处理(在预定时间处理数据块)。
-
可扩展性: 大数据工具通过扩展来处理大量数据,增加更多资源或节点。
-
容错性: 如果节点失败,系统将继续处理,确保数据完整性和可用性。
-
多样的数据来源: 大数据来自许多来源,包括结构化数据库、日志、流或非结构化数据存储库。
使用的大数据工具: Apache Hadoop MapReduce、Apache Spark、Apache Tez、Apache Kafka、Apache Storm、Apache Flink、Amazon Kinesis、IBM Streams、Google Cloud Dataflow
工具概述:
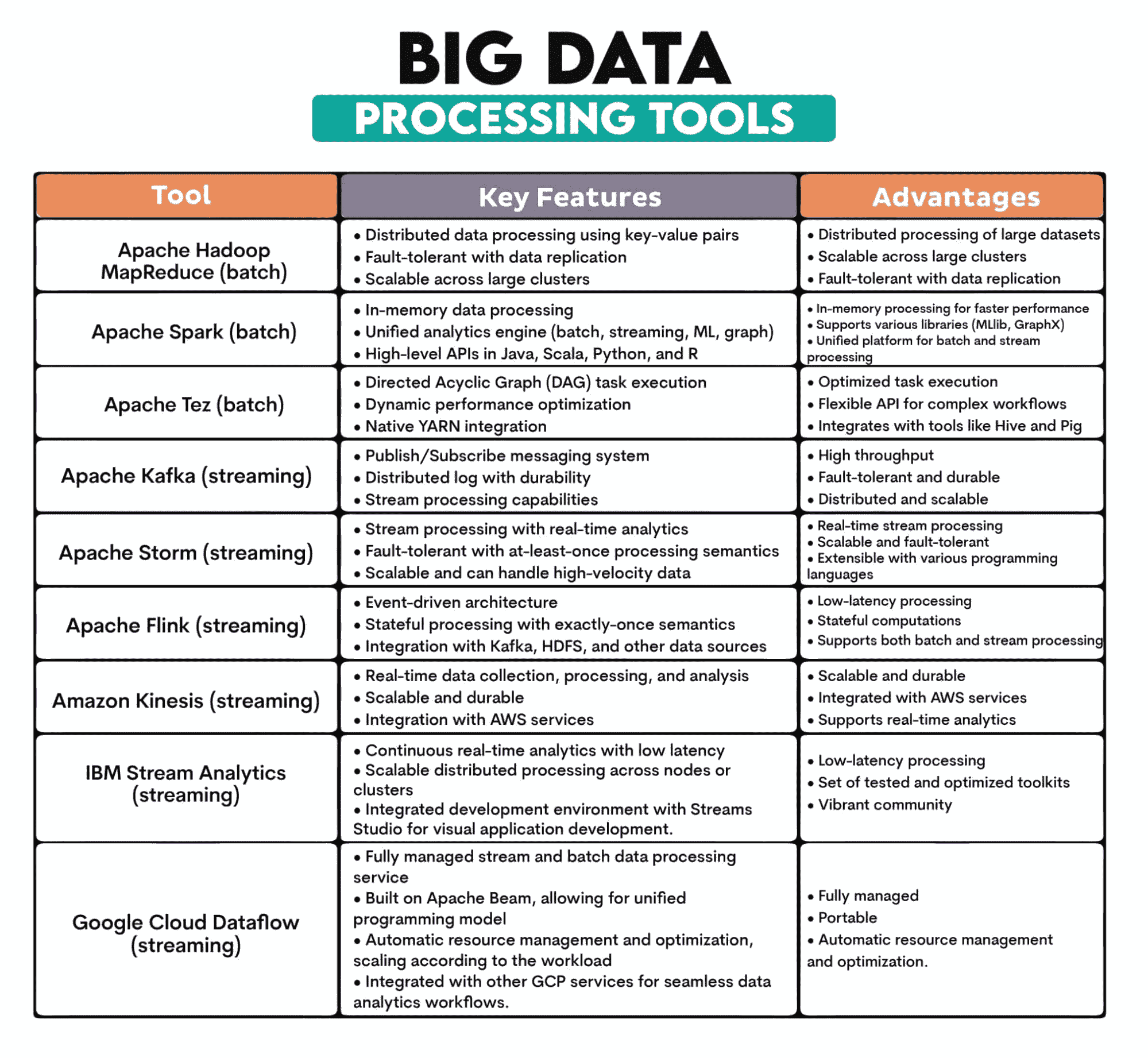
2. 大数据 ETL
这是什么? ETL 是 提取 数据从各种来源,转换 为结构化和可用格式,和 加载 到数据存储系统中以供分析或其他用途。
大数据的特点意味着 ETL 过程需要处理更多来自更多来源的数据。数据通常是半结构化或非结构化的,其转换和存储方式与结构化数据不同。
大数据中的 ETL 通常还需要实时处理数据。
关键特征:
-
数据提取: 从各种异构来源检索数据,包括数据库、日志、API 和文本文件。
-
数据转换: 将提取的数据转换成适合查询、分析或报告的格式。包括数据的清理、丰富、聚合和重新格式化。
-
数据加载: 将转换后的数据存储到目标系统中,例如数据仓库、数据湖或数据库。
-
批处理或实时处理: 实时 ETL 过程在大数据中比批处理更为普遍。
-
数据集成: ETL 将来自不同来源的数据整合起来,确保组织内的数据视图统一。
使用的大数据工具: Apache NiFi、Apache Sqoop、Apache Flume、Talend
工具概述:
| 大数据 ETL 工具 | ||
|---|---|---|
| 工具 | 关键特性 | 优势 |
| Apache NiFi | • 通过基于 Web 的 UI 设计数据流• 数据来源跟踪• 可扩展的处理器架构 | • 视觉界面:易于设计数据流• 支持数据来源• 可通过广泛的处理器扩展 |
| Apache Sqoop | • 在 Hadoop 和数据库之间的大规模数据传输• 并行导入/导出• 压缩和直接导入功能 | • 在 Hadoop 和关系数据库之间的高效数据传输• 并行导入/导出• 增量数据传输功能 |
| Apache Flume | • 基于事件和可配置的架构• 可靠和持久的数据交付• 与 Hadoop 生态系统的本地集成 | • 可扩展和分布式• 容错架构• 可扩展的自定义源、通道和接收器 |
| Talend | • 视觉设计界面• 广泛连接到数据库、应用程序等• 数据质量和分析工具 | • 支持多种数据源的连接器• 图形界面用于设计数据集成流程• 支持数据质量和主数据管理 |
3. 大数据存储
什么是它? 大数据存储必须存储大量以高速生成的各种格式的数据。
存储大数据的三种最明显方式是 NoSQL 数据库、数据湖和数据仓库。
NoSQL 数据库设计用于处理大量结构化和非结构化数据而不需要固定的模式(NoSQL - 不仅仅是 SQL)。这使得它们适应不断变化的数据结构。
与传统的垂直可扩展数据库不同,NoSQL 数据库是水平可扩展的,这意味着它们可以将数据分布到多个服务器上。通过向系统添加更多机器,扩展变得更加容易。它们具有容错性,低延迟(在需要实时数据访问的应用程序中受到青睐),并且在规模扩展时具有成本效益。
数据湖是存储库,存储大量原始数据的本地格式。这简化了数据访问和分析,因为所有数据都位于一个地方。
数据湖具有可扩展性和成本效益。它们提供灵活性(数据以原始形式摄取,结构在读取数据进行分析时定义),支持批处理和实时数据处理,并且可以与数据质量工具集成,从而实现更高级的分析和更丰富的见解。
数据仓库是一个集中式存储库,优化用于分析处理,从多个来源存储数据,并将其转化为适合分析和报告的格式。
它被设计用来存储大量数据,从各种来源进行集成,并允许历史分析,因为数据是按时间维度存储的。
主要特点:
-
可扩展性: 设计为通过增加更多节点或单元进行扩展。
-
分布式架构: 数据通常存储在多个节点或服务器上,确保高可用性和容错性。
-
多种数据格式: 可以处理结构化、半结构化和非结构化数据。
-
耐久性: 一旦存储,数据保持完整且可用,即使在硬件故障的情况下也不受影响。
-
成本效益: 许多大数据存储解决方案被设计为在普通硬件上运行,从而使其在规模化时更具经济性。
使用的大数据工具: MongoDB(基于文档),Cassandra(基于列),Apache HBase(基于列),Neo4j(基于图),Redis(键值存储),Amazon S3,Azure Data Lake,Hadoop 分布式文件系统 (HDFS),Google Big Lake,Amazon Redshift,BigQuery
工具概述:
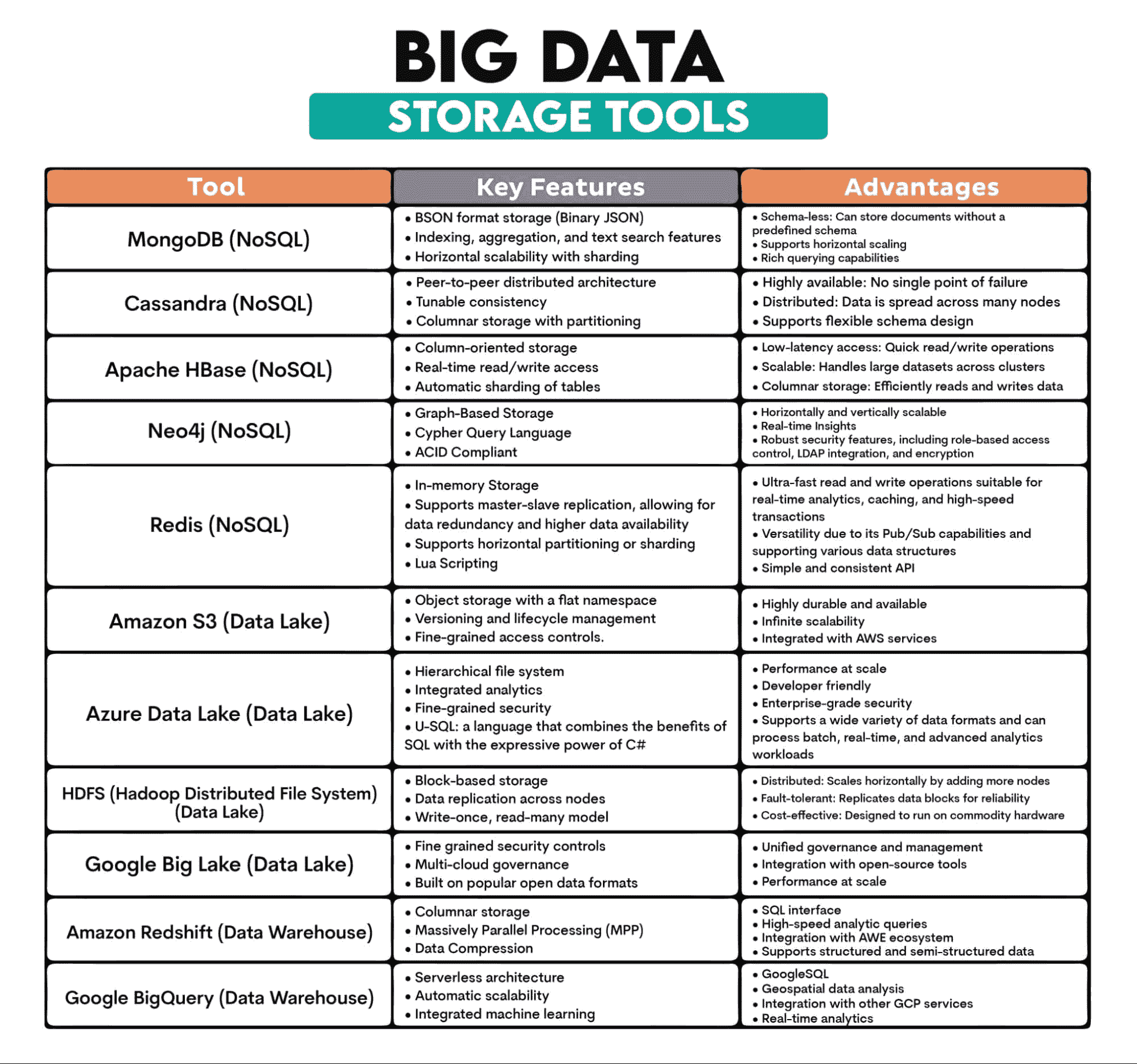
4. 大数据挖掘
这是什么?: 这是发现大型数据集中的模式、关联、异常和统计关系。它涉及机器学习、统计学等学科,并使用数据库系统从数据中提取见解。
挖掘的数据量巨大,庞大的数据量可以揭示在较小数据集中可能不明显的模式。大数据通常来自各种来源,且通常是半结构化或非结构化的。这需要更复杂的预处理和集成技术。与常规数据不同,大数据通常是实时处理的。
用于大数据挖掘的工具必须处理这些内容。为此,它们应用分布式计算,即数据处理分布在多个计算机上。
一些算法可能不适合大数据挖掘,因为这需要可扩展的并行处理算法,例如,SVM,SGD,或梯度提升。
大数据挖掘还采用了探索性数据分析(EDA)技术。EDA 分析数据集以总结其主要特征,通常使用统计图形、图表和信息表。因此,我们将一起讨论大数据挖掘和 EDA 工具。
关键特征:
-
模式识别: 在大型数据集中识别规律或趋势。
-
聚类和分类: 根据相似性或预定义标准对数据点进行分组。
-
关联分析: 发现大型数据库中变量之间的关系。
-
回归分析: 理解和建模变量之间的关系。
-
异常检测: 识别不寻常的模式。
大数据工具使用: Weka,KNIME,RapidMiner,Apache Hive,Apache Pig,Apache Drill,Presto
工具概述:
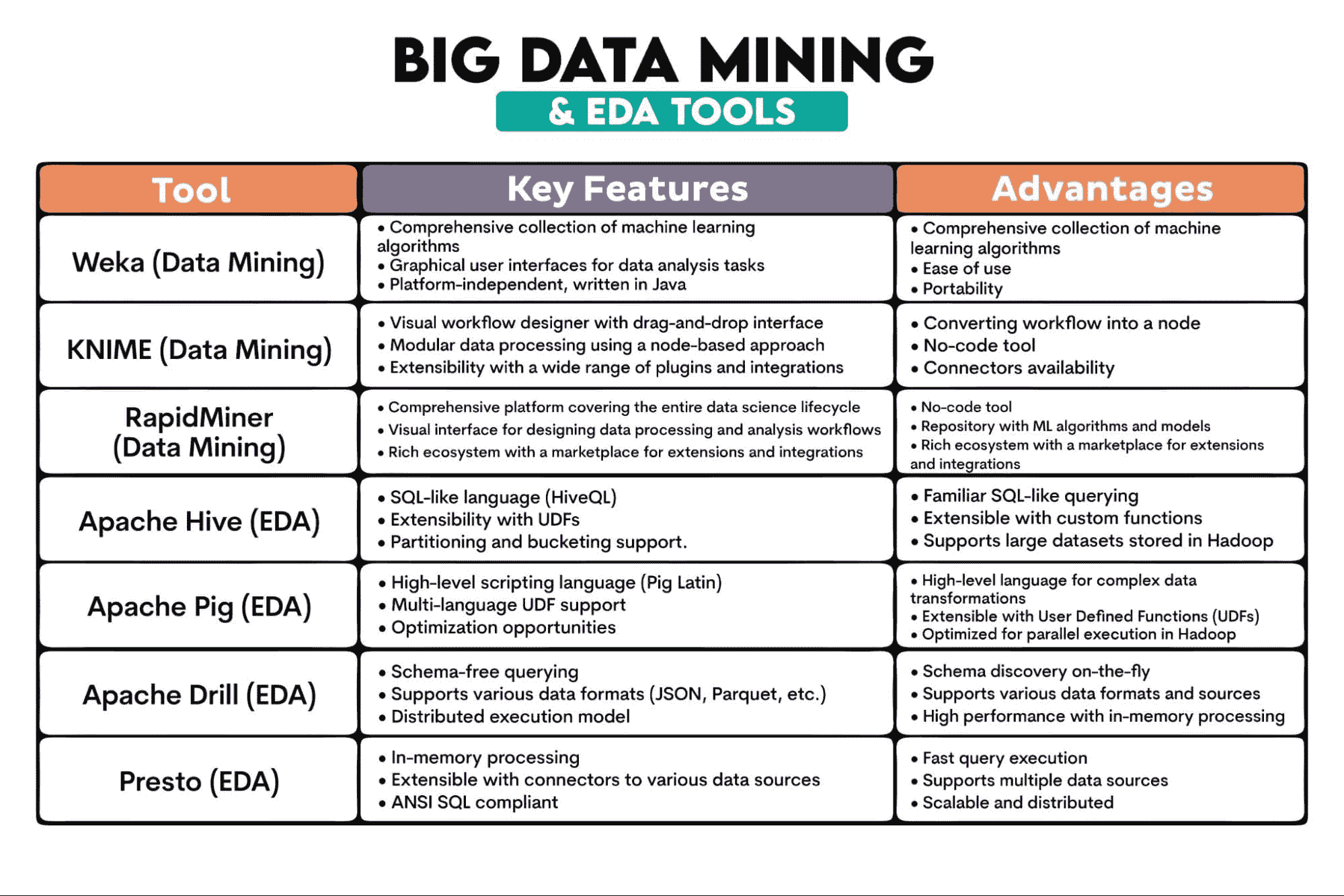
5. 大数据可视化
什么是它?: 它是从庞大的数据集中提取的信息和数据的图形表示。通过使用图表、图形和地图等视觉元素,数据可视化工具提供了一种便于理解数据中的模式、异常值和趋势的方式。
再次强调,大数据的特征,如规模和复杂性,使其与常规数据可视化不同。
关键特征:
-
互动性: 大数据可视化需要互动式仪表盘和报告,允许用户深入查看具体细节并动态探索数据。
-
可扩展性: 大型数据集需要高效处理而不影响性能。
-
多样化的可视化类型: 例如,热力图、地理空间可视化和复杂的网络图。
-
实时可视化: 许多大数据应用需要实时数据流和可视化,以便监控和响应实时数据。
-
与大数据平台的集成: 可视化工具通常与大数据平台无缝集成。
大数据工具使用: Tableau,PowerBI,D3.js,Kibana
工具概述:
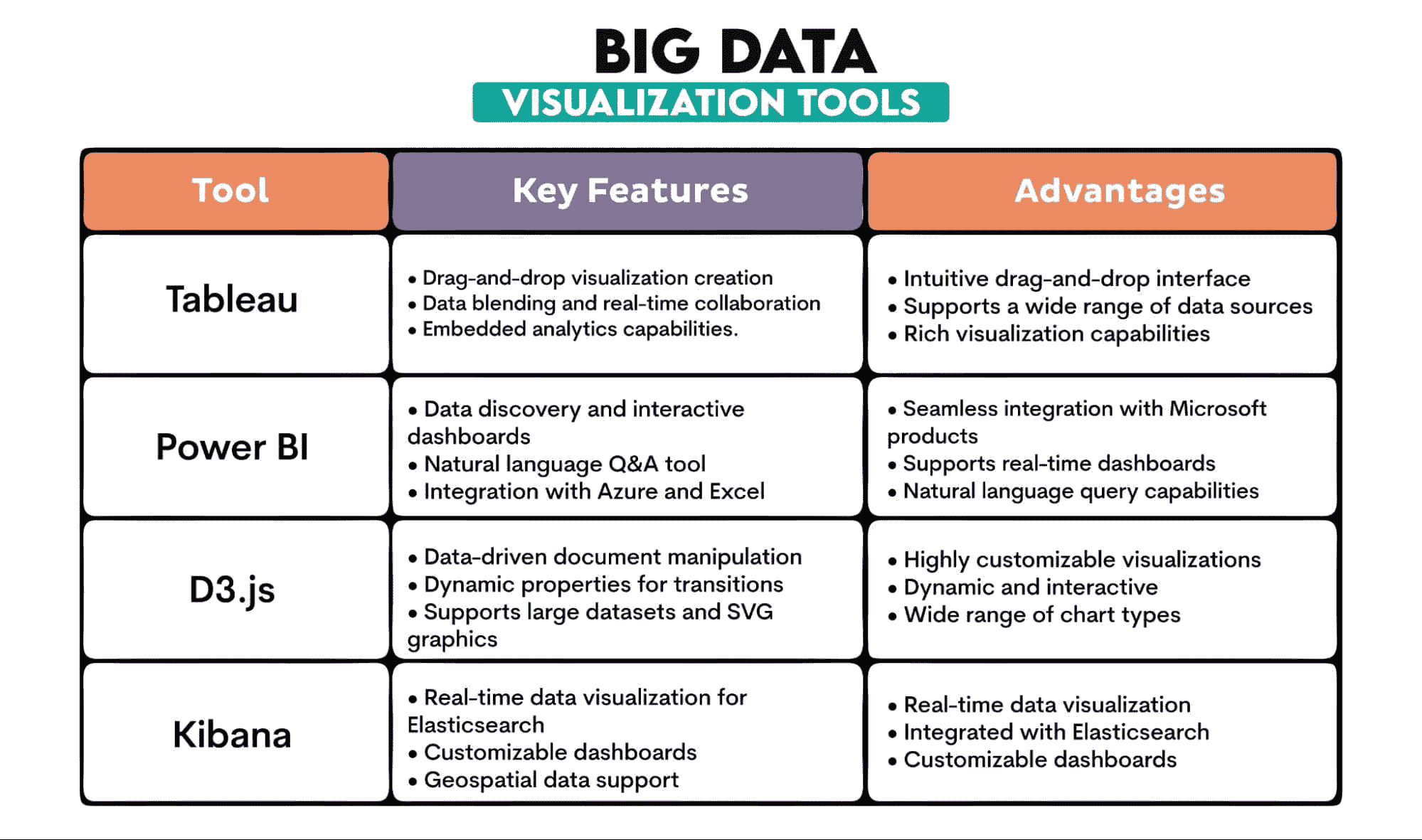
结论
大数据与常规数据非常相似,但又完全不同。它们共享处理数据的技术。但由于大数据的特性,这些技术仅仅在名字上是相同的。否则,它们需要完全不同的方法和工具。
如果你想进入大数据领域,你需要使用各种大数据工具。我们对这些工具的概述应该是一个很好的起点。
内特·罗西迪 是一位数据科学家,从事产品战略工作。他还是一位兼职教授,教授分析学,并且是 StrataScratch 的创始人,这是一个帮助数据科学家准备面试的平台注册平台,提供来自顶级公司的真实面试问题。可以在 Twitter: StrataScratch 或 LinkedIn 上与他联系。
更多相关内容
学习数据科学硕士是否值得?
原文:
www.kdnuggets.com/2019/04/worth-studying-data-science-masters.html
评论
由 Sterling Osborne,曼彻斯特大学
自从完成数据科学硕士课程以来,我接到了一些人询问我对课程的经历以及是否值得推荐。因此,我认为最好总结一下我开始这门课程的决定,我在学习期间取得的成就,以及随后几年的结果。

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 事务
我为什么选择学习数据科学?
那是 2016 年的春天,我快结束在伦敦市最大咨询公司之一的 6 个月实习了。我接受这个角色是为了获得经验,并弄清楚成为精算师是否是我职业生涯的正确方向。我很快发现自己对这个角色的数据分析产生了兴趣,因为我被拉去参加会议,讨论我分析的数据,或者能够自己编写工具来自动化以前的手动任务。然而,我也发现如果我继续进入研究生项目,我将会沿着传统的轨道前进,这让我失去了兴趣,因为那需要多年标准化考试,几乎没有创造性。此外,在这一点上,我的大部分工作都在 Excel 中进行,几乎没有获得编程经验。
就在这时,我也开始探索一个在我的求职中经常出现的神奇术语:数据科学。我来自数学背景,由于英国就业市场的性质,我被推向了会计和精算咨询等传统角色。然而,现在有了一个新的角色,它违背了我对未来职业的所有期望。在成为精算师的过程中,我会通过学习监管标准来解决问题,而数据科学家则被鼓励在商业环境中创造性地寻找解决方案。此外,角色机会不再固定在少数几家公司几乎所有公司都在寻找某种形式的数据科学家,能够进入一个全新的行业,从时尚到金融,都极大地吸引了我的兴趣。
然而,当我开始申请数据科学角色时,很快就显露出我缺乏两项关键技能:应用机器学习和编码。
我的选择是什么?
第一个解决方案是自己教授这些内容,我有统计学经验来学习机器学习,并且在 MatLab 中有足够的编码经验,以至于我有信心可以学习 Python 或 R。然而,如果我这样做的话,我不确定这是否足够,也不确定如何在简历上清晰地展示我新获得的技能给雇主。
我考虑了在线训练营,但它们的内容通常是固定的,我不确定重复他人的工作会如何被雇主接受。此外,没有保证这些训练营对雇主来说是可信的,而且自费也很昂贵。今天,仅仅三年后,大学支持的课程列表使得这成为了一个更为可行的选择,绝对值得考虑,但当时这些课程还不够成熟。不幸的是,训练营是一个昂贵的风险,我不确定是否会有所回报。
因此,我决定寻找大学提供的选项。当时有两种类型的课程符合我的目标;商业分析课程和计算机科学中的机器学习。前者专注于在商业环境中应用分析,但由于这是通过商学院进行的,因此价格更高,一年的学费超过£25,000。后者通过学术研究提供教学,更侧重于教授基础理论而不是应用。此外,由于这是通过计算机科学系开设的学术课程,因此一年的学费大大减少,为£9,000(针对英国公民)。
我选择了什么?
最终,我决定保守一点,投入整整一年时间去攻读学术硕士学位,希望通过项目工作获得机器学习的应用知识,并提高我的编码技能。
因此,我加入了伦敦城市大学计算机科学系的 2016/17 届数据科学硕士班。那年是该大学第二次开设此课程,并且当时是伦敦唯一提供数据科学硕士学位的大学(尽管其他大学也有类似的课程)。
我在课程中学到了什么?
第一学期包括了数据科学的三个主要主题:数据科学基础、机器学习和可视化。每个模块都包括一个作业组件,我们可以选择任何公开可用的数据集来应用我们新学到的方法。通过这些,我很快提高了编程技能,甚至建立了自信,开始分享这些项目。
第二学期我们有两个核心模块,Big Data 和神经计算,并且可以选择两个可选模块。选项列表很全面,使我们能够从计算机视觉到数据架构中选择专业方向。我选择了数据可视化(这是第一学期模块的延续)和软件代理(通过应用强化学习的 AI 基础)。这些模块也包括作业,并且凭借第一学期的基础,我真的能够扩展我的应用并进行创造性思考。Big Data 还介绍了文本数据和自然语言处理。
在这两个学期中,我对大多数数据科学主题有了广泛的了解,并且对核心模块中的机器学习和神经网络有了深刻的知识。当我们进入课程的第一个组成部分,即论文时,我们可以选择在实习角色中完成此任务(并获得延期,以便在工作期间平衡)。我找到了一份合适的角色,定义了我的研究主题,并在接下来的几个月里将我迄今为止获得的所有技能应用于将 AI 应用于业务。
我从课程中获得了所需的技能吗?
我有两个目标需要实现:展示我对机器学习的理解并将这些知识应用于编程。这个课程不仅在我的简历上提供了一个明确的‘勾选框’,而且使我能够继续扩展我的技能,参与越来越有趣的项目。任何职位申请的一部分是要通过初步筛选,我现在能更加一致地做到这一点。此外,当我进入面试阶段时,我有了所有这些项目可以讨论,并真正展现出我对理解的自信,远远超过了我自己单独完成的水平。
硕士学位为我打开了所有我之前一直在敲打的大门,甚至在我公开发布项目后,招聘人员也直接联系了我。最终,我发现自己喜欢论文的研究部分和追求该领域的自由,因此我继续攻读人工智能博士学位。讽刺的是,这是我在 2016 年绝对不会考虑的事情,但由于该领域不断扩展,能够站在前沿确实令人惊叹,特别是因为许多问题需要应用的思维方式,并且适用于商业问题,而不仅仅是理论上的。
我会给考虑进入数据科学领域的人什么建议?
这是我总是很难回答的问题,因为每个人的情况不同,因此我将尝试基于我的经验提供一些建议。简而言之:
-
确立数据科学是否适合你,并找到一个话题或细节来激励自己。对我来说,这就是能够以创造性的方式应用数据分析,成为商业中的宝贵资产,帮助他人改善决策。
-
评估你想要的工作要求什么,以及你的技能组合目前在哪些方面有所不足。虽然我有技术背景,但我没有展示我应用机器学习或编程的能力,需要一些东西来实现这一点。对于我课程中的其他人,他们没有数学或统计背景,因此需要这些来加强他们的知识。
-
回顾你获得这些缺失技能的选项。例如,训练营在行业中越来越被认可,但它们通常遵循单一路径(即在相同数据上学习并应用相同的方法)。这可能对某些人有效,但我希望以独特的方式展示我的能力,让自己在雇主面前脱颖而出。如果你考虑攻读硕士学位,彻底研究课程模块和组织课程的人员,因为不同部门之间(特别是商业和学术学院)会有差异。
-
扩展和挑战自己,通过课程来挑战自己,不要仅仅选择一个涵盖你已经熟悉的主题的课程来完成要求。找到一些具有挑战性的内容,鼓励你发展新的技能。
-
展示你的新技能,通过 GitHub、Kaggle 或你自己的网站在线发布你的项目。建立一个项目组合在任何面试中都比尝试在时间限制内描述这些项目要有用得多。
例如,下面你可以找到我的个人网站和 Kaggle 页面的链接:
[Philip Osborne Data:
这个项目是作为一个在 Python 笔记本中独立学习强化学习(RL)的方法创建的](https://www.philiposbornedata.com/)
希望你在考虑如何进入数据科学领域时能觉得这篇帖子有用,我会尽力回答你关于此的任何问题。
谢谢
Sterling
个人简介:Sterling Osborne 是曼彻斯特大学(英国)人工智能领域的博士研究生。你可以在 Medium 和 YouTube 上找到他。
原文。经许可转载。
相关内容:
-
2019 年典型的数据科学家是怎样的?
-
没有人会告诉你的数据科学职位申请信息
-
如何建立数据科学作品集
相关话题更多内容
集成技术何时是一个好选择?
原文:
www.kdnuggets.com/2022/07/would-ensemble-techniques-good-choice.html

布雷特·乔丹 via Unsplash
在任何决策过程中,你需要收集所有不同类型的数据和信息,拆解这些信息,深入了解,寻求专家意见,等等,然后才能做出坚实的决定。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 部门
这在机器学习过程中与集成技术类似。集成模型将多种模型组合在一起,以帮助预测(决策)过程。单一模型可能没有能力为特定数据集产生正确的预测 - 这增加了高方差、低准确性以及噪声和偏差的风险。通过结合多个模型,我们有效地提高了准确性的可能性。
最简单的例子是决策树 - 一种类似于概率树的模型,它不断分裂数据,根据先前回答的问题来进行预测。
为什么使用集成技术?
为了回答本文的问题,“何时使用集成技术是一个好选择?”当你想提高机器学习模型的性能时 - 就这么简单。
例如,如果你正在进行分类任务并希望提高模型的准确性 - 使用集成技术。如果你想减少回归任务的平均误差 - 使用集成技术。
使用集成学习算法的主要 2 个原因是:
-
提高预测 - 你将获得比仅使用单一模型更好的预测能力。
-
提高稳健性 - 你将获得比仅使用单一模型更稳定的预测结果。
使用集成技术时,你的总体目标应该是减少预测的一般化误差。因此,使用多样化的基础模型将自动降低你的预测误差。
本质上是构建一个更稳定、更可靠、更准确的模型,让你信赖。
有 3 种类型的集成建模技术:
-
Bagging
-
Boosting
-
Stacking
Bagging
袋装法的简称是 Bootstrap Aggregation,该集成建模技术结合了自助采样和聚合形成一个集成模型。它基于创建多个原始训练数据集,建立类似树的结构概率模型,然后进行聚合以得出最终预测。
每个模型学习前一个模型产生的错误,并使用训练数据集的不同子集。袋装法旨在避免数据过拟合并减少预测的方差,可用于回归和分类模型。
随机森林
随机森林是一种袋装法算法,但有一点不同。它使用训练数据的样本子集和特征子集来构建多个决策树。你可以把它看作是多个决策树,以随机方式拟合每个训练集。
分割决策基于特征的随机选择,导致每棵树之间的差异。这会产生更准确的聚合结果和最终预测。
其他示例算法包括:
-
袋装决策树
-
Extra Trees
-
自定义袋装法
提升法
提升法是将弱学习者转变为强学习者的过程。弱学习者由于其能力不足,无法做出准确的预测。通过应用基础学习算法生成新的弱预测规则。这是通过获取数据的随机样本并输入到模型中,然后进行顺序训练,旨在训练弱学习者并试图修正其前身。
提升法的一个示例是 AdaBoost 和 XGBoost
AdaBoost
AdaBoost 是自适应提升的简称,用作提升机器学习算法性能的技术。它利用随机森林的弱学习者概念,在多个弱学习者之上构建模型。
class sklearn.ensemble.AdaBoostClassifier(base_estimator=None, *, n_estimators=50, learning_rate=1.0, algorithm='SAMME.R', random_state=None)
XGBoost
XGBoost 代表极端梯度提升,是最受欢迎的提升算法之一,可用于回归和分类任务。它是一种监督学习算法,旨在通过组合一组较弱的模型来准确预测目标变量。
其他示例算法包括:
-
梯度提升机
-
随机梯度提升
-
LightGBM
何时使用袋装法与提升法?
确定何时使用袋装法或提升法的最简单方法是:
-
如果分类器不稳定且有高方差 - 使用袋装法
-
如果分类器稳定但有高偏差 - 使用提升法
堆叠法
堆叠法是堆叠泛化的简称,与提升法类似;目的是生成更强健的预测模型。这是通过将弱学习者的预测结果用于创建一个强模型来实现的。它通过找出如何最佳地结合多个模型在同一数据集上的预测来完成。
它基本上是在问你‘如果你有多种在特定问题上表现良好的机器学习模型,你如何选择最值得信赖的模型?’
投票法
投票是堆叠的一个示例,但在分类和回归任务中有所不同。
对于回归,预测是基于其他回归模型的平均值。
class sklearn.ensemble.VotingRegressor(estimators, *, weights=None, n_jobs=None, verbose=False)
对于分类任务,可以使用硬投票或软投票。硬投票本质上是选择票数最多的预测,而软投票则是结合每个模型中每个预测的概率,然后选择总概率最高的预测。
class sklearn.ensemble.VotingClassifier(estimators, *, voting='hard', weights=None, n_jobs=None, flatten_transform=True, verbose=False)
其他示例算法包括:
-
加权平均
-
混合
-
堆叠
-
超级学习器
堆叠和装袋/提升有什么区别?
装袋使用决策树,而堆叠使用不同的模型。装袋从训练数据集中抽取样本,而堆叠则在相同的数据集上进行拟合。
提升使用一系列模型,将弱学习者转化为强学习者,以纠正之前模型的预测,而堆叠使用单一模型来学习如何最佳地结合来自贡献模型的预测。
聚合所有内容
你总是需要在尝试解决任务之前理解你想要实现的目标。一旦你做到这一点,你将能够确定你的任务是分类还是回归任务,从而选择最适合的集成算法来提高模型的预测能力和稳健性。
尼莎·阿里亚 是一名数据科学家和自由技术作家。她特别关注提供数据科学职业建议或教程以及数据科学理论知识。她还希望探索人工智能如何/能否有助于人类寿命的不同方式。她是一个热衷学习者,寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关内容
在 AI-JACK 库中封装机器学习技术
原文:
www.kdnuggets.com/2020/07/wrapping-machine-learning-techniques-ai-jack-library-r.html
评论
由Jędrzej Furmann和AI-JACK共同开发
目前,人工智能的前沿技术包括但不限于在一个工具/库中比较多个机器学习模型。然而,手动尝试不同的技术仍然非常普遍,这种做法一旦重复多次,不仅枯燥无味,而且容易出错。当代码量庞大时,降低失败风险变得更加重要,因为调试和测试变得繁琐。考虑到这一点,AI-JACK 应运而生。它是一个机器学习管道加速器,作为 R 语言库设计,旨在更快更好地解决问题。

这是什么?
AI-JACK 以R 语言库的形式编写,尽管它不要求用户进行任何编码,除非用户希望添加自定义功能。它包含多个内置功能,帮助完成整个管道。包括数据加载、预处理、模型训练和版本控制,以及部署等模块,所有这些都可以通过一个配置文件中的几个参数来控制。建模主要使用 H2O API,一个最先进的机器学习框架,提供了许多算法,如 XGBoost、随机森林、线性模型、深度学习、EM 聚类、孤立森林等。
尽管许多功能是内置的,但代码可以以任何方式修改。用户可以在 AI-JACK 基础上添加其他功能或模型。这是该工具的优势:它可以作为许多问题中的完整管道,也可以只是更大过程中的一个步骤。
AI-JACK 在不同的超参数集上训练选定的模型,根据选定的指标选择最佳模型,然后将其输出——元数据、验证结果、特征重要性和模型本身——保存到指定路径。结果还可以以 Web 服务的形式提供,你可以通过 API 访问这些结果。
如何使用 AI-JACK?
为了正常工作,你需要安装 R 运行时。RStudio 作为最常用的文本编辑器,写 R 代码时也会非常方便,尽管 AI-JACK 的基本版本不需要编码,一个简单的笔记本也足够。
AI-JACK还需要一个有效的 Java 运行环境安装。
在使用 AI-JACK 之前,您的数据集通常应该进行预处理。该库仅支持一些基本技术:去除特殊字符、缺失值处理、拆分测试/训练/验证集。数据集可以作为本地 csv 文件加载,或连接到 SQL 数据库。然后,您只需在选定路径中使用 init_aijack 函数初始化项目,并在新创建的配置文件 config_model.R 或 config_clust_model.R 中指定参数,具体取决于您是使用监督学习还是无监督学习。保存配置文件后,运行 main_model.R 或 main_clust_model.R,将训练几个模型。所有需要的文件都会自动保存到选定路径。
如果您正在训练监督模型,csv 输出包括所有技术的特征重要性信息,以及验证结果、创建的列名称(例如,如果模型使用了虚拟变量)、每次执行的准确度分数、可能的错误和有关模型的元数据。
如果你正在使用聚类,AI-JACK 会自动训练三种技术,并保存 png 图表,比较这些模型的轮廓系数。这些技术是 k-means、k-medoids 和期望最大化,它们是无监督技术中最常用的。
详细手册以及开发者联系方式可以在 GitHub 页面找到。AI-JACK 是一个开源项目,因此欢迎贡献!如果你觉得这个库有用,并想帮助开发它,你可以自由地参与其中。
个人简介:Jędrzej Furmann 是一名初级数据科学家和AI-JACK 的共同开发者。
相关:
-
自动化机器学习:免费电子书
-
modelStudio 和互动解释性模型分析的语法
-
实用的超参数优化
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
了解更多相关话题
如何编写更好的 SQL 查询:权威指南 – 第一部分
原文:
www.kdnuggets.com/2017/08/write-better-sql-queries-definitive-guide-part-1.html/2
3. 不要让查询变得比需要的更复杂
数据类型转换引出下一个要点:你不应该过度设计你的查询。尽量保持简单和高效。这可能看起来太简单或愚蠢,尤其是因为查询可能会变得复杂。
然而,你将在接下来的示例中看到,你可以轻易地使简单的查询变得比需要的更复杂。
OR运算符
当你在查询中使用OR运算符时,很可能你没有使用索引。
记住,索引是一种数据结构,可以提高数据库表中数据检索的速度,但代价是:需要额外的写入和额外的存储空间来维护索引数据结构。索引用于快速定位或查找数据,而不必每次访问数据库表时都搜索每一行数据。索引可以通过使用数据库表中的一个或多个列来创建。
如果你不利用数据库中包含的索引,你的查询将不可避免地运行得更慢。因此,最好寻找替代OR运算符的方法;
考虑以下查询:
SELECT driverslicensenr, name
FROM Drivers
WHERE driverslicensenr = 123456
OR driverslicensenr = 678910
OR driverslicensenr = 345678;
你可以通过以下方式替换运算符:
- 带有 IN 的条件;或
SELECT driverslicensenr, name
FROM Drivers
WHERE driverslicensenr IN (123456, 678910, 345678);
- 两个
SELECT语句与一个UNION。
提示:在这里,你需要小心不要不必要地使用UNION操作,因为你会多次遍历同一个表。同时,你需要意识到,当你在查询中使用UNION时,执行时间会增加。UNION操作的替代方案包括:重新制定查询,将所有条件放在一个SELECT语句中,或者使用OUTER JOIN代替UNION。
提示:在这里也要记住,尽管OR—以及接下来会提到的其他运算符—可能不使用索引,但索引查找并不总是优选的!
NOT运算符
当你的查询包含NOT运算符时,很可能索引不会被使用,就像OR运算符一样。这将不可避免地降低查询速度。如果你不知道这里的意思,考虑以下查询:
SELECT driverslicensenr, name
FROM Drivers
WHERE NOT (year > 1980);
这个查询会比你预期的要慢很多,主要是因为它的表达方式比实际需要的要复杂:在这种情况下,最好寻找替代方案。考虑用比较运算符如>、<>或!>来替代NOT;上面的示例确实可以重写成如下形式:
SELECT driverslicensenr, name FROM Drivers WHERE year <= 1980;
这看起来已经整洁多了,不是吗?
AND运算符
AND操作符是另一个不使用索引的操作符,如果以过于复杂和低效的方式使用,如下面的例子,会使查询变慢:
SELECT driverslicensenr, name
FROM Drivers
WHERE year >= 1960 AND year <= 1980;
最好是重写这个查询,并使用BETWEEN操作符:
SELECT driverslicensenr, name
FROM Drivers
WHERE year BETWEEN 1960 AND 1980;
ANY和ALL操作符
ALL操作符也是需要小心的,因为在查询中包含这些操作符时,索引不会被使用。这里的有用替代方案是像MIN或MAX这样的聚合函数。
提示:在使用建议的替代方案时,你应该意识到,像SUM、AVG、MIN、MAX等聚合函数在处理大量行时可能会导致查询时间较长。在这种情况下,你可以尝试减少处理的行数或预先计算这些值。你会再次发现,了解你的环境、查询目标等在决定使用哪种查询时非常重要!
在条件中隔离列
同样地,当一个列在计算或标量函数中使用时,索引也不会被使用。一个可能的解决方案是简单地隔离特定的列,使其不再是计算或函数的一部分。考虑以下示例:
SELECT driverslicensenr, name
FROM Drivers
WHERE year + 10 = 1980;
这看起来有点怪吧?相反,可以重新考虑计算方式,并将查询重写成如下形式:
SELECT driverslicensenr, name
FROM Drivers
WHERE year = 1970;
4. 避免暴力破解
最后一条提示实际上意味着你不应该过度限制查询,因为这可能会影响其性能。这在连接操作和HAVING子句中特别如此。
连接操作
- 表的顺序
当你连接两个表时,考虑表在连接中的顺序可能很重要。如果你发现一个表明显比另一个表大,你可能需要重写查询,以便将最大表放在连接的最后。
- 连接中的冗余条件
当你为连接添加过多条件时,你基本上强迫 SQL 选择某条路径。然而,这条路径可能并不总是性能最优的。
HAVING子句
HAVING子句最初是因为WHERE关键字不能与聚合函数一起使用而添加到 SQL 中的。HAVING通常与GROUP BY子句一起使用,以将返回的行组限制为仅符合某些条件的组。然而,如果你在查询中使用这个子句,索引将不会被使用,正如你已经知道的,这可能会导致查询的性能不佳。
如果你在寻找替代方案,可以考虑使用WHERE子句。考虑以下查询:
SELECT state, COUNT(*)
FROM Drivers
WHERE state IN ('GA', 'TX')
GROUP BY state
ORDER BY state
SELECT state, COUNT(*)
FROM Drivers
GROUP BY state
HAVING state IN ('GA', 'TX')
ORDER BY state
第一个查询使用WHERE子句来限制需要求和的行数,而第二个查询则对表中的所有行进行求和,然后使用HAVING来丢弃计算出的总和。在这种情况下,显然使用WHERE子句的替代方法更好,因为你不会浪费任何资源。
你会看到这不是关于限制结果集,而是关于限制查询中的中间记录数。
注意 这两个子句之间的区别在于 WHERE 子句对单独的行引入条件,而 HAVING 子句对聚合或选择结果引入条件,其中产生了一个结果,如 MIN、 MAX、 SUM… 这是从多行中生成的。
你看,评估查询的质量、编写和重写查询不是一项容易的工作,尤其是在考虑到它们需要尽可能高效的情况下;避免反模式并考虑替代方案也是你在专业环境中编写要在数据库上运行的查询时的责任之一。
这个列表只是一些反模式和提示的小概述,希望对初学者有所帮助;如果你想了解更多资深开发人员认为最常见的反模式,可以查看 这个讨论。
个人简介:Karlijn Willems 是一位数据科学记者,为 DataCamp 社区撰写文章,专注于数据科学教育、最新新闻和热门趋势。她拥有文学、语言学和信息管理方面的学位。
原文。经许可转载。
相关:
-
掌握数据科学的 SQL 七步法
-
SQL 中最被低估的函数
-
使用 SQL 进行统计分析
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
更多相关话题
如何编写更好的 SQL 查询:权威指南 – 第二部分
原文:
www.kdnuggets.com/2017/08/write-better-sql-queries-definitive-guide-part-2.html
作者:卡尔琳·威廉姆斯,数据科学记者及DataCamp贡献者。
编辑注释: 本文是第一部分的续篇,第一部分已于昨日发布,可在此处找到。虽然本文内容可以被视为独立于第一部分,但在继续之前阅读第一部分将极有帮助。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
首篇文章的引言段落如下,以设置教程的总体氛围。
结构化查询语言(SQL)是数据科学行业中必不可少的技能,通常来说,学习这项技能相对容易。然而,大多数人忘记了 SQL 不仅仅是编写查询,这只是走向成功的第一步。确保查询性能良好或符合你所处的上下文是另一回事。
基于集合的方法与过程方法的查询
上述反模式隐含的事实是,它们实际上归结为基于集合的方法与过程方法在构建查询时的区别。
过程方法的查询类似于编程:你告诉系统要做什么以及如何做。
这方面的一个例子是连接中的冗余条件或你滥用HAVING子句的情况,就像上述示例中那样,你通过执行一个函数然后调用另一个函数来查询数据库,或者你使用包含循环、条件、自定义函数(UDF)、游标等逻辑来获得最终结果。在这种方法中,你通常会发现自己先对数据的一个子集进行查询,然后再从数据中请求另一个子集,以此类推。
这种方法常常被称为“逐步”或“逐行”查询,这并不奇怪。
另一种方法是基于集合的方法,你只需指定要做的事情。你的角色是指定你希望从查询中获得的结果集的条件或要求。数据如何检索,则留给内部机制来确定查询的实现方式:你让数据库引擎确定执行查询的最佳算法或处理逻辑。
由于 SQL 是基于集合的,这种方法显然比过程式方法更有效,这也解释了为什么在某些情况下,SQL 可能比代码运行得更快。
提示 集合方法的查询也是数据科学行业中大多数顶级雇主要求你掌握的方法!你经常需要在这两种方法之间切换。
注意 如果你发现自己面对一个过程式查询,你应该考虑重写或重构它。
从查询到执行计划
了解反模式并非静态且会随着你作为 SQL 开发人员的成长而演变,并且考虑替代方案时有很多因素,也意味着避免查询反模式和重写查询可能是一个相当困难的任务。任何帮助都可能派上用场,这就是为什么使用一些工具来优化查询的结构化方法可能是一个好选择。
注意 此外,上一节提到的一些反模式根源于性能问题,例如AND、OR和NOT运算符及其缺乏索引的使用。考虑性能不仅需要更结构化的方法,还需要更深入的方法。
然而,这种结构化且深入的方法大多基于查询计划,正如你记得的,它是将查询首先解析为“解析树”的结果,并准确地定义了每个操作使用的算法以及操作执行的协调方式。
查询优化
如你在介绍中所读到的,可能需要手动检查和调整优化器生成的计划。在这种情况下,你需要通过查看查询计划再次分析你的查询。
要获取这个计划,你需要使用你的数据库管理系统提供的工具。你可能拥有的工具包括以下几种:
- 一些软件包提供了生成查询计划图形表示的工具。看看这个例子:
- 其他工具将能为你提供查询计划的文本描述。例如,Oracle 中的
EXPLAIN PLAN语句,但根据你使用的 RDBMS,指令的名称会有所不同。在其他地方,你可能会找到EXPLAIN(MySQL、PostgreSQL)或EXPLAIN QUERY PLAN(SQLite)。
注意,如果你在使用 PostgreSQL,EXPLAIN和EXPLAIN ANALYZE的区别在于,EXPLAIN只会提供一个描述,说明规划者打算如何执行查询,而不实际运行查询,而EXPLAIN ANALYZE则会实际执行查询并返回期望的与实际的查询计划的分析。一般来说,实际执行计划是你实际运行查询的结果,而估算执行计划是预测它会做什么,而不执行查询。虽然在逻辑上等效,但实际执行计划要有用得多,因为它包含了关于实际执行查询时发生的额外细节和统计信息。
在本节的剩余部分,你将学习更多关于EXPLAIN和ANALYZE的内容,以及如何使用这两个工具来深入了解查询计划和查询的可能性能。为此,你将从一些示例开始,在这些示例中,你将处理两个表:one_million和half_million。
你可以借助EXPLAIN检索表one_million的当前信息;确保将其放在查询的最前面,当运行时,它会给你返回查询计划:
EXPLAIN
SELECT *
FROM one_million;
QUERY PLAN
____________________________________________________
Seq Scan on one_million
(cost=0.00..18584.82 rows=1025082 width=36)
(1 row)
在这种情况下,你会看到查询的成本是0.00..18584.82,行数是1025082。列数的宽度是36。
此外,你还可以借助ANALYZE来更新统计信息。
ANALYZE one_million;
EXPLAIN
SELECT *
FROM one_million;
QUERY PLAN
____________________________________________________
Seq Scan on one_million
(cost=0.00..18334.00 rows=1000000 width=37)
(1 row)
除了EXPLAIN和ANALYZE,你还可以通过EXPLAIN ANALYZE来获取实际执行时间:
EXPLAIN ANALYZE
SELECT *
FROM one_million;
QUERY PLAN
___________________________________________________________
Seq Scan on one_million
(cost=0.00..18334.00 rows=1000000 width=37)
(actual time=0.015..1207.019 rows=1000000 loops=1)
Total runtime: 2320.146 ms
(2 rows)
使用EXPLAIN ANALYZE的缺点显而易见,即查询实际上会被执行,所以要小心!
到目前为止,你看到的所有算法都是Seq Scan(顺序扫描)或全表扫描:这是在数据库上进行的扫描,其中扫描的每一行以顺序(串行)方式读取,并检查找到的列是否满足条件。从性能的角度来看,顺序扫描绝对不是最佳执行计划,因为你仍然在进行全表扫描。然而,当表不适合内存时,它也不是太糟:即使在慢速磁盘上,顺序读取也很快。
当你谈论索引扫描时,你会看到更多内容。
但是,还有其他算法。举个例子,这里是一个连接的查询计划:
EXPLAIN ANALYZE
SELECT *
FROM one_million JOIN half_million
ON (one_million.counter=half_million.counter);
QUERY PLAN
_________________________________________________________________
Hash Join (cost=15417.00..68831.00 rows=500000 width=42)
(actual time=1241.471..5912.553 rows=500000 loops=1)
Hash Cond: (one_million.counter = half_million.counter)
-> Seq Scan on one_million
(cost=0.00..18334.00 rows=1000000 width=37)
(actual time=0.007..1254.027 rows=1000000 loops=1)
-> Hash (cost=7213.00..7213.00 rows=500000 width=5)
(actual time=1241.251..1241.251 rows=500000 loops=1)
Buckets: 4096 Batches: 16 Memory Usage: 770kB
-> Seq Scan on half_million
(cost=0.00..7213.00 rows=500000 width=5)
(actual time=0.008..601.128 rows=500000 loops=1)
Total runtime: 6468.337 ms
你看到查询优化器选择了Hash Join!记住这个操作,因为你需要它来估算查询的时间复杂度。目前,注意half_million.counter上没有索引,你可以在下一个示例中添加:
CREATE INDEX ON half_million(counter);
EXPLAIN ANALYZE
SELECT *
FROM one_million JOIN half_million
ON (one_million.counter=half_million.counter);
QUERY PLAN
________________________________________________________________
Merge Join (cost=4.12..37650.65 rows=500000 width=42)
(actual time=0.033..3272.940 rows=500000 loops=1)
Merge Cond: (one_million.counter = half_million.counter)
-> Index Scan using one_million_counter_idx on one_million
(cost=0.00..32129.34 rows=1000000 width=37)
(actual time=0.011..694.466 rows=500001 loops=1)
-> Index Scan using half_million_counter_idx on half_million
(cost=0.00..14120.29 rows=500000 width=5)
(actual time=0.010..683.674 rows=500000 loops=1)
Total runtime: 3833.310 ms
(5 rows)
你会看到,通过创建索引,查询优化器现在决定使用Merge join,其中发生了Index Scan。
注意 索引扫描和完全表扫描或顺序扫描之间的区别:前者,也称为“表扫描”,扫描数据或索引页面以查找适当的记录,而后者扫描表的每一行。
你会看到总运行时间减少了,性能应该有所提升,但仍有两个索引扫描,这使得内存变得更为重要,特别是当表不能完全加载到内存时。在这种情况下,你首先需要进行完全索引扫描,这些是快速的顺序读取,不成问题,但之后你会有大量随机读取来根据索引值获取行。正是这些随机读取通常比顺序读取慢几个数量级。在这种情况下,完全表扫描确实比完全索引扫描更快。
提示:如果你想了解更多关于EXPLAIN的信息或查看更详细的示例,可以考虑阅读由 Guillaume Lelarge 编写的书籍《Understanding Explain》。
相关话题
使用管道编写干净的 Python 代码
原文:
www.kdnuggets.com/2021/12/write-clean-python-code-pipes.html
由 Khuyen Tran,数据科学实习生
动机
map 和 filter 是两个高效的 Python 方法,用于处理可迭代对象。然而,如果同时使用 map 和 filter,代码可能会显得凌乱。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求

作者提供的图片
如果你可以像下面这样使用管道 | 来对可迭代对象应用多个方法,那不是很好吗?
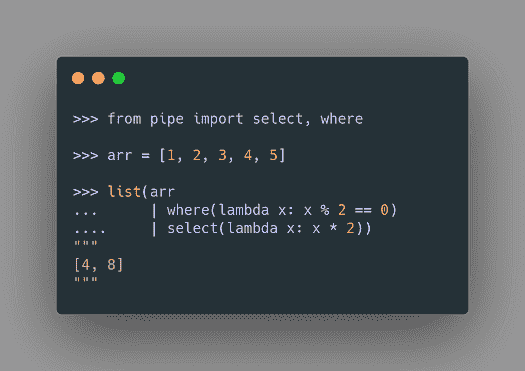
作者提供的图片
Pipe 库允许你做到这一点。
什么是 Pipe?
Pipe 是一个 Python 库,允许你在 Python 中使用管道。一个管道 (|) 将一个方法的结果传递给另一个方法。
我喜欢使用管道,因为当对 Python 可迭代对象应用多个方法时,它使我的代码看起来更简洁。由于管道只提供少量的方法,它也非常容易学习。在这篇文章中,我将展示一些我认为最有用的方法。
要安装 Pipe,请输入:
pip install pipe
Where — 过滤可迭代对象中的元素
类似于 SQL,Pipe 的 where 方法也可以用来过滤可迭代对象中的元素。

作者提供的图片
Select — 对可迭代对象应用函数
select 方法类似于 map 方法。select 将一个方法应用到可迭代对象的每个元素上。
在下面的代码中,我使用 select 将列表中的每个元素乘以 2。

作者提供的图片
现在,你可能会想:既然 where 和 select 的功能与 map 和 filter 相同,我们为什么还需要它们呢?
因为你可以使用管道将一个方法接在另一个方法后面。因此,使用管道可以去除嵌套的括号,使代码更具可读性。
作者提供的图片
展开可迭代对象
chain — 链接一系列可迭代对象
处理嵌套的可迭代对象可能很麻烦。幸运的是,你可以使用 chain 来连接一系列可迭代对象。

作者提供的图片
即使在应用了chain之后,可迭代对象的嵌套程度有所减少,我们仍然得到一个嵌套列表。要处理深度嵌套的列表,我们可以改用traverse。
traverse — 递归展开可迭代对象
traverse方法可以用来递归展开可迭代对象。因此,你可以使用这种方法将深度嵌套的列表转化为平坦的列表。

图片由作者提供
让我们将这种方法与select方法结合,获取字典的值并展平列表。
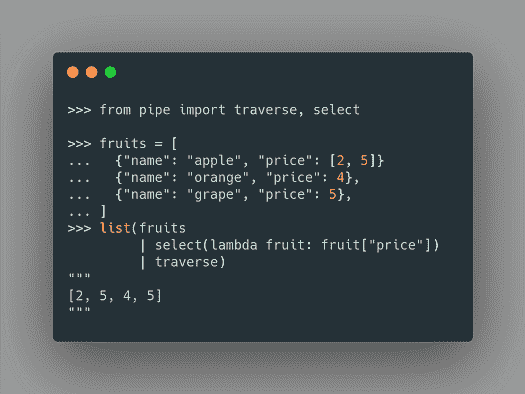
图片由作者提供
相当酷!
列表中的元素分组
有时,使用某个函数对列表中的元素进行分组可能会很有用。这可以通过groupby方法轻松实现。
为了查看这种方法的工作原理,让我们将一个数字列表转化为一个字典,该字典根据数字是偶数还是奇数进行分组。

图片由作者提供
在上面的代码中,我们使用groupby将数字分组到Even组和Odd组。应用这种方法后的输出如下:
[('Even', <itertools._grouper at 0x7fbea8030550>),
('Odd', <itertools._grouper at 0x7fbea80309a0>)]
接下来,我们使用select将一个元组列表转化为一个字典列表,其键是元组中的第一个元素,值是元组中的第二个元素。
[{'Even': [2, 4, 6, 8]}, {'Odd': [1, 3, 5, 7, 9]}]
很酷!为了仅获取大于 2 的值,我们可以在select方法中添加where方法:
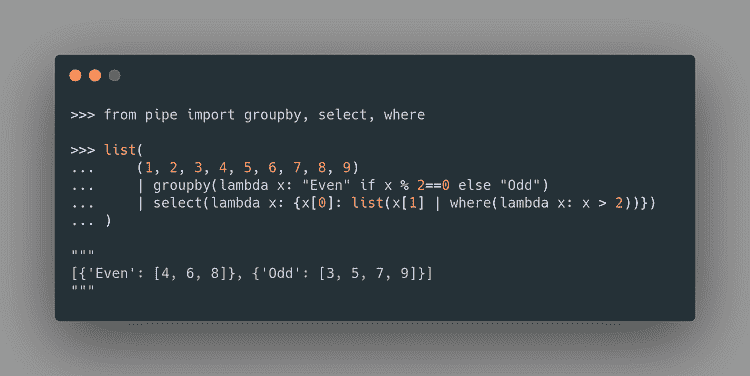
图片由作者提供
请注意,输出中不再包含2和1。
dedup — 使用键去重
dedup方法用于移除列表中的重复项。
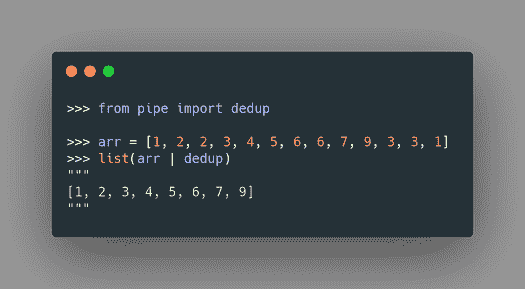
图片由作者提供
这可能听起来不那么有趣,因为set方法也能实现相同的功能。然而,这种方法更为灵活,因为它允许你通过键来获取唯一元素。
例如,你可以使用这种方法获取一个小于 5 的唯一元素,以及一个大于或等于 5 的唯一元素。
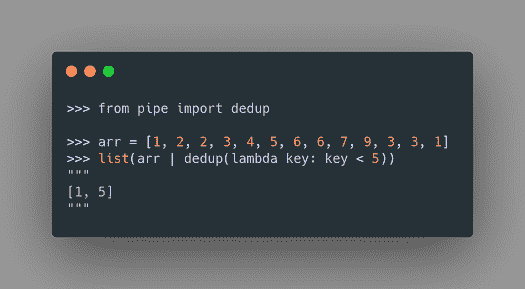
图片由作者提供
现在,让我们将这种方法与select和where结合,以获取具有重复键和None值的字典的值。

图片由作者提供
在上面的代码中,我们:
-
移除具有相同
name的项 -
获取
count的值 -
仅选择整数值。
通过几行代码,我们可以对一个可迭代对象应用多种方法,同时保持代码的简洁。很酷,不是吗?
结论
恭喜!你刚刚学会了如何使用 pipe 保持代码的整洁和简短。希望这篇文章能让你掌握将复杂的迭代操作转化为一行简单代码的知识。
欢迎在此处玩转并分叉本文的源代码:
Data-science/pipe.ipynb at master · khuyentran1401/Data-science
我喜欢撰写基础数据科学概念,并玩弄不同的算法和数据科学工具。你可以通过 LinkedIn 和 Twitter 与我联系。
如果你想查看我撰写的所有文章的代码,请给 这个仓库 点个星。关注我的 Medium,以获取最新的数据科学文章,如下所示:
Python 清洁代码: 使你的 Python 函数更具可读性的 6 个最佳实践
4 个 pre-commit 插件以自动化 Python 代码审查和格式化
个人简介: Khuyen Tran 是一位多产的数据科学作家,撰写了 一系列有用的数据科学主题,包括代码和文章。Khuyen 目前正在寻找一份机器学习工程师、数据科学家或开发者推广角色的职位,特别是在 2022 年 5 月之后的湾区,如果你需要她的技能,请联系她。
原文。经许可转载。
相关:
-
Python 序列的 5 个高级技巧
-
初学者的端到端机器学习指南
-
生成 Python 的电子表格: Mito JupyterLab 扩展
更多相关话题
如何写吸引人的技术博客
原文:
www.kdnuggets.com/2022/04/write-engaging-technical-blogs.html

作者图片
写吸引人的博客是一门艺术,要掌握这门艺术,你需要不断练习。写高质量博客没有捷径,你必须从错误中学习,并随着时间的推移不断改进。你还需要评估趋势,写自己喜欢的内容。使其个性化,提升你的品牌,并增加你的粉丝。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
在这篇博客中,我们将学习写吸引人的技术博客的规则。我们将专注于生成最佳标题、设计吸引人的封面图片、添加趣味事实、用代码块支持教程以及社交媒体推广。
我们将在这篇博客中学习的规则来自于我的个人经验,我已经写了超过 50 篇博客和 40 篇技术文章。我曾因撰写最佳教程而获得 Analytics Vidhya 的奖项,并多次获得 KDnuggets 的奖项。如果你对我的工作感兴趣,可以查看我的 Polywork 和 Deepnote 个人资料。
标题
标题是博客中最重要的部分之一。你应该花至少两个小时来头脑风暴,找出最有可能引起病毒式传播的标题。标题是吸引读者点击博客文章的第一步。如果你的标题引人入胜或为读者提供附加价值,他们最终会阅读全文。写标题的艺术来自于实践,但你也可以使用工具来提高水平。这些工具对我有帮助。互联网充满了 SEO 优化工具,几乎每个平台都有标题生成工具。
博客创意生成器: 它将关键词转换为吸引人的标题。我不认为生成的标题是好的。在我看来,这些工具是为了帮助你,但你需要自己想出一个适合你的标题。

图片来源:hubspot
KDnuggets/Towards Data Science:阅读你领域内其他作者目前的写作内容更好。寻找阅读量最高的博客文章,并尝试写出自己的内容。我相信每天阅读多篇博客会帮助你生成大量新的标题。

图片来源:KDnuggets
Keyword Planner: 从各种平台提取数据,为你提供关键词分析。这些结果包括搜索量、趋势和竞争情况。你可以利用这些参数来选择下一个话题。
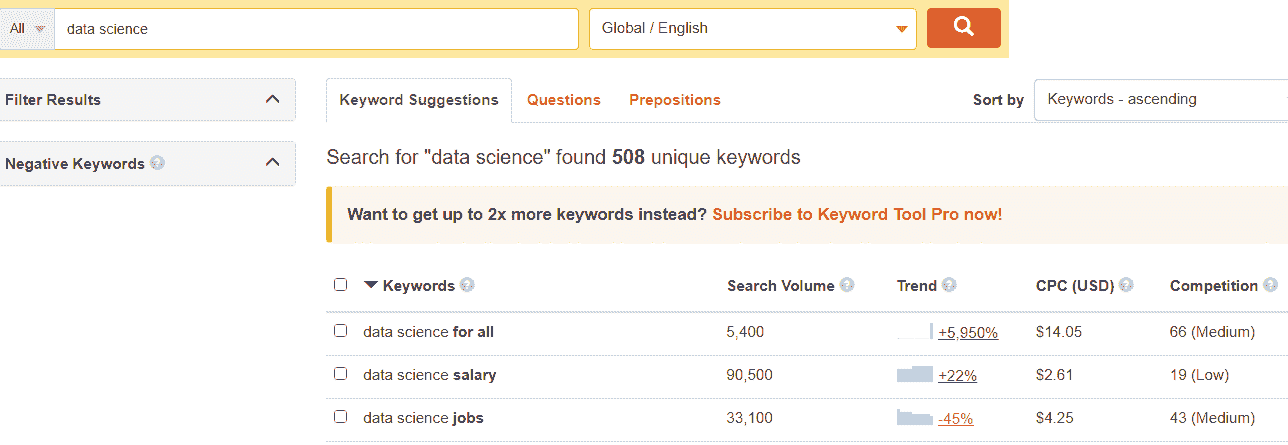
图片来源:keywordtool.io
还有其他免费的工具可以为你服务,例如 Google trends,但你必须自己想出标题。要诚实地对待标题,不要试图通过诱饵标题来吸引读者,因为这种策略只对 TikTok 或 YouTube 有效。
规则
-
使用 Google Trends 获取有关标题的见解。
-
使用免费工具生成博客创意
-
将标题写成问题会激励读者去了解答案
-
尝试新的、有吸引力的标题写作方式
-
在标题中使用“工作”、“钱”或“顶级”以获得更多关注
-
在标题中使用数字和事实
-
不断尝试并从访问量最高的博客中学习。
图片
人类处理图像的速度是阅读文本的 60,000 倍,90%的信息是视觉的,因此封面图像是博客中最重要的部分 - t-sciences.com。这是决定博客成败的因素。你需要通过吸引人的颜色、设计和图像上的文字来传达你的故事。我不能教你如何制作病毒式传播的博客封面,但我可以指导你使用在过去帮助过我的工具。
-
Unsplash: 你可以从这个平台获得免费的照片,你只需选择适合你的正确图像即可。该平台提供超过 1,000,000 张免费图像供下载,并附有作者署名。你会在成千上万的博客文章中看到这些图像,所以这是每个博主的首选工具。
-
Freepik: 你可以获得有限但免费的矢量图。依我看,如果封面图像是动画的,人们点击博客的可能性会更高,这意味着图像应该传达某种故事或信息。使用矢量图为我的博客写作赋予了新的意义,我可以使用插图工具随时编辑矢量图以自定义我的图像。
-
Canva: 这是我生成封面照片的首选工具。你可以在浏览器中轻松编辑然后下载。Canva 提供模板、矢量图、照片和编辑工具。

作者提供的图片
规则
-
使用吸引人的配色方案
-
图像上使用有限的文字
-
要有创意,并使用免费图片
-
使用编辑工具自定义封面
-
确保图片与主题相关
-
简单而简约的设计能够吸引更多的观众
-
不要添加过多元素
有趣易读
如果你的博客内容枯燥且充满科学术语,那么你将失去大部分观众。读者会跳过整篇博客去阅读有趣的事实或数据。现代人的注意力跨度较短,因此你需要制作一篇简短且充满“饼干”的博客。这些“饼干”将帮助提升读者的体验,从而获得忠实的观众。我通常会添加图片、事实和数据、图表、要点、标题、引言和结论。写博客的整体想法是让阅读体验顺畅。

图片由 freepik 提供
规则
-
添加有趣的事实
-
添加笑话可以提升读者体验,即使笑话不好
-
对于解释新的或复杂的想法,要富有创意
-
使用事实和数据来支持你的主张
-
使用信息图表来解释模型架构或算法
-
不要使用高级词汇来解释术语
代码块
就像数学方程式对技术研究论文是必要的,代码块对技术博客也是必不可少的。没有代码块的数据科学或机器学习教程毫无意义。它允许读者自行测试作者提出的主张。代码块还可以提升整体阅读体验,让你能够跟随整个教程。
我看到过多个软件工程师和数据科学家直接跳到代码部分。例如,如果我在寻找一个时间序列的 LSTM 模型,我只对代码和他们如何处理具体问题感兴趣。我会复制代码自己尝试,或将类似的代码整合到我当前的项目中。
生成代码块的工具:
Carbon: 它可以将你的代码转换成一个具有正确语法高亮的吸引人的图片。你会看到许多影响者和数据科学家在社交媒体上使用这个工具或将其添加到博客中。

图片由作者提供
Deepnote Embed Cell: 可以将任何 Jupyter notebook 单元格转换为可分享的代码块及其输出。如下面所示,博客包含一个具有动画效果的交互式 Plotly 图表。你可以根据需要选择移除代码块或同时添加代码和输出。
Gif 由作者提供
Github Gist: 这是技术博主展示项目代码最常用的工具。加载速度快,语法高亮正确,并且兼容大多数平台。
图片由作者提供
规则
-
使用互动代码块
-
生成代码块前格式化你的代码
-
确保语法高亮对用户友好
-
使用 Gif 显示输出
-
确保使用嵌入代码不会增加博客加载时间
个性化
书写你关心的话题。人们会迅速发现你是否在伪造或复制其他作者的作品。不要通过追随趋势来破坏你的品牌。这些趋势会不断变化,很难跟上。确保你的博客是个性化的。书写你个人的经历,好的、坏的和糟糕的。对你的观众要诚实,相信我,这会在长远中帮助你。
我总是添加我在项目中出现问题的选项。我甚至会给出对我有效的技巧。总是考虑读者喜欢什么,并尝试根据这些改进你的博客。如果读者喜欢更多的信息图表,那么尝试添加更多的信息图表。你需要理解你是为人类写作的,所以保持简单易读。没有人对全代码或全科学方程感兴趣。

图片由 Sincerely Media 提供,来源于 Unsplash
规则
-
进行调研
-
写你热爱的东西
-
书写关于好的、坏的和糟糕的经历
-
解释复杂想法时给出真实生活的例子
-
触及读者的内心以提升内容
-
保持简单易读
-
诚实和真实
促销
在发布博客文章后,是推广你工作的最佳时机。为社交媒体帖子写一条简短而吸引人的信息,并根据每个平台个性化。使用标签以增加帖子覆盖率。添加吸引人的图片以促使观众点击帖子,不要局限于几个社交媒体网站。如果你是博客新手,那么你应该使用每一个廉价的策略来使你的博客文章获得关注。请让你的联系人士帮忙推广。如果你足够渴望,我相信你会找到推广博客的方法。
社交媒体平台
-
LinkedIn
-
Dev.to
-
Polywork
-
Twitter
-
Facebook
-
Reddit
-
Hacker News
-
Slack
-
Discord
-
数据科学论坛

规则
-
定制信息
-
在多个社交媒体平台上发布
-
使用标签
-
添加封面照片
-
保持评论区活跃
-
不要过度
最终思考
唯一能让你变得更好的就是学习和适应的能力。从著名的技术作家那里学习,试着解读他们的成功之道。保持活跃在社交媒体上,寻找令人印象深刻的博客文章。如果一篇文章让你点击了它,那么找出原因。
学习如何创建吸引人的封面照片、标题、副标题、事实和数据以及研究技术。推广所有博客文章到所有社交媒体平台,包括 Instagram。不要限制自己,但也不要过度。如果你发现某个平台上的人们没有回应,那么停止在该平台上发布。在这段旅程中,你会遇到许多失败,但最重要的是继续发布并从错误中学习。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些遭受心理疾病困扰的学生。
主题更多信息
如何使用简单的 Python 为数据科学家编写 Web 应用程序
原文:
www.kdnuggets.com/2019/10/write-web-apps-using-simple-python-data-scientists.html
评论
如果没有一个好的展示方式,机器学习项目永远不会真正完成。
过去,一个制作精良的可视化或一小份 PPT 就足以展示数据科学项目,但随着 RShiny 和 Dash 等仪表板工具的出现,一个优秀的数据科学家需要对 Web 框架有一定的了解才能顺利进行。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 工作
而 Web 框架学习起来很困难。我仍然会在所有那些 HTML、CSS 和 Javascript 中感到困惑,进行各种尝试,尽管有时看起来很简单。
更不用说还有许多方法可以实现相同的目标,这让我们这些对 Web 开发作为次要技能的数据科学人员感到困惑。
那么,我们是否注定要学习 Web 框架?还是在半夜为了些许疑问打电话给我们的开发者朋友?
这就是 Streamlit 发挥作用的地方,它兑现了仅使用 Python 创建 Web 应用程序的承诺。
Python 的禅意:简单优于复杂,Streamlit 使创建应用程序变得非常简单。
这篇文章讲述了如何使用 Streamlit 创建支持数据科学项目的应用程序。
要了解更多有关 Streamlit 的架构和思路,请查看这篇优秀的文章,作者之一是Adrien Treuille。
安装
安装方法就是运行以下命令:
pip install streamlit
要查看我们的安装是否成功,只需运行:
streamlit hello
这应该会显示一个提示信息:
您可以在浏览器中访问本地 URL: localhost:8501 来查看 Streamlit 应用程序的实际效果。开发者提供了一些有趣的演示,您可以尽情体验。在回来之前请充分体验一下工具的强大。
Streamlit Hello World
Streamlit 旨在通过简单的 Python 使应用程序开发变得容易。
所以,让我们写一个简单的应用来看看它是否能兑现这个承诺。
在这里,我开始一个简单的应用,我们将其称为 Streamlit 的 Hello World。只需将下面给出的代码粘贴到名为helloworld.py的文件中
import streamlit as stx = st.slider('x')
st.write(x, 'squared is', x * x)
然后,在终端中运行:
streamlit run helloworld.py
完成后,你应该能在浏览器中的localhost:8501看到一个简单的应用,允许你移动滑块并显示结果。

一个简单的滑块小部件应用
这非常简单。在上述应用中,我们使用了 Streamlit 的两个功能:
-
st.slider小部件可以滑动以更改网页应用的输出。 -
以及多功能的
st.write命令。我对它可以写入从图表、数据框到简单文本的任何内容感到惊讶。稍后会详细介绍。
重要提示:记住,每次我们更改小部件的值时,整个应用都会从头到尾重新运行。
Streamlit 小部件
小部件为我们提供了一种控制应用的方式。阅读小部件的最佳地方是API 参考文档,但我将描述一些你可能会使用的最重要的小部件。
1. 滑块
streamlit.slider(*label*, *min_value=None*, *max_value=None*, *value=None*, *step=None*, *format=None*)
我们已经在上面看到st.slider的效果。它可以与 min_value、max_value 和 step 一起使用,以获取范围内的输入。
2. 文本输入
获取用户输入的最简单方式,无论是一些 URL 输入还是文本输入进行情感分析。只需要一个标签来命名文本框。
import streamlit as sturl = st.text_input('Enter URL')
st.write('The Entered URL is', url)
这是应用的外观:

一个简单的文本输入小部件应用
提示: 你可以直接更改文件helloworld.py并刷新浏览器。我工作的方式是打开并更改sublime text中的helloworld.py,然后在浏览器中并排查看更改。
3. 复选框
复选框的一个用例是隐藏或显示应用中的特定部分。另一个用例可能是在函数的参数中设置布尔值。[st.checkbox()](https://streamlit.io/docs/api.html#streamlit.checkbox) 接受一个参数,即小部件标签。在此应用中,复选框用于切换条件语句。
import streamlit as st
import pandas as pd
import numpy as npdf = pd.read_csv("football_data.csv")
if st.checkbox('Show dataframe'):
st.write(df)
一个简单的复选框小部件应用
4. 选择框
我们可以使用[st.selectbox](https://streamlit.io/docs/api.html#streamlit.selectbox)从一系列或列表中进行选择。通常的用例是将其用作简单的下拉列表,以从列表中选择值。
import streamlit as st
import pandas as pd
import numpy as npdf = pd.read_csv("football_data.csv")option = st.selectbox(
'Which Club do you like best?',
df['Club'].unique())'You selected: ', option
一个简单的下拉/选择框小部件应用
5. 多选框
我们也可以从下拉列表中使用多个值。在这里,我们使用st.multiselect来获取多个值作为options变量中的列表。
import streamlit as st
import pandas as pd
import numpy as npdf = pd.read_csv("football_data.csv")options = st.multiselect(
'What are your favorite clubs?', df['Club'].unique())st.write('You selected:', options)
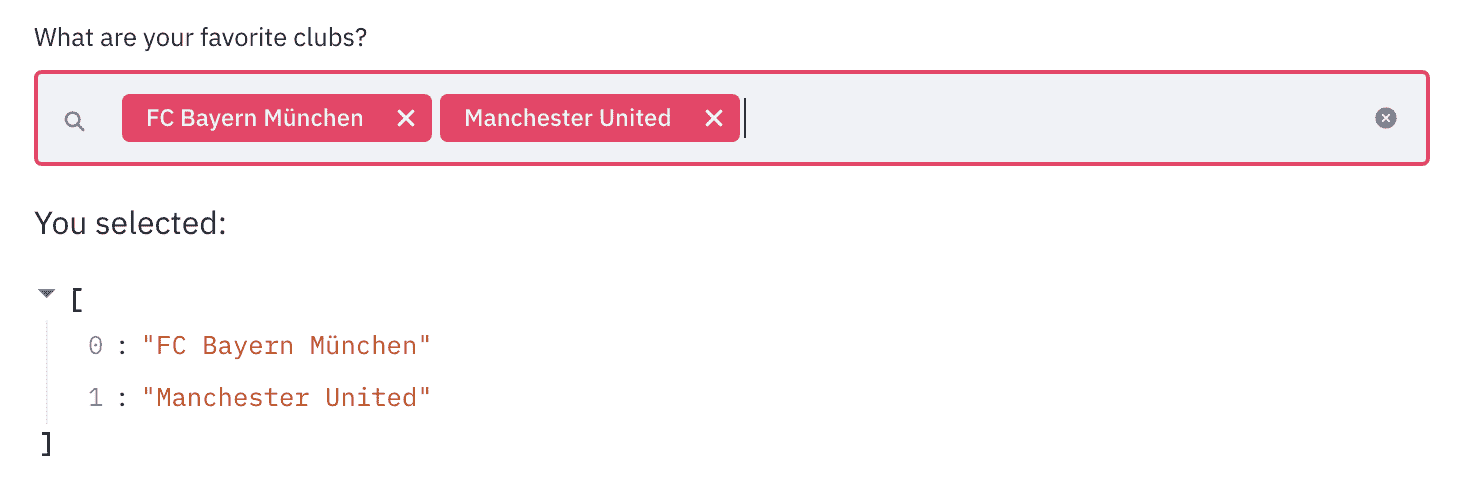
一个简单的多选小部件应用
一步一步创建我们的简单应用
了解了重要的小部件后,我们将创建一个使用多个小部件的简单应用。
为了简单起见,我们将尝试使用 Streamlit 可视化我们的足球数据。借助上述小部件,这相当简单。
import streamlit as st
import pandas as pd
import numpy as npdf = pd.read_csv("football_data.csv")clubs = st.multiselect('Show Player for clubs?', df['Club'].unique())nationalities = st.multiselect('Show Player from Nationalities?', df['Nationality'].unique())# Filter dataframe
new_df = df[(df['Club'].isin(clubs)) & (df['Nationality'].isin(nationalities))]# write dataframe to screen
st.write(new_df)
我们的简单应用程序看起来像:
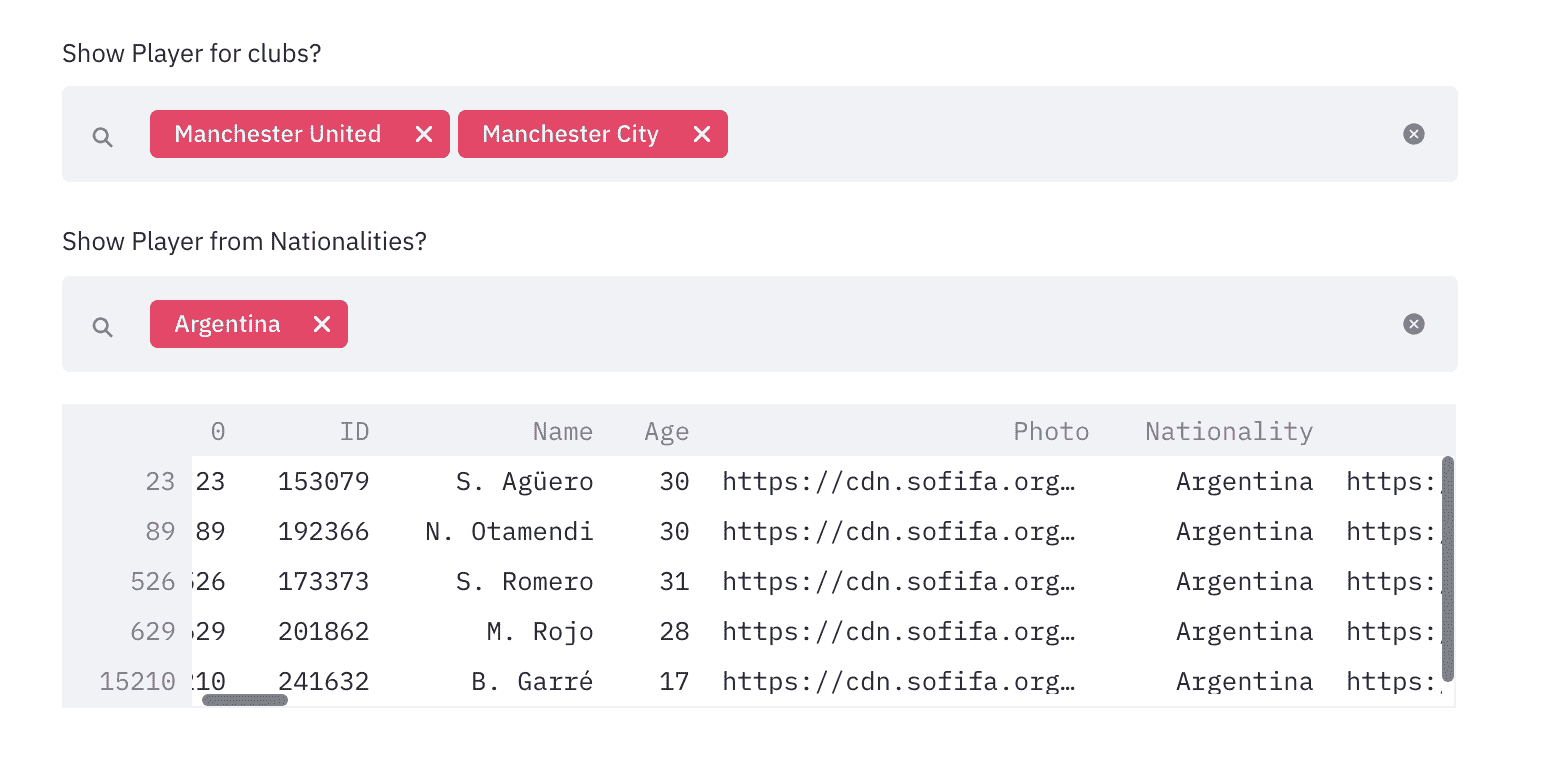
使用多个小部件联合使用
这很简单。但现在看起来相当基础。我们可以添加一些图表吗?
Streamlit 当前支持许多绘图库。Plotly、Bokeh、Matplotlib、Altair 和 Vega 图表 都是其中的一部分。Plotly Express 也可以使用,尽管文档中没有明确说明。它还有一些对 Streamlit 来说是“原生”的内置图表类型,如 st.line_chart 和 st.area_chart。
我们将使用 plotly_express。这是我们简单应用程序的代码。我们仅使用了四个对 Streamlit 的调用,其余部分都是简单的 Python。
import streamlit as st
import pandas as pd
import numpy as np
import plotly_express as pxdf = pd.read_csv("football_data.csv")clubs = st.multiselect('Show Player for clubs?', df['Club'].unique())
nationalities = st.multiselect('Show Player from Nationalities?', df['Nationality'].unique())new_df = df[(df['Club'].isin(clubs)) & (df['Nationality'].isin(nationalities))]
st.write(new_df)# create figure using plotly express
fig = px.scatter(new_df, x ='Overall',y='Age',color='Name')# Plot!
st.plotly_chart(fig)
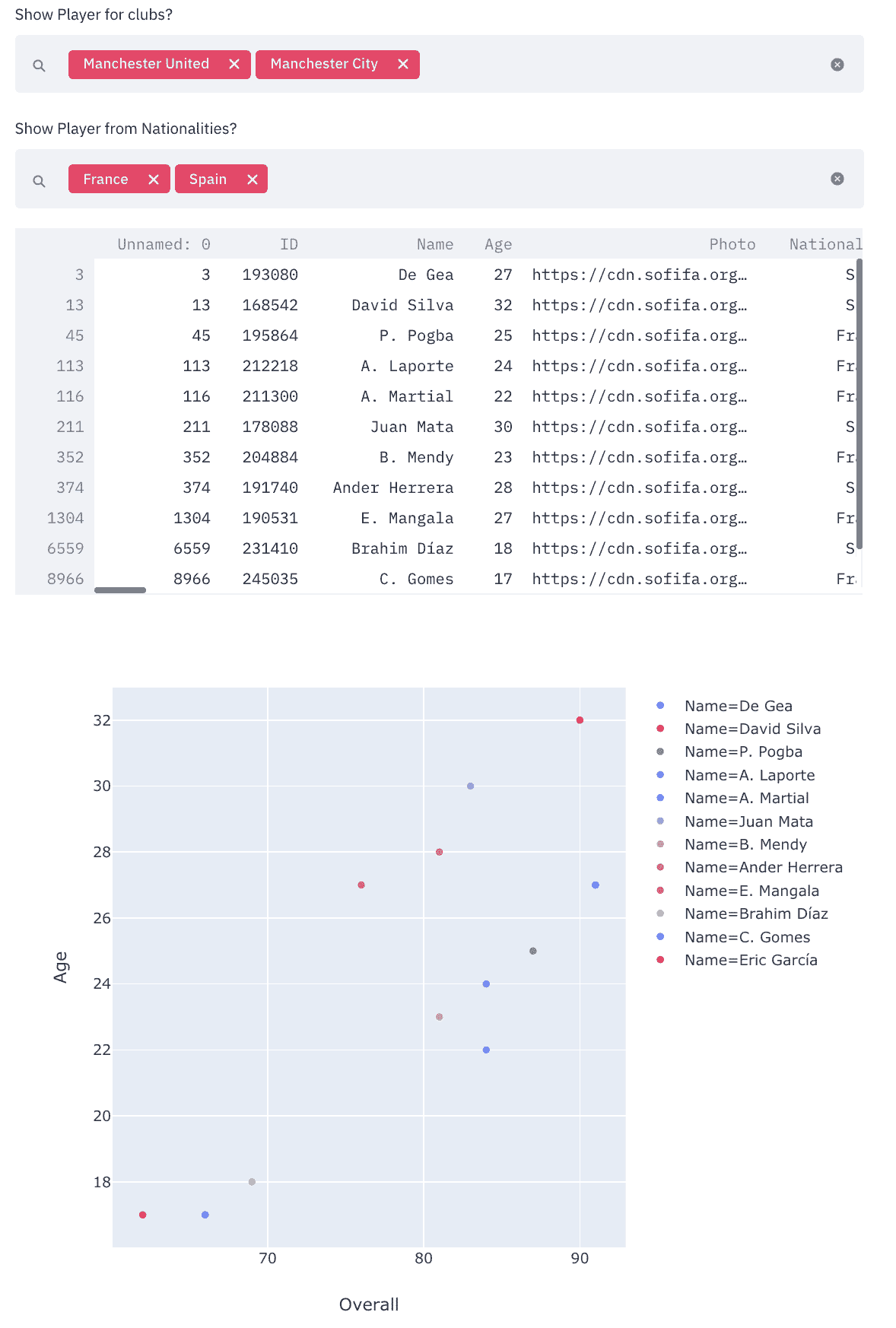
添加图表
改进
一开始我们说每次更改任何小部件时,整个应用程序都会从头到尾运行。当我们创建将服务于深度学习模型或复杂机器学习模型的应用程序时,这并不可行。Streamlit 在这方面通过引入 缓存 来解决了这个问题。
1. 缓存
在我们的简单应用程序中,每当值发生变化时,我们都会一遍又一遍地读取 pandas 数据框。虽然这适用于我们拥有的小数据,但对于大数据或需要大量数据处理的情况,它将不起作用。让我们像下面这样使用 Streamlit 的 st.cache 装饰器函数来使用缓存。
import streamlit as st
import pandas as pd
import numpy as np
import plotly_express as pxdf = st.cache(pd.read_csv)("football_data.csv")
对于更复杂且耗时的函数,只需运行一次,可以使用:
@st.cache
def complex_func(a,b):
DO SOMETHING COMPLEX# Won't run again and again.
complex_func(a,b)
当我们用 Streamlit 的缓存装饰器标记一个函数时,每当函数被调用时,Streamlit 会检查你调用函数时使用的输入参数。
如果这是 Streamlit 第一次看到这些参数,它会运行函数并将结果存储在本地缓存中。
当下次调用函数时,如果那些参数没有改变,Streamlit 知道可以跳过执行函数。它只是使用缓存中的结果。
2. 侧边栏
根据你的偏好,为了更干净的外观,你可能希望将小部件移到侧边栏中,就像 Rshiny 仪表板那样。这很简单。只需在你的小部件代码中添加 ***st.sidebar*** 即可。
import streamlit as st
import pandas as pd
import numpy as np
import plotly_express as pxdf = st.cache(pd.read_csv)("football_data.csv")clubs = st.sidebar.multiselect('Show Player for clubs?', df['Club'].unique())
nationalities = st.sidebar.multiselect('Show Player from Nationalities?', df['Nationality'].unique())new_df = df[(df['Club'].isin(clubs)) & (df['Nationality'].isin(nationalities))]
st.write(new_df)# Create distplot with custom bin_size
fig = px.scatter(new_df, x ='Overall',y='Age',color='Name')# Plot!
st.plotly_chart(fig)
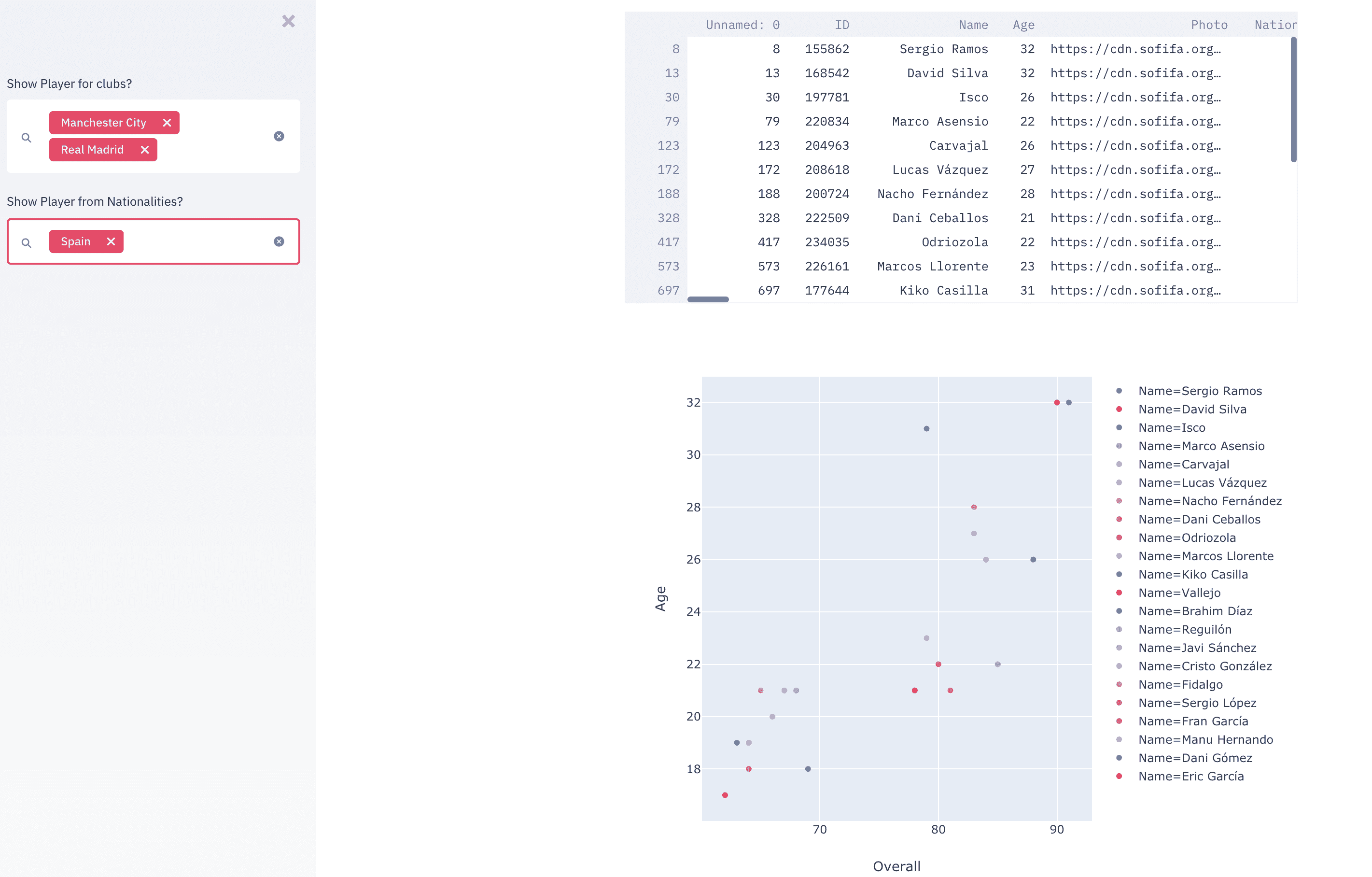
将小部件移动到侧边栏
3. Markdown?
我喜欢用 Markdown 编写。我发现它比 HTML 更简洁,更适合数据科学工作。那么,我们可以在 Streamlit 应用程序中使用 Markdown 吗?
是的,我们可以。有几种方法可以做到这一点。在我看来,最好的方法是使用 Magic commands。Magic commands 允许你像编写注释一样轻松地编写 Markdown。你也可以使用 st.markdown 命令。
import streamlit as st
import pandas as pd
import numpy as np
import plotly_express as px'''
# Club and Nationality AppThis very simple webapp allows you to select and visualize players from certain clubs and certain nationalities.
'''
df = st.cache(pd.read_csv)("football_data.csv")clubs = st.sidebar.multiselect('Show Player for clubs?', df['Club'].unique())
nationalities = st.sidebar.multiselect('Show Player from Nationalities?', df['Nationality'].unique())new_df = df[(df['Club'].isin(clubs)) & (df['Nationality'].isin(nationalities))]
st.write(new_df)# Create distplot with custom bin_size
fig = px.scatter(new_df, x ='Overall',y='Age',color='Name')'''
### Here is a simple chart between player age and overall
'''st.plotly_chart(fig)

我们的最终应用演示
结论
Streamlit 已经使创建应用程序的整个过程变得更加普及,我非常推荐它。
在这篇文章中,我们创建了一个简单的网页应用。但可能性是无穷的。举个例子,这里是来自 Streamlit 网站的面部 GAN。它通过使用相同的部件和缓存指导思想来工作。
我喜欢开发者使用的默认颜色和样式,比我之前用于演示的 Dash 更加舒适。你还可以在你的 Streamlit 应用中加入音频和视频。
此外,Streamlit 是一个免费的开源工具,而不是一个开箱即用的专有网页应用。
以前,每次在演示或展示中做出任何修改时,我都不得不联系我的开发者朋友;现在,这些修改相对而言非常简单。
我计划从现在起在我的工作流程中更多地使用它,考虑到它提供的功能而无需费心劳作,我认为你也应该这样做。
我还不确定它在生产环境中表现如何,但对于小型概念验证项目和演示来说,这简直是一个福音。我计划从现在起在我的工作流程中更多地使用它,考虑到它提供的功能而无需费心劳作,我认为你也应该这样做。
你可以在这里找到最终应用的完整代码。
如果你想了解创建可视化的最佳策略,我推荐一门来自密歇根大学的优秀课程,数据可视化与应用绘图,这也是一个非常不错的Python 数据科学专业课程的一部分。请务必查看一下。
感谢阅读。我还会在未来写更多适合初学者的文章。可以在Medium关注我,或订阅我的博客以获取最新信息。和往常一样,我欢迎反馈和建设性的批评,可以通过 Twitter @mlwhiz 联系我。
另外,一个小的免责声明——这篇文章中可能包含一些相关资源的附属链接,因为分享知识从来不是坏主意。
个人简介:Rahul Agarwal 是 Walmart Labs 的数据科学家。
原文。经许可转载。
相关:
-
数据科学家的 6 条建议
-
Kaggle 的优质特征构建技巧和窍门
-
数据科学家应该知道的 5 个图算法
更多相关内容
使用 Keras 编写不到 30 行代码的第一个神经网络
原文:
www.kdnuggets.com/2019/10/writing-first-neural-net-less-30-lines-code-keras.html
评论
作者 David Gündisch,云架构师

回忆起我刚开始探索人工智能的旅程时,我记得有些概念看起来是多么令人畏惧。阅读关于神经网络是什么的简单解释,很快就会引导你进入一篇每第二句都是你从未见过的符号的科学论文。虽然这些论文包含了不可思议的见解和深度,帮助你建立专业知识,但编写第一个神经网络比听起来要简单得多!
好吧……但什么是神经网络呢???
好问题!在我们开始编写自己的简单神经网络(简称 NN)的 Python 实现之前,我们应该先了解它们是什么,以及它们为什么如此令人兴奋!

HNC Software 联合创始人 Robert Hecht-Nielsen 博士简单地阐述了这一点。
*“…一个由若干简单的、高度互联的处理元素组成的计算系统,通过对外部输入的动态状态响应来处理信息。 — *《神经网络入门:第一部分》,Maureen Caudill,人工智能专家,1989 年 2 月
实质上,神经网络是一组数学表达式,它们非常擅长识别信息或数据中的模式。神经网络通过一种模拟人类感知的方式实现这一点,但与人类通过视觉识别图像不同,神经网络将这些信息以数值形式包含在向量或标量中(一个仅包含一个数字的向量)。
神经网络将信息通过各层传递,其中一层的输出作为下一层的输入。在这些层中,输入通过权重和偏置进行修改,并送入激活函数以映射输出。然后,通过成本函数进行学习,该函数比较实际输出和期望输出,从而帮助函数通过反向传播过程调整权重和偏置,以最小化成本。
我强烈建议你观看下面的视频,以获得深入且直观的解释。
3Blue1Brown 关于神经网络的视频
在我们的示例神经网络实现中,我们将使用 MNIST 数据集。
MNIST 示例数据集
MNIST 可以被视为“Hello World”数据集,因为它能够简洁地展示神经网络的能力。该数据集由手写数字组成,我们将训练我们的神经网络来识别和分类这些数字。
进入 Keras
为了便利实现,我们将使用 Keras 框架。Keras 是一个用 Python 编写的高级 API,运行在流行的框架如 TensorFlow、Theano 等之上,提供了一个抽象层,以减少编写神经网络的固有复杂性。
我鼓励你深入了解 Keras 的 文档,以真正熟悉 API。此外,我强烈推荐 Francois Chollet 的 Deep Learning with Python 一书,这本书启发了本教程。
是时候烧掉一些 GPU 了。
对于本教程,我们将使用带有 TensorFlow 后端的 Keras,因此如果你还没有安装这两个工具,现在是一个好时机。你可以通过在终端中运行这些命令来完成这一安装。当你超越简单的入门示例时,最好设置你的 Anaconda 环境,并用 conda 安装下面的内容。
pip3 install Keras
pip3 install Tensorflow
现在你已经安装了所有工具,打开你最喜欢的 IDE,让我们开始导入所需的 Python 模块吧!
from keras.datasets import mnist
from keras import models
from keras import layers
from keras.utils import to_categorical
Keras 有许多数据集可以帮助你学习,幸运的是,MNIST 是其中之一!模型和层都是帮助我们构建神经网络的模块,而 to_categorical 用于数据编码……但稍后会详细介绍!
现在我们已经导入了所需的模块,我们需要将数据集拆分为训练集和测试集。这可以通过以下几行代码简单完成。
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
在这个示例中,我们的神经网络通过将输出与标记数据进行比较来学习。你可以把它想象成让神经网络猜测大量手写数字,然后将猜测与实际标签进行比较。这一结果将决定模型如何调整其权重和偏差,以最小化总体成本。
在设置了训练和测试数据集之后,我们现在准备构建我们的模型。
network = models.Sequential()
network.add(layers.Dense(784, activation='relu', input_shape=(28 * 28,)))
network.add(layers.Dense(784, activation='relu', input_shape=(28 * 28,)))network.add(layers.Dense(10, activation='softmax'))network.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
我知道……我知道……这可能看起来很多,但让我们一起拆解它!我们初始化一个名为 network 的顺序模型。
network = models.Sequential()
然后我们添加我们的神经网络层。在这个示例中,我们将使用密集层。密集层意味着每个神经元都从前一层的所有神经元接收输入。[784] 和 [10] 代表输出空间的维度,我们可以将其视为后续层的输入数量,由于我们正在尝试解决一个有 10 个可能类别(数字 0 到 9)的分类问题,因此最终层有 10 个单元的潜在输出。激活参数指我们想使用的激活函数,本质上,激活函数基于给定的输入计算输出。最后,[28 * 28] 的输入形状指的是图像的像素宽度和高度。
network.add(layers.Dense(784, activation='relu', input_shape=(28 * 28,)))
network.add(layers.Dense(784, activation='relu', input_shape=(28 * 28,)))
network.add(layers.Dense(10, activation='softmax'))
一旦我们的模型定义完毕,并且我们添加了神经网络层,我们只需使用选择的优化器、选择的损失函数和评估指标来编译模型。
network.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
恭喜!!!你刚刚构建了第一个神经网络!!
现在你可能还有一些问题,例如;什么是 relu 和 softmax?还有,谁是 adam?这些都是有效的问题……这些问题的深入解释稍微超出了我们最初进入神经网络的范围,但我们会在后续的文章中进行讲解。
在将数据输入到新创建的模型之前,我们需要将输入数据重新调整为模型可以读取的格式。我们输入数据的原始形状是[60000, 28, 28],这本质上表示 60000 张像素高度和宽度为 28 x 28 的图像。我们可以重新调整数据形状,并将其分为训练用的[60000]张图像和测试用的[10000]张图像。
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype('float32') / 255
除了重新调整数据外,我们还需要对其进行编码。在这个示例中,我们将使用分类编码,本质上将多个特征转化为数值表示。
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
由于我们的数据集被分为训练集和测试集,模型已经编译,并且数据已经重新调整和编码,我们现在准备训练神经网络!为此,我们将调用fit函数,并传入所需的参数。
network.fit(train_images, train_labels, epochs=5, batch_size=128)
我们传入训练图像及其标签,以及 epoch,这决定了前向传播和反向传播的次数,还有 batch_size,这表示每次前向/反向传播的训练样本数量。
我们还需要设置性能测量参数,以便识别模型的表现如何。
test_loss, test_acc = network.evaluate(test_images, test_labels)
print('test_acc:', test_acc, 'test_loss', test_loss)
然后,瞧!!!你刚刚编写了自己的神经网络,重新调整和编码了数据集,并使模型进行训练!当你第一次运行 Python 脚本时,Keras 将下载 MNIST 数据集并开始训练 5 个周期!
训练周期与测试输出
对于你的测试准确率,你应该得到大约 98%的准确度,这意味着模型在测试时 98%的情况下预测了正确的数字,对于你的第一个神经网络来说,这并不差!实际上,你还需要查看测试和训练结果,以便更好地判断你的模型是否过拟合/欠拟合。
我鼓励你尝试调整层数、优化器和损失函数,以及 epoch 和 batch_size,以查看每个因素对模型整体性能的影响!
你刚刚迈出了在漫长而激动人心的学习旅程中的困难第一步!如果需要任何额外的澄清或反馈,请随时联系!
感谢阅读——保持好奇!????
Bio: David Gündisch 是一位云架构师。他对研究人工智能在哲学、心理学和网络安全领域的应用充满热情。
原文。经许可转载。
相关内容:
-
人工神经网络简介
-
温和介绍 PyTorch 1.2
-
TensorFlow 与 PyTorch 与 Keras 在自然语言处理中的对比
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
正则化是什么以及有什么用?
原文:
www.kdnuggets.com/wtf-is-regularization-and-what-is-it-for

“预防胜于治疗”这句古老的谚语提醒我们,防止问题发生比在问题发生后修复更容易。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 部门
在人工智能(AI)时代,这句谚语强调了通过正则化等技术避免潜在陷阱(如过拟合)的重要性。
在这篇文章中,我们将从正则化的基本原理入手,探讨其在 Sci-kit Learn(机器学习)和 Tensorflow(深度学习)中的应用,并通过比较这些结果来见证其在真实数据集上的变革性力量。让我们开始吧!
什么是正则化?
正则化是机器学习和深度学习中的一个关键概念,旨在防止模型过拟合。
过拟合发生在模型对训练数据学习得过于充分时。这种情况表明你的模型好得令人难以置信。
让我们看看过拟合的表现。
正则化技术调整学习过程,以简化模型,确保其在训练数据上表现良好,并且能够很好地泛化到新数据。我们将探讨两种著名的方法。
正则化类型
在机器学习中,正则化通常应用于线性模型,如线性回归和逻辑回归。在这种情况下,最常见的正则化形式是:
-
L1 正则化(Lasso 回归)
-
L2 正则化(岭回归)
Lasso 正则化通过允许某些系数值为零,鼓励模型只使用最重要的特征,这对特征选择特别有用。
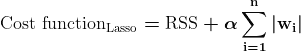
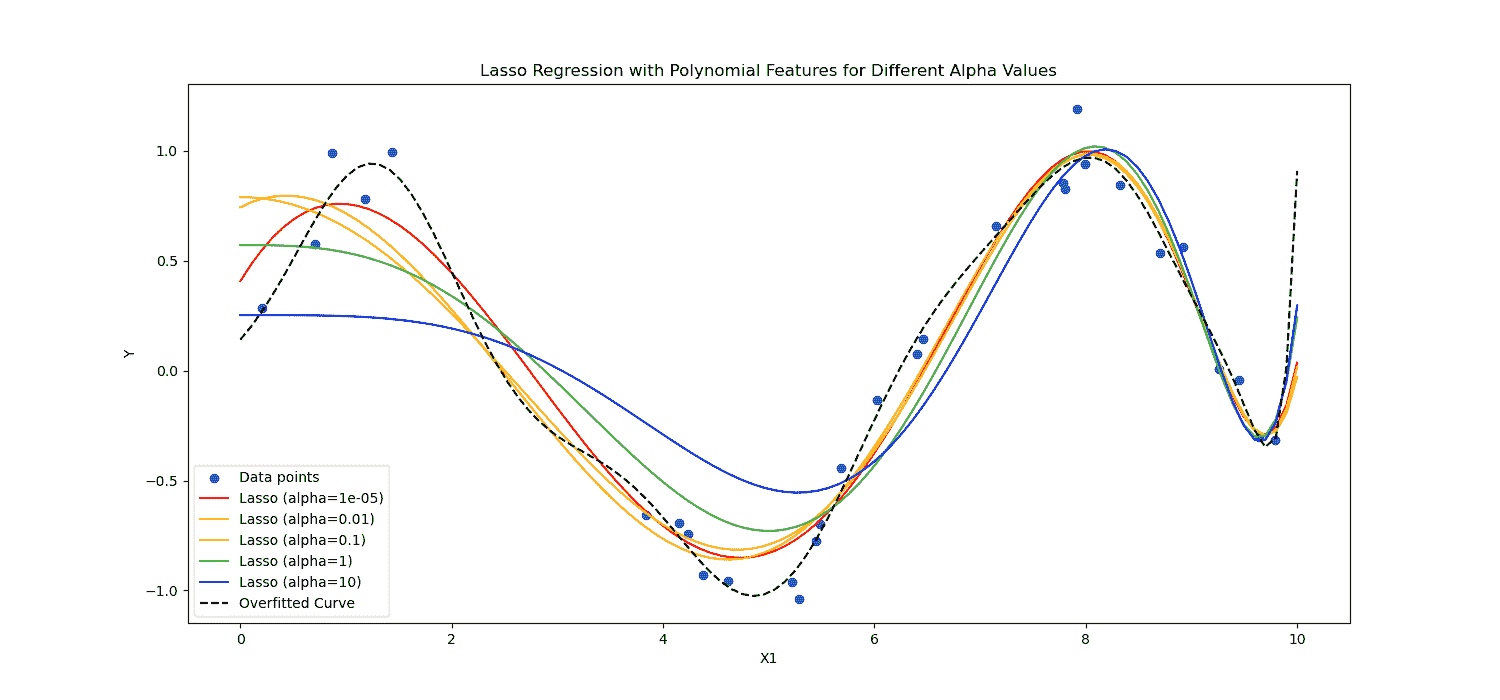
另一方面,岭回归正则化通过惩罚系数值的平方来抑制显著系数。
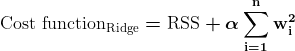
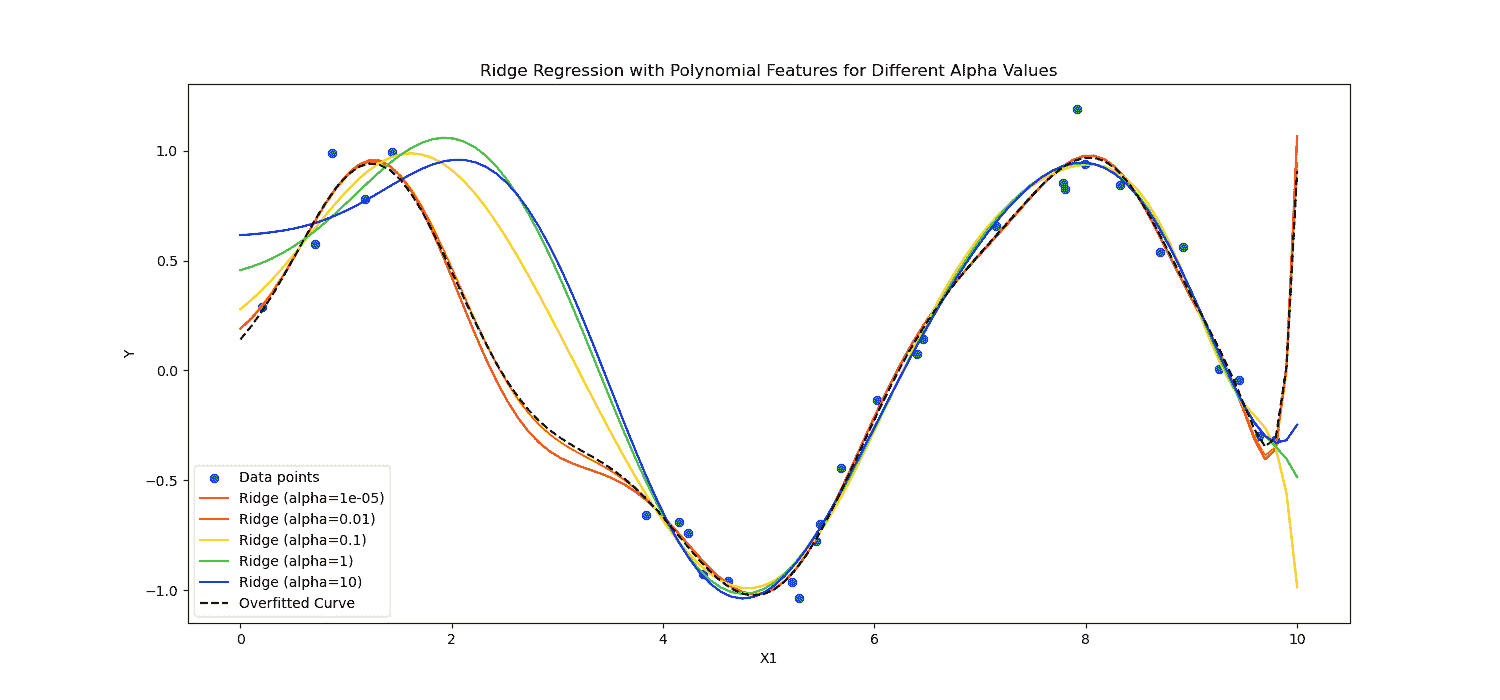
简而言之,它们的计算方式不同。
让我们将这些应用于心脏病患者数据,以查看其在深度学习和机器学习中的效果。
正则化的力量:分析心脏病患者数据
现在,我们将应用正则化来分析心脏病患者数据,以展示正则化的效果。你可以从这里获取数据集。
为了应用机器学习,我们将使用 Scikit-learn;为了应用深度学习,我们将使用 TensorFlow。开始吧!
机器学习中的正则化
Scikit-learn 是最受欢迎的Python 库之一,提供简单高效的数据分析和建模工具。
它包括了各种正则化技术的实现,特别是针对线性模型。
在这里,我们将探讨如何应用 L1(Lasso)和 L2(Ridge)正则化。
在下面的代码中,我们将使用 Ridge(L2)和 Lasso(L1)正则化技术训练逻辑回归。最后,我们将看到详细的报告。让我们看一下代码。
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# Assuming heart_data is already loaded
X = heart_data.drop('target', axis=1)
y = heart_data['target']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Standardize the features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Define regularization values to explore
regularization_values = [0.001, 0.01, 0.1]
# Placeholder for storing performance metrics
performance_metrics = []
# Iterate over regularization values for L1 and L2
for C_value in regularization_values:
# Train and evaluate L1 model
log_reg_l1 = LogisticRegression(penalty='l1', C=C_value, solver='liblinear')
log_reg_l1.fit(X_train_scaled, y_train)
y_pred_l1 = log_reg_l1.predict(X_test_scaled)
accuracy_l1 = accuracy_score(y_test, y_pred_l1)
report_l1 = classification_report(y_test, y_pred_l1)
performance_metrics.append(('L1', C_value, accuracy_l1))
# Train and evaluate L2 model
log_reg_l2 = LogisticRegression(penalty='l2', C=C_value, solver='liblinear')
log_reg_l2.fit(X_train_scaled, y_train)
y_pred_l2 = log_reg_l2.predict(X_test_scaled)
accuracy_l2 = accuracy_score(y_test, y_pred_l2)
report_l2 = classification_report(y_test, y_pred_l2)
performance_metrics.append(('L2', C_value, accuracy_l2))
# Print the performance metrics for all models
print("Model Performance Evaluation:")
print("--------------------------------")
for metric in performance_metrics:
reg_type, C_value, accuracy = metric
print(f"Regularization: {reg_type}, C: {C_value}, Accuracy: {accuracy:.2f}")
这是输出结果。

让我们评估结果。
L1 正则化
-
在 C=0.001 时,准确率显著较低(48%)。这表明模型存在欠拟合,正则化过强。
-
随着 C 增加到 0.01,L1 的准确率保持不变,这表明模型仍然存在欠拟合或正则化过强。
-
在 C=0.1 时,准确率显著提高至 87%,这表明减少正则化强度使模型能够更好地从数据中学习。
L2 正则化
总的来说,L2 正则化表现一致良好,C=0.001 时准确率为 87%,C=0.01 时略微提高至 89%,然后在 C=0.1 时稳定在 87%。
这表明 L2 正则化通常在逻辑回归模型中对这个数据集更宽容、更有效,可能与其性质有关。
深度学习中的正则化
深度学习中使用了几种正则化技术,包括 L1(Lasso)和 L2(Ridge)正则化、丢弃法和提前停止。
在这里,为了重复之前机器学习示例中的操作,我们将应用 L1 和 L2 正则化。这次让我们定义一系列 L1 和 L2 正则化值。
然后,对于所有这些值,我们将训练和评估我们的深度学习模型,并在最后评估结果。
让我们看一下代码。
from tensorflow.keras.regularizers import l1_l2
import numpy as np
# Define a list/grid of L1 and L2 regularization values
l1_values = [0.001, 0.01, 0.1]
l2_values = [0.001, 0.01, 0.1]
# Placeholder for storing performance metrics
performance_metrics = []
# Iterate over all combinations of L1 and L2 values
for l1_val in l1_values:
for l2_val in l2_values:
# Define model with the current combination of L1 and L2
model = Sequential([
Dense(128, activation='relu', input_shape=(X_train_scaled.shape[1],), kernel_regularizer=l1_l2(l1=l1_val, l2=l2_val)),
Dropout(0.5),
Dense(64, activation='relu', kernel_regularizer=l1_l2(l1=l1_val, l2=l2_val)),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
history = model.fit(X_train_scaled, y_train, validation_split=0.2, epochs=100, batch_size=10, verbose=0)
# Evaluate the model
loss, accuracy = model.evaluate(X_test_scaled, y_test, verbose=0)
# Store the performance along with the regularization values
performance_metrics.append((l1_val, l2_val, accuracy))
# Find the best performing model
best_performance = max(performance_metrics, key=lambda x: x[2])
best_l1, best_l2, best_accuracy = best_performance
# After the loop, to print all performance metrics
print("All Model Performances:")
print("L1 Value | L2 Value | Accuracy")
for metrics in performance_metrics:
print(f"{metrics[0]:<8} | {metrics[1]:<8} | {metrics[2]:.3f}")
# After finding the best performance, to print the best model details
print("\nBest Model Performance:")
print("----------------------------")
print(f"Best L1 value: {best_l1}")
print(f"Best L2 value: {best_l2}")
print(f"Best accuracy: {best_accuracy:.3f}")
这是输出结果。
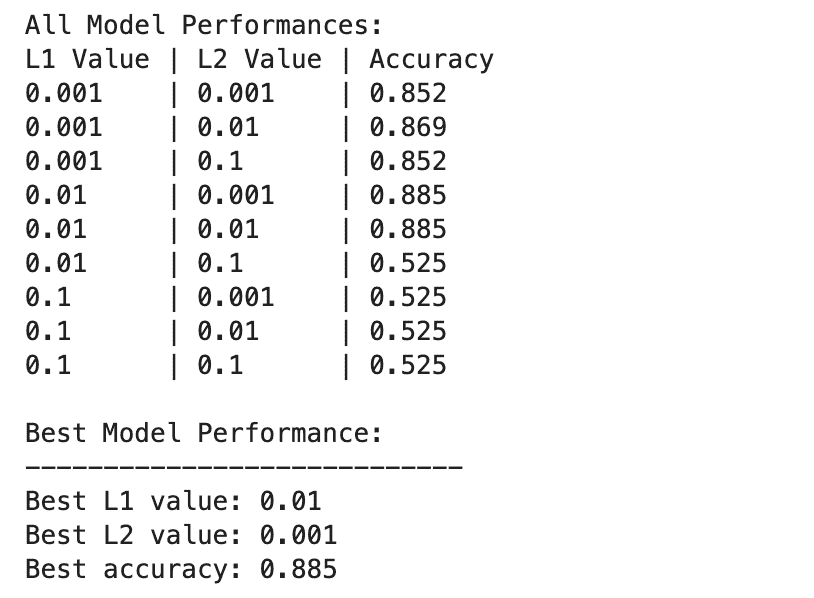
深度学习模型的性能在不同的 L1 和 L2 正则化值组合下差异较大。
最佳性能出现在 L1=0.01 和 L2=0.001 时,准确率为 88.5%,这表明平衡的正则化防止了过拟合,同时允许模型捕捉数据中的潜在模式。
较高的正则化值,特别是在 L1=0.1 或 L2=0.1 时,会大幅降低模型准确性到 52.5%,这表明过度正则化严重限制了模型的学习能力。
机器学习与深度学习中的正则化
让我们比较一下机器学习和深度学习之间的结果。
正则化的有效性:在机器学习和深度学习的背景下,适当的正则化有助于减轻过拟合,但过度正则化会导致欠拟合。最佳正则化强度因情况而异,深度学习模型可能由于其更高的复杂性需要更细致的平衡。
性能: 表现最佳的机器学习模型(L2 与 C=0.01,89%准确率)和表现最佳的深度学习模型(L1=0.01,L2=0.001,88.5%准确率)达到了类似的准确性,证明了两种方法都可以有效正则化,以在该数据集上实现高性能。
正则化策略: L2 正则化在逻辑回归模型中似乎更有效且对 C 的选择不那么敏感,而 L1 和 L2 正则化的组合在深度学习中提供了最佳结果,提供了特征选择和权重惩罚之间的平衡。
正则化的选择和强度应谨慎调整,以平衡学习复杂性与过拟合或欠拟合的风险。
结论
在这一探索过程中,我们揭示了正则化的神秘面纱,展示了它在防止过拟合和确保我们的模型能良好泛化到未见数据中的作用。
应用正则化技术将使你更接近机器学习和深度学习的精通,巩固你的数据科学家工具包。
进入数据项目,尝试在不同场景中对数据进行正则化,例如交付时间预测。我们在这个数据项目中使用了机器学习和深度学习模型。然而,最后我们也提到可能还有改进的空间。那么,为什么不在那里尝试正则化,看看是否有帮助呢?
内特·罗斯迪是一位数据科学家和产品策略专家。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过顶级公司真实面试问题准备面试。内特撰写关于职业市场的最新趋势,提供面试建议,分享数据科学项目,并涵盖所有 SQL 内容。
相关主题
GBM 和 XGBoost 之间的区别是什么?
原文:
www.kdnuggets.com/wtf-is-the-difference-between-gbm-and-xgboost

我相信每个人都知道 GBM 和 XGBoost 这两个算法。它们是许多实际应用和竞赛中的首选算法,因为它们的度量输出通常优于其他模型。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
对于那些不了解 GBM 和 XGBoost 的人,GBM(梯度提升机)和 XGBoost(极端梯度提升)是集成学习方法。集成学习是一种机器学习技术,通过训练和组合多个“弱”模型(通常是决策树)来实现进一步的目的。
该算法基于其名称所示的集成学习提升技术。提升技术是一种方法,试图顺序地结合多个弱学习器,每一个都修正其前任。每个学习器都会从之前的错误中学习并纠正前一个模型的错误。
这就是 GBM 和 XGB 之间的基本相似之处,但差异如何呢?我们将在本文中讨论这一点,让我们深入了解一下吧。
GBM(梯度提升机)
如上所述,GBM 基于提升方法,尝试通过顺序迭代弱学习器以从错误中学习并开发出一个稳健的模型。GBM 通过使用梯度下降法来最小化损失函数,从而在每次迭代中开发出更好的模型。梯度下降是一个在每次迭代中寻找最小函数(例如损失函数)的概念。迭代将持续进行,直到达到停止标准。
关于 GBM 的概念,你可以在下图中查看。
GBM 模型概念(Chhetri et al. (2022))
你可以在上面的图像中看到,对于每次迭代,模型试图最小化损失函数并从之前的错误中学习。最终模型将是所有弱学习器的总和,汇总了模型的所有预测。
XGB(eXtreme Gradient Boosting)及其与 GBM 的不同
XGBoost 或 eXtreme Gradient Boosting 是一种基于梯度提升算法的机器学习算法,由 Tiangqi Chen 和 Carlos Guestrin 于 2016 年开发。从基本层面来看,该算法仍遵循一种顺序策略,以基于梯度下降改进下一个模型。然而,XGBoost 的一些差异使其在性能和速度方面成为最优秀的模型之一。
1. 正则化
正则化是一种机器学习技术,用于避免过拟合。它是一组约束模型过度复杂化并具有差劲泛化能力的方法。由于许多模型对训练数据的拟合过好,正则化成为了一种重要的技术。
GBM 的算法中没有实现正则化,这使得算法只关注于达到最小损失函数。与 GBM 相比,XGBoost 实施了正则化方法来惩罚过拟合的模型。
XGBoost 可以应用两种正则化:L1 正则化(Lasso)和 L2 正则化(Ridge)。L1 正则化试图将特征权重或系数最小化为零(有效地进行特征选择),而 L2 正则化则试图均匀缩小系数(帮助处理多重共线性)。通过实施这两种正则化,XGBoost 可以比 GBM 更好地避免过拟合。
2. 并行化
GBM 的训练时间通常比 XGBoost 慢,因为后者在训练过程中实现了并行化。尽管提升技术可能是顺序的,但并行化仍然可以在 XGBoost 过程中进行。
并行化旨在加速树构建过程,主要是在拆分事件期间。通过利用所有可用的处理核心,XGBoost 的训练时间可以缩短。
说到加速 XGBoost 过程,开发者还将数据预处理为他们开发的数据格式 DMatrix,以提高内存效率和训练速度。
3. 缺失数据处理
我们的训练数据集可能包含缺失数据,我们必须在将其传递给算法之前明确处理。然而,XGBoost 具有内置的缺失数据处理器,而 GBM 没有。
XGBoost 实现了处理缺失数据的技术,称为“感知稀疏拆分”。对于 XGBoost 遇到的任何稀疏数据(缺失数据、密集零值、OHE),模型会从这些数据中学习,并找到最优的拆分点。模型会在拆分过程中确定缺失数据应放置的位置,并查看哪个方向可以最小化损失。
4. 树修剪
GBM 的增长策略是在算法达到负损失时停止分裂。这个策略可能导致次优结果,因为它仅基于局部优化,可能忽视了整体情况。
XGBoost 试图避免 GBM 策略,继续增长树直到设置参数最大深度开始向后剪枝。负损失的分裂会被剪枝,但在某些情况下,负损失分裂未被移除。当分裂达到负损失,但进一步分裂为正时,如果总体分裂为正,仍会保留该分裂。
5. 内置交叉验证
交叉验证是一种评估模型泛化能力和鲁棒性的技术,通过在多个迭代过程中系统地拆分数据来实现。综合结果将显示模型是否过拟合。
通常,机器算法需要外部帮助来实现交叉验证,但 XGBoost 具有内置的交叉验证,可以在训练过程中使用。交叉验证将在每次提升迭代中执行,并确保生成的树是鲁棒的。
结论
GBM 和 XGBoost 是许多实际案例和竞赛中的热门算法。从概念上讲,这两者都是使用弱学习器来实现更好模型的提升算法。然而,它们在算法实现上有一些差异。XGBoost 通过嵌入正则化、执行并行化、改进缺失数据处理、不同的树剪枝策略以及内置交叉验证技术来增强算法。
Cornellius Yudha Wijaya是一名数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 期间,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 在各种 AI 和机器学习话题上撰写文章。
更多相关话题
XGBoost 算法:愿她长久统治
评论
由 Vishal Morde 和 Anurag Setty 合著

照片由 Jared Subia 提供,来源于 Unsplash
(本文与 Venkat Anurag Setty 共同撰写)
我仍然记得十五年前我第一份工作的第一天。我刚刚完成研究生学业,加入了一家全球投资银行担任分析师。在第一天,我不断整理领带,试图记住我学过的所有东西。与此同时,我深深地怀疑自己是否足够适合企业世界。感受到我的焦虑,我的老板微笑着说:
“别担心!你唯一需要知道的就是回归建模!”
我记得当时我在想,“我搞定了!”我了解回归建模,包括线性回归和逻辑回归。我的老板说得对。在我的任期内,我专注于构建基于回归的统计模型。我不是唯一的。事实上,那时回归建模是预测分析领域的无可争议的女王。快进十五年,回归建模的时代已经结束。老女王已逝,新女王以一个独特的名字登场;XGBoost 或极端梯度提升!
XGBoost 是什么?
XGBoost 是一种基于决策树的集成机器学习算法,使用了 梯度提升 框架。在涉及非结构化数据(如图像、文本等)的预测问题中,人工神经网络通常优于所有其他算法或框架。然而,当涉及到小到中型的结构化/表格数据时,基于决策树的算法目前被认为是最优的。请参见下面的图表,了解决策树算法的演变过程。
XGBoost 算法从决策树的演变
XGBoost 算法是华盛顿大学的一个研究项目。Tianqi Chen and Carlos Guestrin 在 2016 年的 SIGKDD 会议上展示了他们的论文,引起了机器学习界的广泛关注。自引入以来,该算法不仅因赢得众多 Kaggle 比赛而受到赞誉,还因在多个前沿行业应用中作为核心驱动力而广泛使用。因此,XGBoost 开源项目拥有一个强大的数据科学家社区,有约 350 位贡献者和约 3,600 次提交,分布在 GitHub 上。该算法在以下方面有所不同:
-
广泛的应用范围:可用于解决回归、分类、排序和用户定义的预测问题。
-
可移植性:在 Windows、Linux 和 OS X 上运行流畅。
-
语言:支持包括 C++、Python、R、Java、Scala 和 Julia 在内的所有主要编程语言。
-
云集成:支持 AWS、Azure 和 Yarn 集群,并与 Flink、Spark 和其他生态系统良好兼容。
如何建立对 XGBoost 的直觉?
决策树在最简单的形式下,易于可视化且相当可解释,但为下一代基于树的算法建立直觉可能有些棘手。请参见下面的简单类比,以更好地理解基于树的算法的演变。

想象一下,你是一个招聘经理,正在面试几位资格出色的候选人。基于树的算法的每一步演变都可以被视为面试过程的一个版本。
-
决策树:每个招聘经理都有一套标准,如教育水平、工作经验年限、面试表现。决策树类似于招聘经理根据他或她自己的标准面试候选人。
-
Bagging:现在想象一下,不再是一个面试官,而是一个面试小组,其中每个面试官都有一票。Bagging 或自助聚合涉及通过民主投票过程结合所有面试官的输入来做出最终决策。
-
随机森林:这是一种基于 bagging 的算法,其主要区别在于仅随机选择一部分特征。换句话说,每个面试官只会测试面试者某些随机选择的资格(例如,技术面试测试编程技能,行为面试评估非技术技能)。
-
提升:这是一种替代方法,其中每个面试官根据前一位面试官的反馈调整评估标准。这种方法通过部署更具动态的评估过程来“提升”面试过程的效率。
-
梯度提升:提升的一种特殊情况,其中通过梯度下降算法最小化错误,例如,战略咨询公司利用案例面试来筛选出不合格的候选人。
-
XGBoost:将 XGBoost 看作是“增强版”的梯度提升(它被称为‘极端梯度提升’,这是有原因的!)。它是软件和硬件优化技术的完美结合,能够在最短时间内使用较少的计算资源获得卓越的结果。
为什么 XGBoost 表现如此出色?
XGBoost 和梯度提升机(GBMs)都是集成树方法,利用梯度下降架构应用提升弱学习者(通常是CARTs)。然而,XGBoost 通过系统优化和算法增强改进了基础的 GBM 框架。
XGBoost 如何优化标准 GBM 算法
系统优化:
-
并行化:XGBoost 在构建树的过程中采用了并行化方法。这是因为用于构建基础学习者的循环具有可交换的性质;外部循环枚举树的叶节点,内部循环计算特征。这种循环嵌套限制了并行化,因为在完成内部循环(计算上更具挑战性)之前,外部循环无法开始。因此,为了提高运行时间,通过对所有实例进行全局扫描和使用并行线程进行排序,来交换循环顺序。这种切换通过抵消计算中的任何并行化开销来提高算法性能。
-
树剪枝:GBM 框架中的树分裂停止准则本质上是贪婪的,并依赖于分裂点的负损失准则。XGBoost 使用指定的‘max_depth’参数,而不是首先使用准则,并开始从后向前剪枝树。这种“深度优先”的方法显著提高了计算性能。
-
硬件优化:该算法旨在高效利用硬件资源。这通过缓存感知来实现,即在每个线程中分配内部缓冲区以存储梯度统计数据。进一步的增强措施,如“外部核心”计算,优化了可用的磁盘空间,同时处理那些无法完全载入内存的大数据帧。
算法增强:
-
正则化:它通过 LASSO (L1) 和 Ridge (L2) 正则化 来惩罚更复杂的模型,从而防止过拟合。
-
稀疏性意识:XGBoost 自然地接受输入的稀疏特征,通过自动‘学习’最佳的缺失值,依据训练损失,并更有效地处理数据中的不同类型的sparsity patterns。
-
加权分位数草图:XGBoost 采用了分布式加权分位数草图算法来有效地在加权数据集中找到最佳的分裂点。
-
交叉验证:该算法在每次迭代中都内置了cross-validation方法,这样就不需要显式地编程进行搜索,也不需要在单次运行中指定确切的提升迭代次数。
证据在哪里?
我们使用了 Scikit-learn 的‘Make_Classification’ 数据包,创建了一个包含 100 万数据点的随机样本,具有 20 个特征(2 个信息性特征和 2 个冗余特征)。我们测试了几种算法,如逻辑回归、随机森林、标准梯度提升和 XGBoost。
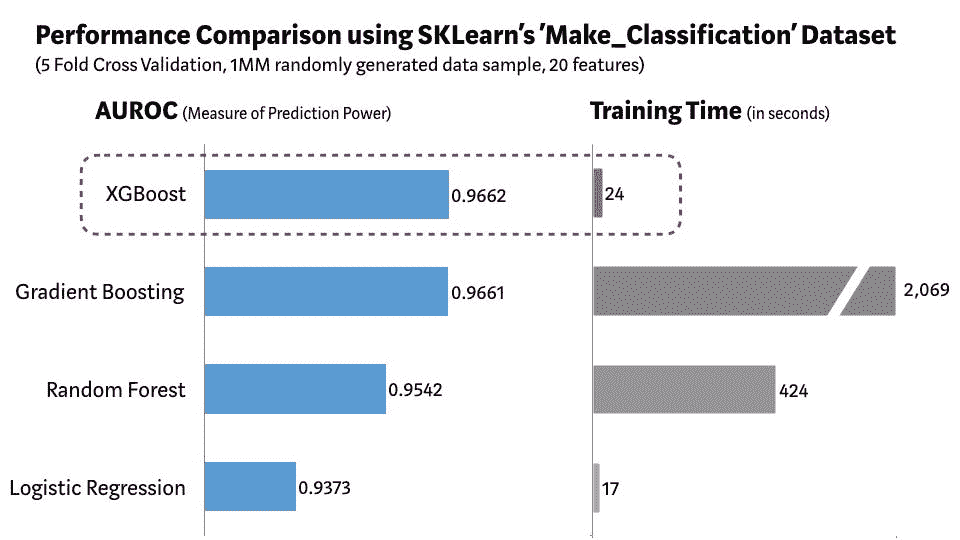
XGBoost 与其他机器学习算法在 SKLearn 的 Make_Classification 数据集上的比较
如上图所示,XGBoost 模型在预测性能和处理时间方面相比其他算法具有最佳的组合。其他严谨的基准测试研究也产生了类似的结果。难怪 XGBoost 在最近的数据科学比赛中被广泛使用。
“当有疑问时,使用 XGBoost”—欧文·张,Kaggle Avito 上的广告点击预测比赛冠军
那么我们是否应该一直使用 XGBoost?
在机器学习(甚至生活中),没有免费的午餐。作为数据科学家,我们必须测试所有可能的算法,以找出最佳算法。此外,选择正确的算法还不够。我们还必须通过调整超参数来为数据集选择正确的算法配置。此外,还有其他因素,如计算复杂性、可解释性和实现的难易程度,这些也是选择获胜算法时需要考虑的。这正是机器学习从科学向艺术转变的地方,但说实话,这也是魔法发生的地方!
未来会怎样?
机器学习是一个非常活跃的研究领域,目前已经有几个可行的替代方案来挑战 XGBoost。微软研究院最近发布了 LightGBM 框架,用于梯度提升,显示出巨大潜力。 CatBoost 由 Yandex 技术开发,已经提供了令人印象深刻的基准结果。我们何时能够拥有一个更好的模型框架来超越 XGBoost,取决于预测性能、灵活性、可解释性和实用性。然而,在强有力的挑战者出现之前,XGBoost 将继续在机器学习领域占据主导地位!
原文。已获转载许可。
个人简介: Vishal Morde 是一位经验丰富的高管和变革性领导者,在数据科学、机器学习、人工智能、大数据和战略分析方面拥有超过 15 年的渐进经验。
资源:
相关:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关话题
XGBoost: 简明技术概述
原文:
www.kdnuggets.com/2017/10/xgboost-concise-technical-overview.html
介绍
“我们的单一 XGBoost 模型可以进入前三名!我们的最终模型只是对不同随机种子的 XGBoost 模型进行平均。”
- Dmitrii Tsybulevskii & Stanislav Semenov,Avito 重复广告检测 Kaggle 比赛的获胜者。
随着整个博客专注于如何仅仅使用 XGBoost 就能提升 Kaggle 比赛中的排名,现在是时候深入探讨 XGBoost 的概念了。
Bagging 算法控制模型的高方差。然而,提升算法被认为更有效,因为它们同时处理偏差和方差(偏差-方差权衡)。
XGBoost 是梯度提升机器(GBM)的实现,用于监督学习。XGBoost 是一个开源的机器学习库,支持 Python、R、Julia、Java、C++、Scala。其突出的特点有:
-
速度
-
对稀疏数据的认识
-
单机、分布式系统及外部计算的实现
-
并行化
工作原理
要理解 XGBoost,我们必须首先理解梯度下降和梯度提升。
a) 梯度下降:
成本函数衡量预测值与实际值的接近程度。理想情况下,我们希望预测值和实际值之间的差异尽可能小。因此,我们希望将成本函数最小化。
与训练模型相关的权重使得模型预测的值接近实际值。因此,与模型相关的权重越好,预测值就越准确,成本函数也就越低。随着训练集记录的增加,权重被学习并更新。
梯度下降是一个迭代优化算法。它是一种用于最小化具有多个变量的函数的方法。因此,梯度下降可以用来最小化成本函数。它首先用初始权重运行模型,然后通过在多个迭代中更新权重来最小化成本函数。
b) 梯度提升:
提升:构建一个由弱学习器组成的集成,其中被误分类的记录被赋予更大的权重(‘提升’),以便在后续模型中正确预测它们。这些弱学习器随后被组合成一个强学习器。有许多提升算法,如 AdaBoost、梯度提升和 XGBoost。后两者是基于树的模型。图 1 展示了一个树集成模型。
图 1:树集成模型预测给定用户是否喜欢计算机游戏。+2,+0.1,-1,+0.9,-0.9 是每个叶子中的预测分数。给定用户的最终预测是每棵树的预测总和。来源
梯度提升将梯度下降和提升的原则应用于监督学习。梯度提升模型(GBM)是按顺序、串行构建的树。在 GBM 中,我们取多个模型的加权和。
-
每个新模型使用梯度下降优化来更新/修正模型需要学习的权重,以达到成本函数的局部最小值。
-
分配给每个模型的权重向量不是通过前一个模型的误分类及其导致的权重增加得出的,而是通过梯度下降优化的权重,以最小化成本函数。梯度下降的结果是模型的相同函数,只是具有更好的参数。
-
梯度提升在每一步中向现有函数添加一个新函数以预测输出。梯度提升的结果是一个完全不同的函数,因为结果是多个函数的加和。
c) XGBoost:
XGBoost 的设计旨在推动提升树计算资源的极限。XGBoost 是 GBM 的一个实现,具有显著改进。GBM 按顺序构建树,而 XGBoost 则是并行化的,这使得 XGBoost 更快。
XGBoost 的特点:
XGBoost 在分布式和内存有限的设置中都具有可扩展性。这种可扩展性归因于多个算法优化。
1. 分裂查找算法:近似算法:
要找到连续特征的最佳分裂,需要将数据排序并完全加载到内存中。如果数据集很大,这可能成为一个问题。
为此使用了一种近似算法。基于特征分布的百分位数提出候选分裂点。连续特征被分箱为基于候选分裂点的桶。通过对桶的汇总统计选择候选分裂点的最佳解决方案。
2. 并行学习的列块:
数据排序是树学习中最耗时的方面。为了减少排序成本,数据存储在称为“块”的内存单位中。每个块的数据显示列按相应的特征值排序。此计算仅需在训练前完成一次,并可在之后重复使用。
块的排序可以独立完成,并可以在 CPU 的并行线程之间分配。分裂查找可以并行化,因为对每一列的统计收集是并行进行的。
3. 用于近似树学习的加权分位数草图:
为了在加权数据集中提出候选分割点,使用了加权分位数草图算法。它对数据的分位数摘要执行合并和修剪操作。
4. 稀疏感知算法:
输入可能由于独热编码、缺失值和零值条目等原因而稀疏。XGBoost 了解数据中的稀疏模式,并仅访问每个节点中的默认方向(非缺失条目)。
5. 缓存感知访问:
为了防止在分割查找过程中出现缓存未命中并确保并行化,每个块选择 2¹⁶ 个示例。
6. 核外计算:
对于不能容纳在主内存中的数据,将数据划分为多个块,并将每个块存储在磁盘上。按列压缩每个块,并在磁盘读取时由独立线程即时解压缩。
7. 正则化学习目标:
要衡量给定一组参数下模型的性能,我们需要定义目标函数。目标函数必须始终包含两个部分:训练损失和正则化。正则化项对模型的复杂性进行惩罚。
Obj(Θ)=L(θ)+ Ω(Θ)
其中 Ω 是正则化项,大多数算法在目标函数中忘记包括该项。然而,XGBoost 包含正则化,从而控制模型的复杂性并防止过拟合。
上述 6 个特性可能在某些算法中单独存在,但 XGBoost 结合了这些技术,形成一个端到端的系统,提供可扩展性和有效的资源利用。
Python 和 R 的实现代码:
这些链接为使用 Python 和 R 实现 XGBoost 提供了良好的起点。
以下 Python 代码在 Pima 印第安人糖尿病数据集 上运行。它预测 Pima 印第安人遗传背景的患者是否会发生糖尿病。该代码受到 Jason Brownlee 教程的启发。
结论
你可以参考 这篇论文,这是 XGBoost 开发者撰写的,以了解其详细工作原理。你还可以在 Github 上找到该项目,并查看 这里 的教程和用例。
然而,XGBoost 不应被视为万灵药。最佳结果可以通过与出色的数据探索和特征工程相结合获得。
相关:
-
XGBoost,Kaggle 上的顶级机器学习方法解析
-
XGBoost,将 Kaggle 上获胜的算法在 Spark 和 Flink 中实现
-
使用鸢尾花数据集的简单 XGBoost 教程
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关主题
XGBoost 详解:用少于 200 行 Python 代码实现 DIY XGBoost 库
原文:
www.kdnuggets.com/2021/05/xgboost-explained-diy-xgboost-library-200-lines-python.html
comments
由 Guillaume Saupin,Verteego 的 CTO 提供

照片由Jens Lelie拍摄,来源于Unsplash
XGBoost 可能是数据科学中使用最广泛的库之一。全球许多数据科学家都在使用它。它是一个非常通用的算法,可用于执行分类、回归以及置信区间,如本文文章所示。但有多少人真正理解它的基本原理呢?
你可能会认为,像 XGBoost 这样表现出色的机器学习算法可能使用了非常复杂和先进的数学方法。你可能会想象它是一个软件工程的杰作。
你部分正确。XGBoost 库确实相当复杂,但如果仅考虑应用于决策树的梯度提升的数学公式,其实并没有那么复杂。
下面你将详细了解如何使用少于 200 行代码,通过梯度提升方法训练回归决策树。
决策树
在深入数学细节之前,让我们回顾一下决策树的基本概念。原理非常简单:将值关联到一组特征,通过遍历二叉树。二叉树的每个节点都附带一个条件;叶子节点包含值。
如果条件为真,我们继续使用左节点进行遍历;如果不成立,我们使用右节点。一旦到达叶子节点,我们就得到了预测结果。
正如常常所说,一图胜千言:
三层决策树。图像由作者提供。
附加到节点的条件可以视为一个决策,因此得名决策树。
这种结构在计算机科学历史上相当古老,并且在几十年里成功使用过。基本实现如下:
堆叠多个树
尽管决策树在许多应用中取得了一些成功,例如专家系统(在 AI 冬季之前),但它仍然是一个非常基础的模型,无法处理现实世界数据中通常遇到的复杂性。
我们通常将这种类型的估算器称为弱模型。
为了克服这一局限性,九十年代出现了将多个弱模型组合起来以创建一个强模型:集成学习。 的想法。
这种方法可以应用于任何类型的模型,但由于决策树简单、快速、通用且易于解释,因此它们被广泛使用。
可以部署各种策略来组合模型。例如,我们可以使用每个模型预测的加权和。甚至更好的是,使用贝叶斯方法根据学习进行组合。
XGBoost 和所有boosting方法使用另一种方法:每个新模型尝试补偿前一个模型的错误。
优化决策树
如上所述,使用决策树进行预测很直接。使用集成学习时,工作并不复杂:我们只需对每个模型的贡献进行求和即可。
真正复杂的是构建树本身!我们如何找到在每个训练数据集节点上应用的最佳条件?这就是数学帮助我们的地方。完整的推导可以在XGBoost 文档中找到。在这里,我们将仅关注本文的感兴趣公式。
和往常一样,在机器学习中,我们希望设置模型参数,以便使模型在训练集上的预测最小化给定的目标:
目标公式。公式由作者提供。
请注意,这个目标由两个部分组成:
-
一种用于测量预测错误的指标。这就是著名的损失函数l(y, y_hat)。
-
另一个omega,用于控制模型复杂性。
如 XGBoost 文档所述,复杂性是目标中非常重要的一部分,它允许我们调整偏差/方差权衡。可以使用许多不同的函数来定义这个正则化项。XGBoost 使用:
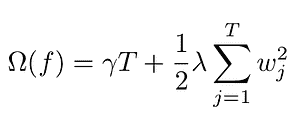
正则化项。公式由作者提供。
这里* T* 是叶子的总数,而w_j 是附加到每个叶子的权重。这意味着较大的权重和较多的叶子会受到惩罚。
由于错误通常是复杂的非线性函数,我们使用二阶泰勒展开对其进行线性化:
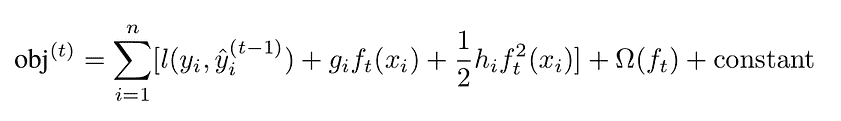
损失的二阶展开。公式由作者提供。
其中:
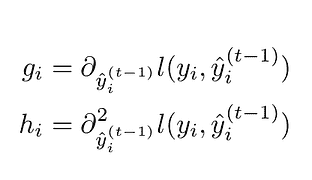
高斯和 Hessian 公式。公式由作者提供。
线性化是针对预测项计算的,因为我们希望估计预测变化时错误的变化。线性化是至关重要的,因为它将简化错误的最小化。
我们希望通过梯度提升实现的目标是找到最佳的delta_y_i,以最小化损失函数,即我们希望找到如何修改现有的树,以使修改改善预测。
在处理树模型时,有两类参数需要考虑:
-
定义树本身的参数:每个节点的条件,树的深度
-
附加到每个叶子的值。这些值就是预测值本身。
探索每个树的配置将过于复杂,因此梯度提升树方法仅考虑将一个节点拆分为两个叶子。这意味着我们必须优化三个参数:
-
拆分值:我们根据什么条件来拆分数据
-
附加到左侧叶子的值
-
附加到右侧叶子的值
在 XGBoost 文档中,关于目标的叶子 j 的最佳值由以下公式给出:
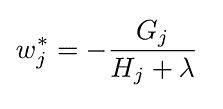
相对于目标的最优叶子值。作者公式。
其中 G_j 是附加到节点 j 的训练点的梯度之和,H_j 是附加到节点 j 的训练点的赫希矩阵之和。
使用此最优参数获得的目标函数的减少量是:
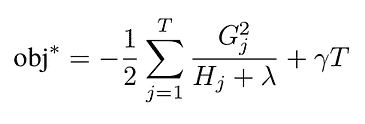
使用最优权重时的目标改善。作者公式。
选择正确的拆分值是使用暴力方法完成的:我们计算每个拆分值的改进,并保留最佳的拆分值。
我们现在拥有所有所需的数学信息,可以通过添加新叶子来提升初始树的性能,以符合给定的目标。
在具体实施之前,让我们花些时间理解这些公式的含义。
理解梯度提升
让我们深入了解权重是如何计算的,以及 G_j 和 H_i 的值。由于它们分别是相对于预测的损失函数的梯度和赫希矩阵,我们必须选择一个损失函数。
我们将专注于平方误差,这是一种常用的损失函数,也是 XGBoost 的默认目标:
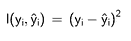
平方误差损失函数。作者公式
这是一个相当简单的公式,其梯度是:
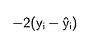
损失函数的梯度。作者公式。
和赫希矩阵:
损失函数的赫希矩阵。作者公式。
因此,如果我们记住最大化误差减少的最优权重公式:
相对于目标的最优叶子值。作者公式。
我们意识到,最优权重,即我们添加到先前预测中的值,是先前预测与实际值之间的平均误差的相反数(当正则化禁用时,即 lambda = 0)。使用平方损失来训练带有梯度提升的决策树仅仅归结为在每个新节点中用平均误差更新预测。
我们还看到 lambda 具有预期的效果,即确保权重不会过大,因为权重与 lambda 成反比。
训练决策树
现在进入简单的部分。假设我们有一个现有的决策树,能够在给定的误差范围内进行预测。我们希望通过分裂一个节点来减少误差并改善附加目标。
实现这一点的算法相当直接:
-
选择一个感兴趣的特征
-
根据所选特征的值对当前节点附加的数据点进行排序
-
选择一个可能的分裂值
-
将此分裂值以下的数据点放入右节点,将以上的数据点放入左节点
-
计算父节点、右节点和左节点的目标减少
-
如果左节点和右节点的目标减少总和大于父节点的目标减少总和,则将分裂值保持为最佳值
-
对每个分裂值进行迭代
-
如果有最佳分裂值,则使用它,并添加两个新节点
-
如果没有分裂改善目标,则不要添加子节点。
生成的代码创建了一个 DecisionTree 类,该类通过一个目标、一组估计器(即树的数量)和一个最大深度进行配置。
正如承诺的代码少于 200 行:
训练的核心编码在函数_find_best_split中。它本质上遵循上述详细步骤。
请注意,为了支持任何类型的目标,而不必手动计算梯度和 Hessian,我们使用自动微分和jax库来自动化计算。
最初,我们从一个只有一个节点的树开始,其叶子节点的值为零。由于我们模仿 XGBoost,我们还使用一个基准分数,设置为待预测值的平均值。
此外,请注意在第 126 行,我们如果达到初始化树时定义的最大深度则停止树的构建。我们还可以使用其他条件,比如每个叶子节点的最小样本数量或新权重的最小值。
另一个非常重要的点是选择用于分裂的特征。这里为了简化起见,特征是随机选择的,但我们本可以使用更智能的策略,例如使用方差最大的特征。
结论
在本文中,我们了解了梯度提升如何训练决策树。为了进一步提高我们的理解,我们编写了训练决策树集成和使用它们进行预测所需的最小行数。
深刻理解我们用于机器学习的算法是绝对关键的。这不仅有助于我们构建更好的模型,更重要的是使我们能够根据需求调整这些模型。
例如,在梯度提升的情况下,调整损失函数是提高预测精度的一个绝佳方法。
简历: Guillaume Saupin 是 Verteego 的首席技术官。
原文。经许可转载。
相关内容:
-
梯度提升决策树 – 概念解释
-
XGBoost:它是什么,何时使用
-
众人拾柴火焰高:集成学习的案例
我们的 3 大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织进行 IT 支持
更多相关内容
XGBoost 和随机森林®与贝叶斯优化
原文:
www.kdnuggets.com/2019/07/xgboost-random-forest-bayesian-optimisation.html
评论
由Edwin Lisowski,Addepto 首席技术官
本文不仅比较了 XGBoost 和随机森林,还尝试解释如何将这两种非常流行的方法与贝叶斯优化结合使用,并讨论这些模型的主要优缺点。XGBoost(XGB)和随机森林(RF)都是集成学习方法,通过结合个别决策树的输出进行预测(分类或回归)(我们假设是基于树的 XGB 或 RF)。
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 需求
深入比较 – XGBoost vs 随机森林
XGBoost 或梯度提升
XGBoost 每次构建一棵决策树。每棵新树都会修正之前训练的决策树所犯的错误。
XGBoost 应用示例
在 Addepto,我们使用 XGBoost 模型解决异常检测问题,例如在监督学习方法中。在这种情况下,XGB 非常有用,因为数据集通常高度不平衡。这些数据集的示例包括用户/消费者交易、能源消耗或移动应用中的用户行为。
优点
由于提升树是通过优化目标函数得出的,基本上 XGB 可以用来解决几乎所有我们可以写出梯度的目标函数。这包括排名和泊松回归等问题,而 RF 较难实现。
缺点
如果数据有噪声,XGB 模型更容易过拟合。训练通常需要更长时间,因为树是顺序构建的。GBM 比 RF 更难调整。通常有三个参数:树的数量、树的深度和学习率,每棵树通常较浅。
随机森林
随机森林(RF)独立训练每棵树,使用数据的随机样本。这种随机性有助于使模型比单棵决策树更稳健。因此,RF 更不容易在训练数据上过拟合。
随机森林应用示例
随机森林差异性已被应用于各种应用中,例如,根据组织标记数据寻找患者的聚类。[1] 随机森林模型在以下两种情况下对于这类应用非常有吸引力:
我们的目标是对具有强相关特征的高维问题具有高预测准确性。
我们的数据集非常嘈杂,并包含大量缺失值,例如,某些属性是类别型或半连续型的。
优点
随机森林中的模型调整比 XGBoost 的要容易。在 RF 中,我们有两个主要参数:每个节点选择的特征数量和决策树的数量。RF 比 XGB 更难以过拟合。
缺点
随机森林算法的主要限制在于大量树木可能会使算法在实时预测中变得缓慢。对于包含具有不同级别数量的类别变量的数据,随机森林对那些具有更多级别的属性存在偏见。
贝叶斯优化是一种优化评估代价高昂的函数的技术。[2] 它为目标函数构建后验分布,并使用高斯过程回归计算该分布中的不确定性,然后使用采集函数来决定采样位置。贝叶斯优化专注于解决以下问题:
max[x∈A] f(x)
在大多数成功的应用中,超参数的维度(x∈R^d)通常是 d < 20。
通常设置 A i 为超矩形(x∈R^d:a[i] ≤ x[i] ≤ b[i])。目标函数是连续的,这对于使用高斯过程回归建模是必要的。它还缺乏像凹性或线性这样的特殊结构,这使得利用这种结构来提高效率的技术变得无效。贝叶斯优化包含两个主要组件:用于建模目标函数的贝叶斯统计模型和用于决定下一个采样点的采集函数。
在根据初始空间填充实验设计评估目标后,它们被迭代地用于分配 N 评估的剩余预算,如下所示:
-
观察初始点
-
当n ≤ N 时
使用所有可用数据更新后验概率分布
让x[n]成为采集函数的最大值
观察y[n] = f(x[n])
增量n
结束循环
-
返回一个解决方案:评估点中最大的
我们可以总结这个问题,说贝叶斯优化是为了黑箱无导数全局优化而设计的。它在机器学习中调整超参数时变得极其流行。
下面是整个优化的图形总结:带有观察值和置信区间的高斯过程与后验分布,以及效用函数,其中最大值表示下一个采样点。
借助实用函数,贝叶斯优化在调优机器学习算法的参数时,比网格搜索或随机搜索技术更高效。它能够有效平衡“探索”和“开发”,以寻找全局最优解。
为了展示贝叶斯优化的实际效果,我们使用了 BayesianOptimization [3] 这个用 Python 编写的库来调优随机森林和 XGBoost 分类算法的超参数。我们需要通过 pip 安装它:
pip install bayesian-optimization
现在让我们训练我们的模型。首先,我们导入所需的库:
#Import libraries
import pandas as pd
import numpy as np
from bayes_opt import BayesianOptimization
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
我们定义了一个函数来运行贝叶斯优化,给定数据、要优化的函数及其超参数:
#Bayesian optimization
def bayesian_optimization(dataset, function, parameters):
X_train, y_train, X_test, y_test = dataset
n_iterations = 5
gp_params = {"alpha": 1e-4}
BO = BayesianOptimization(function, parameters)
BO.maximize(n_iter=n_iterations, **gp_params)
return BO.max
我们定义了优化函数,即随机森林分类器及其超参数 n_estimators、max_depth 和 min_samples_split。此外,我们使用了给定数据集上的交叉验证得分的平均值:
def rfc_optimization(cv_splits):
def function(n_estimators, max_depth, min_samples_split):
return cross_val_score(
RandomForestClassifier(
n_estimators=int(max(n_estimators,0)),
max_depth=int(max(max_depth,1)),
min_samples_split=int(max(min_samples_split,2)),
n_jobs=-1,
random_state=42,
class_weight="balanced"),
X=X_train,
y=y_train,
cv=cv_splits,
scoring="roc_auc",
n_jobs=-1).mean()
parameters = {"n_estimators": (10, 1000),
"max_depth": (1, 150),
"min_samples_split": (2, 10)}
return function, parameters
类似地,我们定义了 XGBoost 分类器的函数和超参数:
def xgb_optimization(cv_splits, eval_set):
def function(eta, gamma, max_depth):
return cross_val_score(
xgb.XGBClassifier(
objective="binary:logistic",
learning_rate=max(eta, 0),
gamma=max(gamma, 0),
max_depth=int(max_depth),
seed=42,
nthread=-1,
scale_pos_weight = len(y_train[y_train == 0])/
len(y_train[y_train == 1])),
X=X_train,
y=y_train,
cv=cv_splits,
scoring="roc_auc",
fit_params={
"early_stopping_rounds": 10,
"eval_metric": "auc",
"eval_set": eval_set},
n_jobs=-1).mean()
parameters = {"eta": (0.001, 0.4),
"gamma": (0, 20),
"max_depth": (1, 2000)}
return function, parameters
现在根据选择的分类器,我们可以优化它并训练模型:
#Train model
def train(X_train, y_train, X_test, y_test, function, parameters):
dataset = (X_train, y_train, X_test, y_test)
cv_splits = 4
best_solution = bayesian_optimization(dataset, function, parameters)
params = best_solution["params"]
model = RandomForestClassifier(
n_estimators=int(max(params["n_estimators"], 0)),
max_depth=int(max(params["max_depth"], 1)),
min_samples_split=int(max(params["min_samples_split"], 2)),
n_jobs=-1,
random_state=42,
class_weight="balanced")
model.fit(X_train, y_train)
return model
作为示例数据,我们使用了来自 AdventureWorksDW2017 SQL Server 数据库的视图 [dbo].[vTargetMail],根据个人数据,我们需要预测一个人是否会购买自行车。通过贝叶斯优化的结果,我们展示了连续函数采样:
| iter | AUC | max_depth | min_samples_split | n_estimators |
|---|---|---|---|---|
| 1 | 0.8549 | 45.88 | 6.099 | 34.82 |
| 2 | 0.8606 | 15.85 | 2.217 | 114.3 |
| 3 | 0.8612 | 47.42 | 8.694 | 306.0 |
| 4 | 0.8416 | 10.09 | 5.987 | 563.0 |
| 5 | 0.7188 | 4.538 | 7.332 | 766.7 |
| 6 | 0.8436 | 100.0 | 2.0 | 448.6 |
| 7 | 0.6529 | 1.012 | 2.213 | 315.6 |
| 8 | 0.8621 | 100.0 | 10.0 | 1e+03 |
| 9 | 0.8431 | 100.0 | 2.0 | 154.1 |
| 10 | 0.653 | 1.0 | 2.0 | 1e+03 |
| 11 | 0.8621 | 100.0 | 10.0 | 668.3 |
| 12 | 0.8437 | 100.0 | 2.0 | 867.3 |
| 13 | 0.637 | 1.0 | 10.0 | 10.0 |
| 14 | 0.8518 | 100.0 | 10.0 | 10.0 |
| 15 | 0.8435 | 100.0 | 2.0 | 317.6 |
| 16 | 0.8621 | 100.0 | 10.0 | 559.7 |
| 17 | 0.8612 | 89.86 | 10.0 | 82.96 |
| 18 | 0.8616 | 49.89 | 10.0 | 212.0 |
| 19 | 0.8622 | 100.0 | 10.0 | 771.7 |
| 20 | 0.8622 | 38.33 | 10.0 | 469.2 |
| 21 | 0.8621 | 39.43 | 10.0 | 638.6 |
| 22 | 0.8622 | 83.73 | 10.0 | 384.9 |
| 23 | 0.8621 | 100.0 | 10.0 | 936.1 |
| 24 | 0.8428 | 54.2 | 2.259 | 122.4 |
| 25 | 0.8617 | 99.62 | 9.856 | 254.8 |
如我们所见,贝叶斯优化在第 23 步找到了最佳参数,这在测试数据集上得到了 0.8622 的 AUC 分数。如果给更多样本进行检查,结果可能会更高。我们优化后的随机森林模型的 ROC AUC 曲线如下所示:
我们提出了一种简单的超参数调优方法,使用贝叶斯优化[4],这是一种比网格搜索或随机搜索方法更快的寻找最优值的方法。
个人简介: Edwin Lisowski 是 Addepto 的首席技术官。他是经验丰富的高级分析顾问,具有在信息技术和服务行业工作的丰富历史。他在预测建模、大数据、云计算和高级分析方面具有丰富的技能。
相关内容:
-
如何自动化超参数优化
-
XGBoost 简介:使用监督学习预测寿命期望
-
随机森林与神经网络:哪个更好,何时使用?
更多相关话题
XGBoost,Kaggle 上的顶级机器学习方法解析
原文:
www.kdnuggets.com/2017/10/xgboost-top-machine-learning-method-kaggle-explained.html

什么是 XGBoost?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
XGBoost 已成为 Kaggle 竞争者和工业界数据科学家广泛使用且非常流行的工具,因为它在大规模问题上的生产环境中经过了实战测试。它是一个高度灵活和多功能的工具,可以处理大多数回归、分类和排序问题以及用户自定义目标函数。作为一个开源软件,它易于访问,可以通过不同的平台和接口使用。该系统的惊人可移植性和兼容性允许在 Windows、Linux 和 OS X 三大操作系统上使用。它还支持在如 AWS、Azure、GCE 等分布式云平台上训练,并且可以轻松连接到如 Flink 和 Spark 等大规模云数据流系统。尽管它是由其创建者(Tianqi Chen)在命令行界面(CLI)中构建和最初使用的,但也可以在 Python、C++、R、Julia、Scala 和 Java 等各种语言和接口中加载和使用。
它的名称代表极端梯度提升,由 Tianqi Chen 开发,现在是 Distributed Machine Learning Community (DMLC)开发的开源库集合的一部分。XGBoost 是梯度提升机器的可扩展且准确的实现,它已被证明能够推动提升树算法计算能力的极限,因为它是为了模型性能和计算速度的目的而构建和开发的。具体而言,它被设计用于充分利用每一位内存和硬件资源来提升树算法。
XGBoost 的实现提供了多种先进的模型调优、计算环境和算法增强功能。它能够执行三种主要形式的梯度提升(梯度提升(GB)、随机 GB 和正则化 GB),并且足够稳健,支持精细调节和正则化参数的添加。根据 Tianqi Chen 的说法,这正是它优于其他库的原因。
“……xgboost 使用了更规范化的模型形式来控制过拟合,这使其表现更佳。”- Tianqi Chen 在Quora
从系统角度来看,该库的可移植性和灵活性允许使用各种计算环境,例如树构建的 CPU 核心并行化;大模型的分布式计算;外存计算;以及缓存优化,以提高硬件使用和效率。
该算法的开发目的是有效减少计算时间,并优化内存资源的使用。实现的重要特性包括处理缺失值(稀疏感知)、支持树构建并行化的块结构以及在训练模型后对新数据进行拟合和提升的能力(持续训练)。
为什么使用 XGBoost?
正如我们之前提到的,这个库的关键特性依赖于模型性能和执行速度。由Szilard Pafka进行的结构化基准测试,展示了 XGBoost 如何超越几种其他知名的梯度树提升实现。
图 1 中的比较帮助我们掌握工具的强大性能,并查看其好处的平衡,即它似乎没有在速度和准确性之间做出牺牲。越来越多的 Kagglers 每天使用它,逐渐明白为什么,它在性能和时间效率之间达到了半完美的平衡。
它是如何工作的?
在深入算法细节之前,让我们设定一些基本定义,以便更容易理解,并对这个流行工具有一个直观和完整的了解。
首先,让我们澄清“boosting”的概念。这是一种集成方法,旨在基于“弱”分类器创建一个强大的分类器(模型)。在这个上下文中,弱和强是指学习者与实际目标变量的相关程度。通过迭代地将模型叠加在一起,前一个模型的错误会被下一个预测器纠正,直到训练数据被模型准确预测或重现。如果你想更深入地了解 boosting,可以查看有关一种流行实现叫做 AdaBoost(自适应提升)的信息,点击这里。
现在,梯度提升还包括一种集成方法,它顺序地添加预测器并纠正先前的模型。然而,与每次迭代后给分类器分配不同权重的方法不同,这种方法将新模型拟合到先前预测的新残差中,然后在添加最新预测时最小化损失。因此,最终你是使用梯度下降来更新你的模型,因此得名梯度提升。这适用于回归和分类问题。XGBoost 特别实现了这个算法,用于决策树提升,并在目标函数中增加了额外的自定义正则化项。
开始使用 XGBoost
无论你使用的是哪个接口,你都可以下载并安装 XGBoost。要了解如何在每个平台上使用它,请按照此链接中的说明操作。你还可以在 这里 找到官方文档和教程。
有关源代码和示例的更多信息,你可以访问这个 DMLC GitHub 仓库。
关于提升和梯度提升的更多信息,以下资源可能会有所帮助:
-
由 Tianqi Chen 发布的官方论文可以从 Arxiv 下载。
-
官方文档 XGBoost 页面
-
这里 是一份很好的演示文稿,它以非常直观的方式总结了数学原理
-
一些 维基百科文章 对于算法的历史和数学原理提供了很好的概述:
感谢 Jason Brownlee 为这篇文章提供的灵感,更多关于 Boosting 和 XGBoost 的资源可以在 他的文章 中找到。
相关:
-
从基准测试快速机器学习算法中得到的经验教训
-
使用鸢尾花数据集的简单 XGBoost 教程
-
XGBoost:在 Spark 和 Flink 中实现最成功的 Kaggle 算法
更多相关话题
Yahoo 发布了有史以来最大的机器学习数据集供研究人员使用
原文:
www.kdnuggets.com/2016/01/yahoo-largest-machine-learning-dataset.html
苏朱·拉詹,Yahoo。
数据是机器学习研究的命脉。然而,真正大规模的数据集的访问权传统上一直是大型公司中的机器学习研究人员和数据科学家的特权,而大多数学术研究人员则无法获得。
Yahoo Labs 的研究科学家们长期以来一直致力于解决受消费者产品启发的大规模机器学习问题。这使我们能够在搜索排名、计算广告、信息检索和核心机器学习等领域推进思维。外部研究社区感兴趣的一个关键方面是将新算法和方法应用于生产流量和从真实产品中收集的大规模数据集。
今天,我们自豪地宣布向研究社区公开发布有史以来最大的机器学习数据集。该数据集包含大约~110B 事件(13.5TB 未压缩)的匿名用户新闻项互动数据,这些数据通过记录大约 2000 万用户从 2015 年 2 月到 2015 年 5 月的用户新闻项互动来收集。
Yahoo 新闻订阅数据集是基于一组匿名用户与多个 Yahoo 网站新闻订阅的互动样本,包括 Yahoo 首页、Yahoo 新闻、Yahoo 体育、Yahoo 财经、Yahoo 电影和 Yahoo 房地产。
Yahoo 主页上的新闻订阅。
我们的目标是促进大规模机器学习和推荐系统领域的独立研究,并帮助缩小工业和学术研究之间的差距。该数据集作为 Yahoo Labs Webscope 数据共享计划的一部分提供,Webscope 是一个包含匿名用户数据的科学有用数据集的参考库,供非商业用途使用。
除了互动数据外,我们还为一部分匿名用户提供了分类的人口统计信息(年龄范围、性别和一般地理数据)。在项方面,我们发布了相关新闻文章的标题、摘要和关键词。互动数据以相关本地时间进行时间戳,并且还包含有关用户访问新闻订阅的设备的部分信息,这使得在上下文推荐和时间数据挖掘方面进行有趣的工作成为可能。
Yahoo Labs 的个性化科学团队在处理 Yahoo 新闻提要数据集的全面版本时非常愉快,这引发了一些引人注目的想法(例如 鸟类、应用程序和用户:可扩展的因子分解机 和 科学推动产品和个性化:超越点击),涉及行为建模、推荐系统、大规模和分布式机器学习、排名、在线算法、内容建模和时间序列挖掘等领域。
我们希望此次数据发布同样能够激励我们的研究同行、数据科学家以及学术界的机器学习爱好者,并帮助他们在广泛的“真实世界”数据集上验证他们的模型。我们坚信,这个数据集可以成为大规模机器学习和推荐系统的基准,我们期待着社区关于我们数据应用的反馈。
祝 2016 年大规模机器学习愉快!
关于我们对用户隐私的处理说明:我们的用户每天都信任我们,我们努力赢得这种信任。我们热忱保护用户的隐私,并 负责任和透明地使用及保护用户个人信息。因此,我们在本项目中发布的数据集已被匿名化。
相关:
-
有趣的社交媒体数据集
-
初学者指南:使用 Apache Spark 进行大数据机器学习
-
前 10 大数据挖掘算法,解析
更多相关主题
什么是支持向量机,为什么我要使用它?
原文:
www.kdnuggets.com/2017/02/yhat-support-vector-machine.html
本文最初发表于Yhat 博客。Yhat是一家总部位于布鲁克林的公司,旨在使数据科学适用于开发者、数据科学家和企业。Yhat 提供一个软件平台,用于以 REST API 的形式部署和管理预测算法,同时消除了与生产环境相关的测试、版本控制、扩展和安全等痛苦的工程障碍。
什么是 SVM?
SVM 是一种监督式机器学习算法,可用于分类或回归问题。它使用一种称为核技巧的技术来转换数据,然后基于这些转换找到可能输出之间的最优边界。简单来说,它进行一些极其复杂的数据转换,然后根据你定义的标签或输出来找出如何分隔数据。
那么,它的优点是什么?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
SVM 能够进行分类和回归。在这篇文章中,我将重点讨论使用 SVM 进行分类。特别是,我将专注于非线性 SVM,即使用非线性核的 SVM。非线性 SVM 意味着算法计算出的边界不一定是一条直线。其优点是可以捕捉到数据点之间更复杂的关系,而不必自己进行困难的转换。缺点是训练时间更长,因为计算量更大。
牛和狼
那么,什么是核技巧?
核技巧将你提供的数据进行变换。输入一些你认为会成为优秀分类器的特征,输出的数据会变得难以识别。这就像解开一段 DNA 链。你从一个看似无害的数据向量开始,经过核技巧处理后,它被解开并复合,直到变成一个更大的数据集,通过查看电子表格无法理解。但这里的魔力在于,通过扩展数据集,你的类别之间的边界变得更加明显,SVM 算法能够计算出一个更为优化的超平面。
设想一下,你是一个农民,你有一个问题——你需要建立一个围栏来保护你的奶牛免受狼群的袭击。但是你该在哪里建围栏呢?如果你是一个非常数据驱动的农民,一种方法是基于奶牛和狼在牧场中的位置来建立一个分类器。通过测试几种不同类型的分类器,我们发现 SVM 在将奶牛与狼群分开方面表现出色。我觉得这些图表也很好地说明了使用非线性分类器的好处。你可以看到逻辑回归和决策树模型都仅使用了直线。

想要重新创建分析吗?
想自己创建这些图表?你可以在终端或你选择的 IDE 中运行代码,但,惊喜的是,我推荐Rodeo。它有一个很棒的弹出图表功能,适合这种分析类型。它还带有 Python,适用于 Windows 机器。此外,多亏了TakenPilot的辛勤工作,它现在运行得非常迅速。
一旦你下载了 Rodeo,你需要从我的 GitHub 上保存原始的cows_and_wolves.txt文件。确保你已经将工作目录设置为保存文件的位置。

好了,现在只需将下面的代码复制粘贴到 Rodeo 中,并运行,无论是逐行还是整个脚本。别忘了,你可以弹出你的绘图标签,移动窗口或调整大小。
让 SVM 来完成艰巨的工作
如果依赖变量和独立变量之间的关系是非线性的,它的准确性不会像 SVM 那样高。变量之间的转换(log(x),(x²))变得不那么重要,因为这些会在算法中被考虑。如果你仍然难以理解,可以尝试跟随这个例子。
假设我们有一个包含绿色和红色点的数据集。当用其坐标绘制时,这些点形成一个红色圆圈,绿色轮廓(看起来非常像孟加拉国的国旗)。
如果我们丢失了三分之一的数据,会发生什么呢?如果我们无法恢复这些数据,并且想要找到一种方法来近似缺失的那三分之一的数据会是什么样子呢?
那么我们如何确定缺失的三分之一是什么样的呢?一种方法可能是使用我们拥有的 80% 数据作为训练集来构建模型。但我们应该使用什么类型的模型呢?让我们尝试一下以下几种:
-
逻辑回归模型
-
决策树
-
SVM
我训练了每个模型,然后使用它们对我们缺失的三分之一数据进行预测。让我们来看看我们预测的形状是什么样的……

跟随
这是用来比较你的逻辑回归模型、决策树和 SVM 的代码。

通过复制并运行上面的代码,跟随 Rodeo!
结果
从图中可以看出,SVM 显然是赢家。但为什么呢?如果你查看决策树和 GLM 模型的预测形状,你会注意到什么?直线边界。我们的输入模型没有包含任何变换来考虑 x、y 和颜色之间的非线性关系。给定一组特定的变换,我们肯定可以让 GLM 和 DT 表现得更好,但为什么要浪费时间呢?没有复杂的变换或缩放,SVM 仅错误分类了 117/5000 个点(98% 的准确率,而 DT 为 51% 和 GLM 为 12%!所有这些错误分类的点都是红色的——因此略微膨胀。
何时不使用
那么为什么不把 SVM 用于所有情况呢?不幸的是,SVM 的魔力也是最大的缺点。复杂的数据变换和结果边界平面非常难以解释。这就是为什么它通常被称为黑箱。相反,GLM 和决策树正好相反。它们的操作非常容易理解,尽管性能有所牺牲。
更多资源
想了解更多关于 SVM 的信息吗?这里有一些我遇到的很好的资源:
-
初学者 SVM 教程:仅仅是基础知识,还有一点点 MIT 的 Zoya Gavrilov 提供的辅助。
-
初学者 SVM 算法的工作原理:视频 由 Thales Sehn Körting 提供
-
中级 生物医学中支持向量机的温和介绍 由 NYU 和 Vanderbilt 提供的幻灯片
-
高级 模式识别中的支持向量机教程 由 Bell Labs 的 Christopher Burges 提供
原文。经许可转载。
相关内容:
-
支持向量机:简明技术概述
-
支持向量机:简单解释
-
Python 中的随机森林
更多相关主题
YOLOv5 PyTorch 教程

使用 YOLOv5 进行 PyTorch 开发
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 在 IT 领域支持你的组织
YOLO,即“你只看一次”的缩写,是一种开源软件工具,因其高效的实时物体检测能力而被广泛使用。YOLO 算法使用卷积神经网络(CNN)模型来检测图像中的物体。
该算法仅需一次前向传播即可检测图像中的所有对象。这使得 YOLO 算法在速度上优于其他算法,成为迄今为止最知名的检测算法之一。
什么是 YOLO 物体检测?
物体检测算法是一种能够在给定帧中检测特定对象或形状的算法。例如,简单的检测算法可能能够检测和识别图像中的形状,如圆形或方形,而更高级的检测算法可以检测更复杂的对象,如人类、自行车、汽车等。
YOLO 算法不仅通过其一次前向传播能力提供了高检测速度和性能,而且还以极高的准确性和精度进行检测。
在本教程中,我们将重点关注YOLOv5,这是 YOLO 软件的第五个也是最新的版本。它最初发布于 2020 年 5 月 18 日。YOLO 开源代码可以在GitHub上找到。我们将使用 YOLO 与著名的 PyTorch 库。
PyTorch是一个基于著名 Torch 库的深度学习开源包。它也是一个基于 Python 的库,通常用于自然语言处理和计算机视觉。
YOLO 算法是如何工作的?
第一步:残差块(将图像划分为更小的网格状框)
在这一步骤中,完整(整体)帧被划分为更小的框或网格。
所有网格都绘制在原始图像上,形状和大小完全一致。这些分割的想法在于每个网格框将检测其内部的不同对象。
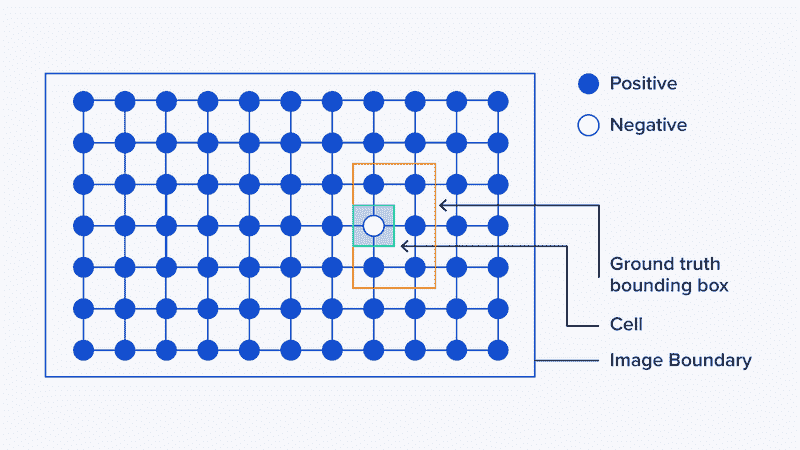
步骤 2:边界框回归(识别边界框中的对象)
在检测到图像中的给定对象后,会绘制一个边界框将其包围。边界框具有诸如中心点、高度、宽度和类别(检测到的对象类型)等参数。
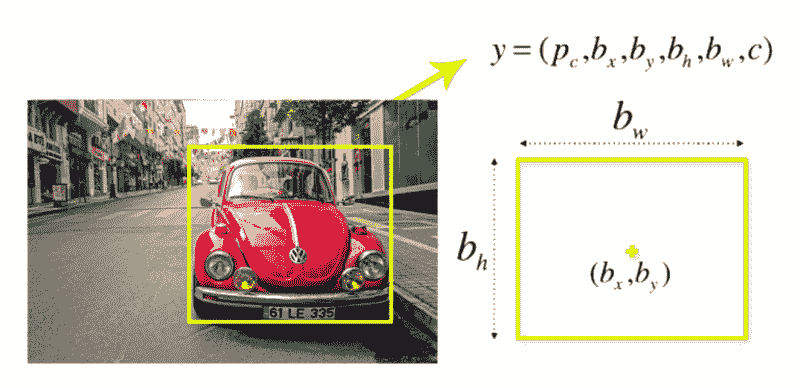
步骤 3:交并比(IOU)

IOU,即交并比,用于计算我们模型的准确性。这是通过量化两个框的交集程度来实现的,这两个框分别是实际值框(图中的红框)和从结果中返回的框(图中的蓝框)。
在本文的教程部分,我们将 IOU 值确定为 40%,这意味着如果两个框的交集低于 40%,则不应考虑该预测。这是为了帮助我们计算预测的准确性。
下面是显示 YOLO 检测算法完整过程的图像

要了解更多关于 YOLO 算法如何工作的详细信息,请查看YOLO 算法简介。
我们希望通过模型实现什么目标?
本教程示例的主要目标是使用 YOLO 算法检测给定图像中的一系列胸部疾病。与任何机器学习模型一样,我们将使用成千上万张胸部扫描图像来运行我们的模型。目标是让 YOLO 算法成功检测出给定图像中的所有病变。
数据集
本教程中使用的VinBigData 512 图像数据集可以在 Kaggle 上找到。数据集分为两部分,训练数据集和测试数据集。训练数据集包含 15,000 张图像,而测试数据集包含 3,000 张。这种数据划分在训练数据集通常是测试数据集的 4 到 5 倍的情况下是比较理想的。
数据集的另一部分包含所有图像的标签。在这个数据集中,每张图像都标记有一个类别名称(发现的胸部疾病),以及类别 ID、图像的宽度和高度等。查看下面的图像以查看所有可用的列。
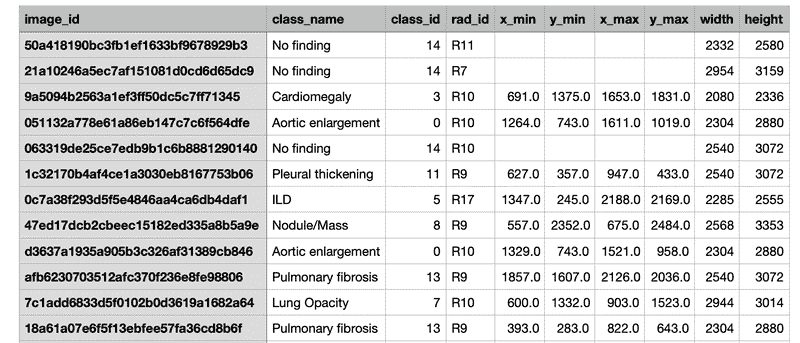
YOLOv5 教程
注意: 你可以在 Kaggle 上查看原始代码。
步骤 1:导入必要的库
首先,我们将在代码的最开始导入所需的库和包。首先,让我们解释一下我们刚刚导入的一些更常见的库。NumPy 是一个开源的 Python 数值库,允许用户创建矩阵并对其执行多种数学操作。
import pandas as pd
import os
import numpy as np
import shutil
import ast
from sklearn import model_selection
from tqdm import tqdm
import wandb
from sklearn.model_selection import GroupKFold\
from IPython.display import Image, clear_output # to display images
from os import listdir
from os.path import isfile
from glob import glob
import yaml
# clear_output()
步骤 2:定义我们的路径
为了简化我们的工作,我们将首先定义训练和测试数据集标签和图像的直接路径。
TRAIN_LABELS_PATH = './vinbigdata/labels/train'
VAL_LABELS_PATH = './vinbigdata/labels/val'
TRAIN_IMAGES_PATH = './vinbigdata/images/train' #12000
VAL_IMAGES_PATH = './vinbigdata/images/val' #3000
External_DIR = '../input/vinbigdata-512-image-dataset/vinbigdata/train' # 15000
os.makedirs(TRAIN_LABELS_PATH, exist_ok = True)
os.makedirs(VAL_LABELS_PATH, exist_ok = True)
os.makedirs(TRAIN_IMAGES_PATH, exist_ok = True)
os.makedirs(VAL_IMAGES_PATH, exist_ok = True)
size = 51
步骤 3:导入和读取文本数据集
在这里,我们将导入和读取文本数据集。这些数据以 CSV 文件格式存储为行和列。
df = pd.read_csv('../input/vinbigdata-512-image-dataset/vinbigdata/train.csv')
df.head()
注意: df.head() 函数打印给定数据集的前 5 行。
步骤 4:过滤和清理数据集
由于没有数据集是完美的,因此大多数时候需要一个过滤过程来优化数据集,从而优化我们模型的性能。在此步骤中,我们将删除任何 class id 等于 14 的行。
这个 class id 代表疾病类别中没有发现的情况。我们删除这个类别的原因是它可能会混淆我们的模型。此外,它还会减慢模型的速度,因为我们的数据集会稍微变大。
df = df[df.class_id!=14].reset_index(drop = True)
步骤 5:计算 YOLO 的边界框坐标
如前所述在‘YOLO 算法如何工作部分’(特别是步骤 1 和 2),YOLO 算法期望数据集以某种格式存在。在这里,我们将遍历数据框并应用一些转换。
以下代码的最终目标是计算每个数据点的新 x-mid、y-mid、宽度和高度维度。
df['x_min'] = df.apply(lambda row: (row.x_min)/row.width, axis = 1)*float(size)
df['y_min'] = df.apply(lambda row: (row.y_min)/row.height, axis = 1)*float(size)
df['x_max'] = df.apply(lambda row: (row.x_max)/row.width, axis =1)*float(size)
df['y_max'] = df.apply(lambda row: (row.y_max)/row.height, axis =1)*float(size)
df['x_mid'] = df.apply(lambda row: (row.x_max+row.x_min)/2, axis =1)
df['y_mid'] = df.apply(lambda row: (row.y_max+row.y_min)/2, axis =1)
df['w'] = df.apply(lambda row: (row.x_max-row.x_min), axis =1)
df['h'] = df.apply(lambda row: (row.y_max-row.y_min), axis =1)
df['x_mid'] /= float(size)
df['y_mid'] /= float(size)
df['w'] /= float(size)
df['h'] /= float(size)
步骤 6:更改提供的数据格式
在代码的这一部分,我们将把数据集中的所有行的给定数据格式更改为以下列:
def preproccess_data(df, labels_path, images_path):
for column, row in tqdm(df.iterrows(), total=len(df)):
attributes = row[
["class_id", "x_mid", "y_mid", "w", "h"]
].values
attributes = np.array(attributes)
np.savetxt(
os.path.join(labels_path, f"{row['image_id']}.txt"),
[attributes],
fmt=["%d", "%f", "%f", "%f", "%f"],
)
shutil.copy(
os.path.join(
"/kaggle/input/vinbigdata-512-image-dataset/vinbigdata/train",
f"{row['image_id']}.png",
),
images_path,
)
然后,我们将运行 preproccess_data 函数两次,一次使用训练数据集及其图像,另一次使用测试数据集及其图像。
preproccess_data(df, TRAIN_LABELS_PATH, TRAIN_IMAGES_PATH)
preproccess_data(val_df, VAL_LABELS_PATH, VAL_IMAGES_PATH)
使用以下代码行,我们将把 YOLOv5 算法克隆到我们的模型中。
!git clone https://github.com/ultralytics/yolov5.git
步骤 7:定义我们模型的类别
在这里,我们将把模型中可用的 14 种胸部疾病定义为类别。这些是可以在数据集的图像中识别的实际疾病。
classes = [ 'Aortic enlargement',
'Atelectasis',
'Calcification',
'Cardiomegaly',
'Consolidation',
'ILD',
'Infiltration',
'Lung Opacity',
'Nodule/Mass',
'Other lesion',
'Pleural effusion',
'Pleural thickening',
'Pneumothorax',
'Pulmonary fibrosis']
data = dict(
train = '../vinbigdata/images/train',
val = '../vinbigdata/images/val',
nc = 14,
names = classes
)
with open('./yolov5/vinbigdata.yaml', 'w') as outfile:
yaml.dump(data, outfile, default_flow_style=False)
f = open('./yolov5/vinbigdata.yaml', 'r')
print('\nyaml:')
print(f.read())
步骤 8:训练模型
首先,我们将打开 YOLOv5 目录。然后,我们将使用 pip 安装 requirements 文件中列出的所有库。
requirements 文件包含代码库运行所需的所有库。我们还将安装其他库,例如 pycocotools、seaborn 和 pandas。
%cd ./yolov5
!pip install -U -r requirements.txt
!pip install pycocotools>=2.0 seaborn>=0.11.0 pandas thop
clear_output()
Wandb,缩写自 weights and biases,允许我们监控给定的神经网络模型。
# b39dd18eed49a73a53fccd7b684ea7ecaed75b08
wandb.login()
现在我们将对提供的 vinbigdata 数据集进行 100 轮的 YOLOv5 训练。我们还将传递一些其他标志,例如 --img 512,表示我们的图像大小为 512 像素, --batch 16 允许我们的模型每批处理 16 张图像。使用 --data ./vinbigdata.yaml 标志,我们将传递我们的数据集,即 vinbigdata.yaml 数据集。
!python train.py --img 512 --batch 16 --epochs 100 --data ./vinbigdata.yaml --cfg models/yolov5x.yaml --weights yolov5x.pt --cache --name vin
第 9 步:评估模型
首先,我们将识别测试数据集目录以及权重目录。
test_dir = (
f"/kaggle/input/vinbigdata-{size}-image-dataset/vinbigdata/test"
)
weights_dir = "./runs/train/vin3/weights/best.pt"
os.listdir("./runs/train/vin3/weights")
在这一部分,我们将使用 detect.py 作为推理工具来检查我们预测的准确性。我们还将传递一些标志,例如 --conf 0.15\,这是模型的置信度阈值。如果检测到的对象的置信度低于 15%,则将其从输出中删除。 --iou 0.4\ 标志告诉我们的模型,如果两个框的交集与并集的比例低于 40%,则应将其移除。
!python detect.py --weights $weights_dir\
--img 512\
--conf 0.15\
--iou 0.4\
--source $test_dir\
--save-txt --save-conf --exist-ok
最后的思考
在这篇文章中,我们解释了 YOLOv5 是什么以及基本的 YOLO 算法是如何工作的。接下来,我们简要说明了 PyTorch。然后我们覆盖了几个使用 YOLO 而不是其他类似检测算法的理由。
最后,我们带您了解了一个能够检测 X 光图像中胸部疾病的机器学习模型。在这个示例中,我们使用 YOLO 作为主要的检测算法来查找和定位胸部病变。然后,我们将每个病变分类为特定的类别或疾病。
如果你对机器学习和构建自己的模型感兴趣,特别是那些需要检测给定图像或视频中多个对象的模型,那么 YOLOv5 绝对值得一试。
Kevin Vu 负责管理 Exxact Corp 博客,并与许多撰写有关深度学习不同方面的才华横溢的作者合作。
原文 经许可转载。
更多相关主题
你的特征很重要?这并不意味着它们是好的
原文:
www.kdnuggets.com/your-features-are-important-it-doesnt-mean-they-are-good
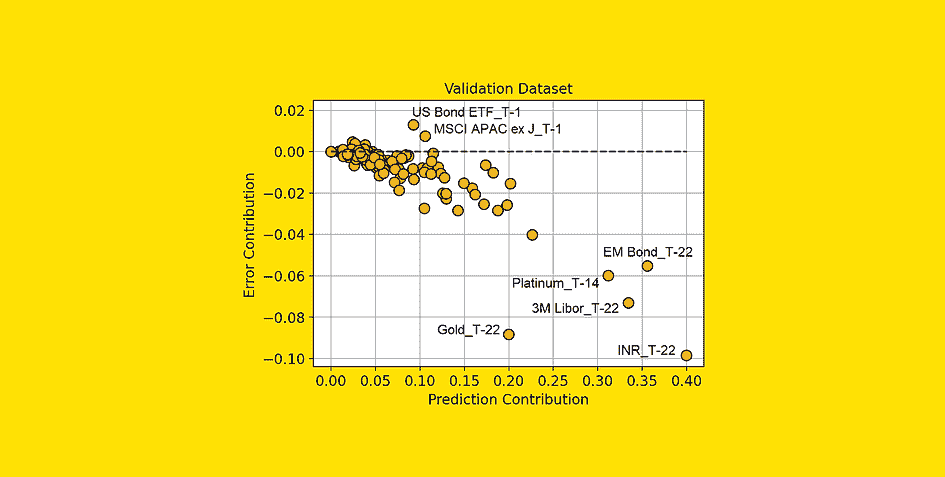
[图片来源:作者]
“重要”和“好”不是同义词
“特征重要性”这个概念在机器学习中被广泛使用,作为最基本的模型解释性类型。例如,它被用于递归特征消除(RFE),以迭代地删除模型中最不重要的特征。
然而,对于这个概念存在一种误解。
一个特征重要并不意味着它对模型有益!
实际上,当我们说一个特征很重要时,这只是意味着这个特征对模型的预测贡献很高。但我们应该考虑到这种贡献可能是错误的。
举个简单的例子:一个数据科学家不小心在模型的特征中忘记了客户 ID。模型将客户 ID 作为一个高度预测的特征。因此,即使这个特征实际上使模型表现更差,因为它不能很好地处理未见过的数据,它也会有很高的特征重要性。
为了使事情更清楚,我们需要区分两个概念:
-
预测贡献:预测中有多少部分是由于特征的存在;这相当于特征重要性。
-
误差贡献:预测误差中有多少部分是由于特征在模型中存在所致。
在本文中,我们将了解如何计算这些量,以及如何利用它们来获得关于预测模型的有价值见解(并加以改进)。
注意:本文集中于回归案例。如果你对分类案例更感兴趣,可以阅读“哪些特征对你的分类模型有害?”
从一个简单的例子开始
假设我们构建了一个模型来预测人们的收入,基于他们的工作、年龄和国籍。现在我们使用模型对三个人进行预测。
因此,我们有了实际值、模型预测和结果误差:

实际值、模型预测和绝对误差(以千美元计)。 [图片来源:作者]
计算“预测贡献”
当我们有一个预测模型时,我们可以将模型预测分解为单个特征带来的贡献。这可以通过 SHAP 值来完成(如果你不知道 SHAP 值的工作原理,你可以阅读我的文章:SHAP 值解释:正如你希望别人向你解释的那样)。
因此,假设这些是相对于我们模型的三个个体的 SHAP 值。
我们模型预测的 SHAP 值(以千美元计)。 [图片由作者提供]
SHAP 值的主要属性是它们是可加性的。这意味着——通过对每一行求和——我们将得到模型对该个体的预测。例如,如果我们取第二行:72k $ +3k $ -22k $ = 53k $,这正是模型对第二个体的预测。
现在,SHAP 值是衡量特征对我们预测的重要性的良好指标。实际上,SHAP 值(绝对值)越高,该特征对特定个体的预测影响越大。注意,我说的是绝对 SHAP 值,因为这里的符号并不重要:一个特征无论是推动预测向上还是向下,都是同样重要的。
因此,特征的预测贡献等于该特征绝对 SHAP 值的平均值。如果你在 Pandas 数据框中存储了 SHAP 值,这就非常简单:
prediction_contribution = shap_values.abs().mean()
在我们的示例中,这就是结果:

预测贡献。 [图片由作者提供]
正如你所见,job显然是最重要的特征,因为平均而言,它占最终预测的 71.67k $。国籍和年龄分别是第二和第三重要的特征。
然而,一个特征占据了最终预测的重要部分并不能说明该特征的性能。为了考虑这个方面,我们需要计算“错误贡献”。
计算“错误贡献”
假设我们想回答以下问题:“如果模型没有job特征,会做出什么预测?”SHAP 值可以让我们回答这个问题。实际上,由于它们是可加的,只需从模型的预测中减去相对于job特征的 SHAP 值即可。
当然,我们可以对每个特征重复这个过程。在 Pandas 中:
y_pred_wo_feature = shap_values.apply(lambda feature: y_pred - feature)
这是结果:
如果我们去掉相应特征,得到的预测。 [图片由作者提供]
这意味着,如果我们没有job这个特征,那么模型会预测第一个个体 20k $,第二个个体-19k $,第三个个体-8k $。相反,如果我们没有age这个特征,模型会预测第一个个体 73k $,第二个个体 50k $,等等。
正如你所见,如果我们去掉不同的特征,每个个体的预测会有很大差异。因此,预测误差也会非常不同。我们可以轻松计算它们:
abs_error_wo_feature = y_pred_wo_feature.apply(lambda feature: (y_true - feature).abs())
结果如下:
如果我们去除相应特征,我们将得到的绝对误差。[图像来自作者]
这些是如果我们去除相应特征将得到的误差。直观地说,如果误差很小,那么去除特征对模型不是问题——甚至是有益的。如果误差很高,那么去除特征就不是一个好主意。
但我们可以做得更多。实际上,我们可以计算完整模型误差和去除特征后误差之间的差异:
error_diff = abs_error_wo_feature.apply(lambda feature: abs_error - feature)
即:
模型的误差与去除特征后误差之间的差异。[图像来自作者]
如果这个数字是:
-
如果是负数,那么特征的存在会导致预测误差的减少,因此该特征对该观察结果有效!
-
如果是正数,那么特征的存在会导致预测误差的增加,因此该特征对该观察结果不好。
我们可以将每个特征的这些值的均值计算为“错误贡献”。 在 Pandas 中:
error_contribution = error_diff.mean()
结果如下:

错误贡献。[图像来自作者]
如果这个值是正数,那么这意味着,平均而言,特征在模型中的存在会导致更高的错误。因此,没有这个特征,预测结果会更好。换句话说,这个特征带来的负面影响大于正面影响!
相反,这个值越负,特征对预测的帮助就越大,因为它的存在会导致较小的误差。
让我们尝试在实际数据集上应用这些概念。
预测黄金回报
以下,我将使用一个来自Pycaret(一个基于MIT 许可证的 Python 库)的数据集。该数据集名为“Gold”,包含金融数据的时间序列。
数据集样本。特征均以百分比表示,因此-4.07 意味着回报为-4.07%。[图像来自作者]
特征包括观察时刻(“T-22”、“T-14”、“T-7”、“T-1”)前 22 天、14 天、7 天和 1 天的金融资产回报。以下是用作预测特征的所有金融资产的详尽列表:

可用资产的列表。每个资产在时间-22、-14、-7 和-1 时被观察。[图像来自作者]
总共有 120 个特征。
目标是预测 22 天后的黄金价格(回报)(“Gold_T+22”)。让我们来看看目标变量。
变量的直方图。 [图像来源:作者]
一旦加载了数据集,我执行了以下步骤:
-
随机划分完整数据集:33%的行分配到训练数据集,另 33%到验证数据集,其余 33%到测试数据集。
-
在训练数据集上训练一个 LightGBM 回归模型。
-
在训练集、验证集和测试集上进行预测,使用在前一步训练的模型。
-
计算训练集、验证集和测试集的 SHAP 值,使用 Python 库“shap”。
-
计算每个特征在每个数据集(训练集、验证集和测试集)上的预测贡献和误差贡献,使用我们在前面段落中看到的代码。
比较预测贡献和误差贡献
让我们比较训练数据集中的误差贡献和预测贡献。我们将使用散点图,点表示模型的 120 个特征。
预测贡献与误差贡献(在训练数据集上)。 [图像来源:作者]
在训练集中,预测贡献和误差贡献之间存在高度负相关。
这也是有道理的:因为模型在训练数据集上学习,它倾向于将高重要性(即高预测贡献)赋予那些导致预测误差大幅减少的特征(即高负误差贡献)。
但这并没有增加太多我们的知识,对吧?
实际上,我们真正关心的是验证数据集。验证数据集实际上是我们关于特征在新数据上表现的最佳代理。因此,让我们在验证集上进行相同的比较。
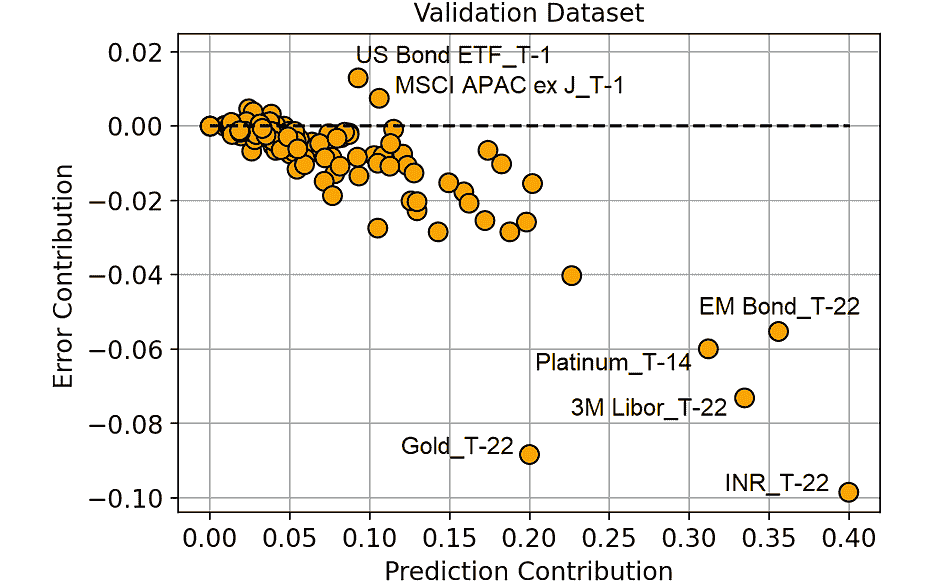
预测贡献与误差贡献(在验证数据集上)。 [图像来源:作者]
从这个图表中,我们可以提取一些更有趣的信息。
图表右下角的特征是模型正确地分配了高重要性的特征,因为它们实际减少了预测误差。
同样,需要注意的是“Gold_T-22”(观测期前 22 天的黄金回报)与模型赋予它的重要性相比,效果非常好。这意味着这个特征可能存在欠拟合。这一信息特别有趣,因为黄金是我们试图预测的资产(“Gold_T+22”)。
另一方面,具有大于 0 的错误贡献的特征正在使我们的预测变差。例如,“US Bond ETF_T-1”平均会将模型预测值改变 0.092%(预测贡献),但会导致模型预测比没有该特征时差 0.013%(错误贡献)。
我们可以假设所有高错误贡献(与其预测贡献相比)的特征可能正在过拟合,或者通常,它们在训练集和验证集上的表现有所不同。
让我们看看哪些特征具有最大的错误贡献。
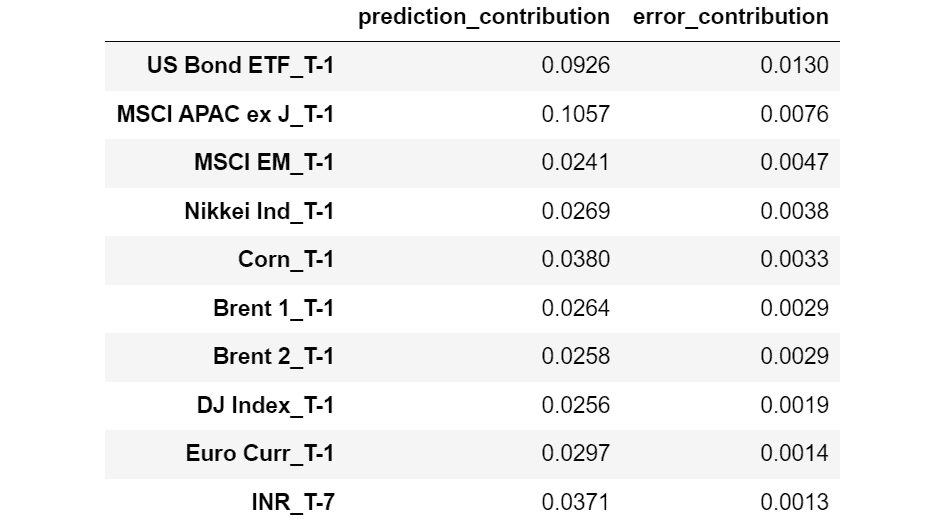
按错误贡献递减排序的特征。 [图像由作者提供]
现在来看错误贡献最低的特征:
按错误贡献递增排序的特征。 [图像由作者提供]
有趣的是,我们可以观察到所有具有较高错误贡献的特征相对于 T-1(观察时刻前 1 天),而几乎所有具有较小错误贡献的特征相对于 T-22(观察时刻前 22 天)。
这似乎表明最新的特征更容易过拟合,而时间较久的特征往往具有更好的泛化能力。
请注意,没有错误贡献,我们永远不会知道这一点。
使用错误贡献的 RFE
传统的递归特征消除(RFE)方法基于移除不重要的特征。这相当于首先移除预测贡献较小的特征。
然而,根据我们在前一段中所说的,首先移除具有最高错误贡献的特征会更有意义。
为了验证我们的直觉,让我们比较这两种方法:
-
传统 RFE:首先移除无用的特征(最低的预测贡献)。
-
我们的 RFE:首先移除有害的特征(最高的错误贡献)。
让我们看看验证集上的结果:
两种策略在验证集上的平均绝对误差。 [图像由作者提供]
每种方法的最佳迭代已被圈出:传统的 RFE(蓝线)是具有 19 个特征的模型,而我们的 RFE(橙线)是具有 17 个特征的模型。
总体而言,看来我们的方法效果很好:移除具有最高错误贡献的特征会导致 MAE consistently 较小,而不是移除具有最高预测贡献的特征。
然而,你可能会认为这只是因为我们过拟合了验证集。毕竟,我们更关心的是在测试集上得到的结果。
那么,让我们在测试集上看一下相同的比较。
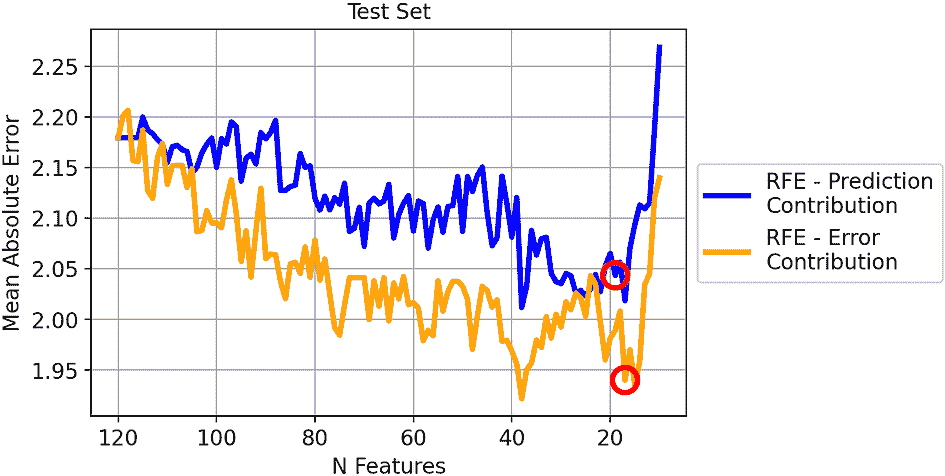
两种策略在测试集上的平均绝对误差。[图片来源作者]
结果与之前类似。即使两条线之间的距离较小,去除最高错误贡献者所得到的 MAE 明显优于去除最低预测贡献者所得到的 MAE。
由于我们选择了在验证集上产生最小 MAE 的模型,让我们看看它们在测试集上的表现:
-
RFE-预测贡献(19 个特征)。测试集上的 MAE:2.04。
-
RFE-错误贡献(17 个特征)。测试集上的 MAE:1.94。
所以,使用我们的方法得到的最佳 MAE 比传统 RFE 好 5%!
结论
特征重要性的概念在机器学习中扮演着基础性的角色。然而,“重要性”这一概念常被误解为“好处”。
为了区分这两个方面,我们引入了两个概念:预测贡献和错误贡献。这两个概念基于验证数据集的 SHAP 值,文章中我们已经看到计算它们的 Python 代码。
我们还在一个真实的金融数据集上进行了尝试(任务是预测黄金价格),并证明基于错误贡献的递归特征消除比基于预测贡献的传统 RFE 具有 5%的更好平均绝对误差。
本文所用的所有代码可以在这个笔记本中找到。
感谢阅读!
萨缪埃尔·马赞提 是 Jakala 的首席数据科学家,目前居住在罗马。他拥有统计学学位,主要研究兴趣包括工业中的机器学习应用。他也是一名自由内容创作者。
原文。转载经许可。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 需求
更多相关话题
零样本学习解释
原文:
www.kdnuggets.com/2022/12/zeroshot-learning-explained.html

布鲁斯·沃灵顿 通过 Unsplash
机器学习模型之所以变得更智能,是因为它们依赖于使用标记数据来帮助它们区分两个相似的物体。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
然而,在没有这些标记数据集的情况下,你在创建最有效和可信赖的机器学习模型时会遇到重大障碍。模型训练阶段的标记数据集是重要的。
深度学习已被广泛用于解决计算机视觉等任务,采用监督学习。然而,就像生活中的许多事物一样,它也有其限制。监督分类需要大量高质量的标记训练数据,以产生一个强健的模型。这意味着分类模型无法处理未见过的类别。
我们都知道训练深度学习模型需要多少计算能力、再训练、时间和金钱。
但是,一个模型是否仍然能够在没有使用训练数据的情况下区分两个物体?是的,这就是所谓的零样本学习。零样本学习是指一个模型在没有收到或使用任何训练示例的情况下完成任务的能力。
人类天生具备零样本学习的能力,不需要付出太多努力。我们的脑海中已经储存了词典,并且能够通过观察物体的物理属性来区分物体,这是由于我们现有的知识基础。我们可以利用这一知识基础来查看物体之间的相似性和差异性,并找到它们之间的联系。
例如,假设我们正在尝试建立一个动物物种的分类模型。根据 OurWorldInData,2021 年计算出有 213 万种物种。因此,如果我们想为动物物种创建最有效的分类模型,我们需要 213 万种不同的类别。同时也需要大量数据。高质量和数量的数据很难获得。
那么零样本学习如何解决这个问题呢?
因为零样本学习不要求模型学习训练数据和分类类别,它使我们可以减少对模型需要标注数据的依赖。
零样本学习过程
以下是你的数据需要包含的内容,以便进行零样本学习。
已见类别
这包括那些以前用于训练模型的数据类别。
未见类别
这包括那些没有用来训练模型的数据类别,新零样本学习模型将进行泛化。
辅助信息
由于未见类别中的数据没有标签,零样本学习将需要辅助信息以便进行学习,发现关联、链接和属性。这可以是词嵌入、描述和语义信息的形式。
零样本学习方法
零样本学习通常用于:
-
基于分类器的方法
-
基于实例的方法
阶段
零样本学习用于为不使用标注数据进行训练的类别构建模型,因此它需要这两个阶段:
1. 训练
训练阶段是学习方法尽可能多地捕捉数据特征的过程。我们可以将其视为学习阶段。
2. 推断
在推断阶段,所有从训练阶段学到的知识都会被应用和利用,以便将样本分类到新的类别集合中。我们可以将其视为预测阶段。
其工作原理是什么?
从已见类别中获得的知识将被转移到未见类别中,这发生在一个高维向量空间中;这被称为语义空间。例如,在图像分类中,语义空间以及图像将经历两个步骤:
1. 联合嵌入空间
这是语义向量和视觉特征向量被投射到的地方。
2. 最高相似度
这是特征与未见类别的特征进行匹配的地方。
图像分类中的零样本学习阶段
为了帮助理解这两个阶段(训练和推断)的过程,我们将它们应用于图像分类。
训练

Jari Hytönen 通过 Unsplash
作为人类,如果你阅读上图右侧的文本,你会立即认为有 4 只小猫在一个棕色的篮子里。但假设你对“小猫”没有任何概念。你会假设篮子里有 4 样东西,被称为“小猫”。一旦你看到更多包含类似“小猫”的图像,你就能够区分“小猫”和其他动物。
当你使用 对比语言-图像预训练(CLIP)进行图像分类的零样本学习时,就会发生这种情况。这被称为辅助信息。
你可能会想,“那只是标记数据”。我理解你为什么会这么想,但它们并不是。辅助信息不是数据的标签,而是一种监督方式,帮助模型在训练阶段进行学习。
当一个零样本学习模型看到足够数量的图像-文本配对时,它将能够区分和理解短语及其如何与图像中的某些模式相关联。通过使用 CLIP 技术的“对比学习”,零样本学习模型已经积累了良好的知识基础,从而能够在分类任务上进行预测。
这是 CLIP 方法的总结,其中训练了一个图像编码器和一个文本编码器,以预测一批(图像,文本)训练示例的正确配对。请参见下图:
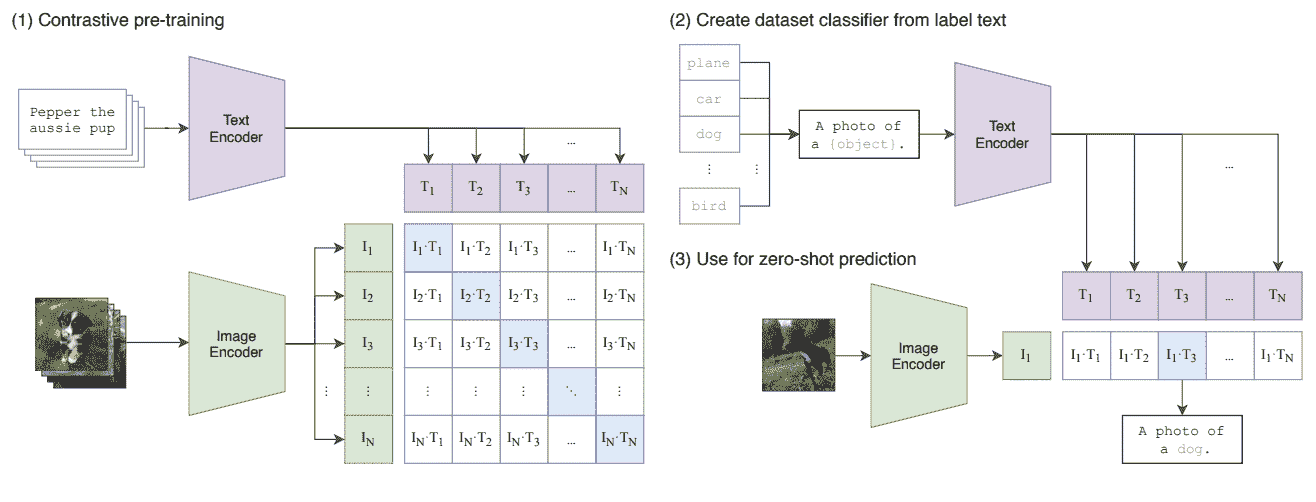
推断
一旦模型完成了训练阶段,它就具备了图像-文本配对的良好知识基础,并且现在可以用来进行预测。但在我们真正开始预测之前,我们需要通过创建一个可能的标签列表来设置分类任务。
例如,继续进行动物物种的图像分类任务,我们需要一个所有动物物种的列表。这些标签中的每一个都将被编码,从 T?到 T?,使用在训练阶段发生的预训练文本编码器。
一旦标签被编码,我们可以通过预训练的图像编码器输入图像。我们将使用距离度量余弦相似度来计算图像编码与每个文本标签编码之间的相似性。
图像的分类是基于与图像最相似的标签进行的。这就是零样本学习在图像分类中的实现方式。
零样本学习的重要性
数据稀缺性
如前所述,高数量和高质量的数据很难获得。与已经具备零样本学习能力的人类不同,机器需要输入标记数据以进行学习,然后才能适应可能自然发生的变化。
如果我们看动物物种的例子,会发现有很多种。随着不同领域类别数量的不断增长,跟上收集标注数据的工作将会非常繁重。
因此,零样本学习对我们变得越来越有价值。越来越多的研究人员对自动属性识别感兴趣,以弥补数据缺乏的问题。
数据标注
零样本学习的另一个好处是其数据标注特性。数据标注可能非常耗费劳力且十分枯燥,因此在过程中可能会导致错误。数据标注需要专家,比如在生物医学数据集上工作的医疗专业人士,这既昂贵又耗时。
总结
零样本学习因数据的上述限制而变得越来越流行。如果你对其能力感兴趣,我推荐你阅读以下几篇论文:
Nisha Arya 是一位数据科学家和自由技术撰稿人。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能在延长人类生命方面的不同方式。她是一个热衷于学习的人,寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关主题
使用命令行中的 TensorFlow 创建您的第一个 GitHub 项目中的 GAN
原文:
www.kdnuggets.com/2018/05/zimbres-first-github-project-gans.html
评论
由 Rubens Zimbres,数据科学家
我从 2016 年开始贡献于 GitHub。自那时起,我的代码库中有超过 100 个不同的文件,包含了我在学习数据科学期间开发的机器学习、深度学习和自然语言处理代码。但它们只是简单的代码库,我没有专注于开发一个 GitHub 项目。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT
在本文中,我将介绍创建您的第一个 GitHub 项目的步骤。我将以生成对抗网络为例。如果您想了解更多关于 GAN 的信息,可以点击我的 PDF 演示文稿查看:
正如您将在我的项目中看到的那样,有一个 main.py 文件,其中包含 GAN 代码,还有一个包含正确运行代码所需库的文件(requirements.txt)。
文件 main.py 包含 GAN 代码本身和运行笔记本所需的参数。这些参数以这种形式插入到 main.py 中:
import argparse
parser = argparse.ArgumentParser(description='')
parser.add_argument('--epoch', dest='nb_epoch', type=int, default=5000, help='# of epochs')
parser.add_argument('--learning_rate', dest='lr', type=float, default=0.0001, help='# learning rate')
parser.add_argument('--sample_size', dest='sample_size', type=int, default=60, help='# sample size')
parser.add_argument('--gen_hidden', dest='gen_hidden', type=int, default=80, help='# hidden nodes in generator')
parser.add_argument('--disc_hidden', dest='disc_hidden', type=int, default=80, help='# hidden nodes in discriminator')
parser.add_argument('--your_login', dest='your_login', type=str, default='rubens', help='# your login name')
args = vars(parser.parse_args())
另一个文件 requirements.txt 包含运行 main.py 文件所需的库,简单形式如下:
tensorflow
numpy
matplotlib
keras
pandas
接下来,我们可以开发一个交互式函数,为用户提供指南,并获取其操作系统,以便代码自定义 Tensorboard 文件存储的文件夹。
var0 = input("Are you using Linux? [y|n]")
if str(var0)=='n':
logs_path = 'C:/Users/'+args['your_login']+'/Anaconda3/envs/Scripts/plot_1'
else:
logs_path = '/home/'+args['your_login']+'/anaconda3/envs/plot_1'
之后我们定义一个包含 GAN 的函数:
def GAN(sample_size):
tf.reset_default_graph()
def generator(x, reuse=False):
with tf.variable_scope('Generator', reuse=reuse):
x = tf.layers.dense(x, units=6 * 6 * 64)
x = tf.nn.relu(x)
x = tf.reshape(x, shape=[-1, 6, 6, 64])
x = tf.layers.conv2d_transpose(x, 32, 4, strides=2)
x = tf.layers.conv2d_transpose(x, 1, 2, strides=2)
x = tf.nn.relu(x)
x = tf.reshape(x, [n,784])
return x
def discriminator(x, reuse=False):
with tf.variable_scope('Discriminator', reuse=reuse):
x = tf.reshape(x, [n,28,28,1])
x = tf.layers.conv2d(x, 32, 5)
x = tf.nn.relu(x)
x = tf.layers.average_pooling2d(x, 2, 2,padding='same')
x = tf.layers.conv2d(x, 64, 5,padding='same')
x = tf.nn.relu(x)
x = tf.layers.average_pooling2d(x, 8, 8)
x = tf.contrib.layers.flatten(x)
x = tf.layers.dense(x, 784)
x = tf.nn.sigmoid(x)
return x
… 等等。文章末尾我将提供我代码库的完整链接。
我们还添加了生成 Tensorboard 的代码行,使用 tf.summary:
损失:
tf.summary.scalar("Generator_Loss", gen_loss)
tf.summary.scalar("Discriminator_Loss", disc_loss)
由生成器生成并由判别器分类的图像:
tf.summary.image('GenSample', tf.reshape(gen_sample, [-1, 28, 28, 1]), 4)
tf.summary.image('stacked_gan', tf.reshape(stacked_gan, [-1, 28, 28, 1]), 4)
还有,权重的直方图:
for i in range(0,11):
with tf.name_scope('layer'+str(i)):
pesos=tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES)
tf.summary.histogram('pesos'+str(i), pesos[i])
然后我们打开 Tensorflow 会话以运行反向传播并生成图像:
with tf.Session() as sess:
sess.run(init)
summary_writer = tf.summary.FileWriter(logs_path, graph=tf.get_default_graph())
for i in range(1, num_steps+1):
batch_x, batch_y=next_batch(batch_size, x_train
, x_train_noisy)
feed_dict = {real_image_input: batch_x, noise_input: batch_y,
disc_target: batch_x, gen_target: batch_y}
_, _, gl, dl,summary2 = sess.run([train_gen, train_disc, gen_loss, disc_loss,summary],
feed_dict=feed_dict)
g = sess.run([stacked_gan], feed_dict={noise_input: batch_y})
h = sess.run([gen_sample], feed_dict={noise_input: batch_y})
summary_writer.add_summary(summary2, i)
if i % show_steps == 0 or i == 1:
print('Epoch %i: Generator Loss: %f, Discriminator Loss: %f' % (i, gl, dl))
最终:
if __name__ == '__main__':
GAN(args[‘sample_size’])
要运行代码,您必须在 Anaconda 文件夹中运行:
$ git clone https://github.com/RubensZimbres/GAN-Project-2018
$ cd GAN-Project-2018
$ conda install --yes --file requirements.txt
$ python main.py --epoch=4000 --learning_rate=0.0001 –your_login=rubens
其中:
Arguments:
--epoch: default=5000
--learning_rate: default=0.0001
--sample_size: default=60
--gen_hidden: # hidden nodes in generator: default=80
--disc_hidden: # hidden nodes in discriminator: default=80
--your_login: your login in your OS: default:rubens
这行代码提供的参数将按如下方式自定义您的 GAN:
num_steps = args['nb_epoch']
learning_rate1=args['lr']
image_dim = 784
gen_hidden_dim = args['gen_hidden']
disc_hidden_dim = args['disc_hidden']
这是你预计得到的输出:
Tensorboard 将在你关闭弹出窗口后启动(GAN 输出与 MNIST 数字)
关闭 MNIST 弹出窗口后,代码通过 main.py 中的以下代码行启动 Tensorboard 服务器:
os.system('tensorboard –logdir='+logs_path)
然后,你可以访问 Tensorboard 提供的 URL,在浏览器中查看训练细节,如标量(训练损失)、图形(GAN 结构)、图像(生成和分类)和直方图(权重)。请查看以下图片。
要访问此项目的详细信息,请访问:github.com/RubensZimbres/GAN-Project-2018
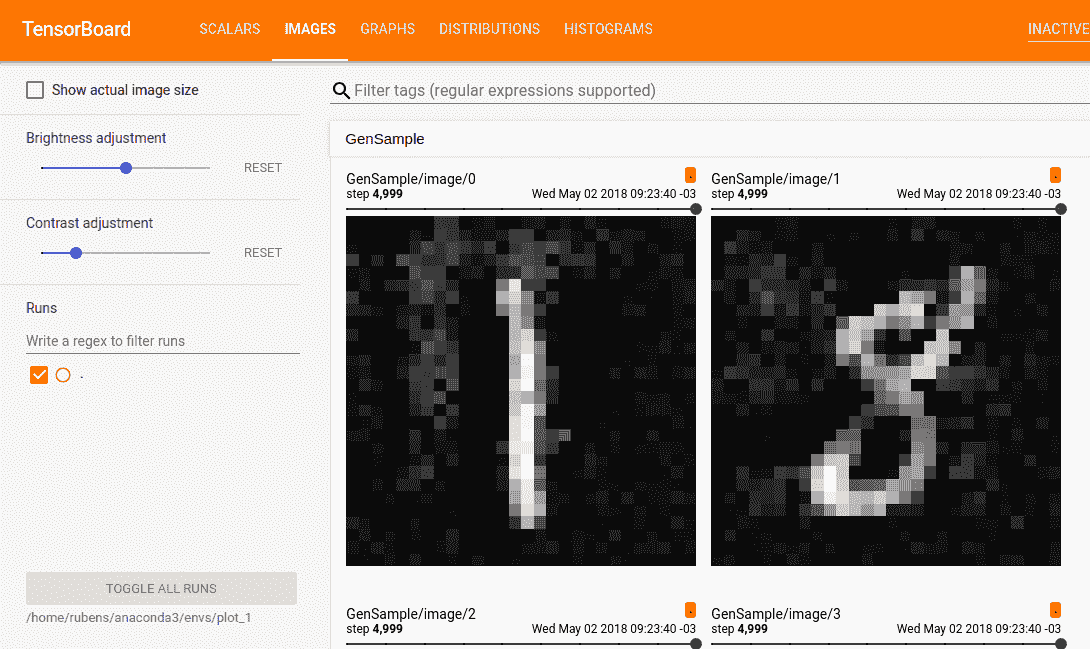
个人简介:Rubens Zimbres,博士,是一位战略家和数据科学家,拥有超过 23 年的客户服务、管理和财务规划经验,曾在战略规划和重组、物理和数字营销、社交网络分析、人员管理、客户数据库分析等领域担任首席执行官和数据科学家。他拥有 13 年市场研究专长和 10 年数据分析经验。
相关:
-
生成对抗网络概述
-
前 20 名 Python AI 和机器学习开源项目
-
我如何不知不觉地为开源做出贡献
更多相关话题
AWS 上的 IoT:来自传感器数据的机器学习模型和仪表板
原文:
www.kdnuggets.com/2018/06/zimbres-iot-aws-machine-learning-dashboard.html
评论
由 Rubens Zimbres, 数据科学家
Google Colab 具有帮助数据科学家在全球范围内进行工作的开源项目。受到这种思维方式的启发,我使用我的笔记本作为 IoT 设备,AWS IoT 作为基础设施,开发了我的第一个 IoT 项目。
所以,我有一个“简单”的想法:从运行 Ubuntu 的笔记本电脑中收集 CPU 温度,发送到 Amazon AWS IoT,保存数据,使其可用于机器学习模型和仪表板。
然而,这个想法的实施相当复杂:首先,开发一个 Python 笔记本,内部运行 Ubuntu 命令行(‘sensors’),收集 CPU 温度,并能够通过合适的安全协议使用 MQTT 连接到 AWS IoT。无需使用像 Mosquitto 这样的 MQTT 代理。
需要在 AWS IoT 创建一个 Thing,获取证书,创建并附加策略,并创建一个 SQL 规则,将数据(JSON)发送到 Cloud Watch 和 Dynamo DB。然后,从 Dynamo DB 到 S3 创建一个数据管道,使数据可用于机器学习模型以及 AWS Quick Sight 仪表板。
让我们从在 Ubuntu 16.04 中安装‘sensors’和在 Anaconda 3 中安装‘AWSIoTPythonSDK’库开始:
$ sudo apt-get install lm-sensors
$ sudo service kmod start
我们来看看‘sensors’命令的样子:
现在,安装 AWSIoTPythonSDK 库:
$ pip install AWSIoTPythonSDK
从 Python 笔记本开始:以下函数用于在延迟 5 秒后收集 CPU 温度:
import subprocess
import shlex
import time
def measure_temp():
temp = subprocess.Popen(shlex.split('sensors -u'),
stdout=subprocess.PIPE,
bufsize=10, universal_newlines=True)
return temp.communicate()
while True:
string=measure_temp()[0]
print(string.split()[8])
time.sleep(5)
然后,我们从 Linux 命令行运行笔记本:
好的。现在这段代码被插入到 AWSIoTPythonSDK 库中的 basicPubSub.py 笔记本中,如下所示:
while True:
if args.mode == 'both' or args.mode == 'publish':
args.message=measure_temp()[0].split()[8]
mess={"reported": {"light": "blue",
"Temperature": measure_temp()[0].split()[8],"timestamp": time.time()
},"timestamp": 1526519248}
args.message=mess
print(measure_temp()[0].split()[8],(time.time()-start)/60,'min')
print(mess,'\n')
message = {}
message['message'] = args.message
message['sequence'] = loopCount
messageJson = json.dumps(message)
myAWSIoTMQTTClient.publish(topic, messageJson, 1)
if args.mode == 'publish':
print('Published topic %s: %s\n' % (topic, messageJson))
loopCount += 1
time.sleep(5)
很棒。我们有一个 Python 笔记本,它将通过 MQTT 协议连接到 AWS IoT Core。现在我们在 AWS IoT 上设置影子(JSON 文件),这类似于 Microsoft 的‘device twin’。注意,由于我只有一个设备,所以我没有在 JSON 文件中插入设备 ID。
{
"desired": {
"light": "green",
"Temperature": 55,
"timestamp": 1526323886
},
"reported": {
"light": "blue",
"Temperature": 55,
"timestamp": 1526323886
},
"delta": {
"light": "green"
}
}
现在我们获得了证书.pem、.key 文件和 rootCA.pem 以确保安全连接。我们在 Ubuntu 中按 CTRL+ALT+T 打开命令行,输入命令并发布到一个主题 '-t':
$ python basicPubSub_adapted.py -e 1212345.iot.us-east-1.amazonaws.com -r rootCA.pem -c 2212345-certificate.pem.crt -k 2212345-private.pem.key -id arn:aws:iot:us-east-1:11231112345:thing/CPUUbuntu -t 'Teste'
我们将在 Linux shell 中收到来自 AWS IoT 连接的反馈,并在 AWS IoT 监控工具中检查(1 分钟后)连接是否成功:
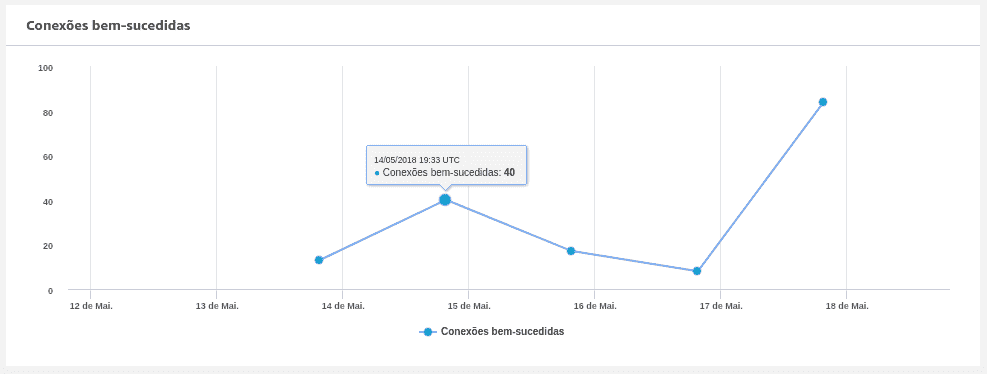
还可以查看消息是否正在发布(橙色区域),以及用于连接的协议(左侧):
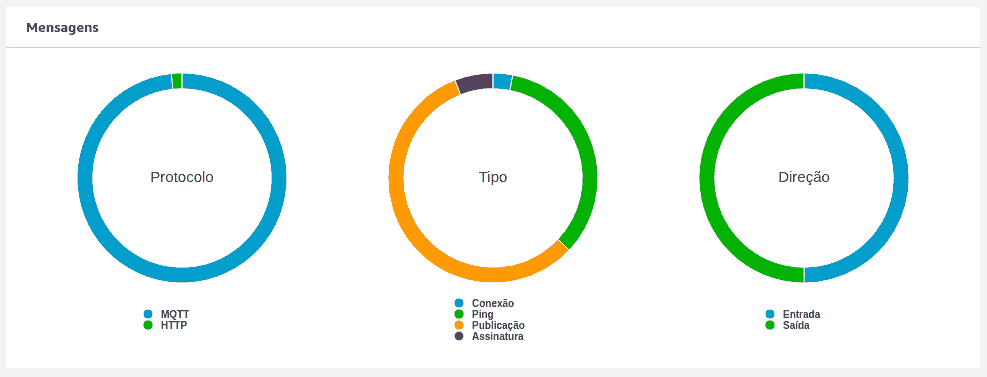
同时,我们可以看到‘shadow’也在更新中(中间):
现在我们创建一个 SQL 规则,将数据发送到 Cloud Watch 和 Dynamo DB,并创建 IAM 角色、策略和权限:
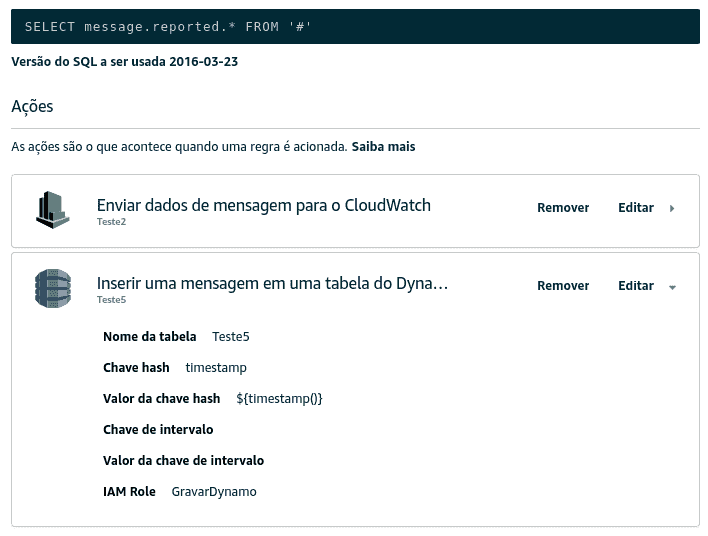
数据随后保存到 DynamoDB,作为 JSON 文件。你可以使用 MessageID 作为主键,而不是时间戳。
现在我们可以在 CloudWatch 中可视化云动态和数据传输:
然后我们创建一个从 DynamoDB 到 S3 的数据管道,以便 QuickSight 使用:
还需要创建一个 JSON 文件并设置 IAM 权限,以便 QuickSight 可以从 S3 存储桶中读取:
{
"fileLocations": [
{
"URIs": [
"https://s3.amazonaws.com/your-bucket/2018-05-19-19-41-16/12345-c2712345-12345"
]
},
{
"URIPrefixes": [
"https://s3.amazonaws.com/your-bucket/2018-05-19-19-41-16/12345-c2712345-12345"
]
}
],
"globalUploadSettings": {
"format": "JSON",
"delimiter": "\n","textqualifier":"'"
}
}
现在我们在 QuickSight 中有了静态的 CPU 温度图。
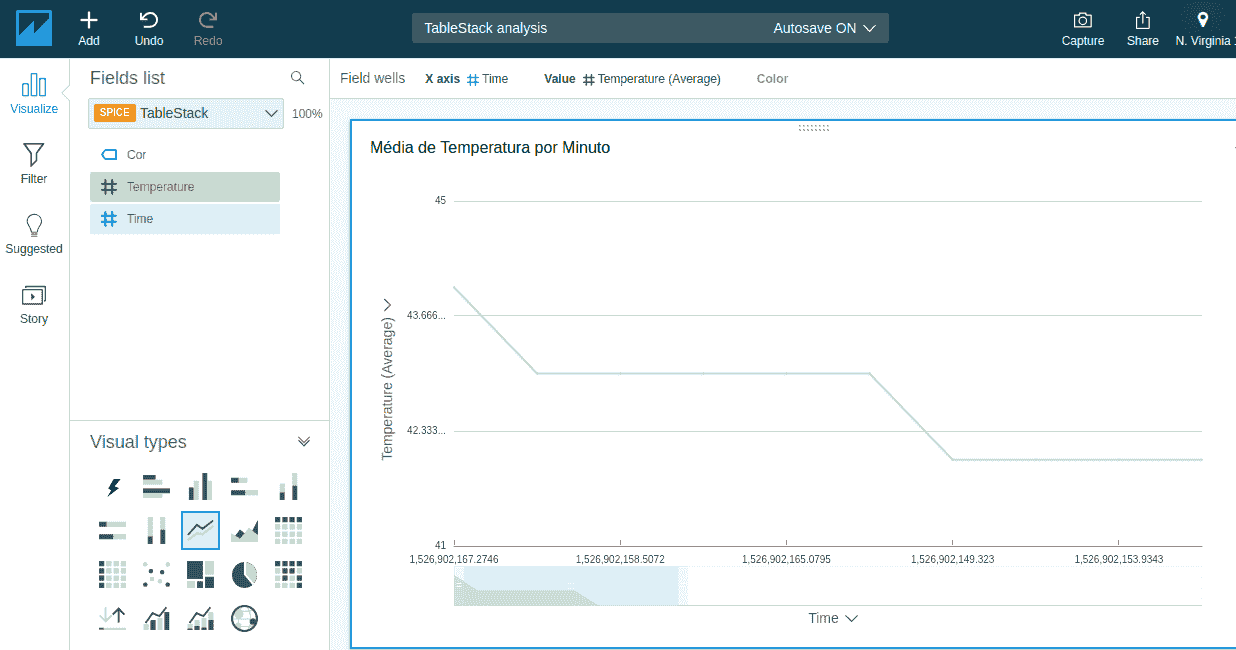
此外,S3 数据(.JSON 文件)现在可用于机器学习模型,如异常检测、预测和分类,使得可以使用 Sage Maker 和深度学习库创建管道 = 有趣。
这是一种很好的方式来接触 Amazon AWS 服务,如 EC2、IoT、Cloud Watch、DynamoDB、S3、Quick Sight 和 Lambda。设置所有这些服务及其依赖关系确实不容易,但这个部分的项目成本不到 1 美元。而且非常有趣!
这是项目第一部分在 AWS 上的流程图:
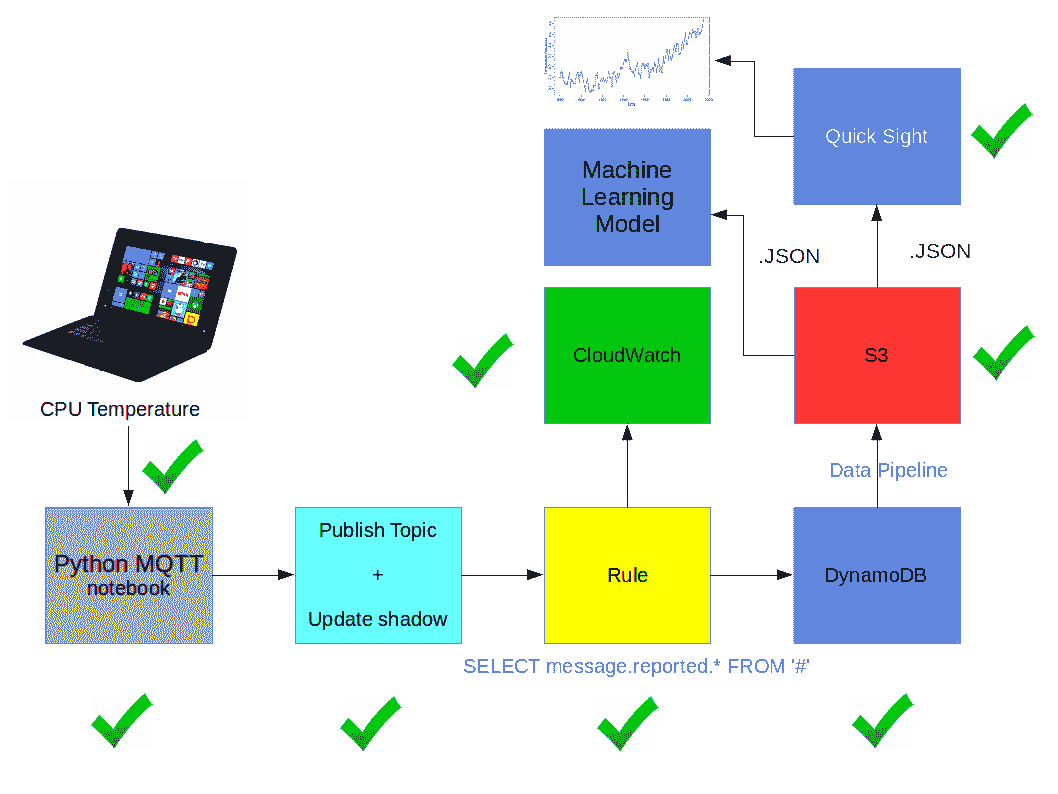
项目第二部分 – 接近实时仪表盘
现在让我们开发第二个解决方案,使用从 AWS IoT 发送到 Kinesis / Firehose 的流数据,然后到 AWS ElasticSearch,最后到 Kibana,形成一个接近实时的仪表盘。你可以选择使用 Lambda 清理和提取数据(也可以不使用),将 AWS IoT 作为输入,AWS Batch 作为输出连接到 Kinesis。无论如何,Kibana 能够解析你的 JSON 文件。
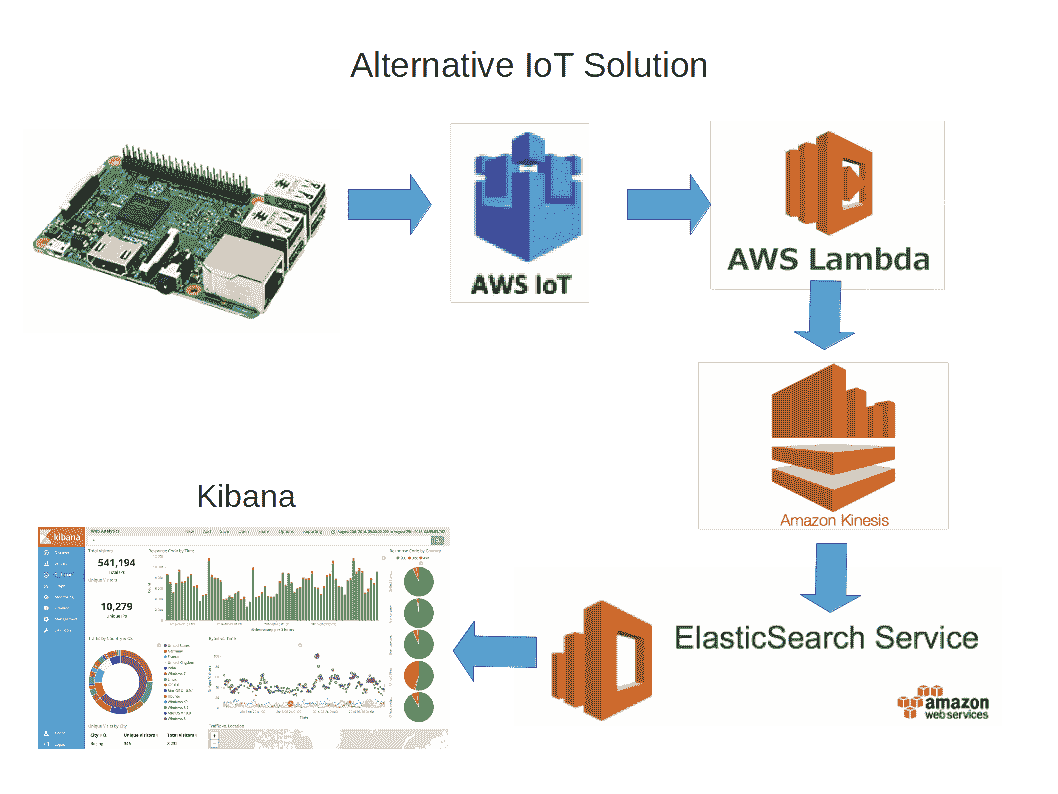
首先,我们必须为 AWS IoT 设置另一条规则,以将遥测数据发送到 Kinesis Firehose 流:
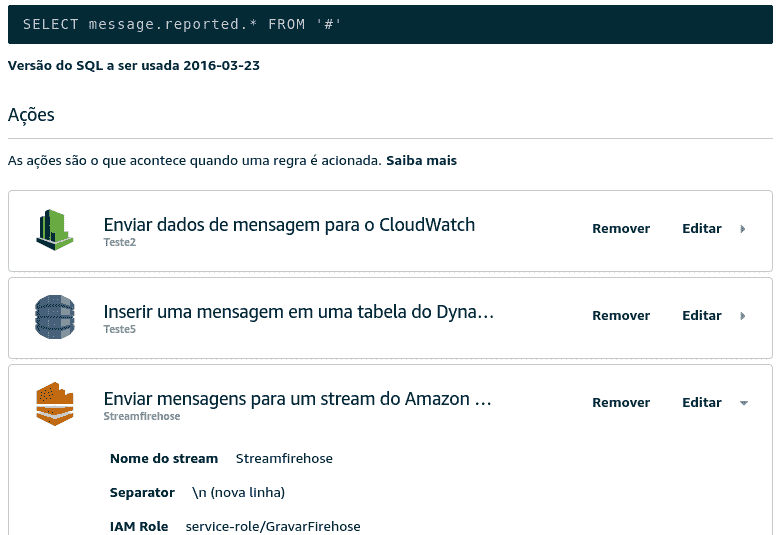
然后创建一个 Elastic Search 域
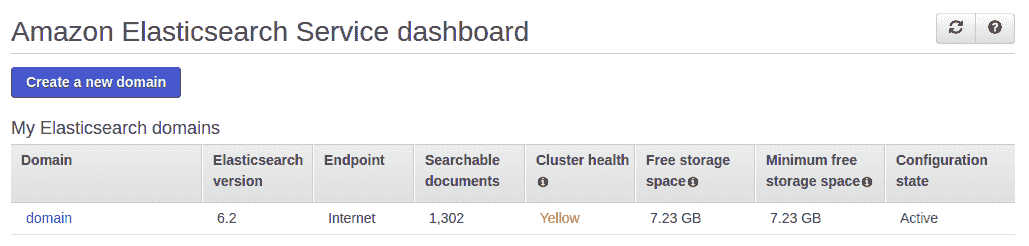
设置对特定 IP 的访问:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": "es:*",
"Resource": "arn:aws:es:us-east-1:12345:domain/domain/*",
"Condition": {
"IpAddress": {
"aws:SourceIp": "178.042.222.33"
}
}
}
]
}
然后我们使用 Kinesis Firehose 创建流和流传输。
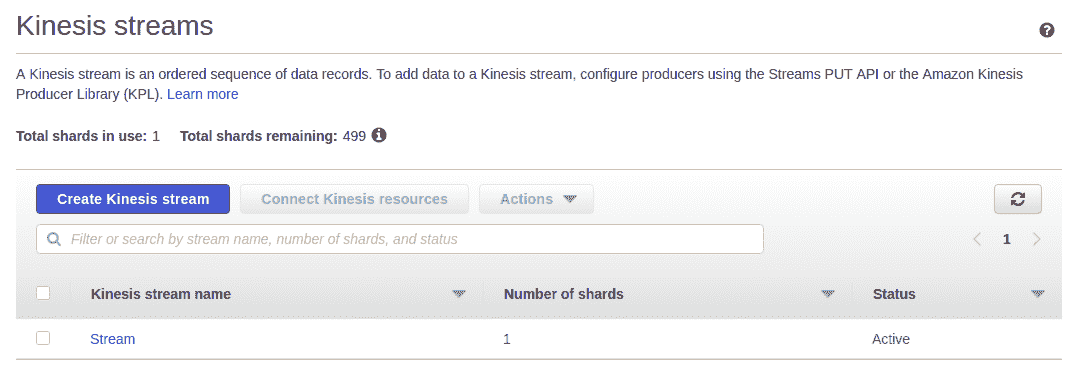
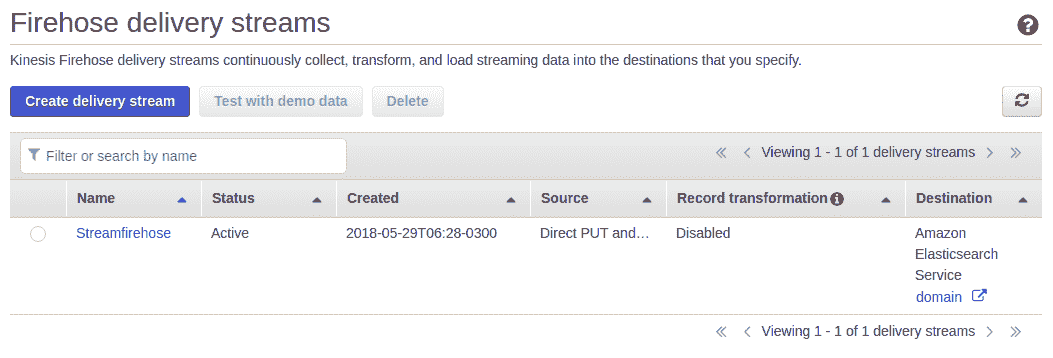
最后,我们将 AWS Elasticsearch 与 Kibana 连接,在 Kibana 的“Dev Tools”中进行调整:
PUT /data
{
"mappings": {
"doc": {
"properties": {
"light":{"type":"text"},
"Temperature": {"type": "integer"},
"timestamp": {"type": "integer"}
}
}
}
}
注意 Elasticsearch 将提供一个 Kibana 端点。最后,我们有了我们的接近实时的 CPU 温度仪表盘。值得注意的是,我们几乎处于实时环境。问题在于 Kibana 每 5 秒(或 15 秒,如果你愿意)更新一次图形,但 Elasticsearch 的最小延迟为 60 秒。
我们现在可以可视化我们的炫酷仪表盘:
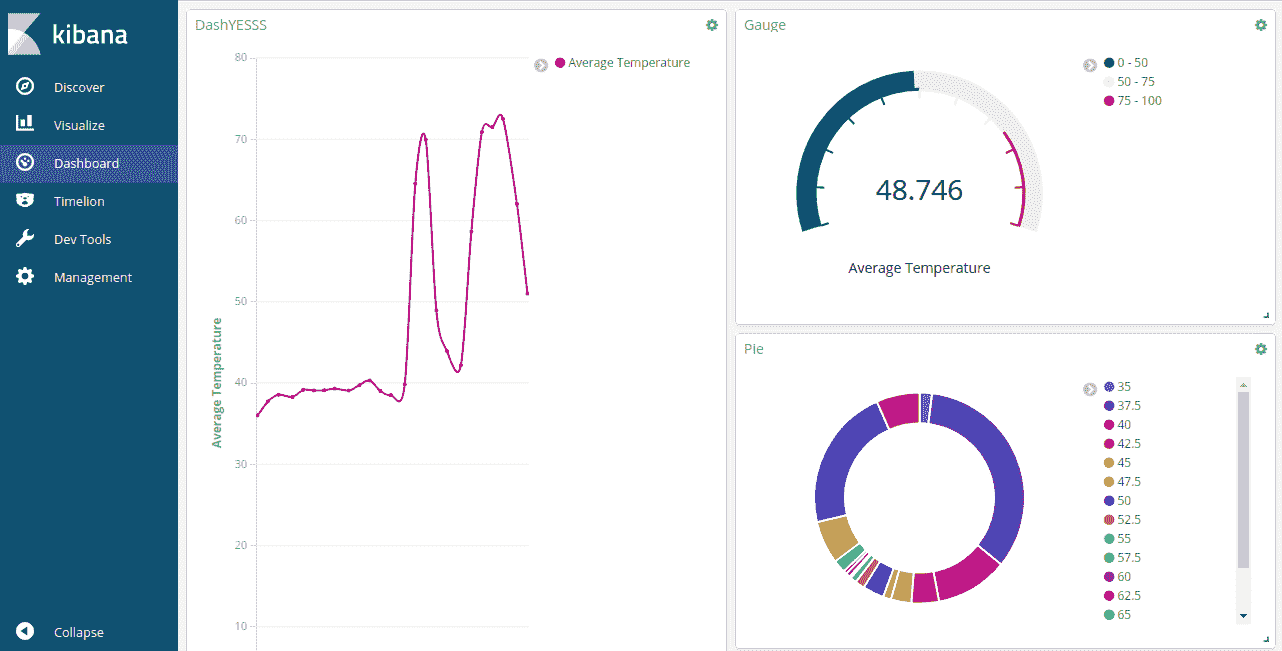
更多信息和文件请访问我的 GitHub - 仓库 2018(CPU 温度 – IoT 项目): github.com/RubensZimbres/Repo-2018
简历: 鲁本斯·津布雷斯 是一名数据科学家,拥有人工智能和细胞自动机方向的商业管理博士学位。目前在电信领域工作,为金融行业和农业开发机器学习、深度学习模型及 IoT 解决方案。
相关:
-
通过命令行在 TensorFlow 中使用 GANs:创建你的第一个 GitHub 项目
-
将“科学”带回数据科学
-
应用于大数据的机器学习,详解
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 需求
更多相关主题


 浙公网安备 33010602011771号
浙公网安备 33010602011771号