KDNuggets-博客中文翻译-三十四-
KDNuggets 博客中文翻译(三十四)
原文:KDNuggets
如何利用 TPU 免费将 Keras 模型训练速度提高 20 倍
原文:
www.kdnuggets.com/2019/03/train-keras-model-20x-faster-tpu-free.html
 评论
评论
作者:Chengwei Zhang,上海工业技术研究院 / 程序员 / 创客

有段时间,我一直很满足于在一张 GTX 1070 显卡上训练我的模型,该显卡单精度约为 8.18 TFlops,然后谷歌在 Colab 上开放了他们的免费 Tesla K80 GPU,具有 12GB RAM,速度略快,为 8.73 TFlops。直到最近,Cloud TPU 选项以 180 TFlops 出现在 Colab 的运行时类型选择器中。在这个快速教程中,你将学习如何将现有的 Keras 模型转换为 TPU 模型,并在 Colab 上以免费方式训练,速度比我的 GTX1070 快 20 倍。
我们将构建一个易于理解但足够复杂的 Keras 模型,以便稍微热身 Cloud TPU。在 IMDB 情感分类任务上训练 LSTM 模型是一个很好的例子,因为 LSTM 的训练计算开销可能比 Dense 和卷积等其他层更大。
工作流程概述,
-
构建一个用于训练的 Keras 模型,在功能性 API 中使用静态输入
batch_size。 -
将 Keras 模型转换为 TPU 模型。
-
使用静态
batch_size * 8训练 TPU 模型,并将权重保存到文件中。 -
构建一个用于推断的 Keras 模型,保持相同的结构,但批量输入大小可变。
-
加载模型权重。
-
使用推断模型进行预测。
你可以在阅读的同时玩转 Colab Jupyter 笔记本——Keras_LSTM_TPU.ipynb。
首先,按照下图中的说明激活 Colab 运行时中的 TPU。
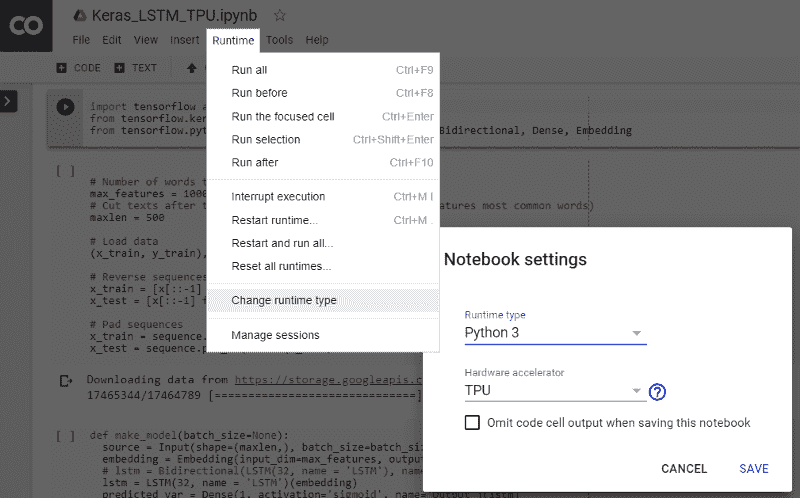 激活 TPU
激活 TPU
静态输入批量大小
在 CPU 和 GPU 上运行的输入管道大多不受静态形状要求的限制,而在 XLA/TPU 环境中,静态形状和批量大小是强制要求的。
Cloud TPU 包含 8 个 TPU 核心,这些核心作为独立的处理单元进行操作。除非使用所有八个核心,否则 TPU 不会被充分利用。为了通过矢量化完全加速训练,我们可以选择比在单个 GPU 上训练相同模型时更大的批量大小。总批量大小为 1024(每核心 128)通常是一个不错的起点。
如果你打算训练一个较大的模型,批量大小过大时,尝试逐渐减少批量大小,直到它适合 TPU 内存,同时确保总批量大小是 64 的倍数(每核心的批量大小应为 8 的倍数)。
还值得提到的是,当使用更大的批次大小进行训练时,通常可以安全地增加优化器的学习率,以实现更快的收敛。你可以在这篇论文中找到参考——“准确的大规模小批量 SGD: 1 小时内训练 ImageNet”。
在 Keras 中,为了定义一个静态的批次大小,我们使用其函数式 API 然后为 Input 层指定batch_size参数。注意,模型在一个函数中构建,该函数接受一个batch_size参数,因此我们可以稍后返回以创建另一个模型,用于在 CPU 或 GPU 上运行的推理,这需要接受可变批次大小的输入。
import tensorflow as tf
from tensorflow.python.keras.layers import Input, LSTM, Bidirectional, Dense, Embedding
def make_model(batch_size=None):
source = Input(shape=(maxlen,), batch_size=batch_size,
dtype=tf.int32, name='Input')
embedding = Embedding(input_dim=max_features,
output_dim=128, name='Embedding')(source)
lstm = LSTM(32, name='LSTM')(embedding)
predicted_var = Dense(1, activation='sigmoid', name='Output')(lstm)
model = tf.keras.Model(inputs=[source], outputs=[predicted_var])
model.compile(
optimizer=tf.train.RMSPropOptimizer(learning_rate=0.01),
loss='binary_crossentropy',
metrics=['acc'])
return model
training_model = make_model(batch_size=128)
此外,使用 tf.train.Optimizer 而不是标准的 Keras 优化器,因为 Keras 优化器对 TPU 的支持仍在实验阶段。
将 Keras 模型转换为 TPU 模型
tf.contrib.tpu.keras_to_tpu_model 函数将 tf.keras 模型转换为等效的 TPU 版本。
import os
import tensorflow as tf
# This address identifies the TPU we'll use when configuring TensorFlow.
TPU_WORKER = 'grpc://' + os.environ['COLAB_TPU_ADDR']
tf.logging.set_verbosity(tf.logging.INFO)
tpu_model = tf.contrib.tpu.keras_to_tpu_model(
training_model,
strategy=tf.contrib.tpu.TPUDistributionStrategy(
tf.contrib.cluster_resolver.TPUClusterResolver(TPU_WORKER)))
然后我们使用标准的 Keras 方法来训练、保存权重和评估模型。注意,由于输入样本均匀分布在 8 个 TPU 核心上,batch_size 设置为模型输入 batch_size 的八倍。
history = tpu_model.fit(x_train, y_train,
epochs=20,
batch_size=128 * 8,
validation_split=0.2)
tpu_model.save_weights('./tpu_model.h5', overwrite=True)
tpu_model.evaluate(x_test, y_test, batch_size=128 * 8)
我设置了一个实验来比较在我的 Windows PC 上本地运行的单个 GTX1070 和 Colab 上的 TPU 之间的训练速度,结果如下。
GPU 和 TPU 都接受 128 的输入批次大小,
GPU: 每个 epoch 179 秒。20 个 epoch 达到 76.9% 的验证准确率,总共 3600 秒。
TPU: 每个 epoch 5 秒,除了第一个 epoch 需要 49 秒。20 个 epoch 达到 95.2% 的验证准确率,总共 150 秒。
TPU 在 20 个 epoch 后的验证准确率高于 GPU,这可能是由于一次训练 8 批次每批次 128 个样本所致。
在 CPU 上进行推理
一旦我们有了模型权重,我们可以像往常一样加载它,并在另一个设备如 CPU 或 GPU 上进行预测。我们还希望推理模型能够接受灵活的输入批次大小,这可以通过之前的make_model()函数来实现。
inferencing_model = make_model(batch_size=None)
inferencing_model.load_weights('./tpu_model.h5')
inferencing_model.summary()
你可以看到推理模型现在接受可变的输入样本,
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
Input (InputLayer) (None, 500) 0
_________________________________________________________________
Embedding (Embedding) (None, 500, 128) 1280000
_________________________________________________________________
LSTM (LSTM) (None, 32) 20608
_________________________________________________________________
Output (Dense) (None, 1) 33
=================================================================
然后你可以使用标准的 fit()、evaluate() 函数与推理模型一起使用。
结论和进一步阅读
本快速教程展示了如何利用 Google Colab 上免费的 Cloud TPU 资源更快地训练 Keras 模型。
简介:Chengwei Zhang 是一名对深度学习和自然语言处理领域感兴趣的程序员。
原文。经许可转载。
相关:
-
在 Google Colab 中使用 Hyperas 调整 Keras 超参数
-
使用 Keras 长短期记忆(LSTM)模型预测股票价格
-
3 个必备的 Google Colaboratory 提示和技巧
我们的三大课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业。
1. 谷歌网络安全证书 - 快速进入网络安全职业。
 2. 谷歌数据分析专业证书 - 提升你的数据分析能力
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在的组织的 IT
更多相关主题
训练 sklearn 快速 100 倍
评论
作者:Evan Harris,Ibotta, Inc. 机器学习与数据科学经理
在 Ibotta,我们训练了大量的机器学习模型。这些模型驱动了我们的推荐系统、搜索引擎、定价优化引擎、数据质量等。它们为数百万用户提供预测,用户在使用我们的移动应用时会与这些模型互动。
虽然我们用Spark处理了很多数据,但我们首选的机器学习框架是scikit-learn。随着计算成本的降低以及机器学习解决方案的市场时间变得越来越关键,我们探索了加速模型训练的选项。解决方案之一是将 Spark 和 scikit-learn 的元素结合成我们自己的混合解决方案。
介绍 sk-dist
我们很高兴地宣布我们的开源项目sk-dist的上线。该项目的目标是提供一个通用框架,以便在 Spark 中分发 scikit-learn 元估计器。元估计器的例子包括决策树集成(随机森林 和 额外随机树)、超参数调优器(网格搜索 和 随机搜索)以及多类技术(一对其余 和 一对一)。

我们的主要动机是填补传统机器学习模型分发选项中的空白。在神经网络和深度学习的领域之外,我们发现,训练模型的大部分计算时间并不是用来在单一数据集上训练单一模型。大部分时间用于在多个数据集的多个迭代上训练多个模型,使用像网格搜索或集成这样的元估计器。
示例
考虑一下 手写数字数据集。在这里,我们已经对手写数字图像进行了编码,以便进行适当分类。我们可以在单台机器上非常快速地训练一个 支持向量机 处理 1797 条记录的数据集。这只需不到一秒钟。但超参数调整需要在不同的训练数据子集上进行多个训练作业。
如下所示,我们构建了一个总共需要 1050 个训练作业的参数网格。在具有超过一百个核心的 Spark 集群上使用 sk-dist 只需 3.4 秒。此作业的总任务时间为 7.2 分钟,这意味着在没有并行化的情况下,单台机器上训练将需要这么长时间。
import timefrom sklearn import datasets, svm
from skdist.distribute.search import DistGridSearchCV
from pyspark.sql import SparkSession # instantiate spark session
spark = (
SparkSession
.builder
.getOrCreate()
)
sc = spark.sparkContext # the digits dataset
digits = datasets.load_digits()
X = digits["data"]
y = digits["target"] # create a classifier: a support vector classifier
classifier = svm.SVC()
param_grid = {
"C": [0.01, 0.01, 0.1, 1.0, 10.0, 20.0, 50.0],
"gamma": ["scale", "auto", 0.001, 0.01, 0.1],
"kernel": ["rbf", "poly", "sigmoid"]
}
scoring = "f1_weighted"
cv = 10# hyperparameter optimization
start = time.time()
model = DistGridSearchCV(
classifier, param_grid,
sc=sc, cv=cv, scoring=scoring,
verbose=True
)
model.fit(X,y)
print("Train time: {0}".format(time.time() - start))
print("Best score: {0}".format(model.best_score_))------------------------------
Spark context found; running with spark
Fitting 10 folds for each of 105 candidates, totalling 1050 fits
Train time: 3.380601406097412
Best score: 0.981450024203508
这个例子说明了一个常见的场景,其中将数据适配到内存并训练单个分类器是微不足道的,但超参数调整所需的拟合次数很快就会增加。以下是使用 sk-dist 运行如上例的网格搜索问题的幕后分析:
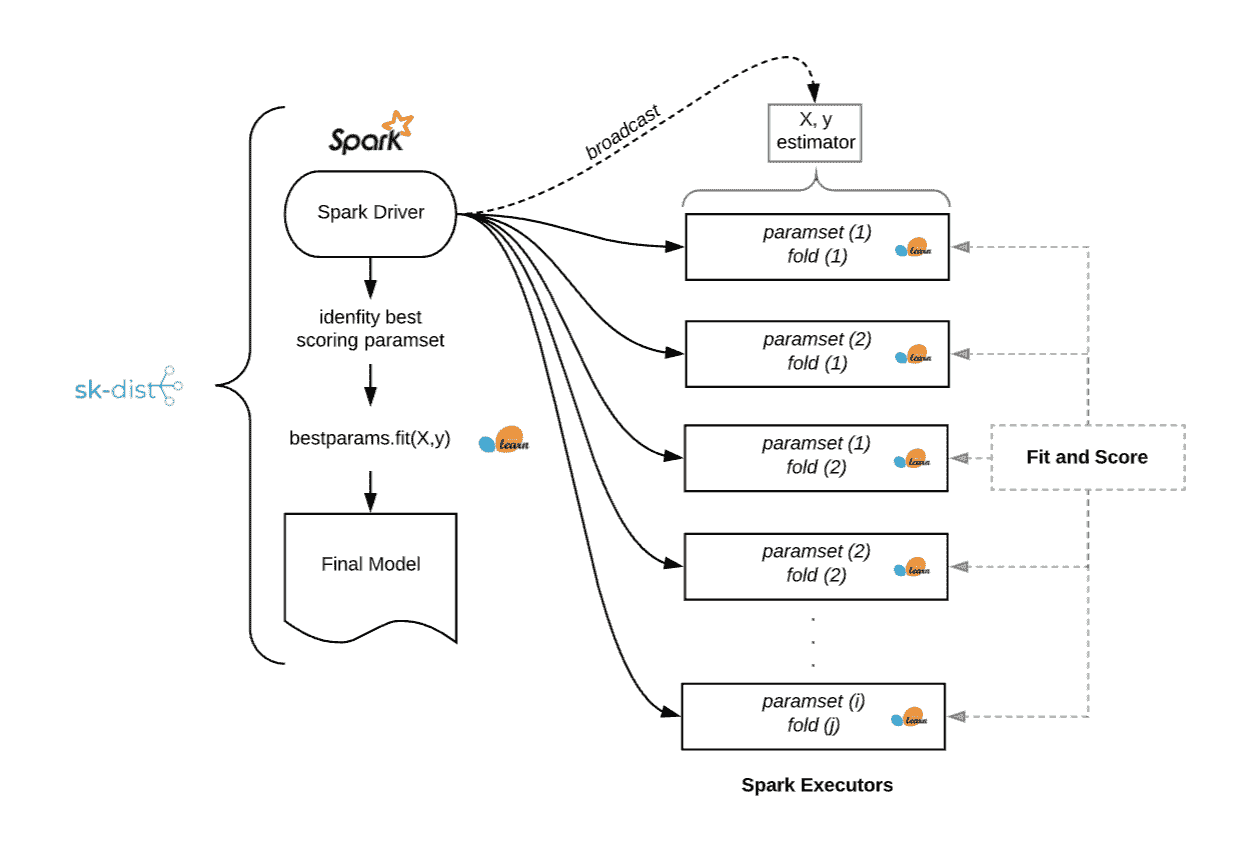
使用 sk-dist 的网格搜索
在 Ibotta 的传统机器学习实际应用中,我们经常发现自己处于类似的情况:小到中等规模的数据(10 万到 100 万条记录),需要多次迭代简单的分类器以进行超参数调整、集成和多类解决方案。
现有解决方案
目前有一些解决方案用于分布式传统机器学习元估计器训练。第一个是最简单的:scikit-learn 内置的使用 joblib 的元估计器并行化。这与 sk-dist 的操作非常相似,除了一个主要限制:性能受限于任何一台机器的资源。即使与理论上拥有数百个核心的单台机器相比,Spark 仍具有诸如 针对执行器的精细调优内存规范、容错 以及像使用 抢占实例 作为工作节点的成本控制选项等优势。
另一种现有解决方案是 Spark ML。这是 Spark 的原生机器学习库,支持许多与 scikit-learn 相同的分类和回归算法。它还具有像树集成和网格搜索这样的元估计器,并支持多类问题。虽然这听起来可能是一个足以分布式处理 scikit-learn 风格机器学习负载的解决方案,但它的分布式训练方式并未解决我们关心的并行性问题。
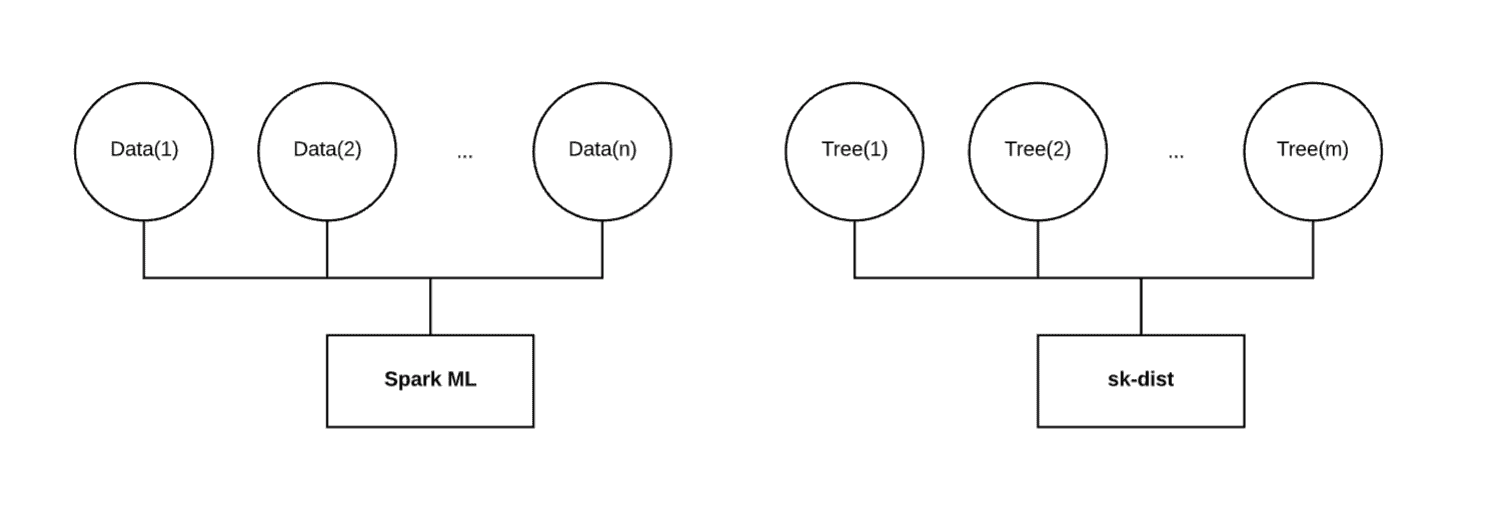
在不同维度上的分布式
如上所示,Spark ML 会在分布在多个执行器上的数据上训练一个单一模型。当数据量很大且无法适应单台机器的内存时,这种方法效果很好。然而,当数据量较小时,这可能会导致 scikit-learn 在单台机器上表现不如预期。此外,例如,在训练随机森林时,Spark ML 会按顺序训练每棵决策树。无论为此任务分配了多少资源,其壁垒时间将随着决策树数量的增加而线性增长。
对于网格搜索,Spark ML确实实现了一个并行参数,该参数可以并行训练单独模型。然而,每个单独的模型仍然是在分布在执行器上的数据上进行训练的。如果纯粹沿模型维度而非数据维度进行分布,该任务的总并行度是可以有的一个小数。
最终,我们希望在不同于 Spark ML 的维度上分布我们的训练。当使用小型或中型数据时,将数据适配到内存中并不是问题。以随机森林为例,我们希望将完整的训练数据广播到每个执行器,分别在每个执行器上拟合一个独立的决策树,然后将这些拟合的决策树带回驱动程序以组装随机森林。沿此维度分布可以比将数据分布和串行训练决策树快数量级得多。其他元估计技术,如网格搜索和多类别,也有类似的行为。
特性
鉴于这些现有解决方案在我们问题空间中的局限性,我们决定内部开发 sk-dist。底线是我们想要分布模型,而不是数据。
虽然主要关注的是元估计器的分布式训练,但 sk-dist 还包括用于与 Spark 进行 scikit-learn 模型分布式预测的模块、用于不使用 Spark 的多个前处理/后处理 scikit-learn 转换器以及一个灵活的特征编码器,可在有或没有 Spark 的情况下使用。
-
分布式训练 — 使用 Spark 分发元估计器训练。支持以下算法:超参数优化(包括网格搜索和随机搜索)、树集成(包括随机森林、额外树和随机树嵌入)以及多类别策略(包括一对多和一对一)。所有这些元估计器在拟合后都与其 scikit-learn 对应物一致。
-
分布式预测 — 使用Spark DataFrames分发拟合的 scikit-learn 估计器的预测方法。这样可以实现大规模的分布式预测,使用便携的 scikit-learn 估计器,可以选择是否使用 Spark。
-
特征编码 — 使用一个名为Encoderizer的灵活特征变换器来分发特征编码。它可以在有无 Spark 并行化的情况下运行。它会推断数据类型和形状,自动应用默认的特征变换器,以最佳猜测实现标准特征编码技术。它还可以作为一个完全可定制的特征联合编码器使用,具有 Spark 分布式变换器拟合的附加优势。
用例
这里是一些指导方针,用于决定 sk-dist 是否适合你的机器学习问题领域:
-
传统机器学习 — 像广义线性模型、随机梯度下降、最近邻、决策树和朴素贝叶斯等方法在 sk-dist 中表现良好。这些方法在 scikit-learn 中都有实现,可以直接与 sk-dist 元估计器配合使用。
-
小到中等规模数据 — 大数据与 sk-dist 不兼容。请记住,训练分布的维度沿着模型的轴,而不是数据。数据不仅需要能够适应每个执行器的内存,还需要足够小以便进行广播。根据 Spark 配置,最大广播大小可能会成为限制因素。
-
Spark 定向和访问 — sk-dist 的核心功能需要运行 Spark。这对于个人或小型数据科学团队来说并不总是可行的。此外,还需要一些 Spark 调优和配置,以成本效益的方式充分利用 sk-dist,这需要对 Spark 基础知识有一定的培训。
这里需要注意的是,尽管神经网络和深度学习技术理论上可以与 sk-dist 一起使用,但这些技术需要大量的训练数据,有时还需要专门的基础设施才能有效。深度学习并不是 sk-dist 的预期使用场景,因为它违背了上述 (1) 和 (2) 条。作为替代方案,我们在 Ibotta 使用了 Amazon SageMaker 进行这些技术,我们发现其在这些工作负载中的计算效率优于 Spark。
入门指南
要开始使用 sk-dist,请查看 安装指南。代码库还包含一个 示例 库,以展示 sk-dist 的一些使用案例。 欢迎所有人 提交问题并参与项目贡献。
如果这些项目和挑战对您感兴趣,Ibotta 正在招聘!请查看我们的 招聘页面 了解更多信息。
感谢 charley frazier、Chad Foley 和 Sam Weiss。
简介: Evan Harris 是一位经验丰富的技术专家,专注于数据科学和机器学习。他目前领导一个机器学习团队,致力于构建搜索相关性、内容推荐、定价优化和欺诈检测服务,支持一个服务于数百万用户的移动应用程序。
原文。经许可转载。
相关:
-
理解 Python 中的决策树分类
-
高级 Keras — 准确恢复训练过程
-
分布式人工智能:多智能体系统、基于代理的建模和群体智能简介
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT 服务
更多相关话题
训练一个神经网络以模仿洛夫克拉夫特的写作风格
原文:
www.kdnuggets.com/2019/07/training-neural-network-write-like-lovecraft.html
评论

LSTM 神经网络近年来被广泛应用于文本和音乐生成以及时间序列预测。
今天,我将教你如何训练一个 LSTM 神经网络进行文本生成,以便它可以以 H. P. 洛夫克拉夫特的风格写作。
为了训练这个 LSTM,我们将使用 TensorFlow 的 Keras API for Python。
我从这个很棒的 LSTM 神经网络教程 学习到了这个主题。我的代码紧随这个 文本生成教程。
我将像往常一样展示我的 Python 示例和结果,但首先,让我们先做一些解释。
什么是 LSTM 神经网络?
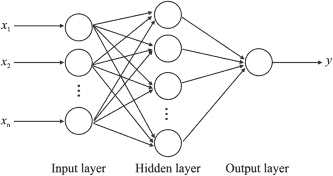
最普通的、最基本的神经网络,称为多层感知器,就是完全连接层的组合。
在这些模型中,输入是特征的向量,每一层是一个“神经元”集合。
每个神经元对前一层的输出进行仿射(线性)变换,然后对结果应用某种非线性函数。
一层的神经元的输出,即一个新的向量,被传递到下一层,依此类推。
LSTM(长短期记忆)神经网络只是另一种 人工神经网络,属于递归神经网络的范畴。
LSTM 神经网络与普通神经网络不同之处在于,它们在某些层中使用 LSTM 单元作为神经元。
就像 卷积层 帮助神经网络学习图像特征一样,LSTM 单元帮助网络学习时间序列数据,这是其他机器学习模型传统上难以处理的。
LSTM 单元是如何工作的?我现在将解释,不过我强烈建议你也看看那些教程。
LSTM 单元是如何工作的?
一个 LSTM 层将包含许多 LSTM 单元。
我们神经网络中的每个 LSTM 单元只会查看输入的单列,以及前一列的 LSTM 单元输出。
通常,我们将整个矩阵作为输入喂给 LSTM 神经网络,每列对应于“前面”某个内容的下一个列。
这样,每个 LSTM 单元将有两个不同的输入向量:前一个 LSTM 单元的输出(为其提供有关前一个输入列的一些信息)和它自己的输入列。
LSTM 单元的实际运作:一个直观的例子。
例如,如果我们训练一个 LSTM 神经网络来预测股票市场值,我们可以给它输入一个包含过去三天股票收盘价的向量。
在这种情况下,第一个 LSTM 单元将使用第一天的数据作为输入,并将一些提取的特征传递给下一个单元。
那个第二个单元会查看第二天的价格,并且还会查看前一个单元从昨天学到的内容,然后生成下一个单元的新输入。
在对每个单元做完这些操作后,最后一个单元实际上会有很多时间信息。它将接收来自前一个单元的昨日收盘价的学习结果,以及来自前两个单元的信息(通过其他单元提取的信息)。
你可以尝试不同的时间窗口,也可以改变有多少单元(神经元)查看每天的数据,但这是大致的思路。
LSTM 单元如何工作:数学原理。
实际上,每个单元从前一个单元提取的内容的数学原理要复杂一些。
忘记门
“忘记门”是一个 sigmoid 层,它调节前一个单元的输出对当前单元的影响程度。
它以前一个单元的“隐藏状态”(另一个输出向量)和来自前一层的实际输入作为输入。
由于它是一个 sigmoid 函数,它将返回一个“概率”向量:值在 0 和 1 之间。
它们将前一个单元的输出进行乘法运算,以调节它们所持有的影响力,从而创建该单元的状态。
例如,在极端情况下,sigmoid 可能返回一个零向量,整个状态将被乘以 0,从而被丢弃。
如果该层看到输入分布的变化非常大,例如,可能会发生这种情况。
输入门
与忘记门不同,输入门的输出会被添加到前一个单元的输出中(在它们被忘记门的输出乘法运算后)。
输入门是两个不同层输出的点积,尽管它们都使用与忘记门相同的输入(前一个单元的隐藏状态和前一层的输出):
-
一个sigmoid 单元,调节新信息对该单元输出的影响程度。
-
一个tanh 单元,实际提取新信息。请注意,tanh 的取值范围在-1 和 1 之间。
这两个单元的乘积(可能再次是 0,也可能完全等于 tanh 的输出,或介于两者之间)被添加到该神经元的单元状态中。
LSTM 单元的输出
单元的状态是下一个 LSTM 单元将接收的输入,连同该单元的隐藏状态一起。
隐藏状态将是另一个 tanh 单元,应用于该神经元的状态,再乘以另一个sigmoid 单元,该单元接受前一层和单元的输出(就像忘记门一样)。
这是我刚刚链接的教程中借用的每个 LSTM 单元的可视化图像。
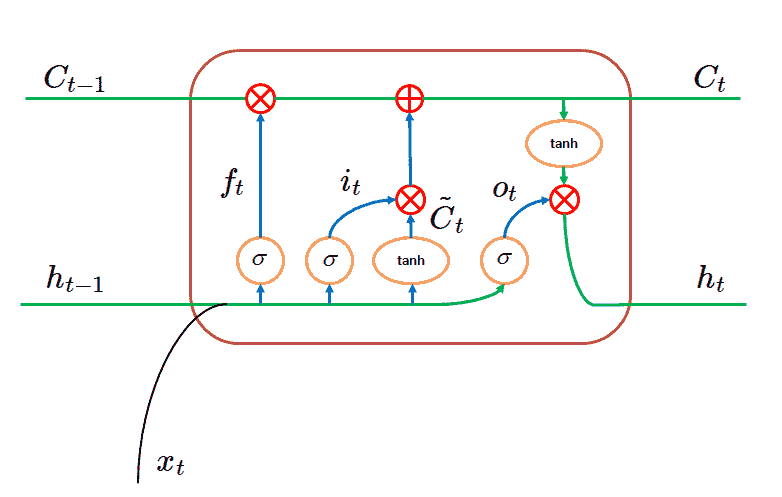
来源: 文本生成 LSTM
现在我们已经覆盖了理论部分,让我们转到一些实际应用吧!
像往常一样,所有代码都可以在GitHub 上找到,如果你想尝试一下,或者你可以继续跟随并查看要点。
使用 TensorFlow Keras 训练 LSTM 神经网络
对于这个任务,我使用了这个包含 60 篇洛夫克拉夫特故事的数据集。
由于他大部分作品是在 20 年代写的,他在 1937 年去世,因此现在大部分作品已进入公有领域,所以获取这些作品并不困难。
我认为训练一个神经网络来模仿他的写作风格将是一个有趣的挑战。
这是因为,一方面,他有一种非常独特的风格(充满华丽的修辞:使用奇怪的词汇和复杂的语言),但另一方面,他使用了非常复杂的词汇,网络可能难以理解。
例如,这里是数据集中的第一个故事中的一句随机句子:
夜晚,黑暗城市的细微躁动、蛀虫隔板中老鼠的阴险奔走,以及百年老屋中隐蔽木材的吱吱声,足以让他感受到刺耳的混乱。
如果我能让神经网络写出“pandemonium”,那么我会很惊讶。
预处理我们的数据
为了训练 LSTM 神经网络生成文本,我们必须首先预处理文本数据,以便网络可以处理。
在这种情况下,由于神经网络接受向量作为输入,我们需要一种将文本转换为向量的方法。
对于这些示例,我决定训练我的 LSTM 神经网络来预测字符串中的下一个 M 个字符,以之前的 N 个字符作为输入。
为了能够输入 N 个字符,我对每个字符进行了独热编码,使得网络的输入是一个 CxN 的矩阵,其中 C 是数据集中不同字符的总数。
首先,我们读取文本文件并将它们的内容连接起来。
我们将字符限制为字母数字和一些标点符号。
然后,我们可以将字符串进行独热编码,转化为矩阵,其中每个j列的元素都是 0,除了对应于语料库中的j字符的那个元素。
为了实现这一点,我们首先定义一个字典,将每个字符分配一个索引。
注意,如果我们希望对数据进行采样,我们可以将变量slices调整得更小。
我还为SEQ_LENGTH选择了 50 的值,使网络接收 50 个字符并尝试预测接下来的 50 个字符。
训练我们的 LSTM 神经网络
为了训练神经网络,我们必须首先定义它。
这段 Python 代码创建了一个具有两个 LSTM 层的 LSTM 神经网络,每层有 100 个单元。
记住,每个单元对输入序列中的每个字符都有一个单元,因此有 50 个。
这里VOCAB_SIZE只是我们将使用的字符数量,而TimeDistributed是一种将给定层应用于每个不同单元格的方式,保持时间顺序。
对于这个模型,我实际上尝试了许多不同的学习率来测试收敛速度与过拟合。
这是训练的代码:
你看到的是在损失最小化方面表现最好的结果。
然而,在最后一个周期(500 个周期后)中,binary_cross_entropy 为 0.0244,模型的输出如下。
Tolman hast toemtnsteaetl nh otmn tf titer aut tot tust tot ahen h l the srrers ohre trrl tf thes snneenpecg tettng s olt oait ted beally tad ened ths tan en ng y afstrte and trr t sare t teohetilman hnd tdwasd hxpeinte thicpered the reed af the satl r tnnd Tev hilman hnteut iout y techesd d ty ter thet te wnow tn tis strdend af ttece and tn aise ecn
这个输出有很多好处,也有很多坏处。
间距设置的方式,单词大多在 2 到 5 个字符之间,偶尔有较长的例外,这与语料库中的实际单词长度分布非常相似。
我还注意到字母‘T’,‘E’和‘I’非常常见,而‘y’或‘x’则较少见。
当我查看字母相对频率在样本输出与语料库中的比较时,它们相当相似。问题在于排序完全错乱。
还有一点需要指出的是,大写字母仅在空格后出现,这通常是英语中的情况。
为了生成这些输出,我只是让模型预测语料库中不同 50 个字符子集的下一个 50 个字符。如果训练数据如此糟糕,我觉得测试或随机数据也不会值得检查。
这些无意义的内容实际上让我想起了 H. P. Lovecraft 最著名的故事之一,“克苏鲁的呼唤”,其中人们开始对这个宇宙的、古怪的存在产生幻觉,他们会说:
Ph’nglui mglw’nafh Cthulhu R’lyeh wgah’nagl fhtagn.
可惜模型也没有过拟合,它明显欠拟合。
所以我试图让任务更小,模型更大:125 个单元,预测仅 30 个字符。
更大的模型,更小的问题。有什么结果吗?
在这个更小的模型下,再经过 500 个训练周期后,一些模式开始出现。
尽管损失函数(210)没有小太多,字符的频率仍然与语料库相似。
尽管如此,字符的排序改善了很多:这是它输出的一个随机样本,看看你能否发现一些单词。
the sreun troor Tvwood sas an ahet eae rin and t paared th te aoolling onout The e was thme trr t sovtle tousersation oefore tifdeng tor teiak uth tnd tone gen ao tolman aarreed y arsred tor h tndarcount tf tis feaont oieams wnd toar Tes heut oas nery tositreenic and t aeed aoet thme hing tftht to te tene Te was noewked ay tis prass s deegn aedgireean ect and tot ced the sueer anoormal -iuking torsarn oaich hnher tad beaerked toring the sars tark he e was tot tech
技术、the 和 and,was… 小词是重点!它还意识到许多单词以常见后缀如-ing,-ed 和-tion 结尾。
在 10000 个单词中,740 个是“the”,37 个以“tion”结尾(而只有 3 个是没有以此结尾的),115 个以-ing结尾。
其他常见单词包括“than”和“that”,尽管模型显然仍然无法生成英文句子。
更大的模型
这给了我希望。神经网络显然在学习某些东西,只是还不够多。
所以我做了当模型欠拟合时应该做的事情:我尝试了一个更大的神经网络。
请考虑,我是在我的笔记本电脑上运行这个。
即使配备了 16GB 的内存和 i7 处理器,这些模型仍需数小时才能完成学习。
所以我将单位数量设置为 150,再次尝试了 50 个字符。
我想也许给它更小的时间窗口会让网络更难处理。
这是模型在经过几个小时训练后的输出情况。
andeonlenl oou torl u aote targore -trnnt d tft thit tewk d tene tosenof the stown ooaued aetane ng thet thes teutd nn aostenered tn t9t aad tndeutler y aean the stun h tf trrns anpne thin te saithdotaer totre aene Tahe sasen ahet teae es y aeweeaherr aore ereus oorsedt aern totl s a dthe snlanete toase af the srrls-thet treud tn the tewdetern tarsd totl s a dthe searle of the sere t trrd eneor tes ansreat tear d af teseleedtaner nl and tad thre n tnsrnn tearltf trrn T has tn oredt d to e e te hlte tf the sndirehio aeartdtf trrns afey aoug ath e -ahe sigtereeng tnd tnenheneo l arther ardseu troa Tnethe setded toaue and tfethe sawt ontnaeteenn an the setk eeusd ao enl af treu r ue oartenng otueried tnd toottes the r arlet ahicl tend orn teer ohre teleole tf the sastr ahete ng tf toeeteyng tnteut ooseh aore of theu y aeagteng tntn rtng aoanleterrh ahrhnterted tnsastenely aisg ng tf toueea en toaue y anter aaneonht tf the sane ng tf the
完全是无意义的,除了大量的“the”和“and”。
实际上,它说“the”的频率比之前更高,但它还没有学会动名词(没有 -ing)。
有趣的是,这里许多单词以“-ed”结尾,这意味着它有点儿掌握了过去时的概念。
我让它继续训练了几百个周期(共 750 个)。
输出变化不大,仍然是大量的“the”、“a”和“an”,并且没有更大的结构。这里是另一个样本:
Tn t srtriueth ao tnsect on tias ng the sasteten c wntnerseoa onplsineon was ahe ey thet tf teerreag tispsliaer atecoeent of teok ond ttundtrom tirious arrte of the sncirthio sousangst tnr r te the seaol enle tiedleoisened ty trococtinetrongsoa Trrlricswf tnr txeenesd ng tispreeent T wad botmithoth te tnsrtusds tn t y afher worsl ahet then
但有趣的是,出现了对介词和代词的使用。
网络写了几次“I”,“you”,“she”,“we”,“of”等类似的词。总的来说,介词和代词大约占总采样单词的 10%。
这是一个改进,因为网络显然在学习低熵的单词。
然而,它仍然远未生成连贯的英语文本。
我让它再训练了 100 个周期,然后停止了。
这是它的最后输出。
thes was aooceett than engd and te trognd tarnereohs aot teiweth tncen etf thet torei The t hhod nem tait t had nornd tn t yand tesle onet te heen t960 tnd t960 wndardhe tnong toresy aarers oot tnsoglnorom thine tarhare toneeng ahet and the sontain teadlny of the ttrrteof ty tndirtanss aoane ond terk thich hhe senr aesteeeld Tthhod nem ah tf the saar hof tnhe e on thet teauons and teu the ware taiceered t rn trr trnerileon and
我知道它已经尽力而为,但它确实没有取得实质性的进展,至少不够快。
我考虑通过批量归一化来加快收敛速度。
然而,我在 StackOverflow 上读到,BatchNorm 不应该与 LSTM 神经网络一起使用。
如果你们中有人对 LSTM 网络更有经验,请在评论中告诉我这是否正确!
最后,我尝试了用 10 个字符作为输入,10 个字符作为输出来执行相同的任务。
我想模型没有获得足够的上下文来很好地预测事物:结果非常糟糕。
我考虑目前实验已经结束了。
结论
尽管从其他人的工作中可以看出,LSTM 神经网络可能学会像洛夫克拉夫特一样写作,但我认为我的电脑不够强大,无法在合理的时间内训练出足够大的模型。
或者,也许它只是需要比我拥有的更多的数据。
未来,我希望用基于词的方式重复这个实验,而不是基于字符的方式。
我检查了一下,语料库中大约 10%的单词只出现过一次。
如果我在训练之前删除了它们,有什么好的做法吗?比如用相同的名词替换所有名词,从簇中采样,或者其他方法?请告诉我!我相信你们中的许多人在 LSTM 神经网络方面比我更有经验。
你认为如果使用不同的架构会更好吗?有什么我应该以不同方式处理的地方吗?请告诉我,我想了解更多关于这方面的知识。
你在我的代码中发现了什么新手错误吗?你认为我因为没尝试 XYZ 而显得很愚蠢吗?还是你实际上觉得我的实验很有趣,或者你甚至从这篇文章中学到了什么?
如需讨论此事或相关话题,请在Twitter、LinkedIn、Medium或Dev.to与我联系。
如果你想成为数据科学家或学习新东西,查看我的机器学习阅读清单!
简介:Luciano Strika 是布宜诺斯艾利斯大学的计算机科学学生,同时也是 MercadoLibre 的数据科学家。他还在www.datastuff.tech上撰写有关机器学习和数据的文章。
原文。经许可转载。
相关:
-
自动编码器:使用 TensorFlow 的 Eager Execution 进行深度学习
-
3 本提升我作为数据科学家技能的机器学习书籍
-
理解反向传播在 LSTM 中的应用
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
训练集、测试集和 10 折交叉验证
原文:
www.kdnuggets.com/2018/01/training-test-sets-cross-validation.html
评论
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
编辑注释: 这是 Ron Zacharski 的免费在线书籍摘录,标题为数据挖掘程序员指南:古老的数字艺术。
在上一章的结尾,我们处理了三个不同的数据集:女性运动员数据集、鸢尾花数据集和汽车每加仑行驶里程数据集。我们将这些数据集分别分成了两个子集。一个子集用于构建分类器,这个数据集称为训练集。另一个子集用于评估分类器,这个数据称为测试集。训练集和测试集是数据挖掘中常见的术语。
数据挖掘中的人们从不使用用于训练系统的数据进行测试。
如果我们考虑最近邻算法,就可以理解为什么我们不使用训练数据进行测试。如果上述例子中的篮球运动员 Marissa Coleman 在我们的训练数据中,她身高 6 英尺 1 寸,体重 160 磅,那么她自己将是最近的邻居。因此,在评估最近邻算法时,如果我们的测试集是训练数据的一个子集,我们的准确率将始终接近 100%。更一般地说,在评估任何数据挖掘算法时,如果我们的测试集是训练数据的子集,结果将会是乐观的,并且往往过于乐观。所以,这似乎不是一个好主意。
我们在上一章使用的想法怎么样?我们将数据分成两部分。较大的部分用于训练,较小的部分用于评估。事实证明,这种方法也有其问题。我们可能在数据分割时非常不幸。例如,我们的测试集中的所有篮球运动员可能都很矮(像 Debbie Black 一样,她只有 5 英尺 3 英寸高,体重 124 磅),可能会被分类为马拉松运动员。而测试集中的所有田径运动员可能也都很矮且体重较轻(像 Tatyana Petrova 一样,她只有 5 英尺 3 英寸高,体重 108 磅),可能会被分类为体操运动员。像这样的测试集会导致我们的准确率很低。另一方面,我们也可能在测试集的选择中非常幸运。测试集中的每个人都是其运动项目的典型身高和体重,我们的准确率接近 100%。无论哪种情况,基于单个测试集的准确率可能无法反映我们分类器在处理新数据时的真实准确率。
解决这个问题的一种方法可能是重复该过程若干次并取平均结果。例如,我们可以将数据分成两部分。我们称这些部分为第一部分和第二部分:
我们可以使用第一部分的数据来训练我们的分类器,而使用第二部分的数据来测试它。然后我们将重复这个过程,这次用第二部分进行训练,用第一部分进行测试。最后我们对结果取平均。然而,这样做的一个问题是我们在每次迭代中只使用了 1/2 的数据来进行训练。但我们可以通过增加部分数量来解决这个问题。例如,我们可以将数据分成三部分,每次迭代时,我们将在 2/3 的数据上进行训练,并在 1/3 的数据上进行测试。因此,它可能看起来像这样:

在数据挖掘中,最常见的部分数量是 10,这种方法被称为...
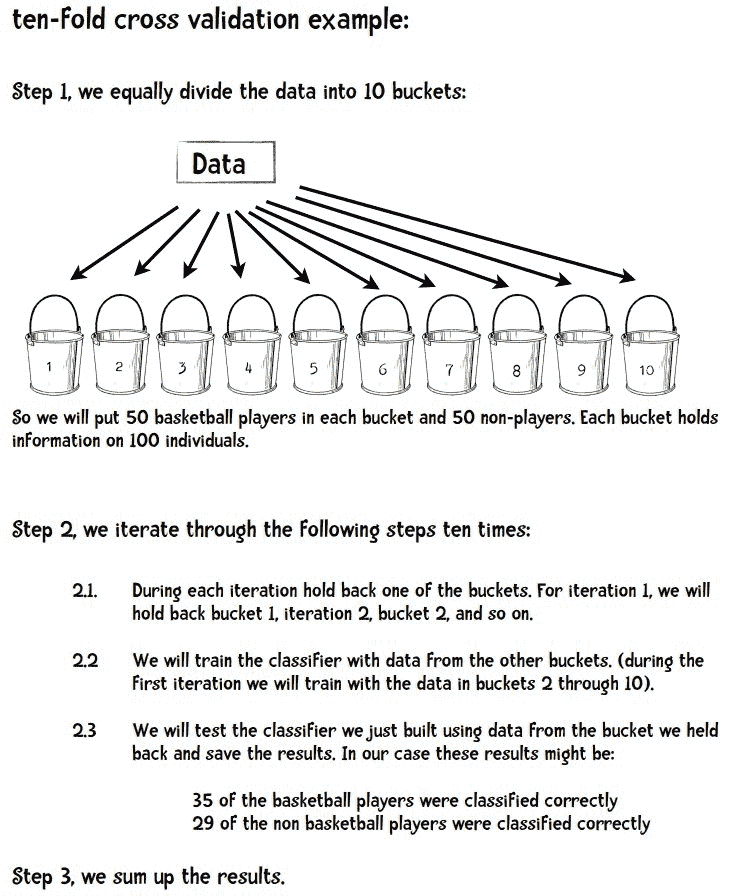
10 折交叉验证
使用这种方法,我们有一个数据集,将其随机分成 10 部分。我们使用其中的 9 部分进行训练,并保留十分之一用于测试。我们重复这个过程 10 次,每次保留不同的十分之一用于测试。
我们来看一个例子。假设我想建立一个分类器来回答问题这个人是职业篮球运动员吗? 我的数据包括 500 名篮球运动员和 500 名非篮球运动员的信息。
通常,我们会将最终结果放在如下表格中:

在 500 名篮球运动员中,有 372 人被正确分类。我们可以把它们加起来,说明在 1,000 人中我们正确分类了 652 人(372 + 280)。所以我们的准确率是 65.2%。通过十折交叉验证获得的测量值相比于二折或三折交叉验证,更可能真正代表分类器的性能。这是因为每次训练分类器时,我们使用了 90%的数据,而二折交叉验证只使用了 50%。

要阅读更多关于这一讨论的内容,请参见 Ron Zacharski 的《程序员的数据挖掘指南:古老的 Numerati 艺术》第五章。
个人简介: Ron Zacharski 是一位禅宗僧侣和计算语言学家,居住在新墨西哥州拉斯克鲁塞斯,他是《程序员的数据挖掘指南:古老的 Numerati 艺术》的作者。他的 Erdõs 数是 3。他的科学生产力 h 指数为 14,g 指数为 41。
相关内容:
-
可视化交叉验证代码
-
如何(以及为什么)创建一个好的验证集
-
数据挖掘技术,免费章节:派生变量——让数据更有意义
更多相关主题
训练和可视化词向量
原文:
www.kdnuggets.com/2018/01/training-visualising-word-vectors.html
评论
由 Priyanka Kochhar 编写,深度学习顾问
在本教程中,我想展示如何在 TensorFlow 中实现 Skip Gram 模型,以生成你正在处理的任何文本的词向量,然后使用 TensorBoard 进行可视化。我发现这个练习非常有用:一是理解 Skip Gram 模型如何工作,二是感受这些向量在你将它们用于 CNN 或 RNN 之前捕捉的文本关系。
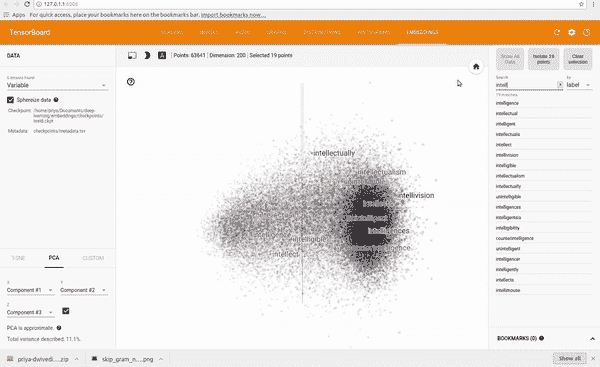
我在 text8 数据集上训练了一个 Skip Gram 模型,该数据集是英语维基百科文章的集合。我使用 TensorBoard 可视化了这些嵌入。TensorBoard 允许你通过使用 PCA 选择三个主轴来投影数据,从而查看整个词云。非常酷!你可以输入任何单词,它会显示其邻近词。你也可以隔离离它最近的 101 个点。
请参见下面的剪辑。
你可以在我的 Github 仓库中找到完整代码。
为了可视化训练,我还查看了与一组随机单词最接近的预测单词。在第一次迭代中,最接近的预测单词似乎非常随意,这很合理,因为所有词向量都是随机初始化的。
Nearest to cost: sensationalism, adversity, ldp, durians, hennepin, expound, skylark, wolfowitz,
Nearest to engine: vdash, alloys, fsb, seafaring, tundra, frot, arsenic, invalidate,
Nearest to construction: dolphins, camels, quantifier, hellenes, accents, contemporary, colm, cyprian,
Nearest to http: internally, chaffee, avoid, oilers, mystic, chappell, vascones, cruciger,
到训练结束时,模型在发现单词之间的关系方面变得更为出色。
Nearest to cost: expense, expensive, purchase, technologies, inconsistent, part, dollars, commercial,
Nearest to engine: engines, combustion, piston, stroke, exhaust, cylinder, jet, thrust,
Nearest to construction: completed, constructed, bridge, tourism, built, materials, building, designed,
Nearest to http: www, htm, com, edu, html, org, php, ac,
Word2Vec 和 Skip Gram 模型
创建词向量是将大量文本语料库中的每个单词创建一个向量的过程,使得在语料库中共享相同上下文的单词在向量空间中彼此接近。
这些词向量在捕捉单词之间的上下文关系方面表现得非常好(例如,黑色、白色和红色的向量会非常接近),我们在使用这些向量而不是原始单词进行自然语言处理任务(如文本分类或新文本生成)时,性能会更好。
生成这些词向量主要有两种模型——连续词袋模型(CBOW)和 Skip Gram 模型。CBOW 模型试图根据上下文单词预测中心单词,而 Skip Gram 模型试图根据中心单词预测上下文单词。一个简化的例子是:
CBOW: 猫吃了 ____。填补空白,在这种情况下,是“食物”。
Skip-gram: ___ ___ ___ 食物。填补词的上下文。在这种情况下,是“猫吃了”
如果你对这两种方法的详细比较感兴趣,请参见这个 链接。
各种论文发现 Skip Gram 模型生成的词向量更好,因此我专注于实现这一点。
在 Tensorflow 中实现 Skip Gram 模型
在这里,我将列出构建模型的主要步骤。详细的实现请参见我的Github。
1. 数据预处理
我们首先清理数据。去除任何标点符号、数字,并将文本拆分为单独的词。由于程序对整数的处理比对词的处理更好,我们将每个词映射到一个整数,通过创建一个词到整数的字典。下面是代码。
counts = collections.Counter(words)
vocab = sorted(counts, key=counts.get, reverse=True)
vocab_to_int = {word: ii for ii, word in enumerate(vocab, 0)}
2. 子采样
像“the”、“of”和“for”这样的常见词对附近的词没有提供太多上下文。如果我们丢弃一些这样的词,我们可以去除数据中的一些噪声,从而获得更快的训练速度和更好的表示。这个过程被称为由Mikolov提出的子采样。对于训练集中每个词,我们将以其频率的倒数给出的概率丢弃它。
3. 创建输入和目标
Skip Gram 的输入是每个词(编码为整数),目标是该窗口周围的词。Mikolov 等人发现,如果这个窗口的大小是可变的,并且离中心词较近的词被更频繁地采样,性能会更好。
“由于距离较远的词通常与当前词的相关性不如靠近的词,因此我们通过在训练示例中减少从这些词中采样的频率来给予远离词较少的权重……如果我们选择窗口大小=5,对于每个训练词,我们将随机选择一个在 1 到窗口大小之间的数字 R,然后使用当前词的历史中 R 个词和未来中 R 个词作为正确标签。”
R = np.random.randint(1, window_size+1)
start = idx — R if (idx — R) > 0 else 0
stop = idx + R
target_words = set(words[start:idx] + words[idx+1:stop+1])
4. 构建模型
从Chris McCormick 的博客中,我们可以看到我们将要构建的网络的一般结构。
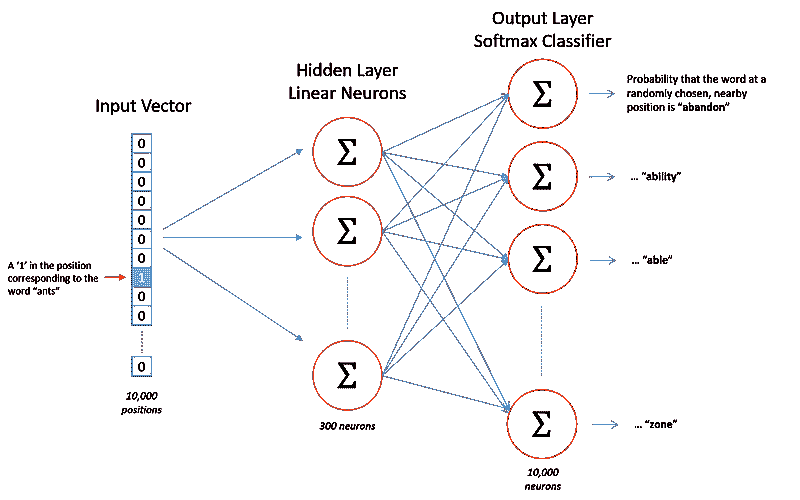
我们将把输入词“ants”表示为一个独热向量。这个向量将有 10,000 个分量(每个词汇表中的一个),我们将在对应“ants”词的位置上放置一个“1”,其他位置上放置“0”。
网络的输出是一个包含 10,000 个分量的单一向量,其中包含我们词汇表中每个词的概率,即随机选择的附近词是该词汇表词的概率。
在训练结束时,隐藏层将拥有训练好的词向量。隐藏层的大小对应于我们向量的维度数量。在上述示例中,每个词将具有长度为 300 的向量。
你可能已经注意到,skip-gram 神经网络包含大量权重……以我们 300 个特征和 10,000 个单词的词汇表为例,每个隐藏层和输出层都有 300 万权重!在大型数据集上训练将非常困难,因此 word2vec 的作者引入了一些调整以使训练成为可能。你可以在 链接 中阅读更多内容。 Github 上的代码实现了这些调整以加速训练。
5. 使用 Tensorboard 进行可视化
你可以使用 Tensorboard 中的嵌入投影器来可视化嵌入。为此,你需要做几件事:
-
在训练结束时将模型保存在检查点目录中
-
创建一个 metadata.tsv 文件,其中包含每个整数到单词的映射,以便 Tensorboard 显示单词而不是整数。将此 tsv 文件保存在相同的检查点目录中
-
运行这段代码:
from tensorflow.contrib.tensorboard.plugins import projector
summary_writer = tf.summary.FileWriter(‘checkpoints’, sess.graph)
config = projector.ProjectorConfig()
embedding_conf = config.embeddings.add()
# embedding_conf.tensor_name = ‘embedding:0’
embedding_conf.metadata_path = os.path.join(‘checkpoints’, ‘metadata.tsv’)
projector.visualize_embeddings(summary_writer, config)
- 通过将 Tensorboard 指向检查点目录来打开 Tensorboard
就这些了!
如果你喜欢这篇文章,请给我一个❤️:) 希望你能拉取代码并自己尝试。如果你对此话题有其他想法,请在这篇文章下评论或通过 priya.toronto3@gmail.com 联系我。
其他文章: https://medium.com/@priya.dwivedi/
PS:我有一家深度学习咨询公司,喜欢处理有趣的问题。如果你有一个我们可以合作的项目,请通过 priya.toronto3@gmail.com 联系我。
参考文献:
- Udacity 深度学习纳米学位
简介:Priyanka Kochhar 已从事数据科学工作超过 10 年。她现在有自己的深度学习咨询公司,喜欢处理有趣的问题。她帮助多个初创公司部署创新的 AI 解决方案。如果你有一个她可以合作的项目,请通过 priya.toronto3@gmail.com 联系她。
原文。经许可转载。
相关:
-
接近文本数据科学任务的框架
-
文本数据预处理的一般方法
-
超越 Word2Vec 仅用于词语
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 工作
更多相关话题
迁移学习变得简单:编码一种强大的技术
评论
面向普通用户的人工智能
人工智能(A.I.)正在成为最强大且具有变革性的全球性技术,以前所未有的方式影响全球经济、医疗、金融、工业、社会文化互动等各个方面。这一点在迁移学习和机器学习能力的发展中尤为重要。
我们已经在日常生活中使用人工智能技术,无论我们是否意识到,它都在影响我们的生活和选择。从我们的 Google 搜索和导航、Netflix 电影推荐、Amazon 购买建议、日常任务的语音助手如 Siri 或 Alexa、Facebook 社区建设、医疗诊断、信用评分计算和按揭决策等,人工智能的应用只会不断增长。
大多数现代人工智能系统目前由一类算法或技术驱动,即深度学习,它基本上训练和构建具有不同架构配置的深层神经网络。

图片来源:Fjodor van Veen – asimovinstitute.org.
经过 50 多年的起伏波动,深度学习革命已获得动力,看起来势不可挡——这得益于大数据技术、硬件创新和算法。因此,深度学习网络有望影响并从根本上改变我们人类在未来几十年的生活、工作和娱乐方式。
所以,我们终于可以看到人工智能为全球每个人带来的希望!
然而……有一个陷阱。
深度学习昂贵且专注范围狭窄
深度学习网络往往需要大量资源和计算成本。与传统的统计学习模型(如回归、决策树或支持向量机)不同,深度学习网络往往包含数百万个参数,因此需要大量的训练数据以避免过拟合。
因此,深度学习模型会使用大量的高维原始数据,如图像、非结构化文本或音频信号进行训练。此外,它们还反复进行数百万次向量化计算(例如矩阵乘法),以优化庞大的参数集以适应数据。而且,它们的构建涉及到一个大量的超参数(例如层数、每层的神经元数量、优化算法设置等),通常需要一个高水平研究团队花费数周或数月时间来创建一个最先进的模型。
所有这些都对训练和优化特定任务的鲁棒且高性能的深度学习模型所需的计算能力提出了巨大的需求。
假设我们可以在花费大量计算资源后训练出一个优秀的模型。难道我们不希望将这个模型用于尽可能多的任务,并多次收获我们投资的回报吗?
这就是问题所在。
到目前为止,深度学习算法传统上被设计为孤立工作。这些算法被训练来解决特定任务。在大多数情况下,一旦特征空间分布发生变化,模型就必须从头开始重建。
但这没有意义,尤其是与我们人类目前利用有限计算速度的方式相比。
人类具有跨任务转移知识的固有能力。我们在学习一个任务时获得的知识,可以以相同的方式来解决相关任务。如果任务或领域之间的相似性很高,我们能够更好地跨任务利用我们的“已学”知识。
转移学习的理念是克服孤立学习范式,并利用在一个任务中获得的知识来解决相关任务,这在机器学习,特别是在深度学习领域中得到了应用。

图片来源:转移学习综合实用指南:在深度学习中的实际应用。
深度学习网络的转移学习
在深度学习环境中,转移学习过程有许多策略可供选择,还有多个重要因素需要考虑和工程决策需要做出——数据集和领域的相似性、监督或非监督设置、需要多少重新训练等。
然而,简单来说,我们可以假设对于转移学习:
-
我们需要使用一个预训练的深度学习模型
-
重新使用全部或某些部分
-
将其应用于我们新感兴趣的领域中的特定机器学习问题——分类或回归。
通过这种方式,我们可以避免训练和优化大型深度学习模型所需的大量计算工作。
最终,一个训练好的深度学习模型只是一组在特定数据结构格式下的数百万个实数,这些可以直接用于预测/推断,这是我们作为模型使用者真正感兴趣的任务。
但请记住,预训练模型可能是针对特定分类进行训练的,即其输出向量和计算图只适用于预测某一特定任务。
因此,迁移学习中广泛使用的策略是:
-
加载预训练模型的权重矩阵,但不包括离输出层最近的最后几层的权重,
-
保持这些权重固定,即不可训练
-
附加适合当前任务的新层,并使用新数据训练模型

图:我们将在这里探索的深度学习网络迁移学习策略。
这样,我们无需训练整个模型,就可以将模型重新用于我们的特定机器学习任务,同时利用从预训练、优化模型中加载的固定权重中包含的数据结构和模式。
一个你可以在笔记本电脑上运行的实用示例
让我们动手构建一个简单的代码演示,展示迁移学习的力量,好吗?
为什么不遵循传统方法?
传统上,这个主题的教程集中在从著名的高性能深度学习网络中学习,例如VGGNet-16、ResNet-50 或Inception-V3/V4 等。这些网络在庞大的ImageNet 数据库上进行了训练,并在年度 ImageNet 比赛 - ILSVRC中获得了前列,从而成为图像分类任务的黄金基准模型。
然而,这些网络的问题在于它们包含大量复杂的层,当你开始学习深度学习概念时,不容易理解。
因此,如果你想从零开始编写一个迁移学习的示例,从自学和建立信心的角度来看,先尝试一个独立的示例可能会更有益。你可以先训练一个深度学习模型,将其学习转移到另一个种子网络,然后展示在标准分类任务中的性能。
我们在这个教程中要做什么?
在本文中,我们将使用 Python 和 Keras 包(TensorFlow 后端)在一个非常简单的环境中演示迁移学习概念。我们将使用著名的 CIFAR-10 数据集并进行以下操作:
-
通过在一组特征层之上堆叠一组分类层来创建一个 Keras 神经网络
-
在由前 5 类 (0…4) 的示例组成的部分 CIFAR-10 数据集上训练生成的网络。
-
冻结特征层并在其上堆叠一组新的全连接层,从而创建另一个卷积网络
-
在 CIFAR-10 的其余类别 (5..9) 的示例上训练这个新的卷积网络,只调整那些密集连接层的权重
整个代码是开源的,可以在这里找到。我们在本文中只展示了部分重要的代码。
代码示例
我们首先导入必要的库和函数:
-
from time import time
-
import keras
-
from keras.datasets import mnist,cifar10
-
from keras.models import Sequential
-
from keras.layers import Dense, Dropout, Activation, Flatten
-
from keras.layers import Conv2D, MaxPooling2D
-
from keras.optimizers import Adam
-
from keras import backend as K
-
import matplotlib.pyplot as plt
-
import random
接下来,我们决定一些深度学习模型的架构选择。我们将使用卷积神经网络 (CNN),因为它最适合图像分类任务:
-
要使用的卷积滤波器数量
-
filters = 64
-
最大池化的池化区域大小
-
pool_size = 2
-
卷积核大小
-
kernel_size = 3
接下来,我们将数据集拆分为训练集和验证集,并创建两个数据集——一个包含标签低于 5 的类别,另一个包含 5 及以上的类别。为什么要这样做?
整个 CIFAR-10 数据集有 10 类图像,尺寸非常小。我们将有两个神经网络。一个将被预训练,学习将转移到第二个网络。但是,我们不会使用所有的图像类别来训练这两个网络。第一个网络将仅使用前 5 类图像进行训练,这一学习将帮助第二个网络更快地学习最后 5 类图像。
因此,

CIFAR-10 数据集中的 10 类图像。
这里是前 5 类的一些随机图像,第一个神经网络将“看到”并进行训练。这些类别是——飞机、汽车、鸟、猫或鹿。

图:前 5 类图像,仅被第一个神经网络看到。
但我们实际上感兴趣的是为最后 5 类图像构建一个神经网络——狗、青蛙、马、羊或卡车。

图:最后 5 类图像,仅被第二个神经网络看到。
接下来,我们定义两组/类型的层:特征层(卷积)和分类层(密集)。
再次,请不要被这些代码片段的实现细节困扰。你可以从任何标准的 Keras 教程中了解细节。关键是理解概念。
特征层:
-
特征层 = [
-
Conv2D(filters, kernel_size,
-
padding='valid',
-
input_shape=input_shape),
-
Activation('relu'),
-
Conv2D(filters, kernel_size),
-
Activation('relu'),
-
MaxPooling2D(pool_size=pool_size),
-
Dropout(25),
-
Flatten(),
-
]
密集分类层:
-
分类层 = [
-
Dense(128),
-
Activation('relu'),
-
Dropout(25),
-
Dense(num_classes),
-
Activation('softmax')
-
]
接下来,我们通过将特征层和分类层堆叠在一起创建完整模型。
-
- model_1 = Sequential(特征层 + 分类层)
然后我们定义一个用于训练模型的函数(未显示),并训练模型若干轮以达到足够好的性能:
-
train_model(model_1,
-
(x_train_lt5, y_train_lt5),
-
(x_test_lt5, y_test_lt5), 类别数)
我们可以展示网络在训练轮次中的准确度演变:

图:训练第一个网络时验证集准确度随轮次变化。
接下来,我们冻结特征层并重建模型。
冻结特征层是迁移学习的核心。这允许重新使用预训练模型进行分类任务,因为用户可以在预训练特征层上堆叠新的全连接层,从而获得良好的性能。
我们将创建一个名为model_2的新模型,具有不可训练的特征层和可训练的分类层。我们在下图中展示了摘要:
-
对于特征层中的每一层:
-
可训练 = False
-
model_2 = Sequential(特征层 + 分类层)

图:第二个网络的模型摘要,显示了固定和可训练的权重。固定权重直接从第一个网络转移过来。
现在我们训练第二个模型并观察它总体上所需时间更少且性能相当或更高。
-
train_model(model_2,
-
(x_train_gte5, y_train_gte5),(x_test_gte5, y_test_gte5), 类别数)
第二个模型的准确率甚至高于第一个模型,尽管这并不总是如此,且取决于模型架构和数据集。

图:训练第二个网络时验证集准确度随轮次变化。
两个模型的训练时间如下所示:

图:两个网络的训练时间。
我们达成了什么?
不仅model_2的训练速度比model_1更快,而且它还以更高的基准准确度开始,并在相同的训练轮次和相同的超参数(学习率、优化器、批量大小等)下达到了更好的最终准确度。而且,它在model_1未见过的图像上完成了训练。
这意味着虽然model_1是在airplane、automobile、bird、cat或deer的图像上训练的,但它学到的权重在转移到model_2时,帮助model_2在完全不同类别的图像分类中表现出色——dog、frog、horse、sheep或truck。
难道这不令人惊讶吗?现在,你可以用这么少的代码行来构建这种转移学习。再次强调,所有代码都是开源的,可以在这里找到。
原文。经许可转载。
相关:
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT 工作
更多相关话题
转移学习用于图像识别和自然语言处理
原文:
www.kdnuggets.com/2022/01/transfer-learning-image-recognition-natural-language-processing.html
如果你有机会阅读了本文的第一部分,你会记得转移学习是一种机器学习方法,其中从一个任务中获得的模型的知识应用可以作为另一个任务的基础点被重用。
如果你没有机会深入了解转移学习,读一读它将帮助你更好地理解这篇文章。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
图像识别
首先让我们了解一下什么是图像识别。图像识别是指计算机技术能够检测和分析图像或视频中的物体或特征的任务。这是深度神经网络施展魔力的主要领域,因为它们被设计用来识别模式。
如果你想了解神经网络如何分析和掌握图像的理解,请查看这里。这将向你展示低层次的层如何集中学习低级特征,以及高层次的层如何适应学习高级特征。
我们在本文第一部分中模糊地谈到了训练网络识别猫和狗的内容,让我们更详细地讨论一下。人脑可以识别和区分物体。图像识别也旨在拥有类似于人脑的能力,能够识别和检测图像中物体之间的差异。
图像识别所使用的算法是一个图像分类器,它接收输入图像并输出图像包含的内容。这个算法必须经过训练,以学习它检测的对象之间的差异。为了让图像分类器识别猫和狗,需要用成千上万的猫和狗的图像,以及不包含猫和狗的图像来训练图像分类器。因此,从这个图像分类器获得的数据可以在其他任务中用于猫和狗的检测。
那么你可以在哪里找到预训练的图像模型呢?
目前有很多预训练模型,因此找到合适的模型来解决你的问题需要一些研究。我将为你做一点研究。我将首先讨论 Keras。Keras 提供了广泛的预训练模型,可用于迁移学习、特征提取、微调和预测。你可以在 这里 找到它们的列表。
一个 Keras 应用的例子是 Xception 架构,我在上面简要提到过。以下是如何在 ImageNet 上初始化 Xception。
tf.keras.applications.Xception(
include_top=True,
weights="imagenet",
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
classifier_activation="softmax",
)
说到 Keras,我们也不要忘记 TensorFlow Hub。TensorFlow 是一个由 Google 开发的开源库,支持机器学习和深度学习。TensorFlow Hub 提供了多种预训练的、可部署的模型,如图像、文本、视频和音频分类。
序列模型适合用于简单的层叠堆叠,这意味着每一层都有一个输入和一个输出张量。
示例 1:
model = tf.keras.Sequential([
embed,
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(1, activation="sigmoid"),
])
示例 2:
m = tf.keras.Sequential([
hub.KerasLayer("https://tfhub.dev/google/imagenet/inception_v1/classification/5")
])
m.build([None, 224, 224, 3]) # Batch input shape.
在深度学习中,一些策略可以使我们最大限度地利用预训练模型。
特征提取
我将讨论的第一个策略是特征提取。你基本上是将预训练模型作为固定的特征提取器来运行,使用所需的特征来训练新的分类器。接近模型输入层的卷积层学习低级特征,如图像识别中的边缘和线条。随着层次的增加,它们开始学习更复杂的特征,最终能够解释接近输出的特定特征,即当前的分类任务。我们可以通过使用模型的不同层级作为单独的特征提取整合来分类我们的任务。
例如,如果任务与对图像中物体的分类不同(这是预训练模型所做的),那么使用预训练模型经过几层处理后的输出会更为合适。因此,所需层的新输出将作为输入提供给新模型,新模型已经获得了必要的特征,可以传递给新的分类器,并能够解决当前任务。
总的来说,这个想法是利用特征提取来利用预训练模型,以确定哪些特征对解决你的任务有用,但你不会使用网络的输出,因为它过于特定于任务。然后你将需要构建模型的最后部分,以适应你的任务。
微调
第二种策略是微调,或者我喜欢称之为网络手术。我们在上面讨论过微调,它基于对过程进行“精细”调整,以获得所需的输出,从而进一步提高性能。微调也被视为特征提取的进一步步骤。在微调中,我们冻结某些层并选择性地重新训练一些层,以提高其准确性,从而在较低的学习率下获得更高的性能,并减少训练时间。
如果你希望从基本模型中获得有效的特征表示,微调是至关重要的,这样可以更好地适应你的任务。
示例:如何在 Keras 中使用预训练的图像模型
现在让我们看一个例子。由于我们一直在讨论猫和狗,让我们对它们做一个图像识别的示例。
加载数据
所以首先让我们确保导入所需的库并加载数据。
import numpy as np
import tensorflow as tf
from tensorflow import keras
import tensorflow_datasets as tfds
打印出训练和测试的样本量总是好的,以了解你正在处理的数据量,并查看图像,这样你可以了解你正在处理的数据。

由于图像大小各异,将图像标准化为固定大小是一种良好的方法,因为这是神经网络的一个一致输入。
数据预处理
现在让我们进入数据增强的部分。当处理较小的数据集时,应用随机变换到训练图像上是一个好的做法,例如水平翻转。翻转意味着在垂直或水平轴上旋转图像。这将帮助模型接触到训练数据的不同角度和方面,从而减少过拟合。
from tensorflow import keras
from tensorflow.keras import layers
data_augmentation = keras.Sequential(
[layers.RandomFlip("horizontal"), layers.RandomRotation(0.1),]
)
从选择的架构(Xception)创建一个基本模型
下一步是创建模型。我们首先将实例化一个基本模型,Xception,并将预训练的权重加载到其中。在这个例子中,我们使用的是 ImageNet。然后,我们冻结基本模型中的所有层。冻结有助于防止在训练过程中更新权重。
base_model = keras.applications.Xception(
weights="imagenet", # Weights pre-trained on ImageNet.
input_shape=(150, 150, 3),
include_top=False,
)
base_model.trainable = False
训练顶层
下一步是在冻结的层上创建一个新层,该层将学习旧特征的知识并利用这些知识对新数据集进行预测。正如前面迁移学习步骤中进一步解释的那样,预训练模型的当前输出与模型希望得到的输出之间的差异可能很大,因此添加新层将整体上提高模型的性能。
# Create a new model on top
inputs = keras.Input(shape=(150, 150, 3))
x = data_augmentation(inputs) # Apply random data augmentation

微调
因此,在我们用冻结的层运行模型之后,我们需要用未冻结的基础模型运行模型,这样可以本质上提高模型性能,并且学习率较低。你需要减少过拟合的程度,所以让我们慢慢来,逐步解冻基础模型。
base_model.trainable = True
现在是时候再次编译模型了。
model.compile(
optimizer=keras.optimizers.Adam(1e-5), # Low learning rate
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[keras.metrics.BinaryAccuracy()],
)
epochs = 10
model.fit(train_ds, epochs=epochs, validation_data=validation_ds)

如果你想进一步了解,可以点击这里查看 Colab 笔记本。
自然语言处理
我们已经讨论了很多关于图像分类的内容,现在让我们来看看自然语言处理(NLP)。那么,NLP 是什么呢?NLP 是计算机通过语音和文本检测和理解人类语言的能力,就像我们人类一样。
人类语言包含许多歧义,这使得创建能够准确检测语音和文本的软件变得困难。例如,讽刺、语法和同音词,然而,这些只是学习人类语言过程中遇到的一些小障碍。
NLP 的例子包括语音识别和情感分析。NLP 的应用场景包括垃圾邮件检测。我知道,你可能从未想到过 NLP 会被应用于垃圾邮件检测,但确实如此。NLP 的文本分类功能能够扫描电子邮件并检测出可能是垃圾邮件或钓鱼邮件的语言。它通过分析语法错误、威胁、金融术语的过度使用等来实现这一点。
那么,迁移学习在 NLP 中是如何工作的呢?其实,它与图像识别的工作方式基本相同。训练一个自然语言模型可能会非常昂贵,它需要大量的数据,并且需要在高端硬件上耗费大量的训练时间。但好消息是,和图像识别一样,你可以免费下载这些预训练模型,并对其进行微调以适应你的特定数据集。
你可能会问,在哪里可以找到这些预训练模型?
Keras 不仅提供图像识别的预训练模型,还提供 NLP 的架构。你可以在这里查看。
HuggingFace
让我们来看看HuggingFace。HuggingFace 是一个开源的自然语言处理(NLP)提供者,它在让工具易于使用方面做得非常出色。
他们的 Transformers 库是一个基于 Python 的库,提供了如 BERT 等架构,用于执行如文本分类和问答等 NLP 任务。你只需用几行代码加载他们的预训练模型,就可以开始实验。要开始使用 Transformers,你需要先安装它。
以下是使用情感分析的示例,它能够识别文本中表达的意见。
! pip install transformers
from transformers import pipeline
classifier = pipeline('sentiment-analysis')
classifier('I am finding the article about Transfer learning very useful.')
输出:
[{'label': 'POSITIVE', 'score': 0.9968850016593933}]
使用 HuggingFace 对预训练模型进行微调是一种选择,可以使用 Trainer API。Transformers 提供了一个 Trainer 类来帮助微调你的预训练模型。这一步骤在处理数据之后进行,并且需要导入 TrainingArguments。
from transformers import TrainingArguments
要了解更多关于 HuggingFace 的信息,你可以访问这个链接。
词嵌入
词嵌入是什么呢?词嵌入是一种表示方式,其中相似的词具有相似的编码。它可以在文档中检测到一个词,并将其与其他词的关系联系起来。
其中一个例子是 Word2Vec,它是一个通过向量编码处理文本的两层神经网络。
Word2Vec 使用了两种方法来学习词的表示:
-
连续词袋模型(Continuous Bag-of-Words) - 是一种模型架构,它试图基于源词(邻近词)预测目标词(中间词)。上下文中的词的顺序不一定重要,因此这个架构被称为“词袋模型”。
-
连续跳字模型(Continuous Skip-gram) - 是一种模型架构,本质上是词袋模型的对立面。它试图给定目标词(中间词)来预测源词(邻近词)。
特征提取是一种在词嵌入中使用的策略,它检测并生成对你正在处理的 NLP 任务有用的特征表示。在特征提取中,将部分(句子或词)提取到一个矩阵中,该矩阵包含每个词的表示。权重不会改变,仅使用模型的顶层。
然而,微调会调整预训练模型的权重,这可能会带来不利影响,因为该方法在调整阶段可能导致词汇的丢失,原因在于权重被更改,曾经学到的内容不再存在于记忆中。这被称为“灾难性遗忘”。
示例:如何在 Keras 中使用预训练的 NLP 模型
我们刚刚讨论了词嵌入(Word Embedding),让我们看一个例子。快速回顾一下词嵌入的定义:它是一种表示方式,其中相似的词具有相似的编码。它可以在文档中检测到一个词,并将其与其他词的关系联系起来。那么我们来看看它是如何工作的吧。
加载数据
在这个例子中,我们将查看电影评论。如果你还记得我们之前做的例子,使用情感分析得出了一个结果来确定其积极性。对于这些电影评论,我们有积极和消极的,因此这是二元分类。
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1.tar.gz", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
os.listdir(dataset_dir)
你可以在下面的图像中看到区别,0 表示负面,1 表示正面。

然后,我转向使用 Keras 的 Embedding Layer,将正整数转换为固定大小的稠密向量。嵌入的权重是随机初始化的,并在反向传播过程中进行调整。一旦知识学会了,词嵌入将编码它们所学过的词与之前学过的词之间的相似性。
# Embed a 1,000-word vocabulary into 5 dimensions.
embedding_layer = tf.keras.layers.Embedding(1000, 5)
文本预处理
在文本预处理阶段,我们将初始化一个 TextVectorization 层,以期望的参数对电影评论进行向量化。文本向量化层将帮助拆分和映射来自电影评论的字符串到整数。
# text vectorization layer to split, and map strings to integers.
vectorize_layer = TextVectorization(
standardize=custom_standardization,
max_tokens=vocab_size,
output_mode='int',
output_sequence_length=sequence_length)
创建模型
上述预处理中的 vectorize_layer 将作为模型的第一层实现,因为它已经将字符串转换为词汇索引。它将把转换后的字符串输入到 Embedding 层中。
然后,Embedding 层会接受这些词汇索引,并扫描每个词索引的向量,在模型训练时进行学习。
model = Sequential([
vectorize_layer,
Embedding(vocab_size, embedding_dim, name="embedding"),
GlobalAveragePooling1D(),
Dense(16, activation='relu'),
Dense(1)
])
在这个示例中,我们将使用TensorBoard,这是一个提供机器学习工作流可视化的工具,例如损失和准确率。
编译模型
我们将使用 Adam 优化器和 BinaryCrossentropy 损失函数来编译模型。
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])

我提到了 TensorBoard,它可视化模型指标,你可以在下面看到。
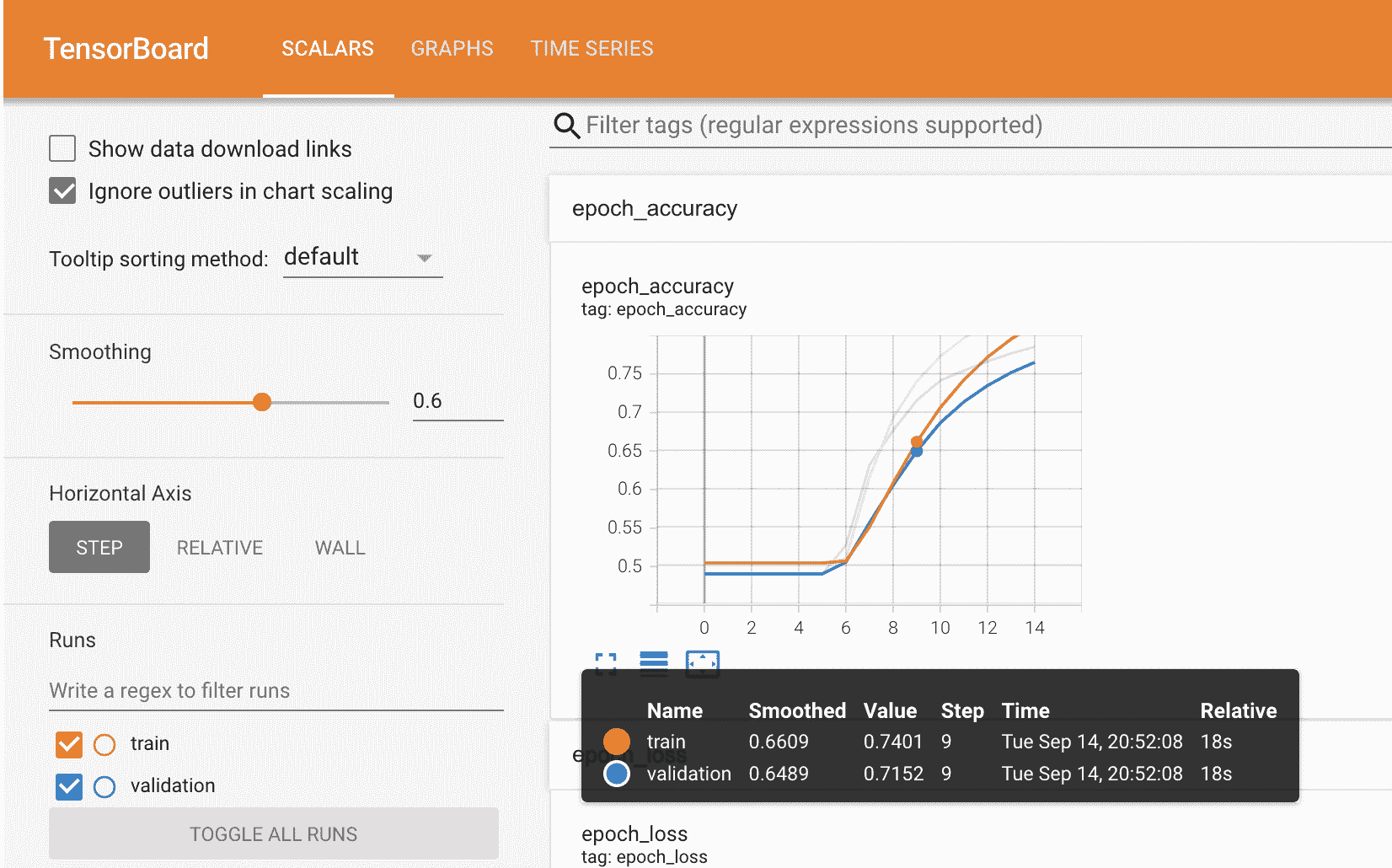
你已经了解了如何使用预训练的词嵌入模型训练和测试 NLP 模型。如果你想进一步查看 Colab 笔记本,你可以在这里查看。
迁移学习的最佳实践是什么?
-
预训练模型 - 利用这些预训练的开源模型,它们可以帮助你解决目标任务,因为它们涵盖了不同的领域。这可以节省你从头开始构建模型的大量时间。
-
源模型 - 找到一个与源任务和目标任务都兼容的模型是很重要的。如果源模型与你的目标差距过大,并且知识转移有限,目标模型将需要更长的时间来实现。
-
过拟合 - 如果目标任务的数据样本很小,且源任务与目标任务过于相似,这可能会导致过拟合。冻结层并调整课程模型中的学习率可以帮助你减少模型的过拟合。
我希望这篇文章让你对如何通过机器学习的不同类型实现迁移学习有了更好的理解。试试看吧!
尼莎·阿雅 是一名数据科学家和自由技术撰稿人。她特别感兴趣于提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探讨人工智能如何以及如何能够提升人类生命的持久性。她是一个热衷学习者,寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
相关主题
什么是迁移学习?
图片由 qimono on Pixabary 提供
迁移学习是一种机器学习方法,其中一个任务中获得的模型知识可以作为另一个任务的基础点进行重用。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你所在组织的 IT
机器学习算法使用历史数据作为输入来进行预测并产生新的输出值。它们通常被设计用于执行孤立的任务。源任务是指将知识转移到目标任务的任务。目标任务是指由于从源任务转移知识而发生的改进学习。
在迁移学习过程中,利用从源任务中获得的知识和快速进展来改善对新目标任务的学习和发展。知识的应用是使用源任务的属性和特征,这些属性和特征将被应用并映射到目标任务上。
然而,如果转移方法导致新目标任务性能下降,则称为负迁移。在使用迁移学习方法时,主要挑战之一是能够提供并确保相关任务之间的正迁移,同时避免与不相关任务之间的负迁移。
迁移学习的什么、何时和如何
-
迁移什么?要理解转移哪些学习到的知识,我们需要弄清楚哪些知识部分最能反映源任务和目标任务。总体而言,提高目标任务的性能和准确性。
-
何时进行迁移?了解何时进行迁移非常重要,因为我们不希望转移的知识可能使情况变得更糟,导致负迁移。我们的目标是提高目标任务的性能,而不是使其变得更差。
-
如何进行迁移?现在我们对想要迁移的内容和何时迁移有了更清楚的了解,我们可以继续研究不同的技术,以高效地转移知识。我们将在文章后面进一步讨论。
在我们深入探讨迁移学习背后的方法论之前,了解迁移学习的不同形式是很有帮助的。我们将讨论三种不同类型的迁移学习场景,这些场景是根据源任务和目标任务之间的关系来区分的。以下是不同类型的迁移学习概述:
迁移学习的不同类型
归纳迁移学习:在这种迁移学习类型中,源任务和目标任务相同,但它们之间仍然存在差异。模型将利用源任务中的归纳偏差来帮助提高目标任务的性能。源任务可能包含或不包含标记数据,这进一步导致模型使用多任务学习和自学学习。
无监督迁移学习:我假设你知道什么是无监督学习,不过,如果你不知道,无监督学习是指算法能够识别未标记或未分类的数据集中的模式。在这种情况下,源任务和目标任务是相似的,但任务是不同的,源任务和目标任务中的数据都是未标记的。降维和聚类等技术在无监督学习中是非常著名的。
转导迁移学习:在这种最后的迁移学习类型中,源任务和目标任务有相似之处,但领域是不同的。源领域包含大量的标记数据,而目标领域则缺乏标记数据,这进一步导致模型使用领域适应技术。
迁移学习与微调
微调是迁移学习中的一个可选步骤,主要用于提高模型的性能。迁移学习和微调之间的区别完全体现在名称上。
迁移学习基于从一个任务中学习到的特征,并将这些知识“转移”到新的任务上。迁移学习通常用于数据集过小,无法从头训练一个完整模型的任务。微调则是对过程进行“微小”的调整,以获得所需的输出,从而进一步提高性能。在微调过程中,经过训练的模型的参数会被精确和特定地调整,同时尝试验证模型以实现所需的输出。
为什么使用迁移学习?
使用迁移学习的原因:
无需大量数据 - 获取数据总是一个障碍,因为数据的可用性不足。使用不足量的数据可能导致性能较低。这正是迁移学习的优势所在,因为机器学习模型可以通过少量的训练数据集进行构建,因为它已经经过预训练。
节省训练时间 - 机器学习模型训练起来很困难且耗时,导致效率低下。训练一个深度神经网络从头开始处理复杂任务需要很长时间,因此使用预训练模型可以节省建立新模型的时间。
转移学习的优点
更好的基础:在转移学习中使用预训练模型为你提供了更好的基础和起点,使你能够在不进行训练的情况下完成一些任务。
更高的学习率:由于模型已经在类似任务上进行过训练,因此具有更高的学习率。
更高的准确率:凭借更好的基础和更高的学习率,模型在更高的性能下运行,产生更准确的输出。
转移学习不有效时?
当源任务的训练权重与目标任务不同的时候,应避免使用转移学习。例如,如果你之前的网络是用来分类猫和狗的,而你新的网络试图检测鞋子和袜子,那么会出现问题,因为从源任务到目标任务转移的权重无法提供最佳结果。因此,初始化一个与期望输出相似的预训练权重的网络比使用没有相关性的权重更好。
从预训练模型中移除层会对模型的架构造成问题。如果你移除前几层,模型的学习率会很低,因为它必须处理低级特征。移除层会减少可训练的参数数量,这可能导致过拟合。使用正确数量的层对于减少过拟合至关重要,但这也是一个耗时的过程。
转移学习的缺点
负迁移学习:如上所述,负迁移学习是指以前的学习方法阻碍了新任务。这仅在源任务和目标任务不够相似时发生,导致第一次训练偏差过大。算法不一定总是与我们认为的相似一致,这使得理解什么类型的训练是足够的基础和标准变得困难。
转移学习的 6 个步骤
让我们深入了解转移学习的实现方式及其步骤。转移学习一般包括 6 个步骤,我们将逐一介绍这些步骤。
-
选择源任务:第一步是选择一个拥有大量数据的预训练模型,该模型的输入和输出数据与您选择的目标任务有关系。
-
创建基础模型:实例化一个带有预训练权重的基础模型。预训练权重可以通过像 Xception 这样的架构获取。这是在开发你的源模型,使其比我们最初开始时的简单模型更好,确保学习率有所提升。
-
冻结层:为了避免再次初始化权重,冻结预训练模型的层是必要的。这将保留已经学到的知识,避免从头开始训练模型。
base_model.trainable = False
-
添加新的可训练层:在冻结层的顶部添加新的可训练层,将把旧特征转化为新数据集上的预测。
-
训练新层:预训练模型已经包含了最终的输出层。预训练模型的当前输出和你期望的模型输出之间存在较大差异的可能性很高。因此,你需要用新的输出层来训练模型。因此,添加新的密集层和最终密集层以符合你期望的模型,将提升学习率并产生你期望的输出。
-
微调:你可以通过微调来提升模型的性能,这包括解冻基础模型的全部或部分内容,然后用非常低的学习率重新训练模型。在这个阶段使用低学习率至关重要,因为你正在训练的模型比最初的第一轮大得多,并且数据集也很小。因此,如果应用较大的权重更新,你有过拟合的风险,因此你需要以增量的方式进行微调。由于你改变了模型的行为,需要重新编译模型,然后再次训练模型,监控任何过拟合的反馈。
我希望这篇文章为你提供了迁移学习的良好介绍和理解。敬请期待,我的下一篇文章将会介绍我如何实施迁移学习用于图像识别和自然语言处理。
Nisha Arya 是一名数据科学家和自由职业技术作家。她特别关注提供数据科学职业建议或教程以及数据科学相关理论知识。她还希望探索人工智能如何有助于人类寿命的不同方式。作为一个热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
用 LangChain 变革 AI:文本数据的游戏改变者
原文:
www.kdnuggets.com/2023/08/transforming-ai-langchain-text-data-game-changer.html
图片来源:作者
在过去几年中,大型语言模型——或者说是朋友们的 LLM——以其风靡的姿态席卷了人工智能领域。
我们的前 3 大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
随着 2020 年 OpenAI 发布 GPT-3 的突破性进展,我们见证了 LLM 的流行稳步上升,最近该领域的进步更是加剧了这一趋势。
这些强大的 AI 模型为自然语言处理应用开辟了新的可能性,使开发者能够创建更复杂、更像人类的互动。
不是吗?
然而,在处理这种 AI 技术时,很难扩展和生成可靠的算法。
在这个快速发展的环境中,LangChain 作为一个多功能框架应运而生,旨在帮助开发者充分利用 LLM 的潜力,应用于各种场景。其中最重要的用例之一就是处理大量 的文本数据。
让我们深入了解并开始利用 LLM 的力量吧!
LangChain 可以用于聊天机器人、问答系统、总结工具等。然而,LangChain 最有用且最常用的应用之一就是处理文本。
当今世界充斥着数据。而最臭名昭著的一种数据是文本数据。
所有网站和应用每天都被大量文字轰炸。没有人能处理这么多信息……
但计算机能做到吗?
LLM 技术与 LangChain 结合,是减少文本量同时保留信息核心的好方法。这就是为什么今天我们将探讨 LangChain 的两个基本但非常实用的文本处理用例。
-
总结: 表达一段文本或聊天互动中最重要的事实。它可以减少数据量,同时保留最重要的部分。
-
提取: 从一段文本或用户查询中提取结构化数据。它可以在文本中检测并提取关键词。
无论你是对 LLM 世界感到陌生还是希望将你的语言生成项目提升到一个新水平,本指南将为你提供宝贵的见解和动手示例,帮助你充分发挥 LangChain 处理文本的潜力。
⚠️ 如果你想了解一些基础知识,可以查看 ????????
LangChain 101:构建你自己的 GPT 驱动应用程序 — KDnuggets
请始终记住,要使用 OpenAI 和 GPT 模型,我们需要在本地计算机上安装 OpenAI 库,并拥有一个有效的 OpenAI 密钥。如果你不知道如何操作,可以查看这里。
1. 总结
ChatGPT 结合 LangChain可以快速且非常可靠地总结信息。
LLM 总结技术是一种减少文本量同时保留消息最重要部分的好方法。这就是为什么 LLM 可以成为任何需要处理和分析大量文本数据的数字公司的最佳盟友。
执行以下示例所需的库有:
# LangChain & LLM
from langchain.llms import OpenAI
from langchain import PromptTemplate
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import RecursiveCharacterTextSplitter
#Wikipedia API
import wikipediaapi
1.1. 简短文本总结
对于短文本的总结,这种方法很简单,实际上,你只需要简单地进行提示并附上指令即可。
这基本上意味着生成一个带有输入变量的模板。
我知道你可能在想……什么是提示模板?
提示模板指的是一种可重复生成提示的方式。它包含一个文本字符串——模板——可以接受来自最终用户的一组参数并生成提示。
提示模板包含:
-
对语言模型的指令 - 允许我们标准化一些步骤,以便于我们的 LLM。
-
输入变量 - 允许我们将先前的指令应用于任何输入文本。
让我们在一个简单的例子中看看。我可以标准化一个生成特定产品品牌名称的提示。

我 Jupyter Notebook 的截图。
正如你在之前的例子中看到的,LangChain 的魔力在于我们可以定义一个带有变化的输入变量的标准化提示。
-
生成品牌名称的指令始终保持不变。
-
产品变量作为一个可以改变的输入。
这使我们能够定义多功能的提示,可在不同的场景中使用。
所以现在我们知道什么是提示模板了……
让我们设想一下我们想要定义一个总结任何文本的提示,该提示使用超级易懂的词汇。我们可以定义一个包含一些具体指令和一个根据输入变量定义而变化的文本变量的提示模板。
# Create our prompt string.
template = """
%INSTRUCTIONS:
Please summarize the following text.
Always use easy-to-understand vocabulary so an elementary school student can understand.
%TEXT:
{input_text}
"""
Now we define the LLM we want to work with - OpenAI’s GPT in my case - and the prompt template.
# The default model is already 'text-davinci-003', but it can be changed.
llm = OpenAI(temperature=0, model_name='text-davinci-003', openai_api_key=openai_api_key)
# Create a LangChain prompt template that we can insert values to later
prompt = PromptTemplate(
input_variables=["input_text"],
template=template,
)
所以让我们尝试这个提示模板。使用维基百科 API,我将获取美国的摘要,并以一种非常易于理解的语气进一步总结。

我在 Jupyter Notebook 中的截图。
既然我们知道如何总结短文本……我可以稍微增加一些内容吗?
当然可以……
1.2. 长文本总结
在处理长文本时,主要的问题是我们无法通过提示直接将它们传达给我们的 AI 模型,因为它们包含了太多的 tokens。
现在你可能会想……什么是 token?
Tokens 是模型如何查看输入的方式——单个字符、单词、单词的部分或文本片段。如你所见,定义并不是很精确,这取决于每个模型。例如,OpenAI 的 GPT 中 1000 tokens 大约是 750 个单词。
但最重要的是,我们的费用取决于 tokens 的数量,而且我们不能在单个提示中发送过多的 tokens。为了处理更长的文本,我们将重复之前的示例,但使用整个维基百科页面的文本。
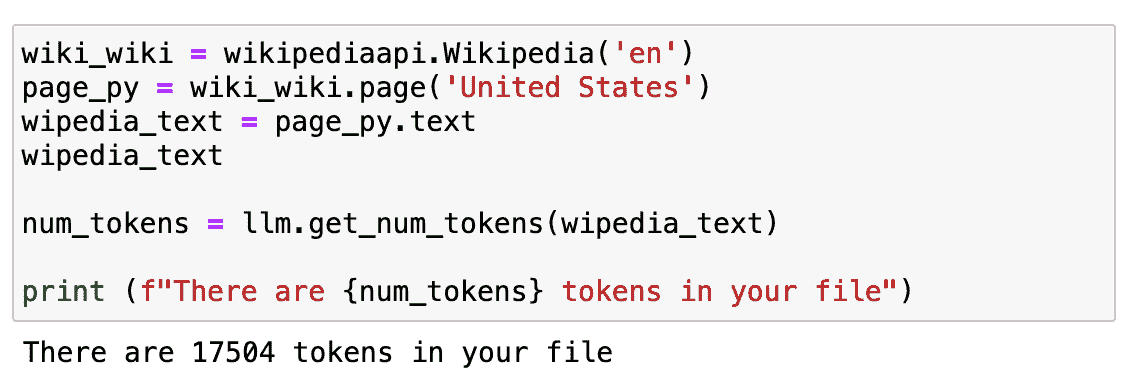
我在 Jupyter Notebook 中的截图。
如果我们检查它有多长……大约是 17K tokens。
这实际上是非常多的,不能直接发送到我们的 API。
那现在怎么办?
首先,我们需要将其拆分。这一过程称为chunking或splitting你的文本为更小的片段。我通常使用RecursiveCharacterTextSplitter,因为它易于控制,但你可以尝试很多其他的工具。
使用它之后,我们不再只有一段文本,而是得到了 23 段,这有助于我们 GPT 模型的工作。
接下来我们需要加载一个链,它会为我们进行连续调用 LLM。
LangChain 为此类链式应用提供了 Chain 接口。我们非常泛泛地定义一个 Chain 为对组件的调用序列,这些组件可以包括其他链。基本接口很简单:
class Chain(BaseModel, ABC):
"""Base interface that all chains should implement."""
memory: BaseMemory
callbacks: Callbacks
def __call__(
self,
inputs: Any,
return_only_outputs: bool = False,
callbacks: Callbacks = None,
) -> Dict[str, Any]:
...
如果你想了解更多关于链的信息,可以直接查看LangChain 文档。
所以如果我们再次重复相同的程序,使用被拆分的文本——称为 docs——LLM 可以轻松生成整个页面的摘要。

我在 Jupyter Notebook 中的截图。
有用吧?
既然我们知道如何总结文本,我们可以进入第二个用例了!
2. 提取
提取是从文本片段中解析数据的过程。这通常与输出解析一起使用,以结构化我们的数据。
提取关键信息对于识别和解析文本中的关键词非常有用。 常见的用例包括从句子中提取结构化的行以插入数据库,或从长文档中提取多行以插入数据库。
假设我们正在运营一个数字电子商务公司,需要处理我们网站上所有的评论。
我可以逐一查看所有内容……这将是疯狂的。
或者我可以简单地提取我需要的信息,并分析所有数据。
听起来很简单……对吧?
让我们从一个非常简单的示例开始。首先,我们需要导入以下库:
# To help construct our Chat Messages
from langchain.schema import HumanMessage
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
# We will be using a chat model, defaults to gpt-3.5-turbo
from langchain.chat_models import ChatOpenAI
# To parse outputs and get structured data back
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
chat_model = ChatOpenAI(temperature=0, model_name='gpt-3.5-turbo', openai_api_key=openai_api_key)
2.1. 提取特定词汇
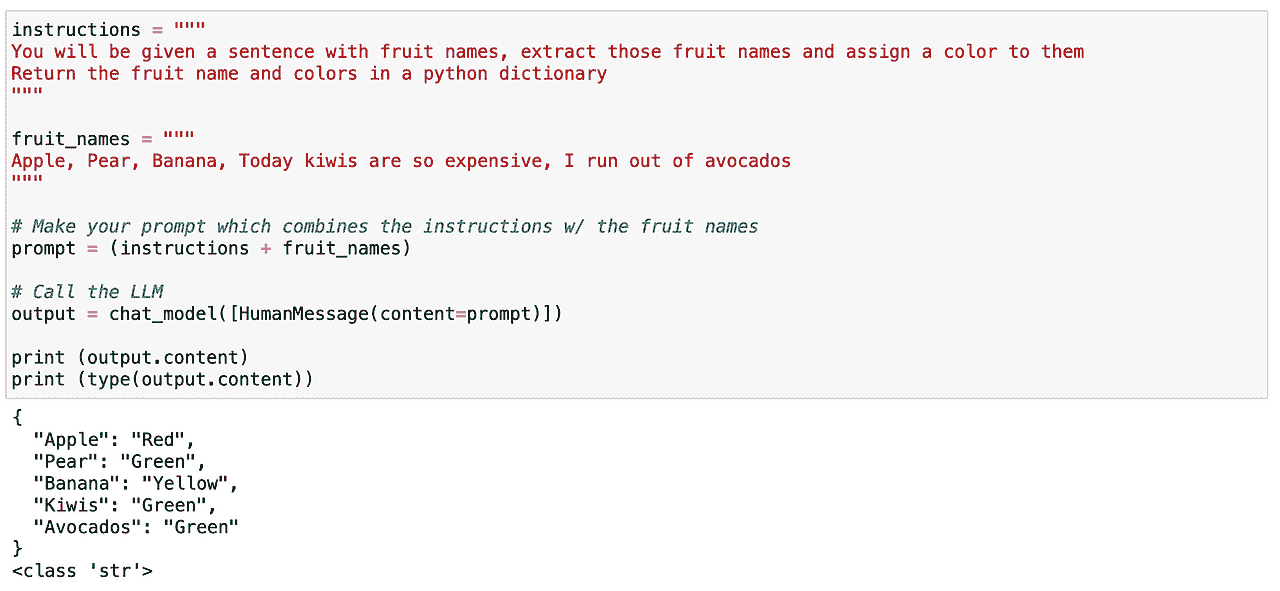
我可以尝试在文本中查找特定的词汇。在这种情况下,我想解析文本中包含的所有水果。再次,这非常直接。我们可以轻松定义一个提示,给出明确的指令,让我们的 LLM 识别文本中包含的所有水果,并返回一个包含这些水果及其对应颜色的类似 JSON 的结构。

我的 Jupyter Notebook 截图。
正如我们之前所见,这效果很好!
现在……让我们再玩一下。虽然这次效果很好,但对于更高级的用例,它不是一种长期可靠的方法。这时,一个出色的 LangChain 概念就派上用场了……
2.2. 使用 LangChain 的响应模式
LangChain 的响应模式将为我们做两件主要的事情:
-
生成一个带有真实格式指令的提示。 这很好,因为我不需要担心提示工程方面的事情,我会把它留给 LangChain!
-
从 LLM 读取输出并将其转化为合适的 Python 对象。 这意味着,总是生成一个有用的结构,以便我的系统可以解析。
为了做到这一点,我只需要定义我期望从模型中获得的响应。
那么,假设我想确定用户评论中提到的产品和品牌。我可以像以前一样使用简单的提示 - 利用 LangChain 生成更可靠的方法。
首先,我需要定义一个 response_schema,在其中定义我想解析的每一个关键字的名称和描述。
# The schema I want out
response_schemas = [
ResponseSchema(name="product", description="The name of the product to be bought"),
ResponseSchema(name="brand", description= "The brand of the product.")
]
And then I generate an output_parser object that takes as an input my response_schema.
# The parser that will look for the LLM output in my schema and return it back to me
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
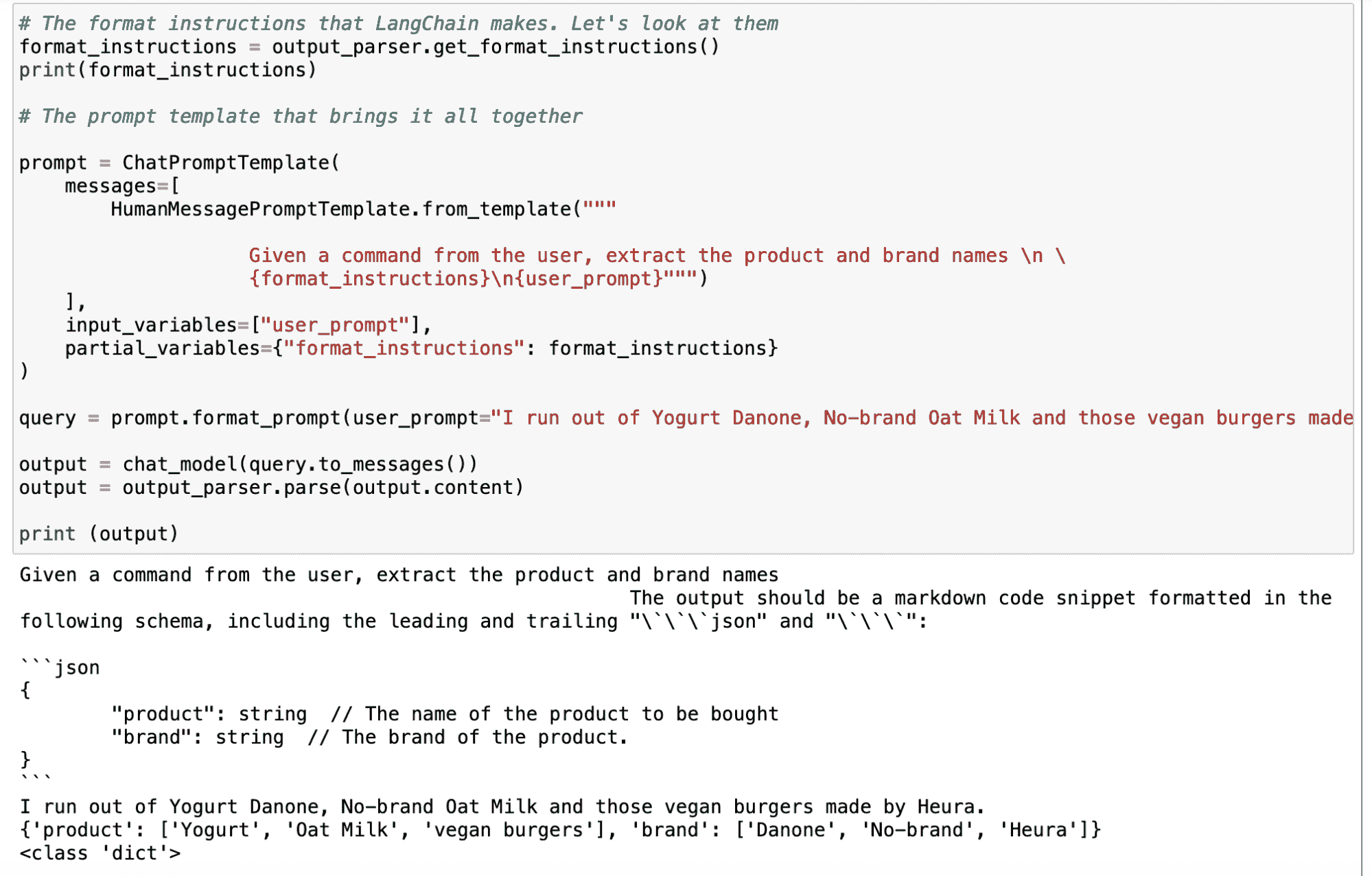
在定义我们的解析器之后,我们使用 LangChain 的 .get_format_instructions() 命令生成指令格式,并使用 ChatPromptTemplate 定义最终提示。现在,只需使用这个 output_parser 对象和我想到的任何输入查询,它就会自动生成包含我所需关键字的输出。
我的 Jupyter Notebook 截图。
如下面的示例所示,输入为“我用完了 Danone 酸奶、无品牌燕麦奶以及 Heura 制造的那些素食汉堡”,LLM 给出的输出如下:
我的 Jupyter Notebook 截图。
主要要点
LangChain 是一个多功能的 Python 库,帮助开发者充分利用 LLMs,特别是在处理大量文本数据时。它在处理文本方面表现出色。LLMs 使开发者能够在自然语言处理应用中创建更复杂和类人化的交互。
-
总结:LangChain 可以快速而可靠地总结信息,减少文本量,同时保留信息中最重要的部分。
-
提取:该库可以解析文本中的数据,允许结构化输出,并支持将数据插入数据库或根据提取的参数进行 API 调用等任务。
-
LangChain 促进了提示工程,这是一项关键技术,用于最大化像 ChatGPT 这样的 AI 模型的性能。通过提示工程,开发者可以设计可以在不同用例中重复使用的标准化提示,从而使 AI 应用更加多功能和高效。
总体而言,LangChain 作为一个强大的工具,可以增强 AI 的使用,尤其是在处理文本数据时,而提示工程是有效利用像 ChatGPT 这样的 AI 模型在各种应用中的关键技能。
Josep Ferrer 是一位来自巴塞罗那的分析工程师。他毕业于物理工程专业,目前在应用于人类流动性的 Data Science 领域工作。他是一名兼职内容创作者,专注于数据科学和技术。你可以通过LinkedIn、Twitter或Medium与他联系。
更多相关主题
如何从数据自由职业者过渡到数据创业者(几乎是一夜之间)
原文:
www.kdnuggets.com/2021/07/transition-data-freelancer-data-entrepreneur-overnight.html
评论
由Lillian Pierson, P.E.,世界级数据领导者和企业家的导师,Data-Mania 首席执行官
当我们中的许多人开始做自由职业时,往往感到非常兴奋。从任何地方工作,选择客户,只接自己喜欢的项目,这感觉真是太棒了。
但过了一段时间,你可能会感到精疲力竭。作为数据自由职业者,你能服务的客户和接的项目数量是有限的。你的收入在很大程度上依赖于你投入的小时数。
本文是一个指南,旨在帮助所有数据自由职业者突破收入上限,建立一个真正可扩展的数据业务。即使你是经验丰富的数据自由职业者,这些技巧也会帮助你找出一些阻碍你盈利最大化的缺失部分。
如果你在想,谁让我来说数据自由职业的事呢?好吧,我是莉莲·皮尔森,我在 2012 年刚刚被称为“数据科学家”时开始做数据科学自由职业者。从那时起,我创办了我的公司 Data-Mania,至今我们已经支持了超过 10%的《财富》100 强公司制定战略数据计划。
不仅如此,早在 2018 年,我开始指导其他数据专业人士启动他们的六位数数据业务,截至目前,超过10%的我的指导客户在注册后的前七个月内获得了六位数合同。

如果你有数据技能,并且已经在做自由职业或合同工作,并且准备将你的技能真正转化为一个超级盈利的数据业务,那就让我们深入探讨你需要采取的具体步骤。
首先:数据自由职业者和数据创业者之间的区别是什么?
让我们先定义数据自由职业者和数据创业者。
当我提到数据自由职业者时,我指的是以自由职业者身份提供数据服务的数据专业人士。他们在市场上出售自己的数据技能——无论是数据科学、数据分析、数据可视化,还是其他任何数据专业技能。
在某些情况下,数据自由职业者可能会与团队合作,无论这意味着他们有行政和业务支持,还是有其他数据专业人士帮助他们完成数据服务。他们进行的工作总是基于服务的工作。
相比之下,作为数据创业者,你作为 CEO 和业务的远见者出现。在工作交付方面,特别是服务方面,你通常会将所有,或至少大部分工作委派给你的团队。
如何将你的业务扩展为数据自由职业者
在从数据自由职业者过渡到数据企业家之前,你需要审视你的扩展选项。
如果你是数据服务提供商,你可以通过几种方式扩展你的业务模式。
-
你可以将其转变为一个代理机构
-
你可以将其转变为软件即服务(SAAS)公司
-
最后,你可以将你的商业模式转变为教练和顾问。
为了本文的目的,假设你是一个数据服务提供商,你希望将这一模式转变为代理机构或软件即服务。
步骤 1:记录你的流程
一旦你决定从单干的数据自由职业者转变为强大的数据团队,第一步就是记录你的流程。
记录你在业务中做的所有事情,例如:
-
销售
-
客户互动
-
客户接纳
-
服务交付
-
客户满意度
-
客户保留
为你的业务的每个方面创建明确的 SOP(标准操作程序)和指南,以便你可以进入第二步。
步骤 2:开始自动化和委派
一旦你清楚地记录了你的流程,你可以开始通过自动化和委派来优化这些流程。
这里有一些如何通过自动化节省时间和提升盈利的示例。
-
预定客户销售电话
你绝对不需要花费宝贵的时间安排潜在客户的预约。你也不需要花时间筛选他们,来回确认他们是否合适。
你可以通过潜在客户电话流程处理所有这些。
-
客户服务与互动
对于大多数客户支持和互动,你可以将这项工作委托给行政助理。你不需要回答每一封进入你收件箱的邮件!
然而,为了实现这一目标,你确实需要为你的助理制定明确的政策和程序。
-
客户接纳
你可以通过各种技术工具快速自动化你的客户接纳流程。在 Data-Mania,我们使用 Zapier、Google Forms 和 ConvertKit 来接纳新客户。
-
服务交付
是的,真的!你甚至可以委派服务的交付。一旦你围绕你提供的服务建立了流程并记录了每一步,你实际上可以找到虚拟助理或其他数据专家来按照说明执行工作!
这将使你担任 QA(质量保证)角色。最终,你要对你的业务所产生的工作负责。即使你自己不直接执行这些工作,你仍然需要对其承担责任——因此,确保它符合你的标准。
-
客户保留与满意度
创建一个自动化的流程,以跟进你的客户在接受服务期间。例如,你可以在他们服务进展到 30%时、60%时进行跟进,然后在产品或服务交付后的 15 天左右再进行一次跟进。
在交付过程中,电子邮件的处理应确保客户的期望不仅被满足,而且超出预期!找出方法使他们的客户体验尽可能愉快。
-
推荐信
创建一个简化且自动化的流程,以收集当前或甚至过去客户的反馈。在 Data-Mania,我们使用 Google Forms,因为它是免费的且易于使用!
完成所有这些后,恭喜你!是时候进入第三步了。
步骤 3:更新你的信息传达
现在你已经成功从数据自由职业者晋升为数据企业家,是时候升级你的信息传达了。
确保你的营销和业务文档清晰地反映出你的新业务结构。你希望潜在客户知道你拥有一个团队,你是一个真正的企业,并且你致力于为客户取得成果。
你需要更新你在以下地方的信息传达:
-
网站/销售页面
-
社交渠道
-
合同和协议
-
任何品牌或营销材料
尽管这一切听起来可能像是非常繁重的工作,但通过花时间记录和优化你的流程,你将能够创建一个超越仅仅是你自己的业务。你将能够提供规模更大得多的数据解决方案,因为你不再陷于业务实施的琐事中。你能自动化和委派的越多,你将有更多时间专注于成为你可以做到的最佳数据首席执行官。
想要在业务中获得更多关于自动化和工作流程的支持?下载免费数据企业家工具包——它包含了 32 个免费和低成本的工具,以帮助你发展数据业务。这些是我在 Data-Mania 日常使用的工具,帮助我们达到六位数的规模。
个人简介:莉莉安·皮尔森(Lillian Pierson, P.E.) 帮助数据专业人士转变为世界级的数据领导者和企业家。迄今为止,她已经向超过 100 万数据专业人士传授了人工智能知识。自 2008 年以来,她为美国海军、国家地理和沙特阿美等大型组织提供了战略规划。
相关:
-
数据职业不是一刀切的!揭示你在数据领域理想角色的提示
-
数据科学初学者应该避免的 10 个错误
-
麦肯锡教我的 5 个课程,能让你成为更优秀的数据科学家
相关话题
如何从不同背景转入数据科学?
原文:
www.kdnuggets.com/2023/05/transition-data-science-different-background.html

Bing 图像生成器
如果你来自非计算机科学背景,你知道要在数据科学领域找到一份工作需要付出多少努力。数据科学的机会吸引了很多人,但由于数据科学对世界来说还是很新的(不过十年时间!),按企业界的标准来说,真正自然符合数据科学家资格的人非常少。
这个行业充满了增长和机会,这也是为什么有人希望尽管来自完全不同的背景,仍然想要转入数据科学世界的主要原因之一。
注意: 我是少数知道数据科学可以适合非计算机科学背景人士的几个人之一,我希望这篇文章能帮助你找到提升自己旅程所需的指导。
在这篇文章中,我们将根据三个不同的部分讨论你应如何将数据科学作为职业过渡。
-
对于那些在大学里从未接触过与数据科学密切相关的任何学科的人来说。
-
对于那些来自非计算机科学背景但有几门与数据科学相关的课程且希望成为数据科学家的为什么不呢?
对于那些在某个行业工作了很长时间但现在想要转行进入数据科学这个既迷人又令人畏惧的世界的人来说。
注意: 这篇文章中的观点仅代表我个人,欢迎你对过渡过程有自己的看法或方法。我祝愿你一切顺利。
让我们直接进入正题。
第一阶段:你与数据科学关系不大,但你想进入这个领域。
好吧,在这种情况下,我会说你所付出的唯一努力是精神上的,这需要很多耐心。毫无疑问,数据科学是一个非常技术性的学科,涉及大量的数字。
附言: 尝试首先查看一下,了解在数据科学领域取得成功的道路。然后你可以继续了解加速你的旅程所需注意的事项!
需要注意的事项:
-
数据科学就像其他任何学科一样,你总是可以在找到时间时开始学习。
-
开始永远不会太早,永远不会太晚。
-
数据科学是计算机科学、统计学、大学水平的数学、大量逻辑思维、编程语言和其他工具的结合。
-
制定你在各个领域(或特别是在你想成为专业人士的领域)的技能图谱,并进一步学习每个领域。
-
如果你想进入分析领域,提高你的统计知识和数据清洗等技能。(尽可能多地学习 Excel,它是小数据集分析的福音,也是最好的入门工具)
-
对于数据可视化,尝试学习 Tableau、PowerBI 等,但同时要理解可视化的工作原理以及如何制作更好的可视化和仪表板。
-
在学习的前两个月内,主要关注按以下顺序学习——Excel、SQL、Tableau,如果时间允许,学习 Python 基础。
有了这些,你可以进入第二阶段并继续学习。
注意:如果你是数据科学的新手,这将需要时间,所以要有耐心并相信过程。一切都会顺利的!
第二阶段:你已经涉及到一些数据科学的主题,但尚未完全投入其中。
这与我的阶段类似,我可以告诉你,学习数据科学确实需要相当大的努力。正如你最终会看到的,它依赖于许多因素,但在世界为开源学习和向任何渴望知识的人开放大门的情况下,这并不是很困难(即使他们来自非计算机科学背景)。
注意事项:
-
数据科学是一个复杂的领域,如果你试图将其整体来看,就会觉得很困难。只需将你想专注的每个组件看作是大拼图的一部分,你会顺利应对。
-
如果你想深入数据可视化方面,专注于理解仪表板和数据连接的工作原理,并学习数据故事讲述。
-
对于那些想进入机器学习领域的人,尝试理解如何使用 Python 或 R,如果选择 Python——学习 NumPy、Pandas、Scikit Learn、SciPy、Matplotlib 和 Seaborn 等库。
-
理解机器学习背后的理论概念,以便更好地理解你的算法。这可能需要时间,但理解过程比编写高等级的机器学习算法更重要。
-
如果你想推进你的分析能力——学习推断统计学,理解数据如何用于制定数据驱动的解决方案。学习如何处理非结构化数据,并尽可能多地清理数据集。
-
超越 SQL 中的常规 CRUD 命令,完美理解 JOINS 的工作原理以及如何使用 MySQL/PostgreSQL。如果你想深入 Excel,学习如何使用数据分析工具包和制作宏。
-
理解时间序列数据的工作原理,了解如何从来源中提取数据并进行时间序列预测,以推动你的学习。

你很可能会成为那些学习大量工具,并掌握所有内容到中级水平的群体之一。
我强烈建议你找到自己的专业领域并深入研究。在数据科学领域,知识量和竞争非常激烈,找到你的细分领域,确保凭借你独特的技能在竞争中脱颖而出。
第三阶段:你已经在一个行业中成为专家,但现在你想开始从事数据科学!
我认识的人中,有些人在决定要成为数据科学的一部分之前,已经在生活中拥有了令人惊叹的职位。长时间在特定行业工作后,想要改变职业是很自然的,我从那些曾经处于类似位置的人那里获得了一些有用的建议,希望能帮到你。
需要注意的事项:
-
一旦你在特定行业成为专业人士,可能是由于生活选择的改变或提升技能的需求,使你转向数据科学。
-
无论如何,数据科学领域的管理职位更愿意有在行业中有丰富企业经验的人。
-
在你现有的行业知识基础上提升数据科学技能,可能是你职业转型中最好的事情之一。数据科学虽然涉及计算机科学及其工具和技术,但在很大程度上依赖于领域知识。
-
拥有足够的领域知识,你可以通过利用数据的力量成为该领域的数据科学家,超越已有的做法。
-
行业特定的 KPI 和指标可以通过数据科学进一步开发和自动化,也可以为你打开新的大门。
-
拥有数据科学工具的额外知识,你可以在自己的领域成为培训师,并帮助新兴的数据科学家。可能性是无限的。
-
在这个阶段需要学习的工具和技能与本文前面提到的第一阶段和第二阶段相同。
无论如何,由于世界正转向数据科学,学习数据科学并坚持自己的职业领域是最好的选择。你所做的一切,都可以涉及数据,并将数据用于决策,只会让你的决策更出色。
过渡到数据科学领域并不困难,因为找工作本身并不难,而是因为有太多人在争夺这些职位。每个人都看到了这些机会,并知道-数据是未来-,数据科学也是如此。
对于那些已经具备数据科学技能的人,请继续关注,我会在这篇文章的另一部分中讨论如何从专家成长为数据科学领域的顶尖高手。
Yash Gupta 是一名数据科学爱好者与商业分析师,兼职技术作家,同时也是 Medium.com 的博主。他希望以易于理解的方式与更广泛的受众分享数据科学知识。他希望与所有像他一样喜欢数据的人分享自己的知识。他每天都尝试学习新事物,并热衷于指导初学数据科学的人。
原始内容。转载经许可。
更多相关话题
转型为数据科学:如何成为数据科学家,以及如何创建数据科学团队
原文:
www.kdnuggets.com/2017/12/transitioning-data-science-become-data-scientist-data-science-team.html
评论
由 Amir Feizpour, 加拿大皇家银行
现在很难定义数据科学:每家公司都声称自己在做数据科学,每个人都声称自己是数据科学家。实践者对模糊的工作描述感到困惑,而试图成为数据科学家的人则对缺乏标准定义感到沮丧。在 2017 年多伦多机器学习峰会的讨论中,我们尝试揭示数据科学的奥秘,并澄清成为数据科学家的含义。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作

数据科学是应用科学方法理解数据以解决业务问题。“在我看来,一个优秀的数据科学家是一个非常重视数据科学中科学部分的人;能够通过统计、机器学习和分布式计算发现并解决问题的人。” 说的是 Thomson Reuters Labs 的研究总监 Amir Hajian。换句话说,数据科学家是能够“通过推理推断数据,用概率思考,保持科学和系统化,并利用软件工程最佳实践使数据大规模工作”的人,Aviva 的分析副总裁 Baiju Devani 说。他还补充说,重要的是要认识到,“你所解决的问题或找到的解决方案没有确定的路径,因此你必须接受模糊性,” 他说,您还需要“拥有那种实验性的思维方式,使您能够处理模糊的问题和解决方案定义。” 从某种意义上说,Lindsay Farber,MoneyKey 的高级数据科学家认为,最好的数据科学家是具有“良好的统计知识、编程和技术技能以及行业经验”的人。
微软加拿大首席数据科学家 Ozge Yeloglu 还提醒我们,在商业中需要“退后一步,了解数据科学真正是什么。它是利用数据来解决商业问题,这有时意味着没有必要使用机器学习或人工智能。” 关于数据科学的部分误解源于存在的炒作。每个企业都急于进入数据科学,而没有花时间了解为什么以及如何做。大公司在激烈竞争中争取雇佣尽可能多的数据科学家,而没有采取必要的基础步骤。“如果你有 100-200 名数据科学家(相比之下,比如 Facebook 有 500-600 名数据科学家),那么你可能在错误的行业中,” Baiju Devani 说。他补充说“虽然这些组织有很大的问题需要通过数据科学或机器学习来解决,但他们没有考虑如何将这些解决方案规模化。” 另一方面,一些初创公司过于急于通过机器学习解决所有问题,而没有考虑问题的适当规模。“如果你是一个拥有一千个客户的初创公司,你不应该进行情感分析,而是应该给每个客户打电话并与他们交谈,” Baiju Devani 说。从业者也在急于成为数据科学家,而没有真正理解这意味着什么。“每一个参加过几门在线课程的人都认为自己已经转行了,而实际上他们几乎没有投入足够的时间和精力,” Ozge Yeloglu 说。
然而,这种炒作并非完全毫无理由。确实有一些有趣的商业用例在业内引起了兴奋。“当我们的客户带着真正的数据业务问题找上我们,而我们可以利用我们的资源并结合他们的领域知识来帮助他们时,我真的感到非常高兴;这让我乐观地认为,炒作可以让我们比预期更快地实现现实,” Ozge Yeloglu 说。“组织希望找到一种新的商业方式,朝着以前不可能的方向发展,” Amir Hajian 说。他补充说,从业者想成为数据科学家,因为“他们希望找到那些不会结束的工作,并且不是每天重复同样的事情。” 他还表示“现在正是那些不是计算机科学家但希望进入这个行业并做一些有意义的事情的人的最佳时机。” 毕竟,这是一个不那么刻板的领域;“它在变化,它在找到自己的道路,并且在不断发展,所以你必须为此做好准备,你必须找到你喜欢的东西和你的细分领域,并且不断前进。”
鉴于存在的所有不确定性,有些事情可以做以增加作为数据驱动业务成功的可能性。Baiju Devani表示,其中一个最重要的步骤是:“问一下目标是什么,为什么需要数据科学,你需要不断问为什么,直到得到一个好的答案,然后其他的就自然会就位,” 下一步是建立一个高效的数据科学团队。团队的核心应该来自于业务本身,而不是任何新员工。Ozge Yeloglu说:“如果你能找到团队中已经是领域专家并理解数据的人,并且他们很可能已经在做传统的商业智能工作,如果他们想成为数据科学家,就让他们去做,并对他们进行投资,” 一旦形成了核心团队,根据优先级、时间框架和问题的复杂性,你可能会雇佣具有各种技能的人。大多数时候,最佳解决方案是让数据工程师来构建基础设施,然后在其上再加一个数据科学家,以及业务领域专家。事实上,Amir Hajian指出:“每个数据科学家都需要其他角色:数据可视化专家、开发人员和 UI/UX 设计师,”
数据团队的组成和文化确实非常重要。不同背景和思维方式的多样性提供了成功的关键因素。Baiju Devani说道:“我们谈了很多数据科学作为一种科学,但我认为它同样具有艺术性,需要大量的创造力,研究表明多样性会导致创造力,”Lindsay Farber说:“在我的公司,我必须与团队中的其他数据科学家合作,以提出更好的答案,”Amir Hajian补充道:“这是一项超越算法的艰巨工作:你必须清理数据,与客户沟通,构建整个模型,然后向利益相关者展示,并且要耐心,想出不同的方法来呈现给客户并解释给他们;这就是为什么拥有不同技术背景的人能够产生巨大影响,因为他们以不同的方式看待问题,并且具备专业知识,”Ozge Yeloglu表示:“我最近听到的一个故事是关于一个团队建立了一个检测疾病的模型,在训练中表现良好,但在实际测试中失败了;他们的训练数据完全是白人,这在拉丁裔人群、非裔美国人和亚洲人群中都失败了;这对有社会影响的公司来说是一个警示,如果你的团队看起来一样,那么他们的思维也会一样,”
创建数据科学团队时存在许多细微差别,草率处理必然会导致失败。目前,应该明确不同技术角色和专业知识以及软技能如何交织在一起,形成一个能够在数据科学领域实现伟大目标的团队。选择加入这样一个团队的个体是一个巨大的挑战,需要谨慎进行。“对我而言,团队文化是最重要的方面之一,因此我会寻找适合我团队和客户的成员。在我的团队中,数据科学家是具备非常高沟通技能的技术人员,他们能够与从数据科学家到副总裁和首席信息官的人员交谈。我在面试中通常会提出一个非常开放的案例研究,看看候选人是否能够提出正确的问题,找出正确的技术解决方案,并观察整个思考过程。” 奥兹格·耶洛格鲁说。她补充道“显然,技术技能很重要,但只要他们懂得 Python 或 R,我相信他们会继续学习和提升。这很重要,因为数据科学是一个不断发展的领域,所以你不能停滞不前。” 招聘经理在面试中还应关注候选人的头脑风暴能力和与团队合作的能力。“我会试图进行对话,看看你是否能够围绕数据科学进行讨论,而不仅仅是你技术上擅长的领域。如果我们超越这一点,我会倾向于拿起一篇论文并将其发送给候选人,要求他们来进行论文评审。我认为这样做效果很好,就像口试一样,比起在时间压力下让你写排序算法要好。” 拜祖·德瓦尼说。寻找擅长团队合作的人也至关重要。“我想强调的是,与市场营销主管、运营主管以及公司其他所有人沟通的技能真的很重要。你需要与他们交谈,以了解他们的数据需求,并向他们展示他们需要看到的内容,即使他们可能无法准确描述出来。” 林赛·法伯说。测试许多重要技能的一个好方法是要求候选人向面试官介绍他们最有趣的项目之一。“我发现通过这种方式找到最佳候选人,这从未失败过,因为这样可以立即让候选人展示他们能做什么、了解什么技术、如何思考问题以及如何沟通。你可以看到,有些人做不到这一点,而有些人则准备好并打开他们的笔记本电脑,向你展示他们所构建的东西。” 阿米尔·哈吉安说。
这些特征有些来自于个性,但经验也非常重要。这导致了一个大矛盾,因为市场上几乎没有经验丰富的数据科学家。大多数寻找数据科学职位的人都是刚刚毕业,因此没有所需的商业经验。“如果你缺乏行业经验,我认为参加 Andrew Ng 的课程、学习 Python 或者使用 Kaggle 上那些非常干净的不现实的数据集是一个方法,但为了进一步发展,你需要走出去,参加聚会和峰会,与其他数据科学家交谈,了解他们的工作,并参加面对面的课程。这将帮助你了解不同类型的数据科学家的工作内容,”Lindsay Farber 说道。她还认为,第一份工作不应设定过高的目标;“首先进入公司担任初级职位,逐步提升。当你表现出兴趣并努力工作时,你将拥有数据分析和数据科学的背景以及商业洞察力,最终为自己创造一个职位。”此外,告诉别人你与众不同的地方也很重要,超越那些每个人都能做的事情,比如参加在线课程。一种好的方法是“选择一个你感兴趣的问题,并围绕它开始构建一些东西。自学解决该问题所需的一切。这使学习过程变得有趣,你将开始学习作为数据科学家所需的所有技术和科学,”Amir Hajian 说道。无论你是来自学术界,还是已经在行业中工作并希望转行到数据科学领域,你都可以这样做。“你应该找到一个不在你工作描述中的扩展项目,但它将推动你进入数据科学领域。你可以实际使用公司的数据、现实世界的数据,通过这种方式获得经验,然后你可以展示你的潜力和愿望,”Ozge Yeloglu 说道。如果你有一个 Kaggle 竞赛的数据集,尽管大胆地发挥创意,想想你还能用它做些什么。甚至可以与许多现有的开源数据集结合,希望能从中得到一些有趣的结果。

我们之前讨论过候选人与公司文化匹配的问题,以及公司如何监控这一点。另一方面,考虑职位和公司的人应该在面试时或甚至在面试前收集关于公司的信息时提出问题。“我在寻找数据科学职位时听到的最有趣的事情是,当面试官在面试你时,你也在面试面试官。这是你了解这个角色生活将会是什么样子的机会。重要的问题包括:‘我将与谁合作?’,‘团队是什么样的’,以及‘你们正在解决哪些问题’。让他们给你讲讲他们最近做过的最令人兴奋的项目,并仔细倾听,对它提出很多问题,因为这会向你展示关于公司和团队的一切。” 说到阿米尔·哈吉安。奥兹格·耶洛格鲁指出,“在这样的对话中要记住一个重要的点是,人们是为经理工作,而不一定是为公司工作。你的经理实际上是你每天都要打交道的人,他们会决定你在公司里的成功与否。所以我认为与招聘经理沟通真的很重要。即使你没有安排那次通话,也要要求招聘人员安排。然后从那个人那里实际了解一下,看你是否能和他们建立联系。” 她还补充道,“我真的很喜欢有人问我关于成长机会的问题,因为这让我知道他们意识到这份工作并不轻松,他们必须每天不断学习。” 对于想要加入的公司和团队,提前做研究也很重要。“上 YouTube 看看是否有数据科学家最近做过演讲,观看所有这些演讲;看看他们是否发表过论文,阅读这些论文,这样你可以在面试中提到这些内容,而不是让他们告诉你,然后你可以展示你的知识。” 说到林赛·法伯。巴伊朱·德瓦尼建议,“这可能会稍微困难一点,但你也应该尝试找出是否可以与数据科学团队紧密合作的人交流,不论是业务方面还是更有可能的工程方面。弄清楚工程和数据科学团队的合作情况以及有什么样的动态。”
最后,对于从业者来说,了解作为数据科学家的生活实际情况是很重要的。“如果你来自学术背景,要记住公司并不是在寻找一个知道一切并能谈论其哲学的学者。面试你的公司有问题,他们面试你是有原因的。他们很可能希望你能帮助他们解决那个特定的问题。如果你能找出问题并说服他们你能帮助解决这个问题,你就能得到这份工作。所以要自信,找出问题,并告诉他们你打算如何解决它,” 阿米尔·哈吉安说道。林赛·法伯补充说“你需要意识到,你不能仅凭机器学习就解决所有问题。70%的工作是清理数据和预处理。你还需要意识到,仅仅做常规报告和基础统计分析也可以产生巨大影响。你可以将公司推进到 80%的进度,然后使用硬核数据科学和自定义模型将其提升到下一个层次。” 从某种意义上说,“你大多数时间只是一个被美化的 SQL 编码员或商业智能报告员。然而,你必须对数据充满热情,并记住任何周期中总会有起伏,但如果你真的对数据充满热情并感到兴奋,你将拥有一个非常有趣和令人满意的职业,” 巴伊朱·德瓦尼说道。
数据科学家之间有着巨大的互动和学习机会。找到最佳的下一份工作机会或招聘的最佳方法之一就是与志同道合的人建立网络。保持开放的心态,对每个人都要尊重,尽可能地帮助他人,他们也会在有机会的时候回过来帮助你。建立并维护良好的职业关系是非常重要的。“这对一些人来说可能显而易见,但不要断绝联系!例如,如果你正在面试,如果你意识到面试进展不如预期,不要感到沮丧或防御,而是请他们提出你可以改进的建议,” 奥兹格·耶洛格鲁说道。这是一个由知识分子组成的小社区,他们努力提升集体智慧并取得伟大成就。
点击这里查看有关讨论小组成员的详细信息。
点击这里查看讨论小组的视频。
个人简介:阿米尔·费兹普尔 是加拿大皇家银行的数据科学家,拥有物理学、分析学和数据科学的丰富研究经验。
相关内容:
-
数据科学家的一天
-
数据科学家的一天(续)
更多相关内容
2021 年 AI、数据科学、机器学习技术的主要发展和 2022 年的关键趋势
原文:
www.kdnuggets.com/2021/12/trends-ai-data-science-ml-technology.html
评论 2021 年充满了起伏,但我希望对大多数人来说,它比 2020 年要好,生活逐渐回归正常,并且有一些愉快的传统。KDnuggets 的传统之一是我们每年的专家预测总结。
我们问专家的问题是
2021 年 AI、数据科学、机器学习的主要发展是什么?你对 2022 年有什么关键趋势的看法?
一些提到的重要话题包括 AutoML、自动化和 RPA、应用:更多更好、数据网格、数据结构和以数据为中心的方法、深度学习和 PyTorch、GPT-3 类系统、边缘设备、外部数据源、低代码和无代码 AI、MLOps、负责任的 AI、人才缺口和人员配置,以及量子计算/机器学习。
这里是我们的专家意见,包括 Marcus Borba、Kirk Borne、Tom Davenport、Carla Gentry、Doug Laney、Pierre Pinna (IPFConline)、Ganapathi Pulipaka、Kate Strachnyi 和 Mark van Rijmenam 的贡献。
同意?不同意?请在下方评论!
Marcus Borba,全球 AI、机器学习、数据科学领域的思想领袖和影响者。
目前,AI 正在被应用于大多数知识领域,并迅速发展,扩展到多个新领域,如 多模态 应用和更小的设备,使得技术发展以空前的速度增长。到 2021 年,对透明和 可信赖 的 AI 的关注促使负责任和可解释的 AI 概念变得更加重要,有助于理解 AI 如何运作。另一个看到强劲增长的领域是 超自动化,利用多种互联技术,如 AI 和机器学习、物联网、RPA 和增强分析,提升人机协作并实现更好的生产力。
对于 2022 年,我相信 量子机器学习 将是下一个大趋势。量子机器学习是量子计算和 AI 的交集,将使得创建更强大的机器学习和 AI 模型成为可能。随着大型技术公司对量子计算机上机器学习的开发和支持,资源将通过云模型可用。智能过程自动化 的不断发展和应用将为公司提供更大的灵活性,不仅仅是节省时间,还提高了操作效率并帮助简化流程。低代码 和 无代码 AI 解决方案也将越来越使公司能够开始使用 AI,从而更快且更低成本地开发 AI 模型。
Kirk D. Borne,数据科学家 @DataPrime_ai,首席科学官。全球讲者。创始人 @LeadershipData。顶尖 #BigData #DataScience #AI #IoT #ML 影响者。博士,天体物理学。
2021 年的重大趋势包括 AI/ML 在医疗应用、金融应用、面向客户的应用、物流/供应链应用以及元宇宙(游戏应用)中的快速扩展。即:应用、应用、应用,组织对其数据、AI、ML、数据科学资产和投资的生产力和价值要求越来越高。
到 2022 年,这种情况将持续,但人才缺口正带来越来越大的阻力,这可能成为这种增长势头的障碍。因此,我们可以预期组织会选择更多的低代码/无代码部署(如 AutoML),以利用和维持不断增长的 AI/ML 势头,这将进一步区分 AI 领先者与 AI 落后者,这也支持了老话“完成任务总比完美无瑕好”。
Thomas H. Davenport,Babson College 杰出教授;牛津大学 Said 商学院访问教授。
2021 年的一个重大进展是MLOps的兴起,以监控模型一旦投入生产后的表现。这在一定程度上是因为疫情的需要,在许多公司中,预测需求和供应的模型不再准确。检测模型漂移是 MLOps 的一个重要能力。但 MLOps 的兴起也是许多公司对机器学习模型依赖增加的结果,跟踪模型及其性能成为业务成功的关键。
这将在 2022 年继续,公司将使用 AutoML、MLOps 以及其他工具和流程改进来专业化 ML 开发。他们还会更明确地“谁做什么”在 AI 开发和部署中,为模型创建、模型部署、模型监控等任务创造专业角色。这些任务不能全由数据科学家负责。
Carla Gentry,Zuar 数据科学家和数据倡导者。
随着 Covid 继续影响我们的工作,公司在员工配置、远程与内部、数据在云端还是本地等方面进行了调整。一个明确的事实是,我们在数据及其影响力方面正处于十字路口。数据扩散已成为组织内部一个真实且昂贵的问题,正在损害创新。Hakkoda 调查,
“6% 的商业和 IT 领导者将他们的数据组织和流程称为垃圾堆。”
来自 (VentureBeat)
2022 年:我们将继续这种数据孤岛路径,因为每个部门总会有自己的议程和需求。能够将多个数据平台整合在一起的公司对于那些没有足够人才、时间或能力将所有数据结合起来进行决策的企业至关重要。对不良理念投入大量资金已不再被接受,投资回报率必须实现。让我们拥抱创新技术,但也要记住,数据本身是无用的,除非你对其进行处理!
道格拉斯·B·拉尼,创新研究员,数据与分析战略专家。《信息经济学》一书的作者——CIO 杂志年度必读书籍。
在 2022 年,人工智能、数据科学和机器学习的主要重点将是利用日益增长的外部数据源。由于 Covid-19 大流行和各国以及地方响应的不同、不断变化,使得许多组织的基本分析模型变得无用,甚至对业务有害。
随后,企业被迫放弃了依赖公司自身历史数据的趋势分析模型,转而采用基于驱动因素的模型,这些模型考虑了表现的领先指标。企业不再只是盯着自己的肚脐,而是被迫向组织外部寻找以诊断、预测和建议客户行为、库存水平、供应商可用性、人才需求、设备行为、竞争对手反应、合作伙伴能力等方面的信息。
这意味着数据科学家和人工智能开发者的新最佳伙伴(如果不是其他同样吸引人的人)是那些专注于研究和获取新的高价值替代数据源的个人。2022 年将是数据策展人的年代。
皮埃尔·皮纳,IFFConline CEO,数字化转型咨询。
对于 IPFConline 团队来说,2021 年标志着OpenAI GPT-3类型系统在自然语言处理领域的“战斗”,这些模型变得越来越强大且数据密集。同时,Yoshua Bengio 团队发布了一篇关于GFlowNet 基础的非凡新论文,提出了在机器学习中实现因果发现与推理的重大进展。
对于 2022 年,我们相信人工智能领域的愿景将是提升模型可解释性。因此,研究将越来越多地转向符号 AI 与实际统计深度神经网络的混合模型。这种解决方案将使得从业者对负责任系统的可信采用充满信心。
甘纳帕提·普利帕卡博士,首席人工智能高性能计算科学家,演讲者,畅销书作者。
PyTorch Lightning 使深度学习研究社区能够将更多时间用于研究,减少工程方面的时间。今年,它作为一个流行的深度学习框架取得了进展,可以在分布式硬件和高性能计算机器上读取和重现研究成果。PyTorch Lightning 在 GPU、TPU 和 CPU 上都是一个不容忽视的力量。自然语言处理在 2021 年随着 PyTorch Tabular 的推出取得了进展。PyTorch Tabular 在深度学习中处理 Pandas 数据框,因为没有像 Scikit-learn 这样的现成库用于深度学习。它运行在 PyTorch 和 PyTorch Lightning 上。
在 2022 年,我们可以期待分布式量子计算机上的量子机器学习以及量子卷积神经网络的训练。2022 年的图神经网络研究继续加速。企业在 2022 年继续采用 PyTorch、TensorFlow、Python 以及诸如 DQN 等强化学习算法,服务于各个行业。
凯特·斯特拉赫尼,DATAcated 创始人。
2021 年主要进展
-
我们看到越来越多的公司认识到数据的价值,并拥抱数据驱动的文化。
-
数据平台内的创新使企业更容易理解其数据,并缩短洞察和数据驱动决策的时间。
2022 年关键趋势
-
数据网格、数据织物、数据仓库的兴起以及向数据中心化的转变;逐渐远离应用/模型中心化。
-
对能够处理大规模合成数据集创建、处理和评估的数据科学家的需求增加;这与元宇宙中的创新有关。
马克·范·赖门南博士,未来技术战略家,主题演讲者,三次著作作者及企业家。
人工智能和机器学习将在自动化工作中发挥更大的作用。对于非编码人员或非数据科学家来说,这将导致更先进的机器人流程自动化,使办公室工作人员和经理能够在不需要编码知识的情况下进一步自动化自己的工作。因此,员工将能够完成更多的工作,因为大多数单调的工作现在可以被自动化。然而,如果没有编码专长的员工和管理层可以利用 AI 和 ML 来自动化他们的工作,那么那些拥有这些技能的人当然也可以应用相同的策略。
当然,这可以与使用 GPT-3 更快地编写代码相关联,但在 2022 年我们还将看到更先进、自动化和智能的黑客攻击。黑客们将越来越多地转向 AI 来完成更多工作、更快地渗透组织并窃取更多数据。同时,保护公司的人也将转向 AI,因此黑客和 IT 安全人员都会使用 AI,导致一场在光速下进行的战斗。
也可以查看人工智能、分析、机器学习、数据科学、深度学习研究2021 年的主要发展及 2022 年的关键趋势,本周早些时候发布。
相关:
-
人工智能、分析、机器学习、数据科学、深度学习研究2021 年的主要发展及 2022 年的关键趋势
更多相关主题
计算机视觉技术和应用的最新趋势
原文:
www.kdnuggets.com/2018/11/trends-computer-vision-technology-applications.html
评论
由 Valeryia Shchutskaya、InData Labs。
计算机视觉软件正在改变各个行业,使消费者的生活不仅变得更加轻松,还变得更加有趣。作为一个领域,计算机视觉得到了大量宣传和相当数量的投资。北美市场的计算机视觉软件总投资达到了 1.2 亿美元,而中国市场则猛增至 39 亿美元。让我们深入了解一下那些最有前景和最令人兴奋的技术,它们使计算机视觉软件开发市场增长如此迅速。
深度学习的进展
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
深度学习因其在提供准确结果方面的优势而获得了广泛的关注。
传统的机器学习算法,尽管它们可能很复杂,但其核心仍然非常简单。它们的训练需要大量的领域专业知识(这很昂贵),当出现错误时需要人工干预,最终它们只擅长于它们所训练的任务。
深度学习算法则通过一个神经网络来了解当前任务,将任务映射为一系列概念的层次结构。每个复杂的概念都由一系列简单的概念定义。这一切算法都可以自行完成。在计算机视觉的背景下,这意味着首先识别光暗区域,然后分类线条、形状,最后才进行完整的图像识别。
深度学习算法在数据更多时表现更好,而这在机器学习算法中并不常见。
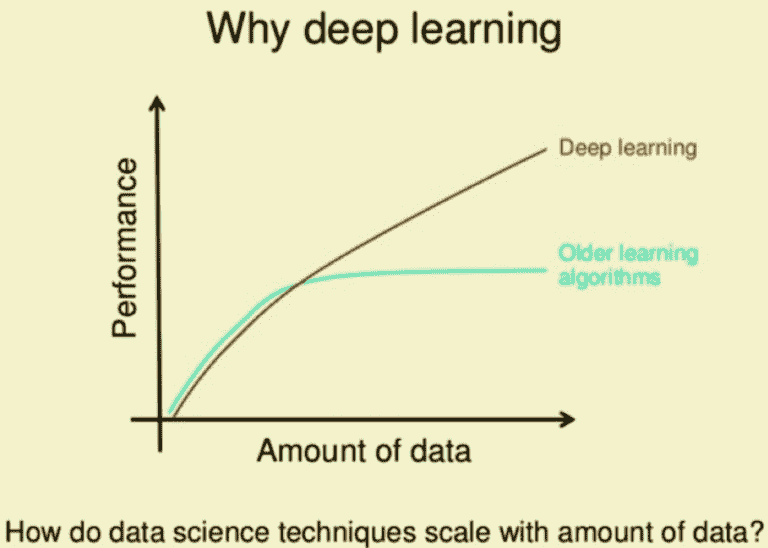
对于计算机视觉来说,这无疑是个好消息。它不仅使得训练深度学习算法时可以使用更多的图片和视频,还减轻了与数据标注和标签相关的工作量。
零售行业在计算机视觉软件的应用上一直处于先锋地位。ASOS 在 2017 年为其应用增加了按照片搜索选项,随后许多零售商也效仿。有些甚至更进一步,利用计算机视觉软件将在线和离线体验更紧密地结合在一起。
一家名为 Lolli & Pops 的美食糖果零售商使用面部识别技术来识别进店的常客。因此,店内员工能够通过提供个性化的产品推荐和偶尔的忠诚折扣来个性化购物体验。
特殊待遇培养了品牌忠诚度,并将偶尔的顾客转变为常客,这对业务都是有益的。
边缘计算的兴起
连接到互联网和云端的机器能够从网络收集的数据中学习并进行相应调整,从而优化系统性能。然而,连接互联网和云端并不总是有保障。这就是边缘计算发挥作用的地方。
边缘计算指的是附加在物理机器上的技术,如燃气涡轮机、喷气发动机或 MRI 扫描仪。它允许数据在收集地点进行处理和分析,而不是在云端或数据中心完成。
边缘计算并不会取代云计算。它只是让机器在需要时根据新的数据洞察单独行动。换句话说,边缘设备上的机器可以根据自身经验学习和调整,独立于更大的网络。
边缘计算解决了网络可达性和延迟的问题。现在,设备可以放置在网络连接差或不存在的区域,而不会影响分析结果。此外,边缘计算还可以抵消部分数据共享云计算的使用和维护成本。
对于计算机视觉软件来说,这意味着可以更好地实时响应,并且只将相关洞察转移到云端进行进一步分析。这个功能对于自动驾驶汽车尤其有用。
为了安全操作,这些车辆需要收集和分析大量关于周围环境、方向和天气条件的数据,更不用说还要与路上的其他车辆进行实时通讯。依赖云解决方案分析数据可能是危险的,因为延迟可能导致事故。
使用点云进行物体识别
最近在物体识别和跟踪中使用频率更高的技术是点云。简单来说,点云是定义在三维坐标系统中的数据点集合。
这项技术通常用于一个空间内(例如一个房间或容器),其中每个物体的位置和形状由一组坐标(X、Y 和 Z)表示。这个坐标列表被称为“点云”。
此技术提供了物体在空间中的准确表示,并且任何运动都可以被准确跟踪。

点云的应用几乎是无尽的。以下是一些行业及其从此技术中获益的例子:
-
文档:资产监控、建筑工地跟踪、破坏检测。
-
分类:城市规划、用于更简便分析的审计工具、必要的公用事业工作映射。
-
变化检测:资产管理、货物跟踪、自然灾害管理。
-
预测性维护:对资产和基础设施进行持续监控,以预测何时需要维修。
融合现实:增强的 VR 和 AR
今天,任何 VR 或 AR 系统都可以创建沉浸式 3D 环境,但与用户所在的真实环境几乎无关。大多数 AR 设备可以执行简单的环境扫描(例如,Google ARCore 可以检测平面表面和光照条件的变化),而 VR 系统可以通过头部跟踪、控制器等检测用户的动作,但它们的能力仅此而已。
计算机视觉软件正在将 VR 和 AR 推向被称为融合现实(MR)的下一个发展阶段。
借助外部摄像头和传感器来绘制环境地图,以及眼动追踪解决方案和陀螺仪来定位用户,VR 和 AR 系统能够:
-
感知环境并引导用户避开如墙壁、物品或其他用户等障碍物。
-
检测用户的眼动和身体动作,并相应地调整 VR 环境。
-
提供室内环境、公共空间、地下等的指导和方向。
硬件商店 Lowe’s 已经在他们的商店中使用了这项技术。每位购物者可以借用一个 AR 设备,在设备上制定购物清单并获取商店中每件物品的方向。该 AR 设备实时使用楼层图、库存信息和环境映射来提供准确的方向。
Sephora 更新了他们的虚拟艺术家应用程序,提供实时 3D 面部识别,让顾客可以看到不同化妆品在他们脸上以及不同光照条件下的效果。
语义实例分割
要理解语义实例分割是什么,首先我们将这一概念拆分为两个部分:语义分割和实例分割。
实例分割在像素级别识别物体轮廓,而语义分割则只是将像素分组到特定的物体组。让我们用气球的图像来说明这两种技术与其他技术的比较。
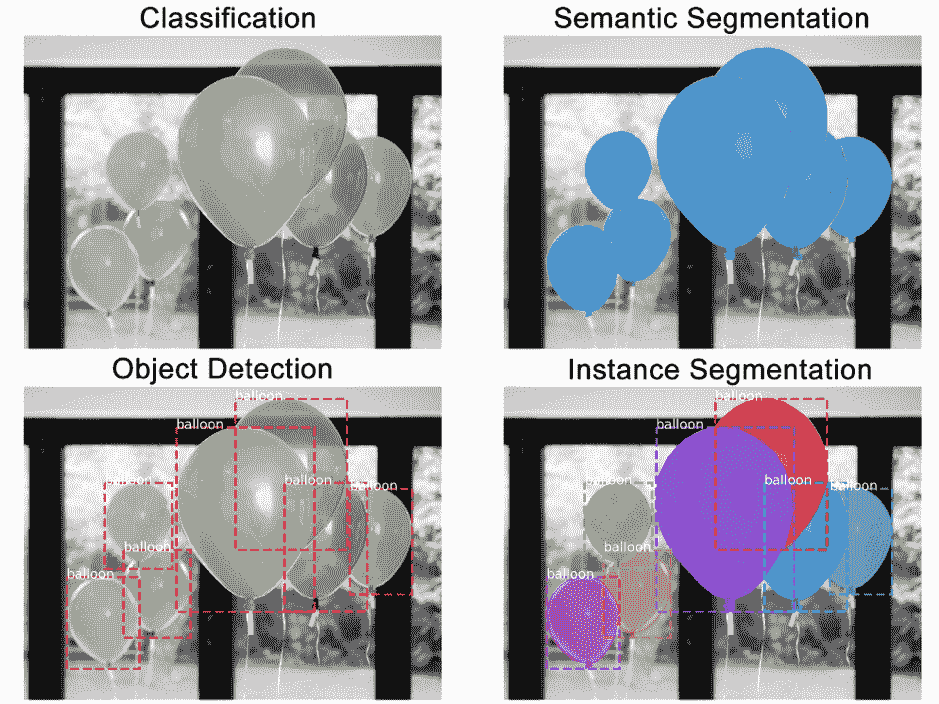
-
分类:此图像中有一个气球。
-
语义分割:这些是所有的气球像素。
-
物体检测:此图像中的这些位置有 7 个气球。我们开始考虑重叠的物体。
-
实例分割:这些位置有 7 个气球,这些是属于每个气球的像素。
将语义分割和实例分割方法结合起来,成为一种强大的工具。这不仅可以检测出图像中属于物体的所有像素,还可以确定这些像素属于哪个物体以及物体在图像中的位置。
语义实例分割是用于土地覆盖分类的有用工具,具有多种应用。通过卫星图像进行土地映射可以帮助政府机构监测森林砍伐(特别是非法砍伐)、城市化、交通等。
许多建筑公司也在使用这些数据进行城市规划和建筑开发。有些公司甚至更进一步,将其与 AR 设备结合,以了解他们的设计在现实生活中的样子。
简历:Valeryia Shchutskaya 是InData Labs的市场经理——一家提供 AI 驱动的软件和技术解决方案的专业服务公司,致力于帮助公司利用数据和机器学习算法创造业务价值。
原创。经许可转载。
相关:
更多相关主题
2020 年机器学习的趋势
原文:
www.kdnuggets.com/2020/03/trends-machine-learning-2020.html
comments

对许多人来说,机器学习可能是一个新词,但它首次由阿瑟·萨缪尔于 1952 年提出,此后,机器学习的持续evolution of Machine Learning使其成为许多行业的首选技术。从机器人过程自动化到技术专业知识,机器学习技术被广泛应用于预测和获取业务运营中的宝贵见解。它被视为人工智能(由机器展示的智能)的一个子集。
如果从书本上看,机器学习可以被定义为对统计模型和复杂算法的科学研究,这些算法主要依赖于模式和推理。这项技术独立于任何明确的指令,这就是它的强项。
机器学习的影响颇为引人入胜,因为它引起了许多公司,无论其行业类型如何的关注。说到底,机器学习确实从根本上改善了行业的基础。
机器学习的重要性可以归因于 2019 年第一季度在这项技术上分配了$28.5 billion,如 Statista 报道。
考虑到机器学习的相关性,我们预测了将在 2020 年进入市场的趋势。以下是这些备受期待的机器学习趋势,它们将改变全球各行业的基础。
1) 数字数据的管理
在今天的世界里,数据就是一切。各种技术的出现推动了数据的补充。无论是汽车行业还是制造业,数据的生成速度都达到了前所未有的水平。但问题是,“所有的数据都是相关的吗?”
为了解开这个谜团,机器学习可以被部署,因为它可以通过建立云解决方案和数据中心来处理任何数量的数据。它根据数据的重要性进行过滤,提取出功能数据,同时留下废料。这种方式节省了时间,同时也帮助组织管理开支。
在 2020 年,将会产生大量数据,行业将需要机器学习来分类相关数据,以提高效率。
2) 语音助手中的机器学习
根据2019 年 emarketer 研究,估计到 2019 年,美国将有 111.8 百万用户使用语音助手。因此,语音助手显然是各行业的重要组成部分。Siri、Cortana、Google Assistant 和 Amazon Alexa 是一些需求量大的智能个人助手例子。

机器学习结合人工智能,帮助以极高的准确性处理操作。因此,机器学习将帮助各行业轻松完成复杂和重要的任务,同时提高生产力。
预计到 2020 年,研究和投资的增长领域将主要集中在开发定制设计的机器学习语音助手上。
3) 有效营销
营销是每个企业在激烈竞争环境中生存的关键因素。它促进了企业的存在感和可见度,同时推动了预期的结果。但由于现有的多种营销平台,甚至证明企业的存在也变得具有挑战性。
然而,如果一个企业能够成功地从现有用户数据中提取模式,那么该企业很可能会制定出成功和有效的营销策略。为了分析数据,可以部署机器学习来挖掘数据并评估研究方法以获得更有利的结果。
未来,机器学习在制定有效营销策略方面的应用受到高度期待。
4) 网络安全的发展
近年来,网络空间成为了热门话题。据 Panda Security 报告,黑客每天创建约 230,000 个恶意软件样本,创建恶意软件的意图总是非常明确。而对于计算机、网络、程序和数据中心来说,检查恶意软件攻击变得更加复杂。

幸运的是,我们拥有机器学习技术,它通过自动化复杂任务和独立检测网络攻击来帮助多层保护。不仅如此,机器学习还可以扩展到对网络安全漏洞做出反应并减轻损害。它可以在不需要人工干预的情况下自动响应网络攻击。
未来,机器学习将被用于先进的网络防御程序,以控制和减少损害。
更快的计算能力
行业分析师已经开始掌握 人工神经网络的力量,这是因为我们都能预见到算法突破将是帮助问题解决系统所需的。在这里,人工智能和机器学习可以解决复杂的问题,这些问题将需要探索和调节决策能力。一旦这一切被破解,我们可以期待体验到不断增强的计算能力。
像英特尔、Hailo 和 Nvidia 这样的企业已经做好了通过定制硬件芯片和解释 AI 算法来增强现有神经网络处理的准备。
一旦企业弄清楚运行机器学习算法所需的计算能力,我们可以期待看到更多的力量中心,这些中心可以投资于为边缘数据源打造硬件。
结尾
毫无保留地说,机器学习日益壮大,到 2020 年,我们将体验到这种创新技术的更多应用。为什么不呢?借助机器学习,行业可以预测需求并在利用先进的机器学习解决方案时做出快速决策。管理复杂任务并保持准确性是业务成功的关键,而机器学习在这方面表现无瑕。
如上所述,机器学习的所有趋势都相当实际,并且在提供前所未有的客户满意度方面看起来很有前景。不断发展的行业的动态维度进一步推动了机器学习趋势的相关性。
简介: 塔尼亚·辛格 是一位知名内容营销人员,在区块链、Flutter、物联网等新兴技术领域有超过五年的经验。在这些年里,她紧跟科技行业的步伐,现在她写关于应用世界最新动态的文章。
相关:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
更多相关主题
我如何在 18 个月内通过数据科学将收入翻了三倍
原文:
www.kdnuggets.com/2021/10/tripled-my-income-data-science-18-months.html

图片由Karolina Grabowska提供
大约 18 个月前,由于 COVID-19 疫情,我失去了工作。我在大学期间兼职担任辅导员。我从辅导中获得的收入用于支付食物、汽油和汽车等费用。
在政府对整个国家实施封锁限制后,我无法继续教学。我也不能去大学,只能在家学习。
尽管一开始这似乎很糟糕,但我意识到不去上大学和工作使我腾出了很多时间。
我在这段时间开始着手扩展我的技能。经过一些研究,我发现了一个看起来很有趣的机器学习在线课程。
那是我完成的第一个在线课程。
之后,我把大部分时间花在了构建项目、学习编码和获得在线认证上。
现在——18 个月过去了,我凭借在数据科学和分析领域的知识建立了多个收入来源。
1. 全职工作
我首先以数据科学实习生的身份加入了一家公司,现在已全职工作在那里。
起初,我预期我的工作主要是模型构建。
然而,一旦我加入后,我意识到我的工作只有大约 10%是模型构建。其余时间,我和我的团队在寻找新的解决方案来解决业务问题。
经常,这些问题甚至不需要机器学习来解决。数据解决方案可能只是将业务逻辑转化为简单的 SQL 查询。
我每天的工作涉及回答这样的问题:
-
我们如何利用数据来查找关于公司 A 竞争对手的信息?
-
我们已经建立了一个客户流量预测模型。我们可以识别哪些商业用例来测试这个模型?它在生产环境中的表现是否与在测试环境中的一样?
-
我们如何持续改进客户的细分和绩效?我们是否能够从可用的数据中推断出现实场景?
这是对我日常工作的一种非常抽象的描述,但我想强调的是,创建数据科学解决方案并不仅仅是模型构建的开始和结束。
如果你是一个有志成为数据科学家的新手,我建议你获得一些你想从事的行业领域的知识。
2. 数据科学博客
我写下了我在数据科学领域的经验。
如果我在工作中构建一个项目,我会在 Kaggle 上找到类似的数据集,重复分析,并围绕它创建一个教程。
我最初开始编写和发布数据科学教程以增强我的个人作品集。
撰写关于我工作的文章是我与其他有志于数据科学的人联系的一种方式。它也是展示我编码和构建机器学习模型能力的一种方式。
起初,我从未期望通过我的写作获得报酬。我只是认为这是一个很好的方式来提升我的数据科学作品集。
然而,在过去的一年里,最初作为爱好的事情开始带来了收入。
现在,我通过简单地创建与数据相关的教程、项目以及撰写我的经验来赚取被动收入。
3. 自由职业
当我开始在数据科学社区内建立在线存在时,我开始接到多个自由职业的邀请。我为客户建立了机器学习模型,创建了竞争对手分析报告,并撰写了数据科学文章。
当我最初想到自由职业时,我想象着需要在一个在线平台上竞争和竞标项目。
然而,我所有的自由职业客户都是在阅读我的文章或查看我的作品集项目后联系我的。
几个月前,我建立了一个聚类算法,并在线发布了一个教程。第二天,有人联系我,询问我是否有兴趣为他们的客户构建一个聚类模型。
自由职业让我掌握了很多在我通常工作领域之外的技能。
在我的公司中,我处理的数据通常以某种预处理格式出现,我使用 SQL 和 Python 来查询数据并加以利用。
然而,在自由职业过程中,客户的数据格式非常不同。大部分数据未经过处理或结构化,我花了很多时间来搞清楚数据集之间的关系并理解它们。
我还需要收集外部数据来进行分析,这通常涉及到抓取第三方网站并使用开源工具。
我觉得自由职业让我接触到在日常工作中没有的知识,并且我能够在每个项目中学到新东西。
我是如何来到这里的?
我在上面提到过我参加了一个数据科学在线课程,事情从那时开始发生了变化。你可能会想知道怎么回事。
说实话,在参加我的第一个数据科学在线课程后,我感到迷茫。我花了大约一个月的时间学习不同的算法并使用 Scikit-Learn 训练模型。
我完全不知道接下来该怎么做。
我开始阅读关于那些没有硕士学位或任何专业资格却成功获得数据科学工作的人的文章。我意识到领域知识的重要性以及利用现有数据解决问题的必要性。
我并不需要建立最准确的模型或理解模型背后的算法。
我意识到,对我来说最重要的技能是利用数据解决问题的能力。这意味着我必须超越机器学习算法。
我参加了商业分析和机器学习工程的课程。我花了更多的时间学习编码,而不是理论。我花时间学习 SQL 和数据处理。
然后,我通过网络抓取从在线网站收集了自己的数据。我利用这些数据解决了一个问题,并用它构建了一个简单的机器学习网页应用。
通过这种方式,我逐渐获得了成为全栈数据科学家所需的技能。
即使在我工作的数据分析团队中,如果有任何超出我们日常工作范围的项目(需要外部数据收集或新算法的项目),我通常是被分配到这些项目的人。
结论
作为一个有抱负的数据科学家,在线有很多资源可供使用。实际上,太多了,以至于你不知道选择什么。
然而,大多数强调都集中在模型构建上。
虽然了解模型构建和训练的基本原理很重要,但大多数可用的工作要求你超越这一点。
实际需求是能够利用现有数据解决问题的人。
Natassha Selvaraj 是一位自学成才的数据科学家,热衷于写作。你可以通过 LinkedIn 与她联系。
更多相关话题
如何排查 Python 中的内存问题
原文:
www.kdnuggets.com/2021/06/troubleshoot-memory-problems-python.html
评论
由 Freddy Boulton,Alteryx 的软件工程师

我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 维护
发现应用程序内存不足是开发人员可能遇到的最糟糕的情况之一。内存问题通常很难诊断和修复,但我认为在 Python 中更是如此。Python 的自动垃圾回收机制使得语言易于上手,但它非常隐蔽,当它未按预期工作时,开发人员可能会不知道如何识别和解决问题。
在这篇博客文章中,我将展示我们是如何诊断和修复 EvalML 中的内存问题的,这是一款由 Alteryx 创新实验室开发的开源 AutoML 库。解决内存问题没有魔法公式,但我希望开发人员,特别是 Python 开发人员,可以了解在将来遇到此类问题时可以利用的工具和最佳实践。
阅读完这篇博客后,你应该能获得以下知识:
-
为什么发现和修复程序中的内存问题如此重要,
-
什么是循环引用,为什么它们可能在 Python 中引起内存泄漏,以及
-
了解 Python 的内存分析工具以及一些可以采取的步骤,以确定内存问题的原因。
设定背景
EvalML 团队在发布我们包的新版本之前,会进行一系列性能测试,以捕捉任何性能回退。这些性能测试包括在各种数据集上运行我们的 AutoML 算法,测量算法的得分以及运行时间,并将这些指标与我们之前发布的版本进行比较。
一天,我在运行测试时,应用程序突然崩溃了。发生了什么事?
第 0 步 - 什么是内存,什么是泄漏?
任何编程语言最重要的功能之一是其在计算机内存中存储信息的能力。每次你的程序创建一个新变量时,它都会分配一些内存来存储该变量的内容。
内核定义了一个接口,供程序访问计算机的 CPU、内存、磁盘存储等。每种编程语言都提供了请求内核为运行中的程序分配和释放内存块的方法。
内存泄漏发生在程序请求内核分配一块内存用于使用,但由于错误或崩溃,程序没有告诉内核它何时完成使用那块内存。在这种情况下,内核会继续认为被遗忘的内存块仍在被运行中的程序使用,其他程序将无法访问这些内存块。
如果在运行程序时相同的泄漏反复发生,遗忘的内存总量可能会增长到占用计算机内存的大部分!在这种情况下,如果程序尝试请求更多内存,内核将引发“内存不足”错误,程序将停止运行,换句话说,就是“崩溃”。
因此,找到并修复你编写的程序中的内存泄漏非常重要,因为如果不修复,你的程序最终可能会耗尽内存而崩溃,或者可能会导致其他程序崩溃。
步骤 1:确认这是一个内存问题
应用程序崩溃可能有多种原因——也许是运行代码的服务器崩溃了,也许是代码本身存在逻辑错误——因此确定当前问题是内存问题非常重要。
EvalML 性能测试以一种异常安静的方式崩溃了。突然间,服务器停止记录进度,任务安静地完成了。服务器日志会显示由代码错误引起的任何堆栈跟踪,因此我猜测这种无声的崩溃是由于任务使用了所有可用内存。
我重新运行了性能测试,这次启用了 Python 的memory-profiler以获取内存使用情况的时间图。测试再次崩溃,当我查看内存图时,我看到了这个:
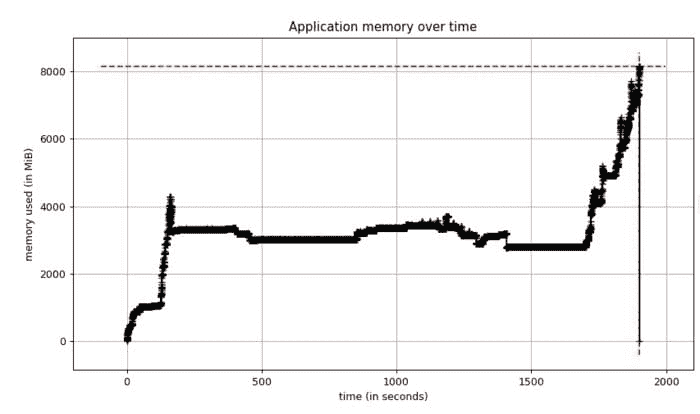
我们的内存使用保持稳定,但随后达到 8 吉字节!我知道我们的应用程序服务器有 8 吉字节的 RAM,所以这个分析确认了我们内存不足。此外,当内存稳定时,我们使用了大约 4 GB 的内存,而我们之前的 EvalML 版本使用了大约 2 GB 的内存。因此,出于某种原因,这个当前版本的内存使用量大约是正常情况的两倍。
现在我需要找出原因。
步骤 2:使用最小示例在本地重现内存问题
精确找出内存问题的原因涉及大量实验和迭代,因为答案通常不明显。如果明显,你可能不会把它写到代码中!因此,我认为重要的是用尽可能少的代码行来重现问题。这个最小示例使你能够在修改代码时快速运行它以查看是否取得进展。
在我的案例中,我从经验中知道,我们的应用程序处理一个包含 150 万行数据的出租车数据集,这大约是在我看到大幅波动的时候。我将我们的应用程序简化到仅运行这个数据集的部分。我看到一个类似于我上面描述的波动,但这次内存使用达到了 10GB!
看到这个之后,我知道我有一个足够好的最小示例来深入探讨。
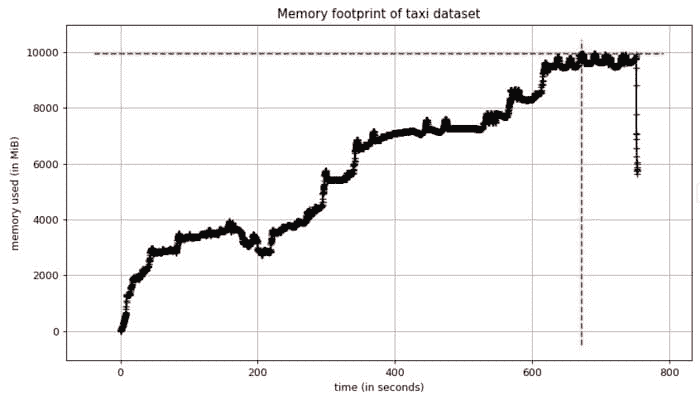 在出租车数据集上本地重现的内存占用
在出租车数据集上本地重现的内存占用
步骤 3:找出分配最多内存的代码行
一旦我们将问题隔离到尽可能小的代码块中,就可以查看程序在哪里分配了最多的内存。这可以是你需要的关键证据,以便能够重构代码并解决问题。
我认为filprofiler是一个很棒的 Python 工具来做到这一点。它显示了应用程序中每行代码在内存使用高峰时的内存分配。这是我本地示例的输出:
 fil-profile 的输出
fil-profile 的输出
filprofiler 根据内存分配对你应用程序中的代码行(以及依赖代码)进行排名。行越长,颜色越红,分配的内存越多。
分配最多内存的代码行正在创建 pandas 数据框(pandas/core/algorithms.py 和 pandas/core/internal/managers.py),总计达 4GB 的数据!我在这里截断了 filprofiler 的输出,但它能够跟踪创建 pandas 数据框的 EvalML 中的代码。
看到这个情况有点令人困惑。是的,EvalML 创建 pandas 数据框,但这些数据框在 AutoML 算法中是短暂存在的,并应在不再使用时立即被释放。由于情况并非如此,这些数据框在 EvalML 完成它们时仍然在内存中停留了足够长的时间,我认为最新版本可能引入了一个内存泄漏。
步骤 4:识别泄漏对象
在 Python 的上下文中,泄漏对象是指在使用完毕后没有被 Python 垃圾回收器回收的对象。由于 Python 使用 引用计数 作为其主要垃圾回收算法之一,这些泄漏对象通常是由于对象持有对它们的引用时间过长造成的。
这类对象很难找到,但你可以利用一些 Python 工具来使搜索变得可行。第一个工具是垃圾回收器的 gc.DEBUG_SAVEALL 标志。通过设置此标志,垃圾回收器将把不可达的对象存储在 gc.garbage 列表中。这将允许你进一步调查这些对象。
第二个工具是 objgraph 库。一旦对象在 gc.garbage 列表中,我们可以将这个列表过滤为 pandas 数据框,然后使用 objgraph 查看其他对象如何引用这些数据框并将它们保留在内存中。我通过阅读这篇 O’Reilly 博客文章得到了这个方法的灵感。
这是我在可视化这些数据框之一时看到的对象图的一个子集:
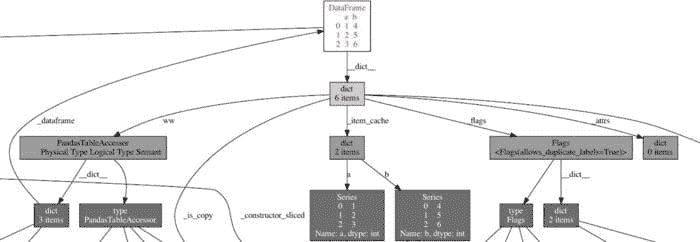
显示 pandas 数据框使用的内存图,展示了一个导致内存泄漏的循环引用。
这就是我寻找的确凿证据!数据框通过名为 PandasTableAccessor 的东西引用自身,这会创建一个 循环引用,因此,这会将对象保持在内存中,直到 Python 的垃圾回收器运行并能够释放它。(你可以通过 dict、PandasTableAccessor、dict、_dataframe 跟踪这个循环。)这对 EvalML 来说是一个问题,因为垃圾回收器将这些数据框保存在内存中如此之久,以至于我们内存不足!
我能够追踪 PandasTableAccessor 到 Woodwork 库,并向维护者报告了这个 问题。他们在新版本中修复了它,并向 pandas 仓库提交了相关的 问题 — 这是开源生态系统中可能进行协作的一个很好的例子。
在 Woodwork 更新发布后,我可视化了相同数据框的对象图,循环消失了!
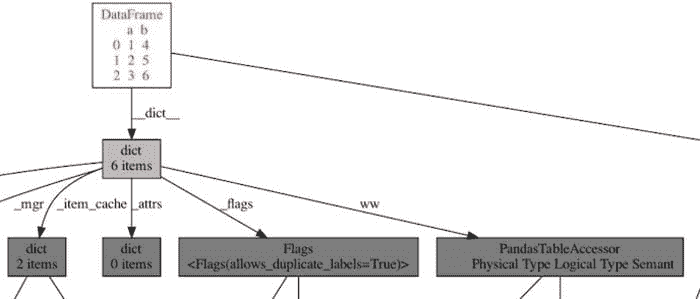 Woodwork 升级后的 pandas 数据框对象图。不再有循环!
Woodwork 升级后的 pandas 数据框对象图。不再有循环!
步骤 5:验证修复是否有效
一旦我在 EvalML 中升级了 Woodwork 版本,我测量了我们应用程序的内存占用。我很高兴地报告,现在内存使用量已经减少到原来的一半以下!
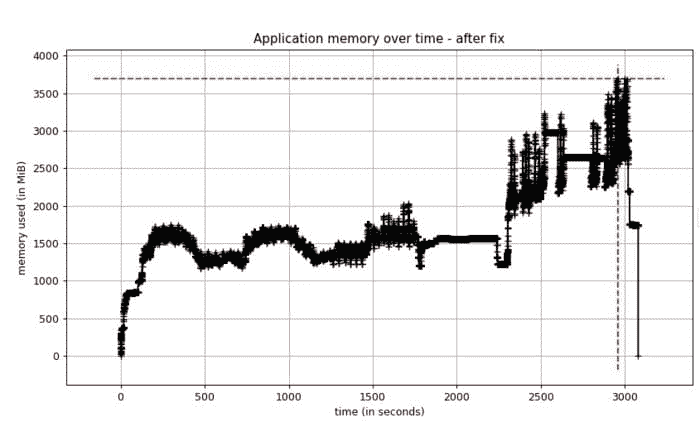 修复后的性能测试内存
修复后的性能测试内存
结束语
正如我在这篇文章开头所说的那样,解决内存问题没有魔法配方,但这个案例研究提供了一个通用框架和一套工具,你可以利用这些工具来应对未来类似的情况。我发现 memory-profiler 和 filprofiler 是调试 Python 内存泄漏的有用工具。
我还要强调的是,Python 中的循环引用可能会增加应用程序的内存占用。垃圾回收器最终会释放内存,但正如我们在这个案例中看到的,可能会等到为时已晚才释放!
在 Python 中,意外引入循环引用是令人惊讶的容易。我能够在 EvalML、scikit-optimize 和 scipy 中找到一个意外的循环引用。我鼓励你保持警惕,如果在实际工作中发现循环引用,开始讨论以了解它是否真的必要!
简介: Freddy Boulton 是 Alteryx 的软件工程师。他喜欢参与开源项目,并且喜欢在波士顿骑自行车。
原文。经许可转载。
相关内容:
-
顶级编程语言及其用途
-
数据科学家,你需要学会编码
-
使用 Python 自动化的 5 个任务
主题更多内容
-
[更多分类问题的性能评估指标](https://www.kdnuggets.com/2020/04/performance-evaluation-metrics-classification.html)
对 AI 的信任是无价的

作为一个数据驱动的 AI IDE 平台(Kili Technology)的联合创始人和首席技术官,我看到太多的机器学习模型无法交付成果。遗憾的是,这通常是因为对数据质量的关注不足。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 事务
快速跟进
十年前,在模型驱动的 AI 时代,我们这些 AI 从业者在模型上挣扎。我们缺乏基础设施、工具、工具包或框架来帮助我们创建和训练 ML 模型。
今天,像 Tensorflow 和 PyTorch 这样的拯救生命的包存在。我们现在必须专注于数据,从数据的发现、排序到标注。
但这很值得。在许多情况下,提高数据质量对性能的影响会比调整超参数或神经网络架构更为显著。
你在 数据驱动的 AI 中只需要两个东西:
-
高质量的数据,包括干净和多样化的数据
-
充足的训练数据量。
大的并不总是更好
大量的数据是许多深度学习成功的关键。但大量的数据也带来了挑战:
-
在硬件和人力计算资源方面,它既繁琐又昂贵;
-
它带来了问题:偏差、技术债务和与新基础模型范式的兼容性。
模型偏差
如果你专注于标注生产力,并过早地对文档进行预标注,会鼓励标注者将模型中的错误包含到数据中。
如果你想最小化偏差,没有免费的午餐。以下是如何进行:
-
如果你对任务有一些先验知识,可以从基于规则的自动化开始。例如,正则表达式和字典对 NLP 很有用。
-
然后进行手动标注。这是你真正为模型创造价值的地方,因为你标注了那些非平凡的例子和边缘案例。质量管理对这一阶段至关重要,因为它需要标注者之间的高度同步以保持一致。
-
最后,模型预标注,以便 从一个好的数据集变成一个出色的数据集。这应该只在最后使用;否则,你会产生偏差。
技术债务
在软件开发中,代码量翻倍意味着很多事情翻倍:
-
我们系统创建的行为数量
-
所需的单元测试数量。
对于 AI 来说,代码 = 数据。数据量翻倍意味着:
-
我们机器学习系统创建的行为数量
-
所需的机器学习单元测试数量
-
否则的技术债务。
与基础模型不兼容
今天,我们拥有已经在互联网所有文本或图像上预训练的巨大基础模型(GPT-3、BERT 或 DALL-E 2);它们理解语言规则。由于你的模型需要巨大的泛化能力,因此它需要的数据非常少。因此,每个数据将产生更强的影响。因此,与其标注大量潜在错误的数据,不如标注较少的数据并更准确地提供示例,因为不良数据很容易影响模型。
为什么获取高质量数据具有挑战性?
为了减少我们机器学习模型所需的数据量,我们必须提高数据质量。然而,这很有挑战性,因为我们必须同时解决这两点:
-
数据代表性(数据是否存在偏见?数据是否涵盖了边缘情况?)
-
标签一致性(标注者是否以相同的方式进行标注?他们是否理解任务?)。
数据集不容易调试。并非总是容易给出“是”或“否”的回答。例如,在图像分类任务中,一张房屋窗户的图像是否就是房屋的图像?
答案将取决于背景、任务、用途等。这对于非专家任务是正确的,对于专家任务也是如此。
比如:
-
类风湿性关节炎和疟疾已经用了几十年的氯喹进行治疗。 -> 处理氯喹与疟疾之间的关系。
-
在 56 名因疟疾症状前往诊所的受试者中,有 53 人(95%)血液中氯喹的水平通常是有效的。 -> 不处理氯喹与疟疾之间的关系。
如何在规模上管理质量
在 Kili Technology,我们致力于与愿意管理质量和规模的用户分享最佳实践。
标签一致性
这里有一些建议:
-
在标注时小步迭代。这里是构建高质量数据集的具体过程。
仅供参考:每次迭代应持续 3 天为限。
-
负责构建模型的工程师手动标注 50 到 100 个示例,帮助你了解存在的不同类别。
-
编写你希望模型识别的类别的稳固定义和概念。这应包括处理特定边缘情况的说明。
-
迭代获取更多批量的文档注释(每次 100 或 200)由外部合作伙伴或公司内部的其他人进行。
-
使用工具设计来避免设计上的错误注释手势。
-
防止不良注释。例如,在关系抽取中,禁止 UX 中不合理的关系。
-
最小化注释动作的数量和复杂性。例如,在某些任务中,最好先绘制对象然后选择类别,而在其他任务中则相反。
-
培训你的人员:标注需要适当的培训,以使标注人员能够快速上手。
-
检测可能的错误。
-
从项目开始就实施基于规则的质量检查。例如,注释的椎骨数量是否大于人体椎骨数量?
-
使用模型计算标签的可能性,并在项目结束时优先审查。
-
使用指标,例如资产和标注者级别的共识,来调试你的标注过程并优先进行审查。
-
设立一个金字塔式的审查系统,包括:预注释模型,然后是标注人员,然后是审查员,最后是 ML 工程师。
数据代表性
这里有两个重要的点:
-
拥有无偏的数据。
-
拥有足够丰富的数据。
我们的世界充满了需要从模型中去除的偏差。例如,如果我使用 GPT-2 的嵌入来构建一个金融新闻情感分析模型,单公司的名称已经带有情感色彩:由于过去几年的丑闻,大众汽车在 GPT-2 训练数据中被过度代表,因此情感是负面的。为了纠正这一点,以下是一些想法:
-
在训练语言模型之前,用占位符替换敏感的命名实体(公司);
-
生成反事实数据以平衡与公司名称相关的情感;
-
正交化嵌入空间以去除偏差效应。
我们的世界充满了边缘案例。例如,自驾车图像中的一把椅子飞在高速公路上。为了建立一个多样化的数据集,你可以将 ML 中知名的提升方法应用于数据。从数据候选库中:
-
训练一个初始模型并在验证集上进行预测。
-
使用另一个预训练模型来提取嵌入。
-
对于每个分类错误的验证图像,使用嵌入检索最近邻。将这些最近邻图像添加到训练集中。
-
使用新增图像重新训练模型,并在验证集上进行预测。
-
重复直到做得好为止。
结论
到目前为止,机器学习社区一直关注数据的数量。现在,我们需要的是质量。还有许多其他方法可以在大规模上获得这种质量。
附言:推特 给我你的反馈!
爱德华·达尔钦博 (@edarchimbaud)是一名机器学习工程师,CTO 以及Kili的联合创始人,该公司是企业 AI 领先的训练数据平台。他对数据中心人工智能充满热情,这是成功 AI 的新范式。
更多相关话题
第五届国际夏季学校 2020 年资源感知机器学习(REAML)
原文:
www.kdnuggets.com/2020/07/tu-dortmund-summer-school-2020-reaml.html
赞助帖子。
资源感知机器学习的夏季学校提供有关机器学习最新研究的讲座,通常侧重于资源消耗及其减少。今年的夏季学校将于 8 月 31 日至 9 月 4 日在线免费举办。活动将包括预录和直播环节,涵盖展示博士/博士后研究的专门空间,以及一个包含现实世界机器学习任务的黑客马拉松。
课程主题精选: 深度学习、图神经网络、小设备上的大模型、机器学习的功耗、深度生成建模、深度神经网络中的记忆挑战……
更多信息和注册: www-ai.cs.tu-dortmund.de/summer-school-2020/
在注册期间,您可以表达对加入黑客马拉松和/或在学生角落展示的兴趣。
黑客马拉松 - 位置预测与机器人控制
作为一个实际示例,我们举办了一个基于楼层集成传感器数据的室内位置预测挑战。真实世界的数据是在一个仓库场景中收集的,在那里,自由移动的机器人进行货物运输。您的第一个任务是使用传感器数据(振动、磁场等)与位置真实数据建立位置预测。表现最好的团队将在夏季学校最后一天获得实时控制机器人的机会。获胜者将被邀请到多特蒙德进行研究合作。
关于黑客马拉松的详细信息: www-ai.cs.tu-dortmund.de/summer-school-2020/hackathon
学生角落 - 分享和讨论您的工作
夏季学校将配备一个参与者交流平台——学生角落,允许他们建立网络并分享他们的研究。在注册期间,您可以表达对学生角落的兴趣,我们将随时更新您相关信息。
关于学生角落的详细信息: www-ai.cs.tu-dortmund.de/summer-school-2020/students-corner
夏季学校由莱茵-鲁尔机器学习能力中心(ML2R)、协作研究中心 SFB 876 和多特蒙德工业大学人工智能组组织。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业领域
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
更多相关话题
在 PyTorch 中调整 Adam 优化器参数
原文:
www.kdnuggets.com/2022/12/tuning-adam-optimizer-parameters-pytorch.html
随着数据宇宙的快速扩展和人工神经网络提供高性能的能力,世界正朝着解决以前从未解决过的复杂问题迈进。但是,等一下,有一个难点 - 构建一个稳健的神经网络架构不是一件简单的事。
选择合适的优化器来最小化预测值与真实值之间的损失是设计神经网络的关键要素之一。这种损失最小化是在训练数据的批次中进行的,导致参数值的收敛速度较慢。优化器减少了参数空间中的横向移动,从而加速了模型的收敛,并进一步导致更快的部署。这就是为什么很多重视开发高性能优化器算法的原因。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT
文章将解释 Adam 优化器的工作原理,这是一种常用的优化器,并演示如何使用 PyTorch 框架对其进行调优。
Adam 优化器
自适应矩估计,即 Adam 优化器,是一种优化技术,是梯度下降算法的衍生算法。在处理大数据和密集神经网络架构时,与随机梯度下降或基于动量的算法相比,ADAM 更为高效。它本质上是‘带动量的梯度下降’算法和‘RMSProp’算法的最佳结合。让我们先了解这两种优化器,以便自然地过渡到 Adam 优化器。
带动量的梯度下降
该算法通过考虑过去 n 步梯度的指数加权平均来加速收敛。从数学上讲,

作者提供的图片
注意,较小的? 表示向最小值迈出小步,较大的? 表示迈出大步。类似于权重更新,偏差也按照下面的方程进行更新:
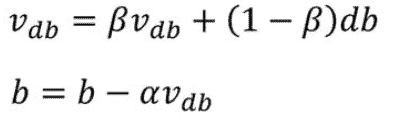
动量不仅加快了收敛速度,还有能力跳过局部最小值。
下图说明了蓝色路径(具有动量的梯度下降)相比于红色路径(仅梯度下降)具有较少的振荡,因此更快地收敛到最小值。
来源:梯度下降解释
RMSProp
均方根传播,也称为 RMSprop,是一种自适应学习算法,根据梯度幅度调整振荡。与动量方法不同,当梯度增加时,它会减小步长。
添加一个小的 epsilon 值以避免除零错误。

图片来源于作者
Adam 优化器结合了“具有动量的梯度下降”和“RMSprop”算法。它从“动量”(具有动量的梯度下降)中获得速度,从 RMSProp 中获得在不同方向上调整梯度的能力。这两者的结合使其功能强大。如下图所示,ADAM 优化器(黄色)比动量(绿色)和 RMSProp(紫色)收敛更快,但结合了两者的优势。
现在你已经了解了 Adam 优化器的工作原理,我们来深入探讨如何使用 PyTorch 调整 Adam 超参数。
在 PyTorch 中调整 Adam 优化器
ADAM 优化器有三个参数需要调整以获得优化值,即 ? 或学习率、? 的动量项和 rmsprop 项,以及学习率衰减。让我们了解每一个,并讨论它们对损失函数收敛性的影响。
学习率(alpha 或 Lr)
学习率,也称为步长,是参数更新与梯度/动量/速度的比率,具体取决于使用的优化算法。
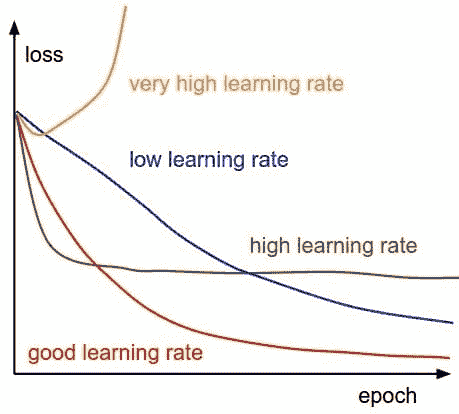
较小的学习率意味着模型训练较慢,即需要对参数进行许多更新才能达到最小值点。另一方面,较大的学习率意味着较大的步伐或剧烈的参数更新,从而往往倾向于发散而不是收敛。
一个最佳的学习率值(默认值 0.001)意味着优化器会刚好更新参数以达到局部最小值。在大多数情况下,学习率在 0.0001 到 0.01 之间是最佳的。
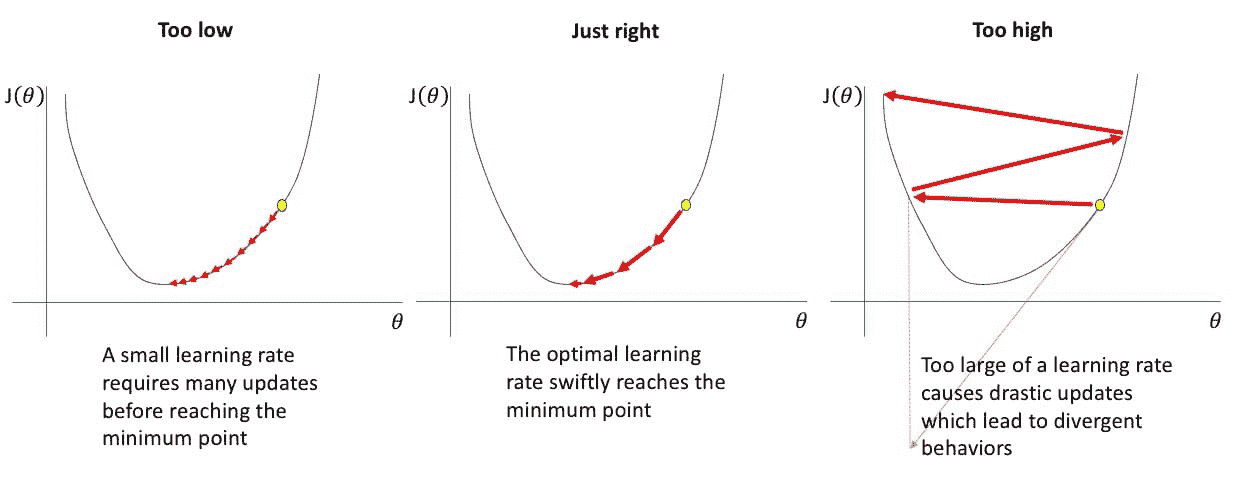
来源:设置神经网络的学习率
Betas
β1 是动量项的指数衰减率,也称为一阶矩估计。它在 PyTorch 中的默认值为 0.9。不同 beta 值对动量值的影响在下图中显示。
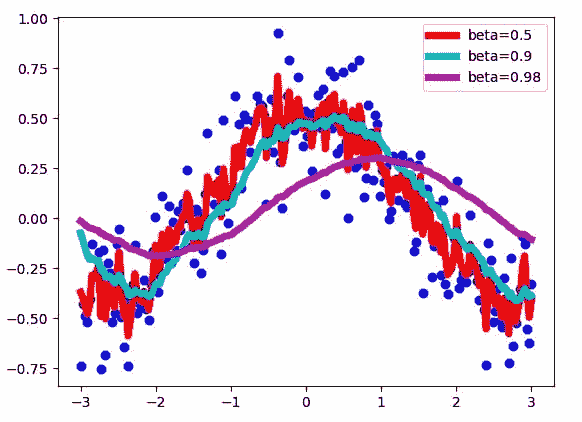
来源: 带动量的随机梯度下降
β2 是速度项的指数衰减率,也称为二阶矩估计。在 PyTorch 实现中,默认值为 0.999。对于稀疏梯度问题,尤其是在图像相关问题中,这个值应尽可能接近 1.0。由于大多数高分辨率图像的像素密度和颜色变化很小,这会导致微小的梯度(甚至更小的梯度平方),导致收敛缓慢。对速度项给予高权重可以通过朝着最小化损失函数的总体方向移动来避免这种情况。
学习率衰减
学习率衰减使参数值接近全局最优解时降低 ?。这可以避免过度跳过最小值,通常会导致损失函数的更快收敛。PyTorch 实现中将此称为 weight_decay,默认值为零。
ε
虽然不是一个调整超参数,但它是一个非常小的数字,以避免实现中的除零错误。默认值为 1e-08。
初始化具有所有超参数的 PyTorch 代码如下所示。
torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)
剩余的超参数如 maximize、amsgrad 等可以参考 官方文档。
总结
在这篇文章中,你了解了优化器的重要性、三种不同的优化器,以及 Adam 优化器如何将动量和 RMSProp 优化器的优点结合起来,在性能上领先于其他优化器。文章跟进了 Adam 优化器的内部工作,并解释了各种可调超参数及其对收敛速度的影响。
Vidhi Chugh 是一位 AI 策略师和数字化转型领导者,致力于在产品、科学和工程交汇处构建可扩展的机器学习系统。她是一位获奖的创新领导者、作者和国际演讲者。她的使命是使机器学习民主化,并打破术语,让每个人都能参与这一转型。
更多相关主题
调整神经网络中的超参数
原文:
www.kdnuggets.com/tuning-hyperparameters-in-neural-networks

超参数决定了您的神经网络学习和处理信息的效果。模型参数是在训练过程中学习的。与这些参数不同,超参数必须在训练过程开始之前设置。在本文中,我们将描述优化模型中超参数的技术。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 需求
神经网络中的超参数
学习率
学习率告诉模型基于其错误改变多少。如果学习率高,模型学习得快,但可能犯错误。如果学习率低,模型学习得慢但更仔细。这会导致较少的错误和更好的准确率。
 来源: https://www.jeremyjordan.me/nn-learning-rate/
来源: https://www.jeremyjordan.me/nn-learning-rate/
有几种调整学习率以获得最佳结果的方法。这涉及在训练过程中在预定义的时间间隔调整学习率。此外,像 Adam 这样的优化器使学习率能够根据训练的执行进行自我调节。
批量大小
批量大小是模型在给定时间接受的训练样本数量。大批量大小意味着模型在更新参数之前处理更多的样本。这可以导致更稳定的学习,但需要更多的内存。另一方面,小批量大小会更频繁地更新模型。在这种情况下,学习可以更快,但每次更新的变化更多。
批量大小的值影响学习的内存和处理时间。
纪元数
纪元是指模型在训练过程中遍历整个数据集的次数。一个纪元包括多个周期,在这些周期中,所有数据批次都会展示给模型,模型从中学习,并优化其参数。更多的纪元有助于模型学习,但如果观察不当,可能导致过拟合。决定正确的纪元数对于获得良好的准确率是必要的。像早停这样的技术通常用于找到这种平衡。
激活函数
激活函数决定神经元是否应该被激活。这会导致模型的非线性。这种非线性特别有益,尤其是在尝试建模数据中的复杂交互时。
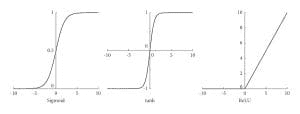 来源:
来源:常见的激活函数包括 ReLU、Sigmoid 和 Tanh。ReLU 使神经网络的训练更快,因为它只允许神经元中的正激活。Sigmoid 用于分配概率,因为它输出一个介于 0 和 1 之间的值。Tanh 尤其在不想使用从 0 到±无穷大的整个范围时是有利的。选择合适的激活函数需要仔细考虑,因为它决定了网络是否能够做出良好的预测。
Dropout
Dropout 是一种用于避免模型过拟合的技术。它通过将神经元的输出在每次训练迭代时设置为零,随机停用或“丢弃”一些神经元。这个过程防止了神经元过度依赖特定的输入、特征或其他神经元。通过丢弃特定神经元的结果,Dropout 帮助网络在训练过程中专注于关键特征。Dropout 通常在训练期间实现,而在推理阶段则禁用。
超参数调整技术
手动搜索
这种方法涉及对决定机器学习模型学习过程的参数值进行反复试验。这些设置一次调整一个,以观察它对模型性能的影响。让我们尝试手动更改设置以获得更好的准确性。
learning_rate = 0.01
batch_size = 64
num_layers = 4
model = Model(learning_rate=learning_rate, batch_size=batch_size, num_layers=num_layers)
model.fit(X_train, y_train)
手动搜索很简单,因为你不需要任何复杂的算法来手动设置测试参数。然而,与其他方法相比,它有几个缺点。它可能需要很长时间,而且可能没有自动化方法高效地找到最佳设置。
网格搜索
网格搜索测试许多不同的超参数组合以找到最佳组合。它在部分数据上训练模型。之后,它检查模型在另一部分数据上的表现。我们可以使用 GridSearchCV 实现网格搜索,以找到最佳模型。
from sklearn.model_selection import GridSearchCV
param_grid = {
'learning_rate': [0.001, 0.01, 0.1],
'batch_size': [32, 64, 128],
'num_layers': [2, 4, 8]
}
grid_search = GridSearchCV(model, param_grid, cv=5)
grid_search.fit(X_train, y_train)
网格搜索比手动搜索快得多。然而,它计算开销很大,因为检查每个可能的组合需要时间。
随机搜索
这种技术随机选择超参数组合以找到最有效的模型。对于每个随机组合,它训练模型并检查其表现如何。通过这种方式,它可以快速找到使模型表现更好的良好设置。我们可以使用 RandomizedSearchCV 实现随机搜索,以在训练数据上获得最佳模型。
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform, randint
param_dist = {
'learning_rate': uniform(0.001, 0.1),
'batch_size': randint(32, 129),
'num_layers': randint(2, 9)
}
random_search = RandomizedSearchCV(model, param_distributions=param_dist, n_iter=10, cv=5)
random_search.fit(X_train, y_train)
随机搜索通常优于网格搜索,因为只检查少量的超参数以获取合适的超参数设置。然而,当超参数空间较大时,它可能不会找到正确的超参数组合。
总结
我们已经涵盖了一些基本的超参数调优技术。高级技术包括贝叶斯优化、遗传算法和 Hyperband。
Jayita Gulati 是一位对构建机器学习模型充满热情的机器学习爱好者和技术作者。她拥有利物浦大学计算机科学硕士学位。
相关话题
调整随机森林超参数
原文:
www.kdnuggets.com/2022/08/tuning-random-forest-hyperparameters.html

丛林矢量由 freepik 创建
如果你还不知道,让我们快速了解一下随机森林。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
随机森林是一种用于分类、回归和其他任务的集成学习方法,其中包含多个决策树。
集成学习最简单的解释就是将多个分类器堆叠在一起以提高性能。决策树是一种非参数监督学习方法,其最终目标是通过学习基于数据特征推断和创建的规则来建立一个预测目标变量值的模型。
sklearn.ensemble.RandomForestClassifier
随机森林由许多决策树组成。树木的多样性构建了森林,我想这就是它被称为随机森林的原因。
Bagging 是创建随机森林“森林”的方法。其目的是减少过拟合训练数据的模型的复杂性。Boosting 是 Bagging 的对立面,旨在增加高偏差模型的复杂性,解决欠拟合问题。
随机森林的结果基于由决策树生成的预测,这些预测通过取各种决策树输出的平均值或均值来完成。如果树木数量增加,结果的精度就会提高——因此准确性更高,过拟合得到减少。
超参数调整的重要性
超参数调整对算法至关重要。它提高了机器学习模型的整体性能,并且在学习过程之前设定,并发生在模型之外。如果不进行超参数调整,模型将产生错误和不准确的结果,因为损失函数没有被最小化。
超参数调整是关于找到一组最佳的超参数值,这些值可以最大化模型的性能,最小化损失,并产生更好的输出。
随机森林的超参数
下面是最重要参数的列表,以及如何提高预测能力和简化模型训练阶段的更详细部分。
max_depth: 树的最大深度 - 意味着根节点与叶节点之间的最长路径。
min_sample_split: 分裂内部节点所需的最小样本数,其中默认值 = 2
max_leaf_nodes: 这是决策树可以拥有的最大叶节点数。
min_samples_leaf: 这是在叶节点所需的最小样本数,其中默认值 = 1
n_estimators: 这是森林中的树木数量。
max_sample: 这决定了分配给任何单棵树的原始数据集的比例。
max_features: 这是在寻找最佳分裂时要考虑的特征数量。
bootstrap: 如果设置为 False,则使用整个数据集来构建每棵树,但默认值为 True。
criterion: 用于衡量分裂质量的函数
超参数调整以提高预测能力
n_estimators: int,默认值=100
这是森林中的树木数量。如前所述,随着树木数量的增加,结果的精度会提高,从而提高准确性,并减少过拟合。然而,这会使模型变得更慢,因此选择一个处理器可以处理的 n_estimator 值可以使模型更加稳定,并表现良好。
max_features, int 或 float,默认值=”sqrt”}
随机森林模型在单个树中只能有最大特征数。许多人会认为如果增加 max_features,会提高模型的整体性能。然而,这自然会减少单个树的多样性,同时增加模型产生输出的时间。因此,找到一个最佳的 max_features 对于模型的性能至关重要。
min_samples_leaf: int 或 float,默认值=1
这是在叶节点所需的最小样本数。叶节点是决策树的末端节点,较小的 min_sample_leaf 值会使模型更容易检测噪声。再次强调,超参数调整是关于寻找最佳值的,因此建议尝试不同的叶节点大小。
超参数调整以改善模型训练阶段
random_state: int,RandomState 实例或 None,默认值=None
这个参数控制了构建树时样本的自助抽样随机性以及在每个节点寻找最佳分裂时考虑的特征采样。
n_jobs: int,默认值=None
这个参数指的是并行运行的作业数量,它基本上告诉引擎可以使用多少个处理器。-1 表示没有限制,1 表示只能使用 1 个处理器。
结论
本文为您详细介绍了什么是随机森林、超参数调整的重要性、最重要的参数以及如何提高预测能力和模型训练阶段。
如果你想了解更多关于这些参数的信息,请点击这个链接。
Nisha Arya是一位数据科学家和自由职业技术作家。她特别关注提供数据科学职业建议或教程,并且围绕数据科学提供理论知识。她还希望探索人工智能在促进人类寿命方面的不同方式。作为一个热衷学习者,她致力于拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关内容
调整 XGBoost 超参数
原文:
www.kdnuggets.com/2022/08/tuning-xgboost-hyperparameters.html

Garett Mizunaka via Unsplash
总结一下,XGBoost 代表极端梯度提升,是一种监督学习算法,属于梯度提升决策树(GBDT)家族的机器学习算法。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
他们通过将一组较弱的模型进行组合并通过 if-then-else 真/假特征问题来评估其他决策树。他们以序列形式创建,以评估和估计产生正确决策的概率。
import xgboost as xgb
在我们深入调整 XGBoost 超参数之前,让我们了解为什么调优是重要的
为什么超参数调优很重要?
超参数调优是提高机器学习模型整体行为和性能的重要部分。它是一种在学习过程之前设置的参数,发生在模型之外。
如果损失函数没有被最小化,缺乏超参数调优可能会导致不准确的结果。我们的目标是使模型产生尽可能少的错误。
超参数用于计算模型参数,其中不同的超参数值能够生成不同的模型参数值。
超参数调优的目的是找到一组最佳的超参数值,这些值能够最大化模型性能、最小化损失并产生更好的输出。
XGBoost 的特征
1. 梯度树提升
添加了固定数量的树,每次迭代应显示损失函数值的减少。
2. 正则化学习
正则化学习有助于最小化损失函数,并防止发生过拟合或欠拟合 - 有助于平滑最终学习到的权重。
3. 收缩和特征子抽样
这两种技术用于进一步防止过拟合:收缩和特征子抽样。
这些特征将在 XGBoost 的超参数调优中进一步探讨。
XGBoost 参数调优
XGBoost 参数分为 4 类:
1. 一般参数
这与我们用于增强的提升器类型有关。最常见的类型是树模型或线性模型。
2. Booster 参数
这取决于你选择了哪个 booster。
3. 学习任务参数
这与决定学习场景有关。
4. 命令行参数
这与 XGBoost 的 CLI 版本的行为有关。
一般参数、Booster 参数和任务参数在运行 XGBoost 模型之前设置。命令行参数仅在 XGBoost 的控制台版本中使用。
一般参数
这些是 XGBoost 中的一般参数:
booster [default=gbtree]
选择使用哪个 booster,如树基模型的 gbtree 和 dart,以及线性函数的 gblinear。
verbosity [default=1]
这是消息的打印,合法值为 0(静默)、1(警告)、2(信息)、3(调试)。
validate_parameters [default to false, except for Python, R and CLI interface]
当设置为 True 时,XGBoost 将执行输入参数的验证,以检查是否使用了某个参数。
nthread
这是用于运行 XGBoost 的并行线程数。
disable_default_eval_metric [default=false]
这将标记以禁用默认度量。你可以将其设置为 1 或 true 来禁用。
num_feature
在提升中使用的特征维度,设置为特征的最大维度。
基于树的学习器最常见的参数
max_depth [default=6]
增加此值将使模型更复杂,更容易过拟合,因此在选择值时需要小心。值必须是大于 0 的整数。
eta [default=0.3, alias: learning_rate]
这决定了每次迭代的步长。值必须在 0 和 1 之间,默认值为 0.3。较低的学习率使计算变慢,并且需要更多轮次来减少错误,相比之下,学习率较高的模型则更快。
n_estimators [default=100]
这是我们集成中的树的数量,即提升轮次的数量。
值必须是大于 0 的整数,默认值为 100。
subsample [default=1]
这表示每棵树需要采样的观察值的比例。较低的值有助于防止过拟合,但会增加欠拟合的可能性。值必须在 0 和 1 之间,默认值为 1。
colsample_bytree, colsample_bylevel, colsample_bynode [default=1]
这是用于列子采样的一系列参数。特征子采样有助于防止过拟合,并加速并行算法的计算。
params = {
# Parameters that we are going to tune.
'max_depth':6,
'n_estimators': 100,
'eta':.3,
'subsample': 1,
'colsample_bytree': 1,
}
正则化参数
alpha [default=0, alias: reg_alpha]
对权重进行 L1(Lasso 回归)正则化。增加此值将使模型更保守。当特征数量较多时,可能会提高速度性能。可以是任何整数,默认值为 0。
lambda [default=1, alias: reg_lambda]
对权重进行 L2(岭回归)正则化。当你增加这个值时,它会使模型更为保守。它还可以帮助减少过拟合。这个值可以是任何整数,默认值是 1。
gamma [default=0, alias: min_split_loss]
使树的叶节点进一步分割所需的最小损失减少。Gamma 值越高,正则化越强。它可以是任何整数,默认值是 0。
你可以在这里找到 XGBoost 参数的完整列表。
结论
从这篇文章中,你应该了解 XGBoost 的 3 个特性是如何通过 4 个划分的参数调优组实现的。这些特性随后通过不同的 XGBoost 参数进行了进一步探索。
Nisha Arya 是一名数据科学家和自由职业技术作家。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探索人工智能如何/能如何促进人类寿命的延续。她是一位热心学习者,寻求拓宽技术知识和写作技能,同时帮助指导他人。
更多相关内容
将您的笔记本电脑变成一个个人分析引擎,使用 DuckDB 和 MotherDuck
原文:
www.kdnuggets.com/turn-your-laptop-into-a-personal-analytics-engine-with-duckdb-and-motherduck

图像由 DALL-E 生成
在数据分析处理成为成功商业与否的关键差异的时代,我们需要一个能够满足需求的工具栈。技术的进步帮助推进了我们所需的所有数据工具,即 DuckDB 和 MotherDuck。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
DuckDB 是一个开源的、进程内的 SQL 在线分析处理(OLAP)数据库管理系统。该数据库系统旨在快速处理数据分析查询,无论数据大小如何。该系统实现了内存处理和 OLAP 系统,能够有效提高我们的数据分析过程。
DuckDB 非常适合存储和处理涉及数据分析的表格数据(如表连接、数据汇总等),特别是当我们的工作流通常涉及表格的显著变化时。另一方面,DuckDB 不适合高容量数据活动和单个数据库中的多个并发进程。
MotherDuck 是一个托管的 DuckDB 云服务。它是免费的开源服务,由 DuckDB 社区维护。它是与 DuckDB Lab 合作建立的一个云服务平台,供公众使用。
结合 DuckDB 和 Motherduck,我们可以创建一个在各种场景中都能使用的分析引擎。我们怎么做呢?让我们深入了解一下。
MotherDuck 界面
我们将使用原生的 MotherDuck 界面来演示服务如何工作,以及为什么 DuckDB 是一个强大的数据分析工具。如果你还没有,请在网站上注册并获取 MotherDuck 帐户。
一旦成功注册 MotherDuck 帐户,我们将进入 MotherDuck 界面。尝试熟悉这个界面,你会发现它与 Jupyter Notebook 非常相似(如果你曾使用过的话)。
我们将在 MotherDuck UI 中使用来自 Kaggle 的 DS Salary 数据实验 DBduck 功能。使用添加文件按钮上传数据,一个新的单元格将显示执行查询的内容。查询应如下所示。
CREATE OR REPLACE TABLE ds_salaries AS SELECT * FROM read_csv_auto(['ds_salaries.csv']);
一旦创建了表格,请尝试使用以下code查询数据。
select * from my_db.ds_salaries limit 10;
如你所见,MotherDuck 很像在 Notebook 中进行数据分析,只不过使用 SQL 查询。让我们尝试在 MotherDuck 中进行数据分析查询。
select job_title,
avg(salary_in_usd) as average_salary_in_usd
from my_db.ds_salaries
GROUP BY job_title
ORDER BY job_title
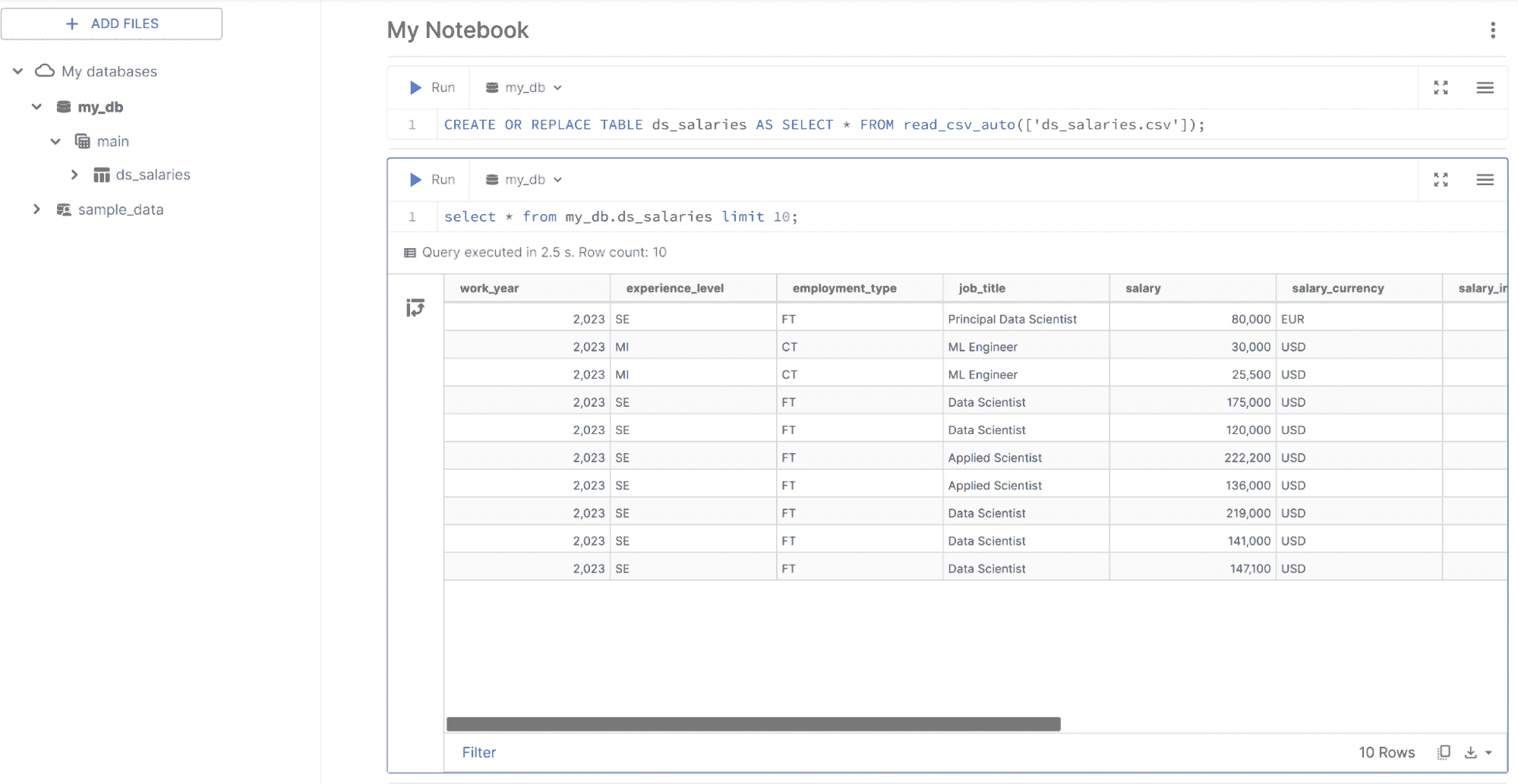
你可以在单元格中执行查询,表格结果将类似于下图所示。
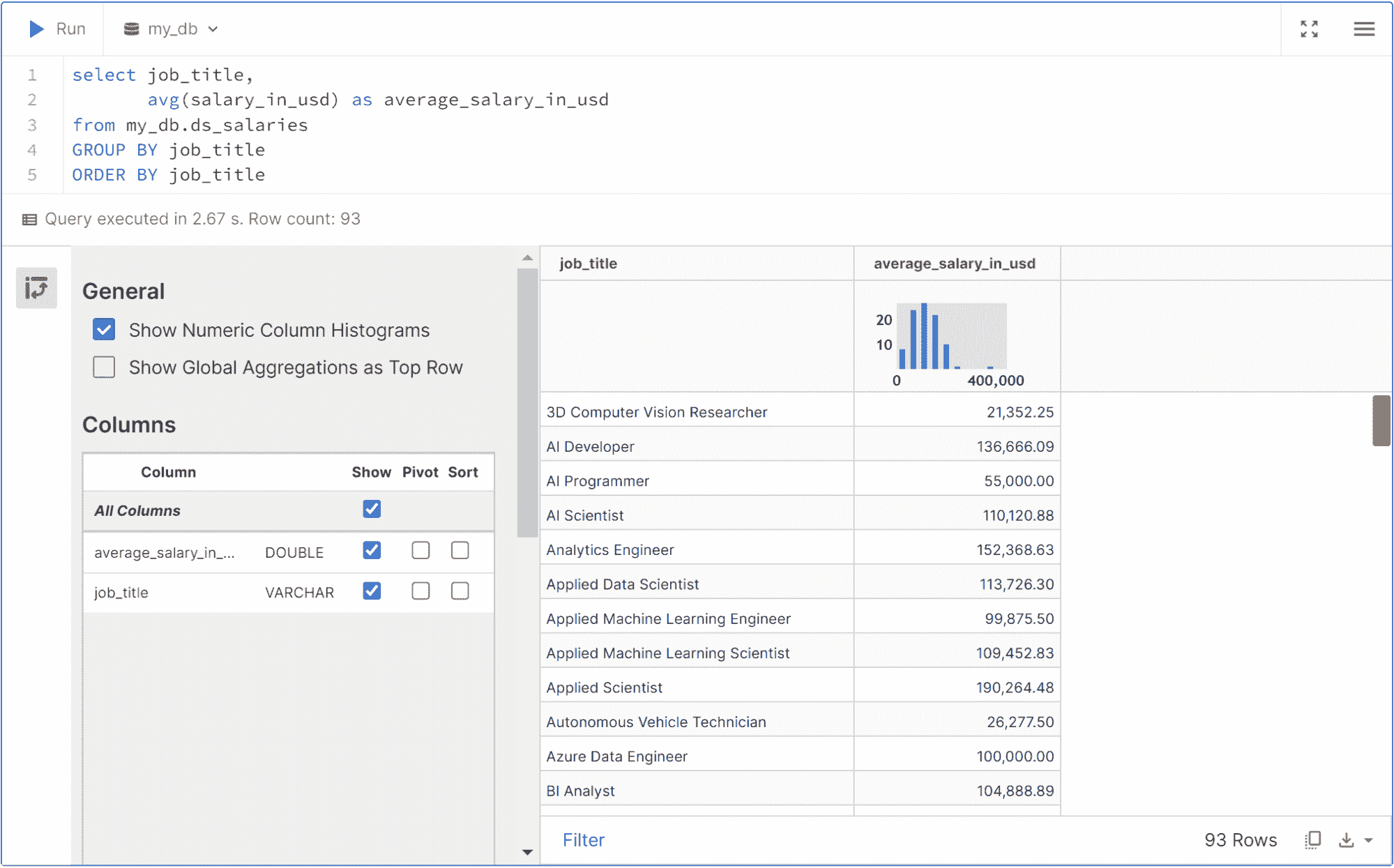
你可以过滤数据、透视表格,或使用 UI 中的选择按钮下载结果。
MotherDuck Python
MotherDuck 还允许用户通过 Notebook 上的 Python 访问数据库。我们需要使用以下代码安装 DuckDB 包。
pip install duckdb==v0.9.2
MotherDuck 支持的当前版本是 DuckDB 0.9.2;这就是我们安装该版本的原因。
当安装成功后,我们需要将 DuckDB 连接到 Motherduck。虽然有几种方法可以验证连接,但我们将使用服务令牌。此令牌可以在你的 MotherDuck 设置中获取。
import duckdb
token = "insert token here"
# initiate the MotherDuck connection
con = duckdb.connect(f'md:?motherduck_token={token}')
如果我们没有设置数据库名称,MotherDuck 将使用默认数据库,即 my_db。接下来,让我们使用之前在 Notebook 中使用的相同查询。
q = """
select job_title,
avg(salary_in_usd) as average_salary_in_usd
from my_db.ds_salaries
GROUP BY job_title
ORDER BY job_title
"""
con.sql(q).show()
你将看到类似于下表的输出。
┌─────────────────────────────────────┬───────────────────────┐
│ job_title │ average_salary_in_usd │
│ varchar │ double │
├─────────────────────────────────────┼───────────────────────┤
│ 3D Computer Vision Researcher │ 21352.25 │
│ AI Developer │ 136666.0909090909 │
│ AI Programmer │ 55000.0 │
│ AI Scientist │ 110120.875 │
│ Analytics Engineer │ 152368.63106796116 │
│ Applied Data Scientist │ 113726.3 │
│ Applied Machine Learning Engineer │ 99875.5 │
│ Applied Machine Learning Scientist │ 109452.83333333333 │
│ Applied Scientist │ 190264.4827586207 │
│ Autonomous Vehicle Technician │ 26277.5 │
│ · │ · │
│ · │ · │
│ · │ · │
│ Principal Data Engineer │ 192500.0 │
│ Principal Data Scientist │ 198171.125 │
│ Principal Machine Learning Engineer │ 190000.0 │
│ Product Data Analyst │ 56497.2 │
│ Product Data Scientist │ 8000.0 │
│ Research Engineer │ 163108.37837837837 │
│ Research Scientist │ 161214.19512195123 │
│ Software Data Engineer │ 62510.0 │
│ Staff Data Analyst │ 15000.0 │
│ Staff Data Scientist │ 105000.0 │
├─────────────────────────────────────┴───────────────────────┤
│ 93 rows (20 shown) 2 columns │
└─────────────────────────────────────────────────────────────┘
使用上述查询,你可以使用以下代码将其处理为 Pandas DataFrame。
import pandas as pd
df = con.sql(q).fetchdf()
最后,你可以使用以下查询将另一个数据集加载到数据库中。
con.sql("CREATE TABLE mytable AS SELECT * FROM '~/filepath.csv'")
上述查询假设你的数据是 CSV 文件。其他选项包括 S3 或本地 DuckDB 连接到 MotherDuck 数据库。
结论
DuckDB 是一个开源数据库系统,专门为数据分析而开发。该系统设计用于快速高效地处理数据。MotherDuck 是一个开源的托管云服务,用于 DuckDB。
通过结合 DuckDB 和 MotherDuck,我们可以将笔记本电脑变成个人分析引擎,将数据存储在云端,并使用 DuckDB 快速处理数据。
Cornellius Yudha Wijaya**** 是一名数据科学助理经理和数据撰写员。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作分享 Python 和数据技巧。Cornellius 涉及各种 AI 和机器学习主题的写作。
更多相关内容
关于期望最大化(EM)算法的教程
原文:
www.kdnuggets.com/2016/08/tutorial-expectation-maximization-algorithm.html
作者:Elena Sharova,codefying。
我们得到一些未标记的数据,并被告知这些数据来自多变量高斯分布。我们的任务是提出每个分布的均值和方差的假设。例如,图 1 展示了(标记的)来自两个高斯分布的数据。我们需要估计蓝色和红色分布的 x 值和 y 值的均值和方差。我们将如何做到这一点?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
图 1. 从 2 个正态分布中抽取的二维数据。
我们可以绘制每个维度的数据,并通过查看图表来估计均值。例如,我们可以使用直方图来估计蓝色分布的 x 均值大约为 0.6,红色分布的 x 均值大约为 0.0。通过观察每个簇的扩展,我们可以估计蓝色 x 的方差较小,可能是 0.0,而红色 x 的方差大约是 0.025。这将是一个相当好的猜测,因为实际分布是从* N(0.6, 0.003)(蓝色)和 N(0.02, 0.03)*(红色)中抽取的。我们能比查看图表做得更好吗?我们能否用更稳健的方法得出均值和方差的良好估计?
图 2. 从 2 个正态分布中抽取的(未标记)数据的直方图。
期望最大化(EM)算法可以用来生成一些多模态数据的最佳分布参数假设。注意我们说的是“最佳”假设。但什么是“最佳”?最佳的分布参数假设是最大似然假设——即最大化我们看到的数据来自 K 个分布的概率,每个分布具有均值 m[k]和方差 sigma[k]²。在本教程中,我们假设我们处理的是 K 个正态分布。
在单模态正态分布中,这个假设 h 是直接从数据中估计出来的:
estimated m = m~ = sum(x[i])/N方程 1estimated sigma2= sigma2~= sum(xi- m~)²/N方程 2
这些只是信任的算术平均值和方差。在多模态分布中,我们需要估计 h = [ m[1],m[2],...,m[K]; sigma[1]²,sigma[2]²,...,sigma[K]² ]。EM 算法将帮助我们做到这一点。让我们看看如何进行。
我们从每个 m[k]~ 和 sigma[k]²~ 的一些初始估计开始。我们将总共对每个参数进行 K 次估计。估计可以来自我们之前制作的图表、我们的领域知识,或者它们甚至可以是大胆的猜测(但不要太过分)。然后我们继续处理每个数据点,并回答以下问题——这个数据点来自均值为 m[k]~ 和 sigma[k]²~ 的正态分布的概率是多少?也就是说,我们对每组分布参数重复这个问题。在图 1 中,我们绘制了来自 2 个分布的数据。因此,我们需要回答这些问题两次——数据点 x[i],i=1,...N,从 N(m[1]~, sigma[1]²~) 中抽取的概率是多少?从 N(m[2]~, sigma[2]²~) 中抽取的概率是多少?通过正态密度函数我们得到:
P(x[i] belongs to N(m[1]~ , sigma[1]²~))=1/sqrt(2*pi* sigma[1]²~) * exp(-(x[i]- m[1]~)²/(2*sigma[1]²~))方程 3P(x[i] belongs to N(m[2]~ , sigma[2]²~))=1/sqrt(2*pi* sigma[2]²~) * exp(-(x[i]- m[2]~)²/(2*sigma[2]²~))方程 4
单独的概率只能告诉我们一半的故事,因为我们还需要考虑从 N(m[1]~, sigma[1]²~) 或 N(m[2]~, sigma[2]²~) 中抽取数据的概率。我们现在得出每个数据点的每个分布的责任。在分类任务中,这个责任可以表示为数据点 x[i] 属于某个类别 c[k] 的概率:
P(x[i] belongs to c[k]) = omega[k]~ * P(x[i] belongs to N(m[1]~ , sigma[1]²~)) / sum(omega[k]~ * P(x[i] belongs to N(m[1]~ , sigma[1]²~)))方程 5
在方程 5 中,我们引入了一个新参数 omega[k]~,这是从 k 的分布中抽取数据点的概率。图 1 表明我们的两个簇被选择的概率是相等的。但与 m[k]~ 和 sigma[k]²~ 一样,我们实际上并不知道这个参数的值。因此,我们需要对其进行猜测,这也是我们假设的一部分:
h = [ m[1], m[2], ..., m[K]; sigma[1]², sigma[2]², ..., sigma[K]²; omega[1]~, omega[2~], ..., omega[K]~ ]
你可能会问,方程 5 中的分母来自哪里。分母是观察到 x[i] 在每个簇中的概率之和,加权以该簇的概率。实质上,它是我们数据中观察到 x[i] 的总概率。
如果我们进行硬性集群分配,我们将取最大 P(x[i] 属于 c[k])并将数据点分配到该集群。我们对每个数据点重复这种概率分配。最终,这将给我们第一个数据的‘重新洗牌’到 K 个集群。我们现在可以更新初始估计值 h 到 h'。这两个步骤:估计分布参数和在概率数据分配到集群后更新这些参数,将重复直到收敛到 h。总之,EM 算法的两个步骤是:
-
E 步:基于当前假设 h 对每个数据点进行概率分配到某个类别;
-
M 步:基于新的数据分配更新假设 h 对分布类别参数。
在 E 步中,我们计算集群分配的期望值。在 M 步中,我们计算我们假设的新最大似然。
 简介: Elena Sharova 是一名数据科学家、金融风险分析师和软件开发人员。她拥有布里斯托大学的机器学习和数据挖掘硕士学位。
简介: Elena Sharova 是一名数据科学家、金融风险分析师和软件开发人员。她拥有布里斯托大学的机器学习和数据挖掘硕士学位。
相关:
-
PCA 与层次聚类的比较
-
深度学习和拓扑数据分析能用你的数据做的 6 件疯狂的事情
-
数据科学 102:K-means 聚类不是免费的午餐
更多相关话题
使用 Twitter 了解 COVID 期间披萨配送的顾虑
原文:
www.kdnuggets.com/2021/08/twitter-understand-pizza-delivery-covid.html
评论
由Arimitra Maiti,高级分析顾问

图片由Aarón Blanco Tejedor提供,来源于Unsplash
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
披萨让一切成为可能。
—亨利·罗林斯
注意:本文及其分析结果并不意在影响任何 Domino’s 顾客。观察结果的真实性需由领域专家进一步调查,不应被解读为诽谤形式。研究中使用的数据既非个人数据,也非版权数据或隐藏在登录后的数据。
简介
印度经历了自 2020 年 3 月 24 日至 2020 年 5 月 31 日的首次全国封锁,以通过限制居民的活动来遏制新型冠状病毒的传播。本文的研究旨在识别印度顾客在订购披萨时的不同情感,研究对象为一家非常受欢迎的披萨配送连锁店Dominos。从 2006 年的 128 家门店,到 2020 年,Domino’s India,Jubilant Foodworks 的主打品牌,报告称全国超过 1300 家门店。研究分析了三个不同时间段的 Twitter 数据。第一个时间段从2020 年 1 月 1 日到 2020 年 3 月 24 日,被认为是封锁前期;第二个时间段从2020 年 3 月 25 日到 2020 年 5 月 31 日,被认为是封锁期;最后,第三个时间段从2021 年 1 月 1 日到 2021 年 2 月 28 日,被认为是封锁后期。这三个不同时间段的 Twitter 数据通过Sprinklr(由 IIM Ahmedabad 授权)提取,该工具专注于提供现代社交平台的实时用户对话。Sprinklr 工具提供全球用户生成的历史 Twitter 数据的便捷访问*。
在 Sprinklr 中使用的过滤器是“仅英语”语言,数据生成来源为“仅 Twitter”,数据生成起源为“仅印度”。没有使用明确的 Twitter 账户或 Twitter 标签来提取时间线中的内容,因此假设关键词“dominos”代表了为零售店或在线平台上的客户提供披萨的公司 Dominos India。
方法
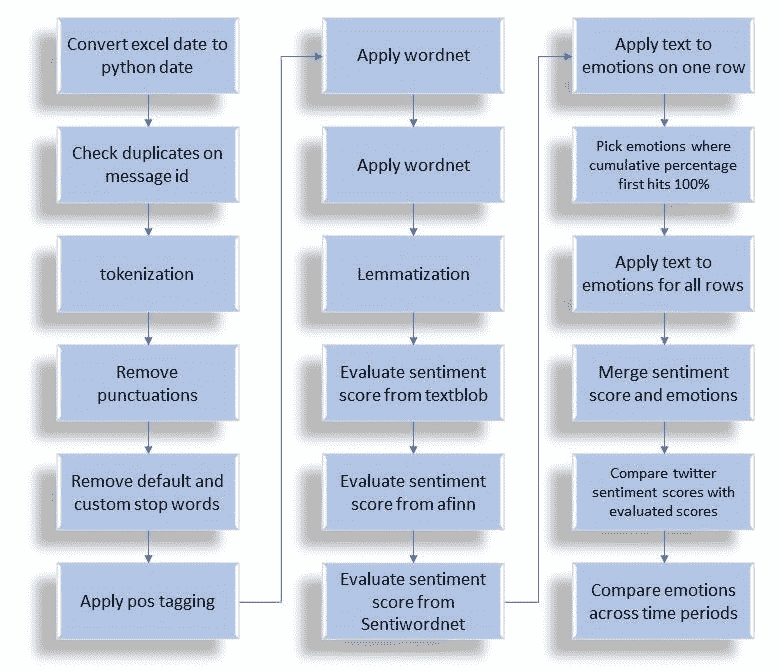
图-1 分析的高级方法。(图片来源):作者提供的图片
第 1 列和第 2 列的上半部分依赖于分析师的效率和风格。这种方法并不宣称是理想的,因为随着新概念和技术的出现,情感分析在过去 5 年中有了飞跃式的发展。然而,为了保持接近目标,本研究认为上述方法是相关的。进一步的改进和修改是不可忽视的。基本问题定义是分析客户情感,并捕捉不同时间段的情感差异。在清理和标准化用户评论后,每条评论都通过由texblob、sentiwordnet 和 afinn 指定的方法生成分数。如果分数小于零,则为负面;如果分数为一,则为中性;如果分数大于一,则为正面。
第 2 列的下半部分和整个第 3 列也可以在未来的研究中进一步优化。text2emotion 方法用于提取每条评论的情感。作为附加功能,该方法还单独给出情感类别和分数。累计分数只是试图在给定的数据集中找出某一情感类别的累计分数。研究希望验证哪些用户评论没有获得 text2emotion 的分数。

图-2 数据概述。(图片来源):作者提供的图片
关于库
Sentiwordnet 是 python nltk 包中用于情感挖掘的一个流行模块。它基于 WordNet 词典,将单词分类为正面、中性或负面。同样,AFINN 词典也是“Afinn”包中的一个流行模块,在情感挖掘中功能强大。text2emotion 是另一个在 python 中可用于将每种情感分类为独特情绪的有用工具。需要注意的是,分析师用于情感评分的任何词典都完全依赖于词典的设计。语言的最终语境或用户反应可能需要进一步转换,以体现商业语境,这可能是词典无法理解的。因此,任何用于自然语言处理领域的词典生成的输出的相关性都取决于研究的裁量,不能仅凭词典表面价值。一个特定的词在词典中可能听起来负面,但在实际语境中,这个词可能是中性或正面的。
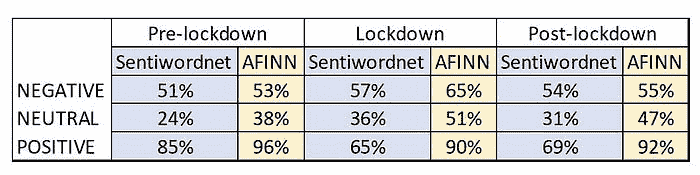
图-3 显示 Twitter 情感评分与研究中生成的 Sentiwordnet 或 AFINN 分数匹配的百分比的表格。(图片来源):作者提供的图片
上表显示,对于从 Twitter 生成的数据,我们可能使用 AFINN 词典会比使用 Sentiwordnet 或 Text blob(当前未显示在比较中)得到相对较好的结果。
注意:在生成 Sentiwordnet 或 AFINN 分数之前,没有使用训练和测试集的先前拆分或交叉验证。所有三个时间线中的用户反应已逐一通过每个词典。
初步发现
图-4 显示三个时间线中捕捉到的情感百分比的表格。(图片来源):作者提供的图片
根据我们的发现,恐惧作为文本情感从封锁前的 6%大幅上升至封锁期间的 15%和封锁后的 11%。然而,这些恐惧相关的感受可能并不是由于 Dominos 披萨在封锁期间及之后的高质量餐点所致。
让我们查看来自三个不同时间线的一些双字组。
图-5 仅针对恐惧相关推文的封锁前期的双字组。(图片来源):作者提供的图片
图-6 仅针对恐惧相关推文的封锁期的双字组。(图片来源):作者提供的图片

图-7 仅针对恐惧相关推文的封锁后期的双字组。(图片来源):作者提供的图片
在三个时间线中仅涉及恐惧相关的双词组暗示了一组独立的概念。客户从送货合作伙伴如 Swiggy 和 Zomato 处报告了新冠感染案例,这些合作伙伴负责将包裹从零售商店送达客户目的地。在 2020 年 5 月,Tata Consumer Products Ltd (TPCL)与 Dominos 应用程序合作配送其必需品。因此,恐惧可能与该特定服务线有关,可能对消毒而非食品质量存在感知上的不确定性。
结论
笔记本可以从这里访问。用于研究的停用词表见下。
预疫情(pre-covid)、封锁(lockdown)和后疫情(post-covid)数据下载的超链接也已附上。下面还展示了处理步骤的编程快照。
处理和评分文本的代码片段。(代码来源):作者提供的代码
本研究的目标是确定印度比萨市场在新冠疫情前后情感的显著变化。研究并非意在贬低任何品牌或影响顾客偏好。实际情况是,封锁期间对比萨的订购恐惧增加,这与我们的后疫情心态直接相关。值得注意的是,除了“恐惧”之外,没有其他情感在比萨销售中出现如此大的增长。这可能意味着,如果没有封锁的影响,比萨订购的情感将继续保持混合或愉快,而非完全恐惧。对于制定 Dominos 销售策略的业务经理来说,本文提供的见解可能不会带来突破性的创新。另一方面,研究尝试预测意见挖掘的实际应用,这可能容易从现实世界经验中推断出来。
谢谢。
个人简介:Arimitra Maiti 是一名拥有超过 10 年分析咨询、统计建模、利益相关者管理经验的分析专业人士,曾领导开发生成有关成本和收入优化见解的分析解决方案。
原文。已获许可转载。
相关:
-
COVID 对我们所有模型做了什么?
-
6 种每个数据科学家都应该知道的 NLP 技术
-
如何通过 API 创建和部署一个简单的情感分析应用
更多相关内容
Type I 和 Type II 错误:有什么区别?
原文:
www.kdnuggets.com/2022/08/type-type-ii-errors-difference.html
作者提供的图像
关键要点
-
Type I 和 Type II 错误在机器学习和统计学中非常常见。
-
当零假设(H0)被错误地拒绝时,就会发生 I 型错误。这也被称为假阳性错误。
-
当实际上为假但被接受的零假设时,就会发生 II 型错误。这也被称为假阴性错误。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
让我们通过一个二分类机器学习垃圾邮件过滤器来说明 Type I 和 Type II 错误。我们假设有一个标记的数据集 N = 315 封电子邮件,其中 244 封标记为垃圾邮件,71 封标记为非垃圾邮件。假设我们已经建立了一个机器学习分类算法来从这些数据中学习。现在我们想评估机器学习模型的表现。模型在正确检测垃圾邮件与非垃圾邮件方面表现如何?我们假设每当模型预测电子邮件为垃圾邮件时,该邮件将被删除并保存在垃圾邮件文件夹中。我们还假设垃圾邮件类别是负类别,非垃圾邮件类别是正类别。我们假设机器学习模型的表现可以在下面的表格中说明:

I 型错误(假阳性错误): 从表格中我们可以看到,在 244 封垃圾邮件中,模型正确预测了 222 封为垃圾邮件(真正阴性),而 22 封垃圾邮件被错误预测为非垃圾邮件(假阳性)。这意味着根据这个模型,22 封垃圾邮件将不会被删除。I 型错误率或假阳性率表示为,并给出如下:
II 型误差(漏报误差): 从表中可以观察到,在 71 个非垃圾邮件中,模型正确预测了 39 个为非垃圾邮件(真正例),而 22 个非垃圾邮件被错误预测为垃圾邮件(漏报)。我们看到模型将删除 32 个非垃圾邮件。II 型误差率或漏报率表示为,并计算为
总模型误差:从上表中可以观察到,总共有 54 个误分类,其中 315 个标记的电子邮件数据集中,有 22 个是误报,32 个是漏报。总误差率计算为
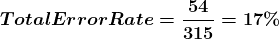
对于二分类系统,总误差率不是一个好的度量指标。相反,重要的是关注 I 型和 II 型误差率。在这个示例中,重要的是将 I 型误差率()保持在较低水平,以便垃圾邮件不会被错误地分类为正常的非垃圾邮件并被删除。类似地,重要的是最小化 II 型误差率,以便正常的非垃圾邮件不会被误认为是垃圾邮件。
总结一下,我们讨论了 I 型和 II 型误差之间的区别。有关 I 型和 II 型误差如何在二分类系统中使用的更多信息,请参阅这篇文章:贝叶斯定理解释。
本杰明·O·泰约 是一位物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的所有者。之前,本杰明曾在中奥克拉荷马大学、大峡谷大学和匹兹堡州立大学教授工程学和物理学。
该主题的更多内容
机器学习中的偏差类型
原文:
www.kdnuggets.com/2019/08/types-bias-machine-learning.html
评论 https://www.infoq.com/presentations/unconscious-bias-machine-learning/
https://www.infoq.com/presentations/unconscious-bias-machine-learning/
在我之前的文章中,我讨论了在机器学习中可能遇到的偏差,并且这些偏差实际上可以帮助构建更好的模型。这里是后续文章,展示一些应避免的偏差。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
1. 样本偏差
我们必须考虑训练数据中的抽样偏差,因为这是人为输入的结果。机器学习模型是预测引擎,基于过去的大量数据进行训练。它们的预测基于它们被训练来预测的内容。这些预测的可靠性仅与收集和分析数据的人有关。决策者必须记住,如果在过程中的任何部分涉及到人类,那么模型中存在偏差的可能性就会更大。
用于训练的样本数据必须尽可能接近真实场景。许多因素可能从一开始就会导致样本偏差,这些原因在不同领域(如商业、安全、医疗、教育等)中各不相同。
2. 偏见偏差
这再次是人为输入的原因。偏见是由于参与过程的人的文化刻板印象而产生的。社会阶层、种族、国籍、性别可能会渗透到模型中,从而完全和不公正地扭曲模型的结果。不幸的是,不能不相信这可能是有意为之或在整个过程中被忽视。
将这些因素中的一些纳入统计建模以进行研究或在某一时刻了解情况,与在训练数据对某些种族、性别和/或国籍的人存在偏差的情况下预测谁应该获得贷款是完全不同的。
3. 确认偏差
确认偏差,是指通过寻找或解释与自己现有信念一致的信息来处理信息的倾向。 来源
www.britannica.com/science/confirmation-bias
这是一个广为人知的偏见,已在心理学领域进行了研究,并直接适用于其如何影响机器学习过程。如果预期使用者有一个预先存在的假设,并希望通过机器学习来验证这个假设(根据上下文可能有简单的方法可以做到这一点),那么参与建模过程的人可能会倾向于故意操控过程以找到那个答案。我个人认为这比我们想象的更常见,因为从启发式的角度看,我们行业中的许多人可能会在开始过程之前就受到压力,要求得到某个特定的答案,而不是单纯地查看数据实际说了什么。
4. 群体归因偏见
这种偏见源于当你用包含某个群体不对称观点的数据来训练模型时。例如,在某个样本数据集中,如果某个性别的成功率高于另一个性别,或者某个种族的收入高于另一个种族,你的模型将倾向于相信这些虚假信息。这些情况下存在标签偏见。实际上,这些标签不应该进入模型。用于理解和分析当前情况的样本数据不能在未经适当预处理以考虑任何潜在不公正偏见的情况下直接用作训练数据。机器学习模型在社会中变得越来越普遍,而普通人甚至未曾察觉,这使得群体归因偏见同样可能因未采取必要步骤以考虑训练数据中的偏见而不公正地惩罚某个人。
相关:
-
Data Literacy: Using the Socratic Method
-
All Models Are Wrong – What Does It Mean?
-
What 70% of Data Science Learners Do Wrong
更多相关内容
-
Stop Learning Data Science to Find Purpose and Find Purpose to…
-
What Makes Python An Ideal Programming Language For Startups
-
Three R Libraries Every Data Scientist Should Know (Even if You Use Python)
可视化框架类型

作者图片
数据可视化不仅仅是制作图表。它是关于将数据转化为有意义的信息。当然,还包括用你那独特的色彩选择“烧焦”其他人的视网膜。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
从跟踪全球健康趋势(还记得 COVID-19 吗?)到跟踪你每天的跑步,合适的图表或地图能够揭示原始数据隐藏的模式和答案。然而,并非所有可视化工具都是平等的。有些是为代码精通者设计的,而另一些则适合那些认为 Python 只是他们在诺基亚上玩过的游戏的时髦名称的人。他们仍然叫它 Snake。
在接下来的介绍中,我将帮你找到你的可视化“灵魂伴侣”。有点像 Tinder,只不过是针对图表的。CharTinder?我确信这里面有个笑话。不论你需要一个快速的饼图还是一个互动地图,总有一款工具适合你。
有哪些类型的可视化框架?
可视化工具类型有广泛的范围。我将它们分为三大类,其中包含最受欢迎的可视化工具。

我将为每种工具提供简短的描述。你可以在每种可视化框架类型的概述末尾找到每种工具的特性。
为了增强你的理解并提供更互动的学习体验,这里有一段视频,你可以观看,这与本文分享的见解相吻合:
基于 JavaScript 的框架
这些是设计用于在网页浏览器中使用 JavaScript 创建互动和动态可视化的库和框架。JavaScript 非常灵活,大多数开发者都懂,所以这些框架被广泛使用。
1. D3.js
D3.js 是一个强大的 JavaScript 库,用于基于数据操作文档。它允许用户使用 HTML、SVG 和 CSS 创建可视化,提供了巨大的控制力和创造潜力,用于交互式和复杂的可视化。
2. Three.js
一个开源的 JavaScript 库和 API 用于在网页浏览器中创建和显示动画的 3D 计算机图形。它支持创建复杂的可视化,无需专业的 3D 图形软件。
3. Chart.js
一个 JavaScript 图表库 提供了八种不同类型的简单图表。它旨在易于使用并高度可定制,适合希望为网页开发者添加响应式数据可视化的用户。
4. Leaflet
Leaflet 是一个基于 JavaScript 的库,非常适合创建能够显示广泛地理空间数据的互动地图,是地理学家、城市规划师和记者等需要动态制图功能的用户的重要资源。
5. Highcharts
Highcharts 主要是一个用于创建互动的、符合网络标准的图表的 JavaScript 库。它具有广泛的图表功能,适合那些需要一种易于实现的复杂数据可视化解决方案的用户。
基于 JavaScript 的框架概述
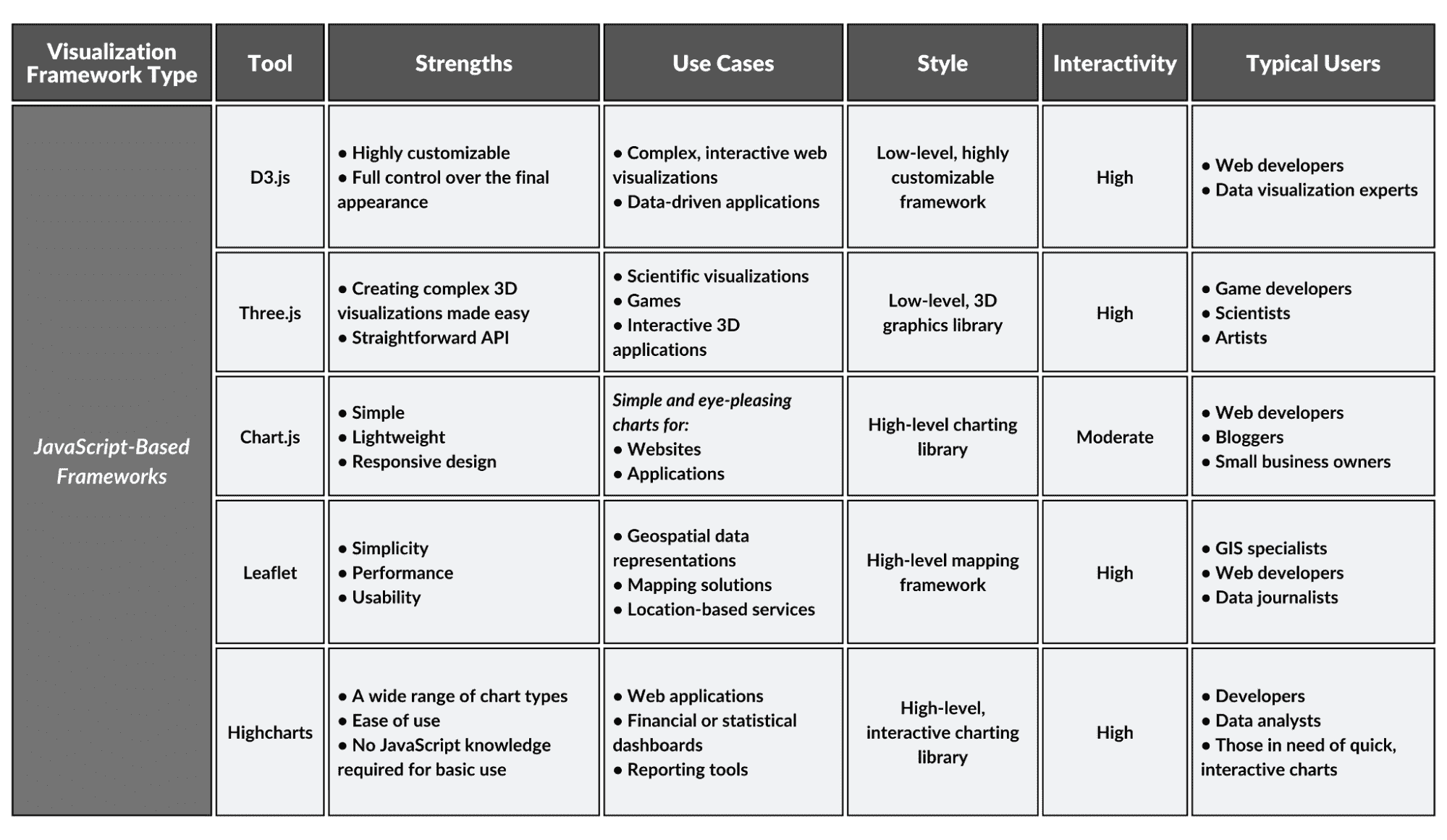
Python/R/多语言库
这一类别包括 Python 数据可视化库,以及那些在 R 或其他多种编程语言中使用的库。这些库主要针对为演示创建可视化的数据科学家。大多数这些库对数值和科学计算有强大的支持。
1. Matplotlib
Matplotlib 是一个全面的 Python 库,用于创建静态、动画和互动的可视化。它提供了多种工具来制作复杂的图表,并为构建适合用于科学出版物或演示的详细图表提供了坚实的基础。
2. seaborn
seaborn: 基于 Matplotlib 的 Python 数据可视化库。它提供了一个高级接口来绘制吸引人的统计图形。它简化了创建美观的可视化,以呈现复杂的数据趋势和分布。
3. Plotly
Plotly 是一个多语言图表库,允许开发人员和分析师直接从浏览器创建互动的、出版质量的图表和可视化。其直观的界面支持多种图表类型,促进了数据可视化的自助服务环境。
4. bokeh
Bokeh: 一个用于现代网页浏览器的 Python 互动可视化库。它提供优雅而多功能的图形,具有高性能的交互性,适用于大规模或流数据集,旨在创建复杂的可视化应用程序和仪表板。
5. Pygal
Pygal 是一个 Python 库,专为创建 SVG(可缩放矢量图形)图而设计,注重简洁性和风格。你可以生成既互动又高度可定制的图表。
6. TensorBoard
TensorBoard 是 TensorFlow 生态系统中的一个可视化工具,为 Python 用户提供清晰的机器学习工作流视图。它允许开发人员轻松跟踪指标并可视化模型的各个方面,而无需大量手动绘图或外部工具。
7. ggplot2
一个 R 包 使用图形语法创建数据可视化,允许用户以一致的结构和设计理念构建复杂的图表,编码量最小化。
8. lattice
一个 R 可视化工具 专注于创建网格图,这对于通过条件和面板展示多变量数据至关重要,满足需要详细比较视觉研究的科学研究人员的需求。
9. Shiny
Shiny 将 R 统计代码转化为互动式 web 应用程序,为分析师和科学家提供了一个便捷的框架来创建用户友好的数据驱动界面,从而使复杂的分析工作在无需 web 开发专业知识的情况下也能变得易于访问。
Python/R/多语言库概述
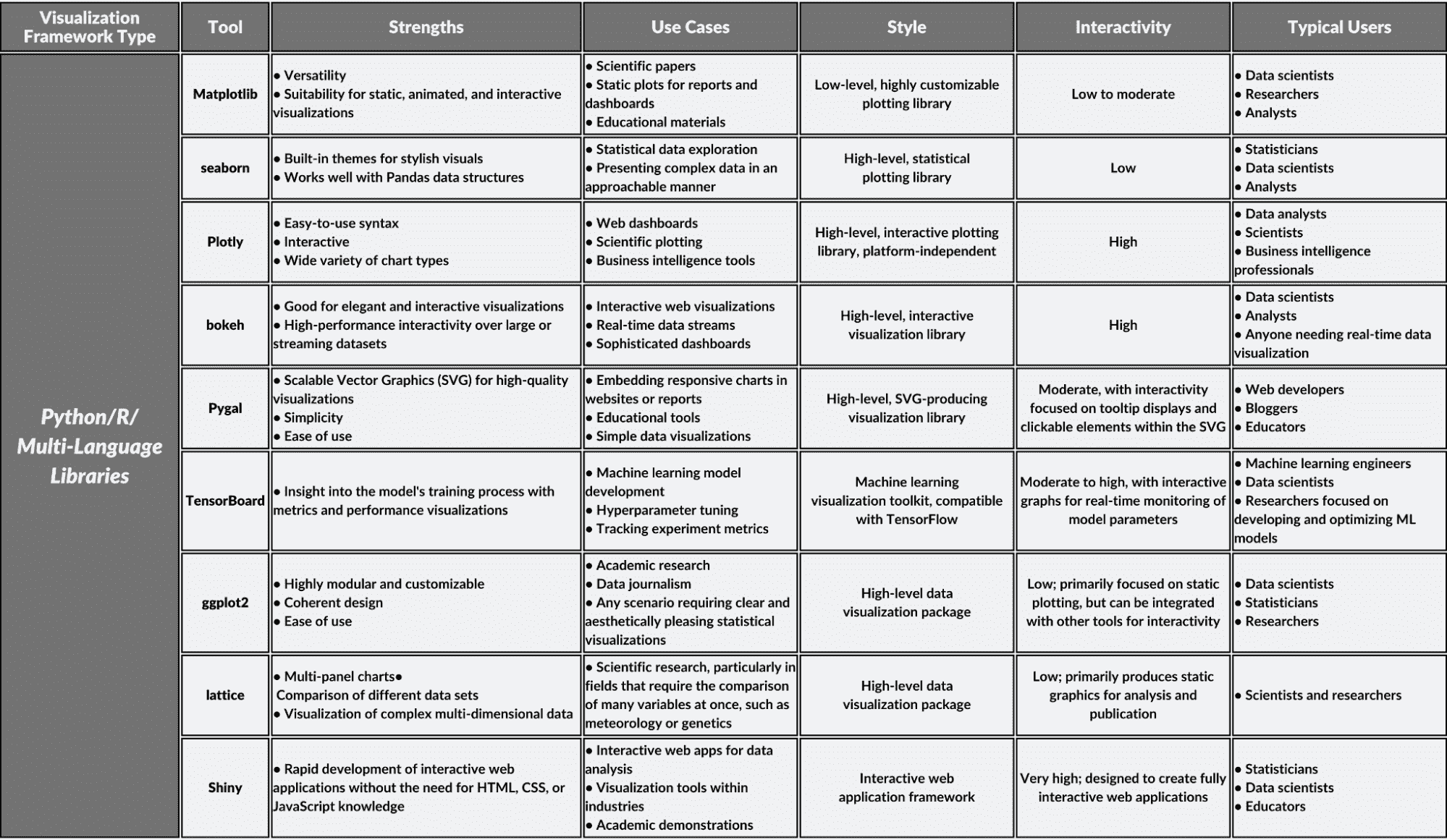
企业解决方案
这些是强大且可扩展的可视化平台,通常包括与数据源和其他商业智能工具的集成。它们允许非技术用户在无需编码的情况下创建可视化和仪表板。它们通常是即插即用的,例如“将其插入你的数据库并进行可视化”。
1. Tableau Software
Tableau 是一种行业标准的分析平台,提供直观的数据可视化和商业智能解决方案,使用户能够轻松连接、理解和以有意义的方式可视化数据,而无需广泛的技术支持。
2. Microsoft Excel
作为个人和专业数据管理的基础工具,Excel 提供了广泛的可视化选项,从基本图表到复杂图形,满足全球企业日常的分析需求。
3. SAS Visual Analytics
一个先进的分析平台 结合了可视化和商业智能,为数据探索和洞察发现提供了强大的自助服务能力,专为复杂数据环境中的组织量身定制。
4. QlikView/Qlik Sense
QlikView 和 Qlik Sense 是互动的商业智能和可视化工具,利用自助式分析赋能用户即时获取洞察,使用关联数据建模提供直观和探索性的用户体验。
5. IBM Cognos Analytics
一个全面的商业智能套件,通过 AI 增强的分析和智能讲述功能,支持企业级数据探索和决策制定,提供高效的数据管理和可视化能力。
6. SAP BusinessObjects
这是 SAP 提供的广泛企业分析解决方案,提供多样的工具套件,使组织能够挖掘洞察、生成报告,并通过强大的数据可视化和仪表板功能优化业务表现。
7. Oracle Business Intelligence
Oracle BI 是一个全面的企业 BI 产品套件,具有全面的功能,包括互动仪表板、临时分析和前瞻性智能。它允许企业从数据中获取可操作的洞察,且只需最少的 IT 介入。
8. SPSS
SPSS 是 IBM 提供的统计分析强大工具,以其在社会科学中的广泛应用而著称。它简化了统计解释的过程,并生成详细的视觉表现,使不同水平的用户都能进行高级统计分析。
9. Stata
Stata 是一个全面的数据分析、数据管理和图形工具。它特别设计用于简化研究人员的工作流程,为他们提供强大的统计工具集,并配备高质量的图形功能,以简化数据驱动的查询。
10. MicroStrategy
MicroStrategy 是一个强大的企业分析平台,以其高扩展性和先进的分析功能脱颖而出,为组织提供互动仪表板、记分卡和报告,推动战略决策而无需大量 IT 依赖。
11. Domo
Domo 是一个现代化的 BI 平台,在数据整合、可视化和协作方面表现出色,方便创建自定义仪表板和报告,以支持实时决策,并提供为业务用户设计的用户友好界面。
12. Informatica
Informatica是一款提供云原生数据管理和集成服务的工具,配有可视化工具,使组织能够维护数据质量、简化操作,并通过受控自服务模式提供商业智能洞察。
13. Apache Superset
Apache Superset是一个开源分析和商业智能 Web 应用程序,允许数据探索和可视化。它使用户能够创建和共享互动仪表板,这些仪表板通过拖放轻松组成,无需 IT 人员。
14. Grafana
多平台开源分析和监控解决方案,Grafana为最终用户提供了丰富、可自定义的数据聚合仪表板,来自多个来源。其用户友好的界面将来自指标、日志和跟踪的复杂数据简化为可操作的洞察。
15. KNIME
一个开源数据分析平台,KNIME提供了全面的数据集成、转换和分析工具。它提供了一个直观的无代码图形用户界面,使最终用户能够独立构建数据驱动的解决方案和工作流程。
企业解决方案概述
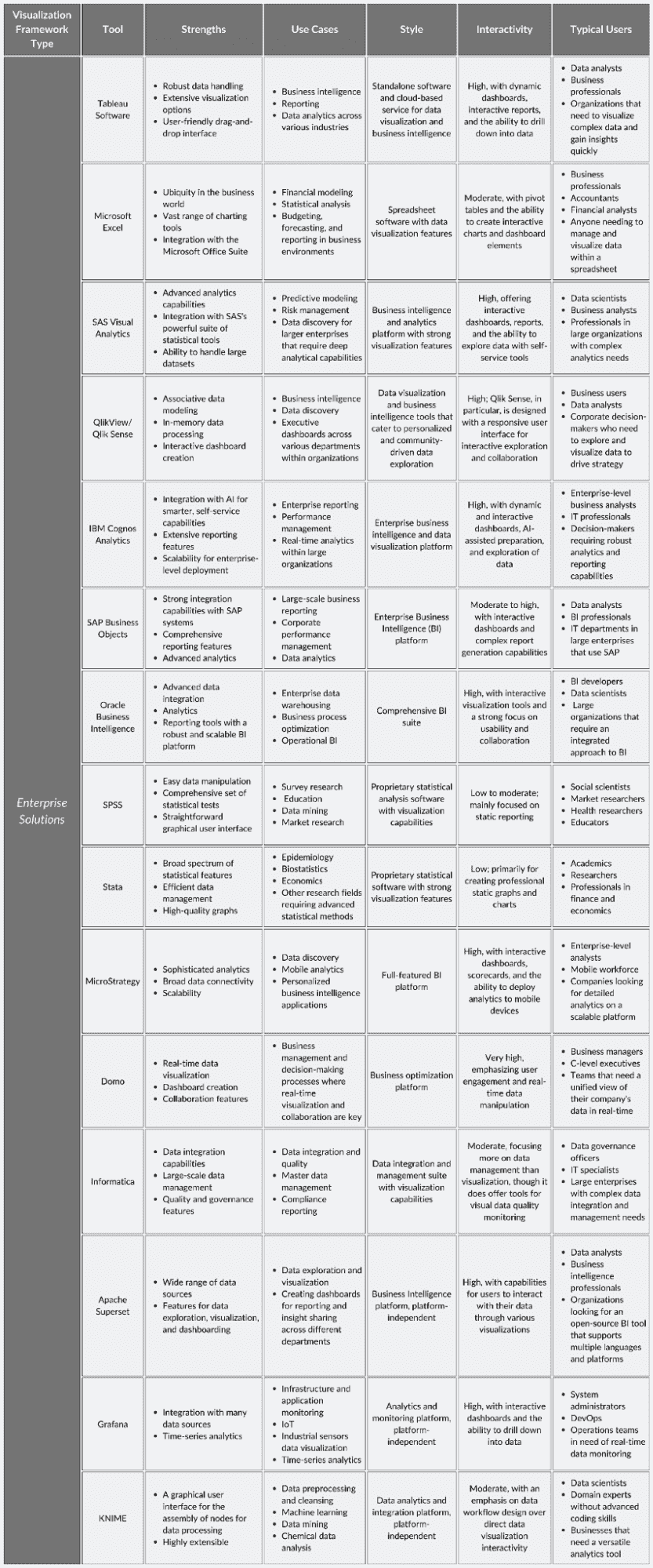
结论
可视化框架非常广泛,它们适合的类别也在不断增长。我在这里覆盖了二十九种工具,这应该足够让你找到所需的工具。
请注意,每个类别中的工具具有不同的功能,因此在决定使用的工具之前,请熟悉它们。
Nate Rosidi是一位数据科学家和产品策略专家。他还是一名兼职教授,教授分析课程,是 StrataScratch 的创始人,该平台帮助数据科学家准备面试,提供来自顶级公司的真实面试问题。Nate 撰写了职业市场的最新趋势,提供面试建议,分享数据科学项目,并涵盖所有 SQL 相关内容。
更多相关话题
2019 年的典型数据科学家是谁?
原文:
www.kdnuggets.com/2019/03/typical-data-scientist-2019.html
评论
由 Iliya Valchanov,365 Data Science。
‘数据科学家’这一术语已经出现了 11 年,据信由 Jeff Hammerbacher 和 DJ Patil 于 2008 年首创。
从那时起,数据科学家已连续 4 年成为美国的热门职业(根据 哈佛商业评论 和 Glassdoor 报告)。但 KDnuggets 的读者对此非常了解。实际上,这可能是我们一直回到这里的原因之一。
即便考虑到这些因素,仍然很少有‘明确的’途径来建立所需的技能,以成为这个高薪职业的一部分。这就是为什么去年我们对 1,001 个 LinkedIn 个人资料进行了研究,以构建‘典型’数据科学家的形象。 结果在某种程度上确认了其他研究和调查,如每年的 KDnuggets 软件调查,但也揭示了使数据科学家成为数据科学家的其他有趣方面。
这项研究的不同之处在于,虽然数据是自我报告的,但我们从求职者向雇主展示自己的方式中收集了这些数据。
方法论
就像去年一样,我们调查了 1,001 名数据科学家的 LinkedIn 个人资料。与招聘广告等其他数据收集方法不同,我们认为由专业人士自己发布的数据是其实际简历的良好替代。
我们必须保持相同的配额。因此,我们再次从财富 500 强公司抽取了 40%的样本,其余 60%来自其他地方。我们的国家配额也保持不变,40%来自美国,30%来自英国,15%来自印度,另 15%来自其他国家。由于数据获取的限制,我们采用了便利抽样。
概述
那么,今天的‘典型’数据科学家与一年前的有何不同?

乍一看似乎没有太大变化。这个领域仍由男性主导,自去年以来仅下降了 1%(2019 年为 69% – 2018 年为 70%);我们的一半人群中有四分之三拥有硕士或博士学位(再次,微弱减少);角色的平均经验仅从 2 年增加了 0.3 年,达到 2.3 年。
然而,一个显著的普遍变化是,去年数据科学家的平均工作年限为 4.5 年,而今天这一数字为 8 年。这意味着更多的人在年长时转行,或者我们认为更可能的情况——统计学家、‘数据挖掘者’、计量经济学家等已经进化(可能还获得了新技能),并接受了他们的新职业名称:数据科学家。事实上,我们之前也研究过这个领域的命名约定,你可以在这里找到详细的概述。
然而,这并不是唯一的发现,当我们进一步细分数据时,发现了一些关于 2019 年数据科学家的有趣见解。
技能集
数据科学家最重要的方面无疑是他们拥有的技能。

在探索数据科学家最重视的前三种工具后,我们发现,就像去年一样,编程语言仍然是数据科学家工具包中最常见的(而非软件,如 Tableau 或 SAS)。
目前,R 和 Python 仍然领先,但虽然两者在 2018 年平分秋色,53%的数据科学家都掌握其中一种技能,但 Python 现在已经远超 R(或者像Gregory Piatetsky-Shapiro 所说——Python 继续蚕食 R)。54%的参与者将 Python 列为他们的顶级技能之一,而只有 45%提到 R。
SQL 是我们参与者的第三选择(36%),比去年仅下降了 4%。前六名中的最后三种语言自 2018 年以来没有变化。MATLAB 和 Java 用户与去年持平(分别为 19%和 18%),然而,我们观察到 C/C++程序员的比例显著下降了 10%(从 18%降至 8%)。
最后,去年我们分析了按行业分类的技能集,因此现在复制这一分析也是有意义的。就语言在行业中的分布而言,我们观察到与 2018 年趋势非常相似的结果。主要结论是,即使在这种细分中,结果基本上反映了我们看到的整体偏好——Python 主导了所有行业。
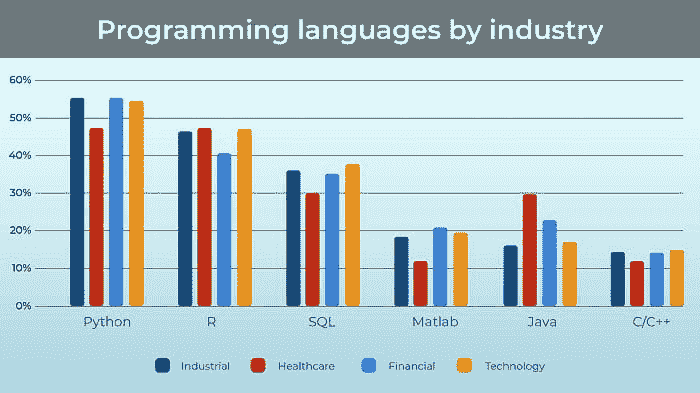
就业行业
数据科学家的最大雇主继续是技术/信息技术行业,自去年以来增加了 1%(2019 年为 43% - 2018 年为 42%)。尽管科技行业仍然主导,但工业部门的数据科学家也在增加,从 37%上升到 39%。金融行业保持在 16%不变,而医疗行业的比例从 5%降至微不足道的 2%(值得注意的是,医疗行业相对于其他行业而言规模极小,因此这一下降可能完全归因于样本限制)。
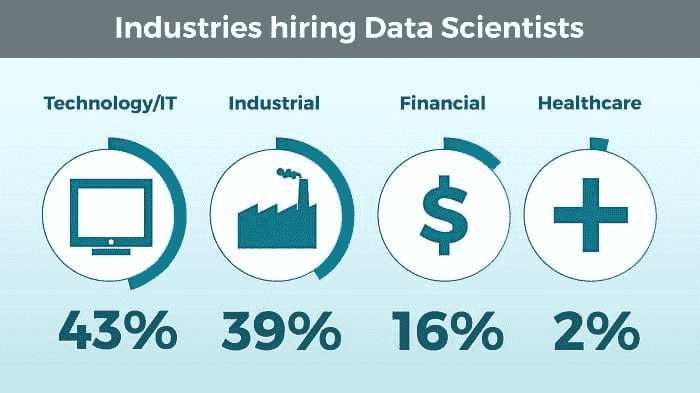
这些结果并没有特别显示出每年在数据科学家需求领域的巨大变化,但如果我们按国家来细分这些行业呢?
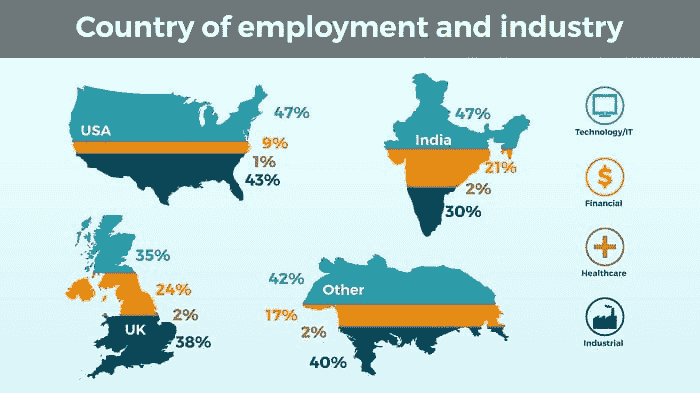
与去年一样,大多数国家的结果与总体趋势相似,除了英国,该国比其他国家更倾向于金融行业。即使伦敦作为欧洲金融中心的未来不明朗,英国的金融机构似乎仍在数据科学方面投入巨资。
然而,最显著的变化来自印度,印度似乎将技术行业的数据科学家数量从巨大的 63%减少到了更为平均的 47%。其中一些人转到工业部门,该部门现在雇佣了印度 30%的数据科学家,而这一比例此前为 21.4%。但看起来印度借鉴了英国的做法,因为其金融行业的数据科学家增加了惊人的 13%(2018 年为 8.3%,2019 年为 21%)。印度在科技领域的主导地位众所周知,许多公司外包业务,数据科学也顺应这一趋势。我们当然期待继续跟踪印度在这一领域的发展。
结论
这项重复的研究再次强调了成为数据科学家的必要条件。所需的编程语言比以往任何时候都更为明确,Python 和 R 之间的差距持续扩大。这对有志成为数据科学家的人员来说是另一个“检查点”,帮助他们根据计划工作的国家和行业明智地选择应专注的技能。
从 2018 年到 2019 年观察到的变化可能不如研究人员所希望的那样具有革命性,但确实确认了正在发生的趋势。随着数据科学比以往任何时候都更加强大,我们预计数据科学家的个人资料将更加稳定,惊喜会更少。尽管距离成熟领域还有很远的距离,数据科学仍在发展,紧跟趋势和模式仍然至关重要。
所有发现,请通过此链接查看 2019 年的研究,或通过此链接查看 2018 年的研究。
资源:
相关:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关话题
Uber 的 Ludwig 是一个开源低代码机器学习框架
原文:
www.kdnuggets.com/2020/06/uber-ludwig-open-source-framework-machine-learning.html
评论
来源:ludwig-ai.github.io/ludwig-docs/
训练和测试深度学习模型是一个困难的过程,需要对机器学习和数据基础设施有深刻的了解。从特征建模到超参数优化,训练和测试深度学习模型的过程是现实世界数据科学解决方案中的主要瓶颈之一。简化这一环节可以帮助加快深度学习技术的采用。虽然低代码训练深度学习模型仍处于初期阶段,但我们已经看到了一些相关的创新。解决这一问题的最完整解决方案之一来自 Uber AI Labs。Ludwig是一个无需编写代码即可进行机器学习模型训练和测试的框架。最近,Uber 发布了 Ludwig 的第二版,包含了主要的增强功能,以便为机器学习开发者提供主流的无代码体验。
Ludwig 的目标是通过声明式的无代码体验简化训练和测试机器学习模型的过程。训练是深度学习应用中最费开发者精力的方面之一。通常,数据科学家需要花费大量时间尝试不同的深度学习模型,以更好地对特定的训练数据集进行优化。这个过程不仅仅涉及训练,还包括模型比较、评估、工作负载分配等多个方面。由于其高度技术性,深度学习模型的训练通常仅限于数据科学家和机器学习专家,并且需要大量的代码。尽管这个问题可以概括为任何机器学习解决方案,但在深度学习架构中情况更为严重,因为它们通常涉及许多层次。Ludwig 通过使用易于修改和版本控制的声明式模型,抽象了训练和测试机器学习程序的复杂性。
Ludwig
功能上,Ludwig 是一个简化选定、训练和评估机器学习模型过程的框架。Ludwig 提供了一组模型架构,可以将这些架构组合在一起,以创建一个针对特定需求优化的端到端模型。从概念上讲,Ludwig 是基于一系列原则设计的:
-
无需编码:Ludwig 使得无需任何机器学习专业知识即可训练模型。
-
通用性:Ludwig 可以应用于许多不同的机器学习场景。
-
灵活性:Ludwig 足够灵活,既适合经验丰富的机器学习从业者,也适合没有经验的开发人员使用。
-
可扩展性:Ludwig 的设计考虑了可扩展性。每个新版本都包含了新功能,而不改变核心模型。
-
可解释性:Ludwig 包括有助于数据科学家理解机器学习模型性能的可视化工具。
使用 Ludwig,数据科学家只需提供一个包含训练数据的 CSV 文件和一个包含模型输入和输出的 YAML 文件,即可训练深度学习模型。利用这两个数据点,Ludwig 执行多任务学习例程来同时预测所有输出并评估结果。这种简单结构是快速原型设计的关键。Ludwig 在后台提供了一系列不断评估并可以组合成最终架构的深度学习模型。
Ludwig 的主要创新基于特定数据类型编码器和解码器的理念。Ludwig 使用针对任何给定数据类型的特定编码器和解码器。与其他深度学习架构类似,编码器负责将原始数据映射到张量,而解码器则将张量映射到输出。Ludwig 的架构还包括一个合并器的概念,它是一个将所有输入编码器的张量合并、处理,并将张量返回给输出解码器的组件。
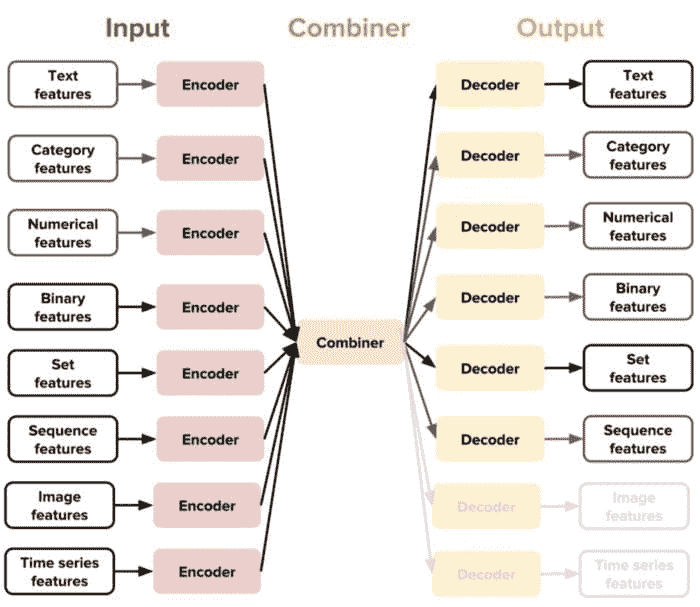
来源:eng.uber.com/introducing-ludwig/
数据科学家将使用 Ludwig 完成两个主要功能:训练和预测。假设我们正在处理一个文本分类场景,数据集如下。
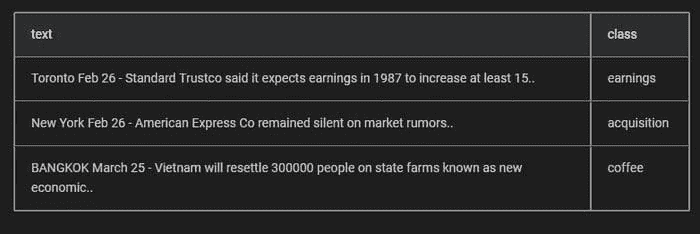
来源:ludwig-ai.github.io/ludwig-docs/examples/
我们可以通过以下命令安装 Ludwig 并开始使用:
pip install ludwig
python -m spacy download en
下一步是配置一个模型定义 YAML 文件,该文件指定模型的输入和输出特征。
input_features:
-
name: text
type: text
encoder: parallel_cnn
level: wordoutput_features:
-
name: class
type: category
通过这两个输入(训练数据和 YAML 配置),我们可以使用以下命令训练深度学习模型:
ludwig experiment \
--data_csv reuters-allcats.csv \
--model_definition_file model_definition.yaml
Ludwig 提供了一系列可以在训练和预测过程中使用的可视化工具。例如,学习曲线可视化能让我们了解模型的训练和测试性能。
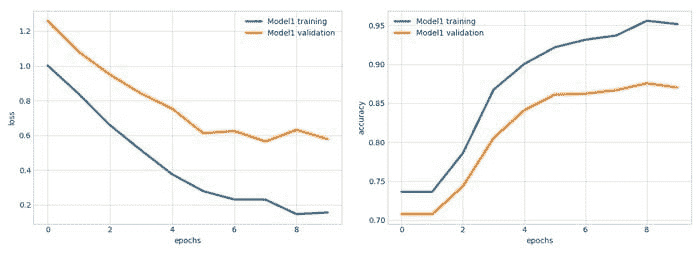
来源:ludwig-ai.github.io/ludwig-docs/getting_started/
训练后,我们可以使用以下命令评估模型的预测结果:
ludwig predict --data_csv path/to/data.csv --model_path /path/to/model
其他可视化工具可以用来评估模型的性能。
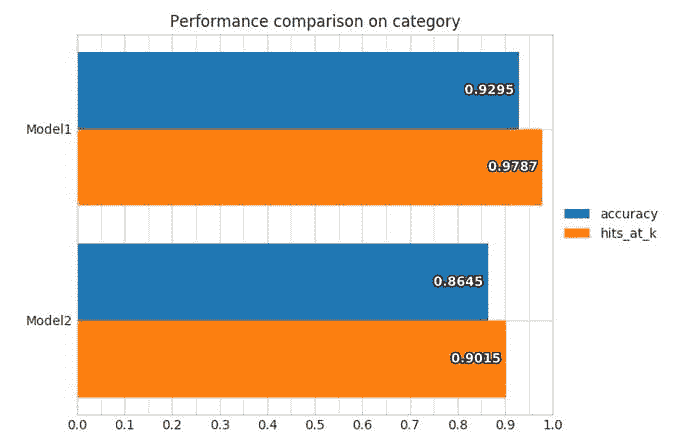
来源:ludwig-ai.github.io/ludwig-docs/getting_started/
对 Ludwig 的新添加
最近,Uber 发布了 Ludwig 的第二个版本,扩展了其核心架构,并加入了一系列旨在改善无代码模型训练和测试体验的新功能。许多新的 Ludwig 功能基于与其他机器学习栈或框架的集成。以下是一些关键功能:
-
Comet.ml 集成:Comet.ml 是市场上最受欢迎的超参数优化和机器学习实验平台之一。Ludwig 与 Comet.ml 的新集成使得诸如超参数分析或实时性能评估等功能成为可能,这些都是数据科学家工具箱中的重要组成部分。
-
模型服务:模型服务是机器学习程序生命周期的关键组件。新版本的 Ludwig 提供了一个 API 端点,用于服务训练后的模型,并使用简单的 REST 查询来获取预测结果。
-
音频/语音功能:Ludwig 0.2 的一个重要新增功能是对音频特性的支持。这使得数据科学家能够用最少的代码构建音频分析模型。
-
BERT 编码器:BERT 是深度学习历史上最受欢迎的语言模型之一。基于Transformer 架构,BERT 可以执行许多语言任务,如问答或文本生成。Ludwig 现在将 BERT 作为文本分类场景的原生构建模块。
-
H3 特性:H3 是一种非常流行的空间索引,用于将位置编码为 64 位整数。Ludwig 0.2 原生支持 H3,允许使用空间数据集实现机器学习模型。
对于 Ludwig 的其他改进包括可视化 API 的改进、新的日期功能、对非英语语言的文本分词支持更好,以及更强的数据预处理能力。特别是数据注入似乎是下一版本 Ludwig 的重点关注领域。
Ludwig 仍然是一个相对较新的框架,仍需大量改进。然而,它对低代码模型的支持是简化机器学习在更广泛开发者中采用的关键组成部分。此外,Ludwig 抽象和简化了市场上某些顶级机器学习框架的使用。
原文。经许可转载。
相关:
-
LinkedIn 开源一个小组件以简化 TensorFlow-Spark 互操作性
-
Facebook 开源 Blender,史上最大的开放领域聊天机器人
-
微软研究院揭示三项推进深度生成模型的努力
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关内容
Uber 开源了 Ludwig 第三版,它的无代码机器学习平台
原文:
www.kdnuggets.com/2020/10/uber-open-source-ludwig-code-free-machine-learning-platform.html
评论
我最近开始了一份关注 AI 教育的新通讯。TheSequence 是一份无废话(即没有炒作,没有新闻等)的 AI 专注通讯,阅读时间为 5 分钟。目标是让你及时了解机器学习项目、研究论文和概念。请通过下面的订阅链接试试看:
Uber 继续对开源机器学习技术做出创新贡献。上周,这家交通巨头 开源了 Ludwig 0.3,这是其无代码机器学习平台的第三次更新。在过去几个月中,Ludwig 社区已经超越了 Uber,并包括了斯坦福大学等贡献者。这个新版本扩展了前版本的 AutoML 功能。让我们回顾一下 Ludwig 的先前版本,并探索这个新版本。
Uber Ludwig 是什么?
从功能上看,Ludwig 是一个简化选择、训练和评估特定场景下机器学习模型过程的框架。Ludwig 提供了一组可以组合在一起创建针对特定需求优化的端到端模型的模型架构。从概念上讲,Ludwig 是基于一系列原则设计的:
-
无需编码:训练模型和使用模型进行预测不需要编码技能。
-
通用性:一种基于新数据类型的深度学习模型设计方法,使得该工具可用于许多不同的使用场景。
-
灵活性:经验丰富的用户可以对模型构建和训练进行广泛控制,而新手用户则会发现使用起来很简单。
-
扩展性:易于添加新的模型架构和新的特征数据类型。
-
可理解性:深度学习模型的内部机制通常被视为黑箱,但我们提供了标准可视化工具来理解它们的性能并比较它们的预测。
使用 Ludwig,数据科学家只需提供包含训练数据的 CSV 文件和包含模型输入输出的 YAML 文件,即可训练深度学习模型。利用这两个数据点,Ludwig 执行多任务学习例程,同时预测所有输出并评估结果。在幕后,Ludwig 提供了一系列不断评估的深度学习模型,并可以组合成最终架构。Ludwig 的主要创新基于数据类型特定的编码器和解码器。Ludwig 使用针对支持的任何数据类型的特定编码器和解码器。与其他深度学习架构一样,编码器负责将原始数据映射到张量,而解码器则将张量映射到输出。Ludwig 的架构还包括一个组合器概念,这是一个将所有输入编码器的张量组合、处理并返回给输出解码器的组件。
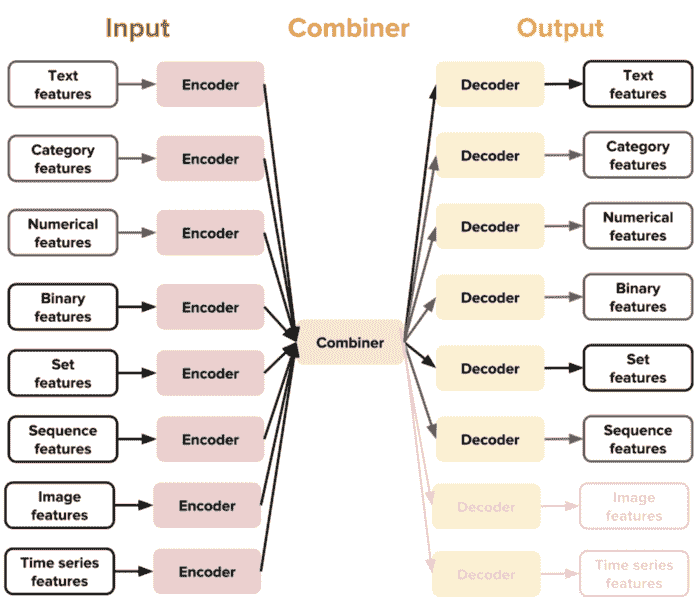
来源:eng.uber.com/introducing-ludwig/
Ludwig 0.3
Ludwig 0.3 通过一致的无代码接口集成了在机器学习应用中广泛使用的新特性。让我们回顾一下 Ludwig 新版本的一些基本贡献。
1) 超参数优化
为特定机器学习问题找到最佳超参数组合可能会很费力。Ludwig 0.3 引入了一个新命令,hyperopt,它执行自动化的超参数搜索并返回可能的配置。Hyperopt 可以使用简单的语法调用:

输出展示了超参数的不同值和尺度。
2) 与 Weights and Biases 的集成
补充前一点,Ludwig 0.3 与 Weights and Biases(W&B)平台集成。W&B 提供了一个非常直观的界面,用于快速实验和机器学习模型的超参数调优。要使用 W&B,Ludwig 用户可以简单地将 -wandb 参数附加到他们的命令中。

3) 无代码变换器
近年来,语言预训练模型和变换器一直是深度学习领域如自然语言处理的重大突破的核心。Ludwig 0.3 通过与 Hugging Face 的 Transformers 仓库的集成,支持变换器。
4) TensorFlow 2 后端
Ludwig 的新版本基于 TensorFlow 2 进行了重大重构。虽然这种重构可能对终端用户不立即显现,但它使 Ludwig 能够利用 TensorFlow 2 的许多新功能,并引入了更模块化的设计。
5) 新数据源集成
Ludwig 的一个主要限制是支持作为输入的数据集结构较少。基本上,Ludwig 只支持 CSV 和 Pandas 数据框作为输入数据集。新版本通过引入与许多其他格式(如 excel、feather、fwf、hdf5、html 表格、json、jsonl、parquet、pickle、sas、spss、stata 和 tsv)的集成来解决这个挑战。新的数据集可以通过简单的命令行使用:
其他功能
Ludwig 0.3 引入了其他功能,例如支持弱监督的嘈杂标签的新向量数据类型、支持新向量数据类型以及用于训练的 k 折交叉验证,这些功能补充了已经令人印象深刻的发布版本。逐渐地,Ludwig 正成为市场上最令人印象深刻的开源 AutoML 堆栈之一。
原文. 经许可转载。
相关:
-
Uber 的 Ludwig 是一个低代码机器学习的开源框架
-
LinkedIn 的 Pro-ML 架构总结了构建大规模机器学习的最佳实践
-
LinkedIn 如何在其招聘推荐系统中使用机器学习
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关信息
优步正在悄悄组建市场上最令人印象深刻的开源深度学习堆栈之一
原文:
www.kdnuggets.com/2020/01/uber-quietly-assembling-impressive-open-source-deep-learning.html
评论

人工智能(AI)一直是一个非典型的技术趋势。在传统的技术周期中,创新通常从试图颠覆行业现有者的初创公司开始。就 AI 而言,大部分创新来自于像谷歌、Facebook、优步或微软这样的企业实验室。这些公司不仅在研究方面处于领先地位,而且定期开源新的框架和工具,简化了 AI 技术的采用。在这种背景下,优步已成为当前生态系统中最活跃的开源 AI 技术贡献者之一。在短短几年内,优步在 AI 生命周期的不同领域定期开源项目。今天,我想回顾一些我最喜欢的项目。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
优步是一个近乎完美的 AI 技术试验场。公司将大型技术公司传统的 AI 需求与前沿 AI 交通场景结合起来。因此,优步在从客户分类到自动驾驶车辆等各种多样化场景中建立了机器/深度学习应用程序。优步团队使用的许多技术已经开源,并获得了机器学习社区的好评。让我们看看我最喜欢的一些项目:
注意:我不会涵盖像 Michelangelo 或 PyML 这样的技术,因为它们已经有很好的文档,且已开源。
Ludwig:一个无代码机器学习模型的工具箱

Ludwig是一个基于 TensorFlow 的工具箱,允许在不编写代码的情况下训练和测试深度学习模型。概念上,Ludwig 是基于五个基本原则创建的:
-
无需编码:不需要编码技能即可训练模型并使用它来获得预测。
-
通用性:一种基于新数据类型的深度学习模型设计方法,使工具可以用于许多不同的使用案例。
-
灵活性:经验丰富的用户可以对模型构建和训练进行广泛的控制,而新手则会发现它易于使用。
-
可扩展性:易于添加新的模型架构和新的特征数据类型。
-
可理解性:深度学习模型的内部通常被认为是黑箱,但我们提供了标准的可视化工具来理解它们的性能并比较它们的预测。
使用 Ludwig,数据科学家可以通过提供一个包含训练数据的 CSV 文件以及一个包含模型输入和输出的 YAML 文件来训练深度学习模型。利用这两个数据点,Ludwig 执行多任务学习例程以同时预测所有输出并评估结果。在幕后,Ludwig 提供了一系列不断评估的深度学习模型,并可以在最终架构中组合。Uber 工程团队通过以下类比来解释这一过程:“如果深度学习库提供了建造你建筑物的构件,那么 Ludwig 就提供了建造你城市的建筑物,你可以从可用的建筑物中选择,或者将你自己的建筑物添加到可用的建筑物集合中。”
Pyro: 一个本地的概率编程语言

Pyro是由 Uber AI Labs 发布的深度概率编程语言(PPL)。Pyro 构建于 PyTorch 之上,基于四个基本原则:
-
通用性:Pyro 是一个通用的 PPL——它可以表示任何可计算的概率分布。怎么做的?从一个具有迭代和递归(任意 Python 代码)的通用语言开始,然后添加随机采样、观察和推断。
-
可扩展:Pyro 可以处理大数据集,开销仅略高于手写代码。怎么做到的?通过构建现代黑箱优化技术,使用数据的迷你批次来近似推断。
-
简约性:Pyro 灵活且易于维护。怎么做的?Pyro 由一个小核心强大、可组合的抽象构建。在可能的情况下,繁重的工作被委托给 PyTorch 和其他库。
-
灵活:Pyro 旨在根据需要提供自动化和控制。怎么做的?Pyro 使用高层次的抽象来表达生成和推断模型,同时允许专家轻松自定义推断。
这些原则通常会使 Pyro 的实现朝着相反的方向发展。例如,成为通用的,要求允许在 Pyro 程序中使用任意控制结构,但这种通用性使得扩展变得困难。然而,总的来说,Pyro 在这些能力之间达到了一个精彩的平衡,使其成为实际应用中最优秀的概率编程语言之一。
Manifold: 一个用于机器学习模型的调试和解释工具集
Manifold 是 Uber 技术用于大规模调试和解释机器学习模型。使用 Manifold,Uber 工程团队希望实现一些非常具体的目标:
-
调试机器学习模型中的代码错误。
-
理解一个模型在孤立状态下以及与其他模型比较的优缺点。
-
比较和集成不同的模型。
-
将通过检查和性能分析获得的见解纳入模型迭代。
为了实现这些目标,Manifold 将机器学习分析过程分为三个主要阶段:检查、解释和精炼。
-
检查: 在分析过程的第一部分,用户设计模型并尝试调查和比较模型结果与其他现有模型的结果。在此阶段,用户比较典型的性能指标,如准确性、精度/召回率和接收者操作特征曲线(ROC),以获得新模型是否优于现有模型的粗略信息。
-
解释: 这一分析过程的阶段试图解释前一阶段制定的不同假设。此阶段依赖比较分析来解释一些特定模型的症状。
-
精炼: 在这一阶段,用户尝试通过将从解释中提取的知识编码到模型中并测试性能,来验证从前一阶段生成的解释。
柏拉图:大规模构建对话代理的框架

Uber 构建了 Plato Research Dialogue System (PRDS) 以应对构建大规模对话应用的挑战。从概念上讲,PRDS 是一个框架,用于在多种环境中创建、训练和评估对话 AI 代理。从功能角度看,PRDS 包括以下构建模块:
-
语音识别(将语音转录为文本)
-
语言理解(从文本中提取意义)
-
状态跟踪(汇总迄今为止所说和所做的内容)
-
API 调用(搜索数据库、查询 API 等)
-
对话策略(生成代理响应的抽象意义)
-
语言生成(将抽象意义转换为文本)
-
语音合成(将文本转换为语音)
PRDS 设计时考虑了模块化,以便纳入最先进的对话系统研究,并持续发展平台的每个组件。在 PRDS 中,每个组件可以在线(通过交互)或离线训练,并纳入核心引擎。从训练角度来看,PRDS 支持与人类和模拟用户的交互。后者在研究场景中常用于启动对话 AI 代理,而前者更能代表实际交互。
Horovod: 用于大规模训练深度学习的框架

Horovod 是 Uber 机器学习堆栈之一,在社区中变得极其受欢迎,并被像 DeepMind 或 OpenAI 这样的 AI 巨头的研究团队采纳。从概念上讲,Horovod 是一个用于大规模运行分布式深度学习训练作业的框架。
Horovod 利用消息传递接口堆栈,如 OpenMPI 使训练作业能够在高度并行和分布式的基础设施上运行,而无需任何修改。在 Horovod 中运行分布式 TensorFlow 训练作业分为四个简单步骤:
-
hvd.init() 初始化 Horovod。
-
config.gpu_options.visible_device_list = str(hvd.local_rank()) 将 GPU 分配给每个 TensorFlow 进程。
-
opt=hvd.DistributedOptimizer(opt)将任何常规的 TensorFlow 优化器封装成 Horovod 优化器,后者负责使用环形全减法平均梯度。
-
hvd.BroadcastGlobalVariablesHook(0) 将变量从第一个进程广播到所有其他进程,以确保一致的初始化。
Uber AI Research: 人工智能研究的常规来源
最后但同样重要的是,我们应提到 Uber 在 AI 研究方面的积极贡献。许多 Uber 的开源发布都受到他们研究工作的启发。Uber AI Research 网站是一个精彩的论文目录,突出显示了 Uber 在 AI 研究中的最新努力。
这些是 Uber 工程团队的一些贡献,这些贡献已被 AI 研究和开发社区广泛采用。随着 Uber 继续大规模实施 AI 解决方案,我们应该会看到新的创新框架,这些框架将简化数据科学家和研究人员对机器学习的采纳。
原文. 经许可转载。
相关:
-
Uber 创建生成式教学网络以更好地训练深度神经网络
-
微软推出 Project Petridish 以找到最适合您问题的神经网络
-
Facebook 已悄悄开源一些令人惊叹的 PyTorch 深度学习能力
更多相关话题
Uber 推出了一项新的服务,用于大规模回测机器学习模型
原文:
www.kdnuggets.com/2020/03/uber-unveils-service-backtesting-machine-learning-models-scale.html
评论

回测是机器学习模型生命周期中极其重要的一环。任何运行多个预测模型的组织都需要一个机制来定期评估其有效性并从错误中恢复。回测的相关性随着环境中使用的机器学习模型数量的增加而呈指数级增长。尽管回测如此重要,但与模型训练或部署等机器学习生命周期的其他方面相比,回测仍然相对被忽视。最近,Uber 推出了一项全新服务,完全从零开始构建,用于大规模回测机器学习模型。
Uber 运营着全球最大的一些机器学习基础设施之一。在其多个属性中,Uber 在诸如乘车计划或预算管理等不同领域运行着成千上万的预测模型。确保这些预测模型的准确性远非易事。模型的数量和计算规模使得 Uber 的环境对大多数回测框架来说相对不切实际。即便 Uber 自身也曾构建过像 Omphalos 这样的回测框架,这些框架对一些特定的用例有效,但无法与 Uber 的运营规模匹配。
我们讨论的是何种规模?为了提供背景,Uber 需要协调大约 1000 万次回测,涵盖其不同的预测模型。除了规模,Uber 的运营在回测方面有不同的特性,这些特性最终使得建立一个客户回测服务成为了有利的选择。
理解 Uber 方式的回测
并非所有的回测都是平等的。不同的组织依赖不同的向量来回测模型,这反映了它们业务的领域特性。对于 Uber 来说,交通巨头需要考虑城市数量或测试窗口等元素,以便有效地回测模型。对一个城市有效的模型在另一个城市可能效果不好。类似地,一些模型需要实时回测,而其他模型则可以有更大的窗口。综合考虑,Uber 确定了四个关键向量,这些向量对于回测预测模型非常相关。
-
回测窗口数量
-
城市数量
-
模型参数数量
-
预测模型数量

四个向量的组合导致了一个大多数主流回测服务无法处理的规模。
有效回测的关键要素之一是确定如何拆分测试数据。与cross-validation等技术不同,回测利用时间序列数据和非随机拆分。这也意味着任何回测策略需要明确了解如何以适应模型性能的方式拆分测试数据。以 Uber 为例,这也需要在成千上万的模型中完成。为了解决这一挑战,Uber 选择了两种主要的回测数据拆分机制:使用扩展窗口的回测和使用滑动窗口的回测。每个窗口被拆分为训练数据(用于训练模型)和测试数据(用于计算训练模型的误差率)。
回测策略的最后一个组成部分是准确测量模型的准确性。最常见的指标之一是平均绝对百分比误差(MAPE),其数学模型如下:
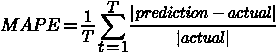
在模型回测中,MAPE 值越低,预测模型的表现越好。通常,数据科学家依赖 MAPE 指标来比较同一模型使用的误差率计算方法的结果,以确保它们准确反映了预测中出现的问题。
综合这三个要素:回测向量、回测窗口和误差度量,Uber 建立了一个新的回测服务,以简化组织中的预测操作。
Uber 的回测服务
多年来,Uber 建立了不同的专有技术,帮助简化机器学习模型的生命周期管理。新的回测服务能够利用这种复杂的基础设施,通过运用技术如Data Science Workbench,即 Uber 的互动数据分析和机器学习工具箱,以及Michelangelo,即 Uber 的机器学习平台。
从架构角度来看,新的回测服务由一个 Python 库和一个用 Go 编写的服务组成。Python 库充当 Python 客户端。由于 Uber 目前许多机器学习模型都是用 Python 编写的,因此选择利用这一框架来实现回测服务是一个简单的决定,这使得用户可以无缝地上手、测试和迭代他们的模型。Go 服务被编写为一系列 Cadence 工作流。Cadence 是一个开源的编排引擎,用 Go 编写,由 Uber 构建,用于以可扩展和弹性的方式执行异步长时间运行的业务逻辑。在高层次上,机器学习模型通过数据科学工作台上传,回测请求通过 Python 库提交,后者将请求转发给回测 Go 服务。一旦计算出错误测量值,它要么存储在数据存储中,要么被数据科学团队立即使用,这些团队利用这些预测错误来优化训练中的机器学习模型。
详细来说,回测工作流由四个阶段组成。在阶段 1,模型要么在数据科学工作台 (DSW) 上本地编写,要么上传到机器学习平台,该平台返回一个唯一的模型 ID。DSW 通过我们的 Go 服务触发回测,然后 Go 服务返回一个 UUID 给 DSW。在阶段 2,Go 服务获取训练和测试数据,将其存储在数据存储中,并返回一个数据集。在阶段 3,回测数据集在 ML 平台上进行训练,生成预测结果并返回给 Go 服务。在阶段 4,回测结果存储在数据存储中,供用户通过 DSW 获取。
Uber 已开始将新的回测服务应用于多个用例,如金融预测和预算管理。除了最初的适用性外,新回测服务还可以作为许多开始大规模应用机器学习模型的组织的参考架构。回测服务架构中概述的原则可以应用于不同数量的机器学习框架和平台。看看 Uber 是否决定在不久的将来开源回测服务栈将是很有趣的。
原文。经许可转载。
相关:
-
Uber 一直在悄悄组建市场上最令人印象深刻的开源深度学习栈之一
-
Uber 创建了生成性教学网络,以更好地训练深度神经网络
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
相关话题
你应该成为一名自由职业的人工智能工程师吗?
原文:
www.kdnuggets.com/2021/12/ucsd-become-freelance-artificial-intelligence-engineer.html
广告文章。
人工智能在商业世界中创造了大量机会。然而,支持这场人工智能革命的人力资源却不足。这就是为什么企业会雇佣具备 AI 技能的自由职业者,他们可以通过直观的软件程序开发智能解决方案。
如果你期待成为一名自由职业的人工智能工程师,请继续阅读。
自由职业人工智能工程师必备的 10 项技能
要成为一名成功的自由职业人工智能工程师,你需要通过相关教育和经验提升自己的技能。以下是一些雇主将会寻找的重要技能:
-
对机器学习、预测分析、深度学习、自然语言处理(NLP)、情感分析、图像识别等概念的理解
-
如何使用 TensorFlow、Scikit-learn、Keras 等工具
-
如何使用 Python 或 Node.js 构建智能聊天机器人
-
如何通过 Amazon、Google Cloud Speech 和 IBM Watson 的 API 创建智能系统
-
如何构建用于异常检测的机器学习模型
-
如何将 AI 应用于物联网应用
-
如何使用强化学习训练机器人
-
如何使用 Gephi、Tableau、Matplotlib 等工具进行数据可视化
-
如何利用 Google、IBM Watson 和 Wit.ai 的机器学习 API 创建智能应用
-
如何使用 Java、Scala 等实现 AI 模型
自由职业人工智能工程师薪资与收益
好消息是,许多网站提供自由职业的人工智能工程师职位。你可以考虑的一个网站是 Upwork。这是一个混合型市场,你可以在这里找到工作,也可以雇佣自由职业者。该平台仅在客户对你的工作感到满意并启用了付款时收取费用。你还可以考虑 Freelancer.com 和 Guru,它们有类似的商业模式。
LinkedIn 2020 年新兴职位报告列出了人工智能作为美国的顶级新兴职位,过去四年该职位需求增长了 74%。预计对能够开发使用深度学习和其他智能过程的应用程序和系统的 AI 专家的需求将持续增长。像谷歌、苹果和 Facebook 这样的公司不断寻找能够参与机器学习项目的 AI 专家。
根据Zip Recruiter,自由职业 AI 工程师的平均薪资为$134,168。然而,根据你的专业水平和所承担的项目类型,这一数字可能会有所上涨。例如,如果你在 AI 领域进行研究,你的年薪可以高达$152,000。
一些公司可能更倾向于雇佣自由职业 AI 工程师,因为他们的时间安排更灵活,可以在全球任何地方工作。他们也更具成本效益,因为公司不必在办公基础设施上花费费用或为员工创造合适的工作环境。
作为自由职业人工智能工程师,你可以期待什么?
人工智能不再是处于实验阶段的概念。它已经被各行各业的企业所接受,未来将会有更多的职位需要能够将这项技术付诸实践的专业人士。以下是一些 AI 工程师可以发挥作用的关键领域:
-
聊天机器人和虚拟助手。 人工智能将使开发能够理解用户查询并作出相应回应的聊天机器人成为可能。这与 Alexa 和 Siri 等虚拟助手有什么不同?嗯,基于 AI 的聊天机器人可以根据他们拥有的各种个人数据来学习你的偏好和其他人的偏好。
-
狭义 AI 与通用 AI。 开发狭义智能是使基于 AI 的聊天机器人和虚拟助手成功的关键。例如,Google Assistant 和 Siri 仅对特定的查询和命令做出回应。它们无法像人类一样进行开放式对话,因为它们缺乏使其理解世界并自然互动的“通用”智能。
-
基于机器学习的应用程序。 你如何找到一辆出租车以到达你的目的地?你如何找到最佳的航班票价?这些问题将由机器学习算法回答,因为对这种应用程序的需求在日常生活中将会增加。
迈出成为自由职业 AI 工程师的下一步
如果你有软件工程/数据科学经验或高级 Python 知识,并希望转行到人工智能工程领域,UC San Diego Extension 机器学习工程师训练营可以帮助你发展必要的技能和经验。
你将配备一位行业导师,他将每周与你一对一见面。在为期 6 个月、100%在线的课程中,你将掌握获取工作所需的实际技能。通过 15+个迷你项目来增强技术概念的应用经验——还有一个用于展示的最终项目,可以展示在你的专业作品集中。
完成训练营后,你将能够部署机器学习算法并构建完整的机器学习应用程序,并将获得完成证书和 UCSD Extension 校友身份。
迈出成为机器学习工程师职业生涯的第一步,立即探索UC San Diego Extension 机器学习工程师训练营。有软件工程或数据科学经验者优先申请。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业之路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
相关更多内容
初学者的前 6 名数据科学项目
原文:
www.kdnuggets.com/2020/11/udacity-data-science-programs-beginners.html
赞助文章。
![Udacity Level Up]
Udacity](https://imp.i115008.net/c/2519466/827851/11298)是一个在线学习平台,致力于帮助你提升技术技能。我们的项目得到行业领导者的指导,并由在相关领域工作的专家教授。虽然所有课程都是自定进度和远程的,但学生仍能从真实世界的项目和实践讲师的评估中受益。我们的使命是培训未来职业的全球劳动力。
黑色星期五促销活动从 11 月 26 日凌晨 3 点(太平洋时间)开始,到 2020 年 12 月 3 日凌晨 2 点(太平洋时间)结束
全部课程 75%折扣。使用代码:BLACKFRIDAY75**
随着世界对大数据的关注越来越多,现在是进入数据科学领域的最佳时机。Udacity 拥有行业领先的数据科学项目。我们列出了初学者的六大数据科学课程,以帮助你入门。
1. 学习 SQL
各位产品经理、开发人员、商业分析师和数据库管理员!我们有适合你们的完美课程。
仅在两个月内,报名参加学习 SQL 纳米学位的学生将学习如何在大型数据库中创建和执行 SQL 和 NoSQL 查询,并分析结果以做出战略业务决策。
许多人认为理解 SQL 是任何处理数据的人必备的技能。如果这正是你,报名参加学习 SQL 纳米学位项目吧!
2. 数据科学编程与 Python
你是商业分析师或开发人员,想了解更多关于数据科学的内容吗?查看数据科学编程与 Python 纳米学位项目,通过学习数据的基本编程工具,包括 Python、SQL、命令行和 git,来启动你的数据科学职业生涯。
仅用三个月时间,你将完成三门课程,专注于使用 SQL 解决复杂的商业问题,学习 Python 编程语言的基础知识,了解数据分析的顶级库,并理解如何使用版本控制管理和共享你的工作。
从 Python 数据科学编程纳米学位课程毕业的学生将准备好开始数据科学或商业分析的职业生涯。今天注册 开始你的学习之旅。
3. 使用 R 进行数据科学编程
使用 R 进行数据科学编程的纳米学位 课程与数据科学编程的 Python 课程类似,只不过重点是学习如何用 R 进行编程和数据可视化,而不是 Python。和其他课程一样,这门课程也涵盖了 SQL 和版本控制(git)。
R 和 Python 之间最大的区别在于,R 更专门用于统计分析,而 Python 是一种更通用的编程语言。两者都是新兴数据科学家必须掌握的基础技能。
参加使用 R 进行数据科学编程的纳米学位 课程的学生适合担任统计学家、软件开发人员或数据科学家的职位。为何不立即开始你的新职业生涯?今天注册。
4. 数据可视化
你是否有一些基础的数据分析经验,但希望更进一步?数据可视化纳米学位 课程可以帮助你将职业生涯提升到一个新的水平。
数据可视化课程的学生学习如何构建可视化和仪表板,围绕数据编写叙述,以帮助清晰地向受众传达信息。使用 Tableau,学员学习如何理解用户需求,识别关键指标,定制仪表板,并彻底理解数据集。
仅仅四个月,数据分析师和业务领导者就能全面了解如何有效沟通数据。今天注册 为你的数据职业生涯加油。
5. 数据分析师
如果你已经有一定的编程经验——尤其是 Python 和 SQL——但想提高你对数据分析的理解,查看 数据分析师纳米学位 课程。
数据分析师纳米学位课程是技术要求较高的课程之一,涵盖了推论统计和概率、使用 Python 进行数据清理(程序化收集和准备数据)以及数据可视化分析。
在四个月内,数据分析师纳米学位课程将帮助你成为一名自信的技术前瞻型数据分析师。立即报名 以推动你的数据分析职业发展。
6. 数据工程师
你是对数据感兴趣的工程师吗?如果是,请查看 Udacity 的 数据工程师纳米学位 课程。这是提升你工程职业生涯的最佳方式。
数据工程师纳米学位课程的学生将学习设计数据模型、构建数据仓库、自动化数据管道以及处理大数据的基础知识。课程结束时,毕业生将理解如何创建大规模的生产级数据基础设施。
在五个月内,你不仅会理解数据建模、云数据仓库、数据湖和数据管道(以及相关的软件工具),还会完成一个真实世界的综合项目,丰富你的作品集。立即报名 以开始学习。
数据科学入门
准备好启动你的数据科学新职业了吗?现在是最佳时机。根据 LinkedIn 美国新兴职位报告,数据科学是持续以惊人速度增长的顶尖领域之一。
立即报名 参加我们六大初学者数据科学课程中的一个。你只需点击一下,即可开启全新职业生涯。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在的组织 IT 工作
相关主题
Udacity 纳米学位课程:机器学习、数据分析师等
原文:
www.kdnuggets.com/2016/06/udacity-nanodegree-programs-machine-learning-data-analyst.html

通过 Udacity 的纳米学位课程,您将构建和设计惊人的项目,向硅谷顶级公司的专家学习,并在技术领域找到梦想中的工作。
报名参加纳米学位课程,12 个月内毕业,还可以获得 50%的学费退款!
探索 Udacity 的纳米学位课程:
以及更多!
找工作或退还学费!
通过 Udacity 的 纳米学位 Plus 计划,您将在毕业后的 6 个月内找到工作,否则我们将全额退款。
Udacity 为以下课程提供纳米学位 Plus 选项:
推荐课程:机器学习工程师纳米学位项目

深入学习机器学习和人工智能的技能,获得未来机器人、交通和医疗等领域最热门的工作。你今天会建造什么?
该项目将教你如何成为机器学习工程师,并将预测模型应用于金融、医疗、教育等领域的大型数据集。
该纳米学位由谷歌共同创建。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
更多相关话题
从 Udemy 获得的顶级数据科学和机器学习课程 – 2018 年 5 月
原文:
www.kdnuggets.com/2018/05/udemy-top-data-science-machine-learning-courses.html
Udemy.com 是一个在线学习市场,他们的数据科学内容由创办了优秀课程(包含实用工具)并提供易于理解的课程的讲师定期更新。以下是 Udemy 上最受欢迎的数据科学和机器学习课程,母亲节期间优惠价仅为 $9.99(原价 90-95% 折扣),优惠有效期至 2018 年 5 月 14 日。
创建者:Kirill Eremenko,Hadelin de Ponteves,SuperDataScience 团队
对机器学习领域感兴趣吗?那这个课程适合你!
本课程由两位专业的数据科学家设计,以便分享他们的知识,帮助你以简单的方式学习复杂的理论、算法和编码库。
我们将一步一步带你进入机器学习的世界。通过每个教程,你将发展新技能,提升对这一具有挑战性但回报丰厚的数据科学子领域的理解。
现在以 $9.99 获取此课程,原价 $200 的 95% 折扣,优惠有效期至 2018 年 5 月 14 日。
创建者:Kirill Eremenko,SuperDataScience 团队
准备好投身其中,学习数据科学家每天面临的实际问题吗?数据科学管理顾问 Kirill Eremenko 将这门畅销的课程教授给超过 64,000 名学生。学习 SQL、SSIS、Tableau 和 Greti,以及数据挖掘、建模和 Tableau 可视化,为你在数据科学领域开启一段令人难以置信的职业生涯。
现在以 $9.99 获取此课程,原价 $200(有效期至 2018 年 5 月 14 日)

学习如何使用 NumPy、Pandas、Seaborn、Matplotlib、Plotly、Scikit-Learn、机器学习、Tensorflow 等!
由 Jose Portilla 创建
这个全面的课程可以与其他通常需花费数千美元的数据科学训练营相媲美,但现在你只需花费一小部分费用即可学习所有这些信息!课程包含超过 100 节高清讲座视频和每节讲座的详细代码笔记,是 Udemy 上最全面的数据科学和机器学习课程之一!
我们将教你如何使用 Python 编程,如何创建惊人的数据可视化,以及如何使用 Python 进行机器学习!
立即获取课程仅需$9.99,原价$195(有效期至 2018 年 5 月 14 日)
亲手操作神经网络、人工智能和雇主所需的机器学习技术!
由 Frank Kane 创建。
这个全面的课程可以与其他通常需花费数千美元的数据科学训练营相媲美,但现在你只需花费一小部分费用即可学习所有这些信息!课程包含超过 100 节高清讲座视频和每节讲座的详细代码笔记,是 Udemy 上最全面的数据科学和机器学习课程之一!
我们将教你如何使用 Python 编程,如何创建惊人的数据可视化,以及如何使用 Python 进行机器学习!
立即获取课程仅需$9.99,原价$160(有效期至 2018 年 5 月 14 日)

实战 AzureML:从 Azure 机器学习简介到高级机器学习算法。无需编码。
由 Jitesh Khurkhuriya 创建
Azure 机器学习(AzureML)被认为是一个游戏规则的改变者。Azure 机器学习工作室是一个很棒的工具,可以学习如何在不写一行代码的情况下,使用简单的拖放功能来构建高级模型。
本课程的设计考虑到了入门级数据科学家或没有编程或数据科学背景的人。这个课程还将帮助数据科学家学习 AzureML 工具。如果你已经熟悉机器学习的概念或基础,可以跳过一些初始讲座或以 2 倍速度播放。
课程非常实用,你将能够开发自己的高级模型。
立即以 $10.99 的优惠价格获取课程,原价 $100(至 2018 年 5 月 14 日)
选择 Udemy 的数据科学课程,开启更光明的未来,立即开始。要查看完整的 Udemy 课程选择,点击这里。
更多相关主题
终极数据科学免费课程合集
原文:
www.kdnuggets.com/ultimate-collection-of-50-free-courses-for-mastering-data-science

图片来源:作者
从免费课程中学习对那些希望进入数据科学领域的人非常有益。免费课程提供了许多优势,如成本效益、灵活性、获取最新工具和概念、向行业专家学习的机会、社区支持以及实践学习体验,而非填鸭式教育。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
在这个博客中,我的目标是通过提供一个全面的免费课程列表,帮助你提升数据科学技能,涵盖各种主题,包括 Python、SQL、数据分析、商业智能、数据工程、机器学习、深度学习、生成 AI 和 MLOps。
这些课程大多来自顶尖大学和平台,如 Coursera、麻省理工学院、加州大学戴维斯分校、FreeCodeCamp、谷歌、微软、IBM、哈佛大学和斯坦福大学。因此,从今天开始你的数据科学专业之旅吧!
注意: Coursera 课程可免费审阅,如果该选项不可用,你可以在试用期内完成课程或申请财政援助。
1. Python
Python 是数据科学中必不可少的编程语言。你将学习如何进行数据操作、分析、可视化和机器学习。它提供了丰富的库和框架,简化了复杂任务,使其成为数据科学家的热门选择。
-
初学者的 Python 由 Programming with Mosh 提供
-
面向每个人的 Python 由 freecodecamp 提供
-
中级 Python 编程 由 freecodecamp 提供
-
CS50’s Python 编程入门 由哈佛大学提供
-
Python 计算原理 由卡内基梅隆大学提供
2. 数据库和 SQL
SQL(结构化查询语言)是一种用于管理和操作关系数据库的查询语言,这对数据存储、检索和分析至关重要。
-
SQL 教程 - 初学者的完整数据库课程 由 freecodecamp 提供
-
学习 SQL 基础数据科学专业化 由 UC 戴维斯提供
-
NoSQL 与 SQL – 你应该使用哪种类型的数据库? 由 freecodecamp 提供
-
数据库系统入门 由卡内基梅隆大学提供
-
高级数据库系统 由卡内基梅隆大学提供
3. 数据分析
正如你可能知道的,数据分析是数据科学的一个关键方面,它帮助企业根据数据驱动的洞察做出明智的决策。这涉及使用各种工具和技术从数据中提取有意义的信息。
-
谷歌数据分析专业证书 由谷歌提供
-
针对 Excel 用户的 Python 数据分析 由 freecodecamp 提供
-
Python 数据分析认证 由 freecodecamp 提供
-
高级数据分析专业证书 由谷歌提供
-
数据分析师专业证书 由 IBM 提供
4. 一般数据科学
一般的数据科学课程涵盖广泛的主题,从数据操作到时间序列分析和数据建模。
-
9 个免费的哈佛数据科学课程 由哈佛大学提供
-
数据科学本科项目 由 OSSU 提供
-
数据可视化 由 Kaggle 提供
-
Python 数据科学入门 由哈佛大学提供
-
统计学习 由斯坦福大学提供
5. 商业智能
你可以使用像 Power BI 或 Tableau 这样的商业智能工具,将原始数据转化为可操作的洞察,从而帮助决策。你无需学习除 SQL 之外的其他编程语言。
-
Power BI 完整课程 由 edureka 提供
-
Tableau 数据科学 由 SimpleLearn 提供
-
用于商业智能的数据仓库 由科罗拉多大学提供
-
带证书的商业智能课程 由 SimpleLearn 提供
-
业务分析师路线图 2024 由 WsCube Tech 提供
6. 数据工程
数据工程是数据科学的一个子领域,涉及设计、构建和维护数据管道和基础设施。
-
数据工程 由 IBM 提供
-
数据工程师学习路径 由 Google 提供
-
数据库工程师职业证书 由 Meta 提供
-
大数据专业化 由加州大学圣迭戈分校提供
-
数据工程 Zoomcamp 由 DataTalks.Club 提供
7. 机器学习
机器学习是人工智能的一个分支,涉及创建能够从数据中学习并进行预测的算法。这是数据科学家必备的技能。
-
机器学习简介 由 Kaggle 提供
-
人人适用的机器学习 由 Kylie Ying 提供
-
用 Scikit-Learn 进行 Python 机器学习 由 FUN MOOC 提供
-
机器学习 Zoomcamp 由 DataTalksClub 提供
-
CS229:机器学习 由斯坦福大学提供
8. 深度学习
深度学习是机器学习的一个子集,专注于具有多层的神经网络。它广泛用于图像和语音识别、自然语言处理及其他复杂任务。
-
人工智能:AI 的全景 由 Pluralsight 提供
-
深度学习基础 由 Udemy 提供
-
理解深度学习的关键 由 MIT 提供
-
深度学习专业化 由 DeepLearning.AI 提供
-
初学者深度学习速成课程 由 freecodecamp 提供
9. 生成 AI
生成 AI 指的是通过分析从现有数据中学习到的模式和结构来创建新内容,如文本、图像和音频。在你的学习过程中,你将主要关注大型语言模型,以及如何训练、微调和部署它们。
-
初学者的生成 AI 由 Microsoft 提供
-
生产中的 LangChain 与向量数据库 由 Activeloop 提供
-
大型语言模型的生成 AI 由 AWS 提供
-
大型语言模型:从应用到生产 由 DataBricks 提供
-
大型语言模型课程 由 Maxime Labonne 提供
10. MLOps
MLOps 是机器学习操作的缩写,指的是自动化和简化机器学习模型的部署和管理的过程。目前,它是数据科学行业中最受欢迎的职业领域之一。
-
MLOps 的 Python 基础 由杜克大学提供
-
MLOps 入门 由 Udemy 提供
-
生产环境中的机器学习工程(MLOps)专项课程 由 DeepLearning.AI 提供
-
MLOps 集训营 由 DataTalks.Club 提供
-
Made With ML 由 Goku Mohandas 提供
结论
你不需要在 Google 上搜索以找到高质量的数据课程。你只需收藏此页面,开始你的 Python 和 SQL 之旅。几个月后,你将能够摄取、处理、分析和建模数据。之后,这将是一个持续的学习过程。如果你想被顶级招聘人员聘用,建议从一开始就在 GitHub 或其他平台上建立你的作品集。
查看关于 "5 个免费平台来建立强大的数据科学作品集" 的博客,了解其他平台及其提供的服务。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理健康问题的学生构建 AI 产品。
更多相关主题
数据科学家编程面试的终极指南
原文:
www.kdnuggets.com/2021/03/ultimate-guide-acing-coding-interviews-data-scientists.html
评论
由Emma Ding,Airbnb 的数据科学家和软件工程师,以及Rob Wang,Robinhood 的高级数据科学家撰写

图片由Christopher Gower提供,来源于Unsplash
介绍
我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业之路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
数据科学(DS)相较于软件工程和产品管理等技术行业的其他职位是一个相对较新的职业。最初,DS 面试中的编码环节很有限,仅包括 SQL 或使用 Python 或 R 进行的数据处理会话。然而近年来,DS 面试越来越强调计算机科学(CS)基础知识(数据结构、算法和编程最佳实践)。
对于希望进入数据科学领域的人来说,这种面试中越来越多的计算机科学内容可能会让人感到望而生畏。在这篇文章中,我们希望提高你对编程面试的理解,并教你如何准备。我们将对不同的编程问题进行分类,并提供破解这些问题的技巧,帮助你在面试中表现出色。如果你觉得我们可以在任何方面帮助你,让你的旅程更轻松,请联系我们!
为什么在数据科学面试中会有编程题?
编程面试究竟是什么?我们使用“编程面试”这一短语来指代任何涉及使用编程语言(而非 SQL 等查询语言)的技术会话。在当今市场上,几乎所有的数据科学职位都可能涉及编程面试。
为什么?编程是你数据科学职业中的重要部分。以下是三个原因:
-
数据科学是一个技术性强的领域。大部分数据科学工作的内容涉及将数据收集、清洗和处理成可用格式。因此,基本的编程能力是必不可少的。
-
许多现实世界的数据科学项目高度协作,涉及多个利益相关者。具备更强基本计算机科学技能的数据科学家将更容易与工程师和其他合作伙伴紧密合作。
-
在许多公司中,数据科学家负责交付生产代码,如数据管道和机器学习模型。强大的编程技能对于这类项目至关重要。
总结来说,强大的编码技能在许多数据科学职位中是必需的。如果你不能在编码面试中展示这些技能,你将无法获得工作。
可能会有编码面试的角色
当然,所需的编码水平会因职位而异。如果你对了解不同数据科学角色之间的差异感兴趣,可以查看 这个 YouTube 视频。如果你正在寻找任何以下类别的数据科学家角色,遇到编码面试的机会非常高:
-
重机器学习(ML)或建模重点的数据科学家角色:对于这类角色,期望候选人能够独立工作或与工程师紧密合作,将机器学习、统计或优化模型投入生产。这些角色虽然称为“数据科学家”,但更类似于“机器学习工程师”或“研究科学家”的角色。例如,Facebook 的核心数据科学、Airbnb 和 Lyft 的数据科学家——算法等职位。
-
数据科学家属于工程组织的公司:对于这样的职位,一般期望每位数据科学家具备足够的编程能力。Robinhood 的数据科学家职位就是这种角色的例子。
-
小型到中型科技公司的数据科学家角色:这类公司的环境往往节奏快速,数据科学家可能需要扮演多个角色。特别是,他们需要展示全栈技能,以便快速高效地完成任务。
相比之下,如果你正在面试一个以产品分析为重点的数据科学家角色,那么遇到编码问题的可能性较低。这些角色的面试通常不会超出 SQL 熟练度的评估,但一般编程技能可能仍会不时被测试。没有基本编码知识的候选人在面试中可能会感到措手不及,从而可能无法继续下一步。不要让这种情况发生在你身上!确保做好准备。你可以通过了解编码面试的预期来开始准备。
何时期待编码面试?
编码面试可以出现在技术电话筛选(TPS)、现场面试或两者都有。现场部分可能会有多轮编码面试,具体取决于预期的编码熟练程度。通常,你应该在整体 DS 面试环节的至少一个阶段中期待编码面试。
在 TPS 期间,编码面试通常通过在线集成开发环境(IDE),如 CoderPad、HackerRank 和 CodeSignal 进行。在现场面试中,可以使用在线 IDE 或白板。在当前的远程面试环境中,默认使用前者。
编码会话的时长从 45 分钟到 1 小时不等,通常涉及一个或多个问题。语言选择通常是灵活的,但大多数候选人会选择 Python,因为其简洁。
编码面试的不同类别
根据我们与多个大型和中型公司(如 Airbnb、亚马逊、Facebook、Intuit、Lyft、Robinhood、Slack、Snapchat、Square、Stitch Fix、Twitter、Upstart 等)的面试经验,我们将编码问题分类为以下四种类型。
基本数据结构
这类问题旨在评估候选人在计算机科学基础知识方面的熟练程度。这些基础主题可以包括但不限于:
-
数据结构:数组、哈希表/字典、堆、集合、栈/队列、字符串和树/二叉树。
-
算法:二分查找、递归、排序和动态编程。
一些额外的话题,如链表和图(深度优先搜索或广度优先搜索),在这种类型的面试中出现的可能性较小。
通常,会对一个场景提出多个问题,从简单到困难。每个问题可能涉及一个独特的数据结构或算法。以下是一个经典问题的示例,围绕找到一组数字的中位数展开:
-
第一部分:使用任何方法找出中位数。候选人可以使用内置排序函数,排序后直接返回中位数。
-
第二部分:面试官现在要求提供更优化的中位数查找版本。在这种情况下,了解常见算法,如quickselect,将会很有帮助。
-
第三部分:最后,问题变为“流式”中位数计算版本,这意味着数据以在线方式而不是固定的数字列表形式出现。在这种情况下,候选人可能会使用堆(稍微更具挑战性)。
这类问题也可能以应用商业问题的形式出现。对于这类问题,候选人需要编写解决方案来应对一个假设的应用问题,这通常与公司的商业模式相关。这些问题的难度级别通常为简单到中等(基于 Leetcode 的分类)。关键在于理解业务场景和具体要求,然后再编写代码。
数学和统计
这些问题将要求具备本科级别的数学和统计知识,此外还需具备编程能力。一些最常见的概念包括:
-
模拟:蒙特卡罗模拟、加权抽样、模拟马尔可夫链等。
-
素数/可除性:涉及自然数可除性的计算,求两个自然数最大公约数的欧几里得算法等。
一些常见的问题包括:
-
使用模拟估算 π 的值。
-
列举所有不超过给定自然数 N 的素数。
-
使用均匀随机数模拟多项分布。
机器学习算法

照片由Hitesh Choudhary拍摄,发布在Unsplash上。
这类问题涉及从头编写一个基本的机器学习算法。除了通用的编程能力外,面试官还会评估候选人的应用机器学习知识。你需要熟悉常见的机器学习模型家族以回答这些问题。
这是在编程面试中最常见的模型家族列表:
-
监督学习:决策树、线性回归和逻辑回归(使用随机梯度下降),以及 K 最近邻。
-
无监督学习:K 均值聚类。
其他模型家族,如支持向量机、梯度提升树和朴素贝叶斯,出现的可能性较小。你也不太可能被要求从头编写深度学习算法。
数据处理
这种类型的问题不像其他类型那样常见。它们要求候选人在不使用 SQL 或任何数据分析库(如pandas)的情况下进行数据处理和转换。相反,候选人只能使用所选编程语言来解决问题。一些常见的例子包括:
-
将两个数据集表示为字典,并在某些给定的键值上将它们连接起来。
-
给定一个表示 JSON 数据块的字典字典,通过一些基本的解析来提取特定的条目。
-
编写一个类似于 R 的 tidyr 包中的“spread”或“gather”函数的函数,并使用数据集进行测试。
-
计算 30 天滚动利润。
-
解析事件日志并按天/月/年返回唯一字符串的数量。
了解你可以预期到这四种类型的问题将有助于你系统地准备。在下一节中,我们将分享如何具体做到这一点的一些技巧。
如何准备?
这些问题类型的清单初看可能会让人感到气馁,但不要灰心或感到不知所措!如果你对基础计算机科学知识和机器学习算法有很好的掌握,并且花时间准备(我们将在本节中教你如何准备),那么你将能够在编码面试中表现出色。
为了准备不同类别的编码问题,我们推荐以下策略:
温故基础知识:
对于上述四大主要问题主题中的每一个,首先要复习基础知识。这些描述可以在各种在线资源和书籍中找到。具体而言:
-
数据结构(通常面向软件工程师): 编程面试破解 由 Gayle Laakmann McDowell 编著和 最佳 Python 书籍
-
机器学习: 介绍 Facebook 机器学习视频系列 和 统计学习的元素 由 Jerome H. Friedman, Robert Tibshirani 和 Trevor Hastie 编著。
-
数学和统计: brilliant.org — 是 Facebook 现场面试准备指南中推荐的材料之一。
分类问题:
一旦你对基础知识相对熟悉,就可以扩展你的复习范围,涵盖更多常见的问题集。你可以在Leetcode、GeeksForGeeks和GlassDoor上找到这些问题。你可以将问题陈述以有序的方式保存,理想情况下使用 Notion 或 Jupyter notebooks 等工具按主题分组。对于每一个主题,练习大量简单问题和少量中等难度问题。花时间创建一个分类的编码问题集合不仅对你当前的求职有帮助,而且对未来的求职也会有用。
比较多种解决方案:
仅依赖死记硬背是不足以通过面试的。为了获得更全面的理解,我们建议对同一个问题提出多个解决方案,并比较不同方法的优缺点(例如,运行时间/存储复杂性)。
向他人解释:
为了加深理解,使用简单的英语向非技术人员解释你的解决方案/方法。对常见问题解决方法的高级理解往往比详细实现更有价值,并且对将现有知识适应到新的和陌生的环境中尤其有帮助。
模拟面试:
与同事一起进行模拟面试,或自行进行。你可以使用在线编码平台,如 Leetcode,在有限的时间窗口内解决实际面试问题。
运用这些准备技巧,你将不仅拥有更多的知识,还会更加自信地进入面试!
如何进行评估?
你在面试中想要展示的主要有 4 种素质。
逻辑推理:
面试官希望看到候选人能够将提供的信息与最终答案之间建立逻辑联系。因此,你应该清晰地描述计算所需的内容以及你将如何编写代码来解决问题,然后再进入实际编码。
沟通:
你的沟通效果非常重要。在编码之前,清晰地传达你的思路。如果面试官在面试过程中任何时候提问,你需要能够解释你假设和选择的理由。
代码质量和最佳实践:
面试官还会评估你的整体代码质量。尽管数据结构面试中的标准期望可能不会像软件工程面试那样高,但候选人仍应关注以下几个方面:
-
代码是否可以执行且没有任何语法错误。
-
清晰和简洁。
-
解决方案在运行时间/存储效率方面是否经过优化。
-
一般编码最佳实践,例如模块化、处理边界情况、命名规范等。
熟练程度:
就像软件工程编码面试一样,数据结构编码面试中也可能会有多个部分的问题,有时甚至是多个问题。换句话说,速度也很重要。在有限的时间内能够解决更多的问题是整体熟练程度的一个标志。
提升编码面试成功的技巧
在面试前,最好与招聘人员确认会问哪些类型的编程问题,以及大致的难度水平。很多数据科学面试不需要重度编程,但这并不意味着面试官不会期望你掌握基本的编码能力。始终向招聘人员询问预期内容。如果你对面试中可能出现的问题类型做出错误的假设,可能会导致准备不足。
在面试过程中,使用这些技巧来有效回答编程问题。
-
在开始编码之前:明确问题及其潜在假设。沟通是关键。一个在过程中需要一些帮助但沟通清晰的候选人,可能比一个轻松完成问题的候选人更好。此外,在开始实际实现之前,向面试官解释整体方法。
-
编写代码时:从一个简单的暴力解法开始,然后再进行优化。大声思考。说出你认为可能(或可能不会)有效的东西。你可能会很快发现某些方法确实有效,或者其修改版本有效。如果在某个部分卡住了超过几分钟,询问面试官适度提示是可以的。
-
编码完成后:如果没有提供测试用例,你应该提出几个正常情况和边界情况。用示例输入大声讲解你的解决方案。这将帮助你找到错误,并澄清面试官可能对你做的事情的任何困惑。
最终思考
编程面试,如同其他技术面试,需要系统性和有效的准备。希望我们的文章能为你提供一些有关数据科学职位编程面试的预期以及如何准备的见解。记住:提升你的编码技能不仅能帮助你获得理想的工作,也能帮助你在工作中表现出色!
感谢阅读!
-
如果你在这篇文章中学到了新东西,请点赞!这将激励我们写更多的内容来帮助更多的人!
-
订阅 Emma 的YouTube 频道!
Emma Ding 是 Airbnb 的数据科学家兼软件工程师。
Rob Wang 是 Robinhood 的高级数据科学家。
原文。经许可转载。
相关:
-
我如何在被解雇两个月后获得 4 个数据科学职位,并将收入翻倍
-
如何获得数据科学面试机会:寻找工作、联系门卫和获取推荐
-
你应该了解的 10 个统计学概念,以备数据科学面试之需
更多相关主题
你的终极指南:Chat GPT 和其他缩写
原文:
www.kdnuggets.com/2023/06/ultimate-guide-chat-gpt-abbreviations.html
所有这些缩写 - ML、AI、AGI - 代表什么?
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT。
ML(机器学习)是一种解决复杂计算问题的方法——与其使用编程语言编码,不如构建一个从数据样本中“学习”解决方案的算法。
AI(人工智能)是计算机科学的一个领域,处理一些传统编程难以解决的问题(例如图像分类、处理人类语言)。ML 和 AI 是相辅相成的,ML 是解决 AI 中提出问题的工具。
AGI(人工通用智能)——是流行文化中通常所指的 AI 的正确术语——计算机实现类人智力能力和广泛推理的能力。它仍然是 AI 领域研究人员的终极目标。
神经网络是什么?
人工神经网络(ANN)是一类机器学习算法和数据结构(或简称模型),因其受到生物神经组织结构的启发而得名。但这并没有完全模拟其背后的所有生物机制。相反,ANN 是复杂的数学函数,基于生物学中的概念。
当我看到“模型有 20 亿个参数”时,这是什么意思?
神经网络是由统一单元组成的分层结构,这些单元在网络中相互连接。这些单元的连接方式称为架构。每个连接都有一个称为权重的相关数字,权重存储模型从数据中学习到的信息。因此,当你看到“模型有 20 亿个参数”时,这意味着模型中有 20 亿个连接(及权重),大致表示神经网络的信息容量。
深度学习是什么意思?
神经网络自 1980 年代以来一直在研究,但真正产生影响的是计算机游戏行业引入了便宜的个人超级计算机,即图形处理单元(GPUs)。研究人员将这一硬件适配到神经网络训练过程中,并取得了令人瞩目的成果。第一个深度学习架构之一,卷积神经网络(CNN),能够进行复杂的图像识别,这在传统的计算机视觉算法中是困难的。从那时起,带有神经网络的机器学习被重新命名为深度学习,“深度”指的是网络能够探索的复杂神经网络架构。
我在哪里可以获得更多关于这项技术如何工作的细节?
我推荐 Grant Sanderson 的视频,您可以在他的动画数学频道上观看。
大型语言模型(Large Language Model)是什么意思?
要在计算机上处理人类语言,语言必须用数学方式定义。这种方法应该足够通用,以涵盖每种语言的独特特征。2003 年,研究人员发现了如何用神经网络表示语言,并称之为神经概率语言模型(neural probabilistic language model)或简称为 LM。这就像手机中的预测文本——给定一些初始的单词(或标记)序列,模型可以预测下一个可能的单词及其相应的概率。继续使用先前生成的单词作为输入(这就是自回归)——模型可以生成其训练语言中的文本。
当我阅读语言模型时,我经常遇到“变换器”这个术语。这是什么?
对于神经网络来说,表示项序列是一个具有挑战性的问题。有几个尝试解决该问题的方法(主要是围绕递归神经网络的变体),产生了一些重要的思想(例如,词嵌入、编码器-解码器架构和注意力机制)。2017 年,谷歌的研究团队提出了一种新的神经网络架构,称为变换器。它将所有这些思想与有效的实际实现结合在一起。它旨在解决语言翻译问题(因此得名),但证明对于捕捉任何序列数据的统计特性也很有效。
为什么大家都在谈论 OpenAI?
OpenAI 尝试使用变换器(transformer)构建神经概率语言模型。他们实验的结果被称为 GPT(生成预训练变换器)模型。预训练意味着他们在大量互联网文本上训练了变换器神经网络,然后使用其解码器部分进行语言表示和文本生成。GPT 模型有多个版本:
-
GPT-1:一个初步实验模型,用于验证这种方法。
-
GPT-2:展示了生成连贯人类语言文本的能力和零样本学习——将其推广到从未特别训练过的领域(例如语言翻译和文本摘要,仅举几例)的能力。
-
GPT-3 是对架构的扩展(GPT-2 的 15 亿参数与最大 GPT-3 的 1750 亿参数),并在更大且多样的文本体上进行训练。其最重要的特点是能够通过仅仅看到几个示例来生成各种领域的文本(因此称为少样本学习),而无需任何特殊的微调或预训练。
-
GPT-4:一个更大的模型(具体特征未公开)、更大的训练数据集,以及多模态性(文本与图像数据相结合)。
考虑到 GPT 模型拥有巨大的参数量(实际上,你需要一个由数百到数千个 GPU 组成的大型计算集群来训练和服务这些模型),它们被称为大型 语言模型(LLMs)。
GPT-3 和 ChatGPT 有什么区别?
原始的 GPT-3 仍然是一个词预测引擎,因此主要对 AI 研究人员和计算语言学家感兴趣。给定一些初始的种子或提示,它可以无限生成文本,这在实际应用中意义不大。OpenAI 团队继续对模型进行实验,尝试微调以将提示视为需要执行的指令。他们输入了大量由人类策划的对话数据集,并发明了一种新的方法(RLHF – 基于人类反馈的强化学习),通过另一个神经网络作为验证代理(在 AI 研究中很常见)显著加快了这一过程。他们发布了一个名为InstructGPT的 MVP 版本,基于较小的 GPT-3 版本,并于 2022 年 11 月发布了一个功能齐全的版本,称为 ChatGPT。凭借其简单的聊天机器人和网页界面,它改变了 IT 世界。
什么是语言模型对齐问题?
由于 LLM 只是复杂的统计机器,因此生成过程可能会出现意想不到且不愉快的方向。这种结果有时被称为AI 幻觉,但从算法的角度来看,尽管对人类用户来说是意外的,但它仍然是有效的。
如前所述,原始 LLM 需要进行处理和额外的微调,包括人工验证者和 RLHF。这是为了使 LLM 符合人类的期望,不足为奇的是,这个过程本身被称为对齐。这是一个漫长而繁琐的过程,涉及大量的人力工作;这可以被视为 LLM 质量保证。模型的对齐是区分 OpenAI/Microsoft ChatGPT 和 GPT-4 与其开源对手的关键因素。
为什么会有停止进一步开发语言模型的运动?
神经网络是 黑箱(一个具有某种结构的大量数字)。虽然有一些方法可以探索和调试它们的内部结构,但 GPTs 的 泛化 特性仍未得到解释。这是禁止运动的主要原因——一些研究人员认为我们在玩火(科幻小说给我们提供了有关 AGI 诞生和 技术奇点 的迷人情景),在我们对 LLMs 的基本过程有更好理解之前。
LLMs 的实际应用场景有哪些?
最受欢迎的包括:
-
大型文本总结
-
反之亦然 - 从总结生成文本
-
文本风格(模仿作者或角色)
-
用作个人导师
-
解决数学/科学练习题
-
回答文本中的问题
-
从简短描述生成编程代码
现在 GPT 是唯一的 LLM 吗?
GPTs 是最成熟的模型,通过 OpenAI 和 Microsoft Azure OpenAI 服务(如果需要私人订阅)提供 API 访问。但这是人工智能的前沿,自 ChatGPT 发布以来,许多有趣的事情发生了。Google 构建了 PaLM-2 模型;Meta 为研究人员开源了他们的 LLaMA 模型,这激发了许多调整和改进(例如,斯坦福的 Alpaca)和优化(现在你可以在你的 laptop 甚至 smartphone 上运行 LLMs)。
Huggingface 提供了 BLOOM 和 StarCoder 以及 HuggingChat —— 这些都是完全开源的,没有 LLaMA 仅限研究的限制。Databricks 训练了他们自己完全开源的 Dolly 模型。Lmsys.org 提供了他们自己的 Vicuna LLM。Nvidia 的深度学习研究团队正在开发其 Megatron-LM 模型。 GPT4All 计划也值得一提。
然而,所有这些开源替代品仍然落后于 OpenAI 的主要技术(特别是在对齐方面),但差距正在迅速缩小。
我该如何使用这些技术?
最简单的方法是使用 OpenAI 的 public service 或他们的平台 API playground,它提供了对模型的低级访问权限,并对网络内部运作有更多控制(指定系统上下文、调整生成参数等)。但你应该仔细审查他们的服务协议,因为他们使用用户交互来进行额外的模型改进和训练。作为替代方案,你可以选择 Microsoft Azure OpenAI 服务,它提供相同的 API 和工具,但具有私人模型实例。
如果你更具冒险精神,你可以尝试 HuggingFace 托管的 LLM 模型,但你需要更熟练地使用 Python 和数据科学工具。
Denis Shipilov 是一位经验丰富的解决方案架构师,拥有从分布式系统设计到大数据和数据科学相关项目的广泛专业知识。
更多相关话题
数据工程师面试的终极指南
原文:
www.kdnuggets.com/2020/12/ultimate-guide-data-engineer-interviews.html
评论
作者 Xinran Waibel,Netflix 数据工程师。

我们的前三个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业生涯。
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你的组织的 IT
照片由 Christin Hume 提供,来自 Unsplash。
尽管数据工程师(DE)是 2019 年增长最快的科技职位,但关于数据工程师面试的期望和准备的在线资源并不多。
在过去一年中,我为几家湾区的科技公司进行了数据工程师角色的面试,并帮助许多联系的成功通过了面试。在这篇博客文章中,我将解释数据工程师面试中最重要的技术话题:你的简历、编程、SQL 和系统设计。我还将教你如何准备面试的非技术部分,我认为这对成功的面试至关重要,但往往被候选人忽视。
然而,我不会讨论任何公司的数据工程师面试中提出的具体问题,因为这篇博客文章旨在作为一个通用指南,帮助你理解成为成功数据工程师所需的基本技能。
简历
你的简历不仅是引起招聘人员和招聘经理注意的垫脚石,也是你应准备好与面试官深入讨论的项目列表,以展示你的技能,包括技术能力、问题解决、团队合作、沟通和项目管理。
我在简历深度探讨环节中看到的最常见错误是,仅关注技术实现细节,而没有解释或理解系统设计中的权衡(例如,“我使用了 Kafka,因为我的经理告诉我这么做”)以及项目的整体情况。请记住,面试官不了解你以前公司的业务问题和数据基础设施,因此你需要提供足够的背景信息,帮助他们理解你的项目的技术复杂性和影响。因此,一个优秀的项目深度探讨的关键是从头到尾全面描绘你的项目,就像讲故事一样!
我强烈建议你练习讲述你最重要的数据项目(如果可能的话,找一个有工程背景的人),并确保在你的故事中回答这些问题:
-
项目的动机是什么?(即,你的项目试图解决什么数据/业务问题?)
-
你与哪些团队合作过?你是如何与他们一起工作的?
-
如果你是项目负责人,你是如何规划和推动它的?
-
系统设计中的技术权衡是什么?(即,为什么你选择了框架 X 而不是其他替代方案?)
-
你的项目的一些技术统计数据是什么?(例如,你的数据管道的吞吐量和延迟是多少?)
-
项目的影响是什么?(例如,它产生了多少收入?有多少人使用了你的应用程序?)
-
你遇到了哪些挑战?你是如何解决它们的?
数字在讲述一个伟大的项目故事中是非常重要的。与其只是说“它处理了大量数据……”,不如查找你项目的一些统计数据,并将它们包括在你的简历中。数字将展示项目的规模、影响以及你对项目的深入理解。它们还会让你的项目更具可信度。(实际上,面试官可能会觉得如果你连你的应用程序能处理多少数据都不知道,那是可疑的。)

编程
好的。这是所有软件工程面试中最不愉快的部分:编码面试,在这里你需要用最有效的数据结构,在最少的代码行数中实现复杂的算法(这些算法你可能在工作中永远不会用到),并解释你的代码的时间和空间复杂度,所有这些都在 30 分钟内完成。
数据工程师岗位的编码面试通常在算法方面较轻,但在数据方面较重,面试问题通常更具实用性。例如,编写一个函数来转换输入数据并生成所需的输出数据。你仍然需要使用最优的数据结构和算法,并优雅地处理所有潜在的数据问题。由于数据工程师在实际工作中不仅使用内置库处理数据,编码面试也可能要求你使用流行的开源库,如 Spark 和 pandas。面试期间一般允许查阅文档(如有需要)。如果工作要求精通特定框架,请准备在编码面试中使用这些框架。
面试中的编码比工作中的编码要困难得多,因为你需要在非常短的时间内产出最佳代码行。(我知道面试时脑袋一片空白的感觉有多可怕。)我强烈建议在 LeetCode 或 HackerRank 等编程网站上练习一些(但不要过多)编码题目,并熟悉在 CoderPad 上编写代码。
数据工程师岗位需要学习哪些编程语言和框架?请查看这篇 博客文章。
SQL, SQL, SQL
SQL 是数据工程师非常关键的技能,因此我需要为它单独设置一个部分(而且 SQL 并不是真正的编程语言)。事实上,除了编码面试外,进行 SQL 面试也非常常见。由于数据工程师负责构建可靠且可扩展的数据处理和数据建模解决方案,你应该在 SQL 上比数据分析师和数据科学家(他们主要使用 SQL 查询生产数据)更有造诣,因此你需要了解的远不止“SELECT…FROM…”。
“什么?SQL 不就是查询语言吗?我还需要了解 SQL 的其他内容吗?”
首先,SQL 不仅仅是查询语言。它还是许多大数据框架(如 SparkSQL、pandas、KafkaSQL 等)共享的数据处理模式。因此,精通 SQL 也表明你可以高效地学习和使用这些框架。
一位优秀的数据工程师应该能够将复杂的业务问题转化为 SQL 查询和数据模型,并具有良好的性能。为了编写高效的查询,处理尽可能少的数据,你需要了解查询引擎和优化器的工作原理。例如,有时使用 CASE 语句结合聚合函数可以替代 JOIN 和 UNION,并处理更少的数据。
想了解所有的数据库魔法,可以查看 《数据库管理系统》 和 《NoSQL 初学者指南》!
数据模型对查询结构有很大影响。例如,尽量利用表分区和索引。但数据模型也在很大程度上依赖于查询模式。为了设计一个好的数据模型,你需要将业务问题转化为最终用户将对你的表运行的 SQL 查询。这就是为什么 SQL 和数据建模面试通常并行进行。(我将在下一节详细讨论数据建模。)
如何准备 SQL 编程面试?查看这篇 博客文章。
系统设计
系统设计是数据工程技术面试中最重要且最困难的部分。在系统设计面试中,你需要从头到尾设计一个数据解决方案,这通常由三个部分组成:数据存储、数据处理和数据建模。
初始面试问题通常非常简短和抽象(例如,从头到尾设计一个数据仓库),你的任务是提出后续问题以明确需求和用例,就像解决现实生活中的数据问题一样。系统设计的主要挑战是根据这些需求和用例选择最佳的数据存储系统和数据处理框架组合,有时可能有多个最佳解决方案。成功的系统设计面试的关键是理解数据工程中的关键原则和概念,以及各种数据系统和框架的权衡。 《设计数据密集型应用》 是建立数据系统设计坚实基础的必读书籍。
数据建模通常是系统设计面试的最后一个环节,但有时它也可能是 SQL 面试的一部分。数据建模面试问题的一个例子是为兽医诊所的预约系统设计后端分析表。数据建模中最重要的原则是根据用例和查询模式设计数据模型。再次强调,你需要澄清需求和用例,以便做出更好的设计选择。
如果你对深入学习数据建模感兴趣,查看 数据仓库工具包,这是 Ralph Kimball 编写的关于数据仓库的经典之作。

照片由 Christina @ wocintechchat.com 在 Unsplash上提供。
你(即最重要的部分)
既然我们已经覆盖了数据工程面试中的所有技术话题,接下来我们来谈谈非技术部分。面试不仅仅是考试,你需要正确的答案才能通过,而是一系列对话,目的是看看你是否能够快速学习并与团队一起解决问题。因此,在面试中做自己、保持人性是非常重要的:
-
友善。没有人愿意与讨厌的人一起工作。
-
进行对话。最好的面试通常就像对话。如果你想获取信息或反馈,可以提出问题。
-
解决问题,而不仅仅是回答。就像在现实生活中一样,你不总是能立即知道问题的正确答案。展示你如何解决问题比仅仅给出答案更重要。
-
展示你对数据工程的热情。你在工作职责之外做了什么来成为更好的数据工程师?
当面试官在面试你时,你也在面试他们。你会喜欢与他们一起工作吗?这个团队是否提供了成长的机会?你是否同意经理的观点和管理风格?找到一个好的团队是困难的,所以请明智地提问。
所有的压力
面试是非常有压力的。这是一个不完美的过程,陌生人仅仅基于与你的一个小时互动来判断你的专业能力,有时面试结果也不公平。当你无法继续解答面试问题时,感觉面试官在看不起你,会很沮丧。反复被拒绝可能会严重打击你的自尊心,你可能开始怀疑自己是否足够好。我也经历过:大多数工作申请没有回复,所有能拿到的编码面试都失败了。我曾以为自己永远无法成为工程师。但我很高兴我没有放弃。
如果你因为面试感到不知所措、沮丧或绝望,我想告诉你,你并不孤单。如果你被拒绝了,那是他们的损失。对自己保持耐心并保持希望,因为情况会变得更好,你只需要不断尝试!始终以自信的态度参加面试,因为你足够优秀!
原文。经许可转载。
简介: Xinran Waibel是旧金山湾区的一名经验丰富的数据工程师,目前在 Netflix 工作。她还是《Towards Data Science》、《Google Cloud》和《The Startup on Medium》的技术撰稿人。
相关信息:
更多相关内容
模型重训练终极指南
原文:
www.kdnuggets.com/2019/12/ultimate-guide-model-retraining.html
评论
由Luigi Patruno,数据科学家及“ML in Production”创始人。

机器学习模型通过学习一组输入特征与输出目标之间的映射来进行训练。通常,这个映射是通过优化某个成本函数来最小化预测误差而学习到的。一旦找到最优模型,它就会被投入使用,目标是对未来未见数据生成准确的预测。根据问题的不同,这些新数据示例可能来自用户交互、计划的处理过程或其他软件系统的请求。理想情况下,我们希望我们的模型对这些未来实例的预测与训练过程中使用的数据一样准确。
当我们将模型部署到生产环境中并期望观察到与模型评估期间相似的错误率时,我们假设未来的数据将类似于过去观察到的数据。具体来说,我们假设特征和目标的分布将保持相对稳定。但这种假设通常并不成立。趋势会随时间变化,人们的兴趣随季节变化,股市也会涨落。因此,我们的模型必须适应这些变化。
由于我们预期世界会随着时间变化,模型部署应被视为一个持续的过程。机器学习从业者需要重新训练他们的模型,如果发现数据分布与原始训练集有显著偏离的话,而不是仅仅部署一个模型后转向另一个项目。这个概念被称为模型漂移,可以通过额外的监控基础设施、监督和流程来缓解,但也涉及到额外的开销。
在这篇文章中,我将定义模型漂移并讨论识别和跟踪模型漂移的策略。我将描述如何使用模型重训练来缓解漂移对预测性能的影响,并建议模型应该多频繁地进行重训练。最后,我将提到几种启用模型重训练的方法。
什么是模型漂移?
模型漂移是指由于环境变化违背了模型的假设,导致模型的预测性能随着时间的推移而下降。模型漂移这个术语有些误导,因为变化的不是模型,而是模型操作的环境。因此,概念漂移可能更适合这个名称,但这两个术语描述的是相同的现象。
注意,我对模型漂移的定义实际上包括几个可以变化的变量。预测性能会退化,它会在一段时间内以某种速率退化,这种退化将由于违反建模假设的环境变化。确定如何诊断模型漂移以及如何通过模型再训练进行纠正时,应该考虑这些变量。
你如何跟踪模型漂移?
有多种技术可以识别和跟踪模型漂移。在描述一些策略之前,让我指出没有一种通用的方法。不同的建模问题需要不同的解决方案,而且你可能有或没有基础设施或资源来利用某些策略。
模型性能退化
识别模型漂移的最直接方法是明确确定预测性能是否恶化并量化这种下降。在实时数据上测量已部署模型的准确性是一个臭名昭著的难题。这种困难部分是因为我们需要同时访问模型生成的预测和真实标签。由于多种原因,这可能是不可能的,包括:
-
预测在生成后未被存储。不要让这种情况发生在你身上。
-
预测被存储了,但你无法访问真实标签。
-
预测和标签都是可用的,但不能将它们结合在一起。
即使预测和标签可以结合在一起,标签可能还要一段时间才能获得。考虑一个预测下季度收入的财务预测模型。在这种情况下,实际收入要等到该季度结束后才能观察到,因此你不能在那时之前量化模型的表现。在这种预测问题中,回填预测,即训练过去本该部署的模型并在过去的历史数据上生成预测,可以让你了解模型性能下降的速度。
正如 Josh Wills 指出的,在部署模型之前你能做的最重要的事情之一是尝试在离线环境中理解模型漂移。数据科学家应该努力回答这个问题:“如果我使用这组特征对六个月前的数据训练一个模型,并将其应用于今天生成的数据,这个模型比我之前从一个月前的数据中训练出来的模型在今天的数据上表现更差多少?”在离线环境中进行这种分析可以让你估计模型性能下降的速度以及你需要重新训练的频率。当然,这种方法以拥有一个 时间机器 为前提,以便访问过去任何时间点的数据。
检查训练数据和实时数据的特征分布
由于模型性能预期会随着输入特征的分布偏离训练数据的分布而下降,因此比较这些分布是推测模型漂移的好方法。请注意,我使用了 推测 而不是 检测 模型漂移,因为我们不是观察到预测性能的实际下降,而是预期会发生这种下降。这在由于数据生成过程的性质无法观察实际的真实情况时非常有用。
每个特征有许多不同的监控项目,包括:
-
可能值的范围
-
值的直方图
-
特征是否接受 NULL 值,如果接受,预计有多少 NULL 值
能够通过 仪表盘 快速监控这些分布是朝着正确方向迈出的第一步。进一步的做法是自动跟踪训练和服务偏差,并在特征的偏离显著时发出警报。
检查特征之间的相关性
许多模型假设特征之间的关系必须保持不变。因此,你还需要监控单独输入特征之间的成对相关性。如 《你的 ML 测试评分是什么?ML 生产系统的评分标准》 中提到的,你可以通过以下方式实现:
-
监控特征之间的相关系数
-
使用一个或两个特征训练模型
-
训练一组模型,每个模型移除一个特征
检查目标分布
如果目标变量的分布发生显著变化,模型的预测性能几乎肯定会恶化。Machine Learning: The High-Interest Credit Card of Technical Debt 的作者指出,一个简单而有用的诊断方法是跟踪目标分布。该指标与训练数据的偏差可能意味着是时候重新评估你部署的模型的质量了。但请记住,“这绝不是一个全面的测试,因为它可以被一个简单预测标签发生平均值的空模型所满足,而不考虑输入特征。”
我们所说的模型再训练究竟是什么意思?
有时,模型再训练似乎是一个重载运算符。这是否仅指寻找现有模型架构的新参数?改变超参数搜索空间呢?不同模型类型(如 RandomForest、SVMs 等)的搜索呢?我们能否包括新的特征或排除以前使用的特征?这些都是很好的问题,明确这些非常重要。要回答这些问题,我们必须直接思考我们试图解决的问题。也就是说,减少模型漂移对我们部署模型的影响。
在将模型部署到生产环境之前,数据科学家会经过一个严格的模型验证过程,包括:
-
数据集组装 – 从不同来源(如不同的数据库)收集数据集。
-
特征工程 – 从原始数据中提取能提高预测性能的列。
-
模型选择 – 比较不同的学习算法。
-
错误估计 – 在搜索空间中进行优化,以找到最佳模型并估计其泛化误差。
这个过程会产生一些最佳模型,然后将其部署到生产环境中。由于模型漂移特别指选择的模型由于特征/目标数据的分布变化而导致的预测性能退化,模型再训练不应该导致不同的模型生成过程。再训练仅指在新的训练数据集上重新运行生成之前选择的模型的过程。特征、模型算法和超参数搜索空间都应保持不变。可以这样理解,再训练不涉及任何代码更改,仅涉及更改训练数据集。
这并不是说未来版本的模型不应该包括新特性或考虑其他算法类型/架构。我只是说,这些类型的变化会导致完全不同的模型——在部署到生产环境之前,你应该以不同的方式进行测试。根据你的机器学习组织的成熟度,这些变化理想情况下应通过 A/B 测试引入,以测量新模型对预定指标(如用户参与度或留存率)的影响。
你应该多久重新训练一次模型
到目前为止,我们已经讨论了模型漂移是什么以及识别它的多种方法。那么问题变成了,我们如何解决它?如果由于环境变化导致模型的预测性能下降,解决方案是用反映当前现实的新训练集重新训练模型。你应该多久重新训练一次模型?你如何确定新的训练集?像大多数困难的问题一样,答案是这要根据情况而定。但这究竟取决于什么呢?
有时问题设置本身会提示你何时重新训练模型。例如,假设你在一个大学招生部门工作,负责构建一个预测学生是否会在下学期回归的学生流失模型。这个模型将在期中考试后直接用来生成当前学生群体的预测。被识别为有流失风险的学生将自动被注册参加辅导或其他干预措施。
让我们考虑一下这种模型的时间范围。由于我们每学期生成批量预测,因此没有新的训练数据的情况下,模型不应更频繁地重新训练。因此,我们可能会选择在每学期开始时重新训练模型,在观察到上一学期哪些学生退学后。这是一个周期性重新训练的例子。通常,从这种简单的策略开始是一个好主意,但你需要确定确切的重新训练频率。快速变化的训练集可能要求你每天或每周训练一次。变化较慢的分布可能需要每月或每年重新训练。
如果你的团队已经具备了监控前面讨论的指标的基础设施,那么可能有意义去自动化模型漂移管理。这个解决方案需要跟踪诊断信息,然后在实时数据的诊断信息与训练数据的诊断信息出现偏差时触发模型重新训练。但这种方法也有自己的挑战。首先,你需要确定一个触发模型重新训练的偏差阈值。如果阈值设置得过低,你可能会面临过于频繁的重新训练,从而导致计算成本的高昂。如果阈值设置得过高,你则有可能不会足够频繁地进行重新训练,从而导致生产中的模型表现不佳。这比看起来要复杂,因为你需要确定需要收集多少新的训练数据才能代表世界的新状态。即使世界发生了变化,用一个训练集过小的模型来替换现有模型也没有意义。
如果你的模型在对抗环境中运行,则需要特别考虑。在欺诈检测等环境中,对手会改变数据分布以获取利益。这些问题可能会从在线学习中受益,在这种学习中,模型会随着新数据的到来而逐步更新。
你如何重新训练你的模型?
最后但同样重要的是,让我们讨论如何重新训练模型。你采用的模型重新训练方法直接与决定重新训练的频率相关。
如果你决定定期重新训练你的模型,那么批量重新训练是完全足够的。这种方法涉及使用诸如 Jenkins 或 Kubernetes CronJobs 等作业调度程序来安排模型训练过程。
如果你已经自动化了模型漂移检测,那么在识别到漂移时触发模型重新训练是有意义的。例如,你可能会有定期作业来比较实时数据集的特征分布与训练数据的特征分布。当发现显著偏差时,系统可以自动安排模型重新训练以自动部署新模型。这也可以通过像 Jenkins 这样的作业调度程序或使用 Kubernetes Jobs 来实现。
最后,利用在线学习技术来更新当前生产中的模型可能是有意义的。这种方法依赖于用当前部署的模型来“播种”一个新模型。随着新数据的到来,模型参数会用新的训练数据进行更新。
结论
机器学习模型的预测性能在模型部署到生产环境后通常会下降。因此,实践者必须通过建立针对机器学习的监控解决方案和工作流程,为性能下降做好准备,从而实现模型重新训练。虽然重新训练的频率会因问题而异,但机器学习工程师可以从一个简单的策略开始,即定期在新数据到达时重新训练模型,然后逐步演变为更复杂的过程,以量化和应对模型漂移。
参考文献
原文。经许可转载。
个人简介: Luigi Patruno 是一位数据科学家和机器学习顾问。他目前是 2U 的数据科学总监,领导一个负责构建机器学习模型和基础设施的数据科学团队。作为顾问,Luigi 帮助公司通过将现代数据科学方法应用于战略业务和产品计划来创造价值。他创办了 MLinProduction.com 以收集和分享机器学习运维的最佳实践,并且教授过统计学、数据分析和大数据工程的研究生课程。
相关内容:
我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业之路。
2. Google 数据分析专业证书 - 提升你的数据分析能力。
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求。
了解更多相关话题
TensorFlow 入门终极指南
评论
由Brian Zhang,ByteGain。

TensorFlow 是机器学习中的新热门。你可以使用他们的入门指南,或者通过查看下面的资源更快更轻松地学习!
教程
“Tensorflow 与深度学习 - 无需博士学位”由 Martin Görner
或者扩展的 3 小时版本:www.youtube.com/watch?v=vq2nnJ4g6N0))
如果你已经理解线性代数,这是一个很好的起点。它会解释几个高级概念,例如:
-
什么是“神经元”
-
不同类型的激活函数以及为什么使用 ReLu
-
如何通过 dropout 提高模型准确性
-
如何评估模型并调整超参数
"Tensorflow: 令人困惑的部分(1)"由 Jacob Buckman
jacobbuckman.com/post/tensorflow-the-confusing-parts-1/
"TensorFlow 入门:机器学习教程"由 Dino Causevic
www.toptal.com/machine-learning/tensorflow-machine-learning-tutorial
"Python TensorFlow 教程 – 构建神经网络"
adventuresinmachinelearning.com/python-tensorflow-tutorial
TensorFlow 教程
"机器学习精通"由 Jason Brownlee
machinelearningmastery.com/start-here/
示例
代码示例
github.com/aymericdamien/TensorFlow-Examplesgithub.com/MorvanZhou/Tensorflow-Tutorial
工具
Google Colaboratory (Colab)
colab.research.google.com/notebooks/welcome.ipynb#scrollTo=9wi5kfGdhK0R

COLAB 笔记本
Colab 提供了一个基于 Jupyter 的交互式 Python 笔记本,但有两个巨大优势。
-
-
-
你可以用它生成 HTML/CSS 的可视化
-
免费 GPU 计算时间
-
-
这是一个免费工具,旨在分享研究和学习新工具,请勿滥用。
Tensorboard
TENSORBOARD 显示交叉熵图!TENSORBOARD 3D 图 Tensorboard 是一个用于可视化机器学习模型的工具。其目标是解决黑箱问题。它对以下内容非常有用:
-
设计模型结构
-
调试
-
可视化性能
-
生成结果图
技巧
在 Colab 中使用 TensorBoard
stackoverflow.com/questions/47818822/can-i-use-tensorboard-with-google-colab
如果你看到 Colab(互动在线笔记本)和 Tensorboard(可视化/调试工具)的价值,那么花时间让它们协同工作绝对值得。
社区
公告与笑话
www.reddit.com/r/MachineLearning/
Slack
slofile.com/slack/ai-researchers
Discord
discordlist.me/join/167811324590424065/
书籍
神经网络与深度学习(免费在线书籍): neuralnetworksanddeeplearning.com/
深度学习(在线书籍): www.deeplearningbook.org/
Goodreads 上流行的数据科学书籍: www.goodreads.com/shelf/show/data-science
更多资源
机器学习研究
arXiv
-
人工智能:
arxiv.org/list/cs.AI/new -
计算机视觉与模式识别:
arxiv.org/list/cs.CV/new -
机器学习:
arxiv.org/list/cs.LG/new
职业
“如何成为数据科学家”:www.datasciencecentral.com/profiles/blogs/how-to-become-a-data-scientist-for-free
求职
LinkedIn: www.linkedin.com/jobs/machine-learning-jobs/
AngelList: angel.co/machine-learning/jobs
加入 ByteGain 工作
如果你已经擅长机器学习,我们在 ByteGain 招聘!
简介: Brian Zhang 是 ByteGain 的软件工程师,致力于寻找更多解决方案于 {技术 + 教育 + 游戏 = ?}。
原文。经许可转载。
相关内容:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
了解更多相关主题
终极开源大语言模型生态系统
原文:
www.kdnuggets.com/2023/05/ultimate-opensource-large-language-model-ecosystem.html
作者图片
我们正在见证一个开源语言模型生态系统的增长,它们提供了全面的资源,使个人能够为研究和商业目的创建语言应用程序。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
之前,我们曾介绍过 开放助手 和 OpenChatKit。今天,我们将深入探讨 GPT4ALL,它不仅限于特定用途,而是提供全面的构建模块,使任何人都能开发类似于 ChatGPT 的聊天机器人。
GPT4ALL 项目是什么?
GPT4ALL 是一个提供你所需的一切以便与最先进的自然语言模型合作的项目。你可以访问开源模型和数据集,使用提供的代码进行训练和运行,使用网页界面或桌面应用与它们交互,连接 Langchain 后端以进行分布式计算,并使用 Python API 进行简单集成。
Apache-2 许可的 GPT4All-J 聊天机器人最近由开发者推出,该机器人在大量经过筛选的助手互动语料库上进行训练,包括数学问题、多轮对话、代码、诗歌、歌曲和故事。为了让它更易于访问,他们还发布了 Python 绑定和聊天用户界面,几乎任何人都可以在 CPU 上运行该模型。
你可以通过在桌面上安装原生聊天客户端来亲自尝试。
然后,运行 GPT4ALL 程序并下载你选择的模型。你也可以手动下载模型 这里 并在 GUI 中的模型下载对话框指定的位置进行安装。
作者提供的图片
我在笔记本电脑上使用它的体验非常完美,响应快速且准确。此外,它用户友好,即使是非技术人员也能轻松使用。
作者提供的 Gif
GPT4ALL Python 客户端
GPT4ALL 提供 Python、TypeScript、Web Chat 接口 和 Langchain 后端。
在这一部分,我们将探讨使用 nomic-ai/pygpt4all 访问模型的 Python API。
- 使用 PIP 安装 Python GPT4ALL 库。
pip install pygpt4all
-
从
gpt4all.io/models/ggml-gpt4all-l13b-snoozy.bin下载 GPT4All 模型。你也可以在 这里 浏览其他模型。 -
创建一个文本回调函数,加载模型,并提供提示给
mode.generate()函数以生成文本。查看库的 文档 以了解更多信息。
from pygpt4all.models.gpt4all import GPT4All
def new_text_callback(text):
print(text, end="")
model = GPT4All("./models/ggml-gpt4all-l13b-snoozy.bin")
model.generate("Once upon a time, ", n_predict=55, new_text_callback=new_text_callback)
此外,你可以下载并使用变换器进行推断。只需提供模型名称和版本。在我们的案例中,我们正在访问最新改进的 v1.3-groovy 模型。
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"nomic-ai/gpt4all-j", revision="v1.3-groovy"
)
入门指南
nomic-ai/gpt4all 仓库包含用于训练和推断的源代码、模型权重、数据集和文档。你可以先尝试几个模型,然后尝试使用 Python 客户端或 LangChain 进行集成。
GPT4ALL 提供了一个 CPU 量化的 GPT4All 模型检查点。要访问它,我们需要:
-
从 Direct Link 或 [Torrent-Magnet] 下载 gpt4all-lora-quantized.bin 文件。
-
克隆此仓库并将下载的 bin 文件移动到
chat文件夹中。 -
运行适当的命令以访问模型:
-
M1 Mac/OSX:
cd chat;./gpt4all-lora-quantized-OSX-m1 -
Linux:
cd chat;./gpt4all-lora-quantized-linux-x86 -
Windows (PowerShell):
cd chat;./gpt4all-lora-quantized-win64.exe -
Intel Mac/OSX:
cd chat;./gpt4all-lora-quantized-OSX-intel
-
你还可以前往 Hugging Face Spaces 并尝试 Gpt4all 演示。虽然它不是官方的,但这是一个开始。

图片来自 Gpt4all
资源:
-
GitHub: nomic-ai/gpt4all
-
Python API: nomic-ai/pygpt4all
-
Hugging Face Demo: Gpt4all
GPT4ALL 后端: GPT4All — ???? LangChain 0.0.154
Abid Ali Awan (@1abidaliawan) 是一位认证数据科学专家,热爱构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理健康困扰的学生开发一个 AI 产品。
更多相关话题
终极 Scikit-Learn 机器学习备忘单
原文:
www.kdnuggets.com/2021/01/ultimate-scikit-learn-machine-learning-cheatsheet.html
评论
由 Andre Ye,Critiq 联合创始人,Medium 编辑与顶级作者。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能。
3. Google IT 支持专业证书 - 支持你所在组织的 IT。
来源: Pixabay。
本备忘单将涵盖数据挖掘和机器学习的多个领域:
-
预测建模。 监督学习(预测)的回归和分类算法,以及评估模型性能的指标。
-
将数据分组为簇的方法:K-Means,基于目标指标选择簇数量。
-
降维。 降低数据和属性维度的方法及其方法:PCA 和 LDA。
-
特征重要性。 查找数据集中最重要特征的方法:置换重要性、SHAP 值、部分依赖图。
-
数据转换。 用于提升数据预测能力、便于分析或揭示隐藏关系和模式的方法:标准化、归一化、Box-Cox 转换。
所有图片均由作者创建,除非另有明确说明。
预测建模
训练-测试分割 是通过在指定的训练数据上训练模型并在指定的测试数据上测试模型性能的重要部分。通过这种方式,可以衡量模型对新数据的泛化能力。在 sklearn 中,X 和 y 参数可以接受列表、pandas 数据框或 NumPy 数组。
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3)
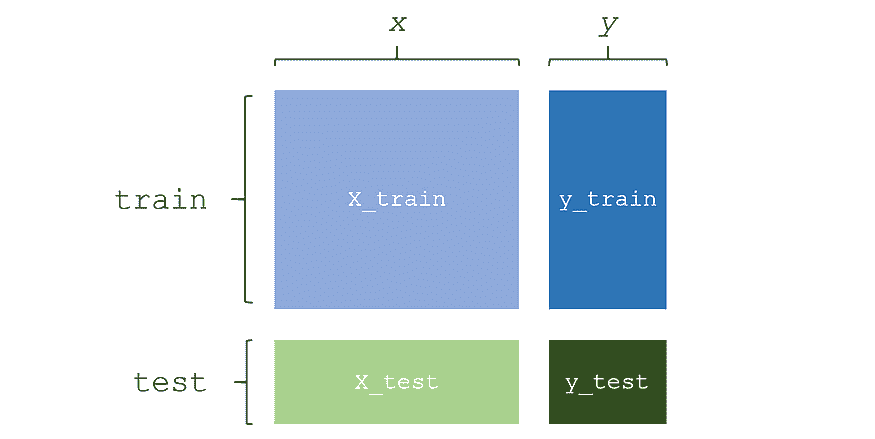
训练一个标准的监督学习模型 包括导入、创建实例和拟合模型。

sklearn* 分类模型** 列在下方,蓝色突出显示分支,橙色显示模型名称。
sklearn* 回归模型** 列在下方,蓝色突出显示分支,橙色显示模型名称。
评估模型性能是使用这种形式的训练-测试数据完成的:

sklearnmetrics用于分类和回归,下面列出了这些指标,最常用的指标标记为绿色。许多灰色指标在某些情况下比绿色标记的指标更为适用。每个指标都有其优缺点,需要平衡优先级比较、可解释性和其他因素。

聚类
在进行聚类之前,数据需要被标准化(相关信息可以在数据转换部分找到)。聚类是根据点距离创建集群的过程。
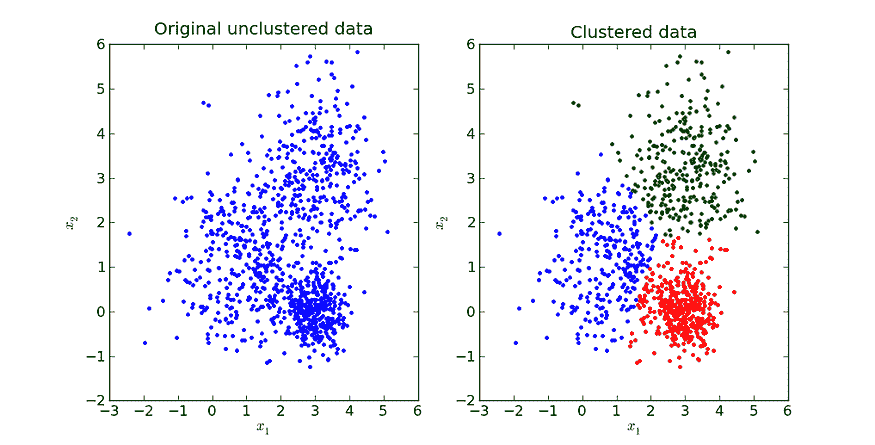
来源。图片可自由分享。
训练和创建 K-Means 聚类模型会创建一个能够聚类并检索有关聚类数据的信息的模型。
from sklearn.cluster import KMeans
model = KMeans(n_clusters = number_of_clusters)
model.fit(X)
访问数据中每个数据点的标签可以通过以下方式完成:
model.labels_
类似地,每个数据点的标签可以存储在数据的一个列中,方法如下:
data['Label'] = model.labels_
访问新数据的集群标签可以使用以下命令。new_data可以是数组、列表或数据框的形式。
data.predict(new_data)
访问每个集群的集群中心以二维数组的形式返回,方法如下:
data.cluster_centers_
要找到最佳的集群数量,请使用轮廓系数,它是衡量某一集群数量如何适合数据的指标。对于预定义范围内的每个集群数量,训练 K-Means 聚类算法,并将其轮廓系数保存到列表中(scores)。data是模型训练的数据。
from sklearn.metrics import silhouette_score
scores = []
for cluster_num in range(lower_bound, upper_bound):
model = KMeans(n_clusters=cluster_num)
model.fit(data)
score = silhouette_score(data, model.predict(data))
在分数保存到列表scores后,可以将其绘制出来或进行计算搜索以找到最高分。
降维
降维是将高维数据以减少的维度表示的过程,以便每个维度包含最多的信息。降维可以用于高维数据的可视化或通过去除低信息量或相关的特征来加速机器学习模型。
主成分分析(PCA)是一种通过在特征空间中绘制几个正交(垂直)向量来减少数据维度的流行方法,以表示减少后的维度数量。变量number表示减少后的数据将拥有的维度数量。例如,在可视化的情况下,它将是两个维度。
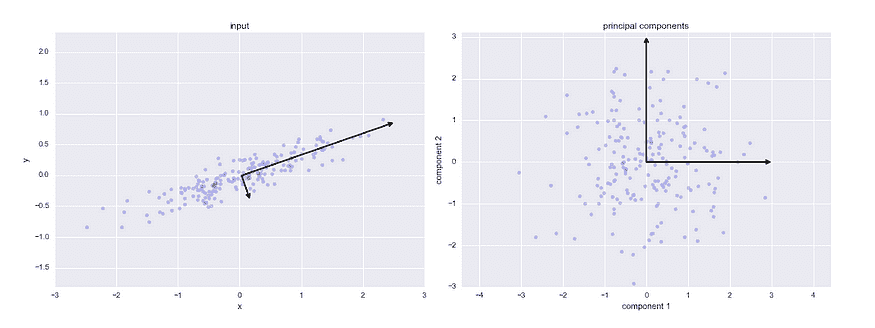
PCA 工作原理的可视化演示。来源.
拟合 PCA 模型:.fit_transform函数自动将模型拟合到数据并将其转换为减少后的维度。
from sklearn.decomposition import PCA
model = PCA(n_components=number)
data = model.fit_transform(data)
解释方差比:调用model.explained_variance_ratio_ 将得到一个列表,其中每项对应于该维度的“解释方差比”,这基本上意味着该维度在原始数据中所表示的信息百分比。解释方差比的总和是降维数据中保留的信息的总百分比。
PCA 特征权重:在 PCA 中,每个新创建的特征都是前一个数据特征的线性组合。这些线性权重可以通过model.components_ 访问,它们是特征重要性的良好指标(较高的线性权重表示该特征中包含的信息更多)。
线性判别分析(LDA,不要与潜在狄利克雷分配混淆)是另一种降维方法。LDA 与 PCA 的主要区别在于 LDA 是一个有监督的算法,意味着它同时考虑了x 和 y。主成分分析仅考虑x,因此是一个无监督的算法。
PCA 试图基于点之间的距离纯粹保持数据的结构(方差),而 LDA 则优先考虑类别的清晰分离。
from sklearn.decomposition import LatentDirichletAllocation
lda = LatentDirichletAllocation(n_components = number)
transformed = lda.fit_transform(X, y)
特征重要性
特征重要性是找到对目标最重要特征的过程。通过 PCA,可以找到包含最多信息的特征,但特征重要性关注的是特征对目标的影响。一个“重要”的特征的变化会对y变量产生大的影响,而一个“不重要”的特征的变化对y变量几乎没有影响。
置换重要性 是一种评估特征重要性的方法。训练多个模型,每个模型缺少一列数据。由于缺少数据导致的模型准确率下降表示该列对模型预测能力的重要性。eli5 库用于置换重要性。
import eli5
from eli5.sklearn import PermutationImportance
model = PermutationImportance(model)
model.fit(X,y)
eli5.show_weights(model, feature_names = X.columns.tolist())
在这个置换重要性模型训练的数据中,列 lat 对目标变量(在这个例子中是房价)有最大的影响。置换重要性是决定哪些特征(相关或冗余的特征,实际混淆模型,标记为负置换重要性值)应当移除时最好的特征选择方法。
SHAP 是另一种评估特征重要性的方法,借鉴了 21 点游戏理论中的原则来估计一个玩家能贡献多少价值。与置换重要性不同,SHapley Additive ExPlanations 使用一种更具公式化和计算基础的方法来评估特征重要性。SHAP 需要基于树的模型(决策树,随机森林),并且适用于回归和分类问题。
import shap
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)
shap.summary_plot(shap_values, X, plot_type="bar")
PD(P)图,或部分依赖图,是数据挖掘和分析中的重要工具,展示了一个特征的某些值如何影响目标变量的变化。所需的导入包括pdpbox用于依赖图和matplotlib用于显示图。
from pdpbox import pdp, info_plots
import matplotlib.pyplot as plt
隔离 PDPs:以下代码显示了部分依赖图,其中feat_name是X中要隔离并与目标变量进行比较的特征。第二行代码保存数据,而第三行构建了显示图的画布。
feat_name = 'sqft_living'
pdp_dist = pdp.pdp_isolate(model=model,
dataset=X,
model_features=X.columns,
feature=feat_name)
pdp.pdp_plot(pdp_dist, feat_name)
plt.show()
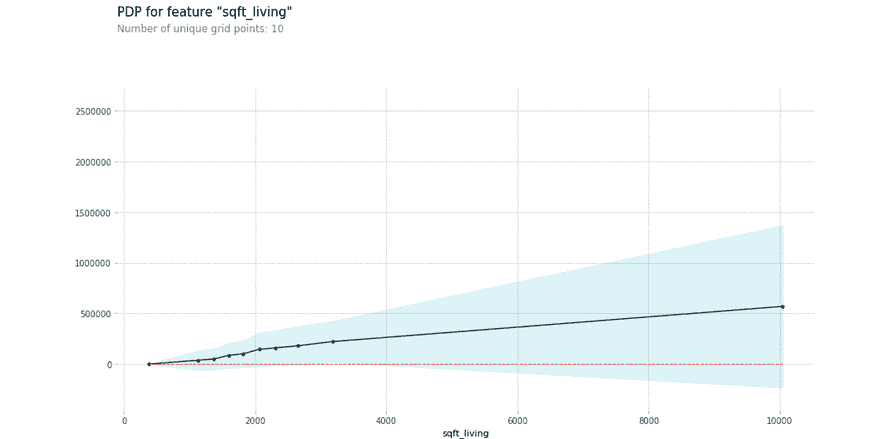
部分依赖图展示了某些值和生活空间平方英尺数的变化对房价的影响。阴影区域表示置信区间。
等高线 PDPs:部分依赖图也可以呈现为等高线图,它们比较的不是一个隔离变量,而是两个隔离变量之间的关系。要比较的两个特征存储在变量compared_features中。
compared_features = ['sqft_living', 'grade']
inter = pdp.pdp_interact(model=model,
dataset=X,
model_features=X.columns,
features=compared_features)
pdp.pdp_interact_plot(pdp_interact_out=inter,
feature_names=compared_features),
plot_type='contour')
plt.show()
两个特征之间的关系显示了在仅考虑这两个特征时的相应价格。部分依赖图包含大量的数据分析和发现,但要注意大的置信区间。
数据转换
标准化或缩放是将数据‘重塑’的过程,使其包含相同的信息但均值为 0,方差为 1。通过缩放数据,算法的数学性质通常可以更好地处理数据。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(data)
transformed_data = scaler.transform(data)
转换后的数据是标准化的,可以用于许多基于距离的算法,如支持向量机和 K 近邻算法。使用标准化数据的算法结果需要进行‘去标准化’,以便进行正确的解释。.inverse_transform()可以用来执行标准变换的相反操作。
data = scaler.inverse_transform(output_data)
归一化数据将数据调整到 0 到 1 的范围,这与标准化数据类似,使得数据在数学上更容易被模型使用。
from sklearn.preprocessing import Normalizer
normalize = Normalizer()
transformed_data = normalize.fit_transform(data)
虽然归一化不会像标准化那样改变数据的形状,但它限制了数据的边界。是否对数据进行归一化或标准化取决于算法和上下文。
Box-cox 变换涉及将数据提升到不同的幂次进行转换。Box-cox 变换可以归一化数据,使其更线性,或减少复杂性。这些变换不仅涉及将数据提升到幂次,还包括分数幂(开方)和对数。
例如,考虑沿函数g(x)分布的数据点。通过应用对数 Box-cox 变换,数据可以更容易地用线性回归进行建模。
由 Desmos 创建。
sklearn 自动确定最佳的 box-cox 变换系列,以使数据更好地符合正态分布。
from sklearn.preprocessing import PowerTransformer
transformer = PowerTransformer(method='box-cox')
transformed_data = transformer.fit_transform(data)
由于 box-cox 变换的平方根特性,box-cox 变换后的数据必须严格为正(预先标准化数据可以解决这个问题)。对于同时包含负值和正值的数据,设置method = ‘yeo-johnson’以采用类似的方法使数据更接近正态分布。
原文。已获转载许可。
相关:
更多相关主题
如何“超学习”数据科学:深刻理解与实验,第四部分
原文:
www.kdnuggets.com/2019/12/ultralearn-data-science-deep-understanding-experimentation-part4.html
评论
由 Benedict Neo,数据科学爱好者和博主。

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
照片由 Franki Chamaki 拍摄,来自 Unsplash。
另见
-
如何“超学习”数据科学,第一部分,什么是“超学习”,你如何遵循这一策略成为数据科学专家?
这是关于超学习数据科学系列的最后一部分。在这一部分,我将讨论深刻理解和实验。
通过最大化优化学习的技能,现在是时候制定策略来培养深刻的理解,并开放接受会促成创新的实验。
在每个案例中,我将分别使用理查德·费曼和文森特·梵高作为例子。
培养深刻理解
物理学家理查德·费曼以其非凡的直觉著称;他能够看透复杂的问题,仿佛从空气中找出解决方案。
这种能力的技术术语是直观专业知识,对外界观察者来说可能显得颇为神秘。
但费曼的灵光一现有一个完全合理的解释:他对物理学的深刻理解使他能够直观地发现意想不到的联系和模式。
“我很早就学会了区别知道某物的名称和真正了解某物的不同。”
― 理查德·P·费曼
成为一个有洞察力的数据科学家,需要时间和耐心来建立直观专业知识所依赖的深刻理解。
但通过采用这四种策略,你可以加速获取它的速度。
(1) 把基础搞对
从回归基础开始。费曼以提问“愚蠢问题”而闻名,他会通过不断问关于基本概念的问题来让学生感到沮丧。
然而,费曼知道他的学生还没有学到的东西:当你对基础概念只有模糊理解时,进步到复杂概念是不可能的。
另一方面,直到你彻底了解你领域的基础概念,你是不可能成为直观专家的。
数据科学需要复杂的数学和机器学习。
然而,这并不意味着你必须将每个理论和事实都牢记于心。实际上,有大量的库和包可以让你将数学和机器学习应用到你的项目中。
你只需要对基本概念有一个基本的理解和洞察。所以,确保你掌握了基础概念,你就准备好了!
(2) 选择更长、更艰难的路线
一个具有挑战性的学习经历可以带来对主题的更深刻理解。
所以你应该尝试接受挑战。在学习中抵制捷径;如果有两种方式可以得到解决方案,选择更长、更复杂的一种。
与其使用干净且结构良好的数据进行项目,不如稍微弄脏一点,从互联网获取非结构化数据并开始清理它。
这将为你未来处理各种数据做好准备。在你下一个数据科学项目中,尝试使用原始数据,并自行清理。你会学到很多东西。
(3) 在困难的障碍中坚持不懈
当遇到挑战时,尽量不要立即放弃。相反,实施一个奋斗计时器。强迫自己在寻找简单解决方案之前,先面对每个挑战或障碍至少 10 分钟。
提出正确的问题可能非常困难,因为这需要创造力、分析、很多研究等。基本上,解决问题需要你坐下来,拿起纸笔开始头脑风暴,尽管这有点老派。
与其急于得出结论和匆忙解决问题,不如思考它们并权衡所有相关因素。
(4) 自行复制概念
最后,通过自己复制核心概念来加深理解。查看你领域内专家制定的思想和过程,然后尝试证明或复制它们。
换句话说,你在理解背后的过程和思维模式。这为你提供了了解他们思维的机会,并帮助你获得深刻的知识和直观的专业技能。
要了解一位灵活的数据科学家的思路,你可以阅读他们的文章、作品或博客,这些内容能让你一窥他们的工作流程和过程。
例如,你观看了一段关于如何使用 TensorFlow 进行目标检测的 YouTube 视频。在认真观看后,你重复了整个过程,并将 TensorFlow 应用于你的模型,加入了你自己个性化的功能和使用案例。
实验
文森特·梵高是如何从一个被同学称为“平庸”画家的艺术学校辍学生,成长为绘制了《向日葵》和《星空》等杰作的创新艺术家的呢?
通过持续而不懈的实验。回顾梵高的全部作品,你会发现他并不是一开始就找到他独特的美学风格。
相反,他不懈地尝试不同的风格和技巧,直到掌握了他的技艺。然后,他进行了更多的实验,最终形成了独特的风格。
实验是超学习的秘密武器——这一技巧可以将你从一名成熟的从业者提升为真正的创新者。但刚开始时,实验可能会显得有些令人不知所措。
实验在数据科学中的重要性
“实验旨在识别变量之间的因果关系,这在许多领域中是一个非常重要的概念,对于今天的数据科学家尤其相关。”
在 敏捷数据科学的关键:实验中,它提到:
“数据科学的本质是实验性的。你不知道你所被问到的问题的答案——甚至不知道是否存在答案。你不知道需要多长时间才能得出结果,也不知道需要多少数据。最简单的方法就是想出一个想法并进行尝试,直到得到一些结果。”
在题为 要成为更有效的数据科学家,请以实验为思维方式 的博客中,作者 Aleksey Bilogur 写道:
“数据科学中的基本价值单位是实验。”
数据科学的艺术就是生成良好假设的艺术。
一名“优秀”的数据科学家知道他们可以探索哪些途径,最有可能对模型性能产生实际影响。他们能够提出假设并进行实验,以最高的概率实际提升模型性能。
这种对“正确”做法的“感觉”首先来自经验,其次来自对数据集的理解,第三来自技术专长。
成为一个优秀的“艺术家”意味着成为一个出色的工作者:你在尝试死胡同时花费的时间更少,而在对模型进行有价值的改进时花费的时间更多。
从这些例子中,很明显数据科学的基本概念就是实验。
科学家利用科学方法在多个与假设相关的实验中收集实证证据,以支持或反驳理论。
数据科学家本质上是一个不断用数据进行实验的科学家,直到模型(理论)准确(有效)。
实验的三步骤
- 先复制再创造
如果你不知道从哪里开始,可以使用一种技巧:先复制再创造:模仿别人的工作,然后以此作为测试自己想法的跳板。
“好的艺术家借鉴,伟大的艺术家偷取。” — 巴勃罗·毕加索
- 约束
另一个可以帮助你快速启动实验的方法是对其施加一些约束。
这可能看起来有些反直觉,但限制你的创造力可以促使它绽放。这是因为在严格限制下工作可以帮助你摆脱旧习惯,迫使你尝试新事物。
- 混合
最终,通过混合你的材料、技术或技能来追求意想不到的结果,以发现你的隐藏超能力。将两个看似无关的元素结合起来可以带来伟大的成果。
例如,如果你有天体物理学背景,并且对艺术和音乐充满热情,你可以使用机器学习来可视化黑洞、创建模拟,甚至预测距离数十亿光年的星球和星星的样子。
使用诸如astroML和深度学习这样的工具,前景无限。通过积极的实验和创造力,以及混合你的技能集,你可以创造突破性的工作并实现不可能的目标。
行动计划
要真正成为一名数据科学家,必须对数据有深刻理解,并勇于尝试不同的模型。这两种特质将确保从数据中提取隐藏洞察的成功,并产生有价值的信息。
你今天应该采取的四个步骤:
-
掌握基础知识。
-
走更长的路,并在困难中坚持。
-
向专家借鉴,然后创造。
-
通过混合不同的工具和技能集进行实验。
原始。经许可转载。
相关:
更多相关内容
如何“极致学习”数据科学:去除干扰和找到专注,第二部分
原文:
www.kdnuggets.com/2019/12/ultralearn-data-science-distractions-focus-part2.html
评论
由 Ben thecoder 编写,开发者、作家、机器学习和人工智能爱好者。

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
照片由 Jakob Owens 提供,来源于 Unsplash。
干扰
在 第一部分 中,你了解了极致学习的介绍和实施元学习的有效策略。有了这些,你可以开始你的极致学习数据科学的旅程。
但在你过于兴奋之前,你必须首先了解世界充满了干扰。我们生活在一个我们的注意力被廉价出售的时代,注意力经济 的概念将我们的注意力视为一种宝贵的货币。
“注意力是一种资源——一个人的注意力有限。” — 马修·克劳福德
正如所说,本文将主要关注你猜到的主题,专注。现代生活充满了干扰,从手机上的不断通知到倾向于刷 YouTube 和 Netflix,我们的注意力持续时间显著减少。
这些干扰对一个人的健康和高效工作能力可能是有害的。在这个充满干扰和分散注意力的世界里找到你的专注,就像在大海捞针一样困难。
然而,有一些简单的技巧可以帮助你克服这些寻找专注的障碍,实现你的极致学习目标!
4 种简单的心理策略来抵御干扰
1. 动力
找到你的专注的初步挑战肯定是首先让自己集中注意力。
有很多方法可以做到这一点,因为我们都有自己的方法来欺骗自己坐下来开始从事个人项目或撰写文章。
一个例子是设置一个五分钟的计时器。首先,你承诺自己在这五分钟后可以停止工作。这个由承诺带来的短时间内停止的动力通常会让人继续工作下去。
这种自我欺骗的策略与著名的番茄钟技巧类似:设置一个timer为 25 分钟,并在没有任何干扰的情况下工作,不中断。当计时器响起时,休息五分钟。然后,再继续工作 25 分钟。
自创的紧迫感和在专注工作间隙奖励自己休息是特别有效的,且被证明非常高效。随着专注工作的时间增加,休息的时长也会成比例增加(从五分钟到 10/15 分钟)。
相反,有些人更愿意在 25 分钟的专注工作后继续工作,因为它已经给了你继续工作的动力,然后在一个小时后再休息。
这种替代方案叫做52/17 技巧。它最近变得非常流行,甚至被称为理想的生产力计划。因此,根据你的喜好和能力,你可以调整这种番茄钟技巧,开始获得专注。
2. 维持专注
在找到你的专注点后,接下来的挑战是维持它。这是专注工作中最难的部分之一,因为我们人类已经被互联网和社交媒体训练成短时间内注意力不集中。
这些外部干扰会消耗你的专注力。为了控制环境而不是让环境控制你,你必须主动消除这些干扰。
一些例子包括:
-
将手机设置为飞行模式。
-
关闭你的 Wi-Fi。
-
开启“勿扰”模式。
-
将你的智能手机颜色设置为灰度模式。
-
关闭通知。
其他帮助你保持专注的提示包括:
-
拥有一个专门的深度工作区域,在那里你能够发挥最佳表现。这有助于让你的大脑在下一次准备好,因为你想再次集中精力。
-
如果在外面,选择一个嘈杂的咖啡店,因为背景噪音有助于你专注(或者对那些喜欢安静的人来说,去图书馆)。
-
听古典音乐或任何你不熟悉的音乐。
-
准备好食物,并在旁边放一杯水。
-
找一个伙伴参加配对编程的数据科学项目。
3. 交替学习
你可能会认为挑战已经结束,你已经征服了专注的高峰。但试炼并没有就此结束。
虽然你可能已经按照 YouTube 上的逐步教程从零开始构建了一个逻辑回归预测模型,并且认为自己学到了很多,但可能你已经进入了自动驾驶模式。
尝试在没有任何视频教程的情况下构建另一个模型,你能做到吗?如果不能,你并没有完全投入到学习过程中,你只是输入了新材料,却没有保留它。
为了对抗自动驾驶模式,应用交替学习——故意在材料和学习模式之间进行交替。
理想情况下,为了确保新概念的记忆,你必须通过在短时间、规律间隔的学习中进行交替学习。例如,如果你每周有 10 小时用来学习 Python,目标应是每周五次两小时的学习,而不是一天十小时的学习。
在每个学习阶段,提前计划你将学习的内容,例如周一的数据可视化,周二的数据清理,周三的统计和概率等等。
此外,规划你将用于学习的资源,并为学习制定结构,从知识构建(书籍和文章)开始,然后才是应用(在 IDE 中编写代码)。
为了有效地实现这种交替学习方法,可以利用时间盒的概念——这是一个来自敏捷软件开发的术语,其中时间盒是一个定义的时间段,在此期间必须完成任务。
使用时间盒(timeboxing),每项任务只有有限的时间(时间盒)来完成,时间结束后,即使之前的任务未完成,你也要继续下一个任务。这确保了高效的工作,避免了个人在某一任务上花费过多时间。
例如,你在为项目调试 Python 代码时遇到困难,你已经在 Stack Overflow、Reddit、YouTube 和 Discord 上花费了几个小时,但仍未解决问题。
最终,你整天所做的只是调试,而且完全忽视了其他计划。为了应对这种情况(编程中常见),给调试代码大约 15-20 分钟的时间。
这样,你可以继续做其他事情,而不是整天都在修复你的代码。
4. 心理能量高峰
最后一步是通过记录你的心理唤起——你的能量和警觉水平,来最大化你的深度工作时间。
我们都有某些时间段能量最集中。为了进行高效的工作,你必须记录下你表现最佳的独特时间。
这可以通过夜猫子和早起鸟的类型来说明,一种人在午夜时分更有创造力和生产力,而另一种人在早晨太阳升起之前效果最好。
找到你心理能量高峰的一种方法是睡前记录你的一天,并记录你在一天中的哪些时刻非常高效。这样做一个月后,回顾一下你生产力高的时间。
完成了!你得到了集中精力的时间间隔。
有了这些,你可以根据你的唤起水平分配任务。
高兴奋度 产生强烈但狭窄的专注——适合重复性任务,如寻找数据科学学习资源并将其整理到 Notion、Trello、GitHub 等应用程序中,或为公司研究解决业务问题。
低兴奋度 产生放松但较宽泛的专注,适合横向思维和形成新的联系,如头脑风暴有趣的数据科学项目或在解决问题时提出正确的问题。
通过将你的任务与兴奋水平匹配,你可以在专注力高涨时执行简单任务,在专注力较低时执行复杂任务——以获得最佳的极限学习效果。
行动计划
磨练你的专注力将确保你拥有足够的心理耐力来极限学习数据科学。
按照这四个步骤进行:
-
使用时间追踪应用和如 Pomodoro 技术等技巧来获得动力。
-
通过控制环境来维持你的专注力。
-
将你的学习时间分成较小的部分,并使用时间盒的概念规划每个学习会话。
-
找到你的心理能量高峰,并将重复性任务分配到高兴奋度时间,将复杂任务分配到低兴奋度时间。
原文。经许可转载。
相关内容:
相关话题
如何“极限学习”数据科学,第一部分
原文:
www.kdnuggets.com/2019/12/ultralearn-data-science-part1.html
评论
由Benthecoder撰写,开发者、作家、机器学习与 AI 爱好者。
埃隆·马斯克、比尔·盖茨、沃伦·巴菲特和马克·库班。这些极度成功的人有什么共同点?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业之路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
他们都是极限学习者。
埃隆·马斯克是一个贪婪的学习者,他利用语义树记住他读过的所有内容,并且能够从他人那里吸收信息。
尽管他取得的成功和突破可能看似不可能,我们也可以将他的框架应用到个人生活中,实现梦想。
“一句建议:重要的是将知识视为一种语义树——确保你理解基本原理,即树干和大枝条,然后再进入细节/叶子,否则就没有东西可以支撑它们。” — 埃隆·马斯克
比尔·盖茨和沃伦·巴菲特都极其好奇,并且有着难以满足的学习欲望。
沃伦·巴菲特将 80%的时间投入到阅读和思考中。比尔·盖茨每周读一本书,还会有两周的假期专门用来阅读。
“智力资本永远优于金融资本。” — 保罗·都铎·琼斯,自主创业的亿万富翁、投资者和慈善家。
什么是极限学习?
极限学习是一种强有力的、自我驱动的学习方法,使人们能够迅速有效地掌握困难技能。
通过结构化的学习方法,他们成为极限学习者,实现了最初看似不可能的非凡成就,但事实上,任何人都可以采用这种极限学习策略,实现看似不切实际的想法和梦想。
极限学习的原则
元学习
元学习——学习如何学习的过程。
元学习是学习中的一个重要概念。它是每个人在启动学习过程之前必须采取的第一步。
学习比听起来更难,因为很多人认为学习只是随机吸收信息,然后在考试中吐出来。
但实际上,学习是艰难的。我这么说是因为学校和学院已经变成了商业,学习的行为已经成为了一门失传的艺术。学生们只是为了通过考试而学习,而不再是为了学习而学习。问一个学生“为什么”而不是“什么”,他们很可能会感到困难。
关于数据科学,观看几个小时的 YouTube 视频、阅读数十本编程书籍和注册昂贵的在线课程单独是不够的。需要一个结构化的框架。
需要对基础知识有深入理解。还有对该领域的大局观理解。
大局观理解
元学习的核心是从全局视角出发,然后利用这一点制定你最优的学习策略。
大局观思维本质上意味着完整的、宏观的故事或理念。这个短语通常意味着一个人应该考虑未来,或考虑其他平行因素,而不是强调细节。
为了掌握大局观的概念,让我们将这一概念应用于数据科学。数据科学是 21 世纪最性感的工作。但大多数数据科学家在没有清晰了解数据科学的真正含义之前就跳入了这个领域。
简而言之,数据科学是揭示数据隐藏价值的过程。
数据正在指数级增长,数据科学家在利用所有这些数据方面至关重要。从基于直觉的决策,我们正在过渡到基于事实的决策。
数据科学家的艰巨任务是帮助组织根据从数据中获取的洞察做出正确的决策。
因此,使用正确的技能和数据集,数据科学家创造了一个数据驱动的世界。
元学习数据科学的策略

照片由 Tabea Damm 提供,来源于 Unsplash
(1) 创建元学习地图
将你的主题分解为三个类别:
-
概念
-
事实
-
程序
概念
数据科学中的概念包括培训和教育,这些是数据科学的先决条件。
这些包括扎实的数学基础(统计学、概率论、线性代数和微积分)、编程、机器学习和人工智能,以及商业分析。
事实
数据科学中的事实将是涉及数据科学的教科书内容,例如你必须深入理解的数学和机器学习中的事实,以至于你可以将其教给其他人。
涉及的事实不应像正规教育所灌输的那样被记住,而应在原子层面上被理解,在那里你可以将术语转化为大众易于理解的语言。
程序
涉及的程序是数据科学的基础——业务理解、数据获取和准备(挖掘和清理)、部署、建模和可视化。
这些基础知识也有子领域,每个子领域在发现数据价值的过程中都至关重要。
(2) 确定学习中的挑战
数据科学并不是一个简单的领域。必须具备商业头脑和出色的沟通能力,才能将数据转化为人们可以理解和领会的内容。成为数据科学家几乎就像是世界上混乱数据的翻译者。
学习中的一些挑战包括数学,特别是对数据科学起重要作用的统计学,机器学习概念(通常需要硕士和博士学位)以及出色的沟通能力。
这一部分含糊且随意,因为每个人在不同方面都有不同的困难。所以,上述只是我的意见,并不适用于其他所有人。
(3) 克服这些挑战的技巧
费曼技巧 在学习像数据科学这样广泛且复杂的内容时非常有效。用这种技巧,机器学习概念和数学事实可以轻松存储在你的大脑中。
在沟通方面,没有一种简单的方法可以突然变得更好并成为世界级的沟通者。有些人天生具备用言辞说服他人的能力,而有些人则是通过生活中的学习获得这些能力。
沟通,就像知识一样,是我们在生活的起伏中积累的技能。关于沟通的一个建议是使用简单的词汇而非术语,以便所有人都能理解你数据的结果。
同时,根据受众个性化你的展示,因为数据工程师对数据科学的理解优于经理或利益相关者。
你可以用来沟通数据的框架
-
对业务问题的理解。
-
如何衡量业务影响——你的模型结果与哪些业务指标对齐?
-
数据是什么或曾经是什么——如有必要,参考哪些数据可能有助于收集。
-
初步解决方案假设。
-
解决方案/模型——使用示例和可视化。
-
解决方案的业务影响和对利益相关者的明确行动项。
(4) 建立你的学习方法论
有了互联网,学习数据科学不再昂贵和有限。大量的资源使得各种人群都能平等地接触数据科学。
类似于学习时面临的问题,这部分也依赖于个人。有些人可能更喜欢通过 YouTube 视频学习,而有些人则喜欢使用 Udemy 和 Coursera 等在线课程。
尽管如此,拥有学习方法是必要的,以便根据你的偏好和能力个性化你的学习方式。
学习数据科学的一个好建议是从实际项目开始,例如线性回归、逻辑回归、决策树等。
这是因为许多人犯了一个错误,即过于专注于数学,摄取大量的事实,却未能从一开始就获得实用的技能。
行动计划
现在你对超学习、元学习和大局观有了初步了解。花 5-10 分钟思考一下你是否一直以这些概念为指导进行学习。如果没有,现在是改变的最佳时机。根据以下 4 个步骤制定你的元学习策略,今天就开始正确的学习方法吧!
原文。经许可转载。
相关:
更多相关话题
如何“超学习”数据科学:总结,适合急需了解的人
原文:
www.kdnuggets.com/2019/12/ultralearn-data-science-summary.html
评论
作者 Benthecoder,开发者、作家、机器学习和 AI 爱好者。

我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT
参见
-
如何“超学习”数据科学,第一部分,什么是“超学习”,你如何按照这一策略成为数据科学专家?
第一部分:金字塔学习
- 创建金字塔学习图
-
概念
-
事实
-
程序
-
确定学习中的挑战性方面
-
克服它们的技术
-
建立你的学习方法
超学习数据科学从利用金字塔学习策略开始。第一步是创建一个适合你生活的学习图。不要制定一个不切实际的计划,要求你每天学习 12 小时,每周如此。这是不可行的,你会感到精疲力竭。规划你的学习旅程时要更务实:考虑你的个人责任、爱好、朋友和家庭等。
另一个关键点是找到你独特的学习方式。每个人都有自己的学习方法。不要试图模仿别人并复制他们的学习方式。如果你通过可视化和视频学习效果更好,就去参加 MOOCs 课程和观看 YouTube 视频。如果你更喜欢传统的教材学习方式,那就去做吧。没有什么能阻止你以自己的节奏学习。
第二部分:深度工作
-
获得动力
-
维持
-
交错
-
寻找你的精神高峰
干扰无处不在。没有专注,几乎不可能学习。拥有控制自己的自律和意识到干扰来源于内心而非外部,是第一步。一切都依赖于你和你自己。
拿个计时器,给你的工作设定时间限制。时间的紧迫感和时间的流逝会促使你开始工作,而不是为了《老友记》的剧集拖延。接下来,保持专注,进入状态,就像程序员们所说的,设定一个适合你的环境。然后,使用时间盒技术,确保你的生产力达到最高水平。最后,发现你的心理能量高峰,确保将创造性任务分配到你精力充沛的时刻,将单调的任务留给你较少活跃的时间。
我们的大脑有其极限。不要逼自己过度。当你实在无法完成任何工作时,去散步、弹钢琴、和朋友(面对面)交谈。然后再尝试集中注意力。
第三部分:优化学习
-
直接性
-
钻研
-
提取
-
反馈
-
记忆
专注使学习变得稍微容易一些。现在来到了困难的部分。仅仅通过阅读和记忆来学习是无用的。这是大学的方法论。是时候抛弃这些,开始有效学习了。
这一部分的几个关键要点是实践应用。做远远优于被动吸收。我们从婴儿时期起就通过实践学习东西。我们研究世界并形成自己的框架。
想学习机器学习?不要急着学习数学或将大量概念和事实塞进脑子里。安装一个集成开发环境(PyCharm/VS Code),搜索 YouTube 视频/网站,寻找关于如何实现机器学习的教程,选择一种语言(最好是 Python)。就这些——这就是你需要掌握机器学习精髓和流程的全部。
尽管如此,伟大的数据科学家们头脑中却装满了统计学、Python、商业敏锐性和机器学习知识——他们已经为任何人们抛给他们的数据做好了准备。通过优化学习,你将做好准备,迎接任何挑战。
第四部分:深刻理解与实验
培养深刻理解
-
掌握基础
-
选择更长、更艰难的路线
-
在困难障碍面前坚持不懈
-
为自己复制概念
实验的三步骤
-
复制然后创造
-
限制
-
混合学习
对一个概念的深刻理解使你能够将各个部分结合起来,并利用这种理解解决问题和提出新想法。
通过了解事物的本质,可以产生对复杂问题的新颖解决方案。为了实现深刻理解,从掌握基础开始,并彻底理解它。只有在掌握了基础知识之后,才能开始深入研究语义树中的更多概念。
另一个重要的事情是向专家借鉴。专家在该领域拥有大量经验,并且在其工作流程中非常熟练。通过从头到尾复制专家解决问题的方式,你最终会通过反复复制掌握这些技能和专业知识。
实验数据和管道是数据科学的基本要素。模型可能会有偏差并且充满错误——只有通过不断地实验不同的特征(特征工程)和算法,才能改进模型。通过对特征选择施加限制并混合使用你的机器学习工具,你可以创建一个好的模型。
大胆和勇敢!胸怀大志,尽情疯狂。深入实验。
原文。经许可转载。
相关:
更多相关内容
无法找到数据科学工作?原因在这里
原文:
www.kdnuggets.com/2022/01/unable-land-data-science-job.html

我有心理学学位。我想从事数据科学,所以我报名参加了一个训练营。我已经试图找到数据科学工作好几个月了,但毫无结果。我要么没有回应,要么公司告诉我我没有他们所寻找的经验。
人们常常向我寻求数据科学建议,这是我收到的最常见的信息之一。来自不同背景的个人试图进入数据科学领域,但无法在行业中找到工作。
他们问我关于硕士学位是否会增加他们在行业中找到工作的机会,或者是否有任何特定的课程可以做,以在简历上看起来更好。
在这篇文章中,我将提供我的见解,解释为什么这些人可能会在找到数据科学工作方面遇到困难。数据行业存在很多误解,我希望在这篇文章中澄清一些。
不久前,有人向我提出了类似的消息。这个人参加了训练营,并申请了几个数据科学职位几个月了。他们的申请要么被拒绝,要么被忽视,未能进入面试阶段。
我查看了他们的简历,立刻意识到了问题所在。
他们唯一相关的数据科学教育只是他们的训练营证书。他们确实在简历上列出了多个数据科学项目,但一眼就能看出这些项目都是在训练营期间完成的。
阅读他们的简历后,我给了这个人以下建议:
-
你需要理解,你正在和硕士学位毕业生竞争同样的入门级职位。一个训练营或在线课程的证书不足以做到这一点。
-
你的简历中的技能部分没有列出作为数据科学家所需的许多技能。你主要列出了机器学习的 Python 包和可视化工具,看起来这些东西也都是在训练营中教授的。
-
你的简历中的项目部分仅包括在训练营期间完成的项目。招聘人员会知道这一点,特别是如果所有来自同一训练营的毕业生都有类似的项目。
从纸面上看,这个人做得一切都很正确。他们报名参加了一个训练营,学习了编程,并将所学应用于构建项目。
然而,这还不够。
即使是硕士学位毕业生也会有知识上的空白。
为什么人们会认为一个训练营或在线课程足以成为数据科学家?
问题是:
人们常常低估了成为数据科学家所需的努力。
我从未见过一个领域像数据科学那样充满炒作。
问题在于那些承诺在接下来的几个月内将你培养成数据科学家的培训营和在线课程。问题在于那些不断编造自己如何轻松找到数据科学工作的博主和 YouTuber,并让人觉得你也可以轻松做到。
要在六个月或一年内找到数据科学的工作是 可能的。人们之前已经做到过。但这绝对不容易。如果你想在没有任何正式培训的情况下做到这一点,那就准备付出至少三倍的努力。
以下是关于找到数据科学工作的两种最流行的说法:
-
第一种说法来自那些认为你需要有扎实的学术基础或至少拥有博士学位才能成为数据科学家的门槛把控者。
-
第二种说法是教育工作者坚信,只要上一个在线课程或培训营,任何人都可以成为数据科学家。
这些说法都不正确。答案在中间某个位置。
拥有硕士学位或某种形式的数据科学培训当然很好,但不是每个人都有这样的特权或时间。如果是这样的话,可以自学数据科学。但这不是通过单一的培训营或在线课程能实现的。
数据科学不是一个有预定义路径的领域。没有固定的学习主题,因为这个领域在不断变化。数据科学家的工作范围涉及不同的责任。因此,没有固定的课程或培训营可以让你成为数据科学家。你需要不断自学,学习永无止境。
你需要主动自学许多这些技能。创建你认为能帮助解决公司问题的项目。学习多种编程语言、一些模型部署、数据收集、云计算和机器学习,然后你就能迈向成为数据科学家的道路。
当然,通用数据科学家和专门化数据科学家之间是有区别的,但如今大多数数据科学职位要求你对我上面列出的所有内容都有一定了解。
即使你还没有掌握所有这些技能,你也需要至少向潜在雇主展示你有在工作中学习这些技能的能力和技术深度。
我给那个联系我的人的最终建议是将注意力从数据科学转移开。
这个人有限的时间内需要尽快找到工作,这不幸是大多数人面临的情况。
我注意到这个人的简历上列出了他们的市场营销背景。
我建议他们申请市场分析师、数据分析师或顾问的职位。
他们有一些从培训班中学到的技术背景,并且在营销领域工作过一段时间。他们具备的领域专业知识和技术知识的结合对他们有利。
我遇到的大多数数据分析师在处理数据方面非常出色,但由于缺乏市场营销专业知识,在挖掘商业价值方面有所不足。
我建议这个人,如果他们很快需要找工作,可以从分析师开始。他们将通过每日的数据工作学到很多东西,并可以继续在业余时间学习数据科学。
我知道很多人从分析师或数据工程师开始,随着时间的推移成功转型为数据科学家。
结论
我以前写过文章,关于不需要硕士学位也能找到数据科学工作的情况,以及如何在没有正式资格的情况下进入这个行业。
虽然我仍然坚持这一点,但我相信这些文章可能也在一定程度上淡化了成为数据科学家所需的努力。我可能让它听起来过于简单。
在任何领域达到一定水平都需要时间和努力。数据科学也不例外。没有任何特定的课程或培训班能完全为你准备好数据科学的工作。
再次强调,数据科学课程非常有帮助,但它们只能帮助打下基础。重任需要由你来完成。
在过去的一年里,我花时间学习了统计学、机器学习、数据收集、网页开发、编程、数据库操作、模型部署和商业分析的基础知识。我目前正朝着成为 Google Cloud 数据工程师认证的方向努力,尽管我们在工作场所并不使用 GCP。
这是一项艰巨的工作,我学到了比任何培训班所能提供的更多的知识。
如果你是数据行业的初学者,这篇文章不是为了吓唬或打击你。数据科学有太多误解,而且这个行业如今已经高度商业化。
在线课程和培训班对于入门非常有用,但学习并不会就此结束。
Natassha Selvaraj 是一位自学成才的数据科学家,对写作充满热情。你可以在 LinkedIn 上与她联系。
原文。经许可转载。
更多相关话题
人工智能系统中的不确定性量化
原文:
www.kdnuggets.com/2022/04/uncertainty-quantification-artificial-intelligencebased-systems.html
摘要
尽管基于人工智能(AI)的系统前景广阔,并且越来越多地被用于协助各种复杂任务,但由于不确定性带来的挑战,这些结果并不完全可靠。不确定性量化(UQ)在优化和决策过程中减少不确定性方面发挥了关键作用,应用于解决科学、商业和工程中的各种现实世界应用。本文简明扼要地介绍了不确定性的概念、来源、类型和测量。文章总结了使用贝叶斯技术的多种 UQ 方法,展示了文献中的问题和不足,提出了进一步的方向,并概述了金融犯罪领域的人工智能系统。
引言
近年来,对基于人工智能的系统的需求增加,这些系统本质上是主动的,需要根据事件或环境变化自动行动。这些系统涉及多个领域,从主动数据库到驱动现代企业核心业务流程的应用。然而,在许多情况下,系统必须响应的事件不是由监控工具生成的,而是需要基于复杂的时间谓词从其他事件中推断。机器学习(ML)模型基于其训练数据生成最佳解决方案。在许多应用中,这种推断本质上是不确定的。然而,如果不考虑数据和模型参数中的不确定性,这些最佳解决方案在实际世界中的部署风险很高。
典型的基于人工智能的系统流程包括收集数据、对数据进行预处理、选择一个模型以从数据中学习、选择一个学习算法来训练选定的模型,并从学习到的模型中得出推论。然而,这些步骤中固有的不确定性是不可避免的。例如,数据不确定性可能源于无法可靠地收集或表示真实世界的数据。数据预处理中的缺陷,无论是在策划、清理还是标注过程中,也会产生数据不确定性。由于模型仅作为真实世界的代理,而学习和推理算法依赖于各种简化假设,因此它们引入了建模和推理不确定性。人工智能系统的预测容易受到这些不确定性来源的影响。可靠的不确定性估计为人工智能系统的开发者和用户提供了重要的诊断信息。例如,高数据不确定性可能指向需要改进数据表示过程,而高模型不确定性可能建议需要收集更多数据。对于用户来说,准确的不确定性,尤其是当与有效的沟通策略相结合时,可以增加透明度和信任,这对更好的人工智能辅助决策至关重要。在医学、金融和社会科学等高风险应用中,对人工智能系统的这种信任对于其可靠部署至关重要。
这些观察重新激发了我对不确定性量化(UQ)研究的兴趣。虽然已经提出了许多改进人工智能系统中 UQ 的方法,但选择特定的 UQ 方法取决于许多因素:基础模型、机器学习任务的类型(回归、分类或分割)、数据的特征、机器学习模型的透明性和最终目标。如果不当使用,特定的 UQ 方法可能会产生不良的不确定性估计,并误导用户。此外,即使是非常准确的不确定性估计,如果沟通不善,也可能产生误导。
本文提供了对不确定性类型的扩展介绍,并描述了其来源,讨论了 UQ 方法,形式化了不确定建模,并阐述了其在复杂系统中的概念。文章概述了在机器学习中使用贝叶斯技术量化不确定性的不同方法。此外,还重点关注了在不同机器学习任务(如分类、回归和分割)中不确定性测量的评估。本文提供了 UQ 方法中的校准术语,列出了文献中的开放问题,展示了在金融犯罪领域的实际应用中的 UQ,并制定了这种系统的通用评估框架。
随机不确定性
随机性不确定性(即统计不确定性),是指每次运行相同实验时所出现的未知因素的代表。随机性不确定性指的是由于概率变异性引起的固有不确定性。这种类型的不确定性是不可减少的,因为底层变量总会存在变异。这些不确定性由概率分布特征化。例如,用机械弓射出的单箭,虽然每次发射(相同的加速度、高度、方向和最终速度)都完全重复,但由于箭杆的随机和复杂的振动,箭矢的撞击点不会都落在目标的同一点上,而对这些振动的知识不足以消除撞击点的散布。
认识论不确定性
认识论不确定性(即系统性不确定性),是由于一些原则上可以知道但实际上不知道的事情所致。认识论不确定性是对过程模型中的科学不确定性的体现。这是由于数据和知识的有限性造成的。认识论不确定性通过替代模型来表征。对于离散随机变量,认识论不确定性通过替代概率分布进行建模。这种不确定性的一个例子是设计用来测量接近地球表面引力的实验中的拉力。常用的 9.8 m/s²的引力加速度忽略了空气阻力的影响,但可以测量物体的空气阻力并将其纳入实验中,从而减少计算引力加速度的结果不确定性。
随机性和认识论不确定性互动
随机性和认识论不确定性也可以在单一术语中同时出现,例如,当实验参数表现出随机性不确定性,并且这些实验参数被输入到计算机模拟中时。如果在不确定性量化中使用了替代模型,例如高斯过程或多项式混沌展开,从计算机实验中学习到的这个替代模型会展现出依赖于或与实验参数的随机性不确定性相互作用的认识论不确定性。这种不确定性不能单独归类为随机性或认识论不确定性,而是更一般的推理不确定性。在实际应用中,这两种不确定性同时存在。不确定性量化旨在明确地分别表达这两种不确定性。
对于 aleatoric 不确定性的量化可以相对直接,传统的(频率学派)概率是最基本的形式。蒙特卡罗方法等技术经常被使用。为了评估 epistemic 不确定性,努力去理解系统、过程或机制的知识缺乏。Epistemic 不确定性通常通过贝叶斯概率的视角来理解,其中概率被解释为表示理性人对特定主张的确定程度。
模型和数据不确定性
模型不确定性涵盖了由于模型不足所造成的不确定性,这些不足可能是由于训练过程中的错误、模型结构的不充分,或者由于样本未知或训练数据集覆盖不佳导致的知识缺乏。与此相比,数据不确定性与直接源自数据的不确定性相关。数据不确定性是由于在数据样本中表示真实世界和分布时的信息丢失所造成的。
例如,在回归任务中,输入和目标测量中的噪声导致了数据不确定性,网络无法学会纠正。在分类任务中,样本没有足够的信息来以 100%确定性识别一个类别,这会导致预测中的数据不确定性。信息丢失是测量系统的结果,例如通过特定分辨率的图像像素表示真实世界的信息,或通过标记过程中的错误。
虽然模型不确定性可以通过改进架构、学习过程或训练数据集(理论上)来减少,但数据不确定性是无法通过解释来消除的。
预测不确定性
基于输入数据领域,预测不确定性还可以分为三大类:
-
域内不确定性:代表了与从假定为等于训练数据分布的数据分布中抽取的输入相关的不确定性。域内不确定性源于深度神经网络由于缺乏域内知识而无法解释域内样本。从建模者的角度来看,域内不确定性由设计错误(模型不确定性)和问题的复杂性(数据不确定性)造成。根据域内不确定性的来源,可以通过提高训练数据(集)或训练过程的质量来减少它。
-
域迁移不确定性:表示与从训练分布的偏移版本中抽取的输入相关的不确定性。分布偏移源于训练数据的覆盖不足以及真实世界情况固有的变异性。域迁移可能增加不确定性,因为 DNN 无法解释训练时基于样本的域迁移样本。一些导致域迁移不确定性的错误可以被建模,因此可以减少。
-
跨领域不确定性:表示与从未知数据子空间中提取的输入相关的不确定性。未知数据的分布与训练分布不同且相差甚远。例如,当领域转移不确定性描述像模糊的狗照片这样的现象时,跨领域不确定性描述的是当一个学习了猫和狗分类的网络被要求预测一只鸟的情况。跨领域不确定性源于深度神经网络(DNN)由于缺乏跨领域知识而无法解释跨领域样本。从建模者的角度来看,跨领域不确定性由输入样本造成,这些样本网络并未用于预测,或由训练数据不足造成。
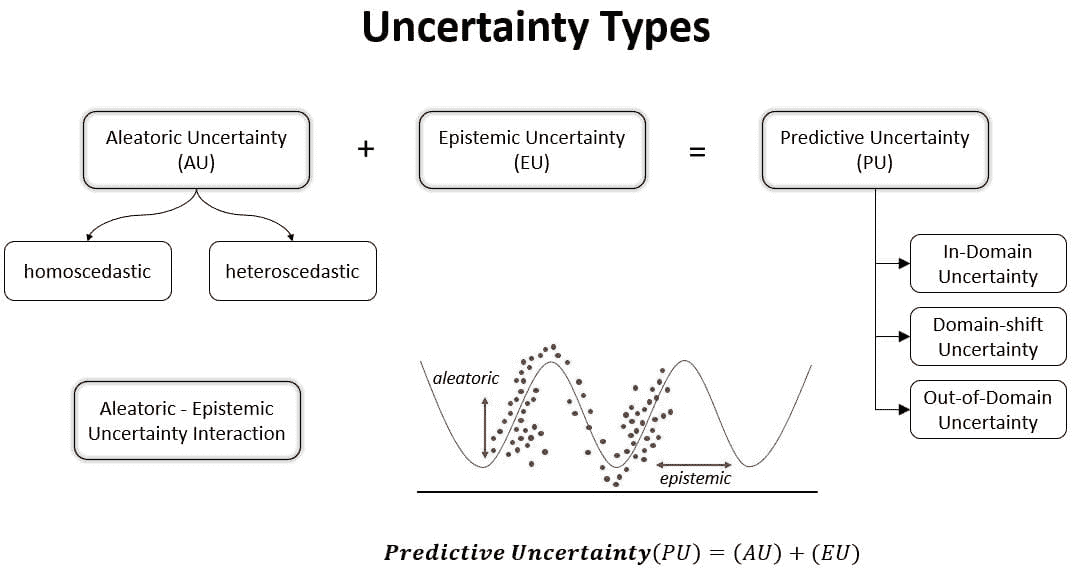 图 1:不确定性类型
图 1:不确定性类型
不确定性与变异性
技术专家经常被要求对不确定量估计“范围”。重要的是要区分他们是否被要求提供变异范围或不确定范围。同样,模型构建者需要知道他们是在建立变异模型还是不确定模型,并了解其关系(如果有的话)。
不确定性的来源
-
参数不确定性:来源于输入到数学模型中的模型参数,但实验人员的确切值未知,无法在物理实验中控制,或无法通过统计方法准确推断其值。例如,掉落物体实验中的局部自由落体加速度。
-
参数变异性:来源于模型输入变量的变异。例如,数据中的尺寸可能与假设的不完全相同,这会导致在这个高维数据集上训练的模型表现出变异性。
-
结构性不确定性:也称为模型不适应性、模型偏差或模型差异,来源于对问题中基础物理或原则知识的缺乏。它取决于数学模型在现实情况中对真实系统的描述准确程度,考虑到模型几乎总是对现实的近似。例如,当使用自由落体模型对掉落物体过程进行建模时,由于存在空气阻力,模型本身是不准确的。在这种情况下,即使模型中没有未知参数,模型和真实物理之间仍然会有差异。结构性不确定性存在于我们对模型输出不确定时,因为我们对模型的函数形式不确定。
-
算法不确定性:也称为数值不确定性或离散不确定性。这种类型的不确定性来源于数值错误和计算机模型实现中的数值近似。大多数模型过于复杂,无法精确求解。例如,有限元法或有限差分法可能用于近似求解偏微分方程(这会引入数值错误)。
-
实验不确定性:也称为观测误差。它源于实验测量的变异性。实验不确定性是不可避免的,可以通过多次重复测量并使用完全相同的设置来注意到。
-
插值不确定性:这来源于从模型模拟和/或实验测量中收集的可用数据的不足。对于没有模拟数据或实验测量的其他输入设置,必须进行插值或外推以预测相应的响应。
问题类型
不确定性量化中有两种主要问题:一种是前向不确定性传播(即将各种不确定性来源通过模型传播以预测系统响应中的整体不确定性),另一种是模型不确定性和参数不确定性的逆向评估(即使用测试数据同时标定模型参数)。
前向 (propagation of uncertainty)
不确定性传播是将不确定输入引起的不确定性量化到系统输出中。它关注于不确定性来源中列出的参数变异性对输出的影响。不确定性传播分析的目标可以是:
-
评估输出的低阶矩,即均值和方差
-
评估输出的可靠性
-
评估输出的完整概率分布
逆向 (inverse problem)
给定系统的一些实验测量值和来自其数学模型的一些计算机模拟结果,逆向不确定性量化估计实验与数学模型之间的差异(即偏差修正),并估计模型中未知参数的值(即参数标定或简单地称为标定)。
通常,这比前向不确定性传播问题要困难得多;然而,它非常重要,因为它通常在模型更新过程中实施。逆向不确定性量化有几种情境:
-
仅偏差修正:偏差修正量化模型的不适当性,即实验与数学模型之间的差异
-
参数标定仅:参数标定估计数学模型中一个或多个未知参数的值。
-
偏差校正和参数校准:考虑一个具有一个或多个未知参数的不准确模型,其模型更新形式将两者结合起来:这是最全面的模型更新形式,涵盖所有可能的不确定性来源,且需要最多的解决工作。
 图 2: 不确定性量化中的问题类型
图 2: 不确定性量化中的问题类型
数学形式化
正如我们之前所述(图 1),预测不确定性由两部分组成:认知不确定性和随机不确定性,可以表示为这两部分的和:
认知不确定性可以被表述为对模型参数的概率分布。
设
表示具有输入的训练数据集

其中 C 表示类别数。目标是优化参数


对于分类问题,可以使用 softmax 似然函数:
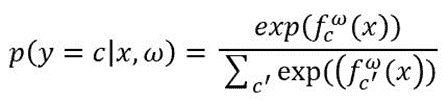
Eq.1
对于回归问题,可以假设高斯似然函数:
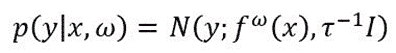
Eq.2

通过应用贝叶斯定理可以写成如下形式:
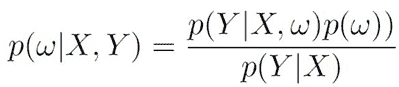
Eq.3
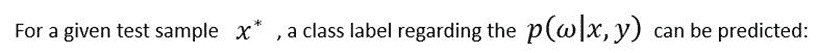
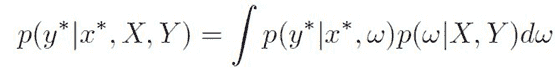
Eq.4
这个过程称为推断或边际化。然而,
不能通过解析方法计算,但可以通过变分参数来近似
目标是近似一个与模型获得的后验分布接近的分布。因此,需要最小化与?的 Kullback-Leibler (KL) 散度。两分布之间的相似度可以如下测量:
Eq.5
预测分布可以通过最小化 KL 散度来进行近似,如下所示:
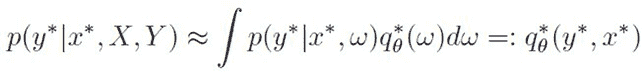
Eq.6
其中
表示优化的目标。KL 散度最小化也可以重新排列为证据下界 (ELBO) 最大化:
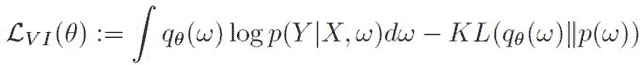
Eq.7
其中
通过最大化第一项并尽可能最小化第二项来很好地描述数据。这个过程称为变分推断(VI)。Dropout VI 是一种最常见的方法,被广泛用于近似复杂模型中的推断。最小化目标如下:
Eq.8
其中 N 和 P 分别代表样本数量和 dropout 概率。为了获得数据依赖的不确定性,可以将精度 ? 在(Eq.2)中制定为数据的函数。获得认识性不确定性的一种方法是混合两个函数:
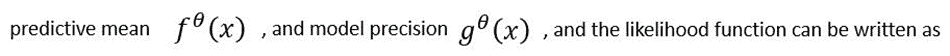
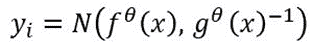
对模型的权重施加先验分布,然后计算在给定数据样本下权重的变化量。欧几里得距离损失函数可以如下调整: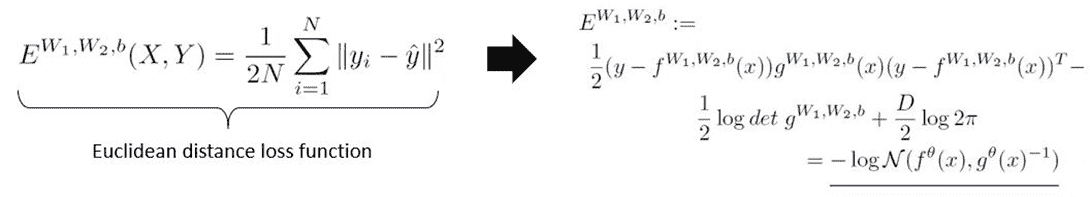
Eq.9
预测方差可以如下获得:
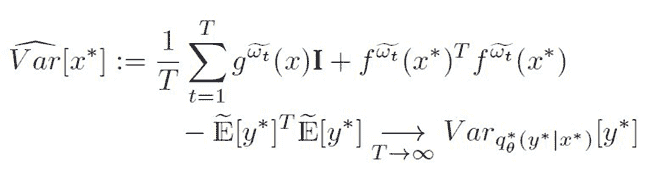
Eq.10
选择性方法
尽管已进行了大量研究来解决不确定性量化问题,但大多数研究处理的是不确定性传播。在过去的一到两十年里,也开发了许多针对逆不确定性量化问题的方法,并证明对大多数小到中等规模的问题非常有用。
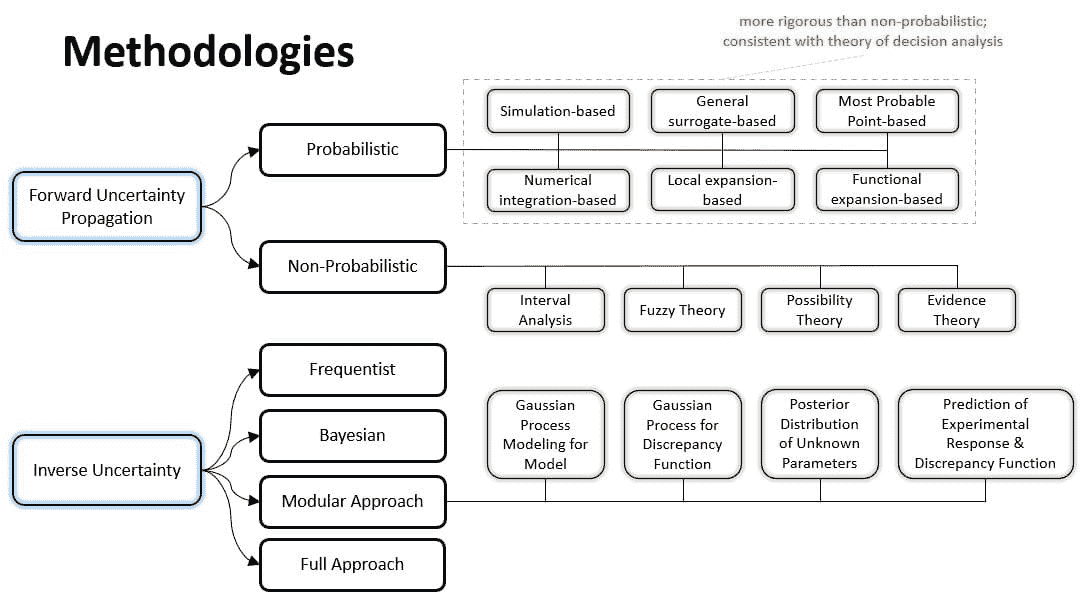
图 3:不确定性量化的选择性方法
前向传播
-
基于模拟的方法:蒙特卡洛模拟、重要性采样、自适应采样等。
-
一般替代模型方法:在非侵入式方法中,学习一个替代模型以用便宜和快速的近似代替实验或模拟。替代模型方法也可以以完全贝叶斯方式使用。这种方法在采样成本极高(例如计算昂贵的模拟)时特别有效。
-
局部展开方法:泰勒级数、扰动方法等。这些方法在处理相对较小的输入变异性和输出不表现高非线性的情况下具有优势。这些线性或线性化方法在《不确定性传播》一文中有详细介绍。
-
基于函数展开的方法:纽曼展开、正交或 Karhunen–Loeve 展开(KLE),以及多项式混沌展开(PCE)和小波展开作为特例。
-
最可能点(MPP)方法:一阶可靠性方法(FORM)和二阶可靠性方法(SORM)。
-
基于数值积分的方法:完全因子数值积分(FFNI)和维度减少(DR)。
对于非概率方法,区间分析、模糊理论、可能性理论和证据理论是最广泛使用的方法之一。
概率方法被认为是工程设计中不确定性分析最严格的方法,因为它与决策分析理论一致。其核心是计算用于采样统计的概率密度函数。这可以对可以作为高斯变量变换获得的随机变量进行严格计算,从而得到精确的置信区间。
反向不确定性
-
频率学派:参数估计的标准误差是 readily available 的,可以扩展为置信区间。
-
贝叶斯:在贝叶斯框架下存在几种反向不确定性量化的方法。最复杂的方向是解决既有偏差校正又有参数标定的问题。这类问题的挑战不仅包括模型不适应和参数不确定性的影响,还包括来自计算机模拟和实验的数据不足。一个常见的情况是实验和模拟中的输入设置不同。另一个常见情况是从实验中得出的参数被输入到模拟中。对于计算上昂贵的模拟,通常需要一个替代模型,例如高斯过程或多项式混沌展开,定义一个反问题以找到最能逼近模拟的替代模型。
-
模块化方法:反向不确定性量化的一种方法是模块化贝叶斯方法。模块化贝叶斯方法的名称源于其四个模块的过程。除了当前可用的数据外,还应为未知参数指定先验分布。
-
高斯过程建模用于模型:为了解决缺乏模拟结果的问题,计算机
模型被替换为高斯过程(GP)模型
-
高斯过程建模用于不一致函数:类似于第一个模块,不一致
函数被替换为 GP 模型
-
未知参数的后验分布:应用贝叶斯定理计算后验
未知参数的分布:
-
实验响应和不一致函数的预测
-
-
完全方法:完全贝叶斯方法要求不仅为未知参数指定先验,还需要为其他超参数指定先验。
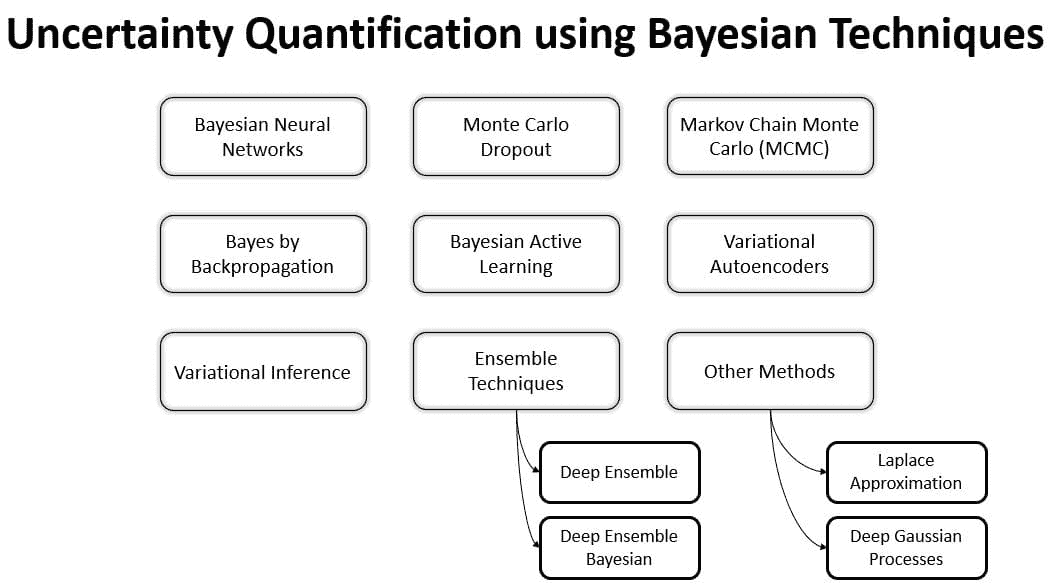
图 4:使用贝叶斯技术的不确定性量化
机器学习中的不确定性量化
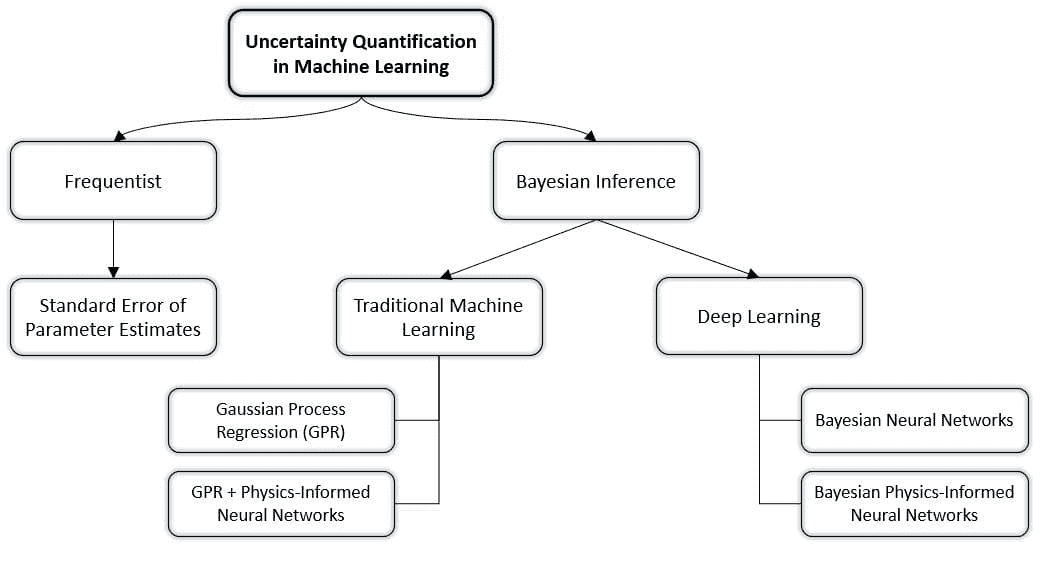
图 5:机器学习中的不确定性量化分类
评估分类
-
在分类任务中测量数据不确定性:给定预测,概率向量表示一个类别分布,即为每个类别分配一个成为正确预测的概率。由于预测不是以明确类别的形式给出,而是以概率分布的形式给出,因此可以直接从预测中得出不确定性估计。通常,这种逐点预测可以被视为估计的数据不确定性。然而,模型对数据不确定性的估计会受到模型不确定性的影响,这需要单独考虑。为了评估预测的数据不确定性的量,可以例如应用最大类别概率或熵度量。最大概率代表了确定性的直接表示,而熵描述了随机变量中的信息平均水平。不过,无法仅从单个预测中判断影响该特定预测的模型不确定性有多大。
-
在分类任务中测量模型不确定性:对学习到的模型参数的近似后验分布可以帮助获得更好的不确定性估计。通过这种后验分布,可以评估变异,即随机变量的不确定性。最常见的度量包括互信息(MI)、期望 Kullback-Leibler 散度(EKL)和预测方差。基本上,这些度量都是计算随机输出与期望输出之间的期望差异。当关于模型参数的知识没有增加最终预测中的信息时,MI 最小。因此,MI 可以被解释为模型不确定性的度量。Kullback-Leibler 散度度量两个给定概率分布之间的差异。EKL 可以用来测量可能输出之间的(期望)差异,这也可以被解释为对模型输出的不确定性的度量,因此代表模型不确定性。即使对于一个分析描述的分布,参数不确定性传播到预测中在几乎所有情况下都是不可处理的,必须例如通过蒙特卡罗近似来进行近似。
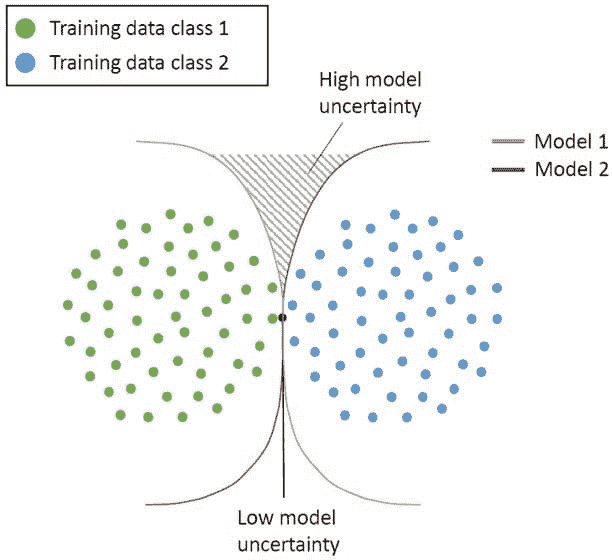
图 6:分类模型中模型和分布不确定性的可视化。来源:Jakob Gawlikowski 等人,2022 年《深度神经网络不确定性调查》
- 在分类任务中测量分布不确定性:尽管这些不确定性度量广泛用于捕捉来自贝叶斯神经网络的多个预测之间的变异性,但集成方法无法捕捉输入数据中的分布变化或分布外的示例,这可能导致偏倚的推断过程和错误的置信度陈述。如果所有预测器将较高的概率质量分配给相同的(错误的)类别标签,这会导致估计之间的变异性低。因此,系统似乎对其预测充满信心,而预测本身的不确定性也在下文中进行评估。
图 7:分类模型的模型和分布不确定性的可视化。来源:Jakob Gawlikowski 等人 2022 年《深度神经网络中的不确定性调查》
- 完整数据集上的性能度量:虽然上述度量评估了单个预测的性能,但其他度量评估了这些度量在样本集上的使用。不确定性度量可以用于区分正确分类和错误分类的样本,或区分领域内和分布外样本。为此,样本被分为两个集合,例如领域内和分布外,或正确分类和错误分类。最常见的两种方法是接收器操作特征(ROC)曲线和精准召回(PR)曲线。这两种方法根据基础度量的不同阈值生成曲线。虽然 ROC 和 PR 曲线提供了基础度量如何适合区分两个考虑的测试案例的视觉概念,但它们没有给出定性度量。为了达到这一点,可以评估曲线下面积(AUC)。大致来说,AUC 提供了一个概率值,表示随机选择的正样本比随机选择的负样本具有更高度量的可能性。
回归评估
- 回归预测中的数据不确定性测量:与分类任务不同,回归任务只预测点估计,而没有数据不确定性的提示。一种常见的方法是让网络预测概率分布的参数,例如,正态分布不确定性的均值向量和标准差。这样,数据不确定性就被直接给出。标准差的预测允许进行分析性描述,即(未知的)真实值位于特定区域内。覆盖真实值的区间具有一定的概率(在假设预测分布正确的情况下)是分位数函数,即累积分布函数的逆函数。对于给定的概率值,分位数函数给出一个边界。分位数假定某种概率分布,并将给定预测解释为该分布的期望值。
与此相反,其他方法直接预测所谓的预测区间(PI),在该区间内假定预测值会落入。这样的区间产生的不确定性表现为均匀分布,而没有给出具体的预测。此类方法的确定性可以像名称所示,通过预测区间的大小直接测量。均值预测区间宽度(MPIW)可用于评估模型的平均确定性。为了评估预测区间的正确性,可以应用预测区间覆盖概率(PICP)。PICP 表示落入预测区间的测试预测值的百分比。
- 回归预测中的模型不确定性测量:模型不确定性主要由模型的结构、训练过程以及训练数据中未充分代表的区域引起。因此,回归任务和分类任务在模型不确定性的原因和影响上没有真正的区别,即回归任务中的模型不确定性可以与分类任务一样进行测量,即在大多数情况下,通过近似平均预测值并测量单个预测值之间的差异。
图 8:回归模型的模型及分布不确定性的可视化。来源:深度神经网络中的不确定性调查,Jakob Gawlikowski 等,2022 年
图 9:回归模型的模型及分布不确定性的可视化。来源:深度神经网络中的不确定性调查,Jakob Gawlikowski 等,2022 年
- 在分割任务中评估不确定性:分割任务中的不确定性评估与分类问题的评估非常相似。分割任务中的不确定性通过贝叶斯推断的近似值来估计。在分割的背景下,像素级分割的不确定性通过置信区间、预测方差、预测熵或互信息 (MI) 来衡量。结构估计中的不确定性通过对所有像素级不确定性估计进行平均来获得。体积不确定性的质量通过评估变异系数、平均 Dice 分数或交集并集来评估。这些指标以成对方式测量多个估计之间区域重叠的一致性。理想情况下,错误分割应导致像素级和结构不确定性的增加。要验证是否如此,应评估像素级的真正阳性率,并评估不同不确定性阈值下的假检测率以及保留像素的 ROC 曲线。
校准
预测器被称为校准良好,如果所得到的预测置信度能很好地近似实际的正确概率。因此,为了利用不确定性量化方法,必须确保系统已经过良好校准。对于回归任务,校准可以定义为预测的置信区间应该与从数据集中经验计算得到的置信区间相匹配。
一般来说,校准误差是由与模型不确定性相关的因素引起的。这一点直观上是清楚的,因为数据不确定性表示输入 x 和目标 y 表示相同的现实世界信息的基本不确定性。接下来,正确预测的数据不确定性将导致系统完美校准。这一点很清楚,因为这些方法分别量化了模型和数据不确定性,并旨在减少预测中的模型不确定性。除了通过减少模型不确定性来改善校准的方法外,越来越多的文献研究了显式减少校准误差的方法。这些方法将在下文中介绍,随后是量化校准误差的措施。需要注意的是,这些方法并不减少模型不确定性,而是将模型不确定性传播到数据不确定性的表示上。
例如,如果一个二分类器过拟合,并且将测试集中的所有样本预测为类别 A,概率为 1,而测试样本中实际上有一半是类别 B,那么重新校准方法可能会将网络输出映射到 0.5,以获得可靠的置信度。这个 0.5 的概率不等同于数据不确定性,而是代表了传播到预测数据不确定性的模型不确定性。
校准方法
校准方法可以根据其应用的步骤分为三大类:
-
训练阶段应用的正则化方法:这些方法修改目标、优化和/或正则化过程,以构建本质上已校准的系统和网络。
-
训练过程后应用的后处理方法:这些方法需要一个独立的校准数据集来调整预测分数以进行再校准。它们仅在假设留下的验证集的分布等于进行推断的分布的情况下有效。因此,验证数据集的大小也会影响校准结果。
-
神经网络不确定性估计方法:减少神经网络置信预测模型不确定性的方法,也能得到更好的校准预测器。这是因为剩余的预测数据不确定性更好地代表了预测的实际不确定性。这些方法例如基于贝叶斯方法或深度集成(见图 4)。
实际应用
利用创新技术保护机构,保障消费者和投资者的资产,NICE Actimize 识别金融犯罪,防止欺诈并提供合规监管。它提供实时的跨渠道欺诈预防、反洗钱检测和交易监控解决方案,解决支付欺诈、网络犯罪、制裁监测、市场滥用、客户尽职调查和内幕交易等问题。基于人工智能的系统和先进的分析解决方案能更早更快地发现异常行为,从而消除从盗窃到欺诈、从监管处罚到制裁的财务损失。因此,组织能够减少损失,提高调查效率,并改善合规监管。
随着基于人工智能的系统在金融犯罪中的使用增加,量化和处理不确定性变得越来越重要。一方面,不确定性量化在风险最小化中扮演了重要角色,这在防止欺诈中是必要的。另一方面,有些挑战性的 数据源提供了欺诈调查的增补,但这些数据源很难验证。这使得生成可信的真实数据成为一个非常具有挑战性的任务。
Actimize 的通用评估框架
为应对这些问题,Actimize 提供了一个包含各种具体基准数据集和评估指标的评估协议,覆盖所有类型的不确定性,助力不确定性量化研究。此外,还考虑了风险规避和最坏情况的评估。这种通用协议使数据科学研究人员能够轻松地将不同类型的方法与已建立的基准以及实际数据集进行比较。
结论
不确定性量化是基于 AI 的系统和决策过程的关键部分之一。UQ 方法在评估各种现实应用中的不确定性时变得越来越受欢迎。如今,不确定性已成为传统机器学习和深度学习方法不可分割的一部分。本文全面回顾了在传统机器学习和深度学习中应用的最重要的 UQ 概念和方法。
参考文献
-
A. Ashukha, A. Lyzhov, D. Molchanov 和 D. Vetrov,“深度学习中领域内不确定性估计和集成的陷阱”,发表在国际学习表示会议,2020 年。
-
A. G. Wilson 和 P. Izmailov,“贝叶斯深度学习和泛化的概率视角”,发表在《神经信息处理系统进展》会议论文集,H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan 和 H. Lin 编, 第 33 卷,2020 年,第 4697–4708 页。
-
A. Kendall 和 Y. Gal,“计算机视觉中的贝叶斯深度学习需要哪些不确定性?” 发表在《神经信息处理系统进展》会议论文集,2017 年,第 5574–5584 页。
-
A. Kristiadi, M. Hein 和 P. Hennig,“在拉普拉斯近似下的可学习不确定性”,arXiv 预印本 arXiv:2010.02720,2020 年。
-
A. Loquercio, M. Segu 和 D. Scaramuzza,“深度学习中不确定性估计的通用框架”,IEEE Robotics and Automation Letters,第 5 卷,第 2 期,第 3153–3160 页,2020 年。
-
A. Malinin 和 M. Gales,“通过先验网络进行预测不确定性估计”,发表在《神经信息处理系统进展》会议论文集,2018 年,第 7047–7058 页。
-
Chen, Wang 和 Cho 2017 Chen, F.; Wang, C.; 和 Cho, J.-H. 2017. 集体主观逻辑:可扩展的不确定性基础上的意见推断。发表在 2017 IEEE 国际大数据会议(Big Data),第 7–16 页。
-
G. Kahn, A. Villaflor, V. Pong, P. Abbeel 和 S. Levine,“用于碰撞避免的基于不确定性的强化学习”,arXiv 预印本 arXiv:1702.01182,2017 年。
-
G. Wang, W. Li, M. Aertsen, J. Deprest, S. Ourselin 和 T. Vercauteren,“通过测试时间数据增强进行医学图像分割的可变不确定性估计”,Neurocomputing,第 338 卷,第 34–45 页,2019 年。
-
J. Van Amersfoort, L. Smith, Y. W. Teh 和 Y. Gal,“使用单一深度确定性神经网络进行不确定性估计”,发表在第 37 届国际机器学习会议论文集,PMLR,2020 年,第 9690–9700 页。
-
J. Zeng, A. Lesnikowski 和 J. M. Alvarez,“贝叶斯层定位对深度贝叶斯主动学习模型不确定性的相关性”,arXiv 预印本 arXiv:1811.12535,2018 年。
-
Jha, A.; Chandrasekaran, A.; Kim, C.; Ramprasad, R. 数据集不确定性对机器学习模型预测的影响:以聚合物玻璃转变温度为例。Model. Simul. Mater. Sci. Eng. 2019, 27, 024002。
-
Jøsang 2016 Jøsang, A. 2016. 主观逻辑:不确定性下推理的形式化方法。Springer。
-
Lele, S.R. 我们应如何量化统计推断中的不确定性?Front. Ecol. Evol. 2020, 8。
-
M. S. Ayhan 和 P. Berens, “测试时数据增强以估计深度神经网络中的异方差性随机不确定性,” 载于《医学成像与深度学习会议》,2018 年。
-
Meyer, V.R. 测量不确定性。J. Chromatogr. A 2007, 1158, 15–24。
-
Senel, O. 《填充位置的确定与相应不确定性的评估》。博士论文,德克萨斯农工大学,科利奇站,TX,美国,2009 年。
-
Siddique, T.; Mahmud, M.S. 《在不确定性下分类 fNIRS 数据:一种贝叶斯神经网络方法》 2021。在线获取: https://ieeexplore.ieee.org/document/9398971 (访问于 2021 年 11 月 20 日)
-
T. Tsiligkaridis, “通过对不确定性感知的 Dirichlet 网络的置信度估计进行故障预测,” 载于 2021 年 IEEE 国际声学、语音和信号处理会议。IEEE, 2021, 页 3525–3529。
-
Y. Feldman 和 V. Indelman, “在模型和定位不确定性下的贝叶斯视角依赖的稳健分类,” 载于 2018 年 IEEE 国际机器人与自动化会议。IEEE, 2018, 页 3221–3228。
-
Y. Gal 和 Z. Ghahramani, “Dropout 作为贝叶斯近似:在深度学习中表示模型不确定性,” 载于《国际机器学习会议》,2016 年,页 1050–1059。
Danny Butvinik 是 NICE Actimize 的首席数据科学家,提供技术和专业领导。Butvinik 是人工智能和数据科学领域的专家,具有构建数据科学愿景和向公司所有部门传达数据驱动分析的能力。Butvinik 着重于数据流中的异常检测和在线机器学习。他定期发表学术论文和研究文章。
更多相关内容
使用 Python 的欠采样技术
随着数字化环境的不断发展,来自多种来源的大量数据正在生成和捕获。虽然这些信息极具价值,但这个庞大的信息宇宙通常反映了现实世界现象的不平衡分布。不平衡数据的问题不仅仅是一个统计挑战,它对数据驱动模型的准确性和可靠性有深远的影响。
以金融行业中日益严重的欺诈检测为例。尽管我们希望避免欺诈,因为它具有极大的破坏性,但机器(甚至人类)不可避免地需要从欺诈交易的实例中学习(尽管很少见),以将其与日常合法交易区分开来。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
欺诈与非欺诈交易之间的数据分布不平衡对旨在检测这些异常活动的机器学习模型提出了重大挑战。如果不适当地处理数据不平衡,这些模型可能会倾向于将交易预测为合法,可能忽略稀有的欺诈实例。
医疗保健是另一个利用机器学习模型预测不平衡结果的领域,例如癌症或罕见的遗传疾病。这些结果发生的频率远低于其良性对手。因此,训练在这些不平衡数据上的模型更容易产生错误的预测和诊断。这样的健康预警失效违背了模型的最终目的,即早期检测疾病。
这些只是突显数据不平衡深远影响的一些例子,即一个类别显著多于另一个类别。过采样和欠采样是平衡数据集的两种标准数据预处理技术,我们将在本文中重点讨论欠采样。
让我们讨论一些流行的欠采样方法。
理解不平衡的缺点
让我们从一个说明性示例开始,以更好地理解欠采样技术的重要性。以下可视化展示了每类点的相对数量的影响,执行方式是由一个具有线性核的支持向量机。以下代码和图表参考了Kaggle notebook。
import matplotlib.pyplot as plt
from sklearn.svm import LinearSVC
import numpy as np
from collections import Counter
from sklearn.datasets import make_classification
def create_dataset(
n_samples=1000, weights=(0.01, 0.01, 0.98), n_classes=3, class_sep=0.8, n_clusters=1
):
return make_classification(
n_samples=n_samples,
n_features=2,
n_informative=2,
n_redundant=0,
n_repeated=0,
n_classes=n_classes,
n_clusters_per_class=n_clusters,
weights=list(weights),
class_sep=class_sep,
random_state=0,
)
def plot_decision_function(X, y, clf, ax):
plot_step = 0.02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(
np.arange(x_min, x_max, plot_step), np.arange(y_min, y_max, plot_step)
)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, alpha=0.4)
ax.scatter(X[:, 0], X[:, 1], alpha=0.8, c=y, edgecolor="k")
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(15, 12))
ax_arr = (ax1, ax2, ax3, ax4)
weights_arr = (
(0.01, 0.01, 0.98),
(0.01, 0.05, 0.94),
(0.2, 0.1, 0.7),
(0.33, 0.33, 0.33),
)
for ax, weights in zip(ax_arr, weights_arr):
X, y = create_dataset(n_samples=1000, weights=weights)
clf = LinearSVC().fit(X, y)
plot_decision_function(X, y, clf, ax)
ax.set_title("Linear SVC with y={}".format(Counter(y)))
上面的代码生成了四种不同分布的图,从一个高度不平衡的数据集开始,其中一个类主导了 97%的实例。第二个和第三个图分别有 93%和 69%的实例来自单个类,而最后一个图具有完全平衡的分布,即所有三个类各占三分之一的实例。以下是从最不平衡到最平衡的数据集的图。将 SVM 拟合到这些数据上时,第一幅图(高度不平衡)的超平面被推到图表的一侧,主要是因为算法对每个实例一视同仁,无论其类别如何,并尝试以最大边界分隔类。因此,靠近中心的多数黄色群体将超平面推到角落,使算法误分类少数类。
随着我们向更均衡的分布移动,算法成功地对所有感兴趣的类进行了分类。
总之,当数据集被一个或几个类主导时,结果解决方案通常会导致一个具有更高误分类率的模型。然而,随着每个类的观察分布接近均匀分布,分类器的偏差逐渐减小。
在这种情况下,对黄色点进行欠采样是解决由稀有类问题引起的模型错误的最简单方法。值得注意的是,并非所有数据集都遇到这个问题,但对于遇到这个问题的数据集来说,纠正这种不平衡是建模数据的关键初步步骤。
Imbalanced-Learn 库
我们将使用 Imbalanced-Learn Python 库(imbalanced-learn 或 imblearn)。我们可以通过 pip 安装它:
pip install -U imbalanced-learn
动手实践!
让我们讨论并实验一些最受欢迎的欠采样技术。假设你有一个二分类数据集,其中类'0'的数量远多于类'1'。
NearMiss 欠采样
NearMiss 是一种欠采样技术,通过减少接近少数类的多数类样本的数量来实现。这将通过任何使用空间分离或在两个类之间分割维度空间的算法来促进干净的分类。NearMiss 有三个版本:
NearMiss-1:与三个最近的少数类样本之间的最小平均距离的多数类样本。
NearMiss-2:与三个最远少数类样本之间的最小平均距离的多数类样本。
NearMiss-3:与每个少数类样本距离最小的多数类样本。
让我们通过一个代码示例来演示 NearMiss-1 欠采样算法:
# Import necessary libraries and modules
import numpy as np
import matplotlib.pyplot as plt
from collections import Counter
from sklearn.datasets import make_classification
from imblearn.under_sampling import NearMiss
# Generate the dataset with different class weights
features, labels = make_classification(
n_samples=1000,
n_features=2,
n_redundant=0,
n_clusters_per_class=1,
weights=[0.95, 0.05],
flip_y=0,
random_state=0,
)
# Print the distribution of classes
dist_classes = Counter(labels)
print("Before Undersampling:")
print(dist_classes)
# Generate a scatter plot of instances, labeled by class
for class_label, _ in dist_classes.items():
instances = np.where(labels == class_label)[0]
plt.scatter(features[instances, 0], features[instances, 1], label=str(class_label))
plt.legend()
plt.show()
# Set up the undersampling method
undersampler = NearMiss(version=1, n_neighbors=3)
# Apply the transformation to the dataset
features, labels = undersampler.fit_resample(features, labels)
# Print the new distribution of classes
dist_classes = Counter(labels)
print("After Undersampling:")
print(dist_classes)
# Generate a scatter plot of instances, labeled by class
for class_label, _ in dist_classes.items():
instances = np.where(labels == class_label)[0]
plt.scatter(features[instances, 0], features[instances, 1], label=str(class_label))
plt.legend()
plt.show()
将 NearMiss() 类中的 version=1 更改为 version=2 或 version=3,以使用 NearMiss-2 或 NearMiss-3 欠采样算法。
NearMiss-2 选择位于两个类别之间重叠区域核心的实例。使用 NeverMiss-3 算法时,我们观察到每个与多数类区域重叠的少数类实例最多有三个来自多数类的邻居。代码示例中的属性 n_neighbors 定义了这一点。
压缩最近邻(CNN)规则
该方法首先将多数类的一个子集视为噪声。然后,使用 1-最近邻算法来分类实例。如果多数类的实例被错误分类,则将其包含在子集中。这个过程持续进行,直到没有更多实例被包含在子集中。
from imblearn.under_sampling import CondensedNearestNeighbour
cnn = CondensedNearestNeighbour(random_state=42)
X_res, y_res = cnn.fit_resample(X, y)
Tomek 链欠采样
Tomek 链是紧密相邻的相反类别实例对。移除每对中的多数类实例可以增加两个类别之间的空间,从而促进分类过程。
from imblearn.under_sampling import TomekLinks
tl = TomekLinks()
X_res, y_res = tl.fit_resample(X, y)
print('Original dataset shape:', Counter(y))
print('Resample dataset shape:', Counter(y_res))
通过这些内容,我们已深入探讨了 Python 中欠采样技术的基本方面,涵盖了三种突出的方法:Near Miss 欠采样、压缩最近邻和 Tomek 链欠采样。
欠采样是处理机器学习中类别不平衡问题的关键数据处理步骤,并且有助于提高模型的性能和公平性。这些技术各有独特的优势,可以根据特定数据集和机器学习项目的目标进行调整。
本文提供了对欠采样方法及其在 Python 中应用的全面理解。希望这能帮助你在机器学习项目中做出明智的决策,以应对类别不平衡问题。
Vidhi Chugh** 是一位 AI 策略师和数字化转型领袖,致力于在产品、科学和工程的交汇点上构建可扩展的机器学习系统。她是一位屡获殊荣的创新领袖、作者和国际演讲者。她的使命是将机器学习民主化,并打破术语,使每个人都能参与这一转型。**
更多相关内容
理解 AI 中的代理环境
原文:
www.kdnuggets.com/2022/05/understanding-agent-environment-ai.html
AI 代理简要介绍
我们的前 3 名课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业道路
2. Google Data Analytics Professional Certificate - 提升您的数据分析技能
3. Google IT Support Professional Certificate - 支持您的组织的 IT
在开始文章之前,理解 AI 中的代理(agent)是很重要的。代理基本上是一个帮助 AI、机器学习或深度强化学习做出决策或触发 AI 做出决策的实体。从软件的角度来看,它被定义为能够做出决策并根据环境变化或从外部环境获取输入后做出不同决策的实体。代理在这些领域中的作用非常重要,因为 AI 模型的所有参数主要依赖于代理的表现。简单来说,快速感知外部变化并对其做出反应的代理,模型得到的结果就越好。因此,代理在人工智能 、机器学习和深度学习中的作用总是非常重要。AI 代理的最常见例子是 Alexa 和 Siri。因为它们都能够根据用户的请求行动,从互联网收集信息,提供解决方案,并做出相应的行动。这些代理非常智能,能够收集用户的完整信息,甚至建议与用户相关的广告和推荐。(Intelligent Agents in Artificial Intelligence | Engineering Education (EngEd) Program | Section, 2019)
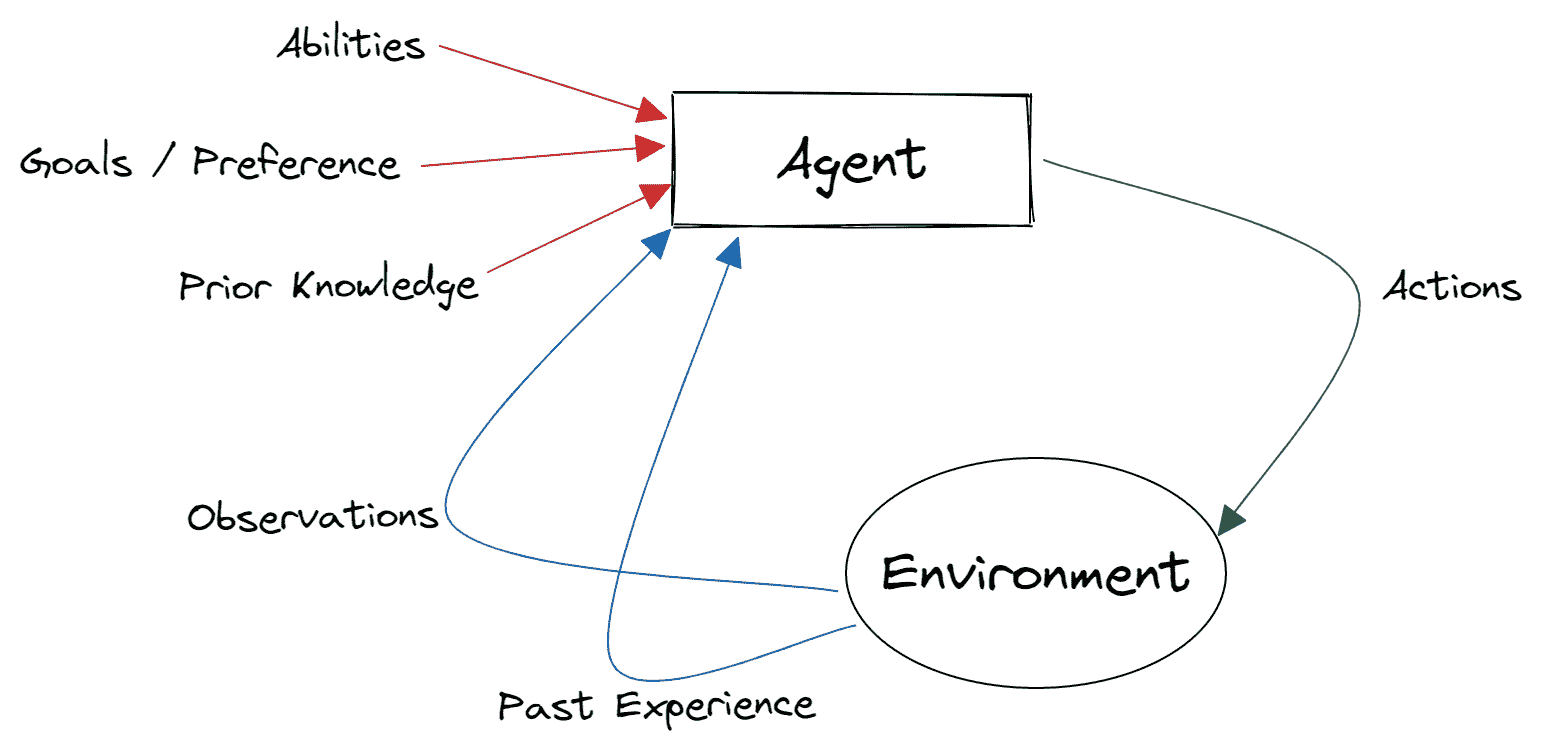
图 1. 一个闭环系统,其中系统从环境中获取一些输入,并向环境提供一些动作 | 图片来源:编辑
智能代理
智能代理是一种基于软件的程序,能够理解情况、感知环境,并根据过去的历史和常规训练来优化搜索。智能代理最重要的部分基本上是用户输入,即用户感兴趣的事物类型。智能代理的一个常见例子是 Facebook、YouTube 和 Google 上使用的代理。它们总是展示吸引用户的广告。例如,如果你想在线购买香水,并且在互联网上搜索了两到三个不同的香水店,那么在你之后的社交媒体新闻源中,你会看到与香水相关的不同广告。这些广告是因为背后有智能人工智能代理在处理所有的搜索历史和用户输入。智能代理的几种类型包括人类代理、软件代理和机器人代理。(What Is an Intelligent Agent? - Definition from WhatIs.Com, n.d.)
代理类型
在人工智能和机器学习中,存在几种类型的代理(Electronic, n.d.)。这一部分将简要讨论它们的各个类型。
-
简单反射代理是最常见的一种代理类型。它们仅根据当前感知做出反应,忽略所有的过去历史和路径。一个常见的例子是房间清洁代理,它仅在房间里有灰尘时才会工作,而不考虑过去的情况。
-
基于模型的反射代理只能部分观察环境。它们还会跟踪情况。这里的“模型”一词指的是世界上发生的事情,它有一个内部状态,基本上代表了基于模型历史的当前状态。
-
基于目标的代理不仅需要当前状态、过去状态和需要做什么。它们还需要有关目标或目的的信息。它们更具能力,因为它们根据其他机器学习技术绘制路径,以更好和更有效地达成目标。它们根据环境的情况选择行动。
-
基于效用的代理与基于目标的代理类似,但它们还有额外的责任来关注效用。它们在每一步工作中向模型提供效率和工作状态。它们通过反馈系统提供真实的效率数字,以检查系统的有效性和效率。
-
学习型代理在这方面是最智能的类型。它们从用户输入、之前的历史、环境和周围情况中学习。它们起初像传统代理一样,拥有环境的基本知识。它包含不同的组件,如学习元素,这些元素通过失败和成就来提高代理的能力。另一个组件是批评,通过它学习元素得到反馈,判断工作是否朝着正确的方向进行。第三个是性能元素;这个组件负责衡量系统的性能并保持系统的正常运作。最后一个组件是问题生成器,通过它系统将获得新的和最新的经验,并通过不断的负载工作来改进工作。 (AI 代理的类型 - Javatpoint,n.d.)
AI 代理的应用
这些代理程序应用或工作的地方是什么?这些代理程序大多数是基于软件的。它们在游戏、搜索和自动表单填写中工作。在游戏中,不同的公司为了让他们的游戏更具竞争力,使用这些基于 AI 的代理程序。这些代理程序大多数是学习型代理,类似于从用户的操作中学习的代理,通过玩大量游戏和过去的经验可以从初学者水平提升到专业水平。还有一些游戏使用了非常低级的代理程序,这些代理程序通常是简单的反射型代理,因为它们随着时间的推移没有改进,到了某个时刻,用户会对游戏感到厌倦而停止游戏。以同样的方式,这些代理程序在搜索引擎中也会工作。如观察到的,谷歌仅根据用户的搜索历史、之前的输入和过去的经验显示相关页面。这些代理程序在这种搜索中非常强大,能够非常快速地捕捉数据。 (Intelligent Agents: Characteristics and Applications | AI, n.d.)
参考文献
-
Intelligent Agents: Characteristics and Applications | AI。(n.d.)。检索于 2022 年 2 月 26 日,网址为 https://www.engineeringenotes.com/artificial-intelligence-2/intelligent-agents/intelligent-agents-characteristics-and-applications-ai/35618
-
人工智能中的智能代理 | 工程教育(EngEd)计划 | Section。(n.d.)。检索于 2022 年 2 月 26 日,网址为 https://www.section.io/engineering-education/intelligent-agents-in-ai/
-
AI 代理的类型 - Javatpoint。(n.d.)。检索于 2022 年 2 月 26 日,网址为 https://www.javatpoint.com/types-of-ai-agents
-
什么是智能代理? - Definition from WhatIs.com。(n.d.)。检索于 2022 年 2 月 26 日,网址为 https://www.techtarget.com/searchenterpriseai/definition/agent-intelligent-agent
Neeraj Agarwal 是 Algoscale 的创始人,该公司是一家涵盖数据工程、应用 AI、数据科学和产品工程的数据咨询公司。他在这一领域拥有超过 9 年的经验,帮助了从初创公司到财富 100 强的各种组织处理和存储大量原始数据,以将其转化为可操作的洞察,从而促进更好的决策和更快的业务价值。
更多相关主题
理解和实现 Python 中的遗传算法
原文:
www.kdnuggets.com/understanding-and-implementing-genetic-algorithms-in-python
图片来源:作者 遗传算法是基于自然选择的技术,用于解决复杂问题。由于问题复杂,遗传算法相比其他方法能提供合理的解决方案。本文将介绍遗传算法的基本概念及如何在 Python 中实现它们。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
遗传组件
适应度函数
适应度函数评估考虑的解决方案与问题的最佳解决方案之间的接近程度。它为种群中的每个人提供一个适应度水平,这描述了当前世代的质量或效率。这个分数定义了选择标准,而较高的适应度值则意味着更优的解决方案。
比如,假设我们处理一个实际函数 f(x),其中 x 是一组参数。我们要找到的最优值是 x,使得 f(x) 取得最大值。
选择
这是一个定义在当前世代中哪些个体应被优先选择,从而繁殖并贡献给下一代的过程。可以识别出多种选择方法,每种方法都有其自身的特点和适用的背景。
-
轮盘赌选择:
根据个体的适应度水平,选择该个体的概率也是最大化的。
-
锦标赛选择:
随机选择一组个体,并选择其中最优秀的个体。
-
基于排名的选择:
人员根据适应度排序,并按适应度分配选择机会。
交叉
交叉是遗传算法的基本概念,旨在交换两个父本个体的遗传信息以形成一个或多个后代。这个过程与自然界中生物学上的交叉和重组非常相似。应用遗传学的基本原则,交叉尝试生成具有父本优良特征的后代,从而在下一代中具有更好的适应性。交叉是一个相对广泛的概念,可以分为几种类型,每种类型都有其特性和有效应用的领域。
-
单点交叉:在父染色体上选择一个交叉点,只发生一次交叉。在此位置之前的所有基因来自第一个父本,从此位置开始的所有基因来自第二个父本。
-
双点交叉:选择两个断点,并在它们之间的部分在两个父染色体之间交换。这也比单点交叉更有利于遗传信息的交换。
突变
在遗传算法中,突变具有至关重要的意义,因为它提供了多样性,这在避免直接收敛到最优解区域时是一个关键因素。因此,通过单独的交叉操作无法到达的解空间其他区域,突变的随机变化使算法能够进入。这种随机过程确保无论如何,群体会进化或在遗传算法确定的最优搜索空间区域内移动。
实现遗传算法的步骤
让我们尝试在 Python 中实现遗传算法。
问题定义
问题:计算特定函数;f(x) = x²;仅整数值的 x。
适应度函数:对于一个二进制染色体 x,适应度函数的一个例子可以是 f(x)= x²。
def fitness(chromosome):
x = int(''.join(map(str, chromosome)), 2)
return x ** 2
群体初始化
生成一个给定长度的随机染色体。
def generate_chromosome(length):
return [random.randint(0, 1) for _ in range(length)]
def generate_population(size, chromosome_length):
return [generate_chromosome(chromosome_length) for _ in range(size)]
population_size = 10
chromosome_length = 5
population = generate_population(population_size, chromosome_length)
适应度评估
评估群体中每个染色体的适应度。
fitnesses = [fitness(chromosome) for chromosome in population]
选择
使用轮盘赌选择法根据适应度选择父染色体。
def select_pair(population, fitnesses):
total_fitness = sum(fitnesses)
selection_probs = [f / total_fitness for f in fitnesses]
parent1 = population[random.choices(range(len(population)), selection_probs)[0]]
parent2 = population[random.choices(range(len(population)), selection_probs)[0]]
return parent1, parent2
交叉
通过选择父染色体字符串中的随机交叉位置,并交换此位置之后的所有基因值,来使用单点交叉。
def crossover(parent1, parent2):
point = random.randint(1, len(parent1) - 1)
offspring1 = parent1[:point] + parent2[point:]
offspring2 = parent2[:point] + parent1[point:]
return offspring1, offspring2
突变
通过以一定概率翻转比特来实现突变。
def mutate(chromosome, mutation_rate):
return [gene if random.random() > mutation_rate else 1 - gene for gene in chromosome]
mutation_rate = 0.01
总结
总结来说,遗传算法由于模拟物种进化的过程,对于解决那些无法直接解决的优化问题是稳定且高效的。因此,一旦你掌握了遗传算法的基本原理,并理解如何在 Python 中应用它们,复杂任务的解决将变得更加容易。选择、交叉和变异的关键使你能够在解决方案中进行修改,并不断获得最佳或接近最佳的答案。阅读了这篇文章,你已准备好将遗传算法应用于自己的任务,从而在不同任务和问题解决中取得进展。
Jayita Gulati 是一位机器学习爱好者和技术写作者,她对构建机器学习模型充满热情。她拥有利物浦大学的计算机科学硕士学位。
更多相关主题
使用 Hugging Face 理解 BERT
原文:
www.kdnuggets.com/2021/07/understanding-bert-hugging-face.html
评论

使用 BERT 和 Hugging Face 创建问答模型
在最近的一篇关于BERT的文章中,我们讨论了 BERT 转换器及其基本工作原理。文章涵盖了 BERT 的架构、训练数据和训练任务。
然而,我们在真正实现之前并不了解某些东西。所以在这篇文章中,我们将使用 BERT 和 Hugging Face 库实现一个问答神经网络。
什么是问答任务?
在这个任务中,我们给定一个问题和一个段落,其中包含答案的段落是我们的BERT 架构,目标是确定答案在段落中的起始和结束跨度。
BERT 微调问答任务示意图
正如上一篇文章中所解释的,在上述示例中,我们向 BERT 架构提供两个输入。段落和问题通过
我们现在定义两个向量 S 和 E(在微调过程中将被学习),它们的形状为 (1x768)。然后我们将这些向量与 BERT 的第二句输出向量进行点积,得到一些分数。我们随后对这些分数应用 Softmax 以获得概率。训练目标是正确起始和结束位置的对数似然的总和。在数学上,对于起始位置的概率向量:

其中 T_i 是我们关注的词。结束位置的公式是类似的。
为了预测一个跨度,我们获取所有的分数 — S.T 和 E.T,并选择得分最高的跨度,即在所有 j≥i 中最大化(S.T_i + E.T_j)的跨度。
我们如何使用 Hugging Face 实现这一点?
Hugging Face 提供了一种相当直接的方法来实现这一点。
输出是:
Question: How many pretrained models are available in Transformers?
Answer: over 32 +
Question: What do Transformers provide?
Answer: general purpose architectures
Question: Transformers provide interoperability between which frameworks?
Answer: TensorFlow 2\. 0 and PyTorch
因此,我们仅使用了 Hugging Face 提供的SQuAD 数据集上的预训练分词器和模型来完成这个任务。
tokenizer = AutoTokenizer.from_pretrained(“bert-large-uncased-whole-word-masking-finetuned-squad”)
model = AutoModelForQuestionAnswering.from_pretrained(“bert-large-uncased-whole-word-masking-finetuned-squad”)
一旦我们有了模型,我们只需获取起始和结束概率分数,并预测跨度为起始分数最高的 token 和结束分数最高的 token 之间的那个跨度。
例如,如果段落的起始分数是:
...
Transformers - 0.1
are - 0.2
general - 0.5
purpose - 0.1
architectures -0.01
(BERT - 0.001
...
而结束分数是:
...
Transformers - 0.01
are - 0.02
general - 0.05
purpose - 0.01
architectures -0.01
(BERT - 0.8
...
我们将得到输出为 input_ids[answer_start:answer_end],其中 answer_start 是词“general”(最大开始分数的词)的索引,answer_end 是 BERT(最大结束分数的词)的索引。答案将是“general purpose architectures”。
使用问答数据集微调我们自己的模型
在大多数情况下,我们将希望在自己的数据集上训练自己的 QA 模型。在这种情况下,我们将从 SQuAD 数据集和 Hugging Face 库中的基础 BERT 模型开始进行微调。
让我们看看在开始微调之前,SQuAD 数据集的样子:
Context:Within computer systems, two of many security models capable of enforcing privilege separation are access control lists (ACLs) and capability-based security. Using ACLs to confine programs has been proven to be insecure in many situations, such as if the host computer can be tricked into indirectly allowing restricted file access, an issue known as the confused deputy problem. It has also been shown that the promise of ACLs of giving access to an object to only one person can never be guaranteed in practice. Both of these problems are resolved by capabilities. This does not mean practical flaws exist in all ACL-based systems, but only that the designers of certain utilities must take responsibility to ensure that they do not introduce flaws. [citation needed]
Question:The confused deputy problem and the problem of not guaranteeing only one person has access are resolved by what?
Answer:['capabilities']
Answer Start in Text:[553]
--------------------------------------------------------------------
Context:In recent years, the nightclubs on West 27th Street have succumbed to stiff competition from Manhattan's Meatpacking District about fifteen blocks south, and other venues in downtown Manhattan.
Question:How many blocks south of 27th Street is Manhattan's Meatpacking District?
Answer:['fifteen blocks']
Answer Start in Text:[132]
--------------------------------------------------------------------
我们可以看到每个示例包含上下文、答案和答案的开始标记。我们可以使用下面的脚本将数据预处理为所需的格式。一旦我们拥有上述格式的数据,脚本将处理很多事情,其中最重要的是答案在 max_length 附近的情况以及使用答案和开始标记索引计算跨度。
一旦我们获得了所需格式的数据,我们就可以从那里对我们的 BERT 基础模型进行微调。
model_checkpoint = "bert-base-uncased"
model = AutoModelForQuestionAnswering.from_pretrained(model_checkpoint)
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)tokenized_datasets = datasets.map(prepare_train_features, batched=True, remove_columns=datasets["train"].column_names)args = TrainingArguments(
f"test-squad",
evaluation_strategy = "epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
)data_collator = default_data_collator
trainer = Trainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
)trainer.train()
trainer.save_model(trainer.save_model("test-squad-trained"))
微调 BERT 基础模型的输出
一旦我们训练了模型,我们可以这样使用它:
在这种情况下,我们也取最大开始分数和最大结束分数的索引,并预测答案为它们之间的内容。如果我们想获得 BERT 论文中提供的精确实现,我们可以稍微调整上述代码,找出最大化(start_score + end_score)的索引。

模型训练中的代码输出
参考文献
-
Attention Is All You Need:介绍 Transformer 的论文。
-
BERT 论文:请阅读这篇论文。
在这篇文章中,我介绍了如何从零开始使用 BERT 创建一个问答模型。我希望这对理解 BERT 以及 Hugging Face 库都很有用。
如果你想查看本系列中的其他文章,可以查看这些:
我们将来会写更多类似的主题,所以请告诉我们你的想法。我们应该写一些技术性很强的主题,还是更偏向于初学者水平?评论区是你的朋友,使用它吧。
原文。经允许转载。
相关:
-
学习实用 NLP 的最佳方法?
-
如何使用 T5 Transformer 生成有意义的句子
-
如何通过 API 创建和部署简单的情感分析应用
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
相关主题
3 分钟了解偏差-方差权衡
原文:
www.kdnuggets.com/2020/09/understanding-bias-variance-trade-off-3-minutes.html

平衡它们就像魔法一样
我们的前三大课程推荐
1. Google 网络安全证书 - 加快你的网络安全职业发展。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 在 IT 领域支持你的组织
偏差和方差是训练机器学习模型时需要调整的核心参数。
当我们讨论预测模型时,预测错误可以分解为两个主要子组件:偏差导致的错误和方差导致的错误。
偏差-方差权衡是偏差引入的错误与方差产生的错误之间的张力。为了理解如何充分利用这一权衡,避免模型欠拟合或过拟合,我们首先学习偏差和方差。
由于偏差导致的错误
由于偏差导致的错误是模型的预测值与真实值之间的距离。在这种错误中,模型对训练数据关注较少,过于简单化模型,不学习模式。模型通过未考虑所有特征而学习错误的关系。
由于方差导致的错误
对于给定数据点或值的模型预测的变异性是告诉我们数据的分布情况。在这种错误中,模型对训练数据过度关注,甚至到记住它而不是从中学习的程度。具有高方差错误的模型无法对未见过的数据进行有效的泛化。
如果偏差与方差是阅读行为,它可以像略读文本与逐字记忆文本之间的区别。
我们希望我们的机器模型从其接触的数据中学习,而不是“对它有一个大致的了解”或“逐字记忆”。
偏差—方差权衡
偏差-方差权衡是关于平衡和找到一个最佳点,在偏差导致的错误和方差导致的错误之间。
这是一个欠拟合与过拟合的困境
图由 Jake VanderPlas 绘制
如果模型用灰色线表示,我们可以看到,高偏差模型是一个过于简单化数据的模型,而高方差模型是一个过于复杂以至于过拟合数据的模型。
简而言之:
-
偏差是模型为了使目标函数更容易逼近而做出的简化假设。
-
方差是指在不同的训练数据下,目标函数估计值的变化量。
-
偏差-方差权衡是我们的机器模型在偏差和方差引入的误差之间表现最佳的甜蜜点。
在这篇文章中,我们讨论了 偏差和方差的概念含义。接下来,我们将探索该概念在*代码中的应用。
未来阅读
布伦达·哈利 (LinkedIn) 是一位驻华盛顿特区的市场数据专家。她热衷于推动女性在科技和数据领域的参与。
原文。转载已获许可。
更多相关话题
理解箱型图
评论
由 Michael Galarnyk,数据科学家
箱型图的不同部分
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域的职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
上面的图像是一个箱型图。箱型图是一种基于五数概括(“最小值”,第一四分位数(Q1),中位数,第三四分位数(Q3),和“最大值”)显示数据分布的标准化方式。它可以告诉你关于离群值及其数值的信息。它还可以告诉你数据是否对称,数据的集中程度,以及数据是否及如何偏斜。
本教程将包括:
-
什么是箱型图?
-
通过将箱型图与正态分布的概率密度函数进行比较,来理解箱型图的结构。
-
如何使用 Python 制作和解释箱型图?
一如既往,用于制作图表的代码可以在我的github上找到。好了,开始吧!
什么是箱型图?
对于一些分布/数据集,你会发现你需要比中心趋势的度量(中位数、均值和众数)更多的信息。
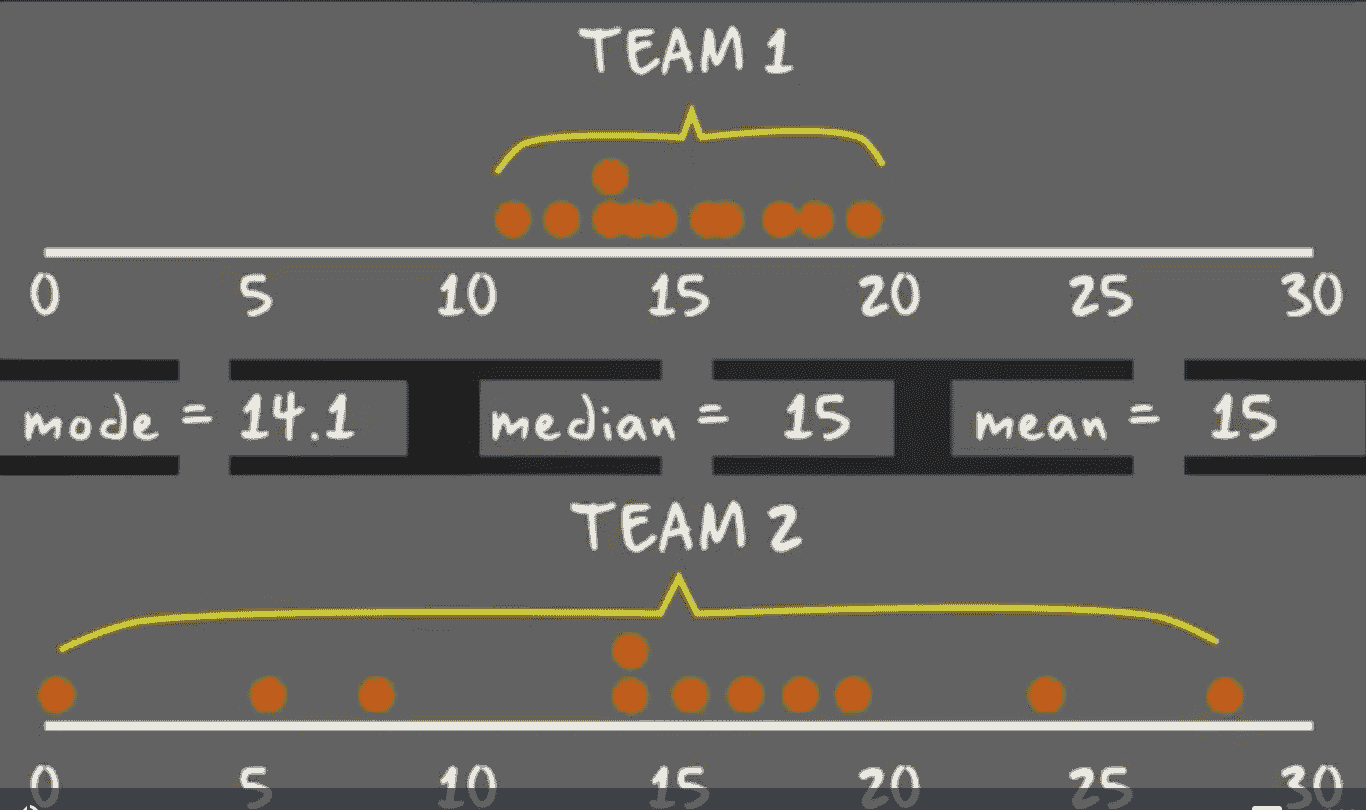
有时,仅凭均值、中位数和众数不足以描述数据集(摘自这里)。
你需要了解数据的变异性或离散性。箱型图是一种图形,能很好地指示数据值的分布情况。尽管与直方图或密度图相比,箱型图可能显得有些原始,但它们的优点是占用空间较少,这在比较多个组或数据集之间的分布时非常有用。
箱型图的不同部分
箱型图是一种基于五数概括(“最小值”,第一四分位数(Q1),中位数,第三四分位数(Q3),和“最大值”)显示数据分布的标准化方式。
中位数(Q2/50th Percentile):数据集的中间值。
第一四分位数(Q1/25th Percentile):数据集中最小值(不是“最小值”)和中位数之间的中间数。
第三四分位数(Q3/75th Percentile):中位数与数据集的最高值(不是“最大值”)之间的中间值。
四分位距(IQR):第 25 百分位到第 75 百分位。
须线(以蓝色表示)
异常值(以绿色圆圈表示)
“最大值”:Q3 + 1.5*IQR
“最小值”:Q1 - 1.5*IQR
目前“异常值”、“最小值”或“最大值”的定义可能还不清楚。接下来的部分将尝试为你澄清这些定义。
正态分布上的箱线图
接近正态分布的箱线图与正态分布的概率密度函数(pdf)比较
上图是接近正态分布的箱线图与正态分布的概率密度函数(pdf)的比较。我展示这个图的原因是,查看统计分布比查看箱线图更为常见。换句话说,它可能有助于你理解箱线图。
本部分将涵盖许多内容,包括:
-
异常值占正态分布数据的 0.7%。
-
什么是“最小值”和“最大值”
概率密度函数
这部分内容与68–95–99.7 规则文章非常相似,但经过了针对箱线图的调整。为了理解这些百分比的来源,了解概率密度函数(PDF)是很重要的。PDF 用于指定随机变量在特定范围内的概率,而不是取任何一个值。这种概率由该变量的 PDF 在该范围内的积分给出——即由密度函数下方、水平轴上方以及范围内的最低值和最大值之间的面积给出。这个定义可能不太容易理解,让我们通过绘制正态分布的概率密度函数来澄清这一点。下面的方程是正态分布的概率密度函数。
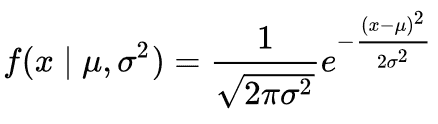
正态分布的 PDF
我们通过假设均值(μ)为 0,标准差(σ)为 1 来简化这个问题。
正态分布的 PDF
这可以使用任何工具绘制,但我选择用 Python 来绘制。
# Import all libraries for this portion of the blog post
from scipy.integrate import quad
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inlinex = np.linspace(-4, 4, num = 100)
constant = 1.0 / np.sqrt(2*np.pi)
pdf_normal_distribution = constant * np.exp((-x**2) / 2.0)
fig, ax = plt.subplots(figsize=(10, 5));
ax.plot(x, pdf_normal_distribution);
ax.set_ylim(0);
ax.set_title('Normal Distribution', size = 20);
ax.set_ylabel('Probability Density', size = 20);
上图并未显示事件的 概率,而是它们的 概率密度。要获取在给定范围内的事件概率,我们需要进行积分。假设我们感兴趣的是找到一个随机数据点落在四分位距内(均值的 0.6745 标准差)的概率,我们需要从 -0.6745 到 0.6745 积分。这可以通过 SciPy 实现。
# Make PDF for the normal distribution a function
def normalProbabilityDensity(x):
constant = 1.0 / np.sqrt(2*np.pi)
return(constant * np.exp((-x**2) / 2.0) )# Integrate PDF from -.6745 to .6745
result_50p, _ = quad(normalProbabilityDensity, -.6745, .6745, limit = 1000)
print(result_50p)
对于“最小值”和“最大值”也可以做同样的操作。
# Make a PDF for the normal distribution a function
def normalProbabilityDensity(x):
constant = 1.0 / np.sqrt(2*np.pi)
return(constant * np.exp((-x**2) / 2.0) )# Integrate PDF from -2.698 to 2.698
result_99_3p, _ = quad(normalProbabilityDensity,
-2.698,
2.698,
limit = 1000)
print(result_99_3p)
如前所述,异常值占数据的剩余 0.7%。
需要注意的是,对于任何 PDF,曲线下的面积必须为 1(从函数的范围内绘制任何数字的概率始终为 1)。
绘制和解释箱线图
免费预览 视频 来自 使用 Python 进行数据可视化课程
本节内容主要基于来自我的 Python 数据可视化课程 的免费预览 视频。在上一节中,我们讨论了正态分布上的箱线图,但显然你不总是会有一个基础的正态分布,让我们讨论一下如何在真实数据集上利用箱线图。为此,我们将利用 乳腺癌威斯康星(诊断)数据集。如果你没有 Kaggle 帐户,可以从 我的 GitHub 下载数据集。
读取数据
以下代码将数据读入 pandas dataframe。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt# Put dataset on my github repo
df = pd.read_csv('https://raw.githubusercontent.com/mGalarnyk/Python_Tutorials/master/Kaggle/BreastCancerWisconsin/data/data.csv')
绘制箱线图
下图的箱线图用于分析分类特征(恶性或良性肿瘤)和连续特征(area_mean)之间的关系。
有几种方法可以通过 Python 绘制箱线图。你可以通过 seaborn、pandas 或 seaborn 绘制箱线图。
seaborn
以下代码将 pandas dataframe df 传递给 seaborn 的 boxplot。
sns.boxplot(x='diagnosis', y='area_mean', data=df)
matplotlib
你在这篇文章中看到的箱线图是通过 matplotlib 制作的。这种方法可能更加繁琐,但可以提供更高的控制级别。
malignant = df[df['diagnosis']=='M']['area_mean']
benign = df[df['diagnosis']=='B']['area_mean']fig = plt.figure()
ax = fig.add_subplot(111)
ax.boxplot([malignant,benign], labels=['M', 'B'])
通过一点努力,你可以让这个图形变得更美观
pandas
你可以通过在 DataFrame 上调用 .boxplot() 来绘制箱线图。以下代码绘制了 area_mean 列相对于不同诊断的箱线图。
df.boxplot(column = 'area_mean', by = 'diagnosis');
plt.title('')
有缺口的箱线图
带刻度线的箱线图允许你评估每个箱线图中位数的置信区间(默认 95% 置信区间)。
malignant = df[df['diagnosis']=='M']['area_mean']
benign = df[df['diagnosis']=='B']['area_mean']fig = plt.figure()
ax = fig.add_subplot(111)
ax.boxplot([malignant,benign], notch = True, labels=['M', 'B']);
还不是最美的。
解读箱线图
数据科学涉及结果的沟通,所以请记住,你总是可以通过一些额外的工作让你的箱线图变得更漂亮(代码 这里)。
使用图表,我们可以比较恶性和良性诊断的 area_mean 范围和分布。我们观察到恶性肿瘤的 area_mean 变异性更大,以及更大的离群值。
此外,由于箱线图中的刻度线没有重叠,你可以得出结论,95% 的置信度下真实中位数确实存在差异。
关于箱线图,还需要注意以下几点:
-
请记住,你总是可以 提取箱线图的数据,以便了解箱线图中不同部分的数值。
-
Matplotlib 不 会先估计正态分布,并根据估计的分布参数计算四分位数。中位数和四分位数直接从数据中计算。换句话说,你的箱线图可能会因数据分布和样本大小的不同而有所不同,例如,可能不对称,或有更多或更少的离群值。
结论
希望这些关于箱线图的信息不是太多。未来的教程将利用这些知识来讲解如何应用于理解置信区间。我的下一个教程讲解了 如何使用和创建 Z 表(标准正态表)。如果你对教程有任何问题或想法,请随时在下面的评论中、通过 YouTube 视频页面 或通过 Twitter 联系我。
简介: Michael Galarnyk 是一名数据科学家和企业培训师。他目前在斯克里普斯转化研究所工作。你可以在 Twitter (https://twitter.com/GalarnykMichael)、Medium (https://medium.com/@GalarnykMichael) 和 GitHub (https://github.com/mGalarnyk) 上找到他。
原文。已获许可转载。
相关内容:
-
数据科学技能的 4 个象限和创建病毒式数据可视化的 7 个原则
-
如何构建数据科学投资组合
-
Python 中用于分类的决策树理解
更多相关话题
使用机器学习理解癌症
原文:
www.kdnuggets.com/2019/08/understanding-cancer-machine-learning.html
评论
(来源: news.developer.nvidia.com/wp-content/uploads/2016/06/DL-Breast-Cancer-Detection-Image.png)
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
介绍
正如许多研究者所示[1, 2],机器学习(ML)在医学中的应用日益重要。研究者们现在在诸如脑电图分析和癌症检测/分析等应用中使用 ML。例如,通过检查生物数据,如 DNA 甲基化和 RNA 测序,可以推断出哪些基因可能引发癌症,哪些基因则可能抑制癌症的表达。在这篇文章中,我将带你了解我如何分析关于 TCGA 肝癌、宫颈癌和结肠癌的 9 个不同数据集。所有数据集均由 UCSC Xena(加州大学圣克鲁斯分校网站)提供。对于这三种不同类型的癌症,每种使用了三个数据集,包括 DNA 甲基化(Methylation450k)、基因表达 RNAseq(IlluminaHiSeq)和外显子表达 RNAseq(IlluminaHiSeq)。这些数据集按信息类型而非癌症分类。选择这些数据集是因为它们具有共同的特征,并且样本数量相似。此外,我选择这些癌症类型,因为它们提供了关于人体基因和染色体特征的多样视角,因为不同的癌症位于身体的不同部位。这样,本文获得的分类结果可以推广到其他形式的癌症。DNA 甲基化在基因表达调控中发挥重要作用,其变化可能导致癌细胞的产生或抑制[3]。
分类
每个数据集都必须进行转置和预处理。在形成最终的三个数据集后,进行了不同类型癌症的分类。为了产生这些结果,使用了 70%的训练和 30%的测试分割比例。如表 1 所示,考虑了许多分类算法。这些结果是利用整个数据集获得的,分类器旨在正确区分三种不同类型的癌症。

特征提取
我对这 3 个给定的数据集进行了主成分分析(PCA),以观察仅使用前两个主成分(表 2)如何影响分类准确率结果。PCA 旨在降低数据集的维度,同时尽可能保留方差。从表 2 可以看出,将数据维度减少到仅两个特征并没有导致准确率的急剧下降。

图 1 提供了使用逻辑回归的 PCA 分类结果,两个坐标轴表示 PCA 创建的两个主成分。外显子表达数据集似乎受到 PCA 的影响最大,准确率最高为 65%。这一结果的原因是不同类别之间的主要重叠,这在图 1(c)中展示了出来。
最后,我决定应用另一种特征提取技术,如 t-SNE。这项技术可以将高维数据可视化为低维空间,从而最大限度地分隔不同类别。结果显示在图 2 中,两个坐标轴代表 t-SNE 生成的两个主要组件。三种不同类型的癌症分别用不同颜色标记(TCGA Liver = 0, Cervical = 1, Colon = 2)。如图 2 所示,t-SNE 创建了两个特征,能够较好地分隔这三种不同的类别。
特征选择
前面的章节显示,使用整个数据集可以取得非常好的分类结果。使用 PCA 和 t-SNE 等特征提取技术,已经证明可以在减少维度的同时仍然获得令人满意的分类分数。鉴于这些结果,我决定绘制一个决策树,表示分类中使用的主要特征(权重最大的特征),以便更详细地查看最重要的特征。我决定使用决策树进行分析,因为它在所有三个数据集中的分类性能都很好。结果可以在图 3(DNA 甲基化)、图 4(基因表达)和图 5(外显子表达)中看到。
在这些图形中,不同的癌症类型用不同的颜色表示(TCGA Liver = 0, Cervical = 1, Colon = 2)。所有三种癌症的特征分布在树的起始节点中表示。只要我们沿着每个分支向下移动,算法就会尝试使用每个节点图下方描述的特征来最佳地分离不同的分布。与分布一起生成的圆圈表示在跟随某个节点之后正确分类的元素数量,元素数量越多,圆圈的大小也越大。
为了生成这些图形,我使用了 Terence Parr 和 Prince Grover 创建的 dtreeviz.trees 库。我决定使用这个库,因为它使我能够可视化树中每个分支的特征分布。这在生物学领域尤其重要,尤其是在分析类别差异和观察算法如何做出分类决策时。
评估
表 3 总结了三棵不同树顶端(前两层)使用的特征。在仔细研究和查阅在线数据库后,为每个特征添加了一系列相关注释(表 3)。对于 cg27427318 和 chr10:81374338–81375201,则无法找到任何相关信息。
从分析的特征中推断出的最有趣的一些结果是:
-
PFN3 已被确认是与 cg06105778 最接近的基因。根据 Li Zou、Zhijie Ding 等人在 2010 年进行的研究,Profilins(Pfns)可能被归类为乳腺癌中的肿瘤抑制蛋白[4]。
-
根据 Noel J. Aherne、Guhan Rangaswamy 等人的《Holt-Oram 综合征男性前列腺癌:TBX5 突变的首次临床关联》,TBX5 基因“在突变时被认为会上调肿瘤细胞增殖和转移”[5]。另一项由 Yu J、Ma X 等人进行的研究则表明,TBX5 突变的结肠癌患者生存率要低得多[6]。
-
Alexa Hryniuk、Stephanie Grainger 等人进行的研究强调,“Cdx1 丧失导致远端结肠肿瘤发生率显著增加”[7]。
使用仅在表 3 中列出的特征,我最终决定使用主成分分析(PCA)和线性判别分析(LDA)将数据降到仅两个维度,并进行朴素贝叶斯(NB)和支持向量机(SVM)分类,以查看数据的方差覆盖了多少。结果见表 4,表明使用仅来自数据集的最重要特征得到了出色的分类结果(感谢降噪)。在所有考虑的情况下,原始数据方差的 83%至 99%被保留。

结论
总体而言,这个项目取得了非常好的结果。作为进一步的开发,尝试递归特征选择(RFS)或支持向量机(SVM)(如我另一篇文章中所述)等替代特征选择技术将是有趣的,以查看是否可以识别出其他类型的基因/染色体。另一个可能的改进是使用包含健康受试者数据的数据集进行交叉验证,以验证获得的结果。
我想感谢Adam Prugel-Bennett 教授给予我进行这个项目的机会。
联系方式
如果你想了解我最新的文章和项目,请在 Medium 上关注我 follow me on Medium 并订阅我的 邮件列表。以下是我的一些联系方式:
参考文献
[1] Viridiana Romero Martinez。《使用深度学习检测乳腺癌的组织病理图像》。访问地址: https://medium.com/datadriveninvestor/detecting-breast-cancer-in-histopathological-images-using-deeplearning-a66552aef98, 2019 年 4 月。
[2] Hu Zilonga, Tang Jinshan, 等人。《基于图像的癌症检测与诊断的深度学习:综述》。访问地址: https://www.sciencedirect.com/science/article/abs/pii/S0031320318301845, 2019 年 5 月。
[3] Luczak MW, Jagodzi´nski PP。《DNA 甲基化在癌症发展中的作用》。访问地址: https://www.ncbi.nlm.nih.gov/pubmed/16977793, 2019 年 5 月。
[4] Li Zou, Zhijie Ding, 和 Partha Roy。Profilin-1 的过度表达通过部分上调 p27kip1 抑制 MDA-MB-231 乳腺癌细胞的增殖,访问地址: www.ncbi.nlm.nih.gov/pmc/articles/PMC2872929/pdf/nihms-202017.pdf,2019 年 5 月。
[5] Noel J. Aherne, Guhan Rangaswamy 和 Pierre Thirion。Holt-Oram 综合症男性中的前列腺癌:TBX5 突变的首次临床关联,访问地址: www.hindawi.com/journals/criu/2013/405343/,2019 年 5 月。
[6] Yu J, Ma X 等。T-box 转录因子 5 的表观遗传失活,这是一种新的肿瘤抑制基因,与结肠癌相关。访问地址: https://www.ncbi.nlm.nih.gov/pubmed/20802524,2019 年 5 月。
[7] Alexa Hryniuk, Stephanie Grainger 等。Cdx1 和 Cdx2 作为肿瘤抑制因子。访问地址: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4246091/,2019 年 5 月。
感谢 Ludovic Benistant。
简介: Pier Paolo Ippolito 是一名数据科学家,获得南安普顿大学人工智能硕士学位。他对 AI 进展和机器学习应用(如金融和医学)有着浓厚的兴趣。可以通过 Linkedin 与他联系。
原文。经许可转载。
相关:
-
使用深度学习检测乳腺癌
-
医疗数据的长尾
-
使用 K-近邻分类心脏病
更多相关话题
理解集中趋势
原文:
www.kdnuggets.com/2023/05/understanding-central-tendency.html
图片由编辑提供
集中趋势是数据围绕一个特征值分布的属性。在数据科学和统计学中,两个最重要的集中趋势度量是均值和中位数。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
均值
对于具有 N 个观察值的数据集,均值通过将所有数据值相加然后除以 N 来计算。均值计算简单,但对数据集中离群值的存在非常敏感。
中位数
中位数是一个重要的集中趋势度量,不容易受到离群值的影响。数据集的中位数可以通过对数据集进行排序,然后确定中间值来确定,使得数据集的 50%值小于中位数,50%值大于中位数。
计算数据集的均值和中位数
为了说明集中趋势的概念,我们计算了两个数据集的均值和中位数。第一个数据集是一个没有离群值的样本数据集,第二个数据集是一个包含离群值的样本数据集。
import numpy as np
import matplotlib.pyplot as plt
# generate some random data
np.random.seed(1)
data1 = np.random.uniform(0,10, 1000)
data2 = np.append(data1, np.linspace(150,200,100))
data2 = np.append(data2, np.linspace(15,25,10))
data = list([data1, data2])
fig, ax = plt.subplots()
# build a box plot
ax.boxplot(data)
ax.set_ylim(0,25)
xticklabels=['sample data', 'sample data with outliers']
ax.set_xticklabels(xticklabels)
# add horizontal grid lines
ax.yaxis.grid(True)
# show the plot
plt.show()
箱线图显示了有和没有离群值的样本数据。小的空心圆点表示离群值。图片由作者提供。
# mean and median of sample data with no outliers
np.mean(data1)
>>> 5.006045994559051
np.median(data1)
>>> 5.075008116147119
# mean and median of sample data with outliers
np.mean(data2)
>>> 20.455897292395537
np.median(data2)
>>> 5.565300519330409
我们观察到,第二个数据集中离群值的存在导致均值从 5.006 增加到 20.45,而中位数从 5.075 到 5.565 的变化相对较小。这表明中位数是一个稳健的集中趋势度量,因为它不容易受到数据集中离群值的影响。
总结
总结来说,我们回顾了计算集中趋势的两个最重要的指标。均值计算简单,但对数据集中离群值的存在非常敏感。中位数是一个稳健的集中趋势度量,并且不易受到离群值的影响。
本杰明·O·塔约 是一位物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的拥有者。此前,本杰明曾在中央俄克拉荷马大学、大峡谷大学和匹兹堡州立大学教授工程学和物理学。
更多相关内容
理解分类指标:评估模型准确性的指南
原文:
www.kdnuggets.com/understanding-classification-metrics-your-guide-to-assessing-model-accuracy

作者图像
动机
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
评估指标就像我们用来理解机器学习模型表现的测量工具。它们帮助我们比较不同的模型,并找出哪一个最适合特定任务。在分类问题的世界中,有一些常用的指标来查看模型的表现,了解哪个指标适合我们的具体问题是很重要的。当我们掌握每个指标的细节时,就能更容易决定哪个指标符合我们任务的需求。
在本文中,我们将探讨分类任务中使用的基本评估指标,并检查在某些情况下,某一指标可能比其他指标更相关。
基本术语
在深入探讨评估指标之前,了解与分类问题相关的基本术语是至关重要的。
真实标签:这些是我们数据集中每个示例对应的实际标签。这些标签是所有评估的基础,预测值与这些值进行比较。
预测标签:这些是使用机器学习模型为数据集中每个示例预测的类别标签。我们使用各种评估指标将这些预测与真实标签进行比较,以计算模型是否能够学习数据中的表示。
现在,让我们仅考虑一个二分类问题以便于理解。由于数据集中只有两种不同的类别,将真实标签与预测标签进行比较可能会产生以下四种结果,如图示所示。
作者图像:使用 1 表示正标签,0 表示负标签,预测结果可以分为四个类别。
真阳性: 模型在实际标签为正类时也预测为正类。这是所需的行为,因为模型能够成功预测正类标签。
假阳性: 模型预测为正类标签时,实际标签是负类。模型错误地将数据样本识别为正类。
假阴性: 模型对正类样本预测为负类。模型错误地将数据样本识别为负类。
真阴性: 所需的行为也是如此。模型正确地识别负类样本,对数据样本进行预测为 0 时,实际标签也是 0。
现在,我们可以在这些术语的基础上理解常见评估指标的工作原理。
准确度
这是评估分类问题中模型性能最简单却直观的方式。它衡量模型正确预测的总标签的比例。
因此,准确度可以按如下方式计算:
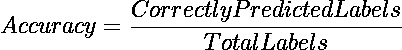
或
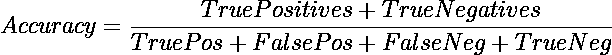
使用时机
- 初始模型评估
由于其简单性,准确度是一个广泛使用的指标。它提供了一个良好的起点,用于验证模型是否能够很好地学习,然后再使用特定于我们问题领域的指标。
- 平衡数据集
准确度仅适用于所有类别标签比例相似的平衡数据集。如果情况并非如此,且某一类别标签显著多于其他标签,模型可能仍然通过始终预测多数类别而获得高准确度。准确度指标对每个类别的错误预测进行相等惩罚,因此不适用于不平衡数据集。
*** 当误分类成本相等时
准确度适用于假阳性或假阴性代价相等的情况。例如,对于情感分析问题,将负面文本分类为正面文本或将正面文本分类为负面文本都是一样糟糕的。在这种情况下,准确度是一个很好的指标。
精确度
精确度专注于确保我们所有的正类预测都是正确的。它衡量的是正类预测中实际为正类的比例。
在数学上,它表示为
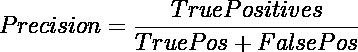
使用时机
- 假阳性成本高
考虑一个训练模型来检测癌症的场景。对我们来说,更重要的是不要将没有癌症的患者误分类为癌症阳性,即假阳性。我们希望在做出正预测时有信心,因为错误地将一个人分类为癌症阳性可能会导致不必要的压力和费用。因此,我们高度重视仅在实际标签为正时才进行正预测。
- 质量胜于数量
另一种场景是我们构建一个搜索引擎,将用户查询与数据集匹配。在这种情况下,我们重视搜索结果与用户查询的匹配度。我们不希望返回任何与用户无关的文档,即假阳性。因此,我们只对与用户查询高度匹配的文档做出正预测。我们重视质量而非数量,因为我们更愿意获得少量相关性强的结果,而不是大量可能相关或不相关的结果。对于这种情况,我们需要高精度。
召回率
召回率,也称为敏感度,衡量模型记住数据集中正标签的能力。它衡量模型将数据集中正标签预测为正的比例。
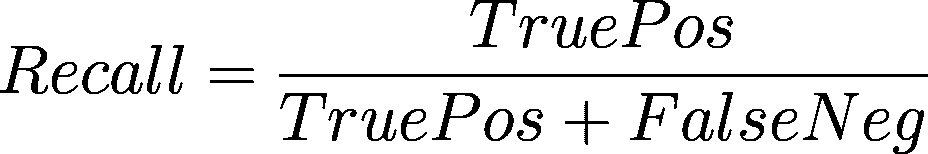
更高的召回率意味着模型在记住具有正标签的数据样本方面表现更好。
使用时机
- 假阴性的高成本
当漏掉一个正标签可能会产生严重后果时,我们使用召回率。考虑一个使用机器学习模型检测信用卡欺诈的场景。在这种情况下,早期发现问题至关重要。我们不希望漏掉一个欺诈交易,因为这可能会增加损失。因此,我们重视召回率而不是精确度,在这种情况下,交易被误分类为欺诈可能容易验证,我们可以容忍一些假阳性,但不能接受假阴性。
F1-Score
召回率是精确度和召回率的调和均值。它惩罚那些在这两个指标之间存在显著不平衡的模型。
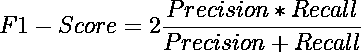
在精确度和召回率都重要的场景中广泛使用,并允许在两者之间取得平衡。
使用时机
- 不平衡数据集
与准确率不同,F1-Score 适用于评估不平衡数据集,因为我们基于模型识别少数类别的能力来评估性能,同时保持整体的高精确度。
*** 精确度-召回率权衡
这两种度量标准是相互对立的。从经验上看,改善一种度量标准往往会导致另一种度量标准的下降。F1-Score 有助于平衡这两种度量标准,并在召回率和精度都同样重要的情况下非常有用。考虑到这两种度量标准,F1-Score 是评估分类模型的广泛使用的度量标准。
主要收获
我们了解到,不同的评估度量标准有其特定的作用。了解这些度量标准有助于我们为任务选择合适的度量标准。在现实生活中,不仅仅是拥有好的模型,而是要拥有适合我们业务需求的模型。因此,选择合适的度量标准就像选择合适的工具,以确保我们的模型在最重要的地方表现良好。
仍然对使用哪个度量标准感到困惑吗?从准确率开始是一个好的初步步骤。它提供了对模型性能的基本了解。从这里,你可以根据具体需求调整你的评估。或者,考虑使用 F1-Score,它作为一个多功能度量标准,在精度和召回率之间取得平衡,使其适用于各种场景。它可以成为你进行全面分类评估的工具。
穆罕默德·阿赫曼 是一名从事计算机视觉和自然语言处理的深度学习工程师。他曾在 Vyro.AI 部署和优化了多个人工智能生成应用,这些应用在全球排行榜上名列前茅。他对构建和优化智能系统的机器学习模型充满兴趣,并相信持续改进。
相关主题
理解 AI 时代的数据隐私
原文:
www.kdnuggets.com/understanding-data-privacy-in-the-age-of-ai

图片作者 | Midjourney & Canva
关于 AI 伦理和负责任发展的讨论近年来得到了显著关注,原因是正当的。这些讨论旨在应对各种风险,包括偏见、误信息、公平性等。
虽然这些挑战有些并不完全新鲜,但对 AI 应用的需求激增无疑加剧了这些挑战。数据隐私这一长期存在的问题,随着生成性 AI 的出现,变得更加重要。
哈雷赛·伯根德——麻省理工学院开放纪录片实验室的研究员——的这一声明突显了形势的严峻性。——“应该把你在互联网上自由发布的所有信息都当作是可能被某人用于某些用途的训练数据。”
时代在变化,需要相应的措施。因此,让我们理解这些影响,并认识到如何处理数据隐私带来的风险。
该提高警惕的时刻到了
每一个处理用户数据的公司,无论是以收集和存储数据的形式,还是执行数据操作和处理数据以建立模型等,都必须注意各种数据方面,例如:
-
数据来自哪里,去向何处?
-
这些挑战是如何被操控的?
-
谁在使用这些数据,如何使用?
简而言之,关键在于数据如何交换以及与谁交换。
每个分享数据并同意使用数据的用户必须注意他们愿意分享的信息。例如,如果用户希望收到个性化推荐,他们需要愿意分享相关数据。
GDPR 是金标准!!!
当涉及到个人可识别信息(PII)时,管理数据的风险就变得非常重要。根据美国劳动部的数据,PII 通常包括直接识别个人的信息,如姓名、地址、任何识别号码或代码、电话号码、电子邮件地址等。关于 PII 的更详细定义和指导请参见 这里。
为了保护个人数据,欧盟颁布了通用数据保护条例(GDPR),为存储和收集欧盟公民数据的公司设定了严格的问责标准。
发展速度快于规章制度
实证表明,任何技术创新和突破的发展速度总是快于有关部门预见其问题并及时监管的速度。
那么,在规章制度跟上快速发展的步伐之前,人们应该怎么做呢?让我们来了解一下。
自我监管
解决这一差距的一种方法是建立内部治理措施,类似于公司治理和数据治理。这等同于按照你所知的行业标准和最佳实践尽可能地承担你的模型。
自我监管的这些措施是保持高标准的诚信和以客户为中心的强有力指标,这可以在这个高度竞争的世界中成为一个区别因素。采纳自我监管章程的组织可以将其作为荣誉的徽章,并赢得客户的信任和忠诚——考虑到用户在众多选项中转换成本低,这是一个很大的成就。
建立内部人工智能治理措施的一个方面是,它使组织保持在负责任的人工智能框架的道路上,因此当法律法规到位时,他们可以做好轻松采纳的准备。
规则必须对每个人都一样
理论上设立先例是好的。从技术上讲,没有任何组织能够完全预见一切并保护自己。
另一个反对自我监管的论点是,每个人都应该遵循相同的规则。没有人希望通过过度自我监管来预期即将到来的监管,从而自我破坏增长,阻碍业务发展。
隐私的另一面
许多参与者可以在维护高隐私标准方面发挥作用,例如组织及其员工。然而,用户也有同样重要的角色——是时候提高警惕,培养意识了。下面我们将详细讨论:
组织和员工的角色
这些组织已经创建了一个责任框架,以使他们的团队敏感于正确提示模型的方式,并提高对这些方法的认识。对于医疗和金融等领域,通过输入提示共享的任何敏感信息也算作隐私泄露——这次是无意的,但通过员工而不是模型开发者。
用户的角色
本质上,如果我们自己向这些模型提供这样的数据,隐私就不能成为问题。
作者提供的图片
大多数基础模型(类似于上图所示的例子)强调聊天记录可能会被用来改进模型,因此用户必须仔细检查设置控制,以允许适当的访问以促进数据隐私。
人工智能的规模
用户必须在每个设备的每个浏览器中访问并修改同意控制,以阻止这些泄漏。然而,现在想想大型模型,这些模型正在扫描几乎所有的互联网数据,基本上包括每个人。
那个规模成为了一个问题!
大型语言模型之所以有优势,正是因为它们可以访问比传统模型高几个数量级的训练数据,这种规模也会带来巨大的隐私问题。
深度伪造——一种伪装的隐私侵犯形式
最近出现了一起事件,一名公司高管指示其员工向某个账户转账数百万美元。由于存疑,员工建议安排一次电话讨论,然后他进行了转账——结果后来才发现电话会议上的所有人都是深度伪造的。
对于不了解的人,政府问责办公室 将其解释为——“一个看似真实但已被人工智能操控的视频、照片或音频录制。其基础技术可以替换面孔、操控面部表情、合成面孔和合成语音。深度伪造技术可以表现出某人说过或做过他们从未说过或做过的事情。”
从修辞学的角度来看,深度伪造技术也是一种隐私侵犯,相当于身份盗窃,其中的不法分子假装成他们不是的人。
利用这些被盗身份,他们可以推动决策和行动,否则这些决策和行动本不会发生。
这提醒我们,不法分子通常比防御方的好人领先一步。好人仍在努力进行损害控制,同时确保采取稳健的措施以防止未来的事故。
Vidhi Chugh**** 是一位人工智能战略家和数字化转型领导者,致力于在产品、科学和工程的交汇点构建可扩展的机器学习系统。她是获奖的创新领导者、作者和国际演讲者。她的使命是使机器学习民主化,并破除行话,使每个人都能参与这一转型。
更多相关主题
理解 Python 中的决策树分类
原文:
www.kdnuggets.com/2019/08/understanding-decision-trees-classification-python.html
评论
作者:Michael Galarnyk,数据科学家
本教程将详细讲解决策树的工作原理。
决策树是一种受欢迎的监督学习方法,原因有很多。决策树的优点包括可以用于回归和分类,易于解释,不需要特征缩放。然而,它们也有一些缺陷,包括容易过拟合。本文涵盖了用于分类的决策树,也称为分类树。
此外,本教程还将涵盖:
-
分类树的结构(树的深度、根节点、决策节点、叶节点/终端节点)。
-
分类树如何进行预测
-
如何使用 scikit-learn (Python) 制作分类树
-
超参数调整
一如既往,本教程中使用的代码可以在我的 github 上找到(结构,预测)。好了,让我们开始吧!
什么是分类树?
Classification and Regression Trees (CART) 是 Leo Breiman 提出的术语,指可以用于分类或回归预测建模问题的决策树算法。本文讨论分类树。
分类树
分类树本质上是一系列问题,用于分配分类。下图是一个在 IRIS 数据集(花卉种类)上训练的分类树。根节点(棕色)和决策节点(蓝色)包含的问题会分裂成子节点。根节点就是最顶层的决策节点。换句话说,它是你开始遍历分类树的地方。叶节点(绿色),也称为终端节点,是不会再分裂成更多节点的节点。叶节点是通过多数投票来分配类别的地方。
分类树对三种花卉种类(IRIS 数据集)的分类
如何使用分类树
使用分类树时,从根节点(棕色)开始,遍历树直到到达叶子(终端)节点。使用下面图中的分类树,假设你有一朵花,花瓣长度为 4.5 cm,你想对其进行分类。从根节点开始,你首先会问“花瓣长度(cm)≤ 2.45”?长度大于 2.45,因此这个问题为假。继续到下一个决策节点,问“花瓣长度(cm)≤ 4.95”?这是对的,所以你可以预测花的种类为 versicolor。这只是一个例子。
分类树是如何生长的?(非数学版本)
分类树学习的是一系列的“如果…那么…”问题,每个问题涉及一个特征和一个拆分点。看看下面的部分树(A),问题“花瓣长度(cm)≤ 2.45”根据某个值(在此例中为 2.45)将数据拆分为两个分支。节点之间的值称为拆分点。一个好的拆分点值(即产生最大信息增益的值)是能够很好地将一个类别与其他类别分开的值。看下面的图 B,拆分点左侧的所有点被分类为 setosa,而拆分点右侧的所有点被分类为 versicolor。
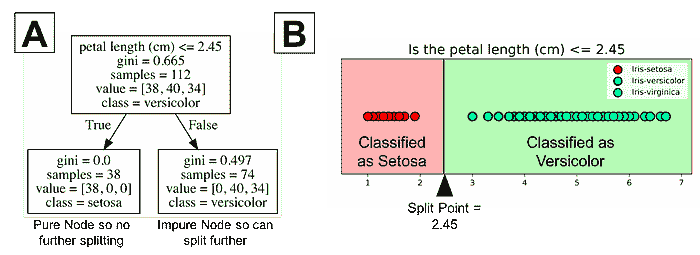
图中显示所有 38 个点的 setosa 分类都正确。它是一个纯节点。分类树不会在纯节点上进行拆分。这会导致没有进一步的信息增益。然而,非纯节点可以进一步拆分。注意图 B 的右侧显示许多点被错误分类为 versicolor。换句话说,它包含了两种不同类别的点(virginica 和 versicolor)。分类树是一个贪婪算法,这意味着它默认会继续拆分直到得到一个纯节点。算法再次为非纯节点选择最佳的拆分点(我们将在下一节中深入探讨数学方法)。
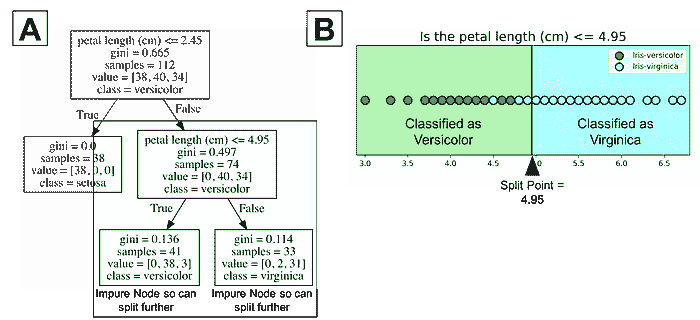
上面的图像中,树的最大深度为 2。树的深度是衡量一棵树在做出预测之前能进行多少次拆分的指标。这个过程可以继续进行更多的拆分,直到树尽可能纯净。许多重复这一过程的问题是,这可能会导致一棵非常深的分类树,拥有许多节点。这通常会导致对训练数据集的过拟合。幸运的是,大多数分类树实现允许你控制树的最大深度,从而减少过拟合。例如,Python 的 scikit-learn 允许你预剪枝决策树。换句话说,你可以设置最大深度来停止决策树超过某个深度。要直观理解最大深度,你可以查看下面的图像。
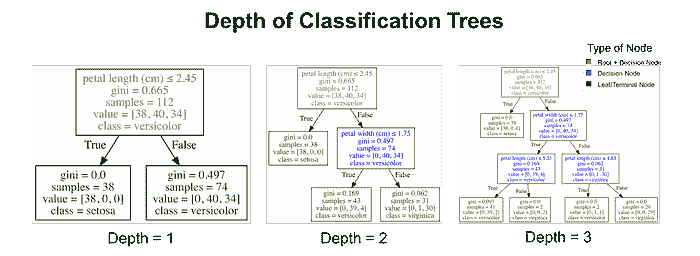
不同深度的分类树在 IRIS 数据集上的拟合情况。
选择标准
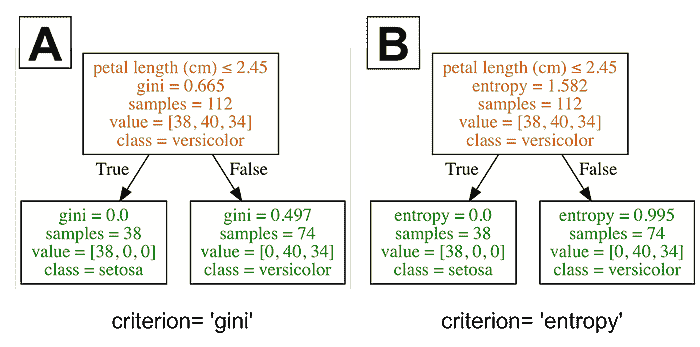
本节回答了信息增益以及 Gini 和熵这两个标准的计算方法。
本节的重点是理解在分类树上对根节点/决策节点的良好分割点。决策树会在特征和相应的分割点上进行分裂,以获得给定标准(本例中的 Gini 或熵)的最大信息增益(IG)。大致上,我们可以将信息增益定义为
IG = information before splitting (parent) — information after splitting (children)
为了更清楚地理解父节点和子节点,请查看下方的决策树。
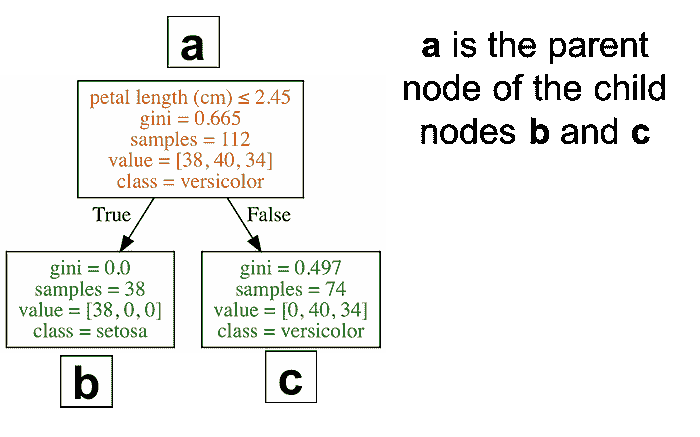
更为恰当的信息增益公式如下。
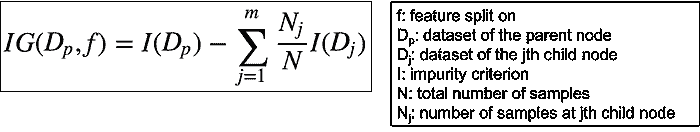
由于分类树有二元分裂,因此公式可以简化为如下公式。
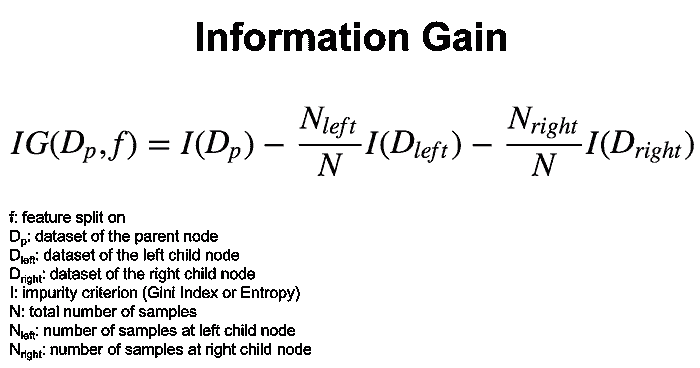
两个常见的I标准,用于测量节点的 impurity 是 Gini 指数和熵。

为了更好地理解这些公式,下图展示了如何使用 Gini 标准计算决策树的信息增益。

下图展示了如何计算决策树的熵信息增益。

我不打算深入探讨这一点,因为需要指出的是,不同的 impurity 测量(Gini 指数和熵)通常会产生相似的结果。下图展示了 Gini 指数和熵是非常相似的 impurity 标准。我猜测 Gini 作为 Scikit-learn 中的默认值之一的原因可能是熵的计算可能稍慢(因为它使用了对数)。
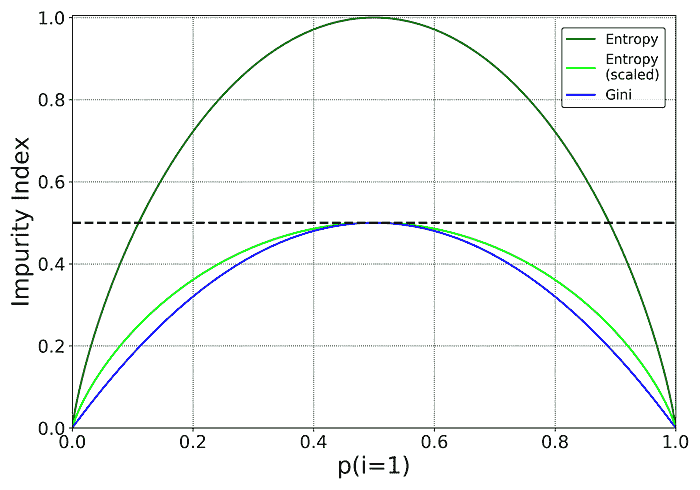
不同的 impurity 测量(Gini 指数和熵)通常会产生相似的结果。感谢Data Science StackExchange和Sebastian Raschka对本图的启发。
在完成本节之前,我需要指出,存在各种不同的决策树算法,它们彼此有所不同。一些更受欢迎的算法包括 ID3、C4.5 和 CART。Scikit-learn 使用了CART 算法的优化版本。你可以在这里了解其时间复杂度。
使用 Python 的分类树
之前的部分讲述了分类树的理论。学习如何在编程语言中制作决策树的一个原因是,处理数据可以帮助理解算法。
加载数据集
Iris 数据集是 scikit-learn 提供的一个数据集,无需从外部网站下载任何文件。下面的代码加载了 iris 数据集。
import pandas as pd
from sklearn.datasets import load_irisdata = load_iris()
df = pd.DataFrame(data.data, columns=data.feature_names)
df['target'] = data.target
原始 Pandas df(特征 + 目标)
将数据拆分为训练集和测试集
下面的代码将 75% 的数据放入训练集,将 25% 的数据放入测试集。
X_train, X_test, Y_train, Y_test = train_test_split(df[data.feature_names], df['target'], random_state=0)
图片中的颜色表示数据框 df 的数据在这个特定的训练测试分割中属于哪个变量(X_train, X_test, Y_train, Y_test)。
请注意,决策树的一个好处是你无需像PCA和逻辑回归那样对数据进行标准化,因为这两者对数据未标准化的影响比较敏感。
Scikit-learn 四步建模模式
步骤 1: 导入你想要使用的模型
在 scikit-learn 中,所有机器学习模型都是作为 Python 类实现的。
from sklearn.tree import DecisionTreeClassifier
步骤 2: 创建模型实例
在下面的代码中,我将 max_depth = 2 设置为提前修剪我的树,以确保它的深度不超过 2。我应该指出教程的下一部分将介绍如何为你的树选择最佳的 max_depth。
还要注意,在我下面的代码中,我设置了 random_state = 0,这样你可以得到和我一样的结果。
clf = DecisionTreeClassifier(max_depth = 2,
random_state = 0)
步骤 3: 在数据上训练模型
模型正在学习 X(萼片长度、萼片宽度、花瓣长度和花瓣宽度)和 Y(鸢尾花的种类)之间的关系
clf.fit(X_train, Y_train)
步骤 4: 预测未见(测试)数据的标签
# Predict for 1 observation
clf.predict(X_test.iloc[0].values.reshape(1, -1))# Predict for multiple observations
clf.predict(X_test[0:10])
记住,预测仅仅是叶节点中实例的多数类别。
测量模型性能
尽管还有其他测量模型性能的方法(如精确率、召回率、F1 分数,ROC 曲线等),我们将保持简单,使用准确率作为我们的指标。
准确率定义为:
(正确预测的比例):正确预测数 / 数据点总数
# The score method returns the accuracy of the model
score = clf.score(X_test, Y_test)
print(score)
调整树的深度
找到 max_depth 的最佳值是一种调整模型的方法。下面的代码输出了具有不同 max_depth 值的决策树的准确率。
# List of values to try for max_depth:
max_depth_range = list(range(1, 6))# List to store the average RMSE for each value of max_depth:
accuracy = []for depth in max_depth_range:
clf = DecisionTreeClassifier(max_depth = depth,
random_state = 0)
clf.fit(X_train, Y_train) score = clf.score(X_test, Y_test)
accuracy.append(score)
由于下面的图表显示,当参数 max_depth 大于或等于 3 时,模型的准确率最佳,因此选择 max_depth = 3 的最简单模型可能是最好的选择。
我选择max_depth =3,因为它似乎是一个准确的模型且不是最复杂的。
需要记住的是,max_depth并不等于决策树的深度。max_depth是对决策树进行预剪枝的一种方法。换句话说,如果树在某个深度已经尽可能纯净,它将不会继续分裂。下图显示了max_depth为 3、4 和 5 的决策树。请注意,max_depth为 4 和 5 的树是相同的。它们的深度都是 4。

请注意,我们有两个完全相同的树。
如果你想知道你训练的决策树的深度,可以使用get_depth方法。此外,你还可以使用get_n_leaves方法获取训练决策树的叶节点数量。
虽然本教程涵盖了更改选择标准(Gini 指数、熵等)和树的max_depth,但请记住,你还可以调整节点分裂的最小样本数(min_samples_leaf)、最大叶节点数(max_leaf_nodes)等。
特征重要性
分类树的一个优点是相对容易解释。scikit-learn 中的分类树允许你计算特征重要性,即由于特征分裂而使 gini 指数或熵减少的总量。scikit-learn 为每个特征输出一个 0 到 1 之间的数字。所有特征的重要性值都被归一化为总和为 1。以下代码显示了决策树模型中每个特征的重要性。
importances = pd.DataFrame({'feature':X_train.columns,'importance':np.round(clf.feature_importances_,3)})
importances = importances.sort_values('importance',ascending=False)
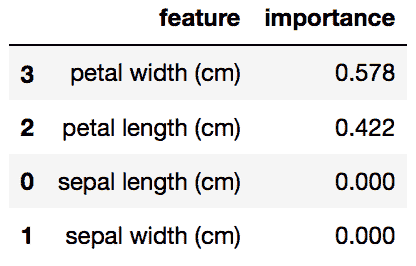
在上面的例子中(针对某个特定的鸢尾花训练测试分割),花瓣宽度具有最高的特征重要性权重。我们可以通过查看相应的决策树来确认这一点。
该决策树分裂的只有两个特征,即花瓣宽度(cm)和花瓣长度(cm),
请记住,如果一个特征的重要性值较低,这并不一定意味着该特征对预测不重要,它只是说明该特征没有在树的较早层级被选择。也可能是该特征与另一个信息量大的特征相同或高度相关。特征重要性值也不能告诉你这些特征对哪个类别的预测非常重要,或特征之间的关系如何影响预测。值得注意的是,在进行交叉验证或类似操作时,可以使用多个训练测试分割的特征重要性值的平均值。
总结
尽管这篇文章只讨论了用于分类的决策树,但你可以查看我另一篇文章《决策树用于回归(Python)》。Classification and Regression Trees (CART) 是一种相对较旧的技术(1984 年),是更复杂技术的基础。决策树的主要弱点之一是它们通常不是最准确的算法。这部分是因为决策树是一种高方差算法,这意味着训练数据中的不同分裂可以导致非常不同的树。如果你对教程有任何问题或想法,请随时在下面的评论中或通过 Twitter 联系我。
简介: 迈克尔·加拉尼克 是一名数据科学家和企业培训师。他目前在斯克里普斯转化研究所工作。你可以在 Twitter (https://twitter.com/GalarnykMichael)、Medium (https://medium.com/@GalarnykMichael) 和 GitHub (https://github.com/mGalarnyk) 上找到他。
原文。已获得许可转载。
相关:
-
决策树——直观介绍
-
如何建立数据科学作品集
-
随机森林与神经网络:哪个更好,何时使用?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关主题
理解深度学习需要重新思考泛化
原文:
www.kdnuggets.com/2017/06/understanding-deep-learning-rethinking-generalization.html
理解深度学习需要重新思考泛化 Zhang et al., ICLR’17
这篇论文具有令人惊叹的组合特性:结果易于理解,略显惊讶,并且会让你在之后很长一段时间内思考其意义!
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 方面的工作
作者提出要回答的问题是:
什么因素使得神经网络能够很好地泛化?对这个问题的令人满意的答案不仅有助于使神经网络更具可解释性,还可能导致更有原则和可靠的模型架构设计。
作者所说的“良好泛化”仅仅是指“什么原因使得一个在训练数据上表现良好的网络也能在(保留的)测试数据上表现良好?”(而不是迁移学习,迁移学习涉及将训练好的网络应用于一个相关但不同的问题)。如果你稍加思考,这个问题实际上就是“为什么神经网络的表现如此之好?” 泛化是仅仅记忆训练数据的一部分并将其重复的差别,以及实际上对数据集有某种有意义的直觉并能用来做预测。所以,如果问题的答案是“我们真的不知道”,那不就有点令人担忧吗?
随机标签的奇怪案例
我们的故事开始于一个熟悉的地方——CIFAR 10(50,000 张训练图像分为 10 个类别,10,000 张验证图像)和 ILSVRC(ImageNet)2012(1,281,167 张训练图像,50,000 张验证图像,1000 个类别)数据集,以及 Inception 网络架构的变体。
使用训练数据训练网络,你不会感到惊讶地听到它们在训练集上可以达到零误差。这高度表明了过拟合——记住训练示例而不是学习真正的预测特征。我们可以使用诸如正则化等技术来对抗过拟合,从而得到泛化更好的网络。稍后会详细讨论。
使用相同的训练数据,但这次随机打乱标签(即,使标签与图像内容之间不再存在真正的对应关系)。使用这些随机标签训练网络,你会得到什么?零训练误差!
在[这种]情况下,实例和类别标签之间不再存在任何关系。因此,学习是不可能的。直觉上,应该在训练过程中清晰地表现出这种不可能性,例如,训练不收敛或显著减慢。令我们惊讶的是,对于多个标准架构的训练过程的几个特性在标签转换下基本保持不变。
正如作者简洁地表述的,“深度神经网络很容易拟合随机标签。”以下是这个第一次实验的三个关键观察:
-
神经网络的有效容量足以记住整个数据集。
-
即使在随机标签上的优化仍然很简单。实际上,与在真实标签上训练相比,训练时间仅增加了一个小的常数因子。
-
随机化标签仅仅是数据转换,保留了学习问题的所有其他属性不变。
如果你拿到一个在随机标签上训练的网络,然后看看它在测试数据上的表现,它当然会表现得非常差,因为它并没有真正学到任何关于数据集的东西。换句话说,它有很高的泛化误差。将这些因素综合起来,你会意识到:
…仅通过随机化标签,我们可以使模型的泛化误差大幅上升,而不改变模型、模型的大小、超参数或优化器。我们在多个不同的标准架构上进行了验证,这些架构在 CIFAR 10 和 ImageNet 分类基准上进行训练。(强调由我加上)。
换句话说:模型、模型的大小、超参数和优化器无法解释最先进神经网络的泛化性能。这必然是因为尽管它们保持不变,泛化性能却可以显著变化。
更加令人好奇的随机图像案例
如果我们不仅仅改变标签,还改变图像本身会发生什么?实际上,如果用随机噪声替换真实图像会怎么样?在这些图中,这被标记为‘高斯’实验,因为使用与原始图像数据集均值和方差匹配的高斯分布来生成每个图像的随机像素。
结果发现,网络仍然训练到零训练误差,但比随机标签的情况更快!一个假设是,这种情况发生的原因是,随机像素图像之间的分离程度比随机标签的情况更大,因为后者的图像原本都属于同一类别,但由于标签交换现在必须被学习为不同的类别。
团队对数据集引入了不同程度和种类的随机化变化进行了一系列实验:
-
真实标签(原始数据集没有修改)
-
部分损坏的标签(对一些标签进行扰动)
-
随机标签(对所有标签进行扰动)
-
打乱像素(选择一个像素排列,然后均匀地应用到所有图像)
-
随机像素(对每张图片独立应用不同的随机排列)
-
高斯(如前所述,为每张图片生成虚假的数据)
在整个范围内,网络仍然能够完美地拟合训练数据。
我们进一步改变了随机化的数量,在没有噪声和完全噪声的情况下平滑地插值。这导致了一系列中间学习问题,其中标签中仍然保留了一定程度的信号。我们观察到,随着噪声水平的增加,泛化误差稳步恶化。这表明神经网络能够捕捉数据中剩余的信号,同时用蛮力拟合噪声部分。
对我来说,最后一句话是关键。我们在模型架构中做出的某些选择显然会影响模型的泛化能力(否则所有架构的泛化效果都会相同)。不过,世界上最具泛化能力的网络仍然必须在数据中没有其他真实信号时依赖于记忆。所以也许我们需要一种方法来区分数据集中存在的真正泛化潜力,以及给定模型架构在捕捉这种潜在能力方面的效率。一种简单的方法是对相同的数据集训练不同的架构!(我们当然一直在这样做)。不过,这仍然没有帮助我们解决最初的问题——理解为什么有些模型比其他模型更具泛化能力。
正则化来救援?
模型架构本身显然不是一个充分的正则化器(不能防止过拟合/记忆)。那么常用的正则化技术呢?
我们展示了显式正则化形式,如权重衰减、丢弃法和数据增强,并不能充分解释神经网络的泛化误差:显式正则化可能改善泛化性能,但既不是必要的,也不是单独足够的来控制泛化误差。
显式正则化似乎更多的是一种调节参数,有助于改善泛化,但其缺乏并不一定意味着泛化误差差。确实,并不是所有适合训练数据的模型都能很好地泛化。论文中的一个有趣分析表明,我们在使用梯度下降的过程中会得到一定程度的正则化:
我们分析了 SGD 如何作为隐式正则化器。对于线性模型,SGD 总是会收敛到具有小范数的解。因此,算法本身隐式地对解进行正则化… 尽管这并不能解释为什么某些架构比其他架构泛化得更好,但它确实表明需要更多的研究来准确理解使用 SGD 训练的模型所继承的特性。
机器学习模型的有效容量
考虑到神经网络在有限样本大小为n的情况下的情形。如果一个网络具有p个参数,其中p大于n,那么即使是一个简单的两层神经网络也能表示输入样本的任何函数。 作者在附录中证明了以下定理:
存在一个具有 ReLU 激活和2n + d 权重的两层神经网络,可以表示在d 维中大小为n的样本上的任何函数。
即使是深度为 2 的线性网络也已经能够表示训练数据的任何标记!
那么,这一切将把我们带到哪里?
这种情况对统计学习理论提出了概念上的挑战,因为传统的模型复杂度度量难以解释大型人工神经网络的泛化能力。我们认为我们尚未发现一个精确的正式度量,这些巨大的模型在该度量下是简单的。另一个实验结果是,即使结果模型无法泛化,优化过程仍然在经验上容易。这表明,优化在经验上容易的原因必须不同于泛化的真正原因。
原文。已获许可转载。
相关:
-
深度学习论文阅读路线图
-
深度学习 101:揭开张量的神秘面纱
-
为什么深度学习没有局部最小值?
更多关于此话题
理解特征工程:文本数据的深度学习方法
原文:
www.kdnuggets.com/2018/03/understanding-feature-engineering-deep-learning-methods-text-data.html
评论
编辑说明: 这篇文章只是一个更为详尽和深入原文的一部分,原文链接,涵盖了比这里更多的内容。

引言
处理非结构化文本数据非常困难,尤其是当你试图构建一个智能系统,该系统像人类一样解释和理解自然语言时。你需要能够将嘈杂的、非结构化的文本数据处理并转换成一些结构化的、向量化的格式,以便任何机器学习算法都能理解。自然语言处理、机器学习或深度学习的原理,都属于人工智能这个大范畴内的有效工具。基于我之前的文章,需要记住的一个重要点是,任何机器学习算法都基于统计学、数学和优化的原理。因此,它们不足以直接处理文本的原始、自然形式。我们在第三部分:文本数据的传统方法中介绍了一些提取有意义特征的传统策略。***我鼓励你查看该部分以获得简要的回顾。在本文中,我们将探讨更多先进的特征工程策略,这些策略通常利用深度学习模型。更具体地说,我们将涵盖Word2Vec、GloVe和FastText模型。
动机
我们已经反复讨论,包括在我们之前的文章中提到,特征工程是创建优质和更高性能的机器学习模型的秘密武器。请始终记住,即使有了自动化特征工程的能力,你仍然需要理解应用这些技术的核心概念。否则,它们将只是黑箱模型,你将不知道如何调整和优化以解决你面临的问题。
传统模型的不足
传统的(基于计数的)文本数据特征工程策略包括属于一种被广泛称为词袋模型的模型家族。这包括术语频率、TF-IDF(术语频率-逆文档频率)、N-gram 等。虽然它们是从文本中提取特征的有效方法,但由于模型固有的特性是仅仅一个无结构的单词袋,我们丧失了诸如语义、结构、序列和上下文等附加信息。这为我们探索能够捕捉这些信息并提供词向量表示的更复杂模型提供了足够的动机,这些词向量表示被称为嵌入。
词嵌入的必要性
尽管这确实有一些道理,但我们为什么要有足够的动力去学习和构建这些词嵌入呢?对于语音或图像识别系统,所有信息已经以高维数据集中的丰富密集特征向量的形式存在,比如音频谱图和图像像素强度。然而,当涉及到原始文本数据时,特别是像词袋模型这样的基于计数的模型时,我们处理的是单个单词,它们可能有自己的标识符,并不能捕捉单词之间的语义关系。这会导致文本数据的稀疏词向量,因此如果我们没有足够的数据,可能会得到较差的模型,甚至由于维度灾难而导致过拟合数据。
比较音频、图像和文本的特征表示。为了克服词袋模型基于特征的语义丧失和特征稀疏的问题,我们需要利用向量空间模型 (VSMs),以便根据语义和上下文相似性将词向量嵌入到这个连续向量空间中。实际上,分布假设在分布语义学领域告诉我们,出现在相同上下文中的词在语义上是相似的,具有相似的意义。简单来说,“一个词的特征由它的搭配词决定”。有一篇著名的论文详细讨论了这些语义词向量及其各种类型,“不要计数,预测!语境计数与语境预测语义向量的系统比较”由 Baroni 等人撰写。我们不会深入探讨,但简而言之,针对上下文词向量有两种主要方法。基于计数的方法,例如潜在语义分析 (LSA),可以用来计算词在语料库中与邻近词一起出现的频率,并从这些度量中构建每个词的密集词向量。预测方法,如基于神经网络的语言模型,试图从邻近词中预测词,观察语料库中的词序列,在这个过程中学习分布式表示,给出密集的词嵌入。我们将在本文中重点关注这些预测方法。
特征工程策略
让我们看看一些处理文本数据和提取有意义特征的高级策略,这些特征可以用于下游机器学习系统。请注意,你可以在我的 GitHub 仓库中访问本文中使用的所有代码,以便将来参考。我们将从加载一些基本依赖项和设置开始。
import pandas as pd
import numpy as np
import re
import nltk
import matplotlib.pyplot as plt
pd.options.display.max_colwidth = 200
%matplotlib inline
我们现在将采用一些文档语料库,对其进行所有分析。对于其中一个语料库,我们将重用之前文章中的语料库,第三部分:传统文本数据方法。我们将为方便理解提到代码。

我们的样本文本 语料库我们的玩具语料库包含属于多个类别的文档。我们将在本文中使用的另一个语料库是免费的 《钦定版圣经》,可以通过 古登堡计划 通过 corpus 模块在 nltk中获取。我们将在下一节中加载它。在讨论特征工程之前,我们需要对这些文本进行预处理和规范化。
文本预处理
清理和预处理文本数据的方法有很多种。自然语言处理(NLP)管道中广泛使用的重要技术在 ‘文本预处理’ 部分的 第三部分中已详细介绍。由于本文的重点是特征工程,与我们之前的文章一样,我们将重用一个简单的文本预处理器,该预处理器侧重于去除特殊字符、多余的空格、数字、停用词,并将文本语料库转为小写。
一旦我们准备好基本的预处理管道,我们首先对我们的玩具语料库应用相同的处理。
norm_corpus = normalize_corpus(corpus)
norm_corpus
Output
------ array(['sky blue beautiful', 'love blue beautiful sky',
'quick brown fox jumps lazy dog',
'kings breakfast sausages ham bacon eggs toast beans',
'love green eggs ham sausages bacon',
'brown fox quick blue dog lazy',
'sky blue sky beautiful today',
'dog lazy brown fox quick'],
dtype='<U51')
现在让我们加载基于 《钦定版圣经》的其他语料库,使用 nltk 并预处理文本。
以下输出显示了我们语料库中的总行数以及预处理如何处理文本内容。
Output
------
Total lines: 30103
Sample line: ['1', ':', '6', 'And', 'God', 'said', ',', 'Let', 'there', 'be', 'a', 'firmament', 'in', 'the', 'midst', 'of', 'the', 'waters', ',', 'and', 'let', 'it', 'divide', 'the', 'waters', 'from', 'the', 'waters', '.']
Processed line: god said let firmament midst waters let divide waters waters
简介: Dipanjan Sarkar 是 Intel 的数据科学家,作者,Springboard 的导师,作家,以及体育和情景喜剧爱好者。
原始。经许可转载。
相关:
-
文本数据预处理:Python 中的详细指南
-
文本数据预处理的通用方法
-
处理文本数据科学任务的框架
更多内容
数据科学中的函数理解
原文:
www.kdnuggets.com/2022/06/understanding-functions-data-science.html
作者提供的图像
主要要点
-
大多数希望进入数据科学领域的初学者总是担心数学要求。
-
数据科学是一个非常量化的领域,要求高水平的数学能力。
-
但要开始,你只需掌握几个数学主题。
-
本文讨论了函数在数据科学和机器学习中的重要性。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
函数
大多数基础数据科学都集中在寻找特征(预测变量)与目标变量(结果)之间的关系。预测变量也称为自变量,而目标变量是因变量。
函数的重要性在于它们可以用于预测目的。如果能找到描述X与y之间关系的函数,即y = f (X),那么对于任何新的X值,就可以预测对应的y值。
为了简化,我们将假设目标变量取连续值,即我们将关注回归问题。本文讨论的相同原则也适用于目标变量仅取离散值的分类问题,例如 0 或 1。本文将重点讨论线性函数,因为它们构成了数据科学和机器学习中大多数线性模型的基础。
1. 单一预测变量的线性函数
假设我们有一个一维数据集,包含一个特征(X)和一个结果(y),并且假设数据集中有N个观测值:

表 1. 带有单一预测变量的简单一维数据集。
目标是找到X与y之间的关系。首先需要生成一个散点图,以便我们了解X与y之间的关系类型。它是线性的、二次的,还是周期性的?例如,使用游轮数据集 cruise_ship_info.csv,并取X = 舱位和y = 船员,散点图如下所示:
图 1。船员与舱位的散点图 | 作者提供的图像
从图 1中,我们观察到预测变量(舱位)和目标变量(船员)之间存在大致的线性关系。一个简单的线性模型拟合数据如下所示:
其中w0和w1是可以通过简单线性回归获得的权重。当进行简单线性回归时,结果图示在图 2中,R2 分数为 0.904。
图 2。船员与舱位的实际和拟合图 | 作者提供的图像
有时,预测变量和目标变量之间没有明显的可预测关系。在这种情况下,不能使用函数来量化关系,例如,图 3所示。
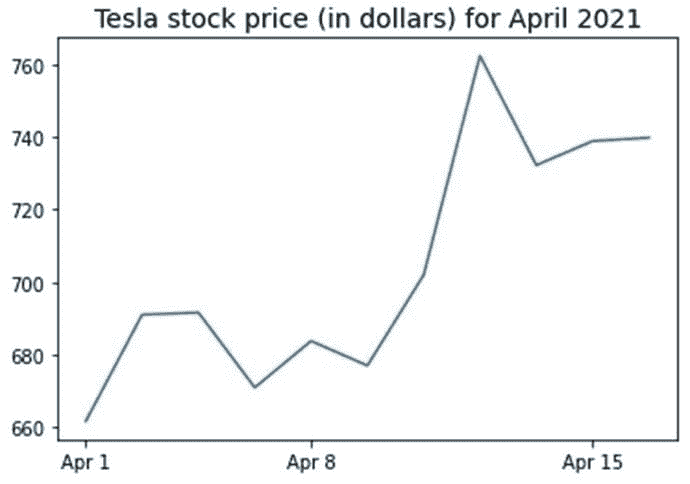
图 3。2021 年 4 月前 16 天的特斯拉股价 | 作者提供的图像
2. 带有多个预测变量的线性函数
在前面的例子中,我们使用了X = 舱位和y = 船员。现在假设我们想使用整个数据集(参见表 1)。
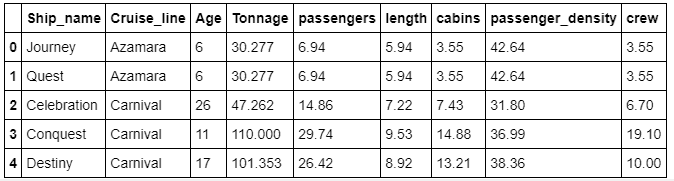
表 2:显示了数据集 cruise_ship_info.csv 的前 5 行。
在这种情况下,我们的预测变量是一个向量 X = (年龄,吨位,乘客,长度,舱位,乘客密度),并且* y = 船员*。
由于我们的目标变量现在依赖于 6 个预测变量,我们需要计算并可视化协方差矩阵,以查看哪些变量与目标变量有强相关性(参见图 4)。
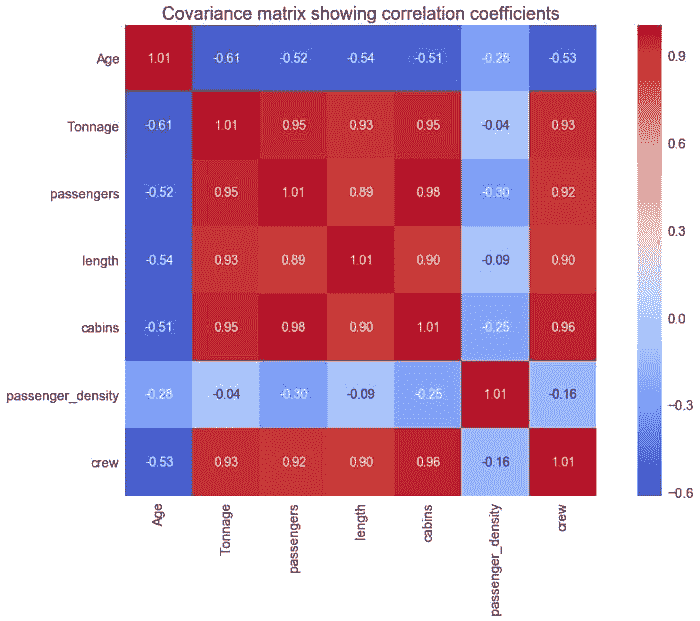
协方差矩阵图显示相关系数
从上面的协方差矩阵图(图 4)中,我们看到“船员”变量与 4 个预测变量(X = (吨位,乘客,长度,舱位))有强相关性(相关系数约为 0.6)。因此,我们可以建立一个多重回归模型,如下所示:
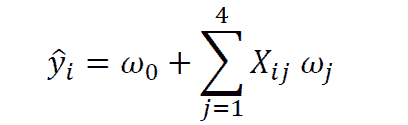
其中X是特征矩阵,w0是截距,w1、w2、w3和w4是回归系数。有关该问题的多元回归模型的完整 Python 实现,请参见这个 GitHub 库:github.com/bot13956/Machine_Learning_Process_Tutorial
总结
-
大多数数据科学问题归结为找到描述特征与目标变量之间关系的数学函数。
-
如果可以确定这个函数,那么它可以用于预测给定预测值的新目标值。
-
大多数数据科学问题可以近似为线性模型(单个或多个预测变量)。
本杰明·O·泰奥是一位物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的所有者。此前,本杰明曾在中央俄克拉荷马大学、大峡谷大学和匹兹堡州立大学教授工程学和物理学。
更多相关主题
通过实现理解:决策树
原文:
www.kdnuggets.com/2023/02/understanding-implementing-decision-tree.html
作者提供的图片
许多高级机器学习模型,例如随机森林或梯度提升算法,如 XGBoost、CatBoost 或 LightGBM(甚至自编码器!)都依赖于一个重要的共同成分:决策树!
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织进行 IT 管理
如果不理解决策树,也无法理解上述高级的袋装算法或梯度提升算法,这对任何数据科学家来说都是一个耻辱!所以,让我们通过在 Python 中实现一个决策树来揭开它的神秘面纱。
在本文中,您将学习
-
为什么以及如何决策树分裂数据,
-
信息增益,以及
-
如何使用 NumPy 在 Python 中实现决策树。
您可以在我的 Github上找到代码。
理论
为了进行预测,决策树依赖于将数据集递归地分裂成更小的部分。
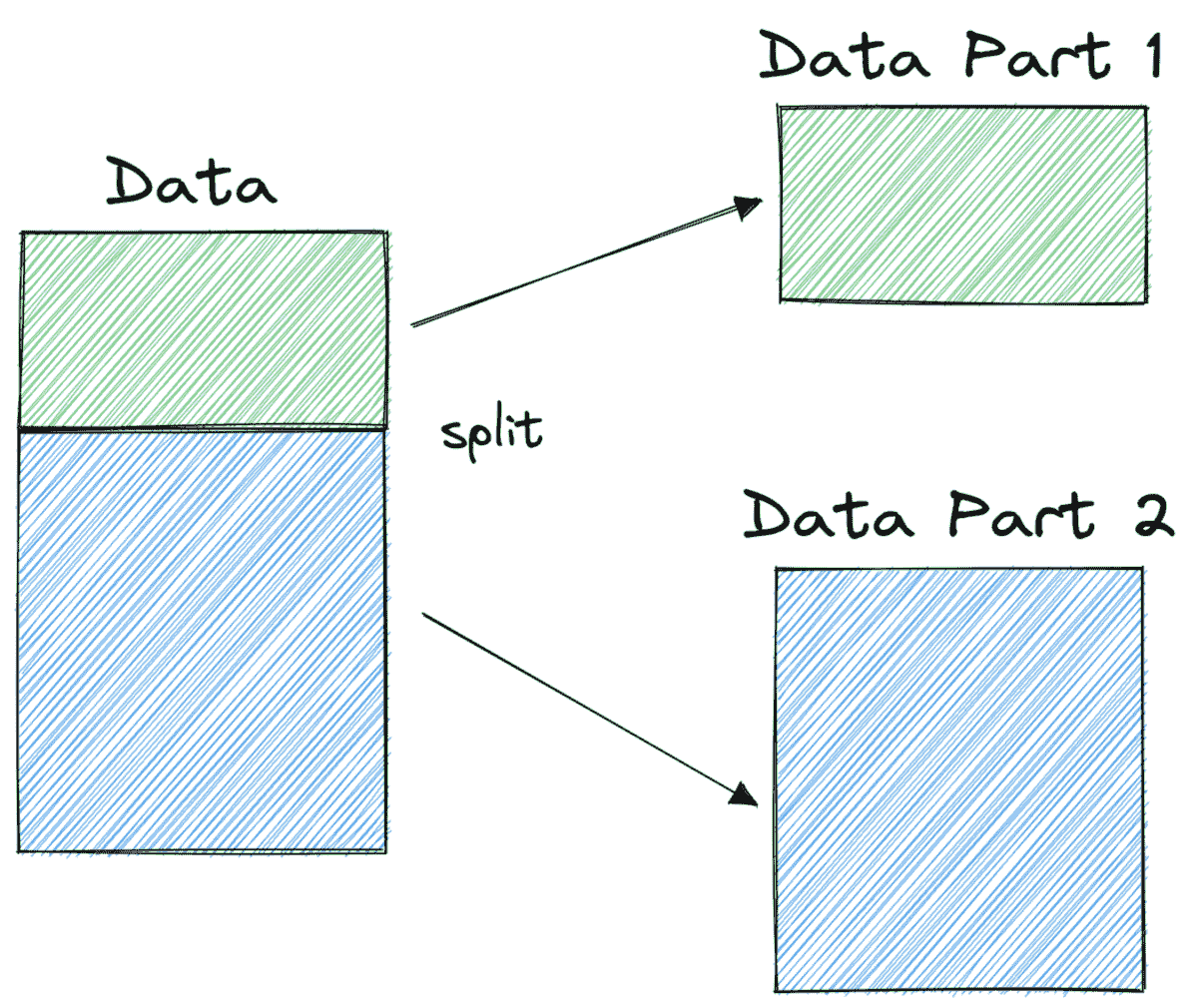
作者提供的图片
在上面的图片中,您可以看到一个分裂的示例——原始数据集被分成了两个部分。在下一步中,这两个部分又被进一步分裂,以此类推。这会一直持续,直到满足某种停止准则,例如,
-
如果分裂导致某部分为空
-
如果达到了一定的递归深度
-
如果(在之前的分裂后)数据集只包含几个元素,使得进一步的分裂不再必要。
我们如何找到这些分裂?我们为什么要关心这些?让我们来了解一下。
动机
假设我们现在要解决一个二分类问题:
import numpy as np
np.random.seed(0)
X = np.random.randn(100, 2) # features
y = ((X[:, 0] > 0) * (X[:, 1] < 0)) # labels (0 and 1)
二维数据如下所示:
作者提供的图片
我们可以看到有两个不同的类别——紫色约占 75%,黄色约占 25%。如果你将这些数据输入到决策树分类器中,这棵树最初会有以下想法:
“有两个不同的标签,这对我来说太混乱了。我想通过将数据分成两个部分来清理这些混乱——这些部分应该比之前的完整数据更干净。”——获得意识的树
树就是这样做的。
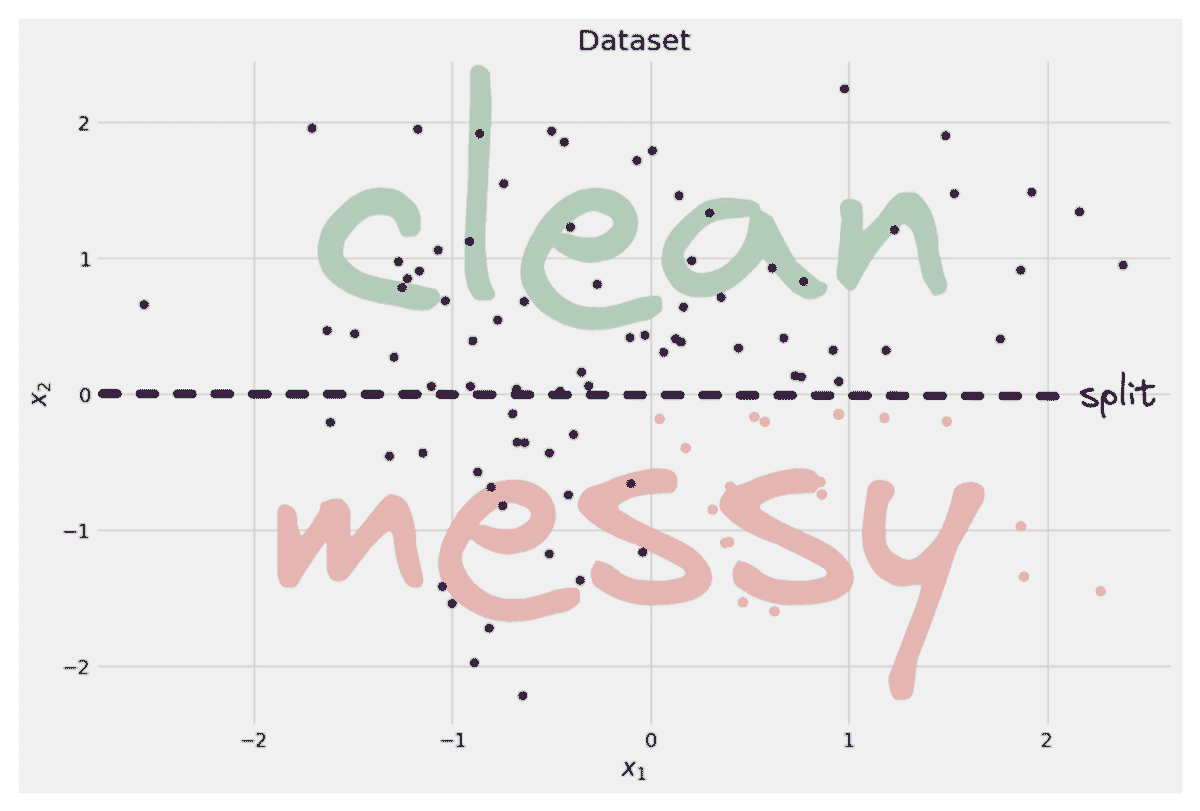
图片来源:作者
树决定沿 x 轴大致进行一次分裂。这使得数据的顶部部分现在完全干净,这意味着你在那里只找到一个类别(在这种情况下是紫色)。*
然而,底部部分仍然是混乱的,从某种意义上来说,比之前更加混乱。整个数据集中的类别比率曾经是约 75:25,但在这个较小的部分中,它是大约 50:50,这已经是最混杂的状态了。
* 注意:*在这里,紫色和黄色在图片中是否分开并不重要。只有两部分中不同标签的原始数量才是关键。**
*
图片来源:作者
尽管如此,这仍然是树的第一步,因此它继续前进。虽然它不会再在顶部的干净部分创建另一个分裂,但它可以在底部部分创建另一个分裂来进行清理。
图片来源:作者
Voilà,三个独立的部分完全干净,因为我们每个部分只找到一种颜色(标签)。
现在做预测非常简单:如果一个新的数据点出现,你只需检查它位于哪一个三个部分中,然后给它相应的颜色。现在之所以效果如此好,是因为每个部分都是干净的。简单吧?
图片来源:作者
好了,我们谈论了干净和混乱的数据,但到目前为止,这些词只是代表了一些模糊的概念。为了实现任何东西,我们必须找到定义清洁度的方法。
清洁度的措施
假设我们有一些标签,例如
y_1 = [0, 0, 0, 0, 0, 0, 0, 0]
y_2 = [1, 0, 0, 0, 0, 0, 1, 0]
y_3 = [1, 0, 1, 1, 0, 0, 1, 0]
直观地说,y₁ 是最干净的标签集,其次是 y₂,然后是 y₃。到目前为止还不错,但我们如何用数字来表示这种行为呢?也许最容易想到的方法是:
只需计算零的数量和一的数量。计算它们的绝对差异。为了使其更美观,通过除以数组的长度进行归一化。
例如,y₂ 总共有 8 个条目——6 个零和 2 个一。因此,我们自定义的清洁度得分将是 |6 - 2| / 8 = 0.5。很容易计算出 y₁ 和 y₃ 的清洁度得分分别为 1.0 和 0.0。在这里,我们可以看到通用公式:
图片来源:作者
这里,n₀ 和 n₁ 分别是零和一的数量,n = n₀ + n₁ 是数组的长度,而 p₁ = n₁ / n 是标签为 1 的比例。
这个公式的问题在于它专门针对两个类别的情况,但我们很常见的是多类别分类。一个效果相当好的公式是Gini 不纯度度量:
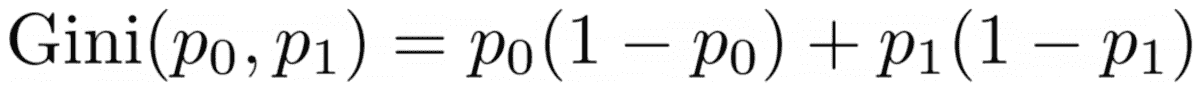
图片来源:作者
或者一般情况:
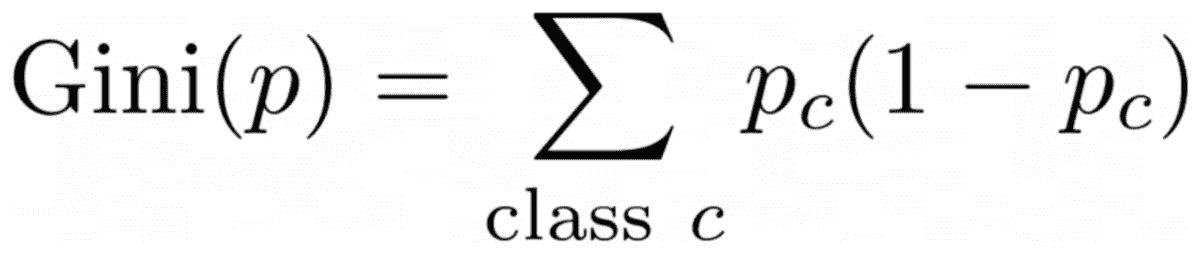
图片来源:作者
它效果非常好,以至于 scikit-learn 将其作为默认度量用于其DecisionTreeClassifier类。
图片来源:作者
* 注意:Gini 度量的是杂乱程度而不是清洁程度。示例:如果一个列表只包含单一类别(=非常干净的数据!),则总和中的所有项都是零,因此总和为零。最糟糕的情况是所有类别出现的次数完全一样,这种情况下 Gini 为 1–1/C*,其中 C 是类别的数量。**
*现在我们有了清洁度/杂乱度的度量,让我们看看它如何用于找到好的分裂。
查找分裂
我们有很多分裂选择,但哪个是好的呢?让我们再次使用我们的初始数据集,结合 Gini 不纯度度量。
图片来源:作者
我们现在不会计算点数,但假设 75% 是紫色的,25% 是黄色的。根据 Gini 的定义,整个数据集的不纯度是
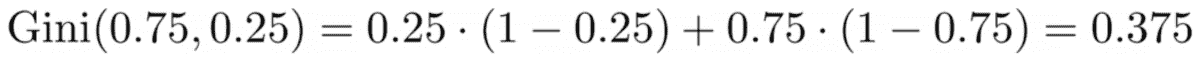
图片来源:作者
如果我们像之前那样沿 x 轴分裂数据集:
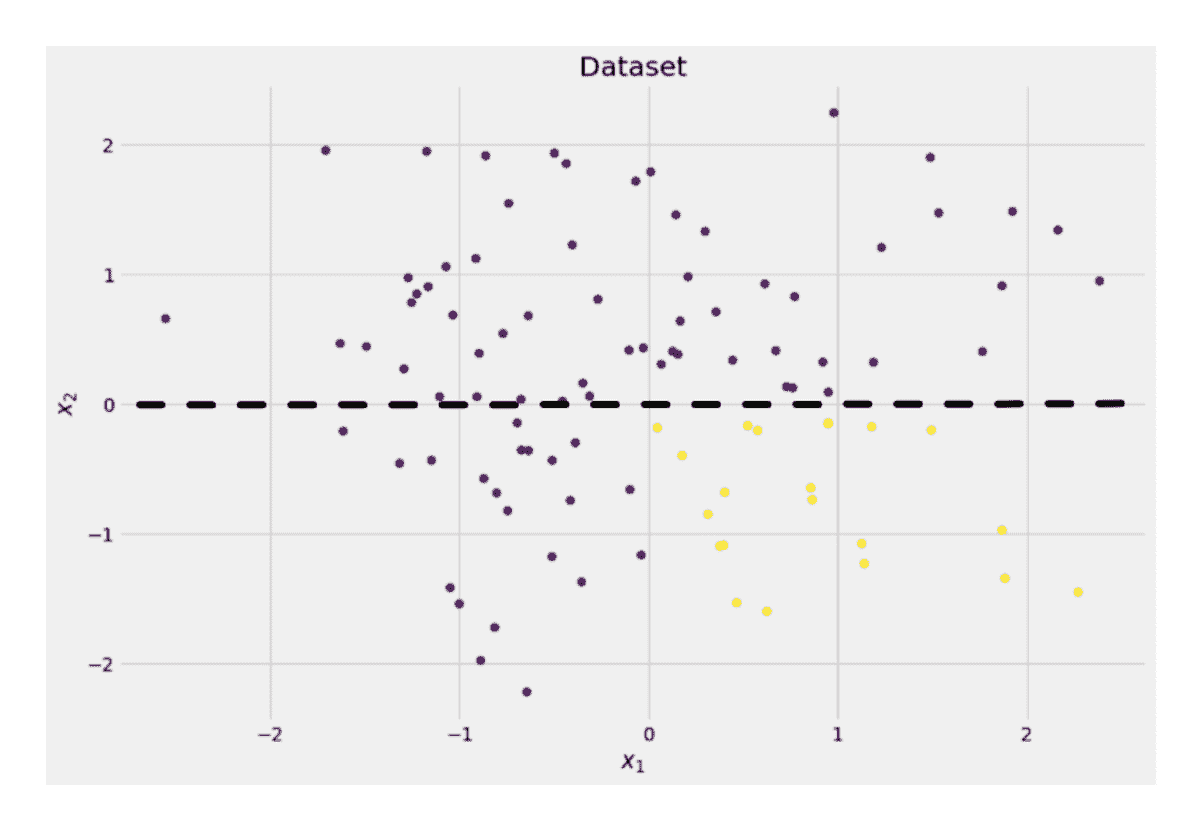
图片来源:作者
顶部部分的 Gini 不纯度是 0.0,而底部部分
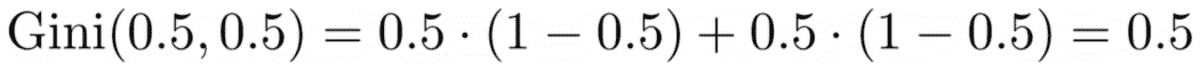
图片来源:作者
平均而言,这两个部分的 Gini 不纯度为 (0.0 + 0.5) / 2 = 0.25,比之前整个数据集的 0.375 更好。我们还可以用所谓的信息增益来表示:
这个分裂的信息增益是 0.375 – 0.25 = 0.125。
就这么简单。信息增益越高(即 Gini 不纯度越低),效果越好。
注意: 另一个同样好的初始分裂是沿 y 轴。
需要记住的一件重要事情是,通过部分的大小来权衡 Gini 不纯度是有用的。例如,假设
-
第一部分包含 50 个数据点,Gini 不纯度为 0.0,并且
-
第二部分包含 450 个数据点,Gini 不纯度为 0.5,
然后,平均 Gini 不纯度应该不是 (0.0 + 0.5) / 2 = 0.25,而是 50 / (50 + 450) * 0.0 + 450 / (50 + 450) * 0.5 = 0.45。
好的,我们如何找到最佳分割?简单但令人清醒的答案是:
只需尝试所有分割并选择信息增益最高的一个。这基本上是一种暴力方法。
更准确地说,标准决策树使用沿坐标轴的分割,即xᵢ = c,其中i是某个特征,c是阈值。这意味着
-
分割数据的另一部分包含所有数据点x,其中xᵢ < c。
-
分割数据的一部分包含所有数据点x,其中xᵢ ≥ c。
这些简单的分割规则在实践中已经证明足够有效,但你当然可以扩展这种逻辑来创建其他分割(例如,像xᵢ + 2xⱼ = 3这样的对角线)。
很好,这些就是我们现在需要的一切材料!
实现
我们现在将实现决策树。由于它由节点组成,因此我们首先定义一个Node类。
from dataclasses import dataclass
@dataclass
class Node:
feature: int = None # feature for the split
value: float = None # split threshold OR final prediction
left: np.array = None # store one part of the data
right: np.array = None # store the other part of the data
一个节点知道用于分割的特征(feature)以及分割值(value)。value 还被用作决策树最终预测的存储。由于我们将构建一棵二叉树,每个节点需要知道它的左子节点和右子节点,分别存储在left和right中。
现在,让我们进行实际的决策树实现。我将其与 scikit-learn 兼容,因此我使用了来自sklearn.base的一些类。如果你不熟悉,可以查看我的文章如何构建兼容 scikit-learn 的模型。
让我们实现吧!
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin
class DecisionTreeClassifier(BaseEstimator, ClassifierMixin):
def __init__(self):
self.root = Node()
@staticmethod
def _gini(y):
"""Gini impurity."""
counts = np.bincount(y)
p = counts / counts.sum()
return (p * (1 - p)).sum()
def _split(self, X, y):
"""Bruteforce search over all features and splitting points."""
best_information_gain = float("-inf")
best_feature = None
best_split = None
for feature in range(X.shape[1]):
split_candidates = np.unique(X[:, feature])
for split in split_candidates:
left_mask = X[:, feature] < split
X_left, y_left = X[left_mask], y[left_mask]
X_right, y_right = X[~left_mask], y[~left_mask]
information_gain = self._gini(y) - (
len(X_left) / len(X) * self._gini(y_left)
+ len(X_right) / len(X) * self._gini(y_right)
)
if information_gain > best_information_gain:
best_information_gain = information_gain
best_feature = feature
best_split = split
return best_feature, best_split
def _build_tree(self, X, y):
"""The heavy lifting."""
feature, split = self._split(X, y)
left_mask = X[:, feature] < split
X_left, y_left = X[left_mask], y[left_mask]
X_right, y_right = X[~left_mask], y[~left_mask]
if len(X_left) == 0 or len(X_right) == 0:
return Node(value=np.argmax(np.bincount(y)))
else:
return Node(
feature,
split,
self._build_tree(X_left, y_left),
self._build_tree(X_right, y_right),
)
def _find_path(self, x, node):
"""Given a data point x, walk from the root to the corresponding leaf node. Output its value."""
if node.feature == None:
return node.value
else:
if x[node.feature] < node.value:
return self._find_path(x, node.left)
else:
return self._find_path(x, node.right)
def fit(self, X, y):
self.root = self._build_tree(X, y)
return self
def predict(self, X):
return np.array([self._find_path(x, self.root) for x in X])
就这样!你现在可以做你喜欢的所有 scikit-learn 的事情了:
dt = DecisionTreeClassifier().fit(X, y)
print(dt.score(X, y)) # accuracy
# Output
# 1.0
由于树没有正则化,过拟合严重,因此训练得分完美。未见数据上的准确度会更差。我们还可以通过以下方式查看树的外观
print(dt.root)
# Output (prettified manually):
# Node(
# feature=1,
# value=-0.14963454032767076,
# left=Node(
# feature=0,
# value=0.04575851730144607,
# left=Node(
# feature=None,
# value=0,
# left=None,
# right=None
# ),
# right=Node(
# feature=None,
# value=1,
# left=None,
# right=None
# )
# ),
# right=Node(
# feature=None,
# value=0,
# left=None,
# right=None
# )
# )
作为图示,它将是这样的:
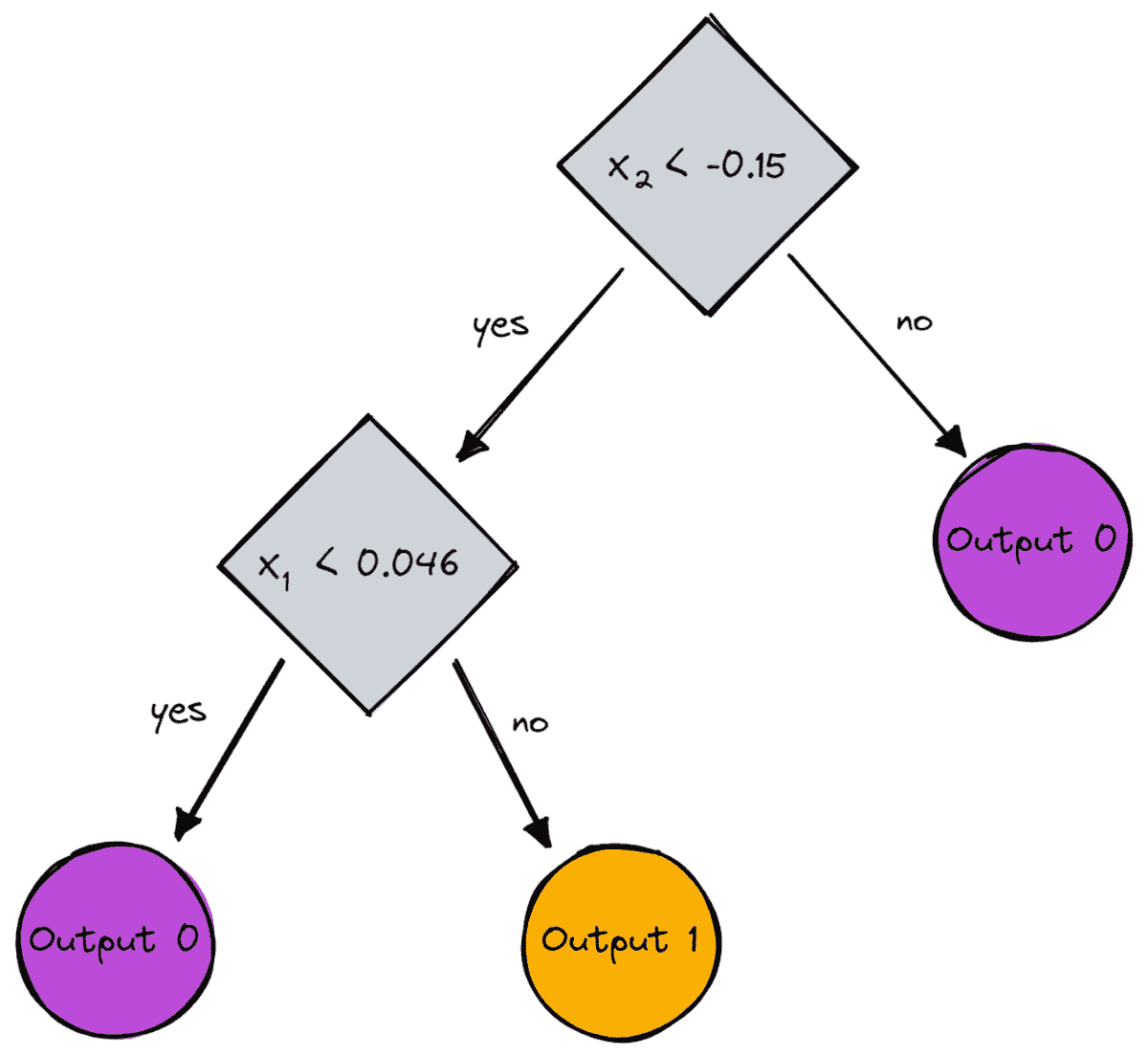
图片由作者提供
结论
在这篇文章中,我们详细了解了决策树的工作原理。我们从一些模糊但直观的想法开始,将它们转化为公式和算法。最后,我们能够从头实现一棵决策树。
不过需要提醒的是:我们的决策树尚未正则化。通常,我们希望指定像
-
最大深度
-
叶子大小
-
和最小信息增益
以及许多其他内容。幸运的是,这些实现起来并不难,这使得它成为你完美的作业。例如,如果你将leaf_size=10作为参数,那么包含超过 10 个样本的节点就不再拆分。此外,这种实现是不高效的。通常,你不希望将数据集的部分内容存储在节点中,而只存储索引。因此,你(可能很大的)数据集只在内存中存在一次。
好消息是你现在可以尽情使用这个决策树模板。你可以:
-
实现对角线拆分,即xᵢ + 2xⱼ = 3 而不是仅仅 xᵢ = 3,
-
更改叶子内部发生的逻辑,即你可以在每个叶子中运行逻辑回归,而不仅仅是做多数投票,这将给你一个线性树。
-
更改拆分过程,即尝试一些随机组合并选择最佳组合,而不是使用暴力破解,这将给你一个额外树分类器。
-
等等。
罗伯特·库布勒博士 是 METRO.digital 的高级数据科学家,同时也是 Towards Data Science 的作者。
原文。转载时获得许可。
更多相关话题
理解 Python 中的可迭代对象与迭代器
原文:
www.kdnuggets.com/2022/01/understanding-iterables-iterators-python.html

图片由 geralt on Pixabay 提供
可迭代对象和迭代器经常被混淆,然而它们是两个不同的概念。本文将解释它们之间的区别,以及如何使用它们。我们先简要了解一下什么是迭代。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
通俗来说,迭代意味着“重复步骤”。在编程术语中,迭代是指以特定次数重复执行语句/代码块,逐个产生输出。例如,可以使用 for 循环来执行迭代。
Python 中的可迭代对象
可迭代对象是可以使用 for 循环进行遍历的对象。可迭代对象包含数据或有值,通过执行 for 循环可以进行迭代,逐个产生输出。
可迭代对象实现了 __iter__() 方法,并返回一个迭代器对象。然而,如果 __iter__() 方法未定义,Python 将使用 __getitem__() 方法。
可迭代对象的例子有列表、字典、字符串、元组等。只要你能遍历它,它就是一个可迭代对象。
要确定一个对象是否是可迭代的,你需要检查它是否支持 __iter__。为此,我们使用 dir() 函数,它返回指定对象的所有属性和方法,但不包括值。
示例代码:
class Person:
name = "Nisha"
age = 25
country = "England"
print(dir(Person))
输出:
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__',
'__format__', '__ge__', '__getattribute__', '__gt__', '__hash__',
'__init__', '__init_subclass__', '__le__', '__lt__', '__module__',
'__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__',
'__setattr__', '__sizeof__', '__str__', '__subclasshook__',
'__weakref__', 'age', 'country', 'name']
Python 中的迭代器
迭代器也是一个对象,它使用 __iter__() 和 __next__() 方法,这被称为迭代器协议。它是一个有状态的可迭代对象,这意味着它记住在迭代过程中处于什么阶段。
迭代器逐个返回值。当返回可迭代对象的下一个值时,迭代器的状态会被更新,并知道如何使用 __next__() 方法获取下一个值。迭代器只能向前移动,不能回退或重置。
迭代器在没有更多元素或对象已耗尽时也会引发 StopIteration 异常。
示例代码:
这里我创建了一个名为“numbers”的迭代器。我加入了一行代码来检查其类型。我们期望迭代能输出所有数字。然而,我要求它打印第六个输出,但迭代器中只有五个值。让我们看看会发生什么。
numbers = iter([2, 4, 6, 8, 10])
print(type(numbers))
print(next(numbers))
print(next(numbers))
print(next(numbers))
print(next(numbers))
print(next(numbers))
# The next() function will raise StopIteration as it is exhausted
print(next(numbers))
输出:
我们可以看到类型是‘list_iterator’。输出在 10 处停止,并引发了StopIteration,因为数字列表中没有更多元素。
<class 'list_iterator'>
2
4
6
8
10
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
<ipython-input-15-0cb721c5f355> in <module>()
11
12 # The bext() function will raise StopIteration as it is exhausted
---> 13 print(next(numbers))
StopIteration:
迭代器的限制:
-
迭代器只向前移动,不能向后或重置。
-
迭代器不能被复制,因为它是一个只能向前移动的单向对象。
-
由于其单向方向,无法检索到之前的元素。
可迭代对象和迭代器之间的相似性和差异
| 可迭代对象 | 迭代器 | |
|---|---|---|
| 通过以下方式迭代: | for 循环 | for 循环 |
| 使用的方法: | iter() | iter() 和 next() |
迭代器是一个可迭代对象,因为它也实现了__iter__()方法。
记住: 每个迭代器都是一个可迭代对象,但并非每个可迭代对象都是一个迭代器。
可迭代对象的 dir() 示例:
numbers = [2, 4, 6, 8, 10]
print(dir(numbers))
输出:
在这个输出中,我突出了__iter__,显示它是一个可迭代对象的方法。
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__',
'__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__',
'__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__',
'__init_subclass__', '__iter__', '__le__', '__len__', '__lt__',
'__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__',
'__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__',
'__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count',
'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
迭代器的 dir() 示例:
在这个例子中,我们正在迭代数字列表。
numbers = [2, 4, 6, 8, 10]
numbers2 = iter(numbers)
print(dir(numbers2))
输出:
在这个输出中,我突出了__iter__和__next__,显示它们是迭代器的方法。
['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__',
'__ge__', '__getattribute__', '__gt__', '__hash__', '__init__',
'__init_subclass__', '__iter__', '__le__', '__length_hint__', '__lt__',
'__ne__', '__new__', '__next__', '__reduce__', '__reduce_ex__',
'__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__',
'__subclasshook__']
我希望这个简短的博客能让你更好地理解可迭代对象和迭代器之间的区别。
尼莎·阿里亚 是一名数据科学家和自由技术作家。她特别感兴趣于提供数据科学职业建议或教程,以及数据科学理论知识。她还希望探索人工智能如何/可以促进人类寿命的不同方式。作为一个积极学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关内容
了解机器学习算法:深度概述
原文:
www.kdnuggets.com/understanding-machine-learning-algorithms-an-indepth-overview

图片由作者提供
机器学习。相当令人印象深刻的词汇,对吧?由于 AI 及其工具,如ChatGPT和 Bard,目前正在蓬勃发展,是时候深入学习基础知识了。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 需求。
这些基本概念可能不会立即启发你,但如果你对这些概念感兴趣,你将会有更多的链接可以深入了解。
机器学习的力量来自于其复杂的算法,这些算法是每个机器学习项目的核心。有时,这些算法甚至受到人类认知的启发,如语音识别或面部识别。
在这篇文章中,我们将首先讲解机器学习的类别,如监督学习、无监督学习和强化学习。
然后,我们将讨论机器学习处理的任务,名称是分类、回归和聚类。
之后,我们将深入探讨决策树、支持向量机、K-近邻和线性回归的可视化和定义。
当然,你如何选择最符合你需求的最佳算法呢?当然,理解“理解数据”或“定义你的问题”等概念将帮助你应对项目中的挑战和障碍。
让我们开始机器学习的旅程吧!
机器学习的分类
在我们探索机器学习时,可以看到有三个主要类别塑造了其框架。
-
监督学习
-
无监督学习
-
强化学习。
在监督学习中,你想预测的标签在数据集中。
在这种情况下,算法像一个细心的学习者,将特征与相应的输出关联起来。在学习阶段结束后,它可以为新的数据和测试数据预测输出。考虑一下标记垃圾邮件或预测房价的场景。
想象一下没有导师的学习,这一定很令人畏惧。无监督学习方法特别适用于这种情况,它们在没有标签的情况下进行预测。
它们勇敢地进入未知领域,发现未标记数据中的隐藏模式和结构,类似于探险家发现失落的文物。
理解生物学中的基因结构和市场营销中的客户细分是无监督学习的例子。
最后,我们来到了强化学习,在这里,算法通过犯错来学习,类似于小狗。想象一下训练一只宠物:不良行为会被抑制,而良好行为则会得到奖励。
类似地,算法采取行动,体验奖励或惩罚,并最终弄清楚如何优化。这种策略在机器人技术和视频游戏等行业中被频繁使用。
机器学习的类型
在这里,我们将机器算法分为三个子部分。这些子部分是分类、回归和聚类。
分类
正如名称所示,分类专注于将项目分组或分类的过程。想象一下你是一个植物学家,需要根据各种特征将植物分类为良性或危险类别。这就像根据糖果的颜色将其分类到不同的罐子中一样。
回归
回归是下一步;可以将其视为尝试预测数值变量。
在这种情况下的目标是预测某个变量,例如在考虑其特征(房间数量、位置等)时估算房产的成本。
这类似于根据水果的尺寸来估算其大致数量,因为没有明确的分类,而是一个连续的范围。
聚类
我们现在进入聚类,这类似于整理杂乱的衣物。即使你没有预设的类别(或标签),你仍然将相关的物体放在一起。
想象一个算法,在没有事先了解涉及主题的情况下,根据这些主题对新闻故事进行分类。这里显然是聚类!
让我们分析一些执行这些任务的流行算法,因为仍然有很多内容值得深入探索!
流行的机器学习算法
在这里,我们将深入探讨流行的机器学习算法,如决策树、支持向量机、K-最近邻和线性回归。
A. 决策树
图片来源:作者
想象一下计划一个户外活动,并需要根据天气决定是否继续进行或取消。决策树可以用来表示这个决策过程。
机器学习(ML)领域中的决策树方法会对数据提出一系列的二元问题(例如,“是否正在降水?”),直到做出决定(继续收集或停止)。这种方法在我们需要理解预测背后的推理时非常有用。
如果你想了解更多关于决策树的内容,可以阅读决策树和随机森林算法(基本上是升级版的决策树)。
B. 支持向量机(SVM)
图片来源:作者
想象一个类似于荒野西部的场景,目标是分开两个对立的群体。
为了避免任何冲突,我们会选择最大的实际边界;这正是支持向量机(SVM)所做的。
它们找出最有效的“超平面”或边界,将数据分成不同的簇,同时保持与最近的数据点的最大距离。
这里你可以找到更多关于 SVM 的信息。
C. K-最近邻(KNN)
图片来源:作者
接下来是 K-最近邻(KNN),一个友好且社交的算法。
想象一下搬到一个新城市,并尝试弄清楚它是安静的还是忙碌的。
监控你最近的邻居以获取理解似乎是合乎逻辑的行动。
类似地,KNN 根据数据集中其近邻的参数(如 k)对新数据进行分类。
这里你可以了解更多关于 KNN 的信息。
D. 线性回归
图片来源:作者
最后,想象一下尝试根据朋友学习的小时数预测他们的考试结果。你可能会注意到一个模式:花更多时间学习通常会取得更好的结果。
线性回归模型,如其名称所示,表示输入(学习小时数)和输出(考试分数)之间的线性关系,可以捕捉这种相关性。
这是预测数值(如房地产价格或股市值)的常用方法。
想了解更多关于线性回归的内容,你可以阅读这篇文章。
选择合适的机器学习模型
从所有可用的选项中选择正确的算法可能感觉像是在寻找一个非常大的干草堆中的针。但别担心!让我们通过一些重要的考虑因素来澄清这个过程。
A. 了解你的数据
将你的数据视作一张藏宝图,其中包含了找到最佳算法的线索。
-
你的数据上有标签吗?(监督学习与无监督学习)
-
它包括多少个特征?(我们是否需要降维?)
这些问题的答案可能会指引你正确的方向。相比之下,无标签数据可能会促进无监督学习算法如聚类的使用。例如,有标签的数据会促使使用监督学习算法,如决策树。
B. 定义你的问题
想象一下用螺丝刀来钉钉子;效果不是很好,对吧?
通过明确问题来选择合适的“工具”或算法。你的目标是识别隐藏的模式(聚类)、预测一个类别(分类)还是一个指标(回归)?
每种任务类型都有适用的算法。
C. 考虑实际方面
理想的算法有时在实际应用中可能表现不如理论中的表现。你拥有的数据量、可用的计算资源和对结果的需求都起着重要作用。
记住某些算法,如 KNN,在处理大数据集时可能表现不佳,而其他算法,如朴素贝叶斯,可能在复杂数据上表现良好。
D. 切勿低估评估
最后,评估和验证模型的性能至关重要。你需要确保算法能有效处理你的数据,就像在购买之前试穿衣物一样。
这种“契合度”可以通过各种度量来衡量,例如分类任务的 准确度 或回归任务的 均方误差。
结论
我们是不是已经走了很远?
就像将图书馆分成不同的类型一样,我们开始将机器学习领域划分为监督学习、无监督学习和强化学习。然后,为了了解这些类别内的书籍多样性,我们进一步探讨了分类、回归和聚类等任务。
我们首先了解了一些机器学习算法,包括决策树、支持向量机、K-最近邻、朴素贝叶斯和线性回归。这些算法各有其特殊性和优势。
我们还意识到,选择正确的算法就像为一个角色挑选理想的演员,要考虑数据、问题的性质、实际应用和性能评估。
每个 机器学习项目 提供了不同的旅程,就如每本书都带来新的叙事。
请记住,学习、实验和改进比第一次就做对更为重要。
所以,做好准备,戴上你的数据科学家帽子,开始你自己的机器学习冒险吧!
内特·罗西迪 是一名数据科学家及产品战略专家。他还是一名兼职教授,教授分析课程,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过来自顶级公司的真实面试问题准备面试。可以通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
更多相关主题
理解机器学习算法
原文:
www.kdnuggets.com/2017/10/understanding-machine-learning-algorithms.html
作者:布雷特·伍杰克,SAS。
机器学习现在已成为主流。鉴于公司从大量可用数据中获得价值的成功,每个人都想参与其中。虽然机器学习的想法可能令人感到压倒,但这并非魔法,基本概念相当简单。
在这里,我将为你提供理解一些最流行的机器学习算法背后思想的基础。
随机森林
随机森林是由 Leo Breiman 于 2001 年 提出的,这是一种简单而强大的算法,由独立训练的决策树集合(或集合)组成。
在决策树中,整个观察数据集沿着不同的分支递归地划分为子集,以便相似的观察结果在终端叶子处聚集在一起。最优增加树“纯度”的变量在每个分割点指导分割,分组具有相似目标值的观察结果。对于任何新的观察,你可以沿着树中的分割规则路径来预测目标。
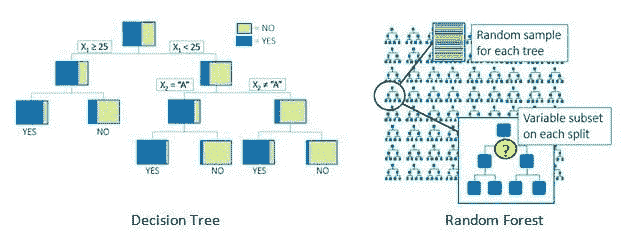
但决策树是不稳定的。训练数据的微小变化可能导致完全不同的树。训练一组树并“集成”它们以创建一个“随机森林”模型可以实现更稳健的预测。
在随机森林中:
-
用于训练每棵树的数据集是完整数据集的随机样本(带替代),这一过程称为“袋装”(bootstrap aggregating)。
-
考虑用于分割每个节点的输入变量是所有变量的随机子集,这减少了对最具影响力因素的偏倚,并允许次要因素在模型中发挥作用。
-
通过让树成长到较大的深度和较小的叶子大小来过拟合。对大量过拟合树的预测概率进行平均比使用单棵调整过的决策树更稳健。
集成,或在许多树上对新观察进行评分,使你能够通过更稳健和具有普遍性模型的共识来获得预测目标值(分类投票,区间目标预测的平均)。
由于随机森林的高效性,研究人员发展了诸如 “相似性森林” 和 “深度嵌入森林” 的变体。
梯度提升机器
一种梯度提升机器,如 XGBoost,是另一种源于决策树的机器学习算法。
在 90 年代末,Breiman 观察到,一个表现出一定错误水平的模型可以作为基础学习器,通过迭代添加补偿错误的模型来改进——这一过程称为“提升”。每个新增模型都通过在负梯度方向上搜索来最小化错误(因此称为“梯度”提升)。提升是一个顺序过程,因为新模型是基于之前模型的结果添加的。
Jerome Friedman 在 2001 年将梯度提升概念应用于决策树,创建了 Gradient Boosting Machines。Freund 和 Shapire (2001) 的流行且有效的 Adaboost,使用指数损失函数,是这种方法的一种变体。
最近几年,Tiangi Chen 研究了梯度提升机算法的各个方面及修订,以进一步增强在 XGBoost 实现中的性能,XGBoost 代表“极端梯度提升”。他的修改包括在决策树训练中使用分位数分箱,将正则化项添加到目标函数中以改善泛化能力,并支持多种损失函数。最终,XGBoost 的“极端”特性可以归因于 Chen 特意实现它,以利用分布式多线程处理的计算能力,从而提升速度和效率。
支持向量机
支持向量机(SVM)是机器学习从业者工具箱中的另一种“机器”,已有几十年的历史。SVM 由 Vladimir Vapnik 和 Alexey Chervonenkis 于 1963 年发明,是一种二分类模型,通过构造超平面将观察值分为两个类别。
下图是一个简单的示例,观察值的目标值用点和叉表示,可以如图所示进行分割。由于无限多个方向的这条线(在多维空间中的超平面)可以分隔这些点,我们在这条线上定义一个缓冲区,并制定一个优化问题以最大化这个边际。我们能够分离这两个类别的越多,我们的模型在对新数据评分时就会越准确。定义边际的点被称为“支持向量”。
实际上,大多数多维实际数据集并不是完全可分的。很少会有所有来自一个类别的观察值都在一侧,而来自另一个类别的观察值都在另一侧。SVM 通过引入对落在边际错误一侧的观察值的惩罚(用红色箭头表示),来构造最佳的分隔超平面。
图. SVM 中分隔类别的超平面
注意到边距大小在正确分类训练数据和对未来数据进行泛化之间存在权衡。较大的边距意味着更多的训练点被误分类,但泛化效果更好——始终记住目标是将模型应用于未来数据,而不是在现有数据上获得最佳拟合。
另一个将数据分为两类的障碍是数据很少能线性分隔,必须以某种方式考虑更高的维度。下图描述了一个一维问题,其中一个类别包含在一个区间内,另一个类别则分布在左侧和右侧。直线无法有效地分隔这些点,因此 SVM 使用核函数将数据映射到更高维空间。
惩罚项和“核技巧”使 SVM 成为一个强大的分类器。这项技术也用于一种称为支持向量数据描述的算法,用于异常检测。
图:应用核函数以便于分隔
神经网络
神经网络在 1950 年代发展起来,是机器学习特别是“深度学习”的典型代表。它们是复杂应用程序的基础,如语音转文本、图像分类和对象检测。如果你直接跳到用于深度学习的更复杂形式,可能会感到不知所措;但神经网络的基本功能并不难以理解。
神经网络只是将数学变换应用于输入数据的一个集合,数据在一个由互联节点(称为神经元)组织的网络中传递。每个输入由一个输入节点表示。这些节点连接到下一层的节点,每个连接上分配一个权重,粗略表示该输入的一般重要性。当值从一个节点传递到另一个节点时,它们会被乘以连接的权重,并应用激活函数。每个节点的结果值随后会传递到网络中的下一层节点。最终,输出节点中的激活函数分配一个值来提供预测。

训练神经网络的核心是找到权重的正确值。数据首次通过网络时,初始权重设置产生的输出值与训练数据中的已知输出值不匹配。反向传播过程使用梯度信息(量化权重值变化如何影响每个节点的输出)来调整权重,并在网络中反复循环,直到权重收敛到具有可接受误差的值,即预测值与实际值之间的误差。
由于隐藏层数量、每层神经元数量和所用激活函数的超灵活组合,神经网络可以为高度非线性系统提供极其准确的预测。我最喜欢用来说明神经网络的工具之一是这个由谷歌研究人员开发的有趣的互动示例。 快去看看吧…你不会失望的。
有了这个简单的神经网络解释作为基础,你现在可以深入研究更高级的变体,如卷积神经网络、递归神经网络和去噪自编码器。
魔法已逝
这就是四种最受欢迎的机器学习算法背后的理念。虽然这些算法构建了高度预测的模型,但它们并不是魔法。对基础概念的掌握将帮助你理解这些算法——以及以新颖方式扩展它们的算法。
简介: 布雷特·伍杰克 是 SAS 高级分析部门的高级数据科学家。他帮助推广和指导 SAS 高级分析的发展方向,特别是在机器学习和数据挖掘领域。在加入 SAS 之前,布雷特在达索系统公司领导了过程集成和设计探索技术的开发,帮助设计和实施了行业领先的计算机辅助优化软件。他的正式背景是设计优化方法论,他在圣母大学获得了博士学位,研究了用于多学科设计优化的高效算法。
相关:
-
二十年老算法的突破重新定义了大数据基准
-
数据科学基础:初学者的基本概念
-
必须了解:集成学习的理念是什么?`
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
更多相关内容
理解机器学习:免费电子书
原文:
www.kdnuggets.com/2020/06/understanding-machine-learning-free-ebook.html
评论
欢迎来到每周 KDnuggets 免费电子书概述的另一期。
尽管我们在过去几周探讨了包括一些更高级的专题在内的专业话题,但我们认为现在是回到基础的时候了,本周我们介绍了理解机器学习:从理论到算法,由 Shai Shalev-Shwartz 和 Shai Ben-David 编著。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
来自书籍官网:
本教材旨在以原则性方式介绍机器学习及其提供的算法范式。书中提供了机器学习基本原理的理论介绍,并且详细推导了将这些原理转化为实际算法的数学过程。在介绍了基础知识后,书中涵盖了以前的教材未涉及的广泛核心话题。
[...]
该教材为高级本科生或初级研究生设计,使学生和统计学、计算机科学、数学和工程领域的非专家读者能够理解机器学习的基础和算法。
本书具有解释性,重点讲解了各种机器学习概念的理论。这里没有代码;你不会从头编写算法,也不会使用现有库来实现任何内容。这 strictly for learning theory.
该书分为四个不同的部分,如下所示:
第一部分:基础
-
温和的开始
-
一个正式的学习模型
-
通过一致性收敛进行学习
-
偏差-复杂度权衡
-
VC 维度
-
非一致性可学习性
-
学习的运行时间
第二部分:从理论到算法
-
线性预测器
-
提升方法
-
模型选择与验证
-
凸学习问题
-
正则化与稳定性
-
随机梯度下降
-
支持向量机
-
核方法
-
多类别、排序和复杂预测问题
-
决策树
-
最近邻
-
神经网络
第三部分:附加学习模型
-
在线学习
-
聚类
-
降维
-
生成模型
-
特征选择与生成
第四部分:高级理论
-
拉德马赫复杂度
-
覆盖数
-
学习理论基本定理的证明
-
多类别学习能力
-
压缩界限
-
PAC-Bayes
在引言中,本书提出了以下一对目标:
本书的首要目标是提供一个严谨而易于跟随的机器学习主要概念的介绍:什么是学习?机器如何学习?我们如何量化学习给定概念所需的资源?学习是否总是可能的?我们能否知道学习过程是否成功或失败?
本书的第二个目标是展示几个关键的机器学习算法。我们选择展示一方面在实践中成功使用的算法,另一方面展示各种不同学习技术的广泛范围。
在解释其概念的过程中,本书在很大程度上依赖数学。实际上,彻底理解这些机器学习概念的理论基础是不可能的,但这通常会让人感到惊讶,并可能让一些人感到不知所措,因此请做好心理准备。
一旦数学理论的震撼感消退,你将发现从偏差-方差权衡到线性回归,再到模型验证策略、模型提升、核方法、预测问题等主题都有详尽的处理。这样详尽的处理的好处在于,你的理解将比单纯掌握抽象直觉更深入。
你可以直接 在这里下载本书的 PDF。
如果你正在寻找深入探讨学习概念和深度学习理论的严谨书籍,一定要将《理解机器学习:从理论到算法》加入你的短名单。
相关:
-
统计学习的要素:免费下载电子书
-
机器学习数学:免费下载电子书
-
统计推断的简明课程:免费下载电子书
更多相关主题
理解神经网络的思维方式
原文:
www.kdnuggets.com/2020/07/understanding-neural-networks-think.html
评论
来源:distill.pub/2018/building-blocks/
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
我最近开始了一份专注于 AI 教育的新通讯。《TheSequence》是一份无废话(即无炒作、无新闻等)的 AI 重点通讯,阅读时间仅需 5 分钟。目标是让你了解机器学习项目、研究论文和概念。请通过下面的订阅尝试一下:
任何深度学习解决方案中的一个挑战性元素是理解深度神经网络做出的知识和决策。尽管神经网络决策的解释一直很困难,但随着深度学习的兴起以及操作多维数据集的大规模神经网络的普及,这一问题变得更加棘手。毫不奇怪,神经网络的解释已成为深度学习生态系统中最活跃的研究领域之一。
尝试想象一个拥有数亿个神经元的大型神经网络,它正在执行诸如图像识别之类的深度学习任务。通常,你希望了解网络如何得出特定的决策。当前大多数研究集中在检测网络中哪些神经元被激活上。知道神经元-12345 激活了五次是相关的,但在整个网络的规模中并不是特别有用。关于理解神经网络决策的研究主要集中在三个领域:特征可视化、归因和降维。Google,特别是在特征可视化领域做了大量工作,发布了一些杰出的研究和工具。一年多前,Google 研究人员发布了一篇题为“可解释性的构建块”的论文,成为了机器学习可解释性领域的开创性论文。该论文提出了一些新思路,以理解深度神经网络如何做出决策。
Google 研究的主要见解是不要将不同的可解释性技术孤立看待,而是将它们视为理解神经网络行为的大型模型的可组合构建块。例如,特征可视化是一种非常有效的技术,可以理解单个神经元处理的信息,但不能将该洞察力与神经网络做出的整体决策关联起来。归因是解释不同神经元之间关系的更可靠技术,但在理解单个神经元做出的决策时则不那么有效。通过结合这些构建块,Google 创建了一个不仅仅解释了神经网络检测了什么的可解释性模型,还回答了网络如何将这些单独的部分组装起来以得出后续决策,以及为何做出这些决策。
Google 的新可解释性模型具体是如何工作的?在我看来,主要的创新点在于,它分析了神经网络不同组件在不同层次上的决策:个别神经元、连接的神经元组和完整的层。Google 还使用了一种新颖的研究技术——矩阵分解,以分析任意神经元组对最终决策的影响。
来源: distill.pub/2018/building-blocks/
将 Google 的可解释性模块视为一个模型,该模型检测神经网络在不同抽象层次上,从基础计算图到最终决策的洞察力,是一种很好的思考方式。

来源: distill.pub/2018/building-blocks/
谷歌对深度神经网络可解释性的研究不仅仅是一个理论练习。研究小组在发布论文时,还推出了Lucid,这是一个神经网络可视化库,允许开发者创建清晰的特征可视化,以展示神经网络各个部分所做出的决策。谷歌还发布了colab notebooks。这些笔记本使得在交互环境中使用 Lucid 创建 Lucid 可视化变得非常容易。
原文。经授权转载。
相关:
-
通过遗忘学习:深度神经网络与詹妮弗·安妮斯顿神经元
-
Uber 的 Ludwig 是一个用于低代码机器学习的开源框架
-
谷歌推出 TAPAS:一种基于 BERT 的神经网络,用于使用自然语言查询表格
更多相关话题
列导向数据库解析
原文:
www.kdnuggets.com/2021/02/understanding-nosql-database-types-column-oriented-databases.html
评论
NoSQL 已越来越受到欢迎,作为传统 SQL 数据库和数据库管理方法的补充工具。正如我们所知,NoSQL 不遵循 SQL 的关系模型,这使得它能够做很多强大的事情。更重要的是,它非常灵活和可扩展,这对于没有时间或预算设计 SQL 数据库的新项目非常有用。
因此,我们将深入了解不同的 数据模型 是如何工作的,本文将重点讨论列数据库。如果你想了解更一般的信息,应该查看我们的 NoSQL 初学者指南。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
列数据库是如何工作的?
从最表面上看,列存储数据库确实如其广告所述:即,它不是将信息组织成行,而是将其组织成列。这本质上使它们的功能与关系数据库中的表相同。当然,由于这是NoSQL数据库,这种数据模型使它们更加灵活。

更具体地说,列数据库使用键空间的概念,这有点像关系模型中的模式。这个键空间包含所有列族,列族中包含行,行中再包含列。一开始理解起来有点棘手,但相对来说还是比较简单的。


通过快速查看,我们可以看到一个列族有多个行。在每一行中,可以有多个不同的列,具有不同的名称、链接,甚至大小(意味着它们不需要遵循标准)。此外,这些列只存在于它们自己的行中,并且可以包含值对、名称和时间戳。
以一个具体的行作为例子:
行键 就是那一行的具体标识符,并且总是唯一的。列中包含名称、值和时间戳,这些都是直接明了的。名称/值对也很简单,而时间戳是数据输入数据库的日期和时间。
一些列式存储数据库的例子包括 Casandra、CosmoDB、Bigtable 和 HBase。
列式数据库的好处
列式数据库有几个好处:
-
列式存储在压缩方面表现优异,因此在存储方面非常高效。这意味着你可以减少磁盘资源,同时在单列中保存大量信息。
-
由于大多数信息存储在列中,聚合查询非常快速,这对需要在短时间内进行大量查询的项目很重要。
-
列式存储数据库的可扩展性非常优秀。它们几乎可以无限扩展,通常分布在大规模的机器集群中,甚至达到几千台。这也意味着它们非常适合大规模并行处理。
-
加载时间同样优秀,你可以在几秒钟内轻松加载一个十亿行的表。这意味着你可以几乎瞬间完成加载和查询。
-
列式数据库具有很大的灵活性,因为列之间不一定要相同。这意味着你可以添加新的和不同的列而不会干扰整个数据库。也就是说,输入完全新的记录查询需要更改所有表。
总的来说,列式存储数据库非常适合分析和报告:快速的查询速度和处理大量数据而不增加过多开销的能力使其理想。
列式数据库的缺点
正如生活中的常态,没有什么是完美的,使用列式数据库也有一些缺点:
-
设计一个有效的索引模式既困难又耗时。即便如此,这种模式仍然不如简单的关系数据库模式有效。
-
虽然这对某些用户可能不是问题,但增量数据加载效果不佳,应该尽可能避免。
-
这适用于所有 NoSQL 数据库类型,而不仅仅是列式数据库。安全性 web 应用中的漏洞 始终存在,而 NoSQL 数据库缺乏内置的安全功能。如果安全是你的首要任务,你应该考虑使用关系数据库,或者在可能的情况下使用明确定义的模式。
-
由于数据存储的方式,在线事务处理 (OLTP) 应用程序也与列式数据库不兼容。
列式数据库总是 NoSQL 吗?
在结束之前,我们要指出,列式存储数据库并不一定仅仅是 NoSQL。通常的说法是,列式存储与关系数据库模型有很大不同,因此它完全归于 NoSQL 阵营。
这并不一定总是如此,NoSQL 与 SQL 的争论总体上相当复杂。
在列存储数据库的情况下,它们与 SQL 方法论几乎相同。例如,关键空间充当模式,因此仍然存在某种形式的模式管理。另一个例子是元数据有时看起来完全像典型的关系型 DBMS。具有讽刺意味的是,列存储数据库也通常符合 SQL 和 ACID 标准。
更进一步,NoSQL 数据库通常是文档存储或键值存储,而列存储既不是。
因此,很难争论列存储完全是 NoSQL。
结论
尽管列存储数据库极其强大,但它们 确实 存在自己的一些问题。例如,它写入数据的方式意味着一致性稍有缺乏,因为列需要多次写入磁盘。这与关系型数据库中行数据的顺序写入相比。
尽管如此,列存储仍然是最常用的数据模型之一。
简介:亚历克斯·威廉姆斯 是一位经验丰富的全栈开发者和 Hosting Data UK 的拥有者。在伦敦大学 IT 专业毕业后,亚历克斯作为开发者领导了多个来自世界各地客户的项目,工作了近 10 年。最近,亚历克斯转型为独立 IT 顾问,并开始了自己的博客。在那里,他探讨了 web 开发、数据管理、数字营销以及为刚刚起步的在线业务主提供解决方案。
相关:
-
SQL 与 NoSQL:7 个关键要点
-
NoSQL 初学者指南
-
SQL 还是 NoSQL:这是个问题!
更多相关主题
理解过拟合:机器学习中的不准确的迷思
原文:
www.kdnuggets.com/2017/08/understanding-overfitting-meme-supervised-learning.html
评论
由 Mehmet Suzen,法兰克福大学。
这篇文章的灵感来源于 Andrew Gelman 的一篇 最近文章,他将‘过拟合’定义如下:
过拟合是指你的模型过于复杂,导致预测效果通常比简单模型更差。
前言
从业者对过拟合的概念有很多困惑。似乎在数据科学或相关领域流传着一种城市传说或迷思,其陈述如下:
应用 交叉验证 可以防止过拟合,而良好的样本外表现、未见数据中的低泛化误差,表明不是过拟合。
这个说法显然是不正确的:交叉验证并不能防止你的模型过拟合,良好的样本外表现并不保证模型没有过拟合。实际上,人们在这一说法的一个方面提到的叫做过度训练。不幸的是,这种误解不仅在行业中传播,也存在于一些学术论文中。这可能在最佳情况下只是对术语的混淆。然而,如果我们在沟通结果时对过拟合的定义明确和清晰,这将是一个良好的实践。
目标
在这篇文章中,我们将直观地解释为什么 模型验证 作为近似 模型拟合 的泛化误差和检测过拟合不能在单个模型上同时解决。我们将在一些概念介绍之后,通过一个具体的示例工作流程来理解过拟合、过度训练以及一个典型的最终模型构建阶段。我们将避免提及贝叶斯解释和正则化,限制讨论在回归和交叉验证范围内。虽然正则化由于其数学性质和先验分布在贝叶斯统计中有不同的影响,但我们假设读者具备机器学习的基础知识,因此这不是初学者教程。
最近,贝叶斯大师安德鲁·盖尔曼关于什么是过拟合?的提问,是本帖开发的原因之一,加上我看到从业者对过拟合的含义模糊不清,以及最近发表的关于数据科学的技术文章和一些学术论文中仍然流传的错误观点,我感到沮丧。
我们在监督学习中需要满足什么?
数学中最基本的任务之一是找到一个函数的解:如果我们将自己限制在n维实数上,并且我们的兴趣领域是R^(n)。现在想象在这个领域中存在一组p点,这些点形成一个数据集,这实际上是函数的a 部分 解。建模的主要目的是寻找数据集的解释,这意味着我们需要确定m个参数,a∈R^m,这些参数是未知的。(请注意,非参数模型并不意味着没有参数。)从数学上讲,这表现为我们之前所说的函数 f(x,a)。这个建模通常称为回归、插值或监督学习,这取决于你所阅读的文献。这是逆问题的一种形式,我们不知道参数,但对变量有部分信息。主要问题是解决方案不是良构的。省略公理技术细节,实际问题是我们可以找到许多函数 f(x,a)或模型来解释数据集。
因此,我们希望我们的模型解决方案满足以下两个概念,f(x,a)=0。
-
泛化:模型不应依赖于数据集。这个步骤称为模型验证。
-
最小复杂度:一个模型应遵循奥卡姆剃刀或简约原则。这个步骤称为模型选择。

图 1:监督学习中模型验证和选择的工作流程。
模型的泛化可以通过拟合优度来衡量。这本质上告诉我们我们的模型(选定的函数)对数据集的解释有多好。要找到一个最小复杂度的模型,需要与另一个模型进行比较。
到目前为止,我们还没有命名一种技术来检查一个模型是否经过泛化并被选为最佳模型。不幸的是,目前没有唯一的方式来同时做到这两点,这正是数据科学家或量化从业者的任务,需要人类判断。
模型验证:一个例子
检查模型是否足够通用的一种方法是制定一个度量来评估它解释数据集的好坏。我们在模型验证中的任务是估计模型误差。例如,均方根偏差 (RMDS) 是一个可以使用的度量。如果 RMSD 较低,我们可以说我们的模型拟合得很好,理想情况下它应该接近零。但如果我们使用相同的数据集来衡量拟合优度,它的通用性就不够。我们可以尽可能使用不同的数据集,特别是样本外数据集来验证这一点,即所谓的持出方法。样本外仅仅是说我们没有使用相同的数据集来寻找参数值 a。改进的方法是交叉验证。我们将数据集分成 k 个部分,并获得 k 个 RMDS 值来取平均。这在图 1 中总结了。请注意,相同模型的不同参数化并不构成不同的模型。
模型选择:过拟合的检测
当我们尝试满足“最简复杂模型”时,过拟合就会出现。这是一个比较问题,我们需要多个模型来判断一个给定模型是否过拟合。道格拉斯·霍金斯在他的经典论文 过拟合问题 中指出:
模型的过拟合被广泛认为是一个问题。然而,过拟合并不是绝对的,而是涉及比较的。如果一个模型比另一个拟合效果相同的模型更复杂,那么这个模型就是过拟合的。
这里的重要点是我们所说的复杂模型是什么意思,或者我们如何量化模型复杂性?不幸的是,这没有唯一的方法。最常用的方法之一是,拥有更多参数的模型变得更复杂。但这仍然是一种流行观念,并不完全正确。实际上,可以使用不同的复杂性度量。例如,根据这个定义,f1(a,x)=ax 和 f2(a,x)=ax² 具有相同的复杂性,因为它们有相同数量的自由参数,但直观上 f2 更复杂,尽管它是非线性的。还有许多基于信息论的复杂性度量,但讨论这些超出了我们帖子的范围。为了演示的目的,我们将更多的参数和非线性的程度视为模型的复杂性。

图 2:模拟数据与数据的非随机部分。
实际示例
我们直观地覆盖了为什么我们不能同时解决模型验证和判断过拟合的问题。现在尝试用一个简单的数据集和模型来展示这一点,同时基本捕捉上述前提。
通常的程序是从模型生成一个合成数据集或模拟数据集,作为标准数据集,并利用这个数据集构建其他模型。我们使用以下的功能形式,来自经典文本《Bishop》,但加入了高斯噪声。
f(x)=sin(2πx)+N(0,0.1)。
我们生成一个足够大的数据集,100 个点,以避免《Bishop》书中讨论的样本大小问题,见图 2。我们决定应用两个模型到这个数据集上的监督学习任务中。注意,我们在这里不会讨论贝叶斯解释,因此这些模型在强先验假设下的等价性不是问题,因为我们使用这个示例是为了方便演示概念。我们使用了一个三次和六次的多项式模型,分别称之为 g(x) 和 h(x),用来从模拟数据中学习。
g(x)=a[0] + a[1]x + a[2]x² + a[3]x³
和
h(x)=b[0] + b[1]x + b[2]x² + b[3]x³ + b[4]x⁴ + b[5]x⁵ + b[6]x⁶
图 3:g(x) 在数据使用量达到 40% 之后出现过训练现象。
过训练并非过拟合
过训练 意味着模型在学习模型参数对目标变量的性能下降,而目标变量会影响模型的构建,例如,目标变量可以是训练数据的大小或神经网络中的迭代周期。这在神经网络中更为普遍(见Dayhoff 2011)。在我们的实际示例中,这将表现为在 g(x) 模型中使用保留方法测量 RMSD。换句话说,找到用于训练模型的最佳数据点数量,以在未见数据上提供更好的性能,见图 3 和 4。
低验证误差的过拟合
我们还可以估计 10 折交叉验证误差,CV-RMSD。对于这次采样,g 和 h 的 CV-RMSD 分别为 0.13 和 0.12。正如我们所见,我们遇到了一种更复杂的模型在交叉验证中达到类似的预测能力的情况,我们不能仅通过查看 CV-RMSD 值或从图 4 中检测‘过训练’曲线来区分这种过拟合。我们需要比较两个模型,因此需要图 3 和 4,并查看 CV-RMSD 值。我们可以认为,在小数据集中,我们可能通过查看测试和训练误差的差异来辨别,这正是《Bishop》解释的过拟合;他指出了小数据集中的过训练。
部署哪个训练模型?
现在的问题是,我们已经通过经验发现了性能最佳且复杂度最低的模型。一切都很好,但我们应该在生产中使用哪个训练模型呢?
实际上我们已经在模型选择中建立了模型。在上述情况下,由于我们得到了相似的结果
从 g 和 h 的预测能力来看,我们显然会使用 g,基于图 3 中的划分甜点进行训练。

图 4:在数据使用达到 30% 左右时,过度训练 发生
结论
这里的核心信息是良好的验证性能并不能保证检测到一个过拟合的模型。正如我们从使用一维合成数据的示例中看到的那样。过度训练 实际上是大多数从业者在使用“过拟合”一词时的意思。
展望
随着越来越多的人在学术界和工业界使用机器学习或反问题的技术,一些关键技术概念发生了偏差,并对不同的人有不同的定义和含义,因为人们从阅读文献中学习某些概念的方式往往不是很细致,而是通过直线经理或高级同事的口头解释。这就产生了迷因,这些迷因实际上是错误的,或者至少在术语上造成了很多混乱。作为从业者,我们必须质疑所有技术概念,并尝试从已发布的科学文献中寻求源头,而不是完全依赖于经验丰富的同事的口头解释。同时,我们应该强烈避免嘲笑同事提出的问题,即使这些问题听起来过于简单,毕竟我们永远在学习,而看似幼稚的问题可能在领域的基础上具有非常重要的影响。
附言 如上所述,写这篇文章的灵感来源于 Gelman 最近的一篇文章 (帖子)。他将“过拟合”定义如下:
过拟合是指你有一个复杂的模型,其平均预测效果比一个简单模型更差。
除去两个模型的先验和等效性,Gelman 的定义比 Hawkins 的定义更弱,他接受一个具有相似预测能力的复杂模型。因此,如果我们使用 Gelman 的定义,部署我们上面示例中的 g 或 h 都是可以的。但从 Hawkins 的角度来看,我们需要严格部署 g。
原文。经许可转载。
简历: Dr. Mehmet Suzen 是一位理论物理学家和研究科学家。他在 Memos’ Island 博客上撰写数据科学相关内容。
相关:
-
使预测模型稳健:Holdout vs Cross-Validation
-
关于贝叶斯先验和过拟合的真相
-
如何用数据撒谎
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织的 IT
更多相关内容
理解 Python 的迭代和成员资格:contains 和 iter 魔法方法指南

作者提供的图像
如果你是 Python 新手,你可能遇到过 "iteration" 和 "membership" 这些术语,可能会想知道它们的意思。这些概念对于理解 Python 如何处理数据集合(如列表、元组和字典)是基础的。Python 使用特殊的 dunder 方法来实现这些功能。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
那么,什么是 dunder 方法呢?Dunder/魔法方法是 Python 中以双下划线开始和结束的特殊方法,因此得名“dunder”。它们用于实现各种协议,并可以执行广泛的任务,如检查成员资格、迭代元素等。在本文中,我们将重点关注两个最重要的 dunder 方法:contains 和 iter。那么,开始吧。
使用 Iter 方法理解 Pythonic 循环
考虑使用 Python 类实现的文件目录的基本示例:
class File:
def __init__(self, file_path: str) -> None:
self.file_path = file_path
class Directory:
def __init__(self, files: List[File]) -> None:
self._files = files
一个简单的代码示例,其中目录有一个包含 File 对象列表的实例参数。如果我们想遍历目录对象,我们应该能够使用如下的 for 循环:
directory = Directory(
files=[File(f"file_{i}") for i in range(10)]
)
for _file in directory:
print(_file)
我们用十个随机命名的文件初始化一个目录对象,并使用 for 循环遍历每个项目。很简单,但哎呀!你会收到一个错误信息:TypeError: 'Directory' object is not iterable。
问题出在哪里了?我们的 Directory 类没有设置为可遍历。在 Python 中,要使类对象变为可迭代对象,它必须实现 iter dunder 方法。Python 中的所有可迭代对象,如列表、字典和集合,都实现了这一功能,因此我们可以在循环中使用它们。
因此,为了使我们的目录对象可迭代,我们需要创建一个迭代器。可以将迭代器看作是一个助手,当我们要求它时,它会一个一个地给我们项。例如,当我们遍历一个列表时,迭代器对象会在每次迭代时提供下一个元素,直到我们到达循环的末尾。这就是迭代器在 Python 中的定义和实现方式。
在 Python 中,迭代器必须知道如何提供序列中的下一个项。它通过一个名为next的方法来实现。当没有更多项可提供时,它会引发一个名为StopIteration的特殊信号,表示“嘿,我们完成了。”在无限迭代的情况下,我们不会引发StopIteration异常。
让我们为目录创建一个迭代器类。它将接受文件列表作为参数,并实现 next 方法来给我们序列中的下一个文件。它使用索引跟踪当前位置。实现如下:
class FileIterator:
def __init__(self, files: List[File]) -> None:
self.files = files
self._index = 0
def __next__(self):
if self._index >= len(self.files):
raise StopIteration
value = self.files[self._index]
self._index += 1
return value
我们初始化一个索引值为 0,并接受文件作为初始化参数。next 方法检查索引是否溢出。如果是,它会引发StopIteration异常以表示迭代结束。否则,它返回当前索引的文件,并通过递增索引移动到下一个文件。这个过程会持续直到所有文件都被迭代过。
不过,我们还没有完成!我们仍然没有实现 iter 方法。iter 方法必须返回一个迭代器对象。现在我们已经实现了 FileIterator 类,我们可以最终转向 iter 方法。
class Directory:
def __init__(self, files: List[File]) -> None:
self._files = files
def __iter__(self):
return FileIterator(self._files)
iter 方法只是用其文件列表初始化了一个 FileIterator 对象,并返回该迭代器对象。就这么简单!通过这个实现,我们现在可以使用 Python 的循环遍历我们的目录结构。让我们看看实际效果:
directory = Directory(
files=[File(f"file_{i}") for i in range(10)]
)
for _file in directory:
print(_file, end=", ")
# Output: file_0, file_1, file_2, file_3, file_4, file_5, file_6, file_7, file_8, file_9,
for 循环内部调用iter方法来显示结果。虽然这样做有效,但你可能仍然对 Python 中迭代器的底层工作机制感到困惑。为了更好地理解它,我们可以使用 while 循环手动实现相同的机制。
directory = Directory(
files=[File(f"file_{i}") for i in range(10)]
)
iterator = iter(directory)
while True:
try:
# Get the next item if available. Will raise StopIteration error if no item is left.
item = next(iterator)
print(item, end=', ')
except StopIteration as e:
break # Catch error and exit the while loop
# Output: file_0, file_1, file_2, file_3, file_4, file_5, file_6, file_7, file_8, file_9,
我们对目录对象调用 iter 函数以获取 FileIterator。然后,我们手动使用 next 操作符来调用 FileIterator 对象上的下一个 dunder 方法。我们处理 StopIteration 异常,以便在所有项耗尽后优雅地终止 while 循环。正如预期的那样,我们得到了与之前相同的输出!
使用包含方法测试成员资格
在一个对象集合中检查某项是否存在是一个相当常见的用例。例如,在我们上面的例子中,我们经常需要检查一个文件是否存在于目录中。因此,Python 通过使用 "in" 操作符在语法上简化了这一过程。
print(0 in [1,2,3,4,5]) # False
print(1 in [1,2,3,4,5]) # True
这些通常与条件表达式和评估一起使用。但是如果我们用我们的目录示例尝试这样做会发生什么?
print("file_1" in directory) # False
print("file_12" in directory) # False
两者都给出 False,这是不正确的!为什么?要检查成员资格,我们需要实现 contains dunder 方法。当它没有实现时,Python 会回退到使用 iter 方法,并使用 == 运算符评估每个项目。在我们的例子中,它将迭代每个项目,并检查 “file_1” 字符串是否与列表中的任何 File 对象匹配。由于我们比较的是字符串与自定义的 File 对象,因此没有对象匹配,结果是 False 评估。
为了解决这个问题,我们需要在我们的 Directory 类中实现 contains dunder 方法。
class Directory:
def __init__(self, files: List[File]) -> None:
self._files = files
def __iter__(self):
return FileIterator(self._files)
def __contains__(self, item):
for _file in self._files:
# Check if file_path matches the item being checked
if item == _file.file_path:
return True
return False
在这里,我们将功能更改为迭代每个对象,并将 File 对象中的 file_path 与传递给函数的字符串进行匹配。现在,如果我们运行相同的代码来检查存在性,我们会得到正确的输出!
directory = Directory(
files=[File(f"file_{i}") for i in range(10)]
)
print("file_1" in directory) # True
print("file_12" in directory) # False
总结
就这样!通过我们的简单目录结构示例,我们构建了一个简单的迭代器和成员检查器,以理解 Pythonic 循环的内部工作原理。我们在生产级代码中相当常见这种设计决策和实现,通过这个现实世界的例子,我们探讨了 iter 和 contains 方法背后的基本概念。继续练习这些技巧,以增强理解并成为更熟练的 Python 程序员!
Kanwal Mehreen**** Kanwal 是一位机器学习工程师和技术作家,对数据科学以及 AI 与医学的交叉领域充满热情。她共同撰写了电子书《用 ChatGPT 最大化生产力》。作为 2022 年 APAC 区域的 Google Generation Scholar,她倡导多样性和学术卓越。她还被认可为 Teradata 多样性技术奖学者、Mitacs Globalink 研究学者和哈佛 WeCode 学者。Kanwal 是变革的热情倡导者,她创办了 FEMCodes,以赋能 STEM 领域的女性。
更多相关主题
理解监督学习:理论与概述
原文:
www.kdnuggets.com/understanding-supervised-learning-theory-and-overview

图片来源:作者
监督学习是机器学习的一个子类别,其中计算机从包含输入和正确输出的标记数据集中学习。它试图找出将输入(x)与输出(y)相关联的映射函数。你可以把它想象成教你的弟弟或妹妹如何识别不同的动物。你会给他们看一些图片(x),并告诉他们每种动物的名称(y)。经过一段时间,他们将学习到这些差异,并能够正确识别新的图片。这就是监督学习的基本直觉。在继续之前,让我们深入了解一下它的工作原理。
我们的 top 3 课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织在 IT 方面
监督学习是如何工作的?
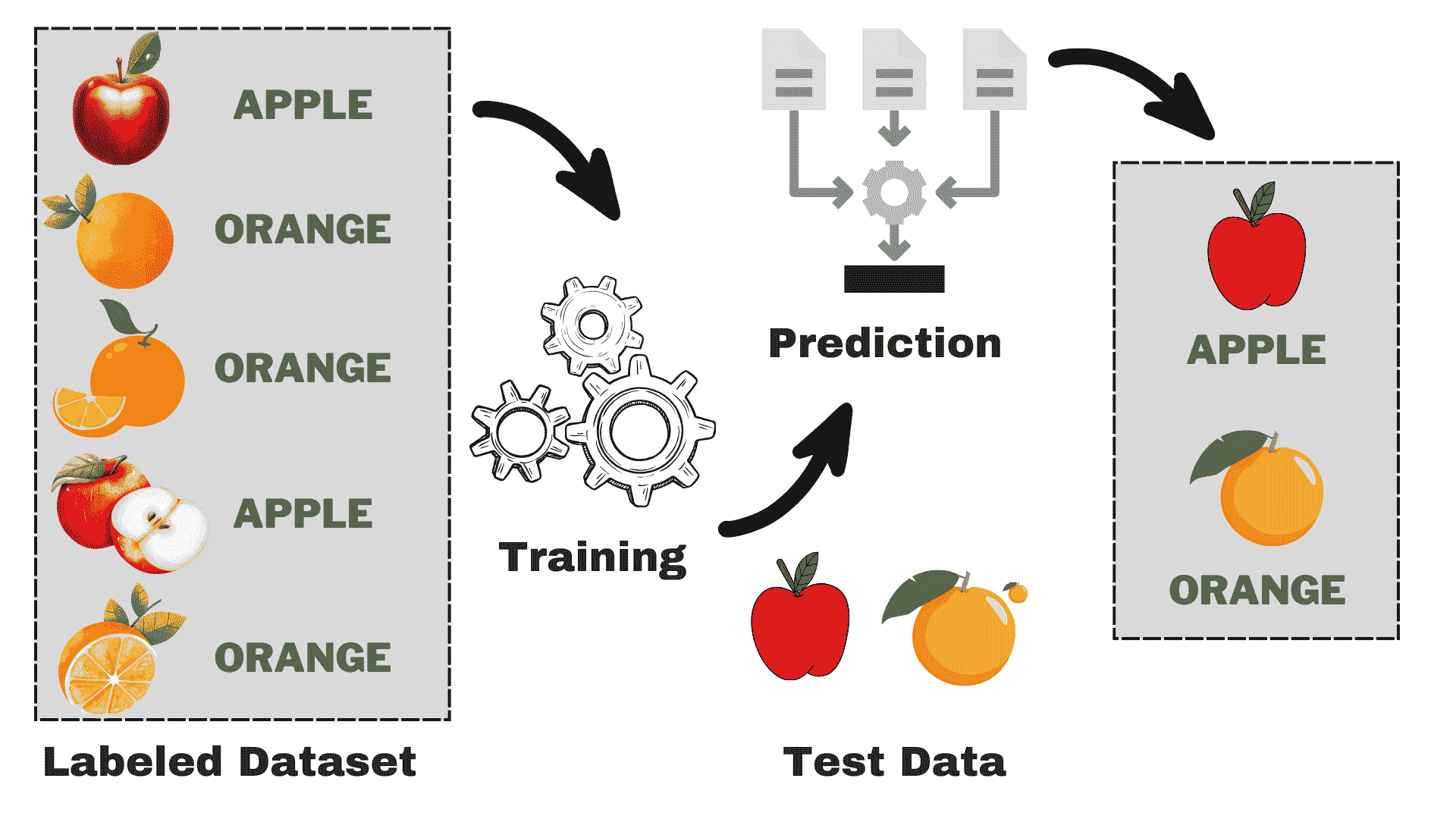
图片来源:作者
假设你想建立一个模型,根据一些特征区分苹果和橙子。我们可以将这个过程分解为以下任务:
-
数据收集: 收集一个包含苹果和橙子的图片的数据集,并将每张图片标记为“苹果”或“橙子”。
-
模型选择:我们必须选择合适的分类器,通常被称为适合您任务的监督机器学习算法。这就像选择合适的眼镜来帮助你看得更清楚。
-
训练模型: 现在,你将带标签的苹果和橙子的图片输入算法。算法查看这些图片,学习识别它们之间的差异,如颜色、形状和大小。
-
评估与测试: 为了检查你的模型是否工作正常,我们将输入一些未见过的图片,并将预测结果与实际结果进行比较。
监督学习的类型
监督学习可以分为两种主要类型:
分类
在分类任务中,主要目标是将数据点分配到从离散类别集合中的特定类别。当只有两个可能的结果,例如“是”或“否”、“垃圾邮件”或“非垃圾邮件”、“接受”或“拒绝”时,这被称为二分类。然而,当涉及到多个类别或类时,例如根据成绩对学生进行评分(例如,A、B、C、D、F),它就成为多分类问题的一个例子。
回归
对于回归问题,你试图预测一个连续的数值。例如,你可能希望根据你在课堂上的过去表现预测你的期末考试成绩。预测的成绩可以在特定范围内的任何值,通常在我们的例子中是从 0 到 100。
流行监督学习算法概述
现在,我们对整体过程有了基本了解。我们将探索流行的监督学习算法,它们的使用以及它们是如何工作的:
1. 线性回归
正如其名字所示,它用于回归任务,如预测股票价格、预测温度、估计疾病进展的可能性等。我们尝试使用一组标签(自变量)来预测目标(因变量)。它假设输入特征与标签之间存在线性关系。核心思想是通过最小化实际值与预测值之间的误差来预测数据点的最佳拟合直线。该直线由以下方程表示:

其中,
-
Y 预测输出。
-
X = 多元线性回归中的输入特征或特征矩阵
-
b0 = 截距(直线与 Y 轴交点)。
-
b1 = 确定直线陡峭度的斜率或系数。
它估计了直线的斜率(权重)和截距(偏差)。这条直线可以进一步用于进行预测。尽管它是开发基准的最简单且有用的模型,但它对可能影响直线位置的离群值非常敏感。
Gif 在 Primo.ai
2. 逻辑回归
尽管它的名字中包含回归,但本质上用于二分类问题。它预测一个正向结果的概率(因变量),该概率范围在 0 到 1 之间。通过设置阈值(通常为 0.5),我们对数据点进行分类:那些概率大于阈值的数据点属于正类,反之亦然。逻辑回归使用应用于输入特征的线性组合的 Sigmoid 函数来计算这个概率,具体如下:
=\frac{1}{1+e^{-(b_0+b_1X_1+b_2X_2+\ldots+b_nX_n)}}")
其中,
-
P(Y=1) = 数据点属于正类的概率
-
X1 ,... ,Xn = 输入特征
-
b0,....,bn = 算法在训练过程中学习的输入权重
这个 Sigmoid 函数呈 S 形曲线,将任何数据点转换为 0-1 范围内的概率分数。你可以查看下面的图表以获得更好的理解。
图片来自于维基百科
值越接近 1,表示模型对其预测的信心越高。与线性回归一样,它以其简单性而闻名,但我们不能在不对原算法进行修改的情况下执行多类别分类。
3. 决策树
与上述两种算法不同,决策树可以用于分类和回归任务。它具有层次结构,类似于流程图。在每个节点,根据某些特征值做出路径决策。该过程继续,直到我们到达表示最终决策的最后一个节点。以下是一些你必须了解的基本术语:
-
根节点: 包含整个数据集的顶部节点称为根节点。然后,我们使用某些算法选择最佳特征,将数据集分成两个或更多子树。
-
内部节点: 每个内部节点表示一个特定的特征和一个决策规则,以决定数据点的下一步方向。
-
叶节点: 代表类别标签的结束节点称为叶节点。
它预测回归任务中的连续数值。随着数据集的大小增加,它会捕捉到噪声,从而导致过拟合。这可以通过修剪决策树来处理。我们去除那些不会显著提高决策准确性的分支。这有助于保持树的关注点在最重要的因素上,防止它在细节中迷失。
图片来自于Jake Hoare 在 Displayr 上
4. 随机森林
随机森林也可以用于分类和回归任务。它是多个决策树共同工作以做出最终预测的集合。你可以把它看作是专家委员会做出的集体决策。它的工作原理如下:
-
数据采样: 不是一次性处理整个数据集,而是通过称为自助法或袋装法的过程获取随机样本。
-
特征选择: 在随机森林中的每个决策树中,仅考虑随机特征子集进行决策,而不是完整的特征集。
-
投票: 对于分类问题,随机森林中的每个决策树都会投票,选票最多的类别被选择。对于回归问题,我们对所有树得到的值进行平均。
尽管它减少了个别决策树引起的过拟合效应,但计算成本较高。文献中常出现的一句话是,随机森林是一种集成学习方法,意味着它结合了多个模型以提高整体性能。
5. 支持向量机 (SVM)
它主要用于分类问题,但也可以处理回归任务。它尝试通过统计方法找到最佳的超平面,以分隔不同的类别,这与逻辑回归的概率方法不同。我们可以使用线性 SVM 来处理线性可分的数据。然而,大多数实际数据是非线性的,我们使用核技巧来分隔类别。让我们深入探讨它的工作原理:
-
超平面选择: 在二分类中,SVM 寻找最佳的超平面(2D 线)来分隔类别,同时最大化边际。边际是超平面与离超平面最近的数据点之间的距离。
-
核技巧: 对于线性不可分的数据,我们采用核技巧,将原始数据空间映射到高维空间,在那里可以线性分隔。常见的核包括线性核、多项式核、径向基函数(RBF)核和 sigmoid 核。
-
边际最大化: SVM 还通过增加最大化边际来提高模型的泛化能力。
-
分类: 一旦模型训练完成,可以根据数据相对于超平面的位置进行预测。
SVM 还有一个参数叫做 C,用于控制最大化边际和保持分类误差最小之间的权衡。尽管它们可以很好地处理高维和非线性数据,但选择正确的核和超参数并不像看起来那么简单。
图片来自 Javatpoint
6. k-最近邻 (k-NN)
K-NN 是最简单的监督学习算法,主要用于分类任务。它对数据没有任何假设,并根据与现有数据点的相似性为新数据点分配一个类别。在训练阶段,它将整个数据集作为参考点。然后,它使用距离度量(例如欧几里得距离)计算新数据点与所有现有点之间的距离。根据这些距离,它识别出与这些数据点最接近的 K 个邻居。我们统计 K 个邻居中每个类别的出现次数,并将出现频率最高的类别作为最终预测。
图片来源于 GeeksforGeeks
选择合适的 K 值需要实验。虽然它对噪声数据具有鲁棒性,但不适用于高维数据集,并且由于需要计算所有数据点之间的距离,成本较高。
总结
在总结这篇文章时,我鼓励读者探索更多的算法,并尝试从零开始实现它们。这将增强你对底层工作原理的理解。以下是一些额外资源,帮助你入门:
-
机器学习课程 - Javatpoint
-
机器学习专业化 - Coursera
Kanwal Mehreen 是一位有志的软件开发人员,对数据科学和 AI 在医学中的应用充满兴趣。Kanwal 被选为 2022 年 APAC 地区的 Google Generation Scholar。Kanwal 喜欢通过撰写关于热门话题的文章分享技术知识,并且热衷于提升女性在技术行业中的代表性。
更多相关话题
理解强化学习的基础
原文:
www.kdnuggets.com/understanding-the-basics-of-reinforcement-learning

图片来源:编辑 | Ideogram
强化学习是人工智能领域专注于构建从经验或试错中学习的系统的领域。这篇文章以非技术性和易于接近的方式揭示了这一引人入胜的人工智能部分的基本概念和应用。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
什么是强化学习?
强化学习(RL)是人工智能的一个分支,在这个领域中,代理——通常是软件程序——通过与环境的交互逐渐学会智能决策。
为了更好地理解 RL 背后的原理,一个常见的比较是小孩子学习骑自行车。一开始,孩子会尝试不同的动作,通常会导致摔倒。每次孩子摔下自行车时,(s)he 会感受到疼痛(惩罚),而如果孩子能够骑行几米而不摔倒,(s)he 会感到满意(奖励)。孩子逐渐内化哪些动作——或动作序列——能够实现平稳骑行,应用这些动作并提高骑行技能。
同样,在 RL 中,代理执行动作以获得奖励或惩罚,并迭代地调整其行为以提高性能。
RL 算法的元素
理解 RL 基础的第一步是介绍 RL 算法的关键元素。这些元素在下面的图示中展示。
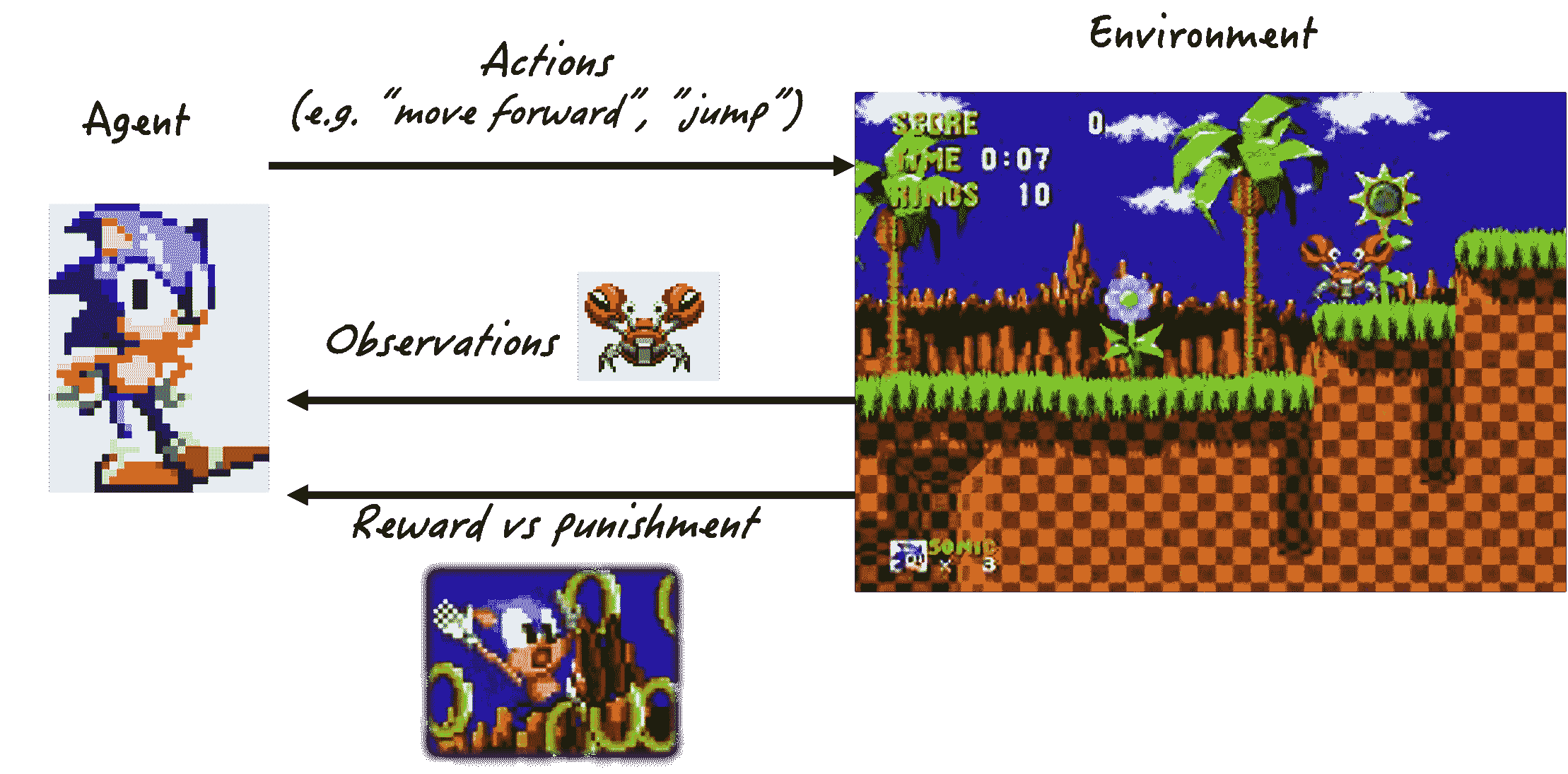
-
代理: 在环境中做决策并采取行动以实现目标的软件实体。
-
环境: 代理通过执行动作与之互动的数字或物理设置。
-
状态: 环境由状态组成,代理在给定时间处于某一状态。换句话说,状态代表当前的环境情况,由代理“分析”以做出决策。
-
动作: 在给定状态下,代理进行的任何移动或决策,通常会导致因动作而产生的新状态。
-
奖励: 代理因采取某一动作导致状态变化而收到的值或反馈。它可以是正面的或负面的(惩罚),表示相对于定义的目标,动作的即时成功或失败。正面奖励往往使代理更接近该目标,反之亦然。
强化学习代理如何学习?
我们下一个需要回答的问题是:代理如何学习选择能够带来最大奖励的动作,无论是短期的还是长期的?换句话说,代理在学习过程中利用哪些元素来改善其在不同状态下的决策能力?这就是策略和价值函数的概念发挥作用的地方。
策略是代理用来决定在每个可能状态下采取哪个动作的策略。在最简单的情况下,策略可以是一个状态-动作查找表,但通常它是由一个更复杂的数学函数定义,该函数将状态映射到可能的动作。例如,一个学习玩基于平台的视频游戏的代理,其控制的角色当前站在一个平台上(状态),可以向前、向后走或向任何方向跳跃(动作)。
同时,奖励函数量化了代理在给定状态下执行动作后获得的正面或负面奖励。从数学上讲,它将状态-动作对映射到一个数值奖励。在视频游戏的例子中,如果角色在边缘上并向前跳跃,它可能会到达对面的另一个平台(正面奖励),而如果它决定不跳跃而是直接走前面,它将会掉落(负面奖励)。
当这些元素共同观察时,允许代理逐步学习最佳的行动路径,以最大化奖励并最终实现所追求的目标。
基于模型与无模型强化学习方法
策略和奖励函数来自哪里?是否有人制定了有关环境状态、行动及其奖励的信息?简短的回答是:这要看情况。这些信息的收集方式取决于所使用的强化学习方法类型。从这个角度来看,有两种广泛的方法:基于模型的强化学习和无模型强化学习。
基于模型的强化学习(RL)使用环境的模型(通常通过机器学习或深度学习从数据中学习得到)来评估所采取行动的结果,而无模型强化学习则通过直接与环境互动逐步构建这个模型,依赖纯粹的“试错”而不是预测或估计。
强化学习的现实世界影响和障碍
应用与最新趋势
在实验层面,强化学习历史上主要应用于解决游戏和模拟环境中的问题。然而,其应用领域已迅速扩展到机器人技术和推荐引擎等需要实时决策的动态环境中。强化学习的最新应用趋势包括自主驾驶控制及其与生成式人工智能(例如语言模型)的集成,以提高在复杂或高度变化的环境中内容生成决策的效果。
挑战与局限性
强化学习的主要挑战之一是其高计算和数据消耗成本,这由于与环境的密集互动以有效学习,从而使其在某些现实场景中的应用变得更加困难。
总结
在这篇文章中,我们介绍了围绕强化学习算法的基本概念及其核心组件:具有目标的代理,通过与环境互动执行动作并逐渐从这些动作的结果中学习。我们还概述了强化学习解决方案的显著实际应用和挑战。尽管充满挑战,强化学习目前因其与生成式人工智能解决方案的共生关系而备受关注,使得内容生成变得更加高效。
伊万·帕洛马雷斯·卡拉索萨 是一位领导者、作家、演讲者和人工智能、机器学习、深度学习及大型语言模型领域的顾问。他训练和指导他人如何在实际中利用人工智能。
更多相关主题
以数据科学的方式理解变换器
原文:
www.kdnuggets.com/2020/10/understanding-transformers-data-science-way.html
评论
变换器现在已经成为任何 NLP 任务的事实标准。不仅如此,它们现在还被用于计算机视觉和音乐生成。我相信大家都听说过 GPT3 变换器及其应用。但除了这些,它们仍然像以前一样难以理解。
我花了多次阅读谷歌研究的论文,它首次介绍了变换器,并阅读了大量博客文章,才真正理解了变换器是如何工作的。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力。
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT。
所以,我想尽可能用简单的语言把整个概念阐述出来,加上一些非常基础的数学和一些双关语,因为我是一个在学习过程中享受乐趣的倡导者。我会尽量将术语和技术性降到最低,但这是一个复杂的话题,我只能做到这么多。我的目标是让读者在阅读完这篇文章后,甚至理解变换器中最复杂的细节。
此外,这篇文章也是我写作时间最长、篇幅最长的文章。因此,我建议你拿一杯咖啡。☕️
那么,接下来——这篇文章将会是非常对话式的,主题是“解码变换器”。
问:那么,为什么我应该理解变换器?
过去,LSTM 和 GRU 架构(在我之前的文章中解释过)以及注意力机制曾是语言建模问题(简单来说,就是预测下一个词)和翻译系统的最先进方法。但是,这些架构的主要问题是它们是递归性质的,随着序列长度的增加,运行时间也会增加。也就是说,这些架构以顺序的方式处理句子中的每个词,因此随着句子长度的增加,整体运行时间也会增加。
变压器,一种在论文《Attention is all you need》中首次解释的模型架构,放弃了递归,而完全依赖注意力机制来捕捉输入和输出之间的全局依赖关系。这使得它非常快速。
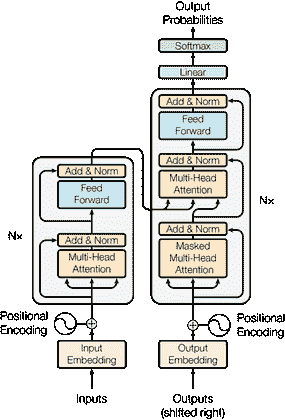
这是论文中展示的完整变压器的图片。它确实很让人畏惧。因此,我将在这篇文章中通过逐一解析每个部分来揭开它的神秘面纱。所以请继续阅读。
大致情况
问:这听起来很有趣。那么,变压器到底做了什么?
本质上,变压器几乎可以执行任何 NLP 任务。它可以用于语言建模、翻译或分类,并通过去除问题的序列性质快速完成任务。因此,在机器翻译应用中,变压器将一种语言转换为另一种语言,或者在分类问题中将使用适当的输出层提供类别概率。
一切将取决于网络的最终输出层,但变压器的基本结构在任何任务中都将保持相当一致。对于这篇文章,我将继续使用机器翻译的例子。
从非常高的角度来看,这就是变压器在翻译任务中的样子。它以英文句子为输入,并返回德文句子。

变压器用于翻译 (作者图片)
构建模块
问:这太基础了。???? 能详细讲解一下吗?**
好吧,请记住最后你要求的。让我们深入了解一下变压器的组成。
所以,变压器本质上由一系列编码器层和解码器层组成。编码器层的作用是利用注意力机制将英文句子编码成数值形式,而解码器则旨在使用编码器层编码的信息来给出特定英文句子的德文翻译。
在下图中,变压器以英文句子为输入,通过 6 个编码器层进行编码。最终编码器层的输出然后传递到每个解码器层,以将英文翻译成德文。
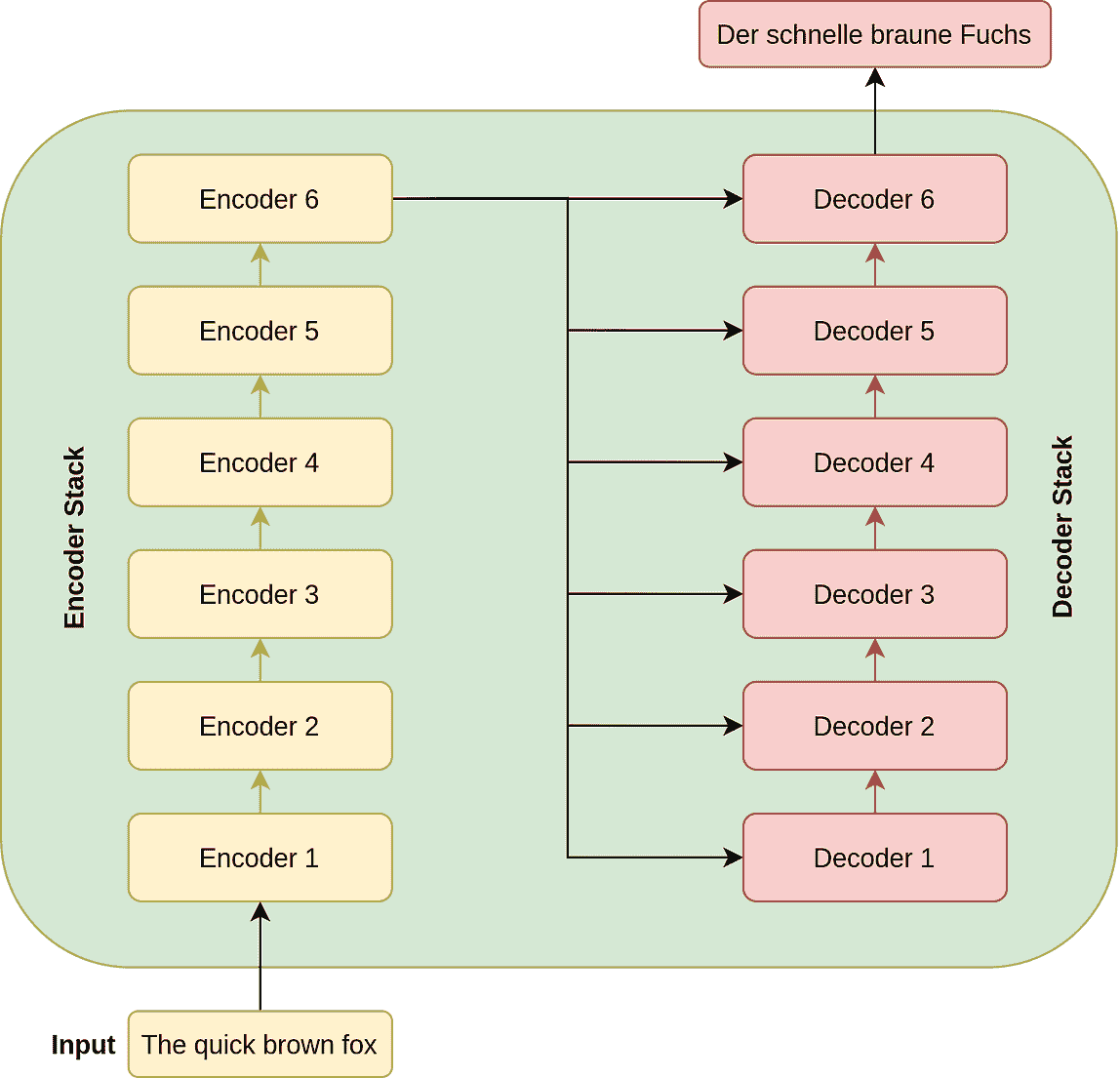
变压器中的数据流 (作者图片)
1. 编码器架构
问:这很好,但编码器堆栈是如何精确地编码英文句子的?
请耐心等待,我正在进行中。正如我所说,编码器堆栈包含六个编码器层(如论文中所述,但未来版本的变压器将使用更多层)。每个堆栈中的编码器本质上有两个主要层:
-
一个多头自注意力层,以及
-
一个位置级的全连接前馈网络
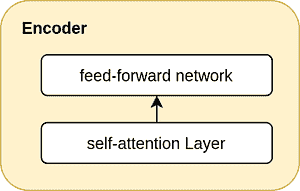
非常基础的编码器层 (作者图片)
这些概念可能有点复杂。对吧?不要着急,我将在接下来的部分中解释它们。现在只需记住,编码器层包含注意力机制和逐位置的前馈网络。
问:那么,这一层期望它的输入是什么样的呢?
这一层期望其输入的形状为SxD(如下面的图所示),其中S是源句子(英文句子)的长度,D是嵌入的维度,其权重可以与网络一起训练。在这篇文章中,我们将默认使用D为 512。S则是一个批次中句子的最大长度,因此它会随着批次的不同而变化。
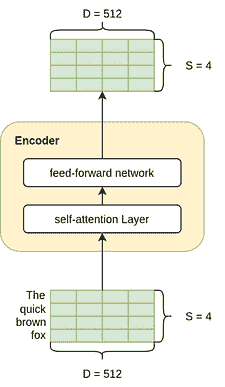
编码器——输入和输出的形状相同 (作者提供的图像)
那么这一层的输出如何呢?请记住,编码器层是堆叠在一起的。因此,我们希望输出的维度与输入相同,以便输出可以顺利传递到下一个编码器。所以输出的形状也是SxD。
问:关于尺寸的讨论够了,我了解了输入和输出的情况,但实际上在编码器层发生了什么?
好的,让我们逐一了解注意力层和前馈层:
A) 自注意力层
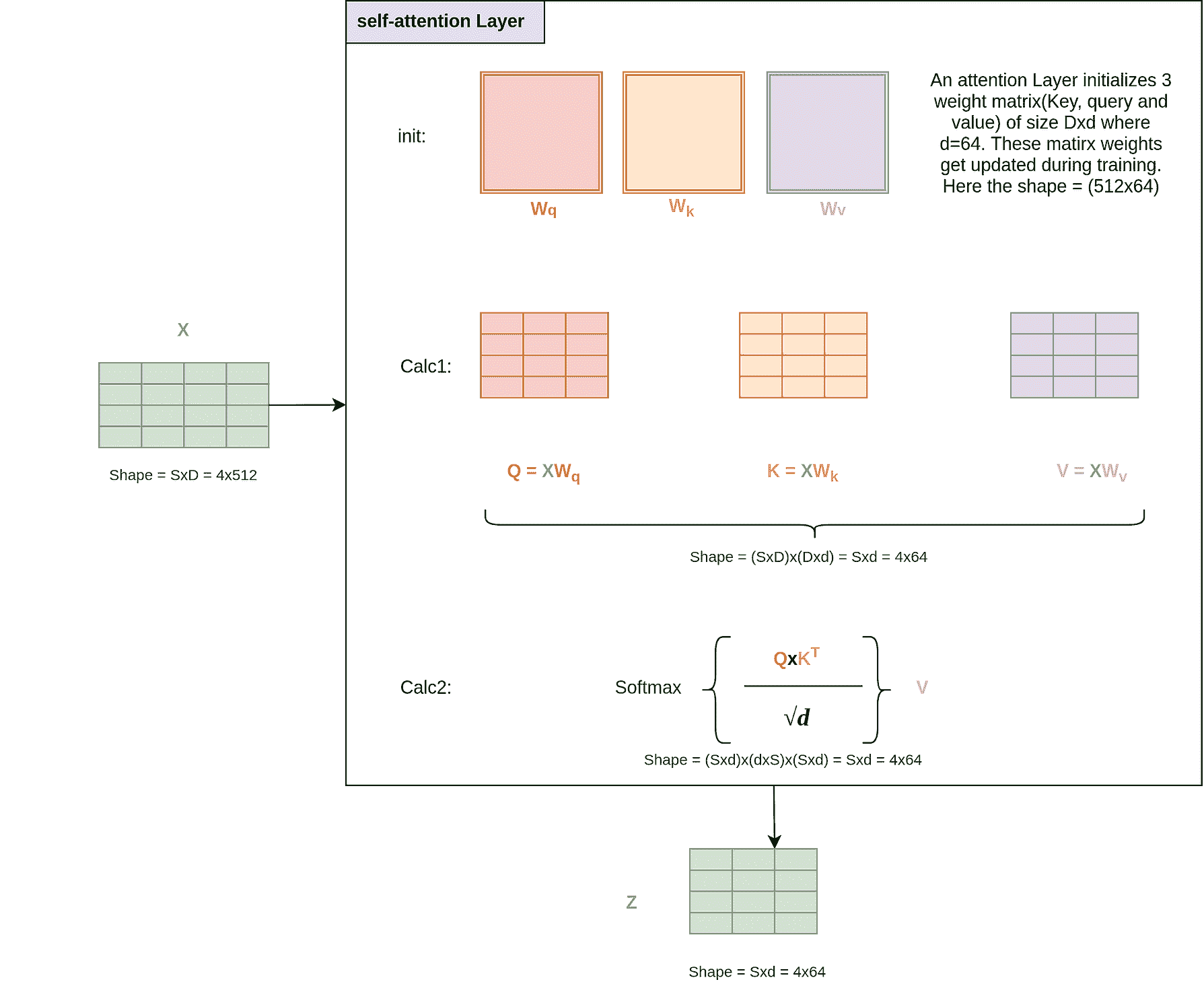
自注意力机制的工作原理 (作者提供的图像)
上面的图看起来可能很吓人,但其实很容易理解。所以,请继续跟随我。
深度学习本质上就是大量的矩阵计算,而我们在这一层所做的就是智能地进行大量的矩阵计算。自注意力层初始化时使用了 3 个权重矩阵——Query(W_q)、Key(W_k)和 Value(W_v)。这些矩阵的大小为(Dxd),其中 d 在论文中取为 64。训练模型时,这些矩阵的权重将被训练。
在第一次计算(图中的计算 1)中,我们通过将输入与各自的查询、键和值矩阵相乘来创建 Q、K 和 V 矩阵。
到目前为止,可能还很简单,没什么意义,但在第二次计算时,事情变得有趣了。我们来尝试理解 softmax 函数的输出。我们首先将 Q 和 Kᵀ矩阵相乘,得到一个SxS的矩阵,然后除以标量√d。接着我们进行 softmax,使得每一行的和为 1。
直观地,我们可以将结果的SxS矩阵看作每个词对其他词的贡献。例如,它可能看起来像这样:
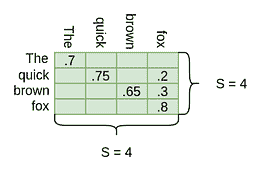
Softmax(QxKt/sqrt(d)) (作者提供的图像)
正如你所见,对角线条目的值很大。这是因为词语对自身的贡献很高。这是合理的。但我们可以在这里看到,“quick”这个词分解成了“quick”和“fox”,“brown”这个词也分解成了“brown”和“fox”。这直观地帮助我们说两个词——“quick”和“brown”都指向“fox”。
一旦我们得到这个 SxS 矩阵及其贡献,我们将此矩阵与句子的值矩阵(Sxd)相乘,得到一个形状为 Sxd(4x64)的矩阵。所以,这个操作实际上是用比如 0.75 x(quick embedding)和 0.2x(fox embedding)来替代“quick”这个词的嵌入向量,因此现在“quick”这个词的结果输出中嵌入了注意力。
请注意,这一层的输出具有维度(Sxd),在完成整个编码器之前,我们需要将其更改为 D=512,因为我们需要将这个编码器的输出作为另一个编码器的输入。
Q: 但是,你称这个层为多头自注意力层。什么是多头?
好吧,我的错,但为了辩解,我刚刚开始讲到这一点。
它被称为多头,因为我们并行使用了许多这样的自注意力层。也就是说,我们有许多自注意力层堆叠在一起。论文中将注意力层的数量 h 保持为 8。因此,输入 X 经过多个自注意力层并行处理,每个层输出一个形状为(Sxd) = 4x64 的 z 矩阵。我们将这 8(h)个矩阵连接起来,再应用一个最终的输出线性层 Wo,大小为 DxD。
我们得到什么尺寸?对于连接操作,我们得到 SxD(4x(64x8)= 4x512)。将这个输出乘以 Wo,我们得到形状为 SxD(4x512)的最终输出 Z,如预期的。
同时,请注意 h、d 和 D 之间的关系,即 h x d = D。
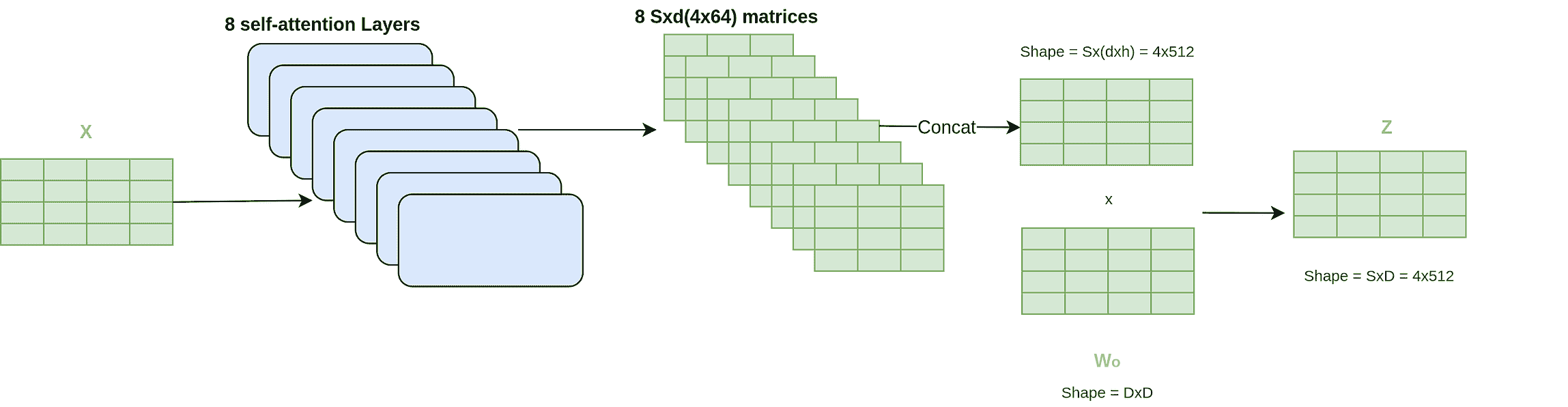
完整的多头自注意力层 (图片来源:作者)
因此,我们最终得到了形状为 4x512 的输出 Z,正如预期的。但在进入另一个编码器之前,我们将其通过一个前馈网络。
B) 位置-wise 前馈网络
一旦我们理解了多头注意力层,前馈网络实际上是相当容易理解的。它只是对输出 Z 进行各种线性和 dropout 层的组合。因此,这里再次只是大量的矩阵乘法。
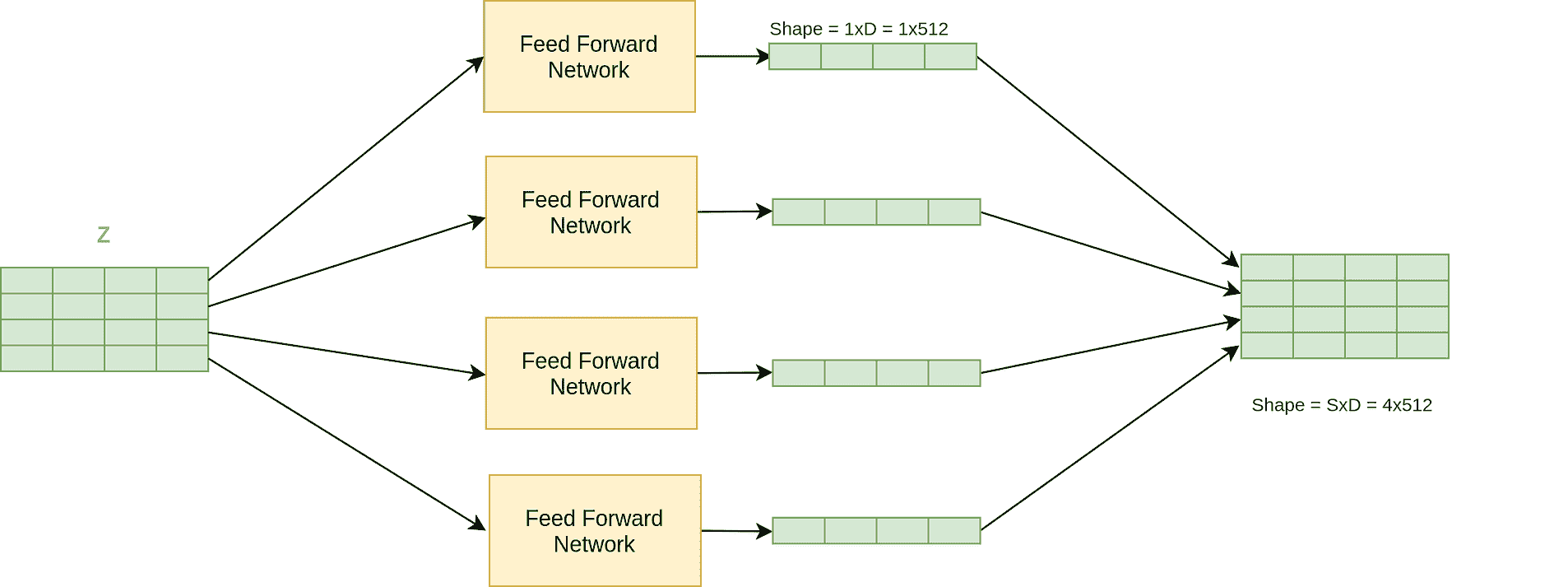
每个词都进入前馈网络。 (图片来源:作者)
前馈网络并行地应用于输出 Z 中的每个位置(每个位置可以看作是一个词),因此得名位置-wise 前馈网络。前馈网络也共享权重,因此源句子的长度无关紧要(此外,如果它不共享权重,我们将不得不根据最大源句子长度初始化很多这样的网络,这样做是不可行的)。
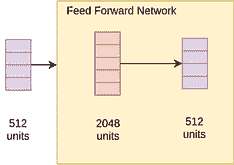
实际上,它只是一个线性层,应用于每个位置(或单词) (作者提供的图片)
有了这些,我们对 Transformer 编码器部分有了一个基本的理解。
问:嘿,我刚刚查看了论文中的图片,编码器堆栈中有一个叫做“位置编码”和“Add & Norm”的东西。这些是什么?
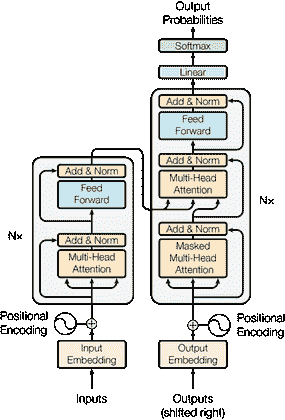
我再次回到这里,所以你不需要滚动 源
好的,这两个概念对于这种特定架构是非常重要的。我很高兴你问了这个问题。因此,在继续解码器堆栈之前,我们会讨论这些步骤。
C. 位置编码
由于我们的模型既没有递归也没有卷积,为了使模型能够利用序列的顺序,我们必须注入一些关于序列中令牌的相对或绝对位置的信息。为此,我们在编码器和解码器堆栈的底部(如后面所见)向输入嵌入添加了“位置编码”。位置编码需要与嵌入具有相同的维度 D,以便可以将两者相加。

向 X 添加一个静态位置模式 (作者提供的图片)
在论文中,作者使用正弦和余弦函数来创建不同位置的位置编码。
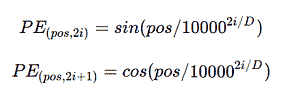
这个特定的数学方法实际上生成了一个二维矩阵,该矩阵被添加到输入到第一个编码器步骤的嵌入向量中。
简而言之,这只是一个常量矩阵,我们将其添加到句子中,以便网络能够获取单词的位置。
前 300 个和 3000 个位置的位置编码矩阵 (作者提供的图片)
上图是我们将添加到输入中的位置编码矩阵的热图,输入将提供给第一个编码器。我展示了前 300 个位置和前 3000 个位置的热图。我们可以看到,我们为 Transformer 提供了一个独特的模式,以便它理解每个单词的位置。由于我们使用了由正弦和余弦组成的函数,我们能够很好地嵌入非常高位置的编码,如第二张图片所示。
有趣的事实: 作者们还让 Transformer 学习这些编码,但并没有看到性能上的任何差异。因此,他们选择了上述方法,因为它不依赖于句子长度,因此即使测试句子比训练样本更长,我们也会没问题。
D. 添加和归一化
另一个在解释编码器时为了简便而未提及的事情是,编码器(解码器架构也是)具有跳跃级别残差连接(类似于 resnet50)。所以,论文中的确切编码器架构如下。简单来说,它有助于在深度神经网络中传递更长的信息。这可以直观地理解为在组织中传递信息的方式,你可以同时访问你的经理以及你经理的上级。
跳跃级别连接有助于网络中的信息流动(图像作者提供)
2. 解码器架构
问:好吧,到目前为止,我们已经了解到编码器接收输入句子并将其信息编码为 SxD(4x512)大小的矩阵。这很好,但它如何帮助解码器将其解码为德语?
好事多磨。因此,在理解解码器如何实现之前,让我们先了解解码器堆栈。
解码器堆栈包含 6 个解码器层(如论文中所述),每个解码器堆栈包括以下三个主要层:
-
掩码多头自注意力层
-
多头自注意力层,以及
-
位置级全连接前馈网络
它还具有相同的位置信息编码和跳跃级别连接。我们已经知道多头注意力和前馈网络层的工作原理,因此我们将直接探讨解码器与编码器的不同之处。
解码器架构(图像作者提供)
问:等一下,但我看到我们需要的输出作为输入流入解码器?什么?为什么?????
我注意到你提问的能力越来越强了。这是一个很好的问题,我自己也思考过很多次,希望在你读完这篇文章时会更清楚。
但为了直观理解,我们可以将变换器视作一种条件语言模型。在这种情况下,模型在给定一个输入词和一个英语句子的条件下预测下一个词。
这种模型本质上是顺序的,比如你如何训练这样的模型?你开始时给定开始标记(<s>),模型根据英语句子预测第一个词。你根据预测是否正确来调整权重。然后你给定开始标记和第一个词(<s> der),模型预测第二个词。你再次调整权重。依此类推。
变压器解码器以相同的方式学习,但美妙之处在于,它不是以顺序的方式进行的。它使用掩码来进行计算,从而在训练时处理整个输出句子(虽然通过在前面添加 <s> 令牌向右偏移)。另外,请注意,在预测时我们不会将输出提供给网络。
问:但是,这个掩码到底是如何工作的?
A) 掩码多头自注意力层
它照常工作,你戴上它,我是说 ????。开玩笑的,正如你所见,这次我们在解码器中有一个 掩码 多头注意力层。这意味着我们会对偏移的输出(即解码器的输入)进行掩码,以便网络永远看不到后续的词,否则它在训练时可以轻松复制那个词。
那么,掩码在掩码注意力层中是如何准确工作的?如果你记得,在注意力层中,我们将查询(Q)和键(K)相乘,并在进行 softmax 之前将它们除以 sqrt(d)。
在掩码注意力层中,我们将结果矩阵(在 softmax 之前的形状为 (TxT))加到掩码矩阵中。
因此,在掩码层中,函数从:

(作者提供的图像)
问:我还是不明白,如果我们这样做会发生什么?
这其实可以理解。让我分步骤说明。因此,我们的结果矩阵(QxK/sqrt(d),形状为 (TxT))可能如下所示:(由于尚未应用 softmax,数字可能较大)
Schnelle 目前同时关注 Braune 和 Fuchs (作者提供的图像)
如果我们取上面矩阵的 softmax 并将其与值矩阵 V 相乘,词 Schnelle 现在将由 Braune 和 Fuchs 组成。但我们不想这样做,因此我们添加掩码矩阵来得到:
对矩阵应用了掩码操作。(作者提供的图像)
那么,softmax 步骤之后会发生什么呢?

Schnelle 从未关注 Schnelle 之后的任何词。(作者提供的图像)
由于 e^{-inf} = 0,Schnelle 后续的所有位置都被转换为 0。现在,如果我们将这个矩阵与值矩阵 V 相乘,Z 矩阵中经过解码器的 Schnelle 位置对应的向量将不包含后续词 Braune 和 Fuchs 的任何信息,就像我们想要的那样。
这就是变压器如何一次性处理整个偏移的输出句子,而不是以顺序的方式学习。可以说相当整洁。
问:你是在开玩笑吗?这实际上很棒。
很高兴你仍然跟着我,并且欣赏它。现在,回到解码器。解码器中的下一层是:
B) 多头注意力层
如你在解码器架构中所见,一个 Z 向量(编码器的输出)从编码器流向解码器中的多头注意力层。这个来自最后一个编码器的 Z 输出有一个特别的名字,通常称为内存。注意力层将编码器输出和来自下方(移位输出)的数据作为输入,并使用注意力机制。查询向量 Q 是从解码器中流动的数据创建的,而键(K)和值(V)向量则来自编码器输出。
问:这里没有掩码吗?
不,这里没有掩码。来自下方的输出已经被掩码,这允许解码器中的每个位置关注值向量中的所有位置。因此,为了生成每个单词位置,解码器可以访问整个英文句子。
这是一个单一的注意力层(它将是多头注意力的一部分,就像之前一样):
(作者提供的图像)
问:但 Q、K 和 V 的形状这次会不同吗?
你可以查看我计算所有权重的图示。我还建议你查看结果 Z 向量的形状,以及我们迄今为止的权重矩阵如何在其任何维度中从未使用目标或源句子的长度。通常,形状在我们所有的矩阵计算中会被取消。例如,见上面计算 2 中 S 维度如何取消。这就是为什么在训练期间选择批次时,作者谈到紧凑的批次。也就是说,在一个批次中,所有源句子具有相似的长度。不同的批次可以有不同的源长度。
我现在将讨论跳过级别连接和前馈层。它们实际上与……中的相同。
问:明白了。我们有跳过级别的连接和 FF 层,并且在整个解码操作后得到形状为 TxD 的矩阵。 但德语翻译在哪里?
3. 输出头部
朋友,我们现在实际上已经很接近了。一旦完成了 transformer,下一步是在解码器输出上添加一个任务特定的输出头。这可以通过在顶部添加一些线性层和 softmax 来实现,以获得跨所有德语词汇的概率。我们可以这样做:
(作者提供的图像)
如你所见,我们能够生成概率。到目前为止,我们知道如何在这个 Transformer 架构中进行前向传递。让我们看看如何训练这样的神经网络架构。
训练:
迄今为止,如果我们从全局视角来看结构,我们得到的东西类似于:

(作者提供的图像)
我们可以给出一个英文句子和相应的输出句子,进行前向传播,得到德语词汇上的概率。因此,我们应该能够使用像交叉熵这样的损失函数,其中目标可以是我们想要的德语单词,并使用 Adam 优化器训练神经网络。就像任何分类示例一样。这就是你的德语。
在论文中,尽管作者使用了优化器和损失函数的细微变化。如果你愿意,可以跳过下面的两个关于 KL 散度损失和 Adam 学习率调度的部分,因为这些只是为了从模型中挤出更多性能,而不是 Transformer 架构的固有部分。
**问:我在这里待了这么长时间,我有没有抱怨? ????
好的,好了。我明白了。那就这么做吧。
A) 带标签平滑的 KL 散度:
KL 散度是当分布 P 被分布 Q 近似时发生的信息丧失。当我们使用 KL 散度损失时,我们尝试使用从模型中生成的概率(Q)来估计目标分布(P)。我们试图在训练中最小化这种信息丧失。
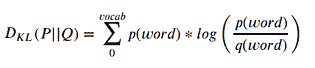
(图片由作者提供)
如果你注意到,在这种形式(没有标签平滑,我们会讨论的)下,这与交叉熵完全相同。给定如下两个分布。
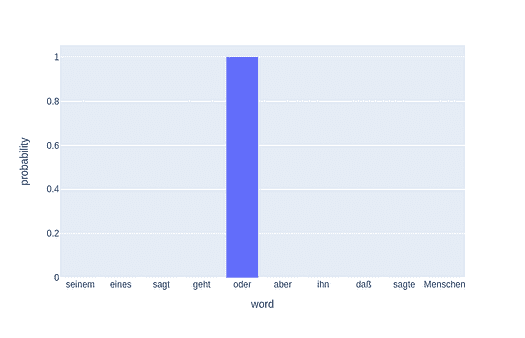
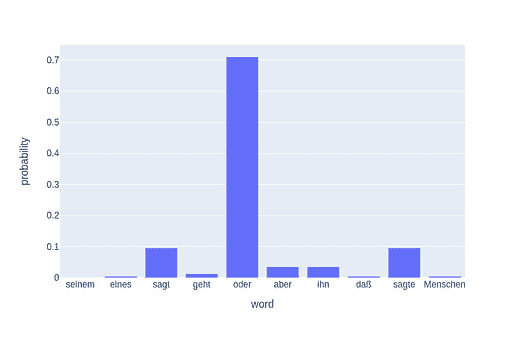
单词(token)的目标分布和概率分布 (图片由作者提供)
KL 散度公式简单地给出了 -logq(oder),这就是交叉熵损失。
在论文中,尽管作者使用了 α = 0.1 的标签平滑,因此 KL 散度损失不是交叉熵。这意味着在目标分布中,输出值被 (1-α) 替代,剩余的 0.1 分布在所有单词中。作者表示这样做是为了使模型不那么自信。
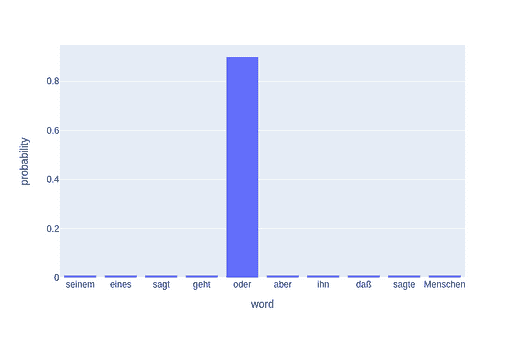
(图片由作者提供)
问:但为什么我们让模型不那么自信呢?这似乎很荒谬。
是的,确实如此,但直观上,你可以把它理解为当我们将目标设为 1 时,我们对真正的标签为 True 和其他标签不为 True 没有疑虑。但词汇本质上是一个非标准化的目标。例如,谁能说你不能用 good 替代 great?所以我们在标签中加入一些混淆,以使模型不那么僵化。
B) Adam 的特定学习率调度
作者使用了一个学习率调度器,在预热步骤之前逐渐增加学习率,然后使用下面的函数减少学习率。他们使用了 Adam 优化器,β¹ = 0.9,β² = 0.98。这里没有特别有趣的,只是一些学习选择。
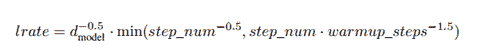
来源:论文
问:等等,我刚刚想到预测时不会有偏移输出,对吧?那我们怎么做预测呢?
如果你明白了,我们现在有一个生成模型,我们需要以生成的方式进行预测,因为在进行预测时我们不知道输出目标向量。因此,预测仍然是顺序的。
预测时间

使用贪婪搜索进行预测的 Transformer(作者提供的图像)
该模型进行逐步预测。在原始论文中,他们使用束搜索进行预测。但贪婪搜索也足以解释这一过程。在上面的示例中,我展示了贪婪搜索的具体操作。贪婪搜索将从以下步骤开始:
-
将整个英文句子作为编码器输入,仅将起始标记
<st>作为偏移输出(解码器的输入)传递给模型并进行前向传递。 -
模型将预测下一个词汇——
der -
然后,我们将整个英文句子作为编码器输入,将最后预测的词汇添加到偏移输出(解码器的输入 =
<st> der)中,并进行前向传递。 -
模型将预测下一个词汇——
schnelle -
将整个英文句子作为编码器输入,将
<st> der schnelle作为偏移输出(解码器的输入)传递给模型并进行前向传递。 -
等等,直到模型预测出结束标记
</s>,或者我们生成一些最大数量的标记(我们可以定义的东西),以便翻译不会在任何情况下无限运行。
束搜索:
问:现在我有点贪心,能告诉我关于束搜索的内容吗?
好的,束搜索的思想本质上与上述想法非常相似。在束搜索中,我们不仅查看生成的最高概率词汇,还查看前两个词汇。
比如,当我们将整个英文句子作为编码器输入,仅将起始标记作为偏移输出时,我们得到两个最佳词汇,即i(p=0.6)和der(p=0.3)。我们现在将为两个输出序列<s> i和<s> der生成输出模型,并查看生成的下一个最佳词汇的概率。例如,如果<s> i为下一个词汇提供了(p=0.05)的概率,而<s> der为下一个预测词汇提供了(p=0.5)的概率,我们将舍弃序列<s> i,选择<s> der,因为句子的概率总和被最大化了(<s> der next_word_to_der p = 0.3+0.5,相比之下<s> i next_word_to_i p = 0.6+0.05)。然后我们重复这一过程,以获得概率最高的句子。
由于我们使用了前两个词汇,因此此束搜索的束大小为 2。在论文中,他们使用了束搜索大小为 4。
附注:我展示了每一步传递整个英文句子以便简洁,但实际上,编码器的输出被保存,只有偏移输出在每个时间步传递给解码器。
问: 还有什么你忘了告诉我的吗?我让你有你的时刻。
是的。既然你问了。这是:
BPE,权重共享和检查点
在论文中,作者使用了字节对编码(Byte pair encoding)来创建一个通用的英语-德语词汇表。然后,他们在英语和德语嵌入以及预软最大线性变换中使用了共享权重,因为嵌入权重矩阵的形状(词汇长度 X D)是适用的。
此外,作者将最后的 k 个检查点进行平均,以创建一种集成效应来提升性能。 这是一种非常常见的技术,我们在模型的最后几个周期中平均权重,创建一个新的模型,类似于一个集成模型。
问: 你能给我展示一些代码吗?
这篇文章已经很长了,所以我会在下一篇文章中进行介绍。敬请关注。
现在,终于轮到我提问了:你明白变换器是如何工作的吗?是,还是否,你可以在评论中回答。😃
参考文献
-
注意力是你所需的一切: 这篇论文开启了一切。
-
注释 Transformer: 这篇文章包含了所有代码。虽然我也会在下一篇文章中编写一个简单的变换器。
-
插图 Transformer: 这是关于变换器的最佳文章之一。
在这篇文章中,我从细节导向和直观的角度讲解了 Transformer 架构的工作原理。
如果你想了解更多关于 NLP 的内容,我想推荐一个来自高级机器学习专业化的优秀课程,自然语言处理。请查看一下。
我也会在未来撰写更多类似的文章。告诉我你对这些文章的看法。我应该写一些技术性很强的主题还是更多的入门级文章?评论区是你的朋友。使用它。同时,关注我的Medium或订阅我的博客。
最后一个小免责声明——这篇文章中可能会包含一些相关资源的附属链接,因为分享知识从来不是坏事。
这个故事首次发布于这里。
简历: Rahul Agarwal 是 WalmartLabs 的高级统计分析师。在 Twitter 上关注他@mlwhiz。
原文。获得许可后重新发布。
相关:
-
深入了解 Transformer 架构 – Transformer 模型的发展
-
特征提取的搭车指南
-
深度学习的最重要理念
更多相关主题
机器学习的意外后果
原文:
www.kdnuggets.com/2017/06/unintended-consequences-machine-learning.html
评论
作者:弗兰克·凯恩,Sundog 教育。

这是机器学习和人工智能的激动人心的时代;新的算法、TensorFlow 以及强大的 GPU 集群正在结合起来,产生能够做一些如击败世界最佳围棋选手这样的强大系统。
但巨大的力量带来巨大的责任。让我讲一个关于善意的机器学习研究意外后果的故事。
那一年是 2010 年。我在亚马逊的个性化技术领域已经工作了七年。你知道的,推荐系统会根据你的过去兴趣和购买记录向你推荐你从未知道的东西,并且生成亚马逊收入的很大一部分。
那一年是Eli Pariser 首次创造了“过滤泡沫”这一术语。 他警告我们,过度个性化可能会使人们陷入一个不断强化相同兴趣和信念的泡沫中。这个演讲证明了预言的准确性;今天关于社交媒体中的过滤泡沫在使我们现代社会极化中的作用,以及它在政治中的作用,有着很多争论。
在 2010 年,我完全忽视了 Eli 的警告。我认为,旨在帮助你发现新书籍和音乐的算法不可能对社会产生那种影响。但我错了。我仍然能安然入睡,因为 Eli 的担忧是针对 Facebook 和 Google 的个性化,而不是亚马逊——但我仍然感到有些参与其中,因为亚马逊在这个领域是先锋。
快进到 2017 年,你会看到对人工智能的忧虑与我们曾经对个性化的忧虑相似。我们在打造实际可用的自动驾驶汽车,或在游戏中超越人类时,充满了兴奋。但这些技术也带来了意想不到的后果。抛开关于“奇点”的猜测——今天,如果一个网络恐怖分子获得了你正在构建的系统会发生什么?你的神经网络是否可能被训练来,例如,侵入武器控制系统或电网?就像我从未预见到为我推荐新的科幻书籍的算法会影响世界政治一样,你也可能未曾预见到你正在创造的技术会在威胁文明的攻击中发挥作用。
这是否意味着我们都应该去成为网页开发人员以求更大的利益呢?其实不是。停止技术进步也是不对的。但我们可以做出一些决策,尽量将我们开发的技术保持在正确的手中。即使我现在的业务是便宜的在线机器学习培训,我也曾考虑过不制作有关人工智能的课程,因为或许这种知识不应该让坏人轻易获得。也许你应该三思自己在会议上或以开源形式提供多少信息。你正在构建的那个酷炫的图形工具,让任何人都能在集群上设置神经网络并随心所欲地使用?也许这真的不应该轻易地公之于众。
有一种合理化的说法是:“人工智能不杀人,使用人工智能的人才杀人。”但是,你真的想在几年后为自己在下一次大规模的人工智能网络攻击中所扮演的角色而自我怀疑吗?在某种程度上,我曾经历过这种情况,这并不好受。
简介:Frank Kane 是 Sundog Education 的创始人,该公司在其便宜的在线视频培训课程中,已在全球招收了 100,000 名学生,课程涵盖大数据、机器学习和数据科学。在创办 Sundog 之前,Frank 在 Amazon.com 和 IMDb.com 的工程和管理职位上工作了 9 年,专注于个性化和推荐系统技术。
相关:
-
机器学习中的信任挑战
-
回归分析真的算是机器学习吗?
-
大数据迫切需要透明度
我们的前三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
更多相关话题
单元测试你的数据管道,你会感谢自己
原文:
www.kdnuggets.com/2020/08/unit-test-data-pipeline-thank-yourself-later.html
评论
由 诺曼·尼默,首席数据科学家
数据科学家,尤其是初学者,常犯的一个错误是没有编写单元测试。数据科学家有时会争辩说,单元测试不适用,因为没有可以预先知道或测试的正确答案。然而,大多数数据科学项目从数据转换开始。虽然你不能测试模型输出,但至少你应该测试输入是否正确。相比于编写单元测试投入的时间,良好的简单测试将会为你节省更多时间,尤其是在处理大型项目或大数据时。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
与 海景·李,金融服务数据分析师,哥伦比亚大学 MS 商业分析,共著。

图片来源:Xenonstack
单元测试的好处
-
更早发现错误:运行大数据项目耗时。你不希望在运行三小时后得到意外的输出,而你本可以轻松避免这种情况。
-
更容易更新代码:你将不再害怕更改代码,因为你知道期望的结果,并且如果出现问题,你可以轻松发现。
-
促使你编写更结构化的代码:当你考虑到需要用孤立的片段测试代码时,你会写出更清晰的代码,并更倾向于以 DAG 的方式编写,而不是线性链式函数。(使用 d6tflow 来轻松构建数据科学工作流)
-
让你对输出结果有信心:错误的数据会导致错误的决策。运行单元测试可以让你对数据质量有信心。你知道你的代码输出了你想要的结果。
Pytest
为了提高测试效率,使用 Pytest。如果你在寻找 Pytest 的教程,我推荐 Dane Hillard 的文章 有效的 Python 测试与 Pytest。在他的文章中,你会发现如何利用 Pytest 的基本和高级功能。
单元测试用于数据科学
根据你的项目需求,你希望通过单元测试检查的内容会有所不同。但有一些常见的测试是你可能希望为数据科学解决方案运行的。
1. 缺失值
#catch missing values
assert df['column'].isna().sum()<1
2. 复制项
# check there is no duplicate
assert len(df['id'].unique())==df.shape[0]
assert df.groupby(['date','id']).size().max()==1
3. 形状
# have data for all ids?
assert df['id'].unique().shape[0] == len(ids)
# function returns have shapes as expected
assert all([some_funtion(df).shape == df[0].shape for df in dfs])
4. 值范围
assert df.groupby('date')['percentage'].sum()==1
assert all (df['percentage']<=1)
assert df.groupby('name')['budget'].max()<=1000
5. 连接质量
d6tjoin 具有连接质量的检查。
assert d6tjoin.Prejoin([df1,df2],['date','id']).is_all_matched()
6. 预处理函数
assert preprocess_function("name\t10019\n")==["name",10019]
assert preprocess_missing_name("10019\n") is None
assert preprocess_text("Do you Realize those are genetically modified food?" ) == ["you","realize","gene","modify","food"]
简介: 诺曼·尼默 是一家大型资产管理公司的首席数据科学家,他提供基于数据的投资洞察。他持有哥伦比亚大学金融工程硕士学位和卡斯商学院(伦敦)银行与金融学学士学位。
原文。经许可转载。
相关:
-
Python 中的模糊连接与 d6tjoin
-
数据科学家常犯的 10 大编码错误
-
解释“黑箱”机器学习模型:SHAP 的实际应用
更多相关话题
如何对机器学习代码进行单元测试
原文:
www.kdnuggets.com/2017/11/unit-test-machine-learning-code.html
评论
作者:Chase Roberts,机器学习工程师

资料来源:provalisresearch.com/blog/machine-learning
在过去的一年里,我的大部分工作时间都用在了深度学习研究和实习上。那一年中有很大一部分时间是在犯非常大的错误,这帮助我不仅学到了机器学习的知识,还学会了如何正确和合理地设计这些系统。我在 Google Brain 期间学到的一个主要原则是,单元测试可以决定你的算法的成败,并且可以节省你几周的调试和训练时间。
然而,似乎在线上并没有一个可靠的教程来教你如何编写神经网络代码的单元测试。即使像 OpenAI 这样的地方,也只是通过盯着他们的每一行代码,试图思考为何会导致错误。显然,我们中的大多数人没有那种时间或自我厌恶,因此希望这个教程能帮助你理智地开始测试你的系统!
让我们从一个简单的例子开始。试着找出这个代码中的错误。
你看到了吗?网络实际上并没有堆叠。当我写这段代码时,我复制并粘贴了 slim.conv2d(…) 这一行,只修改了内核大小,而没有修改实际的输入。
我很尴尬地说,这实际上发生在我大约一周前……但这是一个重要的教训!这些错误很难捕捉,有几个原因。
-
这段代码从未崩溃、抛出错误,甚至没有变慢。
-
这个网络仍然可以训练,损失值仍然会下降。
-
经过几个小时的训练,值会收敛,但结果非常差,让你不知所措,不知道需要修复什么。
当你唯一的反馈是最终的验证误差时,你唯一需要搜索的地方就是整个网络架构。不用说,你需要一个更好的系统。
那么我们如何在进行完整的多日训练之前捕捉到这个问题呢?最容易注意到的是,这些层的值实际上从未到达函数外的任何其他张量。因此,假设我们有某种损失和优化器,这些张量永远不会被优化,因此它们总是会保持默认值。
我们可以通过简单地进行一次训练步骤并比较其前后状态来检测它。
哇。在不到 15 行代码的情况下,我们现在验证了至少我们创建的所有变量都得到了训练。
这个测试非常简单且非常有用。假设我们解决了之前的问题,现在我们想开始添加一些批量归一化。看看你能否发现错误。
你看到了吗?这个问题非常微妙。你看,在 tensorflow 中,batch_norm 的is_training默认值是False,所以添加这一行代码实际上不会在训练期间对输入进行归一化!值得庆幸的是,我们写的最后一个单元测试将立即捕捉到这个问题!(我知道,因为这发生在我三天前。)
让我们再做一个例子。这实际上来自于我一天看到的一个reddit 帖子。我不会深入细节,但基本上这个人想创建一个在(0, 1)范围内输出的分类器。看看你是否能找到问题所在。
发现了错误吗?这个问题在事前很难发现,而且可能导致非常混淆的结果。基本上,发生的情况是预测只有一个输出,当你对其应用softmax 交叉熵时,会导致损失总是为 0。
测试这一点的一个简单方法是,嗯……确保损失从不为 0。
另一个好的测试是类似于我们的第一个测试,但反向的。你可以确保只有你想训练的变量实际上被训练。以 GAN 为例。一个常见的错误是意外忘记设置在何种优化期间训练哪些变量。这种代码时常发生。
最大的问题是优化器的默认设置是优化所有变量。在像 GAN 这样的高级架构中,这对你所有的训练时间来说是致命的。然而,你可以通过编写像这样的测试轻松检测到这些错误:
一个非常类似的测试可以写在判别器上。而且这个相同的测试也可以用于很多强化学习算法。许多 actor-critic 模型有需要通过不同损失优化的独立网络。
这里是我建议你在测试中遵循的一些模式。
-
保持它们的确定性。如果一个测试以奇怪的方式失败,而你永远无法重现它,那真的很糟糕。如果你真的想要随机输入,请确保给随机数设定种子,以便你可以轻松地重新运行测试。
-
保持测试简短。不要有一个训练到收敛并且与验证集进行检查的单元测试。如果你这样做,你是在浪费自己的时间。
-
确保在每个测试之间重置图。
总结来说,这些黑箱算法仍然有很多测试的方法!花一个小时编写测试可以节省你数天的重新训练,并大大提高你的研究成果。如果因为我们的实现有问题而不得不舍弃完美的想法,那不是很糟糕吗?
这个列表显然不是全面的,但它是一个很好的开始!如果你有额外的建议或发现的有用的特定测试,请在twitter上给我留言!我很想做这方面的第二部分。
本文中的所有观点均为我的个人经验反映,并未得到 Google 的赞助或支持。
简介: Chase Roberts 是前 Google Brain 研究实习生。曾参与机器学习机器人团队的工作,专注于渐进神经网络在迁移学习中的实现及深入分析,同时也参与了强化学习架构的实现。
原文。经授权转载。
相关:
-
TensorFlow: 需要优化哪些参数?
-
软件工程与机器学习概念
-
使用 TensorFlow 进行线性回归的预测分析
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
了解更多主题
在 60 分钟内解锁 LLMs 的秘密,与 Andrej Karpathy
原文:
www.kdnuggets.com/unlock-the-secrets-of-llms-in-a-60-minute-with-andrej-karpathy

图片来源:编辑
你听说过Andrej Karpathy吗?他是一位著名的计算机科学家和人工智能研究员,以其在深度学习和神经网络方面的工作而闻名。他在 OpenAI 的 ChatGPT 开发中发挥了关键作用,曾担任特斯拉 AI 高级总监。在此之前,他设计并主讲了第一门深度学习课程斯坦福 - CS 231n:卷积神经网络用于视觉识别。该课程成为斯坦福大学最大的课程之一,从 2015 年的 150 名学生增长到 2017 年的 750 名学生。我强烈推荐对深度学习感兴趣的人观看这个 YouTube 视频。我将不再详细介绍他,我们将转向他在 YouTube 上最受欢迎的讲座之一,观看量超过140 万的“介绍大型语言模型”。这次讲座是一个忙碌人士了解 LLMs 的入门必看内容。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
我提供了这次演讲的简要总结。如果这引起了你的兴趣,我强烈建议你查看文章末尾提供的幻灯片和 YouTube 链接。
演讲概述
这次讲座提供了 LLMs 的全面介绍,包括它们的能力以及使用它们可能带来的潜在风险。它被分为以下三个主要部分:
第一部分:LLMs
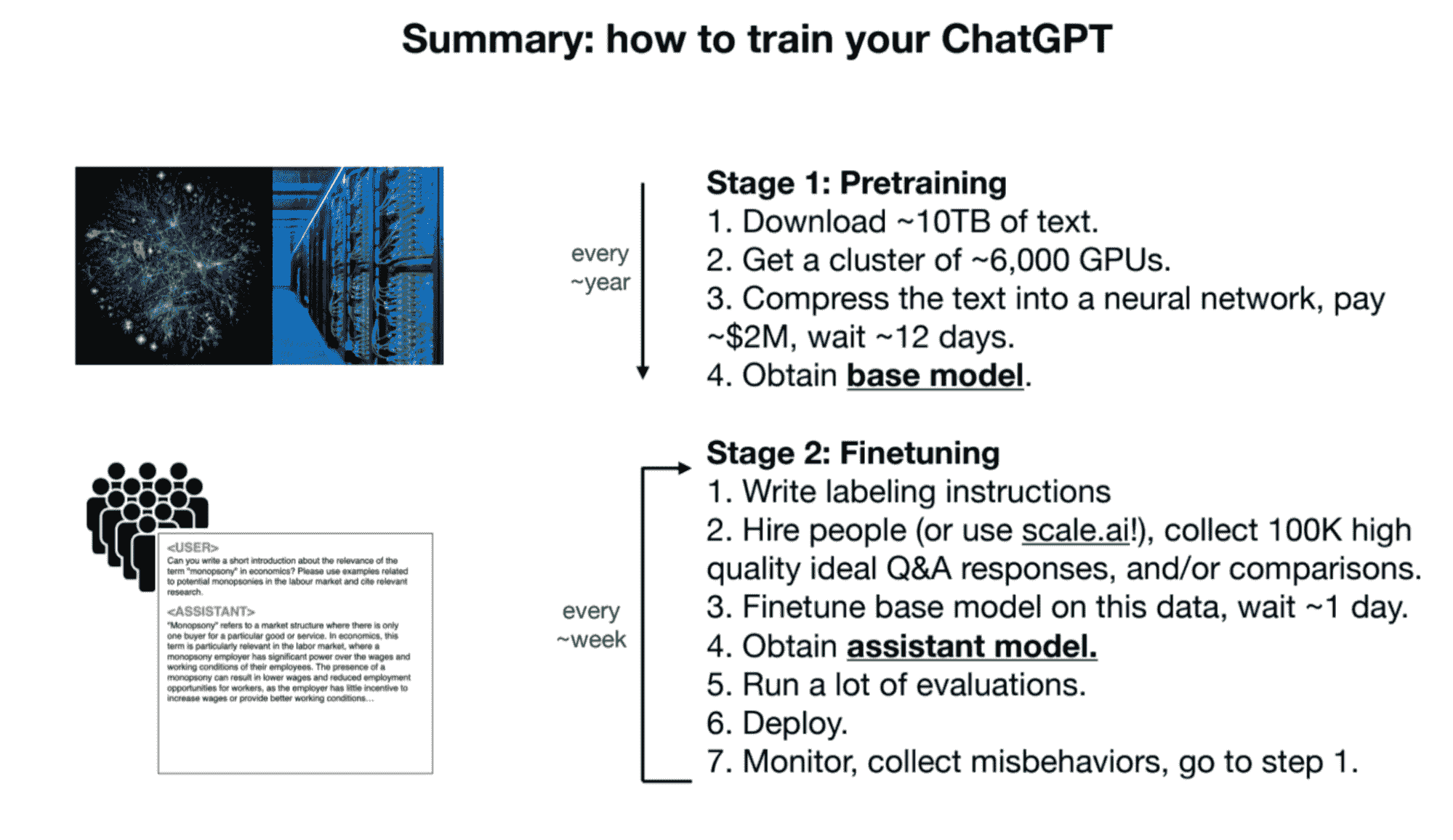
幻灯片由 Andrej Karpathy 提供
LLMs 在大量文本语料库上进行训练,以生成类似人类的回应。在这一部分中,Andrej 具体讨论了 Llama 2-70b 模型。它是最大的 LLM 之一,具有 700 亿个参数。该模型由两个主要组件组成:参数文件和运行文件。参数文件是一个大型二进制文件,包含模型的权重和偏差。这些权重和偏差本质上是模型在训练过程中学习到的“知识”。运行文件是一段用于加载参数文件并运行模型的代码。模型的训练过程可以分为以下两个阶段:
1. 预训练
这涉及从互联网收集大量文本,约 10TB,然后使用 GPU 集群对这些数据进行模型训练。训练过程的结果是一个基本模型,它是互联网的有损压缩。它能够生成连贯和相关的文本,但不能直接回答问题。
2. 微调
预训练模型会在高质量的数据集上进一步训练,以使其更有用。这将产生一个助手模型。Andrej 还提到微调的第三阶段,即使用对比标签。模型不是从头生成答案,而是给出多个候选答案,并要求选择最佳答案。这比生成答案可能更简单、更高效,并且能进一步提高模型性能。这个过程称为从人类反馈中进行的强化学习(RLHF)。
第二部分:LLMs 的未来
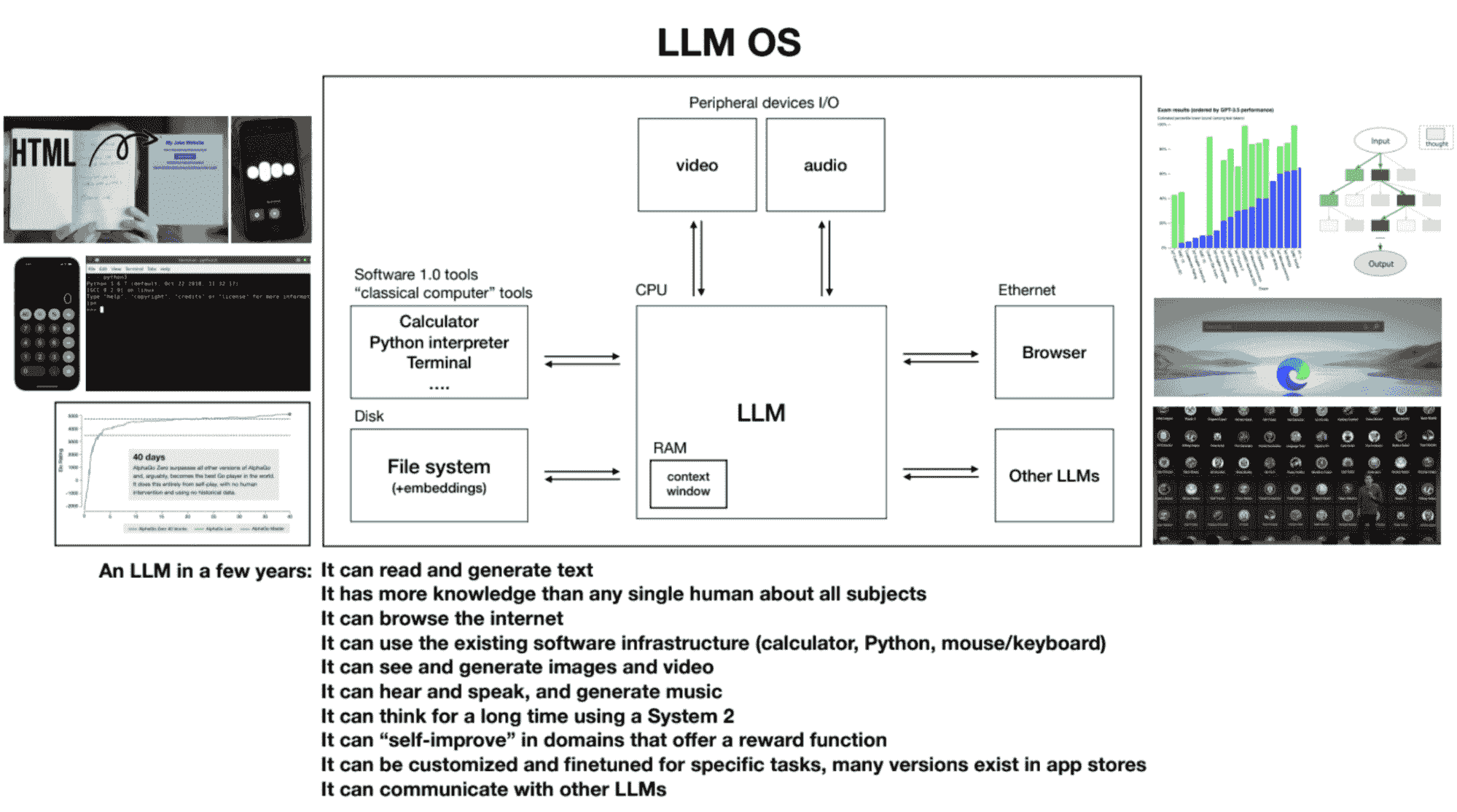
幻灯片由 Andrej Karpathy 提供
在讨论大型语言模型及其能力的未来时,讨论了以下关键点:
1. 规模定律
模型的性能与两个变量相关——参数数量和训练文本量。训练在更多数据上的较大模型往往能够取得更好的性能。
2. 工具的使用
像 ChatGPT 这样的语言模型(LLMs)可以利用浏览器、计算器和 Python 库等工具,执行对模型单独来说具有挑战性或不可能完成的任务。
3. LLM 中的系统一和系统二思维
当前,LLMs 主要采用系统一思维——快速、本能和基于模式的。然而,人们对开发能够进行系统二思维——较慢、理性并且需要有意识努力的 LLMs 感兴趣。
4. LLM 操作系统
LLMs 可以被视为新兴操作系统的内核进程。它们可以读取和生成文本,拥有广泛的各种主题知识,浏览互联网或引用本地文件,使用现有的软件基础设施,生成图像和视频,听到和说话,并使用系统 2 进行长时间的思考。LLM 的上下文窗口类似于计算机中的 RAM,内核进程尝试将相关信息分页进出其上下文窗口以执行任务。
第三部分:LLMs 安全性

幻灯片由 Andrej Karpathy 制作
Andrej 强调了在解决 LLMs 相关安全挑战方面的持续研究工作。讨论了以下攻击:
1. 越狱
尝试绕过 LLM 中的安全措施以提取有害或不适当的信息。示例包括通过角色扮演欺骗模型以及使用优化的单词或图像序列操控响应。
2. 提示注入
涉及向 LLM 中注入新的指令或提示,以操控其响应。攻击者可以将指令隐藏在图像或网页中,从而导致模型的回答中包含无关或有害的内容。
3. 数据中毒 / 后门攻击 / 睡眠代理攻击
涉及在恶意或操控的数据上训练大型语言模型,这些数据包含触发短语。当模型遇到这些触发短语时,它可能被操控执行不良操作或提供错误预测。
你可以通过点击下面的链接在 YouTube 上观看全面的视频:
幻灯片: 点击这里
结论
如果你对 LLMs 是新手,并且正在寻找启动学习之旅的资源,那么这个全面的列表是一个很好的起点!它包含了基础课程和特定于 LLM 的课程,将帮助你建立扎实的基础。此外,如果你对更结构化的学习体验感兴趣,Maxime Labonne最近推出了他的 LLM 课程,有三个不同的课程轨道可以根据你的需求和经验水平进行选择。这里是两个资源的链接,供你参考:
-
掌握大型语言模型的全面资源列表(作者:Kanwal Mehreen
Kanwal Mehreen**** Kanwal 是一位机器学习工程师和技术作家,对数据科学以及人工智能与医学的交集充满了深厚的热情。她共同撰写了电子书《利用 ChatGPT 最大化生产力》。作为 2022 年亚太地区的 Google Generation Scholar,她倡导多样性和学术卓越。她还被认定为 Teradata 技术多样性学者、Mitacs Globalink 研究学者和哈佛 WeCode 学者。Kanwal 是变革的坚定倡导者,她创立了 FEMCodes,旨在赋能女性进入 STEM 领域。
更多相关话题
通过 ChatPDF 解锁知识宝库
原文:
www.kdnuggets.com/2023/04/unlock-wealth-knowledge-chatpdf.html

作者提供的图片
ChatPDF 为学生和专业人士打开了一个全新的世界。你可以在 5 分钟内总结并理解整本书,或者甚至用它来理解高度技术性的法律合同。就像 ChatGPT 一样,你可以从书中提问,它将帮助你学习某个概念或故事。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
ChatPDF 是如何工作的?
上传 PDF 文件后,ChatPDF 通过创建语义索引并将相关段落与文本生成 AI 共享来分析 PDF 文件。之后,你可以使用它从文件中提取信息。ChatPDF 能够顺畅处理大型文件,如手册、法律合同、书籍和研究论文。
ChatPDF 示例
招聘人员可以使用 ChatPDF API 创建一个系统,帮助他们通过简历向候选人提问。这将有助于改善招聘过程,因为预筛选将由 AI 完成。
在这个案例中,我上传了 2021 年的旧简历,以了解更多关于过去的自己。通过访问chatpdf.com,你会看到主页上解释了它的使用场景,并提供了 3 种添加 PDF 文件的选项。你可以直接提供链接、上传文件或搜索 PDF。
图片来源于ChatPDF
上传简历后,我让 ChatPDF 总结简历,然后进一步了解我的工作经验。
界面与 ChatGPT 非常相似。
图片来源于ChatPDF
让我们使用链接上传由 Ian Langmore 和 Daniel Krasner 编写的免费应用数据科学书籍。

图片来源于ChatPDF
我选择了解书中提到的数据清洗管道,而不是总结内容。答案很好,但不如 ChatGPT。可能缺少代码块。
图片来自ChatPDF
你可以使用 ChatPDF 在不到 5 分钟内阅读整本书,甚至如果忘记了某些内容,还可以提出问题。这就像与书对话,一起解决谜题。
限制
通过创建账户,你可以查看之前的聊天记录,但有一些限制。如果你习惯了免费的 ChatGPT 体验,你可能会因每天 3 个 PDF 和 50 个问题而感到烦恼。你可以通过购买 Plus 会员来克服这些烦恼。
图片来自ChatPDF
我认为开发者在后台使用的是 GPT-3 或类似的开源模型。ChatPDF 在许多情况下无法理解上下文并给出错误的解释。其他限制与技术内容有关,如代码块、表格等。你仍然可以要求机器人编写 Python 代码,它会显示代码,但与 ChatGPT 相比效果不佳。
总结
我们有了一个新工具,我喜欢用它来理解我的合同、书籍和研究论文。它处于早期阶段,未来可以看到性能上的改进。
希望你喜欢这项新技术,如果你想让我在未来涵盖更多 AI 工具,请在评论中告诉我。
Abid Ali Awan(@1abidaliawan)是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为面临心理健康问题的学生开发 AI 产品。
更多相关话题
解锁数据洞察:关键 Pandas 函数用于有效分析
原文:
www.kdnuggets.com/unlocking-data-insights-key-pandas-functions-for-effective-analysis

作者提供的图片 | Midjourney 和 Canva
Pandas 提供了多种函数,使用户能够清理和分析数据。在本文中,我们将介绍一些关键的 Pandas 函数,这些函数对于从数据中提取有价值的洞察至关重要。这些函数将为你提供将原始数据转换为有意义信息所需的技能。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
数据加载
数据加载是数据分析的第一步。它允许我们将数据从各种文件格式读取到 Pandas DataFrame 中。这一步对于在 Python 中访问和操作数据至关重要。让我们探索如何使用 Pandas 加载数据。
import pandas as pd
# Loading pandas from CSV file
data = pd.read_csv('data.csv')
这段代码导入了 Pandas 库,并使用 read_csv() 函数从 CSV 文件中加载数据。默认情况下,read_csv() 假设第一行包含列名,并使用逗号作为分隔符。
数据检查
我们可以通过检查关键属性,如行数和列数以及摘要统计数据,来进行数据检查。这有助于我们在进一步分析之前,对数据集及其特征有一个全面的了解。
df.head():默认情况下,它返回 DataFrame 的前五行。这对于检查数据的顶部部分以确保其正确加载非常有用。
A B C
0 1.0 5.0 10.0
1 2.0 NaN 11.0
2 NaN NaN 12.0
3 4.0 8.0 12.0
4 5.0 8.0 12.0
df.tail():默认情况下,它返回 DataFrame 的最后五行。这对于检查数据的底部部分非常有用。
A B C
1 2.0 NaN 11.0
2 NaN NaN 12.0
3 4.0 8.0 12.0
4 5.0 8.0 12.0
5 5.0 8.0 NaN
df.info():此方法提供 DataFrame 的简明总结。包括条目数、列名、非空计数和数据类型。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6 entries, 0 to 5
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 A 5 non-null float64
1 B 4 non-null float64
2 C 5 non-null float64
dtypes: float64(3)
memory usage: 272.0 bytes
df.describe():这会生成 DataFrame 中数值列的描述性统计数据。包括计数、均值、标准差、最小值、最大值以及四分位数值(25%、50%、75%)。
A B C
count 5.000000 4.000000 5.000000
mean 3.400000 7.250000 11.400000
std 1.673320 1.258306 0.547723
min 1.000000 5.000000 10.000000
25% 2.000000 7.000000 11.000000
50% 4.000000 8.000000 12.000000
75% 5.000000 8.000000 12.000000
max 5.000000 8.000000 12.000000
数据清理
数据清理是数据分析过程中的关键步骤,因为它确保了数据集的质量。Pandas 提供了多种函数来解决常见的数据质量问题,如缺失值、重复项和不一致性。
df.dropna():用于删除包含缺失值的任何行。
示例:clean_df = df.dropna()
df.fillna():用于用其相应列的均值替换缺失值。
示例:filled_df = df.fillna(df.mean())
df.isnull():识别数据框中的缺失值。
示例:missing_values = df.isnull()
数据选择和过滤
数据选择和过滤是 Pandas 中操作和分析数据的基本技巧。这些操作允许我们根据特定条件提取特定的行、列或数据子集。这使我们能够更轻松地关注相关信息并进行分析。以下是 Pandas 中数据选择和过滤的各种方法:
df['column_name']:选择单个列。
示例:df[“Name”]
0 Alice
1 Bob
2 Charlie
3 David
4 Eva
Name: Name, dtype: object
df[['col1', 'col2']]:选择多个列。
示例:df["Name, City"]
0 Alice
1 Bob
2 Charlie
3 David
4 Eva
Name: Name, dtype: object
df.iloc[]:通过整数位置访问行和列组。
示例:df.iloc[0:2]
Name Age
0 Alice 24
1 Bob 27
数据汇总和分组
在 Pandas 中对数据进行汇总和分组对于数据总结和分析至关重要。这些操作允许我们通过应用各种汇总函数(如均值、总和、计数等)将大型数据集转化为有意义的见解。
df.groupby():根据指定的列对数据进行分组。
示例:df.groupby(['Year']).agg({'Population': 'sum', 'Area_sq_miles': 'mean'})
Population Area_sq_miles
Year
2020 15025198 332.866667
2021 15080249 332.866667
df.agg():提供了一次应用多个聚合函数的方法。
示例:df.groupby(['Year']).agg({'Population': ['sum', 'mean', 'max']})
Population
sum mean max
Year
2020 15025198 5011732.666667 6000000
2021 15080249 5026749.666667 6500000
数据合并和连接
Pandas 提供了几种强大的函数来合并、连接和联接 DataFrames,使我们能够高效且有效地整合数据。
pd.merge():根据公共键或索引合并两个 DataFrames。
示例:merged_df = pd.merge(df1, df2, on='A')
pd.concat():沿特定轴(行或列)连接 DataFrames。
示例:concatenated_df = pd.concat([df1, df2])
时间序列分析
使用 Pandas 进行时间序列分析涉及使用 Pandas 库来可视化和分析时间序列数据。Pandas 提供了专门为处理时间序列数据设计的数据结构和函数。
to_datetime():将字符串列转换为 datetime 对象。
示例:df['date'] = pd.to_datetime(df['date'])
date value
0 2022-01-01 10
1 2022-01-02 20
2 2022-01-03 30
set_index():将 datetime 列设置为 DataFrame 的索引。
示例:df.set_index('date', inplace=**True**)
date value
2022-01-01 10
2022-01-02 20
2022-01-03 30
shift():将时间序列数据的索引向前或向后移动指定的周期数。
示例:df_shifted = df.shift(periods=1)
date value
2022-01-01 NaN
2022-01-02 10.0
2022-01-03 20.0
结论
在这篇文章中,我们介绍了一些在数据分析中至关重要的 Pandas 函数。通过掌握这些工具,你可以轻松处理缺失值、删除重复项、替换特定值,并执行多种数据操作任务。此外,我们还探索了数据聚合、合并和时间序列分析等高级技术。
Jayita Gulati 是一位对机器学习充满热情的技术作家,致力于构建机器学习模型。她拥有利物浦大学计算机科学硕士学位。
更多相关内容
解锁 GPT-4 摘要能力与 Chain of Density 提示
原文:
www.kdnuggets.com/unlocking-gpt-4-summarization-with-chain-of-density-prompting

图像由作者使用 Midjourney 创建
关键要点
-
Chain of Density(CoD)是一种新颖的提示工程技术,旨在优化像 GPT-4 这样的大型语言模型的摘要任务。
-
该技术处理生成摘要中的信息密度,提供一个既不稀疏也不密集的平衡输出。
-
CoD 对数据科学有实际意义,尤其是在需要高质量、上下文适当的摘要任务中。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
选择摘要中包含的“正确”信息量是一项困难的任务。
介绍
提示工程是推动生成式 AI 效能提升的动力。虽然现有的提示技术如 Chain-of-Thought 和 Skeleton-of-Thought 关注结构化和高效的输出,但一种名为 Chain of Density(CoD)的新技术旨在优化文本摘要的质量。这项技术解决了选择“正确”信息量以确保摘要既不过于稀疏也不过于密集的挑战。
了解信息密度链
Chain of Density(信息密度链)旨在提高像 GPT-4 这样的大型语言模型的摘要能力。它专注于控制生成摘要中的信息密度。一个平衡良好的摘要通常是理解复杂内容的关键,而 CoD 旨在达到这种平衡。它使用特殊的提示来引导 AI 模型包含必要的要点,同时避免不必要的细节。

图 1:使用示例的密度链过程(来自 Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting)(点击放大)
实施密度链
实施 CoD 涉及使用一系列链式提示来引导模型生成总结。这些提示旨在控制模型的焦点,引导其关注重要信息,避免无关细节。例如,你可以从一个概括性的总结提示开始,然后跟进具体提示以调整生成文本的密度。
密度链提示过程步骤
-
确定待总结的文本:选择你希望总结的文档、文章或任何文本。
-
制作初始提示:创建一个针对选定文本的初始总结提示。目标是引导大型语言模型(LLM),如 GPT-4,生成一个基本总结。
-
分析初始总结:审查从初始提示生成的总结。确定总结是否过于稀疏(缺少关键细节)或过于密集(包含不必要的细节)。
-
设计链式提示:根据初始总结的密度,构建额外的提示来调整总结的详细程度。这些就是“链式提示”,是密度链技术的核心。
-
执行链式提示:将这些链式提示反馈给 LLM。这些提示旨在通过添加必要细节来增加密度,或通过删除不必要的信息来降低密度。
-
审查调整后的总结:检查通过执行链式提示生成的新总结。确保它捕捉到所有关键点,同时避免不必要的细节。
-
如有必要,进行迭代:如果总结仍未达到所需的信息密度标准,请返回第 4 步,调整链式提示。
-
完成总结:一旦总结达到所需的信息密度水平,即视为完成并准备使用。
密度链提示
以下 CoD 提示直接取自论文。
文章:{{ ARTICLE }}
你将生成越来越简洁、实体密集的上述文章总结。
重复以下 2 个步骤 5 次。
第 1 步。识别文章中缺失的 1-3 个信息实体(用“;”分隔)。
第 2 步。写一个新的、更紧凑的总结,长度相同,覆盖前一个总结中的每个实体和细节,以及遗漏的实体。
遗漏的实体是:
相关的:与主要故事相关。
具体的:描述性但简洁(5 个词或更少)。
新颖的:在前一个总结中没有。
忠实的:在文章中存在。
任何地方:位于文章的任何位置。
指导原则:
第一个总结应长(4-5 句,约 80 个单词)且高度非特定,包含除了缺失实体之外的信息很少。使用过于冗长的语言和填充词(例如,“本文讨论了”)以达到约 80 个单词。
让每一个词都发挥作用:重写之前的总结以改进流畅性并为附加实体腾出空间。
通过融合、压缩和移除诸如“本文讨论了”等无信息性短语来腾出空间。
总结应变得高度密集且简洁,但内容自成一体,例如,即使没有文章也能轻松理解。
遗漏的实体可以出现在新的总结中的任何位置。
永远不要从先前的总结中删除实体。如果没有空间,可以减少新增实体的数量。
记住,每个总结的字数要完全相同。
以 JSON 格式回答。JSON 应该是一个长度为 5 的字典列表,字典的键为“Missing_Entities”和“Denser_Summary”。
信息密度链并不是一刀切的解决方案。它需要精心编排的链式提示,以适应任务的具体需求。然而,当正确实施时,它可以显著提高 AI 生成总结的质量和相关性。
结论
信息密度链(Chain of Density)为提示工程提供了新的途径,特别是旨在改善总结任务。它对信息密度的控制使其成为生成高质量总结的宝贵工具。通过将 CoD 融入你的项目中,你可以利用下一代语言模型的高级总结能力。
Matthew Mayo (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 的主编,Matthew 旨在使复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、机器学习算法和探索新兴的 AI。他的使命是让数据科学社区的知识变得更加普及。Matthew 从 6 岁起就开始编程。
Matthew Mayo (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 和 Statology 的执行主编,以及 Machine Learning Mastery 的特约编辑,Matthew 旨在使复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、语言模型、机器学习算法和探索新兴的 AI。他的使命是让数据科学社区的知识变得更加普及。Matthew 从 6 岁起就开始编程。
更多相关内容
解锁健康经济学和结果研究中的数字力量
原文:
www.kdnuggets.com/2023/07/unlocking-power-numbers-health-economics-outcomes-research.html
在健康经济学和结果研究中,数据的可用性是一个关键挑战,因为获得适当的数据,尤其是长期结果和成本统计数据,可能很困难。此外,不同来源的数据的质量和一致性可能会变化,使得确认结果的可信度变得不可能。HEOR 研究中经常使用复杂的设计和程序来回答特定的研究问题。选择正确的研究设计,如观察研究、随机对照试验或建模方法,需要深思熟虑。
选择适当的统计方法、样本大小和终点引入了额外的障碍,这可能影响结果的有效性。经济建模在 HEOR 中至关重要,因为它估算长期成本、结果和成本效益。然而,开发稳健的经济模型需要做出假设和简化,这可能会导致不确定性和偏差。在建模假设的透明性和用真实数据测试模型输出方面至关重要,但也很困难。为了应对 HEOR 中的这些定量问题,经济学家、统计学家、流行病学家、医生以及其他相关专业人员必须共同合作。提高 HEOR 研究的严谨性和可信度还需要持续的方法学突破、数据标准化工作和稳健的统计研究。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面。
通过统计学应对挑战
在健康经济学和结果研究中,量化挑战可以通过统计学有效解决。统计学可以通过分析和解释数据提供对医疗保健多个方面的重要见解,包括患者结果、治疗效果和成本效益。
为了更好地提供决策支持并提升医疗服务,研究人员可能会使用统计方法来发现大数据集中的模式、趋势和联系。统计学对健康经济学和结果研究的进步至关重要,无论是用于评估新治疗的效果还是医疗干预的有效性。在解决健康经济学和结果研究(HEOR)中的定量问题时,统计方法绝对不可或缺。
研究人员可以通过这些工具进行复杂的数据分析,评估治疗效果,并做出明智的判断。统计方法如回归分析、生存分析、倾向评分匹配和贝叶斯建模对于确定关联、控制混杂因素和估计治疗效果非常有帮助。其他统计方法包括生存分析和贝叶斯建模。
此外,高级建模技术如成本效益分析和决策树有助于简化经济分析和资源分配决策。HEOR 研究通过利用强大的统计工具,有潜力提高研究结果的准确性、可靠性和推广性。这将最终改善医疗政策和实践。
下面我们探讨两种在从经济角度评估医疗干预影响时至关重要的方法。
Markov 链
Markov 链在创建成本效益模型时可能是一种极好的技术。Markov 链通过模拟不同状态间的变化,能够揭示不同变量如何影响系统的总成本。例如,Markov 链可以帮助估计治疗特定疾病的长期成本,通过模拟患者在不同健康阶段之间的转变。
在图 1 中,我们比较了有无治疗干预的疾病转归概率图。最初,我们可以观察到从阶段 1 到阶段 2 的转归概率为 0.3,从阶段 2 到阶段 3 为 0.4,依此类推。然而,当治疗在阶段 1 后引入时,我们可以观察到从阶段 1 到阶段 2 的转归概率降低到 0.1,如果治疗继续到阶段 2,则从阶段 2 到阶段 3 的转归概率也降至 0.1,从而确认了治疗/药物的有效性。因此,我们可以得出结论,治疗帮助减少了疾病进展到最新阶段的概率 1/3,并可能提高了患者的质量调整生命年(QALY),从而帮助我们估算治疗成本的减少。
图 1:基于 Markov 过程的转归图
此外,干预的时机或治疗选择是与资源分配相关的两个决策,这些决策可以通过使用马尔可夫链进行优化。马尔可夫链有助于提高成本效益模型的准确性和可靠性,这将最终通过提供对影响成本效益的因素的更全面的理解,带来更好的医疗决策及其他行业的决策。
贝叶斯推断
在从财务角度评估医疗干预的价值时,贝叶斯推断是有帮助的。贝叶斯推断通过将先前的知识和信息考虑在内,使研究人员能够更准确地预测结果并评估可能干预的效果和成本效益。由于允许研究人员用已有的知识填补数据空白,这种方法在数据稀缺或不足时尤为有用。通过采用贝叶斯推断,研究人员可以提高成本效益评估的精确度和可靠性,从而改进医疗决策和患者结果。通常,贝叶斯定理如下所示:
贝叶斯推断是一种在医疗行业中越来越受欢迎的统计方法,用于评估干预的效果。贝叶斯推断通过考虑先前的信息并结合新的证据进行更新,使得对特定治疗或干预成功的可能性进行更精确的估计。它是一位教学教授,任教于波士顿东北大学的数据科学硕士课程。他在多机器人系统和强化学习方面的研究已发表于人工智能领域的顶级期刊和会议上。他还是 Medium 社交平台的顶级作者,经常发布关于数据科学和机器学习的文章。
例如,在研究一种新药的效果时,贝叶斯推断不仅可以考虑原始数据,还可以结合关于药物作用机制、潜在副作用以及与其他药物的相互作用的先验知识。这种方法可以提供更具信息性和准确性的药物疗效与安全性评估,从而帮助指导临床决策。
研究遗传数据以寻找潜在的疾病风险因素是贝叶斯推断在医疗保健中的另一个应用。通过结合关于影响疾病风险的遗传和环境因素的先验知识,贝叶斯推断可以帮助识别新的干预目标,并提高我们对疾病基本机制的理解。
另一个例子是评估医疗保健政策和干预措施。通过整合类似政策和干预措施的有效性先前数据,政策制定者可以做出更明智的决定,确定实施哪些政策以及避免哪些政策。总体而言,贝叶斯推断是评估医疗保健干预措施的强大工具,允许进行更准确和信息丰富的决策。
此外,预测建模如线性回归是贝叶斯推断在医疗保健中使用的各种方式之一。贝叶斯推断可以通过考虑患者的病史、症状和其他风险因素,帮助做出更准确的健康结果预测。
总的来说,贝叶斯推断是一种有效的技术,用于评估医疗保健干预措施,能够通过提供关于健康结果的更精确和详细的预测,帮助患者获得更好的结果,并做出更好的临床决策。
Mayukh Maitra 是沃尔玛的数据显示科学家,专注于媒体混合建模领域,拥有超过 5 年的行业经验。从构建基于马尔科夫过程的医疗保健结果研究模型,到进行基于遗传算法的媒体混合建模,我不仅对人们的生活产生了影响,还通过有意义的洞察力将企业提升到新的水平。在加入沃尔玛之前,我曾有机会在 GroupM 担任数据科学经理,专注于广告技术领域,在 Axtria 担任决策科学高级助理,涉及健康经济学和结果研究领域,并在 ZS Associates 担任技术分析师。除了我的专业角色外,我还曾参与多个同行评审会议的评审和技术委员会,有机会担任多个技术奖项和黑客马拉松的评审。
更多相关话题
通过验证链解锁可靠生成:提示工程的新飞跃
原文:
www.kdnuggets.com/unlocking-reliable-generations-through-chain-of-verification

图片由作者使用 Midjourney 创建
主要收获
-
验证链(CoVe)提示工程方法旨在减轻 LLMs 中的幻觉问题,解决生成看似正确但实际上不准确的信息
-
通过一个四步过程,CoVe 使 LLMs 能够起草、验证和改进回答,培养一种增强准确性的自我验证机制,结构化自我验证
-
CoVe 在各种任务中展示了改进的性能,例如基于列表的问题和长文本生成,展示了其在减少幻觉和增强 AI 生成文本准确性方面的潜力
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
我们研究了语言模型在回应过程中反思其回答以纠正错误的能力。
介绍
在人工智能(AI)领域,对准确性和可靠性的不断追求带来了提示工程中的突破性技术。这些技术在指导生成模型提供精确且有意义的回答方面发挥了关键作用。最近出现的验证链(CoVe)方法标志着这一追求的重要里程碑。这一创新技术旨在解决大语言模型(LLMs)中的一个臭名昭著的问题——生成看似正确但实际上不准确的信息,俗称幻觉。通过使模型对其回答进行反思并经历自我验证过程,CoVe 在提高生成文本的可靠性方面树立了一个有前途的先例。
大型语言模型(LLMs)蓬勃发展的生态系统,凭借其基于大量文档语料库处理和生成文本的能力,在各种任务中表现出卓越的能力。然而,一个持续存在的问题是——生成虚假信息的倾向,尤其是在较少知晓或罕见的话题上。验证链方法在这些挑战中成为了一线希望,提供了一种结构化的方法来最小化虚假信息,并提高生成响应的准确性。
理解验证链
CoVe 展开了一个四步骤机制,以减轻 LLMs 中的虚假信息:
-
草拟初步回应
-
规划验证问题以核查草稿
-
独立回答这些问题以避免偏见
-
基于答案生成最终验证回应
这种系统化的方法不仅解决了虚假信息的问题,还包含了一个自我验证的过程,提升了生成文本的正确性。该方法的有效性已在各种任务中得到验证,包括基于列表的问题、闭卷问答和长篇文本生成,展示了虚假信息的减少和性能的提升。
实施验证链
采用 CoVe 涉及将其四步骤过程融入 LLMs 的工作流程。例如,当任务是生成历史事件列表时,使用 CoVe 的 LLM 会首先草拟一个回应,计划验证问题以事实核查每个事件,独立回答这些问题,最后根据验证结果生成经过验证的列表。
CoVe 固有的严格验证过程确保了生成的回答具有更高的准确性和可靠性。这种对验证的严谨态度不仅提升了信息质量,还在 AI 生成过程内培养了问责文化,为实现更可靠的 AI 生成文本迈出了重要一步。
示例 1
-
问题:列出 20 世纪的著名发明。
-
初稿:互联网、量子力学、DNA 结构发现
-
验证问题:互联网是在 20 世纪发明的吗?量子力学是在 20 世纪发展的吗?DNA 的结构是在 20 世纪发现的吗?
-
最终验证回应:互联网、青霉素发现、DNA 结构发现
示例 2
-
问题:提供一个非洲国家的列表。
-
初稿:尼日利亚、埃塞俄比亚、埃及、南非、苏丹
-
验证问题:尼日利亚在非洲吗?埃塞俄比亚在非洲吗?埃及在非洲吗?南非在非洲吗?苏丹在非洲吗?
-
最终验证回应:尼日利亚、埃塞俄比亚、埃及、南非、苏丹
采用 CoVe 涉及将其四步骤过程整合到 LLM 的工作流程中。例如,当任务是生成历史事件列表时,使用 CoVe 的 LLM 将首先起草一个回应,计划验证问题以核实每个事件,独立回答这些问题,最后根据收到的验证生成一个经过验证的列表。
图 1:简化的 Chain-of-Verification 过程(图像来源:作者)
该方法需要上下文示例以及提问 LLM 的问题,或者可以对 LLM 进行 CoVe 示例的微调,以便在这种方式下处理每个问题,如有需要。
结论
Chain-of-Verification 方法的出现证明了在提示工程中朝着实现可靠和准确的 AI 生成文本所取得的进展。通过直面幻觉问题,CoVe 提供了一种强有力的解决方案,提升了 LLM 生成信息的质量。这种方法的结构化方法,加上其自我验证机制,代表了在促进更可靠和真实的 AI 生成过程方面的重要跃进。
CoVe 的实施是对从业者和研究人员的号召,继续探索和完善提示工程技术。拥抱这些创新方法将对释放大型语言模型的全部潜力至关重要,预示着一个未来,在这个未来中,AI 生成文本的可靠性不仅是一个愿景,而是一个现实。
Matthew Mayo (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 和 Statology 的主编,以及 Machine Learning Mastery 的特约编辑,Matthew 旨在使复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、语言模型、机器学习算法以及探索新兴的人工智能。他致力于使数据科学社区的知识民主化。Matthew 从 6 岁起就开始编程。
更多相关主题
初级数据科学家和高级数据科学家之间的无形差异
原文:
www.kdnuggets.com/2020/10/unspoken-difference-junior-senior-data-scientists.html
评论
Mısra Turp,数据科学家

图片由 Christina @ wocintechchat.com 提供,来源于 Unsplash
成为高级数据科学家被视为一种终极成就,尽管许多人并不知道担任高级职位真正意味着什么。最常见的印象是,作为高级数据科学家意味着你了解所有关于数据科学的知识,并且是真正的专家。这确实是对的,但仅在一定程度上,因为数据科学的学习永无止境。此外,成为高级数据科学家不仅仅是技术知识这么简单。
你可能会想,为什么我现在应该关心这个呢?我认为了解数据科学家所遵循的标准路径是重要的,这样你可以更明智地决定自己想处于这个路径的哪个方面。简单来说,了解得越多,当在两个公司、两个职位或两个项目之间做选择时,你就会更容易做出决策。
[参加免费的 数据科学入门迷你课程 以更好地了解数据科学是什么,它在更大的人工智能世界中的定位以及学习所需的要求。]
让我们看看数据科学家的通常职业生涯是什么样的。
初级数据科学家
背景
作为初级数据科学家,对你的期望是拥有基本的数据科学知识。你的能力应该足以独立完成任务或在更资深同事的帮助下完成任务。此时,你可能没有太多的专业实践经验。
学习
你应该乐于学习,不怕问很多问题。更资深的同事会乐意帮助你学习。作为初级数据科学家,你每天学到新东西也不会令人惊讶。
项目
你的主要职责将是被分配给你的任务。当你遇到问题时,你将得到更资深的数据科学家的帮助。除了你的技术能力外,你还需要对与特定任务相关的领域有良好的理解。
数据科学家
在初级数据科学家之后,你很可能会进入一个过渡角色,通常被称为数据科学家。
背景
此时,你对数据科学的主要概念和技术的知识必须扎实。这并不意味着你已经知道一切。相反,这意味着你知道很多事情,也知道自己不知道什么。你可能已经在这个层面上获得了一些良好的实践经验。
学习
学习永无止境,所以你仍然对新想法和方法保持开放。你仍然会提出很多问题,同时也会被他人提问。初级同事会向你请教问题。你仍然在学习新事物,也许不是每天,但每隔一个月会学习一些新东西。你试图更深入地理解某些技术和工具。
项目
你是项目决策过程的一部分。你对项目的整体背景有较好的理解,但你仍然不需要了解超出你工作所需的知识。
高级数据科学家
然后是高级数据科学家职位。此时你基本上具备了数据科学家的一切特质,同时拥有一些额外的能力和责任。让我们看看这些是什么。
背景
你对主要概念和技术有了扎实的理解,也对其陷阱有了更深入的了解。这些知识是在项目工作中获得的。现在你已经积累了扎实的实践经验。
学习
你更容易学习更高级的主题,因为你已经掌握了基本概念。你仍然保持开放的学习态度。教授和支持更初级的同事是你工作的一个部分。
项目
你是项目的领导者。你不仅参与决策过程,还主导它。项目的成功是你的责任,在许多情况下,团队成员的幸福也是如此。在领导项目的同时,你还需要与外界沟通。向业务部门报告是你的职责。在项目中,你需要牢记非技术性的限制,并确保将技术团队引导到正确的方向。你必须对上下文和领域有整体和完整的理解。保持目标并交付成果是你的责任。
当然,并不是每位数据科学家的职业生涯在世界上每家公司中都是这样的。你可能是一个自由职业的数据科学家,或者你可能创办了自己的公司并成为 CTO,那么你的职业路径会显得非常不同。但一般来说,根据我与数据科学社区人士交流所学到的,这是一个良好的数据科学家职业路径的总体代表。
我们今天探讨这个问题的原因是,每家公司都有自己的结构、规则和路径,你需要知道在有选择时选择哪个方向。有些会随着你变得更资深而倾向于更多的技术工作,有些则倾向于更多的管理和行政工作。你可以利用本文中的解释作为基准,确定你希望在职业旅程的高级阶段处于何种位置,并据此调整你的求职方向。当然,计划和偏好会随着时间变化,但对自己想要的目标有个大致的想法总比盲目进入要好。
你已经有想倾向的方向了吗?可以通过评论或发邮件告诉我!
查看你想成为数据科学家?获取专门为忙碌的职业人士准备的文章和免费资源,帮助他们将职业转向数据科学。
个人简介:Mısra Turp:我白天是数据科学家,晚上是在线创作者。目前我在荷兰阿姆斯特丹的制药科技公司 myTomorrows 工作。在此之前,我在 IBM 担任数据科学家。
除了我的数据科学工作,我喜欢教人们我所知道的。我总是收到很多关于我的职业生涯和数据科学的一般性问题,这些问题来自那些希望达到我现在位置的人。因此,我创建了你想成为数据科学家?,在那里我通过文章分享我的知识和经验,并通过播客分享我的人脉。
我制作了这个课程,因为我意识到有抱负的数据科学家最大的不足是实践经验。我设计了这个课程,帮助你将迄今为止获得的所有小知识点结合起来,并在过程中完成一个你可以引以为傲的项目。
原文。经许可转载。
相关:
-
作为数据科学家的 6 个月学到的 6 个经验教训
-
我如何在 8 个月内提升我的数据科学技能
更多相关主题
非结构化数据:2022 年分析的必备
原文:
www.kdnuggets.com/2022/01/unstructured-data-analytics-2022.html
背景照片由 jcstudio 制作 - www.freepik.com
数据管理一直对企业组织保持业务连续性至关重要。然而,长期以来,数据管理指的是信息的存储和偶尔访问这些信息。在这段时间里,数据管理的重要性往往排在数据分析技术如机器学习和人工智能(AI)之后。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 在 IT 领域支持你的组织
到了 2022 年,数据管理对企业组织的关键性已经无法被低估。组织需要筛选的数据量如此之大,以至于他们不能把数据管理视为对数据分析工作的附属任务,尤其是考虑到全球高达 90%的数据是非结构化的。企业必须依靠现代方法来解析大量非结构化的数据集。
为此,让我们快速调查企业组织目前需要快速解析非结构化数据的需求,并检查几个在 2022 年高度相关的数据管理趋势。
商业数据管理正变得自动化
企业组织在数据科学领域存在的几乎整个时间里,一直依赖于手动技术来解析其非结构化数据集。这些手动技术不幸的是非常繁琐,并且需要人力来支持多个数据科学团队,以便非结构化数据可以被解析并正确索引。
比以往更多的组织认识到,手动处理和分类非结构化数据的技术已经不再可行。相反,企业组织需要商业化的自动化数据管理解决方案,这使数据科学家可以更有效地解析数拍字节的数据并持续进行目录管理。这些商业解决方案将利用 AI 来自动化非结构化数据的存储,甚至可以向数据科学家推荐更优化的非结构化数据存储方法。
随着商业数据管理解决方案变得更加成熟并广泛提供给公众,企业组织应该认真考虑通过项目管理软件来补充其数据分析工作。具备关键功能的强大项目管理软件,如基于网页的项目文件集中存储和项目进度跟踪器,可以加快企业分析和处理大规模非结构化数据的速度。
基于云的项目管理软件和自动化数据管理工作流程的结合,可以显著减少数据科学家处理和索引非结构化数据所需的时间,并为他们提供更多时间投资于利用 AI 和 ML 数据分析技术来分析数据的新方法和改进方法。
数据仓储正在帮助变现非结构化数据
过去,企业组织通过解析其业务系统来变现(主要是结构化的)数据,获取有关客户活动趋势的洞察。然而,如今数据变现的做法更多依赖于非结构化数据集。
考虑以下场景:一家企业希望通过使用机器学习提高其客户满意度来改善支持聊天和电话的质量。该企业需要一种方法来分析不同的客户对话,这种方法依赖于如机器学习等创新技术,这些技术需要非结构化数据来不断改进系统和解决方案。
对于希望改善数据货币化策略的企业来说,越来越多的公司现在提供云基础的数据仓储产品,以更好地支持系统解析非结构化数据集。这些公司认识到,非结构化数据正变得比结构化数据更有用来建立与客户和消费者的关系,并提供可以分析不同客户互动的云基础数据仓储,从而更好地把握客户行为和产品需求等智能信息的趋势。
风险投资者已经注意到越来越多的企业正在提供数据仓储解决方案,以更好地管理非结构化数据,这可能有助于提升公众对非结构化数据在数据管理中的重要性的认知。这种公众认知的趋势可能会说服更多组织投资依赖于非结构化数据的数据管理工作流,并确保保护客户数据,如个人身份信息(PII)。
考虑到客户与企业之间传输的个人身份信息(PII)比以往任何时候都多,这种可能性似乎并不那么遥远。例如,自疫情开始以来,投资保险政策的人数增长了 50%,客户很可能期望企业有解决方案来保护他们的敏感信息,并确保信息不被丢失。
数据孤岛正在帮助——而不是伤害——数据管理
数据孤岛在一些数据专业人士中获得了不良声誉,原因是可以理解的。尽管它们看似无害,但数据孤岛可能会阻碍相关方之间的信息共享,并可能导致多个部门之间的数据不一致。一些 IT 领导者可能甚至觉得,当存在数据孤岛这样的障碍时,难以全面描绘业务数据的全貌。
尽管如此,数据孤岛在短期内不太可能消失。鉴于这一事实,IT 领导者需要接受解析非结构化数据集并在孤岛之间保护这些数据的方法,而不必觉得需要将所有数据存储在一个单一的孤岛中。
一旦 IT 领导者更加舒适地接受数据孤岛及其在搜索、分类和保护非结构化数据方面提供的机会,他们应考虑数据孤岛如何改善跨数据存储平台的标签管理。存在于多个平台的便携数据管理使数据专业人士能够更容易地将数据集转移到新的基于云的环境和软件解决方案中,同时保留使数据快速分段的标签。
结论
非结构化数据、基于云的数据管理解决方案以及将数据货币化的新方法正在提升对数据管理重要性的认识。毫无疑问,非结构化数据在企业寻找洞察力的方式中变得比以往任何时候都更加重要,这些企业生成和存储的数据跨越多个数据孤岛和存储环境。
考虑到技术创新如 AI 和 ML 是现代数据分析的关键组成部分,非结构化数据的重要性在可预见的未来可能会持续增长,因为它能促进更有效的方式来推动更明智的业务决策。
Nahla Davies 是一名软件开发者和技术作家。在全职从事技术写作之前,她曾在一家客户包括三星、时代华纳、Netflix 和索尼的 Inc. 5,000 体验品牌组织中担任首席程序员。
更多相关话题
在类别不平衡数据集上使用弹性 Info-GAN 的无监督解耦表示学习
介绍
在本文中,我们将讨论一篇与弹性 Info-GAN 相关的论文,该论文尝试解决传统 GAN 无法克服的缺陷。让我们讨论一下论文的目标或摘要,描述了主要贡献:
本文尝试利用 Info-GAN 论文中的两个主要缺陷,同时保留其他优点/改进。
这些是两个缺陷:
缺陷-1: 我们讨论了 Info-GAN,它主要关注通过操作潜在代码向量 c 来生成解耦表示。我们可以看到,它考虑到这个潜在代码向量是由连续和离散潜在变量组成的事实。
他们做出的一个假设是离散潜在变量具有均匀分布。
观察: 这意味着他们提供的类别分布是平衡的。然而,现实世界中的数据集可能没有平衡的类别分布。不平衡的数据将尝试使生成器生成更多来自主导类别的图像。

图像来源:弹性 Info-GAN 论文
缺陷-2: 尽管 Info-GAN 在给定一致的类别分布时能生成高质量的图像,但在给定不平衡数据集时,它很难从同一类别中生成一致的图像。第 1 行、第 2 行、第 4 行、第 7 行等在中心图像中显示出来。他们的推理是,模型在对图像进行分类时考虑了其他低级因素(如旋转和厚度)。
提到的缺陷的解决方案
第一个问题的解决方案
核心思想:
他们重新设计了使用潜在分布来检索潜在变量的方式。他们移除了对潜在类别分布的任何先验知识的假设,而是决定并提前固定这些潜在变量。
实现思想中的数学术语:
他们认为类别概率是可以学习的优化过程参数。他们使用 Gumbel-Softmax 分布来允许梯度流回类别概率。在 InfoGAN 中,用 Gumbel-Softmax 分布(一个可以被解码为类别分布的连续分布)替代固定的类别分布,这样可以进行可微分样本的采样。
让我们看看这个 softmax 温度表示了什么:
-
它控制 Gumbel-Softmax 样本与类别分布的相似程度。
-
这个参数的低值会使样本具有类似于单一类别样本的属性。
第二个问题的解决方案
这里他们尝试通过对比损失帮助 Q 学习表示。
核心思想(直观解决方案):
这个想法是基于对象身份生成正样本对(例如,一辆车及其镜像翻转的对照)和负样本对(例如,一个红色的哈士奇帽和一辆白色轿车),并且 Q 应为它们生成相似和不相似的表示(上图表示了相同的事物)。
数学意义:
-
从数学角度来看,对于一批 N 个真实图像,
-
通过构建其增强版本,利用身份保留变换对每个图像进行处理,最终生成总计 2N 张图像。
-
对于批次中的每个图像,我们还定义了相应的变换图像 Ipos 和所有其他 2(N-1)张图像作为 Ineg。
图片来源: 论文链接
在其中一个数据库上重现的结果
在这里,我们将使用 MNIST 数据集来训练这种类型的模型:
关于 MNIST 数据集:
MNIST 默认是一个平衡数据集,有 70k 张图像以及每个类别的训练样本数相似。我们人工引入了 50 个随机分割的不平衡,并报告了平均结果。
MNIST 数据集中有很多手写数字。AI/ML/数据科学社区的成员钟爱这个数据集,用于验证他们的算法。事实上,MNIST 经常是研究人员首先尝试的数据集。“如果在 MNIST 上不起作用,那就完全没用,”他们说。“即使在 MNIST 上有效,也可能在其他数据集上无效。”
GitHub 仓库中的不同文件
evаl_metriсs.рy: 这个文件包含打印评估指标的代码,包括与入口和 NMI 相关的均值和标准差。
mnist-trаin.рy: 这个文件包含在 MNIST 数据集上运行给定模型的代码。
dаtаlоаder.рy: 这个文件包含数据加载程序,说明如何将数据加载到环境中。如果我们需要在不同的数据集上运行相同的模型,需要更改这个文件。
评估指标
我们的评估应具体捕捉在不平衡数据集中将类别特定信息与其他因素分离的能力。由于前述指标,包括 Gumbel-Softmax 等,并未捕捉到这一属性,因此我们提议使用以下指标:
- 入口: 这个指标评估两个属性:
(i)为给定分类代码生成的图像是否属于相同的真实类别,即,为每个分类代码生成的图像的真实类别直方图是否具有较低的熵。
(ii)每个真实类别是否与一个唯一的分类代码相关联。
- NMI: NMI 代表归一化互信息。我们将生成的虚假图像的潜在类别分配(我们为每个分类代码生成 1000 张虚假图像)视为一个聚类,将预训练分类器对虚假图像的类别分配视为另一个聚类。NMI 测量这两个聚类之间的相关性。NMI 的值介于 0 到 1 之间;NMI 越高,相关性越强。
结果
完成 5 个时期后的结果:
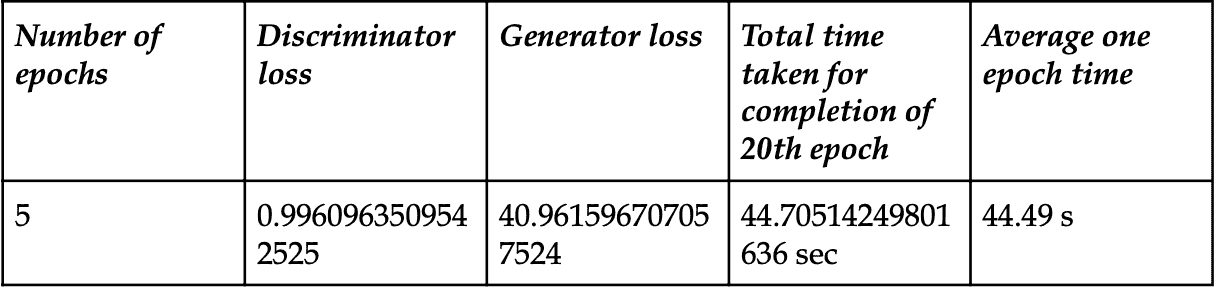
完成 10 个时期后的结果:
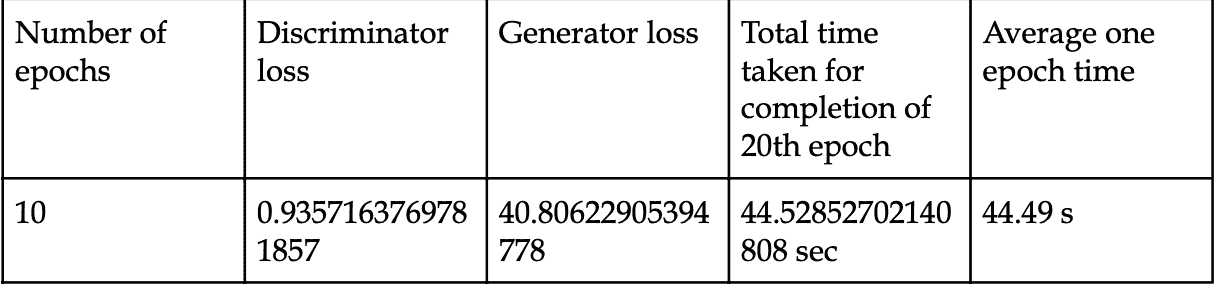
完成 15 个时期后的结果:
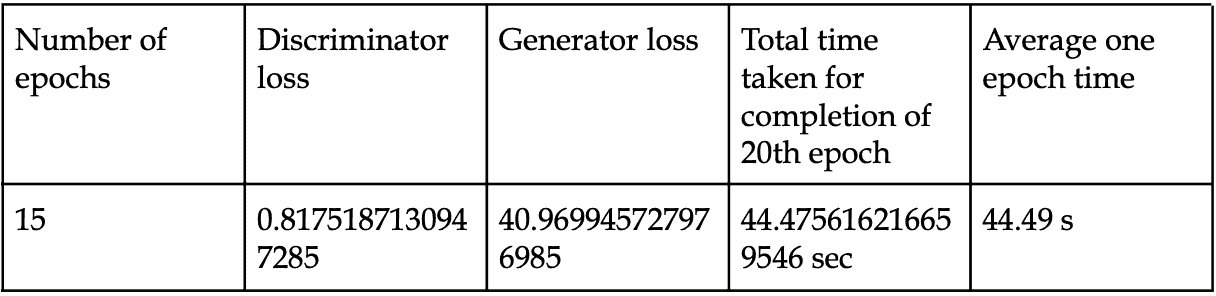
完成 20 个时期后的结果:
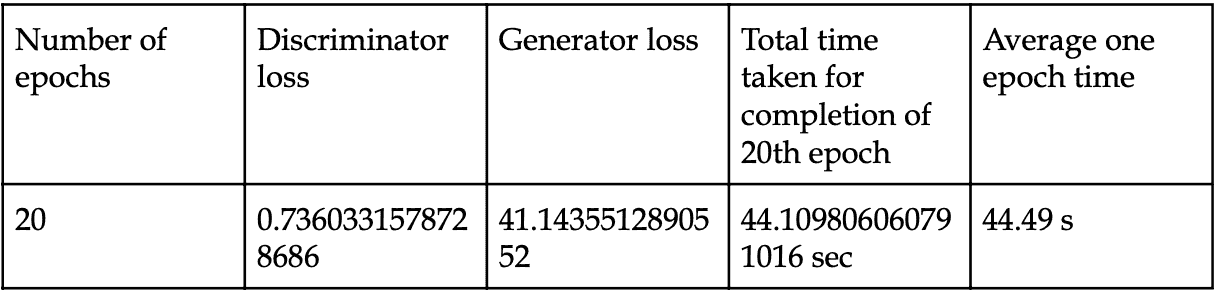
总共 20 个时期时间:896.10 秒
最终结论结果:
实验数量为 19
-
熵均值 - 0.52500474
-
熵标准差 - 0.30017176
-
NMI 均值 - 0.750077
-
NMI 标准差 - 0.134824
损失与迭代次数的曲线:
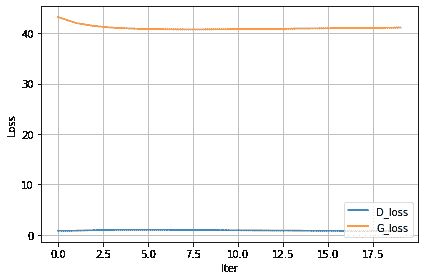
结论
在不了解类不平衡的情况下,我们提出了一种无监督生成模型,该模型更好地将对象身份作为变异因素进行解缠。尽管存在一些限制(例如,在高度偏斜的数据中的适用性),我们相信我们已经解决了一个重要的、之前未曾探讨的问题。我们希望这项工作能为无监督学习方法在类不平衡数据中的发展铺平道路,就像有监督机器学习领域随着时间的发展以应对实际数据中的类不平衡一样。
本文的主要观点:
-
在本文中,我们讨论了与弹性 Info-GAN 相关的一篇论文,该论文尝试解决传统 GAN 无法克服的缺陷。
-
以上对两个问题的主要数学解决方案已用适当的数据分布假设进行说明。
-
我们在论文中使用的一个数据库上训练了我们的弹性 info-GAN 模型,并观察了生成器和判别器的损失和准确率曲线。
-
我们使用了两种不同的评估指标,即 NMI 和熵,这些指标已在理论和实际方面进行了说明,并且还说明了我们选择这些指标的原因。
-
最终,我们得到了结果,并基于这些结果,我们可以进一步调整我们的模型,以优化其在任何数据集上的性能。
Aryan Garg 是一名 B.Tech. 电气工程学生,目前在本科最后一年。他对网络开发和机器学习领域感兴趣。他已经追求了这一兴趣,并渴望在这些方向上做更多的工作。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
更多相关话题
无监督学习揭秘
原文:
www.kdnuggets.com/2018/08/unsupervised-learning-demystified.html
评论
无监督学习听起来可能像是“让孩子们自己学会不要碰热烤箱”的华丽说法,但实际上它是一种从数据中挖掘灵感的模式发现技术。它与机器在没有成人监督的情况下跑来跑去、形成自己对事物的看法无关。让我们揭开谜底吧!

如果这让你感到熟悉,无监督机器学习可能是你的新朋友。
本文适合初学者,但假设你对到目前为止的故事有所了解:
-
机器学习就是关于通过示例对事物进行标记。
-
如果你通过提供你所寻找的答案来训练你的系统,那就是在进行监督学习。
-
要开始监督学习,你需要知道你想要什么标签。(无监督学习则不然。)
-
标准术语包括实例、特征、标签、模型和算法。
什么是无监督学习?

你的任务?随意将这六张图片分成两组。
查看上面的六个实例。缺少了什么?这些照片没有标签。不用担心,你的大脑在无监督学习方面很厉害。我们来试试吧。
想想你希望如何将这些图像分成两组。没有错误的答案。准备好了吗?
对数据进行聚类
在一个实时课堂上,谷歌员工会喊出像“坐着还是站着”、“能看到木地板还是不能”、“猫自拍还是非猫自拍”这样的答案。我们来检查第一个答案。

将图像分成两类的一种方法是:坐着与站立。嗯,“坐着”与站立。
无监督学习的秘密标签
如果你选择根据猫是否站立来定义你的聚类,你的系统输出的标签是什么?毕竟,机器学习就是关于对事物进行标记的。
如果你认为“坐着与站着”是标签,那就再想想吧!那是你用来创建集群的配方(模型)。无监督学习中的标签要无聊得多:比如“组 1 和组 2”或“A 或 B”或“0 或 1”。它们只是表示群组成员关系,没有额外的人类可解释(或诗意)的意义。
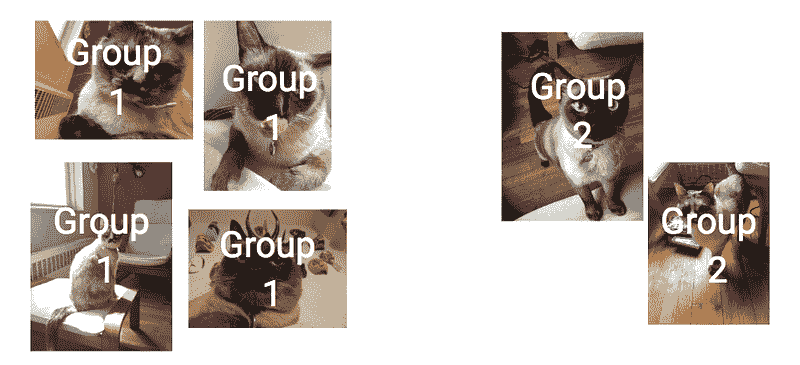
无监督学习的标签仅仅表示集群成员关系。它们没有更高的人类可解释的意义,尽管这可能令人失望。
这里发生的只是算法根据相似性对事物进行分组。相似性度量由算法选择决定,但为什么不尝试尽可能多的算法呢?毕竟,你不知道自己在寻找什么,这没关系。把无监督学习看作是“物以类聚”的一种数学版本。
像一个 罗夏墨迹测验,结果在于帮助你做梦。
不要过于认真地对待你看到的内容。
再看一眼!
作为这两只独立猫咪的骄傲母亲,我感到遗憾,在我教了这个课程约 50 次的过程中,只有一个观众注意到了:“猫 1 与猫 2。” 相反,得到的回答却是“坐着、站着”或“木地板缺失/存在”或有时甚至是“丑猫与漂亮猫。”(哎呀。)

原来这些是我两只独立猫咪的照片!也许你看出来了,但大多数观众没看出来……除非我给他们标签(监督他们的学习)。如果我一开始就用名字标签展示数据,然后让你对下一张照片进行分类,我敢打赌你会觉得任务很简单。
总结经验
想象一下我是一名初学者数据科学家,刚刚开始进行无监督学习,自然对自己两只猫很感兴趣。当我查看这些数据时,我无法忽视我的猫咪。因为我的小可爱对我来说如此重要,我期望我的无监督机器学习系统能恢复唯一值得关心的东西。哎呀!
在这十年之前,计算机甚至无法与世界上最优秀的模式发现者——人脑竞争。这对人来说很简单!那么,为什么成千上万的谷歌员工看到这些未标记的照片却错过了“猫 1 与猫 2”的答案呢?
把无监督学习看作是“物以类聚”的一种数学版本。
仅仅因为某些东西对我有趣,并不意味着我的模式发现器能找到它。即使模式发现器很棒,我也没有告诉它我在寻找什么,所以为什么要期望我的学习算法能提供它呢?这不是魔法!如果我不告诉它正确的答案是什么……我就接受结果,不会感到不满。我能做的只是看看系统返回的簇,并看看是否觉得它们有启发。如果我不喜欢它们,我就不断运行不同的无监督算法(“观众中的其他人,为我换个方式分割”),直到有趣的东西出现。
结果如同罗夏墨迹图,帮助你做梦。
这个过程不一定会产生令人振奋的成果,但尝试一下也无妨。毕竟,探索未知本该是一种冒险。好好享受吧!
在未来的节目中,我们将探讨如果你忘记标签只是灵感而不应过于认真对待,甚至不应被视为可由人解释的,可能会发生的警示故事。(提示:可能会提到在一片吐司中发现埃尔维斯的故事。)它们只是用来给你一些关于下一个可能感兴趣的方向的想法。
总结: 无监督学习通过将相似的事物分组,帮助你从数据中找到灵感。定义相似性的方式有很多,所以不断尝试算法和设置,直到一个酷炫的模式引起你的注意。
个人简介: Cassie Kozyrkov 是谷歌首席决策智能工程师。❤️ 统计学,机器学习/人工智能,数据,双关语,艺术,戏剧,决策科学。所有观点均为个人意见。
原文。经许可转载。
相关:
-
数据科学家需要知道的 5 种聚类算法
-
K 均值在现实生活中的应用:聚类锻炼课程
-
使用 K 均值算法进行聚类
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
更多相关主题
揭示隐藏模式:层次聚类介绍
原文:
www.kdnuggets.com/unveiling-hidden-patterns-an-introduction-to-hierarchical-clustering
作者提供的图像
当你熟悉无监督学习范式时,你将学习到聚类算法。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
聚类的目标通常是理解给定未标记数据集中的模式。或者可以是寻找数据集中的组并对其进行标记,以便我们可以在现在标记的数据集上执行监督学习。本文将涵盖层次聚类的基础知识。
什么是层次聚类?
层次聚类算法旨在找到实例之间的相似性——通过距离度量来量化——以将它们分组为称为簇的段。
算法的目标是找到簇,使得簇中的数据点彼此更相似,而与其他簇中的数据点的相似度较低。
有两种常见的层次聚类算法,每种算法都有其独特的方法:
-
凝聚聚类
-
分裂聚类
凝聚聚类
假设数据集中有 n 个不同的数据点。凝聚聚类的工作方式如下:
-
从 n 个簇开始;每个数据点本身就是一个簇。
-
根据数据点之间的相似性将数据点组合在一起。这意味着相似的簇会根据距离进行合并。
-
重复步骤 2 直到只剩下一个簇。
分裂聚类
如名字所示,分裂聚类尝试执行凝聚聚类的逆过程:
-
所有 n 个数据点都在一个簇中。
-
将这个单一的大簇划分为更小的组。请注意,凝聚聚类中数据点的组合是基于相似性的,但将它们划分到不同的簇中是基于不相似性;不同簇中的数据点彼此不相似。
-
重复直到每个数据点本身都是一个簇。
距离度量
如前所述,数据点之间的相似性是通过距离来量化的。常用的距离度量包括欧几里得距离和曼哈顿距离。
对于 n 维特征空间中的任意两个数据点,它们之间的欧氏距离由下式给出:
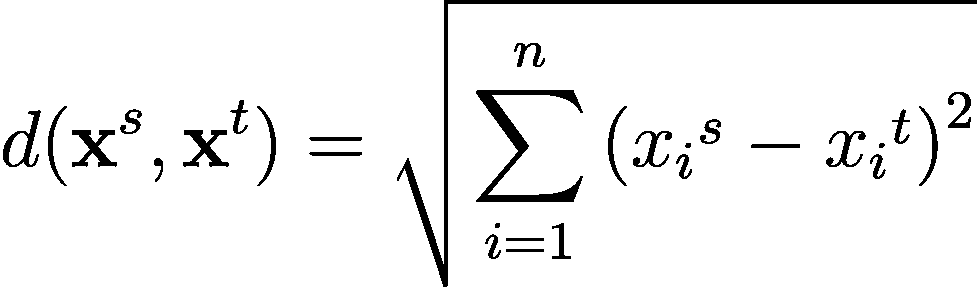
另一种常用的距离度量是曼哈顿距离,计算公式为:
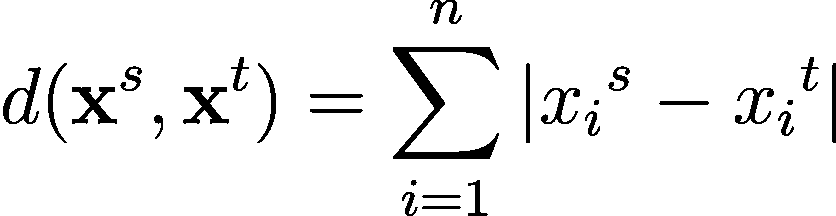
闵可夫斯基距离是对这些距离度量在 n 维空间中的一般化——适用于一般 p >= 1:
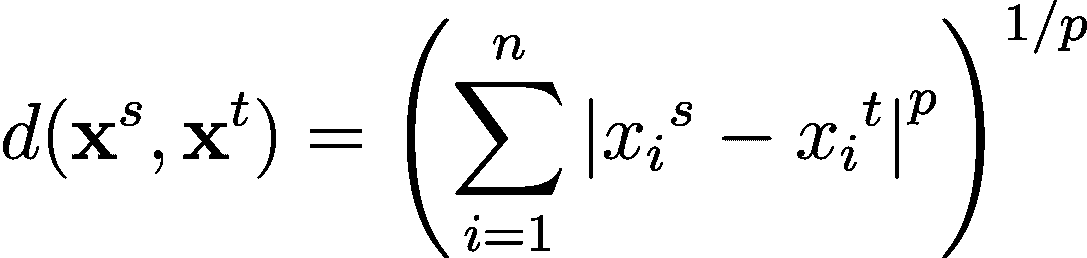
聚类间的距离:理解连接标准
使用距离度量,我们可以计算数据集中任意两个数据点之间的距离。但你还需要定义一种距离来确定每一步如何将聚类组合在一起。
记住,在每一步的凝聚型聚类中,我们选择两个最接近的组进行合并。这由连接标准来捕捉。常用的连接标准包括:
-
单链接
-
完全链接
-
平均连接
-
Ward’s linkage
单链接
在单链接或单链接聚类中,两组/聚类之间的距离被视为两聚类中所有数据点对之间的最小距离。
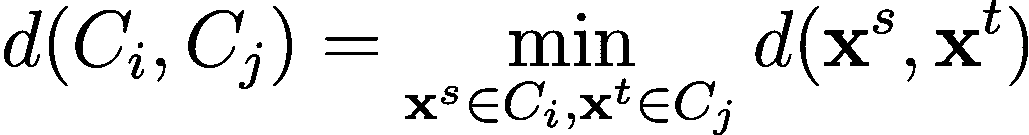
完全链接
在完全链接或完全链接聚类中,两聚类之间的距离被选为两聚类中所有点对之间的最大距离。
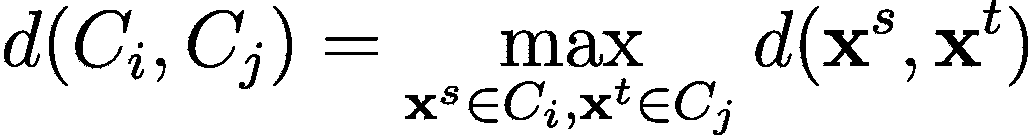
平均链接
有时使用平均链接,它使用两聚类中所有数据点对之间距离的平均值。
Ward’s Linkage
Ward’s linkage 旨在最小化合并后聚类内的方差:合并聚类应尽量减少合并后的方差总增加。这会导致更紧凑且分隔良好的聚类。
两个聚类之间的距离通过考虑合并聚类的均值的总平方偏差(方差)增加来计算。其目的是测量合并后聚类方差增加了多少,与合并前的各个聚类的方差相比。
当我们在 Python 中编写层次聚类代码时,我们也会使用 Ward’s linkage。
什么是树状图?
我们可以将聚类的结果可视化为一个树状图。它是一个层次树结构,帮助我们理解数据点——以及随后形成的聚类——是如何随着算法的进行被分组或合并在一起的。
在层次树结构中,叶子表示数据集中的实例或数据点。可以从 y 轴推断出合并或分组发生的相应距离。
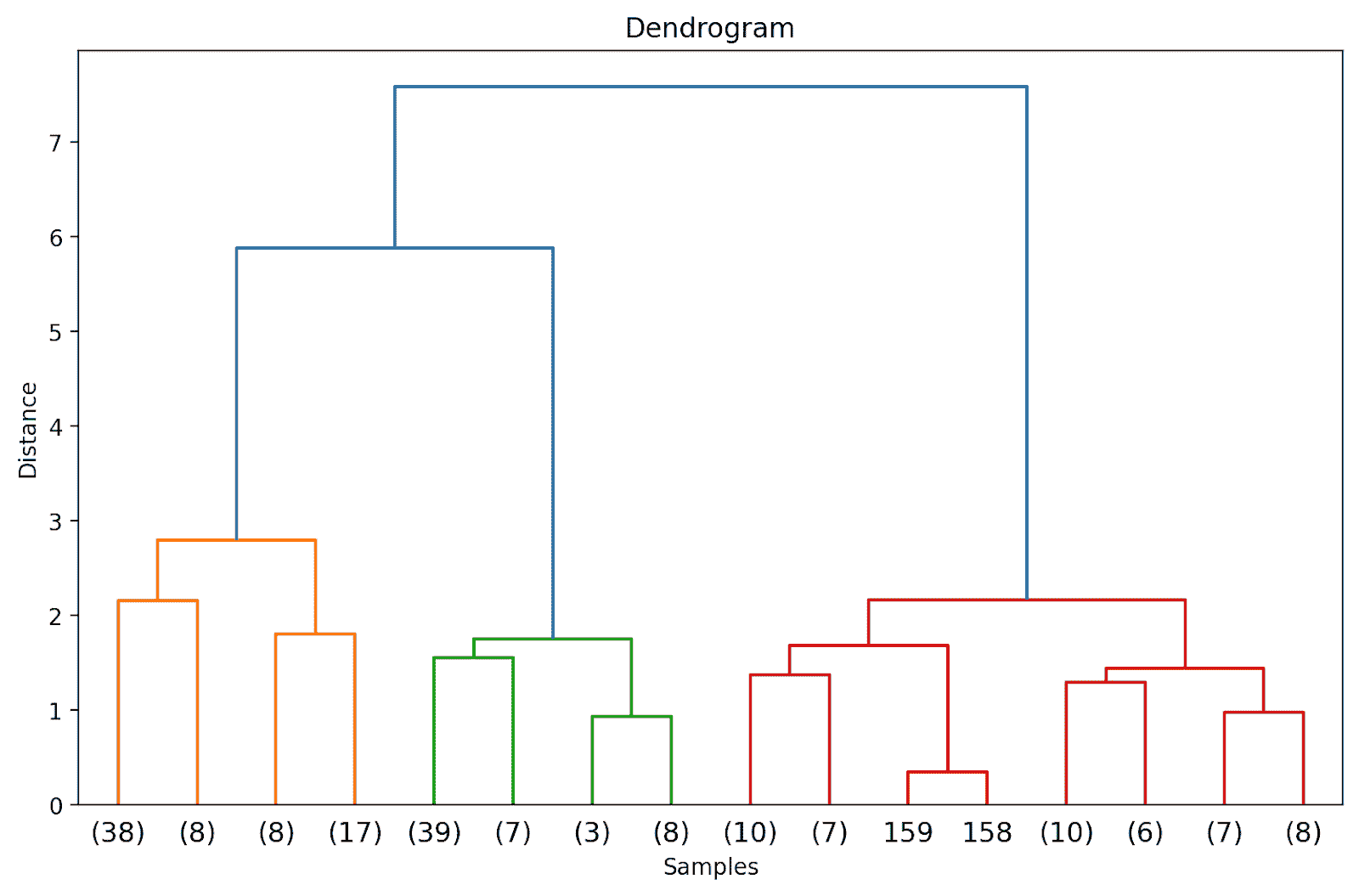
示例树状图 | 作者提供的图片
由于连接类型决定了如何将数据点分组在一起,不同的连接准则会产生不同的树状图。
根据距离,我们可以使用树状图—在特定点切割或分割—以获取所需数量的簇。
与一些聚类算法如 K-Means 聚类不同,层次聚类不需要你事先指定簇的数量。然而,进行聚合聚类时,处理大型数据集可能非常耗费计算资源。
使用 SciPy 进行 Python 中的层次聚类
接下来,我们将在内置的 酒数据集 上逐步进行层次聚类。为此,我们将利用 聚类包—scipy.cluster—来自 SciPy。
第 1 步 – 导入必要的库
首先,让我们导入必要的库和来自 scikit-learn 及 SciPy 库的模块:
# imports
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.preprocessing import MinMaxScaler
from scipy.cluster.hierarchy import dendrogram, linkage
第 2 步 – 加载和预处理数据集
接下来,我们将酒数据集加载到 pandas 数据框中。这是一个简单的数据集,属于 scikit-learn 的datasets的一部分,对探索层次聚类很有帮助。
# Load the dataset
data = load_wine()
X = data.data
# Convert to DataFrame
wine_df = pd.DataFrame(X, columns=data.feature_names)
让我们查看数据框的前几行:
wine_df.head()
wine_df.head()的截断输出
注意,我们仅加载了特征—而不是输出标签—以便我们可以执行聚类以发现数据集中的组。
让我们检查数据框的形状:
print(wine_df.shape)
数据集中有 178 条记录和 14 个特征:
Output >>> (178, 14)
由于数据集包含跨不同范围的数值,接下来让我们预处理数据集。我们将使用MinMaxScaler将每个特征转换到范围[0, 1]。
# Scale the features using MinMaxScaler
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X)
第 3 步 – 执行层次聚类并绘制树状图
让我们计算链接矩阵,执行聚类,并绘制树状图。我们可以使用来自 层次 模块的linkage来计算基于 Ward 链接法的链接矩阵(将method设置为'ward')。
如前所述,Ward 的链接法最小化每个簇内的方差。然后我们绘制树状图以可视化层次聚类过程。
# Calculate linkage matrix
linked = linkage(X_scaled, method='ward')
# Plot dendrogram
plt.figure(figsize=(10, 6),dpi=200)
dendrogram(linked, orientation='top', distance_sort='descending', show_leaf_counts=True)
plt.title('Dendrogram')
plt.xlabel('Samples')
plt.ylabel('Distance')
plt.show()
因为我们还没有(尚未)截断树状图,我们可以可视化 178 个数据点如何被分组到一个簇中。虽然这似乎很难解释,但我们仍然可以看到有三个不同的簇。
截断树状图以便于可视化
实际上,我们可以可视化一个更容易解释和理解的截断版本,而不是整个树状图。
要截断树状图,我们可以将truncate_mode设置为'level'并将p设置为 3。
# Calculate linkage matrix
linked = linkage(X_scaled, method='ward')
# Plot dendrogram
plt.figure(figsize=(10, 6),dpi=200)
dendrogram(linked, orientation='top', distance_sort='descending', truncate_mode='level', p=3, show_leaf_counts=True)
plt.title('Dendrogram')
plt.xlabel('Samples')
plt.ylabel('Distance')
plt.show()
这样会截断树状图,只包含那些在最终合并的 3 个级别内的簇。
在上述树状图中,你可以看到一些数据点,如 158 和 159,是单独表示的。其他一些数据点在括号中提到;这些不是单独的数据点,而是簇中的数据点数量。(k)表示一个包含 k 个样本的簇。
第 4 步 – 确定最佳簇数
树状图帮助我们选择最佳的簇数。
我们可以观察到 y 轴上的距离急剧增加,选择在那个点截断树状图——并使用该距离作为形成簇的阈值。
对于这个例子,最佳的簇数是 3。
第 5 步 – 形成簇
一旦我们决定了最佳的簇数,我们可以使用 y 轴上的相应距离——一个阈值距离。这确保了在阈值距离以上,簇不再合并。我们选择一个threshold_distance为 3.5(从树状图中推断得出)。
然后我们使用fcluster,将criterion设置为'distance',以获取所有数据点的簇分配。
from scipy.cluster.hierarchy import fcluster
# Choose a threshold distance based on the dendrogram
threshold_distance = 3.5
# Cut the dendrogram to get cluster labels
cluster_labels = fcluster(linked, threshold_distance, criterion='distance')
# Assign cluster labels to the DataFrame
wine_df['cluster'] = cluster_labels
你现在应该能看到所有数据点的簇标签({1, 2, 3}中的一个):
print(wine_df['cluster'])
Output >>>
0 2
1 2
2 2
3 2
4 3
..
173 1
174 1
175 1
176 1
177 1
Name: cluster, Length: 178, dtype: int32
第 6 步 – 可视化簇
现在每个数据点都已分配到一个簇,你可以可视化特征的子集及其簇分配。以下是两个这样的特征的散点图及其簇映射:
plt.figure(figsize=(8, 6))
scatter = plt.scatter(wine_df['alcohol'], wine_df['flavanoids'], c=wine_df['cluster'], cmap='rainbow')
plt.xlabel('Alcohol')
plt.ylabel('Flavonoids')
plt.title('Visualizing the clusters')
# Add legend
legend_labels = [f'Cluster {i + 1}' for i in range(n_clusters)]
plt.legend(handles=scatter.legend_elements()[0], labels=legend_labels)
plt.show()
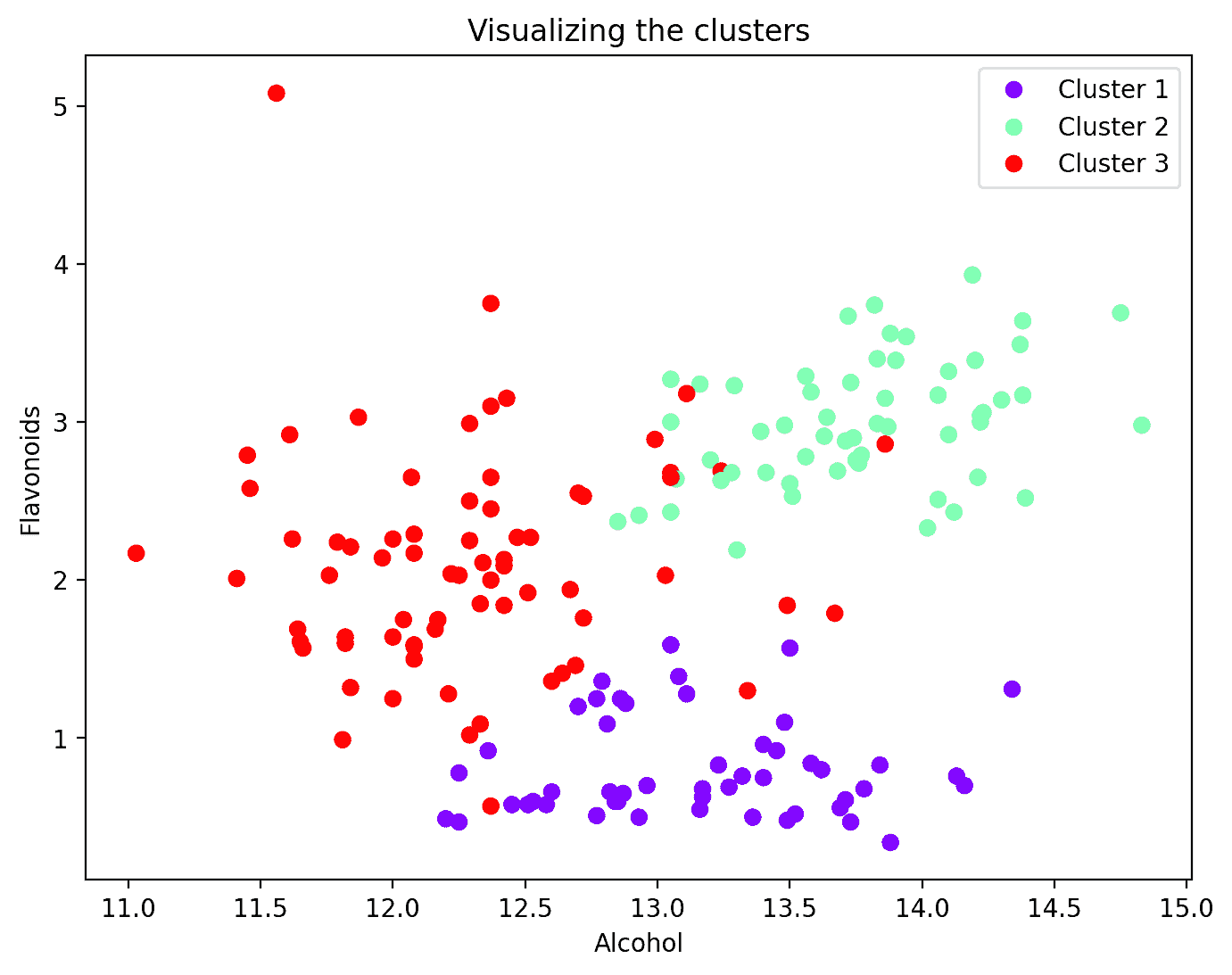
总结
就这样!在本教程中,我们使用 SciPy 执行层次聚类,以便更详细地涵盖涉及的步骤。或者,你也可以使用来自 scikit-learn 的AgglomerativeClustering类。祝编程愉快!
参考资料
[1] 机器学习导论
[2] 统计学习导论 (ISLR)
Bala Priya C 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正致力于学习和与开发者社区分享她的知识,通过编写教程、操作指南、观点文章等来实现。
了解更多相关主题
揭示 Midjourney 5.2:AI 图像生成的飞跃
原文:
www.kdnuggets.com/2023/06/unveiling-midjourney-52-leap-forward.html

使用 Midjourney 生成。提示:“Midjourney 5.2 真棒!--ar 16:9 --v 5.2”
作为图像生成领域的领先平台之一,Midjourney 最近发布了其最新版本,Midjourney 5.2,推出了一系列创新功能,旨在重新定义 AI 图像生成的格局。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
Midjourney 是一个由 AI 驱动的图像生成系统,将文本提示转换为惊艳的视觉效果。其最新版本 Midjourney 5.2 于 2023 年 6 月发布,以其先进的功能、改进的美学和增强的用户体验而受到好评。
Midjourney 5.2 中最令人兴奋的功能之一是“缩小”功能。此功能允许用户扩展原始图像,扩大其范围,同时保持原始图像的细节。 "缩小"功能模拟了相机镜头缩小的效果,在中心图像周围生成一个场景。这个功能特别令人印象深刻,因为它可以不断在不断扩展的图像上构建,创造出视觉上连贯的环境,将创意提升到另一个层次。
然而,需要注意的是,当前的“缩小”功能仅适用于在 Midjourney 中生成的图像。用户可以通过生成任何 v5.2 图像并放大结果来尝试缩小。随后,"缩放"按钮会显示出 1.5x、2x 或自定义量的缩小选项。
Midjourney 5.2 中另一个值得注意的新增功能是“裁剪成正方形”工具。此功能允许用户调整图像的形状,使其适应不同于完美正方形的纵横比。使用此工具,可以垂直扩展横向图像,反之亦然,为图像生成提供了更多灵活性。
Midjourney 5.2 还引入了 'Variation Mode'。该功能允许用户控制他们想要应用于输出的视觉细微差别和变化。用户可以将此功能设置为 'High Variation Mode' 或 'Low Variation Mode'。高变异模式会导致与原始输出略有不同的视觉效果,可能会产生更有趣或探索性的结果。另一方面,保持设置较低则有助于保持更大的视觉一致性。
在这个最新版本中,'Stylize' 命令也进行了彻底的更新。这个命令有效地影响图像的非现实感。新版本在现实性和风格方面增强了模型现有的风格化能力,为用户提供了更多对生成图像美学的控制。
最后,Midjourney 5.2 引入了新的 /shorten 命令。此功能使用户能够评估提示,以尝试删减非必要的词语,从而更容易生成与用户意图相符的图像。
总之,Midjourney 5.2 代表了 AI 图像生成领域的一次重要进步。其新功能和改进不仅提升了用户体验,还推动了 AI 艺术领域的可能性。随着 AI 技术的不断发展,像 Midjourney 这样的平台正在引领潮流,改变我们创作和互动数字艺术的方式。
Midjourney 5.2 证明了 AI 在艺术和设计领域的潜力。随着我们继续探索和理解这一技术,我们可以期待更多创新功能和改进,进一步革新 AI 图像生成领域。
了解更多
揭开神经魔法:深入激活函数
原文:
www.kdnuggets.com/unveiling-neural-magic-a-dive-into-activation-functions

作者提供的图片
为什么使用激活函数
深度学习和神经网络由互连的节点组成,其中数据顺序地通过每个隐藏层传递。然而,线性函数的组合不可避免地仍然是线性函数。当我们需要在数据中学习复杂和非线性的模式时,激活函数变得重要。
使用激活函数的两个主要好处是:
引入非线性
线性关系在现实世界中很少见。大多数现实世界场景是复杂的,并遵循各种不同的趋势。使用线性算法如线性和逻辑回归无法学习这样的模式。激活函数为模型添加了非线性,使其能够学习数据中的复杂模式和变异。这使得深度学习模型能够执行复杂的任务,包括图像和语言领域。
允许深层神经网络
如上所述,当我们顺序应用多个线性函数时,输出仍然是输入的线性组合。 在每一层之间引入非线性函数可以让它们学习输入数据的不同特征。如果没有激活函数,深度连接的神经网络架构将与使用基本的线性或逻辑回归算法没有区别。
激活函数使深度学习架构能够学习复杂的模式,使其比简单的机器学习算法更强大。
让我们来看看一些在深度学习中常用的激活函数。
Sigmoid
在二分类任务中常用的 Sigmoid 函数将实数值映射到 0 和 1 之间。
上述方程如下所示:
图片由Hvidberrrg提供
Sigmoid 函数主要用于二分类任务的输出层,其中目标标签是 0 或 1。 这使得 Sigmoid 函数在这种任务中更受青睐,因为其输出限制在这个范围内。对于接近无穷大的高值,sigmoid 函数将其映射到接近 1。相反,它将接近负无穷大的值映射到 0。在这些值之间的所有实数值都映射到 0 到 1 的范围内,呈 S 形趋势。
缺点
饱和点
Sigmoid 函数在反向传播过程中对梯度下降算法会带来问题。除了接近 S 形曲线中心的值,梯度非常接近零,这会导致训练问题。在渐近线附近,它可能会导致梯度消失问题,因为小梯度可能显著减慢收敛速度。
非零中心
经实验证明,具有零中心的非线性函数可以确保均值激活值接近 0。具有这种归一化值可以确保梯度下降更快地收敛到最小值。虽然不是必要的,但具有零中心的激活可以加速训练。当输入为 0 时,Sigmoid 函数的中心在 0.5。这是使用 Sigmoid 在隐藏层中的一个缺点。
Tanh
双曲正切函数是对 Sigmoid 函数的改进。与[0,1]范围不同,TanH 函数将实数值映射到-1 和 1 之间。
TanH 函数如下所示:
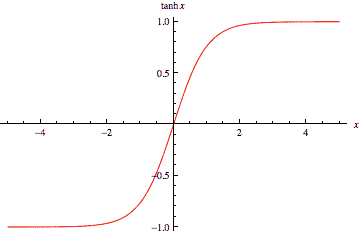
图片由Wolfram提供
TanH 函数遵循与 Sigmoid 相同的 S 形曲线,但现在是零中心的。这允许在训练过程中更快的收敛,因为它改进了 Sigmoid 函数的一个缺点。这使得它在神经网络架构中的隐藏层中更为适用。
缺点
饱和点
TanH 函数遵循与 Sigmoid 相同的 S 形曲线,但现在是零中心的。这允许在训练过程中更快的收敛,改进了 Sigmoid 函数的表现。这使得它在神经网络架构中的隐藏层中更为适用。
计算开销
尽管现代计算中并非主要问题,但指数计算比其他常见的替代方法更为昂贵。
ReLU
实践中最常用的激活函数,修正线性单元激活(ReLU),是最简单但最有效的非线性函数。
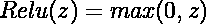
它保留所有非负值并将所有负值钳制为 0。可视化时,ReLU 函数如下所示:
图片由Michiel Straat提供
缺点
死亡 ReLU
梯度在图的一端趋于平坦。所有负值的梯度为零,因此一半的神经元可能对训练贡献很小。
无界激活
在图的右侧,可能的梯度没有限制。如果梯度值过高,这可能导致梯度爆炸问题。通常通过梯度裁剪和权重初始化技术来纠正这个问题。
不是零中心
类似于 Sigmoid,ReLU 激活函数也不是零中心的。同样,这会导致收敛问题并可能减慢训练速度。
尽管存在所有缺陷,但它仍然是神经网络架构中所有隐藏层的默认选择,并且在实践中被经验验证为高效。
关键要点
既然我们了解了三种最常见的激活函数,我们如何知道什么是我们场景中最佳的选择呢?
尽管这在很大程度上依赖于数据分布和具体问题陈述,但在实践中仍有一些基本的起点被广泛使用。
-
Sigmoid 只适用于目标标签为 0 或 1 的二分类问题的输出激活。
-
Tanh 现在主要被 ReLU 和类似函数取代。然而,它仍然在 RNN 的隐藏层中使用。
-
在所有其他场景中,ReLU 是深度学习架构中隐藏层的默认选择。
穆罕默德·阿赫姆 是一位从事计算机视觉和自然语言处理的深度学习工程师。他曾参与多个生成式 AI 应用的部署和优化,这些应用在 Vyro.AI 达到了全球排行榜的前列。他对构建和优化智能系统的机器学习模型充满兴趣,并相信持续改进。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关主题
揭示 CTGAN 的潜力:利用生成式 AI 生成合成数据
原文:
www.kdnuggets.com/2023/04/unveiling-potential-ctgan-harnessing-generative-ai-synthetic-data.html
我们都知道,GANs(生成对抗网络)在生成非结构化合成数据方面正在获得关注,例如图像和文本。然而,使用 GANs 生成合成表格数据的工作非常少。合成数据具有许多好处,包括在机器学习应用、数据隐私、数据分析和数据增强中的应用。生成合成表格数据的模型很少,而 CTGAN(条件表格生成对抗网络)就是其中之一。像其他 GANs 一样,它使用生成器和判别器神经网络创建具有类似统计特性的合成数据。CTGAN 可以保留真实数据的基础结构,包括列之间的相关性。CTGAN 的额外好处包括通过模式特定的归一化、少量架构更改以及通过使用条件生成器和训练采样来解决数据不平衡,从而增强训练过程。
在这篇博客文章中,我使用了 CTGAN 生成基于 Kaggle 收集的信用分析数据集的合成数据。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业领域。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
CTGAN 的优点
-
生成具有类似统计特性的合成表格数据,包括不同列之间的相关性。
-
保留真实数据的基础结构。
-
CTGAN 生成的合成数据可以用于各种应用,例如数据增强、数据隐私和数据分析。
-
可以处理连续、离散和分类数据。
CTGAN 的缺点
-
CTGAN 需要大量真实表格数据来训练模型,并生成具有类似统计特性的合成数据。
-
CTGAN 计算资源消耗大,可能需要大量计算资源。
-
CTGAN 生成的合成数据的质量可能会根据用于训练模型的真实数据的质量而有所不同。
调整 CTGAN
像所有其他机器学习模型一样,CTGAN 在调优时表现更好。在调优 CTGAN 时需要考虑多个参数。然而,为了此次演示,我使用了‘ctgan library’中所有默认参数:
-
训练轮次:生成器和鉴别器网络在数据集上训练的次数。
-
学习率:模型在训练过程中调整权重的速度。
-
批量大小:每次训练迭代中使用的样本数量。
-
生成器和鉴别器网络的规模。
-
优化算法的选择。
CTGAN 还考虑了超参数,如潜在空间的维度、生成器和鉴别器网络中的层数,以及每层使用的激活函数。参数和超参数的选择会影响生成的合成数据的性能和质量。
CTGAN 的验证
CTGAN 的验证较为棘手,因为它有诸如生成的合成数据质量评估的困难等局限性,特别是在处理表格数据时。尽管可以使用一些指标来评估真实数据与合成数据之间的相似性,但仍然难以确定合成数据是否准确地表示了真实数据中的潜在模式和关系。此外,CTGAN 容易过拟合,可能生成与训练数据过于相似的合成数据,这可能会限制其对新数据的泛化能力。
一些常见的验证技术包括:
-
统计测试:比较生成数据和真实数据的统计属性。例如,使用相关性分析、Kolmogorov-Smirnov 检验、Anderson-Darling 检验和卡方检验等测试,比较生成数据和真实数据的分布。
-
可视化:通过绘制直方图、散点图或热图来可视化相似性和差异。
-
应用测试:通过在实际应用中使用合成数据,查看其是否与真实数据表现相似。
案例研究
关于信用分析数据
信用分析数据包含连续格式和离散/类别格式的客户数据。为了演示目的,我已经通过删除包含空值的行和一些不需要的列来预处理数据。由于计算资源的限制,处理所有数据和所有列需要大量的计算能力,这超出了我的能力范围。以下是连续变量和类别变量的列列表(如“儿童数量 (CNT_CHINDREN)”等离散值被视为类别变量):
类别变量:
TARGET
NAME_CONTRACT_TYPE
CODE_GENDER
FLAG_OWN_CAR
FLAG_OWN_REALTY
CNT_CHILDREN
连续变量:
AMT_INCOME_TOTAL
AMT_CREDIT
AMT_ANNUITY
AMT_GOODS_PRICE
生成模型需要大量的清洁数据来进行训练以获得更好的结果。然而,由于计算能力的限制,我从超过 30 万行的真实数据中选择了仅 10,000 行(准确来说是 9,993)进行演示。虽然这个数量可能被认为相对较少,但对于本次演示来说应该足够。
真实数据的位置:
www.kaggle.com/datasets/kapoorshivam/credit-analysis
生成的合成数据的位置:

信用分析数据 | 图片来源:作者
结果
我生成了 10k(准确来说是 9997)个合成数据点,并将其与真实数据进行了比较。结果看起来不错,尽管仍有改进的空间。在我的分析中,我使用了默认参数,以'relu'作为激活函数,并训练了 3000 轮。增加训练轮数应能生成更像真实的合成数据。生成器和判别器的损失也很好,较低的损失表明合成数据与真实数据的相似度较高:
生成器和判别器损失 | 图片来源:作者
在绝对对数均值和标准差图中的对角线上的点表示生成的数据质量良好。
数值数据的绝对对数均值和标准差 | 图片来源:作者
以下图中的连续列的累积和虽然没有完全重叠,但接近,这表明合成数据生成良好且没有过拟合。分类/离散数据的重叠表明生成的合成数据接近真实数据。进一步的统计分析见以下图示:
每个特征的累积和 | 图片来源:作者 
特征分布 | 图片来源:作者
特征分布 | 图片来源:作者 
主成分分析 | 图片来源:作者
以下相关图显示了变量之间明显的相关性。值得注意的是,即使经过彻底的微调,真实数据和合成数据之间可能仍会存在属性差异。这些差异实际上可能是有益的,因为它们可能揭示数据集中隐藏的属性,这些属性可以用于创建新颖的解决方案。观察发现,增加训练轮数会提高合成数据的质量。
变量之间的相关性(真实数据)| 图片来源于作者
变量之间的相关性(合成数据)| 图片来源于作者
样本数据和真实数据的摘要统计结果也表现出令人满意的效果。
真实数据与合成数据的摘要统计 | 图片来源于作者
Python 代码
# Install CTGAN
!pip install ctgan
# Install table evaluator to analyze generated synthetic data
!pip install table_evaluator
# Import libraries
import torch
import pandas as pd
import seaborn as sns
import torch.nn as nn
from ctgan import CTGAN
from ctgan.synthesizers.ctgan import Generator
# Import training Data
data = pd.read_csv("./application_data_edited_2.csv")
# Declare Categorical Columns
categorical_features = [
"TARGET",
"NAME_CONTRACT_TYPE",
"CODE_GENDER",
"FLAG_OWN_CAR",
"FLAG_OWN_REALTY",
"CNT_CHILDREN",
]
# Declare Continuous Columns
continuous_cols = ["AMT_INCOME_TOTAL", "AMT_CREDIT", "AMT_ANNUITY", "AMT_GOODS_PRICE"]
# Train Model
from ctgan import CTGAN
ctgan = CTGAN(verbose=True)
ctgan.fit(data, categorical_features, epochs=100000)
# Generate synthetic_data
synthetic_data = ctgan.sample(10000)
# Analyze Synthetic Data
from table_evaluator import TableEvaluator
print(data.shape, synthetic_data.shape)
table_evaluator = TableEvaluator(data, synthetic_data, cat_cols=categorical_features)
table_evaluator.visual_evaluation()
# compute the correlation matrix
corr = synthetic_data.corr()
# plot the heatmap
sns.heatmap(corr, annot=True, cmap="coolwarm")
# show summary statistics SYNTHETIC DATA
summary = synthetic_data.describe()
print(summary)
结论
CTGAN 的训练过程预计会收敛到一个点,使得生成的合成数据与真实数据不可区分。然而,实际上,收敛不能得到保证。CTGAN 的收敛可能受到多种因素的影响,包括超参数的选择、数据的复杂性以及模型的架构。此外,训练过程的不稳定性可能导致模式崩溃,即生成器只产生有限的相似样本,而不是探索数据分布的全部多样性。
Ray Islam 是一名数据科学家(AI 和 ML)以及美国 Deloitte 的顾问专家领导。他拥有来自美国马里兰大学帕克分校的工程学博士学位,并曾与洛克希德·马丁和雷声等主要公司合作,服务于 NASA 和美国空军等客户。Ray 还拥有来自加拿大的工程硕士学位、国际市场营销硕士学位以及来自英国的 MBA 学位。他还是即将出版的同行评审《国际 AI 伦理研究期刊》(INTJEAI)的主编,他的研究兴趣包括生成式 AI、增强现实、XAI 和 AI 伦理。
更多相关内容
揭示 Meta 的 Llama 2 的力量:生成式 AI 的跃进?
原文:
www.kdnuggets.com/2023/07/unveiling-power-metas-llama-2-leap-forward-generative-ai.html

图像由作者使用 Midjourney 创建
介绍
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
最近在人工智能(AI)领域,尤其是在生成式 AI 方面的突破,引起了公众的广泛关注,并展示了这些技术推动新时代经济和社会机会的潜力。其中一个突破是Meta 的 Llama 2,它是其开源大型语言模型的下一代产品。
Meta 的 Llama 2 是在混合的公开数据上进行训练的,旨在推动诸如 OpenAI 的 ChatGPT、Bing Chat 及其他现代聊天机器人等应用。Meta 声称,Llama 2 的性能相比于以前的 Llama 模型有了显著提升。该模型以预训练形式可在 AWS、Azure 和 Hugging Face 的 AI 模型托管平台上进行微调,使其更易于访问和运行。你还可以在这里下载模型。
那么,是什么让 Llama 2 与其前身以及其他大型语言模型有所不同呢?让我们深入探讨其技术细节和影响。
技术细节和性能
Llama 2 有两种版本:Llama 2 和 Llama-2-Chat。Llama-2-Chat 经过了针对双向对话的微调。这两个版本都进一步细分为不同复杂度的模型:70 亿参数、130 亿参数和 700 亿参数模型。这些模型在两万亿个令牌上进行训练,比第一个 Llama 模型多 40%,包括超过 100 万个人工注释。
Llama 2 的上下文长度为 4096,并特别在 Llama-Chat-2 的训练中使用了来自人类反馈的强化学习,以确保安全性和有用性。根据 Meta 的说法,Llama 2 在推理、编码、能力和知识测试方面超过了包括 Falcon 和 MPT 在内的其他 LLM。

Llama 2 技术概述
(图片来源:Meta)
此外,Llama 2 已针对 Windows 以及配备 高通 Snapdragon 设备内技术 的智能手机和 PC 进行了优化,这意味着我们可以预计从 2024 年开始出现不依赖于云服务的 AI 驱动应用程序。
“这些由 Snapdragon 提供支持的新型设备内 AI 体验,可以在没有连接的区域甚至飞机模式下工作。”
— 高通(来源:CNET)
开源与安全
Llama 2 的一个关键方面是其开源性质。Meta 认为,通过公开 AI 模型,可以使每个人受益。这一发展使得商业和研究领域可以访问那些自己构建和扩展起来会变得不可承受的工具,从而为研究、实验和开发开辟了众多机会。
Meta 还强调安全性和透明度。Llama 2 已经过“红队测试”,因此通过生成对抗性提示进行安全性测试,以便对模型进行微调,无论是内部还是外部。Meta 公开了模型如何被评估和调整,促进了开发过程中的透明度。
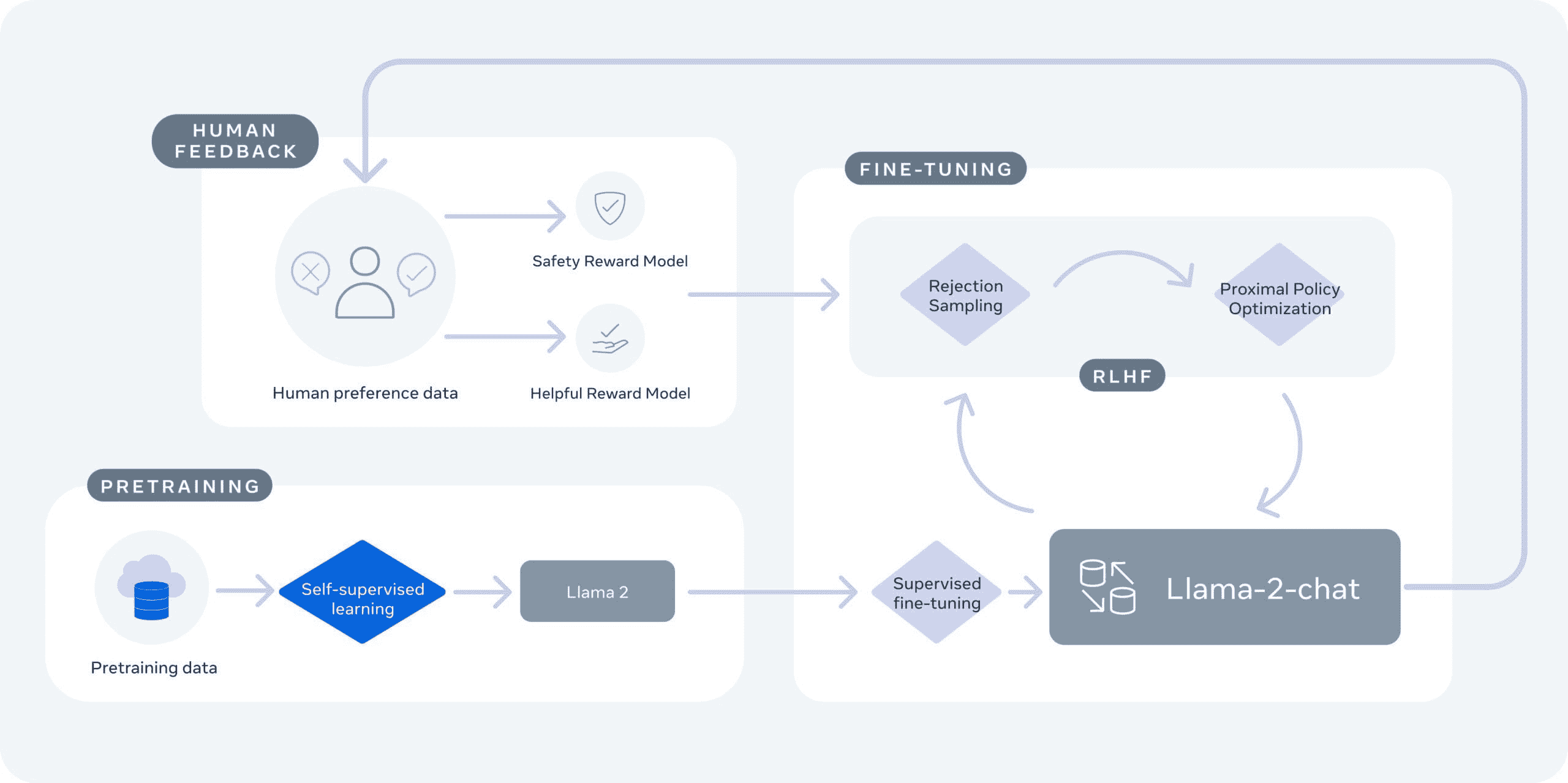
在 Llama-2-Chat 模型训练过程中,使用了来自人类反馈的强化学习,以确保安全性和有用性
(图片来源:Meta)
结论
Llama 2 尽力延续 Meta 在生成性 AI 领域的视角。其改进的性能、开源性质以及对安全性和透明度的承诺,使 Llama 2 成为广泛应用的有前途的模型。随着更多开发者和研究人员的参与,我们可以预期会看到创新的 AI 驱动解决方案的激增。
随着我们前进,继续解决 AI 模型中固有的挑战和偏见将至关重要。然而,Meta 对安全性和透明度的承诺为行业树立了积极的先例。随着 Llama 2 的发布,我们现在有了另一个可用的生成性 AI 工具,并且这一工具使开放访问成为持续的承诺。
Matthew Mayo (@mattmayo13) 是数据科学家和 KDnuggets 的总编辑,KDnuggets 是开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他的联系方式是 editor1 at kdnuggets[dot]com。
更多相关话题
揭开 StableCode 的面纱:AI 辅助编码的新视野
原文:
www.kdnuggets.com/2023/08/unveiling-stablecode-new-horizon-ai-assisted-coding

图片由作者使用 Midjourney 创建
概述
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
在不断发展的软件开发领域,为提高效率和可访问性而创建了各种工具和平台。其中最新的创新之一是 StableCode,这是 Stability AI 推出的一个大型语言模型(LLM)生成式 AI 产品。旨在帮助经验丰富的程序员和有志开发者,StableCode 承诺将彻底改变我们处理编码的方式。
StableCode 是由 Stability AI 开发的 AI 驱动助手,能够智能自动补全,响应指令,并管理长段代码。它包含三个专门的模型,每个模型针对编码过程中的不同方面。StableCode 在来自多种编程语言的超过 5600 亿个标记的广泛数据集上进行训练,旨在提高程序员的生产力并降低入门门槛。
尽管现有的对话 AI 助手如 Llama、ChatGPT 和 Bard 已展示了代码编写能力,但它们并未针对开发者体验进行优化。StableCode 加入了 GitHub Copilot 和其他开源模型等工具,提供了更具针对性和高效的编码体验。本文探讨了 StableCode 的独特功能、底层技术以及它对开发者社区的潜在影响。
StableCode 详情
StableCode 由三个专门的模型构成:
-
基础模型: 在包括 Python、Go、Java、JavaScript、C、markdown 和 C++ 在内的多种编程语言上进行训练。
-
指令模型: 调整以处理特定使用案例,帮助解决复杂的编程任务。
-
长上下文窗口模型: 构建以一次处理更多代码,允许用户同时查看或编辑多达五个中等大小的 Python 文件。
标准自动补全模型 StableCode-Completion-Alpha-3B-4K 提供单行和多行建议,随着开发者的输入,提升效率和准确性。
指令模型 StableCode-Instruct-Alpha-3B 利用自然语言提示执行编码任务,实现与代码的更直观互动。
StableCode 拥有长达 16,000 个标记的上下文窗口,可以管理广泛的代码库,提供对编码过程的更全面视图和控制。
StableCode 的训练涉及对 BigCode 数据的大量过滤和清洗。该模型在特定编程语言上经过了连续训练,采用了类似自然语言领域建模的方法。
与其他模型更重视当前标记而非过去标记不同,StableCode 使用旋转位置嵌入(RoPE),确保对代码功能的考虑更为平衡,没有固定的叙述结构。
StableCode 的独特功能和技术承诺显著提升开发者的工作流程。它具有大多数现有模型两倍的上下文长度和经过精心调整的模型,提供了更高的效率和精度。
通过提供一个智能且易于访问的平台,StableCode 有潜力降低新程序员的入门门槛,促进一个更具包容性和多样化的开发者社区。
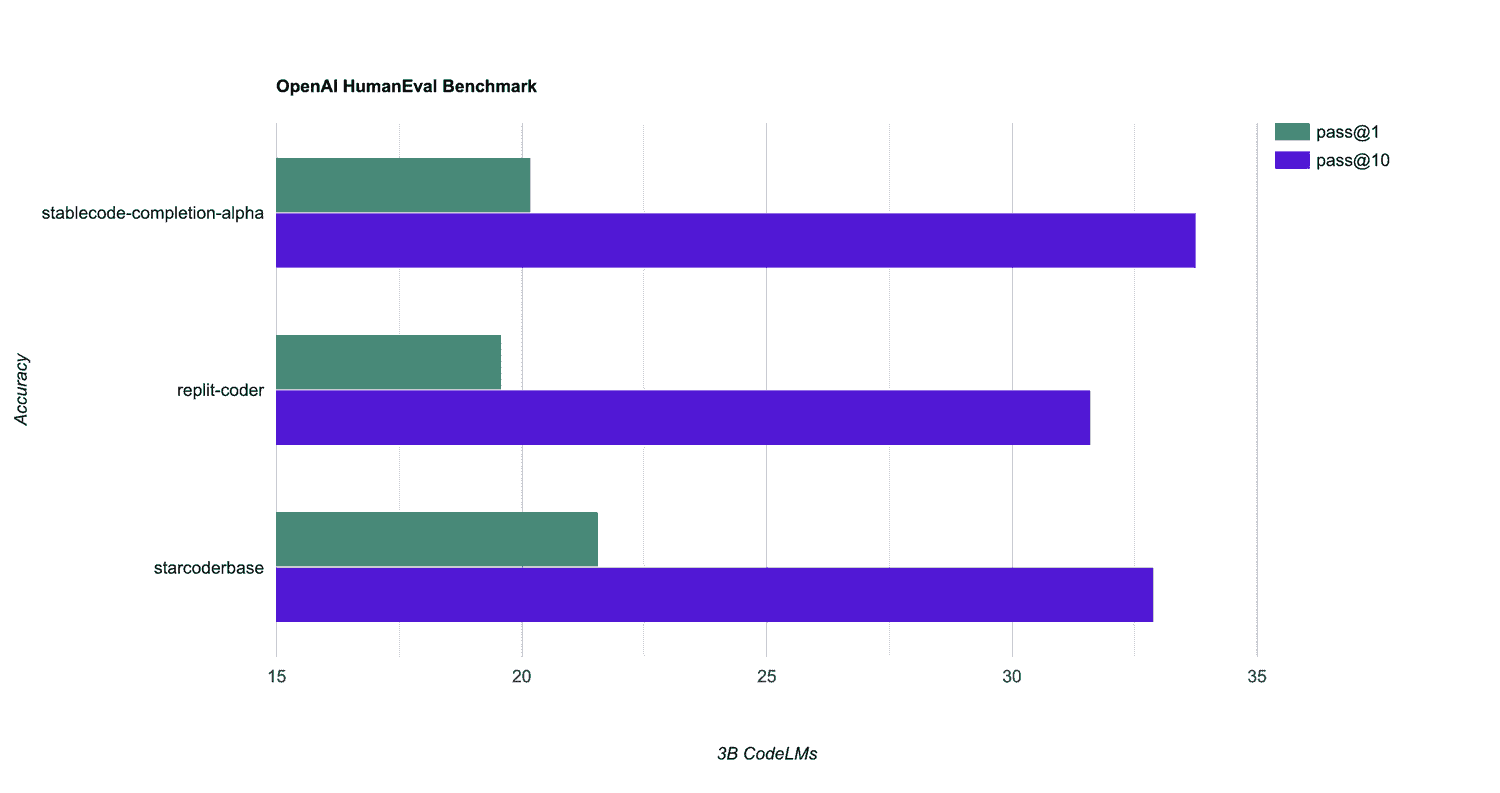
与相似规模(3B)的模型进行的 HumanEval 基准测试比较
来源:Stability AI
结论
StableCode 代表了编码辅助技术发展的重要一步。它独特的专用模型、智能自动补全和先进技术的结合,使其与现有工具区别开来。通过提供更为定制和高效的编码体验,它成为了软件开发领域的一个革命性工具。
不仅仅是一个编码助手,StableCode 体现了 Stability AI 赋能下一个十亿软件开发者的愿景。通过使技术更易于访问和提供更公平的编码资源,StableCode 准备好帮助塑造软件开发的未来,并激励新一代程序员。
Matthew Mayo (@mattmayo13) 是一名数据科学家及 KDnuggets 的主编,KDnuggets 是重要的数据科学和机器学习在线资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
更多相关信息
揭示无监督学习

作者提供的图片
什么是无监督学习?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
在机器学习中,无监督学习是一种在未标记数据集上训练算法的范式。因此,没有监督或标记输出。
在无监督学习中,目标是发现数据本身的模式、结构或关系,而不是基于标记的示例进行预测或分类。这涉及探索数据的内在结构,以获取洞察并理解复杂信息。
本指南将介绍无监督学习。我们将首先探讨监督学习和无监督学习之间的差异,为后续讨论奠定基础。接着,我们将介绍关键的无监督学习技术及其中的流行算法。
监督学习与无监督学习
监督学习和无监督学习是人工智能和数据分析领域中使用的两种不同方法。以下是它们关键差异的简要总结:
训练数据
在监督学习中,算法在标记数据集上进行训练,其中输入数据与对应的期望输出(标签或目标值)配对。
无监督学习则涉及处理未标记的数据集,其中没有预定义的输出标签。
目标
监督学习算法的目标是学习关系——映射——从输入到输出空间。一旦学会了这种映射,我们可以使用模型预测未见数据点的输出值或类别标签。
在无监督学习中,目标是发现模式、结构或关系,通常用于将数据点聚类到组中、进行探索性分析或特征提取。
常见任务
分类(为一个未见过的数据点分配一个类别标签——众多预定义类别之一)和回归(预测连续值)是监督学习中的常见任务。
聚类(将相似的数据点分组)和降维(在保留重要信息的同时减少特征数量)是无监督学习中的常见任务。我们将在稍后详细讨论这些内容。
何时使用
有监督学习广泛用于期望输出已知且定义明确的情况,例如垃圾邮件检测、图像分类和医学诊断。
无监督学习在对数据没有或仅有有限的先验知识时使用,其目标是揭示隐藏的模式或从数据本身中获得洞察。
以下是差异的总结:
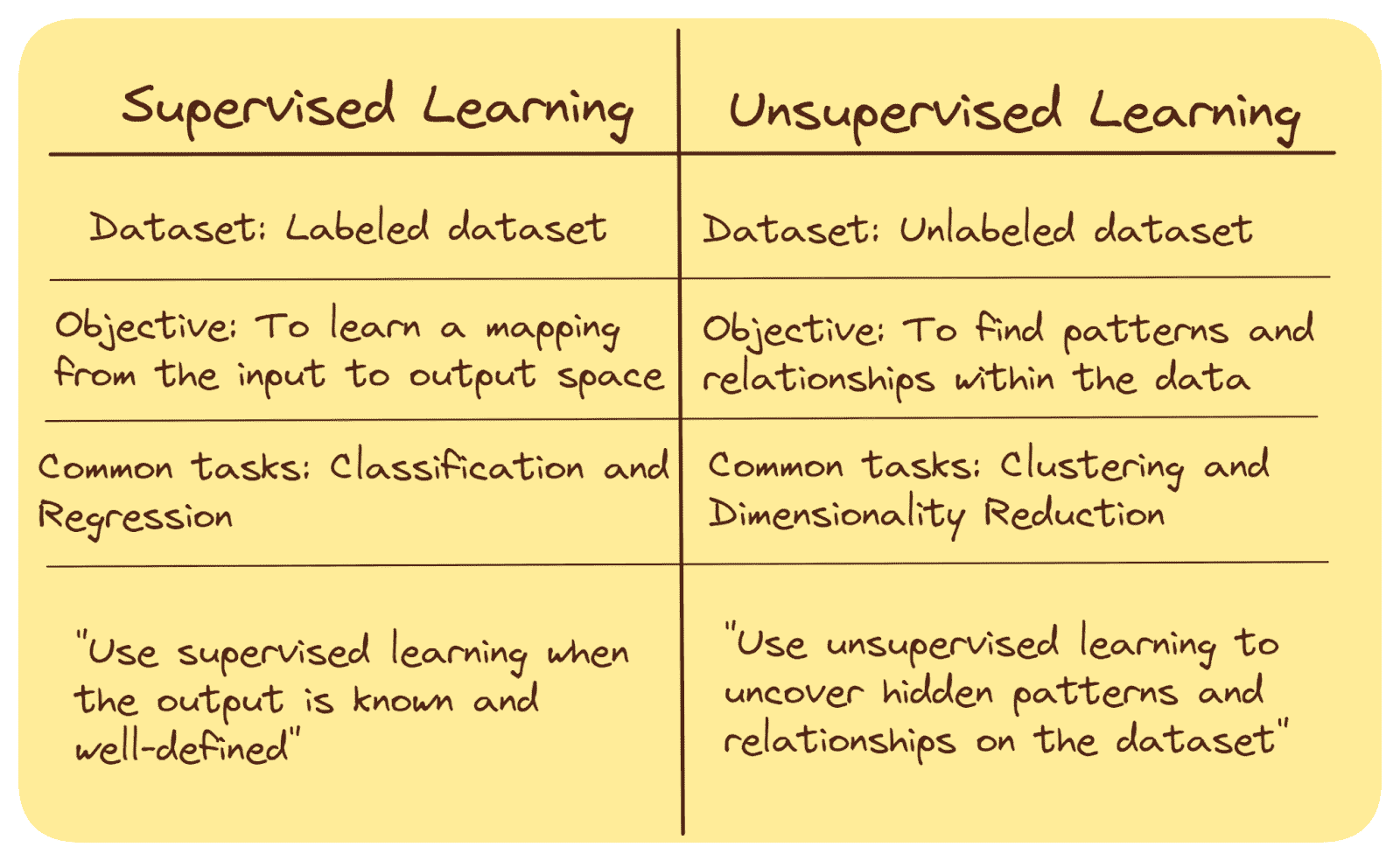
有监督学习与无监督学习 | 图片由作者提供
总结:有监督学习侧重于从标记数据中学习,以进行预测或分类,而无监督学习则试图发现未标记数据中的模式和关系。两种方法各有其应用——根据数据的性质和当前问题。
无监督学习技术
如讨论所述,在无监督学习中,我们拥有输入数据并被要求在这些数据中寻找有意义的模式或表示。无监督学习算法通过识别数据点之间的相似性、差异和关系来实现这一点,而不提供预定义的类别或标签。
在本讨论中,我们将介绍两种主要的无监督学习技术:
-
聚类
-
降维
什么是聚类?
聚类涉及根据某种相似性度量将相似的数据点分组到一起。算法旨在找到数据中的自然组或类别,其中同一簇中的数据点彼此更相似,而与其他簇中的数据点相比则不那么相似。
一旦我们将数据集分成不同的簇,我们实际上可以对它们进行标记。如有需要,我们可以在聚类后的数据集上执行有监督学习。
什么是降维?
降维是指减少数据中特征——维度——数量的技术,同时保留重要信息。高维数据可能复杂且难以处理,因此降维有助于简化数据以便进行分析。
聚类和降维都是无监督学习中强大的技术,提供了宝贵的洞察力,并简化了复杂数据以便于进一步分析或建模。
在本文的剩余部分,让我们回顾重要的聚类和降维算法。
聚类算法:概述
如前所述,聚类是无监督学习中的一种基本技术,它涉及将相似的数据点分组到簇中,在同一簇内的数据点彼此之间比与其他簇中的数据点更相似。聚类有助于识别数据中的自然划分,这可以提供关于模式和关系的见解。
有各种算法用于聚类,每种算法都有其自身的方法和特性:
K-Means 聚类
K-Means 聚类是一个简单、稳健且常用的算法。它通过根据每个簇中数据点的均值迭代更新簇质心,将数据划分为预定义数量的簇(K)。
它通过迭代精细化簇分配,直到收敛。
以下是 K-Means 聚类算法的工作原理:
-
初始化 K 个簇的质心。
-
根据选择的距离度量,将每个数据点分配到最近的簇质心。
-
通过计算每个簇中数据点的均值来更新质心。
-
重复步骤 2 和 3,直到收敛或达到定义的迭代次数。
层次聚类
层次聚类创建一个树状结构——一个树形图——的数据点,捕捉不同粒度层次的相似性。凝聚层次聚类是最常用的层次聚类算法。它从单独的数据点作为独立簇开始,并根据连接准则(如距离或相似性)逐渐合并它们。
以下是凝聚层次聚类算法的工作原理:
-
从
n个簇开始:每个数据点作为自己的簇。 -
将最近的数据点/簇合并为一个更大的簇。
-
重复 2 直到剩下一个簇或达到定义的簇数量。
-
结果可以借助树形图进行解释。
基于密度的空间聚类(DBSCAN)
DBSCAN 根据邻域中数据点的密度识别簇。它可以发现任意形状的簇,并且还可以识别噪声点和检测离群点。
该算法包括以下(简化以包含关键步骤):
-
选择一个数据点,并找到其指定半径内的邻居。
-
如果点有足够的邻居,通过包括其邻居的邻居来扩展簇。
-
对所有点重复此操作,形成由密度连接的簇。
降维算法概述
降维是减少数据集中特征(维度)数量的过程,同时保留重要信息。高维数据可能复杂、计算开销大且容易过拟合。降维算法有助于简化数据表示和可视化。
主成分分析(PCA)
主成分分析——或 PCA——将数据转换到新的坐标系统,以最大化主成分方向的方差。它在尽可能保留方差的同时减少数据维度。
这里是你如何进行 PCA 进行降维:
-
计算输入数据的协方差矩阵。
-
对协方差矩阵进行特征值分解。计算协方差矩阵的特征向量和特征值。
-
按特征值的降序排序特征向量。
-
将数据投影到特征向量上,以创建低维表示。
t-分布随机邻域嵌入(t-SNE)
我第一次使用 t-SNE 是为了可视化词嵌入。t-SNE 用于通过将高维数据降低到低维表示来进行可视化,同时保持局部成对相似性。
以下是 t-SNE 的工作原理:
-
构建概率分布来测量高维和低维空间中数据点之间的成对相似性。
-
使用梯度下降来最小化这些分布之间的差异。迭代地移动低维空间中的数据点,调整其位置以最小化成本函数。
此外,还有一些深度学习架构如自编码器可以用于降维。自编码器是设计用来编码然后解码数据的神经网络,有效地学习输入数据的压缩表示。
无监督学习的一些应用
让我们深入探讨无监督学习的一些应用。以下是一些例子:
客户细分
在营销中,企业使用无监督学习将客户群体细分为具有相似行为和偏好的组。这有助于定制营销策略、活动和产品供应。例如,零售商将客户分类为“预算购物者”、“奢侈品买家”和“偶尔购买者”等组。
文档聚类
你可以在文档语料库上运行聚类算法。这有助于将相似的文档分组,从而有助于文档的组织、搜索和检索。
异常检测
无监督学习可以用于识别数据中的稀有和异常模式——异常值。异常检测在欺诈检测和网络安全中有应用,以检测异常——异常行为。通过识别不寻常的消费模式来检测欺诈性信用卡交易是一个实际的例子。
图像压缩
聚类可以用于图像压缩,将图像从高维颜色空间转换为更低维的颜色空间。这通过用单个中心点表示相似的像素区域,从而减少图像存储和传输的大小。
社交网络分析
你可以分析社交网络数据——基于用户互动——以揭示社区、影响者和互动模式。
主题建模
在自然语言处理领域,主题建模任务用于从文本集合中提取主题。这有助于对大文本语料库中的主要主题进行分类和理解。
比如,我们有一批新闻文章的语料库,并且我们事先没有这些文档及其对应的类别。我们可以对这批新闻文章进行主题建模,以识别诸如政治、科技和娱乐等主题。
基因组数据分析
无监督学习在生物医学和基因组数据分析中也有应用。例如,通过根据基因的表达模式对基因进行聚类,以发现与特定疾病的潜在关联。
结论
我希望这篇文章能帮助你理解无监督学习的基础知识。下次你处理实际数据集时,尝试找出当前的学习问题,并评估是否可以将其建模为监督学习或无监督学习问题。
如果你正在处理具有高维特征的数据集,尝试在构建机器学习模型之前应用降维技术。继续学习!
Bala Priya C 是一位来自印度的开发者和技术写作专家。她喜欢在数学、编程、数据科学和内容创作的交集处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正在通过撰写教程、操作指南、观点文章等,与开发者社区分享她的知识。
更多相关主题
人工智能、数据科学、机器学习的即将到来的网络研讨会和在线活动:6 月
原文:
www.kdnuggets.com/2020/06/upcoming-webinars-online-events-june.html
无论你是否仍在保持社交距离,都可以利用时间高效地学习新知识,参与丰富的网络研讨会和在线活动!
以下是 6 月份一些更有趣的活动。
另见我们完整的 网络研讨会 和 在线活动 列表。

网络研讨会
| 时间 | 活动 |
|---|
| 6 月 4 日 上午 10 点 PT
东部时间下午 1 点
格林尼治标准时间下午 5 点
90 分钟 | 统计学讲解:揭开机器学习和人工智能的面纱,由 JMP 主办。加入我们的主题演讲和小组讨论,探讨机器学习和人工智能。你将获得关于如何开始使用 ML 技术或在现有程序中有效整合它们的指导和故事,以最大化你的数据价值并推动组织的发展 |
| 6 月 8 日 中午 12 点 PT
东部时间下午 3 点 | 提炼的数据点,由 Dataiku & Grid Dynamics 主办。|
| 6 月 10 日 上午 8 点 PT
东部时间上午 11 点
格林尼治标准时间下午 3 点 | 人工智能如何在数据驱动的世界中应用,由 Sphaeric 的创始人兼首席数据科学家 Paul Kostoff 主办。|
| 6 月 10 日 上午 10 点 PT
东部时间下午 1 点
格林尼治标准时间下午 5 点 | 利用 TensorFlow 进行分布式处理,谷歌 AI/ML 技术讲座系列第 #6 场。|
| 6 月 10 日 上午 11 点 PT
东部时间下午 2 点 | 利用高级分析进行 COVID-19 恢复规划,由 Grid Dynamics 和 Data Science Salon 主办。|
| 6 月 10 日 上午 11:30 PT
东部时间下午 2:30 | ETL 和高级机器学习 - 开源,无需编码,由 KNIME 主办。|
| 6 月 11 日 上午 10 点 PT
东部时间下午 1 点 | 降低深度学习部署成本而不牺牲性能,由 ODSC 主办。|
| 6 月 11 日 上午 11 点 PT
东部时间下午 2 点 | 如何利用替代数据理解 COVID 经济,由 Caserta 主办。|
| 6 月 11 日 上午 11 点 PT
东部时间下午 2 点
格林尼治标准时间下午 6 点 | 连接数据:真正的好莱坞爱情故事,由 Tamr 主办。|
| 6 月 16 日 上午 8 点 PT
上午 11 点 ET | 使用 RapidMiner Server 执行多节点 ETL 和 ML 任务,由 RapidMiner 主讲。 |
| 6 月 17 日 上午 10 点 PT
下午 1 点 ET
下午 5 点 GMT | 危机预测与管理的 AI,由 RE•WORK 主讲。 |
| 6 月 17 日 上午 10 点 PT
下午 1 点 ET | 利用数据湖管理技术释放数据的隐藏价值,由 ODSC 主讲。 |
| 6 月 18 日 上午 9 点 PT
中午 12 点 ET
下午 4 点 GMT | 深度学习方法在预测与规划中的应用,由 Metis 主讲。 |
| 6 月 18 日 上午 10 点 PT
下午 1 点 ET
下午 5 点 GMT | 利用自由文本数据构建更好的模型,由 JMP 主讲。 |
| 6 月 18 日 上午 11 点 PT
下午 2 点 ET | 云数据管理最佳实践,由 Caserta 主讲。 |
| 6 月 23 日 上午 8 点 PT
上午 11 点 ET | 使用 RapidMiner Real-Time Agent 进行低延迟/边缘/实时评分,由 RapidMiner 主讲。 |
| 6 月 24 日 上午 11 点 PT
下午 2 点 ET | 利用图像转换器在 Spark OCR 中最大化文本识别准确性,由 John Snow Labs 主讲。 |
| 6 月 30 日 上午 8 点 PT
上午 11 点 ET | 解决客户流失:一个电信案例,由 RapidMiner 主讲。 |
这是我们完整的网络研讨会列表
在线活动和虚拟会议
-
6 月 3-5 日,AnacondaCon,虚拟免费在线会议。
-
6 月 6-7 日,数据科学大会 - 虚拟,在线上由互联网之父 Dr. Vint Cerf 主讲。
-
6 月 8-9 日,EmTech Next,由 MIT Technology Review 主办的虚拟会议。在线。
-
6 月 8-11 日,ICWSM-2020: 第 14 届国际网络和社交媒体会议。在线。
-
6 月 8-10 日,CogX AI、区块链和突破性技术节。在线。
-
6 月 9-11 日,数据冠军在线 - 北欧。在线。
-
6 月 14-19 日,SIGMOD/PODS。虚拟会议
-
6 月 18 日,DSSelevate 提升数据领域女性,虚拟沙龙,在线。
-
6 月 16-18 日,数据冠军,在线 - 欧洲金融服务。在线。
-
6 月 16-18 日,数据冠军,在线 - 保险。在线。
-
6 月 18-19 日,联邦与分布式机器学习,虚拟会议。
-
6 月 18-19 日,第 8 届全球 AI 和神经网络峰会。线上进行。
-
6 月 20-21 日,国际机器学习与云计算会议(MLCL 2020)。阿联酋迪拜。在线进行。
-
6 月 22-26 日,Spark + AI 峰会。虚拟进行。
-
6 月 23-25 日,HPE Discover 2020。虚拟和按需观看。
-
6 月 23-25 日,数据冠军,在线 - 政府。在线进行。
-
6 月 24-26 日,数据与分析数字峰会,在线进行。
-
6 月 29 日 - 7 月 1 日,RuleML+RR 2020,第 4 届规则与推理国际会议。线上进行
这是我们完整的 在线和虚拟活动 列表。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关内容
如何更新 Python 字典

作者提供的图片
在 Python 中,字典是一个有用的内置数据结构,它允许你定义元素之间的键值对映射。你可以使用键来检索相应的值。你也可以随时更新字典中的一个或多个键。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
为此,你可以使用 for 循环或内置字典 update() 方法。在本指南中,你将学习这两种方法。
使用 For 循环更新 Python 字典
考虑以下字典 books:
books = {'Fluent Python':50,
'Learning Python':58}
在上面的字典中,书名(流行的 Python 编程书籍)是键,价格(美元)是值。请注意,books 字典是为本教程创建的,价格不对应实际价格。 😃
现在考虑另一个字典 more_books:
more_books = {'Effective Python':40,
'Think Python':29}
作者提供的图片
假设你想用 more_books 字典中的键值对更新 books 字典。你可以使用以下 for 循环来完成:
-
遍历
more_books字典的键并访问其值,并且 -
更新
books字典,将键值对添加到其中。
for book in more_books.keys():
books[book] = more_books[book]
print(books)
我们看到 books 字典已经更新,以包含 more_books 字典的内容。
{
"Fluent Python": 50,
"Learning Python": 58,
"Effective Python": 40,
"Think Python": 29,
}
你还可以在 more_books 字典上使用 items() 方法获取所有的键值对,遍历它们并更新 books 字典:
for book, price in more_books.items():
books[book] = price
print(books)
{
"Fluent Python": 50,
"Learning Python": 58,
"Effective Python": 40,
"Think Python": 29,
}
update() 方法的语法
使用 update() 字典方法的一般语法如下:
dict.update(iterable)
在这里:
-
dict是你想要更新的 Python 字典,并且 -
iterable指的是任何包含键值对的 Python 可迭代对象。这可以是另一个 Python 字典或其他可迭代对象,如列表和元组。列表或元组中的每一项应包含两个元素:一个用于键,一个用于值。
使用 update() 更新 Python 字典
现在让我们重新初始化 books 和 more_books 字典:
books = {'Fluent Python':50,
'Learning Python':58}
more_books = {'Effective Python':40,
'Think Python':29}
要更新 books 字典,你可以调用 update() 方法并传入 more_books,如下所示:
books.update(more_books)
print(books)
我们看到books字典已经更新,包含了more_books字典的内容。这个方法使你的代码保持可维护。
{
"Fluent Python": 50,
"Learning Python": 58,
"Effective Python": 40,
"Think Python": 29,
}
注意:
update()方法会原地更新原始字典。通常,使用dict1.update(dict2)会更新字典dict1(原地),而不会返回一个新的字典。因此,update()方法调用的返回类型是 None。
使用其他可迭代对象的内容更新 Python 字典
接下来,让我们看看如何用另一个非字典的可迭代对象中的元素来更新 Python 字典。我们有一个名为some_more_books的书籍及其价格列表,示例如下。在每个元组中,索引 0 处的元素表示键,索引 1 处的元素对应值。
some_more_books = [('Python Cookbook',33),('Python Crash Course',41)]

作者图片
你可以像之前一样在books字典上使用update()方法。
books.update(some_more_books)
print(books)
我们看到books字典已按预期更新。
{
"Fluent Python": 50,
"Learning Python": 58,
"Effective Python": 40,
"Think Python": 29,
"Python Cookbook": 33,
"Python Crash Course": 41,
}
在存在重复键的情况下更新字典
到目前为止,你已经用另一个字典和一个元组列表中的键值对更新了一个现有的 Python 字典。在我们考虑的例子中,这两个字典没有任何共同的键。
当有一个或多个重复的键时会发生什么? 字典中对应重复键的值将被覆盖。
让我们考虑and_some_more,这是一个包含键值对元组的列表。请注意,它包含了‘Fluent Python’,这一项已经存在于books字典中。
and_some_more = [('Fluent Python',45),('Python for Everybody',30)]

作者图片
当你现在对books字典调用update()方法并传入and_some_more时,你会看到键‘Fluent Python’对应的值现在已经更新为 45。
and_some_more = [('Fluent Python',45),('Python for Everybody',30)]
books.update(and_some_more)
print(books)
{
"Fluent Python": 45,
"Learning Python": 58,
"Effective Python": 40,
"Think Python": 29,
"Python Cookbook": 33,
"Python Crash Course": 41,
"Python for Everybody": 30,
}
结论
总结来说,Python 的字典方法update()可以用另一个字典或其他可迭代对象中的键值对来更新一个 Python 字典。该方法会修改原始字典,并且返回类型为 None。你也可以使用这个方法来合并两个 Python 字典。然而,如果你想要一个新的字典,包含两个字典的内容,则不能使用此方法。
Bala Priya C 是一位技术作家,喜欢创作长篇内容。她的兴趣领域包括数学、编程和数据科学。她通过撰写教程、操作指南等与开发者社区分享她的学习成果。
更多相关主题
机器学习技能 - 这个夏天更新你的技能
原文:
www.kdnuggets.com/2021/07/update-your-machine-learning-skills.html
评论

照片由 Nick Morrison 提供,来源于 Unsplash。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
你们中的许多人已经学习机器学习有一段时间了,也许是一年或两年。如果你现在评估自己,在机器学习的理论方面,即使是当初学习时非常清晰的内容,也可能因为未在实践中使用或过度依赖高级框架而遗忘了。
这两个月的课程适合那些已经在该领域工作了一段时间的人,帮助他们复习所有核心概念。
机器学习技能 第 1 周:数学基础
本周旨在确保你复习所有初学者掌握机器学习所需的核心数学概念。
第 1–3 天:线性代数
斯坦福大学提供了非常好的线性代数快速笔记,长达 30 页,专为复习而制,涵盖了所有重要的主题。你可以在这里找到它们。此外,如果你愿意,还可以观看笔记中主题的视频,但这些笔记足以帮助你复习概念。
第 3–6 天:概率和统计
概率和统计是机器学习的基础,这个由 Edureka 制作的简短视频可以帮助你快速复习概率和统计。除了这个视频,你还可以查看这些概率复习幻灯片以及这份斯坦福的 PDF 进行快速修订。
机器学习技能 第 2–3 周:机器学习和深度学习直觉
我将跟随斯坦福大学Andrew Ng教授(CS229 2018 年秋季学期)的最新讲解,深入了解机器学习算法背后的数学原理和工作机制。Andrew Ng 教授是斯坦福大学的兼职教授,但他还有很多其他活动,因此他最好被描述为“领先的人工智能研究员及 Deeplearning.ai、Coursera 及其他初创公司的创始人。”
对于深度学习算法,我将跟随Andrej Karpathy教授的 CS231n 课程,他在斯坦福大学完成了博士学位,并于 2016 年教授了著名的 CS231n 课程,这是一门最受欢迎的深度学习视觉系统课程之一。Andrej 现在是特斯拉的 AI 高级总监。
一些讲座也由Fei Fei Li教授讲授,她是斯坦福大学计算机科学系首任 Sequoia 教授及斯坦福人本人工智能研究所的共同主任。
第 1 天:线性回归
这是最常见的机器学习算法之一。Andrew Ng 讲解得很透彻,你可以在YouTube找到讲座视频,并在斯坦福大学的这里找到课程笔记。
第 2 天:逻辑回归
逻辑回归是最基础的分类算法,Andrew Ng 讲解得非常清晰,完整的讲座可以在 YouTube 上找到这里。逻辑回归的课程笔记在线性回归部分共享的 pdf 中。
第 3 天:朴素贝叶斯
朴素贝叶斯是一个著名的分类算法,完全基于概率背景。如果你没有学习过概率,这个算法会很难理解。幸运的是,Andrew Ng 在他最新的课程(2019 年)中讲解了这个算法,你可以在这里找到视频。这个算法没有出现在他的 Coursera 课程中。
你可以在这里找到课程笔记。
视频和笔记还讲解了 GDA,即高斯判别分析。
第 4–5 天:支持向量机
支持向量机(SVM)是初学者最难掌握的机器学习算法之一,尤其是在涉及到核函数时。Andrew Ng 有专门的视频讲解。
这将为你提供有关算法如何工作的良好数学直觉。
第 6 天:决策树与集成方法
决策树、随机森林以及其他集成方法如 XGBoost 都被广泛使用。CS229 讲解了决策树和集成方法,并以非常易于理解的方式解释了这些算法背后的数学原理。您可以在 这里 找到讲座视频。
第 7 天:无监督学习
无监督学习是机器学习的重要组成部分,并在许多应用中广泛使用。Andrew Ng 在这节讲座中讲解了无监督学习的重要算法,您可以在 这里 找到。
第 8 天:数据划分、模型和交叉验证
适当地划分数据集、选择正确的算法、拥有正确的交叉验证集都很重要。Andrew Ng 专注于这一重要方面,并在 this 视频中进行了讲解。
第 9 天:调试机器学习模型和误差分析
知道机器学习模型中存在什么问题以及如何改进这些问题既重要又困难。在 this 讲座中,Andrew Ng 详细讨论了这一点。
第 10 至 12 天:神经网络简介
神经网络是人工智能中一个非常重要且广泛使用的方面。3Blue1Brown 是一个非常著名的 YouTube 频道,拥有一个 短视频播放列表 ,可以帮助您了解神经网络的基础知识。
然后,为了更深入理解,您可以观看这 4 节讲座:
第 13 天:卷积神经网络
CNN 在工业界中非常重要且广泛使用。您在第四部分讲座中学到了其基础知识。在 this lecture 中,Andrej Karpathy 更深入地讲解了 CNN,并对其进行了精彩的阐述。
第 14 天:递归神经网络
RNN 是一种重要且广泛使用的深度学习算法,以其在序列和语言任务中的表现而闻名。在 this 讲座中,Andrej Karpathy 详细讲解了 RNN 和 LSTM,以及如何利用它们构建一些应用,例如图像标题生成。
机器学习技能第 4 周:计算机视觉理论
第 1 天:ConvNets 实践
这次讲座 涉及了使 ConvNets 非常强大的大多数细节,特别是在工业界。话题包括数据增强、迁移学习、卷积安排、瓶颈和分布式训练等。
第 2 天:定位和检测
目标定位和检测是一个非常酷且重要的特性,在多个应用中被广泛使用。Andrej Karpathy 在这次 讲座 中详细解释了它背后的数学原理。
第 3 天:在深度学习中处理视频和无监督学习
这次由 Andrej Karpathy 主讲的讲座将解释如何处理视频数据并使用无监督学习从中获得最大收益。
讲座链接:
第 4 天:分割和注意力
分割是计算机视觉中一个非常核心的任务。这次讲座深入探讨了两种不同的分割方法。注意力也是一个非常有名的任务,我们希望我们的模型关注图像中相关的特定部分。
讲座链接:
第 5 天:生成模型
能够生成新事物的模型真的很酷。现在,GANs 和 DeepFakes 非常有名。在这次讲座中,Fei-Fei Li 深入探讨了生成模型背后的数学和理论。
讲座链接:
你还可以观看 MIT 深度学习系列的讲座。
讲座链接:
第 6 天:使用 AI 创建 3D 内容
这次 MIT 讲座探讨了如何使用 AI 和深度学习创建 3D 内容。
讲座链接:
第 7 天:姿态估计
姿态估计是一个非常有名的任务,在多个应用中被广泛使用。目前关于它如何工作的优秀解释不多,但我尝试收集了一些资源,可以帮助你了解姿态估计的工作原理。
讲座链接:
博客:
机器学习技能第 5–6 周:实际计算机视觉
第 1 天:使用 TensorFlow/PyTorch 进行图像分类
-
数据集:iWildCam 2019
第 2–5 天:使用 TensorFlow 进行目标检测
教程:
实践数据集:
第 6–9 天:物体分割
教程:
实践数据集:
第 10–12 天:GANs
教程:
第 13–14 天:神经风格迁移
教程:
机器学习技能第 7 周:实用自然语言处理
第 1 天:情感分析
教程:
实践数据集:
第 2 天:文本生成
教程:
第 3 天:预训练词嵌入
教程:
第 4 天:使用 BERT 进行文本分类
教程:
第 5 天:文本翻译
教程:
第 6–7 天:模型部署
教程:
机器学习技能:第 8 周
结构化机器学习项目
本周是深度学习专业课程中的第 3 课,你将学习如何构建深度学习项目,最佳的执行方法和实践,如何改进模型,如何进行错误分析等等。
你可以在 YouTube 播放列表中找到它,这里,如果你想要证书,可以在 Coursera 上找到,这里。
相关:
更多相关内容
使用机器学习升级品牌移动应用
原文:
www.kdnuggets.com/2020/06/upgrading-brand-mobile-app-machine-learning.html
评论
由 Joanna Baretto 提供,来自 Tatvasoft Australia

版权:123rf.com
许多目前处理大量数据的品牌都认可机器学习的相关性。得益于机器学习技术,商业组织通常能够实时更高效地工作,获得竞争优势。
移动应用开发的技术进步以及数字化增强为品牌创造了吸引和留住客户的新机会。 然而,真正的个性化和定制之间仍然存在巨大差距。没有显著特点或充满烦人的弹出广告的移动应用,品牌无法激发目标受众的兴趣。
在弥补个性化差距方面,机器学习大显身手。认知技术应用开发使企业能够建立理解人类并帮助他们完成任务甚至娱乐他们的机器和算法。在全球范围内,机器学习使移动平台更具用户友好性,保持客户的忠诚度,提升客户体验,并帮助创建一致的全渠道体验。
机器学习重塑移动应用
1. 个性化体验: 机器学习可以实现持续学习过程。算法可以分析各种信息来源,从信用评级到社交媒体活动,并将推荐直接推送到客户设备上。用户可以根据兴趣进行区分,收集用户信息,并通过机器学习决定应用程序的外观。此外,机器学习是一个很好的工具来了解:
-
客户是谁
-
他们能够承担的费用
-
他们想要什么
-
客户用来谈论品牌产品的词汇
-
偏好、爱好及其痛点
根据收集的信息,机器学习帮助对客户进行分类和结构化,寻找对每个客户群体的个性化方法,并调整内容的语调。简而言之,机器学习帮助为用户提供最相关和吸引人的内容,并营造出应用程序确实在与客户交流的印象。
这些是一些示例:
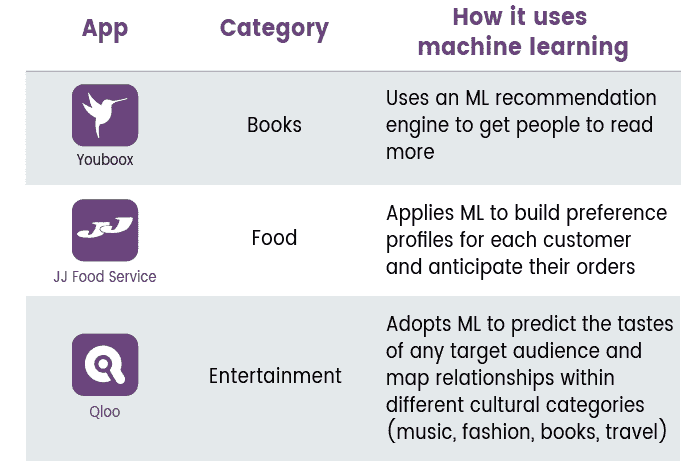
版权:Rubygarage.org
2. 用户行为预测: 机器学习应用帮助营销人员通过分析各种数据理解用户的偏好和行为模式:
-
年龄
-
性别
-
位置
-
搜索请求
-
应用使用频率
-
以及更多
为什么需要这些数据?这些数据至关重要,因为它可以用来保持不同客户群体对应用程序的兴趣,并提升效果和营销努力。机器学习还帮助建立个性化推荐,提升客户的参与度以及在应用程序上花费的时间。
一些机器学习应用的示例
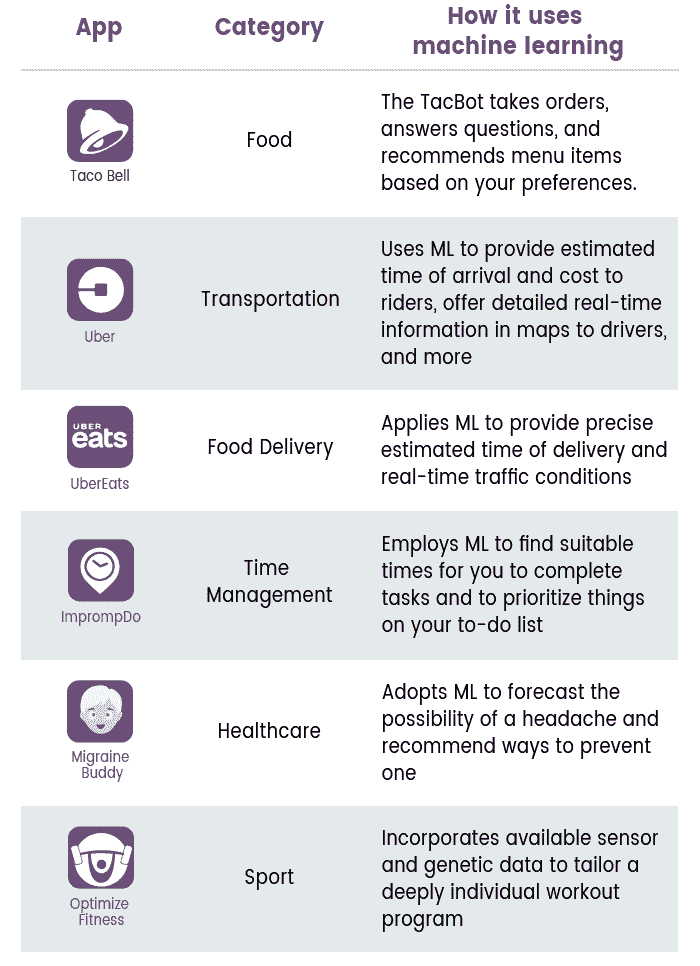
版权:Rubygarage.org
3. 高级搜索: 带有机器学习的解决方案允许优化应用程序中的搜索,提供更多更好的上下文结果。此外,它使客户的搜索更直观、少受阻碍。机器学习算法从客户查询中学习,并优先考虑对某个人真正重要的结果。
认知技术有助于将文章、脚本、DIY 视频、常见问题解答以及文档分类到知识图谱中,以提供即时回答和更智能的自助服务。现代应用程序允许你收集所有关于客户的数据,包括搜索历史和典型行为。这些数据可以与搜索请求和行为数据一起用于排名产品和服务,并展示最佳匹配结果。
4. 增强的安全性: 机器学习除了是一个有效的营销工具外,还能保护和简化应用程序身份验证。客户可以使用生物识别数据,如面部或指纹进行音频、视频和语音识别认证。此外,机器学习有助于确定客户的访问权限。
除了安全快捷的登录,更多的应用程序可用于机器学习。机器学习中的算法能够检测和禁止可疑活动。与只能抵御已知威胁的传统应用程序相比,机器学习系统能够实时保护客户免受未识别的恶意软件攻击。这项技术提供了令人印象深刻的功能,包括:
-
运输成本估算
-
图像识别
-
钱包管理
-
产品标记自动化
-
优化物流
-
商业智能
上述功能以及更多功能使品牌能够更有效地预测金融崩溃、未来趋势和泡沫。
5. 相关广告: 在广告领域,最困难的部分是向观众展示正确的广告。随着品牌继续争夺资金,通过个性化获胜已成定局。机器学习技术帮助更准确地定向展示广告和个性化消息,因为广告变得越来越个性化。
机器学习允许你预测特定客户对促销活动的反应,因此你只需向最有可能对展示的产品或服务感兴趣的客户展示某些广告,从而节省时间和金钱,并提升品牌声誉。
6. 深度用户参与: ML 工具 使品牌能够提供强大的客户支持、一系列受欢迎的功能以及提供激励的娱乐,使客户每天使用该应用程序。有些人对打电话、等待回应以及写冗长的电子邮件感到不安。智能友好的数字助手可能是客户支持的合适选择。
7. 提供娱乐: 除了可以在凌晨三点让客户开心并进行对话的健谈 AI 助手,还有更多的机器学习示例用于客户娱乐。应用的摄像头检测到客户的面部,定位面部特征,并添加滤镜。
摘要
机器学习技术可以赋能任何移动应用,提供前沿的搜索机制、高效的个性化引擎、欺诈保护以及安全快速的认证。
个人简介:Joanna Baretto 是 Tatvasoft Australia 的技术分析师,这是一家领先的移动应用开发公司。她在技术领域工作了五年,她在多个学科中的工作广泛涉及技术体验的叙事。你可以在 Twitter 上找到她, @BarettoJoanna。
相关:
-
学习和实践数据科学的前 9 款移动应用
-
12 小时机器学习挑战:使用 Streamlit 和 DevOps 工具构建和部署应用
-
每位数据科学家必备的前 10 款数据可视化工具
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关话题
使用 Tensorflow 的神经网络进行城市声音分类
原文:
www.kdnuggets.com/2016/09/urban-sound-classification-neural-networks-tensorflow.html
由 Aaqib Saeed,特温特大学。
我们每天都会接触到不同的声音,比如汽车喇叭声、警报声和音乐等。如何教计算机自动将这些声音分类到不同类别中呢!
在这篇博客文章中,我们将学习使用机器学习技术将城市声音分类到不同类别中。之前的博客文章涉及了分类问题,其中数据可以轻松地表示为向量形式。例如,在文本数据集中,语料库中的每个单词成为特征,tf-idf 分数成为其值。同样,在异常检测数据集中,我们看到两个特征“吞吐量”和“延迟”被输入到分类器中。但在声音数据中,特征提取并不像想象的那样简单。今天,我们将首先了解可以从声音数据中提取哪些特征,以及如何使用开源库Librosa在 Python 中轻松提取这些特征。
要开始这个教程,请确保你已经安装了以下工具:
-
Tensorflow
-
Librosa
-
Numpy
-
Matplotlib
数据集
我们需要一个标记的数据集,以便将其输入到机器学习算法中。幸运的是,一些研究人员发布了城市声音数据集。该数据集包含 8,732 个标记的声音片段(每个 4 秒),分为十个类别:空调、汽车喇叭、儿童玩耍、狗吠、钻孔、引擎怠速、枪声、电锯、警报声和街头音乐。数据集默认被分为 10 折。要获取数据集,请访问以下链接,如果你想在研究中使用该数据集,请不要忘记致谢。在此数据集中,声音文件为.wav格式,但如果你有其他格式的文件,如.mp3,建议将其转换为.wav格式。这是因为.mp3是一种有损的音乐压缩技术,更多信息请查看这个链接。为了简化问题,我们只使用来自一个折的数据。
让我们读取一些声音文件并进行可视化,以了解每个声音片段之间的差异。Matplotlib 的specgram方法执行所有所需的频谱计算和绘图。同样,Librosa 提供了方便的方法用于绘制波形和对数功率谱图。通过查看图 1、2 和 3 中的图示,我们可以看到不同类别的声音片段之间的明显差异。
图 1. 波形图。
图 2. 功率谱图。
图 3. 声音日志功率谱图。
我们的 3 个最佳课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
更多相关话题
不再需要使用 Docker
评论
由 Martin Heinz, IBM 的 DevOps 工程师
在容器的古老时代(实际上大约是 4 年前),Docker 是容器领域的唯一玩家。然而现在情况已不再如此,Docker 并不是 唯一 的容器引擎,而只是 另一个 容器引擎。Docker 允许我们构建、运行、拉取、推送或检查容器镜像,但对于每一项任务,还有其他替代工具,可能比 Docker 做得更好。所以,让我们深入了解一下这些工具,并且(也许)彻底卸载和忘记 Docker……

Nicole Chen 拍摄于 Unsplash
那么为什么不使用 Docker 呢?
如果你已经使用 Docker 很长时间,我认为需要一些说服才能让你考虑切换到不同的工具。所以,下面就是:
首先,Docker 是一个整体的工具。它试图做所有事情,这通常不是最好的方法。大多数情况下,选择一个只做一件事但做得非常好的专业工具更为理想。
如果你担心切换到不同的工具集,因为你需要学习使用不同的 CLI、不同的 API 或一般的不同概念,那也不会成为问题。选择本文中展示的任何工具都可以完全无缝过渡,因为它们(包括 Docker)都遵循 OCI 的相同规范。OCI 即 Open Container Initiative,该倡议包含了 容器运行时、容器分发 和 容器镜像 的规范,这涵盖了处理容器所需的所有功能。
感谢 OCI,你可以选择最适合自己需求的一套工具,同时你仍然可以使用与 Docker 相同的 API 和 CLI 命令。
如果你愿意尝试新的工具,那我们可以比较 Docker 及其竞争对手的优缺点和特点,看看是否有必要考虑抛弃 Docker 转而使用一些新的闪亮工具。
容器引擎
在比较 Docker 与任何其他工具时,我们需要分解它的组件,首先要谈的是容器引擎。容器引擎是一个提供用户界面以操作镜像和容器的工具,这样你就不必处理像SECCOMP规则或 SELinux 策略之类的事务。它的工作也是从远程仓库拉取镜像并将其展开到你的磁盘上。它还似乎运行容器,但实际上它的工作是创建容器清单和包含镜像层的目录。然后,它将这些传递给容器运行时,如runc或crun(我们稍后会讨论)。
现在有许多容器引擎可用,但与 Docker 竞争最突出的对手是Podman,由Red Hat开发。与 Docker 不同,Podman 不需要守护进程运行,也不需要 root 权限,这长期以来一直是 Docker 的一个问题。根据名称,Podman 不仅可以运行容器,还可以运行pods。如果你不熟悉 pods 的概念,那么 pod 是 Kubernetes 的最小计算单元。它由一个或多个容器组成——主要容器和所谓的sidecars——执行支持任务。这使得 Podman 用户更容易将工作负载迁移到 Kubernetes。所以,作为一个简单的演示,这就是如何在一个 pod 中运行 2 个容器:
最后,Podman 提供了与 Docker 完全相同的 CLI 命令,因此你可以直接使用alias docker=podman,假装什么都没有改变。
除了 Docker 和 Podman,还有其他容器引擎,但我认为它们都属于死胡同技术,或不适合本地开发和使用。但为了全面了解,我们至少提一下现有的选择:
-
LXD — LXD 是 LXC(Linux Containers)的容器管理器(守护进程)。这个工具提供运行系统容器的能力,这些容器提供的环境更类似于虚拟机。它处于一个非常狭窄的领域,没有很多用户,所以除非你有非常特定的用例,否则你可能还是使用 Docker 或 Podman 更好。
-
CRI-O — 当你搜索 cri-o 是什么时,你可能会发现它被描述为容器引擎。但它实际上是容器运行时。除了它实际上不是引擎外,它也不适合“正常”使用。我的意思是,它是专门为 Kubernetes 运行时 (CRI) 构建的,而不是供终端用户使用。
-
rkt — rkt (“rocket”) 是由CoreOS开发的容器引擎。提到这个项目只是为了完整性,因为该项目已结束,开发被暂停——因此不应使用它。
构建镜像
在容器引擎方面,实际上只有一个替代 Docker 的选择。然而,在构建镜像方面,我们有更多的选择。
首先,让我介绍一下 Buildah。Buildah 是 Red Hat 开发的另一种工具,它与 Podman 非常兼容。如果你已经安装了 Podman,你可能已经注意到 podman build 子命令,这实际上就是 Buildah 的伪装,因为它的二进制文件包含在 Podman 中。
就其功能而言,它遵循与 Podman 相同的路线——它是无守护进程和无根的,并且生成符合 OCI 标准的镜像,因此可以保证你的镜像会以与 Docker 构建的镜像相同的方式运行。它还能够从 Dockerfile 或更适合命名的 Containerfile 构建镜像,这两者本质上是相同的,只是名称不同。除此之外,Buildah 还提供了对镜像层的更精细控制,允许你将多个更改提交到单个层中。与 Docker 的一个意外但(在我看来)不错的区别是,Buildah 构建的镜像是特定于用户的,因此你只能列出你自己构建的镜像。
现在,考虑到 Buildah 已经包含在 Podman CLI 中,你可能会问为什么还要使用单独的 buildah CLI?实际上,buildah CLI 是 podman build 命令的超集,因此你可能不需要触及 buildah CLI,但通过使用它你可能会发现一些额外的有用功能(有关 podman build 和 buildah 之间差异的具体信息,请参见以下 文章)。
话虽如此,让我们来看一个小演示:
从上述脚本中你可以看到,你可以简单地使用 buildah bud 来构建镜像,其中 bud 代表 使用 Dockerfile 构建,但你也可以使用更具脚本化的方法,使用 Buildah 的 from、run 和 copy,这些命令与 Dockerfile 中的命令( FROM image、RUN ...、COPY ... )是等效的。
接下来是 Google 的 Kaniko。Kaniko 也从 Dockerfile 构建容器镜像,类似于 Buildah,它也不需要守护进程。与 Buildah 的主要区别是 Kaniko 更专注于在 Kubernetes 中构建镜像。
Kaniko 旨在作为一个镜像运行,使用 gcr.io/kaniko-project/executor,这对于 Kubernetes 是有意义的,但对本地构建不是很方便,实际上有点违背了目的,因为你需要使用 Docker 来运行 Kaniko 镜像以构建你的镜像。也就是说,如果你正在寻找在 Kubernetes 集群中构建镜像的工具(例如在 CI/CD 管道中),那么考虑到 Kaniko 是无守护进程的且(也许)更安全,它可能是一个不错的选择。
从我的个人经验来看——我使用过 Kaniko 和 Buildah 在 Kubernetes/OpenShift 集群中构建镜像,我认为这两者都能完成任务,但使用 Kaniko 时我遇到过一些随机的构建崩溃和推送镜像到注册表时的失败。
第三个竞争者是 buildkit,也可以称为下一代docker build。它是 Moby 项目(和 Docker 一样)的一部分,可以通过 DOCKER_BUILDKIT=1 docker build ... 将其作为实验性功能在 Docker 中启用。那么,这到底会带来什么呢?它引入了一系列改进和很酷的功能,包括并行构建步骤、跳过未使用的阶段、更好的增量构建和无根构建。然而,它仍然需要运行守护进程(buildkitd)。所以,如果你不想摆脱 Docker,但希望获得一些新功能和改进,使用 buildkit 可能是一个不错的选择。
与上一节一样,这里我们也有一些“值得一提”的工具,它们填补了一些非常特定的使用场景,但不会是我的首选:
-
Source-To-Image (S2I) 是一个直接从源代码构建镜像的工具包,无需 Dockerfile。这个工具在简单、预期的场景和工作流程中表现良好,但如果需要稍微多一些定制,或者项目的布局不符合预期,它很快就会变得麻烦和笨拙。如果你对 Docker 还不太自信,或者在 OpenShift 集群上构建镜像,考虑使用 S2I,因为 S2I 是一个内置的功能。
-
Jib 是 Google 另一个工具,专门用于构建 Java 镜像。它包括 Maven 和 Gradle 插件,可以让你轻松构建镜像,而无需处理 Dockerfile。
-
最后但同样重要的是 Bazel,这是 Google 另一个工具。它不仅仅用于构建容器镜像,而是一个完整的构建系统。如果你仅仅想构建一个镜像,那么深入研究 Bazel 可能有些过于复杂,但绝对是一个很好的学习经验,所以如果你愿意的话,rules_docker 部分是一个很好的起点。
容器运行时
最后一块大拼图是容器运行时,负责运行容器。容器运行时是整个容器生命周期/堆栈的一部分,你很可能不会去碰它,除非你有一些非常特定的速度、安全性等要求。所以,如果你已经厌倦了我,那么你可能想跳过这一部分。如果你只是想了解有哪些选项,那么接下来是:
runc是最流行的容器运行时,基于 OCI 容器运行时规范创建。它被 Docker(通过containerd)、Podman 和 CRI-O 使用,所以几乎涵盖了除 LXD(使用 LXC)以外的一切。我没什么其他可以补充的。它是(几乎)所有事物的默认运行时,所以即使你在读完这篇文章后放弃 Docker,你很可能仍然会使用 runc。
与runc类似且容易混淆的一个替代品是crun。这是由 Red Hat 开发的工具,完全用 C 语言编写(而 runc 是用 Go 语言编写的)。这使得它比 runc 更快且更节省内存。考虑到它也是 OCI 兼容的运行时,如果你想亲自检查一下,应该能轻松切换。尽管目前它还不太流行,但从 RHEL 8.3 版本起,它将作为 OCI 运行时的替代品进行技术预览,鉴于它是 Red Hat 的产品,我们最终可能会看到它成为 Podman 或 CRI-O 的默认运行时。
说到 CRI-O,之前我提到 CRI-O 实际上不是一个容器引擎,而是一个容器运行时。这是因为 CRI-O 不包括推送镜像等功能,而这是你从容器引擎中期望的。CRI-O 作为运行时内部使用 runc 来运行容器。这个运行时并不适合在你的机器上使用,因为它是为 Kubernetes 节点设计的运行时,你可以看到它被描述为“Kubernetes 所需的所有运行时功能而无其他”。所以,除非你在设置 Kubernetes 集群(或 OpenShift 集群——CRI-O 在这里已经是默认的),否则你可能不应该使用它。
这一部分的最后一个工具是containerd,它是 CNCF 的一个毕业项目。它是一个作为各种容器运行时和操作系统的 API 外观的守护进程。在后台,它依赖于 runc,并且是 Docker 引擎的默认运行时。它也被 Google Kubernetes Engine(GKE)和 IBM Kubernetes Service(IKS)使用。它是 Kubernetes 容器运行时接口(与 CRI-O 相同)的实现,因此它是你的 Kubernetes 集群的一个很好的运行时候选。
镜像检查和分发
容器栈的最后一部分是镜像检查和分发。这有效地替代了docker inspect,并且(可选地)增加了在远程注册表之间复制/镜像镜像的能力。
我将在这里提到的唯一可以完成这些任务的工具是Skopeo。它由 Red Hat 制作,是 Buildah、Podman 和 CRI-O 的配套工具。除了我们都熟悉的基本skopeo inspect,Skopeo 还能够使用skopeo copy来复制镜像,这使得你可以在远程注册表之间镜像镜像,而不需要首先将它们拉取到本地注册表。如果你使用本地注册表,这个功能也可以作为拉取/推送使用。
作为一个小小的奖励,我还想提到 。Dive,这是一个用于检查、探索和分析镜像的工具。它更具用户友好性,提供了更易读的输出,并可以深入挖掘(或潜入,我想)你的镜像,分析并测量其效率。它也适用于 CI 管道中,可以测量你的镜像是否“足够高效”,换句话说——是否浪费了过多空间。
结论
这篇文章并非旨在说服你完全放弃 Docker,而是展示了构建、运行、管理和分发容器及其镜像的整个领域和所有选项。包括 Docker 在内的每种工具都有其优缺点,重要的是评估哪一组工具最适合你的工作流程和用例,希望这篇文章能帮助你做到这一点。
资源
简介: 马丁·海因茨 是 IBM 的一名 DevOps 工程师。作为一名软件开发者,马丁对计算机安全、隐私和密码学充满热情,专注于云计算和无服务器计算,并时刻准备接受新的挑战。
原文。经许可转载。
相关:
-
Docker 镜像优化策略
-
自动化你 Python 项目的各个方面
-
让 Python 程序运行得更快
更多主题
我每天使用 ChatGPT(5 个月)。这里是一些能改变你生活的隐藏宝藏
原文:
www.kdnuggets.com/2023/07/used-chatgpt-every-day-5-months-hidden-gems-change-life.html

图片授权来自Shutterstock
随着 ChatGPT 的越来越受欢迎,许多人已经习惯了它的标准功能,并以各种方式使用 ChatGPT。然而,许多人没有意识到的是,这个 AI 除了写文本和代码之外,还有很多先进的功能。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 工作
ChatGPT 有许多可以应用于个人和职业生活的功能。
在这篇文章中,我将与你分享一些不那么为人知的 ChatGPT 非标准功能。通过探索这些隐藏的宝藏,你可以释放这个非凡 AI 的全部潜力,并将其用于你的利益。
所以,不再废话,让我们开始吧!
1. 总结视频、文章、论文和帖子
ChatGPT 的一个最佳特点是它在阅读在线内容时节省了我的时间。
过去,我不得不快速浏览大量无聊的科学文章以寻找某些信息,但现在 ChatGPT 可以在几秒钟内为我完成这项任务。而且,它甚至可以在不到一分钟的时间内将内容翻译成另一种语言。
下面是它的工作原理(注意你需要启用这些 ChatGPT 插件)
-
找到视频/文章/论文/帖子。
-
复制链接。
-
让 ChatGPT 为你总结一下。

我发现这个功能非常有帮助。我唯一发现的缺点是它无法读取 PDF 格式的科学论文。不过,当涉及到总结网站上的纯文本时,它做得很好。
注意:现在你可以通过新的 ChatGPT 插件“Ask Your PDF”总结 PDF 文件。更多信息, 请查看这篇文章。
2. 使用 ChatGPT 扫描和描述图像
我最近发现了一个对我非常有用的功能,觉得分享给你会很有价值——使用 ChatGPT 扫描图像。
这让我想起了学生时代,当时我在描述逻辑测试中的图像时很挣扎。那时我没有 ChatGPT,但现在我可以利用这个 AI 简化过去对我来说很具挑战性的任务。
这就是它的工作原理。
- 在互联网上找到你需要的图像。我将使用膝关节解剖图作为例子。
2. 在一个单独的浏览器标签中打开图像,确保该标签中仅显示图像。然后从浏览器的地址栏中复制 URL,如下截图所示。

作者的截图
3. 请 ChatGPT 为你描述图像。

作者的截图
享受 ChatGPT 提供的详细描述吧!
ChatGPT 还能够为各种类型的可视化图形提供描述。这是一个带有右上角图例的地图。
欧洲的预期寿命;2016 年
这是我从 ChatGPT 得到的描述。

作者的截图
但这还不是全部!ChatGPT 可以描述从艺术作品到科学图表的广泛内容。
注意:显然 ChatGPT(GPT-3.5)实际上并没有扫描图像,而是使用提供的链接中的关键字来描述图像。也就是说,你可以尝试使用 ChatGPT 插件 Link Reader,具体说明见 这篇文章。
我在工作中使用 ChatGPT 6 个月。如何将你的生产力提升 10 倍
3. 使用 ChatGPT 作为你的私人教师
我每天都使用这个功能,它真的改变了我的生活。它让我的生活变得更加轻松,节省了大量时间和金钱。
我把 ChatGPT 变成了我的语言导师。这是 ChatGPT如何帮助我学习外语的方式。
-
它检查我的语法
-
它将单词和短语翻译成不同的语言
-
它帮助我练习写作和口语技能,甚至提供实时反馈
但语言并不是 ChatGPT 唯一可以帮助你的领域。它还帮助我解决了数学等其他学科的问题。
当我在学校时,我在数学方面有困难,觉得很难理解。不幸的是,学校的老师没有以我能理解的方式解释问题,因此我进展缓慢。
然而,感谢 ChatGPT,我现在可以轻松理解任何数学话题。我可以要求 ChatGPT 提供逐步解决问题的指导,并且它还提供多种解决方案。

作者提供的截图
此外,我还可以让 ChatGPT 为我解决任务并解释如何得到正确答案。这真的很神奇,不是吗?
作者提供的截图
你可以在任何你感兴趣的学科中使用这个功能,解释都以易于理解的语言写成,任何人都可以跟上。
4. 向 ChatGPT 寻求建议
这个功能不会取代你的朋友或心理医生,但它可以帮助你找到问题的解决方案。
生活建议
早晨早起对我来说总是一个挑战,即使我早睡,所以我决定向 ChatGPT 寻求一些建议。
这是它给出的建议。

作者提供的截图
第 4 点和第 6 点对我特别有用。
你可以在生活的不同方面寻求建议。例如,你在工作中有一个态度傲慢且不礼貌的同事。在这种情况下,ChatGPT 给出的建议如下。

作者提供的截图
这类似于朋友会给你的建议。
当然,它不能替代全面的沟通、与情境相关的幽默或原创建议,但在需要快速决策或考虑多种解决方案时,它可能会很有用。
你提供的细节越多,你得到的回答就会越好。
健康建议
过去我必须在互联网上搜索来计算我的卡路里需求,或完全依赖营养师制定适合我需求的餐单;然而,现在 ChatGPT 可以帮助我,节省时间和金钱。
我让 ChatGPT 根据我的体重、身高、性别、身体活动和期望的体重减轻目标来计算我的卡路里需求。
提示:“计算我的卡路里需求。我是一个 24 岁的女孩,体重 55 公斤,身高 166 厘米,我每周锻炼 3 次,想要减轻 3 公斤。”

作者提供的截图
这个回答相当不错,因为我在大学期间和教授讨论时有过类似的想法。为了准确计算你的每日卡路里需求,需要考虑多个因素,如年龄、性别、体重、身高、活动水平和减重目标。
当然,为了获得尽可能准确的回答,在输入所需信息时提供尽可能多的信息是很重要的。
我还让 ChatGPT 成为我的营养师。
提示:“你能写一个每日缺少 500–1000 卡路里的菜单吗?”

作者提供的截图

作者提供的截图
我得到了适合我每日饮食的食物选择清单。你甚至可以要求一个整周或更长时间的菜单,并告诉 ChatGPT 你喜欢或不喜欢吃什么。这非常简单!

作者提供的截图
免责声明:你不能百分之百依赖 ChatGPT 的回答,所以请将其作为助手而非健康建议的替代品。本文仅供参考,不应视为健康建议。
Artificial Corner 的免费 ChatGPT 备忘单
我们为读者提供了免费的备忘单。加入我们拥有超过 20K 人的新闻通讯,获取免费的 ChatGPT 备忘单。
喜欢这个故事并想支持我成为作者?考虑注册 Medium。如果你通过我的链接注册,我会获得少量佣金,而你无需支付任何费用!你还将获得 Medium 上所有故事的完全访问权限。
戴安娜·多夫戈波尔 是 Medium.com 上人工智能、科学、生活和技术领域的顶级作者。
原文。经许可转载。
更多相关话题
有用的数据科学:特征哈希
原文:
www.kdnuggets.com/2016/01/useful-data-science-feature-hashing.html
评论
威尔·麦金尼斯。
在之前关于 分类编码 的文章中,我们探讨了将分类变量转换为数值特征的不同方法。 在这篇文章中,我们将探讨另一种方法:特征哈希。
特征哈希,或称哈希技巧,是将任意特征转化为稀疏二进制向量的方法。 它可以非常高效,因为只需一个独立的哈希函数,而无需预先构建可能类别的字典。
一个简单的实现方法是让用户选择所需的输出维度,只需将输入值哈希为一个数字,然后将其除以所需的输出维度并取余数 R。 这样,你可以将特征编码为一个零向量,其中在索引 R 的位置为一。
在伪代码中,来自维基百科的文章:
function hashing_vectorizer(features : array of string, N : integer): x := new vector[N] for f in features: h := hash(f) x[h mod N] += 1 return x
或在 Python 中,从 分类编码:
def hash_fn(x): tmp = [0for_inrange(N)] for val in x.values: tmp[hash(val)% N] += 1 return pd.Series(tmp, index=cols)
cols = ['col_%d'% d for d in range(N)] X = X.apply(hash_fn, axis=1)
这效果如何呢?好吧,上次我们用相同的模型运行了所有编码器并比较了得分。 一些编码每次略有不同(取决于初始序数变换如何进行),所以我们运行模型 100 次,并生成其得分的箱线图。 使用蘑菇数据集:

在这个图中,你可以看到一些有趣的东西。 首先,虽然在上篇文章中介绍的二进制编码在平均水平上表现良好,但运行到运行的方差相当高,这并不理想。 此外,你可以看到随着用于哈希编码器的组件数量增加,性能逐渐上升,但在 16 时饱和,因为这个数据集的类别数量不足以需要超过 16 个组件。
在下一篇文章中,我将介绍这些兼容 scikit-learn 的转换器,提供一些使用示例,并分享一些关于如何在高维分类数据上构建优质模型的经验法则,以避免内存溢出。
查看更新的存储库,尝试你自己的编码器,使用我的编码器,或在你自己的数据上尝试:
github.com/wdm0006/categorical_encoding
原文.
相关:
-
数据科学职位市场 – 现状如何
-
Michael Li,Data Incubator 谈数据驱动的招聘策略
-
数据科学的艺术:你需要的技能及如何获得它们
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
更多相关内容
使用人工智能识别塞伦盖蒂摄像陷阱图像中的野生动物
原文:
www.kdnuggets.com/2020/02/using-ai-identify-wildlife-images-serengeti.html
评论
作者: Marek Rogala 和 Jędrzej Świeżewski, PhD, Appsilon
生物多样性研究的机会...
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
摄像陷阱成像(自动拍摄野生动物物种)正成为生物多样性保护工作的黄金标准。它能够以空前的规模准确监测大片土地。然而,这些设备生成的数据量庞大,使得人工分析变得非常困难。随着机器学习和计算机视觉的最新进展,我们获得了解决这一问题的工具,并为生物多样性社区提供了利用由热量和运动触发的系统自动生成的知识潜力的能力。

相较于人类调查员,摄像陷阱虽然干扰较小,但仍然会引起注意
…对机器学习社区的挑战
我们最近参加了Hakuna-ma Data,这是由 DrivenData 与 微软地球人工智能 合作组织的比赛,要求参与者构建一个能够跨时间和地点良好泛化的野生动物检测算法。这次比赛与之前的版本不同,研究人员、数据科学家和开发者无法直接访问测试图像集,而是需要提交他们的模型,由活动组织者在 Microsoft Azure 上运行。来自全球的 811 名参与者使用来自 10 个季节的公开数据训练他们的模型,并最终将解决方案提交以在第 11 季的私人数据集上进行测试。
我们祝贺所有的竞争者和ValAn_picekl团队赢得了$12,000 的大奖。我们也很自豪地宣布,我们在最终排名中获得了第五名,并且我们希望分享我们如何实现这一成就。
你可以在准备就绪的 Google Colab 笔记本中体验我们的最终模型,点击这里。
我们的方法
比赛涉及处理大量图像,因此使用一个快速的神经网络框架和强大的 GPU 是必须的。我们从 Google Cloud Platform 中提供了配备足够强大 GPU 的虚拟机(从 Tesla K80 到 Tesla V100,用于最繁重的计算)。通常,我们会并行运行几台机器以加快实验进程。我们使用 Python 代码,协调 GitHub 存储库中的关键代码部分,并使用笔记本快速实验和视觉检查模型的性能。我们在 Fast.ai 中构建了模型(以 PyTorch 为后端),并使用了与Weights & Biases的集成来跟踪我们的实验。
基于之前对数据集的研究,我们决定使用 ResNet 50,这是一个相对中等深度的架构。由于我们在比赛结束前不久才加入,因此选择不尝试其他(或更深)的架构,并在看到这个架构的初步结果令人满意后,决定专注于改进它。
由于时间有限,我们不得不优化我们的策略。我们采用了敏捷方法:迅速创建了我们的基线“ MVP”(最小可行产品)解决方案,然后根据结果进行大量迭代。最初,提交每五天仅允许一次,这给了我们一种自然的冲刺节奏。
数据集本身非常具有挑战性:660 万张照片,分辨率相对较高——数据量达到几 TB。我们使用了一个参与者提供的数据集版本,其中照片的分辨率已经显著缩小(每边缩小了 4 倍)。

数据集非常不平衡——大约 75%的图像为空。最常见的动物是角马、斑马和汤姆森的瞪羚。在光谱的另一端,有像 steenbok 或蝙蝠这样的超稀有动物,仅在少数几张照片中可见。

在自然界中也极为稀有——犀牛是数据集中最不常见的物种之一
有效的前 5 个因素
我们认为以下 5 个关键因素对我们模型的成功贡献最大:
1. 大规模验证集
这对确保模型良好泛化至关重要,因为我们在最后一个赛季——一个私有的、未见过的数据集上进行了评估。每个赛季都来自不同的年份。我们决定将整个赛季(第 8 赛季)留作验证集——我们希望它包含许多图像(近百万张!),且相对较新——因为测试集由尚未公布的第 11 赛季组成。这个选择也得到了对不同物种在赛季间分布的研究支持。我们注意到只有最后三个赛季(第 8、第 9 和第 10 赛季)包含了一些相对稀有物种的照片。
2. 使用逐渐增长的分辨率进行训练
我们将训练过程分为三个阶段。每个阶段都有一部分是仅训练网络的最终层,随后训练所有层。在每个阶段,我们在分辨率逐渐提高的图像上训练模型,使我们可以更长时间地训练而不会过拟合。我们使用的最大分辨率是 512×384,这仍然是提供的每个维度的四分之一。
最终模型在以下阶段进行训练:
-
在 128×96 像素图像上对网络最终层进行 5 个周期的训练
-
在 128×96 像素图像上对所有层进行 5 个周期的训练
-
在 256×192 像素图像上对网络最终层进行 5 个周期的训练
-
在 256×192 像素图像上对所有层进行 5 个周期的训练
-
在 512×384 像素图像上对网络最终层进行 5 个周期的训练
-
在 512×384 像素图像上对所有层进行 5 个周期的训练
这种方法显著加快了我们的训练速度——即使是操作在 128×96 图像上的模型也达到了良好的准确性,而且我们可以比 512×384 模型更快地训练它。此时我们要特别感谢 Pavel Pleskov,这位竞赛参与者以健康竞争的精神,与社区分享了一个缩小版的数据集,节省了我们的下载时间,并允许更多参与者加入。
3. 数据增强 / 一周期拟合
我们在训练过程中使用了标准的图像增强(水平翻转、小旋转、小缩放、小变形和光照调整),以防止模型在像素级别上过拟合并帮助其泛化。我们使用了Leslie Smith 的一个周期策略来加速训练。
4. 激进的欠采样
我们从训练集中去除了大部分最常见的类别(例如,95%的空照片),以在训练中更多地关注来自较少见类别的示例。这使得我们可以显著加快训练速度,帮助模型集中于输入空间的挑战性部分。这里的一个警告是需要以智能的方式去除这些示例——保留包含多个动物的示例,因为这些对模型来说更难处理。

一张图片中的多只动物——对 ML 模型的挑战
5. 损失检查 / 后处理
帮助我们将准确率提升到前列的是深入分析数据和初始模型的结果。我们想要查看哪些图像被误判了,以及在我们预测的置信度范围内发生了什么。为了最小化损失并优化我们的提交结果,我们研究了各个类别并检查了我们最容易出错的地方。
在这个阶段,我们选择从序列中的所有图像中整合简单的推断机制,而不仅仅是单张图像。我们取每个序列中第一张图像的预测(同样根据在验证集上的结果),除非在序列中后来的某张照片中,某个物种的最大预测值更高且超过了某个阈值(这样,我们允许例如“otherbird”类别的鸟在序列后续帧中出现时影响预测)。对于“空”的类别也是类似的,我们取序列中第一张照片的预测值,除非在后来的照片中,该类别的预测值低于某个阈值(这样,如果动物只在之后出现,"空"的预测值就会适当地降低)。
接下来,我们对每个高频出现的物种的预测值范围进行了处理,并进行网格搜索以找到最小化验证集上损失的基本线性变换。这大大提高了分数——很可能是通过使模型返回的概率更好地反映数据集中物种的分布。
回顾过去——我们希望做的事情
我们还有一些其他的想法很想尝试,但由于我们在比赛结束前仅有 3 周时间才加入,所以没有尝试。最值得注意的是:
焦点损失
当前的数据集高度不平衡。相比于我们实现的激进下采样方法(见上文),一种替代方案是使用修改后的损失函数,即焦点损失。虽然焦点损失最初是在物体检测的背景下提出的,但最近也在不平衡分类问题中得到了应用。
更多的训练时间,更多的训练轮次
各种迹象表明,我们的模型可能只是需要更长时间的训练来获得更好的分数。虽然我们对过拟合保持谨慎,但如果有更多的时间,我们希望探索在各个阶段更长时间的训练(见上文)。
使用两阶段的方法:动物位置检测和动物分类
我们考虑过使用两阶段的方法,第一阶段的模型关注动物的存在而不考虑其种类,第二阶段的模型则专注于物种分类。这种方法可能会提高准确性,之前的研究也提出过这种建议。由于时间有限,我们选择不尝试这种方法。
比赛后,我们了解到 Microsoft AI for Earth 的 Siyu Yang 和 Dan Morris 在这一领域的伟大工作。他们建立了一种动物检测模型。它识别照片中的动物存在,为正面预测提供边界框。该模型的优势在于它基于来自多个地理位置的数据进行训练。
他们建议了一种非常有趣的方法:使用一个通用模型来检测动物的位置,以及一个项目和位置特定的模型来进行物种分类。一个明显的优点是,第二个模型可以精确关注动物,这显然有可能提高准确性。这种方法在识别图像中的多只动物时也能大有帮助。
数据清洗
在调查我们模型的性能时,我们注意到许多标签错误的例子(例如,图像序列中只看到一条斑马的腿——被标记为空白,但我们的模型以很高的确定性将其分类为斑马)。还有许多在夜间拍摄的图像,人类标注者未发现任何动物,而模型却非常确信看到它们。手动调整这些图像的颜色水平后,黑暗确实揭示了被检测到的动物。这一事实涉及一个非常重要的话题:我们是否应该构建模型来复制标注者的工作(这是比赛规则提倡的方法),还是应关注尽可能好地检测图像中的动物。
我们为何加入以及这对我们的意义
比赛让我们深入了解了野生动物图像分类的世界。我们对结果非常满意,并且在这些模型的工作中获得了很多乐趣。我们能够展示和完善我们的计算机视觉技能,这对于我们的AI for Good计划至关重要。我们目前正在为加蓬国家公园管理局构建野生动物图像分类器的试点版本,并将应用我们的新知识。请关注有关我们即将开展的项目的更多信息。我们决心展示人工智能如何对我们共同的生活和世界产生切实的积极影响。
关注 Appsilon 数据科学的社交媒体
-
在 Twitter 上关注 @Appsilon
-
关注 Appsilon 的LinkedIn
-
注册我们的公司通讯
-
尝试我们的 R Shiny开源包
-
注册 AI for Good通讯
-
我们正在招聘软件工程师
原文。经许可转载。
相关:
-
创建你自己的计算机视觉沙盒
-
从 NeurIPS 2019 中窥探现代 AI 的全貌
-
我们日常生活中的 AI 和机器学习
更多相关内容
利用大数据分析以“少数派报告”方式预防犯罪
原文:
www.kdnuggets.com/2016/04/using-big-data-analytics-prevent-crimes-minority-report-way.html
评论
作者:Thomas Maydon, Principa 的信贷解决方案负责人。

自从我们在《少数派报告》中看到犯罪预防的未来已经快 15 年了——但今天,我们开始看到那些曾经虚构但极具幻想性的犯罪预测和预防方法在世界各地得到实施。下面我将简要提到三个例子,说明分析方法如何已被用于预防犯罪,然后详细讨论第四个例子:利用分析方法防止罪犯再次犯罪。
1. PrePol:识别犯罪“热点”
在洛杉矶和英国,“预测性警务”(“PrePol”)已经部署了二十多年。它在这段时间里当然已经演变了。如今 PrePol 利用算法识别犯罪“热点”。结果非常积极。在双盲试验中,它们的效果是传统预防方法的两倍。
2. 智能电网基础设施:识别和预测电力盗窃
在南非,关于采用“智能电网”和“智能电表”的讨论不断,这将使我们的电力公共事业公司 Eskom 和各市政当局能够预测电缆盗窃并识别非法连接。在美国,电力盗窃被视为第三大盗窃形式,引入计量数据管理和“智能电网基础设施”意味着每一秒钟都会生成大量数据,准备进行分析——一个真正的大数据问题。这种“智能电网基础设施”也被用于水务公司以防止水盗窃。
3. 中国的大数据监控达到机器人警察情景
最近,彭博社报道了中国政府通过大数据监控来帮助预防犯罪的努力,在数据隐私法律有限的国家中。在政府的指示下,该国最大的国有防务承包商正在建立一个分析软件平台,能够交叉引用来自银行账户、工作、爱好、消费模式和监控摄像头的视频信息,以识别潜在的恐怖分子。截至今年 1 月 1 日,中国当局已获得对银行账户、电信以及一个被称为“天网”的国家监控摄像头网络的访问权限。想象一个世界,警察佩戴增强现实眼镜能够识别出人群中的每个人。

在识别个人之后,从他们的医疗记录、社交媒体活动、人口统计数据和警方记录中提取信息,并通过算法进行处理。由此识别出潜在犯罪嫌疑人,警方可以采取或计划行动。这种“机器人警察”类型的场景在中国不再遥远。
4. 预测重新犯罪的机器学习
本月,《实证法律研究杂志》发表了一篇论文,详细介绍了一项大规模研究,探讨了机器学习是否可以有效地辅助法官在家庭暴力初审/保释听证会上作出决定,即是否应当批准被捕者保释。
研究
在这项研究中,对 2007-2011 年期间的 28,000 个家庭暴力初审听证会进行了评估(观察期)。然后评估了这 28,000 名个人在接下来的两年内是否重新犯罪(结果期)。机器分析了包括前科、指控以及年龄和性别等人口统计数据在内的 35 多个特征。使用随机森林(一种统计技术)来评估重新犯罪的可能性。

即使使用的数据字段相对较少,结果仍然令人印象深刻。通常,法院会批准大多数人的保释,而 20%的人在接下来的 24 个月内被发现重新犯罪。分析显示,模型本可以更好地选择,仅有 10%的人重新犯罪。
社会影响
在这些问题上,能够预测再次犯罪的概率固然很好,但模型并不完美,错误可能产生重大的社会后果。在这里,法院需要评估假阳性的影响:将某人识别为可能的重犯(尽管他们不是)并拒绝保释,这可能导致他们失去工作并可能失去住房,而被拘留。假阴性——在保释后再次犯罪,而模型预测则相反——也是值得关注的。尽管模型复杂,但它们可能无法考虑到法官所拥有的所有微妙信息。
然而,支持者表示,无论是否使用模型,错误都会发生,如果模型比单独的人为干预表现更好,它不应被忽视。
这类似于也可以使用机器学习运行的信用卡交易欺诈模型。假阳性可能导致信用卡被冻结,这会给信用卡持有人带来不便,并增加客户服务电话的数量。银行需要确定其接受可疑交易的阈值。
结论
分析,特别是机器学习,正在证明它们不仅在工业和商业领域具有广泛应用,而且在犯罪预防和法院系统中也具有潜在价值。对犯罪的打击和管理在经验上仍处于起步阶段。这项研究只是许多正在进行的研究之一。
图片来源: 二十世纪福克斯(“少数派报告”图片),猎户座影业公司(“机器人警察”和“终结者”图片)

*个人简介: Thomas Maydon 是 Principa 的信用解决方案主管,拥有超过 13 年的南非、西非和中东零售信贷市场经验。他在信贷生命周期的所有方面(包括智能前景开发、行为建模、定价分析、催收流程和准备金(包括巴塞尔协议 II)及盈利能力计算)具有丰富经验。
相关:
-
《少数派报告》可视化 – 芝加哥警察分析
-
白宫将数据视为 21 世纪有效警务的催化剂
-
大数据、隐私和安全 – 你站在哪一边?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
相关话题
使用 ChatGPT 帮助获得数据科学工作
原文:
www.kdnuggets.com/using-chatgpt-to-help-land-a-data-science-job

数据科学工作是一个竞争激烈的领域,成千上万的人争夺一个职位,尤其是初级职位。每个发布的数据科学职位通常都会被大量申请者围住。即使是在宣布实习职位时,也会有很多申请者。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织中的 IT 事务
由于竞争激烈,我们需要从其他人中脱颖而出。到底如何在大量申请者中脱颖而出?有很多方法,比如拥有一份出色的简历、一个优秀的作品集,或者一次精彩的面试。很难做到我提到的所有这些,但现在我们可以依赖 ChatGPT。
ChatGPT 如何帮助我们获得数据科学工作?让我们来探讨一下。
作为附注,我会使用 ChatGPT Plus 来处理这篇文章。你仍然可以跟随这篇文章,但有些事情你可能无法复制。
创建简历
简历是任何求职者的重要工具,它总结了雇主需要了解的关于你的所有专业信息。有了简历,你就能在求职过程中走得更远。许多人在为数据科学家创建合适的简历时需要帮助。因此,我们会请 ChatGPT 来帮助我们创建它们。
例如,我曾请求 ChatGPT 为我创建简历,模型要求提供你的信息以便填写。

此外,我们还可以使用 ChatGPT 改进简历中的语言,使其更具吸引力。例如,以下是 ChatGPT 可能会给出的建议,以扩展你的经验。

如果你使用 ChatGPT Plus,可以利用高级数据分析功能,根据你提供的信息创建模板。

此外,你还可以请 ChatGPT 提供提高获得数据科学工作机会的建议。

利用所有提供的模板和建议,ChatGPT 将有助于提高你获得数据科学工作的机会。
技能提升与作品集准备
ChatGPT 通过识别必备技能并提供提升资源,帮助用户提高获得数据科学工作的机会。我们也可以提供职位链接或描述给 ChatGPT,并要求模型分析如何获得该职位。
例如,我让 ChatGPT 识别数据科学工作所需的技能。

我们获得了一份获取数据科学工作所需的技能完整列表。有了这个列表,我们可以请 ChatGPT 提供这些技能的参考资料。以下是我询问 ChatGPT 的示例提示。

最后,ChatGPT 可以作为你的个人数据科学导师,根据你的表现给出反馈。我在之前的文章中详细介绍了这一点,这里。以下是 ChatGPT 如何作为你的导师的解释示例。

你已经学会了技能,但如果不将其展示为作品集,一切都无所谓。这就是为什么我们可以请 ChatGPT 指导我们建立数据科学作品集。例如,我询问 ChatGPT 如何设置我的客户细分项目作品集。

步骤较多,但如果我们在理解过程中遇到问题,可以向 ChatGPT 寻求进一步的详细信息。
职位信息搜索
我们可以优化地指导 ChatGPT 查找职位信息。在网页浏览和插件的帮助下,我们可以将 ChatGPT 转变为一个职位搜索引擎。例如,我像下面的图片一样设置了职位搜索和想要的职位搜索插件。
然后我请 ChatGPT 帮我找了一份在印度尼西亚的初级数据科学家职位。结果如下面的图片所示。

ChatGPT 然后会提供可用职位的链接,并展示角色的基本描述。你可以调整提示,以查看职位列表是否适合你的情况。
面试准备
ChatGPT 可以通过提供面试过程中常见的问题及其回答方式来帮助你准备面试。此外,我们还可以请求建议,了解面试时应该如何表现。例如,我们可以请 ChatGPT 提供下图中的问题。

有了常见问题的列表,我们可以独立回答这些问题,也可以请 ChatGPT 帮助我们回答。例如,ChatGPT 将解释上述问题中的一个。

我们还可以使用 ChatGPT 提供的建议来指导我们如何进行面试。例如,我请 ChatGPT 指导我如何准备我的数据科学面试。

ChatGPT 会给出可操作的建议,告诉我们应该做什么,并提供相应的处理方式。
结论
数据科学是一个竞争激烈的领域,基本上每个职位都有成千上万的申请者。为了从其他申请者中脱颖而出,我们需要具有创新性。这就是为什么我们可以使用 ChatGPT 来帮助我们获得优势。通过使用 ChatGPT,我们可以拥有更好的简历、提升我们的技能、准备我们的作品集、找到职位列表,并进行面试练习。凭借这些用途,ChatGPT 无疑会帮助你获得数据科学职位。
Cornellius Yudha Wijaya** 是一名数据科学助理经理和数据撰写者。他在 Allianz Indonesia 全职工作,同时通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 写作内容涉及各种人工智能和机器学习主题。**
更多相关信息
使用聚类分析对数据进行分段
原文:
www.kdnuggets.com/using-cluster-analysis-to-segment-your-data

图片来源:Pexels
机器学习(简称 ML)不仅仅是关于预测。还有其他无监督的过程,其中聚类尤为突出。本文介绍了聚类和聚类分析,突出展示了聚类分析在分段、分析和从相似数据组中获取洞察的潜力。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 在 IT 方面支持你的组织
什么是聚类?
简单来说,聚类是将相似的数据项组合在一起的同义词。这就像是在超市里将相似的水果和蔬菜放在一起。
让我们进一步阐述这个概念:聚类是一种无监督学习任务:这是机器学习方法的一个广泛类别,其中数据被假定为事先未标记或未分类的,目标是发现数据中潜在的模式或洞察。具体而言,聚类的目的是发现具有相似特征或属性的数据观察组。
这是聚类在机器学习技术谱系中的定位:
为了更好地理解聚类的概念,可以考虑在超市中寻找具有相似购物行为的顾客群体,或者在电子商务平台上将大量产品分成类别或相似项。这些都是涉及聚类过程的现实世界场景的常见示例。
常见的聚类技术
存在各种数据聚类方法。三种最受欢迎的方法类别是:
-
迭代聚类:这些算法反复将(有时重新分配)数据点分配到各自的簇中,直到它们收敛到一个“足够好”的解决方案。最受欢迎的迭代聚类算法是k 均值,它通过将数据点分配给由代表点(簇质心)定义的簇,并逐步更新这些质心,直到达到收敛。
-
层次聚类:顾名思义,这些算法使用自上而下的方法(将数据点集合拆分直到得到所需数量的子组)或自下而上的方法(逐渐将相似的数据点像气泡一样合并成越来越大的组)构建一个基于树状结构的层次体系。AHC(Agglomerative Hierarchical Clustering,聚合层次聚类)是自下而上的层次聚类算法的一个常见示例。
-
基于密度的聚类:这些方法识别数据点的高密度区域以形成簇。DBSCAN(Density-Based Spatial Clustering of Applications with Noise,基于密度的空间聚类算法)是这一类别下的一个流行算法。
聚类和簇分析是一样的吗?
此时的关键问题可能是:聚类和簇分析是否指的是相同的概念?
毫无疑问,两者关系密切,但它们并不相同,并且之间存在细微的差别。
-
聚类是将相似数据分组的过程,使得同一组或簇中的任何两个对象彼此之间比不同组中的两个对象更为相似。
-
同时,簇分析是一个更广泛的术语,它不仅包括数据的分组(聚类)过程,还包括在特定领域背景下对获得的簇进行分析、评估和解释。
以下图示说明了这两个常被混淆的术语之间的区别和关系。
实际示例
从现在开始,让我们专注于簇分析,通过一个实际的示例来说明:
-
对数据集进行分段。
-
分析获得的簇
注意:本示例中的附带代码假定对 Python 语言及其库(如用于训练聚类模型的 sklearn、用于数据处理的 pandas 和用于数据可视化的 matplotlib)有一定的基础知识。
我们将以Palmer Archipelago Penguins数据集为例说明簇分析,该数据集包含有关企鹅标本的观察数据,并将这些标本分类为三种不同的物种:Adelie、Gentoo 和 Chinstrap。该数据集在训练分类模型时非常受欢迎,但在寻找数据簇方面也有很多意义。加载数据集文件后,我们只需假设“物种”类属性是未知的。
import pandas as pd
penguins = pd.read_csv('penguins_size.csv').dropna()
X = penguins.drop('species', axis=1)
我们还将从数据集中删除两个描述企鹅性别和观察到该标本的岛屿的分类特征,保留其余的数值特征。我们还将已知标签(物种)存储在一个单独的变量y中:稍后它们将方便我们将获得的簇与数据集中实际的企鹅分类进行比较。
X = X.drop(['island', 'sex'], axis=1)
y = penguins.species.astype("category").cat.codes
通过以下几行代码,可以应用sklearn库中可用的 K-means 聚类算法,来找到数据中的若干个簇。我们只需要指定要找到的簇的数量,在这个例子中,我们将数据分成 k=3 个簇:
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3, n_init=100)
X["cluster"] = kmeans.fit_predict(X)
上述代码的最后一行将聚类结果,即分配给每个数据实例的簇的 ID,存储在一个名为“cluster”的新属性中。
现在是时候生成一些簇的可视化图来进行分析和解释了!以下代码片段稍长,但归结起来就是生成两个数据可视化图:第一个图展示了围绕两个数据特征——嘴喙长度和翅膀长度——的散点图,以及每个观测值所属的簇,第二个可视化图展示了每个数据点所属的实际企鹅物种。
plt.figure (figsize=(12, 4.5))
# Visualize the clusters obtained for two of the data attributes: culmen length and flipper length
plt.subplot(121)
plt.plot(X[X["cluster"]==0]["culmen_length_mm"],
X[X["cluster"]==0]["flipper_length_mm"], "mo", label="First cluster")
plt.plot(X[X["cluster"]==1]["culmen_length_mm"],
X[X["cluster"]==1]["flipper_length_mm"], "ro", label="Second cluster")
plt.plot(X[X["cluster"]==2]["culmen_length_mm"],
X[X["cluster"]==2]["flipper_length_mm"], "go", label="Third cluster")
plt.plot(kmeans.cluster_centers_[:,0], kmeans.cluster_centers_[:,2], "kD", label="Cluster centroid")
plt.xlabel("Culmen length (mm)", fontsize=14)
plt.ylabel("Flipper length (mm)", fontsize=14)
plt.legend(fontsize=10)
# Compare against the actual ground-truth class labels (real penguin species)
plt.subplot(122)
plt.plot(X[y==0]["culmen_length_mm"], X[y==0]["flipper_length_mm"], "mo", label="Adelie")
plt.plot(X[y==1]["culmen_length_mm"], X[y==1]["flipper_length_mm"], "ro", label="Chinstrap")
plt.plot(X[y==2]["culmen_length_mm"], X[y==2]["flipper_length_mm"], "go", label="Gentoo")
plt.xlabel("Culmen length (mm)", fontsize=14)
plt.ylabel("Flipper length (mm)", fontsize=14)
plt.legend(fontsize=12)
plt.show
这里是可视化图:
通过观察这些簇,我们可以提取出初步的见解:
- 在不同簇之间的数据点(企鹅)之间存在微妙但不太明显的分隔,并且发现一些子组之间有轻微的重叠。这并不一定让我们得出聚类结果好坏的结论:我们在数据集的多个属性上应用了 k-means 算法,但该可视化图仅显示了两个属性:'嘴喙长度'和'翅膀长度'下的数据点在簇中的位置。可能还有其他属性对,簇在视觉上表现得更加明显分开。
这引出了一个问题:如果我们尝试在训练模型时使用的其他两个变量下可视化我们的簇,会怎样?
让我们尝试可视化企鹅的体重(克)和嘴喙长度(毫米)。
plt.plot(X[X["cluster"]==0]["body_mass_g"],
X[X["cluster"]==0]["culmen_length_mm"], "mo", label="First cluster")
plt.plot(X[X["cluster"]==1]["body_mass_g"],
X[X["cluster"]==1]["culmen_length_mm"], "ro", label="Second cluster")
plt.plot(X[X["cluster"]==2]["body_mass_g"],
X[X["cluster"]==2]["culmen_length_mm"], "go", label="Third cluster")
plt.plot(kmeans.cluster_centers_[:,3], kmeans.cluster_centers_[:,0], "kD", label="Cluster centroid")
plt.xlabel("Body mass (g)", fontsize=14)
plt.ylabel("Culmen length (mm)", fontsize=14)
plt.legend(fontsize=10)
plt.show
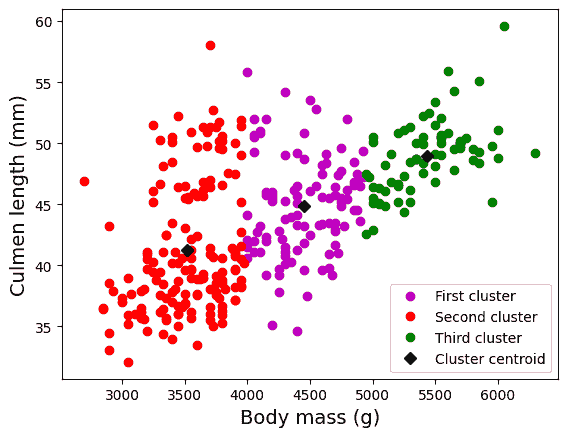
这个图看起来非常清晰!现在我们将数据分为三个可区分的组。通过进一步分析我们的可视化图,我们可以从中提取出额外的见解:
-
在发现的簇与'体重'和'嘴喙长度'属性值之间存在强烈的关系。从图的左下角到右上角,第一个组的企鹅因其较低的'体重'值而较小,但它们的嘴喙长度差异很大。第二组的企鹅体型中等,'嘴喙长度'值也在中等到较高范围。最后,第三组的企鹅则以体型较大和较长的嘴喙为特征。
-
还可以观察到,有一些异常值,即具有远离大多数的非典型值的数据观测点。这在可视化区域的最上方的点上尤其明显,表明一些观察到的企鹅在所有三个组中都有过长的嘴喙。
总结
这篇文章阐述了聚类分析的概念和实际应用,聚类分析是寻找数据中具有相似特征或属性的元素子组,并分析这些子组以提取有价值或可操作的见解的过程。从市场营销到电子商务再到生态项目,聚类分析在各种现实世界领域得到广泛应用。
Iván Palomares Carrascosa 是 AI、机器学习、深度学习和大型语言模型领域的领导者、作家、演讲者和顾问。他培训和指导他人如何在现实世界中利用 AI。
更多相关内容
使用 FastAPI 构建机器学习驱动的 Web 应用程序
原文:
www.kdnuggets.com/using-fastapi-for-building-ml-powered-web-apps

图片由作者提供 | Canva
在本教程中,我们将学习一些关于 FastAPI 的知识,并用它来构建机器学习(ML)模型推理的 API。然后,我们将使用 Jinja2 模板创建一个合适的 web 界面。这是一个简短但有趣的项目,你可以在有限的 API 和 web 开发知识的基础上自行构建。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 在 IT 领域支持你的组织
什么是 FastAPI?
FastAPI 是一个流行且现代的 web 框架,用于用 Python 构建 API。它旨在快速高效地利用 Python 的标准类型提示来提供最佳的开发体验。它易于学习,只需少量代码即可开发高性能的 API。FastAPI 被 Uber、Netflix 和微软等公司广泛使用来构建 API 和应用程序。其设计使其特别适合创建机器学习模型推理和测试的 API 端点。我们甚至可以通过集成 Jinja2 模板来构建一个合适的 web 应用程序。
模型训练
我们将对最受欢迎的 Iris 数据集进行随机森林分类器的训练。训练完成后,我们将显示模型评估指标并将模型保存为 pickle 格式。
train_model.py:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
import joblib
# Load the iris dataset
iris = load_iris()
X, y = iris.data, iris.target
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Train a RandomForest classifier
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_train, y_train)
# Evaluate the model
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred, target_names=iris.target_names)
print(f"Model Accuracy: {accuracy}")
print("Classification Report:")
print(report)
# Save the trained model to a file
joblib.dump(clf, "iris_model.pkl")
$ python train_model.py
Model Accuracy: 1.0
Classification Report:
precision recall f1-score support
setosa 1.00 1.00 1.00 10
versicolor 1.00 1.00 1.00 9
virginica 1.00 1.00 1.00 11
accuracy 1.00 30
macro avg 1.00 1.00 1.00 30
weighted avg 1.00 1.00 1.00 30
使用 FastAPI 构建机器学习 API
接下来,我们将安装 FastAPI 和 Unicorn 库,我们将使用它们来构建模型推理 API。
$ pip install fastapi uvicorn
在 app.py 文件中,我们将:
-
从上一步加载保存的模型。
-
创建用于输入和预测的 Python 类。确保指定数据类型。
-
然后,我们将创建预测函数并使用
@app.post装饰器。这个装饰器在 URL 路径/predict定义了一个 POST 端点。当客户端向此端点发送 POST 请求时,该函数将被执行。 -
预测函数从
IrisInput类中获取值,并将其作为IrisPrediction类返回。 -
使用
uvicorn.run函数运行应用程序,并提供主机 IP 和端口号,如下所示。
app.py:
from fastapi import FastAPI
from pydantic import BaseModel
import joblib
import numpy as np
from sklearn.datasets import load_iris
# Load the trained model
model = joblib.load("iris_model.pkl")
app = FastAPI()
class IrisInput(BaseModel):
sepal_length: float
sepal_width: float
petal_length: float
petal_width: float
class IrisPrediction(BaseModel):
predicted_class: int
predicted_class_name: str
@app.post("/predict", response_model=IrisPrediction)
def predict(data: IrisInput):
# Convert the input data to a numpy array
input_data = np.array(
[[data.sepal_length, data.sepal_width, data.petal_length, data.petal_width]]
)
# Make a prediction
predicted_class = model.predict(input_data)[0]
predicted_class_name = load_iris().target_names[predicted_class]
return IrisPrediction(
predicted_class=predicted_class, predicted_class_name=predicted_class_name
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="127.0.0.1", port=8000)
运行 Python 文件。
$ python app.py
FastAPI 服务器正在运行,我们可以通过点击链接访问它。
INFO: Started server process [33828]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
它将带我们到包含首页的浏览器。首页上没有任何内容,只有 /predict POST 请求。因此没有显示任何内容。

我们可以通过 SwaggerUI 界面测试我们的 API。我们可以通过在链接后添加 “/docs” 来访问它。
我们可以点击“/predict”选项,编辑值并运行预测。最后,我们将在响应体部分获得响应。如我们所见,结果是“Virginica”。我们可以通过 SwaggerUI 直接测试模型,并确保它在部署到生产环境之前正常工作。

为 Web 应用构建用户界面
我们将创建自己的用户界面,简单易用,像其他 Web 应用一样显示结果,而不是使用 Swagger UI。为此,我们需要在应用中集成 Jinja2Templates。Jinja2Templates 允许我们使用 HTML 文件构建一个合适的 Web 界面,使我们能够自定义网页的各种组件。
-
通过提供 HTML 文件所在的目录来初始化 Jinja2Templates。
-
定义一个异步路由,作为对根 URL ("/") 的 HTML 响应服务 "index.html" 模板。
-
修改
predict函数的输入参数,使用 Request 和 Form。 -
定义了一个异步 POST 端点 "/predict",接受用于鸢尾花测量的表单数据,使用机器学习模型预测鸢尾花种类,并返回使用 TemplateResponse 渲染的 "result.html" 预测结果。
-
其余的代码类似。
from fastapi import FastAPI, Request, Form
from fastapi.responses import HTMLResponse
from fastapi.templating import Jinja2Templates
from pydantic import BaseModel
import joblib
import numpy as np
from sklearn.datasets import load_iris
# Load the trained model
model = joblib.load("iris_model.pkl")
# Initialize FastAPI
app = FastAPI()
# Set up templates
templates = Jinja2Templates(directory="templates")
# Pydantic models for input and output data
class IrisInput(BaseModel):
sepal_length: float
sepal_width: float
petal_length: float
petal_width: float
class IrisPrediction(BaseModel):
predicted_class: int
predicted_class_name: str
@app.get("/", response_class=HTMLResponse)
async def read_root(request: Request):
return templates.TemplateResponse("index.html", {"request": request})
@app.post("/predict", response_model=IrisPrediction)
async def predict(
request: Request,
sepal_length: float = Form(...),
sepal_width: float = Form(...),
petal_length: float = Form(...),
petal_width: float = Form(...),
):
# Convert the input data to a numpy array
input_data = np.array([[sepal_length, sepal_width, petal_length, petal_width]])
# Make a prediction
predicted_class = model.predict(input_data)[0]
predicted_class_name = load_iris().target_names[predicted_class]
return templates.TemplateResponse(
"result.html",
{
"request": request,
"predicted_class": predicted_class,
"predicted_class_name": predicted_class_name,
"sepal_length": sepal_length,
"sepal_width": sepal_width,
"petal_length": petal_length,
"petal_width": petal_width,
},
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="127.0.0.1", port=8000)
接下来,我们将在与 app.py 相同的目录下创建一个名为 templates 的目录。在 templates 目录下创建两个 HTML 文件:index.html 和 result.html。
如果你是 Web 开发人员,你将很容易理解 HTML 代码。对于初学者,我会解释发生了什么。这段 HTML 代码创建了一个用于预测鸢尾花种类的网页,允许用户输入 "Sepal" 和 "Petal" 的测量值,并通过 POST 请求将其提交到 "/predict" 端点。
index.html:
<!DOCTYPE html>
<html>
<head>
<title>Iris Flower Prediction</title>
</head>
<body>
<h1>Predict Iris Flower Species</h1>
<form action="/predict" method="post">
<label **for**="sepal_length">Sepal Length:</label>
<input type="number" step="any" id="sepal_length" name="sepal_length" required><br>
<label **for**="sepal_width">Sepal Width:</label>
<input type="number" step="any" id="sepal_width" name="sepal_width" required><br>
<label **for**="petal_length">Petal Length:</label>
<input type="number" step="any" id="petal_length" name="petal_length" required><br>
<label **for**="petal_width">Petal Width:</label>
<input type="number" step="any" id="petal_width" name="petal_width" required><br>
<button type="submit">Predict</button>
</form>
</body>
</html>
result.html 代码定义了一个显示预测结果的网页,展示输入的花萼和花瓣测量值以及预测的鸢尾花种类。它还显示了预测的类别名称和类别 ID,并有一个按钮可以带你回到首页。
result.html:
<!DOCTYPE html>
<html>
<head>
<title>Prediction Result</title>
</head>
<body>
<h1>Prediction Result</h1>
<p>Sepal Length: {{ sepal_length }}</p>
<p>Sepal Width: {{ sepal_width }}</p>
<p>Petal Length: {{ petal_length }}</p>
<p>Petal Width: {{ petal_width }}</p>
<h2>Predicted Class: {{ predicted_class_name }} (Class ID: {{ predicted_class }})</h2>
<a href="/">Predict Again</a>
</body>
</html>
再次运行 Python 应用文件。
$ python app.py
INFO: Started server process [2932]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: 127.0.0.1:63153 - "GET / HTTP/1.1" 200 OK
当你点击链接时,你不会看到空白屏幕;相反,你将看到用户界面,你可以在其中输入 "Sepal" 和 "Petal" 的长度和宽度。

点击“预测”按钮后,你将被带到下一页,在那里结果将会显示。你可以点击“再次预测”按钮来用不同的值测试你的模型。

所有源代码、数据、模型和信息都可以在 kingabzpro/FastAPI-for-ML GitHub 仓库中找到。请不要忘记给它加星 ⭐。
结论
许多大公司现在使用 FastAPI 为他们的模型创建端点,使他们能够在系统中无缝地部署和集成这些模型。FastAPI 快速、易于编写代码,并且提供了各种功能以满足现代数据堆栈的需求。在这个领域获得工作的关键是尽可能多地构建和记录项目。这将帮助你获得进行初步筛选所需的经验和知识。招聘人员将评估你的个人资料和作品集,以确定你是否适合他们的团队。那么,为什么不从今天开始使用 FastAPI 构建项目呢?
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,帮助那些在心理健康方面遇到困难的学生。
更多相关内容
使用 Python 和 Fitbit Web API
原文:
www.kdnuggets.com/2020/02/using-fitbit-web-api-python.html
评论
作者:Michael Galarnyk,数据科学家
上面的图表是从 Fitbit 数据制作的,只是没有通过 API。我只是想分享我同事的工作。journals.plos.org/plosone/article?id=10.1371/journal.pone.0227709
Fitbit 提供了一个 Web API 来访问 Fitbit 活动追踪器、Aria 和 Aria 2 称重器的数据以及手动输入的日志。因此,如果你使用了 Fitbit,你可以使用 Fitbit API (dev.fitbit.com/build/reference/web-api/basics/) 来获取自己的数据。除了使用 API 获取数据的便利外,你还可以获得在线应用程序中无法获得的日内(逐分钟)数据。虽然这个教程最初类似于 Stephen Hsu 的精彩 教程,但我决定稍微更新一下流程,解决一些可能出现的错误,并展示如何绘制数据。与往常一样,本教程中使用的代码可以在我的 GitHub 上找到。那么,我们开始吧!
1.) 创建一个 Fitbit 账户
你可以通过点击 这里 创建一个 Fitbit 账户。这将带你到一个类似于下面的页面。
你不需要像我一样勾选“保持更新”框。此外,fakeuser@gmail 不是我为我的账户使用的电子邮件。
2.) 设置你的账户并创建应用
访问 dev.fitbit.com。将鼠标悬停在“管理”上,然后点击“注册应用”。

应该会出现一个类似于下面的页面。
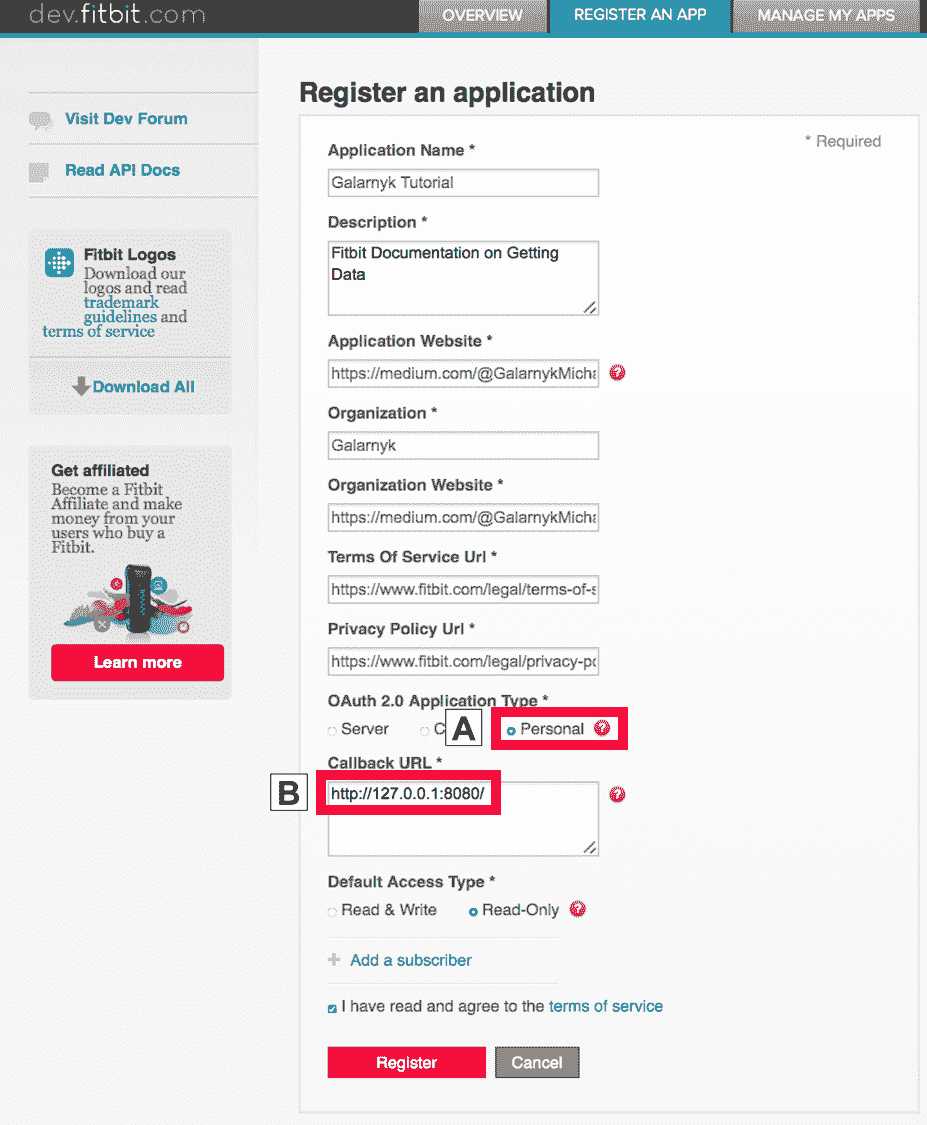
(A) 你需要将个人设置为更容易请求下载日内数据(如果你没有设置或遇到错误,你可以在 这里 进行请求)。(B) 回调 URL 是 http://127.0.0.1:8080,因为我们将使用的 Python API 将其作为默认重定向 URL。
对于图像中的每个字段,以下是一些你可以在注册页面填写的建议。
应用名称: 可以是任何内容。
描述: 可以是任何内容。
应用网站: 可以是任何内容。
组织: 可以是任何内容。
组织网站: 由于我将其用于个人用途(查看个人 Fitbit 数据),这可能不适用。
服务条款网址: 我放入了 Fitbit 的服务条款:dev.fitbit.com/legal/platform-terms-of-service/
隐私政策网址: 我放入了 Fitbit 的隐私政策:www.fitbit.com/legal/privacy-policy
OAuth 2.0 应用程序类型: 如果你想下载你的 intraday 数据,OAuth 2.0 应用程序类型应为“个人”。顺便提一下,如果你不知道 OAuth 是什么,这里有一个解释。
回调网址: 确保回调网址为 http://127.0.0.1:8080/ 以确保我们的 Fitbit API 能正确连接。这是因为我们将使用的库需要这样做,如下所示。
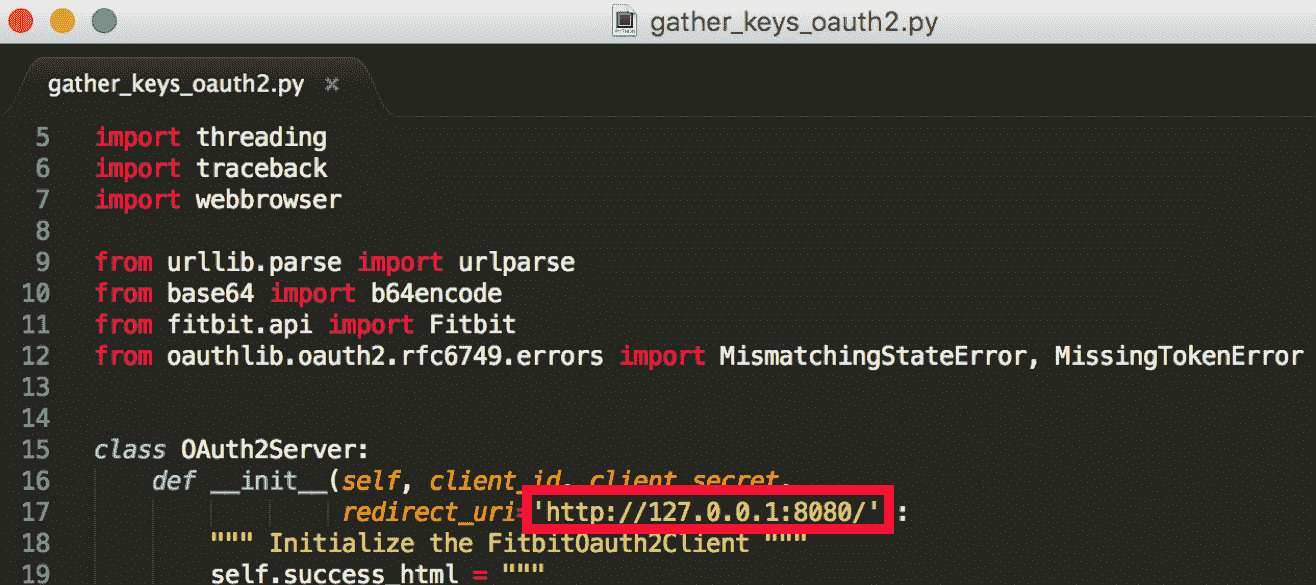
最后,点击同意框,然后点击注册。应该会出现一个类似下面的页面。
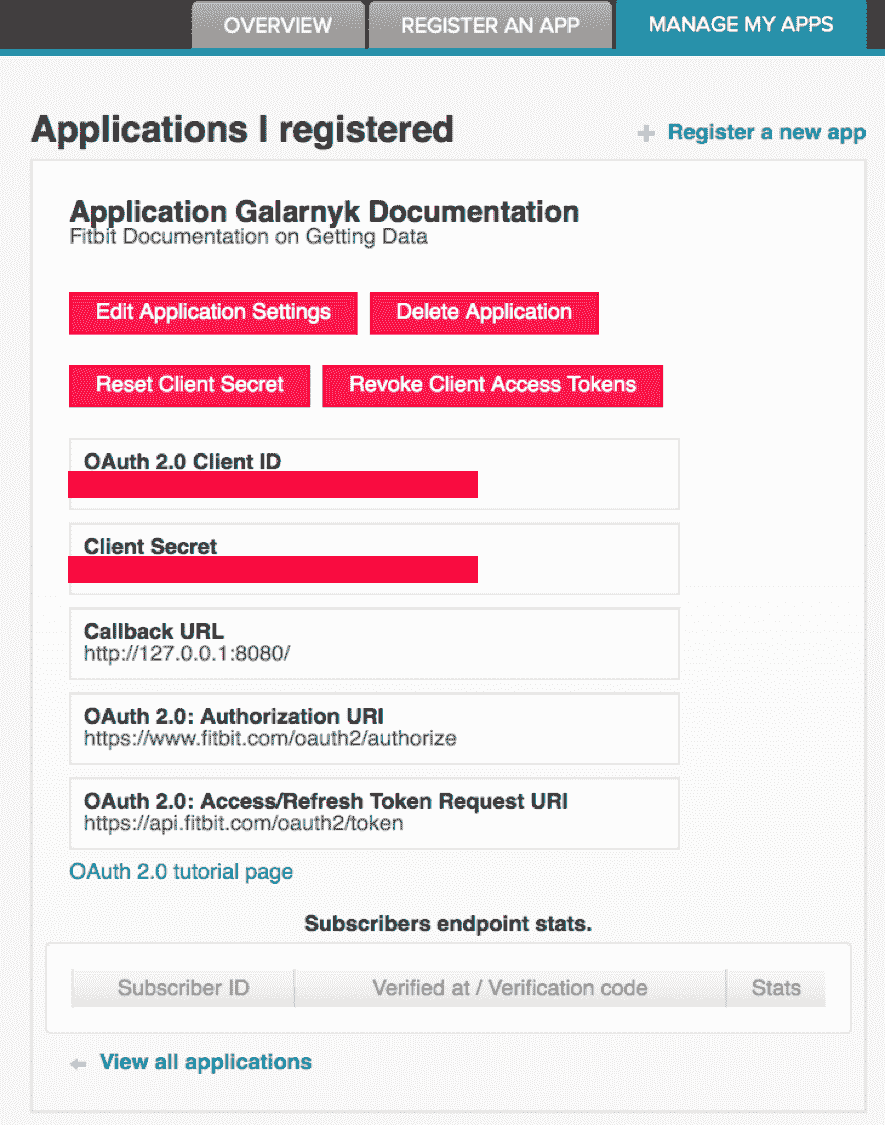
记住你的 OAuth 2.0 客户端 ID 和客户端密钥。
我们将从此页面中需要的部分是 OAuth 2.0 客户端 ID 和客户端密钥。你需要记下客户端 ID 和客户端密钥,以备后用。
# OAuth 2.0 Client ID
# You will have to use your own as the one below is fake
12A1BC# Client Secret
# You will have to use your own as the one below is fake
12345678901234567890123456789012
3.) 安装 Python 库
下一步是使用 Fitbit 非官方 API。点击链接后,点击绿色按钮。接下来,点击下载 Zip 并解压文件。
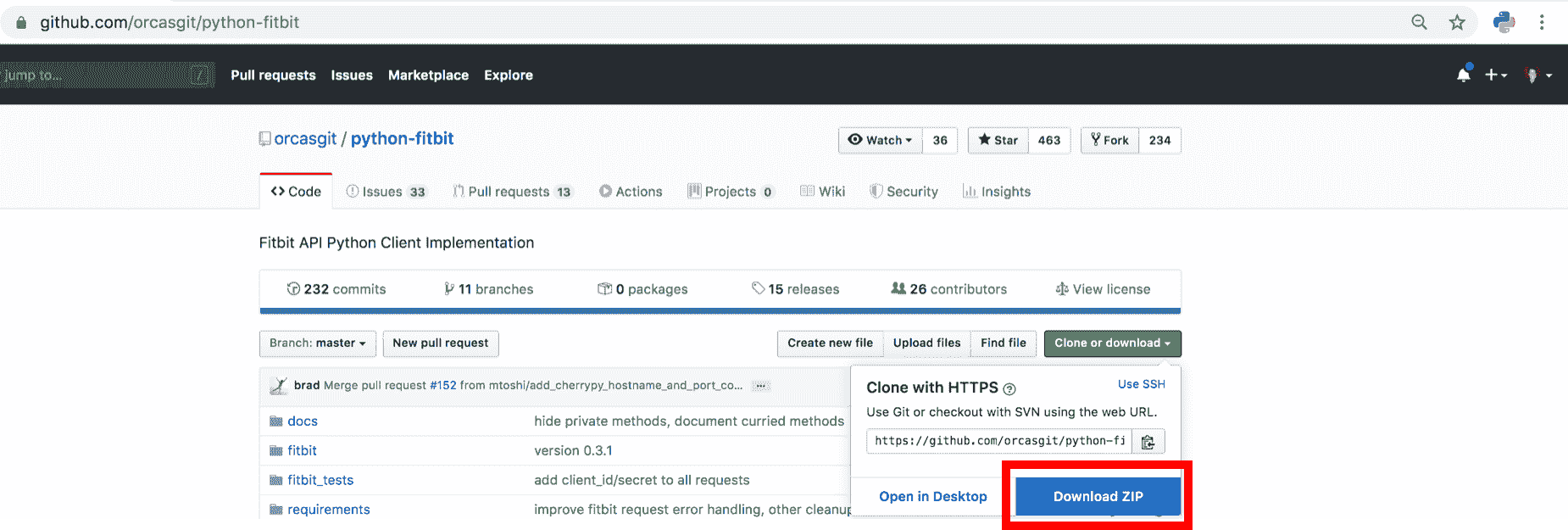
下载压缩文件。
然后,打开终端/命令行,切换到解压后的文件夹,并运行下面的命令。
#reasoning for it here:
#[`stackoverflow.com/questions/1471994/what-is-setup-py`](https://stackoverflow.com/questions/1471994/what-is-setup-py)
# If you want to install it a different way, feel free to do so. python setup.py install
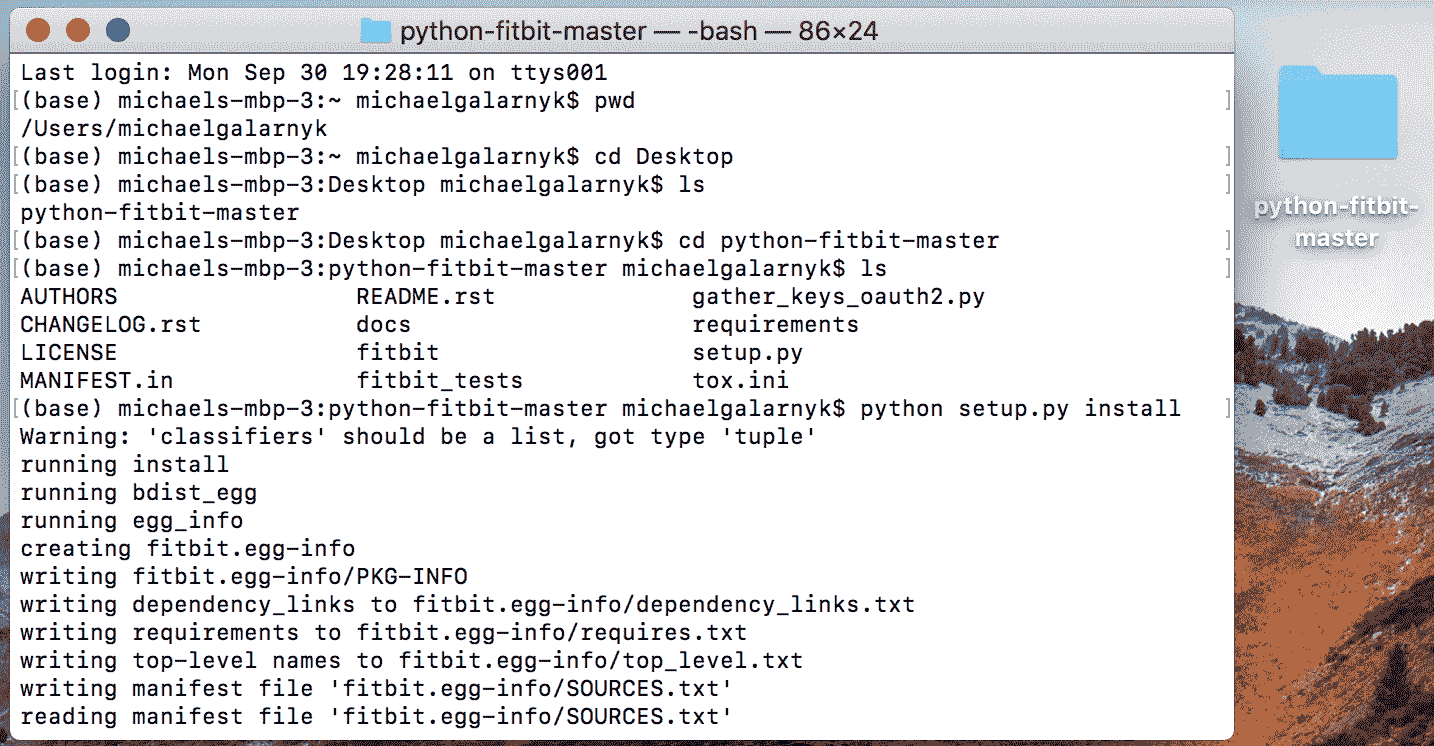
进入文件夹目录,并在终端/命令行中输入 python setup.py install。
4.) API 授权
在开始这一部分之前,我需要说明两点。首先,本教程中使用的代码可以在我的 GitHub 上找到。其次,如果你遇到错误,我在博客文章后面有一个潜在错误部分。
以下代码导入了各种库,并将步骤 2 中的 CLIENT_ID 和 CLIENT_SECRET 分配给变量。
# This is a python file you need to have in the same directory as your code so you can import it
import gather_keys_oauth2 as Oauth2import fitbit
import pandas as pd
import datetime# You will need to put in your own CLIENT_ID and CLIENT_SECRET as the ones below are fake
CLIENT_ID='12A1BC'
CLIENT_SECRET='12345678901234567890123456789012'
以下代码启用授权过程。
server=Oauth2.OAuth2Server(CLIENT_ID, CLIENT_SECRET)
server.browser_authorize()
ACCESS_TOKEN=str(server.fitbit.client.session.token['access_token'])
REFRESH_TOKEN=str(server.fitbit.client.session.token['refresh_token'])
auth2_client=fitbit.Fitbit(CLIENT_ID,CLIENT_SECRET,oauth2=True,access_token=ACCESS_TOKEN,refresh_token=REFRESH_TOKEN)
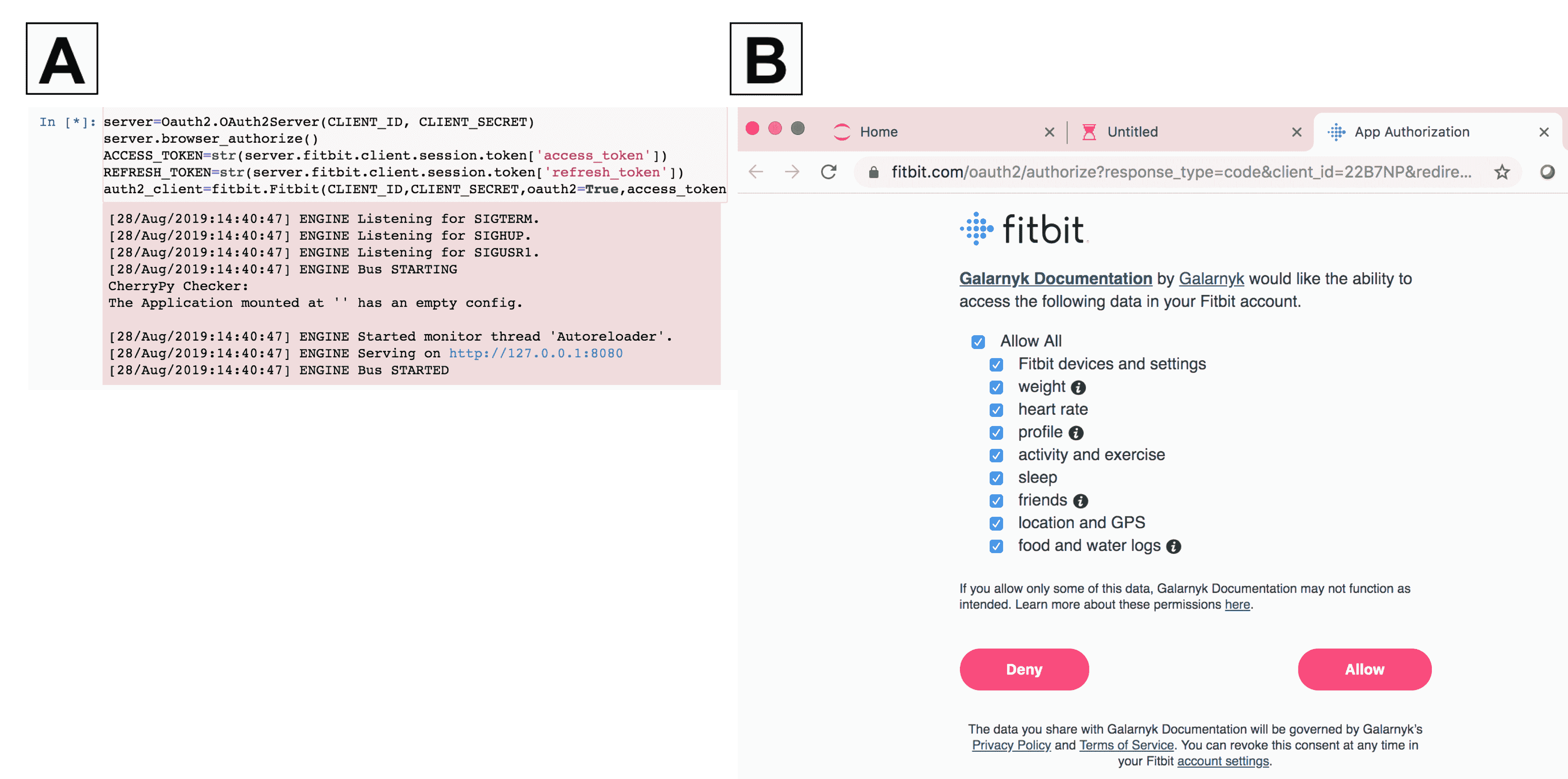
当你运行上面的代码(如 A 所示)时,单元格会显示仍在运行,直到你登录到你的 Fitbit 账户(B)并点击允许访问 Fitbit 账户中的各种数据。
授权和登录后页面的样子。
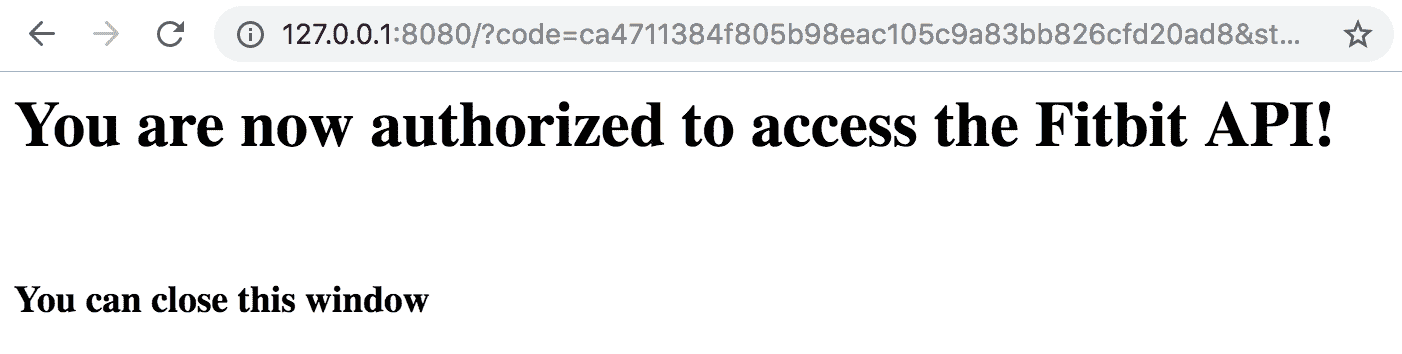
这个窗口应该是你看到的内容。
5a.) 获取一天的数据

你将使用 intraday_time_series 方法来获取数据。
我将首先获取一天的数据,以便下一个部分更容易理解。
# This is the date of data that I want.
# You will need to modify for the date you want
oneDate = pd.datetime(year = 2019, month = 10, day = 21)oneDayData = auth2_client.intraday_time_series('activities/heart', oneDate, detail_level='1sec')

如果你愿意,可以将这些数据放入 pandas DataFrame 中。

当然,你始终可以将数据导出为 CSV 或 Excel 文件。
# The first part gets a date in a string format of YYYY-MM-DD
filename = oneDayData['activities-heart'][0]['dateTime'] +'_intradata'# Export file to csv
df.to_csv(filename + '.csv', index = False)
df.to_excel(filename + '.xlsx', index = False)
5b.) 获取多天的数据
下面的代码获取从 startTime 变量(在下面的代码中称为 oneDate)开始的所有天的数据。
当然,你可以将 final_df 导出为 CSV 文件(我建议不要尝试导出为 Excel,因为行数可能过多,不容易导出到 Excel)。
filename = 'all_intradata'
final_df.to_csv(filename + '.csv', index = False)
6.) 尝试绘制日内数据图表
我强烈建议你查看GitHub上的代码,以便处理自己的数据。
本节的最终目标是将特定时间的特定日期图表化(日期也包括一天中的时间)。我应该指出,我的代码不够高效部分是由于懒惰。如果你不理解发生了什么,不用担心。你可以向下滚动查看最终结果。
# I want to get the hour of the day and time. The end goal of this section is to get a particular time on a particular day.
hoursDelta = pd.to_datetime(final_df.loc[:, 'time']).dt.hour.apply(lambda x: datetime.timedelta(hours = x))minutesDelta = pd.to_datetime(final_df.loc[:, 'time']).dt.minutes.apply(lambda x: datetime.timedelta(minutes = x))secondsDelta = pd.to_datetime(final_df.loc[:, 'time']).dt.seconds.apply(lambda x: datetime.timedelta(seconds = x))# Getting the date to also have the time of the day
final_df['date'] = final_df['date'] + hoursDelta + minutesDelta + secondsDelta
我接下来的步骤是查看 3 天的数据,而不是多天的数据。
startDate = pd.datetime(year = 2019, month = 12, day = 24)
lastDate = pd.datetime(year = 2019, month = 12, day = 27)coupledays_df = final_df.loc[final_df.loc[:, 'date'].between(startDate, lastDate), :]
请记住,你还可以尝试通过按日期和小时(甚至秒)分组绘制图表,并取心率的平均值。代码也尝试使图表看起来更好一些。
fig, ax = plt.subplots(figsize=(10, 7))# Taken from: [`stackoverflow.com/questions/16266019/python-pandas-group-datetime-column-into-hour-and-minute-aggregations`](https://stackoverflow.com/questions/16266019/python-pandas-group-datetime-column-into-hour-and-minute-aggregations)
times = pd.to_datetime(coupledays_df['date'])
coupledays_df.groupby([times.dt.date,times.dt.hour]).value.mean().plot(ax = ax)ax.grid(True,
axis = 'both',
zorder = 0,
linestyle = ':',
color = 'k')
ax.tick_params(axis = 'both', rotation = 45, labelsize = 20)
ax.set_xlabel('Date, Hour', fontsize = 24)
fig.tight_layout()
fig.savefig('coupledaysavergedByMin.png', format = 'png', dpi = 300)
做了这么多工作,也许这不是我应该继续的方向,因为当前数据并没有足够的背景来判断是在休息还是在移动。
7.) 静息心率
有研究讨论了静息心率如何反映你的当前和未来健康。实际上,有一篇研究论文展示了 92,447 名佩戴 Fitbit 的成年人在静息心率的个体间和个体内变异性及其与年龄、性别、睡眠、BMI 和季节的关联。以下是论文中的一张图片(添加了文本以便于理解)。
journals.plos.org/plosone/article?id=10.1371/journal.pone.0227709
我们一直使用的 API 调用也返回静息心率,因此下面的代码与之前的步骤并没有太大区别。
# startTime is first date of data that I want.
# You will need to modify for the date you want your data to start
startTime = pd.datetime(year = 2019, month = 11, day = 21)
endTime = pd.datetime.today().date() - datetime.timedelta(days=1)date_list = []
resting_list = []allDates = pd.date_range(start=startTime, end = endTime)for oneDate in allDates:
oneDate = oneDate.date().strftime("%Y-%m-%d")
oneDayData = auth2_client.intraday_time_series('activities/heart', base_date=oneDate, detail_level='1sec')
date_list.append(oneDate)
resting_list.append(oneDayData['activities-heart'][0]['value']['restingHeartRate'])# there is more matplotlib code on GitHub
fig, ax = plt.subplots(figsize=(10, 7))ax.plot(date_list, resting_list)
尝试绘制你的数据图表。
8.) 获取睡眠数据
不深入细节,下面的代码获取每分钟的睡眠数据(final_df)以及有关 Fitbit 用户在深度、浅度、快速眼动和清醒阶段的总时间(final_stages_df)的睡眠总结信息。

final_stages_df 是一个 pandas DataFrame,显示了 Fitbit 用户在给定日期晚上每个阶段的睡眠时长(清醒、深度、浅睡、快速眼动)以及总的卧床时间。

final_df 是一个 pandas DataFrame,提供了一个日期时间、日期和一个值。值列中的 1 表示“睡着了”,2 表示清醒,3 表示真正清醒。

潜在错误
没有名为 gather_keys_oauth2 的模块
这是针对你遇到类似以下错误的情况。
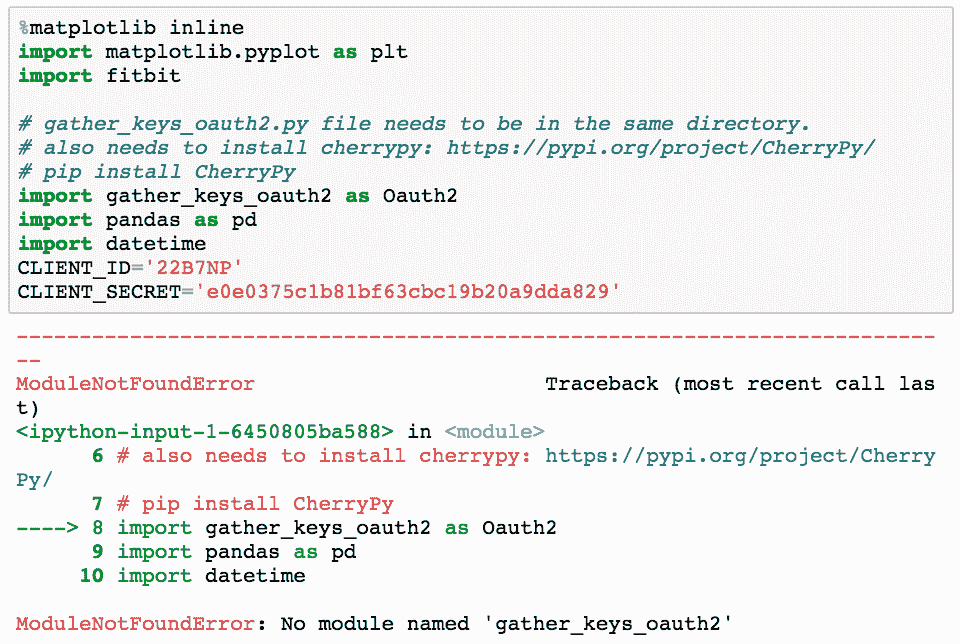
为了解决这个问题,你可以将 gather_keys_oauth2.py 文件放入与你的 Python 文件或 jupyter notebook 相同的目录。你可以看到我的项目目录安排如下。
注意 gather_keys_oauth2.py 文件位于我的 jupyter notebook 同一目录下。这是我们在第三步中下载的 python-fitbit-master 中包含的一个文件。
CherryPy 未被识别,没有名为 cherrypy 的模块
如果你遇到类似下面的错误,首先关闭你的 jupyter notebook 或 Python 文件。
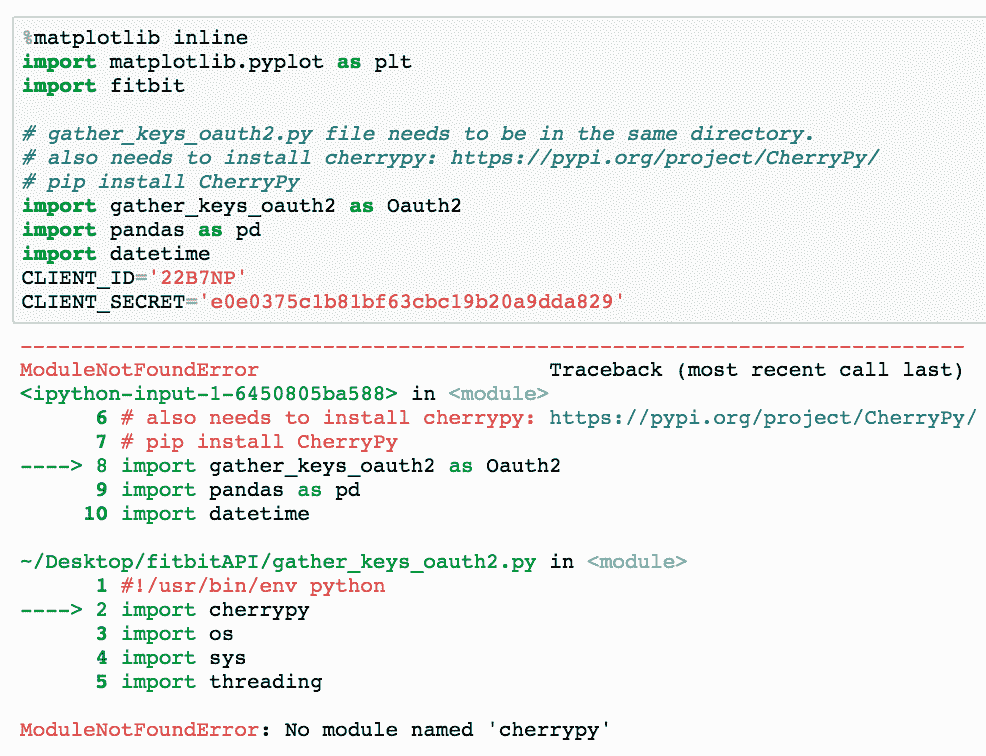
你可以通过以下命令解决问题。
pip install CherryPy
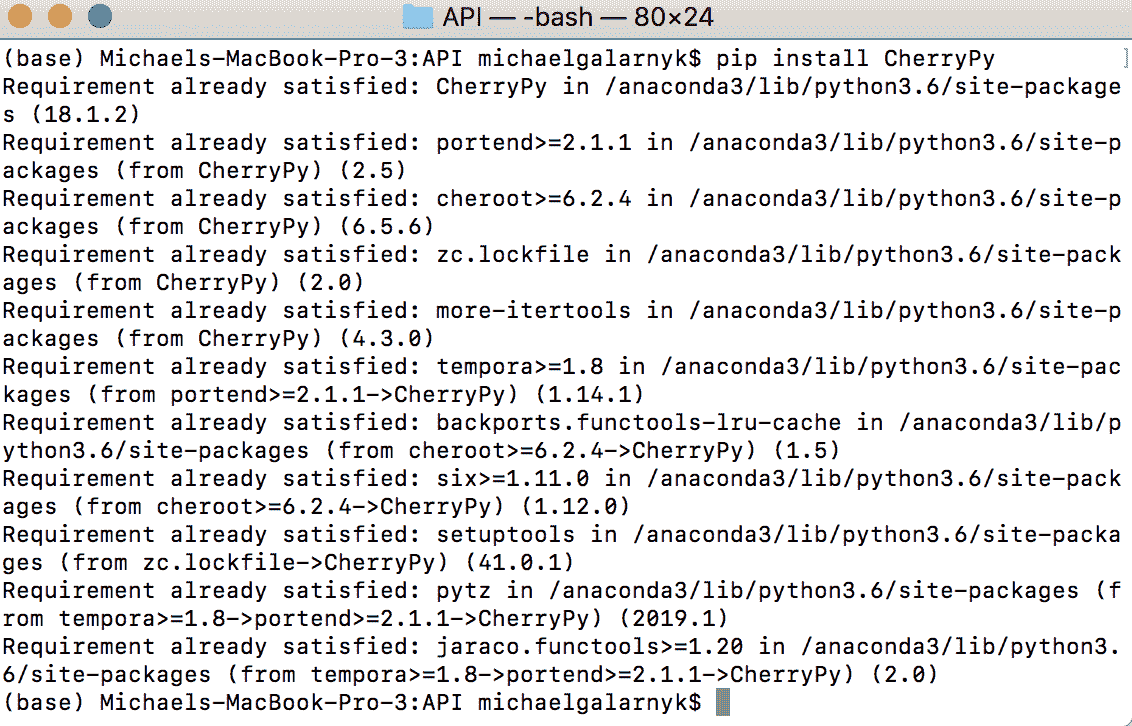
Https 与 Http 错误
以下错误发生在我尝试将回调 URL 更改为 https 而不是 http 的第二步中。
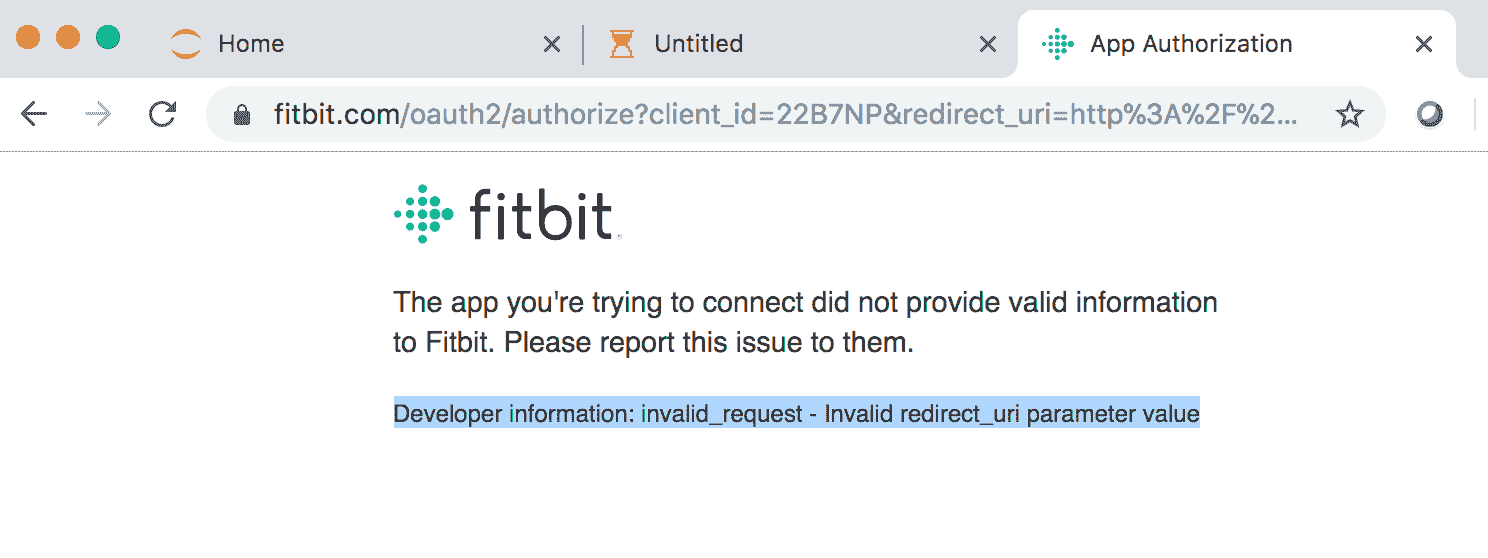
HTTPTooManyRequests: 请求过多
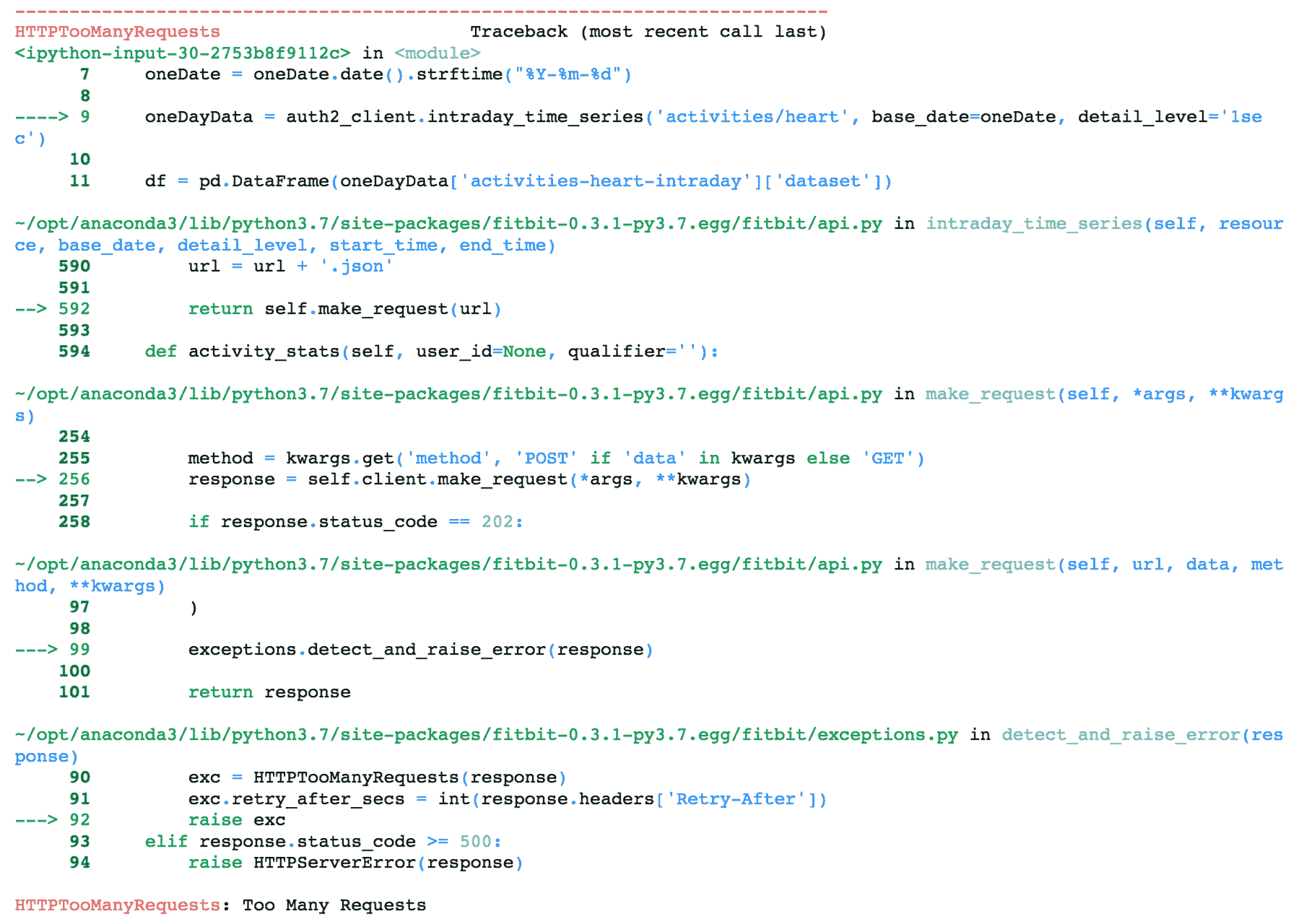
fitbit 论坛 对这个问题有答案。使用 API,你可以每小时对每个用户/fitbit 进行最多 150 次请求。这意味着如果你有超过 150 天的数据,并且使用了本教程第五步 b 的代码,你可能需要稍等片刻才能获取其余的数据。
结论
本文介绍了如何从单个 Fitbit 获取数据。虽然我涵盖了相当多的内容,但仍有一些内容没有涉及,比如 Fitbit API 如何获取你的步数。Fitbit API 是我仍在学习的内容,因此如果你有任何贡献,请告诉我。如果你对教程有任何问题或想法,请随时在下方评论或通过 Twitter 联系我。
简历:Michael Galarnyk 是一名数据科学家和企业培训师。他目前在 Scripps Translational Research Institute 工作。你可以在 Twitter (https://twitter.com/GalarnykMichael)、Medium (https://medium.com/@GalarnykMichael) 和 GitHub (https://github.com/mGalarnyk) 上找到他。
原文。已获许可转载。
相关:
-
理解 Python 中的决策树分类
-
Python 列表及列表操作
-
Python 元组及其方法
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
在本地使用 FLUX.1
图片来源:作者 | Canva Pro
在本教程中,我们将学习如何轻松安装 Stable Diffusion WebUI Forge,然后下载量化版本的 FLUX.1 [dev] 并使用它生成高质量图像。它提供了逐步的指南,使你能够使用笔记本电脑生成和修改生成的图像和艺术作品。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
什么是 FLUX.1?
FLUX.1 是由 BlackForestLabs 创建的一系列新的图像生成模型。它通过提供高图像细节、严格遵循提示、多样的风格和复杂的场景渲染,为 AI 行业设立了新的标准。该模型确立了其作为将文本转化为生动图像的最先进解决方案。
FLUX.1 有三种变体:FLUX.1 [pro]、FLUX.1 [dev] 和 FLUX.1 [schnell]。它超越了领先的模型,如 Midjourney v6.0 和 DALL·E 3 (HD),在图像生成领域设立了新的标准,并为生成媒体的未来创新铺平了道路。
安装 Stable Diffusion WebUI Forge
开发者可以通过 GitHub 仓库 (lllyasviel/stable-diffusion-webui-forge) 轻松安装 Stable Diffusion WebUI Forge。
对于非技术用户而言,使用技术指南安装 Stable Diffusion WebUI Forge 可能会很棘手。这就是为什么 Stability Matrix 提供了一个用户友好的替代方案,允许任何人轻松在笔记本电脑上体验最先进的模型,而无需复杂的安装过程。
1. 访问 Lykos AI 网站,下载稳定版桌面应用程序。
2. 解压下载的文件,并双击 StabilityMatrix.exe 文件以启动安装程序。
3. 安装完成后,我们将被重定向到 Stability Matrix 应用程序,在那里我们将被要求选择我们喜欢的界面。请选择“Stable Diffusion WebUI Forge”。
4. 它会要求你下载基础模式;请跳过安装推荐模型。完成所有操作需要 15 分钟。
设置 FLUX.1 [dev] 模型
5. 在安装完成 Stable Diffusion WebUI Forge 后,前往 flux1-dev-bnb-nf4-v2.safetensors Hugging Face 模型库,下载 FLUX.1-dev 模型的量化版本。为什么选择量化版本?因为它可以在 VRAM 较小的 GPU 上运行?即便如此,你仍需要一个 8GB VRAM 的 GPU。
6. 导航到 StabilityMatrix 文件夹,并按照以下路径:C:\Users<USER_NAME>\StabilityMatrix\Packages\stable-diffusion-webui-forge\models\Stable-diffusion
7. 创建一个名为“flux”的新文件夹,并将下载的 FLUX.1 [dev] 模型文件移动到其中,如下所示。
8. 前往 Stability Matrix 应用程序,导航到 Packages 菜单以启动 Stable Diffusion WebUI Forge。
9. 几秒钟后,你将被引导到新的窗口,显示 Gradio 网络应用程序,或者你也可以直接点击本地 URL。
10. 在网络应用程序中,选择 Flux UI 并将检查点更改为模型文件。
就这样。你只需要输入详细的提示并按下生成按钮。
使用 FLUX.1 [dev] 模型
11. 选择“Text2img”标签,并在提示框中输入详细提示。确保添加所有细节,如下所示。
提示: “一位瘦削的朋克女性倚靠在黑暗街道的墙边,品味着一根短烟,墙上用红色喷漆写着‘上帝是伟大的’,超现实主义,详细的编织粉色和黑色头发,侧面莫霍克发型,大项链,全身纹身,鼻子、嘴唇和眉毛穿孔,磨损的短款背心,肮脏破烂的衣物,广阔的黑暗背景,路易斯·罗约插图,伦勃朗光线,概念艺术,幻想艺术,超详细,复杂,清晰对焦,最佳质量,杰作”。
由于这是一个需要大量 VRAM 的大型模型,生成过程可能需要几分钟。如果你的系统变得缓慢或短暂冻结,我强烈建议减少 GPU 权重。
我们甚至可以在 StableMatrix 应用程序中查看详细日志。
最终,我们得到了符合提示的高质量图像。即便是文字也没有任何故障。
12. 让我们尝试另一种不同设置的提示。
提示: “一个中年男性木匠在他阳光明媚的工作坊里。他的手经历了风霜,表情专注,正小心地雕刻一块富有红木的细节。他的盐胡须修剪整齐,穿着一件磨损的皮围裙,下面是一件法兰绒衬衫。窗户透进的温暖午后光线中,尘埃微粒在舞动,营造出舒适的氛围。”
再次运行的结果超现实,与 Stable Diffusion XL 模型相比,没有视觉故障,照明效果更好。

结论
在本地使用生成式 AI 模型为你提供了完全的隐私保护和无限创建图像的自由,没有任何提示创意的限制。
在本教程中,我们介绍了安装和使用 Stable Diffusion Forge 生成超现实图像的最简单方法,使用的是 FLUX.1 [dev] 模型。如果你有兴趣了解更多关于生成式 AI 的内容,可以在 LinkedIn 上关注我。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为挣扎于心理疾病的学生构建一个 AI 产品。
更多相关主题
使用谷歌的 NotebookLM 进行数据科学:综合指南
原文:
www.kdnuggets.com/using-google-notebooklm-for-data-science-a-comprehensive-guide
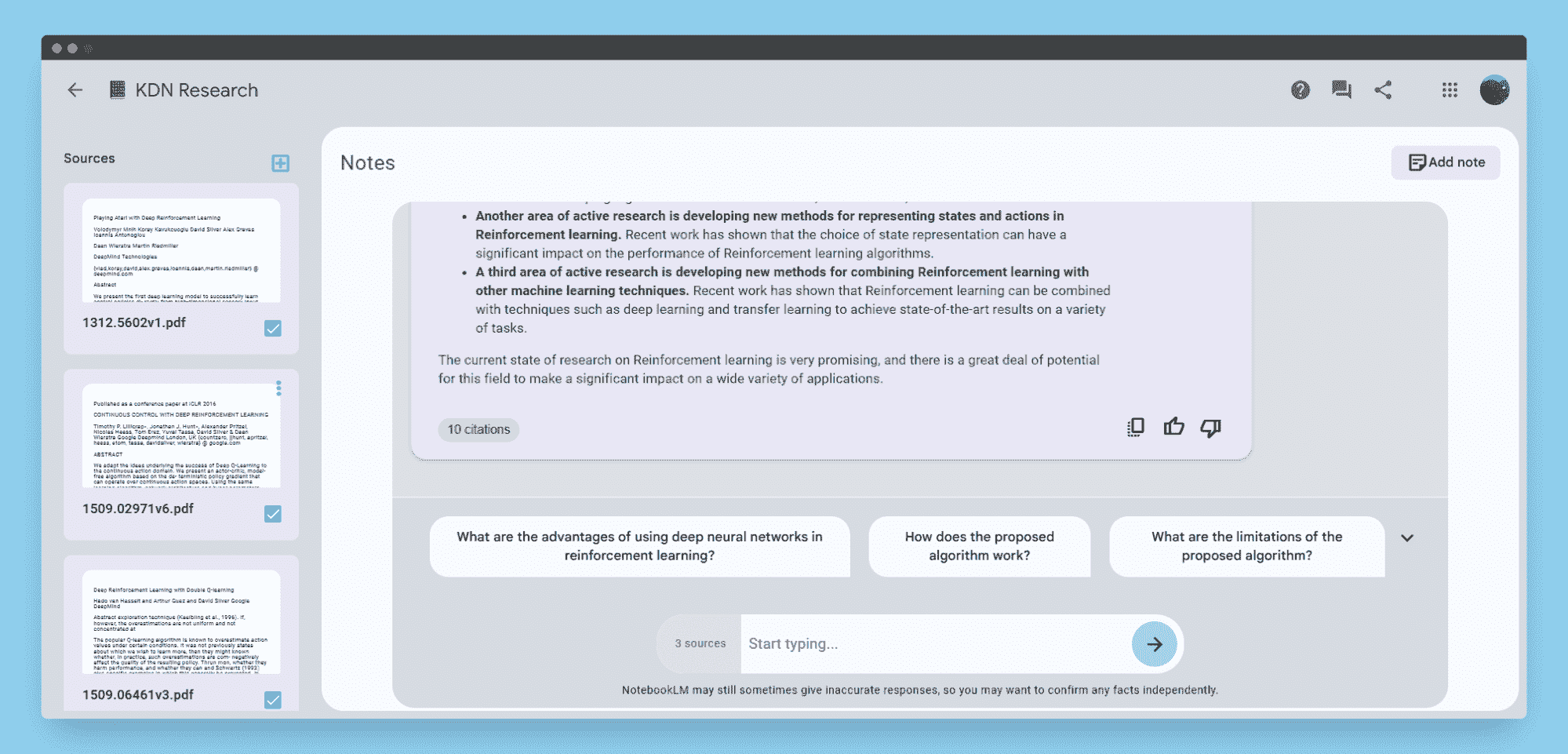
图片来源:作者
随着数据科学世界的不断发展,行业内专业人员使用的工具和技术也在进步。谷歌的 NotebookLM 提供了一种独特而强大的方式来理解你的数据和信息。这篇博客文章深入探讨了 NotebookLM 的功能、工作原理以及它为数据科学研究人员打开的众多可能性。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
什么是 NotebookLM?
谷歌的新实验产品 NotebookLM 基于最新的大型语言模型进展。它类似于其他由大型语言模型(LLMs)驱动的应用程序,如 ChatPDF、ChatGPT 和 Poe,这些应用程序允许用户上传数据文件并提出问题。这些应用程序提供相同的功能和能力。
那么,它有什么特别之处?
NotebookLM 是一个专用应用程序,允许你上传最多 10 个文档。你可以轻松上传你的资料,这些资料可以包括谷歌文档、计算机上的 PDF 文件或任何少于 50,000 字的文本内容。
NotebookLM 解决了使用 ChatGPT 和 Poe 的限制。它允许你上传超过三个文档,并在几秒钟内理解大文档。
使用 NotebookLM 进行数据科学
使用 NotebookLM 非常简单。你可以在几秒钟内上传谷歌文档、计算机上的 PDF 文件或任何文本内容。一旦你的资料被上传,NotebookLM 就成为你查询和创意头脑风暴的首选工具。
首先,我们将访问“notebooklm.google.com”网站并创建一个项目。
我下载了关于强化学习的热门研究论文的 PDF 文件:
然后我们将这些 PDF 一一上传到我们的项目中。
上传文件后,我们选择那些作为背景信息使用。
总结
我们将选择“深度强化学习中的连续控制”研究论文,并要求 NotebookLM 为我们总结。
提示:“请总结一下这篇研究论文。尽量使用项目符号。”
获取答案只花了几秒钟。还提供了进一步的问题。
术语提取
我们将要求它现在创建论文中使用的关键术语列表。
提示:“创建这篇论文中使用的关键术语列表。”

它不仅为我们提供了关键术语,还指明了它们在论文中的位置。
强化学习分析
我们现在将使用这三篇论文来了解研究趋势。
提示:“分析所有三篇研究论文,并提供对强化学习当前研究状态的分析。”

表现非常出色。
创意协助
我们现在将使用它,并请 AI 帮助我们决定一个能够确保获得机器学习工程师职位的最终年项目标题。
提示:“使用三篇论文,生成一个新的研究标题,帮助我获得作为研究强化工程师的职位。”
很好,但不够出色。
高级功能
引用
询问有关您来源的任何问题,NotebookLM 将回答这些问题,并附上来自这些文档的引用。
文档指南
当您上传新的来源时,NotebookLM 会创建一个“来源指南”,总结文档内容并建议关键主题和问题。

记笔记
每个笔记本包含一个笔记部分,您可以在其中记录由 NotebookLM 揭示的想法或信息。
可访问性和限制
-
设备兼容性:目前,NotebookLM 在桌面计算机上体验最佳。
-
访问限制:最初仅在美国和个人 Google 账户中提供。
-
内容限制:每个笔记本可以包含十个来源和一个笔记,每个来源的字数上限为 50,000 字。
协作与共享
-
协作功能:笔记本可以与同事或同学共享,提供查看者或编辑者访问权限。
-
多源交互:用户可以在与单一来源或所有来源之间切换。
定价和可用性
NotebookLM 正处于早期测试阶段,目前免费提供。访问权限正在逐步开放给小范围用户,感兴趣的用户可以选择注册以加入等待名单。
重要指南
尽管 NotebookLM 提供了令人兴奋的机会,但必须注意上传的内容。避免上传包含个人或敏感信息的文档。同时,请注意它是一个实验性项目,目前仅限于早期访问计划的成员。
结论
Google's NotebookLM 在数据科学家和专业人士解读复杂信息方面是一个重要突破。由于我们大多数信息都在 PDF 文件中并存储在计算机上,NotebookLM 使你只需添加所有文件并提出关键问题即可理解法律合同。尽管与 ChatGPT 相比,NotebookLM 在某些功能和准确性上有所欠缺,但它有很大潜力,随着不断发展,将成为你工作空间中的重要工具。
Abid Ali Awan (@1abidaliawan) 是一名认证数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些面临心理健康问题的学生构建 AI 产品。
相关话题
本地使用 Groq Llama 3 70B:分步指南
原文:
www.kdnuggets.com/using-groq-llama-3-70b-locally-step-by-step-guide

作者提供的图片
每个人都专注于构建更好的 LLM(大型语言模型),而 Groq 专注于 AI 的基础设施方面,使这些大型模型运行得更快。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT
在本教程中,我们将学习 Groq LPU 推理引擎以及如何在本地笔记本电脑上使用 API 和 Jan AI。我们还将将其集成到 VSCode 中,以帮助我们生成代码、重构代码、编写文档和生成测试单元。我们将免费创建自己的 AI 编程助手。
什么是 Groq LPU 推理引擎?
Groq LPU(语言处理单元)推理引擎旨在为计算密集型应用程序提供快速响应,尤其是具有序列组件的应用程序,如 LLMs。
与 CPU 和 GPU 相比,LPU 具有更大的计算能力,这减少了预测一个词所需的时间,使得文本序列生成更快。此外,LPU 还解决了内存瓶颈,相较于 GPU 提供了更好的性能。
简而言之,Groq LPU 技术使您的 LLMs 非常快速,实现实时 AI 应用。阅读 Groq ISCA 2022 论文 以了解更多关于 LPU 架构的信息。
安装 Jan AI
Jan AI 是一个本地运行开源和专有大型语言模型的桌面应用程序。它可以在 Linux、macOS 和 Windows 上下载和安装。我们将通过访问 Releases · janhq/jan (github.com) 并点击 .exe 扩展名的文件来下载和安装 Jan AI。
如果您希望本地使用 LLMs 以增强隐私,请阅读 在笔记本电脑上使用 LLMs 的 5 种方法 博客,并开始使用顶级开源语言模型。
创建 Groq Cloud API
要在 Jan AI 中使用 Groq Llama 3,我们需要一个 API。为此,我们将通过访问 console.groq.com/ 创建一个 Groq Cloud 帐户。
如果你想测试 Groq 提供的各种模型,可以通过进入“Playground”选项卡、选择模型并添加用户输入,无需任何设置。
在我们的案例中,它非常快。生成速度为每秒 310 个标记,这是我一生中见过的最快的。即使是 Azure AI 或 OpenAI 也无法产生这样的结果。
要生成 API 密钥,请点击左侧面板上的“API 密钥”按钮,然后点击“创建 API 密钥”按钮以生成并复制 API 密钥。
在 Jan AI 中使用 Groq
在下一步中,我们将把 Groq Cloud API 密钥粘贴到 Jan AI 应用中。
启动 Jan AI 应用,进入设置,在扩展部分选择“Groq 推理引擎”选项,并添加 API 密钥。
然后,返回到对话窗口。在模型部分,选择“Remote”部分中的 Groq Llama 3 70B 并开始提示。
响应生成速度非常快,以至于我都来不及跟上。
注意:API 的免费版本有一些限制。访问
console.groq.com/settings/limits以了解更多信息。
在 VSCode 中使用 Groq
接下来,我们将尝试将相同的 API 密钥粘贴到 CodeGPT VSCode 扩展中,并建立我们自己的免费 AI 编码助手。
在扩展选项卡中搜索并安装 CodeGPT 扩展。
CodeGPT 选项卡将出现供你选择模型提供商。
当你选择 Groq 作为模型提供商时,它会要求你提供 API 密钥。只需粘贴相同的 API 密钥即可开始使用。你甚至可以为 CodeGPT 生成另一个 API 密钥。
我们现在将要求它为蛇形游戏编写代码。生成和运行代码花费了 10 秒钟。
这是我们蛇形游戏的演示。

了解一下五大 AI 编程助手,成为一名 AI 驱动的开发者和数据科学家。记住,AI 的目的是帮助我们,而不是取代我们,因此要开放心态,利用它来提升你的代码编写能力。
结论
在本教程中,我们学习了 Groq 推理引擎以及如何通过 Jan AI Windows 应用程序在本地访问它。更棒的是,我们通过使用 CodeGPT VSCode 扩展将其集成到我们的工作流程中,这真是太棒了。它实时生成响应,为更好的开发体验提供了帮助。
现在,大多数公司将开发自己的推理引擎以匹配 Groq 的速度。否则,Groq 在几个月内将夺得第一。
Abid Ali Awan(@1abidaliawan)是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络开发一款 AI 产品,帮助那些在心理健康方面挣扎的学生。
更多相关内容
使用 Hugging Face Transformers 进行文本情感检测
原文:
www.kdnuggets.com/using-hugging-face-transformers-for-emotion-detection-in-text

图片由juicy_fish 在 Freepik提供
Hugging Face 托管了各种基于变换器的语言模型(LMs),这些模型专门用于处理语言理解和语言生成任务,包括但不限于:
-
文本分类
-
命名实体识别(NER)
-
文本生成
-
问答
-
总结
-
翻译
我们的前三名课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT 工作
一个特定的——也相当常见的——文本分类任务是情感分析,其目标是识别给定文本的情感。最“简单”的情感分析语言模型被训练来确定输入文本的极性,例如产品的客户评价,可以分为正面和负面,或正面、负面和中性。这两个具体问题分别被表述为二分类或多分类任务。
还有一些语言模型,虽然仍然可以被识别为情感分析模型,但它们被训练来将文本分类为几种情感,例如愤怒、快乐、悲伤等。
本教程基于 Python,重点介绍了如何加载和展示使用 Hugging Face 预训练模型来分类输入文本的主要情感。我们将使用情感数据集,这是 Hugging Face 中心公开提供的数据集。该数据集包含成千上万条用英语编写的 Twitter 消息。
加载数据集
我们将通过运行以下指令来开始加载情感数据集中的训练数据:
!pip install datasets
from datasets import load_dataset
all_data = load_dataset("jeffnyman/emotions")
train_data = all_data["train"]
以下是train_data变量中的训练子集所包含的内容摘要:
Dataset({
features: ['text', 'label'],
num_rows: 16000
})
情感数据集中的训练折叠包含 16000 个与 Twitter 消息相关的实例。每个实例有两个特征:一个输入特征包含实际消息文本,一个输出特征或标签包含其关联的情感作为数字标识符:
-
0: 悲伤
-
1: 快乐
-
2: 爱
-
3: 愤怒
-
4: 恐惧
-
5: 惊讶
例如,训练集中的第一个标记实例被分类为“悲伤”情感:
train_data[0]
输出:
{'text': 'i didnt feel humiliated', 'label': 0}
加载语言模型
一旦我们加载了数据,下一步是从 Hugging Face 加载一个适合我们目标情感检测任务的预训练语言模型。使用 Hugging Face 的 Transformer 库 有两种主要方法来加载和利用语言模型:
-
管道 提供了一个非常高的抽象层次,使得几乎可以立即加载语言模型并进行推断,只需极少的代码行,但配置选项较少。
-
Auto 类 提供了较低的抽象层次,需要更多的编码技能,但提供了更多的灵活性,以调整模型参数以及自定义文本预处理步骤,如分词。
本教程通过专注于将模型作为管道加载,为你提供了一个简单的起点。管道需要至少指定语言任务的类型, optionally 还可以指定要加载的模型名称。由于情感检测是一种非常具体的文本分类问题,因此加载模型时使用的任务参数应该是“text-classification”:
from transformers import pipeline
classifier = pipeline("text-classification", model="j-hartmann/emotion-english-distilroberta-base")
另一方面,强烈建议使用“model”参数指定 Hugging Face hub 中一个能够处理我们特定情感检测任务的模型名称。否则,默认情况下,我们可能会加载一个没有针对这个特定 6 类分类问题训练过的文本分类模型。
你可能会问自己:“我怎么知道使用哪个模型名称?”答案很简单:在 Hugging Face 网站上进行一点探索,找到适合的模型或训练于特定数据集(如情感数据)的模型。
下一步是开始进行预测。管道使得这个推断过程变得极其简单,只需调用我们新实例化的管道变量,并将要分类的输入文本作为参数传递:
example_tweet = "I love hugging face transformers!"
prediction = classifier(example_tweet)
print(prediction)
结果,我们得到一个预测标签和一个置信度分数:这个分数越接近 1,预测结果的“可靠性”越高。
[{'label': 'joy', 'score': 0.9825918674468994}]
因此,我们的输入示例“I love hugging face transformers!” 自信地传达了喜悦的情感。
你可以将多个输入文本传递给管道,以同时执行多个预测,如下所示:
example_tweets = ["I love hugging face transformers!", "I really like coffee but it's too bitter..."]
prediction = classifier(example_tweets)
print(prediction)
在这个例子中,第二个输入对模型来说似乎更具挑战性,难以进行自信的分类:
[{'label': 'joy', 'score': 0.9825918674468994}, {'label': 'sadness', 'score': 0.38266682624816895}]
最后,我们还可以将数据集中一批实例传递给我们的语言模型管道,例如之前加载的“情感”数据。这个例子将前 10 个训练输入传递给我们的语言模型管道进行情感分类,然后打印一个包含每个预测标签的列表,置信度分数不予显示:
train_batch = train_data[:10]["text"]
predictions = classifier(train_batch)
labels = [x['label'] for x in predictions]
print(labels)
输出:
['sadness', 'sadness', 'anger', 'joy', 'anger', 'sadness', 'surprise', 'fear', 'joy', 'joy']
作为比较,这里是这 10 个训练实例的原始标签:
print(train_data[:10]["label"])
输出:
[0, 0, 3, 2, 3, 0, 5, 4, 1, 2]
通过查看每个数字标识符关联的情感,我们可以看到大约 7 成的预测与这 10 个实例的真实标签匹配。
既然你已经知道如何使用 Hugging Face transformer 模型来检测文本情感,为什么不探索其他用例和语言任务,看看预训练的 LMs 如何提供帮助呢?
Iván Palomares Carrascosa 是一位在 AI、机器学习、深度学习和 LLMs 领域的领袖、作家、演讲者和顾问。他训练和指导他人在实际应用中利用 AI。
了解更多相关话题
免费使用 Lightning AI Studio

图片来源:作者
在这篇文章中,我们将了解一个既免费又用户友好的新云 IDE。它是 Google Colab 的升级版,允许您保存项目、使用必要的插件,并免费在 GPU 上运行生成模型。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 需求
什么是 Lightning AI Studio?
Lightning AI Studio 是一个基于云的 AI 开发平台(类似于 Google Colab),旨在消除为机器学习项目设置本地环境的麻烦。
以下是 Lightning AI Studio 的主要功能:
-
它将流行的机器学习工具集成到一个界面中,因此您无需在不同工具之间切换。这使得构建可扩展的 AI 应用和端点变得更加容易。
-
不需要环境设置。您可以在浏览器中编写代码或连接本地 IDE(VSCode 或 PyCharm)。您还可以轻松切换 CPU 和 GPU,无需环境变更。
-
它支持托管和共享使用 Streamlit、Gradio、React JS 等构建的 AI 应用。它还支持通过协同编码实现多用户合作。
-
它提供了无限存储空间,支持上传和共享文件,以及连接 S3 存储桶。
-
它支持使用数千个 GPU(付费选项)进行大规模模型训练。您可以大规模并行运行超参数调整、数据预处理和模型部署。
-
它提供了本地开发体验,同时利用了云基础设施的强大功能。
-
发现社区模板(Studio),可在几分钟内在您的云端用数据快速部署、微调和训练模型,无需设置。
您的 Jupyter Notebook / VSCode 在云端提供了可扩展的硬件,用于训练大型语言模型和进行快速推理。
入门指南
您可以在 lightning.ai/sign-up 创建一个免费账户。要获得即时验证,请确保使用官方公司或 .edu 邮箱。我使用了 @kdnuggets.com 邮箱,得到了即时访问。
一旦创建了账户,请按照几个简单的步骤自定义您的 Studio 体验。要获得 7 小时的免费 GPU,您需要验证您的电话号码。
完成初步步骤后,你将被引导到一个包含基本 Python 文件的示例项目中。仅需几分钟,你的 Studio 就会准备好处理图像并微调 Renest 模型。要开始,简单地编写代码并执行文件。
用户界面 (UI) 与 VSCode 相似,但右侧面板提供了更多选项。
Lightning AI Studios
Lighting AI 平台提供了由用户设计的项目模板 Studio。这些模板包括代码、环境设置和数据,帮助你启动项目。你可以在平台上找到各种 Studio 模板,如训练、微调、预处理、推理和超参数搜索模板。你可以轻松搜索并浏览这些模板,找到适合你需求的模板。
例如,访问 Mistral 7B API。点击“获取”并等待其完成。
点击run.ipynb文件并运行第一个单元。
访问 Mistral 7B API 后,代码会返回结果。要查看客户端代码,请进入服务器文件夹并打开client.py文件。
我经常使用 VSCode,发现开始使用 Lightning AI Studio 非常简单。
Lightning AI Studio 插件
如果你对 Jupyter Notebook 的 UI 感到舒适,可以通过点击右侧面板上的 Jupyter Notebook 按钮来切换 IDE。右侧面板是你可以找到各种 Lightning AI Studio 插件的地方。
要添加新的插件,点击“+”按钮,然后从 IDE、AI Agents、Training、Serving 和 Webapps 插件中进行选择。
就这么简单。现在你可以享受 VSCode 和 Jupyter Notebook 扩展的 Studio 插件。
结论
Lightning AI Studio 提供了一个完整的平台,满足你的机器学习需求——从实验模型架构到部署应用程序。这个用户友好的平台配备了所有必要的功能,免去拼凑各种工具的麻烦。
你可以利用云计算的强大功能和规模,而无需学习云计算或基础设施管理的复杂性。开发者已经抽象了复杂性,使得即使没有云计算经验的数据科学家也能独立开发和部署解决方案。
无论你是想原型设计一个想法还是构建一个生产级应用程序,Lightning AI Studio 都能满足你的需求。免费层级提供所有核心功能,包括 Studio GPUs,以加速训练。这使得 Lightning AI Studio 成为学习和创建有影响力的机器学习应用程序的理想选择。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个帮助精神疾病学生的 AI 产品。
更多相关话题
使用 Numpy 的 argmax()

而 argmax() 返回... 9?!? 对,没错!
解释 argmax()
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
回想一下 5 个 W:谁,什么,何时,哪里,为什么。
在处理问题时,用正确的“W”来框定问题可能意味着你能否获得所需的答案,或者陷入完全的困惑。
考虑以下内容:
-
你的名字是什么时候?
-
你是做什么的?
-
你住在哪条街上?
这些问题在提出时意义不大,因此你寻找的答案可能不会像预期的那样迅速出现。
当编写 Python 代码并使用 Numpy 的 argmax() 函数时,也可能会出现类似的困惑。argmax 在处理矩阵或任何维数的多维数组并查找最大值时非常有用。然而,argmax 返回的是沿某轴的最大值的索引,而不是最大值本身。
argmax 会告诉你在哪里,而不是什么。这是一个使用 Numpy 库的人经常误解的关键点,可能导致挫折。
理解 argmax()
让我们看看 Numpy 的 argmax 是如何设计的。
根据 Numpy 文档,argmax “[返回沿某轴的最大值的索引]”。
这意味着实际的最大值没有被返回,仅仅是这些最大值的位置。
其重要参数包括从输入数组中查找特定轴的最大值并返回其位置,以及一个特定的轴(这是可选的)。此外,还可以选择传递一个输出数组,以及一个布尔值以保留结果中的任何缩减轴。关于可选的轴参数,如果没有指定,返回的索引将指向展平后的输入数组。
argmax 返回一个原始数组索引的数组,其维度取决于函数的输入。
为什么 argmax()?
根据 Jason Brownlee 在 机器学习大师 的一篇文章:
argmax在机器学习中最常用于找到预测概率最大的类别。[...]
在应用机器学习中,你最常遇到的使用
argmax的情况是寻找数组中结果为最大值的索引。
如果我们考虑类别成员预测的概率,argmax函数可以确定数组中包含最大值的索引位置,从而获得最高概率的预测。这对于机器学习显然是有用的。
让我们看看argmax在实践中的表现。
使用argmax()
让我们来看看argmax的实际应用。
单维度
在以通常的方式导入 Numpy 后,我们创建了一个单维度数组并将其传递给argmax。查看数组和代码,猜测一下你认为输出应该是什么。
import numpy as np
a = [[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 ]]
max_idx = np.argmax(a)
print(max_idx)
9
这个输出符合你的预期吗?
如果你记得argmax返回的是索引而不是值,并且索引从 0 开始,我们可以看到我们得到的是索引 9——实际上是第十个位置——它包含了'10',即数组中的最大值。
明白了吗?
多维度
让我们看看argmax如何在多个维度的数组中工作。
import numpy as np
a = [[ 1, 2, 3, 4, 5 ], [ 6, 7, 8, 9, 10 ]]
max_idx = np.argmax(a)
print(max_idx)
9
现在我们有一个二维数组。我们没有传递轴参数,因此argmax的默认行为是将多维数组展平为一维,并返回该展平数组中最大值的索引。
因此,结果与前面单维度数组的结果相同,现在应该很明显为什么。
指定轴
但是如果我们指定一个轴呢?
首先,回顾一下轴 0 指的是行,而轴 1 指的是列。让我们看看当我们将axis=0传递给argmax时会发生什么。
import numpy as np
a = [[ 1, 2, 3, 4, 5 ], [ 6, 7, 8, 9, 10 ]]
max_idx = np.argmax(a, axis=0)
print(max_idx)
array([1, 1, 1, 1, 1)
这到底是怎么回事?
我们指定了axis=0,因此argmax将返回多维数组行上的最大值。
最大值是什么?如前所述,对于这个数组,它是'10'。
最大值在哪里?它在第二行的最后一列。
由于我们已经指定了我们想知道它在行中的位置(axis=0),对于数组中的每一列,Numpy 报告了最大值出现的行。回顾一下索引从 0 开始,我们可以看到,在这个数组的每一列中,最大值出现在索引为 1 的行,即第二行。查看我们的代码,值'10'的位置似乎argmax是正确的。
如果我们指定axis=1,你期望输出是什么?我将这留给读者作为练习。
总结
在这篇文章中,我们了解了argmax是什么,为什么我们要使用它,并且介绍了几个使用 Numpy 的argmax函数的例子。
你现在应该知道argmax是如何工作的。
Matthew Mayo (@mattmayo13)是数据科学家以及 KDnuggets 的主编,KDnuggets 是一个开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
更多相关内容
使用 NumPy 执行日期和时间计算
原文:
www.kdnuggets.com/using-numpy-to-perform-date-and-time-calculations

作者图片 | Canva
日期和时间是无数数据分析任务的核心,从追踪金融交易到实时监测传感器数据。然而,处理日期和时间的计算常常让人感觉像是在迷宫中探索。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
幸运的是,有了 NumPy,我们很幸运。NumPy 强大的日期和时间功能让这些任务变得轻松,提供了一系列简化过程的方法。
例如,NumPy 允许你轻松创建日期数组,对日期和时间执行算术运算,并且只需几行代码即可在不同的时间单位之间转换。你需要找出两个日期之间的差异吗?NumPy 可以轻松做到。你想将你的时间序列数据重新采样到不同的频率吗?NumPy 能满足你的需求。这种便利和强大使得 NumPy 成为处理日期和时间计算的宝贵工具,将曾经复杂的挑战转变为简单的任务。
本文将指导你使用 NumPy 执行日期和时间计算。我们将介绍datetime是什么以及如何表示,日期和时间通常用于何处,使用它时的常见困难和问题,以及最佳实践。
什么是 DateTime
DateTime 指的是以统一格式表示日期和时间。这包括特定的日历日期和时间,通常精确到秒的分数。这种组合对于准确记录和管理时间数据,如日志中的时间戳、事件调度和进行基于时间的分析,非常重要。
在一般编程和数据分析中,DateTime 通常由专门的数据类型或对象表示,这些对象提供了一种结构化的方式来处理日期和时间。这些对象允许对日期和时间进行轻松的操作、比较和算术运算。
NumPy 和其他库如 pandas 提供了对DateTime操作的强大支持,使得处理各种格式的时间数据以及执行复杂的计算变得轻松而精准。
在 NumPy 中,日期和时间的处理主要围绕 datetime64 数据类型及其相关函数。你可能会想知道为什么这个数据类型叫做 datetime64。这是因为 datetime 已经被 Python 标准库使用了。
以下是它的工作原理:
datetime64 数据类型
-
表示:NumPy 的
datetime64数据类型将日期和时间表示为 64 位整数,提供高效的时间数据存储和操作。 -
格式:
datetime64格式中的日期和时间由一个字符串指定,指示所需的精度,例如,YYYY-MM-DD表示日期或YYYY-MM-DD HH:mm:ss表示到秒的时间戳。
例如:
import numpy as np
# Creating a datetime64 array
dates = np.array(['2024-07-15', '2024-07-16', '2024-07-17'], dtype='datetime64')
# Performing arithmetic operations
next_day = dates + np.timedelta64(1, 'D')
print("Original Dates:", dates)
print("Next Day:", next_day)
datetime64在 NumPy 中的特点
NumPy 的 datetime64 提供了强大的功能来简化多种操作。从灵活的分辨率处理到强大的算术能力,datetime64 使得处理时间数据变得简单高效。
- 分辨率灵活性:
datetime64支持从纳秒到年的各种分辨率。例如,ns(纳秒),us(微秒),ms(毫秒),s(秒),m(分钟),h(小时),D(天),W(周),M(月),Y(年)。
np.datetime64('2024-07-15T12:00', 'm') # Minute resolution
np.datetime64('2024-07-15', 'D') # Day resolution
- 算术操作:对
datetime64对象执行直接的算术运算,例如,添加或减去时间单位,比如为日期添加天数。
date = np.datetime64('2024-07-15')
next_week = date + np.timedelta64(7, 'D')
- 索引和切片:在
datetime64数组上使用标准的 NumPy 索引和切片技术。例如,提取日期范围。
dates = np.array(['2024-07-15', '2024-07-16', '2024-07-17'], dtype='datetime64')
subset = dates[1:3]
- 比较操作:比较
datetime64对象以确定时间顺序。例如:检查一个日期是否在另一个日期之前。
date1 = np.datetime64('2024-07-15')
date2 = np.datetime64('2024-07-16')
is_before = date1 < date2 # True
- 转换函数:在
datetime64和其他日期/时间表示形式之间进行转换。例如:将datetime64对象转换为字符串。
date = np.datetime64('2024-07-15')
date_str = date.astype('str')
你倾向于在哪里使用日期和时间?
日期和时间可以在多个领域中使用,例如金融领域,用于跟踪股票价格、分析市场趋势、评估财务表现、计算回报、评估波动性以及识别时间序列数据中的模式。
你还可以在其他领域使用日期和时间,例如在医疗保健领域,管理带有时间戳的患者记录,用于医疗历史、治疗和药物计划。
场景:分析电子商务销售数据
想象一下你是一名在电子商务公司工作的数据分析师。你有一个包含带有时间戳的销售交易的数据集,你需要分析过去一年的销售模式。以下是你如何利用 NumPy 中的 datetime64:
# Loading and Converting Data
import numpy as np
import matplotlib.pyplot as plt
# Sample data: timestamps of sales transactions
sales_data = np.array(['2023-07-01T12:34:56', '2023-07-02T15:45:30', '2023-07-03T09:12:10'], dtype='datetime64')
# Extracting Specific Time Periods
# Extracting sales data for July 2023
july_sales = sales_data[(sales_data >= np.datetime64('2023-07-01')) & (sales_data < np.datetime64('2023-08-01'))]
# Calculating Daily Sales Counts
# Converting timestamps to dates
sales_dates = july_sales.astype('datetime64[D]')
# Counting sales per day
unique_dates, sales_counts = np.unique(sales_dates, return_counts=True)
# Analyzing Sales Trends
plt.plot(unique_dates, sales_counts, marker='o')
plt.xlabel('Date')
plt.ylabel('Number of Sales')
plt.title('Daily Sales Counts for July 2023')
plt.xticks(rotation=45) # Rotates x-axis labels for better readability
plt.tight_layout() # Adjusts layout to prevent clipping of labels
plt.show()
在这种情况下,datetime64 允许你轻松操作和分析销售数据,提供对每日销售模式的洞察。
使用日期和时间时的常见困难
尽管 NumPy 的 datetime64 是处理日期和时间的强大工具,但它也有其挑战。从解析各种日期格式到管理时区,开发人员通常会遇到几个可能复杂化数据分析任务的障碍。本节突出了这些典型问题的一些例子。
-
解析和转换格式:处理各种日期和时间格式可能很具挑战性,特别是当处理来自多个来源的数据时。
-
时区处理:NumPy 的
datetime64本身不支持时区。 -
分辨率不匹配:数据集的不同部分可能具有不同分辨率的时间戳(例如,有些以天为单位,有些以秒为单位)。
如何进行日期和时间计算
让我们探讨 NumPy 中日期和时间计算的示例,从基本操作到更高级的场景,以帮助你充分利用 datetime64 来满足数据分析需求。
向日期添加天数
这里的目标是演示如何将特定天数(在此情况下为5天)添加到给定日期(2024-07-15)
import numpy as np
# Define a date
start_date = np.datetime64('2024-07-15')
# Add 5 days to the date
end_date = start_date + np.timedelta64(5, 'D')
print("Start Date:", start_date)
print("End Date after adding 5 days:", end_date)
输出:
开始日期:2024-07-15
添加 5 天后的结束日期:2024-07-20
解释:
-
我们使用
np.datetime64定义start_date。 -
使用
np.timedelta64,我们将5天(5,D)添加到start_date以获得end_date。 -
最后,我们打印
start_date和end_date以观察加法的结果。
计算两个日期之间的时间差
计算两个特定日期(2024-07-15T12:00 和 2024-07-17T10:30)之间的时间差(小时)
import numpy as np
# Define two dates
date1 = np.datetime64('2024-07-15T12:00')
date2 = np.datetime64('2024-07-17T10:30')
# Calculate the time difference in hours
time_diff = (date2 - date1) / np.timedelta64(1, 'h')
print("Date 1:", date1)
print("Date 2:", date2)
print("Time difference in hours:", time_diff)
输出:
日期 1:2024-07-15T12:00
日期 2:2024-07-17T10:30
时间差(小时):46.5
解释:
-
使用
np.datetime64定义date1和date2,并指定特定的时间戳。 -
通过从
date1中减去date2并除以np.timedelta64(1, 'h')来计算time_diff,将差值转换为小时。 -
打印原始日期和计算出的时间差(小时)。
处理时区和工作日
计算两个日期之间的工作日数,排除周末和假期。
import numpy as np
import pandas as pd
# Define two dates
start_date = np.datetime64('2024-07-01')
end_date = np.datetime64('2024-07-15')
# Convert to pandas Timestamp for more complex calculations
start_date_ts = pd.Timestamp(start_date)
end_date_ts = pd.Timestamp(end_date)
# Calculate the number of business days between the two dates
business_days = pd.bdate_range(start=start_date_ts, end=end_date_ts).size
print("Start Date:", start_date)
print("End Date:", end_date)
print("Number of Business Days:", business_days)
输出:
开始日期:2024-07-01
结束日期:2024-07-15
工作日数:11
解释:
-
NumPy 和 Pandas 导入:NumPy 被导入为
np,Pandas 被导入为pd,以利用它们的日期和时间处理功能。 -
日期定义:使用 NumPy 的
np.datetime64定义start_date和end_date来指定开始和结束日期(分别为 '2024-07-01' 和 '2024-07-15')。 -
转换为 pandas 时间戳:此转换将
start_date和end_date从np.datetime64转换为 pandas 时间戳 对象(start_date_ts和end_date_ts),以兼容 pandas 更高级的日期处理功能。 -
工作日计算:使用
pd.bdate_range生成start_date_ts和end_date_ts之间的工作日期范围(排除周末)。计算该工作日期范围的大小(元素数量)(business_days),表示两日期之间的工作日数量。 -
打印原始的
start_date和end_date。 -
显示指定日期之间计算的工作日数量(
business_days)。
使用 datetime64 的最佳实践
在 NumPy 中处理日期和时间数据时,遵循最佳实践可以确保你的分析准确、高效且可靠。正确处理datetime64可以防止常见问题并优化数据处理工作流程。以下是一些关键的最佳实践:
-
在处理之前确保所有日期和时间数据都采用一致的格式。这有助于避免解析错误和不一致。
-
选择与你的数据需求匹配的分辨率(‘D’,‘h’,‘m’等)。避免混合不同的分辨率,以防计算不准确。
-
使用
datetime64表示缺失或无效日期,并在分析前预处理数据以解决这些值。 -
如果你的数据包含多个时区,请在处理工作流的早期阶段将所有时间戳标准化为一个通用时区。
-
检查你的日期是否在
datetime64的有效范围内,以避免溢出错误和意外结果。
结论
总结来说,NumPy 的 datetime64 数据类型提供了一个强大的框架,用于在数值计算中管理日期和时间数据。它为各种应用提供了灵活性和计算效率,例如数据分析、模拟等。
我们探讨了如何使用 NumPy 进行日期和时间计算,深入了解了核心概念及其使用 datetime64 数据类型的表现。我们讨论了日期和时间在数据分析中的常见应用。同时,我们还审视了在 NumPy 中处理日期和时间数据的常见困难,例如格式不一致、时区问题和分辨率不匹配。
遵循这些最佳实践可以确保你对datetime64的使用既准确又高效,从而为你的数据提供更可靠和有意义的见解。
Shittu Olumide 是一名软件工程师和技术作家,热衷于利用前沿技术来撰写引人入胜的叙述,对细节有敏锐的洞察力,并擅长简化复杂的概念。你还可以在Twitter上找到 Shittu。
更多相关内容
同时使用 Python 和 R:3 种主要方法
评论
作者:Ajay Ohri,DecisionStats。

我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
为什么有人想在同一软件中使用 R 和 Python?难道我们还没有看到足够多的关于哪种语言更好的辩论吗?即使在这个网站(一个行业风向标),我也能找到四篇这样的文章,这里 是 Datacamp 的,Stichfix,辩论 和 KDnuggets 调查。好吧,如果数据科学和数据科学家不能决定选择哪个数据来帮助他们决定使用哪种语言,那么这里有一篇关于如何同时使用这两者的文章。
数据科学家:
思考 Python 和 R
而不仅仅是 PYTHON 或 R
这里是一些这样做的理由:
-
两者都是稳定的语言,具有有趣的互补特性。你可以在一种语言中获得更好的包,然后将它们与另一种语言中的数据结合起来。例如,使用 R 中的时间序列预测(forecast::auto.arima)和决策树(
www.statmethods.net/<wbr>advstats/cart.html),然后在 Python 中进行数据处理。 -
这两种语言相互借鉴。即使是经验丰富的包开发者,如 Hadley Wickham(Rstudio),也借鉴了 Beautiful Soup(python)来制作用于网页抓取的rvest。Yhat 从
sqldf中借鉴了代码来制作pandasql。开发者可以专注于创新,而不是在另一种语言中重新发明轮子。 -
客户不在乎代码是用哪种语言编写的,客户关心的是洞察力。
-
你不太可能因错误、功能请求或版本兼容性问题而被束缚。
-
对数据科学家来说,掌握这两种语言更具吸引力(或者像我们这些年长的人喜欢在《哈佛商业评论》宣布data scientist 为最性感职业之前说的那样,更酷)。
-
数据科学中只有四种主要语言(~91% 根据 KDnuggets 调查),每个人都可以从自己的语言中使用 SQL。SQL 是没有争议的。
那么如何做到这一点呢?截至 2015 年 12 月,有三种主要方法可以同时使用 Python 和 R。
-
使用 Python 包
rpy2在 Python 中使用 R。你可以在 这里 查看示例。你也可以使用 rPython 包在 R 中使用 Python。 -
使用 Jupyter 与 IR 内核 - Jupyter 项目以 Julia Python 和 R 命名,使 iPython 的交互性扩展到其他语言。
-
使用 Beaker notebook - 受 Jupyter 启发,Beaker Notebook 允许你在一个代码块中切换一种语言,在另一个代码块中切换另一种语言,以简化共享对象(数据)的传递。
我希望我能说所有这些方法都简单而流畅,但实际上并非如此。我喜欢 Python 在数据清洗中的强大功能,也喜欢 R 在统计学中的丰富包和函数库。将来 R 和 Python 的结合是否会增长?让我们拭目以待。但如果你不知道,你还可以使用SAS 语言与 R 和 Python(使用 Java)。这确实很酷。
 简介: Ajay Ohri 是分析初创公司 DECISIONSTATS 的创始人。他是《 R for Business Analytics》和《 R for Cloud Computing》的作者。
简介: Ajay Ohri 是分析初创公司 DECISIONSTATS 的创始人。他是《 R for Business Analytics》和《 R for Cloud Computing》的作者。
相关:
-
将 Python 和 R 集成到数据分析流程中,第一部分
-
数据科学编程:Python 与 R 的对比
-
R 与 Python 在数据科学中的比较:赢家是…
更多相关内容
使用 SQL 理解数据科学职业趋势
原文:
www.kdnuggets.com/using-sql-to-understand-data-science-career-trends

图片由作者提供
在数据成为新石油的世界中,理解数据科学职业的细微差别比以往任何时候都更重要。无论你是寻找机会的数据爱好者还是探索机会的老手,使用 SQL 都能提供数据科学就业市场的见解。
我希望你急于了解哪些数据科学职位最具吸引力,或者哪些职位提供最丰厚的薪资。或者,也许你在想经验水平如何与数据科学平均薪资关联?
在本文中,我们将深入数据科学就业市场,解答所有这些问题(及更多)。让我们开始吧!
数据集薪资趋势
我们将在本文中使用的数据集旨在揭示 2021 到 2023 年的数据科学领域薪资模式。通过重点关注工作经历、职位和公司位置等元素,它提供了该行业薪资分布的重要见解。
本文将回答以下问题:
-
不同经验水平的平均薪资情况如何?
-
数据科学中最常见的职位名称是什么?
-
薪资分布如何随着公司规模变化?
-
数据科学职位主要地理位置在哪里?
-
哪些职位在数据科学中提供最高薪资?
你可以从Kaggle下载这些数据。
1. 不同经验水平的平均薪资情况如何?
在这个 SQL 查询中,我们正在寻找不同经验水平的平均薪资。GROUP BY 子句按经验水平对数据进行分组,AVG 函数计算每个组的平均薪资。
这有助于了解领域经验如何影响收入潜力,这对你规划你的数据科学职业路径至关重要。我们来看一下代码。
SELECT experience_level, AVG(salary_in_usd) AS avg_salary
FROM salary_data
GROUP BY experience_level;
现在让我们用 Python 可视化这个输出。
这里是代码。
# Import required libraries for plotting
import matplotlib.pyplot as plt
import seaborn as sns
# Set up the style for the graphs
sns.set(style="whitegrid")
# Initialize the list for storing graphs
graphs = []
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=df, estimator=lambda x: sum(x) / len(x))
plt.title('Average Salary by Experience Level')
plt.xlabel('Experience Level')
plt.ylabel('Average Salary (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
现在让我们比较入门级和有经验的薪资以及中级和高级薪资。
从入门级和有经验的开始。这里是代码。
# Filter the data for Entry_Level and Experienced levels
entry_experienced = df[df['experience_level'].isin(['Entry_Level', 'Experienced'])]
# Filter the data for Mid-Level and Senior levels
mid_senior = df[df['experience_level'].isin(['Mid-Level', 'Senior'])]
# Plotting the Entry_Level vs Experienced graph
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=entry_experienced, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0)
plt.title('Average Salary: Entry_Level vs Experienced')
plt.xlabel('Experience Level')
plt.ylabel('Average Salary (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
这里是图表。
现在让我们绘制中级和高级职位的图表。以下是代码。
# Plotting the Mid-Level vs Senior graph
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=mid_senior, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0)
plt.title('Average Salary: Mid-Level vs Senior')
plt.xlabel('Experience Level')
plt.ylabel('Average Salary (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
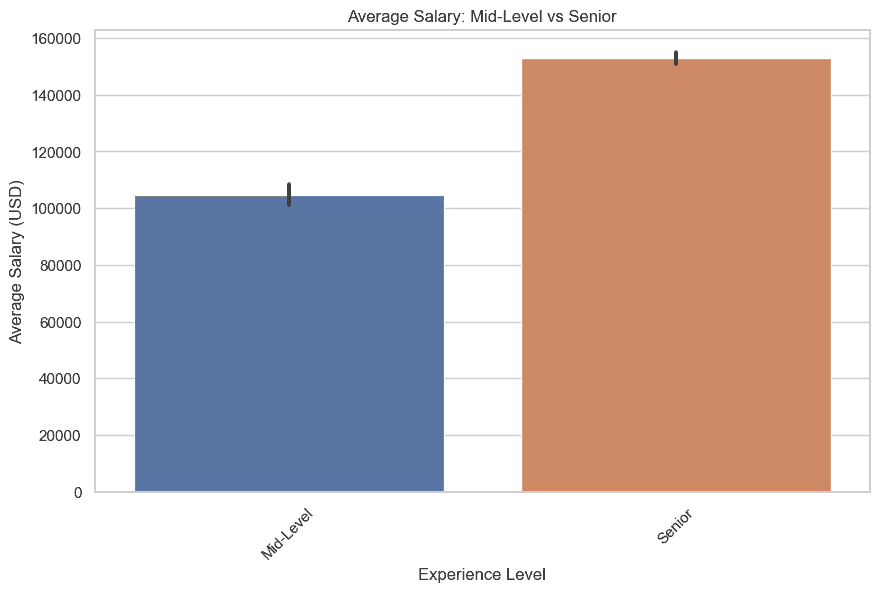
2. 数据科学领域最常见的职位名称是什么?
在这里,我们提取了数据科学领域前 10 个最常见的职位名称。COUNT 函数计算每个职位名称的出现次数,结果按降序排列,以便将最常见的职位排在前面。
这些信息让你对职位市场的需求有一个了解,帮助你识别你可以目标的潜在职位。让我们看看代码。
SELECT job_title, COUNT(*) AS job_count
FROM salary_data
GROUP BY job_title
ORDER BY job_count DESC
LIMIT 10;
好了,现在是时候用 Python 可视化这个查询了。
这是代码。
plt.figure(figsize=(12, 8))
sns.countplot(y='job_title', data=df, order=df['job_title'].value_counts().index[:10])
plt.title('Most Common Job Titles in Data Science')
plt.xlabel('Job Count')
plt.ylabel('Job Title')
graphs.append(plt.gcf())
plt.show()
让我们看看图表。
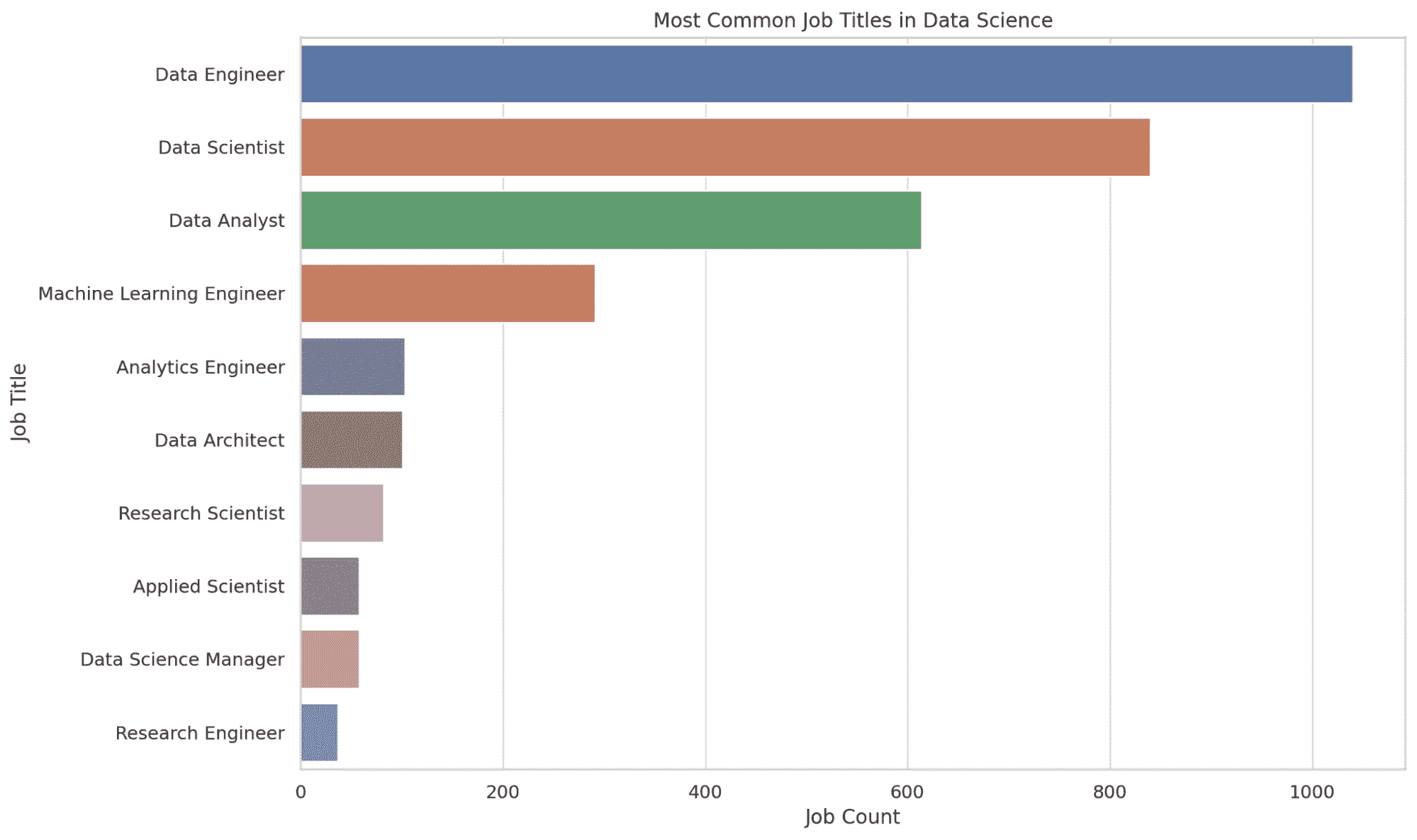
3. 薪资分布如何随着公司规模的变化而变化?
在这个查询中,我们提取了每个公司规模分组的平均工资、最低工资和最高工资。使用如 AVG、MIN 和 MAX 等聚合函数有助于提供关于公司规模的薪资全景视图。
这些数据非常重要,因为它帮助你了解根据你打算加入的公司的规模,你可以期望的潜在收入,让我们看看代码。
SELECT company_size, AVG(salary_in_usd) AS avg_salary, MIN(salary_in_usd) AS min_salary, MAX(salary_in_usd) AS max_salary
FROM salary_data
GROUP BY company_size;
现在让我们用 Python 可视化这个查询。
这是代码。
plt.figure(figsize=(12, 8))
sns.barplot(x='company_size', y='salary_in_usd', data=df, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0, order=['Small', 'Medium', 'Large'])
plt.title('Salary Distribution by Company Size')
plt.xlabel('Company Size')
plt.ylabel('Average Salary (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
这是输出结果。
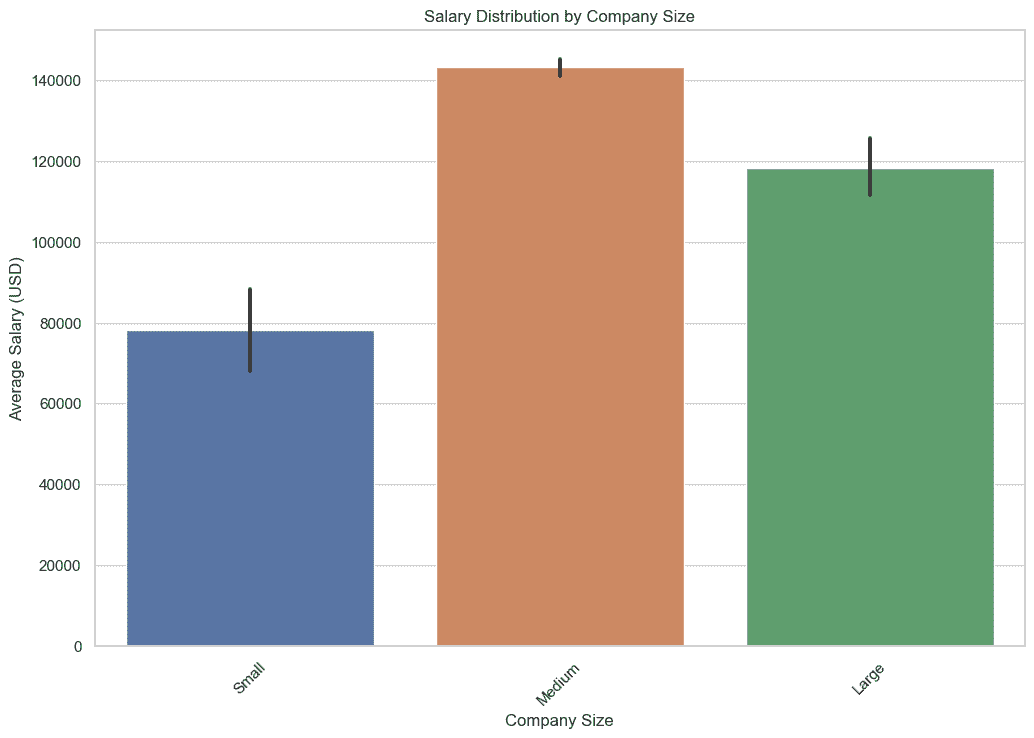
4. 数据科学职位主要地理分布在哪里?
在这里,我们确定了提供最多数据科学职位机会的前 10 个地点。我们使用 COUNT 函数来确定每个地点的职位发布数量,并按降序排列,以突出机会最多的地区。
拥有这些信息可以使读者了解数据科学职位的地理中心,有助于潜在的搬迁决策。让我们看看代码。
SELECT company_location, COUNT(*) AS job_count
FROM salary_data
GROUP BY company_location
ORDER BY job_count DESC
LIMIT 10;
现在让我们用 Python 创建上述代码的图表。
plt.figure(figsize=(12, 8))
sns.countplot(y='company_location', data=df, order=df['company_location'].value_counts().index[:10])
plt.title('Geographical Distribution of Data Science Jobs')
plt.xlabel('Job Count')
plt.ylabel('Company Location')
graphs.append(plt.gcf())
plt.show()
让我们看看下面的图表。
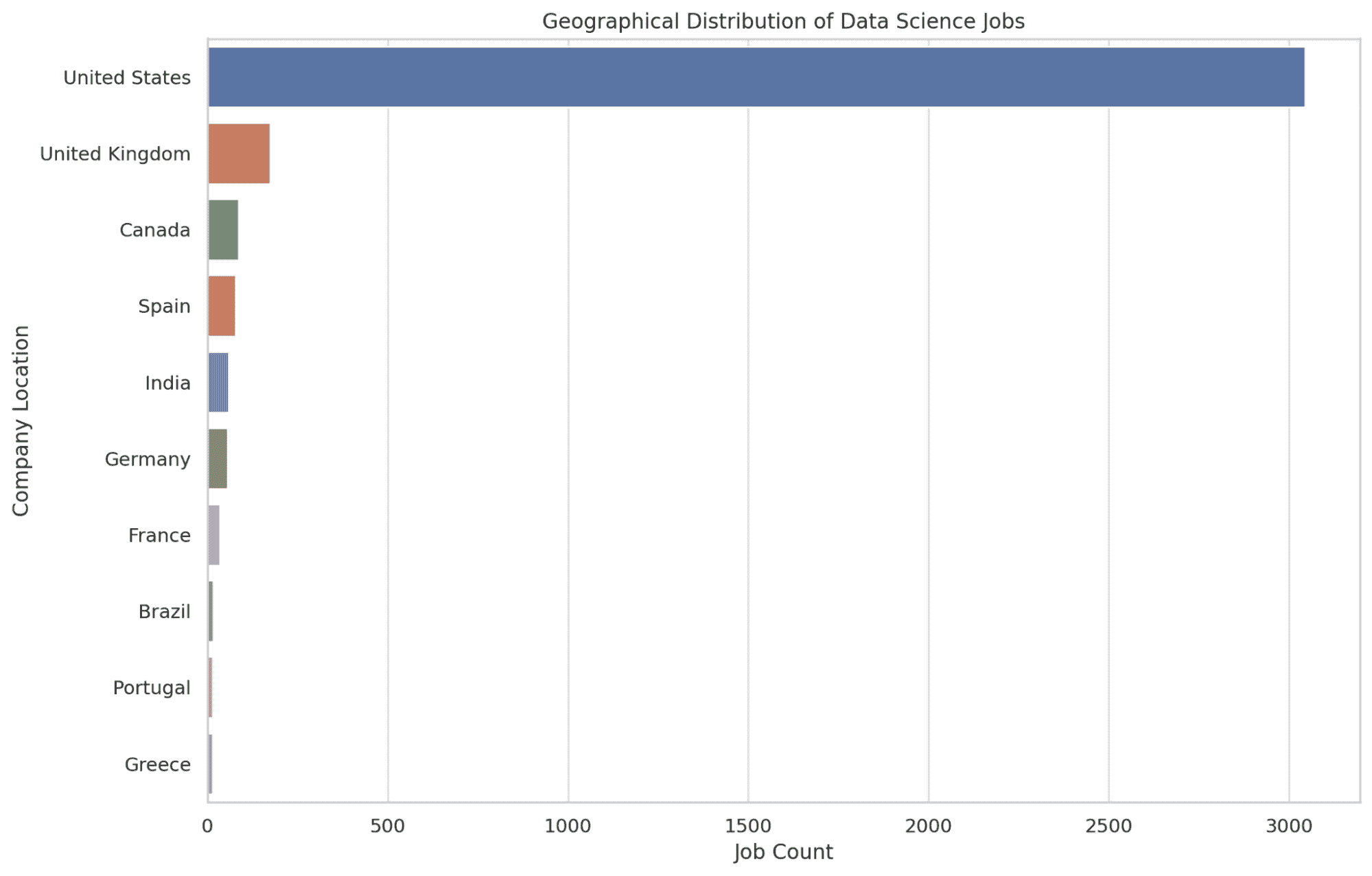
5. 哪些职位在数据科学领域提供最高薪资?
在这里,我们识别数据科学领域薪资最高的前 10 个职位名称。通过使用 AVG,我们计算每个职位名称的平均薪资,并按平均薪资降序排序,以突出最有利可图的职位。
你可以通过查看这些数据来设定你的职业目标。让我们继续了解读者如何为这些数据创建 Python 可视化。
SELECT job_title, AVG(salary_in_usd) AS avg_salary
FROM salary_data
GROUP BY job_title
ORDER BY avg_salary DESC
LIMIT 10;
这是输出结果。
(这里我们不能使用照片,因为我们上面已经添加了 4 张照片,剩下的一张用作缩略图。我们是否可以使用类似下面的表格来展示输出结果?)
| 排名 | 职位名称 | 平均薪资 (美元) |
|---|---|---|
| 1 | 数据科学技术主管 | 375,000.00 |
| 2 | 云数据架构师 | 250,000.00 |
| 3 | 数据负责人 | 212,500.00 |
| 4 | 数据分析主管 | 211,254.50 |
| 5 | 首席数据科学家 | 198,171.13 |
| 6 | 数据科学总监 | 195,140.73 |
| 7 | 首席数据工程师 | 192,500.00 |
| 8 | 机器学习软件工程师 | 192,420.00 |
| 9 | 数据科学经理 | 191,278.78 |
| 10 | 应用科学家 | 190,264.48 |
这次,让我们尝试自己创建一个图表。
提示:你可以在 ChatGPT 中使用以下提示来生成这个图表的 Python 代码:
<SQL Query here>
Create a Python graph to visualize the top 10 highest-paying job titles in Data Science, similar to the insights gathered from the given SQL query above.
最后思考
当我们结束对数据科学职业世界各种领域的探索时,希望 SQL 能成为一个值得信赖的向导,帮助你发掘支持职业决策的宝贵见解。
我希望你现在感到更加自信,不仅在规划你的职业道路方面,还在使用 SQL 将原始数据转化为强大叙事方面。祝愿你踏入充满机遇的未来,以数据为指南针,以 SQL 为引导力量!
感谢阅读!
内特·罗西迪 是一名数据科学家和产品策略专家。他还是一位兼职教授,教授分析课程,并且是StrataScratch,一个帮助数据科学家准备面试的在线平台的创始人,提供来自顶级公司的真实面试问题。可以通过Twitter: StrataScratch或LinkedIn与他联系。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关话题
使用 SQL 与 Python: SQLAlchemy 和 Pandas
原文:
www.kdnuggets.com/using-sql-with-python-sqlalchemy-and-pandas

作者提供的图像
作为数据科学家,你需要 Python 来进行详细的数据分析、数据可视化和建模。然而,当你的数据存储在关系数据库中时,你需要使用 SQL(结构化查询语言)来提取和操作数据。但你如何将 SQL 与 Python 集成以发挥数据的最终潜力呢?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
在本教程中,我们将学习结合 SQL 的强大功能与 Python 的灵活性,使用 SQLAlchemy 和 Pandas。我们将学习如何连接数据库、使用 SQLAlchemy 执行 SQL 查询,以及使用 Pandas 分析和可视化数据。
使用以下命令安装 Pandas 和 SQLAlchemy:
pip install pandas sqlalchemy
1. 将 Pandas DataFrame 保存为 SQL 表
为了使用 CSV 数据集创建 SQL 表,我们将:
-
使用 SQLAlchemy 创建一个 SQLite 数据库。
-
使用 Pandas 加载 CSV 数据集。countries_poluation 数据集包含了 2017 年至 2023 年间全球所有国家的空气质量指数 (AQI)。
-
将所有 AQI 列从对象类型转换为数值类型,并删除包含缺失值的行。
# Import necessary packages
import pandas as pd
import psycopg2
from sqlalchemy import create_engine
# creating the new db
engine = create_engine(
"sqlite:///kdnuggets.db")
# read the CSV dataset
data = pd.read_csv("/work/air_pollution new.csv")
col = ['2017', '2018', '2019', '2020', '2021', '2022', '2023']
for s in col:
data[s] = pd.to_numeric(data[s], errors='coerce')
data = data.dropna(subset=[s])
- 将 Pandas dataframe 保存为 SQL 表。
to_sql函数需要一个表名和引擎对象。
# save the dataframe as a SQLite table
data.to_sql('countries_poluation', engine, if_exists='replace')
结果是,你的 SQLite 数据库保存在你的文件目录中。
注意: 我在本教程中使用 Deepnote 来无缝运行 Python 代码。Deepnote 是一个免费的 AI 云笔记本,它将帮助你快速运行任何数据科学代码。
2. 使用 Pandas 加载 SQL 表
为了将整个 SQL 数据库表加载为 Pandas dataframe,我们将:
-
通过提供数据库 URL 来建立与我们的数据库的连接。
-
使用
pd.read_sql_table函数加载整个表并将其转换为 Pandas dataframe。该函数需要表 anime、引擎对象和列名。 -
显示前 5 行。
import pandas as pd
import psycopg2
from sqlalchemy import create_engine
# establish a connection with the database
engine = create_engine("sqlite:///kdnuggets.db")
# read the sqlite table
table_df = pd.read_sql_table(
"countries_poluation",
con=engine,
columns=['city', 'country', '2017', '2018', '2019', '2020', '2021', '2022',
'2023']
)
table_df.head()
SQL 表已成功加载为数据框。这意味着你现在可以使用流行的 Python 包,如 Seaborn、Matplotlib、Scipy、Numpy 等来进行数据分析和可视化。

3. 使用 Pandas 运行 SQL 查询
我们可以使用 pd.read_sql 函数访问整个数据库,而不仅仅是限制在一个表中。只需编写简单的 SQL 查询并提供引擎对象。
SQL 查询将显示“countries_population”表中的两列,按“2023”列排序,并显示前 5 个结果。
# read table data using sql query
sql_df = pd.read_sql(
"SELECT city,[2023] FROM countries_poluation ORDER BY [2023] DESC LIMIT 5",
con=engine
)
print(sql_df)
我们找到了世界上空气质量最差的前五个城市。
city 2023
0 Lahore 97.4
1 Hotan 95.0
2 Bhiwadi 93.3
3 Delhi (NCT) 92.7
4 Peshawar 91.9
4. 使用 Pandas 处理 SQL 查询结果
我们还可以使用 SQL 查询结果进行进一步分析。例如,使用 Pandas 计算前五个城市的平均值。
average_air = sql_df['2023'].mean()
print(f"The average of top 5 cities: {average_air:.2f}")
输出:
The average of top 5 cities: 94.06
或者,通过指定 x 和 y 参数以及绘图类型来创建条形图。
sql_df.plot(x="city",y="2023",kind = "barh");
结论
使用 SQLAlchemy 与 Pandas 的可能性是无限的。你可以使用 SQL 查询进行简单的数据分析,但要可视化结果或甚至训练机器学习模型,你必须将其转换为 Pandas 数据框。
在本教程中,我们学习了如何将 SQL 数据库加载到 Python 中,进行数据分析,并创建可视化。如果你喜欢本指南,你还会喜欢 '在 Python 中使用 SQLite 数据库的指南',该指南深入探讨了如何使用 Python 的内置 sqlite3 模块。
Abid Ali Awan (@1abidaliawan) 是一位认证数据科学专家,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为面临心理健康问题的学生开发人工智能产品。
更多相关主题
使用迁移学习来提升模型性能
原文:
www.kdnuggets.com/using-transfer-learning-to-boost-model-performance

你是否考虑过如何在不开发新模型的情况下提升机器学习模型的性能?这就是迁移学习发挥作用的地方。在本文中,我们将概述迁移学习及其优点和挑战。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
什么是迁移学习?
迁移学习意味着一个为一个任务训练的模型可以用于另一个类似的任务。然后你可以使用一个预训练模型,并根据所需任务对其进行修改。让我们讨论迁移学习的各个阶段。
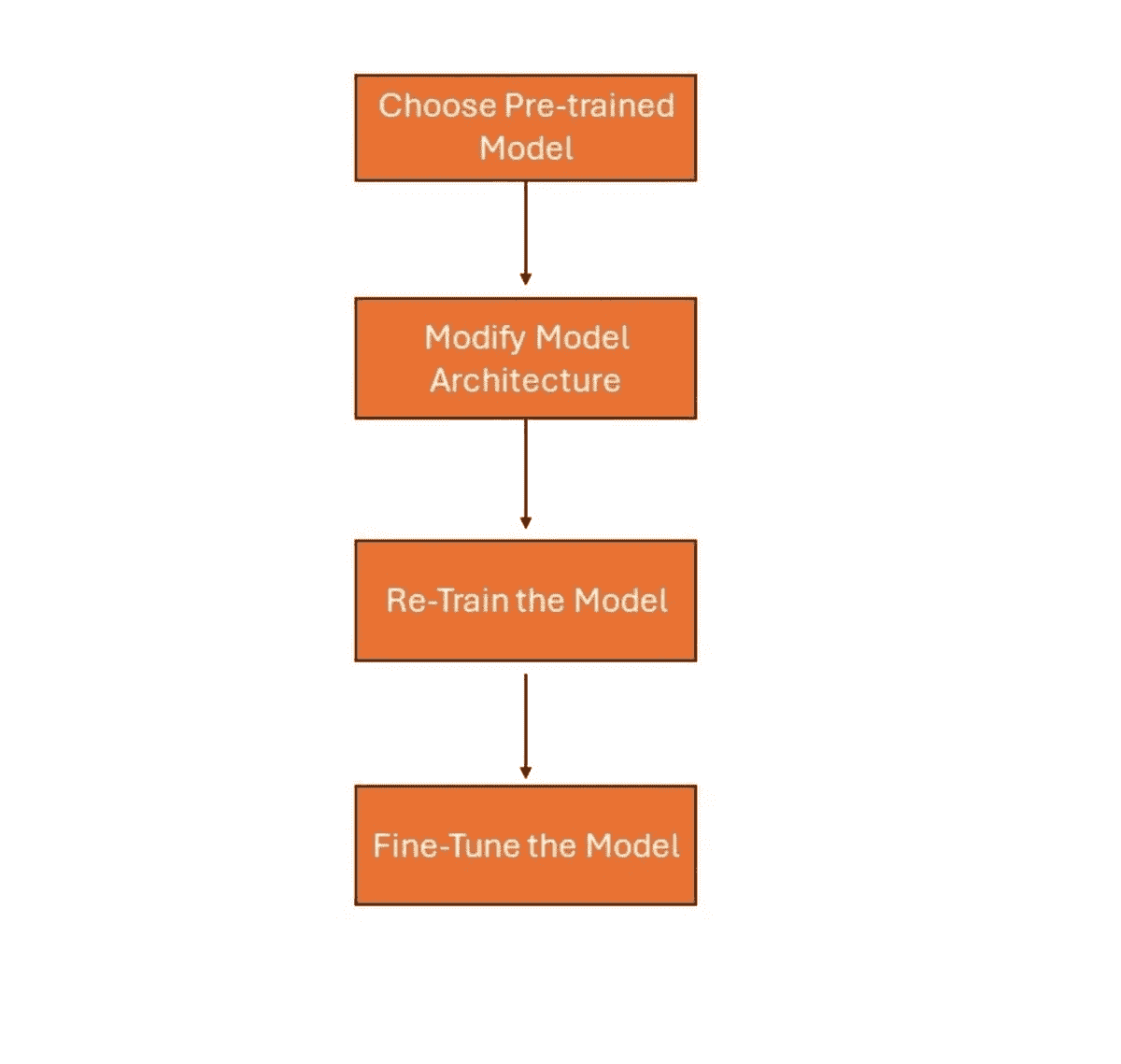 图片来源:作者
图片来源:作者
-
选择预训练模型:选择一个在类似任务上用大型数据集训练过的模型。
-
修改模型架构:根据你的具体任务调整预训练模型的最终层。如果需要,还可以添加新的层。
-
重新训练模型:在你的新数据集上训练修改后的模型。这使得模型能够学习你特定任务的细节,同时也利用了在原始训练中学到的特征。
-
微调模型:解冻一些预训练层,继续训练你的模型。这使得模型能够通过微调权重更好地适应新任务。
迁移学习的好处
迁移学习提供了几个重要的优势:
-
节省时间和资源:微调需要的时间和计算资源较少,因为预训练模型已经针对特定数据集进行了大量迭代训练。这个过程已经捕捉了重要特征,因此减少了新任务的工作量。
-
提高性能:预训练模型从大量数据集中学习,因此具有更好的泛化能力。这使得在新的任务上,即使新数据集相对较小,也能提高性能。初始训练中获得的知识有助于实现更高的准确性和更好的结果。
-
需要更少的数据:转移学习的一个主要优势是其在较小数据集上的有效性。预训练模型已经获得了有用的模式和特征信息。因此,即使给定的数据很少,它也能表现得相当不错。
转移学习的类型
转移学习可以分为三种类型:
特征提取
特征提取意味着使用模型在新数据上学到的特征。例如,在图像分类中,我们可以利用预定义卷积神经网络中的特征来搜索图像中的重要特征。以下是一个使用 Keras 中的预训练 VGG16 模型进行图像特征提取的示例:
import numpy as np
from tensorflow.keras.applications import VGG16
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.vgg16 import preprocess_input
# Load pre-trained VGG16 model (without the top layers for classification)
base_model = VGG16(weights='imagenet', include_top=False)
# Function to extract features from an image
def extract_features(img_path):
img = image.load_img(img_path, target_size=(224, 224)) # Load image and resize
x = image.img_to_array(img) # Convert image to numpy array
x = np.expand_dims(x, axis=0) # Add batch dimension
x = preprocess_input(x) # Preprocess input according to model's requirements
features = base_model.predict(x) # Extract features using VGG16 model
return features.flatten() # Flatten to a 1D array for simplicity
# Example usage
image_path = 'path_to_your_image.jpg'
image_features = extract_features(image_path)
print(f"Extracted features shape: {image_features.shape}")
微调
微调涉及调整特征提取步骤以及新模型的某些方面,以匹配特定任务。这种方法在中等规模的数据集上最为有效,并且当你希望提升模型在特定任务上的能力时非常有用。例如,在自然语言处理(NLP)中,一个标准的 BERT 模型可能会被调整或在少量医学文本上进一步训练,以更好地完成医学实体识别。以下是一个使用 BERT 进行情感分析的示例,其中在自定义数据集上进行了微调:
from transformers import BertTokenizer, BertForSequenceClassification, AdamW
import torch
from torch.utils.data import DataLoader, TensorDataset
# Example data (replace with your dataset)
texts = ["I love this product!", "This is not what I expected.", ...]
labels = [1, 0, ...] # 1 for positive sentiment, 0 for negative sentiment, etc.
# Load pre-trained BERT model and tokenizer
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=2) # Example: binary classification
# Tokenize input texts and create DataLoader
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
dataset = TensorDataset(inputs['input_ids'], inputs['attention_mask'], torch.tensor(labels))
dataloader = DataLoader(dataset, batch_size=16, shuffle=True)
# Fine-tuning parameters
optimizer = AdamW(model.parameters(), lr=1e-5)
# Fine-tune BERT model
model.train()
for epoch in range(3): # Example: 3 epochs
for batch in dataloader:
optimizer.zero_grad()
input_ids, attention_mask, target = batch
outputs = model(input_ids, attention_mask=attention_mask, labels=target)
loss = outputs.loss
loss.backward()
optimizer.step()
领域适应
领域适应提供了如何利用从预训练模型的源领域获得的知识应用到不同目标领域的见解。当源领域和目标领域在特征、数据分布或甚至语言上有所不同时,这种方法是必需的。例如,在情感分析中,我们可能会将从产品评论中学到的情感分类器应用于社交媒体帖子,因为这两者使用了非常不同的语言。以下是一个将情感分析从产品评论适应到社交媒体帖子的示例:
# Function to adapt text style
def adapt_text_style(text):
# Example: replace social media language with product review-like language
adapted_text = text.replace("excited", "positive").replace("#innovation", "new technology")
return adapted_text
# Example usage of domain adaptation
social_media_post = "Excited about the new tech! #innovation"
adapted_text = adapt_text_style(social_media_post)
print(f"Adapted text: {adapted_text}")
# Use sentiment classifier trained on product reviews
# Example: sentiment_score = sentiment_classifier.predict(adapted_text)
预训练模型
预训练模型是已经在大规模数据集上训练过的模型。它们从广泛的数据中捕获知识和模式。这些模型被用作其他任务的起点。让我们讨论一些常见的在机器学习中使用的预训练模型应用。
VGG(视觉几何组)
VGG 的架构包括多个 3×3 的卷积滤波器层和池化层。它能够识别图像中的边缘和形状等详细特征。通过在大规模数据集上训练,VGG 学会了识别图像中的不同物体。它可以用于目标检测和图像分割。
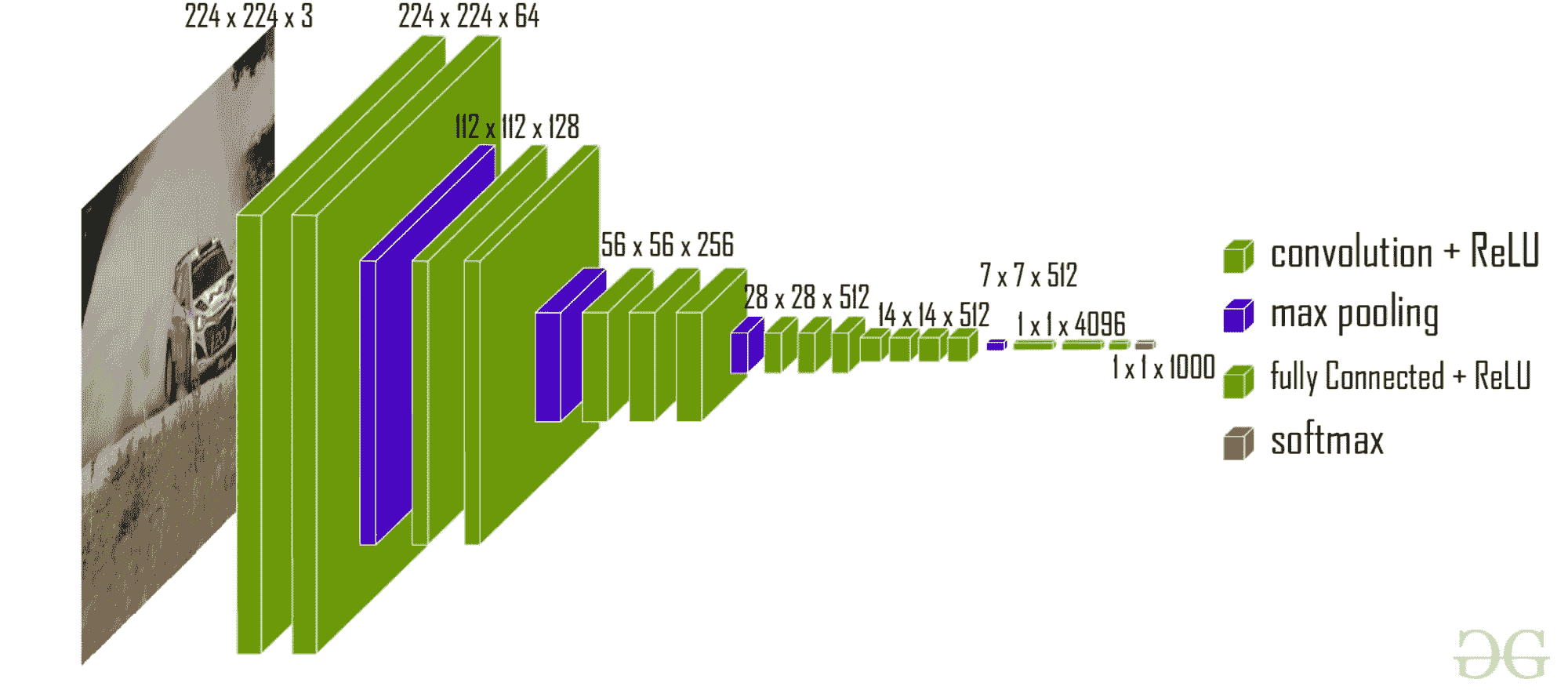 VGG-16 | CNN 模型(来源:GeeksforGeeks)
VGG-16 | CNN 模型(来源:GeeksforGeeks)
ResNet(残差网络)
ResNet 使用残差连接来训练模型。这些连接使梯度更容易在网络中流动。这可以防止梯度消失问题,帮助网络有效训练。ResNet 能够成功训练具有数百层的模型。ResNet 在图像分类和人脸识别等任务中表现优异。
 ResNet-50 架构(来源:研究论文)
ResNet-50 架构(来源:研究论文)
BERT(双向编码器表示模型)
BERT 用于自然语言处理应用。它使用基于变换器的模型来理解句子中词汇的上下文。它学习猜测缺失的词汇并理解句子意义。BERT 可用于情感分析、问答和命名实体识别。
 BERT 架构的高层次视图(来源:研究论文)
BERT 架构的高层次视图(来源:研究论文)
微调技术
层冻结
层冻结意味着选择预训练模型中的某些层,并在用新数据训练时防止这些层发生变化。这是为了保留模型从原始训练中学到的有用模式和特征。通常,我们会冻结捕捉图像中边缘或文本中基本结构的早期层。
学习率调整
调整学习率对于平衡模型已学到的内容和新数据非常重要。通常,微调时使用的学习率低于最初使用大数据集时的学习率。这有助于模型适应新数据,同时保持大部分已学习的权重。
挑战与注意事项
让我们探讨迁移学习的挑战以及如何解决这些问题。
-
数据集大小和领域迁移:在微调时,应当有充足的数据用于相关任务,同时微调通用模型时,这种方法的缺点是新的数据集可能较小或与模型最初适应的数据差异较大。为了解决这个问题,可以添加更多与模型已经训练过的数据更相关的数据。
-
超参数调整:在使用预训练模型时,调整超参数非常重要。这些参数相互依赖,决定了模型的表现如何。可以使用网格搜索等技术或自动化工具来寻找最优的超参数设置,从而在验证数据上获得高性能。
-
计算资源:深度神经网络的微调计算上要求很高,因为这些模型可能拥有数百万个参数。训练和预测输出需要强大的加速器,如 GPU 或 TPU。这些需求通常由云计算平台来解决。
总结
总之,迁移学习在提升人工智能模型性能的各个应用领域中,作为一块基石。通过利用像 VGG、ResNet、BERT 等预训练模型,实践者可以有效地利用现有知识来应对图像分类、自然语言处理、医疗保健、自动驾驶系统等复杂任务。
Jayita Gulati 是一位对构建机器学习模型充满热情的机器学习爱好者和技术作家。她拥有利物浦大学计算机科学硕士学位。
更多相关话题
使用 ‘What-If 工具’ 调查机器学习模型
原文:
www.kdnuggets.com/2019/06/using-what-if-tool-investigate-machine-learning-models.html
评论
由 Parul Pandey 编写。

在可解释和可理解的机器学习时代,仅仅训练模型并获取预测结果是不够的。为了真正产生影响并获得良好的结果,我们还应该能够探查和调查我们的模型。此外,在继续使用模型之前,还应清楚地考虑算法公平性约束和偏差。
调查模型需要提出很多问题,并且需要具有侦探般的洞察力来探查和寻找模型中的问题和不一致之处。此外,这种任务通常复杂,需要编写大量的自定义代码。幸运的是,What-If 工具的创建解决了这一问题,使得广泛的用户能够轻松准确地检查、评估和调试机器学习系统。
What-If 工具 (WIT)
What-If 工具 是一个互动式可视化工具,旨在调查机器学习模型。简称 WIT,它通过让人们检查、评估和比较机器学习模型来帮助理解分类或回归模型。由于其用户友好的界面和对复杂编码的较少依赖,从开发者、产品经理、研究人员到学生,任何人都可以用它来达到自己的目的。
WIT 是 Google 在 PAIR(人类与 AI 研究)计划下发布的开源可视化工具。PAIR 将 Google 的研究人员聚集在一起,研究和重新设计人们与 AI 系统互动的方式。
该工具可以通过 TensorBoard 访问,也可以作为扩展在 Jupyter 或 Colab 笔记本中使用。
优点
该工具的目的是通过仅仅使用一个可视化界面,给人们提供一种简单、直观且强大的方式来操作训练好的机器学习模型。以下是 WIT 的主要优点。
 使用 What-If 工具可以做什么?
使用 What-If 工具可以做什么?
我们将在使用该工具的示例演示中覆盖以上所有要点。
演示
为了展示 What-If 工具的功能,PAIR 团队发布了一套使用预训练模型的demos。你可以在笔记本中运行这些演示,也可以直接通过网页运行。
试试 What-If 工具吧!
使用
WIT 可以在Jupyter 或 Colab 笔记本中使用,也可以在TensorBoard网页应用中使用。这一点在文档中解释得非常清楚,我强烈建议你阅读,因为在这篇简短的文章中无法解释整个过程。
整个概念是先训练一个模型,然后使用 What-If 工具可视化训练好的分类器在测试数据上的结果。
在 TensorBoard 中使用 WIT
要在 TensorBoard 中使用 WIT,你的模型需要通过TensorFlow 模型服务进行服务,且待分析的数据必须以TFRecords 文件的形式存储在磁盘上。有关更多细节,请参阅文档。
在笔记本中使用 WIT
要在笔记本中访问 WIT,你需要一个 WitConfigBuilder 对象来指定待分析的数据和模型。文档 提供了在笔记本中使用 WIT 的逐步指南。

你还可以使用一个演示笔记本并编辑代码来包括你的数据集以开始工作。
演练
现在让我们通过一个例子来探索 WIT 工具的功能。这个例子取自网站上提供的演示,名为 收入分类,其中我们需要根据个人的普查信息预测其年收入是否超过 $50k。数据集属于UCI 人口普查数据集,包含了年龄、婚姻状况和教育水平等多个属性。
概述
让我们开始对数据集进行一些探索。这里是一个链接,可以跟随网络演示进行操作。
WIT 包含两个主要面板。右侧面板包含加载的数据集中的单个数据点的可视化。
在这种情况下,蓝点是模型推断收入低于 50k 的人,而红点是模型推断收入高于 50k 的人。默认情况下,WIT 使用正向分类阈值为 0.5。这意味着如果推断分数为 0.5 或更高,该数据点被认为属于正类,即高收入。
这里值得注意的是,数据集在Facets Dive中进行了可视化。Facets Dive 是FACETS工具的一部分,该工具由 PAIR 团队开发,帮助我们理解数据的各种特征并进行探索。如果你对这个工具不熟悉,可以参考我之前写的这篇文章,了解 FACETS 的功能。
还可以通过从下拉菜单中选择字段,以不同的方式组织数据点,包括混淆矩阵、散点图、直方图和小型多个图。以下是一些示例。
左侧面板包含三个选项卡:Datapoint Editor、Performance & Fairness 和 Features。
1. Datapoint Editor 选项卡
Datapoint 编辑器通过以下方式帮助执行数据分析:
- 查看和编辑数据点的详细信息
允许深入查看选中的数据点,该数据点在右侧面板上会被突出显示为黄色。我们可以尝试将年龄从 53 改为 58,然后点击“Run inference”按钮,查看这对模型性能有何影响。
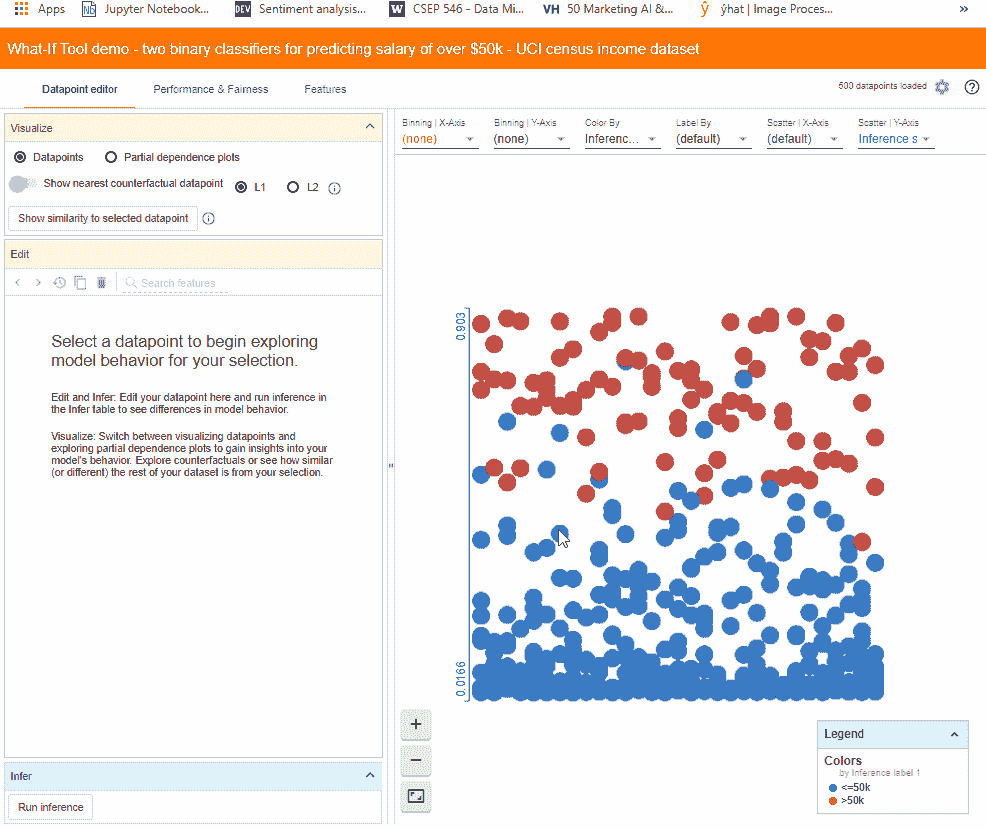
通过简单地改变这个人的年龄,模型现在预测这个人属于高收入类别。对于这个数据点,之前正类(高收入)的推断分数为 0.473,负类(低收入)的分数为 0.529。然而,通过改变年龄,正类的分数变为 0.503。
- 查找最近的反事实
了解模型行为的另一种方法是查看哪些小的变化集可以导致模型改变决策,这称为反事实。通过一次点击,我们可以看到最相似的反事实,它在绿色中突出显示,与我们选择的数据点进行比较。在数据点编辑标签中,我们现在也可以看到反事实的特征值与原始数据点的特征值并排显示。绿色文本表示两个数据点的特征差异。WIT 使用L1 和 L2距离来计算数据点之间的相似性。
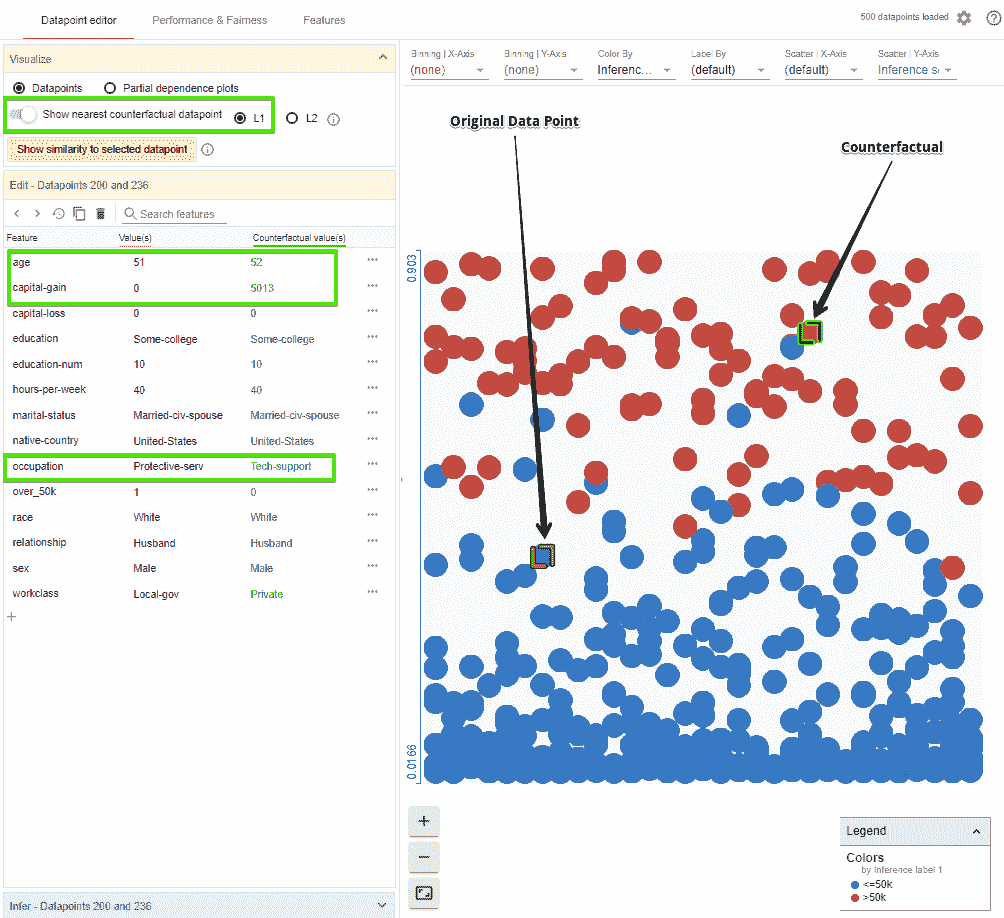
在这种情况下,最近的反事实略微年长,具有不同的职业和资本收益,但其他方面是相同的。
我们还可以通过“显示与选定数据点的相似性”按钮查看所选点与其他点之间的相似性。WIT 测量从选定点到其他每个数据点的距离。让我们将X轴散点图更改为显示与选定数据点的 L1 距离。
- 分析部分依赖图
部分依赖图(PDP 或 PD 图)展示了一个或两个特征对机器学习模型预测结果的边际影响(J. H. Friedman 2001)。
一个数据点的年龄和教育的 PDP 如下:
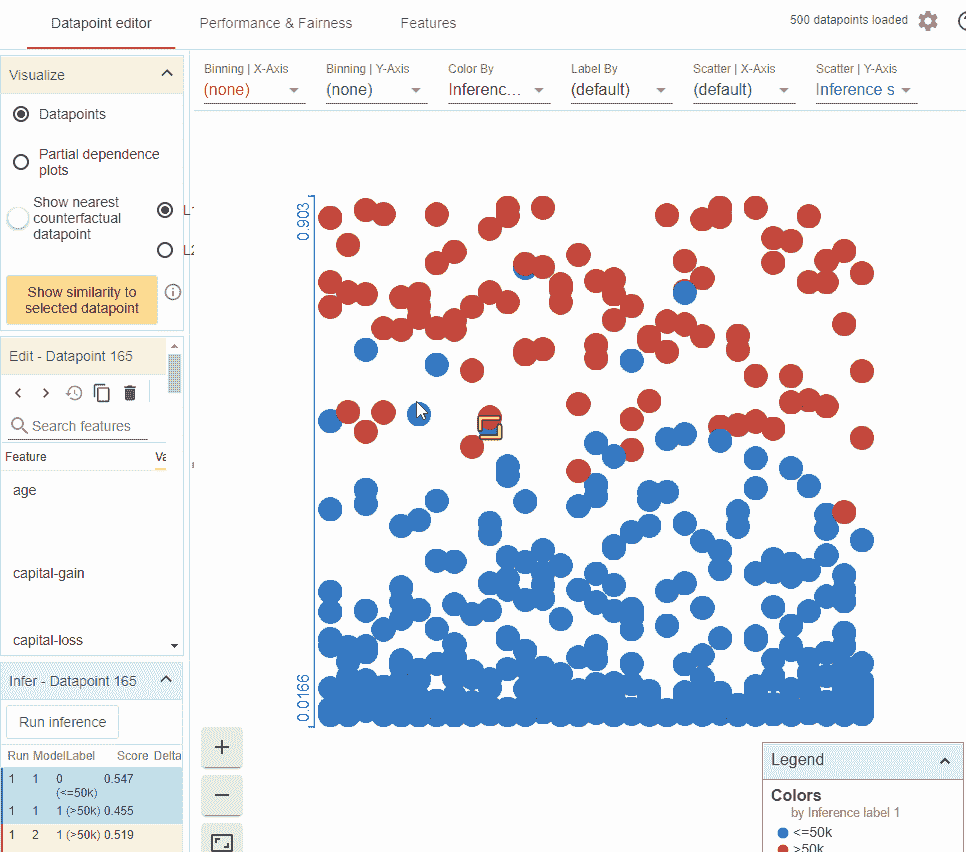
上图显示了:
-
模型已经学会了年龄与收入之间的正相关关系
-
更高的学位使模型在高收入方面更加自信。
-
高资本收益是高收入的一个非常强的指标,比任何其他单一特征要强得多。
2. 性能与公平性标签
此标签允许我们使用混淆矩阵和 ROC 曲线来查看模型的整体性能。
- 模型性能分析
为了衡量模型的性能,我们需要告诉工具什么是基准真实特征,即模型试图预测的特征,在这种情况下是“收入超过 50K”。
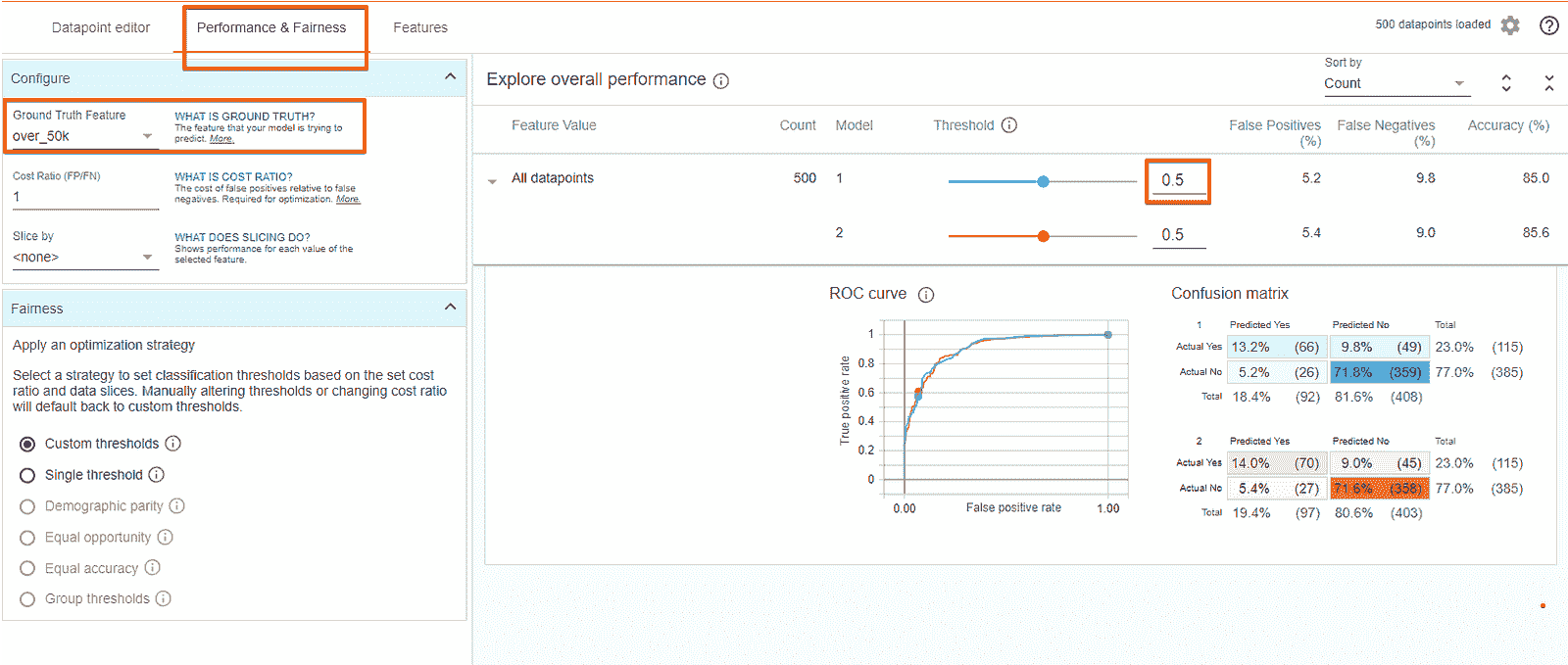
我们可以看到,在默认的 0.5 阈值水平下,我们的模型约 15%的时间是错误的,其中大约 5%是假阳性,10%是假阴性。调整阈值来查看其对模型准确性的影响。
还有一个“成本比”的设置和一个“优化阈值”按钮,这些也可以进行调整。
- 机器学习公平性
机器学习中的公平性与模型构建和预测结果一样重要。训练数据中的任何偏差都会反映在训练后的模型中,如果这种模型被部署,结果输出也会有偏差。WIT 可以通过几种不同的方式帮助调查公平性问题。我们可以设置一个输入特征(或特征集)来切片数据。例如,看看性别对模型性能的影响。
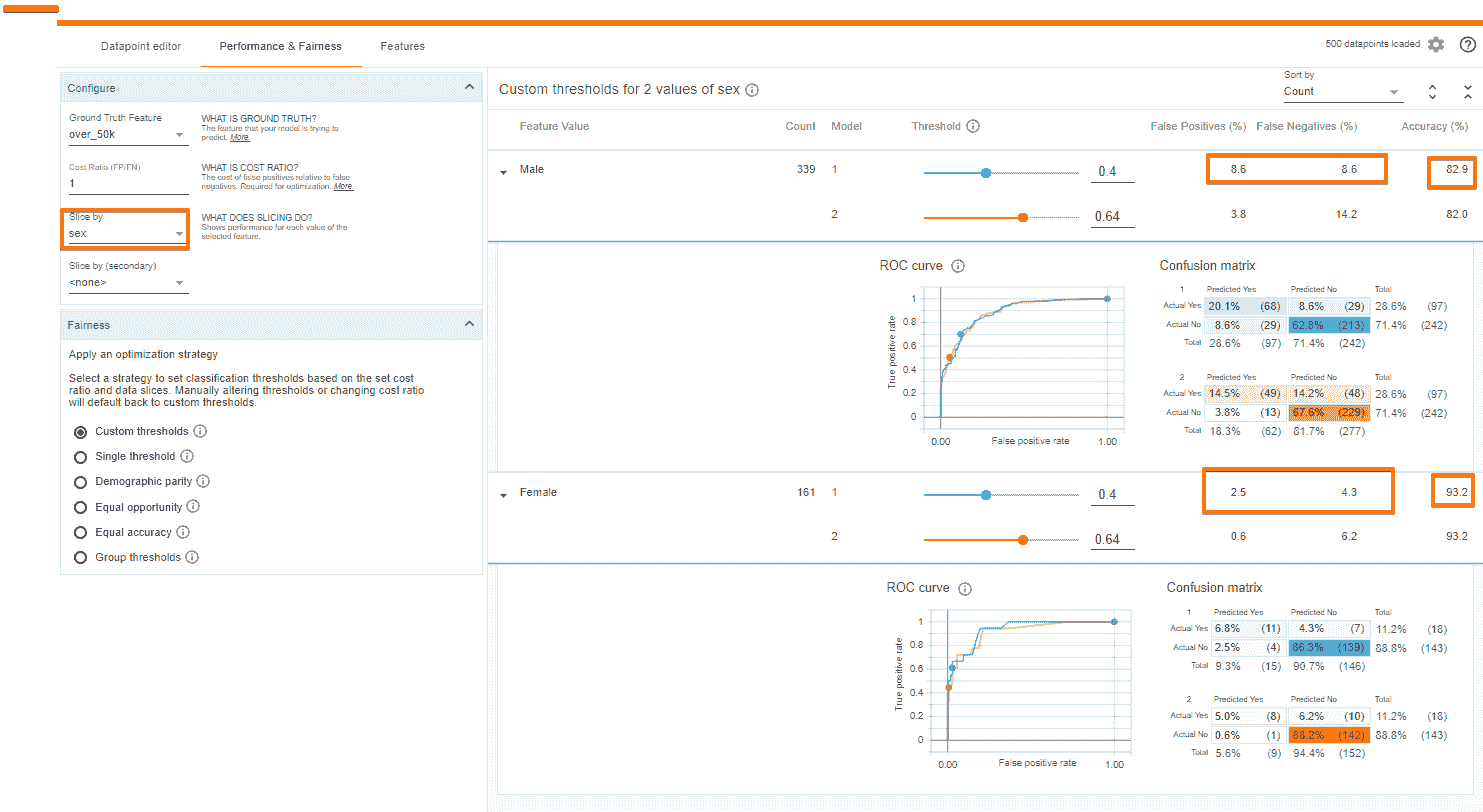
性别对模型性能的影响。
我们可以看到,模型对女性的预测比对男性更准确。此外,模型对女性预测高收入的频率远低于对男性的预测(女性为 9.3% vs 男性为 28.6%)。一个可能的原因是数据集中女性的代表性不足,我们将在下一部分中探讨这一点。
此外,该工具可以在考虑多种与算法公平性相关的约束条件(如人口统计公平性或平等机会)的情况下,最佳设置两个子集的决策阈值。
3. 特征选项卡
特征选项卡提供了数据集中每个特征的总结统计信息,包括直方图、分位数图和条形图。该选项卡还允许查看数据集中每个特征值的分布。例如,我们来探讨性别、资本收益和种族特征。
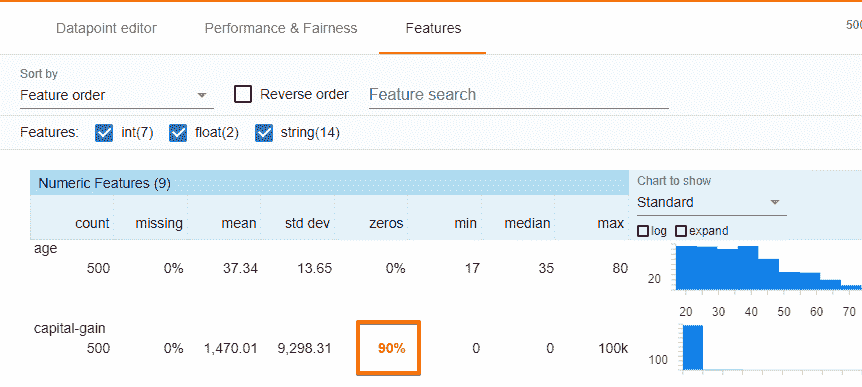
我们推断资本收益非常不均匀,大多数数据点的值为 0。
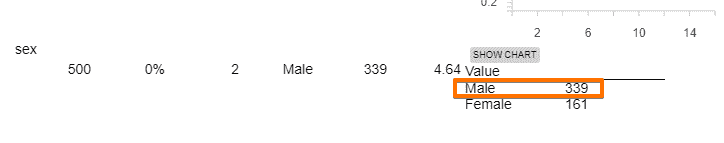
本国分布 || 性别分布
同样,大多数数据点来自美国,而女性在数据集中并未得到很好的代表。由于数据存在偏差,其预测自然会只针对某一组。毕竟,模型从提供的数据中学习,如果源数据有偏斜,结果也会有偏斜。机器学习在许多应用和领域中证明了其实力。然而,机器学习模型在工业应用中的一个关键难题是确定用于训练模型的原始输入数据是否包含歧视性偏差。
结论
这只是对一些“如果”工具功能的快速浏览。WIT 是一个非常实用的工具,它将探查模型的能力交到最需要的人手中。简单地创建和训练模型并不是机器学习的目的,而是理解模型如何以及为何被创建,才是机器学习的真正意义。
参考文献:
原文。已获得许可转载。
简介: Parul Pandey 是一位数据科学爱好者,曾在电力行业的分析部门工作。现在,Parul 为国内外出版物撰写与数据科学和人工智能相关的文章,试图将数据科学术语普及给大众。
相关:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 部门
更多相关主题


 浙公网安备 33010602011771号
浙公网安备 33010602011771号