KDNuggets-博客中文翻译-三十三-
KDNuggets 博客中文翻译(三十三)
原文:KDNuggets
数据科学家必看的前 10 个 TED 演讲
原文:
www.kdnuggets.com/2016/02/top-10-tedtalks-data-scientists.html
 评论
评论
TED 是一个致力于传播值得传播的思想的非盈利组织——通过 TED.com,他们还安排年度会议和本地 TEDx 活动。TEDTalks 将 TED 会议上的最佳思想无偿分享给世界:值得信赖的声音和打破常规的创新者、偶像和天才们,在 18 分钟内讲述他们的故事。数据科学已经成为许多这些演讲的中心。这里,我们根据观看次数收集了前 10 个 TED 演讲。

-
你见过的最佳统计数据 (观看次数: 10,406,507)
你从未见过这样的数据展示。统计学大师汉斯·罗斯林以体育播报员般的戏剧性和紧迫感揭穿了有关所谓“发展中国家”的神话。
-
我如何破解了在线约会 (观看次数: 4,432,687)
艾米·韦布在在线约会中没有好运。她喜欢的约会对象没有回复她,她自己的个人资料则吸引了一片沉默(甚至更糟)。所以,作为数据爱好者的她开始制作电子表格。听听她如何破解在线约会生活的故事——带有令人沮丧、搞笑和改变人生的结果。
-
什么造就了美好的生活?来自最长幸福研究的教训 (观看次数: 3,791,115)
在我们生活的过程中,什么让我们保持幸福和健康?如果你认为是名誉和财富,你并不孤单——但根据精神科医生罗伯特·沃尔丁格的说法,你错了。作为一项 75 年成人发展研究的主任,沃尔丁格对真正的幸福和满足感的数据有着前所未有的获取权限。在这次演讲中,他分享了从研究中得到的三条重要教训以及一些古老的、实用的智慧,关于如何建立一个充实而长久的生活。
-
如何不对世界无知 (观看次数: 2,711,429)
你对这个世界了解多少?汉斯·罗斯林通过他著名的全球人口、健康和收入数据图表(还有一个特别长的指示器),展示了你对自己认为了解的事物可能大错特错的统计概率。参与他的观众问答,然后从汉斯的儿子奥拉那里学习 4 种快速减少无知的方法。
-
全球人口增长,一箱一箱地展示 (观看次数: 2,450,700)
未来 50 年,全球人口将增长到 90 亿——只有通过提高最贫困者的生活标准,我们才能控制人口增长。这是汉斯·罗斯林在 TED@Cannes 上使用色彩丰富的新数据展示技术揭示的矛盾答案(你将会看到)。
-
谁掌控了世界?(观看次数:2,297,109)
詹姆斯·格拉特费尔德研究复杂性:一个相互连接的系统——比如,一群鸟——如何超越其组成部分的总和。事实证明,复杂性理论可以揭示经济运行的很多奥秘。格拉特费尔德分享了一项突破性的研究,讲述了全球经济中的控制如何流动,以及少数人手中权力的集中如何使我们所有人变得脆弱。
-
数据可视化的美(观看次数:2,277,195)
大卫·麦坎德莱斯将复杂的数据集(如全球军事开支、媒体热度、Facebook 状态更新)转化为美观、简洁的图表,揭示出隐藏的模式和联系。他建议,良好的设计是应对信息过载的最佳方式——这可能会改变我们看待世界的方式。
-
揭示城市交汇点与分隔点的社会地图(观看次数:2,277,144)
每个城市都有其社区、圈子和俱乐部,那些隐藏的线条连接并划分了同一个城市中的人们。通过观察人们在线分享的内容,我们可以了解到关于城市的什么?从自己家乡巴尔的摩开始,戴夫·特罗伊一直在可视化城市居民的推文,揭示他们的生活、交谈对象——以及他们不愿意接触的人。
-
对抗伪科学(观看次数:1,891,208)
每天都有新的健康建议新闻报道,但你如何知道这些建议是否正确?医生兼流行病学家本·戈尔德克雷高速展示了证据如何被扭曲,从明显的营养声称到制药行业的微妙把戏。
-
卷曲薯条困境:为什么社交媒体“点赞”比你想象的更有意义(观看次数:1,742,215)
你在 Facebook 上点赞了吗?观看这个演讲,了解 Facebook(以及其他平台)如何通过你的随机点赞和分享猜测出一些令人惊讶的事情。计算机科学家詹妮弗·戈尔贝克解释了这一现象的形成过程,以及这种技术的一些应用并不那么可爱——并说明了她为何认为我们应该将信息的控制权交还给其正当所有者。
我们的三大课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
 2. 谷歌数据分析专业证书 - 提升你的数据分析能力
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
我们希望你能喜欢这些讲座。请告诉我们你最喜欢的数据科学在线讲座。
简历:Devendra Desale(@DevendraDesale) 是一名数据科学研究生,目前从事文本挖掘和大数据技术工作。他还对企业架构和数据驱动的业务感兴趣。当不在电脑前时,他也喜欢参加聚会和探索未知领域。
相关:
-
前 5 名大数据 / 机器学习播客
-
YouTube 上观看次数最多的大数据视频
-
最佳大数据、数据科学、数据挖掘和机器学习播客
更多相关话题
检测 ChatGPT、GPT-4、Bard 和 Claude 的十大工具
原文:
www.kdnuggets.com/2023/05/top-10-tools-detecting-chatgpt-gpt4-bard-llms.html
图片作者:作者
我们生活在一个人工智能(AI)繁荣的时代,每周都有新的可以像人类一样写作的大型语言模型(LLMs)发布。这些模型可以生成高度创意的内容,不幸的是,一些学生和专业人士正在滥用这些工具进行抄袭。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
因此,AI 检测工具已经成为每个教室、工作场所和研究机构的必备工具。本博客中提到的所有工具都是免费的,其中一些甚至带有 Chrome 扩展,以便你可以随时检测内容。
1. GPTZero
GPTZero 已显著提升。它现在具有很高的准确性,易于使用,并且配有 Chrome 扩展。你可以使用它检测各种 AI 生成的文本,包括来自最新模型如 Bard (PalM 2)、ChatGPT、GPT-4 和其他开源模型的文本。它也很快,并且突出显示生成的文本以便于识别。

图片来源:GPTZero
2. OpenAI AI 文本分类器
OpenAI 的 AI 文本分类器 非常准确,但它不提供有关内容的额外信息。我每天都在使用它来维持质量保证,对结果感到满意。它适用于 New Bard、ChatGPT、GPT-4 和其他基于 LLaMA 的模型。
图片来源:OpenAI
3. CopyLeaks
我在 Reddit 的 r/freelanceWriters 子版块中由一位用户介绍了 CopyLeaks。这是一个快速、准确的抄袭检查工具,配有一个简单的 Chrome 扩展。你甚至可以悬停在高亮的文本上以检查 AI 的流行度。它可以检测 Bard、ChatGPT、GPT-4 和其他大型语言模型(LLMs)。

图片来源:CopyLeaks
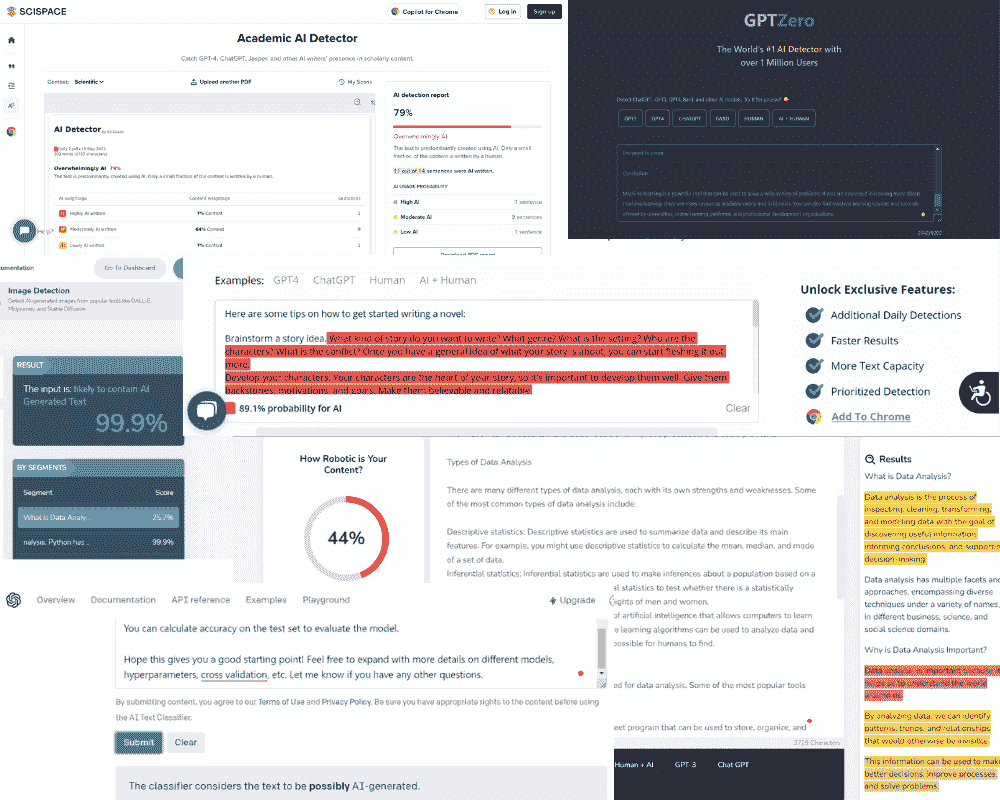
4. SciSpace
SciSpace 的学术 AI 检测器与我提到的其他工具略有不同。它非常准确,但专门设计用于检测 PDF 中的学术内容。目前没有复制粘贴的选项,但技术团队正在努力添加该功能。你可以上传任何类型的学术工作作为 PDF,SciSpace 将生成结果。
我用 Bard、ChatGPT 和 HuggingChat 生成的内容测试了 SciSpace,它准确地检测出了所有内容。
来自 SciSpace 的图片
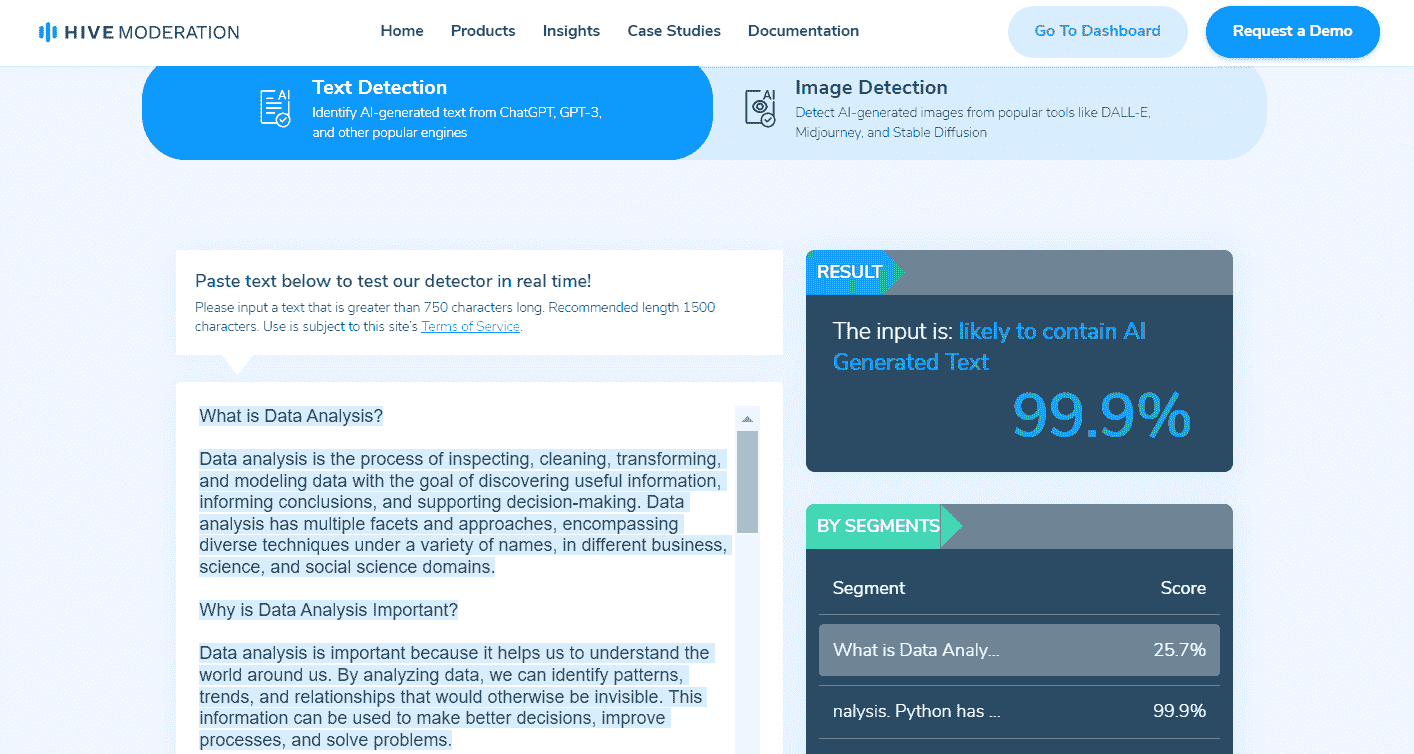
5. Hive Moderation
Hive Moderation 的AI 生成内容检测有时会将人工生成的内容误识别为 AI 生成。为了确保结果可靠,建议在将其作为主要资源使用时备有备用工具。AI 生成内容检测提供带有概率百分比和分段的结果。此外,它还提供了检测来自 DALL-E、Midjourney 和 Stable Diffusion 等平台的 AI 生成图像的能力。
来自 Hive Moderation 的图片
6. Content at Scale
Content at Scale 的 AI 内容检测器使用简单,并且能提供关于可预测性、概率和模式的相当准确的报告。它兼容所有最新的大型语言模型(LLMs),并根据 AI 生成工作的变量概率突出显示内容。

来自 Content at Scale 的图片
7. Hello Simple AI
Hello Simple AI 的ChatGPT 检测器是一个免费的开源工具,可以用于检测由 ChatGPT 生成的文本。它托管在 Hugging Face Spaces 上,提供快速且相当准确的结果。该检测器的准确性不如 OpenAI 分类器,但提供了两个指标(GLTR 和 PPL 概率),可以帮助你判断内容是否由 AI 生成。
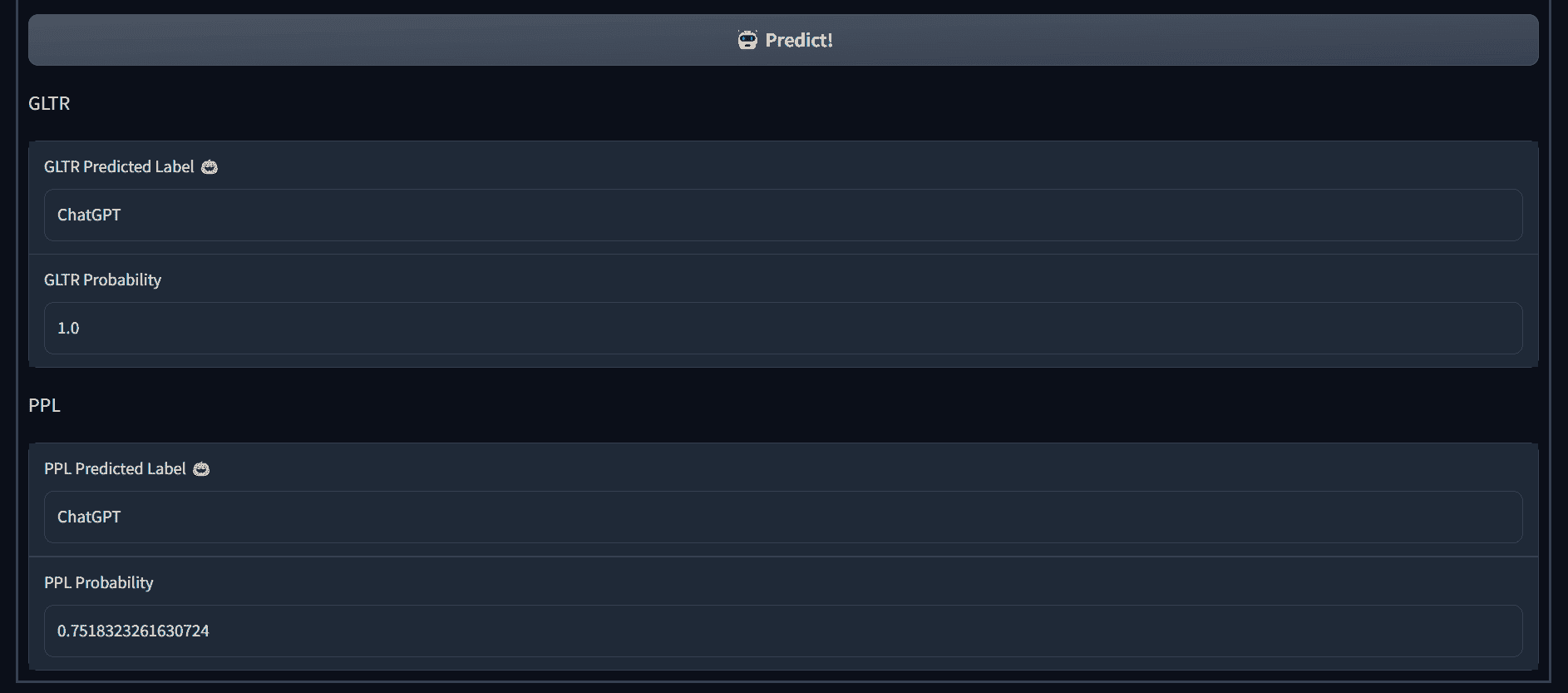
来自 Hugging Face 的图片
8. OpenAI HF Detector
OpenAI 检测器是一个免费的开源工具,可用于检测由 OpenAI 的 GPT 语言模型生成的文本。它托管在 Hugging Face Spaces 上,并提供快速的结果。然而,该检测器可能非常不准确,尤其是在检测 OpenAI 模型的新版本和其他开源大型语言模型时。

来自 Hugging Face 的图片
9. Corrector.app
Corrector.app 的 AI 检测器 是一个相当准确的工具,可以用来检测由 ChatGPT、Bard 和其他旧版本的大型语言模型(LLMs)生成的文本。然而,它无法检测更新版本的 LLM。这是因为 AI 检测器通过分析文本的语法和语义来工作,而更新的 LLM 更擅长生成无法与人类编写的文本区分开的文本。
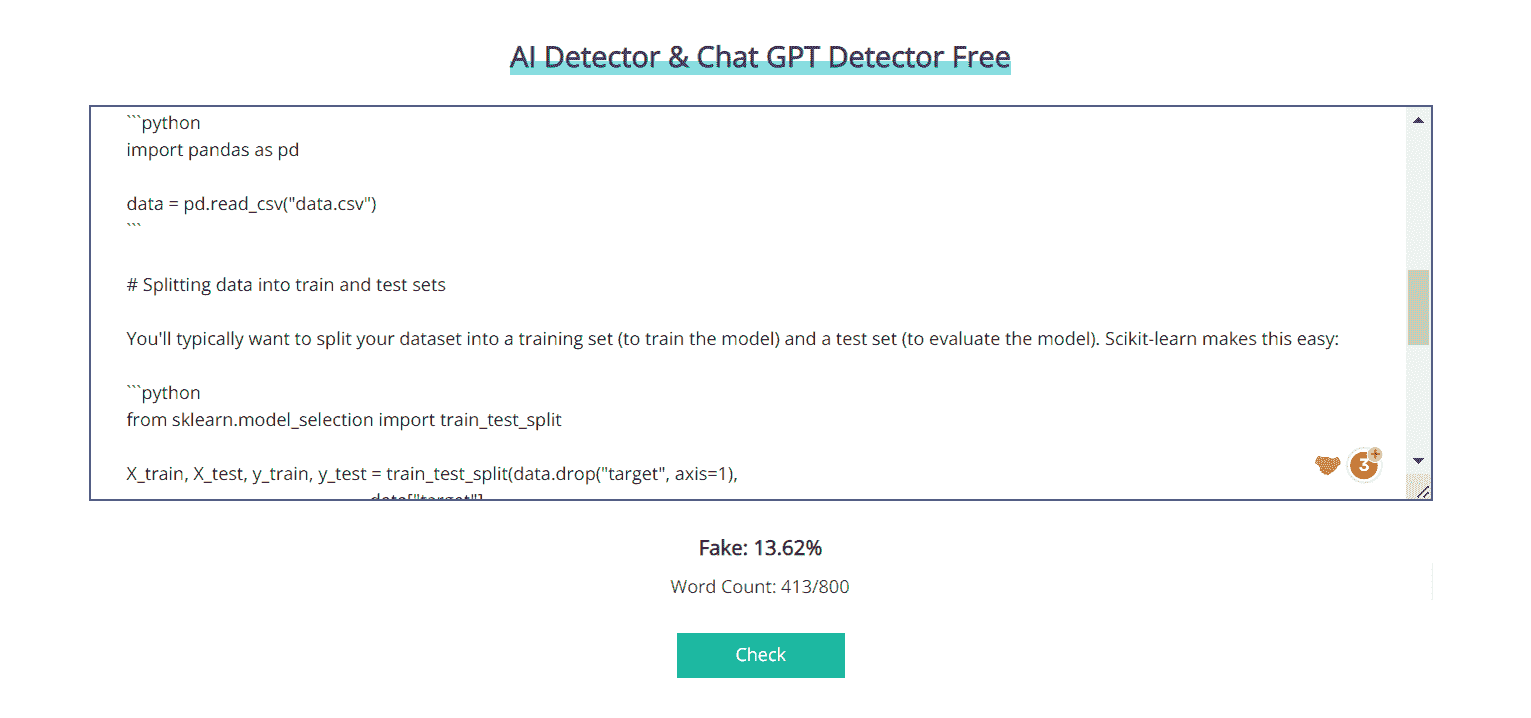
图片来自 Corrector.app
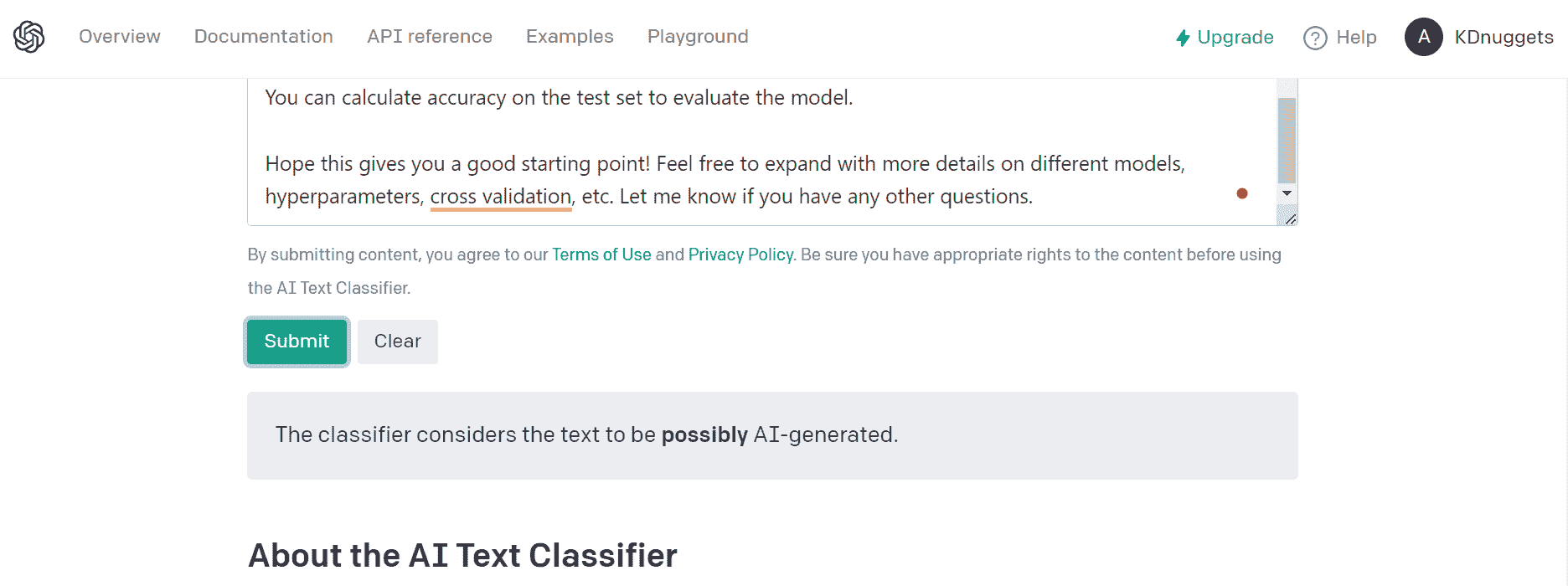
10. Writer.com
Writer.com 的 AI 内容检测器 完成了我们的列表,它被认为是最不准确的选项,字符限制为 1500。它作为备用解决方案,当其他工具不可用或无效时可以使用。
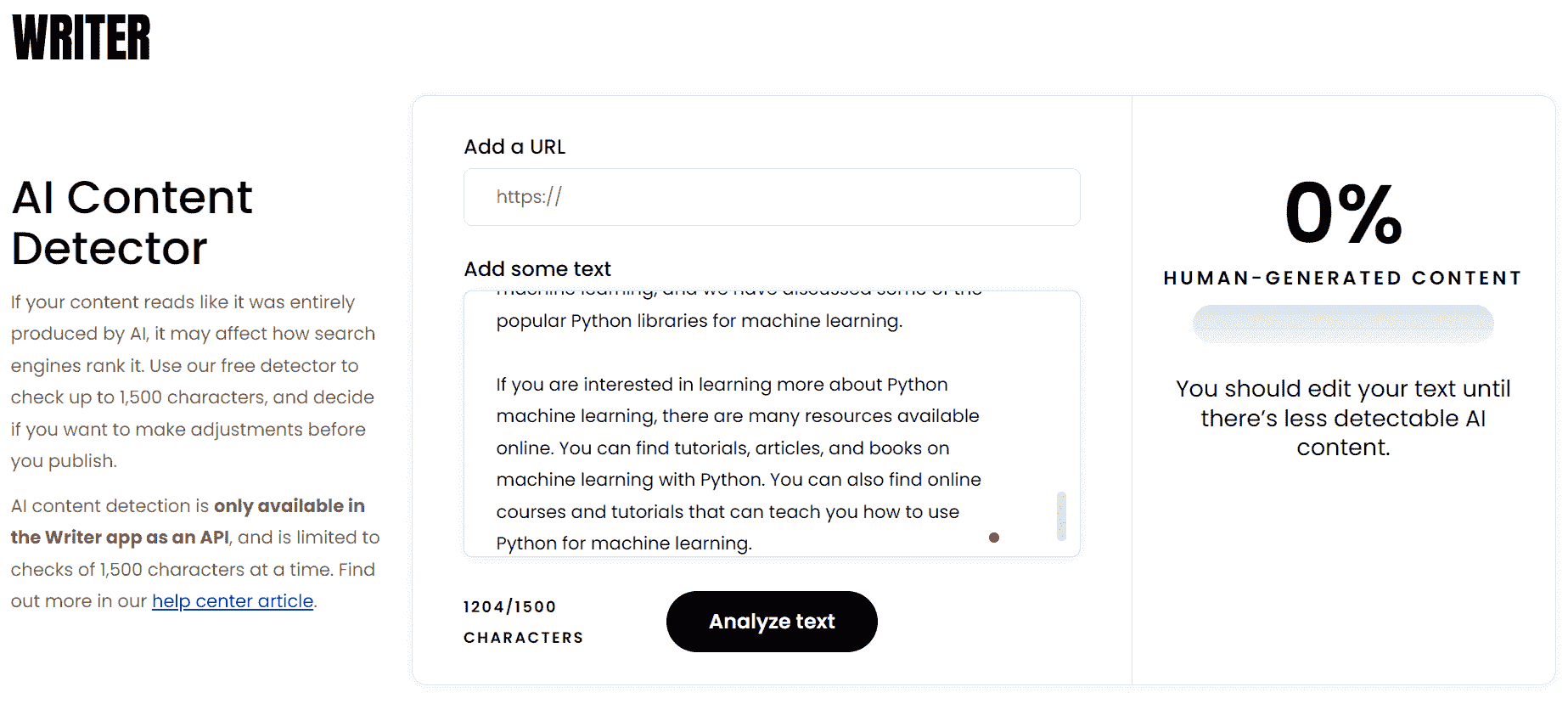
图片来自 Writer.com
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专家,热衷于构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,帮助那些在心理健康方面挣扎的学生。
更多相关话题
深度学习在 Python 中的十大视频
原文:
www.kdnuggets.com/2017/11/top-10-videos-deep-learning-python.html
这个“十大”列表是根据内容质量而非观看次数创建的。为了帮助你选择合适的框架,我们首先从一个比较几个流行 Python DL 库的视频开始。我已经包含了这十大项目的亮点以及我对每一个优缺点的看法,以便你选择最适合你需求的一个。我把最好的留到最后——最全面但免费的 YouTube 深度学习课程 ☺。我们开始吧!
1. 概述:深度学习框架比较(96K 次观看) - 5 分钟
在实际列出最佳 Python 深度学习视频之前,了解 5 个最受欢迎的深度学习框架 - SciKit Learn、TensorFlow、Theano、Keras 和 Caffe 之间的区别非常重要。这个 5 分钟的视频由 Siraj Raval 制作,提供了每个框架优缺点的最佳比较,甚至展示了代码示例的结构,帮助你更好地决定。先从这个视频开始。
2. 播放列表:Sentdex 的 TensorFlow 教程(114K 次观看) - 4.5 小时
Sentdex 的这 14 个视频播放列表是最有条理、解释最全面、简洁却易于跟随的 Python 深度学习教程。它包括了使用 MNIST 数据集的递归神经网络和卷积神经网络的 TensorFlow 实现。
3. 单独教程:TensorFlow 教程 02:卷积神经网络(69.7K 次观看) - 36 分钟
Magnus Pedersen 在 YouTube 频道 Hvass Laboratories 上的这个教程非常值得一看——代码中有出色的注释;此外,讲解者没有中断。观看这个视频来理解 TensorFlow 中的脚本。以后谢谢我 ☺
4. 概述:如何轻松预测股票价格(210K 次观看) - 9 分钟
在这个视频中,Siraj Raval 使用了一种特殊类型的递归神经网络——LSTM 网络。他使用了具有 TensorFlow 后端的 Keras 库。他解释了使用递归网络处理时间序列数据的原因,并用它来预测基于 16 年训练数据的 S&P 500 的每日收盘价。GitHub 代码的链接在视频描述框中给出。
(编辑:可能对过去的数据效果很好,但不能保证对未来的数据有效)
5. 教程:使用 Python 和 Theano 库的深度学习介绍(201K 次观看) - 52 分钟
如果你想在不到一小时内听一个关于 Python 和 Theano 库的讲座,面向初学者,那么你可以参考 Alec Radford 的讲座。与大多数其他讲座不同,这个讲座比较了‘旧’网络与‘现代’网络的特征,即 2000 年前后的网络与 2012 年后的网络。
6. 播放列表: PyTorch 从零到全(3K 观看次数) - 2 小时 15 分钟
在这系列 11 个视频中,Sung Kim 从头开始教你 PyTorch。这个系列的亮点是第 10 讲,他教你如何构建一个基本的 CNN,并通过详细的图示强调 CNN 概念的理解。
7. 单独教程: TensorFlow 教程(43.9K 观看次数) - 49 分钟
这篇由 Edureka 编写的教程实现了使用 TensorFlow 的深度学习。对于 TensorFlow 初学者来说,这是一个非常好的教程。它教授了 TensorFlow 基础知识和数据结构。它还包括一个使用深度学习作为海军雷达识别器的用例——以识别水下障碍物是岩石还是地雷。
8. 播放列表: 用 Python 学深度学习(1.8K 观看次数) - 83 分钟
YouTube 频道‘Machine Learning TV’发布了一系列共 15 个视频,总计 83 分钟,使用 Theano 和 Keras 来实现自动图像标注的深度学习。它展示了如何训练你的第一个深度神经网络,以对 MNIST 数据集中的数字进行分类。它还对如何在 Theano 中加载和重用预训练模型进行了很好的解释。
9. 播放列表: 用 Keras 进行深度学习- Python(30.3K 观看次数) - 85 分钟
YouTube 频道‘The SemiColon’发布了一系列 11 个视频,讲解了使用 Theano 和 Keras 实现聊天机器人的教程。它包括对卷积神经网络、Theano 中的递归神经网络(与 Keras 配合使用)、神经网络和 scikit-learn 库中的反向传播的解释,应用于手写识别(MNIST)数据集。
讲解中穿插了‘呃’和‘啊’,但对用 Word2Vec 构建聊天机器人的解释很好。
10. 免费在线课程: Andrew Ng 的深度学习(完整课程)(28K 观看次数) - 4 周课程
与我之前的金融机器学习顶级视频推荐一样,我将最好的留到最后☺。如果你想从公认的最著名机器学习讲师之一安德鲁·吴那里学习深度学习,那么这个播放列表适合你。这个课程旨在为期 4 周,涵盖 98 个视频,教你深度学习、神经网络、二分类、导数、梯度下降、激活函数、反向传播、正则化、RMSprop、调优、丢弃法、在不同分布上进行训练和测试等内容,使用 Python 代码在 Jupyter notebook 中进行。
相关:
-
Python 深度学习框架概述
-
在哪里学习深度学习- 课程、教程、软件
-
TensorFlow 非常棒- 对深度学习加速的理性看法
我们的前三个课程推荐
1. Google 网络安全证书 - 加速你的网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关内容
金融领域机器学习的十大视频
原文:
www.kdnuggets.com/2017/09/top-10-videos-machine-learning-finance.html
这个“十大”列表是基于最佳内容创建的,而不是准确的观看次数。我还特别注意以温和、一步步的方式带您了解金融领域的机器学习。为了激发您的兴趣,我们首先从关于金融领域机器学习的各种应用的讲座开始。然后,为了便于访问免费的金融数据,提供了一段详细介绍各种数据来源的视频。接下来,为了让您实际操作,我们将转向针对特定金融应用的 R 和 Python 教程。想要深入研究金融领域机器学习的应用?我把最好的留到最后:两个涵盖金融领域机器学习广度的播放列表 😃 让我们开始吧!

1. 讲座: 金融服务公司如何利用数据和分析 (1.7 K 观看次数) - 4 分钟讲座
除了银行利用数据做出信用和定价决策之外,资产管理公司、对冲基金和保险公司也在拥抱数据驱动的决策力量。数据已经成为一种战略资产,因此首席数据官和首席分析官等角色在金融机构中应运而生也就不足为奇了。
2. 讲座: 用于信用风险评估的机器学习 (1.3K 观看次数) - 38 分钟讲座
公司 Zopa 拥有一个基于 Python 的信用风险评估开发和建模管道。它使用机器学习算法和数据可视化来了解客户。视频中讨论了其目标定义技术、针对现有 3000 个变量的特征工程、模型构建和超参数调整,以及 Zopa 在模型堆叠和深度学习方面的经验。
3. 讲座: 免费的金融数据来源 (2 K 观看次数) - 12 分钟视频
了解如何导航以下网站、设置过滤器,并从 Yahoo Finance 和 Google Finance、圣路易斯联邦储备银行、CBOE、Quandl 以及美国财政部提取历史数据。
4. R 教程: Quantmod R 包 (10.7K 观看次数) - 11 分钟教程
使用 R 的 Quantmod 包和 getSymbols()来提取股票数据。本教程还教您如何在图表上显示数据并更改图表参数。
5. R 教程: 使用 R 进行投资组合构建 (21.3 K 观看次数) - 8 分钟教程
这个教程教你如何下载 5 只股票的价格数据,计算有效前沿,并绘制股票在风险-回报空间中的位置。代码 这里
6. R 教程: 在 R 中找到表现最佳的共同/投资基金(3 K 观看次数) - 14 分钟教程
这是一个非常好的教程,教你如何使用 R 中的基本统计学来找出在短期、中期和长期内表现稳定的基金。学习使用散点图绘制 1 年和 3 年的回报,解释图表并标记公司。
7. Python 教程: 在 Python 中预测股票价格(218 K 观看次数) - 7 分钟教程
Siraj Raval 的 YouTube 视频在机器学习领域非常受欢迎。在这里,他教你使用 Python 的 scikit-learn 构建股票价格预测图,包含 40 行代码。构建 3 个预测模型来预测苹果股票的价格,然后将其绘制在图表上,以比较哪种预测模型表现最佳。
8. Python 教程: 使用深度学习预测股票价格(161K 观看次数) - 9 分钟视频
Siraj Raval 将大量信息以高度吸引人和简洁的方式呈现出来,真是令人惊叹。在他另一个视频中,训练数据是从 2000 年 1 月到 2016 年 8 月的 S&P 500 每日收盘价的时间序列。他使用具有 TensorFlow 后端的 Keras 中的 LSTM 网络预测特定日期的收盘价。
9. 播放列表 1:(1.9 K 观看次数)金融机器学习的 42 个视频(教程 + 概念 + 概念讲座)
这 40 多个小时的视频是你学习金融交易基本概念、与交易员的访谈、股票市场纪录片、回测讨论以及机器学习教程以实现各种量化策略的必备资源。虽然这个播放列表可以在组织方面有所改进,因为视频的顺序是随机的。
10. 播放列表 2:(72 K 观看次数)Python 金融教程系列: 24 个视频
最后留下最好的,sentdex 的‘Python 金融编程’播放列表组织得非常好,实现了 Python 中的算法交易。这一播放列表满分 10/10。不过,这只涉及编程教程,并没有理解金融概念的视频。然而,上述播放列表(‘Playlist1’)应该能帮助解决这个问题 😃
相关内容:
-
银行如何利用数据战胜新兴金融公司
-
数据科学如何推动金融科技革命的 7 种方式
-
利用大数据打击金融欺诈
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
更多相关话题
数据科学家的前 12 个必备命令行工具
原文:
www.kdnuggets.com/2018/03/top-12-essential-command-line-tools-data-scientists.html
评论

本文简要概述了十几个类 Unix 操作系统命令行工具,这些工具对数据科学任务可能有用。列表中不包括任何一般的文件管理命令(pwd、ls、mkdir、rm 等)或远程会话管理工具(rsh、ssh 等),而是包括了一些从数据科学角度来看有用的工具,通常与各种程度的数据检查和处理相关。这些工具也都包含在典型的类 Unix 操作系统中。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
这确实很基础,但我鼓励你在适当的时候寻找更多命令示例。工具名称链接到维基百科条目,而不是 man 页面,因为我认为前者对新手更友好。
1. wget
wget 是一个文件检索工具,用于从远程位置下载文件。
wget 的最基本用法如下所示,用于下载远程文件:
~$ wget https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv
--2018-03-20 18:27:21-- https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 151.101.20.133
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|151.101.20.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 3716 (3.6K) [text/plain]
Saving to: ‘iris.csv’
iris.csv
100 [=======================================================================================================>] 3.63K --.-KB/s in 0s
2018-03-20 18:27:21 (19.9 MB/s) - ‘iris.csv’ saved [3716/3716]
2. cat
cat 是一个将文件内容输出到标准输出的工具。名称来源于 concatenate。
更复杂的用例包括将文件合并在一起(实际的连接)、将文件附加到另一个文件、对文件行进行编号等等。
~$ cat iris.csv
sepal_length,sepal_width,petal_length,petal_width,species
5.1,3.5,1.4,0.2,setosa
4.9,3,1.4,0.2,setosa
4.7,3.2,1.3,0.2,setosa
4.6,3.1,1.5,0.2,setosa
5,3.6,1.4,0.2,setosa
...
6.7,3,5.2,2.3,virginica
6.3,2.5,5,1.9,virginica
6.5,3,5.2,2,virginica
6.2,3.4,5.4,2.3,virginica
5.9,3,5.1,1.8,virginica
3. wc
wc 命令用于从文本文件中生成字数统计、行数统计、字节数统计及相关信息。wc 的默认输出,在没有选项时,是一行包含行数、字数(注意每行没有换行的单个字符串被算作一个单词)、字符数和文件名。
~$ wc iris.cs
151 151 3716 iris.csv
4. head
head 将文件的前 n 行(默认 10 行)输出到标准输出。显示的行数可以通过 -n 选项设置。
~$ head -n 5 iris.csv
sepal_length,sepal_width,petal_length,petal_width,species
5.1,3.5,1.4,0.2,setosa
4.9,3,1.4,0.2,setosa
4.7,3.2,1.3,0.2,setosa
4.6,3.1,1.5,0.2,setosa
5. tail
有人猜到 tail 是做什么的吗?
~$ tail -n 5 iris.csv
6.7,3,5.2,2.3,virginica
6.3,2.5,5,1.9,virginica
6.5,3,5.2,2,virginica
6.2,3.4,5.4,2.3,virginica
5.9,3,5.1,1.8,virginica

操作命令行魔法。
6. find
find 是一个用于在文件系统中搜索特定文件的实用程序。
以下命令在当前目录(".")中搜索以“iris”开头并以任意字符("-name 'iris*'")结尾的文件,且文件类型为常规文件("-type f"):
~$ find . -name 'iris*' -type f
./iris.csv
./notebooks/kmeans-sharding-init/sharding/tests/results/iris_time_results.csv
./notebooks/ml-workflows-python-scratch/iris_raw.csv
./notebooks/ml-workflows-python-scratch/iris_clean.csv
...
7. cut
cut 用于从文件中切割出文本行的部分。虽然这些切片可以使用多种标准进行,但cut在从 CSV 文件中提取列数据时非常有用。
这会输出使用逗号作为字段分隔符("-d ','")的 iris.csv 文件的第五列("-f 5"):
~$ cut -d ',' -f 5 iris.csv
species
setosa
setosa
setosa
...
8. uniq
uniq 通过将相同的连续行合并为单一副本,来修改文本文件的输出。单独使用时这可能看起来并不特别有趣,但在构建命令行管道(将一个命令的输出传递到另一个命令的输入)时,这会变得非常有用。
以下内容为我们提供了在第五列中持有的鸢尾花数据集类名称及其计数的唯一统计:
~$ tail -n 150 iris.csv | cut -d "," -f 5 | uniq -c
50 setosa
50 versicolor
50 virginica
牛说什么。
9. awk
awk 实际上不是一个“命令”,而是一个完整的编程语言。它用于处理和提取文本,可以在命令行中以单行命令形式调用。
掌握awk需要一些时间,但在此之前,下面是它能完成的一个示例。考虑到我们的示例文件——iris.csv——相当有限(尤其是在文本多样性方面),这行代码将调用awk,在指定文件("iris.csv")中搜索“setosa”字符串,并逐一打印遇到的项目(保存在$0 变量中):
~$ awk '/setosa/ { print $0 }' iris.csv
5.1,3.5,1.4,0.2,setosa
4.9,3,1.4,0.2,setosa
4.7,3.2,1.3,0.2,setosa
4.6,3.1,1.5,0.2,setosa
5,3.6,1.4,0.2,setosa
10. grep
grep 是另一个文本处理工具,用于字符串和正则表达式匹配。
~$ grep -i "vir" iris.csv
6.3,3.3,6,2.5,virginica
5.8,2.7,5.1,1.9,virginica
7.1,3,5.9,2.1,virginica
...
如果你在命令行中花费了大量时间进行文本处理,grep无疑是一个你会非常熟悉的工具。点击这里查看更多有用的细节。
11. sed
sed 是一个流编辑器,另一种文本处理和转换工具,类似于awk。我们将使用下面这行代码将 iris.csv 文件中“setosa”的出现替换为“iris-setosa”:
~$ sed 's/setosa/iris-setosa/g' iris.csv > output.csv
~$ head output.csv
sepal_length,sepal_width,petal_length,petal_width,species
5.1,3.5,1.4,0.2,iris-setosa
4.9,3,1.4,0.2,iris-setosa
4.7,3.2,1.3,0.2,iris-setosa
...
12. history
history 非常简单,但也非常有用,特别是当你依赖于在命令行中完成的数据准备时。
~$ history
547 tail iris.csv
548 tail -n 150 iris.csv
549 tail -n 150 iris.csv | cut -d "," -f 5 | uniq -c
550 clear
551 history
- 这里有一个简单的介绍,讲述了 12 个实用的命令行工具。这只是数据科学(或其他任何目标)在命令行上可能实现的一小部分。摆脱鼠标的束缚,看看你的生产力如何提高。
相关:
-
命令行中的数据科学:探索数据
-
Docker 如何帮助你成为更高效的数据科学家
-
在 Pandas 中使用 Excel
更多相关话题
成为顶级数据科学家的 13 项技能
原文:
www.kdnuggets.com/2019/07/top-13-skills-become-rockstar-data-scientist.html
评论
作者 Admond Lee,Micron Technology / AI Time Journal / Tech in Asia
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
一周前,我在LinkedIn 上提出了这个问题:
什么使得一个优秀的数据科学家与顶级数据科学家不同?

出乎意料的是,我收到了来自不同领域的许多顶级数据科学家的大量反馈,他们分享了他们的想法和建议——我发现这些内容非常有趣且实用。
为了了解优秀的数据科学家与顶级数据科学家之间的主要区别,我继续在互联网上搜索……直到我找到这篇文章。
所以我提炼了所有信息,并列出了成为顶级数据科学家的技能。
实际上,对于数据科学家来说,掌握以下所有技能是不可能的。但在我看来,这些技能使得一个顶级数据科学家与一个优秀的数据科学家有所不同。
在本文的结尾,我希望你能发现这些技能对你的数据科学家职业生涯有帮助。
让我们开始吧!
1. 教育
数据科学家通常受过高等教育——88% 拥有至少硕士学位,46% 拥有博士学位——尽管有一些显著的例外,但通常需要非常强的教育背景才能发展成为数据科学家所需的深厚知识。要成为数据科学家,你可以获得计算机科学、社会科学、物理科学或统计学的学士学位。最常见的学习领域是数学和统计学(32%),其次是计算机科学(19%)和工程学(16%)。这些课程中的任何学位将为你提供处理和分析大数据所需的技能。
在你的学位课程结束后,你还没有完成。事实是,大多数数据科学家拥有硕士学位或博士学位,他们还会进行在线培训,以学习特定技能,比如如何使用 Hadoop 或大数据查询。因此,你可以报考数据科学、数学、天体物理学或任何其他相关领域的硕士学位课程。你在学位课程中学到的技能将帮助你轻松过渡到数据科学领域。
除了课堂学习之外,你还可以通过开发应用程序、启动博客或探索数据分析来实践课堂上学到的知识,以便进一步学习。
在我看来,只要你能够完成工作,拥有硕士学位或博士学位是可选的。在大多数行业工作范围中,只要你能够解决业务问题,就不需要进行研究和部署前沿的新型机器学习模型。
有用的资源免费电子书: 成为专业数据科学家的 74 个秘诀
2. R 编程
对至少一种分析工具的深入了解,对于数据科学来说通常更倾向于 R。R 专门为数据科学需求而设计。你可以使用 R 解决在数据科学中遇到的任何问题。事实上,43% 的数据科学家使用 R 来解决统计问题。然而,R 有陡峭的学习曲线。
学习起来较为困难,特别是如果你已经掌握了其他编程语言。尽管如此,互联网有许多优秀资源可以帮助你入门 R,例如 Simplilearn 的 R 编程语言数据科学培训。这是一个很好的资源,适合有志于成为数据科学家的你。
3. Python 编程
Python 是我通常看到的数据科学角色中最常见的编程语言,此外还有 Java、Perl 或 C/C++。Python 是数据科学家的优秀编程语言。这也是为什么 O'Reilly 调查中 40% 的受访者将 Python 作为他们的主要编程语言。
由于其多功能性,你可以在数据科学过程中使用 Python 处理几乎所有的步骤。它可以处理各种格式的数据,你可以轻松地将 SQL 表导入到你的代码中。它允许你创建数据集,你可以在 Google 上找到你需要的任何类型的数据集。
你可以通过以下书籍了解更多有关 Python 基础知识及其在数据科学中的应用:
4. Hadoop 平台
虽然这并非总是一个要求,但在许多情况下,它是高度受欢迎的。拥有 Hive 或 Pig 的经验也是一个强有力的卖点。对诸如 Amazon S3 等云工具的熟悉也会有帮助。CrowdFlower 对 3490 个 LinkedIn 数据科学职位的研究表明,Apache Hadoop 被评为数据科学家第二重要的技能,评分为 49%。
作为数据科学家,你可能会遇到数据量超过系统内存或需要将数据发送到不同服务器的情况,这时 Hadoop 就派上用场了。你可以使用 Hadoop 快速地将数据传输到系统上的各个点。这还不是全部。你可以使用 Hadoop 进行数据探索、数据过滤、数据采样和总结。
5. SQL 数据库/编码
尽管 NoSQL 和 Hadoop 已成为数据科学的重要组成部分,但仍然期望候选人能够编写和执行复杂的 SQL 查询。SQL(结构化查询语言)是一种编程语言,可以帮助你进行诸如添加、删除和提取数据等操作。它还可以帮助你执行分析功能和转换数据库结构。
作为数据科学家,你需要精通 SQL。这是因为 SQL 专门设计用于帮助你访问、沟通和处理数据。使用 SQL 查询数据库时,它能为你提供洞察力。它有简洁的命令,可以帮助你节省时间并减少进行复杂查询所需的编程量。学习 SQL 将帮助你更好地理解关系型数据库,并提升你作为数据科学家的个人资料。
6. Apache Spark
Apache Spark 正成为全球最受欢迎的大数据技术。它是一个类似于 Hadoop 的大数据计算框架。唯一的区别是 Spark 比 Hadoop 更快。这是因为 Hadoop 读写磁盘,速度较慢,而 Spark 将计算结果缓存于内存中。
Apache Spark 专门设计用于数据科学,以加速其复杂算法的运行。当处理大量数据时,它有助于传播数据处理,从而节省时间。它还帮助数据科学家处理复杂的非结构化数据集。你可以在一台机器或多台机器的集群上使用它。
Apache Spark 使数据科学家能够防止数据丢失。Apache Spark 的优势在于其速度和平台,使得进行数据科学项目变得容易。通过 Apache Spark,你可以从数据获取到分布式计算中执行分析。
7. 机器学习与人工智能
许多数据科学家在机器学习领域和技术方面不够熟练。这包括神经网络、强化学习、对抗学习等。如果你想在其他数据科学家中脱颖而出,你需要了解机器学习技术,如监督学习、决策树、逻辑回归等。这些技能将帮助你解决基于主要组织结果预测的不同数据科学问题。
数据科学需要在不同的机器学习领域应用技能。Kaggle 在其一项调查中揭示,少数数据专业人士在高级机器学习技能方面具备能力,如监督学习、无监督学习、时间序列、自然语言处理、异常检测、计算机视觉、推荐引擎、生存分析、强化学习和对抗学习。
数据科学涉及处理大量数据集。你可能想熟悉机器学习。
8. 数据可视化
商业世界经常产生大量数据。这些数据需要转换成易于理解的格式。人们天生比起原始数据,更容易理解图表和图形形式的图片。正如一个成语所说,“一图胜千言”。
作为数据科学家,你必须能够使用数据可视化工具,如 ggplot、d3.js 和 Matplotlib、Tableau 来可视化数据。这些工具将帮助你将项目中的复杂结果转换为易于理解的格式。问题在于,很多人不了解序列相关性或 p 值。你需要以视觉方式展示这些术语在结果中所代表的含义。
数据可视化为组织提供了直接处理数据的机会。他们可以快速掌握有助于他们抓住新商业机会并保持领先地位的见解。
特别是,我写了一篇文章,谈论了数据可视化的重要性以及如何用数据创建更好的故事。
9. 非结构化数据
数据科学家能够处理非结构化数据是至关重要的。非结构化数据是指不适合放入数据库表中的未定义内容。例如包括视频、博客文章、客户评价、社交媒体帖子、视频流、音频等。它们是被堆积在一起的繁重文本。整理这些类型的数据是困难的,因为它们没有经过优化。
大多数人将非结构化数据称为“黑暗分析”,因为它的复杂性。处理非结构化数据可以帮助你揭示对决策有用的见解。作为数据科学家,你必须具备理解和操作来自不同平台的非结构化数据的能力。
10. 智力好奇心
“我没有特别的才能。我只是充满了激情的好奇心。”
— 阿尔伯特·爱因斯坦
最近你一定在各处见到过这个短语,尤其是与数据科学家相关。Frank Lo 在他几个月前发布的客座博客中描述了它的含义,并讨论了其他必要的“软技能”。
好奇心可以被定义为获取更多知识的愿望。作为数据科学家,你需要能够提出关于数据的问题,因为数据科学家花费约 80%的时间来发现和准备数据。这是因为数据科学领域发展迅速,你必须学习更多以跟上步伐。
你需要通过在线阅读内容和阅读有关数据科学趋势的相关书籍来定期更新你的知识。不要被互联网飞速流动的大量数据压倒,你必须知道如何理解这些数据。好奇心是你作为数据科学家成功所需的技能之一。例如,最初你可能看不到你所收集的数据中的许多见解。好奇心将使你能够筛选数据以找到答案和更多见解。
11. 商业洞察力
成为一名数据科学家,你需要对你所工作的行业有扎实的理解,并知道你的公司正在尝试解决哪些业务问题。在数据科学方面,能够分辨出哪些问题对业务而言是重要的,以及识别出业务应该如何利用其数据的新方式是至关重要的。
要做到这一点,你必须理解你解决的问题如何影响业务。这就是为什么你需要了解业务运作方式,这样你才能把努力方向引导到正确的地方。
12. 沟通技巧
寻找优秀数据科学家的公司希望找到能够将技术发现清晰流畅地传达给非技术团队(如市场营销或销售部门)的人。数据科学家必须通过提供量化见解来帮助业务做出决策,同时理解非技术同事的需求,以便适当地处理数据。
除了使用公司理解的语言外,你还需要通过数据讲故事来沟通。作为数据科学家,你必须知道如何围绕数据创建故事情节,以便让任何人都能理解。例如,展示一张数据表格不如以讲故事的形式分享数据见解更有效。使用讲故事的方式将帮助你更好地向雇主传达你的发现。
在沟通时,要关注你分析的数据中蕴含的结果和价值。大多数企业主并不关心你分析了什么,他们关心的是这些分析如何能积极地影响他们的业务。学习如何专注于提供价值,并通过沟通建立持久的关系。
13. 团队合作
数据科学家不能单独工作。你需要与公司高管合作制定策略,与产品经理和设计师合作开发更好的产品,与市场人员合作推出更具转化率的营销活动,与客户端和服务器端软件开发人员合作创建数据管道和改进工作流程。你将不得不与组织中的每个人合作,包括你的客户。
本质上,你将与团队成员合作制定用例,以了解业务目标以及解决问题所需的数据。你需要知道如何处理用例,所需的数据以及如何将结果翻译和呈现成所有相关人员都能轻松理解的内容。
最终想法

感谢阅读。
如果你对所需的技能感到不知所措,这完全没问题(我也是!)。
归根结底,这些技能并不是成为数据科学家的必备条件,但它们确实能使你与其他典型的数据科学家有所不同。
我知道你并非普通人。
一如既往,如果你有任何问题或评论,请随时在下方留言反馈,或者你也可以通过LinkedIn与我联系。下次见!????
简介:Admond Lee 被誉为帮助初创公司和各种公司解决数据问题的数据科学家和顾问中的佼佼者,具有强大的数据科学咨询和行业知识专长。你可以在 LinkedIn、Medium、Twitter 和 Facebook 上与他联系,或者预约与他通话,如果你在寻找数据科学咨询服务。
原文。经授权转载。
相关内容:
-
你应该关注的 10 位数据科学领袖
-
如何进入数据科学领域:为有志数据科学家提供的终极问答指南
-
简单却实用的数据清理代码
相关主题
每位数据科学家应具备的 13 项顶级技能
原文:
www.kdnuggets.com/2022/03/top-13-skills-every-data-scientist.html

无论你是已经挤身数据科学领域还是希望进入这个领域,数据科学都是无需正式数据科学教育就能进入的最佳行业之一。如果你能够在没有获得正式学位的情况下培养出工作所需的技能和知识,大多数科技公司乐意让你在技术面试中证明自己,然后录用你。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
然而,没有相关领域的正式学位,很难知道你需要了解什么。这些技术面试会涉及哪些数据科学技能?获得这些知识或能力的最佳途径是什么?
让我带你深入了解你应该具备的 13 项数据科学技能,以成为成功的数据科学家。按照这个大纲,你将拥有一个易于消化的步骤路径来教育自己,并为申请数据科学家职位做好准备。
什么是数据科学?
每天,大约产生 2.5 quintillion 字节的数据,到 2025 年将达到 175 zettabytes 的数据。这些信息的洪流包含强大的见解,可以帮助推动全球变化,从减少碳排放到最大化公司的利润。数据科学旨在尝试理解这些数字并提供可操作的见解,以帮助组织。数据科学家可能会分析 A/B 实验的结果,以优化用户体验,或者确定哪些广告活动或组合能更有效地增加产品销量。
数据科学家做什么?

数据科学家参与从获取数据到为非技术同事生成易于理解的报告的整个过程。数据科学家全程参与数据科学生命周期。数据科学家构建数据管道,结合各种数据源以收集必要的信息。然后,他们清理数据以准备分析。统计分析用于从数据中提取汇总信息。
有时数据科学家还会构建机器学习模型,而在这样做时,他们还必须评估、部署和维护这些机器学习模型,以扩展其影响力和相关性。数据科学家还负责将这些从数据中获得的知识转达给非技术人员,通常以可视化和行动项的形式呈现。这些呈现可以是可视化图、报告、仪表盘或演示文稿。
要深入理解这一点,我们编写了一份终极指南,帮助你了解数据科学的全过程 → “数据科学家做什么?”。
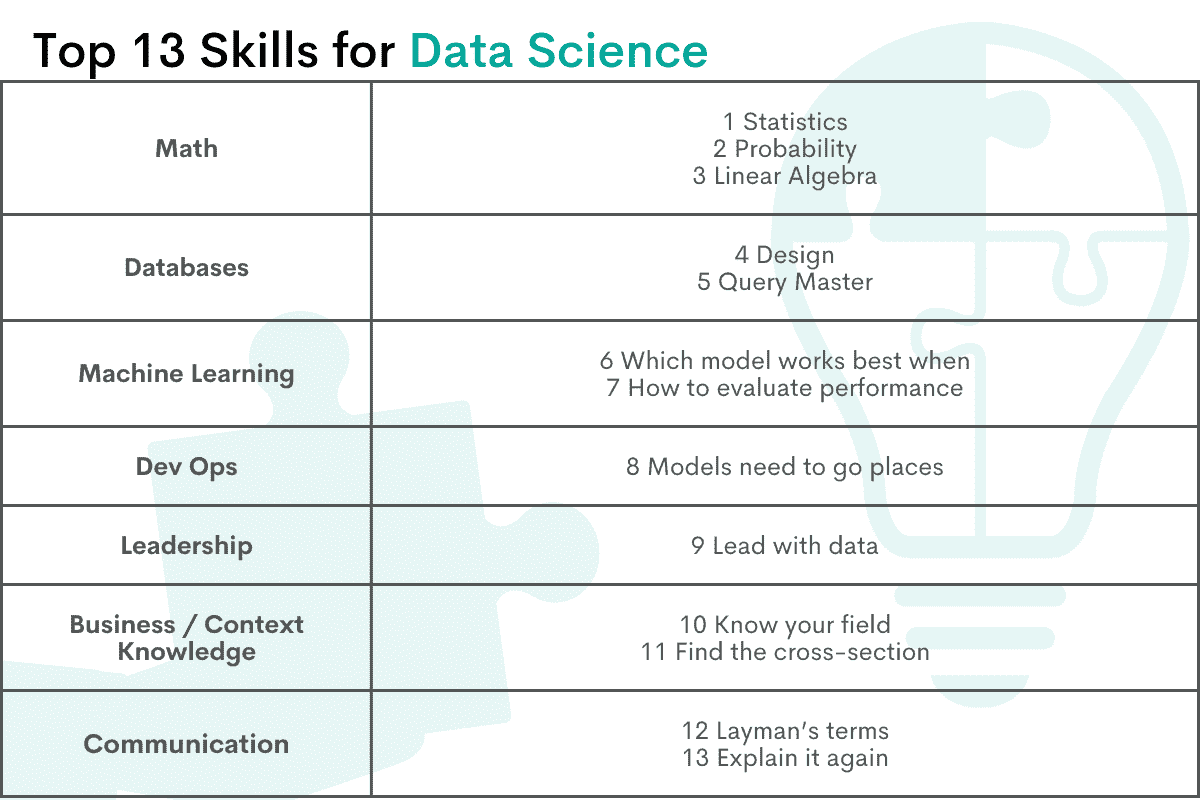
数据科学的前 13 项技能
数学
数学是所有数据科学形式的基础构件。无论你是在寻找数据集的中位数、开发机器学习模型,还是识别 A/B 实验处理是否对指标有显著影响,你都需要精通统计学、概率论和线性代数。
1. 统计学
统计学是分析 A/B 实验所需的数据科学家必备技能之一。你需要回答这样的问题,比如,样本量需要多大才能证明结果是显著的?均值、方差和标准差,以及诸如总体和样本等概念,都是从数据中提取显著意义的关键部分。你应该熟悉描述性统计和推断统计。
2. 概率
概率在分析受偶然因素影响的数据时是一个重要的数据科学家技能。概率论允许对偶然事件进行分析。变量的概率分布在预测分析中起着关键作用。
3. 线性代数
线性代数是机器学习和许多高阶矩阵工作的数学基础。为了有效使用任何机器学习算法,你需要理解其背后的数学,特别是线性代数,以了解所做的假设和存在的不足。
数据库
数据库是存储数据科学家所需“空气”的美丽、优雅的构造。在大数据的世界里,数据库对存储、更新和操作大型数据集至关重要。作为数据科学家,你应该在理论和实践层面上对数据库感到非常舒适。
4. 设计
数据只有在组织良好且干净时才有效。虽然数据或解决方案架构师可能是实际设计数据库的人,但你应该了解数据库为何以特定方式组织及设计策略。了解如何在特定结构中正确存储数据以构建你的模型。
5. 查询大师
SQL、KQL、范围脚本等——你应该熟练掌握任何/所有流行的查询语言。合作团队将需要你快速估算应该朝哪个方向前进。在紧急情况下提取一些干净、准确的汇总数据可以极大提高依赖你的人员的生产力,并且是推动组织内数据驱动决策的一个极好且便利的方法。
机器学习
尽管并非所有数据科学职位都要求你在设计、开发和评估机器学习模型方面感到舒适,但这确实是行业发展的方向。如果你尚未熟练掌握机器学习模型,我建议你花时间掌握这些技能,因为它们对确保你未来的工作安全和保持技能相关性大有帮助。
6. 哪种模型在何时效果最佳
了解哪种机器学习模型在特定情况下效果最佳,取决于你处理的数据是否有标签、无标签、是二进制数据集还是多分组数据集。如果数据是文字、数字、图像等,这也会影响你如何调整和选择模型以最大化性能。
7. 如何评估性能
为了确定你的模型表现如何,你必须能够正确评估它。了解测试数据和训练数据之间的差异、将源数据分为这两种类型的策略,以及在开发和性能评估周期中何时使用每一组数据。
Dev Ops
如果你在数据科学工作中不涉及开发机器学习模型,那么你不必担心部署它们。然而,商业影响的最大潜力在于创建实时预测模型。掌握这些技能是值得的,因为它将显著增加你工作的影响力。
8. 模型需要部署
对于开发机器学习模型的数据科学家,你需要分享你的模型。如果你可以预测用户回应广告的可能性,那么如果预测可以实时生成并通过 API 调用访问,这些知识会更有用。你不仅可以向公司项目经理提供下一个开发领域的想法,还可以为每个最终用户量身定制产品,以最大化参与度、购买量、留存率等。提供实时预测使你能够将数据科学融入产品中。
领导力
9. 以数据为主导
当你将发现传达给公司其他部门时,他们可能会试图将你的话与他们自己的截止日期、优先事项等结合起来。确保你花时间了解他们的情况,以及你的见解如何帮助他们最大化业务影响。数据驱动的决策更可能带来结果,而你的工作是帮助周围的人理解这一点。
业务/背景知识
10. 了解你的领域
你需要了解你所处理数据的背景。如果你查看的是 CT 扫描的图像或超市收据,从这些数据集中提取的数字和不同属性可能意味着非常不同的东西。你应该致力于成为你数据来源的专家,因为这种背景知识将帮助你为分析找到正确的方向。这种知识也将帮助你识别和挑战你的假设,或者至少对其进行考虑。
11. 寻找交集
你需要弄清楚你的技术知识如何与所工作业务领域相结合。一旦你能够识别这种交集,你可以着手寻找新的数据来源,并提出有洞察力的方法来增强你的数据。
沟通
12. 通俗易懂
你的数字和脚本必须输出指导整个团队、部门甚至公司的行动的词汇。了解业务和了解技术同样重要,以便与非技术人员成功沟通。你作为数据科学家的工作是提取组织数据的价值,以改善产品、公司的流程以及员工的生活。找到传达发现的方式,使周围的人理解其重要性以及应采取的行动。
13. 再解释一遍
知道何时强调和重申重要的事情。重复是帮助人们理解复杂概念的重要工具。将所有这些复杂的、精细的结果和模型简化为公司可控的最重要项目。你可能已经花费了大量精力来规范数据集并控制各种因素,但关键在于这些数字和方程式对那些试图改善最终用户产品或服务的人意味着什么。
关于数据科学家重要技能的最终思考
技术数据科学技能是数据科学家工作的基础。虽然数学分析和编码通常被认为是数据科学家最重要的任务,但能够沟通这些发现的意义以及应采取什么措施以推动正确方向同样重要。数据科学家的终极责任是使数据对公司有价值,而唯一的方式是提取可以转化为可衡量的行动项目的洞察,这些行动项目可以通过指标跟踪。做数据驱动决策的倡导者,并向你的组织证明通过数据科学推动产品、内部流程和几乎所有领域的改进的价值。
我们还推荐查看我们的 数据科学家技能终极指南,了解什么能让你保持工作并在数据科学领域取得进步。
内特·罗西迪 是一位数据科学家,专注于产品策略。他还是一名兼职教授,教授分析课程,并且是 StrataScratch、一个帮助数据科学家准备面试的问题平台的创始人。通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
了解更多相关主题
精通数据战略的 15 本书
原文:
www.kdnuggets.com/2022/06/top-15-books-master-data-strategy.html
如果你是一位数据从业者,希望获得领导角色,学习数据管理将是实现目标的重要一步。在这篇文章中,我们列出了 15 本书,涵盖从数据架构(高度技术性)到数据素养(广泛非技术性)的主题,以帮助你提高对端到端最佳实践的理解。

图片由 Gaelle Marcel 提供,来源于 Unsplash
1. 数据管理知识体系(DMBOK)
我们的前三大课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
-
作者:DAMA 国际的各位领导
-
阅读时间:20 小时 5 分钟(588 页)
-
评分:4.8 / 5(397 条总评分)
总结:如果不在这里开始这个列表我会感到遗憾。这本巨著涵盖了 14 个与数据战略相关的实际主题,之后还有 3 个与实施相关的主题。
14 个不同的知识领域最好地由Aiken Pyramid展示,说明这些主题如何相互构建。数据治理构成了金字塔的基础,接下来的层级包括数据架构、数据质量和元数据管理,直到我们到达顶层的数据科学(书中天真地将其称为“大数据”)。
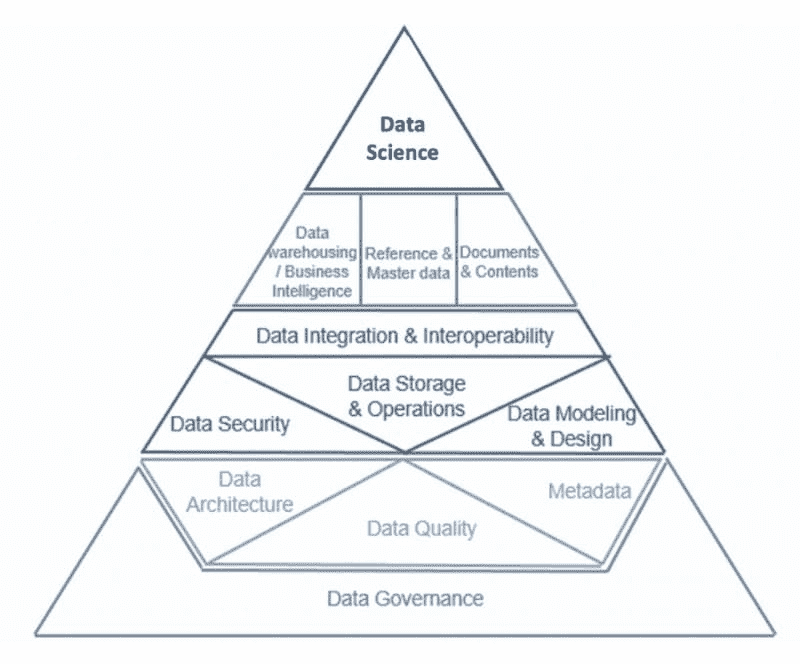
数据管理知识体系(DMBOK) 读起来可能会有些令人沮丧,主要因为它是由 20 多位 DAMA 国际的成员编写的,看似没有连贯的主线。这本值得信赖的书籍目前是第二版——对于第三版,我建议请一个编辑。视频评论在这里。
TL;DR:如果你阅读这本书(或至少浏览大部分内容并标记重要部分),你将准备好参加开放书籍、开放笔记的认证数据管理专业人员 (CDMP) 考试(即你未曾听说过的最佳数据科学认证)。
2. Navigating the Labyrinth
-
作者:劳拉·塞巴斯蒂安-科尔曼
-
阅读时间:6 小时 5 分钟(208 页)
-
评分:4.4 / 5(共 76 条评分)
总结:本书面向那些在组织中实施数据治理并努力克服业务障碍的读者。如果你处于领导职位或需要与高层管理人员协调数据管理,Navigating the Labyrinth 提供了这一复杂领域的指南。
塞巴斯蒂安-科尔曼将数据管理理念、框架和程序转化为一本适合商业的书籍,弥合了技术领域专家和高层决策者之间的差距。这本指南被广泛认为是数据管理总体目标、术语及如何在高层实施数据战略的绝佳概述。
TL;DR:Navigating the Labyrinth 通过经过验证的原则简化了复杂性,这些原则与数据管理知识体系紧密相关,从而提升你对数据管理的整体理解。
3. 数据治理
-
作者:约翰·拉德利
-
阅读时间:8 小时 45 分钟(264 页)
-
评分:4.3 / 5(共 80 条评分)
总结:为什么数据治理对于保持组织的成功是必要的?团队应该如何规划、启动和执行数据治理计划?如何保持程序的持续运作?通过框架和案例研究,本书阐明了如何创建一个成功且具有成本效益的数据治理程序。
鉴于与增长、隐私和安全相关的开销,组织面临着与其数据资产相关的新风险来源。数据治理代表了解决方案。一个强有力的章程将帮助组织在风险和机会之间的危险边界中航行。
本书适用于任何打算创建数据治理程序的经理或团队负责人。数据管理的挑战继续扩大,面临如存储成本、指数级增长、行政管理和安全问题等困难。通过正确的策略,组织可以在节省开支的同时为客户/利益相关者提供更好的服务。
和列表上的许多其他书籍一样,数据治理 与CDMP 专家考试相关,这是CDMP 基础考试之后的下一个考试级别。如果你对本文讨论的任何主题的深入探索感到兴奋,我鼓励你阅读有关在 CDMP 从业者或大师级别获得认可的过程。
总结: 扩展数据操作同时避免风险的解决方案是实施强有力的数据治理。本书将向你展示如何做到这一点。
4. 持续改进的数据质量测量
-
作者: Laura Sebastian-Coleman
-
阅读时间: 12 小时 32 分钟(376 页)
-
评分: 4.1 / 5(总评分 29 条)
总结: 领先专家 Sebastian-Coleman 提供了如何随时间监控和最大化数据质量的指导。它从标准测量概念开始,逐步推进到数据质量不同维度的详细测量技术框架。
本书还提供了用于趋势分析的数据质量结果定义和存储的常见概念模型。此外,它包括了持续测量和监控的通用规范,例如比较和计算,使测量具有意义。
总结: 组织对数据质量的目标应是促进持续的测量,而不是单次活动。

照片由 Jason Leung 供图,来源于 Unsplash
5. 执行数据质量项目:优质数据和可信信息的十个步骤
-
作者: Danette McGilvray
-
阅读时间: 11 小时 45 分钟(352 页)
-
评分: 4.6 / 5(总评分 57 条)
总结: 十个步骤指的是一种系统化的方法,将理解数据质量的概念框架与改进数据质量所需的工具和技术相结合。这本书利用现实世界的项目来突出这些原则如何提升数据质量。
McGilvray 强调,永远不要仅仅为了数据质量本身而处理数据质量,而应将其作为推动组织特定使命的一种方式。十个步骤的方法论可以根据需要进行扩展和缩小,并适用于许多与数据质量相关的情况。
总结: 执行数据质量项目 最近在 2021 年更新。它包括示例、几个模板和执行的实用建议。书中指导读者如何根据组织的独特位置选择下一步最佳行动。
6. 负责任的数据科学
-
作者: Grant Fleming 和 Peter Bruce
-
阅读时间: 10 小时 8 分钟(304 页)
-
评分: 3.5 / 5(共 6 条评分)
总结: 不必再寻找其他资源,本书对最新技术应用于全球最大和最敏感记录时产生的伦理问题进行了深入、实用的探讨。本书指导数据科学家如何实施和审计机器学习模型,以减轻意外的危害。书中提供了解释技术和其他方法的技术实施方案,以减少偏见和不平等。
简评: 负责任的数据科学 阐述了利益相关者应如何实施数据解决方案。根据本书中的指南,数据科学家的角色是将详细的技术分析与伦理社会观察相结合。

照片由 Oladimeji Ajegbile 拍摄,来源于 Unsplash
7. 伦理与数据科学
-
作者: Mike Loukides, Hilary Mason, 和 DJ Patil
-
阅读时间: 1 小时 32 分钟(46 页)
-
评分: 4.4 / 5(共 132 条评分)
总结: 这本简短的指南作为 Kindle 电子书免费提供,讲解了关于伦理数据处理的建议、清单和术语,特别是针对数据科学家。书中列举了几起不道德的数据使用案例,并概述了应采取的推荐措施,以避免未来出现这些问题。
书的基本前提是,伦理数据科学不仅仅需要代码或 誓言。 伦理与数据科学 建议采用每日实践,并实施清单。数据科学家应将客户数据视为自己的数据,感到有权挑战组织的假设,并使用“5 Cs”(同意、清晰、一致、控制和后果)来创造出色的数据产品。
书的结尾附有普林斯顿研究人员撰写的案例研究。书中强调了精益方法论以及利用漏洞赏金发现潜在漏洞的实践。
简评: 本书是一本简单实用的数据科学伦理指南。
8. 利用数据对抗用户流失
-
作者: Dr. Carl Gold
-
阅读时间: 16 小时 20 分钟(504 页)
-
评分: 4.3 / 5(共 16 条评分)
总结: 对于任何希望进入数据科学领域的人来说,这是一本必须阅读的案例研究。利用数据打击流失充满了来自 Dr. Gold 职业生涯的实际例子,直到他担任订阅服务公司 Zuora 的首席数据科学家。
用户流失发生在付费客户离开订阅服务时。对于任何有经常性收入的业务,这是一个关键指标。随着越来越多的公司转向订阅经济,这是数据科学家必须理解的重要业务模型。因此,这本书对于新兴的数据科学家或希望更好地理解这一细分领域的熟练从业者来说,是一个很好的实践项目。
在书中和相关的 Twitch 直播视频中,Dr. Gold 提供了进行流失分析所需的 SQL 和 Python 代码指导。在这两个资源中,Dr. Gold 真的深入探讨了特征工程的过程(即从大量原始数据中寻找和/或生成预测特征)。为了这个项目,Dr. Gold 创建了一个现实的模拟社交网络数据集,以便数据从业者可以通过动手编码跟随他的分析。
简要: 这是一本扎实且实用的指南,适用于所有数据科学家以及任何希望改善客户保留的人。这本书教你如何将原始数据转化为可测量的行为指标,计算客户终身价值,并利用人口统计数据来改进流失预测。

图片由 freddie marriage 拍摄,来源于 Unsplash
9. 数据驱动的科学与工程:机器学习、动态系统和控制
-
作者: Steven N. Brunton 和 J. Nathan Kutz
-
阅读时间: 16 小时 25 分钟(492 页)
-
评分: 4.7 / 5(总共 186 条评价)
总结: 这本书是数据科学的强有力入门书,重点介绍了基础数学原理。阅读这本书可以在数据驱动的决策制定和数据工程最佳实践方面获得优势。
Brunton 和 Kutz 深入探讨了数据分析和机器学习。这包括: 神经网络、Lorenz 系统、降维与变换、奇异值分解(SVD)、傅里叶变换和稀疏采样。
这本书还涉及了动态模式分解、稀疏动态识别算法和控制理论等主题。最后,书中讨论了使用适当正交分解(POD)算法来预测偏微分方程(PDE)的降阶模型(ROM)。
如果这些对你意义不大,也不用担心!!这本书由 Steve Brunton 的 YouTube 频道 支持,该频道提供了另一种增强你对这些概念理解的方法。
简明扼要:这是对数据管道不同管理方法的一个非常好的概述。
10. 数据素养
-
作者:彼得·艾肯和托德·哈伯
-
阅读时间:14 小时 15 分钟(429 页)
-
评分:5 / 5(共 1 条评分)
总结:这是一本扩展数据素养到数十亿人的路线图,本书定义了在当今商业环境中操作和在数据驱动的社会中积极参与所需的知识。
它还描述了如何通过一个 12 步框架在组织内建立数据素养。该部分概述了一个有价值的数据教义。它还描述了数据从业者在提高组织数据素养水平时可能面临的实际问题。
简明扼要:这本书是提高个人和组织数据素养的全面指南。
11. 掌握你的数据
-
作者:安迪·格雷厄姆
-
阅读时间:6 小时 16 分钟(188 页)
-
评分:4.6 / 5(共 7 条评分)
总结:主数据管理(MDM)代表了管理组织数据一致性和完整性的整体挑战的一个缩影。这本书解释了 MDM、其商业理由以及成功的关键策略。
阅读后,你将拥有一个坚实的基础,以在组织中引入 MDM 或改进现有实践。这本书对任何在这一重要领域“冒险”的人来说都是至关重要的。该书的目标读者包括数据专业人士、信息技术人员、项目/程序经理、数据架构师、业务分析师和技术领导者。
简明扼要: “黄金记录”概念是格雷厄姆主数据论述的核心。读者将对这一概念有一个扎实的了解,特别是如何识别组成黄金记录的数据源。

图片由 Arif Riyanto 提供,发布在 Unsplash 上。
12. 数据即服务:提供可重用企业数据服务的框架
-
作者:普什帕克·萨尔卡尔
-
阅读时间:11 小时 48 分钟(354 页)
-
评分:4.3 / 5(共 4 条评分)
摘要: 数据越来越被视为一种资产,可以作为一种服务进行盈利。该书通过各种架构和相关模式的实际案例,展示了公司如何从数据即服务(DaaS)中受益。
该书概述了在任何公司实施数据即服务的全面策略,包括(1)一个可重复使用和适应的面向服务的架构(SOA)框架,(2)向客户提供 DaaS 的计划,以及(3)DaaS 架构每个组件的详细描述。Sarkar 深入探讨了如何通过使用 SOA 原则、行业最佳实践和数据虚拟化、云计算以及数据科学等新兴技术,成功地在异构平台之间收集和分发数据。
概述: 数据即服务 讨论了企业如何通过提供数据服务来创造收入,作为一种收费订阅服务。
13. 敏捷数据仓库设计
-
作者: Lawrence Corr 和 Jim Stagnitto
-
阅读时间: 10 小时 56 分钟(328 页)
-
评分: 4.6 / 5(总共 154 条评分)
摘要: 这本书提供了一个详细的逐步指南,用于捕捉数据仓库和商业智能(DW & BI)需求,并通过与 BI 利益相关者进行“模型风暴”(数据建模+头脑风暴)来将其转化为高性能的维度模型。
此外,读者将了解商业事件分析与建模(BEAM),这是一种用于改善数据仓库设计师、BI 利益相关者和整个 DW & BI 开发团队之间沟通的敏捷维度建模方法。了解更多。
概述: 通过友好的图表和有用的附加资源,Corr 和 Stagnitto 对数据管理领域做出了重要贡献。
14. 数据流动管理:数据集成最佳实践技术与技术
-
作者: April Reeve
-
阅读时间: 6 小时 48 分钟(204 页)
-
评分: 3.6 / 5(总共 12 条评分)
总结:读者将学习管理数据传输的策略、工具和最佳实践。这本书讨论了显著减少管理系统接口复杂性并促进可扩展设计的方法。基于二十多年的专业知识,Reeve 提出了一种供应商中立的数据在计算环境和数据系统之间传输的策略。
总结:典型的组织由几十(甚至上百)个计算系统构成,这些系统在时间的推移中被构建、购买或获得。数据必须集成以进行报告和分析,分享以处理业务交易,并在新系统获得时进行转换。
15. 设计数据密集型应用
-
作者:马丁·克莱普曼
-
阅读时间:20 小时 20 分钟(611 页)
-
评分:4.8 / 5(2440 总评分)
总结:如果你对分布式系统和可扩展性感兴趣,这本书是必读的。它提供了对该领域各种技术的全面理解,并详细描述了每项技术旨在解决的各种问题。通过这本书,你可以快速学习数据管理的最重要概念,并尽可能以有趣的方式掌握它们。
克莱普曼掌握了该领域的最新技术。他始终将计算机科学的相关理论与实际应用案例结合起来。重点主要是构建数据服务时适用的核心原则和思维过程。
总结:如果你从事数据工程、系统设计、云架构或 DevOps,这本书是一个不错的指南。

总结
就这样 — 15 本你需要阅读的书籍,以便掌握数据策略。如果你对深入了解这个领域感到兴奋,你应该考虑注册我的数据策略通讯。每个月,我们都会深入探讨一个与数据管理相关的最新故事,并提供一个特别适合数据从业者的生产力或健康建议。
你也可以考虑备考认证数据管理专家考试。这个 100 题的考试是开放书籍和笔记的,因此可以相对较快地学习并通过。除了提供一个有价值的数据管理领域资质外,CDMP 还提供了你可以在日常工作中使用的实用知识和框架,并帮助你为同事和客户提供结构化建议。
如果你有兴趣了解更多关于考试的信息,可以加入这两个群组:CDMP 学习小组(Facebook)和 数据战略专业人士(LinkedIn)。期待见到你!!
原文。经许可转载。
更多相关内容
机器学习专家的前 15 个框架
原文:
www.kdnuggets.com/2016/04/top-15-frameworks-machine-learning-experts.html
评论

机器学习工程师是工程团队的一部分,负责构建产品和算法,确保其可靠、快速并能够大规模运作。他们与数据科学家紧密合作,以了解理论和业务方面的内容。在机器学习的背景下,主要的区别总结如下:
-
机器学习工程师构建、实施和维护生产环境中的机器学习系统。
-
数据科学家进行研究以生成关于机器学习项目的想法,并进行分析以理解机器学习系统的指标影响。
以下是机器学习工程师框架的列表:
-
Apache Singa 是一个通用的分布式深度学习平台,用于在大型数据集上训练大型深度学习模型。它设计了一个基于层抽象的直观编程模型。支持各种流行的深度学习模型,包括前馈模型(如卷积神经网络 CNN)、能量模型(如限制玻尔兹曼机 RBM)和递归神经网络 RNN。提供了许多内置的层供用户使用。
-
Amazon Machine Learning 是一项使各技能水平的开发者能够轻松使用机器学习技术的服务。Amazon Machine Learning 提供可视化工具和向导,指导你创建机器学习 (ML) 模型,而无需学习复杂的 ML 算法和技术。它连接到存储在 Amazon S3、Redshift 或 RDS 中的数据,并可以在这些数据上运行二元分类、多类分类或回归,以创建模型。
-
Azure ML Studio 允许 Microsoft Azure 用户创建和训练模型,然后将其转化为可以被其他服务使用的 API。用户每个账户可以获得最多 10GB 的存储空间用于模型数据,不过你也可以将自己的 Azure 存储连接到该服务以支持更大的模型。提供了各种算法,既包括 Microsoft 自家的,也包括第三方的。你甚至不需要账户就可以试用该服务;你可以匿名登录,并使用 Azure ML Studio 达到八小时。
-
Caffe 是一个以表达、速度和模块化为目标的深度学习框架。它由伯克利视觉与学习中心(BVLC)和社区贡献者开发。杨庆佳 在 UC Berkeley 博士期间创建了该项目。Caffe 在 BSD 2-Clause license 许可下发布。模型和优化通过配置定义,无需硬编码,用户可以在 CPU 和 GPU 之间切换。速度使得 Caffe 适合研究实验和工业部署。Caffe 可以在单个 NVIDIA K40 GPU 上处理超过 60M 图像每天。
-
H2O 使任何人都能轻松应用数学和预测分析来解决当今最具挑战性的业务问题。它智能地结合了其他机器学习平台中目前没有的独特功能,包括:最佳开源技术、易于使用的 WebUI 和熟悉的界面、对所有常见数据库和文件类型的数据无关支持。使用 H2O,你可以使用现有的语言和工具进行工作。此外,你可以将平台无缝扩展到你的 Hadoop 环境中。
-
大规模在线分析 (MOA) 是最受欢迎的开源数据流挖掘框架,拥有一个非常活跃的成长社区。它包括一系列机器学习算法(分类,回归,聚类,异常检测,概念漂移检测和推荐系统)和评估工具。MOA 与 WEKA 项目相关,也用 Java 编写,同时能够扩展到更具挑战性的问题上。
-
MLlib (Spark) 是 Apache Spark 的机器学习库。其目标是使实际的机器学习可扩展且简单。它包括常见的学习算法和工具,包括分类、回归、聚类、协同过滤、降维,以及较低级别的优化原语和较高级别的管道 API。
-
mlpack 是一个基于 C++ 的机器学习库,最初于 2011 年推出,旨在“可扩展性、速度和易用性”,根据库的创建者。实现 mlpack 可以通过一组命令行可执行文件进行快速“黑箱”操作,也可以通过 C++ API 进行更复杂的工作。Mlpack 提供这些算法作为简单的命令行程序和 C++ 类,然后可以集成到更大规模的机器学习解决方案中。
-
Pattern 是一个用于 Python 编程语言的网络挖掘模块。它提供了数据挖掘工具(Google、Twitter 和 Wikipedia API、网页爬虫、HTML DOM 解析器)、自然语言处理工具(词性标注、n-gram 搜索、情感分析、WordNet)、机器学习工具(向量空间模型、聚类、SVM)、网络分析和
-
Scikit-Learn 通过在现有 Python 包——NumPy、SciPy 和 matplotlib——之上构建,充分发挥了 Python 的广度。生成的库可以用于交互式的“工作台”应用,也可以嵌入到其他软件中并重复使用。该工具包在 BSD 许可证下提供,因此完全开放和可重用。Scikit-learn 包含许多标准 机器学习 任务(如聚类、分类、回归等)所需的工具。由于 scikit-learn 由 大量开发者和机器学习专家的社区 开发,有前途的新技术通常会在相当短的时间内被纳入。
-
Shogun 是最古老、最受尊敬的机器学习库之一,Shogun 创建于 1999 年,用 C++ 编写,但不限于 C++。得益于 SWIG 库,Shogun 可以在 Java、Python、C#、Ruby、R、Lua、Octave 和 Matlab 等语言和环境中透明使用。Shogun 旨在统一大规模学习,适用于广泛的特征类型和学习设置,如分类、回归或探索性数据分析。
-
TensorFlow 是一个用于数值计算的开源软件库,通过数据流图来实现。TensorFlow 实现了所谓的数据流图,其中一批数据(“张量”)可以通过图中描述的一系列算法进行处理。数据在系统中的流动称为“流”——因此得名。图可以使用 C++ 或 Python 组装,并可以在 CPU 或 GPU 上处理。
-
Theano 是一个 Python 库,允许你定义、优化和评估数学表达式,特别是多维数组(numpy.ndarray)的表达式。使用 Theano,可以达到与手工编写的 C 实现相媲美的速度,适用于涉及大量数据的问题。它是在 LISA 实验室编写的,以支持高效机器学习算法的快速开发。Theano 的名字源自 希腊数学家,她可能是毕达哥拉斯的妻子。Theano 在 BSD 许可证下发布。
-
Torch 是一个科学计算框架,广泛支持以 GPU 为主的机器学习算法。由于其易用高效的脚本语言 LuaJIT 和底层的 C/CUDA 实现,Torch 易于使用且高效。Torch 的目标是最大限度地提高科学算法的灵活性和速度,同时使过程极其简单。Torch 拥有一个由社区驱动的大型生态系统,涵盖机器学习、计算机视觉、信号处理、并行处理、图像、视频、音频和网络等领域,并建立在 Lua 社区之上。
-
Veles 是一个用于深度学习应用的分布式平台,虽然它使用 Python 来执行节点之间的自动化和协调,但其核心代码是用 C++ 编写的。数据集可以在输入集群之前进行分析和自动归一化,而 REST API 使训练后的模型能够立即投入生产。它专注于性能和灵活性。它几乎没有硬编码实体,能够训练所有广泛认可的拓扑结构,如全连接网络、卷积网络、递归网络等。
在评论中告诉我们更多关于你喜欢的机器学习框架的事宜。
简介: Devendra Desale(@DevendraDesale) 是一名数据科学研究生,目前从事文本挖掘和大数据技术工作。他还对企业架构和数据驱动的业务感兴趣。在离开电脑时,他也喜欢参加聚会和探索未知领域。
相关:
-
Github 上的前 10 个数据科学资源
-
Github 上的前 10 个数据可视化项目
-
数据科学工具 – 专有供应商仍然重要吗?
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 维护
更多相关内容
2017 年数据科学的 15 个顶级 Python 库
原文:
www.kdnuggets.com/2017/06/top-15-python-libraries-data-science.html
由 Igor Bobriakov,ActiveWizards。
由于 Python 在数据科学行业近年来获得了广泛关注,我想基于近期的经验概述一些对数据科学家和工程师最有用的库。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业之路。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持组织的 IT
由于所有这些库都是开源的,我们添加了来自 Github 的提交次数、贡献者数量和其他指标,这些可以作为库受欢迎程度的代理指标。
核心库。
1. NumPy(提交次数:15980,贡献者:522)
当开始处理 Python 中的科学任务时,人们不可避免地会求助于 Python 的 SciPy Stack,这是一组专门为科学计算设计的软件(不要与 SciPy 库混淆,后者是该堆栈的一部分,还有围绕该堆栈的社区)。我们希望从这里开始。然而,堆栈非常庞大,其中包含十多个库,我们希望重点关注核心包(尤其是最重要的那些)。
最基础的包是 NumPy(即 Numerical Python)。它提供了大量用于 Python 中 n 维数组和矩阵操作的有用功能。该库提供了对 NumPy 数组类型的数学操作的矢量化,这改善了性能,并相应地加速了执行。
2. SciPy(提交次数:17213,贡献者:489)
SciPy 是一个用于工程和科学的软件库。你需要理解 SciPy Stack 和 SciPy Library 之间的区别。SciPy 包含线性代数、优化、积分和统计的模块。SciPy 库的主要功能是建立在 NumPy 之上的,因此其数组大幅使用 NumPy。它通过特定的子模块提供高效的数值例程,如数值积分、优化等。SciPy 所有子模块中的函数都经过良好文档记录——这是其另一大优点。
3. Pandas(提交次数:15089,贡献者:762)
Pandas 是一个 Python 包,旨在使处理“标签化”和“关系型”数据变得简单直观。Pandas 是数据整理的完美工具,旨在快速且轻松地进行数据操作、聚合和可视化。
该库中有两个主要的数据结构:
“Series”——一维

“数据框架”,二维
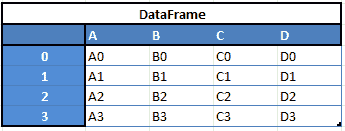
例如,当你想从这两种类型的结构中接收新的 DataFrame 时,你可以通过将一行追加到 DataFrame 中来获得这样的 DF,方法是传递一个 Series:
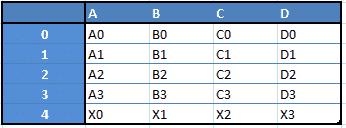
这里仅列出一些你可以使用 Pandas 做的事情:
-
轻松删除和添加 DataFrame 中的列
-
将数据结构转换为 DataFrame 对象
-
处理缺失数据,表示为 NaNs
-
强大的分组功能
Google Trends 历史
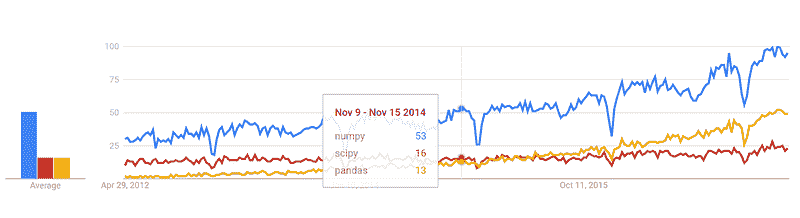
trends.google.com
GitHub 拉取请求历史
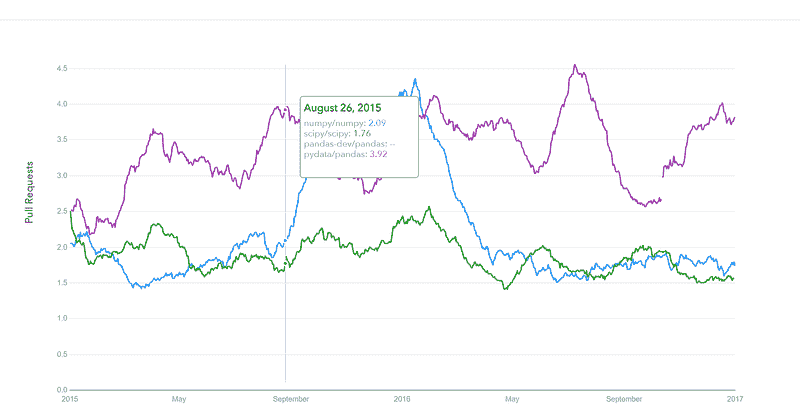
datascience.com/trends
可视化。
4. Matplotlib(提交次数:21754,贡献者:588)
另一个 SciPy Stack 核心包和另一个专门用于生成简单而强大的可视化的 Python 库是 Matplotlib。它是一个顶尖的软件,使 Python(在 NumPy、SciPy 和 Pandas 的帮助下)成为与 MatLab 或 Mathematica 等科学工具的有力竞争者。
然而,该库比较底层,这意味着你需要编写更多代码才能达到高级可视化水平,通常比使用更高级的工具需要更多的努力,但总体努力是值得的。
通过一点努力,你可以制作几乎所有的可视化:
-
线图;
-
散点图;
-
条形图和直方图;
-
饼图;
-
茎叶图;
-
等高线图;
-
箭头图;
-
频谱图。
Matplotlib 还提供了创建标签、网格、图例和许多其他格式化实体的功能。基本上,一切都是可定制的。
该库受不同平台支持,并使用不同的 GUI 工具包来展示结果可视化。各种 IDE(如 IPython)支持 Matplotlib 的功能。
还有一些附加库可以使可视化变得更加容易。
5. Seaborn(提交次数:1699,贡献者:71)
Seaborn 主要集中于统计模型的可视化;这种可视化包括热图,这些图总结数据但仍然描绘整体分布。Seaborn 基于 Matplotlib,并且高度依赖于它。
6. Bokeh(提交次数:15724,贡献者:223)
另一个出色的可视化库是 Bokeh,旨在提供交互式可视化。与之前的库不同,它不依赖于 Matplotlib。正如我们之前提到的,Bokeh 的主要关注点是交互性,并通过现代浏览器以 Data-Driven Documents (d3.js) 风格进行展示。
更多相关主题
2018 年数据科学的前 15 个 Scala 库
原文:
www.kdnuggets.com/2018/02/top-15-scala-libraries-data-science-2018.html
评论
作者:伊戈尔·博布里亚科夫,ActiveWizards

在我们之前的文章中,我们讨论了 顶级 Python 数据科学库。这次我们将重点关注 Scala,近年来它已经成为数据科学家的另一个重要语言。Scala 的流行主要是由于 Spark 的兴起,Spark 是一个大数据处理引擎,使用 Scala 编写,因此提供了原生的 Scala API。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
我们不会在这里深入比较 Scala 与 Python,但重要的是要注意,与 Python 不同,Scala 是编译语言。因此,使用 Scala 编写的代码执行速度要快得多(与纯 Python 相比,而不是像 NumPy 这样的专用库)。
与 Java 相比,Scala 的编写体验更佳,因为通常可以用显著更少的代码行来表达相同的逻辑。Scala 的功能丝毫不逊色于 Java,甚至具有一些更先进的特性。Java 的老手们可能会提出很多反对意见,但毫无疑问,Scala 更适合数据科学任务。
目前,Python 和 R 仍然是快速数据分析、构建、探索和操作强大模型的主要语言,而 Scala 则成为处理大数据的功能性产品开发中的关键语言,因为大数据需要稳定性、灵活性、高速、可扩展性等。在研究阶段,分析和模型通常在 Python 中完成,然后在生产过程中实现到 Scala 中。
为了方便起见,我们准备了一个关于在 Scala 中执行机器学习和数据科学任务的最重要库的全面概述。我们将使用与对应的 Python 工具的类比,以便更好地理解一些重要方面。实际上,只有一个顶级的综合工具构成了 Scala 中数据科学和大数据解决方案开发的基础,这就是 Apache Spark,它配备了多种用 Scala 和 Java 编写的库和工具。让我们详细了解一下它。
数据分析和数学
Breeze(提交次数: 3316, 贡献者: 84)
Breeze 被认为是 Scala 的主要科学计算库。它借鉴了 MATLAB 的数据结构和 Python 的 NumPy 类。Breeze 提供了对数据数组的快速高效操作,并实现了许多其他操作,包括以下内容:
-
矩阵和向量运算,用于创建、转置、填充数字、进行逐元素操作、求逆、计算行列式以及满足几乎所有需求的其他选项。
-
概率和统计函数,包括从统计分布和计算描述性统计(如均值、方差和标准差)到马尔科夫链模型。统计的主要包是
breeze.stats和breeze.stats.distributions -
优化,即对函数进行局部或全局最小值的研究。优化方法存储在
breeze.optimize包中。 -
线性代数: 所有基本操作依赖于 netlib-java 库,使 Breeze 在代数计算中非常快速。
-
信号处理操作,用于处理数字信号。Breeze 中的重要操作示例包括卷积和傅里叶变换,傅里叶变换将给定函数分解为正弦和余弦分量的和。
Breeze 还提供了绘图功能,我们将在下面讨论。
Saddle(提交次数: 184, 贡献者: 10)
另一个用于 Scala 的数据操作工具包是 Saddle。它是 R 和 Python 的 pandas 库在 Scala 中的对应物。与 pandas 或 R 中的数据帧类似,Saddle 基于 Frame 结构(2D 索引矩阵)。
总共有五种主要的数据结构,分别是:
-
Vec(1D 向量)
![]()
-
Mat(2D 矩阵)
![]()
-
Series(1D 索引矩阵)
![]()
-
Frame(2D 索引矩阵)
![]()
-
索引(类似哈希表)
![]()
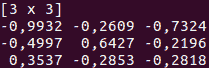
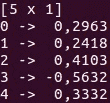
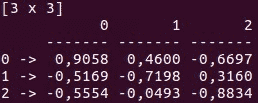
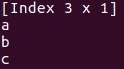
Vec 和 Mat 类是 Series 和 Frame 的基础。你可以在这些数据结构上实现不同的操作,并用于基本的数据分析。Saddle 另一个很棒的特点是对缺失值的强大鲁棒性。/span>
Scalalab(提交次数: 23, 贡献者: 1)
ScalaLab 是 Scala 对 MATLAB 计算功能的实现。此外,ScalaLab 可以直接调用和访问 MATLAB 脚本的结果。
与以前的计算库的主要区别在于 ScalaLab 使用了自己特定领域的语言,称为 ScalaSci。方便的是,ScalaLab 可以访问各种科学 Java 和 Scala 库,因此你可以轻松导入数据,然后使用不同的方法进行操作和计算。大多数技术与 Breeze 和 Saddle 类似。此外,像 Breeze 一样,ScalaLab 也提供绘图功能,允许对结果数据进行进一步解释。
自然语言处理
Epic(提交次数: 1790, 贡献者: 15) & Puck (提交次数: 536, 贡献者: 1)
Scala 具有一些优秀的自然语言处理库,作为 ScalaNLP 的一部分,包括 Epic 和 Puck。这些库主要用作文本解析器,如果你需要解析成千上万的句子,Puck 因其高速和 GPU 使用而更加方便。此外,Epic 被称为一个预测框架,它利用结构化预测来构建复杂系统。
可视化
Breeze-vis (提交次数: 29, 贡献者: 3)
正如名字所示,Breeze-viz 是 Breeze 为 Scala 开发的绘图库。它基于著名的 Java 图表库 JFreeChart,并具有类似 MATLAB 的语法。尽管 Breeze-viz 的机会远少于 MATLAB、Python 中的 matplotlib 或 R,但它在开发和建立新模型的过程中仍然非常有用。
Vegas(提交次数: 210, 贡献者: 14)
另一个用于数据可视化的 Scala 库是 Vegas。它比 Breeze-viz 更加功能强大,允许进行一些绘图规格,如过滤、转换和聚合。它的结构类似于 Python 的 Bokeh 和 Plotly。
Vegas 提供了声明式可视化,允许你主要专注于指定需要对数据做什么,并进一步分析可视化结果,而无需担心代码实现。
机器学习
Smile(提交次数: 1019, 贡献者: 21)
Statistical Machine Intelligence and Learning Engine,简称 Smile,是一个有前景的现代机器学习系统,在某些方面类似于 Python 的 scikit-learn。它使用 Java 开发,也提供了 Scala 的 API。该库将以快速和广泛的应用、高效的内存使用以及大量的机器学习算法(如分类、回归、最近邻搜索、特征选择等)令你惊叹。
Apache Spark MLlib & ML
基于 Spark 的 MLlib 库提供了丰富的机器学习算法。由于是用 Scala 编写的,它还为 Java、Python 和 R 提供了高度功能性的 API,但 Scala 的机会更为灵活。该库由两个独立的包组成:MLlib 和 ML。让我们详细了解它们。
-
MLlib 是一个基于 RDD 的库,包含用于分类、聚类、无监督学习技术的核心机器学习算法,并支持实现基本统计工具,如相关性、假设检验和随机数据生成。
-
ML 是一个较新的库,与 MLlib 不同,它在数据框架和数据集上运行。该库的主要目的是提供构建不同数据转换管道的能力。管道可以被视为一个阶段的序列,其中每个阶段要么是一个 Transformer,它将一个数据框架转换为另一个数据框架,要么是一个 Estimator,一种可以在数据框架上拟合以生成 Transformer 的算法。
每个包都有其优缺点,实际上,应用两者往往更为有效。
DeepLearning.scala (提交次数: 1647, 贡献者: 14)
DeepLearning.scala 是一个替代的机器学习工具包,提供了高效的深度学习解决方案。它利用数学公式通过面向对象编程和函数式编程的结合,创建复杂的动态神经网络。该库使用了各种类型和应用类型类。后者允许同时进行多个计算,这在数据科学家的工具箱中至关重要。值得一提的是,该库的神经网络是程序,并支持所有 Scala 特性。
Summing Bird (提交次数: 1772, 贡献者: 31)
Summingbird 是一个领域特定的数据处理框架,允许批处理和在线 MapReduce 计算的集成,以及混合批处理/在线处理模式。设计该语言的主要推动者是 Twitter 的开发者,他们经常需要编写相同的代码:首先用于批处理,然后再次用于在线处理。
- Summingbird 处理并生成两种类型的数据:流(无限序列的元组)和快照(在某个时间点上数据集的完整状态)。最后,Summingbird 提供了 Storm、Scalding 的平台实现和一个用于测试目的的内存执行引擎。
PredictionIO (提交次数:4343,贡献者:125)
- 当然,我们不能忽视一个用于构建和部署预测引擎的机器学习服务器,名为 PredictionIO。它建立在 Apache Spark、MLlib 和 HBase 之上,并且曾被 Github 评选为最受欢迎的基于 Apache Spark 的机器学习产品。它使你能够轻松高效地构建、评估和部署引擎,实现自己的机器学习模型,并将其集成到你的引擎中。
附加
Akka (提交次数:21430,贡献者:467)
-
由 Scala 的创造公司开发的 Akka 是一个用于在 JVM 上构建分布式应用的并发框架。它使用基于演员的模型,其中一个演员代表一个接收消息并采取适当行动的对象。Akka 取代了之前 Scala 版本中可用的 Actor 类的功能。
-
主要区别,也被认为是最重要的改进,是演员与底层系统之间的额外层,只需演员处理消息,而框架处理所有其他复杂问题。所有演员都是按层次结构排列的,从而创建一个 Actor 系统,这有助于演员之间更高效地互动,并通过将复杂问题拆分为更小的任务来解决复杂问题。
Spray (提交次数:2663,贡献者:74)
- 现在让我们看看 Spray - 一个基于 Akka 构建的 Scala 库套件,用于构建 REST/HTTP web 服务。它保证了异步、非阻塞的基于演员的高性能请求处理,同时内部 Scala DSL 提供了定义 web 服务行为的功能,以及高效且便捷的测试能力。
[Slick ](http://slick.lightbend.com/)(提交次数:1940,贡献者:92)
-
最后但同样重要的是 Slick,它代表了 Scala 语言集成连接工具包。它是一个用于创建和执行数据库查询的库,支持多种数据库,如 H2、MySQL、PostgreSQL 等。一些数据库可以通过 slick-extensions 获得。
-
为了构建查询,Slick 提供了强大的 DSL,使代码看起来就像在使用 Scala 集合一样。Slick 支持简单的 SQL 查询和强类型的多个表的联接。此外,可以使用简单的子查询来构建更复杂的查询。
结论
在这篇文章中,我们概述了一些在执行重要数据科学任务时非常有用的 Scala 库。这些库已被证明在实现最佳结果方面非常有帮助和有效。您还可以查看下面每个提供的库的 GitHub 活动统计数据。
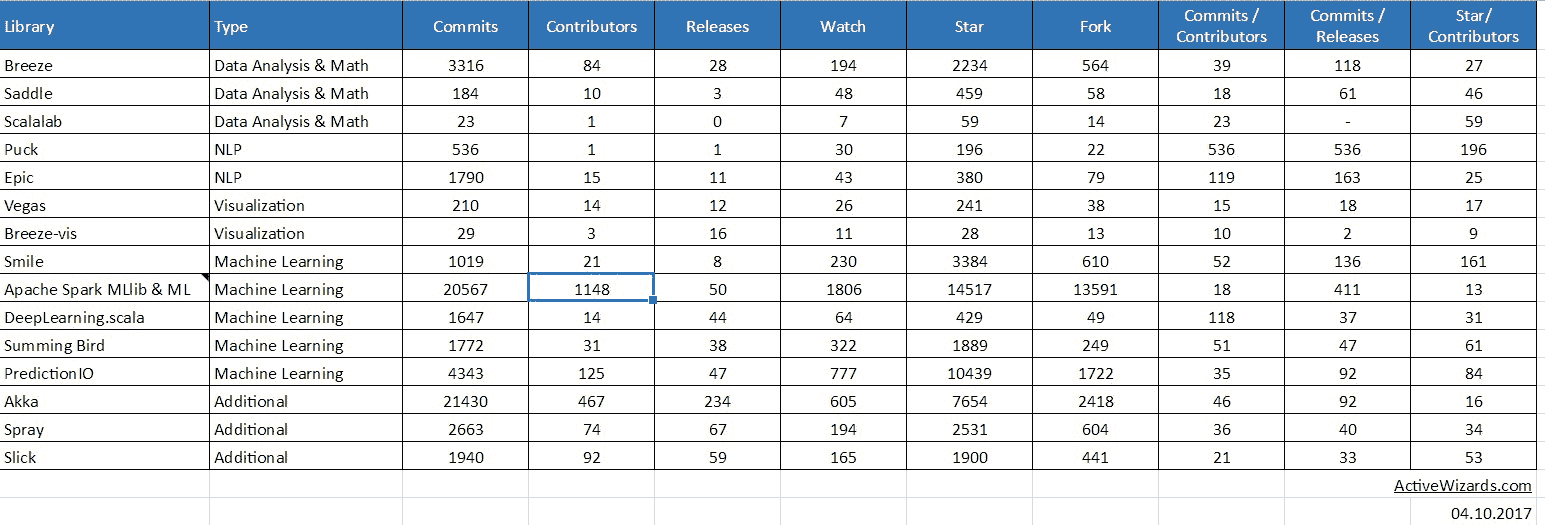
来源:Google 表格
请注意,上述列表并不全面,市场上还有许多适用于不同使用场景的工具。如果您有其他有用的 Scala 库或框架的积极经验,值得添加到此列表中,请随时在下面的评论区分享。
非常感谢您的关注与合作!
 
 简介:伊戈尔·博布里亚科夫 是数据科学家和技术企业家。他帮助创新初创公司实施数据科学计划,并担任 ActiveWizards 机器学习公司的顾问。他还帮助 数据科学学院 开发教育项目。
简介:伊戈尔·博布里亚科夫 是数据科学家和技术企业家。他帮助创新初创公司实施数据科学计划,并担任 ActiveWizards 机器学习公司的顾问。他还帮助 数据科学学院 开发教育项目。
原文。经许可转载。
相关:
-
2017 年最佳 15 个 Python 数据科学库
-
最佳 Python 数据科学包
-
前 20 个 Python 机器学习开源项目,更新版
相关阅读
提升机器学习技能的前 15 个 YouTube 频道
原文:
www.kdnuggets.com/2023/03/top-15-youtube-channels-level-machine-learning-skills.html

作者提供的图片
介绍
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
机器学习是一个快速发展的领域,具有颠覆各种行业的巨大潜力。学习机器学习可能会很复杂,我们常常不知道从哪里开始。随着免费资源的日益增加,我们花费了很多时间来找出最好的资源来提升我们的技能。考虑到这一点,我们编制了前 15 个机器学习频道的列表,提供了宝贵的见解、技巧和教程。
无论你是初学者想要深入了解基础知识,还是专家希望加深自己的知识并跟上最新趋势,这些频道都将提供来自社区顶尖专家和最大品牌的丰富信息。
YouTube 频道列表
以下是 2023 年学习机器学习的前 15 个 YouTube 频道列表:
1. Sentdex
订阅者:1.2M,视频:1,234,观看次数:107M,链接:Sentdex
本频道的拥有者哈里森·金斯利(Harrison Kinsley)创建了广泛的编程教程,涵盖机器学习、Python、金融、数据分析、机器人等。这些教程面向初学者到中级程序员。如果你想从零开始学习机器学习,这个频道是一个很好的起点。
2. DeepLearningAI
订阅者:195 K,视频:326,观看次数:13 M,链接:DeepLearningAI
DeepLearningAI 由著名 AI 研究员安德鲁·吴(Andrew Ng)创立,他是 Google Brain 的创始人之一。他在 Coursera 上的深度学习专业课程拥有大量全球粉丝。该频道提供各种教育内容,包括视频讲座和教程、与领域专家的访谈以及实时问答环节。它还会让观众及时了解机器学习和深度学习领域的最新趋势。
3. 人工智能 — 全面汇总
订阅者:155 K,视频:525,观看次数:17 M,链接:Artificial Intelligence - All in One
这是一个全面的资源,为人工智能的所有内容提供一站式服务。它包括关于 AI 基础、机器学习、深度学习、计算机视觉、自然语言处理等的教程、视频及其他资源。内容旨在让各种背景和技能水平的人都能轻松访问,从初学者到专家。
4. Two Minute Papers
订阅者:1.4 M,视频:753,观看次数:115 M,链接:Two Minute Papers
这是一个由Konrad Kording主持的了不起的频道,以短视频形式总结最新的研究论文。视频涵盖了研究的关键发现、贡献和影响。这个频道特别适合从业者、研究人员或任何希望了解最新发展的人员。
5. Kaggle
订阅者:120 K,视频:349,观看次数:3 M,链接:Kaggle
Kaggle 是数据科学家和机器学习从业者磨练技能的最著名平台之一。这个 YouTube 频道不仅涵盖了初学者和中级观众的各种教程,还 featured 行业内专家的访谈。他们还分享了 Kaggle 竞赛的获胜解决方案,帮助观众向专家学习。
6. Siraj Raval
订阅者:722 K,视频:446,观看次数:46 M,链接:Siraj Raval
Siraj Raval是机器学习领域的知名人物。他的 YouTube 频道涵盖了与机器学习、深度学习、计算机视觉、自然语言处理等相关的主题。他有趣且引人入胜的教学方法使他的内容独特且更易于理解。
7. Jeremy Howard
订阅者:71.3 K,视频:163,观看次数:6 M,链接:Jeremy Howard
Jeremy Howard是fast.ai的联合创始人,以其在深度学习领域的贡献而闻名。他的频道旨在让所有人都能接触到 AI,无论其背景如何。因此,他的视频讲座易于理解和跟随。
8. Applied AI Course
订阅者:82.8 K,视频:519,观看次数:13 M,链接:Applied AI Course
顾名思义,这个频道更注重实用知识而非理论严谨。它讲解了机器学习的核心思想,并通过实际案例研究帮助个人解决现实世界的商业问题并构建他们的 AI 解决方案。
9. Krish Naik
订阅者:711 K,视频:1610,观看次数:69 M,链接:Krish Naik
Krish Naik 是iNeuron的联合创始人,也是一个拥有超过 10 年工业经验的受欢迎教育者。他通过许多实际问题场景讲解机器学习、深度学习和人工智能的各种话题。他的主要目标是让每个人熟悉机器学习和人工智能。
10. StatQuest with Josh Starmer
订阅者:868 K,视频:237,观看次数:44 M,链接:StatQuest with Josh Starmer
这个频道提供有关统计学、数据科学和机器学习的教育内容。他将主要的方法论和概念分解为易于理解的部分。该频道还关注著名机器学习算法的数学基础,这有助于观众更直观地理解这些算法是如何工作的,以及如何有效地将它们应用于现实世界的问题。
11. Daniel Bourke
订阅者:139K,视频:296,观看次数:6 M,链接:Daniel Bourke
Daniel Bourke 是 Udemy 上一门畅销课程的讲师,2023 年深度学习的 PyTorch:从零到精通。他是一位自学成才的机器学习工程师,曾在多个行业中工作。Daniel 带你一步步从绝对初学者成长为机器学习领域的高手。
12. Data School
订阅者:211K,视频:139,观看次数:10 M,链接:数据学校
Kevin Markham 是数据科学教育者,也是_dataschool.io的创始人。这个频道提供深入的教程、网络研讨会和资源,帮助个人建立成功所需的技能。他的频道以对复杂概念的清晰、简明和逐步解释而闻名。
13. 3Blue1Brown
订阅者:4.93 M,视频:127,观看次数:318 M,链接:3Blue1Brown
Grant Sanderson 创建的这个频道以通过引人入胜和直观的动画解释复杂的数学和机器学习概念而闻名。该频道面向更广泛的观众,被认为是数学、数据科学和机器学习领域最好的频道之一。
14. Jeff Heaton
订阅者:73.2 K,视频:534,观看次数:5.6 M,链接:Jeff Heaton
Jeff Heaton 是几本受欢迎的书籍的作者之一,这些书籍可以在这里找到。他使用现实世界的例子来解释复杂的概念。他讲授与机器学习、深度学习、人工智能等相关的概念。这对于初学者在深入学习之前是一个很好的入门书籍。
15. Machine Learning Street Talk
订阅者:41.3 K,视频:97,观看次数:1.8 M,链接:Machine Learning Street Talk
该频道由 Tim Scarfe 管理。频道中经常出现 Keith Duggar 和 Yannic Kilcher。这个频道涵盖了人工智能和机器学习领域的最新发展。他们提供高质量的内容,并邀请 AI 领域的领先思想者对 AI 时事进行深入分析。
结论
总之,我们编制了一份学习的顶级 YouTube 频道的绝佳列表。然而,重要的是要记住,实践与理论同样重要。我们鼓励读者不仅要观看视频和从这些频道中学习,还要通过构建自己的项目和尝试不同的技术来将知识付诸实践。我们也希望听到你在评论区分享你在机器学习旅程中发现的有用资源以及其他推荐的 YouTube 频道。
Kanwal Mehreen 是一名有志的软件开发者,对数据科学以及人工智能在医学中的应用充满热情。Kanwal 于 2022 年被选为 APAC 地区的 Google Generation Scholar。Kanwal 喜欢通过撰写关于热门话题的文章分享技术知识,并且热衷于改善女性在科技行业中的代表性。
更多相关主题
顶级 16 个开源深度学习库和平台
原文:
www.kdnuggets.com/2018/04/top-16-open-source-deep-learning-libraries.html
评论
深度学习是一个持续增长的、流行的机器学习方法家族中的一部分,基于数据表示。作为一个相对较新的概念,大量的资源可能会让那些刚入门或已经深入其中的人感到有些不知所措。与深度学习社区互动,参与目前可用的开源项目是保持最新趋势的好方法。
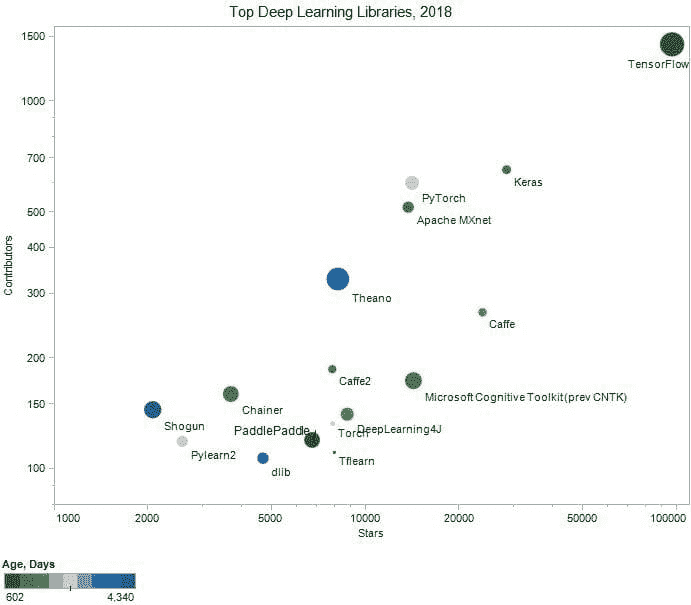
图 1: 按 GitHub 星数和贡献者排序的顶级 16 个开源深度学习库,两个轴均使用对数尺度。圆圈的颜色表示天数(绿色 - 较年轻,蓝色 - 较旧),根据 GitHub 上的“洞察力/贡献者”提供的开始日期计算。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 工作
从各个角度来看,TensorFlow 是无可争议的领导者。Keras、Caffe、微软认知工具包和 PyTorch 完成了前五名。
以下是按星数排序的完整列表,附有简要概述和进一步的链接。我们希望您能通过使用每个库提供的链接来享受合作和学习更多的过程:
-
TensorFlow 最初由在 Google 机器智能研究组织的 Google Brain 团队工作的研究人员和工程师开发。该系统旨在促进机器学习研究,并使从研究原型到生产系统的过渡快速而简便。
Stars: 96655, Contributors: 1432, Commits: 31714, Start: 1-Nov-15. Github URL: TensorFlow.
-
Keras 是一个高级神经网络 API,使用 Python 编写,能够运行在 TensorFlow、CNTK 或 Theano 之上。
Stars: 28385, Contributors: 653, Commits: 4468, Start: 22-Mar-15. Github URL: Keras.
-
Caffe 是一个以表达、速度和模块化为核心的深度学习框架。由伯克利视觉与学习中心(BVLC)及社区贡献者开发。
星标:23750,贡献者:267,提交次数:4128,开始日期:2015 年 9 月 8 日。Github 网址:Caffe。
-
Microsoft Cognitive Toolkit (Previously CNTK) 是一个统一的深度学习工具包,通过有向图描述神经网络的一系列计算步骤。
星标:14243,贡献者:174,提交次数:15613,开始日期:2014 年 7 月 27 日。Github 网址:Microsoft Cognitive Toolkit。
-
PyTorch,Python 中的张量和动态神经网络,具有强大的 GPU 加速。
星标:14101,贡献者:601,提交次数:10733,开始日期:2012 年 1 月 22 日。Github 网址:PyTorch。
-
Apache MXnet 是一个既高效又灵活的深度学习框架。它允许你混合符号式和命令式编程,以最大化效率和生产力。
星标:13699,贡献者:516,提交次数:6953,开始日期:2015 年 4 月 26 日。Github 网址:Apache MXnet。
-
DeepLearning4J 是 Skymind Intelligence Layer 的一部分,其他部分包括 ND4J、DataVec、Arbiter 和 RL4J。它是一个 Apache 2.0 许可的开源分布式神经网络库,使用 Java 和 Scala 编写。
星标:8725,贡献者:141,提交次数:9647,开始日期:2013 年 11 月 24 日。Github 网址:DeepLearning4J。
-
Theano 允许你高效地定义、优化和评估涉及多维数组的数学表达式。然而,在 2017 年 9 月,Theano 宣布在 1.0 版本发布后将停止所有重大开发。尽管如此,它仍然是一个极其强大的库,你可以随时使用它进行深度学习研究。
星标:8141,贡献者:329,提交次数:27974,开始日期:2008 年 1 月 6 日。Github 网址:Theano。
-
TFLearn 是一个建立在 TensorFlow 之上的模块化且透明的深度学习库。它旨在为 TensorFlow 提供更高级的 API,以便于和加速实验,同时保持完全透明和兼容。
星标:7933,贡献者:111,提交次数:589,开始日期:2016 年 3 月 27 日。Github 网址:TFLearn。
-
Torch 是 Torch7 中的主要包,其中定义了多维张量的数据结构及其数学操作。此外,它还提供了许多用于访问文件、序列化任意类型对象和其他实用工具的工具。
星标:7834,贡献者:133,提交:1335,起始日期:2012 年 1 月 22 日。Github 网址:Torch。
-
Caffe2 是一个轻量级、模块化且可扩展的深度学习框架。基于原始的 Caffe,Caffe2 在设计时考虑了表达性、速度和模块化。
星标:7813,贡献者:187,提交:3678,起始日期:2015 年 6 月 21 日。Github 网址:Caffe2。
-
PaddlePaddle(PArallel Distributed Deep LEarning)是一个易于使用、高效、灵活且可扩展的深度学习平台,最初由百度的科学家和工程师开发,旨在将深度学习应用于百度的多个产品。
星标:6726,贡献者:120,提交:13733,起始日期:2016 年 8 月 28 日。Github 网址:PaddlePaddle。
-
DLib 是一个现代的 C++ 工具包,包含机器学习算法和工具,用于在 C++ 中创建复杂软件以解决现实世界的问题。
星标:4676,贡献者:107,提交:7276,起始日期:2008 年 4 月 27 日。Github 网址:DLib。
-
Chainer 是一个基于 Python 的独立开源深度学习框架。Chainer 提供了一种灵活、直观、高性能的方法来实现全范围的深度学习模型,包括最先进的模型,如递归神经网络和变分自编码器。
星标:3685,贡献者:160,提交:13700,起始日期:2015 年 4 月 12 日。Github 网址:Chainer。
-
Neon 是 Nervana 基于 Python 的深度学习库。它在提供高性能的同时,也易于使用。
星标:3466,贡献者:77,提交:1112,起始日期:2015 年 5 月 3 日。Github 网址:Neon。
-
Lasagne 是一个轻量级库,用于在 Theano 中构建和训练神经网络。
星标:3417,贡献者:64,提交:1150,起始日期:2014 年 9 月 7 日。Github 网址:Lasagne。
其他选项:
-
H2O.ai,开源快速可扩展的机器学习平台,用于更智能的应用(深度学习、梯度提升、随机森林、广义线性建模、自动机器学习等)。星标:3017,贡献者:102,提交:22771,起始日期:2014 年 3 月 2 日。Github 网址:h2oai/h2o-3。
-
Apache SINGA。Stars: 1362,Contributors: 31,Commits: 869。Github URL: Apache SINGA。
-
Blocks。Stars: 1099,Contributors: 48,Commits: 3257。Github URL: Blocks。
-
Mocha。Stars: 1031,Contributors: 41,Commits: 1064。Github URL: Mocha。
这就是我们详细列出的顶级深度学习库和平台。如果你知道我们遗漏了哪些,请在评论中告知我们!
贡献者和提交记录于 2018 年 4 月 17 日。
相关:
更多相关内容
高级数据科学项目的 16 个顶级技术数据源
原文:
www.kdnuggets.com/top-16-technical-data-sources-for-advanced-data-science-projects

图片由作者提供
你已经在这些页面上读到(我也写了一些这样的文章)数据科学项目对于发展完整的数据科学技术技能包至关重要。这是事实,它们确实如此。但同样重要的是为你的数据科学项目拥有高质量的数据集。收集优质数据只是数据科学项目的一个阶段,但却是决定项目成败的关键阶段。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
问题是,在哪里找到这些该死的数据?幸运的是,许多网站提供了丰富的数据,适用于各种目的。

图片由作者提供
1. Kaggle
你听说过Kaggle,它可能是数据科学社区中最知名的平台。它托管了各种格式(CSV、JSON、SQLite、BigQuery)和来自多个行业及主题的数据集,如健康、汽车、艺术与娱乐、生物学、社会科学、投资、社交网络、体育等。你也可以根据数据集的技术焦点进行搜索,例如计算机科学、分类、计算机视觉、NLP 或数据可视化。
目前,提供 274,855 个数据集,你不会缺少数据。
Kaggle 的用户友好界面和活跃的社区论坛使其成为初学者和专业人士的绝佳资源。
2. UCI 机器学习库
如果你是机器学习爱好者,UCI 机器学习库应该是你的首选网站。顾名思义,这个库是由加州大学欧文分校(UCI)创建的。他们收集了大量针对机器学习的数据集。这些数据集覆盖了各种主题,因此对那些希望练习和提升机器学习技能的人特别有用。
目前有 653 个数据集;你可以通过数据类型、主题领域、任务、特征数量和实例、以及特征类型来浏览它们。
3. StrataScratch
StrataScratch 提供了 49 个来自实际公司的数据集和项目。这对于那些准备数据科学面试的人特别有益,因为它帮助用户提升技术技能并从数据中提取商业洞察。这允许数据科学项目以实用且与行业相关的方式进行。
这些项目涵盖了各种主题,如数据探索、数据工程、商业分析、回归、分类、自然语言处理(NLP)和聚类。
4. Google 数据集搜索
Google 数据集搜索 是一个旨在在网络上查找数据集的工具。即使你之前没有听说过它,你也已经知道如何使用它。为什么?因为它看起来和工作方式都像是普通的 Google 搜索,只不过它专注于查找数据集。如果你在寻找来自各种来源的数据、学术论文和政府数据库,它非常有用。
5. 亚马逊网络服务(AWS)公共数据集
亚马逊的 AWS 公共数据集 计划是另一个你可以找到大量开放数据的网站。目前有 494 个数据集可用,它是数据科学家非常宝贵的资源。你在那里找到的数据集可以与 AWS 云服务集成。如果你的项目需要更多计算资源,这可能会有所帮助。
可用的数据范围包括基因组学、气象学和天文学等。
6. Data.gov
Data.gov 是一个由美国政府赞助的数据仓库,包含来自各种美国组织的数据。它包括来自 132 个美国组织的 283,935 个数据集。数据种类繁多,包括农业、公共卫生、金融、教育、人口统计、经济学和环境数据。
数据集几乎有 50 种不同格式,其中最受欢迎的包括 HTML、XML、ZIP、CSV、PDF、ArcGIS GeoServices REST API、KML、GeoJSON、JSON 和 TEXT。
7. FiveThirtyEight
FiveThirtyEight由 ABC 新闻提供,是他们文章和图表的数据与代码库。它是数据记者和对统计故事讲述感兴趣的人的完美资源。如果你对涉及时事、政治、体育等项目感兴趣,这里是你的数据来源。
它提供了从 2014 年至今的超过 160 个数据集。
8. 世界银行开放数据
世界银行开放数据提供了围绕全球发展数据的广泛数据集。这些数据包括来自世界各国的经济、环境和社会问题的指标。如果你对全球发展和社会经济话题感兴趣,你可能会在这里找到很多有趣的数据。
9. GitHub
GitHub不仅是一个分享代码的平台。它也可以用来寻找数据项目的数据。许多组织和个人用户在 GitHub 仓库中托管他们的数据集。这些数据覆盖了广泛的话题,通常附有详尽的文档和分析代码。
10. OpenML
OpenML是一个在线机器学习平台。这也意味着你可以访问大量数据。更具体地说,几乎有 5,400 个数据集。它旨在分享、组织和讨论数据以及机器学习实验的结果。OpenML 可以与流行的机器学习环境集成,这对你的数据科学学习是一个加分项。
11. Reddit 数据集
Datasets subreddit是一个由社区驱动的数据来源。人们在 reddit 上分享各种信息。好吧,他们也分享和请求数据集用于数据项目。有时候在那里找到数据比较困难。但这不是因为数据的缺乏。恰恰相反!这个地方充满了数据,这可能使得数据搜索有时显得相当混乱。数据范围从高度特定和不寻常的到更传统的数据集。由于这基本上是一个论坛,你也可以参与讨论并请求对数据集的帮助。
12. Eurostat
欧洲联盟的统计办公室叫做Eurostat,这是一个全面的数据来源。如果你对关于欧盟成员国的高质量统计数据感兴趣,这应该是你的主要数据来源。关于欧盟国家的数据包括经济、人口、健康和贸易等主题。
13. 人道主义数据交换平台(HDX)
HDX是一个开放平台,你可以在这里找到人道主义数据。该平台由联合国人道主义事务协调办公室管理。这个平台提供围绕全球每个国家的人道主义危机和紧急情况的数据。如果你对关注全球问题、灾害响应和人类福利的项目感兴趣,你可能会发现这很有用。
这里有 20,344 个活跃的数据集和 2,570 个归档的数据集,具有各种特征和格式。
14. 疾病控制与预防中心 (CDC)
在CDC上,你可以找到与健康相关的数据。这些数据集专注于各种健康状况、风险因素和公共卫生。如果这些是你感兴趣的话题,你会在这里找到很多有用的数据。
15. 劳工统计局 (BLS)
BLS网站上有大量关于美国经济状况、劳动市场、价格变化、生活质量等的数据。如果你对这些话题感兴趣,你会找到很多优质的数据集。
16. 国家航空航天局 (NASA)
我提到的最后一个数据来源是NASA。那里有大量关于航空航天、应用科学、应用程序、地球科学、管理/操作、原始数据、软件和空间科学的数据。
它有超过 10,000 个数据集,所以不要在其数据宇宙中迷失方向!
结论
我相信这 16 个网站会给你提供足够的数据,直到时间的尽头,这正是我的最终目标!然而,数据的数量并不是一切。
我选择这些网站是因为它们会为你提供非常多样化的数据集,适合各种数据科学项目。数据集的具体内容因行业而异。因此,使用不同的数据集也能让你获得领域知识。
无论你是在深入研究机器学习、数据分析、数据新闻、统计分析还是数据可视化,你都可以依靠这些资源。
现在,你可以开始自己的数据科学项目了!如果需要更多的创意,这里有一些数据科学项目可以作为初学者进行。
Nate Rosidi 是一名数据科学家,专注于产品策略。他还是一名兼职教授,教授分析课程,并且是 StrataScratch 的创始人,该平台帮助数据科学家准备顶级公司的真实面试问题。Nate 写关于职业市场的最新趋势,提供面试建议,分享数据科学项目,并覆盖所有 SQL 内容。
更多相关主题
顶级 18 个数据科学 Facebook 小组
原文:
www.kdnuggets.com/2022/06/top-18-data-science-facebook-groups.html

图片由作者提供
我已经将近七年没有使用 Facebook,现在 Facebook 小组已经发展成了适合人们共同学习和成长的真正社区。我认为这个平台在帮助初学者开始数据科学职业或专家跟踪新趋势方面有很多可提供的内容。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
你会发现高质量的教育和专业内容,因为这些内容都由管理员严格审核。除此之外,成为完全成员是很困难的。一些小组会允许你加入,但管理员会限制你发布内容的权限,直到他们认为你是有价值的社区成员为止。
为什么加入? 如果你在 Facebook 上有太多朋友,并且从他们那里获得信息流,大多数时候这些内容与您所寻找的内容无关。你会感到不堪重负,最终浪费 20 分钟不停地滚动。即使你看到广告,这些广告也会与数据科学相关,Facebook 小组的内容相对较干净。
以下列表包含基于成员数量的前 18 个小组。一些小组很难加入,可能需要一个月的时间才能让你进入小组。所有提到的小组都严格审核,因此你不会看到垃圾邮件、个人推广、广告或题外讨论。
-
人工智能与深度学习 (502.7K 成员)
-
数据科学世界 (356.6K 成员)
-
数据科学 (352.4K 成员)
-
人工智能、机器学习、深度学习 (215.2K 成员)
-
人工智能与机器学习 (176.9K 成员)
-
Python 机器学习与深度学习 (148.8K 成员)
-
数据科学、分析、机器学习、数据挖掘、R、Python (142.6K 成员)
-
Python 机器学习(138.9K 成员)
-
数据挖掘 / 机器学习 / 人工智能(137.1K 成员)
-
大数据、数据科学、数据挖掘与统计(85K 成员)
-
数据科学与 Python(83.7K 成员)
-
数据科学、机器学习、深度学习与人工智能(80.0K 成员)
-
数据分析师(68.1K 成员)
-
人工智能 | 机器学习 | 数据科学 | 深度学习(53.8K 成员)
-
SQL、数据分析与商业智能(42.9K 成员)
-
数据科学教程(18k 成员)
-
数据工程与数据科学(3.8K 成员)
如果你在使用 Facebook 小组推广你的内容,组管理员会禁止你,如果你继续在其他小组发布相同的内容,Facebook 会阻止你发帖。这些限制使这些小组成为学习机器学习、深度学习、数据分析、大数据、商业智能和 SQL 的绝佳地方。你只需加入这些不断壮大的数据科学专业人士和爱好者小组即可。
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一款 AI 产品,帮助那些面临心理健康问题的学生。
更多相关话题
LinkedIn 上的前 18 个数据科学群组
原文:
www.kdnuggets.com/2022/06/top-18-data-science-group-linkedin.html
作者提供的图片
LinkedIn 群组是初学者学习的场所,是分享想法和建立能够帮助你获得梦想工作或转职的新工作的连接的常见场所。这里是拥有相似兴趣的人们通过分享研究论文、讨论新技术、分享教程、提出问题和参加社区主导的活动来交流见解和经验的地方。这些群组由管理员和版主进行监督,提供与数据科学、机器学习、大数据、人工智能、物联网以及商业智能相关的无垃圾信息内容。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
为什么要加入? 如果你有太多的连接人,你会收到来自他们所有人的信息。大多数时候,这些内容与你所寻找的内容无关。我感到不堪重负,最终浪费了 10 分钟的持续滚动。LinkedIn 群组通常比较干净。如果你看到广告,它将与你的主题相关。
机器学习/数据科学群组筛选掉所有噪声,为你提供最佳内容。你可以学习新技术并与其他组员分享你的知识。简而言之,初学者、爱好者和专家通过相互交流共同成长。
以下列表包含基于成员数量的前 18 个群组。某些群组很难加入。群组管理员可能需要一个月的时间才允许你加入。我提到的大多数群组都有严格的管理,因此你不会看到垃圾帖子、自我宣传、广告或主题无关的讨论。
-
人工智能、深度学习、机器学习(473.58K 成员)
-
数据科学中心(435.00K 成员)
-
大数据、数据科学、人工智能、物联网、网络安全和区块链(317.56K 成员)
-
数据挖掘、统计学、大数据、数据可视化、人工智能、机器学习和数据科学(289.38K 成员)
-
商业分析专业人士 - BA、分析、数据分析师、数据科学家 (262.13K 成员)
-
大数据 ?? 数据科学 | 机器学习 | 深度学习 | 人工智能 (147.44K 成员)
-
KDnuggets AI、大数据、数据科学、机器学习群组 (106.78K 成员)
-
人工智能 | 深度学习 | 机器学习 (94.38K 成员)
-
Python 数据科学、机器学习、图形与自然语言处理 (92.40K 成员)
-
数据科学社区 (经过审核) (90.66K 成员)
-
数据科学、机器学习、人工智能、物联网、区块链、BI 与大数据分析 (41.41K 成员)
-
数据科学、大数据、机器学习、人工智能专业人士 | DataScience.US (35.33K 成员)
-
数据科学与机器学习 (34.22K 成员)
-
AI 与 Python、数据科学、人工智能、机器学习、大数据分析与分析 (19.63K 成员)
-
数据可视化与决策科学 (14.39K 成员)
-
Python 用于数据科学和机器学习 (11.42K 成员)
-
分析与数据科学职业 (11.10K 成员)
-
数据科学中的女性 (WiDS) (10.65K 成员)
此外,如果你像我一样是一个小型内容创作者,群组为你提供了成长的机会。我可以把我的作品展示给数十万名专业人士,并获得反馈,而不是仅限于几百名关注者。除此之外,我阅读其他成员分享的博客,了解新的技术和 Python 包。LinkedIn 群组恢复了我对社交媒体平台的信心。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些挣扎于心理健康问题的学生开发一个 AI 产品。
更多相关主题
前 18 名低代码和无代码机器学习平台
原文:
www.kdnuggets.com/2021/09/top-18-low-code-no-code-machine-learning-platforms.html
评论
由 Yulia Gavrilova,serokell.io 的人工智能和技术伦理。
你可能已经听说过“低代码”和“无代码”这两个术语。
低代码 只是意味着减少了编程量。许多元素可以从库中简单地拖放。然而,也可以通过编写自己的代码来定制这些元素,这样可以增加灵活性。
无代码 平台完全不需要编程知识。不同的人,如艺术家、教师、高层管理人员,都可以使用这些平台。他们在工作中需要人工智能,但不想深入编程和计算机科学。无代码解决方案功能有限,但可以快速构建简单的东西。
实际上,无代码和低代码平台之间的界限相当模糊。自称为“无代码”的平台通常仍然留有一些定制空间。
面向初学者的低代码平台
低代码库即使在编程经验有限的情况下也可以使用。
PyCaret
这是一个 开源机器学习库 用 Python 编写,允许你以最少的编码创建和部署机器学习模型。
基本上,PyCaret 是一种低代码替代品,可以用少量的代码替代数百行代码。它极大地提高了软件开发的速度,使初学者更易于使用。PyCaret 是一个 Python 封装库,覆盖了多个机器学习库,如 scikit-learn、XGBoost、Microsoft LightGBM、spaCy 等等。
Auto-ViML
AutoViML 是一个可以让任何人快速构建机器学习模型的工具。它会自动将你的数据通过不同的机器学习模型,以发现哪个模型在每种特定情况下效果最佳。另一个很大的优点是你不需要预处理数据,因为 AutoViML 会自动清理、转换和规范化数据。该程序可以处理不同类型的变量,包括文本、数字和视觉数据。
H2O AutoML
H2O 是一个开源机器学习平台。它提供了部署最广泛使用的机器学习算法的工具,如梯度下降、线性回归、深度人工神经网络等。这个平台的特点是其先进的 AutoML。该功能提供了同时构建多个模型的自动化过程,使你即使没有先前经验也可以创建和测试功能性机器学习模型。
2021 年你应该使用的无代码机器学习平台
这里有一系列无代码平台,您可以探索,如果您希望快速部署机器学习元素并将其与现有软件集成。
Google Cloud Auto ML
这个无代码工具使任何人都能在没有任何机器学习专业知识的情况下训练和部署自定义机器学习模型。该平台支持不同类型的数据,并涵盖了从计算机视觉和视频智能到自然语言处理和翻译等广泛的使用场景。您可以准备和存储数据集,并使用自动化工具进行方便的标记。如果您需要更多的功能和灵活的工具,可以升级到使用 Google Cloud。
Google ML Kit
这个工具包是为希望让其应用程序更具吸引力的 Android 和 iOS 开发者制作的。它的 API 可以用于实现条形码扫描、人脸检测、图像标记等功能,而无需从头创建机器学习模型。所有必要的处理都在用户的移动设备上实时进行,因此您无需担心设置和托管昂贵的服务器。
Teachable Machine
Teachable Machine是 Google 的另一个项目,旨在简化机器学习在应用程序和网站上的使用。由于其用户友好的界面,即使是非技术人员也可以轻松使用该平台。该程序处理图像并允许您训练机器识别和分类照片,同时也处理声音。如果您是新手,这个平台很有趣,并且是免费的。但您需要自己收集和准备用于训练模型的数据。
Runway AI
Runway AI是为没有编程经验的创作者设计的,专注于视频和照片编辑,包括绿幕选项、过滤器和其他有趣的功能。这个工具包可以帮助您通过几次简单的点击扩展您的创造力,将视频转化为顶级的电影艺术。
Lobe
这个ML 平台提供了易于使用的项目模板,即使是您第一次进行机器学习项目也能轻松上手。该项目相对较新,目前仅提供图像分类功能。未来,其创建者还希望推出对象检测和数据分类模板。然而,图像分类器是零售商、广告商和商业专业人士最有用的工具之一,因此一定要了解一下。
Obviously AI
如果你在寻找一个无需编写代码即可基于数据进行预测的便捷工具,Obviously AI 适合你。它可供希望预测收入流、优化业务流程、构建更有效供应链并开展个性化自动营销活动的营销人员和企业主使用。你只需提供数据,选择一列作为创建自定义 ML 算法的基础,然后获取报告即可。
CreateML
CreateML 是 Apple 提供的用户友好的拖放平台,允许你在 Mac 设备上训练模型。它可以帮助你构建分类器和推荐系统。该工具可以处理图像、视频、照片、表格数据和文本。你获得的模型可以在 iOS 应用中测试和部署。你可以预览模型的性能,随时暂停、保存、恢复和扩展你的训练过程。CreateML 允许你在单个项目中同时训练多个模型。它具有标准的 Apple SDK 和包括代码示例和解释性文章的文档。
MakeML
MakeML 使 iOS 开发者能够实现对象分割和对象检测解决方案。使用此工具,你不仅可以在照片中,还可以在视频中勾勒和编辑元素。创建自己的数据集,点击几下即可构建自定义 ML 模型,并将模型集成到你的应用中。该平台还允许你与 AR 一起工作。
Fritz AI
如果你在寻找更令人兴奋的 iOS 和 Android 应用解决方案,你还可以查看 Fritz AI。它在 ML 模型开发中提供了灵活性——你可以在 Studio 中训练自定义模型,也可以使用预训练模型。在程序中,你可以创建或导入自己的数据集,监控模型的性能,并重新训练它。如果你进行 Snapchat 镜头开发,这个工具将帮助你将无代码机器学习添加到你的增强现实滤镜中。
SuperAnnotate
对视频和文本进行注释是一项繁琐的工作,但可以通过 SuperAnnotate 自动化。该解决方案涵盖了跨不同行业的多种情况,如航空摄影、自动驾驶、机器人技术和医学。如果你需要快速处理图像而又不想雇佣整个数据科学团队,我们推荐你查看一下。
https://www.youtube.com/watch?v=qFvWPSqwJa4
Rapid Miner
RapidMiner 是一个为数据挖掘而创建的工具。它基于这样的理念,即业务分析师或数据分析人员不一定需要编程才能完成工作。同时,挖掘需要数据,因此该工具配备了一套优秀的操作符,解决了从各种来源(数据库、文件)获取和处理信息的广泛任务。总体来说,这个工具使得数据分析对任何人都足够简单。
What-If 工具
这是一个非常有用的工具,可以在不编写代码的情况下评估模型的性能。WIT 直观地展示了模型行为如何随时间和不同数据子集的变化而变化。你还可以比较两个模型的性能,看看哪个效果更好。
DataRobot
DataRobot 是一个使业务分析师能够在没有机器学习或编程知识的情况下构建预测分析的平台。该平台使用自动化机器学习(AutoML)在短时间内生成准确的预测模型。DataRobot 提供了一个用户友好的界面来创建机器学习模型。只需几个步骤,公司就可以部署实时预测分析服务。
Nanonets AI
智能文档处理可以通过 Nanonets 实现。它自动捕捉文档中的数据,节省了你数小时的手动文档管理。Nanonets AI 处理未见过的、半结构化的文档,即使这些文档不遵循标准模板,也会自动验证数据,并通过多次使用不断改进。
Monkey Learn Studio
MonkeyLearn Studio 提供了处理文本数据的工具,并旨在被公司使用。这个平台可以自动标记业务数据,例如支持票据或电子邮件。它还帮助可视化数据。MonkeyLearn 使机器学习变得容易,因为它具有现成的机器学习模型,可以在无需编写代码的情况下进行训练和构建。
最后的话
这些工具在它们所具备的功能方面非常酷:无代码平台可让非技术专家或机器学习新手快速部署简单项目。但它们绝不能替代针对高负载、数据密集型项目的定制机器学习模型开发。所以,如果你有一个涉及大数据处理、密集工业过程自动化或敏感预测模型的独特想法,联系我们。我们可以一起思考适合你特定需求的解决方案。
原始内容。经允许转载。
相关:
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
更多相关主题
2023 年成为数据科学家需要掌握的 19 项技能
原文:
www.kdnuggets.com/2023/04/top-19-skills-need-know-2023-data-scientist.html

作者提供的图片
时代在变化。如果你想在 2023 年成为数据科学家,有几个新的技能应该加入你的技能清单,以及你应该已经掌握的现有技能。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 部门
为什么需要如此广泛的技能?部分原因是工作范围的不断扩大。没有人确切知道数据科学家的定义是什么,或者他们应该做什么,更不用说你的未来雇主了。因此,任何涉及数据的内容都会被归入数据科学的范畴,由你来处理。
你需要了解如何清理、转换、统计分析、可视化、沟通和预测数据。不仅如此,新的技术(或最近才进入主流的技术)也可能会被纳入你的工作职责中。
在这篇文章中,我将详细介绍 2023 年成为数据科学家需要掌握的 19 项技能。
这里是最重要的十项技能概述。
作者提供的图片
这些技能将帮助你找到工作、成功通过面试、保持领先,并为晋升进行谈判。在每个部分,我会简要总结每项技能是什么、为什么重要,并提供一些学习这些技能的途径。
1. 数据清理和整理
尽管数据科学家并非 80% 的时间都在清理数据,但数据清理和整理仍然是 2023 年数据科学家需要掌握的最重要的技能之一。
数据清理和整理是什么?
数据清洗和整理是将原始数据转换为可以用于分析的格式的过程。这涉及处理缺失值,去除重复项,处理不一致的数据,并将数据格式化为分析所需的形式。
数据清洗通常指的是去除错误/不准确的值,填补空白,查找重复项,以及确保数据集尽可能干净和可靠。整理数据(或称为处理、调整、修整等)则是指将数据转换成可分析的形式。你需要将其转换或映射成另一种、更易于查看的格式。
为什么在 2023 年成为数据科学家时这很重要?
询问任何数据科学家他们在做什么,他们会提到的第一件事之一就是数据清洗和整理。数据从来不会以干净、可分析的形式进入你的手中,因此知道如何将其整理好是非常重要的。
清洗和整理数据的能力确保你的分析结果是可信的,并有助于避免得出错误的结论。
你可以在哪里学习这个关键技能?
学习数据清洗和整理的选项非常丰富。哈佛在 EdX 上提供了一个课程。你也可以通过清洗和整理免费的原始数据集来进行练习,比如 Common Crawl,它是由超过 500 亿个网页组成的网络爬虫数据(这里),或者巴西的天气数据(这里)。
2. 机器学习
不,这不仅仅是一个流行词!机器学习是任何未来数据科学家必须掌握的一个非常重要的技能。
什么是机器学习?
机器学习是应用算法和统计模型来根据数据做出预测和决策的过程。
这是一种人工智能的子领域,使计算机通过从数据中学习而不是显式编程来提高在特定任务上的表现。它有助于自动化。你会在任何行业中发现它。
为什么在 2023 年成为数据科学家时这很重要?
你需要了解机器学习,因为它是一个快速发展的领域,已成为解决复杂问题和进行预测的关键工具。
机器学习算法可以用于分类图像、识别语音、进行自然语言处理和创建推荐系统。你很难找到一个不进行(或不想进行)这些 ML 辅助任务的行业。
精通机器学习使数据科学家能够从大型复杂的数据集中提取有价值的见解,并开发出能驱动更好业务决策的预测模型。
你可以在哪里学习这个关键技能?
我们在 ScrataScratch 上有一个 超过三十个机器学习项目 的库,展示了这一技能以便你在简历上展示。TensorFlow 也有 一系列出色的免费资源来学习机器学习。
3. 数据可视化

图片由作者提供
这个技能相当显而易见。当你分析数据时,关键利益相关者会希望通过漂亮的图形和图表来理解你的发现。
什么是数据可视化?
数据可视化是创建图表、图形和其他图形的过程,以帮助更容易地理解数据。你将刚刚清理、整理或预测的数据转换成某种视觉格式,既可以与他人沟通趋势,也可以使趋势更容易被发现。
为什么在 2023 年成为数据科学家时这很重要?
在 2023 年,能够可视化数据对数据科学家至关重要。这就像拥有揭示数据中隐藏模式和趋势的秘密超能力,可能在初看时并不明显。而最棒的部分是?你可以以一种既吸引人又令人难忘的方式与他人分享你的发现。作为数据科学家,你将与各种经验水平的团队合作,但一张图比一串数字更容易被理解。
因此,如果你想成为一个能够有效传达洞见和发现的数据科学家,掌握数据可视化的艺术是很重要的。
你可以在哪里学习这个关键技能?
这里有一个列表 介绍了免费的数据可视化学习资源。
4. SQL 和数据库管理
SQL 是结构化查询语言。数据科学家使用 SQL 来处理 SQL 数据库,管理数据库以及执行数据存储任务。
什么是 SQL 和数据库管理?
SQL 是一种非常流行的语言,它允许你访问和操作结构化数据。它与数据库管理密切相关,通常是在 SQL 中进行的。数据库管理基本上是你如何组织、存储和检索数据。SQL 数据库是 2023 年 最受欢迎的后端技术之一,因此不仅仅适用于数据科学。
为什么在 2023 年成为数据科学家时这很重要?
作为数据科学家,你必须跟踪所有的数据,确保它们有序,并在有人需要时检索这些数据。这就是 SQL 和数据库管理让你做到的事情。
你可以在哪里学习这个关键技能?
Coursera 提供了很多很棒且价格合理的数据库管理/管理员课程,你可以尝试一下。你还可以在这里预览一些 SQL 面试问题,这对于测试你的知识很有用。
5. 大数据处理
大数据是一个流行词汇,但它也是一个真实的概念——Oracle 定义它为“包含更大种类的数据,随着时间的推移增加的体量和更高的速度”,即拥有三个 V 的数据。
什么是大数据处理?
大数据处理是指使用像 Hadoop 和 Spark 这样的技术来处理、存储和分析大量数据的能力。
为什么在 2023 年成为数据科学家时这很重要?
在 2023 年,处理大数据的能力对数据科学家至关重要。生成的数据量持续以指数级增长,能够有效地处理和分析这些数据对于做出明智的决策和获得有价值的见解至关重要。那些对大数据处理技术有深刻理解的数据科学家将能够轻松处理大数据集,并最大限度地利用其中的信息。
此外,由于其流行性,将“大数据”加到你的简历上永远不会有坏处。
你可以在哪里学习它?
我喜欢 Simplilearn 的 YouTube 教程系列。
6. 云计算

作者图片
有趣的是——随着越来越多的产品和服务迁移到云端,云计算成为几乎每个技术职位的工作要求,无论是 DevOps 还是数据科学家。
什么是云计算?
云计算是使用像 AWS、Azure 或 Google Cloud 这样的云基础设施和平台来存储和处理数据。这有点像拥有一个可以随时随地访问的虚拟储藏室。与将数据和计算资源存储在本地计算机或服务器上不同,云计算允许组织和数据科学家通过互联网访问这些资源。
为什么在 2023 年成为数据科学家时这很重要?
正如我一直强调的,作为数据科学家,你需要处理的数据量在不断增加。越来越多的公司将数据存储在云端,而不是在本地处理。具备以可扩展和高效的方式存储和处理这些数据的能力变得越来越重要。
云计算为此提供了有效的解决方案,使数据科学家能够访问大量的计算资源和数据存储,而无需昂贵的硬件和基础设施。
你可以在哪里学习它?
好消息是,由于公司拥有各种云服务,许多公司有兴趣免费教你使用它们,以便你能学会使用他们的服务。Google、Microsoft 和 Amazon 都提供了很棒的云计算资源。
7. 数据仓库与 ETL
“等一下,我们刚刚讲过数据库吗?什么是数据仓库?”我听到你在问。
我明白你的感受。有时候,感觉最重要的数据科学技能就是搞清楚所有的缩略语和行话。
数据仓库和 ETL 是什么?
首先,让我们区分数据仓库和数据库。
数据仓库存储多个系统的当前和历史数据,而数据库存储驱动项目所需的当前数据。数据库存储驱动应用程序所需的当前数据,而数据仓库则存储一个或多个系统的当前和历史数据,以预定义和固定的模式分析数据。
简而言之,你会使用数据仓库来存储多个不同项目的数据,而数据库主要存储单个项目的数据。
ETL 是一个涉及数据仓库的过程,ETL 的缩写是提取、转换和加载。ETL 工具将从你想要的任何数据源系统中提取数据,在暂存区进行转换(通常是清洗、操作或“处理”数据),然后将其加载到数据仓库中。
为什么在 2023 年成为数据科学家时这很重要?
我感觉我在每项技能中都重复了这一点,但数据在增长。公司对数据渴求,他们会期待你管理数据。知道如何在可构建的管道中管理数据至关重要。
你可以在哪里学习它?
我建议学习如何使用特定语言,如 SQL 或 Python,来进行正确的 ETL。Datacamp 提供了一个不错的课程来讲解 Python 中的 ETL。Microsoft 提供了一个更中级教程来讲解 SQL 选项。
8. 数据建模与管理
每个数据科学家都是模型专家。我不是在说吉赛尔·邦辰。我指的是创建数据在系统中如何存储和组织的模型。
什么是数据建模和管理?
数据建模和管理是创建数学模型以表示数据的过程,以及管理数据以维护其质量、准确性和有用性。
这涉及到定义数据实体、关系和属性,并实现数据验证、完整性和安全性的过程。
简单来说,数据建模基本上意味着你在创建一个数据如何在雇主的系统中组织和连接的蓝图。你可以把它看作是绘制房屋蓝图。就像蓝图显示不同的房间及其连接方式一样,数据建模展示了不同信息片段之间是如何关联和连接的。
这有助于确保数据以一致且有效的方式存储和使用。
为什么在 2023 年成为数据科学家时这很重要?
作为数据科学家,你将负责确保数据以可访问的方式组织和结构化。数据建模和管理帮助你处理数据、分享数据、确保数据准确,并根据数据做出决策。
你可以在哪里学习它?
微软在他们的博客上有一个很好的简介,时长仅半小时且评价很高。这是一个很好的起点。
9. 数据挖掘

图片由作者提供
许多数据科学术语只是从其他职业中借用过来的,如建模和挖掘。让我们深入了解它的含义及其重要性。
什么是数据挖掘?
数据挖掘是通过诸如聚类、分类和关联规则等技术从数据中提取有用信息的过程。你是在从数据的汪洋中筛选出有用的金矿。(也许“数据淘金”会是这个技能更好的名字!)
为什么在 2023 年成为数据科学家时这很重要?
想象一下:你是 2023 年的数据科学家。你有来自万千不同来源的数据。你使用什么技能来识别这些数据源中的模式?
这就是数据挖掘。
你可以在哪里学习它?
数据挖掘通常在涉及大数据或数据分析的课程中讲授,因为这是这两项技能中相当关键的组成部分。EdX 提供了一些 学习数据挖掘的选项。
10. 深度学习
深度学习与机器学习有微妙的不同!深度学习是机器学习的一个子领域。
什么是深度学习?
深度学习是机器学习的一个方面,专注于创建可以通过多个层次的人工神经网络学习数据模式的算法。(人工神经网络,顺便提一下,是一种模拟人脑结构和功能的机器学习算法。)
为什么在 2023 年成为数据科学家时这很重要?
人工智能在 2023 年变得越来越复杂。了解 AI 和 ML 的基础知识是不够的——你还应该了解前沿技术,因为它们明天就不再是前沿了。深度学习几年前还是新鲜事物,而现在已经成为必需。
数据科学家将被期望在公司拥有大量数据时使用深度学习。它用于图像和视频处理或计算机视觉应用。
你可以在哪里学习这些技能?
我喜欢Simplilearn 的教程作为起点。
成为 2023 年数据科学家还需要了解哪些其他技能?
有许多新兴的技术和方法是值得了解的。这些技术可能更加先进,如生成对抗网络,或更注重软技能,如数据讲述,或专门用于某个领域,如时间序列预测。我会在这里简要总结这些内容:
-
自然语言处理(NLP):处理和理解人类语言的人工智能子领域。聊天机器人使用这一技术。
-
时间序列分析与预测:研究时间数据并使用统计模型对未来事件进行预测。你可能会用这个技能进行销售或收入分析。
-
实验设计与 A/B 测试:设计和进行受控实验以测试假设,并根据数据做出决策的过程。
-
数据讲述:有效地将数据洞察和发现传达给非技术利益相关者的能力。越来越多的利益相关者对数据驱动决策背后的原因感兴趣,因此这至关重要。
-
生成对抗网络(GANs):一种深度学习架构,其中两个神经网络被训练合作生成类似于给定数据集的新数据。
-
迁移学习:一种机器学习技术,其中一个模型在一个任务上进行预训练,然后在相关任务上进行微调,从而提高性能并减少所需的训练数据量。资源有限的小公司会发现这一点特别有用。
-
自动化机器学习(AutoML):自动选择、训练和部署机器学习模型的过程。
-
超参数调优:另一种机器学习子类别。这是通过调整从数据中未学习到的参数(如学习率或隐藏层数量)来优化机器学习模型性能的过程。
-
可解释人工智能(XAI):一个专注于创建透明和可解释算法和模型的人工智能分支,以便人类能够理解其决策过程。同样,这有助于利益相关者理解发生了什么。
如果你想在 2023 年成为数据科学家,这 19 项技能是绝对关键的。真正的好消息是,许多这些技能可以自学,而其他的你可以在像数据或业务分析师这样的初级职位中获得。
学习的一些方法:
-
总是检查 YouTube。那里有很多免费的、全面的资源。我在这里列出了一些,但实际上有无数的视频可以查看。
-
像 Coursera 和 EdX 这样的平台通常提供讲座系列
享受学习这些技能的过程,以便在 2023 年成为数据科学家。
内特·罗西迪 是一位数据科学家,专注于产品策略。他还是一名兼职教授,教授分析学,并且是StrataScratch的创始人,该平台帮助数据科学家通过来自顶级公司的真实面试问题来准备面试。可以通过Twitter: StrataScratch或LinkedIn与他联系。
了解更多主题
2018 年版前 20 篇深度学习论文
原文:
www.kdnuggets.com/2018/03/top-20-deep-learning-papers-2018.html
评论
深度学习,作为机器学习和统计学习的一个子领域,在过去几年取得了令人瞩目的进展。云计算、强大的开源工具以及大量可用的数据是这些突破的关键因素之一。选择前 20 篇论文的标准是使用来自academic.microsoft.com的引用次数。值得提及的是,这些指标变化迅速,因此引用量必须考虑为文章发布时的数字。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
在这份论文列表中,超过 75%的论文涉及深度学习和神经网络,特别是卷积神经网络(CNN)。其中近 50%的论文涉及计算机视觉领域的模式识别应用。我相信像 TensorFlow、Theano 以及 GPU 使用方面的进展,为数据科学家和机器学习工程师拓展这一领域铺平了道路。
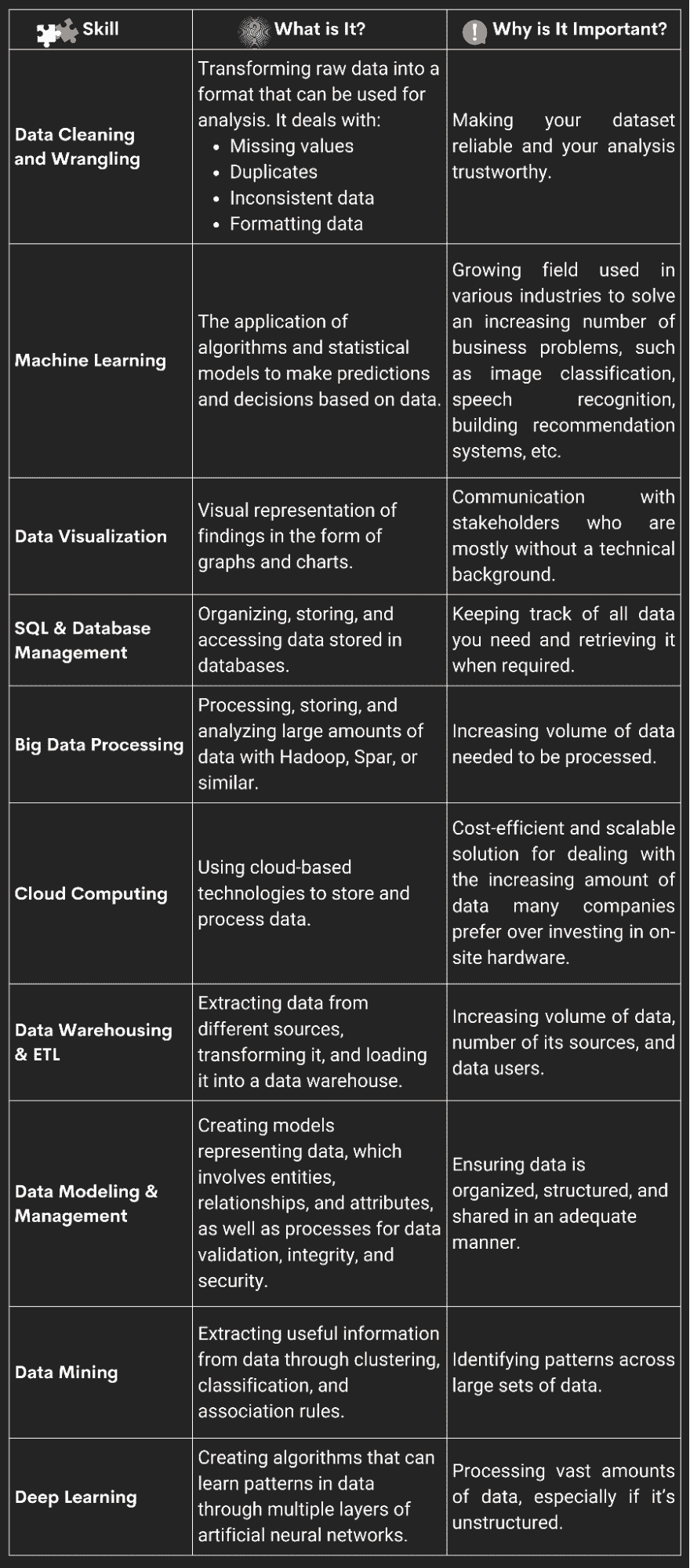
1. 深度学习, 作者:Yann L.、Yoshua B. 和 Geoffrey H.(2015 年)(引用次数:5,716)
深度学习允许由多个处理层组成的计算模型学习具有多个抽象层次的数据表示。这些方法显著提高了语音识别、视觉对象识别、对象检测以及药物发现和基因组学等多个领域的最先进水平。
2. TensorFlow: 大规模异构分布式系统上的机器学习, 作者:Martín A.、Ashish A. B.、Eugene B. C.等(2015 年)(引用次数:2,423)
该系统灵活且可以表达各种算法,包括深度神经网络模型的训练和推理算法,它已被用于研究和在计算机科学及其他领域(如语音识别、计算机视觉、机器人技术、信息检索、自然语言处理、地理信息提取和计算药物发现)中部署机器学习系统。
3. [TensorFlow: 大规模机器学习系统](https://www.usenix.org/system/files/conference/osdi16/osdi16-abadi.pdf rel=),作者:Martín A.、Paul B.、Jianmin C.、Zhifeng C.、Andy D. 等(2016 年)(被引用:2,227)
TensorFlow 支持各种应用,重点是深度神经网络的训练和推理。多个 Google 服务在生产中使用 TensorFlow,我们将其发布为开源项目,并且它已广泛用于机器学习研究。
4. 深度学习中的神经网络,作者:Juergen Schmidhuber(2015 年)(被引用:2,196)
本历史综述简要总结了相关工作,其中大部分来自上一个千年。浅层和深层学习者通过其信用分配路径的深度进行区分,这些路径是可能可学习的因果链。我们回顾了深度监督学习(也回顾了反向传播的历史)、无监督学习、强化学习与进化计算,以及对编码深度和大型网络的短程序的间接搜索。
5. 通过深度强化学习实现人类级控制,作者:Volodymyr M.、Koray K.、David S.、Andrei A. R.、Joel V 等(2015 年)(被引用:2,086)
在这里,我们利用训练深度神经网络的最新进展,开发了一种新型人工智能代理,称为深度 Q 网络,该网络可以通过端到端强化学习直接从高维感官输入中学习成功的策略。我们在经典 Atari 2600 游戏的挑战领域测试了该代理。
6. 更快的 R-CNN: 朝着实时目标检测的区域提议网络,作者:Shaoqing R.、Kaiming H.、Ross B. G. 和 Jian S.(2015 年)(被引用:1,421)
在这项工作中,我们介绍了一种区域提议网络(RPN),它与检测网络共享全图像卷积特征,从而实现几乎零成本的区域提议。RPN 是一种全卷积网络,它同时在每个位置预测对象边界和对象性得分。
7. 用于视觉识别和描述的长期递归卷积网络,作者:Jeff D.、Lisa Anne H.、Sergio G.、Marcus R.、Subhashini V. 等(2015 年)(被引用:1,285)
与当前假设固定空间-时间感受野或简单时间平均的序列处理模型相比,递归卷积模型在空间和时间“层”上都可以是“加倍深度”的。
8. MatConvNet:用于 MATLAB 的卷积神经网络,作者 Andrea Vedaldi 和 Karel Lenc(2015 年)(引用次数:1,148)
它将 CNN 的构建模块暴露为易于使用的 MATLAB 函数,提供了计算线性卷积的滤波器组、特征池化等常用例程。本文档概述了 CNN 及其在 MatConvNet 中的实现,并提供了工具箱中每个计算块的技术细节。
9. 使用深度卷积生成对抗网络的无监督表示学习,作者 Alec R., Luke M. 和 Soumith C.(2015 年)(引用次数:1,054)
在这项工作中,我们希望帮助弥合 CNN 在监督学习和无监督学习中的成功之间的差距。我们引入了一类称为深度卷积生成对抗网络(DCGANs)的 CNN,这些网络具有某些架构约束,并证明它们是无监督学习的强有力候选者。
10. U-Net:用于生物医学图像分割的卷积网络,作者 Olaf R., Philipp F. 和 Thomas B.(2015 年)(引用次数:975)
大多数人一致认为,成功训练深度网络需要成千上万的标注训练样本。本文提出了一种网络和训练策略,依赖于强大的数据增强,以更有效地利用现有的标注样本。
11. 条件随机场作为递归神经网络,作者 Shuai Z., Sadeep J., Bernardino R., Vibhav V. 等(2015 年)(引用次数:760)
我们引入了一种新的卷积神经网络形式,结合了卷积神经网络(CNNs)和基于条件随机场(CRFs)的概率图模型的优点。为此,我们将具有高斯对偶势的条件随机场的均值场近似推断形式化为递归神经网络。
12. 使用深度卷积网络的图像超分辨率,作者 Chao D., Chen C., Kaiming H. 和 Xiaoou T.(2014 年)(引用次数:591)
我们的方法直接学习低分辨率图像与高分辨率图像之间的端到端映射。该映射表示为一个深度卷积神经网络(CNN),它以低分辨率图像为输入,输出高分辨率图像。
13. 超越短片段:用于视频分类的深度网络,作者 Joe Y. Ng, Matthew J. H., Sudheendra V., Oriol V., Rajat M. 和 George T.(2015 年)(引用次数:533)
在这项工作中,我们提出并评估了几种深度神经网络架构,以在比以往尝试的更长时间段内结合视频中的图像信息。
14. Inception-v4、Inception-ResNet 及残差连接对学习的影响,作者 Christian S.、Sergey I.、Vincent V. 和 Alexander A A.(2017)(引用次数:520)
非常深的卷积网络在近年来图像识别性能的最大进展中发挥了核心作用。通过一个包含三个残差网络和一个 Inception-v4 的集合,我们在 ImageNet 分类(CLS)挑战的测试集上实现了 3.08% 的 top-5 错误率。
15. 显著性对象检测:一种判别性区域特征融合方法,作者 Huaizu J.、Jingdong W.、Zejian Y.、Yang W.、Nanning Z. 和 Shipeng Li.(2013)(引用次数:518)
在本文中,我们将显著性图计算公式化为回归问题。我们的方法基于多级图像分割,利用监督学习方法将区域特征向量映射到显著性分数。
16. 视觉 Madlibs: 填空描述生成和问答,作者 Licheng Y.、Eunbyung P.、Alexander C. B. 和 Tamara L. B.(2015)(引用次数:510)
在本文中,我们介绍了一个新的数据集,其中包含 360,001 个针对 10,738 张图像的集中自然语言描述。该数据集,Visual Madlibs 数据集,是通过自动生成的填空模板收集的,旨在收集关于:人物和物体、它们的外观、活动和互动,以及对一般场景或其更广泛背景的推断的目标描述。
17. 深度强化学习的异步方法,作者 Volodymyr M.、Adrià P. B.、Mehdi M.、Alex G.、Tim H. 等(2016)(引用次数:472)
性能最佳的方法是异步变体的演员-评论家方法,它在 Atari 领域超越了当前的最先进水平,同时在单个多核 CPU 上训练的时间仅为 GPU 的一半。此外,我们还展示了异步演员-评论家在各种连续运动控制问题以及在使用视觉输入的随机 3D 迷宫导航新任务中的成功。
18. Theano: 一个用于快速计算数学表达式的 Python 框架,作者 Rami A.、Guillaume A.、Amjad A.、Christof A. 等(2016)(引用次数:451)
Theano 是一个 Python 库,允许高效地定义、优化和评估涉及多维数组的数学表达式。自推出以来,它已成为最常用的 CPU 和 GPU 数学编译器之一,特别是在机器学习社区中,并且显示出稳定的性能提升。
19. 深度学习在野外的面部属性,由 Ziwei L.、Ping L.、Xiaogang W. 和 Xiaoou T. (2015)(引用次数:401)
该框架不仅大幅超越了最先进的技术,而且揭示了有关学习面部表示的有价值的事实。(1)它展示了如何通过不同的预训练策略改善面部定位(LNet)和属性预测(ANet)的性能。(2)它揭示了尽管 LNet 的滤波器仅通过图像级属性标签进行微调,但它们在整个图像上的响应图具有强烈的面部位置指示。
20. 用于文本分类的字符级卷积网络,由 Xiang Z.、Junbo Jake Z. 和 Yann L. (2015)(引用次数:401)
这篇文章提供了对字符级卷积网络(ConvNets)在文本分类中应用的实证探索。我们构建了几个大规模数据集,展示了字符级卷积网络能够实现最先进或具有竞争力的结果。
相关:
更多相关主题
近期机器学习和深度学习的 20 篇重要研究论文
原文:
www.kdnuggets.com/2017/04/top-20-papers-machine-learning.html
comments
近年来,机器学习,尤其是其子领域深度学习,取得了许多令人惊叹的进展,重要的研究论文可能会导致被数十亿人使用的技术突破。该领域的研究发展迅速,为帮助读者监控进展,我们提供了自 2014 年以来发表的最重要的科学论文列表。
我们选择这 20 篇顶级论文的标准是通过引用次数,从三个学术来源中获取数据:scholar.google.com; academic.microsoft.com; 和 semanticscholar.org。由于引用次数在各个来源中有所不同且是估算的,我们列出了来自 academic.microsoft.com 的结果,这略低于其他来源。
对于每篇论文,我们还提供了发表年份、由 semanticscholar.org 提供的高度影响引用次数(HIC)和引用速度(CV)指标。HIC 展示了出版物如何相互建立联系,是识别有意义引用的结果。CV 是过去 3 年每年的加权平均引用次数。对于某些引用,CV 为零,表示 semanticscholar.org 未显示或数据为空。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
这 20 篇论文中,大多数(但不是全部),包括前 8 篇,均涉及深度学习。不过,我们看到很强的多样性——只有一位作者(Yoshua Bengio)有 2 篇论文,这些论文发表在多个不同的期刊上:CoRR(3),ECCV(3),IEEE CVPR(3),NIPS(2),ACM Comp Surveys,ICML,IEEE PAMI,IEEE TKDE,Information Fusion,Int. J. on Computers & EE,JMLR,KDD,和 Neural Networks。前两篇论文的引用次数远高于其他论文。请注意,第二篇论文仅在去年发表。阅读(或重读)它们,了解最新进展。
-
,作者:Hinton, G.E., Krizhevsky, A., Srivastava, N., Sutskever, I., & Salakhutdinov, R.(2014 年)。《机器学习研究杂志》,15, 1929-1958。(引用 2084 次,HIC: 142 , CV: 536)。
概要:关键思想是在训练过程中随机丢弃神经网络中的单元(连同其连接)。这可以防止单元过度共适应。这样显著减少了过拟合,并在其他正则化方法中取得了显著的改进。
-
深度残差学习用于图像识别,作者:He, K., Ren, S., Sun, J., & Zhang, X.(2016 年)。CoRR, abs/1512.03385。(引用 1436 次,HIC: 137 , CV: 582)。
概要:我们提出了一种残差学习框架,以简化训练远比以前使用的网络更深的深度神经网络。我们明确地将层重新定义为相对于层输入的学习残差函数,而不是学习无参考的函数。我们提供了全面的实证证据,显示这些残差网络更易于优化,并且可以从显著增加的深度中获得更高的准确率。
-
批量归一化:通过减少内部协变量偏移来加速深度网络训练,作者:Sergey Ioffe, Christian Szegedy(2015 年)ICML。(引用 946 次,HIC: 56 , CV: 0)。
概要:训练深度神经网络的复杂性在于每一层输入的分布在训练过程中会随着前一层参数的变化而改变。我们将这种现象称为内部协变量偏移,并通过对层输入进行归一化来解决这个问题。应用于最先进的图像分类模型,批量归一化在训练步骤减少 14 倍的情况下实现了相同的准确率,并显著优于原始模型。
-
大规模视频分类与卷积神经网络,作者:Fei-Fei, L., Karpathy, A., Leung, T., Shetty, S., Sukthankar, R., & Toderici, G.(2014 年)。IEEE 计算机视觉与模式识别会议(引用 865 次,HIC: 24 , CV: 239)
概要:卷积神经网络(CNNs)已被确立为解决图像识别问题的强大模型。受到这些结果的鼓舞,我们对 CNN 在大规模视频分类上的表现进行了广泛的实证评估,使用了一个包含 487 个类别的 100 万 YouTube 视频的新数据集。
-
Microsoft COCO: Common Objects in Context,由 Belongie, S.J., Dollár, P., Hays, J., Lin, T., Maire, M., Perona, P., Ramanan, D., & Zitnick, C.L. (2014). ECCV。(引用 830 次,HIC: 78,CV: 279)概述:我们展示了一个新的数据集,旨在通过将物体识别的问题放在更广泛的场景理解问题的背景下,从而推动物体识别的最先进技术。我们的数据集包含 91 种物体类型的照片,这些物体对于 4 岁的孩子来说是容易识别的。最后,我们提供了使用变形部件模型的边界框和分割检测结果的基准性能分析。
-
Learning deep features for scene recognition using places database,由 Lapedriza, À., Oliva, A., Torralba, A., Xiao, J., & Zhou, B. (2014). NIPS。(引用 644 次,HIC: 65,CV: 0)
概述:我们引入了一个新的以场景为中心的数据库,名为 Places,包含超过 700 万张标记的场景图片。我们提出了比较图像数据集的密度和多样性的新方法,并展示了 Places 的密度与其他场景数据集相当,并且具有更多的多样性。
-
Generative adversarial nets,由 Bengio, Y., Courville, A.C., Goodfellow, I.J., Mirza, M., Ozair, S., Pouget-Abadie, J., Warde-Farley, D., & Xu, B. (2014) NIPS。(引用 463 次,HIC: 55,CV: 0)
概述:我们提出了一种通过对抗过程估计生成模型的新框架,其中我们同时训练两个模型:一个捕捉数据分布的生成模型 G 和一个估计样本来自训练数据而非 G 的概率的判别模型 D。
-
High-Speed Tracking with Kernelized Correlation Filters,由 Batista, J., Caseiro, R., Henriques, J.F., & Martins, P. (2015). CoRR, abs/1404.7584。(引用 439 次,HIC: 43,CV: 0)
概述:在大多数现代跟踪器中,为了应对自然图像变化,通常使用平移和缩放的样本补丁训练分类器。我们提出了一个针对数千个平移补丁数据集的分析模型。通过展示得到的数据矩阵是循环的,我们可以使用离散傅里叶变换对其进行对角化,从而减少存储和计算量。
-
A Review on Multi-Label Learning Algorithms,由 Zhang, M., & Zhou, Z. (2014). IEEE TKDE。(引用 436 次,HIC: 7,CV: 91)
概述:本文旨在及时回顾多标签学习研究的问题,其中每个示例由一个实例表示,同时与一组标签相关联。
-
深度神经网络中的特征可转移性如何,由 Bengio, Y., Clune, J., Lipson, H., & Yosinski, J. (2014) 编写。CoRR, abs/1411.1792。(引用次数:402,HIC:14,CV:0)
摘要:我们实验性地量化了深度卷积神经网络中每层神经元的一般性与特异性,并报告了一些令人惊讶的结果。转移性受到两个不同问题的负面影响:(1)高层神经元对其原始任务的专业化,从而牺牲了目标任务的性能,这是预期中的;(2)与将网络分割在共同适应的神经元之间相关的优化困难,这是意料之外的。
-
我们是否需要数百个分类器来解决实际分类问题,由 Amorim, D.G., Barro, S., Cernadas, E., & Delgado, M.F. (2014) 编写。 《机器学习研究杂志》(引用次数:387,HIC:3,CV:0)
摘要:我们评估了来自 17 个家族(判别分析、贝叶斯、神经网络、支持向量机、决策树、基于规则的分类器、提升、袋装、堆叠、随机森林及其他集成方法、广义线性模型、最近邻、偏最小二乘和主成分回归、逻辑回归和多项式回归、多重自适应回归样条和其他方法)的 179 个分类器。我们使用来自 UCI 数据库的 121 个数据集来研究分类器行为,不依赖于数据集的集合。获胜者是用 R 实现的随机森林(RF)版本(通过 caret 访问)和用 C 实现的高斯核 SVM(使用 LibSVM)。
-
知识宝库:一种大规模概率知识融合的方法,由 Dong, X., Gabrilovich, E., Heitz, G., Horn, W., Lao, N., Murphy, K., ... & Zhang, W. (2014 年 8 月) 编写。发表于第 20 届 ACM SIGKDD 国际会议《知识发现与数据挖掘》ACM。(引用次数:334,HIC:7,CV:107)。
摘要:我们介绍了知识宝库,一个 Web 规模的概率知识库,将从 Web 内容中提取的数据(通过文本分析、表格数据、页面结构和人工注释获得)与现有知识库中的先验知识结合用于构建知识库。我们采用了监督机器学习方法来融合不同的信息源。知识宝库比任何已发布的结构化知识库都要大,并具有一个概率推理系统,计算事实正确性的校准概率。
-
可扩展的高维数据最近邻算法,由 Lowe, D.G., & Muja, M. (2014) 编写。IEEE Trans. Pattern Anal. Mach. Intell.(引用次数:324,HIC:11,CV:69)。
摘要:我们提出了新的近似最近邻匹配算法,并与之前的算法进行评估和比较。为了扩展到单台机器内存无法容纳的大型数据集,我们提出了一种分布式最近邻匹配框架,可以与文中描述的任何算法配合使用。
-
极限学习机的趋势:综述,由 Huang, G., Huang, G., Song, S., & You, K.(2015)。Neural Networks,(被引用 323 次,HIC: 0,CV: 0)
摘要:我们旨在报告极限学习机(ELM)在理论研究和实际进展中的当前状态。除了分类和回归之外,ELM 最近已扩展用于聚类、特征选择、表示学习及许多其他学习任务。由于其卓越的效率、简单性和令人印象深刻的泛化性能,ELM 已应用于生物医学工程、计算机视觉、系统识别、控制和机器人等多个领域。
-
概念漂移适应的调研,由 Bifet, A., Bouchachia, A., Gama, J., Pechenizkiy, M., & Zliobaite, I. 编写。ACM Comput. Surv., 2014,(被引用 314 次,HIC: 4,CV: 23)
摘要:这项工作旨在全面介绍概念漂移适应,这指的是当输入数据与目标变量之间的关系随时间变化时的在线监督学习场景。
-
深度卷积激活特征的多尺度无序池化,由 Gong, Y., Guo, R., Lazebnik, S., & Wang, L.(2014)。ECCV(被引用 293 次,HIC: 23,CV: 95)
摘要:为了在不降低其区分能力的情况下提高 CNN 激活的稳定性,本文提出了一种简单而有效的方案——多尺度无序池化(MOP-CNN)。
-
同时检测与分割,由 Arbeláez, P.A., Girshick, R.B., Hariharan, B., & Malik, J.(2014)ECCV,(被引用 286 次,HIC: 23,CV: 94)
摘要:我们旨在检测图像中所有类别的实例,并为每个实例标记属于它的像素。我们称此任务为同时检测与分割(SDS)。
-
特征选择方法综述,由 Chandrashekar, G., & Sahin, F. 编写。Int. J. on Computers & Electrical Engineering,(被引用 279 次,HIC: 1,CV: 58)
摘要:由于数据中存在数百个变量,导致数据维度非常高,文献中提供了许多特征选择方法。
-
使用回归树集成进行一毫秒面部对齐,由 Kazemi, Vahid 和 Josephine Sullivan 发表,IEEE 计算机视觉与模式识别会议 2014 论文集。(被引用 277 次,HIC: 15,CV: 0)
摘要:本文讨论了单张图像的面部对齐问题。我们展示了如何利用回归树的集成来直接从稀疏的像素强度子集估计面部标志位置,达到了高质量预测的超实时性能。
-
多分类器系统作为混合系统的综述,由 Corchado, E., Graña, M., 和 Wozniak, M. (2014) 发表。信息融合,16,3-17。(被引用 269 次,HIC: 1,CV: 22)
摘要:模式分类中的一个当前重点研究方向是多个分类器系统的组合,这些系统可以基于相同或不同的模型和/或数据集构建。
更多相关话题
前 20 大 Python AI 和机器学习开源项目
原文:
www.kdnuggets.com/2018/02/top-20-python-ai-machine-learning-open-source-projects.html
评论
进入机器学习和人工智能领域并非易事。许多有志于此的专业人士和爱好者发现,在今天如此大量的资源面前,很难找到一条合适的路径。这个领域不断发展,我们必须跟上这快速发展的步伐。为了应对这种令人难以承受的演变和创新速度,保持更新和了解机器学习的进展的一个好方法是通过参与许多由高级专业人士每日使用的开源项目和工具,来与社区互动。
在这里,我们更新了信息,并审视了自我们上一个帖子 Top 20 Python Machine Learning Open Source Projects(2016 年 11 月)以来的趋势。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
TensorFlow 已经跃居第一位,贡献者增长达到三位数。Scikit-learn 降至第二位,但仍然拥有非常大的贡献者基础。
与 2016 年相比,贡献者增长最快的项目是
-
TensorFlow,169% 增长,从 493 位贡献者增加到 1324 位贡献者
-
Deap,86% 增长,从 21 位贡献者增加到 39 位贡献者
-
Chainer,83% 增长,从 84 位贡献者增加到 154 位贡献者
-
Gensim,81% 增长,从 145 位贡献者增加到 262 位贡献者
-
Neon,66% 增长,从 47 位贡献者增加到 78 位贡献者
-
Nilearn,50% 增长,从 46 位贡献者增加到 69 位贡献者
2018 年的新内容:
-
Keras,629 位贡献者
-
PyTorch,399 位贡献者
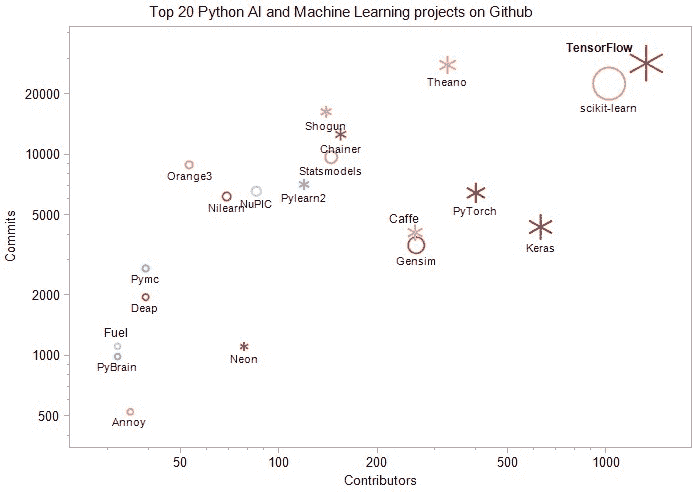
图 1:Github 上前 20 大 Python AI 和机器学习项目。
大小与贡献者数量成正比,颜色表示贡献者数量的变化 - 红色代表较高,蓝色代表较低。雪花形状用于深度学习项目,圆形用于其他项目。
我们看到像 TensorFlow、Theano 和 Caffe 这样的深度学习项目仍然是最受欢迎的。
下列列表按 Github 上贡献者数量的降序排列。贡献者数量的变化与2016 KDnuggets 关于前 20 个 Python 机器学习开源项目的帖子相比。
我们希望你喜欢浏览这些文档页面,以开始合作并学习使用 Python 进行机器学习的方法。
-
TensorFlow 最初由 Google Brain 团队内的研究人员和工程师开发。该系统旨在促进机器学习研究,并使从研究原型到生产系统的过渡快速而简便。
贡献者:1324(增加了 168%),提交次数:28476,星标:92359。Github 网址:Tensorflow
-
Scikit-learn 是用于数据挖掘和数据分析的简单而高效的工具,面向所有人,在各种环境中可重用,基于 NumPy、SciPy 和 matplotlib,开源,商业可用 – BSD 许可证。
贡献者:1019(增加了 39%),提交次数:22575,Github 网址:Scikit-learn
-
Keras 是一个高级神经网络 API,用 Python 编写,可以运行在 TensorFlow、CNTK 或 Theano 之上。
贡献者:629(新增),提交次数:4371,Github 网址:Keras。
-
PyTorch,Python 中的张量和动态神经网络,具有强大的 GPU 加速。
贡献者:399(新增),提交次数:6458,Github 网址:pytorch。
-
Theano 允许你高效地定义、优化和评估涉及多维数组的数学表达式。
贡献者:327(增加了 24%),提交次数:27931,Github 网址:Theano
-
Gensim 是一个免费的 Python 库,具有可扩展的统计语义功能,可以分析纯文本文档的语义结构,并检索语义相似的文档。
贡献者:262(增加了 81%),提交次数:3549,Github 网址:Gensim
-
Caffe 是一个深度学习框架,注重表达力、速度和模块化。由 Berkeley Vision and Learning Center (BVLC) 和社区贡献者开发。
贡献者:260(增加了 21%),提交次数:4099,Github 网址:Caffe
-
Chainer 是一个基于 Python 的独立开源深度学习框架。Chainer 提供了一种灵活、直观且高性能的方法来实现各种深度学习模型,包括诸如递归神经网络和变分自编码器等最先进的模型。
贡献者: 154(增加了 84%),提交次数: 12613,Github URL: Chainer
-
Statsmodels 是一个 Python 模块,允许用户探索数据、估计统计模型并执行统计测试。提供了针对不同数据类型和每个估计器的详细描述统计、统计测试、绘图函数和结果统计。
贡献者: 144(增加了 33%),提交次数: 9729,Github URL: Statsmodels
-
Shogun 是一个机器学习工具箱,提供了广泛的 统一 和 高效 的机器学习(ML)方法。该工具箱无缝地允许轻松组合多种数据表示、算法类别和通用工具。
贡献者: 139(增加了 32%),提交次数: 16362,Github URL: Shogun
-
Pylearn2 是一个机器学习库。它的大部分功能建立在 Theano 之上。这意味着你可以使用数学表达式编写 Pylearn2 插件(新模型、算法等),Theano 将优化并稳定这些表达式,并将其编译为你选择的后端(CPU 或 GPU)。
贡献者: 119(增加了 3.5%),提交次数: 7119,Github URL: Pylearn2
-
NuPIC 是一个基于一种称为分层时间记忆(HTM)的新皮层理论的开源项目。HTM 理论的部分内容已经实现、测试并用于应用中,其他部分仍在开发中。
贡献者: 85(增加了 12%),提交次数: 6588,Github URL: NuPIC
-
Neon 是 Nervana 的基于 Python 的深度学习库。它在提供易用性的同时,能够实现最高性能。
贡献者: 78(增加了 66%),提交次数: 1112,Github URL: Neon
-
Nilearn 是一个用于神经影像数据的快速而简单的统计学习的 Python 模块。它利用了 scikit-learn Python 工具箱进行多变量统计,适用于预测建模、分类、解码或连通性分析等应用。
贡献者: 69(增加了 50%),提交次数: 6198,Github URL: Nilearn
-
Orange3 是开源的机器学习和数据可视化工具,适用于新手和专家。具有大规模工具箱的互动数据分析工作流。
贡献者:53(增加 33%),提交次数:8915,Github 网址:Orange3
-
Pymc 是一个 Python 模块,实现了贝叶斯统计模型和拟合算法,包括马尔可夫链蒙特卡罗。其灵活性和可扩展性使其适用于各种问题。
贡献者:39(增加 5.4%),提交次数:2721,Github 网址:Pymc
-
Deap 是一个新颖的进化计算框架,用于快速原型开发和测试想法。它旨在使算法明确,数据结构透明。它与并行机制如多进程和 SCOOP 完美兼容。
贡献者:39(增加 86%),提交次数:1960,Github 网址:Deap
-
Annoy (近似最近邻 哦耶) 是一个具有 Python 绑定的 C++ 库,用于在空间中搜索与给定查询点接近的点。它还创建了大型只读文件数据结构,这些数据结构映射到内存中,以便多个进程可以共享相同的数据。
贡献者:35(增加 46%),提交次数:527,Github 网址:Annoy
-
PyBrain 是一个模块化的 Python 机器学习库。其目标是提供灵活、易于使用但仍然强大的机器学习算法,并且提供多种预定义的环境用于测试和比较你的算法。
贡献者:32(增加 3%),提交次数:992,Github 网址:PyBrain
-
Fuel 是一个数据管道框架,为你的机器学习模型提供所需的数据。计划由 Blocks 和 Pylearn2 神经网络库使用。
贡献者:32(增加 10%),提交次数:1116,Github 网址:Fuel
贡献者和提交次数的数据记录于 2018 年 2 月。
相关:
更多相关主题
2018 年数据科学的 20 大 Python 库
原文:
www.kdnuggets.com/2018/06/top-20-python-libraries-data-science-2018.html/2
评论
机器学习
10. Scikit-learn (提交次数:22753,贡献者:1084)
这个基于 NumPy 和 SciPy 的 Python 模块是处理数据的最佳库之一。它提供了许多标准机器学习和数据挖掘任务的算法,如聚类、回归、分类、降维和模型选择。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
对库进行了多项增强。交叉验证已被修改,提供了使用多个指标的能力。几种训练方法如最近邻和逻辑回归也进行了小幅改进。最后,一个主要更新是完成了 常见术语和 API 元素词汇表,它介绍了 Scikit-learn 中使用的术语和惯例。
11. XGBoost / LightGBM / CatBoost (提交次数:3277 / 1083 / 1509,贡献者:280 / 79 / 61)
梯度提升是最受欢迎的机器学习算法之一,它通过构建一组逐步改进的基本模型,即决策树。因此,有专门的库设计用于快速便捷地实现这种方法。我们认为 XGBoost、LightGBM 和 CatBoost 值得特别关注。它们都是解决相同问题的竞争者,并且几乎以相同的方式使用。这些库提供了高度优化、可扩展和快速的梯度提升实现,这使得它们在数据科学家和 Kaggle 竞赛者中极为受欢迎,因为许多比赛都借助这些算法赢得了胜利。
12. Eli5 (提交次数:922,贡献者:6)
机器学习模型预测的结果通常不是完全清晰的,这正是 eli5 库帮助解决的挑战。它是一个用于可视化和调试机器学习模型的包,并逐步跟踪算法的工作。它支持 scikit-learn、XGBoost、LightGBM、lightning 和 sklearn-crfsuite 库,并为每个库执行不同的任务。
深度学习
13. TensorFlow (提交: 33339, 贡献者: 1469)
TensorFlow 是一个流行的深度学习和机器学习框架,由 Google Brain 开发。它提供了处理多数据集的人工神经网络的能力。最受欢迎的 TensorFlow 应用包括目标识别、语音识别等。在常规 TensorFlow 之上,还有不同的层辅助工具,如 tflearn、tf-slim、skflow 等。
这个库在新版本发布方面非常迅速,引入了越来越多的新功能。最新的更新包括修复潜在的安全漏洞和改进 TensorFlow 与 GPU 的集成,例如,你可以在一台机器上的多个 GPU 上运行 Estimator 模型。
14. PyTorch(提交: 11306, 贡献者: 635)
PyTorch 是一个大型框架,允许你执行带有 GPU 加速的张量计算,创建动态计算图并自动计算梯度。除此之外,PyTorch 提供了丰富的 API 来解决与神经网络相关的应用。
该库基于 Torch,这是一个用 C 实现并在 Lua 中封装的开源深度学习库。Python API 于 2017 年引入,从那时起,框架逐渐流行,吸引了越来越多的数据科学家。
15. Keras (提交: 4539, 贡献者: 671)
Keras 是一个高级库,用于处理神经网络,运行在 TensorFlow、Theano 之上,现在由于新版本的发布,也可以使用 CNTK 和 MxNet 作为后端。它简化了许多特定任务,并大大减少了单调的代码。然而,它可能不适合一些复杂的任务。
该库经历了性能、可用性、文档和 API 的改进。一些新特性包括 Conv3DTranspose 层、新的 MobileNet 应用和自我归一化网络。
分布式深度学习
16. Dist-keras / elephas / spark-deep-learning (提交: 1125 / 170 / 67, 贡献者: 5 / 13 / 11)
深度学习问题变得至关重要,因为越来越多的应用场景需要相当大的努力和时间。然而,使用像 Apache Spark 这样的分布式计算系统来处理如此大量的数据要容易得多,这也再次拓展了深度学习的可能性。因此,dist-keras、elephas 和 spark-deep-learning 正逐渐受到关注并迅速发展,很难单独挑出其中一个库,因为它们都是为了解决一个共同的任务而设计的。这些包允许你通过 Apache Spark 直接基于 Keras 库训练神经网络。Spark-deep-learning 还提供了创建与 Python 神经网络的管道的工具。
自然语言处理
17. NLTK (提交次数: 13041, 贡献者: 236)
NLTK 是一套库,一个用于自然语言处理的完整平台。借助 NLTK,你可以以多种方式处理和分析文本,对其进行标记和标签,提取信息等。NLTK 也用于原型设计和研究系统的构建。
对该库的改进包括 API 和兼容性的细微变化以及对 CoreNLP 的新接口。
18. SpaCy (提交次数: 8623, 贡献者: 215)
SpaCy 是一个自然语言处理库,提供了出色的示例、API 文档和演示应用程序。该库使用 Cython 语言编写,Cython 是 Python 的 C 扩展。它支持几乎 30 种语言,提供简单的深度学习集成,并承诺强大的稳定性和高准确性。另一个优秀的特点是 spaCy 具有处理整个文档的架构,而无需将文档拆分成短语。
19. Gensim (提交次数: 3603, 贡献者: 273)
Gensim 是一个用于强大语义分析、主题建模和向量空间建模的 Python 库,基于 Numpy 和 Scipy 构建。它提供了流行的 NLP 算法的实现,例如 word2vec。虽然 gensim 有自己的 models.wrappers.fasttext 实现,但 fasttext 库也可以用于高效学习词汇表示。
数据抓取
20. Scrapy (提交次数: 6625, 贡献者: 281)
Scrapy 是一个用于创建爬虫机器人以扫描网页并收集结构化数据的库。此外,Scrapy 还可以从 API 中提取数据。由于其扩展性和可移植性,该库非常方便。
年内取得的进展包括对代理服务器的若干升级以及改进的错误通知和问题识别系统。还有使用scrapy parse的新元数据设置可能性。
结论
这是我们在 2018 年为数据科学提供的丰富的 Python 库集合。与前一年相比,一些新的现代库正在获得越来越多的关注,而那些已经成为数据科学任务经典的库也在不断改进。
再次说明,这里有一张表格显示了 GitHub 活动的详细统计数据。
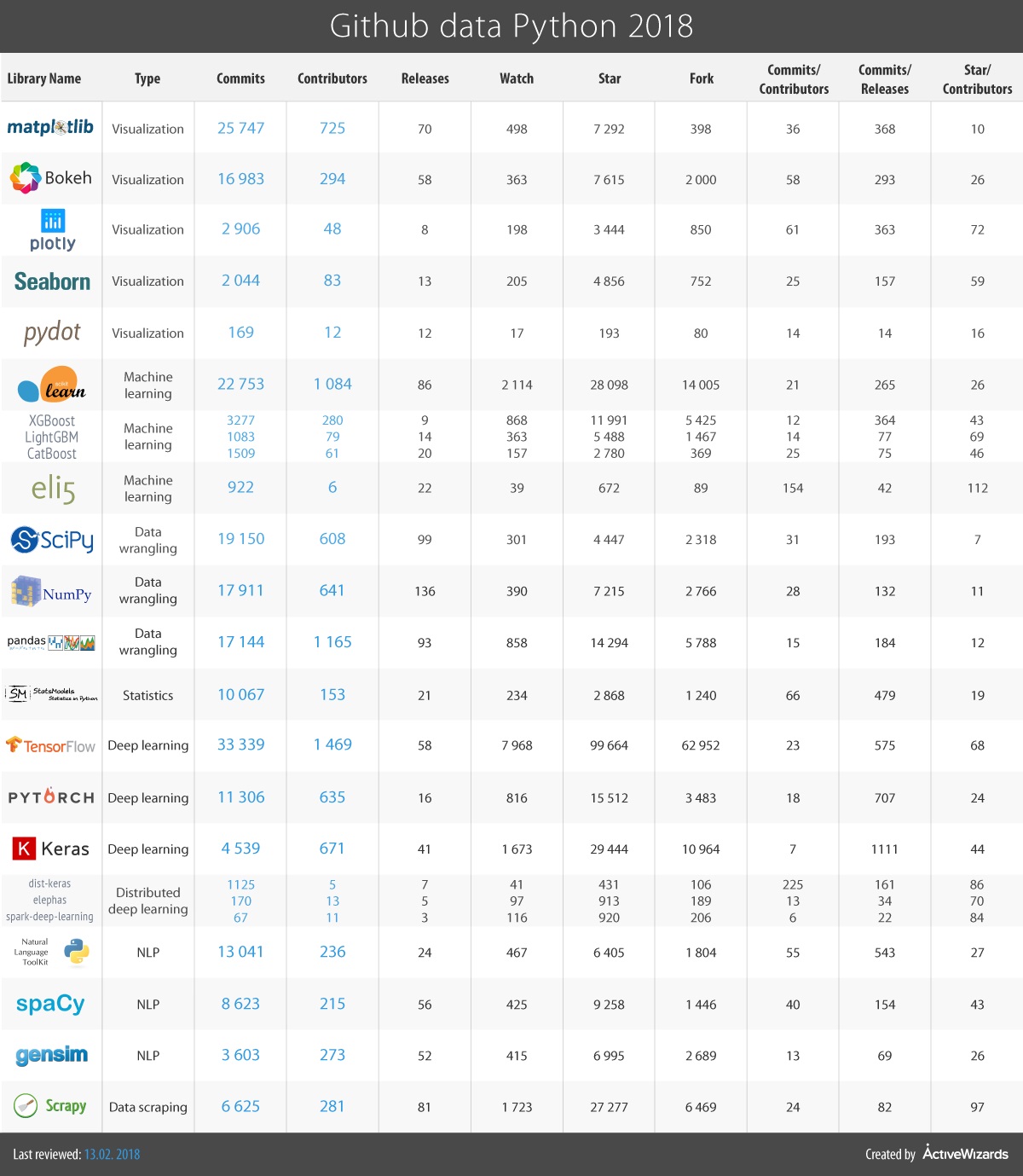
尽管我们今年扩展了我们的列表,但它仍可能没有涵盖一些其他值得关注的优秀和有用的库。因此,请在下方评论区分享您的最爱,以及我们提到的包的任何想法。
感谢您的关注!
ActiveWizards 是一个专注于数据项目(大数据、数据科学、机器学习、数据可视化)的数据科学家和工程师团队。核心专长领域包括数据科学(研究、机器学习算法、可视化和工程)、数据可视化(d3.js、Tableau 等)、大数据工程(Hadoop、Spark、Kafka、Cassandra、HBase、MongoDB 等)以及数据密集型 Web 应用开发(RESTful APIs、Flask、Django、Meteor)。
原文。经授权转载。
相关:
-
2018 年数据科学领域前 20 个 R 库
-
2018 年数据科学领域前 15 个 Scala 库
-
2017 年数据科学领域前 15 个 Python 库
更多相关内容
前 20 大 Python 机器学习开源项目
原文:
www.kdnuggets.com/2015/06/top-20-python-machine-learning-open-source-projects.html
评论 我们分析了 GitHub 上排名前 20 的 Python 机器学习项目,发现 scikit-Learn、PyLearn2 和 NuPic 是贡献最活跃的项目。探索这些受欢迎的项目吧! 图 1:GitHub 上的 Python 机器学习项目,颜色对应于提交/贡献者。Bob、Iepy、Nilearn 和 NuPIC 的数值最高。
图 1:GitHub 上的 Python 机器学习项目,颜色对应于提交/贡献者。Bob、Iepy、Nilearn 和 NuPIC 的数值最高。
-
scikit-learn,18845 次提交,404 位贡献者,www.github.com/scikit-learn/scikit-learn scikit-learn 是一个建立在 SciPy 之上的 Python 机器学习模块。它包含各种分类、回归和聚类算法,包括支持向量机、逻辑回归、朴素贝叶斯、随机森林、梯度提升、k-means 和 DBSCAN,并且设计为与 Python 数值和科学库 NumPy 和 SciPy 互操作。
-
Pylearn2,7027 次提交,117 位贡献者,www.github.com/lisa-lab/pylearn2 Pylearn2 是一个旨在简化机器学习研究的库。它是一个基于 Theano 的库。
-
NuPIC,4392 次提交,60 位贡献者,www.github.com/numenta/nupic Numenta 智能计算平台(NuPIC)是一个实现 HTM 学习算法的机器智能平台。HTM 是对新皮层的详细计算理论。HTM 的核心是基于时间的连续学习算法,用于存储和回忆空间和时间模式。NuPIC 适用于多种问题,特别是异常检测和流数据源预测。
-
Nilearn,2742 次提交,28 位贡献者,www.github.com/nilearn/nilearn Nilearn 是一个用于神经影像数据快速和简单统计学习的 Python 模块。它利用 scikit-learn Python 工具箱进行多变量统计分析,应用包括预测建模、分类、解码或连通性分析。
-
PyBrain,969 次提交,27 位贡献者,www.github.com/pybrain/pybrain PyBrain 是 Python 基于强化学习、人工智能和神经网络库的缩写。其目标是提供灵活、易于使用且强大的机器学习任务算法和多种预定义环境,以测试和比较你的算法。
-
Pattern,943 次提交,20 名贡献者,www.github.com/clips/pattern Pattern 是一个用于 Python 的网络挖掘模块。它拥有数据挖掘、自然语言处理、网络分析和机器学习的工具。它支持向量空间模型、聚类、使用 KNN、SVM、感知机的分类。
-
Fuel,497 次提交,12 名贡献者,www.github.com/mila-udem/fuel Fuel 为你的机器学习模型提供所需的数据。它具有对常见数据集的接口,如 MNIST、CIFAR-10(图像数据集)、Google 的 One Billion Words(文本数据)。它允许你以各种方式迭代数据,例如使用洗牌/顺序示例的小批量。
-
Bob,5080 次提交,11 名贡献者,www.github.com/idiap/bob Bob 是一个免费的信号处理和机器学习工具箱。该工具箱由 Python 和 C++ 混合编写,旨在高效且减少开发时间。它由相当多的包组成,这些包实现了图像、音频和视频处理、机器学习和模式识别的工具。
-
skdata,441 次提交,10 名贡献者,www.github.com/jaberg/skdata Skdata 是一个用于机器学习和统计的数据集库。该模块提供了对玩具问题以及流行的计算机视觉和自然语言处理数据集的标准化 Python 访问。
-
MILK,687 次提交,9 名贡献者,www.github.com/luispedro/milk Milk 是一个 Python 机器学习工具包。它专注于有监督的分类,提供了多种分类器:SVMs、k-NN、随机森林、决策树。它还执行特征选择。这些分类器可以以多种方式组合,形成不同的分类系统。对于无监督学习,
milk支持 k-means 聚类和亲和传播。 -
IEPY,1758 次提交,9 名贡献者,www.github.com/machinalis/iepy IEPY 是一个开源的信息提取工具,专注于关系提取。它针对需要在大型数据集上进行信息提取的用户,尤其是那些希望实验新 IE 算法的科学家。
-
Quepy,131 次提交,9 名贡献者,www.github.com/machinalis/quepy Quepy 是一个 Python 框架,用于将自然语言问题转换为数据库查询语言中的查询。它可以轻松地自定义不同类型的自然语言问题和数据库查询。因此,通过少量编码,你可以构建自己的系统,以自然语言访问你的数据库。目前,Quepy 支持 Sparql 和 MQL 查询语言,并计划扩展到其他数据库查询语言。
-
Hebel, 244 次提交, 5 名贡献者, www.github.com/hannes-brt/hebel Hebel 是一个用于深度学习的库,使用 CUDA 通过 PyCUDA 在 Python 中加速神经网络。它实现了最重要的神经网络模型类型,并提供了各种激活函数和训练方法,如动量、Nesterov 动量、丢弃和提前停止。
-
mlxtend, 135 次提交, 5 名贡献者, www.github.com/rasbt/mlxtend 这是一个包含用于日常数据科学任务的有用工具和扩展的库。
-
nolearn, 192 次提交, 4 名贡献者, www.github.com/dnouri/nolearn 该包包含多个有助于机器学习任务的实用模块。大多数模块与 scikit-learn 一起使用,其他模块则更通用。
-
Ramp, 179 次提交, 4 名贡献者, www.github.com/kvh/ramp Ramp 是一个用于快速原型设计机器学习解决方案的 Python 库。它是一个基于 pandas 的轻量级机器学习框架,可与现有的 Python 机器学习和统计工具(如 scikit-learn、rpy2 等)插件兼容。Ramp 提供了一种简单、声明式的语法,用于快速高效地探索特征、算法和转换。
-
Feature Forge, 219 次提交, 3 名贡献者, www.github.com/machinalis/featureforge 一套用于创建和测试机器学习特征的工具,具有与 scikit-learn 兼容的 API。这个库提供了一套工具,在许多机器学习应用中(分类、聚类、回归等)都可能有用,特别是如果你使用 scikit-learn(尽管如果你使用不同的算法,它也可以工作)。
-
REP, 50 次提交, 3 名贡献者, www.github.com/yandex/rep REP 是一个以一致和可重复的方式进行数据驱动研究的环境。它有一个统一的分类器包装器,适用于各种实现,如 TMVA、Sklearn、XGBoost、uBoost。它可以在集群上并行训练分类器。支持交互式图表。
-
Python 机器学习样本, 15 次提交, 3 名贡献者, www.github.com/awslabs/machine-learning-samples 一个使用 Amazon 机器学习构建的示例应用程序集合。
-
Python-ELM, 17 次提交, 1 名贡献者, www.github.com/dclambert/Python-ELM 这是基于 scikit-learn 的 Extreme Learning Machine 在 Python 中的实现。
本文使用了一些内容来自 www.pansop.com/1039/ 相关:
-
有趣的开源机器学习、数据挖掘、数据科学项目
-
开源机器学习工具
-
真正的数据科学家请站出来!
更多相关主题
前 20 名 Python 机器学习开源项目,已更新
原文:
www.kdnuggets.com/2016/11/top-20-python-machine-learning-open-source-updated.html
继去年分析:前 20 名 Python 机器学习开源项目,今年 KDnuggets 带来最新的前 20 名 Python 机器学习开源项目,更新于 Github。奇怪的是,去年一些最活跃的项目已经变得停滞,还有一些从前 20 名中跌出(考虑贡献和提交),而 13 个新项目进入了前 20 名。

2016 年前 20 名 Python 机器学习开源项目。
-
Scikit-learn 是简单高效的数据挖掘和数据分析工具,人人可用,可在各种背景下重用,基于 NumPy、SciPy 和 matplotlib,开源,可商业使用 – BSD 许可证。
提交次数:21486,贡献者:736,Github URL:Scikit-learn
-
Tensorflow 最初由 Google Brain 团队的研究人员和工程师在 Google 的机器智能研究组织中开发。该系统旨在促进机器学习研究,并使从研究原型到生产系统的过渡快速而简便。
提交次数:10466,贡献者:493,Github URL:Tensorflow
-
Theano 允许你高效地定义、优化和评估涉及多维数组的数学表达式。
提交次数:24108,贡献者:263,Github URL:Theano
-
Caffe 是一个深度学习框架,关注表达性、速度和模块化。由伯克利视觉与学习中心(BVLC)和社区贡献者开发。
提交次数:3801,贡献者:215,Github URL:Caffe
-
Gensim 是一个免费的 Python 库,具有可扩展的统计语义功能,分析纯文本文档的语义结构,检索语义相似的文档。
提交次数:2702,贡献者:145,Github URL:Gensim
-
Pylearn2 是一个机器学习库。其大部分功能基于 Theano。这意味着你可以使用数学表达式编写 Pylearn2 插件(新模型、算法等),Theano 会为你优化和稳定这些表达式,并将其编译到你选择的后端(CPU 或 GPU)。
提交次数: 7100,贡献者: 115,Github 链接: Pylearn2
-
Statsmodels 是一个 Python 模块,允许用户探索数据、估计统计模型和执行统计测试。提供了广泛的描述性统计、统计测试、绘图函数和结果统计,适用于不同类型的数据和每个估计器。
提交次数: 8664,贡献者: 108,Github 链接: Statsmodels
-
Shogun 是一个机器学习工具箱,提供了多种统一和高效的机器学习(ML)方法。该工具箱可以轻松地将多个数据表示、算法类别和通用工具结合在一起。
提交次数: 15172,贡献者: 105,Github 链接: Shogun
-
Chainer 是一个基于 Python 的独立开源深度学习框架。Chainer 提供了一种灵活、直观且高性能的方法来实现各种深度学习模型,包括最先进的模型,如递归神经网络和变分自编码器。
提交次数: 6298,贡献者: 84,Github 链接: Chainer
-
NuPIC 是一个基于新皮层理论的开源项目,称为分层时间记忆(HTM)。HTM 理论的部分已经实现、测试并用于应用中,其他部分仍在开发中。
提交次数: 6088,贡献者: 76,Github 链接: NuPIC
-
Neon 是 Nervana 的基于 Python 的深度学习库。它提供了使用上的便利,同时实现了最高的性能。
提交次数: 875,贡献者: 47,Github 链接: Neon
-
Nilearn 是一个用于对神经影像数据进行快速简便统计学习的 Python 模块。它利用了 scikit-learn Python 工具箱进行多变量统计,应用包括预测建模、分类、解码或连接性分析。
提交次数: 5254,贡献者: 46,Github 链接: Nilearn
-
Orange3 是开源的机器学习和数据可视化工具,适用于新手和专家。具有大量工具箱的互动数据分析工作流。
Commits: 6356, Contributors: 40, Github URL: Orange3
-
Pymc 是一个实现贝叶斯统计模型和拟合算法的 Python 模块,包括马尔可夫链蒙特卡洛。其灵活性和可扩展性使其适用于大量问题。
Commits: 2701, Contributors: 37, Github URL: Pymc
-
PyBrain 是一个用于 Python 的模块化机器学习库。它的目标是提供灵活、易用且强大的机器学习任务算法以及各种预定义环境,以测试和比较你的算法。
Commits: 984, Contributors: 31, Github URL: PyBrain
-
Fuel 是一个数据管道框架,为你的机器学习模型提供所需的数据。计划被Blocks 和 Pylearn2 神经网络库使用。
Commits: 1053, Contributors: 29, Github URL: Fuel
-
PyMVPA 是一个Python 包,旨在简化大数据集的统计学习分析。它提供了一个可扩展的框架,具有高层接口,支持广泛的分类、回归、特征选择、数据导入和导出算法。
Commits: 9258, Contributors: 26, Github URL: PyMVPA
-
Annoy (Approximate Nearest Neighbors Oh Yeah) 是一个带有 Python 绑定的 C++ 库,用于搜索与给定查询点接近的空间中的点。它还创建了大型只读文件基础的数据结构,这些数据结构被映射到内存中,以便许多进程可以共享相同的数据。
Commits: 365, Contributors: 24, Github URL: Annoy
-
Deap 是一个新颖的进化计算框架,用于快速原型开发和测试思想。它旨在使算法明确,并使数据结构透明。它与并行化机制(如多进程)以及SCOOP 完美兼容。
Commits: 1854, Contributors: 21, Github URL: Deap
-
Pattern 是一个用于 Python 编程语言的网页挖掘模块。它集合了数据挖掘(Google + Twitter + Wikipedia API、网络爬虫、HTML DOM 解析器)、自然语言处理(词性标注、n-gram 搜索、情感分析、WordNet)、机器学习(向量空间模型、k-means 聚类、朴素贝叶斯 + k-NN + SVM 分类器)和网络分析(图中心性和可视化)工具。
提交次数:943,贡献者数量:20,Github 网址:Pattern
我们可以在以下图表中看到,PyMVPA 的贡献率高于列表中的所有顶级项目。令人惊讶的是,尽管 Scikit-learn 的贡献者数量最多,但其贡献率却很低。这可能是因为 PyMVPA 是一个新项目,处于开发的早期阶段,导致由于新想法/功能开发、缺陷修复、重构等产生了许多提交。而 Scikit-learn 是一个成熟且稳定的项目,导致改进或缺陷修复的数量较少。

当我们比较 2016 年和 2015 年那些都在前 20 名列表中的项目时,我们可以看到 Pattern、PyBrain 和 Pylearn2 没有重大贡献,也没有新的贡献者。此外,贡献者数量和提交次数之间可以看到一个显著的相关性。贡献者的增加可能导致提交次数的增加,我认为这就是开源项目和社区的魔力;它带来了头脑风暴、新想法和更好的软件工具。

这是 KDnuggets 团队——Prasad 和 Gregory 对 2016 年前 20 名 Python 机器学习开源项目的分析,基于贡献者数量和提交次数。
祝开放源代码和知识共享愉快!
个人简介: Prasad Pore 是一位专注于业务的分析顾问,拥有 8 年的强大且多样化的 IT 经验,业务转型、数据工程、统计建模、机器学习和项目管理方面的技能得到了锤炼。他拥有数据分析硕士学位,专攻业务,和信息技术学士学位。他总是喜欢讨论如何利用技术创新如移动应用程序、物联网、区块链和数据分析来帮助做出更好的商业决策。
相关信息:
-
Github 上的前 10 个数据科学资源
-
Github 上的前 10 个数据可视化项目
-
Github 上的前 10 个深度学习项目
我们的前三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
更多相关主题
2018 年数据科学 Top 20 R 库
原文:
www.kdnuggets.com/2018/05/top-20-r-libraries-data-science-2018.html
评论
由 ActiveWizards 提供

我们的 Top 3 课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
在我们之前的文章中,我们已经讨论了数据科学领域的 Python 和 Scala 的顶级库。但没有 R,这些文章列表就不完整了。这些编程语言在不同的数据科学任务和项目中都很受欢迎,并且各有支持者和反对者。因此,在我们安排这些编程语言如何相互比较时,我们基于经验准备了一些最有用的 R 库,供数据科学家和工程师参考。
R 是数据科学领域一个知名且日益流行的工具。它是一种编程语言和软件环境,主要设计用于统计计算,因此其界面和结构非常适合科学任务。此外,R 拥有其中最成熟的库系统之一,拥有数千个包以解决各种问题。
尽管有许多通用的软件包,我们希望专注于那些提供足够的数据处理、可视化、竞争研究和机器学习能力的软件包。因此,我们准备了一份关于数据科学的 Top 20 R 包的信息图,其中涵盖了库的主要功能和 GitHub 活动,因为所有的库都是开源的。

当然,这份库的列表远未完整,但在我们看来,这里收集了最通用和经过时间考验的工具。还有许多其他特定的库在解决某些任务时可能更高效,所以请随时在评论区分享你的想法和经验。
感谢您的关注!
ActiveWizards 是一个由数据科学家和工程师组成的团队,专注于数据项目(大数据、数据科学、机器学习、数据可视化)。核心专长领域包括数据科学(研究、机器学习算法、可视化和工程)、数据可视化(d3.js、Tableau 及其他)、大数据工程(Hadoop、Spark、Kafka、Cassandra、HBase、MongoDB 及其他),以及数据密集型网页应用开发(RESTful APIs、Flask、Django、Meteor)。
原文。经许可转载。
相关:
-
2017 年数据科学的 15 个顶级 Python 库
-
2018 年数据科学的 15 个顶级 Scala 库
-
金融领域的 7 个数据科学应用案例
更多相关内容
前 20 名 R 机器学习和数据科学包
原文:
www.kdnuggets.com/2015/06/top-20-r-machine-learning-packages.html
评论 CRAN 包仓库 特色 6778 个活跃包。你应该了解哪些呢?这里是分析结果。请参阅文章底部的原始数据链接。
 这些 R 包大多数是 Kagglers 的最爱,得到许多作者的认可,并根据一个包对其他包的依赖进行评级。它们也由用户在 Crantastic.org 上评分和评论。然而,这些用户评分过少,不足以用于分析。
这些 R 包大多数是 Kagglers 的最爱,得到许多作者的认可,并根据一个包对其他包的依赖进行评级。它们也由用户在 Crantastic.org 上评分和评论。然而,这些用户评分过少,不足以用于分析。
让我们通过分析 CRAN 每日下载量来探索从 1 月到 5 月的机器学习包下载量。
-
e1071 潜在类别分析、短时傅里叶变换、模糊聚类、支持向量机、最短路径计算、袋装聚类、朴素贝叶斯分类器等函数 (142479 次下载)
-
rpart 递归分区和回归树。 (135390)
-
igraph 一组网络分析工具。 (122930)
-
nnet 前馈神经网络和多项式对数线性模型。 (108298)
-
randomForest Breiman 和 Cutler 的随机森林用于分类和回归。 (105375)
-
caret 包(Classification And REgression Training 的缩写)是一组函数,旨在简化创建预测模型的过程。 (87151)
-
kernlab 基于核的机器学习实验室。 (62064)
-
glmnet Lasso 和弹性网正则化广义线性模型。 (56948)
-
ROCR 可视化评分分类器的性能。 (51323)
-
gbm 广义提升回归模型。 (44760)
-
party 递归分区实验室。 (43290)
-
arules 挖掘关联规则和频繁项集。 (39654)
-
tree 分类和回归树。 (27882)
-
klaR 分类和可视化。 (27828)
-
RWeka R/Weka 接口。 (26973)
-
ipred 改进的预测器。(22358)
-
lars 最小角回归、套索和前向阶段回归。(19691)
-
earth 多变量自适应回归样条模型。(15901)
-
CORElearn 分类、回归、特征评估和序数评估。(13856)
-
mboost 基于模型的提升。(13078)
有趣的是,一些开源 R 工具正变得越来越受欢迎,例如 Rattle,这是一个用于数据挖掘的 R 图形用户界面(35539 次下载),以及 fastcluster,用于 R 和 Python 的快速层次聚类例程(14214 次下载)。
我们是否遗漏了你的最爱?点亮这个空间并通过告诉我们你使用的 R 包来为社区做出贡献!!
为了完整性,这里是 2015 年 1 月至 5 月的 135 个 R 包下载数据。
简介: Bhavya Geethika 正在伊利诺伊大学芝加哥分校攻读管理信息系统硕士学位。她的兴趣领域包括商业统计与数据挖掘、机器学习和数据驱动的营销。
相关:
-
成为 Kaggle 冠军的十大 R 包
-
机器学习 201:平衡类别是否提高分类器性能?
-
KDnuggets 最佳推文,3 月 14-16 日:Apache Spark 是下一个大事吗?R 元书 – 汇集的最佳 CRAN 帖子
更多相关主题
学习线性代数的前三个免费资源用于机器学习
原文:
www.kdnuggets.com/2022/03/top-3-free-resources-learn-linear-algebra-machine-learning.html

教授教师照片由 freepik 创建 - www.freepik.com
介绍
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
数学是所有机器学习算法的核心。虽然成为数据科学家不需要正式的数学教育,但你需要充分理解该学科的原则,以成功构建出有价值的模型。
在我之前写的一篇文章中,我解释了深入理解机器学习算法所必需的三门数学学科——统计学、微积分和线性代数。
本文将专注于线性代数,因为它是机器学习模型实现的基础。
线性代数概念,如向量化,能够加快计算速度,并在 Pandas、Scipy 和 Scikit-Learn 等库中实现。
PCA 等算法使用矩阵分解技术来减少特征空间的维度。
使用像 Tensorflow 这样的库实现深度学习算法需要对线性代数有基本的了解,因为你需要进行矩阵操作并理解张量的工作原理。
线性代数 — 学习资源
1. 沉浸式线性代数 — 教科书
这本免费的教科书将带你了解线性代数的基础。以下是本书的目录:
-
介绍
-
向量
-
点积
-
向量积
-
高斯消元法
-
矩阵
-
行列式
-
排名
-
线性映射
-
特征值和特征向量
这是线性代数的简单介绍,概念通过互动可视化向读者解释。为了让这个主题更易于理解,本书将话题做了更广泛和抽象的处理,每一章都有示例。
2. 面向编码者的计算线性代数 — FastAI 课程
与传统的线性代数课程手动求解线性方程不同,FastAI 的学习轨迹将演示如何使用计算机实现这些技术。
在这门课程中,你将学习如何使用 NumPy 和 PyTorch 等库在 Python 中进行矩阵计算。
这门课程最棒的地方在于它采取了自上而下的学习方法。虽然大多数数学课程倾向于关注理论,FastAI 的线性代数课程将首先提供代码示例和实际例子,然后再深入到更复杂的细节中。
自上而下的方法使学生更容易集中注意力,因为他们可以首先处理有趣的应用,然后再深入数学内容。
该课程假设你已经具备基础的线性代数知识,因此我建议在参加课程之前阅读上述教材作为前提条件。
3. 线性代数 — MIT 开放课程
这是麻省理工学院开放课程的一个系列视频讲座,已经免费向公众开放。该课程共有 34 个视频讲座,由吉尔伯特·斯特朗教授主讲,他的教学风格直观,将为你提供不同的问题解决视角。
每个章节都有一个问题集,我建议你在继续下一个章节之前先解决每个讲座的问题。
如果你发现问题集不够充分,缺乏练习,你可以通过附带的教材(由同一位教授编写)来补充这门课程——线性代数及其应用。但是,请记住,虽然课程免费提供,但书籍是有费用的。
上述资源是熟悉机器学习算法背后线性代数的绝佳方式。
但是,如果你觉得难以掌握上述材料,我建议你从一些较轻的内容开始,例如 3Blue1Brown’s 或 Khan Academy’s 线性代数课程。这些视频是为完全的数学初学者创建的,在你深入学习上述更复杂的材料之前,它们将作为对该主题的简单介绍。
Natassha Selvaraj 是一位自学成才的数据科学家,对写作充满热情。你可以通过 LinkedIn 联系她。
相关主题
数据科学中的三大统计悖论
原文:
www.kdnuggets.com/2021/04/top-3-statistical-paradoxes-data-science.html
comments
作者 Francesco Casalegno,项目经理和机器学习工程师

悖论违背了我们的预期。照片由Greg & Lois Nunes拍摄,来源于Unsplash。
我们的三大课程推荐
1. Google Cybersecurity Certificate - 加速进入网络安全职业生涯
2. Google Data Analytics Professional Certificate - 提升您的数据分析能力
3. Google IT Support Professional Certificate - 支持您的组织在 IT 领域
观察偏差和子群体差异很容易在任何数据科学应用中产生统计悖论。因此,忽略这些因素可能会完全颠覆我们分析的结论。
确实不罕见观察到令人惊讶的现象,比如子群体****趋势在汇总数据中完全反转。在本文中,我们探讨了数据科学中遇到的三种最常见的统计悖论。
1. 伯克森悖论
一个显著的例子是观察到COVID-19 严重程度与吸烟之间的负相关(例如,参见Wenzel 2020的欧洲委员会审查)。吸烟是呼吸系统疾病的一个已知风险因素,那么我们如何解释这个矛盾呢?
Griffith 2020 近期在《自然》上发表的研究表明,这可能是碰撞偏差的一个例子,也叫做伯克森悖论。为了理解这个悖论,让我们考虑以下图示模型,其中我们包含了第三个随机变量:“住院”。
伯克森悖论:“住院”是“吸烟”和“COVID-19 严重程度”的碰撞变量。(作者提供的图像)
这个第三变量“住院”是前两个变量的碰撞变量。这意味着吸烟和严重 COVID-19 都增加了在医院生病的机会。伯克森悖论正是当我们对碰撞变量进行条件化时产生的,即当我们仅观察住院病人的数据而不是考虑整个群体时。
让我们考虑以下示例数据集。在左图中,我们有整个群体的观察数据,而右图中我们仅考虑住院病人的子集(即我们对碰撞变量进行条件化)。
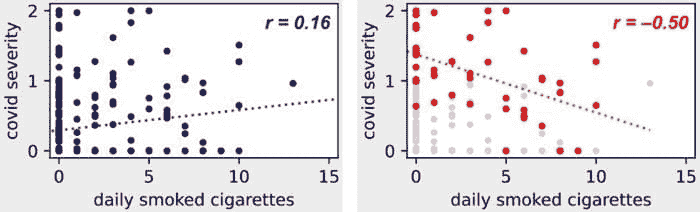
伯克森悖论:如果我们对“住院”这一碰撞变量进行条件化,我们会观察到吸烟与 COVID-19 之间关系的反转!(图片由作者提供)
在左图中,我们可以观察到我们预期的 COVID-19 严重程度与吸烟之间的正相关,因为我们知道吸烟是呼吸系统疾病的风险因素。
但在右图中——我们仅考虑住院病人——我们看到的是相反的趋势!要理解这一点,请考虑以下几点。
-
COVID-19 的高严重程度增加了住院的机会。特别是,如果严重程度 > 1,就需要住院。
-
每天吸几支烟是多种疾病(如心脏病、癌症、糖尿病)的主要风险因素,这些疾病增加了因某种原因住院的可能性。
-
因此,如果住院病人的COVID-19 严重程度较低,他们吸烟的机会反而会更高!事实上,他们必须有不同于 COVID-19 的某种疾病(例如心脏病、癌症、糖尿病)来解释他们的住院,而这种疾病很可能是由吸烟引起的。
这个例子与Berkson 1946中的原始工作非常相似,其中作者注意到医院病人中胆囊炎与糖尿病之间的负相关,尽管糖尿病是胆囊炎的风险因素。
2. 潜在变量
潜在变量的存在可能也会产生两个变量之间的表面倒置相关性。虽然伯克森悖论是因为对碰撞变量进行条件化(因此应该避免),但另一种悖论可以通过对潜在变量进行条件化来修正。
例如,我们考虑部署的消防员数量与火灾中受伤人数之间的关系。我们期望更多的消防员会改善结果(在某种程度上—参见布鲁克斯定律),然而在汇总数据中观察到正相关:部署的消防员越多,受伤人数越多!
为了理解这个悖论,让我们考虑以下图示模型。关键是再次考虑一个第三个随机变量:“火灾严重程度”。
潜在变量悖论: “火灾严重程度”是“部署的消防员数量”和“伤员人数”这两个变量的潜在变量。(图片由作者提供)
这个第三个潜在变量与其他两个变量正相关。确实,更严重的火灾往往会导致更多的伤害,同时它们需要更多的消防员来扑灭。
让我们考虑以下示例数据集。在左侧的图中,我们汇总了所有类型的火灾观察,而在右侧的图中,我们仅考虑了与三种固定火灾严重程度对应的观察(即我们对潜在变量进行条件观察)。
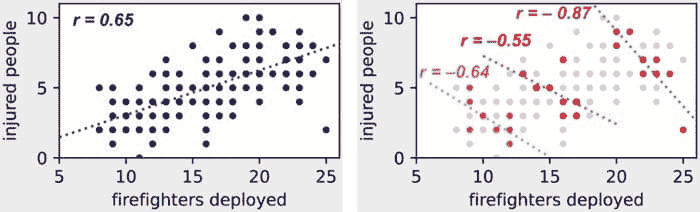
潜在变量: 如果我们对潜在变量“火灾严重程度”进行条件观察,我们会发现部署的消防员数量与伤员人数之间的关系发生了逆转!(图片由作者提供)
在右侧的图中,当我们对火灾严重程度进行条件观察时,我们可以看到预期的负相关。
-
对于给定严重程度的火灾,我们确实可以观察到消防员部署越多,受伤人数越少。
-
如果我们观察更严重的火灾,即使消防员数量和受伤人数都较多,我们也会观察到相同的趋势。
3. 辛普森悖论
辛普森悖论是一种令人惊讶的现象,即在子组中观察到的趋势在子组合并时会发生反转。这通常与数据子组中的类别不平衡有关。
这个悖论的一个臭名昭著的例子来自于Bickel 1975,其中对加利福尼亚大学的录取率进行了分析,以寻找性别歧视的证据,并揭示了两个明显矛盾的事实。
-
一方面,在每个部门他观察到女性申请者的录取率高于男性申请者。
-
另一方面,汇总 数据 显示女性申请者的录取率低于男性申请者。
要了解这如何可能,我们考虑以下包含两个部门 A 部和 B 部的数据集。
-
在 100 名男性申请者中:80 人申请了部门 A,68 人被录取(85%),而 20 人申请了部门 B,12 人被录取(60%)。
-
在 100 名女性申请者中:30 人申请了部门 A,28 人被录取(93%),而 70 人申请了部门 B,46 人被录取(66%)。

辛普森悖论:女性申请者在每个部门中的录取概率更高,但总体女性录取率却低于男性录取率!(图像由作者提供)
这个悖论由以下不等式表达。

辛普森悖论:表面矛盾背后的不等式。(图像由作者提供)
我们现在可以理解我们看似矛盾的观察结果的来源。关键在于两个部门(部门 A:80–30,部门 B:20–70)中的申请者性别存在显著的类别不平衡。事实上,大多数女性学生申请了竞争更激烈的部门 B(录取率较低),而大多数男性学生则申请了竞争较少的部门 A(录取率较高)。这就导致了我们观察到的矛盾现象。
结论
潜在变量、碰撞变量和类别不平衡可以在许多数据科学应用中轻易产生统计悖论。因此,特别关注这些关键点对于正确推导趋势和分析结果至关重要。
个人简介:Francesco Casalegno 是一名项目经理和机器学习工程师,对解决与数据科学相关的各种问题充满热情。他的背景包括软件工程和应用数学。Francesco 总是期待新的挑战,并坚信不断自我提升和与团队一起进步。
原文。经授权转载。
相关:
-
数据科学面试中你应该知道的 10 个统计概念
-
使用 Python 进行拒绝采样
-
数据科学家应该知道的推断统计
更多相关话题
CatBoost ML 带给你的数据的前五大优势,让数据发出咕噜声
原文:
www.kdnuggets.com/2023/02/top-5-advantages-catboost-ml-brings-data-make-purr.html

图片来源:编辑
全球范围内,企业越来越期望他们的决策过程由数据驱动的预测分析系统来提供信息,或者至少应该如此。从及时投资到履行物流,再到防止欺诈,数据在越来越多的工作流程中得到应用,受到越来越多的关注。换句话说,以前常常由数据科学家处理的信息流现在正被对数据黑暗艺术不太熟悉的人查看和操作。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
如今,相对不熟悉数据的人可能会突然承担起既要贡献数据池又要解释机器学习分析的责任。这可能会导致数据对你发出嘶嘶声,而不是合作地咕噜作响。为了减少因数据卫生不佳、过拟合或更糟糕情况带来的潜在问题,CatBoost 跃上厨房桌子,明显展示自己是许多领域的最佳选择。
拥有猫(Boost)的好处
CatBoost 是一个梯度提升机器学习系统,通过为高度分类或包含缺失数据点的数据源提供独特的解决方案,从其他 GBDT 中脱颖而出。实际上,这就是 API 名字的由来,源于 Boosting Categories,而不是某种猫的来源。并排比较显示,CatBoost 在预测交付时间和参数调优时间方面也显著优于 XGBoost 和 LightGBM,同时在其他指标上保持可比性。
在幕后,CatBoost 通过使用按流行度划分的方法来创建对称决策树。通过将特征分组到只有左右两个子节点的单一划分中,与每个特征都有子节点的树相比,所需的处理能力和时间大大减少。这些特征可以是分类的,也可以是数值的。然后,它们可以在树的不同层级进行解析,直到满足目标变量。这有效地对数据进行正则化,防止数据点通过提供多个视角对同一子集形成明确的相关性。这使得 CatBoost 的预测在训练过程中对过拟合和泛化错误具有更强的弹性。
尽管这些观点从数据科学和计算的角度来看显然是有利的,但它们在整个组织中的好处可能不那么明显。
CatBoost,操作支持工具
所以,它在你回到家时不会给你拿拖鞋,它不会以一种充满感情的方式回馈你给予的关心和注意,那么 CatBoost 如何改善你的操作呢?CatBoost 的计算效率如何真正帮助关键业务功能,以及对谁有帮助?CatBoost 算法中有些元素看似与类似的机器学习系统相比只是小差异,但对许多企业来说却转化为巨大的物流红利。
我们将详细分析几个这样的组件,然后再从整体上看看它们的实际应用如何帮助简化流程,并最终节省成本——节省成本是公司里每个人都能理解的语言。随着我们探索,企业可能会意识到一些细致的痛点得到了处理,尤其是当它们曾经被忽视甚至留下伤痕时。
CatBoost 如何让你的数据“脱离困境”的 5 种方法
对于开源 API 中的每一个细节,数据科学家可以立刻看到其实际好处。然而,对于越来越多被要求参与公司数据分析链的非技术团队,以及那些需要批准机器学习工作流的人来说,这些好处显然不那么明显。
1: 无需独热编码
CatBoost 处理分类特征时使用明文,避免了像其他坚持数值输入的 GBDTs 那样需要进行大量预处理。最常见的分类数据预处理方法是通过独热编码对其进行标记,这会将数据拆分为二进制。不过,根据数据的性质,有时使用虚拟、序数、LOO 或贝叶斯目标编码方法更为适用。通过独热编码预处理的分类特征通常会变得庞大,并迅速变得过于维度化。通过 CatBoost 内置的序数编码系统,分类特征被分配了数值,但避免了高维数据的长时间处理和过拟合特征。
尽管这些计算可能发生在云端,但实际的好处包括:
-
由于 API 原生处理基于文本的分类数据,因此所需的计算和数据转换较少,从而减少了错误。
-
与一热编码相比,CatBoost 将数据分解为更少的特征,从而提高了分析团队的简洁性和最终解释性。
-
输入到库中的基于文本的数据会返回相同的文本标签,从而简化了解释。
-
CatBoost 通过使得关注单一特征对模型的贡献变得容易,从而促进深度分析,而不是关注特定特征的特定值,这与一热编码列的情况不同。使用
get_feature_importance()方法,CatBoost 利用 SHAP 值来测量特征,这些值也可以很容易地可视化以进行解释和分析(见下文)。 -
同样,这种对分类数据的使用使得来自不同部门的员工能够更轻松地输入和解释数据。
-
这种可访问性水平允许公司拥有统一的数据流,使公司所有部门都参照同一信息池。那些因为拥有一个实体的多个档案而遭遇部门间混淆的公司知道,这可以节省多少压力和资源。
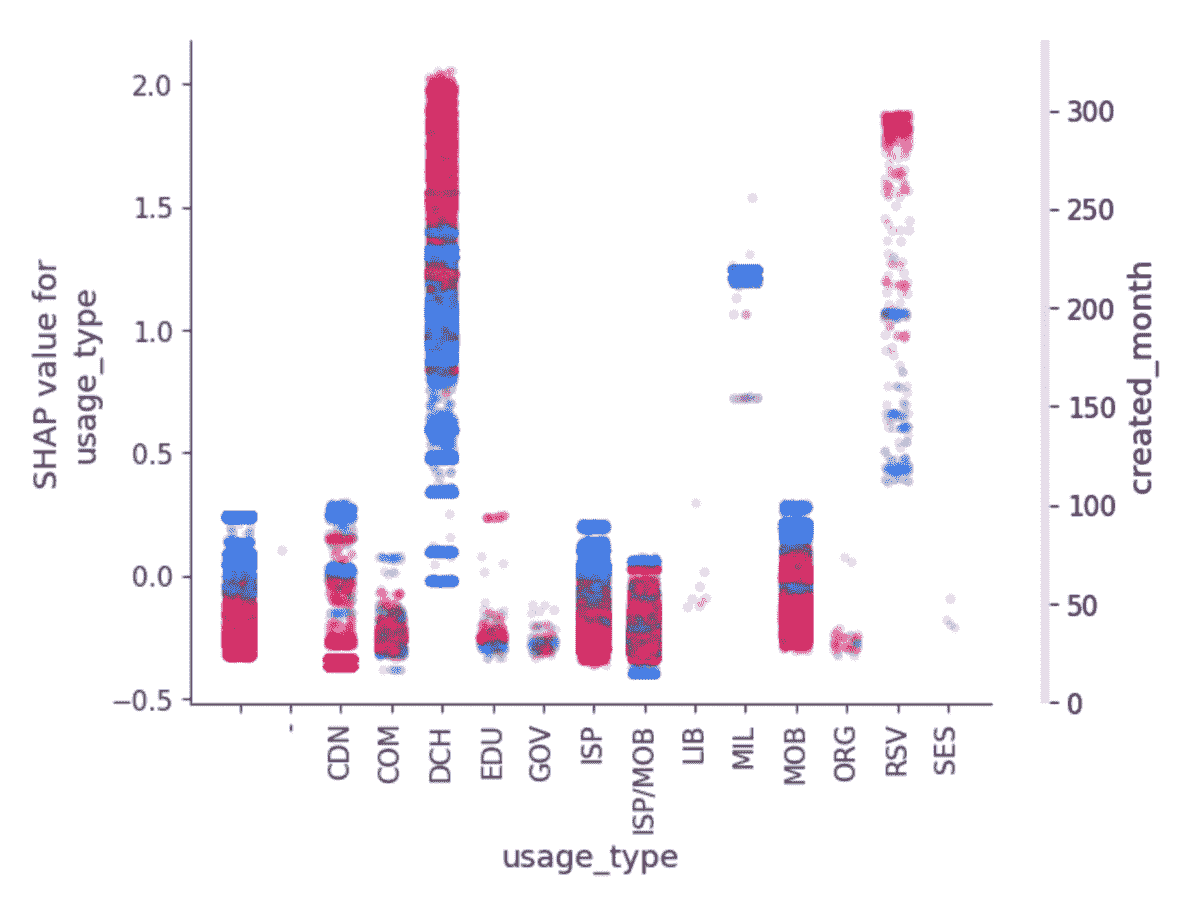
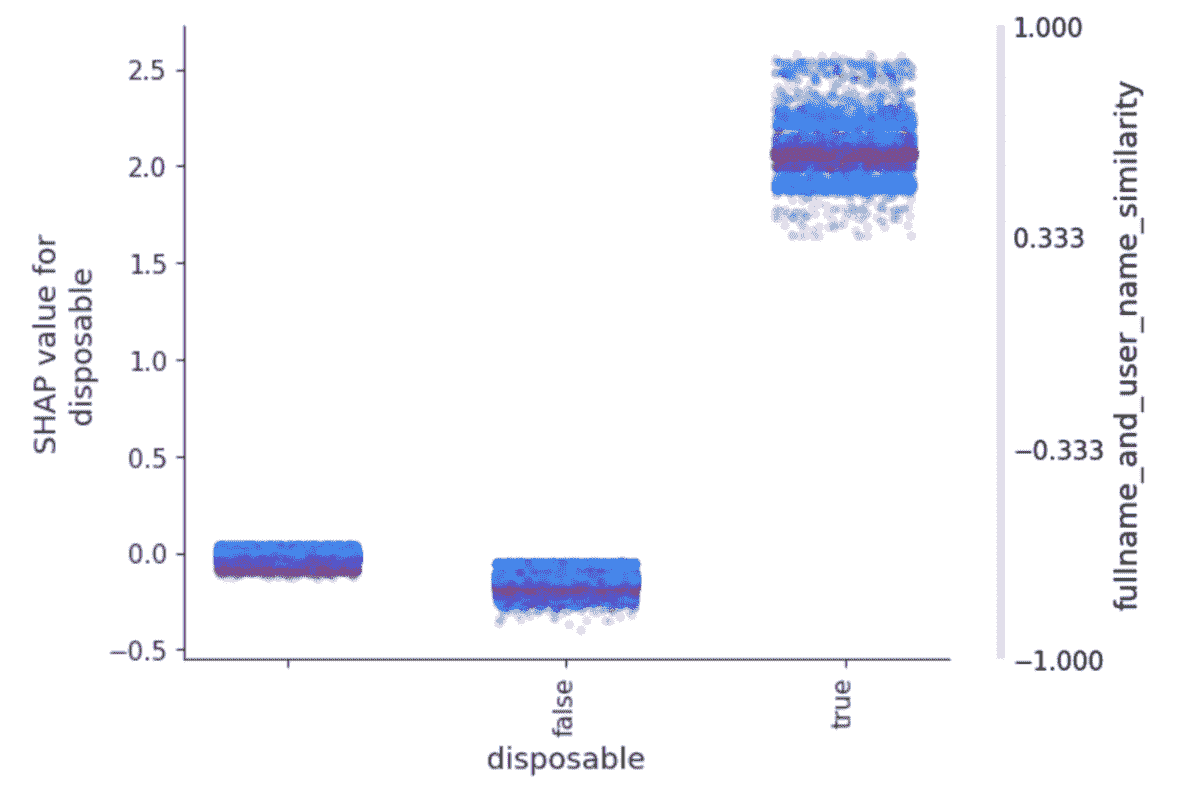
CatBoost 原生托管 SHAP 库,方便进行类似于这些的输出可视化,这些可视化是在欺诈预防数据上训练的。
CatBoost API 的这一方面对于处理本质上较少数值型数据的垂直领域来说是一个明显的优势,比如医疗诊断、欺诈预防、市场细分和广告等领域。这些领域都涉及大量的分类数据,CatBoost 的巧妙处理可以带来益处。
2: 忽略树
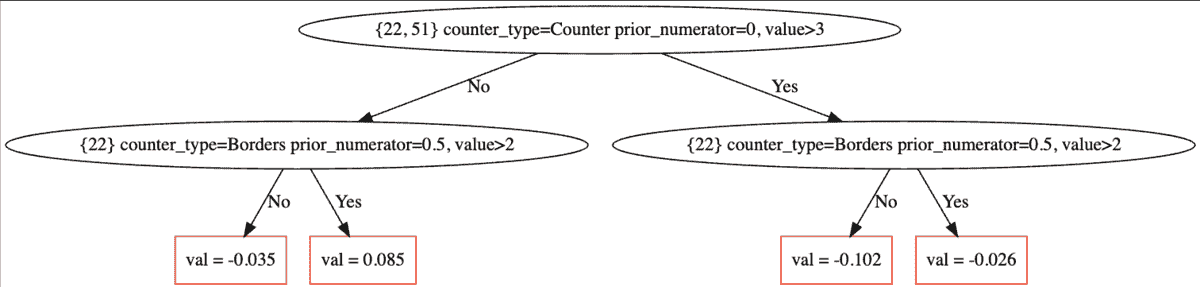
CatBoost 在其梯度提升过程中利用忽略决策树作为基础学习器。这意味着每棵树仅限于一个对称分裂,且两侧由算法内置的特征重要性测量平衡。
与 XGBoost 将节点分裂多次以处理高维特征不同,CatBoost 创建多个层级来分析单一特征。这使得它在以下方面表现出色:
-
优化处理时间和功耗。高维非数值数据在经过 XGBoost 处理时不可避免地需要比 CatBoost 更多的处理时间和功耗。每个节点的单次分裂意味着每次决策的处理速度显著更快,减少了能量消耗并优化了内部或外部的等待时间。
-
正则化和对抗过拟合的鲁棒性。那些利用特征并将树分裂为该特征所有可能结果的算法,通常会发现它们的数据经常过拟合。通过限制树的每一层的复杂性,它本质上通过数据创建了一个更为严格的回归线,一种事实上的正则化。这导致了较少的假阴性和假阳性,这可能会影响你的组织如何以各种方式使用数据。
-
易于解释性。再次,根据行业和自动化的过程,能够解释如何做出给定的机器学习判断可能是有充分理由的。这可能是为了满足客户需求,但也可能是法律合规的一部分,以确保透明公正的实践或进行安全尽职调查。
CatBoost 的“无视树模型”是其处理轻便性的主要来源,也使其成为大型数据集的高度可扩展选项。在处理分类数据时,CatBoost 在快速得出结论的同时,更有效地忽略数据噪声。例如,在市场细分、自动化供应链优化、PPC 广告等领域,嘈杂数据有时是一个看似随机的广告被投放到你的设备上,或者链锁店有过多或过少的某种商品的原因。
3: 数据“Nan 处理”
缺失值的数据集通常在分析中价值较低。在处理数值数据集时,与其让这些缺失值影响模型的稳定性,不如让 CatBoost 自动替换这些缺失值。根据子集的大小,这些值要么通过简单计算替换,要么通过特征之间的机器学习衍生关系替换。这些关系可能只有边际可解释性,但在实际工作过程中,可解释的好处包括:
-
在准确性和假阳性率方面的更好表现,使得 CatBoost 在分析数据的任何地方都能实现更平滑的过程。
-
在防止欺诈的情况下,空值本身可以作为潜在风险的指示器。
-
为每个客户提供定制模型,因为每个客户的过程不同,数据和 nan 比例(数据集中“非数字”条目的比例)也不同。
-
其他领域如医疗保健、银行、客户分析和供应链管理也很好地利用了 NaN 处理——考虑一下数据输入链中的任何人,从新客户到履行代理,可能会倾向于不填写部分表单。这有时可能是懒惰,其他时候可能表明尝试申请欺诈。
值得注意的是,CatBoost 仅原生处理数值数据的 NaN 处理。对于分类数据,应创建类似“空字符串”或“缺失值”的单独类别,以便这些 NaN 值能够在对称分裂中被考虑。
这是一个如何轻松处理分类数据中 NaN 值的示例:
for col in df.columns:
if df[col].dtype.name in ("bool", "object", "category"):
if (df[col].dtype.name == "category" and
("" not in df[col].cat.categories)):
df[col] = df[col].cat.add_categories([""])
df[col] = df[col].fillna("")
4: 并行处理(快速切换)
如上所述,CatBoost 的单一对称分裂对处理能力和预测速度有很大好处。
这主要有两个原因。第一个是对称树结构通过向量乘法进行预测的能力。在其他梯度提升库在树的每一层进行这些计算时,CatBoost 可以将其应用于整棵树,从而大幅加快预测生成速度。
CatBoost 速度的第二个解释是其按流行度排序的特性,它将维度数据分组为两个相等的分支,而不是为每个特征创建一个可能的分支。显然,单次分裂所需的能量少于五次,但这种组织方式有利于并行处理——将数据分割为子集,以便将任务分配到多个处理器上。根据可用的硬件资源,CatBoost 也可以找到最优的并行处理方法。
除了显而易见的低能耗和更快的整体处理之外,考虑一下低效的数据处理可能对客户和合作伙伴体验产生的一些影响:
-
内部工作流程往往充满了小的等待时间,这些等待时间可能会膨胀成更大的等待时间。我们都知道这一点。
-
风险分析、欺诈预防、年龄验证及其他安全措施的等待时间较短,可以提升在线体验。显然,高摩擦等待时间会导致用户流失增加。
5: 可爱度因素
与类似的机器学习算法相比,CatBoost 相当有吸引力。无论机器学习或数据专业知识的水平如何,API 都可以通过其清晰易懂的文档来学习。考虑这些功能的结合:
-
解释超参数调优,以了解正在解决的具体问题
-
自动处理分类数据,包括预处理
-
具有健壮的模型,一般可以开箱即用
-
高级可视化
from catboost import CatBoostRegressor
from sklearn.datasets import load_boston
boston_data = load_boston()
model = CatBoostRegressor(
depth=2, verbose=False, iterations=1).fit(
boston_data['data'], boston_data['target'])
上面的代码块展示了如何在波士顿数据集上训练一个干净且简单的 CatBoost 模型。这是一个很好的例子,说明了 CatBoost 如何创造出比某些其他产品更为友好的环境,尤其是考虑到围绕该产品的大型活跃社区。
这种易用性带来的好处应该很明显,特别是对那些有经验自行上手新型高级商业软件的人而言。一般来说,能够让更多的团队成员参与到数据处理中,而不让他们感到畏惧,对于分配责任和优化资源分配都是很有价值的。
你是 CatBoost 的粉丝还是…
尽管 CatBoost 是专为分类数据设计的,注重速度和效率,但它在处理数值数据方面也同样灵活。不过,也有一些领域可能更适合使用 XGBoost 或 LightGBM。这两种算法是为了速度和可扩展性而设计的,特别是在处理高度维度且不断变化的纯数值数据时。因此,处理非常庞大的、固有的且不断变化的数据集的领域,可能更适合使用这两种 API 之一,比如:
-
财务预测
-
能源分配
-
供应链管理
LightGBM 尤其在处理对处理速度要求极高的地方表现出色,例如自然语言处理和图像识别。
随着数据在越来越数字化的企业空间中的业务功能中变得无处不在,数据解决方案需要变得更加易于接触。像广告、市场分析、客户细分、欺诈预防和医疗治疗这些领域,CatBoost 可能是一个不错的选择。许多金融领域也是如此。虽然它可能永远无法像真正的家猫那样易于接近,但在许多情况下,CatBoost 可能更加友好,当然也更有用。
Gellért Nacsa 是 SEON 的数据科学负责人。他在大学学习应用数学,并曾担任数据分析师、算法设计师和数据科学家。他喜欢玩弄数据、机器学习,并且一直在学习新东西。
相关阅读
前 5 个 AI 编码助手你必须尝试
原文:
www.kdnuggets.com/top-5-ai-coding-assistants-you-must-try

作者提供的图片
AI 编码助手已经成为开发过程中的重要部分,它们在代码生成、理解、项目搜索以及通过提示或代码执行各种任务方面提供帮助。即使是 Google Colab 和 Deepnote 等云 IDE 平台也提供 AI 辅助编码,帮助你生成代码和解决问题。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你在 IT 领域的组织
在这篇文章中,我将分享值得一试的前 5 个 AI 编码助手。它们都提供 VSCode 扩展,并且容易设置。你只需安装它们,便能体验到更新更简便的程序开发方式。
1. GitHub Copilot
GitHub Copilot 是一个利用人工智能帮助程序员更高效编写代码的工具。通过在 VS Code 中安装 Copilot 扩展,开发者可以生成代码、学习代码、自动补全和配置他们的编辑器。
来自 GitHub Copilot 的图片
Copilot 是一个成熟的产品,相比其他工具提供了最新和最准确的建议。通过新的聊天功能,开发者可以使用自然语言生成、修改和改进代码。此外,内联聊天功能允许你直接在文本编辑器中生成代码。
GitHub Copilot 唯一的缺点是它是一个付费工具。然而,如果你是全职开发者或软件工程师,每月支付 $10 也算是划算的。
2. Codeium
Codeium 是一个广泛知名的免费工具,最近获得了越来越多的关注。它提供了 GitHub Copilot 的大多数功能,最棒的是,对于个人用户它是免费的。
作者提供的截图
你可以使用 Codeium 提出与文件相关的问题,它会读取文件并提供上下文相关的答案。此外,你还可以让它重构、解释、改进和解决代码中的错误。
它还包括自动完成,但我建议你继续使用旧的 Python 自动完成,因为 Codeium 的自动完成并不总是准确。然而,Codeium 唯一的缺点是它可能不会总是生成最新版本的代码。
3. Cody
Cody 是一个 AI 驱动的编码助手,旨在帮助你更快地编写和理解代码。它提供类似于 Codeium 的功能,如聊天、命令、代码解释和自动完成。它有免费版和专业版。
截图由作者提供
我使用 Cody 已将近两个月,一直顺利,直到我开始用于数据和机器学习项目。不幸的是,我注意到它没有上下文感知,因此产生了不准确的代码。
然而,在我个人使用 Codeium 和 Cody 的经历中,我发现 Cody 有时无法理解代码,并产生不准确的自动完成建议。这就是为什么我更喜欢 Codeium 而不是 Cody。
4. Code GPT
我最近发现了 Code GPT: Chat & AI Agents,并对它如何集成任何最先进的大型语言模型并提供广泛的功能印象深刻。这个扩展提供了 AI 聊天帮助、代码解释、错误检查、自动完成等功能。如果你可以访问 OpenAI API 或其他平台,你可以免费使用这个扩展。
截图由作者提供
我使用 Google AI、Anthiopic AI 和 OpenAI API 进行了测试。虽然 Claude 2.1 API 速度很快,但我对其准确性并不满意。为了提高其可用性,开发者需要致力于减少自动完成的延迟,并修复生成错误答案的问题。一种可能的解决方案是使用 Codeium 进行自动完成,使用 CodeGPT 进行代码生成和问题解决。
5. Tabnine
Tabnine 是一个 AI 编码助手,能够帮助你加速和简化软件开发过程。它还确保你的代码保持私密、安全和合规。Tabnine 目前被超过一百万开发者使用,并在 VSCode 上有七百万次下载。
Gif 来源于 Tabnine
虽然 Tabnine 的免费版可用,但可能不如 Pro 版有效。如果你想体验更好的编码辅助,投资 Pro 版可能是值得的。然而,免费版的自动完成功能仍然相当快速和准确。
如果你有兴趣尝试 Tabnine,可以利用他们的 90 天试用期。请注意,你需要添加支付信息以访问试用。
结论
AI 驱动的编码助手正在通过提高程序员的效率和生产力来改变软件开发。在这篇文章中,我们介绍了 5 个顶级 AI 编码助手,我认为这些助手应被那些在代码逻辑、格式化和测试方面遇到困难的人使用。
将这些助手之一或多个整合到你的工作流程中,可以提升你的生产力,生成并理解代码,更快解决问题,并更专注于编码。最终,这些 AI 助手让开发者能够花更少的时间在与代码作斗争上,从而专注于创造令人惊叹的软件。在下一个项目中试试它们吧。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一款 AI 产品,帮助那些与心理疾病作斗争的学生。
更多相关内容
2024 年你不能错过的五大 AI 播客
原文:
www.kdnuggets.com/top-5-ai-podcasts-you-cant-miss-in-2024

图片由编辑提供
世界变化飞快。真的很快,有时很难跟上发生了什么、新的事物、如何运作以及我们应该期待什么。播客是随时保持更新的绝佳方式——尤其是在你忙碌的时候。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
我已整理出 2024 年你需要收听的五大 AI 播客,以跟上这一趋势。那么我们开始吧……
1. 商业中的 AI
链接:商业中的 AI
主持人丹尼尔·法杰拉提供了一个面向非技术商业领袖的播客,旨在帮助他们了解 AI 所能带来的机会。在这个播客中,你将了解 AI 的能力,以及如何制定策略并实现投资回报。
每周,主持人将采访顶级 AI 高管,讨论 AI 在商业中的实际应用,从财富 500 强公司到初创企业。
如果你想学习如何进入 AI 商业世界或利用 AI 提升你的公司——这是你要收听的播客。
2. AI 播客
链接:AI 播客
由 NVIDIA 制作,加入他们深入探讨 AI 对我们世界的影响。你将聆听在 AI 领域具有影响力的人物,并了解他们的故事。它不限于科技行业,你将从各种各样的人身上学到东西,例如野生动物、医疗保健等。
想了解 AI 和机器学习对不同领域的影响——请收听!
3. Lex Fridman 播客
Lex Fridman 是 AI 领域著名的采访者。他是 AI 领域的研究者,并与多位在 AI 领域具有影响力的人物进行了深入对话。他的播客包括智能、意识、爱和权力的本质。
通过 Lex Fridman 的播客,你不仅能学习到 AI 的世界,还能了解来自各行各业的生活其他方面。Lex Fridman 在 AI 领域很有名,他的声誉使他能够采访到合适的人,并提出有 AI 知识支持的问题。
4. 20VC
链接:20VC
这是我个人的最爱之一。二十分钟 VC 播客不仅仅是 AI 相关内容,更是关于商业的一般内容。随着世界向生成式 AI 和其他 AI 相关方面的转变——商业世界正在基于这些变化做出回应。
如果你想了解当前和新兴公司如何迅速过渡,这个播客正好提供了这些信息。你将了解 CEO 在做什么,他们如何达到现在的地步以及他们计划在未来如何利用 AI。
想要创业或扩大现有业务——这是你从 CEO、CFO、CTO 等人士那里学习的播客。
5. 交谈机器
链接:交谈机器
他们的口号是“关于机器学习的人工对话”。我们许多人对当今世界 AI 系统的实施有看法——这是完全正常的。这档播客将为听众提供对 AI 和机器学习的学术理解。
如果你是 AI 世界的新手,了解 AI 的技术方面并学习基础知识是很有益的,这将指导你了解今天的 AI 市场。
附加:Eye on AI
链接:Eye on AI
这是一个每两周更新一次的播客,适合那些日程繁忙但希望关注 AI 动态的人。由 Craig S. Smith 主持,在每一期节目中,他将深入采访在 AI 领域产生影响的人。
这可以是机器学习智能的小幅渐进变化,也可以是像亚马逊这样的主要公司在技术领域发生的全球性变化。
了解 AI 如何改变世界!
总结一下
这些是关于 AI 的前五大播客,它们深入探讨了 AI 当前的环境以及它如何改变商业世界和我们的未来。如果你知道社区应该了解的有趣播客,请在评论中分享!
Nisha Arya 是一名数据科学家、自由技术作家、KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及数据科学理论知识。Nisha 涵盖了广泛的话题,并希望探索人工智能如何有助于人类寿命的延续。作为一个热衷学习者,Nisha 寻求扩展她的技术知识和写作技能,同时帮助指导他人。
相关主题
最佳 Jupyter 笔记本扩展前五名
原文:
www.kdnuggets.com/2018/03/top-5-best-jupyter-notebook-extensions.html
评论
由Eliot Andres,自由职业机器学习工程师
笔记本扩展是你可以轻松添加到 Jupyter 笔记本中的插件。最好的安装方法是使用Jupyter NbExtensions Configurator。它会添加一个选项卡,让你启用/禁用扩展:
NbExtensions Configurator 的截图
安装
使用 conda 安装:
conda install -c conda-forge jupyter_contrib_nbextensions
conda install -c conda-forge jupyter_nbextensions_configurator
或者使用 pip:
pip install jupyter_nbextensions_configurator jupyter_contrib_nbextensions
jupyter contrib nbextension install --user
jupyter nbextensions_configurator enable --user
在这里找到更多关于安装的信息
1 - 可折叠标题
在处理大型笔记本时非常有用,可折叠标题允许你折叠笔记本的某些部分。
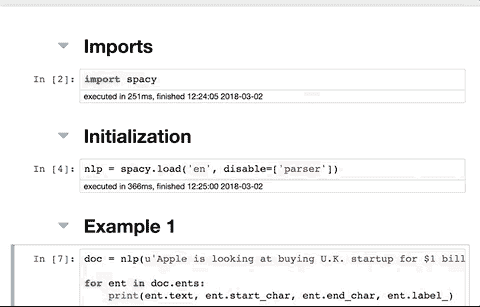
使用可折叠标题
2 - 通知
对于长时间运行的任务,notify 扩展会在笔记本闲置时发送通知。
 使用通知
使用通知
要使用它,请启用扩展,然后在按钮栏中启用。你选择的时间是笔记本必须运行的最短时间,以便你收到通知(请注意,你必须保持笔记本在浏览器中打开才能使通知有效)
3 - 代码折叠

使用代码折叠
4 - tqdm_notebook
这个并不真正是一个笔记本扩展。TQDM 是一个进度条库。但它有时在 Jupyter 笔记本中无法正常工作。感谢Randy Olson的提示:
今天学到:tqdm(#Python 进度条库)有一个专门用于 Jupyter 笔记本的“tqdm_notebook”功能。
不再在我的笔记本中看到混乱的进度条——万岁!
t.co/r0jAQXQ6TMpic.twitter.com/FyYBRm2qE1— Randy Olson (@randal_olson) 2018 年 3 月 2 日
5 - %debug
这不是一个笔记本扩展,而是一个IPython 魔法命令。有关详细解释,我建议阅读完整的推特线程,来自Radek Osmulski。
最近最喜欢的 jupyter 笔记本发现——%debug 魔法:
异常。
插入一个新单元,输入 %debug 并运行它。
一个交互式调试器将打开,带你到异常发生的地方,并允许你四处查看! pic.twitter.com/9DSnSbpu15
— Radek (@radekosmulski) 2017 年 12 月 26 日
6 - 较小的扩展和其他提示
-
%lsmagic: 在单元格中运行此命令以列出所有可用的 IPython 魔法命令
-
禅模式扩展: 移除菜单以减少干扰
-
执行时间扩展: 显示单元格运行所花费的时间
-
autoreload: 自动重新加载外部文件,无需重新启动笔记本。启用方法:
%load_ext autoreload
%autoreload 2
你知道必备的笔记本扩展吗?在推特上联系我或对这篇博客文章进行拉取请求!
编辑于 2018 年 3 月 7 日:
一些人 在 Reddit 提出了更多建议:
-
变量检查器: 在浮动窗口中显示所有变量
-
CodeMirror Keymap: 让你在各种键绑定(如 vim)之间进行选择
-
Scratchpad: 在不修改笔记本文档的情况下执行代码
-
Splitcells: 垂直拆分单元格
简介: Eliot Andres (@eliotandres) 是一名自由机器学习工程师,专注于将模型从原型转移到生产。他对 Tensorflow 和计算机视觉情有独钟
原文。经许可转载。
相关:
-
了解机器学习的 5 件事
-
从笔记本到 JupyterLab - 数据科学 IDE 的演变
-
Fast.ai 第 1 课在 Google Colab(免费 GPU)
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
相关主题
每个数据分析师应该拥有的前五个书签
原文:
www.kdnuggets.com/2022/09/top-5-bookmarks-every-data-analyst.html

图片来源:cottonbro
作为一名高级数据分析师,我的工作通常包括一个或两个大型的基础数据研究项目,以及一些“时间紧迫”的小型项目,分配给不同的团队。在一个典型的工作周,我可能会制作 5 到 7 张图表,编写几个查询,调整一些其他查询,并帮助同事调试他们的工作。我可能会提交 1 到 2 个内部 JIRA 工单,并进行几次 StackOverflow 搜索。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
主要的潜在问题是,有了这些额外的干扰,我只需面对一个随机的临时问题,就可能从手头的更大任务中脱轨。这就是为什么最好的分析师灵活且迅速。他们应对变化,迅速解决琐碎的工作。
事实是,成为一名优秀的分析师完全在于平衡质量与速度。这表现在找到能够提高效率的好工具上。在那一周,我可能会使用半打不同的工具和软件。如果有一件事是所有分析师都一致同意的,那就是没有任何单一工具可以做到所有事情都很出色。这就是为什么我给年轻分析师的最大建议之一是开始收藏在线书签。养成导出这些书签的习惯,以便在换工作或升级电脑时可以带走它们。
这里是每位分析师都应该拥有的前五个书签。一些书签在日常工作中非常有用,而另一些则是特定情况中偶尔使用的。然而,你可能会在某一天需要它们,到那时,它们会为你节省大量的麻烦和时间。
5. Ascii 表格格式化工具
表格格式化工具可以将一块复制/粘贴的数据转换成更加高效且美观的格式。这在多种情况下都很有用。有时我通过 Slack 或电子邮件给同事发送一个快速表格;有时我将数据粘贴到 JIRA 工单中。此外,表格格式化工具在论坛中发布或回答问题(如 Stack Overflow)或在博客中发布数据时也非常有用。诀窍是选择像 Courier New 这样的等宽字体,以使其正确对齐。
//================\\
|| Useful For... ||
|]================[|
|| Slack ||
|| Email ||
|| JIRA tickets ||
|| Stack Overflow ||
|| Code Comments ||
|| Blogging ||
\\================//
选择很多,但我最喜欢的是 ozh.github.io/ascii-tables/。它快速、简单,并提供了很多不同的输出格式选择。此外,Ascii Table Formatter 会自动转换文本而无需点击任何东西;它是即时的!
这里有几个不同的例子:
4. SQL 美化工具
SQL 编写器有两种类型——那些以查询的格式化为荣、让其更易于阅读的人和那些喜欢看世界毁灭的人。无论你是想格式化别人的混乱还是自己的混乱——SQL 美化工具都是必不可少的。
下次你发现自己试图解读如下查询时:
使用 SQL 美化工具,可以立刻将其格式化成这样:
有很多选项,包括可下载的程序、插件和在线版本。我更喜欢在线版本,可以在这里找到:codebeautify.org/sqlformatter。
3. JSON 查看器和转换器
我尽量避免处理 JSON 数据,但不幸的是,有时我别无选择。这就是为什么我在书签中保留了各种 JSON 相关的查看器和转换器。
想要快速浏览 JSON 结构以查看有哪些元素?需要调试为什么你的解析脚本失败?那么我推荐查看 www.convertcsv.com/json-to-csv.htm 和 www.convertcsv.com/csv-to-json.htm 以在表格和 JSON 结构之间转换,以及 jsonviewer.stack.hu/ 进行解析和查看。
2. 图表构建器
构建可视化和仪表板是分析师工作的重要部分。不幸的是,我估计我制作的图表中约有 80% 实际上不是用于仪表板,而是用于回答快速的、临时的问题。对于许多这些任务,启动像 Tableau 这样的专用应用程序或玩弄 Excel 实在是过于繁琐。因此,我需要能够快速构建图表的工具。
在线上有很多快速构建图表的资源,但app.rawgraphs.io/是我最喜欢的。我喜欢它因为它提供了许多鲜为人知的图表类型(如日历热图和圆形打包),这些图表在 Excel 中很难弄清楚。

1. SQL 生成器
大多数分析师实际上并没有记住各种变换的语法。相反,大多数人会回忆起以前的查询,该查询执行了类似的操作,然后在他们的Untitled1.sql、Untitled2.sql和Copy of RevenueQuery_final_final_final(3).sql文件夹中查找,直到找到为止。或者,Google 可以提供帮助,但这需要大量时间来查找正确的问题或具有正确语法的教程。
相反,给自己收藏一个好的 SQL 生成器。SQL 生成器基本上是一个 SQL 查询的模板,它允许你自定义列名和表结构,选择你想要执行的操作,然后为你构建各种不同“风味”的 SQL 语法。
不要再为DATEDIFF()与DATE_DIFF()之间的细微差别感到困扰!我推荐这个:app.rasgoml.com/sql
结论
事实是,作为分析师就是要在质量与速度之间取得平衡。拥有一个可以帮助你在不牺牲质量的情况下节省时间的工具包是提高效率的有效方法。如果你目前没有一个“工具”的书签文件夹,希望这篇文章能为你提供一个良好的起点!
其他的呢?你有没有我遗漏的收藏书签?
社区建议
乔什·贝瑞 (@Twitter) 负责 Rasgo 的面向客户的数据科学,自 2008 年起从事数据和分析行业。乔什在康卡斯特工作了 10 年,建立了数据科学团队,并且是内部开发的康卡斯特功能存储的主要负责人之一——这是市场上最早出现的功能存储之一。在离开康卡斯特后,乔什在 DataRobot 负责构建面向客户的数据科学。在空闲时间,乔什会对有趣的主题进行复杂分析,如棒球、F1 赛车、房地产市场预测等。
原文。经授权转载。
相关主题
前五大数据管理平台
原文:
www.kdnuggets.com/2022/06/top-5-data-management-platforms.html

图片由 Taylor Vick 提供,来源于 Unsplash
是的,确实有很多数据存在;其中一些数据被存储却未被使用。但对于正在使用的数据,它是如何管理的?这就是数据管理平台(DMP)发挥作用的地方。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
数据管理平台(DMP)是一系列工具,旨在帮助组织更有效地收集和管理数据。越来越多的公司开始采用这些工具,因为它们已成为客户分析、销售和营销活动的关键要素。
DMP 帮助这些组织从多个来源分析数据,并以易于解释的方式呈现。它们能够从多种来源(如客户关系管理(CRM)、分析软件等)提取数据。
DMP 的主要受益者通常被认为是数据科学家和工程师。然而,它已被营销团队广泛采用,以帮助他们理解成本并明智地支出。
如果你对 DMP 感兴趣并且难以选择,继续阅读,我将提供前五大 DMP 的列表 - 我不会提供很长的列表,因为这只会让你更加困惑该选择哪个。
Lotame 受众管理

Lotame 受众管理被誉为业界领先的数据管理平台,Lotame 提供了来自电子邮件、博客、CRM 工具等多种信息。他们的主要目标之一是跟踪营销绩效,同时关注隐私和 Cookie 使用问题。它还以帮助统一数据而闻名,同时提供数据解决方案和推动整体绩效。
Cloudera

Cloudera 数据平台提供了从 DataFlow、DataEngineers、DataWarehouse 等各种产品。特别是他们的 DataFlow 帮助您管理从边缘到云的数据,无需编写代码即可开发流应用程序。它还提供高性能、高质量和可扩展性,并具备集群管理、诊断等多种功能。
Permutive

如果您寻求高性能和高隐私;Permutive 适合您——一个基于边缘技术构建的 DMP。Permutive 提供了一种隐私安全的基础设施,帮助出版商和广告商能够安全地全面触达其受众,同时保持对数据的控制。出版商以隐私安全的方式向广告商提供第一方信息,广告商则能够汇总所需信息,以帮助跟踪性能。
Oracle 数据云

Oracle 数据云最初的目标是通过使用数据、指标等来提高广告效果。从那时起,它帮助广告商轻松地与合适的客户建立联系,并能够个性化每一次互动,以增加参与度。它为您提供有关客户的信息,例如他们购买了什么、他们计划去哪里等。
SAS 数据管理

SAS 提供了一种数据管理工具,专门设计用于与各种数据源集成。SAS 数据管理使用点选系统,操作简便,并具有多种管理流程。拖放功能消除了编程的需求,从而节省了大量的时间和资源。它还包括其他功能,如集成过程设计器、连接性和数据访问、元数据管理等。
结论
可以肯定地说,了解客户旅程上的信息可以帮助公司更好地利用数据,提高生产力、销售额并赚取利润!能够连接每个点以及它们之间的关系成为公司的一个重要元素。
当您需要巩固数据及其用途时,DMP 是您的最佳伙伴,使组织能够提供更个性化的服务。
Nisha Arya 是一位数据科学家和自由撰稿人。她特别关注提供数据科学职业建议或教程及理论知识。她还希望探索人工智能如何能够有利于人类寿命的不同方式。作为一个渴望学习的人,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
了解更多相关话题
您项目的前 5 大数据管理工具
原文:
www.kdnuggets.com/top-5-data-management-tools-for-your-projects

数据管理涉及接收、验证和精炼数据,以确保用户的可靠性。数据管理工具能够执行各种功能,如严格的存储、分析、分发和同步数据。它主要用于产品信息管理、客户数据库管理、多媒体资源管理以及行政和财务资源管理。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升您的数据分析水平
3. Google IT 支持专业证书 - 支持您组织的 IT 工作
数据管理可以通过自动化变得更简单,这样可以减少冗余和错误,同时节省时间和成本。这些工具不仅在存储方面很方便,还可以提供数据分析、监控文件使用、更新相关平台和应用等功能。
数据管理工具的主要类型包括:
-
云数据管理工具
-
ETL 和数据集成工具
-
数据转换工具
-
主数据管理 (MDM) 工具
-
数据可视化和分析工具
每个类别在高效管理大数据集方面都有不同的用途。

云数据管理 (AWS) 提供广泛的 云计算服务,使组织能够构建复杂的数据管理管道和分析工作流。主要服务包括 Amazon Redshift,一个数据仓库服务,允许对 PB 级结构化数据进行轻松扩展和 SQL 基础的分析。Amazon Athena 使得能够直接对存储在 S3 中的数据进行无服务器 SQL 查询。AWS 服务创建了一个强大的基于云的平台,用于管理和从大数据集中提取见解。按需付费的定价模式为组织提供了灵活性,并减少了基础设施成本。
🔑 AWS 关键点
-
提供多种工具和数据库
-
按需付费解决方案
-
对于小型企业具有成本效益
✅ 优点
-
包括各种数据库和工具
-
提供全面的解决方案来管理和发展您的数据需求
-
成本效益
-
高度可靠和可用
❌ 缺点
-
使用某些工具可能会因为其复杂的用户界面而感到困难
-
计费可能会令人困惑
-
需要云计算专家
Fivetran 是一个基于云的数据集成平台,自动化数据在源和目标之间的移动和转换。它提供了预构建的连接器,可以轻松地从应用程序、数据库、API 和文件中提取数据,并将其加载到数据仓库和数据湖中。凭借其强大的功能,Fivetran 实现了数据的无缝提取、加载和转换,使数据集成变得轻松。
🔑 Fivetran 关键点
-
完全托管的数据管道
-
无数据限制
-
一个平台解决所有数据移动需求
-
自动化、可靠性和规模
✅ 优点
-
性价比高
-
设置简单明了
-
低代码 ELT 数据操作
-
简单集成
❌ 缺点
-
缺乏自定义功能
-
偶尔会出现延迟
-
同步大量数据可能会很昂贵
dbt (data build tool) 是一个开源平台,用于管理和执行基于 SQL 的数据转换。它允许分析师和数据工程师开发模块化、可重用的转换逻辑,这些逻辑可以应用于数据平台内的各种数据源,如仓库、数据湖或数据库。dbt 处理依赖关系映射、模式编译和转换代码的执行,同时提供重构、文档、测试和版本控制工具。
🔑 dbt 关键点
-
SQL 转换
-
可以在自己的数据仓库、数据湖、数据库或查询引擎中运行
-
版本控制和 CI/CD
-
测试和文档
✅ 优点
-
dbt 转换使用 SQL 编写
-
转换过程已简化
-
转换几乎实时运行
-
诸如 CI/CD、版本控制和协作等操作功能
❌ 缺点
-
不适合非技术用户
-
dbt 仅专注于转换且功能有限
-
对某些数据湖、关系数据库和数据仓库的支持不足
Informatica 是一个企业级主数据管理解决方案,与 IBM 的 InfoSphere 和 Oracle 的 Siebel UCM 竞争。它是一个灵活的多领域解决方案,支持在本地和云中进行主数据管理。Informatica 的一个主要优势是其处理多个领域和主数据关系的能力,无论是在本地还是在云中。它提供了一个集中的平台,通过各种定制应用程序在组织内部对主数据进行整合、探索、管理和共享,从而改善数据质量、治理和业务生产力。
🔑 Informatica 关键点
-
企业级主数据管理解决方案
-
与第三方应用程序的集成
-
模块化配置
-
卓越的可扩展性和安全性
✅ 优点
-
高度有价值的数据清理功能
-
高效的匹配和合并能力,并带有审计追踪
-
精确且一致的主数据管理
❌ 缺点
-
初始设置复杂
-
用户界面过时
-
数据目录和数据市场需要改进
Tableau 是一个出色的数据可视化和商业智能工具,用于分析和可视化大量数据。它帮助用户创建图表、图形、地图、仪表板和故事,以便可视化和分析数据,帮助做出商业决策。Tableau 支持强大的数据探索和挖掘,使用户能够在几秒钟内回答重要问题。没有编程知识的用户可以立即使用 Tableau 开始创建可视化。此外,你可以连接到其他 BI 工具不支持的多个数据源。使用 Tableau,用户可以通过组合和混合各种数据集生成报告。
🔑 Tableau 关键点
-
强大的数据发现和探索工具
-
连接多个数据源
-
使用 Tableau Server 进行集中数据管理
✅ 优点
-
易于使用
-
提供免费社区版
-
多重集成
-
高性能
-
便于共享和协作
❌ 缺点
-
专业版价格昂贵
-
安全性问题
-
缺乏全面的 BI 工具功能
数据管理工具在组织、处理和分析数据以驱动商业洞察中发挥着关键作用。随着数据量的不断增长,拥有强大的工具来管理数据生命周期变得更加重要。
本文概述了五种领先的数据管理解决方案:AWS、Fivetran、dbt、Informatica MDM 和 Tableau。每种工具的用途不同,从处理大规模的云数据到无缝的 ETL 流水线,再到主数据管理和分析。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一种 AI 产品,帮助那些在心理健康方面挣扎的学生。
更多相关话题
精通生成式 AI 的 DataCamp 前五名课程
原文:
www.kdnuggets.com/top-5-datacamp-courses-for-mastering-generative-ai

图片来自 DALL-E 3
生成式 AI 目前正在快速发展,越来越多的人希望参与其中。曾经大家都说数据科学是最性感的职业,但似乎在 2023/2024 年,生成式 AI 职业已领先。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
我们正处于年薪 30 万美元的 AI 提示工程师中,各公司争相推出最佳聊天机器人,如 ChatGPT 的新对手:谷歌的 Gemini 等。似乎现在正是乘上生成式 AI 浪潮的好时机,对吧?
DataCamp的使命是让每个人都能掌握数据技能。公司提供各种课程、播客、博客等,确保组织和个人具备处理实际数据所需的正确技能。
你是否在考虑生成式 AI 职业?现在就通过 DataCamp 的以下生成式 AI 课程启动你的旅程吧。
理解人工智能
链接:理解 AI
级别:初学者
AI 仍然是当今的热门词汇,对我们的经济、各个行业和社会产生了革命性的影响。如果你是 AI 新手,想在不深入的情况下体验一下,这门友好的初学者课程将正好满足你的需求。
该课程深入探讨了 AI 的基础方面及其快速发展的情况,包括动手实践、机器学习、深度学习和生成模型的知识。此课程无需任何编码知识,非常适合初学者!
生成式 AI 概念
链接:生成式 AI 概念
级别:初学者
现在你对 AI 有了更全面的了解,下一步是了解它对当今社会的影响,即学习生成性 AI。生成性 AI 是一种能够创造新内容的 AI 模型,如 ChatGPT,以及其他任务,如 我从使用 ChatGPT 进行数据科学中学到的。
在这门适合初学者的生成性 AI 课程中,你将学习到这项新兴技术如何塑造我们的未来。了解生成性 AI 的工作原理、伦理考量,以及如何充分利用这些工具!
掌握 LLM 概念
链接:大型语言模型概念
级别:中级
过去一年我们一直听到的另一个流行词是 大型语言模型(LLMs)。在这门课程中,你将学习推动 LLM 增长的不同要素,例如深度学习、计算能力以及数据可用性。你将了解 LLM 的基础和构建模块,如自然语言处理(NLP)、微调以及 零样本学习等学习技巧。
深入了解大型语言模型(LLMs)如何在商业和个人领域通过实际例子革新当今社会。
ChatGPT 提示工程师培训课程
级别:专家
如我之前提到的,AI 提示工程师年薪 $300k - 因此,你可以想象这一技能在当今社会中的重要性。大型语言模型(LLMs)能够生成类似人类的文本和其他类型的内容,但其背后的科学就是你提供的提示。
编写有效提示是一种艺术,学习 提示工程 将使你的生成性 AI 之旅更进一步。提示工程是设计和编写特定且独特的提示以从 LLMs 中输出期望响应的能力。要充分利用 LLMs,提示工程是一个必不可少的技能。
使用 OpenAI API
级别:中级/专家
OpenAI 在 AI 市场上一直处于主导地位,其应用包括 ChatGPT。LLMs 已经改变了公司和员工的工作方式,使日常工作变得更加高效。
如果你真的想掌握所有可以获得的好处并提取有价值的商业价值 - 你需要了解 OpenAI 的 API。OpenAI API 具有广泛的潜在应用,这门课程将指导你如何使用 AI 生成独特的输出、文本生成、执行情感分析等。你甚至可以构建一个 自己的聊天机器人 - 以满足你的特定需求!
总结
使用 DataCamp,你可以按自己的节奏在线学习所需的数据技能 - 从非编码基础知识到数据科学和机器学习。立即点击 这里 开始你的 DataCamp 之旅,获取他们的完整内容库、证书和项目。DataCamp 可以让你从零开始到工作就绪 - 立即 开始!
尼莎·阿利亚是一名数据科学家、自由技术作家,并且是 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程,以及数据科学的理论知识。尼莎涵盖了广泛的主题,并希望探索人工智能如何促进人类生命的延续。作为一个热衷学习者,尼莎希望拓宽她的技术知识和写作技能,同时帮助他人。
更多相关内容
GPT-4 的前五大免费替代方案
作者提供的图片
LlaMA 2
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域的职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
LlaMA 2是 Meta AI 发布的一系列最先进的开源大型语言模型。你可以将其用于商业用途,它提供了代码、预训练模型和微调模型。所有资源都可以在 HuggingFace 上获得,你甚至可以通过在HuggingChat上试用模型来体验其性能。通过开放 Llama 2,Meta AI 使研究人员和开发者能够构建由先进语言能力驱动的创新应用。
图片来源:HuggingChat
Claude 2
Claude 2是 Anthropic 最新版本的对话 AI 助手。它具有更好的性能、更长的回答,并且可以通过 API 以及新的公开测试网站 claude.ai 访问。Anthropic 的开发者致力于提升其在编码、数学和逻辑推理等领域的能力,与之前的 Claude 版本相比。例如,Claude 2 最近在律师考试的选择题部分得分为 76.5%,相比 Claude 1.3 的 73.0%有了显著提升。
你可以在Poe上访问所有类型的 Claude 模型,并亲自体验其性能。
图片来源:Poe
PaLM 2
Google AI PaLM 2是 Google 最新的大型语言模型,在高级推理任务方面表现出色,包括代码、数学、分类、问答、翻译、多语言能力和自然语言生成。由于其优化的计算扩展方法、增强的数据集混合和架构改进,它在所有这些能力上超越了之前的最先进的大型语言模型,如原版 PaLM。
你可以通过Bard免费访问它。
虽然有一定的魔力,但仍远未达到 GPT-4 的质量和性能。
图片来自 Bard
Vicuna 1.3
Vicuna-33b-v1.3 是从 LLaMA 微调而来的,经过监督指令微调,使用了从 ShareGPT.com 收集的 125K 对话数据。它是 Open LLM Leaderboard 上众多顶级模型之一。你可以在 HuggingFace 上免费访问该模型或在 lmsys.org 尝试官方演示。

图片来自 lmsys.org
MPT-30B-Chat
MPT-30B-Chat 是一个聊天机器人,经过微调以生成对话。它是通过在多个对话数据集(如 ShareGPT-Vicuna、Camel-AI、GPTeacher、Guanaco、Baize 和一些生成的数据集)上微调 MPT 30B 创建的。MPT-30B-Chat 是 Open LLM 排行榜上的顶级模型之一,你可以在 mosaicml 提供的 Hugging Face Space 上免费体验。
图片来自 MPT-30B-Chat
结论
尽管 GPT-4 仍然封闭且无法访问,但令人兴奋的开源大型语言模型正在出现,任何人都可以使用。像 Anthropic 的 Claude2、Meta 的 LLaMA2 和 MPT-30B 这样的模型在对话能力、推理和多语言多样性方面显示出显著进展。虽然这些模型的规模不如 GPT-4 巨大,但它们的快速进步证明了最先进的语言 AI 仍在迅速发展。它们在数学、编程和逻辑等领域的强项使它们成为许多应用的有效替代品。
在 LlaMA2 模型发布后,高性能模型的热潮涌现,这些模型经过在各种数据集上的微调。你可以在 Open LLM Leaderboard 查看所有这些模型。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络开发一款帮助精神疾病学生的 AI 产品。
更多相关信息
2022 年五大免费云笔记本
原文:
www.kdnuggets.com/2022/04/top-5-free-cloud-notebooks-2022.html

图片由作者提供
我将分享我使用最佳云笔记本的经验,并解释它们为何排名前五。云集成开发环境(IDE)或云 Jupyter 笔记本改变了我对数据科学项目工作的整个看法。这些平台配备了预装的 Python 或 R 软件包,对大多数项目非常有用,几秒钟内你就可以开始工作。
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
在我的笔记本电脑上启动 VSCode 通常需要更多时间,然后我还需要安装缺失的软件包。除了免费的计算资源和预构建环境,云笔记本平台还提供了第三方工具集成、协作和发布选项。在这篇博客中,我们将深入探讨五大云笔记本的最佳功能,以及如何利用它们来改善你当前的数据科学开发环境。
1. Kaggle
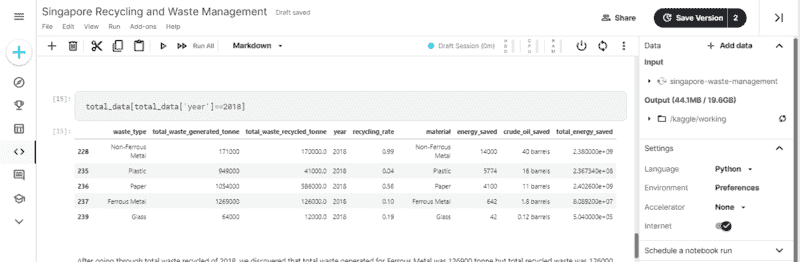
图片来自 Kaggle
Kaggle 提供了一个完整的数据科学和机器学习生态系统。该平台互动性强,由社区驱动,学生和专业人士通过上传数据集、创建笔记本、分享想法和参与竞赛来贡献内容。Kaggle 还提供每周免费无限制的 CPU、30 小时 GPU 和 20 小时 TPU。除此之外,他们还提供无限的公共数据存储和 100 GB 的私人数据存储。Kaggle 是在机器学习项目中进行实验和分享解决方案的终极工具。
功能
-
免费的 CPU、GPU 和 TPU
-
免费存储
-
定时运行的笔记本
-
开源数据集和笔记本
-
Python & R
-
谷歌云集成
-
版本控制
2. Deepnote
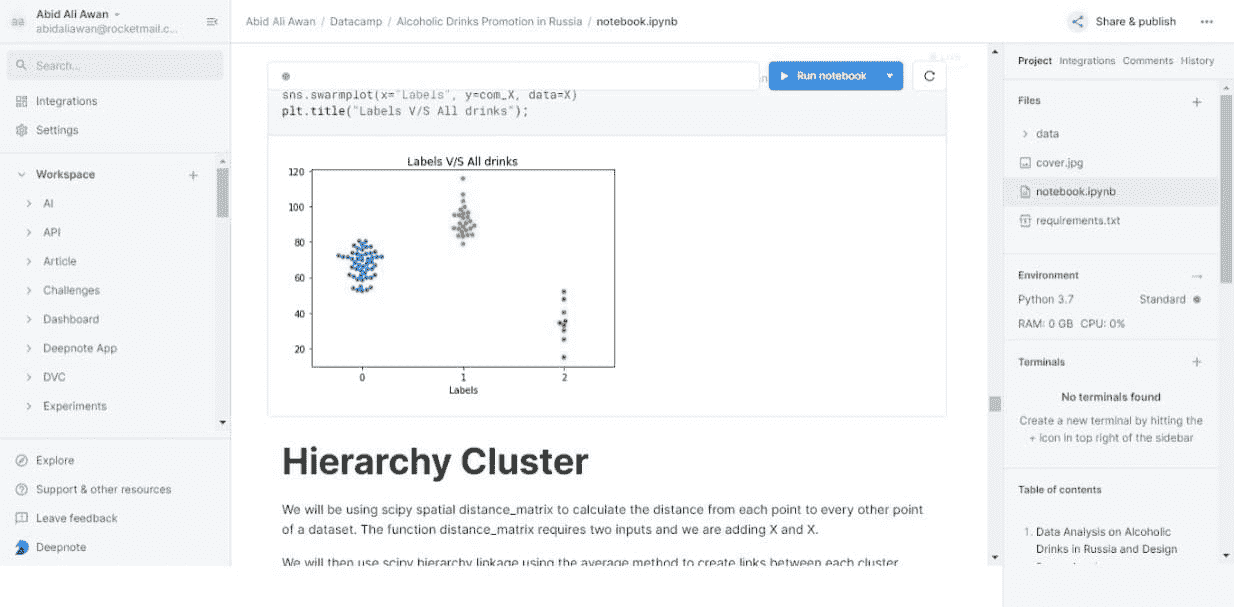
图片来自 Deepnote
Deepnote 是我喜爱的工具。我在上面完成所有工作任务。它是任何类型的数据科学项目的最佳云笔记本平台。我将它排在第二,因为该平台仅提供免费的 CPU。Kaggle 和 Deepnote 都在不断改善 UI 和添加功能,因此我很难决定第一个。Deepnote 是一个基于项目的笔记本平台,提供多种数据库集成和各种关键功能以改善用户体验。你可以在数据科学项目上进行实验,创建自定义环境,实时协作,并发布你的工作。Deepnote 是你所有数据科学项目的一站式服务。
特点
-
免费 CPU 和存储
-
计划中的笔记本运行
-
Python、R 和自定义环境
-
数据库集成
-
用于运行 Streamlit、Tensorboard 等的 Web 服务器
-
实时协作
-
发布和共享笔记本
-
笔记本单元到 Web 应用
-
版本控制
3. Google Colab
图片来自Colab
Google Colab 在机器学习研究者和数据科学家中非常受欢迎。它简单且提供免费的 GPU 和 TPU。我使用 Colab 进行快速代码运行或尝试其他人的研究工作。大多数代码库或研究论文附有 Google Colab 的链接以测试和验证结果。我认为简单性和强大的计算能力使它非常吸引人,适合人们共享和实验机器学习项目。你获得临时存储、免费的但不可靠的 GPU 和 TPU,以及与 Google 云产品(如 Drive)的集成。
特点
-
免费 CPU、GPU 和 TPU
-
免费临时存储
-
仅支持 Python
-
Google 云集成
-
改进的 Jupyter UI
-
快速加载
4. 亚马逊 SageMaker Studio Lab
图片来自Studiolab
亚马逊 SageMaker Studio Lab 是一个新的竞争者,它是一款高质量的产品。该平台非常容易使用。每个会话提供 12 小时的免费 CPU 和 4 小时的 GPU。Studio Lab 的架构和界面基于亚马逊 SageMaker Studio,但功能有限。你只能获得免费的计算、存储以及 Jupyter lab 及其扩展的所有功能。
特点
-
免费 CPU 和 GPU
-
免费有限存储
-
仅支持 Python 和自定义环境
-
快速简洁的 UI
-
Jupyter 扩展
-
高内存
-
教育内容
5. Paperspace Gradient
图片来自Gradient
Gradient 由 Paperspace 提供,是一个专注于机器学习领域的云平台。它提供端到端的 MLOps 解决方案,包括模型和数据存储、部署解决方案和监控。它还提供免费 CPU 和 GPU 用于笔记本。用户界面相当美观且易于导航。为什么排在第 5 位?因为 GPU 大部分时间不可用,用户界面有 Bug 且较慢。还有一些其他平台免费提供的付费功能。Gradient 具有成为市场领导者的巨大潜力,但由于更新和开发较慢,仍在滞后。
功能
-
免费 CPU 和 GPU
-
免费有限存储
-
仅限 Python 环境
-
现代用户界面
-
版本控制有限
-
端到端机器学习解决方案
附加信息

来源于 DataCamp 工作区 的图片
DataCamp 工作区是云笔记本市场中的另一位新竞争者。它具有交互性,并提供所有 Jupyter 笔记本的功能。你仅限于使用 CPU,但 90% 的数据科学项目只需要 CPU。工作区是 DataCamp 课程生态系统的一部分,你可以在这里进行教程项目并参加比赛。该平台还允许你创建个人资料,并以文章的形式分享你的笔记本。我是 DataCamp 的忠实粉丝,我认为未来工作区由于其简单性和与其他 DataCamp 产品的集成,将跻身前五名。
功能
-
免费 CPU
-
免费有限存储
-
交互式用户界面
-
分享与发布
-
与 DataCamp 集成
-
集成了 Git、数据集和模板
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为挣扎于心理疾病的学生构建一个 AI 产品。
更多相关话题
免费的前五大机器学习课程,提升你的技能
原文:
www.kdnuggets.com/top-5-free-machine-learning-courses-to-level-up-your-skills

图片来源 | Midjourney & Canva
如果你来到这篇文章,你可能仍对应用你的机器学习知识感到不自信。这完全可以理解。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
在我们现代社会中,持续学习是唯一不变的事物。这就是为什么,在 AI 和机器学习的浪潮之后,越来越多的人希望提升他们的技能并增强在这些领域的自信心。
无论你是非技术人员还是有技术背景,深入了解 AI 和机器学习都将极为有益。
主要问题是什么?
由于机器学习资源众多,找到高质量且相关的资源可能很困难。这就是为什么在这篇文章中,我将分享我个人最喜欢的来自顶级大学的机器学习课程。
1. DeepLearning.ai 的《人人皆可学生成 AI》
第一个课程必须专注于今年的热词——AI 和 LLMs。由 DeepLearning.AI 设计并由 Andrew Ng 授课的《人人皆可学生成 AI》是一个很好的起点,即使你对这个领域没有任何先验知识。
课程旨在清晰且顺畅地学习生成 AI 的过程,并指导你如何理解生成 AI 的工作原理以及它能做什么(以及不能做什么)。
它包括实践任务,你将学习如何使用生成性 AI 来帮助日常工作,并获得提升提示以从 LLMs 中获得最大价值。此外,你还将深入探讨实际应用,并学习常见用例。
到课程结束时,你将理解大型语言模型、深度学习和生成性 AI 技能的概念。你将能够将你的知识付诸实践,并根据当今机器学习世界的三个核心元素,洞察 AI 对商业和社会的影响。
你还将学习如何将生成性 AI 应用于日常任务,使其立即变得实用和有用。课程可以在 Deeplearning.ai 上免费获取。
2. CS229: 斯坦福大学的机器学习
作为第二个选择,我推荐一个经典的——尽管仍然是最好的免费机器学习课程之一。有许多版本和讲师,但个人推荐由 Andre Ng 主讲的课程,他被广泛认为是最优秀的机器学习讲师之一。
课程提供了一个易于理解的机器学习和统计模式识别的介绍,涵盖了监督学习、无监督学习、学习理论、强化学习和控制等主题。从基础开始,最终涵盖高级概念。该课程非常适合任何希望在机器学习领域获得扎实基础并深入理解该领域的人。
你可以在以下链接找到所有材料,以及对应的 YouTube 视频在以下链接。
3. MIT 的《Python 机器学习》
如果你的目标是用 Python 掌握机器学习,一个好的选择是参加 MIT 特意为此设计的课程。它提供了对机器学习算法和模型的完整介绍,包括深度学习和强化学习,所有内容都通过实践的 Python 项目完成。
如果你是新手,选择一个特定的子领域可能会让人感到不知所措。更好的方式是选择一个覆盖大部分机器学习内容的课程,从而有机会发现你最感兴趣的内容。该课程非常适合希望探索整个机器学习多样化世界的初学者。
4. 帝国理工学院的《机器学习数学》
如果你对数学感到害怕,现在是面对它们的时候了。帝国理工学院设计了一个课程,旨在教授任何希望在机器学习领域建立职业生涯的人所需的基本技能。
数学是机器学习的基础,理解数学原理对于解释 ML 算法产生的结果至关重要。该专业包括三个课程:
-
线性代数
-
多变量微积分
-
主成分分析
每个课程持续 4-6 周,涵盖掌握机器学习算法所需的基础数学概念。
5. fast.ai 的《实用深度学习》
这门免费课程旨在帮助有一定编码经验的人将深度学习和 ML 应用于实际问题。由 fast.ai 开发,这门课程旨在帮助人们成为工业准备好的 AI 开发者。它通过项目驱动的方法涵盖了计算机视觉和自然语言处理等基础主题,从基本概念逐步深入到高级概念。
其主要范围基于:
-
为计算机视觉、自然语言处理、表格分析和协同过滤构建和训练深度学习模型。
-
创建随机森林和回归模型。
-
部署模型。
-
使用 PyTorch,这个全球增长最快的深度学习库,以及像 fastai 和 Hugging Face 这样的热门库。
你可以在 以下网站找到这门课程。
总结
总结来说,有很多资源可以帮助你入门 ML 并提升你当前的知识水平。无论你是初学者还是有一定编码经验的人,这些课程都提供了从基础到复杂的完整介绍。
Josep Ferrer**** 是一位来自巴塞罗那的分析工程师。他毕业于物理工程专业,目前在数据科学领域专注于人类流动性应用。他是一名兼职内容创作者,专注于数据科学和技术。Josep 涵盖了 AI 领域持续爆炸的应用。
更多相关话题
前五名免费机器学习课程
原文:
www.kdnuggets.com/2022/02/top-5-free-machine-learning-courses.html

作者提供的图片
技术行业对机器学习(ML)工程师的需求不断增长。公司们正在尝试整合智能产品以提升利润和增加客户互动。在 LinkedIn 和 Glassdoor 等平台上,AI 相关工作的上升趋势表明,公司正在寻找具有机器学习经验的数据科学家、ML 工程师、MLOps 工程师以及拥有 AI 产品开发背景的数据工程师。随着世界变得越来越智能,为了满足需求,组织们愿意支付 $130K+ 的基本薪资 Glassdoor。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
如果你希望在职业生涯中成长并年薪达到 $130K,那么通过完成一门专业的机器学习课程来开始你的职业生涯。在参加这些课程之前,你需要了解前提条件。几乎所有的课程都希望你具备 Python、统计学和数据科学的经验。高级课程要求你有深度学习框架的实际经验以及对机器学习生态系统的理解。在这篇博客中,我们将了解前五名免费机器学习课程。这些课程的难度从初学者到高级都有。
斯坦福大学的机器学习
机器学习 由斯坦福大学提供,是互联网上最受欢迎和高度评价的在线课程。我大多数同事都参加过安德鲁·吴的各种课程,他们都取得了积极的效果。如果你是一个有 Python 语言经验的初学者,我强烈建议你通过斯坦福大学的免费课程开始你的学习之旅。你还可以支付额外的 $75 来获得证书并获取更多学习资源。

图片来源 Coursera
时长: 61 小时
评分: 4.9
评价: 42,816
级别: 混合
课程将简要介绍机器学习,从线性代数开始,到创建现实世界应用(照片 OCR)。课程包括监督学习、无监督学习、神经网络、核心机器学习算法、优化以及异常检测和推荐系统等现实世界应用。
我在 Coursera 和 Andrew Ng 的课程中有过积极的体验,他以一种全新而有效的方式讲解所有内容。这门课程将帮助你快速启动你的机器学习职业,并为你构建出色的 AI 应用程序奠定坚实的基础。
CS50 的《Python 人工智能入门》(哈佛大学)
CS50 的《Python 人工智能入门》| edX 教授你成为机器学习工程师所需的技能。在这门课程中,你将学习那些催生了游戏引擎、图像分类、机器翻译和股票价格预测等技术的机器学习算法。这是一门免费的课程,但你可以付费获得证书、完整的课程内容以及互动项目。

图片来自 edX
时长: 140 小时
好处: 自主学习,世界顶级大学讲师,职业前景保障
级别: 入门级
课程包括对机器学习框架、图搜索算法、对抗搜索、知识表示、逻辑推理、概率论、贝叶斯网络、马尔可夫模型、约束满足、机器学习、强化学习、神经网络和自然语言处理的实际操作经验。你还将通过参与投资组合项目来学习设计智能系统。
哥伦比亚大学的机器学习
机器学习 | edX 由哥伦比亚大学提供,是一门中级课程,帮助你掌握基本的机器学习算法。这是一门免费的课程,但付费选项将提供额外的功能和证书。

图片来自 edX
时长: 96 小时
级别: 中级
课程包括监督学习(回归/分类)、无监督学习数据建模和分析,以及优化模型性能。课程还涉及 Markov 模型、非负矩阵分解、连续状态空间模型、Laplace 近似、核方法和高斯过程。此课程适合希望深入学习模型架构和算法的个人。
实用深度学习课程
我是Jeremy Howard的忠实粉丝,他的实用深度学习课程 (fast.ai)简直太棒了。你可以享受到评估练习、社区支持以及易于跟随的 YouTube 教程。你还将学习到最先进的模型以及一个易于使用的深度学习框架(fast.ai),它是建立在 PyTorch 之上的。
该课程涵盖了机器学习的所有核心主题,并结合了实际案例。它还包括数据伦理、生产中的机器学习和开发网页应用程序。你会看到许多 fast.ai 的校友在 Google 和 Amazon 工作,因此,如果你对你的职业生涯非常认真并且想要学习能够让你找到工作的机器学习概念,那么请在一个月内完成这门课程,然后进入第二部分。

图片来源:fast.ai
时长: 20 - 60 小时
级别: 初学者到中级
课程包括训练深度学习模型、基于证据的学习、生产中的机器学习、随机梯度下降、数据伦理、表格数据和自然语言处理。每一章都有问题和项目练习,你可以在 Google Colab 或 Gradient 上运行。我强烈推荐你在学习机器学习基础后参加这门课程。该课程帮助我理解了神经网络的深层工作原理,并学会了跳出思维框框。
生产中的机器学习工程
生产中的机器学习工程 (MLOps)适合经验丰富的数据科学家和机器学习工程师。该课程帮助我理解了优化模型性能的数据中心方法,并教授了生产技术,如开发模型管道、管理元数据、项目范围和设计、概念漂移和人类水平的性能。你可以免费审核课程,这意味着你可以访问视频教程、测验和阅读课程内容。你需要支付月费才能访问项目、项目评审和认证。
该专业分为四门课程:
-
生产中的机器学习简介
-
生产中的机器学习数据生命周期
-
生产中的机器学习建模流程
-
生产中的机器学习模型部署

图片来自Coursera
时长: 96 小时
评分: 4.7
级别: 高级
这些课程将帮助你在职业生涯中脱颖而出,并准备你通过使用先进工具来提升 AI 产品的性能。你将学习数据漂移、概念漂移、以数据为中心的方法,开发端到端的机器学习系统,构建数据管道,机器学习操作,并学习在持续监控生产系统中的高级技术。
结论
2022 年是学习机器学习技能的最佳时机。如果你有兴趣开始你的学习之旅,或者想在数据领域中脱颖而出,开始参加这些课程并按时完成它们。这些课程将帮助你建立作品集,并提供必要的技能。免费的课程还提供社区驱动的职业支持,专业人士互相帮助找到合适的工作。
在这篇博客中,我们介绍了五个顶级免费机器学习课程。这些课程培养了能够胜任工作的专业人士,他们在顶尖科技公司工作。课程的排名基于理论、实用性、互动项目与练习、受欢迎程度、真实世界项目以及讲师风格。我希望你喜欢我的工作,如果你对机器学习职业有进一步的问题,请在下方评论。我会尽力回答你的所有问题。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是为那些面临心理健康问题的学生构建一个使用图神经网络的 AI 产品。
更多相关主题
每个人都应该阅读的前 5 本免费机器学习和深度学习电子书
原文:
www.kdnuggets.com/2020/11/top-5-free-machine-learning-deep-learning-ebooks.html
评论
1. 深度学习书籍

这本深度学习书籍由业界顶级专家 Ian Goodfellow、Yoshua Bengio 和 Aaron Courville 编写。这本书是学习所有重要机器学习和深度学习算法背后数学和理论的最佳书籍之一。从前馈网络到自编码器,它涵盖了你所需的一切。
2. 深入深度学习

这是一本互动电子书,涵盖了代码、数学、练习和讨论。它提供了 Numpy/MXNet、PyTorch 和 Tensorflow 的实现。
这本书是一个完整的套件,涵盖了从理论到实际示例的所有内容。
3. Fast.ai 的 Fastbook
这是一本独特的书,以 Jupyter notebooks 的形式发布,免费提供在 Github 上。这些笔记本涵盖了深度学习的介绍,Fastai 和 PyTorch。Fastai 是一个用于深度学习的分层 API。
从这本书中学习的最佳方式是通过 fast.ai 提供的免费深度学习课程。
这本书也可以在 Amazon 以纸质版购买。
4. R 语言中的统计学习简介

这是学习机器学习和统计方法基础理论的最佳书籍之一。它针对的是高年级本科生、硕士生和非数学科学领域的博士生。
这本书包含 R 语言的编码实验和练习。它涵盖了许多重要的机器学习和统计方法。官方网站上还提供了一个 MOOC 链接,包含将近 15 小时的视频。你可以在 这里 找到。
5. 可解释的机器学习

这是我推荐大家阅读的最佳机器学习书籍之一。这本书也是关于如何解释机器学习模型及其预测的最佳指南之一。
根据书的前言
“所有解释方法都进行了深入讲解和批判性讨论。它们如何在幕后工作?它们的优点和缺点是什么?它们的输出如何解释?这本书将帮助你选择并正确应用最适合你机器学习项目的解释方法。”
阅读这本书将大大帮助你提高机器学习模型的效果、分析“为什么它们有效”、“为什么它们无效”以及许多其他问题,这些问题将使你成为更优秀的数据科学家和机器学习工程师。
此外,你可以在 Github 上找到本书的所有代码 这里。
相关:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
更多相关话题
学习高级 SQL 技巧的前 5 个免费资源
原文:
www.kdnuggets.com/top-5-free-resources-for-learning-advanced-sql-techniques

作者提供的图像
互联网充斥着学习 SQL 的资源。当然,大多数都需要付费获得知识。这些资源主要教你基本的或最好的中级 SQL。
问题是,如何学习 SQL并且是免费的。是否有任何资源可以教你高级 SQL 而无需支付?
是的,确实有。事实上,正如我发现的那样,至少有五个。
在寻找课程之前,我必须定义什么是高级 SQL。
什么是高级 SQL?
这不容易确定,因为不同的专家对哪些 SQL 概念可以被认为是高级有不同的看法(以及教学经验)。
不过,我认为可以安全地说,这些主题属于高级 SQL:
-
连接
-
公共表表达式(CTEs)
-
递归公共表表达式(CTEs)
-
子查询和相关子查询
-
窗口函数
-
数据透视和反透视
-
层次查询
-
视图
-
存储和用户定义的过程及函数
-
触发器
-
临时表
-
索引
-
数据规范化
-
性能优化
然而,这个列表还不完整。其他一些也属于高级 SQL 的主题可以被添加进来。怎么判断它们是否属于高级?我有一个高度非科学但有效的方法:如果你不知道某个特定主题的含义,它很可能是高级 SQL。
高级 SQL 的免费资源

作者提供的图像
我在这里列出的资源涵盖了我之前提到的一些或大部分高级 SQL 概念。如果你结合这些资源,你的高级 SQL 知识可以变得更加完善。是的,我知道这需要更多的努力,但这些都是免费的,你还能期待什么呢?
1. Mode SQL 教程
描述:本教程教你在 Mode BI 工具中学习高级 SQL。无需担心你需要学习另一种 SQL 方言;Mode 使用的是标准 SQL。
所有概念都以理论形式详细解释。在每一节中,还有互动练习,你可以通过编写 SQL 查询来解决问题并检查答案。
说到概念,你将学习子查询、窗口函数、SQL 查询优化和数据透视。此外,还有关于数据类型、日期格式和字符串函数的课程。
如果你觉得在这些课程中的某些较少进阶的主题上遇到困难,你可以随时在基础 SQL 和中级 SQL 章节中重新学习。
2. StanfordOnline: 数据库:SQL 的高级主题
资源链接:edX
描述:该课程是斯坦福大学提供的五门数据库课程之一,并由 edX 主办。
在高级主题中,你将学习索引以提高查询性能、事务、数据库约束和触发器以及视图。
完成此课程需要两周时间,每周 8-10 小时。
此外,如果你对这些主题感兴趣,你还可以参加关于OLAP 和递归、建模和理论和半结构化数据的课程。
3. Kaggle 高级 SQL
资源链接:Kaggle 高级 SQL
描述:Kaggle 的这门小课程仅需四小时完成。它涵盖 JOIN 和 UNION、分析(或窗口)函数、嵌套和重复数据以及编写高效查询的技巧。
每节课提供详细的理论解释,并附有实际示例。每节课结束时,你会找到一个链接,该链接会测试你的理解,给出一些编写代码来解决的练习。
4. 高级 SQL(2020 年夏季)
资源链接:YouTube
描述:此视频课程由德国图宾根大学数据库研究组提供讲座。
共有 58 个视频,大多数时长约半小时。内容涵盖子查询、集合操作、GROUP BY 扩展、数据类型、数组、窗口函数、用户定义函数、递归 CTE 等许多主题。
5. Web 极客的 SQL
资源链接:菲利普·格林斯潘个人网站
描述:这本在线书籍由菲利普·格林斯潘编写,他是美国的计算机科学家和教育家。
通过代码和实际示例相结合的理论和实践解释。大多数示例使用 web 服务的数据模型,并以 Oracle SQL 方言编写。
该资源将教你触发器、视图、树、数据库调优等更多内容。
额外福利:几乎免费的资源
作为额外福利,我想加入两个几乎免费的资源:StrataScratch(是的,就是我创办的平台)和 LeetCode,这两个平台提供实际的 SQL 编程面试题。
几乎是免费的,指的是非常便宜?不是,指的是需要付费订阅才能访问所有问题,但也有大量的免费问题。
我们在StrataScratch 上有 75 个免费问题,大多数难度为中等或困难。你一定会找到一些问题来测试你的高级 SQL 知识。为了方便你搜索,我们提供了详细的筛选功能,可以按主题、难度、公司等进行筛选。
还有一个互动代码编辑器,可以用多种 SQL 方言(PostgreSQL、SQL Server、MySQL 和 Oracle)编写解决方案并进行验证。所有问题都有提示和详细解释的官方解决方案。
LeetCode的问题数量与我计算的数量相同。然而,大多数情况下,这些问题被分类为简单或中等,这可能会使寻找高级主题变得稍微困难一些。不过,我相信你一定能找到一些很好的问题来练习我在文章开头提到的主题。像 StrataScratch 一样,LeetCode 也有详细的解决方案和一个互动代码编辑器,支持多种 SQL 方言的代码编写。
总结
就这样——五个免费教授高级 SQL 技巧的资源。它们也是优质资源,有助于更好地学习。
三个资源是经典的在线 SQL 课程,涵盖不同的高级主题。我还加入了一些不同的内容:一个由顶级德国大学提供的 YouTube 课程和一本由公认专家和教育者撰写的在线书籍。
这些资源中涵盖的一些主题有所重叠,但也有些是每个资源独有的。如果你在某个课程中找不到你需要的内容,你可以随时结合这些资源来填补空白。
作为额外福利,有两个面试问题平台,StrataScratch 和 LeetCode,提供了一些免费的问题。
我希望你能发现这些都是学习高级 SQL 的宝贵资源。祝学习愉快!
内特·罗西迪是一名数据科学家,专注于产品战略。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,这个平台帮助数据科学家准备面试,提供来自顶级公司的真实面试问题。内特撰写关于职业市场的最新趋势,提供面试建议,分享数据科学项目,并覆盖所有 SQL 相关内容。
我们的 Top 3 课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织 IT
更多相关主题
数据科学的前五大 Linux 发行版

作者提供的图片
许多在财富 500 强公司工作的开发者和 IT 专业人士使用 Linux 发行版或 MacOS。为什么选择 Linux?因为大多数服务器运行在 Linux 上,并提供 Windows 11 缺乏的各种工具。此外,如果您关注安全性和隐私,那么转向 Linux 是正确的决定。在过去一个月里,我使用 VM VirtualBox 尝试了一些这些发行版,我正在认真考虑将 Linux 作为我的主要系统。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织 IT 方面的需求
在这篇博客中,我们将了解一种我非常喜欢的 Linux 发行版,它支持所有您数据科学实验和机器学习模型训练所需的工具。这些发行版也非常用户友好,您可以在几分钟内完成安装。
1. Ubuntu Desktop
我们都知道 Ubuntu,我认为如果你是开发者或机器学习工程师,你很可能通过 WSL 在 Windows 11 上使用 Ubuntu。由于其用户友好的界面、广泛的文档和庞大的社区支持,Ubuntu 是最受欢迎的 Linux 发行版。

Ubuntu 是 Linux 新手的绝佳选择,其软件仓库中充满了数据科学工具和库,使得设置开发环境变得容易。此外,它是一个稳定的操作系统,提供比 Windows 更长的长期支持。
2. Fedora Workstation
Fedora Workstation 是一个非常成熟且受欢迎的开发者和程序员操作系统。Fedora 的独特之处在于它致力于提供最新的软件和功能,这对于数据科学家寻找最新的软件工具和库的发展至关重要。
它完全免费且没有广告,重视您的数据隐私。此外,它对开源价值的强烈重视确保用户可以访问庞大的免费开源软件(FOSS)工具生态系统。
3. Zorin OS
Zorin OS 正迅速成为我最喜欢的操作系统,因为它的安装简便和预装软件。对于那些从 Windows 或 macOS 过渡过来的人,它特别友好,提供了一个简单而优雅的界面,同时不牺牲性能或功能。
Zorin OS 基于 Ubuntu,因此可以利用其丰富的软件库和支持。对于数据科学家来说,Zorin OS 提供了一个舒适且熟悉的环境,同时仍然展现出 Linux 以其著称的多样性和性能。
4. Pop!_OS
Pop!_OS 是一个流行的 Linux 发行版,预装了 Nvidia GPU 驱动程序。这意味着你无需额外安装任何东西即可开始在 GPU 上训练深度学习模型。它在易用性和预装应用程序方面与 Zorin OS 非常相似。
Pop!_OS 基于 Ubuntu,但通过一个精简且增强的用户界面增加了自己的特色,重点关注生产力和易用性。我能够在几分钟内安装并开始使用 VSCode 进行我的项目。它非常容易导航,并且提供了大量的自定义选项。
5. Manjaro
Manjaro 是一个基于 Arch Linux 的用户友好型 Linux 发行版。与针对更有经验用户的 Arch 不同,Manjaro 提供了 Arch Linux 的所有优点,包括访问 AUR(Arch 用户库),但以更易于安装的包形式呈现。
Manjaro 以其滚动更新模式而闻名,这意味着它会定期收到更新和最新的软件包。它还具有高度的可定制性,允许用户根据自身需求调整操作系统。此外,它提供了广泛的数据科学工具和库,这些工具和库对于开发和部署数据科学解决方案至关重要。
结论
选择适合数据科学的 Linux 发行版取决于个人喜好、特定项目需求以及你对 Linux 环境的舒适程度。
Linux 与 Windows 和 macOS 存在显著差异。因此,建议尝试几种稳定的 Linux 发行版,选择最适合你的那一个。一些专业人士偏好 Arch,而一些则偏好 Ubuntu。最终,这取决于你的个人喜好。
Fedora Workstation、Ubuntu Desktop、Zorin OS、Pop!_OS 和 Manjaro 是数据科学专业人士的热门选择,每种操作系统都有其独特的优点。尝试其中一种或多种发行版将帮助你找到最适合你数据科学之旅的系统。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。当前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些挣扎于心理健康问题的学生。
更多相关话题
机器学习从业者应了解的前五大 API
原文:
www.kdnuggets.com/top-5-machine-learning-apis-practitioners-should-know

作者图片 | Canva
API,即应用程序编程接口,是一组规则和协议,使不同的软件或网络应用能够互相通信和交互,类似于蓝牙连接两个手机进行数据共享和消息传递。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 部门
在这篇博客中,我们将探讨前五大 API,这些 API 可以显著简化机器学习工程师的工作,使他们的工作流程更加顺畅,从而快速而无缝地构建 AI 应用。
1. OpenAI API
OpenAI API 是最受欢迎的机器学习 API 之一。只需支付少量费用,你就可以访问最先进的大型语言模型,如 GPT-4o,以及嵌入、图像生成、文本到语音、语音到文本和内容审查模型。通过 OpenAI API,你可以创建自己的高质量 AI 应用,甚至围绕它建立一家初创公司。然而,使用 OpenAI API 可能会面临两个潜在问题。首先是隐私问题,其次是使用这些模型的成本可能迅速累积,尤其是当你试图围绕它建立公司时。这可能会减少你的扩展利润空间。这时候,其他 API 就显得尤为重要。
2. Kaggle API
Kaggle API 允许你创建自己的模型。这意味着你可以用它来下载数据集和模型,然后使用免费的 GPU 来训练你的模型。所有操作都可以通过 Kaggle 命令行工具完成,真是太棒了。你甚至可以使用 API 保存你微调过的模型、笔记本和数据集。大多数问题都可以通过 Kaggle API 解决。如果你是机器学习领域的专家,还可以利用这个 API 参加竞赛。
3. Hugging Face API
Hugging Face API 是机器学习工程师和研究人员广泛使用的 API。它允许你下载数据集、模型、代码库和空间。它速度快,并且提供了大量自定义选项以下载数据集。此外,你可以使用它创建 Hugging Face Hub 代码库,保存和分享你的模型,开发和发布机器学习 Web 应用程序,并通过支持 GPU 的端点部署机器学习模型。大多数人将其与 Transformers 库一起使用,使得人们只需几行代码即可微调大型机器学习模型。
4. ElevenLabs API
如果你正在寻找一个前沿的声音生成、语音转文本和语音转语音的解决方案,ElevenLabs API 是最佳选择。他们提供自然的声音,为你的产品注入生命。此外,该 API 包括语音克隆、流式传输、异步功能,并支持 29 种语言和 100 多种口音。你甚至可以使用文本生成声音效果。你可以跳过训练自己的模型并追求完美的步骤,直接集成 ElevenLabs API。
5. StabilityAI API
我们已经了解了音频生成 API,现在我们将学习一种名为 Stability AI 的图像生成 API。该 API 可以使用最新的 Stable Diffusion 3 模型生成高质量的 4K 图像。此外,它还可以用来放大和编辑图像,并通过草图、结构和风格进行控制。Stable Fast 3D 模型允许你使用 2D 图像生成 3D 资产。Stability API 的一个最佳功能是,它允许你使用文本提示生成高度逼真的视频。
结论
通过使用机器学习 API,你可以轻松构建、保存和部署生产就绪的 AI 应用程序。这些 API 简化了流程,通过连接各种应用程序,让你可以专注于开发而不是基础设施。从头开始训练自己的机器学习模型变得越来越不常见,因为专业人士越来越依赖 API 来进行模型集成或使用 Hugging Face 生态系统微调现有模型。
在这篇博客中,我们探索了可以帮助你生成文本、图像和音频的 API。此外,你还可以从 Kaggle 和 Hugging Face 等平台获得广泛的数据、模型和代码资源,使得开发复杂的机器学习应用程序比以往更容易。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些面临心理健康问题的学生打造一个人工智能产品。
更多相关内容
专家推荐的前 5 种机器学习最佳实践
原文:
www.kdnuggets.com/2022/09/top-5-machine-learning-practices-recommended-experts.html

介绍
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT 维护
机器学习一直是媒体热炒的话题,越来越多的组织采用这种技术来处理日常任务。机器学习从业者可能能够提出解决方案,但提升模型性能有时可能非常具有挑战性。这需要实践和经验。即使尝试了所有策略,我们仍然经常无法提高模型的准确性。因此,本文旨在通过列出机器学习专家推荐的最佳实践,帮助初学者改进他们的模型结构。
最佳实践
1. 专注于数据
在机器学习的世界中,数据的重要性不容忽视。数据的质量和数量都能显著提升模型性能。这通常比制作机器学习模型本身更耗时和复杂。这个步骤通常被称为数据准备。它可以进一步细分为以下步骤:
-
明确问题 - 为了避免使项目过于复杂,尽量深入了解您要解决的根本问题。将问题分类为分类、回归、聚类或推荐等。这种简单的细分可以帮助您收集最适合您情境的相关数据集。
-
数据收集 - 数据收集可能是一个繁琐的任务。顾名思义,它是收集历史数据以寻找重复模式。数据可以分为结构化(例如 Excel 或 .csv 文件)和非结构化数据(例如照片、视频等)。一些著名的数据集来源包括:
-
数据探索 - 这一步骤涉及利用统计和可视化技术识别数据集中的问题和模式。你需要执行各种任务,如发现异常值、识别数据分布及特征之间的关系、查找不一致和缺失值等。Microsoft Excel 是用于此步骤的一个流行手动工具。
-
数据清洗和验证 - 这涉及到剔除无关信息并通过各种插补工具解决缺失值。识别并删除冗余数据。许多开源选项如OpenRefine和 Pandera等可用于清洗和验证数据。
2. 特征工程
这是另一种提高模型性能和加快数据转换的基本技术。特征工程涉及从已有特征中注入新特征到模型中。它可以帮助我们识别强健的特征并去除相关或冗余的特征。然而,它需要领域专业知识,如果我们的初始基线已经包含多样的特征,可能不可行。让我们通过一个例子来理解这一点。假设你有一个数据集,包含房屋的长度、宽度和价格,如下所示:
与其使用上述数据集,我们可以引入另一个名为“面积”的特征,并仅测量该变量对房价的影响。这个过程属于特征创建的范畴。

类似地,特征转换和特征提取根据我们的项目领域可能会证明有价值。特征转换涉及对特征应用转换函数以获得更好的可视化,而在特征提取中,我们通过仅提取相关特征来压缩数据量。
尽管特征缩放也是特征工程的一部分,我单独讨论了它,以强调其重要性。特征缩放是用于标准化自变量和特征范围的方法。为什么这个步骤如此重要?大多数算法如线性回归、逻辑回归和神经网络使用梯度下降作为优化技术。梯度下降严重依赖于特征的范围来确定向最小值的步长,但我们的大多数数据在范围上变化剧烈。这迫使我们在将数据输入模型之前进行标准化或规范化。对此,最重要的两种技术是:
- 归一化 - 归一化是一种将数据限制在通常范围[0,1]之间的技术,但你也可以定义范围[a,b],其中 a 和 b 是实数。
- 标准化 - 标准化将数据转换为均值为 0,方差为 1。我们首先计算特征的标准差和均值,然后使用以下公式计算新值:
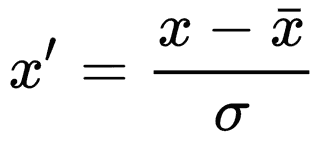
对于哪一种更好的讨论已经很多,一些研究表明,对于高斯分布,标准化更有帮助,因为它不受异常值的影响,反之亦然。但这取决于你所处理的问题类型。因此,强烈建议同时测试两者并比较性能,以找出最适合你的方法。
3. 玩转正则化
你可能遇到过这种情况:你的机器学习模型在训练数据上表现得非常好,但在测试数据上表现不佳。这发生在你的模型过拟合了训练数据。尽管有很多方法可以应对过拟合,比如丢弃层、减少网络容量、提前停止等,但正则化的表现超过所有方法。什么是正则化? 正则化是一种通过缩小系数来防止过拟合的技术。这会导致一个简化的模型,在进行预测时表现得更加高效。正则化有两种类型:
- L1 正则化 - 也被称为套索回归。它通过向系数绝对值的大小添加惩罚,迫使一些系数估计值恰好为零。它形成一个稀疏模型,对特征选择有用。
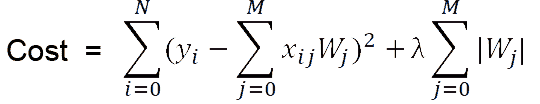
- L2 正则化 - 也被称为岭回归。它通过添加系数绝对值的平方来惩罚模型。因此,它迫使系数的值接近零但不完全为零。它提高了模型的可解释性。
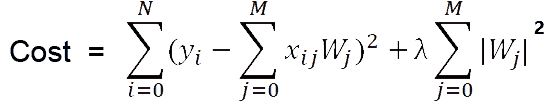
尽管 L2 正则化比 L1 给出更准确的预测,但这以计算能力为代价。在存在异常值的情况下,L2 可能不是最佳选择,因为由于平方的存在,成本会呈指数增长。因此,与 L2 相比,L1 更具鲁棒性。
4. 识别错误
重要的是我们要跟踪模型所犯的错误,以便进行优化。这个任务可以通过各种可视化图来完成,具体取决于待解决问题的类型。以下是一些讨论的内容:
-
分类 - 分类模型是监督学习的一个子集,根据生成的输出将输入分类为一个或多个类别。可以通过各种工具来可视化分类模型,例如:
-
分类报告 - 这是一个评估指标,显示了精确度、F1 分数、召回率和支持度。它提供了对模型性能的整体理解。
-
混淆矩阵 - 它将真实值与预测值进行比较。与分类报告相比,它提供了对单个数据点分类的更深入的见解,而不仅仅是顶层分数。
-
回归 - 回归模型通过提供期望的函数来预测自变量和因变量之间的关系。它在连续空间中进行预测,以下是用于回归的评估指标:
-
残差图 - 它显示水平轴上的自变量和垂直轴上的残差。如果数据点在水平轴上随机分布,则线性模型更适合,反之亦然。
-
预测误差图 - 它显示实际目标与预测值的对比,以提供关于方差的想法。45 度线是预测与模型完全匹配的地方。
5. 超参数调优
超参数是一组不能由算法本身学习的参数,并在学习过程开始之前设置,例如学习率(alpha)、小批量大小、层数、隐藏单元数等。超参数调优 指的是选择最优超参数的过程,以最小化损失函数。在简单的网络中,我们对模型的不同版本和超参数组合进行实验,但对于更复杂的网络,这可能不是合适的选择。在这种情况下,我们根据先前的知识进行最优选择。以下是一些广泛使用的超参数调优方法,以便在超参数空间范围内进行适当的选择:
-
网格搜索 - 这是传统的和最常用的超参数调优方法。它涉及从包含所有可能超参数组合的网格中选择最佳集合。然而,它需要更多的计算能力和时间来执行操作。
-
随机搜索 - 它不是尝试每一种组合,而是从网格中随机选择一组值来找到最优值。与网格搜索相比,它节省了不必要的计算能力和时间。由于没有使用智能,因此运气也起到作用,结果的方差较高。
-
贝叶斯搜索 - 它在应用机器学习中被使用,且优于随机搜索。它利用贝叶斯定理并考虑前一轮的结果,以改进下一轮的结果。它需要一个能够最小化损失的目标函数。它通过创建目标函数的代理概率模型来工作,然后寻找代理模型的最佳超参数,接着将其应用到原始模型中,并更新代理模型,估计目标函数。这一过程会被重复,直到找到原始模型的最佳解。它确实需要较少的迭代,但每次迭代需要较长时间。
在上述方法中,迭代次数、运行时间和性能最大化之间存在权衡。因此,您案例中的理想方法取决于您的优先事项。
结论
机器学习和深度学习需要良好的计算资源和专业知识。构建机器学习模型是一个迭代过程,涉及实现各种技巧以提高整体模型性能。我列出了 ML 专家推荐的一些最佳实践,以便访问您当前模型的不足之处。然而,正如我总是说的,一切都需要足够的实践和耐心,所以请继续从错误中学习。
Kanwal Mehreen 是一名有志的软件开发人员,她相信持续的努力和承诺。她是一名雄心勃勃的程序员,对数据科学和机器学习领域有浓厚的兴趣。
更多相关主题
初学者到专业人士的前 5 大 NLP 备忘单
原文:
www.kdnuggets.com/2022/12/top-5-nlp-cheat-sheets-beginners-professional.html

作者提供的图片
备忘单在复习遗忘的概念或准备技术 NLP 面试时至关重要。它曾经帮助过我,现在我将与您分享 NLP 的最佳资源。
通过查看前 5 大 NLP 备忘单,你将了解 NLP 算法、模型、Python 库、任务、分析技术、性能指标和框架。
NLP 入门工具包备忘单
NLP 入门工具包 是一个基于 Markdown 的备忘单,介绍了 NLP Python 库、任务、框架、数据集、算法和基准。你将通过代码示例了解算法背后的概念。
NLP 入门工具包涵盖了从简单的文本分类到变换器的所有基础知识。此外,你还将学习各种分析技术,以了解数据集。
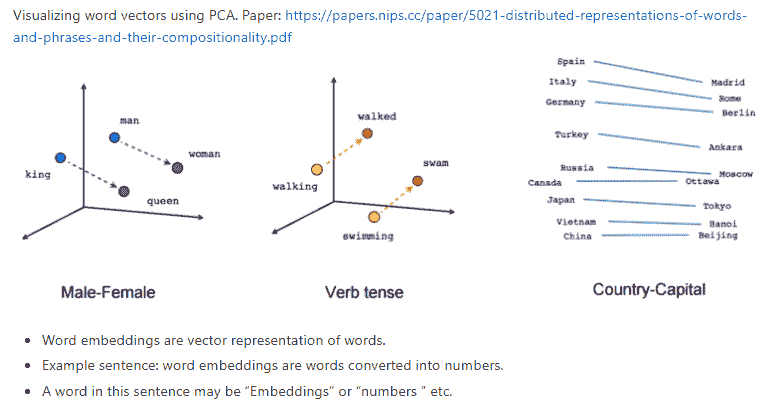
图片来自备忘单
在备忘单中,你将学习到:
-
词嵌入
-
停用词
-
跨度
-
令牌与分词
-
语块与语块化
-
词性标注(POS)
-
词干提取与词形还原
-
句子检测
-
依存解析
-
命名实体识别(NER)
-
文本分类
-
相似度
-
N-gram
-
核方法
-
斯皮尔曼等级相关系数
-
KNN
-
情感分析
-
以及更多
spaCy 备忘单
spaCy 备忘单涵盖了使用 spaCy Python 包的重要 NLP 概念和特性。SpaCy 是一个高级开源 NLP 工具,专门设计用于生产环境,以理解更大量的文本。

图片来自备忘单
在备忘单中,你将学习到:
-
统计模型
-
文档、令牌和跨度
-
标签说明
-
语言特征
-
管道组件
-
可视化
-
词向量与相似度
-
语法迭代器
-
扩展属性
-
基于规则的匹配
NLP 与 NLTK 备忘单
NLP 与 NLTK 备忘单 为你提供了一个关于使用主要是 NLTK 包的 Python 中基本 NLP 任务的参考指南。你将学习到 POS 标注、词形还原、句子解析和文本分类。

图像来自 备忘单
在备忘单中,你将学习:
-
处理文本
-
访问语料库和词汇资源
-
分词
-
词形还原与词干提取
-
词性标注 (POS)
-
句子解析
-
文本分类
-
实体识别 (分块/剔除)
-
Pandas 和命名组的 RegEx
Hugging Face Transformers 文档
Hugging Face Transformers 文档是理解解决 NLP 问题的有效方式。你可以使用该文档学习 API 并在几分钟内训练大型语言模型。它支持 PyTorch、TensorFlow 和 Jax 框架。

图像来自 文档
你可以使用文档执行:
-
机器翻译
-
填补掩码
-
标记分类
-
句子相似度
-
问答
-
摘要生成
-
文本分类
-
文本生成
-
对话
-
文本到语音和自动语音识别
NLP 备忘单
NLP 备忘单涵盖了自然语言处理的各个方面。你将学习构建语言模型、处理序列输入和大词汇量以及上下文嵌入。这个备忘单适合希望深入学习和准备面试的专业人士。

图像来自 备忘单
在备忘单中,你将学习:
-
独热编码向量、Word2Vec 和 GloVe
-
N-gram 语言模型、RNN、深度双向 RNN、GRU 和 LSTM
-
Seq2Seq 模型和注意力机制
-
缩放 softmax 和基于词及字符的模型
-
ELMo、ULMFit 和 Transformer 模型
-
常见问题解答
结论
NLP 备忘单提供了简洁的信息,以复习遗忘的概念,并帮助我们在机器学习面试中取得成功。
我多次使用 NLP 备忘单,主要是在公司寻找具有 NLP 专长的机器学习工程师时。此外,我使用 带代码的论文来了解最新趋势。
希望你喜欢这些备忘单。别忘了关注我在 Twitter 和 LinkedIn上的动态,我会发布关于数据科学的精彩博客。
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些与心理健康问题作斗争的学生。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
更多相关话题
避免从事数据科学职业的 5 大理由
原文:
www.kdnuggets.com/2022/04/top-5-reasons-avoid-data-science-career.html
我们都目睹了数据科学是 21 世纪最性感工作的经典声明。
谁不想获得这样一种特权:确保每个人的金融交易无欺诈,让用户知道他们接下来想观看的是什么视频,并拯救这个世界免于崩溃呢?
数据科学不仅是一个听起来非常酷的工作,而且也是一个非常有回报的职业。因此,这个职业所需的技能必定有些特别。当我说你应该仔细规划数据科学职业时,我绝不是在贬低你学习统计学、概率论、线性代数和最前沿算法的能力。哦,我怎么能忘记编码技能的效率以及在人工智能领域突破的新事物上保持领先。
你可能在上述看似简单的技能清单中是专家,但仍可能无法在数据科学领域取得引人注目的职业成就。
每个人都是天才,但正如爱因斯坦所说:
如果你用鱼的爬树能力来评判它,它将一辈子相信自己很笨。
因此,这篇文章的目的是让你在进入数据科学这个闪亮的大世界之前,对典型数据科学家的性格特征有一个现实检查。
在避免对每个人在数据科学中取得巨大成功的能力进行泛化,并让他们争取一线机会的同时,本文旨在让你在跨入这一领域之前,提前评估自己是否已经做好准备。

来源:freepik pic1 和 freepik pic2
来吧。
1. 工作中的学习
你是否也觉得你在本科阶段学到的内容与实际工作中的内容之间存在巨大的差距?我个人确实有这种感觉。学习理论在数据科学中是不够的——你可能在 Kaggle 上进行了大量的 Titanic 练习,并在精心准备的数据上建立了情感分析。但在实际项目中工作则完全是另一回事。没有人会要求或建议你去构建完成特定项目所需的多项技能之一——你需要在工作中学习并完成任务。老兵们总是关注前沿的先进算法以及现有算法的优缺点。他们不会等待合适的机会敲响他们的门来戴上眼镜熬夜工作。基本上,他们从不陷入“我无所不知”的舒适区。

来源:由 makyzz 创建的背景矢量 - www.freepik.com
2. 挫折
你是否期望在第一次尝试时就能命中靶心并建立一个高度准确的模型?在通过改进 ML 流水线中的多个步骤来迭代模型时,你是否感到沮丧?
-
这可能涉及回到正确的数据收集,收集正确的代表性样本,以不仅用于训练,还用于推理。
-
如果你曾遭遇过错误标签,那么修正标签的责任在于你自己。
-
科学度量如精度、召回率或 RMSE 对于业务关注度最小。将科学数字转化为业务 KPI 并在你的工作中找到价值的责任在于你。
-
数据分布与训练集中的数据分布不同——欢迎进入数据漂移问题的套件。你需要找出何时以及用什么数据重新训练你的模型,以继续获得其回报。
-
你的旅程并未因生产中的一个体面的模型而结束,你需要花费时间记录你构建该模型的所有工作——谁告诉你数据科学是一个人的工作。成功需要一支团队的协作,而这支团队需要你提供的文档来保持一致。
-
在你获得向高管展示结果的荣耀之前,你需要不断重复你的解决方案和结果,以获得技术小组和管理层的批准。虽然这可以确保你的模型在早期接受审查,但有时这会有点困难,需要强大的耐力来应对重复的演示。

来源:由 freepik 创建的人物矢量 - www.freepik.com
3. 自我驱动
你是等待他人指示进行特定分析,还是足够有机会主义和好奇心来关联对业务最有利的事物,并提出改进投资回报率的好点子?你是否需要同行和经理的帮助和验证来确保你做得对,还是对自己的假设和分析有足够的信心?当大量数据摆在你面前时,很难知道从何开始——但那些不怕在数据中动手的人最终也会带回一大笔薪水,玩笑而已。
4. 每个企业都是不同的
如果一个组织拥有领域专家型的数据科学家,那他们真是幸运。我曾经在领域内坚持了一段时间,直到我意识到这限制了我的潜力,并限制了我可以在普遍层面上做出的贡献。
放弃领域标签的决定对我的职业发展至关重要。此外,你需要学习各种特定于组织的工具,因此灵活性是关键。检查一下你是否足够灵活以加入数据科学家的队伍。
5. 一切都关于实验
数据科学和实验是类似的。在对利益相关者喊出“尤里卡”之前,你需要尝试多种方法。你是否能够在经历多次失败后仍保持高容忍度,依然坚韧地以全新的视角看待业务问题?
通常,大多数数据科学家在 99%的时间里都失败了,但仍然能从剩下的 1%的尝试中创造出成功而稳健的解决方案。这一切都在于不断尝试。
移动指针所需的时间,即在构建机器学习模型时向前迈出一步,是非常疲惫和耗费精力的。
哦,还有人告诉你数据科学家将 80%的时间花在收集、清理和转换数据以使其“适合机器学习”,而只有 20%的时间用于实际的模型构建和分析。我敢打赌他们是这样说的。
你需要适应数据科学项目的迭代性质,并从容应对,否则在数据科学行业中生存下来将变得非常困难,更不用说繁荣发展了。
我的两分钱意见
我经常被问到——数据科学家做什么?这篇文章是我在行业中的第一手经验的汇编,同时也是对初入数据科学领域的人的指导。希望它能帮助你一窥真实的行业经验,并为你未来的挑战做好准备。
Vidhi Chugh 是一位获奖的 AI/ML 创新领袖和 AI 伦理学家。她在数据科学、产品和研究的交汇处工作,以提供商业价值和洞察力。她是数据中心科学的倡导者,也是数据治理领域的领先专家,致力于构建值得信赖的 AI 解决方案。
更多相关话题
机器学习项目失败的 5 个主要原因
原文:
www.kdnuggets.com/2021/01/top-5-reasons-why-machine-learning-projects-fail.html
评论
作者 Sudeep Srivastava,Appinventiv 首席执行官

我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
随着每份趋势报告将机器学习吹捧为有助于增长的技术,能够使各行业(跨部门和区域)对客户和收入更加友好,组织们也在效仿,并加倍努力采用机器学习。
尽管机器学习应用开发项目的数量明显增加,但项目失败的数量也几乎相等。机器学习项目失败率的增加在许多方面使得拥有出色 AI 想法的新企业避免实施这些想法。
我们今天文章的意图是帮助你了解机器学习项目失败的许多原因。我们希望这些信息能帮助你规划一个更好的实施方案,从而在机器学习执行的三个阶段:项目前期、项目实施期间和项目后期,降低失败的几率。
机器学习项目失败的主要原因
1. 数据不足
如果图表能告诉你什么,那就是成功的机器学习项目需要大量的数据。为了成功的机器学习项目,企业需要访问干净的数据——相关、有用、无误差且易于访问的数据。
除了拥有干净、结构化的数据外,数据还必须在一个地方——数据仓库、数据湖或某个数据平台——中随时可用,以便进行短期任务和大规模培训。
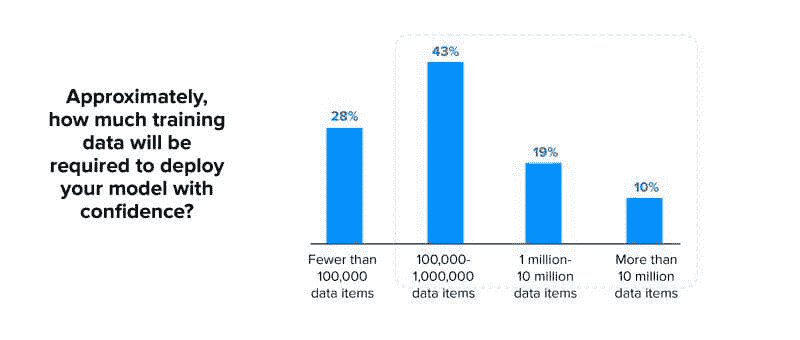
2. 机器学习模型与遗留系统不同步
根据数据科学家的建议,组织往往会添加旨在促进创新的模型,却没有考虑它们与现有“非数字化”文化和遗留系统的契合度。因此,尽管这些解决方案在市场上运行良好,但当与现有系统结合时,采纳的成功率几乎为零。
解决方案在于将从事机器学习项目的团队与管理遗留系统的团队汇聚在一起。随后,应规划项目的里程碑式部署,以帮助实现无摩擦的迁移和轻松采纳。
3. 数据科学家不足
市场上数据科学家严重短缺。虽然有很多工程师完成课程并自称为数据科学家,但真正具备深入分析复杂机器学习项目的技能的人极其有限。根据2020 年企业机器学习状况报告,虽然对机器学习专家的需求持续上升,但在填补这一角色方面的供应却急剧短缺。
4. 更新困难
随着时间的推移,机器学习项目往往会过时,无法继续作为解决业务问题的最佳方案。这通常发生在以下情况:
-
业务情况发生变化
-
用户需求的转变
-
更好的模型不断进入市场。
通常,更新现有机器学习模型既困难又耗时:在许多方面,它等同于建立一个新的数据科学项目。鉴于这些困难,组织通常倾向于继续使用该模型,直到它不再提供结果之后才停止。
5. 缺乏领导的支持
有时,领导者缺乏完成机器学习项目所需的耐心和技术信心。虽然他们支持该项目,因为其周围的声望,但他们却很少关注数据的可访问性、准确性、资金和人力资源需求等方面。
要使机器学习项目成功,确保所有人参与 —— 尤其是董事会成员 —— 是非常重要的,因为即使是他们的一个怀疑也可能导致团队的不安,这会在项目启动之前就注定失败。
离别的话
以上就是阻碍机器学习达到企业和行业所需采纳水平的主要挑战。
解决这些挑战的方案通常在于与一个了解新一代技术在非数字化组织中应用的商业和技术影响的熟练机器学习解决方案提供商合作。他们不仅可以帮助你制定如何整合机器学习项目的工作计划,还可以以最优化的方式采用新系统。
个人简介:Sudeep Srivastava 是 Appinventiv 的首席执行官,他以乐观与计算风险的完美结合而闻名,这种特质贯穿于 Appinventiv 的每一个工作流程中。通过建立一个在移动行业中开拓新思路的品牌,他花时间探索如何将 Appinventiv 推向技术与生活融合的巅峰。
相关:
-
当良好的数据分析未能交付预期结果时
-
学习构建一个端到端的数据科学项目
-
想成为数据科学家?不要从机器学习开始
相关阅读
2021 年最佳 6 个数据科学在线课程
原文:
www.kdnuggets.com/2021/07/top-6-data-science-online-courses.html
评论
照片由 Luke Chesser 提供,来自 Unsplash。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
对于初学者来说,想要进入数据科学行业,面对大量的信息容易感到不知所措。市场上有数百门数据科学课程,很难知道从哪里开始。
当我决定自学数据科学仅仅一年前,我记得自己感到非常迷茫,因为我不知道从哪里开始。我看到机器学习课程的广告,承诺三天内让我成为专家。我读到一些文章坚持认为,除非我拥有数学硕士学位和统计学博士学位,否则不可能成为数据科学家。信息太多了,意见也有很多冲突。
我终于成功地创建了自己的数据科学路线图,自学了编程和机器学习。我成功进入了行业并找到了数据科学的工作。
每天,至少有一个人问我我是如何做到的,如何从零开始学习数据科学并在行业中找到工作。我做了一些研究,并编制了一份你可以用来学习数据科学的在线课程列表。这些课程的教学大纲很好,会为你提供编程、SQL 和机器学习的坚实基础。我在作为数据科学家的日常工作中几乎使用了这些课程中教授的所有概念。
编程

照片由 James Harrison 提供,来自 Unsplash。
如果你想学习数据科学,首先需要学习编程。如果你没有编程经验,我建议从 Python 开始。
互联网上有大量的资源教你 Python 编程,其中一些包括:
这是一个从零开始的 5 门课程的专门课程。专门课程中的第一门课程称为《编程入门》。在这门课程中,你将学习 Python 的基本知识——语法、条件语句、迭代、函数和变量。
该课程不要求任何先修知识,你不需要有技术或数学背景即可开始学习此课程。
专门课程中的下一个课程将教你数据结构。你将学习如何从文件中读取数据并操作列表和字典等数据结构。
专门课程中的第三门课程教你使用 Python 访问网络数据。你将学习使用 API 从网站中提取数据,并使用 Python 处理这些数据。你还将学习从字符串中提取数据,并使用正则表达式清理数据。
接下来,你将学习如何使用 Python 访问和操作数据库。你将学习使用一个名为 SQLite3 的 Python 库操作 SQL 数据库。无需事先了解 SQL 或数据库,你将从头开始学习所有内容。
最后一门课程是一个综合项目。你将利用在其他课程中学到的所有概念,并在综合项目中构建一个端到端的项目。如果你通过了综合项目,你将获得课程证书。
该课程的最大优点是它教会你许多数据收集和存储技术,这些都是数据科学家必知的。
许多其他 Python 和数据科学课程跳过了这些主题,导致你对如何使用 API 或访问网络数据几乎一无所知。
这门入门 Python 课程分为四个部分——Python 基础、Python 列表、函数和 Numpy。
该课程涵盖了 Python 的所有基础知识,包括变量、数学运算、列表操作和函数。
它还教授了一个名为 Numpy 的库的基础知识,数据科学家常用它来操作数组。
该课程的 Python 基础部分是免费的,因此你可以先尝试这部分课程,看看你是否喜欢。
完成初级 Python 课程后,你可以在 DataCamp 上参加这个中级 Python 课程。
该课程将教你如何在 Python 中创建可视化,操作字典和列表,使用 Pandas 等库工作,并通过逻辑过滤数据框。
本专门课程的第一部分——使用 Matplotlib 进行数据可视化是免费的。你可以在决定是否购买整个课程之前先试用一下。
这门课程的一大优势是它教你数据科学中的 Python。它带你学习数据分析库,如 Pandas 和 Numpy,以及可视化工具,如 Matplotlib。
SQL

照片由 Caspar Camille Rubin 提供,来源于 Unsplash。
我给有志于成为数据科学家的最大建议是学习 SQL。我之前从未认为 SQL 是数据科学的重要部分。然而,当我做第一次数据科学实习时,我做的大部分工作都涉及 SQL 的数据处理知识。
为了学习 SQL,我建议你参加 Coursera 上的 SQL for Data Science 课程。
这是一个为期 4 周的课程,假设你没有任何数据库或编程知识。课程的第一部分从 SQL 的数据选择和检索开始。
然后,你将学习如何使用 SQL 中的运算符来过滤数据。作为数据科学家/分析师,根据客户需求过滤数据是我每天的工作内容,因此这门课程的内容非常重要。
在下一个课程中,你将学习 SQL 中的连接操作。你将学习如何将多个数据库链接在一起。这是一项非常强大的技术。我每天处理大型数据库,常常需要使用连接操作来合并它们。
数据科学

照片由 Arseny Togulev 提供,来源于 Unsplash。
到现在为止,你应该已经学会了编程基础。你也应该了解如何使用 Numpy 和 Pandas 进行数据分析,以及如何使用 Matplotlib 进行数据可视化。
现在,你可以进入机器学习领域。
该课程是 IBM 数据科学专业化的一部分。你可以将其作为独立课程学习,并获得该课程的证书,无需完成整个专业化课程。
这门课程将为你提供对机器学习算法的扎实理解。你将学习构建模型来解决监督式机器学习问题,如回归和分类。你还将学习无监督的机器学习算法,如层次聚类。
与 Andrew Ng 的机器学习专业化相比,参加这个课程的一个巨大优势是该课程完全使用 Python 教学。
这个课程还包括一个最终的总结项目,你需要通过它才能获得证书。
Datacamp 的机器学习课程被分为多个独立的课程——监督式机器学习、无监督机器学习、线性分类器和深度学习。
我建议先参加监督式机器学习课程。该课程的第一部分是免费的,所以可以试试看内容是否对你有用。如果你喜欢,可以考虑注册机器学习课程。
大多数在线机器学习课程仅涵盖不同算法的基础知识。这个 Datacamp 课程的一个主要优势是涵盖了像超参数调整和构建管道这样的主题。
当我在 Udemy 上第一次参加数据科学课程时,我的知识存在很多空白,因为我不理解像参数调整和降维这样的主题。我花了很长时间才找到合适的资源来弥补我的学习差距。
这个 Datacamp 的机器学习课程内容似乎非常全面,涵盖了其他课程通常不教授的很多内容。
概述
上面提到的课程列表将为你提供非常强大的数据处理和机器学习基础。然而,要真正成长为数据科学家,你需要超越这些课程。
在空闲时间开始做数据科学项目。根据这些课程中学到的概念,构建实际应用。你可以访问像 Kaggle 这样的站点,获取公开数据集并建立机器学习算法来对这些数据集进行预测。
参加这些课程将为你提供成为数据科学家所需的技能。你将需要通过参与项目来练习并磨练这些技能。
注意: 本文包含附属链接。这意味着,如果你点击并选择购买我上面链接的课程,你的订阅费用的一小部分将归我所有。作为创作者,这帮助我成长并继续创造这样的内容。然而,我只推荐我认为好的课程。上面推荐的课程大纲与我作为数据科学家每天的工作非常契合。**这些课程是我推荐给那些询问如何进入数据行业的人的,我相信它们在你的数据科学之旅中会有用。
感谢你的支持!
个人简介: Natassha Selvaraj正在攻读计算机科学学位,主修数据科学。Natassha 对机器学习领域感兴趣,曾参与过多个相关项目。
相关:
关于此主题的更多内容
数据科学家应该了解 Java 的 6 个主要理由
原文:
www.kdnuggets.com/2020/06/top-6-reasons-data-scientists-know-java.html
评论
由 Malcom Ridgers,BairesDev

我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
Java 是当今最受需求的编程语言之一。它是一种跨平台、实用且强大的语言。全球的开发者使用 Java 构建应用程序、网络工具和软件开发平台。Java 在机器学习和数据科学中也有重要用途。
如果你是数据科学家,你可能比起 Java 更常使用 Python 和 R。根据最近的调查,只有 21%的人在数据科学中使用 Java, 远低于 Python(83%)或 SQL(44%)。大多数人使用 Python 是因为它的 REPL 功能和快速的算法实验。同时,开发者使用 R 进行数据可视化和表示。
作为数据科学家,你应该知道如何使用 Java,因为它提供了创建商业应用程序的各种服务。如上所述,Java 在机器学习和人工智能领域有许多用途。许多大型公司如 Uber、Spotify 和 Airbnb 都是基于 Java 的。像 BairesDev 这样的软件开发公司 使用 Java 构建和维护业务关键应用程序。
数据科学家应该学习 Java 的理由有很多。主要包括:
1. Java 拥有许多出色的数据科学框架。 这些框架为开发者提供了基本功能,并帮助他们节省时间和金钱。流行的机器学习框架包括:
-
Deeplearning4J - 这是一个开源的 Java 深度学习工具包,用于部署神经网络。它可以与 Hadoop 和 Spark 集成。
-
ND4J - 它代表 N 维数组对象用于 Java。它是一个科学计算、信号处理和线性代数的工具包。它具有内置的库,如 numpy 和 MATLAB。
-
Apache Mahout - 这是一个可扩展的分布式代数框架。它有助于分类、聚类和推荐。
Java 也有许多用于数据处理的框架,包括:
-
Hadoop - 这个框架使用 MapReduce 算法在分布式文件系统中存储数据。
-
Kafka - 它使用基于 TCP 的协议进行消息集合抽象,以自然地将消息分组形成线性写入。
2. Java 易于理解。 大多数开发者在使用 Java 编码时感到自信。除了拥有广泛的用户基础外,Java 还是市场上最受追捧的技能之一,因为公司通常使用它来处理所有快速执行的项目。Java 还是一种遗留语言——即它在全球许多主要应用程序和公司中被使用。
3. Java 具有出色的可扩展性。 大多数开发者使用 Java 创建可以根据业务需求进行扩展的应用程序。如果你的公司正在从零开始构建应用程序,Java 是一个优秀的选择,因为 Java 提供了向上扩展和向外扩展的功能以及负载均衡选项。
作为数据科学家,你会发现用 Java 构建复杂应用程序并扩展它们很容易;例如,ApacheSpark 是一个可以用于扩展的分析工具。它也可以用于构建多线程应用程序。
4. Java 具有独特的语法。 Java 的独特语法因其易于理解而在全球范围内被接受。这种语法使开发者能够理解约定、变量要求和编码方法。Java 是强类型的——即每种数据类型都已预定义在语言结构中,所有变量都必须属于某种数据类型。
大多数主要公司为其代码库维护标准的语法。这样可以确保所有开发者按照生产代码库的约定进行编码。Java 帮助他们自动维护标准约定,开发者可以遵守这些约定。
5. Java 运行迅速。 大多数数据科学家使用 Python 进行数据科学应用。你会惊讶地发现,Java 的速度比 Python 快 25 倍。此外,如果你在寻找能够随时进行多重计算的应用程序,Java 的表现优于 Python。
不仅是处理速度,Java 开发在创建产品时所需的时间也比许多其他语言要少。它可以使用业务特定的开发工具,并拥有大量的 IDE 和成熟的功能来创建大规模的商业应用程序。
6. Java 和 OLTP 系统。 在线事务处理系统(OLTP),与数据仓库一起,通常使用主机系统进行批处理。Java 比其他语言更自然地与这种架构结合。您可以将 Java 与 COBOL 和中间件软件集成。
您还可以将 Java 与 OLTP 标准和架构结合使用。对于那些希望投资于在大规模系统上执行数据分析且具有事务处理设计的应用程序的公司,Java 非常合适。
结论
Java 是一种面向对象的、功能多样且独特的语言,提供大量功能。其卓越的性能和速度使其成为市场上最受欢迎的技能之一。它还提供安全功能、网络中心编程和平台独立性。
对于数据科学家,Java 提供了一系列数据科学功能,如数据分析、数据处理、统计分析、数据可视化和 NLP。Java 可以帮助将机器学习算法应用于实际应用程序。它允许您基于批处理和流处理技术构建自适应和预测模型。加上 REPL 和 Lambda 表达式,它简化了大规模应用程序的创建。
如果您正在考虑将 Java 应用于数据科学项目,请毫不犹豫。这是一种非常适合数据科学家和数据工程师的语言。
简介:Malcom Ridgers 是一位专注于软件外包行业的技术专家。他掌握最新的市场动态,并对创新和技术业务的未来充满敏锐的洞察力。
相关内容:
-
Java 可以用于机器学习和数据科学吗?
-
AI 如何帮助管理传染病
-
如何将 Kubeflow 添加到您的 Kubernetes 部署中
更多相关话题
提高你在 Snowflake 上的生产力的 6 大工具
原文:
www.kdnuggets.com/2023/08/top-6-tools-improve-productivity-snowflake.html
编辑者提供的图片
Snowflake 彻底改变了企业存储、处理和分析数据的方式,提供了无与伦比的灵活性、可扩展性和性能。但像任何强大技术一样,为了真正利用其潜力,拥有合适的工具至关重要。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
本文是你在使用 Snowflake 时提升生产力的 6 大工具指南。无论你是在处理数据、整合各种数据源、创建精美可视化还是得出可操作的见解,这些工具都能提升你的效率和效果。
因此,让我们深入探索这些能将你的 Snowflake 操作提升到新水平的生产力工具。
数据准备工具
1. Datameer
图片来自Datameer
Datameer 是一个自助数据准备工具,旨在使处理大数据变得更加可管理。它致力于简化过程并节省时间。
特点:
-
数据发现: Datameer 提供了一个可视化界面,使你更容易探索和理解数据。它的目的是将复杂的内容转变为更易于消化的形式。
-
数据准备: 使用 Datameer,你可以清理、转换和丰富你的数据,为分析做好准备。最棒的是,你不需要深入复杂的编码或脚本。
-
数据探索: Datameer 提供了一系列数据可视化工具,允许你与数据互动。其目的是快速有效地获得洞察。
-
集成: Datameer 可以连接到各种数据源,从传统数据库到复杂的云数据湖。它的目的是将你的所有数据集中在一个地方。
优点:
-
Datameer 的用户友好界面简化了数据发现、准备和探索过程。
-
其数据准备功能允许你清理、转换和丰富数据,而无需复杂的编码。
-
Datameer 能够与各种数据源集成,提供所有数据的统一视图。
缺点:
- 尽管 Datameer 提供了广泛的功能,但可能超出了某些小型企业的需求。
定价:
Datameer 的定价 未在其网站上公开,但你可以与他们的团队安排一次快速通话,以获得满足你团队需求的个性化定价。
使用案例:
假设你是一家大公司的数据分析师。你处理来自各种来源的数据,包括传统数据库和复杂的基于云的数据湖。
使用 Datameer,你可以连接这些数据源,准备数据并在一个超级互动的环境中探索数据。关键在于快速获取洞察,做出推动业务前进的数据驱动决策。
视频下面讨论了 Datameer 和 Snowflake 的一些合作情况。
数据可视化工具
2. Tableau

Tableau 是数据可视化领域的领先工具。它直观的界面和拖放功能使其成为技术用户和非技术用户的友好选择。
Tableau 和 Snowflake 之间的无缝集成使你能够直接从 Snowflake 数据仓库提取数据,将其转化为可操作的洞察。
关键功能:
-
互动仪表盘: 通过互动仪表盘探索和理解你的数据。
-
数据混合: 从多个来源混合数据,以获得全面的数据视图。
-
实时数据分析: 基于最新的数据进行决策,具有实时分析能力。
推荐理由:
Tableau 的用户友好界面和强大的数据可视化能力使其成为希望实现数据访问民主化的企业的绝佳选择。其与 Snowflake 集成带来的流畅数据分析工作流程是另一个重大优点。
定价详情:
Tableau 提供一系列 定价选项,根据你的需求,从每用户每月 70 美元的 Tableau Creator 开始。Tableau Explorer 和 Tableau Viewer 提供更少的功能,价格更低。
学习曲线:
尽管其界面直观,但掌握 Tableau 仍然需要一定的学习曲线。幸运的是,丰富的资源,包括 教程、网络研讨会 和强大的社区,可以帮助用户快速上手。
社区和支持:
Tableau 拥有一个庞大且活跃的用户社区,总是随时准备提供帮助。此外,Tableau 的客户支持也非常出色,提供了全面的知识库、实时支持和专门的支持团队。
用例:
各种规模和行业的企业都转向 Tableau 进行数据可视化。无论是创建交互式仪表板、执行临时分析还是生成报告,Tableau 都能满足你的需求。
数据集成/ETL 工具
3. Fivetran
图片来自 fivetran
Fivetran 是一个基于云的数据集成工具,专注于自动化数据管道。它旨在消除数据集成的麻烦。
功能:
-
自动化数据管道: Fivetran 负责设置、维护和扩展你的数据管道,就像有一个专属的数据管道经理。
-
预构建连接器: Fivetran 提供数百个预构建的连接器,使你可以轻松集成来自各种来源的数据,包括 Snowflake。
-
数据转换: Fivetran 支持在数据仓库内进行数据转换,允许你在数据存储位置直接转换数据。
为何脱颖而出:
-
Fivetran 的自动化数据管道消除了数据集成中的手动工作。
-
它的预构建连接器使得从各种来源集成数据变得简单。
-
Fivetran 对数据仓库内数据转换的支持可以提高数据处理的效率。
注意事项:
-
Fivetran 的高级功能可能需要初学者适应一段时间。
-
Fivetran 的成本可能成为小型组织或初创企业的障碍。
定价:
Fivetran 的定价是 按使用计费,意味着你只需为每月使用的月活跃行(MAR)付费。他们为任何新的连接器提供 14 天的免费使用期,让你在承诺之前可以预测使用情况和定价。
商业智能工具
4. Looker
图片来自 getapp
Looker 是一个现代的商业智能平台,让你公司中的每个人都能从任何地方做出明智的决策。其核心是通过数据赋能用户。
主要功能:
-
自助分析: Looker 允许用户通过几次点击实时探索和发现洞察。它的目标是让数据对每个人都可访问。
-
数据建模: Looker 强大的数据建模层让你可以一次性定义业务指标和逻辑,然后在整个组织中一致使用这些定义。
-
集成: Looker 与 Snowflake 无缝集成,让你能够利用现有的数据仓库。
你可能喜欢的原因:
Looker 的用户友好界面和强大的数据建模能力使其成为希望民主化数据访问的企业的绝佳选择。此外,其与 Snowflake 的集成确保了顺畅的数据分析工作流程。
定价详情:
Looker 的定价 未在其网站上具体披露,但你可以直接联系他们以获取根据你具体需求的报价。
数据治理工具
数据治理涉及数据的管理和保护,确保数据的可靠性、一致性和可访问性。我们在数据治理工具中寻找的理想特性包括:
-
它们应提供全面的数据治理能力,包括数据质量、主数据管理、数据隐私和数据目录。
-
它们应与其他数据平台(包括 Snowflake)无缝集成。
-
它们应易于使用,使组织能够轻松建立强大的数据治理框架。
这一类工具有很多选择。最受欢迎的包括 Collibra 和 Informatica 等。
5. Collibra
图片来自 productresources
Collibra 是一个全面的数据治理平台,提供管理、治理和理解数据的工具。它旨在帮助组织最大化数据的价值。
Collibra 以其强大的数据治理能力、用户友好的界面和广泛的集成选项(包括 Snowflake)脱颖而出。它是那些希望建立强大数据治理框架的组织的绝佳选择。
Collibra 的定价未在其网站上公开,但你可以 直接联系他们 以获得根据你具体需求的报价。
6. Informatica
图片来自 firsteigen
Informatica 是数据集成软件和服务的领先供应商。它提供了一套数据治理工具,旨在确保数据质量、合规性和安全性。
Informatica 结合其全面的数据治理工具套件和强大的数据集成能力,是那些希望提升数据治理的组织的强大选择。此外,它与 Snowflake 的无缝集成使你能够利用现有的数据仓库。
Informatica 更愿意 直接与客户讨论定价,以提供个性化的报价。
结论
现在你已经了解了可以显著提升你在 Snowflake 上生产力的有用工具。这些工具是全球数据专业人士依赖的工具,用于简化工作流程,从数据中获得洞察,并推动决策制定。
但请记住,虽然这些工具都提供了很棒的功能,但考虑它们如何与 Snowflake 集成也很重要。例如,Datameer,据我所知,可以与 Snowflake 无缝集成。这是因为它是专门为 Snowflake 构建的。
探索这些工具,试用它们的功能,看看哪一款最适合你。当然,我们也很想听听你的经历。
你之前使用过这些工具吗?还有其他你非常推荐的工具吗?在评论区分享你的想法,让我们继续讨论吧!
Ndz Anthony 是一位资深 BI 分析师和导师。他喜欢通过与商业智能和企业分析相关的写作进行教育。
更多相关内容
数据科学初学者的前 6 名 YouTube 系列
原文:
www.kdnuggets.com/top-6-youtube-series-for-data-science-beginners
图片由编辑提供
学习新技能可能让人感到望而却步,尤其是当你花费大量时间寻找合适的课程、大学学位或训练营时。在你花费一分钱之前,首先使用可用的免费资源。试试看,看看你是否喜欢,在线学习大部分内容后再决定是否进行认证。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
在这篇文章中,我将介绍每个数据科学初学者都需要收藏的前 X 名 YouTube 系列!
使用 freeCodeCamp 学习 Python
链接: freeCodeCamp
当很多人考虑进入数据科学领域以及学习哪种编程语言时,许多人自然会选择 Python。这是有原因的。它被认为是最好的编程语言之一,并且已经连续多年来名列第一。它包含各种库和框架,并使用易读的代码。
freeCodeCamp 链接的 YouTube 系列是一个 4.5 小时的视频,涵盖了所有内容,让你能够成为 Python 程序员。该视频也提供西班牙语、阿拉伯语、葡萄牙语或印地语版本。
使用 StatQuest 学习统计学
链接: StatQuest
很多训练营有时不会涉及一些对数据科学世界至关重要的元素——统计学就是其中之一。根据个人经验,我进入数据科学领域时对统计学几乎没有理解,因为我的课程从未涉及这方面的内容。我不得不回过头去重新学习很多东西——正确的方式!
在这段旅程中,StatQuest 的 Josh Starmer 让统计学变得有趣且易于学习。统计学对数据科学很重要,也对你的职业发展至关重要。它使你能够更好地理解数据科学是什么以及在创建解决方案时它在整个数据科学工作流程中的重要性。
使用 3Blue1Brown 学习数学
链接: 3Blue1Brown
在学习数据科学的统计/数学方面时,深入一点没有坏处。我这样说是因为这将有利于你的数据科学学习和职业发展。3Blue1Brown是一个以动画形式讲解数学的 YouTube 频道。
频道中有一系列深入探讨线性代数、神经网络和中心极限定理的内容,这将对你的数据科学学习非常有帮助。
使用 DataCamp 进行数据清理
链接:DataCamp
作为一名数据科学家,你将处理大量的数据(这很明显,对吧?)。但在处理数据时,你需要记住,很多数据将会是混乱的,你需要花时间清理数据。这是数据科学工作流程中的第一步,也是非常重要的一步。
在这个与 Data Camp 合作的 YouTube 视频中,你将学习如何获取干净且一致的数据及其不同的技术。实时培训将让你了解你将遇到的数据清理挑战。
使用Krish Naik进行机器学习
链接:Krish Naik
机器学习现在非常热门,而且只会变得更大。在你的数据科学学习旅程中,理解机器学习的复杂性非常重要——这就是为什么我会推荐Krish Naik。
这个链接的视频是对机器学习的 6 小时讲解。我不期望你一次性看完,但在这 6 小时的视频中,你将学习到机器学习的不同方面,从线性回归算法到聚类算法。在学习这些内容时,你将开始理解为什么理解统计学在数据科学中很重要——事情会开始变得有意义。
使用 Simplilearn 进行数据可视化
链接:Simplilearn
在处理数据时,你的工作不仅仅是学习如何清理数据和生成决策过程中的输出。作为数据科学家的一部分,你还需要将你的输出转化为数据可视化。这是为了以其他形式呈现数据,并满足那些技术能力不强的利益相关者。
在这个 Simplilearn 的 YouTube 系列中,你将学习如何使用 Matplotlib、Seaborn 和 Bokeh 创建数据可视化。系列结束时,你将通过分析数据并直观地发现模式,成为数据可视化的专家。
总结一下
一旦你掌握了数据科学的这 6 个方面,你将拥有大量知识和技能,继续学习更具特色的领域,如深度学习或自然语言处理。
免费开始你的数据科学之旅,观看这些 YouTube 系列!
尼莎·阿雅是一名数据科学家、自由技术写作人员,同时也是 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及基于理论的数据科学知识。尼莎涵盖了广泛的主题,并希望探索人工智能如何促进人类寿命的不同方式。作为一个热衷学习的人,尼莎致力于拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关主题
数据科学领域的前 7 大 VSCode 替代品
原文:
www.kdnuggets.com/top-7-alternatives-to-vscode-for-data-science

图片由作者使用 Canva 创建
最初发布于Statology。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
在数据科学和机器学习领域,选择合适的代码编辑器可以显著提高生产力和优化工作流程。以下是一些本地和基于云的 Visual Studio Code 替代品,专门针对数据科学需求。
注意: 各种 IDE 的评价基于我的个人观点和经验。
1. Cursor
Cursor已成为我最喜欢的集成开发环境(IDE)。它具备 VSCode 提供的所有功能。整个代码编辑器为希望快速而准确完成任务的开发者打造,借助 AI 的帮助。Cursor 理解你的代码源,并建议更相关的结果。它比 GitHub Copilot 更出色,拥有许多你会立刻爱上的功能。我在数据科学、机器学习、Python 编程和编写教程中使用过 Cursor。它是我解决代码相关问题的主要工具。

2. Jupyter Notebook
如果你刚开始接触数据科学或已经是该领域的专家,你一定会使用Jupyter Notebook进行日常任务。它被专业人士高度推荐用于撰写数据报告、实验 Python 代码、构建和测试机器学习模型,甚至在生产环境中部署笔记本。它简单且功能丰富,使得数据任务变得容易。现在,Jupyter Notebook 还配备了 AI 助手,可以帮助你生成代码和自动完成。

3. RStudio
如果你在进行数据科学项目时使用 R 语言,那么 RStudio是最佳工具。你可以像使用 Jupyter Notebooks 一样运行 R 笔记本,但功能更强大,并且配备了令人惊叹的功能,让数据可视化和算法测试变得有趣且简单。RStudio 非常适合初学者,如果他们从未使用过任何 IDE。它简单,配备了必要的工具,使你的工作更轻松。

4. Kaggle
Kaggle平台提供了云笔记本,让你可以使用由社区成员分享的数据集、模型和 Python 包来进行数据科学项目。它提供了免费的 GPU 和 TPU 计算,并且提供了无限使用 CPU 计算的机会。你可以保存你的笔记本,与他人分享,甚至参加竞赛赢得奖金。Kaggle 平台的主要优势是其免费访问云笔记本,这使得资源有限的人也能轻松入门数据科学。

5. Deepnote
Deepnote是一个免费的云笔记本,配备了 AI 工具和多种数据集成。它类似于你的本地 IDE,你几乎可以做任何事情:构建应用,生成数据报告,或实验多种机器学习模型。它是我进行代码和数据相关任务的第二个首选工具。它易于使用,配备了令人惊叹的功能,可以让你成为超级数据科学家。我非常喜欢这个平台,希望你也能尝试一下。

6. Google Colab
如果你在寻找一个简单的 IDE 来处理机器学习和深度学习任务,那么你应该看看Google Colab。它提供了免费的但有限的 GPU 和 TPU 访问,并提供免费的 AI 代码生成工具。数据专业人士广泛使用它,每个新的数据工具都有教程发布在 Google Colab 上。它简单、快速,拥有足够的功能来构建和测试数据应用。

7. Amazon Sagemaker Studio Lab
如果你想提升你的 Google Colab 使用体验,那么你应该查看一下 Amazon Sagemaker Studio Lab。它每天提供 8 小时的免费 CPU 和 4 小时的 GPU 计算,并且提供了所有 JupyterLab 提供的必要工具。它快速且适用于各种机器学习深度学习任务。你可以用它来构建你梦寐以求的 AI 应用。

结论
选择正确的 IDE 很重要,因为它可以帮助你更快地学习数据科学,并帮助你应对在学习数据科学和机器学习过程中出现的各种问题。如果你想听我的建议,我建议你从 Kaggle 笔记本开始。它提供了一个预先构建的环境,意味着你不需要设置任何东西,并且它配有成千上万的数据集,你可以立即开始使用。它是完全免费的,并且有社区集成。在掌握编程语言后,我建议你考虑尝试其他适合你的替代方案。目前,Cursor 对我来说表现得非常出色,但未来可能会根据我的工作需求而有所变化。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理疾病困扰的学生构建 AI 产品。
更多相关话题
旅游行业的七大数据科学应用案例
原文:
www.kdnuggets.com/2019/02/top-7-data-science-use-cases-travel.html
评论
由 ActiveWizards 提供

我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT 部门
数据科学为许多行业带来了新的奇妙机会。与这些可能性同时出现的还有不断变化和挑战。旅游和旅行行业也不例外。
旅游业目前正处于上升期。这可以解释为其已变得对更广泛的受众可负担得起。因此,目标市场发生了显著变化,比以往更为广泛。这不再是富裕和贵族的特权。此外,旅游和旅行已成为全球趋势。
为满足不断增长的消费者需求并处理大量数据,数据科学算法至关重要。大数据成为航空公司、酒店、预订网站等各类服务提供商在提升服务方面的关键工具。让我们探讨几个在旅游行业中广泛应用且高效的数据科学案例。
个性化营销和客户细分
人们在某种程度上倾向于欣赏旅行体验的个性化。客户细分意味着根据客户的偏好将所有客户分开,并调整服务堆栈以满足每个群体的需求。因此,关键思想是找到一种适用于所有情况的解决方案。个性化则是一个能够为特定人提供具体服务的技巧。因而,个性化使这一过程更加深入。
个性化营销和客户细分涉及收集用户行为和元数据、CRM 数据、地理位置数据、社交媒体数据,以统一、处理并预测用户未来的偏好。对于旅游行业而言,这些知识至关重要。
客户情感分析
情感分析是无监督学习的一个分支,旨在分析文本数据并识别文本中的情感元素。情感分析使公司所有者或服务提供商能够了解客户对其品牌的真实态度。对于旅行行业来说,客户评价起着重要作用。旅行者通常会阅读在各种网络平台和网站上发布的评论,并据此做出决定。这就是为什么许多现代预订网站将情感分析作为其服务包的一部分,提供给那些希望合作的旅行社、酒店和旅馆。
推荐引擎
一些专家常常将这种用例视为最有效和最有前景的之一。重要的旅行和预订网络平台正在积极使用推荐引擎来进行日常工作。
这些推荐通常是通过将客户的愿望和需求与现有的优惠进行匹配来提供的。一般来说,通过应用数据驱动的推荐引擎解决方案,旅行和旅游公司可以根据之前的搜索和偏好提供租赁交易、替代旅行日期、新的路线、目的地和景点。由于推荐引擎,旅行社和预订服务提供商能够向所有客户提出合适的报价。
路线优化
路线优化在旅行和旅游行业中扮演着重要角色。考虑到不同的目的地、时间表、工作时间和距离,旅行规划可能非常具有挑战性。这就是旅行路线优化的意义所在。
这一优化的关键目标如下:
-
旅行成本最小化
-
时间管理
-
距离最小化
因此,旅行路线优化在提升客户满意度方面发挥了重要作用。
旅行支持机器人
如今,旅行机器人正在真正改变旅行行业,通过提供卓越的旅行安排协助和客户支持。一个 AI 驱动的旅行机器人可以回答问题,节省用户的时间和金钱,组织旅行并建议新的访问地点。24/7 的可访问模式和多语言支持使得旅行机器人成为客户支持的最佳解决方案。
这里最重要的一点是,这些机器人不断学习,因此它们每天都变得更聪明,更有帮助。因此,聊天机器人能够解决主要的旅行和旅游任务。将机器人集成到您的网站中将非常有利。像 JetBlue、Marriott、Ryanair、Hyatt、Hipmunk、Kayak、Booking 等许多公司对此深信不疑。
分析
在获得竞争优势方面,公司寻求最大限度地利用大数据。在决策和行动中,旅行和旅游公司在很大程度上依赖于分析。实时分析和预测分析在旅行行业中有许多应用。
实时分析
实时分析在旅游业中最生动的应用之一是旅游分析。旅游预测模型可以预测特定时期和客户群体的旅行活动。它们的主要任务是识别长期和短期的新交易机会。通过分析以往客户的活动、偏好和购买,企业可以预测未来的商业扩展机会。

预测分析
预测分析在动态定价和公平预测中得到了应用。动态定价和公平预测的实践在旅游业并不陌生。每年,越来越多的公司采用这一技术来吸引尽可能多的客户。
众所周知,价格会随着季节、天气、供应商以及场所、座位和房间的可用性不断变化。借助智能工具,可以同时监控多个网站上的这些价格变化。自学习算法能够收集历史数据,并考虑所有外部因素来预测未来的价格走势。
例如,在酒店行业,这些算法通常用于完成以下任务:
-
避免对不需要特别促销的日期进行折扣
-
提高周末的价格
-
维护官方网站与第三方订票服务提供商之间的信息相关性。
结论
数据科学正在改变旅游业的面貌。它帮助旅游和旅行企业提供独特的旅行体验和高满意度,同时保持个人化的接触。近年来,数据科学已成为最有前途的技术之一,为各个行业带来了变革。它改变了我们的旅行方式和对旅行安排的态度。本文中介绍的用例只是冰山一角。通过应用数据科学和机器学习提供的各种解决方案,旅行业务可以了解客户的需求和偏好,以提供最佳的服务和优惠。
ActiveWizards 是一个专注于数据项目(大数据、数据科学、机器学习、数据可视化)的数据科学家和工程师团队。核心专长领域包括数据科学(研究、机器学习算法、可视化和工程)、数据可视化(d3.js、Tableau 等)、大数据工程(Hadoop、Spark、Kafka、Cassandra、HBase、MongoDB 等)和数据密集型 Web 应用程序开发(RESTful APIs、Flask、Django、Meteor)。
原文。经许可转载。
相关:
-
实用的 Apache Spark 10 分钟
-
2018 年数据科学的前 20 个 Python 库
-
经理的基础数据科学简介
更多相关内容
信任与安全中的前 7 大数据科学应用案例
原文:
www.kdnuggets.com/2019/12/top-7-data-science-use-cases-trust-security.html
评论

我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT
信任和安全是什么?在现代世界中,信任和安全的角色是什么?
我们常常在众多网站和平台上遇到“信任与安全”这个词组。它旨在调节访问者与专家之间的互动,以确保其公平和和平。
从电子商务网站到社交网络,所有平台都需要防止欺诈并为访问者提供高水平的安全性。这些平台尽力赢得访问者的信任。安全可靠的平台预计会被各种各样的人群积极访问,他们渴望沟通、购买、学习等。信任和安全这两个词经常一起使用并不奇怪。这些术语本质上紧密相关。信任是一个多维概念。对品牌、来源等的信任增强了潜在用户的信心和安全感。
欺诈检测
消费者的期望增长极快。所有客户都希望获得优质的体验。因此,建立数字信任和安全对众多服务和产品提供商来说变得至关重要。高层管理人员必须尽力组织一个有效的欺诈管理系统,因为如今保持领先于欺诈变得前所未有的困难。
欺诈和网络犯罪使用先进的技术和方法,这些方法难以检测。改进在线非法活动的复杂机制正在不断发展。多年来建立的客户信任可能在信任违规事件后变成浪费时间。
传统的欺诈检测操作涉及欺诈筛查团队与欺诈检测软件合作,以汇总和整合历史数据。得益于数据科学、算法和 AI 驱动的解决方案,欺诈相关损失的发生率可以最小化。
关于一些现实生活中的例子:
-
Sift Science,全球欺诈检测系统,使用机器学习技术来预测欺诈行为。
-
Yelp、Airbnb 和 Jet.com 使用数据洞察来保护自己免受内容和促销滥用、支付欺诈、虚假账户和账户接管等威胁。
通过应用智能数据技术,声誉风险可以显著降低。前瞻性的组织使用这些创新来检测欺诈、减少退款、进行社区管理和社区监控。
行业知识
增强行业知识带来竞争优势,有助于任何业务的成长。跟踪当前趋势、最新新闻和创新将帮助你确保专业成长和客户信任的高水平。
对个人数据不断增长的需求要求发展策略以提高信任和安全。想一想吧。公司希望客户向他们支付费用并分享个人详细信息,包括信用卡号码等。信任与安全团队已经成为许多公司和组织的组成部分——一个不可避免的部分。这些团队通常关注客户数据保护和防止欺诈活动。
数据科学家作为信任与安全团队的宝贵成员,专注于身份、安全和数字互动问题。数据科学家致力于开发和扩展数据基础设施,进行深入分析,优化统计算法和模型,以提升战略决策。
信任与安全团队努力保护和执行信任与安全策略,解决客户争议,促进金融交易等。他们的职责范围通常取决于公司或组织的类型以及他们所代表的业务领域。
价格优化
公司不再能期望迅速实现高销售。客户在购买习惯和决策上变得越来越复杂。提供的商品和服务种类繁多、质量高、价格优惠对决策过程有重大影响。
价格是一个重要的管理决策。应考虑三种类型的因素:支付意愿、增量利润、目标和约束。智能价格优化包括大数据分析解决方案,帮助预测客户对价格变化的反应,以最大化销售和盈利。
在价格优化中,安全性至关重要。计算的可靠性是最关键的问题之一。这里还提供了对价格螺旋的保护。各种智能预测和警报机制被应用于价格优化范围内,以预测和检测负面影响。
高效的价格优化管理系统使公司在客户眼中更具可靠性。
提升你的技能,与数据科学学校一起学习
对人工智能的信任
信任对互动至关重要。对人工智能的信任可以显著改善客户体验。人工智能引擎和算法可以经过训练以执行各种任务,并促进信任与安全的改善过程。
将人工智能引入信任和安全改进过程为公司和组织开辟了新的机会。借助人工智能驱动的软件,他们现在可以在用户进行欺诈之前检测并禁止可疑活动。此外,还出现了禁止来自同一来源的 IP 的选项,如果该来源被视为不可靠。
人工智能模型可以通过内部和外部数据来检测各种因素。因此,公司可以防止支付欺诈、账户接管或账户滥用。此外,人工智能的引入还减少了偏见。研究发现,人工智能解决方案能够检测到 人眼可能忽视的隐性偏见,但这些偏见却可能造成严重问题。数据科学家能够防止偏见渗入他们的算法和模型,同时保留有用的偏见。
机器人
近年来,聊天机器人显著提高,已经达到了在对话过程中难以区分聊天机器人和人类的阶段。聊天机器人广泛存在。因此,每分钟都有大量的个人数据在聊天机器人之间传输。
个人身份信息的收集对于聊天机器人的操作至关重要。因此,它们可能成为攻击或欺诈的对象。在这种情况下,限制和隐私边界必须被精确定义。信任在信托者在很大程度上依赖于受托人的情况下至关重要。聊天机器人的可靠性可以通过信任评分来确定。信任评分是一种交易登记机制,包含成功验证的交易。
此外,聊天机器人还必须处理滥用行为。除了识别来自客户的滥用行为外,聊天机器人还必须避免滥用他人。
网络安全
在现代世界中,设备和数据的连接性增加了风险。为了最小化这些风险,组织投资于信任和安全团队。
信任与安全团队努力提供高水平的客户安全,并消除欺诈活动。信任与安全团队的关键利益之一是政策执行。
网络安全是一个较高层次的问题。网络安全涵盖了更广泛的范围和问题。其关键任务是保护所有有价值的数据。因此,信任和安全以及网络安全是相互依存的。网络安全拥有大量技术和措施以确保数据的完整性、机密性和可用性。对这些技术以及大规模数据管理和存储系统的信任问题比以往任何时候都更为重要。在个人和财务数据安全问题上,风险每天都在增加。公司和组织面临着寻找新方法以提供足够的安全水平和鼓励客户信任的需求。
由 AI 增强的高级安全工具、实时分析功能和预测算法扩大了保护网络攻击的行动范围。
分析
高级和预测分析技术和系统在公司或组织的信任和安全水平上起着重要作用。高级和预测分析已应用于安全的各个方面,并证明了其效率。
适当的数据分析策略可以解决许多问题。例如,预测分析可以用于事件预测和数据驱动的决策。
此外,分析有助于确定信任丧失的地方。大数据分析提供了监控和分析以前公司无法看到的过程的机会。大数据安全工具涵盖了安全信息和事件管理技术以及性能和可用性监控技术。因此,大数据分析工具可以快速发现网络上的设备并支持事件响应工作流程。
结论
我们生活在一个个人数据因各种网站、平台、媒体和网络的活跃使用而变得公开的时代。通过注册、进入不同系统、在线支付等过程获得的数据,对客户和公司都具有极大的价值。此外,这些信息也引起了诈骗者和公司竞争对手的兴趣。
鼓励客户信任并确保安全感在当今是一项具有挑战性的任务。数据科学通过其智能算法、模型和创新方法成为这场战争中的可靠武器。
随着在线互动的增加,对信任和安全的数据驱动工具和技术的投资也在增加。信任和安全措施的重要性比以往任何时候都更加关键。
ActiveWizards 是一个由数据科学家和工程师组成的团队,专注于数据项目(大数据、数据科学、机器学习、数据可视化)。核心专长领域包括数据科学(研究、机器学习算法、可视化和工程)、数据可视化(d3.js、Tableau 等)、大数据工程(Hadoop、Spark、Kafka、Cassandra、HBase、MongoDB 等)以及数据密集型网络应用开发(RESTful APIs、Flask、Django、Meteor)。
原文。经许可转载。
相关内容:
-
能源和公用事业中的前 10 大数据科学用例
-
金融领域的前 7 大数据科学用例
-
营销中的前 8 大数据科学用例
更多相关主题
前 7 大扩散基础应用及演示
原文:
www.kdnuggets.com/2022/10/top-7-diffusionbased-applications-demos.html

图片由作者提供
我每天都会看到新颖而激动人心的扩散基础应用,完全无法停下来。我看到用于艺术生成的 Photoshop 插件、提供 AI 编辑的网络应用、替换照片中对象的软件以及 3D 扩散。DALLE-2 和 Stable Diffusion 模型已经永远改变了 AI 领域。
我们的前三大课程推荐
1. Google Cybersecurity Certificate - 快速通道进入网络安全职业。
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你所在组织的 IT
在这篇博客中,你将了解到使用扩散基础模型的前 7 大应用。我还提到了应用演示的链接,以便你可以免费测试它们。
如今,研究人员正使用多模态技术来提升机器学习模型的能力。你可以从这些应用中学习,并为毕业项目、研究论文和产品研究提出独特的想法。
Diffuse The Rest
Diffuse The Rest 允许你绘制图画,并通过使用提示生成高质量的逼真艺术。在下面的示例中,我绘制了两个圆圈,并写下了提示“神奇的雪人”以生成高质量的艺术作品。
你甚至可以深入添加更多的线条和颜色,以获得更好的效果。
图像来自 HuggingFace Spaces 演示
Stable Diffusion For Videos
Stable Diffusion For Videos 是一个令人惊叹的项目,它接收两个或更多提示并将其融合以创建视频。它看起来非常真实。它通过探索潜在空间并在文本提示之间变形来构建视频。
你可以在 Hugging Face Space、Replicate 上测试,或者在 Google Colab 上运行。
动图来自 Replicate 演示
潜在扩散
Latent Diffusion 是另一种 OG 文本到图像的 Stable Diffusion 模型版本。演示提供了更多的配置能力,如图像大小、图像质量和多样性尺度。对于初学者,你需要写一个描述性的提示,以生成高质量的图像。
图片来自 HuggingFace Spaces 演示
Stable Diffusion Infinity
Stable Diffusion Infinity 允许你使用窗口和提示来扩展你的图像或艺术作品。如你所见,创作者生成了连衣裙,并扩展了空间以增加深度。
你应该亲自尝试一下。
这只是一个单一示例。你还可以上传多张图像并尝试将它们融合。如果你在提示中什么也不写,它会自动填充该区域。
动图来自 lkwq007/stablediffusion-infinity
Stable Diffusion Conceptualizer
一个 Stable Diffusion Conceptualizer 使用提示和风格标签生成具有特定艺术风格的图像。你可以浏览所有不同的风格,将标签复制粘贴到你的提示中,创造出杰作。我玩各种艺术风格时乐趣无穷。

图片来自 HuggingFace Spaces 演示
Runway Inpainting
Runway Inpainting 是一个简单但强大的工具,可以删除或替换图像中的对象。它挑战了 Photoshop 的主导地位。你可以通过高亮和编写提示来编辑图像。
如你所见,我已经将男人的脸换成了狮子。效果很干净。你可以去掉帽子、替换鞋子,或者在图像中添加对象。图像编辑的可能性是无限的。

图片来源于 HuggingFace Spaces 演示
Whisper To Stable Diffusion
Whisper To Stable Diffusion 是一个方便的工具,用于将语音转换为文本,并利用其生成图像。你甚至可以编辑预测文本以重新运行扩散模型推理。
不用编写长篇提示,你可以直接表达想法,它会为你生成高质量的图像。
来自 HuggingFace Spaces 演示的图像
希望你喜欢我关于基于扩散的应用的简短但有趣的博客。
在接下来的几周里,你将找到以下新且更好的应用:
-
提示到提示的图像编辑
-
使用 2D 扩散的文本到 3D 转换
-
3D 形状生成的扩散模型
-
人体动作扩散应用
-
基于扩散的序列到序列文本生成
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,帮助那些面临心理健康困扰的学生。
更多相关话题
成为数据科学面试高手的 7 个重要备忘单
原文:
www.kdnuggets.com/top-7-essential-cheat-sheets-to-ace-your-data-science-interview

图片来源:作者
找到数据科学工作并非易事。由于公司每个职位都收到数百份申请,您需要在竞争中脱颖而出才能获得面试机会。一旦获得面试机会,您需要展示技术能力和沟通技巧,以证明您是适合这个职位的人。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的信息技术
这就是为什么拥有正确的准备和材料可以给予您关键的优势。在他的最新博客中,我们将介绍每位数据科学候选人在即将到来的面试前应审阅的最重要备忘单。这些备忘单涵盖了从统计学和 Python 到 SQL 和机器学习算法等一系列关键数据科学主题。
1. SQL
结构化查询语言(SQL)用于管理和访问数据库。这是数据科学家所需的最重要技能。除了访问数据外,数据专业人员还使用它对大量数据进行数据分析查询。
无论您准备哪种技术数据面试,SQL 入门指南备忘单都将是一个方便的指南。它将帮助您复习常见的语法并教您如何使用它们。此外,它还将帮助您进行编码面试。
2. 概率与统计
许多数据科学家在日常工作中并不使用概率或统计测试。保持对所有重要术语的更新可能很困难。然而,需要注意的是,您可能会被问及如 A/B 测试、置信区间、假设检验、相关性分析等概念。
如果您担心在面试过程中感到尴尬,可以通过参考概率与统计备忘单来刷新记忆。该备忘单由斯坦福大学提供,包括了面试过程中可能用到的所有基本术语。
3. Pandas
Pandas 是一个 Python 库,主要用于数据清洗、处理、分析、处理和保存。在面试中,你可能会被问到有关此库的各种组件以及如何使用 pandas 分析数据。你还可能被要求执行数据分析并根据你的发现撰写报告。
Pandas 数据清洗备忘单提供了有关各种 pandas 函数的字节大小信息,并带有可视化表示,有助于你在技术和编码面试中。
4. 数据可视化
数据可视化是数据科学家的一项重要技能。虽然数据科学家可能擅长分析数据,但选择合适的图表以有效地传达洞察力却有点棘手。在面试中,如果未能选择最佳图表来展示分析结果,可能会给面试官留下不佳的印象。
为了避免这一陷阱,数据科学家必须查看数据可视化备忘单,以便本能地选择理想的图表来传达他们希望传达的信息给利益相关者。这将帮助你在编码面试和家庭作业中。
5. Scikit-learn
Scikit-learn 是一个广泛使用的 Python 库,提供了广泛的工具和功能,用于实现不同的机器学习算法。作为数据科学家,你可能需要使用各种 Scikit-learn 函数解决基本的回归问题,以进行数据增强、处理、模型训练和优化。
构建和评估机器学习模型是数据科学家工作的重要部分。通过查看Scikit-learn 机器学习备忘单,学习 Scikit-learn 的各种功能是很自然的。
6. Git
Git 是数据科学家必须掌握的一项重要技能,尤其是对于那些在协作团队中工作的人。在任何有多个贡献者的数据科学项目中,Git 能够实现版本控制和代码合并,从而使团队成员能够同时进行代码工作而不会发生运行时冲突。
在被邀请参与项目之前,你必须展示你的 Git 技能。因此,复习 Git for Data Science 备忘单以学习最常用的语法和功能是非常必要的。
7. 数据科学超级备忘单
数据科学超级备忘单有点不同。你将查看它以学习所有重要的理论概念。
你将学习:
-
分布
-
各种机器学习概念
-
模型评估
-
线性回归
-
逻辑回归
-
决策树
-
支持向量机
-
聚类
-
降维
-
自然语言处理
-
神经网络
-
卷积神经网络
-
循环神经网络
-
提升
-
强化学习
-
异常检测
-
时间序列
-
统计学
-
A/B 测试
-
面试前一小时,这份备忘单就是你需要的复习资料。它将帮助你回顾最常被问到的面试问题。
-
我希望你喜欢这份七个必备备忘单的列表。如果你想查看更多类似内容,请告诉我。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为挣扎于心理疾病的学生打造一个 AI 产品。
更多相关话题
数据科学的七大免费云笔记本
原文:
www.kdnuggets.com/top-7-free-cloud-notebooks-for-data-science

作者提供的图片
云笔记本已经成为数据科学家和分析师运行代码和生成分析报告的标准。云笔记本提供基于浏览器的界面来编写和执行代码,无需在本地安装任何东西。此外,还可以访问高端硬件以加速机器学习研究和开发。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
云笔记本平台不仅提供免费的计算资源和预构建环境,还提供第三方工具集成、协作和发布选项。在这篇博客中,我们将深入探讨七大顶级云笔记本及其最佳功能。利用这些功能可以提升你当前的数据科学开发堆栈。
1. Deepnote
Deepnote 目前位居首位。为什么?最近,他们推出了新的功能,这些功能将简化你的开发体验。我喜欢这个平台、团队和社区。此外,我在每个数据科学和机器学习项目中都使用它。
你可以在不到一分钟的时间内启动机器,并受益于预构建的开发环境。它还支持各种编程语言,你可以使用 Docker Hub 创建自己的环境。
我强烈推荐你创建一个账户并亲自体验一下。即使是非技术专业人士,也能通过 Deepnote 的 AI 功能更轻松地编写和调试代码。
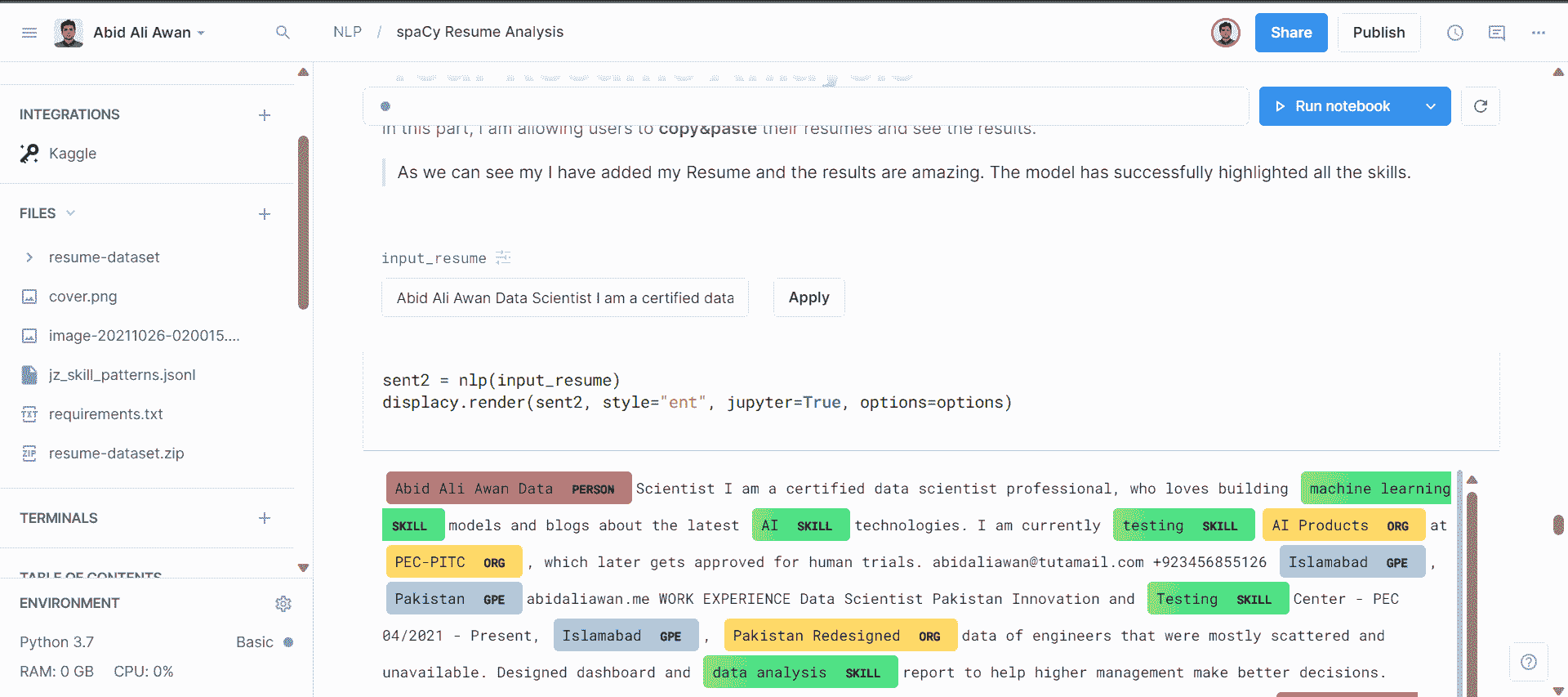
作者提供的图片
2. Kaggle
通过 Deepnote,Kaggle 今年也推出了新功能。例如,他们正在增加新的高性能 GPU、调度运行、模型的专用标签以及快速加载数据集。他们唯一需要改进的是实时协作和评论功能。
使用 Kaggle,你可以免费获得高性能的 CPU、GPU 和 TPU。此外,还可以免费获得存储空间、访问开源数据集和代码、Google Cloud 集成以及版本管理。
当我参与比赛或尝试深度学习模型时,它是我首选的平台。
再次推荐 Kaggle,因为它拥有强大的社区和高端硬件,适合你的 AI 项目。
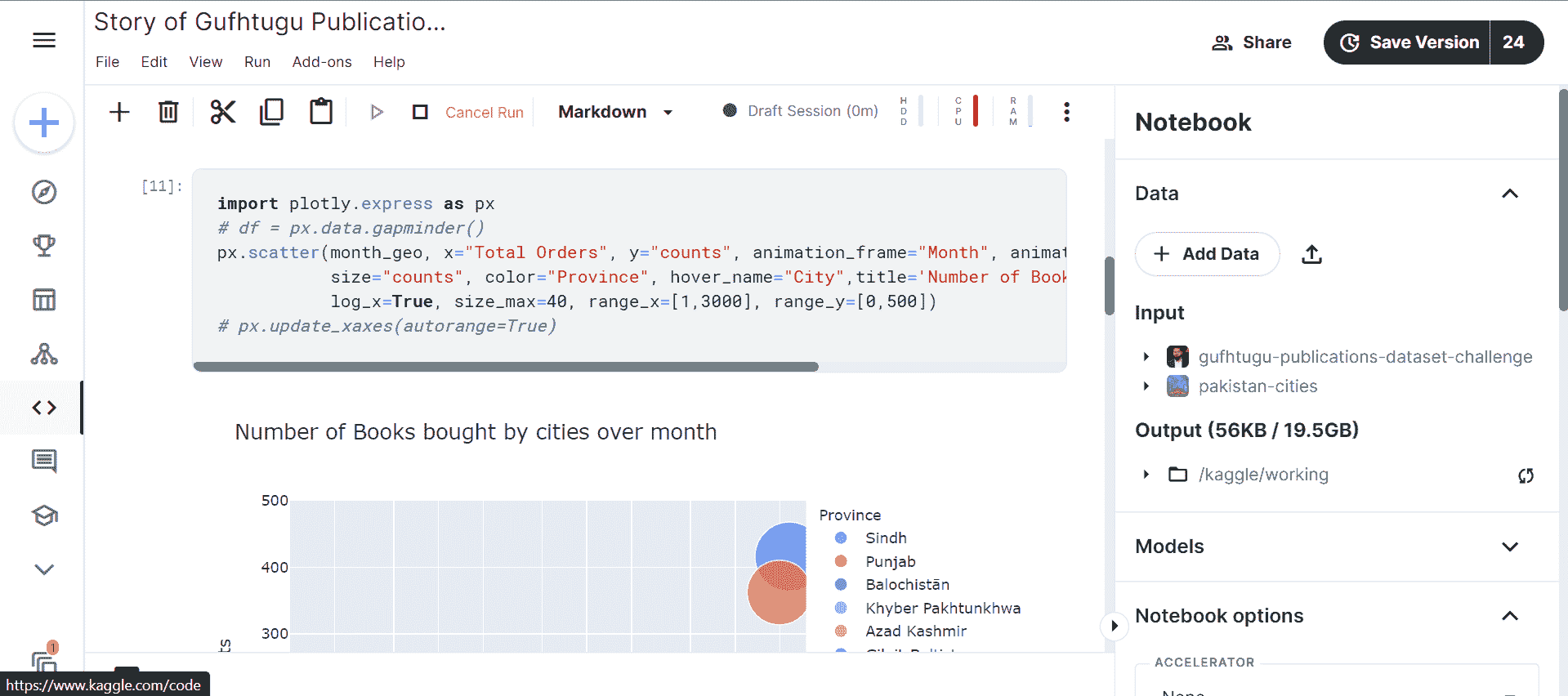
图片来源:作者
3. Hex
Hex现在已经向公众开放,它是处理数据科学和分析任务的热门选择。它提供了类似 Deepnote 的功能,但由于环境加载和代码运行速度较慢,我将它排在第三。它在很多方面也有局限性。
Hex 是一个现代数据工作空间,旨在使数据处理更加轻松和协作。它允许用户连接各种数据源,包括数据库、云存储和 API。一旦连接数据,用户可以在交互式笔记本中使用 SQL 或 Python 直接分析数据。
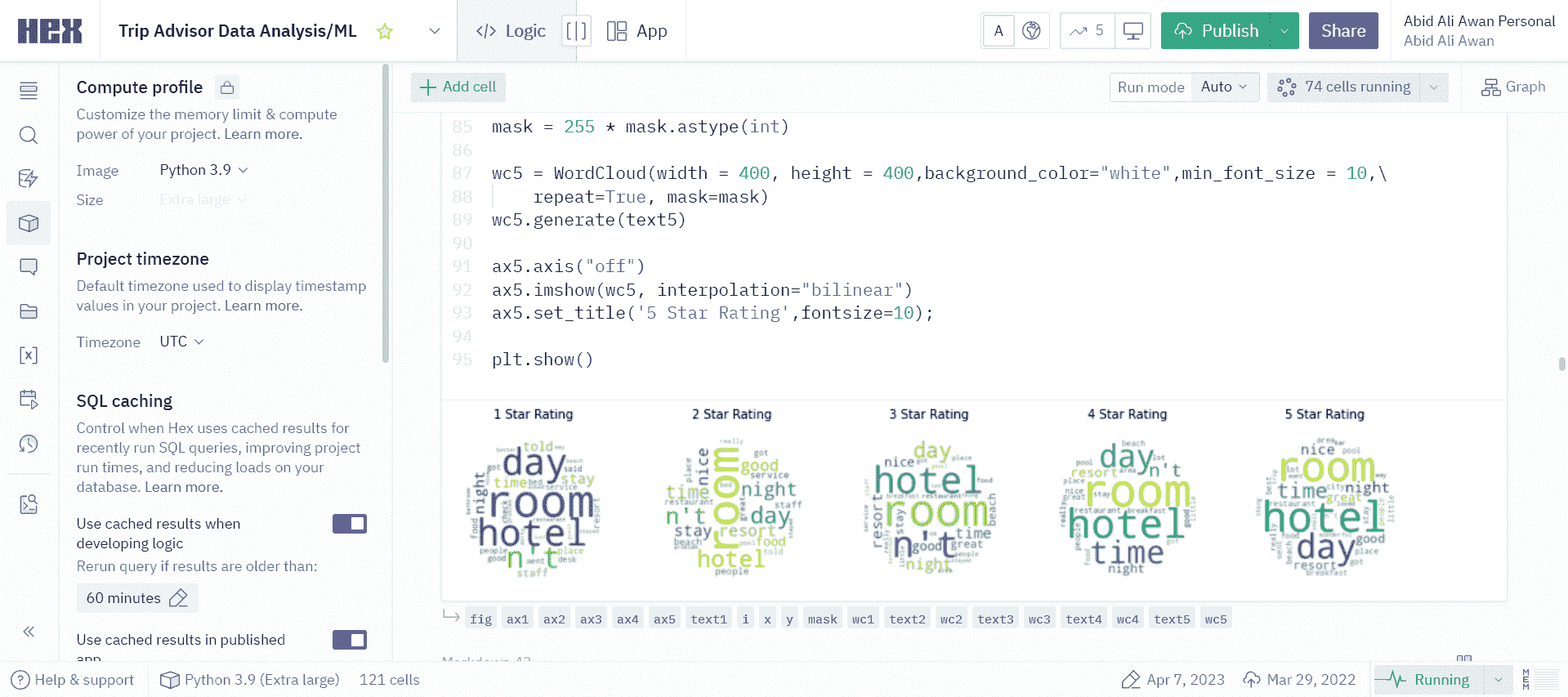
图片来源:作者
4. Noteable
我在Noteable被引入为 ChatGPT 插件时才发现它。在此之前,我完全不知道它的存在。它简单、快速,功能多样。
该平台提供数据连接、加载、版本管理、笔记本发布、实时协作和快速环境加载。这个平台的最佳特点是其简约设计。此外,你可以将其与 ChatGPT 连接,以生成和运行代码并获取输出。这一功能使它在笔记本类别中具有很高的价值。
图片来源:作者
5. Google Colab
Google Colab是我们喜爱和珍惜的老牌云笔记本。我们用它来运行深度学习代码,有时它是一个出色且方便的工具。随着时间的推移,它的免费层级受到了限制,并且更加注重付费选项。
除了轻松访问免费 GPU 和快速加载时间,Google Colab 几乎没有其他优势。它不是一个你每天都想使用的完整数据科学平台。
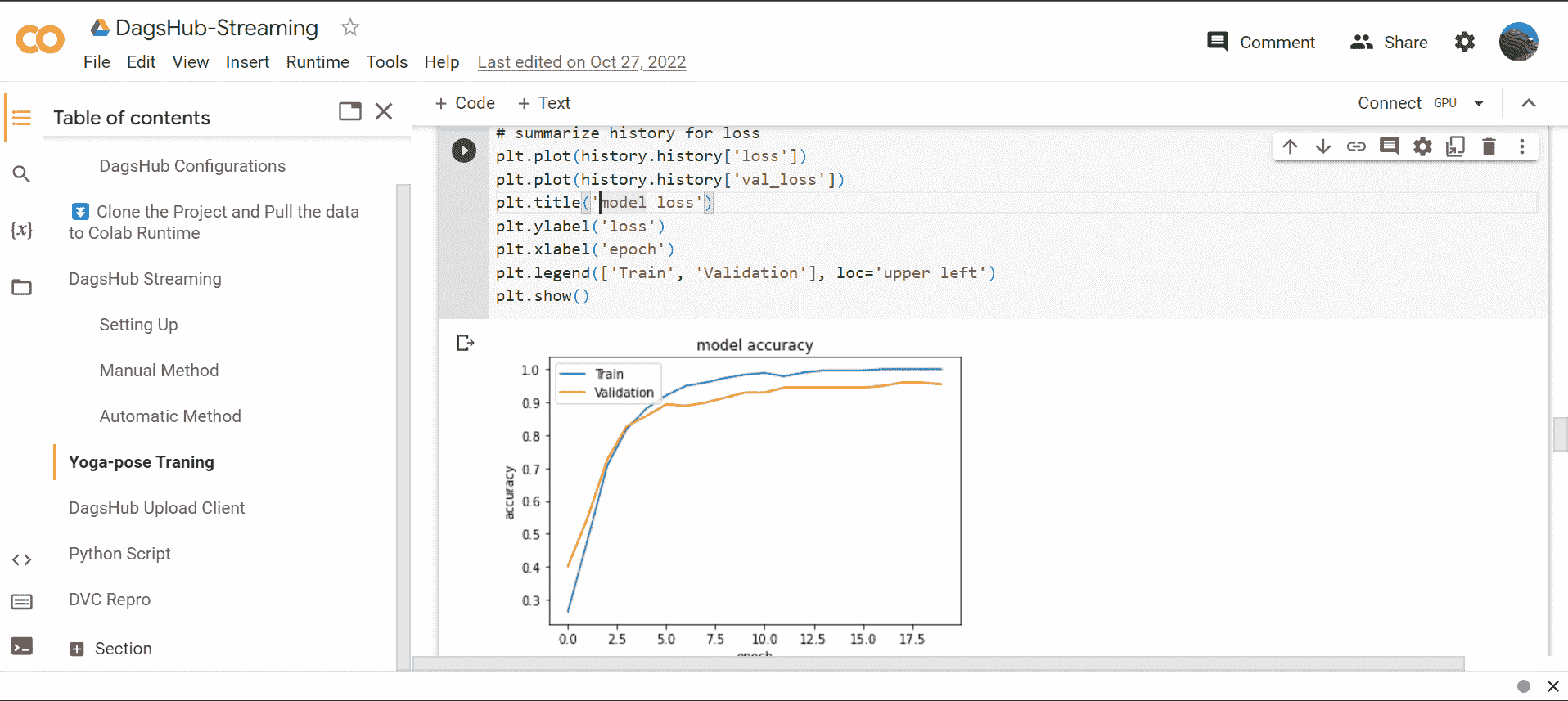
图片来源:作者
6. Naas
Naas以其解决各种问题的数据模板而闻名。这个平台提供了一种低代码解决方案,通过结合自动化、分析和人工智能,创建强大的数据产品。
它的计算能力和功能有限。它确实提供了每月免费信用额度用于运行和执行代码。除此之外,它就是云上的 JupyterLab。
图片来源:作者
7. Datalore
JetBrains Datalore 类似于 Noteable,但速度较慢,缺乏一些关键功能。你还受到计算限制。我曾经在 Datalore 上运行我的代码,但自从其推出以来,平台没有什么改进或变化。看起来 JetBrains 已经忘记了它。
它有一些你可以在 Deepnote 中获得的功能,但对于任何初学者来说,UI 是混乱的。唯一的优点是它提供免费的存储和计算。
作者提供的图片
结论
总之,云笔记本已成为数据科学家和分析师高效完成工作的必备工具。顶级选项提供了极大的价值,包括免费 GPU、简单设置、协作功能和与其他服务的集成。Deepnote 脱颖而出,是功能最全的选项,具备快速环境加载、AI 协助、实时协作和发布能力。
Kaggle 非常适合深度学习,因为它提供了高级硬件访问。Hex 和 Noteable 提供现代化的界面和集成,如 ChatGPT。虽然 Google Colab 等有其特定用途,但 Deepnote 凭借其对端到端数据科学工作流的关注,似乎处于领先地位。无论你选择哪个平台,云笔记本无疑会增强你的数据科学项目和洞察能力。
Abid Ali Awan (@1abidaliawan) 是一位认证数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为心理健康问题的学生开发 AI 产品。
更多相关话题
前 7 大模型部署和服务工具
原文:
www.kdnuggets.com/top-7-model-deployment-and-serving-tools

作者图片
那些将模型简单训练后放在架子上积灰的日子已经过去了。如今,机器学习的真正价值在于它能够增强实际应用并带来切实的商业成果。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT
然而,从训练好的模型到生产环境的过程充满了挑战。在规模化部署模型、确保与现有基础设施的无缝集成,以及保持高性能和可靠性等方面,MLOps 工程师面临着许多难题。
值得庆幸的是,如今有许多强大的 MLOps 工具和框架可以简化和优化模型部署的过程。在这篇博客中,我们将了解 2024 年前 7 大正在彻底改变机器学习(ML)模型部署和使用方式的模型部署和服务工具。
1. MLflow
MLflow 是一个开源平台,简化了整个机器学习生命周期,包括部署。它提供了 Python、R、Java 和 REST API,用于在各种环境中部署模型,如 AWS SageMaker、Azure ML 和 Kubernetes。
MLflow 提供了一个全面的解决方案来管理 ML 项目,具有模型版本控制、实验跟踪、可重复性、模型打包和模型服务等功能。
2. Ray Serve
Ray Serve 是一个基于 Ray 分布式计算框架的可扩展模型服务库。它允许您将模型部署为微服务,并处理底层基础设施,使得模型的扩展和更新变得简单。Ray Serve 支持广泛的 ML 框架,并提供了响应流、动态请求批处理、多节点/多 GPU 服务、版本控制和回滚等功能。
3. Kubeflow
Kubeflow 是一个开源框架,用于在 Kubernetes 上部署和管理机器学习工作流。它提供了一套工具和组件,简化了 ML 模型的部署、扩展和管理。Kubeflow 与 TensorFlow、PyTorch 和 scikit-learn 等流行的 ML 框架集成,并提供了模型训练和服务、实验跟踪、ML 编排、AutoML 和超参数调整等功能。
4. Seldon Core V2
Seldon Core 是一个开源平台,用于部署可以在笔记本电脑上本地运行的机器学习模型,也可以在 Kubernetes 上运行。它提供了一个灵活和可扩展的框架,用于服务各种 ML 框架构建的模型。
Seldon Core 可以使用 Docker 在本地进行测试,然后在 Kubernetes 上进行扩展以用于生产。它允许用户部署单个模型或多步骤管道,并且可以节省基础设施成本。它设计得轻量、可扩展,并与各种云服务提供商兼容。
5. BentoML
BentoML 是一个开源框架,简化了构建、部署和管理机器学习模型的过程。它提供了一个高级 API,将模型打包成称为“bentos”的标准化格式,并支持多种部署选项,包括 AWS Lambda、Docker 和 Kubernetes。
BentoML 的灵活性、性能优化和对各种部署选项的支持使其成为团队构建可靠、可扩展和具有成本效益的 AI 应用程序的宝贵工具。
6. ONNX Runtime
ONNX Runtime 是一个开源的跨平台推理引擎,用于部署 Open Neural Network Exchange (ONNX) 格式的模型。它提供了在各种平台和设备上,包括 CPU、GPU 和 AI 加速器的高性能推理能力。
ONNX Runtime 支持广泛的 ML 框架,如 PyTorch、TensorFlow/Keras、TFLite、scikit-learn 和其他框架。它提供了优化功能以提高性能和效率。
7. TensorFlow Serving
TensorFlow Serving 是一个开源工具,用于在生产环境中服务 TensorFlow 模型。它专为熟悉 TensorFlow 框架的机器学习从业者设计,用于模型跟踪和训练。该工具高度灵活且可扩展,允许将模型部署为 gRPC 或 REST API。
TensorFlow Serving 具有多个功能,如模型版本控制、自动模型加载和批处理,这些功能提升了性能。它与 TensorFlow 生态系统无缝集成,并且可以在 Kubernetes 和 Docker 等各种平台上部署。
结论
上述工具提供了多种功能,可以满足不同的需求。无论你是偏好像 MLflow 或 Kubeflow 这样的端到端工具,还是像 BentoML 或 ONNX Runtime 这样的更专注的解决方案,这些工具都能帮助你优化模型部署过程,并确保你的模型在生产环境中易于访问和扩展。
Abid Ali Awan (@1abidaliawan) 是一位认证数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一款 AI 产品,以帮助那些面临心理健康问题的学生。
更多相关主题
Orange 3 数据挖掘平台的新功能
原文:
www.kdnuggets.com/2015/12/top-7-new-features-orange-3.html/2
5. 专注于交互式可视化。 载入数据,估算距离,绘制层次聚类,选择直方图中的有趣分支,并展示这些数据在 PCA 图中的位置。或者进行 k-means 聚类,绘制其轮廓图,选择轮廓低的实例,并在最具信息量的散点图中揭示这些异常值。交互式可视化可以选择数据子集以供进一步探索,这一直是 Orange 的强大特性之一。在 Orange 3 中,我们通过使每个视觉显示都具有交互性,进一步专注于探索性数据分析。

6. 基于 Numpy 的数据存储。 虽然 Orange 的可视化编程前端变化不大,但在内部有几次重大改造。我们将自定义数据存储实现(旧的 ExampleTable 类)替换为新的(Orange.data.Table),它将实际数据存储在 numpy 数组中。对数据进行操作的算法也不再是 C 库的一部分,而是使用 Cython 代码和高效的 numpy 操作实现的。
7. scikit-learn 算法的封装器。 以 Numpy 为基础的数据存储替代了 Orange 自有的内部数据格式,这只是一个更大愿景的部分:与现在大量的基于 Python 的数据科学库的互操作性。我们喜欢 Orange 提供的算法套件,特别关注符号学习,但也很高兴能够整合提供经过充分测试的强大数据挖掘算法的外部库。例如 scikit-learn,我们礼貌地借用了多个算法。如果其中任何一个尚未包含,Orange 提供了一组简化 scikit-learn 方法封装的类。封装缩短了 scikit-learn 的“知道自己在做什么”和 Orange 的“无论数据和格式如何,它都能工作”哲学之间的差距。
 Ajda Pretnar 是卢布尔雅那大学生物信息学实验室的项目助理。她拥有国际关系硕士学位。她负责编写 Orange 的技术文档、软件测试和管理错误报告。她是数据挖掘教育教程的项目协调员。
Ajda Pretnar 是卢布尔雅那大学生物信息学实验室的项目助理。她拥有国际关系硕士学位。她负责编写 Orange 的技术文档、软件测试和管理错误报告。她是数据挖掘教育教程的项目协调员。
相关内容:
-
数据挖掘、分析、数据科学和知识发现的软件
-
50 个有用的机器学习与预测 API
-
Spark + 深度学习:使用 SparkNet 进行分布式深度神经网络训练
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关话题
-
5 步骤快速上手 Google Cloud Platform
,用于快速构建…](https://www.kdnuggets.com/2023/06/introducing-openchat-free-simple-platform-building-custom-chatbots-minutes.html)
我在数据科学硕士课程中学到的 7 件事
原文:
www.kdnuggets.com/2019/10/top-7-things-learned-data-science-masters.html
评论
由 Dario Radečić, 数据科学学生
其中一些你可能已经熟悉,但我不建议跳过它们——另一个观点总是很有用的。

图片由 Charles DeLoye 提供,来源于 Unsplash
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的捷径。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在的组织的 IT
1. 始终咨询领域专家
所谓“总是”,是指如果你有这样做的余地。
这是学到的第一件事之一。我们被介绍到这个在数据世界中如同摇滚明星般的人物,具体来说是流失建模。听到那句话的时候,可能是我对数据科学的第一个误解被打破的时候。
你可以在这里阅读更多关于他和整个案例的信息:
最近我写了关于递归特征消除——我最常用的特征选择技术之一……
最初我认为数据科学家是一种稀有的物种,只要有合适的数据,就可以做几乎任何事情。但在大多数情况下,事实远非如此。是的,你可以用任何东西分析一切,通过这样做你会发现一些有趣的东西,但这真的是你时间的最佳利用吗?
问问自己,
问题是什么?X 如何与 Y 连接?为什么?
了解这些将引导你朝着解决问题的正确方向前进。这时领域专家就派上用场了。
另一个非常重要的事情是特征工程。这位教授强调,你可以利用领域专家来进行特征工程过程。如果你稍微思考一下,这就会变得合理。
2. 你将大部分时间花在准备数据上
是的,你没看错。
我决定从事数据科学硕士课程的主要原因之一是机器学习——我不太关心数据的内容以及它是如何收集和准备的。由于这种态度,当学期开始时,我感到有些震惊和失望。
当然,如果你在一家有数据工程师和机器学习工程师的大公司工作,这可能不会适用于你,因为你大部分时间都在做机器学习。但如果情况不是这样,你将只有大约 15%的时间用于机器学习。
这其实是很好的。机器学习并不是特别有趣。在你带着大批 F 字词跳到评论区之前,请听我说完。
我认为机器学习并不是特别有趣的原因是,对于大多数项目来说,它归结为尝试几个学习算法,然后对最好的那个进行优化。
如果你在这之前的工作没有做好,即在数据准备过程中,你的模型很可能会很糟糕,而且你也很难对此做出太多改进——只能调整超参数、调整阈值等。
这就是为什么数据准备和探索性分析才是王道,而机器学习只是自然出现的结果。
一旦我意识到自己对机器学习的大部分兴奋感已经消失,我发现我更喜欢数据收集和可视化,因为在这些过程中我学到了最多的关于数据的知识。
我特别喜欢网络爬虫,因为相关的数据集很难找到。如果这听起来是你会喜欢的事情,请查看这篇文章:
使用 Python 和 BeautifulSoup 的强大功能来抓取对你重要的数据。
3. 不要重新发明轮子
库的存在是有原因的。在行动之前先谷歌一下。
我会给你展示一个你可能没有犯的非常简单的‘错误’,但它会帮助你理解这一点。
这涉及到计算中位数的两种方法。中位数定义为:
排序列表中的中间位置。
所以要计算它,你需要实现以下逻辑:
-
对输入列表进行排序
-
检查列表的长度是偶数还是奇数
-
如果是偶数,中位数就是两个中间数字的平均值
-
如果是奇数,中位数就是中间的数字
幸运的是,存在像Numpy这样的库,它们为你完成了所有繁重的工作。只需看一下下面的代码,前 17 行是自己计算中位数,而最后两行则使用 Numpy 的强大功能来实现相同的结果:
中位数计算 — gist.github.com/dradecic/7f295913c01172ffebe84052c8158703
正如我所说,这只是一个你可能没有亲身经历过的微不足道的例子。但是想象一下,你可能因为没有意识到已经有相关的库而徒劳地写了多少行代码。
4. 精通 lambdas 和列表推导式
虽然这并不是数据科学特有的,但我会说我一直在使用列表推导式来进行特征工程,而使用lambda 函数来进行数据清理和准备。
下面是一个简单的特征工程示例。给定一个字符串列表,你需要创建一个变量,如果给定的字符串包含问号(?),则该变量等于 1,否则为 0。你可以看到如何使用和不使用列表推导式来实现这一点(提示:它们节省了大量时间*):
列表推导式示例 — gist.github.com/dradecic/9f23eb0c8073ecc8957f8fd533388cef
现在来说说lambdas,假设你有一个电话号码列表,格式你不喜欢。基本上,你想用‘-’替换‘/’。这是一个几乎微不足道的过程,前提是你的数据集是PandasDataFrame格式:
Lambdas — gist.github.com/dradecic/68e81f6610b26fe8da68e25d217c5052
花一点时间考虑一下你如何将这些应用到你的数据集上。很酷,对吧?
5. 了解你的统计学
如果你没有一直生活在石头下,你会知道统计学在数据科学中的重要性。这是你必须发展的基本技能。
让我引用 Edureka:
统计学用于处理现实世界中的复杂问题,以便数据科学家和分析师可以寻找数据中的有意义的趋势和变化。简单来说,统计学可以通过对数据进行数学计算来得出有意义的见解。[1]
根据我在硕士学习统计学过程中学到的知识,你需要了解统计学,以便能够提出正确的问题。
如果你的统计技能有些生疏,我强烈建议你查看 YouTube 上的 StatQuest 频道,更准确地说,是这个关于统计学基础的播放列表:
统计学播放列表
6. 学习算法和数据结构
如果你不能提供解决方案,那么提出正确的问题(见第 5 点)也没有意义——对吧?
我曾经忽视了算法和数据结构,因为我认为只有软件工程师才需要关注这些内容。说实话,我的想法完全错误。
现在我不是说你必须熟练掌握如何实现二分查找算法,但基本的理解会帮助你更清楚地看到如何在代码中思考——也就是说,如何编写既能完成任务又能尽可能快地完成任务的代码。
对于没有计算机科学背景的人,我强烈推荐这门课程:
请注意:如果你是完全的 Python 初学者,请查看我的另一门课程:完整 Python 培训营以学习……
另外,一定要查看面试问题——它们帮助很大!
7. 超越范围
永远要成为那个工作最努力的人。这会得到回报。
至少在我的案例中,我的团队是根据在一个课程中的初始表现进行评估的。评估标准不是谁知道得最多,因为在第一学期这样做是愚蠢的,而是看谁展现出工作伦理和纪律。
由于那时我没有全职工作,我为这个项目拼尽了全力。因为我这样做了,而其他人没有,所以我被指派到一个为期两年的全面数据科学项目,该项目将作为我的硕士论文。
对了,我能够把这个放到我的简历上。
那么,牺牲了几周的个人生活是否值得?自己判断吧,但我会说是值得的。
参考资料
简介: Dario Radečić 是一位 22 岁的数据科学学生,同时也在该领域工作了一段时间。Medium 和 Towards Data Science 的作者。
原文。经许可转载。
相关:
-
从数据分析师成长为数据科学家的秘密武器
-
2019 年 5 个著名的深度学习课程/学校
-
高级特征工程和预处理的 4 个技巧
更多此主题的内容
前 7 名 YouTube 数据分析课程
原文:
www.kdnuggets.com/2022/02/top-7-youtube-courses-data-analytics.html

作者提供的图片
数据分析是通过进行各种统计分析来理解数据的过程。数据可视化和分析可以提供对公司或整个行业有价值的关键见解。大多数公司通过数据驱动的决策来盈利,并且他们愿意花费大量资金来雇佣合格的数据分析师。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
在这篇博客中,我们将深入探讨 YouTube 上的七个顶级数据分析课程。这些课程是根据内容质量、受欢迎程度和基于项目的学习来挑选的。参与真实项目可以让你对职业路径有一个清晰的了解。这些课程从初学者到中级水平不等,所有课程都可以在 YouTube 上免费获取,并附有项目资源。
使用 Python 进行数据分析:从零到 Pandas
时长: 12 - 20 小时 | 水平: 初学者 - 中级 | 质量: 4.25/5
Python是数据科学领域中最受欢迎的语言,大多数数据分析师使用它来处理和可视化数据。使用 Python 进行数据分析课程适合初学者,因为它教授 Python 编程的基础知识,并详细解释数据处理和可视化工具。课程包括:Jupyter notebook 基础知识、用于数据处理的 Numpy、用于数据操作的 Pandas、使用 Matplotlib 和 Seaborn 进行数据可视化以及探索性数据分析案例研究。
数据分析使用 R 的初学者
时长: 1 - 2 小时 | 水平: 初学者 | 质量: 3.75/5
初学者数据分析由 Edureka 提供,是对R及数据分析世界的快速介绍。R 也是执行统计任务的流行语言之一,它正逐渐成为进行所有数据科学任务的首选工具。课程内容包括;数据分析简介、统计学、数据清理和处理、数据可视化、机器学习、数据分析师的职责,以及通过项目进行的实践学习。前半部分是对数据分析中各种术语的描述性介绍,最后一部分则全是编码。建议你边编码边调试错误,可以暂停或倒回多次以正确理解概念。

图片由作者提供 | 初学者数据分析
SQL 与初学者数据分析
时长: 3 - 5 小时 | 级别: 初学者 - 中级 | 质量: 4/5
SQL 与初学者数据分析由 DataDash 提供,是一个关于 Postgresql 的深入课程,讲解如何使用 SQL 查询来分析数据。课程的第二部分完全关于 Tableau:导入数据集、可视化和创建仪表板。课程的第一部分包括;设置服务器、设置数据库、SQL 语法、数据的导入与导出。第二部分的课程包括 Tableau 的所有内容,从创建交互式地图到预测。强烈推荐这门课程,因为 SQL 在技术行业中需求很高。没有 SQL 知识,你无法获得数据分析职位。
Power BI 与 Tableau 中的数据分析项目
时长: 7 - 10 小时 | 级别: 初学者 - 中级 | 质量: 4.25/5
数据分析项目由 codebasics 提供,是一个基于项目的课程,你将学习在大型公司中如何执行数据分析项目。该项目涉及一家在动态市场中竞争困难的计算机硬件公司。你的主要目标是为高层管理创建一个仪表板,以便他们可以实时监控销售。在第一部分中,你将使用 Power BI 学习数据发现、使用 SQL 进行数据分析、数据学习和 ETL、构建仪表板、获取利益相关者的反馈、发布报告,以及在移动应用程序中访问仪表板。在第二部分中,你将使用 Tableau 完成上述所有任务。
图片由作者提供 | 数据分析项目
Tableau 用于数据可视化
时长: 0.5 - 2 小时 | 级别: 初学者 | 质量: 3.5/5
数据可视化中的 Tableau 由 freecodecamp 提供,是一个涵盖创建数据分析 Tableau 报告所有基本步骤的迷你课程。该项目使用了来自 Kaggle 的著名 Titanic 数据集,以创建互动可视化并探索数据集。课程包括数据导入、简单条形图、定制图表、创建复杂条形图以及创建包含多个图形的报告。数据可视化中的 Tableau 轻便且适合初学者。
Excel 中的数据分析
时长: 4 - 7 小时 | 水平: 初学者 - 中级 | 质量: 3.75/5
Excel 中的数据分析 由 Simplelearn 介绍了工具包和 Excel 函数,如 vlookup、hlookup、sumif/s、countif/s 和 iferror。大多数公司仍在使用 Excel 表格来执行所有数据任务,从维护数据库到预测销售。在本课程中,你将学习 Excel 的基础知识、查找与函数、条件格式化、排序与过滤,以及使用工具包的数据分析。
SPSS 初学者
时长: 2 - 5 小时 | 水平: 中级 | 质量: 3.75/5
SPSS 初学者 由 Datalab 提供了对统计分析工具SPSS的温和介绍,并展示了如何使用它来创建互动的数据分析。SPSS 曾是 2015 年学术研究人员使用的最流行统计工具,尽管它的受欢迎程度显著下降,但在大公司如 Zendesk、Lewis, Inc 和联邦紧急事务管理局中仍然广泛使用。课程涵盖了图表模板、条形图、直方图、散点图、频率、描述性统计、标签与定义、数据输入、数据导入、层次聚类、因子分析和回归分析。

图片由作者提供 | SPSS 初学者 | 模型由 crowf 提供
意见
通过所有课程并尝试在本地机器上重复每一步。跟着代码做可以帮助你更快地学习,甚至可能会提出更好的解决方案来完成相同的任务。博客为你提供了对行业中最流行工具的完整介绍。学习多项技能也可以增加你被梦寐以求的公司录用的机会。
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,他热爱构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为面临心理健康困扰的学生构建一个人工智能产品。
相关话题更多内容
你应该用来替代 Google 的 8 个 AI 搜索引擎
原文:
www.kdnuggets.com/top-8-ai-search-engine-that-you-should-replace-with-google

作者提供的图片
数字领域处于不断变化之中,搜索引擎也不例外。如今,搜索引擎已经不仅仅提供网页链接。它们现在设计了诸如总结、图像生成、互动研究模式和问答聊天机器人等一系列功能。这使得在互联网上进行研究、学习和发现变得更加容易。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
尽管 Google 长期以来一直是主导的搜索引擎,但人工智能 (AI) 的出现为提供独特功能和优势的替代搜索引擎铺平了道路。
在这篇博客中,我们将了解值得考虑的 8 个 AI 驱动的搜索引擎,每一个都带来了独特的搜索智能。
Perplexity AI
Perplexity AI 是一个利用人工智能的搜索引擎,提供的不仅仅是基本的网页链接。
其主要功能包括:
-
回答问题: 它可以回答从简单事实到复杂查询的广泛问题,使用最新的资料。它还允许用户生成代码、总结文章或撰写电子邮件。
-
深入探索话题: Perplexity 的 Copilot 功能引导用户深入话题,使他们能够了解更多内容并探索新的兴趣领域。
-
整理你的资料库: 用户可以按项目或主题将搜索结果组织到“收藏夹”中。
-
与数据互动: Perplexity 允许用户在平台内对文件提出问题并搜索网络。这提供了一个空间中的完整项目视图。
Pro 版的 Perplexity AI 提供了更具对话性的搜索体验。它与用户互动,询问详细信息和偏好,以提供更精确的结果。它还总结了最相关的发现,并从各种来源提取信息。
Bing
微软Bing自 GPT-3.5 发布以来进行了重大升级。现在,它是一个完全功能的 GenAI 搜索引擎,使用如 GPT-4、视觉模型和图像生成模型等大型语言模型,提供全新改进的网页搜索体验。现在,你可以搜索具体答案并获得结果摘要。此外,你还可以与 AI 聊天机器人互动,提出后续问题,甚至与文档聊天,集成 ChatGPT 插件,并在 Bing 平台内设计图形。
Komo AI
Komo AI是一个先进的 AI 驱动搜索工具,旨在提供快速、私密和准确的无广告搜索体验。与 ChatGPT 不同,Komo AI 提供视频、图片和网站的链接,以促进详细研究。它是一个强大的 AI 聊天机器人,经过了包括公共数据集、网络爬虫、人类标签和生成数据在内的各种数据源的训练,使其成为一个强大而高效的搜索工具。
Komo AI 的最佳特点是其简洁性。在欢迎页面上,你只会看到一个搜索框,即使在执行搜索后,你也会收到最少且相关的结果,而不是充满内容的整个页面。
Exa AI
Exa AI是一个先进的搜索引擎,超越了传统的基于关键词的搜索,通过理解查询背后的含义来提供结果。前身为 Metaphor,Exa 允许 LLMs 使用自然语言进行搜索,并从其神经数据库中获取相关网页列表。此外,Exa AI 为 AI 应用设计,提供 AI 聊天对话服务和用于网页搜索的 API。你可以在文档页面找到 Python、Go 和 JavaScript SDK。
You.com
You.com是一个 ChatGPT 风格的 AI 搜索引擎,专注于为用户提供个性化的答案和体验。它结合了自然语言处理、深度学习和知识图谱技术,以理解用户查询并提供准确的结果。
使用 You.com,你可以访问先进的 LLMs、私人模式、区域选择以及强大的工具,如内容和图像生成器以及图像增强器。然而,用户界面可能比较难以导航。
Yep
Yep 是一个提供快速、私人且无广告搜索体验的搜索引擎。它重视用户隐私和内容创作者的利益。Yep 通过使用内容信号、链接信号和自然语言处理来专注于搜索质量,提供相关且准确的搜索结果。
现在,它提供了类似 Bing 的 AI 聊天机器人功能。你可以提出后续问题并获得快速准确的结果。它简单易用,为你的查询提供了相关结果。
Brave
Brave 搜索引擎是一个强大的工具,利用先进的 AI 技术为用户提供增强的搜索体验。
一个显著的特点是 CodeLLM,这是一个专门设计用于编程查询的 AI 工具,通过提供高质量的搜索结果来帮助解决编程问题。此外,该搜索引擎还配备了总结功能,利用人工智能在搜索结果页面顶部生成简洁且相关的摘要,提供用户基于查询的快速和有用的答案。
Andi Search
Andi Search 不仅仅是另一个搜索引擎。它使用先进的生成 AI 和语言模型,提供的不仅仅是链接,而是直接的答案、总结和解释,以对话的语气让你感觉像是在与专家交谈。
Andi Search 提供了类似 ChatGPT 的搜索体验和一个可以深入探讨话题的工作区。通过总结文章和提出后续问题的选项,Andi Search 使快速有效地理解复杂话题变得更加容易。
结论
如果你在寻找更注重隐私的替代方案、AI 驱动的总结功能或更具视觉增强的搜索体验,列表中很可能有一个符合你需求的 AI 搜索引擎。
在我看来,使用新推出的 AI 驱动搜索引擎相比于 Google 可以提供更好的结果,并节省时间和精力,我认为 Google 随着时间的推移变得越来越差。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络开发一个 AI 产品,帮助那些遭受心理疾病困扰的学生。
更多相关主题
2023 年值得加入的 8 大数据科学 Slack 社区
原文:
www.kdnuggets.com/2023/01/top-8-data-science-slack-communities-join-2023.html

作者提供的图片
新年快乐!
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
今年你可能会考虑职业转型,学习新技能,并更加努力进行个人发展。根据美国劳动统计局的数据,预计 2021 年至 2031 年间数据科学家的增长率为 36%。
如果你想进入数据领域,有许多在线资源可供利用,包括书籍、课程、备忘单、社区等。
如果你在寻找学习资源,可以看看这些:
-
从这些 GitHub 库中学习数据科学
-
免费数据管理与数据科学学习 CS639
-
数据科学中你需要多少数学?
-
谷歌建议你在参加他们的机器学习或数据科学课程之前做什么
另一种很好的学习方式是成为社区的一部分。本文特别关注 Slack 社区。Slack 是一个消息应用程序,帮助连接人们并使团队以统一的方式工作。
你可以在 2023 年加入这些数据社区的 Slack 频道。
Datatalks.Club
正如其名称所示,它涵盖了一切与数据相关的内容。这可以包括数据分析、数据科学和机器学习。各种 Slack 频道如#book-of-the-week、#career、#datascience、#events、#ai-memes-for-ai-peeps 等。
他们有每周活动,你可以自由加入,还有一个拥有 12 季的播客。
如果你想加入 Datatalks.Club 的 Slack 社区,请点击此链接:Datatalks.Club Slack
数据科学沙龙
数据科学沙龙是一个独特的会议,已成为一个多样化的社区,拥有一支由资深数据科学家、机器学习工程师等组成的团队。他们旨在将技术专业人士聚集在一起,帮助他们建立网络、成长,并相互学习,寻找可能的创新解决方案。
如果你想加入数据科学沙龙 Slack 社区,请点击此链接:数据科学沙龙 Slack
数据可靠性工程社区
这个 Slack 社区更细化到数据科学的特定问题。这里有广泛的数据工程师和科学家,深入探讨数据可靠性问题及其最佳实践。
如果这是你想要专注或需要更多指导的数据科学方面,这将是一个宝贵的 Slack 频道。
如果你想加入数据可靠性工程社区,请点击此链接:数据可靠性工程社区 Slack。
数据科学家
一个讨论数据科学、数据仓库、BI 相关对话、话题等的社区。你将与领域中的其他人建立联系,并从他们的错误中学习,就像他们从你的错误中学习一样。
如果你想加入数据科学家社区,请点击此链接:数据科学家 Slack。
AI-ML-数据科学爱好者
如果你想要一个更轻松随意的环境,AI-ML-数据科学爱好者 Slack 社区适合你。这里充满了关于数据科学、机器学习和人工智能的普遍讨论。
这是跟踪其他人观点并扩展你的知识库的绝佳方式。
如果你想加入 AI-ML-数据科学爱好者社区,请点击此链接:AI-ML-数据科学爱好者 Slack。
开放数据科学社区
一个关注数据科学相关所有内容的社区。你将获得最新的数据科学文章、对你的学习过程有帮助的教程、代码分享和总体建议。旨在连接来自全球的数据科学专业人士。
如果你想加入开放数据科学社区,请点击此链接:开放数据科学社区 Slack。
Papers with Code
Papers with Code 是一个免费且开放的资源,提供机器学习论文、代码、数据集、方法和评估表。通过社区,你将获得优质的资源来帮助你的学习过程。你将从学习数据科学理论过渡到应用和发展你的技能。
如果您想加入“Paper with Code”社区,请点击此链接:Paper with Code Slack。
KaggleNoobs
如果您希望在数据科学领域取得成功,您需要练习您的编程技能。测试技能的唯一方法是通过项目。作为初学者,Kaggle 将是您最好的伙伴。因此,建议加入 Kaggle 社区,以帮助解答未解的问题并提供特定方面的指导。
如果您想加入 KaggleNoobs 社区,请点击此链接:KaggleNoobs Slack。
结论
Slack 社区不仅是极好的学习资源,还帮助初学者适应全新的领域。您可以从他人的学习过程、项目以及书籍和课程推荐中获得启发。
尼莎·阿雅 是一名数据科学家和自由技术作家。她特别关注提供数据科学职业建议或教程以及基于理论的数据科学知识。她还希望探索人工智能如何有利于人类寿命的不同方式。作为一个热衷的学习者,她寻求扩展她的技术知识和写作技能,同时帮助指导他人。
更多相关主题
游戏中的前 8 大数据科学应用案例
原文:
www.kdnuggets.com/2019/04/top-8-data-science-use-cases-gaming.html
评论
由 ActiveWizards 提供
现在,游戏行业正处于上升期。全球有超过 20 亿玩家,游戏行业成为了巨额收入的资源,这些收入预计将继续增长。随着用户数量的增加,待处理的数据量也在扩大。用户的游戏时间、互动时间、退出点、活动高峰、结果、得分等都为分析提供了丰富的素材。
对于游戏优化和改进的数据价值的理解使专家们寻找将数据科学及其收益应用于游戏业务的新方法。因此,出现了各种具体的数据科学应用案例。以下是我们列出的在游戏中最有效和广泛应用的数据科学用例。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的捷径。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
游戏开发
数据科学在游戏中的一个最令人兴奋的应用是其在游戏开发过程中的使用。游戏的整体构思、功能和设计在保持玩家参与和兴趣方面发挥着关键作用。在这种情况下,从游戏数据中获得的见解非常宝贵。游戏应被视为一种可以衡量其性能的机制,因此可以根据客户的需求进行调整。数据科学用于构建模型、分析和识别优化点、做出预测并增强机器学习算法、识别模式和趋势以指导服务地图和改进游戏模型。
游戏货币化

游戏货币化是收入总体增长的一个重要因素。开发一款设计良好、吸引人且受欢迎的游戏需要大量的时间、金钱和资源。因此,公司的主要目标是使这款游戏对他们有利可图。在这方面,存在三种主要的视频游戏订阅模型:付费游戏、免费游戏和增值游戏。无论如何,大数据分析工具将帮助你确保你的游戏对你是有利可图的。
在某些情况下,你需要识别你最有价值的玩家。因此,你将使用有关社交网络活动、一般游戏活动和客户反馈的数据来对玩家进行细分,研究他们的偏好和行为。
大数据被用来预测行为和优化游戏,以便玩家会再次回来并愿意为游戏付费。
游戏设计
随着现代技术的快速发展,游戏设计已经变成了一门艺术。此外,游戏设计也成为了一个极具人气的领域,为开发者打造成功的职业生涯。它是一个复杂的过程,需要各种编程、可视化和动画技能。
精彩的视觉效果应用不再仅仅是为了让玩家保持参与。游戏数据洞察与开发者的创造力相结合,有助于为游戏创建互动性强且复杂的场景。从游戏分析中获得的洞察用于获取玩家的具体需求,预测游戏瓶颈、推理和时机。新的游戏概念、故事情节和机制都是根据之前获得的数据设计的。
对象识别
逼真的图形、人工智能的应用以及推动图形现实主义的极限现在已经成为游戏开发者和设计师的关键活动之一。图像识别技术被预测将彻底改变游戏行业。与目标检测模型一起,它们被开发者用来创建游戏现实中的自然场景变化和空间运动。
例如,这些模型通常用于区分属于不同队伍的玩家,并向特定角色发出指令。区分形式、对象、障碍物和图形变得更加容易且更快。此外,对象识别模型和算法还用于识别身体动作,以便在屏幕上传达和反映这些动作,从而用于互动游戏。
视觉效果和图形
在视频游戏开发过程中,发明了大量的计算机图形技术。现代技术的兴起也促使了用于创建游戏视觉效果的机制的巨大进步。其中包括游戏中的动作捕捉、实时渲染、摄影测量技术等。

例如,动作捕捉技术可以创建具有更多人性特征和特点的角色。它有助于更自然地渲染情感、面部表情和动作。
现代视频游戏开发者尝试使用先进的算法来突破游戏的视觉界限。实时渲染技术就是为此目的而使用的。摄影测量技术则涉及拍摄摄影数据并将其转换为引人入胜的逼真数字模型。
个性化营销
个性化营销在各个行业中得到积极应用,以避免无用、烦人的和低效的广告。市场营销人员和游戏开发者都对通过创建有意义的营销信息并将其传递给合适的人进行高度针对性的互动感兴趣。在任何情况下,视频游戏提供商都会收集数据,以便更好地吸引观众。
游戏中的个性化营销有助于提高用户活动,同时吸引新用户。这可以通过精准调整广告信息来实现。为了确保你的广告被正确接收,你需要知道哪些玩家对广告有反应,哪些没有。
欺诈检测
游戏世界中的所有操作和决策都很迅速。这些过程的高速度对欺诈者具有很高的吸引力。因此,公司面临着在防止欺诈活动的同时保持高客户满意度的需求。安全问题在所有行业中都具有挑战性。
各种玩家验证解决方案在游戏中得到了广泛应用。实际上,游戏开发者有法律义务使用玩家验证。此外,各种验证技术可以在早期阶段检测到可疑账户和活动。此外,这些技术还用于防止在虚拟游戏世界中相当普遍的身份盗用。

支付欺诈在游戏中也相当常见。欺诈者往往会创建特殊的机器人来获取支付所需的信息。因此,游戏公司需要确保玩家个人信息和交易的高水平安全。
机器学习算法帮助游戏公司应对挑战。它们的应用可以快速识别可疑活动。由于能够处理大量数据,它们使欺诈检测更加自动化和高效。
社会和客户分析
游戏行业在财务上表现非常成功。其不断增长的受欢迎程度导致每几秒钟就有新玩家加入。每天,全世界有数百万人积极玩视频游戏。所有这些人都留下了大量宝贵的数据,这些数据对游戏开发者可能大有裨益。社会数据和客户数据分析对于理解客户对游戏的看法以及制定有效的产品策略至关重要。
社会和客户数据分析使视频行业能够深入了解客户对品牌的态度,并预测客户的购买决策和品牌忠诚度。所谓的社交网络游戏形成了多人在线网络。在这些网络中,玩家积极互动。这种互动通常会导致基于竞争和实现相同目标的兴趣而创建独立的社交社区。客户数据则包含反馈以及帮助细分受众和更好地定制产品的数据。
结论
游戏行业正在呈指数级增长。活跃用户的数量每分钟都在增加,开发游戏的公司的整体收入也在增长。游戏的内部基础设施变得更加复杂,为玩家提供了更多的机会。为用户创造了一个全新的世界和现实。顶级的可视化和设计技术、最新的视觉效果、图形元素以及增强现实效果为客户提供了高水平的满意度。
数据科学已经进入各个行业,并永远改善了它们的运作原则。它将各种业务带到了一个 qualitatively 新的发展水平。游戏行业也不例外。此外,数据科学技术和方法已成为游戏开发、设计、运营及其许多其他功能阶段的不可或缺的一部分。
ActiveWizards 是一个专注于数据项目(大数据、数据科学、机器学习、数据可视化)的数据科学家和工程师团队。核心专业领域包括数据科学(研究、机器学习算法、可视化和工程)、数据可视化(d3.js、Tableau 等)、大数据工程(Hadoop、Spark、Kafka、Cassandra、HBase、MongoDB 等)以及数据密集型 Web 应用开发(RESTful API、Flask、Django、Meteor)。
原文。转载授权。
相关:
-
旅游行业数据科学的前 7 个应用案例
-
制造业数据科学的前 8 个应用案例
-
电信行业数据科学的前 10 个应用案例
更多相关主题
制造业中的前 8 大数据科学应用案例
原文:
www.kdnuggets.com/2019/03/top-8-data-science-use-cases-manufacturing.html
评论
由 ActiveWizards 提供
制造业目前面临着巨大的变革。由于数字世界的快速发展和数据科学的广泛应用,各个领域的人类活动都在寻求改进。现代制造业常被称为工业 4.0,即在第四次工业革命条件下进行的制造,带来了机器人化、自动化和数据的广泛应用。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
存储和处理的数据量每天都在增长。因此,今天的制造公司需要寻找新的解决方案和应用案例来应对这些数据。当然,数据给制造公司带来了好处,因为它可以自动化大规模的过程并加快执行时间。
数据科学被认为将显著改变制造业。让我们考虑几个在制造业中已经变得普遍并为制造商带来好处的数据科学应用案例。
预测分析
预测分析是对当前数据进行分析,以预测和预防问题的发生。制造商对监控公司运作及其高性能非常感兴趣。找到解决问题的最佳方法、克服困难或完全防止问题发生,对使用预测分析的制造商来说是极好的机会。实施预测分析可以处理浪费(过度生产、闲置时间、物流、库存等)。因此,让我们深入探讨预测分析带来的可能解决方案。
故障预测和预防性维护
这两种预测模型都旨在预测设备何时无法执行任务。结果,次要目标可能会实现——防止这些故障发生,或者至少减少它们的数量。这得益于众多的预测技术。
预防性维护通常应用于仍在运行的设备,以减少设备故障的可能性。预防性维护有两种主要类型:基于时间的和基于使用的。预防性维护的最大优势是计划。通过预测设备未来可能出现的问题,制造商可以规划维修的停机时间。这些停机时间通常是为了避免由于更严重问题引起的显著延误和故障。

需求预测与库存管理
需求预测是一个复杂的过程,涉及数据分析以及会计和专家的大量工作。此外,它与库存管理有很强的关系。一个简单的事实可以解释这种相互关系——需求预测使用的是供应链的数据。
对制造商来说,需求预测有很多好处。首先,它提供了更好的库存控制机会,并减少了存储大量无用产品的需求。此外,在线库存管理软件有助于收集对进一步分析非常有用的数据。另一个关键因素是,需求预测的数据输入可以不断更新。因此,可以做出相关的预测。额外的好处在于改善了供应商与制造商的关系,因为双方可以有效地调整库存和供应过程。
需求预测和库存管理考虑了许多因素,其中包括经济或市场等外部因素、原材料的可用性等。通过这种方式,你可以更复杂地了解你的制造业务表现及进一步规划。
价格优化
制造和销售产品涉及考虑许多影响产品价格的因素和标准。从原材料的初始价格到分销成本的所有元素都会对最终产品价格产生影响。当客户发现这个价格太高或太低时会发生什么呢?
价格优化是找到制造商和客户都能接受的最佳价格的过程,即既不太高也不太低。现代价格优化解决方案可以有效地提高你的利润。这些工具聚合并分析来自内部来源和竞争对手的定价及成本数据,并得出优化的价格方案。
在高度竞争的市场和客户需求变化的条件下,价格优化变得必不可少,并且发展成一个持续的过程。
保修分析

制造商每年在支持保修索赔方面花费大量资金。保修索赔揭示了产品质量和可靠性的宝贵信息。它们有助于揭示产品的早期预警或缺陷。
利用这些数据,制造商可以对现有产品进行改进或开发出更有效、更高效的新产品。现代保修分析解决方案帮助制造商处理来自各种来源的大量保修相关数据,并利用这些知识发现保修问题的上升趋势及其发生原因。
机器人化
机器人正在改变制造业的面貌。如今,利用机器人执行日常任务以及那些对人类来说困难或危险的任务已成为一种常态。
制造商每年倾向于投入越来越多的资金用于企业的机器人化。人工智能驱动的机器人模型有助于满足日益增长的需求。此外,工业机器人在提高产品质量方面也发挥了重要作用。每年,升级版的模型都会进入生产线,以彻底革新生产线。它们简单直观。此外,制造机器人对企业来说比以往任何时候都更为实惠。
产品开发
大数据为制造公司在产品开发方面带来了巨大的机会。制造商利用大数据的优势更好地了解客户,以满足需求并满足他们的需求。因此,数据可以用于开发新产品或改进现有产品。
通过使用大数据进行产品开发,制造商可以设计出具有更高客户价值的产品,并将新产品进入市场的风险降到最低。建模和规划时会考虑可操作的洞察力。这些数据可以增强决策过程。此外,数据管理工具被广泛应用于优化分销链的运营方面。
处理客户反馈并将这些数据提供给产品营销人员可能有助于创意生成阶段。因此,可能会开发出对客户更有用、对制造商更有利的新产品。
计算机视觉应用
人工智能驱动的技术和计算机视觉应用在制造过程中主要用于质量控制阶段。在这方面,物体识别、物体检测和分类被证明非常高效。通常,质量控制监测是由人工进行的。然而,现在越来越倾向于依赖计算机视觉而非人工视觉。这些监测系统通常由计算机硬件和软件、相机以及图像捕捉用的照明设备组成。之后,这些图像会通过算法与标准进行比较,以识别差异。
计算机视觉应用的主要优势包括:
-
提高高质量控制
-
降低劳动力成本
-
高速处理能力
-
持续的 24/7 操作能力。
管理供应链风险
供应链一直是复杂且不可预测的。风险一直是制造过程和产品交付的一部分。使用大数据分析来管理供应链风险可能对制造商非常有利。通过分析,企业可以预测潜在的延误并计算问题的发生概率。企业利用分析来识别备用供应商和制定应急计划。
为了跟上不断变化的趋势,实时数据分析的应用至关重要。预测和管理潜在风险对成功的制造业务运营至关重要。
结论
制造领域正因技术发展以及 ML 和 AI 解决方案的出现而发生显著变化。本文提供了数据科学在制造业中应用的几个生动例子,并介绍了这些例子为商业人士带来的好处。
除了预测潜在风险、需求和市场要求外,数据分析还可以帮助保持高质量标准和质量指标。此外,将智能数据技术融入制造业可能有助于预测意外的浪费或问题。大数据可以帮助制造商以更少的时间和金钱实现更多业务目标。
ActiveWizards 是一个专注于数据项目(大数据、数据科学、机器学习、数据可视化)的数据科学家和工程师团队。核心专业领域包括数据科学(研究、机器学习算法、可视化和工程)、数据可视化(d3.js、Tableau 等)、大数据工程(Hadoop、Spark、Kafka、Cassandra、HBase、MongoDB 等)以及数据密集型 Web 应用开发(RESTful APIs、Flask、Django、Meteor)。
原文。转载已获许可。
相关:
-
金融领域数据科学的前 7 大应用场景
-
管理者的数据科学简介
-
前 6 大 Python NLP 库的比较
更多相关话题
营销中的前 8 大数据科学应用场景
原文:
www.kdnuggets.com/2019/11/top-8-data-science-use-cases-marketing.html
评论
由 ActiveWizards 提供

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
在本文中,我们想要突出一些数据科学在营销中的关键应用场景。
数据科学的主要目标是将数据转化为可操作的洞察,营销领域不能忽视这些洞察的应用来获得利益。大数据在营销中提供了更好地理解目标受众的机会。
数据科学主要应用于营销领域的个人画像、搜索引擎优化、客户参与、响应性、实时营销活动。此外,每天都有新的数据科学和分析在营销中的应用方式出现。其中,新兴的应用场景包括数字广告、微目标化、微细分等。
让我们集中注意几个特别值得关注的实例,这些实例在时间的考验中证明了其效率。
客户细分
所有客户都是个体。因此,一刀切的方法根本不够有效。客户细分在这种情况下帮助了营销人员。统计分析的应用使营销人员能够切分数据并将客户分组。
客户细分是根据客户特征中的特定标准的匹配情况将客户分组的过程。
有三种主要的细分类型是最常用的。它们是:
-
基于接触点参与度的细分
-
基于购买模式的细分。
微细分的应用似乎在营销中成为一种上升趋势。微细分远比传统的细分更加先进。它帮助将人们划分为更精确的类别,特别是在行为意图方面。因此,营销行动可以针对即使是最少数的客户群体的偏好进行定制。

实时分析
实时分析证明能够立即将营销洞察融入到活动中。这些实时营销机会得益于社交媒体和通信技术的最近普及。
高效的实时数据分析为公司带来了显著的收入增长。实时算法处理两类数据:客户数据和运营数据。
客户数据提供了对客户需求、偏好和需求的洞察。运营数据反映了客户进行的各种交易、行动和决策。实时数据分析的应用为营销活动带来了效率、速度和高绩效。
实时分析在营销中提供了一个机会:
-
获取更多关于客户的详细信息
-
寻找高效的平台
-
提供独特的客户体验
-
运行实时测试
-
识别最佳的工作实践
-
立即反应和响应。
预测分析
目前,数据易于获取,甚至中型公司也可以访问。这就是为什么预测分析在营销中如此广泛应用。
预测分析是应用统计和机器学习算法以高概率预测未来。营销中有很多机会可以应用预测分析。让我们探讨那些被证明最有效的方法。
预测分析客户行为
聚类模型、预测、协同过滤、回归分析都被应用于发现客户行为中的相关模式,以预测未来的购买趋势。
预测分析用于资格审查和优先排序潜在客户
这里包括预测评分、识别模型和自动化分段。这些与资格审查和优先排序潜在客户有关,以使您的营销工作更有效。应用这些模型,您可以确保最有效的购买意向客户会正确接收到您的行动号召。
预测分析以将正确的产品带入市场
在这种情况下,数据可视化帮助营销团队做出正确的决策,确定市场上应推出的产品或服务。
预测分析用于目标定位
这涉及到一系列预测分析模型,如亲和力分析、响应建模、流失分析。这些模型用于识别最高价值的客户,并在正确的时间向他们提供合适的优惠。
推荐引擎
推荐引擎是提供个性化体验和高满意度的强大工具。市场营销人员应特别关注推荐引擎的应用。
推荐引擎的关键思想是将客户的偏好与他们可能喜欢的产品特征匹配。为此,推荐引擎通常使用以下模型和算法:回归、决策树、K-近邻、支持向量机、神经网络等。
推荐引擎是电子邮件和在线营销活动中关键的目标营销工具。
市场篮子分析
市场篮子分析是指无监督学习数据挖掘技术,旨在学习购买模式并揭示购买之间的共现关系。这些技术的应用可以预测未来的购买决策。
此外,市场篮子分析可以显著提高营销信息的效率。除了营销信息的类型,无论是直接报价、电子邮件、社交媒体、电话还是新闻通讯,您都可以为特定客户提供下一个最佳产品。

营销活动的优化
营销团队的主要任务是创建一个高效、以客户为导向的、有针对性的营销活动,旨在将正确的信息传递给正确的人,在正确的时间。
营销活动的优化涉及应用智能算法和模型,以提高效率。现代技术将自动化引入数据收集和分析过程,减少所花费的时间,提供实时结果,并发现模式中的细微变化。智能数据算法会对每位客户进行个性化处理。因此,高度个性化变得更加可实现。
优化过程包括几个步骤,这些步骤同样重要,需要关注。让我们概述一下这些步骤:
- 选择合适的工具
投资于那些能高效收集和分析数据的工具。确保您选择的工具可以协同工作,以提高您的活动效果。将这些工具与现有系统和数据集成。
- 测量指标
测量指标可以识别需要改进的流程和策略。测量这些参数,并将其与您的营销目标进行比较。
- 得出结论
做出基于数据的正确决策,以使您的营销活动尽可能成功。
线索评分
客户在销售漏斗中的路径充满了各种机会、选项和选择。通过线索评分来识别那些会经过漏斗并选择你的产品或服务的潜在客户。这有什么技巧?
线索评分根据代表每个线索价值的尺度对潜在客户进行排名。每个线索的价值可以有不同的识别方式,但通常被称为热的、温暖的或冷的。
潜在客户评分涉及关于客户的人口统计信息、响应能力、购买历史、偏好、网页浏览、访问、点赞、分享,甚至是他们常反应的电子邮件类型的数据收集。
通过潜在客户评分,销售人员能获取到那些购买意向强烈的合格潜在客户。因此,当产品提供给正确的人群时,销售会有所提升。
最佳活动渠道和内容
所有营销努力的本质是接触到正确的客户。然而,营销领域已经发生了变化,转向了在线世界。因此,公司的主要任务是确保品牌有强大的在线存在。
这里的主要部分是选择最佳的数字营销渠道:电子邮件营销、按点击付费广告、搜索引擎优化、展示广告、社交媒体营销、内容营销、联盟营销、在线公关。选择范围广泛。为了使这一选择更为舒适,可以采取以下步骤:
-
确定目标
-
分配预算
-
确定你的受众。
数字营销挑战会决定品牌可以使用的内容类型。博客文章、文章、视频、故事等。所有这些类型的效果在不同的分发渠道上可能有所不同。
结论
上述应用案例证明了数据科学在各种品牌的营销活动中带来诸多好处的说法。考虑到如今的数据量,关键不仅是保存数据,而是将其用于公司的利益。
将数据转化为有意义的见解对于决策至关重要。我们列出的营销领域数据科学应用案例揭示了数据在这一领域的具体应用特征及其可能产生的实际正面效果。
ActiveWizards 是一个专注于数据项目(大数据、数据科学、机器学习、数据可视化)的数据科学家和工程师团队。核心专长领域包括数据科学(研究、机器学习算法、可视化和工程)、数据可视化(d3.js、Tableau 等)、大数据工程(Hadoop、Spark、Kafka、Cassandra、HBase、MongoDB 等)和数据密集型 Web 应用程序开发(RESTful APIs、Flask、Django、Meteor)。
原文。经授权转载。
相关:
-
能源和公用事业领域的数据科学十大应用案例
-
金融领域的数据科学七大应用案例
-
建筑领域的数据科学八大应用案例
更多相关话题
顶级 9 款移动应用程序用于学习和实践数据科学
原文:
www.kdnuggets.com/2020/01/top-9-mobile-apps-learning-practicing-data-science.html
评论
作者:Andrea Laura,自由撰稿人

我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
随着移动设备和用户的快速增长,移动应用程序已经取代了桌面版本。移动应用改变了执行特定任务的方式。现在,你不需要去餐厅订餐并外带,只需通过一键即可在家中使用食品订购应用程序完成。
用户喜欢移动应用的便利性,他们可以随身携带。人们也应利用移动应用来增加自己在任何感兴趣领域的知识。有许多应用程序提供学习最新技术及其使用方法的机会,以便未来对他们有益。
数据科学是最具发展潜力的技术,正在改变世界以及商业运作方式。它是当今最热门且薪资高的职业之一。这是一项从大型数据集中提取见解的非常关键的工作。
技术工作需要合适的屏幕和大内存来完成任务,但现在许多移动应用已推出,可在任何时间和地点学习数据科学。在雇佣这些应用的开发时,企业应确保移动应用开发者具有正确的知识和技能,并且以前有过类似项目的经验。
查看这些顶级移动应用程序的列表,用于学习和实践数据科学
1. Elevate
一款设计用来训练大脑以提高技能的移动应用。你的课程将包括每天 3 节课。选择的活动基于你前一天活动的表现。你将被问及你薄弱领域的问题。
该应用程序帮助你提升生产力和技能。在应用程序的免费版本中,你只能获得一些有限的活动。如果你想访问更多个性化的训练程序,你需要购买应用程序的高级版本。
2. Lumosity
一个定制的游戏和脑力训练程序,用于挑战你的推理能力。该应用程序帮助你提升英语阅读和写作、逻辑以及数学能力。这些训练课程非常具有吸引力,因为它们挑战你去提高并做得更多。在基本版本中,你仅能获得 3 个练习,但如果你想要更多,可以通过支付一定的订阅费用来获得。
3. MathWorkout
对数字不太在行?不用担心,这个应用程序可以帮助你提高数学技能,使你能在指尖上进行计算。一旦你开始使用这个应用程序进行练习,你肯定会爱上数学。
4. QPython
Python 是一种用于编码的编程语言。Python 提供的一些优势与其他编程语言相比是显著的。现在你可以在手机上舒适地学习这门语言。该应用程序适用于 Android 用户。它在应用商店中评价很高,并且与 Python 2.7 兼容性最佳。该应用程序还可以执行来自 QR 码的 Python 代码和文档。
5. 基本统计学
每个人在学校生活中都学习过基本统计学。这个应用程序帮助用户复习数据科学领域的初级统计学。数据科学是统计学和编码的结合,因此开发者需要了解基本统计学,以从大数据集中获取洞察。这个应用程序可以帮助开发者学习和提高他们的统计学基础。
6. 编程中心
一个受到开发者喜爱的娱乐平台,拥有 5000 个程序和超过 20 门课程。该应用程序涵盖了许多编程语言,如 C、C++、C#、R 编程、人工智能和 Java,用户可以免费使用。
7. Excel 教程
数据科学家必须了解如何使用 Excel。这个应用程序让你学习 Excel 的初级和高级版本。用户可以通过应用程序上的视频教程进行学习。你甚至可以在应用程序中练习你通过视频教程学到的知识。通过 Excel 教程,随时随地学习 Excel。
8. 概率分布
这个应用程序类似于基本统计学应用程序,你可以在手机上可视化各种概率分布。该应用程序仅适用于 Android 用户。
9. Udemy
Udemy 帮助人们学习,提供超过 3200 门课程和不同主题的教程。你可以下载教程进行学习。你需要购买应用程序的高级版本才能访问那些视频。
EndNote
随着移动应用开发行业的繁荣,每天都有新应用上线。用户无法下载所有应用程序,因此应仔细选择对他们有益且能提高生产力的应用程序。尽量花更多时间使用这些应用程序,而不是社交媒体,因为这些应用程序将帮助你在家中舒适地学习和实践数据科学,而无需承担任何费用。
简介:安德里亚·劳拉是一位非常有创意的作家和活跃的贡献者,喜欢分享各种主题的资讯或更新,为读者带来丰富的信息。安德里亚以写作为爱好,推出了许多有趣的主题和信息,吸引读者深入阅读。她的内容被许多主流网站和博客刊登。
相关内容:
-
如何使用简单的 Python 为数据科学家编写 Web 应用程序
-
在 TensorFlow 中比较 MobileNet 模型
更多相关话题
LinkedIn 上前 16 位活跃的大数据和数据科学领袖
原文:
www.kdnuggets.com/2016/09/top-big-data-science-leaders-linkedin.html
评论由 Prasad Pore,KDnuggets。
有很多列表评估谁在 LinkedIn 上有影响力,或谁在大数据/数据科学领域活跃,但我们尚未见到结合这两个标准的列表。KDnuggets 之前的帖子 认识 LinkedIn 上的 11 位大数据与数据科学领袖 关注了 LinkedIn 上拥有大量关注者的人,但其中一些人,如 Hilary Mason,自 2013 年以来未再发表过文章,而其他人主要写作的主题与大数据和数据科学无关。此帖展示了 16 位在过去 3 个月内发布过帖子并且今年至少有 3 篇相关帖子的“大数据和数据科学”领域领袖。关注者数量截至 2016 年 9 月 23 日。

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业领域。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
1. Bernard Marr (801K 关注者) 是畅销商业作者、主题演讲者及大数据、分析和企业绩效领域的顾问。他是世界经济论坛的常客,为《福布斯》撰稿,并被 CEO Journal 誉为当今领先的商业头脑之一,LinkedIn 评选为全球五大商业影响者之一。
最近的帖子:大数据:语音分析的惊人潜力
大数据、人工智能和机器人技术能否引领这种令人毛骨悚然的未来?
2. Josh Bersin (427K 关注者) 是 Bersin by Deloitte 的创始人兼首席顾问。Bersin by Deloitte 是领先的基于研究的信息、基准测试、专业发展和咨询服务提供商,服务于战略人力资源、人才管理、领导力发展、招聘和培训组织。
最近的帖子: 数据证明文化、价值观和职业是雇主品牌的最大驱动因素
3. DJ Patil(306K 关注者)是美国白宫科学技术政策办公室的首席数据科学家。他撰写了关于如何思考数据科学新兴领域的最被引用的文章之一——《数据科学家:21 世纪最性感的工作》。
最近的帖子: 黑客你的夏天
4. Dennis R. Mortensen(136K 关注者)是 x.ai、Visual Revenue、evonax 和 Canvas Interactive 的首席执行官及创始人。他是《数据驱动洞察分析》的作者。
最近的帖子: 人工智能与谬误双重标准
5. Tom Davenport(88K 关注者)是世界著名的思想领袖和作者,Babson College 信息技术与管理的总统特聘教授,MIT 数字商业中心的研究员,德勤分析的独立高级顾问。他是 15 本书和 100 多篇文章的作者或合著者,还帮助组织在分析、信息与知识管理、流程管理和企业系统等领域振兴其管理实践。
最近的帖子: 数据科学家短缺的神话
6. Gregory Piatetsky-Shapiro(59K 关注者),KDnuggets 总裁,是商业分析、数据挖掘和数据科学领域的知名专家。KDnuggets 被评选为最佳大数据推特账户。Gregory 共同创办了 KDD(知识发现与数据挖掘会议)和 SIGKDD(知识发现与数据挖掘的专业组织)。
最近的帖子: 数据科学家使用的顶级算法和方法
KDnuggets 16:n32: 数据科学家曾是最性感的工作……深入了解深度学习
7. 卡拉·詹特里(5 万粉丝)是一名自由职业数据科学家,擅长全面的客户满意度和保留分析、品牌研究和竞争分析、员工保留研究、数据库创建和挖掘、调查创建和分析(新产品和品牌)。她拥有 19 年的行业经验。
最近的帖子: 荣幸成为 O'Reilly 封面女孩
8. 文森特·格兰维尔(2 万粉丝)是 Analytic Bridge 和 Data Science Central 的创始人。文森特曾是剑桥大学和国家统计科学研究所的博士后。
最近的帖子: 20 个数据科学和机器学习主题受到极大关注
9. 柯克·博恩(9500 粉丝)是大数据和数据科学顾问、咨询师、博主、数据科学家、天体物理学家、空间科学家及演讲者。2016 年:全球大数据第 1 位,机器学习第 2 位,物联网第 13 位影响者;2015 年:大数据、第 2 位数据挖掘、第 2 位数据科学影响者。
最近的帖子: 为了所有人的数据科学
10. 鲍勃·高尔利(7300 粉丝)是 Cognitio Corp.的合伙人和联合创始人,《每日威胁简报》的作者和出版人,2007 年 InfoWorld 年度前 25 名 CTO 获奖者,2009 年被《华盛顿人》杂志评为“DC 科技泰坦”,曾担任国防情报局 CTO。他拥有化学学士学位、国家安全事务和军事科学硕士学位以及计算机科学硕士学位。
最近的帖子: 在 10 月 4 日的 Synergy 论坛上帮助设定企业技术的发展方向
明确且不含糊的警告:选举日可能会发生网络攻击,并可能威胁我们的宪法制度
11. Paul Zikopoulos(6,800 粉丝)是获得奖项的国际演讲者和作者(出版了 19 本书,包括《Hadoop for Dummies》、《Big Data Beyond the Hype》等),拥有 350 多篇发表的杂志文章,认可的“大数据”专家,拥有强大的社交影响力和影响者地位。他是 IBM Platform Analytics 部门的副总裁,专注于竞争性大数据技术和技能卓越。
最近的帖子:一些关于 #IBM #DB2 实践者的好链接,现在一般可用……
12. Michael Wu PhD(6,300 粉丝)是 Lithium Technologies 的首席科学家。他开发了 Facebook Engagement Index (FEI),包括指标和一个用于设计和创建新的有效游戏化策略、机制和动态的框架。
最近的帖子:游戏化对当今品牌和消费者的价值
13. Harish Kotadia(4,800 粉丝)是业内公认的大数据和分析领域的思想领袖,拥有超过 13 年的 CRM/分析、BI 项目管理工作经验,服务于美国的财富 500 强客户。他在营销研究、分析和咨询行业担任研究执行官已有五年,曾在领先的 MR 组织如 Gallup 工作。
最近的帖子:5 本关于机器学习的简单快速阅读书籍
14. James Kobielus(4,600 粉丝)是 IBM 的大数据布道者。他是行业老兵,领导 IBM 在大数据、数据科学、企业数据仓库、高级分析、Hadoop、商业智能、数据管理和下一步行动技术方面的思想领导活动。
最近的帖子:当今政治对话的社交分析
**15. 詹姆斯·泰勒 **(4,100 关注者)是决策管理和决策管理系统开发的领先专家。他在业务规则、预测分析和其他决策技术方面有工作经验,以改善运营系统。他是战略顾问、演讲者,曾出版《决策管理系统》(IBM Press)、《智能(足够)系统》(Prentice Hall)等书籍。
最近的帖子:决策为商业规则增加价值,修复分析价值链中的断链
**16. 马克·范·瑞门南 **(3,900 关注者)是大数据、区块链、趋势、物联网和颠覆性创新的国际演讲者。他是 Datafloq 的创始人,Data Donderdag 的联合创始人,The Digital Leadership Initiative 的创始合伙人。
最近的帖子:区块链是什么,为什么如此重要?
相关:
-
在 LinkedIn 上认识 11 位大数据和数据科学领袖
-
大数据 2016:顶级影响者和品牌
-
前 100 名大数据专家
相关文章
分析、数据科学、机器学习和人工智能领域的顶级证书和认证
原文:
www.kdnuggets.com/2019/07/top-certificates-analytics-data-science-machine-learning-ai.html
评论最近,我们调查了欧洲、美国/加拿大和在线的数据科学和分析领域的最佳硕士课程。
然而,硕士学位通常需要 12 到 24 个月,而在当今快节奏的世界中,许多潜在的数据科学家希望更早开始,并且对可以在几周内获得的数据科学/机器学习证书感兴趣。其他一些人已经工作了一段时间,但希望获得一个认证——一个证书——来验证他们在分析/数据科学方面的知识。
本博客展示了我们对分析、数据科学、机器学习和人工智能领域的顶级证书和认证的调查。
注意:这篇文章的数据收集工作完全由Dan Clark完成,我添加了可视化和介绍。所有数据在收集时都是最新的,但所有费用和其他信息显然可能会发生变化。
我们使用认证来指代由专业协会(如 INFORMS)或公司(如 Microsoft)提供的评估。这通常证明一个人已达到较高的专业知识水平。一些公司将其证书称为“认证”,但我们将它们与其他证书一起列入下表 2a 和 2b 中。
证书通常由大学或其他教育机构在完成一个课程或一系列课程后颁发。
表 1:专业协会和主要公司提供的认证
| 组织 | 类型(链接) | 描述 | 学习时长 | 成本(美元) | 备注 |
|---|---|---|---|---|---|
| CAP (INFORMS) | 认证分析师专业 | CAP 是一种独立的验证,证明你对整个分析过程有卓越的知识。 | 自学 | $695 | 常规价格为$695,但 INFORMS 会员价格为$495。 | |
| 数字分析协会 | 网络分析师认证 | 在展示其知识和能力后获得专业认可。 | 未说明 | $649 | |
| EMC Corporation | 数据科学与大数据分析认证 | 这项基于开放课程的培训和认证提供了一个实践者的视角,涵盖了大数据分析所需的技术和工具。 | 未说明 | $600 | $600(视频流),$5,000(讲师指导) | |
| Great Learning(与德克萨斯大学奥斯汀分校合作) | PG 项目 - 人工智能与机器学习 | 通过结合实时互动在线课堂体验、支持和职业指导的辅导学习模型进行授课。 | 1 年/450 学习小时 | $5,500 | $5,500(预付),$7,500(按月分期付款) | |
| SAS | 大数据认证 | 展示你使用处理大数据的工具和技术的能力。 | 未说明 | $2,250 | $299(每月),$2,250(每年) | |
| SAS | 数据科学认证 | 让自己脱颖而出 - 无论你是想换工作、晋升还是提升当前技能。 | 未说明 | $2,250 | $299(每月),$2,250(每年) | |
| TDWI | 认证商业智能专家(CBIP) | 针对 IS/IT 领域的高级人员,特别是在数据管理和商业分析方面。 | 未说明 | $1,799 | |
| CAS Institute | 预测分析认证专家 | 为分析专业人员及其雇主提供专门针对财产/意外保险应用的技能认证机会。 | 建议自学时间 150 小时 | 1320 | 包括在线课程、考试、课程指南、教材和 SMART 学习辅助工具 |
接下来,我们展示了顶级大学的在线证书列表。我们使用了2019 年计算机科学/信息系统排名作为排名依据。
**图 1:人工智能、分析、数据科学、机器学习及相关主题的证书
顶级大学**
以下表格更详细地展示了这些信息。
**表 2a:人工智能、分析、数据科学、机器学习及相关主题的证书
顶级大学**
| 排名 | 大学/组织 | 项目名称 | 学习时长 | 成本 | 在线/校园 |
|---|---|---|---|---|---|
| 1 | edX/MIT | 统计与数据科学微硕士项目 | 1 年(600-840 小时的学习时间) | $1,350 | 在线 |
| 1 | MIT | 机器学习与人工智能专业证书项目 | 不同 | 325 申请费 + 4 门课程,每门$2500-$5500 | 在线 |
| 2 | 斯坦福大学 | 机器学习 | 3 个月 | $5,040 | 在线 |
| 4 | edX/ 伯克利 | 数据科学基础专业证书 | 2-4 个月(64-96 小时的努力) | $267 | 在线 |
| 7 | edX/ 哈佛 | 数据科学专业证书 | 2-4 个月(102-184 小时的努力) | $442 | 在线 |
| 7 | 哈佛扩展学院 | 数据科学证书 | 18 个月 | $11,000 | 在线 |
| 7 | 哈佛 | 数据科学:机器学习 | 8 周 | 未说明 | 在线 |
| 13 | 普林斯顿 | 本科证书项目 | 未说明 | 未说明 | 在线 |
| 17 | 华盛顿大学 | 数据科学证书 | 不同 | 起价 $3,825 | 在线/校园 |
| 17 | 华盛顿大学 | 机器学习证书 | 不同 | $4,035 | 在线 |
| 18 | 哥伦比亚大学 | 数据科学专业成就认证 | 12 个月(12 学分) | $24,216 | 在线/校园 |
| 18 | 哥伦比亚大学 | 机器学习证书 | 3 个月 | $320 | 在线 |
| 18 | edX/ 哥伦比亚大学 | 高管数据科学 | 5 周(每周 7-10 小时) | $312.30 | 在线 |
| 25 | 康奈尔大学 | 机器学习证书 | 3-5 个月 | $3,600 | 在线 |
| 46 | edX/ 加州大学圣地亚哥分校 | 数据科学 | 4 门课程(每门课程 10-15 周,每周 8-10 小时的努力) | $1,260 | 在线 |
| 125 | 西北大学 | 决策者商业分析证书 | 1 年 | $2,750 | 在线 |
| 125 | 西北大学 | 商业分析证书 | 1 年 | $7,980 | 在线 |
| 125 | 佩恩州立大学 | 在线商业分析研究生证书 | 9 学分 | $8,775 | 在线 |
| 125 | 加州大学欧文分校 | 预测分析证书 | 9-24 个月 | $6,625 | 在线 |
| 175 | 亚利桑那州立大学(ASU) | 在线应用商业数据分析本科证书 | 18 学分小时 | 每学分 $595-$1,153(总计 $10,710-$20,754) | 在线 |
| 175 | 亚利桑那州立大学(ASU) | 高等教育在线高级分析研究生证书 | 15 学分小时 | 每学分 $595-$1,153(总计 $8,925-$17,295) | 在线 |
| 175 | 俄亥俄大学 | 在线数据分析证书 | 1 年 | 每学分 $508(俄亥俄居民),$527(非俄亥俄居民) | 在线 |
| 275 | 圣路易斯华盛顿大学 | 数据挖掘与机器学习研究生证书 | 不同 | 未说明 | 在线 |
| 325 | 佛罗里达州立大学 | SAS 编程和数据分析证书 | 未说明 | 未说明 | 在线 |
| 325 | 锡拉丘兹大学 | 数据科学 CAS | 15 学分 | 未说明 | 在线 |
这是来自其他没有排名的大学和教育提供者(如 Coursera)的证书列表。
**表 2b:人工智能、分析、数据科学、机器学习及相关主题的证书
按字母顺序排列的组织和未排名大学**
| 大学/机构 | 课程名称 | 学习时长 | 费用 | 在线/校园 |
|---|---|---|---|---|
| BCS | BCS 人工智能基础证书 | 不同 | 未说明 | 在线 |
| 本特利大学 | 商业分析研究生证书 | 必须在 5 年内完成 | 未说明 | 校园 |
| 布兰迪斯大学 | 学习分析研究生证书 | 15 学分(18 个月) | 每学分 $1,179(总计 $17,685) | 在线 |
| 克拉克大学 | 商业分析证书 | 5 门课程 | $23,125 | 校园 |
| Cognixia | 数据科学认证 | 30 小时的直播培训 | 在线 | |
| Coursera | 数据科学专业 | 8 个月 | 注册后未说明 | 在线 |
| Coursera,由斯坦福大学提供 | 机器学习认证 | 55 小时 | 未说明 | 在线 |
| edX/Microsoft | 微软数据科学专业课程 | 10 门课程(每门课程 16-32 小时)+ 最终项目 | 每门课程 $99(总计 $1,089) | 在线 |
| edX/IBM | 深度学习专业证书 | 2-4 个月(52-104 小时的努力) | $445.50 | 在线 |
| Great Learning(与德克萨斯大学奥斯汀分校合作) | PG 计划 - 人工智能与机器学习 | 不同 | $5,500(预付),每月 $1,000(总计 $7,000) | 在线 |
| Intellipaat | 数据科学认证培训课程 | $193(自学),$348(在线课堂) | 在线 | |
| 俄克拉荷马州立大学 | 商业数据挖掘研究生证书 | 12-18 个月 | 未说明 | 在线 |
| Simplilearn | 数据科学认证 | $1,420(自学),$1,270(在线课堂) | 在线 | |
| Spring People | 数据科学培训 | 在线(12 小时),课堂(2 天) | 未说明 | 在线 |
| 阿肯色大学 | 商业分析证书 | 9 个月 | $11,700 | 在线 |
| 特拉华大学 | 分析:优化大数据证书 | 3 个月,45 学时 | $2,895 | 校园 |
| 新罕布什尔大学 | 数据科学证书 | 4 个月 | $9,600 | 在线 |
| 新罕布什尔大学 | 分析证书 | 10 周 | na | 校园 |
相关:
-
欧洲最佳数据科学与分析硕士项目
-
美国/加拿大最佳数据科学与分析硕士项目,以及
-
最佳数据科学与分析在线硕士项目.
更多相关内容
印度值得考虑的顶级公司
原文:
www.kdnuggets.com/top-companies-in-india-to-consider-for-employment

图片由作者提供
从全球角度来看,初创公司正面临艰难的时刻。考虑到疫情后的影响、大规模裁员、投资者的谨慎态度以及整体竞争激烈等因素。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 工作
所有这些因素使员工处于一个具有挑战性的境地,因为越来越多的人开始担心未来几个月是否还能保住工作。但不确定的时期确实使组织推动边界并进行创新。
印度确实已经展示并证明了这一点。印度科技初创公司生态系统正在不断增长,越来越多的组织在构建 AI 系统,吸引了大量投资者的关注,同时也有越来越多的教育科技公司应运而生,以满足不断增长的需求。
印度拥有全球最大的软件工程师群体之一,该国认识到其所拥有的人才,并决定以此为基础扩展其边界。
所以我们直接进入主题。
1. Fi
Fi是一家成立于 2019 年的公司,创建了一款内置储蓄账户的金融应用程序,使用前沿技术。他们已获得 1320 万美元的种子资金,由红杉资本印度分公司和 Ribbit Capital 领投。如果你想进入金融科技领域,Fi 是一个值得关注的好公司。
该公司一直在寻找具备数据科学和网页开发等技能的候选人。他们曾有过常见的职位名称,如产品经理、风险分析师和后台开发工程师。
2. Sprinto
成立于 2019 年,Sprinto是一家软件开发公司,自动化了快速增长的 SaaS 公司在信息安全合规性和隐私法律方面的需求。该平台与任何云设置兼容,并通过一个单一的仪表盘帮助监控实体级风险和控制。
该公司有常见的职位名称,如全栈工程师、客户体验经理和产品经理,并且在线上有各种空缺职位。
3. Jar
好的,另一个金融科技公司:Jar。Jar 成立于 2021 年,致力于通过储蓄罐的概念重新唤起人们对储蓄的兴趣——这是我们小时候熟悉的概念。他们有一种革命性的方法来从数字交易中提取零散零钱,并将其投资于数字黄金。
他们目前招聘的职位包括软件工程师、移动应用开发者以及具有数据科学背景的其他职位。
4. Zepto
Zepto是一家成立于 2021 年的电子食品杂货公司,由斯坦福大学的退学者 Aadit Palicha 和 Kaivalya Vohra 创办。它不仅是印度增长最快的电子食品杂货公司,而且在最近的 E 轮融资后估值达到 14 亿美元。他们的总部位于孟买,但公司在印度的 10 个主要城市有超过 1000 名员工。
Zepto 的主要职位功能包括运营、工程和销售部门。可以在 LinkedIn 或他们的招聘页面查看可用的职位列表。
5. GoKwik
这个适合那些热爱数据的专业人士。GoKwik是一家数据与技术驱动的公司,致力于民主化购物体验。公司成立于 2020 年,员工约 250 人。
如果你正在寻找一个 100%远程工作的职位,那么 GoKwik 正是你所需要的。他们是一家 100%远程优先的公司,并将继续保持 100%远程,团队成员分布在印度 50 多个城市和城镇。
他们在客户体验经理、产品经理和销售经理等职位上有共同的职位名称,涵盖工程、客户成功和产品管理等不同部门。
6. BluSmart
第一家做到这一点的。BluSmart是印度首个全电动打车出行服务。我们中的一些人对印度的城市及其交通挑战有所了解。BluSmart 通过创造一种可持续的交通方式来应对这一挑战。但不是以成本为代价,而是以高效、实惠、智能、安全和可靠的出行方式。
BluSmart 的主要职位功能包括工程、运营、客户成功和支持部门。最常见的职位名称有软件工程师、产品经理和移动应用开发者。
7. Skyroot Aerospace
好的,这个可能与科技界稍有不同。但我们都听说过印度及其近期在太空领域的工作——听起来非常令人兴奋,参与其中可能更好。Skyroot Aerospace成立于 2018 年,总部位于印度海得拉巴。公司专注于未来主义的太空发射器设计和制造。印度正变得越来越具有竞争力,像 Skyroot Aerospace 这样的公司是你想要参与的创新。
它们不完全属于科技行业,但作为一名科技专业人士,你的技能非常受欢迎且具有可转移性。Skyroot Aerospace 专注于工程、运营和质量保证等职位角色。
结论
随着越来越多的人失业,找工作可能会变得困难。许多人不确定应该关注哪些公司,以及哪些公司具有发展和持续创新的领域。希望这篇文章能更有效地引导你的求职方向,找到值得信赖的初创公司。
Nisha Arya 是一名数据科学家、自由技术作家,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及基于理论的数据科学知识。Nisha 涵盖了广泛的主题,并希望探索人工智能如何有助于延长人类寿命。作为一个热衷的学习者,Nisha 旨在拓宽她的技术知识和写作技能,同时帮助他人。
更多相关话题
2022 年最佳数据分析师认证课程
原文:
www.kdnuggets.com/2022/11/top-data-analyst-certification-courses-2022.html

图片由编辑提供
最近有人问我关于数据分析师角色的问题,以及如何最好地迈向这一职业。我进行了研究,发现了一些在线认证课程,可以为你的数据分析师职业生涯提供启动。
所以你不需要再搜索了,我已经为你整理了这个列表。开始吧。
Google 数据分析专业证书
-
评分:4.8/5
-
课程时长:6 个月(每周学习不到 10 小时)
-
难度:初级水平
进度:100% 自定进度。按你自己的时间学习
由 Google 提供,这门课程为你提供了数据分析领域的热门技能。它包含 8 门课程:
这些课程将让你更好地理解数据的一般情况,如何探索数据,如何使用数据回答特定的业务驱动问题,以及一定程度的编程。这门课程非常受欢迎,最常见的职位包括:初级数据分析师、初级数据科学家、财务分析师、运营分析师等。
IBM 数据分析师专业证书
-
评分:4.6/5
-
课程时长:11 个月(每周学习不到 3 小时)
-
难度:初级水平
-
进度:100% 自定进度。按你自己的时间学习
由 IBM 提供,这门课程为你提供了数据分析的核心原则,并对数据处理、分析技术等有更好的理解。它包含 8 门课程:
这些课程将帮助你启动数据分析师职业生涯,通过提供数据分析的原则和基础,同时获得实践技能。你还将获得项目经验和数据分析工具,如 SQL、Python 和 Jupyter Notebooks,帮助你理解作为数据分析师的日常工作。
Edureka 的数据分析师硕士项目
-
时长:250+小时
-
难度:初学者级别
-
进度:100% 自主学习。根据自己的时间学习
由 Edureka 提供的数据分析师课程增加了你对数据分析专业人员常用工具和系统的知识和专业技能。你将进一步深入学习统计学、R 和 Tableau 数据分析。课程包括 5 个子课程,每个子课程都有更深入的模块:
-
分析的统计学基础
-
R 数据分析认证
-
Tableau 培训与认证
-
Microsoft Power BI 培训
-
AWS S3
如果你想了解更多模块,你可以下载课程大纲。你将深入学习的领域包括:统计学、探索性分析、数据可视化、概率、高级 SAS 程序、Tableau、贝叶斯推断、回归建模等。
DataCamp 的 Python 数据分析师课程
-
编程语言:Python
-
时长:36 小时
-
难度:初级/中级水平
-
进度:100% 自主学习。根据自己的时间学习
如果你希望成为一名专注于 Python 的数据分析师,这门 DataCamp 课程适合你。你将通过互动练习学习如何导入、清理、操作和可视化数据。课程包括 11 个子课程:
-
Python 中的数据科学导论
-
中级 Python
-
使用 Pandas 的数据操作
-
使用 Pandas 合并数据
-
Python 中的统计学导论
-
使用 Seaborn 的数据可视化导论
-
使用 Python 的数据操作
-
使用 Python 导入和清理数据
-
Python 中的探索性数据分析
-
Python 中的采样
-
Python 中的假设检验
你将通过处理真实数据集来获得经验,以帮助你实现所学技能。许多课程忽略了统计学在数据分析中的重要性,但该课程提供了相关知识,并让你通过样本和假设检验进一步探索。
成为数据分析师由 Udacity 提供
-
评分:4.8/5
-
课程时长:4 个月(每周 10 小时学习)
-
难度:初学者水平
-
学习进度:100% 自定进度。按照自己的时间进行学习
-
先决条件:Python 和 SQL
由 Udacity 提供,并与 Kaggle 合作的《使用 Python 和 SQL 进行数据分析》课程,帮助你提升当前编程技能,并改善处理混乱复杂数据集的能力。该课程包含 4 个部分:
-
数据分析入门
-
实用统计学
-
数据处理
-
使用 Python 进行数据可视化
你将参与实际项目、知识、工作区、测验和自定义学习计划,并有进度跟踪器。还将提供技术导师支持和个人职业建议,帮助你获得理想的数据分析师职位。
想了解更多?
这里有一些关于数据分析的其他文章,可以帮助你进一步了解:
-
7 个数据分析面试问题及答案
-
2022 年顶级 YouTube 数据分析课程
Nisha Arya是一位数据科学家和自由技术写作人。她特别感兴趣于提供数据科学职业建议或教程以及数据科学相关的理论知识。她还希望探索人工智能如何对人类寿命的延续产生影响。作为一名热衷学习的人,她希望拓宽自己的技术知识和写作技能,同时帮助指导他人。
相关话题
2023 年需了解的顶级数据 Python 包
原文:
www.kdnuggets.com/2023/01/top-data-python-packages-know-2023.html

图片来自Unsplash,由Clément Hélardot提供
2022 年对任何数据人员来说都是一个优秀的年份,尤其是对于那些使用 Python 的人,因为有许多令人兴奋的包来提升我们的数据能力。已列出了各种必须学习的数据 Python 包 2022,我们可能希望在新的一年中添加一些新东西来改善我们的技术栈。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的轨道
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在的组织的 IT
面对 2023 年,各种 Python 包将改善我们在新的一年的数据工作流程。这些包是什么呢?让我们看看我的推荐。
从数据清理包到机器学习实现,这些是 2023 年你需要了解的顶级数据 Python 包。
1. Pyjanitor
Pyjanitor是一个开源 Python 包,专门为通过方法链进行数据清理而开发,旨在改进 Pandas API 的数据清理功能。
我们知道许多用于数据清理的 Pandas 方法,例如 dropna 来删除所有缺失值。通过 Pyjanitor,数据清理过程将通过在 API 中引入额外的方法而得到提升。它是如何工作的?让我们用示例数据来尝试一下这个包。
我们将使用 Kaggle 许可证下的泰坦尼克号训练数据作为样本。让我们开始安装 Pyjanitor 包。
安装
pip install pyjanitor
在使用 Pyjanitor 进行数据清理之前,我们先查看当前的数据集。
import pandas as pd
df = pd.read_csv('train.csv')
df.head()
输出

作者提供的图片
使用 Pyjanitor 包,我们可以进行各种扩展的数据清理,并实现 Pandas API 的链式方法。让我们通过以下代码看看这个包是如何工作的。
代码示例
import janitor
df.remove_columns(["Cabin"]).expand_column(column_name = 'Embarked').clean_names()
输出

作者提供的图片
通过导入 Pyjanitor 包,它将自动在 Pandas DataFrame 中实现。在上面的代码中,我们使用 Pyjanitor 完成了以下操作:
-
使用 remove_columns 方法删除‘Cabin’列,
-
对‘Embarked’列进行类别编码(独热编码),使用 expand_column 方法,
-
使用 clean_names 方法将所有变量标题名称转换为小写,如果有空格,将用下划线替换。
Pyjanitor 中还有许多我们可以用于数据清理的函数。请参阅他们的文档以获取完整的 API 列表。
2. Pingouin
Pingouin是一个用于任何常见统计活动的开源 Python 包,适用于任何数据科学家。该包通过提供一行代码而设计为简单,同时仍然提供各种统计测试。
安装
pip install pingouin
安装完包后,让我们尝试使用 Pingouin 进行统计分析。例如,我们将使用之前的 Titanic 数据集进行 T 检验和 ANOVA 检验。
代码示例
import pingouin as pg
#T-Test
print('T-Test example')
pg.ttest( df['Age'], df['Fare'])
print('\n')
# ANOVA test
print('ANOVA test example')
pg.anova(data=df, dv='Age', between='SibSp', detailed=True)
输出
图片来源于作者
使用一行代码,Pingouin 在数据框对象中提供统计测试结果。还有许多其他函数可以帮助我们的分析,我们可以在 Pingouin APIs 文档中进行探索。
3. PyCaret
PyCaret是一个开源的 Python 包,用于自动化机器学习工作流。该包提供了一个低代码环境,通过提供端到端的机器学习模型工具,加快模型实验。
在典型的数据科学工作中,存在许多活动,如清理数据、选择模型、进行超参数调整和评估模型。PyCaret 旨在通过将所有必要的代码最小化为尽可能少的行,从而消除所有麻烦。该包将多个机器学习框架集合在一起。让我们尝试使用 PyCaret 以了解更多信息。
安装
pip install pycaret
使用之前的 Titanic 数据集;我们将开发一个模型分类器来预测“Survive”变量。
代码示例
from pycaret.classification import *
clf_exp = setup(data = df, target = 'Survived')
输出
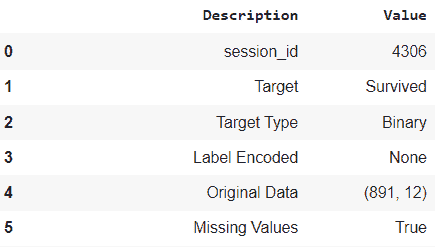
图片来源于作者
在上述代码中,我们使用 setup 函数启动实验。通过传递数据和目标,PyCaret 将推断我们的数据,并基于给定的数据开发机器学习模型。实际输出信息比上面的图像要长,并且对我们建模过程中的发生情况具有洞察力。
让我们查看模型结果,并从训练数据中推断最佳模型。
best_model = compare_models(sort = 'precision')
输出
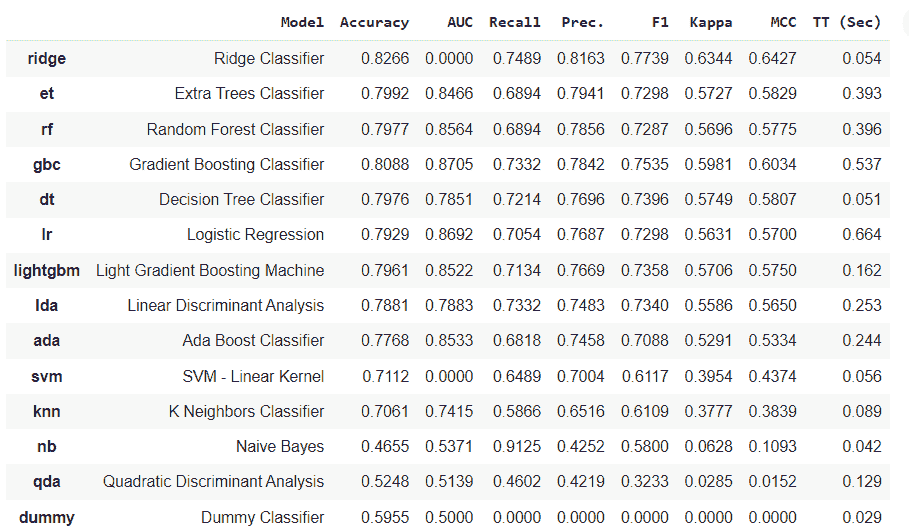
图片来源于作者
print(best_model)
输出

图片由作者提供
PyCaret 分类器实验将训练数据测试到 14 个不同的分类器中,并给出最佳模型。在我们的例子中,它是 RidgeClassifier。
你仍然可以使用 PyCaret 进行许多实验。要探索更多内容,请参考他们的 文档。
4. BentoML
BentoML 是一个开源的 Python 包,用于快速将模型部署到生产环境,并尽可能少的代码行。该包旨在专注于生产化机器学习模型,使用户能够轻松使用。
让我们尝试 BentoML 包并了解它是如何工作的。
安装
pip install bentoml
对于 BentoML 示例,我们将使用 包教程 中的代码,并进行一些修改。
代码示例
我们将使用鸢尾花数据集训练模型分类器。
from sklearn import svm, datasets
iris = datasets.load_iris()
X, y = iris.data, iris.target
iris_clf = svm.SVC()
iris_clf.fit(X, y)
使用 BentoML,我们可以将机器学习模型存储在本地或云端模型存储库中,并在生产环境中检索它。
import bentoml
bentoml.sklearn.save_model("iris_clf", iris_clf)
然后我们可以在 BentoML 环境中使用 runner 实例来使用存储的模型。
# Create a Runner instance and implement a runner instance in local
iris_clf_runner = bentoml.sklearn.get("iris_clf:latest").to_runner()
iris_clf_runner.init_local()
# Using the predictor on unseen data
iris_clf_runner.predict.run([[4.1, 2.3, 5.5, 1.8]])
输出
array([2])
接下来,我们可以通过运行以下代码来初始化 BentoML 中保存的模型服务,以创建一个 Python 文件并启动服务器。
%%writefile service.py
import numpy as np
import bentoml
from bentoml.io import NumpyNdarray
iris_clf_runner = bentoml.sklearn.get("iris_clf:latest").to_runner()
svc = bentoml.Service("iris_clf_service", runners=[iris_clf_runner])
@svc.api(input=NumpyNdarray(), output=NumpyNdarray())
def classify(input_series: np.ndarray) -> np.ndarray:
return iris_clf_runner.predict.run(input_series)
我们通过运行下面的代码来启动服务器。
!bentoml serve service.py:svc --reload
输出

图片由作者提供
输出将显示开发服务器的当前日志以及我们可以访问的位置。如果我们对开发结果满意,我们可以继续进行生产。我建议你参考 文档 以了解生产过程。
5. Streamlit
Streamlit 是一个开源的 Python 包,用于为数据科学家创建自定义 Web 应用。这个包提供了有见地的代码来构建和自定义各种数据应用。让我们尝试这个包来了解它是如何工作的。
安装
pip install streamlit
Streamlit Web 应用通过执行 Python 脚本来运行。那就是为什么我们在使用 streamlit 命令运行之前需要准备脚本。我们可以使用你喜欢的 IDE 或 Jupyter Notebook 来运行下一个示例,但我会展示如何在 Jupyter Notebook 中使用 Streamlit 创建 Web 应用。
代码示例
%%writefile streamlit_example.py
import streamlit as st
import pandas as pd
import numpy as np
st.title('Titanic Data')
data = pd.read_csv('train.csv')
st.write('Shows top 5 of the data')
st.dataframe(data.head())
st.title('Bar Chart Visualization with Age')
col = st.selectbox('Select the categorical columns', data.select_dtypes('object').columns)
st.bar_chart(data, x = col, y='Age')
上述代码会创建一个名为 streamlit_example.py 的脚本,并在我们运行 Streamlit 命令时创建一个类似于下面输出的 Web 应用。
!streamlit run streamlit_example.py
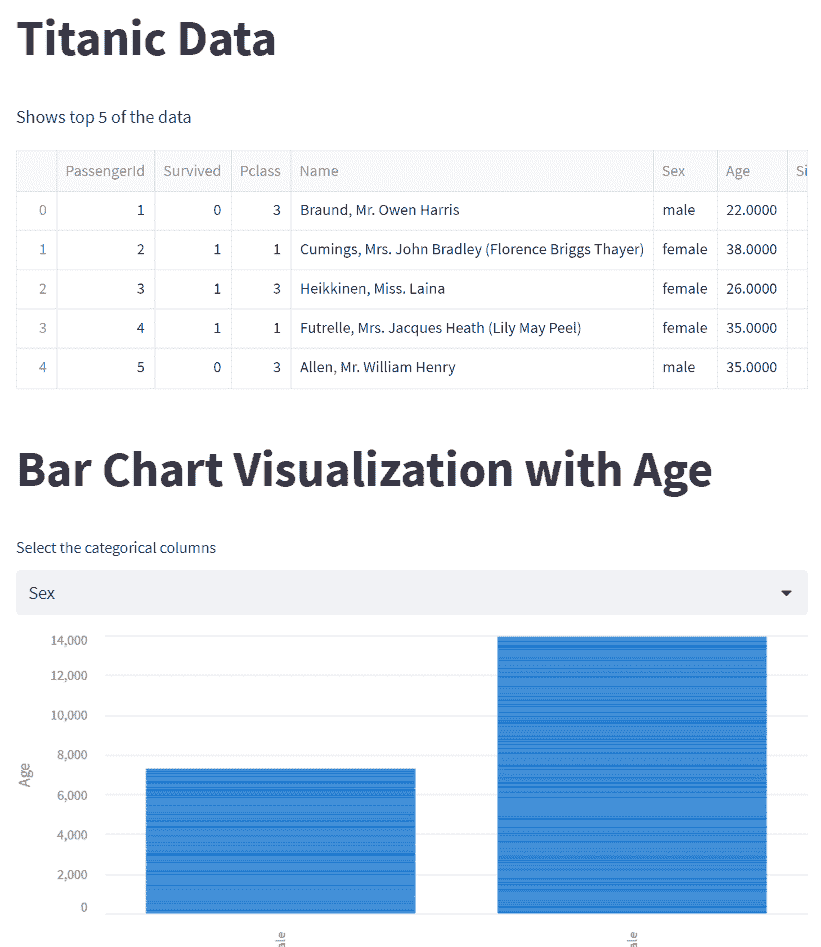
图片由作者提供
这段代码易于学习,你几乎不需要任何时间就能用 Streamlit 创建你的网络应用。如果你想了解更多关于如何使用 Streamlit 包创建的内容,你可以参考文档。
结论
面对 2023 年,我们应当比 2022 年更好地提升我们的数据技能。还有什么比通过学习令人惊叹的 Python 包来扩展我们的数据工具更好的方法呢?这些顶级的 Python 包包括
-
Pyjanitor
-
Pingouin
-
PyCaret
-
BentoML
-
Streamlit
Cornellius Yudha Wijaya 是一名数据科学助理经理和数据撰稿人。在全职工作于印尼安联保险公司期间,他喜欢通过社交媒体和写作平台分享 Python 和数据的技巧。
更多相关主题
2018 年、2019 年最常用的数据科学和机器学习方法
原文:
www.kdnuggets.com/2019/04/top-data-science-machine-learning-methods-2018-2019.html
评论
在最新的 KDnuggets 调查中,读者被问到:
你在 2018/2019 年实际应用中使用了哪些数据科学 / 机器学习方法和算法?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
基于 833 名投票者的结果显示,前 17 种方法与 2017 年的调查相同,尽管顺序稍有不同:
 图 1: 数据科学和机器学习方法的使用情况,2018/2019
图 1: 数据科学和机器学习方法的使用情况,2018/2019
今年受访者使用的前 17 种方法(第 16 位为并列)为:
-
回归
-
决策树 / 规则
-
聚类
-
可视化
-
随机森林
-
统计 - 描述性
-
K-近邻
-
时间序列
-
集成方法
-
文本挖掘
-
PCA
-
提升方法
-
神经网络 - 深度学习
-
梯度提升机
-
异常 / 偏差检测
-
神经网络 - 卷积神经网络(CNNs)
-
支持向量机(SVM)
这反映了 2017 年调查的结果,显示前 10 种方法与 2016 年的调查结果相同(尽管顺序有所不同)。
平均受访者使用了 7.4 种方法/算法,这与 2017 年和 2016 年的结果一致。
下面是今年调查中前几种方法和算法与 2017 年份额的比较。
 图 2: 数据科学和机器学习方法的使用情况,2018/9 对比 2017
图 2: 数据科学和机器学习方法的使用情况,2018/9 对比 2017
今年最显著的增加是在各种神经网络技术的使用上,包括 GANs、RNNs、CNNs、强化学习和原生深度神经网络。遗传算法和进化算法也有所增加,还有“其他方法”。
与 2017 年相比,按 (share2019 / share2017 - 1) 计算,具有最大相对增长的方法和算法有:
-
生成对抗网络(GAN),增长 101.8%,从 2017 年的 2.3% 增长到 2018/9 年的 4.7%
-
神经网络 - 循环神经网络(RNN),上升 56.5%,从 10.5% 上升到 16.5%
-
强化学习,增长 56.1%,从 4.2%提升至 6.6%
-
神经网络 - 卷积,增长 38.8%,从 15.8%提升至 22%
-
其他方法,增长 27.1%,从 6.1%提升至 7.8%
-
遗传/进化算法与方法,增长 25.7%,从 4.8%提升至 6.0%
-
神经网络 - 深度学习,增长 23.5%,从 20.6%提升至 25%
今年的最大下降包括:
-
奇异值分解(SVD),下降 25.4%,从 2017 年的 8.1%降至 2018/9 年的 6.0%
-
支持向量机(SVM),下降 23.3%,从 28.7%降至 22%
-
因子分析,下降 21.2%,从 11.7%降至 9.3%
-
关联规则,下降 20.6%,从 15.4%降至 12.3%
-
主成分分析(PCA),下降 19.3%,从 34.7%降至 28%
-
生存分析,下降 19.1%,从 8.5%降至 6.9%
隶属
按隶属参与情况:
-
行业/自雇,64.9%(541 份回应),平均使用 7.8 种工具
-
学生,15.8%(132 份回应),平均使用 6.1 种工具
-
学术界,9.2%(77 份回应),平均使用 7.9 种工具
-
政府/非营利组织,7.3%(61 份回应),平均使用 5.8 种工具
注意,只有 22 名受访者(❤️%)选择了“其他”,平均使用 7.5 种工具。
区域参与
最终,区域参与情况如下:
欧洲,35.4%
美国/加拿大,30.1%
亚洲,18.8%
拉丁美洲,6.1%
澳大利亚/新西兰,2%
非洲/中东,4.2%
其他,3.2%
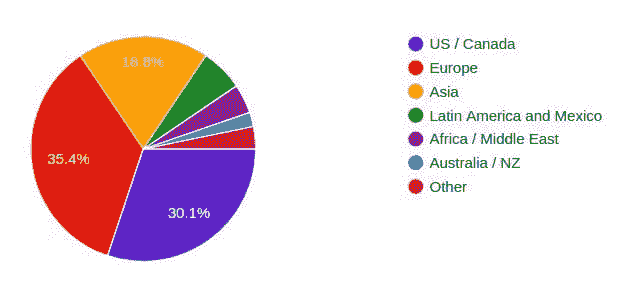 图 3: 区域参与,2018/2019
图 3: 区域参与,2018/2019
感谢所有参与调查的人员,使得这一趋势汇编和分析成为可能。
这是过去调查的结果:
-
分析、数据科学、机器学习应用的趋势与分析(2017)
-
2016 年分析、数据挖掘、数据科学的应用
-
2015 年分析、数据挖掘、数据科学的应用
-
2014 年分析、数据挖掘、数据科学的应用
-
2012 年您将分析/数据挖掘应用于哪里?
-
应用分析/数据挖掘的行业/领域,2011 年。
-
分析/数据挖掘的行业/领域,2010 年。
-
数据挖掘应用,2009 年。
-
数据挖掘应用,2008 年。
-
按行业的数据挖掘应用,2007 年。
-
您应用数据挖掘的行业/领域,2006 年。
更多相关主题
你需要知道的:现代开源数据科学/机器学习生态系统
原文:
www.kdnuggets.com/2019/06/top-data-science-machine-learning-tools.html
comments 最近我们报告了第 20 届年度 KDnuggets 软件调查结果:
Python 领先于 11 个顶级数据科学、机器学习平台:趋势与分析。
正如我们之前所做的(见 2017 年数据科学生态系统,2018 年数据科学生态系统),我们检查了哪些工具属于同一回答 - 用户的技能组合。我们注意到这并不一定意味着所有工具在每个项目中都一起使用,但拥有同时使用工具 X 和 Y 的知识和技能使得在某些项目中同时使用 X 和 Y 的可能性更大。我们看到的结果与这个假设一致。
顶级工具显示出令人惊讶的稳定性 - 我们看到与去年基本相同的模式。
首先,我们选择了至少获得 20%投票的工具。有 11 个这样的工具 - 与去年完全相同的 11 个工具,尽管顺序稍有变化。Keras 从第 10 名上升到第 8 名,Anaconda 从第 6 名上升到第 5 名。Tableau 和 SQL 略微下降。
这个 11 个工具的分界点是自然的,因为第 11 名(Apache Spark,21%)与第 12 名(Microsoft Power BI,13%)之间存在较大的差距。
我们使用了与我们的 2017 年分析 和 2018 年分析 相同的 Lift 衡量标准。
然后我们将关联性最强的工具分组,从 Tensorflow 和 Keras 开始,直到我们得到下面的图 1。通过仅显示 abs(Lift1) > 15% 的关联性,我们使模式更容易被看到。
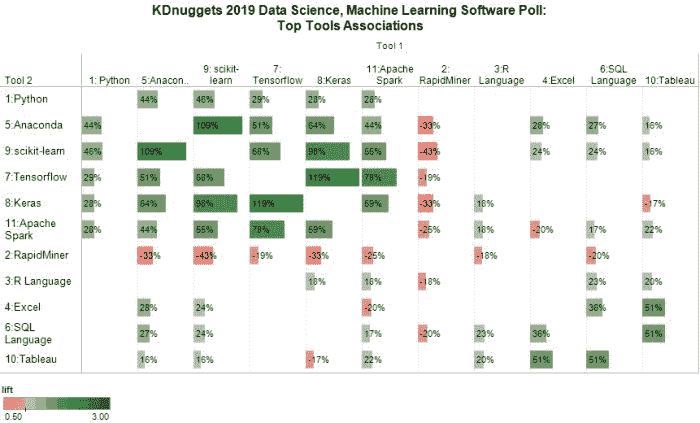
图 1:2019 年数据科学、机器学习顶级工具关联性
条形长度对应的是 lift1 的绝对值,颜色表示 lift 的值(绿色 - 正相关,红色 - 负相关)。
我们注意到现代开源数据科学生态系统中的 6 个主要工具是:Python、Anaconda、scikit-learn、Tensorflow、Keras 和 Apache Spark。这与去年完全相同 - 见下文。
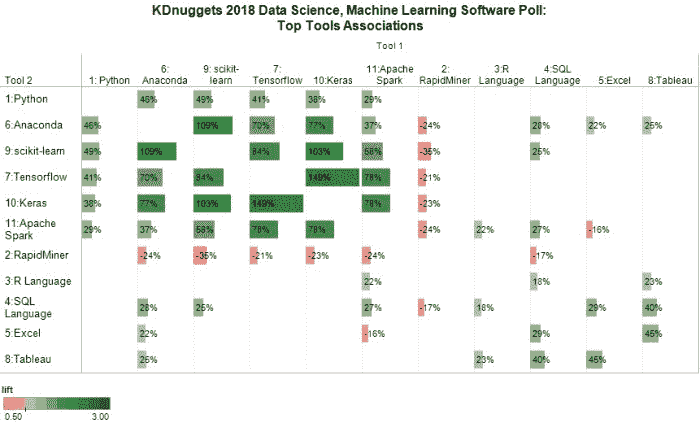
图 1b:2018 年数据科学、机器学习顶级工具关联性
Rapidminer 与上述所有工具的负相关性较小,且与其他工具的关联性也不强。
R 与 Keras、Apache Spark、SQL 和 Tableau 的关联性较小且为正相关。
第二组包括 3 个用于数据科学和机器学习的支持工具,这些工具通常一起使用:SQL、Excel 和 Tableau。
请注意,这张图表相对于对角线是对称的(右上三角形等于左下三角形),但我们包含了两个三角形,因为在完整图表中模式更容易看出。
Lift 定义:
Lift (X & Y) = pct (X & Y) / ( pct (X) * pct (Y) )
其中 pct(X) 是选择 X 的用户百分比。
Lift (X&Y) > 1 表示 X 和 Y 一起出现的频率高于独立时的预期,
如果 X 和 Y 按独立性预期的频率出现,则 Lift=1,并且
如果 X 和 Y 一起出现的频率低于预期,则 Lift < 1(负相关)
为了使差异更容易看出,我们定义了
Lift1 (X & Y) = Lift (X & Y) - 1
Python 与 R
接下来我们考察 Python 与 R。
令 with_Py(X) = 工具 X 在 Python 中的使用百分比,with_R(X) = 工具 X 在 R 中的使用百分比。为了可视化每个工具与 Python 或 R 的接近程度,我们使用了一个非常简单的度量 Bias_Py_R(X) = with_Py(X) - with_R(X),如果工具更多地与 Python 一起使用,则为正值,如果更多地与 R 一起使用,则为负值。
在图 2 中,我们绘制了最受欢迎的工具(至少 90 个投票)的偏向性,可以看到几乎每个工具都偏向 Python。唯一的 3 个例外是 R(显而易见)、微软 SQL Server 和 SAS Base(完全没有偏向)。作为对比,在 类似的 2017 年分析 中,2018 年有 10 个工具偏向 R,2017 年有 3 个 R 偏向的工具。
R 是一个优秀的平台,具有深度和广度,广泛用于数据分析和可视化,目前仍占据约 50% 的份额。然而,展望未来,我们预计 Python 生态系统会有更多的发展和活力。
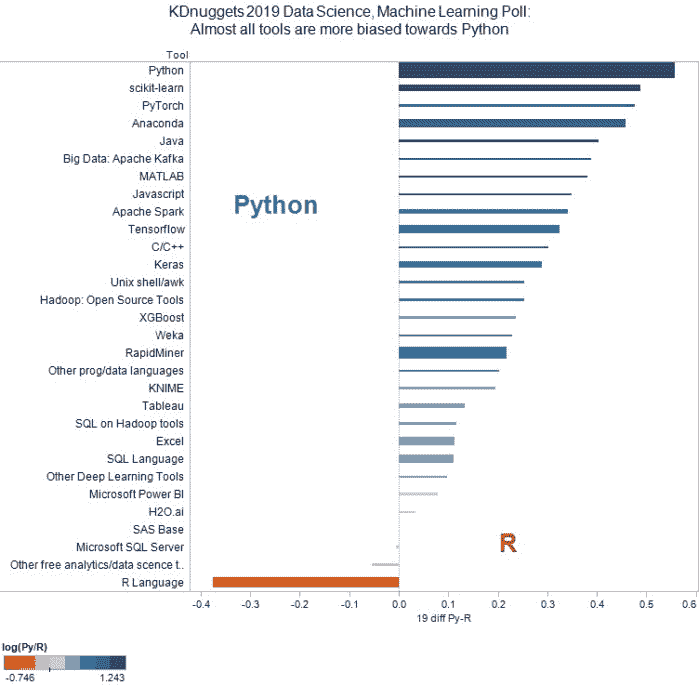 图 2:数据科学、机器学习平台 2019:Python 与 R 偏向性
图 2:数据科学、机器学习平台 2019:Python 与 R 偏向性
我不认为前 11 大平台的份额和关联的相对稳定性表明创新的终结,而只是可能在另一个主要系统 - 也许与 AutoML 相关的某些东西 - 颠覆当前生态系统之前的一个暂停。
大数据与深度学习
最后,我们考察数据科学/机器学习平台和语言与大数据(Hadoop 和 Spark 工具)以及深度学习的关系。
大数据工具的使用比例从 2018 年和 2017 年的 33% 上升到 37.4%。尽管这一增加,绝大多数数据科学家仍然使用中小规模数据,不需要 Hadoop / Spark。
深度学习工具的比例上升到 50%,而 2018 年为 43%,2017 年为 32%。
对于每个工具 X,我们计算它被同一个投票者与大数据(Spark/Hadoop 工具) - 纵轴,以及与深度学习工具(横轴)一起出现的频率。
这里是一个图表,显示了前几个工具(至少 50 个投票),排除了深度学习和大数据工具本身。
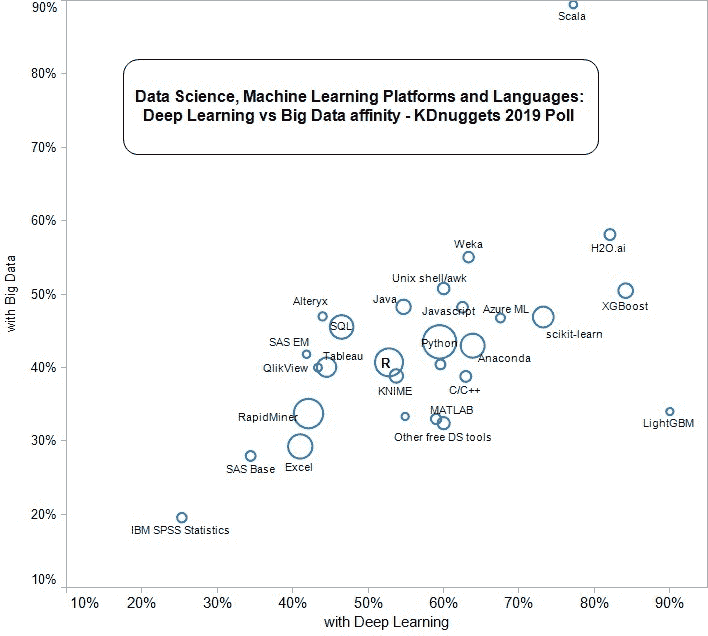 图 3:KDnuggets 2019 数据科学、机器学习调查:深度学习与大数据亲和力
图 3:KDnuggets 2019 数据科学、机器学习调查:深度学习与大数据亲和力
我们注意到,Scala 是在深度学习和大数据领域使用最广泛的语言。图表的右下角较重,几乎每个工具在深度学习中的使用频率都高于在大数据中的使用频率。
有趣的是,最与深度学习相关的工具是 XGBoost 和 LightGBM。
这里是一张表格,显示了不同平台与大数据和深度学习的关联情况,按与深度学习工具的关联度排序。
表 1:顶级数据科学/机器学习软件及其与大数据和深度学习的关联
| 软件 | 2019 统计 | 拥有大数据的比例 | 拥有深度学习的比例 |
|---|---|---|---|
| LightGBM | 50 | 34% | 90% |
| XGBoost | 208 | 50% | 84% |
| H2O.ai | 117 | 58% | 82% |
| Scala | 57 | 89% | 77% |
| scikit-learn | 418 | 47% | 73% |
| Azure ML | 77 | 47% | 68% |
| Anaconda | 556 | 43% | 64% |
| Weka | 109 | 55% | 63% |
| C/C++ | 116 | 39% | 63% |
| Javascript | 112 | 48% | 63% |
| 其他免费数据科学工具 | 145 | 32% | 60% |
| Unix shell/awk | 130 | 51% | 60% |
| 其他编程语言 | 94 | 40% | 60% |
| Python | 1078 | 44% | 59% |
| MATLAB | 100 | 33% | 59% |
| Orange DM | 51 | 33% | 55% |
| Java | 203 | 48% | 55% |
| KNIME | 175 | 39% | 54% |
| R | 764 | 41% | 53% |
| SQL Server | 184 | 34% | 49% |
| SQL | 538 | 46% | 46% |
| MS Power BI | 217 | 38% | 46% |
| Tableau | 362 | 40% | 44% |
| Alteryx | 66 | 47% | 44% |
| QlikView | 60 | 40% | 43% |
| RapidMiner | 839 | 34% | 42% |
| SAS EM | 55 | 42% | 42% |
| Excel | 571 | 29% | 41% |
| SAS Base | 93 | 28% | 34% |
| IBM SPSS Statistics | 87 | 20% | 25% |
相关信息:
-
Python 领先的 11 大数据科学、机器学习平台:趋势与分析。
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
2022 年最佳数据科学播客
原文:
www.kdnuggets.com/2022/06/top-data-science-podcasts-2022.html

Jukka Aalho via Unsplash
播客正在增长,成为人们自我发展的基石。现在几乎每个领域都有播客,为什么不听听关于数据科学的播客呢?
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 加速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
我将提供一份不同的数据科学相关播客清单,帮助你提高对该领域的兴趣,增加当前知识,或帮助你自我发展。
一般数据播客
让我们从谈论所有数据的播客开始,无论是过去、现在还是未来。
数据怀疑者

来源:数据怀疑者
几个月前我第一次输入数据科学播客时,这些播客出现了。Data Skeptic 于 2014 年推出了其播客,专注于数据科学、人工智能、机器学习等类似话题。他们按季节播放,内容包括 K 均值、时间序列、可解释性等。
哈佛数据科学评论播客

来源:哈佛数据科学评论播客
哈佛数据科学评论播客专注于数据科学及其在不同领域的应用和影响。每一期节目被描述为“案例研究”,以强调他们对理解数据使用和做出重要决策的渴望。
香蕉数据播客

来源: 香蕉数据播客
由《香蕉数据播客》的主持人 Christopher Peter Makris 和 Corey Strausman 聚焦于数据科学世界中的最新创新。这个双周播客专注于数据相关的不同领域,从伦理人工智能到机器人宠物。你还可以订阅他们每周的香蕉数据通讯!
O’Reilly 数据秀播客

来源: O’Reilly 数据秀播客
这个播客探讨了推动大数据、数据科学和人工智能的过程、工具和技术。他们的重点是新兴数据技术,涉及深度学习、端到端机器学习、实时分析等相关主题。
可以在 Apple、Stitcher、Google Play 和 RSS 上收听。
DataFramed

来源: DataFramed
这是 DataCamp 自家的数据科学播客。他们目前有 85 集,涵盖了如何建立数据文化和提升数据素养的各种话题。
可以在 Apple、Spotify 和 Google 上收听。
职业建议
数据科学中的女性

来源: 数据科学中的女性
我非常喜欢这个播客,因为可以想象女性进入以男性为主的行业是多么具有挑战性。这个播客由女性数据科学家主持,为其他女性提供建议,帮助她们取得成功。然而,它也包含了许多一般的数据讨论,如‘应用机器学习解决全球食品安全挑战’。
它可以在Apple Podcasts、Google Podcasts、Spotify、Stitcher 和 Overcast 上收听。
SuperDataScience

我推荐的另一个关于数据领域职业建议的播客是SuperDataScience。他们涵盖了从 MLOps、气候变化到法律科技的一系列话题。然而,他们也提供了非常好的内容,帮助人们改变职业路径、应该选择什么样的道路以及可用的不同课程。
它可以在他们的官网上收听,也可以在Apple、Spotify、Stitcher Radio 或 TuneIn 上收听。
The Artists of Data Science

来源:The Artists of Data Science
The Artists of Data Science播客于 2020 年 4 月 8 日播出,至今已有 245 集可供收听。这个播客非常注重数据科学家的自我发展。节目分为采访和“欢乐时光”两部分,听众可以在“欢乐时光”中提问任何与数据科学相关的问题。
它可以在RSS、Apple、Google、Castbox、Overcast、Spotify、Stitcher 和 TuneIn 上收听。
机器学习和人工智能播客
Data Science at Home

主持人 Dr. Francesco Gadaleta 讨论了机器学习、人工智能和算法等不同话题。节目中还包含了对人工智能领域顶尖人物的采访。目前有 197 集供你查看,提供了大量的知识。
Talk Python to Me

如果你使用编程语言 Python 并想了解你可以用它做什么,各种工具、库等;这个播客就是为你准备的。它是由Michael Kennedy主持的每周播客,涵盖了广泛的 Python 话题和其他相关话题。节目格式是与行业专家的轻松 1 小时对话。
可在他们的网站和Apple、Google以及Soundcloud上收听。
Gradient Dissent

Gradient Dissent 是由 Weights & Biases 创建的机器学习播客,由 Lukas Biewald 主持,探讨了机器学习、AI 和深度学习如何被行业领袖采用以及他们如何将这些模型投入生产。
可在Apple、Spotify、Google和YouTube上收听。
In Machines We Trust

这个获奖播客由 Jennifer Strong 主持,探讨了人工智能对我们日常生活的影响。目前有 3 季,其中第二季由 JP Morgan Chase and Co.赞助。这个播客让你更深入了解那些在应对科技力量、AI 发展和后果的人们。
它在Apple Podcast、Spotify、Google Podcasts、Stitcher和TuneIn上都有提供。
数据可视化播客
数据故事

来源: 数据故事
这是由 Enrico Bertini 和 Moritz Stefaner 主办的关于数据可视化的播客。目前有 165 集,他们还有一个 Slack 社区聊天,你可以在这里讨论节目,建议嘉宾,并与其他听众聊天。
数据可视化今天

来源: 数据可视化今天
数据可视化今天由前五角大楼分析师 Alli Torban 主持。它重点讲述了数据如何讲述引人入胜的故事,以及可视化如何使你的数据栩栩如生。目前你可以浏览 72 集。
它在Apple、Google Play、Google Podcasts、Stitcher、SoundCloud和Spotify上都有提供。
总结
还有许多其他与数据相关的播客,如果你知道任何我没有提到的好播客,请在下方评论中告诉我!
Nisha Arya 是一位数据科学家和自由职业技术写作人员。她特别感兴趣于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何/可以提高人类寿命。作为一个热衷学习的人,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
提升技能的顶级数据科学项目
原文:
www.kdnuggets.com/2022/04/top-data-science-projects-build-skills.html

Octavian Dan 通过 Unsplash
如果你正在寻找数据科学的职业,你的作品集是你的优先事项。尽管数据科学需求很高,但它是一个非常竞争的市场。每天都有新人转行进入技术市场,使得招聘经理选择合适的候选人变得困难。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
如果你想在众人中脱颖而出,通过作品集展示你的编码技能是你的最佳选择。招聘经理每天都会听到关于技能的介绍,他们希望看到你的实际能力。
以下是一些数据科学项目的创意列表,你可以用来提升你的技能。我将根据专业水平将它们分类。
1. 初学者数据科学家
Iris 数据
这是一个非常受初学者欢迎的数据集。它多才多艺,易于使用,是探索模式识别时的最佳选择。数据集不大,只有 150 行和 4 列,没有缺失值;因此是初学者简单的数据集。
数据集链接:UCI Iris 数据集
问题/任务类型:分类
Titanic
你可能听说过著名的 Titanic 数据集,无论是通过你的 Bootcamp 课程还是探索数据科学相关的话题。数据被分为两个组:训练集(train.csv)和测试集(test.csv)。
数据集链接:Titanic
问题/任务类型:创建一个机器学习模型来预测 Titanic 乘客的生存
示例作品:Kaggle Titanic 数据集
葡萄酒
如果你对葡萄酒感兴趣,这将是一个有趣的项目。这个数据集将测试你对特征选择、异常值和不平衡数据的理解。数据没有缺失值,非常适合初学者。
数据集链接:UCI 葡萄酒数据集
问题/任务类型:分类
示例作品:sci-kit learn 异常检测葡萄酒数据集 和 sci-kit learn 特征缩放葡萄酒数据集
人口普查收入
这个数据集进一步考验你对如何进行预测的理解。任务是判断一个人是否年收入超过 50K。它包含缺失值,允许你探索不同的数据清理方法。根据你的专业水平,你可以通过支持向量聚类、贝叶斯等方法进行探索。
数据集链接:UCI 人口普查收入
问题/任务类型:分类
示例作品:Kaggle 人口普查收入
2. 中级数据科学家
使用智能手机进行人体活动识别数据集
如果你参加过任何机器学习课程或训练营,你可能会遇到这个数据集。它是一个分类问题,可以用机器学习模型进行探索。这个数据集挑战你将自己从初学者提升到中级。数据集包含 10,299 行和 561 列。
数据集链接:UCI 使用智能手机进行人体活动识别数据集
问题/任务类型:分类、聚类
乳腺癌
这是一个分类数据集,记录了乳腺癌病例的测量数据,包含两类;良性和恶性。数据集包含缺失值,考验你的数据清理技能。你可以探索不同的变量及其相互关系,如果一个变量对另一个变量有影响等。
数据集链接:UCI 威斯康星乳腺癌
问题/任务类型:分类
示例作品:使用机器学习进行乳腺癌预测 和 其他 Kaggle 示例
这个 Twitter 数据集非常受欢迎,如果你想专注于情感分析,这个任务将允许你根据情感对推文进行分类;强烈负面(0),负面(1),中性(2),正面(3),强烈正面(4)。数据集大小为 3MB,包含 31,962 条推文。
数据集链接:Kaggle Twitter 数据集 by Analytics Vidhya
问题/任务类型:分类
示例作品:Kaggle 示例
3. 高级水平
城市声音分类
这是一个分类任务,介绍了音频处理。数据集包含来自 10 个类别的 8,732 个标记的城市声音片段。你可以使用神经网络模型来分类音频中的声音类型。
数据集链接:Analytics Vidhya 城市声音分类
问题/任务类型:分类
示例作品:Shubham Gupta TDS
VoxCeleb
VoxCeleb 是一个音视频数据集,包含从上传到 YouTube 的访谈视频中提取的短片人类语音。这个数据集允许你通过隔离和识别探索语音识别。
该数据集包含两个版本,VoxCeleb1 和 VoxCeleb2。VoxCeleb1 包含超过 100,000 个发言,涉及 1,251 位名人,而 VoxCeleb2 包含超过一百万个发言,涉及 6,112 个身份。
数据集链接:VoxCeleb
问题/任务类型:分类、语音识别
示例作品:qqueing github
VisualQA
VQA 是一个包含有关图像的开放性问题的新数据集。你需要具备计算机视觉、语言和常识知识才能回答。
该数据集包含 265,016 张图像,每张图像至少有 3 个问题,你将被要求使用深度学习来回答有关图像的开放性问题。
数据集链接:visualqa
问题/任务类型:计算机视觉
示例作品:VQA Challenge
结论
我希望这些项目创意能帮助你提升你的作品集,让你更好地理解自己的优点和弱点。帮助你弄清楚需要改进的地方。
如果你有任何建议,请在评论中留下!
Nisha Arya 是一名数据科学家和自由职业技术作家。她特别感兴趣于提供数据科学职业建议或教程及数据科学理论知识。她还希望探索人工智能如何及能够如何促进人类寿命的延续。她是一个热衷学习者,寻求拓宽她的技术知识和写作技能,同时帮助引导他人。
更多相关话题
2022 年顶级数据科学工具
原文:
www.kdnuggets.com/2022/03/top-data-science-tools-2022.html

图片由Fullvector提供
这个列表包括了针对数据领域的初学者和专家的工具。这些工具将帮助你进行数据分析、维护数据库、执行机器学习任务,并最终生成报告。这些工具也帮助我更快地处理新数据集,因此,如果你想在2022年成为超级数据科学家,那么尝试将这些工具添加到你的数据堆栈中吧。
我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织的 IT 工作
这些工具分为五个类别:
-
数据库
-
网络抓取
-
数据分析
-
机器学习
-
报告
数据库

图片由Fullvector提供
DuckDB
DuckDB是一个关系型表导向的数据库管理系统,支持 SQL 查询以生成数据分析。它的设计旨在加快分析查询的工作负载。它还提供了与 R、Python 和 Java 的集成。你可以将其与当前的数据堆栈集成,以生成分析结果。我通常用它来分析.csv文件和存储网络应用日志。欲了解更多信息,请阅读:使用 DuckDB 进行数据分析的指南。
PostgreSQL
PostgreSQL是一个开源的对象关系数据库系统,由社区开发并为社区服务,已经开发了 30 年。它可以处理复杂的查询、处理大量数据,并优化查询运行时间。在开发人员和数据工程师中,它是最受欢迎的数据库。几乎所有的技术面试或测试都涉及某种 PostgreSQL 问题。我使用psycopg2来摄取数据并在 Jupyter 笔记本中进行数据分析。
网络抓取

图片由Fullvector提供
Beautiful Soup
Beautiful Soup是一个用于从 HTML 和 XML 文件中提取数据的 Python 库。如果你是数据工程师或数据科学家,你必须掌握这个工具来从网站中提取数据。在数据收集过程中,你的经理会要求你学习一个新的网页抓取工具,或者让你创建一个 Python 文件来自动化网页抓取。这是创建完全自动化数据管道的重要一步。我使用 Beautiful Soup 来抓取 COVID19 数据和提取各种社交媒体数据。
Zyte
Zyte是一个用于运行网络爬虫和网页抓取程序的云平台。你可以管理你的网络爬虫并运行网页抓取作业。我立刻爱上了它的易用性和完全自动化的网页抓取解决方案。我的网络爬虫仍在运行,收集书籍数据到一个.csv文件中,所以我可以手动下载文件,或者将其与其他数据库集成以创建一个完全自动化的生态系统。如果你是学生,可以注册 GitHub 的教育包,获得 1 个免费永久 Scrapy Cloud 单元——无限的团队成员、项目或请求。
数据分析

图片由Fullvector提供
Python
Python 是数据科学家和机器学习工程师中使用最广泛的语言。你几乎可以在 Python 中找到所有库来执行任何数据相关的任务,从可视化到构建机器学习 API。我通常使用Pandas和Plotly来进行数据处理和可视化。
-
Pandas是一个流行的库,用于执行数据摄取、处理和可视化任务。
-
Seaborn:是 matplotlib.pyplot 的高级版本,可以让你用几行代码创建复杂的数据可视化。
-
Plotly提供了一种交互式的数据可视化方式。我使用它来完成所有的可视化任务,主要是为了打动管理团队。自定义动画和互动性让数据栩栩如生。
R
R 在数据分析和统计学家中相当受欢迎。它被创建用于解决统计问题,现在它已发展成一个完整的数据科学生态系统。R 附带了Tidyverse,这是所有包的母体。
以下是一些著名的包:
-
ggplot2: 用于创建令人惊叹的数据可视化。
-
dplyr: 用于数据扩充和处理。
-
readr: 用于加载 CSV 和 TSV 文件。
Julia
Julia 是一种新兴的编程语言,旨在解决科学问题。随着流行库的引入,Julia 正在成为进行数据实验和生成数据分析报告的首选工具。如果你想了解更多关于 Julia 的数据分析,可以阅读我的 博客。
数据分析软件包:
-
CSV: 用于加载 CSV 文件
-
DataFrames: 用于数据操作和数据分析。
-
Plots: 用于数据可视化。
Tableau
Tableau 是一个无需编码的工具,提供了可视化各种数据的自由。它是我用来可视化地理空间、分类和复杂数据集的首选工具。Tableau 可以与流行的编程语言如 Python 和 R 配合使用,提供端到端的数据科学解决方案。它是免费的,可以与多个数据库集成。最近,我创建了一个仪表板,以便给高层管理人员留下深刻印象。它监控了巴基斯坦工程师的分布情况。
机器学习

图片由 Fullvector 提供
FastAI
FastAI 是一个对初学者友好的库,提供高层组件以实现最先进的机器学习性能。它现在在 Julia 中可用,以提供更好的模型训练性能。FastAI 基于 Pytorch,这是一个设计深度学习解决方案的流行库。我强烈推荐初学者从免费的 课程 开始他们的深度学习之旅。
Scikit-learn
Scikit-learn 被数据分析师、数据科学家和数据工程师用于执行数据处理和机器学习任务。它是一个基于 NumPy、Matplotlib 和 Scipy 的开源库。Scikit-learn 用于简单的预测分析,但不支持高级深度学习问题。我经常用于时间序列、回归和分类问题。
Tensorflow
TensorFlow(TF)提供了一个完整的机器学习生态系统。它支持 CPU、GPU 和 TPU 用于训练复杂的模型。TF 支持基于浏览器的应用程序、移动设备和云生产。如果你需要一个完整的端到端机器学习解决方案,我建议你将 TF 纳入你的数据堆栈。
报告

图片由 Fullvector 提供
Jupyter notebook
Jupyter Notebook 被开发用来提供以文档为中心的体验。它是一个支持所有主要编程语言的 Web 应用程序。这个工具在各级数据科学家中都很受欢迎,无论你是初学者还是专家,它都是创建科学报告的工具。你可以在本地运行 Web 服务器或使用如 Google Colab 的云平台。
Deepnote
Deepnote 是我最喜欢的执行所有数据任务的工具之一。它是一个云笔记本平台,配备了多种集成功能,如 GitHub 和 PostgreSQL。该平台提供免费的 CPU 时间,并允许你以文章形式发布笔记本。最近,他们允许发布交互式数据应用程序,可用于开发仪表板或机器学习前端应用程序。你可以在 Python、R、Julia、Java 或任何首选编程语言中运行你的笔记本。Deepnote 快速、互动,并被成千上万的数据科学家使用。
Dash
Dash 适合构建和部署具有交互用户界面的数据应用程序。你可以创建一个仪表板,并将其用于模型性能监控或监控公司的运营。Dash API 是基于 Plotly.js 和 React.js 构建的。它支持 Python、R 和 Julia,使你能够在 10 分钟内创建用户界面。
结论
数据科学领域仍在不断发展,人们正在学习最新的工具以执行多种任务。大多数公司希望你能够执行数据工程、机器学习和 MLOps 任务。有时,他们会宣称自己在寻找数据科学家,但实际上,他们是在寻找能够自动化工作流程的人。
在这篇博客中,我们学习了关于数据库、网页抓取、数据分析、机器学习和报告工具的内容。在数据科学领域,没有一站式解决所有问题的方案,你需要不断寻找更好的工具以被视为一个合格的员工。所以,如果你希望提高生产力并给老板留下深刻印象,那么开始学习这些工具,以在该领域中脱颖而出。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些在心理健康方面挣扎的学生。
更多相关主题
Quora 上的十大数据科学作家及其最佳建议
原文:
www.kdnuggets.com/2015/09/top-data-science-writers-quora.html
这是 Quora 上十大数据科学作家及其选定答案的列表。

1. William Chen,Quora 数据科学家。85098 次浏览
选定答案: 我该如何成为数据科学家?
从学习 scikit-learn 开始,尝试动手操作,阅读 Data Science London + Scikit-learn 上的教程和论坛,进行简单的合成二分类任务。接下来,多做一些实验,并查看 Titanic: Machine Learning from Disaster 的教程,这涉及到稍微复杂一些的二分类任务(包括分类变量、缺失值等)。
2. Sahil Sareen,Arista Networks 软件工程师,GNOME 基金会成员及游戏开发者。71198 次浏览
选定答案: 我在面试中应如何处理编程问题?
永远记住:将你所思所想大声说出来。
你可能会犯错,但将其视为一种健康的讨论,面试官会在过程中帮助你。几乎从不需要给出正确答案,大多数面试官更关心你的基础知识和思维方式。
3. Gayle Laakmann McDowell,CareerCup 创始人/首席执行官,《Cracking the PM Interview》、《Cracking the Coding Interview》和《Cracking the Tech Career》的作者。41189 次浏览
选定答案: Gayle Laakmann McDowell 会给未来软件工程师的十大职业建议是什么?
7:如果你不想永远做开发者,就要尽快转变。深入获得技术专长非常有价值。但你做开发者的时间长短并不是特别重要。大学毕业几年内,做出选择。你是否愿意在未来的 10、20、30 年里继续做工程师?如果不愿意,赶紧开始转型吧。作为工程师的更多时间对你帮助不大。
4. Ricardo Vladimiro,Miniclip 游戏分析和数据科学负责人。37838 次浏览
精选回答: 我对数学和统计学不是很擅长。我是一个还不错的程序员。我想在机器学习/深度学习方面变得非常优秀。我应该从哪里开始,如何继续?
不擅长数学和统计学是一种误解。试试看:如果你对机器学习感兴趣,开始学习它,更重要的是,进行实践。在实践过程中,你将不得不回到数学和统计学中,复习一些你“不是很擅长”的内容。
5. Jeff Hammerbacher,好奇者。35599 次浏览
精选回答: 为什么 Python 是数据科学家首选的语言?
Python 是一种解释型、动态类型的语言,具有精确且高效的语法。Python 拥有良好的 REPL,新模块可以通过 REPL 的 dir() 和文档字符串进行探索。这是选择 Python 而非 C、C++ 或 Java 的一个原因。
6. Boxun Zhang,Spotify 数据科学家;计算机科学博士。29443 次浏览
精选回答: 什么编程语言最适合机器学习和统计分析?是 R 还是 Python?
使用 R 进行统计分析和机器学习模型原型设计;使用 Python 实现生产环境中的机器学习管道。
R 在数据分析方面比 Python 更好,因为 R 从一开始就是为了统计计算而设计的,并且拥有大量用于各种统计分析的第三方包。
7. Yisong Yue,机器学习研究员。25574 次浏览
精选回答: 机器学习:机器学习是否适合天才?我应该尝试追求它吗?
是的,你完全可以做到!工作伦理和热情比原始的数学和编码能力(无论是什么)更为重要。
当我第一次开始学习机器学习时,我被所有的数学符号和抽象概念所淹没。但随着时间的推移,我获得了能够高效地使用数学来推理不同机器学习方面的舒适感。毕竟,数学只是语言,虽然它是非常精确和严格的。
8. Yilun (Tom) Zhang,学习数据科学(积极使用 R 和 Python),滑铁卢大学统计学和计算数学。26901 次浏览
选择的回答: 如果我有计算机科学学位和一年的入门级数据集工作经验(虽然我没有做过很多机器学习或建模),成为数据科学家需要多久?
拥有计算机科学学位,你应该能够处理大多数编程部分,只是使用不同的库和包而已。更重要的是学习机器学习及数据处理背后的概念和算法。
如果你对它充满热情,我认为不会花太长时间。
9. Alex Kamil。24911 次浏览
选择的回答: 我该如何成为一名数据科学家?(已编辑)
-
了解矩阵分解
-
了解分布式计算
-
了解统计分析
-
了解优化
-
了解机器学习
-
了解信息检索
-
了解信号检测和估计
-
掌握算法和数据结构
-
实践
-
学习工程学
10. Sean Owen,Cloudera 数据科学总监。24564 次浏览
选择的回答: 没有硕士学位且持有非编程科学学位的人能否获得数据科学工作?
很难推荐统计学或工程学的硕士课程,因为这可能是一个过大的跨度。考虑类似“训练营”的项目,这是一种相对便宜且结构化的方式来快速提升你的背景,并尽量找到一个可以投入时间学习的工作。
幸运的是,数据科学如此受欢迎,它是一个可替代的量;人们真的想雇用聪明且渴望工作的人,他们可以处理数据周围的各种问题,大多数职位不需要“全栈数据科学”。
该列表基于 Quora 数据科学作家排名 - 感谢 Xamat Amatriain(Quora 领导工程)提供的提示。
个人简介: Matthew Mayo 是一名计算机科学研究生,目前正在进行将机器学习算法并行化的论文工作。他还是数据挖掘的学生、数据爱好者和有志成为机器学习科学家的学员。
相关:
-
Top /r/MachineLearning Posts, August: 深度学习以许多著名画家的风格绘画
-
8 月的热门故事:如何免费成为数据科学家;数据是丑陋的——数据清洗的故事
-
数据科学和商业智能中按角色分类的薪资
更多相关话题
数据科学领域受欢迎的分布式计算包排名
原文:
www.kdnuggets.com/2018/03/top-distributed-computing-packages-data-science.html
评论
作者 Rachel Allen 和 Michael Li
在数据孵化器我们致力于提供最新的数据科学课程。通过来自企业和政府合作伙伴的反馈,我们提供行业内最受欢迎的数据科学工具和技术培训。我们希望将更多基于数据的方法融入到我们企业数据科学培训和我们为希望成为数据科学家的博士及硕士毕业生提供的免费数据科学奖学金项目的课程开发中。为实现这一目标,我们首先查看并排名了受欢迎的深度学习库。接下来,我们希望分析数据科学领域分布式计算包的受欢迎程度。以下是结果。
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
排名
以下是基于 Github 和 Stack Overflow 活动以及 Google 搜索结果的前 20 名中的 140 个分布式计算包排名。表格显示了标准化分数,其中值为 1 表示高于平均水平一个标准差(平均 = 0)。例如,Apache Hadoop 在 Stack Overflow 活动中高于平均水平 6.6 个标准差,而 Apache Flink 接近平均水平。具体方法见下文。
结果与讨论

包排名是基于等权重的三个组件:GitHub(stars 和 forks)、Stack Overflow(标签和问题)以及 Google 搜索结果数量。这些数据是通过可用的 API 获取的。制定一个全面的分布式计算包列表是棘手的——最终,我们抓取了我们认为具有代表性的三个不同列表。我们选择专注于 140 个框架和分布式编程包(详见下文方法)。计算每个指标的标准化分数使我们能够查看哪些包在每个类别中脱颖而出。完整排名在这里,而原始数据在这里。
Apache Spark 和 Apache Hadoop 各自拥有独特的地位
Apache Spark (1) 是一个极其流行的开源分布式计算框架。Apache Spark 在 GitHub 活动指标中表现突出,其 forks 和 stars 的数量超过均值八个标准差以上。Apache Spark 利用内存数据处理,这使得它比其前身更快,并且能够进行机器学习。它还提供了 Scala 或 Python 的交互式控制台,后者在数据科学家中更受欢迎。尽管 Apache Spark 最初是为 Hadoop 生态系统设计的,但它可以使用多种不同的文件管理系统独立运行。Apache Hadoop (2) 在 Stack Overflow 活动中超越了 Apache Spark。Hadoop 的 Stack Overflow 活动与其他两个指标的脱节,很可能是因为 Apache Hadoop 的含义随着时间的推移而发展。术语“Hadoop”不仅指代框架,还可以指代构成生态系统的所有 Hadoop 相关项目。这导致了 Stack Overflow 分数的某种程度的膨胀。尽管如此,我们名单上的大多数框架和引擎都有 Apache Hadoop 集成。而且它在所有指标中都至少超过了均值两个标准差,巩固了其第二的位置。
Apache Storm 和 Apache Flink 是流行的替代框架,尤其适用于流处理
Apache Storm (4),最初被誉为实时的 Apache Hadoop,是一个仅用于流处理的框架,最适合近实时的分布式计算。它在所有指标上的表现均优于平均水平。虽然 Apache Storm 在大规模处理流数据时表现良好,但它通常与 Apache Kafka (3) 一起使用,后者是一个处理来自实时数据源的原始消息的平台。类似于 Apache Spark,Apache Flink (8) 也是一个既能进行批处理又能进行流处理的框架。然而,Apache Spark 自称为一个可以处理流的批处理器,而 Apache Flink 则适合重型流处理和一些批处理任务。
Stratio Crossdata 是排名最高的数据中心和增长最快的包
Stratio Crossdata (6)通过提供统一的方式访问多个数据存储,扩展了 Apache Spark 的功能。
Stratio Crossdata 使用类似 SQL 的语言和一个 API 来访问多个具有不同性质的数据存储,如 Apache Cassandra、ElasticSearch、Arvo 或 MongoDB。Stratio Crossdata 的 Google 搜索结果数量较上个季度增长了 400%,这是我们列表中 140 个包中增长率最大的。
前 10 名中的两个由 Twitter 开发
在我们列表中的两个 Twitter 项目中,最受欢迎的是 Apache Storm (4),它于 2011 年由 Twitter 捐赠给 Apache 软件基金会。Twitter Heron (9)是 Apache Storm 的直接继任者,于 2016 年 6 月发布。Twitter Heron 提供了改进的实时、容错流处理,其吞吐量高于 Storm。Twitter Heron 的季度增长率达到了 180%,是第五高的。我们将有兴趣看到 Twitter Heron 是否能随着时间的推移进一步攀升。
Hadoop 生态系统主导
Hadoop 生态系统项目是最普遍和广泛采用的分布式计算框架和接口。我们排名前 20 的包中有 17 个是 Hadoop 生态系统的一部分或设计用于与 Apache Spark 或 Apache Hadoop(包括 HDFS)集成的。在 Hadoop 生态系统之外,Hazelcast (10)(一个内存数据网格)、Google BigQuery (12)(一个基于云的大数据分析 Web 服务,使用类似 SQL 的语法)和 Metamarkets Druid (15)(一个实时分析大数据集的框架)在我们的指标中表现良好。
限制
与任何分析一样,在过程中做出了决定。所有源代码和数据都在我们的 Github 页面上。分布式计算包的完整列表来源于几个渠道。
自然,一些存在较长时间的库将有更高的指标,因此排名也更高。唯一考虑这一点的指标是 Google 搜索季度增长率。
数据展示了一些困难:
-
一些库的名称是常见词(onyx、drools、disco),因此确定 Google 搜索结果数量的搜索词包括了额外的描述性词汇(“onyx 平台”,“kiegroup drools”)或别名(“discoproject”)。所有搜索词可以在这里找到。
-
手动检查确认了 Stack Overflow 标签和 Github 仓库位置。
-
Stack Overflow 标签可以在这里找到。
-
Github 仓库名称可以在这里找到。
方法
所有源代码和数据在 我们的 GitHub 页面 上。
我们首先从 这些 四个 来源 中 生成了一个 140 个分布式计算包的列表,然后收集了所有的指标,得出了一个用于排名的索引值。“Github”索引分数基于 stars 和 forks,“Stack Overflow”索引分数基于包含包名的标签和问题,“搜索结果”基于过去五年的谷歌搜索总结果数以及过去三个月相对于前三个月计算的季度增长率。选择谷歌搜索结果数据作为指标而非谷歌趋势数据,因为某一关键词的索引网站数量比搜索该关键词的人数更能可靠地指示该包的使用流行度。此索引排名的计算可以在源代码中找到。
其他一些说明:
-
任何不可用的 Stack Overflow 或计数被转换为零计数。
-
如果不存在 GitHub 存储库,forks 和 stars 记录为零。
-
计数被标准化为均值 0 和偏差 1,然后计算出“Github”和“Stack Overflow”索引分数,再与“搜索结果”结合得出总体索引分数。
所有数据已于 2017 年 9 月 19 日下载。
资源
源代码可在 The Data Incubator's GitHub 上获取。
访问我们的网站了解更多信息:
-
数据科学奖学金 - 一个免费的、全职的为期八周的训练营计划,针对希望在纽约市、华盛顿特区、旧金山和波士顿成为专业数据科学家的博士和硕士毕业生。
-
在线数据科学课程:由我们驻场数据科学专家教授的入门级兼职训练营,基于我们的奖学金课程,为繁忙的专业人士在空闲时间提升数据科学技能。
个人简介: Michael Li 是 The Data Incubator 的创始人兼首席执行官。他曾在 Foursquare 担任数据科学家,在 D.E. Shaw 和 J.P. Morgan 担任量化分析师,也曾在 NASA 担任火箭科学家。他在普林斯顿大学获得博士学位,并作为 Hertz 奖学金获得者完成学业,还在剑桥大学作为 Marshall 奖学金获得者学习了数学 Part III。在 Foursquare,Michael 发现他最喜欢的工作部分是教授和指导聪明的人关于数据科学。他决定创办一家初创公司,让他能够专注于自己真正热爱的事物。
Rachel Kay Allen 是 Booz Allen Hamilton 的首席科学家,曾在 The Data Incubator 担任讲师。
相关:
更多主题
新手机器学习工程师常犯的 6 个错误
原文:
www.kdnuggets.com/2017/10/top-errors-novice-machine-learning-engineers.html
评论

在机器学习中,有很多种方法来构建产品或解决方案,每种方法都有不同的假设。很多时候,如何导航和识别哪些假设是合理的并不明显。新手在机器学习中会犯错,事后往往会觉得很傻。我列出了新手机器学习工程师常犯的顶级错误。希望你能从这些常见错误中学习,并创建出更有价值的解决方案。
认为默认损失函数理所当然
均方误差非常好!它确实是一个很棒的起始默认值,但在实际应用中,这种现成的损失函数很少是你试图解决的业务问题的最佳选择。
以欺诈检测为例。为了与业务目标一致,你真正想要的是根据因欺诈而损失的金额来惩罚假阴性。使用均方误差可能会得到不错的结果,但永远无法获得最先进的结果。
成为机器学习工程师 | 第 3 步:选择你的工具 查看这篇文章,了解你可以使用的不同机器学习工具。
总结: 始终构建一个与解决方案目标紧密匹配的自定义损失函数。
使用一种算法/方法解决所有问题
许多人完成了第一个教程后,会立即开始在他们能想到的每一个用例中使用他们学到的相同算法。它很熟悉,他们认为它会像其他算法一样有效。这是一个错误的假设,会导致较差的结果。
让你的数据为你选择模型。完成数据预处理后,将其输入到多种不同的模型中,并查看结果。你将对哪些模型效果最佳以及哪些模型效果不佳有一个很好的了解。
成为机器学习工程师 | 第 2 步:选择一个过程 查看这篇文章,掌握你的过程。
总结: 如果你发现自己一次又一次地使用相同的算法,这可能意味着你没有获得最佳结果。
忽略异常值
异常值可以是重要的,也可以完全被忽略,这取决于上下文。例如,在污染预测中,空气污染的大幅波动可能会发生,查看这些波动并理解其发生原因是个好主意。如果异常值是由某种传感器错误引起的,忽略它们并将其从数据中删除是安全的。
从模型的角度来看,有些模型对异常值的敏感度高于其他模型。例如,Adaboost 将这些异常值视为“困难”案例,并对异常值施加巨大权重,而决策树可能仅简单地将每个异常值计为一个错误分类。
成为机器学习工程师 | 第 2 步:选择一个过程 介绍了可以用来避免这种错误的最佳实践。
要点: 在开始工作之前,务必仔细查看你的数据,并确定异常值是否应该被忽略或更仔细地审视。
未正确处理周期性特征
一天的小时、星期中的天、年份中的月份以及风向都是周期性特征的例子。许多新的机器学习工程师没有想到将这些特征转换为可以保留信息的表示方式,比如小时 23 和小时 0 彼此接近而不是远离。
以小时为例,处理这种情况的最佳方法是计算正弦和余弦分量,从而将你的周期性特征表示为圆的 (x, y) 坐标。在这种表示中,小时 23 和小时 0 在数值上是紧挨在一起的,就像它们应该的那样。
许多人要求提供代码示例: 在这里
要点: 如果你有周期性特征而没有对其进行转换,你就会给你的模型提供无用的数据。
L1/L2 正则化没有标准化
L1 和 L2 正则化会惩罚大系数,这是正则化线性回归或逻辑回归的常用方法;然而,许多机器学习工程师未意识到在应用正则化之前标准化特征的重要性。
想象一下你有一个线性回归模型,其中交易额是一个特征。对所有特征进行标准化,使它们处于相同的水平,这样正则化对所有特征的影响是相同的。不要让某些特征以分为单位,而其他特征以美元为单位。
要点: 正则化非常好,但如果你没有标准化特征,可能会引发麻烦。
将线性回归或逻辑回归的系数解释为特征重要性
线性回归模型通常会返回每个系数的 p 值。这些系数经常使新手机器学习工程师认为,对于线性模型,系数值越大,特征越重要。实际上这几乎从未成立,因为变量的规模会改变系数的绝对值。如果特征之间具有共线性,系数可能会从一个特征转移到另一个特征。数据集的特征越多,特征之间的共线性可能性越大,简单的特征重要性解释就越不可靠。
收获: 理解哪些特征对结果至关重要很重要,但不要认为你可以仅通过系数来判断。它们通常不能讲述完整的故事。
完成一些项目并获得良好结果可能会让你感觉像赢得了一百万美元。你努力工作,并且有结果证明你做得很好,但就像任何其他行业一样,细节决定成败,甚至华丽的图表也可能隐藏偏差和错误。这份清单并不是详尽无遗的,而只是为了让读者思考可能隐藏在解决方案中的所有小问题。为了取得良好结果,遵循你的流程并始终仔细检查是否有常见错误是非常重要的。
如果你发现这篇文章有用,你将从我的 成为机器学习工程师 | 第 2 步:选择流程 文章中受益匪浅。它帮助你制定一个流程,使你能更好地发现简单错误,取得更好的结果。
原文。已获得许可转载。
简介:Chris Dossman 是一位机器学习研究员和未来的太空矿工。
相关内容:
-
导致糟糕数据可视化的 5 个常见错误
-
数据科学家在与业务人员打交道时常犯的错误
-
使用 Python 通过标准差移除异常值
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关主题
大数据、数据科学和机器学习的前 10 大 Facebook 群组
原文:
www.kdnuggets.com/2016/11/top-facebook-groups-big-data-science-machine-learning.html
评论
曾经,Facebook 用于个人通讯,而 LinkedIn 用于商务。
但简单的世界主导地位对 Facebook 来说还不够,它的目标是通过类似 Workplace for Facebook 的产品来争取更大的商业份额。虽然 Facebook 在大数据和数据科学方面的群组仍然远小于 LinkedIn 在该领域的群组,但它们正在增长,并提供了一个重要的新讨论平台。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
本文介绍了 Facebook 上最大的十个大数据、数据科学和机器学习群组。这些群组的成员超过一万,并按群组规模从大到小的顺序列出,截至 2016 年 11 月 18 日。群组概况基于其在 Facebook.com 上出现的信息。
### 1. machinelearningforum (数据挖掘 / 机器学习 / 人工智能)

这是迄今为止该领域最大的群组,由八名管理员维护(创建于 2007 年 8 月 18 日)。该群组由 29,638 名成员组成,分享对数据挖掘、机器学习、人机交互和人工智能各方面的兴趣。该群组当前的活动是 2016 年 11 月 19-20 日在奥克兰关于 揭秘深度学习与人工智能 的会议,目前已有 1700 名嘉宾表示感兴趣。
2. data.analytics (分析、数据挖掘、预测建模、人工智能)
这是一个有 26,427 名成员的公开群组,由 Guru Talreja 监控已有 8 年。成员每天大约有二十多条帖子。这些帖子包括数据科学和生命科学的网络事件以及用于 R 包的共享文件。

3. BigDataisonline (大数据)
尽管该小组由 21,239 名成员组成,并由两名管理员(Daniyal Bashir 和 Mustafa Ali Qizilbash)维护,但它是一个封闭小组,仅限于大数据讨论。
4. thesqlgeeks (SQL Server Geeks)
该小组已有 17,980 名成员(创建于 2012 年 11 月 18 日)。小组由 Amit R S Bansal(SQL MCM、SQL MVP、SQLMaestros 的 MCT)创建。该小组被介绍为 SSGAS,即亚洲最大 SQL 会议的一个小组 www.sqlservergeeks.com/。2016 年在印度举行的最后一届峰会吸引了 900 多名与会者和 70 多位讲者,进行了 130 多场会议,历时 3 天。
5. hadoop.group (Apache Hadoop Ecosystem)
该小组有 17,080 名成员,创建于 2008 年 3 月 1 日。当前由 Siddharth Tiwari(Dell EMC 研发部门负责人,加入约 5 年前)和 John F.X. Berns(Lazada Group 数据科学部门高级副总裁,加入约 3 年前)维护。虽然该小组对用 Java 编写的分布式计算平台 Hadoop 感兴趣,但它还包括大数据·机器学习的关键标签。最近,他们举办了关于大数据的活动,如“从头开始的 Master Big Data 和 Hadoop”(法语)和“使用 MapReduce 进行面部检测”(2016 年 4 月)。
6. bigdatalearnings (大数据学习)
由 Karan Gulati(微软雷德蒙德总部的 BI/大数据软件开发工程师)于 2012 年创建,该小组现有 16,860 名成员。目前也由 Sudhir Rawat(微软的首席技术顾问)管理。该小组讨论大数据和微软的 Hadoop 分发版即 HDInsight。小组管理员每两周在其 YouTube 频道上举办 Hadoop 和大数据的直播会议 - https://www.youtube.com/user/Debarchans。
7. bigdataanalysis (大数据机器学习)
该小组有 14,549 名成员,由 Min-kyung Kim(BICube CO.,LTD 的首席执行官)于 2013 年创建。最近,小组举办了一次关于“大数据集因果关系研究艺术”的在线网络会议。
8. sqlbangalore (SQLBangalore)
这是一个位于印度班加罗尔的 IT 中心的小组,由班加罗尔.NET UG(BDotNet)、班加罗尔 ITPro UG(BITPro)、SQLPass 和微软支持。小组讨论的话题限于 SQL Server、NoSQL、大数据和 BI。当前小组规模为 13,078 名成员。根据他们的活动信息,他们通常每几个月会举行一次活动,吸引数百名嘉宾。
9. analyticsedge (数据科学与 R)
这是一个由 11,923 名成员组成的封闭群体。该群体创建于 2015 年,由四名管理员维护。他们经常举办 R 语言和数据科学的会议和研讨会。例如,用户会议 欧洲 R 语言 2016 年 10 月 在波兰举办,旨在整合 R 语言的用户。还有在 LinuxWorld Informatics Pvt Ltd 举行的研讨会,讨论实际的行业级话题,例如,使用 Linux 内核或 Redhat/Centos/Fedora 或 Ubuntu/Mint 的 Hadoop 大数据平台。
10. bigdatastatistics(大数据、数据科学、数据挖掘和统计)
这是一个关于大数据、数据科学、数据挖掘和统计的论坛,由 Henrik Nordmark(Profusion 数据科学主管)于 2012 年 12 月 28 日创建。该论坛是一个拥有 10,814 名成员的多元化群体,成员背景和技能各异。论坛设有两个学习资源的主题,一个是在线课程,另一个是书籍。
相关:
-
前 20 名 Python 机器学习开源项目,更新版
-
Agilience 顶级人工智能和机器学习权威
-
算法偏见的基础
更多相关内容
顶级公司询问的问题:100+数据科学面试问题
原文:
www.kdnuggets.com/2017/03/top-firms-100-data-science-interview-questions.html
评论
布伦丹·马丁。
 来自 Glassdoor 的新数据让我们对一些顶级公司在数据科学家面试中常见的问题有了很好的了解。不幸的是,几乎每家公司都要求面试者签署保密协议。由于 Glassdoor 允许匿名,一些勇敢的灵魂给我们提供了一些出色的例子,展示了他们在 Facebook、Google 和微软等顶级公司面试过程中被问到的问题。
来自 Glassdoor 的新数据让我们对一些顶级公司在数据科学家面试中常见的问题有了很好的了解。不幸的是,几乎每家公司都要求面试者签署保密协议。由于 Glassdoor 允许匿名,一些勇敢的灵魂给我们提供了一些出色的例子,展示了他们在 Facebook、Google 和微软等顶级公司面试过程中被问到的问题。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
如果你发现自己无法回答以下一些问题,可以考虑查看一个课程或一本书籍来了解这个主题。
如果你愿意分享你对任何问题的回答,请留下评论,我会将最好的回答添加到帖子中。只需确保用你的真实姓名评论,这样我可以给予你相应的荣誉!
此外,如果你没有看到你被问到的某个特定问题,或者知道一个被问得很多的问题,请在下方评论。我很乐意添加它。
常见问题:
苹果
- 假设你拥有数百万用户,每个用户有数百笔交易,这些交易涉及数万个产品。你会如何将用户分组到有意义的段落中?
微软
-
描述一个你曾经参与的项目以及它带来的影响。
-
你会如何处理具有高基数的分类特征?
-
你会如何总结一个 Twitter 动态?
-
在应用机器学习算法之前,数据清理和处理的步骤是什么?
-
你如何测量数据点之间的距离?
-
定义方差。
-
描述箱线图和直方图的区别以及它们的使用场景。

推特
- 你会使用哪些特征来为用户构建推荐算法?
优步
-
选择任何你喜欢的产品或应用,并描述你会如何改进它。
-
你如何在分布中找到异常值?
-
你会如何调查某个分布中的趋势是否由于异常情况造成的?
-
你如何估计 Uber 对交通和驾驶条件的影响?
-
你会考虑使用哪些指标来跟踪 Uber 的付费广告策略是否有效?你会如何确定理想的客户获取成本?
- 大数据工程师 你能解释一下什么是 REST 吗?
机器学习问题:
-
你为什么使用特征选择?
-
如果两个预测变量高度相关,逻辑回归的系数会有什么影响?系数的置信区间是多少?
-
高斯混合模型和 K-Means 有什么区别?
-
你如何选择 K-Means 中的 k 值?
-
你怎么知道高斯混合模型是否适用?
-
假设一个聚类模型的标签是已知的,你如何评估模型的表现?
Microsoft
-
你为哪个机器学习项目感到自豪?举一个例子。
-
选择任何一种机器学习算法并描述它。
-
描述梯度提升如何工作。
-
数据挖掘 描述决策树模型。
-
数据挖掘 什么是神经网络?
-
解释偏差-方差权衡
-
你如何处理不平衡的二分类问题?
-
L1 正则化和 L2 正则化有什么区别?
Uber
- 你会给 Uber 司机哪些特征来预测他们是否会接受乘车请求?你会使用什么监督学习算法来解决这个问题?你会如何比较算法的结果?
-
说出并描述三种不同的内核函数以及在什么情况下使用每一种。
-
描述一种在机器学习中使用的方法。
-
你如何处理稀疏数据?
IBM
-
你如何防止过拟合?
-
你如何处理数据中的离群值?
-
你如何分析回归模型与分类模型所生成的预测的表现?
-
你如何评估逻辑回归与简单线性回归模型的表现?
-
监督学习和无监督学习有什么区别?
-
什么是交叉验证,你为什么要使用它?
-
用于评估预测模型的矩阵名称是什么?
-
逻辑回归系数与赔率比之间存在什么关系?
-
主成分分析(PCA)与线性判别分析(LDA)和二次判别分析(QDA)之间有什么关系?
-
如果你有一个分类的因变量和一个混合了分类变量和连续变量的自变量,你会使用哪些算法、方法或工具进行分析?
-
业务分析 逻辑回归和线性回归有什么区别?你如何避免局部最小值?
Salesforce
-
你会使用哪些数据和模型来测量流失率/退订率?你如何评估模型的表现?
-
用通俗易懂的方式解释一个机器学习算法,就像你在和一个非技术人员交谈一样。
Capital One
-
你如何构建一个模型来预测信用卡欺诈?
-
你如何处理缺失或不良数据?
-
你如何从已有特征中衍生出新特征?
-
如果你尝试预测客户的性别,但只有 100 个数据点,可能会出现什么问题?
-
假设你获得了两年的交易历史。你会使用哪些特征来预测信用风险?
-
为井字游戏设计一个 AI 程序
Zillow
-
解释过拟合,并说明你可以采取哪些步骤来防止它。
-
为什么 SVM 需要最大化支持向量之间的间隔?
Hadoop:
-
你如何使用 Map/Reduce 将一个非常大的图分割成较小的部分,并根据数据的快速/动态变化并行计算边?
-
数据工程师 给定一个格式为:123, 345234, 678345, 123…的关注者列表,其中第一列是关注者的 ID,第二列是被关注者的 ID。找出所有互相关注的对(例如上面的对 123 和 345)。当列表不适合内存时,你会如何使用 Map/Reduce 来解决这个问题?
Capital One
-
数据工程师 什么是 Hadoop 序列化?
-
解释一个简单的 Map/Reduce 问题。
Hive:
- 数据工程师 编写一个 Hive UDF,返回情感得分。例如,如果 good = 1,bad = -1,average = 0,那么一家餐馆的评价是“食物很好,服务不好”,你的得分可能是 1 – 1 = 0。
Spark:
Capital One
- 数据工程师 解释 RDD 在 Spark 中如何与 Scala 配合工作
统计与概率问题:
-
向非技术人员解释交叉验证。
-
描述一个非正态概率分布及其应用方法。
Microsoft
- 数据挖掘 解释什么是异方差性及如何解决它
- 给定 Twitter 用户数据,你将如何衡量参与度?
Uber
-
一些不同的时间序列预测技术有哪些?
-
解释主成分分析(PCA)及 PCA 使用的方程。
-
你如何解决多重共线性?
-
分析师 写一个方程式,以优化 Twitter 和 Facebook 之间的广告支出。
- 从一副牌中抽取两张相同花色的卡的概率是多少?
IBM
- 什么是 p 值和置信区间?
Capital One
-
数据分析师 如果你有 70 个红色弹珠,而绿色与红色弹珠的比例是 2:7,那么有多少个绿色弹珠?
-
纽约市每日通勤的分布会是什么样的?
-
给定一个骰子,掷六次得到一个 6 的可能性、掷十二次得到至少两个 6 的可能性,还是掷六百次得到至少一百个 6 的可能性更大?
PayPal
- 什么是中心极限定理,你如何证明它?它的应用是什么?
编程与算法:
- 数据分析师 编写一个程序来确定任意二叉树的高度
Microsoft
- 创建一个函数来检查一个词是否是回文。
-
构建一个幂集。
-
如何找到一个非常大数据集的中位数?
Uber
- 数据工程师 编写一个函数,计算给定数字的平方根(精确到小数点后两位)。后续:通过优化函数的缓存机制来避免冗余计算。
-
假设你有两个二进制字符串,编写一个函数将它们相加,而不使用任何内建的字符串转整数转换或解析工具。例如,如果你给你的函数二进制字符串 100 和 111,它应返回 1011。你的解决方案的空间和时间复杂度是什么?
-
编写一个函数,接受两个已排序的列表,并返回它们的并集,结果为排序后的列表。
-
数据工程师 编写一些代码,确定字符串中的括号是否平衡。
-
如何在二叉搜索树中找到第二大的元素?
-
编写一个函数,接受两个已排序的向量并返回一个排序后的向量。
-
如果你有一个不断流入的数字流,你会如何实时找到最频繁的数字?
-
编写一个将一个数字提升到另一个数字的函数,即 pow()函数。
-
将一个大字符串拆分成有效的单词,并将它们存储在字典中。如果字符串无法拆分,返回 false。你的解决方案的复杂度是什么?
Salesforce
-
查找文档中最常用单词的计算复杂度是多少?
-
如果你有 10TB 的非结构化客户数据,你会如何提取有价值的信息?
Capital One
-
数据工程师 你会如何“拆分”两个数组(类似于 SQL 中的 JOIN,但相反)?
-
创建一个执行加法的函数,其中数字由两个链表表示。
-
创建一个计算矩阵和的函数。
-
你会如何使用 Python 读取一个非常大的制表符分隔的数字文件,以统计每个数字的频率?
PayPal
-
编写一个函数,接受一个句子,并打印出每个单词反向的相同句子,时间复杂度为 O(n)。
-
编写一个函数,接受一个数组,将数组拆分成所有可能的两个数组集合,并打印两个数组最小值之间的最大差异,时间复杂度为 O(n)。
-
编写一个进行归并排序的程序。
SQL 问题:
Microsoft
-
数据分析师 定义并解释聚集索引和非聚集索引之间的区别。
-
数据分析师 返回表格行数的不同方法有哪些?
-
数据工程师 如果你有一个原始数据表,你如何使用 SQL 进行 ETL(提取、转换、加载),以获得所需格式的数据?
-
如何编写 SQL 查询来计算涉及两个连接的某个属性的频率表?如果你想对某个属性进行 ORDER BY 或 GROUP BY,你需要做哪些更改?你会如何处理 NULL 值?
- 数据工程师 你会如何提高 ETL(提取、转换、加载)的吞吐量?
思维游戏与问题:
- 假设你有十袋弹珠,每袋有十个弹珠。如果有一袋的重量与其他袋不同,而你只能进行一次称重,你会如何找出哪一袋是不同的?
-
你即将登上飞往西雅图的飞机,并想知道是否应该带伞。你给在西雅图的三位朋友打电话,分别问他们是否下雨。
-
你的每位朋友在⅔的情况下会说实话,而在⅓的情况下会撒谎。如果三位朋友都回答“是的,下雨了”,那么西雅图实际上正在下雨的概率是多少?
Uber
- 想象一下你正在与一家医院合作。病人以泊松分布的方式到达医院,而医生以均匀分布的方式照顾病人。编写一个函数或代码块,输出病人的平均等待时间和医生在随机一天照顾的病人总数。
-
想象一下在一个等边三角形的每个角落都有三只蚂蚁,每只蚂蚁随机选择一个方向并开始沿着三角形的边缘移动。所有蚂蚁不发生碰撞的概率是多少?如果在一个等边多边形的 N 个角落有 N 只蚂蚁呢?
-
100 的阶乘(即 100!)中有多少个末尾零?
- 想象一下你正在爬一个包含 n 阶梯的楼梯,你可以一步迈任何数量的 k 步。你可以用多少种不同的方式到达楼梯的顶部?(这是对原始楼梯问题的修改)
问题来源于Glassdoor
原文。已获转载许可。
相关:
-
7 个更多必须知道的数据科学面试问题和答案
-
17 个更多必须知道的数据科学面试问题和答案,第二部分
-
17 个更多必须知道的数据科学面试问题和答案,第三部分
更多相关话题
数据科学面试中你应知道的五大 SQL 窗口函数
原文:
www.kdnuggets.com/2022/01/top-five-sql-window-functions-know-data-science-interviews.html

SQL 是数据世界中的通用语言,是数据专业人士必须掌握的最重要的技能。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
SQL 之所以如此重要,是因为它是数据处理阶段所需的主要技能。许多数据探索、数据操作、管道开发和仪表板创建都是通过 SQL 完成的。
将优秀的数据科学家与普通的数据科学家区分开来的是,优秀的数据科学家可以充分利用 SQL 的能力来处理数据。完全使用 SQL 的一个重要部分是了解如何使用窗口函数。
说到这里,让我们深入了解一下!
1. 使用 LEAD()和 LAG()计算增量
LEAD()和 LAG()通常用于比较某一度量在某个时间段与前一个时间段的差异。举几个例子…
-
你可以获取每年销售额与前一年销售额之间的增量
-
你可以获取每月注册/转化/网站访问量的增量
-
你可以按月比较用户流失情况
示例:
以下查询展示了如何查询成本的月度百分比变化
with monthly_costs as (
SELECT
date
, monthlycosts
, LEAD(monthlycosts) OVER (ORDER BY date) as
previousCosts
FROM
costs
)SELECT
date
, (monthlycosts - previousCosts) / previousCosts * 100 AS
costPercentChange
FROM monthly_costs
2. 使用 SUM()或 COUNT()计算累积和
通过以 SUM()或 COUNT()开头的窗口函数可以简单地计算运行总和。这是一个强大的工具,当你想展示某个特定指标随时间的增长时尤为有效。更具体地说,它在以下情况下非常有用:
-
获取随时间变化的收入和成本的运行总和
-
获取每个用户在应用上花费的时间的运行总和
-
获取随时间变化的转化运行总和
示例:
以下示例展示了如何包含月度成本的累积和列:
SELECT
date
, monthlycosts
, SUM(monthlycosts) OVER (ORDER BY date) as cumCosts
FROM
cost_table
3. 使用 AVG()进行移动平均
AVG()在窗口函数中非常强大,因为它允许你计算移动平均。
移动平均线是一种简单但有效的短期值预测方法。它们在平滑图表上的波动曲线时也极为有用。通常,移动平均线用于衡量事物的发展方向。
更具体地说……
-
它们可以用来获取每周销售的总体趋势(平均水平是否在上升?)。这将表明公司的增长。
-
它们同样可以用来获取每周转换或网站访问的总体趋势。
示例:
以下查询是获取 10 天移动平均转换率的示例。
SELECT
Date
, dailyConversions
, AVG(dailyConversions) OVER (ORDER BY Date ROWS 10 PRECEDING) AS
10_dayMovingAverage
FROM
conversions
4. ROW_NUMBER()
ROW_NUMBER()在你想要获取首条或最后一条记录时特别有用。例如,如果你有一个记录健身会员到访时间的表格,并且你想获取他们第一次到健身房的日期,你可以通过 PARTITION BY customer(name/id)和 ORDER BY purchase date。然后,为了获取第一行,你只需筛选出 rowNumber 等于一的行。
示例:
这个例子展示了如何使用 ROW_NUMBER()获取每个会员(用户)访问的首次日期。
with numbered_visits as (
SELECT
memberId
, visitDate
, ROW_NUMBER() OVER (PARTITION BY customerId ORDER BY
purchaseDate) as rowNumber
FROM
gym_visits
)SELECT
*
FROM
numbered_visits
WHERE
rowNumber = 1
总结一下,如果你需要获取第一条或最后一条记录,ROW_NUMBER()是实现这一点的好方法。
5. 使用 DENSE_RANK() 进行记录排名
DENSE_RANK()类似于 ROW_NUMBER(),不同之处在于它对相等值返回相同的排名。稠密排名在检索顶级记录时非常有用,例如:
-
如果你想拉取本周观看次数最多的前 10 个 Netflix 节目
-
如果你想基于消费金额获取前 100 个用户
-
如果你想查看 1000 个最不活跃用户的行为
示例:
如果你想按总销售额对你的主要客户进行排名,DENSE_RANK()将是一个合适的函数。
SELECT
customerId
, totalSales
, DENSE_RANK() OVER (ORDER BY totalSales DESC) as rank
FROM
customers
感谢阅读!
就这些了!希望这些对你的面试准备有所帮助——我相信,如果你能完全掌握这 5 个概念,你在大多数 SQL 窗口函数问题中会表现出色。
一如既往,我祝你在学习过程中一切顺利!
Terence Shin 是一位数据爱好者,拥有超过 3 年的 SQL 经验和超过 2 年的 Python 经验,并且是 Towards Data Science 和 KDnuggets 的博客作者。
原文。经许可转载。
更多相关主题
深度学习领域的 8 本必读免费书籍
原文:
www.kdnuggets.com/2018/04/top-free-books-deep-learning.html
评论
深度学习是构成机器学习这一广泛主题的重要部分。虽然相对较新,但其受欢迎程度不断上升,因此人们希望阅读和学习更多关于这一主题的内容。如果能有一个全面的资源列表,集中在一个地方,完全免费且对所有人开放,那将是最理想的。

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
该集合包括有关深度学习各方面的书籍。它从覆盖整体主题的书名开始,然后转向那些可以帮助初学者从机器学习扩展到深度学习的书籍。列表最后是讨论神经网络的书籍,包括介绍主题的书籍和深入探讨网络架构的书籍。
1. 深度学习
由 Ian Goodfellow、Yoshua Bengio 和 Aaron Courville 提供
《深度学习教材》是一个旨在帮助学生和从业者进入机器学习领域,特别是深度学习领域的资源。该书的在线版本现已完成,并将持续免费在线提供。
2. 深度学习教程
由蒙特利尔大学 LISA 实验室提供
由蒙特利尔大学 LISA 实验室开发,这本免费且简明的教程以书籍形式呈现,探讨了机器学习的基础知识。书中强调了使用Theano库(最初由该大学开发)在 Python 中创建深度学习模型。
3. 深度学习:方法与应用
由李登和董宇提供
本书概述了一般深度学习方法论及其在各种信号和信息处理任务中的应用。
作者:Jordi Torres
本书面向那些只有基本机器学习理解的工程师,旨在通过使用 TensorFlow 的动手方法拓展他们在深度学习激动人心领域的知识。
5. 神经网络与深度学习
作者:Michael Nielsen
本书介绍了神经网络,这是一种美丽的生物启发的编程范式,使计算机能够从观察数据中学习。书中还涉及了深度学习,这是一组强大的神经网络学习技术。
6. 神经网络简介
作者:David Kriesel
该书深入探讨了神经网络。神经网络是一种生物启发的数据处理机制,使计算机能够以类似于大脑的技术进行学习,并在教会足够多的解决方案后进行泛化。提供英语和德语版本。
7. 神经网络设计(第二版)
作者:Martin T. Hagan、Howard B. Demuth、Mark H. Beale 和 Orlando D. Jess
《神经网络设计(第二版)》提供了对基本神经网络架构和学习规则的清晰详细的调查。书中强调了对主要神经网络及其训练方法的基本理解。作者还讨论了神经网络在模式识别、聚类、信号处理和控制系统等实际工程问题中的应用。整本书强调了可读性和材料的自然流畅。
作者:Simon Haykin
Simon Haykin 的这本第三版书籍提供了对神经网络的最新处理,内容全面、深入且易读,分为三个部分。书中首先介绍了有监督学习的经典方法,然后转到基于径向基函数(RBF)网络的核方法。书的最后部分致力于正则化理论,这也是机器学习的核心。
相关:
了解更多相关话题
大型语言模型的顶级免费课程
原文:
www.kdnuggets.com/2023/03/top-free-courses-large-language-models.html

作者提供的图片 | 创建于 imgflip
Transformers 确实改变了自然语言处理领域,支撑了所有最先进的 NLP 应用程序。Google Bard、OpenAI 的 ChatGPT 以及其他:它们都由大型(transformer)语言模型驱动,这些模型在庞大的语料库上进行了训练,并进行了强化学习。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
最新的成功案例–OpenAI 的 ChatGPT 基于 GPT-3 家族的大型语言模型。本文列出了帮助你更深入理解大型语言模型的免费课程。
让我们马上开始吧!
斯坦福大学的 CS324:大型语言模型
斯坦福大学的 CS324:大型语言模型 课程涵盖了你需要了解的大型语言模型的所有内容:
-
大型语言模型的能力
-
与大型语言模型相关的危害,如毒性、虚假信息、隐私风险、社会偏见等
-
大型语言模型的建模和训练,包括仅编码器、仅解码器和编码器-解码器架构
-
并行性
-
大型语言模型的扩展和适应
课程材料和建议阅读可以在 课程网站 上找到
普林斯顿大学的理解大型语言模型
COS 597G:理解大型语言模型 由普林斯顿大学提供,是另一个免费的课程,从基础到高级概念都涵盖了大型语言模型。课程材料和建议阅读可以在课程网站上找到,课程大纲包括以下内容:
-
大型语言模型的基础知识。
-
对 BERT、T5 和 GPT 3 的深入评审。
-
提示语言模型。
-
大型语言模型的扩展和风险。
-
基于检索的语言模型。
-
多模态语言模型。
由 ETH 苏黎世提供的大型语言模型
瑞士 ETH 的 Rycolab 提供的大型语言模型课程是一个全新的课程,目前正在进行(2023 年春季)。课程于 2023 年 2 月 21 日正式开始,讲义和推荐阅读将逐步更新在课程网站上。本课程将帮助你学习以下内容:
-
概率基础
-
建模基础
-
神经网络建模和推断
-
训练、微调和推断
-
并行处理和扩展
-
安全性和误用
斯坦福大学的 CS224n: 自然语言处理中的深度学习
由斯坦福大学的克里斯·曼宁教授讲授,CS224n: 自然语言处理中的深度学习是任何对自然语言处理感兴趣的人必修的课程。从传统的 NLP 和语言学概念到大型语言模型和伦理挑战,这门课程提供了该领域全面而扎实的基础。
2021 年冬季和2022 年春季的讲座视频可在 YouTube 上找到。
HuggingFace Transformers 课程
如果你想了解所有关于变换器的信息,并开始构建自己的 NLP 应用程序,用于自然语言推断、摘要、问答等,那么免费的 HuggingFace Transformers 课程是你的最佳选择。
它分为三个部分,帮助你熟悉 HuggingFace 生态系统:
-
使用 HuggingFace 变换器
-
数据集和标记器库
-
构建生产就绪的 NLP 应用程序
大型语言模型的其他有用资源
到目前为止,我们已经覆盖了关于大型语言模型的免费课程。接下来,我们将介绍其他有用的资源来让你初步了解这些内容。
Jay Alammar 关于大型语言模型的文章系列
从《图解变换器》到《在现实世界中应用大规模语言模型与 Cohere》,Jay Alammar 的技术博客是理解自然语言处理细节的最佳资源之一。
理解大型语言模型 - 变革性的阅读清单
Sebastian Raschka整理了《理解大型语言模型 - 变革性的阅读清单》的研究工作。该阅读清单将帮助你了解 NLP 领域的突破:从变换器之前的 RNN 到 Google BERT,再到今天的 ChatGPT。
LangChain
LangChain 是一个 Python 库,帮助你在大型语言模型之上构建有用的应用程序。一些示例包括在特定领域语料库上进行问答、训练代理解决特定问题等。
你可以查看文档,获取有关设置开发环境、入门和 API 参考的信息。
这是LangChain 创始人 Harrison Chase 的 LangChain 演示。
总结
希望你觉得这份关于大型语言模型的资源汇总对你有帮助。我们提供了各种课程、阅读清单及其他有用的资源和框架,帮助你构建自己的强大 LLM 基础应用。
如果你想了解更多关于 ChatGPT 的工作原理,可以查看这份学习 ChatGPT 的免费资源列表。
Bala Priya C 是一位技术写作人,喜欢创作长篇内容。她的兴趣领域包括数学、编程和数据科学。她通过编写教程、操作指南等方式与开发者社区分享她的学习经验。
更多相关话题
2023 年顶级免费数据科学在线课程
原文:
www.kdnuggets.com/2023/03/top-free-data-science-online-courses-2023.html

图片来源: 作者
坚持新的年度决心可能很困难。当你决定转行并学习一项新技能时,这变得更加困难。进入一个你没有任何先验知识的领域可能会让人感到畏惧。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
拥有正确的资源可以帮助你克服恐惧,并坚持你的新年决心。
如果你想进入数据科学领域,但不确定选择哪些课程、书籍或培训营。继续阅读这篇文章,你将找到一份免费的在线数据科学课程列表,帮助你掌握这项新技能。
2023 年优秀免费课程
所有这些课程都是免费的,并且已经获得了数百名学生的高度信任和高评价。
freeCodeCamp 的数据科学 Python 课程
对于许多初学者来说,Python 是首选语言。如果你选择了 Python 作为编程语言,freeCodeCamp 提供的这门免费数据科学 Python 课程是你数据科学职业生涯的一个绝佳起点。
它涵盖以下主题:编程基础、为什么选择 Python、如何安装 Anaconda 和 Python、如何启动 Jupyter Notebook、如何在 iPython Shell 中编码、Python 中的变量和运算符、Python 中的布尔值和比较,以及更多内容。
链接: 数据科学的 Python
哈佛大学的 Python 编程入门课程
哈佛大学提供了一门使用 Python 的编程入门课程。虽然这是一个大学课程,但它是自学的课程,完成大约需要 10 周时间。这个课程专为没有编程基础的学生设计,旨在帮助他们使用 Python 构建数据科学技能。
它涵盖以下主题:函数、变量、条件语句、循环、异常、库、单元测试、文件输入输出、正则表达式、面向对象编程以及更多内容。
链接: Python 编程入门
数据科学:R 基础,由哈佛大学提供
如果你选择了 R 作为你的编程语言,从基础开始总是好的。哈佛大学提供了一个数据科学:R 基础课程,帮助你通过学习和使用 R 编程语言来整理、分析和可视化数据,从而建立一个坚实的基础。
该课程是免费的;但是,你可以支付 149 美元获得认证证书。
链接:数据科学:R 基础
统计学习,由 edX 提供
统计学是数据科学的重要组成部分,你必须掌握它。这门由 edX 提供的统计学习课程将为你提供统计建模和数据科学中使用的主要工具。
它涵盖以下主题:统计学习概述、线性回归、分类、重采样方法、线性模型选择与正则化、超越线性、树基方法、支持向量机、深度学习、生存建模、无监督学习和多重测试。
链接:统计学习
统计基础,由 Josh Starmer 提供
如果你更喜欢观看视频,我强烈推荐 Josh Starmer 的 YouTube 页面,帮助你更好地掌握统计学和概率论的基础知识。你将涵盖与数据科学相关的各种主题,并提供清晰的解释和示例。
链接:统计基础
机器学习专业化,由 Coursera 提供
这门课程由 Landing AI 的创始人兼首席执行官Andrew Ng、deeplearning.ai 的创始人,以及 Coursera 的联***和共同创始人Andrew Ng组织。他构建了一个由 3 门课程组成的机器学习专业化系列:
这些课程是免费的;然而,如果你希望获得认证,则需支付费用。
链接:机器学习专业化
应用机器学习,由 Andreas Mueller 提供
一旦你理解了机器学习的基础,下一步就是学习如何应用它。Andreas Mueller 有一个 YouTube 频道,包含 22 个关于应用机器学习的视频。
你将涵盖的主题包括可视化和 matplotlib、回归的线性模型、梯度提升、模型检查、特征选择等。
链接:应用机器学习
特征工程,由 Kaggle 提供
一旦你知道如何构建模型,你就会想学习如何通过特征工程改进你的模型。Kaggle 提供的这个特征工程课程帮助你学习如何利用特征来提升模型的效果。
课程内容包括:什么是特征工程、互信息、创建特征、使用 k-means 进行聚类、主成分分析和目标编码。
链接: 特征工程
深度学习速成课程 - freeCodeCamp
假设你想更进一步,深入探讨深度学习。我推荐这个由 freeCodeCamp 提供的初学者深度学习速成课程。它将给你一个关于深度学习及其基本元素的良好概述。
你将涵盖的主题包括神经网络介绍、激活函数、损失函数、正则化、卷积神经网络等。
链接: 深度学习速成课程
数据管理与数据科学,威斯康星大学麦迪逊分校
如果你对数据管理特别感兴趣,威斯康星大学麦迪逊分校提供的课程就是为你准备的。
课程分为 6 个部分:数据科学简介、关系数据库与关系代数、MapReduce 模型与 No SQL 系统、预测分析、信息提取与数据整合、以及沟通洞察。
链接: 数据管理与数据科学
总结
有很多现成的资源可以帮助你学习数据科学。总是从免费的资源开始,打下坚实的基础,然后再转向付费或认证课程来帮助你找到工作。然而,许多人在没有付费课程的情况下也找到了工作。
如果你需要更多关于数据科学路径的指导,请阅读:完整的数据科学学习路线图。
Nisha Arya 是一名数据科学家和自由职业技术作家。她特别感兴趣于提供数据科学职业建议或教程以及数据科学理论知识。她还希望探索人工智能如何或能如何有益于人类寿命。作为一名热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
了解更多相关内容
2024 年最佳免费数据科学在线课程
原文:
www.kdnuggets.com/top-free-data-science-online-courses-for-2024

作者提供的图像
我们已经进入新年的第 3 个月了。哇,时间过得真快。话说回来,你们中有多少人能说自己正朝着目标前进,无论是第一季度目标、学习目标等?
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 部门
这很困难。保持对一切的掌控并实现每一个目标是很困难的。
如果学习数据科学是你 2024 年的目标之一,KDNuggets 将帮助你使你的新技能学习和职业转换之旅顺利进行。
我整理了一份免费的在线数据科学课程列表,这些课程将帮助你建立坚实的数据科学知识、技能和最佳实践基础,从而在数据领域取得出色的职业生涯。
理解数据科学
来源: DataCamp
链接: 理解数据科学
如果你是数据科学领域的新手,首先要了解的是基础知识。这个免费课程没有编程内容,将定义什么是数据科学。
你将深入了解数据科学工作流是什么以及数据科学如何应用于现实世界的问题。一旦你对这个领域有了很好的理解,你将会学习数据科学领域内的不同角色。
Python 编程入门
来源: 哈佛大学
链接: Python 编程入门
你决定选择 Python 作为你的编程语言了吗?这是个好主意。
这已经是一门流行的编程语言,现在你可以通过这个自学课程来学习,它大约需要 10 周的时间来完成。这个课程专门为那些没有编程经验或知识的学生设计,旨在通过学习 Python 进入数据科学领域。
涵盖的主题包括:函数、变量、条件语句、循环、异常、库、单元测试、文件 I/O、正则表达式、面向对象编程等。
Python 数据科学工具箱
来源: DataCamp
链接: Python 数据科学工具箱
由于它已经成为近年来最受欢迎的编程语言,完善 Python 编程语言没有坏处。
不需要编程经验或技能,Python 数据科学工具箱课程的第一部分将教你如何有效地分析和可视化数据。该课程包括 13 个视频,你将从数据处理到使用 Matplotlib 绘制数据。
数据科学:R 基础
来自: 哈佛大学
链接: 数据科学:R 基础
也许你没有选择 Python,可能决定选择 R 作为编程语言。不论你决定使用什么——从基础开始总是好的。哈佛大学提供的数据科学:R 基础课程将帮助你建立 R 编程语言的坚实基础——从学习如何整理、分析和可视化数据。
课程是免费的;然而,你可以支付$149 获得经过验证的证书。
统计学习
来自: 斯坦福在线
链接: 统计学习
我常常提到这点,我再说一遍——在数据科学中学习统计学非常重要。edX 的这门统计学习课程将为你提供统计建模和数据科学中使用的主要工具。
课程涵盖以下主题:统计学习概述、线性回归、分类、重采样方法、线性模型选择和正则化、超越线性、基于树的方法、支持向量机、深度学习、生存建模、无监督学习和多重测试。
数据分析
来自: Google
链接: Google 数据分析
你可能听说过这门课程很多次——它非常受欢迎。课程包括 8 个部分,你将学习数据的日常使用、最佳实践和你在新数据科学/分析工作中应该期待的流程。
你将学习如何清理和组织数据以进行分析,并使用电子表格、SQL 和 R 编程进行计算。课程不仅如此,你还将通过创建数据可视化进一步提高你的分析技能,并学习如 Tableau 等工具。
机器学习专业化
来自: Coursera
链接: 机器学习专业化
这门课程由 Andrew Ng(Landing AI 创始人兼 CEO,deeplearning.ai 创始人,Coursera 联合主席及联合创始人)编制。他构建了一个由 3 门课程组成的机器学习专业化系列:
这些课程是免费的;但是,如果你希望获得认证,则需要支付费用。
总结
这 7 门课程帮助你在数据科学的不同方面建立技能,确保你拥有在数据科学工作中出色表现所需的技能和知识。
例如,掌握 Python 编程语言或 R 编程语言。理解学习统计学在数据科学中的重要性,以及它如何影响分析过程。最后但同样重要的是,将所有内容整合起来,并将其应用于机器学习,例如回归和推荐系统。
祝学习愉快!
Nisha Arya 是一名数据科学家、自由技术写作专家,以及 KDnuggets 的编辑和社区经理。她特别感兴趣于提供数据科学职业建议或教程以及围绕数据科学的理论知识。Nisha 涵盖了广泛的主题,并希望探索人工智能如何有利于人类寿命的不同方式。作为一个热衷学习者,Nisha 希望扩展她的技术知识和写作技能,同时帮助指导他人。
更多相关内容
适合初学者的顶级免费 Git GUI 客户端
原文:
www.kdnuggets.com/2022/10/top-free-git-gui-clients-beginners.html
图片来源:作者
Git 是基于终端的软件,让我们能够对文件进行版本控制、与团队协作和维护历史记录。简而言之,它已经成为软件开发的标准工具。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT
大多数软件工程师和开发人员习惯使用基于终端的工具。他们甚至使用 Vim 编写代码,测试程序,并通过终端推送更改。
对于初学者或数据专业人士来说,这是一个完全不同的世界。我们很难记住 Git 终端命令和快捷键。
这就是 Git GUI 发挥作用的地方。GUI 客户端提供了一个适合初学者的环境,您可以通过点击按钮和查看交互式提交历史记录来执行大多数任务。
在这篇文章中,我们将探讨适合初学者的软件来执行所有基于 Git 的任务。我们还将查看其主要功能和缺点,以评估哪些工具在您的独特情况下效果最佳。
前 3 名 Git GUI 客户端
1. GitHub Desktop
图片来源:作者
GitHub Desktop 是最适合初学者的应用程序。它易于操作,您可以实时查看存储库中的更改。请在 Windows 和 macOS 上下载并亲自体验。
您可以使用 GitHub Desktop 跟踪任何远程服务器上的 Git 存储库。为此,您需要提供存储库 URL 和身份验证凭据以克隆并开始处理项目。
功能:
-
轻松地将共同作者添加到您的提交中
-
检出带有拉取请求的分支
-
查看实时 CI 状态
-
语法高亮显示的差异
-
扩展的图像差异支持
-
从应用程序中访问您最喜欢的编辑器或终端
-
社区支持的开源软件
从一开始我就一直在使用 GitHub Desktop。我非常喜欢它,它对我来说非常容易操作。
独立软件的问题在于我必须在编辑器和 Git 客户端之间切换。此外,它缺乏项目管理和开发辅助功能。
2. GitKraken
作者提供的图像
GitKraken 是一个综合的 GitOps 解决方案,旨在提升你的开发体验。你可以邀请团队成员加入工作空间,并在项目上进行协作。它允许你在工作空间内管理所有的远程仓库。
如果你想要一个功能丰富的独立 Git GUI,我建议你立刻安装它。它是免费的,并且将帮助你理解开发过程。
功能:
-
交互式提交历史
-
命令面板
-
内置代码编辑器
-
语法高亮
-
内置增强终端支持
-
检测并警报潜在的合并冲突
-
安全解决合并冲突
-
创建和管理拉取请求
-
交互式变基
-
一键撤销更改
-
团队支持
-
与 GitHub、GitLab、Azure DevOps 和 Bitbucket 集成,创建简化的工作流程
我使用 Gitkraken 已经两年了,我非常喜欢一键撤销功能。你可以创建个人资料并与团队成员互动。
如果你在寻找一种可以满足所有软件需求的软件,Gitkraken 应该是你的选择。
刚开始时,你可能会被众多选项弄得有些困惑,但我相信,几天内你就会理解这些功能的意义。如果不然?那么你可以根据需要随时修改外观,去掉多余的标签。
3. Sourcetree
作者提供的图像
Sourcetree 是另一个免费的 Git GUI 客户端,适用于 Windows 和 MAC。它简单且互动,适合初学者和数据专业人士。它类似于 GitHub Desktop,并且很轻量。你只需安装并开始项目工作即可。
功能:
-
可视化你的代码和图像
-
可视化你的工作,并自信地推送
-
易于丢弃更改、文件和块或行。
-
跟踪你的工作状态
-
可视化进度
-
本地提交搜索
-
交互式变基
-
远程仓库管理器
它比 GitHub Desktop 更加干净、轻便,并且功能更多。如果你使用 Bitbucket 作为远程仓库,我强烈推荐你安装它,并体验流畅的集成。
结论
使用 Git GUI 有助于你快速学习开发过程。你不需要记住命令和设置环境,而是使用图形用户界面来帮助你。
如果你在寻找一个一站式解决方案,涵盖开发、测试、Git、部署和协作,那么我建议你安装 IDE。更推荐的是Visual Studio Code。这些集成开发环境可以实时跟踪更改,为你提供流畅的用户体验。简而言之,你无需在多个应用程序之间切换。
在这篇文章中,我们了解了前三名免费 Git 图形用户界面客户端以及它们对初学者的好处。如果你有兴趣了解更多关于 Git 功能或扩展的内容,请在评论中告诉我,我会尽力在下次写出来。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,以帮助那些面临心理健康问题的学生。
更多相关话题
顶级免费资源来学习 ChatGPT
原文:
www.kdnuggets.com/2023/02/top-free-resources-learn-chatgpt.html

作者提供的图片
到现在,大多数使用互联网的人都知道 ChatGPT 及其功能。但他们对它的工作原理和使用方法缺乏了解。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的捷径。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持组织的 IT 工作。
在这篇博客中,我们将涵盖理解 ChatGPT 基础知识、提升使用 OpenAI API 的技能、微调 GPT 模型和提高提示技巧的免费资源。你还将学习如何使用 ChatGPT 创建应用程序、分析数据并提高生产力。
记住,AI 已经成为常态。你需要开始学习它,以便未来不被淘汰。
备忘单
-
ChatGPT 备忘单:学习 ChatGPT 在 NLP、代码、结构和非结构化输出、媒体类型和元 ChatGPT 的技巧和窍门。
-
OpenAI Cookbook:用于理解 OpenAI API 并利用其构建 ChatGPT 应用程序。它还包含 GPT3、嵌入和微调的代码示例。
书籍
-
终极 ChatGPT 指南:100 个资源,提升你的 ChatGPT 使用体验。
-
ChatGPT 提示的艺术:创建清晰有效提示的指南:学习制定引人入胜且富有信息量的 ChatGPT 提示的策略。
-
软件工程师的 10 个 ChatGPT 提示:学习如何为软件工程任务创建提示。
学习 ChatGPT 提示
-
Learn Prompting:参加一个全面的免费课程,学习关于 AI 提示的所有内容。从 Stable Diffusion 到 LLMs。
-
Awesome ChatGPT Prompts:由开源社区贡献的简单 ChatGPT 提示库。
-
ChatGPT 提示和产品:互动网站,按类别筛选各种提示。
ChatGPT 教程
-
初学者的 Chat GPT 快速入门课程:一个为新手创建 OpenAI 账户并开始使用 ChatGPT 的入门教程。
-
我如何使用 ChatGPT 编码一个完整的网站:使用 ChatGPT 创建一个功能齐全的网站并将其托管在线上。
-
提高生产力的 38 种方法:通过 38 个 Python、JavaScript、HTML、CSS、React 和 SQL 代码示例学习提高生产力。
-
使用 ChatGPT 分析数据:对数据科学家和分析师极力推荐。你可以学习使用 ChatGPT 执行各种分析任务,甚至创建机器学习模型。
博客
-
ChatGPT 作为 Python 编程助手:通过遵循简单的指南提升 Python 编程技能。
-
ChatGPT:你需要知道的一切:用通俗的英语解释 ChatGPT。
-
创建你自己的 ChatGPT:学习如何使用 LoRA 对 LLMs 进行微调,使用最少的资源。
-
检测 ChatGPT、GPT3 和 GPT2 的 5 个免费工具:用于内容审查和防止滥用的 ChatGPT 检测工具。
终极指南
Prompt-Engineering-Guide 是终极资源。它包含用户指南、研究论文、工具和库、数据集、博客以及关于 ChatGPT 的教程。
ChatGPT 是相当新的,人们仍在探索如何将其整合到工作场所。本文提到的学习指南和资源将帮助你入门。它还将帮助你理解如何使用 OpenAI API 来构建你的应用程序或创建令人惊叹的内容。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一款 AI 产品,帮助那些在精神健康方面挣扎的学生。
更多相关话题
顶级 Google AI 和机器学习工具适合每个人
原文:
www.kdnuggets.com/2020/08/top-google-ai-machine-learning-tools.html
comments
由 Claire D. Costa,Digitalogy, LLC 的内容撰写者和战略家。

Google AI 将人工智能的好处带给每个人 (source)。
“我们希望利用人工智能增强人们的能力,使我们能够完成更多的任务,并允许我们花更多时间在创造性工作上。” -- Jeff Dean,Google 高级研究员
将 Google 仅仅称为搜索巨头是不够的,因为它从一个简单的搜索引擎迅速发展成了多个关键 IT 领域创新的驱动力。在过去的几年里,Google 已经将其根深深扎入几乎所有数字领域,无论是智能手机、平板电脑、笔记本电脑等消费电子产品,还是 Android 和 Chrome OS 等基础软件,亦或是由 Google 的人工智能支持的智能软件。
Google 一直在智能软件行业积极创新。凭借多年来在搜索和分析数据方面积累的专业知识,Google 创造了多种工具,如 TensorFlow、ML Kit、Cloud AI 等,供热衷者和初学者尝试理解人工智能的能力。
Google AI 专注于将人工智能的好处带给每个人。
以下各节将详细介绍 Google 如何针对开发者、研究人员和组织等特定用户群体来设计其工具套件,以及他们如何从 Google 的人工智能工具中获益。
对于开发者
随着更多开发者看到人工智能的潜力而深入这一领域,Google 正通过提供多个强大的工具来满足他们不断变化的需求,如:
TensorFlow
革命已经来临!欢迎使用 TensorFlow 2.0。
TensorFlow 是 Google 提供给世界的端到端开源深度学习库,利用 机器学习 改善其各种产品提供的服务。使用 TensorFlow 的工具和库,开发者可以构建高精度且定义明确的机器学习模型。
TensorFlow 提供了顺畅的模型构建和灵活的多设备部署,使得创建和部署复杂的人工智能模型变得轻松。借助强大的社区支持,无论你是新手还是有经验的从业者,都可以获得大量的创意。
来看看一些示例 这里。
ML Kit
ML Kit 将 Google 的机器学习专业知识以强大且易于使用的方式带给移动开发者 (source)。
ML Kit 是一个仅限移动端的 SDK,目前可用于 Android 和 iOS,利用 Google 的机器学习技术为你的移动应用程序提供解决现实世界问题的能力。ML Kit 可以帮助你成功完成由底层机器学习技术驱动的任务,例如:
- 语言识别
将文本传递给 ML Kit -> 获取文本中的检测语言
这支持超过 100 种语言,包括印地语、阿拉伯语、中文等!在这里查看所有支持的语言列表。
拍照 -> 获取图片中的文本

ML Kit 提取图片中存在的任何文本 (source)。
- 图像扫描与标记
拍照 -> 获取图片中的对象列表
- 面部识别
拍照 -> 获取图片中的所有面孔
- 智能回复
传递消息到 ML Kit -> 获取 3 条智能回复
ML Kit 为你提供 3 条智能回复。
- 条形码扫描
拍照 -> 从扫描的条形码/二维码中获取信息

ML Kit 支持从条形码中扫描和提取信息 (source)。
- 与 TensorFlow Lite 的自定义模型集成
通过现成的 API,支持设备端或云端实现多种用例,你可以轻松地将 ML 模型应用到数据中,并通过与 TensorFlow Lite 的自定义集成选项跟踪应用的性能。
此选项允许你将 TensorFlow Lite 模型添加到 ML Kit 并使用它们 (source)。
Google 开源

Google 开源将开源的所有价值带给 Google,将 Google 的所有资源带给开源 (source)。
随着新软件的不断开发,总是需要将其提升到一个新的水平。一旦开发者开始创建开源代码,社区才能积极参与并帮助改进和扩展它。通过自由获取的代码,开发者可以通过访问代码库来修改和扩展代码,通常在此过程中解决复杂问题。
Google 承诺通过鼓励开发者将他们的代码开放给任何有兴趣的人来汇聚开发者。Google 提供了大量免费的开源项目,例如:
-
ClusterFuzz,在过去两年中在多个项目中发现了超过 11000 个漏洞。
-
AutoFlip,智能地重新框定视频以适应现代设备。
-
Blockly,通过拖放代码块提供简单的编码方式,这些代码块甚至可以用于创建业务逻辑。
Fairness Indicators
Google 在其开源倡议中提供了 Fairness Indicators。这是一个提供量化机器学习系统公平性指标的工具。由 TensorFlow 提供支持,其目的是消除机器学习系统中的任何偏见,同时提高公平性并减少不公平偏见对系统和组织的影响。随着需求的增长,Google 设计了这个工具,考虑了各种类型的企业。
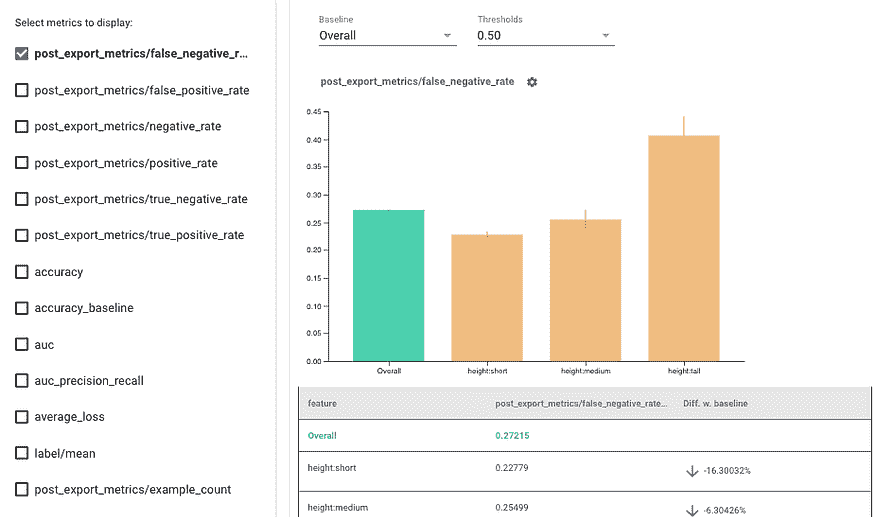
使用 Fairness Indicators 可视化公平性评估指标 (source)。
CoLaboratory
开始使用 Python 与 Google Colaboratory (source)。
Colaboratory 或 Colab 简称是一个在线 Python 代码编辑器和编译器。可以将其视为 Google Docs,但用于 Python,并由 Google Drive 等提供的存储功能支持。使用起来相对简单,消除了跨多个用户共享配置的麻烦,简化了协作过程。它还提供了远程编写代码的能力,可以创建 markdown 以详细解释代码片段。
开始使用 Google Colaboratory (source)。
对于研究人员
在深入研究一个新领域时,广泛的研究是绝对必要的。Google 通过提供现有模型生成的全面而丰富的数据集,这些数据集对用户开放,简化了获取过程,并提供了以下工具:
Google Datasets
对于每个机器学习模型,根本问题是用正确的数据进行训练。Google Datasets 通过提供数据集来解决这个问题。
Google Datasets 是由 Google 策划的一个数据集集合,定期通过分析研究人员的广泛兴趣进行更新。
Google 提供了广泛的数据集类别,包括图像、转录音频、视频和文本。针对各种用户和不同用例,每个类别都提供了详细的数据集介绍和便于访问的下载链接。
一旦用户下载数据集并在数据集上训练他们的模型,他们可以为真实世界场景准备他们的模型。可以通过 Google Dataset Search 搜索更多数据集。
Google Dataset Search
由于互联网中的每个模型都生成其数据集,Google 通过提供搜索功能帮助简化了与其他用户共享数据集的过程。类似于其在网络上搜索任何内容的搜索服务,Google 的数据集搜索可以缩小你寻找数据集的范围。在那里,你可以了解更多关于数据集的信息并获取它。
数据为王,Google 知道这一点
Crowdsource
Google 的另一项举措通过向用户提供有趣的挑战来提高数据集的准确性,要求他们识别各种类别的图片,如图画、字母、报纸、插图等。
在这些类别中,贡献者可以从提供的选项中识别和标记图片,以改善 Google 的服务。如果你有那种竞争精神,开始贡献后,你将获得一个有趣的徽章和成就里程碑。
通过 Google Crowdsource 改进你的产品 (source).
Google Crowdsource 不仅仅在图片上工作,还涉及其他多个领域,如:
-
手写识别
-
面部表情
-
翻译
-
翻译验证
-
图片说明
-
图片标签验证
对于组织
通过密切监控市场,Google 能够识别其服务如何将企业的潜在里程碑转化为已实现的目标。Google 向企业提供的工具可以简化工作流程,并通过采用 AI 和 ML 专业知识达到新的高度。从精准的数据集、定制模型、高性能的云服务等方面,Google 可以为各种规模的企业提供丰富的选择。
一些组织已从 Google 的 AI 工具中获益,如 Lyft、Max Kelsen、eBay 和 Two Sigma 等。组织可以从以下 Google AI 工具中受益。
Cloud TPU

TPU V2 (来源: Google Cloud Platform Blog).
进行所有这些数据计算,机器学习需要高性能系统。为此,Google 构建了其 TPU,即张量处理单元,正是为此而设计的。通过提供所需的强大计算能力,而无需任何本地设置,Cloud TPU 使企业能够通过降低硬件成本向客户提供最佳服务。
企业可以选择其首选的云 TPU,从较少要求的任务到最具挑战性的任务,并从以下提供的选项中选择:
-
Cloud TPU v2
-
Cloud TPU v3
-
Cloud TPU v2 Pod
-
Cloud TPU v3 Pod
云人工智能
云人工智能 使你能够将机器学习能力实施到你的业务中,使其随时准备应对新的挑战。使用云人工智能,企业可以使用谷歌提供的现有模型,也可以自行定制符合自己需求的模型。
云人工智能分为三个组成部分。云人工智能包括 —
-
AI Hub:提供一系列可直接使用的 AI 组件,支持模型的分享和实验。
-
AI Building Blocks:允许开发者将对话、视觉、语言、结构化数据和 Cloud AutoML 能力添加到他们的应用程序中。
-
AI Platform:AI Platform 使数据科学家、工程师和开发者能够迅速将他们的想法转化为实际部署,提供了如 AI Platform Notebooks、深度学习容器、数据标注服务、持续评估、AI Platform Training 等多个服务。
Cloud AutoML
被迪士尼、Imagia、Meredith 等知名品牌使用,Cloud AutoML 使自定义机器学习模型的培训变得轻而易举,以生成高质量的培训数据。与其他谷歌服务完全集成,并且服务间的转移过程无缝对接,你的企业可以通过最大化输出实现其全部潜力。
开始使用 AutoML (source)。
结论
人工智能出现的时间相对较短,但我们随时间发现的进展和应用令人惊叹。考虑到人工智能的好处,企业可以通过早期采用人工智能和机器学习并进行实验,获得竞争优势。
谷歌在这一领域持续进行创新,推出了多个工具,如ML Kit、TensorFlow、Fire Indicators等,服务于包括开发者、研究人员和企业在内的多种用户。通过鼓励使用其云人工智能工具,谷歌试图提升人工智能和机器学习在现实世界中的应用。
其目的是通过精准的评估、协作、改进和部署定制的机器学习模型,来提升用户的生产力和服务质量。
原文。转载时获得许可。
Bio: Claire D. Costa 是 Digitalogy 的内容创作者和市场营销人员,Digitalogy 是一个技术采购和定制匹配市场。
相关内容:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关主题
数据科学家必备的顶级 SQL 功能
原文:
www.kdnuggets.com/2019/08/top-handy-sql-feature-data-scientist.html
评论
由 Saurabh Hooda,Hackr.io

我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
SQL 对数据科学的意义就像自然对生命的重要性一样。没有自然的保护,就没有生命的可能性。没有 SQL 知识的保护,就没有数据科学。
尽管 NoSQL 数据库和像 R 和 Python 这样的编程语言表现非常出色,但每当我们听到“数据”时,首先想到的还是 SQL!Python 确实有优秀的库帮助数据科学家 —— 查看顶级 数据科学 Python 库 —— 但 SQL 仍然是处理数据的首选方式。
为什么?
SQL(结构化查询语言)存在已久,对于许多开发者来说,是一种非常舒适的编程语言。SQL 拥有易于学习的功能,用于组织和检索数据,并对数据执行操作以获得有用的见解。你可以阅读一些常见的 SQL 面试问题,以获取关于 SQL 的基本了解。它也是高效且接近数据的。
如果你对数据库一无所知且从未使用过,应该从基础开始。首先阅读关于 DBMS(数据库管理系统)规范化的内容,这将帮助你理解结构对数据分析的重要性。
如果你从事网页开发,你知道数据是从后端(数据库)获取并呈现在前端(UI)。同样,数据是由用户输入到数据库中的。访问 Squareboat 了解我们如何帮助你进行 网页开发。
话虽如此,让我们现在关注数据科学家应该掌握的 SQL 顶级实用功能。
1. 选择语句
作为数据科学家,你将从不同的表中选择(读取)大量数据,以获取模式、统计信息和其他重要信息。基本的选择查询
select * from <table name>;
可能返回大量记录。在现实世界中,数据库有数百万条记录,如果一个表中有多个列,你会被结果的数量压倒。你可以只选择你需要的列。
select <column1>, <column2> from <table name>;
例如,如果你想知道所有注册学生的姓名和年龄,你可以这样查询数据库 –
select name, age from student;
2. 分组和排序函数(排名和 top n 分析)
大多数时候,你会想要处理你感兴趣的数据子集。例如,如果你想知道使用你产品的青少年数量,你可以通过 where 子句轻松实现。
select name, age from student where age between 13 and 19;
同样,你可以根据年龄对学生进行分组。下面的查询将为你提供每个分支/部门的学生数量(计数)。
select count(student_id), deptt from student group by deptt;
假设你想知道哪个部门的学生最多或最少。你只需使用 order by 子句即可实现。
select count(student_id), deptt from student group by deptt order by count(student_id) desc;
现在,如果我们只想了解那些至少有 10 名学生使用我们产品的部门,我们应该怎么做?
我们可以使用 ‘having’ 子句,它类似于 ‘where’ 子句,但作用于数据组。
select count(student_id), deptt from student group by deptt having count(student_id) >10 order by count(student_id) desc;
从一个庞大的数据集中获取这样的有限数量记录称为 top-n 分析。一些现实生活中的例子包括:得分最高的前 2 名学生、花费最多时间浏览的前 10 名 Facebook 用户、公司销售的前 3 种产品、每月的前 5 名员工、每月表现最差的 3 名等。例如 –
select rownum as toppers, first_name, last_name, total_marks
from (select first_name, last_name
from student
order by total_marks)
where rownum<3;
第一个 select 语句(内联视图)获取按 total_marks 排序的所有记录,而第 2 个语句仅获取前两个(n)顶级记录。
我们很容易在不进行广泛扫描或搜索的情况下获得数据到精确的过滤级别。我们可以进行很多这样的过滤,以进一步满足更多条件。
3. 字符串函数(文本挖掘)
SQL 中有许多有用的字符串函数,就像我们在编程语言中一样。当数据库管理系统本身提供这些功能时,你可以避免编写大量代码,因为它更快。一些常见的字符串函数包括 –
1. upper 和 lower
要将整个字符串转换为大写或小写,我们可以使用此函数。这在我们希望以特定大小写打印内容时非常有用。例如,如果我们希望学生的名字全大写,我们可以使用 upper 函数 –
select UPPER(first_name) from student;
2. replace
如果我们需要将一个或多个字符替换为另一个字符,可以使用此函数。例如,假设我们需要获取没有中划线的手机号码列表。数据库中的值是 1-832-234-1098,我们想将所有连字符替换为空格。
select first_name, REPLACE(phone_number, ‘-‘, ‘ ‘) as number from student;
这将以 1 832 234 1098 的形式呈现值。
3. concat
将两个或多个不同的列或字符串连接成一个结果。例如,如果你想显示全名作为名加姓,可以使用 concat。
select CONCAT(first_name, ‘ ‘, last_name) as fullName from student;
4. substring
就像在编程语言中一样,SQL 的子字符串功能从字符串中提取特定的字符。例如,如果考试表有一个 hall_ticket_no(例如 00019812345),而我们只想要最后几个字符,我们可以将查询写成 –
select substring(hall_ticket_no,7,11) as sequence_num from exam;
子字符串还有两个变体,左侧和右侧,分别获取左侧或右侧的几个字符。在我们上面的例子中,我们也可以使用 RIGHT 函数。
5. len
获取字符串中的字符数。例如 –
select student_profile from student where len(student_profile) < 25;
这将只显示那些描述较短的个人资料。
6. ltrim, rtrim
ltrim 和 rtrim 分别去除字符串的前导和尾随空格。有时数据库条目在开头或结尾有很多空格——可能是用户输入的,或者是程序填充的空格;我们不知道。如果你希望修剪这些空格并展示数据,可以使用这些函数。示例 –
select ltrim(first_name) from student;
要去除前导和尾随空格,你可以使用 –
select trim(first_name) from student;
4. 日期函数
处理日期稍显复杂,但 SQL 可以轻松处理。
有许多函数,如
-
DATEADD – 在现有日期上增加一年
-
TO_DATE – 将字符串转换为日期
-
DATEDIFF – 计算两个给定日期之间的差异
-
DATEPART – 获取日期的特定部分;例如,年份、月份或日期
-
DAY – 获取给定日期的日期
-
CURRENT_TIMESTAMP – 获取日期和时间(时间戳)
上述所有内容对于分析各种类型的数据都非常有用。例如,你可以使用 DATEDIFF 来获取特定时间范围内的数据,或者使用 DAY 函数来找出大多数学生请假的日期,等等。
5. 聚合(统计函数)
聚合函数允许我们从一组数据中找到总和(SUM)、平均值(AVG)、最小值(MIN)、最大值(MAX)和计数(COUNT)。我们使用这些函数与 group by 和 having 子句。例如,如果我们想知道每个部门的学生集体的平均分数百分比,我们可以使用 AVG 函数。
select AVG(total_marks) from students group by deptt;
同样地,要获取特定部门的学生数量,我们可以使用 count。
select count(*) from students group by deptt;
6. 连接
通常,你会想从多个表中整理数据,并仅获取符合某些条件或模式的列。为了从两个或更多表中获取数据,我们使用 SQL 连接。
7. 正则表达式
了解正则表达式非常有用。例如,如果你想验证电话号码、信用卡或任何符合某种模式的数字值,可以使用正则表达式。
例如,如果你想获取以数字开头的电话号码(而不是括号或其他字符),你可以使用 –
select * from contact where phone like '[0-9]%';
你可以使用任何编程语言,如 JavaScript,来完成相同的操作,但它比执行代码更简单、更节省时间。正则表达式也可以用来查找表中某列的特定模式。例如,如果你想获取包含“ya”的学生姓名,你可以使用 LIKE 子句。
select first_name, deptt from student where first_name like ‘%ya%’;
8. 加载和复制数据到数据库
如果你有大量的数据在 Excel 或 .csv 格式中,并且你想将这些数据全部复制到 DBMS 中,SQL 可以为你完成这项工作。
你可以使用 COPY FROM 将数据从文件复制到数据库。同样地,要将数据从数据库复制到文件,可以使用 COPY INTO 命令。
9. 数据分桶
正如我们之前看到的,使用 group by 可以帮助我们获得数据集,以便我们可以通过分析找到趋势和推断业务机会。分桶是用于查找这些分组(大多数情况下是时间戳和数字)并生成直方图的术语。这减少了人工观察错误。例如,通过使用 truncate 函数,我们可以获得一个小数的最接近的四舍五入值。
select truncate (average, 0) from students; -- if the actual value was 78.333, the result will be 78.
同样,date_trunc 用于将日期分组在一起。这在跟踪用户在一段时间内的活动时可能很有用。例如,跟踪在线学习门户中学生在特定日期区间的活动,例如工作日和周末。
了解更多关于数据分桶的信息,请点击这里。
10. 排序
使用 SQL 序列,我们可以按需生成一个升序或降序的数字序列。可以通过提供必要的细节使用 create sequence <sequence_name> 来创建序列。序列不与任何表关联,因此在需要时直接使用序列来检索表值是有用的。调用 next value 函数可以检索下一行,而不是从表中选择。
最终总结
如果你还没有实际操作过 SQL,你应该尝试这些教程。作为一名数据科学家,你可能不会使用 SQL 的所有强大功能。然而,一旦你开始操作数据,你肯定会喜欢深入挖掘。上述列表应该可以帮助你了解作为数据科学家预期使用的功能。请访问这个链接阅读所有重要的数据科学面试问题,并开始打造你的梦想职业。
简介: Saurabh Hooda 曾在全球范围内为电信和金融巨头工作。在 Infosys 和 Sapient 工作了十年后,他创办了自己的第一个创业公司 Leno,旨在解决超本地的书籍共享问题。他对产品营销和分析感兴趣。他的最新项目 Hackr.io 推荐了每种编程语言的最佳 数据科学教程 和在线编程课程。所有教程由编程社区提交并投票。
相关:
-
数据科学家需要 SQL 吗?
-
掌握数据科学 SQL 的 7 个步骤 — 2019 年版
-
Python 数据科学入门
更多相关内容
2022 年数据科学家招聘的顶级行业和雇主
原文:
www.kdnuggets.com/2022/06/top-industries-employers-hiring-data-scientists-2022.html

Eric Prouzet via Unsplash
数据科学的美妙之处在于它已在许多行业中得到了应用,并将这些行业提升到新水平。越来越多的公司正在寻找新的方式以保持竞争力并领先 10 步,因此对数据科学家的需求持续增长。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
数据科学的美妙之处在于你可以在不同的行业之间流动,并带上你的技能。
以下是顶级数据科学行业和积极招聘数据科学家的公司列表。Jobin Thomas 透露,根据 LinkedIn,到 2026 年,这一领域将有 1150 万个职位。
银行业、金融服务和保险 (BFSI)
数据科学的最早应用始于金融行业。该行业对损失和复杂性感到疲惫,但也拥有大量数据。他们引进了数据科学家来帮助解决问题。《2014 CIO 日程:银行/投资视角》探讨了分析和商业智能的投资作为 2014 年 CIO 的首要支出优先事项。
数据科学家们一直在分析大量数据,这有助于决策过程并提供可操作的洞察。
数据科学、机器学习和人工智能在
-
欺诈检测
-
风险建模
-
客户数据的安全和管理
-
客户细分
-
算法交易
-
承销和信用评分
行业内一些顶级雇主包括:
-
摩根大通
-
汇丰银行
-
花旗集团
-
巴克莱银行
医疗保健
数据科学通过设计和评估新的医疗策略,将医疗保健行业提升到新水平。它已被证明能改善健康服务的质量、患者的寿命,并带来更多的行业机会。
数据科学在医疗保健领域应用最广泛的领域之一是药物发现和:
-
更容易的疾病诊断
-
定制预防计划
-
精确的处方和个性化护理
-
后期护理监测
-
医院运营
一些在该行业招聘的顶级雇主包括:
-
葛兰素史克
-
普华永道
-
德勤
网络安全
随着数据、算法等的使用增加,恶意活动的表现也在上升。黑客变得越来越聪明,能够突破最严密的安全系统。
数据科学家利用机器学习和人工智能理解这些恶意攻击的性质和模式,以防止其再次发生。他们可以利用这些信息了解安全系统的局限性以及需要更改或调整的部分来改进系统。
只要我们继续依赖数据来实现短期和长期商业目标,帮助改善医疗行业等,网络安全分析师的需求也将随之增加。
一些在该行业招聘的顶级雇主包括:
-
埃森哲
-
亚马逊
-
IBM
-
Meta
-
微软
零售
尽管疫情导致许多零售店关闭,并且市场行业整体发生了变化,但零售行业对数据科学家的需求却在上升。零售行业关注消费者及其需求,以继续蓬勃发展并保持竞争力。
数据科学家通过分析消费者的行为和模式来帮助零售行业,然后将这些数据用于定价、营销等决策过程中。
数据科学在零售行业可以:
-
分析客户行为
-
分析市场
-
分析客户的过去购买和搜索记录,以创建个性化系统
-
创建推荐系统并通过营销发送
-
通过预测分析提升客户体验
一些在该行业招聘的顶级雇主包括:
-
亚马逊
-
马克斯和斯宾塞
-
拉尔夫·劳伦
汽车行业
数据科学在保持汽车行业竞争力方面发挥了重要作用。该行业包括大量的研究、设计、制造、测试和营销过程。
高级分析技术使得利用摄像头、汽车传感器、图像识别、光线检测等快速开发自动化系统成为可能。
汽车行业将导致:
-
通过认知物联网提高车辆安全性
-
提高生产线的性能
-
及早识别生产线上的缺陷和错误
-
改进管理和物流部门
一些在该行业招聘的顶级雇主包括:
-
大众汽车
-
通用汽车
-
福特
虚拟现实
疫情推动了大量概念在线化以及整体技术的未来。虚拟现实在流行游戏《口袋妖怪 GO》中得到了体现,你可以四处走动寻找实际上并不存在的宝可梦。
虚拟现实利用计算知识、机器学习算法和数据来创造最佳体验。然而,虚拟现实还有更多的潜力尚待开发。
行业内的一些顶级雇主包括:
- Meta
结论
这些并不是唯一寻求数据科学家的行业,还有很多其他行业,包括时尚、美容、石油行业、市场营销等。随着对数据科学家的巨大需求,你将能够在不同的行业之间转移你的技能。
尼莎·阿利亚 是一名数据科学家和自由职业技术写作者。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探索人工智能在提升人类寿命方面的不同方式。她是一个热衷学习的人,致力于拓宽自己的技术知识和写作技能,同时帮助引导他人。
更多相关话题
2021 年招聘数据科学家的顶级行业
评论
图片由 Gerd Altmann 提供,来源于 Pixabay
数据科学作为一个需求旺盛且有利可图的职业道路,已经出现了几年,并且由于几个原因仍然保持如此。首先,公司收集的信息量和类型比以往更多,代表们希望从中获取洞察。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
另一个原因是人们意识到有效使用数据可以增加竞争力,即使在充满挑战的市场环境中。以下是目前招聘数据科学家的六个行业,这些行业可能在可预见的未来继续这样做。
1. 电信
对顶级大数据行业的研究显示,电信和信息技术处于领先地位。此外,预测预计该行业的价值将在 2023 年达到 1052 亿美元,相比 2019 年的 590 亿美元有所增长。例如,南非品牌 Telkom为女性数据科学家创造了机会在公司担任数据科学专家。
电信公司中的商业领导者可以利用数据科学家的专业知识来决定何时何地推出 5G 技术。他们还可以开始分析客户服务电话中的趋势,以检测和解决常见问题。
2. 交通运输
交通部门也有充分的机会依靠数据科学专长。英国政府最近宣布了释放位置数据潜力的意图。相信这些信息可以支持电动汽车充电基础设施、减少排放影响,并使旅行更加安全和愉快等。
另一个趋势是利用骑行者的手机数据来评估人们依赖公共交通服务的频率。洛杉矶的当局已经采取了这种方法。数据科学家可以帮助决策者从收集到的信息中提取有价值的细节。
3. 健康保险
健康保险领域的人们对雇佣数据科学家也更加感兴趣。这有助于他们跟上新兴趋势,例如对自保计划的日益关注。例如,统计数据显示,29.2%的中型雇主选择了自保选项。数据科学家可以评估这种变化,以及追踪其他显著模式。
健康保险公司领导希望了解哪些因素使投保人更可能或更不可能提出索赔,或者哪些地区的客户最多。数据科学可以回答这些问题以及其他问题。
4. 银行 / 财务
银行业的领导者也认识到雇佣数据科学家的价值。在一个例子中,美国银行分析了超过41,000 条社交媒体评论并发现了大量关于购买限制的虚假谣言。代表们随后可以提供澄清,以防止声誉损害。
银行还分析数据以标记可疑的交易或消费模式。他们在决定是否向客户提供贷款时也会这样做。一些银行客户也可以从数据分析中受益,例如如果应用程序功能告诉他们在某个月可能会花费比平常更多的钱。
5. 零售
零售品牌在高管意识到对可用信息有更清晰的理解可以帮助满足客户需求后,雇佣了数据科学家。例如,一项节日购物研究显示,人们在两年的时间里搜索“礼品盒”的频率比其他时间高 1.85 倍。这些结果帮助零售商调整他们的产品。
从 COVID-19 相关困境中恢复的努力 也可能推动零售领域的数据科学家招聘活动。疫情改变了人们的购物方式和购买偏好。数据专家在发现这些新趋势并向零售高管提供所需统计数据以采取行动和增加利润方面将发挥至关重要的作用。
6. 生命科学/制药
数据科学家还将在生命科学和制药领域找到工作。Elaine O’Dwyer 在 Accenture 担任生命科学领域的数据科学家。她说:“项目通常专注于在生命科学行业中应用高级分析,通常结合数据和分析战略设计。我们位于爱尔兰的团队大部分工作涉及商业药品的生产和供应,例如,调度优化以提高质量控制实验室的生产力和效率。”
由于 COVID-19 仍然对全球大部分地区构成严重威胁,这些领域的领导者很可能会意识到数据在应对全球大流行带来的额外压力中至关重要。数据还将帮助这些公司开发新药物、减少错误和最小化召回,无论是用于 COVID-19 治疗还是其他用途。
对招聘数据科学专业人士的需求持续增长
这些只是数据科学家今年及以后可以找到工作的许多行业中的一部分。如今的高管希望摆脱过去主要依赖直觉和经验做决策的做法。数据科学家具备揭示可能被忽视的洞察的知识和技能,使他们对几乎所有行业都具有价值。
简介:Devin Partida 是一位大数据和技术作家,同时也是ReHack.com的主编。
相关链接:
-
如何成为数据科学家
-
将无代码机器学习推向极限
-
如何成功成为自由职业数据科学家
进一步了解这个话题
《数据科学的黄金热潮:数据科学顶级职位及其获取方式》
评论
作者:德文·莫里西

来源:www.maxpixel.net/Hand-Shake-Business-Business-Handshake-Handshake-2998302
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
大约十年前,“大数据”对大多数人来说不过是一个流行词。如今,大数据和分析领域驱动着大部分的商业运营、营销策略、物流决策,以及不断发展的人工智能领域。
从那时起,大数据和云技术已经变得如此普及和常见,以至于任何一家有价值的组织,无论其规模如何,都应该利用大数据分析和技术的洞察——行业报告显示,他们也开始这样做。根据德勤顾问服务的2017 年大数据分析市场研究,2017 年所有被调查公司的大数据采用率上升了 53%,相比 2015 年的 17%有显著增长。
这种采用率是有道理的,因为数字触点在全球范围内迅速扩展。到 2020 年,全球预计将有61 亿智能手机用户,每秒产生大量数据。事实上,我们的数字宇宙中的数据量大约每两年翻一番,并预计到 2020 年达到40,000 艾字节(或 40 万亿千兆字节),根据《基线杂志》的预测。
所有这些因素加起来,形成了一个在现代世界中迅速变得不可或缺的行业——并提供了一些市场上最受追捧的职业。Glassdoor 报告显示,“数据科学家”在 2018 年底名列美国 50 个最佳职位榜首,平均基本薪资为 110,000 美元。
当然,还有许多其他与数据和分析领域相关的职位,毕业生、求职者以及那些寻求职业转型的人都在争取机会来执行这些职位。由于大数据几乎涉及所有行业,那些尚未从事数据和分析工作的人很快也将利用这一技术,以获得不可否认的商业利益。不论你如何看待,工作的未来在于数据。
数据科学淘金热
由于云计算、物联网的兴起,以及由这些技术和连接设备生成的数据的收集和存储,比以往任何时候都需要更多人来从事信息技术领域的工作。实际上,根据美国劳工统计局 2016-2017 年《职业展望手册》(OOH) 的统计数据,计算机和信息技术职业组的就业预计在 2014 至 2024 年的 10 年期间增长 12.5%。这一增长远高于预计的 6.5%的总体就业市场增长,预计将为劳动力市场增加 48.85 万个职位。
大数据的广泛应用多样性不仅解释了 IT 领域职位空缺的高数量,还归因于与数据相关职业中的多彩多样性。一方面,你可能会发现自己从事市场营销,分析客户行为并绘制细分模型,以显著提高客户获取和留存率,基本上是通过分析过去的数据来预测未来趋势。
另一方面,从事数据相关职业也可能侧重于客户数据的安全,而不是数据的分析。Ashley Stein,为 Record Nations 博客撰写,指出任何组织的数据泄露恢复计划的一个重要部分应包括聘请外部专家调查问题。
她写道:“引入专门从事事件响应和差距分析的第三方 IT 专业人员或公司,将使你能够获得对数据泄露的外部视角。”
尽管围绕大数据和分析的职业机会似乎无穷无尽,但战略商业和技术顾问 Bernard Marr 在 2018 年确定了六个最受需求的技术和数据职位。为《福布斯》撰稿,他列出了:
-
数据科学家: 如上所述,数据科学家在 Glassdoor 的榜单中排名第一,拥有$110,000 的中位数基本工资。根据雇主的公司不同,职位可能有所不同,但通常这些人负责收集、处理和分析数据,与团队和数据分析程序一起工作,以从数据中提取意义。
-
商业智能分析师(BIA): BIA 利用数据提供建议,并根据市场和趋势指导组织决策。平均而言,BIA 的年薪在$70k 到$90k 之间。
-
数据库开发人员: 这个职位的名称已经说明了一切,数据库开发人员负责设计、设置或修改与数据库接口的应用程序和代码。数据库开发人员的平均年薪为$90k。
-
数据库管理员: 虽然开发人员通常专注于创建新代码或数据库中的软件,但管理员则专注于正确地设置、安全保护和维护数据库。平均年薪为$80k。
-
数据工程师: 数据工程师在任何分析操作的基础层面工作,设计和构建创建更大数据集的程序。他们的平均年薪为$80k。
-
数据分析经理: 最后但同样重要的是,数据分析经理“理解数据并向团队其他成员传达业务应如何响应数据提供的洞察。” 根据 Marr 的说法,这些经理可以期望年薪达到六位数。
虽然这些职位仅代表整体市场的一小部分,但竞争激烈。因此,执行人员和招聘经理在寻找潜在的大数据员工时关注什么,你可以做些什么来确保在大数据领域获得职业机会?
在大数据领域获得职业机会
根据 Maryville University 关于数据分析毕业生需求增加的帖子,全球的首席执行官都在寻找具备特定知识和技能的候选人,如:
-
受认可大学的商业数据分析教育背景。
-
编程语言和程序的工作知识,如 PYTHON 或 R。
-
学习新编程语言和程序的能力与倾向。
-
良好的团队合作能力以及独立工作的能力。
-
批判性思维和解决问题的技能。
-
具有市场营销、人力资源、网络安全、运输或客户服务等相关领域的大学辅修或工作经验。
这些要点中有些比其他的更重要,但最合格的候选人将会覆盖所有这些要点及更多。例如,理解多种编码/编程语言和工具的重要性不容低估。
在他的文章“2018 年十大大数据技能需求”中,技术作家 Amit Verma 实际上列出了超过 10 种语言和系统,其中一些元素相互嵌套。他具体列出了:
-
Apache Hadoop 及其组件,如 Hive、Pig、HDFS、HBase 和 MapReduce
-
NoSQL 数据库,包括 Couchbase 和 MongoDB
-
数据中心化语言 SQL
-
数据可视化工具,如 QlikView 和 Tableau
-
量化和统计分析工具,如 SAS、SPSS 和 R
-
编程语言,包括 Java、Python、C 和 Scala
-
数据挖掘工具,如 Rapid Miner、Apache Mahout 和 KNIME
显然,每个职位都不同,申请时应该根据具体情况对待。
“由于每个职位所需的计算机技能通常不同,你应该仔细阅读每个职位描述,以了解在简历上列出哪些计算机技能,” Resume Coach 的专家写道。 “然而,如果一个职位需要大量与职位核心相关的技能,你应该在简历上添加一个特定的‘计算机技能’部分以突出这些技能。”
在他关于如何选择数据科学工作的 KDnuggets 文章 中,SuperDataScience 的总监 Kirill Eremenko 表示同意。
他写道:“与任何其他职位一样,申请前一定要彻底阅读职位说明。” “数据科学家注重细节——确保在申请中证明这一点!”
CEO 和招聘经理在寻找潜在的大数据岗位候选人时还关注一个(上文未提及的)质量,那就是“灵活性”或“适应能力”。这是因为大数据和分析领域本身就是一个颠覆性的领域,与其他劳动力相比,假设对类似颠覆性力量具有任何类型的免疫力将是极其愚蠢的。事实上,大数据领域可能已经面临颠覆性的技术变革,研究人员已经开始尝试(并取得了一些成功)如何 使用氯原子和纳米磁铁 存储数据。
通过关注行业趋势,提升硬技能和软技能,你可以在数据科学领域找到一份工作。 注意细节,确保你有优秀的硬技能和软技能的组合,并向前展望。数据科学职业机会很多——确保你主动抓住这些机会。
资源:
相关:
更多相关话题
2022 年数据科学领域的顶级工作和薪资
原文:
www.kdnuggets.com/2022/05/top-jobs-salaries-data-science-2022.html

Shridhar Gupta 通过 Unsplash
在数据科学的世界里,有许多不同的路径可以选择,这些路径具有不同的技能、专长和薪资。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
数据科学是目前最受欢迎的职业之一。由于许多人将数据等同于黄金的价值,能够处理、管理和分析数据的专业人员的需求持续增长。
如果你已经在这个领域工作,你可能在寻找能提升你的知识、技能和工资的机会。如果你想进入这个领域,你可能希望找到既让你感兴趣又能获得良好薪资的工作。
我将介绍数据科学领域的顶级工作及其薪资。这些薪资数据取自 Indeed 薪资。
数据科学家
数据科学家的工作包括管理大型复杂的数据集,并使用预测分析和机器学习生成输出。他们在数据挖掘、算法、机器学习、人工智能和统计工具方面具有熟练的知识,这些知识有助于企业决策。
数据科学家通常拥有计算机科学、数学、数据科学等方面的学位。由于对数据科学家的需求很高,也有一些培训营可供选择。
-
低薪:$78,877
-
平均基本工资:$134,367
-
高薪:$228,892
数据工程师
数据工程师有多种角色,从构建系统到收集和管理数据。他们将原始数据转化为数据科学家和业务智能分析师可以进行解读的信息。
他们的职责包括开发算法、构建和测试管道,确保所有使用的工具和方法符合政府规范。
数据工程师通常拥有计算机科学、软件工程、统计学等方面的学位。
-
低薪:$77,926
-
平均基本工资:$125,322
-
高薪:$201,544
数据分析师
数据分析师是帮助组织解决问题的人。他们收集数据、清理数据并进行解释,以帮助组织做出重要决策。数据分析师需要具备良好的演讲技巧,因为他们需要向利益相关者传达他们的发现。
数据分析师通常拥有数据科学、计算机科学、应用数学等学位。
-
低薪资:$44,464
-
平均基础薪资:$68,769
-
高薪资:$106,360
商业智能分析师
BI 分析师分析对业务重要的数据。他们收集数据、清理数据并分析数据,以提供有关收入、销售、客户互动和市场信息的见解。BI 分析师识别这些模式和趋势,从而发现业务机会。
BI 分析师通常拥有计算机科学、经济学、工商管理等学位。
-
低薪资:$56,950
-
平均基础薪资:$84,119
-
高薪资:$124,249
机器学习工程师
机器学习工程师使用算法解决问题。他们探索数据、识别模式和差异,并可视化数据以帮助得出结论。在呈现结果之前,他们会验证数据的质量和准确性。
他们负责创建程序和算法,以便机器能够在无需人工干预的情况下完成任务。
机器学习工程师通常拥有计算机科学学位,以及相关领域的硕士学位或博士学位。
-
低薪资:$68,791
-
平均基础薪资:$127,430
-
高薪资:$236,055
统计学家
统计学家负责收集、分析和解释数据,以帮助识别趋势和模式。他们随后将这些发现传达给利益相关者,以帮助决策过程和未来策略。
他们对统计理论有很好的理解,以提供有价值的见解并为数据工程师创建新的方法论。他们还精通 SQL、数据挖掘和机器学习工具。
-
低薪资:$60,834
-
平均基础薪资:$95,364
-
高薪资:$149,494
数据库管理
由于世界上有大量数据,你需要一个能够管理、监控和优化数据库的人。他们与 IT 团队紧密合作,以确保数据安全。他们还构建新数据库、备份和恢复数据,以及对数据库进行修改。
数据库管理员通常拥有信息科学或计算机科学学位。
-
低薪资:$60,970
-
平均基础薪资:$90,855
-
高薪资:$135,389
数据架构师
数据架构师负责设计和构建满足业务需求的数据模型。他们将可视化并设计公司的企业数据管理框架,该框架描述了规划、指定、创建、获取、检索、控制和使用数据的工作流程。他们将业务需求转化为技术规范。
大多数数据架构师通常拥有信息技术、计算机科学、计算机工程等相关学位。
-
低薪:$50,308
-
平均基本工资:$85,901
-
高薪:$146,675
结论
对于懂得如何处理数据的专业人士的需求将持续增加。随着需求的不断增长,越来越多的人正在转型进入数据领域。这也会反映在薪资上,随着经验的增长,他们的薪资也会相应增加。
Nisha Arya 是一位数据科学家和自由撰稿人。她特别感兴趣于提供数据科学职业建议、教程以及数据科学理论知识。她还希望探索人工智能如何能够有益于人类寿命的不同方式。作为一个热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关主题
顶级 Javascript 机器学习库
原文:
www.kdnuggets.com/2016/06/top-machine-learning-libraries-javascript.html
目前确实存在一个成熟的机器学习生态系统,或者更准确地说,是一小部分成熟的机器学习生态系统。对于研究而言,无可争议的机器学习生态系统冠军是围绕 Python 及其众多支持数据准备和后续机器学习过程的库展开的,无论是通过 scikit-learn、众多可用的深度学习库,还是自制的、针对特定目标的高度专业化工具。这还没有提到那些在生态系统边缘逐渐成长起来的优秀支持工具,其中一些变得足够完善和有用,以便开辟 自己的最终利基市场。
正如行业人士首先会告诉我的那样,Python 并不是唯一的选择。还有基于 Java 的工具(Deeplearning4j,Weka)、与 Apache Spark 和/或 Hadoop 集成的工具(MLlib,Mahout)、C++ 解决方案(TensorFlow 是用 C++ 编写的,Python 生态系统中的许多其他工具也是如此),甚至还有针对 Clojure、F#、Rust 及其他各种语言、环境和生态系统的工具。

然而,谈到对机器学习友好的编程语言时,Javascript 通常不会被提及。鉴于其强大的 市场份额 和 Atwood 法则,即任何可以用 JavaScript 编写的应用程序,最终都会用 JavaScript 编写,这似乎表明这里可能存在更多的因素。Atwood 法则可能不再像以前那样被视为不争的结论(至少在许多人看来是这样),但可以像争论它在机器学习方面的有效性一样容易地争论它在其他方面的有效性。
那么,为什么不使用 Javascript 呢?这里有一些原因。其中很多原因并不是特定于 Javascript,而是适用于任何非 Python(或非成熟生态系统)的语言。换句话说,这就是现实情况。其他原因涉及速度、代码的易读性和编写难度,以及环境的复杂性等技术问题。
但让我们明确一下:不讨论图灵机、理论计算机科学或统计过程,机器学习可以通过 Javascript 完成。选择?自己编码,或者看看以下内容,这些是 Javascript 中通用机器学习和神经网络库的小样本。有些库实际上也使用了Node.js,要明确一点;如果你不熟悉,请查阅一下。
选择 Javascript“顶级”库的过程更像是艺术而非科学;鉴于该语言选项相对较少,加上寻找使用良好、支持和维护(三者兼备)的项目的挑战,一些主观性是必要的,以得出一个值得关注的列表。

所以,这里是 Javascript 的“顶级”机器学习库。鉴于上述段落,编号不是非常重要,但编号确实使引用项目更容易……而且我喜欢编号。如果你觉得这个列表不能代表该领域的当前产品,欢迎随时给我发推特 @mattmayo13提出建议;我很乐意进行更新或分享有效的意见。
1. 机器学习工具
我们的第一个产品可能没有很多仓库星标,但它是一个通用的机器学习套件,包含大量工具,并且正在积极开发(几小时前更新,非常感谢)。直接来自开发者:
这个库是由 mljs 组织开发的工具的汇编。
mljs组织关注于:
Node.js 和浏览器的机器学习和数值分析工具!
机器学习工具提供了一组包含共享工具和结构的根包;它继续支持各种机器学习功能,包括支持向量机、朴素贝叶斯、K 近邻、PCA、K 均值聚类、神经网络等。这将是那些可以在合适情况下作为通用经典机器学习工作马的套件之一,是 Javascript 对 Scikit-learn 的回答的一部分。
2. 机器学习
这个仓库已经有几年没有更新了,但在当时获得了不少星标。直接来自仓库的 README:
适用于 node.js 的机器学习库。你也可以在浏览器中使用这个库。
替代上述第 1 项的这个潜在选项是另一个通用套件,由 Joon-Ku Kang 编写。它包含了逻辑回归、多层感知机、支持向量机(SVM)、K 近邻算法、决策树等功能。它的 README 中包含了每种算法的示例代码,这意味着你应该能够立即尝试一些东西。你可以在这里查看浏览器中的演示。
3. ConvNetJS
许多人在想到 Javascript 和深度学习时,想到的是斯坦福大学的 Andrej Karpathy,这是有原因的。ConvNetJS 起初是他的一个项目,自我描述为:
JavaScript 中的深度学习。在浏览器中训练卷积神经网络(或普通的神经网络)。
它有很好的文档,以及浏览器中的示例。Karpathy 还写了一篇备受尊敬且广泛阅读的文章,标题为黑客的神经网络指南,可能对考虑使用这些库的人感兴趣。

Karpathy 在 Github 仓库中指出,由于时间不足,该项目不再维护,最近的更新大约是在 10 个月前。我已经有几个月没有使用 ConvNetJS,但上次尝试时运气不错。我推测有经验的 JavaScript 开发者如果有兴趣使用 JavaScript 进行深度学习,仍然能够利用这个代码库,不管它今天是否可以直接使用。
4. Synaptic
软件工程师Juan Cazala负责 Synaptic,它自我描述为“一个不依赖架构的神经网络库,适用于 node.js 和浏览器。”因此,Synaptic 可以用于构建各种神经网络架构。

它的文档非常好,并且 Github README 中的"入门"示例代码展示了少量代码或麻烦下实现几种网络类型。最近的一篇 KDnuggets 教程包括了一个关于使用 Synaptic 构建简单神经网络的详细概述。它也在积极开发中。
5. Mind
Mind 由软件工程师Steven Miller编写。它自我描述为"Javascript 中的灵活神经网络"。
Steven 编写了一个关于使用 Mind 构建神经网络的两部分教程(第一部分, 第二部分),提供了比仅仅使用 Mind 更为详细的信息。
Mind 似乎正在积极开发,因为其最近的更新仅仅是 4 个月前,并且它获得了相当多的星标。总体来看,它似乎是一个为 Javascript 机器学习社区提供的成熟产品。
相关:
-
5 个你不再能忽视的机器学习项目
-
Github 上的前 10 个数据可视化项目
-
在 Javascript 中实现神经网络
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织进行 IT 工作
更多相关话题
顶级机器学习 MOOCs 和在线讲座:全面调查
原文:
www.kdnuggets.com/2016/07/top-machine-learning-moocs-online-lectures.html
由 Pulkit Khandelwal, VIT 大学。
每个人在进入机器学习(和深度学习)领域时都会被大量的 MOOCs 所淹没。在这里,我尝试全面概述这些在互联网上免费提供的课程。你可以将这篇文章作为这篇和这篇旧帖的补充。我将尝试突出一些重要的提示,如课程的难度、这些课程的正确完成顺序以及适合这些课程的受众。你将了解到这些课程如何为你提供一系列技能,以及如何利用它们开发实用的机器学习系统。
另一个重要方面是实现自包含作业所用的语言和软件包。你想使用 MATLAB 还是用 Python 编码,你想使用 Theano、Torch 还是 Caffe?哦,等等!可能是 Tensorflow?你如何选择要深入的包?
也可能是你看了大约五节讲座后发现你跟不上课程,因为你很难理解什么是伪逆?这时,你需要在观看这些机器学习视频之前掌握基础知识!
最后,在观看完讲座并浏览相关论文后,你可能想要设置你的工作站,亲自观察算法的运行效果!
所以,这里有一些在我学习过程中遇到的最佳课程:

机器学习 - Andrew Ng, 斯坦福大学
这门课程是一个起点。几乎每个机器学习工程师或研究者都完成了这门课程,实际上,自首次开设以来,这门 MOOC 拥有全球最大的注册人数。Ng 的课程为我们提供了良好的直觉学习。他绕过了复杂的数学推导和公式,但同时使其足够简单,以便你能掌握概念。他主要关注如何在现实世界场景中使用这些算法,即在课程中提供了大量的实践建议,以便人们可以小心地应用材料。我最喜欢 Ng 的一点是,他指出了工程师在行业中常犯的错误,以及如何避免这些错误。课程中为初学者提供了线性代数和 Octave/MATLAB 的良好教程。作业理论涵盖得足够好,实施也相当直接。
话虽如此,Ng 的课程跳过了许多高层次的机器学习问题和算法。如果你想做一些严肃的研究,那么仅靠这门课程是不够的。此外,这门课程没有过多关注贝叶斯和概率方法,因为这些内容超出了课程目标的范围,且相对高级。作业基于 MATLAB/Octave,这对研究和初步理解概念是有益的,但你可能会想用 Python 或 C 来构建机器学习系统。
如果你对这个领域还很陌生且数学基础尚不够强,千万不要跳过这门课程。
本科生机器学习 - Nando de Freitas,英属哥伦比亚大学
我在 Youtube 上发现了这个课程,由另一位优秀的机器学习研究者Nando de Freitas提供。记得我提到 Ng 跳过了一些概念,不用担心,这门课程来救急了!Nando 通过这些讲座做得非常出色。把它们作为 Ng 课程的补充。Nando 还提供了掌握一些高级概念所需的所有先决条件,如概率、最大值和对数似然。观看所有视频后,你将获得扎实的机器学习背景。他重视数学,而这是 Ng 所忽略的。他还在整个课程中使用了向量化。顺便提一下,完全跳过数学细节可能是非常危险的。
机器学习 - Tom Mitchell,卡内基梅隆大学
Tom Mitchell 的课程是所有机器学习研究者中的最爱。这个课程有多个版本,你可以选择其中任何一个。课程材料和作业简洁明了,概念阐述清晰且直接。线性代数、概率论等先修知识已在初始讲座中覆盖。他接着讲解了机器学习的基本工具,随后是关于概率图模型的讲座。课程的下一部分涉及人工智能、神经网络、主动学习和强化学习。还有两节额外的客座讲座,由Dr. Burr Settles和Prof. Ziv Bar-Joseph主讲。因此,你可以看到数学、机器学习、人工智能、神经网络和深度学习等内容都在这门高水平课程中得到了涵盖。如果你不想浏览其他课程,我推荐在完成 Ng 的课程后学习这门课程。请完成所有讲座、习题、阅读材料、作业、项目,甚至是他的书!

数据学习 - Yaser-Abu Mostafa, EdX 和 CalTech
这门课程被评价为机器学习领域中最具挑战性的课程之一。Abu 将讲座分为理论和实际应用两类。概念理解是他的黄金法则。流畅的讲解和清晰的说明使这门课程成为另一门出色的课程。作业可能是你在互联网上能找到的最好的之一。教授非常受尊敬。在这里你可以找到课程的详细评论。
Udacity 提供了各种免费的机器学习课程,如机器学习入门、监督学习、无监督学习、深度学习和大量的数据科学课程。这些课程各有特色,注重项目实践,并提供了完成这些项目所需的所有工具,从而使你准备好进入行业。开源是他们的口号。一旦你对上述课程中的机器学习有了良好的掌握,自己去探索吧。为了找到工作,掌握这些 MOOCs 是必不可少的,因为它们涵盖了机器学习的各种应用!
深度学习 - Nando de Freitas, 牛津大学
Nando 的高级课程为你提供了深度学习技术和所有基本概念的概述。他举了语音识别、计算机视觉、自然语言处理等应用的例子。你不能在不参考所有提到的文献的情况下完全理解讲座。但是,如果你想了解高级机器学习和神经网络问题的难度以及接下来的步骤,这是一个很好的起点。如果你无法掌握内容,不要害怕。这很困难,属于博士级别。顺便说一句,还有来自 Google DeepMind 的 Alex Graves 和 Karol Kregor 的客座讲座。
一句建议:我建议在深入上述课程之前先学习线性代数和概率论。MIT OCW 和可汗学院提供了极好的内容。尽量掌握直觉。如果你无法理解某些内容,最好暂停视频并重新观看该部分。最后,你需要成为更好的机器学习程序员,并且应尽可能地对代码进行向量化。你可能一开始会用很多 for 循环,但一旦你变得更好,代码向量化应该成为常态!不要被这些东西压倒。按自己的节奏学习!
我推荐以下流程:
前提条件 -> Ng -> Tom Mitchell -> Udacity
简介: Pulkit Khandelwal 是麦吉尔大学计算机科学硕士生。他的兴趣在于计算机视觉和机器学习。
相关内容:
-
顶级 Coursera 数据科学专业化课程:比较与独家见解
-
15 个数据科学数学 MOOC
-
顶级机器学习 MOOC 和在线讲座:全面调查
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织在 IT 领域
更多相关话题
2023 年值得阅读的顶级机器学习论文
原文:
www.kdnuggets.com/2023/03/top-machine-learning-papers-read-2023.html

图片由pch.vector提供,来源于Freepik
机器学习是一个领域广泛的领域,新的研究不断涌现。这是一个热门领域,学术界和工业界不断尝试新事物,以改善我们的日常生活。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
近年来,生成式人工智能因机器学习的应用而改变了世界。例如,ChatGPT 和 Stable Diffusion。即便 2023 年生成式人工智能占主导地位,我们仍应关注更多的机器学习突破。
这里是 2023 年值得阅读的顶级机器学习论文,以确保你不会错过即将出现的趋势。
1) 学习歌曲中的美:神经唱歌声音美化器
唱歌声音美化(SVB)是生成式人工智能中的一项新任务,旨在将业余歌唱声音改善为优美的声音。这正是Liu et al. (2022)研究的目标,他们提出了一种名为神经唱歌声音美化器(NSVB)的新生成模型。
NSVB 是一种使用潜在映射算法的半监督学习模型,作为音高修正器并改善声音音质。这项工作有望改善音乐行业,值得关注。
2) 优化算法的符号发现
深度神经网络模型变得比以往任何时候都大,许多研究已经进行了以简化训练过程。谷歌团队的最新研究(Chen et al. (2023))提出了一种名为 Lion(EvoLved Sign Momentum)的神经网络优化方法。该方法表明,该算法比 Adam 更节省内存,并且需要更小的学习率。这是一项非常出色的研究,展现了许多不容错过的潜力。
3) TimesNet:用于通用时间序列分析的时间 2D 变异建模
时间序列分析在许多业务中是一个常见的应用场景;例如,价格预测、异常检测等。然而,仅基于当前数据(1D 数据)分析时间数据面临许多挑战。这就是为什么Wu 等 (2023)提出了一种新方法,称为 TimesNet,将 1D 数据转化为 2D 数据,在实验中表现出色。你应该阅读这篇论文,以更好地理解这种新方法,它将对未来的时间序列分析大有帮助。
4) OPT:开放预训练变压器语言模型
目前,我们正处于生成 AI 时代,许多大型语言模型被公司密集开发。通常,这类研究不会发布其模型或仅以商业形式提供。然而,Meta AI 研究小组(Zhang 等 (2022))尝试做出相反的做法,公开发布了可与 GPT-3 相媲美的开放预训练变压器(OPT)模型。本文是理解 OPT 模型及其研究细节的绝佳起点,因为该小组在论文中记录了所有细节。
5) REaLTabFormer:使用变压器生成逼真的关系型和表格数据
生成模型不仅限于生成文本或图片,还可以生成表格数据。这些生成的数据通常称为合成数据。虽然已经开发了许多模型来生成合成表格数据,但几乎没有模型能生成关系型合成表格数据。这正是Solatorio 和 Dupriez (2023)研究的目标;即创建一个名为 REaLTabFormer 的模型用于合成关系型数据。实验表明,结果与现有的合成模型非常接近,可以扩展到许多应用中。
6) 强化学习(不)适用于自然语言处理?:自然语言政策优化的基准、基线和构建块
强化学习从概念上讲是自然语言处理任务的一个优秀选择,但事实真的如此吗?这是Ramamurthy 等 (2022)尝试回答的问题。研究人员介绍了各种库和算法,展示了强化学习技术在 NLP 任务中相对于监督方法的优势。如果你想为你的技能集寻找替代方案,这篇论文是值得阅读的。
7) Tune-A-Video:一次性调整图像扩散模型用于文本到视频生成
2022 年文本到图像生成非常流行,而 2023 年则预计会关注文本到视频 (T2V) 能力。研究 Wu et al. (2022) 展示了 T2V 如何在许多方法上扩展。该研究提出了一种新的 Tune-a-Video 方法,支持 T2V 任务,如主体和对象变化、风格迁移、属性编辑等。如果你对文本到视频的研究感兴趣,这是一篇值得阅读的好论文。
8) PyGlove: 高效交换机器学习想法的代码
高效的协作是任何团队成功的关键,尤其是在机器学习领域复杂性日益增加的情况下。为了培养效率,Peng et al. (2023) 提出了一个 PyGlove 库,以便轻松分享机器学习想法。PyGlove 的概念是通过一系列补丁规则来捕捉机器学习研究的过程。这些规则可以在任何实验场景中重复使用,从而提高团队的效率。这项研究尝试解决许多尚未解决的机器学习问题,因此值得阅读。
8) ChatGPT 与人类专家的接近程度?比较语料库、评估和检测
ChatGPT 已经改变了世界。可以肯定地说,随着公众越来越倾向于使用 ChatGPT,趋势将从这里开始上升。然而,ChatGPT 当前的结果与人类专家相比如何?正是这个问题 Guo et al. (2023) 试图回答。该团队尝试收集专家和 ChatGPT 提示结果的数据,并进行了比较。结果显示 ChatGPT 和专家之间存在隐含差异。这项研究是我认为未来会不断被提问的问题,因为生成式 AI 模型会随着时间的推移不断发展,因此值得阅读。
结论
2023 年是机器学习研究的伟大一年,这从当前的趋势中可以看出,特别是生成式 AI,如 ChatGPT 和 Stable Diffusion。我感到有许多有前途的研究不应错过,因为它们显示出可能改变当前标准的有希望的结果。在这篇文章中,我向你展示了 9 篇值得阅读的顶级机器学习论文,涵盖了生成模型、时间序列模型到工作流效率等方面。希望对你有所帮助。
Cornellius Yudha Wijaya 是一名数据科学助理经理和数据撰稿人。在全职工作于印尼安联保险期间,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
更多相关主题
Julia 的顶级机器学习项目
原文:
www.kdnuggets.com/2016/08/top-machine-learning-projects-julia.html
如果你不知道,Julia 是“一个高水平、高性能的动态编程语言,用于技术计算,其语法对其他技术计算环境的用户来说很熟悉。”

我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织在 IT 领域
Julia 快速,并且得到了 Jupyter notebook 环境 的支持和集成。Julia 可以直接调用 C 而无需包装器,将顶级开源 C 和 Fortran 代码集成到其基础库中,并且可以轻松调用 Python。Julia 为并行和云计算而生,受到了分析和科学计算社区的特别关注。根据 KDnuggets 最近的 分析软件调查,Julia 在最常用编程语言的列表中排名第 8。虽然这并未完全击败竞争对手,但 JavaScript 连榜单都没有进入,而 最近的一项关于该语言的顶级机器学习项目却非常受欢迎。
我最初来自计算机科学的背景,之后转向机器学习专门化,因此我选择的工具一直是 Python。当我逼迫自己学习另一种语言时,Julia 成为了我的重点,于是我们来到了这里。
以下是 Julia 的机器学习项目合集。这些项目并不全是机器学习库;其中一个项目是实现机器学习算法的支持功能集合。不幸的是,这些项目的选择并不客观;我发现试图量化和排名不同的项目往往没有什么有趣的结果,并且会削弱这种列表的整体使用价值。因此,所选的项目是我自己决定用于学习 Julia 的冒险中的项目。
一如既往,项目按顺序编号以便于查阅和娱乐。我主观挑选的前五大机器学习项目如下(如有不满,请随意推特联系我):
1. MLBase.jl
这似乎是一个不错的起点。MLBase 自称是“机器学习的瑞士军刀”。MLBase 并不实现任何机器学习算法;它是一个支持工具的集合,例如用于预处理、基于评分的分类、性能评估指标、模型调优等。
MLBase 的文档很好,并附有多个工具的代码示例。
对于我们这些来自 Python 的人来说,这可能是一个潜在的救星。
来自其仓库:
ScikitLearn.jl 实现了流行的 scikit-learn 接口和算法在 Julia 中。它支持 Julia 生态系统中的模型以及 scikit-learn 库中的模型(通过 PyCall.jl)。
ScikitLearn.jl 迅速指出它不是 scikit-learn 的官方移植;然而,它实现了令人放心的接口,并结合了 Python 和 Julia 模型,这使得它成为一个有吸引力的库。
该项目有一个很好的快速入门指南以及多个精彩示例,以 Jupyter 笔记本形式提供。
现在,Julia 本身的机器学习算法。MachineLearning.jl 已经一年没有更新了;然而,考虑到它旨在成为一个通用的 Julia 机器学习库,包含多个算法和支持工具,对于那些在语言中探索机器学习的人来说,它是一个不错的中转站。
项目目标,来自其仓库:
最初,该包将针对在单台机器上内存中适合的数据集的机器学习实践者。长期而言,我希望它不仅能针对更大的数据集,还能对最先进的机器学习研究有价值。
该库目前包含以下算法:决策树分类器、随机森林分类器、基本神经网络和贝叶斯加性回归树。它还包括将数据集拆分为训练集和测试集的功能,以及执行交叉验证。
MachineLearning.jl 的未来可能不明确,但该项目提供了一些基本功能用于实验,并且为在 Julia 中学习机器学习提供了一个环境。
4. Mocha.jl

Mocha 确实满足了你对现代深度学习库的诸多期望。来自其仓库的信息:
Mocha 是一个为 Julia 设计的深度学习框架,灵感来源于 C++ 框架 Caffe。Mocha 中对一般随机梯度求解器和常见层的高效实现可以用于训练深度/浅层(卷积)神经网络,支持(可选的)通过(堆叠)自编码器进行无监督预训练。
Mocha 的文档包含了一系列教程和详尽的用户指南;Mocha 绝对不是一个文档不足的深度学习项目。
TextAnalysis.jl 是一个积极开发的 Julia 文本分析库。它提供了文档预处理、语料库创建、文档词矩阵、TF-IDF、潜在语义分析、潜在狄利克雷分配等功能。如果你对使用 Julia 进行文本分析感兴趣,它似乎是一个不错的起点。
如果你对学习 Julia 感兴趣,这是一个很好的起点。
如果你想找到更多针对 Julia 的特定算法机器学习项目,请点击这里。
相关内容:
-
JavaScript 的顶级机器学习库
-
你不能再忽视的 5 个机器学习项目
-
你不能再忽视的 5 个机器学习项目
更多相关内容
开发者的顶级机器学习软件工具
原文:
www.kdnuggets.com/2019/11/top-machine-learning-software-developers.html
评论
作者:Sandra Parker,QArea 软件开发公司。

今天,感兴趣于机器学习潜力的程序员谈论的是用人工智能构建应用程序以及用于基于 AI 的软件开发的工具。好的例子包括 PyTorch 和 TensorFlow 等解决方案。
然而,机器学习技术正在以另一种有趣的方式影响编程世界。我们谈论的是近期的软件开发解决方案,这些方案利用机器学习算法来简化和优化开发者的工作。在这篇文章中,我们将关注五种这样的工具。其中三种已经在市场上销售,而另外两种仍在测试阶段。如果你是一个希望利用机器学习来更快、更有效地进行软件开发的开发者,请查看这些解决方案。
Kite – 发展中的顶级机器学习工具之一
这个工具主要作为代码补全器。借助机器学习,它可以实时检测你输入的代码,并在你输入时完成它。它经常被列为开发者的最佳工具之一,并且与许多流行的代码编辑解决方案兼容良好。
Kite 使用了一个从 GitHub 获取的工作模型。GitHub 上的代码是公开的,用于创建一个作为 Kite 模型支柱的抽象。因此,该工具能够基于上下文和目的,而不仅仅是文本本身,自动建议和完成代码。
刚推出时,Kite 只能在 Mac 和 Windows 上使用。如今,它也可以在 Linux 上使用。这个工具的缺点是目前仅支持 Python。然而,它也正在开发中以支持 Go 语言。
两年前,Kite 被开源程序员指责处理用户数据不当,并且修改了一个流行的 Atom 插件,该插件用于自动补全代码。然而,Kite 的所有者已解决了这两个问题。最近,Kite 团队宣布,该工具现在可以在用户的 PC 本地执行所有功能,而不再依赖于之前的云端服务。
Codota
这个工具与 Kite 非常相似,因为它使用机器学习生成自动代码补全。它还使用从公开代码中派生的语法树形成的类型。然而,它也有一些不同之处。
Codota 专为 Kotlin 和 Java 语言构建。它是一个基于云的解决方案,可以生成智能自动预测。值得注意的是,Codota 的拥有者表示用户数据不会传输到他们的服务器。只有有限的加密信息从编辑的文档中传输,因为这些信息是预测代码所需的,与范围和上下文相关。
Codota 支持 Linux、Windows 和 Mac 设备。然而,编辑器模式仅适用于 Android Studio、Eclipse 和 IntelliJ,这在你查看该工具支持的语言时是可以理解的。此外,Codota 的创建者提到,其他编程语言的版本正在开发中,预计首个发布的语言是 JavaScript。
这个工具有一个免费版本,它仅从公开访问的代码中创建自动建议。然而,付费版本也可以使用私有代码。你可以在工具的官方网站上请求价格报价。
DeepCode
DeepCode 也是流行的软件开发机器学习工具之一。它的主要功能是检查代码并突出可能存在安全漏洞的部分。与前两个工具类似,DeepCode 从公共存储位置评估代码以识别相似性。不同的是,这个工具还利用模式来查找脆弱区域。
DeepCode 实施了一种在达到关键安全级别之前分析用户输入处理的方法。因此,当任何数据在没有安全验证或许可的情况下从一个点移动到另一个点时,该工具会标记为“受污染”,并提醒你。这个工具能够突出显示的问题包括跨网站脚本、SQL 注入威胁、远程代码执行以及路径遍历攻击。
你可以在像 Bitbucket 和 GitHub 这样的流行代码库中找到使用 DeepCode 完成的分析。这些报告是免费的,可以用于开源项目或少于三十名程序员的私人工作。你也可以使用 DeepCode 来分析你的内部代码托管,需支付费用。
PROSE
由微软创建的这个框架帮助通过示例生成代码。PROSE 代表“使用示例进行程序合成”,可以用来创建其他编程工具,而不是直接作为预测解决方案实施。开发人员可以使用 PROSE 的方式包括通过示例进行文本转换、通过预测进行文件操作和从文本文件中提取数据。
Pix2code
Pix2code 仍处于实验阶段,是一个创新的工具,可以将图形用户界面截图转换为计算机代码。通过使用深度学习技术,该软件可以分析三种不同格式的 GUI:iOS、Android 和 HTML/CSS。然而,由于该工具仍在测试阶段,你只能将其用于学习或作为额外软件开发的基础。
使用机器学习工具进行软件开发的好处
正如你所见,这些创新工具可以协助代码完成、安全措施,甚至代码生成。机器学习带来了巨大的可能性,以及快速高效的软件创建,因此值得深入研究这些工具。不过,任何单一工具都无法在没有经验丰富的软件开发团队的情况下运作。这些工具在节省开发时间方面不可或缺,但规划的初始过程和测试、QA 及部署的最终过程仍需要熟练的开发人员。
个人简介: 桑德拉·帕克 是 QArea 的业务开发人员,QArea 是一家软件开发与 QA 公司,帮助企业通过定制的软件开发和测试加速其业务。
相关:
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关主题
Quora 上排名前 10 的机器学习作家及其最佳建议
原文:
www.kdnuggets.com/2015/09/top-machine-learning-writers-quora.html
作者 Matthew Mayo。
此列表基于 Quora 机器学习作家排名。

1. Yoshua Bengio,机器学习研究员,蒙特利尔大学教授。68379 次浏览
选定的回答: Yoshua Bengio 更喜欢使用限制玻尔兹曼机还是(去噪)自编码器作为深度网络的构建模块?为什么?
科学研究不是关于“偏爱”某个算法。关键在于理解。我对理解 Boltzmann 机和各种自编码器感兴趣。无监督学习的世界广阔无垠。没有明确的赢家,但有很多有趣的问题。至于无监督预训练,去噪自编码器比 RBMs 更容易训练和使用,但结果差不多,所以如果需要选择,我会选择前者。
2. Yisong Yue,机器学习研究员。61209 次浏览
选定的回答: 学术计算机科学研究真的有价值吗?
也许你应该回顾一下深度学习的学术论文?很长时间以来,很多人认为这些论文并不那么有价值。而现在,深度学习和大规模机器学习正在迅速成为一个亿万美金的产业。确实是学术研究为深度学习在工业界的真正繁荣奠定了基础。
3. Gary Simon,统计学教授(退休),纽约大学斯特恩商学院。50098 次浏览
选定的回答: 如果一个事件发生的概率是 10%,为什么在 10 次尝试中不一定会发生?
假设这些尝试是独立的,并且事件的概率不变。
一个类似的问题是:如果一枚硬币有 50%的概率正面朝上,为什么在两次尝试中不一定会发生?
这很容易看穿!
4. Xavier Amatriain,Quora 工程副总裁。39980 次浏览
选定的回答: 我如何学习机器学习?
我主要想表达的是,机器学习既涉及广度也涉及深度。你需要了解最重要算法的基础知识(请参见我对《十大数据挖掘或机器学习算法》问题的回答)。另一方面,你也需要理解算法的低级复杂细节及其实现细节。我认为我描述的方法涵盖了这两个方面,并且我见过它的有效性。
5. William Chen,Quora 数据科学家。30659 次浏览
精选回答: 有什么好的资源可以练习 SQL 以备数据科学面试?
我会通过完成所有的练习来审查 SQLZoo。他们有一个极其便利的界面,你可以直接在他们的网站上编写 SQL 查询,从而在提供的表上运行任意的 SQL 查询。他们还会为你提供答案(在哪里可以找到 SQLZoo 练习的答案?)。
如果有一个特别的概念你应该非常熟悉,那就是复习你的 JOINS——因为这通常被问到,而且容易搞错。
6. Jeff Hammerbacher,好奇者。29996 次浏览
精选回答: 十大数据挖掘或机器学习算法是什么?
这个问题的一个潜在答案来自于 Analytics 1305 [2] 文档:
-
核密度估计和非参数贝叶斯分类器
-
K 均值
-
核主成分分析
-
线性回归
-
邻近(最近,最远,范围,k,分类)
-
非负矩阵分解
-
支持向量机
-
降维
-
快速奇异值分解
-
决策树
-
自助支持向量机
7. Boxun Zhang,Spotify 数据科学家;计算机科学博士。26049 次浏览
精选回答: 成为科技公司(谷歌、微软、脸书等)数据科学家,我需要了解机器学习算法到什么程度?
正如 John L. Miller 和 John Eysman 在他们的回答中指出的,数据科学家从零开始实现机器学习算法的情况非常少见。
然而,我想强调的是实际了解机器学习算法的工作原理,特别是这些算法的局限性。例如:
-
特征工程在随机森林中是否相关?
-
实现随机森林的最佳树算法是什么?为什么?
-
梯度下降的直观解释是什么?
8. Charles H Martin,计算咨询;我们预测事物。25340 次浏览
选定答案: 机器学习工作是否需要博士学位?
可能不是。我认为十年前这是真的。机器学习非常新,那时我们中的一些人试图在公司中开创其应用。如今,我遇到了很多对基础知识有扎实理解并能做出高质量工作的年轻人。
话虽如此,与高级计算机科学类似,如果你想做真正创新的算法工作——例如创造下一个 PageRank 算法——那么博士学位将使你接触到整个领域,你将有时间和自由去发明可能具有革命性的全新事物。
9. 马修·赖,帝国学院计算机硕士生。电气工程师。飞行员。20505 次查看
选定答案: 机器学习的“Hello, World!”程序是什么?
在正方形 (-1, -1)-(-1,1)-(1,-1)-(1,1) 中随机生成一堆点。
将这些点分类,看它们是否在以原点为中心的单位圆内。
它将捕捉到非常严重的错误(相反的梯度方向等),且不需要访问任何数据集。
10. 肖恩·欧文。20318 次查看
选定答案: 数据科学家是去大公司还是初创公司工作更好?
我担心数据质量在各处都是问题,而数据工程是大部分工作。我更喜欢自己做各种事情,但听起来你想更专注于建模。大公司可能会更合适。不过,我建议你先与当前公司谈谈,看看是否可以将你的职责调整到你想要的方向。
简介:马修·梅奥 是一名计算机科学研究生,目前正在进行将机器学习算法并行化的论文研究。他也是数据挖掘的学生、数据爱好者以及一名有志于成为机器学习科学家的未来之星。
相关:
-
顶级 Quora 数据科学作家及其最佳建议
-
顶级 /r/MachineLearning 帖子,8 月:深度学习模仿许多著名画家的风格
-
调查结果:数据科学家在工作中停留时间不长
更多相关话题
避免顶级预测分析陷阱
原文:
www.kdnuggets.com/2017/01/top-predictive-analytics-pitfalls-avoid.html
由 Robin Davies, Principa.

我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
预测分析可以产生惊人的结果。基于历史事件中的观察模式进行未来决策所获得的提升,可能远远超过依赖直觉或凭借轶事事件来进行决策的效果。虽然有许多示例展示了在各行各业中可能获得的提升,但我们最近在零售行业做的测试显示,应用稳定的预测模型使我们在产品接受度上提高了五倍,相较于随机样本。说实话,如果预测分析,特别是机器学习没有取得令人印象深刻的结果,就不会如此受到关注。
阅读我们在使用机器学习预测 2015 年橄榄球世界杯结果时学到的经验教训
但预测模型并不是万无一失的。它们有点像赛马:对变化非常敏感,容易让骑手感到困惑。
机器学习的商品化使得数据科学比以往任何时候都更容易被非数据科学家所接受。考虑到这一点,我和我的同事坐下来思考,我们制定了以下避免的顶级预测分析陷阱清单,以确保你的模型按预期运行:
-
对基础训练数据做出不正确的假设。
匆忙进行过多的假设往往会带来相应的尴尬。花时间理解数据和分布中的趋势、缺失值、异常值等。
-
处理低数据量。
低数据量是数据科学家的痛点——它们可能导致统计上薄弱、不稳定和不可靠的模型。
-
过拟合的问题。
换句话说,创建一个有很多分支的模型,从而似乎提供了更好的目标变量区分,但在现实世界中失败,因为它在模型中引入了太多噪音。
-
训练数据中的偏差。
例如,你只向千禧一代提供了某种产品。那么,猜猜看?千禧一代将在模型中表现得很强。
-
将测试数据包含在训练数据中。
曾经有一些巨大的失败,其中测试数据被包括在训练数据中——这给人一种模型表现会非常好的印象,但实际上导致了一个破损的模型。在预测分析的世界里,如果结果好得令人难以置信,值得花更多时间进行验证,甚至获得第二意见来检查你的工作。
-
未能对提供的数据进行创意处理。
通过创建一些聪明的特征或属性来更好地解释数据中的趋势,可以显著提升预测模型。数据科学家往往只会使用提供的数据,而不会花足够的时间考虑来自底层数据的更具创意的特征,这些特征可以以改进算法无法实现的方式强化模型。
-
期望机器理解业务。
机器还无法搞清楚业务问题是什么,以及如何最佳解决问题。这并不总是简单明了,可能需要一些细致的思考,包括与业务相关方的全面讨论。
-
使用错误的度量标准来衡量模型的表现。
例如,在 10,000 个案例中只有两个案例是欺诈的,9,998 个案例不是欺诈。如果在模型训练中使用的性能度量只是简单的准确率,那么模型将试图最大化准确率。因此,如果它预测所有 10,000 个案例都不是欺诈,那么模型的准确率将达到 99.98%,这看起来非常惊人,但在识别欺诈方面并没有任何实际用途。它仅仅正确地识别了 99.98%的非欺诈实例。因此,对于稀有事件建模(例如欺诈),需要应用其他方法。
-
在非线性交互上使用简单线性模型。
当构建二元分类器时,选择逻辑回归作为首选方法,而实际上特征之间的关系并不是线性的,这种情况很常见。在这种情况下,基于树的模型或支持向量机表现更好。不知道哪些方法适用于哪些问题会导致模型和后续预测的质量差。
-
忽略异常值。 异常值通常需要特别关注,或者应完全忽略,有些建模方法对异常值非常敏感,忘记去除或处理这些异常值会导致模型表现差。
-
进行正则化而没有标准化。
许多实践者没有意识到,在数据标准化之前对模型特征应用正则化的冗余。因为正则化会对尺度较小的特征施加更多惩罚。例如,如果有一个尺度在 3,000 到 10,000 之间的特征,另一个尺度在 0 到 1 之间,另一个在-9,999 到 9,999 之间。
-
未考虑实时评分环境。
实践者有时会被构建最完美模型的目标所分心,但在部署时,模型复杂到无法集成进操作系统。
-
由于操作原因,使用未来将无法获得的特征。
可能会识别出一个非常具有预测性的特征(如性别),但由于法规,该字段不能用于建模,或者该字段的捕获已被暂停,未来可以用于模型。
-
未考虑应用有效预测分析的现实世界影响及可能的后果。
四年前,美国零售商 Target 成为头条新闻,当时《纽约时报》记者查尔斯·杜希格(Charles Duhigg)揭示了Target 的分析模型预测了一名青少年的怀孕,而她的父亲还不知道。正如一些人所指出的,虽然你可以做到,并不意味着你应该这样做。
多年来,我们通过预测分析共同学到了一些宝贵的经验。为什么不利用这些经验呢?如果你想在预测分析领域获得进一步的指导,请联系我们! 我们很高兴与你面谈,分享知识,并了解你的预测分析项目和计划。
原文。经许可转载。
简介: 罗宾·戴维斯是Principa的决策分析主管。罗宾的团队在金融服务、营销和忠诚度领域,使用描述性、预测性和规范性分析技术取得了优异的成绩。
相关:
-
可靠的数据科学:避免最具害的预测陷阱
-
通过 AI 进行物联网的持续改进/持续学习
-
4 个原因你的机器学习模型可能出错(以及如何修复它)
-
Target 真的预测了青少年的怀孕吗?内幕故事
更多相关话题
顶级编程语言及其用途

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
“学习一门新编程语言的唯一方法就是用它编写程序。”
—Dennis Ritchie
世界以惊人的速度在发展,其中很大一部分进步归功于应用程序开发人员。如果你还没有注意到,应用开发近年来已经成为潮流。
每个人都在争取进入应用开发领域,因为它提供了高薪职业路径,如网页开发、数据科学、人工智能等。
但在你开始职业道路并创建你的第一个应用程序之前,你需要首先选择一门编程语言。天啊,实际上有超过 700 种 编程语言 可供选择。
看起来是个疯狂高的数字,对吧?
不用担心。我们整理了这份清单,以尽可能顺利地帮助你做出选择,涵盖一些流行的编程语言及其常见用途。
如果你计划在 2021 年学习一门编程语言,我们建议选择一种现代、广泛使用且拥有大量包或库的语言。
在这一部分,我们将介绍一些符合上述所有标准的广泛使用的编程语言,并分享它们的用途。
1. Python — 人工智能与机器学习

来源:Python 官方网站
-
级别: 初学者
-
热门框架: Django,Flask
-
平台: Web,桌面
-
受欢迎程度: PYPL 人气指数 2021 年 3 月榜单第#1,Tiobe 指数 2021 年 3 月榜单第#3,在 2020 年受到 66.7% StackExchange 开发者的喜爱,并且有 30%的人希望使用,是所有语言中最多的。
由 Guido van Rossum 在 1990 年代开发, 多用途高级 Python 近年来增长非常迅速,成为今天最受欢迎的编程语言之一。
Python 受欢迎的主要原因是 它的初学者友好性,这使得任何人,即使是没有编程背景的人,也能快速上手 Python 并开始创建简单的程序。
但这还不是全部。它还提供了一个异常 丰富的包和库 集合,这些包和库在缩短项目 ETA 方面发挥了关键作用,还有一个强大的志同道合的开发者社区,愿意提供帮助。
这种语言的用途—
尽管 Python 可以用来构建几乎所有东西,但它在处理像人工智能、机器学习、数据分析等技术时表现尤为出色。Python 也对网页开发、创建企业应用程序以及 应用程序的 GUI 非常有用。
Python 被应用于许多领域。以下是一些示例—
额外资源:
-
学习 Python — freecodecamp
-
Python 教程—Python 入门 — 编程与 Mosh
-
Python 教程 — Learnpython.org
2. JavaScript—丰富的互动网页开发

来源: 官方 JavaScript 网站
-
级别: 初学者
-
平台: Web、桌面、前端脚本
-
受欢迎程度: #3 在 2021 年 3 月 PYPL 受欢迎度指数中,#7 在 2021 年 3 月 Tiobe 指数中,2020 年被 58.3% 的 StackExchange 开发者喜爱,18.5%的人希望使用,是所有语言中最多的。
JavaScript 是与 HTML 和 CSS 一起构建互联网的关键编程语言之一。JavaScript 由 Netscape 于 1995 年创建, 该公司发布了著名的 Netscape Navigator 浏览器,旨在消除静态网页的粗糙感,并为其增添一点动态行为。
今天,JavaScript 已成为世界顶级的高级多范式编程语言,作为网络的前端编程语言,处理网页提供的所有互动,如弹窗、警报、事件等。
**这门语言的用途 — **
如果你希望你的应用能够在各种设备上运行,例如智能手机、云端、容器、微控制器以及数百种浏览器,JavaScript 是完美的选择。对于服务器端负载,有 Node.js,一个被成千上万公司使用的经过验证的 JavaScript 运行时。
额外资源:
-
学习 JavaScript — freecodecamp
-
初学者 JavaScript 教程:1 小时学会 JavaScript — Programming with Mosh
-
通过构建七个游戏学习 JavaScript — freecodecamp
3. Java — 企业应用开发

来源 : 官方 Java 网站
-
级别: 中级
-
流行框架: Spring, Hibernate, Strut
-
平台: Web, 移动, 桌面
-
受欢迎程度: #2 排名于 2021 年 3 月 PYPL 流行度指数,#2 排名于 2021 年 3 月 Tiobe 指数,2020 年被44.1%的 StackExchange 开发者喜爱。
Java已经成为构建企业级应用程序的事实上的编程语言超过 20 年。
由 Sun Microsystems 的 James Gosling 于 1995 年创建,面向对象编程语言 Java 自那时起一直作为一个安全、可靠且可扩展的工具服务于开发者。
Java 提供的一些功能使其比其他编程语言更受欢迎,例如垃圾回收能力、向后兼容性、通过 JVM 实现的跨平台性、可移植性和高性能。
Java 的受欢迎程度在《财富》500 强成员中表现得尤为明显,90%的公司使用 Java 来高效管理业务。
**这门语言的用途 — **
除了用于开发强大的业务应用程序外,Java 在 Android 中也被广泛使用,使其成为 Android 开发者的必备技能。Java 还允许开发者为各种行业创建应用程序,如银行、电子交易、电子商务,以及分布式计算应用程序。
额外资源:
-
学习 Java — Codecademy
-
学习 Java 编程 — Programiz
4. R — 数据分析

来源: 官方 R 网站
-
级别: 中级
-
流行工作室: R Studio
-
平台: 主要为桌面
-
受欢迎程度: #7 在 2021 年 3 月的 PYPL 受欢迎指数上。
如果你从事任何形式的数据分析或机器学习项目,你很可能听说过 R。R 编程语言由其创造者 Ross Ihaka 和 Robert Gentleman 于 1993 年首次向公众发布,作为 S 编程语言的实现,特别关注于 统计计算 和 图形建模。
多年来,R 成为处理大量数据分析、图形数据建模、空间和时间序列分析项目的最佳编程语言之一。
R 还通过其功能和扩展提供了出色的可扩展性,给开发人员提供了大量的专业技术和能力。该语言与其他编程语言(如 C、C++、Python、Java 和 .NET)的代码也能非常良好地协作。
该语言的用途——
除了上述提到的一些用途外,R 还可用于行为分析、数据科学以及涉及分类、聚类等的机器学习项目。
额外资源:
-
R 编程教程 — 学习统计计算的基础 — freecodecamp
-
R 编程— Coursera
-
学习 R — Codecademy
5. C/C++ — 操作系统和系统工具

由作者整理。
-
级别: C — 中级到高级,**C++ — **初级到中级
-
流行框架: MFC, .Net, Qt, KDE, GNOME
-
平台: 移动设备、桌面、嵌入式
不管你信不信,C/C++ 编程语言在 20 世纪末期曾经非常流行。为什么?
这是因为 C 和 C++ 都是非常低级的编程语言,提供了极快的性能,这也是它们曾经和现在仍被用于开发操作系统、文件系统和其他系统级应用程序的原因。
C 由 Dennis Ritchie 于 70 年代发布, C++ 作为 C 的扩展,增加了类和许多其他功能,如面向对象特性,由 Bjarne Stroustrup 于 80 年代中期发布。
即使经过近 50 年,这两种编程语言仍被用于创建非常稳固且最快的应用程序。
该语言的用途——
由于 C 和 C++ 都能完全访问底层硬件,它们被用于创建各种应用程序和平台,如系统应用程序、实时系统、物联网、嵌入式系统、游戏、云计算、容器等。
附加资源:
-
初学者 C 编程教程 — freecodecamp
-
C++ 初学者教程 — 全课程 — freecodecamp
-
学习 C++ — Codecademy
-
学习 C — Programiz
6. Golang — 服务器端编程

来源 — 官方 Golang 网站
-
水平: 从初级到中级
-
热门框架: Revel, Beego
-
平台: 跨平台,主要用于桌面
-
受欢迎程度: 2020 年被 62.3% 的 StackExchange 开发者喜爱,需求达到 17.9%,是所有语言中最多的。
Go 或 Golang,是由搜索巨头 Google 开发的编译型编程语言。Golang 于 2009 年创建,是 Google 设计师试图消除公司使用的语言中的所有缺陷,同时保留所有最佳功能的努力。
Golang 快速且具有简单的语法,使任何人都能轻松掌握这门编程语言。它还支持跨平台,使其易于使用且高效。
Go 宣称结合了 C/C++ 的高性能、Python 的简单易用,以及 Java 的高效并发处理。
这门语言的用途 —
Go 主要用于后端技术、云服务、分布式网络、物联网,但也用于创建控制台工具、图形用户界面应用程序和 Web 应用程序。
附加资源:
-
Golang 初学者教程 — freecodecamp
-
Go 教程 — Tutorialspoint
-
介绍 Go — Caleb Doxsey
7. C# — 使用 .NET 进行应用程序和 Web 开发

来源 — Wikipedia C#
-
水平: 中级
-
热门框架: .NET, Xamarin
-
平台: 跨平台,包括移动和企业软件应用
-
受欢迎程度: 在 2021 年 3 月 PYPL 热度指数中排名 #4,在 2021 年 3 月 Tiobe 指数中排名 #5,2020 年被 59.7% 的 StackExchange 开发者喜爱。
C# 是微软开发的编程语言,类似于面向对象的 C,是其 .NET 计划的一部分。这种通用的多范式编程语言 于 2000 年由 Anders Hejlsberg 发布,其语法类似于 C、C++ 和 Java。
对于熟悉这些语言的开发者来说,这是一个巨大的优点。它还提供了相对更快的编译和执行速度以及无缝的可扩展性。
C# 的设计考虑到了 .NET 生态系统,这使得开发者可以访问 Microsoft 提供的各种库和框架。与 Windows 的集成使得 C# 极易使用,甚至非常适合开发基于 Windows 的应用程序。
**这种语言的用途 — **
开发者可以使用 C# 进行一系列项目,包括游戏开发、服务器端编程、网页开发、创建网页表单、移动应用程序等。C# 还用于开发 Windows 平台上的应用程序,特别是 Windows 8 和 10。
附加资源:
8. PHP — 网页开发

来源 — 官方 PHP 网站
-
水平: 初学者
-
流行框架: CakePHP、Larawell、Symfony、Phalcon
-
平台: 跨平台(桌面、移动、网络)后端网页脚本。
-
流行度: #6 在 2021 年 3 月的 PYPL 流行度指数中,#8 在 2021 年 3 月的 Tiobe 指数中。
就像 Guido van Rossum 的 Python 一样,PHP 也由 Rasmus Lerdorf 作为一个副项目最终实现,最初的开发可追溯到 1994 年。
Rasmus 的 PHP 版本最初旨在帮助他维护个人主页,但随着时间的推移,项目演变成支持网页表单和数据库。
目前,PHP 已成为一种通用的脚本语言,被全球广泛使用,主要用于服务器端网页开发。它快速、简单、平台独立,并拥有一个庞大的开源软件社区。
**这种语言的用途 — **
现在许多公司使用 PHP 来创建工具,如 CMS(内容管理系统)、电子商务平台和网页应用程序。PHP 还使得即时创建网页变得极其简单。
9. SQL — 数据管理
SQL,全称结构化查询语言,可能是这个列表中最关键的编程语言之一。
由 Donald D. Chamberlin 和 Raymond F. Boyce 于 1974 年设计,这种专用编程语言在使开发者能够创建和管理表格及数据库以存储关系数据方面发挥了关键作用,涵盖了成千上万的数据字段。
如果没有 SQL,组织将不得不依赖更旧且可能更慢的数据存储和访问方法。有了 SQL,这些任务中的大部分可以在几秒钟内完成。
多年来,SQL 帮助催生了大量的 RDBMS(关系数据库管理系统),这些系统提供了远超表格和数据库创建的功能。
这门语言的用途 —
几乎所有需要处理存储在表格或数据库中的大量数据的项目或行业都通过 RDBMS 使用 SQL。
附加资源:
-
学习 SQL — Codecademy
-
NoSQL 数据库解释 — IBM Cloud
-
编码资源:SQL — Berkeley Boot Camps
10. Swift — 用于 iOS 上的移动应用开发

来源 — 官方 Swift 网站
-
级别: 初学者
-
流行框架: Alamofire, RxSwift, Snapkit
-
平台: 移动设备(特别是 Apple iOS 应用)
-
受欢迎程度: #9 在 2021 年 3 月的 PYPL 流行指数中,2020 年 59.5% 的 StackExchange 开发者都喜爱它。
Apple 对其硬件和软件的全面控制使其能够在其所有设备中提供流畅且一致的体验。这就是 Swift 的作用所在。
Swift 是Apple 自己的编程语言,于 2014 年发布,用以替代其 Objective-C 编程语言。它是一种多范式的通用编程语言,极其高效,并旨在提高开发者的生产力。
Swift 是一种现代编程语言(该列表中最新的),快速、强大,并与 Objective-C 完全兼容。多年来,Swift 经过了许多更新,使其在 Apple 的 iOS、macOS、watchOS 和 tvOS 平台上获得了显著的受欢迎程度。
这门语言的用途 —
配合 Apple 的 Cocoa 和 Cocoa Touch 框架,Swift 可以用于创建几乎所有 Apple 设备上的应用,如 iPhone、iPad、Mac、Watch 和其他设备。
附加资源 —
- Swift 编程入门教程(完整版) — CodeWithChris
结论
现在让我们快速总结一下这篇文章,介绍这些编程语言的重要性及其职业发展机会。每种编程语言都有其自身的优点,你可以从所有选择中进入你感兴趣的领域。
精通 Python 可以帮助你获得行业中薪资最高的前三个职位之一。通过 Python,你可以申请软件工程师、DevOps 工程师、数据科学家,甚至可以在最著名的公司获得丰厚的薪资。
你可以选择定量分析师、数据可视化专家、商业智能专家和数据分析师的职位来使用 R 语言。
关于 JavaScript,JavaScript 开发者的需求很高,虽然薪资水平适中。
但在构建系统工具和操作系统时,没有任何其他语言能比得上 C/C++ 的效率,因为它在 TIOBE 的软件质量指数中继续保持第一的位置。SQL 仍然是处理大型数据库的最佳编程语言之一,而 C# 在 Windows 上表现完美。Swift 在那些希望为 Apple 硬件开发应用的开发者中也越来越受欢迎。至于 PHP 和 Go,它们在行业中继续保持着令人尊敬的位置。
因此,在这 10 种编程语言中,哪一种是你的首选以及如何选择完全取决于你自己。所以请明智地选择!
克莱尔·D·科斯塔 是 Digitalogy 的内容创作者和策略师,她能将你的内容创意转化为清晰、有力、简洁的文字,与读者建立强有力的联系。
更多相关话题
顶级 Python 数据科学面试问题
原文:
www.kdnuggets.com/2021/07/top-python-data-science-interview-questions.html
评论
图片来源:JESHOOTS.COM 在 Unsplash
如果你想在数据科学领域有一份职业,掌握 Python 是必须的。Python 是数据科学中最受欢迎的编程语言,尤其是在机器学习和人工智能方面。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
为了帮助你在数据科学职业生涯中,我准备了数据科学面试中测试的主要 Python 概念。稍后,我将讨论涵盖这些概念的两种主要面试问题类型,这些都是作为数据科学家所需了解的概念。我还会展示几个示例问题,并提供解决方案,帮助你朝正确方向前进。
Python 面试问题的技术概念
本指南并非针对特定公司。因此,如果你有一些数据科学面试安排,我强烈建议你将此指南作为面试中可能出现内容的起点。此外,你还应该尝试寻找一些公司特定的问题,并尝试解决它们。了解一般概念并在实际问题上加以练习是成功的组合。
我不会打扰你以理论性问题。这些问题可能会在面试中出现,但它们也涵盖了编码问题中涉及的技术概念。毕竟,如果你知道如何使用我将要讲述的概念,你可能也知道如何解释它们。
数据科学工作面试中测试的 Python 技术概念包括:
-
数据类型
-
内置数据结构
-
用户定义的数据结构
-
内置函数
-
循环和条件语句
-
外部库(Pandas)
1. 数据类型
数据类型是你应该熟悉的概念。这意味着你应该知道 Python 中最常用的数据类型,它们之间的区别,以及何时和如何使用它们。这些数据类型包括整数(int)、浮点数(float)、复数(complex)、字符串(str)、布尔值(bool)、空值(None)。
2. 内置数据结构
这些是列表、字典、元组和集合。了解这四种内置数据结构将帮助你以便于访问和修改的方式组织和存储数据。
3. 用户定义的数据结构
除了使用内置数据结构,你还应该能够定义和使用一些用户定义的数据结构。这些包括数组、栈、队列、树、链表、图、HashMap。
4. 内置函数
Python 有超过 60 个内置函数。你不需要知道所有这些函数,当然,知道尽可能多的函数总是更好。你不能避免的内置函数包括 abs()、isinstance()、len()、list()、min()、max()、pow()、range()、round()、split()、sorted()、type()。
5. 循环和条件语句
循环用于重复任务,当它们重复执行一段代码时,直到条件语句(真/假测试)告诉它们停止为止。
6. 外部库(Pandas)
虽然使用了多种外部库,但 Pandas 可能是最受欢迎的。它专为金融、社会科学、统计和工程中的实际数据分析而设计。
Python 面试问题类型
这六个技术概念主要通过两种类型的面试问题进行测试。这些问题是:
-
数据处理和分析
-
算法
让我们更详细地看看每个问题。
1. 数据处理和分析
这些问题旨在通过解决 ETL(提取、转换和加载数据)问题并进行一些数据分析来测试上述技术概念。
这是一个来自 Facebook 的示例:
问题: Facebook 在用户尝试进行 2FA(双因素认证)登录平台时会发送短信。为了成功进行 2FA,他们必须确认收到短信。确认短信仅在发送日期有效。不幸的是,数据库存在 ETL 问题,导致好友请求和无效确认记录被插入到日志中,这些日志存储在‘fb_sms_sends’表中。这些消息类型不应存在于表中。幸运的是,‘fb_confirmers’表包含有效的确认记录,你可以使用该表来识别用户确认的短信。
计算 2020 年 8 月 4 日确认的短信文本的百分比。
回答:
import pandas as pd
import numpy as np
df = fb_sms_sends[["ds","type","phone_number"]]
df1 = df[df["type"].isin(['confirmation','friend_request']) == False]
df1_grouped = df1.groupby('ds')['phone_number'].count().reset_index(name='count')
df1_grouped_0804 = df1_grouped[df1_grouped['ds']=='08-04-2020']
df2 = fb_confirmers[["date","phone_number"]]
df3 = pd.merge(df1,df2, how ='left',left_on =["phone_number","ds"], right_on = ["phone_number","date"])
df3_grouped = df3.groupby('date')['phone_number'].count().reset_index(name='confirmed_count')
df3_grouped_0804 = df3_grouped[df3_grouped['date']=='08-04-2020']
result = (float(df3_grouped_0804['confirmed_count'])/df1_grouped_0804['count'])*100
测试你数据分析技能的问题之一是这个来自 Dropbox 的问题:
问题: 编写一个查询,计算市场部和工程部中最高工资之间的差异。只输出工资差异。
回答:
import pandas as pd
import numpy as np
df = pd.merge(db_employee, db_dept, how = 'left',left_on = ['department_id'], right_on=['id'])
df1=df[df["department"]=='engineering']
df_eng = df1.groupby('department')['salary'].max().reset_index(name='eng_salary')
df2=df[df["department"]=='marketing']
df_mkt = df2.groupby('department')['salary'].max().reset_index(name='mkt_salary')
result = pd.DataFrame(df_mkt['mkt_salary'] - df_eng['eng_salary'])
result.columns = ['salary_difference']
result
2. 算法
关于 Python 算法面试题,它们测试您使用算法解决问题的能力。由于算法不限于某一种编程语言,这些问题测试您的逻辑思维和编码能力,尤其是 Python。
例如,您可以遇到这个问题:
问题: 给定一个包含 2-9 的数字的字符串,返回该数字可能代表的所有字母组合。以任何顺序返回答案。
下面是数字到字母的映射(就像在电话按钮上)。注意,1 不映射到任何字母。
答案:
class Solution:
def letterCombinations(self, digits: str) -> List[str]:
# If the input is empty, immediately return an empty answer array
if len(digits) == 0:
return []
# Map all the digits to their corresponding letters
letters = {"2": "abc", "3": "def", "4": "ghi", "5": "jkl",
"6": "mno", "7": "pqrs", "8": "tuv", "9": "wxyz"}
def backtrack(index, path):
# If the path is the same length as digits, we have a complete combination
if len(path) == len(digits):
combinations.append("".join(path))
return # Backtrack
# Get the letters that the current digit maps to, and loop through them
possible_letters = letters[digits[index]]
for letter in possible_letters:
# Add the letter to our current path
path.append(letter)
# Move on to the next digit
backtrack(index + 1, path)
# Backtrack by removing the letter before moving onto the next
path.pop()
# Initiate backtracking with an empty path and starting index of 0
combinations = []
backtrack(0, [])
return combinations
或者它可能会变得更加困难,如以下问题所示:
问题: “编写一个程序,通过填充空单元格来解决数独谜题。数独解必须满足以下所有规则:
-
每个数字 1-9 必须在每一行中各出现一次。
-
每个数字 1-9 必须在每一列中各出现一次。
-
每个数字 1-9 必须在网格的 9 个 3x3 子框中各出现一次。
‘.’ 字符表示空单元格。
答案:
from collections import defaultdict
class Solution:
def solveSudoku(self, board):
"""
:type board: List[List[str]]
:rtype: void Do not return anything, modify board in-place instead.
"""
def could_place(d, row, col):
"""
Check if one could place a number d in (row, col) cell
"""
return not (d in rows[row] or d in columns[col] or \
d in boxes[box_index(row, col)])
def place_number(d, row, col):
"""
Place a number d in (row, col) cell
"""
rows[row][d] += 1
columns[col][d] += 1
boxes[box_index(row, col)][d] += 1
board[row][col] = str(d)
def remove_number(d, row, col):
"""
Remove a number which didn't lead
to a solution
"""
del rows[row][d]
del columns[col][d]
del boxes[box_index(row, col)][d]
board[row][col] = '.'
def place_next_numbers(row, col):
"""
Call backtrack function in recursion
to continue to place numbers
till the moment we have a solution
"""
# if we're in the last cell
# that means we have the solution
if col == N - 1 and row == N - 1:
nonlocal sudoku_solved
sudoku_solved = True
#if not yet
else:
# if we're in the end of the row
# go to the next row
if col == N - 1:
backtrack(row + 1, 0)
# go to the next column
else:
backtrack(row, col + 1)
def backtrack(row = 0, col = 0):
"""
Backtracking
"""
# if the cell is empty
if board[row][col] == '.':
# iterate over all numbers from 1 to 9
for d in range(1, 10):
if could_place(d, row, col):
place_number(d, row, col)
place_next_numbers(row, col)
# if sudoku is solved, there is no need to backtrack
# since the single unique solution is promised
if not sudoku_solved:
remove_number(d, row, col)
else:
place_next_numbers(row, col)
# box size
n = 3
# row size
N = n * n
# lambda function to compute box index
box_index = lambda row, col: (row // n ) * n + col // n
# init rows, columns and boxes
rows = [defaultdict(int) for i in range(N)]
columns = [defaultdict(int) for i in range(N)]
boxes = [defaultdict(int) for i in range(N)]
for i in range(N):
for j in range(N):
if board[i][j] != '.':
d = int(board[i][j])
place_number(d, i, j)
sudoku_solved = False
backtrack()
这将是一个相当复杂的算法,如果您知道如何解决它,那就太好了!
结论
对于数据科学面试,我提到的六个技术概念是必须掌握的。当然,建议您更深入地学习 Python,扩展您的知识。不仅是理论上的,还要通过解决尽可能多的数据处理和分析以及算法问题来进行实践。
对于第一个问题,您可以在StrataScratch上找到大量的示例。您也许可以找到来自您申请工作的公司的问题。而且,当您决定在面试前练习编写 Python 算法时,LeetCode是一个不错的选择。
阅读我关于数据科学的其他文章:SQL 面试问题及答案 和 最常见的数据科学面试问题!
简历:Nate Rosidi 是一名数据科学家兼产品经理。
原文。经许可转载。
相关内容:
-
如何应对 A/B 测试数据科学面试
-
如何在数百名数据科学候选人中脱颖而出?
-
为数据科学面试准备行为问题
更多相关内容
-
[KDnuggets 新闻,5 月 4 日:9 门免费哈佛课程学习数据...] (https://www.kdnuggets.com/2022/n18.html)
前 13 名 Python 深度学习库
原文:
www.kdnuggets.com/2018/11/top-python-deep-learning-libraries.html
评论
Python 在机器学习、人工智能、深度学习和数据科学任务中继续引领潮流。根据 builtwith.com 的数据,45%的科技公司更喜欢使用 Python 来实现人工智能和机器学习。
因此,我们决定开始一系列调查不同类别的Python 库:
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
前 13 名 Python 深度学习库 ✅ - 本文
X 大 Python 强化学习和进化计算库 – 敬请期待!
X 大 Python 数据科学库 – 敬请期待!
当然,这些列表完全是主观的,因为许多库可以轻松地归入多个类别。例如,TensorFlow 包含在此列表中,但 Keras 被省略,出现在机器学习库集合中。这是因为 Keras 更像是一个‘最终用户’库,如 SKLearn,而 TensorFlow 更受研究人员和机器学习工程师类型的欢迎。
一如既往,请随时在下方评论区表达您的挫折/异议/烦恼!
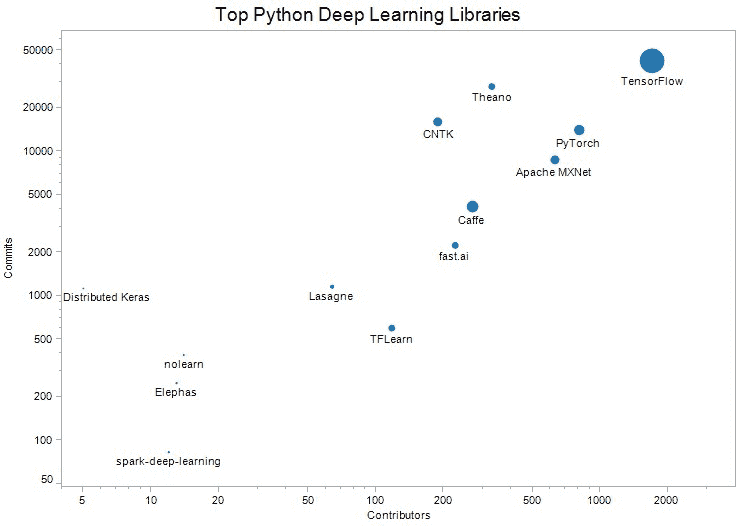
图 1:按提交和贡献者排名的前 13 名 Python 深度学习库。 圆圈大小与星级数量成正比。
现在,让我们来看一下名单(截至 2018 年 10 月 23 日的 GitHub 数据):
1. TensorFlow(贡献者 – 1700,提交 – 42256,星级 – 112591)
TensorFlow 是一个用于数值计算的开源软件库,采用数据流图来进行计算。图中的节点代表数学运算,而图中的边代表在节点之间流动的多维数据数组(张量)。这种灵活的架构使你可以在桌面、服务器或移动设备上的一个或多个 CPU 或 GPU 上部署计算,而无需重写代码。
2. PyTorch(贡献者 – 806,提交 – 14022,星标 – 20243)
PyTorch 是一个 Python 包,提供两个高级特性:
-
类似于 NumPy 的张量计算,具有强大的 GPU 加速
-
基于带有自动微分系统的深度神经网络
你可以在需要时重用你喜欢的 Python 包,如 NumPy、SciPy 和 Cython,以扩展 PyTorch。
3. Apache MXNet(贡献者 – 628,提交 – 8723,星标 – 15447)
Apache MXNet(孵化中)是一个旨在兼顾 效率 和 灵活性 的深度学习框架。它允许你 混合 符号编程和命令式编程 以 最大化 效率和生产力。其核心包含一个动态依赖调度器,可以在运行时自动对符号操作和命令式操作进行并行处理。
4. Theano(贡献者 – 329,提交 – 28033,星标 – 8536)
Theano 是一个 Python 库,允许你高效地定义、优化和评估涉及多维数组的数学表达式。它可以使用 GPU 并执行高效的符号微分。
5. Caffe(贡献者 – 270,提交 – 4152,星标 – 25927)
Caffe 是一个深度学习框架,注重表达、速度和模块化。由伯克利人工智能研究所 (BAIR) / 伯克利视觉与学习中心(BVLC)及社区贡献者开发。
6. fast.ai(贡献者 – 226,提交 – 2237,星标 – 8872)
fastai 库通过现代最佳实践简化了快速而准确的神经网络训练。查看 fastai 网站 以开始使用。该库基于 fast.ai 进行的深度学习最佳实践研究,并包括对 vision、text、tabular 和 collab(协同过滤)模型的“开箱即用”支持。
7. CNTK(贡献者 – 189,提交 – 15979,星标 – 15281)
“微软认知工具包 (cntk.ai) 是一个统一的深度学习工具包,它通过有向图描述神经网络。在这个有向图中,叶节点表示输入值或网络参数,而其他节点表示对其输入的矩阵操作。CNTK 允许用户轻松实现和组合流行的模型类型,如前馈 DNN、卷积网络(CNN)和递归网络(RNN/LSTM)。”
8. TFLearn(贡献者 – 118,提交次数 – 599,星标 – 8632)
“TFlearn 是一个建立在 Tensorflow 之上的模块化和透明的深度学习库。它旨在提供一个更高级的 TensorFlow API,以促进和加速实验,同时保持与 TensorFlow 的完全透明和兼容。”
9. Lasagne(贡献者 – 64,提交次数 – 1157,星标 – 3534)
“Lasagne 是一个轻量级库,用于在 Theano 中构建和训练神经网络。它支持前馈网络,如卷积神经网络(CNN),递归网络包括长短期记忆(LSTM),以及它们的任何组合。”
10. nolearn(贡献者 – 14,提交次数 – 389,星标 – 909)
“nolearn 包含了多个围绕现有神经网络库的包装器和抽象,尤其是 Lasagne,以及一些机器学习实用模块。所有代码均与 scikit-learn 兼容。”
11. Elephas(贡献者 – 13,提交次数 – 249,星标 – 1046)
“Elephas 是一个扩展的 Keras,允许你在大规模上运行分布式深度学习模型。Elephas 目前支持多种应用,包括:”
12. spark-deep-learning(贡献者 – 12,提交次数 – 83,星标 – 1131)
“Deep Learning Pipelines 提供了用于 Python 的可扩展深度学习的高级 API,结合了 Apache Spark。这一库源自 Databricks,并利用 Spark 的两个最强大的方面:”
-
“秉承 Spark 和 Spark MLlib 的精神,它提供了易于使用的 API,使深度学习只需少量代码。”
-
“它利用 Spark 强大的分布式引擎来扩展大规模数据集上的深度学习。”
13. Distributed Keras(贡献者 – 5,提交次数 – 1125,星标 – 523)
“Distributed Keras 是一个构建在 Apache Spark 和 Keras 之上的分布式深度学习框架,专注于“最先进”的分布式优化算法。我们设计了这个框架,使得新分布式优化器可以轻松实现,从而使研究人员能够专注于研究。”
请关注本系列的下一部分——重点讨论强化学习和进化计算库——将在接下来的几周内发布!
相关:
更多相关主题
2018 年数据科学、深度学习、机器学习领域的顶级 Python 库
评论
我们最近发布了一系列文章,探讨了顶级 Python 库,包括数据科学、深度学习和机器学习。随着一年即将结束,我们决定给你一个特别的圣诞礼物,将这些整理成 KDnuggets 官方的 2018 年顶级 Python 库。
一如既往,我们想听听你的意见!如果你认为我们遗漏了任何内容,或对我们的选择有不同看法,请在下面的评论区告诉我们。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
图 1:按 GitHub 星标和贡献者排名的顶级 Python 库。形状大小与提交次数成正比。
所以这就是我们 2018 年顶级的 15 个 Python 库(所有数据截至 2018 年 12 月 16 日):
1 – TensorFlow** (贡献者 – 1757, 提交 – 25756, 星标 – 116765)**
“TensorFlow 是一个开源的软件库,用于通过数据流图进行数值计算。图节点代表数学操作,而图边代表在节点之间流动的多维数据数组(张量)。这种灵活的架构使你能够将计算部署到一个或多个 CPU 或 GPU 上,无论是桌面、服务器还是移动设备上,无需重写代码。”
2 – pandas** (贡献者 – 1360, 提交 – 18441, 星标 – 17388)**
“pandas 是一个 Python 包,提供快速、灵活且富有表现力的数据结构,旨在使处理“关系型”或“标记”数据变得既简单又直观。它旨在成为在 Python 中进行实际的真实世界数据分析的基础高层构建块。”
3 – scikit-learn** (贡献者 – 1218, 提交 – 23509, 星标 – 32326)**
“scikit-learn 是一个建立在 NumPy、SciPy 和 matplotlib 上的 Python 机器学习模块。它提供了简单高效的数据挖掘和数据分析工具。SKLearn 对所有人开放,并可以在各种环境中重用。
4 – PyTorch** (贡献者 – 861,提交 – 15362,星标 – 22763)**
“PyTorch 是一个 Python 包,提供两个高级特性:
-
强大的 GPU 加速的张量计算(如 NumPy)
-
基于磁带自动梯度系统构建的深度神经网络
当需要时,你可以重用你喜欢的 Python 包,如 NumPy、SciPy 和 Cython 来扩展 PyTorch。
5 – Matplotlib** (贡献者 – 778,提交 – 28094,星标 – 8362)**
“Matplotlib 是一个 Python 2D 绘图库,可以生成各种硬拷贝格式和跨平台的交互环境中的出版质量图形。Matplotlib 可用于 Python 脚本、Python 和 IPython shell(类似 MATLAB 或 Mathematica)、Web 应用服务器以及各种图形用户界面工具包。”
6 – Keras** (贡献者 – 856,提交 – 4936,星标 – 36450)**
“Keras 是一个高层次的神经网络 API,用 Python 编写,能够在 TensorFlow、 CNTK 或 Theano 之上运行。它的开发重点是实现快速实验。* 能够以最少的延迟从想法到结果对于进行良好的研究至关重要。*”
7 – NumPy** (贡献者 – 714,提交 – 19399,星标 – 9010)**
“NumPy 是进行科学计算的基本包。它提供了强大的 N 维数组对象、复杂的(广播)函数、集成 C/C++ 和 Fortran 代码的工具以及有用的线性代数、傅里叶变换和随机数功能。”
8 – SciPy** (贡献者 – 676,提交 – 20180,星标 – 5188)**
“SciPy(发音为‘Sigh Pie’)是用于数学、科学和工程的开源软件。它包括统计、优化、积分、线性代数、傅里叶变换、信号和图像处理、常微分方程求解器等模块。”
9 – Apache MXNet** (贡献者 – 653,提交 – 9060,星标 – 15812)**
“Apache MXNet(孵化中)是一个旨在实现高效和灵活的深度学习框架。它允许你混合符号化和命令式编程 以最大化效率和生产力。MXNet 的核心包含一个动态依赖调度器,可以自动并行化符号化和命令式操作。”
10 – Theano** (贡献者 – 333, 提交次数 – 28060, 星标 – 8614)**
“Theano 是一个 Python 库,允许你高效地定义、优化和评估涉及多维数组的数学表达式。它可以使用 GPU 并执行高效的符号微分。”
11 – Bokeh** (贡献者 - 334, 提交次数 - 17395, 星标 - 8649)**
“Bokeh 是一个交互式可视化库,旨在为 Python 提供美观且有意义的数据展示。通过 Bokeh,你可以快速轻松地创建交互式图表、仪表盘和数据应用。”
12 – XGBoost** (贡献者 – 335, 提交次数 – 3557, 星标 – 14389)**
“XGBoost 是一个优化的分布式梯度提升库,旨在具有高效率、灵活性和便携性。它在 梯度提升 框架下实现了机器学习算法。XGBoost 提供了并行树提升(也称为 GBDT、GBM),以快速且准确的方式解决许多数据科学问题。相同的代码可以在主要的分布式环境(Hadoop、SGE、MPI)上运行,并解决超过数十亿个样本的问题。”
13 – Gensim** (贡献者 - 301, 提交次数 - 3687, 星标 - 8295)**
“Gensim 是一个用于 主题建模、文档索引 和 相似性检索 的大规模语料库的 Python 库。目标用户是 自然语言处理 (NLP)和 信息检索 (IR)社区。”
14 – Scrapy** (贡献者 – 297, 提交次数 – 6808, 星标 – 30507)**
“Scrapy 是一个快速的高级网页爬虫和网页抓取框架,用于爬取网站并从其页面提取结构化数据。它可用于从数据挖掘到监控和自动化测试的广泛用途。”
15 - Caffe** (贡献者 – 270, 提交次数 – 4152, 星标 – 26531)**
“Caffe 是一个深度学习框架,旨在表达性、速度和模块化。由 Berkeley AI Research (BAIR)/伯克利视觉与学习中心(BVLC)及社区贡献者开发。”
资源:
相关:
了解更多相关内容
顶级 38 个 Python 数据科学、数据可视化和机器学习库
原文:
www.kdnuggets.com/2020/11/top-python-libraries-data-science-data-visualization-machine-learning.html
自上次我们进行 Python 库汇总以来已经有一段时间了,因此我们借此机会在十一月开始时提供了这样一个新的列表。
我们如何构建这份包含 38 个 Python 数据科学库的列表
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
上次我们在 KDnuggets 做这个时,编辑和作者 Dan Clark 将广泛的 Python 数据科学相关库分成了几个较小的集合,包括数据科学库、机器学习库和深度学习库。虽然将库分成类别本质上是任意的,但在之前的发布时这是合理的。
不过这次,我们将收集到的开源 Python 数据科学库分成了两部分。这篇文章(本篇)涵盖了“数据科学、数据可视化和机器学习”,可以看作是涵盖常见任务的“传统”数据科学工具。第二篇文章,将于下周发布,将覆盖用于构建神经网络的库,以及用于执行自然语言处理和计算机视觉任务的库。
再次强调,这种分离和分类是任意的,有些情况比其他情况更是如此,但我们已尽力将工具按预期用途进行分组,希望这对读者最有帮助。
我们将 Python 数据科学库组织为 6 个类别:
本文所包含的类别,我们认为涵盖了常见的数据科学库——那些可能被数据科学领域的从业者用于通用的、非神经网络、非研究工作的库——包括:
-
数据 - 用于数据管理、操作和其他处理的库
-
数学 - 尽管许多库执行数学任务,但这一小集合专门用于此
-
机器学习 - 不言而喻;不包括主要用于构建神经网络或自动化机器学习过程的库
-
自动化机器学习 - 主要用于自动化机器学习相关过程的库
-
数据可视化 - 主要用于数据可视化功能的库,而非建模、预处理等。
-
解释与探索 - 主要用于探索和解释模型或数据的库
我们的列表由团队一致决定的、代表常用和广泛使用的 Python 数据科学库组成。此外,库必须有一个 Github 仓库才能被纳入。类别没有特定顺序,每个库也没有特定顺序。我们曾考虑按星标或其他指标构建排序,但决定不这样做,以免对库的价值或重要性进行显著的偏颇。它们在此的排列因此完全是随机的。库的描述直接来自 Github 仓库,以某种形式或另一种形式呈现。
感谢 Ahmed Anis 对数据收集的贡献,以及 KDnuggets 其他员工的意见、见解和建议。
请注意,下面的可视化由 Gregory Piatetsky 展示了每个库的类型,通过星标和贡献者进行绘制,其符号大小反映了库在 Github 上的相对提交次数。
图 1:顶级 Python 数据科学、数据可视化和机器学习库
根据星标数量和贡献者数量进行绘制;相对大小按贡献者数量确定
那么,不再废话,以下是 KDnuggets 员工确定的 38 个顶级 Python 数据科学、数据可视化和机器学习库。
最佳 Python 库:数据
1. Apache Spark
星标:27600,提交次数:28197,贡献者:1638
Apache Spark - 一个统一的大规模数据处理分析引擎
2. Pandas
星标:26800,提交次数:24300,贡献者:2126
Pandas 是一个 Python 包,提供快速、灵活和表达力强的数据结构,旨在使处理“关系型”或“标签化”数据变得既简单又直观。它的目标是成为在 Python 中进行实际、现实世界数据分析的基础高层构建块。
3. Dask
星标:7300,提交次数:6149,贡献者:393
任务调度的并行计算
最佳 Python 库:数学
4. Scipy
星标:7500,提交次数:24247,贡献者:914
SciPy(发音为“塞派”)是用于数学、科学和工程的开源软件。它包括统计、优化、积分、线性代数、傅里叶变换、信号和图像处理、常微分方程求解器等模块。
5. Numpy
Stars: 1500, Commits: 24266, Contributors: 1010
Python 科学计算的基础包。
适用于:机器学习的最佳 Python 库
6. Scikit-Learn
Stars: 42500, Commits: 26162, Contributors: 1881
Scikit-learn 是一个基于 SciPy 的 Python 机器学习模块,采用 3-Clause BSD 许可协议分发。
7. XGBoost
Stars: 19900, Commits: 5015, Contributors: 461
可扩展、可移植和分布式的梯度提升 (GBDT, GBRT 或 GBM) 库,支持 Python、R、Java、Scala、C++ 等。可在单机、Hadoop、Spark、Flink 和 DataFlow 上运行
8. LightGBM
Stars: 11600, Commits: 2066, Contributors: 172
基于决策树算法的快速、分布式、高性能梯度提升 (GBT, GBDT, GBRT, GBM 或 MART) 框架,用于排序、分类以及许多其他机器学习任务。
9. Catboost
Stars: 5400, Commits: 12936, Contributors: 188
一个快速、可扩展、高性能的决策树梯度提升库,用于排名、分类、回归和其他机器学习任务,支持 Python、R、Java、C++。支持 CPU 和 GPU 计算。
10. Dlib
Stars: 9500, Commits: 7868, Contributors: 146
Dlib 是一个现代 C++ 工具包,包含机器学习算法和用于创建复杂 C++ 软件的工具,解决实际问题。可以通过 dlib API 与 Python 配合使用
11. Annoy
Stars: 7700, Commits: 778, Contributors: 53
用于内存使用和磁盘读写优化的 C++/Python 近似最近邻算法
12. H20ai
Stars: 500, Commits: 27894, Contributors: 137
开源的快速可扩展机器学习平台,用于更智能的应用:深度学习、梯度提升与 XGBoost、随机森林、广义线性建模(逻辑回归、弹性网)、K-Means、PCA、堆叠集成、自动机器学习 (AutoML) 等。
13. StatsModels
Stars: 5600, Commits: 13446, Contributors: 247
Statsmodels: Python 中的统计建模与计量经济学
14. mlpack
Stars: 3400, Commits: 24575, Contributors: 190
mlpack 是一个直观、快速且灵活的 C++ 机器学习库,具有其他语言的绑定
15. Pattern
Stars: 7600, Commits: 1434, Contributors: 20
Python 的网络挖掘模块,包含抓取、自然语言处理、机器学习、网络分析和可视化工具。
16. Prophet
Stars: 11500, Commits: 595, Contributors: 106
用于生成高质量的时间序列数据预测工具,支持线性或非线性增长和多重季节性。
最佳 Python 库:自动化机器学习
17. TPOT
星标数:7500,提交次数:2282,贡献者数:66
一个 Python 自动化机器学习工具,通过遗传编程优化机器学习管道。
18. auto-sklearn
星标数:4100,提交次数:2343,贡献者数:52
auto-sklearn 是一个自动化机器学习工具包,可替代 scikit-learn 的估计器。
19. Hyperopt-sklearn
星标数:1100,提交次数:188,贡献者数:18
Hyperopt-sklearn 是一个基于 Hyperopt 的模型选择工具,用于在 scikit-learn 中选择机器学习算法。
20. SMAC-3
星标数:529,提交次数:1882,贡献者数:29
顺序模型基础的算法配置
21. scikit-optimize
星标数:1900,提交次数:1540,贡献者数:59
Scikit-Optimize,或 skopt,是一个简单高效的库,用于最小化(非常)昂贵和嘈杂的黑箱函数。它实现了几种顺序模型优化的方法。
22. Nevergrad
星标数:2700,提交次数:663,贡献者数:38
一个用于执行无梯度优化的 Python 工具箱
23. Optuna
星标数:3500,提交次数:7749,贡献者数:97
Optuna 是一个自动超参数优化软件框架,特别为机器学习设计。
最佳 Python 库:数据可视化
24. Apache Superset
星标数:30300,提交次数:5833,贡献者数:492
Apache Superset 是一个数据可视化和数据探索平台
25. Matplotlib
星标数:12300,提交次数:36716,贡献者数:1002
Matplotlib 是一个全面的库,用于在 Python 中创建静态、动画和交互式可视化。
26. Plotly
星标数:7900,提交次数:4604,贡献者数:137
Plotly.py 是一个交互式、开源的、基于浏览器的 Python 图形库
27. Seaborn
星标数:7700,提交次数:2702,贡献者数:126
Seaborn 是一个基于 matplotlib 的 Python 可视化库。它提供了一个高级接口,用于绘制吸引人的统计图形。
28. folium
星标数:4900,提交次数:1443,贡献者数:109
Folium 基于 Python 生态系统的数据处理优势和 Leaflet.js 库的地图绘制优势。你可以在 Python 中处理数据,然后通过 folium 在 Leaflet 地图中进行可视化。
29. Bqplot
星标数:2900,提交次数:3178,贡献者数:45
Bqplot 是一个基于图形语法构造的 Jupyter 2-D 可视化系统。
30. VisPy
星数:2500,提交次数:6352,贡献者:117
VisPy 是一个高性能的 2D/3D 数据可视化库。VisPy 通过 OpenGL 库利用现代图形处理单元(GPU)的计算能力来显示非常大的数据集。VisPy 的应用包括:
31. PyQtgraph
星数:2200,提交次数:2200,贡献者:142
快速数据可视化和 GUI 工具,适用于科学/工程应用
32. Bokeh
星数:1400,提交次数:18726,贡献者:467
Bokeh 是一个用于现代网页浏览器的交互式可视化库。它提供了优雅、简洁的多功能图形构建,并对大规模或流式数据集提供高性能的交互性。
33. Altair
星数:600,提交次数:3031,贡献者:106
Altair 是一个用于 Python 的声明性统计可视化库。使用 Altair,你可以花更多时间理解数据及其意义。
最佳 Python 库:解释与探索
34. eli5
星数:2200,提交次数:1198,贡献者:15
一个用于调试/检查机器学习分类器并解释其预测的库
35. LIME
星数:800,提交次数:501,贡献者:41
Lime:解释任何机器学习分类器的预测
36. SHAP
星数:10400,提交次数:1376,贡献者:96
一种博弈论方法,用于解释任何机器学习模型的输出。
37. YellowBrick
星数:300,提交次数:825,贡献者:92
可视化分析和诊断工具,方便机器学习模型选择。
38. pandas-profiling
星数:6200,提交次数:704,贡献者:47
从 pandas DataFrame 对象创建 HTML 个人报告
更多相关话题
深度学习、自然语言处理与计算机视觉的顶级 Python 库
评论
在之前的文章中,我们查看了 数据科学、数据可视化和机器学习的顶级 Python 库。这次,我们将关注深度学习、自然语言处理和计算机视觉的顶级库。这些类别实际上不需要进一步的说明。
这种分隔和分类是随意的,有时比其他情况更多,但我们尽力将工具按照预期的使用场景进行分组,希望这对读者最有帮助。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
显然,现如今并非所有的 NLP 和 CV 工作都采用深度学习技术,但随着趋势向这种技术转变以获得最先进的结果,我们坚持这种否则随意的分类逻辑。
我们的列表由我们团队共同决定的、代表常用且广泛使用的 Python 库组成。此外,要被列入其中,库必须有一个 Github 仓库。类别没有特定顺序,库在每个类别中也没有特定顺序。我们曾考虑按星数或其他指标进行排序,但为了避免对库的任何感知价值或重要性进行明确偏向,我们决定不这样做。因此,它们在这里的列出是纯粹随机的。库的描述直接来自于 Github 仓库,以某种形式展示。
再次感谢 Ahmed Anis 对数据收集的贡献,以及 KDnuggets 团队其他成员的意见、见解和建议。
请注意,下图由 Gregory Piatetsky 展示了每个库的类型,按星数和贡献者进行绘制,符号大小反映了库在 Github 上的提交次数,采用对数刻度。
 图 1:顶级 Python 库,用于深度学习、自然语言处理和计算机视觉
图 1:顶级 Python 库,用于深度学习、自然语言处理和计算机视觉
按星标数和贡献者数绘制;相对大小由提交日志数决定
那么,废话少说,这里是 KDnuggets 员工评定的 30 个顶级 Python 库,用于深度学习、自然语言处理和计算机视觉。
深度学习
1. TensorFlow
星标:149000,提交:97741,贡献者:2754
TensorFlow 是一个端到端的开源机器学习平台。它拥有全面且灵活的工具、库和社区资源,使研究人员能够推动机器学习的最新技术,并使开发人员能够轻松构建和部署机器学习驱动的应用程序。
2. Keras
星标:50000,提交:5349,贡献者:864
Keras 是一个用 Python 编写的深度学习 API,运行在机器学习平台 TensorFlow 之上。
3. PyTorch
星标:43200,提交:30696,贡献者:1619
Python 中的张量和动态神经网络,具有强大的 GPU 加速
4. fastai
星标:19800,提交:1450,贡献者:607
fastai 简化了使用现代最佳实践训练快速且准确的神经网络
星标:9600,提交:3594,贡献者:317
用于高性能 AI 研究的轻量级 PyTorch 封装。扩展你的模型,而不是样板代码。
6. JAX
星标:10000,提交:5708,贡献者:221
Python+NumPy 程序的可组合变换:微分、矢量化、JIT 到 GPU/TPU 等等
7. MXNet
星标:19100,提交:11387,贡献者:839
轻量级、可移植、灵活的分布式/移动深度学习,支持动态、感知变异的数据流调度器;适用于 Python、R、Julia、Scala、Go、JavaScript 等更多语言
8. Ignite
星标:3100,提交:747,贡献者:112
高级库,帮助灵活且透明地训练和评估 PyTorch 中的神经网络。
自然语言处理
9. FastText
星标:21700,提交:379,贡献者:47
fastText 是一个用于高效学习词表示和句子分类的库。
10. spaCy
星标:17400,提交:11628,贡献者:482
工业级自然语言处理(NLP),使用 Python 和 Cython
11. gensim
星标:11200,提交:4024,贡献者:361
Gensim 是一个 Python 库,用于主题建模、文档索引和大规模语料库的相似性检索。目标用户是自然语言处理(NLP)和信息检索(IR)社区。
12. NLTK
Stars: 9300, Commits: 13990, Contributors: 319
NLTK -- 自然语言工具包 -- 是一个开源 Python 模块、数据集和教程的套件,支持自然语言处理的研究和开发。
Stars: 4300, Commits: 568, Contributors: 64
快速、高效、开放访问的数据集和评估指标,适用于自然语言处理以及 PyTorch、TensorFlow、NumPy 和 Pandas。
Stars: 3800, Commits: 1252, Contributors: 30
快速的最先进的分词器,优化用于研究和生产。
15. Transformers (Huggingface)
Stars: 3500, Commits: 5480, Contributors: 585
Transformers:最先进的自然语言处理,适用于 Pytorch 和 TensorFlow 2.0。
16. Stanza
Stars: 4800, Commits: 1514, Contributors: 19
官方斯坦福 NLP Python 库,支持多种人类语言。
17. TextBlob
Stars: 7300, Commits: 542, Contributors: 24
简单、Pythonic 的文本处理--情感分析、词性标注、名词短语提取、翻译等。
18. PyTorch-NLP
Stars: 1800, Commits: 442, Contributors: 15
PyTorch 自然语言处理(NLP)的基础实用工具。
19. Textacy
Stars: 1500, Commits: 1324, Contributors: 23
一个 Python 库,用于执行各种自然语言处理(NLP)任务,基于高性能的 spaCy 库。
20. Finetune
Stars: 626, Commits: 1405, Contributors: 13
Finetune 是一个库,允许用户利用最先进的预训练 NLP 模型进行各种下游任务。
21. TextHero
Stars: 1900, Commits: 266, Contributors: 17
从零到英雄的文本预处理、表示和可视化。
22. Spark NLP
Stars: 1700, Commits: 4363, Contributors: 50
Spark NLP 是一个构建在 Apache Spark ML 之上的自然语言处理库。
23. GluonNLP
Stars: 2200, Commits: 712, Contributors: 72
GluonNLP 是一个工具包,能够简化文本预处理、数据集加载和神经模型构建,帮助你加速自然语言处理(NLP)研究。
计算机视觉
24. Pillow
Stars: 7800, Commits: 10799, Contributors: 303
Pillow 是友好的 PIL 分支。PIL 是 Python Imaging Library。
25. OpenCV
Stars: 49600, Commits: 29453, Contributors: 1234
开源计算机视觉库
26. scikit-image
Stars: 4000, Commits: 12352, Contributors: 403
Python 中的图像处理
27. Mahotas
Stars: 644, Commits: 1273, Contributors: 25
Mahotas 是一个快速计算机视觉算法库(全部用 C++ 实现以提高速度),操作 numpy 数组。
28. Simple-CV
Stars: 2400, Commits: 2625, Contributors: 69
SimpleCV 是一个开源机器视觉框架,使用 OpenCV 和 Python 编程语言。
29. GluonCV
Stars: 4300, Commits: 774, Contributors: 101
GluonCV 提供了计算机视觉领域的最先进(SOTA)深度学习模型的实现。
30. Torchvision
Stars: 7500, Commits: 1286, Contributors: 334
torchvision 包含流行的数据集、模型架构和计算机视觉的常见图像变换。
相关:
-
数据科学、数据可视化与机器学习的顶级 Python 库
-
前 13 个 Python 深度学习库
-
前 8 个 Python 机器学习库
更多相关内容
顶级 8 个 Python 机器学习库
原文:
www.kdnuggets.com/2018/10/top-python-machine-learning-libraries.html
评论
Python 在机器学习、AI、深度学习和数据科学任务中继续领先。根据 builtwith.com,45% 的科技公司更愿意使用 Python 实现 AI 和机器学习。
因此,我们决定启动一系列调查各类顶级 Python 库的活动:
我们的顶级 3 门课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
顶级 8 个 Python 机器学习库 ✅
顶级 Python AI 库 – 敬请期待!
顶级 X 个 Python 深度学习库 - 敬请期待!
顶级 Python 数据科学库 – 敬请期待!
当然,这些列表完全是主观的,因为许多库可以轻松地放入多个类别。例如,Keras 被包括在这个列表中,但 TensorFlow 被省略,并且出现在深度学习库集合中。这是因为 Keras 更像是一个‘终端用户’库,如同 SKLearn,而 TensorFlow 更吸引研究人员和机器学习工程师。
一如既往,请随时在下面的评论区表达你的挫折/不同意见/烦恼!
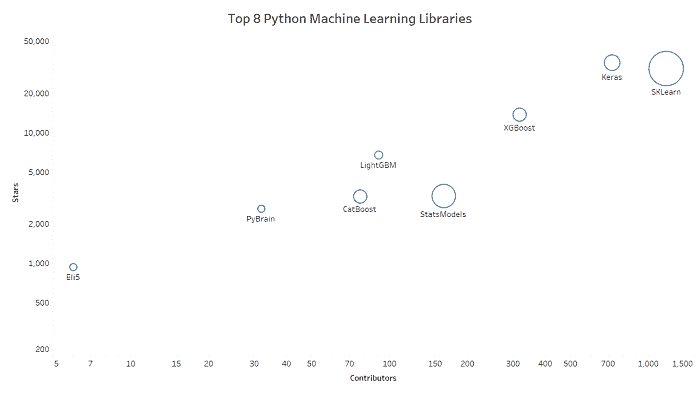
顶级 8 个 Python 机器学习库按 GitHub 贡献者、星标和提交数量排序(圆圈的大小)
现在,让我们进入列表(GitHub 数据截至 2018 年 10 月 3 日):
1. scikit-learn (贡献者 – 1175, 提交 – 23301, 星标 – 30867)
“scikit-learn 是一个用于机器学习的 Python 模块,基于 NumPy、SciPy 和 matplotlib。它提供了简单而高效的数据挖掘和数据分析工具。SKLearn 对每个人都可用,并且可以在各种环境中重复使用。
2. Keras (贡献者 – 726, 提交 – 4818, 星标 – 34066)
“Keras 是一个高级神经网络 API,用 Python 编写,能够运行在 TensorFlow、CNTK 或 Theano 之上。它的开发重点是实现快速实验。能够在最短时间内从想法到结果是做好研究的关键。”
3. XGBoost (贡献者 – 319, 提交记录 – 3454, 星标 – 13630)
“XGBoost 是一个优化的分布式梯度提升库,旨在具有极高的效率、灵活性和可移植性。它在梯度提升框架下实现机器学习算法。XGBoost 提供并行树提升(也称为 GBDT、GBM),以快速且准确的方式解决许多数据科学问题。相同的代码可在主要的分布式环境(Hadoop、SGE、MPI)上运行,并能解决超出数十亿个样本的问题。”
4. StatsModels (贡献者 – 162, 提交记录 – 10837, 星标 – 3275)
“Statsmodels 是一个 Python 包,为统计计算提供对 scipy 的补充,包括描述性统计和统计模型的估计与推断。”
5. LightGBM (贡献者 – 91, 提交记录 – 1272, 星标 – 6736)
“一个快速、分布式、高性能的梯度提升(GBDT、GBRT、GBM 或 MART)框架,基于决策树算法,用于排序、分类和许多其他机器学习任务。它隶属于微软的 DMTK(github.com/microsoft/dmtk) 项目。”
6. CatBoost (贡献者 – 77, 提交记录 – 3304, 星标 – 3241)
“CatBoost 是一种基于梯度提升的机器学习方法,采用决策树。CatBoost 的一些主要优势包括:与其他 GBDT 库相比质量更高,推理速度最佳,支持数值特征和类别特征以及包含数据可视化工具。”
7. PyBrain (贡献者 – 32, 提交记录 – 992, 星标 – 2598)
“PyBrain 是一个用于 Python 的模块化机器学习库。它的目标是提供灵活、易于使用但仍然强大的机器学习任务算法以及各种预定义的环境来测试和比较你的算法。”
8. Eli5 (贡献者 – 6, 提交记录 – 929, 星标 – 932)
“ELI5 是一个 Python 包,帮助调试机器学习分类器并解释其预测。它支持以下框架和包:scikit-learn、XGBoost、LightGBM、lightning 和 sklearn-crfsuite。”
留意接下来几周内发布的系列文章!
相关内容:
更多主题内容
更新版:顶级 Quora 数据科学作者及其最佳建议
原文:
www.kdnuggets.com/2017/07/top-quora-data-science-writers-best-advice-updated.html
本文基于 数据科学中最受欢迎的作者,这是过去 30 天中回答浏览量最多的 10 位作者的数据,数据检索日期为 2017 年 6 月 29 日。
为了避免混淆,请注意这篇文章是由我“撰写”的,但文中包含的所有信息——从问题到答案——与我无关。我只是将这些有价值的回答编辑在一起。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
Quora 上的数据科学主题页面。
1. Håkon Hapnes Strand,数据科学家 - 255,104 次浏览, 173 个回答
摘自对: 什么是“全栈”数据科学家?
我还没有听到过这个表达的使用,但这是我对其含义的看法:
数据科学家构建预测模型。这是他们工作的核心。此外,他们还需要了解一些其他内容:
- 数据工程
- 软件工程
- 业务分析
一个全栈数据科学家能够无缝地执行数据工程师、软件工程师、业务分析师和数据科学家的角色。如果你需要有人开发一个应用程序,全栈数据科学家可以接手。如果你需要有人建立数据仓库,或者分析企业的战略管理过程,全栈数据科学家也可以做到。
2. Mike West,SQL Server 和机器学习爱好者 - 127,776 次浏览,45 个回答
摘自对: Python 在 Scala (+Spark) 崛起的情况下是否仍然在数据科学中相关?
Scala 和 Spark 不是 Python 的对手,它们是朋友。
我已经说过一段时间了。Python 是并将继续是未来十年机器学习的黄金标准。
唯一的 Python 竞争对手是 R,坦率地说,在现实世界中,每个人都在使用 Python。你会在大学层面看到很多 R,但在应用领域则不会。
Python 确实有太多的领先优势。
大数据主要是将任何数据(几乎总是非结构化数据)转化为可以建模的格式。Scala 和 Spark 只是你可以用来处理非常大数据集的工具。
TensorFlow 不是用 Scala 编写的。
不要被一两篇文章迷惑,即使它们是 Andrew Ng 写的。做你自己的研究。
3. Corrin Lakeland - 117,841 次浏览,87 个回答
摘自回答:未来 5 到 10 年,数据科学家将从事什么工作?
这引出了未来的展望。在接下来的五年中,我预计会看到很多目前声称参与其中的公司实际上会尝试在严肃项目中使用它。我预计其中相当一部分项目会失败,整个行业将会更加成熟,对什么有效和无效有更多的理解。
看看现在有多少图形用户界面工具支持机器学习。比如自动聚类数据的 Excel 插件。再过五年,我预计大多数人只会想到这些工具时才会想到数据科学。
十年后,我认为时尚将会真正改变。数据科学将成为其他学科中普遍且被期望的技能,专门的数据科学家可能会被看作有些奇怪。你还会看到一种情况,即系统捕获的数据很常见且正常地适用于数据科学,而不是现在大多数数据的结构方式需要大量的处理。
4. William Chen,Quora 数据科学家 - 117,834 次浏览,195 个回答
摘自回答:你为什么选择从事数据科学而不是量化金融?
我即将列出的所有理由的总结是我选择数据科学是因为我对它更有热情。以下是促使我对数据科学产生热情的 5 个更具体的原因。
- 对新兴和不断增长的职业路径的兴奋 - 这个决定是在 2013 年和 2014 年做出的,那时数据科学比现在更加新颖和不确定。进入一个仍在发展和创新中的领域对我很有吸引力,并且至今仍然如此。我尽量不让自己的决策基于炒作——因此这个点更多的是关于数据科学领域的成长以及它会为我提供一个位置,而不是它的热门程度。
- 对数据科学的熟悉程度 - 这是列表中最弱的理由,但当我需要选择全职工作时,我已经有了两次数据科学相关的实习经历:一次在 Etsy(公司),一次在 Quora(公司)。在这两个实习中我都有很好的经历,所以选择全职从事数据科学对我来说是一个快乐的已知数量。
- 对从事消费者互联网产品的兴趣 - 我对消费者互联网产品有长期的兴趣,自从我获得拨号上网的机会以来,我一直对这个领域的增长感到兴奋。数据科学工作对我来说是一个独特的机会,让我能够成为我一直着迷的消费者互联网世界的一部分。
- 对从事新兴产品的兴趣 - 消费者互联网产品一直让我感兴趣,因为它们存在于不确定的领域中,可能会变得非常重要(或只是失败)。对从事一个可能变得非常重要的产品的兴趣,以及知道自己在其中扮演了一个小角色的诱惑是很大的。
- 对知识共享的承诺 - 我一直致力于分享想法和观点,无论是通过担任哈佛统计学 110 课程的教学助理,还是在 Quora 上尽可能多地写作。科技领域通常有见面会、博客文章、Quora 回答、研讨会和邀请讲座的文化。而在神秘的量化金融领域,情况则有所不同。
5. Clayton Bingham,南加州大学神经工程中心研究员 - 108,512 次浏览,8 个回答
摘录自:在 Python 中,如何使用 BeautifulSoup 将网站数据保存为 CSV?
懒惰的办法是这样做:
一旦你将数据放入数据框中,你可以进行任何解析/格式化操作。或者,如果你只需要这一次,你也可以用 Excel 或其他工具来完成。
希望这对你有帮助!
6. Lili Jiang,Quora 数据科学经理 - 88,461 次浏览,8 个回答
首先,数据科学是否如你所想?
我遇到的 9 位有志数据科学家中,有 10 人将机器学习等同于数据科学。“数据科学”是一个涵盖面广的术语。机器学习只是其中的一部分,但在许多主要科技公司中,产品分析也是数据科学团队的一个重要组成部分。产品分析是一颗隐藏的宝石。它很有趣,但讨论却不多。包括:
- A/B 测试设计
- 设计指标:以视频平台为例。什么是优化的最佳指标,能够最能代表用户满意度?应该是观看的视频数量?观看视频的时间?还是一周内返回观看另一部视频的用户百分比?
- 调查指标变化的原因:为什么这批用户的活动突然激增?
- 理解产品机制:按钮 X 和功能 Y 如何提升产品?我们应该将页面 A 重定向到 B 或 C,还是直接从 A 跳到 C?
- 识别趋势并提供战略建议:用数据论证公司应投资于 ______ 领域,以保持竞争力。
7. Zeeshan Zia,计算机视觉和机器学习博士 - 70,564 次观看,24 个回答
摘自回答:2017 年 AI 是否被过度炒作?
视具体社区而定,既有“是”,也有“不是”。
如果你谈论的是学术研究社区,它并不过度炒作。过去几年里,AI 取得了重大突破,这种庆祝当然是有道理的。
在我自己从事的目标识别领域,我们从~35%的准确率(Pascal VOC 上的平均精度)提高到超过 65%,仅用了 3 到 4 年时间。此前,我们每年进步 1%到 2%,尽管目标识别是计算机视觉中最热门的领域,每年在顶级会议上发表的论文最多。深度学习在强化学习方面也取得了重大突破,这为通用 Atari 游戏的成功奠定了基础,并在预期十几年后战胜了围棋世界冠军!它终于使语音识别达到了可用的准确度水平。
8. Jason T Widjaja,商业和分析极客。喜欢他的兄弟。- 60,837 次观看,167 个回答
摘自回答:关于分析/数据科学炒作的风险是什么?
从根本上说,我认为数据科学不会很快消失。只要:
- 人们总是希望做出更好的决策,
- 人们永远关心未来会发生什么,
- 做得好的个人和公司总是会受益。
- 可用的数据点持续增加,
- 我们拥有的工具和技术不断改进(你明白的)..
...分析和数据科学并不是无处不在的。
免责声明:极度偏见的样本量为一个。
9. Roman Trusov,硕士学位信息技术与数据科学,斯科尔科沃科技学院(2018 年) - 57,815 次观看,139 个回答
摘自回答:数据科学家应该如何处理版本控制,包括管道代码和模型?
为了从版本控制系统中获得最佳效果,最好将它们分开。
像对待其他代码一样将代码保存在版本控制系统中是唯一合理的方式,因为如果你作为数据科学家进行了一些繁重的 ETL,或者你的代码做出的决策可能带来或损失大量金钱,那么它一定会经过代码审查。没有其他方式。
对于一些数据科学家更为典型的事情,我认为将 Jupyter notebooks 存储在版本控制中并不是一个好的做法。你无法在这些笔记本上看到清晰的差异,它们不是“生产代码”,总的来说,当你完成某件事时,你希望推送至少一个“最终版”Python 脚本。Jupyter notebooks 非常适合实验和演示,但在这些情况下之外,总有更好的选择。
10. Shweta Doshi,GreyAtom 联合创始人,数据科学沉浸式学习学校 - 50,866 次观看,123 个回答
你需要熟悉的基本知识分为 3 类,即编程、数学和科学。
作为数据科学家,你将被期望将一个业务问题转化为数据问题,创建预测模型来回答问题,并讲述发现的故事。专注于实现数据的统计方法的统计学家以及专注于管理数据科学团队的数据经理,往往会担任数据科学家角色。
数据科学家是编程与数据科学实施、数据科学理论与数据业务影响之间的桥梁。
相关:
-
前 10 名 Quora 机器学习作家及其最佳建议(更新版)
-
前 10 名 Quora 数据科学作家及其最佳建议
-
Quora 上关于“如何学习机器学习”的最佳建议
更多相关主题
数据清理的顶级 R 包
原文:
www.kdnuggets.com/2019/03/top-r-packages-data-cleaning.html
评论
作者:Anna Kayfitz, StrategicDB Corp的首席执行官

我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
随着每天有数百万或数十亿的数据元素进入你的业务,几乎不可避免地会有一些数据缺乏创建高效商业模型所需的质量。确保你的数据干净应该始终是数据科学工作流的第一步,也是最重要的一步,因为没有它,你将很难看到重要的信息,并可能因为重复、异常或缺失信息而做出错误的决策。
R 是最常用且功能强大的数据编程工具之一,它是一个用于统计计算和图形绘制的开源语言和环境。R 为用户提供了创建数据科学项目所需的所有工具,但无论如何,它的效果取决于输入的数据。因此,R 环境中有许多库可以帮助在项目开始之前进行数据清理和处理。
探索数据
你导入的数据集中的大多数探索工具已经存在于 R 平台中。
总结(数据)
这个实用的命令简要概述了所有的数据属性,显示每个属性的最小值、最大值、中位数、均值和类别分布。这是一种快速发现潜在数据异常的好方法。
紧接着,你可以使用直方图来更好地理解数据的分布。这将可视化显示数据集中或任何你特别希望观察的数值列中的异常值。
plyr 包
你需要安装 plyr 包来创建你的直方图,使用标准的 R 功能来安装库。
Install.packages(“plyr”)
Library(plyr)
Hist(YOUR_DATASET_NAME)
这将创建一个数据的可视化图,以便快速发现任何异常。箱线图可视化使用相同的包,但将数据分为四分位数以进行异常值检测。这两者结合将迅速告诉你是否需要限制数据集或仅在算法或统计建模中使用某些数据段。
纠正错误
R 提供了一些内置方法来纠正数据错误,例如转换值,就像你在 Excel 或 SQL 中使用简单逻辑一样,例如 as.character() 将列转换为字符字符串。
然而,如果你想开始纠正你在直方图或箱线图中看到的错误,还有其他可以做到这一点的附加包。
stringr 包
stringr 包可以通过修剪空白和替换某些不必要的词来帮助清理数据。这些是相当标准的代码片段,如 str_trim(YOUR_DATA_FIELD),它简单地移除空白。
然而,如何去除我们直方图告诉我们存在的异常值呢?这需要比这更复杂一点,但作为基本示例,我们可以告诉 R 用该字段的中位数替换所有的异常值。这将把所有数据聚合在一起,消除异常偏差。
缺失值
在 R 中检查不完整数据并对该字段执行操作非常简单。例如,这个函数将完全消除你选择的数据列中的缺失值。
Na.omit(YOUR_DATA_COLUMN)
根据字段类型,有类似的选项可以用 0 或 N/A 替换空值,从而提高数据集的一致性。
tidyr 包
tidyr 包旨在整理你的数据。它通过识别数据集中的变量并使用提供的工具将它们移动到列中,有三个主要函数:gather()、separate() 和 spread()。
gather() 函数将多个列收集成键值对。例如,假设你有类似的考试分数数据。
| Name | Exam A | Exam B |
|---|---|---|
| John | 55 | 80 |
| Mike | 76 | 90 |
| Sam | 45 | 75 |
gather 函数通过将数据转换成像这样可用的列来工作。
| Name | Exam | Score |
|---|---|---|
| John | A | 55 |
| Mike | A | 76 |
| Sam | A | 45 |
| John | B | 80 |
| Mike | B | 90 |
| Sam | B | 75 |
现在我们真正能够分析考试分数了。separate 和 spread 函数执行类似的操作,你可以在安装了包后探索它们,但最终它们会根据需要调整你的数据。
以下是一些其他可能对 R 中数据清理有用的包
- purr 包
purr 包旨在进行数据处理。它与 plyr 包非常相似,尽管较旧,一些用户发现它更易于使用,并且在功能上更为标准化。
- sqldf 包
许多 R 用户在 SQL 语言中编写代码更为舒适,而不是 R。这个函数允许你在 R studio 中编写 SQL 代码来选择数据元素。
- janitor 包
该包能够通过多个列找到重复项,并轻松从数据框中创建友好的列。它甚至具有一个 get_dupes()函数,用于在多个数据行中查找重复值。如果你希望以更高级的方式去重数据,例如,查找不同的组合或使用模糊逻辑,你可能需要查看一个去重工具。
- splitstackshape 包
这是一个较旧的包,可以处理数据框列中的逗号分隔值。对于调查或文本分析准备非常有用。
R 有大量的包,这篇文章仅触及了它的表面。随着新库不断出现,在开始任何新项目之前,进行研究并选择适合自己的包非常重要。
简介:Anna Kayfitz 是StrategicDB Corp的首席执行官,该公司专注于数据清理和分析。她拥有 Schulich 商学院的 MBA 学位,并在创办 StrategicDB 之前在数据分析和营销领域工作了 10 多年。
资源:
相关:
更多相关话题
机器学习的顶级 R 包
原文:
www.kdnuggets.com/2017/02/top-r-packages-machine-learning.html
由 Michael Li 和 Paul Paczuski,The Data Incubator。
在 The Data Incubator The Data Incubator,我们以拥有最新的数据科学课程为荣。我们的课程很大一部分基于来自企业和政府合作伙伴的反馈,了解他们希望学习的技术。但我们希望采用更加数据驱动的方法来确定我们在 数据科学企业培训 和为希望进入行业的数据科学职业的硕士和博士提供的 免费奖学金 中应该教授的内容。以下是结果。
排名
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
最受欢迎的机器学习包有哪些?让我们来看看基于包下载和社交网站活动的排名。
![]()
值得注意的:OneR: 1 (SO); mlr: 2 (Github); ranger: 4 (Github); SuperLearner: 5 (Github)
排名基于 CRAN (The Comprehensive R Archive Network) 下载的平均排名和 Stack Overflow 活动 (完整排名见 [CSV] )。CRAN 下载数据来自过去一年。Stack Overflow 根据问题正文中的包名以及 'R' 标签的结果数量进行排名。GitHub 排名基于仓库的星标数。详见 方法。
Caret 位居首位,神经网络在其他算法重磅选手中表现突出
也许并不令人惊讶,caret 排在首位。它是一个用于创建机器学习工作流的通用包,与一些特定算法的包良好集成,这些包在排名中紧随其后。
这些包括 e1071(用于 SVM)、rpart(树)、glmnet(nnet)。有关这些包的详细信息,请参见 下面。
排名揭示了 R 包社区的碎片化。几个顶级包,如 rpart 和 tree,实现了相同的算法,这与 Python 的 scikit-learn 的一致性 - 和广度 - 形成了对比。
尽管如此,如果你喜欢 R 的数据处理能力(如 tidyverse),你可以使用这些包来进行一些强大的建模,而不必切换到 Python。此外,随着更多功能被添加到 modelr,一个 tidy 工具,我们可能很快会看到它被纳入这个列表中。
包详情
caret 是一个用于创建机器学习工作流的通用包,并在这个排名中位居榜首。接下来是一些实现特定机器学习算法的包:随机森林(randomForest)、支持向量机(e1071)、分类和回归树(rpart)以及正则化回归模型(glmnet)。
nnet 实现了神经网络,而 tree 包则实现了树结构。party 用于递归分割和二叉树的可视化,arules 用于关联挖掘。SVM 和其他核方法在 kernlab 中实现。h2o 包用于可扩展的机器学习,并且是更大 H2O 项目的一部分。ROCR 用于模型评估,包括 ROC 曲线,而 gbm 实现了梯度提升。更多的分割算法可以通过 RWeka 访问,而 rattle 是一个用于数据挖掘的 R 图形用户界面。
一些包在 Github 上表现突出:mlr 和 SuperLearner 是另外两个提供类似功能的元包,而 ranger 提供了随机森林的 C++ 实现。
最后,OneR 在 Stack Overflow 上排名第一,但 SO API 经常将其自动更正为“one”,所以结果不可靠。
方法
下面,我们描述了得出这个排名的方法论。
第 1 步:获取一个详尽的机器学习包列表
从一开始,我们就设想我们的排名建立在包下载量、Stack Overflow 和 Github 活动的结合上。我们知道存在一些 API 可以提供这些指标。
然而,获得所有 R 包的初步机器学习列表是一项更艰巨的任务。这个列表需要是详尽的、客观的且最新的。一个糟糕的初始列表将会显著影响我们的排名。
询问周围的人有所帮助。一位朋友向我们推荐了 "CRAN 任务视图:机器学习与统计学习",它在底部有一个很好的列表,并且易于抓取。
它的优点在于,软件包列表来自权威来源(CRAN 是“官方” R 包存储库),并且定期更新(最后更新时间:2017 年 1 月 6 日)。感谢作者,托斯滕·霍瑟恩,他通过电子邮件也非常响应。
之前的想法是使用 Google 查找“顶级 R 机器学习包”的列表,然后尝试抓取所有包名称,进行合并,并将该列表作为起点。但抛开工程任务,我们还发现当前可用的列表相对于我们的需求质量较差。它们过时,没有明确指定方法,且往往非常主观。
确定客观指标
一个好的排名需要对“最佳”有明确的定义,并且需要使用好的指标构建。
我们将“最佳”定义为“最受欢迎”。这不一定意味着这些包被广泛喜爱(用户可能因为 API 很糟糕而频繁搜索 Stack Overflow)。
我们为排名选择了 3 个组件:
-
下载量:来自 CRAN 镜像的下载次数
-
Github:包在其主仓库页面上的星标数量
-
Stack Overflow:包含包名称并标记为 'R' 的问题数量
CRAN 下载量
有几个 CRAN 镜像,我们使用了 R-Studio 镜像,因为它具有方便的 API。RStudio 可能是最广泛使用的 R IDE,但它不是唯一的。如果我们汇总了其他 CRAN 镜像的下载量,我们的排名可能会有所改进(虽然可能不会显著)。
GitHub
最初,我们通过查询 Github 的搜索 API 来寻找包的 Github 页面,可能带有“language:R”,但这被证明不可靠。有时很难挑选出正确的 Github 仓库,并且并非所有 R 包都是用 R 语言实现的(搜索 API 中的“language:R”参数似乎指的是仓库使用的最流行的语言)。
相反,我们回到 CRAN 寻找这些网址。每个包都有一个官方 CRAN 页面,其中包括有用的信息,包括源代码链接。这就是我们获取包的 Github 仓库位置的地方。
之后,通过 API 获取 Github 星标很容易。
Stack Overflow
从 Stack Overflow 获取有用结果很棘手。一些 R 包名如 tree 和 earth 存在明显的困难:Stack Overflow 的结果可能没有过滤到仅针对 R 包的结果,因此我们首先在查询中添加了一个 'r' 字符串,这大大帮助了我们。
一个好的(最佳的?)策略是寻找问题正文中的包名,然后添加 'r' 标签(这与添加 'r' 字符串不同)。
构建排名
我们仅在每个 3 个指标中对包进行排名,并取其平均排名。没有复杂的操作。
其他注意事项
所有数据于 2017 年 1 月 19 日下载。CRAN 下载量数据来自过去 365 天:2016 年 1 月 19 日至 2017 年 1 月 19 日。
数据科学的顶级 R 包?
这个项目起初是对“数据科学”顶级包的排名,但我们很快发现范围太广。
数据科学家做许多不同的工作,你几乎可以将任何 R 包归类为帮助数据科学家的工具。我们是否应该包括字符串处理包?数据库读取包怎么样?
另一个更长的项目可以是使用更多的“数据科学”来制定一个关于“数据科学”顶级 R 包的排名。
资源
源代码可在The Data Incubator's Github上获得。如果你有兴趣了解更多,请考虑:
相关:
-
按受欢迎程度排列的前 20 个 R 包
-
R 中的 ARIMA 预测介绍
-
利用 Anaconda 轻松构建和分享 R 包
更多相关话题
大数据、数据科学、分析计划失败的主要原因
原文:
www.kdnuggets.com/2016/12/top-reasons-big-data-science-analytics-fail.html
评论
作者:安基特·马哈詹,RetailMarketingTechnology.com
我在过去 11 年中一直从事数据科学专业工作,并有机会与多个雇主和客户合作,满足他们在金融服务、零售/快消品、电信、媒体与娱乐、数字媒体、教育和技术等多个领域的数据科学需求。在这 11 年中,我观察和参与了数据科学管理实践和企业战略,密切关注了这些计划的成功与失败。我回顾并反思了我认为抑制数据科学战略发展的五个主要原因。
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业领域。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 需求

缺乏来自最高领导层的明确数据科学授权
一些公司加入了数据科学的浪潮,因为他们想成为炒作的一部分,而不是实际价值创造的一部分。这些肤浅的目标往往反映出最高领导层要么对基于数据的战略效果没有充分的信心,要么只是因为一个人的个人喜好(而非真正的知识)而参与了“big data”这一词汇。在缺乏明确数据科学授权作为业务战略输入的情况下,组织目标与数据科学路线图从未同步,导致了不切实际的目标,从而导致了惨败。
抵制接受变革
实施有效的数据科学企业战略的首要任务(无论你的商业模式是 B2B 还是 B2C)是接受变革。通常,僵化的等级制度、部门孤岛和复杂的政治组织动态成为实施中央数据战略的障碍,而这并没有促进真正的创新。每个人都想争取一块蛋糕或整个蛋糕,但却不知道自己是否有资格争取,或不理解拥有部分蛋糕会对生态系统产生的变化。
 一个明确的例子:为了实施几乎实时的活动响应/最佳下一步建议模型并投入生产,可能需要营销、销售、IT、财务等不同部门之间的协同,但由于不同利益相关者的权力游戏和缺乏接受变革的意愿,这种协同有时会失败,这要求协调和统一来自不同来源的数据和输入,并在这些部门的不同关键利益相关者之间建立更紧密的协同(这些部门传统上因各种政治原因一直各自为政)。
一个明确的例子:为了实施几乎实时的活动响应/最佳下一步建议模型并投入生产,可能需要营销、销售、IT、财务等不同部门之间的协同,但由于不同利益相关者的权力游戏和缺乏接受变革的意愿,这种协同有时会失败,这要求协调和统一来自不同来源的数据和输入,并在这些部门的不同关键利益相关者之间建立更紧密的协同(这些部门传统上因各种政治原因一直各自为政)。
如果打破组间的隐性隔阂或障碍,统一数据,数据科学能为组织创造更多价值。政治因素往往成为障碍。即使无法建立中央数据科学结构,也可以创建一个松散的数据科学中心,作为两个团队(例如 IT 和市场营销或与数据战略相关的任何其他业务职能)之间紧密合作的结果,有效地构建解决问题的强大用例,成为其他部门的榜样。如果组织动态甚至不允许这样做,可以创建一个实验数据科学实验室,该实验室不属于特定部门/团队(但仍可自由访问数据源系统进行实验,作为现有技术单位/团队的平行单位/团队),并且免于政治动机驱动的议程,由一个能干、公正的领导者主持(有关更多信息,请参见下一点-‘首选’人选)。
没有提出正确的问题或定义不明确的问题
每个人都有问题,但是否能转化为对业务有直接影响的有用业务指标,往往被忽视。
 有些举措只是为了展示与数据的相关性,而非实际需求。错误的假设被建立,导致众多隐藏的假设,进而产生糟糕的业务用例。有效的数据科学是领域、数据、数学和统计、算法、编程、研究/实验和艺术的健康结合,或简单来说是科学和艺术的结合。我们可以自动化科学,但很难自动化艺术或量化抽象的东西。建模稀有事件非常棘手,最近美国选举就是一个很好的例子,特朗普击败了所有的民意调查、预测,所有专家都面临尴尬局面。
有些举措只是为了展示与数据的相关性,而非实际需求。错误的假设被建立,导致众多隐藏的假设,进而产生糟糕的业务用例。有效的数据科学是领域、数据、数学和统计、算法、编程、研究/实验和艺术的健康结合,或简单来说是科学和艺术的结合。我们可以自动化科学,但很难自动化艺术或量化抽象的东西。建模稀有事件非常棘手,最近美国选举就是一个很好的例子,特朗普击败了所有的民意调查、预测,所有专家都面临尴尬局面。
在组织内部,因政治原因不同的利益相关者之间总是存在着一场常态的争斗,每个利益相关者都希望保护自己的领域或扩展现有的领域。一个‘领域/业务专家’会试图强调该领域或艺术以展示自己的重要性,并在沟通和商业战略方面标榜自己的权威,他们常常提出一些花哨的问题,而不管是否有支持数据,或这些问题是否能转化为有用的指标。数据科学家则会过度强调数学部分,以展示为什么每个问题都需要通过数学来解决,以及如何通过 PCA 来解决供应链优化问题,即使可能根本不需要这样做。数据工程师则会强调技术(数据仓储)或实现部分,以展示他的角色不亚于宇航员。这是一场带有偏见的辩论,往往会让正确的问题被掩盖在背景中。每个人都很重要,但他们需要协调工作。
为什么以及需要部署哪个模型到生产环境,取决于最初的假设/业务问题。这些业务问题必须与具体的目标或指标关联起来,而很多时候这只是一个空白字段,空白字段的指标不符合部署标准。即使一年进行 12 次模型运行或更多,也不符合部署条件,除非你能产生一个与最初假设强相关的业务指标,并且对业务带来增值。
在缺乏正确问题的情况下,技术或实施人员会做什么?实施一个有缺陷的假设——这有意义吗?如果我们颠倒一下情况——在有正确问题但技术实施/算法/模型/样本(在过时样本上表现极差)错误的情况下,这是否有帮助,这又让我回到了上面第 2 点——不同利益相关者之间缺乏协同。一个既具备强大业务/领域背景(大局观)又具备同样强大数据科学背景(核心技术方面的核心数据科学/分析主题)的客观领导者,并且愿意接受变化,可能是你的‘首选’人选,但这些人通常需要较高的报酬,即使你找到这些人,也需要允许他们以自由和权威来建立该生态系统,但这种自由和灵活性通常是缺乏的。由于对系统感到沮丧,他们往往会离开(因为管理层对他们的激情和承诺未给予认可)。
缺乏数据优先级排序
每个组织都有大量的数据来源,因此也会有多个关于这些数据的假设,需要根据我们能从中提取的增量业务价值和数据质量来优先排序。如果没有这些优先级,我们往往会浪费时间和资源在低价值的业务问题上,这些问题在业务结果方面不会带来太多增量价值。为确保这一点,我们需要简化所有业务功能中的数据获取和存储活动,以提高可用于分析的数据质量,然后根据业务价值进行优先排序。每个模型的好坏取决于其数据,这一点需要时刻牢记。
缺乏灵活性
 将数据科学项目视为有明确开始和结果的项目可能是个错误,因为在组织在其分析和数据科学范式中达到稳定之前,它将经历一个广泛的试错阶段(至少几年的时间甚至更久),经历哪些有效,哪些无效,哪些数据相关,哪些模型表现良好,以及哪些模型最终需要部署才能产生有用的业务指标,从而产生增量影响。系统必须具备从错误中快速学习的灵活性和敏捷性,但通常很多人认为分析/数据科学是一种魔法,算法的一键点击将从根本上改变业务结果——没有比这更愚蠢的了。这是一个令人遗憾的现实。
将数据科学项目视为有明确开始和结果的项目可能是个错误,因为在组织在其分析和数据科学范式中达到稳定之前,它将经历一个广泛的试错阶段(至少几年的时间甚至更久),经历哪些有效,哪些无效,哪些数据相关,哪些模型表现良好,以及哪些模型最终需要部署才能产生有用的业务指标,从而产生增量影响。系统必须具备从错误中快速学习的灵活性和敏捷性,但通常很多人认为分析/数据科学是一种魔法,算法的一键点击将从根本上改变业务结果——没有比这更愚蠢的了。这是一个令人遗憾的现实。
我有时会想,人们是否能诚实地反思自己是问题的一部分还是解决方案的一部分。
当然,还有一些额外的原因涉及技能、IT、工具或数据库选择、存储解决方案、能力和资源,但这些问题只有在人员、生态系统和文化挑战得到解决之后才会优先考虑。这些额外的问题属于操作和技术方面的范畴,适合另写一篇文章。
简介:Ankit Mahajan,首席执行官兼总编辑 RetailMarketingTechnology.com,总部位于奥地利和印度
原文。已获转载许可。
相关:
-
特朗普、民调统计及预测房价
-
大数据 + 错误方法 = 大失败
-
大数据项目失败的 3 个原因
更多相关话题
Top /r/MachineLearning 帖子,三月:一份超级严厉的机器学习指南;是 Gaggle 还是 Koogle?!?
原文:
www.kdnuggets.com/2017/04/top-reddit-machine-learning-march.html
在三月的 /r/MachineLearning 中,我们欣赏到了一份超级严厉的机器学习指南,得知 Google 正在收购 Kaggle,从 Salesforce 的首席数据科学家那里获得超监督学习建议,听到 Andrew Ng 退出百度的告别,并了解到更多有关 Distill 的激动人心的信息,这是一个基于网络的“机器学习研究互动视觉期刊”。

过去一个月/r/MachineLearning的前 5 名帖子是:
这本简短而直白的机器学习指南由 /u/thatguydr 编写,他的简洁性令人钦佩。他的整个指南——在随后的讨论中扩展、讨论,并有其他人提供的材料——如下:
首先,阅读该死的 Hastie、Tibshirani 和其他人。第 1-4 章和第七章。如果不理解,就一直读,直到明白为止。
你可以继续阅读剩下的书。如果你愿意,你应该这么做,但我会假设你都知道了。
学习 Andrew Ng 的 Coursera 课程。在 Matlab、Python 和 R 中完成所有练习,确保它们的答案一致。
现在忘掉这些,阅读深度学习书籍。在 Linux 机器上安装 tensorflow 或 torch,并运行示例直到理解。做一些 CNN 和 RNN 的工作,并进行前馈 NNs。
完成所有这些后,去 arXiv 阅读最新的有用论文。文献每隔几个月就会变化,所以要跟上。
这样,你现在可能可以被大多数地方雇用。如果需要简历填充,可以参加一些 Kaggle 比赛。如果有调试问题,使用 StackOverflow。如果有数学问题,多读书。如果有生活问题,我无从知道。
它在诚实和准确性方面都很美妙。我有点不满的是没有生活建议,因为我期待这类人(或女士)会很擅长提供这些建议。
Google 收购了 Kaggle。这不应该是一个巨大的惊喜,考虑到以下几点:
Kaggle 与 Google 也有一段历史,不过那是最近的事。本月早些时候,Google 和 Kaggle 联手举办了一场价值 $100,000 的机器学习竞赛,主题是分类 YouTube 视频。该竞赛也与 Google Cloud Platform 进行了深度集成。
我们将拭目以待谷歌在 Kaggle 上的最终目标是什么,但这里有各种交叉的可能性。根据你对潜在垄断的看法,这个事件要么令人兴奋,要么令人恐惧。但这是一个很好的品牌推广举措,并且可以帮助谷歌扩展其最近成为全球唯一机器学习巨头的兴趣。
来自 Salesforce 首席科学家 Richard Socher 的一条推特建议:

尽管这是一个苹果和橙子的比较(“与其吃一块肉类披萨,不如去砍些木头”),我在某种程度上可以理解他的立场。这将是一个伟大的教育性项目,并且可以支持整个社区,特别是如果他鼓励分享这些精选数据集的话。但实际上,我不认为所有从事无监督学习问题的人都会或应该去标注分类数据。这显然不会推动无监督学习的进展。
在他的 Medium 博客上,Andrew Ng 宣布了他从百度辞职以及他即将到来的计划。剧透警告:他并不会在 Van Nuys 开一家海鲜餐厅:
我将继续致力于引领这一重要的社会变革。除了将大型公司转型为使用 AI,还存在丰富的创业机会以及进一步的 AI 研究。我希望我们所有人都能拥有自动驾驶汽车;可以自然对话的计算机;以及理解我们病痛的医疗机器人。工业革命使人类摆脱了许多重复的体力劳动;我现在希望 AI 能让人类摆脱重复的脑力劳动,例如在交通中驾驶。
祝好,Ng 先生!
Distill 正式推出,由 Google Brain 的创始编辑 Chris Olah 和 Shan Carter 进行规划和管理。撰稿人 Michael Nielsen 写道:
Distill 正在认真对待网络。Distill 文章(至少在其理想和雄心勃勃的形式中)不仅仅是一篇论文。它是一个互动媒介,允许用户——“读者”已不再足够——直接与机器学习模型进行互动。
理想情况下,这类文章会将解释、代码、数据和交互式可视化整合到一个环境中。在这样的环境中,用户可以以传统静态媒体无法实现的方式进行探索。他们可以更改模型,尝试不同的假设,并立即看到结果。这将使他们能够以传统静态媒体无法实现的方式迅速建立理解。
这无疑是一个需要关注的关键资源。祝相关人员好运。

相关:
-
顶级 /r/MachineLearning 帖子,二月:牛津深度 NLP 课程;Scikit-learn 结果的数据可视化
-
顶级 /r/MachineLearning 帖子,一月:TensorFlow 更新;AlphaGo 野外表现;自动驾驶马里奥卡丁车
-
顶级 /r/MachineLearning 帖子,十二月:OpenAI 宇宙;面向编码员的深度学习 MOOC;马斯克:特斯拉变得更棒
我们的前三个课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT 工作
更多相关话题
Top /r/MachineLearning 帖子,十月:不适合工作场所的图像识别、可微分神经计算机、Hinton 在 Coursera 上
原文:
www.kdnuggets.com/2016/11/top-reddit-machine-learning-october.html
 在十月的 /r/MachineLearning 上,事情变得不适合工作场所,DeepMind 继续创新,Hinton 再次成为头条,AI 开放网络被介绍,Stuart Little 拥有了一辆自主驾驶的汽车。
在十月的 /r/MachineLearning 上,事情变得不适合工作场所,DeepMind 继续创新,Hinton 再次成为头条,AI 开放网络被介绍,Stuart Little 拥有了一辆自主驾驶的汽车。
过去一个月/r/MachineLearning 的前五名帖子(不包括子版块的元讨论)是:
如果标题不够清楚的话……
警告:此帖子包含抽象的裸体描绘,可能不适合工作场所

这个在 GitLab 上的项目探讨了 Yahoo 的 open_nsfw,一个用于“工作不适宜(NSFW)分类的深度神经网络,使用深度神经网络 Caffe 模型。”帖子解释了:
Yahoo 最近开源的神经网络 open_nsfw 是一个精调的残差网络,根据其在工作场所使用的适宜性对图像进行 0 到 1 的评分。在文档中,Yahoo 说明:
“定义 NSFW 材料是主观的,识别这些图像的任务并不简单。此外,在一个环境中令人反感的内容在另一个环境中可能是适合的。”
作为双重免责声明,帖子中的合成图像以抽象的方式令人不安,并且不适合工作场所。
然而,这个项目和文章是对技术的合法探讨,远非无意义或色情。这是对研究的真实展示。
2. DeepMind 新的《自然》论文:使用动态外部记忆的混合计算神经网络
这篇来自 DeepMind 的帖子提供了对 最近发表在《自然》上的论文 的概述,介绍了可微分神经计算机。来自文章:
在最近的一项《自然》研究中,我们介绍了一种称为可微分神经计算机的记忆增强神经网络,并展示了它能够利用记忆回答有关复杂结构化数据的问题,包括人工生成的故事、家谱,甚至伦敦地铁图。我们还展示了它能够通过强化学习解决一个方块拼图游戏。
观看可微分神经计算机回答家谱关系问题:
3. Geoffrey Hinton 的《机器学习中的神经网络》课程已经开始。我们还为它创建了一个子论坛 (r/nn4ml)
Geoffrey Hinton 的《机器学习中的神经网络》在 Coursera 上重新开课。虽然你可能错过了前几周的课程,但如果你有兴趣学习这些材料,这是一个很好的入门课程,之前几周的所有材料和视频仍然可以访问。
如标题所述,子版块/r/nn4ml也是一个值得关注的资源,对参加课程的人可能有帮助。特别值得注意的是,子版块上有一个关于组建学习小组以在 TensorFlow 中实现课程内容的讨论。该线程有活动,并提到成员们使用的 Slack 频道,并附有加入说明。活跃的协作社区正在实现神经网络模型用于教育目的。听起来是个好事。
4. 介绍 AI 开放网络:一个 100% 开源的 AI 研究社区

直接来自 AI•ON 网站:
AI•ON 是一个致力于推进人工智能的开放社区:
- 引起对重要但未被充分重视的研究问题的关注。
- 连接研究人员并鼓励开放的科学合作。
- 为希望获得机器学习经验的学生提供学习环境。
以应用研究项目为重点的协作 AI 研究。听起来是个好事。
自动驾驶汽车持续成为头条新闻,但最近引起的关注比以往更多。
这个项目将自动驾驶引入了遥控车。研究人员已经将 Nvidia 最近的论文以紧凑形式实现,结果令人鼓舞:
有关项目实现的详细信息及代码,请查看这篇文章。
相关:
-
顶级 /r/MachineLearning 帖子,九月:开放图像数据集;巨额深度学习资助;高级 ML 课程资料
-
顶级 /r/MachineLearning 帖子,八月:Google Brain AMA,使用 TensorFlow 的图像完成,日本黄瓜种植
-
顶级 /r/MachineLearning 帖子,七月:Google Brain AMA,Geoff Hinton 获得 IEEE 奖章,Hinton ANN 课程上线!
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织进行 IT 工作
更多相关主题
九月份 /r/MachineLearning 热帖:从头实现一个 C++神经网络
原文:
www.kdnuggets.com/2015/10/top-reddit-machine-learning-september.html
作者 Matthew Mayo。
在 /r/MachineLearning 上的九月份,我们找到了一段关于 C++的神经网络教程视频,了解到基于深度学习的汉字手写识别已经超越了人类水平,拿到了一份机器学习算法速查表,将函数式编程与深度学习联系起来,并发现了一个神经网络论文库。
1. 绝对初学者的 C++神经网络 +154
这篇文章是一个戴夫·米勒讲解简单反向传播神经网络的视频,并演示如何在 C++中编写一个。该视频时长约为一小时,根据我个人跟随教程的经验,我可以告诉你,视频运行期间实现手工制作的、功能齐全的神经网络是可以实现的。简短的评论区还包含一些有用的讨论,包括对这本在线深度学习书籍的参考。你可以在这里找到米勒自己编写的神经网络代码。

2. 富士通实现了 96.7%的手写汉字识别率 +151
根据文章,手写汉字的实际人类等效识别率为 96.1%,而富士通以 96.7%的准确率超过了这一水平。遵循近期大量机器学习研究的精神,研究人员选择了深度神经网络作为工具。然而,这并不是你父亲的手写数字识别任务,因为需要识别 3800 个汉字。研究人员还创新性地提出了一种自动变形手写样本的方法,以增加训练样本的数量。
3. 速查表 - 常见机器学习算法的 Python 与 R 代码 +150
这篇文章通过 Analytics Vidhya 汇集了机器学习算法实现(通过库)的集合,分别在 Python 和 R 中实现。相应的代码覆盖了 10 种流行算法的整个建模过程(数据加载、训练、测试),包括决策树、支持向量机和线性回归。备忘单 对于对某种语言(或两种语言)不熟悉的新人以及希望温故或寻求快速复制粘贴解决方案的经验丰富的实施者都同样有用。
4. 神经网络、类型和函数式编程 +142
上个月,Christopher Olah 帮助我们理解了 LSTM 网络,而本月他选择的主题是深度学习:它的起源,它在不远的未来预期和改变后的形式,以及它与函数式编程的联系。Olah 在此提出了一个推测性的理论,即“深度学习研究了优化与函数式编程之间的关系”,将表示等同于类型,并将各种不同的神经网络与其感知的函数式等效物进行比较。尽管 Olah 自己表示“这是一篇相当奇怪的文章,我觉得发布它有点奇怪”,但这篇文章阅读起来非常有趣,帮助我们以全新的视角来看待两个熟悉但不相关的概念。这里是直接链接到论文。
5. 神经网络论文精选列表 +139
在这里!神经网络和深度学习无处不在,软件工程师和神经网络爱好者 Robert S. Dionne 为大家做了个好事,整理并分享了一个 相关论文列表,与我们当前的集体关注密切相关。该列表整齐地按 30 个类别进行展示,如限制玻尔兹曼机、卷积神经网络和并行训练。随着大量深度学习论文的涌现,能够整理和 解释 这些论文的人真是太好了。
简历:Matthew Mayo 是一名计算机科学研究生,目前正在进行关于并行化机器学习算法的论文研究。他还是数据挖掘的学生,数据爱好者,以及一名有志的机器学习科学家。
相关内容:
-
Top /r/MachineLearning 帖子,八月:深度学习以许多著名画家的风格进行绘画
-
Top /r/MachineLearning 帖子,7 月:机器学习视觉介绍、谷歌新专利争议、深度学习和著名艺术
-
Top 5 arXiv 深度学习论文,解析
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关主题
数据科学家使用的顶级 SQL 查询

作者提供的图片
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
我知道“Python”这个词在数据科学的背景下可能是被使用得最多的词。在某种程度上,这有其原因。然而,在这篇文章中,我想专注于 SQL,它在谈论数据科学时常被忽视。我强调谈论,因为在实际应用中,SQL 并没有被忽视。相反,它是数据科学中编程语言的圣三位一体之一:SQL、Python 和 R。
SQL 用于数据查询和操作,但也具有相当可观的数据分析和报告能力。我将展示一些你作为数据科学家需要了解的主要 SQL 概念以及来自 StrataScratch 和 LeetCode 的一些简单示例。
然后,我将提供两个常见的业务场景,其中所有或大部分 SQL 概念必须应用。
数据科学家主要 SQL 概念
这是我将讨论的概念概述。
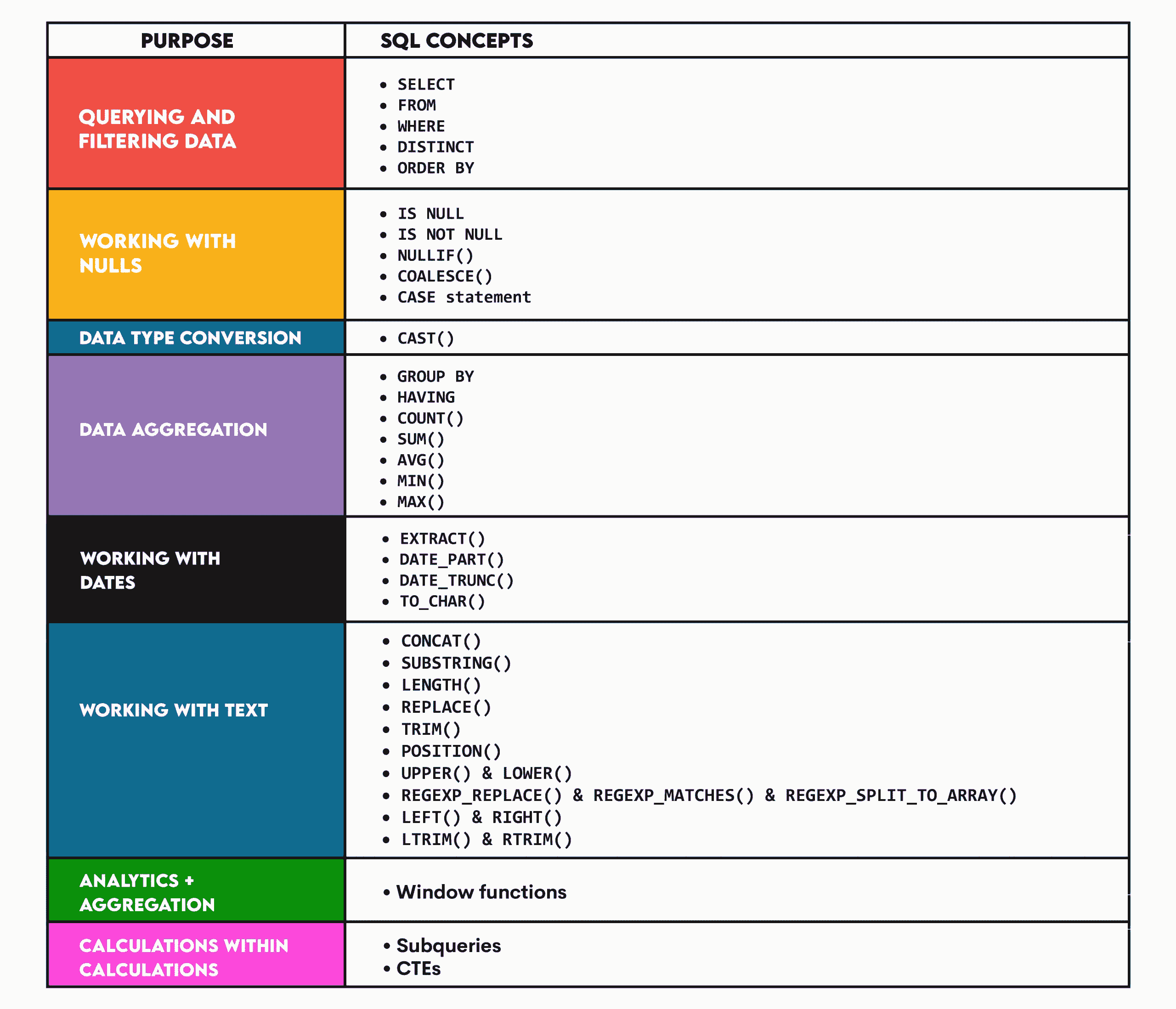
1. 查询和过滤数据
这是作为数据科学家的实际工作通常开始的地方:查询数据库并提取你任务所需的数据。
这通常涉及相对简单的 SELECT 语句,包含 FROM 和 WHERE 子句。要获取唯一值,使用 DISTINCT。如果需要使用多个表,还要添加 JOIN。
你通常需要使用 ORDER BY 来使数据集更加有序。
结合两个表的示例: 你可能需要通过连接两个表并按姓氏排序来列出人员的姓名以及他们所在的城市和州。
SELECT FirstName,
LastName,
City,
State
FROM Person p LEFT JOIN Address a
ON p.PersonId = a.PersonId
ORDER BY LastName ASC;
2. 处理 NULL
NULL 是数据科学家通常不会无动于衷的值——他们要么只要 NULL,要么想要删除它们,或者将它们替换为其他值。
你可以使用 IS NULL 或 IS NOT NULL 在 WHERE 子句中选择有或没有 NULL 的数据。
使用 条件表达式 通常可以用其他值替换 NULL:
-
NULLIF()
-
COALESCE()
-
CASE 语句
IS NULL 示例: 通过此查询,你可以找到所有没有被 ID = 2 的客户推荐的客户。
SELECT name
FROM customer
WHERE referee_id IS NULL OR referee_id <> 2;
COALESCE() 示例:我可以通过这个示例重新编写,说我想查询所有数据,但也添加一列,显示 0% 作为主机响应率,而不是 NULL。
SELECT *,
COALESCE(host_response_rate, '0%') AS edited_host_response_rate
FROM airbnb_search_details;
3. 数据类型转换
作为数据科学家,你会频繁地转换数据。数据通常不会以所需的格式出现,因此你必须将其调整为满足你的需求。这通常使用 CAST() 完成,但也有一些替代方法,具体取决于你的 SQL 版本。
数据类型转换示例: 该查询将星级数据从 VARCHAR 转换为 INTEGER,并移除具有非整数值的值。
SELECT business_name,
review_id,
user_id,
CAST(stars AS INTEGER) AS cast_stars,
review_date,
review_text,
funny,
useful,
cool
FROM yelp_reviews
WHERE stars '?';
4. 数据聚合
为了更好地理解他们正在处理的数据(或者仅仅因为他们需要生成一些报告),数据科学家经常需要对数据进行聚合。
在大多数情况下,你必须使用 聚合函数 和 GROUP BY。一些常见的聚合函数包括:
-
COUNT()
-
SUM()
-
AVG()
-
MIN()
-
MAX()
如果你想要过滤聚合数据,使用 HAVING 而不是 WHERE。
求和示例: 你可以使用此查询对每个用户的银行账户进行求和,并只显示余额超过 1,000 的用户。
SELECT u.name,
SUM(t.amount) AS balance
FROM Users u
JOIN Transactions t
ON u.account = t.account
GROUP BY u.name
HAVING SUM(t.amount) > 10000;
5. 处理日期
对于数据科学家来说,处理日期是很常见的。再说一遍,这些日期格式有时并不符合你的口味或需求。为了最大化日期的灵活性,你有时需要提取日期的部分或重新格式化它们。在 PostgreSQL 中,你最常用这些 日期/时间函数:
-
EXTRACT()
-
DATE_PART()
-
DATE_TRUNC()
-
TO_CHAR()
处理日期的常见操作之一是找出日期之间的差异或添加日期。你可以通过简单地减去或添加这两个值,或者使用专门的函数来完成这项操作,具体取决于你使用的数据库。
提取年份示例: 以下查询从 DATETIME 类型的列中提取年份,以显示 Roxanne Cafe 每年的违规次数。
SELECT EXTRACT(YEAR FROM inspection_date) AS year_of_violation,
COUNT(*) AS n_violations
FROM sf_restaurant_health_violations
WHERE business_name = 'Roxanne Cafe' AND violation_id IS NOT NULL
GROUP BY year_of_violation
ORDER BY year_of_violation ASC;
日期格式化示例:通过以下查询,你可以使用 TO_CHAR() 将开始日期格式化为 'YYYY-MM'。
SELECT TO_CHAR(started_at, 'YYYY-MM'),
COUNT(*) AS n_registrations
FROM noom_signups
GROUP BY 1;
6. 处理文本
除了日期和数字数据外,数据库中经常包含文本值。有时,这些值需要被清理、重新格式化、统一、拆分和合并。由于这些需求,每个数据库都有许多文本函数。在 PostgreSQL 中,一些比较流行的函数有:
-
CONCAT() 或 ||
-
SUBSTRING()
-
LENGTH()
-
REPLACE()
-
TRIM()
-
POSITION()
-
UPPER() & LOWER()
-
REGEXP_REPLACE() & REGEXP_MATCHES() & REGEXP_SPLIT_TO_ARRAY()
-
LEFT() & RIGHT()
-
LTRIM() & RTRIM()
所有数据库中通常都有一些重叠的字符串函数,但每种数据库都有一些独特的函数。
文本长度示例: 此查询使用 LENGTH() 函数根据长度查找无效的推文。
SELECT tweet_id
FROM Tweets
WHERE LENGTH(content) > 15;
7. 排名数据
排名数据是数据科学中常见的任务之一。例如,它可以用来查找最畅销或最滞销的产品、收入最高的季度、按流媒体次数排名的歌曲以及薪水最高和最低的员工。
排名是通过窗口函数完成的(我们将在下一部分详细讨论):
-
ROW_NUMBER()
-
RANK()
-
DENSE_RANK()
排名示例:此查询使用 DENSE_RANK() 函数根据列出的床位数量对房东进行排名。
SELECT host_id,
SUM(n_beds) AS number_of_beds,
DENSE_RANK() OVER(ORDER BY SUM(n_beds) DESC) AS rank
FROM airbnb_apartments
GROUP BY host_id
ORDER BY number_of_beds DESC;
8. 窗口函数
SQL 中的窗口函数允许你计算与当前行相关的行。这种特性不仅用于排名数据。根据窗口函数的类别,它们可以有许多不同的用途。你可以在窗口函数文章中阅读更多信息。然而,它们的主要特性是可以同时显示分析和聚合数据。换句话说,在执行计算时,它们不会合并单独的行。
FIRST_VALUE() 窗口函数示例: 一个窗口函数示例是显示特定年份的最新用户登录。FIRST_VALUE() 窗口函数使这一任务变得更容易。
SELECT DISTINCT user_id,
FIRST_VALUE(time_stamp) OVER (PARTITION BY user_id ORDER BY time_stamp DESC) AS last_stamp
FROM Logins
WHERE EXTRACT(YEAR FROM time_stamp) = 2020;
9. 子查询与 CTE
子查询和 CTE(称为更整洁的子查询)允许你达到更高级的计算水平。通过了解子查询和 CTE,你可以编写复杂的 SQL 查询,在主查询中引用子查询或 CTE 用于子计算。
子查询和 CTE 示例: 以下查询使用子查询找到产品销售的第一年。这些数据然后在主查询的 WHERE 子句中用于过滤数据。
SELECT product_id,
year AS first_year,
quantity,
price
FROM Sales
WHERE (product_id, year) IN (
SELECT product_id,
MIN(year) AS year
FROM Sales
GROUP BY product_id
);
代码可以使用 CTE 代替子查询来编写。
WITH first_year_sales AS (
SELECT product_id,
MIN(year) AS first_year
FROM Sales
GROUP BY product_id
)
SELECT s.product_id,
s.year AS first_year,
s.quantity,
s.price
FROM Sales s
JOIN first_year_sales AS fys
ON s.product_id = fys.product_id AND s.year = fys.first_year;
使用 SQL 的业务示例
现在让我们来看几个业务案例,数据科学家可以使用 SQL 并应用我们之前讨论的所有(或大部分)概念。
寻找最佳销售产品
在这个示例中,你必须了解子查询、数据汇总、处理日期、使用窗口函数排名数据以及过滤输出。
子查询计算每个产品每个月的销售额,并按销售额排序。主查询则简单地选择所需的列,仅保留排名第一的产品,即畅销产品。
SELECT sale_month,
description,
total_paid
FROM
(SELECT DATE_PART('MONTH', invoicedate) AS sale_month,
description,
SUM(unitprice * quantity) AS total_paid,
RANK() OVER (PARTITION BY DATE_PART('MONTH', invoicedate) ORDER BY SUM(unitprice * quantity) DESC) AS sale_rank
FROM online_retail
GROUP BY sale_month,
description) AS ranking_sales
WHERE sale_rank = 1;
计算移动平均
滚动或移动平均是一个常见的业务计算,数据科学家可以应用他们广泛的 SQL 知识,如这个示例所示。
以下代码中的子查询按月份计算收入。主查询然后使用 AVG() 窗口函数计算 3 个月的滚动平均收入。
SELECT t.month,
AVG(t.monthly_revenue) OVER(ORDER BY t.month ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS avg_revenue
FROM
(SELECT TO_CHAR(created_at::DATE, 'YYYY-MM') AS month,
SUM(purchase_amt) AS monthly_revenue
FROM amazon_purchases
WHERE purchase_amt>0
GROUP BY 1
ORDER BY 1) AS t
ORDER BY t.month ASC;
结论
所有这些 SQL 查询展示了如何在数据科学任务中使用 SQL。虽然 SQL 不适用于复杂的统计分析或机器学习,但它非常适合查询、操控、汇总数据和进行计算。
这些示例查询应该能帮助你在工作中。如果你没有数据科学工作,其中许多查询将在你的SQL 面试问题中出现。
内特·罗西迪 是一位数据科学家及产品策略专家。他还是一名兼职教授,教授分析学,是 StrataScratch 的创始人,该平台帮助数据科学家通过来自顶级公司的真实面试问题来准备面试。内特撰写了有关职业市场的最新趋势,提供面试建议,分享数据科学项目,并涵盖所有 SQL 相关内容。
更多相关内容
KDnuggets 推文最佳,1 月 04-10 日:漫画:当自动驾驶车把你带得太远了;大量免费的编程书籍
最受欢迎的 @KDnuggets 推文(1 月 04-10 日)是
转发最多的:
漫画:当 #自动驾驶 车 + #机器学习 把你带得太远了…… #AI t.co/z65aSnd0nn t.co/jXJKLgoDP7 ![自动驾驶车]()

收藏最多的:
大量(我们假设为真正的)免费的 #编程 书籍:t.co/31LzaLStn6 t.co/ledMPOfUPl
观看最多的:
漫画:当 #自动驾驶 车 + #机器学习 把你带得太远了…… #AI t.co/z65aSnd0nn t.co/jXJKLgoDP7
点击最多的:
AI #数据科学 #机器学习:2016 年的主要发展,2017 年的关键趋势 @zacharylipton @jilldyche @goodfellow_ian t.co/1riBvzO8W7 t.co/GrOVzzkRxL
十大最吸引人的推文
-
大量(我们假设为真正的)免费的 #编程 书籍:
t.co/31LzaLStn6t.co/ledMPOfUPl -
AI #数据科学 #机器学习:2016 年的主要发展,2017 年的关键趋势 @zacharylipton @jilldyche @goodfellow_ian
t.co/1riBvzO8W7t.co/GrOVzzkRxL -
Scikit-Learn 备忘单:#Python #机器学习 作者 @willems_karlijn 通过 @DataCamp
t.co/8TuGdniMDOt.co/nmxjCS1mOi -
漫画:当 #自动驾驶 车 + #机器学习 把你带得太远了…… #AI
t.co/z65aSnd0nnt.co/jXJKLgoDP7 -
AI 和 #机器学习 未来 1:背景,作者 Neil Lawrence @lawrennd
t.co/I3YwCfXQEMt.co/eQO7QFIQF8 -
ICYMI 5 个你不能再忽视的 #机器学习 项目,1 月
t.co/iuYcBxKbD9t.co/GmA3Ipc6Jv -
为什么 #决策树 有效:训练 #数据 #机器学习 中错误的概率以指数速度减少
t.co/VUIiN3DtKOt.co/LcDSgKsuxR -
每位员工的收入:黄金比例,还是假象? #劳动力 #分析
t.co/Ey11UVSNtCt.co/JLSbsjCZoR -
AI 和 #机器学习的未来 3:机器学习的特洛伊战争,作者:Neil Lawrence @lawrennd
t.co/q4fXpt4yaHt.co/ofTvj1OJFu -
5 个你不能再忽视的#深度学习项目
t.co/dgie5TYB32t.co/Fmr8Fd3uLT
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
KDnuggets 最受欢迎的推文,3 月 16-18 日:87 项研究显示,准确的数字并不比你编造的数字更有用(Dilbert)
最受欢迎的 @KDnuggets 推文,3 月 16-18 日
最吸引人的 10 条推文
-
87 项研究显示,准确的数字并不比你编造的数字更有用 #Dilbert buff.ly/1HXm17p pic.twitter.com/GZipoZ5Lr4
![87 项研究显示,准确的数字并不比你编造的数字更有用(Dilbert)]()
-
研究人员建立了 Sirius - 一个免费的开源 Siri 版本,使用#深度学习、语音 buff.ly/1x7Xxro pic.twitter.com/63a3GbPG8C
![Sirius - 一个免费的开源 Siri 版本]()
-
PI 艺术:从圆心向外,前 13,689 位π的数字 #数学 buff.ly/1AtnNIf pic.twitter.com/sj6PGgRo0J
![#PI 艺术:从圆心向外,前 13,689 位π的数字]()
-
很棒的教程 + #Python 代码:1 层神经网络 #机器学习 #算法 buff.ly/1HVSivv pic.twitter.com/37KG6OcJDw
-
特征工程:如何转化和创建变量 #机器学习 #数据科学 buff.ly/1BFvoaL pic.twitter.com/iiQVTJd4IU
![特征工程]()
-
数据科学家需要了解的 5 件事关于 Excel:命名范围、排序/过滤、数据透视表 buff.ly/1x7XaNg pic.twitter.com/oMusaVGNSH
-
用#深度学习分类浮游生物 - 国家数据科学竞赛的获胜者解释 @kaggle buff.ly/1BugyPy pic.twitter.com/8GRlY6uxs5
-
给 Yann LeCun 的公开信 - 小数据需要专门的#深度学习 buff.ly/1Cnb3I5 pic.twitter.com/F1GYbz4M8x
-
发出噪音:拥抱#随机性是扩大#机器学习算法的关键 buff.ly/1O0vnmY pic.twitter.com/uaEMMBG6dE
-
为什么#数据引力在#架构#设计中不能被忽视?#访谈与 @mccrory、@Basho buff.ly/1F18gpM pic.twitter.com/DTgmoIOCFs



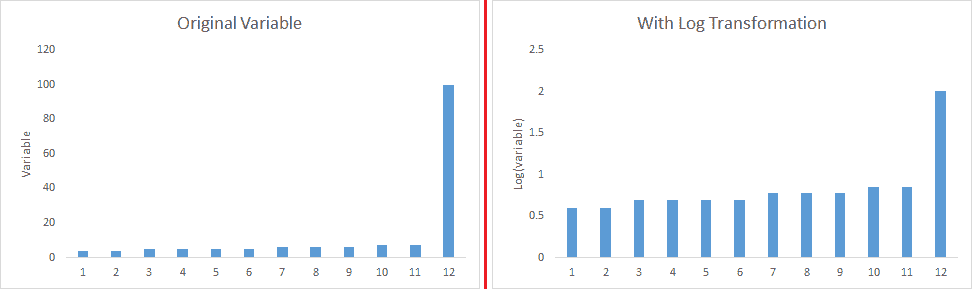
更多相关内容
KDnuggets 推文精华,5 月 13 日至 19 日:线性代数与优化及机器学习:一本教科书
5 月 13 日至 19 日最受欢迎的 @KDnuggets 推文
最被转发:
成为自学的#机器学习工程师所需的一切 t.co/QNOjw6eNEc t.co/hXUjCH9BDP
最受喜爱:
线性代数与优化及机器学习:一本教科书 t.co/jfzjVtFIIH t.co/oRHE5sUycg
最受关注:
线性代数与优化及机器学习:一本教科书 t.co/jfzjVtFIIH t.co/oRHE5sUycg
最具互动性:
线性代数与优化及机器学习:一本教科书 t.co/jfzjVtFIIH t.co/oRHE5sUycg
点击量最高的前 10 条推文
-
线性代数与优化及机器学习:一本教科书
t.co/jfzjVtFIIHt.co/oRHE5sUycg -
成为自学的#机器学习工程师所需的一切
t.co/QNOjw6eNEct.co/hXUjCH9BDP -
SQL 备忘单(2020) - 一个有用的备忘单,记录了一些更常用的 SQL 元素,甚至还有一些不太常见的
t.co/uzPb4resu9t.co/r7MHbZP512 -
《自动化机器学习:免费电子书》 - KDnuggets
t.co/ovSMpsyrSU关于自动化机器学习理论和实践还有很多需要学习的内容。这本免费电子书可以帮助你正确入门。t.co/Www9mDEdgT -
《自动化机器学习:免费电子书》 - KDnuggets
t.co/ovSMpsgR1mt.co/421rvT30wS -
KDnuggets 新漫画探讨了可能是最糟糕的远程医疗例子 ...
t.co/jh1Z1SlztVt.co/mpDJLQu9rM -
24 本最佳(且免费的)书籍来理解机器学习 - KDnuggets
t.co/NeAdMfq09Kt.co/QY60ES68ew -
Scikit-Learn 设计原则
t.co/yxXwRksgKyt.co/g2QbOCZt10 -
《统计学习的元素:免费电子书》 - KDnuggets
t.co/KHiPdBCc6ut.co/dfiawOvvjL -
编程人员数学教授了你为编程职业所需的#数学,集中讲解作为开发者需要掌握的知识。使用代码 kdmath50 来节省@ManningBooks
t.co/k7YGKRmPZit.co/Kv3xFlBgXB
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关主题
KDnuggets 最受欢迎的推文,11 月 2 日至 8 日:35 个物联网开源工具;集成学习者简介
最受欢迎的 @KDnuggets 推文,11 月 02-08 日
最受转发:
35 个物联网开源工具 #KDN t.co/8XxYD7VDH8
最受喜欢:
数据科学基础:集成学习者简介 t.co/nY7mKR76Gt #机器学习 #数据挖掘 @mattmayo13 t.co/bkXYwaoMKP
最受观看:
ICYMI 机器学习工程师需要知道的 10 种算法 t.co/jJGA270FL7 t.co/55wMDMcPFq
点击最多:
ICYMI 21 个必须知道的数据科学面试问题及答案 t.co/mYKUrUT5aK t.co/ZtL2y7ai6e
前 10 条最吸引人的推文
-
ICYMI 21 个必须知道的数据科学面试问题及答案
t.co/mYKUrUT5aKt.co/ZtL2y7ai6e -
ICYMI 大数据科学:期望与现实
t.co/lYYQd0tZGgt.co/qVHCnsmOy3 -
ICYMI 大数据科学:期望与现实
t.co/e2xbCB070Xt.co/wMesDAQnHA -
ICYMI 机器学习工程师需要知道的 10 种算法
t.co/jJGA270FL7t.co/55wMDMcPFq -
对#Git 分支感到困惑?@devbootcamp 制作了这个实用图示
t.co/5u2SmmSsDB -
数据科学基础:集成学习者简介
t.co/nY7mKR76Gt#机器学习 #数据挖掘 @mattmayo13t.co/bkXYwaoMKP -
arXiv 语义知识图谱:一个紧凑的、自动生成的实时遍历和排名模型
t.co/XWancCFSTk#分析t.co/HwsmynPr9q -
人工智能 分类矩阵
t.co/ex8ZfvsmWit.co/qXVTD1VQ7a -
ICYMI 进入机器学习之前阅读的 5 本电子书
t.co/4xxefW3Hlft.co/S4zOsKHUBI -
ICYMI 8 个(简单)步骤学习数据科学
t.co/hpIuL3ut6It.co/HO5RcjhqXU
更多相关话题
KDnuggets 顶级推文,11 月 17-18 日:在学习#Python 时随手备份此秘籍;#BigData 是否是最被炒作的技术?
11 月 17-18 日最受欢迎的 @KDnuggets 推文有
转发最多:
#BigData 是有史以来最被炒作的技术吗?不是(至少目前还不是)
t.co/lzZIFs4FNspic.twitter.com/RaiurvM7h5— Gregory Piatetsky (@kdnuggets) 2014 年 11 月 17 日
最受喜爱:
在学习编程时随时备份此#Python 秘籍 t.co/IIGLXJjzjq t.co/lEPdSvuX8A 
最受关注:
BigData 是否是最被炒作的技术?不是(至少目前还不是) t.co/lzZIFs4FNs http://t.co/RaiurvM7h5
点击最多:
在学习编程时随时备份此#Python 秘籍 t.co/IIGLXJjzjq http://t.co/lEPdSvuX8A
前 10 条最具吸引力的推文
-
在学习编程时随时备份此#Python 秘籍 t.co/IIGLXJjzjq t.co/lEPdSvuX8A
-
BigData 是否是最被炒作的技术?不是(至少目前还不是) t.co/lzZIFs4FNs t.co/RaiurvM7h5
-
如何在 8 个(不那么)简单的步骤中成为数据科学家 - 精美信息图 #BigData t.co/ebZPRjLH1p t.co/GRPZyZw3EX
-
R 和 Hadoop 使得机器学习对每个人都可能 t.co/ROA33LiUvP
-
同意!数据可视化需要展示结论,而非艺术杰作 t.co/lPmV24r70n t.co/qmdLoVs7CK
-
极客与书呆子:文化,#apple,#etsy - 极客;神经科学,哈佛,书呆子;#bigdata 既是极客又是书呆子 t.co/Ok0R3hu3Oo t.co/uaR092QwaX
![极客与书呆子]()
-
《数据科学与商业》,作者 @FakeFoster,Fawcett,优秀的书籍 & MBA 必读书单之一 t.co/kVGVbnTD9V t.co/UJmqGQjLeb
-
唯一需要关注的技能:解决问题 t.co/qFi238ncQf
-
为什么 Azure ML 是机器学习的下一个大趋势? t.co/qc1711ChWZ
-
Bing Predicts 超越行业专家,准确预测美国中期选举的准确率超过 95% t.co/hrPNCrQuYe t.co/cHxLK5yZOw
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 部门。
相关话题
KDnuggets 推文,11 月 21 日至 27 日:管理者数据科学入门 – 思维导图;人工智能简介
11 月 21 日至 27 日最受欢迎的 @KDnuggets 推文如下
转发最多的:
管理者数据科学入门 - 思维导图 t.co/pD0QuhbXqN t.co/MHn0GStsOp
最受喜爱的:
管理者数据科学入门 - 思维导图 t.co/pD0QuhbXqN t.co/MHn0GStsOp
最受欢迎的:
人工智能简介 t.co/QkRdKzPTDV t.co/VhK5ATefKK
点击最多的:
管理者数据科学入门 - 思维导图 t.co/pD0QuhbXqN t.co/MHn0GStsOp
前 10 条最具吸引力的推文
-
管理者数据科学入门 - 思维导图
t.co/pD0QuhbXqNt.co/MHn0GStsOp -
人工智能简介
t.co/QkRdKzPTDVt.co/VhK5ATefKK -
直观理解卷积的#深度学习
t.co/X6xruKljP6t.co/GYHnYaVv5K -
管理者数据科学入门
t.co/pD0QuhbXqNt.co/864afVypuf -
10 个免费的机器学习与数据科学必看课程
t.co/aM7h4AWmFNt.co/lKppfhUhuO -
人工直觉与强化学习,#机器学习 #AI 的下一步
t.co/EtHWqknDcXt.co/G65w0fK5Lh -
大数据游戏板™
t.co/Mmnw8IBko5t.co/nnkMEdzP2w -
最佳 Python IDE 用于数据科学是什么?
t.co/UuDv6s9BIbt.co/BEA9C2hDDV -
漫画:感恩节、大数据与火鸡数据科学。
t.co/C355O0C6FUt.co/SqhMwEQLJV -
10 个免费的机器学习与数据科学必看课程
t.co/aM7h4AWmFNt.co/3pYX26fggu
更多相关内容
数据科学的顶级 YouTube 频道
原文:
www.kdnuggets.com/2021/03/top-youtube-channels-data-science.html
评论
视频是一个很好的学习工具,YouTube 上有大量的数据科学资料等着被消费。然而,发现平台上的优质内容可能很困难,我们往往珍视那些优秀频道的发现。
我并不是告诉你什么你不知道的事情,但我在这里(希望能)帮助缓解在 YouTube 上寻找优质数据科学视频内容的麻烦。这里的想法是采取定性的方法来识别平台上有价值的频道。我们的方法是从直觉出发,认为优质内容应该会导致频道的受欢迎程度,这可以通过订阅者数量来衡量。
不幸的是,按订阅者数量搜索频道并不那么简单,并且由于没有权威的列表来确定哪些频道的内容是或不是“数据科学”,我们还不得不依赖关键词搜索。确定哪些频道最终进入我们的列表的方法如下,首先是我们的 YouTube 搜索标准:
-
搜索词:“数据科学”
-
搜索类型:频道
-
排序依据:观看次数
这些是搜索结果。需要注意的是,这个过程的一个主要警告是,我们必须依赖关键词搜索来识别相关的数据科学内容。
在执行上述搜索后,我们按照这些步骤来最终得到订阅者数量最多的频道列表:
-
我们抓取了前 100 个频道的结果
-
我们排除了任何没有公开订阅者数量的频道
-
我们重新按订阅者数量对列表进行了排序
我们得到的是按订阅者数量排序的前 15 个数据科学内容的 YouTube 频道列表,这是通过我们的关键词搜索词识别的。由于超过 15 个的频道变得不那么有趣,我们在此阈值后中断了列表,以避免淹没读者于过多的视频时长中。
我们还收集了每个频道的总观看次数以及每位订阅者的观看次数,并利用所有这些数据创建了下面的可视化图表,以帮助快速传达这 15 个频道的故事。
图 1. 数据科学的顶级 YouTube 频道
按观看次数和订阅者数量绘制;相对大小按视频数量确定;
按观看次数/订阅者数量的颜色强度
所以这里是按订阅者数量排序的前 15 个数据科学 YouTube 频道,以及来自这些频道本身的简短描述。
1. edureka!
订阅者:2,440 K,视频:4012,观看次数:197 M,开始日期:2012 年 6 月 29 日
我们是一个实时互动的电子学习平台,使命是让每个人都能轻松学习。我们提供由讲师主导的课程,以及 24/7 随时随地的支持,以实现业内最高的课程完成率!我们的实际项目、24*7 支持、个人学习经理确保你的学习目标得以实现!
2. Joma Tech
订阅者:889 K,视频:83,观看次数:55 M,开始日期:2016 年 8 月 31 日
我谈论硅谷生活、大型科技公司、数据科学和软件工程。
3. Simplilearn
订阅者:883 K,视频:2468,观看次数:63 M,开始日期:2009 年 10 月 29 日
Simplilearn 是全球排名第一的在线训练营,致力于帮助人们获得在数字经济中成功所需的技能。
4. StatQuest with Josh Starmer
订阅者:434 K,视频:192,观看次数:21 M,开始日期:2011 年 5 月 23 日
统计学、机器学习和数据科学有时可能看起来非常可怕,但由于每种技术实际上只是由小而简单的步骤组合而成,它们实际上非常简单。我的目标是将主要方法论分解为易于理解的部分。也就是说,我不会简化材料。相反,我会提升你的理解,以使你变得更加聪明。
订阅者:330 K,视频:1129,观看次数:37 M,开始日期:2013 年 4 月 3 日
Great Learning 致力于让任何想要学习的人都能获得优质教育。Great Learning Academy(http://greatlearning.in/academy)致力于支持免费学习,提供 200 多个完全免费的热门职业领域课程。除了视频,你还可以获得完成证书,做作业和项目,参加实时课程,与顶级教师和行业专家互动。所有这些都是免费的。
6. Krish Naik
订阅者:321 K,视频:895,观看次数:21 M,开始日期:2012 年 2 月 10 日
我担任首席数据科学家,开创机器学习、深度学习和计算机视觉领域的工作,同时也是一名教育者和导师,拥有超过 8 年的行业经验。这是我的 YouTube 频道,在这里我用许多实际问题场景讲解机器学习、深度学习和人工智能的各种主题。我已在各种聚会、技术机构和社区组织的论坛上进行了 30 多场关于数据科学、机器学习和人工智能的技术讲座。我的主要目标是让每个人都熟悉机器学习和人工智能。请订阅并支持这个频道。由于我喜欢新技术,这些视频都是免费的,我承诺将来会制作更多有趣的内容。
7. 数据学院
订阅者:165 K,视频:100,观看次数:8.1 M,开始日期:2014 年 4 月 30 日
你是否在学习数据科学,以便获得第一份数据科学工作?你可能对自己“应该”学习的内容感到困惑,并且很难找到你能理解的课程!Data School 让你专注于首先需要掌握的主题,并提供你可以理解的深入教程,无论你的教育背景如何。
8. 365 数据科学
订阅者:161 K,视频:188,观看次数:5.9 M,开始日期:2017 年 8 月 7 日
在 365 数据科学公司,我们每天上班的原因是我们想解决数据科学中最大的难题——教育。
9. Ken Jee
订阅者:123 K,视频:178,观看次数:3.3 M,开始日期:2014 年 2 月 28 日
数据科学和体育分析是我的热情所在。我叫 Ken Jee,过去 5 年里,我一直在数据科学领域从事体育分析工作。我曾在从初创企业到财富 100 强的公司中担任数据科学职位。我从商业和咨询背景转型进入数据科学领域。当我刚开始我的数据科学之旅时,我感到非常迷茫;当时几乎没有资源可以让我学习这个领域。我决定开始制作 YouTube 视频,分享我的经历,并希望帮助其他人进入数据科学和体育分析领域。
10. 数据科学道场
订阅者:67.1 K,视频:246,观看次数:3.6 M,开始日期:2014 年 8 月 6 日
在数据科学道场,我们相信数据科学适合每个人。我们的面对面数据科学训练营已吸引来自全球超过 1,500 家公司的 4,000 多名专业人士参加。我们的频道是展示我们致力于教授各种技能水平数据科学的完美平台!你会发现数据科学和数据工程的教程、社区讨论和课程。
11. 可视化艺术
订阅者:54.7 K,视频:252,观看次数:3.5 M,开始日期:2016 年 8 月 15 日
欢迎来到 ArtofVisualization 频道,这里有最好的 Tableau 和 BI 教程!我们以始终与您分享最新、最前沿的 Tableau 可视化、仪表板及大量提高数据可视化技能的技巧和窍门而自豪!
12. IBM 数据与人工智能
订阅者:43.2 K,视频:229,观看次数:0.6 M,开始日期:2011 年 7 月 18 日
作为认知战略的一部分,组织可以通过数据转变其行业和职业。IBM Analytics 使任何人都能与数据互动,以回答最棘手的业务问题,发现模式并追求突破性的想法。在 IBM,我们提供全面的数据分析方法,包括在影响点提供即时业务价值的专业知识。在这里,你可以找到演示、示例、访谈、技术教程等。
13. 数据科学教程
订阅者: 25.9 K,视频数量: 659,观看次数: 2.5 M,开始日期: 2015 年 11 月 1 日
在这个频道中,我的目标是讲解 R 语言及其编程和统计分析技术。R 语言由于其易于学习的编程语法和丰富的分析包,成为统计学家和研究人员的首选编程语言。
14. Andreas Kretz
订阅者: 19.8 K,视频数量: 306,观看次数: 0.5 M,开始日期: 2017 年 4 月 18 日
我帮助你进入数据工程领域,这是数据科学的基础工作。建立大数据平台。数据科学播客《数据科学的水管工》的主办者,探索如何摄取、处理和存储数据,以使数据科学家能够为客户做出出色的工作。使用像 Hadoop、Spark 和 Kafka 这样的工具。这就是数据工程——数据科学的基础工作。我已经从事这个令人兴奋的工作快八年了 😃
15. 数据科学学院
订阅者: 19.0 K,视频数量: 77,观看次数: 0.5 M,开始日期: 2016 年 2 月 26 日
这是 Data Science Academy Brasil 的官方 YouTube 频道:www.datascienceacademy.com.br
以下是按订阅者数量排序的前 15 个数据科学 YouTube 频道,以及一些额外的数据,帮助你决定这些频道是否可能有你感兴趣的视频内容。祝你观影愉快!
相关:
-
10 分钟内最佳机器学习 YouTube 视频
-
数据科学、数据可视化和机器学习的顶级 Python 库
-
深度学习、自然语言处理和计算机视觉的顶级 Python 库
更多相关主题
学习数据科学的顶级 YouTube 频道
原文:
www.kdnuggets.com/2022/04/top-youtube-channels-learning-data-science.html

Christian Wiediger 通过 Unsplash
随着数据使用的普及,数据科学家的需求也在增加。每天都有新的公司提供训练营,大学也在策划新的课程以满足这种需求。然而,选择合适的内容和最佳资源可能很困难。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织的 IT 工作
由于疫情迫使世界各地的人们在家工作,很多人都在远程学习。我们越来越倾向于通过 Zoom 会议或视频观看讲座。
这是 YouTube 成为人们自我发展和知识增加的重要元素的地方。
以下是提供数据科学学习的 YouTube 频道列表。
1. StatQuest With John Starmer
如果你是数据科学新手,理解统计学和机器学习的概念可能会很困难。John Starmer 于 2011 年 5 月 24 日加入 YouTube,目前有 680K 订阅者。
Starmer 使用图像概念帮助你理解复杂的主题,并逐渐提高你的理解能力。我在第一次接触数据科学时使用了 StatQuest,那时我意识到理解统计概念是多么重要。
他开始他的视频时会有一个简短的吸引人的介绍,唱歌来打破僵局,并让你对学习复杂的理论感到轻松。
2. Krish Naik
Krish Naik 是 iNeuron 的联合创始人,拥有超过 10 年的机器学习、深度学习和计算机视觉经验。Krish Naik 于 2012 年 2 月 11 日加入 YouTube,目前有 542K 订阅者。
Naik 不仅讲解数据科学、机器学习、深度学习等理论和应用,还提供有关进入和在该领域发展的建议和指导。
他在他的 YouTube 频道上还有三种不同类型的会员;数据科学材料、数据科学指导和项目实时数据科学。
3. Simplilearn
Simplilearn 于 2009 年 10 月 29 日加入 YouTube,目前拥有 187 万订阅者。他们旨在帮助人们获得在数字经济中取得成功所需的技能。
他们提供课程和全面的认证程序,并与世界著名大学建立了合作伙伴关系。他们的做法使 85% 的学员获得了晋升或找到了新工作。
他们不仅提供全面的理论和应用数字相关内容的教程;还制作了关于当前市场趋势的视频以及自我发展方面的最佳书籍推荐。
4. freeCodeCamp.org
freeCodeCamp.org 是一个允许你免费学习编程的组织。他们于 2014 年 12 月 16 日加入 YouTube,目前拥有 523 万订阅者。
该频道由 Quincy Larson 创建,他制作了数千个编程教程和视频,并在全球拥有数千个 freeCodeCamp 学习小组。
如果你不确定编程是否适合你,并且想先了解一下,freeCodeCamp.org 是一个不错的起点,因为你不用担心经济压力。
5. Edureka!
Edureka! 是一个实时互动的电子学习平台,于 2012 年 6 月 29 日加入 YouTube,目前拥有 322 万订阅者。
他们提供由讲师主导的课程,这些课程具有全天候的随需支持,并且包含实际项目,以确保学员的学习目标能够实现。
他们涵盖的主题范围广泛,如数据科学、人工智能、大数据、DevOps、区块链、Python、Selenium、Tableau、Android、AWS 架构师、数字营销等。他们还提供关于热门公司、最高薪资职位、编程语言和证书的信息,以帮助你为相关领域做好准备。
6. Corey Schafer
Corey Schafer 专注于为软件开发人员、程序员和工程师创建教程和演练。Schafer 于 2006 年 5 月 31 日加入 YouTube,目前拥有 90.1 万订阅者。
Schafer 的内容并不针对特定的技能水平,他面向初学者到有多年经验的人。Schafer 涵盖了各种主题,如 Python、Git、终端命令、SQL、JavaScript、计算机科学基础等。
7. sentdex
Sentdex 提供从基础到复杂的 Python 编程教程。Sentdex 于 2012 年 12 月 16 日加入 YouTube,目前拥有 111 万订阅者。
Sentdex 涵盖了各种主题的教程,如机器学习、金融、数据分析、机器人技术、网络开发、游戏开发等。
Sentdex 的视频相比其他 YouTube 频道时间较短,但他仍提供了理解主题所需的所有信息,这使得他的视频对那些需要信息且容易因长视频而感到失望的人非常有用。
8. Joma Tech
如果你已经在进行数据科学之旅,但需要一些关于该领域和市场趋势的建议,Joma Tech 就是你需要的人。
Joma Tech 谈论硅谷的生活和主要科技公司。Joma Tech 于 2016 年 8 月 31 日加入 YouTube,目前有 165 万订阅者。
他告诉你作为数据科学家、工程师等你将要做的真实情况,以及有关招聘过程的信息。
Nisha Arya 是一名数据科学家和自由职业技术作家。她特别感兴趣于提供数据科学职业建议或教程以及理论基础知识。她还希望探索人工智能如何有助于人类寿命的不同方式。她是一名热衷学习者,寻求拓宽技术知识和写作技能,同时帮助指导他人。
更多相关主题
顶级 YouTube 机器学习频道
原文:
www.kdnuggets.com/2021/03/top-youtube-machine-learning-channels.html
评论
KDnuggets 最近为你带来了数据科学的顶级 YouTube 频道,采用了定性方法来识别平台上有价值的频道。由于该活动似乎对一些读者有用,我们重复了这个过程,这次为你带来了 YouTube 提供的顶级机器学习频道。
在这一轮中,我们更改了用于确定“顶级”频道的指标。我们保持了定量方法,但调整了具体细节。(此外,我们完全认识到制定标准的行为是一种主观性,但现实中需要做出一些决策。)这次确定哪些频道出现在我们的列表中,始于此 YouTube 搜索标准:
-
搜索词:“机器学习”
-
搜索类型:频道
-
排序依据:相关性
这次搜索的结果收集于 2021 年 3 月 21 日,并在此网址出现过。
提取了前 100 个结果。之后应用了以下数据处理:
-
移除<100K 观看次数的频道
-
移除过去12 个月没有更新的频道
-
按视频/观看次数排序频道
我们计划从结果列表中选取前 X 名以包含在帖子中。然而,由于某些频道创作者最近的争议,我们在主观性的行为中移除了一个频道。虽然我们祝愿该个人一切顺利,但我们无法善意地将其内容纳入我们的推荐列表。
最终,我们将结果截取至前 15 名,如下所示,并包含在以下图像化可视化中。
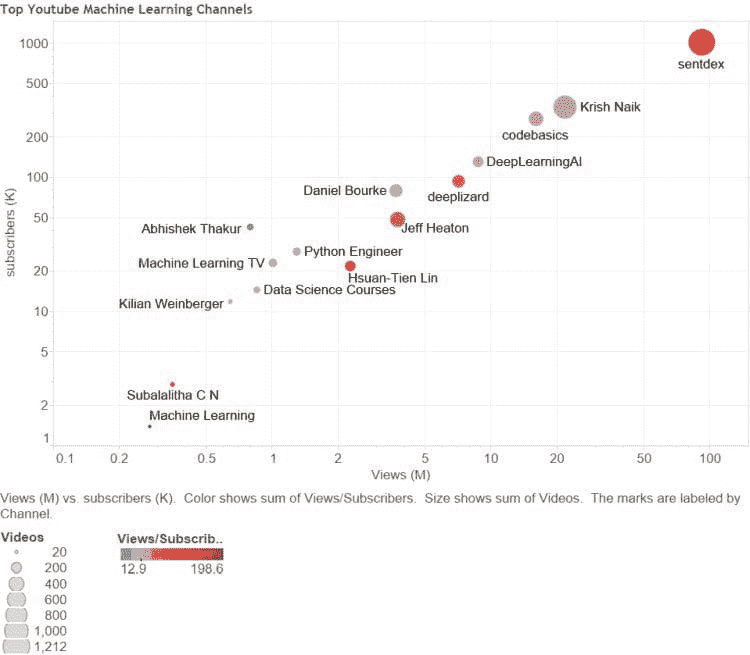
图 1. 顶级 YouTube 机器学习频道
按观看次数和订阅者数量绘制;相对大小按视频数量;
按观看次数/订阅者数量的颜色强度
这里列出了按观看次数/视频数量(或每视频观看次数)排序的前 15 个 YouTube 机器学习频道,并附有直接来自这些频道的简短描述(如有)。
1. sentdex
观看次数/视频:76K,订阅者:1020K,视频:1212,观看次数:92M,观看次数/订阅者:90
“Python 编程教程,超越基础知识。学习机器学习、金融、数据分析、机器人技术、网页开发、游戏开发等。”
2. codebasics
观看次数/视频:44K,订阅者:271K,视频:365,观看次数:16M,观看次数/订阅者:59
“本频道的目标是通过最简单和直观的方式教授编程,以实现这一愿景。我在我的频道上教授简单编程、数据科学、数据分析、人工智能、机器学习、数据结构、软件架构等。”
Views/Video: 42 K, Subscribers: 130 K, Videos: 205, Views: 8.7 M, Views/Subscriber: 67
“欢迎来到 DeepLearning.AI 官方 YouTube 频道!在这里,你可以找到我们 Coursera 程序上关于机器学习的视频以及录制的活动。DeepLearning.AI 在 Coursera 上创建了高质量的 AI 程序,赢得了广泛的全球关注。通过提供教育平台并培养紧密的社区,DeepLearning.AI 成为了任何希望建立 AI 职业的人们的途径。”
4. deeplizard
Views/Video: 25 K, Subscribers: 93.8 K, Videos: 289, Views: 7.1 M, Views/Subscriber: 76
“建立集体智能。”
5. Krish Naik
Views/Video: 24 K, Subscribers: 334 K, Videos: 921, Views: 22 M, Views/Subscriber: 65
“这是我的 YouTube 频道,我在这里讲解机器学习、深度学习和 AI 的各种主题,并提供许多真实世界的问题场景。我在各种聚会、技术机构和社区组织的论坛上进行了超过 30 场关于数据科学、机器学习和 AI 的技术讲座。我的主要目标是让每个人都熟悉机器学习和 AI。”
Views/Video: 17 K, Subscribers: 11.9 K, Videos: 39, Views: .65 M, Views/Subscriber: 54
“Kilian 的频道没有描述,但内容包括康奈尔大学的机器学习讲座,Kilian 是计算机科学副教授。”
Views/Video: 14 K, Subscribers: 1.39 K, Videos: 20, Views: .28 M, Views/Subscriber: 199
“观看行业专家的观点,赚取免费云积分,操作系统课程,现代技术教程,关于 IAAS、PAAS、SAAS、混合云战略的宝贵课程,获取 Meetups、会议的重播和实时信息等等。”
Views/Video: 14 K, Subscribers: 79.4 K, Videos: 270, Views: 3.7 M, Views/Subscriber: 46
“我是一个机器学习工程师,致力于技术与健康的交汇点。我的视频将帮助你更好地学习并保持健康。”
Views/Video: 12 K, Subscribers: 21.8 K, Videos: 195, Views: 2.3 M, Views/Subscriber: 105
“Hsuan-Tien Lin 没有频道描述,但他的视频涉及现代人工智能的机器学习、数据结构与算法、机器学习基础/技术等。他的频道在本文发布时仅发布了约 2 个月的视频,且视频记录中包含英文和中文(我认为)。”
10. Python Engineer
每视频观看数:11 K,订阅者:28 K,视频数量:121,观看总数:1.3 M,每位订阅者观看数:46
“你好,我是 Patrick。我是一个热爱机器学习、计算机视觉和数据科学的软件工程师。我创建免费的内容,以帮助更多人进入这些领域。如果你有任何问题、反馈或评论,请随时给我发消息!我很乐意与你交流 😃”
每视频观看数:10 K,订阅者:14.5 K,视频数量:81,观看总数:.85 M,每位订阅者观看数:59
“没有描述,但 Ali Ghodsi 是滑铁卢大学的教授,也是该大学人工智能研究小组的成员。频道包括讲座视频。”
12. Abhishek Thakur
每视频观看数:9.4 K,订阅者:42.8 K,视频数量:85,观看总数:.8 M,每位订阅者观看数:19
“我制作关于应用机器学习、深度学习和数据科学的视频。我是全球首位 4 次 Kaggle 大师。”
13. Jeff Heaton
每视频观看数:9.1 K,订阅者:48.3 K,视频数量:411,观看总数:3.7 M,每位订阅者观看数:78
“你想学习深度神经网络以及我在机器学习研究中的其他领域,这使我在一些 Kaggle 竞赛中排名前 7-10%吗?如果是的话,请订阅我的频道!我叫 Jeff Heaton,博士。我是一家财富 300 强公司的数据科学副总裁,同时还在顶级大学担任深度学习课程的兼职讲师。”
14. Subalalitha C N
每视频观看数:8.8 K,订阅者:2.87 K,视频数量:40,观看总数:.35 M,每位订阅者观看数:123
“我是 Dr.Subalalitha C.N,目前在印度 SRM 科学与技术学院担任副教授。在这个频道中,你可以找到我关于机器学习、自然语言处理以及算法设计与分析的讲座。”
每视频观看数:8.0 K,订阅者:23.1 K,视频数量:126,观看总数:1.0 M,每位订阅者观看数:43
“这个频道完全围绕机器学习(ML)。它包含了所有有用的资源,帮助机器学习爱好者和计算机科学学生更好地理解这一成功的人工智能分支的概念。”
以下是按每个视频的观看次数排序的前 15 个机器学习 YouTube 频道,并附带一些额外的数据,以帮助你决定这些频道的视频内容是否对你感兴趣。祝你观影愉快!
相关:
-
数据科学的顶级 YouTube 频道
-
10 分钟内最佳机器学习 YouTube 视频
-
数据科学、数据可视化和机器学习的顶级 Python 库
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
更多相关主题
主题建模方法:Top2Vec 与 BERTopic
原文:
www.kdnuggets.com/2023/01/topic-modeling-approaches-top2vec-bertopic.html

图片由 Mikechie Esparagoza 拍摄
每天,我们大多数时候都在处理未标记的文本,而监督学习算法完全无法用于从数据中提取信息。自然语言的一个子领域可以揭示大量文本中的潜在结构。这一学科称为主题建模,专门用于从文本中提取主题。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您所在组织的 IT 工作
在这种情况下,传统的方法,如潜在狄利克雷分配(Latent Dirichlet Allocation)和非负矩阵分解(Non-Negative Matrix Factorization),未能很好地捕捉词之间的关系,因为它们基于词袋模型。
因此,我们将重点关注两种有前景的方法,Top2Vec 和 BERTopic,这些方法通过利用预训练语言模型生成主题,从而解决这些缺陷。让我们开始吧!
Top2Vec
Top2Vec 是一种能够通过使用预训练的词向量和创建有意义的嵌入主题、文档和词向量,自动检测文本中的主题的模型。
在这种方法中,提取主题的过程可以分为不同的步骤:
-
创建语义嵌入:创建联合嵌入的文档和词向量。其思想是,相似的文档在嵌入空间中应更接近,而不相似的文档之间应保持距离。
-
减少文档嵌入的维度:应用降维方法对于在减少高维空间的同时保留大部分文档嵌入的变异性非常重要。此外,这也允许识别密集区域,其中每个点代表一个文档向量。UMAP 是在此步骤中选择的典型降维方法,因为它能够保留高维数据的局部和全局结构。
-
识别文档簇:应用基于密度的聚类方法 HDBScan 来寻找相似文档的密集区域。如果文档不在密集簇中,则被标记为噪声;如果属于密集区域,则被标记为一个标签。
-
在原始嵌入空间中计算质心:质心通过考虑高维空间而不是缩减的嵌入空间来计算。经典策略包括计算所有属于密集区域的文档向量的算术平均值,这些区域是通过 HDBSCAN 在先前步骤中获得的。通过这种方式,为每个簇生成一个主题向量。
-
为每个主题向量找到词汇:与文档向量最近的词向量在语义上是最具代表性的。
Top2Vec 的示例
在本教程中,我们将分析来自data.world的数据集中麦当劳的负面评论。从这些评论中识别主题对跨国公司来说是有价值的,以便改进产品和美国地区的快餐连锁店组织。
import pandas as pd
from top2vec import Top2Vec
file_path = "McDonalds-Yelp-Sentiment-DFE.csv"
df = pd.read_csv(
file_path,
usecols=["_unit_id", "city", "review"],
encoding="unicode_escape",
)
df.head()
docs_bad = df["review"].values.tolist()

通过一行代码,我们将执行之前解释的所有 Top2Vec 步骤。
topic_model = Top2Vec(
docs_bad,
embedding_model="universal-sentence-encoder",
speed="deep-learn",
tokenizer=tok,
ngram_vocab=True,
ngram_vocab_args={"connector_words": "phrases.ENGLISH_CONNECTOR_WORDS"},
)
Top2Vec 的主要论点是:
-
docs_bad: 是一个字符串列表。
-
universal-sentence-encoder: 是选择的预训练嵌入模型。
-
deep-learn: 是一个决定生成文档向量质量的参数。
topic_model.get_num_topics() #3
topic_words, word_scores, topic_nums = topic_model.get_topics(3)
for topic in topic_nums:
topic_model.generate_topic_wordcloud(topic)
最重要的是


从词云中,我们可以推测主题 0 是关于麦当劳服务的一般投诉,如“服务慢”、“服务糟糕”和“订单错误”,而主题 1 和 2 分别指的是早餐食品(麦芬、饼干、鸡蛋)和咖啡(冰咖啡和杯咖啡)。
现在,我们尝试使用两个关键词搜索文档:错误和慢:
(
documents,
document_scores,
document_ids,
) = topic_model.search_documents_by_keywords(
keywords=["wrong", "slow"], num_docs=5
)
for doc, score, doc_id in zip(documents, document_scores, document_ids):
print(f"Document: {doc_id}, Score: {score}")
print("-----------")
print(doc)
print("-----------")
print()
输出:
Document: 707, Score: 0.5517634093633295
-----------
horrible.... that is all. do not go there.
-----------
Document: 930, Score: 0.4242547340973836
-----------
no drive through :-/
-----------
Document: 185, Score: 0.39162203345993046
-----------
the drive through line is terrible. they are painfully slow.
-----------
Document: 181, Score: 0.3775083338082392
-----------
awful service and extremely slow. go elsewhere.
-----------
Document: 846, Score: 0.35400602635951994
-----------
they have bad service and very rude
-----------
BERTopic
“BERTopic 是一种主题建模技术,它利用变换器和 c-TF-IDF 创建密集的簇,从而使主题易于解释,同时保留主题描述中的重要词汇。”
正如名字所示,BERTopic 利用强大的变换器模型来识别文本中的主题。这个主题建模算法的另一个特点是使用 TF-IDF 的变体,称为基于类别的 TF-IDF 变体。
像 Top2Vec 一样,它不需要知道主题的数量,而是自动提取主题。
此外,与 Top2Vec 类似,它是一个涉及不同阶段的算法。前三个步骤是相同的:创建嵌入文档、使用 UMAP 进行降维和使用 HDBScan 进行聚类。
随后的阶段开始与 Top2Vec 有所不同。在使用 HDBSCAN 找到密集区域后,每个主题被标记为一个词袋表示,这个表示考虑了词汇是否出现在文档中。然后,将属于同一集群的文档视为一个唯一文档,并应用 TF-IDF。因此,对于每个主题,我们识别出最相关的词汇,这些词汇应该具有最高的 c-TF-IDF。
BERTopic 示例
我们在相同的数据集上重复分析。
我们将使用 BERTopic 从评论中提取主题:
model_path_bad = 'model/bert_bad'
topic_model_bad = train_bert(docs_bad,model_path_bad)
freq_df = topic_model_bad.get_topic_info()
print("Number of topics: {}".format( len(freq_df)))
freq_df['Percentage'] = round(freq_df['Count']/freq_df['Count'].sum() * 100,2)
freq_df = freq_df.iloc[:,[0,1,3,2]]
freq_df.head()
模型返回的表格提供了关于提取的 14 个主题的信息。主题对应于主题标识符,除了被忽略的所有离群点,这些离群点标记为-1。
现在,我们将进入最有趣的部分,即将我们的主题可视化为互动图表,例如每个主题的最相关术语的可视化、主题间距离图、嵌入空间的二维表示和主题层级。
让我们开始展示前十个主题的条形图。对于每个主题,我们可以观察最重要的词汇,并根据 c-TF-IDF 评分按降序排列。一个词汇的相关性越高,它的评分就越高。
第一个主题包含通用词汇,如位置和食物,主题 1 为顺序和等待,主题 2 为最差和服务,主题 3 为地方和肮脏,等等。
在可视化条形图之后,我们可以查看主题间距离图。我们将 c-TF-IDF 评分的维度降到二维空间,以便在图中可视化这些主题。底部有一个滑块,可以选择将其标记为红色的主题。我们可以注意到,主题被分成了两个不同的集群,一个包含诸如食物、鸡肉和地点等通用主题,另一个则包含不同的负面方面,如最差服务、肮脏、地方和寒冷。
下一张图表展示了评论与主题之间的关系。特别是,它可以帮助理解为何某条评论被分配到特定主题,并与最相关的词汇对齐。例如,我们可以关注红色集群,它对应于主题 2,包含了一些关于最差服务的词汇。这个密集区域中的文档似乎相当负面,比如“糟糕的客户服务和更糟糕的食物”。
TopVec 与 BERTopic 的区别
表面上看,这些方法有许多共同点,如自动确定主题数量、大多数情况下无需预处理、应用 UMAP 降低文档嵌入的维度,然后使用 HDBSCAN 对这些降低的文档嵌入进行建模,但在将主题分配给文档的方式上,它们在根本上是不同的。
Top2Vec 通过寻找靠近聚类中心的单词来创建主题表示。
与 Top2Vec 不同,BERTopic 不考虑聚类中心,而是将聚类中的所有文档视为一个独特的文档,并使用基于类的 TF-IDF 变体提取主题表示。
| Top2Vec | BERTopic |
|---|---|
| 基于聚类中心提取主题的策略。 | 基于 c-TF-IDF 提取主题的策略。 |
| 不支持动态主题建模。 | 支持动态主题建模。 |
| 它为每个主题构建词云,并提供主题、文档和单词的搜索工具。 | 它允许构建互动可视化图,帮助解释提取的主题。 |
参考文献
主题建模是自然语言处理中一个不断发展的领域,应用广泛,包括评论、音频和社交媒体帖子。正如所示,本文概述了 Topi2Vec 和 BERTopic 这两种有前景的方法,它们可以帮助你用少量代码识别主题,并通过数据可视化来解释结果。如果你对这些技术有疑问,或者有其他检测主题的方法建议,请在评论中写下。
尤金妮亚·安内洛 目前是意大利帕多瓦大学信息工程系的研究员。她的研究项目专注于持续学习与异常检测的结合。
更多相关主题
使用 Streamlit 进行话题建模
评论
由 Bryan Patrick Wood,高级数据科学家
创建和部署一个话题建模网页应用程序需要什么?我努力通过使用 Python NLP 包进行话题建模、使用 Streamlit 作为网页应用框架以及使用 Streamlit Sharing 进行部署来找到答案。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织 IT
我曾被指示在一个项目中使用话题建模,因此我已经在一个具有挑战性的实际问题上有了相关技术的直接经验。然而,我遇到了几个意想不到的困难,特别是在与非技术观众分享话题建模结果时。

不久之后,我被咨询在一个大规模运行的产品系统中实施话题建模功能。在这里,我试图帮助的团队在理解话题建模的预期效果以及保持监督学习、半监督学习和无监督学习方法之间的重要区别方面遇到了困难⁸。
这激励我做一些东西来展示,不要告诉,可以这么说。我希望给我接触的人一个可以实际操作的东西。这也是一个很好的借口来使用 Streamlit 并尝试 Streamlit Sharing。我在专业领域中已经宣传了 Streamlit 的一些用例,但实际上我只玩过几个玩具示例。通过 Streamlit Sharing 部署是新的,并引起了我的好奇。
免责声明
首先,应用程序仍然是一个进行中的工作/原型。存在一些尚未实现的功能占位符(例如,使用非负矩阵分解¹)。代码也需要从一个长达 250 行的脚本中重构出来。重点是使足够的部分能够正常工作,以暗示可以实现的强大功能,并且拥有足够的完整应用程序来激发讨论。其次,Streamlit 对文档编程²的支持很好。因此,一些叙述在应用程序中重复出现。因此,如果你已经访问了应用程序,你可以略过接下来的部分。
话题建模
正如我发现的那样,主题建模 对不同的人来说可能意味着不同的东西。主题 和 模型 这两个词足够常见,大多数人可以通过它们来形成对该技术成功所需完成内容的看法。
在没有额外限定的情况下,主题建模 通常指的是用于发现抽象主题 的统计模型类型,这些主题出现在文档集合中。这些技术几乎总是完全无监督的,尽管也存在半监督和监督的变体。在最常用的技术中,且在应用程序中完全实现的技术是潜在狄利克雷分配(LDA)。
从表面上看,LDA 只是将词汇文档关系矩阵(如下图所示)分解为两个关系矩阵:词汇到主题和主题到文档。理论上假设词汇在主题中的分布和主题在文档中的分布,但这更多是对希望理解基础理论的人感兴趣的内容,该理论在其他地方已经有很好的阐述。
这里不深入探讨 LDA 理论:这是一个值得单独撰写博客文章的话题。
我在专业项目中进行了大量实验。那些实验在其上下文之外并不直接有用,我无法分享。我将突出一些代码片段,这些代码片段可能对有志于进行主题建模的人有所帮助。
预处理在所有机器学习问题中至关重要。在 NLP 问题中,相比其他领域,通常有更多的选择。对于主题建模,通常希望在应用建模之前删除各种类型的命名实体。以下函数用于去噪 文本文件。
import pandas as pd
import regex
from gensim.utils import simple_preprocess
from nltk.corpus import stopwords
EMAIL_REGEX_STR = '\S*@\S*'
MENTION_REGEX_STR = '@\S*'
HASHTAG_REGEX_STR = '#\S+'
URL_REGEX_STR = r'((http|https)\:\/\/)?[a-zA-Z0-9\.\/\?\:@\-_=#]+\.([a-zA-Z]){2,6}([a-zA-Z0-9\.\&\/\?\:@\-_=#])*'
def denoise_docs(texts_df: pd.DataFrame, text_column: str):
texts = texts_df[text_column].values.tolist()
remove_regex = regex.compile(f'({EMAIL_REGEX_STR}|{MENTION_REGEX_STR}|{HASHTAG_REGEX_STR}|{URL_REGEX_STR})')
texts = [regex.sub(remove_regex, '', text) for text in texts]
docs = [[w for w in simple_preprocess(doc, deacc=True) if w not in stopwords.words('english')] for doc in texts]
return docs
我还尝试了通过 gensim.models.Phrases 和 gensim.models.phrases.Phraser 使用二元组和三元组短语,但没有看到显著提升。将二元组和三元组本身而不是作为预处理步骤使用可能会更有影响。文档预处理的最后一步是使用 spaCy 进行词形还原。
import pandas as pd
import spacy
def generate_docs(texts_df: pd.DataFrame, text_column: str, ngrams: str = None):
docs = denoise_docs(texts_df, text_column)
# bigram / trigam preprocessing ...
lemmantized_docs = []
nlp = spacy.load('en_core_web_sm', disable=['parser', 'ner'])
for doc in docs:
doc = nlp(' '.join(doc))
lemmantized_docs.append([token.lemma_ for token in doc])
return lemmantized_docs
建模代码是 gensim 的标准做法。
import gensim
from gensim import corpora
def prepare_training_data(docs):
id2word = corpora.Dictionary(docs)
corpus = [id2word.doc2bow(doc) for doc in docs]
return id2word, corpus
def train_model(docs, num_topics: int = 10, per_word_topics: bool = True):
id2word, corpus = prepare_training_data(docs)
model = gensim.models.LdaModel(corpus=corpus, id2word=id2word, num_topics=num_topics, per_word_topics=per_word_topics)
return model
我本打算添加更多建模选项,但时间不够。至少,我将来会添加一个使用 NMF 的选项。根据经验,NMF 可以根据所研究的数据集产生更好的主题。添加任何非无监督的方法将是一个更大的挑战。
在可视化方面,我大量借鉴了 Topic modeling visualization – How to present the results of LDA models?,特别是用于模型结果可视化:这是一个很好的参考,用于可视化主题模型结果。
pyLDAvis⁹ 也是一个很好的主题建模可视化工具,但与嵌入应用程序的兼容性不是很好。Termite plots¹⁰ 是另一种有趣的主题建模可视化工具,使用 textaCy 包 可以在 Python 中实现。
我有时间做的最复杂的可视化是词云,由于已有一个 Python 包可以做到这一点,因此任务非常简单。
from wordcloud import WordCloud
WORDCLOUD_FONT_PATH = r'./data/Inkfree.ttf'
def generate_wordcloud(docs, collocations: bool = False):
wordcloud_text = (' '.join(' '.join(doc) for doc in docs))
wordcloud = WordCloud(font_path=WORDCLOUD_FONT_PATH, width=700, height=600, background_color='white', collocations=collocations).generate(wordcloud_text)
return wordcloud

设置需要稍微调整才能得到看起来不错的效果。添加额外的可视化是我感觉时间不够的主要部分,可能会在以后重新考虑。
Streamlit
Streamlit 是一个开源的 Python 库,它使得创建和共享美观的、定制的机器学习和数据科学 Web 应用变得简单。我将重点讲解创建部分,稍后会讲解共享部分,尽管在受信任的本地网络上共享非常简单。
主要的价值主张是将数据科学或机器学习成果迅速转化为 Web 应用,目的是与那些对 Jupyter notebook 不太舒适的人共享。在这方面它表现出色。我从脚本到 Web 应用只用了几个小时。这使我能够与一群决策者共享一个 Web 应用,他们试图弄清楚主题建模的意义。我对提供方的表现非常满意,接收方也给出了相同的反馈。
另一个好处是它纯粹的 Python 性质(即不涉及 HTML、CSS、JS 等),因此无需要求数据科学家学习他们不感兴趣的复杂 Web 技术。与 Plotly Dash 的比较可能需要单独写一篇博客,但 Dash 的方法更倾向于让 React 在 Python 中更易于实现。它非常专注于
对于大多数考虑使用这项技术的人来说,这可能不是一个大问题,但对于那些有传统 GUI 应用程序框架经验的人来说,值得注意的是 Streamlit 更像是一种立即模式用户界面¹¹。也就是说,每次执行 UI 操作(例如,点击按钮)时,它都会从头到尾重新运行脚本。通过 @cache 装饰器进行的激进缓存允许高效执行:只重新运行每次更改所需的代码。这要求用户做出这些决策,并且参数必须是可哈希的。
它甚至原生支持屏幕录制!有助于向他人展示如何使用你所共享的内容。

这个视频展示了 st.sidebar 上下文管理器的使用:这是应用程序文档、设置甚至导航的基本组件。
https://bpw1621.com/images/streamlit-topic-modeling/streamlit-sidebar.webm
下一个视频展示了如何使用新的st.beta.expander上下文管理器:它非常棒,尤其适合添加用户在阅读后希望折叠的文献展示部分,以便重新获得屏幕空间。
https://bpw1621.com/images/streamlit-topic-modeling/streamlit-expander.webm
我将在应用程序中重点介绍的最后一件事是使用新的st.beta.columns上下文管理器,它用于为每个主题创建一个词云网格。

这是代码
st.subheader('Top N Topic Keywords Wordclouds')
topics = model.show_topics(formatted=False, num_topics=num_topics)
cols = st.beta_columns(3)
colors = random.sample(COLORS, k=len(topics))
for index, topic in enumerate(topics):
wc = WordCloud(font_path=WORDCLOUD_FONT_PATH, width=700, height=600, background_color='white', collocations=collocations, prefer_horizontal=1.0, color_func=lambda *args, **kwargs: colors[index])
with cols[index % 3]:
wc.generate_from_frequencies(dict(topic[1]))
st.image(wc.to_image(), caption=f'Topic #{index}', use_column_width=True)
这里还有大量内容可以深入探讨,但没有什么是不通过自己动手尝试就无法掌握的。
Streamlit Sharing
Streamlit Sharing 的标语相当不错:从 Streamlit 直接免费部署、管理和分享你的应用到全世界。
共享机器学习应用原型的便利性是令人愉快的。我最初在 Amazon AWS EC2 实例上部署,以满足截止日期(如下面所示)。鉴于我在 AWS 的背景和经验,我不会说以这种方式部署过于困难,但我知道一些才华横溢的机器学习专业人士可能在这里遇到过困难。此外,大多数人不愿意将时间花费在角色访问、安全设置、设置 DNS 记录等上面。是的,他们的时间确实更应该花在他们擅长的事情上。
要使用此服务,你需要请求并获得一个帐户。你可以在这里进行操作。你会收到一封事务性电子邮件,让你知道你在等待访问的队列中,但邀请尚未到来。我建议,如果你认为你会很快想要尝试这个,最好立即注册。
一旦获得访问权限,按照上面的 gif 或这里的指示操作是相当简单的。有几件事情需要我在我的 GitHub 仓库上进行迭代,以使一切正常工作,包括
-
正确使用 setup.py / setup.cfg 意味着你不需要 requirements.txt 文件,但服务要求提供一个。
-
机器学习包通常会下载数据和模型
否则,一切都很直接,几次点击就完成了。有关 Streamlit 应用程序部署的官方指导可以在这里找到。
同样重要的是要注意,这绝对不能替代生产部署。每个用户限制为 3 个应用程序。单个应用程序的运行环境限制为最多 1 个 CPU、800 MB 的 RAM 和 800 MB 的专用存储空间。因此,这里并不适合你下一个初创公司的 web 应用,但对于共享快速原型来说是一个极具价值的提案。
总结
如果你读到这里,我想感谢你抽出时间。如果阅读后你对使用该应用程序感兴趣并有反馈,我很乐意听到你的意见。
原型应用程序可以在 Streamlit Sharing⁴上访问,代码可在 Github⁵上找到。计划根据时间安排增强和改进现有功能。计划将我的改进和扩展想法记录在 Github 问题中,以便在有时间时处理。
简介: 布莱恩·帕特里克·伍德 (@bpw1621)是一位高级数据科学家,领导着一个数据科学团队,解决国家面临的一些最重要的挑战。请访问他的个人网站了解更多信息。
原文。经许可转载。
相关:
-
生产就绪的机器学习 NLP API,使用 FastAPI 和 spaCy
-
现在学习自然语言处理的神经网络
-
使用 Streamlit 的新布局选项构建更好的数据应用
相关主题
拓扑数据分析 – 开源实现
原文:
www.kdnuggets.com/2015/11/topological-data-analysis-open-source-implementations.html
作者:Matthew Mayo。
拓扑数据分析(TDA)是一个应用数学领域,目前在分析界引起了各种关注。它使用现代数学概念,如函子,并具有诸如在坐标自由性和对噪声的鲁棒性方面的成功等可取属性。TDA 能够对其实际用途做出一些有力的主张;然而,它是最数学严谨的统计分析领域之一。这篇文章很好地介绍了 TDA 给机器学习领域的读者。

在我们转向现有的开源 TDA 工具之前,让我们先看看 TDA 在工业界的当前驱动力。Ayasdi成立于 2008 年,由Gunnar Carlsson、Gurjeet Singh和Harlan Sexton创办,是 TDA 领域的主要商业参与者,并在斯坦福大学经过十多年的研究后成立。尽管 Ayasdi 今天可以说是 TDA 的主要参与者,但它并非唯一;还有许多活跃的开源项目存在。
想了解更多关于 TDA 的信息吗?这是一个视频,由 Ayasdi 联合创始人兼长期 TDA 研究员 Gunnar Carlsson 简明扼要地解释了 TDA。这个 Github 仓库包含了一个精心挑选的 TDA 学习资源列表,包括温和的非数学介绍和更严格的数学处理。俄亥俄州立大学提供了课程计算拓扑与数据分析,并且课程的大部分笔记和资源可在其网站上获得。
今年早些时候,KDnuggets对 Ayasdi 工程师 Anthony Bak 进行了系列采访,以证明 TDA 意识的日益增强(第一部分,第二部分,第三部分),以及最近的深度学习与拓扑数据分析可以为你的数据做的 6 件疯狂的事。上述链接之一也是最近的精选文章。鉴于这一趋势,未来可能会有更多关于拓扑数据分析的 KDnuggets 文章。
开源 TDA 工具
我们将注意力转向开源 TDA 项目。虽然它目前还不在主流中,并且仍处于早期采用阶段,但值得注意的是,TDA 远非专有技术。Ayasdi 可能是该领域最显著的参与者,但也存在一些开源实现的核心 TDA 组件。Ayasdi 及其工程师甚至为一些这些项目做出了贡献。
以下是几个开源 TDA 项目的列表,包含来自项目来源的简要描述。
Mapper 算法是一种由 Gurjeet Singh、Facundo Mémoli 和 Gunnar Carlsson 发明的拓扑数据分析方法。请参见参考文献[R1]了解更多出版信息。虽然 Mapper 算法本身并不构成一个完整的数据分析工具,但它是处理链的关键部分,包括(最少)过滤函数、Mapper 算法本身和结果的可视化。
Python Mapper 是由 Daniel Müllner 和 Aravindakshan Babu 编写的此工具链的实现。它是开源软件,并在 GNU GPLv3 许可下发布。
由@mlwave 开发的数字识别概念验证 Mapper(Python)
描述:1) 在训练集上使用 MinMaxScaler。2) 对训练集中的前 5000 张图像进行 t-SNE 降维到 2 个组件。3) 在前两个维度上创建重叠区间,并对重叠区域内的点进行聚类。4) 这些聚类然后成为图中的节点。5) 当不同的聚类有一个或多个非唯一成员时,我们绘制一条边。6) 根据每个聚类中点的数量调整节点大小。7) 根据距离第一个维度的最小值为节点着色。8) 在工具提示中显示每个聚类成员的图像。
Dionysus 是一个用于计算持久同调的 C++库。它提供了以下算法的实现:
▪ 持久同调计算
▪ 葡萄园
▪ 持久同调计算
▪ 锯齿形持久同调
提供持久同源性统计分析和密度聚类的工具。为此,本包提供了 R 接口,用于高效的 C++ 库算法,包括 GUDHI、Dionysus 和 PHAT(见 vignette)。
TDAmapper: 使用 Mapper 的拓扑数据分析 (R)
一个用于使用离散莫尔斯理论分析数据集的 R 包,使用了 G. Singh、F. Memoli 和 G. Carlsson(2007)描述的 Mapper 算法。
JavaPlex 库实现了持久同源性及相关技术,这些技术来自计算和应用拓扑学,库的设计旨在易于使用、易于从 Matlab 和基于 Java 的系统访问,以及便于进一步研究项目和方法的扩展。JavaPlex 主要由斯坦福大学的计算拓扑学工作组开发,基于该小组之前的类似包。
这个 C++11 库提供了一组通用工具用于:
▪ 生成点集(敬请期待)
▪ 构建邻域图
▪ 构建细胞复合体
▪ 在有限域上计算 [持久] 同源性
▪ 同源性的并行算法
这个模块包含一些基础的 Kohonen 风格向量量化器的实现:自组织映射(SOM)、神经气体和增长神经气体。Kohonen 风格的向量量化器使用某种明确指定的拓扑来促进原型“神经元”之间的良好分离。
简介: Matthew Mayo 是一名计算机科学研究生,目前正在进行关于并行化机器学习算法的论文工作。他还是数据挖掘的学生、数据爱好者以及有志成为机器学习科学家的研究者。
相关:
-
拓扑分析与机器学习:朋友还是敌人?
-
访谈:Anthony Bak 和 Ayasdi 论利用拓扑摘要的新见解
-
深度学习和拓扑数据分析能对你的数据做的 6 件疯狂的事
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
更多相关话题
针对 Docker 优先的数据科学的 Torus
原文:
www.kdnuggets.com/2018/05/torus-docker-first-data-science.html
评论
由 Alexander Ng, Manifold.ai 提供
随着对人工智能(AI)特别是机器学习(ML)的兴趣增长,越来越多的工程师进入这一热门领域,缺乏事实上的工作标准和框架的问题变得越来越明显。现在,优化 ML 交付流程的新关注点开始获得动力。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
数据科学家在产品交付流程中的参与越来越多,确保他们的工作能在交付过程中存活下来是一个不容忽视的任务。当然,这并不是一个新问题:过去,传统的软件开发团队会将他们的工作“抛过墙”给运营团队,以很少或没有上下文的方式提供生产服务。解决这一不可避免的混乱的社区努力导致了我们现在所称的 DevOps,它打破了开发与运营之间的壁垒,以提高效率和改善产品质量。现在,帮助团队实施精简交付流程的新工具和流程有助于保证开发/生产的一致性。
现在,机器学习领域出现了同样的问题,并且随着对 AI 产品需求的增长而变得越来越严重。一个新的壁垒正在扼杀生产力。随着数据科学团队在工程组织中的崛起,DevOps 将如何变化?我们今天在社区中看到的痛点感觉很熟悉,但在 ML 开发中也有独特的方面。
机器学习工程师的崛起
简单来说,DevOps 领域的解决方案为那些在开发与运营交汇点工作的人员提供了工具。同样,需要一个工具包来帮助那些在数据科学与软件工程交汇点工作的人员。我们称这样的人员为机器学习工程师(MLE)。从高层次来看,MLE 面临的挑战与任何产品开发团队中的软件工程师是一样的:
-
标准化的本地开发环境
-
开发与生产环境的统一
-
标准化的打包和部署流程
此外,ML 开发工作流的某些方面对 MLE 提供了一组不同的挑战:
-
轻松共享开发环境和中间结果,以进行可重复的实验
-
协调运行多个笔记本服务器的隔离项目环境
-
轻松实现垂直和水平扩展,以处理大型数据集或利用额外的计算资源(例如,用于深度学习、优化等)
通过用 DevOps 思维方式来看待 ML 开发,我们可以识别出交付路径上需要改进的几个新领域。这是一个机会,可以构建新的工具和最佳实践,专门赋能 MLE 社区,以便在更短的时间内交付更强健的解决方案。
无论 MLE 工具包最终包含什么,我们非常确定的一点是:Docker 将在 ML 开发生命周期标准中发挥重要作用。
Docker 优先的数据科学
通过转向以 Docker 为优先的工作流,MLE 可以在开发生命周期中受益于许多显著的下游优势,这些优势包括在大数据集上运行工作负载时的易于垂直和水平扩展,以及模型和预测引擎的部署和交付的便捷。运行在容器中的 Docker 镜像提供了一种简单的方法,以确保在不同的开发者笔记本、远程计算集群和生产环境中保证一致的运行时环境。
尽管通过谨慎使用虚拟环境和有序的系统级配置管理也可以实现这种一致性,但容器在新环境的启动/关闭时间和开发者生产力方面仍提供了显著的优势。然而,我们从数据科学社区反复听到的是:我知道 Docker 会让这变得更简单,但我没有时间或资源来设置和弄清楚这一切。
在 Manifold,我们开发了内部工具,以便轻松启动基于 Docker 的机器学习项目开发环境。为了帮助其他数据科学团队采用 Docker,并应用 DevOps 最佳实践来简化机器学习交付管道,我们将不断发展的工具包开源了。我们希望使团队能够轻松地启动新的即用开发环境,并转向 Docker 优先的工作流。
Torus 如何工作?
Torus 1.0 包含一个 Docker 化的 Cookiecutter for Data Science(这是流行的 cookiecutter-data-science 的一个分支)和一个 ML 开发基础 Docker 镜像。通过将项目 cookiecutter 和 Docker 镜像一起使用,你可以在不到五分钟内从冷启动到一个在 Jupyter Notebook 中运行的新项目,并且无需安装任何东西。
在用 cookiecutter 模板实例化一个新项目并运行单个启动命令后,你的本地开发环境将如下所示:
完全配置好的开箱即用 Docker 本地开发设置,适用于数据科学项目。
让我们深入了解一下这里发生了什么:
-
从 Docker Hub 拉取的 ML 基础开发镜像被下载到本地机器。这包括许多常用的数据科学和 ML 库,预安装了 Jupyter Notebook 服务器,并配置了有用的扩展。
-
一个容器被启动并使用基础镜像配置,将你的顶级项目目录挂载为容器上的共享卷。这让你可以在主机机器上使用你喜欢的 IDE 修改代码,并立即在运行时环境中反映更改。
-
已设置端口转发,以便你可以在主机机器上的浏览器中使用运行在容器内的 Notebook 服务器。一个合适的主机端口会动态选择,因此不必担心端口冲突(例如,其他 Notebook 服务器、数据库或笔记本电脑上的其他任何东西)。
-
该项目使用了自己的 Dockerfile 进行搭建,因此你可以安装任何项目特定的包或库,并通过源代码管理与团队共享你的环境。
你可以像平常一样在本地使用你喜欢的浏览器和 IDE 来完成工作,同时你的运行时环境在团队中是 100% 一致的。如果你在机器上处理多个项目,请放心,每个项目都在其自己干净隔离的容器中运行。
打下基础
在 MLE 工具包领域有很多令人兴奋的活动,很容易忘记,在考虑更高阶的平台或框架之前,你需要确保你的团队已做好成功的准备。我们需要 DevOps 运动在 ML 交付管道中为软件工程做出的贡献。转向 Docker 优先的开发工作流是让所有参与交付管道的人——包括你的客户——生活更轻松的第一步。
简介: 亚历山大·吴 是 Manifold(一家 AI 产品工作室)的高级数据工程师。他之前曾在 Kyruus 担任工程师和技术负责人,负责 DevOps 相关工作,还从事过海军的工程工作。他拥有波士顿大学电气工程学士学位。
相关:
更多相关主题
《端到端机器学习平台概览》
原文:
www.kdnuggets.com/2020/07/tour-end-to-end-machine-learning-platforms.html
评论
作者:Ian Hellström,机器学习工程师
机器学习 (ML) 被称为 技术债务的高利贷。虽然启动一个足够好的模型以解决特定业务问题相对容易,但要使该模型在生产环境中正常工作,能够处理杂乱的、不断变化的数据语义和关系,以及演变的架构,并且做到自动化和可靠,这是完全不同的挑战。如果你有兴趣了解一些知名的机器学习平台,你来对地方了!
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
实际上,机器学习生产系统中的代码中只有 5% 是模型本身。将一组机器学习解决方案转变为端到端机器学习平台的是一种架构,它拥抱了旨在加快建模、自动化部署,并确保生产中的可扩展性和可靠性的技术。我之前谈过 精益 D/MLOps,数据和机器学习操作,因为没有数据的机器学习操作毫无意义,所以端到端机器学习平台需要一种整体方法。
CI/CD 基金会推出了一个 MLOps 特殊兴趣小组 (SIG)。他们为端到端机器学习平台确定的步骤如下图所示:

它掩盖了一些不容忽视的细节。例如,服务可能需要不同的技术,具体取决于是否实时进行。可扩展的解决方案通常将模型放在一个容器中,该容器在许多机器的服务集群中运行,并由负载均衡器托管。因此,上述图中的一个框并不意味着实际平台的单一步骤、容器或组件。这不是对图像的批评,而是警告:看似简单的事情在实践中可能并不那么容易。
图表中缺少模型(配置)管理。你可以考虑版本控制、实验管理、运行时统计信息、训练、测试和验证数据集的数据来源跟踪、重训模型的能力(无论是从头开始还是从模型快照增量训练)、超参数值、准确性指标等。
另一个未列出的关键方面是能够检查模型是否存在偏差,例如,通过不同维度切片模型的关键性能指标。许多公司也需要能够热交换模型或并行运行多个模型。前者很重要,以免用户的请求在模型在后台更新时进入空白状态。后者对 A/B 测试或模型验证至关重要。
从 CI/CD 的另一个角度可以在这里找到。它提到了版本控制数据和代码的必要性,这常常被忽视。
Google: TFX
Google 开发TensorFlow eXtended (TFX)的主要动机是将机器学习模型从几个月的生产周期缩短到几周。他们的工程师和科学家面临挑战,因为“当机器学习需要在生产中部署时,实际工作流变得更加复杂。”
TensorFlow 和TFX是免费提供的,尽管后者不如前者成熟,因为它是在 2019 年发布的,晚于 Google 推出其 ML 基础设施两年。
模型性能指标用于部署安全可服务的模型。因此,如果较新的模型表现不如现有模型,它不会被推送到生产环境。在 TFX 术语中,模型不会获得“祝福”。在 TFX 中,这整个过程是自动化的。
这是开源 TFX 组件的快速概览:
-
ExampleGen 处理并拆分输入数据集。
-
StatisticsGen 计算数据集的统计信息。
-
SchemaGen检查统计信息并创建数据模式。
-
ExampleValidator用于检测数据集中的异常和缺失值。
-
Transform对数据集进行特征工程处理。
-
Trainer使用 TensorFlow 训练模型。
-
Evaluator分析训练结果。
-
ModelValidator确保模型可以安全地进行服务。
-
Pusher将模型部署到服务基础设施中。
-
TensorFlow Serving是一个 C++后台,用于服务 TensorFlow 的SavedModel文件。
为了最小化训练/服务的偏差,TensorFlow Transform 在计算图中“冻结”值,使得训练期间发现的相同值在服务时也会被使用。训练时的多个操作在服务时将变成一个固定值。
Uber: Michelangelo
大约在 2015 年,Uber 的机器学习工程师发现了机器学习系统中的隐性技术债务,或者说是机器学习领域中的“但它在我的机器上有效……” Uber 建立了与 ML 模型集成的定制化系统,但在大型工程组织中,这种做法的扩展性并不好。用他们自己的话说,
在创建和管理大规模训练和预测数据的过程中,没有系统来构建可靠、统一且可重复的管道。
这就是他们构建 Michelangelo 的原因。它依赖于 Uber 的事务性和日志数据数据湖,支持离线(批处理)和在线(流式)预测。对于离线预测,容器化的 Spark 作业生成批量预测;对于在线部署,模型在预测服务集群中进行服务,该集群通常由数百台机器组成,这些机器通过负载均衡器进行连接,客户将单独或批量的预测请求发送到这些机器。
与模型管理相关的元数据(例如,训练器的运行时统计信息、模型配置、源流、特征的分布和相对重要性、模型评估指标、标准评估图表、学习的参数值以及总结统计信息)都为每次实验存储。
Michelangelo 可以在同一个服务容器中部署多个模型,这使得从旧版本到新版本的安全过渡以及模型的并行 A/B 测试成为可能。
Michelangelo 的原始版本不支持深度学习在 GPU 上训练的需求,但团队在这段时间里解决了这个问题。当前平台 (current platform) 使用 Spark 的 ML 管道序列化,但增加了一个用于在线服务的附加接口,该接口提供了一个轻量级的单示例(在线)评分方法,能够处理严格的服务级别协议,例如欺诈检测和预防。它通过绕过 Spark SQL 的 Catalyst 优化器的开销来实现这一点。
值得注意的是,Google 和 Uber 都构建了内部协议缓冲解析器和服务表示,避免了默认实现中的瓶颈。
Airbnb: Bighead
Airbnb 在 2016/2017 年建立了自己的 ML 基础设施团队,原因类似。首先,他们在生产中只有少数几个模型,但构建每个模型可能需要长达三个月。其次,模型之间没有一致性。第三,在线预测和离线预测之间存在很大差异。Bighead 是他们努力的成果:
数据管理由内部工具 Zipline 处理。Redspot 是一个托管的、容器化的、多租户 Jupyter notebook 服务。Bighead 库用于数据转换和管道抽象,并包含常见模型框架的封装器。它通过转换保留元数据,因此用于追踪数据源。
Deep Thought 是一个用于在线预测的 REST API。Kubernetes 协调这些服务。对于离线预测,Airbnb 使用他们自己的 Automator。
Netflix: Metaflow
Netflix 遇到了与前述公司类似的问题,这并不令人意外。他们的解决方案是Metaflow,这是一个面向数据科学家的 Python 库,处理数据管理和模型训练,而非预测服务。因此,它不是一个端到端的机器学习平台,可能更适合公司内部使用而非面向用户的场景。当然,它可以通过Kubernetes 或AWS SageMaker 转变为一个完全成熟的解决方案。进一步的服务工具列表可以在这里找到。
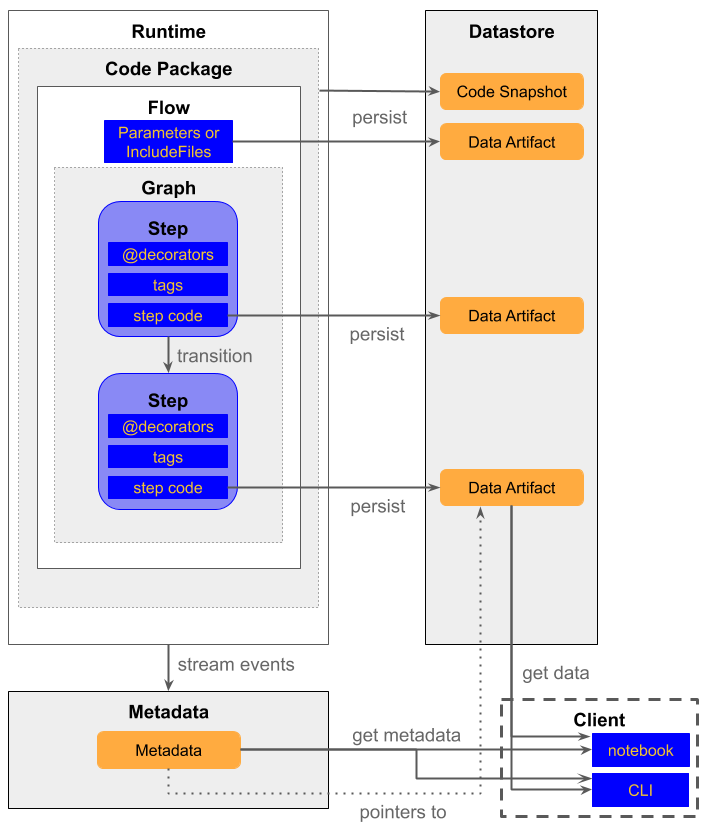
数据科学家将他们的工作流编写为 DAG 步骤,类似于数据工程师在使用 Airflow 时的做法。与 Airflow 类似,你可以使用任何数据科学库,因为对 Metaflow 来说,只要是 Python 代码就会被执行。Metaflow 在后台分发处理和训练。所有代码和数据都会自动快照到 S3,以确保每个模型和实验都有版本历史。Pickle 是默认的模型序列化格式。
开源版尚未内置scheduler。它还鼓励用户‘主要依赖垂直扩展’,尽管他们可以使用 AWS SageMaker 实现水平扩展。它与 AWS 紧密耦合。
Lyft: Flyte
Lyft 开源了他们的云原生平台Flyte,其中数据和机器学习操作汇聚。这与我的D/MLOps 哲学一致——Data(Ops) 对 MLOps 的意义就像燃料对火箭的重要性:没有它,一切都无从谈起。
它建立在 Kubernetes 之上。由于 Lyft 在内部使用它,它可以扩展到至少 7,000 个独特工作流,每月超过 100,000 次执行,1 百万任务和 1,000 万个容器。
Flyte 中的所有实体都是不可变的,因此可以跟踪数据血缘、重现实验和回滚部署。重复任务可以利用任务缓存节省时间和成本。目前支持的任务包括Python、Hive、Presto 和 Spark以及sidecars。从源码来看,它似乎使用了 EKS。
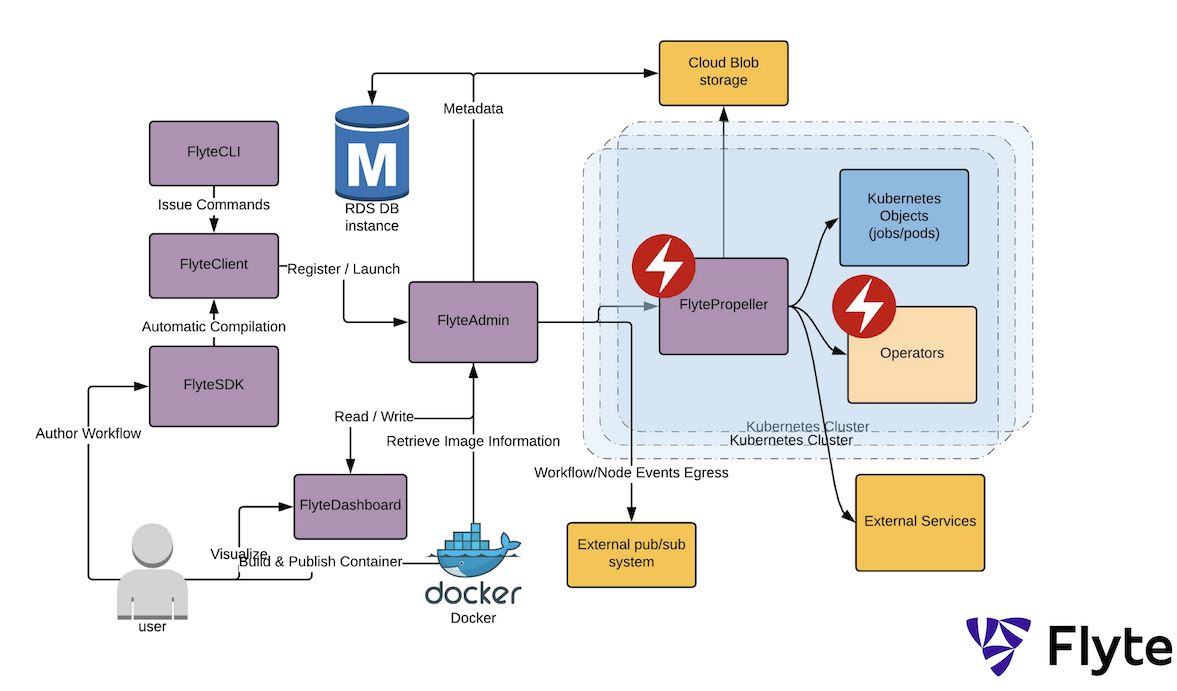
他们还有一个名为Amundsen的数据目录,这与 Spotify 的Lexikon相似。
AWS、Azure、GCP 等。
所有主要的公有云供应商都有自己的机器学习平台解决方案,除了 Oracle 只为某些用例和行业提供预制的基于 ML 的模型。
AWS SageMaker 是一个支持 TensorFlow、Keras、PyTorch 和 MXNet 的完整解决方案。借助SageMaker Neo,可以将模型部署到云端或边缘设备上。它还内置了通过 Amazon Mechanical Turk 对存储在 S3 中的数据进行标注的功能。
Google 没有托管平台,但借助TFX、Kubeflow 和AI Platform,可以将运行模型所需的所有组件连接在一起,包括 CPU、GPU 和 TPU 的支持,调整超参数,以及自动部署到生产环境。即使Spotify也选择了 TFX/Kubeflow-on-GCP 选项。
除了 TensorFlow,还有对scikit-learn 和 XGBoost的支持。自定义容器允许你使用任何框架,如PyTorch。目前还有一个类似 SageMaker Ground Truth 的标注服务处于测试阶段。

Azure 机器学习 支持相当多的 框架,如 scikit-learn、Keras、PyTorch、XGBoost、TensorFlow 和 MXNet。它拥有自己的 D/MLOps 套件,配有大量图表。对那些更喜欢图形界面的人,提供了拖放式模型开发界面,但这伴随有各种 隐患。模型和实验管理按照微软的预期,通过注册表完成。对于生产部署,使用 Azure Kubernetes 服务。控制滚动更新也是 可能的。
IBM Watson 机器学习 提供了点击式机器学习选项 (SPSS) 和对一系列常见 框架 的支持。与其他主要玩家一样,模型可以在 CPU 或 GPU 上训练。 超参数调优 也包含在内。该平台对数据和模型验证的细节不多,因为这些内容在其他 IBM 产品中可用。
尽管 阿里巴巴的 AI 机器学习平台 在一个名称中展示了两个流行词,但并没有改善文档;关于 最佳实践 的部分是用例而非推荐。
无论如何,它在 拖放操作 上花费较多,特别是在数据管理和建模方面,这可能不利于自动化的端到端机器学习平台。该平台支持 TensorFlow、MXNet 和 Caffe 等框架,但它也拥有大量的 传统算法。它包括一个超参数调优器,这也是可以预期的。
模型序列化可以通过PMML、TensorFlow 的 SavedModel 格式或 Caffe 格式完成。请注意,使用PMML、ONNX或PFA 文件的评分引擎可以实现快速部署,但有可能引入训练/服务偏差,因为服务的模型是从不同格式加载的。
荣誉提及
H2O 提供一个平台,包含数据处理、各种算法、交叉验证、超参数调优的网格搜索、特征排名和使用POJO 或 MOJO的模型序列化。
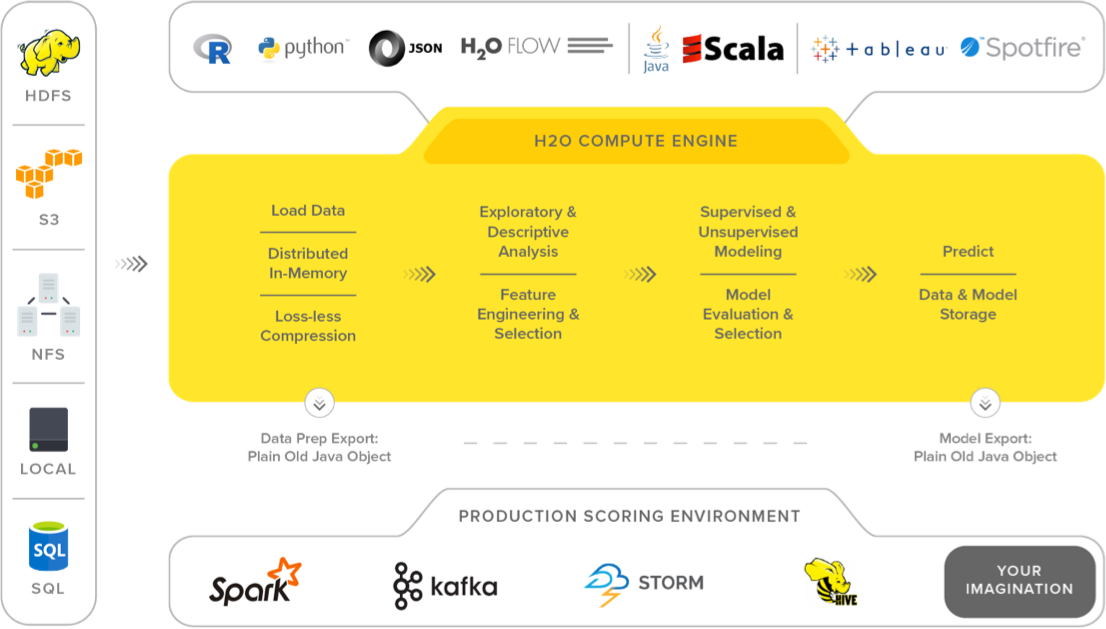
Valohai—芬兰语为“光鲨”,真的!—是一个托管的机器学习平台。它可以运行在私有、公有、混合或多云环境中。
每个操作(或执行)会对 Docker 镜像运行命令,因此与Kubeflow非常相似。主要区别在于,Valohai 为你管理 Kubernetes 部署集群,而 Kubeflow 需要你自己完成。不过,Kubeflow 和 TFX 都带有一些 TensorFlow 相关的工具。使用 Valohai,你需要重用现有的 Docker 镜像或自制镜像,这意味着你可以使用任何机器学习框架,但这种自由必须权衡维护问题。
因此,可以依靠Spark、Horovod、TensorFlow等工具分发训练,或使用最适合你需求和基础设施的工具,但需要你自己填补空白。这也意味着你要负责确保数据转换的兼容性,以避免训练/服务偏差。请注意,它目前仅支持对象存储。
Iguazio 提到可以从笔记本或 IDE 秒级部署,尽管这似乎遗漏了最常见的场景:CI/CD 流水线或像 TFX 的Pusher组件那样的平台。它使用 Kubeflow 进行工作流编排。
Iguazio 确实提供了一个具有统一 API 的特征存储,用于键值对和时间序列。许多现有的产品没有自己的特征存储,尽管大多数大型科技公司都有。特征存储是一个集中管理的地方,具有可重复使用的特征,可以跨模型共享,以加速模型开发。它可以在企业规模上自动化特征工程。例如,从时间戳中,你可以提取许多特征:年份、季节、月份、星期几、一天中的时间、是否是当地假期、自上次相关事件以来经过的时间(新颖性)、在固定窗口内某事件发生的频率等。
SwiftStack AI 针对使用 NVIDIA GPU 进行高吞吐量深度学习,与 RAPIDS 套件配合使用。RAPIDS 提供了库,如 cuML,允许用户使用熟悉的 scikit-learn API,但从 GPU 加速中获益,支持的算法并且还有 cuGraph 用于 GPU 驱动的图分析。
AI Layer 是一个 用于 D/MLOps 的 API。它内置了对多种数据源、编程语言和机器学习框架的支持。

MLflow 由 Databricks 支持,这解释了其与 Spark 的紧密集成。它提供了一个 有限的部署选项集合。例如,将模型导出为 PySpark 中的 矢量化 UDF 对于实时系统并不最为理想,因为 Python UDF 存在 Python 运行时环境与 JVM 之间的通信开销。虽然由于使用了 Apache Arrow(一种内存中的列格式),这种开销不像标准 PySpark UDF 那样大,但它仍然是 不可忽视的。由于 Spark Streaming 是默认的数据摄取解决方案,使用 Spark 的微批处理模型可能仍然难以实现亚秒级延迟。
日志记录支持对于 D/MLOps 至关重要, 仍处于实验阶段。根据文档,MLflow 的重点并不是数据和模型验证,至少在平台本身中不是标准部分。提供托管版本的 MLflow(在 AWS 和 Azure 上),提供 更多功能。
D2iQ 的 KUDO for Kubeflow 是一个基于 Kubeflow 的面向企业客户的平台。与开源 Kubeflow 不同,它配备了 Spark 和 Horovod,以及为主要框架(TensorFlow、PyTorch 和 MXNet)预构建和全面测试的 CPU/GPU 镜像。数据科学家可以在笔记本中进行部署,无需切换上下文。默认情况下,它支持多租户。 Istio 和 Dex 集成以提供额外的安全性和认证。KUDO for Kubeflow 基于 Konvoy,D2iQ 的托管 Kubernetes 平台。它可以在云端、本地、混合环境或边缘运行。也支持气隙集群。
在 Kubernetes 术语中,KUDO for Kubeflow 是一个使用 KUDO 定义的操作符集合,KUDO 是一个声明式工具包,可以使用 YAML 而不是 Go 来创建 Kubernetes 操作符。Cassandra、Elastic、Flink、Kafka、Redis 等的 Kubernetes 统一声明操作符(KUDOs)都是 开源的 ,可以与平台集成。更多细节请参阅 我写的介绍文章。
如果你想了解更多选项,包括可视化工作台,可以查看 这里 或者查看 Gartner 的机器学习和数据科学平台魔力象限。Facebook 还发布了他们的平台 FBLearner Flow(2016 年),以及 LinkedIn(2018 年)和 eBay(2019 年)的详细信息。
简介: Ian Hellström 曾在包括 D2iQ、Spotify、Bosch 和 Sievo 在内的多个公司担任数据和机器学习工程师。他是 D2iQ 企业机器学习平台 KUDO for Kubeflow 的产品经理。他目前居住在德国汉堡。
原文。经许可转载。
相关:
-
如何扩展 Scikit-learn 并使你的机器学习工作流程更加合理
-
外行人数据科学指南 第三部分:数据科学工作流程
-
将机器学习管道部署到云端,使用 Docker 容器
更多相关内容
-
[机器学习算法的全面端到端部署到生产环境中](https://www.kdnuggets.com/2021/12/deployment-machine-learning-algorithm-live-production-environment.html)
现实世界机器学习问题的巡礼
原文:
www.kdnuggets.com/2015/12/tour-real-world-machine-learning-problems.html
由 Jason Brownlee 撰写
 现实世界的例子使机器学习的抽象描述变得具体。
现实世界的例子使机器学习的抽象描述变得具体。
在这篇文章中,你将体验现实世界机器学习问题的巡礼。你将看到机器学习如何在教育、科学、技术和医学等领域实际应用。
每个列出的机器学习问题还包括一个指向公开可用数据集的链接。这意味着,如果某个具体的机器学习问题引起了你的兴趣,你可以下载数据集并立即开始实践。
最受欢迎的 Kaggle 数据集这前 10 个机器学习问题的示例取自于竞争性机器学习网站 Kaggle.com。受欢迎程度基于参与团队的数量。
-
Otto 集团产品分类挑战。根据产品的特征数据将产品分类到 9 个产品类别中的一个。
-
Rossmann 门店销售。根据门店的历史销售数据,预测未来的销售情况。
-
共享单车需求。根据每日单车租赁和天气记录预测未来每日单车租赁需求。
-
分析边缘。根据《纽约时报》文章的详细信息预测哪些新闻文章将会受欢迎。
-
餐厅收入预测。根据餐厅地点的详细信息预测餐厅在某一年的收入。
-
Liberty Mutual 集团:物业检查预测。根据检查过的物业的详细信息预测物业的危险评分。
-
Springleaf 营销响应。根据客户的特征预测他们是否是营销目标。
-
希格斯玻色子机器学习挑战。根据模拟粒子碰撞的描述预测事件是否衰变成希格斯玻色子。
-
森林覆盖类型预测。根据制图变量预测森林覆盖类型。
-
亚马逊员工访问挑战。根据员工的历史资源访问变化预测员工所需的资源。
最受欢迎的研究数据集
接下来的 10 个机器学习问题是加州大学欧文分校机器学习库网站上最受欢迎的问题,该网站传统上托管机器学习研究社区使用的数据集。
-
鸢尾花数据集。根据花朵的厘米测量值预测鸢尾花的种类。
-
成人数据集。根据人口普查数据预测个人年收入是否超过 50,000 美元。
-
葡萄酒数据集。根据葡萄酒的化学分析预测葡萄酒的来源。
-
汽车评估数据集。根据汽车的详细信息预测汽车的安全性。
-
乳腺癌威斯康星数据集。根据乳腺组织的诊断测试结果预测肿块是否为肿瘤。
-
鲍勃数据集。根据鲍勃的测量值预测鲍勃的年龄。
-
葡萄酒质量数据集。根据各种葡萄酒的测量值预测葡萄酒的质量。
-
心脏病数据集。根据患者各种诊断测试的结果预测患者的心脏病程度。
-
扑克手牌数据集。根据扑克手牌数据库预测手牌的质量。
-
使用智能手机进行人类活动识别的数据集。根据智能手机的运动数据预测持有智能手机的人的活动类型。
-
森林火灾数据集。根据气象和其他因素预测森林火灾的烧毁面积。
-
互联网广告数据集。根据网页上的图像详细信息预测图像是否为广告。
最终世界
我们快速浏览了 20 个现实世界的机器学习问题。
这些是全球科学和商业组织提出或研究的实际问题。
更令人兴奋的是,这些多样化的问题都有公开可用的数据集,并且广泛地被研究和理解。
这意味着你可以立即下载数据,探索问题,实施自己的模型,或重现别人的模型。
作者简介
杰森·布朗利是 MachineLearningMastery.com 的主编。他是丈夫、父亲、研究员、作者、专业程序员和机器学习从业者。
相关:
-
5 步真正学习数据科学
-
来自 Quora 的最佳建议:“如何学习机器学习”
-
60+本关于大数据、数据科学、数据挖掘、机器学习、Python、R 等的免费书籍
更多相关主题
自动文本摘要:提取方法
原文:
www.kdnuggets.com/2019/03/towards-automatic-text-summarization.html
评论
由Sciforce。
对于那些进行学术写作的人来说,总结——在保持关键信息内容和整体意义的同时,生成简明流畅的摘要的任务——如果不是噩梦,那就是一个近乎猜测的常规挑战,以确定教授认为重要的内容。尽管基本思路看似简单:找出要点,去除所有意见和细节,然后写几句完美的句子,但任务不可避免地陷入了艰辛与混乱。
另一方面,在现实生活中,我们是完美的总结者:我们可以用一个词描述整部《战争与和平》,无论是“杰作”还是“废话”。我们可以阅读大量关于尖端技术的新闻,并将其总结为“马斯克把特斯拉送上了月球”。
我们期望计算机能够做得更好。人类不完美的地方,情感和意见缺失的人工智能将能够完成这项工作。
故事始于 1950 年代。那时的一项重要研究介绍了一种从文本中提取显著句子的办法,使用单词和短语频率等特征。在这项工作中,Luhl 提议根据高频词的函数加权文档中的句子,忽略非常高频的常见词——这一方法成为了 NLP 的基石之一。
词频图。横坐标表示按频率排序的单个单词
目前,专注于摘要的自然语言处理分支已经出现,涵盖了各种任务:
-
头条(全球新闻);
-
大纲(学生笔记);
-
会议记录;
-
预告片(电影);
-
大纲(肥皂剧列表);
-
书评(书籍、CD、电影等);
-
摘要(电视指南);
-
传记(简历、讣告);
-
摘要(儿童莎士比亚);
-
公告(天气预报/股票市场报告);
-
声音片段(政客对时事的评论);
-
历史(重要事件的年表)。
文本摘要的方法因输入文档的数量(单个或多个)、目的(通用、特定领域或基于查询)和输出(提取式或抽象式)而异。
抽取式总结 指的是识别文本中的重要部分,并逐字生成这些部分,从而产生原文的句子子集;而 抽象总结 则是在对文本进行解释和审查后,以一种新的方式再现重要材料,使用先进的自然语言技术生成一个更短的新文本,从中传达原文的最关键信息。
显然,抽象总结更为先进,并且更接近于人类式的解释。尽管它具有更大的潜力(通常也更吸引研究人员和开发者),但到目前为止,传统方法已被证明能够产生更好的结果。
这就是为什么在这篇博客文章中,我们将简要概述这些传统方法,它们为先进的深度学习技术铺平了道路。
到现在为止,所有抽取式总结的核心包括三个独立的任务:
1) 输入文本的中间表示构建
表示基础的方法有两种类型:主题表示和指示符表示。主题表示将文本转换为中间表示,并解释文本中讨论的主题。用于这一过程的技术在复杂性上有所不同,分为频率驱动的方法、主题词方法、潜在语义分析和贝叶斯主题模型。指示符表示将每个句子描述为重要形式特征(指示符)的列表,如句子长度、在文档中的位置、包含特定短语等。
- 基于表示的句子评分
当生成中间表示后,会为每个句子分配一个重要性评分。在主题表示方法中,句子的评分表示句子解释文本中一些最重要主题的能力。在指示符表示中,评分是通过聚合来自不同加权指示符的证据来计算的。
3) 选择包含若干句子的摘要
总结系统选择最重要的 k 个句子来生成摘要。一些方法使用贪婪算法来选择重要句子,而有些方法则可能将句子的选择转换为一个优化问题,在考虑到应该最大化整体重要性和连贯性,并最小化冗余的约束下,选择一组句子。
让我们更详细地查看我们提到的方法,并概述它们之间的差异:
主题表示方法
主题词
这种常见技术旨在识别描述输入文档主题的词。对最初 Luhn 思路的改进是使用对数似然比检验来识别称为“主题签名”的解释性词。一般来说,有两种计算句子重要性的方法:作为其包含的主题签名数量的函数,或作为句子中主题签名的比例。第一种方法给包含更多词的较长句子更高的分数,而第二种方法则测量主题词的密度。
基于频率的方法
这种方法使用词频作为重要性的指标。这一类别中最常见的两种技术是:词概率和 TF-IDF(词频逆文档频率)。词 w 的概率是通过将词的出现次数 f (w) 除以输入中所有词的总数来确定的(输入可以是单个文档或多个文档)。概率最高的词被认为代表了文档的主题,并被包含在摘要中。TF-IDF 是一种更复杂的技术,它评估词的重要性,并通过给出现于大多数文档中的词以低权重来识别非常常见的词(这些词应被排除在考虑之外)。TF-IDF 让位于基于质心的方法,这种方法通过计算一组特征的显著性来对句子进行排序。在创建文档的 TF-IDF 向量表示后,描述相同主题的文档被聚类在一起,并计算质心——这些伪文档由 TF-IDF 分数高于某个阈值的词组成,并形成聚类。之后,质心被用来识别每个聚类中与主题相关的句子。
潜在语义分析
潜在语义分析 (LSA)是一种基于观察到的词提取文本语义表示的无监督方法。第一步是建立一个词-句子矩阵,其中每一行对应输入中的一个词(n 个词),每一列对应一个句子。矩阵的每个条目是通过 TF-IDF 技术计算的词 i 在句子 j 中的权重。然后对矩阵进行奇异值分解(SVD),将初始矩阵转换为三个矩阵:一个词-主题矩阵,包含词的权重,一个对角矩阵,每一行对应一个主题的权重,以及一个主题-句子矩阵。如果将带权重的对角矩阵与主题-句子矩阵相乘,结果将描述一个句子代表一个主题的程度,换句话说,就是主题 i 在句子 j 中的权重。
话语基础方法
语义分析的逻辑发展是进行话语分析,找到文本单元之间的语义关系,以形成摘要。跨文档关系的研究由 Radev 发起,他提出了跨文档结构理论 (CST) 模型。在他的模型中,词语、短语或句子可以互相连接,如果它们在语义上是相关的。CST 确实对文档摘要有用,可以确定句子的相关性以及处理不同数据源之间的重复、互补和不一致性。然而,这种方法的一个显著限制是 CST 关系必须由人工明确确定。
贝叶斯主题模型
虽然其他方法没有很清晰的概率解释,但贝叶斯主题模型是概率模型,因其能够更详细地描述主题,能够表示在其他方法中丢失的信息。在文本文档的主题建模中,目标是根据对文档语料库的先验分析,推断与某个主题相关的词汇和某个文档中讨论的主题。这可以通过贝叶斯推理来实现,该推理计算事件的概率,基于常识假设的组合以及之前相关事件的结果。该模型通过多次迭代不断改进,其中先验概率会随着观测证据的增加而更新,以产生新的后验概率。
指示符表示方法
第二大类技术旨在基于一组特征来表示文本,并使用这些特征直接对句子进行排名,而不表示输入文本的主题。
图方法
受PageRank 算法的影响,这些方法将文档表示为一个连通图,其中句子形成顶点,句子之间的边表示这两个句子的相似程度。两个句子的相似度通过使用 TF-IDF 权重的余弦相似度来测量,如果相似度大于某个阈值,这些句子就会被连接起来。这种图表示的结果有两个:图中包含的子图创建了文档中涉及的主题,并且重要的句子被识别出来。那些在子图中与许多其他句子连接的句子可能是图的中心,并将被包含在摘要中。由于这种方法不需要特定语言的语言学处理,它可以应用于各种语言[43]。与此同时,这种仅仅测量句子结构的形式而没有语法和语义信息的方式限制了该方法的应用。
机器学习
目前广泛使用的机器学习方法将摘要视为分类问题,尝试应用朴素贝叶斯、决策树、支持向量机、隐马尔可夫模型和条件随机场来获得真实的摘要。事实证明,明确假设句子之间依赖关系的方法(隐马尔可夫模型 和 条件随机场)通常优于其他技术。

图 1:摘要提取马尔可夫模型以提取 2 个主要句子和额外支持句子

图 2:摘要提取马尔可夫模型以提取 3 个句子
然而,分类器的问题在于,如果我们使用监督学习方法进行摘要生成,我们需要一组标记文档来训练分类器,这意味着需要开发一个语料库。一个可能的解决方法是应用半监督方法,将少量标记数据与大量未标记数据结合进行训练。
总体而言,机器学习方法在单文档和多文档摘要生成中都被证明是非常有效和成功的,特别是在特定领域的摘要生成,例如撰写科学论文摘要或传记摘要。
尽管方法丰富,但我们提到的所有摘要方法仍无法生成与人类创建的摘要类似的结果。在许多情况下,生成的摘要在准确性和可读性方面不尽如人意,因为它们未能以有效的方式覆盖数据中的所有语义相关方面,并且之后未能自然地连接句子。
原文。已获得许可转载。
简介:Sciforce 是一家总部位于乌克兰的 IT 公司,专注于基于科学驱动的信息技术开发软件解决方案。我们在许多关键的人工智能技术领域拥有广泛的专业知识,包括数据挖掘、数字信号处理、自然语言处理、机器学习、图像处理和计算机视觉。
资源:
相关:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作。
更多相关话题
TPOT 自动化机器学习竞赛:AutoML 能否击败 Kaggle 上的人类?
原文:
www.kdnuggets.com/2017/06/tpot-automated-machine-learning-competition.html
作者:兰迪·奥尔森,宾夕法尼亚大学。
自动化机器学习(AutoML)预计将在 2017 年对数据科学产生深远的影响。在宾夕法尼亚大学,我们一直在努力开发 TPOT,这是一个最先进的开源 AutoML 工具,可以优化监督学习问题的机器学习管道。
现在我们想看看你能用 TPOT 做些什么。

在接下来的几个月里,我们将挑战你将 TPOT 应用到你在 Kaggle 上找到的任何有趣的数据科学问题。如果你的作品在 Kaggle 问题的排行榜中排名前 25%,我们希望看到 TPOT 如何帮助你实现这一点。
比赛结束时,TPOT 团队将审查所有参赛作品,对其进行排名,并向排名前 3 的参赛作品颁发(奖金!)奖品:$500、$250、$100。比赛结束后,我们还会发布一篇文章,突出展示最佳作品。
参赛作品将根据在 Kaggle 问题上的排名以及提供的技术说明进行评判。
将你的作品通过电子邮件发送到 olsonran@upenn.edu
参赛作品提交截止日期为2017 年 8 月 7 日,获奖者将在接下来的一周内公布。
入门 TPOT
如果你对 TPOT 和 AutoML 不熟悉,你很幸运!我们已经编写了 详细文档,描述了如何使用 TPOT,还有 用户指南 和 API 文档。为了给你一个起点,下面是一个将 TPOT 应用到 scikit-learn 的 MNIST 数据集的基本示例。
这段 Python 代码将会在训练数据上拟合 TPOT,对测试数据进行评分,然后将优化后的管道以 Python 代码的形式导出到文件“tpot_mnist_pipeline.py”。
重要的是,TPOT 使用的机器学习算法可以进行高度定制。实际上,TPOT 可以优化任何遵循 scikit-learn 接口的机器学习算法的管道。你可以在用户指南 这里 阅读有关定制 TPOT 配置的更多信息。
入门 Kaggle
如果您是 Kaggle 新手,他们提供了一个 广泛的竞赛列表,您可以在他们的网站上查看。Kaggle 的经典问题之一是 Titanic 挑战,您需要使用机器学习预测 Titanic 灾难的幸存者。
我们有一个 Jupyter Notebook 教程,指导您使用 TPOT 解决 Kaggle 的 Titanic 挑战的基本方法。
附加比赛说明
-
每个条目必须具有开源许可证,以便我们可以分享和讨论每个人的条目。
-
我们建议使用 Jupyter Notebooks 提交条目,但只要包含代码和写作,任何格式都是可以接受的。
-
条目必须在 8 月 7 日前排名前 25% 才能计入比赛。
-
Kaggle 教程问题,例如 Titanic 问题,将不计入比赛。
-
我们创建了一个 公开的 GitHub 仓库,供任何希望合作提交比赛条目的人使用。
简介:兰迪·奥尔森博士 是宾夕法尼亚大学的博士后研究员。作为 Jason H. Moore 教授研究实验室的成员,他研究生物启发的 AI 及其在生物医学问题上的应用。
原始。已获得许可转载。
相关:
-
自动化机器学习:与 Randy Olson 的采访,TPOT 主要开发者
-
TPOT:一个用于自动化数据科学的 Python 工具
-
自动化机器学习的现状
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT
更多相关主题
如何使用 Python 跟踪 IP 地址的位置
原文:
www.kdnuggets.com/2023/01/track-location-ip-address-python.html
图片由作者提供
我们将使用一个名为 ip2geotools 的 Python 库,该库可以确定 IP 地址的实际位置。这可以确定 IP 地址所在的国家、地区、城市、纬度和经度。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
它支持 IPv4 和 IPv6 地址,并且可以处理单个 IP 地址和 IP 地址列表。但需要注意的是,这个库并不是 100% 准确,结果的准确性取决于所用的数据源和数据的质量。然而,它被广泛使用,社区活跃,所以库会定期更新。
从 IP 地址获取位置
在本节中,我们将讨论提取 IP 地址或 URL 位置的 Python 代码。
1. 导入必要的库
$ pip install ip2geotools
import socket
import requests
from ip2geotools.databases.noncommercial import DbIpCity
from geopy.distance import distance
以下函数用于打印 IP 地址的详细信息,如城市、国家、坐标等。
def printDetails(ip):
res = DbIpCity.get(ip, api_key="free")
print(f"IP Address: {res.ip_address}")
print(f"Location: {res.city}, {res.region}, {res.country}")
print(f"Coordinates: (Lat: {res.latitude}, Lng: {res.longitude})")
2. 从 IP 地址获取位置
ip_add = input("Enter IP: ") # 198.35.26.96
printDetails(ip_add)
输出:
IP Address: 198.35.26.96
Location: San Jose, California, US
Coordinates: (Lat: 37.3361663, Lng: -121.890591)
3. 从 URL 获取位置
url = input("Enter URL: ") # www.youtube.com
ip_add = socket.gethostbyname(url)
printDetails(ip_add)
输出:
Enter the URL: www.youtube.com
IP Address: 173.194.214.91
Location: Mountain View, California, US
Coordinates: (Lat: 37.3893889, Lng: -122.0832101)
一些常见的用例
在这里我们讨论一些用例,比如阻止某些特定国家的 IP 地址或计算两个 IP 地址之间的距离等。
1. 根据位置阻止某些 IP 地址
以下代码查找 IP 地址的位置,然后检查该位置的国家是否在被阻止的国家列表中。
def is_country_blocked(ip_address):
blocked_countries = ["China", "Canada", "India"]
location = DbIpCity.get(ip_address)
if location.country in blocked_countries:
return True
else:
return False
ip_add = input("Enter IP: ") # 198.35.26.96
if is_country_blocked(ip_add) is True:
print(f"IP Address: {ip_add} is blocked")
else:
print(f"IP Address: {ip_add} is allowed")
输出:
Enter the IP Address: 198.35.26.96
IP Address: 198.35.26.96 is allowed
你也可以修改该代码,以允许来自特定国家的 IP 地址。
2. 计算两个 IP 地址之间的距离
以下代码将计算两个 IP 地址位置之间的距离(以公里为单位)。
def calculate_distance(ip1, ip2):
res1 = DbIpCity.get(ip1)
res2 = DbIpCity.get(ip2)
lat1, lon1 = res1.latitude, res1.longitude
lat2, lon2 = res2.latitude, res2.longitude
return distance((lat1, lon1), (lat2, lon2)).km
# Input two IP addresses
ip_add_1 = input("1st IP: ") # 198.35.26.96
ip_add_2 = input("2nd IP: ") # 220.158.144.59
dist = calculate_distance(ip_add_1, ip_add_2)
print(f"Distance between them is {str(dist)}km")
输出:
Enter 1st IP Address: 198.35.26.96
Enter 2nd IP Address: 220.158.144.59
Distance between them is 12790.62320788363km
3. 计算你当前的位置和服务器之间的距离
以下代码将计算你当前的位置和给定 IP 地址位置之间的距离(以公里为单位)。
def get_distance_from_location(ip, lat, lon):
res = DbIpCity.get(ip)
ip_lat, ip_lon = res.latitude, res.longitude
return distance((ip_lat, ip_lon), (lat, lon)).km
server_ip = input("Server's IP: ")
lat = float(input("Your Latitude: "))
lng = float(input("Your Longitude: "))
dist = get_distance_from_location(server_ip, lat, lng)
print(f"Distance between the server and your location is {str(dist)}km")
输出:
Enter your server's IP Address: 208.80.152.201
Enter your current location (Latitude): 26.4710
Enter your current location (Longitude): 73.1134
Distance between the server and your location is 12183.275099919923km
结论
跟踪 IP 地址的位置有几个好处,比如企业可以根据用户的位置提供定向广告。这可以带来更有效的营销活动、更高的转化率,并且能个性化用户体验。
此外,这在欺诈检测中也很有帮助,例如阻止来自特定国家的 IP 地址,以及验证 IP 地址以确保其格式正确。
总之,我希望您喜欢这篇文章并觉得它有帮助。您可以找到完整代码的协作文件。如果您有任何建议或反馈,请通过 LinkedIn 与我联系。
祝您有美好的一天????。
Aryan Garg 是一名 B.Tech 电气工程学生,目前正处于本科最后一年。他对 Web 开发和机器学习领域充满兴趣。他已经追求了这一兴趣,并渴望在这些方向上继续工作。
更多相关主题
传统人工智能与生成式人工智能

作者提供的图像
‘生成式人工智能’是目前流行的下一个热词。不论你工作在哪个领域,你一定听说过这个词。仅在过去 6 个月中,它已经向我们展示了人工智能(AI)的重大进展。它重塑了各个行业,每个人都想涉足其中。
对于你们中的一些人来说,你可能不太了解人工智能的不同子集,而这正是本文的重点。
为了让事情变得清楚。
什么是传统人工智能?
传统人工智能——大多数非技术人员熟知的一部分人工智能。也被称为狭义人工智能或弱人工智能,传统形式的人工智能专注于以智能方式执行特定任务。
我们所知的传统人工智能是语音助手,如 Siri 和 Alexa,它们被设计成响应输入并产生输出。这一切之所以可行,是因为这些人工智能系统通过学习数据、特征等来做出决策和预测。
想象一下你在玩计算机棋类游戏时。计算机并不是在随意制定规则,它知道所有的规则,并利用这些规则来制定下一步的动作。这是一种预定义的策略。
策略。这就是传统人工智能所依赖的基础。它使用一套特定的规则来做出决策,每次都依赖于这些规则。
它接收输入并产生输出——基于规则,而不是创造规则。
什么是生成式人工智能?
现在,谈谈流行词‘生成式人工智能’。正如你可以想象的那样,我强调了传统人工智能是基于规则的,不能创造新事物。那么,生成式人工智能又是什么呢?
是的,你说得对。生成式人工智能具有创造新事物的能力。就像传统人工智能一样,生成式人工智能也学习了大量数据,并利用这些数据做出决策和预测。但不同的是,它不仅仅是一个简单的输入和输出过程。
生成式人工智能接收输入,理解它,并使用输入中的信息创造新事物。它通过数据进行训练,并学习潜在的模式,以便能够基于输入信息生成类似于训练数据的新数据。
到目前为止,你可以使用生成式人工智能来创建不同形式的输出,如文本、图像和音乐,并且还可以用它来帮助你完成如代码补全等任务。
生成式人工智能的例子包括 GPT、Soundful、Synthesia 和 DALL-E 2。
区别
那么,传统人工智能和生成式人工智能之间有什么区别?
能力和应用是主要的区别。
如我之前提到的,传统人工智能基于接收输入并生成输出。输入数据被分析并用于做出决策和预测。如果你寻找的是模式识别,传统人工智能是你的首选。传统人工智能仍然非常流行,并用于支持许多当前的人工智能系统,如聊天机器人和预测分析。它专注于任务特定的应用,这些应用被许多人用于日常任务。
另一方面,生成性人工智能将超越并创建新的数据,这些数据类似于训练数据。如果你寻找的是模式创建,生成性人工智能是你的首选。生成性人工智能为公司开辟了更多的创造性和创新的机会。它可以大幅减少诸如创意过程等任务所花费的时间。它可以写歌词、撰写文章和创建深度伪造图像。在创作和创新重要的地方,生成性人工智能有着将其提升到更高水平的巨大潜力。
总结
总结这篇关于传统人工智能和生成性人工智能的通用文章,你需要理解它们的功能目前还无法交织在一起。例如,生成性人工智能可以与传统人工智能结合,提供更有效的解决方案。另一方面,传统人工智能可以提供特定的输出,这些输出可以进一步分析,以使用生成性人工智能创建个性化内容。
了解两者之间的区别及其在人工智能世界中的具体作用是很重要的。它们都在塑造我们的未来,并在当今社会中被广泛接受。
你现在已经理解了这两者的独特能力,并将在它们继续创新的过程中享受其中的乐趣。
Nisha Arya 是一名数据科学家、自由技术作家以及 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程,以及数据科学的理论知识。她还希望探索人工智能如何能提升人类寿命的不同方式。她是一个热衷学习者,致力于拓宽她的技术知识和写作技能,同时帮助他人。
更多相关主题
如何从零开始训练 BERT 模型
评论
由James Briggs,数据科学家

BERT,但在意大利——作者提供的图片
我的许多文章集中在 BERT——这一模型的出现主导了自然语言处理(NLP)领域,并为语言模型标志着一个新的时代。
对于那些之前可能没有使用过变换器模型(例如 BERT 是什么)的人,过程看起来有点像这样:
-
pip install transformers -
初始化一个预训练的变换器模型——
from_pretrained。 -
在一些数据上进行测试。
-
也许微调模型(再训练一些)。
现在,这是一种很好的方法,但如果我们只做这个,我们就缺乏创建自己变换器模型的理解。
而且,如果我们不能创建自己的变换器模型——我们必须依赖于有一个适合我们问题的预训练模型,但这并不总是可能的:
一些关于非英语 BERT 模型的评论
所以在这篇文章中,我们将探讨构建自己的变换器模型——特别是 BERT 的进一步发展版本,称为 RoBERTa 的步骤。
概述
这个过程有几个步骤,所以在我们深入之前,让我们首先总结一下我们需要做什么。总共有四个关键部分:
-
获取数据
-
构建一个标记器
-
创建输入管道
-
训练模型
一旦我们完成了这些部分,我们将使用我们构建的标记器和模型——并保存它们,以便我们可以像平常一样使用from_pretrained。
获取数据
和任何机器学习项目一样,我们需要数据。在训练变换器模型的数据方面,我们真的有很多选择——我们几乎可以使用任何文本数据。
使用 HuggingFace 的 datasets 库下载 OSCAR 数据集的视频讲解
而且,如果有一件事我们在互联网上有很多——那就是非结构化文本数据。
领域中最大的互联网文本抓取数据集之一是 OSCAR 数据集。
OSCAR 数据集拥有大量不同的语言——从零开始训练的一个最明确的用例是,我们可以将 BERT 应用于一些不太常用的语言,如泰卢固语或纳瓦荷语。
不幸的是,我唯一可以熟练使用的语言是英语——但我的女朋友是意大利人,她——劳拉,将评估我们意大利语 BERT 模型——FiliBERTo 的结果。
因此,要下载 OSCAR 数据集的意大利语部分,我们将使用 HuggingFace 的datasets库——我们可以通过pip install datasets安装它。然后我们用以下命令下载 OSCAR_IT:
让我们来看看dataset对象。
很好,现在让我们将数据存储为在构建分词器时可以使用的格式。我们需要创建一组仅包含数据集中的text特征的纯文本文件,并且我们将使用换行符\n拆分每个样本。
在我们的data/text/oscar_it目录下,我们将找到:

包含我们纯文本 OSCAR 文件的目录
构建分词器
接下来是分词器!使用 transformers 时,我们通常加载一个分词器,和相应的 transformer 模型——分词器是过程中的关键组件。
自定义分词器构建的视频演示
在构建我们的分词器时,我们将输入所有的 OSCAR 数据,指定词汇表大小(分词器中的令牌数)和任何特殊令牌。
现在,RoBERTa 的特殊令牌看起来像这样:
因此,我们确保在分词器的train方法调用中的special_tokens参数中包含它们。
我们的分词器现在准备好了,我们可以将其保存以备后用:
现在我们有两个文件定义了我们新的FiliBERTo分词器:
-
merges.txt — 执行文本到令牌的初始映射
-
vocab.json — 将令牌映射到令牌 ID
有了这些,我们可以继续初始化我们的分词器,以便像使用任何其他from_pretrained分词器一样使用它。
初始化分词器
我们首先使用之前构建的两个文件初始化分词器——使用简单的from_pretrained:
现在我们的分词器准备好了,我们可以尝试使用它编码一些文本。编码时,我们使用通常使用的两种方法,encode和encode_batch。
从编码对象tokens中,我们将提取input_ids和attention_mask张量,以便与 FiliBERTo 一起使用。
创建输入管道
我们训练过程的输入管道是整个过程中的复杂部分。它包括我们处理原始的 OSCAR 训练数据,将其转换,并加载到DataLoader中以备训练。
MLM 输入管道的视频演示
准备数据
我们将从一个样本开始,并处理准备逻辑。
首先,我们需要打开文件——之前保存为.txt文件的相同文件。我们根据换行符\n拆分每个文件,因为这标识了单独的样本。
然后我们使用tokenizer对数据进行编码——确保包括像max_length、padding和truncation这样的关键参数。
现在我们可以继续创建张量——我们将通过掩码语言建模(MLM)训练我们的模型。因此,我们需要三个张量:
-
input_ids — 我们的token_ids,其中~15%的令牌被掩码令牌
<mask>遮蔽。 -
attention_mask — 一个1和0的张量,标记‘真实’令牌/填充令牌的位置——用于注意力计算。
-
labels — 我们的token_ids,没有遮蔽。
如果你不熟悉 MLM,我已经在这里解释过了。
我们的attention_mask和labels张量直接从我们的batch中提取。然而,input_ids张量需要更多关注,对于这个张量,我们将约 15%的标记进行掩码处理——为它们分配标记 ID 3。
在最终输出中,我们可以看到部分编码的input_ids张量。第一个标记 ID 是1——[CLS]标记。张量中点缀着几个3标记 ID——这些是我们新添加的[MASK]标记。
构建 DataLoader
接下来,我们定义我们的Dataset类——我们用它来初始化我们三个编码的张量作为 PyTorch torch.utils.data.Dataset对象。
最终,我们的dataset被加载到一个 PyTorch DataLoader对象中——我们在训练期间用来将数据加载到模型中。
训练模型
我们训练所需的两个东西是我们的DataLoader和一个模型。我们有DataLoader——但没有模型。
初始化模型
对于训练,我们需要一个原始(未预训练的)BERTLMHeadModel。为了创建它,我们首先需要创建一个 RoBERTa 配置对象来描述我们希望用来初始化 FiliBERTo 的参数。
然后,我们导入并初始化我们的 RoBERTa 模型,附带语言建模(LM)头。
训练准备
在进入训练循环之前,我们需要设置一些东西。首先,我们设置 GPU/CPU 使用情况。然后,我们激活模型的训练模式——最后,初始化我们的优化器。
训练
最后——训练时间!我们就像平常训练 PyTorch 时那样训练。
如果我们前往 Tensorboard,我们会发现我们的损失随时间的变化——看起来很有希望。
损失/时间——图表中显示了多个训练会话的综合情况
实际测试
现在是时候进行真正的测试了。我们设置一个 MLM 管道——并请 Laura 评估结果。你可以在这里 22:44 观看视频评论:
我们首先初始化一个pipeline对象,使用'fill-mask'参数。然后开始这样测试我们的模型:
“ciao come va?”是正确的答案!这就是我的意大利语水平——所以,让我们交给 Laura 吧。
我们从“buongiorno, come va?”——或“早安,你好吗?”开始:
第一个答案,“buongiorno, chi va?”意思是“早安,谁在那?”——即毫无意义。但我们的第二个答案是正确的!
接下来是一个稍微复杂一点的短语,“ciao, dove ci incontriamo oggi pomeriggio?”——或“你好,我们今天下午在哪里见面?”:
我们得到了一些更积极的结果:
✅ "hi, where do we see each other this afternoon?"
✅ "hi, where do we meet this afternoon?"
❌ "hi, where here we are this afternoon?"
✅ "hi, where are we meeting this afternoon?"
✅ "hi, where do we meet this afternoon?"
最后,再来一个更复杂的句子,“cosa sarebbe successo se avessimo scelto un altro giorno?”——或“如果我们选择了另一天,会发生什么?”:
我们在这里也返回了几个好的答案:
✅ "what would have happened if we had chosen another day?"
✅ "what would have happened if I had chosen another day?"
✅ "what would have happened if they had chosen another day?"
✅ "what would have happened if you had chosen another day?"
❌ "what would have happened if another day was chosen?"
总体来看,我们的模型通过了 Laura 的测试——现在我们有了一个称为 FiliBERTo 的意大利语模型!
这就是从头开始训练 BERT 模型的流程!
我们已经涵盖了大量内容,从获取和格式化数据开始,一直到使用语言建模训练我们的原始 BERT 模型。
希望您喜欢这篇文章!如果您有任何问题,请通过 Twitter 或在下方评论中告诉我。如果您希望获得更多类似的内容,我也会在 YouTube 上发布。
感谢阅读!
70% 折扣!自然语言处理:Python 中的 NLP 与 Transformers
Transformer 模型是现代 NLP 的事实标准。它们已经证明自己是最具表现力的…
除非另有说明,所有图片均由作者提供
简介:詹姆斯·布里格斯 是一位数据科学家,专注于自然语言处理,工作于金融行业,总部设在英国伦敦。他还是一名自由职业的导师、作家和内容创作者。您可以通过电子邮件联系作者(jamescalam94@gmail.com)。
原文。经许可转载。
相关:
-
如何将 Transformers 应用于任意长度文本
-
使用 Hugging Face 理解 BERT
-
使用 BERT 进行主题建模
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 部门
相关主题
让你的深度学习训练更快:FreezeOut
原文:
www.kdnuggets.com/2017/08/train-deep-learning-faster-freezeout.html
深度神经网络有许多可学习的参数用于进行推断。这通常在两个方面构成问题:有时,模型的预测不够准确,同时训练所需时间也很长。
在之前的文章中,我们介绍了 让你的深度学习模型训练更快更精准:Snapshot Ensembling — 用 1 的成本实现 M 个模型。
本文讨论了使用一种新颖的方法减少训练时间,对准确性几乎没有影响。
FreezeOut — 通过逐步冻结层加速训练
本文作者提出了一种通过冻结层来提高训练速度的方法。他们尝试了几种不同的冻结层的方法,并展示了训练速度的提高对准确性影响很小(或没有影响)。
冻结一层是什么意思?
冻结一层可以防止其权重被修改。这种技术常用于迁移学习,其中基础模型(在其他数据集上训练过的)被冻结。
冻结如何影响模型的速度?
如果你不想修改某一层的权重,可以完全避免对该层的反向传播,从而显著提高速度。例如,如果你冻结了模型的一半,训练模型将只需比完全可训练模型少一半的时间。
另一方面,你仍然需要训练模型,因此如果冻结得太早,将会得到不准确的预测。
什么是‘新颖’的方法?
作者展示了一种逐层冻结的方式,尽可能快地冻结每一层,从而减少反向传播的次数,从而降低训练时间。
起初,整个模型是可训练的(和普通模型完全一样)。经过几次迭代后,第一层被冻结,其余模型继续训练。再经过几次迭代,下一层被冻结,以此类推。
学习率退火
作者们使用了学习率退火来控制模型的学习率。他们使用的显著不同的技术是逐层而不是整个模型来改变学习率。他们使用了以下方程:
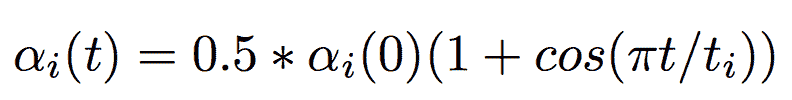
方程 2.0:α是学习率。t是迭代次数。i表示模型的第 i 层。
方程 2.0 解释
子i表示第 i 层。因此α子i表示第 i 层的学习率。类似地,t[i]表示第 i 层训练的迭代次数。t表示整个模型的总迭代次数。
这表示第 i 层的初始学习率。
作者们尝试了方程 2.1 的不同值
方程式 2.1 的初始学习率
作者们尝试了缩放初始学习率,使每层被训练的时间相等。
记住,由于模型的第一层会首先停止训练,因此它会被训练最少的时间。为了解决这个问题,他们对每层的学习率进行了缩放。
进行缩放是为了确保所有层的权重在权重空间中均匀移动,即被训练时间最长的层(后面的层)具有较低的学习率。
作者们还尝试了立方缩放,即将 t 子 i 的值替换为其立方。
图 2.1:DenseNet 上的性能与误差
作者们增加了更多的基准测试,他们的方法在仅3%的准确率下降下提高了约20%的训练速度,而在无下降的情况下提高了15%。
对于不利用跳跃连接的模型(例如 VGG-16),他们的方法效果不是很好。在这些网络中,准确率和加速并没有明显差异。
我的额外技巧
作者们正在逐步停止每层的训练,并且不再计算反向传递。他们似乎遗漏了利用预计算层激活。通过这样做,你甚至可以防止计算前向传递。
什么是预计算
这是转移学习中使用的技巧。这是一般工作流程。
-
冻结你不想修改的层
-
计算从冻结层到最后一层的激活(对你的整个数据集)
-
将这些激活保存到磁盘
-
使用这些激活作为可训练层的输入
由于层是逐步冻结的,新的模型现在可以视为一个独立模型(一个更小的模型),它只接收最后一层的输出作为输入。每冻结一层,可以重复这个过程。
这样做加上FreezeOut将会大幅减少训练时间,同时不会以任何方式影响其他指标(如准确率)。
结论
我展示了 2 种(以及我自己的一半)非常近期和新颖的技术,通过微调学习率来提高准确率和降低训练时间。同时,通过尽可能添加预计算,使用我自己提出的方法可以显著加快速度。
原文。经授权转载。
简介: Harshvardhan Gupta 在 HackerNoon 上撰写文章。
相关:
-
让你的深度学习模型更快更精准:Snapshot Ensembling — 用 1 的成本获得 M 个模型
-
DeepSense:用于时间序列移动传感数据处理的统一深度学习框架
-
如何从训练数据中挤出更多价值
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
主题更多
如何使用 BERT Transformer 和 spaCy 3 训练联合实体和关系提取分类器
原文:
www.kdnuggets.com/2021/06/train-joint-entities-relation-extraction-classifier-bert-spacy.html
评论
作者 Walid Amamou,UBIAI 创始人

介绍
自然语言处理技术最有用的应用之一是从非结构化文本中提取信息——合同、财务文件、医疗记录等——这使得自动数据查询成为可能,以得出新的见解。传统上,命名实体识别被广泛用于识别文本中的实体,并存储数据以进行高级查询和过滤。然而,如果我们想从语义上理解非结构化文本,仅仅依靠 NER 是不够的,因为我们不知道实体之间的关系。进行联合 NER 和关系提取将开启通过知识图谱进行信息检索的全新方式,你可以在不同节点之间导航,发现隐藏的关系。因此,联合执行这些任务将是有益的。
基于我之前的文章,我们微调了一个 BERT 模型用于 NER,现在我们将使用 spaCy 的新 Thinc 库在管道中添加关系提取。我们按照spaCy 的文档中概述的步骤训练关系提取模型。我们将比较使用 transformers 和 tok2vec 算法的关系分类器的性能。最后,我们将在网上找到的职位描述上测试模型。
关系分类:
从本质上讲,关系提取模型是一个分类器,用于预测给定实体对{e1, e2}的关系r。在 transformers 的情况下,这个分类器被添加到输出的隐藏状态之上。有关关系提取的更多信息,请阅读这篇出色的文章,概述了微调 transformer 模型进行关系分类的理论。
我们将微调的预训练模型是 roberta-base 模型,但你可以使用 huggingface 库中任何可用的预训练模型,只需在配置文件中输入模型名称即可(见下文)。
在本教程中,我们将提取两个实体{Experience, Skills}之间的关系作为Experience_in,以及{Diploma, Diploma_major}之间的关系作为Degree_in。目标是提取特定技能所需的经验年限和与所需文凭相关的文凭专业。你当然可以训练自己的关系分类器以适应自己的用例,例如在健康记录中查找症状的因果关系或在财务文档中查找公司收购。可能性是无限的……
在本教程中,我们将仅涵盖实体关系抽取部分。有关使用 spaCy 3 对 BERT NER 进行微调的详细信息,请参考我的上一篇文章。
数据标注:
如在我的上一篇文章中所述,我们使用UBIAI文本标注工具进行联合实体和关系标注,因为它的多功能接口允许我们轻松切换实体和关系标注(见下图):

UBIAI 的联合实体和关系标注接口
对于本教程,我仅标注了大约 100 个包含实体和关系的文档。对于生产环境,我们肯定需要更多的标注数据。
数据准备:
在训练模型之前,我们需要将标注数据转换为二进制 spacy 文件。我们首先将 UBIAI 生成的标注拆分为训练/开发/测试,并分别保存。我们修改了代码来创建适用于我们标注的二进制文件(转换代码)。
我们对训练、开发和测试数据集重复此步骤,以生成三个二进制的 spacy 文件(文件可在 GitHub 上获取)。
关系抽取模型训练:
对于训练,我们将提供来自黄金语料库的实体,并在这些实体上训练分类器。
-
打开一个新的 Google Colab 项目,并确保在笔记本设置中选择 GPU 作为硬件加速器。通过运行:!nvidia-smi 来确保启用 GPU。
-
安装 spacy-nightly:
!pip install -U spacy-nightly --pre
- 安装 wheel 包并克隆 spacy 的关系抽取仓库:
!pip install -U pip setuptools wheel
!python -m spacy project clone tutorials/rel_component
- 安装 transformer 管道和 spacy transformers 库:
!python -m spacy download en_core_web_trf
!pip install -U spacy transformers
-
切换到 rel_component 文件夹:cd rel_component
-
在 rel_component 中创建一个名为“data”的文件夹,并将训练、开发和测试的二进制文件上传到其中:

训练文件夹
- 打开 project.yml 文件并更新训练、开发和测试路径:
train_file: "data/relations_training.spacy"dev_file: "data/relations_dev.spacy"test_file: "data/relations_test.spacy"
- 如果你想使用不同的语言,可以通过进入 configs/rel_trf.cfg 并输入模型名称来更改预训练的 Transformer 模型:
[components.transformer.model]@architectures = "spacy-transformers.TransformerModel.v1"name = "roberta-base" # Transformer model from huggingfacetokenizer_config = {"use_fast": true}
- 在开始训练之前,我们将 configs/rel_trf.cfg 中的 max_length 从默认的 100 个标记减少到 20,以提高模型的效率。max_length 对应于 最大距离,超出此距离的两个实体将不会被考虑进行关系分类。因此,同一文档中的两个实体将被分类,只要它们之间的最大距离(以标记数量计)在范围内。
[components.relation_extractor.model.create_instance_tensor.get_instances]@misc = "rel_instance_generator.v1"max_length = 20
- 我们终于准备好训练和评估关系提取模型;只需运行以下命令:
!spacy project run train_gpu # command to train train transformers
!spacy project run evaluate # command to evaluate on test dataset
你应该开始看到 P、R 和 F 分数开始更新:

模型训练进行中
模型训练完成后,测试数据集的评估将立即开始,并显示预测标签与实际标签的对比。模型将保存在名为“training”的文件夹中,并附带模型的评分。
要训练非 Transformer 模型 tok2vec,请运行以下命令:
!spacy project run train_cpu # command to train train tok2vec
!spacy project run evaluate
我们可以比较这两种模型的性能:
# Transformer model
"performance":{"rel_micro_p":0.8476190476,"rel_micro_r":0.9468085106,"rel_micro_f":0.8944723618,}
# Tok2vec model
"performance":{"rel_micro_p":0.8604651163,"rel_micro_r":0.7872340426,"rel_micro_f":0.8222222222,}
基于 Transformer 的模型在精度和召回率方面显著优于 tok2vec,展示了在处理少量标注数据时 Transformer 的有效性。
联合实体和关系提取管道:
假设我们已经训练了一个 Transformer NER 模型,如我的 上一篇文章 中所述,我们将从在线找到的工作描述中提取实体(这些数据既不属于训练集也不属于开发集),并将其输入到关系提取模型中进行分类。
-
安装 spacy transformers 和 transformer pipeline
-
加载 NER 模型并提取实体:
import spacynlp = spacy.load("NER Model Repo/model-best")Text=['''2+ years of non-internship professional software development experience
Programming experience with at least one modern language such as Java, C++, or C# including object-oriented design.1+ years of experience contributing to the architecture and design (architecture, design patterns, reliability and scaling) of new and current systems.Bachelor / MS Degree in Computer Science. Preferably a PhD in data science.8+ years of professional experience in software development. 2+ years of experience in project management.Experience in mentoring junior software engineers to improve their skills, and make them more effective, product software engineers.Experience in data structures, algorithm design, complexity analysis, object-oriented design.3+ years experience in at least one modern programming language such as Java, Scala, Python, C++, C#Experience in professional software engineering practices & best practices for the full software development life cycle, including coding standards, code reviews, source control management, build processes, testing, and operationsExperience in communicating with users, other technical teams, and management to collect requirements, describe software product features, and technical designs.Experience with building complex software systems that have been successfully delivered to customersProven ability to take a project from scoping requirements through actual launch of the project, with experience in the subsequent operation of the system in production''']for doc in nlp.pipe(text, disable=["tagger"]): print(f"spans: {[(e.start, e.text, e.label_) for e in doc.ents]}")
- 我们打印提取的实体:
spans: [(0, '2+ years', 'EXPERIENCE'), (7, 'professional software development', 'SKILLS'), (12, 'Programming', 'SKILLS'), (22, 'Java', 'SKILLS'), (24, 'C++', 'SKILLS'), (27, 'C#', 'SKILLS'), (30, 'object-oriented design', 'SKILLS'), (36, '1+ years', 'EXPERIENCE'), (41, 'contributing to the', 'SKILLS'), (46, 'design', 'SKILLS'), (48, 'architecture', 'SKILLS'), (50, 'design patterns', 'SKILLS'), (55, 'scaling', 'SKILLS'), (60, 'current systems', 'SKILLS'), (64, 'Bachelor', 'DIPLOMA'), (68, 'Computer Science', 'DIPLOMA_MAJOR'), (75, '8+ years', 'EXPERIENCE'), (82, 'software development', 'SKILLS'), (88, 'mentoring junior software engineers', 'SKILLS'), (103, 'product software engineers', 'SKILLS'), (110, 'data structures', 'SKILLS'), (113, 'algorithm design', 'SKILLS'), (116, 'complexity analysis', 'SKILLS'), (119, 'object-oriented design', 'SKILLS'), (135, 'Java', 'SKILLS'), (137, 'Scala', 'SKILLS'), (139, 'Python', 'SKILLS'), (141, 'C++', 'SKILLS'), (143, 'C#', 'SKILLS'), (148, 'professional software engineering', 'SKILLS'), (151, 'practices', 'SKILLS'), (153, 'best practices', 'SKILLS'), (158, 'software development', 'SKILLS'), (164, 'coding', 'SKILLS'), (167, 'code reviews', 'SKILLS'), (170, 'source control management', 'SKILLS'), (174, 'build processes', 'SKILLS'), (177, 'testing', 'SKILLS'), (180, 'operations', 'SKILLS'), (184, 'communicating', 'SKILLS'), (193, 'management', 'SKILLS'), (199, 'software product', 'SKILLS'), (204, 'technical designs', 'SKILLS'), (210, 'building complex software systems', 'SKILLS'), (229, 'scoping requirements', 'SKILLS')]
我们成功提取了所有的技能、工作经验年限、文凭和文凭专业!接下来我们加载关系提取模型,并分类实体之间的关系。
注意:确保从脚本文件夹中复制 rel_pipe 和 rel_model 到你的主文件夹:

脚本文件夹
import randomimport typerfrom pathlib import Pathimport spacyfrom spacy.tokens import DocBin, Docfrom spacy.training.example import Examplefrom rel_pipe import make_relation_extractor, score_relationsfrom rel_model import create_relation_model, create_classification_layer, create_instances, create_tensors# We load the relation extraction (REL) modelnlp2 = spacy.load("training/model-best")# We take the entities generated from the NER pipeline and input them to the REL pipelinefor name, proc in nlp2.pipeline:
doc = proc(doc)# Here, we split the paragraph into sentences and apply the relation extraction for each pair of entities found in each sentence.for value, rel_dict in doc._.rel.items():
for sent in doc.sents:
for e in sent.ents:
for b in sent.ents:
if e.start == value[0] and b.start == value[1]:
if rel_dict['EXPERIENCE_IN'] >=0.9 :
print(f" entities: {e.text, b.text} --> predicted relation: {rel_dict}")
在这里,我们显示所有具有关系 Experience_in 且置信度高于 90% 的实体:
"entities":("2+ years", "professional software development"") --> **predicted relation**":
{"DEGREE_IN":1.2778723e-07,"EXPERIENCE_IN":0.9694631}"entities":"(""1+ years", "contributing to the"") -->
**predicted relation**":
{"DEGREE_IN":1.4581254e-07,"EXPERIENCE_IN":0.9205434}"entities":"(""1+ years","design"") -->
**predicted relation**":
{"DEGREE_IN":1.8895419e-07,"EXPERIENCE_IN":0.94121873}"entities":"(""1+ years","architecture"") -->
**predicted relation**":
{"DEGREE_IN":1.9635708e-07,"EXPERIENCE_IN":0.9399484}"entities":"(""1+ years","design patterns"") -->
**predicted relation**":
{"DEGREE_IN":1.9823732e-07,"EXPERIENCE_IN":0.9423302}"entities":"(""1+ years", "scaling"") -->
**predicted relation**":
{"DEGREE_IN":1.892173e-07,"EXPERIENCE_IN":0.96628445}entities: ('2+ years', 'project management') -->
**predicted relation**:
{'DEGREE_IN': 5.175297e-07, 'EXPERIENCE_IN': 0.9911635}"entities":"(""8+ years","software development"") -->
**predicted relation**":
{"DEGREE_IN":4.914319e-08,"EXPERIENCE_IN":0.994812}"entities":"(""3+ years","Java"") -->
**predicted relation**":
{"DEGREE_IN":9.288566e-08,"EXPERIENCE_IN":0.99975795}"entities":"(""3+ years","Scala"") -->
**predicted relation**":
{"DEGREE_IN":2.8477e-07,"EXPERIENCE_IN":0.99982494}"entities":"(""3+ years","Python"") -->
**predicted relation**":
{"DEGREE_IN":3.3149718e-07,"EXPERIENCE_IN":0.9998517}"entities":"(""3+ years","C++"") -->
**predicted relation**":
{"DEGREE_IN":2.2569053e-07,"EXPERIENCE_IN":0.99986637}
值得注意的是,我们几乎能够正确提取所有的经验年限及其相应的技能,没有假阳性或假阴性!
让我们查看具有关系 Degree_in 的实体:
entities: ('Bachelor / MS', 'Computer Science') -->
predicted relation:
{'DEGREE_IN': 0.9943974, 'EXPERIENCE_IN':1.8361954e-09} entities: ('PhD', 'data science') --> predicted relation: {'DEGREE_IN': 0.98883855, 'EXPERIENCE_IN': 5.2092592e-09}
再次,我们成功提取了所有文凭和文凭专业之间的关系!
这再次展示了如何利用少量标注数据将 Transformer 模型微调到你特定的领域,无论是用于 NER 还是关系提取。
仅用一百份注释文档,我们就能够训练出表现良好的关系分类器。此外,我们可以利用这个初始模型自动注释更多的未标记数据,并进行最小的修正。这可以显著加快注释过程并提升模型表现。
结论:
Transformer 确实改变了 NLP 领域,我特别期待它们在信息提取中的应用。我要感谢 explosion AI(spaCy 开发者)和 huggingface 提供的开源解决方案,促进了 Transformer 的采用。
如果你需要为项目进行数据注释,不要犹豫尝试 UBIAI 注释工具。我们提供多种可编程标签解决方案(如 ML 自动注释、正则表达式、字典等),以减少人工注释。
最后,查看 这篇文章 以学习如何利用 NER 和关系提取模型构建知识图谱并提取新见解。
如果你有任何评论,请在下方留言或发送邮件至 admin@ubiai.tools!
简历: Walid Amamou 是 UBIAI 的创始人,该工具用于 NLP 应用注释,并拥有物理学博士学位。
原始文章。转载许可。
相关:
-
如何使用 spaCy 3 微调 BERT Transformer
-
使用 BERT 构建求职知识图谱
-
微调 Transformer 模型以识别发票
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关话题


 浙公网安备 33010602011771号
浙公网安备 33010602011771号