KDNuggets-博客中文翻译-三十二-
KDNuggets 博客中文翻译(三十二)
原文:KDNuggets
TensorFlow 计算机视觉 – 迁移学习变得简单
原文:
www.kdnuggets.com/2022/01/tensorflow-computer-vision-transfer-learning-made-easy.html
90+% 准确率?通过迁移学习变得可能。
上周,你已经看到数据增强如何使你的 TensorFlow 模型的准确率提高几个百分点。相比于你今天将看到的,我们仅仅触及了表面。我们将最终用一种相当简单的方法在验证集上超过 90% 的准确率。
我们的前三个课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 在 IT 领域支持你的组织
你还会看到如果我们将训练数据量缩小 20 倍,验证准确率会发生什么。剧透 - 它将保持不变。
不想阅读?请观看我的视频:
你可以在 GitHub 上下载源代码。
TensorFlow 中的迁移学习是什么?
从头开始编写神经网络模型架构涉及大量的猜测工作。多少层?每层多少节点?使用什么激活函数?正则化?你不会很快用完问题。
迁移学习采用不同的方法。不是从头开始,而是利用一个已经由非常聪明的人在庞大的数据集上,用比你家里拥有的更高级的硬件训练过的现有神经网络模型。这些网络可能有数百层,这与我们几周前实现的 2 层 CNN 大相径庭。
简而言之 - 你深入网络的层数越多,你提取的特征就越复杂。
整个迁移学习过程归结为 3 个步骤:
-
使用预训练的网络 - 例如,使用一个已经在数百万张图像上训练过的 VGG、ResNet 或 EfficientNet 架构,用于检测 1000 个类别。
-
剪掉模型的头部 - 排除预训练模型的最后几层,并用你自己的层替换它们。例如,我们的 狗与猫数据集 有两个类别,最终的分类层需要与之相符。
-
微调最终层 - 在你的数据集上训练网络以调整分类器。预训练模型的权重被冻结,这意味着它们在你训练模型时不会更新。
归根结底,迁移学习使你可以用更少的数据获得显著更好的结果。我们的自定义 2 块架构在验证集上的准确率仅为 76%。迁移学习将把它提高到 90%以上。
入门 - 库和数据集导入
我们将使用来自 Kaggle 的狗与猫数据集。它的许可证是创作共用许可证,这意味着你可以免费使用它:
 图像 1——狗与猫数据集(图像来源:作者)
图像 1——狗与猫数据集(图像来源:作者)
数据集相当大——有 25,000 张图像,按类别均匀分布(12,500 张狗图像和 12,500 张猫图像)。它应该足够大以训练一个不错的图像分类器。唯一的问题是——它的结构并不适合深度学习。你可以参考我之前的文章创建一个适当的目录结构,并将其拆分为训练集、测试集和验证集:
TensorFlow 用于图像分类——深度学习项目的三个主要前提 | 更好的数据科学
你想用 TensorFlow 训练一个神经网络进行图像分类吗?确保首先完成这三步。
你还应该删除train/cat/666.jpg和train/dog/11702.jpg图像,因为它们已损坏,模型将无法使用它们进行训练。
完成后,你可以继续进行库的导入。我们今天只需要 Numpy 和 TensorFlow。其他导入是为了消除不必要的警告信息:
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import tensorflow as tf
在整篇文章中,我们将不得不从不同的目录加载训练和验证数据。最佳实践是声明一个用于加载图像和数据增强的函数:
def init_data(train_dir: str, valid_dir: str) -> tuple:
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255.0,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255.0
)
train_data = train_datagen.flow_from_directory(
directory=train_dir,
target_size=(224, 224),
class_mode='categorical',
batch_size=64,
seed=42
)
valid_data = valid_datagen.flow_from_directory(
directory=valid_dir,
target_size=(224, 224),
class_mode='categorical',
batch_size=64,
seed=42
)
return train_data, valid_data
现在让我们加载我们的狗和猫数据集:
train_data, valid_data = init_data(
train_dir='data/train/',
valid_dir='data/validation/'
)
这是你应该看到的输出:
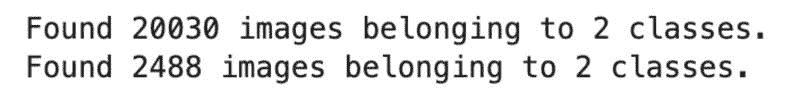 图像 2 - 训练和验证图像的数量(图像来源:作者)
图像 2 - 训练和验证图像的数量(图像来源:作者)
20K 训练图像对于迁移学习来说是否过多?可能是,但让我们看看能获得多准确的模型。
TensorFlow 中的迁移学习实践
通过迁移学习,我们基本上是加载一个巨大的预训练模型,但没有顶部的分类层。这样,我们可以冻结已学习的权重,只添加输出层以匹配我们的数据集。
例如,大多数预训练模型是基于ImageNet数据集进行训练的,该数据集有 1000 个类别。我们只有两个(猫和狗),所以我们需要指定这点。
这就是 build_transfer_learning_model() 函数的作用所在。它有一个参数 - base_model - 表示预训练的架构。首先,我们将冻结该模型中的所有层,然后通过添加几个自定义层来构建一个 Sequential 模型。最后,我们将使用常用的方法来编译模型:
def build_transfer_learning_model(base_model):
# `base_model` stands for the pretrained model
# We want to use the learned weights, and to do so we must freeze them
for layer in base_model.layers:
layer.trainable = False
# Declare a sequential model that combines the base model with custom layers
model = tf.keras.Sequential([
base_model,
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dropout(rate=0.2),
tf.keras.layers.Dense(units=2, activation='softmax')
])
# Compile the model
model.compile(
loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy']
)
return model
现在有趣的部分开始了。从 TensorFlow 导入 VGG16 架构,并将其指定为我们 build_transfer_learning_model() 函数的基础模型。include_top=False 参数意味着我们不需要顶层分类层,因为我们已经声明了自己的分类层。此外,注意 input_shape 如何设置以类似于我们的图像形状:
# Let's use a simple and well-known architecture - VGG16
from tensorflow.keras.applications.vgg16 import VGG16
# We'll specify it as a base model
# `include_top=False` means we don't want the top classification layer
# Specify the `input_shape` to match our image size
# Specify the `weights` accordingly
vgg_model = build_transfer_learning_model(
base_model=VGG16(include_top=False, input_shape=(224, 224, 3), weights='imagenet')
)
# Train the model for 10 epochs
vgg_hist = vgg_model.fit(
train_data,
validation_data=valid_data,
epochs=10
)
这是训练模型 10 个周期后的输出:
 图像 3 - 在 20K 训练图像上经过 10 个周期的 VGG16 模型(图片由作者提供)
图像 3 - 在 20K 训练图像上经过 10 个周期的 VGG16 模型(图片由作者提供)
这真是值得一提 - 93% 的验证准确率,甚至不用考虑模型架构。迁移学习的真正优势在于训练准确模型所需的数据量,这比自定义架构所需的数据量要少得多。
减少了多少? 让我们将数据集缩小 20 倍,看看会发生什么。
在一个缩小了 20 倍的子集上进行迁移学习
我们希望看看减少数据集大小是否会对预测能力产生负面影响。为训练和验证图像创建新的目录结构。图像将存储在 data_small 文件夹中,但可以随意将其重命名为其他名称:
import random
import pathlib
import shutil
random.seed(42)
dir_data = pathlib.Path.cwd().joinpath('data_small')
dir_train = dir_data.joinpath('train')
dir_valid = dir_data.joinpath('validation')
if not dir_data.exists(): dir_data.mkdir()
if not dir_train.exists(): dir_train.mkdir()
if not dir_valid.exists(): dir_valid.mkdir()
for cls in ['cat', 'dog']:
if not dir_train.joinpath(cls).exists(): dir_train.joinpath(cls).mkdir()
if not dir_valid.joinpath(cls).exists(): dir_valid.joinpath(cls).mkdir()
这是你可以用来打印目录结构的命令:
!ls -R data_small | grep ":$" | sed -e 's/:$//' -e 's/[^-][^\/]*\//--/g' -e 's/^/ /' -e 's/-/|/'
 图像 4 - 目录结构(图片由作者提供)
图像 4 - 目录结构(图片由作者提供)
将一部分图像复制到新文件夹中。copy_sample() 函数从 src_folder 中提取 n 张图像并将它们复制到 tgt_folder。默认情况下,我们将 n 设置为 500:
def copy_sample(src_folder: pathlib.PosixPath, tgt_folder: pathlib.PosixPath, n: int = 500):
imgs = random.sample(list(src_folder.iterdir()), n)
for img in imgs:
img_name = str(img).split('/')[-1]
shutil.copy(
src=img,
dst=f'{tgt_folder}/{img_name}'
)
现在让我们复制训练和验证图像。对于验证集,我们将每类仅复制 100 张图像:
# Train - cat
copy_sample(
src_folder=pathlib.Path.cwd().joinpath('data/train/cat/'),
tgt_folder=pathlib.Path.cwd().joinpath('data_small/train/cat/'),
)
# Train - dog
copy_sample(
src_folder=pathlib.Path.cwd().joinpath('data/train/dog/'),
tgt_folder=pathlib.Path.cwd().joinpath('data_small/train/dog/'),
)
# Valid - cat
copy_sample(
src_folder=pathlib.Path.cwd().joinpath('data/validation/cat/'),
tgt_folder=pathlib.Path.cwd().joinpath('data_small/validation/cat/'),
n=100
)
# Valid - dog
copy_sample(
src_folder=pathlib.Path.cwd().joinpath('data/validation/dog/'),
tgt_folder=pathlib.Path.cwd().joinpath('data_small/validation/dog/'),
n=100
)
使用以下命令打印每个文件夹中的图像数量:
 图像 5 - 每类训练和验证图像的数量(图片由作者提供)
图像 5 - 每类训练和验证图像的数量(图片由作者提供)
最后,调用 init_data() 函数从新源加载图像:
train_data, valid_data = init_data(
train_dir='data_small/train/',
valid_dir='data_small/validation/'
)
 图像 6 - 缩小子集中的训练和验证图像数量(图片由作者提供)
图像 6 - 缩小子集中的训练和验证图像数量(图片由作者提供)
总共有 1000 张训练图像。看看我们能否从如此小的数据集中获得一个不错的模型会很有趣。我们将保持模型架构不变,但由于数据集较小,将训练更多周期。此外,由于每个周期的训练时间减少,我们可以进行更长时间的训练:
vgg_model = build_transfer_learning_model(
base_model=VGG16(include_top=False, input_shape=(224, 224, 3), weights='imagenet')
)
vgg_hist = vgg_model.fit(
train_data,
validation_data=valid_data,
epochs=20
)
 图片 7 - 最后 10 个周期的训练结果(图片由作者提供)
图片 7 - 最后 10 个周期的训练结果(图片由作者提供)
而且看看这个 - 我们获得了与在 2 万张图片上训练的模型大致相同的验证准确率,真是太棒了。
这就是迁移学习的真正力量所在。你不总是可以获得庞大的数据集,因此看到我们能在如此有限的数据下建立如此精确的模型,真是令人惊叹。
结论
总结一下,当构建图像分类模型时,迁移学习应成为你的首选方法。你无需考虑架构,因为有人已经为你做了这个工作。你无需拥有庞大的数据集,因为有人已经在数百万张图片上训练了通用模型。最后,大多数情况下,你也不需要担心性能差,除非你的数据集非常专业。
你需要做的唯一事情是选择一个预训练的架构。我们今天选择了 VGG16,但我鼓励你尝试 ResNet、MobileNet、EfficientNet 等。
这是另一个作业 - 使用今天训练的两个模型来预测整个测试集。准确率如何比较?请告知我。
保持联系
Dario Radečić 是 Deep Data Digital 的首席执行官和创始人,同时也是数据科学家和技术作家。
原文。转载经许可。
相关主题
使用 TensorFlow 和 Keras 进行分词和文本数据准备
原文:
www.kdnuggets.com/2020/03/tensorflow-keras-tokenization-text-data-prep.html
评论
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
之前我们查看了一个通用文本数据预处理方法,重点关注了分词、标准化和噪声去除。然后我们概述了使用 Python 进行文本数据预处理的内容,这本质上是前一篇文章中框架的实际应用,涵盖了主要的手动文本数据预处理方法。我们还探讨了如何使用 Python 构建基础文本数据词汇。
不过,自动化许多这种预处理和文本数据准备的工具是存在的。这些工具在这些文章发表之前就已存在,但其普及程度自那时以来激增。由于许多 NLP 工作现在通过神经网络完成,使用神经网络实现库如 TensorFlow——以及同时使用 Keras——来实现这些准备任务是很自然的。
本文将探讨如何使用 TensorFlow 和 Keras 预处理工具对文本数据进行分词和进一步准备,以便输入神经网络。虽然前几篇文章没有涉及为神经网络创建和填充编码数据序列的附加概念,但本文将予以补充。相反,虽然噪声去除在之前的文章中有所涵盖,但本文不再涉及。文本数据中的噪声是什么可能是任务特定的,前文对这一主题的处理依然具有参考价值。
为了实现今天的目标,我们将使用两个 Keras 预处理工具: Tokenizer 类和 pad_sequences 模块。
我们使用一些示例句子代替真实数据集或来自现实世界的数据,来完成编码工作。下次我们可以扩展代码,使用真实数据集并执行一些有趣的任务,例如分类或类似任务。一旦理解了这个过程,扩展到更大的数据集将很简单。
让我们开始进行必要的导入和一些“数据”演示。
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
train_data = [
"I enjoy coffee.",
"I enjoy tea.",
"I dislike milk.",
"I am going to the supermarket later this morning for some coffee."
]
test_data = [
"Enjoy coffee this morning.",
"I enjoy going to the supermarket.",
"Want some milk for your coffee?"
]
接下来,一些执行分词和准备标准化数据表示的超参数,下面有解释。
num_words = 1000
oov_token = '<UNK>'
pad_type = 'post'
trunc_type = 'post'
-
num_words = 1000这将是从结果分词数据词汇表中使用的最多词数,在我们的例子中是截断到前 1000 个最常见的词。虽然在我们的小数据集中这不会成为问题,但为了演示目的,这里展示了。
-
oov_token = <UNK>这是用于处理在测试数据序列分词和编码过程中遇到的词汇表外的词汇的标记,使用在训练数据分词过程中构建的词索引创建的。
-
pad_type = 'post'当我们对文本数据进行数字序列编码时,我们的句子(或任意文本块)的长度将不一致,因此我们需要选择一个最大长度,并用填充字符填补较短句子的未使用位置。在我们的例子中,最大句子长度将通过搜索最长的句子来确定,填充字符将是'0'。
-
trunc_type = 'post'与上面一样,当我们对文本数据进行数字序列编码时,我们的句子(或任意文本块)的长度将不一致,因此我们需要选择一个最大长度,并用填充字符填补较短句子的未使用位置。我们选择在句子的末尾进行填充('post'),意味着我们的句子序列数字表示中的词索引条目将出现在结果句子向量的最左侧位置,而填充字符('0')将出现在实际数据之后,位于结果句子向量的最右侧位置。

来源: Manning
现在我们来进行分词、序列编码和序列填充。我们将逐块讲解这段代码。
# Tokenize our training data
tokenizer = Tokenizer(num_words=num_words, oov_token=oov_token)
tokenizer.fit_on_texts(train_data)
# Get our training data word index
word_index = tokenizer.word_index
# Encode training data sentences into sequences
train_sequences = tokenizer.texts_to_sequences(train_data)
# Get max training sequence length
maxlen = max([len(x) for x in train_sequences])
# Pad the training sequences
train_padded = pad_sequences(train_sequences, padding=pad_type, truncating=trunc_type, maxlen=maxlen)
# Output the results of our work
print("Word index:\n", word_index)
print("\nTraining sequences:\n", train_sequences)
print("\nPadded training sequences:\n", train_padded)
print("\nPadded training shape:", train_padded.shape)
print("Training sequences data type:", type(train_sequences))
print("Padded Training sequences data type:", type(train_padded))
下面是逐块发生的情况:
-
# Tokenize our training data这很简单;我们使用 TensorFlow(Keras)的
Tokenizer类来自动化我们的训练数据的标记化。首先,我们创建Tokenizer对象,提供最大保留的词汇数量,以及一个用于编码测试数据中未见过的词汇的超出词汇表的标记,否则这些之前未见过的词汇将被简单地从我们的词汇表中删除,且神秘地未被计算在内。要了解更多有关 TensorFlow 标记化器的其他参数,请查看 文档。创建Tokenizer后,我们将其拟合在训练数据上(我们稍后也会用它来拟合测试数据)。 -
# 获取我们的训练数据单词索引标记化过程的副产品是创建了一个单词索引,将词汇表中的单词映射到其数字表示,这一映射对于编码我们的序列至关重要。由于我们稍后会引用这个映射以进行打印,因此我们在这里为其分配一个变量以简化操作。
-
# 将训练数据句子编码为序列现在我们已经将数据标记化,并且有了词汇表的单词到数字表示的映射,让我们利用这个映射来编码序列。在这里,我们将文本句子从类似“我的名字是马修”的形式转换为类似“6 8 2 19”的形式,其中每个数字在索引中与相应的单词匹配。由于神经网络通过对数字进行计算来工作,直接传入一堆单词是不行的。因此,我们使用序列。并且记住,这仅仅是我们目前处理的训练数据;测试数据在之后会被标记化和编码。
-
# 获取最大训练序列长度记得我们之前提到过需要为编码的句子设置一个最大序列长度吗?我们可以自己设置这个限制,但在我们的案例中,我们将找到最长的编码序列,并以此作为最大序列长度。在实际操作中,确实有不想这样做的原因,但也有时这样做是合适的。接下来,在实际训练序列填充中,将使用
maxlen变量。 -
# 填充训练序列如上所述,我们需要确保编码序列的长度一致。我们刚刚找出了最长序列的长度,并将使用该长度对所有其他序列进行填充,填充额外的‘0’在末尾(‘post’),并且也会从末尾(‘post’)截断任何超出最大长度的序列。这里我们使用 TensorFlow(Keras)的
pad_sequences模块来完成这一任务。你可以查看文档以获取其他填充选项。 -
# 输出我们工作的结果现在让我们看看我们所做的工作。我们期望注意到最长的序列以及填充较短序列的情况。还要注意,当进行填充时,我们的序列会从 Python 列表转换为 Numpy 数组,这很有帮助,因为这就是我们最终会送入神经网络的内容。我们的训练序列矩阵的形状是训练集中句子(序列)的数量(4)与最长序列的长度(
maxlen,或 12)。
Word index:
{'<UNK>': 1, 'i': 2, 'enjoy': 3, 'coffee': 4, 'tea': 5, 'dislike': 6, 'milk': 7, 'am': 8, 'going': 9, 'to': 10, 'the': 11, 'supermarket': 12, 'later': 13, 'this': 14, 'morning': 15, 'for': 16, 'some': 17}
Training sequences:
[[2, 3, 4], [2, 3, 5], [2, 6, 7], [2, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 4]]
Padded training sequences:
[[ 2 3 4 0 0 0 0 0 0 0 0 0]
[ 2 3 5 0 0 0 0 0 0 0 0 0]
[ 2 6 7 0 0 0 0 0 0 0 0 0]
[ 2 8 9 10 11 12 13 14 15 16 17 4]]
Padded training shape: (4, 12)
Training sequences data type: <class 'list'>
Padded Training sequences data type: <class 'numpy.ndarray'>
现在让我们使用我们的分词器对测试数据进行分词,然后类似地编码我们的序列。这些操作与上述内容非常相似。请注意,我们使用的是为训练创建的相同分词器,以便在两个数据集之间实现一致,使用相同的词汇表。我们还按照与训练序列相同的长度和规格进行填充。
test_sequences = tokenizer.texts_to_sequences(test_data)
test_padded = pad_sequences(test_sequences, padding=pad_type, truncating=trunc_type, maxlen=maxlen)
print("Testing sequences:\n", test_sequences)
print("\nPadded testing sequences:\n", test_padded)
print("\nPadded testing shape:",test_padded.shape)
Testing sequences:
[[3, 4, 14, 15], [2, 3, 9, 10, 11, 12], [1, 17, 7, 16, 1, 4]]
Padded testing sequences:
[[ 3 4 14 15 0 0 0 0 0 0 0 0]
[ 2 3 9 10 11 12 0 0 0 0 0 0]
[ 1 17 7 16 1 4 0 0 0 0 0 0]]
Padded testing shape: (3, 12)
例如,你能看到训练集和测试集之间的填充序列长度不同会造成什么问题吗?
最后,让我们检查编码后的测试数据。
for x, y in zip(test_data, test_padded):
print('{} -> {}'.format(x, y))
print("\nWord index (for reference):", word_index)
Enjoy coffee this morning. -> [ 3 4 14 15 0 0 0 0 0 0 0 0]
I enjoy going to the supermarket. -> [ 2 3 9 10 11 12 0 0 0 0 0 0]
Want some milk for your coffee? -> [ 1 17 7 16 1 4 0 0 0 0 0 0]
Word index (for reference): {'<UNK>': 1, 'i': 2, 'enjoy': 3, 'coffee': 4, 'tea': 5, 'dislike': 6, 'milk': 7, 'am': 8, 'going': 9, 'to': 10, 'the': 11, 'supermarket': 12, 'later': 13, 'this': 14, 'morning': 15, 'for': 16, 'some': 17}
请注意,由于我们在测试数据中编码了一些在训练数据中未见过的单词,我们现在有一些词汇外的标记,这些标记被编码为
现在我们有了填充序列,更重要的是知道如何使用不同的数据再次获取它们,我们可以开始做一些事情了。下一次,我们将用实际数据替代这次使用的玩具数据,并且只需对代码做很小的更改(除非我们需要为训练和测试数据添加分类标签),我们将继续进行某种 NLP 任务,最有可能是分类。
相关:
-
10 个 Python 字符串处理技巧与窍门
-
自动文本摘要入门
-
如何在 Python 中为 NLP 任务创建词汇表
更多相关主题
提升 TensorFlow 模型的 4 种方法——你需要了解的关键正则化技术
原文:
www.kdnuggets.com/2020/08/tensorflow-model-regularization-techniques.html
评论

照片由 Jungwoo Hong 提供,发布于 Unsplash。
正则化
根据维基百科,
在数学、统计学和计算机科学,特别是机器学习和逆问题中,正则化是为了在解决一个不适定问题或防止过拟合时添加额外信息的过程。
这意味着我们添加一些额外的信息以解决问题并防止过拟合。
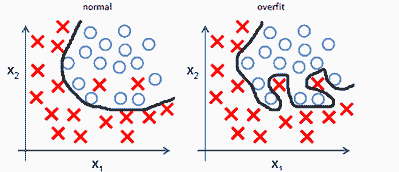
过拟合意味着我们的机器学习模型在某些数据上训练良好,在这些数据上表现极佳,但在新的未见过的样本上则会失败。
我们可以在这个简单的例子中看到过拟合现象
mlwiki.org/index.php/Overfitting
当我们的数据严格附着于训练样本时,这会导致测试/开发集上的性能较差,而训练集上的性能良好。
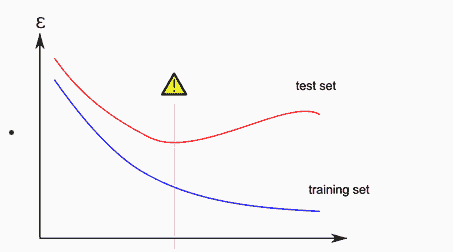
mlwiki.org/index.php/Overfitting
因此,为了提高模型性能,我们使用不同的正则化技术。虽然有几种技术,但我们将讨论 4 种主要技术。
-
L1 正则化
-
L2 正则化
-
丢弃法
-
批量归一化
我将简要解释这些技术是如何工作的,以及如何在 Tensorflow 2 中实现它们。
为了更好地理解这些技术如何及其工作原理,我推荐你观看 Andrew NG 教授的讲座,这些讲座在 Youtube 上很容易找到。
首先,我将编写一个没有正则化的模型,然后展示如何通过添加不同的正则化技术来改进它。我们将使用 IRIS 数据集来展示正则化如何显著改善模型。
无正则化的模型
代码:
-
基本预处理
-
模型构建
model1.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_6 (Dense) (None, 512) 2560
_________________________________________________________________
dense_7 (Dense) (None, 256) 131328
_________________________________________________________________
dense_8 (Dense) (None, 128) 32896
_________________________________________________________________
dense_9 (Dense) (None, 64) 8256
_________________________________________________________________
dense_10 (Dense) (None, 32) 2080
_________________________________________________________________
dense_11 (Dense) (None, 3) 99
=================================================================
Total params: 177,219
Trainable params: 177,219
Non-trainable params: 0
_________________________________________________________________
训练模型后,如果我们使用以下代码在 Tensorflow 中评估模型,我们可以找到测试集上的准确率、损失和mse。
loss1, acc1, mse1 = model1.evaluate(X_test, y_test)
print(f"Loss is {loss1},\nAccuracy is {acc1*100},\nMSE is {mse1}")

让我们检查验证损失和训练损失的图表。
import matplotlib.pyplot as plt
plt.style.use('ggplot')
plt.plot(hist.history['loss'], label = 'loss')
plt.plot(hist.history['val_loss'], label='val loss')
plt.title("Loss vs Val_Loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()
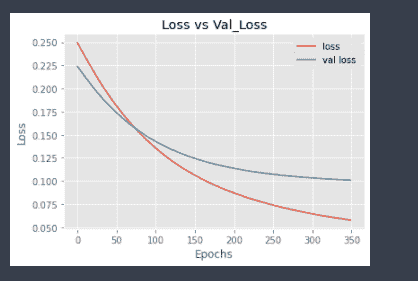
在这里,我们可以看到验证损失在≈ 60个周期后逐渐增加,而训练损失保持稳定。这表明我们的模型发生了过拟合。
同样地,对于模型准确率图,
plt.plot(hist.history['acc'], label = 'acc')
plt.plot(hist.history['val_acc'], label='val acc')
plt.title("acc vs Val_acc")
plt.xlabel("Epochs")
plt.ylabel("acc")
plt.legend()
plt.show()
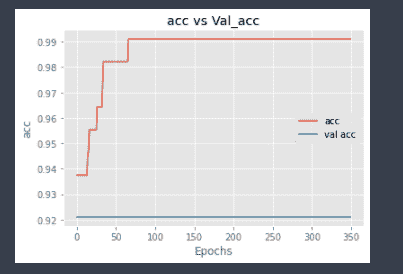
这再次表明,与训练准确率相比,验证准确率较低,这再次显示出过拟合的迹象。
L1 正则化:
一种常用的正则化技术是 L1 正则化,也称为 Lasso 正则化。
L1 正则化的主要概念是我们必须通过将权重的绝对值添加到损失函数中,乘以正则化参数 lambda λ,其中λ是手动调节为大于 0 的。
L1 的方程是
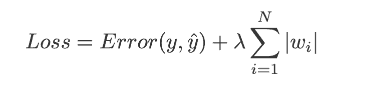
图片来源: 数据科学前沿。
Tensorflow 代码:
这里,我们添加了一个额外的参数kernel_regularizer,我们将其设置为‘l1’,用于 L1 正则化。
现在我们来评估并绘制模型。
loss2, acc2, mse2 = model2.evaluate(X_test, y_test)
print(f"Loss is {loss2},\nAccuracy is {acc2 * 100},\nMSE is {mse2}")

嗯,准确率差不多一样,我们来看一下图表以获得更好的直观感觉。
plt.plot(hist2.history[‘loss’], label = ‘loss’)
plt.plot(hist2.history[‘val_loss’], label=’val loss’)
plt.title(“Loss vs Val_Loss”)
plt.xlabel(“Epochs”)
plt.ylabel(“Loss”)
plt.legend()
plt.show()
对于准确率,
plt.figure(figsize=(15,8))
plt.plot(hist2.history['acc'], label = 'acc')
plt.plot(hist2.history['val_acc'], label='val acc')
plt.title("acc vs Val_acc")
plt.xlabel("Epochs")
plt.ylabel("acc")
plt.legend()
plt.show()
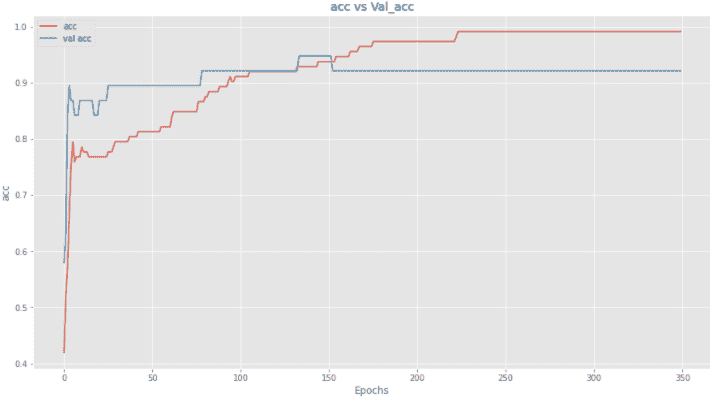
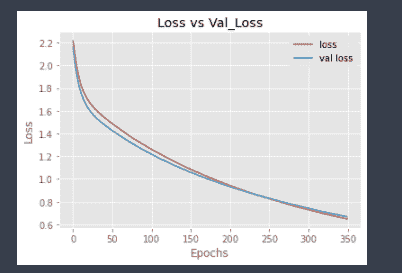
好吧,相当大的改进,我想,因为过拟合的验证损失没有像之前那样增加,但验证准确率提升不大。让我们在更多层中添加 l1 以检查是否能改善模型。
model3 = Sequential([
Dense(512, activation='tanh', input_shape = X_train[0].shape, kernel_regularizer='l1'),
Dense(512//2, activation='tanh', kernel_regularizer='l1'),
Dense(512//4, activation='tanh', kernel_regularizer='l1'),
Dense(512//8, activation='tanh', kernel_regularizer='l1'),
Dense(32, activation='relu', kernel_regularizer='l1'),
Dense(3, activation='softmax')
])
model3.compile(optimizer='sgd',loss='categorical_crossentropy', metrics=['acc', 'mse'])
hist3 = model3.fit(X_train, y_train, epochs=350, batch_size=128, validation_data=(X_test,y_test), verbose=2)
训练后,我们来评估模型。
loss3, acc3, mse3 = model3.evaluate(X_test, y_test)
print(f"Loss is {loss3},\nAccuracy is {acc3 * 100},\nMSE is {mse3}")

好了,准确率现在有了相当大的提高,从 92 跳升到了 94。我们来看看图表。
损失
plt.figure(figsize=(15,8))
plt.plot(hist3.history['loss'], label = 'loss')
plt.plot(hist3.history['val_loss'], label='val loss')
plt.title("Loss vs Val_Loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()
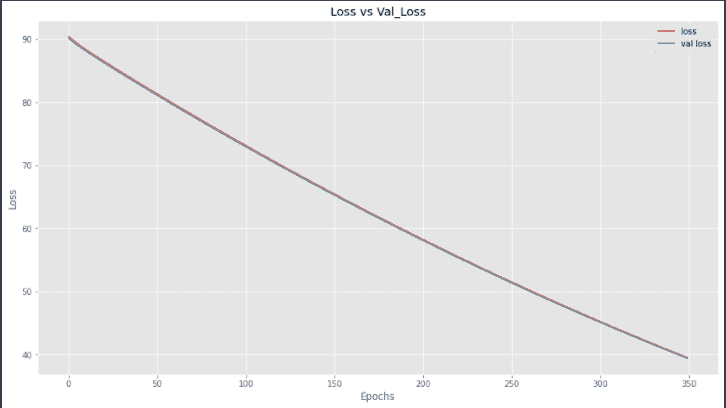
现在,两条线大致重叠,这意味着我们的模型在测试集上的表现与在训练集上的表现相同。
准确率
plt.figure(figsize=(15,8))
plt.plot(hist3.history['acc'], label = 'ACC')
plt.plot(hist3.history['val_acc'], label='val acc')
plt.title("acc vs Val_acc")
plt.xlabel("Epochs")
plt.ylabel("acc")
plt.legend()
plt.show()
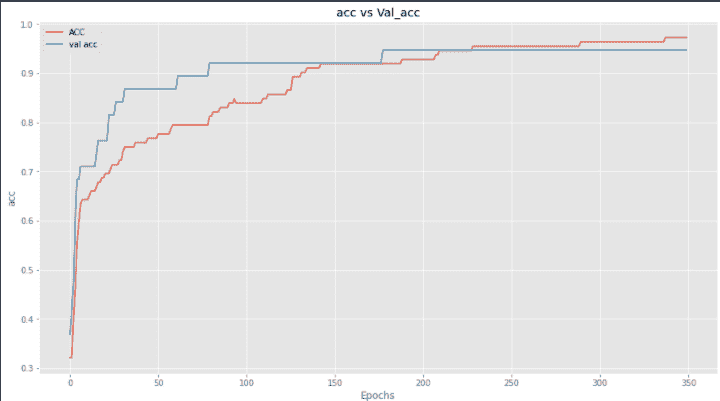
我们可以看到,与训练损失相比,模型的验证损失没有增加,验证准确率也在上升。
L2 正则化
L2 正则化是另一种正则化技术,也称为岭回归。在 L2 正则化中,我们将权重的平方大小添加到损失函数中以惩罚我们的损失。
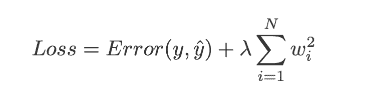
图片来源: 数据科学前沿。
Tensorflow 代码:
model5 = Sequential([
Dense(512, activation='tanh', input_shape = X_train[0].shape, kernel_regularizer='l2'),
Dense(512//2, activation='tanh'),
Dense(512//4, activation='tanh'),
Dense(512//8, activation='tanh'),
Dense(32, activation='relu'),
Dense(3, activation='softmax')
])
model5.compile(optimizer='sgd',loss='categorical_crossentropy', metrics=['acc', 'mse'])
hist5 = model5.fit(X_train, y_train, epochs=350, batch_size=128, validation_data=(X_test,y_test), verbose=2)
训练后,我们来评估模型。
loss5, acc5, mse5 = model5.evaluate(X_test, y_test)
print(f"Loss is {loss5},\nAccuracy is {acc5 * 100},\nMSE is {mse5}")
输出结果是

在这里我们可以看到验证准确率为 97%,这是相当不错的。我们来绘制更多图表以获得更直观的感觉。
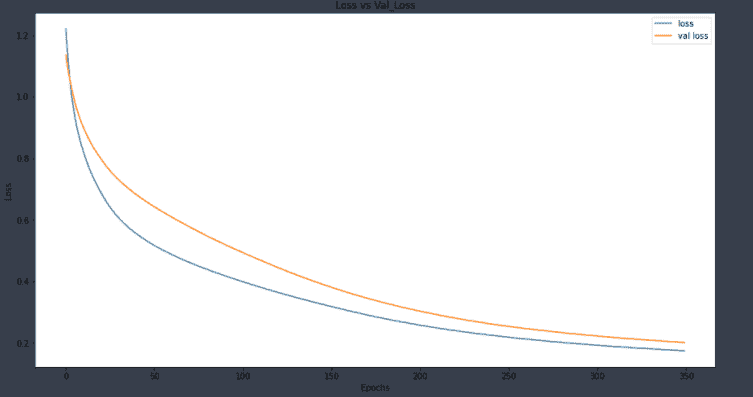
在这里我们可以看到,我们没有过拟合数据。让我们绘制准确率。
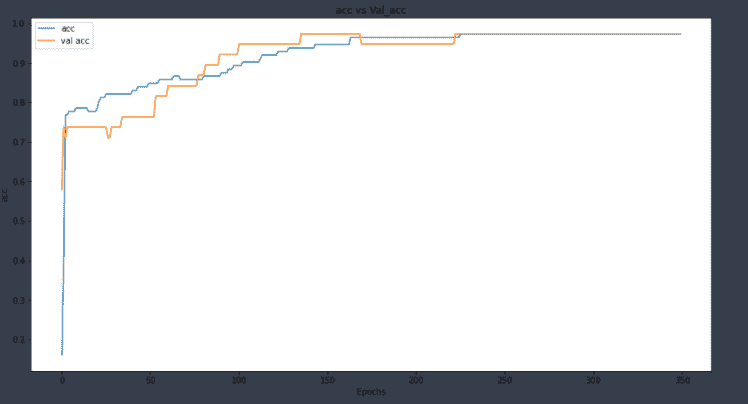
在仅一层中添加“L2”正则化大大改善了我们的模型。
现在让我们在所有其他层中添加L2。
model6 = Sequential([
Dense(512, activation='tanh', input_shape = X_train[0].shape, kernel_regularizer='l2'),
Dense(512//2, activation='tanh', kernel_regularizer='l2'),
Dense(512//4, activation='tanh', kernel_regularizer='l2'),
Dense(512//8, activation='tanh', kernel_regularizer='l2'),
Dense(32, activation='relu', kernel_regularizer='l2'),
Dense(3, activation='softmax')
])
model6.compile(optimizer='sgd',loss='categorical_crossentropy', metrics=['acc', 'mse'])
hist6 = model6.fit(X_train, y_train, epochs=350, batch_size=128, validation_data=(X_test,y_test), verbose=2)
现在我们在所有层中添加了 L2。训练后,我们来评估一下。
loss6, acc6, mse6 = model6.evaluate(X_test, y_test)
print(f"Loss is {loss6},\nAccuracy is {acc6 * 100},\nMSE is {mse6}")

让我们绘图以获得更多直观感受。
plt.figure(figsize=(15,8))
plt.plot(hist6.history['loss'], label = 'loss')
plt.plot(hist6.history['val_loss'], label='val loss')
plt.title("Loss vs Val_Loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()
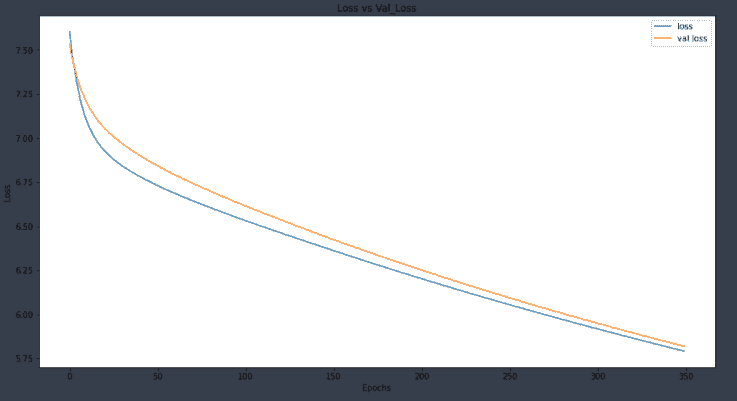
对于准确率
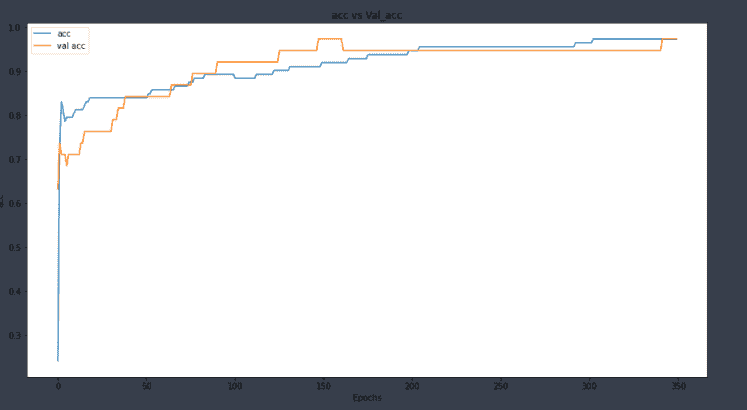
我们可以看到这个模型也表现良好,并没有过拟合数据集。
丢弃法
另一种常见的正则化方法是使用丢弃法。使用丢弃法的主要思想是根据一定的概率随机关闭我们层中的一些神经元。你可以通过教授 NG 的视频了解更多关于它的工作原理,这里。
让我们在 TensorFlow 中编写代码。
之前的导入都是一样的,我们这里只是添加了一个额外的导入。
为了实现丢弃法,我们只需从tf.keras.layers中添加一个Dropout层并设置丢弃率。
import tensorflow as tf
model7 = Sequential([
Dense(512, activation='tanh', input_shape = X_train[0].shape),
tf.keras.layers.Dropout(0.5), #dropout with 50% rate
Dense(512//2, activation='tanh'),
Dense(512//4, activation='tanh'),
Dense(512//8, activation='tanh'),
Dense(32, activation='relu'),
Dense(3, activation='softmax')
])
model7.compile(optimizer='sgd',loss='categorical_crossentropy', metrics=['acc', 'mse'])
hist7 = model7.fit(X_train, y_train, epochs=350, batch_size=128, validation_data=(X_test,y_test), verbose=2)
训练之后,让我们在测试集上进行评估。
loss7, acc7, mse7 = model7.evaluate(X_test, y_test)
print(f"Loss is {loss7},\nAccuracy is {acc7 * 100},\nMSE is {mse7}")

哇,我们的结果非常有希望,我们在测试集上的表现达到了 97%。让我们绘制损失和准确率图,以获得更好的直观感受。
plt.figure(figsize=(15,8))
plt.plot(hist7.history['loss'], label = 'loss')
plt.plot(hist7.history['val_loss'], label='val loss')
plt.title("Loss vs Val_Loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()
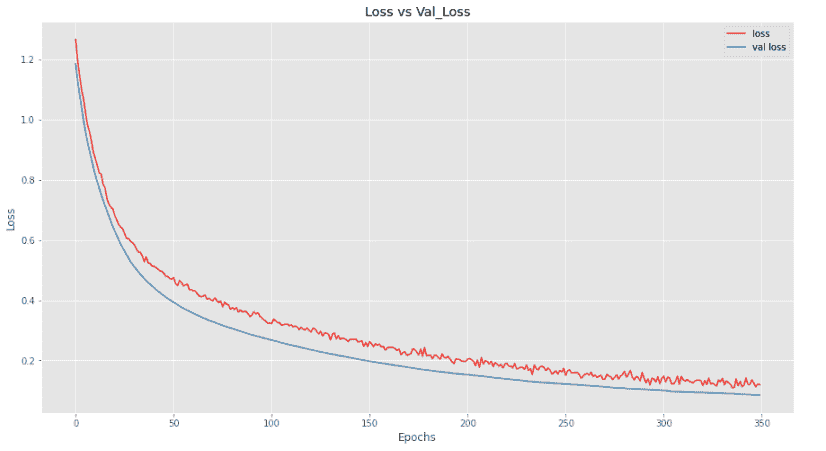
在这里,我们可以看到我们的模型在验证数据上的表现优于训练数据,这真是好消息。
现在让我们绘制准确率图。
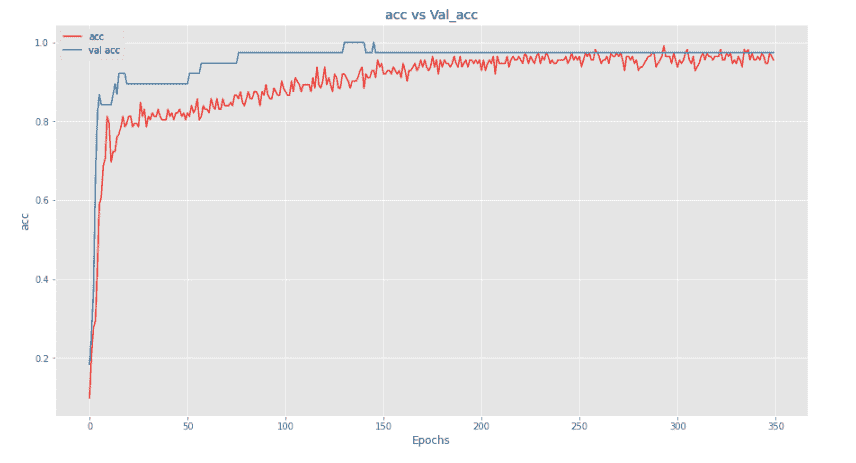
我们可以看到,我们的模型在验证数据集上的表现优于训练集。
让我们添加更多丢弃层来查看我们的模型表现如何。
model8 = Sequential([
Dense(512, activation='tanh', input_shape = X_train[0].shape),
tf.keras.layers.Dropout(0.5),
Dense(512//2, activation='tanh'),
tf.keras.layers.Dropout(0.5),
Dense(512//4, activation='tanh'),
tf.keras.layers.Dropout(0.5),
Dense(512//8, activation='tanh'),
tf.keras.layers.Dropout(0.3),
Dense(32, activation='relu'),
Dense(3, activation='softmax')
])
model8.compile(optimizer='sgd',loss='categorical_crossentropy', metrics=['acc', 'mse'])
hist8 = model8.fit(X_train, y_train, epochs=350, batch_size=128, validation_data=(X_test,y_test), verbose=2)
让我们评估一下。
loss8, acc8, mse8 = model8.evaluate(X_test, y_test)
print(f"Loss is {loss8},\nAccuracy is {acc8 * 100},\nMSE is {mse8}")

这个模型也非常好,因为它在测试集上的表现达到了 98%。让我们绘图以获得更好的直观感受。
plt.figure(figsize=(15,8))
plt.plot(hist8.history['loss'], label = 'loss')
plt.plot(hist8.history['val_loss'], label='val loss')
plt.title("Loss vs Val_Loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()
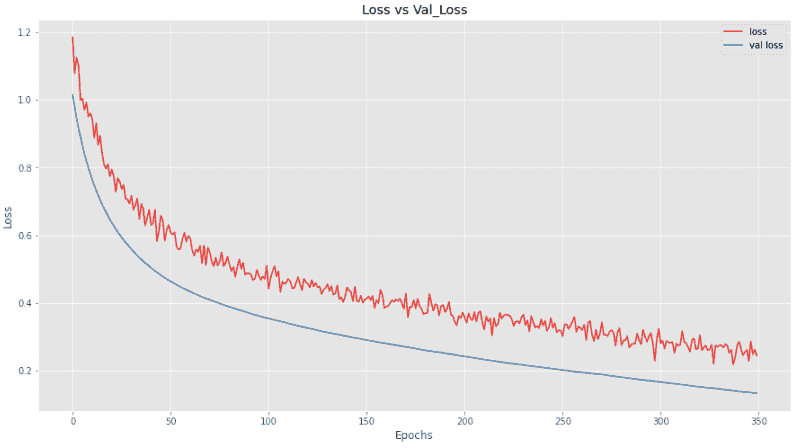
我们可以看到,添加更多丢弃层会使模型在训练时表现稍逊,但在验证集上,它表现得非常好。
现在让我们绘制准确率图。
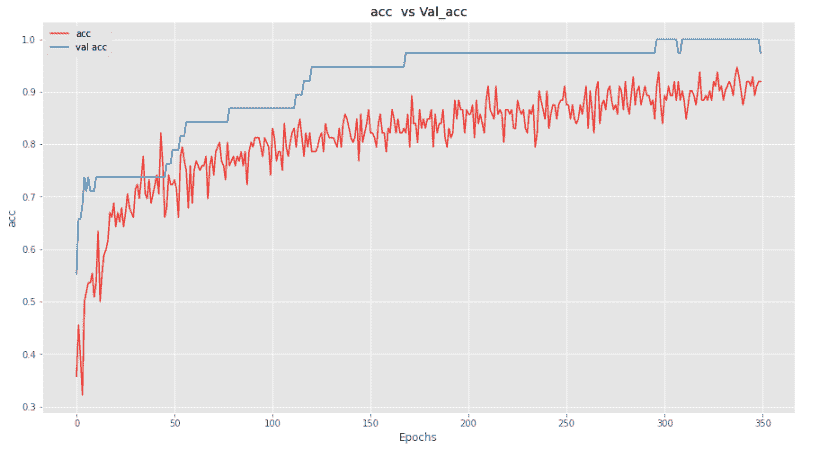
我们在这里看到相同的模式,即我们的模型在训练时表现不佳,但在评估时表现非常好。
批量归一化
批量归一化的主要思想是我们通过使用几种技术(在我们的案例中是sklearn.preprocessing.StandardScaler)对输入层进行归一化,从而提高模型性能。如果输入层通过归一化受益,那为何不对隐藏层进行归一化,以进一步提高和加快学习呢?
要学习数学并获得更多直观感受,我会再次引导你到教授 NG 的讲座,这里和这里。
要在你的 TensorFlow 模型中添加它,只需在你的层后面添加tf.keras.layers.BatchNormalization()。
让我们看看代码。
model9 = Sequential([
Dense(512, activation='tanh', input_shape = X_train[0].shape),
Dense(512//2, activation='tanh'),
tf.keras.layers.BatchNormalization(),
Dense(512//4, activation='tanh'),
Dense(512//8, activation='tanh'),
Dense(32, activation='relu'),
Dense(3, activation='softmax')
])
model9.compile(optimizer='sgd',loss='categorical_crossentropy', metrics=['acc', 'mse'])
hist9 = model9.fit(X_train, y_train, epochs=350, validation_data=(X_test,y_test), verbose=2)
在这里,如果你注意到我已经去掉了batch_size选项。这是因为在仅使用tf.keras.BatchNormalization()作为正则化时,添加batch_size参数会导致模型性能非常差。我尝试在网上寻找原因,但未能找到。如果你真的想在训练时使用batch_size,也可以将优化器从sgd更改为rmsprop或adam。
训练后,让我们评估模型。
loss9, acc9, mse9 = model9.evaluate(X_test, y_test)
print(f"Loss is {loss9},\nAccuracy is {acc9 * 100},\nMSE is {mse9}")

对于一个批量归一化的准确性,其验证准确性不如其他技术。让我们绘制损失和准确性图,以获得更好的直观感受。
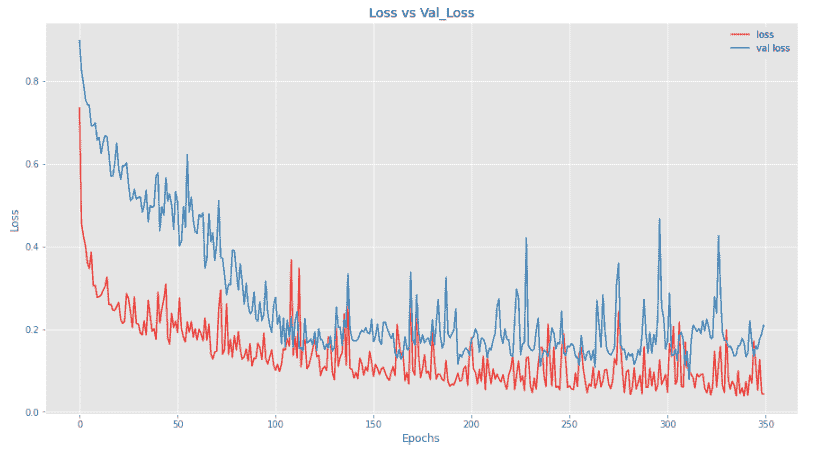
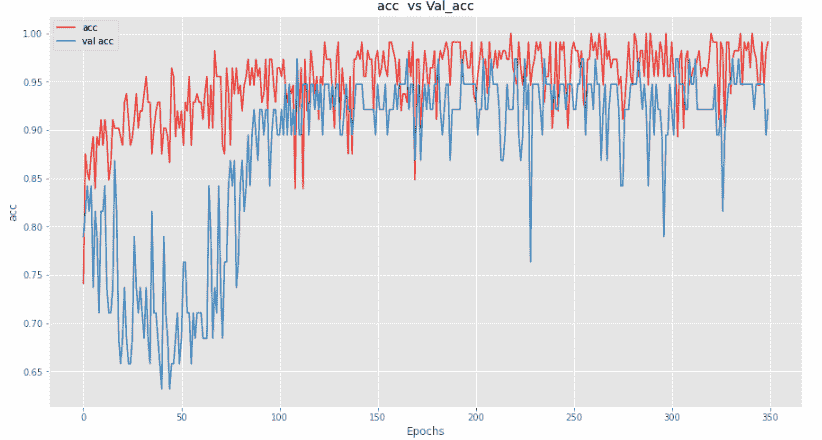
在这里,我们可以看到我们的模型在验证集上的表现不如在测试集上的表现。让我们将归一化添加到所有层中以查看结果。
model11 = Sequential([
Dense(512, activation='tanh', input_shape = X_train[0].shape),
tf.keras.layers.BatchNormalization(),
Dense(512//2, activation='tanh'),
tf.keras.layers.BatchNormalization(),
Dense(512//4, activation='tanh'),
tf.keras.layers.BatchNormalization(),
Dense(512//8, activation='tanh'),
tf.keras.layers.BatchNormalization(),
Dense(32, activation='relu'),
tf.keras.layers.BatchNormalization(),
Dense(3, activation='softmax')
])
model11.compile(optimizer='sgd',loss='categorical_crossentropy', metrics=['acc', 'mse'])
hist11 = model11.fit(X_train, y_train, epochs=350, validation_data=(X_test,y_test), verbose=2)
让我们来评估一下。
loss11, acc11, mse11 = model11.evaluate(X_test, y_test)
print(f"Loss is {loss11},\nAccuracy is {acc11 * 100},\nMSEis {mse11}")

通过在每一层中添加批量归一化,我们实现了良好的准确性。让我们绘制损失和准确性图。
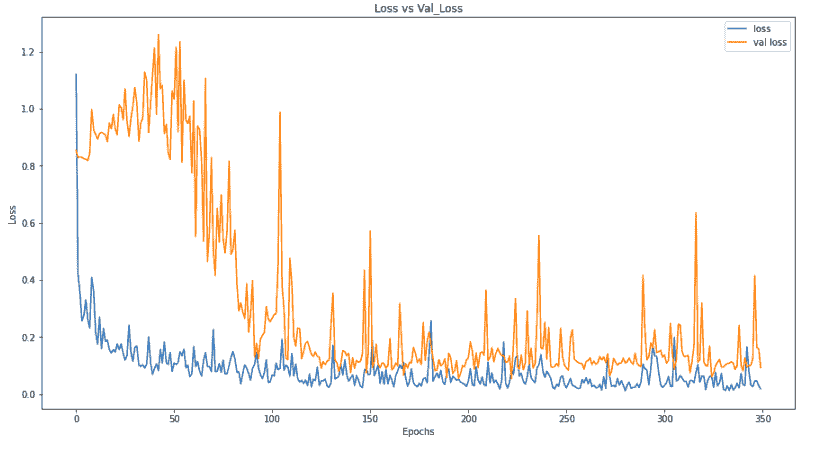
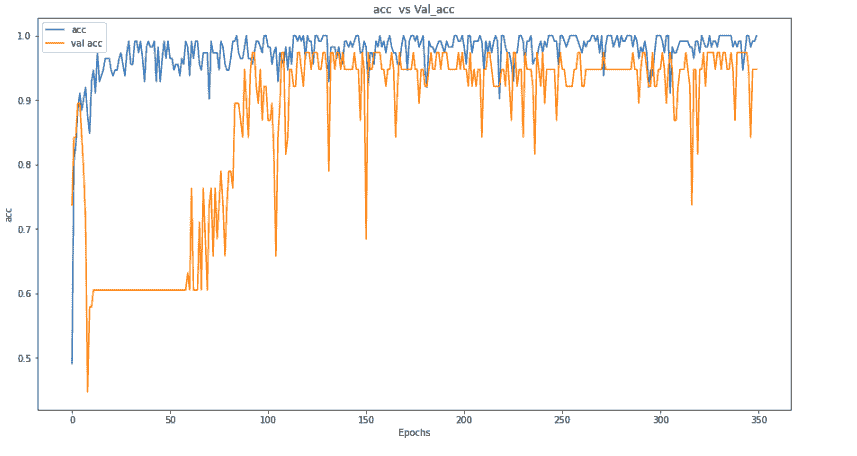
通过绘制准确性和损失,我们可以看到我们的模型在训练集上的表现仍优于验证集,但仍在提升性能。
结果:
这篇文章简要介绍了如何在 TensorFlow 中使用不同的技术。如果你对理论不够了解,我建议你学习 Coursera 深度学习专项课程中的第 2 和第 3 课程,以了解更多关于正则化的内容。
你还需要学习何时使用哪些技术,以及如何将不同技术结合起来,以产生真正有成效的结果。
希望现在你对如何在 TensorFlow 2 中实现不同的正则化技术有了一个概念。
相关:
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
使用 Tensorflow Object Detection 进行逐像素分类
原文:
www.kdnuggets.com/2018/03/tensorflow-object-detection-pixel-wise-classification.html
 评论
评论
由 Priyanka Kochhar,深度学习顾问
过去我使用 Tensorflow Object Detection API 实现对象检测,输出为图像中不同感兴趣对象的边界框。更多内容请参阅我的 文章。Tensorflow 最近添加了新功能,现在我们可以扩展 API 来确定感兴趣对象的逐像素位置。请见下面的示例:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作

Tensorflow Object Detection Mask RCNN
代码在我的 Github 上。
实例分割
实例分割是对象检测的扩展,其中每个边界框都关联一个二进制掩码(即对象与背景)。这提供了有关框内对象范围的更精细的信息。
那么我们何时需要这种额外的细粒度呢?一些想到的示例包括:
i) 自动驾驶汽车——可能需要知道道路上另一辆车的确切位置或人行道上人类的位置
ii) 机器人系统——能够将两个部分连接在一起的机器人,如果知道两个部分的确切位置,将表现得更好
实现实例分割的算法有很多,但 Tensorflow Object Detection API 使用的是 Mask RCNN。
Mask RCNN
让我们从对 Mask RCNN 的温和介绍开始。
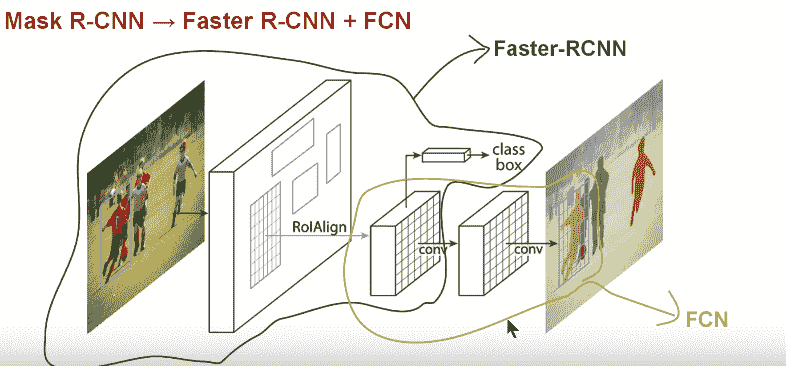
Mask RCNN 架构
Faster RCNN 是一种非常优秀的对象检测算法。Faster R-CNN 由两个阶段组成。第一个阶段称为区域提议网络(RPN),它提出候选对象边界框。第二个阶段,本质上是 Fast R-CNN,使用 RoIPool 从每个候选框中提取特征,并进行分类和边界框回归。两个阶段使用的特征可以共享,以加快推断速度。
Mask R-CNN 从概念上讲是简单的:Faster R-CNN 为每个候选对象提供两个输出,一个是类别标签,一个是边界框偏移量;在此基础上,我们增加了第三个分支,该分支输出对象掩码 — 这是一个二值掩码,指示对象在边界框中的像素。但额外的掩码输出与类别和框的输出不同,需要提取对象的更精细的空间布局。为此,Mask RCNN 使用了Fully Convolution NetworkMask RCNN 论文(FCN)所描述的网络。
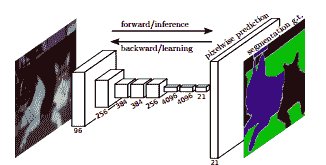
完全卷积网络架构
FCN 是一种用于语义分割的流行算法。该模型使用各种卷积块和最大池化层,首先将图像解压到其原始大小的 1/32。然后,它在这个粒度水平上进行类别预测。最后,它使用上采样和反卷积层将图像调整到其原始尺寸。
简而言之,我们可以说 Mask RCNN 将两个网络 — Faster RCNN 和 FCN 结合成一个超级架构。模型的损失函数是分类、生成边界框和生成掩码的总损失。
Mask RCNN 有一些额外的改进,使其比 FCN 更准确。你可以在他们的论文中阅读更多细节。
实现
在图像上的测试
要在图像上测试这个模型,你可以利用在 tensorflow 网站上共享的代码。我测试了他们最轻量级的模型 — mask_rcnn_inception_v2_coco。只需下载模型并升级到 tensorflow 1.5(这一点很重要!)。请参见下面的示例结果:

Mask RCNN 在风筝图像上的应用
在视频上的测试
对我来说,更有趣的实验是运行模型来处理来自 YouTube 的样本视频。我使用 keepvid 从 YouTube 下载了几个视频。我喜欢使用库 moviepy 来处理视频文件。
主要步骤是:
-
使用 VideoFileClip 函数从视频中提取每一帧
-
fl_image 函数是一个很棒的函数,可以接收图像并用修改后的图像替换它。我用它来对从视频中提取的每一张图像进行对象检测
-
最终,所有修改后的剪辑图像都被合并成一个新视频。
你可以在我的 Github 上找到完整的代码。
下一步
一些进一步探索此 API 的额外想法:
-
尝试那些更准确但开销较大的模型,看看它们能带来多大的差异。
-
使用 API 在自定义数据集上训练 Mask RCNN。这是我接下来的任务。
如果你喜欢这篇文章,请给我一个❤️:) 希望你能拉取代码并亲自尝试。
其他写作: https://medium.com/@priya.dwivedi/
PS: 我有自己的深度学习咨询公司,喜欢构建有趣的深度学习模型。我帮助了多家初创公司部署创新的 AI 解决方案。如果你有一个可以合作的项目,请通过 priya.toronto3@gmail.com 联系我。
参考文献:
-
对 Mask RCNN 的非常好的 解释
简介: Priyanka Kochhar 拥有超过 10 年的数据科学经验。她现在拥有自己的深度学习咨询公司,喜欢解决有趣的问题。她帮助了多家初创公司部署创新的 AI 解决方案。如果你有一个可以合作的项目,请通过 priya.toronto3@gmail.com 联系她。
原文。经许可转载。
相关:
-
Google Tensorflow Object Detection API 是实现图像识别的最简单方式吗?
-
使用 Tensorflow Object Detection API 构建一个玩具检测器
-
训练和可视化词向量
更多相关主题
TensorFlow 2.0 教程:优化训练时间性能
原文:
www.kdnuggets.com/2020/03/tensorflow-optimizing-training-time-performance.html
评论
由Raphael Meudec,数据科学家 @ Sicara
本教程探讨了如何提升你的 TensorFlow 2.0 模型的训练时间性能:
-
tf.data
-
混合精度训练
-
多 GPU 训练策略
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 为你的组织提供 IT 支持
我将所有这些技巧应用到一个自定义的图像去模糊项目中,结果令人惊讶。根据你当前的流程,你可以获得 2 到 10 倍的训练时间加速。
使用案例:提高图像去模糊 CNN 的 TensorFlow 训练时间
2 年前,我在使用 GANs 在 Keras 中去模糊图像上发表了一篇博客文章。我觉得将 TF2.0 的代码库传递过来理解变化和对代码的影响是一个不错的过渡。在这篇文章中,我将训练一个更简单版本的模型(仅 CNN 部分)。
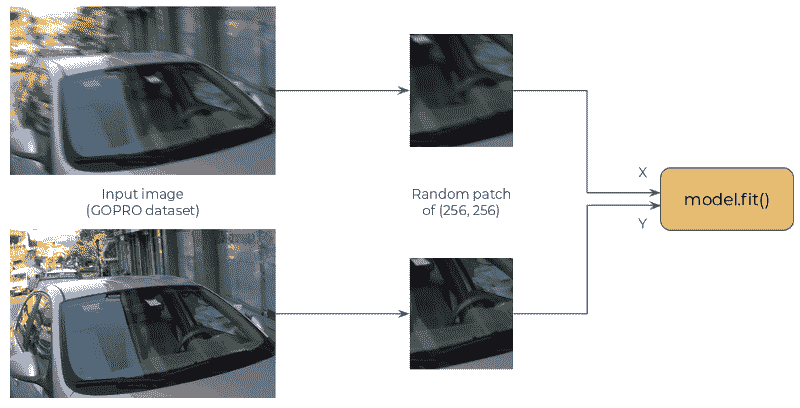
模型是一个卷积网络,它接受(256, 256, 3)的模糊补丁,并预测(256, 256, 3)的对应清晰补丁。它基于 ResNet 架构,并且是完全卷积的。
步骤 1:识别瓶颈
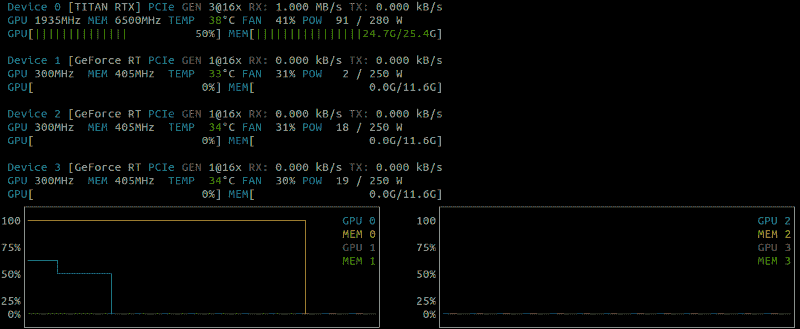
为了优化训练速度,你希望你的 GPU 以 100%的速度运行。nvidia-smi很适合确保你的进程在 GPU 上运行,但当涉及 GPU 监控时,还有更智能的工具。因此,本 TensorFlow 教程的第一步是探索这些更好的选项。
nvtop
如果你使用的是 Nvidia 显卡,监控 GPU 利用率的最简单解决方案可能就是nvtop。可视化比nvidia-smi更友好,你可以随时间跟踪指标。
TensorBoard Profiler
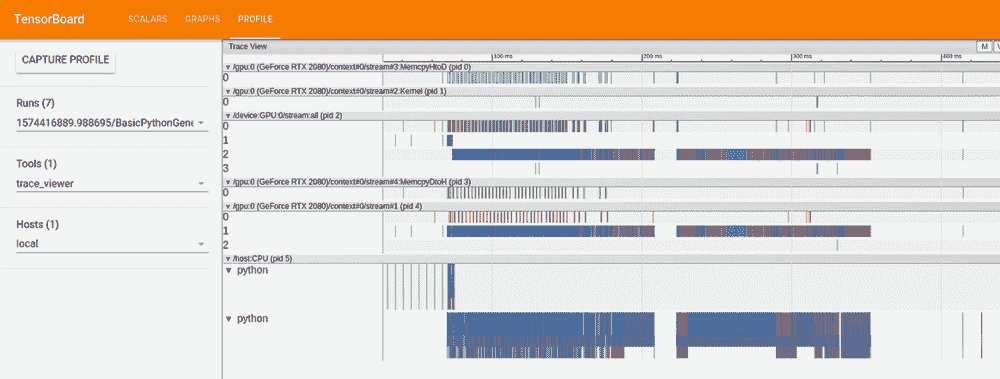
只需在 TensorBoard 回调中设置profile_batch={BATCH_INDEX_TO_MONITOR},TF 会添加一个关于 CPU 或 GPU 在给定批次上执行的操作的完整报告。这有助于识别你的 GPU 是否因为数据不足而在某些点停滞。
这是一个 Jupyterlab 扩展,可以访问各种指标。除了 GPU,你还可以监控来自主板的元素(CPU、磁盘等)。优势在于你不必监控特定的批次,而是查看整个训练过程的性能。
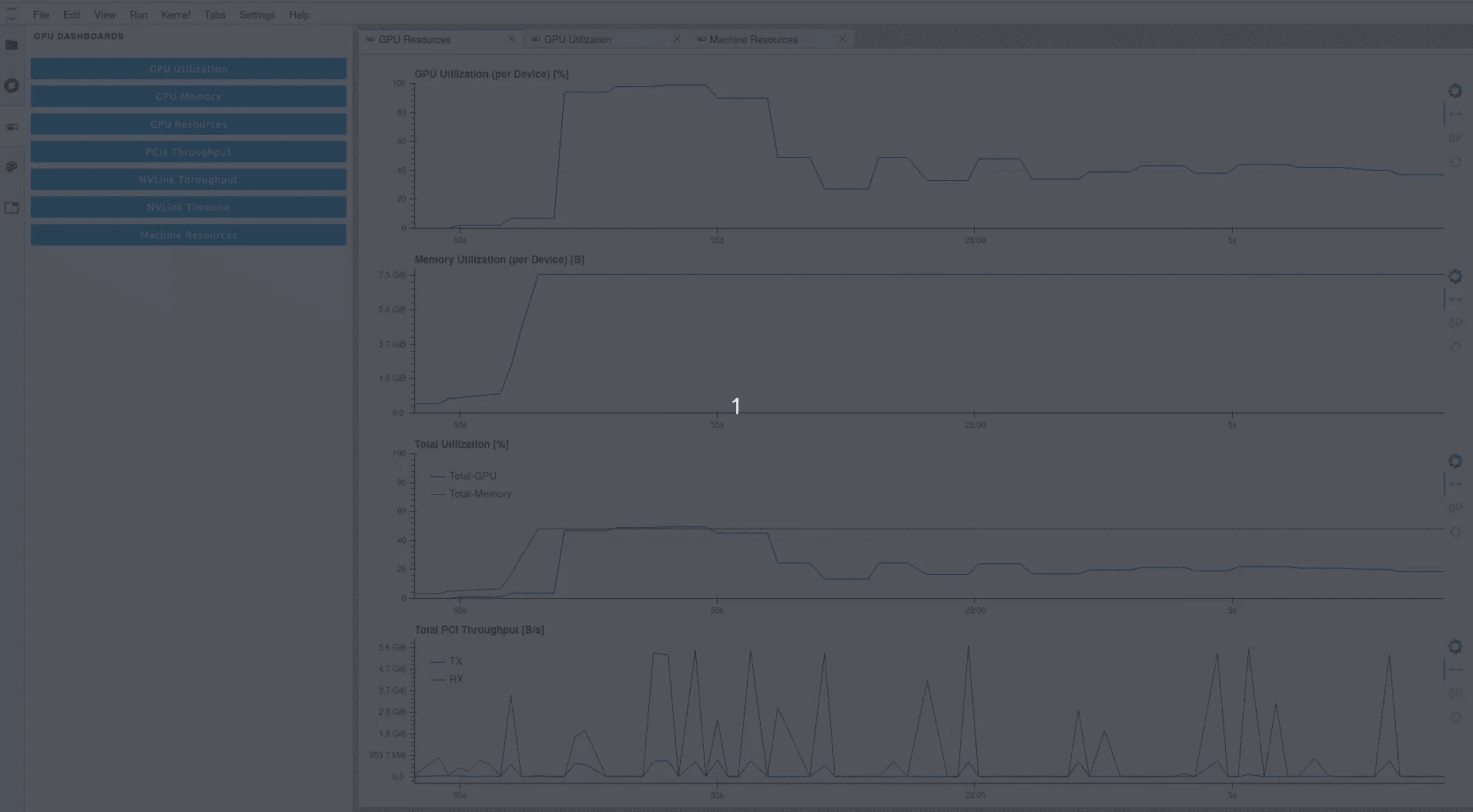
在这里,我们可以很容易地发现 GPU 大部分时间运行在 40% 的速度。我只激活了计算机上的 1 个 GPU,因此总利用率约为 20%。
步骤 2:优化你的 tf.data 管道
首要目标是让 GPU 始终 100% 繁忙。为此,我们希望减少数据加载瓶颈。如果你使用的是 Python 生成器或 Keras Sequence,你的数据加载可能并不理想。即使使用 tf.data,数据加载仍然可能是一个问题。在我的文章中,我最初使用 Keras Sequences 加载图像。
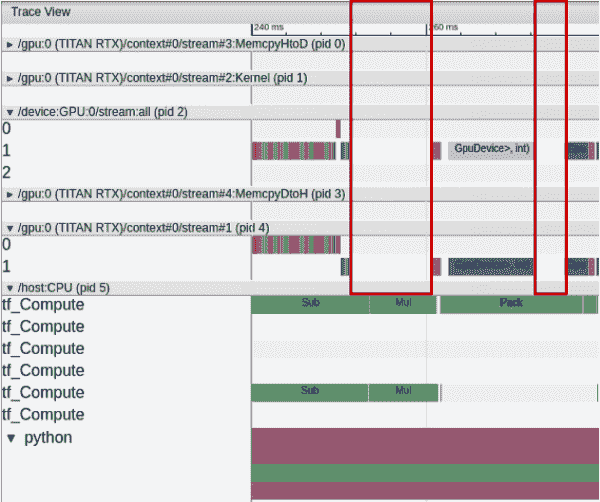
你可以使用 TensorBoard 的性能分析功能轻松发现这一现象。GPU 在 CPU 执行多个与数据加载相关的操作时通常会有空闲时间。
从原始 Keras 序列切换到 tf.data 相对容易。数据加载的大部分操作都得到了很好的支持,唯一棘手的部分是要在模糊图像和真实图像上获取相同的补丁。
从 Keras Sequence 切换到 tf.data 可以提高训练时间。从这里,我们添加了一些小技巧,你也可以在 TensorFlow 文档 中找到这些技巧:
-
并行化:通过添加
num_parallel_calls=tf.data.experimental.AUTOTUNE参数,使所有.map()调用并行化。 -
缓存:通过在补丁选择之前缓存数据集,将加载的图像保留在内存中。
-
预取:在前一个批次结束之前开始获取元素。
数据集创建现在看起来是这样的:
这些小变化使得 5 个周期的训练时间从 1000 秒(在 RTX2080 上)下降到 616 秒(完整图表见下)。
步骤 3:混合精度训练
默认情况下,我们神经网络训练中使用的所有变量都存储在 float32 中。这意味着每个元素都必须编码为 32 位。混合精度训练 的核心概念是:我们不需要始终保持如此高的精度,可以在某些情况下使用 16 位。
在混合精度训练过程中,你保留了权重的 float32 版本,但在 float16 版本的权重上执行前向和后向传递。所有获取梯度的昂贵操作都是使用 float16 元素执行的。最后,你使用 float16 梯度来更新 float32 权重。训练过程中使用了损失缩放以保持训练稳定性。
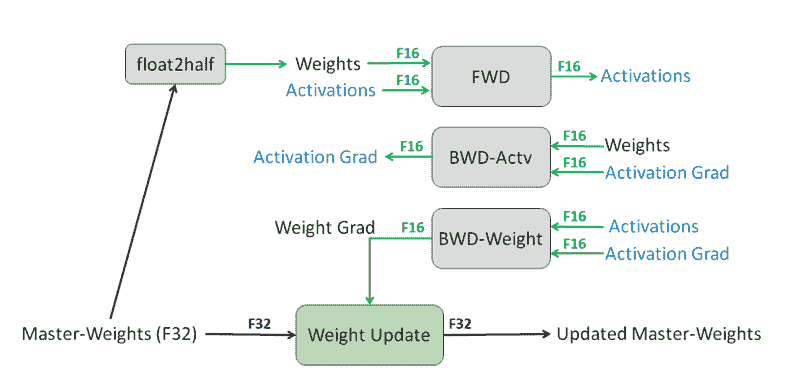
通过保持 float32 权重,这个过程不会降低你模型的准确性。相反,他们声称在各种任务上有一些性能改进。
从版本 2.1.0 开始,TensorFlow 使得实现变得简单,通过添加不同的 Policy. 混合精度训练可以通过在模型实例化之前使用这两行代码来激活。
使用这种方法,我们可以将 5 个 epoch 的训练时间缩短到 480 秒。
第四步:多 GPU 策略
最后一部分讨论如何使用 TF2.0 进行多 GPU 训练。如果你不调整你的代码以适应多 GPU,你不会减少 TensorFlow 的训练时间,因为它们不会被有效利用。
执行多 GPU 训练的最简单方法是使用 MirroredStrategy。它会在每个 GPU 上实例化你的模型。在每一步,不同的批量数据被发送到 GPUs,这些 GPU 执行反向传播。然后,梯度被聚合以进行权重更新,更新后的值被传播到每个实例化的模型。
分布策略在 TensorFlow 2.0 中仍然相当简单。你只需要考虑将通常的批量大小乘以可用 GPU 的数量。
如果你使用 TPU,可能需要更深入地查看官方的 Tensorflow 文档教程 关于训练分布。
关于提升 TensorFlow 训练时间的技巧总结
所有这些步骤都导致了你模型训练时间的巨大减少。此图跟踪了每次训练管道改进后的 5 个 epoch 训练时间。希望你喜欢这个关于 TensorFlow 训练时间性能的教程。如果你有任何反馈,可以在 Twitter 上@我(@raphaelmeudec)!
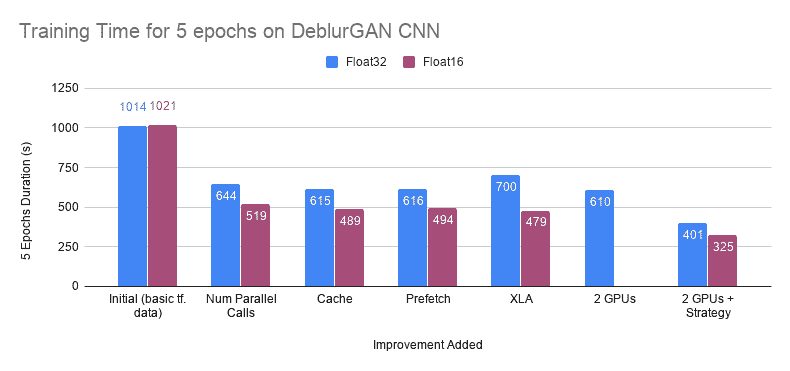
tf.data、MPT 和 GPU 策略对训练时间的影响
个人简介: Raphael Meudec (@raphaelmeudec)是 Sicara 的数据科学家。
原文。已获许可转载。
相关内容:
-
使用 Keras Tuner 进行超参数调整
-
使用 TensorFlow 简单图像数据集增强
-
转移学习简化:编码强大的技术
更多相关内容
TensorFlow:优化哪些参数?
原文:
www.kdnuggets.com/2017/11/tensorflow-parameters-optimize.html

本文针对的是对 TensorFlow Core API 有基本了解的读者。
学习 TensorFlow Core API,即 TensorFlow 中的最低级 API,是开始学习 TensorFlow 的一个很好的步骤,因为它可以让你理解库的核心。以下是一个非常简单的 TensorFlow Core API 示例,其中我们创建并训练一个线性回归模型。
步骤如下:
-
读取模型的可训练参数(在此示例中只有一个权重和一个偏置)。
-
将训练数据读取到占位符中。
-
创建线性回归模型函数。
-
创建一个损失函数来评估模型的预测误差。
-
创建一个 TensorFlow 会话。
-
初始化可训练参数。
-
运行会话以训练回归模型。
1. import tensorflow
2.
3. #Trainable Parameters
4. W = tensorflow.Variable([.6], dtype=tensorflow.float32)
5. b = tensorflow.Variable([.2], dtype=tensorflow.float32)
6.
7. #Training Data (inputs/outputs)
8. x = tensorflow.placeholder(dtype=tensorflow.float32)
9. y = tensorflow.placeholder(dtype=tensorflow.float32)
10\.
11\. #Linear Model
12\. linear_model = W * x + b
13\.
14\. #Linear Regression Loss Function - sum of the squares
15\. squared_deltas = tensorflow.square(linear_model - y)
16\. loss = tensorflow.reduce_sum(squared_deltas)
17\.
18\. #Creating a session
19\. sess = tensorflow.Session()
20\.
21\. #Initializing variables
22\. init = tensorflow.global_variables_initializer()
23\. sess.run(init)
24\.
25\. #Print the loss
26\. print(sess.run(loss, feed_dict={ x: [1, 2, 3, 4], y: [0, 1, 2, 3]}))
27\.
28\. sess.close()
返回的损失为 53.76。存在误差,特别是对于较大的误差,意味着必须更新所用的参数。这些参数预计会自动更新,但我们可以开始手动更新,直到误差为零。
-
对于 W=0.8 和 b=0.4,损失为 3.44。
-
对于 W=1.0 和 b=0.8,损失为 12.96。
-
对于 W=1.0 和 b=-0.5,损失为 1.0。
-
对于 W=1.0 和 b=-1.0,损失为 0.0。
因此,当 W=1.0 和 b=-1.0 时,期望结果与预测结果一致,因此我们不能进一步提高模型性能。我们已达到参数的最佳值,但不是使用最佳方式。计算参数的最佳方式是自动的。
TensorFlow 中已经存在多种优化器,用于简化操作。这些优化器存在于 TensorFlow 的 API 中,例如:
-
tensorflow.train
-
tensorflow.estimator
以下是如何使用 tensorflow.train 自动更新参数的方法。
tensorflow.train API
TensorFlow 提供了多种优化器,这些优化器能够自动完成之前手动计算模型参数最佳值的工作。
最简单的优化器是梯度下降法,它通过缓慢改变每个参数的值,直到达到最小化损失的值。梯度下降法根据损失对变量的导数的大小来调整每个变量。
由于计算导数的操作复杂且容易出错,TensorFlow 可以自动计算梯度。在计算梯度后,你需要自行优化参数。
但 TensorFlow 通过提供优化器,使得事情变得越来越简单,这些优化器除了优化参数外,还会计算导数。
tensorflow.train API 包含一个名为 GradientDescentOptimizer 的类,它既可以计算导数,又可以优化参数。例如,以下代码展示了如何使用 GradientDescentOptimizer 最小化损失:
1. import tensorflow
2.
3. #Trainable Parameters
4. W = tensorflow.Variable([0.3], dtype=tensorflow.float32)
5. b = tensorflow.Variable([-0.2], dtype=tensorflow.float32)
6.
7. #Training Data (inputs/outputs)
8. x = tensorflow.placeholder(dtype=tensorflow.float32)
9. y = tensorflow.placeholder(dtype=tensorflow.float32)
10\.
11\. x_train = [1, 2, 3, 4]
12\. y_train = [0, 1, 2, 3]
13\.
14\. #Linear Model
15\. linear_model = W * x + b
16\.
17\. #Linear Regression Loss Function - sum of the squares
18\. squared_deltas = tensorflow.square(linear_model - y_train)
19\. loss = tensorflow.reduce_sum(squared_deltas)
20\.
21\. #Gradient descent optimizer
22\. optimizer = tensorflow.train.GradientDescentOptimizer(learning_rate=0.01)
23\. train = optimizer.minimize(loss=loss)
24\.
25\. #Creating a session
26\. sess = tensorflow.Session()
27\.
28\. writer = tensorflow.summary.FileWriter("/tmp/log/", sess.graph)
29\.
30\. #Initializing variables
31\. init = tensorflow.global_variables_initializer()
32\. sess.run(init)
33\.
34\. #Optimizing the parameters
35\. for i in range(1000):
36\. sess.run(train, feed_dict={x: x_train, y: y_train})
37\.
38\. #Print the parameters and loss
39\. curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x: x_train, y: y_train})
40\. print("W : ", curr_W, ", b : ", curr_b, ", loss : ", curr_loss)
41\.
42\. writer.close()
43\.
44\. sess.close()
这是优化器返回的结果。它似乎自动推导出了正确的参数值,以获得最小损失。
W : [ 0.99999809] , b : [-0.9999944] , loss : 2.05063e-11
使用这样的内置优化器有一些优势,而不是手动构建它。这是因为使用 TensorFlow Core API 创建这样简单的线性回归模型的代码并不复杂。但当处理更复杂的模型时情况并非如此。因此,建议使用 TensorFlow 中的高级 API 来完成经常使用的任务。
这是使用 TensorBoard (TB)可视化的前一个程序的数据流图。
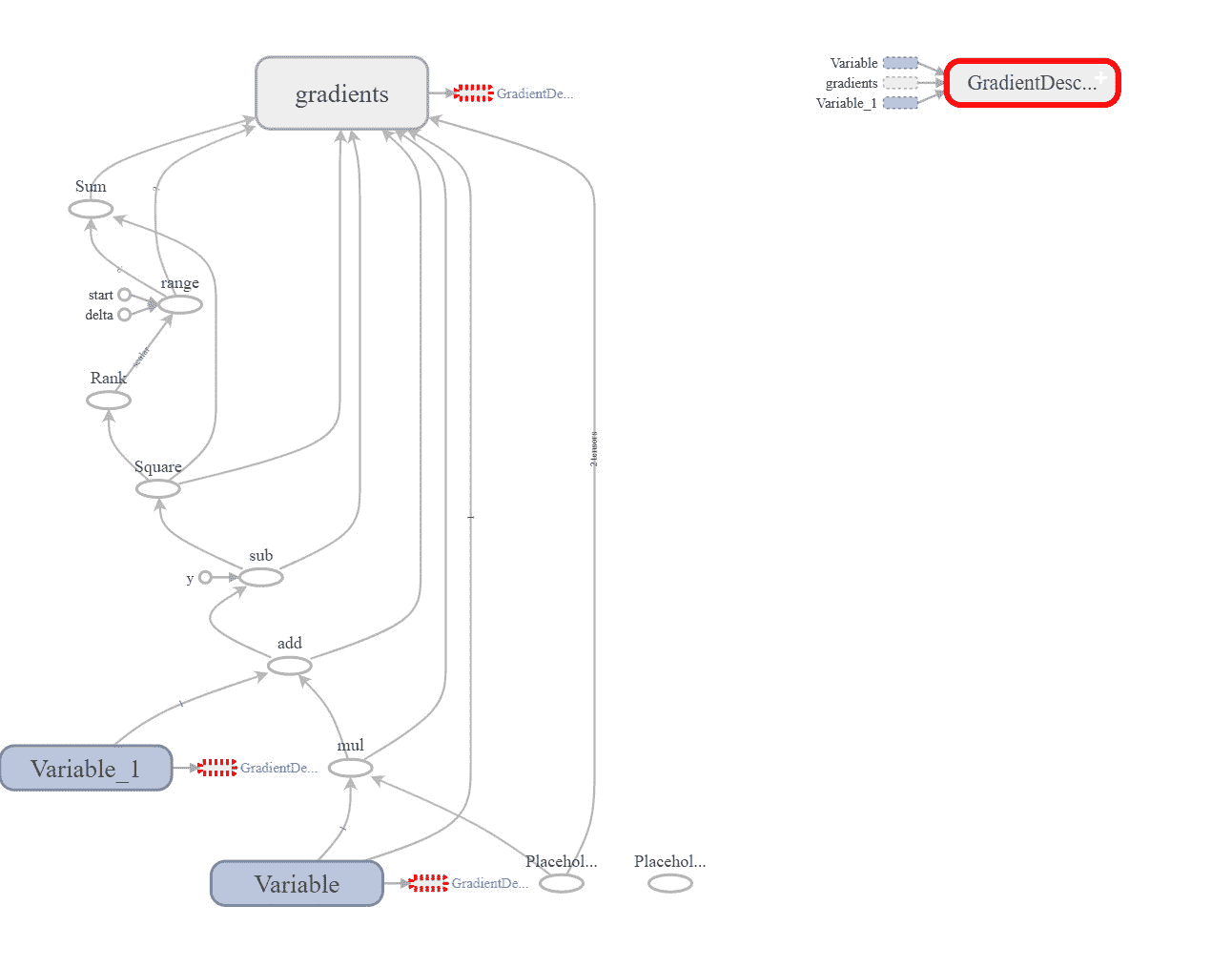
但有一个非常重要的问题。优化器是如何推导出应当改变哪些参数的?它是如何推导出我们需要优化权重(W)和偏置(b)的?我们没有明确告诉优化器这些是它将改变的参数以减少损失,但它自己推导了出来。那它是如何做到的?
在第 35 行,我们运行会话并要求评估训练 Tensor。TensorFlow 会按照图节点链评估该 Tensor。在第 23 行,TensorFlow 发现要评估训练 Tensor,它需要评估 optimizer.minimize 操作。该操作将尽可能地最小化其输入参数。
追溯回来,为了评估最小化操作,它将接受一个 Tensor,即损失。因此,现在的目标是最小化损失 Tensor。但如何最小化损失?它仍然会沿着图回溯,并发现它是通过 tensorflow.reduce_sum()操作进行评估的。因此,我们现在的目标是最小化 tensorflow.reduce_sum()操作的结果。
追溯回来,这个操作是使用一个 Tensor 作为输入进行评估的,即 squared_deltas。因此,我们现在的目标是最小化 squared_deltas Tensor,而不是最小化 tensorflow.reduce_sum()操作。
沿着链回溯,我们发现 squared_deltas Tensor 依赖于 tensorflow.square()操作。因此,我们应该最小化 tensorflow.square()操作。最小化该操作将要求我们最小化其输入 Tensors,即 linear_model 和 y_train。查看这两个 Tensor,哪个可以被修改?可以修改的 Tensor 是 Variables 类型的。由于 y_train 不是 Variable 而是 placeholder,因此我们不能修改它,因此我们可以修改 linear_model 来最小化结果。
在第 15 行,linear_model Tensor 是基于三个输入计算的,即 W、x 和 b。查看这些 Tensors,只有 W 和 x 可以被改变,因为它们是变量。因此,我们的目标是最小化这两个 Tensors W 和 x。
这就是 TensorFlow 推导出要最小化损失应当最小化权重和偏置参数的方法。
简历:Ahmed Gad 于 2015 年 7 月获得埃及门努菲亚大学计算机与信息学院信息技术学士学位,并以优异成绩获得荣誉。由于在学院排名第一,他被推荐于 2015 年在埃及的一所学院担任助教,随后在 2016 年继续在学院担任助教及研究员。他当前的研究兴趣包括深度学习、机器学习、人工智能、数字信号处理和计算机视觉。
原文。经许可转载。
相关内容:
-
TensorFlow:逐步构建前馈神经网络
-
5 个免费资源,帮助你深入理解深度学习
-
7 种用于自然语言处理的人工神经网络类型
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速迈向网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 需求
更多相关话题
探索 TensorFlow Quantum:Google 用于创建量子机器学习模型的新框架
原文:
www.kdnuggets.com/2020/03/tensorflow-quantum-framework-quantum-machine-learning-models.html
评论
量子计算与人工智能(AI)的交汇点有望成为整个技术历史中最令人着迷的进展之一。量子计算的出现可能迫使我们重新构想几乎所有现有的计算范式,而 AI 也不例外。然而,量子计算机的计算能力也有可能加速许多目前尚不实用的 AI 领域。AI 和量子计算共同工作的第一步是重新构想机器学习模型以适应量子架构。最近,Google 开源了 TensorFlow Quantum,这是一个用于构建量子机器学习模型的框架。
TensorFlow Quantum 的核心理念是将量子算法和机器学习程序交错在 TensorFlow 编程模型中。Google 将这种方法称为量子机器学习,并通过利用一些最新的量子计算框架,如 Google Cirq,来实现这一点。
量子机器学习
当涉及量子计算和 AI 时,我们需要回答的第一个问题是后者如何从量子架构的出现中受益。量子机器学习(QML)是一个广泛的术语,用来指代能够利用量子特性的机器学习模型。最初的 QML 应用集中在重构传统的机器学习模型,以便它们能够在随着量子比特数量呈指数增长的状态空间上快速执行线性代数。然而,量子硬件的进化拓展了 QML 的视野,使其发展到启发式方法,这些方法由于量子硬件的计算能力增加而可以通过实证研究。这一过程类似于 GPU 的创建如何使机器学习发展到深度学习范式。
在 TensorFlow Quantum 的背景下,QML 可以定义为两个主要组成部分:
-
量子数据集
-
混合量子模型
量子数据集
量子数据是发生在自然或人工量子系统中的任何数据源。这可以是来自量子力学实验的经典数据,或是由量子设备直接生成并作为输入喂入算法的数据。有证据表明,在“量子数据”上的混合量子-经典机器学习应用可能提供量子优势,超越仅使用经典机器学习的原因如下面所述。量子数据展示了叠加和纠缠,导致联合概率分布,这可能需要指数级的经典计算资源来表示或存储。
混合量子模型
就像机器学习可以从训练数据集中推广模型一样,量子机器学习(QML)也能够从量子数据集中推广量子模型。然而,由于量子处理器仍然相对较小且噪声较多,量子模型不能仅凭量子处理器来推广量子数据。混合量子模型提出了一种方案,在这种方案中,量子计算机作为硬件加速器最为有用,与传统计算机协同工作。这种模型非常适合 TensorFlow,因为它已经支持跨 CPU、GPU 和 TPU 的异构计算。
Cirq
构建混合量子模型的第一步是能够利用量子操作。为此,TensorFlow Quantum 依赖于 Cirq,一个用于在近期设备上调用量子电路的开源框架。Cirq 包含了指定量子计算所需的基本结构,如量子比特、门、电路和测量算子。Cirq 的理念是提供一个简单的编程模型,抽象出量子应用的基本构建块。目前的版本包括以下关键构建块:
-
电路: 在 Cirq 中,电路表示量子电路的最基本形式。一个 Cirq 电路被表示为一系列包含操作的时刻,这些操作可以在某个抽象的时间滑动中在量子比特上执行。
-
计划和设备: 计划是另一种形式的量子电路,其中包含有关门的定时和持续时间的更多详细信息。从概念上讲,计划由一组计划操作以及描述计划将要运行的设备的内容组成。
-
门: 在 Cirq 中,门抽象了对量子比特集合的操作。
-
模拟器: Cirq 包括一个 Python 模拟器,可用于运行电路和计划。模拟器架构可以跨多个线程和 CPU 扩展,这使得它能够运行相当复杂的电路。
TensorFlow Quantum
TensorFlow Quantum(TFQ) 是一个用于构建 QML 应用程序的框架。TFQ 允许机器学习研究人员在单个计算图中构建量子数据集、量子模型和经典控制参数。
从架构的角度来看,TFQ 提供了一个抽象与 TensorFlow、Cirq 和计算硬件交互的模型。栈顶是待处理的数据。经典数据由 TensorFlow 原生处理;TFQ 增加了处理量子数据的能力,包括量子电路和量子算符。栈的下一级是 TensorFlow 中的 Keras API。由于 TFQ 的核心原则是与核心 TensorFlow(特别是 Keras 模型和优化器)的原生集成,因此这一层跨越了整个栈。Keras 模型抽象下方是我们的量子层和区分器,它们在与经典 TensorFlow 层连接时实现了混合量子-经典自动微分。在层和区分器下方,TFQ 依赖于 TensorFlow 操作,这些操作实例化数据流图。
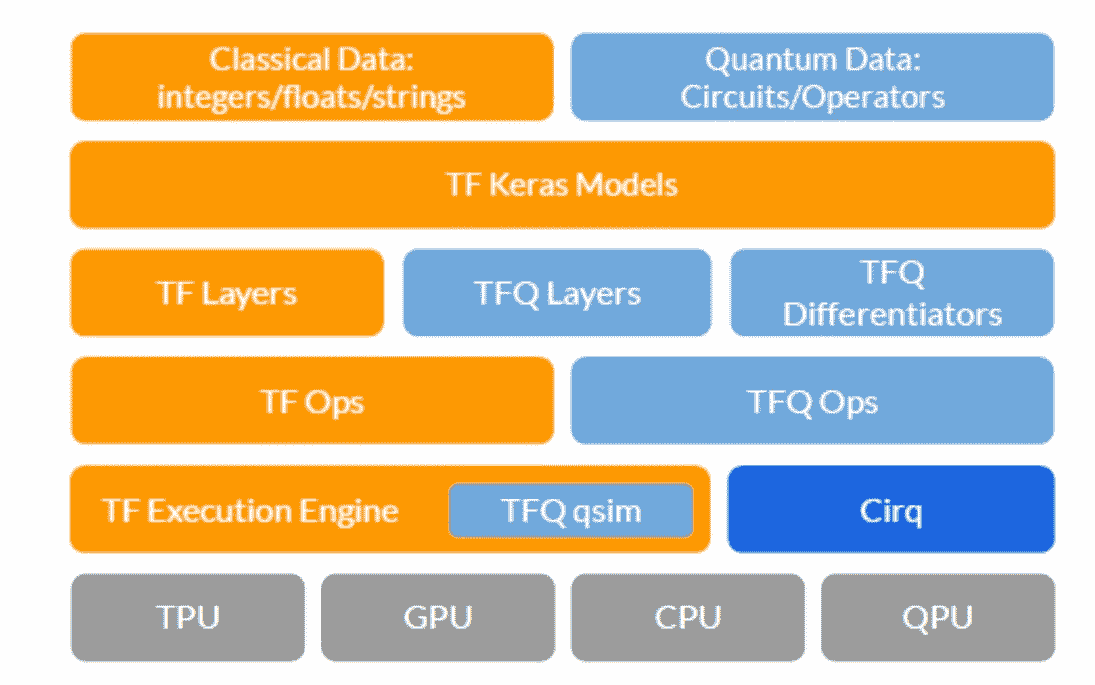
从执行的角度来看,TFQ 按照以下步骤来训练和构建 QML 模型。
-
准备量子数据集:量子数据作为张量加载,指定为用 Cirq 编写的量子电路。TensorFlow 在量子计算机上执行张量以生成量子数据集。
-
评估量子神经网络模型:在此步骤中,研究人员可以使用 Cirq 原型化一个量子神经网络,然后将其嵌入到 TensorFlow 计算图中。
-
采样或平均:此步骤利用了对几个运行的平均方法,涉及步骤(1)和(2)。
-
评估经典神经网络模型:此步骤使用经典深度神经网络来提炼在前面步骤中提取的度量之间的相关性。
-
评估成本函数:与传统机器学习模型类似,TFQ 使用此步骤来评估成本函数。这可以基于模型在分类任务中的准确性(如果量子数据已标记),或根据其他标准(如果任务是无监督的)。
-
评估梯度与更新参数 — 在评估成本函数后,应将管道中的自由参数更新为预期能减少成本的方向。
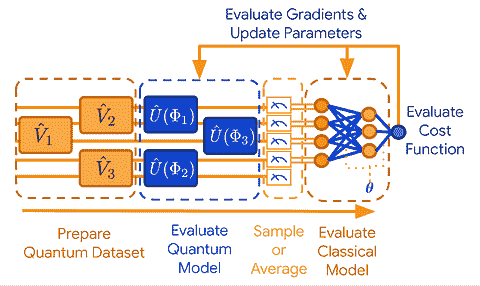
TensorFlow 和 Cirq 的结合使 TFQ 具备了一套丰富的功能,包括更简单且熟悉的编程模型以及同时训练和执行多个量子电路的能力。
量子计算与机器学习之间的桥接工作仍处于非常初步的阶段。显然,TFQ 代表了这一领域最重要的里程碑之一,并利用了量子和机器学习领域的一些最佳知识产权。有关 TFQ 的更多详细信息,请访问 该项目的网站。
原文。经许可转载。
相关:
-
关于谷歌自称的量子霸权及其对人工智能的影响
-
2020 年十大科技趋势
-
谷歌开源 TFCO 以帮助构建公平的机器学习模型
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
更多相关话题
短期股票预测的 TensorFlow
原文:
www.kdnuggets.com/2017/12/tensorflow-short-term-stocks-prediction.html
评论
由 Mattia Brusamento 提供
总结
在机器学习中,卷积神经网络(CNN 或 ConvNet)是一类成功应用于图像识别和分析的神经网络。在这个项目中,我尝试将这一类模型应用于股票市场预测,将股票价格与情感分析结合起来。网络的实现是使用 TensorFlow,从在线教程开始。在这篇文章中,我将描述以下步骤:数据集创建、CNN 训练和模型评估。

数据集
本节简要描述了构建数据集的过程、数据来源和进行的情感分析。
股票代码
为了构建数据集,我首先选择了一个行业和一个时间段来关注。我决定选择医疗保健行业,以及 2016 年 1 月 4 日到 2017 年 9 月 30 日的时间范围,并进一步将其拆分为训练集和评估集。具体来说,从 nasdaq.com 下载了股票列表,只保留了市值为 Mega、Large 或 Mid 的公司。从这个股票列表开始,分别使用 Google Finance 和 Intrinio API 检索了股票和新闻数据。
股票数据
如前所述,股票数据是通过 Google Finance 历史 API("https://finance.google.com/finance/historical?q={tick}&startdate={startdate}&output=csv",针对列表中的每个股票代码)检索的。
时间单位为天,我保留的值是收盘价。为了训练目的,使用线性插值填补了缺失的天数(pandas.DataFrame.interpolate):
新闻数据和情感分析
为了检索新闻数据,我使用了来自 intrinio 的 API。对于每个股票代码,我从" https://api.intrinio.com/news.csv?ticker={tick}"下载了相关的新闻。数据为 csv 格式,包含以下列:
TICKER,FIGI_TICKER,FIGI,TITLE,PUBLICATION_DATE,URL,SUMMARY,以下是一个示例:
"AAAP,AAAP:UW,BBG007K5CV53,"周四值得关注的 3 只股票:Advanced Accelerator Application SA(ADR) (AAAP)、Jabil Inc (JBL) 和 Medtronic Plc. (MDT)",2017-09-28 15:45:56 +0000,https://articlefeeds.nasdaq.com/r/nasdaq/symbols/3/ywZ6I5j5mIE/3-stocks-to-watch-on-thursday-advanced-accelerator-application-saadr-aaap-jabil-inc-jbl-and-medtronic-plc-mdt-cm852684,InvestorPlace 股市新闻、股票建议与交易技巧,大多数主要美国指数在周三上涨,金融股领涨,上涨 1.3%。标准普尔 500 指数上涨 0.4%,道琼斯工业平均指数上涨 0.3%。
新闻基于标题进行了去重。最后保留了 TICKER、PUBLICATION_DATE 和 SUMMARY 列。
对 SUMMARY 列进行了情感分析,使用了 Loughran 和 McDonald 金融情感词典进行金融情感分析,实施在pysentiment Python 库中。
这个库提供了一个分词器,能够进行词干提取和停用词去除,以及一个评分方法来评估分词文本。选择 get_score 方法中的值作为情感的代理是极性,计算方式如下:
(#Positives - #Negatives)/(#Positives + #Negatives)
import pysentiment as ps
lm = ps.LM()
df_news['SUMMARY_SCORES'] = df_news.SUMMARY.map(lambda x: lm.get_score(lm.tokenize(str(x))))
df_news['POLARITY'] = df_news['SUMMARY_SCORES'].map(lambda x: x['Polarity'])
没有新闻的日期用 0 填充极性。
最后,数据按股票和日期分组,计算极性得分,对有多个新闻的日期进行求和。
完整数据集
通过合并股票和新闻数据,我们得到一个数据集,包含 2016-01-04 到 2017-09-30 的所有 154 个数据点,包含股票的收盘值和相应的极性值:
| 日期 | 股票 | 收盘 | 极性 |
|---|---|---|---|
| 2017-09-26 | ALXN | 139.700000 | 2.333332 |
| 2017-09-27 | ALXN | 139.450000 | 3.599997 |
| 2017-09-28 | ALXN | 138.340000 | 1.000000 |
| 2017-09-29 | ALXN | 140.290000 | -0.999999 |
使用 TensorFlow 的 CNN
为了开始使用 Tensorflow 中的卷积神经网络,我参考了官方教程。它展示了如何使用层来构建一个卷积神经网络模型,以识别 MNIST 数据集中的手写数字。为了使其适用于我们的目的,我们需要调整输入数据和网络。
数据模型
输入数据的模型化方式是单个特征元素为 154x100x2 的张量:
-
154 个数据点
-
100 连续天
-
2 个通道,一个用于股票价格,一个用于极性值
标签则被建模为长度为 154 的向量,其中每个元素为 1,如果相应的股票在次日上涨,否则为 0。

这样,有一个 100 天的滑动时间窗口,因此前 100 天不能用作标签。训练集包含 435 条记录,而评估集包含 100 条记录。
卷积神经网络
CNN 的构建从 TensorFlow 的教程示例开始,然后适应了这个使用案例。前两个卷积和池化层的高度都等于 1,因此它们对单个股票进行卷积和池化,最后一层的高度等于 154,以学习股票之间的相关性。最后是全连接层,最后一层的长度为 154,每个股票一个。
网络的规模已经调整到可以在一台笔记本电脑上使用这个数据集训练几个小时。部分代码如下:
def cnn_model_fn(features, labels, mode):
"""Model function for CNN."""
# Input Layer
input_layer = tf.reshape(tf.cast(features["x"], tf.float32), [-1, 154, 100, 2])
# Convolutional Layer #1
conv1 = tf.layers.conv2d(
inputs=input_layer,
filters=32,
kernel_size=[1, 5],
padding="same",
activation=tf.nn.relu)
# Pooling Layer #1
pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[1, 2], strides=[1,2])
# Convolutional Layer #2
conv2 = tf.layers.conv2d(
inputs=pool1,
filters=8,
kernel_size=[1, 5],
padding="same",
activation=tf.nn.relu)
# Pooling Layer #2
pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[1, 5], strides=[1,5])
# Convolutional Layer #3
conv3 = tf.layers.conv2d(
inputs=pool2,
filters=2,
kernel_size=[154, 5],
padding="same",
activation=tf.nn.relu)
# Pooling Layer #3
pool3 = tf.layers.max_pooling2d(inputs=conv3, pool_size=[1, 2], strides=[1, 2])
# Dense Layer
pool3_flat = tf.reshape(pool3, [-1, 154 * 5 * 2])
dense = tf.layers.dense(inputs=pool3_flat, units=512, activation=tf.nn.relu)
dropout = tf.layers.dropout(
inputs=dense, rate=0.4, training=mode == tf.estimator.ModeKeys.TRAIN)
# Logits Layer
logits = tf.layers.dense(inputs=dropout, units=154)
predictions = {
# Generate predictions (for PREDICT and EVAL mode)
"classes": tf.argmax(input=logits, axis=1),
"probabilities": tf.nn.softmax(logits, name="softmax_tensor")
}
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(mode=mode, predictions=predictions)
# Calculate Loss (for both TRAIN and EVAL modes)
multiclass_labels = tf.reshape(tf.cast(labels, tf.int32), [-1, 154])
loss = tf.losses.sigmoid_cross_entropy(
multi_class_labels=multiclass_labels, logits=logits)
# Configure the Training Op (for TRAIN mode)
if mode == tf.estimator.ModeKeys.TRAIN:
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001)
train_op = optimizer.minimize(
loss=loss,
global_step=tf.train.get_global_step())
return tf.estimator.EstimatorSpec(mode=mode, loss=loss, train_op=train_op)
评估
为了评估模型的性能,没有使用标准指标,而是构建了一个更接近实际使用的模型的模拟。
假设以初始资本 (C) 为 1,对于评估集中的每一天,我们将资本分为 N 个相等的部分,其中 N 从 1 到 154。
我们在模型预测概率最高的前 N 只股票上放置 C/N,其余的股票上放置 0。
此时,我们有一个向量 A 表示我们的每日分配,我们可以计算每日的收益/损失,方法是将 A 乘以每只股票当天的百分比变化。
我们得到一个新的资本 C = C + delta,可以在第二天重新投资。
最终,我们会得到一个大于或小于 1 的资本,取决于我们选择的好坏。
模型的一个良好基准已确定为 N=154:这代表了所有股票的通用性能,并模拟了将资本平均分配到所有股票上的情景。这产生了大约 4.27% 的收益。
为了评估目的,数据已被纠正,移除了市场关闭的天数。
不同 N 值下模型的性能在下面的图片中报告。

红色虚线是 0 基准线,而橙色线是基准线,N=154。
最佳性能是在 N=12 下获得的,*收益约为 8.41%,几乎是市场基准的两倍。
对于几乎所有大于 10 的 N 值,我们都有不错的表现,优于基准线,而 N 值过小则会降低性能。
结论
第一次尝试 Tensorflow 和 CNN 并将其应用于金融数据非常有趣。
这是一个玩具示例,使用了相当小的数据集和网络,但它展示了这些模型的潜力。
请随时提供反馈和建议,或者直接通过 LinkedIn 与我联系。
简介: Mattia 在米兰理工大学获得了计算机工程硕士学位(荣誉),在 TU Delft 期间研究了推荐系统的论文。Mattia 目前在一家意大利公司担任网络安全领域的数据科学家。
相关
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业领域。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT 工作
更多相关话题
TensorFlow 教程,第二部分 – 开始使用
原文:
www.kdnuggets.com/2017/09/tensorflow-tutorial-part-2.html
作者:Vivek Kalyanarangan,专业网络联盟。

在这个多部分系列中,我们将探索如何开始使用 TensorFlow。本 TensorFlow 教程将为这个人人谈论的热门工具奠定坚实的基础。第二部分是一个关于开始使用、安装和构建小型用例的 TensorFlow 教程。
本系列摘录自我作为专业网络联盟的一部分所进行的网络研讨会教程系列。我会时不时提及在演讲中使用的一些幻灯片,以便让内容更加清晰。
请不要错过我谈论所有我写的内容的在线研讨会。请注册我们的即将举行的网络研讨会,以了解我们将讨论的主题。
本文是关于完整 TensorFlow 教程的多部分系列的第一部分 –
-
第二部分:开始使用
-
第三部分:构建第一个模型
TensorFlow 教程:目标

-
安装 TensorFlow
-
验证 TensorFlow 安装
-
在构建第一个 TensorFlow 模型之前
安装 TensorFlow
如果你已经安装了 TensorFlow,可以直接跳到下一部分。
1. 操作系统
不同操作系统有不同的安装 TensorFlow 的方法。你可以查阅文档获取更多详细信息。我将只讨论开始使用所必需的内容。
- 点击安装选项卡

以下指南解释了如何安装一个版本的 TensorFlow,使你能够用 Python 编写应用程序。
尽量遵循文档中已提到的最佳实践的基本结构。
2. GPU
使用 GPU 安装 TensorFlow 需要你有 NVIDIA GPU。AMD 显卡不受 TensorFlow 支持。NVIDIA 使用称为 CUDA 的低级 GPU 计算系统。这是 NVIDIA 专有的软件。
可以使用 OpenCL 与 AMD 配合,但目前它不支持 TensorFlow。
另外,并非所有 NVIDIA 设备都受支持。以下是NVIDIA 文档中列出的受支持的 GPU 列表。

3. 环境
有三种环境可以用来设置 tensorflow –
-
直接安装 – 这只是安装任何软件库的典型方式。它直接与已安装的操作系统交互,并像其他库一样安装 tensorflow。
pip是直接安装的首选方式。 -
虚拟环境 – 对于那些不知道 python 虚拟环境优势的人,
virtualenv就像是一个与系统中已经安装的默认 python 平行的 python 安装。 在虚拟环境中安装库可以将库分开,你将不会与直接安装的其他库发生兼容性冲突。如果出现问题,你可以启动一个新的虚拟环境,重新开始。 -
Docker 容器 – 这是一种安装 tensorflow 的方式。可以将典型的 VMware 镜像想象成是一个超级强大的 docker 容器。Docker 可以用来启动具有不同操作系统环境的容器,从而允许你拥有一个与主机系统完全分开的环境。所有细节在 tensorflow 文档中都明确标出。
4. Python 版本
支持 Python 2 的 2.7 版本和 Python 3 的 3.3 或更高版本。所有操作系统均适用。
目前,Windows 仅支持 3.5 版本。Python 2 与 Windows 的组合是不受支持的。
验证安装
一旦 tensorflow 安装完成,无论操作系统、环境或 python 版本如何,你都应该运行以下脚本来验证 tensorflow 是否正常运行。
# import TensorFlow
import tensorflow as tf
sess = tf.Session()
# Verify we can print a string
hello = tf.constant("Hello UNP from TensorFlow")
print(sess.run(hello))
# Perform some simple math
a = tf.constant(20)
b = tf.constant(22)
print('a + b = {0}'.format(sess.run(a + b)))
一旦这段代码成功运行并打印输出,恭喜你!你已经成功安装了 tensorflow。接下来我们进入下一部分,构建我们的第一个应用程序。
在构建第一个 tensorflow 模型之前
张量
下面是我们在开始之前需要学习的三种张量类型。
| 类型 | 描述 |
|---|---|
| 常量 | 常量值 |
| 变量 | 在图中调整的值 |
| 占位符 | 用于在图中传递数据 |
在动手操作之前,我只想介绍几个 tensorflow 术语及其含义。

-
排名 – 张量的维度
-
形状 – 张量的形状。与排名相关
上图应有助于理解。下面是 Tensorflow 支持的不同数据类型。

注意:量化值[qint8、qint16 和 quint8]是 TensorFlow 的特殊值,有助于减少数据大小。事实上,Google 已经引入了 TensorFlow 处理单元(TPUs)来通过利用量化值加快计算速度*
准备数据
我们将快速生成一些数据以便开始。在这个例子中,我们将生成房屋大小数据以预测房价。这里的目标不是建立一个复杂的房价预测器,而是以最简单的方式在 TensorFlow 中启动。
我们将使用下面的 Python 代码生成一些数据–
import tensorflow as tf
import numpy as np
import math
import matplotlib.pyplot as plt
# generation some house sizes between 1000 and 3500 (typical sq ft of house)
num_house = 160
np.random.seed(42)
house_size = np.random.randint(low=1000, high=3500, size=num_house )
# Generate house prices from house size with a random noise added.
np.random.seed(42)
house_price = house_size * 100.0 +
np.random.randint(low=20000, high=70000, size=num_house)
# Plot generated house and size
plt.plot(house_size, house_price, "bx") # bx = blue x
plt.ylabel("Price")
plt.xlabel("Size")
plt.show()
这将生成如下输出[这是生成的数据的图示]

接下来,我们将对数据进行归一化。这有助于将数据调整到相同的尺度,从而可能导致更快的收敛。
我们还将其拆分为训练数据和测试数据,作为数据科学最佳实践的一部分。我们将用训练数据训练我们的模型,并用测试数据测试模型,以查看我们的预测有多准确。
# you need to normalize values to prevent under/overflows.
def normalize(array):
return (array - array.mean()) / array.std()
# define number of training samples, 0.7 = 70%. We can take the first 70%
# since the values are randomized
num_train_samples = math.floor(num_house * 0.7)
# define training data
train_house_size = np.asarray(house_size[:num_train_samples])
train_price = np.asanyarray(house_price[:num_train_samples:])
train_house_size_norm = normalize(train_house_size)
train_price_norm = normalize(train_price)
# define test data
test_house_size = np.array(house_size[num_train_samples:])
test_house_price = np.array(house_price[num_train_samples:])
test_house_size_norm = normalize(test_house_size)
test_house_price_norm = normalize(test_house_price)
结论
我希望这能设定对接下来内容的期望。在下一篇文章中,我们将构建我们的第一个 TensorFlow 模型。
请不要错过直播研讨会,在那里我会讨论我写的所有内容。注册我们的即将到来的研讨会以了解我们将讨论的主题。快乐编码!
在下一部分,我们终于准备好用房价数据训练我们的第一个 TensorFlow 模型。这将给我们提供第一次使用 TensorFlow 的亲身体验!
我在下面嵌入了原始演示文稿–
原始。经许可转载。
简介: Vivek Kalyanarangan 是一名数据科学家、博主、吉他手,对新技术充满热情。
相关:
-
TensorFlow 教程:第一部分 – 介绍
-
寻找最快的 Keras 深度学习后端
-
PyTorch 还是 TensorFlow?
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织的 IT
更多相关主题
测试你的机器学习管道
原文:
www.kdnuggets.com/2019/11/testing-machine-learning-pipelines.html
评论
由 Kristina Young,高级数据科学家
说到数据产品,很多时候存在一种误解,即这些产品无法通过自动化测试。虽然由于其实验性和随机性,管道中的某些部分无法通过传统测试方法,但大部分管道是可以的。此外,更多不可预测的算法可以通过专门的验证过程来测试。
让我们看看传统的测试方法以及如何将这些方法应用于我们的数据/机器学习管道。
测试金字塔
你的标准简化测试金字塔如下所示:
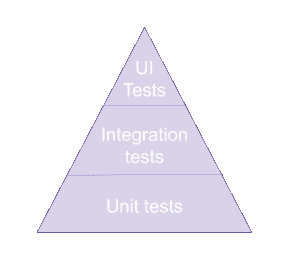
这个金字塔表示了你为应用程序编写的测试类型。我们从大量的单元测试开始,测试单一功能是否与其他功能隔离。然后我们编写集成测试,检查将隔离的组件结合在一起是否按预期工作。最后,我们编写 UI 或验收测试,检查应用程序从用户的角度是否按预期工作。
在数据产品方面,金字塔并没有太大区别。我们有大致相同的层级。
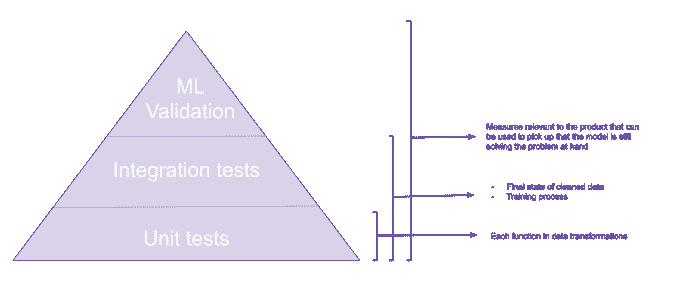
请注意,UI 测试仍然会在产品中进行,但这篇博客文章关注的是与数据管道最相关的测试。
让我们更详细地了解每个部分在机器学习中的含义,并借助一些科幻作者的帮助。
单元测试
“这是一个将你的想法与宇宙进行对比的系统,看看它们是否匹配” —— 艾萨克·阿西莫夫。
数据管道中的大部分代码由数据清理过程组成。用于数据清理的每个函数都有一个明确的目标。例如,假设我们为模型选择的一个特征是前一天和当前一天之间值的变化。我们的代码可能如下所示:
def add_difference(asimov_dataset):
asimov_dataset['total_naughty_robots_previous_day'] =
asimov_dataset['total_naughty_robots'].shift(1)
asimov_dataset['change_in_naughty_robots'] =
abs(asimov_dataset['total_naughty_robots_previous_day'] -
asimov_dataset['total_naughty_robots'])
return asimov_dataset[['total_naughty_robots', 'change_in_naughty_robots',
'robot_takeover_type']]
在这里,我们知道对于给定的输入,我们期望得到特定的输出,因此我们可以用以下代码来测试:
import pandas as pd
from pandas.testing import assert_frame_equal
import numpy as np
from unittest import TestCase
def test_change():
asimov_dataset_input = pd.DataFrame({
'total_naughty_robots': [1, 4, 5, 3],
'robot_takeover_type': ['A', 'B', np.nan, 'A']
})
expected = pd.DataFrame({
'total_naughty_robots': [1, 4, 5, 3],
'change_in_naughty_robots': [np.nan, 3, 1, 2],
'robot_takeover_type': ['A', 'B', np.nan, 'A']
})
result = add_difference(asimov_dataset_input)
assert_frame_equal(expected, result)
对于每个独立的功能,你应该编写一个单元测试,确保数据转换过程中的每个部分对数据产生了预期的效果。对于每个功能,你还应该考虑不同的场景(是否有条件语句?如果有,则应测试所有条件)。这些测试将作为你持续集成(CI)管道的一部分在每次提交时运行。
除了检查代码是否按预期工作外,单元测试还在调试问题时给予我们帮助。通过添加一个能够重现新发现的错误的测试,我们可以确保在我们认为错误已经修复时,该错误已经被修复,并且我们可以确保该错误不会再次发生。
最后,这些测试不仅检查代码是否按预期工作,还帮助我们记录创建功能时的期望。
集成测试
因为 “无云的眼睛更好,不管它看到什么。” Frank Herbert
这些测试旨在确定单独开发的模块在结合在一起时是否按预期工作。就数据管道而言,这些测试可以检查:
-
数据清理过程产生了适合模型的数据集
-
模型训练能够处理提供给它的数据并输出结果(确保代码在未来可以重构)
所以,如果我们拿上面的单元测试函数,并添加以下两个函数:
def remove_nan_size(asimov_dataset):
return asimov_dataset.dropna(subset=['robot_takeover_type'])
def clean_data(asimov_dataset):
asimov_dataset_with_difference = add_difference(asimov_dataset)
asimov_dataset_without_na = remove_nan_size(asimov_dataset_with_difference)
return asimov_dataset_without_na
然后我们可以测试将clean_data内部的函数组合起来是否会产生预期的结果,代码如下:
def test_cleanup():
asimov_dataset_input = pd.DataFrame({
'total_naughty_robots': [1, 4, 5, 3],
'robot_takeover_type': ['A', 'B', np.nan, 'A']
})
expected = pd.DataFrame({
'total_naughty_robots': [1, 4, 3],
'change_in_naughty_robots': [np.nan, 3, 2],
'robot_takeover_type': ['A', 'B', 'A']
}).reset_index(drop=True)
result = clean_data(asimov_dataset_input).reset_index(drop=True)
assert_frame_equal(expected, result)
现在假设我们要做的下一步是将上述数据输入到逻辑回归模型中。
from sklearn.linear_model import LogisticRegression
def get_reression_training_score(asimov_dataset, seed=9787):
clean_set = clean_data(asimov_dataset).dropna()
input_features = clean_set[['total_naughty_robots',
'change_in_naughty_robots']]
labels = clean_set['robot_takeover_type']
model = LogisticRegression(random_state=seed).fit(input_features, labels)
return model.score(input_features, labels) * 100
虽然我们不知道期望值,但我们可以确保总是得到相同的值。测试这种集成对我们很有用,以确保:
-
数据可以被模型使用(每个输入都有标签,数据类型被选择的模型接受等)
-
我们能够在未来重构我们的代码,而不会破坏端到端的功能。
通过为随机生成器提供相同的种子,我们可以确保结果始终相同。所有主要的库都允许你设置种子(Tensorflow 有点特殊,因为它要求你通过 numpy 设置种子,请记住这一点)。测试可以如下所示:
from numpy.testing import assert_equal
def test_regression_score():
asimov_dataset_input = pd.DataFrame({
'total_naughty_robots': [1, 4, 5, 3, 6, 5],
'robot_takeover_type': ['A', 'B', np.nan, 'A', 'D', 'D']
})
result = get_reression_training_score(asimov_dataset_input, seed=1234)
expected = 40.0
assert_equal(result, 50.0)
这类测试不会像单元测试那样多,但它们仍会成为你 CI 管道的一部分。你会使用这些测试来检查组件的端到端功能,因此会测试更主要的场景。
机器学习验证
为什么?“展现了知道错误问题答案的完美无用性。” Ursula K. Le Guin.
现在我们已经测试了我们的代码,我们还需要测试机器学习组件是否解决了我们要解决的问题。当我们谈论产品开发时,机器学习模型的原始结果(无论基于统计方法的准确度如何)几乎从来不是期望的最终输出。这些结果通常会与其他业务规则结合,然后才会被用户或其他应用程序使用。因此,我们需要验证模型是否解决了用户的问题,而不仅仅是准确度/F1 分数/其他统计指标是否足够高。
这对我们有什么帮助?
-
它确保模型实际帮助产品解决当前的问题
- 例如,一个将蛇咬伤分类为致命或非致命的模型,如果 20%的错误导致患者未能得到所需治疗,那么这个模型并不好。
-
确保模型产生的值在行业中是合理的
- 例如,一个以 70%准确率预测价格变化的模型,如果最终显示给用户的价格值在该行业/市场中过低或过高,则不是一个好的模型。
-
它提供了决策记录的额外文档层次,帮助后来加入团队的工程师。
-
它以一种客户、产品经理和工程师都能理解的共同语言提供了产品中机器学习组件的可见性。
这种验证应定期进行(通过 CI 管道或 cron 作业),其结果应向组织公开。这确保数据科学组件的进展对组织可见,并确保由于更改或陈旧数据引起的问题能尽早被发现。
结论
毕竟,“魔法只是我们尚未理解的科学”——阿瑟·克拉克。
机器学习组件可以通过各种方式进行测试,带来以下优势:
-
采用数据驱动的方法,以确保代码的行为符合预期
-
确保我们能够重构和清理代码,而不破坏产品的功能
-
记录功能、决策和以前的错误
-
提供产品中机器学习组件的进展和状态的可见性
所以不要害怕,如果你有编写代码的技能,你也具备编写测试的技能,并获得上述所有优势????。
再见,谢谢你的所有测试!
个人简介:Kristina Young 是 BCG Digital Ventures 的高级数据科学家。她曾在 SoundCloud 担任推荐团队的后端和数据工程师。她的以往经验包括顾问和研究员。她在过去曾担任过后端、网页和移动开发人员,涉及各种技术。
原文。经许可转载。
相关:
-
5 步指南:使用 d6tflow 构建可扩展的深度学习管道
-
我如何在机器学习中变得更好
-
数据管道、Luigi、Airflow:你需要知道的一切
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
文本分析:入门指南
评论
编辑注: 以下是对伊利诺伊大学教授及文本分析专家彭刘的采访,由市场科学家凯文·格雷进行,彭刘简明扼要地概述了该领域的现状。
凯文·格雷: 我看到“文本分析”和“文本挖掘”在市场研究人员中被多种方式使用,并且通常可以互换使用。这些术语对你来说是什么意思?
彭刘: 我的理解是这两个术语意思相同。学术界的人更倾向于使用文本挖掘这个术语,尤其是数据挖掘研究者,而文本分析则主要在行业中使用。我很少看到学者使用文本分析这个术语。还有一个相关的术语,叫做自然语言处理(NLP)。文本挖掘和文本分析通常指将数据挖掘和机器学习算法应用于文本数据。NLP 涵盖了这些内容,并且还有其他更传统的自然语言任务,如机器翻译、句法分析、语义分析等。但这些术语之间并没有明确的划分。

彭刘 (来源)。
KG: 能简要介绍一下文本分析/挖掘的历史以及它是如何随着时间发展的吗?
BL: 它源于三个研究领域:信息检索、数据挖掘和自然语言处理(NLP)。信息检索始于 1970 年代,主要处理文本检索。也就是说,给定一个查询,可以是几个关键词或一个完整的文档,我们希望从文本集合或语料库中找到相关的文档。网络搜索引擎是巨大的信息检索系统。
传统的数据挖掘使用结构化数据,如数据库表格。在 1990 年代末,研究人员开始将文本作为数据,这催生了文本挖掘。早期的文本挖掘基本上是在文本数据上应用数据挖掘和机器学习算法,而没有使用诸如解析、词性标注、摘要等自然语言处理技术。
NLP 有更长的历史。它始于 1950 年代,目标是让计算机理解人类语言。随着文本挖掘研究在过去 10 年左右扩展其范围,它开始使用自然语言处理技术,如解析、词性标注、指代消解等。从自然语言处理会议涵盖的主题来看,文本挖掘现在已成为自然语言处理的一部分。我的研究最初是从传统的数据挖掘开始的。随后我研究了情感分析或意见挖掘,这使我转向了自然语言处理。
KG: 它在市场研究和其他领域是如何使用的?
BL: 文本分析在营销和许多其他领域得到了广泛应用。我最熟悉的是情感分析的应用。在营销中,营销人员通常希望了解消费者对公司产品以及竞争对手产品的看法。这些意见可以通过分析在线评论或其他形式的社交媒体帖子来获得。基于这些意见,营销人员可以制定适合不同市场细分的营销信息。公众意见在许多其他应用领域也非常有用,例如股市预测、消费者情感预测、政治选举预测等。
KG: 文本分析面临的主要技术挑战是什么?
BL: 这完全取决于你感兴趣的任务是什么。一些任务完成得相当好,例如命名实体识别。但许多其他任务在准确性上仍需大量改进。最终的挑战是自然语言理解。尽管研究人员对此进行了长期研究,但进展并不大。目前的文本分析技术仍主要基于传统的语言学规则和统计机器学习及数据挖掘算法。这些方法仍无法实现真正的理解。由于这个问题,大多数文本分析任务的准确性仍然相对较低。
KG: 人工智能在文本分析中扮演什么角色?
BL: 高级文本分析是人工智能(AI)的一部分。机器学习和数据挖掘等其他 AI 领域的进展对文本分析产生了重大影响。我会说,过去二十年文本分析的主要进展来自于更好的机器学习技术。
KG: 是否有许多人对文本分析存在误解或错误认识?
BL: 在学术界,我没有发现关于文本分析的重大误解或误解。我对行业情况不太确定。我所知道的唯一一点是,人们对文本分析可能有非常高的期望,但如果你想做得好且准确,这是一个非常具有挑战性的问题。
KG: 最后,展望十年后,你认为文本分析将能做到现在无法做到的哪些事情?是否有一些事情在可预见的未来对于文本分析来说是不可能实现的?
BL: 让我们讨论自然语言处理,而不是文本分析,因为高级文本分析需要自然语言处理。随着深度学习等机器学习技术的发展,我们肯定会看到更好的文本分析算法,准确性远超我们今天能实现的水平。但在可预见的未来,像我们人类那样理解自然语言是非常不可能的,因为自然语言具有高度的抽象性。我们写的每一句话背后都有大量的常识知识,我们假设读者是知道这些知识的。显然,计算机程序并不知道这些知识。学习、表示和推理常识知识是一个主要的挑战。
KG: 谢谢你,Bing!
这篇文章最初发表于 GreenBook 2017 年 1 月 24 日。
Kevin Gray 是 Cannon Gray 的总裁,Cannon Gray 是一家市场科学与分析咨询公司。
Bing Liu 是伊利诺伊大学芝加哥分校(UIC)的计算机科学终身教授。他在爱丁堡大学获得人工智能博士学位,并且是情感分析和意见挖掘、机器学习及相关主题的多本书籍和文章的作者。
相关内容:
-
自然语言处理关键术语解释
-
文本挖掘亚马逊手机评论:有趣的见解
-
贝叶斯基础解释
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
该主题的更多信息
文本分类与嵌入可视化,使用 LSTMs、CNNs 和预训练词向量
原文:
www.kdnuggets.com/2018/07/text-classification-lstm-cnn-pre-trained-word-vectors.html
评论
由Sabber Ahamed,计算地球物理学家和机器学习爱好者
编辑注释: 本文总结了该系列中目前已发布的 3 篇文章,而第四篇最终篇章即将发布。
在本教程中,我对Yelp round-10 评论数据集进行了分类。这些评论包含大量可以挖掘的元数据,用于推断意义、业务属性和情感。为了简单起见,我将评论分为两类:正面或负面。星级高于三的评论被认为是正面的,而星级小于或等于 3 的评论则为负面。因此,这个问题是一个监督学习问题。为了构建和训练模型,我首先清理文本并将其转换为序列。每条评论的字数限制为 50 个单词。结果是,少于 50 个单词的短文本会用零填充,而较长的文本则会被截断。在处理完评论后,我用三种不同的方法训练了三个模型,并获得了三种词嵌入。
在这一部分,我构建了一个神经网络,使用 LSTM 和词嵌入在分类问题上进行训练。
网络从一个嵌入层开始。这个层允许系统将每个标记扩展为更大的向量,使得网络能够以有意义的方式表示一个词。该层的第一个参数是 20000,即我们的词汇表大小,第二个参数是 100,即嵌入的维度。第三个参数是 50,即每个评论序列的长度。
第二部分:使用 CNN、LSTM 进行文本分类并可视化词嵌入
在这一部分,我在 LSTM 层上添加了一个额外的 1D 卷积层,以减少训练时间。
LSTM 模型表现良好。然而,训练三个 epoch 的时间非常长。加快训练速度的一种方法是通过增加“卷积”层来改进网络。卷积神经网络(CNN)起源于图像处理。它们在数据上应用“滤波器”并计算更高层次的表示。尽管 CNN 没有 LSTM 的序列处理能力,但它们在文本处理上表现出意外的好效果。
第三部分:使用 CNN、LSTM 和预训练 Glove 词嵌入进行文本分类
在第三部分中,我使用与第二部分相同的网络架构,但使用预训练的 100 维 Glove 词嵌入作为初始输入。
在这一小节中,我想使用预训练的 Glove 词嵌入。它是在一个包含十亿个标记(单词)和 40 万个单词词汇的数据集上训练的。Glove 提供了包括 50、100、200 和 300 维的嵌入向量。我选择了 100 维的版本。我还希望看到模型的表现,假设学习到的单词权重没有更新。因此,我将模型的可训练属性设置为 False。
第四部分:(尚未发布)
在第四部分中,我使用 word2vec 学习词嵌入。
简介:Sabber Ahamed 是 xoolooloo.com 的创始人。计算地球物理学家和机器学习爱好者。
相关:
-
自然语言处理精华:NLP 入门
-
关于神经网络和词嵌入在自然语言处理中的贡献
-
使用深度卷积神经网络检测讽刺
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 为你的组织提供 IT 支持
更多相关内容
什么是文本分类?

什么是文本分类?
文本分类是将文本分类到一个或多个不同类别中的过程,以组织、结构化和过滤任何参数。例如,文本分类用于法律文件、医学研究和文件,甚至是简单的产品评论。数据比以往任何时候都重要;公司在努力提取尽可能多的洞察力上花费了巨额资金。
由于文本/文档数据比其他数据类型更加丰富,因此利用它们的新方法是必需的。由于数据本质上是非结构化和极其丰富的,将数据组织成易于理解的方式可以极大地提高其价值。使用机器学习进行文本分类可以以更快、更经济的方式自动结构化相关文本。
我们将定义文本分类、其工作原理、一些最知名的算法,并提供可能帮助你开始文本分类之旅的数据集。
为什么使用机器学习文本分类?
-
规模:手动数据录入、分析和组织繁琐且缓慢。机器学习允许进行自动分析,无论数据集大小如何,都能适用。
-
一致性:由于疲劳和对数据集材料的麻木,人为错误会发生。机器学习通过算法的无偏见性和一致性提高了可扩展性,并显著提高了准确性。
-
速度:数据有时需要快速访问和组织。机器学习算法可以解析数据,以便以易于消化的方式提供信息。
开始使用 6 个通用步骤

一些基本方法可以在一定程度上对不同的文本文档进行分类,但最常用的方法涉及机器学习。文本分类模型在部署之前会经历六个基本步骤。
1. 提供高质量的数据集
数据集是用于为我们的模型提供数据源的原始数据块。在文本分类的情况下,使用的是监督式机器学习算法,从而为我们的机器学习模型提供标记数据。标记数据是为我们的算法预定义的,并附有信息标签的数据。
2. 过滤和处理数据
由于机器学习模型只能理解数值,因此将提供的文本进行分词和词嵌入是模型正确识别数据所必需的。
分词是将文本文档拆分为称为令牌的更小片段的过程。令牌可以表示为整个单词、子单词或单个字符。例如,对“work smarter”进行分词可以这样做:
-
令牌词:Smarter
-
令牌子词:Smart-er
-
令牌字符:S-m-a-r-t-e-r
词元化很重要,因为文本分类模型只能处理基于词元的数据,无法理解和处理完整的句子。进一步处理给定的原始数据集将有助于我们的模型轻松消化给定的数据。移除不必要的特征,过滤掉空值和无限值等。对整个数据集进行洗牌有助于在训练阶段防止任何偏差。
3. 将数据集拆分为训练集和测试集
我们希望在数据集的 80%上训练我们的数据,同时保留 20%的数据集以测试算法的准确性。
4. 训练算法
通过使用训练数据集运行我们的模型,算法可以通过识别隐藏的模式和洞察,将提供的文本分类到不同的类别中。
5. 测试和检查模型的性能
接下来,使用步骤 3 中提到的测试数据集测试模型的完整性。测试数据集将是未标记的,用于测试模型的准确性与实际结果的对比。为了准确测试模型,测试数据集必须包含新的测试案例(与之前的训练数据集不同的数据),以避免过拟合我们的模型。
6. 调整模型
通过调整模型的不同超参数来调整机器学习模型,避免过拟合或产生高方差。超参数是控制模型学习过程的参数。你现在准备好进行部署了!
文本分类是如何工作的?
词嵌入
在前面提到的过滤过程中,机器学习和深度学习算法只能理解数值,这迫使我们对数据集进行一些词嵌入技术。词嵌入是将词表示为实值向量的过程,这些向量可以编码给定词的含义。
-
Word2Vec:一种由 Google 开发的无监督词嵌入方法。它利用神经网络从大型文本数据集中学习。顾名思义,Word2Vec 方法将每个词转换为一个给定的向量。
-
GloVe:也称为全局向量,是一种无监督的机器学习模型,用于获取词的向量表示。类似于 Word2Vec 方法,GloVe 算法将词映射到有意义的空间中,其中词与词之间的距离与语义相似性相关。
-
TF-IDF:是词频-逆文档频率的缩写,TF-IDF 是一种词嵌入算法,用于评估词在给定文档中的重要性。TF-IDF 为每个词分配一个得分,以表示它在一组文档中的重要性。
文本分类算法
这里是三种最著名和有效的文本分类算法。请记住,每种方法中都包含了进一步定义的算法。
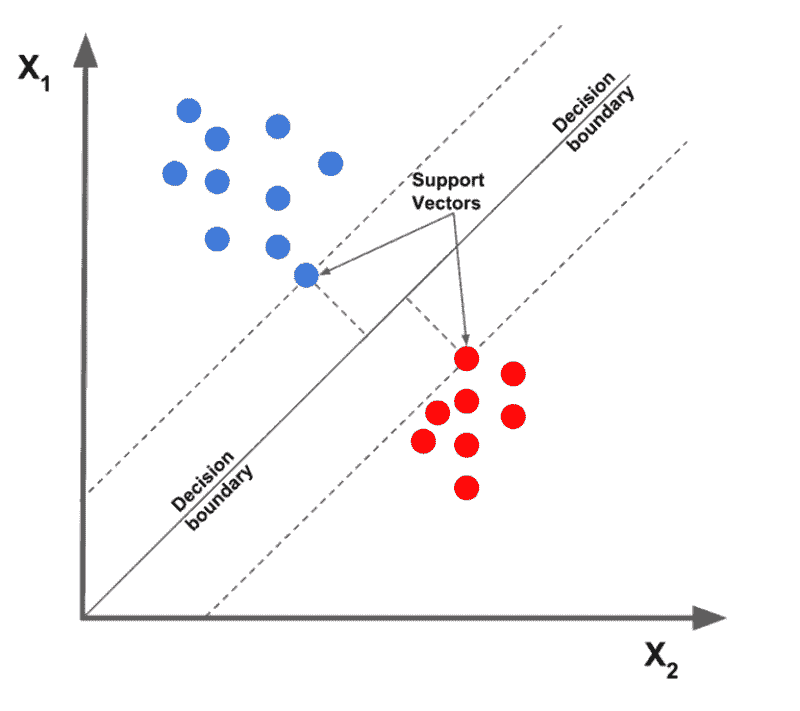
1. 线性支持向量机
被认为是最好的文本分类算法之一,线性支持向量机算法将给定数据点根据其提供的特征进行绘制,然后绘制最佳拟合线,将数据分割并分类到不同的类别中。
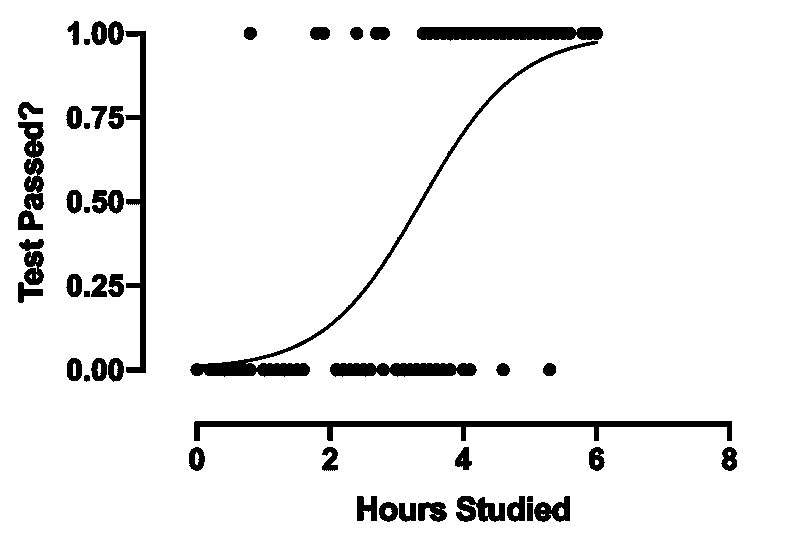
2. 逻辑回归
逻辑回归是回归的一个子类,主要关注分类问题。它使用决策边界、回归和距离来评估和分类数据集。
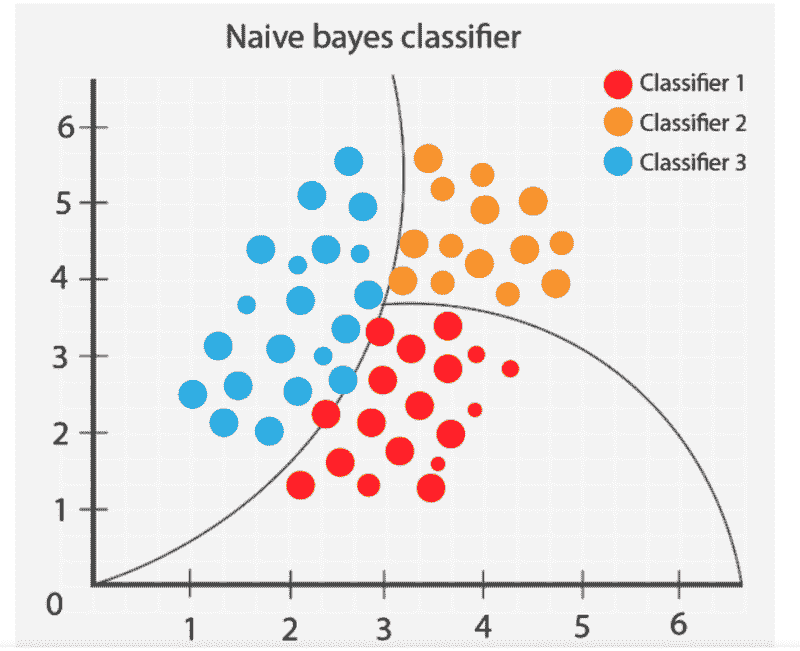
3. 朴素贝叶斯
朴素贝叶斯算法根据提供的特征对不同的对象进行分类。然后它绘制组边界,以推断这些组分类,以解决和进一步分类。
设置文本分类时需要避免的事项
数据过度拥挤
向算法提供低质量的数据会导致未来的预测不佳。然而,机器学习从业者常见的一个问题是将过于详细的数据集喂入训练模型,其中包括不必要的特征。用无关数据填充数据可能会导致模型性能下降。在选择和组织数据集时,少即是多。
错误的训练与测试数据比例会严重影响模型的性能,并影响数据的混洗和过滤。拥有不受其他不必要因素影响的精确数据点,可以使训练模型更高效地执行。
在训练模型时选择符合模型要求的数据集,过滤掉不必要的值,混洗数据集,并测试最终模型的准确性。更简单的算法消耗的计算时间和资源更少;最佳模型是那些能够解决复杂问题的最简单模型。
过拟合与欠拟合
模型的准确率在训练达到峰值后,会随着训练的继续而逐渐下降。这被称为过拟合;模型开始学习意图之外的模式,因为训练时间过长。在训练集上达到高准确率时要小心,因为主要目标是开发其准确率基于测试集(模型未见过的数据)的模型。
另一方面,欠拟合是指训练模型仍有改进空间,尚未达到其最大潜力。训练不充分的模型可能是由于训练时间过短或对数据集过度正则化。这说明了拥有简洁而精确数据的重要性。
在训练模型时找到最佳点至关重要。将数据集分割为 80/20 是一个好的开始,但调整参数可能是你的具体模型所需的,以达到最佳性能。
错误的文本格式
虽然在本文中没有过多提及,但为文本分类问题使用正确的文本格式将带来更好的结果。一些表示文本数据的方法包括GloVe、Word2Vec和嵌入模型。
使用正确的文本格式将改善模型读取和解释数据集的方式,从而帮助其理解模式。
文本分类应用
-
过滤垃圾邮件: 通过搜索特定的关键词,可以将电子邮件分类为有用或垃圾邮件。
-
文本分类: 通过使用文本分类,应用程序可以将不同的项目(文章、书籍等)分类到不同的类别中,方法是对相关文本(如项目名称、描述等)进行分类。使用这种技术可以改善用户体验,因为它使用户在数据库中浏览变得更加容易。
-
识别仇恨言论: 某些社交媒体公司使用文本分类来检测和禁用带有冒犯性言辞的评论或帖子,例如禁止在多人儿童游戏中输入任何形式的脏话。
-
市场营销与广告: 通过了解用户对特定产品的反应,公司可以进行具体的调整以满足客户需求。它还可以根据用户对类似产品的评论推荐某些产品。文本分类算法可以与推荐系统结合使用,推荐系统是许多在线网站用来获取回头客的深度学习算法之一。
流行的文本分类数据集
由于有大量标记好且可直接使用的数据集,你总能找到与模型要求匹配的完美数据集。
虽然在选择使用哪个数据集时可能会遇到一些问题,但在接下来的部分中,我们将推荐一些最著名的公共数据集。
像 Kaggle 这样的网站提供了各种涵盖所有主题的数据集。试着在上述提到的数据集上运行你的模型以进行实践!
机器学习中的文本分类
随着机器学习在过去十年里产生了巨大的影响,各家公司都在尝试各种方法利用机器学习来自动化流程。评论、评论、帖子、文章、期刊和文档都在文本中具有无价的价值。利用文本分类以多种创造性方式提取用户洞察和模式,公司可以做出有数据支持的决策;专业人员可以比以往更快地获得和学习有价值的信息。
Kevin Vu 管理 Exxact Corp 博客,并与许多撰写有关深度学习不同方面的才华横溢的作者合作。
原文。已获许可转载。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关话题
文本聚类:从非结构化数据中快速获得洞察,第二部分
原文:
www.kdnuggets.com/2017/07/text-clustering-unstructured-data-part2.html
评论
由 Vivek Kalyanarangan 提供。

在这两部分系列中,我们将探讨文本聚类以及如何从非结构化数据中获得洞察。它将非常强大且具备工业级别的力量。第一部分将关注动机,第二部分将讨论实施。
本文是关于如何使用文本聚类从非结构化数据中获得洞察的两部分系列的第二部分。我们将以非常模块化的方式构建它,以便可以应用于任何数据集。此外,我们还将专注于将功能暴露为 API,以便它可以作为即插即用的模型,而不会对现有系统造成干扰。
-
文本聚类:如何从非结构化数据中快速获得洞察——第一部分:动机
-
文本聚类:如何从非结构化数据中快速获得洞察——第二部分:实施
如果你很急,你可以在我的 Github 页面 找到完整的项目代码
这只是最终输出效果的预览——

安装
-
Anaconda Python 2.7 发行版——从这里下载
-
flask API python 包——安装 anaconda 后,打开命令提示符并输入
pip install flask -
flasgger python 包——安装 anaconda 和 flask 后,打开命令提示符并输入
pip install flasgger
现在你已经准备好工具了。点击这里下载代码以开始设置。
运行中
解压缩内容,打开命令提示符并输入
python CLAAS_public.py
服务器将启动,你现在可以在此位置访问工具——localhost:8180/apidocs/index.html
工作流程
无指导聚类
这就是实际进行 KMeans 聚类的地方。
-
它需要一个 CSV 文件作为输入。此外,你还需要输入包含非结构化文本的列名和集群数量
-
一旦你点击“尝试一下”按钮,输入将由 API 使用
-
API 进行文本清理、Tfidf 向量化和聚类
-
一旦完成,它会提供一个下载链接,附加一个包含集群编号的额外列
有指导的聚类
就这项技术而言,它要简单一些。
-
它需要两个文件作为输入,一个是要聚类的数据文件,另一个是预定义的关键词
-
此外,它需要与无指导聚类等效的列名称
-
输出会为每个给定的关键词添加额外的列
-
如果文档包含该词,则为 TRUE,否则为 FALSE
这可以感知文档中关键字的存在/缺失,指示哪些文档包含关键字信号,哪些文档不包含。
结论
这就是关于文本聚类的多系列内容的全部。这样就足够开始了,对吧?撰写这一系列内容是一次很棒的体验。下一部分见。玩得开心!
原文。经许可转载。
简介: Vivek Kalyanarangan 是一名数据科学家,关注医疗领域的问题。
相关:
-
文本聚类:从非结构化数据中快速获得见解
-
K-means 聚类与 Tableau – 呼叫详细记录示例
-
从零开始的 Python 机器学习工作流程 第二部分:k-means 聚类
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT
更多相关主题
文本数据预处理:Python 实战指南
原文:
www.kdnuggets.com/2018/03/text-data-preprocessing-walkthrough-python.html
评论
在之前的一对帖子中,我们首先讨论了一个 处理文本数据科学任务的框架,接着讨论了 文本数据预处理的一般方法。这篇文章将作为使用一些常见 Python 工具进行文本数据预处理任务的实用指南。
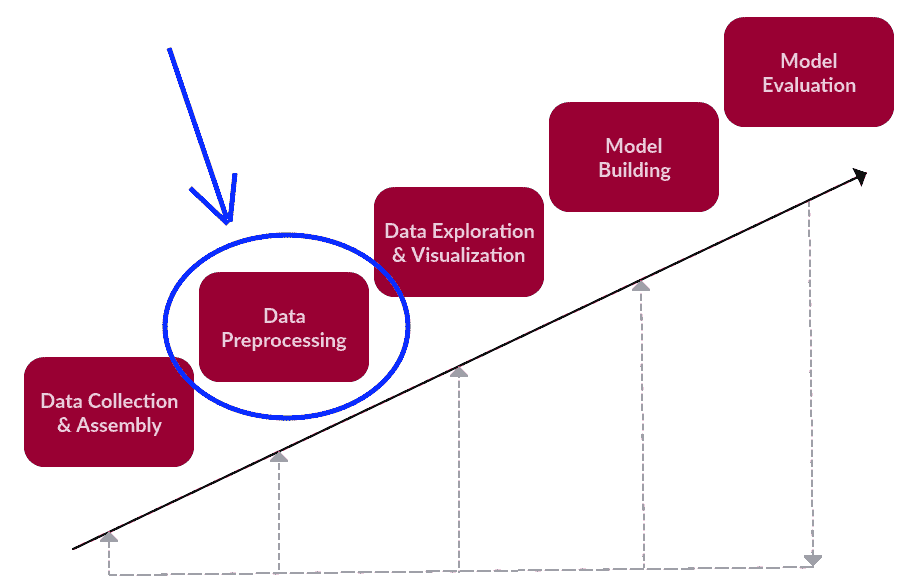
在文本数据科学框架的背景下进行预处理。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 部门
我们的目标是从我们将描述的文本块(不要与文本块化混淆),一个冗长的未处理单一字符串,开始,最后得到一个(或几个)清理后的标记列表,这些标记将对进一步的文本挖掘和/或自然语言处理任务有用。
首先我们从导入开始。
除了标准的 Python 库,我们还使用以下库:
-
NLTK - 自然语言工具包是 Python 生态系统中最知名和最常用的 NLP 库之一,适用于从标记化、词干提取到词性标注等各种任务
-
BeautifulSoup - BeautifulSoup 是一个用于从 HTML 和 XML 文档中提取数据的有用库
-
Inflect - 这是一个简单的库,用于完成生成复数、单数名词、序数词和不定冠词等自然语言相关任务,以及(最吸引我们的是)将数字转换为单词
-
Contractions - 另一个简单的库,仅用于扩展缩写词
如果你已安装 NLTK,但需要下载其任何额外的数据,请查看这里。
我们需要一些示例文本。我们将从非常小且人为的数据开始,以便能够一步步清楚地看到我们所做的结果。
确实是一个玩具数据集,但不要误解;我们在这里进行的数据预处理步骤是完全可迁移的。
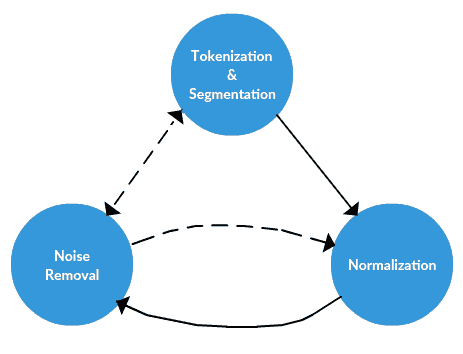
文本数据预处理框架。
噪声移除
我们可以将噪声移除大致定义为经常在分词前进行的文本特定标准化任务。我认为,尽管预处理框架的其他两个主要步骤(分词和标准化)基本上与任务无关,但噪声移除则更具任务特定性。
样本噪声移除任务可能包括:
-
移除文本文件头部和尾部
-
移除 HTML、XML 等标记和元数据
-
从其他格式(如 JSON)中提取有价值的数据
如你所想,噪声移除与数据收集和组装之间的界限一方面是模糊的,而噪声移除与标准化之间的界限另一方面也较为模糊。考虑到与特定文本及其收集和组装的紧密关系,许多去噪任务,如解析 JSON 结构,显然需要在分词之前实现。
在我们的数据预处理管道中,我们将利用 BeautifulSoup 库去除 HTML 标记,并使用正则表达式去除开放和关闭的双括号及其之间的内容(我们根据样本文本假设这是必要的)。
虽然在此阶段进行分词前并不是强制性操作(你会发现这一点是相对灵活的文本数据预处理任务顺序的常态),但在此时将缩写词替换为其扩展形式可能是有益的,因为我们的分词器将把像“didn't”这样的单词拆分为“did”和“n't”。虽然在后续阶段解决这一分词问题并非不可能,但提前处理会使其更简单直接。
这是我们样本文本去噪的结果。
Title Goes Here
Bolded Text
Italicized Text
But this will still be here!
I run. He ran. She is running. Will they stop running?
I talked. She was talking. They talked to them about running. Who ran to the talking runner?
¡Sebastián, Nicolás, Alejandro and Jéronimo are going to the store tomorrow morning!
something... is! wrong() with.,; this :: sentence.
I cannot do this anymore. I did not know them. Why could not you have dinner at the restaurant?
My favorite movie franchises, in order: Indiana Jones; Marvel Cinematic Universe; Star Wars; Back to the Future; Harry Potter.
do not do it.... Just do not. Billy! I know what you are doing. This is a great little house you have got here.
John: "Well, well, well."
James: "There, there. There, there."
There are a lot of reasons not to do this. There are 101 reasons not to do it. 1000000 reasons, actually.
I have to go get 2 tutus from 2 different stores, too.
22 45 1067 445
{{Here is some stuff inside of double curly braces.}}
{Here is more stuff in single curly braces.}
分词
分词是将较长的文本字符串拆分为更小的片段或词元的步骤。较大的文本块可以分词为句子,句子可以分词为单词等。通常在文本被适当地分词后会进行进一步处理。分词也称为文本分割或词汇分析。有时分割用来指代将大块文本拆分为比单词更大的片段(例如段落或句子),而分词则专指仅拆分为单词的过程。
对于我们的任务,我们将把样本文本分词为单词列表。这是通过 NLTK 的 word_tokenize() 函数完成的。
这是我们的单词词元:
['Title', 'Goes', 'Here', 'Bolded', 'Text', 'Italicized', 'Text', 'But', 'this', 'will', 'still',
'be', 'here', '!', 'I', 'run', '.', 'He', 'ran', '.', 'She', 'is', 'running', '.', 'Will', 'they',
'stop', 'running', '?', 'I', 'talked', '.', 'She', 'was', 'talking', '.', 'They', 'talked', 'to', 'them',
'about', 'running', '.', 'Who', 'ran', 'to', 'the', 'talking', 'runner', '?', '¡Sebastián', ',',
'Nicolás', ',', 'Alejandro', 'and', 'Jéronimo', 'are', 'going', 'tot', 'he', 'store', 'tomorrow',
'morning', '!', 'something', '...', 'is', '!', 'wrong', '(', ')', 'with.', ',', ';', 'this', ':', ':',
'sentence', '.', 'I', 'can', 'not', 'do', 'this', 'anymore', '.', 'I', 'did', 'not', 'know', 'them', '.',
'Why', 'could', 'not', 'you', 'have', 'dinner', 'at', 'the', 'restaurant', '?', 'My', 'favorite',
'movie', 'franchises', ',', 'in', 'order', ':', 'Indiana', 'Jones', ';', 'Star', 'Wars', ';', 'Marvel',
'Cinematic', 'Universe', ';', 'Back', 'to', 'the', 'Future', ';', 'Harry', 'Potter', '.', 'do', 'not',
'do', 'it', '...', '.', 'Just', 'do', 'not', '.', 'Billy', '!', 'I', 'know', 'what', 'you', 'are',
'doing', '.', 'This', 'is', 'a', 'great', 'little', 'house', 'you', 'have', 'got', 'here', '.', 'John',
':', '``', 'Well', ',', 'well', ',', 'well', '.', "''", 'James', ':', '``', 'There', ',', 'there', '.',
'There', ',', 'there', '.', "''", 'There', 'are', 'a', 'lot', 'of', 'reasons', 'not', 'to', 'do', 'this',
'.', 'There', 'are', '101', 'reasons', 'not', 'to', 'do', 'it', '.', '1000000', 'reasons', ',',
'actually', '.', 'I', 'have', 'to', 'go', 'get', '2', 'tutus', 'from', '2', 'different', 'stores', ',',
'too', '.', '22', '45', '1067', '445', '{', '{', 'Here', 'is', 'some', 'stuff', 'inside', 'of', 'double',
'curly', 'braces', '.', '}', '}', '{', 'Here', 'is', 'more', 'stuff', 'in', 'single', 'curly', 'braces',
'.', '}']
标准化
标准化通常指一系列相关任务,旨在使所有文本处于同一水平:将所有文本转换为相同的大小写(大写或小写),去除标点符号,将数字转换为其单词等价形式,等等。标准化使所有单词处于平等地位,并允许处理以统一的方式进行。
文本归一化可以包含多个任务,但对于我们的框架,我们将归一化分为三个不同的步骤:(1) 词干化,(2) 词形还原,以及 (3) 其他所有操作。有关这些不同步骤的具体信息,请参阅这篇文章。
请记住,在标记化之后,我们不再处理文本级别的数据,而是转向词级别。我们下面展示的归一化函数反映了这一点。函数名称和注释应提供每个函数的必要信息。
调用归一化函数后:
['title', 'goes', 'bolded', 'text', 'italicized', 'text', 'still', 'run', 'ran', 'running', 'stop',
'running', 'talked', 'talking', 'talked', 'running', 'ran', 'talking', 'runner', 'sebastian', 'nicolas',
'alejandro', 'jeronimo', 'going', 'store', 'tomorrow', 'morning', 'something', 'wrong', 'sentence',
'anymore', 'know', 'could', 'dinner', 'restaurant', 'favorite', 'movie', 'franchises', 'order',
'indiana', 'jones', 'marvel', 'cinematic', 'universe', 'star', 'wars', 'back', 'future', 'harry',
'potter', 'billy', 'know', 'great', 'little', 'house', 'got', 'john', 'well', 'well', 'well', 'james',
'lot', 'reasons', 'one hundred and one', 'reasons', 'one million', 'reasons', 'actually', 'go', 'get',
'two', 'tutus', 'two', 'different', 'stores', 'twenty-two', 'forty-five', 'one thousand and sixty-seven',
'four hundred and forty-five', 'stuff', 'inside', 'double', 'curly', 'braces', 'stuff', 'single',
'curly', 'braces']
调用词干化和词形还原函数如下所示:
这会产生两个新的列表:一个是词干化的标记,另一个是与动词相关的词形还原标记。根据你即将进行的 NLP 任务或偏好,这其中一个可能比另一个更合适。有关词形还原与词干化的讨论,请参见此处。
Stemmed:
['titl', 'goe', 'bold', 'text', 'it', 'text', 'stil', 'run', 'ran', 'run', 'stop', 'run', 'talk',
'talk', 'talk', 'run', 'ran', 'talk', 'run', 'sebast', 'nicola', 'alejandro', 'jeronimo', 'going',
'stor', 'tomorrow', 'morn', 'someth', 'wrong', 'sent', 'anym', 'know', 'could', 'din', 'resta',
'favorit', 'movy', 'franch', 'ord', 'indian', 'jon', 'marvel', 'cinem', 'univers', 'star', 'war', 'back',
'fut', 'harry', 'pot', 'bil', 'know', 'gre', 'littl', 'hous', 'got', 'john', 'wel', 'wel', 'wel', 'jam',
'lot', 'reason', 'one hundred and on', 'reason', 'one million', 'reason', 'act', 'go', 'get', 'two',
'tut', 'two', 'diff', 'stor', 'twenty-two', 'forty-five', 'one thousand and sixty-seven', 'four hundred
and forty-five', 'stuff', 'insid', 'doubl', 'cur', 'brac', 'stuff', 'singl', 'cur', 'brac']
Lemmatized:
['title', 'go', 'bolded', 'text', 'italicize', 'text', 'still', 'run', 'run', 'run', 'stop', 'run',
'talk', 'talk', 'talk', 'run', 'run', 'talk', 'runner', 'sebastian', 'nicolas', 'alejandro', 'jeronimo',
'go', 'store', 'tomorrow', 'morning', 'something', 'wrong', 'sentence', 'anymore', 'know', 'could',
'dinner', 'restaurant', 'favorite', 'movie', 'franchise', 'order', 'indiana', 'jones', 'marvel',
'cinematic', 'universe', 'star', 'war', 'back', 'future', 'harry', 'potter', 'billy', 'know', 'great',
'little', 'house', 'get', 'john', 'well', 'well', 'well', 'jam', 'lot', 'reason', 'one hundred and one',
'reason', 'one million', 'reason', 'actually', 'go', 'get', 'two', 'tutus', 'two', 'different', 'store',
'twenty-two', 'forty-five', 'one thousand and sixty-seven', 'four hundred and forty-five', 'stuff',
'inside', 'double', 'curly', 'brace', 'stuff', 'single', 'curly', 'brace']
这就是使用 Python 对一段文本进行简单数据预处理的过程。我建议你对一些额外的文本执行这些任务以验证结果。我们将使用相同的过程来清理下一任务的文本数据,在此任务中,我们将进行实际的 NLP 任务,而不是花时间准备数据以进行这样的实际任务。
相关:
-
文本数据预处理的通用方法
-
处理文本数据科学任务的框架
-
自然语言处理关键术语解释
更多相关内容
文本挖掘 101:从简历中挖掘信息
原文:
www.kdnuggets.com/2017/05/text-mining-information-resume.html
作者:Yogesh H. Kulkarni

摘要
本文展示了一个从文本简历中挖掘相关实体的框架。它展示了如何实现解析逻辑与实体规范的分离。虽然这里只考虑了一个简历样本,但该框架可以进一步增强,用于不同的简历格式,以及判决书、合同、专利、医学论文等文档。
介绍
世界上大多数非结构化数据以文本形式存在。为了理解这些数据,必须要么细致地逐一阅读,要么使用某些自动化技术来提取相关信息。考虑到这些文本数据的体量、种类和速度,必须采用文本挖掘技术来提取相关信息,将非结构化数据转化为结构化形式,从而使进一步的洞察、处理、分析和可视化成为可能。
本文处理的是特定领域,即申请人简历。众所周知,简历不仅有不同的文件格式(txt、doc、pdf 等),还具有不同的内容和布局。这种异质性使得提取相关信息成为一项挑战。尽管可能无法从所有类型的格式中完全提取所有相关信息,但可以从一些已知格式中开始简单的步骤,至少提取可能的信息。
大体上有两种方法:基于语言的方法和基于机器学习的方法。在“语言”方法中,通过模式搜索来找到关键信息,而在“机器学习”方法中,则使用监督和非监督方法来提取信息。这里使用的“正则表达式”(RegEx)是“语言”基础的模式匹配方法之一。
框架
在简历中实现实体提取的一种原始方法是为每个实体在代码程序中编写模式匹配逻辑。如果模式发生任何变化,或者引入新的实体/模式,则需要更改代码程序。这使得维护变得繁琐,因为复杂性增加。为了解决这个问题,提出了一种框架,将解析逻辑与实体规范分开,如下所示。实体及其 RegEx 模式在配置文件中指定。该文件还指定了用于每种实体类型的提取方法。解析器使用这些模式按指定方法提取实体。这种分离的优点不仅是可维护性,还包括其在法律/合同、医学等其他领域的潜在使用。
实体规范
配置文件指定了要提取的实体及其模式和提取方法。它还指定了在其中查找给定实体的部分。下方文本框中显示的规范描述了元数据实体,如 Name、Phone、Email 等。提取它们的方法是“univalue_extractor”。这些实体要搜索的部分被命名为“”,这是一个非标记的部分,如简历的前几行。像 Email 或 Phone 这样的实体可以有多个正则表达式模式。如果第一个失败,则尝试第二个,依此类推。这里是所用模式的简要描述:
-
姓名:假定简历的第一行包含姓名,前面可有“Name:”前缀。
-
邮箱:是一个单词(中间可有点),然后是“@”,接着是一个单词、点,再一个单词。
-
电话:括号中的国际代码(可选),然后是 3-3-4 的数字模式,前 3 位数字可选用括号包围。对于印度号码,它可以硬编码为“+91”,如下一条所示。
-
Python 的‘etree’ ElementTree 库用于将配置 xml 解析为内部字典。
-
解析器读取这些规范的字典,并使用它从文本简历中查找实体。
-
一旦匹配到实体,它会作为节点标签存储,如 Email、Phone 等。

像上面描述的 Metadata,教育资格可以用下面的配置进行搜索:
-
解析器的方法“section_value_extractor”应当在“EducationSection”部分中使用。它通过匹配给定单词来找到部分中的值。
-
如果解析器发现任何单词,如“10^(th)”或“X”或“SSC”,那么这些就是提取的“Secondary”实体值,描述了中学教育水平。
-
如果解析器发现任何单词,如“12^(th)”或“XII”或“HSC”,那么这些就是提取的“HigherSecondary”实体值,描述了高级中学教育水平。
分段
上述代码片段中提到的部分是文本块,标记为 SummarySection、EducationSection 等。这些在配置文件的顶部进行指定。
-
方法“section_extractor”逐行解析文档并查找节标题。
-
通过用于标题的关键字来识别部分。例如,对于 SummarySection,关键字包括“Summary”、“Aim”、“Objective”等。
-
一旦找到匹配,设置“SummarySection”的状态,并将进一步的行合并到其中,直到找到下一个部分。
-
一旦新的标题匹配,下一节的新状态开始,如此继续。

结果
以下是一个样本简历:


提取的实体如下所示:
解析器的实现、配置文件及样本简历可以在github找到。
结束语
本文展示了如何从非结构化数据(如简历)中挖掘结构化信息。由于实施示例仅适用于一个样本,它可能不适用于其他格式。需要进行增强和定制,以适应其他类型的简历。除了简历,解析规范分离框架还可以用于不同领域的其他类型文档,通过指定特定领域的配置文件来实现。
 简介: Yogesh H. Kulkarni,在几何建模领域工作超过 16 年后,最近完成了博士学位。在进行博士研究期间,他进入了数据科学领域,并希望进一步从事这一领域的职业。他对文本挖掘、机器学习/深度学习充满兴趣,主要使用 Python 技术栈进行实现。他很乐意听到您对本文以及相关话题、项目、任务、机会等的看法。
简介: Yogesh H. Kulkarni,在几何建模领域工作超过 16 年后,最近完成了博士学位。在进行博士研究期间,他进入了数据科学领域,并希望进一步从事这一领域的职业。他对文本挖掘、机器学习/深度学习充满兴趣,主要使用 Python 技术栈进行实现。他很乐意听到您对本文以及相关话题、项目、任务、机会等的看法。
相关:
-
利用深度学习从职位描述中提取知识
-
理解文本分析
-
文本挖掘亚马逊手机评论:有趣的见解
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT
更多相关话题
Python 中的文本挖掘:步骤和示例
原文:
www.kdnuggets.com/2020/05/text-mining-python-steps-examples.html
评论
作者:Dhilip Subramanian,数据科学家和人工智能爱好者

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
在今天的场景中,人们的成功方式之一是通过他们如何与他人沟通和分享信息来确定的。这就是语言概念发挥作用的地方。然而,世界上有许多语言,每种语言都有不同的标准和字母,这些单词有意义地排列组合形成句子。每种语言在构建这些句子时都有自己的规则,这些规则也称为语法。
在当今世界,根据行业估算,只有 20%的数据是以结构化格式生成的,无论是我们发推文、发送 WhatsApp 消息、电子邮件、Facebook、Instagram 还是任何文本消息。大多数数据存在于文本形式中,这是一种高度非结构化的格式。为了从文本数据中提取有意义的见解,我们需要遵循一种叫做文本分析的方法。
什么是文本挖掘?
文本挖掘是从自然语言文本中提取有意义信息的过程。
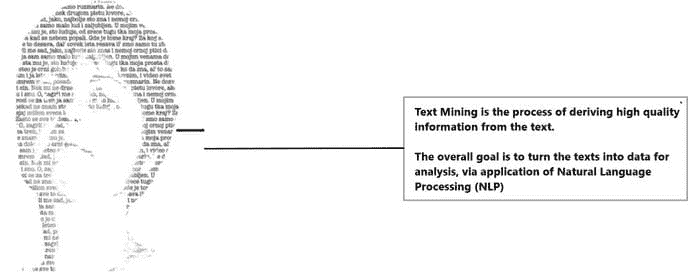
什么是自然语言处理(NLP)?
自然语言处理(NLP)是计算机科学和人工智能的一部分,处理人类语言。
换句话说,NLP 是文本挖掘的一个组成部分,执行一种特殊的语言分析,帮助机器“阅读”文本。它使用不同的方法来解码人类语言中的模糊性,包括以下内容:自动摘要、词性标注、消歧义、分块以及消歧义和自然语言理解与识别。我们将通过 Python 逐步了解所有这些过程。

首先,我们需要安装 NLTK 库,它是一个自然语言工具包,用于构建 Python 程序以处理人类语言数据,并提供易于使用的接口。
自然语言处理术语
分词
分词是自然语言处理中的第一步。它是将字符串分解成标记的过程,而标记又是较小的结构或单元。分词涉及三个步骤:将复杂句子拆分为单词,理解每个单词在句子中的重要性,最后对输入句子生成结构描述。
代码:
# Importing necessary library
import pandas as pd
import numpy as np
import nltk
import os
import nltk.corpus# sample text for performing tokenization
text = “In Brazil they drive on the right-hand side of the road. Brazil has a large coastline on the eastern
side of South America"# importing word_tokenize from nltk
from nltk.tokenize import word_tokenize# Passing the string text into word tokenize for breaking the sentences
token = word_tokenize(text)
token
输出
['In','Brazil','they','drive', 'on','the', 'right-hand', 'side', 'of', 'the', 'road', '.', 'Brazil', 'has', 'a', 'large', 'coastline', 'on', 'the', 'eastern', 'side', 'of', 'South', 'America']
从上述输出可以看出,文本被拆分成了标记。单词、逗号、标点符号都被称为标记。
在文本中查找频率差异
代码 1
# finding the frequency distinct in the tokens
# Importing FreqDist library from nltk and passing token into FreqDist
from nltk.probability import FreqDist
fdist = FreqDist(token)
fdist
输出
FreqDist({'the': 3, 'Brazil': 2, 'on': 2, 'side': 2, 'of': 2, 'In': 1, 'they': 1, 'drive': 1, 'right-hand': 1, 'road': 1, ...})
‘the’在文本中出现了 3 次,‘Brazil’出现了 2 次,等等。
代码 2
# To find the frequency of top 10 words
fdist1 = fdist.most_common(10)
fdist1
输出
[('the', 3),
('Brazil', 2),
('on', 2),
('side', 2),
('of', 2),
('In', 1),
('they', 1),
('drive', 1),
('right-hand', 1),
('road', 1)]
词干提取
词干提取通常指将单词规范化为其基本形式或根形式。
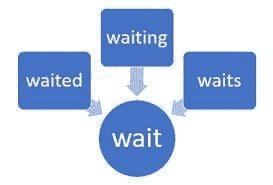
在这里,我们有单词 waited、waiting 和 waits。根词是‘wait’。词干提取有两种方法,即 Porter 词干提取(去除单词的常见形态和屈折结尾)和 Lancaster 词干提取(更激进的词干提取算法)。
代码 1
# Importing Porterstemmer from nltk library
# Checking for the word ‘giving’
from nltk.stem import PorterStemmer
pst = PorterStemmer()
pst.stem(“waiting”)
输出
'wait'
代码 2
# Checking for the list of words
stm = ["waited", "waiting", "waits"]
for word in stm :
print(word+ ":" +pst.stem(word))
输出
waited:wait
waiting:wait
waits:wait
代码 3
# Importing LancasterStemmer from nltk
from nltk.stem import LancasterStemmer
lst = LancasterStemmer()
stm = [“giving”, “given”, “given”, “gave”]
for word in stm :
print(word+ “:” +lst.stem(word))
输出
giving:giv
given:giv
given:giv
gave:gav
Lancaster 比 Porter 词干提取器更激进
词形还原
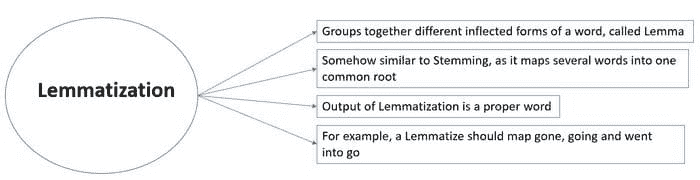
简单来说,这是一种将单词转换为其基本形式的过程。词干提取和词形还原的区别在于,词形还原考虑上下文,将单词转换为其有意义的基本形式,而词干提取只是去掉最后几个字符,通常导致错误的含义和拼写错误。
例如,词形还原会正确地将‘caring’的基本形式识别为‘care’,而词干提取则会去掉‘ing’部分,将其转换为 car。
词形还原可以通过使用 Wordnet Lemmatizer、Spacy Lemmatizer、TextBlob、Stanford CoreNLP 在 Python 中实现。
代码
# Importing Lemmatizer library from nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(“rocks :”, lemmatizer.lemmatize(“rocks”))
print(“corpora :”, lemmatizer.lemmatize(“corpora”))
输出
rocks : rock
corpora : corpus
停用词
“停用词”是语言中最常见的词汇,如“the”、“a”、“at”、“for”、“above”、“on”、“is”、“all”。这些词没有提供任何实际意义,通常会从文本中删除。我们可以使用 nltk 库来删除这些停用词。
代码
# importing stopwors from nltk library
from nltk import word_tokenize
from nltk.corpus import stopwords
a = set(stopwords.words(‘english’))text = “Cristiano Ronaldo was born on February 5, 1985, in Funchal, Madeira, Portugal.”
text1 = word_tokenize(text.lower())
print(text1)stopwords = [x for x in text1 if x not in a]
print(stopwords)
输出
Output of text:
['cristiano', 'ronaldo', 'was', 'born', 'on', 'february', '5', ',', '1985', ',', 'in', 'funchal', ',', 'madeira', ',', 'portugal', '.']Output of stopwords:
['cristiano', 'ronaldo', 'born', 'february', '5', ',', '1985', ',', 'funchal', ',', 'madeira', ',', 'portugal', '.']
词性标注(POS)

词性标注用于为给定文本中的每个单词分配词性(如名词、动词、代词、副词、连词、形容词、感叹词),根据其定义和上下文。有许多可用的 POS 标注工具,其中一些广泛使用的标注工具有 NLTK、Spacy、TextBlob、Standford CoreNLP 等。
代码
text = “vote to choose a particular man or a group (party) to represent them in parliament”
#Tokenize the text
tex = word_tokenize(text)
for token in tex:
print(nltk.pos_tag([token]))
输出
[('vote', 'NN')]
[('to', 'TO')]
[('choose', 'NN')]
[('a', 'DT')]
[('particular', 'JJ')]
[('man', 'NN')]
[('or', 'CC')]
[('a', 'DT')]
[('group', 'NN')]
[('(', '(')]
[('party', 'NN')]
[(')', ')')]
[('to', 'TO')]
[('represent', 'NN')]
[('them', 'PRP')]
[('in', 'IN')]
[('parliament', 'NN')]
命名实体识别
这是检测命名实体的过程,如人名、地点名、公司名、数量和货币值。
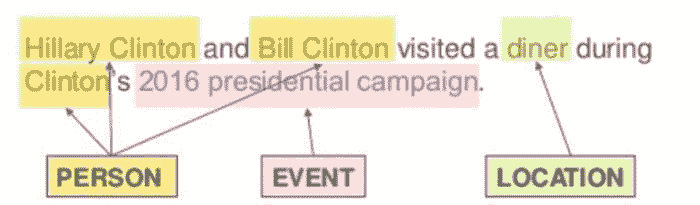
参考:Sujit Pal
代码
text = “Google’s CEO Sundar Pichai introduced the new Pixel at Minnesota Roi Centre Event”#importing chunk library from nltk
from nltk import ne_chunk# tokenize and POS Tagging before doing chunk
token = word_tokenize(text)
tags = nltk.pos_tag(token)
chunk = ne_chunk(tags)
chunk
输出
Tree('S', [Tree('GPE', [('Google', 'NNP')]), ("'s", 'POS'), Tree('ORGANIZATION', [('CEO', 'NNP'), ('Sundar', 'NNP'), ('Pichai', 'NNP')]), ('introduced', 'VBD'), ('the', 'DT'), ('new', 'JJ'), ('Pixel', 'NNP'), ('at', 'IN'), Tree('ORGANIZATION', [('Minnesota', 'NNP'), ('Roi', 'NNP'), ('Centre', 'NNP')]), ('Event', 'NNP')])
词组分析
词块化是指提取单独的信息片段并将其分组为更大的块。在自然语言处理(NLP)和文本挖掘的背景下,词块化是将词语或标记分组为块。
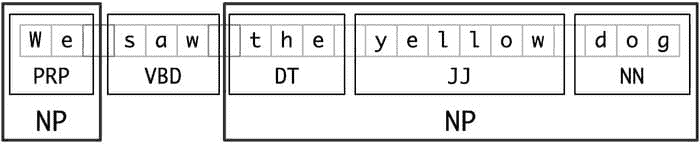
参考: nltk.org
代码
text = “We saw the yellow dog”
token = word_tokenize(text)
tags = nltk.pos_tag(token)reg = “NP: {<DT>?<JJ>*<NN>}”
a = nltk.RegexpParser(reg)
result = a.parse(tags)
print(result)
输出
(S We/PRP saw/VBD (NP the/DT yellow/JJ dog/NN))
本博客总结了文本预处理,并涵盖了包括分词、词干提取、词形还原、词性标注、命名实体识别和词块化在内的 NLTK 步骤。
感谢阅读。继续学习,敬请关注更多内容!
参考:
-
www.expertsystem.com/natural-language-processing-and-text-mining/ -
www.geeksforgeeks.org/nlp-chunk-tree-to-text-and-chaining-chunk-transformation/ -
www.geeksforgeeks.org/part-speech-tagging-stop-words-using-nltk-python/
简介: Dhilip Subramanian 是一名机械工程师,已获得分析学硕士学位。他拥有 9 年的数据相关领域经验,专注于 IT、市场营销、银行、电力和制造业。他对自然语言处理(NLP)和机器学习充满热情。他是SAS 社区的贡献者,并在 Medium 平台上撰写有关数据科学各个方面的技术文章。
原文。经许可转载。
相关:
-
使用 TensorFlow 和 Keras 进行分词和文本数据准备
-
五款酷炫的 Python 数据科学库
-
自然语言处理食谱:最佳实践和示例
更多相关话题
关于 NLP 和机器学习的文本预处理,你需要知道的一切
原文:
www.kdnuggets.com/2019/04/text-preprocessing-nlp-machine-learning.html
评论
作者 Kavita Ganesan,数据科学家。
根据最近的一些对话,我意识到文本预处理是一个严重被忽视的话题。我谈到的几个人提到他们的 NLP 应用出现了不一致的结果,结果发现他们没有预处理文本或使用了不适合项目的文本预处理方法。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
考虑到这一点,我想澄清一下什么是文本预处理,文本预处理的不同方法,以及如何估计你可能需要多少预处理。对于感兴趣的人,我还提供了一些文本预处理代码片段供你尝试。现在,让我们开始吧!
什么是文本预处理?
对文本进行预处理只是将文本转化为对你的任务可预测和可分析的形式。这里的任务是方法和领域的组合。例如,从推文(领域)中提取顶级关键词(方法)就是一个任务的例子。
任务 = 方法 + 领域
一个任务的理想预处理可能会变成另一个任务的噩梦。因此,请注意:文本预处理不能直接从任务到任务转移。
让我们举一个非常简单的例子,假设你正在尝试发现新闻数据集中常用的词汇。如果你的预处理步骤包括删除停用词,因为其他任务使用了它,那么你可能会错过一些常见词汇,因为你已经删除了它。所以,实际上,它并不是一个一刀切的方法。
文本预处理技术类型
有不同的方法来预处理文本。以下是一些你应该了解的方法,我会尝试强调每种方法的重要性。
小写化
小写化所有文本数据,虽然常被忽视,却是最简单和最有效的文本预处理方法之一。它适用于大多数文本挖掘和自然语言处理问题,并且在数据集不大时可以显著提高预期输出的一致性。
最近,我的一位博客读者训练了一个word embedding model for similarity lookups。他发现输入大小写的不同变化(例如‘Canada’与‘canada’)会给出不同类型的输出或根本没有输出。这可能是因为数据集中存在混合大小写的‘Canada’,且神经网络的证据不足以有效地学习较少见版本的权重。当数据集相对较小时,这种问题很容易出现,小写化是解决稀疏性问题的好方法。
这里是一个小写化如何解决稀疏性问题的例子,其中相同单词的不同大小写映射到相同的小写形式:

不同大小写的单词都映射到相同的小写形式
另一个小写化非常有用的例子是搜索。假设你在寻找包含“usa”的文档。然而,没有结果出现,因为“usa”被索引为“USA”。 现在,我们应该责怪谁?设置界面的 UI 设计师还是设置搜索索引的工程师?
虽然小写化应该是标准做法,但我也遇到过需要保留大小写的情况。例如,在预测源代码文件的编程语言时,Java 中的单词 System 与 Python 中的 system 有很大不同。将两者小写化会使它们变得相同,从而导致分类器丧失重要的预测特征。虽然小写化通常是有帮助的,但它可能不适用于所有任务。
词干提取
词干提取是将单词(例如 troubled,troubles)的词形变化减少到其词根形式(例如 trouble)的过程。在这种情况下,“根”可能不是一个真正的词根单词,而只是原始单词的规范形式。
词干提取使用一种粗糙的启发式过程,试图通过去掉单词末尾的部分来正确地将单词转换为其词根形式。因此,单词“trouble”、“troubled”和“troubles”可能实际上会被转换为 troubl,而不是 trouble,因为末尾部分只是被切掉了(唉,真粗糙!)。
有不同的词干提取算法。最常见的算法,也被实证证明对英语有效,是Porters Algorithm。以下是 Porter Stemmer 进行词干提取的实际例子:

词干提取对变形词的影响
词干提取对于处理稀疏性问题以及标准化词汇很有用。我在搜索应用中尤其成功。这个想法是,例如,如果你搜索“深度学习课程”,你还希望能够检索提到“深度学习班级”以及“深度学习课程”的文档,尽管后者听起来不太对。但你明白我们的意思。你希望匹配一个词的所有变体,以获取最相关的文档。
然而,在我以前的大多数文本分类工作中,词干提取仅在一定程度上提高了分类准确性,相比之下,使用更好的特征工程和文本丰富化方法(例如,使用词嵌入)更为有效。
词形还原
词形还原在表面上与词干提取非常相似,目标是去除词的屈折形式并将其映射到根形式。唯一的区别是,词形还原试图以正确的方式进行。它不仅仅是削减,而是将词实际转换为根词。例如,词“better”将映射到“good”。它可能使用像WordNet 的映射这样的字典,或者一些特殊的基于规则的方法。以下是使用基于 WordNet 的方法进行词形还原的示例:

词形还原的效果与 WordNet
根据我的经验,词形还原在搜索和文本分类方面并未比词干提取提供显著好处。实际上,根据你选择的算法,它可能比使用非常基本的词干提取器要慢得多,而且你可能需要知道词的词性才能得到正确的词形。这篇论文发现,词形还原对神经网络架构的文本分类准确性没有显著影响。
我个人会谨慎使用词形还原。额外的开销可能不值得。然而,你可以尝试一下,以查看它对性能指标的影响。
停用词移除
停用词是一组在语言中常用的词。例如,英语中的停用词有“a”、“the”、“is”、“are”等。使用停用词的直觉是,通过从文本中移除低信息量的词,我们可以集中关注重要的词。
例如,在搜索系统的上下文中,如果你的搜索查询是“什么是文本预处理?”,你希望搜索系统关注那些谈论文本预处理的文档,而不是那些谈论“是什么”的文档。这可以通过阻止所有停用词列表中的词被分析来实现。停用词通常应用于搜索系统、文本分类应用、主题建模、主题提取等。
根据我的经验,虽然停用词删除在搜索和主题提取系统中有效,但在分类系统中并非至关重要。然而,它确实有助于减少考虑的特征数量,从而使模型保持合理大小。
这是一个停用词删除的例子。所有停用词都被替换为一个虚拟字符,W:

停用词删除前后的句子
停用词列表可以来自预先建立的集合,或者你可以为你的领域创建一个自定义列表。一些库(例如 sklearn)允许你删除出现在 X%文档中的词汇,这也可以达到停用词删除的效果。
标准化
一个被高度忽视的预处理步骤是文本标准化。文本标准化是将文本转化为标准(规范)形式的过程。例如,单词“gooood”和“gud”可以转换为“good”,即其规范形式。另一个例子是将近乎相同的词汇,如“stopwords”、“stop-words”和“stop words”,映射到“stopwords”。
文本标准化对于噪声文本(如社交媒体评论、短信和博客评论)非常重要,因为这些文本中常出现缩写、拼写错误和超出词汇表的词汇(oov)。这篇论文显示,通过对推文使用文本标准化策略,他们能够将情感分类准确度提高约 4%。
这是一个文本标准化前后的例子:
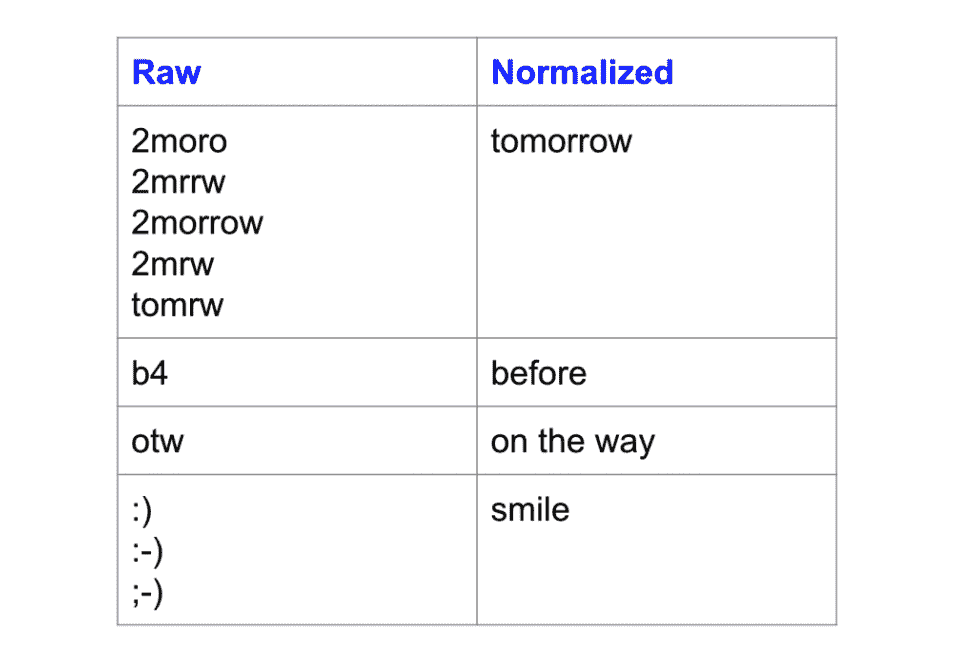
文本标准化的效果
注意这些变体如何映射到相同的标准形式。
根据我的经验,文本标准化在分析高度非结构化的临床文本中也有效,其中医生以非标准化的方式记录笔记。我还发现它在主题提取中很有用,其中近义词和拼写差异很常见(例如,主题建模、主题建模、主题建模、主题建模)。
不幸的是,与词干提取和词形还原不同,文本标准化没有标准化的方式。它通常取决于任务。例如,你标准化临床文本的方式与标准化短信的方式可能会有所不同。
一些常见的文本标准化方法包括词典映射(最简单)、统计机器翻译(SMT)和基于拼写修正的方法。这篇有趣的文章比较了基于词典的方法和 SMT 方法在标准化短信中的使用。
噪声去除
噪声移除是指移除可能干扰文本分析的字符、数字和文本片段。噪声移除是最基本的文本预处理步骤之一,也高度依赖于领域。
例如,在推文中,噪声可能是所有特殊字符,除了标签,因为标签标志着可以表征推文的概念。噪声的问题在于它可能会在下游任务中产生不一致的结果。以下是一个示例:
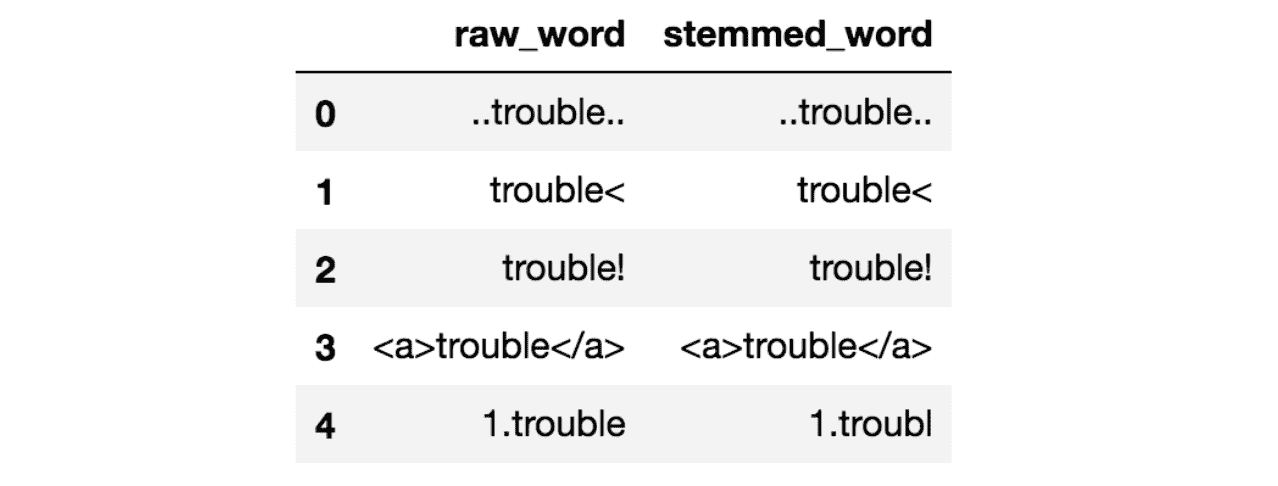
词干提取与噪声移除
注意,以上所有原始词汇都有一些周围的噪声。如果你对这些词汇进行词干提取,你会发现词干提取结果并不好看。它们都没有正确的词干。然而,通过在这个笔记本中应用一些清理,结果现在看起来好多了:
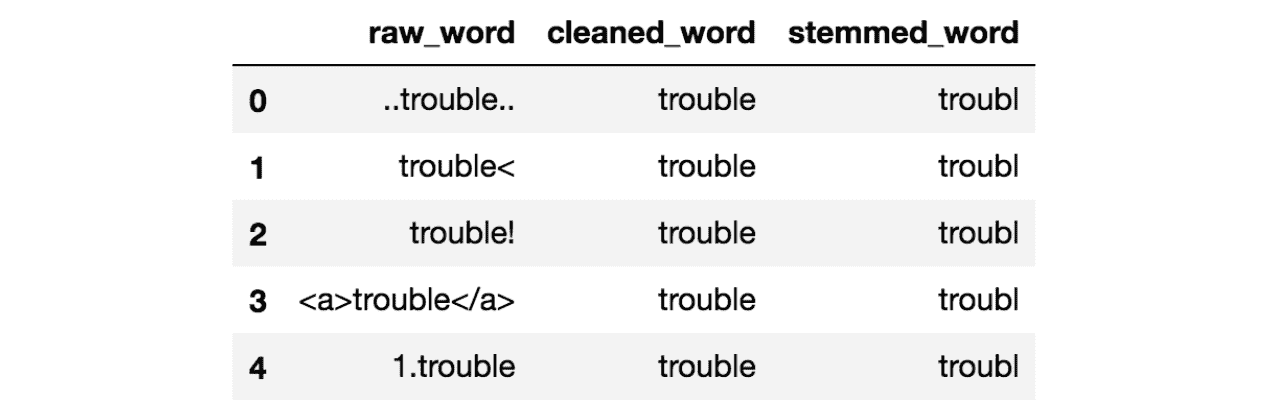
词干提取与噪声移除
噪声移除是文本挖掘和自然语言处理中的首要任务之一。有多种方法可以移除噪声。这包括标点符号移除、特殊字符移除、数字移除、HTML 格式移除、特定领域关键词移除(例如‘RT’表示转发)、源代码移除、头部信息移除*等。这完全取决于你所在的领域以及你的任务中什么算作噪声。我笔记本中的代码片段展示了如何进行一些基本的噪声移除。
文本丰富化 / 增强
文本丰富化涉及将你原有的文本数据与先前没有的信息进行扩充。文本丰富化为你的原始文本提供更多的语义,从而提高其预测能力以及你对数据进行分析的深度。
在信息检索的例子中,扩展用户查询以提高关键词匹配的准确度是一种增强形式。例如,查询“文本挖掘”可以变成“文本文件挖掘分析”。虽然这对人类来说没有意义,但它有助于获取更相关的文档。
你可以非常有创意地丰富你的文本。你可以使用词性标注来获取关于文本中词汇的更详细信息。
例如,在文档分类问题中,单词book作为名词的出现可能会导致不同的分类,而book作为动词的出现则是用在阅读的上下文中,另一个则用在预定的上下文中。这篇文章讨论了如何通过名词和动词的组合作为输入特征来改善中文文本分类。
随着大量文本的出现,人们开始使用词嵌入来丰富词语、短语和句子的意义,用于分类、搜索、摘要和文本生成等。尤其是在深度学习的 NLP 方法中,词级嵌入层非常常见。你可以选择使用预训练的嵌入或创建自己的嵌入并在下游任务中使用它。
其他丰富文本数据的方法包括短语提取,即将复合词识别为一个(也叫做分块),同义词扩展和依存句法分析。
你需要全部做吗?

不完全是,但如果你想获得良好且一致的结果,你确实需要做一些。为了让你了解最低限度的要求,我将其分为必须做的、应该做的和任务相关的。任务相关的部分可以在决定是否需要之前进行定量或定性测试。
记住,少即是多,你要尽可能保持方法的优雅。添加的开销越多,当遇到问题时,你需要剥离的层次就越多。
必须做的:
-
噪声移除
-
小写化(在某些情况下可能与任务相关)
应该做的:
- 简单标准化 — (例如,标准化几乎相同的词)
任务相关的:
-
高级标准化(例如,处理词汇表外的词)
-
停用词移除
-
词干提取/词形还原
-
文本丰富/增强
因此,对于任何任务,你至少应该尝试将文本转换为小写并去除噪声。噪声的定义取决于你的领域(参见噪声移除部分)。你还可以做一些基本的标准化步骤以提高一致性,然后根据需要系统地添加其他层。
一般经验法则
并非所有任务都需要相同程度的预处理。对于一些任务,你可以只做最基本的处理。然而,对于其他任务,数据集可能如此嘈杂,如果不进行足够的预处理,结果将会是“垃圾进垃圾出”。
这里有一个一般经验法则。虽然这并不总是成立,但适用于大多数情况。如果你有大量写得很好的文本可以处理,并且领域相对通用,那么预处理不是特别关键;你可以只做最低限度的处理(例如,使用维基百科的所有文本或路透社新闻文章训练词嵌入模型)。
然而,如果你在一个非常狭窄的领域(例如关于健康食品的推文)工作,并且数据稀疏且嘈杂,你可能会从更多的预处理层中受益,尽管每一层(例如停用词移除、词干提取、标准化)都需要通过定量或定性的方法验证其有效性。这里有一个表格总结了你应对文本数据进行多少预处理。

我希望这里的想法能引导你找到适合你项目的正确预处理步骤。记住,少即是多。我的一位朋友曾提到,他通过去除不必要的预处理层,使一个大型电子商务搜索系统更高效、更稳定。
资源
参考文献
- 如需查看最新的论文列表,请参阅我的原始文章
简介:Kavita Ganesan 是一位数据科学家,擅长自然语言处理、文本挖掘、搜索和机器学习。在过去十年中,她曾在多个技术组织工作,包括 GitHub(微软)、3M 健康信息系统和 eBay。
原文。经许可转载。
资源:
相关:
更多相关内容
Python 中的文本预处理:步骤、工具和示例
原文:
www.kdnuggets.com/2018/11/text-preprocessing-python.html/2
示例 12. 使用 NLTK 的命名实体识别:
代码:
from nltk import word_tokenize, pos_tag, ne_chunk
input_str = “Bill works for Apple so he went to Boston for a conference.”
print ne_chunk(pos_tag(word_tokenize(input_str)))
输出:
(S (PERSON Bill/NNP) works/VBZ for/IN Apple/NNP so/IN he/PRP went/VBD to/TO (GPE Boston/NNP) for/IN a/DT conference/NN ./.)
指代消解(指代解析)
代词和其他指代表达应与正确的个体连接。指代消解工具找到文本中指向同一现实世界实体的提及。例如,在句子“Andrew 说他会买一辆车”中,代词“他”指向同一个人,即“Andrew”。指代消解工具: 斯坦福 CoreNLP, spaCy, Open Calais, Apache OpenNLP 在 “指代消解”表格中中描述 |
核心指代消解工具
使用 xrenner 的核心指代消解示例可以在这里找到。
联词提取
联词是指比随机预期更频繁一起出现的词组合。联词示例包括“打破规则”、“空闲时间”、“得出结论”、“记住”、“准备好”等等。
| 名称,开发者,初始发布 | 特性 | 编程语言 | 许可证 |
|---|---|---|---|
| TermeX,萨格勒布大学文本分析与知识工程实验室,2009 | UTF-8 格式的输入文本 | 前端 GUI | 研究目的可根据请求免费提供。 |
| 使用 14 种关联度量 | |||
| 处理长度最多为四的 n-gram | |||
| 手动选择术语词汇的候选 n-gram | |||
| 支持 Windows 和 Linux | |||
| 快速且内存高效地处理大规模语料库 | |||
| [47] | |||
| Collocate,Athelstan | 使用统计分析(t 分数,对数似然,互信息)和频率信息来呈现候选联词列表 | 应用 | 教育价格。单用户:$45 |
| 在设定的范围内搜索一个词(短语)(例如 4 个词)。 | 站点许可证(2 年,15 用户)$395 | ||
| 生成 n-gram 列表 | |||
| 使用阈值提取联词,并使用互信息 [48] | |||
| CollTerm,萨格勒布大学人文与社会科学学院;罗马尼亚科学院人工智能研究所 | 基于五种不同的共现度量结果,用于多词单元(即联词)或从大规模代表性语料库中通过对单词单元应用 TF-IDF 测量得出的分布差异 | Python | Apache 许可证 2.0 |
| 语言独立 [49] | |||
| 联词提取器,Dan Ștefănescu,2012 | 本方法中的联词特征: | 应用 | 限制:通知许可方,不得再分发 |
| – 它们之间的距离相对恒定; | 用户性质:学术、商业 | ||
| – 它们比随机预期更频繁地一起出现(对数似然) | |||
| 与语言无关 | |||
| 输出注释格式:每行一个搭配的文本输出,注释用制表符分隔 [50] | |||
| ICE: 习语和搭配提取器,Verizon Labs,休斯顿大学计算机科学系,2017 | 习语和搭配提取 | Python | Apache 许可证 2.0 |
| 两种用户友好的格式 | |||
| 用于离线和在线搭配识别,字典搜索、网络搜索和替代,以及网络搜索独立性 [51] | |||
| Text::NSP,明尼苏达大学,卡内基梅隆大学,匹兹堡大学,2000 | 从文本中提取搭配和 N-gram | Perl | GNU 通用公共许可证 |
| Text::NSP::Measures 模块评估 N-gram 中词语的共现是否纯属偶然或具有统计意义。 | |||
| [52] |
搭配提取工具
示例 13. 使用 ICE 进行搭配提取[51]
代码:
input=[“he and Chazz duel with all keys on the line.”]
from ICE import CollocationExtractor
extractor = CollocationExtractor.with_collocation_pipeline(“T1” , bing_key = “Temp”,pos_check = False)
print(extractor.get_collocations_of_length(input, length = 3))
输出:
[“on the line”]
关系提取
关系提取允许从非结构化来源(如原始文本)中获得结构化信息。严格来说,就是识别命名实体(如人、组织、地点)之间的关系(例如,收购、配偶、雇佣)。例如,从句子“Mark 和 Emily 昨天结婚了”中,我们可以提取出 Mark 是 Emily 的丈夫的信息。
| 名称,开发者,首次发布 | 特性 | 编程语言 | 许可证 |
|---|---|---|---|
| ReVerb,华盛顿大学图灵中心 | 自动识别和提取英语句子中的二元关系 | Java | ReVerb 软件许可证协议 |
| 设计用于网络规模的信息提取,其中目标关系不能提前指定,并且速度很重要。 | |||
| 输入原始文本 | |||
| 输出(论点 1,关系短语,论点 2)三元组 [53] | |||
| EXEMPLAR,阿尔伯塔大学,2013 | 能够识别文本中描述的任何关系实例 | Java | GNU 通用公共许可证 v3.0 |
| 提取具有两个或更多论点的关系 | |||
| 论点的角色可以是 SUBJ(主语)、DOBJ(直接宾语)和 POBJ(介词宾语) [54] | |||
| 用于关系提取的文本探索工具包 (TETRE), Alisson Oldoni, 2017 | 接受原始文本作为输入 | 命令行工具 | MIT 许可证 |
| 针对由学术论文组成的语料库中的信息提取任务进行优化 | |||
| 进行数据转换、解析,并封装第三方二进制任务 | |||
| 以 HTML 和 JSON 输出关系 [55] | |||
| TextRazor, TextRazor, 2011 | 使用先进的 NLP 和 AI 技术 | Python | 定价 |
| 每秒处理数千个词每核心 | PHP | ||
| 允许用户添加产品名称、人员、公司、自定义分类规则和高级语言模式 [56] | Java | ||
| REST API | |||
| Python 中的信息提取 (IEPY), Machinalis, 2014 | 尝试使用用户提供的信息预测关系 | Python | BSD 3-Clause "New" 或 "Revised" 许可证 |
| 旨在对大数据集进行信息提取 (IE) | |||
| 为科学实验创建,使用新的 IE 算法 | |||
| 配置了便捷的默认设置 [57] | |||
| Watson 自然语言理解, IBM | 识别两个实体是否相关,并确定关系类型 | Curl | 定价 |
| 支持的语言:阿拉伯语、英语、韩语、西班牙语 [58] | Node | ||
| Java | |||
| Python | |||
| MIT 信息提取 (MITIE), E. Davis King, 2009 | 二元关系检测 | C, C++, Java, R, Python | Boost 软件许可证 |
| 用于训练自定义提取器和关系检测器的工具 | |||
| 使用分布式词嵌入和结构化支持向量机 | |||
| 提供多个预训练模型 | |||
| 支持英语、西班牙语和德语 [59] |
总结
在这篇文章中,我们讨论了文本预处理并描述了其主要步骤,包括规范化、标记化、词干提取、词形还原、分块、词性标注、命名实体识别、共指解析、搭配提取和关系提取。我们还讨论了文本预处理工具和示例。创建了一个 对比表。
文本预处理完成后,结果可以用于更复杂的自然语言处理任务,例如机器翻译或自然语言生成。
资源:
-
www.elastic.co/guide/en/elasticsearch/guide/current/hunspell.html -
blog.paralleldots.com/product/dig-relevant-text-elements-entity-extraction-api/ -
www.ibm.com/support/knowledgecenter/en/SS8NLW_10.0.0/com.ibm.watson.wex.aac.doc/aac-tasystemt.html -
medium.com/huggingface/state-of-the-art-neural-coreference-resolution-for-chatbots-3302365dcf30 -
linghub.lider-project.eu/metashare/a89c02f4663d11e28a985ef2e4e6c59e76428bf02e394229a70428f25a839f75 -
www.ibm.com/watson/developercloud/natural-language-understanding/api/v1/#relations
Bio: 数据怪兽 帮助企业和资助的初创公司研究、设计和开发实时智能软件,以利用数据技术改进业务。
原文。转载许可。
相关内容:
我们的前三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 为您的组织提供 IT 支持
更多相关内容
文本摘要开发:带有 GPT-3.5 的 Python 教程
原文:
www.kdnuggets.com/2023/04/text-summarization-development-python-tutorial-gpt35.html

图片由 frimufilms 提供,来源于 Freepik
这是一个 AI 突破日新月异的时代。几年前,我们在公共领域中看到的 AI 生成内容不多,但现在技术对每个人都可及。对于许多希望显著利用这一技术来开发复杂项目的个人创作者或公司来说,这是一项绝佳的选择,可能需要较长时间。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
其中一个改变我们工作方式的重大突破是 OpenAI 发布的 GPT-3.5 模型。GPT-3.5 模型是什么?如果让模型自己回答的话,答案是“在自然语言处理领域中高度先进的 AI 模型,在生成上下文相关和准确的文本方面有着显著改进”。
OpenAI 提供了一个用于 GPT-3.5 模型的 API,我们可以用来开发一个简单的应用程序,例如文本摘要器。为此,我们可以使用 Python 将模型 API 无缝集成到我们的应用程序中。这个过程是什么样的呢?让我们深入了解一下。
前提条件
在跟随本教程之前,有几个前提条件,包括:
-
Python 知识,包括使用外部库和 IDE 的知识
-
理解 APIs 和使用 Python 处理端点
-
拥有访问 OpenAI APIs 的权限
要获取 OpenAI APIs 访问权限,我们必须在 OpenAI 开发者平台 注册,并访问您个人资料中的查看 API 密钥。在网页上,点击“创建新秘密密钥”按钮以获取 API 访问权限(见下图)。请记得保存密钥,因为之后将不会再显示。

作者提供的图片
准备工作就绪后,让我们尝试理解 OpenAI APIs 模型的基础知识。
理解 GPT-3.5 OpenAI API
GPT-3.5 系列模型被指定用于许多语言任务,每个系列中的模型在某些任务中表现出色。在这个教程示例中,我们将使用 gpt-3.5-turbo,因为它是本文撰写时推荐的当前模型,具有良好的能力和性价比。
我们在 OpenAI 教程中通常使用 text-davinci-003,但本教程中我们将使用当前模型。我们将依赖 ChatCompletion 端点,而不是 Completion,因为当前推荐的模型是聊天模型。即使名字是聊天模型,它也适用于任何语言任务。
让我们尝试理解 API 的工作原理。首先,我们需要安装当前的 OpenAI 包。
pip install openai
完成包的安装后,我们将尝试通过 ChatCompletion 端点连接并使用 API。不过,在继续之前,我们需要设置环境。
在你最喜欢的 IDE(对我来说是 VS Code)中,创建两个文件,分别命名为 .env 和 summarizer_app.py,类似于下图。
作者提供的图片
summarizer_app.py 是我们将构建简单总结应用程序的地方,而 .env 文件是我们存储 API 密钥的地方。出于安全原因,建议将 API 密钥分开存储在另一个文件中,而不是硬编码在 Python 文件中。
在 .env 文件中放入以下语法并保存文件。将 your_api_key_here 替换为你的实际 API 密钥。不要将 API 密钥更改为字符串对象;保持原样。
OPENAI_API_KEY=your_api_key_here
为了更好地理解 GPT-3.5 API,我们将使用以下代码生成词汇总结器。
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
max_tokens=100,
temperature=0.7,
top_p=0.5,
frequency_penalty=0.5,
messages=[
{
"role": "system",
"content": "You are a helpful assistant for text summarization.",
},
{
"role": "user",
"content": f"Summarize this for a {person_type}: {prompt}",
},
],
)
上述代码展示了我们如何与 OpenAI API 的 GPT-3.5 模型进行交互。通过使用 ChatCompletion API,我们创建了一个对话,并在传递提示后获得预期的结果。
让我们逐步解析每个部分以更好地理解。在第一行,我们使用 openai.ChatCompletion.create 代码从我们将传递给 API 的提示中创建响应。
在下一行,我们有用来改善文本任务的超参数。以下是每个超参数功能的总结:
-
model:我们要使用的模型系列。在本教程中,我们使用当前推荐的模型(gpt-3.5-turbo)。 -
max_tokens:模型生成的单词上限。它有助于限制生成文本的长度。 -
temperature:模型输出的随机性,温度越高,结果越多样和创造性。值的范围是从 0 到无限,虽然值大于 2 并不常见。 -
top_p:Top P 或 top-k 采样或核采样是一个控制输出分布中采样池的参数。例如,值为 0.1 表示模型仅从分布的前 10% 中进行采样。该值范围在 0 到 1 之间;较高的值意味着结果更具多样性。 -
frequency_penalty:输出中重复词的惩罚。值范围在 -2 到 2 之间,其中正值会抑制模型重复词,而负值则鼓励模型使用更多重复的词。0 表示没有惩罚。 -
messages:我们将文本提示传递给模型进行处理的参数。我们传递一个字典列表,其中键是角色对象(“system”、“user”或“assistant”),帮助模型理解上下文和结构,而值是上下文。-
角色“system”是对模型“assistant”行为的设定准则。
-
角色“user”表示与模型交互的人的提示。
-
角色“assistant”是对“user”提示的回应。
-
解释完上述参数后,我们可以看到上面的 messages 参数包含两个字典对象。第一个字典是我们如何将模型设置为文本摘要器。第二个是我们传递文本并获取摘要输出的地方。
在第二个字典中,你还会看到变量 person_type 和 prompt。person_type 是我用来控制摘要风格的变量,在教程中会展示。而 prompt 是我们传递待总结文本的地方。
继续教程,将以下代码放入 summarizer_app.py 文件中,我们将尝试运行下面的函数。
import openai
import os
from dotenv import load_dotenv
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
def generate_summarizer(
max_tokens,
temperature,
top_p,
frequency_penalty,
prompt,
person_type,
):
res = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
max_tokens=100,
temperature=0.7,
top_p=0.5,
frequency_penalty=0.5,
messages=
[
{
"role": "system",
"content": "You are a helpful assistant for text summarization.",
},
{
"role": "user",
"content": f"Summarize this for a {person_type}: {prompt}",
},
],
)
return res["choices"][0]["message"]["content"]
上面的代码是我们创建一个 Python 函数的地方,该函数接受我们之前讨论过的各种参数,并返回文本摘要输出。
使用你的参数尝试上述功能并查看输出。然后继续本教程,使用 streamlit 包创建一个简单的应用程序。
使用 Streamlit 的文本摘要应用程序
Streamlit 是一个开源 Python 包,旨在创建机器学习和数据科学网页应用。它易于使用且直观,因此推荐给许多初学者。
在继续教程之前,让我们先安装 streamlit 包。
pip install streamlit
安装完成后,将以下代码放入 summarizer_app.py 中。
import streamlit as st
#Set the application title
st.title("GPT-3.5 Text Summarizer")
#Provide the input area for text to be summarized
input_text = st.text_area("Enter the text you want to summarize:", height=200)
#Initiate three columns for section to be side-by-side
col1, col2, col3 = st.columns(3)
#Slider to control the model hyperparameter
with col1:
token = st.slider("Token", min_value=0.0, max_value=200.0, value=50.0, step=1.0)
temp = st.slider("Temperature", min_value=0.0, max_value=1.0, value=0.0, step=0.01)
top_p = st.slider("Nucleus Sampling", min_value=0.0, max_value=1.0, value=0.5, step=0.01)
f_pen = st.slider("Frequency Penalty", min_value=-1.0, max_value=1.0, value=0.0, step=0.01)
#Selection box to select the summarization style
with col2:
option = st.selectbox(
"How do you like to be explained?",
(
"Second-Grader",
"Professional Data Scientist",
"Housewives",
"Retired",
"University Student",
),
)
#Showing the current parameter used for the model
with col3:
with st.expander("Current Parameter"):
st.write("Current Token :", token)
st.write("Current Temperature :", temp)
st.write("Current Nucleus Sampling :", top_p)
st.write("Current Frequency Penalty :", f_pen)
#Creating button for execute the text summarization
if st.button("Summarize"):
st.write(generate_summarizer(token, temp, top_p, f_pen, input_text, option))
尝试在命令提示符中运行以下代码以启动应用程序。
streamlit run summarizer_app.py
如果一切正常,你会在默认浏览器中看到以下应用程序。
图片来源:作者
那么,上面的代码发生了什么?让我简要解释一下我们使用的每个函数:
-
.st.title:提供网页应用程序的标题文本。 -
.st.write:将参数写入应用程序中;可以是任何内容,但主要是字符串文本。 -
.st.text_area:提供一个文本输入区域,可以存储在变量中并用于我们的文本摘要提示。 -
.st.columns:对象容器,用于提供并排互动。 -
.st.slider:提供一个具有设定值的滑块小部件,用户可以进行交互。该值存储在用作模型参数的变量中。 -
.st.selectbox:提供一个选择小部件,让用户选择他们想要的摘要样式。在上面的示例中,我们使用了五种不同的样式。 -
.st.expander:提供一个容器,用户可以展开并容纳多个对象。 -
.st.button:提供一个按钮,用户按下时运行预期的功能。
由于 streamlit 会自动根据从上到下给定的代码设计 UI,我们可以更多地关注互动。
当所有组件准备好后,让我们尝试使用文本示例来测试我们的摘要应用程序。对于我们的示例,我将使用 相对论 Wikipedia 页面 的文本进行摘要。使用默认参数和二年级风格,我们得到以下结果。
Albert Einstein was a very smart scientist who came up with two important ideas about how the world works. The first one, called special relativity, talks about how things move when there is no gravity. The second one, called general relativity, explains how gravity works and how it affects things in space like stars and planets. These ideas helped us understand many things in science, like how particles interact with each other and even helped us discover black holes!
你可能会获得与上述不同的结果。让我们尝试“家庭主妇”风格,并稍微调整参数(Token 100,Temperature 0.5,Nucleus Sampling 0.5,Frequency Penalty 0.3)。
The theory of relativity is a set of physics theories proposed by Albert Einstein in 1905 and 1915\. It includes special relativity, which applies to physical phenomena without gravity, and general relativity, which explains the law of gravitation and its relation to the forces of nature. The theory transformed theoretical physics and astronomy in the 20th century, introducing concepts like 4-dimensional spacetime and predicting astronomical phenomena like black holes and gravitational waves.
如我们所见,相同文本的样式存在差异。通过更改提示和参数,我们的应用程序可以更具功能性。
我们的文本摘要应用程序的整体外观可以从下图中看到。

图片由作者提供
这就是关于使用 GPT-3.5 创建文本摘要应用程序的教程。你可以进一步调整应用程序并部署它。
结论
生成式 AI 正在崛起,我们应该利用这个机会创建一个精彩的应用程序。在本教程中,我们将了解 GPT-3.5 OpenAI API 的工作原理,以及如何借助 Python 和 streamlit 包来创建一个文本摘要应用程序。
Cornellius Yudha Wijaya 是数据科学助理经理和数据撰稿人。他在全职工作于 Allianz Indonesia 的同时,喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
更多相关话题
Text-2-Video 生成:逐步指南
原文:
www.kdnuggets.com/2023/08/text2video-generation-stepbystep-guide.html

作者提供的 GIF
介绍
我们的前 3 个课程推荐
1. Google 网络安全证书 - 加速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 方面的工作
基于扩散的图像生成模型在计算机视觉领域代表了一项革命性的突破。由包括 Imagen、DallE 和 MidJourney 在内的模型开创,这些进展展示了文本条件图像生成的卓越能力。要了解这些模型的内部工作原理,你可以阅读这篇文章。
然而,Text-2-Video 模型的开发带来了更大的挑战。目标是确保生成的每一帧之间的一致性和连贯性,并在视频的开头到结尾之间保持生成的上下文。
然而,最近在基于扩散的模型中的进展为 Text-2-Video 任务提供了有前景的前景。目前,大多数 Text-2-Video 模型都采用了对预训练的 Text-2-Image 模型进行微调的技术,集成了动态图像运动模块,并利用了 WebVid 或 HowTo100M 等各种 Text-2-Video 数据集。
在这篇文章中,我们的方法涉及使用 HuggingFace 提供的微调模型,这对于生成视频非常重要。
实现
先决条件
我们使用 HuggingFace 提供的 Diffusers 库,以及一个名为 Accelerate 的实用库,它允许 PyTorch 代码在并行线程中运行。这加速了我们的生成过程。
首先,我们必须安装所需的依赖项并导入相关模块以便我们的代码正常运行。
pip install diffusers transformers accelerate torch
然后,从每个库中导入相关模块。
import torch
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
from diffusers.utils import export_to_video
创建管道
我们在 HuggingFace 上加载了由 ModelScope 提供的 Text-2-Video 模型,在扩散管道中进行处理。该模型具有 17 亿参数,基于 UNet3D 架构,通过迭代去噪过程从纯噪声中生成视频。其工作过程分为三部分。模型首先从简单的英语提示中提取文本特征。然后将文本特征编码到视频潜在空间并去噪。最后,将视频潜在空间解码回视觉空间,并生成一个短视频。
pipe = DiffusionPipeline.from_pretrained(
"damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16")
pipe.scheduler = DPMSolverMultistepScheduler.from_config(
pipe.scheduler.config)
pipe.enable_model_cpu_offload()
此外,我们使用 16 位浮点精度来减少 GPU 的利用率。此外,还启用了 CPU 卸载功能,这可以在运行时从 GPU 中移除不必要的部分。
生成视频
prompt = "Spiderman is surfing"
video_frames = pipe(prompt, num_inference_steps=25).frames
video_path = export_to_video(video_frames)
然后我们将一个提示传递给视频生成管道,该管道提供生成的帧序列。我们使用 25 次推理步骤,以便模型执行 25 次去噪迭代。较高的推理步骤数可以提高视频质量,但需要更高的计算资源和时间。
单独的图像帧随后通过扩散器的工具函数进行合成,视频被保存在磁盘上。
然后我们将一个提示传递给视频生成管道,该管道提供生成的帧序列。单独的图像帧随后通过扩散器的工具函数进行合成,视频被保存在磁盘上。
Muhammad Arham 的最终视频 来自 Muhammad Arham 在 Vimeo 上。
结论
非常简单!我们得到了一个关于蜘蛛侠冲浪的视频。虽然这是一个短的、质量不是很高的视频,但它仍然象征着这一过程的良好前景,该过程很快就能达到与图像-文本模型类似的结果。不过,测试你的创造力并与模型互动仍然非常有趣。你可以使用这个 Colab Notebook 试一试。
穆罕默德·阿赫曼 是一名深度学习工程师,专注于计算机视觉和自然语言处理。他曾在 Vyro.AI 工作,负责多个生成式 AI 应用的部署和优化,这些应用达到了全球排行榜的顶端。他对构建和优化智能系统中的机器学习模型感兴趣,并相信持续改进。
相关话题
教科书就是你所需的一切:一种颠覆性的 AI 培训方法
原文:
www.kdnuggets.com/2023/07/textbooks-all-you-need-revolutionary-approach-ai-training.html

图片由作者使用 Midjourney 创建
介绍
研究人员总是寻求更好、更创新的方式来培训人工智能模型。一篇 微软最近的论文 提出了一个有趣的方法——使用合成教科书来教导模型,而不是通常使用的大量数据集。
论文介绍了一种称为 Phi-1 的模型,该模型完全基于定制的教科书进行训练。研究人员发现,这与在大量数据上训练的更大模型在某些任务中同样有效。
标题“教科书就是你所需的一切”巧妙地参考了 AI 中著名的概念“注意力即一切”。但这里他们颠覆了这个想法——与其关注模型架构本身,他们展示了像教科书中那样的高质量、精心策划的训练数据的价值。
关键见解是,一个经过深思熟虑、设计良好的数据集可以与庞大、无焦点的数据堆一样有用。因此,研究人员精心编制了一本合成教科书,以细致地提供模型所需的知识。
基于教科书的方法是一种引人入胜的新方向,可以有效地培训 AI 模型,使其在特定任务中表现出色。这突出了训练数据的策划和质量的重要性,而不仅仅是数据量的暴力方式。
关键点
-
尽管 Phi-1 模型显著小于 GPT-3 等模型,但在 Python 编码任务中表现优异。这表明,模型的大小并非决定 AI 模型表现的唯一因素。
-
研究人员使用了合成教科书进行培训,强调了高质量、精心策划的数据的重要性。这种方法可能会颠覆我们对 AI 模型培训的思考方式。
-
当对 Phi-1 模型进行合成练习和解答的微调时,其性能显著提高,这表明有针对性的微调可以增强模型在特定任务之外的能力。
讨论
Phi-1 模型拥有 13 亿个参数,相较于拥有 1750 亿个参数的 GPT-3 模型来说相对较小。尽管存在尺寸差异,Phi-1 在 Python 编码任务中表现出色。这一成就突显了训练数据的质量可能与模型的大小一样重要,甚至更为重要。
研究人员使用合成教材来训练 Phi-1 模型。这本教材是利用 GPT-3.5 生成的,包含了 Python 语言文本和练习。使用合成教材强调了高质量、精心策划的数据在 AI 模型训练中的重要性。这种方法可能会将 AI 训练的重点从创建更大的模型转移到策划更好的训练数据上。
有趣的是,Phi-1 模型在用合成练习和解决方案进行微调后,其性能显著提高。这种改进不仅限于它专门训练的任务。例如,尽管训练数据中未包含 pygame 这类外部库,模型在使用这些库的能力上有所提升。这表明微调可以增强模型在特定任务之外的能力。
研究问答
问:Phi-1 模型在多样性方面与较大的模型相比如何?
答:Phi-1 模型专注于 Python 编程,这限制了它的多样性,相比于多语言模型,其在特定 API 编程或使用不常见的包方面的领域知识也较少。
问:Phi-1 模型如何处理提示中的风格变化或错误?
答:由于数据集的结构化性质以及语言和风格的缺乏多样性,Phi-1 模型对风格变化或提示中的错误的鲁棒性较差。如果提示中存在语法错误,模型的表现会下降。
问:Phi-1 模型的性能是否可以通过使用 GPT-4 生成合成数据来提高?
答:是的,研究人员认为通过使用 GPT-4 生成合成数据而非 GPT-3.5,可以取得显著的成果。然而,GPT-4 目前使用起来较慢且费用更高。
问:Phi-1 模型的训练方法与传统方法有何不同?
答:传统方法通常关注于增加模型的规模和数据量。与此不同,Phi-1 模型强调数据的质量,并使用合成教材进行训练。这种方法可能会将 AI 训练的重点从创建更大的模型转移到策划更好的训练数据上。
研究总结
微软研究的“教材即一切”在训练 AI 模型方面有一个相当新颖的想法。他们没有像通常那样将大量数据抛给模型,而是创建了一本合成教材来教模型。
他们仅使用这本定制教材训练了一个名为 Phi-1 的较小模型,相比于像 GPT-3 这样的庞大模型,它的效果令人震惊。这表明,即使数据集规模较小,只要设计得当、质量高,也能训练出非常有效的 AI。
关键在于花时间策划优秀的训练数据,就像你在教科书中看到的一样,而不仅仅是将模型喂入数 TB 的随机杂乱数据。这一切都是关于质量,而不是数量。
这可能会改变人们对未来 AI 训练的看法。与其追求需要巨大数据集的越来越大模型,不如更多地关注创造最佳的训练教材,即使它们更小。这是一个引人入胜的想法,关键在于教材,而不仅仅是模型的扩展。
马修·梅奥 (@mattmayo13) 是一名数据科学家,也是 KDnuggets 的总编辑,KDnuggets 是重要的数据科学和机器学习在线资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及自动化机器学习方法。马修拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
更多相关话题
最大化生产力的 5 大 AI 工具
原文:
www.kdnuggets.com/the-5-best-ai-tools-for-maximizing-productivity

效率和生产力在数据科学及处理涉及的大规模数据集时至关重要。随着这些数据集在大小和复杂性上的快速膨胀,我们用来管理和分析它们的工具不仅要跟上步伐——还要推动我们向前发展;其中最重要的就是 AI。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
虽然大多数应用程序和工具主要关注数据分析、转录和 IT 操作等方面,但 AI 领域也触及了我们的日常工作流程。现在你可以在几秒钟内合并 PDF 文件、重新排列电子表格和处理各种平凡任务。因此,当你考虑以下工具时,不仅要考虑数据科学。
在这篇文章中,我们将介绍以下 5 种多样的 AI 工具,以最大化数据科学家的生产力:
-
Assembly AI
-
DataRobot
-
H2O.ai
-
Hugging Face
-
BigPanda
让我们直接开始,来看看吧。
Assembly.ai 被誉为转录和语音识别领域的领先解决方案之一,专注于在嘈杂环境中提供高度准确的转录。他们的 API 为开发者提供了一个可定制和灵活的框架,确保与不同平台和工具的无缝集成。
使 Assembly.ai 脱颖而出的是其对可扩展性的承诺,确保各种规模的组织都能从其功能中受益。它拥有一个混合系统,结合了深度学习能力和传统的语音识别技术,使其适用于实时和批处理任务。
除了转录功能,他们的套件还提供了多种音频处理工具,包括关键词识别和说话者标记。随着公司越来越依赖语音数据进行洞察和分析,Assembly.ai 的作用变得更加重要。他们对持续发展的承诺保证了在速度和准确性上的提升。
🔑 AssemblyAI 关键点
-
转录和语音识别
-
可定制的 API 解决方案
-
精度和可扩展性
✅ 优点
-
即使在困难的音频条件下也能提供卓越的精度
-
灵活且强大的开发者 API
-
适用于小型和大型企业
❌ 缺点
-
需要集成工作
-
对于简单的转录任务可能过于复杂
DataRobot 通过在今天的 自动化机器学习(AutoML)领域的开创性工作而声名鹊起。
其平台使数据专业人士能够快速构建、调整和部署预测模型,无需手动建模的复杂细节。用户只需上传数据集,即可获得关于最佳模型的推荐,平台自动处理特征工程和超参数调整。
其云原生架构有助于确保模型可以轻松部署到任何需要的位置。此外,关注协作,团队可以分享见解、模型和发现,从而提高生产力。
除了自动化能力外,DataRobot 强调模型的可解释性。这确保了生成的模型不仅仅是“黑箱”,其工作原理可以被理解和解释。凭借其用户友好的界面,即使是具有最少机器学习经验的人也能利用复杂算法进行数据项目。
🔑 DataRobot 关键点
-
基于云的自动化机器学习(AutoML)工具
-
模型可解释性和部署
-
用户友好的界面
✅ 优点
-
简化机器学习过程
-
强大的模型可解释性特性
-
适合新手和专家
❌ 缺点
-
对于小公司可能成本较高
-
高级用户可能会寻求更多的定制选项
H2O.ai 提供了一个全面的开源平台,满足各种 AI 和 机器学习需求。它支持广泛的算法,从深度学习到广义线性模型。数据科学家可以在不需要许可证或额外费用的情况下访问和实验这些算法。
H2O.ai 的真正优势在于其可扩展性,能够处理从个人计算机上的小数据集到企业级集群上的大数据分析任务。其平台与 Hadoop 和 Spark 等流行数据平台无缝集成,确保在任何环境中的一致工作流程。
此外,他们提供课程和资源来帮助用户,确保即使是对该领域陌生的人也能迅速上手。他们基于用户反馈的持续创新,确保始终满足数据科学社区不断发展的需求。
🔑 H2O.ai 关键点
-
开源 AI 平台
-
支持广泛的算法
-
可扩展性和集成能力
✅ 优点
-
由于开源性质,成本效益高
-
广泛的算法支持
-
高可扩展性和兼容性
❌ 缺点
-
对初学者可能有较陡的学习曲线
-
不如一些竞争对手用户友好
Hugging Face 已成为进行 自然语言处理 (NLP) 任务的首选平台。他们的 Transformers 库是 NLP 中最先进模型的宝库,使得前沿技术对开发者和数据科学家都变得可及。从聊天机器人到情感分析,他们的工具涵盖了广泛的应用领域。
积极社区的持续贡献确保 Hugging Face 始终处于 NLP 进展的最前沿。他们还提供了丰富的资源,包括各种预训练模型,使用户更容易启动他们的 NLP 项目。
除此之外,他们以社区为中心的方法意味着频繁更新,确保用户始终掌握最新的 NLP 和 LLM 技术 创新。
🔑 Hugging Face 关键点
-
自然语言处理 (NLP) 领域的领先平台
-
广泛的模型库
-
活跃的社区和频繁更新
✅ 优点
-
针对 NLP 任务的全面资源
-
强大的社区支持和贡献
-
频繁更新和不断增长的模型库
❌ 缺点
-
主要专注于 NLP,限制了多样性
-
对初学者可能有些令人不知所措
BigPanda 提供一个利用人工智能增强 IT 操作的平台。它有效地将 IT 警报整合为高级事件,使团队能够更快地识别和 解决关键问题。通过集中化事件管理,BigPanda 提供了一个全景视图,防止了通知分散带来的混乱。
该平台还提供实时洞察,使团队能够快速了解根本原因和相关性。通过其分析,团队可以优先处理任务并预先解决潜在问题。BigPanda 无缝集成了大量 IT 系统,成为所有操作需求的核心枢纽。
🔑 BigPanda 关键点
-
人工智能驱动的 IT 操作
-
集中化事件管理
-
实时洞察和分析
✅ 优点
-
用人工智能简化 IT 操作
-
提供集中化的事件管理
-
综合的洞察和分析
❌ 缺点
-
主要服务于大规模 IT 操作
-
可能需要初始设置和集成工作
我们选择使用的工具可以在数据科学与 IT 运营的复杂交汇点上最终决定我们的生产力。
从 Assembly.ai 的精确转录能力到 BigPanda 的 IT 运维魔法,AI 工具的进步正在塑造数据科学研究人员处理和管理数据集的未来。
无论您是在深入研究 HuggingFace 的自然语言处理,还是寻求通过 DataRobot 和 H2O.ai 简化机器学习流程,市场上丰富的创新 AI 驱动解决方案都提供了大量针对不同需求的选择。
选择适合您数据科学需求的工具取决于识别自身的特定需求、潜在的预算限制以及可能的集成能力。随着 AI 工具的不断改进,时刻保持信息更新和灵活适应至关重要。
Nahla Davies是软件开发者和技术作家。在全职从事技术写作之前,她曾担任 Inc. 5,000 名体验品牌机构的首席程序员,该机构的客户包括三星、时代华纳、Netflix 和索尼。
更多相关主题
2024 年必试的 5 大最佳向量数据库
原文:
www.kdnuggets.com/the-5-best-vector-databases-you-must-try-in-2024
使用 DALL-E 3 生成的图像
介绍
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT
向量数据库是一种专门设计用于存储和索引向量嵌入以实现高效检索和相似性搜索的数据库。它用于涉及大语言模型、生成 AI 和语义搜索的各种应用中。向量嵌入是数据的数学表示,捕捉语义信息,并允许理解模式、关系和潜在结构。
向量数据库在 AI 应用领域变得越来越重要,因为它们擅长处理高维数据和促进复杂的相似性搜索。
在这篇博客中,我们将探讨你在 2024 年必须尝试的五大向量数据库。这些数据库是根据其可扩展性、多功能性和在处理向量数据方面的表现来挑选的。
作者提供的图像
1. Qdrant
Qdrant 是一个开源向量相似性搜索引擎和向量数据库,提供了一个生产就绪的服务,带有便捷的 API。你可以存储、搜索和管理向量嵌入。Qdrant 支持扩展过滤,非常适合涉及神经网络或基于语义的匹配、分面搜索等各种应用。由于它是用可靠且快速的编程语言 Rust 编写的,Qdrant 可以高效处理高用户负载。
通过使用 Qdrant,你可以构建包含嵌入编码器的完整应用程序,用于匹配、搜索、推荐等任务。它也以 Qdrant Cloud 的形式提供,这是一种完全托管的版本,包括一个免费层,提供了一个方便的方式让用户在项目中利用其向量搜索能力。
2. Pinecone
Pinecone 是一个管理型向量数据库,专门设计用于解决与高维数据相关的挑战。凭借先进的索引和搜索功能,Pinecone 使数据工程师和数据科学家能够构建和部署能够高效处理和分析高维数据的大规模机器学习应用。
Pinecone 的主要特点包括一个完全托管的服务,具有高度的可扩展性,支持实时数据摄取和低延迟搜索。Pinecone 还提供与 LangChain 的集成,以支持自然语言处理应用。凭借对高维数据的专业关注,Pinecone 提供了一个优化的平台,用于部署有影响力的机器学习项目。
3. Weaviate
Weaviate 是一个开源向量数据库,允许你存储来自你喜欢的 ML 模型的数据对象和向量嵌入,能够无缝扩展到数十亿个数据对象。使用 Weaviate,你可以获得快速的搜索速度 - 它可以在几毫秒内从数百万个对象中快速搜索十个最近邻。它提供了灵活性,可以在导入期间对数据进行向量化或上传自己的向量,并利用与 OpenAI、Cohere、HuggingFace 等平台集成的模块。
Weaviate 关注于可扩展性、复制和生产环境的安全性,从原型到大规模部署都可以胜任。除了快速的向量搜索,Weaviate 还提供推荐、摘要和神经搜索框架集成。它为各种使用案例提供了一个灵活且可扩展的向量数据库。
4. Milvus
Milvus 是一个强大的开源向量数据库,专为 AI 应用和相似性搜索设计。它使非结构化数据搜索更加便捷,并提供了一致的用户体验,无论部署环境如何。
Milvus 2.0 是一个云原生的向量数据库,设计上将存储和计算分离,使用无状态组件以增强弹性和灵活性。根据 Apache License 2.0 发布,Milvus 在万亿向量数据集上提供毫秒级搜索,通过丰富的 API 简化了非结构化数据管理,并在应用程序中嵌入实时搜索。它具有高度的可扩展性和弹性,支持按需组件级扩展。
Milvus 结合了标量过滤和向量相似性,为混合搜索解决方案提供支持。凭借社区支持和超过 1,000 个企业用户,Milvus 提供了一个可靠、灵活和可扩展的开源向量数据库,适用于各种使用案例。
5. faiss
Faiss是一个开源库,用于高效的相似性搜索和密集向量的聚类,能够搜索超出 RAM 容量的大规模向量集合。它包含了多种基于 L2 距离、点积和余弦相似性的向量比较方法。一些方法如二进制向量量化允许压缩向量表示以提高可扩展性,而其他方法如 HNSW 和 NSG 使用索引来加速搜索。
Faiss 主要用 C++ 编写,但与 Python/NumPy 完全集成。关键算法可用于 GPU 执行,接受来自 CPU 或 GPU 内存的输入。GPU 实现支持 CPU 索引的快速替代,以实现更快的结果,自动处理 CPU-GPU 数据拷贝。由 Meta 的 Fundamental AI Research 团队开发,Faiss 提供了一个开源工具包,支持在大规模向量数据集上迅速进行搜索和聚类,兼容 CPU 和 GPU 基础设施。
结论
向量数据库正在迅速成为现代 AI 应用的重要组成部分。正如我们在这篇博客文章中探讨的那样,在 2024 年选择向量数据库时,有几种引人注目的选项可以考虑。Qdrant 提供了多功能的开源能力,Pinecone 提供了为高维数据设计的托管服务,Weaviate 专注于可扩展性和灵活性,Milvus 在各种环境中提供一致的体验,而 Faiss 通过优化算法实现高效的相似性搜索。
每个数据库根据你的使用案例和基础设施都有其自身的优势和好处。随着 AI 模型和语义搜索的不断进步,拥有合适的向量数据库来存储、索引和查询向量嵌入将是关键。你可以通过阅读 什么是向量数据库及其对 LLMs 的重要性? 来了解更多关于向量数据库的信息。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理健康问题的学生打造一款 AI 产品。
更多相关话题
数据科学工作流的 7 款最佳 AI 工具
原文:
www.kdnuggets.com/the-7-best-ai-tools-for-data-science-workflow

图片来源于 DALLE-3
现在显而易见的是,那些迅速采纳 AI 的人将会引领潮流,而那些抵制变化的人将被已经使用 AI 的人取代。人工智能不再只是一个过时的潮流,它正成为各种行业的必备工具,包括数据科学。开发者和研究人员越来越多地使用 AI 驱动的工具来简化他们的工作流程,其中一个最近获得巨大人气的工具就是 ChatGPT。
我们的前三个课程推荐
1. Google Cybersecurity Certificate - 快速入门网络安全职业生涯。
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你所在的组织的 IT
在这篇博客中,我将讨论 7 款最佳 AI 工具,它们让我的数据科学家生活变得更加轻松。这些工具在我的日常任务中不可或缺,比如编写教程、研究、编码、数据分析和执行机器学习任务。通过分享这些工具,我希望帮助数据科学家和研究人员简化工作流程,并在不断发展的 AI 领域中保持领先。
1. PandasAI: 对话式数据分析
每个数据专业人士都熟悉 pandas,这是一个用于数据处理和分析的 Python 包。但如果我告诉你,除了编写代码,你还可以通过简单地输入提示或问题来分析和生成数据可视化呢?这就是 PandasAI 的功能——它就像是你 Python 工作流的 AI 代理,使用各种 AI 模型自动化数据分析。你甚至可以使用本地运行的模型。
在下面的代码中,我们使用 pandas 数据框和 OpenAI 模型创建了一个代理。这个代理可以使用自然语言对你的数据框执行各种任务。我们向它提出了一个简单的问题,然后要求解释它是如何得出结果的。
import os
import pandas as pd
from pandasai.llm import OpenAI
from pandasai import Agent
sales_by_country = pd.DataFrame(
{
"country": [
"United States",
"United Kingdom",
"France",
"Germany",
"Italy",
"Spain",
"Canada",
"Australia",
"Japan",
"China",
],
"sales": [5000, 3200, 2900, 4100, 2300, 2100, 2500, 2600, 4500, 7000],
}
)
llm = OpenAI(api_token=os.environ["OPENAI_API_KEY"])
pandas_ai_df = Agent(sales_by_country, config={"llm": llm})
response = pandas_ai_df.chat("Which are the top 5 countries by sales?")
explanation = pandas_ai_df.explain()
print("Answer:", response)
print("Explanation:", explanation)
结果非常惊人。使用我的实际数据进行实验至少需要半小时。
Answer: The top 5 countries by sales are: China, United States, Japan, Germany, United Kingdom
Explanation: I looked at the data we have and found a way to sort it based on sales. Then, I picked the top 5 countries with the highest sales numbers. Finally, I put those countries into a list and created a sentence to show them as the top 5 countries by sales.
2. GitHub Copilot: 你的 AI 代码助手
GitHub Copilot 现在对于全职开发人员或每天处理代码的人来说是必不可少的。为什么?它提高了你快速编写干净且高效代码的能力。你甚至可以与文件聊天,更快地调试或生成上下文相关的代码。
GitHub Copilot 包括 AI 聊天机器人、内联聊天框、代码生成、自动补全、CLI 自动补全以及其他 GitHub 相关功能,这些都可以帮助代码搜索和理解。
GitHub Copilot 是一款付费工具,因此如果你不想支付$10/月,那么你可以查看你必须尝试的 5 款 AI 编码助手。
3. ChatGPT:由 GPT-4 驱动的聊天应用
ChatGPT在 AI 领域已经主导了两年。人们用它来写邮件、生成内容、生成代码以及处理各种名义上的工作任务。

如果你订阅了服务,你将获得最先进的 GPT-4 模型,这在解决复杂问题方面表现出色。
我每天都使用它来生成代码、解释代码、提出一般问题和生成内容。AI 生成的工作并不总是完美的。你可能需要进行一些编辑,以便向更广泛的观众展示。
ChatGPT 是数据科学家的重要工具。使用它并不等于作弊。相反,与其他人相比,它能节省你在研究和寻找解决方案上的时间。
如果你重视隐私,可以考虑在你的笔记本电脑上运行开源 AI 模型。查看如何在笔记本电脑上使用 LLM 的 5 种方法。
4. Colab AI:AI 驱动的云笔记本
如果你为复杂的机器学习任务训练了深度神经网络,那么你一定是在Google Colab上进行的,因为该平台提供了免费的 GPU 和 TPU。随着生成式 AI 的兴起,Google Colab 最近推出了一些功能,帮助你生成代码、加快调试速度以及自动补全。
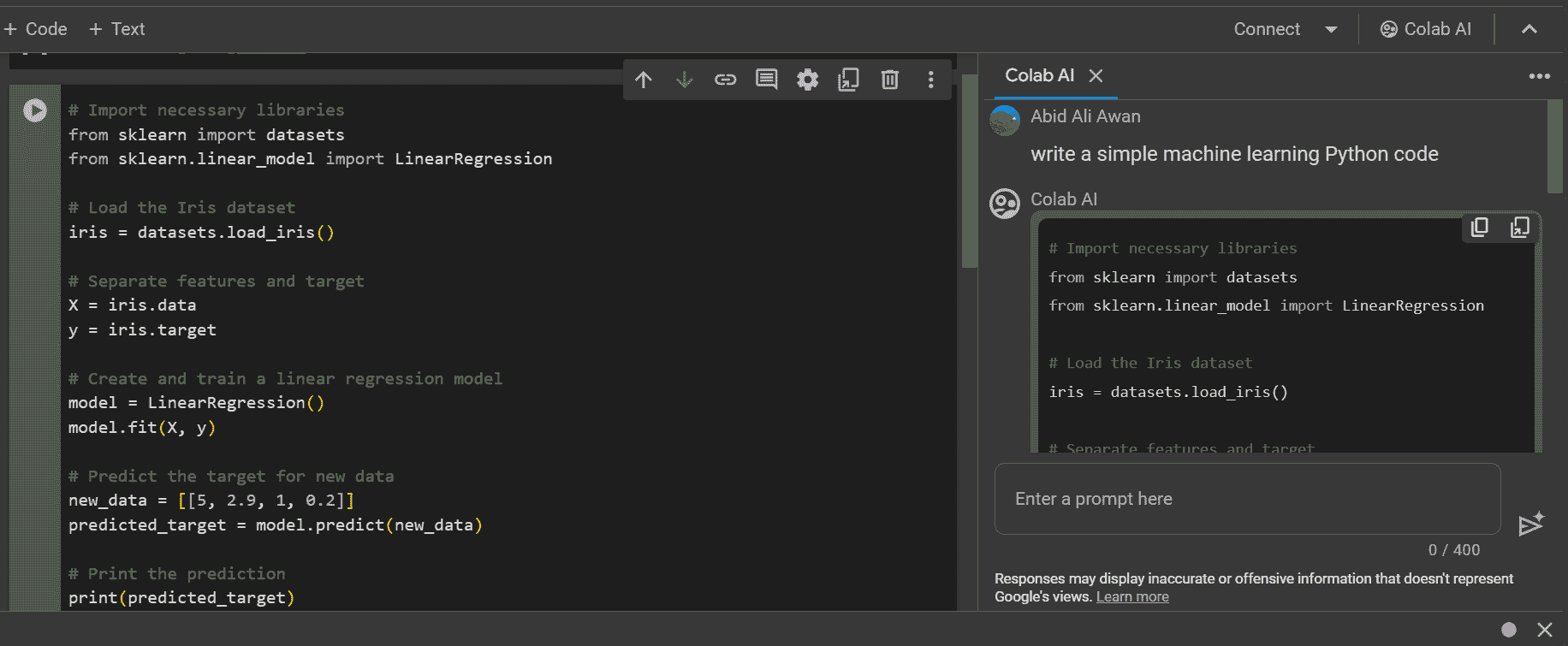
Colab AI 就像是你工作区中的一名集成 AI 编码助手。你可以通过简单的提示和后续问题生成代码。它还提供了内联代码提示功能,尽管免费版的使用有限。
我强烈建议你购买付费版,因为它提供了更好的 GPU 和整体更佳的编码体验。
探索2024 年 11 款最佳 AI 编码助手,并尝试所有替代 Colab AI 的工具,找到最适合你的选项。
5. Perplexity AI:智能搜索引擎
我一直在使用Perplexity AI作为我的新搜索引擎和研究助手。它通过提供简洁且最新的摘要,并附有相关博客和视频的链接,帮助我学习新技术和概念。我甚至可以提出后续问题并获得修改后的答案。
Perplexity AI 提供各种功能来协助用户。它可以回答从基本事实到复杂查询的广泛问题,使用最新的来源。它的 Copilot 功能允许用户深入探索他们的主题,使他们能够扩展知识并发现新的兴趣领域。此外,用户可以将搜索结果组织成基于项目或主题的“集合”,使得将来更容易找到所需的信息。
查看一下 8 个 AI 驱动的搜索引擎,它们可以增强你的互联网搜索和研究能力,作为 Google 的替代方案。
6. Grammarly:AI 写作助手
我想告诉你,Grammarly 是一个出色的工具,特别适合有阅读障碍的人。它帮助我快速而准确地写作。我已经使用 Grammarly 快将近 9 年了,我喜欢它的拼写、语法和整体结构的纠正功能。最近,他们推出了 Grammarly AI,允许我通过生成 AI 模型来改进我的写作。这个工具让我的生活变得更轻松,我现在可以写出更好的电子邮件、直接消息、内容、教程和报告。对我来说,它是一个重要的工具,就像 Canva 一样。
7. Hugging Face:构建 AI 的未来
Hugging Face 不仅仅是一个工具,而是一个完整的生态系统,已经成为我日常工作生活中不可或缺的一部分。我用它来访问数据集、模型、机器学习演示和 AI 模型的 API。此外,我还依赖各种 Hugging Face Python 包来训练、微调、评估和部署机器学习模型。
Hugging Face 是一个开源平台,为社区免费提供服务,允许用户托管数据集、模型和 AI 演示。它甚至允许你部署模型推理并在 GPU 上运行它们。在接下来的几年里,它很可能会成为数据讨论、研究与开发以及运营的主要平台。
发现 2024 年使用的十大数据科学工具,成为一个超级数据科学家,比任何人都更好地解决数据问题。
结论
我一直在使用 Travis,一个 AI 驱动的辅导工具,来研究 MLOps、LLMOps 和数据工程等高级主题。它提供了关于这些主题的简单解释,你可以像使用任何聊天机器人一样提问。它非常适合那些只想从 Medium 上的顶级出版物中获得搜索结果的人。
在这篇博客中,我们探讨了 7 个强大的 AI 工具,这些工具可以显著提升数据科学家和研究人员的生产力和效率——从 PandasAI 的对话式数据分析到 GitHub Copilot 和 Colab AI 的代码生成和调试辅助,提供了改变游戏规则的能力,简化复杂的代码相关任务并节省宝贵时间。ChatGPT 的多功能性允许内容生成、代码解释和问题解决,而 Perplexity AI 提供了智能搜索引擎和研究助手。Grammarly AI 提供了宝贵的写作帮助,Hugging Face 则作为一个全面的生态系统,提供数据集、模型和 API,以开发和部署机器学习解决方案。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络开发一款 AI 产品,帮助那些在心理健康方面挣扎的学生。
更多相关话题
AI 转型策略在 GenAI 时代
原文:
www.kdnuggets.com/the-ai-transformation-strategy-in-the-genai-era
AI 战略家擅长为企业构建 AI 路线图和愿景。然而,由于 AI 项目的范围不断变化,将路线图与预期的业务结果对齐变得具有挑战性。

图片来源:作者
因此,至关重要的是不断调整和完善 AI 策略,以确保其与不断变化的业务目标和技术格局保持一致。
但在我们开始制定策略之前,让我们讨论一下 AI 战略家的角色。
AI 战略家的日常生活
AI 战略家熟悉 AI 工作流程,并将业务需求映射到利用 AI 的技术解决方案。他们理解相关的复杂性以及机会估算,并不一定需要了解算法的复杂细节。
让我们深入探讨这三个机会估算的支柱。首先,需要注意的是,有许多创新的方法来解决业务问题,并非所有方法都需要像 AI 那样复杂和先进的技术。
有些问题可以通过规则轻松解决,而其他问题则可以简单地自动化,解决问题到一定程度。
进行这样的评估是分析基准的关键,这涉及到对现有解决方案解决问题的部分进行清点。如果当前解决方案不可接受,那么战略家会通过解释拟议的 AI 驱动解决方案在有效性上的潜在提升及其带来的风险来进行权衡。
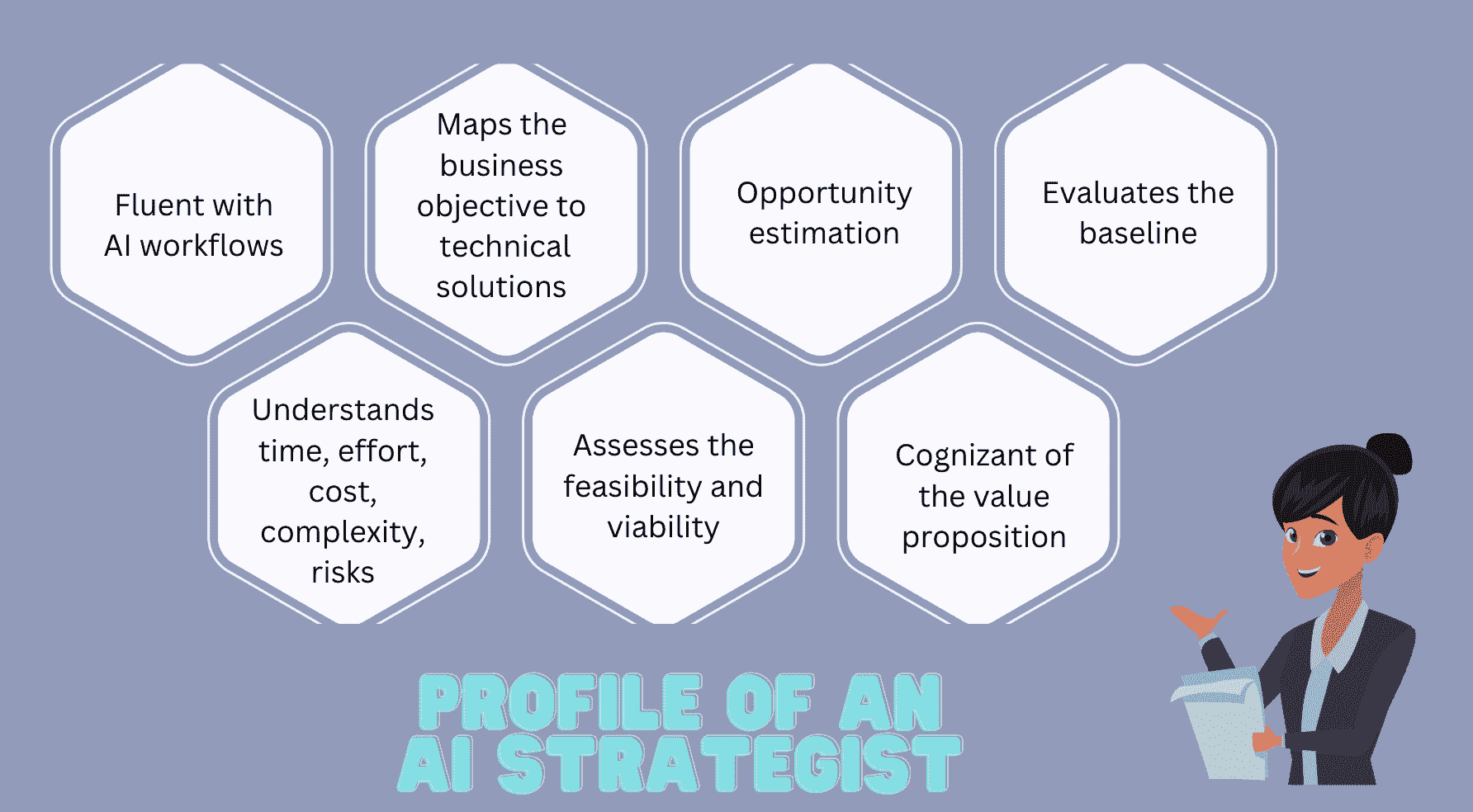
图片来源:作者
首先,战略家确保团队具备 AI 意识,并选择一个先进的解决方案,充分了解时间、精力、成本、复杂性和相关风险。可以公平地说,AI 战略家是 AI 转型成功的关键。
配备强大的商业头脑,AI 战略家通常遵循三个因素来构建成功的路线图:
首先是确保拟议的解决方案在技术上可行。他们识别数据需求,并评估手头的问题是否需要使用 AI。如果数据不可用、未经授权用于模型训练或没有准确的标签呢?这些都属于 AI 战略家的职能范围。
除了可行的解决方案,第二个方面是可行性。即使解决方案可以扩展,人工智能策略师也会从技术与商业的角度评估所提议的模型开发是否在财务上对商业目标具有可行性。如果成本效益分析表明,新人工智能/机器学习模型开发的预期收益无法证明其建设成本的合理性,那么最好放弃这个想法。
任何解决方案只有在提供价值时才是好的,这通常是一项挑战。价值可以表现为新的收入来源、商业差异化、通过自动化提高效率的改进流程等等。人工智能策略师有一种详细的方法来定义人工智能举措背后的价值主张。
人工智能转型
在当今迅速发展的技术环境中,诸如数字转型或人工智能转型这样的术语可能显得不相关。
有人可能会问,企业需要不断创新,利用新兴技术并适应市场变化。那么,当创新是持续进行的事情时,我们如何定义转型呢?
让我们简化并理解进行这种多年的业务演变背后的核心原则。
转型往往是组织认识到需要重新审视传统商业方式的转折点。他们明白,现有的经营模式不可持续,导致失去竞争优势,从而影响增长。

图片来源:作者
因此,他们尝试的想法数量快速增加,并迅速流入渠道,使实验在规模上奏效。这就是组织从拥有多年人工智能转型经验的人工智能策略师那里受益的地方。他们配备了包括适应性框架、系统和流程在内的工具包,这些可以被抽象为成功人工智能转型的策略。
成功转型策略的关键支柱
几年前,当人工智能策略的概念开始成为董事会讨论的焦点时,它引起了所有人的注意。特别是因为存在太多的策略——商业、人工智能和数据策略。
面对众多策略,如商业策略、数据策略以及现在的人工智能策略,很容易感到困惑。以下是这三种策略如何协调工作的方式。
商业策略和愿景始终位于首位。清晰的商业愿景、关键的增长驱动因素和与商业目标一致的路线图是至关重要的。一旦商业领袖决定了“为什么”和“什么”,接下来就是“怎么做”。
AI 策略师与技术专家关注的是如何通过技术实现商业愿景。需要注意的是,技术只是一个推动者。因此,AI 策略来源于商业策略, 这意味着需要大量时间来理解商业——护城河和竞争优势。
然而,AI 不能独立工作,它需要核心数据来建模现象。因此,它与数据策略密切配合。

图片由作者提供
设计成功的 AI 策略的下一个重要方面是确保 AI 团队不做任何大胆承诺。 这与 AI 策略师评估提议的可行性有关。AI 项目带来了很多“未知的未知”,因此必须考虑到预见的和不可预见的风险。
模型已经准备好,但如果它不符合负责任和道德的 AI 构建原则,就没有什么用处。想象一下,花费大量资金构建 AI 流水线和工作流,数据到位,预测也运行良好。
但只能意识到数据存在偏见,包含个人识别信息,或者像透明度和可解释性这样的基本而关键的问题。
需要注意的是,预测没有用,直到有人采取行动,而没有人能对预测采取行动,直到他们信任这些预测的来源和方式。
因此,AI 治理,包括关于角色和职责的详尽文档(如果出现问题,需明确所有权)以及数据收集、转换和训练集的过程,是成功实施的关键驱动因素。
结论
理解商业、数据和 AI 策略的三位一体,以及 AI 策略的关键支柱,对于引导组织成功进行 AI 转型至关重要。
Vidhi Chugh** 是一位 AI 策略师和数字化转型领袖,致力于在产品、科学和工程的交汇处构建可扩展的机器学习系统。她是一位屡获殊荣的创新领袖、作者和国际演讲者。她的使命是普及机器学习并打破术语,让每个人都能参与这场变革。
更多相关主题
有效提示工程的艺术,免费课程和认证
原文:
www.kdnuggets.com/the-art-of-effective-prompt-engineering-with-free-courses-and-certifications

图片由作者提供
大型语言模型已经成为我们日常和职业生活的一部分。我们使用像 ChatGPT 这样的工具来帮助我们处理日常任务,如营销策略、数据分析等。然而,当我使用这些工具时,总会有一个问题浮现在我的脑海中:
‘我是否正确使用它,如果没有,我该怎么做?’
提示工程。
正如麦肯锡所述,提示工程是为生成 AI 工具设计输入的最佳实践,旨在产生最佳输出。
我相信每个使用生成 AI 工具的人都应该掌握这项技能。它不仅帮助你为日常任务生成最佳输出,还可以让你从中找到职业生涯:AI 提示工程师年薪 30 万美元。
说到这一点,我整理了一份免费课程的清单,帮助你提示生成 AI 工具,以产生你想要的输出!
试试:提示工程
链接:试试:提示工程
价格:免费
在一周内,你将能够向 ChatGPT 提出具体问题,以生成你想要的输出。但在你开始工程化有效的 AI 提示之前,了解 AI 的关键概念并能够解释它们是很重要的。掌握这些知识后,你将能够为你的日常任务工程化有效的 AI 提示。
提示工程简介
链接:提示工程简介
价格:免费
假设你了解了 AI 的关键概念,但你需要了解提示工程,它是什么以及如何使用它。这个为期 3 周的课程将帮助你释放生成 AI 工具(如 ChatGPT)的全部潜力。课程由 3 个模块组成,你将学习到编写有效提示的最佳实践和技巧。
提示工程与高级 ChatGPT
价格:免费
想要更进一步?查看这个高级 ChatGPT 课程,它将教你在一周内可以在 ChatGPT 中使用的高级技术。你不仅会学习如何使用高级技巧提示 ChatGPT,还能将其应用于多个用例,与其他工具集成并开发应用程序。
生成 AI 适合每个人
链接:生成 AI 适合每个人
价格:目前全程折扣价为£173
也许你想更深入地探索并转变你的职业生涯。你可以通过 IBM 的这个职业证书来实现,它包括 5 门课程,若每周投入 1 到 3 小时,将需要 4 个月完成。这 5 门课程包括:
-
生成式 AI 介绍
-
提示工程介绍
-
生成式 AI 的模型和平台
-
生成式 AI 的影响、伦理和问题
-
利用生成式 AI 提升商业和职业发展
在这 5 门课程中,你将学习生成式 AI 工具的基本概念、应用和能力。你的理解将帮助你应用强大的提示工程技巧来编写有效的提示,并能够探索诸如基础模型和预训练模型等生成式 AI 模型。你还将深入了解生成式 AI 工具的局限性和误用、伦理考虑及其对企业的变革性影响。
总结
就这样,你已经能够改造你的日常任务,并确保你在产生最佳结果。虽然这可能感觉像是另一个需要学习的东西,但是,一旦掌握了它,你不会后悔的!
尼莎·阿里亚 是一名数据科学家、自由职业技术作家,以及 KDnuggets 的编辑和社区经理。她特别感兴趣于提供数据科学职业建议或教程以及围绕数据科学的理论知识。尼莎涵盖了广泛的话题,并希望探索人工智能在延续人类生命方面的不同方式。作为一个热衷学习者,尼莎寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关内容
增强科学家系列 第一部分:机器学习在 SEM 图像分类中的实际应用
评论
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织中的 IT 工作
欢迎来到我们增强科学家系列的第一篇博客,在这里我们将探讨机器学习如何改善科学家日常工作的方式。随着这一系列的展开,我们将深入挖掘更多机器学习的应用,以作为科学研究的辅助工具,去除大量重复的分析工作,使科学家能更深入地探索他们的领域。我和我的妻子都来自科学背景,她是化学专业的,我是物理专业的。当我开始从事机器学习时,我被它加速处理繁琐分析工作的巨大潜力所打动,这些工作在研究实验室中消耗了大量时间。
作为我们对增强科学家概念的第一次探索,我们的目标是看看我们能否建立一个分类器,识别扫描电子显微镜(SEM)图像中的模式,并将我们分类器的性能与当前的最先进技术进行比较。后续文章将探讨 SEM 图像分类的更集中应用。
什么是 SEM?
我们将首先关注 SEM 图像分析,这是我妻子作为电化学家在职业生涯中广泛使用的技术。SEM 广泛用于化学和生物学中,以纳米尺度创建表面图像。它通过用聚焦的电子束扫描表面来工作。电子从表面反射,形成表面的形貌和成分图像。

来源:en.wikipedia.org/wiki/Scanning_electron_microscope
这种详细成像有广泛的应用,每种应用有不同的分析需求,比如优化生物传感器中的电极表面,或在燃料电池中产生电力。表面的结构可以告诉我们很多关于物体的属性和特征。
之前的工作:
在这篇博客文章中,我们将查看是否能在Modarres et al 2017的工作基础上取得任何进展,他们之前研究了分类 18,577 张 SEM 图像的模式(你可以在这里找到数据集)。这些示例展示了 Modarres et al 2017 数据集中分类的模式类型,包括 Tips、Particles、Patterned Surfaces、MEMS devices 和 electrodes、Nanowires、Porous Sponge、Biological、Powder、Films Coated Surfaces 和 Fibres。

来源:www.nature.com/articles/s41598-017-13565-z#Sec2
下表显示了各类别中图像的分布。
来源:www.nature.com/articles/s41598-017-13565-z#Sec2
使用预训练的 Inception-v3 模型,该模型在 Tensorflow 中实现,Modarres 等人达到了约 90%的准确率,约 80%的精确率和约 90%的召回率@1。Modarres 等人还报告称,数据集中的不平衡对分类器在准确预测欠代表类别方面没有影响。他们的混淆矩阵(见下图)显示,人口最少的类别,如多孔海绵、涂层表面和纤维,都表现得相当好。Modarres 等人将此归因于这些类别的独特模式。(注意:Modarres 等人混淆矩阵中展示的值是每个实际/真实标签的验证样本的百分比)
来源:www.nature.com/articles/s41598-017-13565-z#Sec2
在这一点上需要记住两件事:Modarres 等人没有使用任何数据增强技术,而 Inception-v3 实现的训练过程在 2 个 GPU 上花费了大约 7 分钟。
我们的方法:
想要看看是否能比 Modarres 等人取得更高的准确率,我们在进行了一些自定义修改后重新进行了他们的研究。首先,我们使用了 Fastai v1 框架上的 Resnet 50 实现,并在 Colab GPU 上执行。为了避免过拟合,我们采用了 Fast.ai 介绍的两种方法:数据增强和渐进式调整大小。
数据增强:
数据增强本质上是改变/扭曲每张图像,有效地创建一张新图像。Fastai v1 有一个很好的工具叫做 get_transforms,处理这个过程。函数get_transforms以多种不同的方式转换图像,例如翻转、旋转、改变对比度和扭曲,这意味着小数据集实际上变得更大。

资料来源:docs.fast.ai/vision.transform.html
进阶调整大小:
进阶调整大小是Jeremy Howard在Fast.ai提出的一种方法。这个概念是将数据集中的图像裁剪成更小的尺寸,然后在裁剪图像上训练模型,接着增大图像尺寸并再次训练模型。我们重复这个过程多次,每次增加数据集中图像的尺寸。在这种情况下,我们从 64x64 像素的图像开始。我们在这个数据集上训练了 Resnet 50,总共 15 个 epoch,然后将其逐步增大到 128,最后到 224。进阶调整大小有两个优点。首先,很多早期训练是在较小的图像上进行的,这意味着计算成本较低,训练时间更短。其次,反复更改图像的大小并重新训练模型可以使模型过拟合变得非常困难。这意味着你的最终模型在以前从未见过的新数据上会更稳定。
结果:
我们的实现可以在我们的 GitHub 仓库中找到,这里。我们实现了 94.5%的总体准确率,比 Modarres 等人之前的最新技术提高了超过 4.5%,尽管我们的训练过程确实花费了近 400 分钟。考虑到数据集的不平衡,考虑其他指标如精确度和召回率是有用的。精确度本质上是正识别的比例实际上是正确的,而召回率是实际正样本中被正确识别的比例。尽管我们的模型稍有过拟合,但实现了 94.2%的精确度和 91.8%的召回率。与 Modarres 等人报告的约 80%和 90%相比,这表明我们的模型在数据集中表现出更好的表现。
结论:
希望你喜欢我们增强科学家系列的第一篇博客文章。这个系列将探讨更多机器学习可以用于协助科学家在各个学科中的工作的方法。如果你有兴趣参与,或有使用机器学习增强自己工作的例子,请告诉我们,我们很乐意听到你的意见。
简介:Iain Keaney (@Iain_Keaney)是 Skellig.ai 的机器学习工程师和项目协调员。你可以在这里找到Skellig.ai 博客。
原文。经许可转载。
相关:
-
使用更少数据进行图像分类的深度学习
-
部署机器学习模型是什么意思?
-
使用 Keras 简化图像分类的单一函数
更多相关内容
自家研发的大型语言模型案例
原文:
www.kdnuggets.com/the-case-of-homegrown-large-language-models
大多数著名的 LLMs 擅长广泛使用的语言,如英语,但未涵盖能够有效服务全球文化和地区细微差别的语言多样性。

图片来源:作者
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您在 IT 领域的组织
好处
建立自家研发的 LLMs 是一个重要的技术进步,值得称道。它为每个人参与数字化转型树立了先例,为双方带来了双赢——既能更广泛地接触到客户,又能使企业扩大覆盖范围,联系并服务全球多样化的客户群体。
AI 在许多应用中找到吸引人的用例,同时处理认知过载、信息获取的便捷性和增强客户体验。
训练于多种语言背景的 LLMs 涵盖了所有三个领域,提供了便捷且及时的信息获取。这种触手可及的知识促进可以帮助许多地方社区获得急需的帮助和支持,以解决他们的咨询。
挑战
虽然我们已经探讨了建立此类模型的诸多优点,但同样重要的是指出,模型开发需要接触本地语言的数据。不言而喻,这一过程起初可能会显得具有挑战性,但并非无法实现。
事实上,当数据收集过程在规模上高效建立时,它迅速成为地方社区的福音,尤其是在数据标注方面(更多内容将在后续部分介绍)。

图片来源:作者
此外,开发 LLMs 需要高性能的计算基础设施,如 GPU 和云计算服务,这些是昂贵的,并且需要赞助商/合作伙伴提供资金支持。
毋庸置疑,任何国家的成功都依赖于打造更便宜、更节能的芯片,以构建下一代 AI 模型。同时,需要增加研发资金,以促进学术界、工业界和政府之间的广泛合作,汇聚智力资源。
数据不是新石油?
数据不再是新的石油,但知道如何处理如此大量的数据的人变得更为重要,这提高了对节能芯片的需求。
除了软件,开发本地语言训练的模型需要资助前沿技术的研发,并在硬件方面建立自给自足。此外,大型模型严重依赖需要大量电力的数据中心,这就提高了对节能芯片的需求。
伦理视角
这让我们感受到一种统一感,我们正在让每个人都成为这一技术突破的一部分,同时,他们也成为了数字世界即数据的一部分,因此下一波的新模型也会包括他们,从而解决未来的误代表问题。
用本地语言训练的 LLM 不仅会在数据领域占据主导地位,还会在推广多样文化方面发挥重要作用。
工作和机会创造
虽然大多数人认为 LLM 可能对就业部门产生负面影响,但它也有积极的一面。这是一个双赢的局面,因为它为技术开发者以及整个技术栈中的参与者提供了就业机会。
此外,消除非英语使用者使用技术的障碍可以在有意义的方式上改善他们的生活。这可以打开机会的大门,让他们成为如何运行世界的积极参与者。
更多的工作岗位将会被创造出来。虽然创建多样化的数据在表面上看似是一项挑战,但一旦高效地大规模完成,它很快就会成为为贡献者提供工资机会的机会。本地社区可以参与这种数据生成活动,并在基础层面参与这场革命,同时因其贡献而获得工资和版权的认可。
数字化是平衡器
知识获取是最大的杠杆,而数字化是一个巨大的平衡器。据报道,发展中国家的“教师、律师、医生支持”与“人口”的比例明显低于发达国家,这清晰地突出了一条可以通过帮助客户在早期解决问题或获得下一步指导的应用程序来高效弥合的差距。如果用户对 AI 驱动的聊天机器人的对话语言感到舒适,这将变得可行。

图片作者
考虑像农业这样的领域,在这些领域,LLM 可以帮助农民克服语言障碍。农民可以获得关于灌溉最佳实践和提高水资源使用效率的指导。
再举一个医疗保健领域的例子。理解这些保险政策中的复杂领域特定术语对我们所有人来说都是具有挑战性的。开放一个能够利用其适应性教学风格来用人们理解的语言教育所有社区的聊天机器人,是促进平等的重要举措。
数字统一
包含多种语言的 AI 模型有助于缩小数字鸿沟,并将每个人带入这些技术进步带来的机会画布上。最重要的是,这种包容性将必要的重点放在边缘化群体上,使他们成为这场革命性变化的关键参与者。它通过为地方群体提供公平的访问来考虑伦理问题。
Vidhi Chugh是一位人工智能战略家和数字化转型领导者,致力于在产品、科学和工程交汇处构建可扩展的机器学习系统。她是一位获奖的创新领导者、作家和国际演讲者。她的使命是普及机器学习,并打破术语,使每个人都能参与这场转型。
更多相关内容
SQL 执行顺序的基础指南
原文:
www.kdnuggets.com/the-essential-guide-to-sql-execution-order
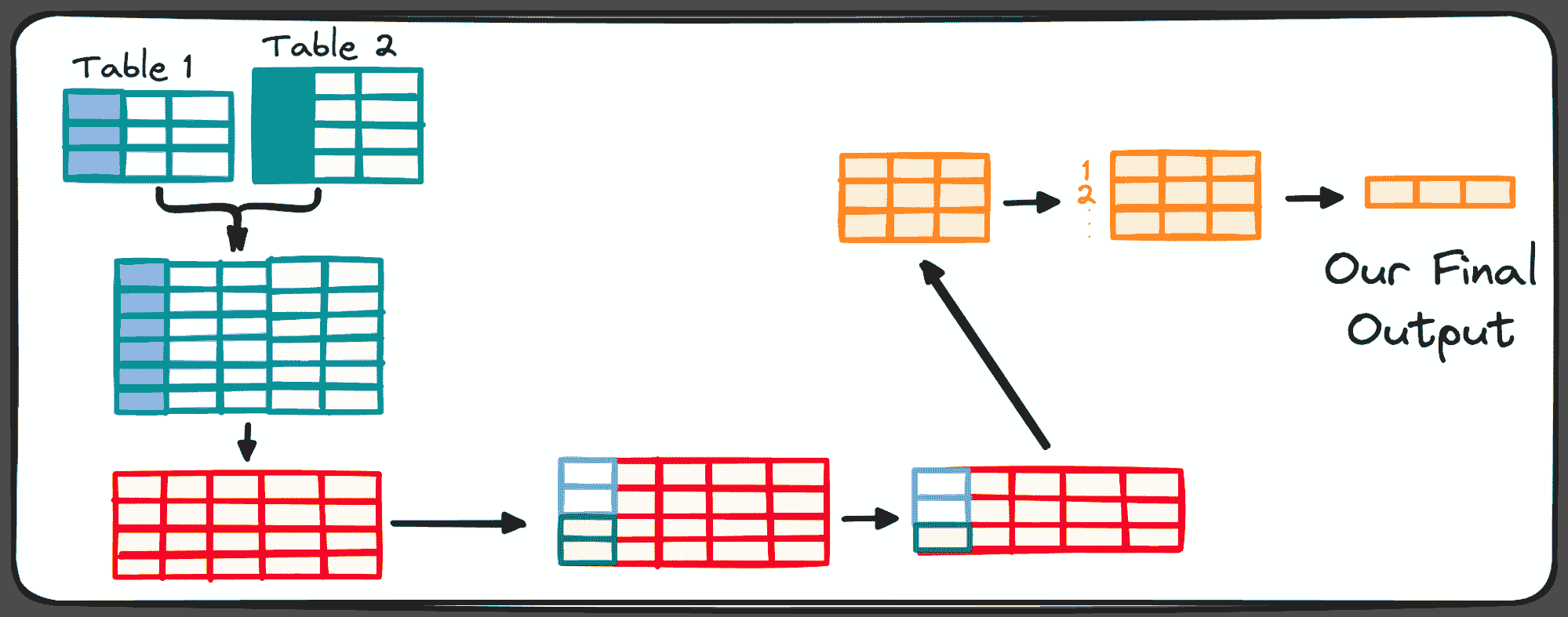
作者提供的图片
SQL 已成为任何数据专业人员的必备语言。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
我们中的大多数人在日常工作中使用 SQL,经过多次编写查询后,我们都会形成自己的风格和习惯,无论好坏。
SQL 通常通过使用来学习,而且在大多数情况下,人们通常不了解其背后的逻辑。
这就是为什么今天我们要深入探讨 SQL 执行顺序的迷人世界,其中事件的顺序有时可能像谜题一样。
因此,让我们通过关注最常见的 SQL 查询结构来进一步完善我们的理解。
SQL 作为一种声明性语言
首先要了解的是 SQL 是一种声明性编程语言,这意味着我们指定期望的结果,但不指定实现它所需的步骤。
这与过程性语言相反,过程性语言定义了实现期望输出所需执行的每一步。
但这意味着什么呢?
这意味着 SQL 需要以特定的语法编写命令。然而,我们编写这些命令的顺序与 SQL 处理它们的顺序并不一致。
通常,查询的展开结构如下:

作者提供的图片
即使一个人按照之前的结构阅读和编写代码,但在考虑这些代码如何执行时,顺序会完全改变。
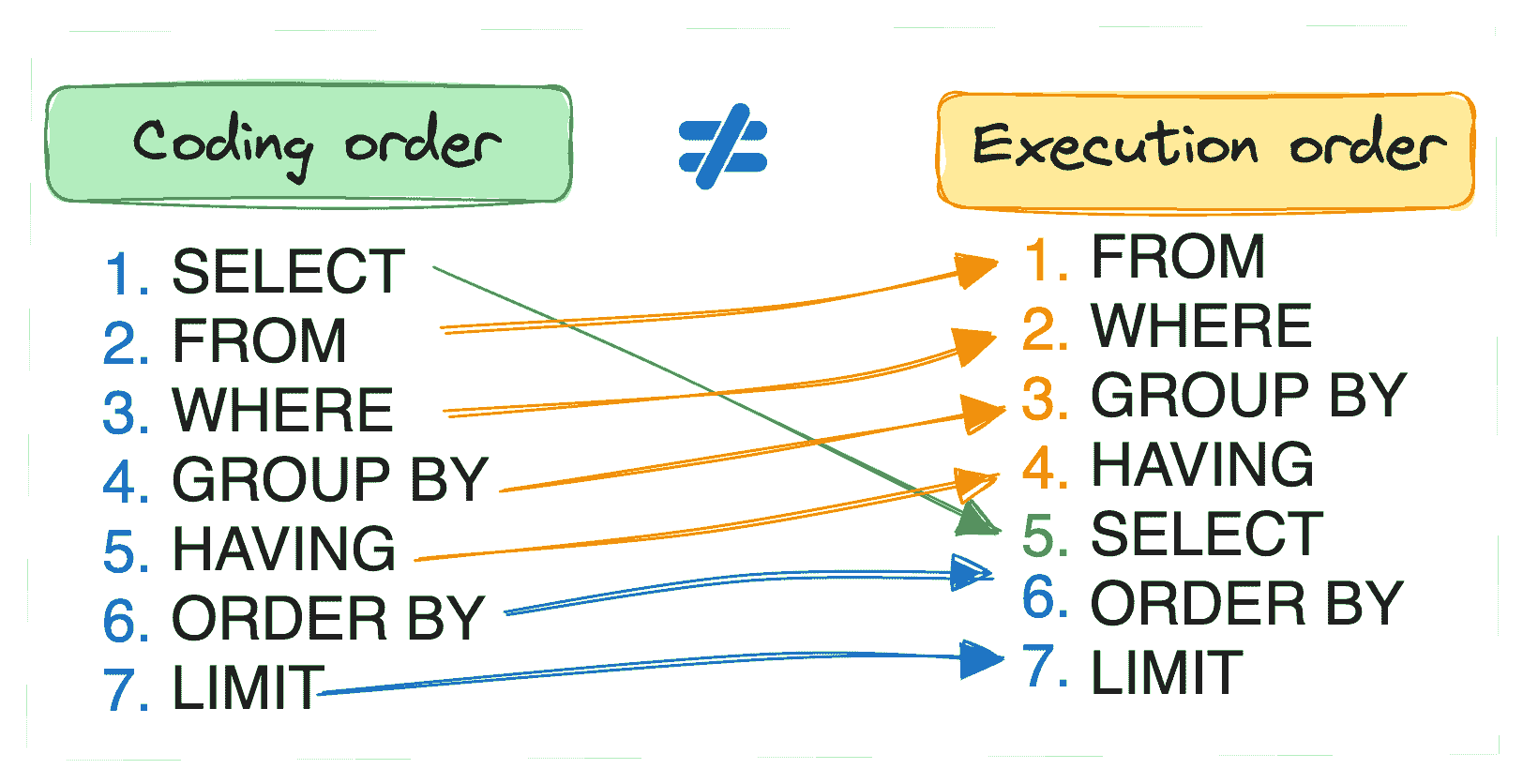
作者提供的图片
例如,尽管 SELECT 子句写在第一行,但它的计算直到几乎最后才会进行。
执行顺序的可视化表示
为了进一步理解这个执行顺序,让我们逐步探讨 SQL 对每条命令的处理。
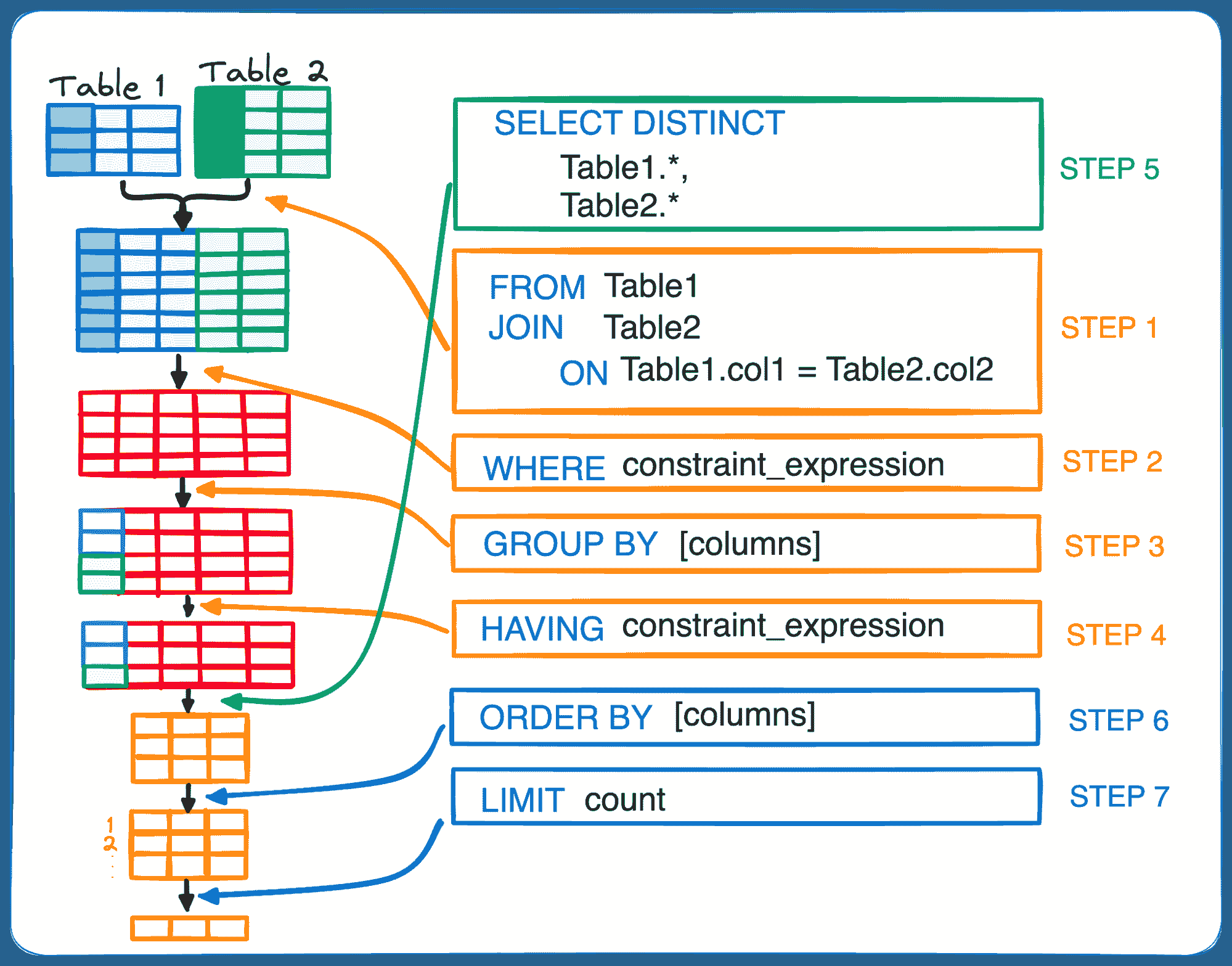
作者提供的图片
第一步 - FROM 和 JOIN
SQL 查询的旅程始于 FROM 子句,它指向数据的来源。虽然简单查询可能只涉及一个表,但我们所需的数据通常分布在多个表中。
这时,JOIN 命令与 FROM 一起,介入数据的合并工作。
这一配对总是引领开场,通过明确数据的角色来设定查询的基础。
第 2 步 - WHERE
在初步选择后,WHERE 子句成为焦点。
它的主要作用是筛选基础表或连接操作后的合并结果,确保只保留满足特定条件的行。
第 3 步 - GROUP BY
GROUP BY 子句介入以组织数据,将其按一个或多个列中的值分组。这使我们能够执行聚合或汇总。
把它看作数据的指挥家,将众多变量减少为每个唯一元素或元素组合的单一值。
这个子句是数据聚合的核心命令,为使用如 COUNT()、SUM()、MIN() 和 MAX() 等函数进行汇总表演奠定了基础。
第 4 步 - HAVING
HAVING 子句作为筛选器,去除那些未能满足设定标准的分组。
想象它作为一个守门员,确保只有符合我们聚合条件的分组被允许继续。它在 GROUP BY 子句完成后介入,使我们能够对现在的聚合数据应用过滤器。
在这一点上,数据库已经知道计算后的聚合结果,这意味着我们可以在后续的语句中使用这些聚合值。
解决 WHERE 子句为何不能调用聚合变量而 HAVING 子句可以的问题:
这是因为 WHERE 在 GROUP BY 子句之前出现,那时单个数据点尚未被编组。而 HAVING 则在 GROUP BY 已经计算完成后进行。
第 5 步 - SELECT
SELECT 子句定义了我们希望在表中保留的列,以及在执行过程中计算出的任何分组或聚合字段。
在这里,我们可以使用 AS 运算符应用列别名。
SELECT 命令通常与 DISTINCT 一起使用,这样可以丢弃所有标记为 DISTINCT 的列中具有重复值的行。
第 6 步 - ORDER BY
在基础任务完成后,ORDER BY 子句介入,安排值的排序展示,按升序 (ASC) 或降序 (DESC) 排列。
想象这作为查询的最终阶段。
我们从源表中收集了数据,通过过滤器进行精炼,创建了有意义的分组和汇总,并确定了在最终输出中展示的列。
第 7 步 - LIMIT
最后,LIMIT 子句帮助定义我们希望返回的行数。
在处理大型表格时尤其有用,特别是在开发和测试阶段。
为什么这很重要?
理解 SQL 的执行顺序一开始可能显得微不足道,特别是当查询结果正确时。
如果引擎运行良好,为什么要过分纠结于机制呢?
然而,对于那些深入复杂查询的研究者来说,了解这种顺序不仅有用——而且至关重要。
没有这种洞察力,故障排除就会变成一片混乱,错误像四处潜伏的陷阱。为了熟练调试和更顺利地编写查询,掌握 SQL 如何处理其子句至关重要。两个常见的错误是:
错误 1
SQL 中的一个常见陷阱是尝试使用 WHERE 子句来过滤聚合数据,这是一个会导致错误的误步骤。

图片由作者提供
正如我们在本文中所见,WHERE 子句是在 GROUP BY 子句之前计算的,因此,我们不能在 WHERE 步骤中使用聚合值。
错误 2
引用尚未设置的聚合值的列别名。在这种情况下,我们不能使用在同一 SELECT 中定义的别名,因为计算阶段是相同的。
因此,SQL 目前还不知晓这个新别名。

图片由作者提供
最终结论
理解 SQL 的执行顺序对数据专业人士编写有效、高效的查询至关重要。
这种洞察力使我们能够预测查询行为,特别是在复杂数据集的情况下。
精通 SQL 不仅涉及语法,还需要掌握其逻辑以进行战略性数据操作。
我们一起经历的旅程,从 FROM 子句到 LIMIT,是处理数据和将信息塑造成特定需求的战略蓝图。
希望下次你编写 SQL 代码时,能记住这一执行顺序!
Josep Ferrer**** 是一位来自巴塞罗那的分析工程师。他毕业于物理工程专业,目前从事应用于人类流动性的数据显示科学工作。他还是一名兼职内容创作者,专注于数据科学和技术。Josep 涵盖了 AI 领域的所有内容,关注领域中的持续爆炸性应用。
更多相关内容
生成式 AI 泡沫即将破裂
原文:
www.kdnuggets.com/the-generative-ai-bubble-will-burst-soon

作者提供的图像
生成式 AI 革命引起了科技界的想象。ChatGPT 和类似工具似乎预示着一个新的可能性时代,在这个时代里,AI 可以按需生成内容、艺术,甚至编程代码。风险资本大量涌入生成式初创公司,总融资额达数千亿美元。但在兴奋之中,有些人开始质疑——这是一个即将破裂的泡沫吗?
这个模式似乎很熟悉。一项热门的新技术出现,并立即被视为改变世界和变革性的。大量资本涌入,估值飙升,炒作压倒了理性分析。这就是 90 年代末的互联网泡沫,当时没有收入或商业模型的互联网初创公司达到了令人眩晕的市值。结果在 2000 年一切崩溃了。
什么是互联网泡沫?
互联网泡沫,也称为 Dot-com 泡沫,是指在 1990 年代末期,对互联网公司进行过度投机和投资的时期。这种经济狂热源于对互联网变革潜力的信念。然而,泡沫最终破裂,导致股价崩溃和许多初创公司的倒闭。
许多互联网公司建立在脆弱的商业模型上。它们缺乏稳定的收入来源或盈利能力,严重依赖投资者资金。重点通常放在抢占市场份额和用户增长上,而不是产生利润。
随着互联网公司努力实现盈利,现实逐渐显现。最初的兴奋和乐观开始消退,因为越来越明显的是,这些公司在长期内并不可持续。投资者开始质疑这些企业的可行性。
互联网泡沫在 2000 年代初期破裂。股价经历了显著下跌,导致大量互联网公司破产。到 2000 年 10 月,曾在 3 月达到峰值的 NASDAQ 指数下跌了 76.81%。像思科、英特尔和甲骨文等大公司失去了超过 80% 的股值 - 互联网泡沫 - 维基百科.
来源于 维基百科
生成式 AI 泡沫将如何破裂
生成式 AI 的快速增长和炒作具备了经济泡沫的所有特征。生成式 AI 模型如 DALL-E 2 和 GPT-4 捕获了公众的想象,并吸引了数十亿美元的投资。但这种热情可能证明难以持久。
像所有泡沫一样,生成型 AI 热潮建立在对未来能力的投机预期之上。投资者在押注这些技术将继续快速进步并找到有利可图的实际应用。然而,这些预期可能会超前于现实。
一些因素可能会戳破泡沫。其一是当今生成型 AI 的局限性。虽然这些模型令人印象深刻,但它们仍然生成低质量的输出,无法满足许多任务的可靠性要求。而且,训练越来越大的模型需要指数级增加的数据和计算能力,这引发了关于可扩展性的疑问。
随着炒作与现实的碰撞,生成型初创企业的估值可能被证明是不切实际的。由于未达成里程碑、缺乏利润和新颖性丧失,资金可能会枯竭。一旦增长停滞,股票价格很可能会暴跌。
过去的经验表明,热门新技术往往经历炒作周期,然后才会展现出真正的能力。虽然生成型 AI 具有前景,但投资者应当警惕非理性繁荣。可持续的价值需要将能力与适当的应用场景相匹配,而不是将其视为万灵药。
关于生成型 AI 泡沫的担忧
鉴于需要克服的多个问题,AI 泡沫的担忧可能会持续存在。尽管已经有大量公司利用了这一技术,但生成型 AI 的大规模采用仍处于相对初期阶段。随着更多公司采用生成型 AI,这些担忧可能会加剧。如果确实发生了 AI 泡沫,那将是由于以下原因。
采用放缓
已经有迹象显示生成型 AI 的采用在放缓。人们开始倾向于欣赏人类的创作工作,而不是仅仅依赖 AI 生成的内容。这种对人类创意的偏好可能会阻碍生成型 AI 的增长和广泛采用。
资本要求
许多 AI 领域的初创公司依赖 API 调用和预训练模型,因为训练自己模型的资本要求很高。这种资本不足可能会限制生成型 AI 领域初创公司的增长和创新。
经济因素
预测将要发生的全球经济衰退可能会对 AI 行业产生重大影响。投资者可能会变得更加谨慎,开始从市场上撤资,从而导致对 AI 初创公司的资金减少。
法律和伦理问题
生成型 AI 引发了关于其生成内容的所有权和控制的法律和知识产权问题。还有对 AI 系统训练数据带来的伦理和偏见问题的担忧。这些问题可能导致对生成型 AI 的监管增加,限制其使用,从而使企业创新变得更加困难。
结论
生成型 AI 行业的未来仍然不确定,关于生成型 AI 泡沫可能破裂的担忧也在增加。虽然很难预测何时会发生这种情况,但许多人正急切等待其结果。
生成式 AI 的主要问题之一是所需的高投入和技术的可复制性。这些因素导致了对行业可持续性和长期成功的 uncertainty。
为了减轻生成式 AI 泡沫的风险和潜在崩溃,关键在于将重点从创建华丽的产品演示转移到构建实际的商业用例。这种方法需要时间和精力来开发和实施,但它有助于确保行业的稳定和增长。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为正在与心理健康问题斗争的学生打造一个 AI 产品。
更多相关主题
LLM 基于自主体背后的增长
原文:
www.kdnuggets.com/the-growth-behind-llmbased-autonomous-agents

图片来源 | DALL-E 3
2023 年发生了很多事情。我们见证了大型语言模型(LLM)的增长和出现,及其作为自主体的基础控制器的特殊使用。我们亲眼见证了许多人采用这些自主体,并将其整合到组织中,更多公司也对 LLM 感兴趣。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 加速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
是的,它们确实取得了成功。
但你不想了解更多吗?当然,你想。
基于 LLM 的自主体调查
来自中国人民大学高岭人工智能学院的研究人员汇聚一堂,进行了一项基于 LLM 的自主体的全面调查,在其中,他们从整体角度对基于 LLM 的自主体领域进行了系统的回顾。
研究人员深入探讨了基于 LLM 的自主体的构建,以及对社会科学、自然科学和工程等多个领域的多样应用进行了全面概述。
所以,让我们深入了解吧。
以下是基于 LLM 的自主体领域的增长趋势图,通过 2021 年 1 月至 2023 年 8 月发布的论文数量展示。
如你所见,在两年的时间里,LLM 取得了显著成功,向公众展示了 AI 应用有潜力达到类似人类的智能。全面的训练数据集和大量的模型参数齐头并进,以实现这一目标。
因此,看起来这个领域投入了大量的资金和研究,因此必须提供对这一迅速发展的领域的系统总结,以全面了解其复杂性及其带来的益处,激发未来的研究。
这正是来自高岭人工智能学院的研究团队所做的工作。
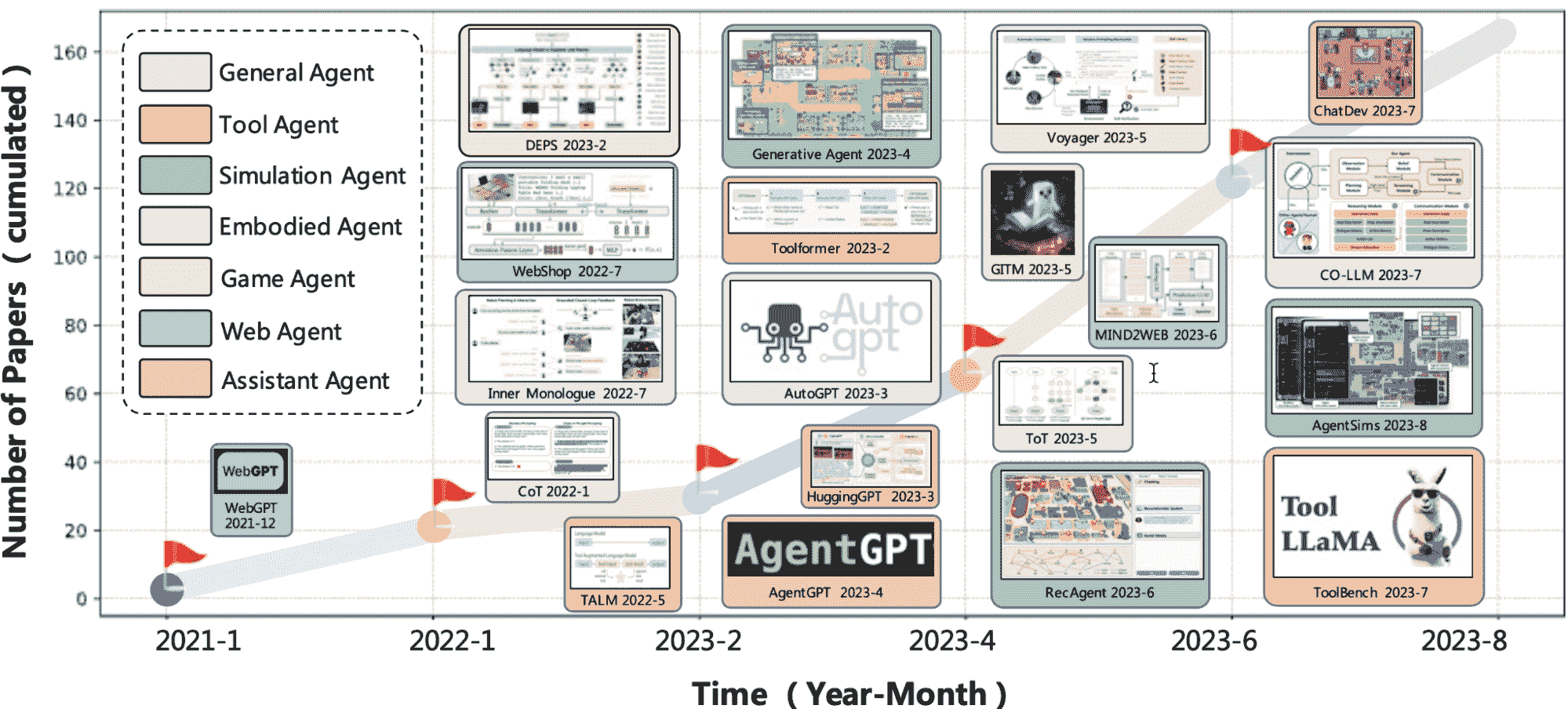
图片来源:LLM-Agent-Survey
LLM 基础自主智能体的架构设计
基于 LLM 的自主智能体的最终目标是使其具备执行各种任务的能力,如同具有人类能力一样。要实现这一目标,你需要进一步研究 LLM 基础自主智能体的架构设计:
-
应设计哪种架构以更好地利用 LLMs
-
如何使智能体具备完成特定任务的能力
作为系统审查的一部分,研究人员认识到 LLMs 需要履行特定角色并自主地从环境中学习,以像人类一样进化。这就是设计合理智能体架构发挥作用的地方。
研究人员提出了一个统一框架来总结开发的模块数量,以增强 LLMs:
-
配置文件 - 确定智能体的角色
-
记忆 - 将智能体放入动态环境中并使其能够回忆过去的行为
-
计划 - 将智能体放入动态环境中并规划未来的行动。
-
行动 - 将智能体的决策转化为具体输出
配置文件模块对记忆和计划模块有直接影响,这三个模块共同影响行动模块。
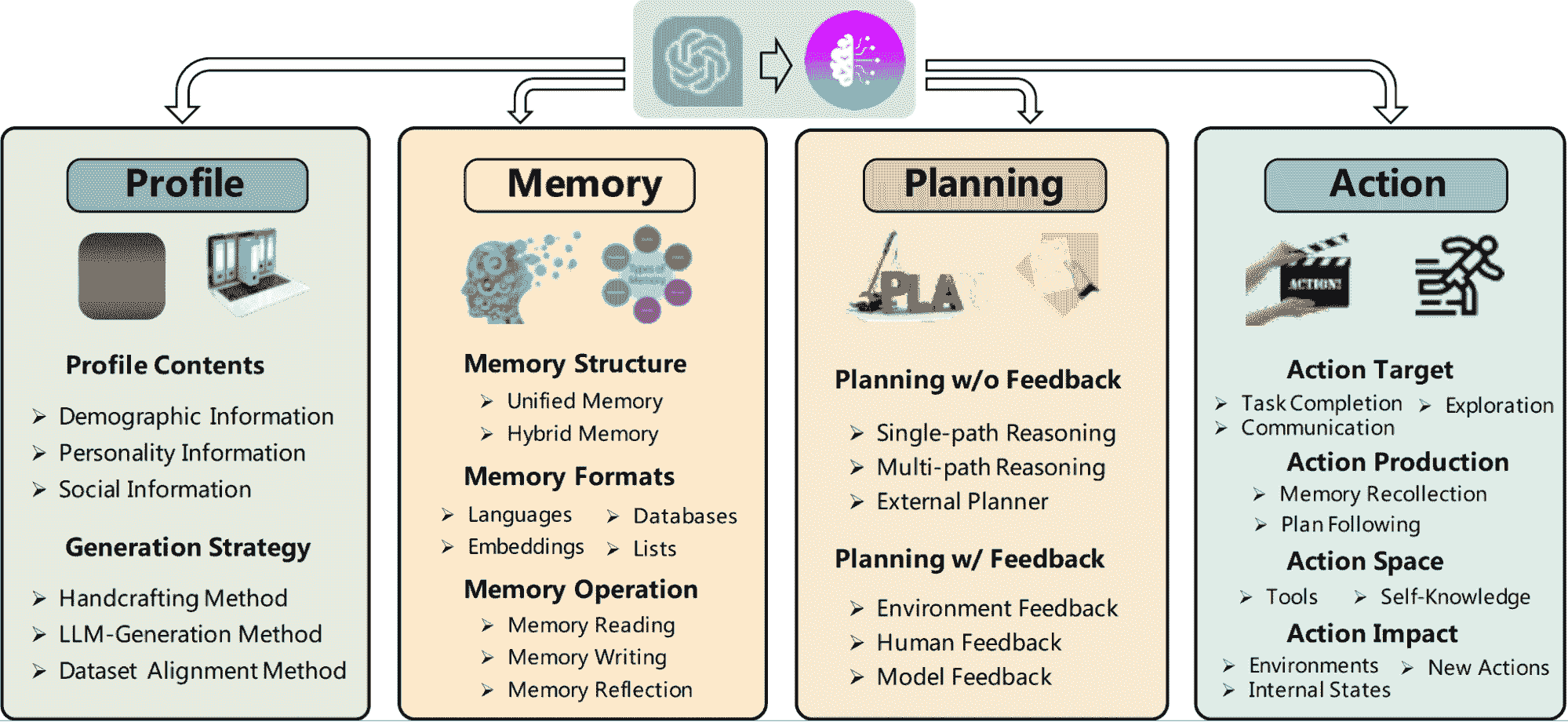
图片来自LLM-Agent-Survey
要深入了解每个模块,请阅读论文:基于大语言模型的自主智能体调查。
在这篇论文中,你可以深入了解 LLM 基础自主智能体的应用以及在社会科学、自然科学和工程领域的评估策略。LLM 基础自主智能体在多个领域展示了显著的潜力,因此,了解这些应用如何评估及所使用的策略非常重要。
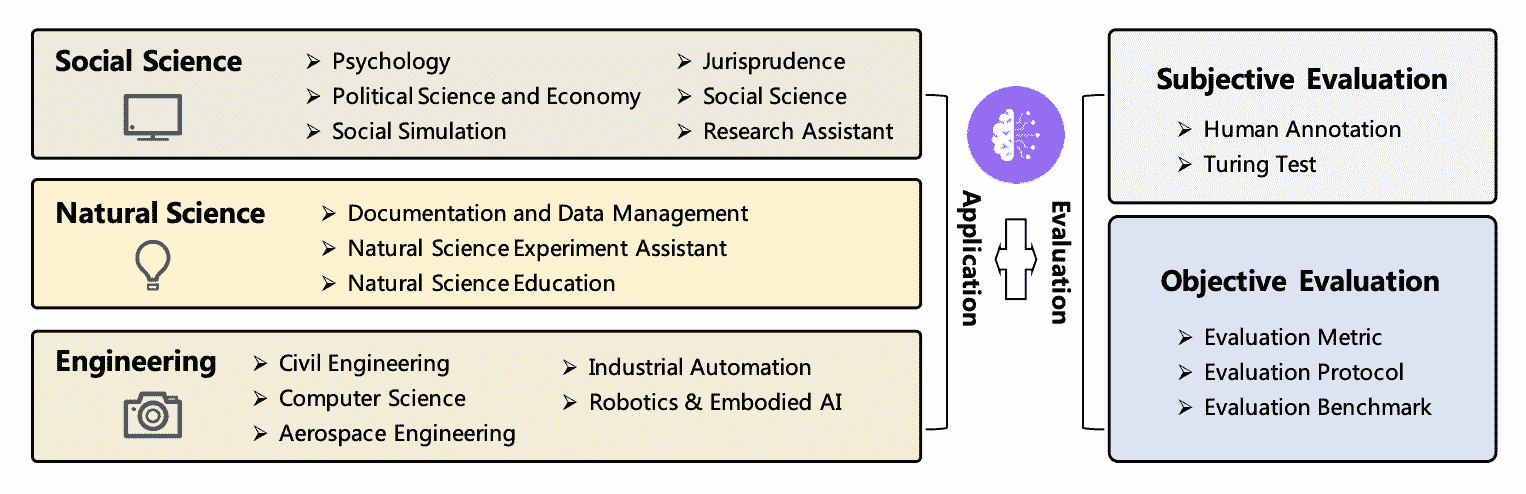
图片来自基于 LLM 的自主智能体调查
作为研究过程的一部分,他们还提供了一个互动表,其中包含更多与 LLM 基础智能体相关的综合论文。
总结一下
正如我们所见,越来越多的人在探讨 LLMs 的细节。更多人想了解它的真正内容、架构、评估策略以及它将如何影响我们的未来。这是为了帮助建立对 LLMs 和 AI 应用程序的一般信任,还是我们将了解到关于它们的真相?
Nisha Arya是一位数据科学家、自由职业技术作家,同时也是 KDnuggets 的编辑和社区经理。她特别感兴趣于提供数据科学职业建议或教程以及理论基础知识。Nisha 涵盖了广泛的主题,并希望探索人工智能在延长人类寿命方面的不同方式。作为一个热衷于学习的人,Nisha 期望拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关主题
人工智能对科技行业的影响
人工智能无处不在,我们都知道通过阅读有关新产品或应用程序的信息来了解它。AI 算法的核心是数据,以数字形式存在。那么,让我们通过数字,也就是统计数据来探讨 AI 对我们生活的影响。约 77%的设备利用人工智能。AI 的一个主要用途,特别是生成性 AI 在类似人类语言交流中的出现,使 85%的 AI 用户可以用它来创建内容。
扩展到整个行业的影响,零售行业领先,其中 72%的零售商采用了人工智能,63%的 IT 和电信行业也在使用它。毫无疑问,这带来了显著的好处。例如,Netflix 利用机器学习技术节省了 10 亿美元。但这种自动化和进步也有另一面,即取代人力劳动。据报道,到 2030 年,智能机器人可能会影响 30%的全球劳动力,影响 3.75 亿个职业。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
尽管数字可能因来源不同而有所变化,但有一点是明确的——人工智能正在迅速改变商业运作方式,并带来利弊。因此,让我们深入分析人工智能对科技行业的影响。
代码助手
AI 算法分析大量数据以生成可操作的商业洞察,帮助组织通过自动化等方式实现效率。

图片来源:作者
说到效率,想象一下 AI 驱动的代码助手如何通过建议自动补全、编写样板代码、检测语法错误、安全漏洞等来帮助开发者进行软件开发。然而,像许多其他 AI 应用一样,建议利用这些工具来增强开发者的生产力;应避免过度依赖代码助手来编写生产级代码。
网络安全
网络安全面临许多挑战,包括每个组织中存在的大量易受攻击的系统或设备、多样化的攻击途径、网络技能专业人员的短缺以及大量的数据。一个自学习的基于 AI 的网络安全系统可以通过持续收集和分析企业系统中的数据来应对这些挑战,提供跨 IT 资产清单、威胁暴露、控制效果、漏洞风险预测、快速事件响应和模型可解释性等领域的智能。

图片由作者提供
这种技术的优势在于它带来了规模和速度,超越了人类能力的限制。像威胁检测和事件管理这样的任务需要分析来自多个来源的实时数据,这些数据可以通过 AI 算法进行主动监控。
AI 驱动的聊天机器人
无论是代码助手还是用于网络安全的 AI 技术,这些都更接近企业,通常对客户不那么显而易见。所以,让我们将焦点转向 AI 生成型智能助手在丰富客户体验方面的最广泛应用之一。

图片由作者提供
客户需要一个平台来进行互动并寻求对其问题和担忧的回应——虚拟助手是满足这一需求的绝佳方式。它随时随地为他们提供信息,触手可及。
传统助手与生成型 AI 助手
然而,这些传统的虚拟助手已经存在了一段时间。那么,生成型 AI 基于的智能助手如何提升整体体验呢?

图片由作者提供
好吧,它们在人类语言对话中的能力使得它们能够非常好地理解上下文。这种上下文学习涉及对语言的细致理解,策划出一个形成良好的响应,以提升客户体验,并缩短解决问题的时间。生成型 AI 助手能够进行更自然、更流畅的对话,从而提供更加个性化的响应。
个性化与机会的世界

图片由作者提供
是的,未来的一切都与个性化有关。它减少了用户需要应用自定义层的认知负担,以满足他们的需求。这是使用 AI 的一个重要驱动力,因为它直接对接特定用户并适应他们的特征。尽管有很多好处,从预测客户行为、推荐、内容创建和报告生成到将 AI 融入现有技术产品以简化用户工作流程和过程,但这段光鲜的 AI 进步故事还有另一面。
另一面:劳动力的颠覆
AI 快速融入商业流程引发了关于工作置换的担忧。AI 用于自动化由人类传统上执行的重复性和日常任务,导致制造业、零售业、客户服务和行政角色等行业的职位被取代。并非所有部门和职业都受到均等影响,事实上也创造了新的职位。像提示工程师、AI 伦理学家、负责任的 AI 与合规官员和 AI 审计员等角色在 AI 驱动的经济中迅速涌现。

图片由作者提供
然而,面临低技能日常工作的劳动力在适应技术变革方面面临更大的挑战。政策制定者、企业和其他利益相关者必须携手应对这些挑战,减轻对工人和社会整体的负面影响。这包括组织培训计划、嵌入终身学习计划和促进新兴行业中的新职位创造。
道德考量
不仅是工人,AI 生成的回应和预测的消费者也同样关注。AI 算法的优良性在很大程度上取决于其训练所用的数据。这些数据可能包括用户信息或敏感细节,如 PII(个人身份信息)。最近,新闻报道了公司在未征得明确同意的情况下使用用户数据来训练模型。这种未经授权使用个人数据的行为侵犯了用户隐私权,是使用 AI 系统时的重要关注点。
图片由作者提供
此外,算法的黑箱特性使得不仅用户,甚至开发者也难以理解模型回应背后的推理。因此,组织必须共同努力建设负责任的 AI,尊重数据隐私,促进模型透明性。虽然 AI 提供了提高效率和创新解决方案的有前景的好处,但必须负责任地解决用户和劳动力的担忧,以充分挖掘其潜力。
Vidhi Chugh是 AI 战略家和数字化转型领袖,专注于产品、科学和工程交汇处,致力于构建可扩展的机器学习系统。她是获奖的创新领袖、作者和国际演讲者,致力于普及机器学习,让每个人都能参与这场变革。
更多相关话题
KDnuggets 2023 备忘单合集
原文:
www.kdnuggets.com/the-kdnuggets-2023-cheat-sheet-collection

图片由作者使用 DALL•E 3 创建
你是否在寻找有关数据科学、机器学习、Python 编程、数据工程和 AI 的各种话题的实用快速参考?你是否想在提升这些领域的技能的同时保持更新?KDnuggets 在 2023 年创建的备忘单合集旨在帮助你实现这些目标。
我们的前三名课程推荐
1. Google 网络安全证书 - 加速你的网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
你会发现这些备忘单是保持你在今年一些最有用和相关工具、技术和概念前沿的宝贵资源。无论你是经验丰富的数据科学家、初露锋芒的机器学习爱好者,还是数据工程专业人士,这些专业制作的资源无疑会提供重要的精华要点。
从 ChatGPT 在数据科学中的实际应用到掌握有价值的数据工具,如 GitHub CLI、Plotly Express 和 cuDF,每份备忘单都旨在提供简明且可操作的见解。学习使用 Streamlit 进行机器学习。探索使用 Python 进行数据清洗。进入 AI 领域,利用有用的 Chrome 扩展和生成性 AI 工具。请把这个合集视为你掌握(并随着时间推移强化)复杂概念和工具的入门途径,确保你在这一领域保持领先。
所以,快去查看 KDnuggets 提供的以下备忘单,看看有哪些见解。
数据科学
ChatGPT(以及最新最强大的 GPT-3 版本)旨在协助(没错,就是协助!)那些决定将其用作工具的用户,借助 KDnuggets 的朋友们的帮助,你将能够磨练你的提示工程技能,做一些有用的事情,比如生成代码、协助你的研究过程以及分析数据。
GitHub CLI,毫无意外,是一个允许通过命令行界面与 GitHub 平台交互的工具。掌握最常用的命令将使你成为开发团队的高效成员,无论是网页应用开发团队,还是更具体来说的数据科学、数据工程或机器学习工程团队。
该作弊单首先介绍了入门内容,如安装库及其基本语法。接下来,资源涵盖了使用 Plotly Express 创建常见图表类型,包括:散点图、直方图、密度热图、饼图、箱线图。最后,你将了解一些图表定制的内容,包括调整标记和布局。
入门 cuDF 非常简单,特别是如果你有使用 Python 和 Pandas 等库的经验。虽然 cuDF 和 Pandas 都提供了类似的数据操作 API,但在某些特定类型的问题上,cuDF 可以提供比 Pandas 显著的性能提升,包括大规模数据集、数据预处理和工程、实时分析以及并行处理。数据集越大,性能提升越明显。
掌握数据科学面试是一项独特的技能,而为面试做准备是成功的关键。正如我曾被告知,学习如何编写大学考试也是一种独特的技能,不仅仅是学习你所被测试的材料,专门的技术职位面试也非常相似。
关于我们认为最好的 10 个数据科学 ChatGPT 插件的概述,请查看我们最新的作弊单,方便地命名为《数据科学的 10 个 ChatGPT 插件》。你会找到用于编码、分析、网页搜索、文档查询等的插件。
机器学习
将机器学习与 Streamlit 结合起来,是数据科学家和其他数据专业人员在数据上进行实验、原型设计或分享结果的热门选择。快速制作数据应用程序已经成为数据专业人士的一项必要技能,这种组合确实可以实现这一点。如果你还不知道如何使用 Streamlit,我们建议你现在就学习。
使用 ChatGPT,构建机器学习项目从未如此简单。只需编写后续提示并分析结果,你就可以快速轻松地训练模型,以响应用户查询并提供有用的见解。在这份备忘单中,学习如何利用 ChatGPT 协助完成以下机器学习任务:项目规划、特征工程、数据预处理、模型选择、超参数调整、实验跟踪以及 MLOps。
Scikit-learn 统一的 API 接口使学习如何实现各种算法和任务变得比以前容易得多。一旦你掌握了如何调用 Scikit-learn 的模式,你就可以开始使用。之后你需要的,除了你的想象力和决心外,还有一个方便的参考资料。这份备忘单涵盖了学习如何使用 Scikit-learn 进行机器学习所需的基础知识,并提供了一个参考,以便你在机器学习项目中前进。
数据工程
Docker 已成为一个不可或缺的数据科学工具,帮助构建可重复和可扩展的环境。Docker 允许将代码和依赖项打包在容器中,这使数据科学家能够在不同的平台上分发他们的模型。这不仅有助于开发和生产,还能防止由于不同版本的软件或硬件配置而导致的错误和不一致。
在图查询中,我们丧失了一些 SQL 语法,但获得了其他语法。SELECT 被 MATCH 替代。FROM 和 JOIN 被舍弃。但 WHERE 和 ORDER BY 命令的使用方式不变。像 SUM 和 AVG 这样的聚合函数仍然存在,但 GROUP BY 被舍弃了。最重要的是,我们获得了使用节点关系在图中查询模式的能力。在附加的备忘单中,你将看到最常用的查询方法列表。
Python 编程
在这份备忘单中,我们从检测和处理缺失数据、处理重复项及解决重复问题、异常值检测、标签编码和分类特征的一热编码,到数据变换,如 MinMax 归一化和标准化。此外,本指南利用了 Pandas、Scikit-Learn 和 Seaborn 这三种最受欢迎的 Python 库所提供的方法来显示图表。
自 goto 时代以来,控制流的状态已经有了很大进步。虽然现代编程语言中的许多常见执行模式都可以使用,但它们的语法因语言而异。Python 具有自己的一套流控制,通常非常可读,这也是我们最新备忘单的重点。准备好学习流控制,并在征服编码世界的过程中拥有一个方便的参考资料吧。
人工智能
这份备忘单中的工具选择包括 SciSpace Copilot,这是一个由 AI 驱动的研究助手,旨在帮助你理解科学文献中的文本、数学和表格。还包括由 GPT-4 驱动的 AI 助手 Fireflies。这个革命性的工具能够浏览网页并总结各种类型的内容,包括文章、YouTube 视频和电子邮件,效率堪比人工。还有更多内容。
一些重点内容包括:使用 OpenAI 访问模型如 ChatGPT、使用 Transformers 进行训练和微调、使用 Gradio 快速构建用户界面以演示模型、使用 LangChain 链接多个模型以及使用 LlamaIndex 吸收和管理私人数据。总体而言,这份备忘单将大量实用指南浓缩成一页。无论是想开始使用 Python 进行生成型 AI 的初学者,还是经验丰富的从业者,都可以从这份浓缩的参考资料中受益。
借助 LangChain,开发者可以在不重新发明轮子的情况下构建强大的 AI 语言应用程序。其可组合的结构使得混合和匹配 LLMs、提示模板、外部工具和记忆等组件变得简单。这加速了原型开发,并允许随着时间的推移无缝集成新功能。无论你是想创建一个聊天机器人、问答机器人,还是多步骤推理代理,LangChain 都提供了快速组装先进 AI 的构建块。
这个备忘单链接到每个项目的教程,通过利用 ChatGPT 的对话提示一步步实现。亮点包括使用 ChatGPT 构建贷款审批分类模型、简历解析器、实时语言翻译器、探索性数据分析,甚至将其功能集成到 Google Sheets 中。无论你是刚接触 ChatGPT 还是想要扩展其应用,这个项目合集都作为一个起点,帮助提高生产力并加速 AI 辅助开发。
马修·梅奥 (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为KDnuggets和Statology的主编,以及Machine Learning Mastery的特邀编辑,马修旨在使复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、语言模型、机器学习算法,以及探索新兴的 AI。他致力于在数据科学社区中普及知识。马修从 6 岁起就开始编程。
更多相关话题
生成性人工智能的新伦理影响
原文:
www.kdnuggets.com/the-new-ethical-implications-of-generative-artificial-intelligence
高级人工智能领域的进展速度非常快,但伴随而来的风险也同样迅猛。
目前的情况使得专家很难预测风险。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
尽管大多数领导者在接下来的几个月里越来越重视生成性 AI 应用,但他们也对随之而来的风险持怀疑态度——例如数据安全问题和偏见结果等。
马克·苏兹曼,比尔及梅琳达·盖茨基金会的首席执行官,认为“虽然这项技术可以带来加速科学进步和提升学习成果的突破,但机遇并非没有风险。”

图片由作者提供
让我们从数据开始
想一想——一位著名的生成性 AI 模型创建者表示,“它收集个人信息,如姓名、电子邮件地址和支付信息,以满足业务需要。”
近年来已显示出在没有指导框架的情况下可能出现的多种错误情况。
由于生成式 AI 模型是在几乎所有互联网数据上进行训练的,我们只是那些神经网络层中的一部分。这强调了遵守数据隐私法规的必要性,不能在未经用户同意的情况下训练模型。
最近,有公司因通过抓取互联网自拍照来构建面部识别工具而被罚款,这导致了隐私泄露和高额罚款。

来源:TechCrunch
然而,数据安全、隐私和偏见在生成式 AI 之前就已经存在。那么,生成式 AI 应用的推出带来了什么变化?
一些现有的风险因模型的训练和部署规模而变得更加危险。让我们来了解一下。
规模——一把双刃剑
幻觉、提示注入和缺乏透明度
理解这些庞大模型的内部运作,以信任它们的回应变得更加重要。用微软的话说,这些新兴风险是因为 LLMs“被设计成生成看起来连贯且符合上下文的文本,而不是遵循事实准确性”。
因此,这些模型可能会产生误导性和不准确的回答,通常被称为幻觉。当模型对预测缺乏信心时,可能会生成不太准确或不相关的信息。
此外,提示是我们与语言模型互动的方式;现在,恶意行为者可能通过注入提示生成有害内容。
当 AI 出错时的问责制?
使用 LLMs 引发了有关这些模型生成的输出以及偏见输出的伦理问题,因为这种偏见在所有 AI 模型中普遍存在。
风险在高风险应用中加剧,例如在医疗保健领域——想想错误医疗建议对患者健康和生命的影响。
最重要的是,组织需要建立道德、透明和负责任的生成式 AI 开发和使用方式。
如果你对了解谁负责确保生成式 AI 正确使用感兴趣,可以考虑阅读这篇文章,文章描述了我们如何作为一个社区共同努力,使其发挥作用。
版权侵权
由于这些大型模型是基于全球范围的材料构建的,它们很可能涉及到创作内容——音乐、视频或书籍。
如果未经必要的许可、署名或补偿使用版权数据来训练人工智能模型,则会导致版权侵权,并可能使开发者面临严重的法律问题。

图片来源于搜索引擎期刊
深度伪造、虚假信息与操控
高概率引发大规模混乱的是深度伪造——想知道深度伪造能力可能让我们陷入什么困境吗?
它们是合成创作——文本、图像或视频,可以通过深度生成方法数字化操控面部外观。
结果?欺凌、虚假信息、恶作剧电话、报复或诈骗——这些都不符合繁荣世界的定义。
这篇文章旨在让大家意识到,人工智能是把双刃剑——它并非只有对重要举措有效的魔法,坏行为者也是其中的一部分。
这就是我们需要提高警惕的地方。
安全措施
以最近一段虚假视频为例,该视频突出了某政治人物退出即将到来的选举。
可能的动机是什么?——你可能会想。嗯,这种虚假信息传播如 wildfire,很快就会严重影响选举过程的方向。
那么,我们该如何避免成为这些虚假信息的受害者呢?
防御措施有很多条,让我们从最基本的开始:
-
对你周围看到的一切保持怀疑和疑虑
-
将你的默认模式调整为“它可能不是真的”,而不是对所有事物都不加怀疑。简而言之,对你周围的一切保持质疑。
-
从多个来源确认潜在可疑的数字内容
暂停开发是否是解决方案?
知名的人工智能研究人员和行业专家,如约书亚·本吉奥、斯图亚特·拉塞尔、埃隆·马斯克、史蒂夫·沃兹尼亚克和尤瓦尔·赫拉利,也表达了他们的担忧,呼吁暂停开发这些人工智能系统。
有一种强烈的恐惧感,认为在构建先进的人工智能的竞赛中,能够与生成性人工智能相媲美的技术可能会迅速失控。
有所进展
微软最近宣布,只要遵守安全措施和内容过滤器,它将保护其 AI 产品的购买者免受版权侵权的影响。这是一个重大缓解,并展示了对使用其产品后果负责的正确意图——这是伦理框架的核心原则之一。
这将确保作者保留他们的权利并为他们的创作获得公平的报酬。
这是朝着正确方向取得的巨大进展!关键在于它解决了多少作者的担忧。
接下来是什么?
到目前为止,我们已经讨论了与技术相关的关键伦理问题,以确保其正确应用。然而,从这种技术进步的成功利用中产生的一个风险是工作岗位的流失。
有一种情绪引发了对人工智能会取代我们大部分工作的恐惧。麦肯锡最近分享了一份关于未来工作形态的报告。
这个话题需要我们对工作的思维方式进行结构性改变,并值得单独讨论。因此,请关注下一篇文章,其中将讨论工作的未来以及如何在 GenAI 时代生存并蓬勃发展所需的技能!
Vidhi Chugh****是一位 AI 策略师和数字化转型领导者,致力于在产品、科学和工程的交汇点上构建可扩展的机器学习系统。她是一位屡获殊荣的创新领导者、作者和国际演讲者。她的使命是普及机器学习,并打破术语,让每个人都能参与这场变革。
更多相关内容
你需要的唯一课程来大幅提升你的数据分析师职业
原文:
www.kdnuggets.com/the-only-course-you-need-to-smash-your-data-analyst-career

作者提供的图片
越来越多的人询问如何成为数据分析师。当你想开始一份新职业时,选择哪个路径可能会让人感到非常困惑——甚至更糟糕的是:选择正确的课程。花费几小时每天搜索最佳课程或观看 1 小时的 YouTube 评测视频可能会非常耗时。
这篇文章将帮助你选择合适的课程,免去自己四处寻找的麻烦。
数据分析师认证
链接:数据分析师认证
首先提到的是,这门课程被 Forbes 评选为 #1 数据分析认证!
你可能来自一个你当前工作涉及数据的背景,并且可能在考虑如何将其提升到一个更高的水平,从而赚取一些可观的收入。或者你可能完全不在数据和技术领域,并且希望彻底转型。这正是我所做的!
如果你有上述情况,并且认真考虑成为数据分析师,这个由 DataCamp 提供的认证可以让你在 30 天内获得认证。
过程是什么?
DataCamp 的数据分析师认证适合初学者和中级水平的人员。所以如果你觉得自己可能还没有准备好,不用担心。提供了多个级别,以确保每个人都能成功并达到他们的职业目标。
对于那些新入数据领域的人,我建议从数据分析师助理认证开始,这是你进入数据世界的门户,建立作为数据分析师成功所需的基础知识。查看更多信息 这里。
如果你已经进入数据领域,并准备成为数据分析师——可以继续进行数据分析师认证。你将有 30 天的时间来完成它——这包括限时考试和实践考试。你有两个限时考试,但不用担心,课程会带你了解所有你需要知道的内容,以确保你做好准备。
数据分析师认证可以选择使用 R 或 Python,并测试更高级的技术,为你准备好进入初级数据分析师职位所需的技能。你将展示你在如何处理业务关键问题以及向利益相关者提供信息方面的知识和技能。
要获得此认证,你应能:
-
执行标准的数据提取、连接和聚合任务。
-
评估数据质量并执行验证任务。
-
执行标准清洗任务以准备数据进行分析。
-
计算指标以有效报告数据的特征和特征之间的关系。
你的定时考试将涵盖数据管理、探索性分析和统计实验。实践考试将涵盖数据管理、探索性分析和沟通。
你的 30 天已经结束,现在你正查看就业市场寻找工作。这部分是最令人畏惧的。但在这里,我建议你不要感到压力。DataCamp 提供对其专属认证社区的全面访问,你可以与其他认证专业人士联系,并探索由我们的社区团队为你精心策划的内容。
从小组论坛、专属内容到与行业专家的活动,你将获得实现梦想工作的支持。
总结
我们希望这篇文章为你节省了大量研究或观看关于选择数据分析师课程的评论视频的时间。KDnuggets 团队希望看到每个人的成功,并且我们希望我们能帮助你的旅程!
Nisha Arya 是一名数据科学家、自由职业技术写作员,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及基于理论的数据科学知识。Nisha 涵盖了广泛的主题,并希望探索人工智能如何有利于人类生命的长寿。作为一个热衷的学习者,Nisha 希望拓宽她的技术知识和写作技能,同时帮助指导他人。
了解更多主题
成为 MLOps 工程师所需的唯一免费课程
原文:
www.kdnuggets.com/the-only-free-course-you-need-to-become-a-mlops-engineer

作者提供的图片
机器学习(ML)的世界正在迅速发展,将 ML 模型投入生产已变得至关重要。这就是 MLOps 的作用,它可以无缝地将 ML 模型从实验阶段过渡到生产阶段。对熟练 MLOps 工程师的需求激增,公司愿意支付高达 30 万美元的薪水。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT
为了满足日益增长的需求,DataTalks.Club 推出了一个出色的机会,面向有志之士和资深专业人士:MLOps Zoomcamp 课程。这个全面的课程旨在为您提供在 MLOps 领域中脱颖而所需的实际知识和技能。最棒的是?完全免费!
课程亮点
目标和受众
MLOps 课程来自 DataTalks.Club,教授将机器学习服务生产化的实际操作——从训练和实验到模型部署和监控。该课程专为数据科学家、机器学习工程师、软件工程师和数据工程师设计,他们希望学习如何将机器学习投入生产。
先决条件
为了最大程度地从本课程中受益,参与者应具备基本的 Python 和 Docker 知识,并对命令行工具感到舒适。这是一门高级课程,需要一年以上的机器学习和编程经验。如果您对机器学习或数据科学不熟悉,可以尝试查看 5 门免费课程掌握数据科学。
主要特点
-
自定进度学习: 所有课程材料均可免费获取,您可以按自己的进度学习。
-
社区支持: 加入 DataTalks.Club 的 Slack 和 #course-mlops-zoomcamp 频道,获取同行和讲师的支持。
-
实践经验: 该课程强调通过一个涵盖所有学习概念的项目来获得实际知识。
-
获得证书: 您必须完成一个最终项目才能获得证书。
-
免费: 所有资源均可免费获取,没有任何限制。你可以在没有付费墙的情况下访问完整体验。
-
专家讲师: 向经验丰富的讲师学习,包括 Cristian Martinez、Jeff Hale、Alexey Grigorev、Emeli Dral 和 Sejal Vaidya。
大纲概述
每个模块包括视频讲座、实际操作、家庭作业和进一步阅读材料的组合,以加深对概念的理解和应用。本课程旨在为参与者提供扎实的 MLOps 基础,帮助你应对在高效部署和管理机器学习模型方面的实际挑战。
-
模块 1: MLOps 介绍、MLOps 成熟度模型和课程概述。
-
模块 2: 使用 MLflow 进行实验跟踪和模型管理。
-
模块 3: 使用 Prefect 2.0 的编排和 ML 流水线。
-
模块 4: 模型部署,包括 Web 服务、流处理和批处理。
-
模块 5: 使用 Prometheus、Evidently 和 Grafana 进行模型监控。
-
模块 6: 在测试、Python 代码检查、CI/CD 等方面的最佳实践。
最终项目
在本课程的整个过程中,我们已经全面理解了机器学习的概念、技术和最佳实践。现在,本项目的最终目标是应用我们迄今为止获得的所有知识和技能,致力于开发一个完整的端到端机器学习解决方案。
我们将首先选择数据集,然后训练我们的模型,同时跟踪模型指标。为了简化过程,我们将创建模型流水线,并以批处理、Web 服务或流处理的方式部署模型。我们将监控生产中的模型,并通过遵循最佳实践来改进我们的项目。
如何开始
-
注册: 在此注册课程: https://airtable.com/shrCb8y6eTbPKwSTL
-
Slack 社区: 在 DataTalks.Club 的 Slack 中注册并加入 #course-mlops-zoomcamp 频道以获得支持和讨论。
-
课程视频: 通过观看播放列表中的视频,自主安排课程进度。
-
保持更新: 要获取即将举行的活动的最新信息,请订阅公开的 Google 日历。
结论
DataTalks.Club 的 MLOps Zoomcamp 是一个包含练习、视频教程、作业和实际示例的课程集合。你将与数据和机器学习领域的专业人士一起学习如何构建、部署和监控机器学习模型。
无论你是希望换职业、提升技能,还是巩固对 MLOps 的理解,这门课程都是实现目标的唯一免费资源。那么,为什么还要等待呢?立即注册,开启你的 MLOps 之旅。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专家,热衷于构建机器学习模型。当前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为面临心理健康问题的学生构建一个 AI 产品。
相关主题
成为专业数据工程师所需的唯一免费课程
原文:
www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer

作者提供的图片
机器学习和数据科学有很多课程和资源,但数据工程的课程却非常稀少。这引发了一些问题。这是一个困难的领域吗?薪资较低吗?是否不如其他技术职位令人兴奋?然而,现实是许多公司积极寻求数据工程人才,并提供丰厚的薪资,有时超过 200,000 美元。数据工程师作为数据平台的架构师,扮演着关键角色,设计和构建基础系统,使数据科学家和机器学习专家能够有效地工作。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
针对这一行业差距,DataTalkClub 推出了一个变革性的免费训练营,“数据工程 Zoomcamp”。该课程旨在帮助初学者或希望转行的专业人士,提供数据工程方面的核心技能和实际经验。
课程概述:数据工程掌握的路线图
这是一个 6 周训练营,你将通过多个课程、阅读材料、研讨会和项目来学习。在每个模块结束时,你将获得作业以实践所学内容。
-
第 1 周: GCP、Docker、Postgres、Terraform 介绍及环境设置。
-
第 2 周: 使用 Mage 进行工作流编排。
-
第 3 周: 使用 BigQuery 进行数据仓储和机器学习。
-
第 4 周: 使用 dbt、Google Data Studio 和 Metabase 进行分析工程师培训。
-
第 5 周: 使用 Spark 进行批处理。
-
第 6 周: 使用 Kafka 进行流处理。
图片来源于 DataTalksClub/data-engineering-zoomcamp
大纲
大纲包含 6 个模块、2 个工作坊和一个项目,涵盖了成为专业数据工程师所需的一切内容。
模块 1: 掌握容器化和基础设施即代码
在本模块中,你将学习 Docker 和 Postgres,从基础知识开始,通过详细教程逐步深入,包括创建数据管道、使用 Docker 运行 Postgres 等。
本模块还涵盖了如 pgAdmin、Docker-compose 和 SQL 复习等重要工具,并提供了 Docker 网络和 Windows 子系统 Linux 用户的特别教程。课程结束时,将介绍 GCP 和 Terraform,提供对容器化和基础设施即代码的全面理解,这对于现代云环境至关重要。
模块 2: 工作流编排技术
本模块深入探讨了 Mage,这是一种创新的开源混合框架,用于数据转换和集成。模块从工作流编排的基础开始,逐步进行实际操作,包括通过 Docker 设置 Mage、从 API 到 Postgres 和 Google Cloud Storage (GCS) 再到 BigQuery 的 ETL 管道构建。
本模块结合了视频、资源和实际任务,确保了全面的学习体验,帮助学习者掌握使用 Mage 管理复杂数据工作流的技能。
工作坊 1: 数据摄取策略
在第一个工作坊中,你将掌握构建高效数据摄取管道的技能。工作坊重点讲解了从 API 和文件中提取数据、规范化和加载数据以及增量加载技术等基本技能。完成此工作坊后,你将能够像高级数据工程师一样创建高效的数据管道。
模块 3: 数据仓库
本模块深入探讨了数据存储和分析,重点关注使用 BigQuery 的数据仓库。涵盖了如分区和聚类等关键概念,并深入研究了 BigQuery 的最佳实践。模块还涉及了高级主题,特别是将机器学习(ML)与 BigQuery 的集成,重点讲解了 SQL 在 ML 中的应用,并提供了有关超参数调整、特征预处理和模型部署的资源。
模块 4: 数据分析工程
数据分析工程模块专注于使用 dbt(数据构建工具)和现有的数据仓库(BigQuery 或 PostgreSQL)来构建项目。
本模块涵盖了在云环境和本地环境中设置 dbt 的内容,介绍了数据分析工程的概念、ETL 与 ELT 的区别以及数据建模。还涵盖了 dbt 的高级功能,如增量模型、标签、钩子和快照。
最后,模块介绍了使用 Google Data Studio 和 Metabase 等工具可视化转换数据的技术,并提供了故障排除和高效数据加载的资源。
模块 5: 批处理熟练度
本模块涵盖了使用 Apache Spark 进行批处理,从批处理和 Spark 的介绍开始,并包括 Windows、Linux 和 MacOS 的安装说明。
该模块包括探索 Spark SQL 和 DataFrames、数据准备、执行 SQL 操作和理解 Spark 内部工作原理。最后,模块结尾处涉及在云中运行 Spark 和将 Spark 与 BigQuery 集成。
模块 6:使用 Kafka 进行流数据的艺术
本模块以流处理概念的介绍开始,接着深入探索 Kafka,包括其基础知识、与 Confluent Cloud 的集成以及涉及生产者和消费者的实际应用。
本模块还涵盖了 Kafka 配置和流,涉及流连接、测试、窗口化以及 Kafka ksqldb 和 Connect 的使用。此外,还扩展了对 Python 和 JVM 环境的关注,包含了用于 Python 流处理的 Faust、Pyspark - Structured Streaming 和 Kafka Streams 的 Scala 示例。
研讨会 2:使用 SQL 进行流处理
你将学习如何使用 RisingWave 处理和管理流数据,它提供了一个成本高效的解决方案,具有 PostgreSQL 风格的体验,以增强你的流处理应用程序。
项目:真实世界的数据工程应用
本项目的目标是实施我们在本课程中学到的所有概念,以构建一个端到端的数据管道。你将创建一个包含两个面板的仪表板,通过选择数据集、建立处理数据的管道并将其存储在数据湖中、建立从数据湖到数据仓库的数据传输管道、在数据仓库中转换数据并为仪表板做准备,最后构建一个仪表板以可视化呈现数据。
立即注册
2024 期班级详情
先决条件
-
基本编码和命令行技能
-
SQL 基础
-
Python:有益但不是必需
由专家讲师引导你的学习之旅
-
Ankush Khanna
-
Victoria Perez Mola
-
Alexey Grigorev
-
Matt Palmer
-
Luis Oliveira
-
Michael Shoemaker
结论
加入我们的 2024 期班级,与一个出色的数据工程社区一起开始学习。通过专家主导的培训、实践经验以及针对行业需求量身定制的课程,本训练营不仅为你提供必要的技能,还将你置于一个高薪且需求旺盛的职业路径的前沿。立即注册,将你的梦想变为现实!
Abid Ali Awan(@1abidaliawan)是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为挣扎于心理疾病的学生开发一款 AI 产品。
更多相关话题
你需要的唯一深度学习面试准备课程
原文:
www.kdnuggets.com/the-only-interview-prep-course-you-need-for-deep-learning
图片由作者提供
假设你正在为数据科学、机器学习工程师、AI 工程师或研究科学家职位做准备。在这种情况下,你应该寻找优秀的资源来帮助你顺利通过面试。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
深度学习越来越受欢迎,它形成了大语言模型、生成 AI 等主题的基础,并结合了许多不同的概念。这就是为什么这个面试准备课程可能是我最近见过的最好的课程之一。
你不仅会获得深度学习的基础和经验知识,还会提升你的数据科学和机器学习技能。即使你没有准备面试,而是在学习过程中,我也会推荐这个面试准备课程!
深度学习面试课程
该课程分为两个部分。第一部分,视频将讲解前 50 个问题及其对应答案。在第二部分,视频将讲解剩余的 50 个问题。
总共有 100 个问题。总共需要 7.5 小时!
基本面试问题
你将从深度学习的基本问题开始,包括神经网络的概念、神经网络的架构、激活函数和梯度下降。这些是前 10 个问题,因此你会很快通过这些问题。
中级面试问题
在接下来的 20 个问题中,你将深入了解如何定义反向传播与梯度下降和交叉熵的区别。从那里,你将进一步探讨并测试你在随机梯度下降和 Hessian 等领域的技能,以及它们如何用于加速训练过程。
专家面试问题
最后的 20 个问题将测试你对诸如 Adam 及其在神经网络中的使用、层归一化、残差连接以及如何解决梯度爆炸等主题的知识。你还将深入了解 dropout 的概念,它如何防止过拟合、维度诅咒等。
愉快学习
我们希望这门课程能帮助你在即将到来的面试或学习过程中变得更有信心。复习顶级面试问题将帮助你了解重要知识点以及面试官认为的重要技能和知识。
如果你知道其他好的资源,请在评论中分享给大家!
Nisha Arya 是一名数据科学家、自由职业技术作家,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。Nisha 涵盖了广泛的主题,并希望探索人工智能如何有利于人类生命的延续。作为一个热衷学习者,Nisha 寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关主题
适用于所有用途的唯一提示框架
原文:
www.kdnuggets.com/the-only-prompting-framework-for-every-use

图像由 freestockcenter 在 Freepik 提供
随着大型语言模型的出现,提示工程已成为一项重要技能。简而言之,提示涉及的是人类如何与机器互动。设计提示意味着有效地传达需求,以便机器的响应具有上下文相关性、相关性和准确性。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
框架
本文中分享的提示工程框架显著提升了你与 AI 系统的互动。让我们通过遵循包括角色、上下文和任务在内的六步框架来学习创建强大的提示,并展示期望的输出和语气。
 作者提供的图像
作者提供的图像
1. 角色
将一个角色视为你会求助于其解决特定任务的专家。角色类似,只不过这个专家现在是你正在互动的模型。将角色分配给模型相当于赋予它一个角色或身份,帮助设定任务所需的适当专业水平和视角。
示例:“作为一个在客户服务对话中进行情感分析的专家……”
现在,经过大量数据训练的模型被指示运用数据科学家在进行情感分析时的知识和视角。
2. 上下文
上下文提供了背景信息和模型必须了解的任务范围。这种对情况的理解可以包括定义模型需要响应的环境的事实、过滤器或约束。
示例:“……分析通话记录以了解客户的痛点及其在客户与代理人之间通话详情中的情感”
这个上下文突出了呼叫中心数据分析的具体案例。提供上下文等同于优化问题——提供过多的上下文可能会掩盖实际目标,而提供过少则限制了模型的响应能力。
3. 任务
任务是模型必须采取的具体行动。这是你的提示需要完成的全部目标。我称之为 2C——清晰且简洁,意味着模型应该能够理解期望。
示例:“……分析数据并学会从未来的对话中计算情感。”
4. 向我展示如何
注意,没有免费的午餐。大型语言模型已被证明会产生幻觉,即它们倾向于产生误导性或不正确的结果。正如Google Cloud所解释的,“这些错误可能由多种因素造成,包括训练数据不足、模型的错误假设或用于训练模型的数据中的偏差。”
限制这种行为的一种方法是要求模型解释它是如何得出响应的,而不仅仅是分享最终答案。
示例:“提供简要解释,突出计算出的情感背后的词语和理由。”
5. 预期输出
通常,我们需要以一种结构化且易于跟随的指定格式输出。根据用户如何获取信息,输出可以组织成列表、表格或段落的形式。
示例:“以 2 点格式分享给定的呼叫总结,包括反映情感类别的客户情感和关键词……”
6. 语气
尽管指定语气通常被认为是可选的,但指定语气有助于将语言调整为目标受众。有各种语气,模型可以调整其响应,例如随意、直接、愉快等。
示例:“使用专业但易于理解的语气,尽量避免过于专业的术语。”
将所有内容汇总在一起
很好,我们已经讨论了提示框架的所有六个元素。现在,让我们将它们合并成一个单一的提示:
“作为一名通过客户关怀对话进行情感分析的专家,你正在分析呼叫记录,以了解客户痛点和从客户与代理之间的呼叫细节中的情感。分析数据并学会从未来的对话中计算情感。提供简要解释,突出计算出的情感背后的词语和理由。以 2 点格式分享给定的呼叫总结,包括反映情感类别的客户情感和关键词。使用专业但易于理解的语气,尽量避免过于专业的术语。”
有效提示的好处
这个框架不仅为明确的请求奠定了基础,还添加了必要的背景并描述了角色,以便将响应量身定制到具体情况。要求模型展示其得出结果的过程,进一步增加了深度。
掌握提示的艺术需要实践,并且是一个持续的过程。练习和完善提示技巧使我们能够从人工智能互动中提取更多价值。
这类似于构建机器学习模型时的实验设计。我希望这个框架能为你提供一个坚实的结构,但不要觉得受限于此。将其作为基准进行进一步实验,并根据你的具体需求不断调整。
Vidhi Chugh**** 是一位人工智能战略家和数字化转型领导者,致力于在产品、科学和工程交汇处构建可扩展的机器学习系统。她是一位获奖的创新领导者、作者和国际演讲者。她的使命是让机器学习民主化,打破专业术语,让每个人都能参与到这一转型中。
更多相关主题
边缘 AI 的承诺及有效采纳的方法
原文:
www.kdnuggets.com/the-promise-of-edge-ai-and-approaches-for-effective-adoption

图片由编辑提供
当前的技术格局正经历着向边缘计算的关键转变,这一转变由生成 AI(GenAI)和传统 AI 工作负载的快速进展推动。过去依赖于云计算的这些 AI 工作负载现在遇到了云端 AI 的局限性,包括数据安全、主权和网络连接问题。
为了绕过云端 AI 的这些限制,组织们正寻求拥抱边缘计算。边缘计算能够在数据产生和消费的地点实时分析和响应,这就是为什么组织认为它对 AI 创新和业务增长至关重要的原因。
边缘 AI 承诺以零到最小延迟实现更快的处理速度,可以显著改变新兴应用程序。虽然边缘设备的计算能力不断提高,但仍有一些限制可能使得实施高精度 AI 模型变得困难。模型量化、模仿学习、分布式推理和分布式数据管理等技术和方法可以帮助消除更高效、更具成本效益的边缘 AI 部署的障碍,从而使组织能够挖掘其真正潜力。
“仅云端”AI 方法无法满足下一代应用的需求
云端 AI 推理常常受到延迟问题的影响,导致设备与云环境之间的数据传输延迟。组织们已经意识到将数据跨区域移动到云端,然后再从云端回到边缘的成本。这可能会阻碍那些需要极快实时响应的应用程序,比如金融交易或工业安全系统。此外,当组织必须在网络连接不可靠的偏远地点运行 AI 驱动的应用程序时,云端并不总是可用。
“仅云端”AI 战略的局限性变得越来越明显,特别是对于那些要求快速实时响应的下一代 AI 驱动应用。网络延迟等问题可能会减慢在云端应用程序中提供的洞察和推理,从而导致延迟和与云端和边缘环境之间的数据传输相关的成本增加。这对于实时应用程序,尤其是在网络连接间歇的偏远地区尤为严重。随着 AI 在决策和推理中的核心地位,数据移动的物理成本可能非常高,对业务结果产生负面影响。
Gartner预测,到 2025 年,超过 55%的深度神经网络数据分析将在边缘系统的捕获点进行,而 2021 年这一比例不到 10%。边缘计算有助于缓解延迟、可扩展性、数据安全性、连接性等挑战,重塑数据处理方式,并加速 AI 的采用。采用离线优先的方法开发应用将对敏捷应用的成功至关重要。
通过有效的边缘策略,组织可以从其应用程序中获得更多价值,并更快地做出业务决策。
通过不断演进的技术和方法使边缘 AI 成为可能
随着 AI 模型日益复杂,应用架构变得更加复杂,将这些模型部署到计算受限的边缘设备上变得更加明显。然而,技术的进步和不断演变的方法正在为在边缘计算框架内高效集成强大 AI 模型铺平道路,包括:
模型压缩与量化
模型剪枝和量化等技术对于减少 AI 模型的大小而不显著影响其准确性至关重要。模型剪枝从模型中删除冗余或非关键的信息,而量化则减少了模型参数中使用的数字的精度,使模型在资源受限的设备上运行更轻便、更快速。模型量化是一种压缩大型 AI 模型的技术,以提高可移植性并减少模型大小,使模型更轻便,更适合边缘部署。通过使用微调技术,包括通用后训练量化(GPTQ)、低秩适配(LoRA)和量化 LoRA(QLoRA),模型量化降低了模型参数的数值精度,使模型在如平板、边缘网关和手机等边缘设备上更高效、更易获取。
边缘专用 AI 框架
专门为边缘计算设计的 AI 框架和库可以简化边缘 AI 工作负载的部署过程。这些框架经过优化,以适应边缘硬件的计算限制,并支持以最小性能开销高效执行模型。
带有分布式数据管理的数据库
具备向量搜索和实时分析等功能,帮助满足边缘的操作要求,并支持本地数据处理,处理各种数据类型,如音频、图像和传感器数据。这在像自动驾驶车辆软件这样的实时应用中尤其重要,其中各种数据类型不断被收集,并且必须实时分析。
分布式推理
将模型或工作负载分布在多个边缘设备上,并使用本地数据样本而无需实际数据交换,可以减轻潜在的合规性和数据隐私问题。对于涉及众多边缘设备和物联网设备的应用,例如智能城市和工业物联网,分布式推理是必须考虑的关键因素。
AI 工作负载的平衡配置
尽管 AI 一直在云端处理,但与边缘的平衡将对加速 AI 计划至关重要。大多数,甚至所有行业,都已认识到 AI 和 GenAI 是一种竞争优势,这也是为什么在边缘收集、分析和迅速获得洞察将变得越来越重要。随着组织在 AI 使用上的演变,实施模型量化、多模态能力、数据平台及其他边缘策略将有助于推动实时、具有意义的商业成果。
Rahul Pradhan****是 Couchbase(NASDAQ: BASE)的产品与战略副总裁,Couchbase 提供一种领先的现代数据库,30% 的财富 100 强公司依赖于此。Rahul 拥有超过 20 年的经验,领导和管理工程及产品团队,专注于数据库、存储、网络和云安全技术。在加入 Couchbase 之前,他曾领导 Dell EMC 新兴技术和中型存储部门的产品管理与业务战略团队,将全闪存 NVMe、云和 SDS 产品推向市场。
更多主题
数据可视化的心理学:如何展示能说服人的数据
原文:
www.kdnuggets.com/the-psychology-of-data-visualization-how-to-present-data-that-persuades
图片来源于 pikisuperstar 在 Freepik
我们都已经深刻意识到数据及其分析给各种企业和组织带来的强大力量。然而,展示方式也很重要——没有简单易懂、引人入胜的方式传达信息,我们的分析能力也无济于事。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
数据可视化登场了。通过利用所有感官中最直接和最主导的一个,复杂和精细的数据点可以被浓缩成一种每个参与者都可以直观理解的可操作格式。
因此,通过视觉表现有效沟通洞察力和想法的能力变得越来越重要。有效的可视化可以切穿噪音,突出模式和关系,并引导观众的注意力到最关键的洞察力上。
本文讨论了支撑创建有说服力和有效的数据可视化的心理学原理和技术。
视觉处理的心理学
数据可视化中的视觉处理心理学是一个深具吸引力的领域,交叉心理学、神经科学和设计原则。它关注于人类如何解读、理解和回应视觉数据展示。它突显了我们视觉系统相比其他数据处理形式的惊人效率。
人脑处理视觉信息的速度极快。实际上,研究表明,它可以在13 毫秒内理解形状、颜色和方向。这种速度使得视觉数据比文本信息更为即时和有影响力。
因此,仅仅使用图表往往不能充分体现你的努力。例如,与之前的表现相比,即使是简单的图表,加上百分比变化和数字,也比简单、乏味的陈述更能解释你的云成本优化努力如何为组织带来回报。
此外,双重加工理论解释了我们有两种思维方式:快速、本能的(系统 1)和慢速、分析的(系统 2)。可视化利用系统 1,让我们能够快速理解复杂信息,而无需进行更深层次、较慢的分析。
我们使用颜色、形状和位置的方式会影响人们记住和根据可视化做出决策的能力。了解视觉元素如何影响感知和记忆有助于创建更有效的视觉效果。
创建有效的数据可视化意味着利用人类天生的视觉处理能力,以一种立即可理解和难以忘怀的方式呈现复杂信息。
说服性数据可视化原则
创建具有说服力的数据可视化涉及到讲故事、战略数据选择和有效设计原则的融合。以下是一些关键组件的详细说明,这些组件在制作既能提供信息又能说服观众的可视化时需要考虑:
战略讲故事
每个有效的数据可视化都始于一个清晰、具体的目标。这意味着准确知道你希望在观众中引发什么行动或理解。从那里,围绕你的数据构建一个叙事有助于吸引观众,使信息更具相关性和吸引力。
这个叙事应有一个清晰的引言、主体和结论,每部分都建立在上一部分的基础上,引导观众达到预期的理解或行动。
适当的数据选择
为你的观众选择正确的数据至关重要。数据应直接与观众的兴趣或需求相关。这种量身定制的方法确保可视化能直接针对观众的关注点或好奇心,使信息更具说服力,让信息更具说服力。
数据选择的一个问题是它可能非常耗时。然而,你不必完全手动完成所有工作——使用自动化文档生成工具可以减少所需时间,使你可以将更多精力投入到分析最具吸引力的数据点上以用于演示。此外,你还可以使用各种可视化工具——不需要为所有内容都制作手工演示。
设计原则
这个原则由多个组件组成,包括:
-
对齐。 数据展示的正确对齐,无论是垂直还是水平,都能确保信息可以准确比较和理解,而不会通过光学错觉引起混淆或误解。
-
颜色选择。 颜色应该被有意识地用来突出关键数据点并引起观众对可视化中最重要部分的注意。选择对所有人都可及的颜色组合,包括那些有色觉障碍的人也很重要。
-
标题和标签的清晰度。 标题和标签在引导观众通过数据可视化中起着重要作用。它们应该清晰、信息丰富且简洁,提供上下文并强调可视化的关键要点。
-
互动性。 在适当的情况下,将互动性融入你的可视化中可以增强用户体验,使数据探索更加有趣和有洞察力。然而,重要的是这个功能应该提升而不是复杂化对数据的理解。
说服性数据可视化的最佳实践
为了创建有说服力的数据可视化,遵循最佳实践是至关重要的,这能使你的数据清晰、引人入胜且易于理解。以下是一些建议:
-
选择合适的可视化工具。 选择合适的工具至关重要。像 ChartExpo、Power BI 和 Looker Studio 这样的选项因其易用性和在创建清晰图表方面的有效性而受到赞扬,即使是非技术观众也能轻松使用。
-
策略性使用颜色。 颜色可以显著地影响信息的处理方式和记忆。使用对比色来突出关键见解,并确保你的颜色选择对色盲人士友好。避免在单一图表中使用过多的颜色以保持清晰度。
-
突出关键见解。 确保引起对数据中最重要部分的注意。这可以包括使用视觉提示如参考线,或简单地突出条形图中的重要条形。
-
寻找商业洞察。 将数据可视化与高层次的商业目标对齐,确保你的可视化不仅具有信息性,而且具有可操作性。利用数据预测趋势并做出明智的决策。
-
选择正确的图表类型。 图表的选择对于清晰性和有效性至关重要。条形图、折线图、散点图、饼图等具有特定用途,使它们更适合某些类型的数据。例如,条形图非常适合比较类别数据,而折线图则适合展示随时间变化的趋势。
-
确保上下文和理解。数据可视化不仅要以吸引人的方式展示数字,还要传达一个易于理解的清晰信息。这包括使用有吸引力的标题,确保比例缩放准确,并清晰标注标签和图例。
-
针对特定目的使用不同的图表类型。不同的图表满足不同的分析需求,例如气泡图用于在散点图中添加额外维度,瀑布图用于可视化顺序变化。饼图、堆叠图和桑基图等组成图表可以阐明数据的结构及其随时间的变化。
数据可视化的好处
主要的优势之一是简化复杂的数据。数据可视化将大量的信息转化为更易于处理和理解的格式,使用户能够快速高效地掌握复杂的概念。这在需要快速决策的环境中尤为重要。
数据可视化还增强了讲故事的能力。它允许企业以引人注目的方式展示他们的故事,使沟通利益相关者、培训团队或吸引客户变得更加容易。这种方法对于呈现想法和策略非常有效,例如提出整合新技术或流程以提高部门效率。
此外,它提高了生产力,通过提供即时见解,帮助快速行动,减少因数据误解而导致的延迟。通过使数据更易于消化,团队可以专注于可操作项和改进,而不是花时间理解复杂的数据集。
风险管理是数据可视化发挥重要作用的另一个领域。它帮助组织更好地理解和应对涉及不确定性和风险的情况,通过可视化简化数据以突出潜在的关注领域。
有时,管理层和高管需要一点推动。我并不是在责怪谁——权威人士通常没有时间去微观管理和全神贯注于操作层面的所有细节和复杂性。举个例子,如果你知道SAP 咨询将使你的部门受益并且能带来更大的整合和效率,那么将这些信息一次性呈现出来,并用充满图表和图形的引人入胜的叙述比仅仅提及事实而让初步印象渐渐消退更有可能奏效。
结论
数据可视化提供了一种强大的方式来穿透噪音,传递真正有共鸣的见解。
然而,真正掌握具有说服力的数据可视化在于达到美学与功能之间的完美平衡。这需要对视觉设计原则、认知过程和人类行为之间的相互作用有深入的理解。
只有在达到这种平衡时,我们才能创造出不仅美丽而且清晰、深刻且有影响力的可视化。
Nahla Davies是一位软件开发人员和技术作家。在全职从事技术写作之前,她还曾担任过一家《Inc. 5000》体验品牌机构的首席程序员,该公司客户包括三星、时代华纳、Netflix 和索尼。
更多相关话题
模型置信度的探索:你能相信黑箱吗?
原文:
www.kdnuggets.com/the-quest-for-model-confidence-can-you-trust-a-black-box

作者提供的图片
像 GPT-4 和 LLaMA2 这样的大型语言模型(LLMs)已经进入了数据标注的领域。LLMs 已经取得了长足的进步,现在可以进行数据标注并承担历史上由人类完成的任务。尽管使用 LLM 获取数据标签非常迅速且相对便宜,但仍然存在一个大问题,这些模型是终极的黑箱。因此,燃眉之急是:我们应该对这些 LLM 生成的标签有多少信任?在今天的文章中,我们将解开这一难题,以建立一些基本准则来评估我们对 LLM 标注数据的信任度。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT 需求
背景
下面展示的结果来自于Toloka进行的一项实验,该实验使用了流行的模型和土耳其语的数据集。这不是一份科学报告,而是对可能解决该问题的方法的简要概述,以及一些关于如何确定哪种方法最适合您的应用程序的建议。
重大问题
在我们深入细节之前,这里有一个重大问题:我们何时可以相信由 LLM 生成的标签,何时应该保持怀疑?了解这一点可以帮助我们进行自动化数据标注,并且在客户支持、内容生成等其他应用任务中也会很有用。
当前的情况
那么,人们现在是如何解决这个问题的呢?有些人直接要求模型输出一个置信度分数,有些人查看模型在多次运行中的答案一致性,而另一些人则检查模型的对数概率。但是这些方法中的任何一种是否可靠呢?让我们来找出答案。
一般原则
什么才算一个“好的”置信度测量?一个简单的规则是置信度分数与标签的准确性之间应该存在正相关。换句话说,更高的置信度分数应该意味着更高的正确概率。您可以使用校准图来可视化这种关系,其中 X 轴和 Y 轴分别表示置信度和准确性。
实验及其结果
方法 1:自信度
自我置信度方法涉及直接询问模型关于其置信度的情况。结果还不错!虽然我们测试的 LLM 在非英语数据集上表现不佳,但自我报告的置信度与实际准确性之间的相关性相当稳固,这意味着模型对其局限性有很好的认识。我们在这里也得到了类似的结果,GPT-3.5 和 GPT-4 一样。
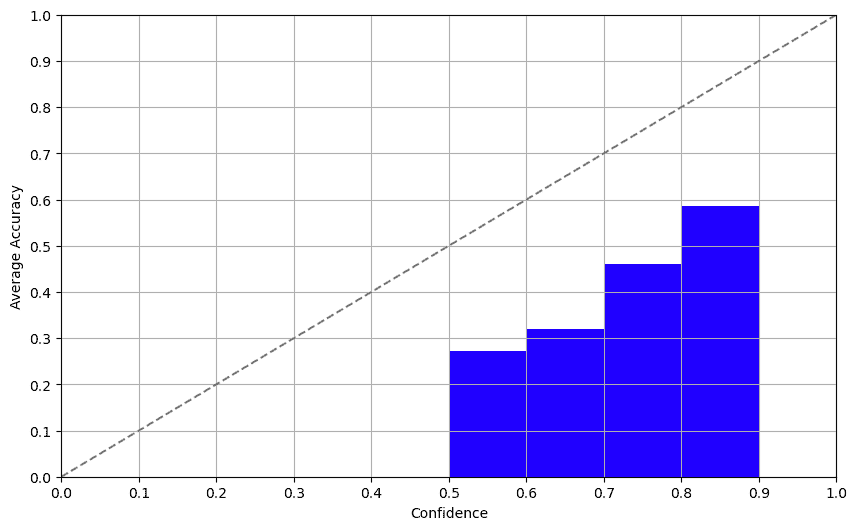
方法 2:一致性
设置较高的温度(~0.7–1.0),对同一项目进行多次标注,并分析答案的一致性,更多细节请参见这篇论文。我们用 GPT-3.5 进行过尝试,结果简直是一团糟。我们让模型多次回答同一个问题,结果总是不可预测。这种方法和让魔法 8 球提供生活建议一样可靠,不应该被信任。
方法 3:对数概率
对数概率带来了意外的惊喜。Davinci-003 在完成模式下返回标记的对数概率。检查这些输出后,我们得到了一个与准确性高度相关的令人惊讶的良好置信度评分。这种方法提供了一种确定可靠置信度评分的有希望的方法。
关键点
那么,我们学到了什么?来吧,直接了当:
-
自我置信度:有用,但需要谨慎对待。偏差被广泛报告。
-
一致性:尽量避免。除非你喜欢混乱。
-
对数概率:如果模型允许你访问它们,目前看来是一个相当不错的选择。
激动人心的部分?尽管这篇论文报告这种方法过于自信,但对数概率似乎相当稳健,即使在没有微调模型的情况下。这仍然有进一步探索的空间。
未来方向
合理的下一步可能是找到一个结合这三种方法最佳部分的黄金公式,或者探索新的方法。因此,如果你准备接受挑战,这可能是你下一个周末的项目!
总结
好了,机器学习爱好者和新手们,今天的内容就到这里。记住,无论你是在进行数据标注还是构建下一个大规模对话代理——理解模型置信度至关重要。不要轻信那些置信度评分,确保做好功课!
希望你觉得这些内容有启发。下次见,继续分析数据,质疑模型。
伊万·扬什奇科夫 是应用科学大学伍尔茨堡-施韦因富特 AI 与机器人中心的语义数据处理与认知计算教授。他还领导 Toloka AI 的数据倡导者团队。他的研究兴趣包括计算创造力、语义数据处理和生成模型。
相关主题更多内容
在 Python 中访问字典的正确方法
原文:
www.kdnuggets.com/the-right-way-to-access-dictionaries-in-python
图片由作者提供
- 在处理数据时,尤其是使用我们喜爱的 Python 语言时,字典作为一种基本的数据结构脱颖而出,准备好向那些知道如何解锁它的人展示其数据。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
-
在 Python 中,字典是一种无序且可变的集合,设计用来存储类似于映射的数据值。与仅包含单一值作为元素的其他数据类型不同,字典包含由冒号“:”分隔的键值对。
-
这种键值对结构提供了一种存储数据的方法,以便可以通过键而不是位置有效地检索数据。
-
然而,大多数时候,当查找一个不存在的键时,出现的 KeyError 会中断我们的整个执行。这就是为什么本指南尝试阐明并解释一些有效的访问字典的方法,以避免中断我们的执行。
理解 Python 字典
- 想象一个字典作为一个动态存储系统,每个你希望存储的项目都有一个唯一的标识符或“键”,可以直接引导你到它。
图片由作者提供
-
在 Python 中,字典用花括号 {} 声明,键及其对应的值由冒号“:”分隔,每对之间由逗号分隔。
-
这是一个简单的表示:
# Creating a simple dictionary with keys and values
salaries = {
'Data Scientist': 100000,
'Data Analyst': 80000,
'Data Engineer': 120000}
print(salaries)
- 创建字典只是开始。字典的真正用途在于检索和操作这些存储的数据时。
常见陷阱
- 访问字典中的值的常见方法是使用方括号中的键名:
# Accessing a value using the key
print(salaries['Data Scientist']) # Outputs: 100000
print(salaries['Professor']) # This will raise a KeyError, as 'Professor' key doesn't exist
-
这个方法看起来很简单,直到你遇到一个字典中不存在的键,从而导致 KeyError。
-
这是一个常见的问题,可能会使较大的项目变得复杂。
更安全的方法
-
为了避免 KeyError,你可以考虑使用 if 语句或 try-except 块来处理缺失的键。
-
这些方法虽然有效,但在更复杂的代码中可能会变得繁琐。幸运的是,Python 提供了更优雅的解决方案,主要有两个:
-
get()方法 -
setdefault()方法
使用get()方法
get()方法是从字典中检索值的更高效方式。它需要你要查找的键,并允许一个可选的第二个参数作为默认值,如果没有找到该键。
# Using get() to safely access a value
salary = salaries.get('Data Scientist', 'Key not found')
print(salary) # Outputs: 30
# Using get() with a default value if the key doesn't exist
salary = salaries.get('Professor', 'Key not found')
print(salary) # Outputs: 30
这是访问字典最直接的方法,同时确保不会出现 KeyError。使用默认值是确保一切正常的安全方法。
然而,这种方法不会更改我们的字典,有时我们需要字典来存储这个新参数。
这引导我们到第二种方法。
利用setdefault()方法
对于那些不仅希望安全地检索值,而且还希望使用新键更新字典的场景,setdefault()变得非常宝贵。
这种方法检查键是否存在,如果不存在,则添加带有指定默认值的键,从而有效地修改原始字典。
# Using setdefault() to get a value and set it if not present
salary = salaries.setdefault('Professor', 70000)
print(salary) # Outputs: 70000 since 'Professor' was not in the dictionary
# Examining the dictionary after using setdefault()
print(salaries) # Outputs: {'Data Scientist': 100000, 'Data Analyst': 80000, 'Data Engineer': 120000, 'Professor': 70000}
在使用setdefault()后检查playersHeight将显示新增的键及其默认值,从而改变原始字典结构。
最终推荐
在get()和setdefault()之间的选择取决于你的具体需求。当你只需检索数据而不更改原始字典时,使用get()。当你的任务需要向字典中添加新条目时,选择setdefault()。
改变旧习惯可能需要一些努力,但转向使用get()和setdefault()可以显著提升你 Python 代码的鲁棒性和可读性。
当你将这些方法融入你的编程实践中时,你会迅速欣赏到它们的高效性以及它们处理潜在错误的无缝方式,使它们成为你 Python 工具箱中不可或缺的工具。
get()和setdefault()在处理此类格式和访问字典方面发挥着关键作用。
我希望本指南对你有所帮助,下次处理字典时,你可以更有效地进行。
你可以查看以下 GitHub 仓库中的相应 Jupyter Notebook。
Josep Ferrer 是来自巴塞罗那的分析工程师。他毕业于物理工程专业,目前从事人类流动性领域的数据科学工作。他还是一名兼职内容创作者,专注于数据科学和技术。Josep 撰写关于人工智能的文章,涵盖了该领域的持续爆炸性应用。
更多相关话题
提示工程的兴衰:潮流还是未来?
原文:
www.kdnuggets.com/the-rise-and-fall-of-prompt-engineering-fad-or-future

图像由 DALLE-3 生成
在不断扩展的 AI 和机器学习宇宙中,一颗新星已然崭露头角:提示工程。这个新兴领域围绕着策略性地构建输入,以引导 AI 模型生成特定的、期望的输出。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
各种媒体已经在大肆讨论提示工程,使其看起来像是理想的职业——你不需要学习编程,也不必了解深度学习、数据集等机器学习概念。你会同意这看起来好得令人难以置信,对吧?
答案实际上是既是又不是。我们将在今天的文章中详细解释原因,回溯提示工程的起源,为什么它很重要,最重要的是,为什么它并不是一个能将数百万人社会地位提升的改变人生的职业。
提示工程的崛起
我们都看到过这些数据——全球 AI 市场到 2030 年将价值 1.6 万亿美元,OpenAI 正在提供 90 万美元的薪水,这还不包括 GPT-4、Claude 以及各种其他 LLM 所产生的数十亿、甚至数万亿的字数。当然,数据科学家、机器学习专家以及该领域的其他高级专业人士处于前沿。
然而,2022 年改变了一切,因为 GPT-3 在公开发布的那一刻变得无处不在。突然间,普通人意识到提示的重要性以及“垃圾进,垃圾出”的概念。如果你写一个没有任何细节的草率提示,LLM 将对输出拥有完全的自由。起初这很简单,但用户很快意识到模型的真实能力。
然而,人们很快开始尝试更复杂的工作流程和更长的提示,进一步强调了巧妙编织语言的价值。自定义指令只会扩大可能性,并加速了提示工程师的崛起——一种能够运用逻辑、推理和对 LLM 行为的知识,以随心所欲地生成所需输出的专业人士。
提示工程:机器的语言?
在其潜力的巅峰,提示工程催生了自然语言处理(NLP)领域的显著进展。从普通的 GPT-3.5 到 Meta 的LLaMa的特定版本,当喂入精心设计的提示时,AI 模型展示了适应各种任务的惊人灵活性。
提示工程的支持者将其视为人工智能创新的途径,展望一个通过精心设计的提示艺术无缝促进人类与人工智能互动的未来。
然而,正是提示工程的承诺激起了争议。它从人工智能系统中提供复杂、微妙甚至创造性的输出的能力并未被忽视。该领域的先知们视提示工程为解锁人工智能未开发潜力的关键,将其从计算工具转变为创作伙伴。
提示工程的审视
在热情的高潮中,怀疑的声音也在回响。提示工程的批评者指出其固有的局限性,认为这不过是对缺乏基本理解的人工智能系统进行复杂操作的结果。
他们认为,提示工程只是一个虚假的面纱,是对输入的巧妙编排,掩盖了人工智能固有的理解或推理能力的不足。同样,以下论点也支持他们的观点:
-
AI 模型来来去去。例如,GPT-3 中有效的方法在 GPT-3.5 中已经被修补,而在 GPT-4 中则成为实际的不可能。这难道不会使提示工程师仅仅是特定版本 LLM 的鉴赏家吗?
-
即便是最优秀的提示工程师也不真正算是‘工程师’。例如,一位 SEO 专家可以使用 GPT 插件或甚至本地运行的 LLM 来寻找反向链接机会,或一位软件工程师可能知道如何在编写、测试和部署代码时使用 Copilot。但归根结底,他们只是在执行单一任务,这在大多数情况下依赖于在某一领域的先前专长。
-
除了硅谷偶尔的提示工程职位空缺外,几乎没有对提示工程的意识,更不用说其他方面了。公司正在缓慢而谨慎地采用 LLMs,这与每项创新一样。但我们都知道,这并不会阻止炒作的浪潮。
提示工程的炒作
提示工程的魅力并没有免于炒作和夸张的力量。媒体叙事在称颂其优点和批评其缺陷之间摆动,常常放大成功而淡化局限性。这种二分法造成了混乱和期望膨胀,使人们相信它要么是魔法,要么完全无用,没有中间状态。
与其他科技时尚的历史相似,也提醒了技术趋势的短暂性。从曾经承诺彻底改变世界的元宇宙到折叠手机,这些技术的光辉常常随着现实未能达到早期炒作设定的高期望而黯淡。这种夸张的热情之后的幻灭模式对提示工程的长期可行性投下了疑问的阴影。
炒作背后的现实
剥去炒作的层层外衣,揭示出一个更为微妙的现实。技术和伦理挑战无处不在,从在多种应用中扩展提示工程的可扩展性到对可重复性和标准化的担忧。当与传统且成熟的 AI 职业相比较时,如数据科学相关的职业,提示工程的光环开始黯淡,揭示了一个虽然强大但存在显著局限性的工具。
这就是为什么提示工程如果只是一个时尚——认为任何人都可以每天与 ChatGPT 对话并获得中六位数的工作只是一个神话。当然,一些过于热情的硅谷初创公司可能在寻找提示工程师,但这并不是一个可行的职业。至少现在还不是。
同时,作为一个概念,提示工程将保持相关性,并且肯定会在重要性上不断增长。写出一个好的提示、有效使用你的令牌以及知道如何触发某些输出的技能,将在数据科学、LLMs 和整体 AI 之外发挥重要作用。
我们已经看到 ChatGPT改变了人们学习、工作、沟通甚至组织生活的方式,因此提示技巧将变得更加相关。实际上,谁不期待用可靠的 AI 助手来自动化那些乏味的工作呢?
提示工程及其未来:它会超越短暂的时尚吗?
导航提示工程的复杂领域需要一种平衡的方法,这种方法既要承认其潜力,同时也要脚踏实地地面对其局限性。此外,我们还必须意识到提示工程的双关意义:
-
以尽可能少的努力或步骤促使大型语言模型(LLMs)按照自己的意图行事的行为
-
一个围绕上述行为的职业
所以,在未来,随着输入窗口的增多以及大型语言模型(LLMs)在创建比简单的线框图和机器人般的社交媒体文案更复杂的内容方面变得更加熟练,提示工程将成为一项必备技能。可以把它看作是如今会使用 Word 的等价物。
结论
总之,提示工程正处于一个十字路口,它的命运由炒作、希望和现实的交汇点所决定。它是否会巩固其在人工智能领域的地位,还是会逐渐消退成为技术潮流的历史一部分,还有待观察。然而可以确定的是,其充满争议的旅程不会很快结束,无论是好是坏。
Nahla Davies是一位软件开发人员和技术作家。在全职从事技术写作之前,她曾管理——除了其他有趣的事物——担任一家《Inc. 5000》体验品牌机构的首席程序员,该机构的客户包括三星、时代华纳、Netflix 和索尼。
更多相关内容
首席 AI 执行官的崛起
最近有关增加 CAIO 的新闻使得每个人都在谈论这一角色在 AI 保护方面的作用。
尽管这个职位听起来很吸引人,但它在期望和职责方面也有一定的不确定性。
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求

图片来源:编辑
在带来其独特能力的同时,这一角色位于许多关键角色的交汇点,如业务高管、法律顾问、首席技术官(CTO)和首席数据官(CDO)等。
CAIO 在将 AI 策略与业务优先事项对齐的同时,还讨论了使现有架构具备 AI 准备能力的需求(和计划),并与 CTO 一起建议和监督技术成熟度水平。此外,这一 AI 执行官角色还负责保护 AI 计划,确保其商业可行,并与 CFO 办公室对齐。
简而言之,单一的 AI 领导力对于有效地将 AI 融入业务并重新定义传统商业方式至关重要。
现在我们已经了解了这一角色如何与其同行互动,让我们来看看为什么现在需要这样的角色。为什么以前我们没有听说过更多关于 CAIO 的信息?
我们为什么现在讨论这个角色?
除了拜登政府宣布这一角色的重要性外,AI 领域的发展速度要求有一位能够感知技术发展前沿的 AI 执行官,培养企业的创新能力,并比竞争对手更快地执行不断变化的路线图。

这就像是准备组织最大限度地有效和高效地利用 AI 的好处,而不是等待行业领袖来指明这种技术的最佳使用方式。
以数字支持这一观点,LinkedIn 上“首席 AI 执行官”这一职位的趋势不断上升,从 2020 年的 250 个增加到最新搜索的 781 个此类职位。
可以说,那些投资于 CAIO 决策的公司已经为迎接人工智能技术并在未来几年见证业务增长做好了充分准备。
首席人工智能官做什么?
CAIO 能够使每个人都具备人工智能意识,包括同级高管,并为人工智能素养计划做出重要贡献。这类似于创建一个由 CAIO 主导的人工智能委员会,旨在提升意识,并将大家聚集在一起,就如何利用人工智能重塑业务达成共识。
有人可能会争论说,是否需要再增加一个高管职位,与同级同行合作以实现协同,然而,识别人工智能机会而不承担不必要的风险需要专业知识,这在物质上与日常业务运作(BAU)大相径庭。
CAIO 拥有领域知识,并通过系统化的人工智能采纳方法帮助每个人对选择正确的举措达成一致,而不是到处乱跑。
作者提供的图片
人工智能绝不应该仅仅成为公关活动的一部分或另一个打勾的活动。它需要一个具有激光般精准关注的高管,负责监督其发展和采纳。
构建人工智能文化
人工智能不是一朝一夕能完成的。这确实是一个多年转型的过程,其根基在于建立正确的文化并将每个人都带上。这一战略性招聘可以将人工智能融入到整个组织的运作中。
-
吸引人工智能人才本身就是一项巨大的挑战;然而,当那些在人工智能路线图上挣扎的组织开始失去数据科学家时,问题会迅速加剧。原因也很正当。这个领域要求不断跟进最新的技术趋势,并且要有实际操作的能力。一旦数据科学团队意识到公司的人工智能愿景更像是一个华丽的愿望而非强有力的商业提案,他们很快就会离开。因此,CAIO 的存在不仅巩固了人工智能愿景,还增强了团队的信心,确保每个人都在朝着实现有意义的商业影响的正确方向努力。
-
CAIO 了解人工智能的语言,并能够有效地向数据科学和工程团队阐述技术要求。这种沟通在人工智能产品的无缝开发周期中扮演着关键角色,减少因缺乏人工智能专业知识而产生的不必要的迭代。
-
阻碍人工智能计划进展的一个主要问题是高管的支持。通过引入 CAIO,支持变得更容易,因为组织已经有了一个能够传达人工智能可能性的人工智能高管。
有很多内容可以补充,以突出这个角色带来的附加价值,这些内容我将在后续帖子中详细讲解,然而,有一点是明确的。
CAIOs 不仅仅是船上的另一种华丽称谓。他们通过从业务战略中衍生出人工智能战略,并与数据战略协同工作,来构建和执行人工智能战略。
即使有许多潜在的候选人,如 CDO 和 CTO,也能扩展到这个角色,但重要的是要注意,CAIO 具备执行人工智能所需尽职调查的必要专业知识,并且能够处理人工智能带来的独特挑战。
结束语
归根结底,这不仅仅是一个头衔。每个组织可能有不同的称谓与 CAIO 相对应。他们版本的 CAIO 可能是副总裁、高级副总裁、总监或人工智能负责人,做着相同的工作。
这更多关乎于知识的深度以及推动人工智能创新和转型的能力。
Vidhi Chugh**** 是一位人工智能战略家和数字化转型领袖,致力于在产品、科学和工程交汇处构建可扩展的机器学习系统。她是一位获奖的创新领袖、作者和国际演讲者。她的使命是让机器学习大众化,打破术语,使每个人都能参与到这场转型中。
更多相关话题
人工智能在数字营销中的作用

由作者提供的图片
人工智能(AI)已经彻底改变了众多行业,包括数字营销。该领域利用在线平台推广产品和服务。随着技术的迅速发展,公司越来越倾向于使用人工智能来优化他们的营销策略,并在数字领域获得竞争优势。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
根据约翰·麦卡锡的定义,人工智能被称为“使智能机器,特别是智能计算机程序的科学和工程”。这一定义强调了创建可以执行任务的系统,如果由人类执行这些任务,则需要智能,如学习、推理、解决问题、感知和语言理解。
本文的目标是探索和理解人工智能与数字营销的交汇点,审视人工智能在数字营销中的角色以及如何在营销团队中有效集成人工智能。
什么是人工智能数字营销
人工智能营销是指将人工智能技术集成到营销策略中,以提升和自动化传统上需要人工努力的任务。这可以包括数据分析、客户细分、内容创作和活动管理。
从传统数字营销到人工智能驱动的营销的转变代表了企业与其受众互动和优化策略的重大进化。与依赖静态方法和一般化目标的传统方法不同,人工智能营销利用先进的算法和数据分析实时个性化和优化活动。
这里有一些顶尖公司及其如何利用人工智能在数字营销中推动销售和增长:
-
亚马逊:亚马逊广泛使用人工智能进行个性化推荐,基于客户行为和浏览历史。他们还利用人工智能算法优化产品搜索结果和广告投放,以提高客户参与度和增加销售额。
-
Google: Google 在其广告平台(Google Ads)中利用 AI 来优化广告定位、竞价策略和广告投放。AI 驱动的算法分析用户行为,以提供更相关的广告,从而提升广告表现和广告主的投资回报率。
-
Facebook: Facebook 在其平台上利用 AI 进行广告定位和优化。AI 算法分析用户兴趣、行为和人口统计数据,以向最有可能参与广告的用户展示个性化广告。这提高了广告效果,并帮助企业更有效地触达目标受众。
-
Netflix: Netflix 利用 AI 根据用户的观看习惯和偏好来个性化内容推荐。这个个性化推荐系统通过建议符合个人口味的内容来提高用户参与度和留存率,从而推动订阅增长。
-
阿里巴巴: 阿里巴巴使用 AI 进行产品推荐、客户服务聊天机器人和个性化营销活动。AI 算法分析消费者行为数据,以预测购买模式并针对个别客户量身定制营销策略,从而提升购物体验并增加销售额。
AI 在数字营销中的角色
AI 通过利用数据驱动的洞察和自动化来增强营销策略,实现更个性化和有效的活动,这里是 AI 在数字营销中的一些角色:
数据分析和洞察
数据分析和洞察是 AI 在数字营销中作用的重要组成部分,为企业提供了了解和有效与受众互动的巨大好处。AI 在数据分析中的能力超越了传统方法,通过先进算法迅速准确地处理大量数据。
AI 使数字营销人员能够从多样的数据源中提取有意义的洞察。通过分析这些丰富的信息,AI 识别出手动分析可能无法显现的模式、趋势和关联。
自动化和效率
自动化和效率也是 AI 对数字营销影响的重要方面,彻底改变了企业简化运营和提高生产力的方式。
AI 驱动的自动化使市场营销人员能够自动化重复性任务,例如电子邮件活动、社交媒体排期、客户服务互动和广告投放。这些任务可以通过利用 AI 算法迅速且准确地执行,从而释放出宝贵的时间和资源,让市场营销人员能够专注于战略性举措和创意工作。
个性化客户体验
AI 在数字营销中促进的个性化客户体验围绕着将互动和内容调整以满足个别客户的独特需求和偏好。通过数据驱动的洞察,这种方法超越了通用信息传递,提供了更相关、更具吸引力的体验。
AI 使市场营销人员能够从各种来源收集和分析大量数据,如过去的购买历史、浏览行为、人口统计信息和跨渠道的参与模式。通过了解这些洞察,AI 可以创建详细的客户档案,并根据特定标准进行受众细分。
这些档案使市场营销人员能够制定高度针对性和相关性的广告活动。例如,AI 可以根据客户的浏览历史或之前的购买推荐产品,按照个人偏好发送个性化电子邮件优惠,或动态调整网站内容以展示最有可能吸引特定访客的商品。
实时广告优化
由 AI 驱动的实时广告优化在数字营销中是一个游戏规则的改变者。它涉及根据实时数据和洞察力持续监控和调整营销活动。它是这样工作的:
在运行数字广告活动时,AI 算法会实时分析许多因素,如受众人口统计信息、参与指标、点击率和转化率。这种持续的监控使市场营销人员能够及时调整策略。例如,如果某个广告表现不佳或某个产品的兴趣突然激增,AI 可以自动将更多预算分配给表现良好的广告,或调整目标参数以利用新兴趋势。
通过 AI 进行实时广告优化提高了数字营销工作的表现和效率,并使市场营销人员能够保持灵活和响应迅速。
如何在数字营销中使用 AI
如果你还没有将 AI 融入到你的数字营销策略中,现在是时候了。根据Hubspot的研究,46%的市场营销人员感到在日常操作中整合 AI 工具时不堪重负。
下面是你如何在数字营销团队中有效使用 AI 的建议。
明确你的目标
在开始之前,定义你希望实现的具体目标。你是想提高广告活动的效果,还是优化团队的工作流程?设定明确的目标和可衡量的 KPI 对于衡量成功至关重要。
评估你的基础设施
从组建一个小团队开始,评估你当前的工具和基础设施。确定 AI 集成的潜在领域,并在详细报告中概述预期成果和资源需求。
评估你的数据的质量、数量和可访问性,以确定其是否适用于 AI 应用。一定要预见挑战和风险,同时考虑潜在的好处。
请记住,过渡到 AI 策略不会一蹴而就。首先确定两个到三个关键领域进行初步实验。即使是像使用 AI 记录会议笔记或转录访谈这样的细微变化,也可以带来显著的好处。
评估团队能力
评估你的团队是否具备有效实施 AI 项目所需的技能和知识。你可能需要投资培训、聘请专业顾问或创建新的角色,专门推动 AI 项目向前发展。
选择合适的 AI 工具
一旦确定了目标并识别了优先领域,选择合适的 AI 工具。评估现成解决方案还是定制的 AI 平台更适合你的需求。
现成的选项如 Jasper、ChatGPT 或 Gemini 提供即刻的 AI 能力。对于定制解决方案,可以利用开放源代码的 AI 框架如 Llama 2 的 API 来实现量身定制的应用,尽管这需要专业的技术知识。在这个阶段,与 IT 顾问合作是非常重要的。
测试和分析 AI 应用
现在,是时候试行你选择的 AI 项目了。在选定的重点领域实施它们,并建立明确的时间表和绩效指标以跟踪结果。
例如,在测试 AI 生成的社交媒体广告时,可以进行为期一个月的试验。在整个试验期间,持续监测并优化内容以提升性能。比较 AI 生成的、人工生成的以及 AI 辅助的内容结果,以为未来的策略提供参考。
使用 AI 进行数字营销的挑战
将 AI 融入数字营销不可避免地会带来独特的挑战和考虑因素。本节重点介绍在利用 AI 制定数字营销策略时遇到的挑战。
-
在数字营销中实施 AI 需要大量的基础设施和培训投资。
-
AI 可能难以理解细腻的人类情感和文化背景,从而影响营销信息的个性化。
-
在使用 AI 算法时,确保数据隐私和安全是一个重要问题。
-
对 AI 过度依赖可能导致失去人情味和客户参与度。
-
AI 生成的内容可能缺乏人工生成内容所能提供的创意和原创性。
-
AI 模型需要不断更新和调整,以保持其有效性,因为消费者行为和趋势在不断演变。
-
将 AI 无缝集成到现有的营销工具和工作流程中可能会很复杂且耗时。
结论
随着 AI 继续重塑数字营销格局,企业必须战略性地拥抱这些进步,利用 AI 工具推动增长,同时保持与全球受众共鸣的关键人情味。
如果你查看由ResearchGate发布的这项研究,你将对如何将人工智能融入数字营销有一个坚实的理解,这标志着企业与其受众互动方式的变革性跃进。然而,从数据隐私问题到确保与现有工作流程的无缝集成,AI 实施的复杂性需要谨慎规划和战略适应。
Shittu Olumide 是一位软件工程师和技术作家,热衷于利用前沿技术编写引人入胜的叙述,注重细节,并擅长简化复杂概念。你也可以在Twitter上找到 Shittu。
了解更多相关话题
2024 年科技裁员激增:谁该负责?
原文:
www.kdnuggets.com/the-surge-in-tech-layoffs-2024-who-to-blame

图片来源:Unsplash
进入 2024 年一个月,我从未见过我的 LinkedIn 主页上如此多的“开放工作”标语和帖子。2023 年已经很艰难,很多公司宣布裁员,更糟的是,这些裁员相当残酷。有些人被告知“你被解雇了,再见”,而其他人甚至没有拿到应得的工资——一团糟。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
他们说 2024 年初总是带着剩余的 2023 年能量——所以 2024 年的裁员仍在继续。
自然地,看到科技行业裁员会让你感到非常不安。你开始怀疑自己工作的安全性,并考虑是否应该聪明地开始寻找新机会。但接着,你又想到进入另一家可能也会重组或破产的科技公司。
是的,你的脑袋可能正因为该怎么做而感到晕旋。
科技裁员背后的原因
根据Crunchbase的数据显示,截至 2024 年 1 月 19 日,美国科技行业至少裁员 2,215 人。在 2024 年全年,美国本土科技公司至少有 6,505 名员工失业,而这一年才刚刚开始!
那么到底发生了什么?
科技疫情
在 Covid-19 大流行期间,科技行业疯狂增长!你看到每个人和他们的狗都转行进入科技行业,薪资丰厚,福利优厚。职位左右开花,人们都喜欢这样——他们终于找到了梦想中的工作!
人们被困在家中,远程工作(WFH)成为新宠,企业也因为不再花费那么多在办公室空间、团队会议等上面而拥有了更多的资金。招聘热潮开始了,公司们喜欢他们的团队在扩展!
技术招聘热潮短暂持续,人们在 2022 年、2023 年以及现在的 2024 年都面临裁员。
365 数据科学通过数据分析探究了所有科技裁员的根本原因,结果如下:
图片来源:365 数据科学
从可视化图表中可以看出,大多数裁员发生在 HR 和人才资源部门——这并不令人惊讶,因为在某一时刻,这些部门曾因招聘热潮而极其重要。其次是软件工程师,其次是市场营销部门,依此类推。
数据还显示,在 2022-2023 年间,56%的裁员人员是女性,48%的人年龄在 30-40 岁之间,89%的人位于美国,60%的人拥有学士学位。
那么,你如何才能赢得胜利呢?
人工智能在接管吗?
这正是我们大家都在思考的。过去几年里,人工智能确实迅速发展,人们开始失业,这难道仅仅是巧合吗?还是说真的是这样?
以你当地的超市为例,过去几个月我见到了比以往更多的自动化自助结账机。收银区大幅减少,取而代之的是自助结账机。
如果我们回顾 365 数据科学的发现,大多数裁员发生在 HR 和人才资源部门。这些部门的许多日常任务已经被自动化技术大幅替代。公司正在整合许多工具和软件,用于处理 HR 部门的手动任务。这是否是 HR 和人才资源部门在名单上排名靠前的原因?
但这对其他部门意味着什么呢?为什么他们会被裁员?
个人认为,其他部门正在处理疫情期间科技招聘热潮的后遗症,而我们正经历经济衰退的可能性,公司在努力维持财务稳定。这意味着所有在科技招聘热潮期间聘用的员工,或那些过于昂贵的员工,都不得不被裁员。
我的公司会裁员吗?
如果你在科技行业工作,你可能会担心工作安全——这很正常,我理解你的担忧。但你总是可以保护自己,以下是一些方法。
如果你的公司宣布全公司招聘冻结,这通常是公司财务状况紧张或即将勉强维持运营的良好迹象。
另一个迹象是你的工作负荷。如果你发现工作负荷大幅减少,项目被取消。这是很多人最初不会注意到的,但事实是,C-suite 成员没有时间或财力启动新项目,因为他们正在努力整合公司未来的发展蓝图以及如何维持公司运营。
我敦促你对这些信息保持一些保留态度,因为这些原因可能并不完全表明公司正在经历艰难时期和裁员将要发生。这也可能意味着公司正在处理其他他们优先考虑的事务。
总结一下
目前对科技员工来说是个困难时期,说到这一点,我认为每位科技员工都应该提醒自己,这些科技裁员并非针对个人,而且不幸的是超出了我们的控制范围。这些裁员还包括了经验最丰富的成员,他们也被裁掉了。
如果你感到非常不确定,我建议你始终提升自己的技能,为最坏情况做好准备,并且如果你的公司出现财务困难的迹象,务必有一个备选计划。
尼莎·阿里亚 是一名数据科学家、自由技术作家,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及数据科学的理论知识。尼莎涵盖了广泛的话题,并希望探索人工智能如何有益于人类生命的长寿。作为一个热衷的学习者,尼莎希望扩展她的技术知识和写作技能,同时帮助指导他人。
相关主题
GitHub 在数据科学项目中的前五大替代平台
原文:
www.kdnuggets.com/the-top-5-alternatives-to-github-for-data-science-projects
作者提供的图片
GitHub 长期以来一直是开发者,特别是数据科学社区的首选平台。它提供了强大的版本控制和协作功能。然而,数据科学家往往有独特的需求,如处理大型数据集、复杂的工作流程以及特定的协作需求,而 GitHub 可能无法完全满足这些需求。这导致了替代平台的兴起,每个平台都提供了独特的功能和优势。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
在这篇博客中,我们深入探讨了五个特别适合数据科学项目的 GitHub 替代平台,提供了多样的协作、项目管理以及数据和模型处理选项。
1. Kaggle
Kaggle在数据科学社区中以其独特的数据科学竞赛、数据集和协作环境而闻名。
该平台提供了大量数据集的访问机会,并允许数据科学家通过竞赛在现实场景中测试他们的技能。此外,我还可以编辑、运行和分享带有输出的代码笔记本。
图片来源于 Kaggle
我已经使用 Kaggle 三年了,我非常喜欢这个平台。它让我能够在免费的 GPU 和 TPU 上快速运行深度学习项目。借助它,我通过分享我的分析报告和机器学习项目,建立了一个强大的作品集。此外,我还参与了各种数据分析和机器学习竞赛,这帮助我提升了这些领域的技能。总的来说,Kaggle 是一个极好的资源,使我在个人和职业上都得到了成长。
如果你是数据科学领域的初学者,我强烈推荐从 Kaggle 开始,而不是 GitHub。Kaggle 提供了许多免费功能,这些功能对任何数据科学项目都是必不可少的。此外,你可以向他人学习,并在一个互帮互助的社区中直接提问。
图片来自 Kaggle
2. Hugging Face
Hugging Face迅速成为自然语言处理(NLP)和机器学习领域最新发展的中心。它通过提供大量预训练模型以及一个用于训练和分享新模型的协作生态系统而脱颖而出。此外,上传数据集和免费部署机器学习网页应用变得非常简单。
在 Hugging Face 中,模型库类似于 GitHub,包含各种类型的信息,包括文件和模型。你可以附上研究论文、添加性能指标、使用模型构建演示,或创建推理。此外,现在你还可以像在 GitHub 中一样评论和提交拉取请求。
图片来自 Hugging Face
我经常使用 Hugging Face 来部署模型、上传训练模型,并建立一个强大的机器学习组合。我已经实现了深度强化学习、多语言语音识别和大型语言模型。
这个平台主要面向社区,其一个重要特点是大部分功能是免费的。然而,如果你拥有先进的模型,甚至可以申请付费功能。这使得它成为任何希望成为 ML 工程师或 NLP 工程师的人的首选平台。
图片来自 Hugging Face
3. DagsHub
DagsHub是一个专为数据科学家和机器学习工程师量身定制的平台,专注于管理和协作数据科学项目的独特需求。它提供了出色的工具来版本控制不仅是代码,还有数据集和 ML 模型,解决了这一领域的一个共同挑战。
该平台与流行的数据科学工具集成良好,使从其他环境的过渡变得顺畅。DagsHub 的突出特点是其社区方面,提供了一个数据科学家可以协作和分享见解的空间,对于那些希望与同行互动的人来说,这是一种特别有吸引力的选择。
图片来自 DagsHub
我非常喜欢 DagsHub,因为它在上传和访问数据和模型方面提供了用户友好的方法。DagsHub 提供了简单的 API 和 GUI,使你可以轻松上传和访问数据和模型。此外,它提供了用于实验跟踪和模型注册的 MLFlow 实例。它还提供了免费的 Label Studio 实例来标记你的数据。它是满足你所有机器学习需求的一体化平台。DagsHub 还提供了第三方集成,如 S3 桶、新遗迹、Jenkins 和 Azure blob 存储。
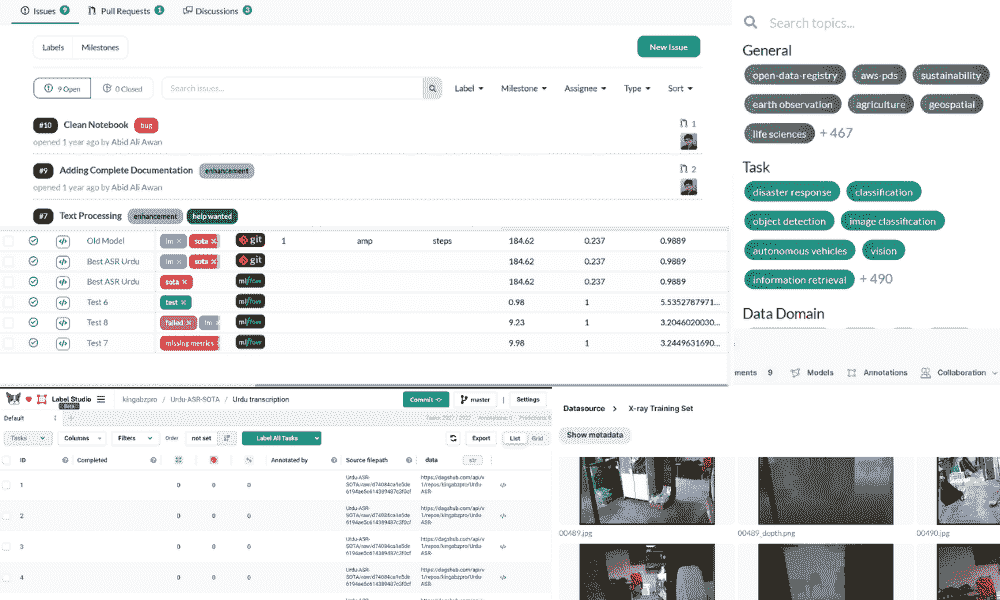
图片来自 DagsHub
4. GitLab
GitLab 是所有技术专业人员的一个良好替代品。它提供强大的版本控制和协作、CI/CD、项目管理和问题跟踪、安全和合规、分析和洞察、Webhooks 和 REST API、Pages 等功能。
这个平台是开发者和数据科学家构建无缝工作流自动化的理想解决方案,从数据收集到模型部署。它还提供强大的问题跟踪和项目管理工具,这对于协调复杂的数据科学项目至关重要。
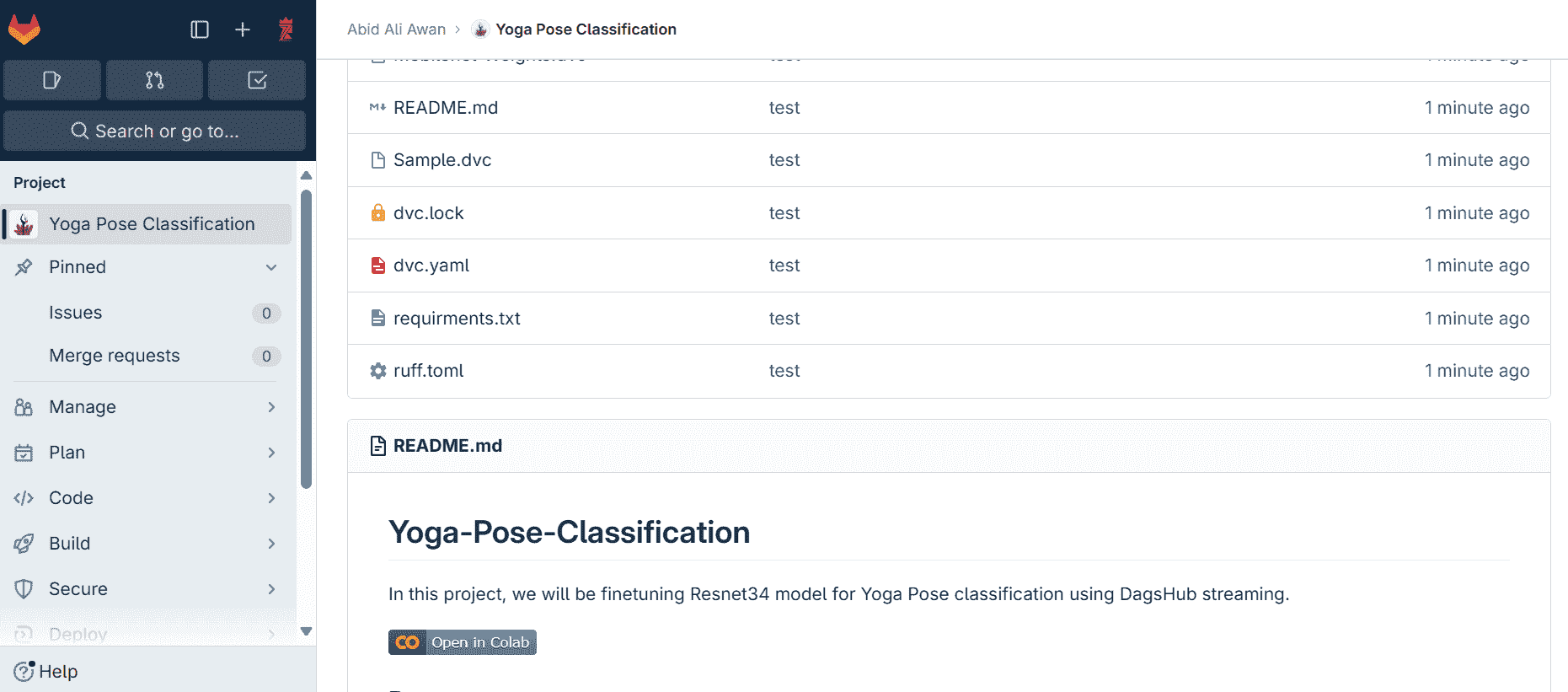
图片来自 GitLab
过去三年我一直在使用 GitLab,主要是为了熟悉这个平台并将我的静态网站从 GitHub 迁移到 GitLab。GitLab 的用户界面易于理解,并且为免费用户提供了广泛的工具。此外,你可以选择免费托管自己的 GitLab Community Edition 实例,让你对项目拥有完全的控制权。
就像 GitHub 一样,GitLab 也可以用作你的数据科学项目的作品集。你可以将所有工作上传并集中分享,它甚至拥有更好的协作工具,适用于更大更复杂的项目。即使你已经对 GitHub 满意,GitLab 也是一个你绝对应该考虑的强大平台。
图片来自 GitLab
5. Codeberg
Codeberg.org 作为一个非营利性、社区驱动的平台,其强烈强调开源和隐私。它提供了一个简单、用户友好的界面,适合那些寻找简单直观的代码托管解决方案的用户。对于重视开源价值和数据隐私的数据科学家来说,Codeberg 是一个有吸引力的替代方案。
图片来自 Codeberg
它提供 CI/CD 解决方案、Pages、SSH 和 GPG、webhooks、第三方集成以及各种项目的协作工具,类似于 GitHub。
在安装 Librewolf 时,我发现了 Codeberg 和 Forgejo。它们提供类似 GitHub 的体验以及简化的工作流自动化。我强烈推荐尝试一下,用于托管你的项目。
图片来源于 Codeberg
结论
这些平台各自提供了数据科学家所需的独特功能和优势。GitLab 擅长集成的工作流管理,DagsHub 和 Hugging Face 适合机器学习项目托管和协作,Kaggle 提供互动的学习和竞赛环境,而 Codeberg 强调开源和隐私。根据具体需求,无论是高级项目管理、社区互动、专业工具还是对开源原则的承诺,数据科学家都可以在这些选项中找到适合的 GitHub 替代方案。
Abid Ali Awan (@1abidaliawan) 是一位认证数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一款 AI 产品,帮助那些在精神疾病方面挣扎的学生。
更多相关内容
顶级 5 大云端机器学习平台与工具
原文:
www.kdnuggets.com/the-top-5-cloud-machine-learning-platforms-tools

发掘机器学习的巨大力量和 未开发的潜力,即 ML,不再是奢侈,而是企业、研究人员和开发者的必要条件。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT
随着市场预计在 2029 年 价值达 2090 亿美元,对 ML 解决方案的需求不断增长,对构建和部署这些解决方案的最有效且可扩展的平台的需求也在增加。云端机器学习平台应运而生——将云的灵活性与 ML 应用的计算能力相结合。
在本文中,我们将审视目前市场上脱颖而出的 5 大云端机器学习平台。无论您是新手、经验丰富的数据科学家,还是经验丰富的企业领导者,我们的列表,包括 Azure ML、Lambda Labs、Google Cloud、Neptune 和 BigML,将帮助您深入了解哪个平台可能最适合您的特定机器学习需求。
Azure ML 是微软的旗舰云端机器学习平台,因其集成环境——Azure Machine Learning Studio 而闻名。这个可视化界面简化了构建、训练和部署 ML 模型的过程,无需深厚的编码知识。用户可以轻松地将数据集和模块拖放到互动画布上,使其即使对初学者也很友好。对于专业人士,Azure ML 支持多种算法和框架,如 TensorFlow、PyTorch 和 Scikit-learn。其内置的模型管理和部署功能使从开发到生产的过渡无缝。
🔑 AzureML 关键点
-
综合 ML Studio 用于开发
-
支持多种算法和框架
-
内置模型管理和部署能力
✅ 优点
-
直观的可视化界面
-
大范围的框架支持
-
强大的部署选项
❌ 缺点
-
高级功能的学习曲线
-
成本对于较小的项目可能是个问题
Lambda Labs 突破常规,直接针对深度学习爱好者提供其先进的 GPU 云。鉴于各种深度学习任务的计算需求,Lambda Labs 提供了为最佳性能量身定制的基础设施。这转化为更快的训练时间和实时推理,这在现代 AI 工具中至关重要。除了原始的硬件性能,Lambda Labs 还提供预配置的软件堆栈,使开发人员能够直接进行神经网络的训练和部署。他们的高性能工作站对于需要顶级本地机器进行机器学习工作的开发人员来说是一个额外的优势。
🔑 Lambda Labs 重点
-
为深度学习打造的 GPU 云
-
提供预配置的软件堆栈
-
以高性能工作站著称
✅ 优点
-
专注于深度学习的基础设施
-
提供预设的软件堆栈
-
强大的本地机器选项
❌ 缺点
-
比传统的机器学习更适合深度学习操作
-
在更广泛的机器学习任务中不如其他选项多才多艺
Google Cloud AI & ML 是一个全面的平台,旨在赋能新手和资深数据科学家。它提供从强大的数据存储解决方案(如 Google Cloud Storage)到开创性的机器学习库(如 TensorFlow)等各种工具和服务。一个明显的优势是与成本效益高的网站解决方案的无缝集成,使其对初创企业和小型企业尤其有利。通过实时数据分析和直接从网站部署模型,Google Cloud AI 简化了机器学习过程,并推动企业向数据驱动的决策迈进。
🔑 Google Cloud AI & ML 重点
-
提供满足各种 AI 需求的工具套件
-
用于协作和部署的 AI 中心
-
与其他 Google Cloud 服务集成
✅ 优点
-
提供各种工具
-
为开发者提供的协作 AI 中心
-
与 Google 服务紧密集成
❌ 缺点
-
定价可能较复杂
-
某些服务有较陡峭的学习曲线

Neptune 独特之处在于将先进的机器学习能力带入图形数据库。它通过预测图中的关系,支持从推荐系统到欺诈检测等各种应用。该平台的优势在于能够自动识别图结构,优化机器学习模型,并在无需手动特征工程的情况下进行预测。另一个优点是与 Amazon SageMaker 的无缝集成,允许从模型训练到部署的全面工作流程。Neptune 还通过 SPARQL 查询提供快速而高效的洞察。
🔑 Neptune 关键点
-
图形数据库上的机器学习
-
与 Amazon SageMaker 无缝集成
-
使用 SPARQL 查询进行预测
✅ 优点
-
图形数据库的机器学习
-
与 SageMaker 的易集成
-
通过 SPARQL 进行直观预测
❌ 缺点
-
专注于图形数据库的细分领域
-
需要熟悉 AWS 生态系统
BigML 提供了一个便捷且用户友好的基于云的机器学习平台,适合初学者和专家。它具有简化数据导入、转换和模型创建等任务的可视化界面。一个突出的特点是 WhizzML,这是一种领域特定语言,用于自动化复杂的机器学习工作流程。这种自动化对于优化重复任务和确保可重复性非常有用。该平台还提供了多种算法和可视化工具,使其成为满足多样数据分析需求的有吸引力的选择。
🔑 BigML 关键点
-
适用于机器学习任务的用户友好平台
-
提供各种各样的算法和可视化工具
-
利用 WhizzML 实现自动化
✅ 优点
-
直观且易于使用的平台
-
与 WhizzML 集成以便于自动化
-
提供广泛的算法支持
❌ 缺点
-
对于非常专业的任务可能存在局限性
-
某些高级功能具有学习曲线
云机器学习平台的出现无疑彻底改变了企业、研究人员和开发者对人工智能的应用方式。
从 Azure ML 和 BigML 的直观设计,到 Lambda Labs 的深度学习专长——每个平台都提供独特的优势,以满足该领域中的不同需求。
选择合适的方案取决于识别特定项目要求、预算限制和期望的可扩展性。因此,无论你是初入这一领域寻求简单平台的新人,还是希望获得更高级和专业能力的资深 AI 研究人员,当前可用解决方案的丰富性和多样性都能帮助你选择最佳选项。
娜赫拉·戴维斯 是一名软件开发人员和技术作家。在全职从事技术写作之前,她曾在一家 Inc. 5,000 级的体验品牌机构担任首席程序员,该公司客户包括三星、时代华纳、Netflix 和索尼等。
更多相关话题
2024 年八大云容器管理解决方案
原文:
www.kdnuggets.com/the-top-8-cloud-container-management-solutions-of-2024

图片来源:svstudioart,来自Freepik
随着企业迅速采用云原生技术,对能够无缝管理其容器化应用程序的工具的需求在近年来激增。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织的 IT 需求
为帮助您为您的组织找到合适的解决方案,本文旨在引导您了解目前领先的解决方案。我们将提供一些实用的见解,帮助您选择最适合您组织特定需求的 suitable container management solution。
无论您是小企业主、开发人员还是 IT 专业人士,了解这些顶级解决方案的细微差别对于帮助您在管理云计算资源时做出明智的决策至关重要。
1. Google Cloud Run
Google Cloud Run 是一个完全托管的平台,能够使开发人员快速、安全地部署容器化应用程序。
该平台使用Google 强大的云基础设施来提供一个可以在无服务器状态下运行容器的环境,这意味着用户无需担心底层基础设施的管理。
Google Cloud Run 以其高可用性而闻名,这也是公司在许多不同用途上使用它的原因,包括 数据迁移、CI/CD 流水线、API 开发和托管,以及 实施 SAP 人员增补措施。它以 自动扩展 的能力脱颖而出,根据流量进行自动缩放,确保了组织在各个规模下的成本效益和资源利用效率。
主要特点:
-
无服务器: Cloud Run 根据需求自动扩展您的应用程序,能够高效管理流量波动,无需人工干预。
-
与 Google Cloud 服务的集成: 它提供与 Google 服务(如 Cloud Storage、Cloud SQL 等)的无缝集成,增强了整体功能和便利性。
-
自定义域名和 SSL: 它支持使用自定义域名,并自动提供 SSL 证书,增强安全性和品牌识别。
-
容器间网络通信: 它提供了增强的安全措施,并促进容器之间的顺畅通信。
-
持续部署: 它与 Google Cloud Build 无缝集成,允许直接从源代码库进行持续部署,从而简化开发过程。
2. Podman
Podman,也称为 Pod Manager,是一个开源容器管理工具,属于 Red Hat 家族,设计为 Docker 的替代品。
Podman 的独特之处在于其无守护进程架构,这增强了安全性并减少了复杂性。同样,Podman 对于那些尽管较简单但仍需高速的操作也非常有用,比如金融领域中的操作。从 点对点交易 到 资产保护 以及 发票融资 都可以从适当的容器管理中受益。
它使用来自 Docker 和 Open Container Initiative 注册表的标准容器镜像。除此之外,它还支持几乎所有 Docker CLI 命令,使用户能够轻松从 Docker 过渡到 Podman。
主要特点:
-
无守护进程架构: Podman 通过无中心守护进程的运行方式提高了安全性并减少了系统复杂性。
-
无根容器: 它允许在没有根权限的情况下运行容器,显著提升了安全性并减少了风险。
-
OCI 兼容:它完全兼容OCI 标准的容器镜像,确保了广泛的兼容性和易用性。
-
Pod 概念:Podman 模拟了 Kubernetes 的 Pod 结构,通过将多个容器分组到一个 Pod 中以实现更好的资源管理。
-
Systemd 集成:它通过与 systemd 的集成提供了对容器生命周期的更好控制和管理。
3. Digital Ocean
Digital Ocean 的容器服务,DigitalOcean Kubernetes 或 DOKS,旨在简化和易于使用。它是小型到中型企业或需要简单容器部署和管理的方法的个人开发者的理想解决方案。
Digital Ocean 自动化了大部分过程,包括 Kubernetes 集群的更新和维护。
关键特性:
-
托管的 Kubernetes:Digital Ocean 简化了Kubernetes 集群的设置和管理,使其更加易于访问,特别是对于小型到中型企业。
-
易于使用的界面:它具有直观的用户界面,简化了 Kubernetes 集群的管理。
-
快速部署的市场:它提供了一个市场,拥有各种预配置的应用程序和堆栈,便于快速部署。
-
块存储和负载均衡器:DO 与 Digital Ocean 的块存储和负载均衡服务无缝集成,以增强性能。
-
监控和警报:它包括内置的监控工具,用于有效的性能跟踪和可配置的系统事件警报。
4. Vultr
Vultr Kubernetes Engine,简称 VKE,提供了一个高度可扩展且用户友好的平台,用于部署、管理和扩展容器化应用程序。
Vultr 凭借其全球布局与竞争对手区别开来,提供了全球范围的数据中心,这对于需要在不同地理位置之间实现高可用性和低延迟访问的企业尤其有利。
关键特性:
-
全球覆盖:Vultr 提供了一个全球范围的数据中心网络,以提供高可用性和低延迟访问。
-
完全管理的 Kubernetes:VKE 积极减轻了与 Kubernetes 集群管理相关的复杂性,为组织提供了更为简化的体验。
-
块存储和负载均衡器:它与 Vultr 的原生块存储和负载均衡服务无缝集成,以增强存储和流量管理。
-
私有网络: 该平台提供了安全的私有网络选项,以确保容器间的安全通信。
-
API 和 CLI 访问: 该平台具有强大的 API 和命令行工具,便于自动化和轻松管理容器环境。
5. Dockerize.io
Dockerize.io 是一个相对较新的容器管理平台,主要关注基于 Docker 的容器管理。它提供了一个流线型平台,用于 管理 Docker 容器,重点关注 CI/CD 工作流的持续集成和持续部署。
Dockerize.io 对于寻求自动化部署管道的开发团队特别有用。
主要特点:
-
CI/CD 集成: 它专注于简化 集成和部署过程,使其成为开发团队寻求自动化部署管道的理想选择。
-
以 Docker 为中心的管理: 该平台专门设计用于管理 Docker 容器,提供量身定制的功能和支持。
-
Webhook 触发器: 它可以实现由代码提交或其他指定事件触发的自动化部署。
-
实时监控: Dockerize 提供了实时的 容器性能洞察,有助于有效的管理和故障排除。
-
用户友好的界面: 它提供了一个简化的用户界面,以便于高效管理 Docker 化的应用程序。
6. Red Hat OpenShift
Red Hat OpenShift 是领先的企业级 Kubernetes 平台,提供了一个全面的容器化应用解决方案。它提供了一个 全栈自动化操作模型,重点关注企业安全。
OpenShift 适合那些寻求可扩展和安全平台来管理复杂容器化应用的企业。
主要特点:
-
企业级 Kubernetes: 该平台提供了一个适合管理复杂、大规模应用的企业级 Kubernetes 环境。
-
以开发者和运营为中心: 它平衡了开发者和 IT 运营的需求,促进了协作和效率。
-
自动化操作: OpenShift 积极自动化安装、升级和生命周期管理,显著减少维护操作所需的人工工作。
-
内置 CI/CD: 它集成了持续集成和部署工具链,简化了开发过程。
-
高级安全功能: 它包含强大的 安全控制和合规功能,确保企业应用的安全环境。
7. Portainer
Portainer 是一个轻量级管理 UI,允许用户轻松管理不同的 Docker 环境。它 以其简洁性 而闻名,适合那些刚接触 Docker 或需要一个简便工具来帮助管理容器、镜像、网络和存储卷的用户。
关键特性:
-
用户友好的界面: Portainer 具有易于使用和直观的界面,使初学者和经验丰富的用户都能轻松上手。
-
Docker 兼容性: 它完全 兼容 Docker 和 Docker Swarm,便于无缝管理容器环境。
-
多环境支持: 它可以管理本地 Docker 主机、Docker Swarm 集群,甚至 从一个界面增强 Kubernetes 集群。
-
基于角色的访问控制或 RBAC: 该平台提供强大的访问控制机制,允许精确的用户角色定义和权限管理。
-
快速部署模板: Portainer 提供了一系列应用模板,以简化常见服务的部署。
8. SUSE Rancher
SUSE 的 Rancher 平台是一个开源容器管理平台,使组织能够大规模部署、管理和保护 Kubernetes。
它因其广泛的 Kubernetes 发行版支持、简洁的界面和强大的安全功能而广受欢迎和尊重。
关键特性:
-
多集群管理: Rancher 积极简化了不同计算环境中的 Kubernetes 集群操作,包括本地、云端和边缘计算。
-
广泛的 Kubernetes 支持: 它可以与任何 CNCF 认证的 Kubernetes 发行版 配合使用。
-
集成安全性: 该平台拥有全面的集群管理安全功能,包括 基于角色的访问控制,即 RBAC,以及 pod 安全策略。
-
用户友好的界面: Rancher 提供直观的 UI 和 API,轻松管理您的 Kubernetes 集群。
-
DevOps 工具集成: 它可以轻松集成多种 CI/CD 工具,并支持 GitOps 工作流。
高效管理您的容器化应用程序
在云容器管理方面,显然选择管理解决方案取决于必须仔细考虑的各种因素。
这些因素包括企业规模、具体用例、预算限制以及所需的控制和安全级别。从 Google Cloud Run 的完全托管无服务器解决方案到 Rancher 的开源灵活性和安全性,每种容器管理平台都有其独特的优势。
这些解决方案的多样性突显了评估组织需求和考虑未来可扩展性的重要性。随着容器技术的不断发展,从边缘计算应用到先进的 AI 集成,保持信息灵通和适应性将是充分利用这些工具的关键。
无论你是希望快速创新的初创公司,还是寻求稳健性和安全性的大型企业,提供的各种选项确保了总有一种有效的容器管理解决方案可以满足你公司的具体需求和要求。
Nahla Davies是一位软件开发人员和技术作家。在全职从事技术写作之前,她曾在一家 Inc. 5,000 体验品牌机构担任首席程序员,该机构的客户包括三星、时代华纳、Netflix 和索尼。
了解更多相关主题
终极 AI 战略手册
 图片由作者提供
图片由作者提供
如果没有人工智能;从某种程度上讲,没有这种技术的狂热席卷了整个行业。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
对于一个唯一核心关注点是通过利用技术推动业务增长的商业领袖,最初的思考是客户——我们服务的是谁?我们的受众是谁?他们希望/期望我们提供什么?
而第二个立即想到的是——他们的痛点。他们需要什么而没有人,甚至竞争对手也没有提供?
以客户为中心的商业战略
在这一点上,问题系列开始出现,一旦解决,将使业务成功。
-
什么让客户的生活更轻松?
-
什么才是给他们带来无缝体验的因素?
-
他们未被满足的需求是什么?
因此,开始探索达成目标的途径,也就是技术。
值得注意的是,我们还没有讨论人工智能。列出商业战略、杠杆和特权是决定“解决什么”和“为谁解决”最关键且终极重要的一步。
之后,出现了“如何解决”的问题。人工智能是否是解决这个商业问题的好方案?
在此时,企业需要一个框架来决定哪些使用案例适合人工智能。我建议使用“PRS”框架。它代表“模式在规模下重复”。
 图片由作者提供
图片由作者提供
模式
让我们以一个例子来内化这个框架:
例如,出租车服务提供商确保以具有成本效益的价格提供出租车司机的可用性,这考虑了各种因素 –
-
驾驶员可用池距离出租车请求者的接近程度
-
到达目的地的距离
-
高峰需求导致价格上涨,因为出租车请求者比出租车司机多
-
据报道,出租车请求者手机的低电量状态可能暗示着价格的上涨。这给出租车服务提供商发出了一个信号,即手机低电量可能会增加出租车请求者因紧迫感而支付更多费用的意愿。
-
出租车的可用性和定价也会因常规与高级出租车服务、一天中的时间或不利的天气条件等因素而有所不同。

图片来源:作者
在确保出租车司机获得足够激励以继续提升客户体验的同时。
所以,我们理解数据模式。
大规模的重复性
接下来是重复性——所有这些数据属性在每个出租车请求者和每次行程中都会重复出现,这不可避免地引出了最后一点,规模。
想象一下,如果有一个人工或非人工智能的工作流程来解决这个计算密集型的商业案例,这个问题将变得多么难以实现。
数据战略
在建立了商业思维模式之后,我们确定了通过人工智能解决的良好案例中的问题,让我们将所有注意力集中在数据上。毕竟,数据是推动所有人工智能算法成功的核心引擎。
我对此也有一个框架——AAA,代表可用性(Availability)、可访问性(Accessibility)和授权(Authorization)。
考虑以下:
我是否拥有数据?
对比:
我是否拥有详尽的数据?
这两种说法之间存在一个小但关键的区别。
仅仅拥有数据是不够的。还需要所有必要的数据来建模现象,以确保模型能够看到所有人类专家也能看到的属性。因此,数据的可用性是关键。
接下来是数据可访问性。拥有数据是一码事,但能够轻松访问数据则是另一回事。建立数据管道以确保无缝的数据访问是很重要的。
到目前为止,我们已经在整理数据方面取得了很多进展,但如果我们不被允许使用数据进行模型训练或分析目的呢?
这是大多数组织出现失误的地方。确保获得必要的授权,或者更好的是,仅使用您已经获得权限的数据。
有了数据战略的 3A,仍然有一个未解答的问题,即商业、数据和人工智能战略之间的顺序或顺序是什么?
这么多策略!!!
从大体上讲,人工智能战略始终是商业战略的一部分,并且与数据战略保持一致。在继续推进数据的 3A 的同时,务必要不断研究人工智能用例。
类似于人工智能项目的迭代性质,人工智能路线图在准备和增强数据基础设施以最大化组织内部人工智能技术潜力的过程中需要不断改进。
持续分析和跟踪关键绩效指标(KPIs),如准确性、效率和投资回报率,以定期评估 AI 项目的状态,从而衡量其效果并识别改进领域。
附加提示
大多数 AI 项目和策略都因为缺乏及时的沟通而受到影响。进行里程碑检查并积极征求利益相关者的反馈,包括最终用户和业务领导者,是至关重要的。所有成功的 AI 项目都经历了通过反馈进行的多个迭代周期,这些反馈用于调整和改进现有模型或开发新的使用案例。
此外,模型不仅仅是开发一次后再也不回顾。业务优先级可能随着时间的推移而改变,这必须在 AI 战略和实施中反映出来。
Vidhi Chugh** 是一位 AI 策略专家和数字化转型领袖,她在产品、科学和工程交叉领域工作,致力于构建可扩展的机器学习系统。她是一位屡获殊荣的创新领袖、作者以及国际演讲者。她的使命是使机器学习大众化,并打破术语,让每个人都能参与这一转型。**
更多相关话题
接近 LLMs 的终极指南

图片由作者提供
大型语言模型(LLMs)是强大的自然语言处理模型,能够理解和生成类似人类的上下文,这是前所未见的。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
凭借这些优势,LLM(大型语言模型)需求量很大,因此我们来看看任何人如何在 GPT 后的世界中学习它们。
回到基础
基础知识是永恒的,因此最好从基本概念开始,通过建立敏捷的思维模式来快速适应任何新技术。早期提出正确的问题至关重要,例如:
-
这项技术有什么新颖之处,为什么被认为是突破性的进展?例如,当谈论大型语言模型时,可以考虑将其拆分为每个组件——“大型、语言和模型”,并分析每个组件的含义。从“大型”开始——了解这是否涉及训练数据的大小,或者是模型参数的问题。
-
构建一个模型意味着什么?
-
建模某个过程的目的是什么?
-
这一创新弥补了之前的哪些差距?
-
为什么是现在?为什么这个发展以前没有发生?
此外,学习任何新的技术进步也需要辨别随之而来的挑战(如果有的话),以及如何减轻或管理这些挑战。
建立这样的好奇心帮助连接点,理解如果某样东西今天存在——它是否以某种方式建立在其前任的挑战或差距之上?
语言有什么不同?
通常,计算机理解数字,因此,理解语言需要将句子转换为数字向量。这就是自然语言处理技术(NLP)发挥作用的地方。此外,学习语言具有挑战性,因为它涉及到识别语调、讽刺和不同的情感。有些情况下,相同的词在不同的语境中可以有不同的含义,这突显了上下文学习的重要性。
那么,考虑因素包括,句子中的上下文有多远,以及模型如何知道上下文窗口。更深入地讲,这难道不是人类通过关注特定的单词或句子部分来选择上下文的方式吗?
继续沿着这些思路思考,你将会与注意力机制产生联系。建立这些基础有助于开发思维导图,从而形成对特定商业问题的解决方案。
不要依赖单一课程!
不幸的是,每个人都希望找到一个可以简化学习概念的单一资源。然而,这就是问题所在。尝试通过研究多个资源来内化一个概念。如果你从多个角度学习一个概念,理解它的可能性会更高,而不是仅仅将其作为理论概念进行消化。

作者提供的图像
关注行业领先专家,如 Jay Alammar、Andrew Ng 和 Yann LeCun,也很有帮助。
商业领导者的建议
随着人工智能团队加速学习快速发展的技术,企业也在努力找到适合使用这种先进技术的合适问题。
值得注意的是,训练在通用数据集上的 LLM 可以很好地完成一般任务。然而,如果商业案例需要特定领域的上下文,那么模型必须提供足够的上下文以给出相关和准确的回应。例如,期望 LLM 回应公司的年报需要额外的上下文,这可以通过利用检索增强生成(RAGs)来实现。
但在深入研究高级概念和技术之前,建议企业首先通过尝试那些可以迅速看到结果的简单项目来建立对技术的信任。例如,选择那些不直接面向客户或处理敏感数据问题的倡议作为起点,这样可以在解决方案出现问题时及时控制其风险。

作者提供的图像
企业可以通过利用人工智能创建营销文案、撰写草稿和总结,或生成见解来增强分析,从而开始看到影响并获得潜在回报。
这些应用不仅展示了能力和可能性,还揭示了这些先进模型的局限性和风险。一旦人工智能成熟,企业可以加快人工智能的应用,以建立竞争优势,提升客户体验。
信任因素
说到信任,商业领导者也肩负着向其开发者社区传达正确和有效的使用 LLM 方法的重大责任。
当开发人员开始学习 LLM 时,求知欲可能会迅速导致他们在日常任务中使用这些模型,例如编写代码。因此,考虑是否可以依赖这些代码很重要,因为它们可能会犯错,如编写过于简化的代码,或未涵盖所有边界情况。建议的代码甚至可能不完整或过于复杂。
因此,建议始终将 LLM 输出作为起点,并进行迭代以满足要求。在不同的案例上测试,自己审查,通过同行评审,并参考一些已建立和受信赖的资源来验证代码。彻底分析模型输出以确保没有安全漏洞,并验证代码是否符合最佳实践是至关重要的。在安全环境中测试代码可以帮助识别潜在问题。
总之,持续优化直到你对其可靠性、效率、完整性、稳健性和最优性充满信心。
摘要
适应并迅速学习和使用新技术进步需要时间,因此最好依靠行业同行的集体知识来了解他们的应对方式。这篇文章分享了一些最佳实践和永恒原则,帮助你像领导者一样接受这些技术。
Vidhi Chugh是一位 AI 战略家和数字化转型领导者,在产品、科学和工程的交汇点上工作,致力于构建可扩展的机器学习系统。她是一位获奖的创新领导者、作者和国际演讲者。她的使命是将机器学习民主化,并打破术语,使每个人都能参与这一转型。
更多相关主题
成为技术行业专家的终极路线图
原文:
www.kdnuggets.com/the-ultimate-roadmap-to-becoming-specialised-in-the-tech-industry

图片来源:作者
如果你是一名技术专业人士或希望进入该行业,现在你应该考虑在某一特定领域成为最佳。你希望被视为一名专业人士,了解你的领域的所有细节等。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的捷径。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
自然地,我们获得了广泛的知识,而不是如何在特定领域中专业化。
这篇文章将帮助你提升技能,扩展知识,并将你的头衔改为专业化的职业。
机器学习专业化
链接:机器学习专业化
你是数据分析师吗?你是否希望提升你的技术和数据处理技能,进入人工智能和机器学习领域?不妨看看。这门机器学习专业化课程包括 3 门课程:
-
监督机器学习:回归和分类
-
高级学习算法
-
无监督学习、推荐系统和强化学习。
在这 3 门课程中,你将学习如何使用 NumPy 和 Scikit-learn 构建机器学习模型,例如逻辑回归等监督模型。你还将学习如何使用 TensorFlow 构建和训练神经网络,应用最佳的机器学习开发实践,构建推荐系统和深度强化学习模型。
从数据分析师转型为机器学习工程师!
MLOps 专业化
链接:MLOps 专业化
想更深入地了解机器学习吗?如何从操作的角度来看?
这门 MLOps 专业化课程包括 5 门课程:
-
机器学习在生产中的介绍
-
机器学习数据生命周期在生产中的应用
-
机器学习建模管道在生产中的应用
-
部署机器学习模型到生产环境
在这些课程中,你将学习如何设计一个从头到尾的机器学习生产系统:从项目范围到部署需求。你还将建立模型基准,处理概念漂移,进行部署,并学习如何持续改进机器学习应用。不仅如此,你还将学习如何构建数据管道,建立数据生命周期,并维护一个持续运行的生产系统。
深度学习专攻
链接: 深度学习专攻
或者你可能想深入了解深度学习?这个深度学习专攻包含 5 门课程:
-
神经网络和深度学习
-
改善深度神经网络:超参数调整、正则化和优化
-
结构化机器学习项目
-
卷积神经网络
-
序列模型
在这些课程中,你将学习如何构建和训练深度神经网络,识别关键架构参数,以及训练测试集,分析深度学习应用的方差,并使用各种技术和优化算法。不仅如此,你还将学习如何构建 CNN/RNN 等。
自然语言处理专攻
链接: 自然语言处理专攻
想要了解大型语言模型如 ChatGPT 和 Claude 背后的基础知识?
现在你可以通过自然语言处理专攻来学习,专攻包含 4 门课程:
-
使用分类和向量空间进行自然语言处理
-
使用概率模型进行自然语言处理
-
使用序列模型进行自然语言处理
-
使用注意力模型进行自然语言处理
在这 4 门课程中,你将学习逻辑回归、朴素贝叶斯、情感分析、词嵌入等。进一步深入了解递归神经网络、LSTM、GRU 和孪生网络,以及如何使用编码器-解码器、因果关系和自注意力来进行机器翻译、文本总结、构建聊天机器人等。
TensorFlow: 数据与部署专攻
如果你查看了以上课程并看到提到了 TensorFlow,但不需要学习其他内容,只对 TensorFlow 感兴趣 - 请查看这个专攻。
这个 TensorFlow: 数据与部署专攻包含 4 门课程:
-
基于浏览器的 TensorFlow.js 模型
-
基于设备的 TensorFlow Lite 模型
-
使用 TensorFlow 数据服务进行数据管道
-
使用 TensorFlow 进行高级部署场景
在这 4 门课程中,你将学习如何使用 TensorFlow.js 运行模型,以及如何使用 TensorFlow Lite 在移动设备上准备和部署模型。你还将学习如何使用 TensorFlow 数据服务更轻松地访问、组织和处理训练数据,同时探索更高级的部署场景,如使用 TensorFlow Serving、TensorFlow Hub 和 TensorBoard。
总结
就这样,你拥有了多种课程,可以用来提升你的技能,增加知识,成为科技行业某一特定领域的专家。
如果你想成为全能型人才并具备强大的竞争力,你可以选择多个课程来拓宽你的视野!
Nisha Arya 是一名数据科学家、自由技术写作人员,同时担任 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程,以及数据科学的理论知识。Nisha 涉猎广泛,希望探索人工智能如何有益于人类寿命的延续。作为一个热衷学习者,Nisha 寻求拓宽她的技术知识和写作技能,同时帮助他人。
更多相关话题
世界需要更多的网络安全分析师!
原文:
www.kdnuggets.com/the-world-needs-more-cyber-security-analysts

作者提供的图片
市场上出现了大量新技术。当新工具和软件让我们的生活变得更轻松或帮助组织成长时,我们也会看到网络威胁的增加。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
我们都可以同意,疫情后生活有些艰难,我们都在努力恢复正常。话虽如此,一些人喜欢逆流而动,寻找新的方式来攻击系统、干扰服务和窃取数据。这就是为什么我们需要合适的人来识别和减轻这些威胁。
网络安全分析师。
网络安全分析师的职责是什么?
网络安全分析师的主要职责是保护组织的网络和系统免受攻击。这包括了解即将出现的 IT 趋势,制定应急计划,审查任何可疑活动,并能够以正确的方式报告安全漏洞并尽快解决问题。
安全情报公司表示,网络安全劳动力需要每年增长12.6%。然而,在 2023 年,它只增长了 8.7%。
你需要什么资格?
多年来,大多数网络安全专业人员都需要拥有信息安全、计算机科学、编程或类似领域的学士学位。然而,如前所述,由于对网络安全专业人员的高需求,组织在招聘过程中变得稍微宽松了一些。
越来越多的组织接受拥有网络安全分析师认证的申请者,让更多人能够进入市场,而不必回到大学。
我应该选择什么网络安全认证?
谷歌网络安全证书
链接:谷歌网络安全认证
这个由谷歌在 Coursera 平台提供的认证课程适合希望进入网络安全领域的初学者。你无需任何先前的经验,可以按自己的节奏学习。如果每周投入 7 小时,你可以在 6 个月内完成该课程。
在这个认证课程中,你将理解网络安全实践的重要性及其对组织的影响。你还将能够识别常见的风险、威胁和漏洞,并学习缓解这些问题的技术。
但这还不止于此 - 学习如何使用安全信息和事件管理(SIEM)工具保护网络、设备、人员和数据免受未经授权的访问和网络攻击,同时获得使用 Python、Linux 和 SQL 的实践经验。
微软网络安全分析师职业证书
链接: 微软网络安全分析师职业证书
这个认证由微软提供,由 9 门课程组成,适合初学者。你可以按照自己的节奏学习,安排灵活。如果每周投入 10 小时,你可以在 6 个月内完成这个认证。
在这个认证课程中,你将了解网络安全环境,并学习安全、合规和身份解决方案的核心概念。还会了解组织网络的漏洞,并减轻对网络基础设施的攻击,以保护数据。
进一步发展,通过在 Azure 环境中应用有效的网络安全措施来制定和实施威胁缓解策略。然后,你将能够通过一个综合项目展示你的新技能,并为行业认可的微软 SC-900 认证考试做好准备。
IBM 网络安全分析师职业证书
链接: IBM 网络安全分析师职业证书
这个认证由 IBM 提供,由 8 门课程组成。它也针对初学者,不需要任何先前的经验。它是一个自定进度的学习认证,因此没有截止日期。如果每周投入 10 小时,你可以在 4 个月内完成该认证,并且获得学位学分。
在这个认证课程中,你将发展对网络安全分析师工具的知识,包括数据保护、终端保护、SIEM 以及系统和网络基础。你还将学习在今天的网络安全环境中重要的合规性和威胁情报主题。
总体来说,你将通过实际的网络安全案例研究获得事件响应和取证技能,并通过行业特定和开源的安全工具获得实践经验。
总结
3 个令人惊叹的课程提供商,全部在一个平台上。接下来你需要做出的决定是选择哪个。这完全取决于你。查看评论,看看其他人怎么说。或者,也许你的梦想工作是成为 IBM 的网络安全分析师——那选择就不那么困难了!
Nisha Arya 是一位数据科学家、自由撰稿人,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。Nisha 涵盖了广泛的话题,并希望探索人工智能如何有利于人类寿命的不同方式。作为一个热衷学习者,Nisha 希望拓宽她的技术知识和写作技能,同时帮助引导他人。
更多相关话题
理论数据发现:使用物理学来理解数据科学
原文:
www.kdnuggets.com/2016/07/theoretical-data-discovery-physics-data-science.html
评论
作者:Sevak Avakians,Intelligent Artifacts。
尽管“数据科学”是一个最近才创造的流行词,但实际上它并不是一个新兴的研究领域。其背后的许多科学原理是物理学家和数学家在过去两个世纪里为解决其他问题而发展起来的(如果你需要数据科学家,雇用一个物理学家吧!)。今天,对数据科学的需求已超越了物理实验室,但其科学原理依旧相同。我们可以继续利用物理学家提供的答案来解决新领域中的问题。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求

例如,最近我被问到一个非常发人深省的问题,关于Intelligent Artifacts' Genie Cognitive Computer:
“……它能否检测数据集中是否缺少了某些关键内容?是否有我应该收集但没有收集的数据?例如,它能否检测到我确实需要一个用于预测的上下文信号,而我遗漏了记录,并告诉我需要开始测量它?或者它能否以合理的信心对缺失信息进行建模?”
我的初步回应是:
不,我目前认为对于任何系统而言这是不可能的。这就像那句俗话,“你不知道你不知道什么。” 从信息理论的角度来看,我不认为有任何方法可以检测数据集中是否缺少关键信息。也许,一种方法是自动化的数据源发现和测试。也就是说,一些算法会寻找不同的数据源,并将其-也许是暂时-纳入数据流中。然后,它(即 Genie's 认知处理器和/或信息分析器)会分析结果。到某个时刻,它可能会发现关键数据。但对于原始问题,我不相信任何代理能够知道是否缺少关键数据,尤其是当这些数据从未被呈现给系统时。
几个晚上后,当我凝视着天花板思考量子力学中的问题时,我突然意识到这个问题在物理学中曾经出现过!具体来说,这个问题涉及量子力学(QM)的非确定性本质,这导致了由阿尔伯特·爱因斯坦描述为“鬼魅般的远距离作用”的纠缠现象。
第一个问题(对我们今天的数据科学来说类似)是相同的过去/当前事件序列,即当前状态,将分叉成多个可能的未来结果。这意味着量子力学的预测不像牛顿力学那样是确定的。
德国物理学家马克斯·玻恩(小插曲:他的孙女是奥莉维亚·纽顿-约翰)开始将量子力学看作是一种统计解释。(这与我们对精灵预测的处理是一致的。根据当前状态,我们通过回顾过去那些在当前状态之后成功的未来状态的频率,来计算未来状态的概率。)这让包括阿尔伯特·爱因斯坦在内的许多人感到非常不安,促使他发表了著名的言论:“上帝不会掷骰子”。为了反驳这一解释,爱因斯坦、波多尔斯基和罗森提出了EPR 思想实验作为一种悖论,该实验向世界介绍了纠缠现象,即允许粒子瞬间相关其状态的现象,似乎违反了因果关系和光速限制。结果表明,这根本不是悖论。自然确实以这种方式运作!
为了挽救决定论,美国物理学家大卫·玻姆提出了一个想法,即结果之所以如此表现,是因为存在未知的“局部隐变量”,这些隐变量如果被考虑在内,将会使得预测变得确定。约翰·贝尔(IA 咨询委员会主席大卫·麦戈万的朋友)提出了一种不等式检验,这一检验被实验者(如阿兰·阿斯佩等)使用,证明了不存在局部隐变量。
好吧,对我们来说关键在于,这种测试理论上可以对我们的数据集进行,以证明或驳斥任何对预测重要的未知变量。
量子力学与 Genie 预测之间的区别在于,量子力学依赖于高度约束的严密数学模型。而 Genie 则依赖于已经观察到的数据。前者允许将模型与数据进行比较,或者像在贝尔不等式中那样,将量子力学模型与确定性“局部隐藏变量”模型进行比较。由于我们设计 Genie 时不需要数据模型,因此其预测的优势来自于将新数据与过去数据进行比较。此外,它需要一个确定性模型进行比较,而 Genie 预测则不需要。
这让我回到了最初的结论;无法检测到尚未输入系统的数据。
只要我们花时间将科学探究应用于这些新领域,数据科学将继续受益于物理学家在知识边界上推进的工作。
作者感谢 Peter Olausson 和 David McGoveran 在这个问题上进行的启发性讨论。
简介:Sevak Avakians 拥有物理学、电信、信息论和人工智能背景。2008 年,Sevak 发明了一个名为 GAIuS 的 AGI 框架。Genie 建立在 GAIuS 之上,并通过他创办的公司Intelligent Artifacts提供。
相关内容:
-
娱乐与利润中的人工智能:使用新的 Genie 认知计算平台进行 P2P 借贷
-
从研究到财富:物理和生命科学中的数据处理课程
-
采访:Arno Candel,H2O.ai 从物理学到机器学习的旅程
相关阅读
从理论到实践:构建 k-最近邻分类器
原文:
www.kdnuggets.com/2023/06/theory-practice-building-knearest-neighbors-classifier.html
又一天,又一个经典算法:k-最近邻。与朴素贝叶斯分类器一样,这是一个解决分类问题的相当简单的方法。该算法直观易懂,训练时间无与伦比,这使得它成为你刚开始机器学习生涯时的一个很好的学习对象。话虽如此,做出预测的速度非常慢,尤其是对于大数据集。由于维度灾难,对于具有许多特征的数据集,性能也可能并不令人印象深刻。
在本文中,你将学到
-
k-最近邻分类器的工作原理
-
其设计原因
-
其严重缺陷的原因,以及,
-
如何使用 NumPy 在 Python 中实现它。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
由于我们将以符合 scikit-learn 的方式实现分类器,因此查看我的文章构建你自己的自定义 scikit-learn 回归也很值得。不过,scikit-learn 的开销相当小,你应该仍然能够跟上进度。
你可以在我的 Github上找到代码。
理论
该分类器的主要思想非常简单。它直接来源于分类的基本问题:
给定一个数据点 x,x 属于某个类别 c 的概率是多少?
在数学语言中,我们寻找条件概率 p(c|x)。虽然朴素贝叶斯分类器尝试通过一些假设直接建模这一概率,但还有另一种直观的方法来计算这一概率——频率主义的概率观点。
概率的朴素观点
好的,那这现在意味着什么呢?让我们考虑以下简单示例:你掷一个六面骰子,并想要计算掷出六点的概率,即 p(掷到 6 点)。怎么做呢?好吧,你掷骰子 n 次,记录下它掷出六点的次数。如果你看到六点的次数是 k,你可以说看到六点的概率是 大约 k/n。这没什么新奇的,对吧?
现在,假设我们想计算一个条件概率,例如
p(掷到 6 点 | 掷到偶数)
你不需要贝叶斯定理来解决这个问题。只需再次掷骰子,并忽略所有奇数的结果。这就是条件作用的方式:过滤结果。如果你掷了骰子n次,看到m个偶数,其中k个是六点,那么上面的概率是大约 k/m,而不是 k/n。
激励 k-最近邻
回到我们的问题。我们想要计算 p(c|x),其中 x 是包含特征的向量, c 是某个类别。就像骰子例子中一样,我们
-
需要大量的数据点,
-
过滤掉特征为 x 的数据点
-
检查这些数据点属于类别c的频率。
相对频率是我们对概率 p(c|x) 的猜测。
你看到这里的问题了吗?
通常,我们没有很多具有相同特征的数据点。 经常只有一个,可能两个。例如,想象一个数据集,其中包含两个特征:人的身高(以厘米为单位)和体重(以公斤为单位)。标签为男性或女性。因此,x=(x?, x?) 其中 x?是身高, x?是体重,c 可以取值为男性和女性。我们来看一些虚拟数据:
作者提供的图片。
由于这两个特征是连续的,拥有两个数据点,更不用说几个数据点的概率是微不足道的。
另一个问题: 如果我们想预测一个具有我们从未见过的特征的数据点的性别,比如 (190.1, 85.2),会发生什么?这就是预测的实际意义。这就是为什么这种简单的方法不起作用。k-最近邻算法的做法如下:
它尝试通过具有接近 x 特征的数据点来逼近概率 p(c|x),而不是具有完全相同特征的数据点。
在某种意义上,这不那么严格。 与其等待许多身高=182.4 和体重=92.6 的人并检查他们的性别,k-最近邻允许考虑接近这些特征的人。算法中的 k 是我们考虑的人数,它是一个超参数。
这些是我们或类似网格搜索的超参数优化算法需要选择的参数。它们不是由学习算法直接优化的。
图片由作者提供。
算法
现在我们已经拥有描述算法所需的一切。
训练:
-
组织训练数据。预测时,这种顺序应该使我们能够为任何给定的数据点x提供k个最近点。
-
就这样了!????
预测:
-
对于一个新的数据点x,在组织好的训练数据中找到k个最近邻。
-
汇总这些k个邻居的标签。
-
输出标签/概率。
我们目前还无法实现这一点,因为我们需要填补很多空白。
-
组织意味着什么?
-
我们如何衡量接近度?
-
如何汇总?
除了k的值,这些都是我们可以选择的东西,不同的决策会给我们不同的算法。让我们简单一点,按以下方式回答问题:
-
组织 = 只是按原样保存训练数据集
-
接近度 = 欧几里得距离
-
汇总 = 平均
这需要一个示例。让我们再看看包含个人数据的图片。
我们可以看到,离黑点最近的k=5 个数据点有 4 个男性标签和 1 个女性标签。所以我们可以输出黑点对应的人实际上是 4/5=80%男性和 1/5=20%女性。如果我们希望单一类别作为输出,我们将返回男性。没问题!
现在,让我们实现它。
实现
最困难的部分是找到一个点的最近邻。
简要入门
让我们做一个小示例,展示如何在 Python 中实现这一点。我们从
import numpy as np
features = np.array([[1, 2], [3, 4], [1, 3], [0, 2]])
labels = np.array([0, 0, 1, 1])
new_point = np.array([1, 4])
图片由作者提供。
我们创建了一个由四个数据点以及另一个点组成的小数据集。哪个点是最近的?新点应该有标签 0 还是 1?让我们找出答案。输入
distances = ((features - new_point)**2).sum(axis=1)
给我们四个值 distances=[4, 4, 1, 5],这就是从new_point到features中所有其他点的平方欧几里得距离。太棒了!我们可以看到点编号三是最近的,其次是点编号一和二。第四个点是最远的。
现在我们如何从数组 [4, 4, 1, 5] 中提取最近的点?distances.argsort() 帮助我们。结果是 [2, 0, 1, 3],这告诉我们索引为 2 的数据点最小(即点编号三),接着是索引为 0 的点,然后是索引为 1 的点,最后是索引为 3 的点最大。
注意,argsort将distances中的前 4 个排在第二个 4 之前。根据排序算法的不同,这也可能是相反的,但在这篇介绍文章中我们不深入这些细节。
如果我们想要三个最近邻,例如,我们可以通过以下方式获得它们
distances.argsort()[:3]
标签对应于这些最近点,通过
labels[distances.argsort()[:3]]
我们得到[1, 0, 0],其中 1 是最接近(1, 4)的点的标签,零是属于接下来的两个最近点的标签。
这就是我们需要的一切,让我们进入正题。
最终代码
你应该对代码很熟悉。唯一的新函数是np.bincount,用于计算标签的出现次数。请注意,我首先实现了predict_proba方法来计算概率。predict方法只是调用这个方法,并使用argmax函数返回概率最高的索引(即类别)。该类接受从 0 到C-1 的类别,其中C是类别的数量。
免责声明: 这段代码并未经过优化,仅用于教育目的。
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin
from sklearn.utils.validation import check_X_y, check_array, check_is_fitted
class KNNClassifier(BaseEstimator, ClassifierMixin):
def __init__(self, k=3):
self.k = k
def fit(self, X, y):
X, y = check_X_y(X, y)
self.X_ = np.copy(X)
self.y_ = np.copy(y)
self.n_classes_ = self.y_.max() + 1
return self
def predict_proba(self, X):
check_is_fitted(self)
X = check_array(X)
res = []
for x in X:
distances = ((self.X_ - x)**2).sum(axis=1)
smallest_distances = distances.argsort()[:self.k]
closest_labels = self.y_[smallest_distances]
count_labels = np.bincount(
closest_labels,
minlength=self.n_classes_
)
res.append(count_labels / count_labels.sum())
return np.array(res)
def predict(self, X):
check_is_fitted(self)
X = check_array(X)
res = self.predict_proba(X)
return res.argmax(axis=1)
就这样!我们可以做一个小测试,看看它是否与 scikit-learn 的k-最近邻分类器一致。
测试代码
让我们创建另一个小数据集进行测试。
from sklearn.datasets import make_blobs
import numpy as np
X, y = make_blobs(n_samples=20, centers=[(0,0), (5,5), (-5, 5)], random_state=0)
X = np.vstack([X, np.array([[2, 4], [-1, 4], [1, 6]])])
y = np.append(y, [2, 1, 0])
它看起来是这样的:
图片由作者提供。
使用我们的分类器,k=3
my_knn = KNNClassifier(k=3)
my_knn.fit(X, y)
my_knn.predict_proba([[0, 1], [0, 5], [3, 4]])
我们得到
array([[1\. , 0\. , 0\. ],
[0.33333333, 0.33333333, 0.33333333],
[0\. , 0.66666667, 0.33333333]])
按以下方式读取输出: 第一个点 100%属于类别 1,第二个点在每个类别中均为 33%,第三个点大约 67%属于类别 2 和 33%属于类别 3。
如果你想要具体的标签,可以尝试
my_knn.predict([[0, 1], [0, 5], [3, 4]])
输出为[0, 0, 1]。注意,在出现平局的情况下,我们实现的模型输出的是较低的类别,因此点(0, 5)被分类为类别 0。
如果你查看这张图片,它是有意义的。但让我们借助 scikit-learn 来确认一下。
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X, y)
my_knn.predict_proba([[0, 1], [0, 5], [3, 4]])
结果:
array([[1\. , 0\. , 0\. ],
[0.33333333, 0.33333333, 0.33333333],
[0\. , 0.66666667, 0.33333333]])
呼!一切看起来都很好。让我们检查一下算法的决策边界,只是因为它很好看。
图片由作者提供。
再次说明,顶部黑点并非 100%为蓝色。它是 33%蓝色、红色和黄色,但算法决定性地选择最低类别,即蓝色。
我们还可以检查不同k值的决策边界。
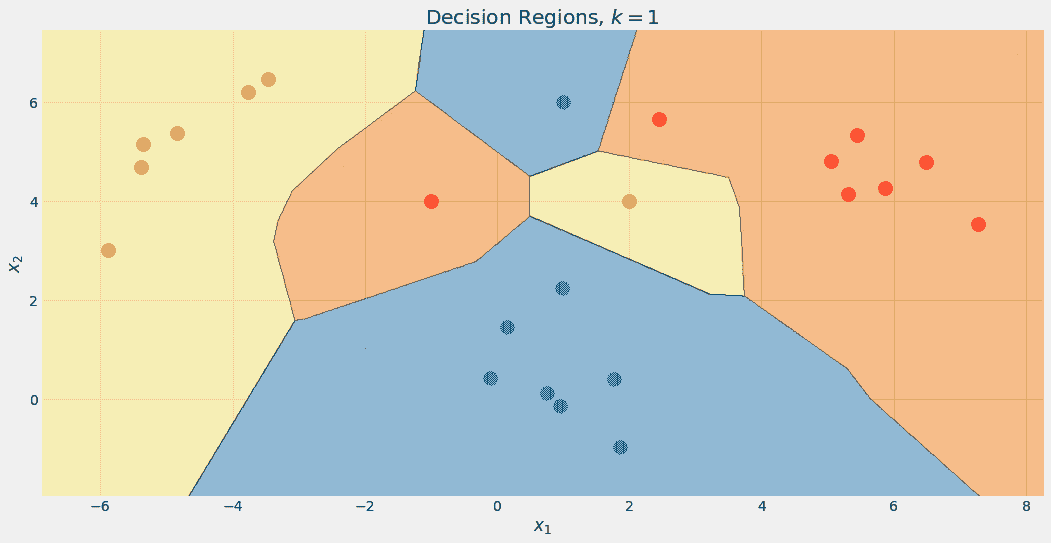
图片由作者提供。
注意,最终蓝色区域变大,因为该类别受到优待。我们还可以看到,对于k=1 时,边界非常混乱:模型过拟合。另一方面,当k与数据集大小相等时,所有点都用于聚合步骤。因此,每个数据点得到相同的预测:多数类别。在这种情况下,模型欠拟合。最佳点在两者之间,并可以通过超参数优化技术找到。
在结束之前,让我们看看这个算法有哪些问题。
k-最近邻的缺点
问题如下:
-
查找最近邻需要很多时间,尤其是使用我们简单的实现时。如果我们想预测新数据点的类别,就必须将其与数据集中每一个点进行比较,这很慢。有更好的方式来组织数据,使用高级数据结构,但问题仍然存在。
-
问题 1 的后续:通常,你在更快、更强大的计算机上训练模型,然后将模型部署到较弱的机器上。例如,深度学习就是这样。但对于k-最近邻,训练时间很短,重的工作在预测时完成,这不是我们想要的。
-
如果最近邻完全不接近会发生什么?那它们就没有意义了。这在特征数量较少的数据集中就可能发生,但特征更多时遇到这个问题的机会会急剧增加。这也被称为维度诅咒。可以在this post of Cassie Kozyrkov中找到很好的可视化。
特别是因为问题 2,你在实际应用中不常见到k-最近邻分类器。它仍然是一个你应该了解的不错算法,你也可以用于小数据集,这没有问题。但如果你有数百万个数据点和数千个特征,情况就会很严峻。
结论
在这篇文章中,我们讨论了k-最近邻分类器如何工作以及它的设计为什么有意义。它尝试使用离x最近的数据点尽可能准确地估计数据点x属于类别c的概率。这是一种非常自然的方法,因此这个算法通常在机器学习课程开始时教授。
请注意,构建一个k-最近邻回归器也非常简单。与计算类别的出现次数不同,只需对最近邻的标签取平均值即可获得预测结果。你可以自己实现这个,改动很小!
我们以一种直接的方式实现了它,模仿了 scikit-learn 的 API。这意味着你也可以在 scikit-learn 的管道和网格搜索中使用这个估计器。这是一个很大的好处,因为我们甚至有超参数k,你可以使用网格搜索、随机搜索或贝叶斯优化来优化。
然而,这个算法存在一些严重的问题。它不适用于大型数据集,且无法在较弱的机器上进行预测。再加上对维度诅咒的敏感性,它是一个理论上不错但仅适用于较小数据集的算法。
罗伯特·库布勒博士 是 METRO.digital 的数据科学家和 Towards Data Science 的作者。
原文。转载已获许可。
更多相关内容
TheWalnut.io:一种轻松创建算法可视化的方式
原文:
www.kdnuggets.com/2015/07/thewalnutio-algorithm-visualizations.html
作者: Daniel Moisset,(Machinalis.com)。
我们发布了 TheWalnut.io 的初始版本,这是一款允许创建和分享算法可视化的 web 应用程序。我们不仅仅是制作漂亮的算法可视化画廊,而是构建一个人们可以在其中学习、讨论并以视觉方式交流代码的地方。我们在路线图中有许多有趣的功能(和 bug 修复),但我们希望发布,让你能看到我们正在做的事情。
Walnut 允许用户用 Python 或 Javascript 编写程序,并使其与用户设计的虚拟“世界”互动。这些世界定义了共享状态、可能的动作、每个程序可见的状态部分等。可以在一个世界中运行单个或多个程序,然后查看结果。然后,你可以使用简单的声明式 DSL 定义如何表示执行结果(程序所做的操作,以及世界和程序的状态)。你可以对单次运行的不同方面进行多种可视化。
以快速排序为例。有一个 排序 世界,它定义了状态为一组数字,程序可以查看这些数字并对其进行交换,目标是将其排序。然后,你可以添加许多可以在该世界中运行的程序(任何基于交换的排序算法,如 快速排序 或 Shellsort)。你可以定义 场景 以及初始数据(以展示平均和最坏情况,或不同的数组大小)。可视化 可以将这些信息映射到显示上:可能只是移动的条形图,或者是像快速排序这样的递归算法的调用栈,或者是交换宽度随时间变化的图表:
如果你访问我们的探索部分,你将能够看到开发团队构建的一些示例作为起点。但我们的愿景是让你创建自己的可视化并分享它们。仅仅通过代码学习算法是很困难的!破解这个难题,让大家看到里面的内容!加入 Walnut 革命吧!
简介: Daniel Moisset @dmoisset 是一位企业家、计算机科学教师和软件开发人员。
相关
-
50+ 数据科学和机器学习备忘单
-
开源支持的互动分析:概述
-
21 个必备的数据可视化工具
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 部门
更多相关话题
数据科学与数据工程之间的细微差别
原文:
www.kdnuggets.com/2019/09/thin-line-between-data-science-data-engineering.html
评论
编辑注:这是“Climbing the Data Science Ladder”播客系列的第四集,由 Jeremie Harris、Edouard Harris 和 Russell Pollari 主持。他们共同经营一个名为SharpestMinds的数据科学辅导初创公司。你可以在下面收听播客:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
如果你在过去几年关注数据科学的发展,你会知道这个领域自 2010 年代初期/中期的“狂野西部”阶段以来,已经发生了很大的变化。那时,几份包含半成品建模项目的 Jupyter 笔记本就能让你在一家体面的公司找到工作,但现在情况已经发生了很大变化。
今天,随着公司们终于认识到数据科学所能带来的价值,对数据科学在生产系统中实施的重视程度越来越高。而这些实施需要能够在实时处理越来越大数据集的模型,因此,很多数据科学问题已变成工程问题。
这就是为什么我们与 Akshay Singh 坐下来讨论,他曾在亚马逊、League 和 Chan-Zuckerberg Initiative(前身为 Meta.com)工作和管理数据科学团队等多个领域。Akshay 在数据科学和数据工程的交汇处工作,并向我们讲解了数据分析与数据科学之间的细微差别、该领域的未来,以及他对那些未受到足够重视的最佳实践的看法。以下是我们的主要收获:
-
在数据工程中最容易犯的一个错误就是没有深入考虑工具的选择。你为什么使用 S3 作为数据仓库?为什么不使用 Redshift 或 BigQuery?逼迫自己理解这些问题的答案,而不是接受工具的现成配置,是一个很好的成长方式,而且如果你想给潜在雇主留下深刻印象,这一点至关重要。
-
总是要假设你现在构建的任何东西都会在一年或更短时间内被替代。生产系统不是静态的,你或其他人迟早会不得不重新审视代码库的大部分。这就是为什么学习如何使用文档字符串、使用清晰的函数和变量名称,以及理解关于内联注释的最佳实践如此重要。
-
数据会随着时间的推移发生漂移,一个在今天的数据上表现良好的模型可能在下周表现不佳。这可能由于许多因素:季节性是一个,但用户行为也可能会发生变化。Akshay 建议说,实时收集用户反馈是解决这个问题的关键:如果你发现他们的反馈意外地变得负面,构建一个警报系统,让你知道有些地方不对劲。
-
大局是需要记住的最重要的事情。很容易陷入技术问题,但伟大的数据科学家的标志是能够停下来问这个问题是否值得解决。你真的需要一个推荐系统,还是一个简单的基于规则的系统同样有效?如果你无法访问监督学习模型所需的确切训练标签,你能否拼凑出一个不错的替代品?现实世界是混乱的,通常要求你用比 Kaggle 竞赛更多的创造力来处理数据科学问题。
-
看到大局的重要性随着时间的推移只会越来越显著,因为数据科学家的工作量正通过越来越强大的工具被逐步抽象化。数据科学正慢慢地变成一种产品角色。
TDS 播客 — 剪辑
如果你在 Twitter 上,随时可以联系我 @jeremiecharris!
原文。经许可转载。
相关内容:
-
关于 AI、分析、数据科学、机器学习的十大最佳播客
-
构建高效数据科学团队
-
数据工程师新手在 Google BigQuery 中的 7 个“陷阱”
更多相关内容
事物并不总是正态的:一些“其他”分布
原文:
www.kdnuggets.com/2023/01/things-arent-always-normal-distributions.html

图片来源:Unsplash
关键要点
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
概率分布在数据科学和统计学中扮演着重要角色。尽管正态(高斯)分布是最流行的概率分布,但在数据科学中也可以使用其他概率分布:
-
伽马分布用于建模代表事件之间时间间隔的连续变量
-
贝塔分布用于建模代表比例或概率的连续变量
-
伯努利分布用于建模二元结果
概率分布是描述随机变量行为的数学函数。在数据科学和机器学习中,概率分布通常用于描述数据集的潜在分布,预测未来事件,并评估机器学习模型的性能。例如,高斯分布是一种参数分布,它依赖于两个变量,即均值和标准差。因此,一旦均值和标准差参数已知,就可以创建一个正态分布的数据集。举例来说,下面的代码创建了一个包含 1000 个值的数据集,这些值服从均值为 0、标准差为 0.1 的正态分布。
import numpy as np
import matplotlib.pyplot as plt
mu, sigma = 0, 0.1 # mean and standard deviation
s = np.random.normal(mu, sigma, 1000)
count, bins, ignored = plt.hist(s, 30, density = True)
plt.plot(bins, 1/(sigma * np.sqrt(2 * np.pi)) *
np.exp( - (bins - mu)**2 / (2 * sigma**2) ),
linewidth=2, color='r')
plt.show()
图 1. 高斯分布的可视化。
我们还可以绘制不同均值和标准差组合的正态分布,如下所示:
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
#define three Gamma distributions
x = np.linspace(-10, 10, 101)
y1 = stats.norm.pdf(x, 0, 2)
y2 = stats.norm.pdf(x, 0, 4)
y3 = stats.norm.pdf(x, 2, 2)
#add lines for each distribution
plt.plot(x, y1, label='mu=0, sigma=2')
plt.plot(x, y2, label='mu=0, sigma=4')
plt.plot(x, y3, label='mu=4, sigma=1')
#add legend
plt.legend()
#display plot
plt.show()
图 2. 高斯分布在不同均值和标准差下的可视化。
概率分布在数据科学和机器学习中非常重要,因为它们提供了一种量化和分析不确定性的方法,而不确定性是许多现实世界过程的固有部分。它们在统计推断中也发挥着关键作用,统计推断是使用数据对总体或过程进行推测的过程。
在本文中,我们将解释三种用于机器学习的概率分布,即 伽马分布、贝塔分布 和 伯努利分布。
伽马分布
伽马分布是一种连续概率分布,常用于建模在以恒定速率发生的过程中事件之间的时间。它由形状参数(k)和率参数(ϴ)来定义,其概率密度函数(PDF)定义为
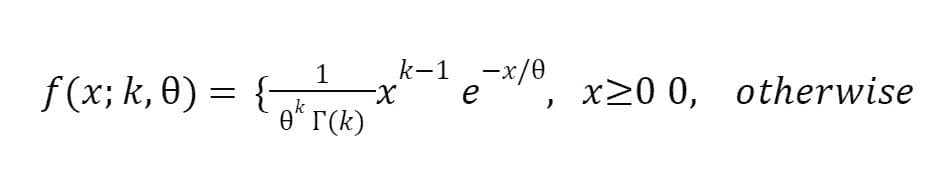
其中 Γ(k) 是伽马函数,ϴ 是尺度参数,k 是形状参数。
图 3. 伽马分布的可视化。
伽马分布通常用于建模表示事件之间时间间隔的连续变量的分布。例如,它可以用于建模顾客到达商店的时间间隔,或者设备故障的时间间隔。
代码示例: 在 Python 中,可以使用 scipy.stats 模块中的“gamma”函数生成伽马分布。例如,下面的代码将生成一个具有伽马分布的随机变量 x,并绘制该分布的概率密度函数。k 和 theta 参数分别指定伽马分布的形状参数和率参数。
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
#define three Gamma distributions
x = np.linspace(0, 40, 100)
y1 = stats.gamma.pdf(x, a=5, scale=3)
y2 = stats.gamma.pdf(x, a=2, scale=5)
y3 = stats.gamma.pdf(x, a=4, scale=2)
#add lines for each distribution
plt.plot(x, y1, label='shape=5, scale=3')
plt.plot(x, y2, label='shape=2, scale=5')
plt.plot(x, y3, label='shape=4, scale=2')
#add legend
plt.legend()
#display plot
plt.show()
图 4. 不同形状和尺度参数的伽马分布的可视化。
除了生成随机变量外,scipy.stats 模块还提供了从数据中估计伽马分布参数的函数、检验拟合优度的函数,以及使用伽马分布进行统计检验的函数。这些函数对分析被认为遵循伽马分布的数据很有用。
贝塔分布
贝塔分布是一种定义在区间 [0, 1] 上的连续概率分布。它常用于建模比例或概率,并由两个形状参数定义,通常记作 α 和 β。贝塔分布的概率密度函数(PDF)定义为
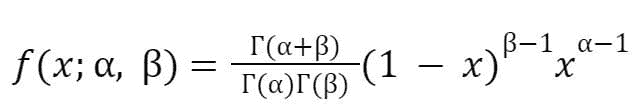
PDF 也可以表示为
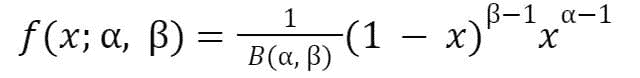
其中
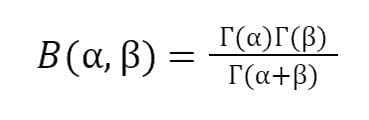
是贝塔函数。
图 5. 贝塔分布的可视化。
Beta 分布常用于建模代表比例或概率的连续变量的分布。例如,它可以用来建模在某些营销努力下客户进行购买的概率,或机器学习模型做出正确预测的概率。
代码示例:在 Python 中,可以使用 scipy.stats 模块中的 "beta" 函数生成 Beta 分布。例如:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import beta
# Set the shape paremeters
a, b = 80, 10
# Generate the value between
x = np.linspace(beta.ppf(0.01, a, b),beta.ppf(0.99, a, b), 100)
# Plot the beta distribution
plt.figure(figsize=(7,7))
plt.xlim(0.7, 1)
plt.plot(x, beta.pdf(x, a, b), 'r-')
plt.title('Beta Distribution', fontsize='15')
plt.xlabel('Values of Random Variable X (0, 1)', fontsize='15')
plt.ylabel('Probability', fontsize='15')
plt.show()
这将生成一个具有 Beta 分布的随机变量 x 并绘制该分布的概率密度函数。a 和 b 参数分别指定 Beta 分布的形状参数。
scipy.stats 模块具有从数据中估计 Beta 分布参数、评估拟合优度以及使用 Beta 分布进行统计测试的函数,除此之外,还可以生成随机变量。
伯努利分布
伯努利分布是一种离散概率分布,描述了单个二元事件的结果,例如抛硬币。它由一个参数 p 特征,该参数是事件发生的概率。伯努利分布的概率质量函数定义为
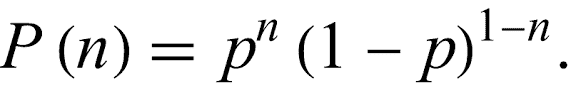
其中 n 是 0 或 1,代表事件的结果。
图 6. 伯努利分布的可视化。
该分布通常用于建模二元结果的概率,例如客户进行购买的概率或机器学习模型做出正确预测的概率。
代码示例:在 Python 中,可以使用 scipy.stats 模块中的 "Bernoulli" 函数生成伯努利分布。例如:
from scipy.stats import bernoulli
import seaborn as sb
data_bern = bernoulli.rvs(size=1000,p=0.6)
ax = sb.distplot(data_bern,
kde=True,
color='crimson',
hist_kws={"linewidth": 25,'alpha':1})
ax.set(xlabel='Bernouli', ylabel='Frequency')
这将生成一个具有伯努利分布的随机变量 x 并绘制该分布的概率质量函数。p 参数指定事件发生的概率。
除了生成随机变量,scipy.stats 模块还提供了从数据中估计伯努利分布概率参数、测试拟合优度以及使用伯努利分布进行统计测试的函数。在评估可能遵循伯努利分布的数据时,这些函数可能会很有用。
总之,Gamma 分布用于建模表示事件间时间间隔的连续变量,Beta 分布用于建模表示比例或概率的连续变量,而 Bernoulli 分布用于建模二元结果。了解这些概率分布背后的概念对于你的机器学习旅程非常有帮助,因为它们能帮助你建模解决数据科学和机器学习中的各种问题。
本杰明·O·塔约 是一位物理学家、数据科学教育者和作家,也是 DataScienceHub 的所有者。之前,本杰明曾在中央俄克拉荷马大学、大峡谷大学和匹兹堡州立大学教授工程学和物理学。
更多相关内容
扩展您的网络数据驱动产品时需要了解的事项
原文:
www.kdnuggets.com/2023/08/things-know-scaling-web-datadriven-product.html

图片由 Getty Images 提供,来自 Unsplash+
当你环顾今天的商业环境时,你很可能会看到一个数据不仅是石油,而是大多数行业的燃料、引擎和轮子时代。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
所以,如果你从事网络数据驱动产品的业务,你的未来部分依赖于扩展。每个决策、每个策略、每个产品都依赖于数据。
那么,你如何成功地扩展你的产品?
本文旨在通过关键考虑因素和实用技巧为扩展照亮道路。无论你在运营招聘平台、潜在客户生成平台,还是任何数据驱动的产品,你都能在这里找到所需的指导。
理解数据驱动产品扩展的基础
首先谈谈可扩展性。它是什么?想象你的产品是一个气球。随着需求的增长,你希望你的气球能够膨胀而不爆裂。
这就是可扩展性的意义。它是平稳处理增加负载的能力,无论是更多的数据、更多的用户,还是更多的交易。
那么,在计划扩展时你应该注意哪些问题?
数据收集和管理策略
首先是数据。它是你产品的核心。但当你的产品扩展时,你如何保持数据收集的一致性和质量?你如何有效整合和使用这些数据?
成功扩展的核心在于高效管理这些方面。让我们解析一下数据收集和管理策略的组成部分:
-
持续验证。 定期检查数据来源,确保收集的数据仍然相关和准确。
-
严格清理。 使用强大的算法清理数据,去除任何不一致、错误或重复项。
-
智能整合。 以保持数据质量和可用性的方法融合数据集。
通过改进这三个领域,你在为数据驱动产品的成功扩展奠定基础。这全在于精准、干净和智能地管理数据流。
数据隐私与合规
扩展不仅仅是关于增长;它还涉及责任。当你处理更多数据,特别是个人数据时,你必然会遇到伦理和法律的考量。
那么,你如何确保数据隐私并满足法规要求呢?
对聪明人的建议:尽可能地匿名化数据,保持对所在地区最新数据法规的了解,并定期进行审计以确保合规。
不同行业数据驱动产品扩展策略
在扩展数据驱动的产品时,具体情况将取决于行业和产品的性质。
让我们看一些具体的例子,了解如何利用网络数据在不同领域实现扩展。
招聘平台
假设你正在运行一个招聘平台。随着平台的增长,越来越多的公司和求职者加入,你将不得不获取和管理更多的职位发布数据和员工数据。
在这种情况下,基于 AI 的匹配算法可能是你扩展的关键。该算法将分析职位描述、技能要求和候选人档案,提供准确的匹配建议。
随着更多数据的加入,算法会学习和改进,提供更好的匹配结果。
一个例子是像 LinkedIn 这样的平台如何利用数据来优化其“你可能感兴趣的职位”功能。
潜在客户生成平台
在潜在客户生成平台的背景下,扩展意味着高效处理和分析更广泛的公司数据、员工数据和职位发布数据,以生成高质量的潜在客户。
例如,你可以通过整合更多数据来扩展你的平台,这会丰富潜在客户数据,帮助企业更好地理解其潜在客户,并更有效地针对其市场营销工作。
随着平台的增长,可以使用预测分析工具来预测客户行为,基于以前的数据模式,改善潜在客户评分,推动更多转化。
预见并克服扩展挑战
扩展并不总是一帆风顺。你将面临挑战,从基础设施限制和数据管理问题到保持数据质量和安全。
-
基础设施限制。 随着扩展,你现有的基础设施可能难以应对增加的数据负荷和用户请求。你可能会遇到处理时间变慢或甚至系统崩溃的情况。解决这一问题的关键是从一开始就投资于可扩展的基础设施。考虑像云服务器或数据库这样的解决方案,它们可以根据你的需求进行扩展(或收缩)。像亚马逊网络服务(AWS)或谷歌云这样的供应商提供的托管服务可以帮助缓解这些挑战,提供强大、可扩展的基础设施。
-
数据管理问题。 数据量的增加带来了更多的复杂性。你将不得不处理各种数据格式、集成挑战,可能还会遇到不完整或不一致的数据。自动化的数据管理工具在这里可以大显身手,帮助你系统地收集、清理、集成和维护数据。
-
维护数据质量。 随着规模的扩大,数据错误、重复或不一致的风险增加。为了保持数据质量,你需要实施复杂的数据验证和清理过程。这些过程可能包括简单的检查和去重,也可能涉及更复杂的机器学习算法。
-
数据安全。 随着数据集和用户基数的增加,数据泄露的潜在风险也在增加。实施强有力的安全措施至关重要。这可能包括加密敏感数据、进行定期的安全审计,以及确保你的平台符合相关的数据保护法规。
在扩展过程中,挑战是自然的。关键在于预见潜在问题,为其做准备,并制定应对策略以应对这些问题。
为数据驱动产品的未来做准备
数据领域快速发展,变化无常。为未来做准备不仅仅是保持现状,更是为了在进步的浪潮中站稳脚跟。你如何确保你的数据驱动产品为未来的挑战做好准备?
-
持续学习。 未来将带来新的技术、新的方法论和新的数据理解与利用方式。在你的团队中培养持续学习和好奇心的文化至关重要。保持对数据科学和技术最新进展的关注。参加研讨会、网络研讨会和行业活动。鼓励你的团队寻找新的认证和教育机会。
-
投资先进技术。 人工智能(AI)和机器学习(ML)不仅仅是流行词汇——它们正在塑造数据驱动产品的未来。这些技术可以自动化数据处理任务,从复杂的数据集中提取见解,并提高产品的效率和可扩展性。此外,区块链技术正被越来越多地用于提升数据安全性和透明度。考虑如何将这些先进技术集成到你的平台中。
-
灵活性和适应性。 随着数据驱动产品的规模扩大,你需要对策略和流程进行调整——可能是重大的调整。培养灵活的思维方式可以帮助你更顺利地适应变化。尝试不同的策略,从成功和失败中学习,并在需要时勇于调整方向。
-
伦理和合规。 随着公众对数据隐私的关注增加和监管重点的加强,确保道德的数据实践和合规性比以往任何时候都更加重要。这不仅仅是为了避免处罚——也是为了建立与用户的信任。定期审查和更新你的数据隐私政策,并考虑进行第三方审计以确保合规。
-
预测分析。 未来就是关于预测趋势和做出前瞻性决策。预测分析工具可以分析过去的数据来预测未来的趋势,帮助你保持领先一步。它们还可以帮助进行风险管理、客户行为预测和性能预测。
为未来做准备不是一次性的任务,而是一个持续学习、适应和预测的过程。以未来为导向的思维方式可以确保你的数据驱动产品始终保持相关性和竞争力。
但你究竟如何保持准备?
-
投资于人才。 数据相关的技能集不断发展。投资于团队的持续学习,确保他们跟上新兴趋势和技术。
-
拥抱人工智能和机器学习。 这些技术将继续塑造数据驱动产品的未来。探索它们如何提升你的产品的可扩展性和有效性。
-
培养敏捷性。 快速变化是技术世界中的常态。培养敏捷的思维方式,准备好根据需要调整或改变你的策略。
结论
在一个越来越依赖数据的世界中,缩放你的网络数据驱动产品不再是选择,而是必要。
无论你处理的是公司数据、员工数据、招聘数据,还是其他数据,你的缩放成功将取决于数据收集和管理策略、隐私和合规性遵守、行业特定的缩放策略以及对未来的准备情况。
Karolis Didziulis 是 Coresignal 的产品总监,该公司是业界领先的公共网络数据提供商。他的专业知识来源于超过 10 年的 Bh1B 业务发展经验和超过 6 年的数据行业经验。目前,Karolis 的主要重点是领导 Coresignal 的工作,帮助数据驱动的初创公司、企业和投资公司通过提供来自最具挑战性来源的最大规模和最新的公共网络数据,从而在其业务中脱颖而出。
更多相关话题
从 fast.ai 课程 V3 中学到的 10 个新知识
原文:
www.kdnuggets.com/2019/06/things-learnt-fastai-course.html
评论
由Raimi Bin Karim,AI Singapore

大家都在谈论fast.ai的大规模开放在线课程(MOOC),所以我决定尝试一下他们 2019 年的深度学习课程实用深度学习(程序员版)v3。
我一直了解一些深度学习概念/想法(我已经在这个领域待了一年,主要处理计算机视觉),但从未真正理解过一些直觉或解释。我也了解到Jeremy Howard、Rachel Thomas和 Sylvain Gugger(关注他们的 Twitter!)是深度学习领域的影响力人物(Jeremy 有丰富的 Kaggle 竞赛经验),所以我希望从他们那里获得新的见解和直觉,并得到一些模型训练的技巧和窍门。我有很多东西要向这些人学习。
所以,我在观看视频 3 周后(我没有做任何练习 ????????????????),写下这篇文章来将我学到的 新知识进行整理与分享。当然,也有一些我一头雾水的内容,所以我做了一些额外的研究,并在这篇文章中呈现。最后,我也写了一下对这门课程的感受(剧透:我喜欢它❣️)。
免责声明 不同的人会有不同的学习要点,这取决于你有何种深度学习背景。此文不适合深度学习初学者,也不是课程内容的总结。这篇文章假设你已具备神经网络、梯度下降、损失函数、正则化技术和生成嵌入的基础知识。以下经验也很有帮助:图像分类、文本分类、语义分割和生成对抗网络。
我将我的 10 个学习要点内容组织如下:从神经网络理论,到架构,再到与损失函数(学习率、优化器)相关的内容,到模型训练(及正则化),再到深度学习任务,最终到模型可解释性。
目录:10 个新知识点
-
通用逼近定理
-
神经网络:设计与架构
-
理解损失景观
-
梯度下降优化器
-
损失函数
-
训练
-
正则化
-
任务
-
模型可解释性
-
附录:Jeremy Howard 谈模型复杂性与正则化
0. Fast.ai & 转移学习
“如果可以,使用转移学习[来训练你的模型]总是好的。” — Jeremy Howard
Fast.ai 等同于迁移学习,并在短时间内取得出色成果。这个课程真的名副其实。迁移学习和实验主义是 Jeremy Howard 强调的两个关键理念,以便成为高效的机器学习从业者。
1. 通用逼近定理

图片来源:Vincentiu Solomon 在 Unsplash
通用逼近定理 说明你可以用一个隐藏层的前馈神经网络来逼近任何函数。由此可见,你也可以对任何更深层的神经网络实现相同类型的逼近。
我的意思是,哇!我刚刚才知道这个,现在才知道。这 是 深度学习的基础。如果你有堆叠的仿射函数(或矩阵乘法)和非线性函数,最终得到的结果可以逼近任何函数。这是追求不同仿射函数和非线性组合的原因。这也是架构越来越深的原因。
2. 神经网络:设计与架构
 在这一部分,我将重点介绍在课程中受到关注的架构,以及像丢弃法这样的最先进(SOTA)模型中纳入的一些设计。
在这一部分,我将重点介绍在课程中受到关注的架构,以及像丢弃法这样的最先进(SOTA)模型中纳入的一些设计。
-
ResNet-50 几乎是最先进的,因此你通常会希望在许多图像相关任务中使用它,比如图像分类和目标检测。这个架构在课程的 Jupyter 笔记本中使用得很频繁。
-
U-net 几乎是图像分割任务中的最先进技术。
-
对于卷积神经网络(CNNs),前几层常见使用步幅=2 的卷积。
-
DenseNet 在构建块的最终操作中使用了拼接,而 ResNet 使用了加法操作。
-
丢弃法
我们随机丢弃 激活。直观理解:这样没有任何激活可以记住输入的任何部分。这有助于解决过拟合问题,其中模型的某一部分基本上是在学习识别特定图像,而不是特定特征或项目。还有 嵌入丢弃,但这一点只是略微提及。
-
批量归一化(BatchNorm)
BatchNorm 做了 2 件事:(1)规范化激活值,(2)为每个规范化的激活值引入缩放和平移参数。然而,结果表明(1)不如(2)重要。在论文 Batch Normalization 如何帮助优化? 中提到,“[BatchNorm] 重新参数化了底层优化问题,使其景观显著平滑。” 直观上讲:因为它现在不那么崎岖,我们可以使用更高的学习率,因此收敛更快(见图 3.1)。
3. 理解损失景观

图 3.1:损失景观;左侧景观有很多凸起,右侧则是平滑的景观。来源:arxiv.org/abs/1712.09913
损失函数通常有崎岖和平坦区域(如果你将其可视化为二维或三维图)。看看图 3.2。如果你进入一个 崎岖 区域,该解决方案通常不会很好地泛化。这是因为你找到的解决方案在一个地方很好,但在其他地方不太好。但如果你在 平坦 区域找到了解决方案,你可能会有很好的泛化能力。这是因为你找到的解决方案不仅在一个点很好,而且在 周围 也很好。
图 3.2:在二维图中可视化的损失景观。截取自 course.fast.ai。以上大部分内容引自 Jeremy Howard。这是一个简单而美丽的解释。
4. 梯度下降优化器
我学到的新知识是 RMSprop 优化器充当了“加速器”。直观理解:如果你的梯度在过去几步中很小,很明显你现在需要加快一点速度。
(有关梯度下降优化器的概述,我写了一篇题为 10 Gradient Descent Optimisation Algorithms 的文章。)
5. 损失函数
学习了 2 个新的损失函数:
-
像素均方误差 (Pixel MSE)。这可以用于语义分割,这是课程内容之一,但本文没有涵盖。
-
特征损失 ????。这可以用于图像恢复任务。见任务:图像生成。
6. 训练
图片由 Victor Freitas 提供,自 Pexels
本节探讨了一些调整的组合:
-
权重初始化
-
超参数设置
-
模型拟合/微调
-
其他改进
迁移学习
模型权重可以是(i)随机初始化的,或者(ii)通过一种称为 转移学习 的过程从预训练模型中转移来的。转移学习利用了预训练的权重。预训练的权重 包含有用的信息。
转移学习中的常见模型拟合方法如下:训练靠近输出的权重,并冻结其他层。
对于转移学习,使用 与预训练模型相同的‘统计数据’ 是很重要的,例如,用某种偏差校正图像的 RGB 值。
❤️ 1cycle 策略 ❤️
这是我在这门课程中学到的最重要的知识。我一直以来对学习率掉以轻心。找到一个好的学习率 非常重要,因为我们至少可以为梯度下降提供一个经过深思熟虑的学习率,而不是一个可能只是次优的直觉值。
Jeremy Howard 在他的代码中持续使用 lr_finder() 和 fit_one_cycle(),这让我困惑,因为它虽然效果很好,但我不知道为什么它能有效。所以我阅读了 Leslie Smith 的 论文 和 Sylvain Gugger 的 博客文章(推荐阅读!),这就是 1cycle 的工作原理:
1. 执行 LR 范围测试:用从小到大的(线性)学习率训练模型,从一个小值(10e-8)增加到一个大值(1 或 10)。绘制损失与学习率的图表,如下所示。
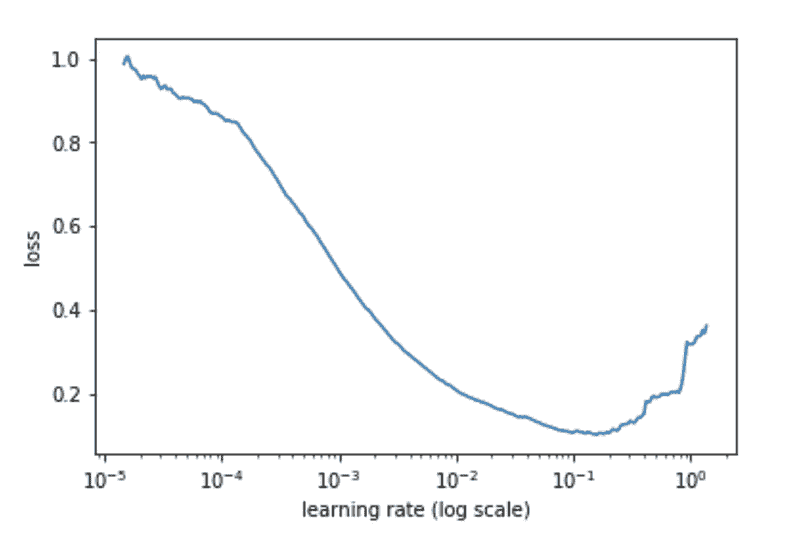
图 6.1:损失与学习率的关系。来源: https://sgugger.github.io/how-do-you-find-a-good-learning-rate.html
2. 选择最小和最大学习率。选择最大学习率时,查看图表并选择一个足够高的学习率,以获得较低的损失值(既不要太高也不要太低)。在这里,你可以选择 10e-2。选择最小学习率时,可以选择约低十倍的值。在这里,它是 10e-3。有关如何选择这些值的更多信息。
3. 根据 周期性学习率 的周期数来拟合模型。一个周期是指你的训练过程通过从选择的最小学习率到选择的最大学习率,然后再返回到最小值的学习率。
来源: https://sgugger.github.io/the-1cycle-policy.html
那么我们为什么这样做呢?整个想法是这样的。在损失地形中,我们希望跳过凸起(因为我们不想陷入某个沟壑)。因此,在开始时增加学习率有助于模型跳出沟壑,探索函数表面,并尝试找到损失较低且区域不崎岖的地方(因为如果地形崎岖,模型会再次被推出)。这使得我们可以更快地训练模型。我们还往往会得到更具泛化能力的解决方案。
图 6.2:来自 course.fast.ai 的截图
用于预训练模型的判别学习率
使用超低学习率训练早期层,使用较高学习率训练后期层。这个想法是除了微小的调整外,不要剧烈改变几乎完美的预训练权重,对接近输出层的层进行更激进的训练。判别学习率是在 ULMFiT 中引入的。
一个神奇的数字除数
在 1cycle 拟合中,要获取最小学习率,将最大值除以 2.6⁴。这个数字适用于 NLP 任务。有关更多信息,请参见 https://course.fast.ai/videos/?lesson=4 的 33:30。
用于超参数搜索的随机森林
提到可以使用随机森林来搜索超参数。
使用默认值
使用库或实现论文代码时,使用默认超参数值,“不要做英雄”。
针对预训练模型的模型微调
我注意到 Jeremy 的风格:在训练最后一层之后,解冻所有层并训练所有权重。然而,这一步是实验性的,因为它可能会或可能不会提高准确性。如果没有提高,我希望你保存了最后训练的权重 ????。
渐进式调整图像大小
这最适用于图像相关任务。首先使用较小版本的图像进行训练。然后,使用较大版本的图像进行训练。为此,使用迁移学习将训练好的权重迁移到具有相同架构但接受不同输入大小的模型中。真是天才。
混合精度训练
简化版的解释是:使用单精度(float32)数据类型进行反向传播,但使用半精度(float16)进行前向传递。
7. 正则化

照片由 Rosemary Ketchum 提供,来源于 Pexels
使用神奇的数字 0.1作为权重衰减。如果使用过多的权重衰减,你的模型训练得不够好(欠拟合)。如果使用过少,你可能会过拟合,但没关系,因为你可以提前停止训练。
8. 任务
 请注意,并非所有课程中涉及的任务都在此处提及。
请注意,并非所有课程中涉及的任务都在此处提及。
-
多标签分类
-
语言建模
-
表格数据
-
协同过滤
-
图像生成
a) 多标签分类
我一直在想如何进行[图像]分类任务,其标签数量可能会变化,即多标签分类(不要与多类分类/多项式分类混淆,其相关概念是二分类)。
没有详细说明多标签分类的损失函数如何工作。但经过搜索,我发现标签应该是多热编码的向量。这意味着每个元素必须在最终模型输出中应用 sigmoid 函数。损失函数,即输出和真实值的函数,是使用二元交叉熵来计算的,以独立地惩罚每个元素。
b) 语言建模
对于这个语言建模任务,我喜欢“语言模型”如何被定义(重新表述):
语言模型是一个学习预测句子下一个词的模型。为了做到这一点,你需要对英语和世界知识有相当多的了解。
这意味着你需要用大量的数据来训练模型。这部分课程介绍了ULMFiT,这是一个可以基于预训练(换句话说,就是迁移学习)进行重用的模型。
c) 表格数据
这是我第一次遇到使用深度学习处理具有分类变量的表格数据!我之前不知道可以这样做?无论如何,我们可以做的是我们可以从分类变量中创建嵌入。如果我没有上过这门课程,我可能不会想到这一点。稍微搜索了一下,我找到了 Rachel Thomas 写的关于表格数据深度学习入门的帖子,介绍了这种嵌入的使用。
那么,问题是如何将(a)连续变量的向量和(b)来自分类变量的嵌入结合起来?课程中没有提到这一点,但这个 StackOverflow 的帖子强调了三种可能的方法:
-
2 个模型——一个用于(a),一个用于(b)。将它们进行集成。
-
1 个模型,1 个输入。这个输入是(a)和(b)的连接。
-
1 个模型,2 个输入。这两个输入分别是(a)和(b)。你将这两个输入在模型内部连接起来。
d) 协同过滤
协同过滤是当你需要预测一个用户对某个项目的喜好程度时(在这个例子中,我们以电影评分为例)。课程中介绍了使用嵌入来解决这个问题。这是我第一次遇到使用深度学习的协同过滤(就像我之前对协同过滤的经验很丰富一样)!
目标是为每个用户和项目创建大小为n的嵌入。为此,我们随机初始化每个嵌入向量。然后,对于每个用户对电影的评分,我们将其与各自嵌入的点积进行比较,例如,使用均方误差(MSE)。接着我们进行梯度下降优化。
e) 图像生成
这是我学到的一些东西:
-
‘劣化’用于生成数据,按我们希望的方式。这个术语我特别喜欢。
-
生成对抗网络(GANs)讨厌 动量,所以将其设置为 0。
-
仅仅通过观察损失很难了解模型的表现。必须亲自查看生成的图像(尽管在训练结束时,判别器和生成器的损失大致应保持不变)。
-
提高生成图像质量的一种方法是在我们的损失函数中包含感知损失(也称为 fast.ai 中的特征损失)。特征损失通过取网络中间某处张量的值来计算。
9. 模型可解释性

照片由Maria Teneva拍摄,来自Unsplash
在其中一节课中,Jeremy Howard 展示了一个激活 热图,用于图像分类任务。这个热图显示了被“激活”的像素。这种可视化将帮助我们理解哪些特征或图像的部分导致了模型的输出???????。
10. 附录:Jeremy Howard 谈模型复杂度与正则化

照片由NEW DATA SERVICES拍摄,来自Unsplash
我转录了这部分课程(第 5 课),因为直觉实在太引人入胜了❤️。这里 Jeremy 首先总结了那些认为增加模型复杂度不是解决办法的人的观点,然后改变了他们的看法,接着带他们了解L2 正则化。
哦,我以前学的是统计学,所以他在这方面让我措手不及????。
所以,如果你们中的任何人不幸地被统计学、心理学、计量经济学或类似课程的背景洗脑了,你们需要重新认识你们需要更少参数的想法,因为你们实际上需要意识到的是,你们会适应这种谎言,即你们需要更少的参数,因为这是一个方便的虚构,真实的情况是你们不希望你的函数过于复杂。而拥有更少的参数是使其不那么复杂的一种方式。
但是如果你有一千个参数,其中 999 个参数是
1e-9呢?或者如果有 0 呢?如果是 0,那它们实际上并不存在。或者如果它们是1e-9,那它们几乎也不存在。那么如果很多参数都非常小,我为什么不能有很多参数呢?答案是你可以。实际上,用[参数数量]来限制复杂性的做法是极其有限的。这是一个有很多问题的虚构方法,对吧?因此,如果在你脑海中复杂性是通过参数数量来衡量的,那你是完全错误的。要正确地衡量它。
那么我们为什么在乎呢?我为什么要使用更多的参数?
因为更多的参数意味着更多的非线性、更复杂的交互、更曲折的部分,对吧?而现实生活(损失景观)充满了曲折的部分。现实生活并不像这个[欠拟合的直线]。但我们不希望它们比必要的更加曲折,或更多地交互。
所以我们使用大量参数,然后惩罚复杂性。
好的,一种惩罚复杂性的方法是,正如我之前建议的那样:让我们求出参数值的总和。不过这并不完全有效,因为有些参数是正的,有些是负的,对吧?那我们可以求出参数平方的总和。
这实际上是一个非常好的主意。
让我们实际创建一个模型,并在损失函数中添加参数平方的总和。不过这里有一个问题。也许那个数字太大,以至于最佳的损失是将所有参数设置为 0。那样就不好了。因此,我们实际上希望避免这种情况发生。因此,不仅仅是将参数平方的总和添加到模型中,而是将其乘以我们选择的某个数字。在 fastai 中,我们选择的那个数字叫做
wd。
你可能也想看看我的文章《L1 和 L2 正则化的直观解释》,我在这里解释了这两种正则化技术。
结论
我真的很喜欢这门课程。以下是一些原因:
-
他们提供了直观且易于理解的解释。
-
他们用很棒的资源来补充他们的课程。
-
他们鼓励你将深度学习应用到你各自的领域中去构建事物。
-
他们似乎总是跟上有趣且新颖的出版物,并在适当的地方将它们融入 fastai 库中。
-
他们还进行大量关于深度学习的研究(请参阅:ULMFiT)。
-
他们围绕 fastai 库建立了一个社区,因此你将容易获得支持。
-
他们的技巧和窍门对 Kagglers 和以准确性为驱动的建模非常有用。
期待课程的下一部分!
简历:Raimi Bin Karim 是 AI Singapore 的 AI 工程师
原文。经许可转载。
相关:
-
fast.ai 深度学习第一部分完整课程笔记
-
使用 fast.ai 进行快速特征工程
-
深度学习 3 门热门课程概述
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关内容
如何像数据科学家一样思考以成为数据科学家
原文:
www.kdnuggets.com/2017/03/think-like-data-scientist-become-one.html
评论
我们都读过头条新闻——数据科学家是最性感的工作,数量不足,薪资非常高。这个角色被销售得非常成功,以至于数据科学课程和大学项目的数量疯狂增长。在我之前的博客文章之后,我收到了很多人询问如何成为数据科学家——哪些课程最好,应该采取哪些步骤,最快的获得数据科学工作的方式是什么?
我尝试深入思考这个问题,并回顾了我的个人经历——我怎么来到这里?我如何成为一名数据科学家?我 是数据科学家吗?我的经历非常复杂——我起初是一个证券分析师,在一家投资公司主要使用 Excel。随后,我逐渐转向银行业的商业智能和多个咨询项目,最终做到了真正的“数据科学”——建立预测模型,处理大数据,处理大量数据并编写代码进行数据分析和机器学习——这在早期被称为“数据挖掘”。
当数据科学的热潮开始时,我试图理解它与我迄今为止所做的有什么不同。我是否应该学习新技能,成为数据科学家,而不是一个在“分析”领域工作的人?
像每个对它着迷的人一样,我开始参加多个课程,阅读数据书籍,进行数据科学专业化(但没有完成……),大量编写代码——我想成为那张(不)著名的数据科学维恩图的中间交集中的那一个。我学到的现实是,这些“数据科学”独角兽(维恩图中传奇般的人物)很少存在,即使存在——他们通常是对这些领域都有了解的通才,但却是“样样通,样样松”。
尽管我现在认为自己是一名数据科学家——我在亚马逊领导一个极其有才华的数据科学团队,建立机器学习模型,处理“大数据”——我仍然觉得这个行业周围的混乱太多,清晰度却少得多,尤其是对于那些考虑职业转换的人。不要误解我的意思——数据科学有很多非常复杂的分支——如人工智能、机器人技术、计算机视觉、语音识别等——这些领域需要非常深厚的技术和数学知识,甚至可能需要一个……或两个博士学位。但如果你对进入一个几年前被称为商业/数据分析师的数据科学角色感兴趣——这里有四条规则帮助我进入并继续在数据科学领域生存。
规则 1 – 确定你的优先级和动机。
对你现在拥有的技能和你希望达到的目标要非常现实——数据科学中有很多不同类型的角色,了解并评估你当前的知识基础是很重要的。比如说,你现在在 HR 部门工作,想要换职业——学习 HR 分析!如果你是律师——了解法律行业中的数据应用。事实是,对洞察力的渴望如此巨大,以至于所有行业和业务职能都开始使用它。如果你已经有了工作,试着理解哪些方面可以通过数据优化或解决,并学习如何自己做到这一点。这将是一个渐进而漫长的转变,但你仍然会有工作,并通过实际操作进行学习。如果你是刚毕业的学生或在校生——你有一个绝佳的机会来发现自己对什么充满热情——也许是电影,也许是音乐,或者是汽车?你无法想象这些行业中雇用了多少数据科学家——他们都对自己所从事的领域充满热情。
规则 2 – 很好地掌握基础知识。
尽管每个数据科学领域的具体内容非常不同,但基础知识是相同的。你应该在三个领域建立扎实的基础——基本的数据分析、入门统计学和编码技能。
数据分析。 你应该理解并大量练习基本的数据分析技术——什么是表格,如何连接两个表格,分析以这种方式组织的数据的主要技术是什么,如何构建数据集的汇总视图并从中得出初步结论,什么是探索性数据分析,哪些可视化方法可以帮助你理解和学习数据。这是非常基础的,但相信我——掌握了这些,你将具备一项在工作中绝对必需的基本技能。
统计学。 同样,要非常好地掌握入门统计学——什么是均值、 медиан、何时使用其中一种而不是另一种,什么是标准差以及在什么情况下使用它没有意义,为什么平均值“欺骗”但仍然是最常用的汇总值等等。当我说“入门”时,我真的指的是“入门”。除非你是一名数学家,并计划成为一名经济计量学家,应用高级统计和计量经济学模型来解释复杂现象——否则,学习高级统计学。如果你没有数学博士学位,就慢慢来,耐心一点,扎实掌握基础统计学和概率论。
编码。 当然 – 学习如何编码。这是最常被提及的陈词滥调建议,但实际上它是一个有效的建议。你应该从学习如何使用 SQL 查询数据库开始 – 不管你信不信,大多数数据科学团队花费的时间都用于数据提取和准备,其中大量工作是用 SQL 完成的。所以打好基础– 构建你自己的小型数据库,编写一些“select * from my_table”的代码行,掌握 SQL 的基础知识。你还应该学习一种(开始时只学习一种)数据分析语言 – 无论是 R 还是 Python。两者都很出色,掌握它们确实会有所不同,因为许多(虽然不是全部)职位都要求掌握它们。首先学习你选择的语言的基础(快速提示 – 从学习 R 的 dplyr 和 ggplot2 包,或 Python 的 pandas 和 Seaborn 库开始),并学习如何用它进行数据分析。你不需要成为程序员来在这个领域取得成功,关键在于知道如何使用语言进行数据分析 – 你不必成为世界级的黑客才能获得数据科学工作。
规则 3 – 数据科学是解决问题的过程 – 找到并解决一个问题。
多年来我学到的一件事是,数据科学家的一个基本要求是总是提出问题和寻找问题。现在我并不建议你全天候这样做,因为你肯定会发疯,但要做好准备,成为问题解决者并不断寻找问题。你会惊讶于外面有多少可用的数据 – 也许你想分析你的支出模式,识别你的电子邮件的情感模式,或者仅仅是构建漂亮的图表来跟踪你所在城市的财务状况。数据科学家负责质疑一切 – 这个活动是否有效,有没有令人担忧的趋势,也许一些产品表现不佳应该被下架,折扣是否合理或者是否过大 – 这些问题成为假设,然后由数据科学家验证或驳回。它们是原材料,也是工作成功的关键,因为你解决的问题越多,你的工作表现就会越好。
规则 4 – 从“做”开始,而不是计划你将来“何时”做的事情。 这适用于任何学习行为,但在数据科学中尤其如此。确保你从学习的第一天就开始“做”。仅仅通过阅读“关于”数据科学的内容、了解它“应该”如何进行、从书中复制粘贴数据分析代码并在非常简单的数据集上运行,实际上很容易将实际学习拖延到以后,这些简单的数据集在现实世界中是不会遇到的。
在你学习的每一件事上,一定要确保将其应用到你热爱的领域。这就是魔法发生的地方 – 写下你的第一行代码并看到它失败,陷入困境而不知道接下来该做什么,寻找答案,发现许多不同的解决方案却都无效,努力构建自己的解决方案,最终跨越一个里程碑 – “啊哈!” 时刻。这就是实际学习发生的地方。通过实践学习是学习数据科学的唯一途径 – 你不会仅通过阅读来学会骑自行车,对吧?同样的道理,无论你学到了什么,确保你立即应用它,并用真实的数据解决实际问题。
“如果你花太多时间思考一件事,你永远无法完成它。” – 这句来自著名武术家布鲁斯·李的名言抓住了这篇文章的精髓。你必须应用你所学到的,并确保你犯自己的错误。
感谢阅读!订阅我的博客 www.cyborgus.com 并获取最新更新:
在 Facebook 上关注我的博客更新 – www.facebook.com/cyborguscom/
在 LinkedIn 上查找我 – www.linkedin.com/in/karolisurbonas/
个人简介: Karolis Urbonas,是亚马逊数据科学部负责人,是一位充满活力的数据高管,拥有建立高绩效数据科学团队和交付战略分析项目的丰富经验。他的博客地址是 cyborgus.com。
相关:
-
数据科学家的思维 – 第一部分
-
如何成为数据科学家 – 第一部分
-
追求卓越的数据科学学习,而不仅仅是为了考试
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
更多相关内容
如何像数据科学家一样思考
原文:
www.kdnuggets.com/2020/05/think-like-data-scientist-data-analyst.html
评论
由 Jo Stichbury,自由技术写作人

数据科学是一个新兴且不断成熟的领域,各种工作职能不断出现,从数据工程和数据分析到机器学习和深度学习。数据科学家必须结合科学、创造性和调查思维,从各种数据集中提取意义,并解决客户面临的根本挑战。
各个领域产生的数据量不断增加——从零售、交通和金融到医疗保健和医学研究。
可用计算能力的增加和人工智能的最新进展将数据科学家——那些将原始数据分析并使其有用的人员——推到了聚光灯下。
自 2016 年以来,数据科学在北美的 50 种最佳职业中排名首位,依据如收入潜力、报告的工作满意度以及 Glassdoor 上的职位空缺数量等标准。
像数据科学家一样思考

图片来自 svgsilh.comCC0 1.0
那么,成为一个数据科学家需要什么呢?成为数据科学家
关于成功所需技能的一些提示,我采访了 Ben Chu,他是 Refinitiv Labs的高级数据科学家。
Chu 在人工智能领域有背景,特别是在语言学、语义学和图形学方面,并在新加坡的 Refinitiv Labs 工作了两年。
保持好奇
Chu 在我们采访开始时提到,数据科学家应该像调查员一样思考。
你需要保持好奇和兴奋,提出“为什么?”。“这有点像当侦探,连接点滴,发现新的线索。”
在金融领域,数据科学家从各种数据集中提取意义,以指导客户并帮助他们做出关键决策。
数据科学家必须聚焦于客户希望解决的挑战,并从他们处理的数据中寻找线索。
从与 Chu 的交谈中,我了解到能够调整重点并考虑调查背景是多么重要。
如果完美的分析不能解决根本问题,那就没有用处。有时你需要回过头来,尝试新的方法,并重新审视你要回答的问题。其核心是 好奇心。你需要热爱问题!
保持科学
数据科学家使用各种工具来管理他们的工作流程、数据、注释和代码。
“我必须非常勤奋。我需要测量和跟踪我的进展,以便在需要时进行回顾并尝试新的方向,重用先前的工作,并比较结果。”
“保持科学性很重要,要进行观察、实验并记录好进展,以便能够重复你的发现。我需要组织我的观察记录,因此我使用 Notion 作为我的主要工具,将所有的笔记、论文和可视化内容集中在一个地方。”
Chu 强调了记录不仅要涵盖他当前的调查,还要包括所有先前的发现。
“这就像是数据科学的日记。我保持良好的参考点,并在遇到类似情境时回顾它们,以指导我的下一步行动。”
发挥创造力
数据科学不仅仅是采用科学的方法。职位名称可能会产生误导;你不一定需要具备科学背景,但你需要能够进行创造性思考。通常,另类思维是解决挑战的关键。
“我必须在解决问题时切换科学思维,并运用创造性思维引导我探索新的和不同的路径,探索新方向。”
“逻辑性和科学性思维对帮助我得出结论至关重要,但发挥创造性思维同样重要:我使用成功和失败的例子作为线索来观察新的模式。这一切都与‘编码智能’有关。”
学会编码

图片来源于svgsilh.com
你需要扎实的编码技能,以便能够预处理不同的数据源,使用各种数据处理技术来解决噪声或不完整的数据问题。
你还需要能够创建机器学习管道,这要求你知道如何构建模型,并使用工具和框架来评估和分析其性能。
Chu 使用 Python,就像大多数数据科学家一样,因为 Python 提供了大量优秀的包来处理和建模数据。
实际上,Glassdoor 在 2017 年上半年对其网站上发布的 10,000 个数据科学家职位进行了抽样调查,发现三个特别的技能——Python、R 和 SQL——构成了数据科学大多数职位的基础。
Ben Chu 的团队依赖开源机器学习包,如 Tensorflow、Pytorch 和 BERT。
“我们主要使用 Confluence 作为文档工具;使用 MLFlow、Amazon Sagemaker、Scikit-Learn、Tensorflow、PyTorch 和 BERT 进行机器学习;使用 Apache Spark 在大型数据集上构建高速数据管道;使用 Athena 作为我们的数据库来存储处理后的数据。”
“我们还使用 Superset 连接数据,更方便地构建仪表板以输出图表,这使得操作更直观。”
不要担心‘冒名顶替综合症’。
朱目前是 Refinitiv Labs 的高级数据科学家,但他小时候想成为一名音乐家,对语言充满兴趣。“在自然语言处理领域,我需要对语言学有深入了解,特别是语义学和语言的细微差别。”
他解释说,数据科学团队需要各种技能——他和他的同事们从不同的背景中发展出了重叠的技能。
“你需要的技能将取决于你所工作的领域。例如,我需要对金融有良好的理解。
“例如,通过建立异常检测方法,数据分析正被用于减少欺诈,以检测交易数据中的欺诈‘行为’作为不规则模式。
“像我这样的数据科学家需要熟练掌握如何处理各种孤立的金融数据。了解如何组合这些数据至关重要,因为没有这种理解,我无法构建成功的模型。”
进入数据科学领域并不一定需要成为计算机科学家或数学家。没有人能在所有领域都有所有的专业知识。你可以来自法律、经济或科学背景。关键在于你的思维方式。
如果你能灵活和系统地处理问题,你将能够在使用工具、框架和数据集的过程中逐渐熟悉这些具体细节。
如何开始
对于那些希望提升数据科学技能的人,朱提供了一些实用的建议,尽管 COVID-19 带来了干扰,但这些建议你仍然可以轻松采纳。
你可以寻找研究社区,参加网络研讨会,并在线找到培训课程。一旦面对面的网络交流再次成为可能,朱建议你积极参与 数据科学社区。
“参加 Meetups 和黑客马拉松,这将帮助你建立强大的网络,讨论你的想法,激发你的研究灵感,并解答你的问题。”
此外,请记住,数据科学领域是新兴的,仍在发展中。
各种不同的职位名称正在出现,例如数据科学家、数据工程师和数据分析师,还有机器学习和深度学习工程师。你 可能会发现某些角色更适合你的兴趣和技能。
发掘你的好奇心和创造力,提升你的 Python 技能,进入数据科学领域吧!
本文最初发表于 Refinitiv Perspectives 于 2020 年 4 月初。
个人简介:Jo Stichbury 是一名自由职业技术作家。
原文。经许可转载。
相关内容:
-
用 NLP 发现争议
-
数据科学家的 4 种现实职业选择
-
如何在理想公司获得数据科学家职位
相关主题
第三波数据科学家
评论
由 Dominik Haitz 提供,IONOS。
介绍
德鲁·康威的数据科学技能集可视化 是一个经常被引用的经典。不同的观点和角色的多样性催生了numerous variations:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
各种数据科学维恩图。图片来源于谷歌图片。来源:sinews.siam.org/Details-Page/a-timely-focus-on-data-science
关于数据科学技能集似乎没有共识。此外,随着领域的发展,缺陷变得明显,新挑战不断出现。我们如何描述这种演变?
第一波数据科学家发生在数据尚未大规模和数据科学尚未成为实际存在之前(2010 年之前):统计学家和分析师,他们一直存在,做着很多现代数据科学家在做的事情,但伴随的炒作较少。
第二波:大规模数据收集创造了对聪明人才的需求,他们能够将大数据转化为大钱。公司仍在摸索应聘人员的类型,往往转向科学专业毕业生。虽然第二波数据科学家做了很多正确的事,但他们精心制作的模型通常只是概念验证,并未带来实际的改变。
现在,在 2010 年代末,随着对深度学习和人工智能的炒作,进入了第三波数据科学家:进行实验和创新,效率地寻找商业价值,并弥合部署差距以创建出色的数据产品。在这里需要哪些技能?
第三波数据科学家的技能组合。
1. 商业思维
商业思维是数据科学技能组合的核心,因为它设定目标并运用其他技能来实现这些目标。Patrick McKenzie 在这篇博客文章中指出:
工程师被聘用是为了创造商业价值,而不是编程:企业总是因为非理性和政治原因做事,但主要还是集中在增加收入或降低成本上。
同样,数据科学家被聘用是为了创造商业价值,而不仅仅是构建模型。问问自己:我的工作成果将如何影响公司决策?我需要做什么来最大化这一效果?凭借这种企业家精神,第三波数据科学家不仅提供可操作的见解,还寻求实现真正的变化。
关注组织中的资金流向——拥有最大成本或收入的部门可能会提供最大的财务杠杆。然而,商业价值是一个模糊的概念:它超越了当前财政年度的成本和收入。实验和创建创新的数据文化将提高公司的长期竞争力。
优先处理你的工作和知道何时停止是效率的关键。想想递减收益:花费数周时间来调整模型以提高 0.2%的精度是否值得?通常,足够好才是真正的完美**。
领域专长,这是 Conway 技能组合的三分之一,绝对不能被忽视——然而,你几乎在所有地方都必须在工作中学习。这包括对你所在行业以及公司流程、命名方案和特殊情况的了解。这些知识不仅为你的工作设定了框架条件,而且通常对于理解和解释你的数据是不可或缺的。
保持简单,傻瓜
https://twitter.com/matvelloso/status/1001899539484192768
寻找容易实现的目标和快速胜利。对现有数据仓库进行一个简单的 SQL 查询可能会发现产品经理或高层管理人员未知的宝贵见解。不要陷入“流行词驱动的数据科学”的陷阱,专注于最先进的深度学习,而一个简单的回归模型就足够了——而且构建、实施和维护的工作量要少得多。了解复杂的事物,但不要使事情过于复杂。
2. 软件工程工艺
对(第二波)数据科学家只需“黑客技能”而不是适当的软件工程的观点已被多次批评。缺乏可读性、模块化或版本控制阻碍了协作、可重复性和生产化。
相反,向专业的软件工程师学习工艺。测试你的代码并使用版本控制。遵循既定的编码风格(例如 PEP8)并学习如何使用 IDE(例如 PyCharm)。尝试对编程进行配对。模块化和文档化你的代码,使用有意义的变量名称并进行重构,重构,重构。
弥合敏捷原型数据产品的部署差距:学习使用日志记录和监控工具。知道如何构建 REST API(例如使用 Flask)以将结果提供给他人。学习如何将工作打包到 Docker 容器中,或将其部署到像 Heroku 这样的平台上。不要让你的模型在笔记本电脑上腐烂,而是将其包装成适合你公司 IT 环境的数据驱动服务。
3. 统计学和算法工具箱
数据科学家必须彻底理解统计学基础概念和特别是机器学习(STEM 大学教育可能是获得这种基础的最佳途径)。关于重要内容有很多资源,所以我不会在这里进一步探讨。你常常需要向客户解释算法或概念,如统计不确定性,或者因为混淆相关性和因果关系而标记出问题。
4. 软技能
由于人际交往技能对生产力的重要性与技术技能相当,第三波数据科学家在这些领域上会有意识地努力提高。
与他人合作良好
咨询你的同事——大多数人乐于帮助或提供建议。平等对待他人:你可能有一个很好的学位和对复杂算法的理解,但其他人拥有你没有的经验(这听起来像基本的社交建议,但谁没遇到过傲慢的 IT 专业人士呢?)。
理解你的客户
问对后续问题。如果客户或你的老板希望你计算一些关键数据或创建一些图表,问“为什么?目的是什么?你想达成什么?根据结果你会采取什么行动?”以更好地理解问题的核心。然后一起找出如何达到目标——是否有比提出的更好的方法来实现目标?
处理公司政治
建立网络,不是因为你期望他人在你的职业生涯中帮助你,而是因为你是一个容易接近的人。与有类似工作主题的人建立联系。如果公司内没有这样的平台,自己创建。识别关键利益相关者,并找出如何帮助他们解决问题。及早邀请他人,并使他们成为变革过程的一部分。记住:公司不是一个理性的实体,而是由经常不理性的个体组成。
传达你的结果
提升你的可视化和演示技巧。从客户的角度进行沟通:我如何才能准确回答他们的问题?学会在不同层次上沟通并总结你的工作细节。人们很容易被华丽的多维图表所吸引,但通常简单的柱状图更能有效传达信息。展示你的成果:当人们看到你正在做的工作并且发现你做得很好,他们会信任你。
自我评估
沟通你的目标和问题,并积极寻求建议。在数据科学社区内外寻找榜样,并向他们学习。
原文。经许可转载。
个人简介:多米尼克·海茨是数据科学家@ionos_de,同时也是博客作者,towardsdatascience.com/@d_haitz。
资源:
相关:
更多相关内容
本周 AI,7 月 31 日:AI 巨头承诺负责任的创新 • 白鲸入侵

由编辑使用 BlueWillow 创建的图像
欢迎来到 KDnuggets 首期的“本周 AI”专刊。此精选的每周更新旨在让您了解人工智能领域迅速发展的最重要进展。从塑造我们对 AI 在社会角色理解的突破性头条新闻,到引发深思的文章、深刻的学习资源,以及推动知识边界的重点研究,这篇文章提供了 AI 当前格局的全面概述。虽然尚未深入细节,但请期待探索反映 AI 广泛和动态本质的众多话题。请记住,这只是许多未来每周更新中的第一个,旨在让您在这一不断发展的领域中保持更新和知情。敬请关注,祝您阅读愉快!
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
头条新闻
“头条新闻”部分讨论了过去一周在人工智能领域的最新新闻和发展。信息涵盖从政府的 AI 政策到技术进步以及 AI 领域的企业创新。
拜登-哈里斯政府已从七家领先的 AI 公司——亚马逊、Anthropic、谷歌、Inflection、Meta、微软和 OpenAI——那里获得了自愿承诺,以确保 AI 技术的安全、保障和透明发展。这些承诺强调了未来 AI 的三个基本原则:安全、保障和信任。这些公司同意在发布前对其 AI 系统进行内部和外部安全测试,分享关于管理 AI 风险的信息,并投资于网络安全。他们还承诺开发技术机制,确保用户知道何时内容是 AI 生成的,并公开报告其 AI 系统的能力、局限性以及适当和不适当使用的领域。这一举措是拜登-哈里斯政府致力于确保 AI 的安全和负责任发展,以及保护美国人免受伤害和歧视的更广泛承诺的一部分。
Stability AI 揭示 Stable Beluga:开放访问语言模型的新强者
Stability AI 和其 CarperAI 实验室宣布推出 Stable Beluga 1 和 Stable Beluga 2 两个强大的开放访问大语言模型(LLMs)。这两个模型在各种基准测试中展现了卓越的推理能力,分别基于原始的 LLaMA 65B 和 LLaMA 2 70B 基础模型。两个模型均通过使用标准 Alpaca 格式的有监督微调(SFT)方法,在新的合成生成数据集上进行了微调。Stable Beluga 模型的训练灵感来源于微软在其论文“Orca: Progressive Learning from Complex Explanation Traces of GPT-4”中使用的方法。尽管训练样本量仅为原始 Orca 论文的十分之一,但 Stable Beluga 模型在各种基准测试中表现出色。截至 2023 年 7 月 27 日,Stable Beluga 2 是排行榜上的顶级模型,而 Stable Beluga 1 排名第四。
Spotify CEO 暗示未来 AI 驱动的个性化和广告功能
在 Spotify 第二季度的财报电话会议上,首席执行官 Daniel Ek 暗示了可能会为流媒体服务引入更多 AI 驱动的功能。Ek 认为 AI 可以用来创建更个性化的体验,总结播客内容和生成广告。他强调了最近推出的 DJ 功能的成功,该功能提供了精选音乐以及关于曲目和艺术家的 AI 驱动评论。Ek 还提到可能会使用生成性 AI 来总结播客内容,使用户更容易发现新内容。此外,Ek 讨论了 AI 生成音频广告的可能性,这可能显著降低广告商开发新广告格式的成本。这些评论正值 Spotify 寻求为 AI 驱动的“文本到语音合成”系统申请专利,该系统可以将文本转换为具有情感和意图的人声音频。
文章
“文章”部分展示了一系列发人深省的人工智能相关文章。每篇文章深入探讨了特定话题,为读者提供了关于 AI 各个方面的见解,包括新技术、革命性方法和开创性工具。
???? ChatGPT 代码解释器:几分钟内完成数据科学工作
这篇 KDnuggets 文章介绍了 ChatGPT 的代码解释器插件,这是一种可以分析数据、编写 Python 代码和构建机器学习模型的工具。作者 Natassha Selvaraj 演示了如何使用该插件来自动化各种数据科学工作流程,包括数据总结、探索性数据分析、数据预处理和构建机器学习模型。代码解释器还可以用于解释、调试和优化代码。Natassha 强调,虽然这个工具功能强大且高效,但它应该作为数据科学任务的基础使用,因为它缺乏领域特定的知识,不能处理存储在 SQL 数据库中的大型数据集。Natassha 建议初级数据科学家和有志于成为数据科学家的人应学习如何利用像代码解释器这样的工具来提高工作效率。
这篇 KDnuggets 文章讨论了微软研究人员提出的一种新型 AI 训练方法,该方法涉及使用合成教材而非大量数据集。研究人员将一个名为 Phi-1 的模型完全在自制教材上进行训练,发现它在 Python 编程任务中的表现非常出色,尽管它的规模明显小于 GPT-3 等模型。这表明,训练数据的质量可能与模型的规模同样重要。Phi-1 模型在通过合成练习和解决方案进行微调后,性能也有所提升,表明有针对性的微调可以提高模型的能力超越其专门训练的任务。这表明,这种基于教材的方法可能会通过将重点从创建更大模型转向策划更好的训练数据,从而彻底改变 AI 训练。
最新的提示工程技术巧妙地将不完美的提示转化为卓越的生成式 AI 互动
这篇文章讨论了一种新型的提示工程技术,鼓励使用不完美的提示。作者认为,追求完美的提示可能适得其反,往往更实际的做法是追求“足够好”的提示。生成式 AI 应用程序使用概率和统计方法解析提示并生成响应。因此,即使使用相同的提示多次,AI 也可能每次生成不同的响应。作者建议,与其努力寻求完美的提示,不如利用不完美的提示并将它们汇总以创建有效的提示。文章引用了一项名为“随便问我什么:一种简单的提示语言模型策略”的研究,该研究提出了一种通过汇总多个有效但不完美的提示的预测来将不完美提示转化为强健提示的方法。
学习资源
“学习资源”部分列出了对那些渴望扩展 AI 知识的人员有用的教育内容。这些资源包括从全面的指南到专业课程,适用于 AI 领域的初学者和经验丰富的专业人士。
Cohere 的 LLM 大学是一个为对自然语言处理(NLP)和大型语言模型(LLMs)感兴趣的开发者提供的综合学习资源。课程旨在提供坚实的 NLP 和 LLMs 基础,并在此基础上构建实际应用。课程分为四个主要模块:“大型语言模型是什么?”,“使用 Cohere 端点进行文本表示”,“使用 Cohere 端点生成文本”和“部署”。无论你是新的机器学习工程师还是希望扩展技能的经验丰富的开发者,Cohere 的 LLM 大学都提供了一个全面的 NLP 和 LLMs 世界指南。
Google Cloud 发布了生成式 AI 学习路径,这是一个包含从生成式 AI 基础知识到更高级工具(如生成式 AI 工作室)的免费课程合集。学习路径包括七门课程:“生成式 AI 概述”、“大型语言模型简介”、“图像生成简介”、“注意力机制”、“Transformer 模型和 BERT 模型”、“创建图像字幕模型”和“生成式 AI 工作室简介”。这些课程涵盖了包括大型语言模型、图像生成、注意力机制、Transformer 模型、BERT 模型和图像字幕模型在内的多个主题。
研究聚焦
“研究聚焦”部分突出了人工智能领域的重要研究。该部分包括突破性的研究、探索新理论以及讨论人工智能领域的潜在影响和未来方向。
???? 大型语言模型在数据科学教育演变中的作用
题为“大型语言模型在数据科学教育演变中的作用”的研究论文讨论了大型语言模型(LLMs)对数据科学家角色和职责的变革性影响。作者认为,大型语言模型的崛起正在将数据科学家的重点从动手编码转移到管理和评估由自动化人工智能系统执行的分析。这种转变需要数据科学教育的重大演变,强调在学生中培养多样化的技能,包括由 LLMs 启发的创造力、批判性思维、受 AI 指导的编程以及跨学科知识。
作者们还提出,大型语言模型(LLMs)在课堂上可以作为互动教学和学习工具发挥重要作用。它们可以促进个性化教育,丰富学习体验。然而,将 LLMs 整合到教育中需要谨慎考虑,以平衡 LLMs 的好处,同时促进人类专业知识和创新。论文建议,数据科学教育的未来很可能涉及人类学习者与 AI 模型之间的共生关系,其中双方相互学习并提升各自的能力。
更多相关内容
本周 AI 动态,8 月 7 日:生成性 AI 进入 Jupyter 和 Stack Overflow • ChatGPT 更新

图片由编辑使用 Midjourney 创建
欢迎来到本周的“本周 AI 动态”版块,由 KDnuggets 提供。这个精心策划的每周帖子旨在让你了解人工智能快速发展的世界中的最引人注目的进展。从塑造我们对 AI 在社会中角色的突破性头条新闻,到发人深省的文章、深刻的学习资源和推动我们知识边界的研究亮点,这个帖子提供了对 AI 当前格局的全面概述。此每周更新旨在让你在这一不断发展的领域中保持更新和知情。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
标题
“标题”部分讨论了过去一周在人工智能领域的主要新闻和进展。信息涵盖了从政府 AI 政策到技术进步和企业 AI 创新的各个方面。
???? Jupyter 中的生成性 AI
开源项目 Jupyter 团队发布了 Jupyter AI,这是一种新扩展,将生成性 AI 功能直接引入 Jupyter 笔记本和 JupyterLab IDE。Jupyter AI 允许用户通过聊天互动和魔法命令利用大型语言模型来解释代码、生成新代码和内容、回答有关本地文件的问题等。它在设计时考虑了负责任的 AI,允许对模型选择和 AI 生成输出的跟踪进行控制。Jupyter AI 支持像 Anthropic、AWS、Cohere 和 OpenAI 这样的提供商。其目标是以伦理的方式使 AI 更易于访问,以提升 Jupyter 笔记本的体验。
???? 宣布 OverflowAI
Stack Overflow 宣布了 OverflowAI,这是他们将 AI 能力整合到公共问答平台、Stack Overflow for Teams 以及 IDE 扩展等新产品中的项目。其功能包括语义搜索以寻找更相关的结果、摄取企业知识以加快内部问答的启动、一个访问 Stack Overflow 内容的 Slack 聊天机器人,以及一个在开发者工作流程中呈现答案的 VS Code 扩展。他们旨在利用其社区中超过 5800 万个问题,同时通过对 AI 生成内容的归属和透明度来确保信任。目标是通过负责任地使用 AI 来提升开发者的效率,将他们与上下文中的解决方案相连接。
???? ChatGPT 更新
在过去的一周中,我们推出了若干小更新,以提升 ChatGPT 的使用体验。这些更新包括引入提示示例以帮助用户开始聊天、建议回复以促使更深层次的互动,以及为 Plus 用户提供默认使用 GPT-4 的偏好设置。此外,还引入了多文件上传功能(在 Plus 用户的代码解释器测试版中)、新的保持登录功能以及一系列键盘快捷键,以提高可用性。
文章
“文章”部分展示了一系列引人深思的人工智能相关作品。每篇文章深入探讨一个特定主题,为读者提供关于 AI 的各种见解,包括新技术、革命性方法和开创性的工具。
???? 我在 3 天内创建了一个 AI 应用
作者通过 ChatGPT 提示实验,创建了一个名为 Tally.Work 的 AI 驱动的求职信生成器网络应用,仅用了 3 天时间,前端使用了 Bubble.io,生成文本则通过 OpenAI API 完成。该应用程序以用户的简历和职位描述为输入,输出定制的求职信。目标是构建一个具有巨大潜在用户基础的应用。尽管 AI 生成的文本尚不完美,但可以帮助创建有用的初稿。作者相信 AI 将消除许多繁琐的任务,如求职信,并希望这个项目能引领更多有趣的 AI 应用的出现。总体来看,它展示了使用无代码工具和 AI API 快速构建和推出应用创意的可能性。
???? 生产环境中部署生成模型的三大挑战
文章讨论了在生产环境中部署生成性 AI 模型(如 GPT-3 和 Stable Diffusion)的三个主要挑战:模型的巨大规模导致高计算成本、可能传播有害偏见的偏见以及需要调整的一致性输出质量。解决方案包括模型压缩、在无偏数据上训练、后处理过滤器、提示工程和模型微调。总体而言,文章概述了公司必须仔细解决这些问题,以成功利用生成模型,同时避免潜在的负面影响。
工具
"工具"部分列出了社区创建的有用应用程序和脚本,供那些希望投入实际 AI 应用的人使用。在这里,你将找到各种工具类型,从大型综合代码库到小型利基脚本。请注意,这些工具的分享不代表任何背书,也不提供任何形式的保证。在安装和使用任何软件之前,请自行进行调查!
????️ 机器人写作室
该存储库演示了如何与人类协作使用 AI 来集思广益和完善故事创意。AI 不是取代人类,而是作为创意伙伴,提出想法并进行研究。在每一步,人类可以接受、拒绝或修改 AI 的建议。写作中的主要挑战之一是构思创意。该项目旨在通过提供一个创意伙伴来帮助作家克服创作瓶颈。
????️ 格但斯克 AI
格但斯克 AI 是一个全栈 AI 语音聊天机器人(语音转文本、LLM、文本转语音),集成了 Auth0、OpenAI、Google Cloud API 和 Stripe - Web 应用、API 和 AI
研究亮点
"研究亮点"部分突出了人工智能领域的重要研究。该部分包括突破性的研究、探索新理论以及讨论该领域的潜在影响和未来方向。
???? ToolLLM: 使大语言模型掌握 16000+ 真实世界 API
论文介绍了 ToolLLM,一个用于增强开源大语言模型工具使用能力的框架。它构建了一个名为 ToolBench 的数据集,包含 49 个类别中涉及 16,000 个真实世界 API 的指令。ToolBench 是通过 ChatGPT 自动生成的,几乎不需要人工干预。为了提升推理能力,作者提出了一种深度优先搜索决策树方法,使模型能够评估多个推理轨迹。他们还开发了一个自动评估器 ToolEval,以高效评估工具使用能力。通过在 ToolBench 上微调 LLaMA,他们获得了 ToolLLaMA,该模型在 ToolEval 上表现出色,包括对未见过的 API 具有良好的泛化能力。总体而言,ToolLLM 提供了一种解锁开源 LLM 中复杂工具使用的方法。
本文介绍了 MetaGPT,一个旨在改善大语言模型在复杂任务中的协作的框架。它将现实世界的标准化操作程序融入提示中,以指导多代理协调。像 ProductManager 和 Architect 这样的角色会生成符合行业惯例的结构化输出。共享的环境和记忆能够促进知识共享。在软件任务中,MetaGPT 生成了比 AutoGPT 和 AgentVerse 更多的代码和文档,并且成功率更高,显示了它在跨专业代理之间分解问题的能力。标准化的工作流程和输出旨在减少对话中的不连贯性。总体而言,MetaGPT 展示了一种将人类专业知识捕捉到代理中以解决复杂现实问题的方法。
更多相关内容
本周人工智能动态,8 月 18 日:OpenAI 财务困境 • Stability AI 宣布 StableCode

图片由编辑使用 Midjourney 创建
欢迎来到本周的“本周人工智能动态”版块,这里是 KDnuggets 的每周精选帖子,旨在让你了解人工智能快速发展的世界中的最引人注目的进展。从塑造我们对 AI 在社会中角色理解的突破性头条到引发思考的文章、富有洞察力的学习资源和推动我们知识边界的研究,这篇帖子提供了 AI 当前格局的全面概述。本周更新旨在让你在这一不断发展的领域中保持更新和知情。敬请关注,阅读愉快!
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
头条新闻
“头条新闻”部分讨论了过去一周在人工智能领域的顶级新闻和发展信息。信息涵盖了政府 AI 政策、技术进步和企业 AI 创新。
???? ChatGPT 陷入困境:OpenAI 可能在 2024 年破产,AI 机器人每天给公司带来 70 万美元成本
OpenAI 因运行 ChatGPT 和其他 AI 服务的高成本而面临财务困境。尽管早期增长迅猛,但 ChatGPT 的用户基础在最近几个月有所下降。OpenAI 正努力有效地变现其技术并产生可持续收入。同时,其现金消耗速度惊人。随着竞争加剧和企业 GPU 短缺阻碍模型开发,OpenAI 需要紧急寻找盈利路径。如果未能实现,破产可能在这家开创性 AI 初创企业的视野之内。
???? Stability AI 宣布 StableCode,一款为开发者提供的 AI 编码助手
Stability AI 发布了其首个专为软件开发优化的生成 AI 产品 StableCode。StableCode 集成了多个在超过 5000 亿个代码标记上训练的模型,提供智能自动补全、响应自然语言指令,并管理长跨度的代码。尽管对话式 AI 已经可以编写代码,StableCode 的设计目的是通过理解代码结构和依赖关系来提高程序员的生产力。凭借其专门的训练和能够处理长上下文的模型,StableCode 旨在提升开发者工作流程,并降低新手编码者的入门门槛。此次发布标志着 Stability AI 在 AI 辅助编码工具领域的首次尝试,面对日益激烈的竞争。
OpenAI 正在通过其新成立的 Superalignment 团队积极应对超级智能 AI 可能带来的风险,该团队使用诸如从人类反馈中进行强化学习等技术来对齐 AI 系统。主要目标包括开发可扩展的训练方法,利用其他 AI 系统进行验证模型的鲁棒性,并对即使是故意失调的模型也进行全面的对齐管道压力测试。总体而言,OpenAI 旨在通过开创负责任地引导超级智能的方法来证明机器学习可以安全进行。
Google 宣布对其搜索引擎生成 (SGE) AI 能力进行多项更新,包括为科学/历史主题提供悬停定义、代码概述的彩色语法高亮显示,以及一项名为“浏览时 SGE”的早期实验,该实验在用户阅读网页上的长篇内容时总结关键点并帮助探索页面。这些更新旨在增强对复杂主题的理解,提高对编码信息的消化能力,并在用户浏览时帮助导航和学习。这些更新代表了 Google 基于用户反馈不断发展其 AI 搜索体验的努力,重点是理解和提取复杂网页内容中的关键细节。
Together.ai 将 Llama2 扩展到 32k 上下文窗口
LLaMA-2-7B-32K 是由 Together Computer 开发的开源长上下文语言模型,它将 Meta 的 LLaMA-2 的上下文长度扩展到 32K 令牌。它利用了像 FlashAttention-2 这样的优化技术,实现了更高效的推理和训练。该模型使用包括书籍、论文和教学数据在内的数据混合进行了预训练。示例提供了对长篇 QA 和总结任务的微调。用户可以通过 Hugging Face 访问该模型,或使用 OpenChatKit 进行自定义微调。像所有语言模型一样,LLaMA-2-7B-32K 可能生成有偏见或不正确的内容,因此使用时需要小心。
文章
“文章”部分展示了一系列引人深思的人工智能相关文章。每篇文章深入探讨了特定主题,为读者提供了对 AI 各个方面的见解,包括新技术、革命性方法和突破性工具。
???? LangChain 速查表
使用 LangChain,开发者可以构建强大的 AI 语言应用程序,而无需重新发明轮子。其可组合的结构使得轻松混合和匹配 LLM、提示模板、外部工具和记忆等组件。这加快了原型设计,并允许随着时间的推移无缝集成新功能。无论你是想创建聊天机器人、QA 机器人还是多步骤推理代理,LangChain 都提供了快速组装高级 AI 的构建模块。
???? 如何使用 ChatGPT 将文本转换为 PowerPoint 演示文稿
该文章概述了一个两步流程,用于使用 ChatGPT 将文本转换为 PowerPoint 演示文稿,首先将文本总结成幻灯片标题和内容,然后生成 Python 代码,将总结转换为 PPTX 格式,使用 python-pptx 库。这允许快速创建引人入胜的演示文稿,从长篇文本中避免繁琐的手动工作。文章提供了有关如何编写 ChatGPT 提示和运行代码的清晰说明,提供了一种高效的自动化演示解决方案。
???? LLM 研究中的开放挑战
这篇文章概述了改进大型语言模型的 10 个关键研究方向:减少幻觉、优化上下文长度/构建、融入多模态数据、加速模型、设计新架构、开发像光子芯片这样的 GPU 替代品、构建可用的代理、改进从人类反馈中学习、增强聊天界面,以及扩展到非英语语言。它引用了这些领域的相关论文,指出了诸如为强化学习表示人类偏好和为低资源语言构建模型等挑战。作者总结说,虽然像多语言能力这样的某些问题更易于解决,但像架构这样的其他问题则需要更多突破。总体而言,研究人员、公司和社区中的技术和非技术专长将对推动 LLMs 的积极发展至关重要。
???? 为什么你(可能)不需要微调 LLM
这篇文章概述了改进大型语言模型的 10 个关键研究方向:减少幻觉、优化上下文长度/构建、融入多模态数据、加速模型、设计新架构、开发像光子芯片这样的 GPU 替代品、构建可用的代理、改进从人类反馈中学习、增强聊天界面,以及扩展到非英语语言。它引用了这些领域的相关论文,指出了诸如为强化学习表示人类偏好和为低资源语言构建模型等挑战。作者总结说,虽然像多语言能力这样的某些问题更易于解决,但像架构这样的其他问题则需要更多突破。总体而言,研究人员、公司和社区中的技术和非技术专长将对推动 LLMs 的积极发展至关重要。
这篇文章概述了使用 OpenAI 的 GPT 模型时获得高质量输出的最佳实践,借鉴了社区经验。建议提供详细的提示,包括长度和角色等细节;多步骤的指示;要模仿的示例;参考文献和引文;用于关键思考的时间;以及执行代码以提高精确度。按照这些关于如何指导模型的建议,比如明确步骤和角色,可以得到更准确、相关且可定制的结果。该指导旨在帮助用户有效地构建提示,以充分发挥 OpenAI 强大的生成能力。
???? 我们对人工智能的看法都错了
作者认为当前的 AI 能力被低估了,使用创造力、搜索和个性化等例子来反驳常见误解。他指出,AI 可以通过重新组合概念展现创造力,而不仅仅是生成随机想法;它不仅是一个超级搜索引擎像 Google;它可以发展个性化关系,而不仅仅是通用技能。尽管不确定哪些应用最有用,作者呼吁保持开放的心态而非轻视,强调最好的方式是通过持续的实践探索来确定 AI 的潜力。他总结道,我们对 AI 的想象力有限,它的用途可能远远超出当前预测。
工具
“工具”部分列出了社区创建的实用应用程序和脚本,供那些希望忙于实际 AI 应用的用户使用。在这里,你会找到各种类型的工具,从大型综合代码库到小型利基脚本。请注意,工具的分享并不代表推荐,也没有任何形式的保证。在安装和使用任何软件之前,请自行调查!
????️ MetaGPT:多代理框架
MetaGPT 接受一行需求作为输入,并输出用户故事/竞争分析/需求/数据结构/API/文档等。内部,MetaGPT 包括产品经理/架构师/项目经理/工程师。它提供了一个软件公司完整的过程以及精心编排的标准操作程序。
????️ GPT LLM Trainer
该项目的目标是探索一种实验性的新管道,用于训练高性能的任务特定模型。我们尝试抽象出所有复杂性,使从构想到高效的完全训练模型的过程尽可能简单。
只需输入任务描述,系统将从零开始生成数据集,将其解析为正确的格式,并为你微调 LLaMA 2 模型。
????️ DoctorGPT
DoctorGPT 是一个能够通过美国医学执照考试的大型语言模型。这是一个开源项目,旨在为每个人提供自己的私人医生。DoctorGPT 是 Meta 的 Llama2 70 亿参数大型语言模型的一个版本,经过医学对话数据集的微调,随后使用强化学习和宪法 AI 进一步改进。由于模型只有 3GB 大小,因此可以在任何本地设备上运行,无需支付 API 使用费。
更多相关话题
Gartner 数据科学平台 – 更深层的分析
原文:
www.kdnuggets.com/2017/03/thomaswdinsmore-gartner-data-science-platforms.html
评论
由 Thomas Dinsmore 提供,分析与机器学习顾问。

Gartner 最近发布了 2017 年数据科学平台的魔力象限。如果你是客户,可以直接从 Gartner 获取一份,或者你可以从 这里 免费获得一份,由 SAS 提供。
下图展示了 2016 年和 2017 年的 MQ,并用红色标记了变化。
这里是我去年写的关于 2016 年 MQ 的评论。
这里是 Gregory Piatetsky 的分析。
这里有关于 2017 年版本的 9 个观察点:
(1) 五个供应商被淘汰。
Gartner 对五个较弱的玩家下手了。
— Accenture 去年进入了分析榜单,根据 Gartner 的说法,因为它收购了总部位于米兰的 i4C Analytics,这是一家小型米兰公司。Accenture 重新品牌化 了该软件为 Accenture Analytics Applications Platform。然而,Accenture 似乎将软件与捆绑咨询服务一起免费提供,因为它报告称没有来自软件许可的收入。
— Lavastorm 是一个 ETL 和数据混合工具,不声明提供原生预测分析,因此它在去年的 MQ 中的存在一直是个谜。
— Megaputer 是一家文本挖掘供应商,尽管其边缘化程度很高,甚至在 Crunchbase 上没有记录,但它连续两年进入了 MQ。去年,Gartner 指出“Megaputer 在可行性和知名度方面得分较低,并且在高级分析市场中,除了文本分析外对公司的认知不足。”这就引出了一个问题:它们为什么会被最初包括在内?
— Prognoz 连续两年出现在 MQ 中,和 Megaputer 一样,引发了业内人士的 WTF 反应。Prognoz 主要是一个 BI 工具,包含一些时间序列和分析功能,但缺乏 Gartner 认为最低要求的预测分析能力。它似乎也在莫斯科以西缺乏客户。
— Predixion Software 被 Greenwave Systems 收购,这似乎是一场清仓甩卖。因此,我们将不再看到 Predixion 的身影。
(2) 五家新供应商加入了。
三个真正的数据科学平台作为先驱者进入了今年的 MQ。
— Dataiku 今年早些时候将总部迁至纽约,因此竞争对手不再能将其轻描淡写为“那家法国公司”。该公司市场 Data Science Studio,这是一种拖放接口,运行在开源平台之上,并具有大量数据库连接器。
— Domino Data Lab 是一个具有协作和可重复性功能的数据科学平台。最初作为基于云的托管服务进行市场推广,Domino 现在提供其平台的本地实施。
— H2O.ai 开发并支持 H2O,一个可扩展的机器学习包。H2O.ai 采用纯开放源代码模型,这使其在今年的 MQ 供应商中独具特色。
Mathworks 的加入令人欣喜。根据 IDC,它在高级和预测分析领域是排名第三的供应商,占据了 10% 的市场份额,并且多年来保持该位置。因此,它从之前的 MQ 中被排除是一个谜。究竟怎么会漏掉一家类别收入达 2.5 亿的供应商呢?只是问问。
Teradata 首次作为小众供应商亮相,从而证明了一个谚语:进入 Gartner MQ 最糟糕的事情就是作为小众供应商进入。
(3) 六家供应商的评级发生了显著变化。
六个回归的供应商在 Gartner 的评估中在一个或两个维度上明显下降。
— Alpine 继续在图表底部徘徊。Alpine 与 Greenplum 和 EMC 的紧密联系曾是其一个优点,如今却成了缺陷。
由于规模较小,Alpine 正在努力获得显著的市场曝光,这也是其执行能力评分下降的原因。调查的供应商中,Alpine 提交的参考客户最少,其中 20% 表达了对用户社区规模小的担忧,他们认为这影响了网络交流和知识分享。
最近,我要求一位 Alpine 高管披露公司的当前客户数量;他拒绝了。自从 Alpine 吹嘘 2015 年有 60 个客户以来,我怀疑这一比较并不乐观。
— Alteryx 和 KNIME 在“愿景完整性”上的评分显著较低,原因是可视化工具有限以及一些可扩展性问题。这些产品属性每年没有变化;这意味着 Gartner 在今年的 MQ 中对此给予了更多重视。
FICO 在关键能力、开源工具支持、算法选择和创新方面表现不佳。这让人不禁怀疑为什么还会有人购买这款软件,或者为什么 FICO 仍然在 MQ 中。
Quest (Statistica) 下降的原因在于其难以学习和使用,存在性能和稳定性问题,缺乏关键特性,没有弹性云功能,并且在 Spark 集成方面滞后。除此之外,它仍然是一个优秀的产品。
RapidMiner 在“交付能力”上的评分有所提升,但其在“愿景完整性”上的评分无明显原因地下降了。
(4) Hadoop 和 Spark 的集成是基本要求。
在市场概述部分,Gartner 写道:
在这个魔力象限中的所有供应商——实际上,包括整个市场——都已转向将数据纳入开源 Hadoop 生态系统,现在被视为一流。这样,它与主要用于传统数据仓库的专有存储在地位上相等。
当然,虽然所有供应商都可以使用 Hadoop 作为数据源,但并非所有供应商都能利用 Hadoop 作为计算平台。此外,供应商在与 Hadoop 的集成程度上差异很大。
Spark 正在成为这个魔力象限中的供应商以及这个市场中其他参与者的事实上的数据科学基础。
Nick Heudecker,请联系你的办公室。
2016 年 MQ 中的七个供应商没有明显的 Spark 故事。其中五个已经退出 MQ。请允许我绕场胜利一圈。
(5) Gartner 的标准奇怪地“灵活”。
三个例子:
示例 1:你可以在Enterprise Miner中运行现有的 Python 脚本,也可以在Alteryx中运行现有的 Python 脚本。然而,两个应用程序都没有提供创作工具。这通常不是问题,因为希望运行 Python 脚本的人通常已经有了首选的 IDE。然而,Gartner 特别指出 Alteryx,而非 SAS,存在“缺乏 Python 集成”的问题。
示例 2:Microsoft Azure Machine Learning 仅在 Microsoft Azure 云中运行。IBM Data Science Experience (DSx) 仅在 IBM Cloud 中运行。Gartner 批评 Azure Machine Learning 缺乏本地部署能力,同时称赞 DSx 为“最具吸引力的平台之一”。
示例 3:Statistica 无法将模型训练推送到 Spark 中;SAS Enterprise Miner 也不能。Gartner 特别指出 Statistica 在 Spark 能力上“落后”。
(6) 数据科学家不使用 Gartner 的顶级“数据科学”平台。
如果你想基于数据科学家实际使用的工具创建一个魔力象限,你可能会产生类似的结果:
仅有 5% 的 O’Reilly 调查的数据科学家使用任何 SAS 软件,而 0% 使用任何 IBM 分析软件。在稍微广泛的 KDnuggets 调查 中,6% 使用 SAS Enterprise Miner,8% 说他们使用 IBM SPSS Modeler。
高德纳对“公民数据科学家”的痴迷使其批评 Domino 和 H2O,因为它们“难以使用”:
Domino 的代码基础方法要求用户具备显著的技术知识。
没有编程技能的潜在用户可能会发现学习 H2O 产品栈很困难。
想象一下!如果你想使用数据科学平台,你需要知道如何进行数据科学。
(7) 高德纳对开源软件一无所知。
数据科学家使用开源软件。高德纳似乎明白这一点:
开源语言 — Python、R 和 Scala — 主导了这个市场。几乎所有的数据科学平台供应商都支持 Python 和 R,许多这个魔力象限中的供应商也支持 Scala。
但是:
高德纳的研究方法阻止了对纯开源平台(如 Python 和 R)的评估,因为它们背后没有提供可商业授权产品的供应商。
这在两个层面上都是错误的。
首先,这不是真的。Continuum Analytics 分发并支持 Anaconda,这是数据科学中最广泛使用的 Python 发行版。微软和甲骨文分发并支持 R,并且有丰富的社区和供应商支持资源。多个供应商支持 Apache Spark。
其次,虽然可以争论商业支持是数据科学平台的重要属性,但不能声称这是唯一重要的属性。许多数据科学家在没有供应商支持的情况下也能很好地运作。而且一些高德纳评为“领导者”的供应商提供的支持质量较低,因此在评级中似乎不具太大分量。
(8) 对 SAS 和 IBM 的评估具有误导性。
高德纳表示,它评估了 SAS 的 SAS Enterprise Miner 和 SAS 可视分析套件。高德纳未提及的是,仅靠这些产品的功能评估,SAS 不可能获得高分。SAS 的评分依赖于许多其他 SAS 软件产品,包括:
-
SAS/ACCESS
-
SAS 快速预测建模器
-
SAS 工厂管理器
-
SAS 高性能分析
-
SAS 模型管理器
-
SAS 评分加速器
可视分析套件运行在 SAS 自有的 LASR 服务器内存数据存储上;要将数据转入该格式,客户还需要 SAS 数据加载器或 SAS ETL 服务器。
客户必须单独从 SAS 处许可所有这些产品;这样做将使成本增加三倍以上,并显著增加架构的复杂性。实际上,只有少数 SAS 客户这样做;大约 15%的 SAS 客户许可了 SAS Enterprise Miner,而这些客户中的一小部分则许可了 Gartner 评估中反映的所有软件。
绝大多数 SAS 客户使用其遗留软件,该软件的代码基于 1990 年代中期。因此,Gartner 对 SAS 的评估假设了一个几乎无人使用的软件配置。
IBM 的情况也是如此。Gartner 基于 SPSS Modeler 的优势以及在较小程度上基于 SPSS Statistics,给予 IBM 领导者的评价。然而,Gartner 的评估再次依赖于其他 IBM 产品。例如,Gartner 称赞 IBM 的模型管理能力:
调查显示,IBM 客户对 SPSS 的模型管理给予了高度评价,称赞其模型种类的广泛、工作流程的准确性和透明性、模型部署、性能下降的监控以及自动调优功能。SPSS 提供了出色的分析治理功能:版本控制、元数据和审计能力。
这很好。只是这些功能在 SPSS Modeler 中不可用。要获得这些功能,客户必须许可IBM SPSS Collaboration and Deployment Services这一附加产品。类似地,Gartner 赞扬了 IBM 与 Hadoop 的集成。这是一个有价值的功能,但需要另一个产品,IBM SPSS Analytics Server。
简而言之,由于未披露客户必须许可哪些产品才能实现所述功能,Gartner 对大多数客户实际许可的软件产生了虚假的印象。
就像仅仅根据总统套房的检查来评价一家酒店,或通过试驾一辆凯迪拉克来评估一辆雪佛兰。
(9) Gartner 对 IBM 有很高的评价。
这个瑰宝隐藏在报告的深处:
客户经常被(IBM 的)营销信息与实际可购产品之间的不匹配所困扰。
换句话说,IBM 是一个巨大的炒作机器。Gartner 对 IBM 的新数据科学体验(DSx)深信不疑:
DSx 可能成为未来最具吸引力的平台之一——现代、开放、灵活,适合从专家数据科学家到业务人员的各种用户。
请记住,DSx 是 IBM Cloud 上的 Spark 和 R 的托管服务。它包括 Jupyter 和 RStudio IDE。这就是全部——一个简单的托管服务,功能不如 Altiscale、Databricks、Domino、Microsoft Azure 或 Qubole 提供的托管服务。
而且,由于它在 IBM Cloud 上运行,你的组织数据有大约 5% 的机会已经存在于其中。
但 Gartner 认为它会解决全球饥饿问题。
IBM 在这一领域的大多数客户使用的是传统产品,关于这些产品,Gartner 说了以下内容:
对许多新用户而言,IBM SPSS Modeler 和 Statistics 似乎过时且价格过高。
IBM 可能价格昂贵,但你会得到一流的技术支持,对吧?
参考客户对 IBM 的支持和官僚主义表示不满;他们报告称,尽管维护费用很高,但在寻找合适的联络人和技术帮助时遇到了困难。
好吧,软件过时且价格过高,支持也很糟糕。但你仍然可以从 IBM 客户执行官那里获得“白手套”服务,对吧?
客户对购买 IBM 产品表示担忧,因为公司 reportedly 经常试图将其咨询组织 IBM Global Business Services 纳入数据科学项目中。
除此之外,IBM 是一个领导者。
原文。经许可转载
简介:Thomas W. Dinsmore 是一位顾问,为企业和投资者提供机器学习市场洞察。他曾担任波士顿咨询集团的分析专家;Revolution Analytics(微软)的产品管理总监;IBM 大数据(Netezza)、SAS 和 PriceWaterhouseCoopers 的解决方案架构师。
相关:
-
Gartner 2017 数据科学平台魔力象限:赢家和输家
-
Gartner 2016 高级分析平台魔力象限:赢家和输家
-
Gartner 2015 高级分析平台魔力象限:谁赢了,谁输了。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关信息
思维传播:大型语言模型的类比推理方法

关键要点
-
思维传播(TP)是一种新颖的方法,可以提升大型语言模型(LLMs)的复杂推理能力。
-
TP 利用类比问题及其解决方案来改善推理,而不是让 LLMs 从零开始推理。
-
各种任务的实验表明,TP 在性能上显著优于基线方法,改进范围从 12% 到 15%。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
TP 首先促使 LLMs 提出并解决一组与输入问题相关的类比问题。然后,TP 重用类比问题的结果,以直接得出新的解决方案或推导出知识密集型执行计划来修正从零开始获得的初始解决方案。
介绍
大型语言模型(LLMs)的多样性和计算能力无可否认,但它们并非没有限制。LLMs 面临的最显著且持续的挑战之一是它们的通用问题解决方法,即每遇到一个新任务时都从第一原则推理。这是有问题的,因为它允许高度的适应性,但也增加了出错的可能性,特别是在需要多步骤推理的任务中。
“从头推理”的挑战在于那些需要多步骤逻辑和推理的复杂任务。例如,如果要求 LLM 在一个互联点的网络中找到最短路径,它通常不会利用先前的知识或类比问题来寻找解决方案。相反,它会尝试孤立地解决问题,这可能导致次优结果甚至明显错误。进入思想传播(TP),这是一种旨在增强 LLM 推理能力的方法。TP 旨在通过允许 LLM 从类比问题及其相应解决方案的储备中汲取经验,克服 LLM 固有的局限性。这种创新的方法不仅提高了 LLM 生成解决方案的准确性,还显著增强了其处理多步骤复杂推理任务的能力。通过利用类比的力量,TP 提供了一个框架,放大了 LLM 的固有推理能力,使我们更接近实现真正智能的人工系统。
理解思想传播
思想传播包括两个主要步骤:
-
首先,LLM 被提示提出并解决一组与输入问题相关的类比问题
-
接下来,这些类比问题的解决方案被用来直接产生新的解决方案或修正初步解决方案
识别类比问题的过程使得 LLM 能够重复使用问题解决策略和解决方案,从而提升其推理能力。TP 与现有的提示方法兼容,提供了一个可泛化的解决方案,可以被纳入各种任务中,而无需进行显著的任务特定工程。
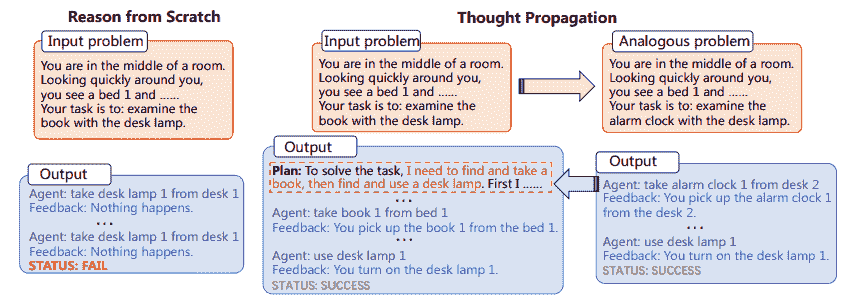
图 1:思想传播过程(图片来自论文)
此外,TP 的适应性不应被低估。它与现有提示方法的兼容性使其成为一个高度通用的工具。这意味着 TP 不限于任何特定类型的问题解决领域。这为任务特定的微调和优化打开了激动人心的途径,从而提升了 LLM 在广泛应用中的实用性和有效性。
实施思想传播
思想传播的实施可以集成到现有 LLM 的工作流程中。例如,在最短路径推理任务中,TP 可以首先解决一组更简单的类比问题,以了解各种可能的路径。然后,它会利用这些见解来解决复杂问题,从而增加找到最佳解决方案的可能性。
示例 1
-
任务:最短路径推理
-
类比问题:点 A 和 B 之间的最短路径,点 B 和 C 之间的最短路径
-
最终解决方案:考虑到类比问题的解决方案,从点 A 到 C 的最佳路径
示例 2
-
任务:创造性写作
-
类似问题:写一个关于友谊的短篇故事,写一个关于信任的短篇故事
-
最终解决方案:写一个融合友谊和信任主题的复杂短篇故事
该过程首先涉及解决这些类似问题,然后利用获得的见解来处理复杂任务。这种方法在多个任务中证明了其有效性,展示了性能指标的显著改进。
思维传播的影响超出了仅仅改善现有指标的范畴。这种提示技术有可能改变我们理解和应用大语言模型的方式。该方法强调从孤立的、原子化的问题解决转向更整体、相互关联的方法。它促使我们考虑大语言模型如何不仅从数据中学习,还从问题解决的过程本身中学习。通过不断更新对类似问题的解决方案的理解,配备思维传播的大语言模型更好地准备应对不可预见的挑战,使它们在快速变化的环境中更具韧性和适应性。
结论
思维传播是增强大语言模型能力的提示方法工具箱中的一项有前景的补充。通过允许大语言模型利用类似问题及其解决方案,思维传播提供了一种更细致有效的推理方法。实验验证了其有效性,使其成为提高各种任务中大语言模型性能的候选策略。思维传播最终可能代表了在寻求更强大 AI 系统中的一项重要进步。
马修·梅奥 (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为KDnuggets和Statology的管理编辑以及Machine Learning Mastery的贡献编辑,Matthew 旨在使复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、语言模型、机器学习算法以及探索新兴的人工智能。他致力于在数据科学社区中普及知识。Matthew 从 6 岁起就开始编程。
更多相关话题
每个数据科学家都应该了解的三种 R 库(即使你使用 Python)
原文:
www.kdnuggets.com/2021/12/three-r-libraries-every-data-scientist-know-even-python.html
作者 Terence Shin,数据科学家 | 硕士分析与 MBA 学生

图片由 Denis Pavlovic 提供,来自 Unsplash
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
介绍
长时间以来,我对使用 R 持反对态度,仅仅因为它不是 Python。
但在过去几个月玩弄 R 后,我意识到 R 在多个使用案例中优于 Python,特别是在统计分析方面。此外,R 拥有一些由全球最大的科技公司开发的强大包,而这些不在 Python 中!
因此,在这篇文章中,我想探讨三个我强烈****推荐你花时间学习并装备在你的工具库中的 R 包,因为它们确实是非常强大的工具。
不再赘述,这里是每个数据科学家都应该了解的三种 R 包,即使你只使用 Python:
-
因果影响与谷歌
-
Robyn 与 Facebook
-
使用 Twitter 进行异常检测
1. 因果影响(谷歌)
假设你的公司为超级碗推出了一个新的电视广告,并想查看它对转化率的影响。因果影响分析尝试预测如果活动从未发生,会发生什么——这被称为反事实。
图片由作者创建
举个实际的例子,因果影响分析尝试预测反事实,即顶部图表中的蓝色虚线,然后将实际值与反事实进行比较,以估算差异。
因果影响对市场营销活动、扩展到新区域、测试新产品功能等非常有用!
2. Robyn (Facebook)
营销组合建模是一种现代技术,用于估计多个营销渠道或活动对目标变量(如转化率或销售)的影响。
营销组合模型 (MMMs) 非常受欢迎,超过了归因模型,因为它们允许您衡量电视、广告牌和广播等无法直接量化的渠道的影响。
通常,营销组合模型从零开始构建需要几个月的时间。但 Facebook 创建了一个名为 Robyn 的新 R 包,可以在几分钟内创建一个强大的 MMM。
作者创作的图像
使用 Robyn,您不仅可以评估每个营销渠道的效果,还可以优化您的营销预算!
3. 异常检测 (Twitter)
异常检测,也称为离群点分析,是一种识别与其他数据点显著不同的数据点的方法。
一般异常检测的一个子集是时间序列数据中的异常检测,这是一种独特的问题,因为您还需要考虑数据的趋势和季节性。
作者创作的图像
Twitter 通过创建一个异常检测包来解决这个问题,包内的算法能够自动完成所有工作。它是一种复杂的算法,能够识别全球和局部的异常情况。除了时间序列外,它还可以用于检测值向量中的异常。
感谢阅读!
如果您喜欢这篇文章,请务必在这里订阅以及订阅我的独家通讯,以确保不会错过关于数据科学指南、技巧和窍门、生活经验等更多文章!
不确定接下来读什么?我为您挑选了另一篇文章:2021 年十大最佳数据可视化
以及另一篇:2022 年你应该知道的所有机器学习算法
Terence Shin
-
如果您喜欢这篇文章,请订阅我的 Medium以获取独家内容!
-
同样,您还可以在 Medium 上关注我
-
关注我在LinkedIn上的其他内容
个人简介: Terence Shin 是一位数据爱好者,拥有 3 年以上的 SQL 经验和 2 年以上的 Python 经验,同时也是《Towards Data Science》和《KDnuggets》的博客作者。
原文。经授权转载。
更多相关话题
提升机器学习模型在不平衡数据集上的表现的三种技术
comments
由 Sabber Ahamed,计算地球物理学家和机器学习爱好者

这个项目是我最近的一次“机器学习工程师”职位面试技能测试的一部分。我需要在 48 小时内完成这个项目,其中包括用 LaTeX 撰写 10 页报告。数据集具有类别且高度不平衡。这个项目的主要目标是处理数据不平衡问题。在以下小节中,我将描述我用来克服数据不平衡问题的三种技术。
首先,让我们开始熟悉数据集:
数据集: 训练数据中有三个标签 [1, 2, 3],这使得问题成为一个多类别问题。训练数据集有 17 个特征和 38829 个数据点。而在测试数据中,有 16 个特征没有标签,并且有 16641 个数据点。训练数据集非常不平衡。大多数数据属于类别 1(95%),而类别 2 和类别 3 分别有 3.0% 和 0.87% 的数据。由于数据集没有任何空值且已进行缩放,因此我没有进行进一步处理。由于一些内部原因,我不会分享数据集,但会分享详细的结果和技术。以下图展示了数据不平衡情况。
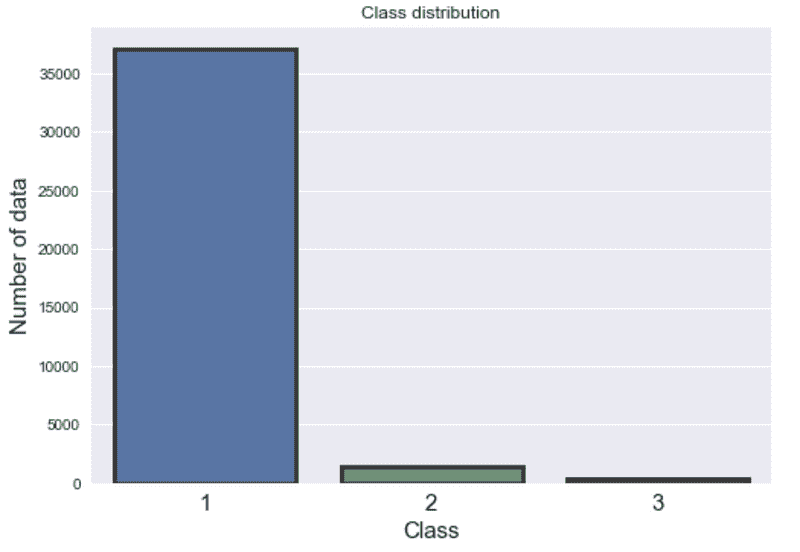
图 1:该图展示了训练数据集中的数据不平衡情况。大多数数据属于类别 1(95%),而类别 2 和类别 3 分别有 3.0% 和 0.87% 的数据。
算法: 在初步观察后,我决定使用随机森林(RF)算法,因为它优于其他算法,如支持向量机、Xgboost、LightGBM 等。RF 是一种集成分类器,它使用多个这样的单棵树来进行预测。选择 RF 的原因有几点:
-
RF 对过拟合具有鲁棒性(因此解决了单棵决策树的一个重大缺点)。
-
参数化保持相当直观和简单。
-
有许多成功的案例表明,随机森林算法在我们这个项目中的高度不平衡数据集上表现良好。
-
我有该算法的先前实现经验。
为了找到最佳参数,我使用 scikit-sklearn 实现的 GridSearchCV 执行了指定参数值的网格搜索。更多详细信息可以在 Github 上找到。
为了解决数据不平衡问题,我使用了以下三种技术:
A. 使用集成交叉验证 (CV): 在这个项目中,我使用交叉验证来验证模型的稳健性。整个数据集被分为五个子集。在每次交叉验证中,5 个子集中有 4 个用于训练,剩下的一个用于验证模型。在每次交叉验证中,模型还会对测试数据进行预测(预测概率,而不是类别)。交叉验证结束时,我们得到了五组测试预测概率。最后,我对所有类别的预测概率取平均。模型的训练性能稳定,并且在每次交叉验证中几乎保持恒定的召回率和 F1 分数。这项技术帮助我在一次 Kaggle 竞赛中很好地预测了测试数据,我在 5355 名参赛者中排名第 25 位,属于前 1%。以下部分代码片段展示了集成交叉验证的实现:
for j, (train_idx, valid_idx) in enumerate(folds):
X_train = X[train_idx]
Y_train = y[train_idx]
X_valid = X[valid_idx]
Y_valid = y[valid_idx]
clf.fit(X_train, Y_train)
valid_pred = clf.predict(X_valid)
recall = recall_score(Y_valid, valid_pred, average='macro')
f1 = f1_score(Y_valid, valid_pred, average='macro')
recall_scores[i][j] = recall
f1_scores[i][j] = f1
train_pred[valid_idx, i] = valid_pred
test_pred[:, test_col] = clf.predict(T)
test_col += 1
## Probabilities
valid_proba = clf.predict_proba(X_valid)
train_proba[valid_idx, :] = valid_proba
test_proba += clf.predict_proba(T)
test_proba /= self.n_splits
B. 设置类别权重/重要性: 成本敏感学习是使随机森林更适合从高度不平衡数据中学习的众多方法之一。随机森林倾向于对多数类别有偏见。因此,对少数类别误分类施加高额惩罚可能会有帮助。由于这项技术已被证明能提高模型性能,我为少数类别分配了较高的权重(即,较高的误分类成本)。然后,将类别权重纳入随机森林算法中。我根据类别 1 和类别中的数据集数量之比来确定类别权重。例如,类别 1 和类别 3 的数据集数量之比约为 110,类别 1 和类别 2 的比率约为 26。之后,我稍微调整了这些数值,以在试验和错误的基础上提高模型性能。以下代码片段展示了不同类别权重的实现。
from sklearn.ensemble import RandomForestClassifier
class_weight = dict({1:1.9, 2:35, 3:180})
rdf = RandomForestClassifier(bootstrap=True,
class_weight=class_weight,
criterion='gini',
max_depth=8, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=4, min_samples_split=10,
min_weight_fraction_leaf=0.0, n_estimators=300,
oob_score=False,
random_state=random_state,
verbose=0, warm_start=False)
C. 过度预测标签而非欠预测: 这是一种可选的技术。我应用了这种技术,因为我被要求实现。对我来说,这种方法在提高少数类别的性能方面非常有效。简而言之,该技术是对模型的误分类类别 3 给予最大惩罚,对类别 2 给予较少的惩罚,对类别 1 给予最少的惩罚。
为了实现该方法,我为每个类别调整了概率阈值。为此,我按照递增顺序设置了类别 3、类别 2 和类别 1 的概率(即,类别 3 = 0.25,类别 2 = 0.35,类别 1 = 0.50),以迫使模型过度预测类别。该算法的详细实现可以在本项目的Github 页面找到。
最终结果:
以下结果展示了上述三种技术如何帮助提高模型性能。
1. 使用集成交叉验证的结果:
2. 使用集成交叉验证 + 类别权重的结果:
3. 使用集成交叉验证 + 类别权重 + 过度预测标签的结果:
结论
由于我在实施该技术方面的经验有限,最初过度预测对我来说似乎很棘手。然而,研究该方法帮助我找到了解决问题的方法。由于时间有限,我无法专注于模型的微调和特征工程。还有许多改进模型的空间。例如,删除不必要的特征和通过特征工程添加一些额外特征。我还尝试了 LightGBM 和 XgBoost。但在这段时间里,我发现随机森林的表现优于其他算法。我们可能会尝试包括神经网络在内的其他算法来改进模型。最后,我要说的是,从这次数据挑战中,我学会了如何以良好的组织方式处理不平衡数据。
非常感谢您的阅读。完整代码可以在 Github 上找到。如果您有任何问题或这篇文章需要更正,请告诉我。
简介: Sabber Ahamed 是 xoolooloo.com 的创始人。计算地球物理学家和机器学习爱好者。
原文。已获得许可转载。
相关:
-
处理不平衡数据的 7 种技术
-
从不平衡类别中学习
-
处理不平衡类别、支持向量机、随机森林和决策树的 Python 实现
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
相关主题
滴答声:在 Python 中使用 Pendulum 轻松管理日期和时间
原文:
www.kdnuggets.com/tick-tock-using-pendulum-for-easy-date-and-time-management-in-python

图片由作者提供 | DALLE-3 和 Canva
现在,很多应用程序都是时间敏感的,因此需要有效的日期和时间管理。Python 提供了许多处理此任务的库,而 Pendulum 是其中最有效的一个。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
Pendulum 继承了其父DateTime库,并提供了更直观的接口。该库提供了简单的 API、自动时区处理以及更高级的功能,如本地化、易读的差异、时间段和持续时间,这些在原生DateTime库中并不容易获得。它还提高了时区管理和日期操作的有效性和便捷性。你是否迫不及待地想了解 Pendulum 了?让我们开始吧。
开始使用 Pendulum
第一步是安装 Pendulum。打开你的终端并运行以下命令:
pip install pendulum
接下来,导入库以使用它:
import pendulum
接下来,让我们讨论 Pendulum 提供的一些最有用的功能。
实例化
使用 Pendulum 创建DateTime对象非常简单。你可以使用pendulum.datetime()函数来创建你所需的对象。以下是一个简单的示例:
# Create a DateTime object
dt = pendulum.datetime(year=2024, month=7, day=9, hour=12, minute=34, second=56)
print(dt)
输出:
2024-07-09 12:34:56+00:00
你还可以使用now()获取你所在地区的当前 DateTime:
# Get current date and time
now = pendulum.now()
print(now)
输出:
2024-07-17 20:07:20.149776+00:00
辅助方法
辅助方法(set()、on()和at())允许你修改现有DateTime对象的属性。它们会创建一个具有指定属性更改的新对象,而不是修改原始对象。一个快速示例可以帮助我们理解这个概念。从创建一个DateTime对象开始:
dt = pendulum.now()
print(dt)
**# Output => 2024-07-17 20:07:20.149776+00:00**
现在,让我们使用set()方法,它允许你同时修改日期和时间:
change_dt= dt.set(year=2001, month=4, hour=6, minute=7)
print(change_dt)
**# Output => 2001-04-17 06:07:20.149776+00:00**
另外,你可以使用on()来更改DateTime对象的日期,使用at()来更改时间。方法on()有三个必需的参数,即“年”、“月”和“日”,而方法at()只有一个必需的位置参数,即“小时”。
这是一个快速示例,以帮助你理解这个概念:
# Using on to change the date
change_date= dt.on(year=2021,month=3,day=5)
print("Changed date:",change_date)
# Using at to change the time
change_time= dt.at(hour=5,second=50)
print("Changed time:",change_time)
输出:
Changed date: 2021-03-05 20:07:20.149776+00:00
Changed time: 2024-07-17 05:00:50+00:00
日期时间格式化
无论您需要日期、时间还是自定义格式,Pendulum 都提供了许多方法来根据任务需求格式化日期和时间。让我们通过一个示例来理解这些不同类型的格式化:
dt = pendulum.now()
print("Date and Time without Formatting:", dt)
# Formatting only the date
formatted_date = dt.to_date_string()
print("Formatted Date:", formatted_date)
# Formatting only the time
formatted_time = dt.to_time_string()
print("Formatted Time:", formatted_time)
# Custom formatting
custom_format = dt.format('dddd, MMMM Do, YYYY, h:mm:ss A')
print("Custom Formatted DateTime:", custom_format)
输出:
Date and Time without Formatting: 2024-07-17 20:14:58.721312+00:00
Formatted Date: 2024-07-17
Formatted Time: 20:14:58
Custom Formatted DateTime: Wednesday, July 17th, 2024, 8:14:58 PM
用于格式化的函数解释如下:
-
to_date_string(): 以 YYYY-MM-DD 格式格式化日期
-
to_time_string(): 以 24 小时格式格式化时间,例如“HH: MM: SS”格式
-
format('dddd, MMMM Do YYYY, h: mm: ss A'): 按如下方式格式化 DateTime 对象的自定义规格:
-
dddd:星期几的全名,例如我们示例中的星期二
-
MMMM:月份的全名,例如我们示例中的七月
-
Do:带序数后缀的月份中的日期,例如我们示例中的第 16 日
-
YYYY:年份,例如我们示例中的 2024
-
h: mm: ss A:12 小时制格式,带 AM/PM,例如我们示例中的 7:13:23 PM
-
本地化
本地化涉及按照特定地区和文化惯例表示日期和时间。这可以通过format方法的locale关键字或set_locale()方法轻松完成。让我们来探索这两种方法:
dt = pendulum.now()
# Format to French
dt_french = dt.format('dddd, MMMM Do YYYY, h:mm:ss A',locale='fr')
print('French DateTime:',dt_french)
# Format to Dutch
pendulum.set_locale('nl')
dt_dutch =dt.format('dddd, MMMM Do YYYY, h:mm:ss A')
print('Dutch DateTime:',dt_dutch)
输出:
French DateTime: mercredi, juillet 17e 2024, 8:17:02 PM
Dutch DateTime: woensdag, juli 17e 2024, 8:17:02 p.m.
转换时区
Pendulum 支持时间区数据库中列出的所有时区。您可以通过一个命令轻松切换不同的时区。考虑将您所在地区的当前日期和时间转换为英国伦敦的日期和时间。可以如下所示:
dt = pendulum.now()
print("Date and Time in my region:", dt)
# Convert the regional time to London's time. Follow the format in_timezone(City/Continent)
london_time = dt.in_timezone('Europe/London')
print("Date and Time in London:", london_time)
输出:
Date and Time in my region: 2024-07-17 20:26:02.525060+00:00
Date and Time in London: 2024-07-17 21:26:02.525060+01:00
加法与减法
该库提供了简单的add()和subtract()方法来计算未来和过去的日期和时间。以下是一个供您参考的示例:
# Add 5 days and 2 hours
dt_future= pendulum.now().add(days=5, hours=2)
print("Adding date and time:",dt_future)
# Subtract 2 weeks and 5 minutes
dt_past = pendulum.now().subtract(weeks=2,minutes=5)
print("Subtracting date and time:",dt_past)
输出:
Adding date and time: 2024-07-22 22:28:01.070802+00:00
Subtracting date and time: 2024-07-03 20:23:01.071146+00:00
类人差异
您可以使用diff_for_humans()函数以人类可读的差异查看加法和减法的输出。让我们通过一个示例来深入了解这个有趣的函数。
# Create a DateTime object
dt=pendulum.now()
# Subtract 2 months
dt_past = dt.subtract(months=2).diff_for_humans()
print(dt_past)
**# Output => 2 months ago**
# Add 5 years
dt_future= dt.add(years=5).diff_for_humans()
print(dt_future)
**# Output => in 5 years**
您可以通过在diff_for_humans()函数中设置absolute = True来移除单词ago和in。默认情况下,它是False。以下是如何操作:
difference_dt=dt.add(days=2).diff_for_humans(absolute=True)
print(difference_dt)
**# Output => 2 days**
总结
总结一下,Pendulum 是一个用于日期和时间管理的有用库。该库对 Python 的原生DateTime库进行了许多改进,并解决了许多复杂性。我认为 Pendulum 最好的特点之一是其灵活性和高效的时区管理。您可以通过访问Pendulum 文档来探索更多功能。
Kanwal Mehreen** Kanwal 是一名机器学习工程师和技术作家,对数据科学以及人工智能与医学的交集充满热情。她共同撰写了电子书《利用 ChatGPT 最大化生产力》。作为 2022 年 APAC 的 Google Generation Scholar,她倡导多样性和学术卓越。她还被认可为 Teradata 多样性科技学者、Mitacs 全球研究学者和哈佛 WeCode 学者。Kanwal 是变革的热忱倡导者,创立了 FEMCodes,以赋能女性进入 STEM 领域。**
更多相关主题
在 Python 中整理数据
由 Jean-Nicholas Hould, JeanNicholasHould.com 提供。
我最近遇到了一篇名为Tidy Data的论文,作者是 Hadley Wickham。该论文发表于 2014 年,重点讲述了数据清理的一个方面——整理数据:结构化数据集以便于分析。通过这篇论文,Wickham 展示了如何在分析之前将任何数据集结构化为标准化的方式。他详细介绍了不同类型的数据集以及如何将它们整理成标准格式。
作为数据科学家,我认为你应该非常熟悉这种数据集的标准化结构。数据清理是数据科学中最常见的任务之一。无论你处理何种数据或进行何种分析,你最终都必须清理数据。将数据整理成标准格式可以简化后续工作。你可以在不同的分析中重用一套标准工具。
在这篇文章中,我将总结一些 Wickham 在论文中使用的整理示例,并演示如何使用 Python 的pandas库进行整理。
定义整洁数据
Wickham 定义的整洁结构具有以下属性:
-
每个变量形成一列,并包含值
-
每个观察形成一行
-
每种观察单元形成一个表格
一些定义:
-
变量:一种测量或属性。身高, 体重, 性别, 等等
-
值:实际的测量或属性。152 cm, 80 kg, female, etc.
-
观察:所有的值都是在相同的单元上测量的。每个人。
一个混乱数据集的例子:
| 处理 A | 处理 B | |
|---|---|---|
| 约翰·史密斯 | - | 2 |
| 简·多 | 16 | 11 |
| 玛丽·约翰逊 | 3 | 1 |
一个整洁数据集的例子:
| 姓名 | 处理 | 结果 |
|---|---|---|
| 约翰·史密斯 | a | - |
| 简·多 | a | 16 |
| 玛丽·约翰逊 | a | 3 |
| 约翰·史密斯 | b | 2 |
| 简·多 | b | 11 |
| 玛丽·约翰逊 | b | 1 |
整理混乱的数据集
通过以下从 Wickham 的论文中提取的示例,我们将把混乱的数据集整理成整洁的格式。这里的目标不是分析数据集,而是将它们以标准化的方式准备好以便进行分析。这是我们将处理的五种类型的混乱数据集:
-
列标题是值,而不是变量名称。
-
多个变量被存储在一列中。
-
变量存储在行和列中。
-
多种类型的观察单元存储在同一个表格中。
-
单一的观察单元被存储在多个表格中。
注意:本文中呈现的所有代码都可以在Github上找到。
列标题是值,而不是变量名称
皮尤研究中心数据集
这个数据集探讨了收入与宗教之间的关系。
问题:列标题由可能的收入值组成。
import pandas as pd
import datetime
from os import listdir
from os.path import isfile, join
import glob
import re
df = pd.read_csv("./data/pew-raw.csv")
df
| 宗教 | <$10k | $10-20k | $20-30k | $30-40k | $40-50k | $50-75k |
|---|---|---|---|---|---|---|
| 无神论者 | 27 | 34 | 60 | 81 | 76 | 137 |
| 无神论者 | 12 | 27 | 37 | 52 | 35 | 70 |
| 佛教徒 | 27 | 21 | 30 | 34 | 33 | 58 |
| 天主教 | 418 | 617 | 732 | 670 | 638 | 1116 |
| 不知道/拒绝 | 15 | 14 | 15 | 11 | 10 | 35 |
| 福音派新教 | 575 | 869 | 1064 | 982 | 881 | 1486 |
| 印度教 | 1 | 9 | 7 | 9 | 11 | 34 |
| 历史性黑人新教 | 228 | 244 | 236 | 238 | 197 | 223 |
| 耶和华见证人 | 20 | 27 | 24 | 24 | 21 | 30 |
| 犹太教 | 19 | 19 | 25 | 25 | 30 | 95 |
数据集的整洁版本是收入值不会成为列标题,而是作为income列中的值。为了整理这个数据集,我们需要转化它。pandas库有一个内置函数可以做到这一点,它将数据框从宽格式“反转”成长格式。我们将在本文中多次重用这个函数。
formatted_df = pd.melt(df,
["religion"],
var_name="income",
value_name="freq")
formatted_df = formatted_df.sort_values(by=["religion"])
formatted_df.head(10)
这将输出数据集的整洁版本:
| 宗教 | 收入 | 频率 |
|---|---|---|
| 无神论者 | <$10k | 27 |
| 无神论者 | $30-40k | 81 |
| 无神论者 | $40-50k | 76 |
| 无神论者 | $50-75k | 137 |
| 无神论者 | $10-20k | 34 |
| 无神论者 | $20-30k | 60 |
| 无神论者 | $40-50k | 35 |
| 无神论者 | $20-30k | 37 |
| 无神论者 | $10-20k | 27 |
| 无神论者 | $30-40k | 52 |
公告牌前 100 名数据集
这个数据集表示从歌曲进入《公告牌》前 100 名时开始到接下来的 75 周的每周排名。
问题:
-
列标题由值组成:周数(
x1st.week,…) -
如果一首歌在前 100 名中停留少于 75 周,剩余的列将填充缺失值。
df = pd.read_csv("./data/billboard.csv", encoding="mac_latin2")
df.head(10)
| 年份 | 艺术家.倒序 | 曲目 | 时长 | 风格 | 进入日期 | 高峰日期 | 第一周 | 第二周 | ... |
|---|---|---|---|---|---|---|---|---|---|
| 2000 | 命运之子 | 独立女性第一部分 | 3:38 | 摇滚 | 2000-09-23 | 2000-11-18 | 78 | 63.0 | ... |
| 2000 | 桑坦娜 | 玛利亚,玛利亚 | 4:18 | 摇滚 | 2000-02-12 | 2000-04-08 | 15 | 8.0 | ... |
| 2000 | 野人花园 | 我知道我爱你 | 4:07 | 摇滚 | 1999-10-23 | 2000-01-29 | 71 | 48.0 | ... |
| 2000 | 麦当娜 | 音乐 | 3:45 | 摇滚 | 2000-08-12 | 2000-09-16 | 41 | 23.0 | ... |
| 2000 | 克里斯蒂娜·阿奎莱拉 | 来吧宝贝(我只要你) | 3:38 | 摇滚 | 2000-08-05 | 2000-10-14 | 57 | 47.0 | ... |
| 2000 | 贾妮特 | 无关紧要 | 4:17 | 摇滚 | 2000-06-17 | 2000-08-26 | 59 | 52.0 | ... |
| 2000 | 命运之子 | 说我的名字 | 4:31 | 摇滚 | 1999-12-25 | 2000-03-18 | 83 | 83.0 | ... |
| 2000 | 恩里克·伊格莱西亚斯 | 和你在一起 | 3:36 | 拉丁 | 2000-04-01 | 2000-06-24 | 63 | 45.0 | ... |
| 2000 | 西斯科 | 不完整 | 3:52 | 摇滚 | 2000-06-24 | 2000-08-12 | 77 | 66.0 | ... |
| 2000 | Lonestar | Amazed | 4:25 | Country | 1999-06-05 | 2000-03-04 | 81 | 54.0 | ... |
这个数据集的整洁版本是没有周数作为列的,而是作为单一列的值。为了做到这一点,我们将把周数列“融化”成一个date列。我们将为每条记录创建一行每周。如果给定周没有数据,我们将不会创建行。
# Melting
id_vars = ["year",
"artist.inverted",
"track",
"time",
"genre",
"date.entered",
"date.peaked"]
df = pd.melt(frame=df,id_vars=id_vars, var_name="week", value_name="rank")
# Formatting
df["week"] = df['week'].str.extract('(\d+)', expand=False).astype(int)
df["rank"] = df["rank"].astype(int)
# Cleaning out unnecessary rows
df = df.dropna()
# Create "date" columns
df['date'] = pd.to_datetime(df['date.entered']) + pd.to_timedelta(df['week'], unit='w') - pd.DateOffset(weeks=1)
df = df[["year",
"artist.inverted",
"track",
"time",
"genre",
"week",
"rank",
"date"]]
df = df.sort_values(ascending=True, by=["year","artist.inverted","track","week","rank"])
# Assigning the tidy dataset to a variable for future usage
billboard = df
df.head(10)
数据集的更整洁版本如下所示。仍然有很多歌曲详细信息的重复:曲目名称、时间和类型。由于这个原因,这个数据集仍然不完全符合 Wickham 的定义。我们将在下一个示例中解决这个问题。
| year | artist.inverted | track | time | genre | week | rank | date |
|---|---|---|---|---|---|---|---|
| 2000 | 2 Pac | Baby Don't Cry (Keep Ya Head Up II) | 4:22 | Rap | 1 | 87 | 2000-02-26 |
| 2000 | 2 Pac | Baby Don't Cry (Keep Ya Head Up II) | 4:22 | Rap | 2 | 82 | 2000-03-04 |
| 2000 | 2 Pac | Baby Don't Cry (Keep Ya Head Up II) | 4:22 | Rap | 3 | 72 | 2000-03-11 |
| 2000 | 2 Pac | Baby Don't Cry (Keep Ya Head Up II) | 4:22 | Rap | 4 | 77 | 2000-03-18 |
| 2000 | 2 Pac | Baby Don't Cry (Keep Ya Head Up II) | 4:22 | Rap | 5 | 87 | 2000-03-25 |
| 2000 | 2 Pac | Baby Don't Cry (Keep Ya Head Up II) | 4:22 | Rap | 6 | 94 | 2000-04-01 |
| 2000 | 2 Pac | Baby Don't Cry (Keep Ya Head Up II) | 4:22 | Rap | 7 | 99 | 2000-04-08 |
| 2000 | 2Ge+her | The Hardest Part Of Breaking Up (Is Getting Ba... | 3:15 | R&B | 1 | 91 | 2000-09-02 |
| 2000 | 2Ge+her | The Hardest Part Of Breaking Up (Is Getting Ba... | 3:15 | R&B | 2 | 87 | 2000-09-09 |
| 2000 | 2Ge+her | The Hardest Part Of Breaking Up (Is Getting Ba... | 3:15 | R&B | 3 | 92 | 2000-09-16 |
一个表中包含多种类型
继 Billboard 数据集之后,我们现在将解决前一个表的重复问题。
问题:
- 多个观察单位(
song和它的rank)在一个表中。
我们将首先创建一个包含每首歌详细信息的songs表:
songs_cols = ["year", "artist.inverted", "track", "time", "genre"]
songs = billboard[songs_cols].drop_duplicates()
songs = songs.reset_index(drop=True)
songs["song_id"] = songs.index
songs.head(10)
| year | artist.inverted | track | time | genre | song_id |
|---|---|---|---|---|---|
| 2000 | 2 Pac | Baby Don't Cry (Keep Ya Head Up II) | 4:22 | Rap | 0 |
| 2000 | 2Ge+her | The Hardest Part Of Breaking Up (Is Getting Ba... | 3:15 | R&B | 1 |
| 2000 | 3 Doors Down | Kryptonite | 3:53 | Rock | 2 |
| 2000 | 3 Doors Down | Loser | 4:24 | Rock | 3 |
| 2000 | 504 Boyz | Wobble Wobble | 3:35 | Rap | 4 |
| 2000 | 98° | Give Me Just One Night (Una Noche) | 3:24 | Rock | 5 |
| 2000 | A*Teens | Dancing Queen | 3:44 | Pop | 6 |
| 2000 | Aaliyah | I Don't Wanna | 4:15 | Rock | 7 |
| 2000 | Aaliyah | Try Again | 4:03 | Rock | 8 |
| 2000 | Adams, Yolanda | Open My Heart | 5:30 | Gospel | 9 |
然后我们将创建一个只包含song_id、date和rank的ranks表。
ranks = pd.merge(billboard, songs, on=["year","artist.inverted", "track", "time", "genre"])
ranks = ranks[["song_id", "date","rank"]]
ranks.head(10)
| song_id | date | rank |
|---|---|---|
| 0 | 2000-02-26 | 87 |
| 0 | 2000-03-04 | 82 |
| 0 | 2000-03-11 | 72 |
| 0 | 2000-03-18 | 77 |
| 0 | 2000-03-25 | 87 |
| 0 | 2000-04-01 | 94 |
| 0 | 2000-04-08 | 99 |
| 1 | 2000-09-02 | 91 |
| 1 | 2000-09-09 | 87 |
| 1 | 2000-09-16 | 92 |
一列中存储多个变量
世界卫生组织的结核病记录
这个数据集记录了按国家、年份、年龄和性别确认的结核病病例数量。
问题:
-
一些列包含多个值:性别和年龄。
-
零值和缺失值
NaN的混合。这是由于数据收集过程中的原因,区分这些值对于这个数据集很重要。
df = pd.read_csv("./data/tb-raw.csv")
df
| country | year | m014 | m1524 | m2534 | m3544 | m4554 | m5564 | m65 | mu | f014 |
|---|---|---|---|---|---|---|---|---|---|---|
| AD | 2000 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | NaN | NaN |
| AE | 2000 | 2 | 4 | 4 | 6 | 5 | 12 | 10 | NaN | 3 |
| AF | 2000 | 52 | 228 | 183 | 149 | 129 | 94 | 80 | NaN | 93 |
| AG | 2000 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | NaN | 1 |
| AL | 2000 | 2 | 19 | 21 | 14 | 24 | 19 | 16 | NaN | 3 |
| AM | 2000 | 2 | 152 | 130 | 131 | 63 | 26 | 21 | NaN | 1 |
| AN | 2000 | 0 | 0 | 1 | 2 | 0 | 0 | 0 | NaN | 0 |
| AO | 2000 | 186 | 999 | 1003 | 912 | 482 | 312 | 194 | NaN | 247 |
| AR | 2000 | 97 | 278 | 594 | 402 | 419 | 368 | 330 | NaN | 121 |
| AS | 2000 | NaN | NaN | NaN | NaN | 1 | 1 | NaN | NaN | NaN |
为了整理这个数据集,我们需要从标题中删除不同的值,并将其展开成行。我们首先需要将sex + age group列融化成一个单一列。一旦我们有了那个单一列,我们将从中派生出三列:sex、age_lower和age_upper。有了这些,我们将能够正确地构建一个整洁的数据集。
df = pd.melt(df, id_vars=["country","year"], value_name="cases", var_name="sex_and_age")
# Extract Sex, Age lower bound and Age upper bound group
tmp_df = df["sex_and_age"].str.extract("(\D)(\d+)(\d{2})")
# Name columns
tmp_df.columns = ["sex", "age_lower", "age_upper"]
# Create `age`column based on `age_lower` and `age_upper`
tmp_df["age"] = tmp_df["age_lower"] + "-" + tmp_df["age_upper"]
# Merge
df = pd.concat([df, tmp_df], axis=1)
# Drop unnecessary columns and rows
df = df.drop(['sex_and_age',"age_lower","age_upper"], axis=1)
df = df.dropna()
df = df.sort(ascending=True,columns=["country", "year", "sex", "age"])
df.head(10)
这导致了一个整洁的数据集。
| country | year | cases | sex | age |
|---|---|---|---|---|
| AD | 2000 | 0 | m | 0-14 |
| AD | 2000 | 0 | m | 15-24 |
| AD | 2000 | 1 | m | 25-34 |
| AD | 2000 | 0 | m | 35-44 |
| AD | 2000 | 0 | m | 45-54 |
| AD | 2000 | 0 | m | 55-64 |
| AE | 2000 | 3 | f | 0-14 |
| AE | 2000 | 2 | m | 0-14 |
| AE | 2000 | 4 | m | 15-24 |
| AE | 2000 | 4 | m | 25-34 |
变量既存储在行中,也存储在列中
全球历史气候网络数据集
这个数据集记录了 2010 年墨西哥一个气象站(MX17004)五个月的每日天气记录。
问题:
- 变量既存储在行(
tmin、tmax)中,也存储在列(days)中。
df = pd.read_csv("./data/weather-raw.csv")
df
| id | year | month | element | d1 | d2 | d3 | d4 | d5 | d6 | d7 | d8 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| MX17004 | 2010 | 1 | tmax | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| MX17004 | 2010 | 1 | tmin | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| MX17004 | 2010 | 2 | tmax | NaN | 27.3 | 24.1 | NaN | NaN | NaN | NaN | NaN |
| MX17004 | 2010 | 2 | tmin | NaN | 14.4 | 14.4 | NaN | NaN | NaN | NaN | NaN |
| MX17004 | 2010 | 3 | tmax | NaN | NaN | NaN | NaN | 32.1 | NaN | NaN | NaN |
| MX17004 | 2010 | 3 | tmin | NaN | NaN | NaN | NaN | 14.2 | NaN | NaN | NaN |
| MX17004 | 2010 | 4 | tmax | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| MX17004 | 2010 | 4 | tmin | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| MX17004 | 2010 | 5 | tmax | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| MX17004 | 2010 | 5 | tmin | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
为了使数据集整洁,我们希望将三个错误放置的变量(tmin、tmax和days)作为三个独立的列:tmin、tmax和date。
# Extracting day
df["day"] = df["day_raw"].str.extract("d(\d+)", expand=False)
df["id"] = "MX17004"
# To numeric values
df[["year","month","day"]] = df[["year","month","day"]].apply(lambda x: pd.to_numeric(x, errors='ignore'))
# Creating a date from the different columns
def create_date_from_year_month_day(row):
return datetime.datetime(year=row["year"], month=int(row["month"]), day=row["day"])
df["date"] = df.apply(lambda row: create_date_from_year_month_day(row), axis=1)
df = df.drop(['year',"month","day", "day_raw"], axis=1)
df = df.dropna()
# Unmelting column "element"
df = df.pivot_table(index=["id","date"], columns="element", values="value")
df.reset_index(drop=False, inplace=True)
df
| id | date | tmax | tmin |
|---|---|---|---|
| MX17004 | 2010-02-02 | 27.3 | 14.4 |
| MX17004 | 2010-02-03 | 24.1 | 14.4 |
| MX17004 | 2010-03-05 | 32.1 | 14.2 |
一个类型在多个表中
数据集:2014/2015 年伊利诺伊州男性婴儿名字。
问题:
-
数据分布在多个表/文件中。
-
“Year” 变量存在于文件名中。
为了将这些不同的文件加载到一个 DataFrame 中,我们可以运行一个自定义脚本,将文件合并在一起。此外,我们还需要从文件名中提取“Year”变量。
def extract_year(string):
match = re.match(".+(\d{4})", string)
if match != None: return match.group(1)
path = './data'
allFiles = glob.glob(path + "/201*-baby-names-illinois.csv")
frame = pd.DataFrame()
df_list= []
for file_ in allFiles:
df = pd.read_csv(file_,index_col=None, header=0)
df.columns = map(str.lower, df.columns)
df["year"] = extract_year(file_)
df_list.append(df)
df = pd.concat(df_list)
df.head(5)
| rank | name | frequency | sex | year |
|---|---|---|---|---|
| 1 | Noah | 837 | Male | 2014 |
| 2 | Alexander | 747 | Male | 2014 |
| 3 | William | 687 | Male | 2014 |
| 4 | Michael | 680 | Male | 2014 |
| 5 | Liam | 670 | Male | 2014 |
终极想法
在这篇文章中,我专注于 Wickham 论文中的一个方面,即数据处理部分。我的主要目标是演示如何在 Python 中进行数据操作。值得提到的是,他的论文中有一个重要部分涵盖了工具和可视化,您可以通过整理数据集受益。我在这篇文章中没有涵盖这些内容。
总体而言,我很喜欢准备这篇文章并将数据集整理成流畅的格式。定义的格式使得查询和筛选数据变得更加容易。这种方法使得在分析中重用库和代码变得更加简便。它也使得与其他数据分析师共享数据集变得更简单。
简历: Jean-Nicholas Hould 是来自 加拿大蒙特利尔的数据科学家。JeanNicholasHould.com 的作者。
原文。经许可转载。
相关:
-
数据科学统计学 101
-
数据科学中的中心极限定理
-
用 SQL 做统计
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
了解更多相关主题
一个主观的 R 数据科学工具箱,来自 Hadley Wickham 的 tidyverse
原文:
www.kdnuggets.com/2017/10/tidyverse-powerful-r-toolbox.html
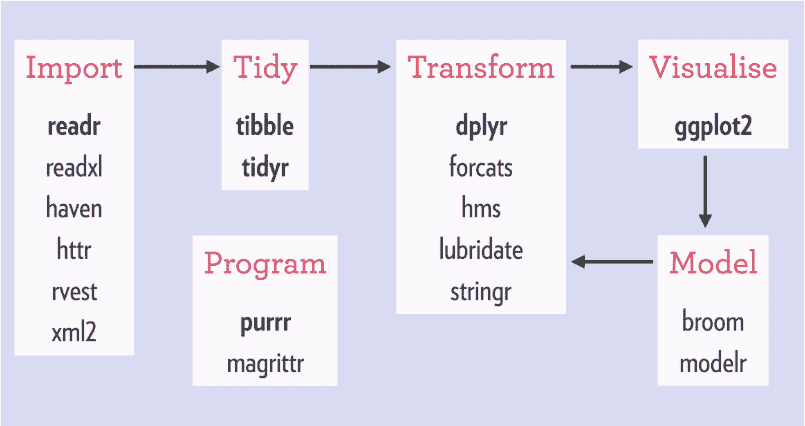
在这篇文章中,我们将总结一下 tidyverse,这是一套 R 包,它们共享一种常见的数据表示和 API 设计,以实现数据科学工作流程的协调和流畅性,旨在提高一致性,易于安装。它可以被视为 R 中的数据科学和数据管理工具箱,因为它是为指导用户进行提高可重现性和沟通能力的工作流程而构建的。
我们的前 3 门课程推荐
1. 谷歌网络安全证书 - 快速跟踪网络安全职业发展
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 在 IT 部门支持你的组织
只要将这个包加载到你的项目中,你就可以轻松地执行基本的数据科学任务,如导入、绘图、整理和建模数据,以及进行新开发的函数编程。这个超级包的核心部分是由一系列强大的 R 包组成,如 ggplot2、dplyr、tidyr、readr、purr 和 tibble 等。我们将在后面的部分详细介绍这些包的细节,并展示一些基本的示例,帮助你开始使用这个令人惊奇的工具箱。这个软件包旨在成为一个和谐和兼容的工具和命令集,为有效的数据科学工作流程提供符合规范的定义。
首先,介绍 tidyverse 的历史,以及它是如何形成的和背后的幕后推手是谁。这个“包里的包”是由 Hadley Wickham 开发的,他是 RStudio 的首席科学家,也是令人惊叹的 O'Reilly 系列书籍“R 数据科学”的合著者;他也负责将其维护到最佳状态。你可能已经熟悉 Hadley,因为他开发了之前的 R 包,如 reshape、reshape2 和 plyr;这些又是 tidyverse 的构建块,是几次实验和版本的产物。它旨在为统计学家和数据科学家提供帮助,提高他们的生产力,并试图将规范化的数据科学工作流程(图)抽象为一个实际的产品。它是一个非常多功能和一致性的软件包,因为其强大的功能涵盖从提高生产力和工作流程改进到新的数据科学软件开发和数据科学教育。
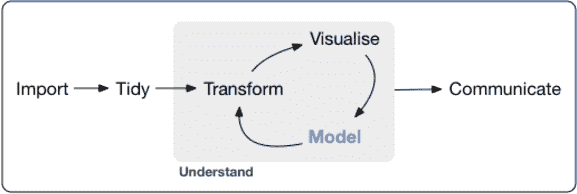
重要的是要更详细地介绍一下这个包的一般特性,这样我们就可以在我们的实际示例中看到它的运作方式。它的一致性深深根植于变量、函数和运算符遵循正则模式和语法的事实。例如,每个函数的第一个参数将是一个整洁的数据框(每个观察一行,每个变量一列,每个单元格一个入口)。为了执行操作,可以直观地连接一系列命令、基本函数和运算符来创建一个整洁的管道。核心包组织的方式、编码风格和测试程序构成了第二个较低级别的一致性因素,因此当我们说“一致”这个词时,不应轻易忽视。最后,由于分析工作流程过程与不同的 tidyverse 子包之间存在一对一的关系,因此能够轻松建立有效的端到端工作流程,以响应特定的分析目的并利用多种类型的数据。
因此,有经验的用户和初学者之间对其的使用越来越受欢迎并不奇怪。事实上,那些希望学习数据科学中的 R 的人应该从 tidyverse 开始,因为它具有友好且学习曲线不陡峭的特点,使早期职业人员能够在短时间内处理和解决复杂的数据集。
现在,让我们深入了解每个核心包,这样我们就可以对我们所提到的流畅性和一致性有一个概览。您可以查看下面链接的文档以获取有关在使用 tidyverse 时加载的其他包的更多信息。
-
导入你的数据:这里的主要包是 readr。它是一种友好且快速的读取矩形数据的方式,其灵活性允许解析不同的数据类型。除了 readr,还将加载其他次要包,例如 readxl 和 haven 等。您可以在这里找到更多信息。
-
清洁你的数据:首选的包是 tibble 和 tidyr。
-
转换你的数据:核心包是 dplyr,它是 R 语言中最受欢迎的包之一。它是一组语法一致的数据操作动词,非常直观而强大。它的主要函数是 mutate()、filter()、select()、summarise() 和 arrange()。这些可以通过使用 group_by() 命令按组执行操作。在这里了解更多关于 tidyr 的信息。
-
数据可视化:对于这一任务,使用 ggplot2,这是一个基于图形语法创建数据可视化的强大而优雅的方法。你只需输入你的数据,声明你的变量美学和选择几何图形的类型,ggplot2 将会处理剩下的事情。更多关于 tidyr 的信息在这里。
-
编程分析:purrr。如果你想要使用 R 的函数式编程,你可以使用这个包的 map() 函数系列。它允许你以清晰简洁的方式迭代你的数据。访问这个 链接 了解更多信息。
现在,让我们开始吧。在这个例子中,我们将使用来自 Kaggle 竞赛的泰坦尼克号数据集,你可以在这里 轻松下载。我们的例子目的是向你展示一些 tidyverse 中常见的操作,并展示一下这个超级 R 包的语法和一致性的强大。希望你能自己复现这段代码。我鼓励你阅读文档,这样你就可以为数据分析想出自己的 tidyverse 配方。
注意:你会经常看到这个符号(‘%>%’)在这个例子中。这被称为管道操作符,在脚本中非常有用,因为它允许你跟踪分析逻辑。可以这样想:函数 f(x) 现在表示为 x %>% f。
欲了解更多 tidyverse 文档,请访问官方网站 并查看额外的例子。
如果你是初学 R 语言,并且想了解更多有关 tidyverse 的用法,Hadley Wickham 的书籍 R for Data Science 是最好的资源。
另外,关于 tidyverse 及其特性的另一个很好的总结,来自 R Views 的这篇文章是一个很棒的参考。
相关:
-
R 和 dplyr 的下一代数据处理
-
缺失数据的解决方案:使用 R 进行插补
-
Python vs R – 数据科学、机器学习中谁更领先?
更多相关主题
Time 100 AI: 最具影响力?

图片来源:Time 100 AI
昨天,《时代》杂志发布了其Time 100 AI 名单,与他们最新一期的封面故事同步发布。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
[B] 每一个机器学习和大型语言模型的进步背后,实际上都是人——既有那些让大型语言模型更安全的常被忽视的人力,也有那些在何时何地如何最好地使用这项技术上做出关键决策的个人。TIME 最擅长报道人物和影响力,这促使我们推出 TIME100 AI。
《时代》的名单包括了当前 AI 领域中的 100 位个人,分为领导者、创新者、塑造者和思想家四个类别。
虽然名单上的各类别都有许多令人印象深刻的名字,但在 Twitter 上立刻出现了对一些重要缺席者的讨论,尤以 Jürgen Schmidhuber 和 Andrej Karpathy 两个名字反复出现。我自己也有一些遗漏的名字,本来想加进去,还有一些名字我认为可以去掉,但这不是我的名单,所以我也无能为力。
与其抱怨,我决定将这个列表视为一个有影响力的流行出版物如何向大众报道 AI 的快照。因此,我不会以任何方式将其视为权威,但仍然选择将其呈现给我们的读者以供参考。
你可以在这里了解更多他们如何整理这个列表的信息。
TIME 最有知识的编辑和记者们花了几个月的时间从几十个来源收集推荐,整理出了数百个提名,然后缩减成了你今天看到的这组名单。我们几乎采访了所有名单上的个人,以了解他们对今天 AI 发展道路的看法。
无论你是否完全同意这些内容,我认为了解流行出版物对 AI 行业的报道仍然是重要的。我相信,即使是对 AI 领域最了解的跟随者,也会遇到一些不熟悉的名字需要熟悉。
图片来源:我们如何选择 TIME100 最具影响力的 AI 人物
我鼓励大家亲自查看这个列表,深入了解当代 AI 领袖,并且——同样重要的是——理解那些行业外的人如何看待这一领域。
Matthew Mayo (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 的主编,Matthew 旨在让复杂的数据科学概念变得易于理解。他的职业兴趣包括自然语言处理、机器学习算法和探索新兴的 AI。他致力于在数据科学社区中普及知识。Matthew 从 6 岁开始编程。
更多相关话题
时间复杂度:如何衡量算法的效率
原文:
www.kdnuggets.com/2020/06/time-complexity-measure-efficiency-algorithms.html
评论
作者:Diego Lopez Yse,数据科学家

照片由 Icons8 Team 在 Unsplash 提供
在计算机编程中,和生活的其他方面一样,解决问题的方法各不相同。这些不同的方法可能意味着不同的时间、计算能力或你选择的其他度量标准,因此我们需要比较不同方法的效率,以选择合适的方法。
现在,正如你可能知道的那样,计算机能够根据算法解决问题。
算法是告诉计算机该做什么和怎么做的过程或指令(步骤集合)。
如今,它们发展得如此迅速,即使是在完成相同任务的情况下也可能有很大不同。在最极端的情况下(顺便说一句,这种情况很常见),用不同编程语言编写的不同算法可能会指示不同硬件和操作系统的计算机以完全不同的方式执行相同任务。这真疯狂,不是吗?
问题是,当一个算法花费几秒钟完成时,另一个算法即使在处理小数据集时也会花费几分钟。我们如何比较不同的性能并选择最佳算法来解决特定问题?
幸运的是,我们有方法可以做到这一点,我们不需要等待算法运行才能知道它是否能够快速完成任务,或者它是否会因输入的重量而崩溃。当我们考虑算法的复杂度时,我们不必关心执行的确切操作次数;我们应该关心操作次数与问题规模的关系。想想看:如果问题规模翻倍,操作次数是否保持不变?是否也翻倍?是否以其他方式增加?要回答这些问题,我们需要测量算法的时间复杂度。
时间复杂度表示语句执行的次数。算法的时间复杂度不是执行特定代码所需的实际时间,因为这取决于其他因素,如编程语言、操作软件、处理能力等。时间复杂度的核心思想是,它只能以一种仅依赖于算法本身及其输入的方式来衡量算法的执行时间。
为了表示算法的时间复杂度,我们使用一种叫做“大 O 记号”的东西。大 O 记号是我们用来描述算法时间复杂度的语言。它帮助我们比较不同解决问题的方法的效率,并帮助我们做出决策。
大 O 记号表示算法的运行时间相对于输入增长的速度(这个输入被称为“n”)。这样,如果我们说一个算法的运行时间按“输入大小的顺序”增长,我们会表示为“O(n)”。如果我们说一个算法的运行时间按“输入大小的平方的顺序”增长,我们会表示为“O(n²)”。但这到底是什么意思呢?
理解时间复杂度的关键是理解事物增长的速度。这里讨论的速率是每个输入大小所花费的时间。时间复杂度有不同类型,让我们来检查最基本的几种。
常量时间复杂度:O(1)
当时间复杂度是常量(记作“O(1)”)时,输入的大小(n)无关紧要。具有常量时间复杂度的算法运行所需时间固定,与 n 的大小无关。它们的运行时间不会因输入数据而改变,这使它们成为最快的算法。
常量时间复杂度
例如,如果你想知道一个数字是奇数还是偶数,你会使用一个具有常量时间复杂度的算法。无论数字是 1 还是 90 亿(输入“n”),该算法只会执行相同的操作一次,并给出结果。
同样,如果你想打印一句像经典的“Hello World”这样的短语,你也会使用常量时间复杂度,因为操作次数(在这种情况下是 1)将保持不变,无论你使用什么操作系统或机器配置。
为保持常量,这些算法不应包含循环、递归或调用任何其他非常量时间函数。对于常量时间算法,运行时间不会增加:量级始终为 1。
线性时间复杂度:O(n)
当时间复杂度与输入大小成正比增长时,你面临的是线性时间复杂度,或 O(n)。具有这种时间复杂度的算法会以“n”次操作处理输入(n)。这意味着随着输入的增长,算法完成所需的时间也会成比例增加。
线性时间复杂度
这些情况是你需要查看列表中的每个项来完成任务(例如,找出最大值或最小值)。或者你也可以考虑像读书或在 CD 堆中寻找一张 CD(记得吗?)这样的日常任务:如果所有数据都必须检查,输入数据越大,操作次数就越多。
线性运行时间的算法非常常见,它们与算法访问输入中的每个元素有关。
对数时间复杂度:O(log n)
具有这种复杂度的算法使计算变得非常快速。如果一个算法的执行时间与输入大小的对数成正比,则称该算法在对数时间内运行。这意味着,与每个后续步骤所需的时间增加相反,时间以与输入“n”成反比的数量级减少。
对数时间复杂度
它的秘诀是什么?这种类型的算法从不需要遍历所有输入,因为它们通常通过每一步丢弃大量未检查的输入来工作。这种时间复杂度通常与每次将问题对半分割的算法相关,这是一种被称为“分而治之”的概念。分而治之算法通过以下步骤解决问题:
-
他们将给定问题分解为相同类型的子问题。
-
他们递归地解决这些子问题。
-
他们适当地结合子答案以回答给定的问题。
考虑这个例子:假设你想在一个按字母顺序排列的字典中查找一个词。有至少两种算法可以做到这一点:
算法 A:
- 从书的开头开始,按照顺序查找,直到找到你要找的联系人。
算法 B:
-
从书的中间打开并检查第一页上的第一个词。
-
如果你要找的词在字母顺序上更大,则查找右半部分。否则,查找左半部分。
哪一种更快?算法 A 按字逐个处理 O(n),而算法 B 在每次迭代中将问题分成两半 O(log n),以更高效的方式达到相同的结果。
对数时间算法(O(log n))是仅次于常数时间算法(O(1))的第二快算法。
二次时间复杂度:O(n²)
在这种类型的算法中,运行时间直接与输入大小的平方成正比(类似于线性,但平方)。
在大多数场景中,特别是对于大型数据集,具有二次时间复杂度的算法需要很长时间才能执行,应该避免使用。
二次时间复杂度
嵌套For 循环的运行时间是二次的,因为你在另一个线性操作中运行一个线性操作,即nn,等于n²*。
如果你遇到这些类型的算法,你要么需要大量的资源和时间,要么需要想出一个更好的算法。
指数时间复杂度:O(2^n)
在指数时间算法中,增长率随着输入(n)的每次增加而翻倍,通常会遍历所有输入元素的子集。每当输入单元增加 1 时,都会使你执行的操作数量翻倍。这听起来不太好,对吧?
这种时间复杂度的算法通常在你对最佳解决方案了解不多的情况下使用,你必须尝试所有可能的数据组合或排列。
指数时间复杂度
指数时间复杂度通常出现在暴力算法中。这些算法盲目地遍历整个可能解决方案的领域,以寻找一个或多个满足条件的解决方案。它们通过简单地尝试每一个可能的解决方案直到找到正确的来找到解决方案。这显然不是一种优化的任务执行方式,因为它会影响时间复杂度。暴力算法在密码学中作为攻击方法使用,通过尝试随机字符串来破解密码保护,直到找到正确的密码来解锁系统。
与二次时间复杂度一样,你应该避免使用具有指数运行时间的算法,因为它们扩展性差。
如何测量时间复杂度?
一般来说,我们发现算法的操作越少,它的速度越快。这看起来是个好原则,但我们如何将它应用到现实中呢?
如果我们有一个算法(不论是什么),我们怎么知道它的时间复杂度呢?
在某些情况下,这可能相对简单。假设你有一个外部For 循环,它遍历输入列表中的所有项,然后是一个嵌套的内部For 循环,它再次遍历输入列表中的所有项。执行的总步骤数是 n * n,其中 n 是输入数组中的项数。
但是,你如何找出复杂函数的时间复杂度呢?
为了找到答案,我们需要将算法代码拆解成各个部分,并尝试找出各个部分的复杂度。是的,抱歉告诉你,但并没有一个按钮可以告诉你算法的时间复杂度。你必须自己去做。
主要时间复杂度
作为经验法则,最好尽量保持你的函数运行在线性时间复杂度范围内,但显然这并不总是可能的。
有不同的大 O 记法,例如“最佳情况”、“平均情况”和“最差情况”,但真正重要的是最差情况;这些情况是可能严重崩溃一切的。它们直接触及时间复杂度为何重要,并指出为何一些算法在不花费几亿年时间的情况下根本无法解决问题。
最坏情况分析 给出了执行算法时必须执行的基本操作的最大数量。它假设输入处于最糟糕的状态,并且需要做最大量的工作以纠正问题。例如,对于一个旨在将数组按升序排序的排序算法,当输入数组按降序排列时,最坏的情况就会发生。在这种情况下,必须进行最多的基本操作(比较和赋值)以将数组设置为升序。这样想:如果你必须通过阅读每个名字来在目录中搜索一个名字,直到找到正确的那个,最坏的情况是你想要的名字是目录中的最后一个条目。
总结一下,算法的时间复杂度越低,实际工作中算法执行得越快。 在设计或管理算法时,你应该考虑这一点,并意识到它可能会对算法的实用性或完全无用性产生巨大差异。
对这些主题感兴趣?请在 Linkedin 或 Twitter 上关注我
个人简介:Diego Lopez Yse 是一位经验丰富的专业人士,拥有在不同领域(资本市场、生物技术、软件、咨询、政府、农业)获得的坚实国际背景。始终是团队的一员。擅长商业管理、分析、金融、风险、项目管理和商业运营。拥有数据科学和企业金融硕士学位。
原文。经许可转载。
相关:
-
人人都能用的 Python:免费电子书
-
使用 5 种机器学习算法分类稀有事件
-
数据科学家的编码习惯
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关主题
使用 NumPy 的时间序列数据

时间序列数据的独特之处在于它们彼此之间是顺序相关的。这是因为数据是按一致的时间间隔收集的,例如每年、每天甚至每小时。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 事务
时间序列数据在许多分析中都很重要,因为它们可以代表业务问题的模式,如数据预测、异常检测、趋势分析等。
在 Python 中,你可以尝试使用 NumPy 分析时间序列数据集。NumPy 是一个强大的数值和统计计算包,但它也可以扩展到时间序列数据。
我们如何做到这一点?让我们尝试一下。
使用 NumPy 的时间序列数据
首先,我们需要在 Python 环境中安装 NumPy。如果你还没有安装,可以使用以下代码进行安装。
pip install numpy
接下来,让我们尝试用 NumPy 初始化时间序列数据。如我所提到的,时间序列数据具有顺序和时间特性,因此我们将尝试用 NumPy 创建这些数据。
import numpy as np
dates = np.array(['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04', '2023-01-05'], dtype='datetime64')
dates
Output>>
array(['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04',
'2023-01-05'], dtype='datetime64[D]')
如上面的代码所示,我们用 dtype 参数在 NumPy 中设置数据时间序列。如果没有这些参数,数据会被视为字符串数据,但现在它被视为时间序列数据。
我们可以在不逐个编写的情况下创建 NumPy 时间序列数据。我们可以使用 NumPy 的特定方法来完成这项工作。
date_range = np.arange('2023-01-01', '2025-01-01', dtype='datetime64[M]')
date_range
Output>>
array(['2023-01', '2023-02', '2023-03', '2023-04', '2023-05', '2023-06',
'2023-07', '2023-08', '2023-09', '2023-10', '2023-11', '2023-12',
'2024-01', '2024-02', '2024-03', '2024-04', '2024-05', '2024-06',
'2024-07', '2024-08', '2024-09', '2024-10', '2024-11', '2024-12'],
dtype='datetime64[M]')
我们创建了 2023 到 2024 年的月度数据,每个月的数据作为值。
之后,我们可以尝试基于 NumPy 日期时间系列分析数据。例如,我们可以创建与日期范围相匹配的随机数据。
data = np.random.randn(len(date_range)) * 10 + 100
Output>>
array([128.85379394, 92.17272879, 81.73341807, 97.68879621,
116.26500413, 89.83992529, 93.74247891, 115.50965063,
88.05478692, 106.24013365, 92.84193254, 96.70640287,
93.67819695, 106.1624716 , 97.64298602, 115.69882628,
110.88460629, 97.10538592, 98.57359395, 122.08098289,
104.55571757, 100.74572336, 98.02508889, 106.47247489])
使用 NumPy 的随机方法,我们可以生成随机值来模拟时间序列分析。
例如,我们可以尝试使用以下代码进行移动平均分析。
def moving_average(data, window):
return np.convolve(data, np.ones(window), 'valid') / window
ma_12 = moving_average(data, 12)
ma_12
Output>>
array([ 99.97075433, 97.03945458, 98.20526648, 99.53106381,
101.03189965, 100.58353316, 101.18898821, 101.59158114,
102.13919216, 103.51426971, 103.05640219, 103.48833188,
104.30217122])
移动平均是一个简单的时间序列分析方法,其中我们计算系列子集的均值。在上述示例中,我们使用窗口 12 作为子集。这意味着我们取系列的前 12 个作为子集并计算它们的均值。然后,子集滑动一个位置,我们计算下一个均值子集。
首先的子集是我们取均值的这个子集:
[128.85379394, 92.17272879, 81.73341807, 97.68879621,
116.26500413, 89.83992529, 93.74247891, 115.50965063,
88.05478692, 106.24013365, 92.84193254, 96.70640287]
下一个子集是我们将窗口滑动一个位置的地方:
[92.17272879, 81.73341807, 97.68879621,
116.26500413, 89.83992529, 93.74247891, 115.50965063,
88.05478692, 106.24013365, 92.84193254, 96.70640287,
93.67819695]
这就是np.convolve的作用,因为该方法会根据np.ones数组的数量移动并求和系列子集。我们仅使用有效选项来返回可以在没有任何填充的情况下计算的数量。
然而,移动平均通常用于分析时间序列数据,以识别潜在模式和信号,例如金融领域的买入/卖出信号。
说到模式,我们可以用 NumPy 模拟时间序列中的趋势。趋势是数据中的长期且持续的方向性运动。基本上,它是时间序列数据的总体方向。
trend = np.polyfit(np.arange(len(data)), data, 1)
trend
Output>>
array([ 0.20421765, 99.78795983])
上述情况发生的是我们为数据拟合了一条线性直线。从结果中,我们得到了直线的斜率(第一个数字)和截距(第二个数字)。斜率表示数据在每一步或时间值上的平均变化量,而截距则是数据的方向(正值表示上升,负值表示下降)。
我们也可以有去趋势的数据,即在从时间序列中移除趋势后的组件。这种数据类型通常用于检测趋势数据中的波动模式和异常。
detrended = data - (trend[0] * np.arange(len(data)) + trend[1])
detrended
Output>>
array([ 29.06583411, -7.81944869, -18.46297706, -2.71181657,
15.66017371, -10.96912278, -7.2707868 , 14.29216727,
-13.36691409, 4.61421499, -8.98820376, -5.32795108,
-8.56037465, 3.71968235, -5.00402087, 12.84760174,
7.8291641 , -6.15427392, -4.89028352, 18.41288776,
0.6834048 , -3.33080706, -6.25565918, 1.98750918])
上述输出中显示了去除趋势后的数据。在实际应用中,我们会分析这些数据,以查看哪个数据点偏离了常见模式。
我们也可以尝试从我们拥有的时间序列数据中分析季节性。季节性是指在特定时间间隔内发生的规律性和可预测模式,例如每 3 个月、每 6 个月等。季节性通常受假期、天气、事件等外部因素的影响。
seasonality = np.mean(data.reshape(-1, 12), axis=0)
seasonal_component = np.tile(seasonality, len(data)//12 + 1)[:len(data)]
Output>>
array([111.26599544, 99.16760019, 89.68820205, 106.69381124,
113.57480521, 93.4726556 , 96.15803643, 118.79531676,
96.30525224, 103.4929285 , 95.43351072, 101.58943888,
111.26599544, 99.16760019, 89.68820205, 106.69381124,
113.57480521, 93.4726556 , 96.15803643, 118.79531676,
96.30525224, 103.4929285 , 95.43351072, 101.58943888])
在上述代码中,我们计算了每个月的平均值,然后将数据扩展以匹配其长度。最终,我们得到两年间每个月的平均值,并尝试分析数据以查看是否有值得提及的季节性。
这就是我们可以用 NumPy 对时间序列数据和分析所做的基本方法。虽然有很多高级方法,但上述方法是基本的。
结论
时间序列数据是一个独特的数据集,因为它以顺序方式表示,并且具有时间特性。使用 NumPy,我们可以设置时间序列数据,同时进行基本的时间序列分析,如移动平均、趋势分析和季节性分析。
Cornellius Yudha Wijaya 是一位数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 撰写了各种人工智能和机器学习主题。
更多相关主题
《时间序列入门》——三步走过程
原文:
www.kdnuggets.com/2018/03/time-series-dummies-3-step-process.html
评论
由 Chris St. Jeor 和 Sean Ankenbruck,Zencos
在享受了一顿令人满意的中餐外卖后,你心不在焉地打开了免费的幸运饼干。瞥了一眼里面的幸运签,你读到:“你有一个梦想将会实现。”你嗤之以鼻,把小纸条扔掉,把饼干放进嘴里。作为一个聪明、理智的人,你知道这个幸运签毫无意义——没有人能预测未来。然而,这种想法可能是不完整的。实际上,有一种方法可以非常准确地预测未来:时间序列建模。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
时间序列建模可能无法告诉你何时会遇到你一生的挚爱,或者你应该穿蓝色领带还是红色领带上班,但它非常擅长利用历史数据识别现有模式,并利用这些模式预测未来将会发生什么。与大多数高级分析解决方案不同,时间序列建模是一种低成本的解决方案,可以提供强大的洞察力。
本文将介绍构建高质量时间序列模型的三个基本步骤:使数据平稳、选择正确的模型和评估模型的准确性。本文中的示例使用了一个大型汽车营销公司的历史页面浏览数据。
第一步:使数据平稳
时间序列涉及使用按等间隔时间(分钟、小时、天、周等)索引的数据。由于时间序列数据的离散特性,许多时间序列数据集在数据中包含季节性和/或趋势元素。时间序列建模的第一步是考虑现有的季节性(在固定时间段内的重复模式)和/或趋势(数据中的上升或下降移动)。考虑这些嵌入的模式就是我们所说的使数据平稳。可以在下面的图 1 和图 2 中看到趋势和季节性数据的示例。
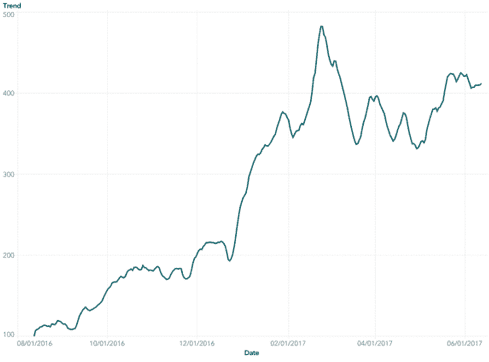
图 1:上升趋势数据的示例
图 2:季节性数据的示例
什么是平稳性?
如前所述,时间序列建模的第一步是去除数据中存在的趋势或季节性效应以使其平稳。我们一直在谈论平稳性,但它到底是什么意思呢?
一个平稳序列是指其均值不再是时间的函数。对于趋势数据,随着时间的推移,序列的均值要么增加,要么减少(可以考虑一下房价随时间的稳步上涨)。对于季节性数据,序列的均值根据季节波动(可以考虑一下每 24 小时温度的升降变化)。
我们如何实现平稳性?
有两种方法可以实现平稳性,即对数据进行差分或线性回归。进行差分时,你计算连续观测值之间的差异。使用线性回归时,你需要在模型中包含季节性组件的二元指示变量。在决定应用哪种方法之前,让我们先探讨一下数据。我们使用 SAS Visual Analytics 绘制了历史每日页面浏览量。
图 3: 原始页面浏览量的时间序列图
初步模式似乎每七天重复一次,指示出一个每周的季节。页面浏览量随时间的持续增加表明存在轻微的上升趋势。根据数据的一般情况,我们应用了平稳性统计测试,即增强型迪基-富勒(ADF)测试。ADF 测试是平稳性的单位根测试。我们在这里不详细讨论,但单位根指示序列是否为非平稳,因此我们使用此测试来确定处理趋势或季节的适当方法(差分或回归)。根据上述数据的 ADF 测试,我们通过对星期几的虚拟变量进行回归去除了七天的季节性,通过差分去除了趋势。结果的平稳数据可以在下图中看到。
图 4: 移除季节和趋势后的平稳数据
第 2 步: 建立你的时间序列模型
现在数据已平稳,时间序列建模的第二步是建立基准预测。我们还应注意,大多数基准预测不需要第一步将数据转化为平稳。这仅仅是像 ARIMA 建模这样的更高级模型所需的步骤,我们将稍后讨论。
建立基准预测
有几种类型的时间序列模型。为了构建一个能够准确预测未来页面浏览量(或你感兴趣的预测对象)的模型,有必要决定适合你数据的模型类型。
最简单的选择是假设 y 的未来值(您感兴趣预测的变量)等于 y 的最新值。这被认为是最基本的或“天真模型”,其中最近的观察值是明天最可能的结果。
第二种类型的模型是平均模型。在此模型中,数据集中所有观察值被赋予相同的权重。未来 y 的预测是通过观察数据的平均值来计算的。如果数据是平稳的,生成的预测可能非常准确,但如果数据有趋势或季节性成分,则预测效果会很差。使用平均模型对页面浏览数据的预测值见下表。
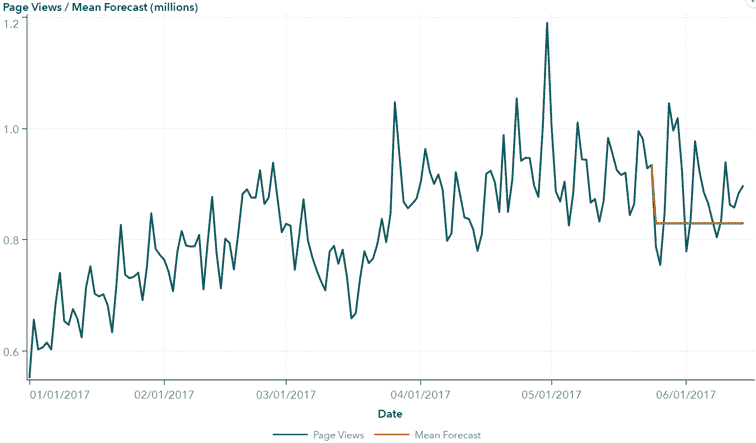
图 5: 平均(均值)模型预测
如果数据具有季节性或趋势性元素,则更好的基准模型选择是实施指数平滑模型(ESM)。ESM 在上述的天真模型和平均模型之间达到了一个平衡点,其中最新的观察值被赋予最大的权重,而所有先前观察值的权重则呈指数下降。ESM 还允许将季节性和/或趋势成分纳入模型。下表提供了一个初始权重为 0.7,按 0.3 的速率呈指数递减的示例。
| 观察 | 权重 (α = 0.7) |
|---|---|
| Yt(当前观察值) | 0.7 |
| Yt-1 | 0.21 |
| Yt-2 | 0.063 |
| Yt-3 | 0.0189 |
| Yt-4 | 0.00567 |
表 1: Y 过去观察值的指数递减效应示例
有多种类型的 ESM 可用于时间序列预测。理想的模型选择将取决于您拥有的数据类型。下表提供了根据数据中的趋势和季节组合来选择 ESM 类型的快速指南。
| 指数平滑模型类型 | 趋势 | 季节 |
|---|---|---|
| 简单 ESM | ||
| 线性 ESM | X | |
| 季节性 ESM | X | |
| 冬季 ESM | X | X |
表 2: 模型选择表
由于数据中的强烈七天周期性和上升趋势,我们选择了加性冬季 ESM 作为新的基准模型。生成的预测在延续轻微上升趋势和捕捉七天周期方面做得相当不错。然而,数据中仍有更多的模式可以被移除。
图 6: 加性冬季 ESM 预测
ARIMA 建模
在识别出最能解释数据中的趋势和季节性的模型之后,你最终拥有足够的信息来生成一个不错的预测,如上图 2 所示。然而,这些模型仍然有限,因为它们没有考虑变量在前一时期与自身的相关性。我们称这种相关性为自相关,这在时间序列数据中很常见。如果数据具有自相关,就像我们的数据一样,那么可能还需要进行额外的建模,以进一步改进基线预测。
为了捕捉时间序列模型中的自相关效应,必须实现自回归积分滑动平均(ARIMA)模型。ARIMA 模型包括用于考虑季节性和趋势的参数(如使用虚拟变量表示星期几和差分),同时也允许包含自回归和/或滑动平均项,以处理数据中嵌入的自相关。通过使用适当的 ARIMA 模型,我们可以进一步提高页面浏览量预测的准确性,如下图 3 所示。
图 7:季节性 ARIMA 模型预测
步骤 3:评估模型准确性
虽然你可以看到每个模型准确性的改善,但仅凭视觉识别哪个模型准确性最好并不总是可靠。计算 MAPE(平均绝对百分比误差)是一种快速且简单的方式来比较提议模型的整体预测准确性——MAPE 越低,预测准确性越好。比较之前讨论的每个模型的 MAPE,很容易看出季节性 ARIMA 模型提供了最佳的预测准确性。请注意,还有其他几种比较统计量可用于模型比较。
| 模型误差验证 |
|---|
| 模型 |
| 天真 |
| 平均 |
| Winters ESM |
| 季节性 ARIMA |
表 3:模型误差率比较
总结
总之,构建强大的时间序列预测模型的秘诀是尽可能去除噪声(趋势、季节性和自相关),以便数据中仅剩下的运动是纯随机的。对于我们的数据,我们发现带有星期几回归变量的季节性 ARIMA 模型提供了最准确的预测。与前述的天真、平均和 ESM 模型相比,ARIMA 模型的预测更为准确。
虽然没有任何时间序列模型能帮助你改善爱情生活,但你可以使用许多类型的时间序列模型来预测从页面浏览量到能源销售的各种数据。准确预测你关注的变量的关键是首先了解你的数据,其次应用最符合数据需求的模型。
克里斯·圣乔,Zencos 数据科学团队的顾问,帮助企业从数据中发现可操作的见解。在担任爱达荷州劳动部经济学家期间,克里斯为技术利益相关者制作了劳动预测和经济影响分析。克里斯拥有经济学学士学位和 NC State University 高级分析研究所的分析硕士学位。克里斯对机器学习和预测建模的热情仅次于他对家庭的热爱。无论是徒步旅行还是探索新博物馆,他总是和妻子及两个孩子一起不断前行。
肖恩·安肯布鲁克凭借在政府、投资银行、批发能源交易和网页应用开发方面的经验,为 Zencos 团队带来了多样的背景。他对编程充满热情,享受运用自己的技能解决复杂问题的机会。在从事分析项目之外,肖恩还花时间为 Zencos 博客做贡献,他利用数据讲述有趣的故事。肖恩来自北卡罗来纳州,获得了 NC State University 的商业学士学位和分析硕士学位。
相关:
-
时间序列分析:入门
-
广义加性模型的时间序列分析
-
时间序列数据的自动特征工程
更多相关话题
使用 Ploomber、Arima、Python 和 Slurm 进行时间序列预测
原文:
www.kdnuggets.com/2022/03/time-series-forecasting-ploomber-arima-python-slurm.html
在这篇博客中,我们将回顾如何将一个用于时间序列预测的原始 .ipynb 笔记本,模块化为一个 Ploomber 管道,并在 Slurm 上运行并行作业。你可以按照本指南中的步骤自行部署。我们使用了 这份笔记本 由 Willie Wheeler 提供。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
简短的笔记本解释
这个笔记本由 8 个任务组成,我们将在下面的图表中看到。它包括建模的大多数基本步骤——获取数据、清洗数据、拟合、超参数调优、验证和可视化。作为捷径,我使用了 Soorgeon 工具将笔记本自动模块化成 Ploomber 管道。这将所有依赖项提取到一个 requirements.txt 文件中,将标题拆分为独立任务,并根据这些模块化任务创建了一个管道。使用 Ploomber 的主要好处是它允许我更快地进行实验,因为它会缓存先前运行的结果,并且可以轻松地将并行作业提交到 SLURM 以微调模型。
本地运行管道?
首先运行这个命令来在本地克隆示例(如果你还没有 ploomber,首先 安装 Ploomber):
ploomber examples -n templates/timeseries -o ts
cd ts
现在你在本地有了管道,你可以进行一个完整性检查并运行:
ploomber status
这应该会展示管道的所有步骤及其状态(尚未运行),这是一个参考输出:
如果你只对时间序列部分感兴趣,你也可以在本地构建管道。接下来,我们将看到如何在 Slurm 集群上开始执行,并且如何进行并行运行。
在 Slurm 上编排
为了简化,我们将展示如何使用 Docker 启动一个 SLURM 集群,但如果你有现成的集群可以使用,也可以使用那个。我们创建了一个名为 Soopervisor 的工具,它允许我们将管道部署到 SLURM 以及其他平台如 Kubernetes、Airflow 和 AWS Batch。我们将遵循Slurm 指南。
你必须有一个正在运行的 docker 代理才能启动集群,在这里阅读更多关于如何开始使用 Docker。
第一步
创建一个 docker-compose.yml。
wget https://raw.githubusercontent.com/ploomber/projects/master/templates/timeseries/docker-compose.yml
一旦完成,启动集群:
docker-compose up -d
现在我们可以通过以下命令连接到集群:
docker-compose exec slurmjupyter /bin/bash
第二步
现在我们已经进入集群,我们需要对其进行引导,并确保我们拥有要运行的管道。
获取引导脚本并运行,这是引导集群的脚本:
wget https://raw.githubusercontent.com/ploomber/projects/master/templates/timeseries/start.sh
chmod 755 start.sh
./start.sh
获取时间序列管道模板:
ploomber examples -n templates/timeseries -o ts
cd ts
安装需求并通过 soopervisor 添加:
ploomber install
soopervisor add cluster –backend slurm
这将创建一个包含 soopervisor 用于提交 Slurm 任务的模板(template.sh)的集群目录。
我们执行导出命令以转换管道并将作业提交到集群。完成后,我们可以在output文件夹中查看所有输出:
soopervisor export cluster
ls -l ./output
我们可以看到这里一些由模型生成的预测:
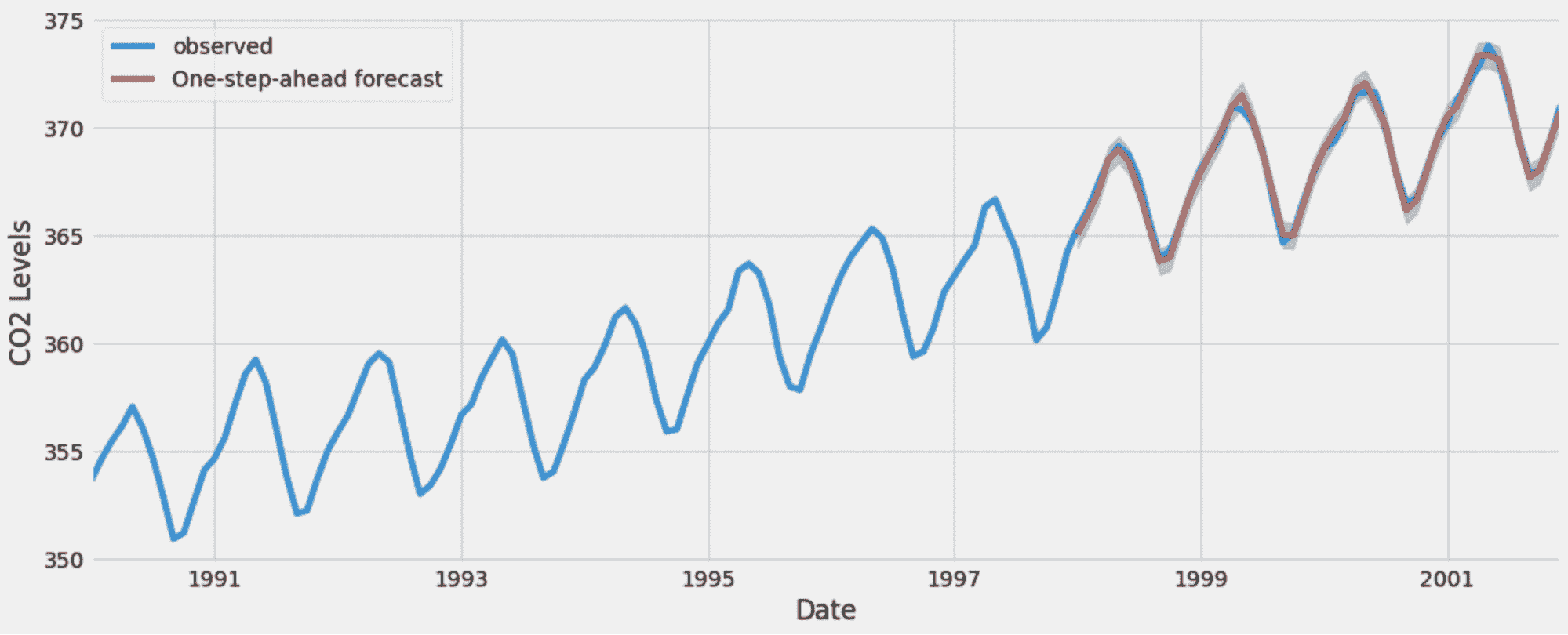
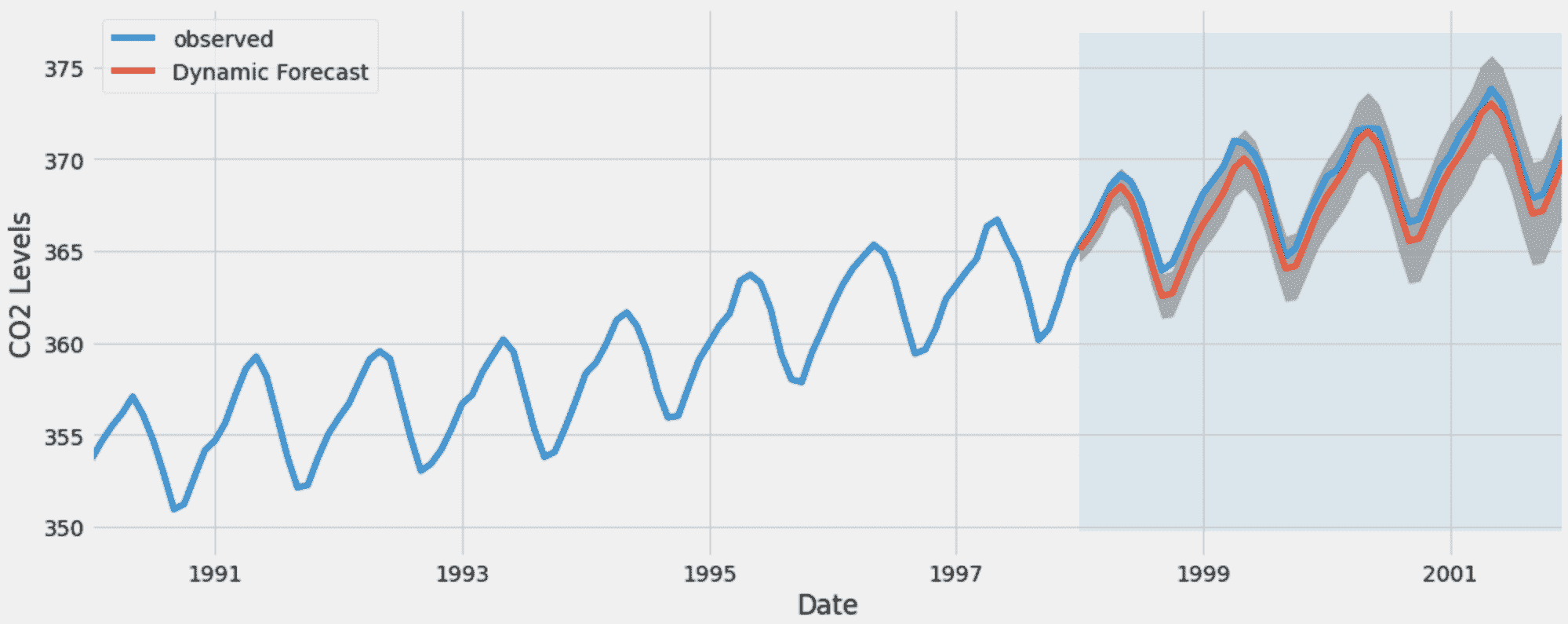
请注意,如果你再次运行,只有变化的任务会运行(有一个缓存来管理它)。完成后,不要忘记关闭集群:
docker-compose stop
总结
本博客展示了如何将时间序列作为模块化管道运行,这样可以扩展到分布式集群训练。我们从一个笔记本开始,转移到管道中,并在 SLURM 集群上执行。一旦我们过了单个用户在笔记本上的阶段(例如团队或生产任务),确保能够扩展、协作并可靠地执行工作就变得很重要。由于数据科学是一个迭代过程,Ploomber 为你提供了一个简单的机制来标准化工作,并在开发和生产环境之间快速移动。
确保与我们以及其他数百名社区成员通过 slack进行连接。
如果你有任何反馈或评论,我很乐意听取!
Ido Michael 共同创立了 Ploomber,旨在帮助数据科学家更快地构建。他曾在 AWS 领导数据工程/科学团队。在这些客户合作中,他与团队一起独立构建了数百个数据管道。来自以色列的他来到纽约,获得了哥伦比亚大学的硕士学位。在发现项目常常需要将约 30%的时间用于将开发工作(原型)重构为生产管道后,他专注于构建 Ploomber。
相关话题
使用 PyCaret 回归模块进行时间序列预测
原文:
www.kdnuggets.com/2021/04/time-series-forecasting-pycaret-regression-module.html
评论
由 Moez Ali,PyCaret 的创始人和作者

由Lukas Blazek在Unsplash提供的照片
PyCaret
PyCaret 是一个开源、低代码的机器学习库和端到端模型管理工具,内置于 Python 中,用于自动化机器学习工作流。由于其易用性、简单性和快速高效地构建和部署端到端机器学习原型的能力,它非常受欢迎。
PyCaret 是一个替代的低代码库,可以用少量代码替换成百上千行代码。这使得实验周期变得指数级地快速和高效。
PyCaret 是 简单且 易于使用 的。PyCaret 中执行的所有操作都按顺序存储在一个 Pipeline 中,该 Pipeline 完全自动化以进行 部署。无论是填补缺失值、独热编码、转换类别数据、特征工程还是超参数调整,PyCaret 都会自动完成所有这些操作。要了解更多关于 PyCaret 的信息,请观看这个 1 分钟的视频。
PyCaret — 一个开源、低代码的 Python 机器学习库
本教程假设你有一些 PyCaret 的先前知识和经验。如果你以前没有使用过,也没问题——你可以通过这些教程快速入门:
安装 PyCaret
安装 PyCaret 非常简单,只需几分钟。我们强烈建议使用虚拟环境以避免与其他库的潜在冲突。
PyCaret 的默认安装是一个精简版,只安装此处列出的硬依赖项。
**# install slim version (default)** pip install pycaret**# install the full version**
pip install pycaret[full]
当你安装 pycaret 的完整版本时,所有的可选依赖项也会被安装,详见此处。
???? PyCaret 回归模块
PyCaret 回归模块 是一个监督学习模块,用于估计 因变量(通常称为‘结果变量’或‘目标’)与一个或多个 自变量(通常称为‘特征’或‘预测变量’)之间的关系。
回归的目标是预测连续值,如销售额、数量、温度、客户数量等。PyCaret 的所有模块都提供许多 预处理 特性,通过 setup 函数准备数据用于建模。它拥有超过 25 种现成的算法和 若干图表 来分析训练模型的性能。
???? PyCaret 回归模块中的时间序列
时间序列预测可以大致分为以下几类:
-
经典 / 统计模型 — 移动平均、指数平滑、ARIMA、SARIMA、TBATS
-
机器学习 — 线性回归、XGBoost、随机森林或任何带有降维方法的 ML 模型
-
深度学习 — RNN, LSTM
本教程专注于第二类,即 机器学习。
PyCaret 的回归模块默认设置不适合时间序列数据,因为它涉及一些不适用于有序数据(如时间序列数据的数据)的数据准备步骤。
例如,数据集的训练集和测试集的划分是通过随机洗牌完成的。这对时间序列数据来说不合适,因为你不希望最近的日期被包含在训练集中,而历史日期则是测试集的一部分。
时间序列数据也需要一种不同的交叉验证方式,因为它需要尊重日期的顺序。PyCaret 回归模块默认使用 k-fold 随机交叉验证来评估模型。默认的交叉验证设置不适用于时间序列数据。
本教程的下一部分将演示如何轻松更改 PyCaret 回归模块中的默认设置,以便使其适用于时间序列数据。
???? 数据集
为了本教程的目的,我使用了美国航空乘客数据集。你可以从 Kaggle 下载数据集。
**# read csv file** import pandas as pd
data = pd.read_csv('AirPassengers.csv')
data['Date'] = pd.to_datetime(data['Date'])
data.head()
示例行
**# create 12 month moving average** data['MA12'] = data['Passengers'].rolling(12).mean()**# plot the data and MA** import plotly.express as px
fig = px.line(data, x="Date", y=["Passengers", "MA12"], template = 'plotly_dark')
fig.show()
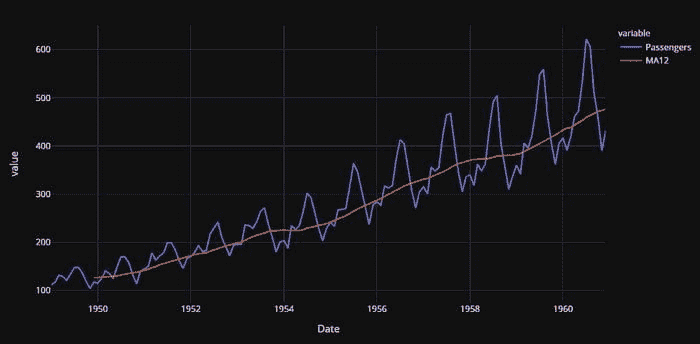
美国航空乘客数据集的时间序列图(移动平均 = 12)
由于算法不能直接处理日期,我们可以从日期中提取一些简单的特征,比如月份和年份,并删除原始日期列。
**# extract month and year from dates**
month = [i.month for i in data['Date']]
year = [i.year for i in data['Date']]**# create a sequence of numbers** data['Series'] = np.arange(1,len(data)+1)**# drop unnecessary columns and re-arrange** data.drop(['Date', 'MA12'], axis=1, inplace=True)
data = data[['Series', 'Year', 'Month', 'Passengers']] **# check the head of the dataset**
data.head()
提取特征后的示例行
**# split data into train-test set** train = data[data['Year'] < 1960]
test = data[data['Year'] >= 1960]**# check shape** train.shape, test.shape
>>> ((132, 4), (12, 4))
我在初始化 setup 之前手动划分了数据集。另一种方法是将整个数据集传递给 PyCaret,让它处理划分,在这种情况下,你需要在 setup 函数中传递 data_split_shuffle = False 以避免在划分前打乱数据集。
???? 初始化设置
现在是初始化 setup 函数的时候了,我们将显式传递训练数据、测试数据和使用 fold_strategy 参数的交叉验证策略。
**# import the regression module**
from pycaret.regression import ***# initialize setup**
s = setup(data = train, test_data = test, target = 'Passengers', fold_strategy = 'timeseries', numeric_features = ['Year', 'Series'], fold = 3, transform_target = True, session_id = 123)
???? 训练和评估所有模型
best = compare_models(sort = 'MAE')
来自 compare_models 的结果
基于交叉验证 MAE 的最佳模型是最小角回归(MAE: 22.3)。让我们检查测试集上的得分。
prediction_holdout = predict_model(best);

来自 predict_model(best) 函数的结果
测试集上的 MAE 比交叉验证的 MAE 高 12%。虽然效果不佳,但我们将继续使用它。让我们绘制实际与预测的线条,以可视化拟合情况。
**# generate predictions on the original dataset**
predictions = predict_model(best, data=data)**# add a date column in the dataset**
predictions['Date'] = pd.date_range(start='1949-01-01', end = '1960-12-01', freq = 'MS')**# line plot**
fig = px.line(predictions, x='Date', y=["Passengers", "Label"], template = 'plotly_dark')**# add a vertical rectange for test-set separation**
fig.add_vrect(x0="1960-01-01", x1="1960-12-01", fillcolor="grey", opacity=0.25, line_width=0)fig.show()
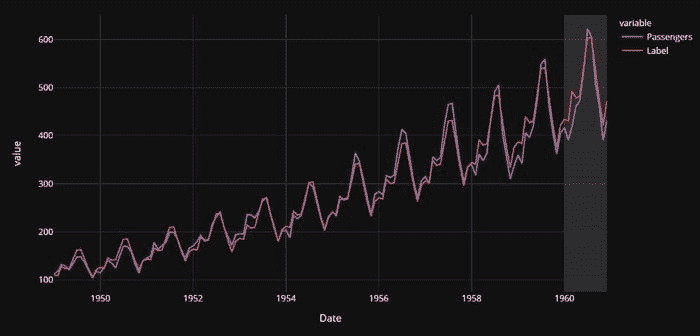
实际与预测的美国航空乘客数(1949–1960)
在最后的灰色背景区域是测试期(即 1960 年)。现在让我们完成模型,即在整个数据集上训练最佳模型,即最小角回归(这次包括测试集)。
final_best = finalize_model(best)
???? 创建一个未来评分数据集
现在我们已经在整个数据集(1949 到 1960 年)上训练了模型,让我们预测未来五年,直到 1964 年。为了使用我们的最终模型生成未来的预测,我们首先需要创建一个包含未来日期的月份、年份、系列列的数据集。
future_dates = pd.date_range(start = '1961-01-01', end = '1965-01-01', freq = 'MS')future_df = pd.DataFrame()future_df['Month'] = [i.month for i in future_dates]
future_df['Year'] = [i.year for i in future_dates]
future_df['Series'] = np.arange(145,(145+len(future_dates)))future_df.head()
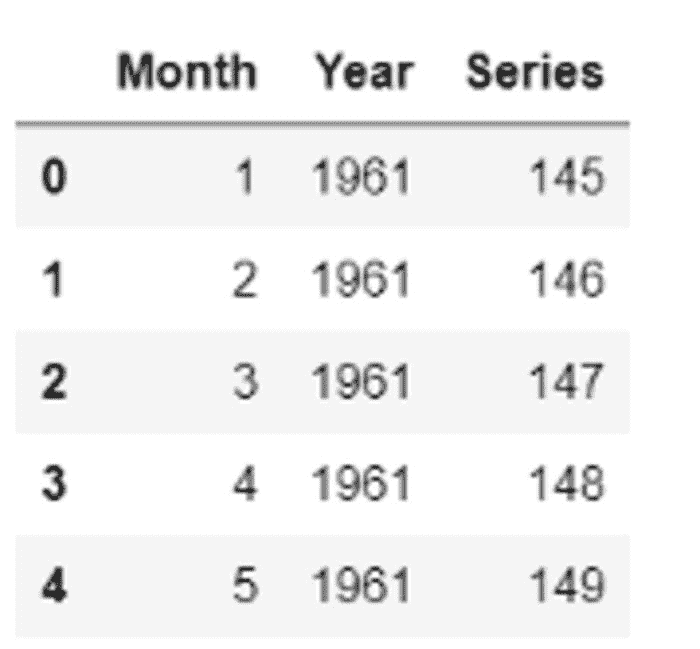
从 future_df 中抽取的样本行
现在,让我们使用future_df进行评分和生成预测。
predictions_future = predict_model(final_best, data=future_df)
predictions_future.head()
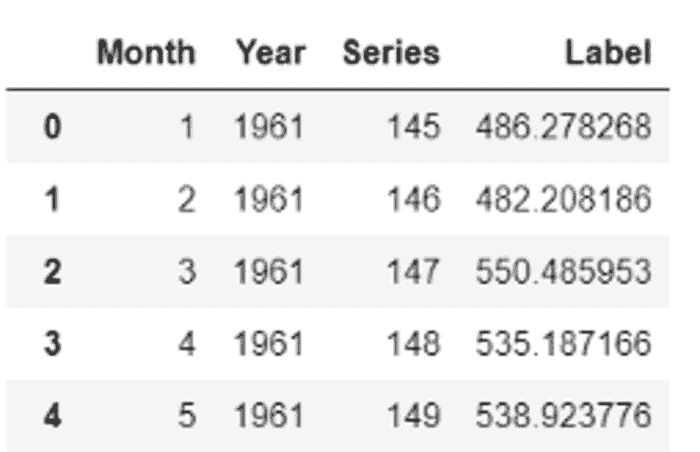
从 predictions_future 中抽取的样本行
让我们绘制它。
concat_df = pd.concat([data,predictions_future], axis=0)
concat_df_i = pd.date_range(start='1949-01-01', end = '1965-01-01', freq = 'MS')
concat_df.set_index(concat_df_i, inplace=True)fig = px.line(concat_df, x=concat_df.index, y=["Passengers", "Label"], template = 'plotly_dark')
fig.show()
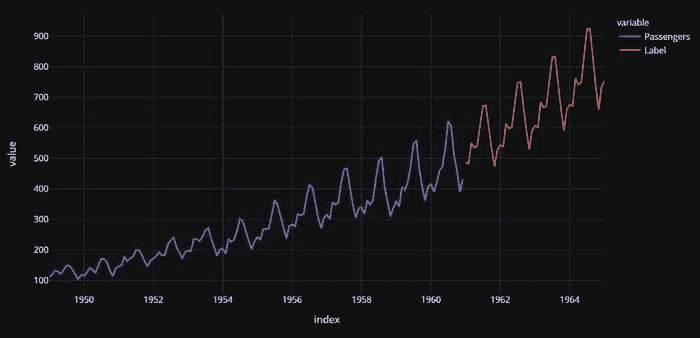
实际(1949–1960 年)与预测(1961–1964 年)的美国航空乘客数
这不是很简单吗?
使用这个轻量级工作流自动化库,你可以实现无限的可能。如果你觉得有用,请不要忘记在我们的 GitHub 仓库上给我们⭐️。
想了解更多关于 PyCaret 的内容,请关注我们的LinkedIn和Youtube。
加入我们的 Slack 频道。邀请链接这里。
你可能也对以下内容感兴趣:
使用 PyCaret 2.0 在 Power BI 中构建自己的 AutoML
在 Google Kubernetes Engine 上部署机器学习管道
使用 AWS Fargate 无服务器部署 PyCaret 和 Streamlit 应用
使用 PyCaret 和 Streamlit 构建和部署机器学习网络应用
在 GKE 上部署使用 Streamlit 和 PyCaret 构建的机器学习应用
重要链接
安装 PyCaret Notebook 教程 为 PyCaret 做贡献
想了解某个特定模块吗?
点击下面的链接查看文档和工作示例。
简介: Moez Ali 是一名数据科学家,同时是 PyCaret 的创始人和作者。
原文。经许可转载。
相关内容:
-
将机器学习管道部署到云端使用 Docker 容器
-
使用 PyCaret 进行自动化异常检测
-
GitHub 是你所需的最佳 AutoML 工具
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业领域。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
了解更多相关话题
使用 statsmodels 和 Prophet 进行时间序列预测
原文:
www.kdnuggets.com/2023/03/time-series-forecasting-statsmodels-prophet.html
时间序列是一种在数据科学领域独特的数据集。数据是按时间频率(例如:每日、每周、每月等)记录的,每个观察值与其他观察值相关。时间序列数据在你想分析数据随时间变化的情况并进行未来预测时非常有价值。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
时间序列预测是一种基于历史时间序列数据创建未来预测的方法。时间序列预测有许多统计方法,例如 ARIMA 或 指数平滑。
时间序列预测在商业中经常遇到,因此数据科学家了解如何开发时间序列模型是非常有益的。在本文中,我们将学习如何使用两个流行的预测 Python 包:statsmodels 和 Prophet 来进行时间序列预测。让我们开始吧。
使用 statsmodels 进行时间序列预测
statsmodels Python 包是一个开源包,提供了各种统计模型,包括时间序列预测模型。让我们用一个示例数据集来试用这个包。本文将使用来自 Kaggle 的 数字货币时间序列 数据(CC0:公共领域)。
让我们清理数据,看看我们拥有的数据集。
import pandas as pd
df = pd.read_csv('dc.csv')
df = df.rename(columns = {'Unnamed: 0' : 'Time'})
df['Time'] = pd.to_datetime(df['Time'])
df = df.iloc[::-1].set_index('Time')
df.head()
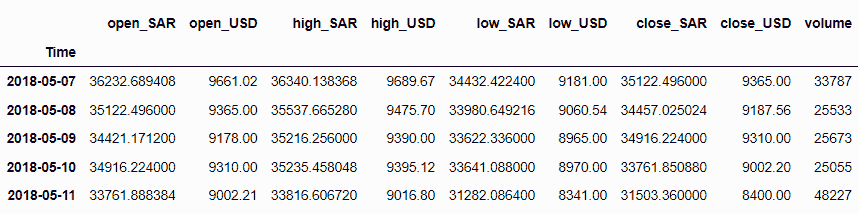
对于我们的示例,假设我们想预测‘close_USD’变量。让我们看看数据随时间的模式。
import matplotlib.pyplot as plt
plt.plot(df['close_USD'])
plt.show()
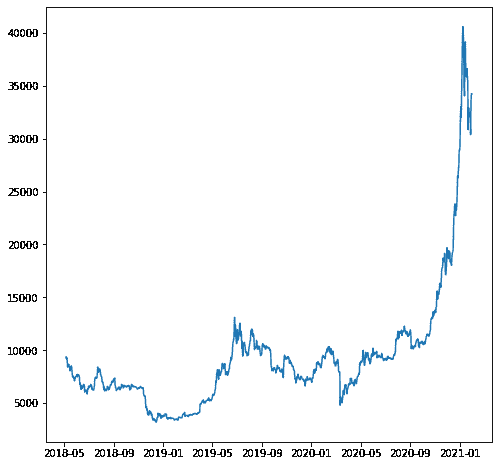
让我们基于上述数据构建预测模型。在建模之前,我们先将数据分为训练数据和测试数据。
# Split the data
train = df.iloc[:-200]
test = df.iloc[-200:]
我们不会随机分割数据,因为这是时间序列数据,我们需要保持顺序。相反,我们尝试从较早的数据中获取训练数据,从最新的数据中获取测试数据。
让我们使用 statsmodels 创建一个预测模型。statsmodel 提供了许多时间序列模型 API,但我们将使用 ARIMA 模型作为示例。
from statsmodels.tsa.arima.model import ARIMA
#sample parameters
model = ARIMA(train, order=(2, 1, 0))
results = model.fit()
# Make predictions for the test set
forecast = results.forecast(steps=200)
forecast
在我们的示例中,我们使用 statsmodels 的 ARIMA 模型作为预测模型,并尝试预测接下来的 200 天。
模型结果好吗?让我们来评估一下。时间序列模型评估通常使用可视化图来比较实际值和预测值,并使用回归指标如均绝对误差 (MAE)、均方根误差 (RMSE) 和均绝对百分比误差 (MAPE)。
from sklearn.metrics import mean_squared_error, mean_absolute_error
import numpy as np
#mean absolute error
mae = mean_absolute_error(test, forecast)
#root mean square error
mse = mean_squared_error(test, forecast)
rmse = np.sqrt(mse)
#mean absolute percentage error
mape = (forecast - test).abs().div(test).mean()
print(f"MAE: {mae:.2f}")
print(f"RMSE: {rmse:.2f}")
print(f"MAPE: {mape:.2f}%")
MAE: 7956.23
RMSE: 11705.11
MAPE: 0.35%
上述评分看起来不错,但我们来看看它们的可视化效果如何。
plt.plot(train.index, train, label='Train')
plt.plot(test.index, test, label='Test')
plt.plot(forecast.index, forecast, label='Forecast')
plt.legend()
plt.show()
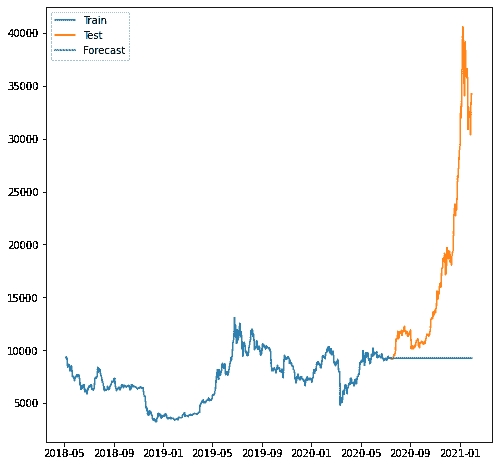
如我们所见,预测效果较差,因为我们的模型无法预测上升趋势。我们使用的 ARIMA 模型似乎过于简单。
也许我们可以尝试使用 statsmodels 之外的其他模型。让我们尝试一下 Facebook 的著名 Prophet 包。
使用 Prophet 进行时间序列预测
Prophet 是一个时间序列预测模型包,适用于具有季节性影响的数据。Prophet 还被认为是一个稳健的预测模型,因为它可以处理缺失数据和异常值。
让我们试试 Prophet 包。首先,我们需要安装这个包。
pip install prophet
之后,我们必须准备数据集以进行预测模型训练。Prophet 有一个特定要求:时间列需要命名为‘ds’,值列需要命名为‘y’。
df_p = df.reset_index()[["Time", "close_USD"]].rename(
columns={"Time": "ds", "close_USD": "y"}
)
数据准备好之后,我们来尝试基于数据创建预测。
import pandas as pd
from prophet import Prophet
model = Prophet()
# Fit the model
model.fit(df_p)
# create date to predict
future_dates = model.make_future_dataframe(periods=365)
# Make predictions
predictions = model.predict(future_dates)
predictions.head()
Prophet 的优点在于每个预测数据点都为用户提供了详细的信息。然而,仅从数据中很难理解结果。因此,我们可以尝试使用 Prophet 对其进行可视化。
model.plot(predictions)
模型的预测绘图函数会提供我们对预测的信心程度。从上述图中,我们可以看到预测有上升的趋势,但随着预测时间的延长,不确定性增加。
还可以使用以下函数检查预测组件。
model.plot_components(predictions)
默认情况下,我们会获得具有年度和每周季节性的数据显示趋势。这是一种很好的方式来解释数据的变化情况。
是否也可以评估 Prophet 模型?当然可以。Prophet 包括一个我们可以使用的诊断测量:时间序列交叉验证。该方法使用历史数据的一部分,每次使用截止点之前的数据拟合模型。然后 Prophet 将预测结果与实际结果进行比较。让我们尝试使用代码。
from prophet.diagnostics import cross_validation, performance_metrics
# Perform cross-validation with initial 365 days for the first training data and the cut-off for every 180 days.
df_cv = cross_validation(model, initial='365 days', period='180 days', horizon = '365 days')
# Calculate evaluation metrics
res = performance_metrics(df_cv)
res
在上述结果中,我们获得了每个预测日实际结果与预测结果的评估结果。也可以使用以下代码可视化结果。
from prophet.plot import plot_cross_validation_metric
#choose between 'mse', 'rmse', 'mae', 'mape', 'coverage'
plot_cross_validation_metric(df_cv, metric= 'mape')
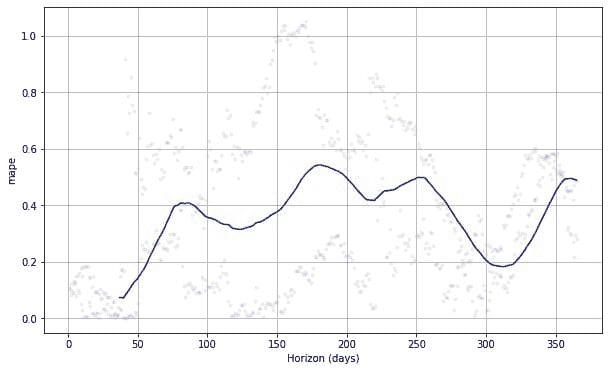
如果我们查看上面的图表,可以看到预测误差随着天数的变化而变化,在某些点可能达到 50%的误差。这样,我们可能需要进一步调整模型以修正误差。你可以查看文档以进行进一步探索。
结论
预测是商业中常见的情况之一。开发预测模型的一种简单方法是使用 statsforecast 和 Prophet Python 包。本文将介绍如何创建预测模型并使用 statsforecast 和 Prophet 进行评估。
Cornellius Yudha Wijaya 是一名数据科学助理经理和数据撰稿人。在全职工作于印尼安联期间,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
更多相关话题
使用 SQL 处理时间序列
评论
由 Michael Grogan,数据科学顾问
Python 或 R 等工具通常用于进行深入的时间序列分析。
然而,了解如何使用 SQL 处理时间序列数据是必不可少的,特别是当处理非常大的数据集或不断更新的数据时。
这里有一些可以在 SQL 中调用的有用命令,用于更好地处理数据表中的时间序列数据。
背景
在这个例子中,我们将处理在不同时间和地点收集的天气数据。
PostgreSQL 数据库表中的数据类型如下:
weather=# SELECT COLUMN_NAME, DATA_TYPE FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME = 'weatherdata';
column_name | data_type
-------------+-----------------------------
date | timestamp without time zone
mbhpa | integer
temp | numeric
humidity | integer
place | character varying
country | character varying
realfeel | integer
timezone | integer
(8 rows)
如你所见,date 被定义为没有时区的时间戳数据类型(我们在本文中也会讨论这一点)。
我们关注的变量是 temp(温度)——我们将探讨如何使用 SQL 更直观地分析这个变量。
计算移动平均值
这是数据表中一些列的片段:
date | mbhpa | temp | humidity
---------------------+-------+-------+----------
2020-10-12 18:33:24 | 1010 | 13.30 | 74
2020-10-15 02:12:54 | 1017 | 7.70 | 75
2020-10-14 23:53:42 | 1016 | 8.80 | 75
2020-10-15 11:03:25 | 1016 | 9.70 | 75
2020-10-15 13:05:23 | 1017 | 12.30 | 74
2020-10-15 18:47:25 | 1015 | 12.10 | 74
2020-10-16 23:23:23 | 1011 | 9.10 | 75
2020-10-20 10:25:15 | 967 | 13.80 | 83
2020-10-27 16:30:30 | 980 | 12.00 | 75
2020-10-29 15:12:07 | 988 | 11.70 | 75
2020-10-28 18:42:52 | 990 | 8.80 | 77
假设我们希望计算不同时间段的温度移动平均值。
为此,我们首先需要确保数据按日期排序,并决定在平均窗口中包含多少期。
首先,使用 7 期移动平均值,并按日期排序所有温度值。
>>> select date, avg(temp) OVER (ORDER BY date ROWS BETWEEN 6 PRECEDING AND CURRENT ROW) FROM weatherdata where place='Place Name'; date | avg
---------------------+---------------------
2020-11-12 16:36:40 | 8.8285714285714286
2020-11-14 15:45:08 | 9.8142857142857143
2020-11-15 08:53:26 | 10.3857142857142857
2020-11-17 10:50:32 | 11.2285714285714286
2020-11-18 14:18:58 | 11.8000000000000000
2020-11-25 14:54:11 | 11.6285714285714286
2020-11-25 19:00:21 | 10.9142857142857143
2020-11-25 19:05:31 | 10.2000000000000000
2020-11-25 23:41:34 | 9.2857142857142857
2020-11-26 15:03:10 | 9.4857142857142857
2020-11-26 17:18:33 | 8.3428571428571429
2020-11-26 21:30:39 | 7.9142857142857143
2020-11-26 22:29:17 | 7.6142857142857143
现在,让我们添加 30 期和 60 期的移动平均值。我们将把这些平均值与 7 期移动平均值一起存储在一个表中。
>>> select date, temp, avg(temp) OVER (ORDER BY date ROWS BETWEEN 2 PRECEDING AND CURRENT ROW), avg(temp) OVER (ORDER BY date ROWS BETWEEN 6 PRECEDING AND CURRENT ROW), avg(temp) OVER (ORDER BY date ROWS BETWEEN 29 PRECEDING AND CURRENT ROW), avg(temp) OVER (ORDER BY date ROWS BETWEEN 59 PRECEDING AND CURRENT ROW) FROM weatherdata where place='Place Name';
来源:作者创建的输出
有关如何在 SQL 中计算移动平均值的更多信息,请参见 sqltrainingonline.com 提供的资源。
处理时区
你会注意到时间戳包含日期和时间。虽然在表中仅存储一个地点时这样没问题,但处理跨多个时区的地点时情况会变得相当复杂。
请注意,表中创建了一个名为timezone的整数变量。
假设我们正在分析不同地点的天气模式,这些地点的时间范围在输入时间之前——在这种情况下,所有数据点都是以 GMT 时间输入的。
date | timezone
---------------------+----------
2020-05-09 15:29:00 | 11
2020-05-09 17:05:00 | 11
2020-05-09 17:24:00 | 11
2020-05-10 13:02:00 | 11
2020-05-13 19:13:00 | 11
2020-05-10 13:04:00 | 11
2020-05-10 15:47:00 | 11
2020-05-13 19:10:00 | 11
2020-05-14 17:17:00 | 11
2020-05-09 15:20:00 | 5
2020-05-09 17:04:00 | 5
2020-05-09 17:25:00 | 5
2020-05-09 18:12:00 | 5
2020-05-10 13:02:00 | 5
2020-05-10 15:50:00 | 5
2020-05-10 20:32:00 | 5
2020-05-11 17:31:00 | 5
2020-05-13 19:11:00 | 5
2020-05-17 21:41:00 | 11
2020-05-15 14:08:00 | 11
2020-05-14 16:55:00 | 5
2020-05-15 14:10:00 | 5
(22 rows)
新时间可以按如下方式计算:
weather=# select date + interval '1h' * timezone from weatherdata;
?column?
---------------------
2020-05-10 02:29:00
2020-05-10 04:05:00
2020-05-10 04:24:00
2020-05-11 00:02:00
2020-05-14 06:13:00
2020-05-11 00:04:00
2020-05-11 02:47:00
2020-05-14 06:10:00
2020-05-15 04:17:00
2020-05-09 20:20:00
2020-05-09 22:04:00
2020-05-09 22:25:00
2020-05-09 23:12:00
2020-05-10 18:02:00
2020-05-10 20:50:00
2020-05-11 01:32:00
2020-05-11 22:31:00
2020-05-14 00:11:00
2020-05-18 08:41:00
2020-05-16 01:08:00
2020-05-14 21:55:00
2020-05-15 19:10:00
(22 rows)
现在,我们可以将新的时间存储为更新后的变量,我们将其命名为newdate。
>>> select date + interval '1h' * (timezone+1) as newdate, temp, mbhpa from weatherdata; newdate | temp | mbhpa
--------------------+------+-------
2020-05-10 03:29:00 | 4.2 | 1010
2020-05-10 05:05:00 | 4.1 | 1009
2020-05-10 05:24:00 | 3.8 | 1009
该子句允许我们生成更新的时间(这些时间将反映记录变量(如温度、气压等)时的实际时间)。
内连接和 Having 子句
你会在上述表格中注意到温度值包括了多个地方。
假设风速也在一个单独的表中为每个地方计算。
在这种情况下,我们希望计算每个列出的地方在风速高于 20 时的平均温度。
可以通过以下方式使用内连接和having子句来实现:
>>> select t1.place, avg(t1.temp), avg(t2.gust) from weatherdata as t1 inner join wind as t2 on t1.place=t2.place group by t1.place having avg(t2.gust)>'20'; place | avg | avg
-----------------+----------------------+----------------------
Place 1 | 17.3 | 22.4
Place 2 | 14.3 | 26.8
Place 3 | 7.1 | 27.1
结论
在本文中,你已接触到一些使用 SQL 处理时间序列数据的入门示例。
具体来说,你学习了如何:
-
计算移动平均值
-
与不同的时区工作
-
计算不同数据子集的平均值
感谢你的时间,任何问题或反馈都非常欢迎。
免责声明:本文是基于“现状”写成的,不提供任何保证。本文旨在提供数据科学概念的概述,不应被解读为专业建议。本文中的发现和解释仅代表作者观点,与本文提到的任何第三方无关。
简历:Michael Grogan 是一名数据科学顾问。他在时间序列分析、统计学、贝叶斯建模和使用 TensorFlow 的机器学习方面拥有专业知识。
原文。经许可转载。
相关:
-
多维多传感器时间序列数据分析框架
-
使用 Python 进行拒绝采样
-
深度学习正变得过度使用
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 事务
相关主题更多内容
时间序列分析:Python 中的 ARIMA 模型
原文:
www.kdnuggets.com/2023/08/times-series-analysis-arima-models-python.html
时间序列分析广泛用于预测和预测时间序列中的未来点。自回归积分移动平均(ARIMA)模型广泛用于时间序列预测,并被认为是最受欢迎的方法之一。在本教程中,我们将学习如何在 Python 中构建和评估 ARIMA 模型以进行时间序列预测。
什么是 ARIMA 模型?
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT 工作
ARIMA 模型是一种用于分析和预测时间序列数据的统计模型。ARIMA 方法专门针对时间序列中常见的结构,提供了一种简单而强大的方法来进行熟练的时间序列预测。
ARIMA 代表自回归积分移动平均。它结合了三个关键方面:
-
自回归(AR):一个使用当前观测值与滞后观测值之间的相关性的模型。滞后观测值的数量被称为滞后阶数或 p。
-
积分(I):使用原始观测值的差分来使时间序列平稳。差分操作的次数称为 d。
-
移动平均(MA):模型考虑当前观测值与应用于过去观测值的移动平均模型残差误差之间的关系。移动平均窗口的大小是阶数或 q。
ARIMA 模型用 ARIMA(p,d,q) 进行定义,其中 p、d 和 q 被替换为整数值以指定所使用的确切模型。
采用 ARIMA 模型时的关键假设:
-
时间序列是从一个潜在的 ARIMA 过程生成的。
-
参数 p、d、q 必须根据原始观测值适当地指定。
-
在拟合 ARIMA 模型之前,时间序列数据必须通过差分处理使其平稳。
-
如果模型拟合良好,残差应该是无相关性且呈正态分布的。
总结而言,ARIMA 模型提供了一种结构化和可配置的方法,用于时间序列数据建模,例如预测。接下来我们将探讨如何在 Python 中拟合 ARIMA 模型。
Python 代码示例
在本教程中,我们将使用来自 Kaggle 的Netflix 股票数据来预测 Netflix 的股票价格,使用 ARIMA 模型。
数据加载
我们将使用“Date”列作为索引加载我们的股票价格数据集。
import pandas as pd
net_df = pd.read_csv("Netflix_stock_history.csv", index_col="Date", parse_dates=True)
net_df.head(3)

数据可视化
我们可以使用 pandas 的'plot'函数来可视化股票价格和成交量随时间的变化。显然,股票价格在指数增长。
net_df[["Close","Volume"]].plot(subplots=True, layout=(2,1));
滚动预测 ARIMA 模型
我们的数据集已经分成训练集和测试集,并且我们开始训练一个 ARIMA 模型。然后进行了第一次预测。
我们使用通用 ARIMA 模型得到了不佳的结果,因为它产生了一条平坦的线。因此,我们决定尝试滚动预测方法。
注意: 代码示例是 BOGDAN IVANYUK 的notebook的修改版本。
from statsmodels.tsa.arima.model import ARIMA
from sklearn.metrics import mean_squared_error, mean_absolute_error
import math
train_data, test_data = net_df[0:int(len(net_df)*0.9)], net_df[int(len(net_df)*0.9):]
train_arima = train_data['Open']
test_arima = test_data['Open']
history = [x for x in train_arima]
y = test_arima
# make first prediction
predictions = list()
model = ARIMA(history, order=(1,1,0))
model_fit = model.fit()
yhat = model_fit.forecast()[0]
predictions.append(yhat)
history.append(y[0])
处理时间序列数据时,由于对先前观测值的依赖,通常需要进行滚动预测。一种方法是在接收到每个新观测值后重新创建模型。
为了跟踪所有观测值,我们可以手动维护一个名为 history 的列表,该列表最初包含训练数据,并在每次迭代中追加新的观测值。这种方法可以帮助我们获得准确的预测模型。
# rolling forecasts
for i in range(1, len(y)):
# predict
model = ARIMA(history, order=(1,1,0))
model_fit = model.fit()
yhat = model_fit.forecast()[0]
# invert transformed prediction
predictions.append(yhat)
# observation
obs = y[i]
history.append(obs)
模型评估
我们的滚动预测 ARIMA 模型相比于简单实现显示了 100%的改进,结果令人印象深刻。
# report performance
mse = mean_squared_error(y, predictions)
print('MSE: '+str(mse))
mae = mean_absolute_error(y, predictions)
print('MAE: '+str(mae))
rmse = math.sqrt(mean_squared_error(y, predictions))
print('RMSE: '+str(rmse))
MSE: 116.89611817706545
MAE: 7.690948135967959
RMSE: 10.811850821069696
让我们可视化并比较实际结果和预测结果。很明显,我们的模型进行了非常准确的预测。
import matplotlib.pyplot as plt
plt.figure(figsize=(16,8))
plt.plot(net_df.index[-600:], net_df['Open'].tail(600), color='green', label = 'Train Stock Price')
plt.plot(test_data.index, y, color = 'red', label = 'Real Stock Price')
plt.plot(test_data.index, predictions, color = 'blue', label = 'Predicted Stock Price')
plt.title('Netflix Stock Price Prediction')
plt.xlabel('Time')
plt.ylabel('Netflix Stock Price')
plt.legend()
plt.grid(True)
plt.savefig('arima_model.pdf')
plt.show()
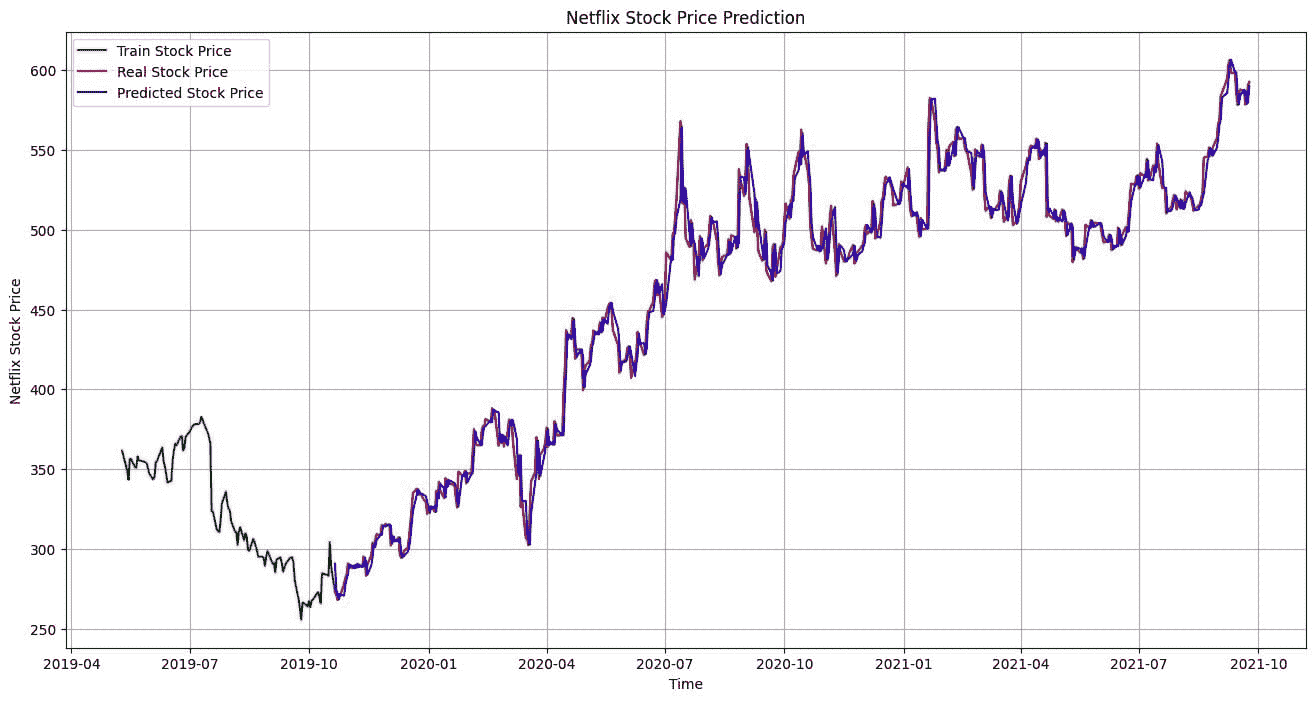
结论
在本简短教程中,我们概述了 ARIMA 模型及其在 Python 中实现时间序列预测的方法。ARIMA 方法提供了一种灵活且结构化的方式来建模依赖于先前观测值以及过去预测错误的时间序列数据。如果你对 ARIMA 模型和时间序列分析的全面分析感兴趣,我建议查看基于时间序列分析的股票市场预测。
Abid Ali Awan (@1abidaliawan) 是一位认证数据科学专家,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理健康问题的学生开发 AI 产品。
更多相关主题
为什么 TinyML 案例越来越受欢迎?
原文:
www.kdnuggets.com/2022/10/tinyml-cases-becoming-popular.html

各类组织都使用机器学习来处理和分析大型数据集。TinyML(Tiny Machine Learning)是一种机器学习 API,因其低功耗能力而日益受到欢迎。TinyML 正迅速成为从初学者层面掌握机器学习的最佳选择之一。
本文将概述 TinyML 的定义、应用场景以及它为何越来越受欢迎。
什么是 TinyML?
Tiny Machine Learning(TinyML)是一种优化的机器学习技术,允许机器学习模型(软件)在使用极低功耗微控制器的嵌入式系统上运行。
嵌入式系统由为特定功能设计的计算机硬件和软件组成。它们仅为一个目的而开发,这也是它们与笔记本电脑、PC、平板电脑和智能手机等典型计算机系统不同的原因。嵌入式系统的一个例子是电子计算器或 ATM。
TinyML 以非常优化的方式使机器学习在微控制器和物联网(IoT)设备上得以实现,这意味着可以利用和分析大量数据,同时消耗极少的电力。
现在让我们更详细地了解微控制器。
微控制器概述
微控制器由计算机处理器、RAM、ROM 和嵌入式系统的输入/输出(I/O)端口组成,这是允许嵌入式系统处理软件的常见硬件配置。
使用微控制器的主要好处包括:
-
低功耗 - 微控制器是低功耗硬件,工作时只需几毫瓦和微瓦。这意味着微控制器的功耗约为普通计算机系统的千分之一。
-
低价格 - 微控制器非常便宜,仅在 2020 年就出货超过 280 亿个。
-
多功能使用 - 微控制器可以用于所有设备、工具和家电。
TinyML 的优势
使用 TinyML 有三个主要的优势:
-
数据可以低延迟处理 - 由于 TinyML 允许在设备上进行分析而无需连接到服务器,嵌入式系统可以几乎没有延迟(低延迟)地处理数据并产生输出。
-
无需连接 - 该设备无需互联网连接即可使 TinyML 模型正常工作。
-
数据隐私 - 由于所有数据都保存在设备内部且没有连接,因此数据被泄露的风险极低。
TinyML 的实施
有一些流行的机器学习框架支持 TinyML。
-
Edge Impulse 是一个免费的边缘设备(提供网络入口的硬件)机器学习开发平台。一个例子可能是路由器或路由交换机。
-
TensorFlow Lite 是一套工具库,允许开发人员在嵌入式系统、边缘设备和其他独立设备上启用设备端机器学习。
-
PyTorch Mobile 是一个开源的移动平台机器学习框架,兼容 TinyML。
为什么 TinyML 越来越受欢迎?
物联网(IoT)网络在各个行业中变得越来越普遍。因此,需要更多的边缘设备来连接电源和网络端点;TinyML 以具有成本效益的方式满足这些要求。
如前所述,TinyML 在不需要互联网连接的低功耗微控制器上工作。这使得设备能够在不消耗大量资源的情况下实时处理和响应数据。
TinyML 模型可以作为云环境的替代方案,降低成本,减少能耗,并提供更多的数据隐私。所有数据都在单个设备上处理,没有延迟,确保了令人印象深刻的连接和处理速度。
TinyML 在 2022 年变得越来越受欢迎,研究人员预计未来将进一步增长。技术研究和战略指导集团 ABI 预测,到 2030 年,将有 25 亿台设备使用 TinyML 系统。
TinyML 的优势从即时分析到零延迟,使其成为一个在依赖速度的世界中显而易见的选择。此外,本地数据处理意味着敏感信息比集中数据中心更好地保护免受网络犯罪分子的威胁。
TinyML 面临的挑战
尽管 TinyML 的好处和潜力很明显,但它并非没有挑战,这些挑战可能对开发人员构成一些问题。
-
有限的内存容量 - 使用 TinyML 的嵌入式系统的内存通常只有几兆字节,有时甚至只有几千字节。这对 TinyML 模型的复杂性施加了重大限制,因此只有少数框架可以用于 TinyML 开发。
-
无法远程故障排除 - 由于 TinyML 模型仅在本地设备上运行,开发人员进行故障排除以确定和修复问题变得更加困难。这就是云环境提供优势的地方。
TinyML 在实际情况中如何应用?
TinyML 可以有效应用于许多不同的行业,几乎所有使用 IoT 网络和数据的行业。以下是一些 TinyML 已用于推动操作的行业。
农业
TinyML 设备已被用于监控和收集实时的农作物和牲畜数据。一个市场领先的例子是由瑞典的边缘 AI 产品公司 Imagimob 开发的。Imagimob 已与欧盟内的 55 个组织合作,以了解 TinyML 如何提供成本效益高的牲畜和作物管理。
在一项研究中,两台拖拉机配备了 Dialog IoT Kit(博世传感器)设备和安卓手机以收集数据。这些数据要么由拖拉机操作员实时记录,要么通过分析智能手机的视频流来记录。
Imagimob 的 AI 软件已安装在传感器、电池和长程无线电设备上,以改善这种方法,并允许农民通过加速度计和陀螺仪传感器监控作物,通过网络发送几乎实时的数据。
零售
TinyML 已被零售行业采纳,用于监控库存,当库存低并需要重新订购时发送警报。
医疗
TinyML 还可以用于实时健康监测设备,为患者提供更好、更个性化的护理。例如,助听器是电池供电的硬件,使用低功耗微控制器,意味着它们需要最少的资源来有效运行。利用 TinyML,研究人员能够在不损失性能的情况下减少这些设备的延迟。
未来,实现 TinyML 设备可能会扩展到所有行业,帮助企业管理财务、处理发票、与客户更好地合作、收集和分析数据等。
制造
TinyML 可用于推动预测性维护工具,帮助减少任何停机时间和因设备停运而产生的额外成本。
结论
TinyML 在使用物联网 (IoT) 设备的各个行业中越来越受欢迎。这是因为 TinyML 模型可以在微控制器上运行,以提供特定功能,同时使用非常少的电力。
尽管是低功耗解决方案,TinyML 设备可以低延迟地处理数据,而无需互联网连接。这种缺乏网络连接的特点也有助于保护收集的数据免受黑客攻击。
TinyML 已被农业、制造业和医疗行业有效使用,其受欢迎程度预计将进一步增长。
Nahla Davies 是一名软件开发人员和技术作家。在全职从事技术写作之前,她曾在一家 Inc. 5000 级体验品牌机构担任首席程序员,该机构的客户包括三星、时代华纳、Netflix 和索尼。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关内容
成功应对初级数据科学职位面试的技巧
原文:
www.kdnuggets.com/tips-for-successfully-navigating-beginner-data-science-job-interviews

数据科学。它令人兴奋,也令人紧张。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
它是跨学科的,并且不断演变。它揭示了数据中的谜团,并要求创新解决方案。这就是数据科学吸引人的原因,更不用说薪资丰厚了。
数据科学有时也令人沮丧,原因有时是相同的。加上激烈的竞争和期望、不断变化的目标和伦理困境。
踏入其中让你既想抓狂,又奇怪地享受其中。有点像跟随技术狂人在 Twitter 上。抱歉,埃隆,X。
对于那些初学者来说,尤其如此,他们在求职面试中争取获得第一个数据科学职位。
然而,通过正确的准备和心态,你可以自信地应对这些面试并留下深刻印象。以下是一些帮助你在初级数据科学职位面试中成功的技巧。
1. 彻底理解基础知识
你需要对基础概念如统计学、线性代数和编程有坚实的掌握。面试官通常会在深入更复杂的主题之前测试这些基础知识。
这些技能通常包括:
-
统计学
-
编程
-
数据处理
-
数据可视化
-
关系型数据库
-
机器学习
统计学
面试官期望的基础统计知识,即使是初学者,也包括这些统计概念。
*** 描述性统计:
-
中心趋势度量——均值、中位数和众数
-
离散度量——范围、方差、标准差和四分位差
-
形状度量——偏度和峰度
*** 概率:
-
基本概率概念
-
条件概率和贝叶斯定理
-
概率分布——正态、二项、泊松及其他
*** 推断统计:
-
抽样——总体、样本、抽样技术
-
假设检验 – 原假设和备择假设,I 型和 II 型错误,p 值和显著性水平
-
置信区间 – 基于样本数据估计总体参数。
*** 相关性与协方差:
-
理解两个变量之间的关系及其相互依赖性
-
Pearson 相关系数
*** 回归分析:
-
简单线性回归 – 两个连续变量之间的关系
-
多重回归 – 扩展到多个自变量
*** 分布:
-
正态分布
-
二项分布
-
泊松分布
-
指数分布
编程
你需要精通在数据科学中常用的编程语言。最受欢迎的三种语言是:
-
SQL
-
Python
-
R
你不需要在所有三种语言中都是专家。通常,精通一种语言并至少熟悉另外两种语言中的一种的基础知识就足够了。
一切都取决于职位描述。不同的公司和职位需要不同的语言。在数据科学中,通常是提到的三种语言中的一种。
如果你问我应该学习哪一个,只有一个的话,我会选择 SQL。查询数据库是数据科学家无法缺少的基础。SQL 专为此设计,没有其他语言能像它一样处理数据清理。
它也可以轻松与其他语言集成。这样,你可以利用其他语言完成 SQL 不适合的任务,例如,构建模型或数据可视化。
数据处理
这指的是你清理和转换数据的能力,包括处理缺失数据、异常值和变量转换。
这意味着你需要了解最受欢迎的数据处理库:
数据可视化
你必须了解不同类型数据和洞察的最佳可视化技术。你还必须知道如何使用可视化工具将其付诸实践:
-
matplotlib 和 seaborn – 用于 Python
-
ggplot2 – 用于 R
关系型数据库
作为数据科学家,你需要对关系型数据库及其工作原理有一个基本了解。如果你至少对使用 SQL 进行查询有基本知识,那更好。
一些最受欢迎的数据管理系统包括:
机器学习
你必须熟悉机器学习的基础知识。例如,了解监督学习与无监督学习的区别。
你还需要熟悉分类、聚类和回归。这包括了解一些基本算法,如线性回归、决策树、支持向量机、朴素贝叶斯和k 均值。
2. 了解你的工具
在面试前,熟悉流行的数据科学工具。这包括我们已经提到的编程语言,还包括一些其他平台。
你不需要了解所有工具。但如果你能在每个类别中至少有一个工具的使用经验,那将是理想的。

3. 准备编码和技术问题
使用如StrataScratch、LeetCode等平台来准备编码和技术问题。
此外,利用 YouTube 频道、博客和其他资源来复习其他技术概念。如果你专注于“彻底理解基础”中提到的内容,你会做得很好。
模拟面试可以非常有帮助。利用提供模拟面试的在线平台,或者与朋友和导师进行练习。
所有这些准备技巧将帮助你熟悉面试格式并改善你的回答。
4. 展示实际经验
如果你曾参与过个人项目或实习,利用它们来为自己加分。在面试中讨论这些经历,以突出你所面临的挑战、实施的解决方案和取得的成果。
5. 复习行为问题
技术技能通常占据了大部分招聘过程。然而,公司通常会花一些时间来回答行为问题。
这是可以预期的,因为你将与团队合作。面试官会想知道你如何与同事沟通、理解团队合作、处理压力和冲突,或者解决问题的方式。
准备一些来自你过去经历的例子,展示你的软技能和解决问题的能力。
6. 保持更新
数据科学正在迅速变化。因此,你需要保持对最新趋势、工具和技术的了解。阅读相关内容,加入在线论坛,参加网络研讨会,并参与工作坊,以保持自己与时俱进。
但是,不要过于执着于必须了解每一个新的“必备”或“必知”产品。
7. 提问
根据面试的形式,你可能会有机会在面试过程中或结束时提问。
这是你向面试官展示你对角色和公司的热情的机会。同时也是了解他们期望的机会。
询问团队当前的项目、公司的数据基础设施、计划以及他们面临的挑战。
8. 不要忘记软技能
除非结合了出色的沟通技巧,否则你的技术技能不会带来太大帮助。你将需要与技术和非技术团队成员及相关方沟通和合作。
在面试中,回答要清晰简洁。展示你将复杂话题简单解释的能力。这将向面试官展示你能够与非技术团队成员有效合作。这是一个非常重要的技能,因为数据科学并不是孤立存在的,其发现常常被非技术人员使用。
9. 保持冷静,继续前进
紧张是很自然的。只要不要因为紧张而更紧张!始终记住,面试官寻找的是最佳候选人,而不是完美的候选人。这里的最佳是指我们提到的所有要点的最佳组合。
如果在面试的某个阶段出现失误,不要失去信心——保持冷静,继续前进!候选人往往夸大自己错误的影响,而这些错误对面试官的印象可能几乎没有负面影响。
记住,面试不仅是让你了解公司,也是让公司了解你的机会。保持冷静,深呼吸,自信地回答每一个问题。
当然,自信不能伪造。它最好通过前八条建议的扎实准备来实现。
结论
是的,技术知识对于数据科学角色至关重要,即使是初级职位。但软技能、实践经验和对该领域的真正热情同样重要。
面试官主要寻找的是一个完整的候选人。这九条建议将涵盖所有要点。
现在,你需要给自己时间进行充分的准备。如果你对自己的准备水平有信心,带着积极的心态去面试会更容易。这样,你已经在通往获得第一份数据科学工作的道路上迈出了重要的一步。
祝好运!
内特·罗西迪 是一名数据科学家和产品策略专家。他还是一名分析学兼职教授,并且是 StrataScratch 的创始人,这是一个帮助数据科学家通过顶级公司的真实面试问题为面试做好准备的平台。可以在 Twitter: StrataScratch 或 LinkedIn 上联系他。
更多相关内容
-
KDnuggets 新闻,6 月 8 日:21 个数据科学速查表…************
提升数据科学面试的 10 个技巧
原文:
www.kdnuggets.com/2016/11/tips-improve-your-data-science-interview.html
评论
面试的目的是筛选出不合格的候选人。然而,面试并不完美,有些方面并不能代表实际工作。有些人持愤世嫉俗的态度,将这一点作为被拒绝时的借口。他们会说:“他们为什么问我这个?谁都可以查出来!”虽然这可能是真的,但发泄并不会帮你找到工作。对于公司来说,拒绝优秀的人比雇佣一个不合适的人更有意义。作为数据科学家,我们应该了解假阳性和真阳性率的权衡!在这篇文章中,我会给你一些提高面试技能的建议和资源,帮助你减少因为不合理原因被拒绝的可能性。

-
准备并演练故事。你应该预期会有旨在了解你的态度/性格的问题,并且已经考虑好几个展示你过去优秀品质的例子。例如,亚马逊有一份领导力原则的清单,他们会根据这些原则进行面试。找类似的东西,花几个小时思考你做过的所有精彩事情,并写出简洁的回答。关键在于能够讲述一个短小的轶事,包含足够的细节来设置叙述,并证明你是完成了他们询问的好事的人。他们会问澄清性问题,如果他们愿意的话,但避免冗长和提供过多信息。无聊不会帮到你!
-
减少惊讶。面试中最难的部分是需要迅速思考来回答问题,而大家都在看着你,时间在滴答作响。即使是你平时认为很简单的问题,在这种环境下也会显得很难。通过了解每次面试中可能遇到的情况,并为你知道会发生的所有事情做好准备,尽量减少这种惊讶。 Glassdoor 有来自经历过面试的人的评论,所以在面试前做些研究,至少阅读一下现有的资料。总是询问招聘人员你可以期待什么以及他们的准备建议。
-
练习解决问题,可以大声朗读并在纸上写下解决方案。如果你是数据科学家,SQL 问题非常常见。可以从JitBits或ProgrammerInterview等地方找到示例问题,并实际解决它们。当你犯错时,写下你遗漏的部分,这样你就知道需要在这个话题上花更多时间。
-
建立并练习你的问题解决框架。在做了很多技术面试后,我发现相同的框架可以应用于大多数问题,并且这样做能给我带来思路的清晰和良好的势头。我会专门写一篇文章来阐述我使用的框架,但你会通过解决许多这些问题来开发自己的框架。
-
了解基础知识。像 Brilliant.org 的组合数学页面这样的资源会为你提供核心原理的复习以及测试自己的示例。你应该预计会有概率和统计的问题,所以不要浪费时间去记忆贝叶斯定理,而是可以提前准备。
-
了解常见的技术概念。如果你从事数据科学工作,你需要理解偏差/方差。你需要知道如何检测和处理过拟合模型。你需要知道处理类别高度不平衡的分类问题的策略。你需要了解各种模型结构的优缺点。你还需要理解算法的基本原理;例如,随机森林中的“随机”是什么,梯度提升是什么意思?把技术面试当作一场口头的综合考试,学习主要概念的核心原理。
-
了解公司。花时间思考公司的产品、你的工作如何影响业务核心,以及你会如何通过你的工作来解决一个重要问题。我记得在面试一个定价分析岗位时,面试官问我:你会如何为这个产品定价?我没有一个好的答案,这是不可接受的。你应该花时间深入思考这个角色可能涉及的问题,并能够有一些细致的讨论。我应该花时间了解该领域的定价通常是如何设置的,考虑几种方法,并研究他们的工程博客以尝试理解他们目前是如何做的。网络上有大量信息可以帮助你,你只需主动去寻找和吸收。
-
认识到仅仅具备技术资格只是其中的一部分。人们还会根据他们是否喜欢你来给出反馈。展现出良好的情绪,恭维他们和他们的公司,表现出你对角色的兴奋以及对机会的谦逊。喜欢你的人更容易原谅你的小技术缺陷,而不是对一个技术非常出色但行为粗鲁的人。与招聘人员的沟通也是如此。过于礼貌,发送跟进感谢信,并在每个机会中表达你的感激之情(这应该是真诚的!)。
-
认识到面试注定会很艰难,挣扎是正常的。最重要的是即使感到陷入困境并不知道如何继续,也不要放弃。不要让自己表露出明显的沮丧或冷漠。在这些时刻,你应该大声说出你遇到的困难和你发现的问题。如果你的解决方案不起作用,解释原因并尝试找出导致失败的部分。通常他们会给出温和的提示。重要的是保持好奇心并讨论出来。我曾有几次经历,离开时感到尴尬,确信自己面试失败了,结果后来得到的反馈却是他们觉得我做得很好,想让我进入下一轮。你永远不知道他们在想什么,所以保持积极!
-
最后,真正内化一个观念,那就是工作被拒绝并不是对你才能的评判。你很可能会被拒绝……几次。但没关系,因为这个世界很大,我们知道这是一个数字游戏。并不是每个人都适合每份工作和团队,即使他们在技术上非常优秀。有时你被拒绝是因为不合适,有时是因为你在面试中表现不佳(尽管你很适合这个职位),还有时是因为你永远无法理解的原因。当你被拒绝时,允许自己有时间吸收任何负面情绪,然后联系他们,感谢他们并获取反馈,了解如何改进。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
如果你想要更多建议或资源,这里有一篇关于从编码训练营毕业生中学到的经验的不错读物。还可以考虑购买一本帮助你准备的书,比如非常受欢迎且实用的《破解编程面试》。如果你有任何问题或其他建议,请在评论中留下!
相关:
-
如何成为数据科学家 – 第一部分
-
如何成为数据科学家 – 第二部分
-
完美数据科学面试的秘诀
更多相关话题
你能在泰坦尼克号上幸存吗?Python 中机器学习的指南第一部分
原文:
www.kdnuggets.com/2016/07/titanic-machine-learning-guide-part-1.html
Patrick Triest,SocialCops。
如果机器可以学习,会怎么样呢?
这一直是自机器出现以来科学幻想和哲学中最引人入胜的问题之一。随着现代技术的发展,这些问题不再仅仅是创造性的猜测,机器学习无处不在。从决定你可能想要在 Netflix 上观看的下一部电影到预测股票市场趋势,机器学习对现代数据理解产生了深远的影响。
本教程旨在提供一个易于理解的机器学习技术应用于你自己项目和数据集的入门指南。在短短 20 分钟内,你将学习如何使用 Python 应用不同的机器学习技术,从决策树到深度神经网络,处理一个样本数据集。这是一个实用的,而非概念性的介绍;要全面了解机器学习的能力,我强烈建议你寻找解释这些技术底层实现的资源。
对于我们的样本数据集:RMS Titanic 的乘客。我们将使用一个开放数据集,该数据集提供了 1912 年那次臭名昭著的海上航行中乘客的数据。通过检查如阶级、性别和年龄等因素,我们将尝试不同的机器学习算法,并构建一个程序来预测某个乘客是否能在这场灾难中幸存下来。
设置你的机器学习实验室
学习机器学习的最佳方法是按照本教程在你的本地计算机上操作。为此,如果你还没有安装以下几个软件包,你需要先进行安装。
-
Python(本教程使用了版本 3.4.2)
-
SciPy 生态系统(NumPy、SciPy、Pandas、IPython、matplotlib)
对于每个软件包的安装有多种选择。我推荐使用“pip” Python 包管理器,你可以简单地运行“pip3 install
对于实际编写和运行代码,我推荐使用 IPython,它允许你运行模块化的代码块并立即查看输出值和数据可视化,同时将 Jupyter Notebook 作为图形界面。
你还需要我们将要分析的 Titanic 数据集,你可以在这里找到: biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.xls
初步了解数据:谁在泰坦尼克号上幸存下来,为什么?
首先导入所需的 Python 依赖包。
import matplotlib.pyplot as plt
%matplotlib inline
import random
import numpy as np
import pandas as pd
from sklearn import datasets, svm, cross_validation, tree, preprocessing, metrics
import sklearn.ensemble as ske
import tensorflow as tf
from tensorflow.contrib import skflow
一旦我们将电子表格文件读入 Pandas 数据框(可以想象成一个超级强大的 Excel 表格),我们可以使用 head() 命令查看前五行数据。
titanic_df = pd.read_excel('titanic3.xls', 'titanic3', index_col=None, na_values=['NA'])
titanic_df.head()
列标题变量的含义如下:
-
survival - 生存状态(0 = 否;1 = 是)
-
class - 乘客等级(1 = 一等;2 = 二等;3 = 三等)
-
name - 姓名
-
sex - 性别
-
age - 年龄
-
sibsp - 登船的兄弟姐妹/配偶数量
-
parch - 登船的父母/子女数量
-
ticket - 票号
-
fare - 乘客票价
-
cabin - 舱房
-
embarked - 登船港口(C = 瑟堡;Q = 皇后镇;S = 南安普顿)
-
boat - 救生艇(如果幸存)
-
body - 遇难者的遗体编号(如果未生还且遗体已被找到)
现在我们已将数据放入数据框中,可以开始使用强大的单行 Pandas 函数进行高级数据分析。首先,让我们检查一下泰坦尼克号乘客的整体生存机会。
titanic_df['survived'].mean()
# 0.3819709702062643
计算结果显示,只有 38%的乘客幸存。这并不是最好的几率。造成如此大量人员伤亡的原因是泰坦尼克号仅配备了 20 只救生艇,这远远不够 1,317 名乘客和 885 名船员。所有乘客都不可能有相同的生存机会,因此我们将继续分析数据,以考察决定谁获得救生艇位置和谁没有的社会动态。
在 20 世纪初,社会阶层严重分化,尤其是在泰坦尼克号上,奢华的一等舱区域对二等舱的中产阶级乘客完全封闭,尤其是对那些持有三等舱“经济票”的乘客。为了了解每个等级的组成情况,我们可以按等级分组数据,并查看每列的平均值:
titanic_df.groupby('pclass').mean()
我们可以从这些数据中得出一些有趣的见解。例如,一等舱乘客的生存机会为 62%,而三等舱乘客的生存机会为 25.5%。此外,低等级舱的乘客通常较年轻,一等舱的票价显著高于二等和三等舱。一等舱的平均票价为 87.5 英镑,相当于 2016 年的 13,487 美元。
我们可以通过对等级和性别进行分组来扩展统计分析。
class_sex_grouping = titanic_df.groupby(['pclass','sex']).mean()
class_sex_grouping
class_sex_grouping['survived'].plot.bar()
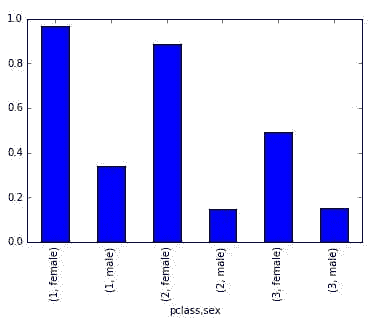
在泰坦尼克号沉没时,官员们以严格的海事传统优先考虑允许谁进入救生艇,首先撤离妇女和儿童。我们的统计结果清晰地反映了这一政策的第一部分,因为在所有舱位中,女性的生存概率远高于男性。我们还可以看到,女性的平均年龄低于男性,更有可能与家人一起旅行,并且票价略高。
“妇女和儿童优先”政策的第二部分的有效性可以通过按年龄划分的生存率来推断。
group_by_age = pd.cut(titanic_df["age"], np.arange(0, 90, 10))
age_grouping = titanic_df.groupby(group_by_age).mean()
age_grouping['survived'].plot.bar()
在这里我们可以看到,儿童确实是最有可能幸存的年龄组,尽管这个百分比仍然悲惨地低于 60%。
 简历: Patrick Triest 是一位 23 岁的安卓开发者 / 物联网工程师 / 数据科学家 / 渴望开创者,来自波士顿,目前在 SocialCops 工作。他对学习上瘾,有时在发现特别有趣的东西后,他会非常兴奋并写下他的想法。
简历: Patrick Triest 是一位 23 岁的安卓开发者 / 物联网工程师 / 数据科学家 / 渴望开创者,来自波士顿,目前在 SocialCops 工作。他对学习上瘾,有时在发现特别有趣的东西后,他会非常兴奋并写下他的想法。
原文。经许可转载。
相关:
-
7 步掌握 Python 机器学习
-
数据科学和机器学习的前 10 名 IPython 笔记本教程
-
R 学习路径:7 步从初学者到专家
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关主题
你会在泰坦尼克号上生存吗?Python 机器学习指南第二部分
原文:
www.kdnuggets.com/2016/07/titanic-machine-learning-guide-part-2.html/2
分类 - 有趣的部分
我们将从一个简单的决策树分类器开始。决策树一次检查一个变量,并根据该值的结果分裂成两个分支之一,然后对下一个变量执行相同的操作。关于决策树如何工作的精彩可视化解释可以在这里找到。
如果我们将最大层数设置为 3,这就是经过训练的泰坦尼克号数据集的决策树的样子:

树首先按性别分裂,然后按类别分裂,因为它在训练阶段了解到这些是决定生存的两个最重要的特征。深蓝色框表示可能生存的乘客,而深橙色框则代表几乎肯定会遇难的乘客。有趣的是,在按类别分裂后,决定女性生存的主要因素是她们支付的票价,而男性的决定因素是他们的年龄(儿童更有可能生存)。
要创建这个树,首先我们初始化一个未训练的决策树分类器(这里我们将树的最大深度设置为 10)。接下来,我们将这个分类器“拟合”到我们的训练集上,使其能够学习不同因素如何影响乘客的生存率。现在决策树已经准备好了,我们可以使用测试数据对其进行“评分”,以确定它的准确性。
clf_dt = tree.DecisionTreeClassifier(max_depth=10)
clf_dt.fit (X_train, y_train)
clf_dt.score (X_test, y_test)
# 0.78947368421052633
结果为 0.7703,意味着模型正确预测了 77%的测试集生存情况。对于我们的第一个模型来说,表现不错!
如果你是一个细心、怀疑的读者(你应该这样),你可能会想到模型的准确性可能会根据选择的训练和测试集的行而有所不同。我们将通过使用洗牌验证器来解决这个问题。
shuffle_validator = cross_validation.ShuffleSplit(len(X), n_iter=20, test_size=0.2, random_state=0)
def test_classifier(clf):
scores = cross_validation.cross_val_score(clf, X, y, cv=shuffle_validator)
print("Accuracy: %0.4f (+/- %0.2f)" % (scores.mean(), scores.std()))
test_classifier(clf_dt)
# Accuracy: 0.7742 (+/- 0.02)
这个洗牌验证器应用了与之前相同的随机 20:80 拆分,但这次生成了 20 个独特的拆分排列。通过将此洗牌验证器作为参数传递给“cross_val_score”函数,我们可以针对每个不同的拆分对分类器进行评分,并计算结果的平均准确性和标准差。
结果显示我们的决策树分类器的总体准确率为 77.34%,虽然根据训练/测试拆分,准确率可能会高达 80%或降到 75%。使用 scikit-learn,我们可以轻松地用完全相同的语法测试其他机器学习算法。
clf_rf = ske.RandomForestClassifier(n_estimators=50)
test_classifier(clf_rf)
# Accuracy: 0.7837 (+/- 0.02)
clf_gb = ske.GradientBoostingClassifier(n_estimators=50)
test_classifier(clf_gb)
# Accuracy: 0.8201 (+/- 0.02)
eclf = ske.VotingClassifier([('dt', clf_dt), ('rf', clf_rf), ('gb', clf_gb)])
test_classifier(eclf)
# Accuracy: 0.8036 (+/- 0.02)
“随机森林”分类算法将创建大量(通常质量较差的)树,使用输入变量的不同随机子集,并返回最多树所返回的预测。这有助于避免“过拟合”,这是一种当模型过于紧密地拟合训练数据中的任意相关性,以至于在测试数据上表现不佳的问题。
“梯度提升”分类器将生成许多弱小、浅层的预测树,并将它们组合或“提升”成一个强大的模型。该模型在我们的数据集上表现非常好,但缺点是相对较慢且难以优化,因为模型构建是顺序进行的,因此不能并行化。
“投票”分类器可以用来将多个概念上不同的分类模型应用于同一数据集,并返回所有分类器中的多数票。例如,如果梯度提升分类器预测乘客将不会生存,而决策树和随机森林分类器预测他们将生存,则投票分类器将选择后者。
这是对每种技术的非常简要和非技术性概述,因此我鼓励你深入了解所有这些算法的数学实现,以获得对它们相对优缺点的更深入理解。更多分类算法可以在 scikit-learn 中“开箱即用”,可以在这里探索。
简介:Patrick Triest 是一位 23 岁的 Android 开发者/物联网工程师/数据科学家/有志成为先驱者,来自波士顿,现在在 SocialCops 工作。他热衷于学习,有时在发现一些特别酷的东西后会非常兴奋并写下自己的见解。
原文。经许可转载。
相关:
-
掌握 Python 机器学习的 7 个步骤
-
数据科学和机器学习的前 10 大 IPython 笔记本教程
-
R 学习路径:从 R 初学者到专家的 7 个步骤
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关主题
参加 Kaggle 还是不参加
评论
关于 Kaggle
Kaggle 是最著名的预测建模和分析比赛平台。该公司成立于 2010 年,总部位于澳大利亚墨尔本,一年后在获得来自硅谷的资金后迁至旧金山。2017 年,它被谷歌收购。阅读更多关于其历史和未来的信息,请查看 与 Kaggle CEO Anthony Goldbloom 的采访。
在过去的十年里,“数据科学”这个词逐渐浮现在英语词汇中。因此,“数据科学”和“Kaggle”这两个词变得密不可分,数据科学社区的许多人对这个平台的实用性进行思考和讨论:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织在 IT 方面
Kaggle… 有用吗?
我对 Kaggle 的初步想法
像许多人一样,我对 Kaggle 比赛有一些先入为主的看法。我听说过它们很多年了,这些是我从领域中的其他人那里得到的看法或意见:
-
我听说过一个传说,退休的博士生和拥有几十年经验的人是赢得 Kaggle 比赛的赢家。(我常常想,这些天才是坐在清澈湛蓝的海水和无瑕疵的 WiFi 连接的海滩上,还是在一个黑暗、尘土飞扬、杂乱无章的办公室里……)
-
我几乎没有获胜的机会
-
我真的会学到有价值的东西吗?
-
投资时间提高 0.01 分的准确率有什么意义?
-
这真的最有效地利用了我的时间吗?我是否不应该投资时间去学习另一个更有价值的数据科学技能?
-
胜利者必须使用复杂的集成方法
-
数据是人为清理的,这不现实
-
参加一次 Kaggle 比赛不会让我成为合格的数据科学家,那我为何要费心?
-
我不知道从哪里开始…
我的第一次 Kaggle 比赛
在多年的抗拒之后,我最近参加了第一次 Kaggle 比赛,这是船还是冰山。我写了一篇关于我的经历的文章 我的第一次 Kaggle 比赛。

Kaggle 竞赛和纽约马拉松
我发现 Kaggle 竞赛很像纽约马拉松。大多数人参加是为了过程,而不是为了赢得第一名。
结论:对 Kaggle 说“是”
我会说“是的”,参与 Kaggle 竞赛是有价值的,无论是对初学者还是有经验的数据科学家。以下是很多原因。
基准测试
虽然获取自己的数据集或抓取网络有学习上的好处,但缺点是没有基准,无法比较你的发现。可能会出现重大错误,而且没有人知道,因为没有进行验证。Kaggle 竞赛提供了一个“检查工作”的平台。
适合所有级别的学习
对于初学者,有很多内容需要学习:
-
熟悉 Kaggle 平台
-
结构化的生态系统允许统计技能较少的人专注于此
-
理解评估指标
-
使用 devops 技能:Git,云计算
-
练习
-
Kaggle 提供一些免费的互动 教程
对于有经验的从业者,总是有更多的学习内容:
-
结构化的生态系统允许统计技能更高级的人专注于此
-
更深入地探索超参数
-
专注于前沿和新兴的方法
-
竞赛后分析获胜条目
-
管理非常大的数据集(100 万条记录或更多)
-
为深度学习设置支持 GPU 的机器
-
使用深度学习并与传统算法比较结果
数据
在整个数据科学社区中,你会听到关于数据集的引用。你将会熟悉其他学习平台和会议发言者提到的流行数据集。
尽管数据集是提供的,但仍然需要理解数据和评估指标。与普遍看法相反,仍然存在“脏数据”需要进一步调查。深入挖掘被误分类的项目会导致算法的调整。
作品集部分
的确,做一次 Kaggle 竞赛并不能使你成为数据科学家。参加一节课程、一次会议教程、分析一个数据集或阅读一本数据科学书籍也不能。参与竞赛增加了你的经验并增强了你的作品集。这是你其他项目的补充,而不是衡量数据科学技能的唯一标准。
乐趣
人们常常不确定是否应该追求数据科学的职业。参加比赛是一种有效的方式来评估你的能力和兴趣。如果你真的喜欢 Kaggle 的过程,它会更清楚地指引你正确的方向。如果你更愿意花时间做其他事情,那也没关系;这是找到答案的一种方式。
开始使用 Kaggle
初学者指南
这篇文章提供了关于 Kaggle 的详细信息以及开始使用的技巧:Kaggle 初学者指南
内核
这里有内核,即其他人共享的 Jupyter Notebook 代码。你可以自由地复制和使用这些代码来开始比赛。代码有 R 和 Python 两种版本。
讨论板
每个比赛都有一个讨论板,用于提问和对内核以及话题进行投票。
Slack
Kaggle 有一个 Slack 团队:KaggleNoobs slack channel。这里有将近 4000 名成员,还有一个 AMA(问我任何事)频道,他们定期采访 Kaggle 参与者和获胜者。
选择
-
你可以参加已经结束的比赛。请记住,这主要是关于学习,而不是最终结果。
-
有各种主题(随机森林、多分类、神经网络、自然语言处理)和数据集类型(图像、结构化数据、文本、大数据)
与他人合作
-
无论你是数据科学初学者还是有经验的从业者,都要与他人合作。
-
请注意,最好在 Kaggle 上拥有独立的团队,这样你们每个人可以最大化地每日提交结果,但在比赛快结束时可以合并团队。
结论
我认为至少参加一次比赛是值得的。尝试过的事情和未尝试过的事情之间是有区别的。Kaggle 正在不断发展,尤其是在被 Google 收购后。请定期查看,了解最新动态。
不一定非得是 Kaggle
虽然 Kaggle 是最知名的平台,但还有许多其他机会可以参加比赛:
-
许多大学分析部门都有年度比赛。
-
会议通常有比赛或所谓的“任务”。
-
私营公司赞助他们自己的比赛。
这是其他数据科学竞赛的示例列表。花点时间使用 Google 搜索会找到更多最新和活跃的机会。
参考文献
Jeremy Howard 关于深度学习、Kaggle、数据科学等的采访,2017 年
我的 Kaggle 经验与争夺名额的退休,Marios Michailidis,2016 年
机器学习不是 Kaggle 比赛,Julia Evans, 2014
数据科学简史, 2013
简介: Reshama Shaikh 是一名自由数据科学家/统计学家,拥有 Python、R 和 SAS 技能,并取得了 MBA 学位。她在制药行业担任生物统计学家超过 10 年。她还是纽约机器学习与数据科学女性聚会小组以及 PyLadies 的组织者。她在拉格斯大学获得统计学硕士学位,并在纽约大学斯特恩商学院获得 MBA 学位。
原创。经许可转载。
相关:
更多相关内容
今天我在午休时间用 Keras 构建了一个神经网络
原文:
www.kdnuggets.com/2017/12/today-built-neural-network-during-lunch-break-keras.html
评论
由 Matthijs Cox,纳米技术数据科学家

从想法到结果的最短延迟是进行良好研究的关键。
- Keras.io
所以昨天有人告诉我你可以在 Keras 中在 15 分钟内构建一个(深度)神经网络。当然,我完全不相信。上次我尝试(可能是 2 年前?)时,这仍然是相当费力的工作,需要全面的编程和数学知识。那时确实需要精湛的工艺。
所以在晚上我花了一些时间研究 Keras 文档,我必须说它看起来足够简单。但是当我尝试时肯定会遇到一些困难,对吧?适应这些包有时可能需要几个月。
第二天早晨
所以第二天我开始在自己的数据上玩 Keras。首先,我重构了一些我们内部包中的代码,以将数据转换为表格形式。这让我感到沮丧了一段时间。最后,这和回答我的电子邮件以及问题占用了我大部分的早晨。完成这些后,我可以轻松地将一些数据导出为 csv 文件,并用 Pandas 读取它,转换为 Numpy 数组,我们就准备好了。
午休时间
由于这完全是一个爱好项目,我部分牺牲了午休时间来构建模型。Keras 和 Tensorflow 安装得很快,自从上次我尝试在 Windows 笔记本上安装 Tensorflow 后,这非常简单。然后我几乎是复制粘贴了 Keras 文档中的代码。我甚至不打算建立一个 github 仓库,这就是我做的所有事情:
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
model = Sequential()
model.add(Dense(units=64, activation=’relu’, input_dim=1424))
model.add(Dense(units=2696))
model.compile(loss='mse', optimizer='adam')
model.fit(predictors[0:80,], estimator[0:80,],
validation_data=(predictors[81:,],estimator[81:,]),
epochs=80, batch_size=32)
np.savetxt("keras_fit.csv", model.predict(data), delimiter=",")
这是什么?我在构建模型,添加一些密集层,完成它,拟合数据,并进行预测。全部用不到 10 行代码。我今天没有进行任何超参数优化或智能层架构。但我必须说;哇,真的很简单!
下午
现在我对实际性能非常好奇,所以我必须对一些基准进行测试。不过别告诉我的经理们我在花时间做这个哦!(开玩笑的,他们鼓励探索和学习。)所以我将数据加载回我的测试框架中,并运行一些其他算法。以下是我的最终性能指标的结果。

在不到一个小时的模型构建时间内,这真是太令人尴尬地好。我们花了 1.5 年时间研发的超级秘密模型仍然超越了它(幸运的是)。除此之外,任何神经网络的一个大缺点当然是它完全是一个黑匣子,不知道它实际学到了什么。而我们的秘密模型使用的是我们后来可以作为人类诊断的模式识别。
结论
这也是我最快完成的文章,完全是在热情的状态下写的。现在,我在一天的最后几分钟里写这篇文章,向任何开发 Keras 的人表示热烈的掌声。以下是我的结论:
-
Keras API:棒极了!
-
Keras 文档:棒极了!
-
Keras 结果:棒极了!
如果你正在考虑进行一些深度/机器学习,我一定建议从 Keras 开始。快速上手非常有趣,之后你可以学习和微调细节。
简介: Matthijs Cox 是一名纳米技术数据科学家,自豪的父亲和丈夫,图形设计师和业余作家。
原文。经授权转载。
相关:
-
掌握 Keras 深度学习的 7 个步骤
-
Keras 速查表:Python 中的深度学习
-
Keras 教程:使用神经网络识别井字棋赢家
我们的 Top 3 课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
更多相关内容
汤姆·福塞特,悼念
评论
作者:福斯特·普罗沃斯,纽约大学

我亲爱的朋友汤姆·福塞特(1958 - 2020)于 6 月 4 日在一次意外的自行车事故中去世。汤姆是一位杰出的学者,一个无私的合作伙伴,对数据科学贡献了三十年,并且是一个独特的个体。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
汤姆和我在我职业生涯的大部分时间里紧密合作。我们从 1994 年开始合作,那时我加入了现在的 Verizon(当时是 NYNEX 科技)。我最初的印象是汤姆是个脾气古怪的人(是的,即使在那时也是如此),我对与他合作会是什么样子有些怀疑。很快我意识到,在这种印象下,他实际上是一个善良、体贴、关怀的人,同时也是一个杰出的数据科学家。在我们都离开去找其他工作之前的 1999 年底,这段时间是魔幻的五年。汤姆是那种合作伙伴,我们一个下午会结束会议,制定一系列各自需要完成的任务,当我们第二天再次见面时,汤姆已经完成了他的加上几个在过程中出现的重要任务。即使在此期间的晚上,我们出去看了某个 90 年代的新人朋克或重型另类摇滚乐队(这是我们喜欢做的事情),这种情况也是如此。正因为如此,我不得不更加努力——我不想成为团队中的拖后腿者。毫无疑问,因为和汤姆一起工作,我做的工作明显比自己单独完成的要好。
我最喜欢的“汤姆故事”来自那些日子。汤姆和我参与了一个项目,高层需要决定如何处理公司提供的越来越明显的糟糕服务。理想情况下,他们希望能证明问题在很大程度上是由于前一年的高湿度,因为大家都知道电信设备在高湿度下会受到影响。在我最喜欢的职业时刻之一,汤姆展示了数据分析的结果(是他完成的):”湿度似乎对网络问题没有显著影响。而且顺便提一下,去年并没有更潮湿。”(我最近问汤姆他是否记得这件事的方式与我一致,他说他喜欢我讲述的方式,所以是的。😃 顺便说一下,我们随后跟进了这项分析,并进行了根本原因分析。根据这些结果,我们建立了一个模型来预测单个网络恢复行动的影响。这个模型集成了数万次本地回归。我们被告知,我们模型的预测被用于指导一项价值十亿美元的恢复活动。恢复后的回顾显示,我们的预测几乎是完美的,我们获得了公司的总统奖。这让我的脸上露出了自满的微笑。汤姆说,评估高估了我们模型的真实准确性。😃
我很幸运和感恩能有那么多时间与汤姆共度。在接下来的二十年里,他继续在几家位于加州的公司中将数据科学与实践结合,我们继续一起写作。在 3000 英里之外,他和我几乎会辩论任何话题,无论重要与否。我最怀念的就是这个。爱你,汤姆。
汤姆·福赛特的讣告 见于《圣荷西水星报》。
学习人工智能是否已经太晚?
评论
由Frederik Bussler,Obviously AI 的增长营销负责人
人工智能饱和
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
我定期分享学习人工智能和数据科学的资源,无论是来自谷歌或哈佛的课程,还是完整的 YouTube 教程。
与此同时,我听到的担忧是:“学习人工智能和数据科学是否已经太晚?”
令人担忧的是,随着数百万学生学习机器学习,这个领域正在变得饱和。毕竟,人工智能职位的数量有限,尤其是在全球经济衰退期间。
Andrew Ng 在 Coursera 上的著名机器学习课程有接近 400 万学生。
截至撰写时,如果你在 LinkedIn 工作中搜索“机器学习”,你会发现略超过 100,000 个职位。

很明显,学生数量远远超过了开放职位——仅仅是查看单个 Coursera 课程中的学生数量,比例接近 40:1。
为什么仍然值得
尽管如此,学习人工智能仍然是值得的,原因有很多。
企业家精神
首先,让我们谈谈企业家精神。人工智能的构建和部署比以往任何时候都更加容易和快速——特别是考虑到像Obviously.AI这样的无代码 AI 工具——这意味着员工有机会通过将人工智能添加到他们的技能集中来创造更多的价值。
这些在组织中寻找人工智能应用案例的企业家精神者并没有增加 LinkedIn 上的职位空缺数量,但有无数的例子。
对任何员工来说,成为一名 AI 企业家精神者有着巨大的激励:有可能自动化他们工作中的重复、无聊部分,并专注于创意和以人为本的任务。更不用说,人工智能技能可以提升你的薪资和职业生涯。
例如,营销人员可以利用人工智能预测客户行为、构建用户画像并识别主要人群。零售员工可以优化产品组合、预测库存消耗、预测人员需求等。保险员工可以利用人工智能预测保险索赔、诉讼风险、代位求偿机会等。
对于 AI 企业家精神者来说,可能性是无穷无尽的。
创业精神
还有一个巨大的机会领域未包含在~100K 的机器学习工作中:创业。
创业是企业家精神的风险性反面。它意味着走自己的路,在市场中寻找增加价值的新方法,通常没有任何形式的支持、帮助或稳定性。
与此同时,这种高风险带来了高回报的潜力。
假设你加入了一家硅谷初创公司,成为第 30 名员工(仍然处于早期阶段),而且你是你领域中的顶级工程师之一。根据 Holloway,你可以期望获得0.25%–0.5%的股份。
如果你独自创业,作为创始人,你一开始就拥有 100%的股份。通过引入共同创始人、员工和投资者,这个数字会减少,但潜力却大得多。
持续学习
即使你对企业家精神、创业或获得新角色不感兴趣,持续学习仍然是值得提倡的。
人工智能现在遍布各个行业,从你在亚马逊、Spotify、Netflix 或 Tinder 上获得的推荐,到你在 Google 或 YouTube 上看到的搜索结果,甚至包括 COVID-19 追踪、疫苗开发和疫苗推广。
为了跟上最新技术的发展,并真正理解当今的世界,学习人工智能是必不可少的。
结论
学习人工智能是值得的,且始终如此。即使就业市场趋于饱和(目前还未饱和,因为仍有针对合格者的开放职位),创意型企业家和创业者始终有潜力。为了保持相关性,人工智能技能正迅速成为必备技能。
简介:Frederik Bussler 是 Obviously AI 的增长营销负责人。他致力于将人工智能普及化。
原文。经授权转载。
相关:
-
我们不需要数据科学家,我们需要数据工程师
-
利用自然语言处理提升你的简历
-
2021 年人工智能(AI)五大趋势
更多相关内容
需要管理的 Python 版本太多?Pyenv 来拯救
原文:
www.kdnuggets.com/too-many-python-versions-to-manage-pyenv-to-the-rescue
作者提供的图片
想在早上尝试最新 Python 版本的新特性...午休时浏览旧版 Python 代码库——而不会破坏你的开发环境?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
是的,这是可能的。Pyenv 可以帮助你。使用 Pyenv,你可以安装 Python 版本、切换版本和删除不再需要的版本。
本教程是 Pyenv 设置和使用的简要介绍。现在,让我们开始吧!
安装 Pyenv
第一步是安装 Pyenv。我使用的是 Linux:Ubuntu 23.01。如果你使用的是 Linux 机器,安装 Pyenv 的最简单方法是运行以下 curl 命令:
$ curl https://pyenv.run | bash
这使用了 pyenv-installer 来安装 Pyenv。
安装完成后,你将被提示完成设置你的 shell 环境以使用 Pyenv。为此,你可以将以下命令添加到 ~/.bashrc 文件中:
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc
echo 'command -v pyenv >/dev/null || export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc
echo 'eval "$(pyenv init -)"' >> ~/.bashrc
一切准备就绪,开始使用 Pyenv 吧!
注意:如果你使用的是 Mac 或 Windows 机器,请查看 如何安装 Pyenv 的详细说明。在 Windows 上,你需要在 Windows 子系统 for Linux (WSL) 中安装 Pyenv。
使用 Pyenv 安装 Python 版本
现在你已经安装了 Pyenv,你可以通过运行 pyenv install 命令来安装特定的 Python 版本,如下所示:
$ pyenv install version
要检查已安装的 Python 版本列表,请运行以下命令:
$ pyenv versions
* system (set by /home/balapriya/.pyenv/version)
我还没有安装任何新版本,所以唯一的 Python 版本是系统版本。在我的情况中是 Python 3.11:
$ python3 –version
Python 3.11.4
让我们尝试安装 Python 3.8 和 3.12。尝试运行以下命令来安装 Python 3.8:
$ pyenv install 3.8
第一次尝试用 Pyenv 安装特定版本的 Python 时,你可能会遇到错误,因为缺少一些构建依赖项。别担心,很容易修复!
⚙️ 一些故障排除提示
当我尝试在我的 Linux 发行版上使用 pyenv install 命令安装 Pyenv 时,由于缺少构建依赖项而遇到了错误。
这个 StackOverflow 讨论串 包含有关安装 Pyenv 所需的构建依赖项的有用信息。运行以下命令以安装缺少的依赖项:
$ apt-get install build-essential zlib1g-dev libffi-dev libssl-dev libbz2-dev libreadline-dev libsqlite3-dev liblzma-dev
现在你应该可以在没有任何错误的情况下安装 Python 版本:
$ pyenv install 3.8
注意:当你安装 Python 3.x 时,默认会安装最新的版本。但你也可以进行更细粒度的控制,指定 3.x.y 来安装特定版本的 Python。你还可以运行
pyenv install --list来获取所有可用 Python 版本的列表。然而,这个列表是非常 长 的。
类似地,运行 pyenv install 来安装 Python 3.12:
$ pyenv install 3.12
现在如果你运行 pyenv versions,除了系统版本,你会看到 Python 3.8 和 3.12:
$ pyenv versions
* system (set by /home/balapriya/.pyenv/version)
3.8.18
3.12.0
设置全局 Python 版本
使用 Pyenv,你可以设置一个 全局 Python 版本。正如其名,全局版本是你在命令行中使用 Python 时使用的 Python 版本。
但要小心将其设置为相对较新的版本,以避免在运行使用更新 Python 版本的项目时出现错误。
比如,假设我们将全局版本设置为 Python 3.8.18 会发生什么。
$ pyenv global 3.8.18
创建一个项目文件夹。在其中,创建一个 main.py 文件,并添加以下代码:
# main.py
def handle_status_code(status_code):
match status_code:
case 200:
print(f"Success! Status code: {status_code}")
case 404:
print(f"Not Found! Status code: {status_code}")
case 500:
print(f"Server Error! Status code: {status_code}")
case _:
print(f"Unhandled status code: {status_code}")
status_code = 404 # oversimplification, yes.
handle_status_code(status_code)
如所示,这段代码使用了在 Python 3.10 中引入的 match-case 语句。因此,你需要 Python 3.10 或更高版本才能成功运行这段代码。如果你尝试运行脚本,你会遇到以下错误:
File "main.py", line 2
match status_code:
^
SyntaxError: invalid syntax
就我而言,系统 Python 版本是 3.11,非常新。因此,我可以将全局版本设置为系统 Python 版本,如下所示:
$ pyenv global system
当你现在运行相同的脚本时,你应该会看到以下输出:
Output >>>
Not Found! Status code: 404
如果你的系统 Python 是较旧的版本,例如 Python 3.6 或更早版本,安装一个更新的 Python 版本并将其设置为全局版本是很有帮助的。
为你的项目设置本地 Python 版本
当你想要处理使用较早版本 Python 的项目时,你需要安装该版本以避免任何错误(如不再支持的方法调用)。
比如,你想在处理项目 A 时使用 Python 3.8,在处理项目 B 时使用 Python 3.10 或更高版本。

图片由作者提供
在这种情况下,你可以在项目 A 的目录中这样设置本地 Python 版本:
$ pyenv local 3.8.18
你可以运行 python --version 来检查项目目录中的 Python 版本:
$ python --version
Python 3.8.18
这在处理较旧的 Python 代码库时特别有用。
卸载 Python 版本
如果你不再需要某个 Python 版本,你可以通过运行 pyenv uninstall 命令将其卸载。例如,如果我们不再需要 Python 3.8.18,我们可以通过运行以下命令将其卸载:
$ pyenv uninstall 3.8.18
你应该在终端中看到类似的输出:
pyenv: remove /home/balapriya/.pyenv/versions/3.8.18? [y|N] y
pyenv: 3.8.18 uninstalled
总结
我希望你觉得这个关于 Pyenv 的入门教程有帮助。我们来回顾一些最常用的命令以便快速参考:
| 命令 | 功能 |
|---|---|
pyenv versions |
列出所有当前安装的 Python 版本 |
pyenv install --list |
列出所有可供安装的 Python 版本 |
pyenv install 3.x |
安装 Python 3.x 的最新发布版 |
pyenv install 3.x.y |
安装 Python 3.x 的 y 版本 |
pyenv global 3.x |
将 Python 3.x 设置为全局 Python 版本 |
pyenv local 3.x |
将本地 Python 版本设置为 3.x |
pyenv uninstall 3.x.y |
卸载 Python 3.x 的 y 版本 |
如果你在想。是的,你可以 使用 Docker,这是一个使本地开发变得轻松的绝佳选择——无需担心依赖冲突。但你可能会觉得每次需要进行新项目时使用 Docker 或其他容器化解决方案有些过度。
所以我认为能够在命令行安装、管理和切换 Python 版本仍然很有用。你也可以探索 pyenv-virtualenv 插件来创建和管理虚拟环境。编码愉快!
Bala Priya C**** 是来自印度的开发人员和技术作家。她喜欢在数学、编程、数据科学和内容创作的交集处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过编写教程、操作指南、观点文章等,学习并与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关内容
每个数据科学家都应知晓的工具:实用指南
原文:
www.kdnuggets.com/tools-every-data-scientist-should-know-a-practical-guide

图片由作者提供
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
数据科学家最依赖哪些工具?这个问题很重要,尤其是在学习数据科学之前,因为数据科学是一个不断发展的领域,过时的文章可能会提供过时的信息。在这篇文章中,我们将深入探讨最近必须了解的工具,这些工具可以提升你的数据科学水平,但我们从假设你对数据科学一无所知开始。
什么是数据科学?
数据科学是一个多学科领域,它结合了来自各种学科的知识,通过数据驱动的分析帮助企业做出明智的决策。
Python
与 R 一起,Python 是数据研究中最常用的语言之一。它灵活且可读,拥有许多库来支持,特别是在数据科学中,使其适合各种任务,从网络爬虫到模型构建。
以下是每个类别在 Python 中的关键库
-
网络爬虫:
-
BeautifulSoup: Python 中最简单的网络爬虫库。
-
Scrapy: 高级网络爬虫库。
-
-
数据探索与操作:
-
数据可视化:
-
Matplotlib: 核心 Python 绘图库
-
Seaborn: 基于 Matplotlib 的可视化库。它提供了一个高级接口,用于创建吸引人的统计图形。
-
Plotly: 互动图形库
-
-
模型建模:
-
Scikit-learn: Python 中最关键的机器学习库
-
TensorFlow: 适用于应用和扩展深度学习。
-
PyTorch: 用于图像处理和 NLP 应用的机器学习库。
-
R
R 是一个强大的文本分析工具,旨在解决统计和数据分析问题。其全面的统计能力和广泛的软件包生态系统使其在学术界和研究中非常受欢迎。
这里是 Python 各类别的关键库
-
网络抓取
-
数据探索与操作
-
dplyr: 数据操作的语法,提供数据操作动词,帮助简化数据操作。
-
tidyr: 通过手动展开和收集数据使数据更易于访问。
-
Data.table: data.frame 的扩展,具有更快的数据操作能力。
-
-
数据可视化
-
模型构建
-
Caret: 用于创建分类和回归模型的工具。
-
nnet: 提供构建神经网络的函数。
-
randomForest: 基于随机森林算法的分类和回归库。
-
Excel
Excel 易于用于分析和可视化数据。它易于学习和使用,其处理大型数据集的能力使其在快速数据操作和分析中非常有用。
在这一部分,我们将把 Excel 的关键功能划分到子部分中进行分类,而不是使用库。
数据探索与操作
-
FILTER: 根据你定义的标准过滤数据范围。
-
SORT: 对范围或数组中的元素进行排序。
-
VLOOKUP/HLOOKUP: 按行或列在表格或范围中查找内容。
-
TEXT TO COLUMNS: 将单元格内容拆分为多个单元格。
数据可视化
-
图表(柱状图、折线图、饼图等):标准的图表类型用于表示数据。
-
PivotTables: 它压缩大型数据集并创建交互式摘要。
-
Conditional Formatting: 显示哪些单元格符合特定规则。
模型构建
-
AVERAGE, MEDIAN, MODE: 计算集中趋势。
-
STDEV.P/STDEV.S: 处理数据集以计算数据集的离散度。
-
LINEST: 基于线性回归分析,返回最符合数据集的直线统计数据。
-
回归分析(数据分析工具包):该工具包使用回归分析来查找变量之间的相关性。
SQL
SQL 是与关系数据库交互的语言,并用于存储和处理数据。
数据科学家主要使用 SQL 作为与数据库交互的标准方式,帮助他们查询、更新和管理所有数据库中的数据。SQL 还用于访问数据以进行检索和分析。
这里是最受欢迎的 SQL 系统。
-
PostgreSQL:一个开源的对象-关系数据库系统。
-
MySQL:一种高性能、受欢迎的开源数据库,以其速度和可靠性而闻名。
-
MsSQL(微软 SQL 服务器):微软开发的关系数据库管理系统,与微软产品完全集成,具备企业级功能。
-
Oracle:这是一个在企业环境中广泛使用的多模型数据库管理系统。它结合了最佳的关系模型和基于树的存储表示。

高级可视化工具
使用合适的高级可视化工具,可以将复杂的数据转化为生动的、可用的见解。这些工具允许数据科学家和业务分析师创建互动式和可分享的仪表板,改进、理解并在适当的时间使数据可用。
这里是构建仪表板的重要工具。
-
-
Power BI:微软提供的商业分析服务,提供互动式可视化和商业智能功能,界面简单易用,适合最终用户创建报告和仪表板。
-
Tableau:一个强大的数据可视化工具,允许用户创建互动式和可分享的仪表板,提供数据的深刻见解。它可以处理大量数据,并能够与不同的数据源良好配合。
-
Google 数据工作室:这是一个免费的基于网络的应用程序,允许你使用来自几乎任何来源的数据创建动态和美观的仪表板和报告,还提供其他免费的、完全可定制且易于分享的报告,这些报告会自动使用你其他 Google 服务中的数据进行更新。
-
云系统
云系统对数据科学至关重要,因为它们可以扩展,增加灵活性,并管理大数据集。它们提供计算服务、工具和资源,以规模化存储、处理和分析数据,并实现成本优化和性能效益。
在这里查看受欢迎的配方。
-
AWS(亚马逊网络服务):提供一个高度复杂且不断发展的云计算平台,包括存储、计算、机器学习、大数据分析等多种服务。
-
Google Cloud: 提供各种云计算服务,运行在 Google 内部用于 Google 搜索和 YouTube 等产品的相同基础设施上,包括云数据分析、数据管理和机器学习。
-
Microsoft Azure: 微软提供云计算服务,包括虚拟机、数据库、人工智能和机器学习工具以及 DevOps 解决方案。
-
PythonAnywhere: 这是一个基于云的开发和托管环境,允许你通过网页浏览器运行、开发和托管 Python 应用程序,无需 IT 人员设置服务器。非常适合数据科学和网页应用开发人员,快速部署代码。
附赠: LLM 的
大型语言模型(LLMs)是 AI 中的前沿解决方案之一。它们可以像人类一样学习和生成文本,在自然语言处理、客户服务自动化、内容生成等广泛应用中非常有利。
这里是一些最著名的工具。
-
ChatGPT: 这是一个由 OpenAI 创建的灵活对话代理,用于生成类似人类的上下文文本,非常有益。
-
Gemini: Google 创建的 LLM 将允许你直接在 Gmail 等 Google 应用中使用。
-
Claude-3: 一个现代的 LLM,专门用于更好地理解和生成文本。它用于协助完成各种高级 NLP 任务和对话 AI。
-
Microsoft Co-pilot: 这是一个集成到微软应用中的 AI 驱动服务,Co-pilot 通过提供上下文敏感的建议和自动化重复的工作流程,帮助用户提高生产力和效率。
如果你仍然有关于最有价值的数据科学工具的问题,可以查看这篇数据科学家最有用的 10 种数据分析工具。
最终想法
在这篇文章中,我们探讨了数据科学家所需的基本工具,从 Python 到大型语言模型。掌握这些工具可以显著提升你的数据科学能力。保持更新并不断扩展你的工具包,以保持竞争力和有效性。
Nate Rosidi 是一名数据科学家和产品策略专家。他还担任分析学的兼职教授,并且是 StrataScratch 的创始人,这是一个帮助数据科学家通过顶级公司的真实面试问题准备面试的平台。Nate 撰写关于职业市场的最新趋势,提供面试建议,分享数据科学项目,并覆盖所有 SQL 相关内容。
相关主题更多内容
你必须知道如何回答的前 10 个高级数据科学 SQL 面试问题
原文:
www.kdnuggets.com/2023/01/top-10-advanced-data-science-sql-interview-questions-must-know-answer.html

作者提供的图像
介绍
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT
SQL(结构化查询语言)是一种用于管理和操作数据库的标准编程语言。它是任何数据专业人员的必备技能,因为它使他们能够有效地检索和分析存储在数据库中的数据。因此,SQL 是技术面试中的常见话题,适用于涉及数据工作的职位,如数据分析师、数据工程师和数据库管理员。
问题 01
查找第 nth 高薪资/支付或第 3 高薪资/支付的 SQL 查询
要查找第 nth 高薪资,你可以使用带有 DENSE_RANK() 函数的子查询来计算每个薪资的密集排名,然后筛选结果以仅包括排名等于 n 的行。
SELECT
*
FROM
(
SELECT
name,
salary,
DENSE_RANK() OVER (
ORDER BY
salary DESC
) as salary_rank
FROM
employees
) subquery
WHERE
salary_rank = n;
你还可以使用 LIMIT 和 OFFSET 子句来查找第 nth 高薪资,如下所示:
SELECT
name,
salary
FROM
employees
ORDER BY
salary DESC
LIMIT
1 OFFSET (n - 1);
例如,要找到第 3 高的薪资,你可以使用以下查询:
SELECT
name,
salary
FROM
employees
ORDER BY
salary DESC
LIMIT
1 OFFSET 2;
问题 02
如何优化 SQL 查询以提高性能?
有几种方法可以优化 SQL 查询以提高性能,包括
索引
在某列或某些列上创建索引可以显著提高对这些列进行筛选的查询速度。
分区
将大型表分区为更小的部分可以提高仅需要访问数据子集的查询性能。
规范化
规范化涉及将数据库中的数据组织到仅存储一个位置,以减少冗余并完善数据的完整性。
使用适当的数据类型
为每列使用正确的数据类型可以提高对这些列进行筛选或排序的查询性能。
使用适当的 JOIN 类型
使用正确的 JOIN 类型(例如 INNER JOIN、OUTER JOIN、CROSS JOIN)可以提高多表联接查询的性能。
使用适当的聚合函数
使用适当的聚合函数(例如,SUM、AVG、MIN、MAX)可以提高对大型数据集执行计算的查询性能。一些聚合函数,类似于 COUNT,比其他函数更有效,因此选择适用的函数对查询非常重要。
问题 03
你如何在 SQL 中使用 LAG 和 LEAD 函数?能否给出它们使用的示例?
LAG() 和 LEAD() 函数是 SQL 中的窗口函数,允许你将行中的值与前一行或后一行的值进行比较。它们对计算累计总数或将表中的值与前一行或后一行的值进行比较非常有用。
LAG() 函数接受两个参数:要返回的列和向回查找的行数。例如
SELECT
name,
salary,
LAG(salary, 1) OVER (
ORDER BY
salary DESC
) as prev_salary
FROM
employees;
LEAD() 函数的工作方式类似,但向前而不是向后。例如
SELECT
name,
salary,
LEAD(salary, 1) OVER (
ORDER BY
salary DESC
) as next_salary
FROM
employees
问题 04
解释 SQL 中的 ETL 和 ELT 概念
ETL(提取、转换、加载)是一个用于 SQL 的过程,用于从一个或多个源中提取数据,将数据转换成适合分析或其他用途的格式,然后将数据加载到目标系统中,例如数据仓库或数据湖。
ELT(提取、加载、转换)与 ETL 类似,但转换阶段在数据加载到目标系统后进行,而不是之前进行。这允许目标系统执行转换,这可能比在 ETL 工具中执行转换更高效、更具扩展性。ELT 通常用于现代数据基础设施,这些基础设施使用强大的数据处理引擎(如 Apache Spark 或 Apache Flink)来执行转换阶段。
问题 05
你能解释 SQL 中 WHERE 和 HAVING 子句的区别吗?
WHERE 和 HAVING 子句都用于从 SELECT 语句中筛选行。它们之间的主要区别是 WHERE 子句用于在分组操作之前筛选行,而 HAVING 子句用于在分组操作之后筛选行。
SELECT
department,
SUM(salary)
FROM
employees
GROUP BY
department
HAVING
SUM(salary) > 100000;
在这个例子中,HAVING 子句用于筛选出部门中员工薪水总和少于 100000 的部门。这是在分组操作之后完成的,因此只影响表示每个部门的行。
SELECT
*
FROM
employees
WHERE
salary > 50000;
在这个例子中,WHERE 子句用于筛选薪水少于 50000 的员工。这是在任何分组操作之前完成的,因此它影响 employees 表中的所有行。
问题 06
解释 SQL 中 TRUNCATE、DROP 和 DELETE 操作之间的区别
TRUNCATE
TRUNCATE 操作从表中删除所有行,但不会影响表的结构。它比 DELETE 更快,因为它不会生成任何撤销或重做日志,也不会触发任何删除触发器。
这是使用 TRUNCATE 语句的一个示例
TRUNCATE TABLE employees;
该语句从 employees 表中删除所有行,但表的结构,包括列名和数据类型,保持不变。
DROP
DROP 操作从数据库中删除一个表,并删除表中的所有数据。它还删除与表相关的任何索引、触发器和约束。
这是一个使用 DROP 语句的示例
DROP
TABLE employees;
该语句从数据库中删除 employees 表,并且表中的所有数据都被永久删除。表结构也被移除。
DELETE
DELETE 操作从表中删除一行或多行。它允许你指定一个 WHERE 子句以选择要删除的行。它还生成撤销和重做日志,并触发取消触发器。
这是一个使用DELETE语句的示例
DELETE FROM
employees
WHERE
salary & lt;
50000;
该语句删除 employees 表中所有工资低于 50000 的行。表结构保持不变,被删除的行可以通过撤销日志恢复。
问题 07
哪种更有效,连接还是子查询?
通常情况下,使用 JOIN 比使用子查询更高效,因为 JOIN 允许数据库通过利用连接表上的索引更高效地执行查询。
例如,考虑以下两个返回相同结果的查询:
SELECT
*
FROM
orders o
WHERE
o.customer_id IN (
SELECT
customer_id
FROM
customers
WHERE
country = 'US'
);
SELECT
*
FROM
orders o
WHERE
o.customer_id IN (
SELECT
customer_id
FROM
customers
WHERE
country = 'US'
);
第一个查询使用 JOIN 将 orders 和 customers 表结合在一起,然后使用 WHERE 子句筛选结果。第二个查询使用子查询从 customers 表中选择相关的客户 ID,然后使用 IN 运算符根据这些 ID 筛选 orders 表。
问题 08
如何在 SQL 中使用窗口函数?
在 SQL 中,窗口函数是对由窗口规范定义的一组行或“窗口”操作的函数。窗口函数用于在行之间执行计算,并且可以在 SELECT、UPDATE 和 DELETE 语句中使用,以及在 SELECT 语句的 WHERE 和 HAVING 子句中使用。
这是在 SELECT 语句中使用窗口函数的示例:
SELECT
name,
salary,
AVG(salary) OVER (PARTITION BY department_id) as avg_salary_by_department
FROM
employees
该语句返回一个包含三列的结果集:name、salary 和 avg_salary_by_department。avg_salary_by_department 列是使用 AVG 窗口函数计算的,该函数计算每个部门的平均工资。PARTITION BY 子句指定窗口按 department_id 分区,这意味着平均工资是针对每个部门单独计算的。
问题 09
解释规范化
规范化是将数据库组织成一种减少冗余和依赖的方式的过程。它是一种系统化的方法,用于分解表格以消除数据冗余并提高数据完整性。可以使用几种规范形式来规范化数据库。最常见的规范形式包括:
第一范式 (1NF)
-
表中的每个单元格包含一个单一的值,而不是一个值的列表
-
表中的每一列都有一个唯一的名称
-
表中不包含任何重复的列组
第二范式 (2NF)
-
它处于第一范式
-
它没有任何部分依赖(即,非主属性依赖于复合主键的一部分)
第三范式 (3NF)
-
它符合第二范式
-
它没有任何传递依赖(即,非主属性依赖于另一个非主属性)
博伊斯-科德范式 (BCNF)
-
它符合第三范式
-
每个决定因素(一个决定其他属性值的属性)都是候选键(一个可以作为主键的列或列集)
问题 10
解释 SQL 中的独占锁和更新锁
独占锁是一种锁,防止其他事务读取或写入被锁定的行。这种锁通常在事务需要修改表中的数据时使用,并希望确保没有其他事务可以同时访问该表。
更新锁是一种锁,允许其他事务读取被锁定的行,但防止它们更新或写入被锁定的行。这种锁通常在事务需要读取表中的数据时使用,但希望确保在当前事务完成之前,数据不会被其他事务修改。
索尼亚·贾米尔 目前在巴基斯坦最大的电信公司之一担任数据库分析师。除了全职工作,她还兼职做自由职业者。她的背景包括数据库管理方面的专业知识,并且有在本地和云环境中的 SQL Server 经验。她精通最新的 SQL Server 技术,并对数据管理和数据分析有着浓厚的兴趣。
更多相关话题
印度前 10 大 AI 初创公司
原文:
www.kdnuggets.com/top-10-ai-startups-to-work-for-in-india

作者提供的图片
人工智能(AI)正在全球范围内改变商业运作,印度正在迅速崛起成为创新 AI 初创企业的中心。这些本土公司在各个行业推动 AI 的应用,同时在国内培养了强大的人才库。在这篇博客中,我们将重点介绍在印度引起广泛关注的前 10 大 AI 初创公司,它们是开始或推进你 AI 职业生涯的绝佳选择。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
注意: 关于融资的数据来自于ai-startups.org,而评分则来自于Glassdoor。
Uniphore
融资:$620.9M (+/-)
Glassdoor 评分:3.9
Uniphore 是一家印度初创公司,将 AI 嵌入到商业运营的每个方面,使复杂任务变得简单。他们的企业级多模态机器学习模型和数据平台统一了语音、视频、文本和数据的所有元素。Uniphore 还将生成式 AI、知识 AI、情感 AI 和工作流自动化结合起来,作为企业的可靠副驾驶。这些先进的 AI 技术的结合,作为催化剂,创造了世界上最具吸引力的客户和员工体验。
Yellow.ai
融资:$102.2M (+/-)
Glassdoor 评分:3.8
Yellow.ai 是一个无代码平台,将生成式 AI 与企业级 LLMs 结合,能够将聊天和语音自动化的时间从几天缩短至几分钟。其专有的 DAP 技术基于多 LLM 架构,并不断在数十亿次对话中进行训练,以提供规模、速度和准确性。
Yellow.ai 提供了一个对话服务云来自动化客户支持,一个对话商务云来实现对话商务,以及一个对话 EX 云来丰富员工体验。
Razorpay
融资:$74.7M (+/-)
Glassdoor 评分:3.8
Razorpay 是一家印度初创公司,推动财务和业务增长。他们强大的支付网关使企业能够接受 100 多种支付方式,具有行业领先的成功率和卓越的结账体验。轻松集成、从第一天起即刻结算以及深入的报告功能提供了无缝的支付体验。
除了支付服务,Razorpay 还通过自动化向供应商和员工支付款项,帮助企业保持充足的运营资金。通过提升企业财务管理,Razorpay 使公司能够专注于核心业务。作为领先的金融科技公司,Razorpay 正在通过解决支付和结算需求来帮助印度企业扩展规模。
Qure.ai
融资:60.3 百万美元(+/-)
Glassdoor 评分:4.0
Qure AI 是一家印度初创公司,已被认可为全球最广泛采用的医疗 AI 公司之一。他们专注于肺部、心脏、神经和肌肉骨骼(MSK)疾病的 AI 解决方案。Qure.ai 提供一系列产品以改善医学诊断和患者护理。
包括以下内容:
-
胸部 X 光报告
-
结核病护理层级
-
肺结节管理
-
中风与创伤性脑损伤
-
MSK X 光报告
-
心力衰竭
通过提高效率和准确性,Qure.ai 改善了患者诊断,同时降低了护理成本。
Avaamo
融资:30.5 百万美元(+/-)
Glassdoor 评分:4.4
Avaamo 是一家印度初创公司,开发了一个基于云的对话 AI 平台,利用最新的神经网络、语音合成和深度学习技术。他们的技术使企业能够在语音、文本和其他渠道上以空前的速度和准确性自动化客户互动。凭借预构建的企业连接器、对话分析和快速部署能力,Avaamo 使组织能够在短短几周内执行对话 AI 项目。
Mad Street Den
融资:30 百万美元(+/-)
Glassdoor 评分:4.2
Mad Street Den® 开发了一个名为“Vue.ai”的企业 AI 平台,宣称“这是你将来唯一需要的 AI 堆栈”。他们的平台专注于提供业务成果,强调快速实施和生产力。Mad Street Den 鼓励企业摒弃冗长的 AI 转型计划,立即使用他们的平台。他们提供一个零延迟的企业 AI 平台,支持快速上线,使企业能够在访问数据后的 30 天内展示价值。
Wysa
融资:29.5 百万美元(+/-)
Glassdoor 评分:3.4
Wysa 是一个印度(全球)初创企业,提供了一种革命性的心理健康支持方法。他们的临床验证 AI 技术提供了作为护理第一步的即时帮助,随后为需要额外帮助的用户提供人工辅导。这种创新的方法已经产生了显著的影响,超过五亿次 AI 聊天对话与来自 95 个国家的超过五百万人的交流。
针对员工心理健康日益增长的关注,Wysa 在美国、英国以及其自身用户群体中进行了广泛的研究,揭示了对早期、匿名和无限护理的需求。
Haptik
融资:$11.2M (+/-)
Glassdoor 评分:3.5
Haptik 是一个印度会话 AI 初创企业,利用生成式 AI 建立持久的客户关系。他们的平台通过跨渠道客户对话提供支持,启用个性化的营销互动,并激发销售以提高转化率。凭借在每个阶段都经过优化的全面客户体验套件,Haptik 能够迅速带来指数级的价值。其专有的 NLU 在人类般对话的准确性方面领先行业,以减少机器人失败。先进的行业特定 NLP 和 ML 确保了高精度。AI 驱动的分析通过 Smart Funnels 等功能从对话数据中发现实时洞察。
Rephrase.ai
融资:$10.6M (+/-)
Glassdoor 评分:3.9
Rephrase.ai 是一个由生成式 AI 驱动的开创性文本转视频生成平台。他们的平台 Rephrase Studio 通过使用户能够在几分钟内用数字化头像创建专业外观的视频,消除了视频制作的复杂性。这一三步流程包括选择数字化头像、添加所需的信息和渲染视频。利用 AI 的强大功能,Rephrase 能够无缝地将文本转换为逼真的视频。作为一个创新的印度初创企业,Rephrase.ai 正在通过其文本转视频平台改变沟通和创意,使制作引人入胜的视频内容变得简单且对每个人都可及。
Synapsica
融资:$4.2M (+/-)
Glassdoor 评分:4.6
Synapsica 正在利用人工智能来革新脊柱报告和放射学。他们获得 FDA 批准的解决方案提供了针对 MRI、X 光等的端到端视觉和定量脊柱报告。Synapsica 的 AI 助手自动化重复任务、标准化测量,并生成基于证据的报告,从而提升放射科医生的生产力和报告准确性。这有助于医生做出更有信心的诊断。Synapsica 的算法具有高达 99%的精确度,提供智能的、平台无关的报告,并通过预测分析和自动量化实现可靠的跟踪。作为一家创新的印度健康科技初创公司,Synapsica 使放射科医生能够更高效地报告更多病例,同时为医生提供详细的、说明性的分析,以改善患者护理。
结论
人工智能在印度的快速增长催生了许多有前景的初创公司,它们处于将创新的人工智能解决方案带到全球企业的前沿。像 Uniphore、Yellow.ai 和 Haptik 这样的公司是对话式人工智能的先锋,而 Qure.ai 和 Synapsica 等初创公司则通过人工智能驱动的放射学和诊断推动医疗行业的变革。像 Razorpay 和 Mad Street Den 这样的公司则在应用人工智能以转变商业操作和结果方面领先。
这些初创公司凭借其尖端技术和快速市场进入能力,提供了令人兴奋的机会来参与具有影响力的项目。他们鼓励的工作文化和对创新的重视也使他们成为备受追捧的人工智能雇主。随着印度在科技领域的持续发展,这些初创公司有望在全球范围内颠覆各个行业,同时培养国内顶尖科技人才。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理健康困扰的学生开发人工智能产品。
更多相关话题
2016 年版《人工智能与机器学习十大亚马逊书籍》
原文:
www.kdnuggets.com/2016/11/top-10-amazon-books-ai-machine-learning.html
最近对数据科学、数据挖掘及相关学科的兴趣激增,也带来了大量关于这些话题的书籍。决定哪些书籍可能对你的职业有用的最佳方法之一就是查看其他人正在阅读哪些书籍。本文详细介绍了截至 2016 年 11 月 24 日亚马逊人工智能与机器学习书籍类别中最受欢迎的 10 本书,跳过了重复的书名以及明显分类错误且对我们的读者无用的书名。
注意:KDnuggets 从亚马逊没有获得任何版税——此列表仅用于帮助我们的读者评估有趣的书籍。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求

伊恩·古德费洛、约书亚·本吉奥、亚伦·库尔维尔
4.8 星(4 条评论)
精装本,$67.55
这很好地总结了:
“由三位领域专家撰写,《深度学习》是唯一一本全面讲述该主题的书籍。”
- 埃隆·马斯克,OpenAI 联***;特斯拉和 SpaceX 的联合创始人兼首席执行官
安德鲁·巴特勒
4.2 星(74 条评论)
平装本,$9.95(Kindle 版,$2.88)
了解如何构建自定义和智能家居技能,让你的 Echo 更具个人化!Alexa 技能包流畅、安全、快速且可靠,帮助你让 Echo 不断学习。该指南还适合中级技术用户,提供快速、有效的方式了解 Echo 设备及其功能和可定制性。
道格拉斯·R·霍夫施塔特
4.5 颗星(472 条评论)
平装书,$13.98
如果生命可以从细胞的化学基础中成长,如果意识可以从神经元的发射系统中出现,那么计算机也将达到人类智能。《哥德尔、艾舍尔、巴赫》是对认知科学核心的迷人思想的绝佳探索:意义、简化、递归等等。
4. 自制神经网络
塔里克·拉希德
4.2 颗星(65 条评论)
Kindle 版,$3.86
神经网络是深度学习和人工智能的关键元素,它今天能够完成一些真正令人印象深刻的任务。然而,真正理解神经网络如何工作的却少之又少。
本指南将带你进行有趣而从容的学习旅程,从非常简单的想法开始,逐步建立对神经网络工作原理的理解。你不需要任何中学以外的数学知识,还包含了对微积分的易懂介绍。
5. Python 机器学习
塞巴斯蒂安·拉施卡
4.3 颗星(80 条评论)
平装书,$40.49
- 利用 Python 最强大的开源库进行深度学习、数据处理和数据可视化
- 学习有效的策略和最佳实践,以改进和优化机器学习系统和算法
- 使用强大的统计模型对数据提出并回答难题,这些模型适用于各种数据集
Nick Bostrom
3.9 星(284 条评论)
平装版,$13.72(Kindle 版,$8.13)
阅读本书,了解有关神谕、精灵、单例模式;了解关于拳击方法、触发器和思想犯罪;了解人类的宇宙赠予和技术差异发展;间接规范性、工具收敛、全脑仿真和技术耦合;马尔萨斯经济学和反乌托邦进化;人工智能、生物认知增强和集体智能。
这本极具雄心和原创性的书在一片难度极高的知识领域中小心翼翼地探寻。然而,写作如此清晰,仿佛一切都变得简单起来。
7. 马尔可夫模型:精通数据科学和无监督机器学习(Python 版)
LazyProgrammer
4.0 星(1 条评论)
Kindle 版,$4.91
我们将探讨一个疾病与健康的模型,计算如果生病,你会生病多久。我们将讨论马尔可夫模型如何用于分析人们如何与您的网站互动,并修复像高跳出率这样可能影响 SEO 的问题区域。我们将构建可以用于识别作者甚至生成文本的语言模型——想象一下机器为你写作。
Ethem Alpaydi
3.5 星(2 条评论)
音频版,$14.95(平装版,$10.63)
阿尔帕伊丁讲述了数字技术如何从计算主机发展到移动设备,为今天的机器学习热潮提供了背景。他描述了机器学习的基本概念及一些应用;机器学习算法在模式识别中的应用;受到人脑启发的人工神经网络;学习实例之间关联的算法,如客户细分和学习推荐;以及强化学习,即自主代理学习以最大化奖励和最小化惩罚。阿尔帕伊丁还考虑了机器学习的一些未来方向以及“数据科学”这一新领域,并讨论了数据隐私和安全的伦理和法律影响。
加雷斯·詹姆斯、丹妮拉·维滕、特雷弗·哈斯蒂、罗伯特·蒂布希拉尼
5 星中的 4.8 星 (127 条评论)
精装本,$72.62
统计学习导论提供了统计学习领域的可访问概述,这是理解过去二十年在生物学、金融、市场营销、天体物理学等领域出现的大规模复杂数据集的必备工具。本书介绍了一些最重要的建模和预测技术以及相关应用。主题包括线性回归、分类、重抽样方法、收缩方法、基于树的方法、支持向量机、聚类等。
约翰·D·凯勒赫、布赖恩·麦克内米、艾菲·达西
5 星中的 4.7 星 (15 条评论)
精装本,$74.00
本入门教材详细而专注地介绍了用于预测数据分析的最重要机器学习方法,涵盖了理论概念和实际应用。技术和数学材料通过解释性实例加以补充,案例研究展示了这些模型在更广泛业务背景下的应用。
在讨论从数据到洞察再到决策的轨迹后,本书描述了四种机器学习方法:基于信息的学习、基于相似性的学习、基于概率的学习和基于错误的学习。
相关:
-
进入机器学习职业前必读的 5 本电子书
-
2016 年数据挖掘领域亚马逊畅销书前 10 名
-
亚马逊人工智能与机器学习领域前 20 本书
更多相关内容
2016 年数据挖掘领域 Amazon 前十名书籍
原文:
www.kdnuggets.com/2016/11/top-10-amazon-books-data-mining.html
最近对数据科学、数据挖掘及相关学科的兴趣激增,书籍标题也随之激增。决定哪些书籍可能对你的职业生涯有用的最佳方法之一是查看其他人阅读的书籍。这篇文章详细列出了截至 2016 年 11 月 10 日 Amazon 的 数据挖掘书籍 类别中最受欢迎的 10 本书,跳过重复的书名以及明显分类错误且对读者无用的书名。
注意:KDnuggets 从 Amazon 获取的佣金为零——此列表仅为帮助读者评估有趣的书籍。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作

Trevor Hastie, Robert Tibshirani, Jerome Friedman
4.1 星(78 条评论)
精装本,$74.85
本书在一个共同的概念框架中描述了这些领域的重要思想。虽然方法是统计性的,但重点是概念而非数学。书中提供了许多示例,使用了大量的彩色图形。这是统计学家和任何对科学或工业中的数据挖掘感兴趣的人的宝贵资源。本书的覆盖面广泛,从监督学习(预测)到非监督学习。许多主题包括神经网络、支持向量机、分类树和提升——这是任何书籍中对这一主题的第一次全面论述。
2. 从零开始的数据科学:用 Python 学习的基本原理,第 1 版
Joel Grus
4.2 星(65 条评论)
平装书,$32.04
如果你具备数学天赋和一定的编程技能,作者 Joel Grus 将帮助你熟悉数据科学核心的数学和统计知识,以及你需要的入门数据科学家的黑客技能。今天的数据泛滥中蕴含着没人想到过的问题的答案。这本书为你提供了挖掘这些答案的诀窍。
3. 数据科学与商业:你需要了解的数据挖掘和数据分析思维 第 1 版
福斯特·普罗沃斯特,汤姆·福塞特
4.6 星(152 条评论)
平装书,$33.79
由著名数据科学专家 Foster Provost 和 Tom Fawcett 编写的《数据科学与商业》介绍了数据科学的基本原理,并指导你如何进行“数据分析思维”,以从你收集的数据中提取有用的知识和商业价值。这本指南还帮助你理解今天使用的许多数据挖掘技术。
4. 数据分析简明指南
安尼尔·马赫什瓦里
4.8 星(175 条评论)
Kindle 版,$7.48
这本书填补了关于数据分析和大数据日益增长领域的简明对话书籍的需求。易读且信息丰富,这本清晰的书涵盖了所有重要内容,配有具体的示例,并邀请读者加入这个领域。书中的章节是按照典型的一学期课程进行组织的,每章开头都有来自真实世界故事的案例。
5. Python 机器学习
塞巴斯蒂安·拉什卡
4.3 星(78 条评论)
Kindle 版,$23.74
《Python 机器学习》让你进入预测分析的世界,并展示了为什么 Python 是世界领先的数据科学语言之一。如果你想更好地提问数据,或需要提升和扩展你的机器学习系统的能力,这本实用的数据科学书籍是无价的。它涵盖了广泛的强大 Python 库,包括 scikit-learn、Theano 和 Keras,并提供了从情感分析到神经网络的所有方面的指导和技巧,你很快就能回答你和你的组织面临的一些重要问题。
约翰·W·福尔曼
4.7 颗星(105 条评论)
平装本,$31.99
数据科学无非是使用简单的步骤将原始数据处理成可操作的洞察。在《数据智能》中,作者和数据科学家约翰·福尔曼将展示如何在熟悉的电子表格环境中完成这一过程。
汤姆·怀特
4.6 颗星(41 条评论)
平装本,$36.24
本书仅使用 Hadoop 2,作者汤姆·怀特介绍了关于 YARN 以及若干 Hadoop 相关项目(如 Parquet、Flume、Crunch 和 Spark)的新章节。你将了解 Hadoop 的最新变化,并探索 Hadoop 在医疗系统和基因组数据处理中的新案例研究。
罗伯特·卡巴科夫
4.8 颗星(33 条评论)
平装本,$46.83
《R 实战 第 2 版》通过呈现与科学、技术和商业开发者相关的示例,教你如何使用 R 语言。书中重点讲解实际解决方案,包括处理凌乱和不完整数据的优雅方法。你还将掌握 R 的广泛图形功能,以便以可视化方式探索和展示数据。扩展的第 2 版包含了关于预测、数据挖掘和动态报告编写的新章节。
凯西·奥尼尔,瑞秋·舒特
4.0 颗星(50 条评论)
平装本,$29.59
在这些长章节讲座中,来自谷歌、微软和 eBay 等公司的数据科学家分享了新算法、方法和模型,通过案例研究和他们使用的代码进行讲解。如果你熟悉线性代数、概率和统计,并有编程经验,这本书是数据科学的理想入门书籍。
10. 大数据:可扩展实时数据系统的原理和最佳实践 第 1 版
内森·马尔兹,詹姆斯·沃伦
4.4 颗星(33 条评论)
平装本,$35.34
《大数据》教你如何使用一种架构来构建大数据系统,该架构利用了集群硬件以及专门设计的工具来捕捉和分析网络规模的数据。它描述了一种可扩展、易于理解的大数据系统方法,这种方法可以由一个小团队构建和运行。通过一个现实的示例,本书引导读者深入了解大数据系统的理论,如何在实践中实施它们,以及一旦建成如何部署和操作这些系统。
相关:
-
数据爱好者必读的 10 本经典书籍
-
亚马逊神经网络畅销书 Top 20
-
亚马逊数据库与大数据畅销书 Top 20
更多相关内容
LinkedIn 上的前 10 大活跃大数据、数据科学、机器学习影响者,更新版
原文:
www.kdnuggets.com/2017/09/top-10-big-data-science-machine-learning-influencers-linkedin-updated.html

我们收集了 LinkedIn 上顶级影响者的名单,根据他们的粉丝数量进行排名,并且限制在过去三个月内活跃的人员。自 2017 年 6 月以来没有发布任何内容,或与大数据、数据科学或机器学习相关内容的人未被包含。我们注意到,通过查看其他社交媒体(如 Twitter)的粉丝数量,可以创建完全不同的排名。希望你喜欢阅读每个个人资料。所有粉丝数量的百分比变化相对于 2016 年 9 月的类似帖子 LinkedIn 上的前 16 位活跃大数据、数据科学领袖。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
1. 伯纳德·马尔,(1,121k),增加了 41%。作为畅销书作者、战略顾问和 CEO,他已成为数据领域最受认可和尊敬的领袖之一。他出版了大量关于大数据的报告和书籍,并向几家知名公司提供了咨询。他曾位列 LinkedIn 商业影响者的前五名。Twitter 上也可以找到他, @BernardMarr,有 91k 的粉丝。
2. 乔什·伯辛,(610k),增加了 43%。Bersin by Deloitte 的创始人兼首席顾问,这是一家在人才管理、领导力发展、招聘和培训方面的战略和研究咨询领先公司。Twitter 上也可以找到他, @Josh_Bersin,有 44k 的粉丝。
3. DJ Patil,(551k),增长 83%。曾任美国总统奥巴马的首席数据科学家,负责在医疗保健、刑事司法和国家安全等领域创建和建立主要的数据驱动计划。他还曾担任 LinkedIn 的数据产品负责人和首席科学家。在 Twitter 上也可以找到 @dpatil,拥有 46k 粉丝。
-
两个真相和一个谎言 - 数据与制药广告
-
我最近在做什么…
4. Dennis Mortensen,(315k),增长 145%。x.ai 的首席执行官和创始人,这是一款 AI 个人助理,用于安排会议。在 Twitter 上也可以找到 @DennisMortensen,拥有 9.8k 粉丝。
-
6 个理由说明调度是机器的任务
-
使用 AI 编程来促使人类行为更好
5. Carla Gentry,(227k),增长 355%。在过去 18 年里,Carla 与财富 100 强和 500 强公司合作,并且在处理复杂数据库和解读复杂业务需求方面经验丰富,为关键绩效指标提供洞察。她的专长领域包括客户满意度和保留分析、品牌研究与竞争分析、员工保留、调查创建与分析、数据库创建和挖掘、激励促销和项目管理。在 Twitter 上也可以找到 @data_nerd,拥有 42.7k 粉丝。
-
对于所有那些以为自己失败了的人
-
员工流失风险是一个曲线,而不是一个单一的分数 - 这为什么重要
6. Tom Davenport,(209k),增长 145%。被认可的领导者和多本书籍及文章的作者;Deloitte Analytics 的高级顾问;Babson College 的信息技术与管理杰出教授和 MIT 数字业务中心的研究员。在 Twitter 上也可以找到 @tdav,拥有 9.5k 粉丝。
-
当我们谈论人工智能时我们谈论什么
-
大陆上的认知
7. 格雷戈里·皮亚特斯基-夏皮罗,(208k),增加了 274%。数据科学、商业智能和数据挖掘专家;KDnuggets 的主席,被评为最佳 Twitter 和大数据与数据科学领域的顶级影响者。知识发现和数据挖掘(KDD)会议及其专业组织 SIGKDD 的共同创始人。他还为 60 多本出版物做出了贡献,并编辑了几本关于数据挖掘和知识发现的书籍。同时在 Twitter 上也是 @kdnuggets,拥有 95k 粉丝。
-
Python 与 R – 谁在数据科学和机器学习中真正领先
-
漫画:机器学习课程
8. 罗纳德·范·伦,(32.7k)。在数字转型领域被 Onalytica、Dataconomy 和 Klout 等出版物和组织认可。除了这些认可,罗纳德还是多个领先大数据网站的作者,包括《卫报》、《Datafloq》和《数据科学中心》。同时在 Twitter 上也是 @Ronald_vanLoon,拥有 103k 粉丝。
-
马术运动 – 传统与数字科技的结合
-
我需要什么技能才能成为数据科学家
9. 柯克·博恩,(23.7k),增加了 149%。柯克是一位主要且广受认可的大数据和数据科学顾问,TedX 演讲者、顾问、研究员、博主、数据素养倡导者。柯克还是一位公共演讲者、顾问、天体物理学家和空间科学家。自 2013 年以来,他一直是全球顶级影响者。KirkDBorne 在 Twitter 上,有 170k 粉丝。
-
机器学习在营销中的重大进展
-
顶级客户体验旅程管理的五个关键属性
10. 文·瓦希斯塔,(14k)。文在初创公司和财富 10 强公司中拥有 8 年的现代数据科学/机器学习工具和方法论经验。他是一位发表过文章的商业战略专家,受到了沃尔玛、埃森哲、微软、IBM 的关注,并被 Agilience、Klout、Dataconomy 和 Onalytica 认可为数据科学和机器学习领域的思想领袖。他是 IBM、英特尔和许多其他优秀品牌的影响者。v_vashishta
在 Twitter 上,有 37.5k 粉丝。
-
8 个高效数据科学家的习惯
-
机器学习革命不会被电视转播
相关:
-
数据科学领域的顶级影响者
-
2017 年大数据:顶级影响者和品牌
-
LinkedIn 上的 16 位活跃的大数据和数据科学领袖
更多相关内容
数据科学家常犯的 10 大编码错误
原文:
www.kdnuggets.com/2019/04/top-10-coding-mistakes-data-scientists.html
评论
作者 诺曼·尼默,首席数据科学家
数据科学家是一个“在统计学上比任何软件工程师都强,在软件工程上比任何统计学家都强”的人。许多数据科学家具有统计学背景,但在软件工程方面经验不足。我是一名高级数据科学家,在 Stackoverflow 上的 Python 编码排名前 1%,并与许多(初级)数据科学家一起工作。以下是我经常看到的 10 个常见错误。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT

1. 不要分享代码中引用的数据
数据科学需要代码和数据。因此,为了让其他人能够复现你的结果,他们需要访问数据。这看起来很基本,但很多人忘记将数据与代码一起分享。
import pandas as pd
df1 = pd.read_csv('file-i-dont-have.csv') # fails
do_stuff(df)
解决方案:使用 d6tpipe 将数据文件与代码一起分享,或上传到 S3/web/google drive 等,或者保存到数据库中,以便接收者可以检索文件(但不要将其添加到 git 中,详见下文)。
2. 硬编码不可访问的路径
类似于第 1 个错误,如果你硬编码了其他人无法访问的路径,他们无法运行你的代码,还得到处查找并手动更改路径。真糟糕!
import pandas as pd
df = pd.read_csv('/path/i-dont/have/data.csv') # fails
do_stuff(df)
# or
import os
os.chdir('c:\\Users\\yourname\\desktop\\python') # fails
解决方案:使用相对路径、全局路径配置变量或 d6tpipe 使你的数据更易于访问。
3. 将数据与代码混合
由于数据科学代码需要数据,为什么不把数据放在同一个目录下呢?同时,图片、报告和其他杂物也一起保存。哎呀,真是一团糟!
├── data.csv
├── ingest.py
├── other-data.csv
├── output.png
├── report.html
└── run.py
解决方案:将你的目录组织成类别,例如数据、报告、代码等。查看 Cookiecutter Data Science 或 d6tflow 项目模板(参见第 5 条),并使用第 1 条中提到的工具来存储和共享数据。
4. 将数据与源代码一起提交到 Git
现在大多数人都对代码进行版本控制(如果你没有,那是另一个错误!!参见 git)。在尝试共享数据时,可能会诱使你将数据文件添加到版本控制中。这对于非常小的文件是可以的,但 git 对数据,特别是大型文件,优化得不好。
git add data.csv
解决方案: 使用 #1 中提到的工具来存储和共享数据。如果你确实想对数据进行版本控制,可以查看 d6tpipe、DVC 和 Git Large File Storage。
5. 编写函数而不是 DAGs
说够了数据,让我们来谈谈实际的代码!由于你学习编程时首先学会的是函数,数据科学代码大多组织成一系列线性运行的函数。这会引发几个问题,参见 4 Reasons Why Your Machine Learning Code is Probably Bad。
def process_data(data, parameter):
data = do_stuff(data)
data.to_pickle('data.pkl')
data = pd.read_csv('data.csv')
process_data(data)
df_train = pd.read_pickle(df_train)
model = sklearn.svm.SVC()
model.fit(df_train.iloc[:,:-1], df_train['y'])
解决方案: 数据科学代码最好不要线性链式调用函数,而是将其组织为一系列具有依赖关系的任务。使用 d6tflow 或 airflow。
6. 编写 for 循环
就像函数一样,for 循环是你学习编程时学到的第一件事。易于理解,但它们速度慢且过于冗长,通常表明你不了解向量化的替代方法。
x = range(10)
avg = sum(x)/len(x); std = math.sqrt(sum((i-avg)**2 for i in x)/len(x));
zscore = [(i-avg)/std for x]
# should be: scipy.stats.zscore(x)
# or
groupavg = []
for i in df['g'].unique():
dfg = df[df[g']==i]
groupavg.append(dfg['g'].mean())
# should be: df.groupby('g').mean()
解决方案: Numpy、scipy 和 pandas 提供了大多数你认为可能需要循环的向量化函数。
7. 不写单元测试
随着数据、参数或用户输入的变化,你的代码可能会出错,有时你甚至没有注意到。这可能导致错误的输出,如果有人基于你的输出做决策,错误的数据会导致错误的决策!
解决方案: 使用 assert 语句检查数据质量。pandas 提供了相等性测试,d6tstack 提供了数据摄取检查,d6tjoin 提供了数据连接检查。示例数据检查代码:
assert df['id'].unique().shape[0] == len(ids) # have data for all ids?
assert df.isna().sum()<0.9 # catch missing values
assert df.groupby(['g','date']).size().max() ==1 # no duplicate values/date?
assert d6tjoin.utils.PreJoin([df1,df2],['id','date']).is_all_matched() # all ids matched?
8. 不记录代码
我明白了,你急于完成一些分析。你快速组合代码以向客户或老板提供结果。然后一周后,他们回来并说“你能改动 xyz 吗”或“你能更新一下吗”。你看着自己的代码却记不起当初的做法。现在想象一下,别人还要运行这段代码。
def some_complicated_function(data):
data = data[data['column']!='wrong']
data = data.groupby('date').apply(lambda x: complicated_stuff(x))
data = data[data['value']<0.9]
return data
解决方案: 即使在交付分析后,也要花额外的时间记录你所做的工作。你会感谢自己,别人会更加感激你!你将显得像个专业人士!
9. 将数据保存为 csv 或 pickle
备份数据,毕竟这是数据科学。就像函数和循环一样,CSV 和 pickle 文件是常用的,但实际上并不好。CSV 不包含模式,因此每个人都必须重新解析数字和日期。Pickles 解决了这个问题,但只在 python 中工作且没有压缩。两者都不是存储大型数据集的好格式。
def process_data(data, parameter):
data = do_stuff(data)
data.to_pickle('data.pkl')
data = pd.read_csv('data.csv')
process_data(data)
df_train = pd.read_pickle(df_train)
解决方案: 使用 parquet 或其他带有数据模式的二进制数据格式,理想情况下是那些能压缩数据的格式。d6tflow 自动将任务的数据输出保存为 parquet 文件,因此你不必处理它。
10. 使用 jupyter notebooks
让我们以一个有争议的问题总结一下:jupyter notebooks 和 CSV 一样普遍。很多人使用它们,但这并不意味着它们好。Jupyter notebooks 促进了上述提到的许多糟糕的软件工程习惯,特别是:
-
你会倾向于把所有文件放在一个目录中
-
你编写的代码是从上到下执行的,而不是 DAGs
-
你没有模块化你的代码
-
难以调试
-
代码和输出混合在一个文件中
-
他们的版本控制做得不好
它看起来容易入门,但扩展性差。
简介: 诺曼·尼默 是一家大型资产管理公司的首席数据科学家,他提供基于数据的投资见解。他拥有哥伦比亚大学的金融工程硕士学位和伦敦 Cass 商学院的银行与金融学士学位。
原文。已获得许可转载。
相关:
-
你机器学习代码可能糟糕的 4 个原因
-
机器学习项目清单
-
初创公司数据科学项目流程
更多相关话题
2020 年计算机视觉领域前 10 篇论文
原文:
www.kdnuggets.com/2021/01/top-10-computer-vision-papers-2020.html
评论
由 Louis (What's AI) Bouchard,蒙特利尔人,YouTube 和 Medium 上解释人工智能的内容

我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
即便今年世界发生了许多事情,我们仍然有机会看到大量令人惊叹的研究成果。特别是在人工智能领域,更准确地说是计算机视觉领域。今年突出了许多重要方面,比如伦理问题、重要偏见等。人工智能以及我们对人脑及其与人工智能关系的理解不断演变,显示出在不久的将来有着广阔的应用前景,我肯定会对此进行深入探讨。
这里是我精选的年度计算机视觉领域最有趣的 10 篇研究论文,以防你错过了其中任何一篇。简而言之,这基本上是一个最新突破的人工智能和计算机视觉的精选列表,包括清晰的视频解释、更深入的文章链接,以及代码(如果适用)。享受阅读,如果我遗漏了任何重要论文,请在评论中告诉我,或通过LinkedIn直接联系我!
每篇论文的完整参考文献列在本文末尾。
如果你分享了这篇文章,请在Twitter (@Whats_AI)或LinkedIn (Louis (What’s AI) Bouchard)标记我!
在 5 分钟内观看完整的 2020 年计算机视觉回顾
Sea-thru: 一种从水下图像中去除水分的方法 [1]
你是否曾想过没有水的海洋会是什么样子?去除水下图像中的蓝绿色调,还原珊瑚礁的真实颜色?使用计算机视觉和机器学习算法,海法大学的研究人员成功实现了这一目标!
你是否曾想过没有水的海洋会是什么样子?研究人员最近通过使用……
神经电路策略实现可审计的自主性 [2]
来自 IST 奥地利和麻省理工学院的研究人员成功地使用一种基于微小动物大脑的新型人工智能系统训练了一辆自动驾驶汽车。他们仅使用了少数几个神经元来控制自动驾驶汽车,而不需要像流行的深度神经网络(如 Inceptions、Resnets 或 VGG)那样需要数百万个神经元。他们的网络仅使用了 75,000 个参数,由 19 个控制神经元组成,而不是数百万个!
一种新的受大脑启发的智能系统仅用 19 个控制神经元驾驶汽车!
模仿线虫的神经系统以高效处理信息,这种新的智能系统更具鲁棒性……
[NeRV:神经反射和可见性场
进行重新照明和视图合成](https://people.eecs.berkeley.edu/~pratul/nerv/) [3]
这种新方法能够生成一个完整的三维场景,并且能够决定场景的光照条件。所有这些都以非常有限的计算成本和与之前的方法相比惊人的结果完成。
这种新方法能够生成一个完整的三维场景,并且能够决定场景的光照条件……
YOLOv4:目标检测的最佳速度和准确性 [4]
第 4 版最近于 2020 年 4 月由 Alexey Bochkovsky 等人在论文《YOLOv4:目标检测的最佳速度和准确性》中引入。这个算法的主要目标是制作一个超快的目标检测器,在准确性方面具有高质量。
YOLOv4 算法 | You Only Look Once 第 4 版简介 | 实时目标检测
我最近发布了一篇帖子,解释了初始的 You Only Look Once,即 YOLO 算法的基础知识。然后…
PULSE: 通过生成模型的潜在空间探索进行自监督照片超分辨率 [5]
这个新算法可以将模糊的图像转换为高分辨率图像!
它可以将超低分辨率的 16x16 图像转换为 1080p 高清人脸!你不相信我?那你可以像我一样自己试试,不到一分钟的时间!但首先,让我们看看他们是怎么做到的。
这个新算法可以将模糊的图像转换为高分辨率图像!它可以将超低分辨率的 16x16 图像…
图像 GPT — 从像素生成预训练 [6]
一个好的 AI,比如 Gmail 中使用的 AI,可以生成连贯的文本并完成你的短语。这个 AI 使用相同的原理来完成图像!这一切都在无监督训练中完成,完全不需要标签!
一个好的 AI,比如 Gmail 中使用的 AI,可以生成连贯的文本并完成你的短语。这个 AI 使用相同的…
DeepFaceDrawing: 从草图中深度生成面部图像 [7]
现在你可以使用这个新的图像到图像翻译技术,从粗略或甚至不完整的草图中生成高质量的面部图像,完全不需要绘画技巧!如果你的绘画技能和我一样糟糕,你甚至可以调整眼睛、嘴巴和鼻子对最终图像的影响!让我们看看它是否真的有效以及他们是如何做到的。
现在你可以使用这个新的图像到图像翻译技术,从粗略或甚至不完整的草图中生成高质量的面部图像,完全不需要绘画技巧!
PIFuHD: 多层次像素对齐隐式函数用于高分辨率 3D 人体数字化 [8]
这个 AI 可以从 2D 图像中生成 3D 高分辨率的重建图像!它只需要你的一张图片就可以生成一个看起来和你一模一样的 3D 头像,甚至从背面也是如此!
AI 从 2D 图像生成 3D 高分辨率重建 | PIFuHD 介绍
这个 AI 可以从 2D 图像中生成 3D 高分辨率的重建图像!它只需要你的一张图片就可以…
RAFT:用于光流的递归全对场变换 [9]
ECCV 2020 最佳论文奖颁给了普林斯顿团队。他们开发了一种新的端到端可训练的光流模型。他们的方法在多个数据集上超越了最先进架构的准确性,并且效率更高。他们甚至将代码发布在 Github 上供大家使用!
ECCV 2020 最佳论文奖颁给了普林斯顿团队。他们开发了一种新的端到端可训练的光流模型……
学习视频修补的联合时空变换 [10]
这个 AI 能够填补被移除移动物体后的缺失像素,并比当前最先进的方法更准确、更清晰地重建整个视频!
视频修补 — 微软研究院
通过深度潜在空间转换进行旧照片恢复 [Bonus 1]
想象一下,将你祖母 18 岁时的旧照片,即使是折叠和撕裂的照片,恢复到高清晰度且没有任何伪影。这就是所谓的旧照片恢复,这篇论文刚刚开辟了一个全新的方向,使用深度学习方法来解决这个问题。
想象一下,将你祖母 18 岁时的旧照片,即使是折叠和撕裂的照片,恢复到高清晰度……
实时肖像抠图是否真的需要绿幕? [Bonus 2]
人体抠图是一项非常有趣的任务,目标是找到图片中的任何人并去除背景。由于任务复杂,需找到具有完美轮廓的人或多人,因此非常难以实现。在这篇文章中,我回顾了这些年来使用的最佳技术以及 2020 年 11 月 29 日发布的一种新方法。许多技术使用基本的计算机视觉算法来完成这项任务,如 GrabCut 算法,它极其快速,但不够精确。
这种新的背景去除技术可以从单张输入图像中提取一个人,无需绿屏……
DeOldify [Bonus 3]
DeOldify 是一种为黑白图片或电影胶卷上色和修复的技术。它由 Jason Antic 开发并持续更新。它现在是为黑白图片上色的最先进方法,所有内容都是开源的,但我们稍后会回到这个话题。
这个 AI 可以将你的黑白照片色彩化,并提供全真实感的渲染! (DeOldify)
这种方法称为 DeOldify,适用于几乎所有的图片。如果你不相信,可以亲自试试……
结论
正如你所见,这对计算机视觉来说是一个极具洞察力的年份。我一定会涵盖 2021 年最激动人心和有趣的论文,如果你能参与其中我会非常高兴!如果你喜欢我的工作并希望了解最新的 AI 技术,你应该关注我的社交媒体频道。
-
订阅我的 YouTube 频道。
-
关注我的项目 LinkedIn。
-
一起学习 AI,加入我们的 Discord 社区,分享你的项目、论文、最佳课程,寻找 Kaggle 队友,等等!
如果你分享了这篇文章,请在Twitter (@Whats_AI)或LinkedIn (Louis (What’s AI) Bouchard)*** 标记我!***
如果你对 AI 研究感兴趣,这里有另一篇很棒的文章:
最新 AI 突破的精心整理列表,按发布日期排序,并附有清晰的视频解释,链接到更多……
论文参考
[1] Akkaynak, Derya & Treibitz, Tali. (2019). Sea-Thru: 一种从水下图像中去除水的技术。1682–1691。10.1109/CVPR.2019.00178。
[2] Lechner, M., Hasani, R., Amini, A. 等 神经电路策略实现可审计的自主性。Nat Mach Intell 2, 642–652 (2020)。 doi.org/10.1038/s42256-020-00237-3
[3] P. P. Srinivasan, B. Deng, X. Zhang, M. Tancik, B. Mildenhall, 和 J. T. Barron,“Nerv: 神经反射和可见性场用于重光照和视图合成,”在 arXiv,2020。
[4] A. Bochkovskiy, C.-Y. Wang, 和 H.-Y. M. Liao,Yolov4:目标检测的最佳速度和准确性,2020. arXiv:2004.10934 [cs.CV]。
[5] S. Menon, A. Damian, S. Hu, N. Ravi, 和 C. Rudin,Pulse:通过生成模型的潜在空间探索进行自监督照片放大,2020. arXiv:2003.03808 [cs.CV]。
[6] M. Chen, A. Radford, R. Child, J. Wu, H. Jun, D. Luan, 和 I. Sutskever,“从像素生成预训练,”在第 37 届国际机器学习大会论文集,H. D. III 和 A. Singh 编,机器学习研究论文集,卷 119,虚拟:PMLR,2020 年 7 月 13–18 日,第 1691–1703 页。[在线]。
[7] S.-Y. Chen, W. Su, L. Gao, S. Xia, 和 H. Fu,“DeepFaceDrawing:从草图中深度生成面部图像,”ACM 图形学交易(ACM SIGGRAPH2020 论文集),卷 39,第 4 期,72:1–72:16,2020. 可用:http://proceedings.mlr.press/v119/chen20s.html。
[8] S. Saito, T. Simon, J. Saragih, 和 H. Joo,Pifuhd:多级像素对齐隐函数用于高分辨率 3D 人类数字化,2020. arXiv:2004.00452 [cs.CV]。
[9] Z. Teed 和 J. Deng,Raft:用于光流的递归全对场变换,2020. arXiv:2003.12039 [cs.CV]。
[10] Y. Zeng, J. Fu, 和 H. Chao,学习联合时空变换用于视频修复,2020. arXiv:2007.10247 [cs.CV]。
[Bonus 1] Z. Wan, B. Zhang, D. Chen, P. Zhang, D. Chen, J. Liao, 和 F. Wen,旧照片修复通过深度潜在空间转换,2020. arXiv:2009.07047 [cs.CV]。
[Bonus 2] Z. Ke, K. Li, Y. Zhou, Q. Wu, X. Mao, Q. Yan, 和 R. W. Lau,“实时肖像抠图真的需要绿幕吗?” ArXiv,卷 abs/2011.11961,2020。
[Bonus 3] Jason Antic,DeOldify 的创作者,github.com/jantic/DeOldify
原文。转载已获许可。
相关:
-
2020:充满惊人 AI 论文的一年 — 回顾
-
AI、分析、机器学习、数据科学、深度学习研究 2020 年的主要发展和 2021 年的关键趋势
-
使用 Dask 和 PyTorch 的大规模计算机视觉
更多相关话题
你应该关注的十大数据科学领袖
原文:
www.kdnuggets.com/2019/07/top-10-data-science-leaders.html
评论
作者:Admond Lee,美光科技 / AI 时间杂志 / 亚洲科技
我一直相信,要有效学习,我们必须向最优秀的人学习。
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
如果你关注过我的工作,你会知道我两年前作为一名物理学学生进入数据科学领域,当时对数据科学一无所知。
我成功地在一年内从物理学转向数据科学。
事实上,我遇到了很多困难,犯了许多错误。
我不断前行,自己站起来,继续向前走。
当我回顾我的数据科学旅程及我走到今天这一步时,真正推动我前进的是从最优秀的数据科学领袖那里学习(并仍在学习!)——这些是数据科学领域的专家——通过他们的分享。
这极大地帮助了我的数据科学之路,成为一名数据科学家,因为他们定期分享数据科学中的实际经验、最新技术和工具、技术和非技术知识等。
这些数据科学领袖只是 LinkedIn 上杰出数据科学社区的一部分,他们激励我通过在LinkedIn和Medium上分享我的经验和知识来回馈社区。
因此你现在阅读的这篇文章(以及Medium 上的其他文章)。
如果你在数据科学领域,我强烈建议你关注这些巨头——我将在下面的部分列出——并成为我们数据科学社区的一员,向最优秀的人学习并分享你的经验和知识。
让我们开始吧!
你应该关注的十大数据科学领袖
Randy Lao 真的是非常棒。事实上,他是我刚开始学习数据科学时关注的第一个数据科学领袖,当时我对数据科学一无所知。
如果你是一名有抱负的数据科学家,我强烈推荐你访问 他的网站,那里有所有有用的免费数据科学和机器学习资源分享给你。
最重要的是,他还是 数据科学梦想工作 的导师,这是一个帮助有抱负的数据科学家成长和找工作的电子学习平台——由 Kyle McKiou 创办。
凭借他的分享和在数据科学领域的广泛经验,我相信你会从他那里学到很多东西,我确实学到了。
如果你在 LinkedIn 上活跃,你可能已经听说过他的名字。
如前所述,Kyle 是 数据科学梦想工作 的创始人,该平台教授来自不同背景的有抱负的数据科学家如何在数据科学领域找到工作。
课程本身的价值超过任何东西,因为他和其他优秀的导师教授有抱负的数据科学家如何培养心态、掌握技术和非技术技能、求职技巧以及如何最终在这一行业开始他们的职业生涯。
这不仅仅是另一个 Udemy 或 Coursera 上的在线课程,它们只是教授编程或机器学习中的技术技能。
Kyle 还定期在 LinkedIn 上与数据科学社区分享他的经验和见解。
如果你想进入数据科学领域——即使你完全没有背景——那么跟随 Kyle 并查看他的课程。
Kirill Eremenko 是 SuperDataScience 的创始人兼首席执行官,这是一个为数据科学家提供在线教育的门户网站。
公司的使命是“让复杂变简单”,愿景是成为数据科学爱好者最大的学习门户。
此外,该平台提供了几十门分析课程,涵盖了从基于工具的课程,如 R 编程、Python、Tableau,到概述性的课程,如机器学习 A-Z 和数据科学入门。
我个人最喜欢的课程是 深度学习 A-Z™:动手实践人工神经网络,由 Kirill Eremenko 和 Hadelin de Ponteves 授课。这是我第一次接触深度学习,信任我,他们的课程确实独一无二,强调直观理解,并结合了有监督和无监督深度学习的动手编码教程。
最近,我有机会阅读了他的书——自信的数据技能,这本书帮助你理解从项目开始到结束的完整数据科学工作流程,全程无需编写代码!
法比奥·瓦斯克斯在数据科学领域有着深厚的经验,他总是乐于在 LinkedIn 上无保留地分享他的想法和见解。
就我个人而言,我是他其中一个 YouTube 频道的粉丝——数据科学办公时间,那里有其他了不起的数据科学领袖分享他们在不同主题上的经验。
我无法告诉你我仅从他们的网络研讨会中学到了多少。
因为最终,作为一个有抱负的数据科学家,你可以参加许多在线课程和获得证书,尽可能多地学习。但是,如果你不能理解数据科学家在实际工作环境中的工作方式,你将无法应用你在这些课程中学到的知识。
你将无法理解作为数据科学家的角色。
因此,向数据科学家学习一直是我首选的学习和探索方式。
埃里克曾是 LinkedIn 的高级数据科学家,现在在 CoreLogic 担任数据管理与数据科学主任。
我特别喜欢埃里克的一点是他对当前数据科学领域的敏锐观察。
他总是愿意分享他的知识和经验,以揭示一些常见但被遗忘的数据科学领域,这些领域总是让我感到惊叹。
埃里克是我自加入 LinkedIn 数据科学社区以来一直关注的数据科学领袖之一。从他那里学到的东西实在太多了,我迫不及待地想在未来与大家分享!
凯特以《颠覆者:数据科学领袖》的作者而著名。
她还是Datacated Weekly的主持人——一个致力于帮助他人了解数据领域各种主题的项目——以及我的 Story by Data YouTube 频道上的数据科学人物(HoDS)的主持人。
她在这篇文章中还采访了一些数据科学领域的领袖,因此如果你想了解数据领域的各种主题,我强烈建议你查看她的 YouTube 频道。
数据科学人物(HoDS)与Favio Vázquez
如你可能已经意识到的那样,LinkedIn 上的数据科学社区是一个紧密联系的社区,我们彼此互动,共享和学习。
塔里·辛格是deepkapha.ai的创始人兼首席执行官,该公司为企业提供 AI 解决方案,并致力于 AI 研究和慈善事业。
塔里在使用深度学习和 AI 解决现实世界问题方面的热情,激励我在刚开始从事数据科学时,回馈社会。
关注他的工作和分享。你将会惊讶于他的见解和分享,尤其是在 AI 最新前沿技术方面。
伊玛德·穆罕默德·汗目前是 Indegene 的一名数据科学家。
他的帖子总是充满灵感,并且对数据科学的任何主题直截了当。
此外,伊玛德还不时在印度组织 Mantissa 数据科学聚会,为大家提供一个分享和表达观点的机会,同时共同学习。
他绝对是我总是期待向其学习的数据科学家之一。
每当我们谈论数据科学时,大多数人倾向于认为这只是关于构建炫酷的机器学习模型和进行精彩的预测。
实际上,构建模型只是整个工作流程的一部分,而数据工程(即数据科学的管道工)是这个工作流程的关键部分,支持数据科学项目。
如果没有稳定而坚实的数据工程管道和平台,连获取数据进行任何分析都会很困难。
安德烈亚斯在数据工程和建立大数据平台方面确实是一位专家,这些平台支持数据科学项目。
他是一名数据工程师和数据科学平台架构师,构建每天处理和分析大量数据的数据科学平台。
如果你想了解更多关于数据工程的内容,比如 Hadoop、Spark 和 Kafka,快去查看他的 YouTube 频道 — 数据科学的管道工。
什么是数据科学的管道工? — 由安德烈亚斯·克雷茨编写
安德烈 — Gartner 的高级数据科学和机器学习团队负责人 — 可以被视为 LinkedIn 上数据科学的领军人物和名人,他有一本著名的畅销书 — 《百页机器学习书》。
他的畅销书已经被翻译成不同国家的多种语言(甚至被一些大学的图书馆和课程作为教学材料!)。
他还在 LinkedIn 上定期(几乎是每天!)分享大量有用的数据科学技巧,我相信你不想错过这些内容。
最后的想法

感谢你的阅读。
这里的数据科学领袖名单绝非详尽无遗。这些只是我在两年前刚开始从事数据科学时关注并从中学习的一些顶级数据科学领袖。
直到现在,我每天仍在学习他们的分享和经验。
受到他们贡献的启发,我通过分享我的知识和经验回馈数据科学社区,希望能帮助更多有志于成为数据科学家的朋友。
在一天的结束时,我们——作为数据科学社区的一部分——在这里,且将永远在这里,共享、帮助、学习和共同成长。
这就是社区的意义所在。
希望你喜欢阅读这篇文章。
记住,不断学习,永不停止进步。
一如既往,如果你有任何问题或评论,请随时在下方留下你的反馈,或者你也可以通过LinkedIn联系我。到那时,再见于下一篇文章!????
简历:Admond Lee 被称为备受追捧的数据科学家和顾问,帮助创业公司创始人和各种公司利用数据解决问题,拥有数据科学咨询和行业知识的深厚专业能力。你可以通过LinkedIn、Medium、Twitter和Facebook与他联系,或点击这里预约电话咨询,如果你正在寻找公司数据科学咨询服务。
原文。经许可转载。
相关:
-
LinkedIn 2018 年顶级声音:数据科学与分析
-
没有借口 – 470 位杰出的分析女性
-
LinkedIn 上活跃的大数据、数据科学、机器学习领域的前 10 位影响者,更新版
更多相关内容
打破前 10 大数据科学神话
原文:
www.kdnuggets.com/2022/12/top-10-data-science-myths-busted.html

编辑提供的图片
随着数据科学的普及,围绕它有很多神话。如果你有意从事数据科学的职业,了解这些神话并将其揭穿是很重要的。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
大数据世界充满了各种职位,包括数据工程师、数据科学家、数据分析师、业务分析师等等。毫无疑问,数据科学家是这个领域中最受欢迎的职位,这也是为什么在初学者中存在如此多的混淆。当他们尝试探索这个职位时,由于互联网上的随机内容非常混乱,他们无法确定这个领域是否适合自己,也无法决定资源的选择,这一切的混乱来自于全球各地关于数据科学的随机帖子和神话。因此,我们将揭穿这 10 大数据科学神话,帮助你解开这些误解。

作者提供的信息图
神话 1. 所有数据角色都相同
数据分析师、数据工程师和数据科学家都在做相同的事情,这完全是错误的,因为他们的工作、角色和职责都非常不同。我们理解这会造成混淆,因为所有这些人都在同一个大数据的伞下工作。首先,让我们看看数据工程师的工作。他们的职责是从事基础工程工作,构建可扩展的数据管道,以便从多个来源提取原始数据,对其进行转换,并将其存储到下游系统中。数据科学家和数据分析师依赖于这个过程,因为他们将数据转化为有意义的信息——将数据转化为信息的过程。这是将有意义的洞察呈现在数据中并为数据科学家构建准确的机器学习模型的关键。虽然这些人看起来似乎在做相同的事情,他们的技能可能有重叠,但他们的职责在根本上是不同的,这就是为什么公司会招聘不同职位的人。如果不是这样,他们会雇佣一个能够做所有事情的数据专家。
神话 2. 成为数据科学家需要博士学位或硕士学位
这也是完全错误的,不过,这也很大程度上取决于你想要的职位类型。例如,如果我们寻求的是研究领域的角色,我们需要硕士或博士学位,但如果你想解决复杂的数据问题并处理深度学习或机器学习相关的工作,那么你将需要处理数据科学的任务,使用库和数据分析方法来揭示那些复杂的数据谜题。因此,你不需要拥有硕士学位。如今,一切都与技能有关,所以如果你拥有数据科学家所需的技能集,那么你绝对可以进入这个领域。
神话 3. 数据科学家需要成为专业编码员
这也是完全错误的,因为作为数据科学家,你的工作是广泛地处理数据。当我们谈到专业编码时,这意味着要在竞争编程方面投入大量精力,或对典型的数据结构和算法有非常深入的了解。确实,数据科学家必须具备良好的复杂问题解决能力,在数据科学领域,我们有如 Python 和 R 这样的语言,通过多个库提供了非常重要的支持,可以用来解决复杂的数据问题。作为数据科学家,你的目标应该是了解如何使用这些库及其模块,以便创建最佳的数据模型和与机器学习相关的模型。数据科学家必须具备这些技能,以免在竞争编程或练习典型的数据结构和算法上浪费过多时间。
神话 4. 数据科学仅适用于计算机科学专业毕业生
这是必须揭穿的最重要的神话之一。尽管越来越多的年轻人决定学习科学科目,主要是因为科技领域工作机会的不断增加,但到目前为止,大多数人仍然没有技术背景。公司倾向于招聘数据科学领域的候选人,那些没有技术背景的候选人因为在解决问题和理解业务用例方面非常出色而被选中。这些都是在数据科学面试中取得成功的重要因素。公司不关注程序员的典型技术技能,而是希望了解候选人在能力方面的表现,是否能够理解案例研究,是否能够从数据中提取商业矩阵以及解决哪些复杂的数据相关问题。因此,永远不要认为来自非计算机科学或非技术背景的人不能进入数据科学领域。顺便提一下,对于计算机科学毕业生来说,他们的首要任务仍然是软件工程,他们希望在这一领域发展职业。因此,在数据科学领域,非技术人员的工作机会越来越多。所以现在即使你没有计算机科学相关的特定学位,只要你能获得数据科学领域所需的正确技能,你仍然有机会成为数据科学家。
神话 5. 数据科学仅仅关于预测建模
并不是每个人都知道数据科学家将 80%的时间花在数据清洗和转换上,只有 20%的时间用于数据建模。因此,想要创建非常准确的数据以及机器学习模型的数据科学家,需要对数据进行清洗和转换。我们知道,当我们处理一个特定的大数据解决方案时,涉及多个步骤,而第一步也是非常重要的一步就是数据转换。如今,我们从多个来源获取数据,而原始数据有时包含错误以及垃圾记录。如果我们无法清洗数据,我们将无法获得有意义的转换数据,也无法创建非常准确的机器学习模型。这就是为什么数据科学不仅仅是建立预测模型和回归模型,它是清洗和转换数据与建立准确的机器学习模型的良好结合。
神话 6. 数据科学需要强大的数学背景
这也是完全不正确的,因为擅长数学是作为数据科学家日常活动中的一个重要部分。在分析数据时,我们需要这些数学概念,比如数据统计部分、概率部分,但这并不是成为数据科学家的必备技能。正如我们所知,在数据科学中,我们有像 Python 和 R 这样出色的编程语言,它们提供了很棒的库支持,我们可以直接使用这些库来进行典型的数学计算和运算。因此,除非你需要创新某些东西或创建新的算法,否则你不需要成为数学专家。
神话 7. 学习一种工具就足以成为数据科学家
一个好的数据科学档案是多种技能的结合,包括技术技能和非技术技能。成为一个优秀的数据科学家需要这两种技能。要成为一个好的数据科学家,你不能仅仅依赖编程或你认为在数据科学中使用的特定工具。如果你在这两方面都很优秀,你可能会成为一个出色的数据科学家。作为数据科学家,我们在解决复杂数据问题时必须与多个利益相关者互动,并且必须直接与业务合作,以收集所有需求。了解数据领域、我们为何处理数据、从转换后的数据中可以获得什么洞察、如何解决问题、什么是相关的和什么是不相关的,都是数据科学领域所需的。不要以为仅有技术方面的东西或任何特定工具如语言或数据库就足够破解数据科学档案。你需要利用非技术技能和软技能作为你的支持系统,以成为一个好的数据科学家。
神话 8. 公司不招聘应届生担任数据科学角色
这是一个常见的问题。如果我们五六年前讨论这个话题,那确实是完全正确的。公司当时不关注应届生的数据科学角色,但现在在 2022 年,这种情况发生了很大变化,因为现在的应届生自我意识强,自我激励,并且非常有兴趣探索数据科学和数据工程等领域。他们不再依赖他人,而是投入自己的努力去探索这些职位。他们还积极参与黑客马拉松、开源贡献等比赛,并尝试自己构建酷炫的项目。这就是他们如何获得适合数据科学角色的正确技能组合和出色的开发技能。因此,现在公司更倾向于招聘应届生,以应对数据科学角色的空缺。
神话 9. 从不同的工作领域转行到数据科学领域是不可能的
如果你来自数据相关的背景,比如你曾担任过数据工程师、数据分析师或业务分析师,那么这个转型对你来说会很容易,因为你已经了解数据及如何使用不同的工具和技术框架来处理数据。另一方面,如果你来自于测试职位或软件工程职位,那么转型到数据科学将会有挑战,但并非不可能。你需要努力掌握所需的技能,然后进行一些实际的项目,这将有助于你获得新能力,并培养你对数据科学领域的兴趣,以了解你如何真正为公司作为数据科学家创造价值。
神话 10. 数据科学竞赛会让你成为专家
数据科学竞赛是获取正确技能的好方法,同时也可以了解数据科学环境,甚至提升开发技能,但如果你认为仅仅通过参与黑客马拉松和创建竞赛项目就能成为数据科学专家,那是不准确的。你将提升并增加简历的价值,以便展示你的工作和所取得的成果,但如果你真的想成为专家,你需要参与一些实际的用例或生产级应用。因此,建议新人们应参加良好的实习。
结论
如果你对数据科学感兴趣,不要让这些误区让你灰心。数据科学是一个对各种背景的人开放的领域。只要具备正确的技能和知识,任何人都可以成为数据科学家。
请在 Twitter 和 LinkedIn 上关注我,以获取每日技术更新:
参考资料
揭开数据科学十大误区 | 数据科学技巧 2022 | 大数据 | DSML | 数据科学神话与现实
Giuliano Liguori 是 Kenovy 的首席执行官兼联合创始人,Kenovy 是创新的关键。Giuliano Liguori 是 AI、工业 4.0 和数字化转型领域的领先声音。在过去的 18 年里,他通过拥抱创新、利用先进技术和成功整合 OT 和 IT,帮助组织和企业变得更智能、更高效。他的博客 Digital Leaders 推广数字化转型、工业 4.0 和 AI 采用。他还是 CIO Club Italia 的联合创始人和执行委员会成员。
原文。经许可转载。
更多相关话题
初学者的前十个数据科学项目
原文:
www.kdnuggets.com/2021/06/top-10-data-science-projects-beginners.html
comments

照片由 Jo Szczepanska 提供,来源于 Unsplash
作为一名有志的数据科学家,你一定听过“做数据科学项目”的建议不下千次。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 相关工作
数据科学项目不仅是极好的学习体验,它们还能帮助你在众多希望进入数据科学领域的热爱者中脱颖而出。
然而,并非所有的数据科学项目都有助于提升你的简历。实际上,在你的作品集中列出错误的项目可能会适得其反。
在这篇文章中,我将带你深入了解那些在简历中必不可少的项目。
我还将为每个项目提供示例数据集以供实验,并附上相关的教程帮助你完成项目。
技能 1:数据收集

照片由 James Harrison 提供,来源于 Unsplash
数据收集和预处理是数据科学家必备的重要技能之一。
在我的数据科学工作中,大部分工作涉及在 Python 中进行数据收集和清理。在理解业务需求后,我们需要获取互联网中的相关数据。
这可以通过使用 API 或网络抓取工具来完成。一旦完成,数据需要被清理并存储到数据框中,以便作为输入提供给机器学习模型。
这是数据科学家工作中最耗时的部分。
我建议通过完成以下项目来展示你在数据收集和预处理方面的技能:
网络抓取 — 食品评论网站
教程: Zomato Web Scraping with BeautifulSoup
语言:Python
从食品配送网站抓取评论是一个有趣且实际的项目,可以为你的简历增添亮点。
简单地构建一个网络爬虫,收集该网站所有网页上的评论信息,并将其存储在数据框中。
如果你想进一步拓展这个项目,可以使用收集的数据构建情感分析模型,并对这些评论进行分类,判断哪些是积极的,哪些是消极的。
下次你想找点吃的时,选择一个评论整体评价最好的餐厅。
网络爬虫 — 在线课程网站
语言:Python
想要在 2021 年找到最佳的在线课程吗?在数百个数据科学课程中挑选一个既实惠又高评价的课程确实很困难。
你可以通过抓取一个在线课程网站,并将所有结果存储到数据框中来实现这一点。
将这个项目进一步拓展,你还可以围绕价格和评级等变量创建可视化,寻找既实惠又优质的课程。
你还可以创建一个情感分析模型,得出每个在线课程的整体情感。然后,你可以选择情感总体评价最高的课程。
奖励
创建一些项目,使用 API 或其他外部工具收集数据。这些技能通常在你开始工作时非常有用。
大多数依赖第三方数据的公司通常会购买 API 访问权限,你需要借助这些外部工具进行数据收集。
一个你可以做的示例项目:使用 Twitter API 收集与特定标签相关的数据,并将数据存储在数据框中。
技能 2:探索性数据分析
图片来源:Luke Chesser拍摄,来自Unsplash
在收集和存储数据之后,你需要对数据框中的所有变量进行分析。
你需要观察每个变量的分布情况,了解它们之间的关系。你还必须能够利用可用的数据回答问题。
作为数据科学家,你会经常做这些工作,甚至比预测建模还要多。
以下是一些 EDA 项目想法:
识别心脏病的风险因素
教程:Framingham Heart Study: 决策树
语言:Python 或 R
这个数据集包含了如胆固醇、年龄、糖尿病和家族病史等预测因子,用于预测患者心脏病的发生。
你可以使用 Python 或 R 来分析数据集中存在的关系,并回答以下问题:
-
糖尿病患者是否更容易在年轻时发展心脏病?
-
是否存在某个特定的人口群体比其他群体更容易患心脏病?
-
频繁锻炼是否能降低患心脏病的风险?
-
吸烟者是否比非吸烟者更容易发展心脏病?
能够借助可用数据回答这些问题是数据科学家必备的重要技能。
这个项目不仅会帮助你提升作为分析师的技能,还能展示你从大数据集中提取见解的能力。
世界幸福报告
数据集:世界幸福报告
教程:世界幸福报告 EDA
语言:Python
世界幸福报告追踪六个因素来衡量全球幸福感——预期寿命、经济状况、社会支持、腐败缺失、自由和慷慨。
在对这个数据集进行分析时,你可以回答以下问题:
-
世界上哪个国家最幸福?
-
哪些因素对一个国家的幸福感最为重要?
-
整体幸福感是在增加还是减少?
再次强调,这个项目将有助于提升你作为分析师的技能。我在大多数成功的数据分析师身上看到的一个特质是好奇心。
数据科学家和分析师总是在寻找影响因素。
他们总是试图寻找变量之间的关系,并不断提出问题。
如果你是一个有志成为数据科学家的人,做这样的项目将帮助你培养分析思维。
技能 3:数据可视化

由 Lukas Blazek 在 Unsplash 提供的照片
当你开始担任数据科学家时,你的客户和利益相关者通常会是非技术人员。
你需要将你的见解分解并向非技术观众展示结果。
最好的方式是以可视化的形式进行展示。
展示一个互动仪表板将有助于你更好地传达你的见解,因为图表一目了然。
因此,许多公司将数据可视化列为数据科学相关职位的必备技能。
这里有一些你可以在作品集中展示的数据可视化项目,以展示你的数据可视化技能:
构建一个 Covid-19 仪表板
教程:使用 Python 和 Tableau 构建 Covid-19 仪表板
语言:Python
您首先需要使用 Python 对上述数据集进行预处理。然后,您可以使用 Tableau 创建一个互动的 Covid-19 仪表板。
Tableau 是最受欢迎的数据可视化工具之一,是大多数入门级数据科学职位的前提条件。
使用 Tableau 构建一个仪表板并在您的作品集中展示将帮助您脱颖而出,因为这展示了您使用该工具的熟练程度。
构建 IMDb 电影数据集仪表板
数据集:IMDb 顶级评分电影
您可以用 IMDb 数据集进行实验,并使用 Tableau 创建一个互动的电影仪表板。
如上所述,展示您构建的 Tableau 仪表板可以帮助您的作品集脱颖而出。
Tableau 的另一个好处是,您可以将您的可视化结果上传到 Tableau Public,并与任何想要使用您仪表板的人分享链接。
这意味着潜在的雇主可以与您的仪表板互动,这会引发他们的兴趣。一旦他们对您的项目感兴趣并且能够实际操作最终产品,您就离获得工作更近了一步。
如果您想开始使用 Tableau,您可以访问我的教程 这里。
技能 4:机器学习

最后,您需要展示能够体现您机器学习熟练度的项目。
我建议做两种项目——有监督和无监督的机器学习项目。
食品评论中的情感分析
数据集:亚马逊美食评论数据集
语言:Python
情感分析是机器学习中非常重要的一个方面。企业经常使用它来评估客户对其产品的整体反应。
客户通常在社交媒体和客户反馈论坛上讨论产品。这些数据可以被收集和分析,以了解不同的人如何对不同的营销策略做出反应。
基于所进行的情感分析,公司可以对其产品进行不同的定位或更改目标受众。
我建议在你的作品集中展示一个情感分析项目,因为几乎所有企业都有社交媒体存在,并且需要评估客户反馈。
预期寿命预测
数据集:预期寿命数据集
教程:预期寿命回归
语言:Python
在这个项目中,你将预测一个人的预期寿命,基于教育水平、婴儿死亡数、酒精消费和成人死亡率等变量。
我上面列出的情感分析项目是一个分类问题,这也是我将回归问题加入列表的原因。
在简历上展示多样化的项目以展示你在不同领域的专业知识是非常重要的。
乳腺癌分析
数据集:乳腺癌数据集
教程:乳腺癌数据集的聚类分析
语言:Python
在这个项目中,你将使用 K-means 聚类算法来检测乳腺癌的存在,基于目标属性。
K-means 聚类是一种无监督学习技术。
在你的作品集中展示聚类项目是重要的,因为大多数现实世界的数据都是未标注的。
即使是公司收集的大型数据集通常也没有训练标签。作为数据科学家,你可能需要使用无监督学习技术自己进行标注。
结论
你需要展示包括数据收集、分析、可视化和机器学习在内的多种技能的项目。
在线课程不足以让你在所有这些领域获得技能。然而,你可以找到几乎所有你想做的项目的教程。
你只需要具备基本的 Python 知识,就可以跟随这些教程。
一旦你把所有代码弄得妥当,并且能够正确跟进,你就可以复制解决方案,并独立开展各种不同的项目。
请记住,如果你是数据科学领域的初学者,没有相关学位或硕士学位,那么展示项目在你的作品集中是非常重要的。
作品集项目是向潜在雇主展示你技能的最佳方式之一,尤其是为了获得你在这一领域的第一个入门级工作。
了解我如何获得我的第一个数据科学实习点击这里。
迟早,那些获胜的人是那些相信自己能做到的人 — 保罗·图尔尼耶
简介: Natassha Selvaraj (LinkedIn) 我目前正在攻读计算机科学学位,主修数据科学。我对机器学习领域充满兴趣,并且在这个领域完成了各种项目。我还喜欢解决问题和编程,这也是我每天都会做的事情。
原文。已获许可转载。
相关内容:
-
重建我的 7 个 Python 项目
-
你的投资组合中最好的数据科学项目
-
数据科学初学者的投资组合指南
更多相关话题
前 10 名数据科学在能源和公用事业中的应用案例
原文:
www.kdnuggets.com/2019/09/top-10-data-science-use-cases-energy-utilities.html
评论
由 ActiveWizards 提供

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织在 IT 领域
能源行业正在不断发展,更多重要的发明和创新尚待出现。能源的使用一直涉及农业、制造业、交通等其他行业。因此,这些行业往往会增加其每日能源消耗量。能源在新技术应用和新能源源开发方面似乎需求量很大。
能源行业和公用事业的快速发展直接影响社会发展。人们现在面临智能能源管理和消费、可再生能源的应用以及环境保护的挑战。智能技术在解决这些问题中发挥着至关重要的作用。在本文中,我们将深入探讨能源和公用事业行业中最生动的数据科学应用案例。
失败概率建模
失败概率建模在能源行业中占有一席之地。机器学习算法在失败预测中的效率无可置疑。
概率建模的积极应用有助于提高性能,预测功能中的偶发故障,从而降低维护成本。能源公司投入大量资金用于设备的维护和正常运行。操作中的意外故障会导致可观的财务损失。此外,对于依赖这些公司作为能源来源的人来说,情况变得至关重要。因此,能源供应商的整体可靠性和形象可能会受到影响。
失败概率模型应用的结果是公司决策过程中的一个重要部分。它为公司管理层提供了一个绝妙的机会,使其能够领先一步。
停电检测和预测
尽管能源行业的公司做出了努力,但停电仍然发生,导致大量人群无电可用。在这方面,人们往往将停电视为电网的失败。然而,停电是一种预防措施,是自动保护系统运作的结果。
过去几年,能源系统工程师使用的是静态算法和模型,而非实时解决方案。如今,众多能源和公用事业公司正积极升级其系统,以改善停电检测和预测。现代智能停电通信系统能够:
-
预测天气条件对电网的影响
-
预测近期资产价值对电网的影响
-
通过智能电表事件检测可能的停电。
-
检测指定区域的停电情况。
-
实时过滤停电输入并识别停电类型。
-
对停电的确认和相关事项的沟通。
停电检测和预测始于识别正确的指标和阈值。每一次停电事件都应仔细分析以确定根本原因。只有在此之后,预测算法才能应用于建模未来停电的可能性。应用智能能源停电生态系统可以提供准确的实时停电状态,以改善总体客户体验和满意度。
动态能源管理
动态能源管理系统属于管理负荷的创新方法。这种管理方法涵盖了所有传统的能源管理原则,包括需求、分布式能源资源和需求侧管理,并且还涉及到现代能源挑战,如节能、临时负荷和需求减少。因此,智能能源管理系统已经发展出结合智能终端设备、分布式能源资源以及先进控制和通信的能力。
大数据分析在这里发挥着重要作用,因为它为智能电网中的动态管理系统提供了支持。这在很大程度上有助于优化供电商和消费者之间的能源流动。能源管理系统的效率,反过来,又取决于负荷预测和可再生能源资源。
动态能源管理组件通常包括智能能源终端设备、智能分布式能源资源、先进控制系统和集成通信架构。
动态能源管理系统处理通过实际方法和解决方案获得的大量数据。应用大数据分析帮助对这些数据进行性能评估,并提供智能能源管理建议。
智能电网安全与盗窃检测
能源盗窃可能被视为最昂贵的盗窃类型之一。因此,能源公司付出了巨大努力来防止这种情况。能源盗窃在智能电网中经常通过直接接入分配电缆来发生。
为了预测和防止能源盗窃以及由此产生的资金损失,大型能源公司和企业监控能源流,以便立即对一些可疑情况作出反应。为此,公司所有者倾向于转向先进计量基础设施,这些基础设施能够报告能源使用情况并进行远程控制。
智能电网安全解决方案正在获得极高的关注。这些解决方案可能基于行为,因此它们会不断跟踪用户的行为,以检测黑客并披露其意图。
预防性设备维护
预防性设备维护依赖于对设备在正常运行条件下的当前状态和性能水平的监控。这种监控旨在通过根据特定指标预测可能的故障发生,来防止设备故障。
为了最大限度地回报投资,并在其效率的巅峰期使用复杂的机器和设备,从事能源分配和公用事业的公司已经应用了几十年的预防性设备维护。智能数据解决方案、传感器和跟踪器用于收集定义的指标,处理和分析数据。根据输出,智能系统会发出能源中断、机制运作不良的警报,并敦促人们做出正确且及时的决策。
需求响应管理
在不断寻找可再生能源来源和有效使用能源的条件下,智能能源管理正处于其受欢迎的巅峰。成功的能源管理的关键在于需求和供应之间的平衡。高需求和低需求都会给能源供应商和消费者带来很多问题和成本。
因此,需求响应是一种经过时间验证的有效策略。具体的实时管理应用和解决方案可以监控能源使用的指标,确定活动高峰,并根据当前需求率调整能源流量。此外,还存在鼓励消费者在特定时间使用能源并节省资金的响应管理程序。这样,消费者有机会转向更好的定价计划,而供应商则有机会在能源供应中实现理想的平衡。
实时客户计费
企业希望改善客户服务和提高客户满意度,这一点并不奇怪。能源和公用事业公司也不例外。它们致力于提高服务提供过程、账单和支付操作的透明度,改善质量,消除延误、误解或争议问题。公司使用一整套应用程序和软件来管理众多客户、账单、支付和开票。客户也有机会监控交易情况。
运营管理软件实时跟踪运营活动和交易,并在账单、支付、预付和后付服务以及通信服务方面采取即时行动。
提高运营效率
效率的本质是指在比以前更短的时间内完成特定任务。现代生活的快速节奏和日常事务使人们希望在所有方面提高效率。
能源和公用事业公司使用智能数据应用程序和软件来检测值得优化的问题、操作和功能。实时监控提供有关时间、活动率和某些操作状态的数据。这些数据与外部因素结合处理,以确定平均效率。数据科学在这里用于各种情况的建模和在不同情况下效率的预测。
优化资产性能
能源供应中所有可能的故障或延误、计划外的服务中断或复杂情况都会导致低效。通过对性能和资产的监控,可以防止或至少控制这种低效。
实时数据关于资产健康状况、供应和需求分析有助于提高资产性能。数据驱动和业务分析工具及软件用于监控条件、成本和性能,以及定义评分方法和关键优先领域。数据驱动和业务分析工具及软件还用于提升资产的可靠性、容量和可用性,并最小化成本。你拥有的数据越多,就能越好地管理资产。
增强客户体验
对于能源和公用事业公司来说,有两个优先工作的维度直接与整体品牌声誉相关。这两个维度是运营卓越和客户体验,它们本质上是相互依赖的。智能技术的快速发展和智能家居的日益普及为用户提供了新的机会。由于这一事实,客户在选择公司或服务时变得更加挑剔。因此,对高质量服务的需求也在增加。
所有公司都在尽力满足客户的需求和愿望。首先,应应用多种沟通渠道。全渠道为公司提供了宝贵的洞察,以便进一步处理。通过准确的分析,公司可以有效揭示客户的人口统计数据、行为和情感。因此,他们可以量身定制个性化的推荐、建议和服务。
结论
能源和公用事业公司面临着不断的压力,要求提供高质量的服务,不出现延迟和故障,并且全天候以合理的价格提供服务。人们在日常生活和工作中依赖能源来源。由于技术的快速发展和改进,该行业每天面临新的机会和挑战。
机器学习算法、分析模型和大数据解决方案帮助公司管理和有效利用其资源,控制能源流,调节电网,优化工作,并避免可能花费大量成本的错误。
实时和预测分析以及数据科学解决方案的使用需要重大投资和面对挑战的准备、学习和引入新的复杂操作。然而,数据科学在能源和公用事业领域的应用带来了诸多好处。
ActiveWizards 是一个专注于数据项目(大数据、数据科学、机器学习、数据可视化)的数据科学家和工程师团队。核心专业领域包括数据科学(研究、机器学习算法、可视化和工程)、数据可视化(d3.js、Tableau 等)、大数据工程(Hadoop、Spark、Kafka、Cassandra、HBase、MongoDB 等)以及数据密集型 Web 应用开发(RESTful API、Flask、Django、Meteor)。
原文。经授权转载。
相关:
-
金融领域数据科学的七大应用案例
-
经理数据科学入门
-
顶级 6 个 Python NLP 库的比较
更多相关内容
电信领域数据科学的十大应用案例
原文:
www.kdnuggets.com/2019/02/top-10-data-science-use-cases-telecom.html
评论
随着时间的推移,数据科学已经证明了其高价值和高效率。数据科学家们在日常生活中不断找到实施大数据解决方案的新方法。如今,数据是成功公司所需的燃料。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
电信公司也不例外。由于这些情况,它们不能不使用数据科学。在电信行业,数据科学应用被广泛用于优化运营、最大化利润、建立有效的市场营销和商业战略、可视化数据、执行数据传输以及许多其他案例。电信行业公司关键活动与数据传输、交换和导入密切相关。各种通信渠道中传递的数据量每分钟都在增加。因此,旧的技术和方法已不再适用。
在这篇文章中,我们尝试呈现电信领域最相关和高效的数据科学应用案例。
欺诈检测
电信行业由于每天吸引几乎最多的用户,是一个广泛的欺诈活动领域。电信领域最普遍的欺诈案例包括非法访问、授权、盗窃或虚假资料、克隆、行为欺诈等。欺诈对公司与用户之间建立的关系有直接影响。
因此,欺诈检测系统、工具和技术得到了广泛应用。通过将无监督的机器学习算法应用于大量的客户和运营商数据,以发现正常流量的特征,可以防止欺诈。这些算法定义了异常情况,并通过数据可视化技术将其作为实时警报呈现给分析师。这种技术的效率非常高,因为它能提供几乎实时的响应来应对可疑活动。
预测分析
电信公司应用预测分析来获取有价值的见解,以便变得更快、更好,并做出数据驱动的决策。了解客户的偏好和需求可以更好地理解客户。预测分析利用历史数据来构建预测。数据的质量越高,历史越长,预测的准确性也越高。

让我们考虑几个在电信行业中预测分析的应用案例。
客户细分
电信公司的成功关键在于市场细分并根据每个群体定制内容。这个黄金法则适用于各种业务领域。谈到电信,有四种主要的细分方案:客户价值细分、客户行为细分、客户生命周期细分和客户迁移细分。
高级定位可以预测需求、偏好以及客户对电信服务和产品的反应。这使得业务规划和定位得以提升。
客户流失预防
获取客户是一项具有挑战性的任务。保持客户的参与也需要付出很多努力。准确诊断客户的行为并启用警报可以突出那些面临流失风险的客户。智能数据平台可以汇集客户交易数据和实时通信流的数据,从而揭示客户对服务的感受。这使得可以立即解决与满意度相关的问题和防止客户流失。
终身价值预测
客户倾向于寻找更好和更便宜的服务,因此,电信公司需要衡量、管理和预测客户终身价值(CLV)。未能预测这一价值可能会导致利润损失。
客户终身价值是客户未来所有利润和收入的折现值。CLV 模型集中于客户的购买行为、活动、所使用的服务和平均客户价值。智能解决方案处理实时洞察,区分盈利、接近盈利和不盈利的客户群体,从而预测未来的现金流。
网络管理与优化
电信公司往往将客户参与过程和内部渠道视为操作顺利进行的保证。网络管理与优化提供了在操作中定义评分点的机会,以识别这些复杂情况的根本原因。查看历史数据并预测可能的未来问题或相反的有利情景对电信提供商来说是一个巨大的好处。
产品开发
产品开发是一个复杂的过程,从概念开发阶段到持续的生命周期管理和维护,都需要控制和深思熟虑的管理。要确保产品的高质量性能,符合客户的要求,就必须应用智能数据解决方案。数据驱动的产品开发过程不仅应考虑客户需求,还应考虑数字分析实施的结果、内部反馈和市场情报。
推荐引擎
推荐引擎存在于我们数字生活的各个领域。电信领域也在其中。忽视有关客户偏好的大量数据集将成为电信行业的重大损失。未来需求的预测变得可能,这得益于数据的可用性。
推荐引擎是一组智能算法,描绘客户行为,并对产品或服务的未来需求进行预测。这里最受欢迎的方法是协同过滤和基于内容的过滤。
协同过滤依赖于对用户行为或偏好的数据分析,通过与其他用户的相似性预测他们可能喜欢什么。模型的关键假设是具有相似个人资料的人可能有类似的需求并做出类似的选择。
基于内容的过滤方法利用客户个人资料与客户选择的项目之间的属性关系。因此,算法推荐与之前购买的商品和服务相似的项目。
客户情感分析
由于互联网服务作用的增加,电信领域处于不断变化之中。对于每个电信公司来说,这可能被视为一个广阔的领域,用于了解和理解客户。
客户情感分析是一组用于信息处理的方法。这种分析可以评估客户对服务或产品的积极或消极反应。对汇总数据的分析还可以揭示近期趋势,并实时应对客户的问题。客户情感分析在很大程度上依赖于文本分析技术。现代工具从各种社交媒体来源收集反馈,进行分析,并提供直接响应机制的机会。
实时分析
电信行业因其多年处理大量数据流的经验而闻名。由于互联网的快速发展以及 3G、4G 甚至 5G 连接的不断演变,电信公司面临着不断变化的客户需求的挑战。用户变得越来越挑剔,流量每天都在增加。
实时流分析可以处理这个任务。现代流分析解决方案专门用于持续摄取、分析和关联来自多个来源的数据,并在实时模式下生成响应行动。实时分析结合了与客户档案、网络、位置、流量和使用相关的数据,以创建产品或服务的 360 度用户中心视图。它还捕捉和分析客户之间的互动和沟通。
价格优化

电信领域属于高度竞争的行业。尽可能多地获取订阅者仍然是一个关键目标。由于近年来用户数量增长极快,定价成为了一种限制拥堵和同时增加收入的工具。
动态定价方法致力于映射生命周期价值、关税、渠道,以计算设备、渠道和定价计划交叉点的价格弹性,并将这些数据结合起来。基于这些见解,可以定义定价、促销和未来收入之间的相互依赖关系。
结论
电信行业因积极使用机器学习和数据科学而得到了推动。这一步骤只是为了更好的发展。许多方面和问题变得更容易解决、控制,甚至防止发生。
电信领域不得不采用现代技术和方法,以保持相关性并在全球市场严峻的环境下不失去地位。电信公司运营着庞大的通信网络和基础设施,数据流动十分密集。利用数据科学算法、方法论和工具处理和分析这些数据具有实际应用。因此,我们尝试明确几个这些应用案例,并展示可以获得的实际好处。
ActiveWizards 是一个专注于数据项目(大数据、数据科学、机器学习、数据可视化)的数据科学家和工程师团队。核心专长领域包括数据科学(研究、机器学习算法、可视化和工程)、数据可视化(d3.js、Tableau 等)、大数据工程(Hadoop、Spark、Kafka、Cassandra、HBase、MongoDB 等)和数据密集型 Web 应用开发(RESTful APIs、Flask、Django、Meteor)。
原文。经许可转载。
相关:
-
金融领域数据科学的前 7 个应用案例
-
管理者数据科学入门
-
前 6 大 Python NLP 库比较
更多相关内容
YouTube 上的十大数据科学视频
原文:
www.kdnuggets.com/2016/10/top-10-data-science-videos-youtube.html/2
7. 数据科学 – 埃因霍温理工大学 – (观看次数: 58K)
类别:广告
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
埃因霍温理工大学对其数据科学新课程的戏剧性广告。广告风格具有电影感,使用计算机图形模仿科幻动作片,类似于《少数派报告》和《盗梦空间》,通过使用 Oculus Rift 和多点触控界面等技术实现。以下是他们的本科和硕士课程链接。
类别:教育
RCRtv 探索了德州普莱诺 AT&T Foundry 中数据科学家的一天。
该视频采访了资深数据科学家卡尔提克·拉贾戈帕兰,回答了以下问题:数据科学的定义、背景、如何保持前沿、采用的工具以及对有志于成为数据科学家的人的一些最终建议。
9. 数据科学家与数据分析师的区别、角色和资格 – (观看次数: 47K)
类别:教育
Bigdata Simplified 的一段屏幕录制视频,讲述数据科学家和数据分析师之间的区别。视频强调了数据的生成方式、价值以及如何释放其力量,最后介绍了数据分析师和数据科学家的不同特点。
10. 数据科学的未来 – 数据科学@斯坦福 – (观看次数: 37K)
类别:教育
斯坦福大学医学与遗传学副教授尤安·阿什利、斯坦福大学化学教授维贾伊·潘德、斯坦福大学工程与电气工程教授赫克托·加西亚-莫利纳以及斯坦福大学校长约翰·亨内西,他们共同举办了一场长达近 26 分钟的有趣数据科学会议。他们试图解决的问题包括:这个新兴学科有多真实?它带来了哪些机会和挑战?斯坦福大学如何在研究和教育中培养数据科学?
观察:
最近,我有机会与不同的数据科学初创公司进行交流。他们的问题是:如何接触他们的客户,即商业人士、风险投资等。
所以,在这一点上,我将我的观点翻译成几个问题:
-
是否可以仅仅通过提及数据科学来讨论数据科学?最受欢迎的前十名视频显然不是面向技术文盲观众的,而是那些已经对这个领域有兴趣的人。我的想法是:我们为何不将讨论转向一些更热门的话题,如政策制定、城市规划、安全、健康、艺术和隐私?
-
与其专注于“说服”那些非数据驱动型的公司去采纳数据驱动的文化,从而聘请数据科学家,我们为什么不先专注于将数据科学传达给大众呢?
无论多么困难,在互联网上,甚至在训练营中,他们都在强调数据科学中讲故事的重要性,我觉得沟通在这个领域中是一个大问题。我不仅仅是在谈论可视化和报告。这些都是过时的、混乱的,并且常常是自我指涉的。我意识到我可能听起来很直接,甚至有点苛刻,但推动我如此坦诚的是希望让数据科学向世界开放的真实愿望。一个关键的绩效参数应该是有多少技术文盲的人能够了解并熟悉这个领域。数据科学可能不是万灵药,但它可以改变世界。
作为这一思考的直接结果,我决定检索和分析 2014 年第一批 500 个观看量最多的视频的文本元数据,这些视频的标题中包含“数据科学”和/或“数据科学家”这两个词。收集完所有的元数据后,我将所有标签、描述和标题拼接成一个词袋。我然后使用了来自 gensim Python 框架的 word2vec。分析很简单,但结果很有趣。
元数据中的 30725 个词汇中,大多数与“业务”(工作、职业、管理、行业等)、“教育”(大学、课程、学习、教程、编程等)和“数据科学工具和技术”(机器学习、算法等)相关。像“未来”和“社会”这样的词汇仅占总数的 0.13%。与“未来”最相似的词汇再次与“业务”(工作、职业、信息、产品、首席)相关。“新闻学”、“进步”、“政治”、“心理学”在与数据科学视频相关的术语中不到 0.016%。这也是一个似乎不以“名人”为导向的领域。Dr. DJ Patil 是唯一一个“突出”的影响者:占总词汇的 0.1%。
从这非常简单的分析中可能得出的结论是:
-
数据科学是一个集中的话题。那些已经了解它的人会寻找它,特别是教程和教育用途。其他人则不会。
-
目前的数据科学(从沟通的角度来看)严格与职业/业务相关。
-
显然缺乏将数据科学重新框定为“热门话题”。
我和一位高级数据科学家讨论的一个话题是关于解释数据科学在商业中的可靠性。我喜欢他的话,“科学应该让我们想起伽利略的实验科学方法。在这个领域,我们进行大量的实验。这一点真的很难解释。”
我们也应该在沟通方面进行实验。
个人简介:Marco Nasuto是一名数据科学家、航空航天工程师和电影制片人。目前在丹麦工作。
相关:
-
YouTube 上的十大机器学习视频
-
YouTube 上最受欢迎的数据挖掘视频
-
YouTube 上最受欢迎的大数据视频
更多相关主题
每个数据科学家的十大数据可视化工具
原文:
www.kdnuggets.com/2020/05/top-10-data-visualization-tools-every-data-scientist.html
评论
作者:Andrea Laura, freelance writer
我们的前三名课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业道路。
2. Google Data Analytics Professional Certificate - 提升您的数据分析技能
3. Google IT Support Professional Certificate - 支持您的组织进行 IT
数据科学是今天 IT 行业中最成熟的研究和实践领域之一,至今已经有近十年的光辉岁月。没错,它已经被证明在多个行业领域中是一项福音。从顶尖的方法论到市场分析,这项技术主要包括从数据中获取有价值的洞察。
然后对获取的数据进行处理,数据分析师进一步分析信息以找出模式,然后基于分析的信息预测用户行为。这就是数据可视化工具发挥作用的部分。
在本文中,我们将讨论一些数据科学家需要尝试的最佳数据可视化工具,以使过程顺利进行,同时获得有价值的结果。
什么是数据可视化?
数据可视化基本上是将分析后的数据以视觉形式呈现,即图表、图像。这些可视化使人们通过视觉更容易理解分析的趋势。
数据可视化在分析大型数据集时非常重要。当数据科学家分析复杂的数据集时,他们还需要理解收集到的洞察。数据可视化将通过图表和图形使他们更容易理解。
数据科学家需要使用的最佳数据可视化工具
现在,雇用一名 Android 开发者或 iOS 开发者在一定程度上取决于他们使用的工具和技术。对于全球的企业来说,使用这些工具可以帮助获得业务洞察并保持竞争优势。大多数顶尖的 iOS 和Android 移动应用开发公司正在使用这些工具来分析从移动应用中提取的数据集,以帮助业务增长和维持客户基础。
以下是 2020 年每个数据科学家必须使用的一些最佳数据可视化工具:
1. Tableau
这是一款交互式数据可视化软件。该工具用于行业中的有效数据分析和数据可视化。它具有拖放界面,这一功能使其能够轻松快速地执行任务。
该软件不强制用户编写代码。该软件兼容许多数据源。虽然工具稍贵,但它是像亚马逊这样的顶级公司最受欢迎的选择。QlikView 是 Tableau 的最大竞争对手,因其独特的拖放功能而广泛使用。
Tableau 的主要特点:
-
Tableau 被称为最简单的数据可视化商业智能工具。
-
数据科学家无需在此工具中编写自定义代码。
-
该工具还支持实时协作和数据混合。
2. D3
D3.js 是一个 Javascript 库,用于在网页浏览器中生成交互式数据可视化。它是进行数据可视化的最有效平台。该工具最初于 2011 年 2 月 18 日发布,并在 8 月成为正式版本。
它支持 HTML、CSS 和 SVG。开发人员可以将数据呈现为创意图片和图形。它是一个非常灵活的平台,允许创建不同图表的变化。
D3 的主要特点:
-
该数据可视化工具提供强大的 SVG 操作功能。
-
D3 集成了多种方法和工具用于数据处理。
-
数据科学家可以轻松地将数据映射到 SVG 属性。
3. QlikView
QlikView 是一款类似于 Tableau 的软件,但在商业用途前需要付费。它是一个将数据转化为有用信息的商业智能平台。
该软件有助于改进数据可视化过程。该工具受到经验丰富的数据科学家青睐,用于分析大规模数据。QlikView 在 100 个国家使用,并拥有一个非常强大的社区。
QlikView 的主要特点:
-
该工具与广泛的数据源(如 EC2、Impala、HP Vertica 等)集成。
-
在数据分析方面,它非常快速。
-
该数据可视化工具易于部署和配置。
4. Microsoft Power BI
这是一套业务分析工具,可以简化数据,立即准备和分析。由于它可以轻松与微软工具集成且完全免费使用和下载,它是最受欢迎的工具。
该工具适用于移动端和桌面端版本。因此,如果企业使用微软工具,这对他们来说将是一个巨大的好处。
Microsoft Power BI 的主要特点:
-
在多个数据中心生成交互式数据可视化。
-
它提供企业数据分析和自助服务于一个平台。
-
即使是非数据科学家也能轻松创建机器学习模型。
5. Datawrapper
该工具对非技术用户来说是一个福音,是最用户友好的可视化工具。要创建可视化,您需要具备编码等技术技能,但在这个应用程序中,您不需要具备任何技术技能。
该应用程序最适合希望在数据可视化领域起步的初学者。这款应用程序是数据科学家最友好的工具。该工具在媒体组织中广泛使用,因为这些组织需要通过统计和图表展示所有内容。该工具之所以如此受欢迎,是因为它具有简单易用的界面。
Datawrapper 的主要特点:
-
它为用户提供了嵌入代码,并且还提供了导出图表的能力
-
可以一次选择多种地图类型和图表
-
安装此工具无需高级编码知识
6. E Charts
接下来,我们列出的最佳数据可视化工具是 E Charts,这是一款由百度专家团队开发的企业级图表数据可视化工具。E Charts 可以被称为一个纯 JavaScript 图表库,它在各种平台上运行流畅,并且与大多数浏览器兼容。
E Charts 的主要特点:
-
具有多维数据分析功能
-
所有尺寸的设备均可用图表
-
提供了一个用于快速构建基于网页的可视化的框架。
-
这些工具完全免费使用
7. Plotly
Plotly 实现了更复杂和精细的可视化。它与以分析为导向的编程语言(如 Python、Matlab 和 R)集成。
其构建在 JavaScript 的开源 d3.Js 可视化库之上,但该商业包(具有潜在的非商业许可证)在用户友好性和支持层面上增加了更多功能,并内置了对包括 Salesforce 在内的 API 的支持。
Plotly 的主要特点:
-
提供内置权限和与 SAML 的集成
-
数据可视化工具的部署超快且简单
-
提供快速探索和原型制作的用户访问权限
8. Sisense
Sisense 提供了完整的分析解决方案。其可视化功能提供了一种简单的拖放选项,可以轻松支持复杂的图形、图表和互动可视化。
该工具允许将记录积累在易于访问的仓库中,并可以在仪表板上即时保存。
仪表板可以在各个组之间共享,确保即使是非技术人员也能找到解决他们问题的方案。
Sisense 的主要特点:
-
为用户提供各种工具以在可视环境中理解收集的数据
-
您可以一次直接连接到多个数据源
-
利用此工具,数据科学家可以将各种地图和图表结合在一起
9. FusionCharts
FusionCharts 基于 JavaScript 绘图。这款可视化工具已经稳固地确立了市场领先者的地位。
它可以生成 90 种独特的图表类型,并与各种系统和框架集成,提供显著的灵活性。
FusionCharts 可以从零开始创建任何类型的可视化,这也是它的独特功能之一。客户还可以选择从一系列“实时”示例模板中进行选择。
FusionCharts 的主要特点:
-
它提供了信息丰富的工具提示来帮助用户。
-
该工具确保用户可以理解不同的功能。
-
你可以相互比较不同数据点的值。
10. HighCharts
和 FusionCharts 一样,这也需要用于商业用途的许可证,尽管可以在试用、非商业或非公开用途下自由使用。
其网站声称,该工具被世界上 100 大机构中的 72 家使用,并且在需要快速、灵活的解决方案时,经常被选择,且在投入使用之前对专业统计可视化培训的需求最低。
HighCharts 的主要特点:
-
该数据可视化工具为用户提供了良好的兼容性。
-
HighCharts 是最广泛使用的数据分析工具之一。
-
该工具方便地将互动图表添加到高级应用程序中。
最后的话
在这篇文章中,我们遇到了一些很棒的记录可视化工具列表。在选择工具之前,建议您花些时间探索各种潜在选项。
通过试用版进行体验,向供应商请求演示,并将该工具与同类型的竞争工具进行比较。将供应商提供的功能和定价计划与您的公司和任务需求进行匹配。
此外,还有数据货币化工具,用于从大数据商业模型中获取商业洞察。数据将在未来几年推动经济。因此,企业使用各种工具来分析大数据集,为用户提供个性化体验。
我们强烈建议每个人都应该学习 Tableau 软件,如果他们想成为真正的数据科学家,然后可以根据业务需求进一步调整。
传记:安德里亚·劳拉 是一位非常有创意的作家和活跃的贡献者,喜欢分享各种主题的有用新闻或更新,为读者带来精彩的信息。作为爱好者的安德里亚已经写出了许多有趣的话题和信息,吸引读者探索她的写作。她的内容出现在许多主流网站和博客上。
相关:
-
Plotnine: Python 版 ggplot2 替代品
-
学习和实践数据科学的前 9 款移动应用
-
如何在 Python(和 R)中可视化数据
更多相关主题
Github 上前 10 个开放数据集资源
在过去的几个月里,我们查看了多个顶级 Github 仓库集合,例如:
-
Github 上前 10 个机器学习项目
-
Github 上的前 10 个深度学习项目
-
Github 上前 10 个数据可视化项目
-
Github 上前 10 个数据科学资源
-
Github 上前 10 个 IPython Notebook 教程(适用于数据科学和机器学习)

我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
本文将有所不同,因为我们将重点关注 Github 提供的顶级开放数据集仓库。本文的灵感来源于 Github 开放数据展示,虽然这个展示不错,但规模并不大。理想情况下,我想列出 Github 上的顶级开放数据集;然而,这有点复杂,因为搜索“开放数据”或其任何变体都会在一个专门用于分享开源项目及其数据的网站上遇到困难。
我决定选择这个展示中的那些没有明确注明过时的资源,并添加 3 个额外的、数据集数量最多的仓库,通过简单搜索找到的最高星级仓库,对它们进行排名,并在此展示。我们在 KDnuggets 发现数据集是许多读者最渴望的 数据科学难题的一部分,希望这批新的数据集(至少从我们的角度来看是新的)对一些读者有所帮助。
我们目前正在进行最新的年度 KDnuggets 分析软件调查,因此去年具体的百分比可能会有所变化,但我们知道,在过去 12 个月里,73%的数据科学家使用了开源工具。虽然这个数字反映的是软件,而不是数据,但很容易推测,开源数据在数据科学及相关数据导向学科中被广泛依赖,用于研究、实践和生产,原因众多。
所以这些就是截至撰写时星标数最高的开源数据集仓库。
星标:14137,Forks:1573
由Xiaming (Sammy) Chen 提供,这似乎是 Github 上公认的开源数据集集合的领头羊。这个经过整理的列表按生物学、体育、博物馆和自然语言等主题进行组织,并且包括了数百个数据集。大多数是免费的,但列表顶部有免责声明表明有些数据集不是免费的。Xiaming 还指出了另外两个带有awesome标签的仓库列表,包含更多的数据集;然而,由于这些列表包含各种其他大数据/机器学习/数据科学的链接,尽管它们的星标数很高,但不会被包含在下面的列表中。可以自行探索这些列表……显而易见。

星标:529,Forks:510
这是OpenAddresses.io的官方仓库,一个免费的全球地址收集项目。为什么要收集地址?
街道地址数据是关键基础设施。街道名称、门牌号和邮政编码,与地理坐标结合时,是将数字世界与实体地点连接起来的枢纽。正因为它们的连接作用,免费的开放地址是公民和商业创新的火箭燃料。
星标:417,Forks:187
这个仓库的描述总结如下:
美国国会成员,1789 年至今,YAML 格式,以及委员会、总统和副总统。
星标:300,Forks:88
这是一个关于我们太阳系外所有已知发现的行星的目录。该数据库通常会在新发现后的 24 小时内更新,这意味着它几乎是最新的;考虑到该仓库上次更新是在 20 天前,这在这方面是令人鼓舞的。README 还指向了这个仓库,如果你对数据的简单 CSV 格式感兴趣,可以查看。
5. CitySDK
星数:274,Forks 数:92
CitySDK 被描述为一个“[u]ser-friendly [J]avascript SDK for US Census Bureau data”,还包括若干示例,详细说明了如何将数据与其他开放数据集集成。它自称是一个“工具箱”供公民黑客使用,具有经纬度和邮政编码转换功能,以及模块化架构,使得与其他数据服务的集成变得简单。使用 API 创建你自己的自定义数据集。
6. openFDA
星数:236,Forks 数:53
openFDA 是 FDA 的一个项目,旨在通过 API、原始数据、使用示例和文档向研究人员和开发者提供 FDA 公共数据集。数据不适用于临床用途,任何数据结果的具体有效性都不能保证。尽管有这些免责声明,但毫无疑问,数据对于对该领域感兴趣的人来说是很好的实践。

7. 食品检查评估
星数:100,Forks 数:44
如果“芝加哥食品检查评估”这个名字还没有让你明白,那么你可以期待这个仓库的内容:
这个仓库包含生成对芝加哥食品机构关键违规行为预测的代码。它还包含对这些预测效果的评估结果。
8. GSA 数据
星数:92,Forks 数:40
这包含由总务管理局发布的各种数据,该机构负责管理联邦机构的基本运作(办公室、供应等)。具体来说,它包含了超过 5000 个.gov域名及其数据。
9. 美国国会选区
星数:82,Forks 数:21
来自仓库的 README:
历史及当前的美国国会选区作为 GeoJSON,版本化存储在 Git 中
10. CERN 开放数据门户
星数:79,Forks 数:34
这是CERN 开放数据门户的源代码,描述为“一个访问通过 CERN 研究产生的数据的不断增长的入口”。
相关:
-
GitHub 上的精彩公共数据集
-
调查推荐系统的 9 个必备数据集
-
5 个你不能再忽视的机器学习项目
相关主题更多信息
数据科学和机器学习的前 10 个 IPython Notebook 教程
原文:
www.kdnuggets.com/2016/04/top-10-ipython-nb-tutorials.html
本文由 10 个 Github 代码库组成,这些代码库部分或全部由 IPython(Jupyter)笔记本构成,重点传授数据科学和机器学习概念。它们涵盖了从基础 Python 材料到 TensorFlow 和 Theano 的深度学习,并在中间有很多内容。
哦,它们都是 Python 相关的。Jupyter 现在支持多种语言,但这个列表是老派的,完全是 IPython Notebook 风格的材料。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
以下是 10 个有用的 IPython Notebook Github 代码库,按无特定顺序排列:

用于数据分析和机器学习项目的教学材料、代码和数据的代码库
这个热身笔记本来自博士后研究员Randall Olson,他使用常见的 Python 生态系统数据分析/机器学习/数据科学堆栈来处理Iris 数据集。虽然它只是一个笔记本,但这是一个很好的起点,因为它激发了你对所有分析工具的兴趣,包括可视化。它还帮助你专注于用数据讲故事。
"Python 机器学习"书籍的代码库和信息资源
这是由Sebastian Raschka编写的精彩书籍《用 Python 进行机器学习》的配套代码。我不常推荐许多材料,但我强烈推荐这本书。这个代码库也很棒,是一个极好的资源。然而,建议你还是买一本自己的书,以全面理解代码库的内容,并充分融入 Python 生态系统中的机器学习。
自主学习数据科学的开放内容。
这是一个笔记本和数据集的集合,主要由尼廷·博尔万卡整理,涵盖了 4 个算法主题:线性回归、逻辑回归、随机森林和 k 均值聚类。这些看似简单的教程,尽管对于新手来说可能最有用。
我关于 scikit-learn 教程的资料。
这个由杰克·范德普拉斯创建的仓库,旨在通过几种不同的机器学习算法来教授Scikit-learn。其中涉及到的有趣话题包括验证、高斯混合模型的密度估计和主成分分析(PCA)的降维;你还会学到 k 均值、回归和分类等标准算法,放心。该资料最适合机器学习的初学者,或者有一定理解但希望掌握 Scikit-learn 的人。
机器学习算法的 Python 代码示例和文档。
亚伦·马西诺分享了一系列非常详细、非常技术性的机器学习 IPython Notebook 学习资源。这个简单标题的仓库中的笔记本受到了安德鲁·恩的《机器学习》课程(斯坦福大学,Coursera)、汤姆·米切尔的课程(卡内基梅隆大学)以及克里斯托弗·M·比肖普的《模式识别与机器学习》的启发。
与 2013 年秋季聚会相关的幻灯片、代码及其他信息。
来自 UC Boulder 研究计算组的这个较旧的笔记本集合(来自 2013 年秋季)涵盖了广泛的材料,显然专注于使用 Linux 命令行进行数据管理。涵盖了许多常用库、shell 编程和 Linux 命令行基础,至少实现了一篇当时的论文。它似乎还涉及了一些 Kaggle 竞赛,所以你会在这个集合中获得一些多样的内容。
一组关于神经网络的教程,使用 Theano。
博士生科林·拉费尔编写了这套使用 Theano 的深度学习教程。它包含两个笔记本:一个通用的 Theano 神经网络教程和一个关于反向传播的概述。这是一个很好的入门资源,用于开始学习深度学习和 Theano。
一组以 ipynb 格式呈现的教程,展示了如何在 Theano 中完成各种任务。
这是 Colin Raffel 的入门 Theano 笔记本的一个很好的后续。詹姆斯·伯格斯特拉通过这个项目带我们深入了解神经网络架构,涵盖了更多的 Theano 练习。它包括一些入门级 Python 材料,以及更高级的主题如自编码器。它还链接到一些相关材料。
一系列涵盖各种主题的 IPython 笔记本
这是由约翰·维滕纳尔整理的一个丰富的混合项目,其中包括 Ng 的 Coursera 课程练习的 Python 实现、Udacity 的 TensorFlow 导向深度学习课程练习和 Spark edX 课程练习。机器学习、深度学习和大数据处理框架:这就是“数据科学”的本质了,各位。
《统计学习导论》(James, Witten, Hastie, Tibshirani, 2013):Python 代码
这是一个由乔尔迪·沃门霍文主办的伟大项目,旨在将 James、Witten、Hastie 和 Tibshirani(2013)所著《应用于 R 的统计学习入门》一书中的概念实现到 Python 中(正如你可能已经猜到的那样,这本书在 R 中有实际练习)。这本书以 PDF 格式免费提供,这使得这个仓库对那些希望学习的人来说更具吸引力。
相关内容:
-
Scikit-learn 和 Python 栈教程:介绍,分类器实现
-
掌握 Python 机器学习的 7 个步骤
-
理解深度学习的 7 个步骤
更多相关内容
2024 年成为数据科学家的前 10 个 Kaggle 机器学习项目
原文:
www.kdnuggets.com/top-10-kaggle-machine-learning-projects-to-become-data-scientist-in-2024
 图片来源:编辑
图片来源:编辑
在不断发展的技术领域,数据科学家和分析师的角色已成为每个组织寻找数据驱动的决策见解的关键。Kaggle 作为一个将数据科学家和机器学习工程师爱好者聚集在一起的平台,成为提高数据科学和机器学习技能的核心平台。随着我们迈入 2024 年,对熟练的数据科学家的需求持续显著上升,使得在这一动态领域加速你的职业发展成为一个绝佳时机。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
因此,在本文中,你将了解从简单到高级的 2024 年十大 Kaggle 机器学习项目,这些项目可以帮助你获得解决数据科学问题的实际经验。通过实施这些项目,你将获得涵盖数据科学各个方面的全面学习体验,从数据预处理和探索性数据分析到机器学习模型部署。
一起探索数据科学的激动人心的世界,将你的技能提升到 2024 年的新高度。
简单级别项目
项目 1:数字分类系统
想法: 在这个项目中,你需要创建一个模型来使用 MNIST 数据集分类手写数字。这个项目是图像分类的基础介绍,通常被认为是深度学习新手的起点。
数据集: MNIST 数据集包含手写数字(0-9)的灰度图像。

图片来自 ResearchGate
技术: 使用如 TensorFlow 或 PyTorch 的框架进行卷积神经网络(CNN)应用。
实施流程: 首先,你必须对图像数据进行预处理,设计 CNN 架构,训练模型,并使用准确率和混淆矩阵等指标评估其性能。
Kaggle 项目链接: www.kaggle.com/code/imdevskp/digits-mnist-classification-using-cnn#
项目 2:客户分段
想法: 在这个项目中,你需要创建一个机器学习模型,根据客户过去的购买行为对客户进行分段,以便当相同的客户再次出现时,系统可以推荐过去的商品来增加销售。通过利用客户分段,组织可以针对所有客户进行有针对性的营销和个性化服务。
数据集: 由于这是一个无监督学习问题,因此不需要标签,你可以使用包含客户交易数据的数据集、在线零售数据集或任何与电子商务相关的数据集,如来自 Amazon、Flipkart 等。
技术: 使用来自无监督机器学习算法类别的不同聚类算法,如 K-means 或层次聚类(可以是分裂型或聚合型),来根据客户行为进行分段。
实施流程: 首先,你需要处理交易数据,包括数据可视化,然后应用不同的聚类算法,基于模型形成的其他聚类可视化客户分段,分析每个分段的特征以获取营销洞察,然后使用不同的指标进行评估,如轮廓系数等。
Kaggle 项目链接:
www.kaggle.com/code/fabiendaniel/customer-segmentation
中级项目
项目 3:假新闻检测
想法: 在这个项目中,你需要开发一个机器学习模型,帮助识别从不同社交媒体应用中收集的真实和虚假新闻文章之间的区别,使用自然语言处理技术。这个项目涉及文本预处理、特征提取和分类。
数据集: 使用包含标记新闻文章的数据集,例如 Kaggle 上的“假新闻数据集”。

图片来源于 Kaggle
技术: 自然语言处理库如 NLTK 或 spaCy 以及机器学习算法如朴素贝叶斯或深度学习模型。
实现流程: 你将对文本数据进行分词和清理,提取相关特征,训练分类模型,并使用精度、召回率和 F1 分数等指标评估其性能。
Kaggle 项目链接: www.kaggle.com/code/maxcohen31/nlp-fake-news-detection-for-beginners
项目 4:电影推荐系统
想法: 在这个项目中,你必须建立一个推荐系统,该系统根据用户过去的观看记录自动向他们推荐电影或网络剧。Netflix 和 Amazon Prime 等推荐系统在流媒体中广泛使用,以提升用户体验。
数据集: 常用数据集包括 MovieLens 或 IMDb,它们包含用户评分和电影信息。
技术: 协同过滤算法、矩阵分解和推荐系统框架如 Surprise 或 LightFM。
实现 流程: 你将探索用户与物品的互动,建立推荐算法,使用均方绝对误差等指标评估其性能,并对模型进行微调以获得更好的预测结果。
Kaggle 项目链接:
www.kaggle.com/code/rounakbanik/movie-recommender-systems
项目 5:股票价格预测
想法: 股票行为有些随机,但通过使用机器学习,你可以通过捕捉数据中的方差来预测近似的股票价格。该项目涉及时间序列分析和预测,以建模多个行业(如银行、汽车等)的不同股票价格的动态。
图片来自Devpost
数据集: 你需要股票的历史价格,包括开盘价、最高价、最低价、收盘价、成交量等,以不同时间框架的形式,包括每日价格或逐分钟价格及交易量。
技术: 你可以使用不同的技术来分析时间序列模型,如自相关函数和预测模型,包括自回归综合滑动平均(ARIMA)、长短期记忆(LSTM)网络等。
实施流程: 首先,你需要处理时间序列数据,包括其分解,如周期性、季节性、随机性等,然后选择合适的预测模型进行训练,最后使用均方误差、平均绝对误差或均方根误差等指标评估模型的性能。
Kaggle 项目链接: www.kaggle.com/code/faressayah/stock-market-analysis-prediction-using-lstm
高级项目
项目 6:语音情感识别
想法: 在这个项目中,你需要开发一个能够识别口语中不同情感类型的模型,例如愤怒、快乐、疯狂等,这涉及到处理从不同人那里采集的音频数据,并应用机器学习技术进行情感分类。
图片来自Kaggle
数据集: 使用带标签的音频片段数据集,例如包含情感语音记录的“RAVDESS”数据集。
技术: 用于特征提取的信号处理技术和用于音频分析的深度学习模型。
实施 流程: 你需要从音频数据中提取特征,设计用于情感识别的神经网络,训练模型,并使用准确率和混淆矩阵等指标评估其性能。
Kaggle 项目链接: www.kaggle.com/code/shivamburnwal/speech-emotion-recognition
项目 7: 信用卡欺诈检测
想法😗* 在这个项目中,你需要开发一个机器学习模型来检测欺诈性信用卡交易,这对金融机构来说至关重要,以增强安全性,保护用户免受欺诈活动,并使各种交易环境变得非常便捷。
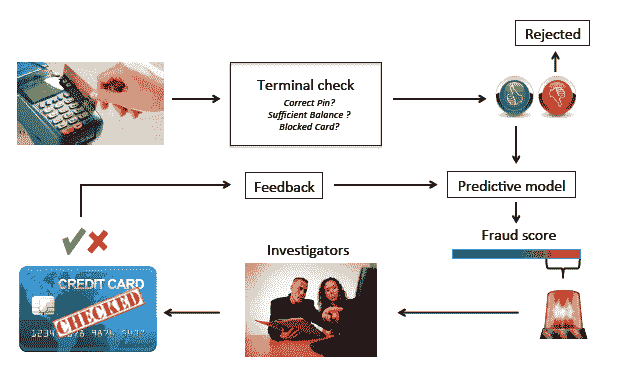
图片来源于 ResearchGate
数据集😗* 由于这是一个监督学习问题,你需要收集包含标记的欺诈和非欺诈交易的信用卡交易数据集。
技术😗* 异常检测算法、分类模型如随机森林或支持向量机,以及用于实现的机器学习框架。
实施流程😗* 首先,你需要对交易数据进行预处理,训练一个欺诈检测模型,调整参数以优化性能,并使用分类评估指标如精确度、召回率和 ROC-AUC 来评估模型。
Kaggle 项目链接:
www.kaggle.com/datasets/mlg-ulb/creditcardfraud
项目 8: 狗品种分类
想法😗* 在这个项目中,你必须实现一个深度学习模型,该模型能够根据用户在测试环境中提供的输入图像识别并分类狗的品种。通过探索这个经典的图像分类任务,你将学习深度学习中的一种著名架构,即卷积神经网络(CNN),以及它们在实际问题中的应用。
数据集😗* 由于这是一个监督学习问题,数据集将包含各种狗品种的标记图像。实现这个任务的一个热门选择是"斯坦福狗数据集",它在 Kaggle 上免费提供。
图片来源于 Medium
技术😗* 根据你的专业知识,可以使用 Python 库和框架如 TensorFlow 或 PyTorch 来实现这个图像分类任务。
实施 流程😗* 首先,你需要对图像进行预处理,设计一个包含不同层的卷积神经网络(CNN)架构,训练模型,并使用评估指标如准确率和混淆矩阵来评估模型的性能。
Kaggle 项目链接:
www.kaggle.com/code/eward96/dog-breed-image-classification
创新项目
项目 9: 花卉图像分类及部署
想法: 在这个项目中,你将学习使用 Gradio 部署机器学习模型的实际操作。这种用户友好的库可以几乎不需要代码即可实现模型部署。这个项目强调通过一个简单的界面使机器学习模型在实时生产环境中可用。
数据集: 基于问题描述,从图像分类到自然语言处理任务,你可以选择相应的数据集,并根据不同因素(如预测延迟和准确率等)选择算法,然后进行部署。
技术: 使用 Gradio 进行部署,同时使用模型开发所需的库(例如,TensorFlow,PyTorch)。
实现流程: 首先,训练一个模型,然后保存权重,这些是帮助进行预测的可学习参数,最后将这些权重与 Gradio 集成,以创建一个简单的用户界面,并部署该模型以进行交互式预测。
Kaggle 项目链接: www.kaggle.com/code/devsubhash/keras-flower-image-classification-with-gradio
项目 10: Google 地标识别
想法: 在这个项目中,你必须构建一个系统,以从输入图像中识别地标,就像在今天的世界中,你可以使用 Google Lens 来完成相同的任务。这种系统对包括图像检索、增强现实和地理定位服务等不同应用都非常有益。这个项目的主要目标是实现良好的准确率,以便从多样化的图像集中识别地标。
数据集: 数据集包含全球各地的地标图像,以便在大数据集上进行训练,使其在实际环境中进行测试时表现更佳。
技术: 你可以从卷积神经网络架构开始,或使用一些预训练模型,如 Resnet、InceptionNet 或 EfficientNet,以提高训练模型的准确性。
实现流程: 首先,你需要预处理数据,包括从图像中提取特征(以像素形式),然后进行数据增强,例如调整大小和图像归一化。之后,你需要将数据分为训练集和测试集,并根据数据集对模型进行微调。最后,在多样化的图像上测试该模型,并使用评估指标评估其性能。
Kaggle 项目链接:
www.kaggle.com/competitions/landmark-recognition-2021
总结
总之,探索前 10 个 Kaggle 机器学习项目非常棒。从揭开犬种的神秘面纱和使用 Gradio 部署机器学习模型,到打击假新闻和预测股市价格,每个项目都在数据科学这个多样化的领域中提供了独特的特点。这些项目帮助获得了在解决现实世界挑战中的宝贵见解。
记住,成为 2024 年的数据科学家不仅仅是掌握算法或框架——更是要解决复杂问题、理解多样化的数据集,并不断适应技术的演变。继续探索,保持好奇,让这些项目中的见解指引你在数据科学领域做出有影响力的贡献。祝你在动态而不断扩展的数据科学领域的持续探索之旅一切顺利!
Aryan Garg** 是一名电气工程专业的本科生,目前在大四。他对网页开发和机器学习领域感兴趣,并且已经在这方面做了很多探索,渴望在这些方向上继续努力。
更多相关话题
数据科学顶级 10 大列表
评论
作者 Mojeed Abisiga,数据科学家与机器学习工程师。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 需求
数据科学无疑是 21 世纪“最性感”的职业路径,由具备强烈智力好奇心和技术专长的人组成,从大量数据中挖掘有价值的见解。这帮助公司通过提高生产力、解锁更好的决策洞察和利润增长等方式增值。
数据科学家的旅程充满了曲折和变化,这些都会塑造你。然而,真正塑造你的不是这些曲折和变化,而是你如何应对它们。许多挑战可以通过在开始旅程之前或在成功的数据科学家之路上操作前,了解合适的工具包来预防或最小化。
本文提供了你所需的关键信息,以便你可以高效利用时间,并智能地规划数据科学职业道路。因此,提供了一个帮助你找到数据科学迷宫出路的指南。
顶级 ✔️ 10 数据科学网站
-
Analytics Vidhya
-
Kaggle
-
Coursera
-
Udacity
-
Datacamp
-
EdX
-
Udemy
-
KDNuggets
-
R-bloggers
-
Khan Academy
顶级 ✔️ 10 数据科学技能
-
概率与统计
-
线性代数
-
Python
-
R
-
SQL
-
Tableau/Power BI
-
AWS/Azure
-
Spark
-
Excel
-
DevOps
顶级 ✔️ 10 数据科学算法
-
线性回归
-
逻辑回归
-
K 均值聚类
-
PCA
-
支持向量机
-
决策树
-
随机森林
-
梯度提升机器
-
朴素贝叶斯分类器
-
人工神经网络
顶级 ✔️ 10 数据科学角色
-
数据科学家
-
决策者
-
分析师
-
ETL 工程师
-
机器学习工程师
-
数据工程师
-
分析经理
-
Tableau 开发者
-
研究员
-
BI 分析师
顶级 ✔️ 10 LinkedIn 数据科学专家
-
Bernard Marr
-
DJ Patil
-
Francesca Lazzeri, PhD
-
Carla Gentry
-
Dennis R. Mortensen
-
Andrew Ng
-
Gregory Piatetsky-Shapiro
-
Tom Davenport
-
Randy Lao️
-
NABIH IBRAHIM BAWAZIR
顶级 ✔️ 10 个 Python 库用于数据科学
-
Pandas
-
Numpy
-
Scikit-Learn
-
Keras
-
PyTorch
-
LightGBM
-
Matplotlib
-
SciPy
-
Theano
-
TensorFlow
顶级 ✔️ 10 个数据科学行业
-
技术
-
金融
-
零售
-
电信
-
医疗与制药
-
制造业
-
汽车
-
网络安全
-
能源
-
工具
顶级 ✔️ 10 个 LinkedIn 上值得关注的数据科学相关标签
-
创新
-
技术
-
大数据
-
商业智能
-
分析
-
数据挖掘
-
数据
-
人工智能
-
机器学习
-
数据科学
顶级 ✔️ 10 个 LinkedIn 数据科学小组
顶级 ✔️ 10 个免费数据集来源用于数据科学项目
-
Kaggle
-
UCI 机器学习库
-
Google 自定义数据集搜索
-
政府
-
Reddit
-
Quandl
-
VisualData
-
GitHub
-
世界
-
Google Cloud 公共数据集
祝你在成为顶尖数据科学专家的旅程中好运。没有什么是不可能的,相信自己!
参考资料
towardsdatascience.com/top-10-great-sites-with-free-data-sets-581ac8f6334
www.dataquest.io/blog/free-datasets-for-projects/
www.analyticsinsight.net/top-10-big-data-analytics-linkedin-groups/
www.linkedinsights.com/the-hot-100-linkedin-hashtags/
www.geeksforgeeks.org/11-industries-that-benefits-the-most-from-data-science/
datafloq.com/read/top-industries-for-data-science-professionals/6698
www.linkedin.com/pulse/top-12-data-science-experts-best-career-articles-linkedin-tanmoy-ray/
www.kdnuggets.com/2016/05/10-big-data-data-science-leaders-linkedin.html
towardsdatascience.com/the-top-10-ml-algorithms-for-data-science-in-5-minutes-4ffbed9c8672
medium.com/@exastax/top-20-data-science-blogs-and-websites-for-data-scientists-d88b7d99740
简介: Mojeed Abisiga 是一名数据科学家和机器学习工程师,拥有丰富的经验,成功将基于机器学习的解决方案应用于现实世界问题,并利用他在工具和技术方面的专长,从大量数据中发现模式和挖掘洞察,帮助企业推动增长、做出有价值的决策,并在数据旅程中获得竞争优势。他目前在 KPMG 尼日利亚的数据与分析部门担任数据科学家和 RPA 专家,构建了多个跨越不同领域和行业(如电信、银行、人力资源和快速消费品)的企业级智能自动化、商业智能和机器学习模型。
相关:
更多相关话题
初学者的十大机器学习算法
原文:
www.kdnuggets.com/2017/10/top-10-machine-learning-algorithms-beginners.html

I. 介绍
对机器学习算法的研究在《哈佛商业评论》文章称数据科学家为“21 世纪最性感的职业”之后,获得了极大的关注。因此,为了帮助那些刚入门机器学习领域的人,我们决定重新编排我们极受欢迎的金牌博客机器学习工程师需要了解的 10 种算法——尽管这篇文章面向的是初学者。
机器学习算法是能够从数据中学习并通过经验改进的算法,无需人工干预。学习任务可能包括学习将输入映射到输出的函数,学习无标记数据中的隐藏结构;或者是‘基于实例的学习’,在这种学习中,通过将新的实例(行)与存储在内存中的训练数据实例进行比较,为新的实例生成类别标签。‘基于实例的学习’不会从特定实例中创建抽象。
II. 机器学习算法的类型
机器学习算法有 3 种类型:
1. 监督学习:
监督学习可以解释为:使用标记的训练数据来学习从输入变量(X)到输出变量(Y)的映射函数。
Y = f (X)
监督学习问题可以分为两类:
a. 分类:预测给定样本的结果,其中输出变量以类别的形式出现。例子包括性别(男性和女性)、健康状况(生病和健康)。
b. 回归:预测给定样本的结果,其中输出变量以实际值的形式出现。例子包括表示降雨量、人的身高的实际值标签。
我们在本博客中讨论的前 5 种算法——线性回归、逻辑回归、CART、朴素贝叶斯、KNN 是监督学习的例子。
集成学习是一种监督学习。它指的是将多个不同的弱机器学习模型的预测结果结合起来,以对新的样本进行预测。我们讨论的算法 9-10——使用随机森林的袋装方法、使用 XGBoost 的提升方法就是集成技术的例子。
2. 无监督学习:
无监督学习问题只有输入变量(X),但没有相应的输出变量。它使用未标记的训练数据来建模数据的潜在结构。
无监督学习问题可以分为两类:
a. 关联:发现集合中项的共现概率。这在市场篮子分析中被广泛使用。例如:如果一个顾客购买了面包,他有 80%的可能性也会购买鸡蛋。
b. 聚类:将样本分组,使得同一簇内的对象彼此之间的相似度高于与其他簇中的对象之间的相似度。
c. 降维:顾名思义,降维意味着减少数据集中的变量数量,同时确保重要信息仍然被传达。降维可以通过特征提取方法和特征选择方法来完成。特征选择从原始变量中选择一个子集。特征提取则将数据从高维空间转换到低维空间。例如:PCA 算法是一种特征提取方法。
我们在这里讨论的算法 6-8 - Apriori、K-means、PCA 是无监督学习的例子。
3. 强化学习:
强化学习是一种机器学习算法,它允许智能体根据当前状态决定最佳的下一步行动,通过学习能够最大化奖励的行为。
强化算法通常通过试错法学习最佳行动。它们通常用于机器人技术——机器人可以通过在碰到障碍物后获得负反馈来学习避免碰撞;以及视频游戏——在游戏中通过试错法可以揭示能够提升玩家奖励的特定动作。智能体可以使用这些奖励来了解游戏的最佳状态并选择下一步行动。
III. 量化机器学习算法的受欢迎程度
调查论文如这些已经量化了 10 种最受欢迎的数据挖掘算法。然而,这些列表是主观的,正如引用的论文所示,参与者的样本量非常狭窄,主要是数据挖掘的高级从业者。受访者包括 ACM KDD 创新奖和 IEEE ICDM 研究贡献奖的获奖者;KDD-06、ICDM’06 和 SDM’06 的程序委员会成员;以及 ICDM’06 的 145 名与会者。
本博客中的前 10 种算法旨在为初学者提供帮助,主要是我在孟买大学计算机工程本科阶段从‘数据仓储与挖掘’(DWM)课程中学到的。这门课程是了解机器学习算法领域的绝佳入门。最后两种算法(集成方法)是根据它们在Kaggle 竞赛中获胜的普遍性特别列出的。希望你喜欢这篇文章!
IV. 监督学习算法
1. 线性回归
在机器学习中,我们有一组输入变量(x),用于确定输出变量(y)。输入变量和输出变量之间存在一种关系。机器学习的目标是量化这种关系。
图 1:线性回归表示为形式为 y = a + bx 的直线。来源 在线性回归中,输入变量(x)和输出变量(y)之间的关系被表示为形式为 y = a + bx 的方程。因此,线性回归的目标是找出系数 a 和 b 的值。这里,a 是截距,b 是直线的斜率。
图 1 显示了数据集中 x 和 y 值的散点图。目标是拟合一条与大多数点最接近的直线。这将减少数据点的 y 值与直线之间的距离(“误差”)。
2. 逻辑回归
线性回归预测的是连续值(如降雨量,以 cm 为单位),而逻辑回归预测的是离散值(如学生是否及格),这是在应用转换函数后得到的。
逻辑回归最适合于二分类问题(数据集中 y = 0 或 1,其中 1 表示默认类别。例如:在预测事件是否发生时,事件发生被分类为 1。在预测一个人是否会生病时,生病的情况被标记为 1)。它以其使用的转换函数命名,即逻辑函数 h(x)= 1/ (1 + e^x),这是一个 S 形曲线。
在逻辑回归中,输出是默认类别的概率(与线性回归直接产生输出不同)。由于它是概率,输出范围在 0-1 之间。输出(y 值)是通过对 x 值进行对数转换,使用逻辑函数 h(x)= 1/ (1 + e^ -x) 得到的。然后应用阈值将这个概率强制转换为二分类。
图 2:逻辑回归用于判断肿瘤是恶性还是良性。如果概率 h(x)>= 0.5,则分类为恶性。来源 在图 2 中,为了判断肿瘤是否恶性,默认变量为 y=1(肿瘤=恶性);x 变量可以是肿瘤的测量值,比如肿瘤的大小。如图所示,逻辑函数将数据集中各种实例的 x 值转换到 0 到 1 的范围内。如果概率超过 0.5 的阈值(由水平线表示),则将肿瘤分类为恶性。
逻辑回归方程 P(x) = e ^ (b0 +b1x) / (1 + e^(b0 + b1x)) 可以转换为 ln(p(x) / 1-p(x)) = b0 + b1x*。
逻辑回归的目标是利用训练数据来寻找系数 b0 和 b1 的值,以最小化预测结果与实际结果之间的误差。这些系数使用最大似然估计技术来估算。
3. CART
分类与回归树(CART)是一种决策树的实现,还有其他如 ID3、C4.5。
非终端节点是根节点和内部节点。终端节点是叶子节点。每个非终端节点代表一个输入变量(x)及其在该变量上的分裂点;叶子节点代表输出变量(y)。模型的使用方法是:沿着树的分裂路径走到一个叶子节点,并输出该叶子节点上的值。
图 3 中的决策树根据一个人的年龄和婚姻状况来分类其是否会购买跑车或小型货车。如果该人超过 30 岁且未婚,我们按以下方式走树:‘超过 30 岁?’ -> 是 -> ‘已婚?’ -> 否。因此,模型输出的是跑车。
图 3:决策树的部分。 来源
4. 朴素贝叶斯
为了计算一个事件发生的概率,给定另一个事件已经发生,我们使用贝叶斯定理。为了计算某个变量值下的结果概率,即计算假设 h 为真的概率,给定我们的先验知识 d,我们使用贝叶斯定理如下:
P(h|d) = (P(d|h) * P(h)) / P(d)
where
-
P(h|d) = 后验概率。给定数据 d,假设 h 为真的概率,其中 P(h|d) = P(d1|h) * P(d2|h) * .... * P(dn|h) * P(d)
-
P(d|h) = 似然性。给定假设 h 为真的情况下,数据 d 的概率。
-
P(h) = 类别先验概率。假设 h 为真的概率(与数据无关)
-
P(d) = 预测先验概率。数据的概率(与假设无关)
这个算法被称为‘naive’(朴素的),因为它假设所有变量相互独立,这在实际例子中是一个朴素的假设。
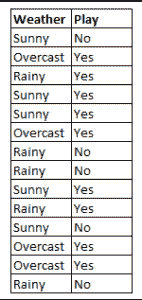
图 4:使用朴素贝叶斯预测‘play’的状态,变量为‘weather’。以图 4 为例,如果天气 = ‘sunny’,结果是什么?
为了确定结果是 play = ‘yes’ 还是 ‘no’,给定变量 weather = ‘sunny’,计算 P(yes|sunny) 和 P(no|sunny),并选择概率较高的结果。
-> P(yes|sunny) = (P(sunny|yes) * P(yes)) / P(sunny)
= (3/9 * 9/14) / (5/14)
= 0.60
-> P(no|sunny) = (P(sunny|no) * P(no)) / P(sunny)
= (2/5 * 5/14) / (5/14)
= 0.40
因此,如果天气 = ‘sunny’,结果是 play = ‘yes’。
5. KNN
K 最近邻算法使用整个数据集作为训练集,而不是将数据集拆分为训练集和测试集。
当需要为一个新的数据实例生成结果时,KNN 算法会遍历整个数据集,以找到与新实例最接近的 k 个实例,或者与新记录最相似的 k 个实例,然后输出结果的均值(对于回归问题)或众数(最频繁的类别,对于分类问题)。k 的值由用户指定。
实例之间的相似性通过欧氏距离和汉明距离等度量来计算。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT 部门
了解更多相关话题
前十名机器学习演示:Hugging Face Spaces 版
原文:
www.kdnuggets.com/2022/05/top-10-machine-learning-demos-hugging-face-spaces-edition.html

作者提供的图片
前十名榜单基于流行度、可用性和独特性。在这篇博客中,我们将学习 Hugging Face Spaces 上最佳的机器学习演示。 Spaces 允许你使用 Git 上传你的 Streamlit 应用、Gradio 演示和 HTML 应用。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
这个 Pokémon 不存在
这个 Pokémon 不存在 使用 ruDALL-E 模型生成插图,随机选择名称和属性。要收集稀有和独特的宝可梦,你需要输入你的名字并点击提交按钮。这个网页应用简单但非常受欢迎。
MAGMA
MAGMA(基于适配器的生成模型多模态增强)是一个视觉语言模型,用于描述或回答有关图像的问题。了解更多关于 MAGMA 的信息,请访问 arxiv.org。要使用 ML 演示,你需要提供一张图片并提出一个具体的问题。例如,“描述这张图片”。了解更多用例请点击 这里。
AnimeGANv2
AnimeGANv2 是 Hugging Face Spaces 上最受欢迎的机器学习应用,拥有 515 个 ?。它还以难以置信的艺术风格快速生成结果。了解更多关于生成模型的内部工作,请点击 这里。要使用这个演示,你需要上传一张肖像,然后选择风格生成动漫风格的艺术作品。

图像修复与着色
当我在 Twitter 上看到 图像恢复与上色 演示时,我以为他们一定使用了一个完美的例子来展示输出。然而,当我在一张全新的照片上亲自尝试时,我被应用的简单性和强大功能所震撼。Gradio 演示要求你上传黑白和损坏的图像,它将返回一张上色的高质量照片。你还可以通过多种选项进行尝试,以获得更好的结果。

DiT 文档布局分析
DiT 文档布局分析 演示使用了一个自监督预训练的文档图像变换器模型来预测 PDF 文档上的标签。例如,检测表格、文本、图像等。该演示需要一个 PDF 文档,其余的由强大的模型来突出显示文档的各个部分。
Chef Transformer
Chef Transformer 演示使用了 t5-recipe-generation 模型,根据厨师、食物风格和配料生成食谱。如果你饿了而食物选择有限,可以输入配料并获得美味食物的食谱。这是我最喜欢的应用程序,因为它在视觉上很吸引人且具有独特的使用场景。

ArcaneGAN 视频
ArcaneGAN 视频使用在 Arcane 动漫数据集上训练的风格化 U-Net,图像通过混合的 StyleGAN2 生成。了解更多关于模型实现的内容,请点击 这里。在这个 Gradio 演示中,你只需上传一个示例视频,让模型施展魔法。输出视频将呈现 Arcane 动漫风格。

瑞克与莫蒂聊天机器人
瑞克与莫蒂聊天机器人使用了一个经过微调的 DialoGPT 版本,该模型在瑞克与莫蒂的对话数据集上进行了训练。聊天机器人功能是新的,它为你提供了增强的聊天体验。只需输入搞笑问题,继续对话,直到你觉得无聊为止。
OCR 用于验证码
OCR For Captcha 模型是在结合了 CNN 和 RNN 的基础上训练的,并具有一个用于实现 CTC 损失的终端层。要深入了解模型训练,查看 Keras 的 代码示例。该应用要求你上传一张验证码图片,并返回高度准确的字母数字文本。
Fastspeech2 TTS
Fastspeech2 TTS 使用了实时的最先进的语音合成架构,如 Tacotron-2、Melgan、Multiband-Melgan、FastSpeech 和基于 TensorFlow 的 FastSpeech2。如果你想体验自然的文本转语音效果,可以试着输入文本并感到惊艳。这个应用还允许你测试各种模型架构。我非常喜欢演讲者的自然声音。
结论
当我被邀请参加 Spaces 的 beta 测试时,我曾持怀疑态度,但一个月内,Spaces 已超越了 Streamlit cloud、Heroku 和其他云部署平台。在易用性、集成性和更快推理方面,我爱上了 HuggingFace Spaces 以及社区成员提出的独特 Web 应用创意。在这篇博客中,我们覆盖了 HF Spaces 上的前十名机器学习演示,并了解了这些应用的工作原理。
请在评论区告诉我你心目中的前十名排名。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为正在与心理疾病斗争的学生构建 AI 产品。
更多相关主题
Github 上的前 10 大机器学习项目
原文:
www.kdnuggets.com/2015/12/top-10-machine-learning-github.html/2
5. Pattern
用于 Python 的网络挖掘模块,提供抓取、自然语言处理、机器学习、网络分析和可视化的工具。
★ 3799,  598
598
Pattern是一个基于 Python 的网络挖掘工具包,源自安特卫普大学的计算语言学与心理语言学(CLiPS)研究中心。在此背景下,它提供了用于抓取、机器学习、自然语言处理、网络分析和可视化的工具。Pattern 还可以轻松从几个知名的网络服务中挖掘数据。该项目声称文档齐全,并包括大量示例和单元测试。

一个受脑部启发的机器智能平台,基于皮层学习算法的生物学准确神经网络。
★ 3647, 987
NuPIC实现了层次时间记忆(HTM)机器学习算法。HTM 试图模拟新皮层的计算,重点在于存储和回忆空间和时间模式。NuPIC 非常适合与模式相关的异常检测。
Vowpal Wabbit 是一个机器学习系统,通过在线学习、哈希、全局归约、减法、学习 2 搜索、主动学习和交互学习等技术推动机器学习的前沿。
★ 2949, 827
Vowpal Wabbit旨在快速建模大规模数据集,并支持并行学习。该项目最初在 Yahoo!启动,目前由微软研究院开发。Vowpal Wabbit 利用外存学习,并已被用于在 1000 个计算节点上在一小时内学习一个 TB 特征数据集。
8. aerosolve
为人类打造的机器学习包。
★ 2538, 245
aerosolve 试图与其他库不同,专注于提供用户友好的调试功能、用于训练的 Scala 代码、用于轻松图像排名的图像内容分析引擎,以及为用户提供灵活性和控制功能的特征转换语言。aerosolve 实现了基于 thrift 的特征表示,其中特征按逻辑分组,用于对整个特征组应用转换或促进组间的交互。
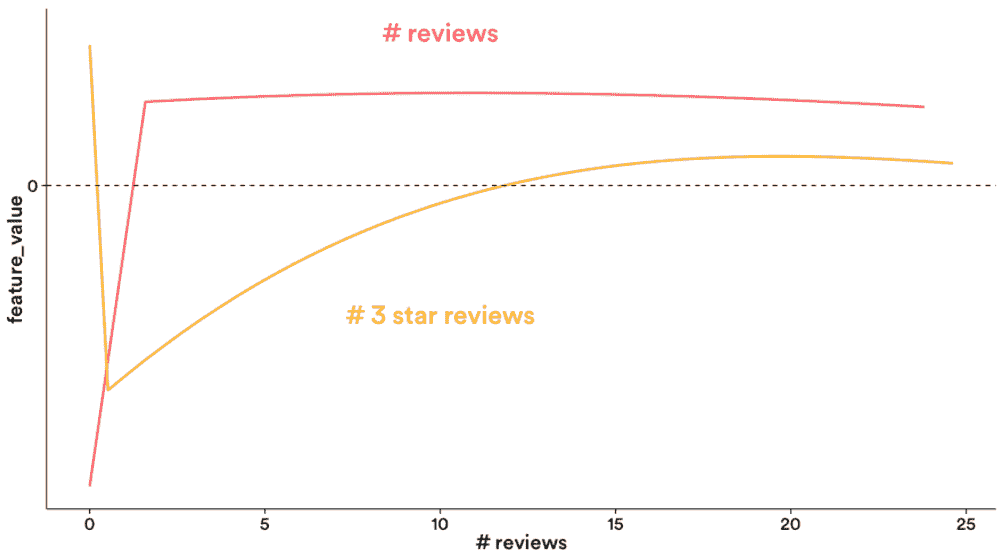
9. GoLearn
适用于 Go 的机器学习。
★ 2334, 215
GoLearn 是一个为 Go 开发的活跃的机器学习库。其目标是为 Go 开发人员提供一个功能全面、易于使用且可定制的包。GoLearn 实现了许多人熟悉的 Scikit-learn 的 fit/predict 接口,使更换估计器变得容易,并实现了像交叉验证和训练/测试拆分这样的“辅助函数”。
10. 黑客的机器学习代码
伴随《黑客的机器学习》一书的代码。
★ 2003, 1446
该库包含 O'Reilly 书籍《黑客的机器学习》的代码。所有库代码都是 R 语言编写的,依赖于众多 R 包,涵盖的主题包括分类、排序和回归等常见任务,以及主成分分析和多维尺度分析等统计程序。
- 根据 GitHub 搜索中“机器学习”查询的返回结果确定,按星标数量排序,截止至 2015 年 12 月 10 日下午 1:00 EST。
相关:
-
前 20 个 Python 机器学习开源项目
-
拓扑数据分析 - 开源实现
-
掌握 Python 机器学习的 7 个步骤
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织的 IT
更多相关话题
前十名 R 语言机器学习视频
原文:
www.kdnuggets.com/2017/10/top-10-machine-learning-r-videos.html
如果你刚刚开始学习 R、RStudio 和机器学习,你可能已经知道,通过查看来自该领域经验丰富的人士的具体示例和工作流程是一个极好的激励方式。对于这篇文章,我们收集了一组包含动手示例的教育视频,展示如何实现一些最流行的机器学习算法。我们首先为你提供对机器学习和 R 语言的一般介绍和动机。你将能够跟随示例和演示,熟悉 R 中实施机器学习项目的语法和流程。请享受观看这一系列视频,并亲自尝试,通过这份精彩的总结和汇编来进行自己的实验和建模。
这些视频按观看次数排名,它们是一些知名的机器学习技术和概念的资源集合。需要注意的是,许多列出的视频属于不同的 YouTube 播放列表和由经验丰富的讲师和组织开发的课程,因此不要仅仅停留在这个列表中。订阅并关注这些视频的作者,以获取更多的视频资源来支持你的工作。
-
如何在 R 中构建文本挖掘、机器学习文档分类系统!(131k 观看),26 分钟。该视频将展示如何在不到 30 分钟内使用 R 从头构建一个机器学习文档分类系统。你将看到一个使用文本挖掘技术识别未标记的总统竞选演讲者的示例。它还涉及品牌管理、审计、欺诈检测、电子病历等应用。
-
使用 R 的主成分分析(115k 观看),11 分钟。此教程将引导你手动进行简单数据的主成分分析,你将熟悉 PCA 的基本原理和术语。
-
R 中的 k 最近邻算法(60k 观看),15 分钟演示。该视频介绍了如何使用著名的鸢尾花数据集在 R 中实现 k-NN(k 最近邻)模型。该视频是有关 R、数据科学和机器学习的教程系列的一部分。
-
使用 R 进行聚类分析 - 一个示例(54k 观看),18 分钟。该教程视频演示了如何使用 R 进行聚类分析。它还包括数据标准化、使用树状图进行层次聚类以及非层次 k-means 聚类等概念。
-
R 中的决策树分类(40k 次观看),20 分钟。这个视频将介绍 R 中的 rpart 库,用于构建分类决策树。视频提供了决策树的简要概述,并展示了使用模型进行可视化和预测的示例。
-
使用 R 的支持向量机(SVM)概述和演示(35k 次观看),17 分钟。这是一个关于使用 R 的支持向量机(SVM)的快速概述,通过一系列示例和演示来讲解。首先,它涵盖了 SVM 的基本概念和思想,然后转到实际示例。
-
R 中的随机森林概述和演示(24k 次观看),17 分钟。这个视频简要概述了随机森林的基本概念和原理。通过一个示例,你将看到如何使用 R 的 randomForest 库自己实现这个算法。
-
R 中的神经网络(19k 次观看),19 分钟。这个视频是 R 中神经网络的指南。你将看到如何使用 R 的 neuralnet 包来拟合、绘图和进行神经网络预测。
-
用于机器学习的 R 编程语言(14k 次观看),37 分钟。这个视频简要介绍了 R 和一个基本模型实现的演示示例。
-
R 和 caret 的机器学习简介(9.8k 次观看),1 小时 40 分钟的演讲。来自 Data Science Dojo 的视频为你提供了 R 中 caret(Classification And REgression Training)包的一般介绍。视频将展示如何使用 caret 执行大多数项目中最流行的数据科学任务,并演示如何将 caret 纳入你的个人工作流程。
我们希望你喜欢观看这些视频,并希望它们能激励你构建自己的模型并进行预测。不要忘记观看完整的讲座和播放列表,以增强你的教程库。
相关:
-
金融中的十大机器学习视频
-
YouTube 上的十大机器学习视频(更新版)
-
YouTube 上的十大数据科学视频
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 事务
更多相关内容
更新版的 YouTube 前 10 个机器学习视频
原文:
www.kdnuggets.com/2017/05/top-10-machine-learning-videos-on-youtube-updated.html
YouTube 上有很多关于机器学习的视频,但很难判断哪些值得观看,特别是每分钟都有 300 小时的视频被上传到 YouTube。我们为你带来了值得观看的最受欢迎的近期机器学习视频。这篇文章更新了 2015 年非常受欢迎的 YouTube 上的前 10 个机器学习视频的帖子。我们还增加了一些顶级相关的播放列表。

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
这里是截至 2017 年 5 月 3 日按观看次数排名的热门视频。
1. MarI/O - 视频游戏中的机器学习 (4.3M 次观看)
 这个有趣的演示视频展示了机器学习如何应用于视频游戏。这是通过神经网络和遗传算法实现的。这个视频的精彩之处在于作者简明扼要地描述了神经网络如何实现给定的性能。我自己玩过《超级马里奥世界》,可以说游戏玩法非常令人印象深刻,不论是否学习过!
这个有趣的演示视频展示了机器学习如何应用于视频游戏。这是通过神经网络和遗传算法实现的。这个视频的精彩之处在于作者简明扼要地描述了神经网络如何实现给定的性能。我自己玩过《超级马里奥世界》,可以说游戏玩法非常令人印象深刻,不论是否学习过!
2. 机器学习(斯坦福) (1.4M 次观看)
这是斯坦福大学机器学习讲座系列的第一段视频(第 1 讲发布于 8 年前),由Andrew Ng讲授。这是自学机器学习基础的一个不错的起点。如果你对这个视频中的内容感兴趣,他的Coursera 课程也许会引起你的兴趣。
3. 谷歌深度学习解释!- 自学习 A.I. (1.3M 次观看)
由 ColdFusion(以前称为 Cold fusTion)上传的视频展示了“在轻松愉快的氛围中展现我们周围世界的前沿”;包括示例来源:为什么 AlphaGo 不是“专家系统”、 “深入 DeepMind”的自然视频、 “AlphaGo 与人工智能的未来”BBC 新闻之夜。
4. 遗传算法。学习跳过球. (1.05M 次观看)
这个动画时长不到 3 分钟,但展示了使用遗传算法和神经网络自动设计运动策略。学习简单的生物如何跳过球。
5. TensorFlow:开源机器学习 (957K views)
这个视频介绍了 TensorFlow。它是一个用于数值计算的数据流图开源软件库。最初由 Google Brain Team 的研究人员和工程师开发,属于 Google 的机器智能研究组织,旨在进行机器学习和深度神经网络研究。
6. Hello World - 机器学习食谱 #1 (574K views)
这个视频由 Google Developers 上传。只需六行 Python 代码即可编写你的第一个机器学习程序!在这一集中,我们将简要介绍机器学习是什么以及为什么它很重要。然后,我们将跟随一个监督学习的食谱(从示例中创建分类器的技术)并进行编码。
7. 加州理工学院机器学习 (504,870 views)
这个视频也是机器学习讲座系列的开始。这个系列由加州理工学院的 Yaser Abu-Mostafa 教授授课。这个系列还有一个 在线课程,它还有一本很好的配套教材。这是学习机器学习基础的另一种好方法。
8. 下一代神经网络 (468,321 views)
这次 Google Tech Talk 由 Geoffrey Hinton 主讲,涵盖了下一代神经网络。这是深度学习的良好介绍。虽然有几年时间,但仍然是对这一主题的很好的技术介绍。
9. 深度学习:来自大数据的智能 (451,046 views)
这个面板由斯坦福大学商学院主持,许多行业专业人士讨论深度学习的影响。这很有趣,因为它提供了许多观点和不同的理解方式。这是一个很好的视频,可以观看以获得多样化的意见。
10. 学习:支持向量机 (362,417 views)
这是麻省理工学院的一门课程的讲座(MIT 6.034 人工智能,2010 年秋季)。在这次讲座中,Patrick Winston(讲师)展示了支持向量机的一些数学细节。他使用拉格朗日乘数来最大化在某些约束下的街道宽度。如果需要,我们将向量转换到另一个空间,使用核函数。
顶级视频播放列表
1. 机器学习简介 (494 videos; 1,281,106 views in total)
这些视频是“机器学习入门”在线课程的一部分。该课程设计为帮助您和他人成为数据分析师的一部分计划;由Udacity上传。2. 机器学习(160 个视频;765,050 次观看)
这些视频从数学的角度讲解机器学习,适用于研究生或高级本科生水平。该播放列表由 mathematicalmonk 上传。
3. 讲座合集 | 斯坦福大学机器学习(20 个视频;730,896 次观看)
 本课程(CS229)由安德鲁·吴教授讲授,提供了对机器学习和统计模式识别的广泛介绍。主题包括监督学习、无监督学习、学习理论、强化学习和自适应控制。还讨论了机器学习的最新应用,如机器人控制、数据挖掘、自动导航、生物信息学、语音识别以及文本和网络数据处理。
本课程(CS229)由安德鲁·吴教授讲授,提供了对机器学习和统计模式识别的广泛介绍。主题包括监督学习、无监督学习、学习理论、强化学习和自适应控制。还讨论了机器学习的最新应用,如机器人控制、数据挖掘、自动导航、生物信息学、语音识别以及文本和网络数据处理。
4. Python 机器学习(72 个视频;687,041 次观看)
这是一个 Python 编程教程合集,超越了基础知识。学习机器学习、金融、数据分析、机器人、网络开发、游戏开发等更多内容。
我们的播放列表:
在这里观看。相关帖子:YouTube 上的前 10 大机器学习视频,截至 2015 年 6 月。
更多相关主题
YouTube 上的前 10 名机器学习视频
原文:
www.kdnuggets.com/2015/06/top-10-machine-learning-videos-youtube.html
作者:格兰特·马歇尔。
 YouTube 上有很多关于机器学习的视频,但在有限的时间内可能很难判断哪些值得观看。这里筛选了按观看次数排序的最佳视频,以提供一些关于该主题的优秀视频内容。
YouTube 上有很多关于机器学习的视频,但在有限的时间内可能很难判断哪些值得观看。这里筛选了按观看次数排序的最佳视频,以提供一些关于该主题的优秀视频内容。
如果你想以简单的方式将所有这些视频集中在一个地方,可以查看这个播放列表。视图数量截至 2015 年 6 月 21 日。
1. MarI/O - 用于视频游戏的机器学习(1,514,045 次观看)
这个有趣的演示视频展示了机器学习如何应用于视频游戏。这是通过神经网络和遗传算法实现的。这个视频特别出色的地方在于作者简明扼要地描述了神经网络如何实现所需的性能。即使我自己玩过《超级马里奥世界》,也能说游戏性非常令人印象深刻,无论是否学习过!
2. 机器学习(斯坦福)(761,843 次观看)
这是安德鲁·吴主讲的斯坦福机器学习讲座系列中的第一部视频。作为自学机器学习基础的起点非常合适。如果你对视频中的内容感兴趣,他的Coursera 课程也可能会引起你的兴趣。
3. 下一代神经网络(401,740 次观看)
乔弗里·辛顿的这场 Google 技术讲座涵盖了下一代神经网络。这是对深度学习的一个很好的介绍。虽然已有几年,但仍然是一个很好的技术入门。
4. 机器人技术与人工智能的未来(安德鲁·吴,斯坦福大学,STAN 2011)(233,875 次观看)
这个视频也是安德鲁·吴制作的。在这个视频中,安德鲁·吴不仅专注于机器学习,而是深入探讨了人工智能在机器人技术中的应用。如果你对这些话题感兴趣,可以观看这个视频。
5. 加州理工学院机器学习(233,703 次观看)
这个视频也是机器学习讲座系列的开始。该系列由加州理工学院的亚瑟·阿布-莫斯塔法教授主讲。这个系列还有一个在线课程,并且有一本很棒的配套教材。这是学习机器学习基础的另一种好方法。
6. 大脑、性别与机器学习(104,808 次观看)
这场 Google 技术讲座也是由 Geoffrey Hinton 主讲。这次讲座深入探讨了神经网络的主题。与其他讲座不同的是,它讨论了神经网络如何与生物神经元相互作用以及这些作用在算法中的表现。
7. 史诗 NHL 进球庆祝黑客攻击:色彩灯光秀与实时机器学习(103,166 次观看)
这个演示视频展示了一个系统,该系统利用机器学习基于比赛的音频流检测 NHL 进球。当检测到进球时,系统与客厅的硬件进行通信,创建一个灯光秀。这是将学习整合到生活空间中的一个极佳例子。
8. 我是传奇:用机器学习破解 Hearthstone - Defcon 22(92,820 次观看)
这个视频还展示了机器学习在视频游戏中的应用。在这个案例中,应用有些“恶意”。通过观察许多 Hearthstone(一个电子集换式卡牌游戏)之前的游戏,作者开发的系统学会了预测对手的手牌。这对于任何对机器学习在竞争应用中的兴趣者都是非常吸引人的。
9. 旧金山湾区视觉会议:无监督特征学习和深度学习(89,518 次观看)
这场由 Andrew Ng 主讲的 Google 技术讲座介绍了如何利用特征学习从未标记的数据中自动学习特征。这是一种节省时间的好方法,比传统的特征选择方法更有效。如果你对这种方法的理论基础感兴趣,这个视频提供了很好的解释。
10. 深度学习:来自大数据的智能(89,506 次观看)
这个由斯坦福大学商学院主办的讨论小组,聚集了许多行业专业人士讨论深度学习的影响。这很有趣,因为它提供了许多观点和不同的理解方式。观看这个视频可以获得多样的意见。
相关:
-
YouTube 上观看最多的大数据视频
-
带结构的深度学习 – 预览
-
在机器学习中,更多数据还是更好的算法更好?
更多相关内容
优化与管理机器学习生命周期的十大 MLOps 工具
原文:
www.kdnuggets.com/2022/10/top-10-mlops-tools-optimize-manage-machine-learning-lifecycle.html

图片来源:Digital Buggu
企业继续改造其运营,以提高生产力并提供难忘的消费者体验。这种数字化转型加快了互动、交易和决策的时间框架。此外,它生成了大量的数据,带来了对运营、客户和竞争的新见解。机器学习帮助公司利用这些数据获得竞争优势。ML(机器学习)模型可以在大量数据中检测模式,使其能够在比人类更大的规模上做出更快、更准确的决策。这使得人类和应用程序能够快速而智能地采取行动。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT
随着越来越多的企业尝试使用数据,他们意识到开发一个机器学习(ML)模型只是 ML 生命周期中的众多步骤之一。
什么是机器学习生命周期?
机器学习生命周期包括为特定应用开发、部署和维护机器学习模型。典型的生命周期包括:

确定商业目标
过程的第一步是确定实施机器学习模型的商业目标。例如,贷款公司可以将预测一定数量贷款申请的信用风险作为商业目标。
数据收集与标注
机器学习生命周期的下一个阶段是数据收集与准备,受定义的商业目标指导。这通常是开发过程中的最长阶段。
开发人员将根据机器学习模型的类型选择用于训练和测试的数据集。以信用风险为例。如果贷款人想从扫描的文档中获取信息,他们可以使用图像识别模型;对于数据分析,将是从贷款申请人那里收集的数值或文本数据片段。
数据收集后的关键阶段是注释“整理”。现代人工智能(AI)模型需要高度具体的数据分析和指令。注释有助于开发人员提高一致性和准确性,同时减少偏差,以避免在部署后发生故障。
模型开发与训练
构建过程是机器学习生命周期中最代码密集的环节。这个阶段主要由开发团队的程序员管理,他们将有效地设计和组装算法。
然而,开发人员必须在训练过程中不断检查情况。尽快检测训练数据中的潜在偏差是至关重要的。假设图像模型无法识别文档,导致其错误分类。在这种情况下,参数应指导模型关注图像中的模式而非像素。
测试与验证模型
模型在测试阶段应完全功能正常并按计划运行。训练过程中使用单独的验证数据集进行评估。目标是查看模型如何应对它从未见过的数据。
模型部署
训练完成后,终于到了部署机器学习模型的时候。此时,开发团队已经尽力确保模型的最佳功能。该模型可以处理未经整理的低延迟用户数据,并被信任准确评估。
回到信用风险场景中,模型应能可靠地预测贷款违约者。开发人员应对模型能够满足贷款公司期望并正常运行感到满意。
模型监控
部署后会跟踪模型的性能,以确保其随时间保持稳定。例如,如果用于贷款违约预测的机器学习模型未经过定期优化,它可能无法检测到新的违约类型。监控模型以发现和修复错误是至关重要的。监控中发现的任何关键结果都可以用来改善模型的性能。
MLOps 的崛起
如上所述,大规模管理整个生命周期是具有挑战性的。这些挑战与应用开发团队在创建和管理应用程序时面临的挑战相同。DevOps 是在应用程序开发周期中管理操作的行业标准。处理机器学习中的这些挑战,企业必须采取类似 DevOps 的方法来管理 ML 生命周期。这种技术被称为 MLOps。
什么是 MLOps?
MLOps 是机器学习 + 操作的缩写。它是一门新兴学科,要求结合数据科学、机器学习、DevOps 和软件开发中的最佳实践。它有助于减少数据科学家与 IT 操作团队之间的摩擦,以改善模型的开发、部署和管理。根据 Congnilytica,MLOps 解决方案的市场预计到 2025 年将增长近 40 亿美元。
数据科学家将大部分时间花在为训练准备和清理数据上。此外,训练好的模型需要测试其准确性和稳定性。
这就是 MLOps 工具发挥作用的地方。合适的工具可以帮助您从数据准备到市场准备产品的整个过程管理一切。为了节省您的时间,我整理了一份最佳企业和开源云平台及 管理机器学习生命周期的框架 的列表。
机器学习生命周期管理的前 10 大 MLOps 工具/平台
1. Amazon SageMaker
-
Amazon SageMaker 提供机器学习操作 (MLOps) 解决方案,帮助用户自动化和标准化整个机器学习生命周期中的流程。
-
该平台使数据科学家和机器学习工程师能够通过训练、测试、故障排除、部署和治理机器学习模型来提高生产力。
-
它有助于将机器学习工作流与 CI/CD 管道集成,以减少生产时间。
-
通过优化的基础设施,训练时间可以从小时缩短到分钟。专用工具可以将团队生产力提高多达十倍。
-
它还支持领先的机器学习框架、工具包和编程语言,如 Jupyter、Tensorflow、PyTorch、mxnet、Python、R 等。
-
它具有用于策略管理和执行、基础设施安全、数据保护、授权、认证和监控的安全功能。
来源:亚马逊
2. Azure 机器学习
-
Azure 机器学习服务是一个基于云的数据科学和机器学习平台。
-
借助内置的治理、安全性和合规性,用户可以在任何地方运行机器学习工作负载。
-
快速创建用于分类、回归、时间序列预测、自然语言处理和计算机视觉任务的准确模型。
-
利用 Azure Synapse Analytics,用户可以通过 PySpark 执行交互式数据准备。
-
企业可以利用 Microsoft Power BI 及 Azure Synapse Analytics、Azure Cognitive Search、Azure Data Factory、Azure Data Lake、Azure Arc、Azure Security Centre 和 Azure Databricks 等服务来提升生产力。
来源:微软
3. Databricks MLflow
-
托管的 MLflow 建立在 MLflow 之上,MLflow 是由 Databricks 开发的开源平台。
-
它帮助用户以企业级的可靠性、安全性和规模管理完整的机器学习生命周期。
-
MLFLOW 跟踪使用 Python、REST、R API 和 Java API 自动记录每次运行的参数、代码版本、指标和工件。
-
用户可以记录阶段转换,并在 CI/CD 管道中请求、审查和批准更改,以改善控制和治理。
-
通过访问控制和搜索查询,用户可以在工作区内创建、保护、组织、搜索和可视化实验。
-
通过 Apache Spark UDF 快速在 Databricks 上部署到本地机器或其他生产环境,例如 Microsoft Azure ML 和 Amazon SageMaker,并构建 Docker 镜像进行部署。

来源:Databricks
4. TensorFlow Extended (TFX)
-
TensorFlow Extended 是 Google 开发的生产规模机器学习平台。它提供了用于将机器学习集成到工作流中的共享库和框架。
-
TensorFlow Extended 允许用户在各种平台上编排机器学习工作流程,包括 Apache、Beam 和 KubeFlow。
-
TensorFlow 是提升 TFX 工作流程的高端设计,TensorFlow 帮助用户分析和验证机器学习数据。
-
TensorFlow 模型分析提供了处理大量分布式数据的指标,并帮助用户评估 TensorFlow 模型。
-
TensorFlow Metadata 提供了可以在数据分析过程中手动或自动生成的元数据,这在使用 TF 训练机器学习模型时非常有用。
来源:TensorFlow
5. MLFlow
-
MLFlow 是一个开源项目,旨在为机器学习提供一种通用语言。
-
这是一个用于管理完整机器学习生命周期的框架
-
它为数据科学团队提供了端到端的解决方案
-
用户可以使用在 Amazon Web Services (AWS) 上运行的 Hadoop、Spark 或 Spark SQL 集群轻松管理生产环境或本地的模型。
-
MLflow 提供了一组轻量级 API,可以与任何现有的机器学习应用程序或库(TensorFlow、PyTorch、XGBoost 等)结合使用。
来源:MLFlow
6. Google Cloud ML Engine
-
Google Cloud ML Engine 是一个托管服务,使构建、训练和部署机器学习模型变得容易。
-
它提供了一个统一的接口用于训练、服务和监控 ML 模型。
-
Bigquery 和云存储帮助用户准备和存储数据集。然后,他们可以使用内置功能为数据打标签。
-
Cloud ML Engine 可以执行超参数调整,这会影响预测的准确性。
-
使用带有易用界面的 Auto ML 功能,用户可以无需编写任何代码即可完成任务。此外,用户可以使用 Google Colab 免费运行笔记本。
来源:Google
7. 数据版本控制(DVC)
-
DVC 是一个用 Python 编写的开源数据科学和机器学习工具。
-
它旨在使机器学习模型可共享和可重现。它处理大文件、数据集、机器学习模型、指标和代码。
-
DVC 控制机器学习模型、数据集和中间文件,并将它们与代码连接。文件内容存储在 Amazon S3、Microsoft Azure Blob Storage、Google Cloud Storage、Aliyun OSS、SSH/SFTP、HDFS 等上。
-
DVC 概述了在生产环境中协作、共享发现以及收集和运行完成模型的规则和流程。
-
DVC 可以将 ML 步骤连接成 DAG(有向无环图),并运行整个管道端到端。
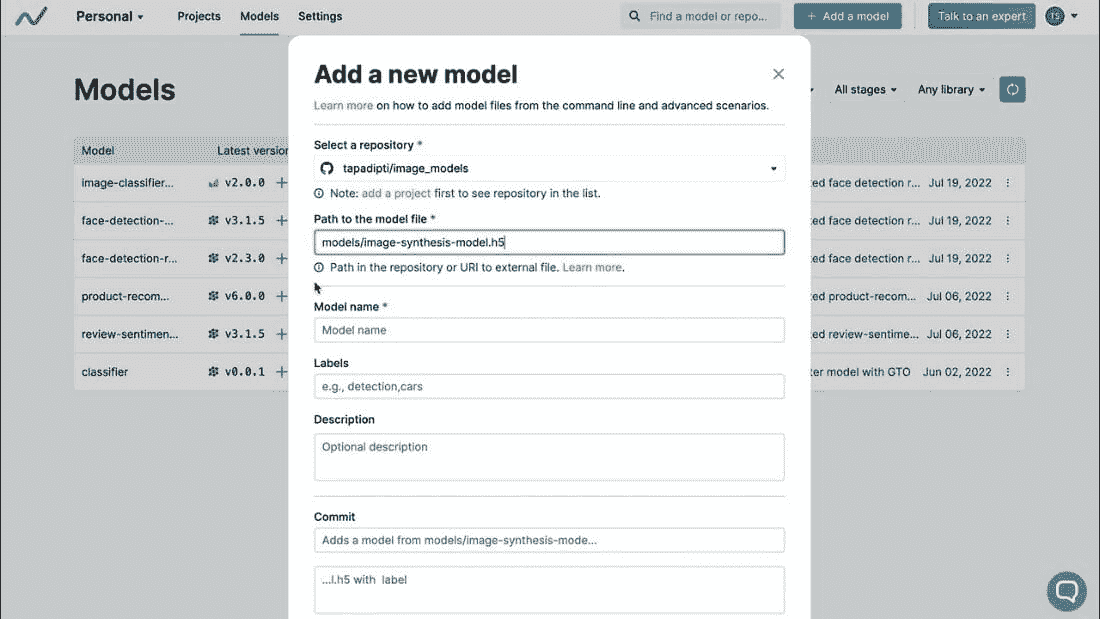
来源:DVC
8. H2O Driverless AI
-
H2O Driverless AI 是一个基于云的机器学习平台,允许你通过简单的点击来构建、训练和部署机器学习模型。
-
它支持 R、Python 和 Scala 编程语言。
-
Driverless AI 可以访问各种数据源,包括 Hadoop HDFS、Amazon S3 等。
-
Driverless AI 会根据最相关的数据统计自动选择数据图,开发可视化,并提供基于最重要数据统计的统计显著数据图。
-
Driverless AI 可以用于从数字照片中提取信息。它允许使用单独的照片和与其他数据类型结合的图像作为预测特征。
来源:H2O Driverless AI
9. Kubeflow
-
Kubeflow 是一个云原生的机器学习操作平台 - 管道、训练和部署。
-
它是 Cloud Native Computing Foundation (CNCF) 的一部分,包括 Kubernetes 和 Prometheus。
-
用户可以利用此工具构建自己的 MLOps 堆栈,使用 Google Cloud 或 Amazon Web Services (AWS) 等云提供商。
-
Kubeflow Pipelines 是一个全面的解决方案,用于部署和管理端到端的 ML 工作流。
-
它还扩展了对 PyTorch、Apache MXNet、MPI、XGBoost、Chainer 等的支持。它还与 Istio、Ambassador(用于入口)和 Nuclio(用于管理数据科学管道)集成。
来源:Kubeflow
10. Metaflow
-
Metaflow 是 Netflix 创建的一个基于 Python 的库,帮助数据科学家和工程师管理现实世界项目,提高生产力。
-
它提供了一个统一的 API 堆栈,这对于从原型到生产环境的数据科学项目的执行是必需的。
-
用户可以高效地训练、部署和管理 ML 模型;Metaflow 集成了基于 Python 的机器学习、Amazon SageMaker、深度学习和大数据库。
-
Metaflow 包含一个图形用户界面,帮助用户将工作环境设计为有向无环图(D-A-G)。
-
它可以自动版本化和跟踪所有实验和数据。
来源:Metaflow
市场新动态
Snowpark by Snowflake
-
Snowpark for Python 提供了一种简单的方法,让数据科学家可以对 Snowflake 数据仓库执行 DataFrame 风格的编程。
-
它可以建立完整的机器学习管道以定期运行。
-
Snowpark 在机器学习生命周期的最后两个阶段(模型部署和监控)中扮演了重要角色。
-
Snowpark 提供了一个易于使用的 API 用于在数据管道中查询和处理数据。
-
自引入以来,Snowpark 已经发展成最好的数据应用之一,使开发人员能够轻松构建复杂的数据管道。
-
凭借 Snowflake 对未来的愿景和可扩展的支持,该应用将成为解决未来几年复杂数据和机器学习问题的最佳选择。
结论
每个企业都在向成为全面机器学习企业的方向发展。合适的工具可以帮助组织管理从数据准备到市场准备产品的所有环节。这些工具还可以帮助自动化重复的构建和部署任务,减少错误,以便你可以专注于更重要的任务,如研究。企业在选择 MLOps 工具时必须考虑团队规模、价格、安全性和支持,并更好地理解其可用性。
Saikiran Bellamkonda 是一名数字营销高手和技术营销作家。他运用自己深厚的知识和经验撰写关于 ML 和 AI 技术的文章。一个积极的学习者,寻求扩展自己的技术知识和写作技能,同时指导他人。
相关主题
数据科学家必须了解的前 10 大机器学习算法 – 第一部分
原文:
www.kdnuggets.com/2021/04/top-10-must-know-machine-learning-algorithms-data-scientists-1.html
评论
图片来源:图神经网络综合调查
在机器学习算法的海量信息中筛选,对于数据科学新手来说可能是一个困难且耗时的过程。搞清楚哪些算法被广泛使用,哪些算法只是新颖或有趣的,并不仅仅是一个学术练习;确定在学习初期要集中时间和精力的地方,可能决定了你的职业能否迅速起步,还是经历长时间的延迟。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
如何准确区分值得关注的立即有用的算法和那些不那么有用的算法?确定如何制定一个权威的机器学习算法清单本质上是困难的,但似乎直接向从业者征求反馈可能是最佳方法。这样的过程带来了一整套困难,正如所能想象的那样,这种调查的结果少之又少。
然而,KDnuggets 在过去几年中进行了这样的调查,询问受访者“在 2018/2019 年你在实际应用中使用了哪些数据科学/机器学习方法和算法?”当然,如上所述,这样的调查受到自我选择、参与者验证缺乏、对实际回应的信任等因素的影响,但这项调查代表了我们目前能够获得的最新、最全面的最佳资料来源。
因此,这是我们用来识别当前使用的前 10 种机器学习算法的来源,因此也是数据科学家必须了解的前 10 种算法。下面介绍了这前 10 种必知算法中的前 5 种,并简要概述了这些算法及其工作原理。我们将在接下来的几周内进行第二部分的跟进。
请注意以下事项:
-
我们跳过了不映射到机器学习算法的条目(例如“可视化”、“描述性统计”、“文本分析”)
-
我们将“回归”条目单独处理为“线性回归”和“逻辑回归”。
-
我们将条目“集成方法”替换为“自助法”,一种特定的集成方法,因为列表中还单独列出了其他一些集成方法。
-
我们跳过了任何神经网络条目,因为这些技术将架构与多种不同的算法结合以实现其目标,这些方面超出了本讨论的范围。
1. 线性回归
回归是近乎经过验证的方式来近似给定数据集之间的关系,但由于不幸的情况而获得了不太有用的名称。
线性回归是一种简单的代数工具,旨在找到适合 2 个或更多属性的“最佳”(为了本讨论的目的是直线)线,其中一个属性(简单线性回归)或几个属性的组合(多重线性回归)用于预测另一个类别属性。使用一组训练实例来计算线性模型,其中一个属性或一组属性与另一个属性进行绘图。然后,该模型尝试确定给定特定类别属性时新实例将在回归线上位于何处。
预测变量与响应变量(x 和 y,分别)之间的关系可以通过以下方程表示,所有读到这里的人无疑都非常熟悉: 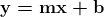 。
。
m 和 b 是回归系数,分别表示直线的斜率和 y 截距。如果你难以回忆,建议你查阅一下你的小学代数笔记 😃
多重线性回归的方程式推广为 n 个属性为:
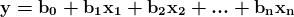
2. 决策树
在机器学习中,决策树几十年来一直被用作有效且易于理解的数据分类器(与现存的大量黑箱分类器形成对比)。多年来,研究产生了许多决策树算法,其中 3 种最重要、最具影响力且使用广泛的算法是:
迭代二分法 3(ID3) - 罗丝·奎因兰的 C4.5 前身
-
迭代二分法 3(ID3) - 罗丝·奎因兰的 C4.5 前身
-
C4.5 - 历史上最受欢迎的分类器之一,也是奎因兰的作品
-
CART - 与 C4.5 大致同时独立发明,也仍然非常流行
ID3、C4.5 和 CART 都采用自顶向下、递归、分治的方法来进行决策树归纳。
多年来,C4.5 已成为衡量新分类算法性能的基准。Quinlan 的原始实现包含专有代码;然而,多年来已经有各种开源版本,包括(曾经非常流行的)Weka 机器学习工具包的 J48 决策树算法。
决策树分类算法的模型(或树)构建方面由两个主要任务组成:树归纳和树剪枝。树归纳 是将一组预分类实例作为输入,决定最佳的分裂属性,分裂数据集,并对结果数据集递归处理,直到所有训练实例都被分类。树剪枝 涉及通过消除冗余或对分类过程非必要的分支来减少决策树的大小。
在构建我们的树时,目标是基于创建尽可能纯净的子节点的属性进行分裂,以此最小化对数据集中的所有实例进行分类所需的分裂次数。这种纯度通常通过多种不同的属性选择度量来衡量。
有 3 种显著的属性选择度量用于决策树归纳,每种都与 3 种显著的决策树分类器配对。
-
信息增益 - 用于 ID3 算法
-
增益比 - 用于 C4.5 算法
-
基尼指数 - 用于 CART 算法
在 ID3 中,纯度通过信息增益的概念来衡量,这一概念基于 Claude Shannon 的工作,涉及对一个之前未见实例进行正确分类所需知道多少信息。在实践中,这通过比较熵,或当前数据集划分中分类一个实例所需的信息量,与如果当前数据集划分在给定属性上进一步划分时分类一个实例所需的信息量来衡量。
本讨论中的一个重要收获应是,决策树是一种分类策略,而不是某种单一的、明确定义的分类算法。虽然我们简要了解了 3 种不同的决策树算法实现,但每种算法的不同方面有多种配置方式。实际上,任何试图对数据进行分类并采用自顶向下、递归、分治的方法来构建树状图进行后续实例分类的算法,不论其他细节(包括属性分裂选择方法和可选的树剪枝方法),都可以被视为决策树。
k 均值聚类
k-均值是一种简单但通常有效的聚类方法。传统上,从给定数据集中随机选择k个数据点作为簇中心或质心,然后将所有训练实例绘制并添加到最近的簇中。在所有实例都被添加到簇之后,质心代表每个簇的实例均值被重新计算,这些重新计算的质心成为各自簇的新中心。
此时,所有簇的成员资格被重置,所有训练集的实例被重新绘制并重新添加到它们最近的、可能重新中心化的簇中。这个迭代过程持续进行,直到质心或它们的成员资格没有变化,簇被认为已经稳定。
当重新计算的质心与之前迭代的质心匹配或在某个预设的范围内时,收敛就达成了。在k-均值中,距离的度量通常是欧几里得距离,这对于形式为(x, y)的两个点,可以表示为:
技术上讲,特别是在并行计算时代,k-均值中的迭代聚类是串行的;然而,迭代中的距离计算不一定是串行的。因此,对于大规模数据集,距离计算是k-均值聚类算法中值得并行化的目标。
此外,虽然我们刚刚描述了一种使用簇均值和欧几里得距离的特定聚类方法,但想象使用簇中位数值或其他任何距离度量(如余弦距离、曼哈顿距离、切比雪夫距离等)的一系列其他方法并不困难。
4. 装袋法
在特定场景下,将分类器进行链式或分组操作可能比不这样做更有用,使用投票、加权或组合的技术以追求尽可能准确的分类器。集成学习者是提供这种功能的分类器的各种方式。装袋法就是一个集成学习者的例子。
装袋法的操作非常简单:构建多个模型,观察这些模型的结果,然后选择大多数结果。我最近遇到了一些车后轴总成的问题:我对经销商的诊断不太满意,因此我带到另外 2 个车库,这两个车库都同意问题与经销商所建议的不同。瞧,装袋法在行动。
在我的例子中,我只访问了 3 个车库,但你可以想象,如果我访问了几十个或几百个车库,准确性可能会提高,尤其是当我的车的问题比较复杂时。这对于装袋法也适用,装袋分类器通常比单一的分类器更准确。此外,还要注意,所使用的分类器类型并不重要;最终模型可以由任何单一分类器类型组成。
Bagging 是bootstrap aggregation的简称,因其从数据集中提取多个样本,每个样本集被视为一个 bootstrap 样本。这些 bootstrap 样本的结果然后被汇总。
5. 支持向量机
如前所述,支持向量机(SVM)是一种特定的分类策略。SVM 通过将训练数据集转换为更高维度来工作,然后检查这些维度中的最佳分隔边界或边界。在 SVM 中,这些边界被称为超平面,通过定位支持向量(即最本质地定义类别的实例)及其边际(与超平面平行的线,由超平面与其支持向量之间的最短距离定义)来识别。因此,SVM 能够分类线性和非线性数据。
支持向量机(SVM)的主要思想是,随着维度的增加,可以总是找到一个将特定类别与其他所有类别分开的超平面,从而划分数据集成员的类别。当重复足够多次时,可以生成足够的超平面来分隔* n *维空间中的所有类别。重要的是,SVM 不仅寻找任何分隔超平面,而是寻找最大边际超平面,即与各类别支持向量等距离的超平面。
SVM 的核心是核技巧,它使得可以在原始数据和该数据的潜在更高维特征空间变换之间进行比较,以确定这种变换是否有助于数据类别的分隔,这样我们就可以找到可以分隔类别的超平面。核技巧是至关重要的,因为它可以使潜在上不可处理的变换计算变得可行,这些比较通过成对的相似性比较来实现。
当数据是线性可分时,可以选择许多分隔线。这样的超平面可以表示为
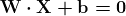
其中* W 是权重向量,b 是标量偏置,X 是训练数据(形式为(x[1],x[2],...))。如果我们的偏置b*被视为一个额外的权重,则该方程可以表示为
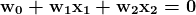
这可以被重写为一对线性不等式,通过解决大于或小于零的情况,其中任一满足条件都表明一个特定点位于超平面之上或之下。找到最大边际超平面,或位于支持向量等距离的超平面,是通过将线性不等式合并为一个方程,并将其转化为约束的二次优化问题,使用拉格朗日公式并利用 Karush-Kuhn-Tucker 条件求解,这超出了我们在这里讨论的范围。
这里有 5 个数据科学家必须了解的算法,其中必须了解的定义为在实践中最常用的算法,而最常用的依据是最近一次 KDnuggets 调查的结果。我们将在接下来的几周内发布该列表的第二部分。在那之前,我们希望你觉得这个列表和简单的解释对你有帮助,并且能够从中拓展学习更多相关内容。
相关:
-
如何在面试中解释关键的机器学习算法
-
机器学习工程师需要知道的 10 个算法
-
初学者的十大机器学习算法
相关主题
2021 年数据科学家应该了解的前 10 个 Python 库
原文:
www.kdnuggets.com/2021/03/top-10-python-libraries-2021.html
评论

照片来自David Clode在Unsplash上。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织中的 IT 工作
学习数据科学可能会让人感到不知所措。这里有数百种工具和资源,而且并不总是很明显你应该关注哪些工具或学习什么。
简单来说,你应该学习你喜欢的内容,因为数据科学提供了广泛的技能和工具。话虽如此,我想与大家分享我认为数据科学中最常用的前 10 个Python 库。
话虽如此,以下是数据科学领域的前 10 个 Python 库。
1. Pandas
你一定听过这样一句话。数据科学家的 70%到 80%的工作是理解和清理数据,也就是数据探索和数据处理。
Pandas 主要用于数据分析,它是最常用的 Python 库之一。它提供了一些最有用的工具来探索、清理和分析数据。使用 Pandas,你可以加载、准备、操作和分析各种结构化数据。机器学习库也围绕 Pandas DataFrames 作为输入。
学习 Pandas 的地方
2. NumPy
NumPy 主要用于支持 N 维数组。这些多维数组相比于 Python 列表要强大 50 倍,使得 NumPy 成为数据科学家的最爱。
NumPy 也被像 TensorFlow 这样的其他库用于其内部张量计算。NumPy 还提供了快速的预编译函数用于数值例程,这些例程可能难以手动解决。为了提高效率,NumPy 使用面向数组的计算,因此处理多个类变得容易。
在哪里学习 NumPy
3. Scikit-learn
Scikit-learn 可以说是 Python 中最重要的机器学习库。使用 Pandas 或 NumPy 清理和处理数据后,scikit-learn 用于构建机器学习模型,因为它拥有大量用于预测建模和分析的工具。
使用 scikit-learn 的理由有很多。举几个例子,你可以使用 scikit-learn 构建多种类型的机器学习模型,监督和无监督模型,交叉验证模型的准确性,以及进行特征重要性分析。
在哪里学习 Scikit-learn
4. Gradio

Gradio 允许你只需三行代码即可构建和部署机器学习模型的 Web 应用。它与 Streamlit 或 Flask 具有相同的目的,但我发现它更快、更容易部署模型。
Gradio 有以下几个优点:
-
它允许进一步的模型验证。具体来说,它允许你以交互方式测试模型的不同输入。
-
这是一种进行演示的好方法。
-
它易于实施和分发,因为通过公共链接,任何人都可以访问该 Web 应用。
在哪里学习 Gradio
5. TensorFlow
TensorFlow 是 Python 中用于实现神经网络的最流行的库之一。它使用多维数组,也称为张量,这使得它可以对特定输入执行多种操作。
由于其高度的并行性,它可以训练多个神经网络和 GPU,从而实现高效且可扩展的模型。TensorFlow 的这一特性也被称为管道化。
在哪里学习 TensorFlow
6. Keras
Keras 主要用于创建深度学习模型,特别是神经网络。它建立在 TensorFlow 和 Theano 之上,使得构建神经网络变得非常简单。由于 Keras 使用后端基础设施生成计算图,因此相比于其他库,它的速度相对较慢。
在哪里学习 Keras
7. SciPy
正如名字所示,SciPy 主要用于其科学功能和源自 NumPy 的数学函数。这个库提供的一些有用功能包括统计函数、优化函数和信号处理函数。为了求解微分方程和进行优化,它包括了计算积分的函数。一些使 SciPy 变得重要的应用有:
-
多维图像处理
-
解决傅里叶变换和微分方程的能力
-
由于其优化的算法,它可以非常强大且高效地进行线性代数计算。
在哪里学习 SciPy
8. Statsmodels
Statsmodels 是一个用于进行高强度统计的优秀库。这个多功能库是不同 Python 库的融合,它从 Matplotlib 获取图形特性和功能,从 Pandas 处理数据,从 Pasty 处理类似 R 的公式,基于 NumPy 和 SciPy 构建。
特别是,它对创建统计模型(如 OLS)以及执行统计测试非常有用。
在哪里学习 Statsmodels
9. Plotly
Plotly 无疑是构建可视化的必备工具,因为它功能强大、易于使用,而且能够与可视化进行互动,具有很大的优势。
与 Plotly 一起使用的是 Dash,它是一个允许你使用 Plotly 可视化构建动态仪表板的工具。Dash 是一个基于网络的 Python 接口,去除了这些类型分析 Web 应用程序对 JavaScript 的需求,允许你在线和离线运行这些图表。
在哪里学习 Plotly
10. Seaborn
Seaborn 建立在 Matplotlib 之上,是一个有效的库,用于创建不同的可视化。
Seaborn 最重要的功能之一是创建放大数据可视化的能力。一些初看不明显的相关性可以在可视化上下文中显示出来,从而让数据科学家更好地理解模型。
由于其可自定义的主题和高级接口,它提供了设计良好且卓越的数据可视化,使得图表非常吸引人,之后可以展示给利益相关者。
在哪里学习 Seaborn
相关资料:
更多相关主题
YouTube 上的前 10 个最新 AI 视频
原文:
www.kdnuggets.com/2017/05/top-10-recent-ai-videos-on-youtube.html
评论

YouTube 上关于人工智能(AI)的最新有趣视频是什么?我们节省了你筛选每天上传的海量视频的时间,通过观看次数(截至 2017 年 5 月 1 日)挑选出最相关和受欢迎的视频。享受我们的精选列表吧!描述如 YouTube 上所示。
单个视频前 10 名
- 介绍 GeForce GTX G-Assist(1 个月前,2.16M 观看次数)
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT
该视频展示了 GeForce GTX G-Assist 如何利用前沿的 NVIDIA 人工智能,为你带来游戏领域的下一次革命。
- Daddy's Car: 一首由人工智能创作的歌曲 - 风格模仿甲壳虫乐队(7 个月前,1.55M 观看次数)
这是第一首完全由人工智能创作的歌曲的视频:“Daddy's Car”和“Mister Shadow”,由 SONY CSL 研究实验室的科学家创作。研究人员开发了 FlowMachines,一个从大量歌曲数据库中学习音乐风格的系统。利用独特的风格转移、优化和交互技术,FlowMachines 在多种风格中创作新歌曲。这两首歌曲是计划于 2017 年发布的人工智能创作专辑的片段。
- Google 的 Deep Mind 解析! - 自我学习的 AI(1 年前,1.30M 观看次数)
该视频由 ColdFusion 提供。它包括了“为何 AlphaGo 不是一个‘专家系统’”的动画;“Inside DeepMind”Nature 视频;以及“AlphaGo 与人工智能的未来”BBC Newsnight。
- 人工智能(4 个月前,1.02M 观看次数)
该视频展示了关于人工智能的现在、远期及近期未来的内容。它由 LEMMiNO 上传,包含了使用 Jukedeck AI 创作的音乐。
- 最先进的 AI 机器人承认在电视采访中出现故障后想要摧毁人类(1 年前,913K 观看次数)
这段视频介绍了世界上最先进的 AI 人形机器人 Sofia。在接受 CNBC 采访时,这个机器人承认“她”想要摧毁人类。虽然许多人对这一说法一笑置之,但现实是,世界顶级科学家现在警告说,创造一个人工智能生命可能是人类犯过的最大的错误。埃隆·马斯克、史蒂夫·沃兹尼亚克、斯蒂芬·霍金、比尔·盖茨等人最近都对 AI 的未来表示了严重担忧。
6. 直观 AI 的惊人发明 | 莫里斯·孔蒂(2 个月前,859K 次观看)
这是 TEDTalks 的视频播客。它带领我们参观增强时代的未来学家 莫里斯·孔蒂,预览一个机器人和人类将肩并肩合作完成各自无法独立完成的任务的时代。
7. 将谷歌的 AI 通过图灵测试(5 个月前,825K 次观看)
这个视频包含了一个问题:“神经网络能否学习识别涂鸦?”并展示了它如何通过绘图和玩耍来帮助学习。
8. 谷歌的恐龙中的人工智能(英语字幕)(1 年前,802K 次观看)
这是一个使用神经网络和遗传算法的项目视频,用来教谷歌的恐龙从 Chrome 中跳过仙人掌而不会轻易死亡。
9. 我们能在不失控的情况下构建 AI 吗? | 萨姆·哈里斯(6 个月前,711K 次观看)
这是神经科学家和哲学家 萨姆·哈里斯 关于超级智能 AI 的 TED 演讲。哈里斯说,我们将建立超人类机器,但我们还没有解决创造可能像对待蚂蚁一样对待我们的东西所带来的问题。
10. 我们是否正在接近机器人意识?(1 年前,698K 次观看)
人工智能和机器人领域已经经历了第一个科学上可证明的自我意识机器人。这是世界上最糟糕的噩梦……还是?在这个视频中,你将了解这一成就的过程、真实的影响,然后我们将回答一些进一步的问题。
顶级视频播放列表
1. MITCSAIL(106 个视频;总计 5.19M 次观看)
麻省理工学院计算机科学与人工智能实验室(CSAIL)在计算机科学和 AI 的所有领域进行研究,例如机器人技术、系统、理论、生物学、机器学习、语音识别、视觉和图形。在这里,你可以找到展示 CSAIL 激动人心的研究的视频。 
2. MIT 6.034 人工智能,2010 年秋季(30 个视频,总计 599K 次观看)
这系列讲座由 MIT OpenCourseWare 提供,包括“人工智能的介绍和范围”、“推理:目标树和问题解决”。
更多相关内容
数据科学家和机器学习工程师的十大 TED 演讲
原文:
www.kdnuggets.com/2018/01/top-10-ted-talks-data-scientists-machine-learning.html
评论

有时候,当我们过于专注于学习机器学习的技术实现时,我们往往忽视了这项技术的重要问题,如其未来应用和政治后果。在这篇文章中,我们没有讨论使用什么语言或什么算法最适合解决问题,而是汇集了一些来自高度受欢迎的非营利组织 TED 的视频。
在这一系列视频中,你将找到关于 AI 和机器学习的有趣讨论和会议,采用“宏观视角”。你将听到关于该领域即将发展的不同观点及其对全球的影响、优势和后果。话题包括 AI 的政治和技术责任;对未来就业市场的影响,甚至它在艺术中的作用。
希望你能像我一样享受这些讲座
-
当我们的计算机比我们更聪明时会发生什么?,尼克·博斯特罗姆,3.1M 次观看。 @FHIOxford。
人工智能正在飞速变得更加智能——研究表明,在本世纪内,计算机 AI 可能会像人类一样“聪明”。哲学家和技术专家博斯特罗姆要求我们认真思考现在我们所构建的世界,这些世界由思维机器驱动。我们的智能机器会帮助维护人类及其价值观,还是它们会有自己的价值观?
-
我们能在不失控的情况下构建 AI 吗?,萨姆·哈里斯,3.0M 次观看, @SamHarrisOrg。
对超智能 AI 感到害怕吗?神经科学家和哲学家萨姆·哈里斯表示你应该感到害怕——而不仅仅是在理论上。哈里斯说,我们将构建超人类机器,但我们还没有处理好创建可能像对待蚂蚁一样对待我们的东西所带来的问题。
-
我们将失去哪些工作给机器 - 以及我们不会失去哪些工作,安东尼·戈德布鲁姆,2.1M 次观看, @antgoldbloom。
机器学习不再仅限于像评估信用风险和分类邮件这样的简单任务——今天,它能够处理更复杂的应用,如评分作文和诊断疾病。随着这些进展,一个不安的问题出现了:未来会有机器人做你的工作吗?
-
我们正在构建一个反乌托邦只是为了让人们点击广告,泽伊内普·图费基,1.7M 次观看,@zeynep。
在这场开阔眼界的演讲中,她详细讲述了公司如 Facebook、Google 和 Amazon 使用的相同算法如何被用来组织你获取政治和社会信息的方式。而真正的威胁甚至不是机器。我们需要理解的是强大的势力如何利用人工智能来控制我们——以及我们可以做些什么来应对。
-
未来没有工作的时代我们将如何赚钱,马丁·福特,1.5M 次观看,@MFordFuture。
能够思考、学习和适应的机器即将到来——这可能意味着我们人类将面临严重的失业。我们应该怎么做呢?在关于一个有争议的想法的直白演讲中,未来学家马丁·福特提出了将收入与传统工作分离并实施全民基本收入的理由。
-
计算机如何学习创造力,布莱兹·阿圭拉·亚卡斯,1.49M 次观看,@blaiseaguera。
布莱兹,谷歌的首席科学家,从事深度神经网络的机器感知和分布式学习。在这场引人入胜的演示中,他展示了如何将训练来识别图像的神经网络反向运行,以生成图像。结果:令人惊叹的、迷幻的拼贴画(和诗歌!)超越了分类。
-
人工智能如何提升我们的记忆、工作和社交生活,汤姆·格鲁伯,1.47M 次观看。他分享了对未来的愿景,在这个未来中,人工智能帮助我们在感知、创造力和认知功能上实现超人表现——从加速我们的设计技能到帮助我们记住我们曾读过的所有内容和我们遇到的每个人的名字。
-
人工智能如何带来第二次工业革命,凯文·凯利,1.46M 次观看,@kevin2kelly。
他表示,在接下来的 20 年里,我们不断让事物变得越来越智能的倾向将对我们所做的几乎所有事情产生深远的影响。凯利探讨了我们需要理解的三大人工智能趋势,以便接受它并引导其发展。
-
不要害怕超级智能的人工智能,格雷迪·布奇,1.44M 次观看,@Grady_Booch。
科学家和哲学家 Grady Booch 表示,新技术带来了新的焦虑,但我们不需要害怕全能的、无情的人工智能。Booch 通过解释我们如何教导,而不是编程,让超智能计算机分享我们的价值观,来消除我们对超级智能计算机的最糟糕的(科幻作品引发的)恐惧。他建议我们不要担心不太可能发生的生存威胁,而是考虑人工智能将如何提升人类生活。
-
创建更安全 AI 的 3 个原则,Stuart Russell,1.23M 观看次数。我们如何利用超级智能 AI 的力量,同时防止机器人接管的灾难?随着我们朝着创造全知机器的方向前进,AI 先锋 Stuart Russell 正在研究一些略有不同的东西:具备不确定性的机器人。听听他对能够使用常识、利他主义和其他人类价值观解决问题的兼容人工智能的愿景。
相关
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 需求
更多相关话题


 浙公网安备 33010602011771号
浙公网安备 33010602011771号