KDNuggets-博客中文翻译-三十-
KDNuggets 博客中文翻译(三十)
原文:KDNuggets
将你的数据科学职业生涯提升到新水平
原文:
www.kdnuggets.com/2021/12/sas-advance-data-science-career-next-level.html
赞助广告。
数据科学职业路径的增长速度和吸引力空前强劲。事实上,自 2012 年以来,数据科学职位增长了 650%。此外,美国劳工统计局预测到 2026 年职位数量将增加约 28%,这相当于约1150 万个新职位。你很难找到一个不将数据科学融入关键业务功能的行业。
我们的前三个课程推荐
 1. Google 网络安全证书 - 快速进入网络安全职业道路。
1. Google 网络安全证书 - 快速进入网络安全职业道路。
 2. Google 数据分析专业证书 - 提升你的数据分析技能
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
无论你是刚刚起步还是经验丰富的专业人士,SAS 提供了广泛的实操课程,帮助数据科学专业人士在职业生涯中取得进步并保持领先:
-
SAS^(®)数据科学学院 通过 SAS 的深入培训和专业认证掌握成为数据科学家的必要技能。利用 免费 30 天试用。
-
专为数据科学家设计,该项目涵盖数据策展技术的 SAS 主题,包括使用 Hadoop 进行大数据准备。
-
通过学习预测建模、文本分析、实验和优化技术来扩展你的分析技能。
-
AI 和机器学习专业 学习如何将 AI 和机器学习应用于业务问题,并理解分析生命周期的每一步。
-
使用 SAS^(®)** Viya^(®**) 通过深入的教学和免费的 SAS 软件互动练习来建立机器学习技能。
-
我们全面的培训工具帮助您学习 SAS,扩展员工知识,衡量价值并培训新员工。拥有超过 100 门电子学习课程,适合每个人!
为了支持您的数据科学职业之旅,SAS 还提供了免费资源——从白皮书和文章到播客和视频教程,选择丰富。通过访问 数据科学资源中心 开始,或在 数据科学家学习之旅 系列中注册免费网络研讨会。

更多相关话题
SAS®视觉数据科学决策,由 SAS® Viya®驱动:免费试用
原文:
www.kdnuggets.com/2021/06/sas-viya-visual-data-science-free-trial.html
赞助帖子。
由 Lindsay Marshall撰写

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
能够解读和分析数据的组织在数字经济中具备了获胜的条件。在 COVID-19 之后,Gartner 表示 69%的董事会已经加快了他们的数字业务计划。分析是整个企业的重要投资,组织需要对所选择的供应商充满信心。为何不免费发现 SAS®如何帮助你准备、探索、分析和可视化你的数据?
使用 SAS 视觉数据科学决策(VDSD)试用版,你可以获得终极的分析体验,免费访问所有 SAS Viya 分析功能,时间为 14 天。 SAS 视觉数据科学决策提供涵盖整个分析生命周期的终极体验——从数据管理、模型开发,到模型部署和决策。
SAS 视觉数据科学决策由 SAS® Viya®驱动,我们的 AI、分析和数据管理平台,运行在现代、可扩展的架构上,使得每时每刻的决策都充满信心。
这个免费试用版为你提供对 SAS Viya 功能的访问,包括:
-
数据访问、数据准备、数据质量与信息目录
-
高级流程步骤与信息治理
-
可视化与报告
-
统计学
-
矩阵编程
-
机器学习与深度学习
-
模型部署与管理
-
预测
-
文本分析
-
优化
-
计量经济学
-
数字决策
-
事件流分析
尝试一个,或全部尝试。所有这些都包含在您的免费试用中。
每个用户可以上传 1GB 的非个人识别信息(PII)数据。支持以下常用数据源:Microsoft Excel 电子表格、CSV 文件和 SAS 数据集。
您还可以从您的组织中添加最多四个用户(包括您自己,总共五个用户)到此试用体验中。每个用户只需一个 SAS 账户即可开始使用。改进的注册和试用体验确保您将比以往更快地学习新的分析和 AI 能力,并且如果需要,您还可以选择延长使用时间。我们已为 VDSD 中包含的许多数据管理、分析和 AI 功能预加载数据集和预构建管道,并且如果您有问题,可以从用户社区、支持页面和教程中获得快速支持。
为什么等待?今天就开始您的免费 SAS 试用吧!
相关主题
用数据科学拯救莎拉·康纳
原文:
www.kdnuggets.com/2021/10/save-sarah-connor-data-science.html
评论
作者:彼得·科兹洛夫,数据分析硕士,拥有超过 30 年的不同行业经验。
下面的图片发生了什么?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 服务。
我们在这里看到数据窃贼了吗?

图片 1. 来自 1984 年上映的《终结者》电影的镜头。
这是 1984 年的加州。我们可能会认出未来的加州州长阿诺德·施瓦辛格,他在电影《终结者》中扮演了直接针对加州人的角色。他正在使用在电话亭里找到的电话簿。
终结者是数据窃贼吗?实际上,他并不是,因为在 1984 年,这类个人数据是公开可用的。
近年来个人信息处理的认知发生了显著变化,并且有一些迹象:
-
(欧洲) 一般数据保护条例 (GDPR) 于 2018 年 5 月 25 日实施。
-
(澳大利亚) 消费者数据权利 (CDR) 从 2019 年 9 月 1 日起生效。
-
(美国) 健康保险流通与问责法案 (HIPAA) 预计在 2021 年会有变更。
今天,加州人对数据隐私非常重视,根据 2019 年 10 月 11 日签署的加州消费者隐私法案 (CCPA)。加州人走在前面,为每一条不合规的客户记录附上了价格标签。价格范围在每条记录 100 到 750 美元之间。
数据隐私的最佳实践是什么?美国监管机构 HIPAA 一直是健康行业以及其他行业的数据隐私模范。它传播知识,并为隐私数据处理方法提供明确的定义。HIPAA 区分了安全港和专家判定方法。我们将比较这些数据模糊化的方法。
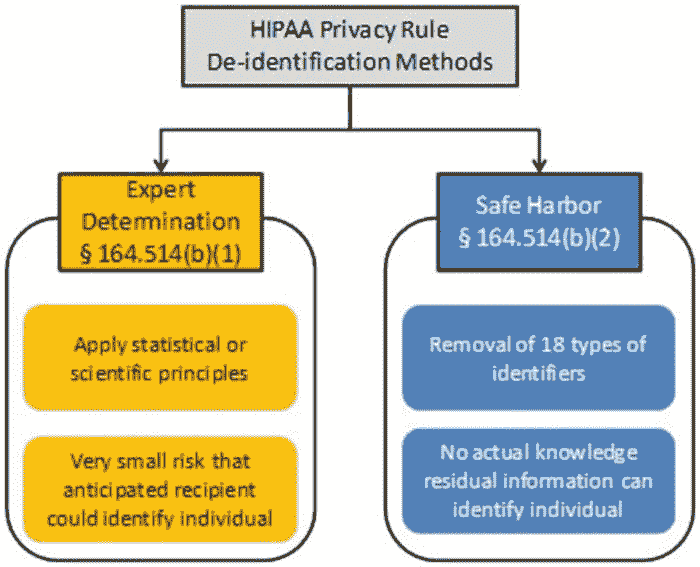
图片 2. HIPAA 推荐的去标识化方法。来自美国卫生与公共服务部的插图。
专家鉴定由合格的统计学家/数据科学家提供作为客观风险评估。相比之下,Safe Harbour 是一个让企业自己完成这项工作的配方。
“Safe Harbour”是一个非常引人注目的概念,因为它基于一套简单的规则来移除明确的标识符。例如,前两个标识符是个人的姓名和小于州的地理细分。完整的标识符列表可以在这里找到。除了移除密钥外,我们还需要确保没有留下识别个人的信息。这可能是由于微密钥(如非常罕见的疾病或独特的治疗参数)而成为一个挑战。Safe Harbour 是基于规则的,因此在考虑数据的实际内容和微密钥时过于僵化。技术科学期刊中的文章A Re-identification of Patients in Maine and Vermont Statewide Hospital Data演示了 3.2%的 Safe Harbour 数据通过地方出版物重新识别为个人。
专家鉴定方法可以考虑数据研究的目的,并在研究背景中容忍各种混淆方法:
-
扰乱
-
加密
-
目录替换
-
屏蔽
-
标记化
-
数据模糊
-
噪声添加
-
聚合
专家鉴定使我们能够在产生的信息丧失与个人信息泄露的概率之间取得平衡,并确保信息处理的意义得以保留。
让我们讨论一个例子。
我们的任务是进行客户研究并减少数据风险。我们想要将城市与农村客户通过 Safe Harbour 和专家鉴定进行比较。我们将使用两个记录和四个字段的数据示例。我们假设为研究记录收集的顺序在内部数据集中是随机的,并且收集的“有价值客户数据”不会逐行公开。我们还假设以下数据集在一个诊所中可用,作为本练习的外部数据源:
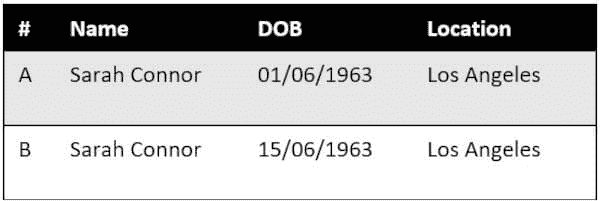
表 1. 外部数据源的数据示例。
我们的 Safe Harbour 混淆要求我们从出生日期(DOB)中移除姓名、日期和月份,并将位置仅替换为州:

表 2. Safe Harbour 数据混淆的示例。
对于数据泄漏,我们有两个关注点:
-
泄露的数据与外部源结合以利用出生日期。
-
从我们的内部数据集中可能推测出出生日期。
P(DOB 公开|Ext|Int) 是当内部和外部数据泄露时出生日期公开的概率。由于我们在内部数据集中有两个具有相同出生年份(YOB)和地点的记录,因此有一半的机会可以将“1963,加利福尼亚”匹配到外部来源的出生日期。
P(DOB 公开|Int) 是当攻击者尝试从我们的内部数据集中恢复出生日期时的出生日期公开概率。1963 年有 365 天,内部数据集中没有其他信息来猜测这样一个大日期范围中的具体日期。
专家判断方法分为两个步骤。首先,我们尽量保留最大的信息,其次,我们通过调整保留的数据来审查这种“数据储存”,以符合研究目的。

表 3. 数据示例的专家判断数据混淆的第一次尝试。
P(DOB 公开|Ext|Int) 与 Safe Harbor 数据集中的值相同。
P(DOB 公开|Int) 是 30 分之一的几率,比之前的情况更高。根据我们的任意决策,这个 P 值可以被接受为低风险或中等风险。
在第一次专家判断混淆尝试中,我们设法保留了姓名、地点和出生日期到月份级别。问题在于这些混淆结果是否与研究目的对齐。更仔细地对齐城乡客户研究,可以排除姓名,仅标记客户年龄组为成人和儿童。
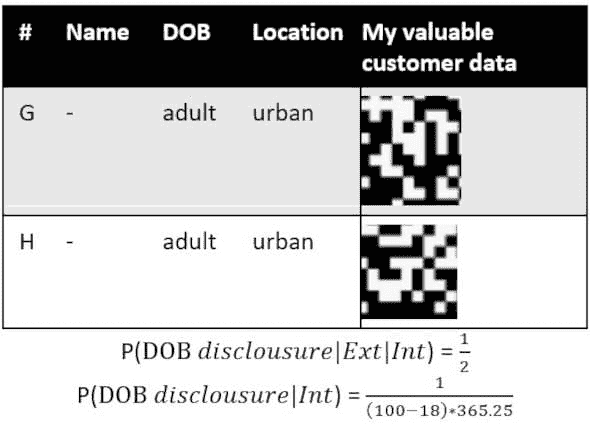
表 4. 数据示例的专家判断数据混淆的第二次尝试。
P(DOB 公开|Ext|Int) 的值没有变化。
P(DOB 公开|Int) 是基于最大成人年龄 100(你也可以使用更保守的数字,例如平均寿命)的估算值。其他两个参数是最小成人年龄 18 和每年的平均天数 365.25。第二次专家判断混淆的 P(DOB 公开|Int) 明显低于 Safe Harbor 实施的结果。
对这两种 HIPAA 混淆方法的数据示例的最终比较:
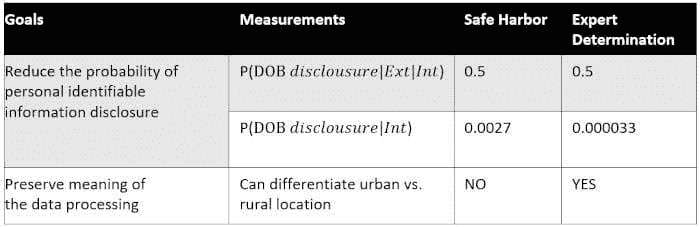
表 5. 比较 HIPAA 方法对数据示例和研究目的的影响。
所选的数据示例和研究目的旨在展示专家判断方法相较于 Safe Harbour 的灵活性。专家判断的主要优势在于,该方法不仅处理了披露的概率,同时还允许我们控制相关的信息丢失。使用专家判断数据示例混淆的数据样本允许我们进行城乡对比研究,而 Safe Harbour 则不允许。
或许这个例子会证明,问题的最简单解决方案并不总是合适的,应用最佳而非最快的解决方案可以拯救莎拉·康纳免于被终结者发现。
相关:
更多主题
在 TensorFlow 中保存和加载模型——为什么这很重要以及如何做到
原文:
www.kdnuggets.com/2021/02/saving-loading-models-tensorflow.html
评论

照片由 Nana Smirnova 提供,来自 Unsplash。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
在本文中,我们将讨论以下主题
-
保存深度学习模型的重要性(一般而言,不限于 TensorFlow)。
-
如何在 TensorFlow 2 中保存深度学习模型,以及不同类型、类别和保存模型的技术。
-
在 TensorFlow 2 中加载保存的模型。
保存深度学习模型的重要性
记住,在梯度下降中,我们根据误差或损失函数更新权重和偏差。
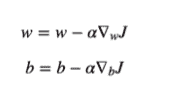
现在想象一下,你训练了一个模型数千个周期,可能是几天、几周甚至几小时,并且得到了相当好的权重,这意味着你的模型表现非常好,然后当你关闭程序/Jupyter notebook 时丢失了所有权重。
当你想在另一个应用程序中重用该模型而没有保存进度时,这将变成一个更繁琐的问题。你必须从头开始训练,这可能浪费你几个小时或几天。
实际上,你可以想象这样一个场景:你已经编码了一个准确率超过 99%、精确度极高的面部识别模型应用,且训练该模型在大数据集上花费了大约 30 小时。现在,如果你没有保存模型,而你希望在任何应用程序中使用它,你将不得不重新训练整个模型 30 小时。
这就是为什么保存模型是一个非常重要的步骤,只需额外的几行代码就能节省大量时间和资源。
在 TensorFlow 2 中保存模型
在 TensorFlow 中保存模型权重有 2 种不同的格式。第一种是TensorFlow 原生格式,第二种是hdf5 格式,也称为h5 或HDF 格式。
另外,还有 2 种不同的保存模型的方法。
-
简单且不复杂的方法,但不提供自由度。
-
使用回调来保存模型,允许你进行很多自由操作,例如每个 epoch 保存,保存每隔 n 个示例后等。
我们将详细讨论这两种方法。
让我们首先加载重要的 Python 库和数据集。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Conv2D, MaxPooling2D
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data() #cifar10 dataset
x_train = x_train / 255.0 #normalizing images
x_test = x_test / 255.0
简单方法
在 TensorFlow 中保存模型的简单方法是使用 Tensorflow.Keras.models 的内置函数“模型保存与序列化 API”,即 save_weights 方法。
假设我们有一个 TensorFlow 中的顺序模型。
model = Sequential([
Conv2D(filters=16, input_shape=(32, 32, 3), kernel_size=(3, 3), activation='relu', name='conv_1'),
MaxPooling2D(pool_size=(4, 4), name='pool_1'),
tf.keras.layers.BatchNormalization(),
Flatten(name='flatten'),
Dense(units=32, activation='relu', name='dense_1'),
tf.keras.layers.Dropout(0.5),
Dense(units=10, activation='softmax', name='dense_2')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
现在我们使用 model.fit 函数在 TensorFlow 中拟合模型。
hist = model.fit(x_train,y_train,epochs=5, batch_size=512)
我们可以通过以下方式评估模型的性能,
loss, acc = model.evaluate(x_test, y_test, verbose=0)
print(f"test accuracy {acc*100}")
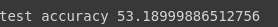
现在,我们只需调用 model.save 函数并传入 filepath 作为参数,就可以保存模型。
-
模型架构
-
模型权重
-
模型优化器状态(以便你可以从中断处继续训练)
model.save('myModel.h5')
现在添加扩展名很重要。如果你添加 .h5 作为扩展名,它会将模型保存为 hdf5 格式,如果没有提供扩展名,模型将以 TensorFlow 原生格式保存。
现在,当模型保存在当前目录中的 myModel.h5 文件时,你可以通过以下方式在新程序中或同一程序中作为不同模型加载它,
new_model = tf.keras.models.load_model('my_model.h5') #same file path
我们可以通过以下方式检查新加载模型的准确率,
loss, acc = new_model.evaluate(x_test, y_test, verbose=0)
print(f"test accuracy {acc*100}")
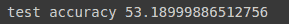
我们可以看到我们得到的准确率与旧模型完全相同。
我们可以通过检查模型摘要进一步确认。
newmodel.summary()
新的摘要与我们原始模型的摘要完全相同。
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv_1 (Conv2D) (None, 30, 30, 16) 448
_________________________________________________________________
pool_1 (MaxPooling2D) (None, 7, 7, 16) 0
_________________________________________________________________
batch_normalization (BatchNo (None, 7, 7, 16) 64
_________________________________________________________________
flatten (Flatten) (None, 784) 0
_________________________________________________________________
dense_1 (Dense) (None, 32) 25120
_________________________________________________________________
dropout (Dropout) (None, 32) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 330
=================================================================
Total params: 25,962
Trainable params: 25,930
Non-trainable params: 32
_________________________________________________________________
同样,我们可以通过以下方式以 TensorFlow 原生格式保存权重,
new_model.save('newmodel')
看看我们在名称后没有添加任何文件格式。这会将我们的模型以 TensorFlow 原生格式保存在 newmodel 文件夹中。如果我们查看该文件夹,我们可以检查文件的
!dir newmodel
这个命令只会在 jupyter notebook 中运行,因此你也可以打开文件夹查看文件。
你将始终有 1 个文件和 2 个文件夹,它们是:
-
assets (文件夹)
-
pb
-
variables (文件夹)
我们稍后会查看这些文件夹和文件是什么。但要简单地加载模型,我们只需提供用于保存模型的路径名,例如
other_model = tf.keras.models.load_model('newmodel')
你可以通过检查其 summary 或评估结果来确认它是相同的模型。
现在以简单的方法仅保存 权重,你只需在模型上调用内置函数 save_weights。
让我们使用同一个旧模型,
model = Sequential([
Conv2D(filters=16, input_shape=(32, 32, 3), kernel_size=(3, 3), activation='relu', name='conv_1'),
MaxPooling2D(pool_size=(4, 4), name='pool_1'),
tf.keras.layers.BatchNormalization(),
Flatten(name='flatten'),
Dense(units=32, activation='relu', name='dense_1'),
tf.keras.layers.Dropout(0.5),
Dense(units=10, activation='softmax', name='dense_2')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
并训练几个 epoch。
model.fit(x_train,y_train,epochs=5, batch_size=512)
现在你可以简单地通过以下方式保存权重,
path = 'weights_folder/my_weights'
model.save_weights(path)
这将创建一个名为 weights_folder 的文件夹,并将权重以 TensorFlow 原生格式保存,文件名为 my_weights。它将包含 3 个文件。
-
checkpoint
-
data-00000-of-00001
-
index
让我们看看这些文件。
- ****my_weights.index
这个文件告诉 TensorFlow 权重存储的位置。当在分布式系统上运行模型时,可能会有不同的 分片,这意味着整个模型可能需要从多个来源重新组合。在上一个笔记本中,你在一台机器上创建了一个单一模型,所以只有一个 分片,所有权重都存储在同一个地方。
- my_weights.data-00000-of-00001
该文件包含模型的实际权重。它是这三个文件中最大的。回想一下,你训练的模型有大约 14000 个参数,这意味着这个文件的大小大约是每个保存的权重 12 字节。
- 检查点
这个文件是迄今为止最小的。实际上小到我们可以直接查看。它是一个人类可读的文件,包含以下文本,
model_checkpoint_path: "my_weights"
all_model_checkpoint_paths: "my_weights"
现在,当你保存了权重后,你可以通过简单地调用来加载它们,
model.load_weights(path)
这将会在特定路径加载该模型的权重。
或者,你可以仅通过 hdf5 格式保存权重,方法是,
model.save_weights('my_weights.h5')
这将会在你的工作目录中创建一个 my_weights.h5 文件,你可以通过 model.load_weights('my_weights.h5') 轻松加载它们。
重要提示
当你为模型加载权重时,你需要有该模型的正确架构。
例如:
你不能将我们刚创建的 模型 的权重加载到具有 1 个 Dense 层的顺序模型中,因为两者不兼容。所以你可能会想,保存权重的用途是什么?
好吧,答案是,如果你在看一些大型的 SOTA 应用,比如 YOLO,或者类似的东西,它们会给你源代码。但是,在你的机器上训练它们是一项漫长的任务,所以它们也会给你在不同 epochs 上的预训练权重,例如,如果你想查看这个模型在 50 epochs 时的表现,那么你可以加载保存的 50 epochs 权重,以此类推。这样,你可以根据模型在 X 次训练 epochs 上的表现检查模型的性能,而无需明确训练它。
TensorFlow 原生格式与 hdf5,什么时候使用哪一个?
你已经看到,使用 .h5 格式简单而干净,因为它只创建一个单一的文件,而使用 TensorFlow 原生格式会创建多个文件夹和文件,这样不易阅读。所以,你可能会想,为什么我们还要使用 TensorFlow 原生格式?答案是,在 TensorFlow 原生格式中,一切都是结构化的,并且组织得井井有条。例如,.pb 文件包含结构数据,可以被多种语言加载。TF 原生格式的一些优点列在下面。
TensorFlow 原生格式的优点
-
TensorFlow’s Serving 在你想将模型投入生产时使用它。
-
语言无关 — 二进制格式可以被多种语言读取(如 Java、Python、Objective-C 和 C++ 等)。
-
自 0 版以来建议使用,你可以查看 TensorFlow 的官方序列化指南,它推荐使用 TensorFlow 原生格式。
-
保存模型的各种元数据,如优化器信息、损失、学习率等,这些信息以后可能会有帮助。
缺点
-
SavedModel 在概念上比单个文件更难理解
-
创建一个单独的文件夹来存储权重。
h5 的优势
-
用于保存可能不是表格数据的大型数据。
-
常见的文件保存格式。
-
所有内容保存在一个文件中(权重、损失、使用的优化器)
缺点
- 不能与 TensorFlow Serving 一起使用,但你可以通过 experimental.export_saved_model(model, 'path_to_saved_model') 将其简单转换为 .pb 格式
应该使用什么
如果你在服务或部署模型时不打算使用 TensorFlow,为了简便起见,你可以使用 .hdf5 格式,但如果你打算使用 TensorFlow 服务,那么你应该使用 tensorflow 原生格式。
学习成果
在这篇文章中,你学到了
-
为什么你应该保存你的机器学习模型。
-
如何仅使用简单的方法保存模型权重。
-
如何使用简单的方法保存完整模型。
-
在 TensorFlow 原生格式或 HDF5 格式中保存。
-
TensorFlow 原生格式和 HDF5 格式的区别以及该使用什么。
欲了解更多详情,请查看:
相关:
更多相关主题
告别Print():使用日志模块进行有效调试
原文:
www.kdnuggets.com/say-goodbye-to-print-use-logging-module-for-effective-debugging

作者提供的图片 | DALLE-3 & Canva
许多人开始编程时会通过 YouTube 视频学习,为了简单起见,他们通常使用print()语句来跟踪错误。这是可以理解的,但随着初学者养成这个习惯,它可能会变得问题重重。虽然这些语句对于简单的脚本可能有效,但随着代码库的扩展,这种方法变得非常低效。因此,在这篇文章中,我将向你介绍 Python 内置的日志模块,它解决了这个问题。我们将看到什么是日志记录,它与print()语句的区别,以及一个实用的例子来全面了解其功能。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在的组织进行 IT 工作
为什么使用日志模块而不是Print()?
当我们谈论调试时,Python 的日志模块提供了比简单的print()语句更详细的信息。这包括时间戳、模块名称、日志级别以及错误发生的行号等。这些额外的细节帮助我们更有效地理解代码的行为。我们想要记录的信息取决于应用程序的需求和开发者的偏好。因此,在进一步探讨之前,我们先讨论一下日志级别及其设置方法。
日志级别
你可以通过这些日志级别控制你想看到的信息量。每个日志级别都有一个数值,表示其严重性,数值越高表示事件越严重。例如,如果你将日志级别设置为WARNING,你是在告诉日志模块只显示WARNING级别或更高级别的消息。这意味着你将看不到DEBUG、INFO或其他较低严重性的消息。这样,你可以集中关注重要事件,忽略噪音。
这是一个展示每个日志级别所代表的详细信息的表格:
| 日志级别 | 数值 | 目的 |
|---|---|---|
| DEBUG | 10 | 提供详细的信息以诊断与代码相关的问题,例如打印变量值和函数调用跟踪。 |
| INFO | 20 | 用于确认程序按预期工作,比如显示启动消息和进度指示器。 |
| WARNING | 30 | 表示一个潜在的问题,这可能不会中断程序的执行,但可能会在以后引发问题。 |
| ERROR | 40 | 表示代码的意外行为,这影响了其功能,如异常、语法错误或内存不足错误。 |
| CRITICAL | 50 | 表示严重错误,可能导致程序终止,如系统崩溃或致命错误。 |
设置日志模块
要使用日志模块,你需要按照一些配置步骤。这包括创建日志记录器、设置日志级别、创建格式化程序以及定义一个或多个处理器。处理器基本上决定将日志消息发送到哪里,比如控制台或文件。让我们从一个简单的例子开始。我们将设置日志模块做两件事:首先,它将在控制台上显示消息,为我们提供有用的信息(在 INFO 级别)。其次,它将把更详细的消息保存到文件中(在 DEBUG 级别)。希望你能跟上!
1. 设置日志级别
日志记录器的默认级别设置为 WARNING。在我们的例子中,我们的两个处理器被设置为 DEBUG 和 INFO 级别。因此,为了确保所有消息都得到适当处理,我们必须将日志记录器的级别设置为所有处理器中的最低级别,在这种情况下是 DEBUG。
import logging
# Create a logger
logger = logging.getLogger(__name__)
# Set logger level to DEBUG
logger.setLevel(logging.DEBUG)
2. 创建一个格式化程序
你可以使用格式化程序个性化你的日志信息。这些格式化程序决定日志信息的显示方式。在这里,我们将设置格式化程序以包含时间戳、日志级别和消息内容,使用以下命令:
formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
3. 创建处理器
正如之前讨论的,处理器管理日志信息的发送位置。我们将创建两个处理器:一个控制台处理器,用于将消息记录到控制台,一个文件处理器,用于将日志消息写入名为 'app.log' 的文件。
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
console_handler.setFormatter(formatter)
file_handler = logging.FileHandler('app.log')
file_handler.setLevel(logging.DEBUG)
file_handler.setFormatter(formatter)
然后使用 addHandler() 方法将两个处理器添加到日志记录器中。
logger.addHandler(console_handler)
logger.addHandler(file_handler)
4. 测试日志设置
现在我们的设置完成了,在转到实际示例之前,让我们测试一下它是否正常工作。我们可以如下记录一些消息:
logger.debug('This is a debug message')
logger.info('This is an info message')
logger.warning('This is a warning message')
logger.error('This is an error message')
logger.critical('This is a critical message')
当你运行这段代码时,你应该会看到日志信息被打印到控制台并写入名为 'app.log' 的文件中,格式如下:
控制台
2024-05-18 11:51:44,187 - INFO - This is an info message
2024-05-18 11:51:44,187 - WARNING - This is a warning message
2024-05-18 11:51:44,187 - ERROR - This is an error message
2024-05-18 11:51:44,187 - CRITICAL - This is a critical message
app.log
2024-05-18 11:51:44,187 - DEBUG - This is a debug message
2024-05-18 11:51:44,187 - INFO - This is an info message
2024-05-18 11:51:44,187 - WARNING - This is a warning message
2024-05-18 11:51:44,187 - ERROR - This is an error message
2024-05-18 11:51:44,187 - CRITICAL - This is a critical message
在 Web 应用程序中记录用户活动
在这个简单的示例中,我们将创建一个基本的网络应用程序,使用 Python 的 logging 模块记录用户活动。这个应用程序将有两个端点:一个用于记录成功的登录尝试,另一个用于记录失败的登录尝试(INFO 表示成功,WARNING 表示失败)。
1. 设置你的环境
在开始之前,设置你的虚拟环境并安装 Flask:
python -m venv myenv
# For Mac
source myenv/bin/activate
#Install flask
pip install flask
2. 创建一个简单的 Flask 应用程序
当你向/login端点发送一个包含用户名和密码参数的 POST 请求时,服务器将检查凭据是否有效。如果有效,记录器会使用 logger.info() 记录事件,以表示登录尝试成功。然而,如果凭据无效,记录器会使用 logger.error() 记录事件,标记为登录尝试失败。
#Making Imports
from flask import Flask, request
import logging
import os
# Initialize the Flask app
app = Flask(__name__)
# Configure logging
if not os.path.exists('logs'):
os.makedirs('logs')
log_file = 'logs/app.log'
logging.basicConfig(filename=log_file, level=logging.DEBUG, format='%(asctime)s - %(levelname)s - %(message)s')
log = logging.getLogger(__name__)
# Define route and handler
@app.route('/login', methods=['POST'])
def login():
log.info('Received login request')
username = request.form['username']
password = request.form['password']
if username == 'admin' and password == 'password':
log.info('Login successful')
return 'Welcome, admin!'
else:
log.error('Invalid credentials')
return 'Invalid username or password', 401
if __name__ == '__main__':
app.run(debug=True)
3. 测试应用程序
要测试应用程序,请运行 Python 脚本,并使用 Web 浏览器或类似 curl 的工具访问/login端点。例如:
测试用例 01
curl -X POST -d "username=admin&password=password" http://localhost:5000/login
输出
Welcome, admin!
测试用例 02
curl -X POST -d "username=admin&password=wrongpassword" http://localhost:5000/login
输出
Invalid username or password
app.log
2024-05-18 12:36:56,845 - INFO - Received login request
2024-05-18 12:36:56,846 - INFO - Login successful
2024-05-18 12:36:56,847 - INFO - 127.0.0.1 - - [18/May/2024 12:36:56] "POST /login HTTP/1.1" 200 -
2024-05-18 12:37:00,960 - INFO - Received login request
2024-05-18 12:37:00,960 - ERROR - Invalid credentials
2024-05-18 12:37:00,960 - INFO - 127.0.0.1 - - [18/May/2024 12:37:00] "POST /login HTTP/1.1" 200 -
总结
这篇文章到此为止。我强烈建议将日志记录作为你的编码常规的一部分。这是保持代码清洁和简化调试的好方法。如果你想深入了解,可以查看 Python 日志记录文档 以获取更多功能和高级技术。如果你希望进一步提升你的 Python 技能,欢迎查阅我其他的一些文章:
Kanwal Mehreen**** Kanwal 是一名机器学习工程师和技术作家,对数据科学及其与医学的交汇点充满热情。她共同撰写了电子书《利用 ChatGPT 最大化生产力》。作为 2022 年 APAC 的 Google Generation Scholar,她倡导多样性和学术卓越。她还被认可为 Teradata 多样性技术学者、Mitacs Globalink 研究学者以及哈佛 WeCode 学者。Kanwal 是变革的坚定倡导者,创立了 FEMCodes 以赋能 STEM 领域的女性。
更多相关话题
数据科学中的可扩展性挑战与策略
原文:
www.kdnuggets.com/scalability-challenges-strategies-in-data-science

图片由编辑 | Midjourney
每天生成的数据量庞大,在数据科学领域带来了许多挑战和机遇。由于数据量巨大,可扩展性成为了首要关注点,因为传统的数据处理方法在面对这些庞大的数据量时显得力不从心。通过学习如何解决可扩展性问题,数据科学家可以在各个行业和领域中开启创新、决策和问题解决的新可能性。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
本文探讨了数据科学家和组织面临的多方面可扩展性挑战,分析了管理、处理和从海量数据集中提取洞察的复杂性。它还概述了为克服这些障碍而设计的策略和技术,以便充分发挥大数据的潜力。
可扩展性挑战
首先我们来看一些可扩展性面临的最大挑战。
数据量
存储大规模数据集非常困难,因为涉及的数据量巨大。传统的存储解决方案通常难以扩展。分布式存储系统通过将数据分散到多个服务器上来帮助解决这个问题。然而,管理这些系统非常复杂。确保数据的完整性和冗余性至关重要。如果没有优化的系统,数据检索可能会很慢。像索引和缓存这样的技术可以提高检索速度。
模型训练
使用大数据训练机器学习模型需要大量的资源和时间。复杂的算法需要强大的计算机来处理大规模的数据集。高性能硬件如 GPU 和 TPU 可以加速训练。高效的数据处理管道对于快速训练至关重要。分布式计算框架有助于分担工作负载。适当的资源分配可以减少训练时间并提高准确性。
资源管理
良好的资源管理对可扩展性至关重要。管理不善会增加成本并减慢处理速度。根据需求分配资源是必要的。监控使用情况有助于发现问题并提升性能。自动扩展根据需要调整资源。这保持计算能力、内存和存储的高效使用。平衡资源可以提升性能并降低成本。
实时数据处理
实时数据需要快速处理。延迟可能会影响像金融交易和实时监控这样的应用。这些系统依赖最新信息做出准确决策。低延迟的数据管道对快速处理至关重要。流处理框架处理高吞吐量的数据。实时处理基础设施必须强大且可扩展。确保可靠性和容错能力对于防止停机至关重要。结合高速存储和高效算法是处理实时数据需求的关键。
| 挑战 | 描述 | 关键考虑因素 |
|---|---|---|
| 数据量 | 高效存储和管理大型数据集 |
-
传统存储解决方案通常不够充分
-
对分布式存储系统的需求
-
数据完整性和冗余的重要性
-
优化数据检索速度
|
| 模型训练 | 处理大型数据集以进行机器学习模型训练 |
|---|
-
对计算资源的高需求
-
高性能硬件(GPU、TPU)的需求
-
高效数据处理管道的重要性
-
分布式计算框架的利用
|
| 资源管理 | 高效分配和利用计算资源 |
|---|
-
对处理速度和成本的影响
-
动态资源分配的重要性
-
需要持续监控资源使用情况
-
自动扩展系统的好处
|
| 实时数据处理 | 实时处理和分析数据以获得即时洞察 |
|---|
-
在金融交易等应用中的关键性
-
对低延迟数据管道的需求
-
流处理框架的重要性
-
平衡可靠性和容错能力
|
应对可扩展性挑战的策略
识别挑战后,我们现在转向一些应对策略。
并行计算
并行计算将任务分割成较小的子任务,这些子任务在多个处理器或机器上同时运行。这通过利用多个资源的计算能力组合来提升处理速度和效率。这对于科学模拟、数据分析和机器学习训练中的大规模计算至关重要。将工作负载分布到并行单元有助于系统有效扩展,提升整体性能和响应能力,以满足不断增长的需求。
数据分区
数据分区将大型数据集拆分为分布在多个存储位置或节点的小部分。每个部分可以独立处理,帮助系统高效地管理大量数据。这种方法减少了对单个资源的压力,并支持并行处理,加快了数据检索速度并提高了整体系统性能。数据分区对于高效处理大数据至关重要。
数据存储解决方案
实施可扩展的数据存储解决方案涉及部署设计用来高效且经济地处理大量数据的系统。这些解决方案包括分布式文件系统、基于云的存储服务以及能够水平扩展以适应增长的可扩展数据库。可扩展存储解决方案提供快速的数据访问和高效的管理。它们对于管理现代应用程序中数据的快速增长、保持性能以及有效满足可扩展性要求至关重要。
可扩展数据科学的工具和技术
存在许多工具和技术用于实现应对可扩展性的各种策略。这些是一些突出的工具。
Apache Hadoop
Apache Hadoop 是一个用于处理大量数据的开源工具。它将数据分布到多台计算机上,并进行并行处理。Hadoop 包含 HDFS 用于存储和 MapReduce 用于处理。这种设置高效地处理大数据。
Apache Spark
Apache Spark 是一个快速的大数据处理工具。它支持 Java、Python 和 R 语言。Spark 使用内存计算来加快数据处理速度。它处理大型数据集和复杂的分析,支持分布式集群。
Google BigQuery
Google BigQuery 是一个自动处理所有操作的数据仓库。它允许使用 SQL 查询快速分析大型数据集。BigQuery 以高性能和低延迟处理大量数据,非常适合数据分析和商业洞察。
MongoDB
MongoDB 是一个用于非结构化数据的 NoSQL 数据库。它使用灵活的模式将各种数据类型存储在一个数据库中。MongoDB 设计用于跨多个服务器进行水平扩展,使其非常适合可扩展和灵活的应用程序。
Amazon S3(简单存储服务)
Amazon S3 是 AWS 提供的基于云的存储服务。它为任何大小的数据提供可扩展的存储。S3 提供安全可靠的数据存储,适用于大型数据集,并确保高可用性和耐用性。
Kubernetes
Kubernetes 是一个用于管理容器应用的开源工具。它自动化了容器的设置、扩展和管理。Kubernetes 确保在不同环境下的平稳运行,非常适合高效处理大规模应用程序。
可扩展数据科学的最佳实践
最后,让我们看看一些数据科学可扩展性的最佳实践。
模型优化
优化机器学习模型涉及调整参数、选择正确的算法以及使用集成学习或深度学习等技术。这些方法有助于提高模型的准确性和效率。优化后的模型能够更好地处理大数据集和复杂任务,提升数据科学工作流中的性能和可扩展性。
持续监控与自动扩展
对数据管道、模型性能和资源利用率的持续监控对于可扩展性是必要的。它可以识别系统中的瓶颈和低效之处。云环境中的自动扩展机制根据工作负载需求调整资源,从而确保最佳性能和成本效益。
云计算
云计算平台,如 AWS、Google Cloud Platform(GCP)和 Microsoft Azure,提供可扩展的数据存储、处理和分析基础设施。这些平台提供灵活性。它们允许组织根据需要扩展或缩减资源。云服务比本地解决方案便宜,提供了高效管理数据的工具。
数据安全
在处理大规模数据集时,维护数据安全和遵守法规(例如,GDPR、HIPAA)至关重要。加密可以在传输和存储过程中保护数据安全。访问控制限制只有授权人员才能进入。数据匿名化技术有助于保护个人信息,确保符合法规要求,并增强数据安全。
总结
总之,解决数据科学中的可扩展性挑战涉及使用诸如并行计算、数据分区和可扩展存储等策略。这些方法提高了处理大数据集和复杂任务的效率。最佳实践,如模型优化和云计算,有助于满足数据需求。
Jayita Gulati 是一位机器学习爱好者和技术作者,她对构建机器学习模型充满热情。她拥有利物浦大学的计算机科学硕士学位。
更多相关话题
可扩展的图机器学习:我们能攀登的高峰?
原文:
www.kdnuggets.com/2019/12/scalable-graph-machine-learning.html
评论
由Kevin Jung,CSIRO Data61 的软件工程师。
图机器学习仍然是一个相对较新且正在发展的研究领域,带来了大量的复杂性和挑战。其中一个既让我们着迷又让我们感到愤怒的挑战就是——扩展性。
两种方法早期被确立为利用网络信息的标准方法:图卷积网络 [1](用于图形的强大神经网络架构)和 Node2Vec [2](用于图形的表示学习的算法框架)。这两种方法对于从高度连接的数据集中提取洞见非常有用。
但我亲身体验到,当尝试应用图机器学习技术来识别比特币区块链数据中的欺诈行为时,扩展性是最大的障碍。我们使用的比特币区块链图包含数百万个钱包(节点)和数十亿个交易(边),这使得大多数图机器学习方法不可行。
在这篇文章中,我们将更详细地探讨图机器学习方法的扩展性:它是什么,它为什么困难,以及一种试图直接应对这一挑战的方法示例。
什么是图机器学习?
首先,让我们确保我们对图机器学习的定义达成共识。
当我们说‘图’时,我们指的是一种将数据表示为具有连接的实体的方式。从数学的角度来看,我们称实体为节点或顶点,连接为边。一组顶点V和一组边E组成一个图G = (V, E)。
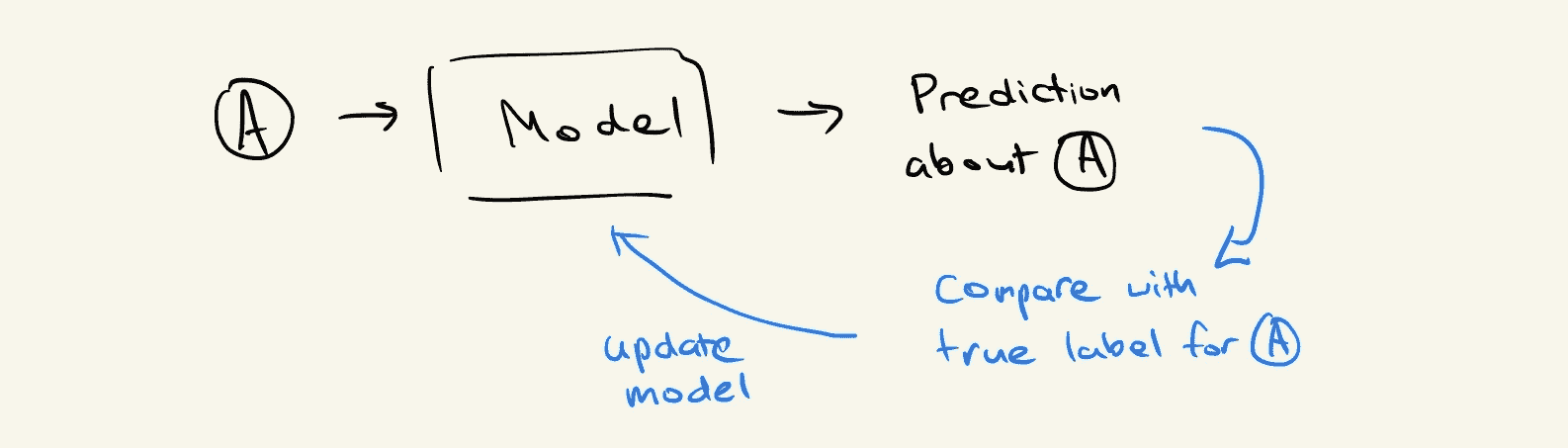
图机器学习是一种可以自然地从图结构数据中学习并进行预测的机器学习技术。我们可以将机器学习视为学习某种转换函数;y = f(x),其中x是数据的一部分,而y是我们想要预测的东西。
比如我们以检测欺诈比特币地址为例,我们知道区块链上所有地址的账户余额。一个非常简单的模型可能会学到,如果一个地址的账户余额为零,则它不太可能是欺诈性的。换句话说,当x为零时,我们的函数f(x)表示一个接近零的值(即非欺诈性):

我们可以同意,仅仅查看一个地址的账户余额并不足以解决这样的问题。因此,此时我们可以考虑如何工程化额外特征,以便为我们的模型提供更多关于每个地址行为的信息。
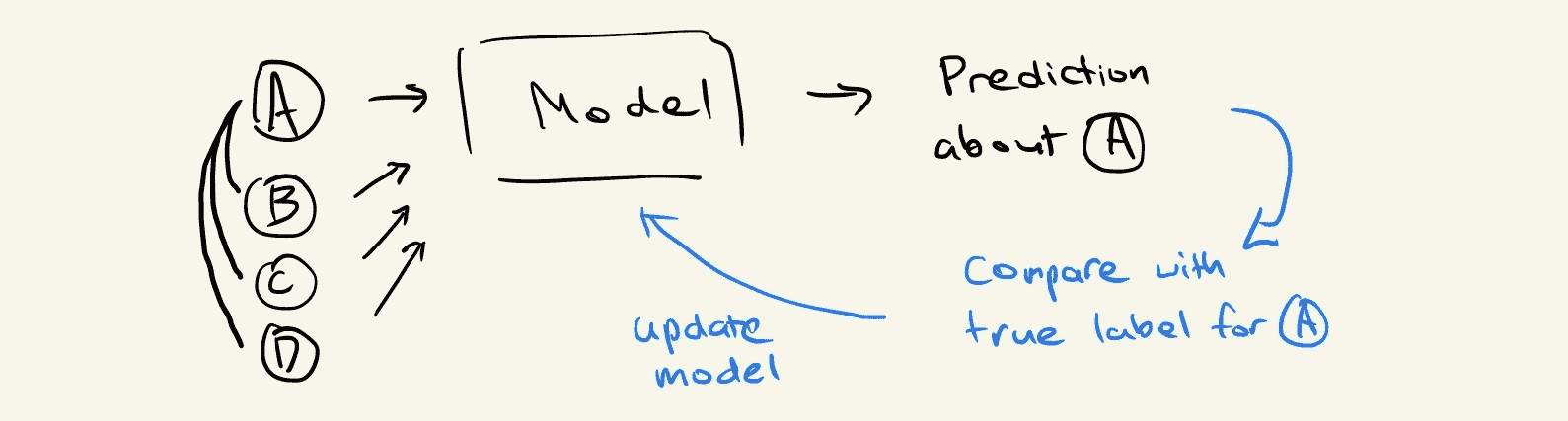
我们已经拥有了来自比特币付款人和收款人之间交易的丰富网络结构。通过设计一个利用这些信息的模型,我们将对结果更有信心:
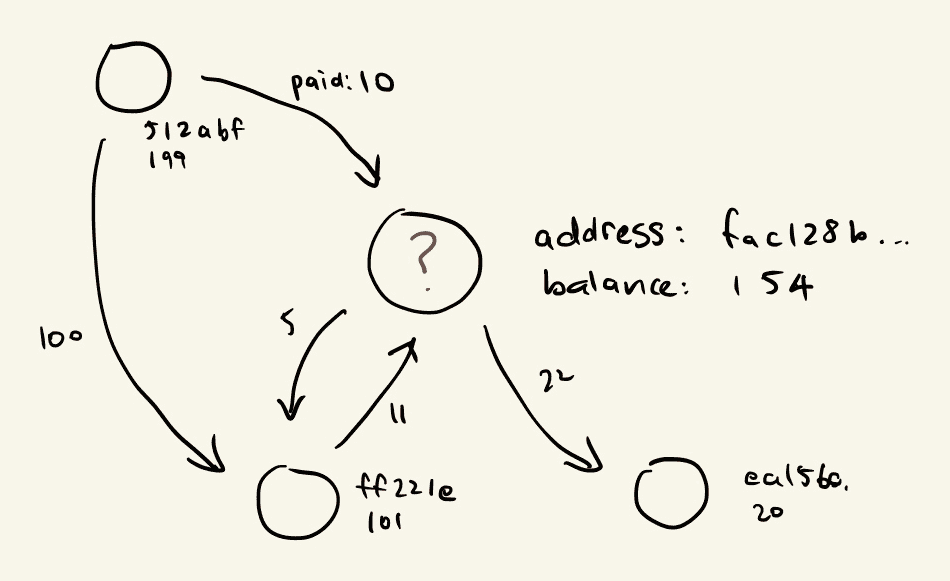
我们希望对地址进行预测,不仅基于其账户余额,还基于与其他地址进行的交易。我们可以尝试将f公式化为f(x, x’₀, x’₁, …),其中x’ᵢ是由我们的图结构定义的x的局部邻域中的其他数据点。
实现这一点的一种方法是利用邻接矩阵形式的图结构。将输入数据与邻接矩阵(或其某种规范化形式)相乘的效果是将数据点与其相邻点线性组合。
以下是一个有三个节点的图的邻接矩阵表示以及一组特征:
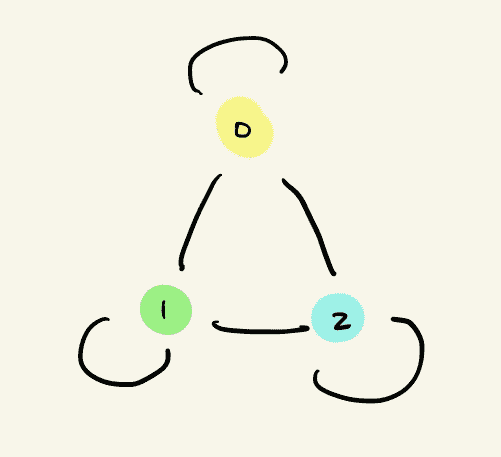
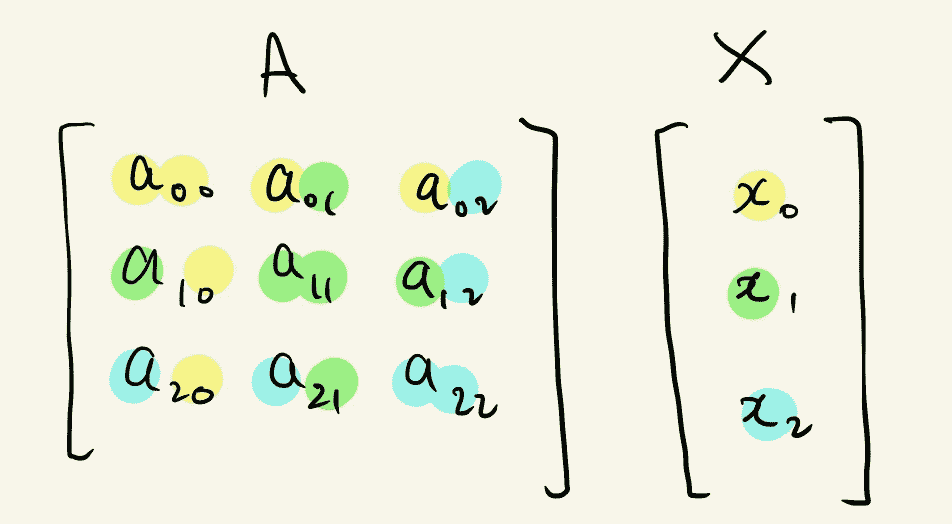
节点 0 的邻域可以被聚合为:
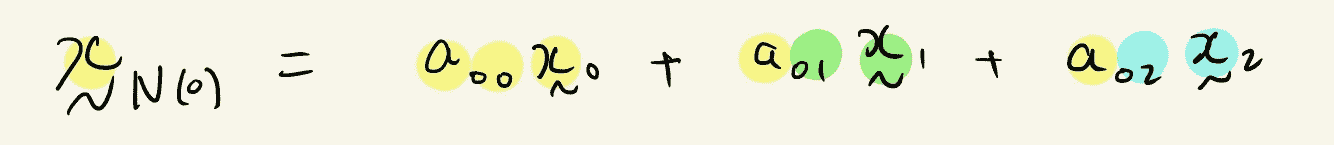
这是诸如图卷积网络等算法遵循的基本高层原理。一般而言,局部邻域信息的聚合是递归应用的,以增加汇集在一起进行节点预测的局部网络的规模。(阅读 StellarGraph 的文章了解你的邻居:图上的机器学习以获得更彻底的概念介绍)。
什么是可扩展的?
一个可扩展的山是一个人们可以攀登的山。一个可扩展的系统是一个能够处理不断增长的需求的系统。一个可扩展的图机器学习方法应该是一个能够处理不断增长的数据规模的方法……这也恰好是一座巨大的山。
在这里,我将争论简单地在节点邻域之间聚合的基本原理是不可扩展的,并描述算法必须解决的问题,以便被认为是可扩展的。
第一个问题源于一个节点可以任意连接到图中的许多其他节点——甚至是整个图。
在更传统的深度学习管道中,如果我们想要预测关于x的某些内容,我们只需x本身的信息。但考虑到图结构,为了预测关于x的某些内容,我们可能需要从整个数据集中聚合信息。随着数据集的不断增大,我们突然需要聚合 TB 级的数据才能对单个数据点进行预测。这听起来并不那么可扩展。
第二个问题的解释涉及理解传导算法和归纳算法之间的区别。
归纳算法尝试发现世界的一般规则。模型以数据为基础,对未见过的数据进行预测。
传导算法试图通过不泛化一个通用模型来为数据集中的未标记数据做出更好的预测。
当我们试图解决现实世界中的问题时,我们面临着数据不是静态的挑战。每天可能会出现数以千计的新数据,这就是为什么可扩展性如此重要的原因。但许多图机器学习方法由于从整个数据集中聚合信息的方式,天生具有传导性,而不是仅仅查看单一的数据实例。
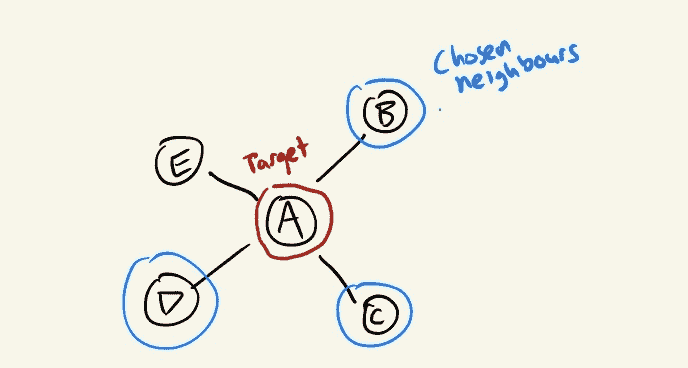
让我们看一个更具体的示例来演示这个问题。考虑一个在图中与三个其他节点 B、C 和 D 相连的节点 A:
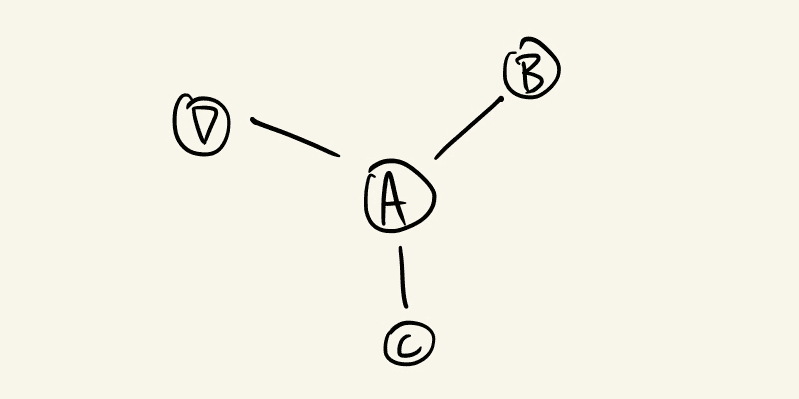
如果我们没有应用任何复杂的图方法,我们将简单地学习一个从 A 的特征到更有用的指标的映射;例如,我们想对节点做出的预测:
然而,由于我们希望利用图结构,我们最终将 B、C 和 D 的特征作为我们学习的函数的输入:
想象一下,当我们训练完模型后,未来某个时刻到达了一个新的数据点,它恰好与我们原始节点 A 相连。我们最终学习了一个没有考虑到这一连接的函数,因此我们陷入了一个不确定我们训练的模型是否对新数据集有效的情况。
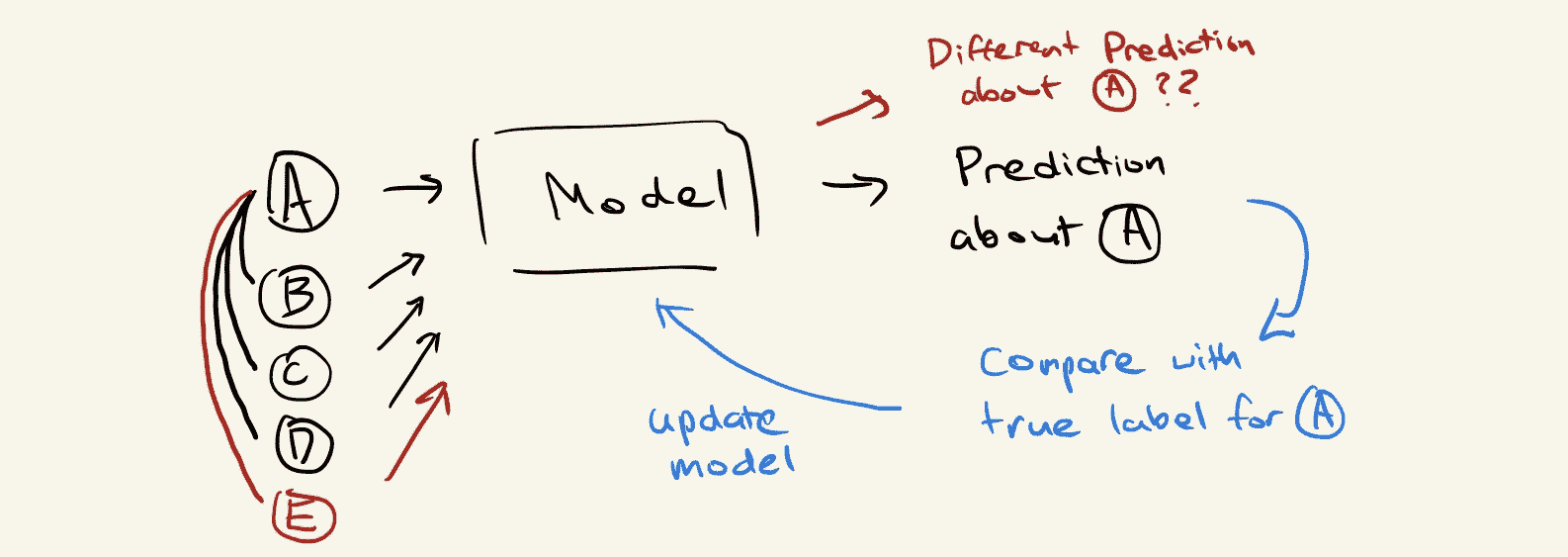
节点 E 和边 AE 被引入,导致模型在聚合邻域信息以对 A 进行新的预测时也带入了 E 的特征。
到目前为止,我们对图算法的理解表明,它们通常不太具备良好的可扩展性,尤其是当算法具有传导性质时。接下来,我们将探讨一种试图解决这些挑战的算法。
引入 GraphSAGE
许多算法试图通过引入某种形式的采样来解决图机器学习中的可扩展性问题。在本节中我们将讨论的一种特定方法是邻居采样方法,它是由 GraphSAGE [3] 算法引入的。
GraphSAGE 中的 SAGE 代表采样和聚合,简单来说就是:“对于每个节点,从其局部邻域中取样节点,并聚合它们的特征。”
“取样其邻居”和“聚合特征”这两个概念听起来比较模糊,因此我们来探讨一下它们实际意味着什么。
GraphSAGE 规定我们对任何给定节点的局部邻域进行固定大小的采样。这立即解决了我们需要从整个数据集中汇总信息的第一个问题。但这样做我们牺牲了什么呢?
-
首先最明显的一点是,进行采样意味着我们正在对邻域的实际情况进行近似。根据我们选择的样本大小,它可能对我们的目的足够好,但仍然是一种近似。
-
我们放弃了模型从节点的连接程度中学习的机会。对于 GraphSAGE,拥有五个邻居的节点与拥有 50 个邻居的节点看起来完全相同,因为我们总是对每个节点采样相同数量的邻居。
-
最终,我们可能会进入一个世界,在这个世界中,我们可以根据当时采样到的邻居做出不同的节点预测。
根据我们希望解决的问题和对数据的了解,我们可以尝试猜测这些问题可能如何影响我们的结果,并决定 GraphSAGE 是否适合特定的用例。
聚合特征可以通过多种不同的方式完成,但每种方式都可以描述为一个函数,该函数从采样的邻域中获取特征列表并输出一个“聚合”的特征向量。
例如,均值聚合器简单地对特征进行逐元素均值计算:
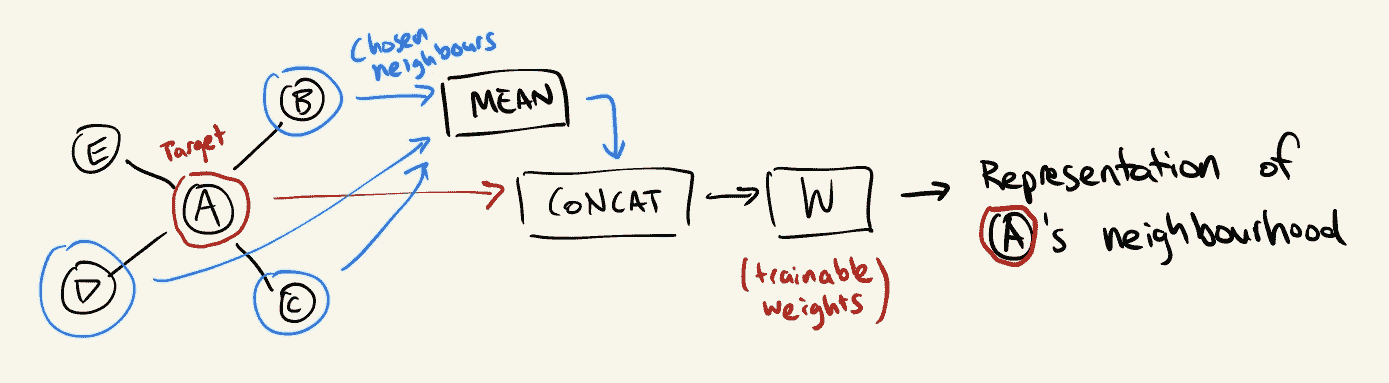
GraphSAGE 平均聚合器。
然后我们可以应用第二个聚合步骤,将节点自身及其聚合邻居的特征结合起来。上述演示的简单方法是将两个特征向量连接起来,并用一组可训练的权重进行乘法运算。
GraphSAGE 的局部采样特性为我们提供了归纳算法和扩展机制。我们还可以选择聚合方法,为模型提供一些灵活性。尽管这些好处有代价,我们需要牺牲模型性能来换取可扩展性。然而,就我们的目的而言,GraphSAGE 算法为在比特币数据集上扩展图机器学习提供了一个良好的方法。
成功,但不是没有挑战
GraphSAGE 提出了邻域采样的方法来克服一些扩展性挑战。具体而言,它:
-
为我们提供了一个良好的近似,同时限制了进行预测时的输入大小;并且
-
允许使用归纳算法。
这是一个实质性的突破,但并未完全解决问题。
1. 高效采样仍然困难
为了在不引入偏差的情况下对节点的邻居进行采样,你仍然需要遍历所有邻居。这意味着虽然 GraphSAGE 确实限制了神经网络的输入大小,但填充输入所需的步骤涉及浏览整个图,这可能是非常昂贵的。
2. 即使在采样的情况下,邻域聚合仍然聚合了大量数据
即使在固定的邻域大小下,递归地应用这种方案意味着邻域大小会指数级增长。例如,如果我们每次选择 10 个随机邻居,但在三个递归步骤上应用聚合,这最终会导致邻域大小为 10³。
3. 分布式数据为基于图的方法引入了更多挑战
大数据生态系统的很多部分围绕着分发数据以启用并行化的工作负载,并根据需求提供水平扩展的能力。然而,天真地分发图数据会引入一个重大问题,因为没有保证邻域聚合可以在没有网络通信的情况下完成。这使得基于图的方法处于一个需要付出在网络中传输数据成本或错过利用大数据技术来启用管道的价值的位置。
仍然有许多困难需要克服,以及更多探索需要进行,以使可扩展的图机器学习变得更加实用。我个人将密切关注这个领域的新进展。
如果你想了解更多关于图机器学习的信息,欢迎下载开源的StellarGraph Python 库或通过stellargraph.io联系我们。
这项工作得到了 CSIRO 的 Data61 支持,这是澳大利亚领先的数字研究网络。
参考文献
-
图卷积网络(GCN):具有图卷积网络的半监督分类。Thomas N. Kipf, Max Welling。国际学习表征会议(ICLR),2017 年
-
Node2Vec:网络的可扩展特征学习。A. Grover, J. Leskovec。ACM SIGKDD 国际知识发现与数据挖掘会议(KDD),2016 年。
-
大规模图的归纳表示学习。W.L. Hamilton, R. Ying, 和 J. Leskovec。神经信息处理系统(NIPS),2017 年。
原文。经许可转载。
简介: Kevin Jung 是 CSIRO Data61 团队中的一名软件工程师,该团队是澳大利亚领先的数字研究网络StellarGraph。
相关:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
更多相关主题
使用 Pandas UDFs 的可扩展 Python 代码:数据科学应用
原文:
www.kdnuggets.com/2019/06/scalable-python-code-pandas-udfs.html
 评论
评论
作者 Ben Weber,Zynga 的数据科学家及 Mischief 顾问
 来源:
来源:pxhere.com/en/photo/1417846
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织进行 IT 管理
PySpark 是一个非常强大的工具,因为它能够让 Python 代码从单台机器扩展到大型集群。虽然像 MLlib 这样的库提供了对数据科学家在这种环境中可能想要执行的标准任务的良好支持,但 Python 库提供了在分布式环境中未配置的广泛功能。虽然像 Koalas 这样的库应该可以更容易地将 Python 库移植到 PySpark 中,但在可扩展运行时所需的库集合与支持分布式执行的库之间仍然存在差距。这篇文章讨论了如何使用 Spark 2.3+中的 Pandas UDFs 功能来弥合这一差距。
我遇到了 Pandas UDFs,因为我需要一种方法来扩展我在 Zynga 开发的项目的自动特征工程。我们有几十款游戏,事件分类各异,需要一种自动化方法来为不同模型生成特征。计划是使用 Featuretools 库来完成这一任务,但面临的挑战是它仅支持在单台机器上的 Pandas。我们的用例需要扩展到大型集群,并且我们需要以并行和分布式模式运行 Python 库。我在 2019 年 Spark 峰会上展示了我们实现这一规模的方法。
我们采取的方法是首先在 Spark 集群中的驱动节点上使用数据样本执行任务,然后使用 Pandas UDFs 扩展到完整的数据集,以处理数十亿条记录。我们在建模管道的特征生成步骤中使用了这种方法。这种方法也可以应用于数据科学工作流中的不同步骤,并且可以用于数据科学之外的领域。我们在以下 Medium 文章中对我们的方法进行了深入探讨:
[Zynga 的 Portfolio-Scale 机器学习
自动化处理数十款游戏的预测建模medium.com](https://medium.com/zynga-engineering/portfolio-scale-machine-learning-at-zynga-bda8e29ee561)
这篇文章通过一个例子展示了如何使用 Pandas UDFs 扩展批量预测管道的模型应用步骤,但 UDFs 的使用案例远比博客中涵盖的要广泛。
数据科学应用
Pandas UDFs 可以用于数据科学中的各种应用,从特征生成到统计测试再到分布式模型应用。然而,这种扩展 Python 的方法并不限于数据科学,只要你可以将数据编码为数据框并将任务分解为子问题,它可以应用于各种领域。为了展示 Pandas UDFs 如何用于扩展 Python 代码,我们将通过一个示例演示,其中批处理过程用于创建购买可能性模型,首先使用单台机器,然后使用集群扩展到可能的数十亿条记录。此帖子的完整源代码可在github上获取,我们将使用的库已预安装在 Databricks 社区版中。
我们笔记本中的第一步是加载我们将用于执行分布式模型应用的库。我们需要 Pandas 来加载数据集和实现用户定义的函数,需要 sklearn 来构建分类模型,以及用于定义 UDF 的 pyspark 库。
接下来,我们将加载一个数据集以构建分类模型。在这个代码片段中,一个 CSV 文件被急切地加载到内存中,使用 Pandas 的read_csv函数,然后转换为 Spark 数据框。代码还为每条记录附加了一个唯一 ID 和一个用于分发数据框的分区 ID。
该步骤的输出见下表。Spark 数据框是记录的集合,每条记录指定用户是否以前购买过目录中的一组游戏,标签指定用户是否购买了新游戏发行,user_id 和 partition_id 字段是使用上面代码片段中的 Spark SQL 语句生成的。

现在我们有一个 Spark 数据框,可以用来执行建模任务。然而,对于这个例子,我们将专注于当将数据集的样本拉取到驱动节点时可以执行的任务。运行 toPandas() 命令时,整个数据框会被急切地提取到驱动节点的内存中。由于我们处理的是一个小数据集,这种做法没问题。但在使用 toPandas 函数之前,最好先对数据集进行采样。一旦将数据框拉取到驱动节点后,我们可以使用 sklearn 来构建逻辑回归模型。
只要你的完整数据集能够适应内存,你可以使用下面展示的单机方法将 sklearn 模型应用于新的数据框。然而,如果需要对数百万或数十亿条记录进行评分,这种单机方法可能会失败。
这一阶段的结果是一个包含用户 ID 和模型预测的数据框。
在笔记本的最后一步,我们将使用 Pandas UDF 来扩展模型应用过程。我们可以使用 Pandas UDF 将数据集分布到 Spark 集群中,而不是将整个数据集拉取到驱动节点的内存中,并使用 pyarrow 在 Spark 和 Pandas 数据框表示之间进行转换。结果与上面的代码片段相同,但在这种情况下,数据框分布在集群的工作节点上,任务在集群上并行执行。
结果与之前相同,但计算现在已从驱动节点转移到工作节点集群。这个过程的输入和输出是一个 Spark 数据框,即使我们使用 Pandas 在 UDF 内执行任务。

有关设置 Pandas UDF 的更多详细信息,请查看我之前关于如何开始使用 PySpark 的帖子。
PySpark 是一种用于大规模执行探索性数据分析、构建机器学习管道的优秀语言,等等 towardsdatascience.com
这是一个介绍,展示了如何将 sklearn 处理从 Spark 集群的驱动节点移动到工作节点。我还使用了这个功能,将 Featuretools 库扩展到处理数十亿条记录并创建数百个预测模型。
结论
Pandas UDFs 是一种功能,允许 Python 代码在分布式环境中运行,即使该库最初是为单节点执行开发的。数据科学家在构建可扩展的数据管道时可以受益于这一功能,但许多不同领域也可以从这一新功能中获益。我提供了一个批处理模型应用的示例,并链接到一个使用 Pandas UDFs 进行自动化特征生成的项目。UDFs 的许多应用尚未被探索,现在为 Python 开发者提供了新的计算规模。
简介:Ben Weber 是 Zynga 的杰出数据科学家以及 Mischief 的顾问。
原文。已获得许可转载。
相关:
-
Optimus v2:简化的数据科学工作流
-
Swiftapply – 自动化高效的 pandas apply 操作
-
使用 Apache Spark 进行深度学习:第一部分
更多相关主题
SQL 中的可扩展随机行选择
原文:
www.kdnuggets.com/2018/04/scalable-select-random-rows-sql.html
评论
作者:Pavel Tiunov,Statsbot

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT 部门
如果您刚刚进入大数据领域,并且还从 Google Analytics 或 Mixpanel 等工具迁移过来进行网络分析,您可能注意到了性能差异。Google Analytics 可以在几秒钟内显示预定义的报告,而在您的数据仓库中对相同数据的相同查询可能需要几分钟甚至更长时间。这样的性能提升是通过选择随机行或sampling technique实现的。让我们学习如何在 SQL 中选择随机行。
样本与总体
在我们开始进行抽样实现之前,值得提及一些抽样基础知识。抽样是基于从某些总体中选择个体的子集来描述该总体的属性。因此,如果您有一些事件数据,您可以选择一个唯一用户及其事件的子集来计算描述所有用户行为的指标。另一方面,如果您选择一个事件子集,它不会准确描述总体的行为。
鉴于这一事实,我们假设所有应用了抽样的数据集都有唯一的用户标识符。此外,如果您同时拥有匿名用户标识符和授权用户标识符,我们建议使用后者,因为它提供更准确的结果。
在 SQL 中选择随机行
有很多不同的方法可以用来选择用户子集,您可以查看这些方法中的多种选择。我们只考虑其中最明显和最简单实现的两种方法:简单随机抽样和系统抽样。
简单随机采样可以实现为给每个用户一个唯一的编号,范围从 0 到 N-1,然后从 0 到 N-1 中选择 X 个随机数。N 表示用户的总数,X 是样本大小。尽管这种方法易于理解,但在 SQL 环境中实现起来有点棘手,主要是因为随机数生成器输出在样本大小达到数十亿时不太稳定。此外,也不清楚如何在时间上获得均匀分布的样本。
考虑到这一点,我们将使用系统采样,它可以从 SQL 实现的角度克服这些障碍。简单的系统采样可以实现为在指定间隔内从每 M 个用户中选择一个用户。在这种情况下,样本大小将等于 N / M。选择 M 个用户中的一个,同时保持样本桶间的均匀分布,是这种方法的主要挑战。让我们看看如何在 SQL 中实现这一点。
序列生成的用户标识符
如果你的用户 ID 是生成的严格序列的整数且没有间隙(如由 AUTO_INCREMENT 主键字段生成的那样),你就很幸运。在这种情况下,你可以将系统采样实现得非常简单:
select * from events where ABS(MOD(user_id, 10)) = 7
这个 SQL 查询和下面的所有 SQL 查询都采用标准 BigQuery SQL。在这个示例中,我们从 10 个用户中选择一个,这是一个 10% 的样本。7 是采样桶的随机数,它可以是 0 到 9 之间的任何数字。我们使用 MOD 操作来创建代表在这种情况下除以 10 余数的采样桶。很容易证明,如果 user_id 是严格的整数序列,则当用户数量足够高时,用户计数在所有采样桶中是均匀分布的。
要估计事件数量,例如,你可以写如下内容:
select count(*) * 10 as events_count from events where ABS(MOD(user_id, 10)) = 7
请注意这个查询中的乘以 10。考虑到我们使用了 10% 的样本,所有估计的加性度量应按 1/10% 进行缩放,以匹配实际值。
我们可以质疑这种采样方法对特定数据集的准确性。你可以通过检查采样桶内分布的均匀性来估计。为此,你可以查询如下内容:
select ABS(MOD(user_id, 10)), count(distinct user_id) from events GROUP BY 1
让我们考虑这个查询的一些示例结果:

我们可以计算这些采样桶大小的 alpha 系数为 0.01 的均值和置信区间。该 置信区间 将等于采样桶平均大小的 0.01%。这意味着有 99% 的概率,采样桶大小的差异不超过 0.01%。不同的度量值与这些采样桶计算的统计数据相关联但并不继承它。因此,为了计算事件计数估计的精度,你可以计算每个样本的事件计数如下:
select ABS(MOD(user_id, 10)), count(*) * 10 from events GROUP BY 1
然后计算这些事件计数的绝对和相对置信区间,如用户计数的情况,以获得事件计数估计的精度。
字符串标识符和其他用户标识符
如果您有字符串用户标识符或整数,但不是严格的整数序列标识符,您需要一种均匀地将所有用户 ID 分配到不同采样桶中的方法。 这 可以通过哈希函数完成。并非所有哈希函数在不同情况下都能实现均匀分布。您可以检查 smhasher 测试套件的结果,以检查特定哈希函数的效果。
例如,在 BigQuery 中,您可以使用 FARM_FINGERPRINT 哈希函数来准备选择样本:
select * from events where ABS(MOD(FARM_FINGERPRINT(string_user_id), 10)) = 7
FARM_FINGERPRINT 可以替换为任何合适的哈希函数,例如 Presto 中的 xxhash64,或者甚至是 Redshift 中的 md5 和 strtol 的组合。
如同序列生成的用户标识符一样,您可以检查均匀性统计数据:
select ABS(MOD(FARM_FINGERPRINT(string_user_id), 10)), count(distinct string_user_id) from events GROUP BY 1
常见陷阱
通常,采样可以将您的 SQL 查询执行时间减少 5-10 倍而不会对精度造成危害,但仍然存在需要谨慎的情况。这主要是由于样本大小引起的采样偏差问题。当您感兴趣的指标在样本之间的离散度过高时,即使样本量足够大,也可能发生这种情况。
例如,您可能对某些稀有事件计数感兴趣,比如一个 B2C 网站上的企业演示请求,尽管该网站有大量流量。如果企业演示请求的数量约为每月 100 个事件,而您的月活跃用户约为 1M,那么采样可能会导致企业演示请求数量的估计误差显著。一般而言,在这种情况下应避免在 SQL 中随机采样行,或使用 更复杂的方法。
和往常一样,请随时留下您的评论或 联系我们的团队 以获取帮助。
原文。经许可转载。
相关:
-
计算客户终生价值:SQL 示例
-
业务分析的 SQL 窗口函数教程
-
SQL 客户保留分析指南
更多相关主题
使用 Dataflow 扩展计算机视觉模型
原文:
www.kdnuggets.com/2020/07/scaling-computer-vision-models-dataflow.html
评论
作者 Pablo Soto,Pento 的创始合伙人

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
我们将简要介绍 Google Cloud 服务 Dataflow,以及它如何以无服务器的方式运行数百万张图像的预测。无需创建集群,无需维护,您只需为您使用的部分付费。我们将首先提供一个背景,说明我们为什么认为这很重要,简要介绍几个概念,然后直接进入一个用例。
扩展机器学习模型是困难且昂贵的。主要有两个原因:基础设施成本高,以及您的实验管道缓慢,导致机器学习团队不断等待结果。
很容易低估拥有一个等待结果的机器学习团队的费用。这不仅仅是因为浪费的时间,还因为人们会感到沮丧并最终失去动力。
优化您的机器学习实验过程的一种方法是建立和管理自己的基础设施。这在大公司中很常见,但对于小公司来说,这往往代价高昂。
传统的软件开发几年前面临类似的挑战,企业需要扩展,这主要是由业务需求驱动的(服务/API/网站缓慢不适合扩展)。云服务提供商看到了提供服务的机会,这些服务允许公司在没有前期成本的情况下扩展。他们主要通过两种方式来解决这个问题:易于管理的服务和无服务器服务。后者对没有大规模 DevOps 团队或资金不足以支付自己基础设施的小公司尤其具有吸引力。
机器学习中也出现了类似的趋势。这次是由机器学习人才的稀缺和高成本驱动的。像软件一样,小公司无法投入大量资金创建定制的优化基础设施,这需要一支专家团队来构建和维护。
云服务提供商看到了通过提供无服务器解决方案来增加价值的机会。特别是 GCP 已经这样做了一段时间。GCP AI Platform 提供了 ML 项目每个阶段的不同服务。但他们也依靠其他服务来帮助解决 ML 挑战。
Dataflow 是什么?
Dataflow 是一个完全托管的处理服务,它使用 Apache Beam 作为其编程模型来定义和执行管道。Dataflow 是 Beam 支持的 许多运行器 之一。
Apache Beam 提供了一个可移植的 API 层,用于构建复杂的数据并行处理管道,这些管道可以在多种执行引擎或运行器上执行。
Dataflow 特别有一些有趣的特性:
-
完全托管
-
自动缩放
-
简单实现
什么是 Apache Beam?
如上所述,Beam 是一个用于定义和执行处理管道的编程模型。它提供了一个接口来创建可以在多种环境(如 Spark、Hadoop、Dataflow)中执行的处理管道。
用例:使用预训练的 ResNet50 提取图像特征
作为计算机视觉工程师,我们经常需要使用 CNN 模型提取嵌入特征。在这里,我们将介绍如何构建一个数据流管道,该管道使用预训练的 ResNet50 生成图像特征嵌入。我们的管道将包括 3 个简单步骤:
-
加载图像
-
提取特征
-
存储特征
为了实现我们的管道,我们将使用 Apache Beam Python SDK、Keras、Pillow 和 Click。由于我们将使用非 Python 依赖项,我们必须按照 这里 所述的方式来构建我们的代码。
我们需要做的第一件事是创建一个管道配置:
if local:
# Execute pipeline in your local machine.
runner_options = {
"runner": "DirectRunner",
}
else:
runner_options = {
"runner": "DataflowRunner",
"temp_location": "...",
"staging_location.": "...",
"max_num_workers": max_num_workers,
}
options = PipelineOptions(
project=project_id,
job_name=job_name,
region=region,
**runner_options
)
options.view_as(SetupOptions).save_main_session = True
options.view_as(SetupOptions).setup_file = os.path.join(
pathlib.Path(__file__).parent.absolute(), "..", "setup.py")
如你所见,根据我们是在本地执行管道还是在 Dataflow 上执行,选项会有所不同。
然后我们需要创建一个 管道:
with beam.Pipeline(options=options) as p:
...
p 是我们的管道,向管道中添加新步骤时使用操作符 | ,如下所示:
p = p | Task();
如果你想明确命名步骤,你可以使用操作符 >>:
p = p | ("task_name" >> Task());
现在我们需要指定管道的步骤。有多种实现方式:
-
内置实现:BigQuery 连接器、ReadFile 等
-
自定义实现:Map、Filter、ParDo
(p
| "source" >> ReadFromText(input_path)
| "load" >> beam.Map(load)
| "extract" >> beam.Map(extract)
| "store" >> beam.ParDo(store, output_path))
在这里你可以看到我们已经添加了上述三个步骤。我们从 Google Cloud 的 CSV 文件中加载图像路径,然后加载图像,提取它们的嵌入,并将它们存储在 Google Cloud Storage 中。
在我们管道中的所有步骤中,我们期望接收一个输入并返回一个输出。为了应用这些类型的步骤,我们必须使用方法 beam.Map。另外,如果你处理的是可能接收/返回零个或多个输入/输出的步骤,你可以使用 beam.ParDo。
现在管道已经定义,我们来看一下实现细节。
加载图像
在这一步中,我们需要从 GCS 下载图像,将其加载为 Pillow 图像,调整大小,并将其转换为 numpy 数组对象。之所以在一个步骤中下载和调整大小,是为了减少管道步骤之间的数据传输,从而降低成本。
def load(path):
"""
Receives an image path and returns a dictionary containing
the image path and a resized version of the image as a np.array.
"""
buf = GcsIO().open(path, mime_type="image/jpeg")
img = Image.open(io.BytesIO(buf.read()))
img = img.resize((IMAGE_HEIGHT, IMAGE_WIDTH), Image.ANTIALIAS)
return {"path": path, "image": np.array(img)}
Beam 提供了一组 内置连接器 来处理 I/O。
提取特征
在这一步中,我们需要加载 ResNet 模型并运行预测。为了避免在同一工作节点上多次加载模型,FeatureExtractor 类中添加了一个单例包装器。一旦提取了嵌入,我们将其添加到项目字典中,由于不再需要将完整图像加载到内存中,我们将其从字典中删除。
def singleton(cls):
instances = {}
def get_instance(*args, **kwargs):
if cls not in instances:
instances[cls] = cls(*args, **kwargs)
return instances[cls]
return get_instance
@singleton
class Extractor:
"""
Extract image embeddings using a pre-trained ResNet50 model.
"""
def __init__(self):
self.model = ResNet50(
input_shape=(IMAGE_WIDTH, IMAGE_HEIGHT, 3),
include_top=False,
weights="imagenet",
pooling=None,
)
def extract(self, image):
return self.model.predict(np.expand_dims(image, axis=0))[0]
def extract(item):
"""
Extracts the feature embedding from item["image"].
"""
extractor = Extractor()
item["embedding"] = extractor.extract(item["image"])
# We do not longer need the image, remove it from the dictonary to free memory.
del item["image"]
return item
存储特征
现在我们有了嵌入,只需将其存储在 GCS 中即可。
def store(item, output_path):
"""
Store the image embeddings item["embedding"] in GCS.
"""
name = item["path"].split("/")[-1].split(".")[0]
path = os.path.join(output_path, f"{name}.npy")
fin = io.BytesIO()
np.save(fin, item["embedding"])
fout = beam.io.gcp.gcsio.GcsIO().open(path, mode="w")
fin.seek(0)
fout.write(fin.read())
Dataflow 允许你指定机器类型、工作节点数量、目标等,提供了大量的灵活性来找到适合当前任务的配置。你可以在 这里查看所有选项。
一旦你运行 Dataflow 管道,你将会在你的机器上看到关于执行状态的日志。另一种选择是使用 Dataflow Web UI。你可以在 文档 中了解更多信息。
你可以在 这里查看完整代码。
Apache Beam 还支持将管道分支。例如,如果你想创建嵌入的 2D 可视化,可以通过以下方式分支你的管道:
p = (
p
| "source" >> ReadFromText(input_path)
| "load" >> beam.Map(load)
| "extract" >> beam.Map(extract)))
(p | "store" >> beam.ParDo(store, output_path))
(p | "reduce_dim" >> beam.ParDo(reduce_dim))
这允许 Beam 独立执行 store 和 reduce_dim,提供更多优化管道的灵活性,从而提高性能。
扩展
Dataflow 提供了 多种配置,允许你以非常简单的方式自定义你希望的扩展方式。默认情况下,它会选择提升性能的值。在执行过程中,Dataflow 会更改配置以优化性能,例如调整工作节点的数量、机器类型等。
你可以让 Dataflow 每次运行管道时找到最佳配置。但如果你已经知道你的作业需要的资源,如内存量、是否 CPU 密集型、外部服务(即你的数据库或 API 容量)支持的最大吞吐量,最好直接指定这些信息。这将帮助 Dataflow 更快地收敛到正确的配置,加快执行速度并降低成本。
Dataflow 应足以满足大多数小型/中型公司扩展的需求。作为参考,Dataflow 能以每秒 5k 张图像的速度执行上述用例,最多使用 1k 名工人。这里是Dataflow 配额的列表,主要限制为 1k 名工人。
摘要
Apache Beam 是一种简单的编程模型,允许你以结构化的方式执行 ML 步骤,并在不同环境中运行。其中之一是 Dataflow,Beam 执行引擎,它是完全托管的,支持自动扩展,并允许我们针对不同目标进行优化。
Dataflow 是一个优秀的工具,可以在大规模运行你的 ML 模型,而无需过多的前期投资或维护。它提供了一个简单的 API,并拥有一个活跃的开源社区。本文展示了如何使用 Apache Beam 构建图像嵌入提取器,并扩展到数百万张图像。这样,你可以在不担心基础设施的情况下节省数百美元,同时加速实验过程。
资源
Python 示例:
简历: 帕布罗·索托 是Pento 的创始合伙人,专注于机器学习。
原文. 经许可转载。
相关:
-
使用 Tensorflow.js 实现计算机视觉应用的 6 个简单步骤
-
使用机器学习和计算机视觉进行作物疾病检测
-
使用深度学习自动旋转图像
更多相关内容
通过 Apache Gobblin 扩展数据管理
原文:
www.kdnuggets.com/2023/01/scaling-data-management-apache-gobblin.html
大数据管理的挑战
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的 IT 组织
在现代世界,大多数企业依赖大数据和分析的力量来推动其增长、战略投资和客户参与。大数据是目标广告、个性化营销、产品推荐、洞察生成、价格优化、情感分析、预测分析等的基础。
数据通常从多个来源收集,经过转换、存储,并在本地或云端的数据湖中处理。虽然数据的初步摄取相对简单,可以通过内部开发的自定义脚本或传统的 ETL(提取、转换、加载)工具实现,但问题很快会变得复杂且昂贵,公司必须:
-
管理整个数据生命周期 - 以满足清理和合规要求
-
优化存储 - 以减少相关成本
-
简化架构 - 通过重用计算基础设施
-
增量处理数据 - 通过强大的状态管理
-
在批量和流数据上应用相同的政策 - 避免重复劳动
-
在本地和云端之间迁移 - 以最小的努力
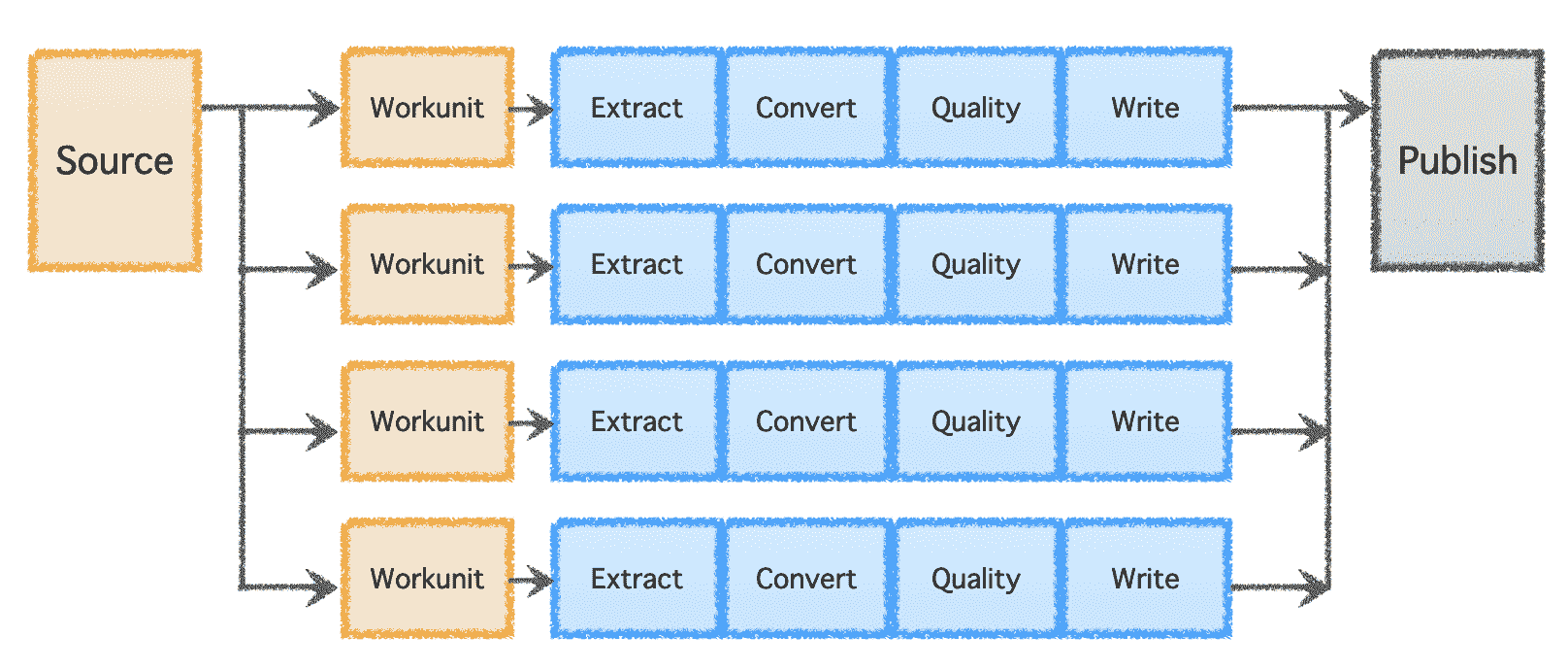
这就是Apache Gobblin,一个开源的数据管理和集成系统的用武之地。Apache Gobblin 提供了无与伦比的功能,可以根据业务需求选择整体或部分使用。
使用 Gobblin 简化大数据管理
在本节中,我们将深入探讨 Apache Gobblin 的各种功能,帮助解决之前概述的挑战。
管理整个数据生命周期
Apache Gobblin 提供了一系列功能来构建数据管道,支持对数据集的所有生命周期操作。
-
数据摄取 - 从多个来源到各种目的地,包括数据库、Rest API、FTP/SFTP 服务器、文件存储、如 Salesforce 和 Dynamics 等 CRM 系统,等等。
-
复制数据 - 在多个数据湖之间,通过 Distcp-NG 为 Hadoop 分布式文件系统提供专门的功能。
-
清理数据 - 使用基于时间的、新近 K、版本化或组合政策等保留政策。
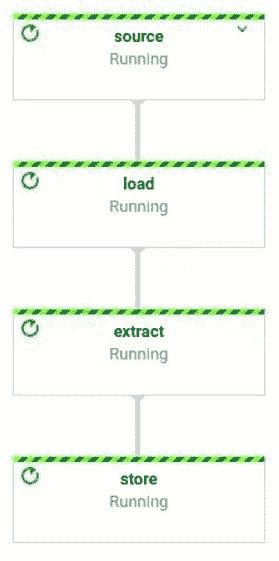
Gobblin 的逻辑管道包括一个确定工作分配并创建“工作单元”('Workunits')的“源”('Source')。这些“工作单元”随后被提取执行为“任务”('Tasks'),任务包括数据提取、转换、质量检查和写入目标。最后一步,“数据发布”('Data Publish'),验证管道的成功执行,并在目标支持的情况下原子性地提交输出数据。
图片由作者提供
优化存储
Apache Gobblin 可以通过在数据摄取或复制后进行后处理(例如压缩或格式转换),帮助减少所需的存储量。
-
压缩 - 对数据进行后处理,以基于所有字段或关键字段去重,修剪数据以保留具有最新时间戳的唯一记录。
-
Avro 到 ORC - 作为一种专用格式转换机制,将流行的行基 Avro 格式转换为超优化的列基 ORC 格式。
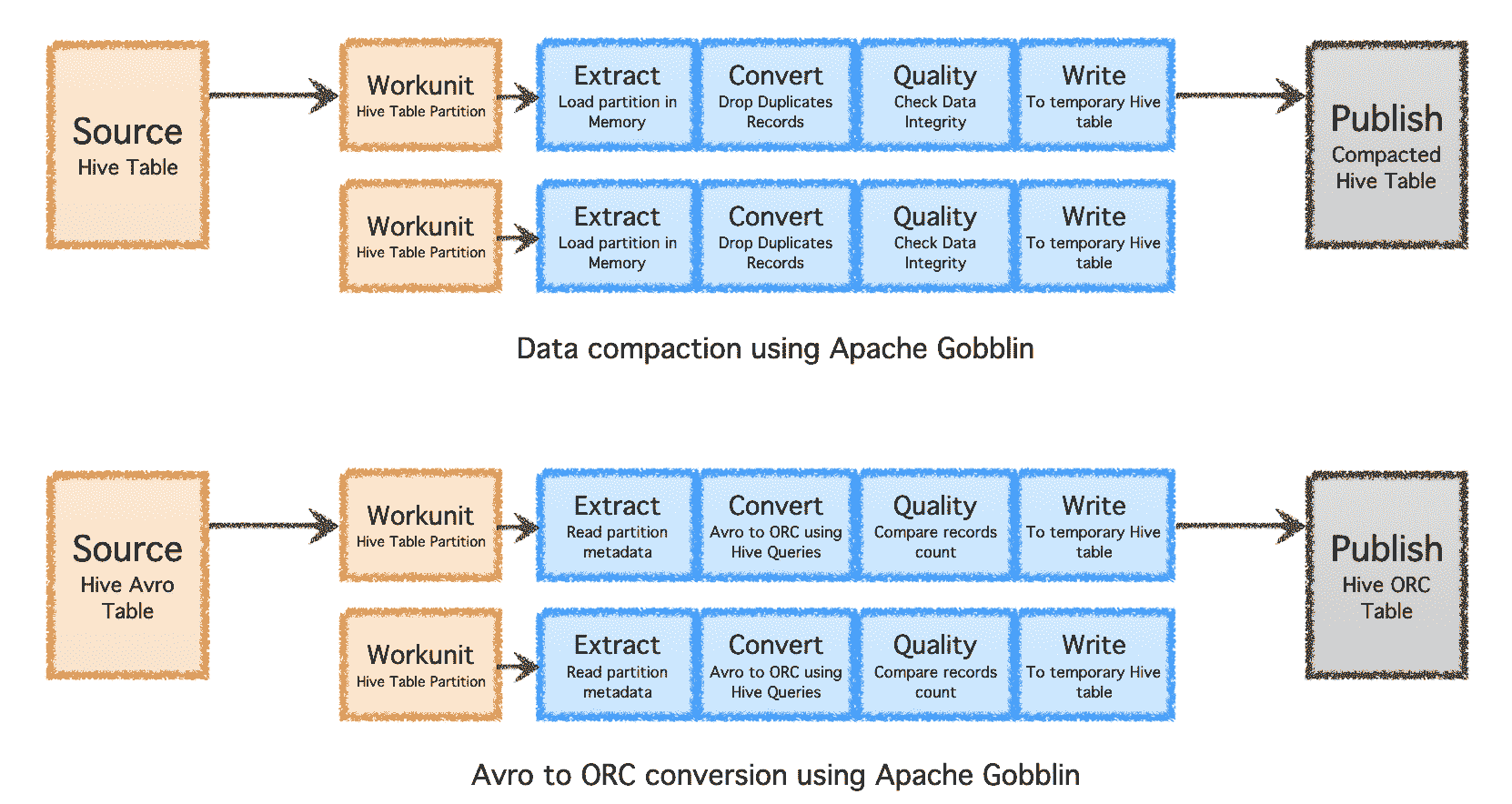
图片由作者提供
简化架构
根据公司的阶段(从初创公司到企业)、规模需求及其各自的架构,公司倾向于建立或发展他们的数据基础设施。Apache Gobblin 非常灵活,支持多种执行模型。
-
独立模式 - 作为单独进程在裸金属主机上运行,即单个主机,适用于简单用例和低需求情况。
-
MapReduce 模式 - 作为一个 MapReduce 作业在 Hadoop 基础设施上运行,用于处理范围为 PB 规模的大数据集。
-
集群模式:独立 - 作为一个集群运行,由 Apache Helix 和 Apache Zookeeper 支持,部署在一组裸金属机器或主机上,以处理大规模独立于 Hadoop MR 框架的工作负载。
-
集群模式:Yarn - 作为一个集群在原生 Yarn 上运行,无需 Hadoop MR 框架。
-
集群模式:AWS - 作为一个集群在亚马逊公共云服务(即 AWS)上运行,用于托管在 AWS 上的基础设施。
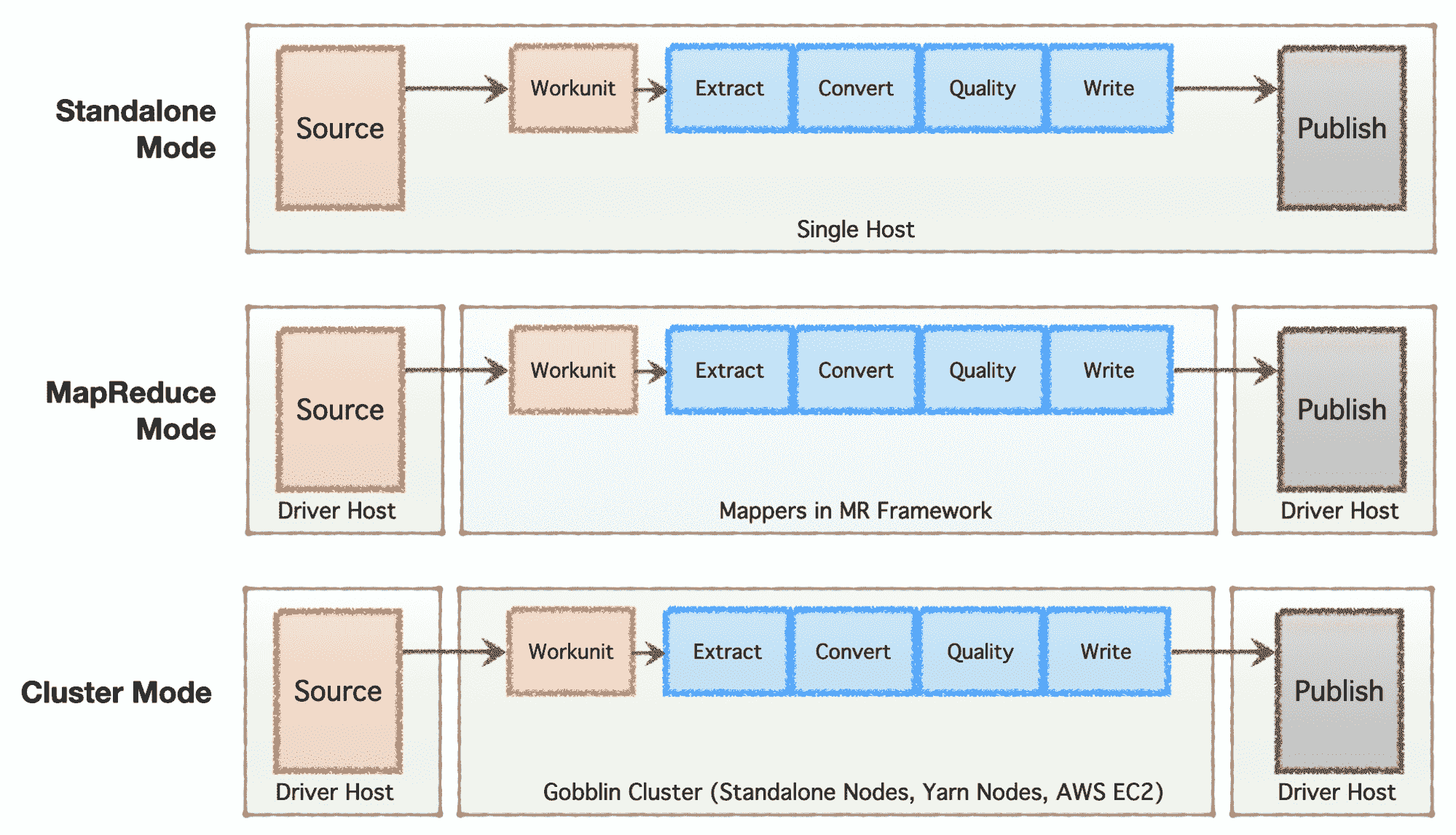
图片由作者提供
增量处理数据
在具有多个数据管道和高数据量的大规模环境下,数据需要批量处理并随时间处理。因此,需要进行检查点,以便数据管道能够从上次中断的地方恢复并继续进行。Apache Gobblin 支持低水位和高水位,并通过 HDFS、AWS S3、MySQL 等提供强大的状态管理语义。
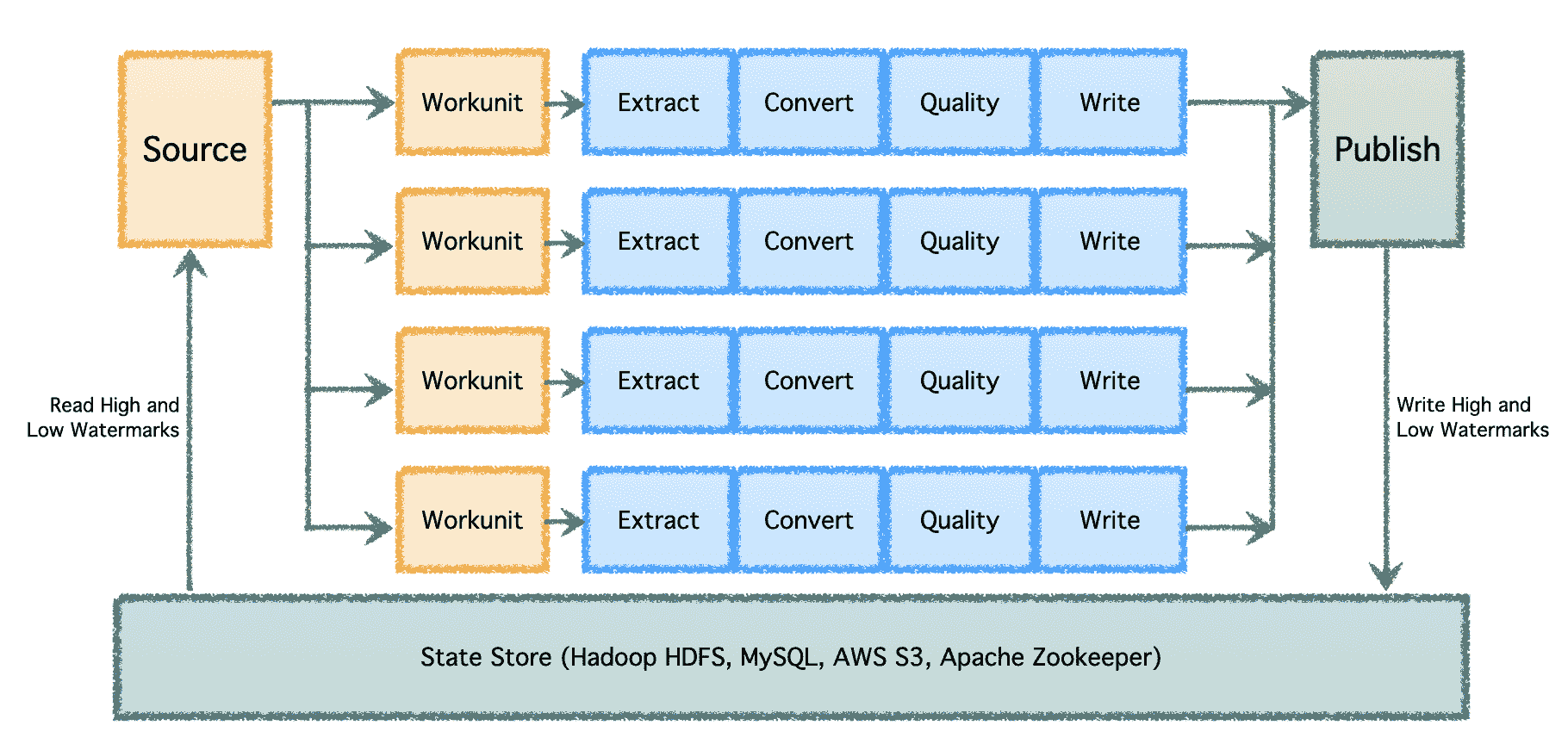
图片由作者提供
批处理和流数据的相同策略
目前大多数数据管道需要编写两次,一次用于批量数据,一次用于近线或流数据。这会加倍工作量,并在应用于不同类型管道的策略和算法中引入不一致。Apache Gobblin 通过允许用户编写一次管道并在批量和流数据上运行来解决这个问题,如果在 Gobblin 集群模式、AWS 模式或 Yarn 模式中使用 Gobblin。
在本地和云之间迁移
由于其多功能模式可以在单台机器、节点集群或云上运行,Apache Gobblin 可以在本地和云上部署和使用。因此,用户可以根据具体需求,仅需编写一次数据管道,并与 Gobblin 部署一起轻松迁移本地和云之间。
由于其高度灵活的架构、强大的功能以及支持和处理极大数据量的能力,Apache Gobblin 被主要技术公司 用于生产基础设施,并且是今天任何大数据基础设施部署的必备工具。
有关 Apache Gobblin 及其使用方式的更多细节可以在 gobblin.apache.org 找到。
Abhishek Tiwari 是 LinkedIn 的高级经理,负责领导公司的大数据管道组织。他还是 Apache 软件基金会的 Apache Gobblin 副总裁以及英国计算机学会的会员。
更多相关话题
扩展您的数据战略
评论

我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织在 IT 方面
适用于数据相关增长痛点的企业指南
快速增长的公司同时享有两个独特的优势。它们能够利用小而强大的团队,拥有积极的态度,并迅速将产品特性推向市场。同时,为了维持快速扩展,它们有实际的动机同样重视建立可持续增长的基本实践。这意味着要管理数字化转型,以利用新技术的好处,并管理越来越多的同时进行且相互关联的项目。更不用说在这些项目和流程交汇处,通常会有大量的数据在流动!随着数据呈指数增长,这一独特的位置可以被用来制定一个强大且长期的数据战略。
在 SSENSE,我们尝试通过数据驱动的解决方案来解决大规模问题。在这种背景下,商业关系可能迅速变得复杂,识别数据中的模式和行为可能变得越来越具有挑战性。如果您定期启动与组织中现有功能和流程紧密交织的新项目,那么您将无法再建立孤立的、一锤子买卖的解决方案。您的运营已经增长到值得制定企业数据战略的程度。在本文中,我将基于我之前的专业经验,展示我对一致性数据战略的愿景。尽管本文的目的是不是详细描述我们在 SSENSE 的具体数据战略,但许多主要原则都从中汲取了灵感。
数据战略
无论你在数据驱动的旅程中处于何种阶段,拥有一个数据策略都能帮助解锁数据的潜力,使组织能够将数据视为关键资产。数据策略是一个旨在改善组织内数据使用方法、实践和流程的计划,并确保数据的使用是可持续和可复制的。由于数据由不同业务部门生成和使用,这些部门有着不同的实践和责任,因此,拥有一个委员会来监督组织内的数据策略对业务成功至关重要。根据你在旅程中的位置,可能没有数据策略也是可以的,但这会导致不同部门自行解决数据问题,进而浪费资源,部门孤立运作,组织的凝聚力日益下降。我已经将这种严峻的可能性浓缩成一句话,因此从现在开始,让我们专注于积极和建设性的想法。
良好数据策略的组成部分
一个稳健的数据策略通常应涵盖以下核心主题:
语义 — 识别数据并定义其含义
这涉及到理解组织数据的所有核心实体,如:客户、位置、产品、交易及其关系。在操作的早期阶段,将这些关系表示在关系数据库模式中是可以的,但随着各种数据类型、流程和存储格式的发展,拥有一个管理的数据目录,包含定义、含义和关系,将不同系统连接起来是非常重要的。
通过如数据湖这样的单一接口结合数据的新方法,有助于避免管理和使用组织数据时遇到的许多问题和复杂性。即便如此,将术语、元数据和关系整合到一个目录下使访问和使用数据变得更加简单。对于每个数据字段,这样的目录可能包括定义、来源、位置、领域、用例、利益相关者等。
治理 — 建立并沟通适当的数据使用政策和机制
数据治理的概念通常似乎仅限于用户和分析环境,但实际上,我们在每个操作中都在使用和生成数据。一旦数据从创建它的应用程序中解耦,组织应该定义数据的规则和细节,以便所有利益相关者都能理解如何使用数据。
一个强有力的治理模型概述了安全细节、访问权限、高层次的转换逻辑、命名约定和数据使用规则。在一个数据驱动的组织中,强有力的治理模型不应被视为用户的一个压倒性的障碍,也不应作为限制数据访问的手段。相反,它应该使组织中的所有成员能够负责任和有效地使用数据。
存储和供应 — 以一种可访问且直观的结构持久化数据
企业不断处于数字化转型的状态。我们应该将其视为常态,以利用新技术的好处,并且不能忽视我们在组织内部生成越来越多的数据。数据存储是技术栈的基本能力之一。确定一个应用程序或业务流程的正确数据存储对于确保存储技术的正确使用至关重要。
借助上述提到的适当数据目录,组织能够确保存在实际的方式来存储业务应用程序的数据,同时使其对所有相关方易于访问和共享。
数据存储类型的具体选择,无论是 SQL、图数据库、数据仓库等,都应根据具体情况来决定,以最好地满足所存储数据及其利益相关者的需求。
一个好的数据存储策略确保所有数据都被高效地存储,以适应其使用场景,同时为中心化的数据共享过程奠定基础。
过程 — 在不同的系统中移动和合并数据,以提供统一且一致的访问点
对于数据和业务分析师而言,来自应用程序的原始数据是知识的宝贵财富。如果今天无法识别其业务影响,那么将数据存储和转化以便未来使用是明智的。处理数据是数据策略的一个重要组成部分,它将原始数据转化为成品。因此,它将来自业务应用程序的数据转化为可用于数据驱动决策的资产。
如果每个新项目都需要工程师和分析师从多个来源处理原始数据,这将是巨大的时间和精力浪费!同样重要的是,如果一个组织期望其开发人员花费大量时间在临时基础上构建逻辑以匹配和链接来自多个数据源的实体,这将浪费宝贵的人力资源。
如果你没有提前准备,快速增长的公司将会遇到这个严峻的现实,其绩效将开始停滞。当然,你可以通过增强技术人才来掩盖这种行为,但这并不能消除问题。
实施一个统一且集中的数据处理、清洗、合并和转化策略,使组织能够正确利用数据并保持灵活性。实际上,这部分的数据策略可能是最关键的,因为它使最终用户能够更快地使用数据。
数据委员会的框架
为了成功有效地使用数据,重要的是要聚集合适的利益相关者,以便组织能够在推动数据战略时产生最大的价值。根据你当前的能力和背景,这个委员会应该由以下团队的成员组成:
-
技术方向:监督更广泛的架构影响和技术创新的变化。
-
软件工程:实施并评估新产品和/或功能的可行性。
-
产品:管理软件产品的范围和复杂性,并在短期和长期收益之间进行权衡。确定如何利用数据来实现他们的业务目标。
-
数据运营:对组织的数据有深入理解的数据管理者,负责报告、分析和数据标准。
-
数据科学:定义如何使用数据来开发模型和生成洞察。
-
数据工程:构建从所有数据生成源提取、收集和简化数据的管道,将数据转化为业务可以使用的数据。
-
法律:监督数据使用的隐私、伦理问题和法律影响。
-
高层:定义数据如何帮助公司实现业务目标的高层战略。
如果你之前没有数据委员会,这些问题可能是由较小的软件或数据领导者单位处理的。这对于较小和简单的操作可能有效,但它不适合规模化。根据你的成长阶段,你的委员会可以更小或更大。然而,它应当代表或涵盖上述团队及其职责的关切。
结论
像实施新的业务战略或技术应用一样,实施数据战略是一个不断发展的过程。理解数据战略的必要性以及一个监督其实施的委员会是一个好的开始。组织的成员开始将数据视为一个战略资产,它能够更好地理解他们的业务,以及如何利用数据来创造价值。
对你想要达到的清晰愿景使得数据委员会的成员能够利用他们独特的技能和经验来设计一个适合组织的路线图。
确定所有数据实体、数据源、定义和关系的过程应该是第一步。下一步是定义数据使用的治理标准,以及将所有数据源链接在一起的系统。数据战略中的每个过程都应该有关键的利益相关者来推动该部分过程。例如,来自数据报告和运营团队的成员最有可能适合推动数据治理标准。利用你的数据委员会的专业知识可以确保你能够快速有效地交付和实施数据战略。
参考文献
编辑评论 Deanna Chow、Liela Touré 和 Prateek Sanyal。
想和我们一起工作吗?点击 这里 查看 SSENSE 的所有职位空缺!
简介: Javier Bosch 是 SSENSE 的高级数据科学家。
原文。经授权转载。
相关内容:
-
怀念严格类型化模式
-
推荐系统指标:比较苹果、橙子和香蕉
-
数据湖中的模式演变
更多相关主题
数据科学家与数据工程师之间的墙
原文:
www.kdnuggets.com/2020/02/scaling-wall-data-scientist-data-engineer.html
评论
由 Byron Allen,Servian 的 ML 工程师

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
来源: Chris Gonzalez。
对我来说,今天机器学习(ML)中最令人兴奋的事情,并不在于深度学习或强化学习的前沿,而是如何管理模型以及数据科学家和数据工程师如何有效地作为团队合作。掌握这些,将引导组织实现更有效和可持续的机器学习应用。
遗憾的是,“科学家”和“工程师”之间存在一堵墙。Databricks 的联合创始人兼产品副总裁 Andy Konwinski 和其他人,在最近的一篇关于 MLFlow 的博客文章中指出了一些关键的障碍。Databricks 表示:“构建生产级机器学习应用程序具有挑战性,因为目前没有标准化的方法来记录实验、确保可重复的运行以及管理和部署模型。”
许多今天应用机器学习的主要挑战——无论是技术、商业还是社会方面——的起因在于数据随时间的失衡以及机器学习工件的管理和利用。一个模型可能表现得非常好,但如果底层数据发生漂移且工件未被用来评估性能,那么你的模型将无法很好地泛化或适当地更新。这个问题处于一个模糊地带,既涉及数据科学家,也涉及工程师。

来源: burak kostak。
换句话说,问题的关键在于机器学习中缺少 CI/CD 的原则。如果你的环境发生变化,比如输入数据,而模型没有在其构建目标的背景下进行定期评估,导致其随时间失去相关性和价值,那么即使你可以创建一个非常好的“黑箱”模型也没有意义。这是一个难以解决的问题,因为提供数据的工程师和设计模型的科学家之间的关系并不和谐。
这个挑战有实际的例子。想想那些预测希拉里·克林顿会赢的预测,以及其他几种机器学习的失误。从自动驾驶汽车撞死无辜行人到有偏见的人工智能,已经出现了一些大的失误,我认为这些问题通常起源于数据科学和工程之间的灰色地带。

来源: Kayla Velasquez。
也就是说,机器学习对我们的社会产生了负面和积极的影响。更积极、商业性较少的例子包括electricityMap,它使用机器学习来映射全球电力的环境影响;机器学习在癌症研究中目前帮助我们更早、更准确地检测几种癌症类型;由人工智能驱动的传感器推动Agriculture朝着满足全球日益增长的食品需求迈进。
墙
因此,正确处理生产机器学习(ML),尤其是模型管理,是至关重要的。然而,回到一点,数据科学家和数据工程师并不总是使用相同的语言。
数据科学家往往缺乏对其模型如何在一个不断摄取新数据、整合新代码、被最终用户调用并且偶尔出现多种失败情况的环境中运行的理解(即生产环境)。另一方面,许多数据工程师对机器学习了解不足,不理解他们投入生产的东西以及对组织的影响。
这两个角色往往在没有足够考虑彼此的情况下运作,尽管它们占据了相同的空间。“那不是我的工作”不是正确的态度。为了生产出可靠、可持续和适应性强的产品,这两个角色必须更加有效地协作。
爬墙
交流的第一步是建立共同的词汇——对语义进行某种程度的标准化,从而讨论挑战或相关挑战。自然,这充满了挑战——只要问几个不同的人数据湖是什么,你很可能会得到至少两个不同的答案,甚至更多。
我开发了被称为 ProductionML 价值链和 ProductionML 框架的通用参考点。

我们将生产化 ML 的过程分解为五个重叠的概念,这些概念通常被分开考虑。虽然引入这样一个整体框架可能会增加复杂性和相互依赖性——但实际上,这些复杂性和相互依赖性已经存在——忽视它们只是将问题推迟到未来。
通过在设计你的生产 ML 管道时考虑邻近概念——你开始引入那种难以捉摸的可靠性、可持续性和适应性。
ProductionML 框架
ProductionML 价值链是对运营数据科学和工程团队以便将模型部署到最终用户所需内容的高层描述。自然还有更技术和详细的理解——我称之为 ProductionML 框架(有些人可能称之为持续智能)。
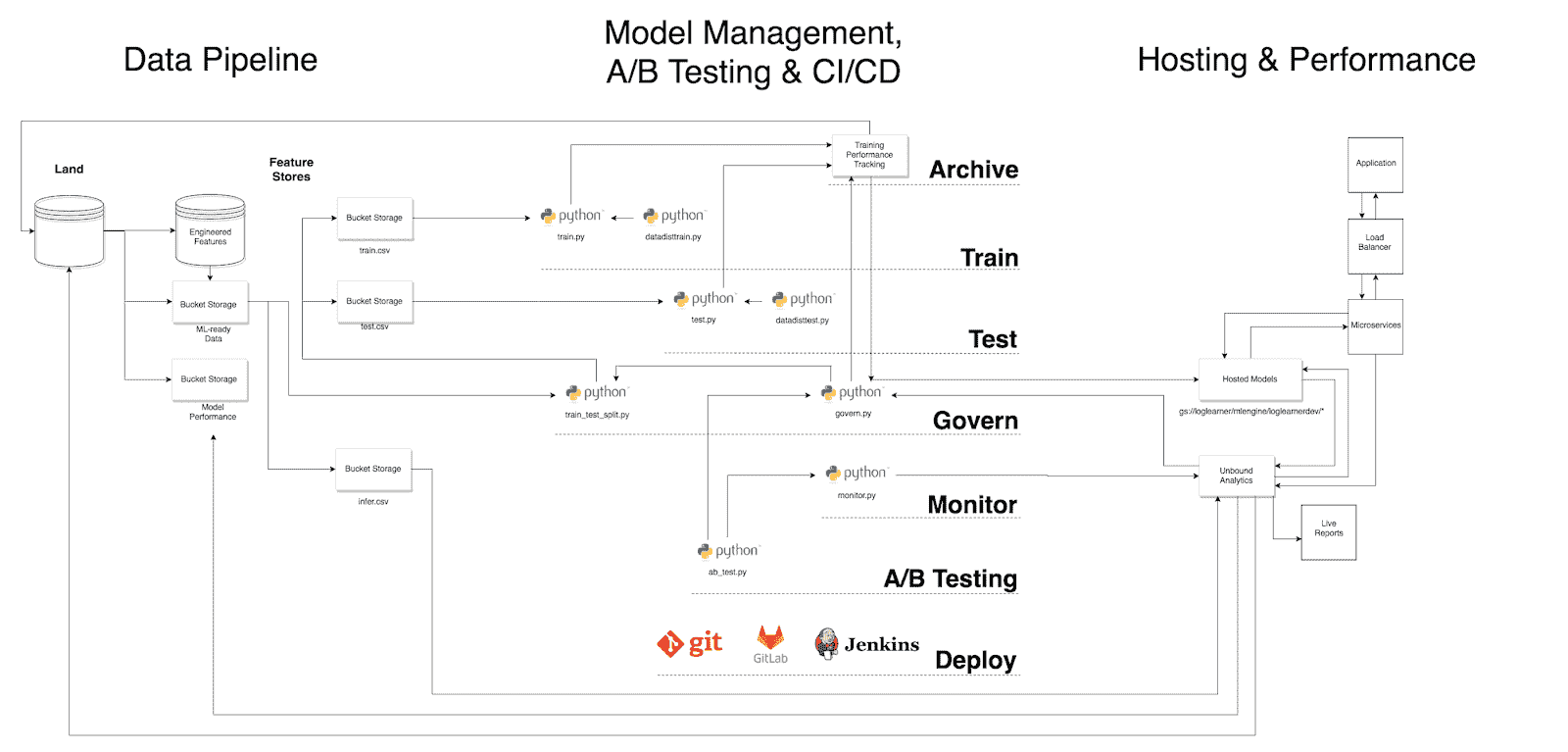
ProductionML 框架。
这个框架是在经过几轮对商业 MLOps 工具、开源选项和内部 PoC 的实验之后开发的。它旨在指导 ProductionML 项目的未来发展,特别是那些需要数据科学家和工程师共同参与的生产 ML 方面。
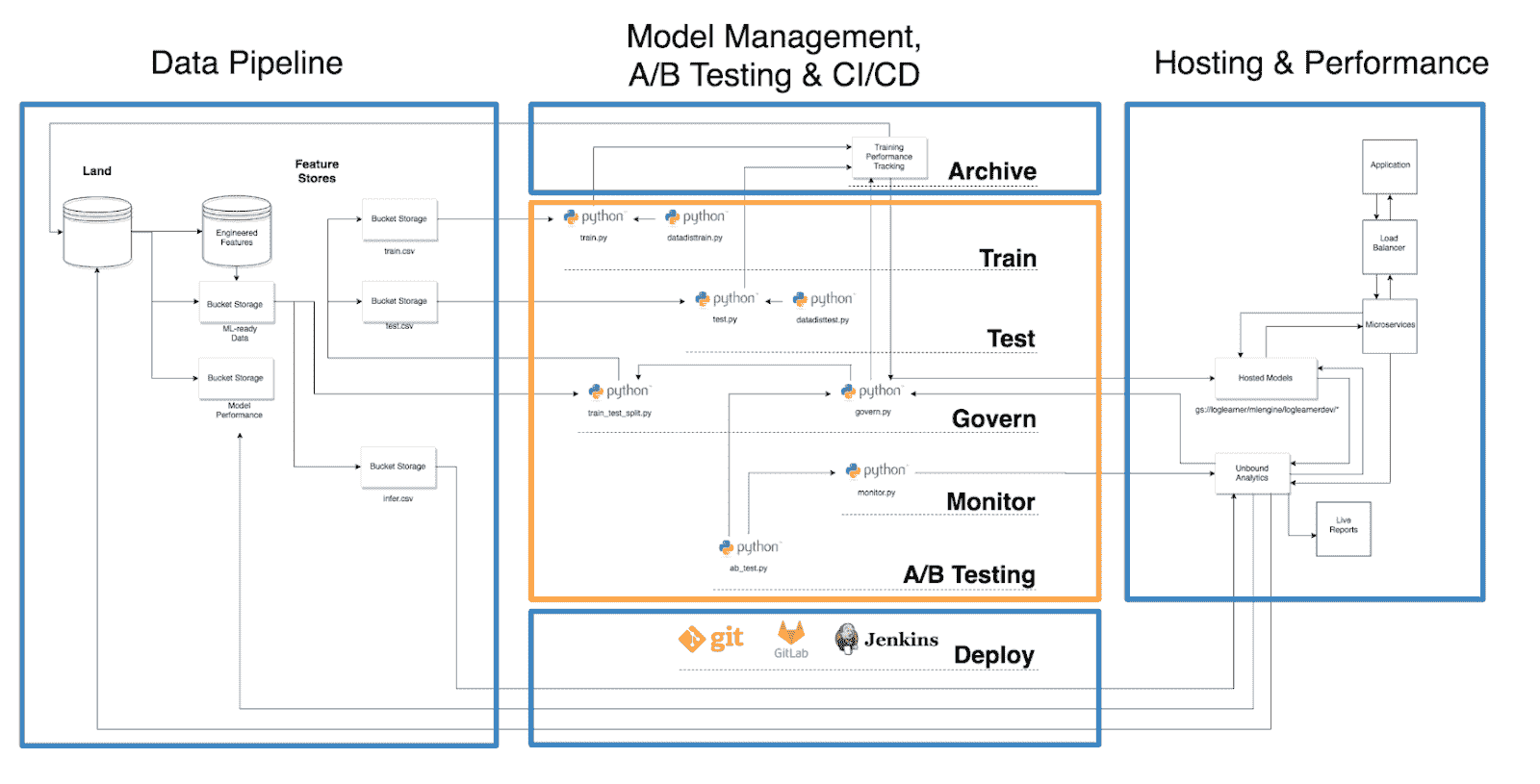
橙色的数据科学和蓝色的数据工程/DevOps。
如果你对这些方面不太熟悉,请参见橙色的“数据科学”和蓝色的“数据工程/DevOps”。
如你所见,“训练性能跟踪”机制(例如,MLFlow)和 Govern 机制在这个架构中处于核心位置。这是因为每个工件,包括指标、参数和图形,都必须在训练和测试阶段进行归档。此外,被称为模型管理的东西与模型如何被管理是根本相关的,这利用了那些模型工件。
Govern 机制将工件和业务规则结合起来,以推动适当的模型,或更具体地说,是估算器的生产,同时根据特定于用例的规则对其他模型进行标记。这也被称为模型版本控制,但使用“govern”一词是为了避免与版本控制混淆,并强调该机制在监督模型管理中的核心作用。
黄金枪?
我们都在这段旅程中。我们都在尝试攀登这面墙。市场上有许多优秀的工具,但迄今为止,没有人拥有一把金色的枪……

来源:mrgarethm — 黄金枪 — 国际间谍博物馆。
从我的角度来看,MLFlow 取得了巨大进展,它解答了关于模型管理和工件归档的某些问题。其他产品也类似地解决了相对具体的问题——尽管它们的优势可能体现在生产 ML 价值链的其他部分。这在 Google Cloud ML Engine 和 AWS Sagemaker 中可以看到。最近,GCP 发布了 AutoML Tables 的测试版,但即便如此,也无法完全满足所有需求,尽管接近了。
牢记这一持续存在的差异,科学家和工程师之间拥有共同的词汇和框架作为基础至关重要。
墙太高了吗?根据我的经验,答案是否定的,但这并不意味着生产 ML 不复杂。
必须的詹姆斯·邦德名言
M:所以如果我听得没错的话,斯卡拉曼加逃脱了——坐在一辆长出翅膀的车里!
问:哦,这完全可行,先生。事实上,我们现在正在研发一款。
或许这就是你应该如何越过那面墙……
原文。经许可转载。
相关:
更多相关话题
使用 Jupysql 和 GitHub Actions 安排和运行 ETL
原文:
www.kdnuggets.com/2023/05/schedule-run-etls-jupysql-github-actions.html
作者提供的图片
在本博客中你将实现:
-
了解 ETL 和 JupySQL 的基本概念
-
使用公共企鹅数据集并执行 ETL。
-
在 GitHub Actions 上安排我们构建的 ETL。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
介绍
在这份简短而信息丰富的指南中,我们旨在为你提供对 ETL(提取、转换、加载)和 JupySQL 这一灵活且多功能工具的基本概念的全面理解,该工具允许从 Jupyter 中无缝地进行基于 SQL 的 ETL 操作。
我们的主要关注点将是演示如何通过 JupySQL 这一流行且强大的 Python 库有效地执行 ETL 操作,同时强调通过 GitHub Actions 安排完整的 ETL 笔记本的自动化 ETL 过程的好处。
但首先,什么是 ETL?
现在,让我们深入了解细节。ETL(提取、转换、加载)是数据管理中至关重要的过程,它涉及从各种来源提取数据,将提取的数据转换为可用格式,并将转换后的数据加载到目标数据库或数据仓库中。它是数据分析、数据科学、数据集成和数据迁移等多个目的的关键过程。另一方面,JupySQL 是一个广泛使用的 Python 库,它通过 SQL 查询的强大功能简化了与数据库的交互。通过使用 JupySQL,数据科学家和分析师可以轻松执行 SQL 查询,操作数据框,并在 Jupyter 笔记本中与数据库交互。
为什么 ETL 很重要?
ETL 在数据分析和商业智能中扮演着重要角色。它们帮助企业从各种来源收集数据,包括社交媒体、网页、传感器以及其他内部和外部系统。通过这样做,企业可以获得其运营、客户和市场趋势的整体视图。
提取数据后,ETL 将其转换为结构化格式,例如关系数据库,这使企业能够轻松分析和操作数据。通过转换数据,ETL 可以清理、验证和标准化数据,使其更易于理解和分析。
最终,ETL 将数据加载到数据库或数据仓库中,企业可以轻松访问这些数据。通过这样做,ETL 使企业能够访问准确和最新的信息,从而做出明智的决策。
什么是 JupySQL?
JupySQL 是 Jupyter 笔记本的一个扩展,允许您使用 SQL 查询与数据库进行交互。它提供了一种方便的方式,直接从 Jupyter 笔记本访问数据库和数据仓库,使您能够执行复杂的数据操作和分析。
JupySQL 支持多种数据库管理系统,包括 SQLite、MySQL、PostgreSQL、DuckDB、Oracle、Snowflake 等(查看左侧的集成部分了解更多信息)。您可以使用标准连接字符串或通过环境变量连接到数据库。
为什么选择 JupySQL?
JupySQL 是一个强大的工具,便于在 Jupyter 笔记本中直接使用 SQL 查询与数据库进行交互。为了高效和准确地执行数据提取和转换过程,在通过 JupySQL 执行 ETL 时有几个关键因素需要考虑。JupySQL 为用户提供了与数据源交互并轻松进行数据转换的必要工具。为了节省宝贵的时间和精力,同时确保一致性和可靠性,通过 GitHub Actions 调度完整的 ETL 笔记本来自动化 ETL 过程可能是一个改变游戏规则的选择。通过利用 JupySQL,用户可以实现数据交互性(Jupyter)和易用性及 SQL 连接性(JupySQL)的最佳结合,从而简化数据管理过程,使数据科学家和分析师能够专注于他们的核心能力——生成有价值的见解和报告。
开始使用 JupySQL
要使用 JupySQL,您需要使用 pip 安装它。您可以运行以下命令:
!pip install jupysql --quiet
安装后,您可以使用以下命令在 Jupyter 笔记本中加载扩展:
%load_ext sql
加载扩展后,您可以使用以下命令连接到数据库:
%sql dialect://username:password@host:port/database
例如,要连接到本地 DuckDB 数据库,您可以使用以下命令:
%sql duckdb://
使用 JupySQL 执行 ETL
使用 JupySQL 执行 ETL 时,我们将遵循标准 ETL 流程,其中包括以下步骤:
-
提取数据
-
转换数据
-
加载数据
-
提取数据
提取数据
要使用 JupySQL 提取数据,我们需要连接到源数据库并执行查询以检索数据。例如,要从 MySQL 数据库中提取数据,我们可以使用以下命令:
%sql mysql://username:password@host:port/database
data = %sql SELECT * FROM mytable
该命令使用指定的连接字符串连接到 MySQL 数据库,并从“mytable”表中检索所有数据。数据存储在名为“data”的变量中,作为 Pandas DataFrame。
注意:我们还可以使用 %%sql df << 将数据保存到 df 变量中
由于我们将通过 DuckDB 在本地运行,我们可以直接提取一个公共数据集并立即开始工作。我们将获取我们的样本数据集(我们将通过 csv 文件处理企鹅数据集):
from urllib.request import urlretrieve
_ = urlretrieve(
"https://raw.githubusercontent.com/mwaskom/seaborn-data/master/penguins.csv",
"penguins.csv",
)
我们可以获取数据的样本,以检查我们是否已连接并且可以查询数据:
SELECT *
FROM penguins.csv
LIMIT 3
转换数据
提取数据后,通常需要将其转换为更适合分析的格式。此步骤可能包括数据清理、数据过滤、数据聚合和合并来自多个来源的数据。以下是一些常见的数据转换技术:
-
清理数据:数据清理涉及删除或修复数据中的错误、不一致性或缺失值。例如,你可能会删除缺失值的行,将缺失值替换为均值或中位数,或修正错别字或格式错误。
-
过滤数据:数据过滤涉及选择符合特定标准的数据子集。例如,你可以过滤数据,仅包含特定日期范围的记录,或符合某一阈值的记录。
-
聚合数据:数据聚合涉及通过计算统计数据(如某个变量的总和、均值、中位数或计数)来总结数据。例如,你可以按月或按产品类别聚合销售数据。
-
合并数据:数据合并涉及将来自多个来源的数据合并为一个数据集。例如,你可以合并关系数据库中不同表的数据,或合并不同文件中的数据。
在 JupySQL 中,你可以使用 Pandas DataFrame 方法进行数据转换,也可以使用原生 SQL。例如,你可以使用 rename 方法重命名列,使用 dropna 方法删除缺失值,使用 astype 方法转换数据类型。我将演示如何使用 pandas 或 SQL 来完成这些操作。
- 注意:你可以使用
%sql或%%sql,了解它们之间的区别,请查看 这里
这是一个如何使用 Pandas 和 JupySQL 替代方案进行数据转换的示例:
# Rename columns
df = data.rename(columns={'old_column_name': 'new_column_name'}) # Pandas
%%sql df <<
SELECT *, old_column_name
AS new_column_name
FROM data; # JupySQL
# Remove missing values
data = data.dropna() # Pandas
%%sql df <<
SELECT *
FROM data
WHERE column_name IS NOT NULL; # JupySQL single column, can add conditions to all columns as needed.
# Convert data types
data['date_column'] = data['date_column'].astype('datetime64[ns]') # Pandas
%sql df <<
SELECT *,
CAST(date_column AS timestamp) AS date_column
FROM data # Jupysql
# Filter data
filtered_data = data[data['sales'] > 1000] # Pandas
%%sql df <<
SELECT * FROM data
WHERE sales > 1000; # JupySQL
# Aggregate data
monthly_sales = data.groupby(['year', 'month'])['sales'].sum() # Pandas
%%sql df <<
SELECT year, month,
SUM(sales) as monthly_sales
FROM data
GROUP BY year, month # JupySQL
# Combine data
merged_data = pd.merge(data1, data2, on='key_column') # Pandas
%%sql df <<
SELECT * FROM data1
JOIN data2
ON data1.key_column = data2.key_column; # JupySQL
在我们的示例中,我们将使用简单的转换方式,类似于上述代码。我们将清理数据中的 NA,并将一列(species)拆分成 3 列(分别命名为每种物种):
# Combine data
merged_data = pd.merge(data1, data2, on='key_column') # Pandas
%%sql df <<
SELECT * FROM data1
JOIN data2
ON data1.key_column = data2.key_column; # JupySQL
SELECT *
FROM penguins.csv
WHERE species IS NOT NULL AND island IS NOT NULL AND bill_length_mm IS NOT NULL AND bill_depth_mm IS NOT NULL
AND flipper_length_mm IS NOT NULL AND body_mass_g IS NOT NULL AND sex IS NOT NULL;
# Map the species column into classifiers
transformed_df = transformed_df.DataFrame().dropna()
transformed_df["mapped_species"] = transformed_df.species.map(
{"Adelie": 0, "Chinstrap": 1, "Gentoo": 2}
)
transformed_df.drop("species", inplace=True, axis=1)
# Checking our transformed data
transformed_df.head()
加载数据
转换数据后,我们需要将数据加载到目标数据库或数据仓库中。我们可以使用 ipython-sql 连接到目标数据库并执行 SQL 查询以加载数据。例如,要将数据加载到 PostgreSQL 数据库中,我们可以使用以下命令:
%sql postgresql://username:password@host:port/database
%sql DROP TABLE IF EXISTS mytable;
%sql CREATE TABLE mytable (column1 datatype1, column2 datatype2, ...);
%sql COPY mytable FROM '/path/to/datafile.csv' DELIMITER ',' CSV HEADER;
此命令使用指定的连接字符串连接到 PostgreSQL 数据库,删除“mytable”表(如果存在),创建一个具有指定列和数据类型的新表,并从 CSV 文件中加载数据。
由于我们的用例是本地使用 DuckDB,我们可以简单地将新创建的 transformed_df 保存为 CSV 文件,但我们也可以使用上面的代码片段根据我们的用例将其保存到数据库或数据仓库中。
运行以下步骤以将新数据保存为 CSV 文件:
transformed_df.to_csv("transformed_data.csv")
我们可以看到一个名为 transformed_data.csv 的新文件被创建了。在下一步中,我们将看到如何自动化这个过程并通过 GitHub 消耗最终文件。
GitHub actions 上的调度
我们流程中的最后一步是通过 GitHub actions 执行完整的 notebook。为此,我们可以使用 ploomber-engine,它允许你调度 notebooks,以及其他 notebook 功能,如分析、调试等。如果需要,我们可以向 notebook 传递外部参数,并将其制作成通用模板。
- 注意:我们的 notebook 文件正在加载一个公共数据集,并在本地 ETL 后保存,我们可以轻松地更改为使用任何数据集,并将其加载到 S3,作为仪表盘可视化数据等。
对于我们的示例,我们可以使用这个示例 ci.yml 文件(这是设置 GitHub 工作流的文件),并将其放入我们的代码库中,最终文件应位于 .github/workflows/ci.yml 下。
ci.yml 文件的内容:
name: CI
on:
push:
pull_request:
schedule:
- cron: '0 0 4 * *'
# These permissions are needed to interact with GitHub's OIDC Token endpoint.
permissions:
id-token: write
contents: read
jobs:
report:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Python ${{ matrix.python-version }}
uses: conda-incubator/setup-miniconda@v2
with:
python-version: '3.10'
miniconda-version: latest
activate-environment: conda-env
channels: conda-forge, defaults
- name: Run notebook
env:
PLOOMBER_STATS_ENABLED: false
PYTHON_VERSION: '3.10'
shell: bash -l {0}
run: |
eval "$(conda shell.bash hook)"
# pip install -r requirements.txt
pip install jupysql pandas ploomber-engine --quiet
ploomber-engine --log-output posthog.ipynb report.ipynb
- uses: actions/upload-artifact@v3
if: always()
with:
name: Transformed_data
path: transformed_data.csv
在这个 CI 示例中,我还添加了一个计划触发器,这个任务将每晚凌晨 4 点运行。
结论
ETL 是数据分析和商业智能的重要过程。它们帮助企业从各种来源收集、转换和加载数据,使分析和做出明智决策变得更加容易。JupySQL 是一个强大的工具,允许你直接在 Jupyter notebooks 中使用 SQL 查询与数据库交互。结合 GitHub actions,我们可以创建强大的工作流,这些工作流可以被调度并帮助我们将数据处理到最终阶段。
使用 JupySQL,你可以轻松高效地执行 ETL,允许你以结构化格式提取、转换和加载数据,同时 GitHub actions 分配计算资源并设置环境。
Ido Michael 共同创办了 Ploomber,旨在帮助数据科学家更快地构建。他曾在 AWS 领导数据工程/科学团队。在这些客户互动中,他和团队一起单独构建了数百个数据管道。来自以色列的他来到纽约攻读哥伦比亚大学的硕士学位。他专注于构建 Ploomber,因为他发现项目通常将大约 30% 的时间用于将开发工作(原型)重构为生产管道。
更多相关主题
识别可能更好预测的变量
原文:
www.kdnuggets.com/2017/02/schmarzo-variables-better-predictors.html
我喜欢书籍《点球成金》中所传授的数据科学概念的简洁性。每个人都想直接跳入那些内容丰富、高度技术性的数据库书籍。但我建议我的学生先从《点球成金》开始。这本书很好地展现了数据科学的力量(而且电影不算,因为我妻子看了后只记得“布拉德·皮特真帅!”... 哎)。我最喜欢的课程之一就是对数据科学的定义:
数据科学就是识别那些 可能 是更好表现预测指标的变量和指标
我们的前三个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业生涯。
2. Google Data Analytics Professional Certificate - 提升你的数据分析水平
3. Google IT Support Professional Certificate - 支持你的组织进行 IT 方面的工作
这个直接的定义为定义业务利益相关者和数据科学团队的角色和责任奠定了基础:
-
业务利益相关者负责识别(头脑风暴)那些 可能 是更好表现预测指标的变量和指标,并且
-
数据科学团队负责量化哪些变量和指标实际上 是 更好的表现预测指标
这种方法利用了业务利益相关者最了解的内容——即业务。同时,这种方法也利用了数据科学团队最了解的内容——即数据转换、数据丰富、数据探索和分析建模。完美的数据科学团队!
注意:词汇“might” 可能是数据科学定义中最重要的词汇。业务利益相关者必须感到舒适,能够头脑风暴不同的变量和指标,这些变量和指标 可能 更好地预测表现,而不必担心他们的想法会被评判。我们的一些最佳想法来自那些声音通常不会被听到的人。我们的大数据愿景研讨会过程将所有想法视为值得考虑的。如果你不接受这一概念,你可能会限制业务利益相关者的创造性思维,或者更糟的是,错过可能有价值的数据洞察。
这篇博客旨在扩展数据科学团队用来识别(和量化)哪些变量和指标 是 更好预测表现的方式。让我通过一个例子来说明。
我们最近与一家金融服务机构合作,他们要求我们预测客户流失者,即识别哪些客户有可能结束与组织的关系。正如我们在大数据愿景研讨会中通常做的那样,我们与业务利益相关者举行了促进性头脑风暴会议,以识别可能是更好预测绩效的变量和指标(见图 1)。
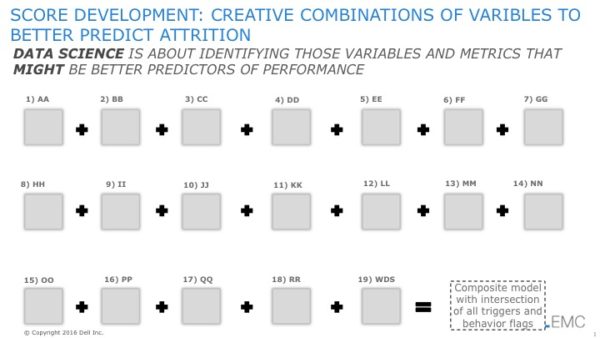
图 1: 头脑风暴可能是更好预测变量和指标
注意:由于客户的竞争优势原因,我不得不模糊处理我们识别出的确切指标。是的,我喜欢这样!
从这些变量和指标的列表中,数据科学团队寻求创建一个“流失评分”,用于识别(或评分)有风险的客户。数据科学团队采纳了迭代的“快速失败/更快学习”过程,测试不同的变量和指标组合。数据科学团队测试了不同的数据增强和转化技术以及不同的分析算法,并尝试了不同变量和指标的组合,以查看哪些变量组合产生了最佳结果(见图 2)。
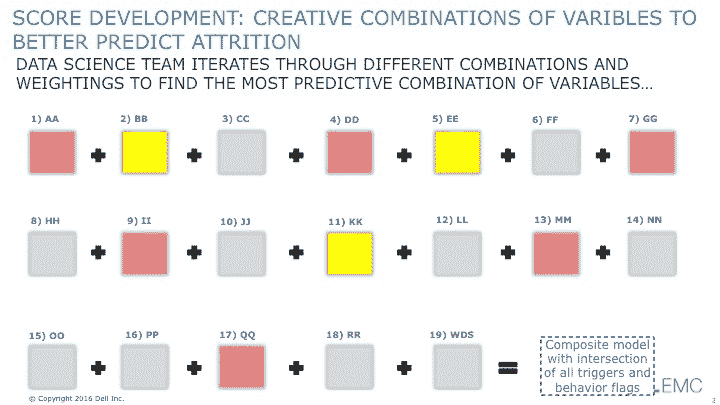
图 2: 探索不同的变量和指标组合
数据科学团队面临的挑战是不能满足于第一个“有效”的模型。数据科学团队需要不断突破极限,因此,需要在测试不同的变量组合时经历足够多的失败,才能对最终模型的结果充满信心。
经过大量的测试和失败——以及测试和失败——再测试和失败,数据科学团队提出了一个“流失评分”模型,该模型经过足够的失败,使他们对结果充满信心(见图 3)。
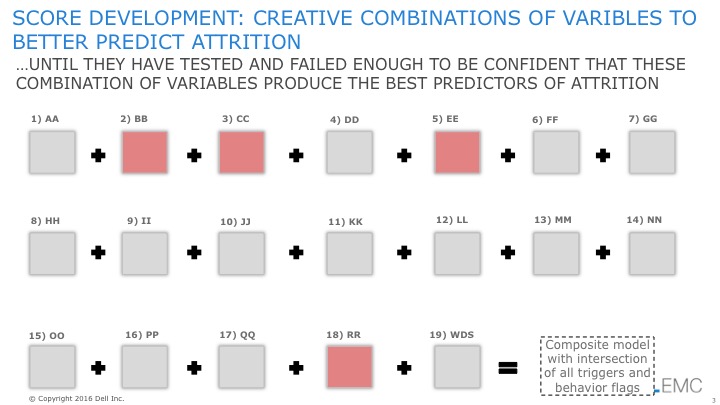
图 3: 识别出更好的预测变量和指标
我们需要一种方法,能够充分发挥项目中每个人的作用——业务利益相关者进行变量和指标的头脑风暴,以及数据科学团队创造性地测试不同的组合。此次参与的最终结果相当令人印象深刻(见图 4):
-
Dell EMC 过程生成了一个模型,识别出了约 59% 的流失者
-
作为基准,American Express 宣布了一种成功的流失模型,识别出 24%的流失客户(来源:“预测分析如何应对 American Express 的客户流失”)。
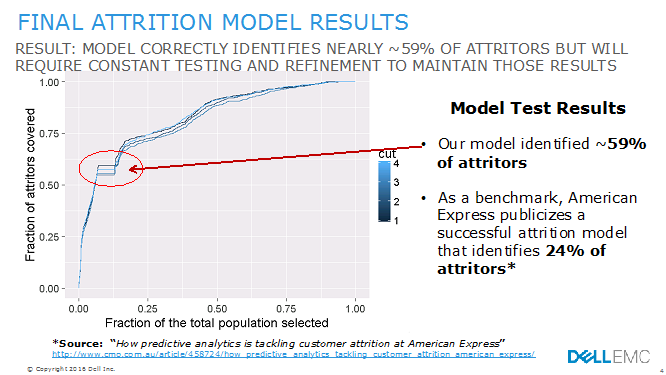
图 4: 最终流失模型结果
将不同变量和指标结合起来的创造性数据科学过程高度依赖于业务利益相关者头脑风暴练习的成功。如果业务利益相关者没有在这一过程中早期参与,并被允许创造性地思考哪些变量和指标可能是更好的绩效预测因素,那么数据科学团队将寻求测试的变量和指标的集合将受到限制。换句话说,数据科学过程的成功和可操作评分的创建高度依赖于业务利益相关者在过程开始时的创造性参与。
这就是我们大数据愿景研讨会过程的力量。
如果你有兴趣了解更多关于戴尔 EMC 大数据愿景研讨会的信息,请查看下面的博客:
原文。已获许可转载。
相关:
-
公民数据科学家、巨型虾和其他无意义的描述
-
物联网(IoT)挑战:呼救的传感器
-
确定数据的经济价值
更多相关主题
让数据科学回归“科学”
评论
作者:Rubens Zimbres,数据科学家及机器学习研究员。
最近,我看到很多关于数据科学领域的炒作,以及很多新手加入这个领域。但在我看来,数据科学中的“科学”究竟是什么?科学方法来解决问题,是应对问题并提供最佳解决方案的最好方式。如果你开始数据分析时只是简单地陈述假设并应用机器学习算法,那么这就是错误的方法。
我们的三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
下面的图片展示了科学研究所需的步骤,包括相应的数据分析和模拟。实际上,这是我在博士论文中做的草图。简而言之,我研究了过去 27 年的商业管理文献,并试图开发一种知识上颠覆性的方式来衡量和预测服务质量,将商业管理与电气工程概念相结合。在 4 年的过程中,我进行了定性-定量纵向研究,并使用基于代理的建模开发了一个模拟,试图找到一种可以模拟人类行为的 5 状态细胞自动机规则。我探讨了复杂性概念、自组织系统、秩序的涌现和社会网络。
一篇论文发表在 Elsevier 的《电子计算机科学理论笔记》(Electronic Notes in Theoretical Computer Science)(2009),标题为《社交网络中质量感知的动态:一种基于细胞自动机的美学服务模型》。

我从科学方法中学到的一件事是,在解决问题时要摆脱先验和后验偏见。先验偏见发生在你以预先设定的想法开始分析时。在这种情况下,你的发现只会确认你最初陈述的内容,因为整个研究过程都存在偏见。后验偏见发生在你开始分析某事时,但实际上你已经知道结果是什么,这样整个过程也会有偏见。
一旦你摆脱了对问题的先入为主的想法,你会找到解决问题的新方法。在数据科学过程中,这一点至关重要,因为创造力能让你对整个环境有一个清晰的认识。
首先,什么是业务问题?你想实现什么目标?你是想利用利润、投资回报吗?你是否清楚你的业务如何为客户增加价值?什么是价值?客户到底是谁?客户的需求和认知是什么?你打算如何获取这些数据?是否有市场研究可以与业务数据一起使用?
要开始构建科学的解决问题的方法,首先定义问题、文献中的空白(如果你是硕士或博士生)或业务需求:发生了什么,想要实现什么,策略和数据分析的受益者(利益相关者)是谁,何时开始和结束,使用什么资源和算法,如何实现目标以及为什么?
在评估所有这些变量并制作思维导图后,问问自己:问题中涉及了什么类型的知识?假设你正在处理客户流失问题。是什么让人们离开你的业务?当然,任何人都可以对原因有直觉,但请记住,科学文章是比随机猜测更有价值的知识来源。
假设客户离开是因为他们没有看到业务中的价值。价值是一些独特的东西,通常由人力资源提供,无法被复制,也没有竞争对手能提供。这带来了竞争优势、更多利润、忠诚度、口碑宣传和回购。
注意到到目前为止我们甚至没有考虑假设和算法。只有在准确知道问题中涉及哪些变量之后,我们才会制定假设。假设你认为利润受到对产品质量的正面客户认知和关于你公司的高口碑广告的影响。这就是名义网络,你在其中绘制相关性和因果关系。在数据科学中,你需要了解客户的认知,并且是否存在口碑广告。然后你会发现你在处理不同的数据集,一个是市场研究数据,另一个是社交媒体推荐。你还有另一个包含公司财务数据的数据集(包含利润数据)。
现在是时候选择了:你是选择定量方法,使用市场研究数据集和财务数据中的结构化数据吗?但社交媒体是非结构化的,因此你必须使用自然语言处理进行定性分析。更糟糕的是,你想进行纵向分析,将数据转换为时间序列并用 ARIMA 进行分析。啊,利润可以通过深度神经网络来预测,使用市场研究数据、财务数据和社交媒体中的词嵌入作为特征!
现在我们进入了数据科学家的乐趣:算法、分类、回归、深度学习、无监督学习、准确性、过拟合、偏差-方差权衡、超参数调优。乐趣开始了!
是的,乐趣已经开始,但请注意,在这个具体案例中,我们在到达算法之前经历了一段漫长的旅程。在研究问题的规划方面有整个过程。不能仅仅“应用算法”并检查拟合和过拟合的度量。另一个大问题是,当你对发生的事情有一个完整的认识时,你通常会发现需要的数据并不存在。
然后是你算法的验证过程。关于模型的外部有效性(泛化能力)有很多讨论:你的模型在训练集和测试集上的表现良好,几乎没有过拟合,但这些发现是否适用于新情况?你的测试集分布是否能复制现实世界场景?是的,但我们不能忘记其他类型的验证,例如:
-
实证验证: 与现实的比较成功
-
概念验证: 你的机器学习模型成功地将自然系统转化为数学语言
-
内部验证: 你的代码没有错误
-
你的模型是否展现了遍历性(在人工智能和复杂行为不存在时的稳定性)和同方差性
在验证你的数据分析结果后,你将确认或拒绝假设,并向高层管理人员建议战略举措。请注意,数据科学家需要商业管理人员的全面参与才能成功。数据分析和建模的发现必须为战略决策、市场定位、产品发布、品牌形象等多个领域提供洞察。
所以,数据科学中的科学不仅仅涉及机器学习、深度学习、自然语言处理、人工智能算法和公式。这不仅仅是 STEM。它涉及我们从学术界借鉴的一种跨学科且严谨的方法,旨在为企业带来超出平均水平的利润,常常涉及心理学、博弈论、商业管理、复杂性、非线性效应和复杂因果关系。
简介:鲁本斯·辛布雷斯 是一名数据科学家,拥有电气工程方向的工商管理硕士和博士学位。他的研究重点是机器学习、深度学习和自然语言处理。
相关:
-
应用于大数据的机器学习,解释
-
特征选择的实际重要性
-
教学数据科学过程
更多相关内容
科学债务——对数据科学意味着什么?
评论
由David Robinson,Datacamp 提供
在软件工程中,一个非常有用的概念是技术债务。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
技术债务发生在工程师选择了一个快速但不理想的解决方案,或者没有花时间建立可持续的基础设施。也许他们正在使用一种在团队和代码库扩展时不够灵活的方法(例如硬编码“魔法数字”),或出于便利而非适当性使用工具(“我们将用 PHP 编写 DevOps 基础设施,因为这是我们团队已经掌握的”)。无论如何,这是一种看起来最初有效,但在长期中会带来真正挑战的情况,比如推迟功能发布和难以修复的漏洞。

在我担任DataCamp 首席数据科学家的新工作中,我一直在思考数据科学在企业中的角色,并与该领域的其他专业人士讨论。在今年早些时候的一个讨论小组上,我意识到数据科学家有一个大致相当于这一概念的东西:“科学债务。”
科学债务是指团队在数据分析、实验实践和监控中采取的捷径,这些捷径可能会带来长期的负面影响。 当你听到这样的陈述时:
-
“我们没有足够的时间进行随机测试,让我们直接上线吧”
-
“初步估计,这个效应可能是线性的”
-
“这可能是一个混淆因素,但我们稍后会研究这个问题”
-
“至少在方向上是准确的”
你听到的是一些“借用”的科学债务。
示例:WidgetCorp
大多数工程师对公司在面对技术债务时的感觉有所了解。一个面临科学债务的公司会是什么样子?
想象一个小型初创公司 WidgetCorp 正在开发一款 B2B 产品,并决定他们的销售策略。某一年,他们决定开始将销售重点放在较大的企业客户上。他们注意到,随着这种新策略的实施,他们的月收入有所增加。他们因此受到鼓舞,并在接下来几年中聘请了半打有大型客户经验的销售人员,投入营销和设计工作,将其作为品牌的一部分。
几年后,这种策略似乎没有带来预期的效果:他们的收入陷入困境,早期的成功没有重现。他们聘请了一位分析师,查看了他们的销售数据,并发现实际上他们从未在向大公司销售时获得更高的投资回报率。在早期那一年,他们的收入上升是因为季节性效应(秋冬季节对小部件的需求增加),这与一些随机噪声和轶事(例如“SmallCompany.com 是浪费时间,但我们刚刚与 Megabiz 签署了一份大单!”)叠加在一起。
WidgetCorp 承担了过多的科学债务。

这可能发生的几种方式:
他们基于有缺陷的分析做出了不可逆转的决定。 对于指标,快速查看并欣慰地发现它们朝着正确的方向发展是合理的。但一旦公司在产品、销售和市场营销上做出了改变,就很难再进行调整。在做出重大业务变动之前,值得确保数据能够支持这些决策:即确保他们已经考虑了季节性影响,并应用了适当的统计测试。
缺乏监控。在早期,可能没有足够的数据来判断大型客户是否是更好的投资。但是随着更多数据的收集,值得不断测试这个假设,形式可以是仪表板或季度报告。如果没有进行跟踪,即使他们获得了数据,也没有人会注意到这个假设被证伪了。
数据基础设施的缺乏:也许在公司早期,潜在客户被锁定在销售 CRM 系统中,而会计数据则存储在通过电子邮件传送的 Excel 电子表格中。即便公司内有专门的分析师,他们也可能无法轻易获取相关数据(例如,将销售成功与公司规模联系起来)。即使理论上可以通过一些努力将数据集结合起来,懒惰盲点 也可能让每个人都完全避免进行分析。这是一个技术债务和科学债务常常一起出现的领域,因为解决科学问题需要工程方面的努力。
传播不准确的传说。假设 WidgetCorp 的 CEO 进行了一系列公司范围的演讲和公开博客文章,传达的信息是“WidgetCorp 的未来是服务大公司!”产品团队开始习惯性地优先考虑这个方向的功能,每次失败都归咎于“我想我们没有足够专注于大客户”。这种“文化惯性”可能非常难以扭转,即使高管团队愿意公开承认他们的错误(这并不是保证的!)。
几乎每个经验丰富的数据科学家都有至少一些这样的故事,即使是来自其他成功的公司。这些故事对科学债务的意义就像Daily WTF对技术债务的意义一样。
科学债务总是坏的吗?
完全不是!

我在自己的分析中经常走捷径。对一个功能发布进行随机实验有时成本过高,尤其是当用户数量相对较少或变化相当无争议时(例如,你不会对拼写错误修正进行 A/B 测试)。尽管相关性不意味着因果关系,但在做出商业决策时,它通常比什么都没有要好。
将其与技术债务相比是有用的:一个小型工程团队的首要目标通常是快速构建一个最小可行产品,而不是过度工程一个他们认为在遥远的未来会非常稳健的系统。(科学债务中的等价物通常被称为过度思考,例如:“是的,我认为我们可以在检查销售交易成功与否时控制天气,但我很确定你在过度思考这个问题。”)与财务债务的比较也是有意义的:公司在成长过程中通常会承担债务(或类似地,放弃股份)。就像你不能在不借钱的情况下建立一家公司一样,你不能在确定每个决策都得到充分数据支持的情况下建立公司。
技术债务和科学债务中重要的是要记住长期成本。
如果你没有...
利用它先获得一些有价值的东西
定期支付利息
将其视为一种可能最终需要全额偿还的负债
不符合这些标准的代码不是债务,它只是低质量的工作。
— 实践开发者 (@practicingdev) 2018 年 2 月 26 日
错误的决策代价高昂,不关注数据是一种风险。我们可以对这种风险是否值得进行成本效益分析,但不应将其视为“数据科学家总是找借口”的表现。
为什么还要称之为“债务”?
对于数据科学家或分析师来说,这篇文章可能听起来相当明显。当然,忽视统计严谨性是有缺陷的,那么为什么还要给它一个“流行术语”的名字呢?因为它将这个概念放在了高管和经理们易于理解的术语中。
再次回到技术债务。个人工程师可能有很多原因想要编写“干净的代码”:他们欣赏代码的优雅,他们想给同行留下深刻印象,或者他们是完美主义者,拖延其他工作。这些原因对非技术员工通常并不重要,他们关心的是产品特性和可靠性。技术债务的框架帮助强调公司因不投资架构而失去的东西:即使产品看起来在正常工作,缺陷在实际的金钱和时间上也会有长期的成本。
工程师: 我很烦恼不同的内部项目使用不同的命名规范。
首席技术官: 对不起让你烦恼了,但代码就是代码,我不明白你为什么要在这上面浪费时间。
工程师: 我们不一致的命名规范就是技术债务:它使新开发者更难学习系统。
首席技术官: 我一直在寻找减少我们入职时间的方法!好主意,告诉我你需要什么来解决它。
同样,科学家,尤其是来自学术背景的科学家,通常对揭示现实中的真相有特别的兴趣。因此,“我想分析 X 是否是这里的一个混杂因素”的想法可能听起来像是一种奢侈,而不是一个迫切的商业需求。统计学家尤其喜欢发现数学方法中的缺陷。因此,当数据科学家说“我们不能使用那个方法,Jones 等人在 2012 年证明了它在渐近上是不一致的”时,非技术同事可能会认为他们在过度思考,甚至是炫耀。将其框架化为我们实际上冒的风险有助于传达为何花时间去做是值得的。
我们如何有效地管理科学债务?
-
让数据科学家“支付利息”。正如不是每个工程项目都会带来新特性一样,不是每次分析都会带来令人兴奋的发现或新颖的算法。有些时间需要花费在确认或证伪现有假设上。乔纳森·诺利斯关于数据科学工作的优先级排序有一篇很好的文章,他在文章中将这一象限描述为“提供证明”。
-
构建数据工程流程: 正如之前所描述的,公司可能会陷入科学债务的一个原因是分析师可能无法轻松访问他们需要的数据。这些数据可能被锁在尚未被摄取的平台中,或存储在需要手动编辑的 Google 表格中。将相关数据摄取到数据仓库或数据湖中,可以使数据科学家更有可能进行相关发现。
-
重新审视旧的分析:早期阶段公司进入科学债务的一个常见原因是数据不足以得出可靠的结论。即使你还没有足够的数据,也不意味着你应该忘记这个问题。有时,我会在日历上安排时间以便在预期有足够数据时进行分析,即使这可能要几个月。这样也可以帮助确认一个重要的分析是否仍然相关:就像你会随着时间跟踪 KPI 一样,你也要跟踪结论是否仍然正确。
-
让数据专业知识在公司内部传播。就像一个不能编程的人可能不会认识到技术债务一样,一个没有分析和理解数据经验的人可能不会认识到科学债务。这是另一个在公司内部实现数据科学民主化的理由,正如我们在 DataCamp 所做的。
简介:David Robinson,是 DataCamp 的首席数据科学家,使用 R 和 Python 进行工作。
原文。经许可转载。
相关:
更多相关主题
scikit-feature: 开源特征选择库(Python)
原文:
www.kdnuggets.com/2016/03/scikit-feature-open-source-feature-selection-python.html
作者:Jundong Li,ASU。
scikit-feature 是一个在亚利桑那州立大学开发的开源特征选择库,基于 Python。它建立在广泛使用的机器学习包 scikit-learn 以及两个科学计算包 Numpy 和 Scipy 之上。scikit-feature 包含约 40 种流行的特征选择算法,包括传统特征选择算法以及一些结构化和流式特征选择算法。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT

它作为一个平台,促进特征选择的应用、研究和比较研究。它旨在共享在特征选择研究中开发的广泛使用的特征选择算法,并为研究人员和实践者提供便利,以进行新的特征选择算法的实证评估。
目前,scikit-feature 包含以下类别的监督和无监督特征选择算法:
-
基于相似性的特征选择
-
基于信息论的特征选择
-
稀疏学习基础的特征选择
-
基于统计的特征选择
-
基于包装器的特征选择
-
结构特征选择
-
流式特征选择
此外,scikit-feature 还提供了许多基准特征选择数据集,并提供了如何通过分类或聚类任务评估特征选择算法的示例。
要下载 scikit-feature,请访问其附加信息网站:featureselection.asu.edu/
如果你需要更多信息,请联系亚利桑那州立大学的 Jundong Li(firstname.lastname@asu.edu)。
简介:Jundong Li 是亚利桑那州立大学计算机科学与工程博士生。他的研究兴趣包括数据挖掘、机器学习及其在社交媒体中的应用。
相关:
-
数据科学机器,或‘如何进行特征工程’
-
构建机器学习系统的 20 条经验
-
数据维度减少的七种技术
更多相关话题
Scikit Flow: 使用 TensorFlow 和 Scikit-learn 轻松进行深度学习
原文:
www.kdnuggets.com/2016/02/scikit-flow-easy-deep-learning-tensorflow-scikit-learn.html
评论
Google 的 TensorFlow 自 2015 年 11 月起公开发布,毫无疑问,在短短几个月内,它对机器学习以及深度学习产生了影响。通过博客文章、学术论文和各种网络教程,有广泛的接受证据。
当然,估计真正的采纳率是困难的,但 TensorFlow 的 Github 仓库有 几乎是两倍的星标数量 比下一个最多星标的机器学习项目 Scikit-learn 和最接近的深度学习项目 Berkeley Vision and Learning Center 的 Caffe。虽然这不能具体指示 TensorFlow 已经成为该领域的领导者,但可以相当容易地推测,鉴于其相对较新的发布,Google 的深度学习库引起了相当大的兴趣和使用。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT

大多数情况下,TensorFlow 相对简单易用,没有使用该库经验的神经网络爱好者可以查看给定网络的代码并直观地理解其内容。语法可能会更加直接和简洁,而不使用任何包装器,但显然有原因不这样做。从技术上讲,TensorFlow 是“一个用于数据流图的数值计算的开源软件库”,虽然它(主要)用于机器学习和深度学习研究(及生产),但该系统足够通用,可以应用于广泛的其他领域。如果 TensorFlow 更加深度学习友好,这种特性可能会削弱其在其他潜在领域的适用性。
# A simple Hello World! using TensorFlow
import tensorflow as tf
hello = tf.constant('Hello, TensorFlow!')
sess = tf.Session()
sess.run(hello)
# -> Hello, TensorFlow!
然而,许多机器学习研究人员和从业者使用 Python 的原因之一,是因为其快速原型设计能力。TensorFlow 本身并不一定禁止这种快速周转,但确实存在某种学习曲线,特别是如果你对其他类似的库,如 Theano,不熟悉的话。
但如果你可以快速上手 TensorFlow 并几乎立即开始训练神经网络,而不需要学习额外的语法或配置怎么办?这正是 Scikit Flow 的作用。然而,我会稍微偏离一下话题。
Scikit-learn + TensorFlow = Scikit Flow
Scikit-learn 作为 事实 上的官方 Python 通用机器学习框架,拥有丰富的历史。虽然我相信这句话会(并且可以)引起争议,也许它有点强烈,但不可否认的是,Scikit-learn 在 Python 机器学习生态系统中占据了重要地位,并且在机器学习领域也如此。

其易用性和标准化接口与此有关。例如,Scikit-learn 利用简单的 fit/predict 工作流模型 来实现其分类算法。这使得构建、训练和测试模型变得非常简单。一个典型逻辑回归模型的测试/训练相关代码可能看起来像这样:
from sklearn.linear_model import LogisticRegression
from sklearn import datasets, metrics
iris = datasets.load_iris()
classifier = LogisticRegression()
classifier.fit(iris.data, iris.target)
score = metrics.accuracy_score(iris.target, classifier.predict(iris.data))
print("Accuracy: %f" % score)
想尝试一个朴素贝叶斯分类器?这不需要太多更改:
from sklearn.naive_bayes import GaussianNB
from sklearn import datasets, metrics
iris = datasets.load_iris()
classifier = GaussianNB()
classifier.fit(iris.data, iris.target)
score = metrics.accuracy_score(iris.target, classifier.predict(iris.data))
print("Accuracy: %f" % score)
唯一的变化是在第一行的导入语句和分类器实例化语句。鉴于此,我们可以轻松看到 Scikit 模型接口的一致性和简洁性。即使在阅读之前你对此一无所知,你也已经明白了,因为它很简单。尽管当然,机器学习管道的内容远不止于上述的 7 行代码,但这 7 行涵盖了一个重要且广泛的方面,并且无论分类器如何都一样。
现在回到 Scikit Flow (skflow):既然(几乎)每个 Python 机器学习生态系统中的人都对 Scikit-learn 有一定了解,那么如果你能立即利用 TensorFlow 的建模能力,同时保留 Scikit-learn 的语法简洁性呢?Scikit Flow(名字本身就暗示了这种利用和引导)官方的介绍如下:
这是 TensorFlow 的简化接口,用于让人们开始进行预测分析和数据挖掘。
实际上,更明确地说,Scikit Flow 是 TensorFlow 深度学习库的高级封装器,它允许使用简洁、熟悉的 Scikit-learn 方法来训练和拟合神经网络。
为了回答“为什么选择 Scikit Flow?”的问题,它的仓库 README 解释了:
为了使从 Scikit Learn 的单行机器学习世界过渡到更开放的构建不同形状的 ML 模型的世界变得更加顺畅,你可以从使用 fit/predict 开始,随着你逐渐适应,再逐步过渡到 TensorFlow APIs。
重要的是,Scikit Flow 是 Google 推出的官方 TensorFlow 项目;这不是一个被破解的第三方解决方案……并不是说这样做有什么问题。完全没有。但 Google 开发、发布并支持这个项目的事实,应该能给你足够的信心,它确实会使这两个库按承诺协同工作。它也很受欢迎;在写这篇文章时,Scikit Flow 的仓库拥有近 1700 个星标。
讨论
现在我们将查看几个示例。如果你想在家尝试,请确保你已安装以下内容:
-
Python: 2.7, 3.4+
-
Scikit learn: 0.16, 0.17, 0.18+
-
Tensorflow: 0.6+
Scikit Flow 可以使用 pip 通过以下一行代码轻松安装:
>>> pip install git+git://github.com/tensorflow/skflow.git
首先,我们将查看在 Scikit Flow 中实现通用线性分类器的方法。
import skflow
from sklearn import datasets, metrics
iris = datasets.load_iris()
classifier = skflow.TensorFlowLinearClassifier(n_classes=3)
classifier.fit(iris.data, iris.target)
score = metrics.accuracy_score(iris.target, classifier.predict(iris.data))
print("Accuracy: %f" % score)
如上所示,上述示例遵循了 Scikit-learn 的类似 fit/predict 模型。如果你查看早期的 Scikit-learn 模型,你会发现它们与上述示例的相似性。
但这只是一个线性分类器,并不是真正的深度学习。真正展现 Scikit Flow 强大功能的是深度神经网络。一个通用的三层神经网络,具有 10、20 和 10 个隐藏节点,可以通过如下代码轻松实现:
import skflow
from sklearn import datasets, metrics
iris = datasets.load_iris()
classifier = skflow.TensorFlowDNNClassifier(hidden_units=[10, 20, 10], n_classes=3)
classifier.fit(iris.data, iris.target)
score = metrics.accuracy_score(iris.target, classifier.predict(iris.data))
print("Accuracy: %f" % score)
再次强调,变化非常小。我们没有使用前一个示例中的 TensorFlowLinearClassifier,而是使用了 TensorFlowDNNClassifier,这使我们能够在 7 行(大量辅助)代码中构建、训练和测试一个深度神经分类器。我们仅明确指定了节点数和隐藏层数。Scikit Flow 还提供了一个标准的递归神经网络,一些额外的分类器,作为一个早期的工作和官方 TensorFlow 项目之一,可以认为将很快增加其他标准架构和分类器。
若要进行几乎完全相同的比较,请查看 Scikit Flow 和“原始” TensorFlow 对 MNIST 图像分类器的实现。Github 仓库中还有 更多示例(包括一个有趣的示例,它与 Dask 并行处理引擎接口,用于核心外数据分类)。
Scikit Flow 也允许在低级 TensorFlow 之间进行混合交互。对于那些有兴趣在较低级别创建架构,然后通过高级接口进行训练和测试的人来说,Scikit Flow 可能是一个不错的选择。它也可能有助于深度架构的分布性;当共享在较低级别创建的架构时,为其他人提供熟悉的 Scikit-learn 接口进行训练和测试可能不是一个坏主意,当然,这取决于具体情况。
结论
虽然 skflow 可能没有“原始” TensorFlow 的灵活性,但高级抽象允许快速原型设计神经网络。它还使深度学习和 TensorFlow 的新手几乎可以立即变得高效。考虑到 TensorFlow 代码仍然可以与之并行编写,在需要时有机会混合代码并提供更大的灵活性。
Scikit Flow 可能会在其他情况下找到市场,比如模型共享或管理较低级别网络的训练和测试,看来谷歌确实推出了一个设计良好的 TensorFlow 附加组件,这个附加组件肯定不会阻碍其进一步的采用。
更新:来自 Scikit Flow 开发者的 新 Reddit 帖子 正在征求添加功能的意见。有什么想法吗?可以在那儿留言。
简介:Matthew Mayo 是一名计算机科学研究生,目前正在撰写关于并行化机器学习算法的论文。他还是数据挖掘的学生、数据爱好者和有志于成为机器学习科学家的人。
相关:
-
TensorFlow 令人失望 – 谷歌深度学习表现平平
-
微软深度学习带来创新功能 – CNTK 显示出潜力
-
7 步理解深度学习
更多相关话题
Scikit-learn 机器学习备忘单
原文:
www.kdnuggets.com/2022/12/scikit-learn-machine-learning-cheatsheet.html
你的工具包中的机器学习工具
你想开始学习机器学习。你对机器学习概念有基础了解。你会 Python。你该怎么办?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
最明显的答案是开始使用Scikit-learn。Scikit-learn 是一个开源的 Python 库,用于各种预测数据分析任务。你可以执行分类、回归、聚类、降维、模型调优和数据预处理等任务。
Scikit-learn 的统一 API 接口使得学习如何实现各种算法和任务变得比其他方法更容易。一旦你掌握了如何调用 Scikit-learn 的方法,你就能顺利开展。除此之外,你所需要的就是一个实用的参考资料,再加上你的想象力和决心。
KDnuggets 整理了你所需的一切。这个备忘单涵盖了学习如何使用 Scikit-learn 进行机器学习所需的基础知识,并为你推进机器学习项目提供了参考。备忘单中包含了你将反复使用的最常见功能。请看下面以确认。
你可以在这里下载备忘单。
在备忘单中,你会找到以下常见 Scikit-learn 任务的实用参考:
-
数据加载
-
将数据集拆分为训练集和测试集
-
数据预处理
-
执行监督机器学习任务
-
执行无监督机器学习任务
-
模型拟合
-
预测
-
评估
-
交叉验证
-
模型调优
不需要再等一分钟来掌握机器学习从业者工具箱中最常用的工具之一。一旦你安装了Scikit-learn,只需按照备忘单中的相关代码片段进行操作即可开始使用。只要记得在进展过程中随时准备好它。
立即查看,并随时回来获取更多信息。
更多相关话题
Scikit-Learn 与 MLR 在机器学习中的对比
原文:
www.kdnuggets.com/2019/09/scikit-learn-mlr-machine-learning.html
评论

Scikit-Learn 以其易于理解的 Python 用户 API 而闻名,而 MLR 成为了流行的 Caret 包的替代品,提供了更多的算法库和简单的超参数调整方式。这两个包因许多人在分析工作中倾向于使用 Python 进行机器学习而 R 用于统计分析而处于竞争状态。
使用 Python 的一个原因可能是当前用于机器学习的 R 包通过其他包含算法的包提供。这些包通过 MLR 调用,但仍需额外安装。甚至外部特征选择库也需要,且它们还有其他外部依赖需要满足。
Scikit-Learn 被称为一个统一的 API,提供多个机器学习算法,无需用户调用更多库。
这绝不会贬低 R。 R 在数据科学领域仍然是一个主要组成部分,不论在线调查如何说。任何有统计学或数学背景的人都会知道为什么你应该使用 R(即使他们自己不使用,它们也认识到它的吸引力)。
现在我们将查看用户如何通过典型的机器学习工作流。我们将使用 Scikit-Learn 中的 Logistic Regression 和 MLR 中的决策树。
创建你的训练和测试数据
-
Scikit-Learn
-
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size)这是在 Scikit-Learn 中分割数据集的最简单方法。test_size 用于确定数据的百分比进入测试集。train_test_split 将自动在一行代码中创建训练集和测试集。x 是特征集,y 是目标变量。
-
-
MLR
-
train <- sample(1:nrow(data), 0.8 * nrow(data)) -
test <- setdiff(1:nrow(train), train) -
MLR 没有内置的函数来子集数据集,因此用户需要依赖其他 R 函数。这是创建 80/20 训练测试集的一个例子。
-
选择算法
-
Scikit-Learn
-
LogisticRegression()分类器可以通过调用一个明显命名的函数来选择和初始化,这样便于识别。
-
-
MLR
-
makeLearner('classif.rpart')算法被称为学习器,这个函数被调用以初始化它。 -
makeClassifTask(data=, target=)如果我们进行分类,我们需要调用此函数来初始化分类任务。此函数将接受两个参数:训练数据和目标变量的名称。
-
超参数调整
在任何一个软件包中,调整超参数都有一个流程。你首先需要指定要改变哪些参数以及这些参数的范围。然后进行网格搜索或随机搜索,以找到最佳的参数组合,从而获得最佳结果(即,最小化错误或最大化准确度)。
-
Scikit-Learn
-
penalty = ['l2'] -
C = np.logspace(0, 4, 10) -
dual= [False] -
max_iter= [100,110,120,130,140] -
hyperparameters = dict(C=C, penalty=penalty, dual=dual, max_iter=max_iter) -
GridSearchCV(logreg, hyperparameters, cv=5, verbose=0) -
clf.fit(x_train, y_train)
-
-
MLR
-
makeParamSet( makeDiscreteParam("minsplit", values=seq(5,10,1)), makeDiscreteParam("minbucket", values=seq(round(5/3,0), round(10/3,0), 1)), makeNumericParam("cp", lower = 0.01, upper = 0.05), makeDiscreteParam("maxcompete", values=6), makeDiscreteParam("usesurrogate", values=0), makeDiscreteParam("maxdepth", values=10) ) -
ctrl = makeTuneControlGrid() -
rdesc = makeResampleDesc("CV", iters = 3L, stratify=TRUE) -
tuneParams(learner=dt_prob, resampling=rdesc, measures=list(tpr,auc, fnr, mmce, tnr, setAggregation(tpr, test.sd)), par.set=dt_param, control=ctrl, task=dt_task, show.info = TRUE) ) -
setHyperPars(learner, par.vals = tuneParams$x)
-
训练
两个软件包都提供了一行代码来训练模型。
-
Scikit-Learn
LogisticRegression().fit(x_train50, y_train50)
-
MLR
train(learner, task)
这可以说是过程中的较简单步骤。最艰巨的步骤是调整超参数和特征选择。
预测
就像训练模型一样,预测也可以通过一行代码完成。
-
Scikit-Learn
LogisticRegression().predict(x_test)
-
MLR
predict(trained model, newdata)
Scikit-learn 将返回一个预测标签的数组,而 MLR 将返回一个预测标签的数据框。
模型评估
评估监督分类器最流行的方法是混淆矩阵,从中可以获得准确度、错误率、精确度、召回率等。
-
Scikit-Learn
-
confusion_matrix(y_test, prediction)OR -
classification_report(y_test,prediction)
-
-
MLR
-
performance(prediction, measures = list(tpr,auc,mmce, acc,tnr))OR -
calculateROCMeasures(prediction)
-
两个软件包都提供了多种获取混淆矩阵的方法。然而,为了以最简单的方式获得信息性视图,Python 可能没有 R 那么直观。第一个 Python 代码只会返回一个没有标签的矩阵。用户必须返回文档中解读哪些列和行对应于哪些类别。 第二种方法提供了更好且更具信息性的输出,但它仅会生成精确度、召回率、F1 分数和支持度。这些也是在不平衡分类问题中更重要的性能衡量标准。
决策阈值调整(即,改变分类阈值)
分类问题中的阈值是将每个实例分类到预测类别的给定概率。默认阈值通常为 0.5(即 50%)。这是在 Python 和 R 中进行机器学习时的一个主要差异。R 提供了一行代码解决方案来调整阈值以应对类别不平衡。而 Python 没有内置函数来实现这一点,用户需要通过定义自定义脚本/函数来编程操作阈值。

一对显示决策阈值的图表。
-
Scikit-Learn
- 在 Scikit-Learn 中没有一种标准的阈值设置方式。查看这篇文章了解你可以自己实现的一种方法:在 Scikit-Learn 中微调分类器
-
MLR
-
setThreshold(prediction, threshold)这行
mlr中的代码将自动更改你的阈值,并可以作为参数传递,以计算你的新性能指标(即混淆矩阵)。
-
结论
最终,MLR 和 Scikit-Learn 在处理机器学习时各有优缺点。我们的比较集中在使用其中一种进行机器学习,并不意味着使用其中一种而不是另一种。了解这两者能为该领域的人提供真正的竞争优势。对过程的概念性理解将使得使用这两种工具更为容易。
原文。经许可转载。
相关:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关主题
Scikit-Learn 及更多用于机器学习的合成数据集生成工具
原文:
www.kdnuggets.com/2019/09/scikit-learn-synthetic-dataset.html
评论
越来越明显的是,大型科技巨头如谷歌、Facebook 和微软在他们最新的机器学习算法和工具方面非常慷慨(他们免费提供这些资源),因为目前进入算法世界的门槛相当低。开源社区和工具(如 scikit-learn)取得了长足的进展,大量开源项目正在推动数据科学、数字分析和机器学习的发展。站在 2018 年,我们可以安全地说,算法、编程框架和机器学习包(甚至教程和学习这些技术的课程)并不是稀缺资源,而是高质量数据才是。
这通常在数据科学(DS)和机器学习(ML)从业者面临的一个棘手问题,即调整和优化这些算法时。值得指出的是,本文涉及的是算法调查、教学学习和模型原型制作的数据稀缺性,而非扩展和运行商业操作。讨论的并非如何获取你正在开发的酷炫旅行或时尚应用的优质数据。这类消费者、社交或行为数据收集有其自身的问题。然而,即使是像获取优质数据集来测试某种算法方法的局限性和多变性这样的简单事情,也往往并不那么简单。
为什么你需要一个合成数据集?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
如果你从零开始学习,最明智的建议是从简单的小规模数据集开始,这样你可以将其绘制在二维图中,以直观地理解模式,并亲自查看机器学习算法的工作效果。
然而,随着数据维度的爆炸,视觉判断必须扩展到更复杂的事项——如学习和样本复杂性、计算效率、类别不平衡等概念。
此时,实验灵活性和数据集性质之间的权衡开始发挥作用。你总是可以找到一个大型真实数据集来实践算法。但那仍然是一个固定的数据集,具有固定的样本数量、固定的底层模式以及固定的类别分离程度,在正负样本之间。你还必须调查,
-
选择的测试数据和训练数据的比例如何影响算法的性能和鲁棒性。
-
在面对不同程度的类别不平衡时,度量指标的鲁棒性如何。
-
需要进行何种偏差-方差权衡。
-
算法在训练数据和测试数据中的各种噪声特征下的表现如何(即标签中的噪声以及特征集中的噪声)。
-
你如何实验并揭示你的机器学习算法的弱点?
事实证明,使用单一的真实数据集来完成这些任务是相当困难的,因此,你必须愿意使用合成数据,这些数据在足够随机的情况下捕捉到真实数据集的所有变化,但又足够可控,以帮助你科学地研究你正在构建的特定机器学习流程的优缺点。
尽管我们在本文中不会讨论这个问题,但可以很容易地评估这种合成数据集在敏感应用中的潜在好处——例如医学分类或金融建模,在这些领域,获取高质量标注数据集通常是昂贵且禁止的。
合成数据集在机器学习中的基本特征
目前理解到的是,合成数据集是通过编程生成的,而不是来源于任何类型的社会或科学实验、商业交易数据、传感器读数或手动标注的图像。然而,这些数据集绝不是完全随机的,生成和使用合成数据进行机器学习必须由一些总体需求指导。特别是,
-
数据可以是数值型、二进制型或分类型(有序或无序),特征的数量和数据集的长度可以是任意的。
-
必须存在一定程度的随机性,但同时,用户应能够选择多种统计分布作为数据的基础,即底层随机过程可以被精确控制和调整。
-
如果用于分类算法,则类别分离的程度应该是可控的,以使学习问题变得简单或困难。
-
随机噪声可以以可控的方式插入。
-
生成速度应足够高,以便对各种数据集进行实验,这些数据集适用于特定的 ML 算法,即,如果合成数据是基于真实数据集的数据增强,那么增强算法必须具有计算效率。
-
对于回归问题,可以使用复杂的非线性生成过程来获取数据——实际物理模型可能会对此有所帮助。
在下一节中,我们将展示如何使用一些最流行的 ML 库和编程技术来生成合适的数据集。
使用 scikit-learn 和 Numpy 生成标准的回归、分类和聚类数据集
Scikit-learn 是基于 Python 的数据科学软件栈中最流行的 ML 库。除了优化良好的 ML 例程和管道构建方法外,它还拥有一套强大的合成数据生成工具方法。
使用 scikit-learn 进行回归
Scikit-learn 的 dataset.make_regression 函数可以创建随机回归问题,具有任意数量的输入特征、输出目标以及可控的信息耦合程度。

使用 Scikit-learn 进行分类
类似于上面的回归函数,dataset.make_classification 生成一个随机的多类分类问题,具有可控的类别分离和添加的噪声。如果需要,你也可以随机翻转任何百分比的输出标记来创建更难的分类数据集。

使用 Scikit-learn 进行聚类
scikit-learn 的工具函数可以生成各种聚类问题。最简单的方法是使用 datasets.make_blobs,它生成具有可控距离参数的任意数量的聚类。

在测试基于相似度的聚类算法或高斯混合模型时,生成具有特定形状的聚类是有用的。我们可以使用 datasets.make_circles 函数来完成这项任务。


在测试使用支持向量机(SVM)算法的非线性核方法、最近邻方法如k-NN,或甚至测试简单神经网络时,通常建议使用特定形状的数据进行实验。我们可以使用 dataset.make_moon 函数生成具有可控噪声的数据。

使用 Scikit-learn 的高斯混合模型
高斯混合模型(GMM)是研究无监督学习和文本处理/NLP 任务中的主题建模的迷人对象。以下是一个简单函数的示例,展示了为此类模型生成合成数据的简便性:
import numpy as np
import matplotlib.pyplot as plt
import random
def gen_GMM(N=1000,n_comp=3, mu=[-1,0,1],sigma=[1,1,1],mult=[1,1,1]):
"""
Generates a Gaussian mixture model data, from a given list of Gaussian components
N: Number of total samples (data points)
n_comp: Number of Gaussian components
mu: List of mean values of the Gaussian components
sigma: List of sigma (std. dev) values of the Gaussian components
mult: (Optional) list of multiplier for the Gaussian components
) """
assert n_comp == len(mu), "The length of the list of mean values does not match number of Gaussian components"
assert n_comp == len(sigma), "The length of the list of sigma values does not match number of Gaussian components"
assert n_comp == len(mult), "The length of the list of multiplier values does not match number of Gaussian components"
rand_samples = []
for i in range(N):
pivot = random.uniform(0,n_comp)
j = int(pivot)
rand_samples.append(mult[j]*random.gauss(mu[j],sigma[j]))
return np.array(rand_samples)




超越 scikit-learn:从符号输入生成合成数据
虽然上述功能对许多问题可能足够,但生成的数据是真正随机的,用户对实际机制的控制较少。
生成过程的分析。在许多情况下,可能需要一种可控的方式来基于明确的解析函数(涉及线性、非线性、理性或甚至超越项)生成回归或分类问题。以下文章展示了如何结合符号数学包 SymPy 和 SciPy 的函数从给定的符号表达式生成合成的回归和分类问题。

从给定的符号表达式生成的回归数据集。

从给定的符号表达式生成的分类数据集。
使用 scikit-image 进行图像数据增强
深度学习系统和算法是数据的贪婪消费者。然而,为了测试深度学习算法的局限性和鲁棒性,通常需要通过细微的图像变化来馈送算法。Scikit-image 是一个出色的图像处理库,基于与 scikit-learn 相同的设计原则和 API 模式,提供了数百种实用的函数来完成这一图像数据增强任务。
以下文章很好地提供了这些想法的全面概述:
我们展示了一些选定的增强过程示例,从单一图像开始,并对其进行数十种变化,有效地扩展数据集的流形,创建一个巨大的合成数据集,以稳健的方式训练深度学习模型。
色调、饱和度、明度通道

裁剪

随机噪声

旋转

漩涡效果

带分割的随机图像合成器
NVIDIA 提供了一个名为 NDDS 的 UE4 插件,旨在帮助计算机视觉研究人员导出高质量的合成图像及其元数据。它支持图像、分割、深度、物体姿态、边界框、关键点和自定义模板。除了导出工具,插件还包含各种组件,支持生成随机图像用于数据增强和目标检测算法训练。随机化工具包括照明、物体、相机位置、姿态、纹理和干扰物。这些组件使深度学习工程师能够轻松创建随机场景以训练他们的 CNN。以下是 Github 链接,
使用 pydbgen 生成分类数据
Pydbgen是一个轻量级纯 Python 库,用于生成随机有用条目(如姓名、地址、信用卡号、日期、时间、公司名称、职位名称、车牌号等),并将其保存到 Pandas 数据框对象、SQLite 数据库文件中的表格或 MS Excel 文件中。你可以在这里阅读文档。以下是描述其用法和工具的文章,
这里有一些说明性的示例,



合成时间序列数据集
有许多论文和代码库用于生成合成时间序列数据,这些数据使用在现实生活中的多变量时间序列中观察到的特殊函数和模式。以下 Github 链接提供了一个简单的示例:

合成音频信号数据集
音频/语音处理是深度学习从业者和机器学习爱好者特别感兴趣的领域。谷歌的 NSynth 数据集是一个合成生成的(使用神经自编码器和人类及启发式标记的组合)短音频文件库,声音由各种类型的乐器发出。以下是该数据集的详细描述。
强化学习的合成环境
OpenAI Gym
用于强化学习的合成学习环境中最伟大的资源是OpenAI Gym。它包含了大量的预编程环境,用户可以在这些环境中实施他们的强化学习算法,以进行性能基准测试或解决潜在的弱点。

随机网格世界
对于强化学习的初学者来说,练习和实验一个简单的网格世界通常会有所帮助,在这个网格世界中,智能体必须穿越迷宫以到达一个终端状态,每一步和终端状态都有给定的奖励/惩罚。
只需几行简单的代码,就可以合成任意大小和复杂度的网格世界环境(用户指定终端状态和奖励向量的分布)。
查看这个 Github 仓库,获取灵感和代码示例。
github.com/tirthajyoti/RL_basics
总结
在本文中,我们介绍了一些用于机器学习的合成数据生成示例。读者应当明确,这些示例并不是数据生成技术的详尽列表。实际上,除了 scikit-learn 之外,许多商业应用也提供了相同的服务,因为需要用多样的数据来训练 ML 模型的需求正在快速增长。然而,如果你作为数据科学家或 ML 工程师,创建自己的合成数据生成编程方法,这将为你的组织节省资金和资源,避免投资于第三方应用程序,同时也能让你以整体和有机的方式规划 ML 流水线的开发。
希望你喜欢这篇文章,并且可以很快在你的项目中开始使用这里描述的一些技术。
原文。经许可转载。
相关内容:
更多相关内容
使用 Scikit-learn 的填补器

什么是填补器?
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
如果你的数据集中存在缺失值,你可以删除缺失值所在的行或列。这种方法并不推荐,因为它会减少数据量,可能导致数据分析偏离实际情况。相反,我们应该使用不受缺失值影响的机器学习算法,或使用填补器来填充缺失的信息。
填补器是一种用于填充数据集中缺失值的估算器。对于数值型数据,它使用均值、中位数和常量。对于类别型数据,它使用最常用值和常量值。你也可以训练你的模型来预测缺失的标签。
在本教程中,我们将学习 Scikit-learn 的SimpleImputer、IterativeImputer 和 KNNImputer。我们还将创建一个管道来填补类别和数值特征,并将其输入到机器学习模型中。
如何使用 Scikit-learn 的填补器
scikit-learn的填补函数为我们提供了一个简单的填充选项,只需几行代码。我们可以集成这些填补器,创建管道以重现结果并改进机器学习开发过程。
入门指南
我们将使用Deepnote环境,它类似于 Jupyter Notebook,但在云端运行。
要从Kaggle下载并解压数据,你需要安装 Kaggle Python 包,并使用 API 下载太空船泰坦尼克号数据集。最后,将数据解压到数据集文件夹中。
%%capture
!pip install kaggle
!kaggle competitions download -c spaceship-titanic
!unzip -d ./dataset spaceship-titanic
接下来,我们将导入所需的 Python 包用于数据摄取、填补以及创建转换管道。
import numpy as np
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer,KNNImputer
from sklearn.pipeline import FeatureUnion,make_pipeline,Pipeline
from sklearn.compose import ColumnTransformer
Spaceship Titanic数据集是 Kaggle 入门预测比赛的一部分。它包括训练、测试和提交的 CSV 文件。我们将使用train.csv,其中包含宇宙飞船上的乘客信息。
pandas 的read_csv()函数读取 train.csv 并显示数据框。
df = pd.read_csv("dataset/train.csv")
df
数据分析
在本节中,我们将探讨缺失值的列,但首先需要检查数据集的形状。它有 8693 行和 14 列。
df.shape
>>> (8693, 14)
我们现在将基于列显示缺失值的数量和百分比。为了在数据框中显示它,我们将创建一个新的缺失值数据框,并对NA Count列应用样式渐变。
NA = pd.DataFrame(data=[df.isna().sum().tolist(), ["{:.2f}".format(i)+'%' \
for i in (df.isna().sum()/df.shape[0]*100).tolist()]],
columns=df.columns, index=['NA Count', 'NA Percent']).transpose()
NA.style.background_gradient(cmap="Pastel1_r", subset=['NA Count'])
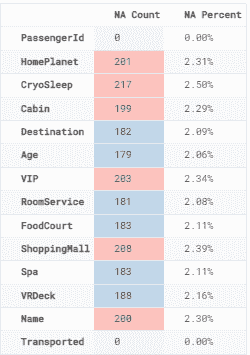
除了PassengerID和Transported之外,每一列都有缺失值。
数值数据插补
我们将利用缺失列的信息,将其分为类别列和数值列。我们将对它们采取不同的处理方式。
对于数值插补,我们将选择Age列并显示缺失值的数量。这将帮助我们验证插补前后的结果。
all_col = df.columns
cat_na = ['HomePlanet', 'CryoSleep','Destination','VIP']
num_na = ['Age','RoomService', 'FoodCourt', 'ShoppingMall', 'Spa', 'VRDeck']
data1 = df.copy()
data2 = df.copy()
data1['Age'].isna().sum()
>>> 179
data1.Age[0:5]
>>> 0 39.0
>>> 1 24.0
>>> 2 58.0
>>> 3 33.0
>>> 4 16.0
接下来,我们将使用 sklearn 的SimpleImputer并将其应用于Age列。它将用列的average值替换缺失数据。
正如我们所观察到的,Age列中没有剩余的缺失值。
imp = SimpleImputer(strategy='mean')
data1['Age'] = imp.fit_transform(data1['Age'].values.reshape(-1, 1) )
data1['Age'].isna().sum()
>>> 0
对于数值列,你可以使用constant、mean和median策略,对于类别列,你可以使用most_frequent和constant策略。
类别数据插补
对于类别数据插补,我们将使用包含 201 个缺失值的HomePlanet列。
data1['HomePlanet'].isna().sum()
>>> 201
data1.HomePlanet[0:5]
>>> 0 Europa
>>> 1 Earth
>>> 2 Europa
>>> 3 Europa
>>> 4 Earth
为了填充类别缺失值,我们将使用带有most_frequent策略的SimpleImputer。
imp = SimpleImputer(strategy="most_frequent")
data1['HomePlanet'] = imp.fit_transform(data1['HomePlanet'].values.reshape(-1, 1))
我们已经填充了 HomePlanet 列中的所有缺失值。
data1['HomePlanet'].isna().sum()
>>> 0
多变量插补器
在单变量插补器中,缺失值是通过相同的特征计算的,而在多变量插补器中,算法使用所有可用特征维度来预测缺失值。
我们将一次性填充数值列,正如我们所看到的,它们都有 150+的缺失值。
data2[num_na].isna().sum()
>>> Age 179
>>> RoomService 181
>>> FoodCourt 183
>>> ShoppingMall 208
>>> Spa 183
>>> VRDeck 188
我们将使用IterativeImputer,设置max_iter为 10,以估计和填充数值列中的缺失值。该算法将在估计值时考虑所有列。
imp = IterativeImputer(max_iter=10, random_state=0)
data2[num_na] = imp.fit_transform(data2[num_na])
data2[num_na].isna().sum()
>>> Age 0
>>> RoomService 0
>>> FoodCourt 0
>>> ShoppingMall 0
>>> Spa 0
>>> VRDeck 0
机器学习中的类别和数值数据插补
为什么选择 Scikit-learn 的插补器?除了插补器外,机器学习框架还提供特征转换、数据处理、管道和机器学习算法。它们都能无缝集成。只需几行代码,你就可以在任何数据集上进行插补、归一化、转换和训练你的模型。
在本节中,我们将学习如何在机器学习项目中集成插补器以获得更好的结果。
-
首先,我们将从 sklearn 中导入相关函数。
-
然后,我们将删除不相关的列以创建 X 和 Y 变量。我们的目标列是“Transported”。
-
之后,我们将数据分割为训练集和测试集。
from sklearn.preprocessing import LabelEncoder, StandardScaler, OrdinalEncoder
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
X,y = df.drop(['Transported','PassengerId','Name','Cabin'],axis = 1) , df['Transported']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=100, random_state=0)
要创建数值和类别转换数据管道,我们将使用 sklearn 的 Pipeline 函数。
对于 numeric_transformer,我们使用了:
-
KNNImputer 使用 2 个 n_neighbors 和均匀的 weights
-
在第二步中,我们使用了StandardScaler的默认配置。
对于 categorical_transformer,我们使用了:
-
SimpleImputer 使用 most_frequent 策略
-
在第二步中,我们使用了OrdinalEncoder,将类别转换为数字。
numeric_transformer = Pipeline(steps=[
('imputer', KNNImputer(n_neighbors=2, weights="uniform")),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OrdinalEncoder())])
现在,我们将使用 ColumnTransformer 处理和转换训练特征。对于 numeric_transformer,我们提供了一组数值列,对于 categorical_transformer,我们将使用一组类别列。
注意:我们只是准备了管道和转换器。我们还没有处理任何数据。
preprocessor = ColumnTransformer(
remainder = 'passthrough',
transformers=[
('numeric', numeric_transformer, num_na),
('categorical', categorical_transformer, cat_na)
])
最后,我们将创建一个包含处理器和DecisionTreeClassifier的转换管道,用于二分类任务。该管道将首先处理和转换数据,然后训练分类模型。
transform = Pipeline(
steps=[
("processing", preprocessor),
("DecisionTreeClassifier", DecisionTreeClassifier()),
]
)
这就是魔法发生的地方。我们将使用transform管道来拟合训练数据集。之后,我们将使用测试数据集来评估我们的模型。
我们在默认配置下得到了75% 的准确率。不错!!!
model = transform.fit(X_train,y_train)
model.score(X_test, y_test)
>>> 0.75
接下来,我们将在测试数据集上进行预测,并创建结构化的分类报告。
from sklearn.metrics import classification_report
prediction = model.predict(X_test)
print(classification_report(prediction, y_test))
如我们所见,我们对True和False类有稳定的得分。
precision recall f1-score support
False 0.70 0.74 0.72 43
True 0.80 0.75 0.77 57
accuracy 0.75 100
macro avg 0.75 0.75 0.75 100
weighted avg 0.75 0.75 0.75 100
结论
为了获得更高的准确性,数据科学家们正在使用深度学习方法来插补缺失值。再次,你需要决定构建系统所需的时间和资源,以及它带来的价值。在大多数情况下,Scikit-learn 的插补器提供了更大的价值,并且我们只需几行代码就能插补整个数据集。
在这篇博客中,我们了解了插补及 Scikit-learn 库如何估计缺失值。我们还了解了单变量、变量间、多变量、类别和数值插补。在最后部分,我们使用了数据管道、列转换器和机器学习管道来插补、转换、训练和评估我们的模型。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为有心理疾病困扰的学生构建 AI 产品。
更多相关话题
迅速搜索数百万文档中的数千个关键词
原文:
www.kdnuggets.com/2017/09/search-millions-documents-thousands-keywords.html
评论
由 Vikash Singh, Belong.co。

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
假设你有一个文档,你想知道它是否提到 python(一个你关心的术语)
-------------------------------------------------------------------------
Document: I am a python developer.
Term: python
-------------------------------------------------------------------------
你想检查文档中是否包含 python 这个词。因此你打开文档,按 ctrl+f 并搜索 'python'。然后你找到了它 😃
现在假设你有 100 个这样的术语:[python, java, github, medium, 等等]
你将用一段简单的 python 代码打开文档。循环检查每个术语,看看术语是否存在。
-------------------------------------------------------------------------
Open (document)
for each term in terms:
if term is present in document: print(term)
-------------------------------------------------------------------------
现在假设你有 100 个文档。你可以在循环中打开每个文档。每个文档中你搜索每个术语。
-------------------------------------------------------------------------
for document in documents:
Open (document)
for each term in terms:
if term is present in document: print(term)
-------------------------------------------------------------------------
现在假设 java 应该与 Java 匹配,但不包括 javascript。
更好的是,java 应该与 j2ee 和 Java 都匹配,但不包括 java script。
(j2ee 和 java 是同义词,你注意到 java script 中的空格了吗?)
现在变得有趣了。你怎么做呢?
我们去年遇到了这个问题 @Belong.co。我们注意到人们用多种方式谈论相同的术语。Big apple 可以指 big apple 或 New York。幸运的是,我们有一些上下文。当我们的文档提到 Python 时,它 99.99% 的情况下指的是编程语言,而不是动物。
但这并没有简化我们的问题。Java 和 j2ee 对我们来说是一样的,但不包括 java script。那么如何从数百万个文档中提取这些信息呢?
正如你所想的,我们编写了一段 正则表达式 基础的代码。对于 100 万个文档和 2K 个关键词,这段代码运行了 24 小时。生活变得美好了 😃
但很快我们扩展到几百万个文档和 10K+ 个关键词。于是相同的代码现在需要 10 多天才能运行。因此我们开始寻找更好的方法。
我在办公室问了问,Vinay 建议我查看基于 Trie 字典的方法。Suresh 建议使用Aho Corasick 算法。在Stack overflow上得到了类似的建议。
事实证明,Aho Corasick 算法可以在对文档的一次扫描中同时搜索所有关键词。这真是太棒了。
在示例输入上的 flashtext 演示。
我编写了基于 Trie 数据结构的自定义实现以适应我们的用例。它运行得相当不错。使用这种算法的关键词提取过程需要 15 分钟。比起基于正则表达式的方法减少了 10 多天的时间。
-------------------------------------------------------------------------
Input: I love j2ee. Keyword: j2ee=>Java
# *Which is basically saying j2ee means Java* Output: ['Java']
-------------------------------------------------------------------------
现在关键词提取效果很好。因此,我还添加了在文档中用同义词替换关键词的功能。
Say you want to replace ‘New Delhi’ with ‘NCR region’ in a document.
Input: I live in New Delhi.
Output: I live in NCR region.
我们能够在多个项目中利用这个库。这也是我们决定将其开源的原因。这里是代码的链接 😃 github.com/vi3k6i5/flashtext
使用起来非常简单:[Python 代码即将发布]
-------------------------------------------------------------------------
$ pip install flashtext
>>> from flashtext.keyword import KeywordProcessor
>>> keyword_processor = KeywordProcessor()
>>> keyword_processor.add_keyword('j2ee', 'Java')
>>> keyword_processor.add_keyword('Python')
>>> keyword_processor.extract_keywords('I work on python and j2ee')
# output: ['Python', 'Java']
关键词替换:
>>> keyword_processor.add_keyword('New Delhi', 'NCR region')
>>> keyword_processor.replace_keywords('I live in New Delhi.')
# output: 'I live in NCR region.'
-------------------------------------------------------------------------
这非常有用,因为它有助于术语扩展。比如你想将RC car替换为Remote Control car在产品目录中。或者你想将Electrocardiogram提取为ECG。这两者都很容易做到。
如果你认识从事实体识别或 NER 或 NLP 或 Word2vec 的人,请将这篇博客分享给他们。这一库对我们在这些领域非常有用。我相信它对其他人也会有帮助。
干杯 😃
原文。转载经许可。
个人简介:Vikash Singh 是 belong.co 的数据科学家,处理大量文本以及基于词嵌入的多个项目。
相关:
-
Python 超越 R,成为数据科学和机器学习平台的领导者
-
5 个免费的自然语言处理深度学习入门资源
-
文本挖掘 101:从简历中挖掘信息
更多相关主题
我的秘密武器,帮助我在 Kaggle 比赛中进入前 2%
原文:
www.kdnuggets.com/2018/11/secret-sauce-top-kaggle-competition.html
评论
由 Abhay Pawar, Instacart。
参加 Kaggle 比赛很有趣且上瘾!在过去的几年里,我开发了一些标准方法来探索特征并构建更好的机器学习模型。这些简单但强大的技术帮助我在 Instacart 市场篮子分析 比赛中获得了前 2% 的排名,我在 Kaggle 之外也使用这些技术。让我们直接进入正题!
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
在数值数据上构建任何监督学习模型的最重要方面之一是充分理解特征。查看模型的部分依赖图有助于你了解模型输出如何随特征变化。
但这些图的问题在于它们是使用训练模型创建的。如果我们能够直接从训练数据创建这些图,它将有助于我们更好地理解基础数据。实际上,它可以帮助你完成以下所有任务:
-
特征理解
-
识别噪声特征 (最有趣的部分!)
-
特征工程
-
特征重要性
-
特征调试
-
泄漏检测和理解
-
模型监控
为了使其易于访问,我决定将这些技术放入 Python 包 featexp,在本文中,我们将看看如何使用它进行特征探索。我们将使用 Kaggle 上的 Home Credit Default Risk 竞赛的应用数据集。该竞赛的任务是使用提供的数据预测违约者。
- 特征理解
特征与目标的散点图无帮助
如果因变量(目标)是二值的,散点图就不起作用,因为所有点要么在 0,要么在 1。对于连续目标,数据点过多会使理解目标与特征的趋势变得困难。Featexp 创建了更好的图表来帮助解决这个问题。我们来试试吧!
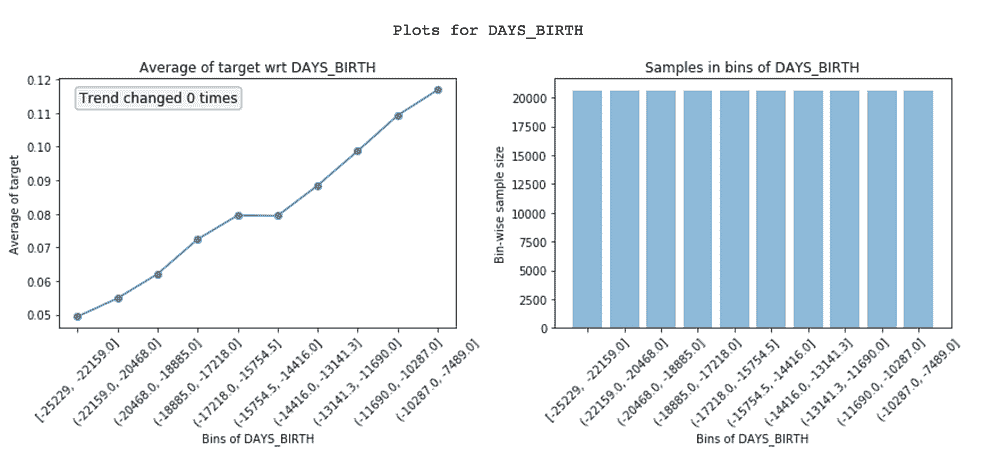
DAYS_BIRTH(年龄)的特征与目标图
Featexp 创建了一个数值特征的等人口区间(X 轴)。然后计算每个区间的目标均值,并将其绘制在上面的左侧图中。在我们的例子中,目标均值就是违约率。图表告诉我们,高负值的 DAYS_BIRTH(较大年龄)的客户违约率较低。这是合理的,因为年轻人通常更容易违约。这些图表帮助我们了解特征对客户的影响以及它如何影响模型。右侧的图表显示了每个区间的客户数量。
- 识别噪声特征
噪声特征会导致过拟合,识别这些特征并不容易。在 featexp 中,你可以传递一个测试集,并比较训练集/测试集中的特征趋势以识别噪声特征。这个测试集不是实际的测试集,而是你的本地测试集/验证集,你对其目标是知道的。
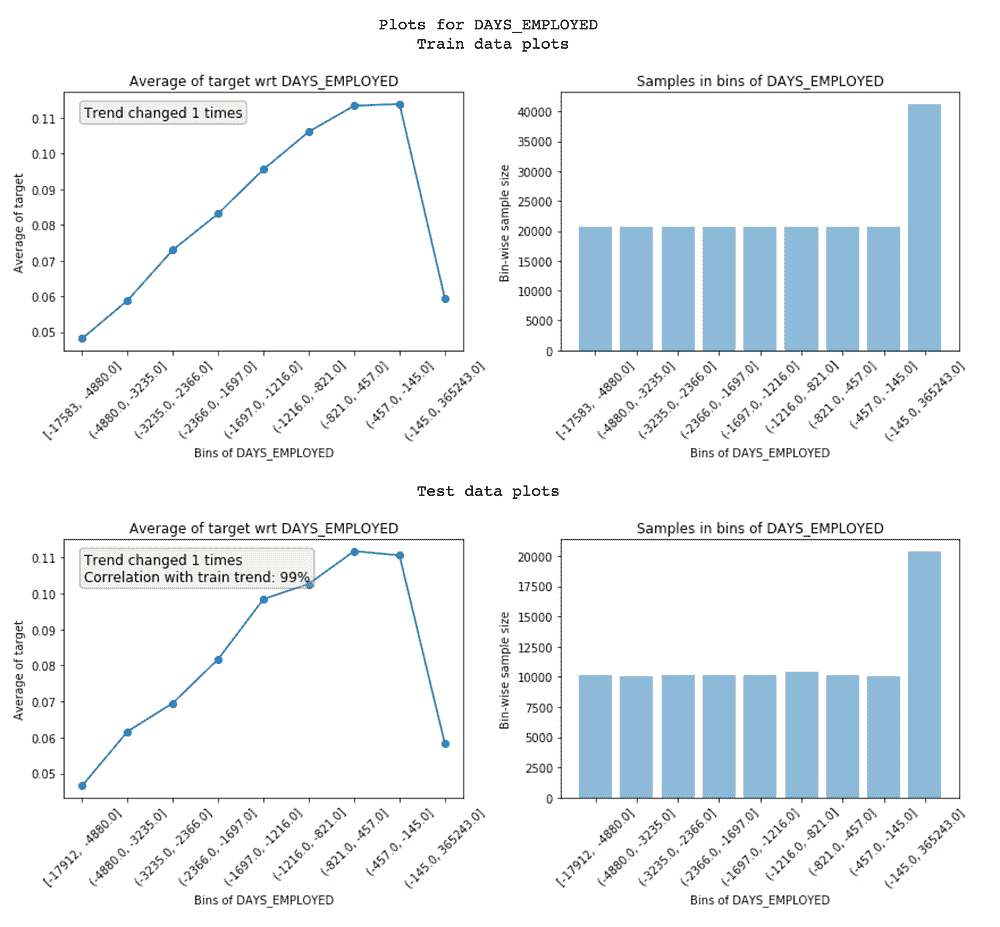
训练集和测试集中的特征趋势比较
Featexp 计算两个指标以显示在这些图表上,这有助于评估噪声。
-
趋势相关性(在测试图中看到):如果一个特征在训练集和评估集中的趋势不同,则可能导致过拟合。这是因为模型正在学习一些在测试数据中不适用的内容。趋势相关性有助于理解训练/测试趋势的相似程度,计算时使用训练集和测试集中区间的目标均值。上述特征的相关性为 99%。看起来不噪声!
-
趋势变化:趋势方向的突然和重复变化可能暗示噪声。但这种趋势变化也可能发生,因为该区间在其他特征方面有很大不同,因此其默认率无法与其他区间进行比较。
下述特征没有保持相同的趋势,因此其趋势相关性较低,为 85%。这两个指标可以用来去掉噪声特征。
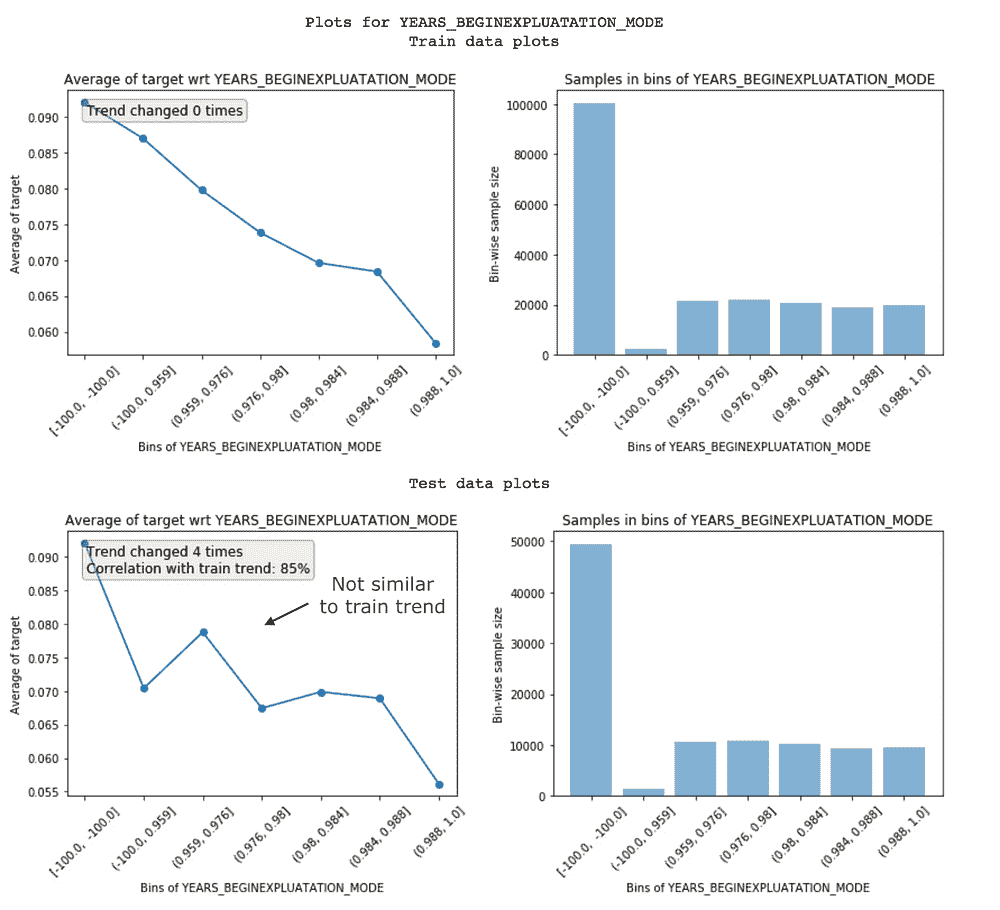
噪声特征示例
在特征数量较多且它们彼此相关时,去掉低趋势相关性的特征效果很好。这样可以减少过拟合,其他相关特征可以避免信息丢失。同时,也要注意不要去掉过多重要特征,否则可能会导致性能下降。此外,你不能仅通过特征重要性来识别这些噪声特征,因为它们可能非常重要,但仍然非常嘈杂!
使用不同时间段的测试数据效果更好,因为这样你可以确保特征趋势随时间保持一致。
get_trend_stats()函数在 featexp 中返回一个包含每个特征趋势相关性和变化的数据框。
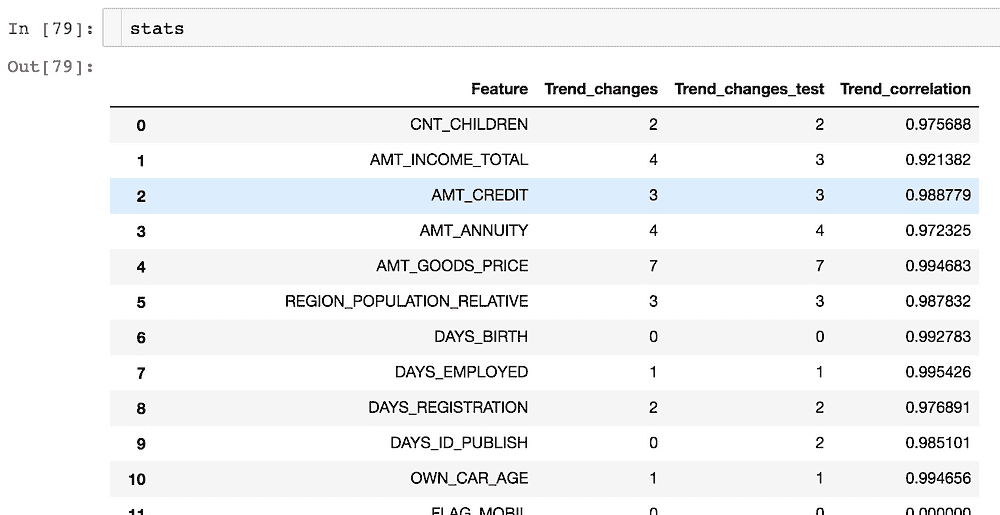
get_trend_stats()返回的数据框
让我们实际尝试在数据中丢弃趋势相关性低的特征,看看结果是否有所改善。
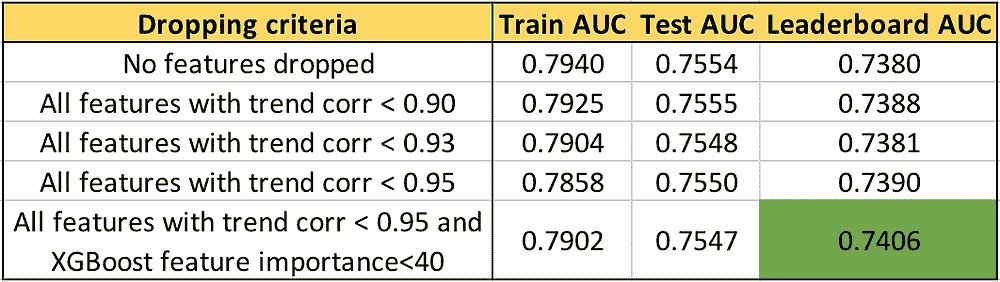
不同特征选择下的 AUC 与趋势相关性
我们可以看到,丢弃特征的趋势相关性阈值越高,排行榜(LB)AUC 越高。 不丢弃重要特征可以进一步提高 LB AUC 到 0.74。值得注意且令人担忧的是测试 AUC 没有像 LB AUC 那样变化。确保验证策略正确,使得本地测试 AUC 跟随 LB AUC 也很重要。完整代码可以在featexp_demo笔记本中找到。
- 特征工程
通过查看这些图,你可以获得创建更好特征的洞见。对数据有更好的理解可以导致更好的特征工程。但除此之外,它还可以帮助你改进现有特征。让我们再看一个特征 EXT_SOURCE_1:
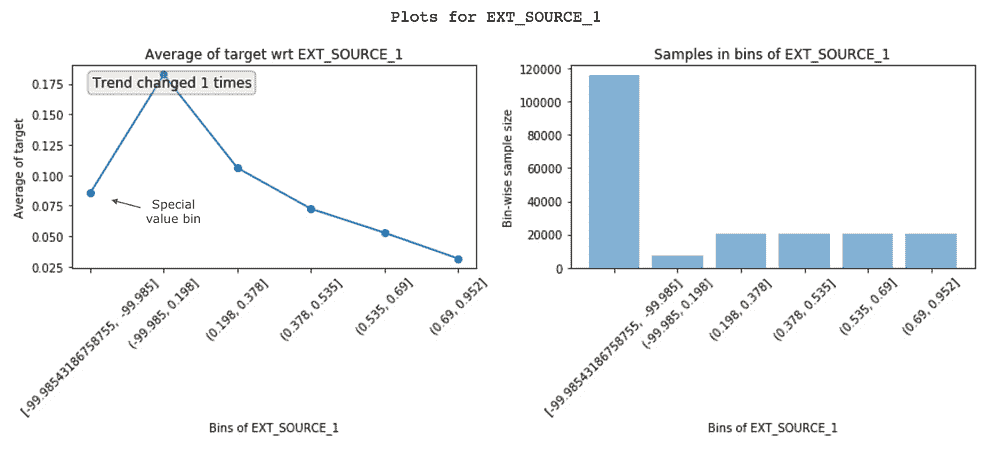
EXT_SOURCE_1 的特征与目标关系图
具有高 EXT_SOURCE_1 值的客户违约率较低。但,第一个区间(~8%的违约率)并没有跟随特征趋势(先上升再下降)。这个区间只有-99.985 左右的负值和一个大的人口基数。这可能意味着这些是特殊值,因此不符合特征趋势。幸运的是,非线性模型在学习这种关系时不会有问题。但是,对于像逻辑回归这样的线性模型,这些特殊值和空值(将作为单独的区间显示)应该用具有类似违约率的区间的值进行填补,而不是简单地用特征均值填补。
- 特征重要性
Featexp 还可以帮助你评估特征的重要性。DAYS_BIRTH 和 EXT_SOURCE_1 都有较好的趋势。然而,EXT_SOURCE_1 的人口集中在特殊值区间,意味着该特征对大多数客户的信息相同,因此不能很好地区分他们。这表明它可能没有 DAYS_BIRTH 重要。根据 XGBoost 模型的特征重要性,DAYS_BIRTH 实际上比 EXT_SOURCE_1 更重要。
- 特征调试
查看 Featexp 的图可以帮助你通过以下两种方式捕捉复杂特征工程代码中的错误:
零变异特征只显示一个区间
-
检查特征的总体分布是否正常。我个人因为一些小错误多次遇到类似上图的极端情况。
-
在查看这些图表之前,始终假设特征趋势会是什么样的。特征趋势看起来与预期不符可能暗示某些问题。坦率地说,假设趋势的过程使得构建机器学习模型变得更加有趣!
-
泄漏检测
目标到特征的数据泄漏会导致过拟合。泄漏特征具有较高的特征重要性。然而,理解特征泄漏的原因是困难的。查看 featexp 图表可以帮助你解决这个问题。
下面的特征在‘空值’分箱中的违约率为 0%,在所有其他分箱中的违约率为 100%。显然,这是泄漏的极端案例。该特征仅在客户违约时有值。根据特征的性质,这可能是由于错误,或者该特征仅为违约者填充(在这种情况下应删除)。了解泄漏特征的问题有助于更快地进行调试。
理解特征为何会泄漏
- 模型监控
由于 featexp 计算了两个数据集之间的趋势相关性,因此可以轻松用于模型监控。每次模型重新训练时,可以将新的训练数据与经过充分测试的训练数据进行比较(通常是第一次构建模型时的训练数据)。趋势相关性可以帮助你监控特征与目标之间的关系是否发生了变化。
这些简单的操作一直帮助我在实际生活中和在 Kaggle 上构建更好的模型。使用 featexp 只需 15 分钟就能查看这些图表,这绝对值得,因为你在此之后不会盲目操作。
个人简介: Abhay Pawar 目前在 Instacart 担任高级机器学习工程师,隶属于搜索与发现团队。他处理大规模机器学习问题,帮助 Instacart 提升服务质量。
原文。经许可转载。
资源:
相关内容:
更多相关话题
成功数据科学面试的秘诀
原文:
www.kdnuggets.com/2019/07/secrets-data-science-interview.html
评论
作者 Himanshu Jain,数据科学家 / 机器学习工程师 & Suresh Venkatasubramanian,首席数据科学家

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT
那么,你已经被邀请参加数据科学面试……但你是否对如何破解数据科学面试感到困惑?你是否担心在数据科学面试中被拒绝?你是否对数据科学面试的准备感到困惑?如果你有上述问题,那么你来对地方了。我们希望分享我们在被面试者和面试官的经历中学到的东西。
你正在阅读本文档,这反映了你在成为成功数据科学家的认真态度。在数据科学领域——一个已经很广泛且快速扩展的领域——接受面试对你作为候选人来说,是一种挑战,对面试官而言也是如此。面试试图在几轮每轮持续一个小时的时间里评估你的数据科学能力,而你的学习则是终身的。这使得面试官(我们曾经也是!)处于一个不值得羡慕的位置,即如何评估像你这样非常热情和知识渊博的人? 好的面试官将你视为潜在的未来同事:他们需要你的帮助。我们相信,如果你是面试官,而我们是被面试者,你可能会希望我们按照以下提到的内容进行配合。
如何开始?
一切都从你简历上写的内容开始。预计会有基于你简历中与数据科学相关的任何内容的问题。理解这些问题可能涉及你过去的经历(> 三年),但不要因此感到困扰。我们相信你能够在简历上的任何内容上给出一个很好的答复。请重温你的过去。重新熟悉你的过去。考虑到你过去用方法 X 解决了某个问题,如果现在要解决它,你是否有更好的方法 Y?同时问问自己:我是否在简历上写了一些内容只是为了让面试官留下深刻印象,但不希望他们基于这些内容提出问题?如果你是面试官,你会觉得这样公平吗?注意:这也适用于简历中存在的技术博客和 GitHub 链接。
问题解决:开放性与封闭性
你的数据科学深度将根据你解决问题的能力来评估。这些问题可能是:
-
给定一个需求,如何解决它。例如,你的业务正在失去客户,找出原因和解决方案。
-
给定一个解决方案,是否可以改进?例如,现有解决方案的‘转化率’为 90%,你将如何将其提高到 91%。
你是否能够重用你过去的方法,并使其在一个新的但不同的背景下发挥作用?你是否也能在最近学到的知识背景下重新思考你旧的方法?
这些是开放性问题,可能在面试范围内没有完整的解决方案。记住,这些问题不是为了从你那里免费获得价值十亿美元的创业点子或可专利的创意;恰恰相反,这些问题纯粹是为了评估你的问题解决能力。实际上,其中一些问题可能与面试官在工作中试图解决的数据科学问题有一定的共鸣。
现在我们已经完成了开放性问题,这里有一些封闭性问题的示例:推导 CNN 的反向传播,解释梯度提升等。前者帮助面试官评估你对未计划情况的反应,而后者则建立了一个根植于标准理解的基线筛选。尽力在这两方面都表现出色。练习是关键。
机器学习
数据科学使用机器学习作为关键技术之一。是的,它也可能使用神经科学、行为经济学、博弈论、统计力学、复杂性理论、非欧几里得几何以及你擅长的诸多领域。然而,你在行业背景下需要解决的问题要求对机器学习技术有扎实的知识作为主要技能;面试官会很高兴你在其他主题上也很专业,但请确保你在机器学习方面也要成为专家。
这就是他们如何评估你的机器学习技能。
-
标准机器学习课程和书籍中涵盖的主题:CS229(斯坦福)、CS4780(康奈尔)、6–034(MIT)、PRML(Chris Bishop)、大规模数据集挖掘。<在此处添加你喜欢的课程和书籍。> 注意:PRML 仅作参考,我们不是说你必须通读整本书。尽可能通过这些标准书籍的阅读来加强课程内容。
-
简历中提到的机器学习方法但并非课程或书籍的一部分。
-
机器学习的数学基础:线性代数、概率与统计、多变量微积分、优化基础(通常这些在标准 ML 课程中会涵盖)
深度学习
你是一个深度学习高手。尽管你有很强的自信,为什么我们仍然认为你需要对‘传统’机器学习有扎实的理解呢?深度学习模型的‘黑箱’特性(你可能完全不同意)使得面试官很难知道你做了什么与模型做了什么。然而,传统机器学习似乎是所有候选人的一个良好的共同点。一个构建了双向 LSTM 但不知道 SVM 如何工作的人的形象如何?请继续展示你的深度学习技能,但在用你的机器学习能力证明一两点之后再进行展示。
你应该知道为什么你选择了某一模型/算法/方法/架构而不是其他的。超参数在深度学习中扮演了关键角色。对模型调优有一个扎实的理解至关重要。一个好模型和一个不那么好的模型之间的差异可能就在于你对超参数的选择。
我们推荐在面试前阅读以下材料:
-
deeplearning.ai 在 Coursera 提供的深度学习专业化(5 门课程)
-
Geoff Hinton 的神经网络课程来自 Coursera,可以更深入地理解概念。
-
一个全面的深度学习课程,涵盖编码器
www.cse.iitm.ac.in/~miteshk/CS7015.html -
从长远来看,你可以阅读由 Yoshua Bengio 和 Ian Goodfellow 编著的深度学习书籍。
注意:我们没有说你必须阅读所有这些内容。通过阅读高质量的内容获得的对主题的熟悉感,会让你在各种情况下更有信心。
工具经验
公司优先考虑那些不仅能提出良好数据科学解决方案,还能有效使用正确工具实施解决方案的候选人。如果你能使自己熟悉行业中可用的工具,将会非常有利。你应该至少了解 Python 或 R 语言,了解用于机器学习算法的 scikit-learn 库,了解用于深度学习的 Keras / TensorFlow / PyTorch / Caffe。不要忽视查询语言,例如 HQL、SQL,以及分布式框架如 Hadoop 和 Spark。好的组织都有这些技能的培训项目。被选中的候选人通常会参加这些培训课程。对上述工具的熟悉程度能为你的候选资格提供必要的优势。尽一切可能在被选中后接受培训。这将使你接触到组织解决的问题,并有机会与组织中的其他科学家互动。这些都是新加入者必须获得的重要经验。
模型的生产化和部署
面试官希望你了解机器学习模型的使用方式、如何进行生产化和部署,以及模型的整体端到端架构。招聘一个不了解自己模型如何被客户/服务/用户/产品使用的人员是非常困难的。如果没有部署,你所做的只是一个概念验证(POC)。即便是最好的情况下,它也只是能在你的笔记本电脑上进行演示。为了使你的机器学习模型发挥作用,它需要成为软件管道的一部分。了解如何与工程师协作进行模型部署。做好卷起袖子、主动行动的准备。通过这样做,你会提升自己在团队中的价值和地位。
模型的生命周期管理
作为一名优秀的数据科学家,你应该了解机器学习模型的完整生命周期。你应该知道当你试图建模的世界发生变化时你的模型应该如何变化。(这种情况比你想象的更频繁,因为现实世界不受你的控制。)你将决定你的模型需要多频繁地重新训练以保持新鲜感。你也可能希望自动化重新训练过程,以节省宝贵的时间。将节省下来的时间用于模型性能的改进。为自己创造机会,解释你如何管理模型的生命周期。
调试机器学习模型
调试是软件行业中非常重要的技能。如果软件无法调试,它的风险就会很高。你应该深入了解你的模型。你需要了解你所使用算法的内部细节。你应该知道如何进行根本原因分析和调试你的模型。面试官希望你知道当模型存在高偏差或高方差时如何改进结果,如何避免梯度爆炸和梯度消失,以及如何在训练过程中优化内存等。
为什么逆序链表仍然是个好主意?
虽然数据结构和算法被外包到各种包中,但你从数据中做出推断的能力仍然受到你对算法和数据结构理解的帮助。虽然面试官不会要求你实现跳表或平衡 k-d 树,但他们仍然希望你理解算法的时间复杂度,熟悉基本的数据结构,如链表、栈、树、哈希表和堆,并对排序、最短路径、字符串处理等算法感到熟悉。换句话说,就是数据结构和算法的基本问题。你可能认为通过这种方式来评判你是不合适的,但记住,你正在让竞争变得更简单。我们相信你完全能够胜任。
了解公司
你被邀请面试的事实表明你的之前经验被人力资源部门和招聘经理(HM)视为潜在的合适人选。不要止步于此!你有责任研究并了解你被邀请面试的团队在做什么,以及你如何能带来价值——这是一个很好的区分点。
当被问到“你还有什么问题吗?”时,你应该问些什么?
注意,这不是让你与面试官亲密的邀请。保持正式和礼貌,就像你在面试过程中一直保持的那样。
这是展示你如何作为数据科学团队一部分的机会。这也是一个引导面试官了解你在面试中未涉及的优势的机会。例如,你可能擅长代码评审。你可以询问代码评审是如何进行的。你可以强调你喜欢的方法,比如走查。你可能想知道使用的开发平台。你可以询问团队是否有开源贡献者(如果你是其中之一,这是重新强调的时机)。你可以问一下交付周期。如果团队分布在不同的时区,了解互动如何进行。如果适用,分享你在这种团队中的工作经验。
询问是否可以大致了解面试官参与的项目。这些问题比想知道远程工作政策或数据科学家的典型工作日如何要好得多。仔细措辞这些问题,因为你不是面试官!当然,最好只问两个问题,因为随后的对话不会给你更多的机会。所以请谨慎选择,并根据面试的具体情况来决定。最重要的是,做一个耐心的倾听者,这是令人难忘的对话的关键。
注意:不要试图通过夸张的表现来催眠面试官。始终保持庄重。记住,没有任何工作比你的尊严更重要。
一些有用的提示
-
请获取澄清。如果你认为问题不明确,可以向面试官提出澄清问题。实际上,这是数据科学家一个重要的技能,即理解需求。你提出这些问题的时间越早越好,因为这可以节省时间,从而帮助面试官更好地评估你。
-
不要把讨论移开到非机器学习的主题。假设你对某个话题没有深入了解,但面试官在那个方向提问。相信我们,转移话题不是一个好主意,原因有三个。
-
这是 unethical 的,完毕。
-
如果成功了,你可能会被分配到一些你在面试中没有准备深入研究的工作。
-
在大多数情况下,这不起作用。面试官和你一样聪明,他们知道你在尝试回避或转移话题。你最终会留下不好的印象。
承认自己对某个话题不太熟悉是很 honorable 的。如果可能,你仍然可以尝试基于基本原理进行回答,并提出澄清问题。如果不行,也不用担心,面试官会从你的简历中转到另一个话题。
处理拒绝
如果这次没有成功,请放心,面试官并不是为了好玩而进行面试。公司在评估你时投入了大量时间和金钱,如果你未能成功,这只是意味着你需要更多的准备。你并没有被拒绝,只有你的申请被拒绝了。此外,考虑到你之外,还有许多其他聪明且有能力的候选人也在面试你申请的职位。选择只有少数候选人是这个过程的自然特性。如果不是你,这对你来说并不是世界末日。(坦白说,不要让任何人对你拥有这种权力。)记下面试中问到的问题,不要带有任何评判。但不要立即分析;等一两天让自己恢复冷静。然后在没有怨恨的情况下反思你如何在下一次成为更好的候选人。找出改进的机会并制定行动计划,开始付诸实践,因为停留在过去或处于无所作为的状态没有意义。公司非常期待你在下一个周期再次申请(与 HR 确认时间)——我们中的许多人在被录用之前申请了不止一次。你的 HR 联系人也会努力提供反馈,但请……请……请……不要开始反驳链。在这种情况下像数据科学家一样行为:如果数据(面试结果)与你的假设(你的准备)不一致,调整假设,即下次做得更好。
好吧,这可能听起来有点哲学。然而,我们认为这对提升你的候选人素质和作为一个更好的人来说是实际而重要的。发展两种自我意识:内部和外部。前者是关于你对自己的意识;后者是关于你对他人对你的看法的意识。如何将这两者结合起来,以创造一个有益的面试体验应该是清楚的。我们建议你阅读塔莎·尤里奇的《Insight》。
什么是公平的面试?
你可能会想,这似乎是一个冗长且充满虚伪友善的列表,在以一种做作的方式对我提出许多要求(这不是本意,也不是真正的虚伪友善;不过对于冗长的部分抱歉)。你可能会想,在公平的面试过程中,你究竟会得到什么。以下是我们为候选人提供的内容。你也可以期望其他知名组织提供类似的体验。
公平评估。
-
不会有类似于:我想了一个 10 位随机数,猜对它。 不,我们不期望你给出我们心目中的答案;只要是正确的答案,你的答案和我们的答案一样好。
-
我们不会将我们的个性投射到你身上。例如,我觉得简单,因此你也应该觉得简单。
-
期望你在问题结束的瞬间给出答案。在你回答之前,我们完全可以倾听你的沉默或思考。
-
没有技巧性问题或误导性问题。
-
我们两天前了解到的东西,我们不期望你能终身记住。因此,尽管我们最近读了一些很棒的 Medium 文章,让我们觉得自己像天才一样,但我们不会基于这些文章提问(哽咽!)。
-
几个不好的回答会被整体表现良好所弥补。
与你的经验和知识有关的问题。
- 如果你的简历足够丰富以至于被邀请面试,那么它足够丰富以便我们将问题限制在简历的内容范围内。简历中没有的东西是你不擅长的良好证据。这不包括基本的机器学习概念。
礼貌对待。
-
面试官会自我介绍。
-
面试官会告诉你面试的结构。
-
面试官会询问你是否需要饮料。
-
面试官会关注你。
-
面试官绝不会做任何不道德的事情。例如,对你现在或过去的组织或教育机构发表粗鲁或讽刺的评论;鼓励你违反保密协议。
-
面试官绝不会让你感到不适。例如,他们不会威逼你或嘲笑你的回答。
-
面试官会陪你吃午餐,或者把你交给其他人带你去午餐。
祝你准备顺利,愿力量与你同在!!!
我们非常希望听到您的反馈。别忘了与我们分享这些技巧如何帮助您破解数据科学面试的经历。
联系我们:
-
Suresh(沃尔玛实验室首席数据科学家) — suresh.venkatasubramanian@gmail.com
-
Himanshu(沃尔玛实验室数据科学家) — himanshu6589@gmail.com
免责声明:上述观点仅为个人观点,不应被解读为我们组织的正式立场。然而,我们确实希望任何专业组织都能有一个公平的筛选过程,以反映上述提到的要点。
Himanshu Jain 是沃尔玛实验室的数据科学家 / 机器学习工程师。
Suresh Venkatasubramanian 是沃尔玛实验室的首席数据科学家。
原文。经许可转载。
相关:
-
破解数据科学家面试
-
职业转型到数据科学的逐步指南 – 第一部分
-
机器学习工程职位是什么样的
更多相关话题
Segment Anything Model: 图像分割的基础模型
原文:
www.kdnuggets.com/2023/07/segment-anything-model-foundation-model-image-segmentation.html
分割,即识别属于对象的图像像素,是计算机视觉的核心。这一过程用于从科学成像到照片编辑的各种应用,技术专家必须具备高度的技能,并拥有大量标注数据的 AI 基础设施,以进行准确建模。
Meta AI 最近揭晓了其 Segment Anything 项目,这是一个图像分割数据集和模型,包含 Segment Anything Model (SAM) 和 SA-1B 掩模数据集,这是迄今为止最大的数据集,旨在支持计算机视觉基础模型的进一步研究。他们为研究用途提供了 SA-1B,而 SAM 则在 Apache 2.0 开源许可证下授权,任何人都可以使用这个 演示 来尝试 SAM 和你的图像!
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作

Segment Anything Model / 图像由 Meta AI 提供
朝着泛化分割任务的方向前进
之前,分割问题通常采用两类方法:
-
交互式分割,用户通过迭代地优化掩模来指导分割任务。
-
自动分割允许选择性地分割如猫或椅子等物体类别,但这需要大量标注对象用于训练(例如,数千个甚至数万个分割猫的例子),以及计算资源和技术专长来训练分割模型。两种方法都没有提供一种通用的、完全自动的分割解决方案。
SAM 在一个模型中使用了交互式和自动化分割。提出的界面支持灵活使用,通过工程化的提示(如点击、框选或文本)使得各种分割任务成为可能。
SAM 的开发使用了一个广泛的高质量数据集,其中包含超过十亿个掩码,这些掩码是该项目的一部分,赋予了它对训练期间未观察到的新类型物体和图像进行泛化的能力。因此,实践者无需再收集自己的分割数据或专门为其用例量身定制模型。
这些能力使得 SAM 能够在任务和领域之间进行泛化,这是其他图像分割软件之前从未做到的。
SAM 的功能和应用场景
SAM 具有强大的功能,使得分割任务更加高效:
- 各种输入提示:引导分割的提示使用户能够轻松执行不同的分割任务,无需额外的训练要求。你可以使用交互式点和框进行分割,自动分割图像中的所有内容,并为模糊提示生成多个有效的掩码。在下图中,我们可以看到通过输入文本提示完成了某些物体的分割。
使用文本提示框的边界框。
-
与其他系统的集成:SAM 可以接受来自其他系统的输入提示,例如未来可能会接受来自 AR/VR 头显的用户视线并选择物体。
-
可扩展输出:输出的掩码可以作为其他 AI 系统的输入。例如,物体掩码可以在视频中进行跟踪、启用图像编辑应用、提升到 3D 空间,甚至可以用于创意用途,例如合成。
-
零样本泛化:SAM 已经发展出了对物体的理解,使其能够快速适应不熟悉的物体,而无需额外的训练。
-
多重掩码生成:当面对物体分割的不确定性时,SAM 可以生成多个有效的掩码,为解决实际环境中的分割问题提供重要帮助。
-
实时掩码生成:SAM 可以在预计算图像嵌入后,实时生成任何提示的分割掩码,实现与模型的实时交互。
理解 SAM:它是如何工作的?
SAM 模型概述 / 图片来源于 Segment Anything
近年来,自然语言处理和计算机视觉领域的一项重要进展是基础模型,这些模型通过“提示”实现了对新数据集和任务的零样本和少样本学习。Meta AI 研究人员训练 SAM,以便为任何提示返回有效的分割掩码,例如前景/背景点、粗略的框/掩码、自由形式文本或指示图像中目标物体的任何信息。
有效的掩码意味着即使提示可能指代多个对象(例如:衬衫上的一个点可能代表它本身或穿着它的人),其输出应仅为一个对象提供合理的掩码?—?从而预训练模型并通过提示解决一般下游分割任务。
研究人员观察到,预训练任务和交互式数据收集对模型设计施加了特定的限制。最重要的是,实时模拟必须在 CPU 上高效运行,以允许标注者实时交互使用 SAM 进行高效标注。尽管运行时限制导致了质量和运行时限制之间的权衡,但简单设计在实际中产生了令人满意的结果。
在 SAM 的底层,一个图像编码器为图像生成一次性嵌入,而一个轻量级编码器将任何提示实时转换为嵌入向量。这些信息源随后由一个轻量级解码器结合,该解码器根据用 SAM 计算的图像嵌入预测分割掩码,因此 SAM 可以在 Web 浏览器中为任何给定提示在 50 毫秒内生成分段。
构建 SA-1B:分割 10 亿个掩码
构建和训练模型需要访问一个在训练开始时不存在的庞大而多样的数据池。今天的分割数据集发布是迄今为止最大的。标注者使用 SAM 交互式标注图像,然后用这些新数据更新 SAM?—?重复这一周期多次,以不断优化模型和数据集。
SAM 使得收集分割掩码比以往更快,每个掩码交互式标注只需 14 秒;这一过程比使用快速标注界面的边界框标注(仅需 7 秒)慢两倍。可比的大规模分割数据收集工作包括 COCO 完全手动多边形掩码标注,耗时约 10 小时;SAM 模型辅助的标注工作甚至更快;其每个掩码的标注时间比之前的模型辅助大规模数据标注快了 6.5 倍,而数据标注时间则慢了 2 倍!
仅通过交互式标注掩码不足以生成 SA-1B 数据集,因此开发了一个数据引擎。该数据引擎包含三个“齿轮”,首先是辅助标注者,然后是与辅助标注结合的完全自动化标注,以增加收集的掩码的多样性,最后是数据集扩展的完全自动化掩码创建。
根据人类评估研究,SA-1B 最终数据集包含超过 11 亿个分割掩码,采集自 1100 万张有许可和隐私保护的图像,这些掩码的数量是现有任何分割数据集的 4 倍。经过这些人类评估验证,这些掩码与之前手动注释的数据集相比,展现了更高的质量和多样性。
SA-1B 的图像来自多个国家的图像提供商,代表了不同的地理区域和收入水平。虽然某些地理区域仍然代表性不足,但 SA-1B 由于其图像数量更多和对所有区域的总体覆盖更好,因此提供了更大的代表性。
研究人员进行测试,旨在揭示模型在性别表现、肤色感知、年龄范围以及呈现人物的感知年龄方面的任何偏见,发现 SAM 模型在各个群体中表现相似。他们希望这能使最终的工作在实际应用中更加公平。
虽然 SA-1B 促进了研究成果,但它也可以使其他研究人员训练基础模型以进行图像分割。此外,这些数据可能成为具有附加注释的新数据集的基础。
未来的工作与总结
Meta AI 研究人员希望通过共享他们的研究和数据集,可以加速图像分割和图像与视频理解领域的研究。由于这个分割模型可以作为更大系统的一部分来执行这一功能。
在这篇文章中,我们介绍了什么是 SAM 及其能力和使用案例。随后,我们介绍了它是如何工作的,以及它是如何训练的,以便概述模型。最后,我们以未来愿景和工作总结了文章。如果你想了解更多关于 SAM 的信息,确保阅读论文并尝试演示。
参考文献
Youssef Rafaat 是一位计算机视觉研究员和数据科学家。他的研究专注于为医疗保健应用开发实时计算机视觉算法。他还在营销、金融和医疗领域担任数据科学家超过 3 年。
更多相关话题
如何为您的数据科学问题选择初始模型
原文:
www.kdnuggets.com/2021/08/select-initial-model-data-science-problem.html
评论
由 Zachary Warnes,数据科学家

照片由 Cesar Carlevarino Aragon 提供,来源于 Unsplash
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT 工作
本文旨在帮助新手或有志的数据科学家决定在问题中使用哪个模型。
本文不会涉及数据处理。希望您知道这是数据科学家工作的主要部分。我假设您已有一些数据,并希望了解如何进行预测。
简单模型
有很多模型可供选择,并且似乎有无尽的变体。
通常只需进行轻微的调整即可将回归模型更改为分类模型,反之亦然。幸运的是,这项工作已经通过标准的 Python 监督学习包为您完成。因此,您只需选择您想要的选项即可。
有很多模型可以选择:
-
决策树
-
支持向量机(SVM)
-
朴素贝叶斯
-
K-最近邻
-
神经网络
-
梯度提升
-
随机森林
列表还在继续,但考虑从两个模型之一开始。
线性回归 & 逻辑回归

照片由 iMattSmart 提供,来源于 Unsplash
是的,像 xgboost、BERT 和 GPT-3 这样的高级模型确实存在,但从这两个开始吧。
注意:逻辑回归有一个不幸的名称。该模型用于分类,但由于历史原因,名称得以保留。*
我建议将名称更改为像线性分类这样的直接命名,以消除这种混淆。但是,我在行业中还没有那样的影响力。
线性回归
**from** **sklearn.linear_model** **import** LinearRegression
**import** **numpy** **as** **np**X = np.array([[2, 3], [5, 6], [8,9], [10, 11]])
y = np.dot(X, np.array([1, 2])) + 1
reg = LinearRegression().fit(X, y)
reg.score(X, y)
逻辑回归
**from** **sklearn.linear_model** **import** LogisticRegression
**from** **sklearn.datasets** **import** load_breast_cancer
X, y = load_breast_cancer(return_X_y=**True**)
clf = LogisticRegression(solver='liblinear', random_state=10).fit(X, y)
clf.score(X,y)
为什么选择这些模型?
为什么要从这些简单模型开始? 因为可能您的问题不需要任何复杂的模型。
如果只是为了获得稍微提高的准确率而投入大量精力和花费在 AWS 上的费用,那么这是不值得的。
这两种模型已经研究了几十年,是一些在机器学习中最为理解透彻的模型。
它们易于解释。 两种模型都是线性的,因此它们的输入以一种可以手动计算的方式转化为输出。
给自己减轻一些头疼的麻烦。
即使你是一名经验丰富的数据科学家,你也应该了解这些模型在你的问题上的表现,主要是因为它们非常容易实现和测试。
我曾经犯过这种错误。我曾经直接深入并构建复杂的模型。以为我使用的 xgboost 模型在总体上是更优的,因此它应该是我的起始模型。结果发现,线性回归模型的表现只差几个百分点。线性回归被使用是因为它更简单且更易解释。
这里涉及到一定的自我认知。

图片由Sebastian Herrmann提供,来源于Unsplash
你可能想要展示你对这些复杂模型的理解及其使用方法。但有时它们设置、训练和维护起来并不实际。仅仅因为一个模型可以使用并不意味着它应该被使用。
不要浪费时间。某个足够好且被使用的模型总是比复杂但没人使用或理解的模型更好。
希望现在你能从简单开始,使用这些模型中的一个。
第一个问题
我的问题是分类问题还是回归问题?
你的问题是回归问题吗?
你是否试图预测一个连续的输出?
线性回归(作者拍摄)
某物的价格,比如房子、产品或股票?回归。
某事物将持续多长时间,比如飞行时长、制造时间或用户在你的博客上花费的时间?回归。
从线性回归开始。绘制你的线性回归并评估这个模型。
保持目前的表现。如果它已经足够好,符合你的问题需求,那么就继续使用它。否则,你可以开始尝试其他模型。
你的问题是分类问题吗?
你是否试图预测一个二元输出或多个唯一且离散的输出?
逻辑回归(作者拍摄)
你是否试图确定某人是否会从你的商店购买东西或赢得比赛?分类。
你是否需要一个简单的“是”或“否”来回答你面临的问题?分类。
从逻辑回归开始,绘制你的数据或其子集的散点图并标记不同的类别。也许已经存在明显的模式。
再次评估模型,如果你仍然需要提高性能,则以此为基准。但从这里开始。
结论
可能,那些阅读过这些内容的人会发现自己处于类似的情况中,选择使用什么模型。然后决定你的问题非常适合你读过的论文中的新模型。结果是,花费数小时调整这个复杂模型,最终却是一个更简单的模型胜出。
不一定是因为性能,而是因为它们简单且易于解释。
节省时间和精力。只需从线性回归和逻辑回归开始。
简介:扎卡里·沃恩斯 是 Pacmed 的数据科学家,他不断寻求新的挑战。多年前,扎卡里认识到解决新问题和克服障碍是学习和发展新技能的最快方式,因此他不断地将自己置于新的环境中,以便从每一个新挑战中受益。
原始内容。经许可转载。
相关:
-
数据科学和机器学习中的基础线性代数
-
你应该使用线性回归模型而非神经网络的 3 个理由
-
10 个机器学习模型训练错误
主题更多
如何使用 [ ]、.loc、iloc、.at 和 .iat 选择 Pandas 中的行和列
原文:
www.kdnuggets.com/2019/06/select-rows-columns-pandas.html
![如何使用 [ ]、.loc、iloc、.at 和 .iat 选择 Pandas 中的行和列](../Images/702ba22e874a73b4bd1f47dd5e07b6a6.png)
图片来源:catalyststuff 在 Freepik
你可以在 这里 下载本教程的 Jupyter notebook。
在这篇博客中,我将展示如何使用 [ ]、.loc、.iloc、.at 和 .iat 在 Pandas 中选择数据子集。我将使用托管在 UCI 网站上的葡萄酒质量数据集。该数据记录了北葡萄牙成千上万种红酒和白酒的 11 种化学性质(如糖、柠檬酸、酒精、pH 等)以及葡萄酒的质量,质量以 1 到 10 的等级记录。我们只查看红酒的数据。
首先,我导入了 Pandas 库,并将数据集读取到数据框中。

这里是数据框的前 5 行:
wine_df.head()

我重命名了列,以便在未来操作中更容易调用列名。
wine_df.columns = ['fixed_acidity', 'volatile_acidity', 'citric_acid',
'residual_sugar', 'chlorides', 'free_sulfur_dioxide',
'total_sulfur_dioxide','density','pH','sulphates',
'alcohol', 'quality']
选择列的不同方法
选择单列
要选择第一列 'fixed_acidity',你可以将列名作为字符串传递给索引操作符。
你也可以使用点操作符执行相同的任务。

选择多个列
要选择多个列,你可以将列名列表传递给索引操作符。
wine_four = wine_df[['fixed_acidity', 'volatile_acidity','citric_acid', 'residual_sugar']]
另外,你也可以将所有列分配给一个列表变量,并将该变量传递给索引操作符。
cols = ['fixed_acidity', 'volatile_acidity','citric_acid', 'residual_sugar']
wine_list_four = wine_four[cols]
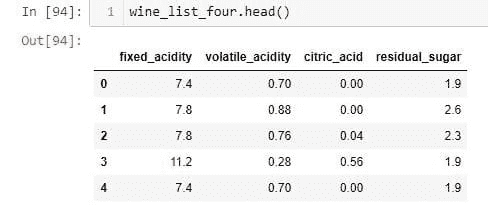
使用 "select_dtypes" 和 "filter" 方法选择列
要使用 select_dtypes 方法选择列,你首先应找出每种数据类型的列数。
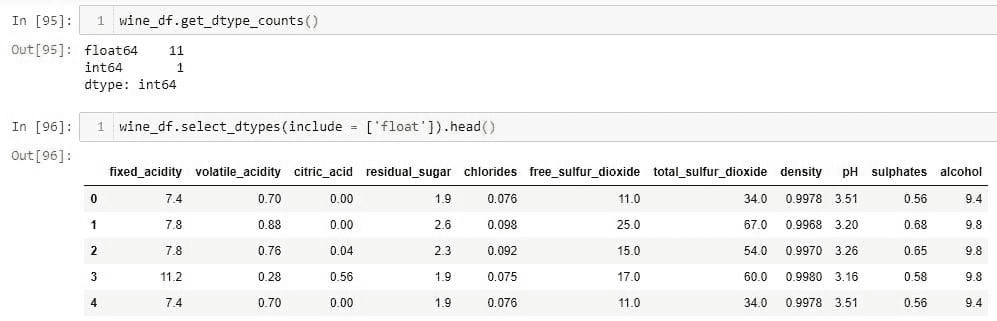
在这个例子中,有 11 列是浮点型数据,一列是整数型数据。要仅选择浮点型列,使用 wine_df.select_dtypes(include = ['float'])。select_dtypes 方法的 include 参数接受一个数据类型列表。列表值可以是字符串或 Python 对象。
你还可以使用 filter 方法根据列名或索引标签选择列。
在上述示例中,filter方法返回包含确切字符串'acid'的列。like参数接受一个字符串作为输入,并返回包含该字符串的列。
你可以在filter方法中使用regex参数来进行正则表达式匹配。
在这里,我首先重命名了ph和quality列。然后,我将正则表达式参数传递给filter方法,以查找所有包含数字的列。
改变列的顺序
我想要改变列的顺序。

wine_df.columns 显示了所有列名。我将列名组织成三个列表变量,并将这些变量连接起来以获得最终的列顺序。

我使用 Set 模块检查new_cols是否包含所有原始列。
然后,我将new_cols变量传递给索引操作符,并将结果 DataFrame 存储在变量"wine_df_2"中。现在,wine_df_2 DataFrame 中的列按我想要的顺序排列。
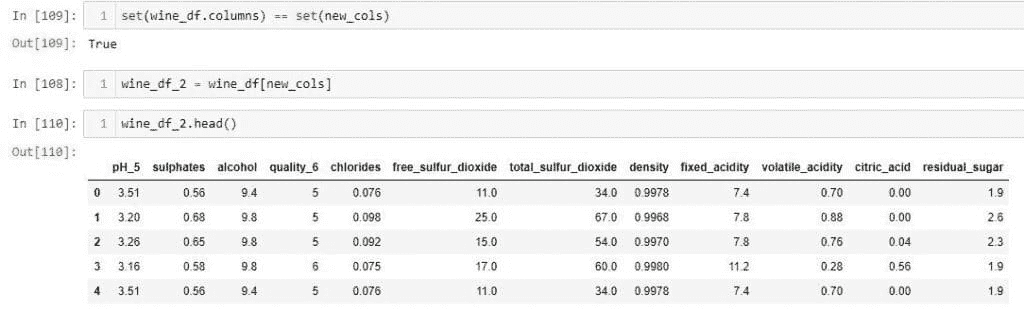
选择行的不同方法
使用.iloc 和 loc 选择行
现在,让我们看看如何使用.iloc 和 loc 从我们的 DataFrame 中选择行。为了更好地说明这一概念,我从“density”列中删除了所有重复行,并将wine_df DataFrame 的索引更改为“density”。
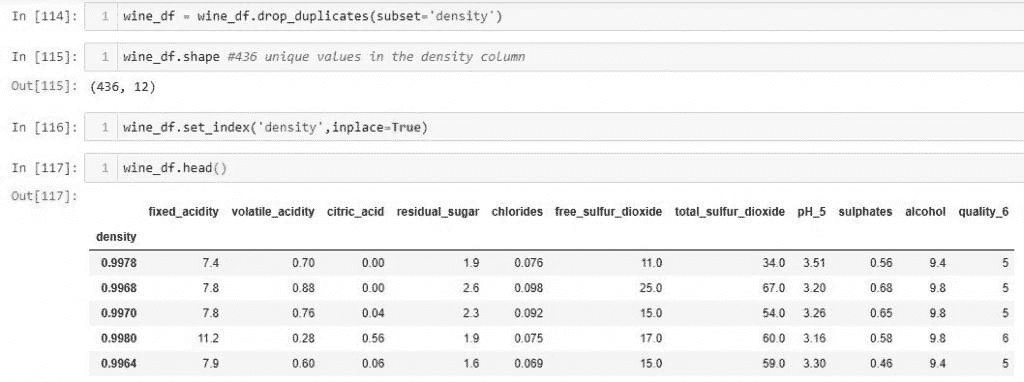
要选择wine_df DataFrame 中的第三行,我将数字 2 传递给.iloc索引器。
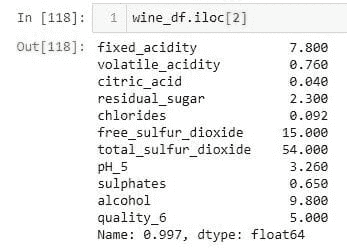
为了做同样的事情,我使用.loc索引器。
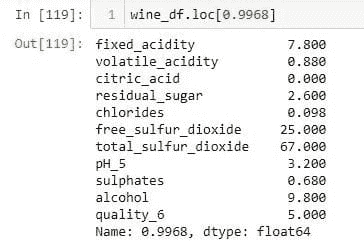
要选择具有不同索引位置的行,我将一个列表传递给.iloc索引器。

我将一系列密度值传递给.iloc索引器,以重现上述 DataFrame。

你可以使用切片来选择多行。这类似于在 Python 中切片列表。

上述操作选择了第 2、第 3 和第 4 行。
你可以使用loc来执行相同的操作。
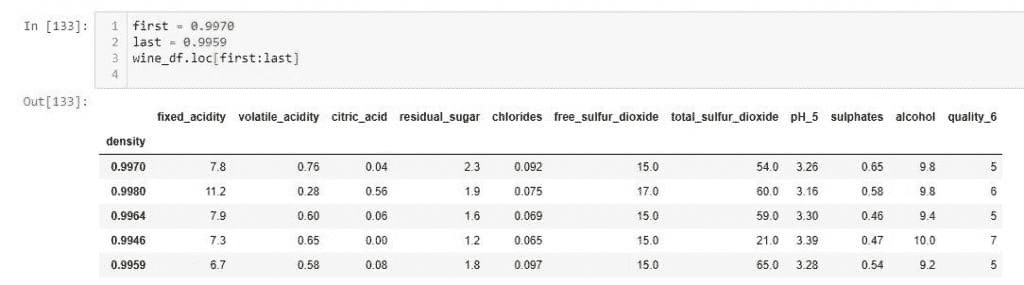
在这里,我选择了索引之间的行 0.9970 和 0.9959。
同时选择行和列
你必须在.iloc和loc索引器中传递行和列的参数,以同时选择行和列。行和列的值可以是标量值、列表、切片对象或布尔值。
选择所有行,以及第 4、第 5 和第 7 列:
要复制上述 DataFrame,将列名作为列表传递给 .loc 索引器:
选择不连续的行和列
要选择特定数量的行和列,你可以使用 .iloc 进行如下操作。

要选择特定数量的行和列,你可以使用 .loc 进行如下操作。
要从 DataFrame 中选择单一值,你可以执行以下操作。

你可以使用切片来选择特定的列。
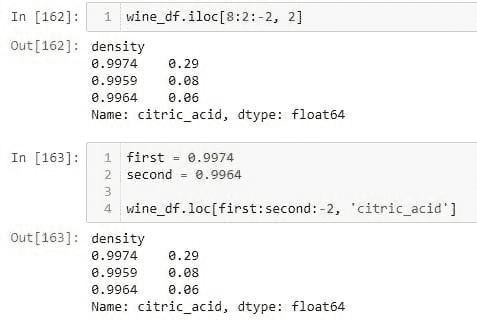
要同时选择行和列,你需要理解方括号中逗号的使用。逗号左侧的参数总是根据行索引选择行,而逗号右侧的参数总是根据列索引选择列。
如果你想选择一组行和所有列,你不需要在逗号后使用冒号。
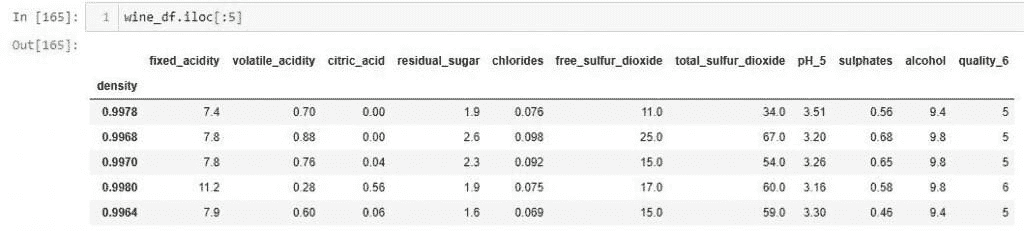
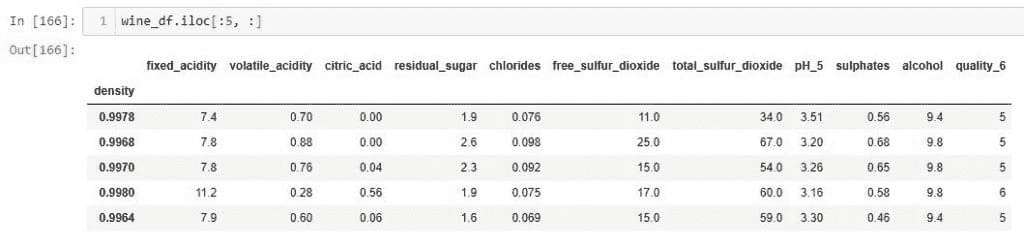
使用 "get_loc" 和 "index" 方法选择行和列
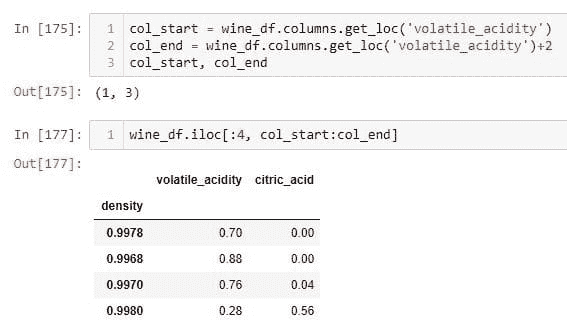
在上述示例中,我使用 get_loc 方法查找列 'volatile_acidity' 的整数位置,并将其赋值给变量 col_start。然后,我再次使用 get_loc 方法查找比 'volatile_acidity' 列多 2 个整数值的列的位置,并将其赋值给变量 col_end。接着,我使用 iloc 方法选择前 4 行,以及 col_start 和 col_end 列。如果你将索引标签传递给 get_loc 方法,它将返回其整数位置。
你可以使用 .loc 执行类似的操作。以下显示了如何选择第 3 到第 7 行,以及从 "volatile_acidity" 到 "chlorides" 的列。
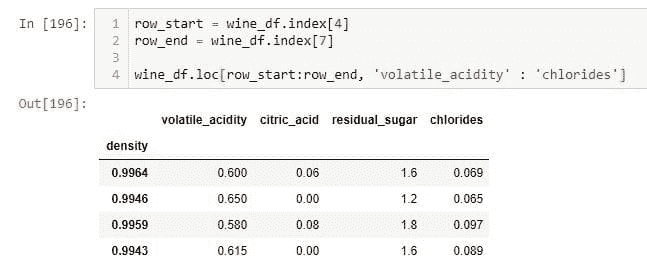
使用 .iat 和 .at 进行子选择
索引器 .iat 和 .at 比 .iloc 和 .loc 更快,用于从 DataFrame 中选择单个元素。
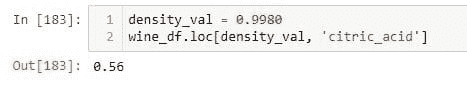


我将撰写更多关于使用 Pandas 操作数据的教程。敬请关注!
参考文献
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 为你的组织提供 IT 支持
更多相关主题
如何选择支持向量机核
原文:
www.kdnuggets.com/2016/06/select-support-vector-machine-kernels.html
对于一个任意的数据集,你通常不知道哪个核可能效果最好。我建议首先从最简单的假设空间开始——因为你对数据了解不多——然后逐步过渡到更复杂的假设空间。因此,如果你的数据集线性可分,线性核表现良好;然而,如果你的数据集不是线性可分的,线性核就不够用了(几乎是字面上的意思;)。
为了简化(以及可视化目的),我们假设我们的数据集仅包含 2 个维度。下面,我绘制了在鸢尾花数据集的 2 个特征上线性 SVM 的决策区域:
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面

这完全可以正常工作。接下来是 RBF 核 SVM:

现在,看起来线性和 RBF 核 SVM 在这个数据集上都可以表现得很好。那么,为什么要偏好更简单的线性假设呢?在这种情况下考虑奥卡姆剃刀原则。线性 SVM 是一个参数模型,而 RBF 核 SVM 则不是,后者的复杂性随着训练集的大小增加。不仅训练 RBF 核 SVM 更昂贵,你还需要保留核矩阵,并且在预测时将数据投影到这个“无限”的更高维空间使数据变得线性可分的代价也更高。此外,你还需要调整更多的超参数,因此模型选择也更昂贵!最后,更复杂的模型更容易过拟合!
好吧,我刚才说的关于核方法的内容听起来都非常负面,但这实际上取决于数据集。例如,如果你的数据不是线性可分的,那么使用线性分类器就没有意义了:

在这种情况下,RBF 核会更有意义:

无论如何,我不会过于纠结于多项式核。在实践中,它在效率(计算和预测)方面的作用较小。因此,经验法则是:对于线性问题使用线性 SVM(或逻辑回归),对于非线性问题使用如径向基函数核等非线性核。
RBF 核 SVM 的决策区域实际上也是一个线性决策区域。RBF 核 SVM 所做的实际上是创建特征的非线性组合,将样本提升到一个更高维的特征空间,在那里你可以使用线性决策边界来分隔你的类别:

好的,上面我给你展示了一个直观的例子,我们可以在 2 维空间中可视化我们的数据……但在实际问题中,即数据集有超过 2 个维度时,我们该如何处理?在这里,我们需要关注我们的目标函数:最小化铰链损失。我们会设置一个超参数搜索(例如网格搜索),并将不同的核函数相互比较。根据损失函数(或像准确率、F1、MCC、ROC auc 等性能指标),我们可以确定哪个核函数对于给定任务是“合适的”。
简历: 塞巴斯蒂安·拉施卡 是一位‘数据科学家’和机器学习爱好者,对 Python 及开源充满热情。《Python 机器学习》的作者。密歇根州立大学。
原文。经许可转载。
相关:
-
深度学习何时比 SVM 或随机森林更有效?
-
分类作为学习机器的发展
-
为什么从头实现机器学习算法?
更多相关话题
选择最佳机器学习算法以解决回归问题
原文:
www.kdnuggets.com/2018/08/selecting-best-machine-learning-algorithm-regression-problem.html
评论

在处理任何类型的机器学习(ML)问题时,有许多不同的算法可供选择。在机器学习中,有一个称为“无免费午餐”定理的理论,该定理基本上表示没有一种 ML 算法对所有问题都最好。不同 ML 算法的性能很大程度上依赖于数据的大小和结构。因此,正确的算法选择通常不明确,除非我们通过简单的试验和错误直接测试算法。
但是,每种机器学习(ML)算法都有其优缺点,我们可以以此作为指导。虽然一种算法并不总是优于另一种,但每种算法都有一些特性,我们可以利用这些特性快速选择合适的算法并调整超参数。我们将查看一些针对回归问题的突出的机器学习算法,并根据它们的优缺点制定使用指南。本文将作为选择最佳机器学习算法以解决回归问题的一个很好的参考!
线性和多项式回归
线性回归
从简单的情况开始,单变量线性回归是一种用于建模单个输入自变量(特征变量)与输出因变量之间关系的技术,即使用线性模型(即一条直线)。更一般的情况是多变量线性回归,其中创建一个模型来表示多个自变量(特征变量)与输出因变量之间的关系。模型仍然是线性的,即输出是输入变量的线性组合。
还有一种第三种更一般的情况叫做多项式回归,其中模型变成了特征变量的非线性组合,即可能包含指数变量、正弦和余弦等。这需要了解数据如何与输出相关。回归模型可以使用随机梯度下降(SGD)进行训练。
优点:
-
模型建立快速,特别适用于需要建模的关系不非常复杂且数据量不大的情况。
-
线性回归容易理解,这对商业决策非常有价值。
缺点:
-
对于非线性数据,多项式回归的设计可能非常具有挑战性,因为必须对数据的结构和特征变量之间的关系有一些了解。
-
由于上述原因,这些模型在处理高度复杂的数据时不如其他模型。
神经网络
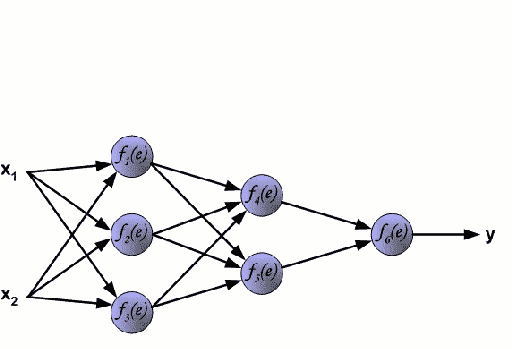
神经网络
神经网络由一组互相连接的节点组成,这些节点称为神经元。数据中的输入特征变量作为多变量线性组合传递给这些神经元,其中每个特征变量乘以的值称为权重。然后,对这个线性组合应用非线性,使神经网络能够建模复杂的非线性关系。神经网络可以拥有多个层,其中一层的输出以相同的方式传递给下一层。在输出处,通常不应用非线性。神经网络使用随机梯度下降(SGD)和反向传播算法(在上面的 GIF 中显示)进行训练。
优点:
-
由于神经网络可以拥有许多层(因此有多个参数)和非线性,它们在建模高度复杂的非线性关系方面非常有效。
-
我们通常不必担心数据的结构,因为神经网络在学习几乎任何类型的特征变量关系时都非常灵活。
-
研究一致表明,只要给网络更多的训练数据,无论是全新的还是通过增强原始数据集得到的,都能提升网络的性能。
缺点:
-
由于这些模型的复杂性,它们不容易解释和理解。
-
它们的训练可能非常具有挑战性且计算密集,需要仔细调整超参数和设置学习率计划。
-
它们需要大量数据才能达到高性能,且在“小数据”情况下通常被其他机器学习算法超越。
回归树和随机森林
随机森林
从基础情况开始,决策树是一个直观的模型,在这个模型中,人们沿着树的分支向下遍历,并根据节点的决策选择下一个要进入的分支。树的归纳任务是将一组训练实例作为输入,决定最适合拆分的属性,拆分数据集,然后对结果拆分的数据集进行递归,直到所有训练实例都被分类。在构建树时,目标是基于属性进行拆分,以创建尽可能纯净的子节点,这将使分类数据集中的所有实例所需的拆分次数最小化。纯度通过信息增益的概念来衡量,这与需要了解多少关于一个先前未见的实例以便正确分类有关。在实践中,通过比较熵,即分类当前数据集分区中的单个实例所需的信息量,与如果对当前数据集分区进行进一步拆分的情况下分类单个实例所需的信息量来进行测量。
随机森林仅仅是决策树的集成。输入向量通过多个决策树进行计算。对于回归,所有树的输出值取平均;对于分类,使用投票机制来确定最终类别。
优点:
-
擅长学习复杂的、高度非线性的关系。它们通常能够实现相当高的性能,优于多项式回归,并且通常与神经网络相当。
-
非常容易解释和理解。尽管最终训练的模型可以学习复杂的关系,但在训练过程中建立的决策边界容易理解且实用。
缺点:
-
由于决策树训练的性质,它们可能容易出现严重的过拟合。一个完成的决策树模型可能过于复杂,并包含不必要的结构。尽管通过适当的树修剪和更大的随机森林集成可以在一定程度上缓解这个问题。
-
使用更大的随机森林集成来实现更高的性能有其缺点,包括速度较慢和需要更多的内存。
结论
哇!这就是你的优缺点!在下一篇文章中,我们将探讨不同分类模型的优缺点。希望你喜欢这篇文章并学到了一些新知识。如果有收获,欢迎点赞。
简介: George Seif 是一名认证的极客和人工智能/机器学习工程师。
原文。经许可转载。
相关:
-
接收器操作特性曲线揭秘(Python 版)
-
Python 中的 5 个快速简单的数据可视化示例(附代码)
-
数据科学家需要了解的 5 种聚类算法
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能。
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求。
更多相关内容
如何说服你的老板数据分析的必要性
原文:
www.kdnuggets.com/2019/08/sell-boss-need-data-analytics.html
评论
数据分析相对较新,但有许多应用场景。公司已经收集信息好几代了。然而,最近技术工具让他们能够评估这些信息,并根据其指示做出明智的决策。由于数据科学是一个新兴领域,一些商业领袖对采纳它有所犹豫,或者希望以令人沮丧的慢速推进。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织的 IT
如果你是一名数据科学专业人士,发现自己处于这种情况可能会特别限制你的发展。以下是一些你可以向老板说明为何分析投资对公司来说是明智之举的方法。
1. 使用易懂的语言
首先要做的是抵制用高深语言堆砌你的推介的冲动。许多你能熟练说出的“大数据”定义对你的老板来说可能就像外语一样。想好要说什么时,尽量将你的词汇和语气保持朴实。
你甚至可以在接触你的老板之前,将你的信息传达给一个对数据分析完全陌生的朋友。问问他们是否理解了你说的内容,以及在任何时候是否感到困惑。还可以征求他们对如何使演示更适合没有广泛数据分析知识的人的意见。
2. 专注于竞争优势
竞争是商业领袖们非常了解的话题。他们知道,无法竞争通常会导致公司倒闭或在市场上遭遇激烈的困境。
因此,值得向你的老板提及,许多商业领袖认识到大数据投资与竞争力提升之间的关系。NewVantage Partners 发布了其 2019 年大数据与人工智能执行调查 以了解这些技术相关的投资模式。调查显示,超过 91% 的受访者加快了他们在大数据和人工智能(AI)方面的投资步伐。
此外,大约相同比例的人提到他们认为技术投资对于转型成为敏捷和竞争力强的企业是必要的。来自福特汽车、Capital One 和 Aetna 的代表是提供反馈的品牌之一。像这样知名品牌看到竞争与大数据投资之间的联系,可能会鼓励你的老板效仿。
3. 理解你老板的动机
向高层管理人员推销创意与对待其他职位的人的方法不同。公司领导无需像低层员工那样通过层级批准事务。
这意味着整体决策过程变得更短。你可以通过借鉴销售人员的方法来促进事情的发展——并增加老板决定支持你的可能性。花时间了解权威人物的动机。换句话说,考虑一下他们在批准大数据投资后最可能想要达成的目标。
利润当然是其中的一部分,但你可能需要更深入地了解你老板的关切所在。例如,大数据可能解决哪些问题,从而影响盈利能力?
在一个案例中,Georgia-Pacific 希望采取更先进的方法来处理数据,并使用了亚马逊网络服务(AWS)来帮助。该公司知道一些机械的停机可能每年使公司损失数百万美元。它利用数据分析帮助预测一些设备故障提前三个月。花时间思考公司中现有的痛点,大数据可能解决这些问题。然后,在你的陈述中留出一些时间,强调为什么分析可能提供如此有前景的可能性。
4. 强调分析工具可以使数据对所有人更加可及
你的老板可能担心增加公司的投资会使数据科学家提取更多的洞见,而让其他人知之甚少。然而,一些公司利用分析的方式打破了信息可能带来的障碍。
在一个数据科学成功案例中,TD 银行希望使分析师更容易利用公司的信息,而无需过多依赖数据科学家。最终,这使得数据集对所有需要使用的人更加可用。TD 银行还花时间评估哪些工具可以帮助实现这个目标。
如果你的老板觉得分析会使公司的信息仅对数据专家开放,积极主动地缓解这种担忧。你可以建议老板制定数据分析工具的必备功能清单,然后提出花时间研究哪些软件具备这些功能。
5. 尽可能引用统计数据
除了提到使用数据分析并获得令人满意结果的公司外,尽量在向老板推销时包括统计数据。如果你能找到与节省资金、提高生产力或改善客户互动相关的信息,那是最理想的。
如果你能提到你所在行业的一家公司在将预算更多地分配到数据科学后一年获得了 72%的成本节省,而不是仅仅说它取得了显著增长,那会更有影响力。尽可能具体地描述你老板可能在引入数据科学后看到的好处。
6. 讨论你的老板可能在没有分析的情况下错过的事情
数据分析软件的一个主要优势是它能从大量信息中提取结果,所需时间远少于人工。你可以在讨论未引入数据科学可能导致公司信息不足时牢记这一点。
例如,数据分析可能显示千禧一代对某个营销活动反应不佳,但 40-50 岁的人群最喜欢它。这可能表明某个城市是新分支机构的理想位置,基于来自希望在那里开设分支的客户的呼叫数量。
角度要明确,让人清楚数据分析投资在当今时代越来越必要。它们使人们比没有这种技术时了解更多信息。
耐心和自信有很大作用
除了记住这些建议外,还要记住,可能需要与老板进行多次严肃的谈话,才能说服他们批准数据分析。如果你对自己所说的内容充满信心,也会有所帮助。
如果你的老板问你无法回答的问题,说明你会找出他们需要了解的内容并反馈给他们。采取这种方式表明你既细心又坚持不懈。
个人简介: 凯拉·马修斯 在《The Week》、《The Data Center Journal》和《VentureBeat》等出版物上讨论技术和大数据,已经写作超过五年。要阅读凯拉更多的文章,订阅她的博客 Productivity Bytes。
相关:
-
为什么数据专业人士应当谈判每一个工作机会
-
如何展示你的数据科学工作的影响
-
6 个逐渐热衷于预测分析和预测的行业
了解更多相关话题
语义搜索与向量数据库
使用Ideogram.ai生成的图像
我相信我们大多数人都使用过搜索引擎。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
甚至有一句话叫“只需谷歌一下。”这句话意味着你应该使用谷歌的搜索引擎来寻找答案。这就是谷歌现在可以被普遍识别为搜索引擎的方式。
为什么搜索引擎如此有价值?搜索引擎允许用户使用有限的查询输入轻松获取互联网信息,并根据相关性和质量组织这些信息。反过来,搜索使得获取之前无法获得的大量知识成为可能。
传统上,搜索引擎获取信息的方法是基于词汇匹配或单词匹配。它运作良好,但有时结果可能不够准确,因为用户意图与输入文本不同。
例如,“红色连衣裙在黑暗中拍摄”这个输入可能有双重含义,特别是词语“拍摄”。更可能的含义是红色连衣裙的照片是在黑暗中拍摄的,但传统的搜索引擎不会理解这一点。这就是语义搜索兴起的原因。
语义搜索可以定义为一种考虑单词和句子含义的搜索引擎。语义搜索的结果是匹配查询含义的信息,这与传统搜索通过单词匹配查询的方式相对。
在自然语言处理(NLP)领域,向量数据库通过利用表示文本意义的高维向量的存储、索引和检索,显著提高了语义搜索能力。因此,语义搜索和向量数据库是密切相关的领域。
本文将讨论语义搜索以及如何使用向量数据库。有了这些信息,让我们深入了解吧。
语义搜索如何工作
让我们在向量数据库的背景下讨论语义搜索。
语义搜索的思路基于文本的意义,但我们如何捕捉这些信息呢?计算机无法像人类一样拥有感觉或知识,这意味着“意义”这个词需要指代其他东西。在语义搜索中,“意义”一词将成为适合有意义检索的知识表示。
意义表示形式是嵌入,将文本转换为带有数值信息的向量。例如,我们可以使用 OpenAI 嵌入模型将句子“I want to learn about Semantic Search”进行转换。
[-0.027598874643445015, 0.005403674207627773, -0.03200408071279526, -0.0026835924945771694, -0.01792600005865097,...]
那么,这个数值向量是如何捕捉意义的呢?让我们退一步看。你上面看到的结果是句子的嵌入结果。如果你替换了上面句子中的任何一个单词,嵌入输出会有所不同。即使是一个单词也会有不同的嵌入输出。
如果我们看整个图景,单个词语的嵌入与完整句子的嵌入会有显著不同,因为句子嵌入考虑了词语之间的关系和句子的整体意义,而这些在单个词语的嵌入中没有体现。这意味着每个词、句子和文本在其嵌入结果中都是独一无二的。这就是嵌入如何捕捉意义,而不是词汇匹配的方式。
那么,语义搜索如何利用向量工作呢?语义搜索的目的是将你的语料库嵌入到一个向量空间中。这允许每个数据点提供信息(文本、句子、文档等)并成为一个坐标点。查询输入在搜索时会通过嵌入处理成向量,进入相同的向量空间。我们会使用向量相似性度量,如余弦相似度,从我们的语料库中找到与查询输入最接近的嵌入。为了更好地理解,你可以查看下面的图像。
作者提供的图片
每个文档嵌入坐标被放置在向量空间中,查询嵌入也被放置在向量空间中。理论上,与输入的语义意义最接近的文档将被选中。
然而,维护包含所有坐标的向量空间将是一个巨大的任务,尤其是在大规模语料库的情况下。向量数据库更适合存储向量,而不是整个向量空间,因为它允许更好的向量计算,并能随着数据的增长保持效率。
在下面的图像中可以看到使用向量数据库进行语义搜索的高级过程。
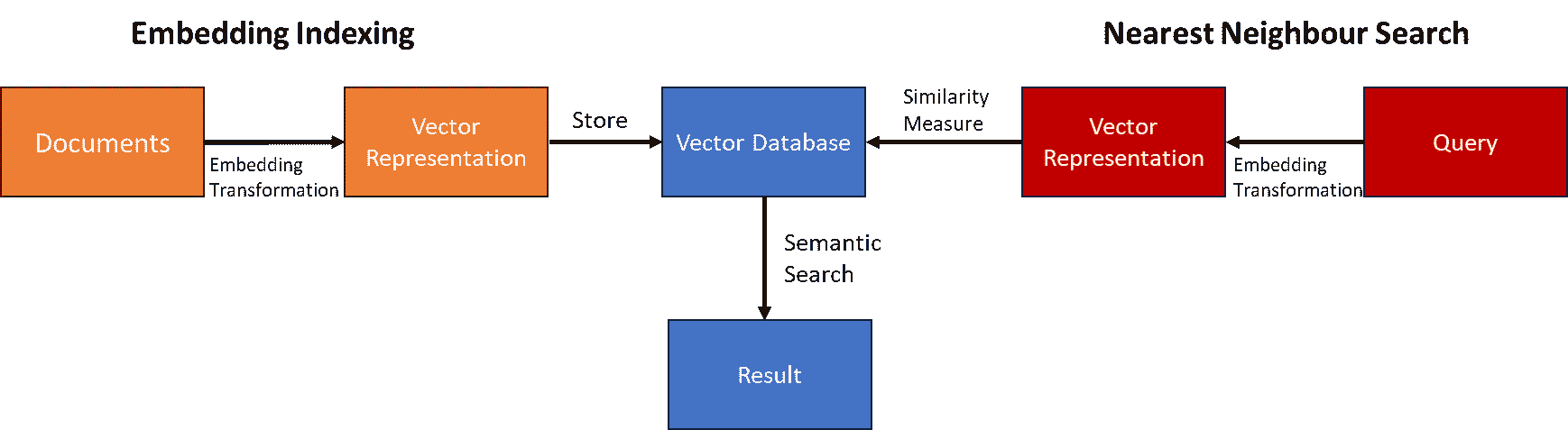
作者提供的图片
在下一节中,我们将通过一个 Python 示例进行语义搜索。
Python 实现
在本文中,我们将使用开源向量数据库 Weaviate。为了教学目的,我们还使用 Weaviate 云服务(WCS)来存储我们的向量。
首先,我们需要安装 Weaviate Python 包。
pip install weaviate-client
接下来,请通过Weaviate Console注册他们的免费集群,并确保获得集群 URL 和 API 密钥。
对于数据集示例,我们将使用Kaggle 的法律文本数据。为了简化操作,我们还将只使用前 100 行数据。
import pandas as pd
data = pd.read_csv('legal_text_classification.csv', nrows = 100)
图片来源:作者
接下来,我们将把所有数据存储到 Weaviate 云服务上的向量数据库中。为此,我们需要设置与数据库的连接。
import weaviate
import os
import requests
import json
cluster_url = "YOUR_CLUSTER_URL"
wcs_api_key = "YOUR_WCS_API_KEY"
Openai_api_key ="YOUR_OPENAI_API_KEY"
client = weaviate.connect_to_wcs(
cluster_url=cluster_url,
auth_credentials=weaviate.auth.AuthApiKey(wcs_api_key),
headers={
"X-OpenAI-Api-Key": openai_api_key
}
)
接下来,我们需要连接到 Weaviate 云服务,并创建一个类(类似于 SQL 中的表)来存储所有文本数据。
import weaviate.classes as wvc
client.connect()
legal_cases = client.collections.create(
name="LegalCases",
vectorizer_config=wvc.config.Configure.Vectorizer.text2vec_openai(),
generative_config=wvc.config.Configure.Generative.openai()
)
在上面的代码中,我们创建了一个使用 OpenAI Embedding 模型的 LegalCases 类。在后台,存储在 LegalCases 类中的任何文本对象都会经过 OpenAI Embedding 模型,并作为嵌入向量进行存储。
让我们尝试将法律文本数据存储到向量数据库中。为此,你可以使用以下代码。
sent_to_vdb = data.to_dict(orient='records')
legal_cases.data.insert_many(sent_to_vdb)
你应该会在 Weaviate 集群中看到你的法律文本数据已经存储在那里。
向量数据库准备好后,让我们尝试语义搜索。Weaviate API 使这变得更加简单,如下代码所示。在下面的示例中,我们将尝试查找发生在澳大利亚的案件。
response = legal_cases.query.near_text(
query="Cases in Australia",
limit=2
)
for i in range(len(response.objects)):
print(response.objects[i].properties)
结果如下所示。
{'case_title': 'Castlemaine Tooheys Ltd v South Australia [1986] HCA 58 ; (1986) 161 CLR 148', 'case_id': 'Case11', 'case_text': 'Hexal Australia Pty Ltd v Roche Therapeutics Inc (2005) 66 IPR 325, the likelihood of irreparable harm was regarded by Stone J as, indeed, a separate element that had to be established by an applicant for an interlocutory injunction. Her Honour cited the well-known passage from the judgment of Mason ACJ in Castlemaine Tooheys Ltd v South Australia [1986] HCA 58 ; (1986) 161 CLR 148 (at 153) as support for that proposition.', 'case_outcome': 'cited'}
{'case_title': 'Deputy Commissioner of Taxation v ACN 080 122 587 Pty Ltd [2005] NSWSC 1247', 'case_id': 'Case97', 'case_text': 'both propositions are of some novelty in circumstances such as the present, counsel is correct in submitting that there is some support to be derived from the decisions of Young CJ in Eq in Deputy Commissioner of Taxation v ACN 080 122 587 Pty Ltd [2005] NSWSC 1247 and Austin J in Re Currabubula Holdings Pty Ltd (in liq); Ex parte Lord (2004) 48 ACSR 734; (2004) 22 ACLC 858, at least so far as standing is concerned.', 'case_outcome': 'cited'}
如你所见,我们得到了两个不同的结果。在第一个案例中,文档中直接提到了“澳大利亚”这个词,因此更容易找到。然而,第二个结果中没有任何“澳大利亚”这个词。但语义搜索可以找到它,因为有与“澳大利亚”相关的词汇,比如“NSWSC”(新南威尔士州最高法院的缩写)或“Currabubula”(澳大利亚的一个村庄)。
传统的词汇匹配可能会遗漏第二条记录,但语义搜索更加准确,因为它考虑了文档的含义。
这就是使用向量数据库进行简单语义搜索的实现。
结论
尽管传统的基于词汇匹配的搜索引擎主导了互联网的信息获取,但这种方法存在一个缺陷,即无法捕捉用户意图。这一局限性催生了语义搜索,一种能够解释文档查询含义的搜索引擎方法。通过向量数据库的增强,语义搜索的能力变得更加高效。
在本文中,我们探讨了语义搜索的工作原理以及如何使用开源的 Weaviate 向量数据库进行 Python 实现。希望这对你有所帮助!
Cornellius Yudha Wijaya 是数据科学助理经理和数据撰稿人。在 Allianz Indonesia 全职工作时,他喜欢通过社交媒体和写作分享 Python 和数据技巧。Cornellius 涉及多种 AI 和机器学习主题的撰写。
更多相关话题
语义分割:维基百科、应用和资源
原文:
www.kdnuggets.com/2018/10/semantic-segmentation-wiki-applications-resources.html
评论
由Prerak Mody提供。
近年来,以深度学习为核心的机器学习技术引起了关注。自动驾驶汽车已经融入了需要算法从输入的图像中识别和学习的深度学习过程。让我们探讨一下语义分割需求的演变。
计算机视觉的最初应用需要识别基本元素,如边缘(线条和曲线)或梯度。然而,像素级别的图像理解只有在全像素语义分割这一术语出现后才出现。它将属于同一目标的图像部分进行聚类,从而开启了众多应用的大门。
识别每个像素或将像素分组并分配 classID 的过程经历了以下步骤:
-
图像分类——识别图像中存在的内容
-
对象识别(及检测)——识别图像中存在的内容及其位置(通过边界框)
-
语义分割——识别图像中存在的内容及其位置(通过找到所有属于该内容的像素)
所以,让我们来看看……
什么是语义分割?
语义分割是一个经典的计算机视觉问题,它涉及将某些原始数据(例如,2D 图像)作为输入,并将其转换为突出显示感兴趣区域的掩码。许多人使用全像素语义分割这一术语,其中图像中的每个像素都根据它属于哪个目标分配一个 classID。
早期的计算机视觉问题只找到像边缘(线条和曲线)或梯度这样的元素,但它们从未能像人类一样在像素级别上理解图像。语义分割将属于同一目标的图像部分进行聚类,解决了这个问题,因此在许多领域得到了应用。
请注意,语义分割与其他基于图像的任务相比,确实有很大不同和进步,例如,
-
图像分类 识别图像中存在的内容。
-
对象识别(及检测) 识别图像中存在的内容及其位置(通过边界框)。
-
语义分割 识别图像中存在的内容及其位置(通过找到所有属于该内容的像素)。
你的机器学习模型是否需要识别输入 2D 原始图像中的每一个像素?在这种情况下,全像素语义分割注释是你机器学习模型的关键。全像素语义分割将图像中的每个像素分配一个 classID,取决于它属于哪个感兴趣的对象。
那么我们就定义一下语义分割的类型,以更好地理解其概念。
语义分割的类型
-
标准语义分割也称为全像素语义分割。它是将每个像素分类为属于某一对象类别的过程。
-
实例感知语义分割是标准语义分割或全像素语义分割的一个子类型。它不仅将每个像素分类为属于某个对象类别,还为该类别分配实体 ID。
让我们探索语义分割的一些应用领域,以更好地理解这种过程的需求。
语义分割的特性
为了理解图像分割的特性,我们也来看看其他常见的图像分类技术。
这次,我将介绍这三种方法,包括图像分割。
1) 图像分类……“识别图像是什么”
2) 图像检测(识别)“识别图像中的位置”
3) 图像分割……“识别意义”
-
图像分类围绕着识别图像是什么的概念。例如,分类的寿司故事图像被逐一分类为“这是三文鱼,这个多少钱,这个很硬”。Amazon Rekognition最近从Amazon发布的对象和场景检测也属于这种图像分类。最初反映的有“杯子、智能手机和瓶子”,但 Amazon Rekognition 现在将整个图像标记为“杯子”和“咖啡杯”。这样,它在多个对象进入图像的场景中无法使用。在这种情况下,你将使用“图像检测(检测)”。
-
图像检测围绕着识别“有什么”以及“它在哪里”的概念。
-
图像分割围绕着识别图像区域的概念。图像分割被称为语义分割,它为每个像素标记该像素所表示的意义,而不是检测整个图像或图像的一部分。既然查看图像更容易,我们来看看实际的图像。
语义分割的应用
- GeoSensing – 用于土地使用

语义分割问题也可以视为分类问题,其中每个像素被分类为一系列对象类别中的一个。因此,卫星影像的土地使用映射有其应用场景。土地覆盖信息对于各种应用非常重要,例如监测森林砍伐和城市化区域。
要识别卫星图像中每个像素的土地覆盖类型(例如,城市、农业、水域等),土地覆盖分类可以视为多类别的语义分割任务。道路和建筑物检测也是交通管理、城市规划和道路监控的重要研究课题。
公开可用的大规模数据集较少(例如:SpaceNet),而数据标注始终是分割任务的瓶颈。
- 用于自动驾驶
自动驾驶是一项复杂的机器人任务,需要在不断变化的环境中进行感知、规划和执行。由于安全至关重要,这项任务还需要以极高的精确度完成。语义分割提供关于道路上空闲空间的信息,并检测车道标记和交通标志。

- 用于人脸分割

人脸的语义分割通常涉及皮肤、头发、眼睛、鼻子、嘴巴和背景等类别。人脸分割在许多计算机视觉的面部应用中非常有用,例如性别、表情、年龄和种族的估计。影响人脸分割数据集和模型开发的显著因素包括光照条件的变化、面部表情、面部朝向、遮挡和图像分辨率。
- 时尚 – 服装项分类

与其他任务相比,服装解析是一项非常复杂的任务,因为它涉及大量类别。这与一般的对象或场景分割问题不同,因为细粒度的服装分类需要基于服装语义、人类姿态的变异性以及可能的大量类别进行更高层次的判断。服装解析在视觉领域得到了积极研究,因为它在现实世界应用中具有巨大的价值,例如电子商务。一些数据集如 Fashionista 和 CFPD 数据集提供了对服装项语义分割的开放访问。
- 精准农业

精准农业机器人可以减少需要在田地中喷洒的除草剂量,作物和杂草的语义分割实时协助它们触发除草行动。这些先进的农业图像视觉技术可以减少对农业的人工监控。
原文. 已获许可转载。
简介:Prerak Mody 是 Playment 的计算机视觉研究员。Prerak 喜欢探索数据分析如何用于改善城市的市政设施,阅读世界金融相关内容,并且目前对强化学习领域非常感兴趣。
相关内容:
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织 IT
更多相关主题
Python 中的情感分析:超越词袋模型
原文:
www.kdnuggets.com/sentiment-analysis-in-python-going-beyond-bag-of-words

图片由 DALL-E 创建
你知道通过情感分析可以在一定程度上预测选举结果吗?数据科学在应用于现实生活情境时比处理模拟数据集更有趣且非常有用。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
在本文中,我们将使用 Twitter 数据进行一个简要的案例研究。最后,你将看到一个对现实生活有重大影响的案例研究,这肯定会引起你的兴趣。但首先,让我们从基础开始。
什么是情感分析?
情感分析是一种预测情感的方法,就像数字心理学家一样。借助这个你创建的心理学家,你将掌控你分析文本的命运。你可以像著名心理学家弗洛伊德一样进行分析,或者只是像一个心理学家一样存在,每次会话收费 10 美元。
就像你的心理学家倾听和理解你的情感一样,情感分析对文本(如评论、评价或推文)做了同样的事情,正如我们在下一节中将要做的那样。为了做到这一点,让我们开始对准备好的数据集进行案例研究。
案例研究:Twitter 数据的情感分析
为了进行情感分析,我们将使用来自 Kaggle 的数据集。这个数据集是通过使用 Twitter API 收集的。这里是这个数据集的链接:www.kaggle.com/datasets/kazanova/sentiment140
现在,让我们开始探索数据集。
探索数据集
现在,在进行情感分析之前,让我们探索一下数据集。要读取它,请使用编码。因为这个原因,我们将在之后添加列名。你可以增加数据探索的方法。Head、info 和 describe 方法会给你很好的提示;让我们看看代码。
import pandas as pd
data = pd.read_csv('training.csv', encoding='ISO-8859-1', header=None)
column_names = ['target', 'ids', 'date', 'flag', 'user', 'text']
data.columns = column_names
head = data.head()
info = data.info()
describe = data.describe()
head, info, describe
这是输出结果。
当然,如果您的项目没有图像限制,您可以逐一运行这些方法。让我们看看我们从这些探索方法中获得的见解。
见解
-
数据集包含 160 万条推文,任何列中都没有缺失值。
-
每条推文都有一个目标情感(0 表示负面,2 表示中性,4 表示正面)、一个 ID、一个时间戳、一个标志(查询或'NO_QUERY')、用户名和文本。
-
情感目标是平衡的,正负标签数量相等。
可视化数据集
太棒了,我们对数据集有了统计和结构上的知识。现在,让我们创建一些可视化图表来描绘它。现在,我们都知道最尖锐的情感,正面和负面。为了查看哪些单词会被使用,我们将使用一个叫做wordcloud的 python 库。
该库将根据数据集中单词的频率可视化数据集。如果单词使用频繁,你可以通过查看其大小来理解它们,这与单词的使用量呈正相关,单词越大,使用频率越高。
但首先,我们需要选择正面和负面推文,并使用python join 方法将它们合并。让我们看看代码。
# Separate positive and negative tweets based on the 'target' column
positive_tweets = data[data['target'] == 4]['text']
negative_tweets = data[data['target'] == 0]['text']
# Sample some positive and negative tweets to create word clouds
sample_positive_text = " ".join(text for text in positive_tweets.sample(frac=0.1, random_state=23))
sample_negative_text = " ".join(text for text in negative_tweets.sample(frac=0.1, random_state=23))
# Generate word cloud images for both positive and negative sentiments
wordcloud_positive = WordCloud(width=800, height=400, max_words=200, background_color="white").generate(sample_positive_text)
wordcloud_negative = WordCloud(width=800, height=400, max_words=200, background_color="white").generate(sample_negative_text)
# Display the generated image using matplotlib
plt.figure(figsize=(15, 7.5))
# Positive word cloud
plt.subplot(1, 2, 1)
plt.imshow(wordcloud_positive, interpolation='bilinear')
plt.title('Positive Tweets Word Cloud')
plt.axis("off")
# Negative word cloud
plt.subplot(1, 2, 2)
plt.imshow(wordcloud_negative, interpolation='bilinear')
plt.title('Negative Tweets Word Cloud')
plt.axis("off")
plt.show()
这是输出结果。
图中的“Thank”和“now”词语看起来更积极。然而,“work”和“now”则显得有趣,因为这些词似乎经常出现在负面推文中。
情感分析
执行情感分析,我们将遵循以下步骤;
-
预处理文本数据
-
拆分数据集
-
向量化数据集
-
数据转换
-
标签编码
-
训练神经网络
-
训练模型
-
评估模型(带绘图)
现在,处理 160 万条推文可能对你的计算机或平台来说是一个巨大的工作量;因此,我最初选择了 5 万条正面推文和 5 万条负面推文。
# Since we need to use a smaller dataset due to resource constraints, let's sample 100k tweets
# Balanced sampling: 50k positive and 50k negative
sample_size_per_class = 50000
positive_sample = data[data['target'] == 4].sample(n=sample_size_per_class, random_state=23)
negative_sample = data[data['target'] == 0].sample(n=sample_size_per_class, random_state=23)
# Combine the samples into one dataset
balanced_sample = pd.concat([positive_sample, negative_sample])
# Check the balance of the sampled data
balanced_sample['target'].value_counts()
接下来,让我们建立神经网络。
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(max_features=10000, ngram_range=(1, 2))
# Train and test split
X_train, X_val, y_train, y_val = train_test_split(balanced_sample['text'], balanced_sample['target'], test_size=0.2, random_state=23)
# After vectorizing the text data using TF-IDF
X_train_vectorized = vectorizer.fit_transform(X_train)
X_val_vectorized = vectorizer.transform(X_val)
# Convert the sparse matrix to a dense matrix
X_train_vectorized = X_train_vectorized.todense()
X_val_vectorized = X_val_vectorized.todense()
# Convert labels to one-hot encoding
encoder = LabelEncoder()
y_train_encoded = to_categorical(encoder.fit_transform(y_train))
y_val_encoded = to_categorical(encoder.transform(y_val))
# Define a simple neural network model
model = Sequential()
model.add(Dense(512, input_shape=(X_train_vectorized.shape[1],), activation='relu'))
model.add(Dense(2, activation='softmax')) # 2 because we have two classes
# Compile the model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Train the model over epochs
history = model.fit(X_train_vectorized, y_train_encoded, epochs=10, batch_size=128,
validation_data=(X_val_vectorized, y_val_encoded), verbose=1)
# Plotting the model accuracy over epochs
plt.figure(figsize=(10, 6))
plt.plot(history.history['accuracy'], label='Train Accuracy', marker='o')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy', marker='o')
plt.title('Model Accuracy over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.grid(True)
plt.show()
这是输出结果。
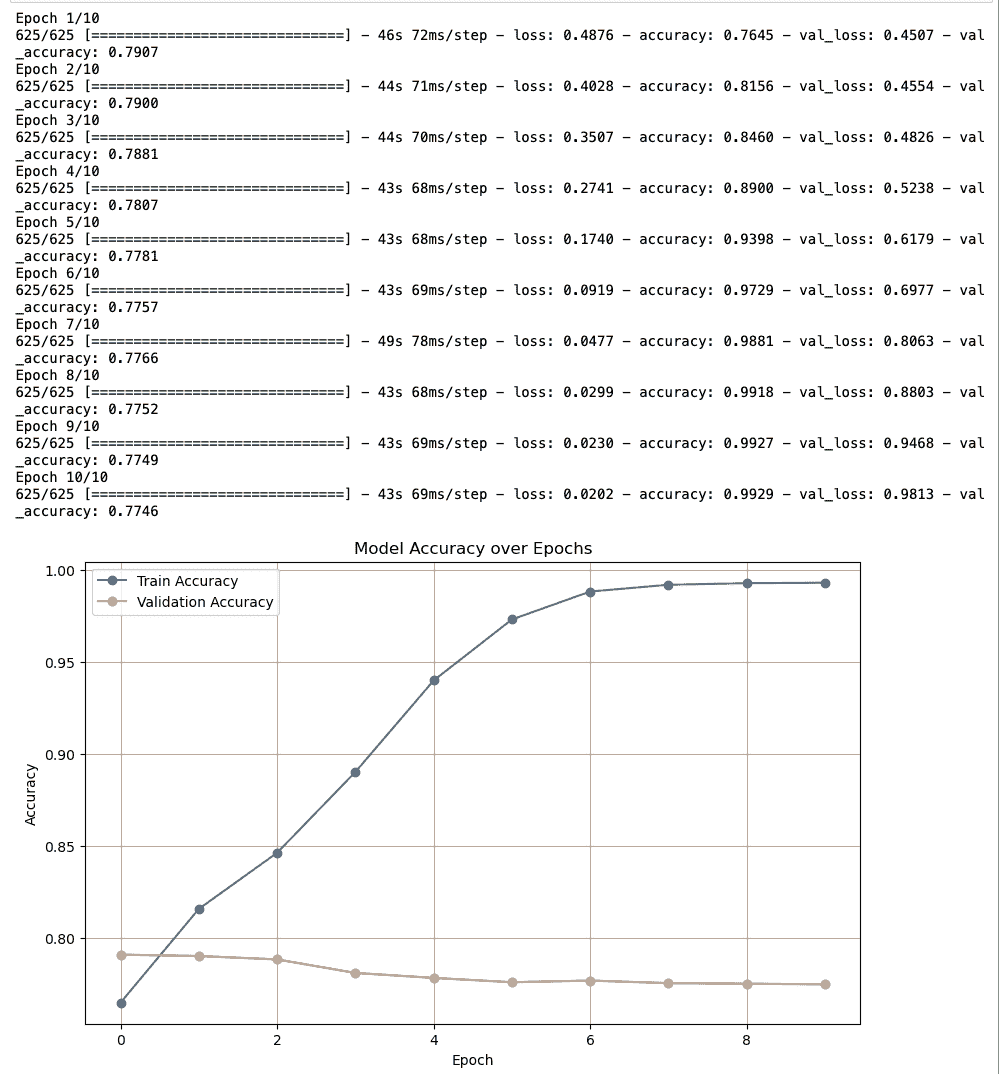
情感分析的最终见解
-
训练准确率:准确率从接近 80%开始,并在第十个周期内不断增加到接近 100%。所以,模型看起来在有效学习。
-
验证准确率:验证准确率再次从 80%左右开始,并迅速稳定增长,这可能表明模型未能对未见数据进行泛化。
案例研究建议:总统选举情感分析
在本文开始时,你的兴趣被激发了。现在,让我们解释一下背后的真实故事。
论文《使用机器学习算法预测推特选举结果》,
发表在《计算机科学与通信的最新进展》中,介绍了一种基于机器学习的方法来预测选举结果。这里可以阅读全文。
总之,他们进行了情感分析,并在 2019 年 AP 大会选举中达到了 94.2%的准确率。看起来他们确实非常接近。
如果你计划做一个作品集项目、类似的研究,或者打算在这个案例研究的基础上进一步深入,你可以使用 Twitter API 或 x API。以下是计划:developer.twitter.com/en/products/twitter-api

在重大体育或政治事件后,你可以对 Twitter 上的话题标签进行情感分析。在 2024 年,许多国家(如美国)将举行选举,你可以查看新闻。
最后的想法
数据科学的力量在这个例子中得到了真正的体现。今年,我们将见证全球范围内的众多选举,因此如果你希望吸引对你的项目的关注,这可能是一个好主意。如果你是一个初学者,正在寻找学习数据科学的方法,你可以在 StrataScratch 上找到许多现实生活中的项目、数据科学面试问题和博客文章,如数据科学项目。
Nate Rosidi 是一位数据科学家和产品策略专家。他还是一名兼职教授,教授分析课程,并且是 StrataScratch 的创始人,该平台帮助数据科学家准备面试,提供来自顶级公司的真实面试问题。Nate 撰写了关于职业市场最新趋势的文章,提供面试建议,分享数据科学项目,并覆盖所有 SQL 相关内容。
更多相关主题
使用 R 在 Cloud Run 上进行无服务器机器学习
原文:
www.kdnuggets.com/2020/02/serverless-machine-learning-r-cloud-run.html
评论
作者 Timothy Lin,数据科学家,计量经济学家
每位数据科学家面临的主要挑战之一是模型部署。除非你是那些幸运的少数人之一,拥有大量数据工程师来帮助你部署模型,否则在企业项目中这确实是一个问题。我甚至没有暗示模型需要准备好生产使用,但即使是将模型和见解提供给业务用户这样一个看似简单的问题,也比实际需要的要麻烦得多。过去解决这个问题主要有两种方法:
-
每次请求的临时手动运行
-
将代码托管在服务器上并编写 API 接口以使结果可用
这两种方法代表了一个光谱的两端。临时运行太过繁琐,客户通常会要求某种自助服务界面,但要获得一个永久服务器来托管你的代码则要运气好。事实证明还有一种第三种方法——无服务器方法!AWS Lambdas 和 Google Cloud Platform Cloud Functions 确实开辟了一种新的结果服务方式,而无需管理任何基础设施。如果你可以访问云,这是一个非常有吸引力的选项。
如果你来自 JavaScript 或 Python 领域,你可能已经使用过这些工具。云函数的问题在于它限制于特定环境。然而,随着 GCP 的 Cloud Run 的引入,我们不再受此问题的限制。Cloud Run 允许在云上提供自定义 Docker 镜像,从而为无服务器领域开辟了许多有趣的可能性。这意味着 R 用户也终于有了开发和部署无服务器机器学习模型的方式!????
这篇文章记录了我在使用 Cloud Run 时的一些经验,希望能作为一个好的参考模板,供任何可能想尝试的人使用。我从两个其他来源中获得了灵感,即 Mark 的博客 和 Eric 的文章。Mark 实际上在 CRAN 上有一个自动化一些部署工作的包,Eric 还介绍了持续集成管道的一些内容,所以一定要去看看。
这篇文章更像是一个实用指南,包含一个分析师可能开发并希望部署的真实世界机器学习应用,这使得应用变得更加具体和有用。这也是一个非常有趣的小副项目。
如果你是一个编程人员,你可以跳过剩下的文章,直接查看 github 代码,否则继续阅读 😃
我的项目会在 Cloud Run 上运行吗?
Cloud run 并不是万能的。查看 需求规格说明 和 限制 以获取更多详细信息,但这里有一些你应该注意的限制。
-
状态不会被持久化(如果你想持久化它们,你需要一个外部数据库)
-
最大内存限制为 2GB
-
容器必须在收到请求后的 4 分钟内启动服务器,并在 15 分钟后超时
这使其非常适合短时间计算,但不适合需要大量内存或非常 CPU 密集的任务。15 分钟实际上还算不错!你可能可以运行一些回归分析、决策树,甚至解决线性规划问题,但可能无法训练神经网络。
Twitter 项目 ????
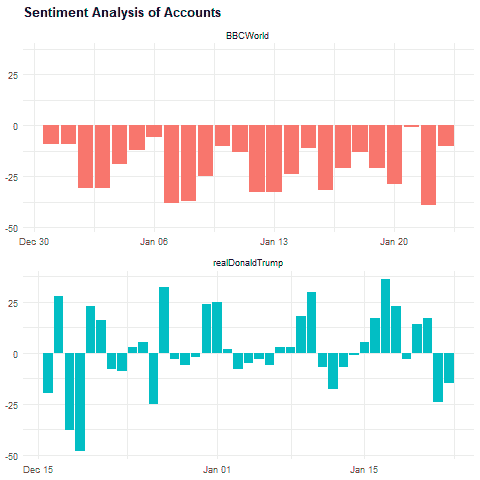
这是我有趣的 serverless-ml 周末项目:一个分析 Twitter 领域的应用程序。我想生成两个图表:一个比较推文频率随时间变化的图表,以及另一个对推文进行情感分析的图表。作为额外奖励,我决定使其具有交互性——这意味着既提供静态图表,也提供交互式 plotly 结果。
我使用的主要包有:rtweet, dplyr, ggplot2, tidytext, tidyr 和 stringr。如果你对 tidytext 不熟悉,可以查看我之前的一些帖子,例如 2017 年的这篇,分析了食谱书。
rtweet 提供了一个方便的 API 来收集用户时间线信息。你需要一个 Twitter API 账户才能开始使用。这是一个简单的过程,你可以在这里注册: developer.twitter.com/en/apply-for-access。
注意这四个密钥/令牌。它们应该作为环境变量保存在你的系统中。²这四个密钥对应于 tweet.R 文件中的 API_KEY、API_SECRET_KEY、ACCESS_TOKEN 和 ACCESS_SECRET,并将在需要时以编程方式检索。
Tweet.R
不会深入探讨数据科学代码,但你可以在 这里查看。重要的是,我们将每一部分封装成函数,然后在主 API 路由文件 (app.R) 中调用这些函数。
对于情感分析,我们通过字典匹配来统计正面和负面词汇的数量。³ 词汇字典来自于Bing Liu et al.。这是否需要外部数据库?实际上不需要 - 外部依赖项或数据文件是可以的,只要它们是无状态的。我们可以将其与我们的 docker 文件一起打包,或者在这种情况下,它随 tidytext 包一起安装!
App.R
这个文件包含了服务逻辑。我们使用plumber package,它允许我们通过一些标记在 R 中创建 REST API。你可以通过使用#* @param标记来指定查询参数,并指定返回的输出类型,如#* @png用于静态图像,或#* @html用于 html。
作为额外的好处,还有一个开箱即用的选项来使 htmlwidgets 工作(#* @serializer htmlwidget)。这使得我们的 plotly 结果展示变得非常简单。我决定为每个图创建两个路径,一个静态的和一个 plotly 交互式的。所以总共有四个路径:
-
/frequency (ggplot)
-
/html/frequency (plotly)
-
/sentiment (ggplot)
-
/html/sentiment (plotly)
这些函数都接受两个参数:n - 推文数量,以及users,这可以是一个用逗号分隔的用户 ID 列表,我们将通过 rtweet 查询 Twitter API 获取相关信息。
Server.R
这段代码启动了我们的 plumber 服务器。我们通过环境变量(PORT)推断端口。
这就是 R 代码的全部内容。现在你应该有一个可以在本地计算机上运行的应用程序了。接下来,我们将深入探讨 ML-ops 的复杂细节 ????♀。这涉及到使用 Docker 打包我们的依赖项,并将其部署到云端。
Docker
Docker 是一个将不同的软件、配置和环境打包成容器的平台,这些容器整洁地封装了你的应用程序。最终用户只需要列出安装步骤以构建镜像,然后可以在 docker 平台上运行????。
为了启动配置,我们在官方的r-base image上进行构建。这是一个 Linux 镜像,我们需要安装一些额外的依赖项以使应用程序正常工作,即 rtweet 的 libssl-dev 和处理 htmlwidgets 的 pandoc。这是我们的Dockerfile的开始:
FROM r-base
RUN apt-get update -qq && apt-get install -y \
git-core \
libssl-dev \
libcurl4-gnutls-dev \
pandoc
接下来,我们将目录中的脚本复制到容器中的应用程序目录,并使用 Rscript 函数安装必要的 R 库:
WORKDIR /usr/src/app
# Copy local code to the container image.
COPY . .
# Install any R packages
RUN Rscript -e "install.packages('plumber')"
RUN Rscript -e "install.packages(c('rtweet', 'dplyr', 'ggplot2', 'plotly', 'tidytext', 'tidyr', 'stringr'))"
我们暴露端口 8000(这主要用于文档),并在容器启动时运行服务器:
EXPOSE 8000
# Run the web service on container startup.
CMD [ "Rscript", "server.R"]
让我们构建 docker 镜像并运行它:
docker build -t ${IMAGE} .
docker run -p 8000:8000 -e PORT=8000 -e API_KEY -e API_SECRET_KEY -e ACCESS_TOKEN -e ACCESS_SECRET ${IMAGE}
${IMAGE}这里代表你可以分配给镜像的名称。还记得我们需要的环境变量吗?Plumber 的端口和访问推特 API 的 API 密钥?我们在运行容器时将其传递给容器。注意:构建过程相当长,镜像大小为 1.22GB。⁴
如果图像成功运行,你应该能够在浏览器上访问这些路由。现在,我们可以将它从本地机器带到网络上!
Cloud Run
你可以使用我的deploy.sh脚本作为构建和部署镜像的指南。在这样做之前,我建议你将 Cloud Run Admin 角色分配给运行脚本的账户或用户,以确保其正确部署。你可以通过 GCP 内的IAM 面板完成。
在脚本中,我程序化地检索了项目 ID,但可以用你的 GCP 项目替换它。脚本的作用是将本地 docker 镜像上传到 Google 的容器仓库,并运行 cloud run 从仓库中部署镜像:
gcloud alpha run deploy \
--image="gcr.io/${PROJECT_ID}/${IMAGE}:1.0.0" \
--region="us-central1" \
--platform managed \
--memory=512Mi \
--port=8000 \
--set-env-vars API_KEY=${API_KEY},API_SECRET_KEY=${API_SECRET_KEY},ACCESS_TOKEN=${ACCESS_TOKEN},ACCESS_SECRET=${ACCESS_SECRET} \
--allow-unauthenticated
我们添加了allow-unauthenticated来允许公共流量,并增加了内存,因为默认内存太低。你可以先从默认的 256MB 开始,但如果遇到任何错误,请检查 cloud run 日志,这对调试任何错误非常有用。如果一切顺利,你应该会看到这样的图像:
我们的推特项目现在成功托管在 Cloud Run 上!
测试一下
有趣的部分来了 - 尝试一下,实时可视化和分析推特数据吧!
你可以尝试我的托管 cloud run 服务,使用上面列出的 4 个端点之一:twitter-r-cvdvxo3vga-uc.a.run.app/
一些有趣的例子!
奥巴马推文的频率
在推特上拥有 1.12 亿粉丝的最受关注人物实际上并不常常发推 ????:
twitter-r-cvdvxo3vga-uc.a.run.app/frequency?n=500&users=BarackObama
BBCworld 和 realDonaldTrump 的情感分析对比
伤心!⁵
twitter-r-cvdvxo3vga-uc.a.run.app/sentiment?n=1000&users=BBCWorld,realDonaldTrump
政治家和娱乐圈人士有什么共同之处?
它们 overwhelmingly positive(在这里我们使用我们的 plotly html 端点)
twitter-r-cvdvxo3vga-uc.a.run.app/html/sentiment?n=500&users=narendramodi,TheEllenShow
结论
这就是本次无服务器 + R 教程的全部内容。希望你能学到一些有用的东西,或者至少觉得 Twitter 分析很有趣 😃。拥有这个应用程序的好处是,你可以用你选择的任何账号(甚至你自己的)分析实时 Twitter 频率或情感图,因此随意尝试吧。⁶
-
使用无服务器架构还有一些非常好的好处,比如按秒计费、自动扩展的容器,这使得它非常适合部署爱好项目。
-
如果你在 R 环境中,可以调用
Sys.setenv()或者直接使用 CLI 导出。 -
我花了大约 15 分钟来构建这个镜像。这是 R 的一个缺点 - 它对于数据分析非常方便,但对生产环境不太友好。
-
从 realDonaldTrump 抓取数据存在一些问题 (
github.com/ropensci/rtweet/issues/382) -
只要使用量没有突然激增并超过免费套餐限制,我会尽可能保持它运行。
简介:Timothy Lin 是一名数据科学家和计量经济学家。Timothy 有兴趣将数据科学技术应用于解决商业问题。他为多个公司提供咨询,涉及大数据分析、消费者研究和图论等项目。在工作之外,他常常思考如何在生产环境中更好地部署模型,并在 www.timlrx.com 上博客分享他的最新发现。
原文。经许可转载。
相关:
-
R 用户的客户细分
-
R 中 K-最近邻的初学者指南:从零到英雄
-
2019 年 Stackoverflow 调查中的 R 用户薪资
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织的 IT 工作
了解更多内容
ML 模型服务:常见模式
原文:
www.kdnuggets.com/2021/10/serving-ml-models-production-common-patterns.html
评论
由 Simon Mo、Edward Oakes 和 Michael Galarnyk 撰写
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
本文基于 Simon Mo 在 Ray Summit 2021 上的“生产中的机器学习模式”讲座。
在过去几年中,我们听取了来自多个不同行业的 ML 从业者的意见,以改进围绕 ML 生产用例的工具。通过这些反馈,我们发现了生产中机器学习的 4 种常见模式:管道、集成、业务逻辑和在线学习。在 ML 服务领域,实现这些模式通常涉及开发的便利性和生产准备性的权衡。Ray Serve旨在支持这些模式,既易于开发,又具备生产准备性。它是一个可扩展的可编程服务框架,建立在Ray之上,帮助你扩展微服务和生产中的 ML 模型。
本文涵盖:
-
什么是 Ray Serve
-
Ray Serve 在 ML 服务领域的位置
-
生产中 ML 的一些常见模式
-
如何使用 Ray Serve 实现这些模式
什么是 Ray Serve?
Ray Serve 建立在 Ray 分布式计算平台之上,使其能够轻松扩展到多个机器,无论是在数据中心还是云中。
Ray Serve 是一个易于使用的可扩展模型服务库,建立在 Ray 之上。该库的一些优势包括:
-
可扩展性:横向扩展到数百个进程或机器,同时保持开销在单数字毫秒内
-
多模型组合:轻松组合多个模型,将模型服务与业务逻辑混合,并独立扩展组件,无需复杂的微服务。
-
批处理:原生支持批处理请求,以更好地利用硬件并提高吞吐量。
-
FastAPI 集成: 轻松扩展现有的 FastAPI 服务器,或使用其简单优雅的 API 为你的模型定义 HTTP 接口。
-
框架无关:使用一个工具包服务从基于 PyTorch、Tensorflow 和 Keras 构建的深度学习模型,到 Scikit-Learn 模型,再到 任意 Python 业务逻辑。
你可以通过查看 Ray Serve 快速入门 开始使用 Ray Serve。
Ray Serve 在 ML 服务领域的适配
上图显示,在 ML 服务领域,通常存在开发简易性与生产就绪性之间的权衡。
Web 框架
部署 ML 服务时,人们通常从最简单的开箱即用系统开始,例如 Flask 或 FastAPI。然而,尽管它们可以很好地提供单次预测,并在概念验证中表现良好,但它们无法实现高性能,扩展通常成本高昂。
自定义工具
如果 web 框架失败,团队通常会转向某种自定义工具,通过将多个工具粘合在一起来使系统准备好投入生产。然而,这些自定义工具通常难以开发、部署和管理。
专门化系统
有一类专门的系统用于在生产环境中部署和管理 ML 模型。虽然这些系统在管理和服务 ML 模型方面表现出色,但它们通常不如 web 框架灵活,并且学习曲线往往较高。
Ray Serve
Ray Serve 是一个专注于 ML 模型服务的 web 框架。它旨在易于使用、易于部署,并且适合生产环境。
Ray Serve 有什么不同?

有这么多工具用于训练和服务一个模型。这些工具帮助你很好地运行和部署一个模型。问题在于,现实中的机器学习通常没有那么简单。在生产环境中,你可能会遇到以下问题:
-
处理基础设施以超越一个模型的拷贝进行扩展。
-
需要处理复杂的 YAML 配置文件、学习自定义工具,并开发 MLOps 专业知识。
-
遇到可扩展性或性能问题,无法实现业务 SLA 目标。
-
许多工具非常昂贵,且通常会导致资源的利用不足。
扩展单个模型已经足够困难。对于许多生产中的机器学习用例,我们观察到复杂的工作负载需要将多个不同的模型组合在一起。Ray Serve 天生适用于涉及多个节点的多个模型的这种用例。你可以查看这部分讲座,我们深入探讨了 Ray Serve 的架构组件。
生产中的机器学习模型模式
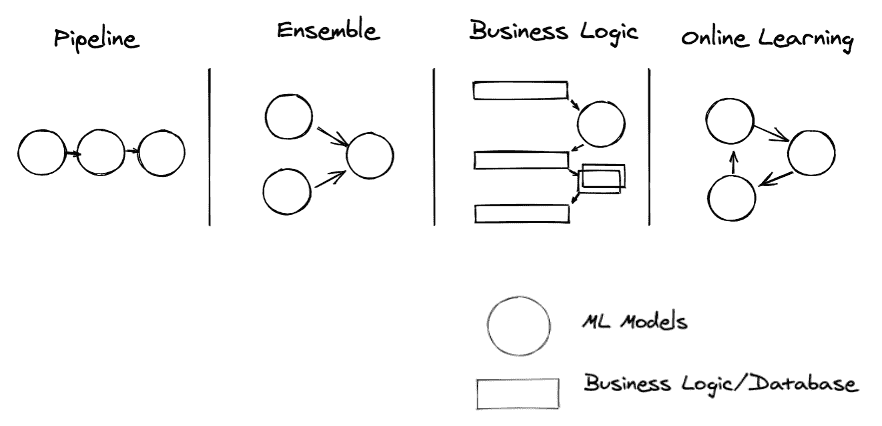
生产中的大部分机器学习应用遵循 4 种模型模式:
-
管道
-
集成
-
业务逻辑
-
在线学习
本节将描述这些模式中的每一种,展示它们的使用方式,讲解现有工具如何实现它们,并展示 Ray Serve 如何解决这些挑战。
管道模式
一个典型的计算机视觉管道
上面的图示展示了一个典型的计算机视觉管道,该管道使用多个深度学习模型为图像中的物体生成描述。该管道包括以下步骤:
-
原始图像经过常见的预处理,如图像解码、增强和裁剪。
-
检测分类器模型用于识别边界框和类别。它是一只猫。
-
图像被传递到关键点检测模型中,以识别物体的姿势。对于猫的图像,模型可以识别像爪子、脖子和头部这样的关键点。
-
最后,一个 NLP 合成模型生成图像所展示的类别。在这个例子中,是一只站立的猫。
典型的管道很少只包含一个模型。为了解决现实中的问题,机器学习应用通常使用多个不同的模型来执行即使是简单的任务。一般而言,管道将一个特定任务拆分为多个步骤,每个步骤由机器学习算法或某些过程解决。现在让我们来看看几个你可能已经熟悉的管道。
Scikit-Learn 管道
Pipeline([(‘scaler’, StandardScaler()), (‘svc’, SVC())])
scikit-learn 的管道可以用于将多个“模型”和“处理对象”结合在一起。
推荐系统
[EmbeddingLookup(), FeatureInteraction(), NearestNeighbors(), Ranking()]
推荐系统中有常见的管道模式。像在亚马逊和YouTube中看到的物品和视频推荐,通常经过多个阶段,如嵌入查找、特征交互、最近邻模型和排名模型。
常见预处理
[HeavyWeightMLMegaModel(), DecisionTree()/BoostingModel()]
一些非常常见的用例中,使用了大量的机器学习模型来处理文本或图像的常见处理。例如,在 Facebook,FAIR 的机器学习研究人员团队创建了用于视觉和文本的最先进的重量级模型。然后,不同的产品团队创建下游模型来解决他们的业务用例(例如,自杀预防),通过使用随机森林实现较小的模型。共享的常见预处理步骤通常会被具体化为特征存储管道。
一般管道实施选项

在 Ray Serve 之前,实现管道通常意味着你必须在将模型封装在网络服务器中或使用许多专门的微服务之间进行选择。
一般来说,实现管道有两种方法:将你的模型封装在一个网络服务器中,或者使用许多专门的微服务。
将模型封装在网络服务器中
上图的左侧显示了在网络处理路径中以循环方式运行的模型。每当请求到来时,模型会被加载(也可以被缓存)并通过管道运行。虽然这种方法简单易行,但主要缺陷是难以扩展,并且性能较差,因为每个请求都被顺序处理。
许多专门的微服务
上图的右侧显示了许多专门的微服务,你基本上为每个模型构建和部署一个微服务。这些微服务可以是本地机器学习平台,Kubeflow,甚至是像 AWS SageMaker这样的托管服务。然而,随着模型数量的增加,复杂性和操作成本急剧上升。
在 Ray Serve 中实现管道
@serve.deployment
class Featurizer: …
@serve.deployment
class Predictor: …
@serve.deployment
class Orchestrator
def __init__(self):
self.featurizer = Featurizer.get_handle()
self.predictor = Predictor.get_handle()
async def __call__(self, inp):
feat = await self.featurizer.remote(inp)
predicted = await self.predictor.remote(feat)
return predicted
if __name__ == “__main__”:
Featurizer.deploy()
Predictor.deploy()
Orchestrator.deploy()
伪代码展示了 Ray Serve 如何允许部署调用其他部署
在 Ray Serve 中,你可以在你的部署内直接调用其他部署。在上面的代码中,有三个部署。Featurizer和Predictor只是包含模型的常规部署。Orchestrator接收网络输入,通过 featurizer handle 将其传递给特征提取过程,然后将计算出的特征传递给预测过程。接口只是 Python,你无需学习任何新的框架或领域特定语言。
Ray Serve 通过一种名为 ServeHandle 的机制实现这一点,它赋予你将所有内容嵌入到网络服务器中的类似灵活性,而不会牺牲性能或可扩展性。它允许你直接调用存在于其他节点上其他进程中的其他部署。这使你能够单独扩展每个部署,并在副本之间进行负载均衡。
如果你想深入了解它是如何工作的,查看 Simon Mo 演讲的这一部分 以了解 Ray Serve 的架构。如果你想了解生产中的计算机视觉管道的示例,查看 Robovision 如何使用 5 个 ML 模型进行车辆检测。
集成模式
在许多生产使用案例中,管道是合适的。然而,管道的一个限制是,给定的下游模型往往有许多上游模型。这时,集成就显得很有用。
集成使用案例
集成模式涉及将一个或多个模型的输出混合。在某些情况下,它们也被称为模型堆叠。以下是三种集成模式的使用案例。
模型更新
新模型随着时间的推移不断开发和训练。这意味着在生产中总会有新版本的模型。问题在于,你如何确保新模型在实时在线流量场景中有效和性能良好?一种方法是将部分流量通过新模型。你仍然选择已知良好的模型的输出,但你也在收集新版本模型的实时输出以进行验证。
聚合
最广为人知的使用案例是聚合。对于回归模型,多模型的输出会被平均。对于分类模型,输出将是多个模型输出的投票结果。例如,如果两个模型投票选猫,一个模型投票选狗,则聚合后的输出将是猫。聚合有助于对抗单个模型的不准确性,并且通常使输出更准确和“安全”。
动态选择
集成模型的另一个使用案例是根据输入属性动态进行模型选择。例如,如果输入包含猫,则使用模型 A,因为它专门针对猫。如果输入包含狗,则使用模型 B,因为它专门针对狗。请注意,这种动态选择并不一定意味着管道本身必须是静态的。它也可以根据用户反馈选择模型。
通用集成实现选项

在 Ray Serve 之前,实现集成通常意味着你必须在将模型封装在网络服务器中或使用许多专门的微服务之间做出选择。
集成实现面临与管道相同的问题。虽然将模型封装在网络服务器中很简单,但性能却不足。当使用专门的微服务时,随着微服务数量的增加,你会面临大量的操作开销。
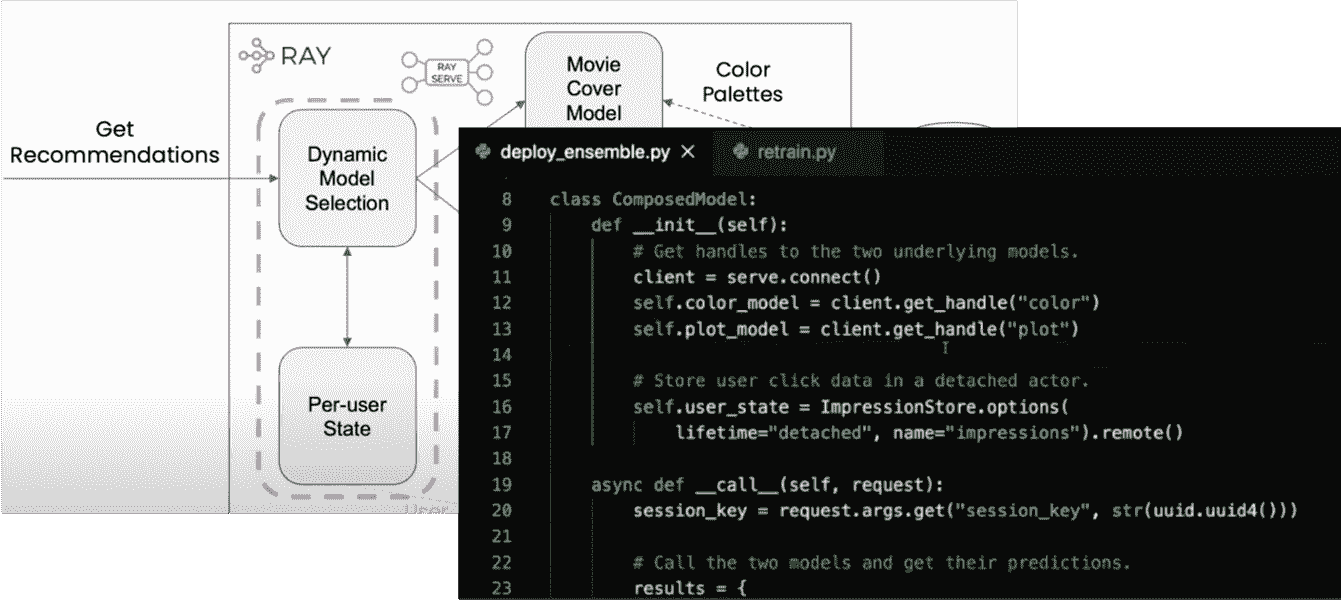
2020 Anyscale 演示中的集成示例
使用 Ray Serve,这种模式非常简单。你可以查看2020 Anyscale 演示,以了解如何利用 Ray Serve 的处理机制来执行动态模型选择。
另一个使用 Ray Serve 进行集成的例子是 Wildlife Studios 将多个分类器的输出结合起来进行单一预测。你可以查看他们如何用 Ray Serve 提供游戏内优惠速度提高 3 倍。
业务逻辑模式
生产化机器学习将始终涉及业务逻辑。没有模型可以单独存在并自行处理请求。业务逻辑模式涉及到所有常见 ML 任务中与 ML 模型推理无关的内容。这包括:
-
关系记录的数据库查询
-
对外部服务的 Web API 调用
-
特征存储查找预计算特征向量
-
特征转换,如数据验证、编码和解码。
一般业务逻辑实施选项
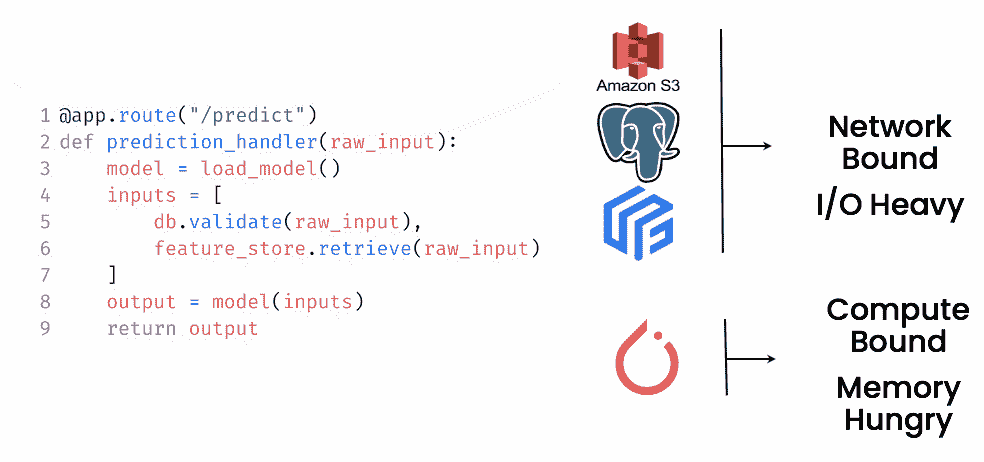
上述 web 处理程序的伪代码执行以下操作:
-
它加载模型(假设从 S3)
-
验证来自数据库的输入
-
从特征存储中查找一些预计算的特征。
仅在 web 处理程序完成这些业务逻辑步骤后,输入才会传递给 ML 模型。问题在于模型推理和业务逻辑的要求导致服务器既受网络限制又受计算限制。这是因为模型加载步骤、数据库查询和特征存储查询是网络限制和 I/O 密集型的,而模型推理则受计算限制且内存需求大。这些因素的组合导致了资源利用效率低下。扩展将会很昂贵。
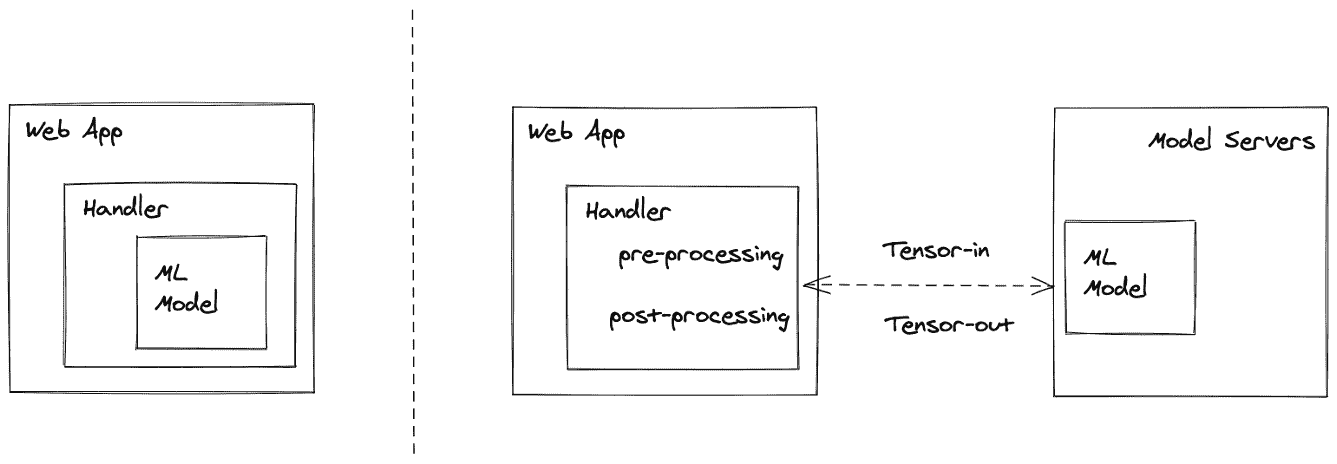
Web 处理程序方法(左)和微服务方法(右)
提高利用率的一种常见方法是将模型拆分到模型服务器或微服务中。
Web 应用程序纯粹受网络限制,而模型服务器则受计算限制。然而,一个常见的问题是二者之间的接口。如果你把过多的业务逻辑放入模型服务器,那么模型服务器将变成网络限制和计算限制调用的混合体。
如果你让模型服务器成为纯模型服务器,那么你就会遇到“张量输入,张量输出”接口问题。模型服务器的输入类型通常仅限于张量或其某种替代形式。这使得保持预处理、后处理和业务逻辑与模型本身的同步变得困难。
在训练过程中,由于处理逻辑和模型紧密耦合,因此很难推理处理逻辑与模型本身之间的交互,但在服务时,它们被拆分到两个服务器和两个实现中。
无论是 Web 处理程序方法还是微服务方法都不令人满意。
在 Ray Serve 中实现业务逻辑
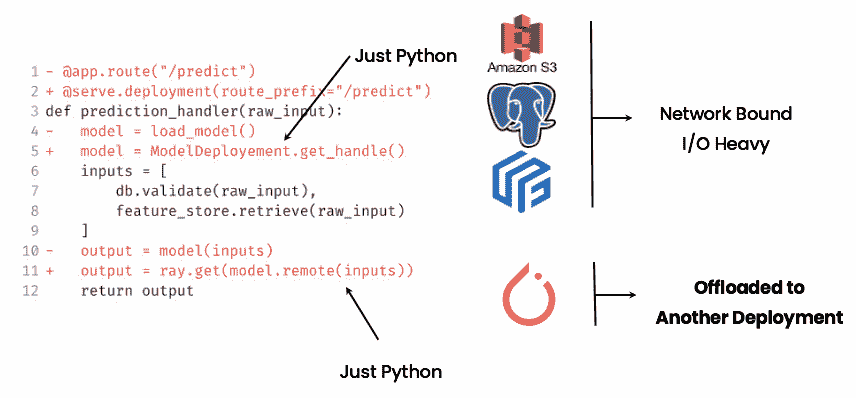
Ray Serve 中的业务逻辑
使用 Ray Serve,你只需对旧的 Web 服务器进行一些简单的更改,就可以缓解上述问题。你可以检索一个包装了模型的 ServeHandle,而不是直接加载模型,将计算任务卸载到另一个部署中。所有数据类型都被保留,不需要编写“tensor-in, tensor-out” API 调用--你可以直接传入普通的 Python 类型。此外,模型部署类可以保留在同一个文件中,与预测处理程序一起部署。这使得理解和调试代码变得简单。model.remote 看起来只是一个函数,你可以轻松追踪到模型部署类。
通过这种方式,Ray Serve 帮助你将业务逻辑和推理拆分为两个独立的组件,一个 I/O 密集型,另一个计算密集型。这使你可以单独扩展每个组件,而不会失去部署的便利性。此外,因为 model.remote 只是一个函数调用,所以比单独的外部服务更容易测试和调试。
Ray Serve FastAPI 集成
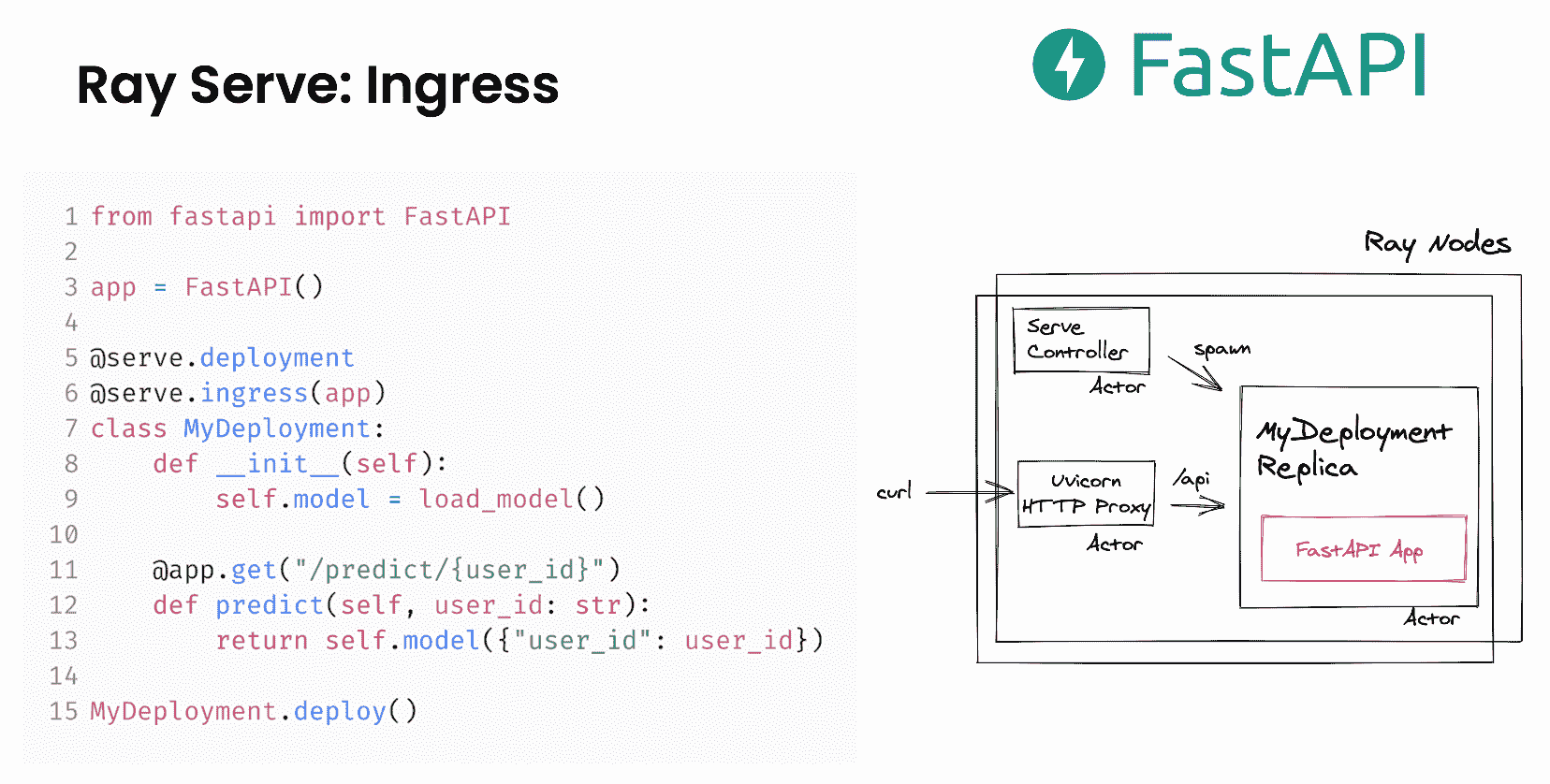
Ray Serve: 使用 FastAPI 的入口
实现业务逻辑和其他模式的一个重要部分是身份验证和输入验证。Ray Serve 本地集成了 FastAPI,这是一个类型安全且符合人体工程学的 Web 框架。FastAPI 具有自动依赖注入、类型检查和验证以及 OpenAPI 文档生成等功能。
使用 Ray Serve,你可以直接将 FastAPI 应用对象传入,并使用 @serve.ingress 装饰器。这个装饰器确保所有现有的 FastAPI 路由仍然有效,并且你可以通过部署类附加新的路由,以便像加载的模型和网络数据库连接这样的状态可以轻松管理。在架构上,我们只是确保你的 FastAPI 应用正确地嵌入到副本演员中,并且 FastAPI 应用可以在多个 Ray 节点上扩展。
在线学习
在线学习是一种新兴模式,使用越来越广泛。它指的是在生产中运行的模型不断被更新、训练、验证和部署。以下是在线学习模式的三个用例。
动态学习模型权重
有动态学习模型权重的使用案例。当用户与你的服务互动时,这些更新的模型权重可以有助于为每个用户或群体提供个性化的模型。
Ant Group 的在线学习示例(图片由 Ant Group 提供)
一个在线学习的案例研究包括 Ant Group 的在线资源分配业务解决方案。该模型从离线数据中训练,然后与实时流数据源结合,最后提供实时流量。值得注意的是,在线学习系统比静态服务系统复杂得多。在这种情况下,将模型放在 Web 服务器中,甚至拆分成多个微服务,都无法帮助实现。
动态学习参数以协调模型
还有一些使用案例是学习参数以协调或组合模型,例如,学习用户喜欢哪个模型。这通常出现在模型选择场景或上下文赌博算法中。
强化学习
强化学习是机器学习的一个分支,训练智能体与环境进行互动。环境可以是物理世界或模拟环境。你可以在这里了解强化学习,并查看如何使用 Ray Serve 部署 RL 模型这里。
结论
Ray Serve 易于开发并准备投入生产。
本文介绍了生产环境中机器学习的 4 种主要模式,Ray Serve 如何帮助你原生扩展和处理复杂架构,以及生产中的机器学习通常意味着许多模型在生产。Ray Serve 在分布式运行时 Ray 的基础上,考虑了所有这些因素。如果你对 Ray 感兴趣,可以查看文档,加入我们的讨论区,并查看白皮书!如果你有兴趣与我们合作,使 Ray 的使用变得更容易,我们正在招聘!
原文。转载授权。
相关:
-
使用 PyTorch 和 Ray 入门分布式机器学习
-
如何加速 Scikit-Learn 模型训练
-
如何构建数据科学投资组合
关于这个话题的更多内容
使用 TensorFlow Serving 部署训练好的模型到生产环境
评论
照片由 Kate Townsend 提供,来源于 Unsplash
一旦你训练了一个 TensorFlow 模型,并且它准备好部署,你可能会想将其移动到生产环境中。幸运的是,TensorFlow 提供了一种方法来以最小的努力完成这项工作。在本文中,我们将使用一个预训练模型,保存它,并使用 TensorFlow Serving 提供服务。让我们开始吧!
TensorFlow ModelServer
TensorFlow Serving 是一个专门用于将机器学习模型投入生产的系统。TensorFlow 的 ModelServer 提供对 RESTful API 的支持。不过,在使用之前,我们需要先安装它。首先,让我们将其添加为软件包源。
echo "deb [arch=amd64] [`storage.googleapis.com/tensorflow-serving-apt`](https://storage.googleapis.com/tensorflow-serving-apt) stable tensorflow-model-server tensorflow-model-server-universal" | sudo tee /etc/apt/sources.list.d/tensorflow-serving.list && curl [`storage.googleapis.com/tensorflow-serving-apt/tensorflow-serving.release.pub.gpg`](https://storage.googleapis.com/tensorflow-serving-apt/tensorflow-serving.release.pub.gpg) | sudo apt-key add -
现在可以通过更新系统并使用 apt-get 安装 TensorFlow ModelServer。
$ sudo apt-get update$ sudo apt-get install tensorflow-model-server
开发模型
接下来,让我们使用一个预训练模型来创建我们希望提供的模型。在这种情况下,我们将使用一个版本的 VGG16,其权重在 ImageNet 上进行了预训练。为了使其正常工作,我们必须先完成几个导入:
-
VGG16架构 -
image用于处理图像文件 -
preprocess_input用于预处理图像输入 -
decode_predictions用于显示概率和类别名称
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.vgg16 import preprocess_input, decode_predictions
import numpy as np
接下来,我们使用 ImageNet 权重定义模型。
model = VGG16(weights=’imagenet’)
模型准备好后,我们可以尝试一个示例预测。我们首先定义图像文件(一个狮子)的路径,并使用 image 加载它。
img_path = ‘lion.jpg’
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
在预处理后,我们可以使用它进行预测。我们可以看到它能够以 99% 的准确率预测图像是狮子。
preds = model.predict(x)
# decode the results into a list of tuples (class, description, probability)
# (one such list for each sample in the batch)
print(‘Predicted:’, decode_predictions(preds, top=3)[0])# Predicted: [('n02129165', 'lion', 0.9999999), ('n02130308',
# 'cheetah', 7.703386e-08), ('n02128385', 'leopard', 6.330456e-09)]
现在我们有了模型,我们可以将其保存,以便为 TensorFlow 提供服务做好准备。
保存模型
现在让我们保存这个模型。请注意,我们将其保存到一个/1文件夹中以指示模型版本。这是关键的,特别是当你希望自动提供新的模型版本时。稍后会详细介绍。
model.save(‘vgg16/1’)
使用 TensorFlow ModelServer 运行服务器
让我们首先定义用于服务的配置:
-
name是我们模型的名称——在这种情况下,我们将其命名为vgg16。 -
base_path是我们保存模型的位置的绝对路径。请确保将其更改为您自己的路径。 -
model_platform显然是 TensorFlow。 -
model_version_policy使我们能够指定模型版本信息。
现在我们可以运行命令来从命令行提供模型:
-
rest_api_port=8000意味着我们的 REST API 将在 8000 端口提供服务。 -
model_config_file定义了我们之前定义的配置文件。 -
model_config_file_poll_wait_seconds表示检查配置文件更改之前的等待时间。例如,将配置文件中的版本更改为 2 会自动服务模型的版本 2。这是因为在这种情况下配置文件的更改每 300 秒检查一次。
tensorflow_model_server — rest_api_port=8000 — model_config_file=models.config — model_config_file_poll_wait_seconds=300
使用 REST API 进行预测
此时,我们的模型的 REST API 可以在这里找到: localhost:8000/v1/models/vgg16/versions/1:predict。
我们可以使用这个端点进行预测。为此,我们需要将 JSON 格式的数据传递给端点。为了达到这一目的 — 并非双关 — 我们将使用 Python 中的 *json* 模块。为了向端点发出请求,我们将使用 requests Python 包。
让我们开始导入这两个模块。
import json
import requests
记住,x 变量包含了预处理的图像。我们将创建包含该图像的 JSON 数据。像其他 RESTFUL 请求一样,我们将内容类型设置为 application/json。然后,我们向端点发出请求,同时传递头信息和数据。获得预测结果后,我们将其解码,就像在本文开头一样。

使用 Docker 服务模型
还有一种更快更简短的方式来服务 TensorFlow 模型——使用 Docker。这实际上是推荐的方法,但了解之前的方法很重要,以防你在特定用例中需要它。使用 Docker 服务模型就像拉取 TensorFlow Serving 镜像 并挂载你的模型一样简单。
使用 Docker 安装 后,运行此代码来拉取 TensorFlow Serving 镜像。
docker pull tensorflow/serving
现在让我们使用那个图像来服务模型。这可以通过 docker run 和传递一些参数来完成:
-
-p 8501:8501表示容器的 8501 端口将在本地主机的 8501 端口上可访问。 -
— name用于为我们的容器命名——选择你喜欢的名称。我在这个例子中选择了tf_vgg_server。 -
— mount type=bind,source=/media/derrick/5EAD61BA2C09C31B/Notebooks/Python/serving/saved_tf_model,target=/models/vgg16表示模型将被挂载到 Docker 容器中的/models/vgg16。 -
-e MODEL_NAME=vgg16表明 TensorFlow Serving 应该加载名为vgg16的模型。 -
-t tensorflow/serving表示我们正在使用之前拉取的tensorflow/serving镜像。 -
&表示在后台运行命令。
在你的终端中运行下面的代码。
docker run -p 8501:8501 --name tf_vgg_server --mount type=bind,source=/media/derrick/5EAD61BA2C09C31B/Notebooks/Python/serving/saved_tf_model,target=/models/vgg16 -e MODEL_NAME=vgg16 -t tensorflow/serving &
现在我们可以使用 REST API 端点进行预测,就像之前一样。

很明显,我们得到了相同的结果。通过这一点,我们已经看到如何在有无 Docker 的情况下服务 TensorFlow 模型。
最后的想法
这篇文章来自 TensorFlow,将为你提供更多关于 TensorFlow Serving 架构的信息。如果你想深入了解,可以参考这个资源。
你还可以探索使用标准的TensorFlow ModelServer来进行构建。在这篇文章中,我们专注于使用 CPU 进行服务,但你也可以探索如何在 GPU 上服务。
这个仓库包含链接到更多关于 TensorFlow Serving 的教程。希望这篇文章对你有所帮助!
mwitiderrick/TensorFlow-Serving
提供 TensorFlow 模型服务。通过在 GitHub 上创建账户,参与 mwitiderrick/TensorFlow-Serving 的开发。
个人简介:Derrick Mwiti 是一名数据科学家,对分享知识充满热情。他通过 Heartbeat、Towards Data Science、Datacamp、Neptune AI、KDnuggets 等博客积极贡献于数据科学社区。他的内容在互联网上的浏览量已超过一百万次。Derrick 还是一名作者和在线讲师。他还与各种机构合作实施数据科学解决方案,并提升其员工技能。Derrick 在多媒体大学学习数学和计算机科学,同时也是 Meltwater 创业技术学院的校友。如果你对数据科学、机器学习和深度学习感兴趣,你可以查看他的完整数据科学与机器学习 Python 训练营课程。
原文。转载已获许可。
相关内容:
-
处理机器学习中的数据不平衡
-
如何将 PyTorch Lightning 模型部署到生产环境
-
AI 不仅仅是一个模型:完成工作流程成功的四个步骤
我们的前三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织在 IT 方面
更多相关内容
应用于 Pandas DataFrames 的集合操作
原文:
www.kdnuggets.com/2019/11/set-operations-applied-pandas-dataframes.html
评论
由 Eduardo Corrêa Gonçalves,ENCE/IBGE
介绍
在某些实际情况中,将 pandas DataFrame 视为一个 数学集合 可能是有趣的。在这种情况下,DataFrame 的每一行可以被视为集合的 元素 或 成员。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
那么问题变成了:为什么这会有用?答案是这样的。正如我们所知,数据科学问题通常需要分析来自多个来源的数据。在数据分析过程中,你可能会遇到需要比较两个或多个 DataFrames 的内容,以确定它们是否有共同的元素(行)的问题。在本教程中,你将学习集合操作是执行此类任务的最佳和最自然的技术之一。
实际示例
假设你有两个 DataFrames,分别命名为 P 和 S,它们分别包含注册了 SQL 和 Python 两门不同课程的学生的姓名和电子邮件。

考虑你需要回答以下问题:
-
这两个 DataFrames 中有多少不同的学生?
-
是否有学生同时注册了 Python 和 SQL 课程?
-
哪些学生在上 Python 课程,但没有上 SQL 课程(反之亦然)?
如果将 DataFrames 视为两个不同的数学集合,答案可以通过简单的方式获得。然后,你只需要应用基本的 并集、交集 和 差集 操作:
P ∪ S,即 P 和 S 的并集,是在 P 或 S 或两者中都存在的元素的集合。注意元素(学生)Elizabeth 在结果中只出现一次。
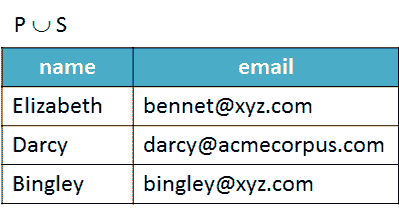
P ∩ S,即 P 和 S 的交集,是既在 P 中又在 S 中的元素的集合。现在,只有 Elizabeth 出现,因为她是两个集合中的唯一一个。

P − S,即 P 和 S 的差集,是包含所有在 P 中但不在 S 中的元素的集合:

请注意,S − P 与 P − S 是不同的:

重要的是要指出,对这些操作应用的 DataFrames 必须具有相同的属性(如示例中所示)。
Pandas 中的集合操作
尽管 pandas 没有提供专门的集合操作方法,但我们可以通过以下方法轻松模拟这些操作:
-
并集:concat() + drop_duplicates()
-
交集:merge()
-
差集:isin() + 布尔索引
在下面的程序中,我们演示了如何做到这一点。代码列表后给出了详细的解释。
结果如下所示:
------------------------------
all students (UNION):
name email
0 Elizabeth bennet@xyz.com
1 Darcy darcy@acmecorpus.com
2 Bingley bingley@xyz.com
------------------------------
Students enrolled in both courses (INTERSECTION):
name email
0 Elizabeth bennet@xyz.com
------------------------------
Python students who are not taking SQL (DIFFERENCE):
name email
1 Darcy darcy@acmecorpus.com
------------------------------
SQL students who are not taking Python (DIFFERENCE):
name email
0 Bingley bingley@xyz.com
这是对代码的完整解释。最初,我们创建了两个 DataFrame,P(Python 学生)和 S(SQL 学生)。创建完成后,它们被提交给程序的第二部分中的三种集合操作。
并集
为了执行并集操作,我们应用了两个方法:concat() 然后是 drop_duplicates()。第一个方法实现数据的连接,即将一个 DataFrame 的行放在另一个 DataFrame 的行下方。因此,以下语句:
all_students = pd.concat([P, S], ignore_index = True)
生成一个由 4 行组成的 DataFrame(P 中 2 行加上 S 中 2 行)。
name email
0 Elizabeth bennet@xyz.com
1 Darcy darcy@acmecorpus.com
2 Bingley bingley@xyz.com
3 Elizabeth bennet@xyz.com
然而,请注意,有两行指的是 Elizabeth,因为她是唯一一个同时注册了两个课程的学生。为了只保留一个该元素的出现,只需使用 drop_duplicates() 方法:
all_students = all_students.drop_duplicates()
name email
0 Elizabeth bennet@xyz.com
1 Darcy darcy@acmecorpus.com
2 Bingley bingley@xyz.com
交集
多功能的 merge() 方法被用来执行交集操作。该方法可以用来以不同的方式组合或连接 DataFrame。然而,当在涉及两个兼容 DataFrame 的操作中未指定任何参数时,它会生成它们的交集:
sql_and_python = P.merge(S)
name email
0 Elizabeth bennet@xyz.com
差集
差集操作的代码稍微复杂一些。如我们所知,两集合 P 和 S 之间的差集是一个旨在确定 P 中不属于 S 的元素的操作。在 pandas 中,我们可以使用isin()方法结合布尔索引来实现这一操作:
python_only = P[P.email.isin(S.email) == False]
为了说明这一点,我们将其分为两部分。第一部分是:
P.email.isin(S.email)
上述命令生成一个布尔结构,指出 DataFrame P 中哪些电子邮件存在于 S 中:
0 True
1 False
这个布尔结构随后用于过滤 P 中的行:
python_only = P[P.email.isin(S.email) == False]
name email
1 Darcy darcy@acmecorpus.com
获取未学习 Python 的 SQL 学生是类似的操作:
sql_only = S[S.email.isin(P.email) == False]
name email
0 Bingley bingley@xyz.com
参考文献/进一步阅读
Pandas 文档
pandas.pydata.org/pandas-docs/stable/
斯坦福哲学百科全书 - 基本集合论
plato.stanford.edu/entries/set-theory/basic-set-theory.html
詹妮弗·维多姆 - 关系代数 2 第一部分
www.youtube.com/watch?v=r_h9yBnNh0U
个人简介: Eduardo Corrêa Gonçalves 在巴西地理与统计研究所(IBGE)担任数据库管理员,并在国家统计科学学院(ENCE/IBGE)担任助理教授。他参与了不同经济和农业调查的数据库建模和实施的各个阶段,例如:“企业中央登记统计”、“市级牲畜统计”和“农业生产系统调查”。他的研究、教学和专业活动集中在算法、人工智能和数据库领域。
相关内容:
-
5 个 Pandas 高级功能及其使用方法
-
了解你的数据:第一部分
-
25 个 Pandas 小技巧
相关话题更多内容
如何在 Jupyter Notebook 上设置 Julia
原文:
www.kdnuggets.com/2022/11/setup-julia-jupyter-notebook.html

图片由作者提供
Julia 是一种高级通用语言,旨在进行高性能计算。由于自然语言语法、更快的代码执行速度和强大的机器学习生态系统,它在数据社区和研究人员中越来越受欢迎。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
由于集成笔记本的普及,数据科学家和研究人员现在在 Jupyter Notebook 上运行 Python、R、Bash、Scala、Ruby 和 SQL。现在,我们将学习如何安装 Julia 并将其配置到 Jupyter notebook 中。此外,我们将加载 CSV 文件并执行时间序列数据可视化。
在 Jupyter Notebook 上设置 Julia
Julia 可以通过在 REPL 中运行代码或执行 .jl 文件来使用,但在 Jupyter notebook 中运行代码可以给我们更多的实验控制权。你可以在笔记本中进行数据分析、训练机器学习模型,甚至创建一个 Julia 软件包。
步骤 1:下载并安装软件包
你可以通过访问官方网站下载并安装当前稳定版的 Julia。稳定版可用于 Windows、Linux 和 macOS。
我花了几分钟下载并安装了适用于 Windows 的 Julia。要运行 Julia REPL,你可以在 PowerShell、终端或 Bash 中输入“julia”。你也可以在开始菜单中找到 Julia 图标并点击它以启动 REPL。
步骤 2:安装 IJulia
要将 Julia 与 Jupyter Notebook 集成,你需要安装Ijulia软件包。
在 Julia REPL 中,输入:
using Pkg
Pkg.add("IJulia")
图片由作者提供 | Julia REPL
你也可以通过输入“]”进入包菜单来安装 Julia 软件包。之后输入 add Ijulia 来安装该软件包。

图片由作者提供 | 安装 Ijulia
步骤 3:在 Jupyter Notebook 中运行 Julia
我们现在准备使用 Jupyter Notebook。启动 Jupyter notebook,点击新建按钮并选择Julia环境。
作者提供的图像 | Jupyter Notebook
对于 VSCode,创建一个新的 Jupyter Notebook 文件,并通过点击内核名称将内核从 Python 更改为 Julia,如下所示。
现在我们有 R、Python 和 Julia 环境。你可以根据需求在它们之间切换。
作者提供的图像 | VScode Jupyter Notebook
开始使用 Julia
安装 Julia 后,我们来写一个简单的代码来打印文本。与 Python 一样,它顺利执行了命令。
作者提供的图像 | Jupyter Notebook 上的代码执行
print("Visit KDnuggets.com for more cheat sheets and additional learning resources.")
>>> Visit KDnuggets.com for more cheat sheets and additional learning resources.
安装包
你可以在 Jupyter 单元格中通过输入 using Pkg 和 Pkg.add(<Package Name>) 来安装任何 Julia 包。
我们将安装 DataFrame、CSV、Plots、PyPlot 和 RollingFunctions。
using Pkg
Pkg.add("DataFrames")
Pkg.add("CSV")
Pkg.add("Plots")
Pkg.add("PyPlot")
Pkg.add("RollingFunctions")
读取 CSV 文件
要访问包,你需要输入 **using** 然后输入所有包名,包名之间用逗号“,”分隔。
接下来,我们将下载美国 COVID 跟踪数据,并将 CSV 文件保存为“covid_us.csv”。
然后,我们将使用 CSV.read 来读取 CSV 文件并将其转换为 DataFrame。我们将选择“date”和“totalTestResultsIncrease”两个列,并更改日期格式。
最后,我们将:
-
过滤结果以移除负值
-
将 dataframe 按升序排序
-
显示最后 5 行。
using Downloads, DataFrames, CSV, Plots, Dates
download_covid = Downloads.download("https://api.covidtracking.com/v1/us/daily.csv",
"covid_us.csv")
columns = [:date, :totalTestResultsIncrease]
fmt = "yyyymmdd"
t = Dict(:date=>Date)
covid_df = CSV.read("covid_us.csv",
DataFrame,
dateformat=fmt,
select=columns,
types=t)
covid_df = sort(filter(row -> row.totalTestResultsIncrease > 0, covid_df))
last(covid_df,5)
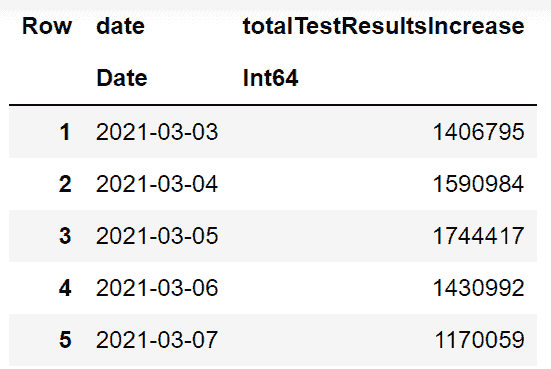
数据可视化与 Plot 和 RollingFunctions
我已修改 Jonathan Dinu 的代码,以显示美国总测试能力的条形图。
我们将使用 Plot.jl 显示条形图,并使用 RollingFunctions.jl 获取 7 天的总测试结果平均值。
using RollingFunctions
# plot daily test increase as sticks
Plots.plot(covid_df.date,
covid_df.totalTestResultsIncrease,
seriestype=:sticks,
label="Test Increase",
title = "USA Total Testing Capacity",
lw = 2)
# 7-day average using rolling mean
window = 7
average = rollmean(covid_df.totalTestResultsIncrease, window)
# we mutate the existing plot
Plots.plot!(covid_df.date,
cat(zeros(window - 1), average, dims=1),
label="7-day Average",
lw=3)
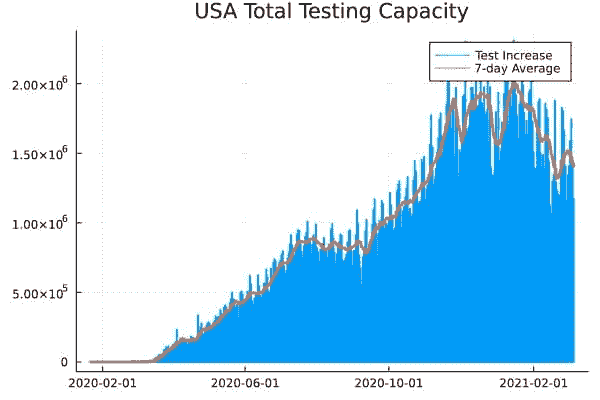
这太棒了。
你可以通过访问 Julia Packages 网页,轻松找到在 Julia 中的替代 Python 和 R 数据分析包。
结论
Julia 易于使用,且代码执行速度比 Python 快。如果你正在从 R 和 Matlab 过渡到 Julia,语法和包生态系统将让你感觉自然。
这是一种通用语言,最近由于完全基于 Julia 构建的本地包提供了更快的训练和推理时间,开始吸引机器学习社区。
如果你有任何关于 Julia 的问题,可以在评论中问我。你还可以加入 Julia 社区,使用 Slack、Discord 和 Discourse 了解最新动态。
Abid Ali Awan (@1abidaliawan) 是一位认证数据科学专家,热衷于构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个人工智能产品,帮助那些面临心理健康困扰的学生。
了解更多此主题
在 AWS EC2 上设置和使用 JupyterHub (TLJH)
原文:
www.kdnuggets.com/2023/01/setup-jupyterhub-tljh-aws-ec2.html
视频教程
Jupyter Notebook 是一个开源应用程序,广泛用于学术界和工业界。该交互式计算应用程序由渲染使用 Markdown 语法编写的说明性文本的单元和执行编程代码(包括 Python、R、Julia 和 Scala)的单元组成。这意味着笔记本可以在同一文档中包含文本、代码和可视化内容。Jupyter Notebook 可以在本地机器上使用,或者如我在以前的教程中提到的,在云端 使用。然而,问题是 Jupyter Notebook 仅设计为单用户使用。JupyterHub 旨在解决这个问题。JupyterHub 是一个多用户、容器友好的(例如 Docker、Kubernetes 等)Jupyter Notebook 版本,旨在为拥有许多好处的组织提供服务,包括:
-
管理用户和身份验证(例如 PAM、OAuth、SSO 等)
-
在云中(例如 AWS、Azure、Google Cloud 等)或在您自己的硬件(本地)上创建可共享、可扩展且可自定义的计算资源和数据科学环境
-
减轻用户的安装和维护任务。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域的职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT 管理
JupyterHub 有两个版本:
-
Zero-to-JupyterHub (ZTJH),一个基于 Kubernetes 的 JupyterHub 多节点版本
-
Littlest JupyterHub (TLJH) 是 JupyterHub 的单节点版本。
本教程在很大程度上超越了官方 JupyterHub 设置教程中如何在 AWS 上设置 JupyterHub (TLJH),希望图像和YouTube 视频能使您在这个 15 步以上的过程中特别少遇到问题。
1). 访问 Amazon Web Services 的网站 并点击“登录”(如果没有 AWS 账户,请创建一个)。

在登录页面,选择根用户(A)或IAM 用户(B)。输入你的电子邮件。如果你是 IAM 用户,请确保拥有适当的权限,以便至少可以创建 AWS EC2 实例。
官方教程强调,你应该根据 JupyterHub 用户的位置选择 AWS 区域。
点击EC2。如果没有看到它,请使用屏幕顶部的搜索栏输入 EC2。
在仪表板 | EC2 管理控制台中,点击实例。如果这个屏幕看起来有些不同,请注意我已切换到新 EC2 体验。
点击启动实例(按钮也可能标记为启动实例)。
为你的实例命名并[可选]添加标签。AWS 表示“标签是你分配给 AWS 资源的标记。” 我建议你给实例一个名称和标签,以识别实例的用途(例如,MyJupyterHubTutorial)。
转到应用程序和操作系统镜像(Amazon Machine Image)并选择 Ubuntu 18.04 LTS 版本,Ubuntu 20.04 LTS(本教程使用的版本),Ubuntu 22.04 LTS(如果选择此 AMI,请参见潜在错误部分),或 TLJH 支持的其他版本。
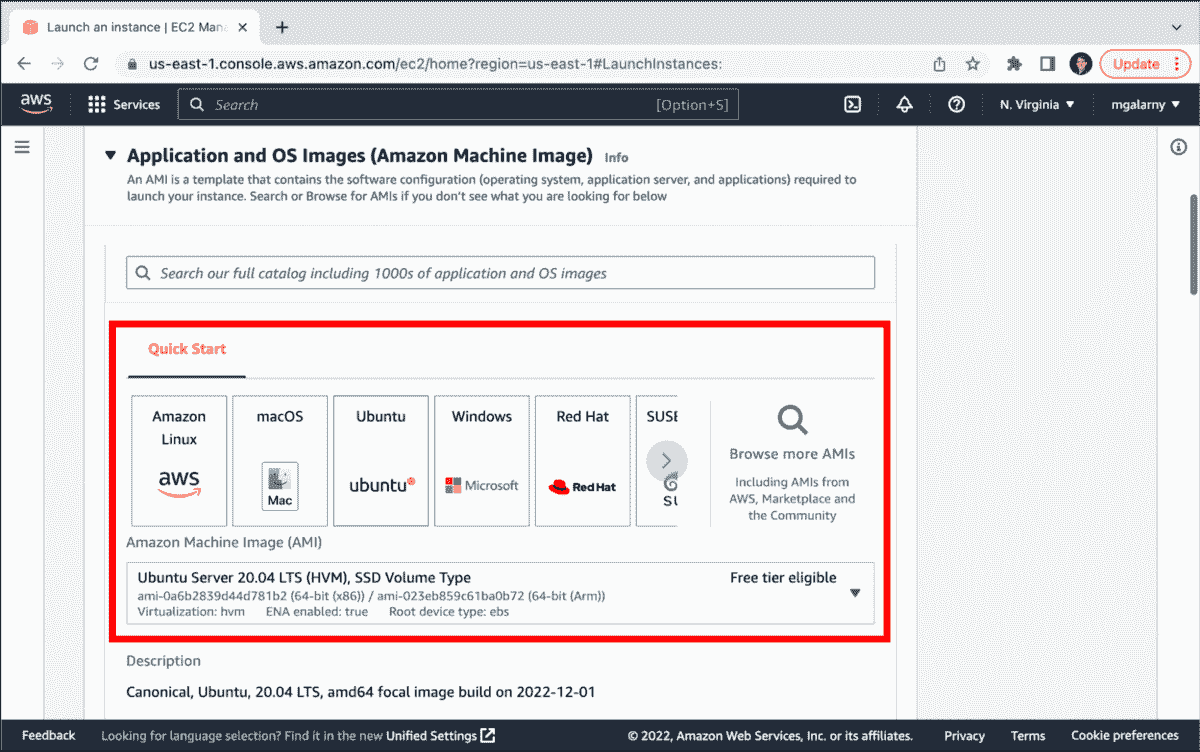
转到实例类型。在选择实例之前,我强烈推荐查看 每个实例的费用 以及 JupyterHub 的指南,了解根据并发用户数量估算 所需的内存 / GPU / 磁盘空间。基本上,你至少需要使用具有 1GB+(基本上 t2.micro 或更高)的 RAM 的服务器,但我发现 8GB+(t2.large 或更高)更适合我的需求(教学和数据科学实践)。如果我知道使用 JupyterHub 的人会执行需要多个核心的任务(特别是使用 Ray/Dask/Spark),我会选择具有更多 vCPU 的实例(t2.micro: 1 vCPU, t2.large: 2vCPU, t2.2xlarge: 8vCPU)。
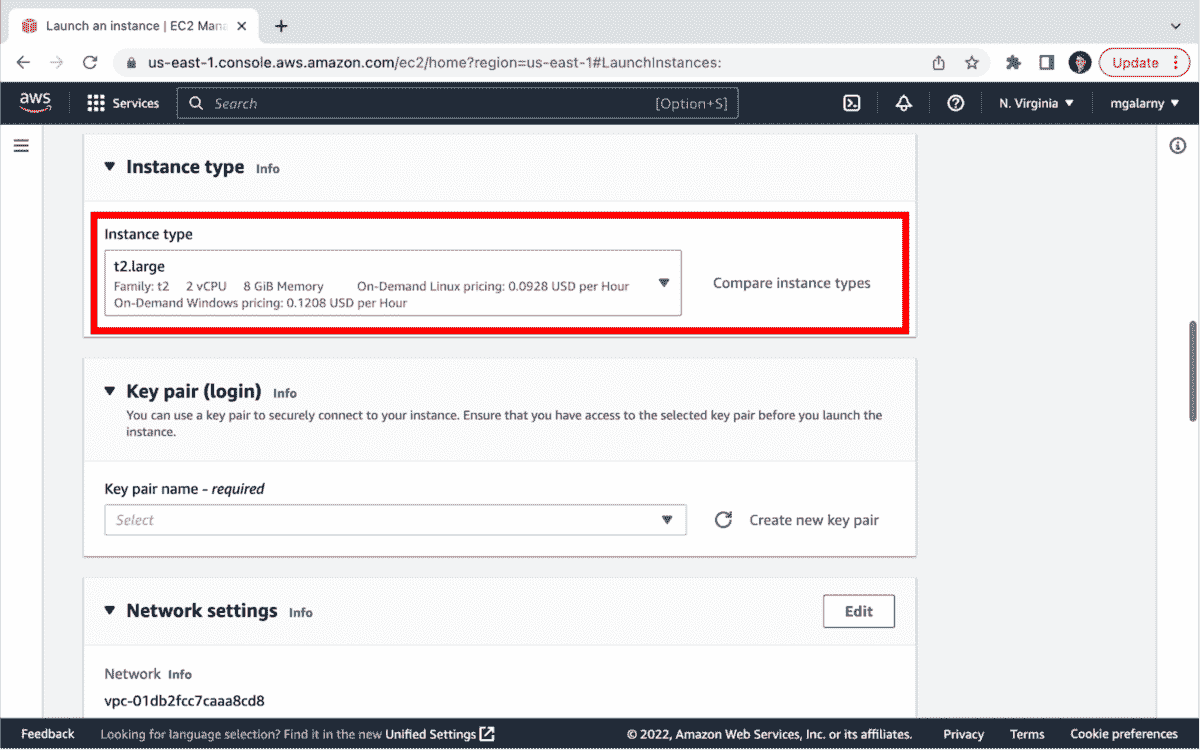
确保记住使用 AWS 会产生费用(除非你有免费积分)。
8). 转到密钥对(登录)。选择一个现有的密钥对或创建新密钥对(如下图所示)。如果创建密钥对,请务必下载并将其保存在安全的地方。您将无法替换它。选择密钥对是一个重要步骤,因为您需要密钥才能通过 SSH 访问您的实例或轻松下载文件。
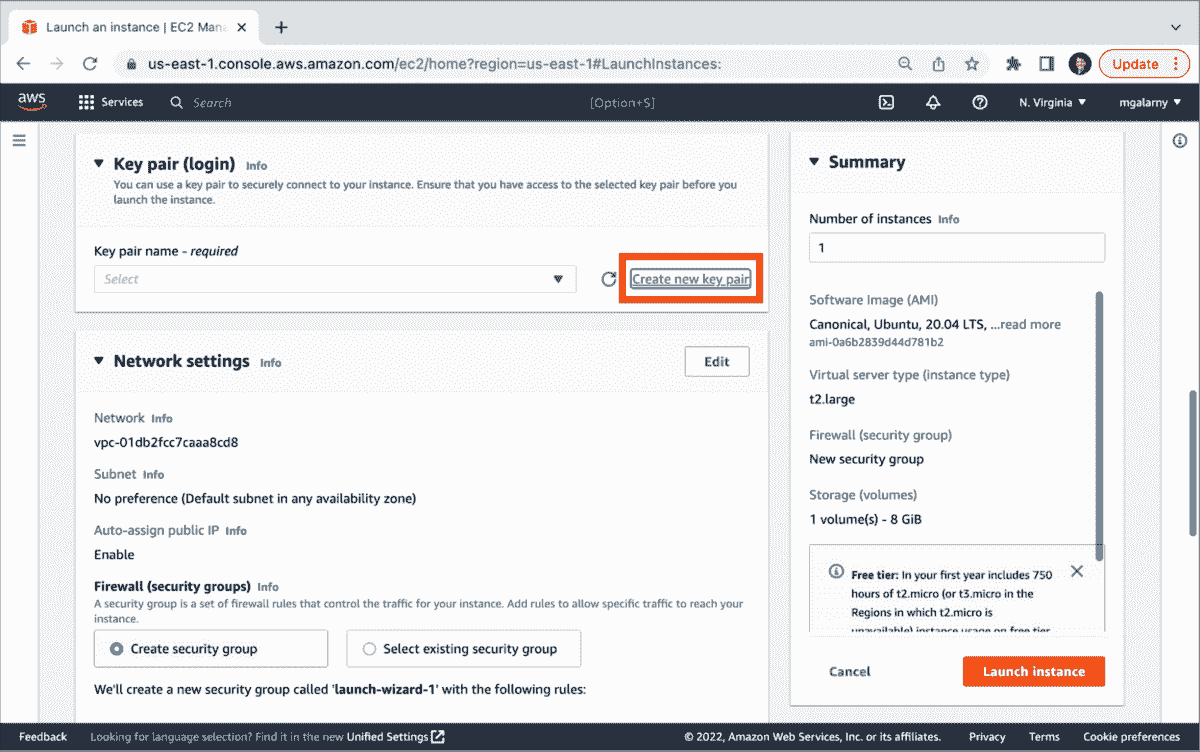
点击创建新密钥对后,输入您的密钥对名称(例如,MyJupyterHubTutorial_pem),然后点击创建密钥对(下图的右下角)。
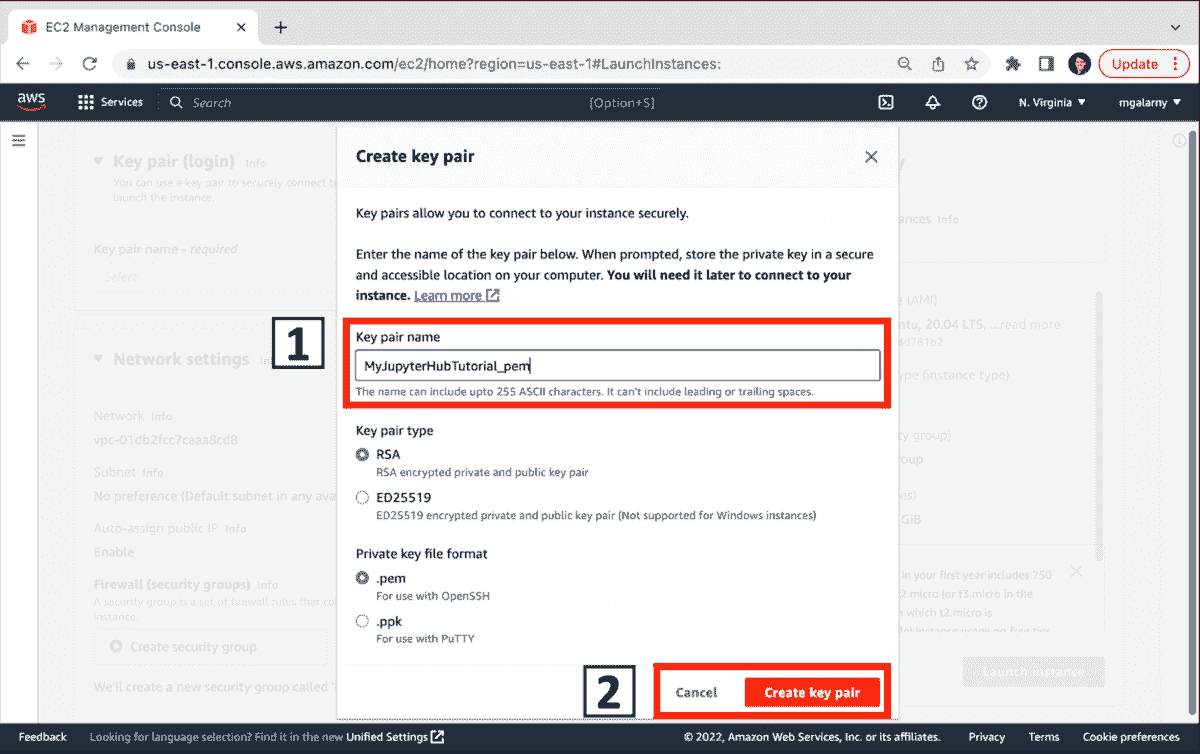
注意: 如果您使用的是 Windows,可以选择 ppk 格式。然而,我更喜欢在 Windows 上使用 GOW(如我的通过 SSH 连接到 EC2 实例教程所示),这样您可以在 Windows 上使用 pem 文件(而无需 PuTTY)。
9). 转到网络设置。这是教程的部分,您可以在其中创建安全组或选择现有的安全组。这将影响如何访问您的实例。在本教程中,您可能需要检查以下内容
-
允许 SSH 流量
-
允许来自互联网的 HTTPS 流量(您可以在启动 EC2 实例后启用 HTTPS)
-
允许来自互联网的 HTTP 流量
点击这些选项将创建 3 个安全组。
可选地,您还可以通过点击编辑来查看这些安全组。这也将允许您更改安全组名称。
在此图像中,安全组 1 允许使用端口 22 进行 SSH 访问(图像来自我尝试使用 Ubuntu 22.04 而不是 Ubuntu 20.04 时的情况)。
10). 转到配置存储。这允许您选择所需的存储量(GiB 数量)以及卷类型(例如,gp2、gp3、io1、io2、sc1、st1、标准)。对于本教程,我选择的是第 6 步中所选 AMI 的默认存储(gp2)。
在此图像中,安全组 1 允许使用端口 22 进行 SSH 访问(图像来自我尝试使用 Ubuntu 22.04 而不是 Ubuntu 20.04 时的情况)。如果您喜欢使用不同的存储类型,如 gp3,请告诉我。gp3 似乎比 gp2 更具成本效益。
- 转到高级详情,然后向下滚动到用户数据。
这个步骤涉及提供一个在启动实例时运行的命令脚本。下面的安装脚本将安装 JupyterHub(安装程序做了什么)。在将文本粘贴到用户数据之前,至少需要将
#!/bin/bash
curl -L https://tljh.jupyter.org/bootstrap.py \
| sudo python3 - \
--admin <admin-user-name> \
--show-progress-page
代码说明: 代码--show-progress-page将在实例启动后不久创建一个临时的“TLJH 正在构建”进度页面,这样你可以很快看到安装是否顺利。
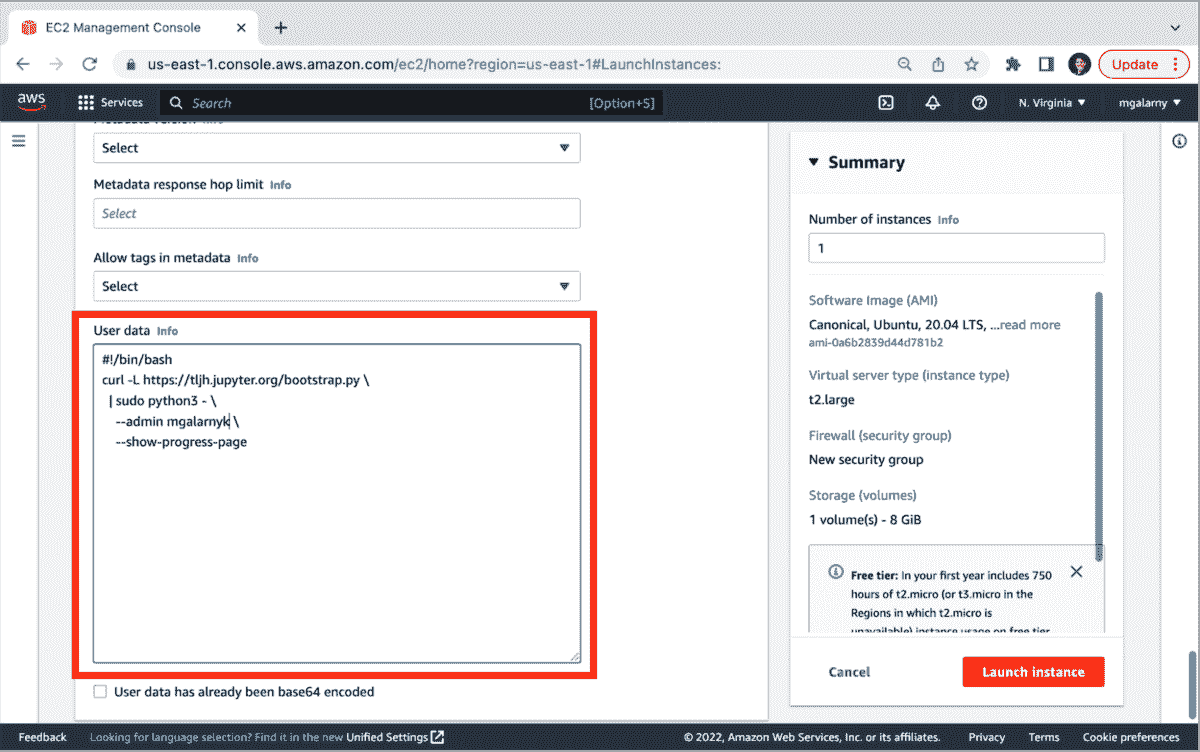
注意,如果你在启动 JupyterHub 后想要进行更改,你可以随时安装额外的 conda、pip 或 apt 包,以及添加/移除管理员用户。
12). 转到摘要并点击启动实例。
13). 在启动状态通知屏幕上,点击链接。它会带你到EC2 管理控制台。
14). 你现在应该在 EC2 管理控制台中。这个步骤需要一点耐心,因为你需要等待 JupyterHub 安装完成。官方文档说这可能需要 10 分钟以上(对我来说要快得多)。
这是你可以找到公共地址的一个位置
你可以通过将公共地址复制到浏览器中查看服务器是否正在设置(我推荐使用 chrome)。
几分钟后,将公共地址复制到新的标签页中,系统会要求你登录。
你可以在这里学习如何为 JupyterHub 设置 HTTPS 和 SSL。
15). 输入在第 11 步中指定的管理员用户名(例如 mgalarnyk)并输入一个可以是 7 个字符或更长的密码。
注意,第 11 步中的安装脚本可能已经被修改以添加密码、添加额外的管理员用户、在用户环境中安装 python 包以及安装插件。
点击“登录”,欢迎使用 JupyterHub!
如果您想在启动 JupyterHub 后进行更改,可以随时安装额外的 conda、pip 或 apt 包,以及添加/删除管理员用户。
潜在错误
404 页面未找到
可能有多种原因导致此错误。如果在“请稍候,您的 TLJH 正在设置中”屏幕后出现此错误,可能只是将地址复制到另一个标签页中。
‘连接被拒绝’错误在重启服务器后
查看官方文档以了解如何解决此问题。
无法访问此网站
我最初想使用 Ubuntu 22.04 创建此教程,但当我在浏览器中输入 IP 地址时遇到了此错误(当然,还有其他原因可能导致错误)。如果您想使用 Ubuntu 22.04,解决此问题的一个可能方法是检查 EC2 管理控制台中的系统日志,以确认是否为 curl 问题,并根据此 askubuntu 帖子的建议修改安装脚本。
结论
本教程介绍了如何在 AWS 上设置 Jupyterhub (TLJH)。安装可能需要相当长的时间进行设置,并且管理起来可能会更久。如果您不想处理安装和维护服务器,您可以使用Saturn Cloud这样的产品。不管怎样,如果您对教程有疑问或意见,欢迎通过YouTube或Twitter与我联系。
迈克尔·加拉尼克 是一名数据科学专家,目前在 Parallel Domain 担任产品营销内容负责人。
更多相关话题
如何为机器学习设置 Python 环境
原文:
www.kdnuggets.com/2019/02/setup-python-environment-machine-learning.html
评论

设置您的 Python 环境以进行机器学习可能是一项棘手的任务。如果您以前从未设置过这样的环境,可能会花费数小时尝试不同的命令来使其正常工作。但我们只想直接进入机器学习!
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT
在本教程中,您将学习如何设置一个稳定的Python 机器学习开发环境。您将能够直接深入到机器学习中,再也不必担心安装软件包的问题。
(1) 设置 Python 3 和 Pip
第一步是安装 pip,一个 Python 包管理工具:
sudo apt-get install python3-pip
使用 pip,我们可以通过简单的pip install *your_package*安装任何在Python 包索引中的 Python 包。很快您将看到我们如何用它来设置我们的虚拟环境*。
接下来,我们将设置 Python 3 为运行pip或python命令时的默认版本。这使得使用 Python 3 更加方便。如果我们不这样做,那么如果我们想使用 Python 3,就必须记住每次输入pip3和python3!
为了强制将 Python 3 设置为默认版本,我们将修改~/.bashrc文件。从命令行执行以下命令来查看该文件:
nano ~/.bashrc
向下滚动到# 一些更多的 ls 别名部分,并添加以下行:
alias python='python3'
保存文件并重新加载您的更改:
source ~/.bashrc
哇!Python 3 现在是您的默认 Python!您可以通过简单地在命令行运行python *your_program*来使用它。
(2) 创建一个虚拟环境
现在我们将设置一个虚拟环境。在这个环境中,我们将安装进行机器学习所需的所有 Python 包。
我们使用虚拟环境来分隔我们的编码设置。想象一下,如果你在某个时刻想在电脑上做两个不同的项目,而这两个项目需要不同版本的不同库。如果将它们都放在同一个工作环境中可能会很混乱,你可能会遇到库版本冲突的问题。你的项目 1 的 ML 代码需要numpy的 1.0 版本,但项目 2 需要 1.15 版本。糟糕!
虚拟环境允许我们隔离工作区域,以避免这些冲突。
首先,安装相关的包:
sudo pip install virtualenv virtualenvwrapper
一旦我们安装了 virtualenv 和 virtualenvwrapper,我们将需要再次编辑我们的~/.bashrc文件。将这 3 行放在文件底部并保存。
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
source /usr/local/bin/virtualenvwrapper.sh
保存文件并重新加载更改:
source ~/.bashrc
很好!现在我们可以像这样创建我们的虚拟环境:
mkvirtualenv ml
我们刚刚创建了一个名为ml的虚拟环境。要进入它,请执行以下操作:
workon ml
很棒!在ml虚拟环境中进行的任何库安装都会被隔离在其中,不会与其他环境冲突!因此,每当你想运行依赖于ml环境中安装的库的代码时,只需首先使用workon命令进入该环境,然后像平常一样运行你的代码。
如果你需要退出虚拟环境,请运行以下命令:
deactivate
(3) 安装机器学习库
现在我们可以安装我们的 ML 库了!我们将使用最常用的库:
-
numpy: 处理矩阵,尤其是数学运算
-
scipy: 科学和技术计算
-
pandas: 数据处理、操作和分析
-
matplotlib: 数据可视化
-
scikit learn: 机器学习
这是一个简单的小技巧,可以一次性安装所有这些库!创建一个requirements.txt文件,并列出你希望安装的所有包,如下所示:
numpy
scipy
pandas
matplotlib
scikit-learn
一旦完成,只需执行以下命令:
pip install -r requirements.txt
看!Pip 会一次性安装文件中列出的所有包。
恭喜,你的环境已设置好,你准备好进行机器学习了!
想要学习?
关注我 twitter,我会发布最新最精彩的 AI、技术和科学内容!
Bio: George Seif 是一名认证极客和 AI / 机器学习工程师。
原文。转载已获许可。
相关:
-
为你的回归问题选择最佳机器学习算法
-
数据科学家需要了解的 5 种聚类算法
-
Python 中的 5 种快速简单的数据可视化(附代码)
更多相关主题
掌握 Python 机器学习的 7 个步骤
原文:
www.kdnuggets.com/2017/03/seven-more-steps-machine-learning-python.html/2
第 4 步:更多集成方法
第一篇文章仅涉及单一的集成方法:随机森林(RF)。多年来,RF 作为一种顶级分类器取得了巨大成功,但它肯定不是唯一的集成分类器。我们将查看 bagging、boosting 和 voting。
给我一个提升。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
首先,阅读这两个集成学习者的概述,第一个是一般性的,第二个是与 Scikit-learn 相关的:
-
集成学习者简介,作者:Matthew Mayo
-
Scikit-learn 中的集成方法,Scikit-learn 文档
然后,在转向新的集成方法之前,先通过这里的新教程重新熟悉随机森林:
- Python 中的随机森林,来自 Yhat
Bagging、boosting 和 voting 都是不同形式的集成分类器。它们都涉及构建多个模型;然而,算法、数据和最终如何组合结果在这些方案中有所不同。
-
Bagging 从相同的分类算法构建多个模型,同时使用来自训练集的不同(独立)数据样本 -- Scikit-learn 实现了 BaggingClassifier
-
Boosting 从相同的分类算法构建多个模型,将模型一个接一个地串联,以提升每个后续模型的学习效果 -- Scikit-learn 实现了 AdaBoost
-
Voting 从不同的分类算法构建多个模型,并使用标准来确定如何最好地组合这些模型 -- Scikit-learn 实现了 VotingClassifier
那么,为什么要组合模型?从一个具体的角度来看,以下是 偏差-方差权衡 的概述,特别是与提升(boosting)相关的内容,来自 Scikit-learn 文档:
- 单一估计器与自助法:偏差-方差分解,Scikit-learn 文档
现在你已经阅读了一些关于集成学习的一般介绍材料,并对几个具体的集成分类器有了基本的了解,请跟随这个介绍,学习如何使用 Scikit-learn 在 Python 中实现集成分类器,参考 Machine Learning Mastery 的内容:
- Python 中的集成机器学习算法与 scikit-learn,作者:Jason Brownlee
第 5 步:梯度提升
我们的下一步仍然在集成分类器的领域,重点关注当代最受欢迎的机器学习算法之一。梯度提升在最近的机器学习中产生了显著影响,成为(值得注意的)Kaggle 竞赛中最常用和成功的算法之一。
给我一个梯度提升。
首先,阅读梯度提升的概述:
接下来,了解为什么梯度提升是 Kaggle 竞赛中“最成功”的方法:
-
一位 Kaggle 大师解释梯度提升,作者:Ben Gorman
尽管 Scikit-learn 自带梯度提升实现,我们将有所不同,使用 XGBoost 库,因为 它被指出是更快速的实现。
以下链接提供了有关 XGBoost 库以及梯度提升的一些额外信息(出于必要):
现在,跟随这个教程,将所有内容汇总在一起:
- 使用 Python 的 XGBoost 梯度提升树指南,作者:Jesse Steinweg-Woods
你还可以跟随这些更简洁的示例进行巩固:
-
鸢尾数据集和 XGBoost 简单教程,作者:Ieva Zarina
第 6 步:更多降维
降维是通过利用过程将用于模型构建的变量从初始数量减少到减少后的数量,以获得一组主变量。
降维有 2 种主要形式:
以下是对一对常见特征提取方法的介绍。
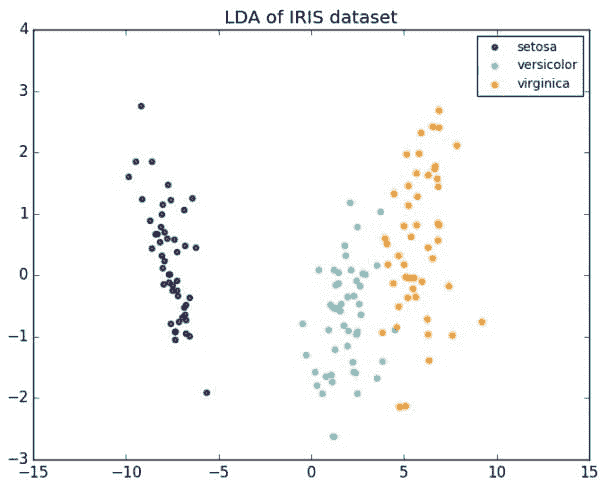
Iris 数据集的 LDA。
主成分分析(PCA) 是一种统计程序,使用正交变换将可能相关变量的观测集转换为称为主成分的线性无关变量集。主成分的数量小于或等于原始变量的数量。该变换被定义为使第一个主成分具有最大的可能方差(即解释数据中尽可能多的变异)[.]
上述定义来自 PCA 维基百科条目,如果感兴趣,可以进一步阅读。然而,以下概述式教程非常全面:
- 3 个简单步骤中的主成分分析,作者:Sebastian Raschka
线性判别分析(LDA) 是费舍尔线性判别的推广,这是一种用于统计学、模式识别和机器学习的方法,旨在找到特征的线性组合,以表征或区分两个或多个类别的对象或事件。得到的组合可以用作线性分类器,或者更常见的是,在后续分类之前用于降维。
LDA 与方差分析(ANOVA)和回归分析密切相关,这些方法也试图将一个因变量表示为其他特征或测量的线性组合。然而,ANOVA 使用分类的自变量和连续的因变量,而判别分析具有连续的自变量和分类的因变量(即类别标签)。
上述定义也来自维基百科。此外,以下内容的阅读也很全面:
- 线性判别分析 – 一步步详解,作者:Sebastian Raschka
对于降维,您是否对 PCA 和 LDA 之间的实际区别感到困惑?Sebastian Raschka 阐明了:
线性判别分析(LDA)和主成分分析(PCA)都是常用于降维的线性变换技术。PCA 可以被描述为一种“无监督”算法,因为它“忽略”了类别标签,其目标是找到最大化数据集方差的方向(即所谓的主成分)。与 PCA 相对,LDA 是“有监督”的,它计算出“线性判别”方向,这些方向表示最大化多个类别间隔的轴。
关于这一点的简要阐述,请阅读以下内容:
- LDA 和 PCA 在降维中的区别是什么?,作者:Sebastian Raschka
第 7 步:更多深度学习
原始的 7 步骤... 文章提供了神经网络和深度学习的入门点。如果你已经顺利完成了前面的内容,并希望巩固对神经网络的理解,并练习实现一些常见的神经网络模型,那么继续学习毫无疑问是有意义的。
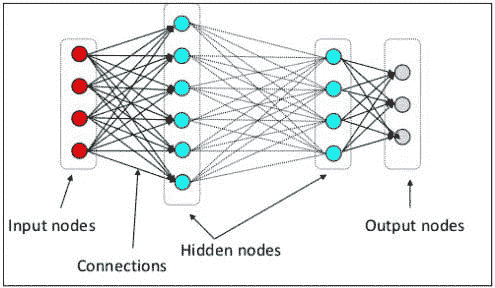
深度神经网络的许多层。
首先,查看一些深度学习基础材料:
-
深度学习关键术语解析,作者:Matthew Mayo
-
理解深度学习的 7 个步骤,作者:Matthew Mayo
接下来,尝试一些关于 TensorFlow 的入门概述教程,Google 的“开源机器智能软件库”,实际上是一个深度学习框架,并且几乎是当代事实上的首选神经网络工具:
-
Tensorflow 最温和的介绍 – 第一部分,作者:Soon Hin Khor
-
Tensorflow 最温和的介绍 – 第二部分,作者:Soon Hin Khor
-
Tensorflow 最温和的介绍 – 第三部分,作者:Soon Hin Khor
-
Tensorflow 最温和的介绍 – 第四部分,作者:Soon Hin Khor
最后,尝试直接从 TensorFlow 网站上的这些教程中动手实践,这些教程实现了一些最流行和常见的神经网络模型:
此外,一篇专注于深度学习的 7 步骤... 文章目前正在制作中,将重点讨论使用位于 TensorFlow 之上的高级 API 来提高实践者实现模型的便捷性和灵活性。完成后,我也会在这里添加一个链接。
相关:
-
进入机器学习职业前阅读的 5 本电子书
-
理解深度学习的 7 个步骤
-
机器学习关键术语解释
更多相关话题
7 步掌握 Keras 深度学习
原文:
www.kdnuggets.com/2017/10/seven-steps-deep-learning-keras.html

神经网络框架、库和 API 的选择并不缺乏,对于任何有兴趣开始深度学习的人来说都是如此。那么... 为什么选择 Keras?
Keras 是一个高级神经网络 API,帮助引领深度学习和人工智能的商品化。它运行在许多低级库之上,作为后端使用,包括 TensorFlow、Theano、CNTK 和 PlaidML。Keras 代码是可移植的,这意味着你可以使用 Theano 作为后端在 Keras 中实现一个神经网络,然后指定后端为 TensorFlow,代码无需进一步更改。数据科学家和机器学习专家 Charles Martin 总结了 这句话(在回应该帖子时):
我们已经可以使用这些算法超过 10 年了。虽然不是很容易获得,但对于一个优秀的黑客来说还是可以访问的。在我看来,最重要的进展来自 Google Keras,它将非常强大、现代的 AI 算法商品化,而这些算法之前不仅无法获得,还被认为是不可用的。
Keras 是一个易于使用的神经网络库,促进了简单而直观的语法。它还面向神经网络技术的使用者而非开发者,至少在某种程度上是这样。这两个群体之间的界限并不十分明确;到底什么构成了机器学习算法的设计与实现,什么又算是修改已经准备好的算法呢?这有点像“先有鸡还是先有蛋”的问题,并不适合在这里讨论。然而,我会主张,或许比其他任何已建立的主流神经网络库更适合于数据科学实践的是 Keras。事实上,我认为 Keras 是任何使用神经网络的数据科学家工具箱中的一个重要工具。
本教程旨在让你尽快熟悉 Keras,使你能够迅速上手。如果你已经熟悉神经网络,这并不是特别困难的任务。为此,理解神经网络是首选——尽管第一步中会简要介绍——以及对其他机器学习框架的一些经验。除此之外,不需要对 Keras 有特定的经验。
步骤 1: 神经网络基础
本文汇集了一些神经网络“入门”资源。
步骤 2: Keras 基础
首先,Keras 到底是什么?为何不直接从项目网站了解?阅读整个主页(这只需几分钟),特别注意“30 秒了解 Keras”,这应该足以让你了解 Keras 的简单易用。
当前主要版本的 Keras 发布说明(写作时的版本)可以在这里找到。花几分钟时间阅读它们:
DataCamp 的 Karlijn Willems 创建了一个方便的 Keras 备忘单,我推荐你下载并随时查阅。即使有些内容可能现在还不太明白,但很快你就会明白,这个参考资料无疑会很有用。我桌上就有一份打印版。
- Keras 备忘单,作者:Karlijn Willems
最后也是最重要的,要熟悉 Keras 文档,它非常优秀并且解释了所有内容。请将其收藏。
第三步:Keras 概述
Valerio Maggio 在 2017 年 PyData 伦敦大会上做了一个精彩的教程演讲,标题为“十步走向 Keras”。要深入了解 Keras 是什么、它与其他库的比较,以及如何使用它来完成任务,请花 90 分钟观看这个视频。绝对值得花时间来全面了解 Keras。
然后查看以下几页文档,以了解 Keras 如何进行模型实现。
如果你仍然对为何选择 Keras 而非 TensorFlow 存有疑问(你没有观看视频,对吧?),请阅读此文:
- TensorFlow 还是 Keras?我应该学习哪个?,作者:Aakash Nain
最后,关于如何更改 Keras 后端的信息,请参阅以下文档页面:
第四步:Keras 的初步操作
让我们做一件每个人在开始使用新的深度学习库时都会做的事情:实现一个简单的逻辑回归模型。
如果你在前一步中观看了 Valerio 的视频,那么你可能已经获得了所需的信息。如果没有,请参考他在讲座中的笔记本。理想情况下,你应阅读整篇内容,以获得 TensorFlow、Theano 和 Keras 的实现代码的优秀比较。然而,如果你只对 Keras 代码感兴趣,可以跳到大约中间部分。
- 多层全连接网络,由 Valerio Maggio
下面展示的 Keras 代码(直接取自 Maggio 的笔记本)完成任务的美感应该是显而易见的。注意,此时数据预处理已经完成。
实现逻辑回归,如上所述,是一件事,但现在让我们尝试一些更值得称之为神经网络的东西,带有一个隐藏层。
首先,确保你查看了以下 Keras 文档页面,描述了 Sequenial 模型(如上所述)和 Layers。
现在,跟随这个基本的神经网络实现,它学习一些关于井字棋游戏结果的内容。
- Keras 教程:用神经网络识别井字棋赢家,由 Matthew Mayo
完成这些步骤后,你应该准备好实现一些更复杂的架构。
第 5 步:实现卷积神经网络
要在 Keras 中实现卷积神经网络(CNN),首先阅读其卷积层的文档:
之后,查看以下两个关于 Keras 中的 CNN 的教程。第一个教程速度较慢,涵盖了你现在应该知道的大部分内容,而第二个则涉及了一些额外的话题,如避免过拟合。这不一定是非此即彼的方法;你可能会在两个写作中找到有价值的内容:
-
Keras 教程:Python 深度学习的终极初学者指南,由 Elite Data Science
-
卷积神经网络简介,由 Mike Irvine
要了解更多关于卷积神经网络的一般知识,可以尝试 Brandon Rohrer 的视频:
阅读配套博客文章。
第 6 步:实现递归神经网络
要在 Keras 中实现递归神经网络(RNN),首先阅读其递归层的文档:
之后,尝试 Chris Albon 的这个教程,实施长短期记忆(LSTM)网络——一种主流的 RNN 类型——用于文本分类:
要了解更多关于递归神经网络的一般知识,可以尝试 Brandon Rohrer 的视频:
阅读 配套幻灯片。
第七步:下一步是什么?
到现在为止,你应该对 Keras 有了扎实的理解,包括为什么使用它、在某些情况下它相比其他库的优势,以及如何使用它来实现各种网络架构。你现在是专家了,对吧?
好吧,可能不是。但希望你已经掌握了基础。当你想要超越基础时,下一步最好的选择可能是 Keras 的官方教程:
之后,查看 Keras 示例目录,其中包括视觉模型示例、文本与序列示例、生成模型示例等。
另外,如何挑战自己来微调一下你在前面的步骤中实现的一些模型呢?改变优化器,添加另一层,尝试不同的激活函数。或者使用一些 Keras 评估指标来回顾并评估你的模型性能。Keras 文档是一个很好的起点:
祝你使用 Keras 顺利。
相关:
-
掌握数据准备的 7 个步骤
-
掌握 Python 机器学习的 7 个步骤
-
掌握 Python 机器学习的更多 7 个步骤
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
掌握 Python 机器学习的 7 个步骤
原文:
www.kdnuggets.com/2015/11/seven-steps-machine-learning-python.html/2
第 4 步:开始使用 Python 进行机器学习
-
Python。完成。
-
机器学习基础知识。完成。
-
Numpy。完成。
-
Pandas。完成。
-
Matplotlib。完成。
时候到了。让我们开始使用 Python 的事实上的标准机器学习库 scikit-learn 来实现机器学习算法。
scikit-learn 流程图。
许多后续教程和练习将由 iPython(Jupyter)Notebook 驱动,这是一种执行 Python 的互动环境。这些 iPython notebooks 可以选择在线查看或下载到自己的计算机上进行本地互动。
- iPython Notebook 概述来自斯坦福大学
另外,请注意下面的教程来自多个在线来源。所有 Notebook 都已注明作者;如果出于某种原因,你发现某些人的工作没有得到适当的署名,请告诉我,我们会尽快纠正情况。特别地,我想对 Jake VanderPlas、Randal Olson、Donne Martin、Kevin Markham 和 Colin Raffel 表示感谢,感谢他们提供的精彩免费资源。
我们首先介绍用于初步了解 scikit-learn 的教程。我建议在进入下一步之前按顺序完成这些教程。
scikit-learn 的一般介绍,涵盖了 k 最近邻算法,这是 Python 最常用的通用机器学习库:
- scikit-learn 入门,作者:Jake VanderPlas
更深入和扩展的介绍,包括一个从头到尾使用著名数据集的入门项目:
- 示例机器学习 Notebook,作者:Randal Olson
重点关注在 scikit-learn 中评估不同模型的策略,涵盖训练/测试数据集的拆分:
- 模型评估,作者:Kevin Markham
第 5 步:使用 Python 的机器学习主题
在 scikit-learn 打下基础后,我们可以继续深入探讨各种常见且有用的算法。我们从 k-means 聚类开始,它是最著名的机器学习算法之一。它是一种简单且常常有效的无监督学习问题解决方法:
- k-means 聚类,作者:Jake VanderPlas
接下来,我们回到分类问题,看看一种历史上最受欢迎的分类方法:
从分类问题,我们来看连续的数值预测:
- 线性回归,作者:Jake VanderPlas
然后,我们可以通过逻辑回归利用回归来解决分类问题:
- 逻辑回归,作者:Kevin Markham
第 6 步:使用 Python 进行高级机器学习主题
我们已经初步了解了 scikit-learn,现在我们将注意力转向一些更高级的主题。首先是支持向量机,这是一种依赖于数据高维空间复杂变换的非线性分类器。
- 支持向量机,作者:Jake VanderPlas
接下来,通过 Kaggle Titanic 竞赛 实践,我们将研究一种集成分类器——随机森林:
- Kaggle Titanic 竞赛(带随机森林),作者:Donne Martin
降维是一种减少问题中考虑变量数量的方法。主成分分析是一种特定形式的无监督降维方法:
- 降维,作者:Jake VanderPlas
在进入最后一步之前,我们可以花点时间考虑一下,我们在相对较短的时间内已经走了很长一段路。
使用 Python 及其机器学习库,我们已经涵盖了一些最常见且知名的机器学习算法(k-近邻、k-means 聚类、支持向量机),研究了一种强大的集成技术(随机森林),并检查了一些额外的机器学习支持任务(降维、模型验证技术)。随着基础机器学习技能的掌握,我们已经开始为自己建立一个有用的工具包。
在总结之前,我们将再添加一个受欢迎的工具。
第 7 步:Python 中的深度学习
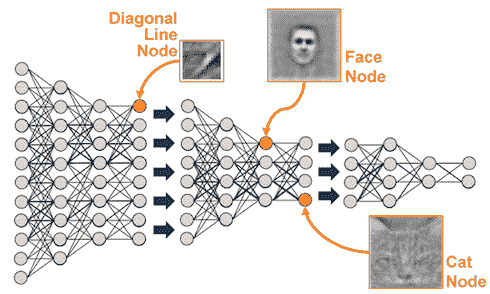
学习是深刻的。
深度学习无处不在!深度学习建立在几几十年的神经网络研究基础上,但最近几年的进展显著提升了深度神经网络的感知能力和普遍兴趣。如果你对深度学习不熟悉,KDnuggets 有很多文章 详细介绍了这项技术的众多近期创新、成就和荣誉。
这最后一步并不声称是任何形式的深度学习诊所;我们将查看两个领先的现代 Python 深度学习库中的几个简单网络实现。对于那些有兴趣深入了解深度学习的人,我推荐从以下免费的在线书籍开始:
Theano 是我们将要查看的第一个 Python 深度学习库。来自作者的介绍:
Theano 是一个 Python 库,可以高效地定义、优化和评估涉及多维数组的数学表达式。
以下关于 Theano 的深度学习入门教程虽然较长,但非常好,描述详尽且评论丰富:
我们将要测试的另一个库是 Caffe。再一次,来自作者的介绍:
Caffe 是一个深度学习框架,旨在注重表达、速度和模块化。它由伯克利视觉与学习中心(BVLC)和社区贡献者开发。
本教程是本文的点睛之笔。虽然我们上面已经介绍了一些有趣的示例,但没有一个能与以下示例相比,那就是使用 Caffe 实现Google 的 #DeepDream。好好享受吧!理解本教程后,可以尝试一下,让你的处理器自主“做梦”。
我没有承诺这会很快或容易,但如果你花时间并遵循上述 7 个步骤,你完全可以在多种机器学习算法及其在 Python 中的实现方面取得合理的熟练程度和理解,包括一些处于当前深度学习研究前沿的库。
个人简介:Matthew Mayo 是一名计算机科学研究生,目前正在撰写关于并行化机器学习算法的论文。他还是数据挖掘的学生、数据爱好者,并且是一位有抱负的机器学习科学家。
相关内容:
-
前 20 名数据科学 MOOC
-
60+ 本关于大数据、数据科学、数据挖掘、机器学习、Python、R 等的免费书籍
-
15 门数据科学数学 MOOC
更多相关内容
掌握数据科学 SQL 的 7 个步骤
原文:
www.kdnuggets.com/2016/06/seven-steps-mastering-sql-data-science.html/2
第 4 步:创建、删除、删除
我们的第二组命令包括那些用于创建和删除表以及删除记录的命令。理解这不断增长的命令集合,突然之间,许多可以称之为常规数据管理和查询的操作变得可实现(当然,需要实践)。
创建
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的 IT 组织
删除
删除
第 5 步:视图与连接
进入一些稍微复杂的 SQL 主题。首先,我们来看一下视图,可以将其视为由查询结果填充的虚拟表,适用于包括应用开发、数据安全和简化数据共享在内的多种场景。
首先,了解一下视图是什么:
对于数据科学领域的初学者,我会把视图称为“可有可无”。由于重点可能更多放在数据探索上,我会说下一个主题——连接,是“必须掌握”的。
阅读有关连接是什么以及它们的重要性(并获取一些示例):
连接有不同的类型,学习 SQL 时可能会涉及其中一个较复杂的主题是将它们搞清楚。这实际上更多是 SQL 易用性的证明,而不是学习连接的实际难度。
观看解释内连接的视频,然后查看外连接和交叉连接的视频:

SQL 连接的可视化表示。
查看这个 SQL 连接的可视化表示:
最后,这个教程回顾了连接和视图:
第 6 步:数据科学中的 SQL
好的,你在学习 SQL 上已经取得了一些进展。你可以查询一些数据,创建和管理一些表格,如果需要还可以创建视图,甚至在一些更复杂的查询中使用连接。但你为什么要学习这些呢?是为了数据科学,对吧?让我们暂时离开技术,来了解一下这个话题。
这里有几个讨论 SQL 在数据科学中可以用于什么的讨论:
第 7 步:SQL 与 Python、R 的集成
我们经常会发现 SQL 被嵌入在用其他编程语言编写的软件中,作为更大系统的一部分。例如,在 web 开发中,你可能会发现 PHP 或 Ruby 或其他语言通过 SQL 调用数据库,以输入、修改或检索应用程序相关的数据。在数据科学中,你可能会看到 SQL 被调用作为某些用 Python 或 R 编写的应用程序的一部分。因此,了解这些语言如何与 SQL 配合并不是坏主意。

使用 Python 和 SQLite 执行 SQL 查询。
Python
要了解 Python 和 SQL 如何协同工作,请阅读 Sebastian Raschka 关于在 Python 中使用 SQLite 的精彩详细文章:
R
这里有一对资源用于实现 R 和 SQL 的集成,它们从不同的角度探讨了这一主题:
进一步
如果你觉得不断阅读 SQL 相关的内容并进行练习是你的节奏,我推荐你阅读以下(免费提供的)书籍:
- 通过艰难的方式学习 SQL,作者 Zed A. Shaw
相关:
-
掌握 Python 中机器学习的 7 个步骤
-
理解深度学习的 7 个步骤
-
R 学习路径:从初学者到专家的 7 个步骤
更多关于此主题
-
掌握 SQL、Python、数据清理、数据…的指南合集
tps://www.kdnuggets.com/2022/06/7-steps-mastering-python-data-science.html)
理解计算机视觉的 7 个步骤
原文:
www.kdnuggets.com/2016/08/seven-steps-understanding-computer-vision.html
作者:Pulkit Khandelwal,VIT 大学。
如果我们希望机器能够思考,我们需要教会它们看。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 事务
-Fei Fei Li,斯坦福人工智能实验室 和 斯坦福视觉实验室的主任
学习和计算使机器能够更好地理解图像的上下文,并构建真正理解智能的视觉系统。大量的图像和视频内容促使科学界理解和识别其中的模式,以揭示我们未曾察觉的细节。计算机视觉从图像中生成数学模型;计算机图形学从模型中绘制图像,最后图像处理将图像作为输入,输出另一张图像。
计算机视觉是一个交叉领域,借鉴了人工智能、数字图像处理、机器学习、深度学习、模式识别、概率图模型、科学计算及大量数学等领域的概念。因此,将此文章作为进入该领域的起点。我会尽可能在这篇文章中覆盖尽可能多的内容,但仍会有许多高级主题和一些有趣的内容可能会被遗漏(也许会在后续文章中提及?)。
步骤 1 - 背景调查
一如既往,通过概率、统计学、线性代数、微积分(包括微分和积分)的本科课程奠定基础。简要了解一下矩阵微积分也会有所帮助。此外,我的经验表明,如果你对数字信号处理有一些了解,会更容易掌握概念。
在实现方面,我建议具备MATLAB和 Python 的背景。查看Sentdex(一个 YouTube 频道),获取你所需的所有 Python 科学编程知识。请记住,计算机视觉完全依赖于计算编程。
你可能还想看看概率图模型(尽管这是一个非常高级的主题)。你可以稍后再回到这方面的内容。
步骤 2 - 数字图像处理
观看杜克大学的 Guillermo Sapiro 教授的视频。课程内容非常全面,包含大量练习。你可以在 YouTube 上找到这些视频,或者等到 2016 年 9 月 Coursera 的下一个课程开始。
参考书籍《数字图像处理》(作者:Gonzalez 和 Woods)。根据课程在 MATLAB 上的示例进行学习。
步骤 3 - 计算机视觉
完成数字图像处理后,下一步是理解各种图像和视频内容应用中公式背后的数学模型。佛罗里达大学的 Mubarak Shah 教授的计算机视觉课程是一个很好的入门课程,涵盖了所有构建高级材料所需的基本概念。
观看这些视频,并通过跟随Georgia Tech 教授 James Hays的计算机视觉课程项目来实现学到的概念和算法。这些作业也在 MATLAB 上进行。不要跳过这些。只有从头实现这些算法和方程,你才能深入理解它们。
步骤 4 - 高级计算机视觉
按照前三个步骤,你将为学习高级材料做好准备。
Coursera 提供的人工视觉中的离散推理为你提供了计算机视觉的概率图模型和数学超负荷。虽然 Coursera 已从网站上移除了这些内容,但你应该能在互联网上找到。事情现在看起来很有趣,并且肯定会让你感受到如何为机器视觉系统构建复杂却简单的模型。这个课程也应该成为你开始阅读学术论文的一个踏脚石。
步骤 5 - 引入 Python 和开源
让我们进入 Python。
有许多包,如OpenCV、PIL、vlfeat等。现在是将其他人构建的包应用到你的项目中的最佳时机。无需从头实现所有功能。
你可以找到许多很好的博客和视频来入门用 Python 编程计算机视觉。我推荐这本书,它应该足够了。去试试吧!看看 MATLAB 和 Python 如何帮助你实现算法。
步骤 6 - 机器学习和卷积神经网络
关于机器学习入门的帖子实在太多了。
查看这里、这里和这里。
从现在开始,你最好坚持使用 Python。快速浏览一下用 Python 构建机器学习系统和Python 机器学习。
在深度学习热潮下,你现在进入了计算机视觉的当前研究工作:卷积神经网络(ConvNets)的使用。斯坦福大学的 CS231n: 视觉识别中的卷积神经网络是一个全面的课程。虽然官方网页上的视频已被删除,但你可以很容易地在 Youtube 上找到重新上传的内容。

步骤 7 - 我应该如何进一步探索?
你可能觉得我已经给了你太多信息。但还有很多东西需要探索。
一个好的方法是查看一些多伦多大学的 Sanja Fidler和James Hays的研究生研讨课程,从中了解计算机视觉的当前研究方向,通过丰富的学术论文。
另一种可能的方法是关注顶级会议的顶级论文,如 CVPR,ICCV,ECCV,BMVC。或者,你可以关注 pyimagesearch.com 或 computervisionblog.com 或 aishack.in。在 videolectures.net 上观看计算机视觉及相关领域的无尽讲座和演讲!
总之,你已经涵盖了计算机视觉的历史,从滤波器、特征检测器和描述符、相机模型、跟踪器到识别、分割以及最新的神经网络和深度学习进展。在下一篇文章中,我将列出值得关注的顶级博客,在随后的文章中,我将介绍与计算机视觉相关的所有时间最重要的论文。
简介: Pulkit Khandelwal 是麦吉尔大学计算机科学硕士的新生。他的兴趣在于计算机视觉和机器学习。
相关内容:
-
理解深度学习的 7 个步骤
-
理解 NoSQL 数据库的 7 个步骤
-
掌握数据科学 SQL 的 7 个步骤
更多相关内容
SHAP: 用 Python 解释任何机器学习模型
原文:
www.kdnuggets.com/2022/11/shap-explain-machine-learning-model-python.html
动机
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
假设你正在训练一个机器学习模型,预测某个人是否会点击广告。在接收到有关某个人的一些信息后,模型预测该人不会点击广告。
图片由作者提供
但为什么模型会有这样的预测?每个特征对预测的贡献有多大?如果能看到一个图示,展示每个特征对预测的贡献情况,会不会很不错呢?
图片由作者提供
这时 Shapley 值就派上用场了。
什么是 Shapley 值?
Shapley 值是一种游戏理论方法,涉及在联盟中公平地分配收益和成本。
由于每个参与者对联盟的贡献不同,Shapley 值确保每个参与者根据他们的贡献获得公平的份额。
图片由作者提供
一个简单的例子
Shapley 值用于解决各种问题,涉及对每个工作者/特征在一个小组中的贡献进行质疑。为了理解 Shapley 值如何工作,假设你的公司刚刚进行了 A/B 测试,测试了不同的广告策略组合。
每种策略在特定月份的收入如下:
-
无广告:$150
-
社交媒体:$300
-
谷歌广告:$200
-
邮件营销:$350
-
社交媒体和谷歌广告 $320
-
社交媒体和邮件营销:$400
-
谷歌广告和邮件营销:$350
-
邮件营销、谷歌广告和社交媒体:$450
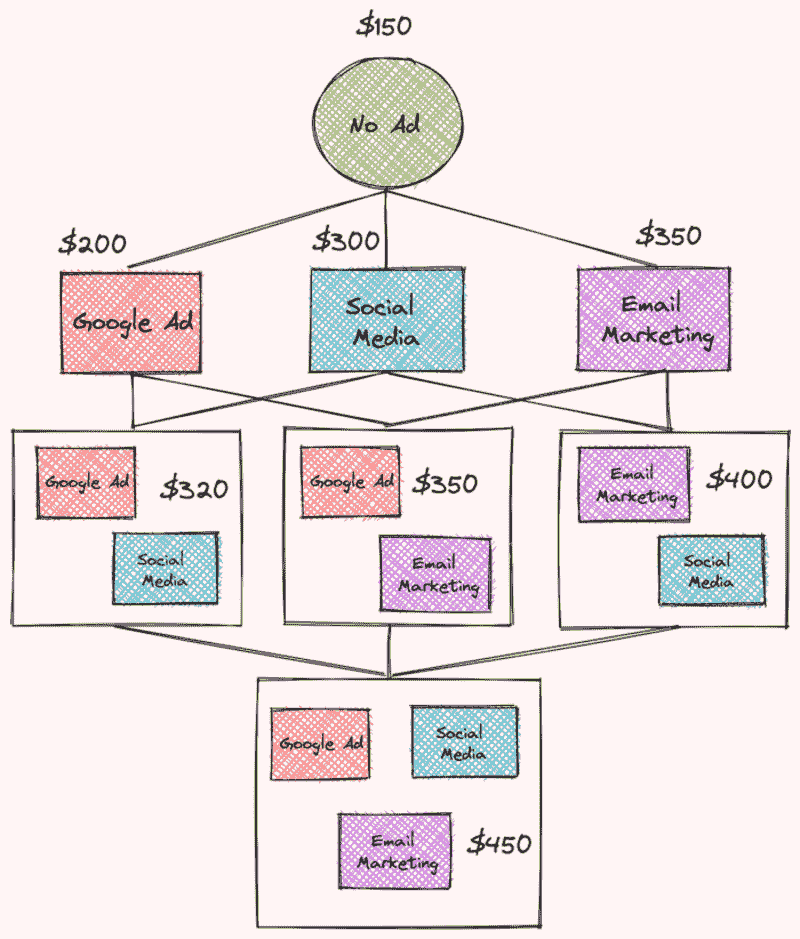
图片由作者提供
使用三种广告与不使用广告之间的收入差为 $300。每种广告对这一差异的贡献有多少?
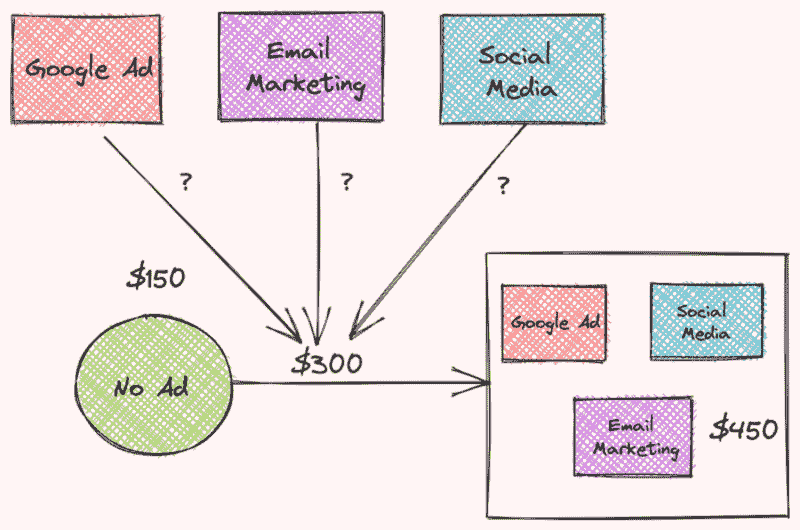
图片由作者提供
我们可以通过计算每种广告类型的 Shapley 值来找出结果。这篇文章提供了一种出色的计算 Shap 值的方法。我将在这里总结。
我们首先计算 Google 广告对公司收入的总贡献。Google 广告的总贡献可以通过以下公式计算:

图片由作者提供
让我们找出 Google 广告的边际贡献及其权重。
查找 Google 广告的边际贡献
首先,我们将找到 Google 广告对以下组合的边际贡献:
-
无广告
-
Google 广告 + 社交媒体
-
Google 广告 + 邮件营销
-
Google 广告 + 邮件营销 + 社交媒体
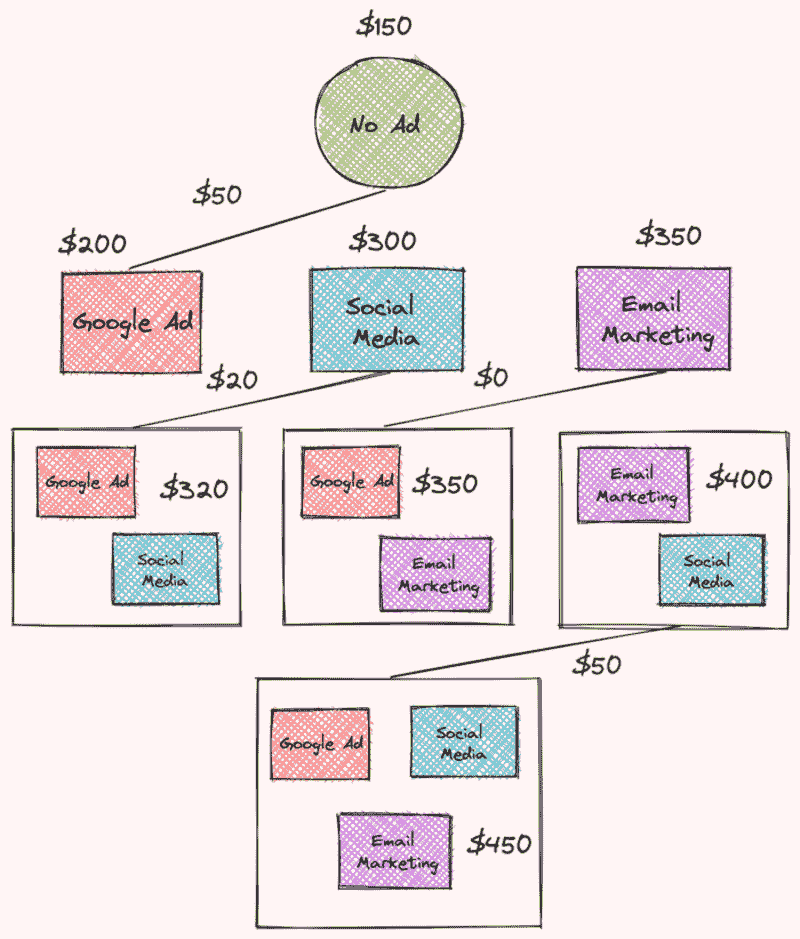
图片由作者提供
Google 广告对无广告的边际贡献是:

图片由作者提供
Google 广告对 Google 广告和社交媒体组合的边际贡献是:

图片由作者提供
Google 广告对 Google 广告和邮件营销组合的边际贡献是:

图片由作者提供
Google 广告对 Google 广告、邮件营销和社交媒体组合的边际贡献是:

图片由作者提供
查找权重
为了找到权重,我们将不同广告策略的组合组织成如下多个层级。每个层级对应每个组合中的广告策略数量。
然后我们将根据每个层级中的边数分配权重。我们看到:
-
第一层包含3 条边,所以每条边的权重将是1/3
-
第二层包含6 条边,所以每条边的权重将是1/6
-
第三层包含3 条边,所以每条边的权重将是1/3
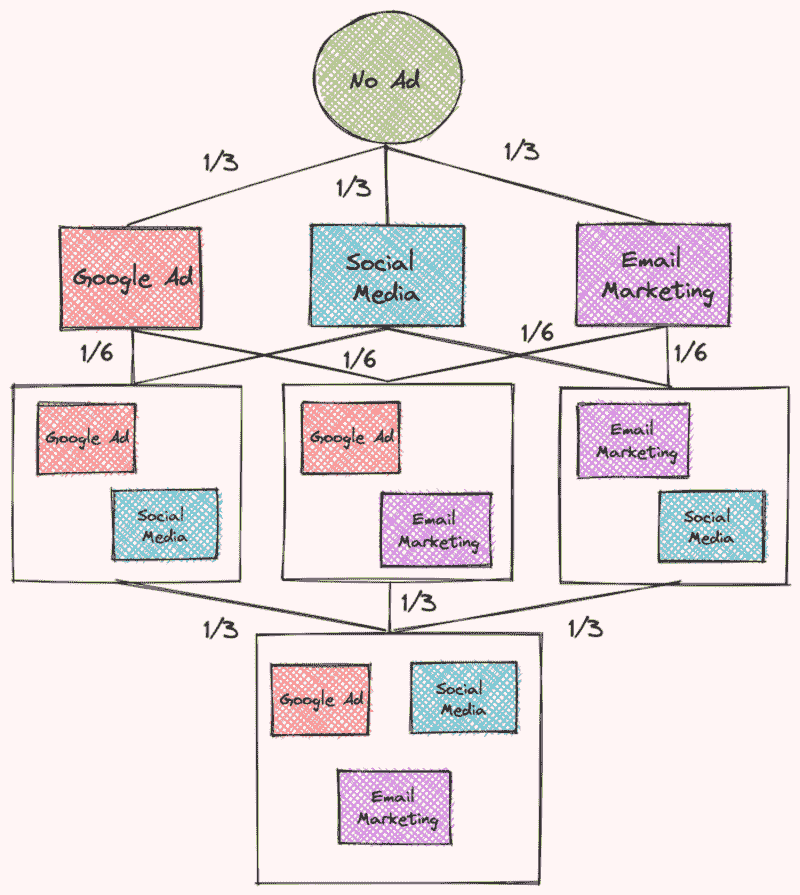
图片由作者提供
查找 Google 广告的总贡献
现在我们准备好根据之前找到的权重和边际贡献来找出 Google 广告的总贡献!
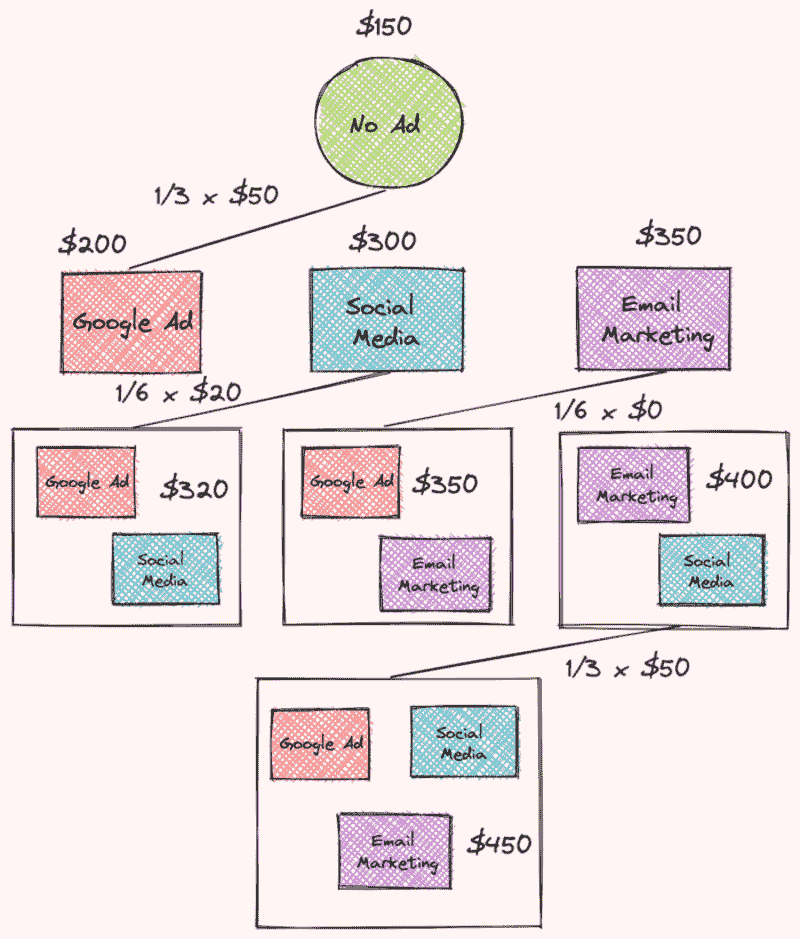
图片由作者提供
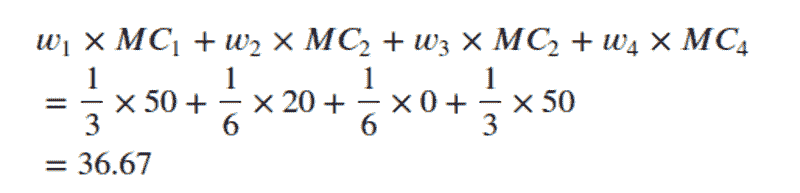
图片由作者提供
太棒了!所以 Google 广告对使用三种广告策略和不使用广告之间的总收入差异贡献了 $36.67。36.67 是 Google 广告的 Shapley 值。
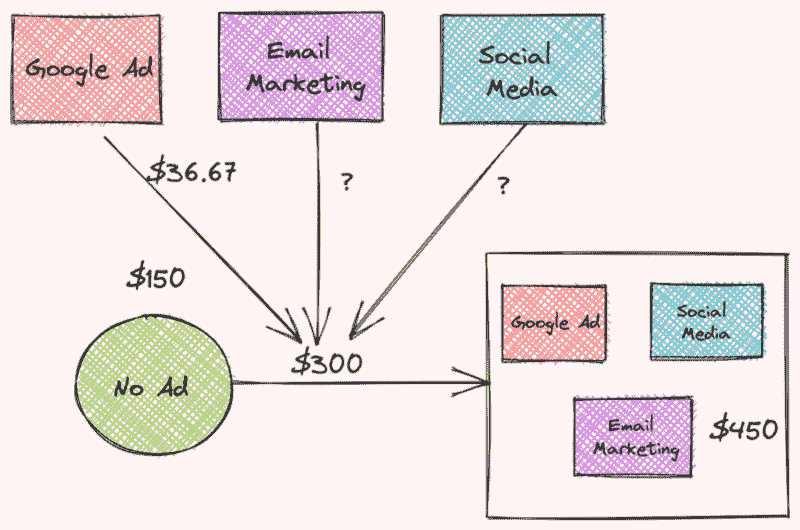
图片由作者提供
对另外两种广告策略重复上述步骤,我们可以看到:
-
电子邮件营销贡献了 $151.67
-
社交媒体贡献了 $111.67
-
Google 广告贡献了 $36.67
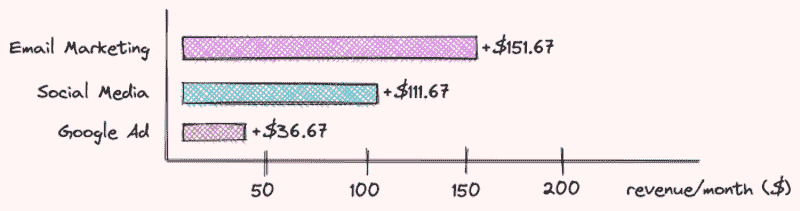
图片由作者提供
它们总共贡献了 $300,来说明使用三种不同广告类型和不使用广告之间的差异!很酷,对吧?
现在我们了解了 Shapley 值,让我们看看如何使用它来解释机器学习模型。
SHAP — 在 Python 中解释任何机器学习模型
SHAP 是一个使用 Shapley 值来解释任何机器学习模型输出的 Python 库。
要安装 SHAP,请输入:
pip install shap
训练模型
为了理解 SHAP 的工作原理,我们将使用一个 广告数据集 进行实验:
我们将构建一个机器学习模型来预测用户是否点击了广告,基于关于该用户的一些信息。
我们将使用 Patsy 将 DataFrame 转换为特征数组和目标值数组:
将数据分成训练集和测试集:
接下来,我们将使用 XGBoost 构建一个模型并进行预测:
为了查看模型的表现,我们将使用 F1 分数:
0.9619047619047619
非常好!
解释模型
模型在预测用户是否点击了广告方面表现良好。但它是如何得出这些预测的? 每个特征对最终预测和平均预测之间的差异贡献了多少?
请注意,这个问题与我们在文章开头讨论的问题非常相似。
这就是为什么找出每个特征的 Shapley 值可以帮助我们确定它们的贡献。获得特征 i 重要性的步骤,与之前类似,其中 i 是特征的索引。
-
获取所有不包含特征 i 的子集
-
找出特征 i 对每个子集的边际贡献
-
聚合所有边际贡献以计算特征 i 的贡献
要使用 SHAP 找到 Shapley 值,只需将训练好的模型插入到 shap.Explainer 中:
SHAP 瀑布图
可视化第一次预测的解释:
图片由作者提供
哦!现在我们知道了每个特征对第一次预测的贡献。以上图表的解释如下:

图片由作者提供
-
蓝色条形图显示了某个特征降低预测值的程度。
-
红色条形图显示了某一特征对预测值的影响程度。
-
负值表示点击广告的概率小于 0.5
对于这些子集,SHAP 不会移除某个特征再重新训练模型,而是将该特征替换为该特征的平均值,然后生成预测。
我们应当期望总贡献等于预测与均值预测之间的差值。让我们来检查一下:
图片由作者提供
太棒了!它们是相等的。
可视化第二次预测的解释:
图片由作者提供
SHAP 总结图
我们可以使用 SHAP 总结图可视化这些特征在多个实例中的整体影响,而不是查看每个个体实例。
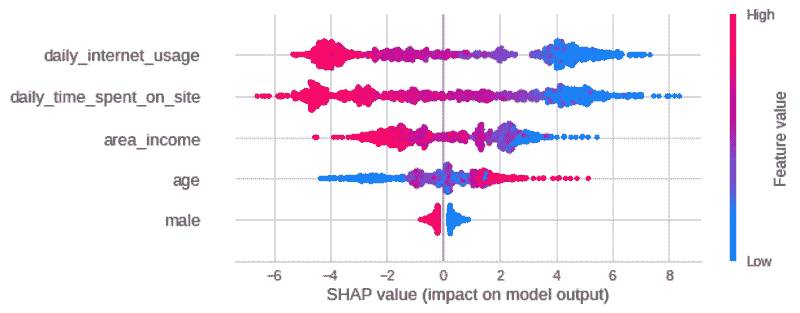
图片由作者提供
SHAP 总结图告诉我们数据集中最重要的特征及其影响范围。
从上图中,我们可以获得一些关于模型预测的有趣见解:
-
用户的每日互联网使用对是否点击广告有最强的影响。
-
随着每日互联网使用的增加,用户不太可能点击广告**。
-
随着每日网站使用时间的增加,用户不太可能点击广告。
-
随着区域收入的增加,用户不太可能点击广告。
-
随着年龄增加,用户更可能点击广告。
-
如果用户是男性,那么该用户不太可能点击广告。
SHAP 条形图
我们还可以使用 SHAP 条形图获取全局特征重要性图。
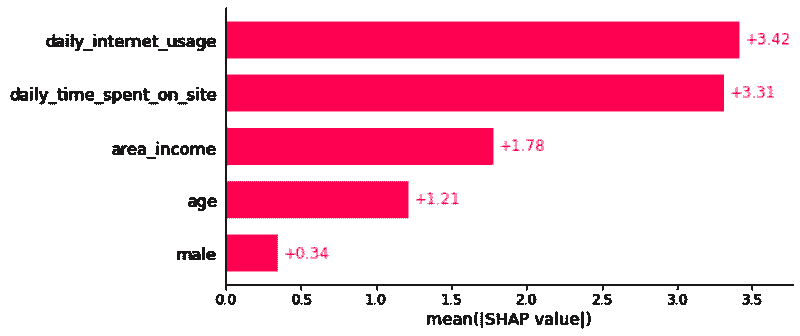
图片由作者提供
SHAP 依赖散点图
我们可以使用 SHAP 依赖散点图观察单个特征对所有模型预测的影响。
每日互联网使用时间
每日互联网使用特征的散点图:
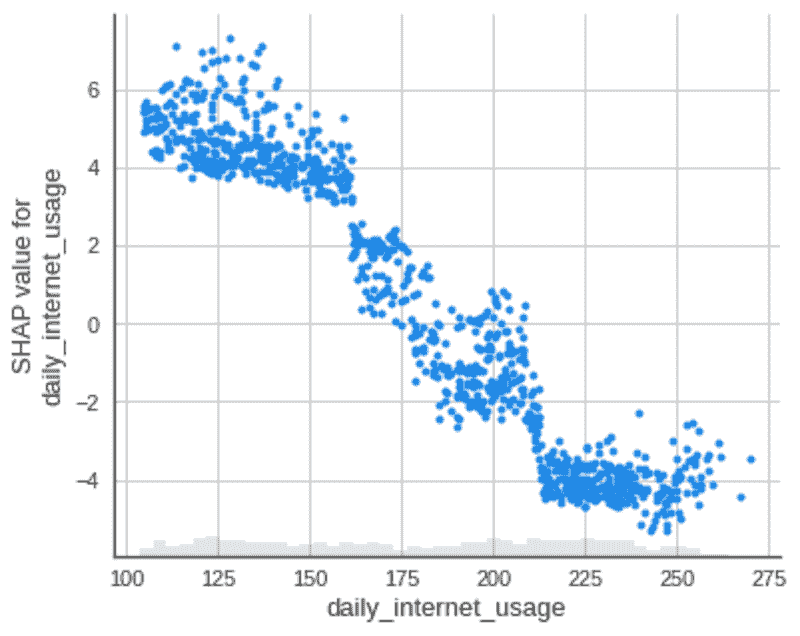
图片由作者提供
从上图中,我们可以看到,随着每日互联网使用时间的增加,SHAP 值下降。这验证了我们在之前图中看到的情况。
我们还可以通过在同一图中添加 color=shap_values 来观察每日互联网使用特征与其他特征之间的交互。
散点图将尝试挑选出与每日互联网使用最强交互的特征列,即每日网站使用时间。
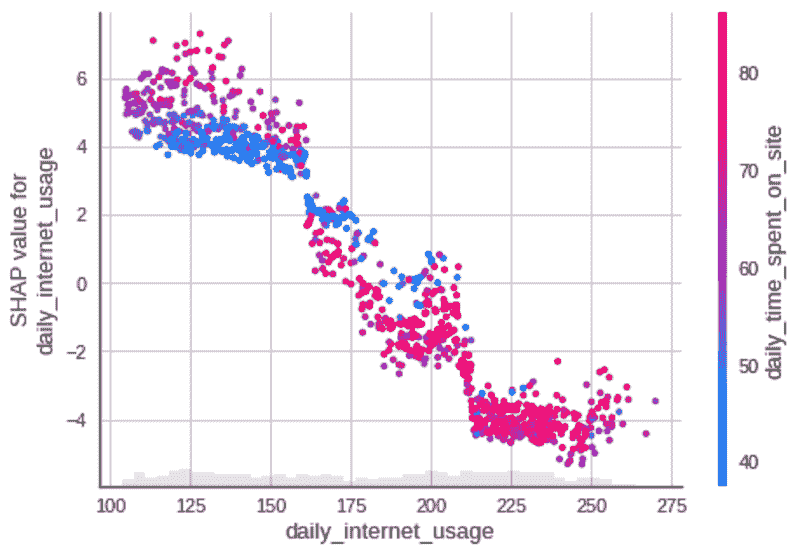
作者提供的图片
酷!从上面的图表中,我们可以看到,使用互联网每天 150 分钟且每天在网站上花费时间较少的人更有可能点击广告。
让我们看看其他特征的散点图:
每日网站使用时间
作者提供的图片
区域收入
作者提供的图片
年龄
作者提供的图片
性别
作者提供的图片
SHAP 交互图
你还可以通过 SHAP 交互值汇总图观察特征之间的交互矩阵。在这个图中,主要效应位于对角线上,而交互效应则位于对角线之外。
作者提供的图片
非常酷!
结论
恭喜!你刚刚学习了 Shapey 值以及如何使用它来解释机器学习模型。希望这篇文章能为你提供必要的知识,以便用 Python 解释你自己的机器学习模型。
我建议查看SHAP 的文档,以了解 SHAP 的其他应用。
参考
Mazzanti, S. (2021 年 4 月 21 日)。SHAP 以我希望有人向我解释的方式进行了说明。Medium。于 2021 年 9 月 23 日获取,来源:towardsdatascience.com/shap-explained-the-way-i-wish-someone-explained-it-to-me-ab81cc69ef30.
Khuyen Tran 是一位高产的数据科学作家,撰写了一系列令人印象深刻的有用数据科学主题以及代码和文章。Khuyen 目前正在寻找 Bay Area 的机器学习工程师角色、数据科学家角色或开发者推广者角色,预计从 2022 年 5 月开始,如果你在寻找具备她技能的人才,请联系她。
原文。经许可转载。
更多相关主题
使用 SHAP 值进行机器学习模型可解释性
原文:
www.kdnuggets.com/2023/08/shap-values-model-interpretability-machine-learning.html
图片来源:作者
机器学习可解释性
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
机器学习可解释性是指解释和理解机器学习模型如何进行预测的技术。随着模型变得越来越复杂,解释其内部逻辑和获得对其行为的洞察变得越来越重要。
这很重要,因为机器学习模型通常用于做出具有现实世界影响的决策,如医疗、金融和刑事司法领域。没有可解释性,很难知道机器学习模型是否在做出良好的决策,或者是否存在偏见。
在机器学习可解释性方面,有各种技术可供考虑。一种流行的方法是确定特征重要性分数,这揭示了对模型预测影响最大的特征。SKlearn 模型默认提供特征重要性分数,但你还可以利用 SHAP、Lime 和 Yellowbrick 等工具,以更好地可视化和理解机器学习结果。
本教程将介绍 SHAP 值以及如何使用 SHAP Python 包解释机器学习结果。
什么是 SHAP 值?
SHAP 值基于博弈论中的 Shapley 值。在博弈论中,Shapley 值帮助确定在协作游戏中每个玩家对总回报的贡献。
对于机器学习模型,每个特征被视为一个“玩家”。特征的 Shapley 值代表该特征在所有可能的特征组合中的平均贡献量。
具体来说,SHAP 值是通过比较模型在某一特征存在与不存在时的预测来计算的。这是针对数据集中的每个特征和每个样本进行迭代完成的。
通过为每个预测分配每个特征的重要性值,SHAP 值提供了一个局部、一致的解释,说明模型如何运作。它们揭示了哪些特征对特定预测有最大的影响,无论是正面还是负面。这对于理解复杂的机器学习模型,如深度神经网络,具有重要价值。
开始使用 SHAP 值
在本节中,我们将使用来自 Kaggle 的 手机价格分类 数据集来构建和分析多分类模型。我们将根据特征(如 ram、大小等)对手机价格进行分类。目标变量是 price_range,其值为 0(低成本)、1(中等成本)、2(高成本)和 3(非常高成本)。
注意: 带有输出的代码源可以在 Deepnote 工作区 获得。
安装 SHAP
使用 pip 或 conda 命令在系统上安装 shap 非常简单。
pip install shap
或
conda install -c conda-forge shap
加载数据
数据集干净且组织良好,类别已使用标签编码器转换为数字。
import pandas as pd
mobile = pd.read_csv("train.csv")
mobile.head()
准备数据
首先,我们将识别依赖变量和独立变量,然后将它们拆分为单独的训练集和测试集。
from sklearn.model_selection import train_test_split
X = mobile.drop('price_range', axis=1)
y = mobile.pop('price_range')
# Train and test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
训练和评估模型
之后,我们将使用训练集训练我们的随机森林分类器模型,并在测试集上评估其性能。我们得到了 87%的准确率,这相当不错,并且我们的模型总体上非常平衡。
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
# Model fitting
rf = RandomForestClassifier()
rf.fit(X_train, y_train)
# Prediction
y_pred = rf.predict(X_test)
# Model evaluation
print(classification_report(y_pred, y_test))
precision recall f1-score support
0 0.95 0.91 0.93 141
1 0.83 0.81 0.82 153
2 0.80 0.85 0.83 158
3 0.93 0.93 0.93 148
accuracy 0.87 600
macro avg 0.88 0.87 0.88 600
weighted avg 0.87 0.87 0.87 600
计算 SHAP 值
在这部分,我们将创建一个 SHAP 树解释器,并使用它计算测试集的 SHAP 值。
import shap
shap.initjs()
# Calculate SHAP values
explainer = shap.TreeExplainer(rf)
shap_values = explainer.shap_values(X_test)
总结图
总结图是模型中每个特征重要性的图形表示。它是理解模型如何做出预测以及识别最重要特征的有用工具。
在我们的案例中,它显示了每个目标类别的特征重要性。结果表明,“ram”、“电池电量”和手机大小在确定价格范围方面起着重要作用。
# Summarize the effects of features
shap.summary_plot(shap_values, X_test)
我们现在将可视化类别“0”的未来重要性。我们可以清楚地看到,ram、电池和手机大小对预测低成本手机有负面影响。
shap.summary_plot(shap_values[0], X_test)
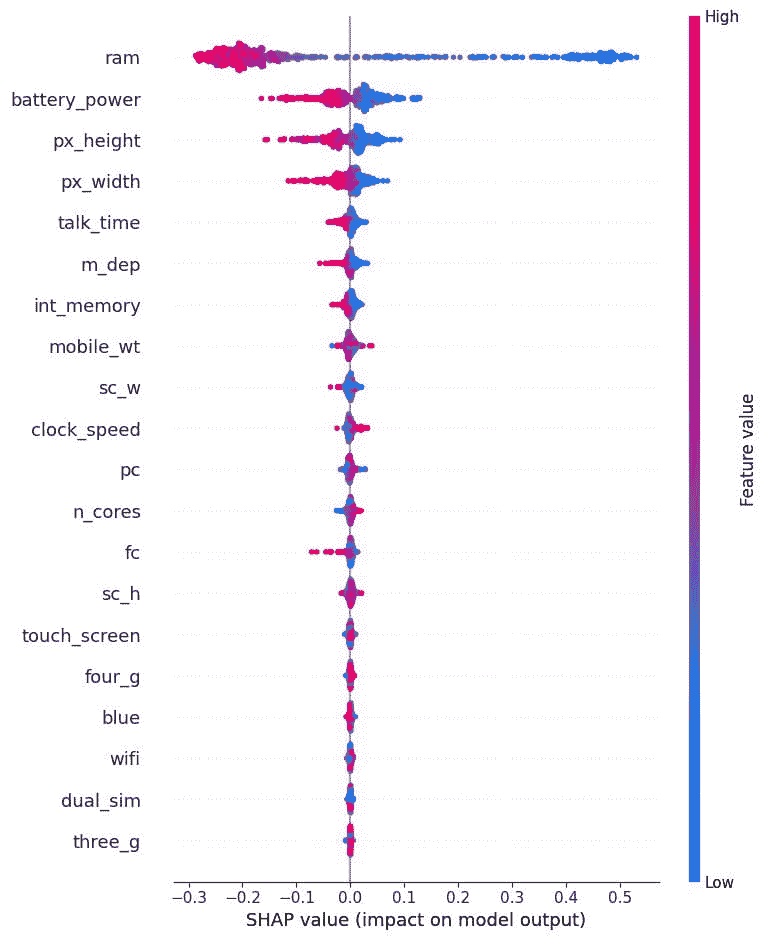
依赖性图
依赖性图是一种散点图,显示了模型预测如何受到特定特征的影响。在这个例子中,特征是“电池电量”。
图的 x 轴显示了“电池电量”的值,y 轴显示了 SHAP 值。当电池电量超过 1200 时,它开始对低端手机型号的分类产生负面影响。
shap.dependence_plot("battery_power", shap_values[0], X_test,interaction_index="ram")
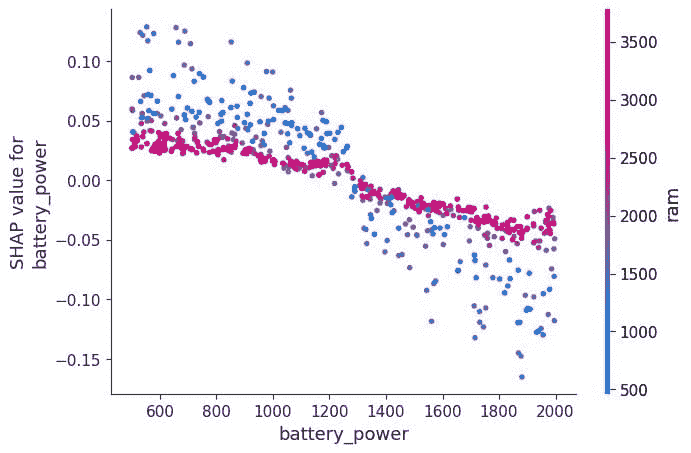
力量图
让我们将焦点缩小到一个样本上。具体来说,我们将更仔细地查看第 12 个样本,以了解哪些特征导致了“0”的结果。为此,我们将使用力量图,并输入预期值、SHAP 值和测试样本。
事实证明,内存、手机尺寸和时钟速度对模型的影响更大。我们还注意到,由于 f(x)值较低,模型不会预测“0”类别。
shap.plots.force(explainer.expected_value[0], shap_values[0][12,:], X_test.iloc[12, :], matplotlib = True)
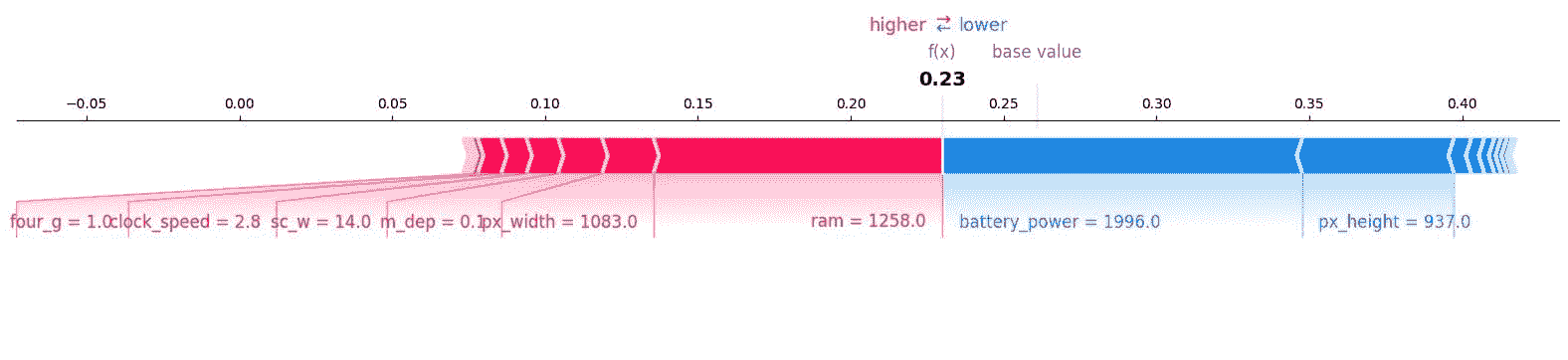
我们现在将可视化类别“1”的力量图,我们可以看到这是正确的类别。
shap.plots.force(explainer.expected_value[1], shap_values[1][12, :], X_test.iloc[12, :],matplotlib = True)
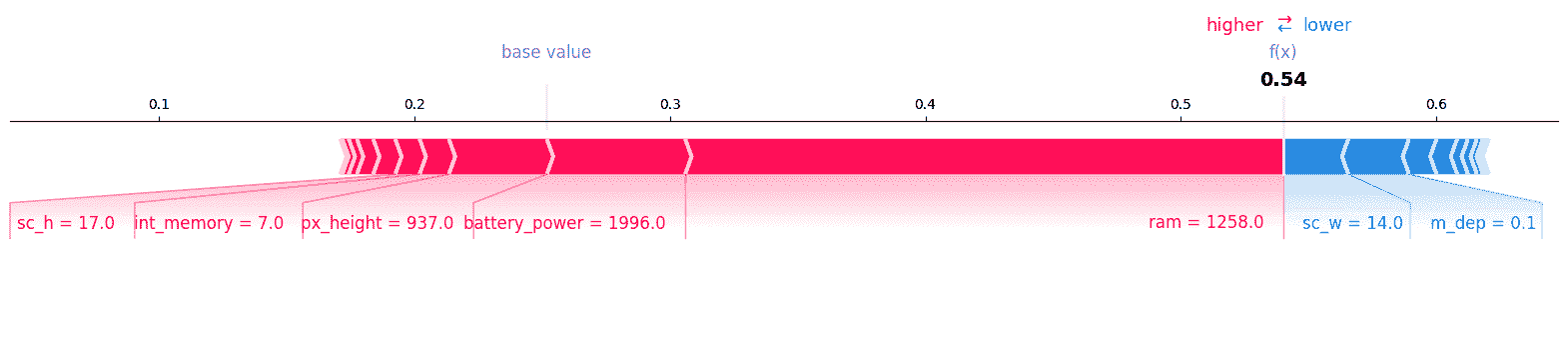
我们可以通过检查测试集的第 12 条记录来确认我们的预测。
y_test.iloc[12]
>>> 1
决策图
决策图可以是理解机器学习模型决策过程的有用工具。它们可以帮助我们识别对模型预测最重要的特征,并识别潜在的偏差。
为了更好地理解影响模型对类别“1”预测的因素,我们将检查决策图。根据该图,手机高度对模型有负面影响,而内存对模型有正面影响。
shap.decision_plot(explainer.expected_value[1], shap_values[1][12,:], X_test.columns)
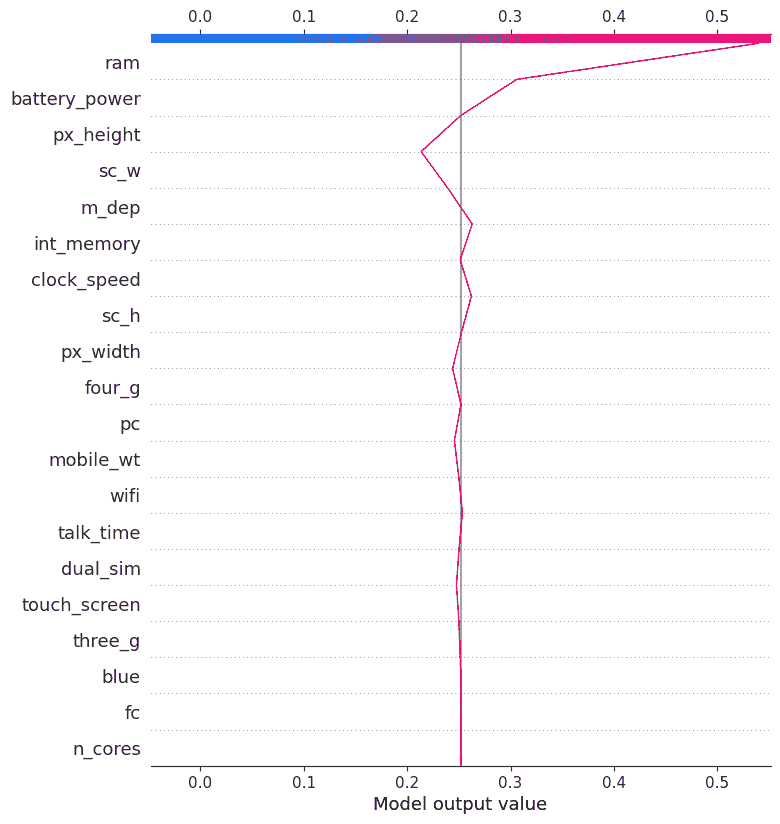
结论
在这篇博客文章中,我们介绍了 SHAP 值,这是一种解释机器学习模型输出的方法。我们展示了如何使用 SHAP 值解释单个预测和模型的整体表现。我们还提供了 SHAP 值在实际应用中的示例。
随着机器学习扩展到敏感领域如医疗、金融和自动驾驶,解释性和可解释性将变得更加重要。SHAP 值提供了一种灵活且一致的方法来解释预测和模型行为。它可以用来深入了解模型如何进行预测,识别潜在的偏差,并改善模型的性能。
Abid Ali Awan (@1abidaliawan) 是一名认证数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些在心理健康方面挣扎的学生。
更多相关话题
Shapash:使机器学习模型可理解
原文:
www.kdnuggets.com/2021/04/shapash-machine-learning-models-understandable.html
评论
由Yann Golhen,MAIF,首席数据科学家。
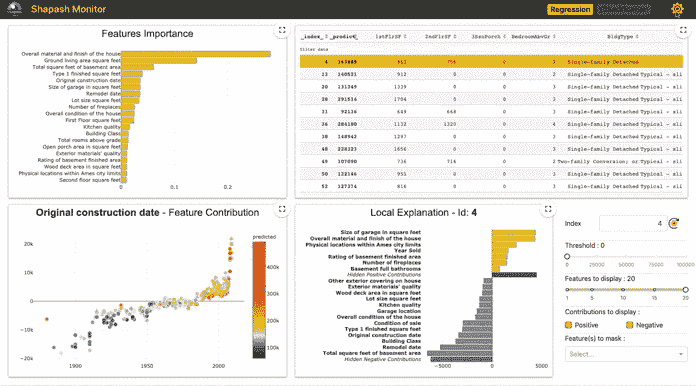
Shapash由MAIF提供,是一个 Python 工具包,旨在帮助数据科学家理解机器学习模型。它使得与非数据专家(如业务分析师、经理和最终用户)分享和讨论模型可解释性变得更加容易。
具体来说,Shapash 提供易于阅读的可视化和一个Web 应用程序。Shapash 使用适当的措辞(预处理逆/后处理)展示结果。在操作环境中,Shapash 非常有用,因为它使数据科学家能够从探索到生产中使用可解释性:你可以轻松地在生产中部署局部可解释性,为每个预测/推荐附上局部可解释性的摘要。
在这篇文章中,我们将介绍 Shapash 的主要特性以及它的运作方式。我们将通过一个具体的案例来说明这个库的实现。
背景元素
模型的可解释性和可理解性是热点话题。关于这些话题有很多文章、出版物和开源贡献。所有这些贡献并不涉及相同的问题和挑战。
大多数数据科学家使用这些技术有很多原因:更好地理解他们的模型,检查模型的一致性和公正性,以及进行调试。
然而,这里还有更多内容:
可理解性对教育目的很重要。可理解的机器学习模型可以与非数据专家进行讨论:业务分析师、最终用户等。
具体来说,我们的数据科学项目中涉及非专业人员的两个步骤:
探索性步骤 & 模型拟合
在这一步骤中,数据科学家和业务分析师讨论所面临的关键问题,并定义他们将整合到项目中的核心数据。这需要对主题和我们建模的问题的主要驱动因素有深入的理解。
为此,数据科学家研究全局可解释性、特征重要性以及模型的主要特征所扮演的角色。他们还可以局部查看一些个体,特别是异常值。在这个阶段,Web 应用程序很有趣,因为他们需要查看可视化和图形。与业务分析师讨论这些结果是有意义的,因为这有助于挑战方法并验证模型。
在生产环境中部署模型
就是这样!模型已验证、部署并为最终用户提供预测。局部可解释性能为他们带来很大价值,前提是能够提供一个良好、有用且易于理解的总结。这对他们有两个原因:
-
透明性带来信任:用户会信任模型,如果他们理解模型。
-
人类保持控制:没有模型是 100%可靠的。当用户可以理解算法的输出时,如果他们认为算法建议基于不正确的数据,他们可以推翻这些建议。
Shapash 已被开发用来帮助数据科学家满足这些需求。

Shapash 的关键特性
-
易于阅读的可视化,适合所有人。
-
一个网页应用:要理解模型的工作原理,你需要查看多个图表、特征重要性和特征对模型的全局贡献。网页应用是一个有用的工具。
-
多种方法展示结果并使用适当的措辞(预处理逆转,后处理)。你可以轻松添加数据字典,category-encoders对象,或 sklearn ColumnTransformer以获得更明确的输出。
-
函数可以轻松保存Pickle文件并将结果导出为表格。
-
可解释性总结:总结是可配置的,以适应你的需求并关注局部可解释性的关键点。
-
能够轻松部署到生产环境中,并为每个操作应用(批处理或 API)提供局部可解释性总结。
-
Shapash 有多种使用方式:它可以用来轻松访问结果或改进措辞。显示结果只需很少的参数。但是,你对数据集进行清理和文档记录的工作越多,结果对最终用户就会越清晰。
Shapash 适用于回归、二分类或多分类问题。它兼容许多模型:Catboost、Xgboost、LightGBM、Sklearn Ensemble、线性模型、SVM。
Shapash 基于使用 Shap(Shapley 值)、Lime 或任何允许计算可加局部贡献的技术的局部贡献。
安装
你可以通过 pip 安装这个包:
$pip install shapash
Shapash 演示
让我们在一个具体的数据集上使用 Shapash。在本文的其余部分,我们将展示 Shapash 如何探索模型。
我们将使用来自Kaggle的著名“房价”数据集来拟合回归模型并预测房价!让我们开始加载数据集:
import pandas as pd
from shapash.data.data_loader import data_loading
house_df, house_dict = data_loading('house_prices')
y_df=house_df['SalePrice'].to_frame()
X_df=house_df[house_df.columns.difference(['SalePrice'])]
house_df.head(3)

编码分类特征:
from category_encoders import OrdinalEncoder
categorical_features = [col for col in X_df.columns if X_df[col].dtype == 'object']
encoder = OrdinalEncoder(cols=categorical_features).fit(X_df)
X_df=encoder.transform(X_df)
训练、测试拆分和模型拟合:
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
Xtrain, Xtest, ytrain, ytest = train_test_split(X_df, y_df, train_size=0.75)
reg = RandomForestRegressor(n_estimators=200, min_samples_leaf=2).fit(Xtrain,ytrain)
并预测测试数据:
y_pred = pd.DataFrame(reg.predict(Xtest), columns=['pred'], index=Xtest.index)
让我们发现并使用 Shapash SmartExplainer。
第 1 步 — 导入
from shapash.explainer.smart_explainer import SmartExplainer
第 2 步 — 初始化 SmartExplainer 对象
xpl = SmartExplainer(features_dict=house_dict) # Optional parameter
- features_dict:字典,指定 x pd.DataFrame 中每个列名的含义。
第 3 步 — 编译
xpl.compile(
x=Xtest,
model=regressor,
preprocessing=encoder,# Optional: use inverse_transform method
y_pred=y_pred # Optional
)
编译方法允许使用另一个可选参数:后处理。它提供了应用新函数的可能性,以便更好地措辞(正则表达式、映射字典等)。
现在,我们可以显示结果并了解回归模型是如何工作的!
步骤 4 — 启动 Web 应用
app = xpl.run_app()
Web 应用链接出现在 Jupyter 输出中(访问演示 这里)。
这个 Web 应用有四个部分:
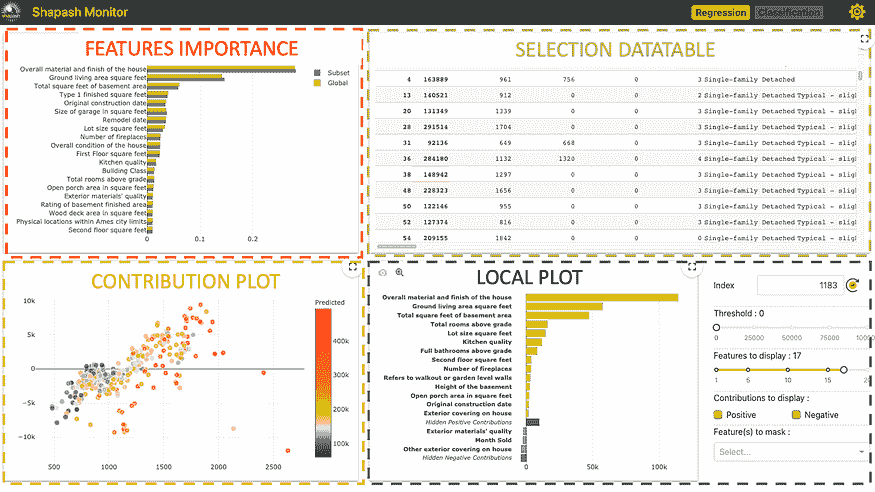
每个图表都可以帮助轻松探索模型。
特征重要性: 你可以点击每个特征来更新下面的贡献图。
贡献图: 特征如何影响预测?显示每个特征的本地贡献的提琴图或散点图。
本地图:
-
本地解释:哪些特征对预测值贡献最大。
-
你可以使用多个按钮/滑块/列表来配置本地可解释性的摘要。我们将在下面描述使用过滤器方法可以操作的不同参数。
-
这个 Web 应用是一个有用的工具,可以与业务分析师讨论总结可解释性的最佳方法,以满足操作需求。
选择表格: 允许 Web 应用用户选择:
-
一个子集,用于集中探索此子集
-
显示与之关联的本地解释的单行
如何使用数据表来选择子集?在表格顶部,位于你想用来过滤的列名称下方,指定:
-
=值, >值, <值
-
如果你想选择包含特定单词的每一行,只需输入那个单词而不带“=”
这个 Web 应用提供了一些选项(右上角按钮)。最重要的选项可能是样本的大小(默认:1000)。为了避免延迟,Web 应用依赖于样本来显示结果。使用此选项来修改样本大小。
结束应用程序:
app.kill()
步骤 5 — 图表
所有图表都可以在 jupyter notebooks 中查看,下面的段落描述了每个图表的关键点。
特征重要性
该参数允许比较子集中特征的重要性。它有助于检测子集中的特定行为。
subset = [ 168, 54, 995, 799, 310, 322, 1374,
1106, 232, 645, 1170, 1229, 703, 66,
886, 160, 191, 1183, 1037, 991, 482,
725, 410, 59, 28, 719, 337, 36 ]
xpl.plot.features_importance(selection=subset)
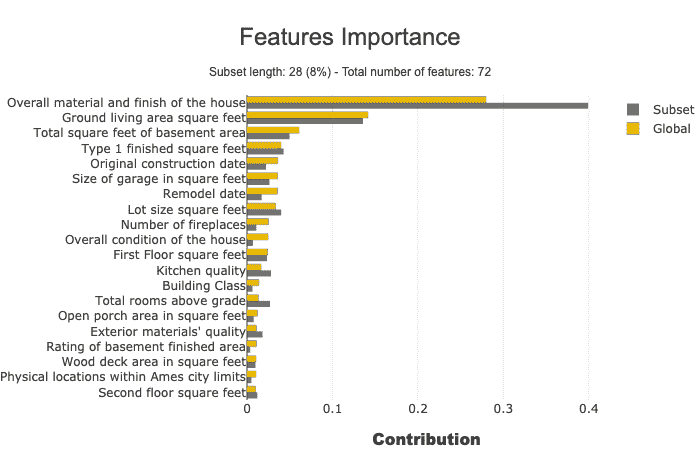
贡献图
贡献图用于回答如下问题:
特征如何影响我的预测?它是否有正面贡献?特征的贡献是增加的还是减少的?是否存在阈值效应?对于分类变量,每种模态的贡献如何?此图完成了特征重要性对于可解释性的展示,使得模型对特征影响的全球理解更加清晰。
此图表上有几个参数。请注意,显示的图表会根据您对分类变量还是连续变量(小提琴图或散点图)以及您处理的用例类型(回归、分类)进行调整。
xpl.plot.contribution_plot("OverallQual")
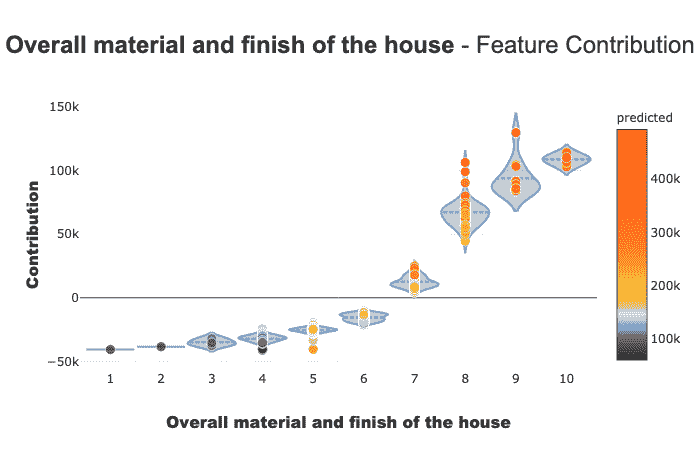
应用于连续特征的贡献图。
分类案例:泰坦尼克号分类器——应用于分类特征的贡献图。
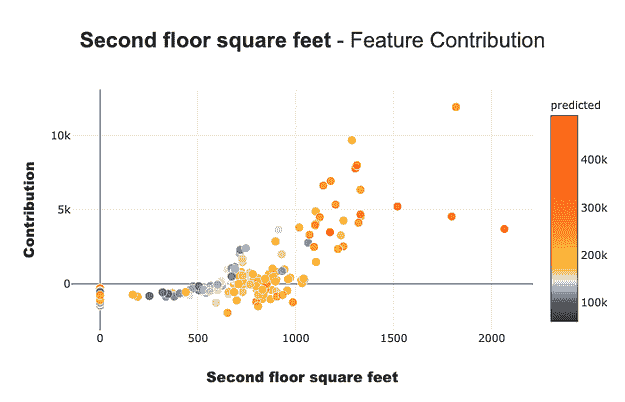
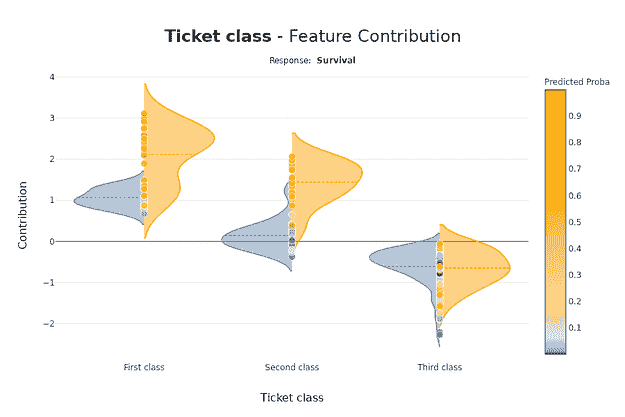
局部图
您可以使用局部图来进行模型的局部解释。
filter()和local_plot()方法允许您测试和选择总结模型所捕捉信号的最佳方式。您可以在探索阶段使用它。然后,您可以在生产环境中部署此总结,使最终用户能够在几秒钟内了解每个推荐的最有影响力的标准。
我们将发布第二篇文章,解释如何在生产中部署局部解释性。
结合 filter 和 local_plot 方法
使用filter方法来指定如何总结局部解释性。您有四个参数可以配置您的总结:
-
max_contrib: 显示的标准最大数量
-
threshold: 显示标准所需的贡献的最小值(绝对值)
-
positive: 仅显示正贡献?负贡献?(默认 None)
-
features_to_hide: 不想显示的特征列表
在定义了这些参数后,我们可以使用local_plot()方法显示结果,或使用to_pandas()方法导出结果。
xpl.filter(max_contrib=8,threshold=100)
xpl.plot.local_plot(index=560)
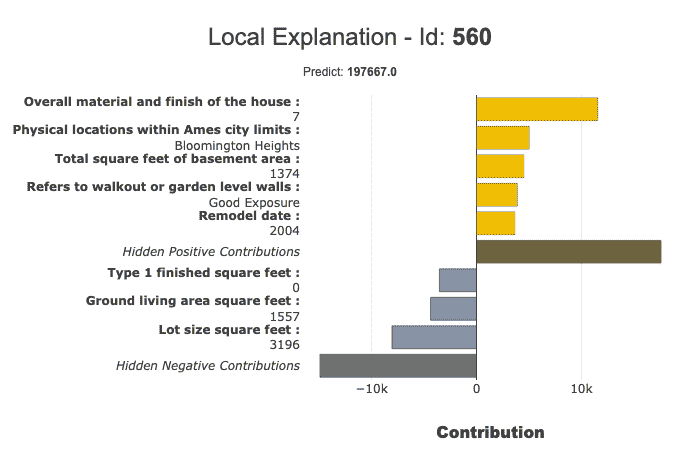
导出到 pandas DataFrame:
xpl.filter(max_contrib=3,threshold=1000)
summary_df = xpl.to_pandas()
summary_df.head()
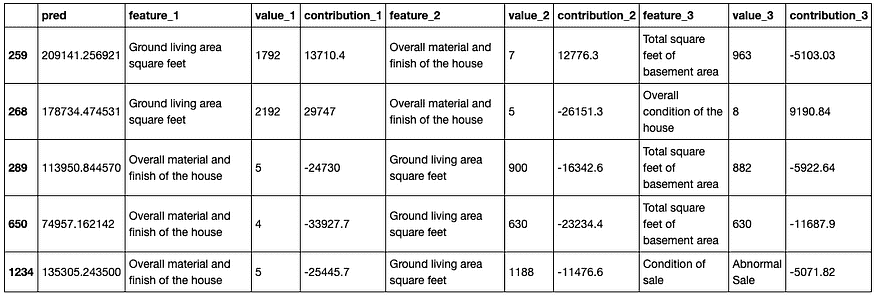
比较图
使用compare_plot()方法,SmartExplainer 对象使得理解为什么两个或更多个体的预测值不同成为可能。最具决定性的标准出现在图表的顶部。
xpl.plot.compare_plot(row_num=[0, 1, 2, 3, 4], max_features=8)
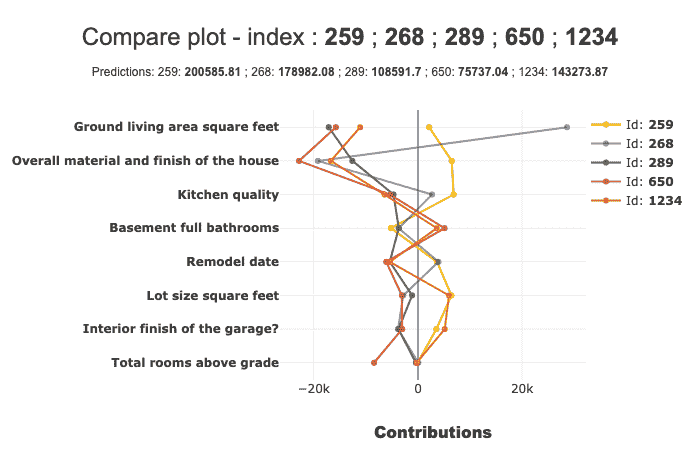
我们希望 Shapash 在建立对人工智能的信任方面有所帮助。感谢所有给予反馈和建议的人……Shapash 是开源的!欢迎通过评论此帖或直接在GitHub 讨论中贡献。
原文。经许可转载。
相关:
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关话题
通过通用 API 分享您的机器学习模型
原文:
www.kdnuggets.com/2020/02/sharing-machine-learning-models-common-api.html
评论
作者 Álvaro López García,西班牙国家研究委员会(CSIC)

我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 工作
构建机器学习模型的数据科学家没有简单且通用的方法与同事或任何感兴趣的使用者分享他们开发的应用。整个模型(即代码和所需的任何配置资源)可以被分享,但这要求接收者具备足够的知识来执行它。在大多数情况下,我们只是想分享模型以展示其功能(给其他同事或对我们预测模型感兴趣的公司),因此没有必要分享整个实验。
正如已经在KDnuggets中展示的那样,在我们共同工作的互联世界中,最直接的方法是通过 HTTP 端点公开模型,以便潜在用户可以通过网络远程访问。这可能听起来很简单,但开发一个合适且正确的 REST API 并不是一项容易的任务。数据科学家需要掌握 API 编程、网络、REST 语义、安全性等知识。此外,如果每个科学家都提出一个实现,我们将得到大量不同且不可互操作的 API,这些 API 大致上完成相同的工作,导致生态系统碎片化。
介绍DEEPaaS API: 一个基于aiohttp构建的机器学习、深度学习和人工智能 REST API 框架。DEEPaaS 是一个软件组件,允许通过 HTTP 端点公开 Python 模型的功能(使用您选择的框架实现)。它不需要对原始代码进行修改,并提供自定义选项(输入参数、预期输出等)供科学家选择。
DEEPaaS API 遵循OpenAPI 规范(OAS),因此它允许人类和计算机发现并理解底层模型的能力、输入参数和输出值,而无需检查模型的源代码。
让我们通过一个演示示例来看一下它是如何工作的。
将模型插入 DEEPaaS
为了更好地说明如何将模型与 DEEPaaS 集成,我们将使用scikit-learn中最知名的示例之一:一个针对IRIS 数据集训练的支持向量机。在这个简单的示例中,我们定义了两个不同的函数,一个用于训练,一个用于执行预测,如下所示:
from joblib import dump, load
import numpy
from sklearn import svm
from sklearn import datasets
def train():
clf = svm.SVC()
X, y = datasets.load_iris(return_X_y=True)
clf.fit(X, y)
dump(clf, 'iris.joblib')
def predict(data):
clf = load('iris.joblib')
data = numpy.array(data).reshape(1, -1)
prediction = clf.predict(data)
return {"labels": prediction.tolist()}
如你所见,训练函数会将训练好的模型持久化到磁盘,遵循scikit-learn 的教程。接下来的操作是定义训练和预测调用的输入参数。由于这个示例相当简单,我们仅定义预测调用的输入参数。通常,你需要在一个不同的文件中完成这项工作,以避免干扰你的代码,但为了简化,我们将这个特殊函数与我们的 IRIS SVM 一同添加:
from joblib import dump, load
import numpy
from sklearn import svm
from sklearn import datasets
from webargs import fields, validate
def train():
clf = svm.SVC()
X, y = datasets.load_iris(return_X_y=True)
clf.fit(X, y)
dump(clf, 'iris.joblib')
def predict(data):
clf = load('iris.joblib')
data = numpy.array(data).reshape(1, -1)
prediction = clf.predict(data)
return {"labels": prediction.tolist()}
def get_predict_args():
args = {
"data": fields.List(
fields.Float(),
required=True,
description="Data to make a prediction. The IRIS dataset expects "
"for values containing the Sepal Length, Sepal Width, "
"Petal Length and Petal Width.",
validate=validate.Length(equal=4),
),
}
return args
最后一步是为了将其与 DEEPaaS API 集成,你需要使其可安装(你应该这样做)并使用Python 的 setuptools定义一个入口点。这个入口点将被 DEEPaaS 用来了解如何加载以及如何将不同的函数连接到定义的端点。我们当前使用deepaas.model.v2入口点命名空间,因此我们可以按如下方式创建setup.py文件:
from distutils.core import setup
setup(
name='test-iris-with-deepaas',
version='1.0',
description='This is an SVM trained with the IRIS dataset',
author='Álvaro López',
author_email='aloga@ifca.unican.es',
py_modules="iris-deepaas.py",
dependencies=['joblib', 'scikit-learn'],
entry_points={
'deepaas.v2.model': ['iris=iris-deepaas'],
}
)
安装和运行 DEEPaaS
一旦你的代码准备好,你只需安装你的模块和 DEEPaaS API,以便它能够检测到并通过 API 暴露其功能。为了简化操作,我们可以创建一个虚拟环境并在其中安装所有内容:
$ virtualenv env --python=python3
(...)
$ source env/bin/activate
(env) $ pip3 install .
(...)
(env) $ pip3 install deepaas
(...)
(env) $ deepaas-run
## ###
## ###### ##
.##### ##### #######. .#####.
## ## ## // ## // ## ## ##
##. .## ### ### // ### ## ##
## ## #### #### #####.
Hybrid-DataCloud ##
Welcome to the DEEPaaS API API endpoint. You can directly browse to the
API documentation endpoint to check the API using the builtint Swagger UI
or you can use any of our endpoints.
API documentation: http://127.0.0.1:5000/ui
API specification: http://127.0.0.1:5000/swagger.json
V2 endpoint: http://127.0.0.1:5000/v2
-------------------------------------------------------------------------
2020-02-04 13:10:50.027 21186 INFO deepaas [-] Starting DEEPaaS version 1.0.0
2020-02-04 13:10:50.231 21186 INFO deepaas.api [-] Serving loaded V2 models: ['iris-deepaas']
访问 API 并进行训练和预测
如果一切顺利,你现在应该能够将浏览器指向控制台中打印的 URL(http://127.0.0.1:5000/ui),并看到一个美观的Swagger UI,它将允许你与模型进行交互。
由于这是一个简单的示例,我们没有提供训练好的模型,因此首先需要进行训练。这将调用train()函数并保存训练好的 SVM 以备后用。你可以通过 UI 进行此操作,或者通过命令行:
curl -s -X POST "http://127.0.0.1:5000/v2/models/iris-deepaas/train/" -H "accept: application/json" | python -mjson.tool
{
"date": "2020-02-04 13:14:49.655061",
"uuid": "16a3141af5674a45b61cba124443c18f",
"status": "running"
}
训练将异步进行,以便 API 不会阻塞。你可以从 UI 检查其状态,或者使用以下调用:
curl -s -X GET "http://127.0.0.1:5000/v2/models/iris-deepaas/train/" | python -mjson.tool
[
{
"date": "2020-02-04 13:14:49.655061",
"uuid": "16a3141af5674a45b61cba124443c18f",
"status": "done"
}
]
现在模型已经训练完成,我们可以进行预测。IRIS 数据集包含 3 种不同类型的鸢尾花(Setosa, Versicolour 和 Virginica)的花瓣和萼片长度。样本有四列,分别对应萼片长度、萼片宽度、花瓣长度和花瓣宽度。在我们的示例中,让我们尝试获取 [5.1. 3.5, 1.4, 0.2] 的观察结果,并查看结果。你可以通过 UI 或命令行如下进行操作:
curl -s -X POST "http://127.0.0.1:5000/v2/models/iris-deepaas/predict/?data=5.1&data=3.5&data=1.4&data=0.2" -H "accept: application/json" | python -mjson.tool
{
"predictions": {
"labels": [
0
]
},
"status": "OK"
}
正如你所见,结果包含了我们的 SVM 执行的预测。在这种情况下,输入数据的标签是 0,这确实是正确的。
结论
在这个简单的示例中,我们展示了机器学习从业者如何通过 DEEPaaS API 曝露任何基于 Python 的模型,而不是开发自己制作的 API。这样,数据科学家可以专注于他们的工作,而不必担心编写和开发复杂的 REST 应用程序。此外,使用通用 API,不同模块将共享相同的接口,使其更易于在生产中部署并被不同程序员使用。
个人简介:Álvaro López García (@Alvaretas) 是 西班牙国家研究委员会 (CSIC) 高级计算与电子科学组的研究员,从事分布式计算工作。他是 DEEP-Hybrid-DataCloud H2020 项目的项目协调员,正在建立一个用于在欧洲分布式电子基础设施上进行机器学习和深度学习的平台。
相关:
-
如何在 5 分钟内使用 Flask 构建机器学习模型 API
-
构建一个 Flask API 来自动提取命名实体使用 SpaCy
更多相关主题
短期有趣课程助你迅速掌握生成式 AI
原文:
www.kdnuggets.com/short-and-fun-courses-to-get-you-up-to-speed-about-generative-ai

图片由作者提供
如果你不是技术专业人士,或者你想进入技术行业,你可能已经听说了很多关于生成式 AI 的事情。每个人都在谈论它,各种组织也在争取一份蛋糕,这其中有很多钱。
但它是什么,在哪里可以学习到呢?
幸运的是,你来对地方了。
在这篇文章中,我将介绍一些短小有趣的课程,让你快速了解生成式 AI。
生成式 AI 概念
这是理解生成式 AI、其基本概念及其对当今社会影响的第一步。生成式 AI 是一种能够创建新内容的 AI 模型,例如 ChatGPT,也能执行其他任务。在这门面向初学者的生成式 AI 课程中,你将学习这项新兴技术如何塑造我们的未来。了解生成式 AI 如何工作、伦理考虑,以及如何最大化利用这些工具!
每个人的生成式 AI
在仅仅 5 小时内,你可以了解生成式 AI 是什么、如何工作、它的常见用例,以及这项技术能做什么和不能做什么。你还将深入了解如何思考生成式 AI 项目的生命周期,从构想到发布,包括如何构建有效的提示。还将了解生成式 AI 技术对个人、企业和社会带来的潜在机会和风险。
生成式 AI 营销专业化
链接:生成式 AI 营销专业化
也许你是一名营销人员,你想知道如何在日常工作中利用生成式 AI,以及如何改善你的工作流程并实现目标。
在 1 个月内,你可以学习生成式 AI 的基础知识,实践创建标志、营销内容和服务。你还将学习如何审查和部署营销及客户服务的聊天机器人,以及如何实施 AI 营销策略,以应对各种战略内部和外部的考虑。
高管和商业领袖的生成式 AI
你是经理、商业高管,还是行业领袖,并且你想了解更多关于生成式 AI 的知识?我假设你是,因为你希望在市场中保持竞争力。
在本课程中,你将了解生成式 AI 在商业中的历史和影响,数据在商业 AI 中的重要性,以及信任、透明度和治理的重要性。通过你所学的内容,你可以将生成式 AI 应用到客户服务和应用程序现代化等关键用例中。
总结
生成式 AI 不仅仅意味着技术专业人士可以利用它。它是塑造所有其他行业和我们未来的科技行业的重要组成部分。了解它及其如何融入你的战略将使你保持领先!
Nisha Arya 是一位数据科学家、自由技术作家,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程和理论知识。Nisha 涵盖了广泛的主题,并希望探索人工智能如何有助于人类生命的持久性。作为一名热衷学习者,Nisha 寻求扩展她的技术知识和写作技能,同时帮助指导他人。
相关主题
下一 5 年会出现数据科学工作短缺吗?
原文:
www.kdnuggets.com/2021/06/shortage-data-science-jobs-5-years.html
评论
由Pranjal Saxena,数据科学家,人工智能顶级作者

照片来源:Andrea Piacquadio 来自 Pexels
我们的三大推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
我在数据科学领域已经待了半个十年,自从 Python 编程开始流行。在 2016 年,那时神经网络和深度学习还只是一些流行词汇。那时,谷歌自动驾驶汽车和强化学习引起了轰动。但大多数数据科学爱好者甚至对神经网络的工作原理一无所知。
到了 2021 年,大多数公司都在采用数据科学策略,通过自动化不同的场景来提高收入,并用一个数据科学家取代数十个 IT 人员,这个数据科学家可以利用各种自动化工具如 BluePrism、UI Path、Python 和机器学习算法来完成这些 IT 人员的任务。
这就是为什么我们大多数人都在努力学习 Python、机器学习、分析、深度学习。为什么?因为数据科学家在行业中的价值极高。而且,人们在数据科学领域的薪资也在大幅上涨。
但是,你知道在今天,这些“自动化任务正在通过另一种自动化策略进行自动化”吗?整个数据科学流程正通过单一工具进行自动化。
在 2019 年,数据科学家需要花费数天时间进行数据收集、数据清理、特征选择,但现在市场上已有许多工具可以在几分钟内完成这些任务。
另一方面,我们尝试了不同的机器学习库,如逻辑回归、随机森林、提升机器、朴素贝叶斯及其他数据科学库,以找到更好的模型。
但是,今天,我们有像 H2O、PyCaret 和许多其他云服务提供商这样的工具,它们可以在相同的数据上使用其他 30 到 50 个机器学习库的组合来进行相同的模型选择,从而为你的数据提供最优的机器学习算法,并且误差最小。
事情现在正以快速的速度变化。而且,我们的价值正在以某种方式下降,因为每个人都将信任那些尝试超过二十种机器学习算法的工具,而不是我们这样只尝试了几个机器学习库以获得较低准确率的人。
严峻的现实
到目前为止,我们讨论了某些自动化工具在机器学习领域的表现情况。这些工具表现得比我们更好,因为我们使用了有限的机器学习算法知识。而这些工具通过自动化整个 EDA 过程,结合多个库来获得更高效的结果,在更短的时间内提供最佳结果。
但对于深度学习领域,我们的掌握程度不如机器学习领域,并且处理能力有限。市场上也有很多工具,这些工具在拥有最佳处理器方面投入了大量资金。
深度学习涉及更多的数据、处理能力和复杂的神经网络,需要更多的处理能力来提供更准确的结果。
当我们谈论深度学习时,它以处理非结构化数据而闻名。而且,我们 95%的时间是在这里处理图像和测试数据。目标检测、图像分割、构建聊天机器人、情感分析、文档相似性是著名的应用场景。
但是,处理这些应用场景需要了解不同的深度学习算法,如卷积神经网络、递归神经网络、U-Net、沙漏网络、YOLO 等,这些模型需要大量的处理能力来处理更多数据,以提高准确性。
关键在于,今天是 2021 年,公司正在投入大量资金来自动化这些完整的流程。而我们却忙于理解基础的机器学习和深度学习模型,尽管我们没有投资者,无法负担高端机器。
每家公司都意识到这一点,因此五年后,当这些云启用的数据科学工具变得更加高效,并且能够在更短的时间内提供更好的准确性时,为什么公司还会投资于雇佣我们,而不是购买这些工具的订阅呢?
希望之光
当所有这些事情都将自动化时,你可能会思考数据科学爱好者的未来。是否会出现工作短缺,还是招聘人数会减少?
好吧,当我们换个角度思考时,事情会变得更容易。确实,公司将继续关注机器学习的自动化工作流程。但请记住,没有公司希望依赖另一家公司来完成他们的工作。
每家公司都旨在构建自己的产品,以便不依赖于他人,能够建立自己的自动化系统,然后在市场上销售以赚取更多的收入。所以,是的,确实需要能够帮助行业建立自动化系统的数据科学家,这些系统可以自动化机器学习和深度学习的任务。
最后,我们可以说数据科学家的角色将是通过优化结果来自动化管道。因此,最终我们将自动化机器学习工作流的管道,让自动化决定数据中最佳的特征,并使用精心挑选的算法得出最佳结果。
最后的思考
我们已经看到,由于公司将采用自动化的数据科学管道,未来五年将缺乏数据科学工作。但与此同时,也会对能够自动化数据科学管道的数据科学家有很高的需求。
根据我的想法,要自动化这些管道,我们首先需要了解机器学习算法,以建立更好的自动化系统,这最终将带来更多的就业机会。
那么,你有什么想法呢?我很想听听你的意见。希望你喜欢这篇文章。请继续关注更多相关的文章。我发布关于实时数据科学场景及其用例的文章。
感谢阅读!
提升 Python 编程技能的实用功能
你不需要导入 TensorFlow 就能打印“hello world”
觉得这个故事有趣吗?在 Medium 上关注我 (Pranjal)。如果你想私下联系我,请通过Linkedin与我连接。如果你想直接在邮箱中获取更多关于数据科学和技术的精彩文章,可以订阅我的免费新闻通讯:Pranjal’s Newsletter。
原文。经授权转载。
相关内容:
-
数据科学家、数据工程师及其他数据职业解析
-
如何成为数据科学家的指南(逐步方法)
-
这些软技能可能决定你的数据科学职业成败
更多相关话题
你是否应该成为数据科学家?
原文:
www.kdnuggets.com/2018/12/should-i-become-a-data-scientist.html
评论
作者:Sarah Nooravi,MobilityWare,LinkedIn 数据科学和分析领域顶尖声音
有很多文章试图详细说明如何成为数据科学家的步骤。“很简单!你是应届毕业生吗?做这个……你是职业转换吗?做那个……而且确保你专注于最重要的技能:编程、统计学、机器学习、讲故事、数据库、大数据……需要资源?看看 Andrew Ng 的 Coursera ML 课程……”。虽然这些都是你决定从事数据科学职业后需要考虑的重要事项,但我希望回答一个应该在所有这些之前提出的问题。这个问题应该是每个有志成为数据科学家的人的脑海中出现的:“我应该成为数据科学家吗?”这个问题在你尝试回答如何之前,先解决为什么的问题。是什么让你对这个领域感到吸引,并且让你在接下来的多年里保持激动?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
为了回答这个问题,了解我们如何到达这里以及我们要去哪里非常重要。因为通过全面了解数据科学的全貌,你可以确定数据科学是否对你有意义。
一切的起点……
在计算机科学、数据技术、可视化、数学和统计学汇聚成我们今天所称的数据科学之前,这些领域曾各自存在——独立地为我们现在能够开发的工具和产品奠定基础,例如 Oculus、谷歌助手、亚马逊 Alexa、自动驾驶汽车、推荐引擎等。
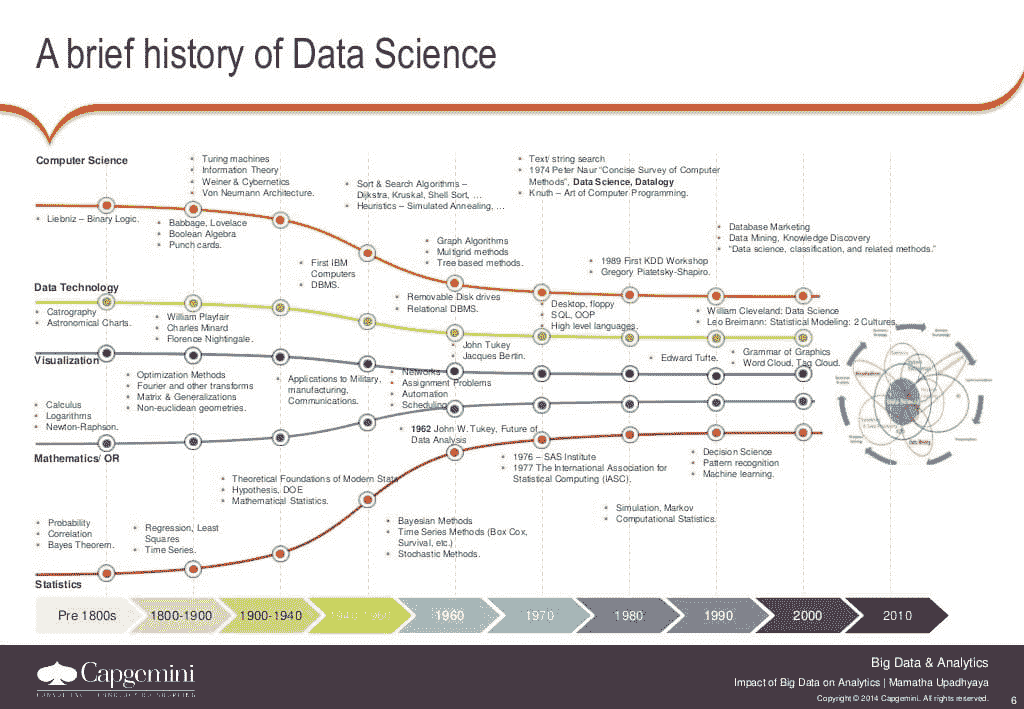
基础概念已经存在了几十年……早期的科学家追溯到 1800 年前,来自各个领域,致力于开发我们的第一台计算机、微积分、概率论以及像 CNN、强化学习、最小二乘回归这样的算法。随着数据和计算能力的爆炸式增长,我们能够复兴这些数十年的旧思想,并将其应用于现实世界的问题。
在 2009 年和 2012 年,麦肯锡和《哈佛商业评论》发表了文章,吹捧数据科学家的角色,展示了他们如何革新企业运作方式,并且将对未来业务成功至关重要。他们不仅看到了数据驱动方法的优势,还认识到在未来保持竞争力和相关性的重要性,并利用预测分析。同一时期,2011 年,Andrew Ng 推出了一个免费的机器学习在线课程,AI FOMO(错过恐惧症)也随之产生。
我们现在的情况…
公司开始寻找高技能的人才,帮助他们收集、存储、可视化和解读所有数据。“你想要这个头衔和高薪?你可以得到!只是请尽快来。”由于对他们真正需要什么了解甚少,招聘广告纷纷发布。
如果你今天搜索 ZipRecruiter,你会发现目前有超过 19 万个开放的数据科学职位,每个职位都在寻找他们自己的数据独角兽。因此,为了吸引人才进入这个领域,数据科学家的定义很快就扩展了,各公司和个人对数据科学家的定义也有所不同。
另一方面,候选人们看到了一个巨大的机会:一个高薪、高需求的职业,并承诺提供工作保障和荣耀。每个人都急于发展所有正确的技能,目标只有一个:担任“21 世纪的性别歧视职位”。
我们有需求,也有供应,那么问题出在哪里呢?实际上,问题不在于支持这种需求和利用这种热潮的项目不足。似乎每天都有新的课程开发出来,以满足有志于进入该领域的数据科学家的需求:硕士课程、训练营和在线课程。这是一场制作合适课程的军备竞赛,并承诺在完成课程后获得机器学习的工作。“没有博士学位?没问题。只需三到六个月和小额投资约 1-1.5 万元,你毕业后将确保获得高薪工作。”(眨眼)
这些项目旨在成为数据科学的一站式服务:你将学习编程、可视化、建模——应有尽有。你很快会发现,许多(当然不是全部)面临的业务问题可以使用类似的方法来解决,所以如果你想应用某种算法,很有可能已经有一个现成的库可以帮助你做到这一点。简单吧?
稍等一下…
如果你一直在关注,你会发现到目前为止有几个重要的点:
-
由于超前,许多公司在尚未开始收集正确数据之前就雇佣了数据科学家(即,他们正在遭受AI 的冷启动问题),这意味着你需要参与数据管道的每一个步骤,包括数据收集、存储和可视化,然后才能进行建模。
-
急于获得数据科学工作(通过上述提到的一种方法)意味着你将与数十万名处于相同位置的人竞争。预计他们会有与你类似的项目和经验。为了让自己脱颖而出,你需要找到一种方式来区分自己:展示你的创造力和坚韧。

- 你很可能不会从零开始开发算法。除非你有大量额外时间,否则你更可能依赖现有的、值得信赖的库。除非你必须开发特定于你使用案例的东西,否则为什么要与一群帮助开发这些库的博士们竞争,并冒着将不够优化的东西投入生产的风险呢?
未来会怎样…
我相信,从这里起,将会有几个重大变化。
首先,数据科学家的角色将会在所需技能和对商业预期影响方面变得明确。其次,AI 模型的自动化将会到来。不相信我?像 Google AutoML 这样的产品和 TPot 这样的软件包已经在发生这种情况。曾经最具技术挑战性和吸引力的工作部分将被自动化。正如现在所说的:“没有机器学习专长?没问题!”
我们所走的轨迹的含义是:
-
数据工程师或数据分析师将不再被错误地给予“真正”的数据科学家的头衔或薪资,这可能会减少市场上数据科学家的数量。
-
人类的洞察力和监督将变得越来越重要。不是说技术专长会变得不重要,但将分析与业务连接起来的能力以及了解软件如何与人互动的能力将会增加(即数据科学的人的一面)。
-
最后,由于机器学习部分的工作表现最为一致,它将是第一个被自动化的部分(我们已经看到这一点)。这意味着,数据科学家将带来的大部分价值将涉及混乱数据的统一、建模准备和评估。
因此,当你试图回答“你是否应该成为数据科学家?”这个问题时,想象一下自己在整个炒作周期中。你能看到自己在一个快速增长和不断发展的领域中成长,这将以各种方式挑战你吗?你能否快速适应变化?如果可以,那么这是适合你的职业……欢迎加入。
个人简介:Sarah Nooravi 是 MobilityWare 的市场分析师,也是 LinkedIn 数据科学和分析领域的顶尖声音。
资源:
相关内容:
更多相关内容
如何展示你的数据科学工作的影响
原文:
www.kdnuggets.com/2019/07/showcase-impact-data-science-work.html
评论
无论你现在是数据科学家,还是试图进入这一领域,学习如何向他人——如潜在雇主——传达你的技能影响至关重要。

图片来源。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
毕竟,雇佣你的人员可能并不一定具备数据科学的工作知识,他们的主要关注点可能是建立一个能够满足公司所有需求的有能力的团队。
也许你已经在数据科学领域工作,想要争取一个薪资更高、责任更大的职位。如果是这样,负责决定晋升的人员可能会难以确定你的能力如何适应业务需求。
下面是五个实用的方法,帮助你向他人传达你的数据科学成就的意义。
1. 避免使用行业术语
如果你对数据科学及其术语有一定了解,可能会特别难以摆脱这些术语和定义,并且记住其他人对这一主题的理解水平并不相同。在讨论你的数据科学工作时,尽量避免使用可能让其他人不断困惑的语言。
接下来,思考一下你在数据科学项目中使用的技能集,别人可以理解其重要性。例如,你可以谈谈你是如何从零开始构建数据科学项目,以及完成这个过程需要识别问题、清理数据、分析信息、选择模型等。
如果你选择易于理解的语言而不是数据科学的行话,你的听众更容易理解你的项目为何重要,并得出你必须运用多种技能才能成功的结论。
2. 使用类比来表达你的观点
依赖类比也可能很有用。将你的数据科学工作与几乎所有人都能理解的例子关联起来,无论他们的背景如何。有一位专业人士需要说服一个没有数据专业知识的团队,证明建立一个集中化的元数据仓库的价值。她最终使用了安迪·沃霍尔著名的汤罐罐头流行艺术作品来与听众达成共识。
她让他们想象汤是数据,罐子是数据库,标签是元数据。然后,他们设想如果他们的储藏室里满是没有标签的汤罐会有多么困难。她通过将这种情景与缺乏元数据仓库如何为最终用户带来不必要的困惑联系起来,来传达她的信息,并获得了她想要的理解。
询问自己是否有类似的方式将类比应用于你的数据科学工作,以强调其重要性。如果你在争取上级批准一个需要额外资金或时间的数据科学项目时遇到困难,这种方法可能特别有价值。
3. 将过去的数据科学项目结果应用于公司面临的问题
在理想情况下,你的投资组合中会有适用于每个可能给你面试机会的公司的数据科学项目。由于这不太可能,你需要做下一步最好事情,通过不同的视角看待项目 —— 从公司的需求角度。查看你迄今为止完成的项目,然后评估你的专长如何适应公司的当前需求或未来计划。
例如,如果你投资组合中的某个数据科学项目涉及机器学习或神经网络,你可能会关注其效率或基于价值的指标。这将有助于解释你认为你专长与自动化能力的结合能够帮助公司达到下一个水平的信念。
在与潜在雇主会面时,不要展示你的完整数据科学投资组合,而是选择一两个最符合公司面临问题的项目。这样,你可以证明你已对公司进行了调研,并深入思考了数据科学如何使企业受益。
4. 提及任何获得的数据科学奖项
如果你参加过任何数据科学比赛并成为获奖者,请务必提到这一成就,以及使结果更加显著的相关细节。
例如,如果你讨论了成千上万来自世界各地的人参与其中,并且你最终成为了顶尖选手,这意味着评审小组认为你的项目或创意是有价值的。
那么,雇主应该更容易得出结论,认为你的工作具有其他人在具有挑战性的环境中认可的卓越因素,并且你可以将这些才能带到公司。
5. 在简历中突出可量化的数据科学影响
无论你是尝试为新雇主争取数据科学职位,还是发现自己在晋升的竞争中,你可能都会翻出简历,确保它是最新的,以便决策者能够获得有关你的最相关的信息。
你还可以在撰写更好的简历时展示数据科学项目的影响,尤其是如果你已经有在实际工作中应用这些项目的经验。在详细阐述你的职责部分时,特别强调你参与的项目如何为公司带来了具体的好处。
当雇主 审查数据科学作品集 时,他们寻找证据来证明所做的工作带来了直接的公司或客户价值,或从原始数据中生成了有用的见解。你可以通过指明类似“编写了一个从多个数据库聚合数据的脚本,并在数据分析过程中提高了用户生产力,平均提高了 40%”的内容来总结你在实现这些结果中的角色。
此外,鼓励阅读你简历的人通过查看你提供的作品集来参考你所指定的项目。这样,他们可以通过阅读简历中的条目获得最终结果的概览,然后深入了解细节。
首先考虑你的受众
当你将这五个技巧付诸实践时,始终记住以受众能理解的方式展示你工作的里程碑。这种方法无疑需要根据每个公司、个人或团队来调整你的信息,这没关系。
额外的努力将带来积极的结果,因为你会发现即使是对数据科学了解不深的人也能够突出你的价值。
相关:
更多相关主题
《SIAM 数据科学丛书》
原文:
www.kdnuggets.com/2019/01/siam-book-series-data-science.html
赞助文章。
 SIAM 很高兴宣布推出一套关于数据科学的 新书系列。该系列中的书籍将探讨数据科学的数学基础前沿研究,并提供对其卓越成功背后直觉的洞察。
SIAM 很高兴宣布推出一套关于数据科学的 新书系列。该系列中的书籍将探讨数据科学的数学基础前沿研究,并提供对其卓越成功背后直觉的洞察。
我们的前三个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业轨道
2. Google Data Analytics Professional Certificate - 提升你的数据分析能力
3. Google IT Support Professional Certificate - 支持你的组织 IT
从专著、关于新兴趋势的深入论文、覆盖面广的教程、互动笔记本、最前沿的调查研究、学术研究回顾,到教科书和教育材料,这些书籍将适合广泛的受众(数据科学家、计算机科学家、数学家、统计学家、工程师、物理学家和生命科学家),并且对所有职业阶段——学生、研究人员、从业者、教育者——以及所有就业领域——学术界、工业界、政府部门、教育部门——都具有相关性。
作为丛书主编,Ilse C.F. Ipsen 指出:
“虽然关于数据科学的工作很多,但人们需要帮助来寻找、理解、理清思路并弄清如何应用它。目标是出版最前沿的研究,且内容针对数据科学广泛受众中的特定群体量身定制:为学生提供实践教科书,为研究人员提供重点专著,为 DIY 爱好者提供教程,为希望仅仅了解整体情况的人提供最前沿的调查研究。”
Ipsen 认为,SIAM 具备实现这些目标的良好条件,因为“SIAM 涵盖了广泛的计算研究领域,其成员来自多样化的就业情况。这为拥有大量专业知识和经验的作者提供了广泛的资源。”
请联系 Ilse C.F. Ipsen (ipsen@ncsu.edu) 或 Elizabeth Greenspan (greenspan@siam.org) 讨论书籍创意。了解更多关于这一新兴领域的信息,请访问 SIAM 的数据科学资源,并参与 SIAM 活动小组 和 学生分会。 订阅 SIAM 通讯 以获取最新信息。该信息也列在 SI 新闻博客 上。
作者 SIAM:
工业与应用数学学会 (SIAM) 总部位于宾夕法尼亚州费城,是一个国际性组织,拥有超过 14,000 名会员,包括应用和计算数学家、计算机科学家、工程师、物理学家和其他科学家。会员包括来自 100 多个国家的研究人员、教育工作者、学生和从业人员,他们在工业、政府、实验室和学术界工作。
Ilse C.F. Ipsen 是北卡罗来纳州立大学的数学教授,同时也是 AAAS 和 SIAM 的会员。她的主要研究领域包括数值线性代数、随机算法、概率数值学和数值分析。
相关主题更多内容
Sibyl:Google 的大规模机器学习系统
原文:
www.kdnuggets.com/2014/08/sibyl-google-system-large-scale-machine-learning.html
我们的生活正越来越多地受益于机器学习。以 Google 为例,Google 的搜索自动补全总是能节省我的时间。YouTube 推荐我们可能会稍后观看的视频列表,而 Gmail 的垃圾邮件检测系统帮助我们过滤垃圾邮件,尽管它有时会出错。
我一直很好奇 Google 是如何处理如此大量的数据的。
Sibyl 是 Google 最大的机器学习平台之一,广泛应用于 Google 产品的排名和评分,如 YouTube、Android 应用、Gmail 和 Google+。上个月,Google Research 的首席工程师 Tushar Chandra 在 IEEE/IFIP 可靠系统与网络国际会议(DSN 2014)上讲述了 Sibyl 的应用情况。
 上表可能给你一个关于 Sibyl 处理问题规模的概念。表中显示的“每个示例的特征数量”实际上是“每个示例的活动特征数量”。每个示例的原始特征数量将接近 10 亿。只要每个示例是稀疏的,Sibyl 可以处理超过 1000 亿个示例和 1000 亿维度的数据。然而,如果使用像随机梯度下降这样的简单迭代算法,甚至 Vowpal Wabbit,将需要多年才能处理整个数据。
上表可能给你一个关于 Sibyl 处理问题规模的概念。表中显示的“每个示例的特征数量”实际上是“每个示例的活动特征数量”。每个示例的原始特征数量将接近 10 亿。只要每个示例是稀疏的,Sibyl 可以处理超过 1000 亿个示例和 1000 亿维度的数据。然而,如果使用像随机梯度下降这样的简单迭代算法,甚至 Vowpal Wabbit,将需要多年才能处理整个数据。
另一方面,准确性非常重要。机器学习通常会带来 10%以上的改进,这正在成为行业的“最佳实践”。对于 Google 来说,1%的准确性提升意味着数百万美元。因此,人们在改进机器学习解决方案上投入了大量的精力。事实上,Sibyl 使用了在多台机器上运行的 Parallel Boosting Algorithm。
 上面的示意图是 Sibyl 系统的核心,其中每一步都可以并行完成。我将跳过细节。对算法感兴趣的人可以阅读 Collins, Schapire 和 Singer 的论文。
上面的示意图是 Sibyl 系统的核心,其中每一步都可以并行完成。我将跳过细节。对算法感兴趣的人可以阅读 Collins, Schapire 和 Singer 的论文。
正如 Tushar 所说,Sibyl 是唯一一个没有内部分布式系统的大规模机器学习系统。MapReduce 和 Google 文件系统提供了所需的分布式系统支持。Parallel Boosting Algorithm 使其成为可能,因为它非常适合 MapReduce 和 GFS。

他们将实例输入到 Mapper 中,每个特征被分配给一个 Reducer。在 Mapper 和 Reducer 之间,使用了 Parallel Boosting Algorithm。
通常需要 10-50 次迭代才能收敛。
Tushar 还介绍了一些设计原则,如使用 GFS 进行通信、列式数据存储、使用特征字典、将模型和统计信息存储在 RAM 中以及优化多核处理等,这些原则我在我的文章中不会一一列举。
Sibyl 将会更加快速高效,如果设计时采用这些原则。例如,正如第一个表格所示,系统通过使用列式数据存储将训练数据压缩多达 80%,从而提高效率。通过特征整数化,每个特征的字节数可以小至 0.67。
你可以在视频中找到更多细节
DSN 2014 主旨演讲:“Sibyl:Google 大规模机器学习系统”
Ran Bi 是纽约大学数据科学项目的硕士生。在她的 NYU 学习期间,她参与了多个机器学习、深度学习以及大数据分析项目。
相关内容:
-
OpenML:分享、发现和执行机器学习
-
当 Watson 遇上机器学习
-
Vowpal Wabbit:大数据上的快速学习
-
PredictionIO 为开源机器学习服务器融资 250 万美元
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析水平
3. Google IT 支持专业证书 - 支持您的组织 IT
更多相关话题
健全的数据科学:避免最棘手的预测陷阱
原文:
www.kdnuggets.com/2017/01/siegel-data-science-avoiding-prediction-pitfall.html

在 《预测分析:预测谁会点击、购买、撒谎或死亡,修订版》* 的更新版中,我展示了尽管数据科学和预测分析的爆炸性流行承诺了巨大的价值,但一个常见的错误应用很容易适得其反。只有应用了一个基本却常被忽视的安全措施,数字分析才能真正发挥作用。*
预测正在蓬勃发展。数据科学家被誉为“21 世纪最性感的职业”(正如托马斯·达文波特教授和美国首席数据科学家 D.J. Patil 在 2012 年所宣称)。在数据洪流的推动下,我们进入了预测发现的黄金时代。一系列分析产生了大量丰富、有价值且有时令人惊讶的洞察:[i]
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织在 IT 领域
• 喜欢在 Facebook 上点赞卷曲薯条的人更聪明。
• 正确的大写输入表示信用值得信赖。
• 使用 Chrome 和 Firefox 浏览器的员工表现更佳。
• 跳过早餐的男性面临更高的冠心病风险。
• 持有信用卡的用户去看牙医的信用风险较低。
• 高犯罪率的社区需要更多的 Uber 乘车服务。
看起来很有趣?在开始之前,请注意:这次数据探索的狂欢必须通过严格的质量控制来加以驯服。很容易出错、崩溃,或者至少让自己出丑。
2012 年,《西雅图时报》的一篇文章引人注目地揭示了一项预测发现:“橙色的二手车最不容易成为‘柠檬车’。”[ii] 这一洞察源于一项预测分析竞赛,旨在识别哪些二手车是糟糕的选择(柠檬车)。虽然关于其他汽车属性的信息也被揭示——如品牌、型号、年份、配置等级和尺寸——但橙色车的明显优势引起了最多关注。面对困惑的表情,数据专家提供了创造性的解释,例如选择不寻常车颜色的车主往往对车辆有更多的“联系”并且更加关爱。
单独审视,“橙色柠檬”发现从数学角度来看似乎是可靠的。以下是具体结果:
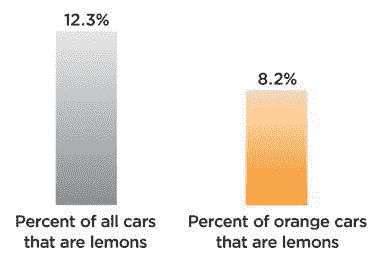
这表明橙色汽车变成柠檬的几率比平均水平低三分之一。换句话说,如果你购买一辆非橙色的汽车,你的风险增加了 50%。
确立的统计数据似乎支持这一“色彩丰富”的发现。正式评估表明,这具有统计显著性,意味着这个模式仅仅是随机出现的机会很小。似乎可以安全地假设这一发现是可靠的。更具体地说,一项标准数学测试表明,如果橙色汽车实际上不更可靠,这一趋势出现在数据中的机会不到 1%。
但事情发生了严重错误。后来的“橙色汽车”洞察被证明结论不确。统计测试以一种有缺陷的方式进行;媒体也过早地报道了这一发现。随着数据量的增加,应用常见的统计方法可能会陷入潜在的陷阱。
大数据的小陷阱
世界上的问题在于愚蠢的人过于自信,而聪明的人却充满怀疑。
—伯特兰·罗素
大数据带来了巨大的潜力——但也伴随巨大的危险。随着数据的增加,一个独特的陷阱常常欺骗即便是最聪明的数据科学家。这一隐秘的危险可能会破坏评估统计显著性的过程,这一过程是科学可靠性的黄金标准。这个危险确实不容小觑!虚假的发现可能会导致灾难。你可能会购买一辆橙色汽车——或接受一个无效的医疗程序——完全没有正当理由。正如格言所说,错误的信息比没有信息更糟;错置的自信往往难以再现。
这种危险似乎很矛盾。如果数据如此宝贵,我们为什么要因获取越来越多的数据而遭受困扰?统计学早已建议,拥有更多的例子更好。更长的案例列表提供了更细致评估趋势的手段。你能想象更多数据的弊端是什么吗?正如你将看到的,这是一个发人深省、戏剧性的情节反转。
科学的命运——以及夜间的安稳——取决于防范危险。经验发现的概念正岌岌可危。为了充分利用今天数据爆炸的非凡机会,我们需要一种万无一失的方法来确定观察到的趋势是否真实,而不是数据的随机产物。我们如何重新确认科学的可信声誉?
统计学以一种非常特定的方式处理这个挑战。它告诉我们即使效果不真实,观察到的趋势随机出现的概率。这就是说,它回答了这个问题:[iii]
统计学可以回答的问题: 如果橙色汽车的可靠性实际上与二手车一样,那么这种强烈的趋势——将橙色汽车描绘为更可靠——在数据中出现的概率有多大,仅仅是随机机会?
在数据发现中,总是存在我们可能被随机性所欺骗的可能性,就像纳西姆·尼古拉斯·塔勒布在他那本引人注目的书中所提到的那样。书中揭示了人们倾向于为自己的成功和失败寻找毫无根据的解释,而不是将许多事件正确归因于纯粹的随机性。这种失败的科学解药是概率,塔勒布亲切地称之为“应用怀疑论的一个分支”。
统计学是我们用来衡量概率的资源。它通过计算如果橙色汽车实际上没有优势时,观察到的数据随机出现的概率来回答上述橙色汽车问题。计算考虑了数据量——在这种情况下,有 72,983 辆二手车,涵盖 15 种颜色,其中 415 辆是橙色的。[iv]
对问题的计算答案: 低于 0.68%
看起来是一个安全的选择。常规做法认为这种风险可以接受,足够低到至少可以暂时相信数据。但不要急于购买一辆橙色汽车——或者为此事在报纸上撰写文章。
出错原因:累积风险
在中国,当你是百万分之一时,就有 1300 人和你一模一样。
—比尔·盖茨
那么,如果只有 1%的机会我们会被随机性误导,那出了什么问题?
实验者的错误在于没有考虑到运行许多小风险,这些小风险加起来变成了一个大风险……
[i] 有关这些发现的更多细节,请参见我书中“奇异和令人惊讶的见解”部分,PDF 在线版可在www.PredictiveNotes.com获取。有关本文章总体主题的进一步阅读,请参阅同一文档中的“广泛搜索的进一步阅读”部分。
[ii] 这一发现还被赫芬顿邮报、纽约时报、国家公共电台、华尔街日报以及纽约时报畅销书大数据:一场将改变我们生活、工作和思维方式的革命报道。
[iii] 橙色汽车没有优势的观点称为零假设。如果零假设为真,那么观察到的效果在数据中出现的概率称为p 值。如果 p 值足够低,例如低于 1%或 5%,那么研究人员通常会拒绝零假设,认为这种情况不太可能,从而将其视为对发现的支持,这样就被认为是统计显著的。
[iv] 适用的统计方法是单侧比例相等假设检验,其计算的 p 值低于 0.0068。
原文发表于OR/MS Today。已获许可转载。
相关内容:
-
4 个原因导致你的机器学习模型出错(及如何修复)
-
提高回归模型鲁棒性的一个巧妙技巧
-
避免过拟合的大创意:可重复使用的保留集以保持适应性数据分析的有效性
更多相关话题
数据质量在成功的机器学习模型中的重要性
原文:
www.kdnuggets.com/2022/03/significance-data-quality-making-successful-machine-learning-model.html

来源:商业照片由 frimufilms 创建 - www.freepik.com
介绍
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
人工智能已经成为一个流行词,并且非常普遍。市场上启用 AI 的应用程序显著增加。我们也‘幸运地’拥有强大的基础设施和先进的算法。然而,这并没有使将你的机器学习项目推向生产变得更容易。

来源: 聊天机器人矢量图由 roserodionova 创建 - www.freepik.com
数据质量的问题并不是新鲜事,它自机器学习(ML)应用的开始以来就引起了关注。
机器从历史数据中学习统计关联,性能取决于其训练数据。因此,高质量的数据成为机器学习管道的基本构建块。机器学习模型的表现只能与其训练数据的质量相匹配。
以数据为中心 vs 以算法为中心
让我和你分享两个场景——假设你已经完成了初步的探索性数据分析,并且对模型的表现感到非常兴奋。然而,令你失望的是(这在数据科学家的生活中时有发生 😃),模型的结果并没有达到业务的接受标准。在这种情况下,考虑到数据科学领域的重复性,你的下一步措施是什么:
-
分析错误的预测,并将其与输入数据关联,以调查可能的异常和之前忽视的数据模式。
-
或者,你可以采取前瞻性的办法,直接进阶到更复杂的算法。
简而言之,依赖更高级的机器学习算法以提高准确度,如果数据无法为机器提供良好的信号,将不会取得显著效果。这在 Andrew Ng 关于“MLOps:从模型中心到数据中心 AI”的讲座中阐述得非常清楚。
数据质量评估
机器学习算法需要在单一视图中进行训练,即扁平结构。由于大多数组织维护多个数据源,将多个数据源合并以将所有必要的属性放入单一扁平文件的过程是一个耗时且资源(领域专业知识)密集的过程。
在此步骤中,数据暴露于多个错误源,需要严格的同行评审,以确保领域建立的逻辑已被传达、理解、编程和实施得当。
由于数据仓库整合了来自多个来源的数据,数据采集、清理、转换、链接和整合相关的质量问题变得至关重要。
大多数数据科学家认为,数据准备、清理和转换占用了模型构建的大部分时间——这绝对是事实。因此,建议不要急于将数据输入模型,而是进行全面的数据质量检查。虽然可以对数据执行的检查数量和类型可能非常主观,但我们将讨论在准备数据质量评分和评估数据质量时需要检查的一些关键因素:
维护数据质量的技术:
-
缺失数据插补
-
异常值检测
-
数据转换
-
降维
-
交叉验证
-
自助取样
质量、质量、质量
让我们检查一下如何提高数据质量:
-
-
所有标注员并不相同: 数据来自多个来源。多个供应商在收集和标注数据时采取了不同的方法,对数据的最终用途有不同的理解。在同一供应商的数据标注中,由于监督员接收要求并将指导方针传达给不同的团队成员,所有人都根据自己的理解进行标注,这样数据不一致的情况可能会出现。
- 对供应商端的质量检查、对消费者端遵循共享指导方针的验证将有助于实现一致的标注。
-
唯一记录: 识别出唯一标识单个记录的一组属性非常重要,并且需要领域专家的验证。在这组属性上删除重复项,将得到模型训练所需的唯一记录。这组属性作为执行数据集上的多个聚合和转换操作的关键,如计算滚动平均值、填补空值、缺失值插补(下一点会详细说明)等。
-
如何处理缺失数据? 数据的系统性缺失会导致数据集的偏差,并需要深入调查。此外,从数据中删除缺失值较多的观察结果可能会导致某些群体(如性别或种族)的数据被剔除。因此,数据被误表示会产生偏见的结果,不仅在模型输出级别上存在缺陷,而且违反了伦理和负责任使用 AI 的公平原则。另一种发现缺失属性的方法是“随机”。盲目地由于高缺失率而删除某个重要属性可能会通过降低模型的预测能力来伤害模型。
- 最常见的填补缺失值的方法是通过在特定维度级别的均值。例如,使用从德里到班加罗尔路线的平均转换数来填补某一天该路线的缺失值。类似地,可以计算所有高流量路线的平均值,如德里到孟买、德里到加尔各答、德里到钦奈,以填补缺失的转换值。
-
-
扁平化结构: 大多数组织没有集中式数据仓库,并且在为决策制定机器学习模型时面临缺乏结构化数据的问题。例如,网络安全解决方案需要将来自网络、云端和终端的多种资源的数据标准化为一个单一视图,以便对之前遇到的攻击/威胁进行算法训练。
高质量数据的好处
大规模理解你的数据
现在,我们已经讨论了一些数据质量可能下降的关键领域,让我们看看你如何使用 TensorFlow 数据验证来大规模理解你的数据:
-
TFDV 提供了描述性分析,并显示了数据的统计分布——均值、最小值、最大值、标准差等。
-
理解数据模式是非常关键的——特征、其值和数据类型。
-
一旦你了解了基线数据分布,重要的是要关注异常行为。TFDV 突出显示了超出领域的值,从而指导你检测错误。
-
它通过叠加训练数据和测试数据的分布,显示了它们之间的漂移。
TensorFlow 的文档展示了如何使用 TFDV 分析数据并提高数据质量。我强烈建议你尝试在 Colab 上使用 TFDV 代码对你的数据集进行操作。
以下是出租车数据的数值和分类数据的统计分析:
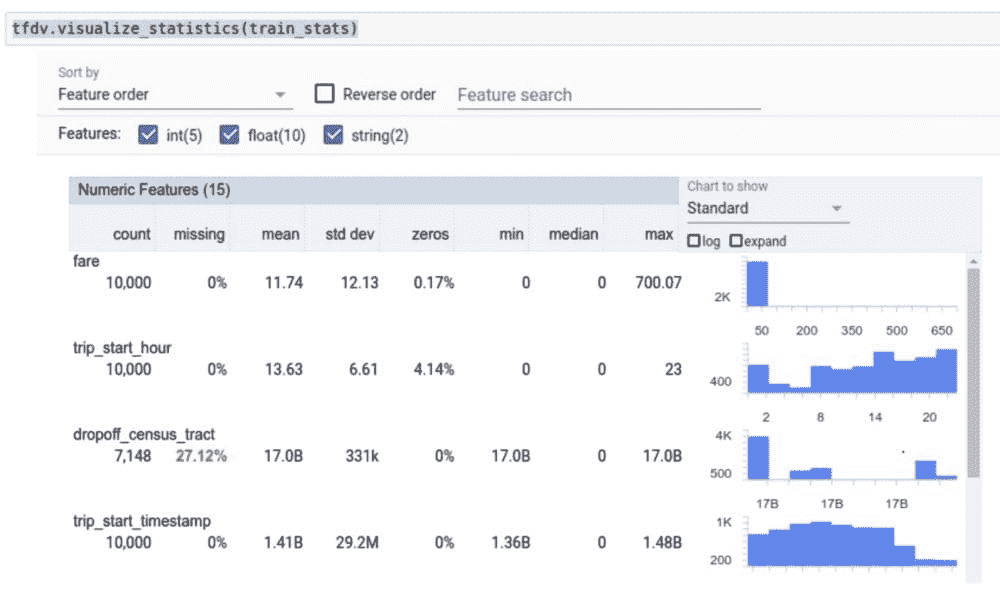
总计,右侧可视化中缺失值的百分比有助于更好地理解数据。
pickup_census_tract 中包含所有缺失值的记录,因此没有信号供 ML 算法进一步学习。可以根据这一 EDA 进行筛选。
数据漂移: 这是部署模型管道中最关键的部分,可能会发生在训练数据和测试数据之间的时间跨度内,或者在多天的训练数据之间。
ML 算法的表现基于训练数据和测试数据具有类似特征的假设,违反此假设将导致模型性能下降。
谷歌在这个 Colab 笔记本中分享了代码。
期待听到您在维护和使用高质量数据方面的一些最佳实践。
参考资料
Vidhi Chugh 是一位获奖的 AI/ML 创新领袖和 AI 伦理学家。她在数据科学、产品和研究的交叉点上工作,以提供商业价值和洞察。她倡导数据驱动的科学,并在数据治理方面是一位领先专家,致力于构建值得信赖的 AI 解决方案。
更多相关话题
使用 PyTorch 计算简单导数
原文:
www.kdnuggets.com/2018/05/simple-derivatives-pytorch.html
评论
使用 PyTorch 求导数很简单。像许多其他神经网络库一样,PyTorch 包含一个自动微分包 [autograd](https://pytorch.org/docs/master/autograd.html),它完成了繁重的工作。但在 PyTorch 中,导数的计算似乎尤其简单。
我希望在第一次学习如何将 导数和神经网络的实际应用结合起来时,有一些具体的例子,展示如何使用这样的神经网络包来找出简单的导数并进行计算,这些计算与神经网络中的计算图分开。PyTorch 的架构使得这种教学示例变得容易。
我不太确定这是否对那些想了解 PyTorch 如何实现自动微分、如何实际计算导数,甚至是学习“寻找导数”是什么意思的人有用,但我们还是试试看吧。也许这对这些人都没有帮助。 😃

首先,我们需要一个函数来找出导数。我们随意使用这个:
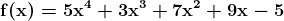
我们应该记住,函数的导数可以被解释为切线的斜率,以及函数的变化率。
在我们使用 PyTorch 找出这个函数的导数之前,让我们先手动计算一下:
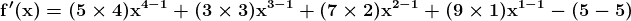
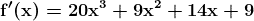
上述是我们原始函数的 一阶导数。
现在让我们找出给定 x 值的导数函数值。我们随意使用 2:
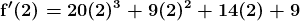
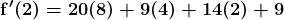
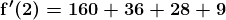
对 x = 2 求导数函数的结果是 233。这可以解释为在公式中,当 x = 2 时,y 对 x 的变化率是 233。
使用 autograd 查找并求解导数
我们如何使用 PyTorch 的 autograd 包做与上面相同的事情?
首先,我们需要将原始函数在 Python 中表示为如下形式:
y = 5*x**4 + 3*x**3 + 7*x**2 + 9*x - 5
import torch
x = torch.autograd.Variable(torch.Tensor([2]),requires_grad=True)
y = 5*x**4 + 3*x**3 + 7*x**2 + 9*x - 5
y.backward()
x.grad
上述代码逐行解释:
-
导入 torch 库
-
定义我们想计算导数的函数
-
将我们想要计算其导数的值(2)定义为 PyTorch
Variable对象,并指定它应以能够跟踪计算图中连接位置的方式进行实例化,以便通过链式法则 (requires_grad) 执行微分。 -
使用
autograd的[backward()](https://pytorch.org/docs/master/autograd.html#torch.autograd.backward)计算梯度的总和,使用链式法则 -
输出 x 张量的
grad属性中存储的值,如下所示
tensor([ 233.])
这个值 233 与我们上面手动计算的结果一致。
若要进一步使用 PyTorch,包括使用 autograd 包和 Tensor 对象构建一些基础神经网络,我建议查看官方的 PyTorch 60 分钟快速教程 或 这个教程。
相关:
-
PyTorch 张量基础
-
什么是张量?!?
-
提升你的数据科学技能。学习线性代数。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关内容
创建一个简单的 Docker 数据科学镜像
原文:
www.kdnuggets.com/2023/08/simple-docker-data-science-image.html

作者使用 Midjourney 创建的图像
为什么选择 Docker 来进行数据科学?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
作为数据科学家,拥有一个标准化且可移植的分析和建模环境至关重要。 Docker 提供了一种创建可重用和可共享数据科学环境的绝佳方式。在本文中,我们将详细介绍如何使用 Docker 设置基本的数据科学环境。
我们为什么要考虑使用 Docker 呢?Docker 允许数据科学家为他们的工作创建隔离且可重复的环境。使用 Docker 的一些关键优势包括:
-
一致性 - 相同的环境可以在不同的机器上复制。再也没有“在我的机器上能用”的问题。
-
可移植性 - Docker 环境可以轻松地在多个平台之间共享和部署。
-
隔离性 - 容器隔离了不同项目所需的依赖项和库。再也没有冲突了!
-
可扩展性 - 通过启动更多容器,轻松扩展在 Docker 内构建的应用程序。
-
协作 - Docker 通过允许团队共享开发环境来促进协作。
第 1 步:创建 Dockerfile
任何 Docker 环境的起点是 Dockerfile。这个文本文件包含了构建 Docker 镜像的指令。
让我们创建一个 Python 数据科学环境的基本 Dockerfile,并将其保存为没有扩展名的 'Dockerfile'。
# Use official Python image
FROM python:3.9-slim-buster
# Set environment variable
ENV PYTHONUNBUFFERED 1
# Install Python libraries
RUN pip install numpy pandas matplotlib scikit-learn jupyter
# Run Jupyter by default
CMD ["jupyter", "lab", "--ip='0.0.0.0'", "--allow-root"]
这个 Dockerfile 使用了 官方 Python 镜像,并在其上安装了一些流行的数据科学库。最后一行定义了在启动容器时运行 Jupyter Lab 的默认命令。
第 2 步:构建 Docker 镜像
现在我们可以使用docker build命令构建镜像:
docker build -t ds-python .
这将根据我们的 Dockerfile 创建一个标记为ds-python的镜像。
构建镜像可能需要几分钟,因为所有的依赖项都在安装中。完成后,我们可以使用docker images查看本地 Docker 镜像。
第 3 步:运行容器
镜像构建完成后,我们现在可以启动一个容器:
docker run -p 8888:8888 ds-python
这将启动一个 Jupyter Lab 实例,并将主机的 8888 端口映射到容器的 8888 端口。
现在我们可以在浏览器中导航到 localhost:8888 来访问 Jupyter 并开始运行笔记本!
第 4 步:共享和部署镜像
Docker 的一个主要好处是能够在不同环境之间共享和部署镜像。
要将镜像保存为 tar 归档,运行:
docker save -o ds-python.tar ds-python
这个 tar 包可以通过以下命令在任何其他安装了 Docker 的系统上加载:
docker load -i ds-python.tar
我们还可以将镜像推送到 Docker 注册中心,如 Docker Hub,以便与他人公开或在组织内部私下共享。
要将镜像推送到 Docker Hub:
-
如果您还没有 Docker Hub 账户,请创建一个
-
使用
docker login从命令行登录到 Docker Hub -
使用您的 Docker Hub 用户名标记镜像:
docker tag ds-python yourusername/ds-python -
推送镜像:
docker push yourusername/ds-python
ds-python 镜像现在托管在 Docker Hub 上。其他用户可以通过运行以下命令来拉取镜像:
docker pull yourusername/ds-python
对于私有仓库,您可以创建一个组织并添加用户。这允许您在团队内部安全地共享 Docker 镜像。
第 5 步:加载和运行镜像
要在另一台系统上加载和运行 Docker 镜像:
-
将
ds-python.tar文件复制到新系统 -
使用
docker load -i ds-python.tar加载镜像 -
使用
docker run -p 8888:8888 ds-python启动一个容器 -
在
localhost:8888访问 Jupyter Lab
就是这样!ds-python 镜像现在已准备好在新系统上使用。
最终想法
这为您提供了使用 Docker 设置可重现的数据科学环境的快速入门指南。还需要考虑一些额外的最佳实践:
-
使用像 Python slim 这样的较小基础镜像来优化镜像大小
-
利用 Docker 卷进行数据持久化和共享
-
遵循安全原则,如避免以 root 用户身份运行容器
-
使用 Docker Compose 定义和运行多容器应用程序
我希望您觉得这个介绍有帮助。Docker 为简化和扩展数据科学工作流程提供了很多可能性。
Matthew Mayo (@mattmayo13) 是数据科学家以及 KDnuggets 的总编辑,该网站是开创性的数据科学和机器学习在线资源。他的兴趣包括自然语言处理、算法设计和优化、无监督学习、神经网络以及自动化机器学习方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系到。
更多相关内容
简单快速的数据流用于机器学习项目
原文:
www.kdnuggets.com/2022/11/simple-fast-data-streaming-machine-learning-projects.html

图像作者
你是否曾经想过为什么你必须等待 DVC 拉取所有文件才能访问单个文件?也许你创建了自定义脚本来解决这个问题。但如果我告诉你还有更好的解决方案,你会如何想?
直接数据访问 使你能够轻松加载来自 DagsHub DVC 服务器的单个或多个文件。你还可以使用上传 API 上传单个文件或多个文件。这将帮助你节省时间,因为你无需拉取整个数据集来推送单个文件。
直接数据访问在所有类型的 Python 库中表现更好,特别是那些使用高功能级别的库。在训练机器学习模型的情况下,你可以将数据直接加载到 DataLoader 中,开始训练或微调模型。
在本教程中,我们将深入研究 DagsHub 的直接数据访问,并使用 FastAI-2 和直接数据访问训练简单的瑜伽姿势分类模型。
开始使用直接数据访问
直接数据访问附带了 DagsHub 客户端 API。你可以根据需要从 DagsHub 服务器访问文件,而不是使用 dvc pull 下载所有数据。
流式传输的文件与保存在本地磁盘上的文件无异。你可以提供一个本地文件路径,它会从 DagsHub 拉取文件。
使用 GitHub URL 和 pip 命令安装 DagsHub API。
!pip install git+https://github.com/DagsHub/client.git
或者
!pip install dagshub
注意: 目前,直接数据访问功能处于测试版,有一些小问题。
手动方法
手动方法允许你使用 DagsHubFilesystem 流式传输文件。
你只需替换:
| Python API | DagsHub 文件系统 |
|---|---|
| open() | fs.open() |
| os.stat() | fs.stat() |
| os.listdir() | fs.listdir() |
| os.scandir() | fs.scandir() |
如果你在 Git 仓库中,你不需要提供配置参数。
要覆盖自动检测的配置,请使用:
-
repo_url
-
username
-
Password
如果你在 Git 仓库外部,你也可以使用 project_root 参数指向项目目录。
在这个例子中,我们创建了一个 DagsHubFilesystem 并使用 listdir() 显示了文件和文件夹的列表。
from dagshub.streaming import DagsHubFilesystem
fs = DagsHubFilesystem()
fs.listdir()
它显示了在本地目录中不可用但在 DVC 服务器上的“Mobilenet-Weights”和“Saved_Models”文件夹。简而言之,你可以访问在 DagsHub 仓库中看到的所有文件,而无需执行 dvc pull 命令。
['Mobilenet-Weights',
'Mobilenet-Weights.dvc',
'.git',
'dvc.lock',
'.gitignore',
'README.md',
'src',
'Saved_Models',
'LICENSE',
'Data',
'dvc.yaml',
'.dvc',
'requirments.txt',
'.dagshub-streaming',
'.dvcignore']
自动方法
install_hooks 允许 Python 库(某些例外情况适用)像访问系统上的文件一样访问 DVC 跟踪的文件。它简单且快速。
在下面的示例中,我们调用了install_hooks()并使用 PIL.Image 显示了一张女人做下犬瑜伽姿势的图片。
from PIL import Image
from dagshub.streaming import install_hooks
install_hooks()
Image.open("./Data/Yoga Pose/Downdog/00000011.jpg")

我知道,这就像魔法一样。它也会让你惊讶于更快的加载时间。
注意: 使用 DagsHubFilesystem 或 install_hooks 命令时,会要求你生成一个临时 OAuth 密钥以增加安全性。
使用 Direct Data Access 进行瑜伽姿势分类
在本教程中,我们将使用 Direct Data Access 对 Resnet34 模型进行微调,数据集为瑜伽姿势数据集。该数据集包括 5 类瑜伽姿势图像,图像是通过 Bing API 提取的。

作者提供的图片
设置
你可以 fork 并克隆我的仓库,并在 Google Colab 或 Jupyter Notebook 上运行下面的命令。该命令需要一个分支名称、仓库名称、用户名和访问令牌。你可以简单地用你的配置替换占位符。
注意: 请确保你在仓库内部以激活流媒体功能。
!git clone -b {BRANCH} https://{DAGSHUB_USER_NAME}:{DAGSHUB_TOKEN}@dagshub.com/{DAGSHUB_USER_NAME}/{DAGSHUB_REPO_NAME}.git
%cd {DAGSHUB_REPO_NAME}
如果你在开始时遇到问题,可以查看Colab 笔记本。
接下来,我们将导入 Pytorch、FastAI、os 和 Matplotlib。该项目基于 FastAI 框架。阅读文档以了解更多信息。
import torch
import matplotlib.pyplot as plt
from fastai.vision.all import *
from fastai.metrics import error_rate, accuracy
import os
数据加载器
在调用 install_hooks()之后,我们可以通过:ImageDataloaders自动访问文件。
加载和下载 18.1 MB 数据集花费了 6.54 秒。这相比使用dvc pull + ImageDataLoaders 的 73.84 秒要快。
%%time
from dagshub.streaming import install_hooks
install_hooks()
path = Path('./Data/Yoga Pose')
data = ImageDataLoaders.from_folder(path, valid_pct=0.2, item_tfms=Resize(224))
CPU times: user 1.68 s, sys: 914 ms, total: 2.59 s
Wall time: 6.54 s
可视化
我们的数据集非常简单,包括各种带标签的瑜伽姿势。我们将使用它来训练我们的模型。Resnet34 不需要大量数据,即使是几百张图像也能提供最先进的结果。
data.show_batch()

模型微调
在我们开始微调之前,我们需要设置 MLflow 以跟踪实验。DagsHub 提供了一个免费的 MLflow 服务器。你只需设置跟踪 URI,我们就可以开始了。你可以通过点击仓库页面上的绿色按钮(Remote)并通过 MLflow 选项卡访问 URI。
get_experiment_id函数生成并返回实验 ID。
import mlflow
mlflow.set_tracking_uri(os.getenv("MLFLOW_TRACKING_URI"))
def get_experiment_id(name):
exp = mlflow.get_experiment_by_name(name)
if exp is None:
exp_id = mlflow.create_experiment(name)
return exp_id
return exp.experiment_id
exp_id = get_experiment_id("yoga_colab")
之后,使用 mlflow.fastai.autolog()激活跟踪功能。它将记录实验并将其发送到 DagsHub 上的 MLflow 服务器。
最后,我们将用 resnet34 构建我们的学习器,并将指标设置为准确率和错误率。
%%time
mlflow.fastai.autolog()
learn = vision_learner(data, resnet34, metrics=[accuracy, error_rate])
with mlflow.start_run(experiment_id=exp_id) as run:
learn.fine_tune(3)
微调 3 个 epoch 后,我们获得了 95.9%的准确率和 0.04 的损失,取得了最先进的结果。
| epoch | train_loss | valid_loss | accuracy | error_rate | time |
|---|---|---|---|---|---|
| 0 | 0.368970 | 0.154318 | 0.954315 | 0.045685 | 00:05 |
| 1 | 0.220782 | 0.127155 | 0.964467 | 0.035533 | 00:05 |
| 2 | 0.145330 | 0.116135 | 0.959391 | 0.040609 | 00:05 |
CPU times: user 12.4 s, sys: 4.55 s, total: 16.9 s
Wall time: 1min 14s
注意: 如果你使用 Colab 训练模型,你需要设置标签以将提交与实验结果关联,使用:
mlflow.set_tag('mlflow.source.git.commit', "<commit-id>")
保存模型并用于推断和可重复性。
os.mkdir("/content/Yoga-Pose-Classification/Saved_Models/")
learn.save("/content/Yoga-Pose-Classification/Saved_Models/my_model", with_opt=False)
简单预测
让我们从训练集中获取一张随机图像来预测标签。正如你所见,我们以 99.99% 的确定性获得了 Downdog 标签。
files = get_image_files("/content/Yoga-Pose-Classification/Data/Yoga Pose/Downdog")
learn.predict(files[0])
>>> ('Downdog',
TensorBase(0),
TensorBase([9.9999e-01, 8.2240e-07, 9.9132e-06, 5.6985e-07, 9.2867e-07]))
评估
模型评估显示模型准确地预测了所有图像。
learn.show_results()

MLflow
你可以使用 DagsHub 实验标签查看过去的实验和结果。我最初使用 Keras MobilenetV3 和其他各种模型进行训练。最后,我选择了 FastAI 和 Resnet34,以获得更简单和更好的结果。
图片来自 kingabzpro/Yoga-Pose-Classification
DagsHub 数据上传 API
流式传输是双向的。你也可以使用 DagsHub 上传 API 上传单个或多个文件。
为了在未见过的数据上测试我们的模型,让我们从 Google 下载瑜伽姿势图像。我们将上传这些图像,并通过流式传输访问它们进行预测。
图片来自 Google 搜索
我们将使用 upload.Repo 创建一个 repo 对象。这将帮助我们通过用户名、访问令牌、仓库名称和分支直接上传文件。
注意: 上传时,你甚至不需要克隆任何 Git 仓库。
from dagshub.upload import Repo
repo = Repo(
owner=DAGSHUB_USER_NAME,
name=DAGSHUB_REPO_NAME,
branch=BRANCH,
username=DAGSHUB_USER_NAME,
password=DAGSHUB_TOKEN,
)
上传多个文件
要上传多个文件,我们需要提供一个文件夹目录。如果文件夹名称不存在,它会为你创建一个。
在下一步中,我们使用循环添加 2 个新的瑜伽姿势图像文件,并使用消息和版本控制提交。
通过使用版本控制,你可以上传由 Git 或 DVC 跟踪的文件。
ds = repo.directory("Sample")
file_list = ["/content/yoga1.jpeg", "/content/yoga2.jpeg"]
for file1 in file_list:
ds.add(file1)
ds.commit("multiple files upload", versioning="dvc")
文件已成功上传。太棒了!!!
这真是太棒了。
当我第一次上传文件而不克隆 Git 仓库并拉取 DVC 数据时,我非常高兴。
上传单个文件
你也可以通过提供本地文件和仓库文件路径来使用单行上传文件。这样,你可以将文件上传到任何文件夹中。
在我们的例子中,我们使用消息和 DVC 版本控制将第三个文件上传到 Sample 文件夹。
repo.upload(
file="/content/yoga3.jpeg",
path="Sample/yoga3.jpeg",
commit_message="yoga single file upload",
versioning="dvc",
)
第三张图像已成功上传到 DagsHub 仓库。
模型预测
现在,我们将使用上传的图像来预测瑜伽姿势。
%%time
install_hooks()
from PIL import Image
import IPython.display as display
img_loc = "./Sample/yoga3.jpeg"
img = Image.open(img_loc)
display.display(img)
learn.predict(img_loc)
该模型已以 99.9% 的准确度预测了 Warrior2 姿势。

CPU times: user 56.7 ms, sys: 2.14 ms, total: 58.8 ms
Wall time: 62.2 ms
('Warrior2',
TensorBase(4),
TensorBase([3.8390e-05, 5.2042e-04, 7.9451e-05, 5.5486e-06, 9.9936e-01]))
注意: 要访问最近上传的文件,您必须再次运行
install_hooks()。
基准测试
尽管 DagsHub 的直接数据访问仍处于 Beta 阶段,但它显示出了良好的前景。通过流式处理,我们加载图像文件的速度比 dvc pull 快 11 倍。尽管 Beta 版本中仍有一些小的错误,但总体来说,我对 DagsHub 团队感到印象深刻,他们提出了一个令人惊叹的解决方案。
| 流式处理(s) | 非流式处理(s) | |
|---|---|---|
| 数据加载器 | 6.54 | 73.84 |
| 培训 | 74 | 72 |
| 总计 | 80.54 | 145.84 |
Abid Ali Awan (@1abidaliawan) 是一位认证数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个人工智能产品,帮助那些患有心理疾病的学生。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
更多相关内容
机器学习可视化简易指南
原文:
www.kdnuggets.com/2022/04/simple-guide-machine-learning-visualisations.html
残差图。图像由作者提供。
在开发机器学习模型时,一个重要的步骤是评估性能。根据你处理的机器学习问题类型,一般有多种度量标准可以选择来执行这一步骤。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
然而,单独查看一两个数字并不能总是帮助我们做出正确的模型选择。例如,一个单一的错误度量并不能告诉我们错误的分布情况。它不能回答像模型在少数几次情况下错误很大,还是产生了许多较小错误这样的问题?
也必须以可视化方式检查模型性能,因为图表或图形可以揭示我们可能从单一度量中遗漏的信息。
Yellowbrick 是一个 Python 库,致力于简化创建丰富的机器学习模型可视化的过程,这些模型是使用 Scikit-learn 开发的。
在接下来的文章中,我将介绍这个便捷的机器学习工具,并提供代码示例,创建一些最常见的机器学习可视化。
混淆矩阵
混淆矩阵是一种简单的方式,用于直观地评估分类器的预测正确频率。
为了说明混淆矩阵,我使用了一个称为“糖尿病”的数据集。该数据集包含患者的一些特征,如体重指数、2 小时血清胰岛素测量值和年龄,并有一列指示患者是否被检测出糖尿病。目标是利用这些数据构建一个可以预测糖尿病阳性结果的模型。
以下代码通过 Scikit-learn API 导入该数据集。
在二分类问题中,模型预测可能有四种潜在的结果。
真正例: 模型正确地预测了正面的结果,例如患者的糖尿病测试结果为阳性,模型预测结果也是阳性。
假阳性: 模型错误地预测了正结果,例如,患者的糖尿病测试结果为阴性,但模型预测为阳性。
真阴性: 模型正确地预测了负结果,例如,患者的糖尿病测试结果为阴性,且模型预测为阴性。
假阴性: 模型错误地预测了负结果,例如,患者的糖尿病测试结果为阳性,但模型预测为阴性。
混淆矩阵在网格中可视化了这些可能结果的计数。下面的代码使用 Yellowbrick ConfusionMatrix 可视化工具生成模型的混淆矩阵。
混淆矩阵。图片由作者提供。
ROC 曲线
分类器的初始输出不是标签,而是某个观察值属于某个类别的概率。
然后,这个概率被转换为一个类别,通过选择一个阈值。例如,我们可能会说,如果患者测试为阳性的概率超过 0.5,我们就赋予正标签。
根据模型、数据和使用场景,我们可能会选择一个阈值来优化特定的结果。在糖尿病示例中,漏掉一个正结果可能会有生命危险,因此我们希望最小化假阴性。调整分类器的阈值是一种优化结果的方法,ROC 曲线是可视化这种权衡的一种方式。
下面的代码使用 Yellowbrick 构建 ROC 曲线。
ROC 曲线。图片由作者提供。
ROC 曲线将真正例率与假阳性率进行绘制。通过这个,我们可以评估降低或提高分类阈值的影响。
精确度-召回率曲线
ROC 曲线并不总是评估分类器的最佳方法。如果类别不平衡(一个类别的观测值远多于另一个类别),ROC 曲线的结果可能会产生误导。
在这些情况下,精确度-召回率曲线通常是更好的选择。
让我们快速回顾一下精确度和召回率的定义。
精确度 衡量模型在正确识别正类方面的表现。换句话说,在所有正类的预测中,有多少实际上是正确的?
召回率 告诉我们模型在正确预测数据集中所有正观察值方面的表现如何。
精确度和召回率之间通常存在权衡。例如,您可能会为了提高精确度而牺牲召回率。
精确度-召回率曲线显示了在不同分类阈值下的权衡。
下面的代码使用 Yellowbrick 库生成糖尿病分类器的精确度-召回率曲线。
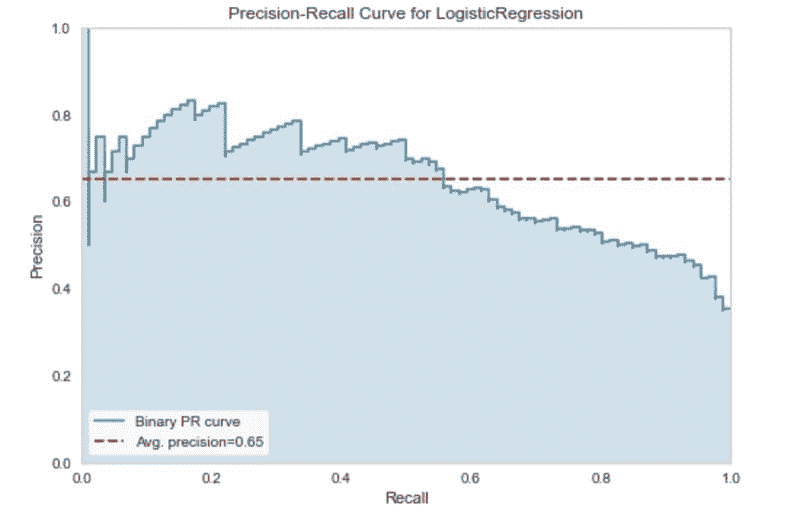
精确率-召回率曲线。图像由作者提供。
集群间距离
Yellowbrick 库还包含了一组用于分析聚类算法的可视化工具。评估聚类模型性能的常见方式是使用集群间距离图。
集群间距离图绘制了每个集群中心的嵌入,并可视化了集群间的距离及基于会员分布的每个集群的相对大小。
我们可以通过仅使用特征(X)将糖尿病数据集转化为聚类问题。
在对数据进行聚类之前,我们可以使用流行的肘部法来找到最佳的集群数目。Yellowbrick 为此提供了方法。
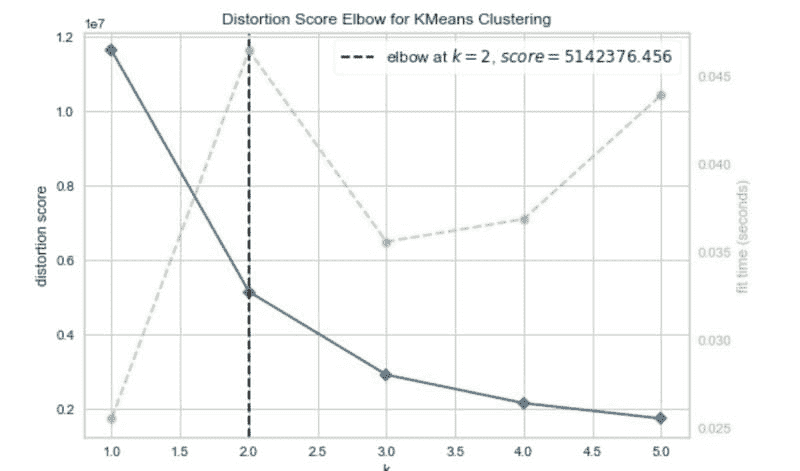
肘部法。图像由作者提供。
肘部曲线表明两个集群是最佳的。
现在让我们为数据集绘制集群间图,选择两个集群。
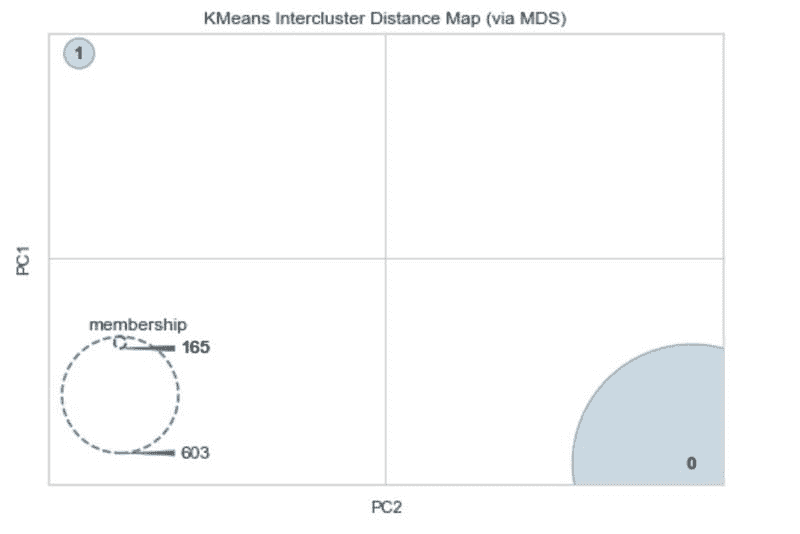
集群间距离图。图像由作者提供。
从中我们可以看到两个集群之间有很大的分离。会员分布表明一个集群有 165 个观测值,而另一个有 603 个。这与糖尿病数据集中两个类别的平衡相近,分别为 268 和 500 个观测值。
残差图
基于回归的机器学习模型有其独特的可视化方式。Yellowbrick 也对此提供了支持。
为了说明回归问题的可视化,我们将使用糖尿病数据集的一个变体,该数据集可以通过 Scikit-learn API 获得。这个数据集与本文早期使用的那个数据集具有相似的特征,但目标是基线后一年疾病进展的定量测量。
在回归中,视觉化残差是一种分析模型性能的方法。残差是观察值与模型预测值之间的差异。它们是量化回归模型误差的一种方式。
下面的代码生成一个简单回归模型的残差图。
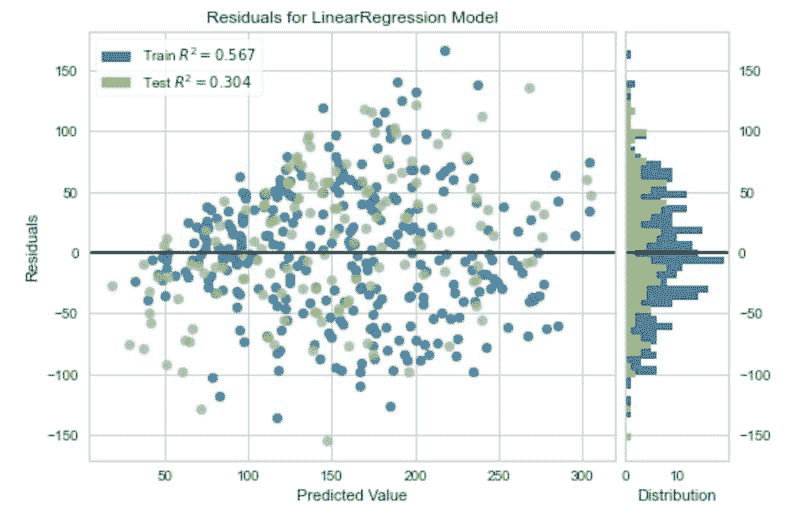
残差图。图像由作者提供。
Yellowbrick 库提供的基于回归的模型的其他可用可视化包括:
-
预测误差图。
-
Alpha 选择。
-
Cook's 距离。
Yellowbrick Python 库提供了快速创建机器学习可视化的方法,适用于使用 Scikit-learn 开发的模型。除了评估模型性能的可视化外,Yellowbrick 还提供了工具来可视化交叉验证、学习曲线和特征重要性。此外,还提供了文本建模可视化的功能。
正如文章中所述,单一评估指标模型可能有用,在某些情况下,如果你有一个简单的问题并且在比较不同的模型,这可能是足够的。然而,更多的时候,为模型性能创建可视化是获得对机器学习模型有效性真正理解的重要补充步骤。
如果你想了解更多关于单一评估指标的内容,我以前写过一篇文章涵盖了分类评估指标,还有一篇关于回归的文章。
*** 衡量分类性能的 8 个指标
丽贝卡·维克里 是一位数据科学家,拥有丰富的数据分析、机器学习和数据工程经验。12 年的 SQL 经验,4 年以上的 Python、R、Apache Airflow 和 Google Analytics 经验。
原文。经许可转载。
更多相关内容
在本地处理中到大型数据的简单方法
原文:
www.kdnuggets.com/2017/12/simple-medium-big-data-locally.html
评论
由 Francisco Juretig 创作,nitroproc 的作者
作为数据科学家,我们通常会接触到从几十万到几亿条记录的数据集,可能还有几十列或几百列。这些数据通常以 csv 文件的形式接收,并通过多种方式处理,最终目的是在 Python 或 R 中运行复杂的机器学习算法。然而,这些数据通常无法完全载入到内存中,因此需要设计替代工具。当然,所有这些数据可以分配到集群中并在那里处理,但这需要繁琐的上传文件过程、支付服务器时间费用、处理敏感数据时的安全问题、相当复杂的编程技巧,并花费时间下载结果。当然,本地 Spark 会话总是可以创建,但学习曲线很陡峭,对初学者来说,安装可能具有挑战性(尤其是当目标是偶尔处理几个大文件时)。在本文中,我们关注于处理这类数据集的简单技术(包括安装和运行)。
第一个选项:循环遍历文件
Python 或 R 总是可以用来快速遍历文件。在这种情况下,我们将用它来遍历一个非常大的文件。数据集如下:5,379,074 个观测值和 8 列,包括整数、日期和字符串,文件大小为 212 兆字节。

我们将为处理这个文件生成一个类。在这个类中,我们将定义两个简单的操作,第一个将计算最大值,第二个将筛选出特定名称的记录。在最后三行中,我们实例化这个类并调用它的方法。请注意,我们没有使用 pandas.read_csv,因为这个数据集通常无法适应内存(具体取决于你的计算机)。另外,请注意我们排除了第一条记录,因为它包含文件头。

问题在于,在大多数实际场景中,只要我们从简单的子集操作偏离,代码的复杂性就会惊人地增加。例如,即使是编写一个简单的文件排序程序也是极其复杂的,更不用说处理缺失值、多个变量类型、日期格式等了。更糟糕的是,大多数数据处理操作都需要良好的排序实现:合并、转置和汇总不仅本身困难,而且总是需要对数据进行排序,以便在合理的时间内运行。
第二种选择:SAS
SAS 多年来一直是统计分析的最佳软件。除了其卓越的统计方法实现外,SAS 还允许我们轻松处理数亿个观察值。它通过使用硬盘存储数据,而不是 RAM 内存(如大多数软件所做的),来实现这一点。此外,这些文件可以有数千列。SAS 编程语言非常简单且灵活。例如,读取一个文件并对其排序可以用很少的代码实现:
Data customer_data;
infile “./sales.csv” lrecl=32767 missover;
input User_id: 8\. Salesman: $10\. Date: mmddyy8\. Customername: $10\. City:$3\. Country: $6\.
Discount: $9\. Promo: 8.;
run;
proc sort data = customer_data;
by User_id;
run;
SAS 的一个常被忽视但非常强大的功能是其日志文件。它们是识别异常观察值、缺失值和不正常结果的极其强大的工具。例如,在合并两个包含数百万个观察值的文件时,你可以通过查看两个文件中读取的观察值数量与输出中写入的数量,立即识别出问题。
你通常不会发现任何限制或约束。然而,对于极大的文件,使用集群上运行的 Spark 的分布式环境会更方便(但这超出了本文的范围)。不幸的是,SAS 许可证通常非常昂贵,并且仅能在计算机上运行。
第三种选择:nitroproc
nitroproc 是一款免费的跨平台软件(目前支持 Windows/MacOS/Android/iOS),专为数据处理设计(特别适合数据科学家)。它可以通过 Python 或 R 以批处理模式调用。类似于 SAS,它被设计为使用硬盘进行操作,因此对数据大小几乎没有限制。它的脚本可以部署到任何设备上,语法不需修改(除非显然需要处理正确的输入文件路径)。在本文中,我们将展示如何使用 Windows 和 Android 版本(iOS 版本也可以从 App Store 下载)。它处理不同的变量类型、文件格式和缺失值。当前版本允许你进行排序、合并、筛选、子集、计算虚拟变量、聚合以及其他许多传统数据科学家使用的数据处理操作。类似于 SAS,nitroproc 生成非常强大的日志,用于识别异常数据、错误合并等。此外,它还生成另一个日志文件,称为 logtracer,用于逻辑分析脚本中不同指令的关系。
按一个关键字段排序 540 万个观察值
在这个示例中,我们将在 PC 和一部(旧版)Android 手机上对一个非常大的文件进行排序,仅为展示 nitroproc 的强大功能。我们将使用图 1 中相同的数据集——540 万条记录的数据集。请记住,这个数据集有 5,379,074 个观察值和 8 列,包含整数、日期和字符串,文件大小为 212 兆字节。在这种情况下,我们将按其第一列(User_id)进行排序。
你可以从www.nitroproc.com/download.html下载 csv 文件,以复制我们在此处展示的结果。在这种情况下,我建议你在手机连接到 PC/Mac 且后台没有其他进程运行的情况下运行测试。
语法非常简单,我们只需写:
sort(file=sales.csv,by=[User_id],coltypes=[int,string,dd/mm/yyyy,string,string,string,int,int], order=[asc], outname = result.csv, out_first_row = true)
所有参数都非常自解释。Order 指定我们是需要升序还是降序,out_first_row 用于指定是否要输出文件头。你可能会注意到我们没有指定任何头部,因为 csv 已经包含它们。如果它们没有包含,我们需要输入 headers=[colum_name1,…,column_namek]。对于 PC,我们需要指定正确的文件路径,但对于 Android 和 iOS 版本,只需文件名即可,因为文件路径会自动恢复(对于 Android 使用/Downloads 文件夹,对于 iPhone/iPad 使用 App 文件夹 – 可通过 iTunes 访问)。
排序在 nitroproc 中尤其重要,因为它用于合并文件、总结文件和其他操作。
PC 版本
在一台标准的(2012 年)Intel i5-4430 @3.00 GHz 桌面电脑和一块标准的 Seagate 500GB ST500DM002 硬盘上,完成需要 1 分 25 秒(参见图 3:nitroproc 生成的日志文件 - PC 版本)。在最新的 Intel 设备上,例如 i7-4970k,并且使用固态硬盘,脚本将至少快 3 倍(通过超频可以达到更高的速度)。
Android 版本
在 Android 7.0 Nougat 的 Nexus 5x 上运行相同的脚本要慢得多(图 4 nitroproc 生成的日志文件 - Android 版本,但它仍然运行良好)。这款手机发布于 2015 年,配备了 1.8GHz 的处理器(请注意,这不是一款高端手机)。如图 1 所示,完成需要 15 分钟。在最新的(2017 年)高端 Android 手机上,你应该期望在一半的时间内运行这个脚本(7 分钟)。由于几乎不使用 RAM,nitroproc 可以在内存不足的系统中很好地运行。
iOS 版本
最后,看看 iOS 版本在 iPhone 8 Plus(A11 Bionic 芯片)上的输出。这些结果让我惊讶,如同之前的基准测试没有给我这样的惊喜(我曾经是个热衷的超频爱好者)。苹果声称 iPhone 8 和 X 是最快的手机,但这可能是低估了。你可以看到它在 2 分钟 42 秒内排序文件,比我们的桌面 Intel CPU 所需的时间少不到两倍(考虑到 PC 消耗超过 250 瓦,而 iPhone 8 约为 6.96 瓦),并且比普通的 Android 手机快了将近 5.5 倍。对于 iPhone 8 Plus(以及 iPhone X,因为它们共享相同的芯片),一个更准确的说法是,它是工程上的奇迹,提供了与桌面游戏 CPU 类似的性能,而后者消耗了 35 倍的电力。考虑到 nitroproc 在 I/O 操作方面非常密集,而在这种情况下,有数亿次读写操作,因为有很多中间操作。A11 及其操作系统能够如此快速地从硬盘移动如此多的数据,几乎是超现实的。
相关
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 工作
更多相关话题
简单的面向对象编程的混合如何能提升你的深度学习原型
评论
介绍
本文不适合经验丰富的软件工程师。本文面向的数据科学家和机器学习(ML)从业者,像我一样,他们没有软件工程背景。
我们在工作中大量使用 Python。为什么?因为它对 ML 和数据科学社区非常出色。
它正在成为现代数据驱动分析和人工智能(AI)应用程序中增长最快的主要语言。
然而,它也被用于简单的脚本目的,比如自动化操作、测试假设、创建用于头脑风暴的交互式图表、控制实验室仪器等。
但问题在于。
用于软件开发的 Python 和用于脚本编写的 Python 并不完全相同——至少在数据科学领域如此。
脚本编程(大多数情况下)是你为自己编写的代码。软件是你(和其他团队成员)为他人编写的代码集合。
明智的做法是承认,当(大多数)数据科学家,他们没有软件工程背景时,编写用于 AI/ML 模型和统计分析的 Python 程序,他们往往是为了自己。
他们只是想快速找到隐藏在数据中的模式的核心。不加深思地进行,不考虑普通用户的需求——用户。
他们编写了一段代码来生成丰富美观的图表。但他们并没有从中创建一个函数,以便以后使用。
他们从标准库中导入了大量的方法和类。但他们并没有通过继承创建自己的子类并为其添加方法以扩展功能。
函数、继承、方法、类——这些是稳健的面向对象编程(OOP)的核心,但如果你只是想创建一个包含数据分析和图表的 Jupyter 笔记本,它们是可以有所回避的。
你可以避免使用 OOP 原则的最初痛苦,但这几乎总是会使你的 Notebook 代码无法重用和扩展。
简而言之,那段代码只对你有用(直到你忘记了具体编码的逻辑),而对其他人没有任何帮助。
不过,可读性(从而可重用性)至关重要。这是你所生产的代码真正的价值所在。不仅仅是为了自己,而是为了他人。
实际上,数据科学家Will Koehrsen刚刚写了一篇关于这个理念的精彩文章。
《代码大全:软件构建实用手册》的经验教训及其在数据科学中的应用。
最重要的是,数以百计的热门 MOOC 或在线数据科学和 AI/ML 课程也没有强调这方面的编码,因为这对年轻的、充满热情的学习者来说感觉是一种负担。他/她来到这里是为了学习酷炫的算法和神经网络优化,而不是 Python 中的面向对象编程(OOP)。因此,这一方面仍然被忽视。
那么,你可以做些什么呢?
简单的 OOP 混合可以使你的深度学习(DL)代码更加高效。
我不是软件工程师,也从未在我的生活中担任过这一职务。因此,当我开始探索机器学习和数据科学时,我写了大量粗糙、不可重用的代码。
我正在逐渐改进自己的编码风格,通过简单的增强使其对全世界的任何人更有用。
我发现,开始在你的数据科学代码中混合 OOP 原则并不需要太多努力。
即使你一生中从未上过软件工程课程,一些理念也可能会自然地浮现。你所需要做的就是站在他人的角度思考,考虑那个人如何以建设性的方式使用你的代码。
-
如果你的分析中有一个代码块出现了多次(无论是完全相同的形式还是稍有变化的形式),你能将其制作成一个函数吗?
-
当你制作这样的函数时,哪些参数将会被传递?其中哪些可以是可选的?默认值是什么?
-
如果你遇到一种情况,不知道需要传递多少参数,你是否使用了 Python 提供的*args、**kwargs?
-
你是否为那个函数写了文档字符串,以便让其他人知道该函数的功能和期望的参数,或许还包括一个示例?
-
当你收集了一堆这样的实用函数后,你是否还在使用同一个 Notebook,还是 切换到一个新的、干净的 Notebook 并仅调用“from my_utility_script import func1, func2, func3”(你是否将 my_utility_script 创建为一个简单的 Python 文件,而不是 Jupyter Notebook)?
-
你是否将my_utility_script放在一个目录中, 在同一目录下放置一个init.py 文件(即使是空白的),并将其设为 Python 模块以便像 NumPy 或 Pandas 一样可以导入?
-
你是否考虑不仅仅是从像 NumPy 和 TensorFlow 这样的优秀包中导入类和方法,而是 向它们添加你自己的方法并扩展其功能?
我说的这些到底是什么意思?让我们通过一个简单的案例来演示——一个使用fashion MNIST 数据集的深度学习图像分类问题。
深度学习分类任务的案例说明:
方法
详细的 Notebook 见我的 Github 仓库。鼓励你浏览它,并为自己的使用和扩展进行分叉。
代码对构建出色的软件至关重要,但未必适合 Medium 文章,因为你阅读这些文章是为了获得见解,而不是进行调试或重构练习。
因此,我将挑选一些代码片段,并尝试指出我在此 Notebook 中如何尝试编码之前详细介绍的一些原则。
核心机器学习任务与更高阶的业务问题
核心机器学习任务很简单——为 fashion MNIST 数据集构建一个深度学习分类器,这是对原始著名 MNIST 手写数字数据集的有趣变体。Fashion MNIST 包含 60,000 张 28 x 28 像素的训练图像——与时尚相关的物体,例如帽子、鞋子、裤子、T 恤、连衣裙等。它还包括 10,000 张用于模型验证和测试的测试图像。

Fashion MNIST (https://github.com/zalandoresearch/fashion-mnist)
但是如果围绕这个核心机器学习任务有一个更高阶的优化或视觉分析问题——模型架构复杂性如何影响达到期望准确度所需的最小训练轮次?
应该让读者明白,我们为什么要关注这样的问题。因为这与整体业务优化相关。训练神经网络不是一个简单的计算问题。因此,调查 为达到目标性能指标所需的最少训练努力,以及架构选择如何影响这一点 是有意义的。
在这个例子中,我们甚至不会使用卷积网络,因为一个简单的密集连接神经网络可以实现相当高的准确度,实际上,稍微不理想的性能是为了说明我们提出的高阶优化问题的主要点。
我们的解决方案
所以,我们必须解决两个问题 -
-
如何确定达到期望准确度目标所需的最小轮次?
-
模型的具体架构如何影响这个数字或训练行为?
为了实现目标,我们将使用两个简单的面向对象原则,
-
创建一个 从基类对象继承的类
-
创建实用函数并从紧凑的代码块中调用它们,这些代码块可以呈现给外部用户以进行高阶优化和分析。
展示良好实践的代码片段
这里我们展示了一些代码片段,以说明如何利用简单的面向对象原则来实现我们的解决方案。这些片段带有注释,便于理解。
首先,我们继承一个 Keras 类,并编写我们自己的子类,添加一个用于检查训练准确度的方法,并根据该值采取行动。

这个 简单回调 结果是 动态控制训练轮次——当准确率达到所需阈值时,训练会自动停止。

我们将 Keras 模型构建代码放在一个实用函数中,以便通过一些函数参数的简单用户输入,可以生成具有任意层数和架构(只要它们是密集连接的)的模型。

我们甚至可以将编译和训练代码放入一个实用函数中,以 方便地在高阶优化循环中使用这些超参数。

接下来是可视化的阶段。在这里,我们仍然遵循功能化的实践。通用的绘图函数将原始数据作为输入。然而,如果我们有特定的绘图目的,如绘制训练集准确率的演变并显示它如何与目标进行比较,那么我们的绘图函数应该仅接受深度学习模型作为输入并生成所需的图表。
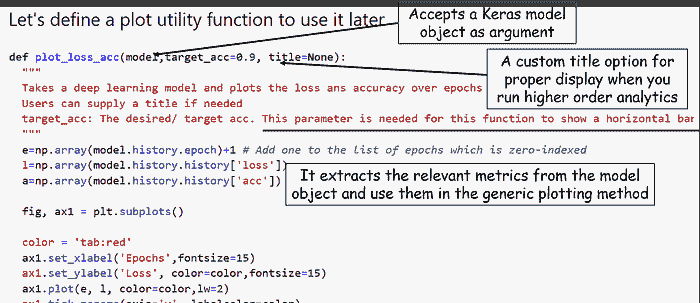
一个典型的结果如下所示,
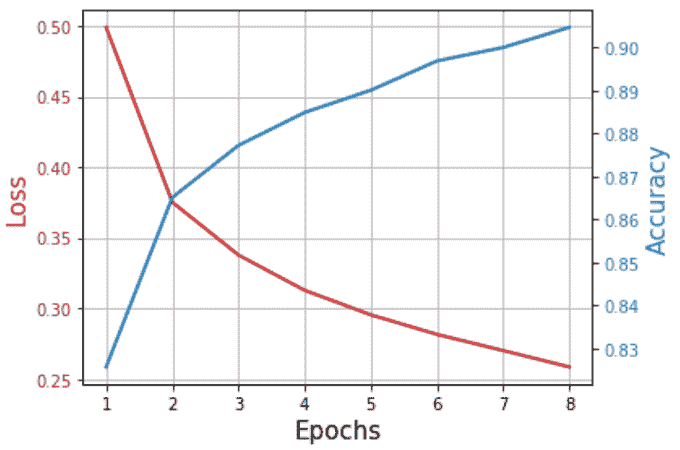
最终的分析代码——超级紧凑且简单
现在我们可以利用之前定义的所有函数和类,将它们整合在一起完成更高阶的任务。
因此,我们的最终代码将非常紧凑,但它将生成与上述相同的有趣的损失和准确率图表,针对各种准确率阈值和神经网络架构。
这将使用户能够使用极少量的代码来生成关于性能指标(在此情况下为准确率)和神经网络架构的可视化分析。这是构建优化机器学习系统的第一步。
我们生成了一些案例用于调查,

我们最终的分析/优化代码简洁且易于高层用户理解,不需要了解 Keras 模型构建或回调类的复杂性。
这就是面向对象编程的核心原则——抽象复杂性层次,我们能够为我们的深度学习任务实现这一点。
请注意,我们如何将print_msg=False传递给类实例。在初步检查/调试时我们需要基本的状态打印,但在优化任务中我们应该静默执行分析。如果我们在类定义中没有这个参数,那么我们将没有办法停止打印调试信息。
我们展示了一些代表性结果,这些结果是从执行上面的代码块自动生成的。它清楚地展示了通过极少量的高级代码,我们能够生成可视化分析,以判断各种神经网络架构在不同性能指标水平上的相对性能。这使得用户在不调整底层函数的情况下,能够轻松地根据自己的性能需求判断模型的选择。
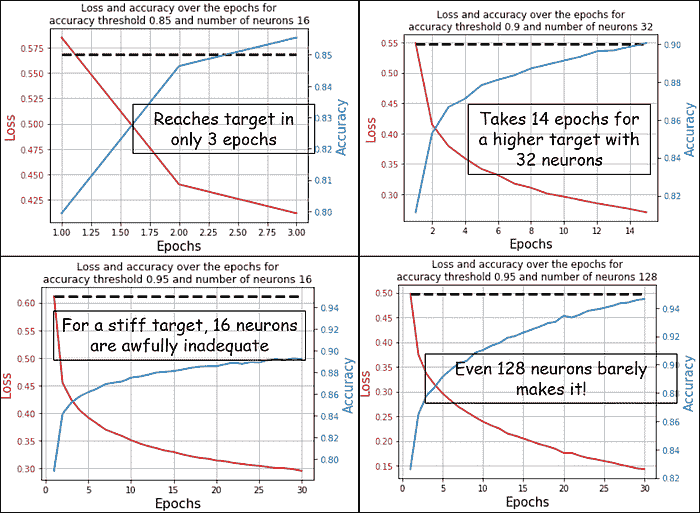
另请注意每个图表的自定义标题。这些标题清晰地阐明了目标性能和神经网络的复杂性,从而使分析变得简单。
这只是对绘图实用函数的小小补充,但这展示了在创建这些函数时需要细致规划。如果我们没有为该函数规划这样的参数,就无法为每个图生成自定义标题。这种对 API(应用程序接口)的细致规划是良好面向对象编程的一部分。
最后,将脚本转化为一个简单的 Python 模块。
到目前为止,你可能在使用 Jupyter 笔记本,但你可能希望将这个练习转化为一个整洁的 Python 模块,你可以随时导入。
就像你写“from matplotlib import pyplot”一样,你可以在任何地方导入这些实用函数(Keras 模型构建、训练和绘图)。
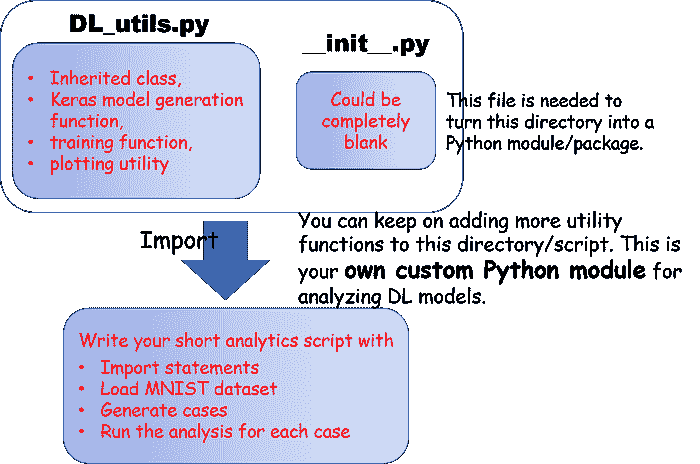
总结与结论
我们展示了一些简单的良好实践,借鉴了面向对象编程,以应用于深度学习分析任务。对于经验丰富的软件开发人员来说,这些做法可能显得微不足道,但这篇文章是为那些可能没有这种背景但应该理解将这些良好实践融入他们的机器学习工作流程的重要性的初学数据科学家们准备的。
冒着重复自己的风险,让我再次总结一下好的实践,
-
每当有机会时,将重复的代码块转化为实用函数。
-
仔细考虑函数的 API,即需要哪些最少的参数集以及它们如何服务于更高层次的编程任务。
-
不要忘记为函数编写文档字符串,即使它只是一个单行描述。
-
如果你开始积累许多与同一对象相关的实用函数,考虑将该对象转化为类,并将这些实用函数作为方法。
-
每当有机会时扩展类功能,通过继承来完成复杂的分析。
-
不要停留在 Jupyter 笔记本上。将它们转化为可执行脚本并放入小模块中。养成模块化工作的习惯,这样可以方便地被任何人、任何地方重用和扩展。
谁知道呢,当你积累了足够多的有用类和子模块时,你可能会在 Python 包存储库(PyPi 服务器)上发布一个实用包。那时你将有资格炫耀发布一个原创的开源包 😃
如果你有任何问题或想法,请通过tirthajyoti[AT]gmail.com联系作者。此外,你还可以查看作者的GitHub 代码库,获取 Python、R 或 MATLAB 中的有趣代码片段和机器学习资源。如果你像我一样,对机器学习/数据科学充满热情,请随时在 LinkedIn 上添加我或在 Twitter 上关注我。
个人简介:Tirthajyoti Sarkar 是 ON Semiconductor 的高级首席工程师,专注于基于深度学习/机器学习的设计自动化项目。
原文。经授权转载。
相关内容:
-
使用 Python 进行优化:如何用最少的风险赚取最多的财富?
-
如何在 Python 中检查回归模型的质量?
-
数学编程——提升数据科学水平的关键习惯
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 需求
更多相关主题
如何在 Python 中创建一个简单的神经网络
原文:
www.kdnuggets.com/2018/10/simple-neural-network-python.html
评论
由 迈克尔·J·加尔巴德博士 提供
神经网络(NN),也称为人工神经网络(ANN),是机器学习领域中一种学习算法的子集,松散地基于生物神经网络的概念。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT 管理
安德雷·布列祖克,一位在德国工作的机器学习专家,拥有超过五年的经验,他表示:“神经网络正在彻底改变机器学习,因为它们能够高效地建模广泛领域和行业中的复杂抽象。”
基本上,人工神经网络包括以下组件:
-
一个接收数据并传递数据的输入层
-
隐藏层
-
一个输出层
-
层间权重
-
为每个隐藏层使用特定的激活函数。在这个简单的神经网络 Python 教程中,我们将使用 Sigmoid 激活函数。
神经网络有多种类型。在这个项目中,我们将创建前馈神经网络或感知神经网络。这种类型的人工神经网络直接从前到后传递数据。
训练前馈神经元通常需要反向传播,这为网络提供了相应的输入和输出集。当输入数据传递到神经元时,它会被处理并生成输出。
下面是一个展示简单神经网络结构的图示:
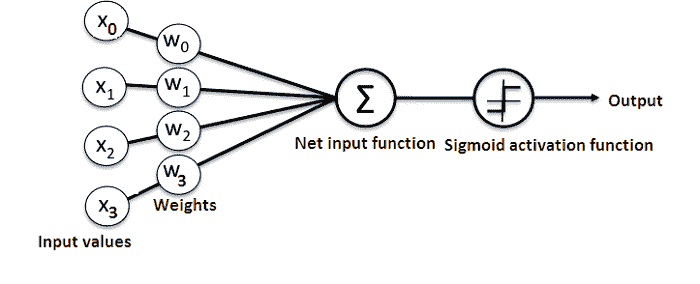
而且,理解神经网络如何工作的最佳方法是从头开始学习如何构建一个(不使用任何库)。
在本文中,我们将演示如何使用 Python 编程语言创建一个简单的神经网络。
问题
下面是一个展示问题的表格。
| 输入 | 输出 | ||
|---|---|---|---|
| 训练数据 1 | 0 | 0 | 1 |
| 训练数据 2 | 1 | 1 | 1 |
| 训练数据 3 | 1 | 0 | 1 |
| 训练数据 4 | 0 | 1 | 1 |
| 新情况 | 1 | 0 | 0 |
我们将训练神经网络,使其在提供新的数据集时能够预测正确的输出值。
如表中所示,输出的值总是等于输入部分的第一个值。因此,我们期望输出值 (?) 为 1。
让我们看看是否可以使用一些 Python 代码来获得相同的结果(在继续阅读之前,您可以在本文末尾查看这个项目的代码)。
创建 NeuralNetwork 类
我们将在 Python 中创建一个 NeuralNetwork 类,以训练神经元以给出准确的预测。该类还将具有其他辅助函数。
尽管在这个简单的神经网络示例中我们不会使用神经网络库,但我们将导入numpy库以协助计算。
该库提供了以下四个重要方法:
-
exp—用于生成自然指数
-
数组—用于生成矩阵
-
点积—用于矩阵乘法
-
随机—用于生成随机数。请注意,我们将对随机数进行种子设置,以确保其有效分布。
- 应用 Sigmoid 函数
我们将使用 Sigmoid 函数,它绘制了一个典型的“S”形曲线,作为神经网络的激活函数。
该函数可以将任何值映射到 0 到 1 的范围内。它将帮助我们标准化输入的加权和。
之后,我们将创建 Sigmoid 函数的导数,以帮助计算对权重的必要调整。
Sigmoid 函数的输出可以用来生成其导数。例如,如果输出变量为“x”,则其导数为 x * (1-x)。
- 训练模型
这是我们将教神经网络进行准确预测的阶段。每个输入都会有一个权重—正的或负的。
这意味着输入具有大正权重或大负权重会对结果输出产生更大影响。
记住,我们最初开始时将每个权重分配给一个随机数。
这是我们在这个神经网络示例问题中使用的训练过程步骤:
-
我们从训练数据集中获取输入,根据其权重进行了一些调整,并通过计算 ANN 输出的方法将其转移。
-
我们计算了反向传播的错误率。在这种情况下,它是神经元预测输出与训练数据集预期输出之间的差异。
-
根据获得的错误程度,我们使用 错误加权导数公式 进行了一些微调。
-
我们将这个过程迭代了任意次数,共 15,000 次。在每次迭代中,整个训练集会同时处理。
我们使用了“.T”函数将矩阵从水平位置转置到垂直位置。因此,数字将以这种方式存储:
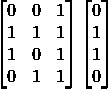
最终,神经元的权重将针对提供的训练数据进行优化。因此,如果神经元被要求处理一个新的情况,而这个情况与之前的情况相同,它可以做出准确的预测。这就是反向传播的过程。
总结
最后,我们初始化了 NeuralNetwork 类并运行了代码。
这是有关如何在 Python 项目中创建神经网络的完整代码:
import numpy as np
class NeuralNetwork():
def __init__(self):
# seeding for random number generation
np.random.seed(1)
#converting weights to a 3 by 1 matrix with values from -1 to 1 and mean of 0
self.synaptic_weights = 2 * np.random.random((3, 1)) - 1
def sigmoid(self, x):
#applying the sigmoid function
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(self, x):
#computing derivative to the Sigmoid function
return x * (1 - x)
def train(self, training_inputs, training_outputs, training_iterations):
#training the model to make accurate predictions while adjusting weights continually
for iteration in range(training_iterations):
#siphon the training data via the neuron
output = self.think(training_inputs)
#computing error rate for back-propagation
error = training_outputs - output
#performing weight adjustments
adjustments = np.dot(training_inputs.T, error * self.sigmoid_derivative(output))
self.synaptic_weights += adjustments
def think(self, inputs):
#passing the inputs via the neuron to get output
#converting values to floats
inputs = inputs.astype(float)
output = self.sigmoid(np.dot(inputs, self.synaptic_weights))
return output
if __name__ == "__main__":
#initializing the neuron class
neural_network = NeuralNetwork()
print("Beginning Randomly Generated Weights: ")
print(neural_network.synaptic_weights)
#training data consisting of 4 examples--3 input values and 1 output
training_inputs = np.array([[0,0,1],
[1,1,1],
[1,0,1],
[0,1,1]])
training_outputs = np.array([[0,1,1,0]]).T
#training taking place
neural_network.train(training_inputs, training_outputs, 15000)
print("Ending Weights After Training: ")
print(neural_network.synaptic_weights)
user_input_one = str(input("User Input One: "))
user_input_two = str(input("User Input Two: "))
user_input_three = str(input("User Input Three: "))
print("Considering New Situation: ", user_input_one, user_input_two, user_input_three)
print("New Output data: ")
print(neural_network.think(np.array([user_input_one, user_input_two, user_input_three])))
print("Wow, we did it!")
这是运行代码后的输出:
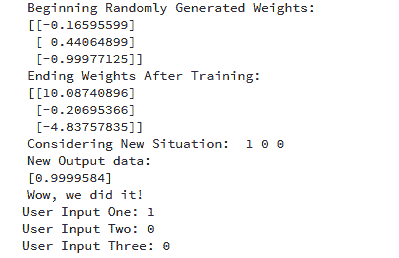
我们成功创建了一个简单的神经网络。
神经元首先分配了一些随机权重。之后,它使用训练样本进行自我训练。
因此,如果它被展示了一个新的情况 [1,0,0],它给出了 0.9999584 的值。
你记得我们想要的正确答案是 1 吗?
那么,这非常接近——考虑到 Sigmoid 函数的输出值在 0 和 1 之间。
当然,我们仅使用了一个神经元网络来完成这个简单的任务。如果我们将几千个这样的人工神经网络连接在一起呢?我们是否能够 100% 模拟人类大脑的工作方式?
你有任何问题或评论吗?
请在下面提供它们。
个人简介:Michael J. Garbade 博士 是位于洛杉矶的区块链教育公司 LiveEdu 的创始人兼首席执行官。这是世界领先的平台,致力于为人们提供在未来技术领域(包括机器学习)中创建完整产品的实用技能。
相关内容:
更多相关主题
使用 HuggingFace Transformers 的简单 NLP 管道
原文:
www.kdnuggets.com/2023/02/simple-nlp-pipelines-huggingface-transformers.html
图片来源:编辑
HuggingFace 的 transformers 是一个提供 API 和用户友好工具的广泛软件包,用于处理最先进的预训练模型,涵盖语言、视觉、音频和多模态领域。它包含超过 170 个预训练模型,并支持 PyTorch、TensorFlow 和 JAX 等框架,并能够在这些框架之间进行互操作。该库也友好于部署,因为它允许将模型转换为 ONNX 和 TorchScript 格式。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
在这篇博客中,我们将特别探讨 transformers 的 pipelines 功能,该功能可以轻松用于推理。管道提供了复杂代码的抽象,并提供简单的 API,用于执行多个任务,例如文本摘要、问答、命名实体识别、文本生成和文本分类等。最棒的是,这些 API 允许从预处理到模型评估的所有任务,只需几行代码,而无需大量计算资源。
现在,让我们直接深入吧!
第一步是使用以下命令安装 transformers 包 -
!pip install transformers
接下来,我们将使用 pipeline 结构来实现不同的任务。
from transformers import pipeline
该管道允许指定多个参数,如 task、model、device、batch size 以及其他特定任务的参数。
让我们从第一个任务开始。
1. 文本摘要
该任务的输入是一个文本语料库,模型将根据参数中提到的期望长度输出摘要。在这里,我们将最小长度设置为 5,最大长度设置为 30。
summarizer = pipeline(
"summarization", model="t5-base", tokenizer="t5-base", framework="tf"
)
input = "Parents need to know that Top Gun is a blockbuster 1980s action thriller starring Tom Cruise that's chock full of narrow escapes, chases, and battles. But there are also violent and upsetting scenes, particularly the death of a main character, which make it too intense for younger kids. There's also one graphic-for-its-time sex scene (though no explicit nudity) and quite a few shirtless men in locker rooms and, in one iconic sequence, on a beach volleyball court. Winning is the most important thing to all the pilots, who try to intimidate one another with plenty of posturing and banter -- though when push comes to shove, loyalty and friendship have important roles to play, too. While sexism is noticeable and almost all characters are men, two strong women help keep some of the objectification in check."
summarizer(input, min_length=5, max_length=30)
输出:
[
{
"summary_text": "1980s action thriller starring Tom Cruise is chock-full of escapes, chases, battles "
}
]
还可以从其他为摘要任务微调的模型中选择,如 bart-large-cnn、t5-small、t5-large、t5-3b、t5-11b。你可以在 这里 查看可用模型的完整列表。
2. 问答
在此任务中,我们提供一个问题和一个上下文。模型将根据最高概率分数从上下文中选择答案。它还提供了文本的起始和结束位置。
qa_pipeline = pipeline(model="deepset/roberta-base-squad2")
qa_pipeline(
question="Where do I work?",
context="I work as a Data Scientist at a lab in University of Montreal. I like to develop my own algorithms.",
)
输出:
{
"score": 0.6422629356384277,
"start": 39,
"end": 61,
"answer": "University of Montreal",
}
参考这里查看问答任务的可用模型的完整列表。
3. 命名实体识别
命名实体识别涉及根据人名、组织名、地点名等来识别和分类单词。输入基本上是一个句子,模型将确定命名实体及其类别以及在文本中的相应位置。
ner_classifier = pipeline(
model="dslim/bert-base-NER-uncased", aggregation_strategy="simple"
)
sentence = "I like to travel in Montreal."
entity = ner_classifier(sentence)
print(entity)
输出:
[
{
"entity_group": "LOC",
"score": 0.9976745,
"word": "montreal",
"start": 20,
"end": 28,
}
]
查阅这里了解其他可用模型的选项。
4. 词性标注
词性标注对于对文本进行分类以及提供相关的词性(例如一个词是否是名词、代词、动词等)非常有用。模型返回标注了词性的单词及其概率分数和相应的位置。
pos_tagger = pipeline(
model="vblagoje/bert-english-uncased-finetuned-pos",
aggregation_strategy="simple",
)
pos_tagger("I am an artist and I live in Dublin")
输出:
[
{
"entity_group": "PRON",
"score": 0.9994804,
"word": "i",
"start": 0,
"end": 1,
},
{
"entity_group": "VERB",
"score": 0.9970591,
"word": "live",
"start": 2,
"end": 6,
},
{
"entity_group": "ADP",
"score": 0.9993111,
"word": "in",
"start": 7,
"end": 9,
},
{
"entity_group": "PROPN",
"score": 0.99831414,
"word": "dublin",
"start": 10,
"end": 16,
},
]
5. 文本分类
我们将进行情感分析并根据语气对文本进行分类。
text_classifier = pipeline(
model="distilbert-base-uncased-finetuned-sst-2-english"
)
text_classifier("This movie is horrible!")
输出:
[{'label': 'NEGATIVE', 'score': 0.9997865557670593}]
让我们再尝试几个例子。
text_classifier("I loved the narration of the movie!")
输出:
[{'label': 'POSITIVE', 'score': 0.9998612403869629}]
文本分类模型的完整列表可以在这里找到。
6. 文本生成:
text_generator = pipeline(model="gpt2")
text_generator("If it is sunny today then ", do_sample=False)
输出:
[
{
"generated_text": "If it is sunny today then \xa0it will be cloudy tomorrow."
}
]
访问这里获取文本生成模型的完整列表。
7. 文本翻译:
在这里,我们将把文本的语言从一种语言翻译成另一种语言。例如,我们选择了从英语到法语的翻译。我们使用了基础的 t5-small 模型,但你可以在这里访问其他高级模型。
en_fr_translator = pipeline("translation_en_to_fr", model='t5-small')
en_fr_translator("Hi, How are you?")
输出:
[{'translation_text': 'Bonjour, Comment êtes-vous ?'}]
结论
你已经到达了最后,真棒!如果你跟随了整个过程,你学习了如何使用 Transformers 创建基础的 NLP 管道。参考 HuggingFace 的官方文档以查看 NLP 中的其他有趣应用,如零样本文本分类或表格问答。要处理你自己的数据集或实现其他领域(如视觉、音频或多模态)的模型,请查看这里。
Yesha Shastri 是一位热情的 AI 开发者和作家,正在蒙特利尔大学攻读机器学习硕士学位。Yesha 对探索负责任的 AI 技术以解决对社会有益的挑战充满兴趣,并与社区分享她的学习成果。
更多相关内容
比较、绘制和评估回归模型的简单 Python 包
原文:
www.kdnuggets.com/2020/11/simple-python-package-comparing-plotting-evaluating-regression-models.html
评论
由 Ajay Arunachalam,厄尔布鲁大学
我一直相信将人工智能和机器学习民主化,并以这种方式传播知识,以满足更广泛的受众,充分利用人工智能的力量。与此相关的尝试是开发了 Python 包“regressormetricgraphplot”,旨在帮助用户通过单行代码绘制评估指标图,方便地比较不同广泛使用的回归模型指标。通过这个实用程序包,它还显著降低了从业者以业余的方式评估不同机器学习算法的门槛,将其应用于他们日常的预测回归问题中。
在我们深入了解包的详细信息之前,让我们以简单的术语理解一些基本概念。
一般来说,建模管道包括预处理阶段、拟合机器学习算法,然后进行评估。下图示例展示了集成学习的建模步骤。块 A 包括数据处理,如清洗、整理、聚合、衍生新特征、特征选择等。块 B 和 C 描述了集成学习,其中预处理后的数据输入到 Layer-1 的各个模型中,这些模型经过评估和调整。Layer-2 的输入包括来自之前 Layer-1 的预测,然后使用投票集成方案得出最终预测。结果通过平均值结合起来。最后,块 D 展示了模型评估和结果解释。数据按(70:30 的比例)分为训练数据和测试数据。使用了三个独立的机器学习算法,即线性回归、随机森林和 XGBoost。所有模型都使用了调整过的参数,最后使用了投票回归模型。
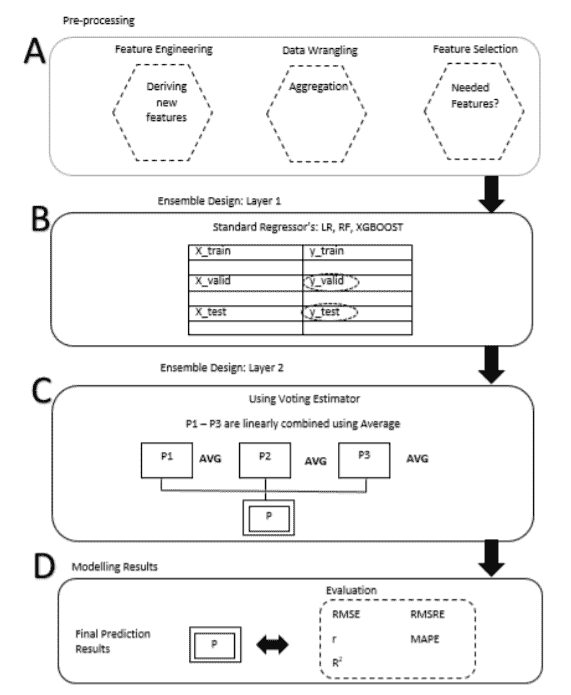
建模管道集成学习示例
使用了不同的回归指标进行评估。让我们讨论每个指标的公式及其对应的简单解释。

投票回归器是一个集成的元估计器,它在整个数据集上拟合基础回归器。然后,它将各个预测值取平均以形成最终预测,如下所示。
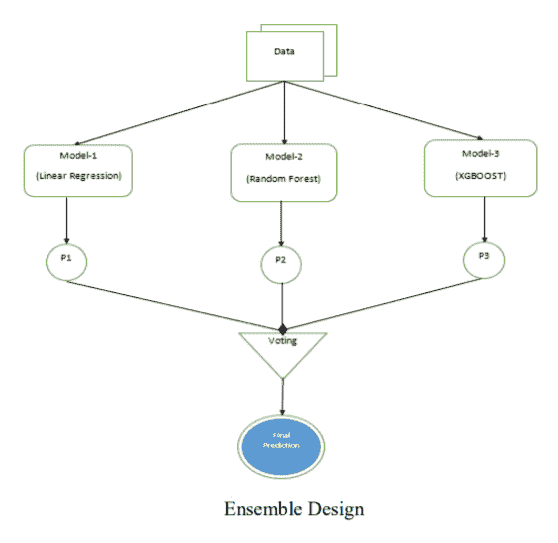
入门
终端安装
$ pip install regressormetricgraphplot
$ git clone https://github.com/ajayarunachalam/RegressorMetricGraphPlot
$ cd RegressorMetricGraphPlot
$ python setup.py install
笔记本
!git clone https://github.com/ajayarunachalam/RegressorMetricGraphPlot.git
cd RegressorMetricGraphPlot/
只需将行‘*from CompareModels import ’替换为‘from regressioncomparemetricplot import CompareModels’
按照演示示例中的其余部分进行操作 [这里] — (github.com/ajayarunachalam/RegressorMetricGraphPlot/blob/main/regressormetricgraphplot/demo.ipynb)
使用 Anaconda 安装
如果你使用 Anaconda 安装了 Python,可以运行以下命令开始使用:
# Clone the repository
git clone https://github.com/ajayarunachalam/RegressorMetricGraphPlot.git
cd RegressorMetricGraphPlot
# Create new conda environment with Python 3.6
conda create — new your-env-name python=3.6
# Activate the environment
conda activate your-env-name
# Install conda dependencies
conda install — yes — file conda_requirements.txt
# Instal pip dependencies
pip install requirements.txt
代码讲解

使用方法
plot = CompareModels()
plot.add(model_name=“Linear Regression”, y_test=y_test, y_pred=y_pred)
plot.show(figsize=(10, 5))
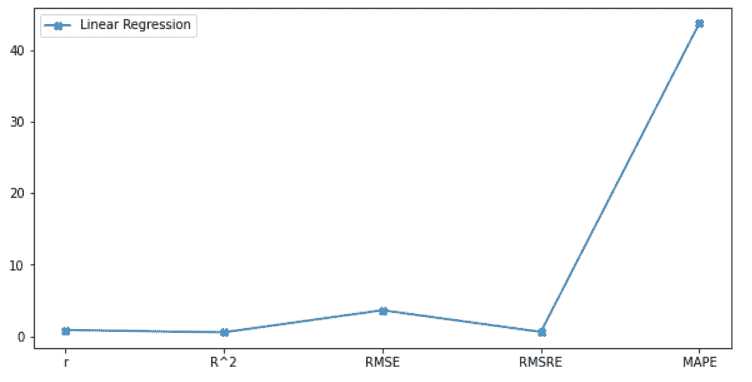
# Metrics
CompareModels.R2AndRMSE(y_test=y_test, y_pred=y_pred)
完整演示
综合演示可以在 Demo.ipynb 文件中找到。
联系方式
如果你想添加一些度量指标实现或示例,可以随意添加。你可以通过 ajay.arunachalam08@gmail.com 联系我。
继续学习与分享知识!!!
简介:Ajay Arunachalam (个人网站) 是瑞典厄勒布鲁大学应用自主传感器系统中心的人工智能博士后研究员。在此之前,他曾在 True Corporation 一家通讯集团担任数据科学家,处理 PB 级数据,构建和部署深度模型。他坚信,在我们完全接受 AI 的力量之前,AI 系统的透明度是当务之急。怀着这一理念,他一直致力于让 AI 普及化,并倾向于构建可解释的模型。他的兴趣在于应用人工智能、机器学习、深度学习、深度强化学习和自然语言处理,特别是学习好的表示。从他在实际问题上的经验来看,他完全承认找到好的表示是设计能够解决有趣且具有挑战性的实际问题的关键,这些问题超越了人类智能,并最终为我们解释复杂的数据。他设想的目标是学习能够从未标记和标记数据中学习特征表示的算法,可以在有无人工互动的情况下进行指导,并且在不同的抽象层次上,以便桥接低级数据和高级抽象概念之间的差距。
原文。经许可转载。
相关:
-
机器学习中的模型评估指标
-
PyCaret 2.1 上线:有什么新变化?
-
KNN 中最常用的距离度量及其使用场景
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域。
更多相关话题
使用 Python 进行文本相似性检测的简单问答(QA)系统
原文:
www.kdnuggets.com/2020/04/simple-question-answering-systems-text-similarity-python.html
评论
由 Andrew Zola,Artmotion 的内容经理
人工智能(AI)不再是一个唤起科幻电影画面的抽象概念。今天,AI 已经有了显著的进展,现在能够识别语音、做出决策,并与人类一起完成更大规模的任务。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
所以,与其担心试图征服地球的机器人,我们更应该关注像 Alexa、Siri 或客服聊天机器人这样的智能算法。这些智能算法究竟是如何像人类一样与我们互动和沟通的呢?
答案在于 问答(QA)系统 的基础上构建,这些系统基于机器学习(ML)和 自然语言处理(NLP)。
什么是 QA 系统?
QA 系统可以被描述为 一种提供正确简短回答的技术,而不是给出可能答案的列表。在这种情况下,QA 系统被设计为对文本相似性保持警觉,并回答以自然语言提出的问题。
但有些系统还通过图像来获取信息以回答问题。例如,当你点击图像框以证明你不是机器人时,实际上是在教导智能算法有关特定图像中的内容。
这只有得益于像谷歌的 双向编码器表示(BERT) 等 NLP 技术。任何想要构建 QA 系统的人都可以利用 NLP 和训练机器学习算法,以回答特定领域(或定义集合)或通用(开放式)问题。
网上有大量的数据集和资源,因此你可以迅速开始训练智能算法,以学习和处理海量的人类语言数据。
为了提高效率和准确性,NLP 程序还使用推理和概率来猜测正确答案。随着时间的推移,它们在这方面变得非常擅长!
对于企业来说,部署 QA 系统的好处在于它们非常用户友好。一旦企业 QA 系统构建完成,任何人都可以使用。实际上,如果你曾经与 Alexa 互动或使用过 Google Translate,你就体验过 NLP 的实际应用。
在企业环境中,它们可以用于远超聊天机器人和语音助手的功能。例如,可以训练智能算法执行以下任务:
-
管理(查找并将信息上下文化,以自动化搜索、修改和管理文档的过程)
-
客户服务(利用聊天机器人与客户互动,同时通过分析个人资料、短语和其他数据来识别潜在的新客户)
-
市场营销(通过关注在线对公司或品牌的提及)
但回到当前话题,让我们看看它是如何工作的。
如何构建一个可靠的 QA 系统?
为了以技术性和易于理解的方式回答问题,我将向你展示如何基于字符串相似度测量构建一个简单的 QA 系统,并使用封闭域进行数据源。
以下示例基于 Ojokoh 和 Ayokunle 的研究,基于模糊的答案排名在问答社区。
具有近似匹配功能的 QA 系统很简单,如下:
在这种情况下,我们将使用一个包含问题-答案对的小数据集,存储在一个CSV 文件中。在实际应用中,企业将使用高度专业化的数据库,其中包含数十万个样本。
先决条件
要运行这些示例,你需要 Python 3,Jupyter Lab 和 python-Levenshtein 模块。
首先加载数据:
py` import pandas as pd data = pd.read_csv('qa.csv') # 此函数用于获取可打印的结果 def getResults(questions, fn): def getResult(q): answer, score, prediction = fn(q) return [q, prediction, answer, score] return pd.DataFrame(list(map(getResult, questions)), columns=["Q", "Prediction", "A", "Score"]) test_data = [ "埃及的人口是多少?", "埃及的人口是多少", "美洲豹的尾巴有多长?", "你知道美洲豹尾巴的长度吗?", "北极熊什么时候可以隐身?", "我能看到北极动物吗?", "芬兰的某个城市" ] data ```py ````
| 问题 | 答案 |
|---|---|
| 谁确定了沸点的依赖性? | 安德斯·摄尔修斯 |
| 甲虫是昆虫吗? | 是的 |
| 加拿大的两种官方语言是英语和法语吗? | 是的 |
| 埃及的人口是多少? | 超过 7800 万 |
| 芬兰最大城市是什么? | 大赫尔辛基 |
| 列支敦士登的国家货币是什么? | 瑞士法郎 |
| 北极熊能在红外摄影下被看到吗? | 北极熊在红外线下几乎不可见 |
| 特斯拉什么时候演示了无线通信... | 1893 |
| 小提琴是用什么材料制成的? | 不同类型的木材 |
| 豹子的尾巴有多长? | 60 到 110 厘米 |
在最简单的形式下,QA 系统只能在问题和答案完全匹配时回答问题。
py` 导入 re 定义 getNaiveAnswer(q): # 正则表达式帮助处理一些标点符号 row = data.loc[data['Question'].str.contains(re.sub(r"[^\w'\s)]+", "", q),case=False)] 如果 len(row) > 0: 返回 row["Answer"].values[0], 1, row["Question"].values[0] 返回 "对不起,我没听懂你说的。", 0, "" getResults(test_data, getNaiveAnswer) ```py ````
| Q | 预测 | A | 分数 | |
|---|---|---|---|---|
| 1 | 埃及的人口是多少? | 埃及的人口是多少? | 超过 7800 万 | 1 |
| 2 | 埃及的人口是多少 | 对不起,我没听懂你说的。 | 0 | |
| 3 | 豹子的尾巴有多长? | 豹子的尾巴有多长? | 60 到 110 厘米 | 1 |
| 4 | 你知道豹子的尾巴有多长吗? | 对不起,我没听懂你说的。 | 0 | |
| 5 | 北极熊什么时候可以隐形? | 对不起,我没听懂你说的。 | 0 | |
| 6 | 我可以看到北极动物吗? | 对不起,我没听懂你说的。 | 0 | |
| 7 | 芬兰的某个城市 | 对不起,我没听懂你说的。 | 0 |
如上所示,一个小小的语法错误可以迅速破坏整个过程。如果使用源文本和查询文本的字符串预处理,例如去除标点符号、转换为小写等,也会得到相同的结果。
那我们如何改善我们的结果呢?
为了改善结果,让我们稍微改变一下,使用近似字符串匹配。在这种情况下,我们的系统将能够接受语法错误和文本中的细微差别。
部署近似字符串匹配协议有很多方法,但在我们的示例中,我们将使用一种被称为莱文斯坦距离的字符串度量实现。在这种情况下,两个词之间的距离是将一个词改变为另一个词所需的最少单字符编辑(插入、删除或替换)次数。
让我们在系统上部署莱文斯坦 Python 模块。它包含一组我们可以进行实验的近似字符串匹配函数。
py` 从 Levenshtein 导入 ratio def getApproximateAnswer(q): max_score = 0 answer = "" prediction = "" for idx, row in data.iterrows(): score = ratio(row["Question"], q) if score >= 0.9: # 我确定,停在这里 return row["Answer"], score, row["Question"] elif score > max_score: # 我不确定,继续 max_score = score answer = row["Answer"] prediction = row["Question"] if max_score > 0.8: return answer, max_score, prediction return "对不起,我没听懂。", max_score, prediction getResults(test_data, getApproximateAnswer) ```py ````
| Q | 预测 | A | 得分 | |
|---|---|---|---|---|
| 1 | 埃及的人口是多少? | 埃及的人口是多少? | 超过 7800 万 | 1.000000 |
| 2 | 埃及的人口是多少 | 埃及的人口是多少? | 超过 7800 万 | 0.935484 |
| 3 | 豹子的尾巴有多长? | 豹子的尾巴有多长? | 60 到 110 厘米 | 1.000000 |
| 4 | 你知道豹子的尾巴长吗? | 豹子的尾巴有多长? | 对不起,我没听懂。 | 0.657143 |
| 5 | 北极熊什么时候会变得隐形? | 北极熊在红外线摄影下能否被看到... | 对不起,我没听懂。 | 0.517647 |
| 6 | 我能看到北极动物吗? | 芬兰的哪个城市最大? | 对不起,我没听懂。 | 0.426230 |
| 7 | 芬兰的哪个城市最大? | 对不起,我没听懂。 | 0.642857 |
从上述内容可以看出,即使是小的语法错误也能生成正确的答案(得分低于 1.0 也是完全可以接受的)。
为了使我们的 QA 系统更好,继续调整我们函数的 max_score 系数以便更具包容性。
py` 从 Levenshtein 导入 ratio def getApproximateAnswer2(q): max_score = 0 answer = "" prediction = "" for idx, row in data.iterrows(): score = ratio(row["Question"], q) if score >= 0.9: # 我确定,停在这里 return row["Answer"], score, row["Question"] elif score > max_score: # 我不确定,继续 max_score = score answer = row["Answer"] prediction = row["Question"] if max_score > 0.3: # 阈值降低 return answer, max_score, prediction return "对不起,我没听懂。", max_score, prediction getResults(test_data, getApproximateAnswer2) ```py ````
| Q | 预测 | A | 得分 | |
|---|---|---|---|---|
| 0 | 埃及的人口是多少? | 埃及的人口是多少? | 超过 7800 万 | 1.000000 |
| 1 | 埃及的人口是多少 | 埃及的人口是多少? | 超过 7800 万 | 0.935484 |
| 2 | 豹子的尾巴有多长? | 豹子的尾巴有多长? | 60 到 110 厘米 | 1.000000 |
| 3 | 你知道豹子的尾巴长吗? | 豹子的尾巴有多长? | 60 到 110 厘米 | 0.657143 |
| 4 | 北极熊何时可以隐形? | 北极熊在红外摄影下是否能被看到... | 北极熊在红外线下几乎看不见... | 0.517647 |
| 5 | 我能看到北极动物吗? | 芬兰最大的城市是什么? | 大赫尔辛基 | 0.426230 |
| 6 | 芬兰的某个城市 | 芬兰最大的城市是什么? | 大赫尔辛基 | 0.642857 |
上述结果表明,即使使用不同的词汇,系统也能给出正确的答案。但如果你仔细查看,第五个结果看起来像是一个假阳性。
这意味着我们必须提升到一个新水平,并利用像 Facebook 和 Google 这样的公司提供的先进库来克服这些挑战。
上面的例子是如何工作的一个简单演示。代码相当简单,不适合处理大规模数据集上的大量数据和迭代。
由 Google 开发的知名 BERT 库更适合企业任务。你已经接触过的 AI 驱动的 QA 系统使用了更先进的数据库,并进行持续的机器学习。
你在构建企业 QA 系统方面有什么经验?你遇到了哪些挑战?你是如何克服它们的?在下面的评论部分分享你的想法和经验。
这篇文章的源代码可以在这里找到。
个人简介: Andrew Zola (@DrewZola) 是 Artmotion 的内容经理:一个为你的数据提供银行服务的公司。他有很多兴趣爱好,但主要是写关于技术的文章。此外,学习新事物和与不同观众建立联系一直让 Andrew 感到惊讶和兴奋。
相关:
-
这款微软神经网络能以最少的训练回答有关风景图片的问题
-
Salesforce 开源一个使用 Wikipedia 进行开放域问答的框架
-
为什么你不应该使用 MS MARCO 来评估语义搜索
更多相关话题
使用 HuggingFace Pipelines 和 Streamlit 回答问题
原文:
www.kdnuggets.com/2021/10/simple-question-answering-web-app-hugging-face-pipelines.html
图片由 Arek Socha 提供,来源于 Pixabay
当你将几个突出的数据科学库、一些好主意和 Python 结合在一起时,有很多项目可能性。本文将展示这有多么简单,以及实现有趣内容所需的代码行数。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
HuggingFace 的 Transformers 库充满了可以开箱即用的 SOTA NLP 模型,也可以针对特定用途和高性能进行微调。该库的管道可以总结为:
这些管道是使用模型进行推理的绝佳简便方式。这些管道是抽象了库中大部分复杂代码的对象,提供了一个简单的 API,专注于多个任务,包括命名实体识别、掩码语言建模、情感分析、特征提取和问答。
我们在这里不会进一步解释 Transformer 管道,但你可以阅读 这篇文章,了解如何创建一个简单的情感分析 API 应用,利用 HuggingFace 的库来实现。
如果你还不了解 Streamlit,这是一个 30,000 英尺的概述:
Streamlit 可以将数据脚本转化为可共享的网页应用,仅需几分钟。全部使用 Python,完全免费,无需前端经验。
你可以在 这里 阅读更深入的介绍,了解如何使用 Streamlit 实现一个项目。
Streamlit 和 Transformer 库的管道可以帮助简化数据科学项目的实施。将两者结合,这种实施的便捷性更为显著。
让我们来看一下创建一个功能性 web 应用程序所需的完整代码。下面这个简洁的脚本完成了创建问答应用程序所需的一切。
import streamlit as st
from transformers import pipeline
def load_file():
"""Load text from file"""
uploaded_file = st.file_uploader("Upload Files",type=['txt'])
if uploaded_file is not None:
if uploaded_file.type == "text/plain":
raw_text = str(uploaded_file.read(),"utf-8")
return raw_text
if __name__ == "__main__":
# App title and description
st.title("Answering questions from text")
st.write("Upload text, pose questions, get answers")
# Load file
raw_text = load_file()
if raw_text != None and raw_text != '':
# Display text
with st.expander("See text"):
st.write(raw_text)
# Perform question answering
question_answerer = pipeline('question-answering')
answer = ''
question = st.text_input('Ask a question')
if question != '' and raw_text != '':
answer = question_answerer({
'question': question,
'context': raw_text
})
st.write(answer)
现在让我们让 web 应用程序启动并运行。假设你已经将上述脚本保存为 nlp_question_answering.py,下面的代码将完成这项工作:
streamlit run nlp_question_answering.py
这应该会打开你的浏览器和网络应用程序。为了演示,我将点击“浏览文件”按钮并选择一篇最近的热门 KDnuggets 文章,“避免这些让你看起来像数据新手的五种行为”,这篇文章我已经复制并清除了所有非必要的文本。一旦完成,Transformer 问答管道将会建立,因此应用程序将运行几秒钟。
如果你对这个话题感兴趣,可以阅读整篇文章(非常好);否则,以下是相关摘录:
除非是一个代表你客户群的焦点小组(我甚至对焦点小组的调查结果有疑虑,但那是另一个话题),30 个数据点通常不会给你任何可靠的见解。
现在让我们使用“提问”字段提一个问题,并检查响应:
What usually won’t give you any robust insights?
{
"score":0.9823936820030212
"start":1891
"end":1905
"answer":"30 data points"
}
我们对第一个问题有一个相当有信心的答案。太好了!
现在来看一下这个摘录:
尝试这个:在构建任何数据产品之前与利益相关者沟通。理解当前阶段的业务需求:如果是初创公司,我敢打赌你的利益相关者不会太在意你构建的数据可视化的格式和颜色,而是更关注数据的准确性及其背后的见解。同样,真正理解受众和使用场景;例如,如果数据产品是为了让非技术受众定期使用,你应该花更多时间在一个精致且简单的用户界面上。
让我们提出几个与第二个摘录相关的问题,并查看回应。
Who should you talk to before you start building any data products?
{
"score":0.7892400026321411
"start":6930
"end":6947
"answer":"your stakeholders"
}
利益相关者会想要关注什么?
{
"score":0.3485959768295288
"start":7195
"end":7264
"answer":"accuracy of the data behind the visualizations and insights from them"
}
你应该真正理解什么?
{
"score":0.599153995513916
"start":7294
"end":7319
"answer":"the audience and use case"
}
你可以看到我们提出的问题的不同答案的置信度评分。自己尝试一下这个应用程序,看看当你问它没有答案的问题时会发生什么。
我希望这能对你演示如何将 Python 库与一些好主意结合起来的过程有所帮助。通过添加一些复杂的层次,这样的项目可以成为分享给其他数据科学家或潜在雇主的项目组合中的有用补充。
Matthew Mayo (@mattmayo13) 是一名数据科学家,同时也是 KDnuggets 的总编辑,该网站是开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系到。
更多相关主题
2022 年技术专家薪资指南
原文:
www.kdnuggets.com/2022/07/simple-salary-guide-tech-experts-2022.html

Towfiqu barbhuiya 通过 Unsplash
这是一个简单的指南,列出了不同技术职业的薪资。所有信息均来自Indeed 的薪资信息。这些数据基于人们对其工作的评价,并提供给 Indeed 薪资信息;因此,您需要对此持保留态度。根据您的位置、经验和公司,这些数据可能会有所不同。下面的图片提供了更多解释。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT 维护
薪资薪酬等级:
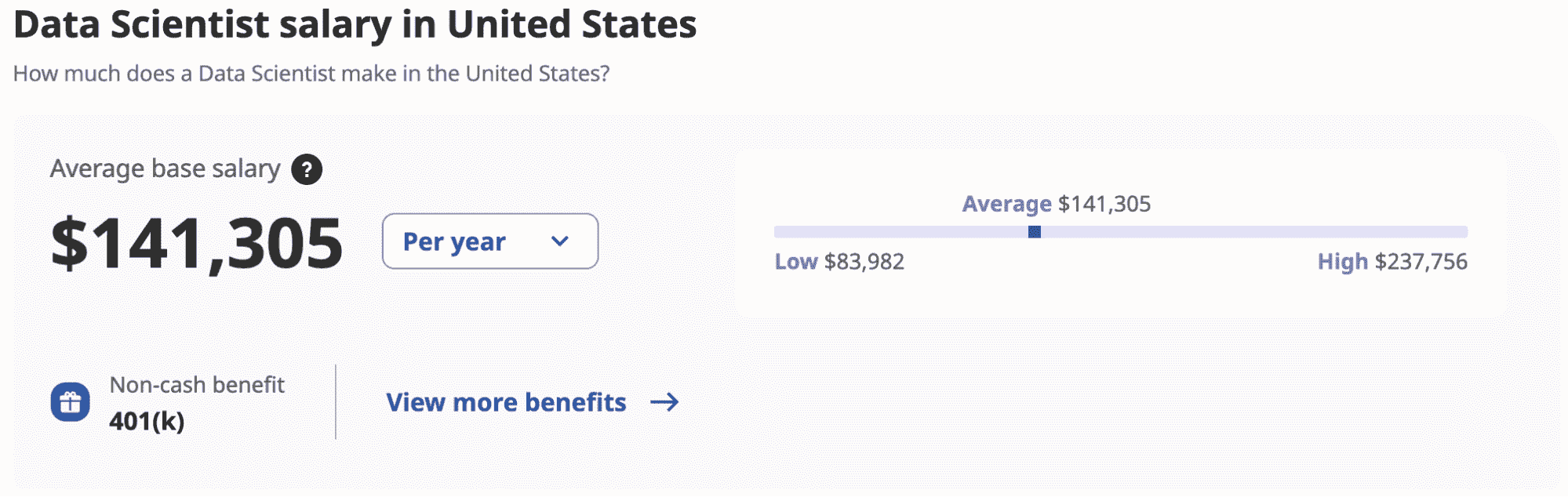
来源:Indeed
按地点划分的薪资:
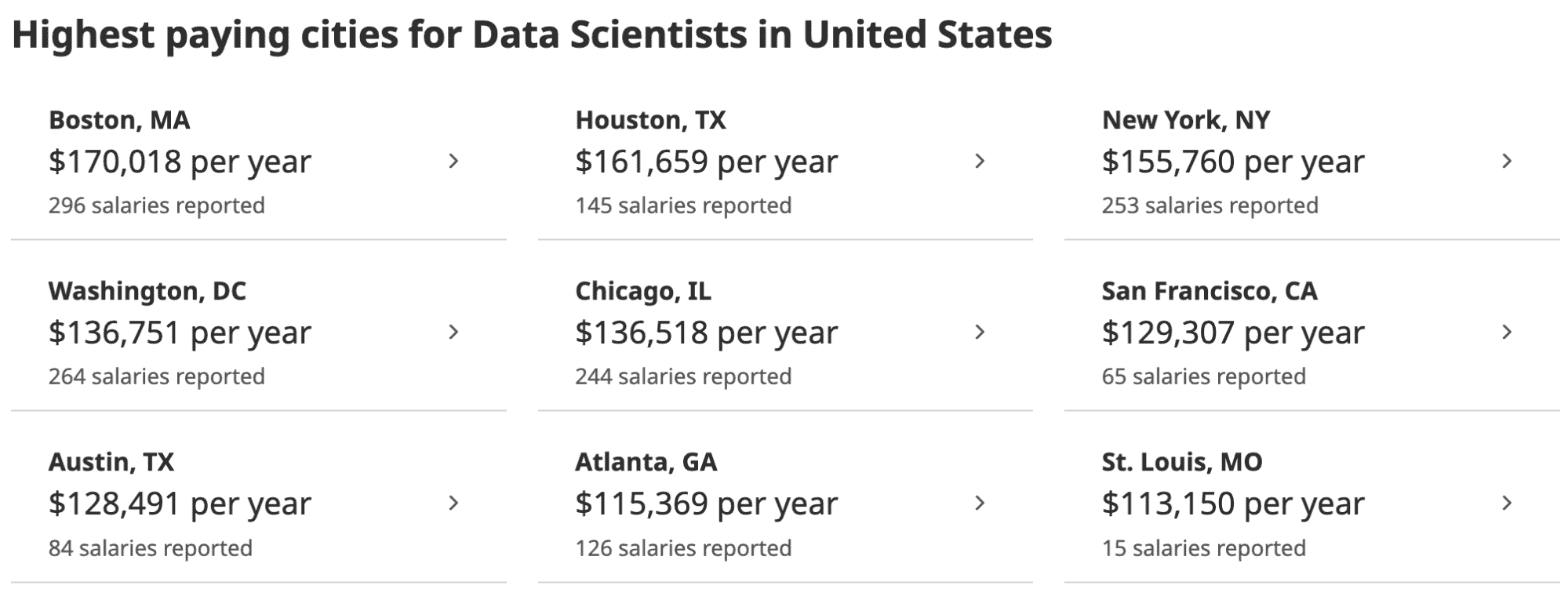
来源:Indeed
数据科学家
数据科学家是数据团队中处理数据、发现模式和分析数据的人;无论数据是结构化还是非结构化。他们通过分析将这些结果进一步解释,以帮助自己和高层决策过程。他们通常来自计算机科学、统计学或数学背景。
| 职位 | 低 | 平均 | 高 |
|---|---|---|---|
| 数据科学家 | $83,460 | $140,772 | $237,440 |
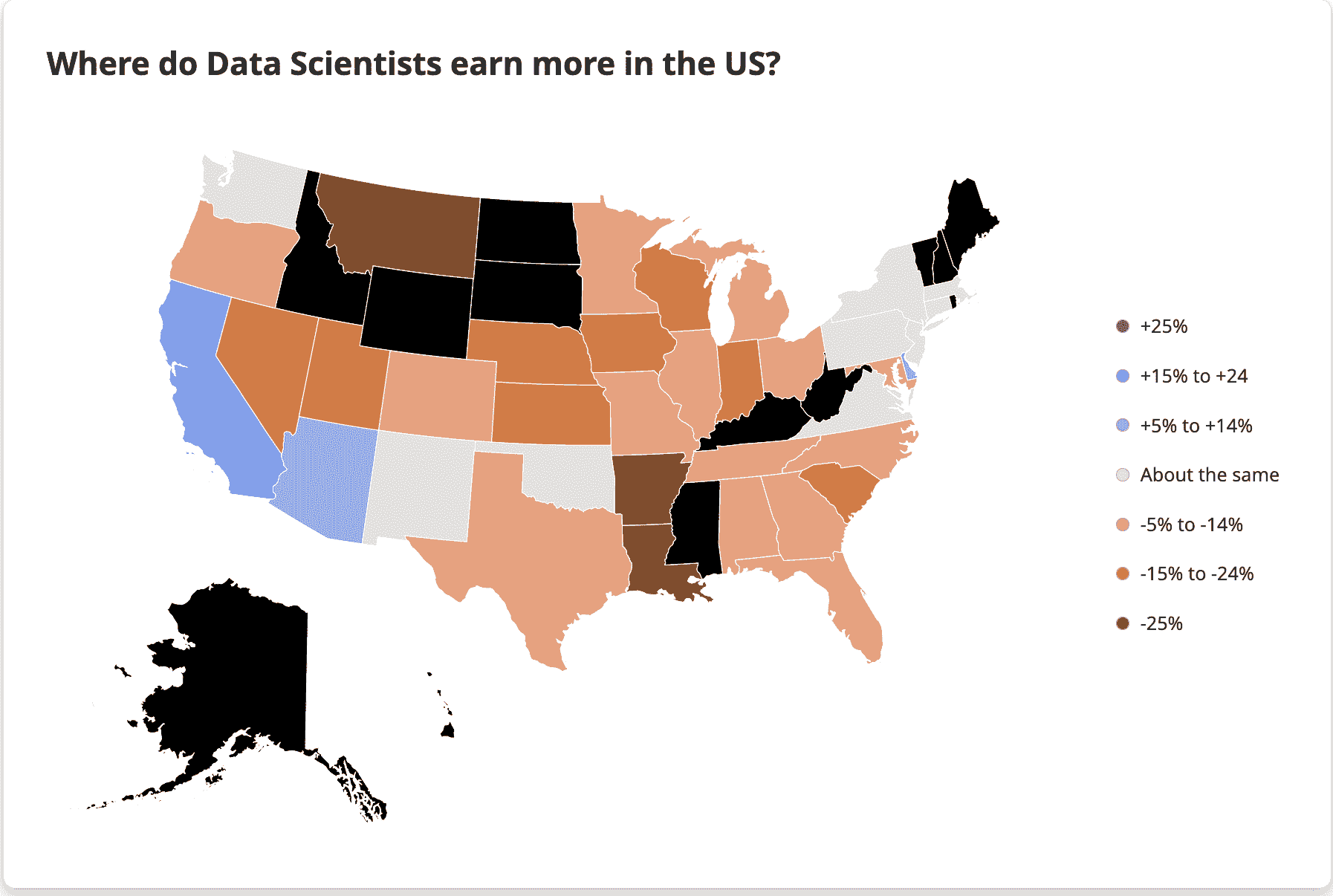
来源:Indeed
数据工程师
数据工程师的技能与数据科学家相似。然而,他们的主要职责是构建系统,这些系统能够整理、管理和转换原始的结构化和非结构化数据,以便数据科学家和其他需要进行解释的分析师使用。
| 职位 | 低 | 平均 | 高 |
|---|---|---|---|
| 数据工程师 | $77,872 | $125,974 | $203,789 |
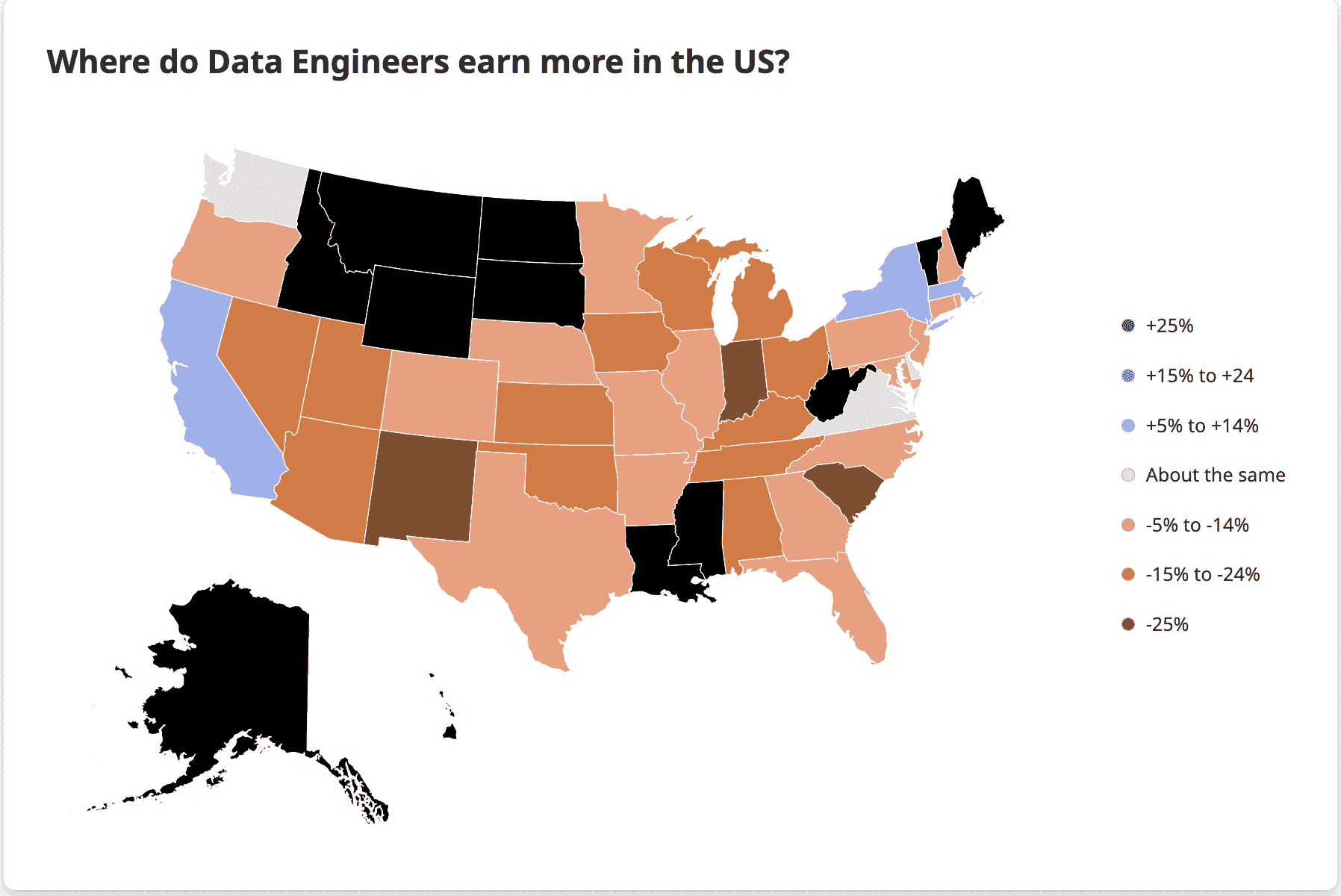
来源:Indeed
Python 开发者
在涉及 Python 时,Python 开发者可以被视为多面手。他们可以是网页开发者、数据分析师或软件工程师。
| 职位 | 低 | 平均 | 高 |
|---|---|---|---|
| Python 开发者 | $71,632 | $114,684 | $183,612 |
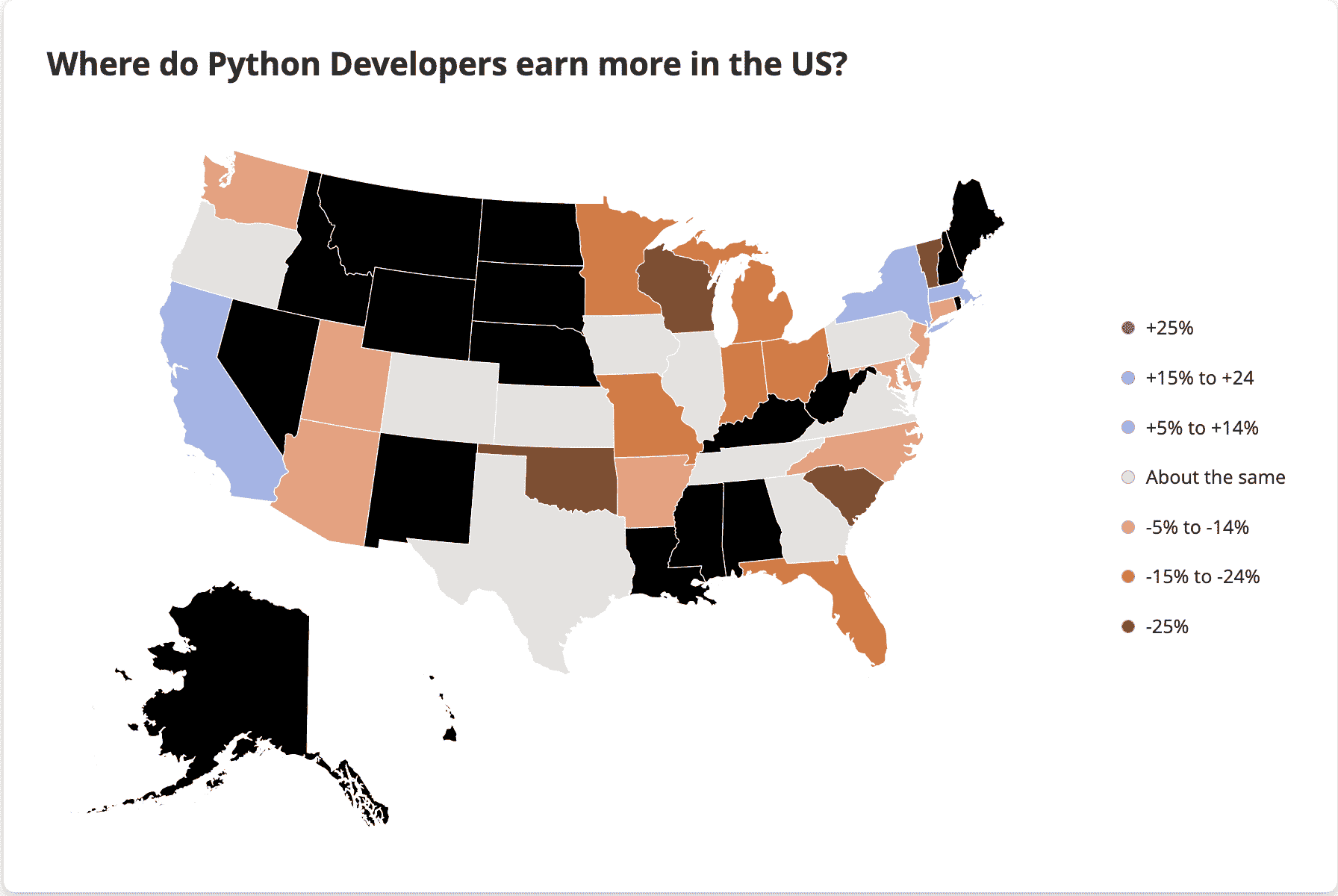
来源:Indeed
数据架构师
数据架构师专注于组织的数据基础设施。他们运用计算机科学和设计技能来分析、解释和审查数据基础设施,以实施合适的解决方案,如数据库。这有助于组织更好地存储和管理数据。
| 职位 | 低 | 平均 | 高 |
|---|---|---|---|
| 数据架构师 | $50,023 | $85,344 | $145,605 |
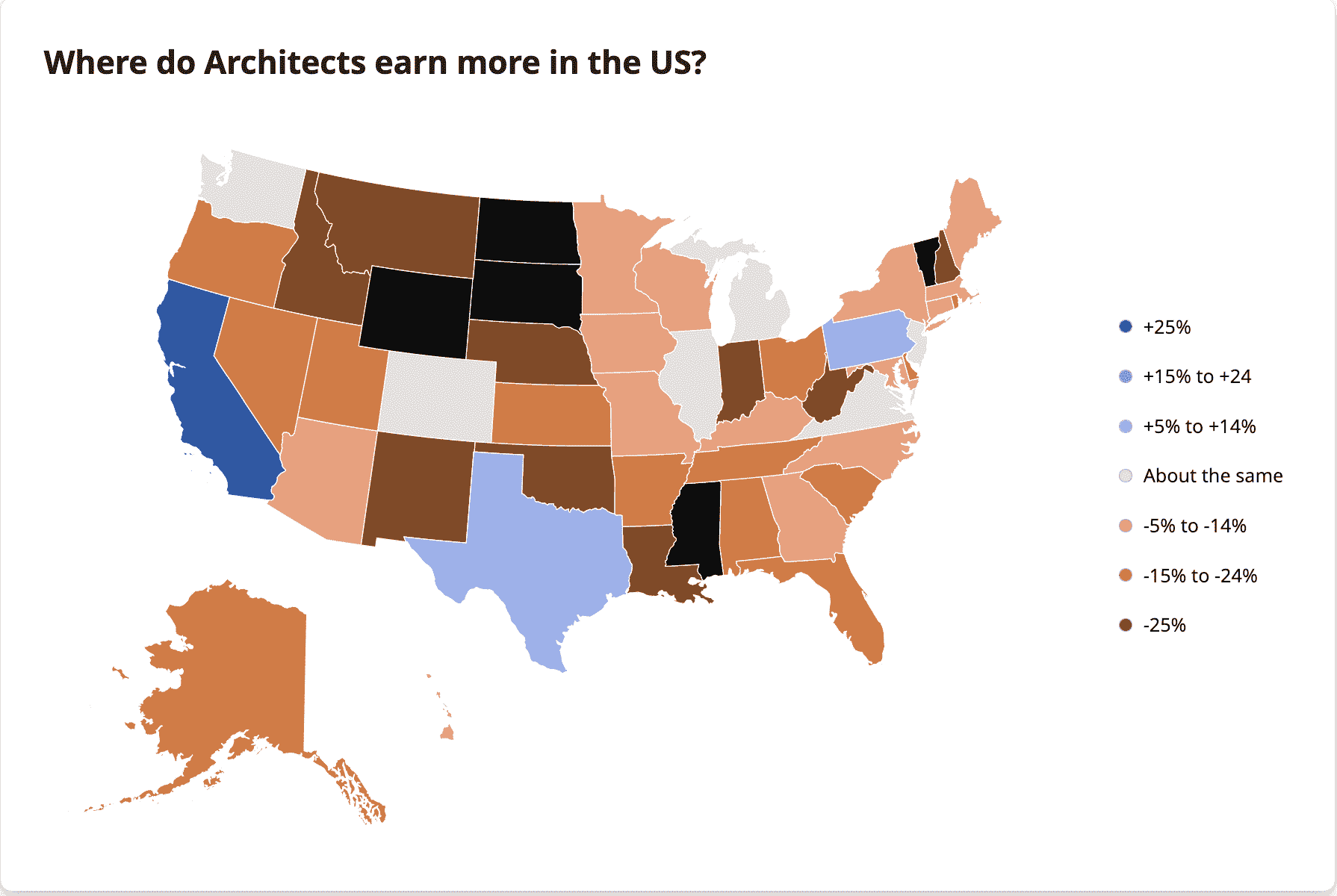
来源:Indeed
数据分析师
数据分析师收集和解释数据,以识别关键见解以及这些见解如何解决问题。他们使用这些信息,并与高层管理人员及其他利益相关者沟通,以改善决策过程。
| 职位 | 低 | 平均 | 高 |
|---|---|---|---|
| 数据分析师 | $44,884 | $69,068 | $106,282 |
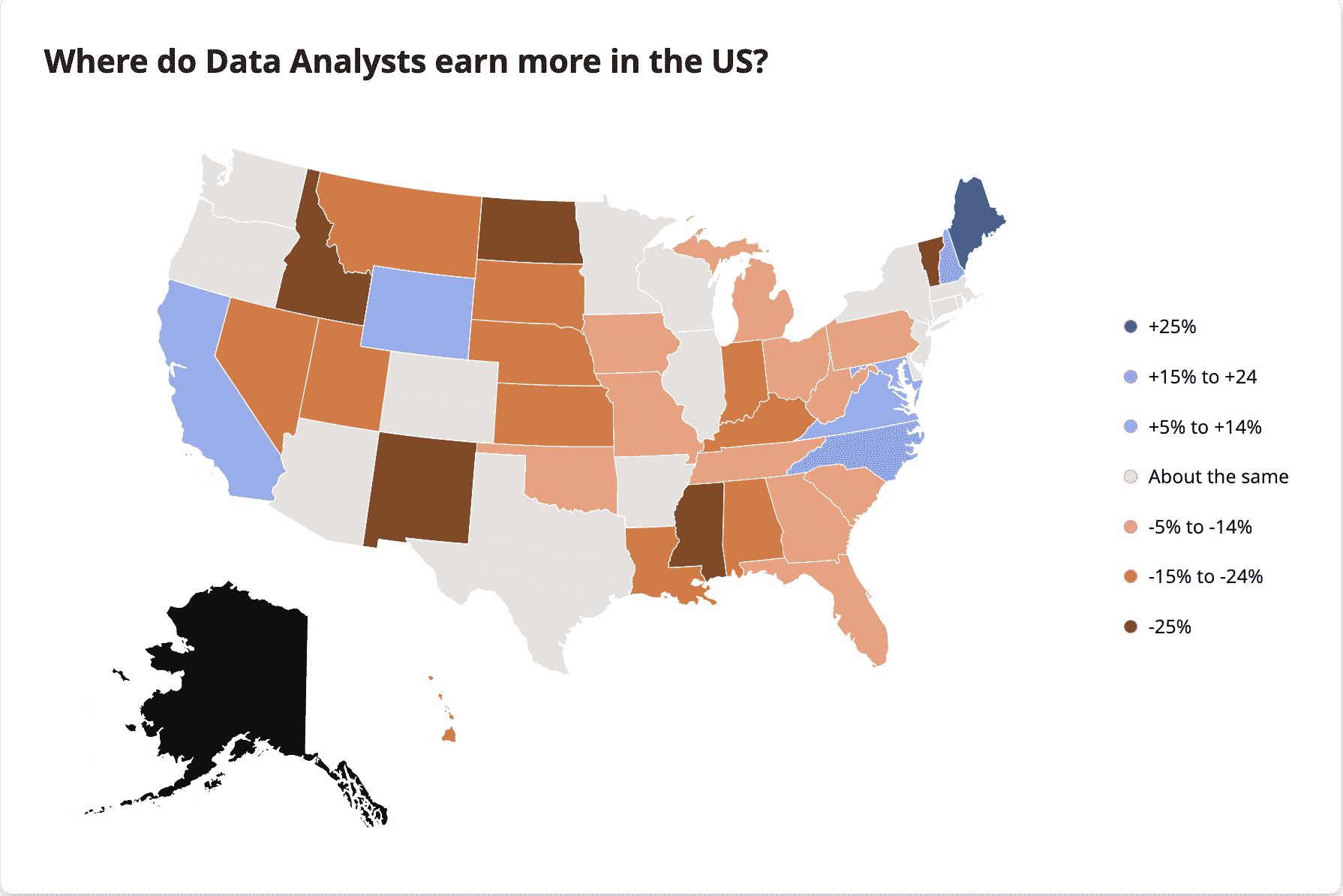
来源:Indeed
业务分析师
业务分析师类似于数据分析师,他们帮助识别业务中可以改进的不同领域。他们通过收集和记录数据,然后分析数据并进行进一步评估,来提出解决方案,帮助向高层管理人员和利益相关者展示这些解决方案。
| 职位 | 低 | 平均 | 高 |
|---|---|---|---|
| 业务分析师 | $52,738 | $79,347 | $119,383 |
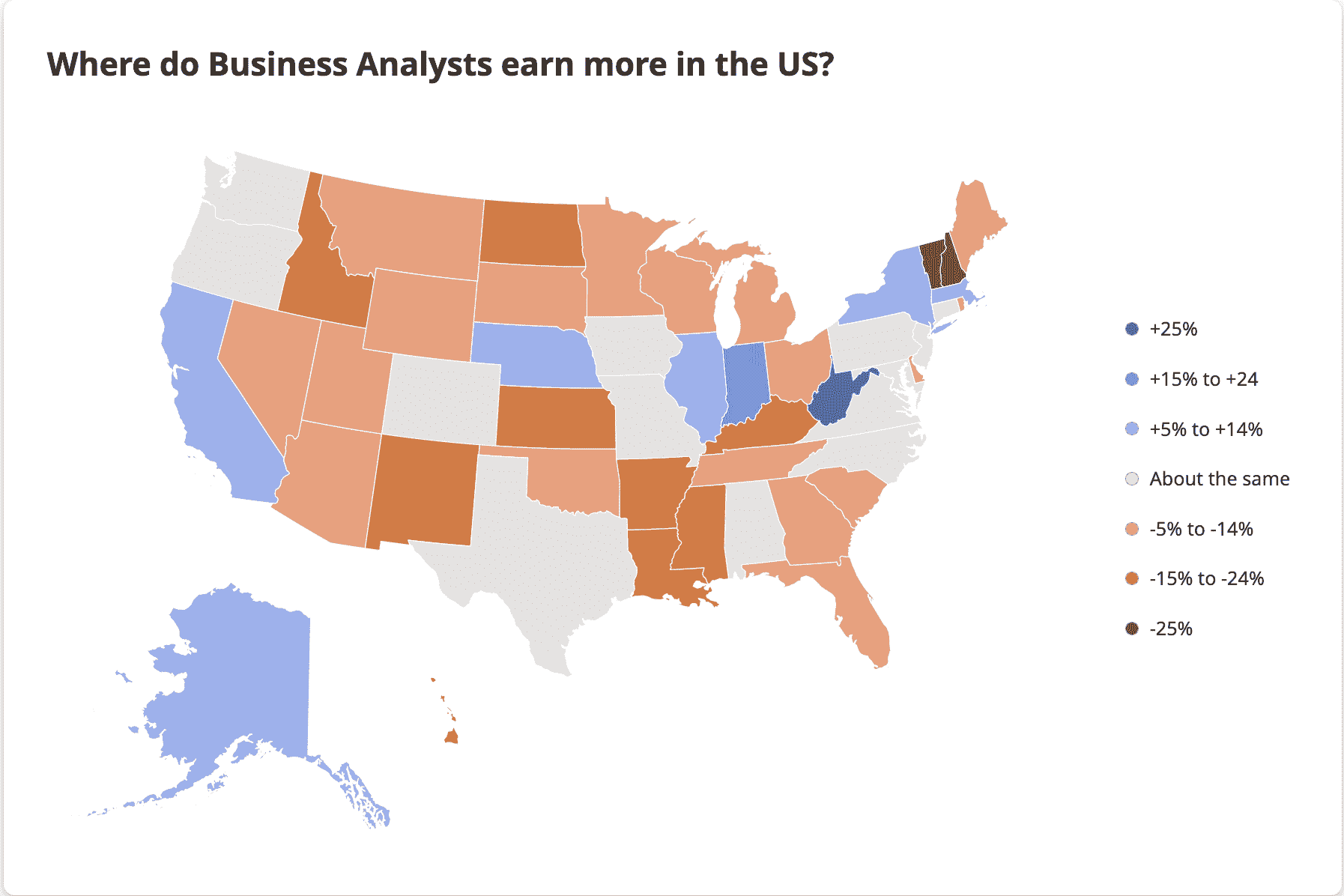
来源:Indeed
数据库管理员
数据库难以管理,因此数据库管理员需要确保数据库高效运行。他们与数据架构师密切合作,构建和组织不同的数据系统,以确保它们安全且高效运行。
| 职位 | 低 | 平均 | 高 |
|---|---|---|---|
| 数据库管理员 | $60,420 | $90,041 | $134,183 |
来源:Indeed
网络安全专家
网络安全专家运用他们的技术技能来创建和实施正确的安全解决方案,覆盖计算机硬件和软件系统。他们确保组织的系统、数据及更多方面在内部和外部都免受任何威胁的侵害。
| 职位 | 低 | 平均 | 高 |
|---|---|---|---|
| 网络安全专家 | $77,260 | $108,671 | $152,853 |
来源:Indeed
机器学习工程师
机器学习工程师通常具有硕士学位和/或计算机科学或相关学科的博士学位。他们的主要工作是研究、构建、测试和设计人工智能系统,这些系统在预测模型中产生准确结果。随着深度学习的兴起,他们变得越来越受欢迎。
| 职位 | 低 | 平均 | 高 |
|---|---|---|---|
| 机器学习工程师 | $66,040 | $124,850 | $236,030 |

来源:Indeed
统计学家
统计学家的角色是通过应用数学知识来解决问题。他们应用这些统计方法和模型,通过收集、分析和解释数据来帮助解决实际问题,这些数据可以用于帮助决策过程。
| 职位 | 低 | 平均 | 高 |
|---|---|---|---|
| 统计学家 | $62,503 | $97,353 | $151,633 |

来源:Indeed
DevOps 工程师
DevOps 工程师负责引入新的流程、工具和方法,以改进当前的软件开发生命周期。这包括部署、代码、测试系统、总体维护和执行正确的更新。
| 职位 | 低 | 平均 | 高 |
|---|---|---|---|
| DevOps 工程师 | $79,687 | $117,652 | $173,704 |

来源:Indeed
云计算工程师
云计算工程师负责与云计算相关的任何任务。这包括设计、管理、支持、未来规划和维护。他们也可以被称为云架构师或云软件工程师。随着越来越多的组织将其功能转移到云端,他们的需求日益增加。
| 职位 | 低 | 平均 | 高 |
|---|---|---|---|
| 云计算工程师 | $77,235 | $120,712 | $188,663 |
来源:Indeed
Java 开发人员
Java 开发人员负责设计基于 Java 的应用程序,并进一步管理其开发和维护。他们参与产品的开发生命周期,并与团队中的其他成员如网页开发人员和软件工程师密切合作,以帮助将基于 Java 的知识、专业技能和产品整合到业务的应用程序、软件等中。
| 职位 | 低 | 平均 | 高 |
|---|---|---|---|
| Java 开发人员 | $72,505 | $111,840 | $172,514 |
来源:Indeed
技术作家
技术作家并不特定于技术领域,但他们在其中非常重要。他们创建文档、操作指南、白皮书、博客和可视化,向用户展示特定产品如何工作。随着更多公司使用技术以及科技初创企业的兴起,他们成为组织成长中非常宝贵的资产。
这是按小时计算的。
| 职位 | 低 | 平均 | 高 |
|---|---|---|---|
| 技术作家 | $22.03 | $35.21 | $56.27 |
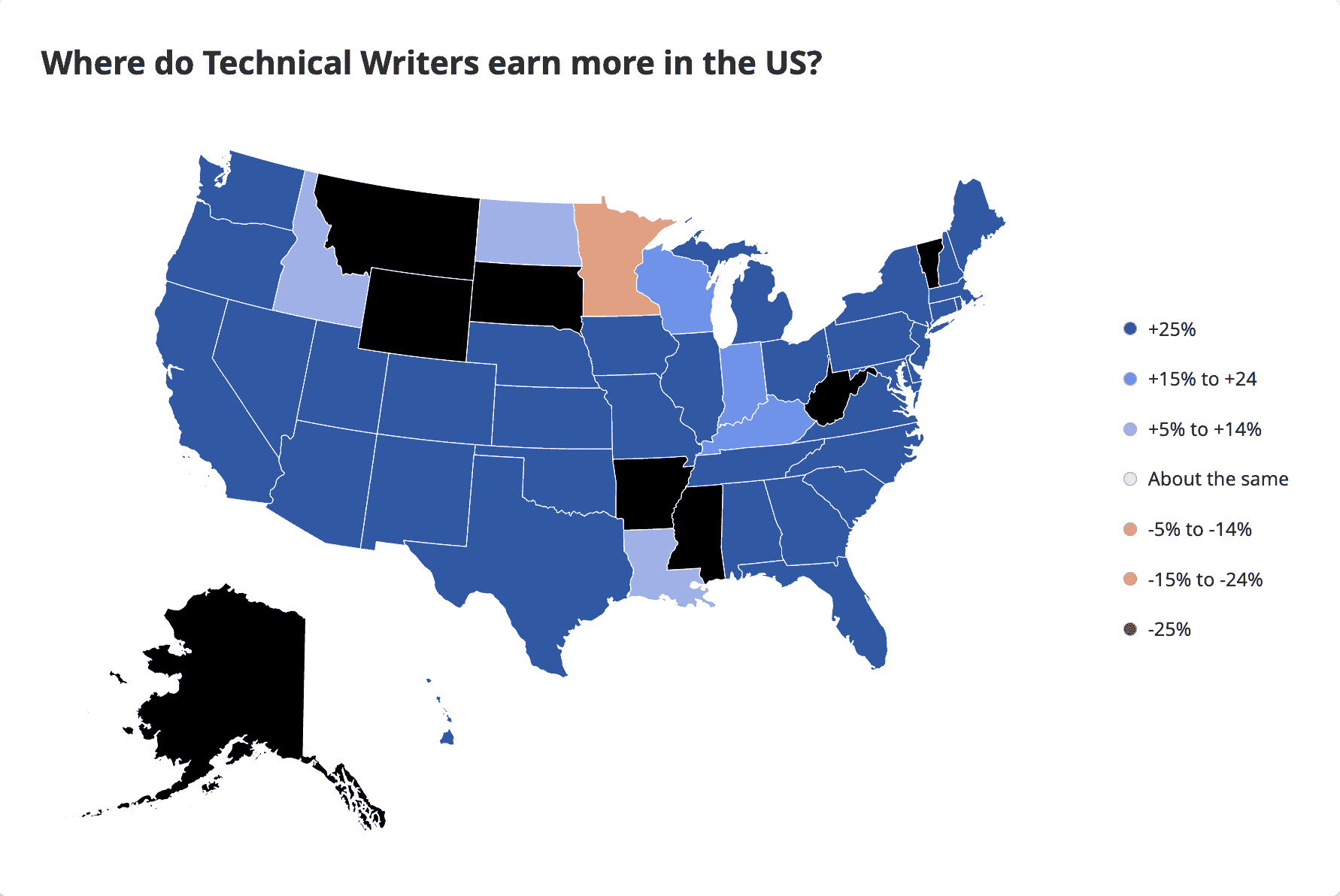
来源:Indeed
结论
还有其他平台可以用来比较薪资,例如Glassdoor。不同公司会有不同的薪资提供,所以这是一个简单的指南,帮助你更好地了解情况。
Nisha Arya 是一位数据科学家和自由职业技术作家。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探索人工智能如何能够促进人类寿命的不同方式。她是一个热衷学习者,寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
构建神经网络的简单入门指南
原文:
www.kdnuggets.com/2018/02/simple-starter-guide-build-neural-network.html
评论
由 Jeff Hu,机器学习爱好者

图片来源于 media.scmagazine.com
从今天开始,你将能够通过 PyTorch 编程并构建一个原始的 前馈神经网络(FNN)。这是 FNN 的 Python Jupyter 代码库:github.com/yhuag/neural-network-lab
本指南作为基础实践工作,引导你从头开始构建神经网络。大多数数学概念和科学决策被省略。你可以自由研究更多内容。
入门
- 请确保你的计算机上安装了 Python 和 PyTorch:
- 通过控制台命令检查 Python 安装的正确性:
python -V
输出应为Python 3.6.3或更高版本
- 打开一个存储库(文件夹)并创建你的第一个神经网络文件:
mkdir fnn-tuto
cd fnn-tuto
touch fnn.py
开始编写代码
所有以下代码应写在fnn.py文件中
导入 PyTorch
它将 PyTorch 加载到代码中。太好了!好的开始是成功的一半。
初始化超参数
超参数是设置在前的强大参数,不会随神经网络训练而更新。
下载 MNIST 数据集
MNIST 是一个包含大量手写数字(即 0 到 9)的巨大数据库,旨在用于图像处理。
加载数据集
下载 MNIST 数据集后,我们将其加载到代码中。
注意:我们打乱了 train_dataset 的加载过程,以使学习过程独立于数据顺序,但 test_loader 的顺序保持不变,以检查我们是否能处理未指定的输入偏差顺序。
构建前馈神经网络
现在我们已经准备好了数据集。我们将开始构建神经网络。概念性示意图如下:
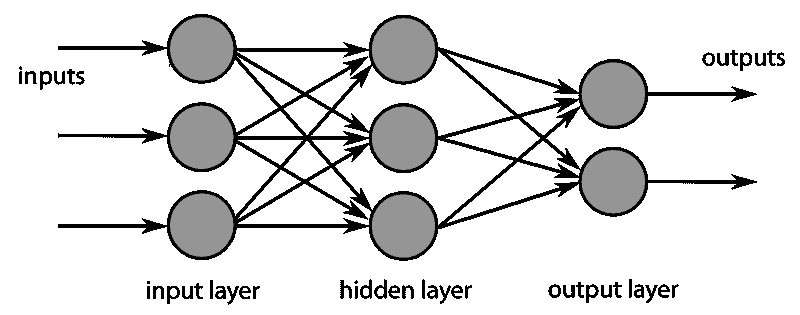
FNN 图片来源于 web.utk.edu/
前馈神经网络模型结构
FNN 包括两个全连接层(即 fc1 和 fc2)以及一个非线性 ReLU 层在中间。通常我们称这种结构为1-hidden layer FNN,不计算输出层(fc2)。
通过执行前向传播,输入图像(x)可以通过神经网络,生成一个输出(out),展示它属于 10 个类别中的每一个的可能性。例如,一张猫的图像可能对狗类有 0.8 的可能性,对飞机类有 0.3 的可能性。
实例化 FNN
我们现在根据我们的结构创建一个真正的 FNN。
net = Net(input_size, hidden_size, num_classes)
启用 GPU
注意: 你可以启用这一行以在 GPU 上运行代码
# net.cuda() # You can comment out this line to disable GPU
选择损失函数和优化器
损失函数(criterion)决定了如何将输出与类别进行比较,这决定了神经网络的表现好坏。而优化器选择了一种更新权重的方法,以便收敛并找到这个神经网络中最佳的权重。
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=learning_rate)
训练 FNN 模型
这个过程可能需要 3 到 5 分钟,具体取决于你的机器。详细解释已在以下代码中的注释 (#) 中列出。
测试 FNN 模型
与训练神经网络类似,我们还需要加载批次的测试图像并收集输出。不同之处在于:
-
无损失和权重计算
-
无权重更新
-
具有正确的预测计算
保存训练好的 FNN 模型以备将来使用
我们将训练好的模型保存为一个可以稍后加载和使用的pickle文件。
torch.save(net.state_dict(), ‘fnn_model.pkl’)
恭喜!你已经完成了第一个前馈神经网络的构建!
接下来是什么
保存并关闭文件。开始在控制台运行文件:
python fnn.py
你将看到训练过程如下:

感谢你的时间,希望你喜欢这个教程。所有代码可以在这里找到!
个人简介:Jeff Hu (Github) 是一位台湾的机器学习爱好者和区块链开发者。他专注于自然语言处理和深度学习工作,同时在闲暇时是一名魔术师和诗人。
原文。转载已获许可。
相关内容:
-
今天我在午休时用 Keras 构建了一个神经网络
-
PyTorch 还是 TensorFlow?
-
用 Keras 精通深度学习的 7 个步骤
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
更多相关话题
使用谷歌 CoLaboratory 创建一个简单的文本分类器
原文:
www.kdnuggets.com/2018/03/simple-text-classifier-google-colaboratory.html
评论
由 Sudipto Dasgupta, Flipkart.
平台:谷歌凭借 CoLaboratory 这一内部数据科学平台再次取得成功,该平台对任何人免费开放。它提供了 Jupyter 的几个好处,包括免费的 GPU 时间、便捷的代码共享和存储、不需要安装软件、使用 Chrome 浏览器编码,并兼容 Python 语言和访问 scikit-learn 等模块。这是在使人工智能和数据对所有人可及方面迈出的真正伟大的一步。
背景:我在一家电子商务公司工作,在业务中误发货是普遍现象。当系统收到关于误发货的信息时,一组专家会阅读客户对每个案件生成的评论,以确定如何调查。由于开放文本字段难以控制,客户可以自由发布可能无法采取行动或有时甚至无法理解的消息。阅读评论需要相当长的时间,鉴于以前的标记信息,垃圾评论可以通过文本分类算法轻松标记。以下是一个简单的分类器,它可以在有足够的训练数据和均衡标签分布的情况下生成高准确度的标签。

加载语料库:训练数据包括两列,第一列包含评论,第二列包含标签(0 和 1)。首先,我们使用以下代码将数据加载到 colab 环境中 -
从 google.colab 导入 files
导入 pandas 作为 pd
导入 io
uploaded = files.upload()
df = pd.read_csv(io.StringIO(uploaded['data_train.csv'].decode('utf-8')),header=None)
执行此代码块(在 colab 中称为单元格)会生成一个上传小部件,通过它需要上传训练数据。操作完成后,列将被赋予名称引用 –
raw_text = df[0]
y = df[1]
预处理:
尽管有几种不同的方法进行分类,但我使用的方法涉及 NLTK python 包。
词干提取涉及将派生词还原为其基本形式。例如,‘fish’是‘fishing’、‘fished’和‘fisher’等词的词根。Martin Porter 的算法是一个流行的词干提取工具,可以在 NLTK 中找到。停用词是从特征提取角度来看,对句子意义贡献不大的词。像‘after’、‘few’、‘right’等词经常被搜索引擎忽略。常见停用词的列表可以在此处找到。我通过以下命令从 NLTK 导入了‘PorterStemmer’和‘Stopwords’。
import nltk
nltk.download('stopwords'),nltk.download('porter_test')
另一个预处理步骤是使用正则表达式或‘re’模块。这包括去除空格、制表符、标点符号,最后将所有文本转换为小写。此步骤通常称为规范化。创建了一个名为‘pre_process’的函数来将所有这些步骤实现为一行代码,适用于任何文本或文本块。
#Text PreProcessing Function Creation
stop_words = nltk.corpus.stopwords.words('english')
ps = nltk.PorterStemmer()
import re
def pre_process(txt):
z = re.sub("[^a-zA-Z]", " ", str(txt))
z = re.sub(r'[^\w\d\s]', ' ', z)
z = re.sub(r'\s+', ' ', z)
z = re.sub(r'^\s+|\s+?$', '', z.lower())
return ' '.join(ps.stem(term)
for term in z.split()
if term not in set(stop_words)
)
现在让我们看看这个函数对文本的作用,使用代码对语料库中的前 5 条评论进行处理。
##Testing whether processing works
processed = raw_text.apply(pre_process)
print('Original Comment\n',raw_text.head(10),'\n\nTransformed Comment\n',processed.head())
运行单元格会生成以下输出,你可以比较这些行以查看预处理步骤的综合效果。
原始评论###
项目与显示的图片不符
cmbissue :- 客户打电话要求退货和...
不同的项目
表盘颜色是白色,我订购的是黑色项目...
质量问题且价格标签缺失
转换后的评论###
显示的项目图片
cmbissucust call return refund due discript ...
不同的项目
dial color white order blackitem receivvari...
issuqualiti price tag miss
分词: 让我们考虑句子——‘你好吗?’。显然,程序无法理解单词,它们只理解字符。因此,如果采用词袋模型,句子‘你好吗?’和‘好吗 你’是相同的。然而,句子的二元组将会不同。二元组是 n-grams 的子集,n-grams 是由基本对、音节或单词组成的集合。n-grams 在自然语言处理和其他领域如 DNA 测序中都非常流行!二元组是:
‘你好吗?’ ---- ‘你好吗’ , ‘好吗 你’
‘你好吗?’ ---- ‘你好吗’ , ‘好吗 你’
二元组生成代码是:
创建单字法和二字法向量
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer =TfidfVectorizer(ngram_range=(1,2))
X_ngrams=vectorizer.fit_transform(processed)
词频(tf)衡量每个 n-gram 在每个训练示例中的出现次数。这个值会通过逆文档频率(idf)进行加权,以确保对每个类别具有独特性的词或词对具有更高的权重,而常见的 n-grams 具有较低的权重。
创建分类器:一旦特征由前一段代码生成,下一步就是使用数据拟合模型。数据按 80/20 的比例分割,并使用(二元)逻辑回归进行建模。
训练/测试拆分
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X_ngrams,y,test_size=0.2,stratify=y)
运行分类器
from sklearn.linear_model import 逻辑回归
clf=逻辑回归()
clf.fit(X_train,y_train)
在这一点上,可以使用如 F1 分数这样的指标来评估模型性能。
机器已经学会了!

接下来,我们需要一个包装函数来将珍珠与垃圾分开。
def pearl_or_junk(message):# 包装函数
if clf.predict(vectorizer.transform([pre_process(message)])):
return '珍珠'
else****:
return '垃圾'
就这样!包装函数可以处理评论列,以分类评论是否有用。可以使用以下代码传递示例文件:
上传 =文件.upload()
测试数据=pd.read_csv(io.StringIO(uploaded['test_file.csv'].decode('utf-8')),header=None)
测试数据[1]=测试数据[0].apply(pearl_or_junk)
测试数据.to_csv('newfile.csv', index =None, header =False)
文件.下载('newfile.csv')
该代码将为每行评论创建一个带有‘珍珠’和‘垃圾’标签的列,您会在名为‘newfile’的文件中找到这些列,该文件将自动下载到您的系统中。
接下来做什么? 如我之前所述,这是一段简单的代码,还有很多改进的空间。如果训练数据中存在类别不平衡,该模型将预测占主导地位的类别,为了解决这个问题,可能需要使用如 SMOTE 这样的重采样技术。
有几种 NLP 技术如词形还原,可以提升预处理效果。通常,将 n-gram 增加到 3 或 4 的组合会增加机器的负担,而在我的情况下,它只是给了我一个信息,说它太累了,无法处理如此复杂的内容。仅供参考,二元组在稀疏矩阵中生成了超过 36,000 个特征。想象一下,如果你增加 N 会发生什么。
建模非常简单。模型堆叠可能有助于提高准确性,而 Naïve Bayes 或 SVC 等其他算法在处理这些问题时表现更好。我没有尝试神经网络,但如果训练数据足够大,它也可能给出更好的结果。谷歌 Colab 也提供了免费的 GPU,所以值得一试。

尽管我在 Jupyter 中创建了这段代码,但将其迁移到 Colaboratory 是非常轻松的。感谢你,谷歌!
标签:NLP;机器学习;回归;
简介:
Sudipto Dasgupta 目前在 Flipkart India Pvt. Ltd. 担任流程设计专员,这是印度最大的电子商务组织。他在软件、市场研究、教育和供应链等领域有超过 15 年的业务分析经验。他是经验丰富的六西格玛大师黑带和项目管理专业人士(PMP),拥有数学和统计学的教育背景。他对数据科学有着积极的兴趣。
相关:
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您所在组织的 IT 工作
相关主题
使用这个 Python 库进行简单的文本抓取、解析和处理
原文:
www.kdnuggets.com/2021/10/simple-text-scraping-parsing-processing-python-library.html
评论
由 Peter Lawrence 在 Unsplash 上拍摄的照片
寻找一个帮助抓取、解析、处理和提取新闻文章元数据的库? Newspaper 可以提供帮助。Newspaper 是一个 "[n]ews, full-text, and article metadata extraction in Python 3" 库。我会以最尊敬的态度说,Newspaper 是一个快速而简单的文本解析和处理库。它不是万无一失的,并且不会总能满足你对每篇文章的所有需求。然而,它通常能非常好地完成任务,并且速度很快。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速通往网络安全职业生涯的捷径。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
让我们开始,以便查看你能多快、多容易地利用这个库。如果你使用的是 Python 3,安装可以通过以下方式完成:
pip install newspaper3k
安装后,Newspaper 非常易于使用。
让我们导入这个库,定义一个我们想用来处理的网页文章,并下载这篇文章。我们将使用最近的 KDnuggets 文章 避免这五种让你看起来像数据新手的行为 来进行这些操作。
from newspaper import Article
kdn_article = Article(url="https://www.kdnuggets.com/2021/10/avoid-five-behaviors-data-novice.html", language='en')
kdn_article.download()
现在,让我们看看我们下载了什么。
# Print out the raw article
print(kdn_article.html)
<!DOCTYPE html>
<html lang="en-US">
<head profile="https://gmpg.org/xfn/11">
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<meta name=viewport content="width=device-width, initial-scale=1">
...
<!-- Dynamic page generated in 1.581 seconds. -->
<!-- Cached page generated by WP-Super-Cache on 2021-10-28 20:02:56 -->
<!-- Compression = gzip -->
这是文章的整个 HTML 页面。这不是很有用;我们先移除第一个处理步骤,使用 Newspaper 解析文章。完成后,我们打印解析后的文章文本。
# Parse the article, print parsed content
kdn_article.parse()
print(kdn_article.text)
If you are new to the Data Science industry or a well-versed veteran in all things data and analytics, there are always key pitfalls that each of us can easily slide into if we are not careful. These behaviors not only make us appear like novices, but they can risk our position as a trustworthy, likable data partner with stakeholder.
...
Original. Reposted with permission.
Bio: Tessa Xie is a Data scientist in the AV industry, and ex-McKinsey, and 3x Top Medium Writer. Tessa is also at the tip of the data spear by day, a writer by night, and a painter, diver, and much more on the weekends.
Related:
看起来更好。我们已移除了与下载的文章无关的 HTML,并从剩余的 HTML 中提取了有用的文本。
让我们看看可以从解析的文章中提取哪些元数据。
# Article title
print(kdn_article.title)
Avoid These Five Behaviors That Make You Look Like A Data Novice
# Article's top image
print(kdn_article.top_image)
https://www.kdnuggets.com/wp-content/uploads/avoid-five-behaviors-data-novice.jpg
# All article images
print(kdn_article.images)
{'https://www.kdnuggets.com/wp-content/uploads/envelope.png',
'https://www.kdnuggets.com/wp-content/uploads/tripled-my-income-data-science-18-months-small.jpg',
'https://www.kdnuggets.com/wp-content/uploads/avoid-five-behaviors-data-novice.jpg',
'https://www.kdnuggets.com/images/in_c48.png',
'https://www.kdnuggets.com/images/fb_c48.png',
'https://www.kdnuggets.com/images/tw_c48.png',
'https://www.kdnuggets.com/images/menu-30.png',
'https://www.kdnuggets.com/images/search-icon.png'}
# Article author
print(kdn_article.authors)
# Article publication date
print(kdn_article.publish_date)
[]
None
从上述内容可以看出,某些元数据已经被轻松提取,而在出版日期和作者的情况下,Newspaper 结果为空。这就是我在文章开头提到的;库并非魔法,如果文章格式不利于 Newspaper 的模式匹配,这些元数据的识别和提取将不会发生。
了解你可以用解析过的文章 这里 完成的其他任务。
接下来是更有趣的内容……一旦下载并解析了文章,还可以使用 Newspaper 内置的 NLP 功能来处理,方法如下:
# Perform higher level processing on article
kdn_article.nlp()
下面是我们可以对处理过的文章执行的一些任务。
# Article keywords
print(kdn_article.keywords)
['avoid', 'data', 'dont', 'instead', 'things', 'insights', 'novice', 'work', 'quality', 'understand', 'behaviors', 'stakeholders', 'look', 'sample']
# Article summary
print(kdn_article.summary)
If you are new to the Data Science industry or a well-versed veteran in all things data and analytics, there are always key pitfalls that each of us can easily slide into if we are not careful.
There are noticeable differences between people who are new to the data world and those who truly understand how to handle data and be helpful data partners.
So as a data expert, you should know better than trusting data quality at face value.
But in reality, unless you are an ML engineer, you rarely need 10-layer neural networks in your day-to-day data work.
Make sure to QC your data and sanity-check your insights, and always caveat findings when data quality or the sample size is a concern.
这无疑比上面解析的文章元数据提取更有趣,尽管从文章中提取的处理和解析数据肯定都很有用。
请记住,有许多方法可以使用各种不同的库和工具来自动总结文章;然而,Newspaper 提供了一种方法,能够在一行代码中提供合理的结果,无需测试参数。你可以将其与我之前的文章 《自动文本总结入门》 中使用简单词频方法在 Python 中实现类似的提取总结过程进行比较,你会发现需要更多的代码来获得类似的结果。
只对利用 Newspaper 的总结功能感兴趣?这是一个快速的、自包含的示例:
from newspaper import Article
cnn_article = Article(url="https://www.cnn.com/2021/10/28/tech/facebook-mark-zuckerberg-keynote-announcements/index.html", language='en')
cnn_article.download()
cnn_article.parse()
cnn_article.nlp()
print(cnn_article.summary)
The company formerly known as Facebook also said in a press release that it plans to begin trading under the stock ticker "MVRS" on December 1.
Facebook is one of the most used products in the history of the world," Zuckerberg said on Thursday.
"Today we're seen as a social media company," he added, "but in our DNA, we are a company that builds technology to connect people.
But on Zuckerberg's personal Facebook page , his job title was changed to: "Founder and CEO at Meta."
When asked by The Verge if he would remain CEO at Facebook in the next 5 years, he said: "Probably.
就是这样。
了解更多你可以用处理过的文章 这里 完成的任务。
Newspaper 并不完美,存在一些限制,但你可以看到它调用和利用的速度和简便程度,即使在遇到一些限制的情况下也很有用。就个人而言,我编写了自己的代码来执行上述步骤中的许多任务,并且还利用了几个不同的库来完成其他任务,通常需要更多的努力。
实际上,你可以用这个库完成更多的任务,我鼓励你 调查可能性。希望你能够在自己的项目中使用 Newspaper。
相关:
-
使用 HuggingFace Pipelines 的简单问答 Web 应用
-
应用语言技术:实用方法
-
Python 中的日期处理和特征工程
相关主题
你需要从敏捷中借鉴的两个简单技巧
原文:
www.kdnuggets.com/2021/11/simple-things-steal-agile-data-science-analytics.html
comments
由 Jon Loyens, data.world 的首席产品官和联合创始人

照片由 Murilo Viviani 提供,发布在 Unsplash
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域的职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织的 IT 部门
将软件开发生命周期的各个方面应用于数据科学、工程和分析现在非常流行——这是一件好事。无论是讨论 将数据转换视为代码, 采纳 DataOps 和敏捷数据治理实践, 将数据视为产品,还是考虑 数据网格 架构(本质上是将微服务基础应用于数据和分析堆栈),世界正在逐渐最终 视数据和分析为团队运动。但如果你想赢得这场比赛,你需要找到让玩家互动和协作的方式,捕捉知识,并使更多人能够参与进来。
现在有一股疯狂的潮流,借鉴软件开发社区的成功,特别是在促进数据科学和分析方面的更好协作和团队合作。伟大的艺术家会借鉴,而作为一个经常谈论 敏捷数据治理 的人,我也会这样做!
但并不是每个人都支持这样一种观点:如果我们都像软件工程师和产品经理那样做就能得救。人们指出了有关数据隐私、偏见、有效性和其他问题的非常有效的问题,这使得分析和数据科学的输出比典型的敏捷软件项目要敏感得多。还很明显,涉及数据和分析的工作通常会涉及比典型软件项目更广泛的相关方,最终导致关键决策。
从积极的方面来看,包容性、迭代性强且真正涉及所有相关方的敏捷实践有可能将数据生产者(数据工程师和管理员)与数据消费者(数据科学家和分析师)以真正有意义的方式结合起来。这可以促进强大的数据驱动文化和大大提高数据素养。
在我的日常工作中,我们构建了一个data catalog平台,企业如世界上最大的物流房地产公司 Prologis 正在使用它。通过使用案例驱动的敏捷方法开发其分析和数据治理实践,Prologis 能够以真正具有变革性的方式部署它。
历史上,我们组织采用了自上而下的‘煮海’方法进行数据治理,这对我们不起作用。我们知道必须通过关注用户体验到的最大痛苦和烦恼来彻底改变我们的方法。然后,我们让这些实际数据驱动我们的数据治理计划扩展。简而言之,通过根据业务用例优先级迭代地部署数据目录是重新激发员工对我们治理计划兴趣的关键。”
— Luke Slotwinski,Prologis IT 数据与分析副总裁
执行数据目录化计划可能还不适合你,但如果我告诉你,有两个简单的敏捷理念你可以立即实施,它们将大大提高你的数据和分析工作质量,并开始促进共享理解和数据素养,你会如何?这两个理念是同行评审和完成定义。
同行评审
在软件开发中,代码(或同行)审查的理念远早于著名的 Github “Pull Request” 功能,后者允许工程师在代码发布前对彼此的工作进行评论。我第一次在 Steve McConnell 的 Code Complete 一书中读到这一技术——该书最初出版于 1992 年!让队友对你的工作进行复查并提出你可能遗漏的建议,具有简单的力量和美感。对于特别复杂的代码,两位工程师可能会逐行审查,作者实时向审查者解释代码的工作原理。这还有助于重要的知识传递,确保团队中不止一个人了解代码的工作方式,避免了可怕的“公交车因素 1”。
将这种审查方式作为流程的一部分是非常有影响力的。另一个好处(特别是因为我们现在几乎都生活在远程世界中)是,这些审查中捕获的评论可以在几乎没有额外努力的情况下大幅改善你的数据和分析文档工作。不过需要注意的是,审查应集中在同行数据科学家或分析师如何完成分析上,无论是逐行代码还是逐步说明可视化的创建过程。这不是利益相关者或最终用户验收测试。(在软件中,类比就像让用户点击原型并认为完成了)。
这一点不能被过分强调:同行审查者会发现你的技术中的错误,或提出商业利益相关者无法提供的建议(尤其是当分析恰好确认了某种信念或先入为主的偏见时)。在流程中增加这一步骤将积极影响跨部门协作、整体数据素养,并对分析质量或交付的数据模型产生巨大的影响。我建议你 Google “Good Code Read Practices” 以获取大量关于如何做好这件事的文章,并考虑如何将其适应你公司内的数据和分析最佳实践。
完成的定义
在同行评审会议中真正能产生差异的,是拥有一个优秀的“完成定义”。“完成定义”这一概念源于软件开发领域的 Scrum 方法论,其核心思想是,当用户故事完成时,应有一个简单而明确的检查清单,以确保作为工程师(以及审阅者),你已达标。拥有一个所有数据科学家、分析师和工程师同意使用的简单清单,以签署工作,可以显著提升数据工作的质量和一致性。
然而,对于分析和数据工程工作的完成定义,你可能需要为分析工作和数据建模工作分别制定定义。我们使用了一些定义,这些可能也是你组织的良好起点:
数据科学和分析的完成定义
-
假设已明确阐述
-
方法已审查偏差
-
数据源已明确
-
新数据源/建模已提交给数据工程
-
方法已阅读并可在同行环境中重复使用
-
轴、特征、领域定义明确
-
结论和行动步骤已记录
-
审查合规性
-
公开征求意见或重用
数据建模的完成定义
-
数据字典已编写
-
现有业务术语和相关指标已链接
-
新业务术语已提交
-
转换代码已审查
-
遵循数据架构风格(Kimball、Data vault 等)
-
遵循“不要重复自己”原则
-
测试已编写,数据概况已充分记录/理解
-
审查合规性
-
公开征求意见或重用
当我们在 data.world 采用了dbt来建模我们的内部数据和分析时,拥有这些完成定义(特别是针对数据建模的定义)对于建立我们完成分析工程工作的基线至关重要。它确保了即使在学习新工具时,我们在审查彼此的工作时也保持一致。这使得我们在迁移到 Snowflake 时,将新数据模型导入数据仓库的效率翻倍。
采用此实践
每当你采纳像同行评审或拥有“完成定义”这样的新实践时,将它们纳入你今天使用的项目管理工具中是很重要的——你甚至不需要任何新的数据或分析基础设施来做到这一点。通常,只需将像 JIRA 这样的软件过程工具适应到你的数据和分析实践中即可满足要求。如果你围绕用户故事组织分析工作,将“同行评审”步骤添加到像 JIRA 这样的工具中是非常简单的。使用 JIRA 的敏捷看板也很简单,已经包含了审查步骤:
图片作者提供
如果你实际上拥有数据目录,为数据资产添加“审核中”标志也是非常有帮助的,并且可以与项目管理工具同步。这些标志可以用来分配审阅者,或者让使用者知道资产是否已经准备好使用。
作者提供的图片
在数据和分析中赢得胜利与敏捷
在这篇文章的开头,我提到我曾从敏捷软件开发原则中汲取灵感,并将其应用于数据和分析工作。你知道吗?我将继续从敏捷中汲取灵感,因为我相信创建协作的、数据驱动的文化,在这种文化中,数据和分析的透明性和信任至关重要。同行评审和遵循对数据和分析工作有明确理解的完成定义是非常有价值且简单的想法,你今天就可以采纳。没有比这更容易实施的变化,也没有比这对数据质量和组织内的共享理解产生更大积极影响的变化了。
我很乐意听听任何在数据和分析流程或治理工作流中采纳这些或其他敏捷方法的人的意见!
简介: Jon Loyens 是 data.world 的首席产品官和联合创始人,data.world 是现代数据栈的数据目录。他是推动数据驱动文化的热情倡导者,根植于开放性和透明性。在过去的职业生涯中,Jon 曾担任 HomeAway 的旅行产品工程副总裁和 Bazaarvoice 的工程副总裁。作为一位长期的奥斯汀科技高管,他经历了数据和分析作为民主化力量的趋势的崛起。Jon 将 A/B 测试和数据驱动的产品管理引入 Bazaarvoice,并大幅扩展了 HomeAway 的数据项目。
原文。转载已获许可。
相关:
-
数据科学可以敏捷吗?将最佳敏捷实践应用于你的数据科学流程
-
敏捷数据标注:它是什么以及你为什么需要它
-
如何让敏捷团队为大数据分析发挥作用
更多相关主题
PostgreSQL 查询优化的简单技巧
原文:
www.kdnuggets.com/2018/06/simple-tips-postgresql-query-optimization.html
评论
由 Pavel Tiunov 撰写,Statsbot

单个查询优化技巧可以将你的数据库性能提升 100 倍。曾经我们建议一位拥有 10TB 数据库的客户使用基于日期的多列索引。结果,他们的日期范围查询速度提升了 112 倍。在这篇文章中,我们分享了五个简单但仍然强大的 PostgreSQL 查询优化技巧。
虽然我们通常建议客户使用这些技巧来优化分析查询(例如聚合查询),但本文对于任何其他类型的查询仍然非常有帮助。
为了简化起见,我们在测试数据集上运行了本文的示例。虽然这不会显示实际的性能改进,但你会发现我们的建议能解决大量的优化问题,并在实际情况中表现良好。
Explain analyze
Postgres 有一个很酷的扩展功能,称为EXPLAIN ANALYZE,扩展了著名的EXPLAIN命令。不同之处在于,EXPLAIN 根据收集的数据库统计信息显示查询成本,而EXPLAIN ANALYZE 实际运行它以显示每个阶段处理的时间。
我们强烈建议使用EXPLAIN ANALYZE,因为有很多情况下EXPLAIN显示的查询成本较高,而实际执行时间则较短,反之亦然。最重要的是,EXPLAIN 命令将帮助你了解是否使用了特定的索引以及如何使用。
查看索引的能力是学习 PostgreSQL 查询优化的第一步。
每个查询一个索引
索引是你表的物化副本。它们仅包含表的特定列,因此你可以快速根据这些列中的值查找数据。Postgres 中的索引还存储行标识符或行地址,以加速原始表扫描。
这总是存储空间和查询时间之间的权衡,许多索引可能会引入 DML 操作的开销。然而,当读取查询性能是优先考虑的(如商业分析中的情况),这种方法通常是有效的。
我们建议为每个独特的查询创建一个索引以获得更好的性能。请继续阅读本文,了解如何为特定查询创建索引。
使用多个列的索引
让我们查看以下简单查询的 explain analyze 计划,未使用索引:
EXPLAIN ANALYZE SELECT line_items.product_id, SUM(line_items.price)
FROM line_items
WHERE product_id > 80
GROUP BY 1
Explain analyze 返回:
HashAggregate (cost=13.81..14.52 rows=71 width=12) (actual time=0.137..0.141 rows=20 loops=1)
Group Key: product_id
-> Seq Scan on line_items (cost=0.00..13.25 rows=112 width=8) (actual time=0.017..0.082 rows=112 loops=1)
Filter: (product_id > 80)
Rows Removed by Filter: 388
Planning time: 0.082 ms
Execution time: 0.187 ms
这个查询扫描所有行项,找到 id 大于 80 的产品,然后按该产品 id 对所有值进行求和。
现在我们将为这个表添加索引:
CREATE INDEX items_product_id ON line_items(product_id)
我们创建了一个B-树索引,该索引只包含一个列:product_id。在阅读了大量关于使用索引的好处的文章后,人们可能会期待这样的操作能提升查询性能。抱歉,坏消息。
由于我们需要在上述查询中对价格列进行求和,我们仍然需要扫描原始表。根据表的统计信息,Postgres 将选择扫描原始表而不是索引。问题在于,索引缺少price列。
我们可以通过添加价格列来调整此索引,如下所示:
CREATE INDEX items_product_id_price ON line_items(product_id, price)
如果我们重新运行解释计划,我们会看到我们的索引在第四行:
GroupAggregate (cost=0.27..7.50 rows=71 width=12) (actual time=0.034..0.090 rows=20 loops=1)
Group Key: product_id
-> Index Only Scan using items_product_id_price on line_items (cost=0.27..6.23 rows=112 width=8) (actual time=0.024..0.049 rows=112 loops=1)
Index Cond: (product_id > 80)
Heap Fetches: 0
Planning time: 0.271 ms
Execution time: 0.136 ms
但是,将价格列放在首位会如何影响 PostgreSQL 查询优化呢?
多列索引中的列顺序
好吧,我们发现前一个查询中使用了多列索引,因为我们包含了这两列。有趣的是,我们在定义索引时可以使用这些列的另一种顺序:
CREATE INDEX items_product_id_price_reversed ON line_items(price, product_id)
如果我们重新运行解释分析,我们将看到items_product_id_price_reversed没有被使用。这是因为该索引首先按price排序,然后按product_id排序。使用这个索引将导致全索引扫描,这几乎等同于扫描整个表。这就是为什么 Postgres 选择对原始表进行扫描的原因。
将用于过滤器中具有最大唯一值数量的列放在第一位是一种良好的实践。
过滤器 + 连接
现在是时候找出特定连接查询的最佳索引集合了,该查询还有一些过滤条件。通常,你可以通过反复试验来获得最佳结果。
就像在简单过滤的情况下,选择最具限制性的过滤条件并为其添加索引。
让我们考虑一个示例:
SELECT orders.product_id, SUM(line_items.price)
FROM line_items
LEFT JOIN orders ON line_items.order_id = orders.id
WHERE line_items.created_at BETWEEN '2018-01-01' and '2018-01-02'
GROUP BY 1
在这里,我们基于order_id进行连接,并在created_at上进行过滤。这样,我们可以创建一个多列索引,其中created_at排在第一位,order_id排在第二位,price排在第三位:
CREATE INDEX line_items_created_at_order_id_price ON line_items(created_at, order_id, price)
我们将得到以下解释计划:
GroupAggregate (cost=12.62..12.64 rows=1 width=12) (actual time=0.029..0.029 rows=1 loops=1)
Group Key: orders.product_id
-> Sort (cost=12.62..12.62 rows=1 width=8) (actual time=0.025..0.026 rows=1 loops=1)
Sort Key: orders.product_id
Sort Method: quicksort Memory: 25kB
-> Nested Loop Left Join (cost=0.56..12.61 rows=1 width=8) (actual time=0.015..0.017 rows=1 loops=1)
-> Index Only Scan using line_items_created_at_order_id_price on line_items (cost=0.27..4.29 rows=1 width=8) (actual time=0.009..0.010 rows=1 loops=1)
Index Cond: ((created_at >= '2018-01-01 00:00:00'::timestamp without time zone) AND (created_at <= '2018-01-02 00:00:00'::timestamp without time zone))
Heap Fetches: 0
-> Index Scan using orders_pkey on orders (cost=0.29..8.30 rows=1 width=8) (actual time=0.004..0.005 rows=1 loops=1)
Index Cond: (line_items.order_id = id)
Planning time: 0.303 ms
Execution time: 0.072 ms
如你所见,line_items_created_at_order_id_price用于通过日期条件减少扫描。之后,它使用orders_pkey索引扫描与订单连接。
日期列通常是多列索引中最适合作为第一列的候选者,因为它以可预测的方式减少了扫描吞吐量。
结论
我们的 PostgreSQL 查询优化技巧将帮助你将查询速度提高 10-100 倍,适用于多 GB 数据库。它们可以以 80/20 的方式解决大多数性能瓶颈。这并不意味着你不应该使用EXPLAIN来双重检查你的查询,以适应实际的场景。
原文。经许可转载。
相关:
-
SQL 中的随机行可扩展选择
-
SQL 窗口函数商业分析教程
-
计算客户生命周期价值:SQL 示例
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能。
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求。
相关话题
Python 中计时代码的一种简单方法
原文:
www.kdnuggets.com/2021/03/simple-way-time-code-python.html
评论
由 Edward Krueger,高级数据科学家和技术负责人 & Douglas Franklin,有志数据科学家和教学助理

Brad Neathery 的照片,来源于 Unsplash
介绍
我们的目标是创建一种简单的方法来计时 Python 中的函数。我们通过使用 Python 的库 functools 和 time 编写一个装饰器来实现。然后将此装饰器应用于我们感兴趣的函数。
计时装饰器:@timefunc
下面的代码代表了一个常见的装饰器模式,具有可重用和灵活的结构。注意 functool.wraps 的位置。它是我们闭包的装饰器。这个装饰器保留了 func 的元数据,因为它传递给了闭包。
在第 16 行,functools 在我们的打印语句中变得重要,我们访问 func.__name__。如果我们没有使用 functools.wraps 来装饰我们的闭包,就会返回错误的名称。
这个装饰器返回传递给 timefunc() 的函数的运行时间。在第 13 行,start 启动计时。然后,第 14 行的 result 存储 func(*args, **kwargs) 的值。之后,计算 time_elapsed。打印语句报告 func 的名称和执行时间。
使用 @ 符号应用 timefunc
在 Python 中,装饰器可以很容易地通过 @ 符号应用。并非所有装饰器的应用都使用这种语法,但所有 @ 符号都是装饰器的应用。
我们使用 @ 符号将 single_thread 装饰为 timefunc。
现在 single_thread 被装饰后,当它在第 13 行被调用时,我们将看到它的 func.__name__ 和运行时间。
timefunc 装饰的 single_thread 的输出
如果你想了解它是如何工作的,下面我们将深入探讨编写一个用于计时函数的装饰器的原因和方法。
为什么有人可能会对一个函数进行计时
原因相对简单。更快的函数就是更好的函数。
时间就是金钱,朋友。—— Gazlowe
计时装饰器向我们展示函数的运行时间。我们可以将装饰器应用于多个版本的函数,对它们进行基准测试,并选择最快的一个。此外,在测试代码时,了解执行所需的时间也很有用。计划有五分钟的运行时间?这是一个不错的时间段,可以起身活动一下腿部,或者重新填充咖啡!
在 Python 中编写装饰器函数时,我们依赖于 functools 和对作用域的了解。让我们深入了解作用域和装饰。
装饰、闭包和作用域
装饰是 Python 中的一种设计模式,它允许你修改函数的行为。装饰器是一个接收函数并返回修改后函数的函数。
在编写闭包和装饰器时,你必须牢记每个函数的作用域。在 Python 中,函数定义作用域。闭包可以访问返回它们的函数的作用域;装饰器的作用域。
在传递给闭包时,保存装饰函数的元数据非常重要。了解我们的作用域可以让我们正确地使用functools.wraps装饰我们的闭包。
有关这些概念的更多信息,请阅读这篇三分钟的文章。
如何使用装饰器增强函数的行为
关于这个装饰器的重用性
请注意,func作为参数在第 7 行被传入。然后在第 11 行,我们将*args, **kwargs传递给闭包。这些*args, **kwargs用于计算第 10 行中func(*args, **kwargs)的result。
*args和**kwargs的灵活性使得timefunc能够在几乎任何函数上工作。我们闭包的打印语句旨在访问函数的__name__、args、kwargs和result,以创建一个有用的计时输出。
结论
装饰是一种增强函数行为的强大工具。通过编写一个计时装饰器,你可以获得一个优雅、可重用的模式来跟踪函数的运行时间。
随意将timefunc复制到你的代码库中,或者你可以尝试编写自己的计时装饰器!
爱德华·克鲁格 是 Business Laboratory 的高级数据科学家和技术主管,并且是德克萨斯大学奥斯汀分校麦库姆斯商学院的讲师。
道格拉斯·弗兰克林 是德克萨斯大学奥斯汀分校麦库姆斯商学院的教学助理。
原文。经许可转载。
相关:
-
数据科学家在 Python 中常犯的 15 个错误(及如何修复)
-
如何使用 Modin 加速 Pandas
-
11 个完整 EDA(探索性数据分析)必备代码块
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关话题
使用 Iris 数据集的简单 XGBoost 教程
原文:
www.kdnuggets.com/2017/03/simple-xgboost-tutorial-iris-dataset.html
作者:Ieva Zarina,软件开发员,Nordigen。
我有机会开始使用 xgboost 机器学习算法,它快速且显示出 良好的结果。在这里,我将使用 iris 数据集 进行多分类预测,数据集来自 scikit-learn。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作

XGBoost 算法 (source)。
安装 Anaconda 和 xgboost
为了处理数据,我需要安装各种 Python 科学库。我发现最好的方法是使用 Anaconda。它可以简单地安装所有库,并帮助 安装新的库。你可以下载适用于 Windows 的安装程序,但如果你想在 Linux 服务器上安装,只需将以下内容复制粘贴到终端:
wget http://repo.continuum.io/archive/Anaconda2-4.0.0-Linux-x86_64.sh
bash Anaconda2-4.0.0-Linux-x86_64.sh -b -p $HOME/anaconda
echo 'export PATH="$HOME/anaconda/bin:$PATH"' >> ~/.bashrc
bash
在此之后,使用 conda 安装 pip,你将需要它来安装 xgboost。重要的是使用 Anaconda(在 Anaconda 的目录中)来安装它,以便 pip 也能在那里安装其他库:
conda install -y pip
现在,一个非常重要的步骤:预先安装 xgboost Python 包 的依赖项。根据经验,我会安装这些依赖项:
sudo apt-get install -y make g++ build-essential gfortran libatlas-base-dev liblapacke-dev python-dev python-setuptools libsm6 libxrender1
我升级了我的 Python 虚拟环境,以避免 trouble 与 Python 版本相关的问题:
pip install --upgrade virtualenv
最后,我可以用 pip 安装 xgboost(祈祷好运):
pip install xgboost
此命令安装最新版本的 xgboost,但如果你想使用之前的版本,只需指定:
pip install xgboost==0.4a30
现在测试一下是否一切正常 – 在终端中输入 python 并尝试导入 xgboost:
import xgboost as xgb
如果没有看到错误 – 完美。
Xgboost 与 Iris 数据集的演示
在这里,我将使用 Iris 数据集来展示如何使用 Xgboost 的简单示例。
首先,你加载数据集来自 sklearn,其中 X 是数据,y 是类别标签:
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
然后你将数据拆分成 80-20%的训练集和测试集,拆分:
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
接下来,你需要从 numpy 数组创建 Xgboost 特定的DMatrix数据格式。Xgboost 可以直接处理 numpy 数组,加载 svmlignt 文件及其他格式。以下是如何处理numpy 数组:
import xgboost as xgb
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
如果你想使用 svmlight 以减少内存消耗,首先导出numpy 数组到svmlight 格式,然后只需将文件名传递给 DMatrix:
import xgboost as xgb
from sklearn.datasets import dump_svmlight_file
dump_svmlight_file(X_train, y_train, 'dtrain.svm', zero_based=True)
dump_svmlight_file(X_test, y_test, 'dtest.svm', zero_based=True)
dtrain_svm = xgb.DMatrix('dtrain.svm')
dtest_svm = xgb.DMatrix('dtest.svm')
现在为了让 Xgboost 工作,你需要设置参数:
param = {
'max_depth': 3, # the maximum depth of each tree
'eta': 0.3, # the training step for each iteration
'silent': 1, # logging mode - quiet
'objective': 'multi:softprob', # error evaluation for multiclass training
'num_class': 3} # the number of classes that exist in this datset
num_round = 20 # the number of training iterations
不同的数据集在不同的参数下表现不同。一个参数组合的结果可能很低,而另一个可能非常好。你可以查看这个 Kaggle 脚本了解如何寻找最佳参数。通常尝试 eta 0.1、0.2、0.3,max_depth 在 2 到 10 的范围内,num_round 在几百左右。
训练
最终训练可以开始。你只需输入:
bst = xgb.train(param, dtrain, num_round)
要查看模型的样子,你也可以将其导出为人类可读的形式:
bst.dump_model('dump.raw.txt')
它看起来像这样(f0、f1、f2 是特征):
booster[0]:
0:[f2<2.45] yes=1,no=2,missing=1
1:leaf=0.426036
2:leaf=-0.218845
booster[1]:
0:[f2<2.45] yes=1,no=2,missing=1
1:leaf=-0.213018
2:[f3<1.75] yes=3,no=4,missing=3
3:[f2<4.95] yes=5,no=6,missing=5
5:leaf=0.409091
6:leaf=-9.75349e-009
4:[f2<4.85] yes=7,no=8,missing=7
7:leaf=-7.66345e-009
8:leaf=-0.210219
....
你可以看到每棵树的深度不超过设置的 3 层。
使用模型来预测类别测试集的类别:
preds = bst.predict(dtest)
但预测结果看起来像这样:
[[ 0.00563804 0.97755206 0.01680986]
[ 0.98254657 0.01395847 0.00349498]
[ 0.0036375 0.00615226 0.99021029]
[ 0.00564738 0.97917044 0.0151822 ]
[ 0.00540075 0.93640935 0.0581899 ]
....
在这里,每一列代表类别 0、1 或 2。对于每一行,你需要选择概率最高的那一列:
import numpy as np
best_preds = np.asarray([np.argmax(line) for line in preds])
现在你会得到一个包含预测类别的漂亮列表:
[1, 0, 2, 1, 1, ...]
确定此预测的准确率:
from sklearn.metrics import precision_score
print precision_score(y_test, best_preds, average='macro')
# >> 1.0
完美!现在保存模型以备后用:
from sklearn.externals import joblib
joblib.dump(bst, 'bst_model.pkl', compress=True)
# bst = joblib.load('bst_model.pkl') # load it later
现在你有一个保存下来的工作模型,并准备进行更多预测。
查看完整代码在github或下方:
简介: Ieva Zarina 是 Nordigen 的软件开发人员。
原始链接。经许可转载。
相关:
-
掌握 Python 机器学习的 7 个额外步骤
-
我在 Python 中从头实现分类器的学习经历
-
XGBoost:在 Spark 和 Flink 中实现获胜的 Kaggle 算法
更多相关主题
简单而实用的数据清洗代码
原文:
www.kdnuggets.com/2019/02/simple-yet-practical-data-cleaning-codes.html
评论
由 Admond Lee,美光科技 / AI Time Journal / Tech in Asia

在我的一篇文章—我的第一次数据科学家实习中,我谈到了数据清洗(数据预处理、数据清理……无论它是什么)是多么重要,以及它如何轻易占据整个数据科学工作流程的 40%-70%。世界是不完美的,数据也是如此。
垃圾进,垃圾出
现实世界的数据是肮脏的,作为数据科学家——也就是数据清理者,我们应该在进行任何数据分析或模型构建之前进行数据清洗,以确保数据的最大质量。
长话短说,在数据科学领域待了相当长一段时间后,我确实感受到了在进行数据分析、可视化和模型构建之前进行数据清洗的痛苦。
无论你是否承认,数据清洗并不是一项简单的任务,大多数时候它耗时且枯燥,但这个过程却重要得不可忽视。
如果你经历过这个过程,你会理解我的意思。这也是我写这篇文章的原因,以帮助你更好地进行数据清洗。
更顺畅的数据清洗方法。
为什么这篇文章对你很重要?
一周前,我在 LinkedIn 上发布了帖子,询问和回答了一些有抱负的数据科学家和数据科学专业人士面临的关于数据科学的热门问题。
如果你一直关注我的工作,我正在致力于在 LinkedIn 上民主化分享学习环境,特别关注数据科学,通过在 LinkedIn 上发起讨论,汇聚有抱负的数据科学家、数据科学家及其他不同专业和背景的数据专业人士。如果你想参与这些关于数据科学的有趣话题讨论,可以随时关注我在LinkedIn。你会惊讶于数据科学社区的参与性和支持性。] ????
我在评论中收到了一些有趣的问题。然而,有一个特别的问题是由Anirban提出的,这让我最终决定写一篇文章来回答这个问题,因为我一直不时收到类似的问题。
实际上,不久前我意识到某些数据在数据清洗时有类似的模式。这时我开始整理和编写一些我认为适用于其他常见场景的数据清洗代码——我的数据清洗小工具箱。
由于常见场景涉及不同类型的数据集,本文更多地着重于展示和解释代码的用途,以便你可以轻松地进行插拔使用。
在本文的最后,我希望你会发现这些代码有用,并且能使你的数据清洗过程更快速、高效。
开始吧!
我的数据清洗小工具箱
在以下代码片段中,代码被写成函数以便于自我解释。你可以直接使用这些代码,而无需将其放入函数中,只需稍微修改参数即可。
1. 删除多个列
def drop_multiple_col(col_names_list, df):
'''
AIM -> Drop multiple columns based on their column names
INPUT -> List of column names, df
OUTPUT -> updated df with dropped columns
------
'''
df.drop(col_names_list, axis=1, inplace=True)
return df
有时,并非所有列在我们的分析中都是有用的。因此,df.drop 可以派上用场,用于删除你指定的选定列。
2. 更改数据类型
def change_dtypes(col_int, col_float, df):
'''
AIM -> Changing dtypes to save memory
INPUT -> List of column names (int, float), df
OUTPUT -> updated df with smaller memory
------
'''
df[col_int] = df[col_int].astype('int32')
df[col_float] = df[col_float].astype('float32')
当数据集变得更大时,我们需要转换dtypes以节省内存。如果你有兴趣了解如何使用 Pandas 处理大数据,我强烈建议你查看这篇文章——为什么及如何使用 Pandas 处理大数据。
3. 将分类变量转换为数值变量
def convert_cat2num(df):
# Convert categorical variable to numerical variable
num_encode = {'col_1' : {'YES':1, 'NO':0},
'col_2' : {'WON':1, 'LOSE':0, 'DRAW':0}}
df.replace(num_encode, inplace=True)
一些机器学习模型要求变量为数值格式。这时我们需要将分类变量转换为数值变量,然后再将其输入模型。就数据可视化而言,我建议保留分类变量,以便更明确地解释和理解。
4. 检查缺失数据
def check_missing_data(df):
# check for any missing data in the df (display in descending order)
return df.isnull().sum().sort_values(ascending=False)
如果你想检查每列缺失数据的数量,这是最快的方法。这能让你更好地了解哪些列缺失数据较多,从而决定下一步的数据清洗和分析行动。
5. 删除列中的字符串
def remove_col_str(df):
# remove a portion of string in a dataframe column - col_1
df['col_1'].replace('\n', '', regex=True, inplace=True)
# remove all the characters after &# (including &#) for column - col_1
df['col_1'].replace(' &#.*', '', regex=True, inplace=True)
可能会遇到新行字符或其他奇怪的符号出现在字符串列中。可以通过使用df['col_1'].replace来轻松处理,其中col_1是数据框df中的一列。
6. 删除列中的空格
def remove_col_white_space(df,col):
# remove white space at the beginning of string
df[col] = df[col].str.lstrip()
当数据很混乱时,一切皆有可能。看到字符串开头有一些空格并不罕见。因此,当你想要删除列中字符串开头的空格时,这种方法非常有用。
7. 按条件连接两个字符串列
def concat_col_str_condition(df):
# concat 2 columns with strings if the last 3 letters of the first column are 'pil'
mask = df['col_1'].str.endswith('pil', na=False)
col_new = df[mask]['col_1'] + df[mask]['col_2']
col_new.replace('pil', ' ', regex=True, inplace=True) # replace the 'pil' with emtpy space
这在你想要有条件地合并两个包含字符串的列时非常有用。例如,你希望将第一列与第二列连接起来,如果第一列中的字符串以某些字母结尾。根据你的需要,连接后还可以去掉这些结尾字母。
8. 将时间戳(从字符串到日期时间格式)转换
def convert_str_datetime(df):
'''
AIM -> Convert datetime(String) to datetime(format we want)
INPUT -> df
OUTPUT -> updated df with new datetime format
------
'''
df.insert(loc=2, column='timestamp', value=pd.to_datetime(df.transdate, format='%Y-%m-%d %H:%M:%S.%f'))
在处理时间序列数据时,我们可能会遇到字符串格式的时间戳列。这意味着我们可能需要将字符串格式转换为日期时间格式——具体格式根据需求指定——以便用数据进行有意义的分析和展示。
最后的想法

感谢阅读。
代码本质上实现起来相对简单。希望这个小工具箱的清理数据方法能让你更有信心进行数据清理,并提供更广泛的视角,了解数据集通常的样子。
一如既往,如果你有任何问题或评论,请随时在下面留下反馈,或者通过 LinkedIn 联系我。到那时,再见于下一篇文章! 🤗
简历: Admond Lee 是一名大数据工程师,实际操作中的数据科学家。他目前在美光科技、AI Time Journal 和 Tech in Asia 工作。他一直在帮助初创公司创始人和各种公司利用深度数据科学和行业专业知识解决问题。你可以通过 LinkedIn、Medium、Twitter 和 Facebook 联系他。
原文。已获授权重新发布。
相关:
-
特征预处理笔记:什么、为什么和怎么做
-
财务数据分析 – 数据处理 1:贷款资格预测
-
用 Python 整理数据
我们的前三大课程推荐
![]() 1. Google 网络安全证书 - 快速进入网络安全职业
1. Google 网络安全证书 - 快速进入网络安全职业![]() 2. Google 数据分析专业证书 - 提升你的数据分析技能
2. Google 数据分析专业证书 - 提升你的数据分析技能![]() 3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关话题
通过 Pandas 管道简化数据处理
原文:
www.kdnuggets.com/2022/08/simplify-data-processing-pandas-pipeline.html
图片由作者提供
介绍
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
在 R 语言中,我们使用%>%创建管道,并对数据集执行多个操作。类似地,为了创建机器学习管道,我们使用 scikit-learn 的 Pipeline 处理数据、构建和评估模型。那么,在 Python 中创建数据管道时我们用什么?我们使用 pandas 的 pipe 来应用可链式函数。
Pandas 管道教程
在本教程中,我们将学习创建 pandas 管道,并添加多个链式函数以执行数据处理和可视化。
我们将使用 Deepnote 环境运行代码,并展示外观清晰的 pandas 数据框。
入门
我们将使用read_csv()从 Kaggle 加载并展示 Mall Customer Segmentation 数据集。
import pandas as pd
data = pd.read_csv("Mall_Customers.csv")
data
它包含客户 ID、年龄、性别、收入和消费评分。
创建数据处理函数
现在编写简单的 Python 函数,这些函数接受一个或多个参数。每个函数必须以数据框作为第一个参数,以创建链式管道。
-
filter_male_income: 该函数接受两个列,并筛选出年收入大于 15 的男性客户数据。
-
mean_group: 它按单列对数据框进行分组并计算均值,并删除 CustomerID 列。
-
uppercase_column_name: 它将列名转换为大写。
-
bar_plot: 该函数使用单列并绘制条形图。它在后台使用
matplotlib.pyplot。
*# filtering by Gender and Annual Income*
def filter_male_income(dataframe, col1,col2):
return data[(data[col1] == "Male") & (data[col2] >= 15) ]
*# groupby mean and dropping ID columns*
def mean_group(dataframe, col):
return dataframe.groupby(col).mean().drop("CustomerID",axis=1)
*# changing column names to uppercase*
def uppercase_column_name(dataframe):
dataframe.columns = dataframe.columns.str.upper()
return dataframe
*# plot bar chart using pandas*
def bar_plot(dataframe, col):
return dataframe.plot(kind="bar", y=col, figsize=(15,10))
带有一个函数的管道
在这一部分,我们将创建一个包含单一函数的简单管道。我们将在 pandas dataframe(data)后添加.pipe(),并添加一个有两个参数的函数。在我们的案例中,这两个列是“Gender”和“Annual Income (k$)”。
data.pipe(filter_male_income, col1="Gender", col2="Annual Income (k$)")
带有多个函数的管道
让我们尝试一个稍复杂的示例,向管道中添加 2 个函数。要添加其他函数,只需在第一个管道函数后添加.pipe()。我们可以在数据管道中添加任意多个带有多个参数的管道。结果是可重复的,代码可读且简洁。
在我们的案例中,我们已筛选了数据集,按“年龄”分组,并将列名转换为大写字母。
这很简单,就像启动一个 Python 函数一样。
data.pipe(filter_male_income, col1="Gender", col2="Annual Income (k$)").pipe(
mean_group, "Age"
).pipe(uppercase_column_name)
一个完整的管道
一个完整的管道处理数据并显示一些分析结果。在我们的案例中,它是一个客户的年收入与年龄的简单条形图。我们已筛选数据框,按年龄分组,将列转换为大写字母,并绘制了条形图。
data.pipe(filter_male_income, col1="Gender", col2="Annual Income (k$)").pipe(
mean_group, "Age"
).pipe(uppercase_column_name).pipe(bar_plot,"ANNUAL INCOME (K$)")
结论
管道可以应用于 pandas 数据框和系列。在数据处理和实验阶段,它非常有效。在这里,你可以轻松切换函数以获得最佳解决方案。管道允许我们以结构化和组织化的方式将多个函数合并为单一操作。它是干净、可读且可重复的。你可以用它来简化数据处理阶段。
在本教程中,我们学习了 pandas 管道函数及其使用案例。我们还创建了单个和多个函数的多个管道。管道函数还可以用于高级过程,如数据分析、数据可视化和机器学习任务。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些在心理健康方面挣扎的学生构建一个 AI 产品。
相关主题
使用 Python 和 Scikit-learn 简化决策树的可解释性
原文:
www.kdnuggets.com/2017/05/simplifying-decision-tree-interpretation-decision-rules-python.html
在讨论分类器时,与许多更复杂的分类器(尤其是黑箱类型的分类器)相比,决策树通常被认为是容易解释的模型。这通常是正确的。
这尤其适用于从简单数据中创建的相对简单的模型。对于从大量(高维)数据中构建的复杂决策树,这一点就不那么适用了。即使是其他看似简单但深度和/或宽度较大的决策树,重分支的情况也可能很难追踪。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你在 IT 领域的组织
简洁的文本表示可以很好地总结决策树模型。此外,某些文本表示的功能超出了总结能力。例如,自动生成能够通过传递实例对未来数据进行分类的函数,在特定情况下可能会有所帮助。但我们不要偏离主题——可解释性是我们在这里讨论的目标。
本文将探讨几种简化决策树表示及其最终可解释性的方法。所有代码均为 Python,决策树建模使用 Scikit-learn。
构建分类器
首先,让我们使用我最喜欢的数据集,通过使用Scikit-learn 的决策树分类器在 Python 中构建一个简单的决策树,指定信息增益作为标准,其余则使用默认设置。由于在这篇文章中我们不关注对未见实例的分类,因此我们不会拆分数据,而是直接使用整个数据集来构建分类器。
import numpy as np
from sklearn import datasets
from sklearn import tree
# Load iris
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Build decision tree classifier
dt = tree.DecisionTreeClassifier(criterion='entropy')
dt.fit(X, y)
视觉化模型的表示
解释决策树的最简单方法之一是通过视觉效果,这可以通过 Scikit-learn 和这几行代码实现:
dotfile = open("dt.dot", 'w')
tree.export_graphviz(dt, out_file=dotfile, feature_names=iris.feature_names)
dotfile.close()
将创建的文件(在我们的示例中为'dt.dot')的内容复制到graphviz 渲染工具,我们可以得到以下决策树表示:
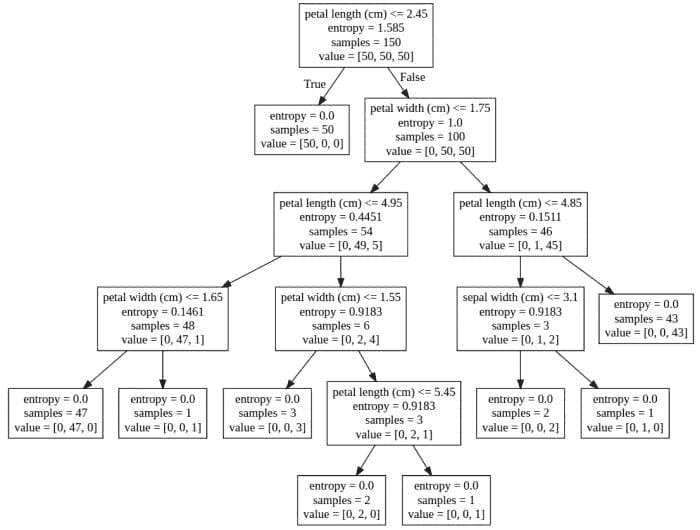
使用graphviz 渲染代理的决策树的可视化表示
将模型表示为一个函数
如本文开头所述,我们将探讨几种文本表示决策树的不同方法。
第一个是将决策树模型表示为一个函数。
from sklearn.tree import _tree
def tree_to_code(tree, feature_names):
"""
Outputs a decision tree model as a Python function
Parameters:
-----------
tree: decision tree model
The decision tree to represent as a function
feature_names: list
The feature names of the dataset used for building the decision tree
"""
tree_ = tree.tree_
feature_name = [
feature_names[i] if i != _tree.TREE_UNDEFINED else "undefined!"
for i in tree_.feature
]
print("def tree({}):".format(", ".join(feature_names)))
def recurse(node, depth):
indent = " " * depth
if tree_.feature[node] != _tree.TREE_UNDEFINED:
name = feature_name[node]
threshold = tree_.threshold[node]
print("{}if {} <= {}:".format(indent, name, threshold))
recurse(tree_.children_left[node], depth + 1)
print("{}else: # if {} > {}".format(indent, name, threshold))
recurse(tree_.children_right[node], depth + 1)
else:
print("{}return {}".format(indent, tree_.value[node]))
recurse(0, 1)
让我们调用这个函数并查看结果:
tree_to_code(dt, list(iris.feature_names))
def tree(sepal length (cm), sepal width (cm), petal length (cm), petal width (cm)):
if petal length (cm) <= 2.45000004768:
return [[ 50\. 0\. 0.]]
else: # if petal length (cm) > 2.45000004768
if petal width (cm) <= 1.75:
if petal length (cm) <= 4.94999980927:
if petal width (cm) <= 1.65000009537:
return [[ 0\. 47\. 0.]]
else: # if petal width (cm) > 1.65000009537
return [[ 0\. 0\. 1.]]
else: # if petal length (cm) > 4.94999980927
if petal width (cm) <= 1.54999995232:
return [[ 0\. 0\. 3.]]
else: # if petal width (cm) > 1.54999995232
if petal length (cm) <= 5.44999980927:
return [[ 0\. 2\. 0.]]
else: # if petal length (cm) > 5.44999980927
return [[ 0\. 0\. 1.]]
else: # if petal width (cm) > 1.75
if petal length (cm) <= 4.85000038147:
if sepal length (cm) <= 5.94999980927:
return [[ 0\. 1\. 0.]]
else: # if sepal length (cm) > 5.94999980927
return [[ 0\. 0\. 2.]]
else: # if petal length (cm) > 4.85000038147
return [[ 0\. 0\. 43.]]
有趣。让我们看看通过剥离一些“不必要的功能”是否可以提高可解释性,前提是这些功能不是必需的。
将模型表示为伪代码
接下来,对上述代码的轻微修改实现了本文标题所承诺的目标:一组用于表示决策树的决策规则,以略微少一点 Python 风格的伪代码形式。
def tree_to_pseudo(tree, feature_names):
"""
Outputs a decision tree model as if/then pseudocode
Parameters:
-----------
tree: decision tree model
The decision tree to represent as pseudocode
feature_names: list
The feature names of the dataset used for building the decision tree
"""
left = tree.tree_.children_left
right = tree.tree_.children_right
threshold = tree.tree_.threshold
features = [feature_names[i] for i in tree.tree_.feature]
value = tree.tree_.value
def recurse(left, right, threshold, features, node, depth=0):
indent = " " * depth
if (threshold[node] != -2):
print(indent,"if ( " + features[node] + " <= " + str(threshold[node]) + " ) {")
if left[node] != -1:
recurse (left, right, threshold, features, left[node], depth+1)
print(indent,"} else {")
if right[node] != -1:
recurse (left, right, threshold, features, right[node], depth+1)
print(indent,"}")
else:
print(indent,"return " + str(value[node]))
recurse(left, right, threshold, features, 0)
让我们测试这个函数:
tree_to_pseudo(dt, list(iris.feature_names))
if ( petal length (cm) <= 2.45000004768 ) {
return [[ 50\. 0\. 0.]]
} else {
if ( petal width (cm) <= 1.75 ) {
if ( petal length (cm) <= 4.94999980927 ) {
if ( petal width (cm) <= 1.65000009537 ) {
return [[ 0\. 47\. 0.]]
} else {
return [[ 0\. 0\. 1.]]
}
} else {
if ( petal width (cm) <= 1.54999995232 ) {
return [[ 0\. 0\. 3.]]
} else {
if ( petal length (cm) <= 5.44999980927 ) {
return [[ 0\. 2\. 0.]]
} else {
return [[ 0\. 0\. 1.]]
}
}
}
} else {
if ( petal length (cm) <= 4.85000038147 ) {
if ( sepal length (cm) <= 5.94999980927 ) {
return [[ 0\. 1\. 0.]]
} else {
return [[ 0\. 0\. 2.]]
}
} else {
return [[ 0\. 0\. 43.]]
}
}
}
这看起来也不错,在我计算机科学训练的思维中,使用恰当的 C 风格大括号使得代码比之前的尝试更具可读性。
这些珍宝让我想修改代码以获得真正的决策规则,我计划在完成本文后进行尝试。如果有任何值得注意的进展,我会回来在这里发布我的发现。
马修·梅奥 (@mattmayo13)是一名数据科学家,也是 KDnuggets 的主编,这是一个开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络和自动化机器学习方法。马修拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
了解更多相关内容
使用管道在 Scikit-Learn 中简化混合特征类型预处理
原文:
www.kdnuggets.com/2020/06/simplifying-mixed-feature-type-preprocessing-scikit-learn-pipelines.html
评论
假设我们要在 Python 中执行混合特征类型的预处理。为了我们的目的,假设这包括:
-
缩放数值型值
-
将分类值转换为独热编码
-
填充所有缺失值
进一步说,我们希望这尽可能地无痛、自动化,并集成到我们的机器学习工作流中。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 在 IT 方面支持你的组织
在 Python 机器学习生态系统中,以前可能通过直接操作 Pandas DataFrames 和/或使用 Numpy ndarray 操作,可能还结合一些 Scikit-learn 模块来实现,根据个人的偏好。虽然这些方法仍然完全可以接受,但现在所有这些操作也可以仅通过 Scikit-learn 完成。采用这种方法,它几乎可以完全自动化,并可以集成到 Scikit-learn 管道中,实现无缝实施和更容易的重现性。
所以让我们看看如何利用 Scikit-learn 轻松完成上述所有操作。

首先,导入我们在整个过程中所需的一切:
from sklearn.datasets import fetch_openml
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.compose import make_column_selector as selector
为了演示,我们使用泰坦尼克号数据集。我知道,我知道……很无聊。但它混合了数值型和分类变量,易于理解,而且大多数人对它有一定的熟悉度。所以让我们获取数据,读取它,并快速查看一下,以理解我们的特征预处理如何与特定数据相关。
# Fetch Titanic dataset
titanic = fetch_openml('titanic', version=1, as_frame=True) X = titanic.frame.drop('survived', axis=1)
y = titanic.frame['survived']
让我们回顾一下特征数据类型。
X.dtypes
name object
address float64
sex category
age float64
sibsp float64
parch float64
ticket object
fare float64
cabin object
embarked category
boat object
body float64
home.dest object
dtype: object
注意数值型和非数值型特征类型。我们将以无缝且有些自动化的方式对这些不同类型进行预处理。
在 0.20 版本中引入的ColumnTransformer旨在将 Scikit-learn 的变换器应用于单个数据集列,无论该列位于 Numpy 数组还是 Pandas DataFrame 中。
该估算器允许对输入的不同列或列子集进行单独变换,每个变换器生成的特征将被连接成一个单一的特征空间。这对于异质数据或列数据很有用,以将多个特征提取机制或变换合并为一个变换器。
这意味着你能够将单独的变换器应用于单独的列。这可能意味着,对于 Titanic 数据集,我们可能想要缩放数值列,并对分类列进行独热编码。也可能需要用列的中位数填补缺失的数值,并在特征缩放和编码之前用常数填补缺失的分类值。
为此,让我们创建一对Pipeline对象,分别用于上述的数值和分类变换。
# Scale numeric values
num_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
# One-hot encode categorical values
cat_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
现在让我们将这些变换器添加到ColumnTransfer对象中。我们可以指定具体应用这些变换的列,也可以使用列选择器来自动化这个过程。注意这一行
from sklearn.compose import make_column_selector as selector
从上述导入中。在下面的代码中,我们创建了一个num_transformer和一个cat_transformer,并将它们分别应用于所有float64类型的列和所有category类型的列。
preprocessor = ColumnTransformer(
transformers=[
('num', num_transformer, selector(dtype_include='float64')),
('cat', cat_transformer, selector(dtype_include='category'))])
如果你想将这添加到一个更完整的机器学习管道中,包括一个分类器,可以尝试如下:
clf = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', LogisticRegression())])
就这样。通过最小的努力,自动化预处理包括特征缩放、独热编码和缺失值插补,成为 Scikit-learn 管道的一部分。我将实际的变换和分类器的训练(如果你愿意的话,就是管道执行)留给读者作为练习。
除了更容易的可重复性、自动化的预处理应用于训练和随后测试数据的正确方式以及管道集成外,这种方法还允许轻松调整和修改预处理,而无需完全重做任务的早期部分。
这不会否定对特征选择、提取和工程的深思熟虑的必要性,但列变换器和列选择器的组合可以帮助轻松自动化一些数据预处理任务中更为单调的方面。
你可以在这里找到更多信息。
相关:
-
特征预处理笔记:什么,为什么,以及怎么做
-
Python 中的数据集拆分最佳实践
-
k-means 聚类的质心初始化方法
更多相关内容
完整指南:选择最佳机器学习课程
原文:
www.kdnuggets.com/2018/11/simplilearn-complete-guide-machine-learning-course.html
赞助广告。
由Simplilearn提供
为什么你应该选择机器学习作为职业?
随着机器学习市场规模预计将从 2016 年的 10.3 亿美元增长到 2022 年的 88.1 亿美元,可以说机器学习几乎正在接管世界。随着这一趋势,市场对了解机器学习各个方面的专业人士的需求也在增长。
根据《福布斯》的报道,从 2013 年到 2017 年,机器学习专利以 34%的年复合增长率(CAGR)增长,这使其成为所有授予专利中增长最快的第三类。此外,国际数据公司(IDC)预测,人工智能和机器学习的支出将从 2017 年的 120 亿美元增加到 2021 年的 576 亿美元。即使是Deloitte Global也预测,2018 年机器学习的试点和实施数量将是 2017 年的两倍,到 2020 年将再翻一番。

考虑到所有这些事实,可以说,机器学习作为一个行业正在持续增长。现在是通过报名参加一个机器学习课程来进入机器学习领域的最佳时机,该课程将提供实践知识,让你的未来更加光明。
在了解不同学习机器学习的方法之前,先看看机器学习的基础知识、不同类型的机器学习以及机器学习的各种应用。
学习机器学习的不同方法
- 在线机器学习课程
学习 机器学习 的最佳方法之一是报名参加在线教育项目或在线课程。市场上有多个在线课程提供商,以及不同的在线学习模式。你可以选择自学课程、虚拟课堂课程,或者两者结合的课程。在线学习的主要好处之一是它提供的灵活性。你可以在一天中的任何时间、最方便的时候进行学习,这与传统的课堂学习不同。此外,在线学习还可以节省大量时间,因为你不需要到实际地点上课。然而,你需要一个良好且稳定的互联网连接。根据你报名的具体项目,你也可能需要适应通过视频或聊天会话与他人互动。
- 大学课程 / 大学学位
在大学学习可以让你与教授面对面互动,但你无法获得在线课程所提供的灵活时间安排。此外,大学学位课程在培养实践技能方面通常并不理想。这是因为大学课程更多关注学术基础,而不是与行业专业人士互动和合作。当涉及到报考大学课程时,这通常意味着追求两年或四年的学位。
现如今,在科技行业取得成功并不一定需要这么多的高等教育。上技术学校或获得在线认证通常已经足够。事实上,许多行业专业人士倾向于认为,较短、更集中的学习实际上更好,因为你只关注你想学的内容。这也意味着你可以更快地完成你的学习计划。
- 通过自学 / 在职学习机器学习
任何对机器学习有基本了解的人都可以通过在线博客和资料来提升自己的技能。YouTube 上也有一些很棒的资源,比如 Simplilearn 提供的 机器学习播放列表,它提供了优秀的机器学习基础视频。但通过自学的最大缺点是学习基础知识会花费更长的时间,而且你可能会犯一些可避免但非常昂贵的错误。你也没有机会向行业专业人士学习和互动。自学时你可能会发现时间管理也很困难。
通过在线课程学习机器学习的好处
- 它以职业为导向
一个专业的机器学习课程在你希望在短时间内实现特定职业目标时非常合适。针对各种项目的专注课程可以教你如何在现实生活中应用机器学习。比如构建一个预测房价的模型,使用 LR 算法或 KNN 算法构建一个钓鱼网站检测器,或者构建一个 MNIST 分类器,这些项目提供了针对专业人士在特定领域提升技能的内容,而不是广泛的教育。大学学位通常有更长的、不确定的投资回报期,因为它们往往不针对特定目标。
- 节省时间
一个机器学习认证课程通常需要一到六个月的时间来完成,这取决于你的目标。另一方面,大学学位可能需要四年或更长时间。如果你打算通过专业学位来进一步教育,那么你需要的时间会更多。考虑到一个好的认证课程往往能提供你成功所需的所有技能,因此在追求机器学习职业时,是否真的需要这些年数的学业是值得质疑的。
- 节省成本
机器学习认证的费用不如大学学位昂贵,原因有几个:
-
-
认证课程的时长较短,因此,运营成本自然较低。
-
大多数知名的机器学习认证课程,比如Simplilearn 的机器学习认证课程,都是完全在线的,因此没有运营成本。学生也不需要担心上课时的交通和生活费用。另一方面,获得大学学位通常需要到校访问,这会增加整体教育费用。
-
-
灵活性
获得机器学习认证的一个巨大优势是,大多数课程都可以在线完成,只要你有良好的互联网连接,你就可以在任何地方学习。无论你是在家中、通勤途中,还是在度假,在线学习都能让你灵活地在任何地方和任何设备上学习。
- 培训非常吸引人
所有知名的在线认证提供者都依靠学生反馈来确定哪些讲师优秀,哪些不尽如人意。他们在设计未来的教育项目时会利用这些建设性的反馈。即使是拥有多年大学经验的资深教授,仍可能无法提供你所期望的实践学习体验或个性化关注。
- 个性化学习
在线学习可以帮助学生利用他们的优势,减少弱点,重点关注各种项目、实验室和知名助教的指导,比如Simplilearn 的课程所提供的那样。
好的在线机器学习课程
- Simplilearn 的机器学习认证课程
Simplilearn 的机器学习认证课程提供有关机器学习概念和技术的实用学习,包括监督学习和无监督学习、数学和启发式方面,以及动手建模来开发算法,并为机器学习工程师的角色做好准备。
一位机器学习专家通过在线实时课程进行授课。学生还可以终身访问自学模块。你可以通过四个实际的行业项目来实践所学的内容。该教育项目还提供来自教师的专门辅导,这些教师也是行业专家。
- Coursera 的机器学习课程
这个课程也是一个受欢迎的选择。它为学生提供了各种概念和深入的机器学习知识。然而,你可能需要在动手练习上做出一些妥协。你可能会发现这个课程灵活,可以根据你的方便安排课程,但学生可能无法终身访问学习材料和讲师支持。
- edX 的机器学习课程
哥伦比亚大学通过 edX 提供此课程。你可能会发现它更具权威性,但同样,你可能需要面对排课的灵活性问题,因为你会受限于大学的规定。此外,你可能无法频繁与讲师互动,也可能需要学习更多学术概念,而非从事实际的现实世界项目。
还有许多其他在线机器学习课程提供者,但上述一些是最受欢迎的选择。你可以根据自己的要求和他们提供的选择来选择其中任何一个。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织的 IT
更多相关话题
辛普森悖论及其在数据科学中的影响
原文:
www.kdnuggets.com/2023/03/simpson-paradox-implications-data-science.html
作者提供的图片
数据科学家、数据工程师和机器学习工程师大部分时间都在分析数据,并从中得出统计结论。然而,对于这些专业人员及任何查看数据的人来说,具备对真实世界的良好直觉是一项重要的技能。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
数据包含了几个变量,你可以考虑这些变量,但值得注意的是,它产生了有限维度的表示。在这里,你需要超越数据,发现隐藏的现实,以及如何将其应用到数据集中。
辛普森悖论向我们证明了在解释数据时保持怀疑的必要性,并确保我们应用真实世界的观点——不要仅仅从数据的角度看待问题。
什么是辛普森悖论?
1972 年,科林·R·布莱斯引入了“辛普森悖论”这一名称,也称为辛普森反转、尤尔-辛普森效应、合并悖论或反转悖论。
辛普森悖论指的是,当数据被分组时,某个趋势或结果出现,但当数据合并时,该趋势或结果会反转或消失。这是一个统计学悖论,根据数据如何分组,它可以从相同的数据得出两个相反的结论。
加州大学伯克利分校与辛普森悖论
辛普森悖论的一个经典例子是加州大学伯克利分校关于研究生招生性别偏见的研究。1973 年,在学年开始时,加州大学伯克利分校的研究生院录取了约 44%的男性申请者和 35%的女性申请者。学校担心可能会面临诉讼,因此请统计学家彼得·比克尔查看数据。
研究发现,在 6 个部门中,有 4 个部门存在显著的性别偏见,偏向女性,而在剩余的 2 个部门中没有显著的性别偏见。团队的发现显示,女性申请的是整体申请者比例较小的部门。
在辛普森悖论中,你需要考虑现实世界中的场景和可能隐藏的变量,这些变量不容易通过数据解释。在这个例子中,隐藏变量是更多女性申请了特定部门。这影响了被接受申请者的总体百分比,从而展示出数据最初存在的反向趋势。
团队随后得出结论,当他们考虑将学校划分为不同部门时,数据输出发生了变化。
下图解释了数据分组时趋势如何反转:
图片来自 维基百科
辛普森悖论使得数据处理变得更加复杂,并使决策过程变得更加困难。
如果你开始以不同的方式重新抽样数据,你会得出不同的结论。这自然会使你更难选择一个特定的准确结论来进一步深入。这意味着团队将不得不找到一个公平代表数据的最佳结论。
为什么辛普森悖论在数据科学中很重要?
在处理与数据相关的项目时,我们通常专注于数据并试图解释其想要传达的故事。但如果我们应用现实世界的知识,它会告诉我们一个完全不同的故事。
理解这一点的重要性为我们提供了更多机会,深入分析数据,帮助决策过程。辛普森悖论关注于分析洞察不足和项目知识整体缺乏如何误导我们并做出错误决策。
例如,我们看到实时数据分析的使用正在增加。越来越多的团队正在实施这一技术,以帮助检测模式,并利用这些洞察在短时间内做出决策。在关注如何基于当前实时数据改进公司时,实时数据分析是有效的。然而,这些短时间内的分析可能会导致误导性的信息,并掩盖数据展示的整体真实趋势。
错误的数据分析可能会阻碍公司发展。我们都知道,错误的决策总是会阻碍公司。因此,考虑辛普森悖论可以帮助公司理解数据的局限性、数据驱动因素和不同变量,并保持偏差低。
辛普森悖论帮助提醒数据工作者了解数据的重要性及其数据直觉水平。这时,许多数据专业人员的软技能将会显现,如批判性思维。
目标是寻找数据中存在的隐藏偏差和变量,这些可能在初次观察或高水平分析时不易发现。
结论
关于辛普森悖论需要考虑的一点是,过度的数据聚合可能很快变得无用,并开始引入偏差。另一方面,如果我们不聚合数据,数据可能会在信息和潜在模式上受到限制。
为了避免辛普森悖论,你需要彻底审查你的数据,并确保对当前的业务问题有良好的理解。
Nisha Arya 是 KDnuggets 的数据科学家、自由撰稿人和社区经理。她特别感兴趣于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能在延长人类寿命方面的不同方式。作为一个热心学习者,她寻求拓宽技术知识和写作技能,同时帮助指导他人。
更多相关内容
一个简化使用 Keras 进行图像分类的单一函数
原文:
www.kdnuggets.com/2019/09/single-function-streamline-image-classification-keras.html
评论
介绍
关于深度学习框架,如Keras和PyTorch,以及它们是如何强大且易于使用来构建和操作优秀的深度学习模型,已经有很多文章进行了讨论。
已经有很多教程/文章讨论了模型架构和优化器——例如卷积、最大池化、优化器如ADAM或RMSprop。
如果你只想要一个功能,能够自动从磁盘上的指定目录中提取图片,并返回一个完全训练好的神经网络模型,随时可以用于预测,这该怎么办?
因此,在本文中,我们专注于如何使用 Keras(TensorFlow)API 中的几个实用方法来简化此类模型的训练(特别是用于分类任务),并进行适当的数据预处理。
基本上,我们想要的是,
-
获取一些数据
-
将它们放入按类别排列的目录/文件夹中
-
使用最少的代码/麻烦训练神经网络模型
最终,我们的目标是编写一个实用工具函数,它只需输入存放训练图片的文件夹名称,就可以返回一个完全训练好的 CNN 模型。
数据集
我们在这个演示中使用了一个包含 4000 多张花卉图片的数据集。该数据集可以通过从 Kaggle 网站下载。
数据收集基于 Flickr、Google 图片、Yandex 图片。这些图片被分成五个类别,
-
雏菊,
-
郁金香,
-
玫瑰,
-
向日葵,
-
蒲公英。
每个类别大约有 800 张照片。照片分辨率不高,大约为 320 x 240 像素。照片的大小不一致,具有不同的比例。
然而,它们已经整齐地组织在五个目录中,并以相应的类别标签命名。我们可以利用这种组织方式,应用 Keras 方法来简化我们卷积网络的训练。
代码仓库
完整的 Jupyter notebook 见我的 GitHub 仓库中的这里。如果你喜欢,可以随意 Fork 并扩展它,并给它一个星标。
我们将在本文中使用代码的部分片段来展示重要的部分以作说明。
是否应该使用 GPU?
推荐在 GPU 上运行此脚本(使用 TensorFlow-GPU),因为我们将构建一个具有五个卷积层的 CNN,因此如果不使用某种 GPU,处理成千上万张图片的训练过程可能会计算密集且较慢。
对于 Flowers 数据集,在我那台配置较低的笔记本电脑上(配有 NVidia GTX 1060 Ti GPU(6 GB 视频 RAM)、Core i-7 8770 CPU、16 GB DDR4 RAM),单个 epoch 大约需要 1 分钟。
或者,你可以利用Google Colab,但加载和预处理数据集 可能会有些麻烦。
数据预处理
家务工作和显示图像
请注意,笔记本代码数据预处理部分的第一部分对于神经网络的训练不是必需的。这段代码仅用于说明目的,并展示一些训练图像作为示例。
在我的笔记本电脑上,数据存储在比我的笔记本文件夹高一级的文件夹中。这里是组织结构,
使用一些基本的 Python 代码,我们可以遍历子目录,计算图像数量,并展示其中的一些示例。
一些雏菊的图片,

还有一些美丽的玫瑰,

请注意,图片的大小和纵横比各不相同。
构建 ImageDataGenerator 对象
这就是实际魔法发生的地方。
ImageDataGenerator 类的官方描述 说 "生成带有实时数据增强的张量图像数据批次。这些数据将被循环处理(以批次形式)。"
基本上,它可以用来 增强图像数据,提供大量内置的预处理功能,如缩放、平移、旋转、噪声、去白化等。现在,我们只使用 rescale 属性将图像张量值缩放到 0 和 1 之间。
这里有一篇关于该类的有用文章。
使用 Keras ImageDataGenerator 进行图像增强
一个关于将我们自定义生成器与 Keras 的 ImageDataGenerator 结合使用以执行各种操作的博客…
但对于当前演示来说,这个类的真正实用性在于超实用的方法 flow_from_directory,它可以 一个接一个地从指定目录中提取图像文件。
请注意,这个目录必须是所有单独类的子目录可以单独存储的顶级目录。flow_from_directory方法会自动扫描所有子目录,并获取带有适当标签的图像。
我们可以指定类名(就像我们在这里使用classes参数一样),但这是可选的。不过,稍后我们会看到,这对于从大量数据中选择性训练是多么有用。
另一个有用的参数是target_size,它使我们能够将源图像调整为统一的 200 x 200 尺寸,无论原始图像的大小如何。这是一种通过简单函数参数进行的酷炫图像处理。
我们还指定了批量大小。如果你不指定batch_size,默认情况下将设置为 32。
我们选择class_mode为categorical,因为我们在这里进行的是多类分类。
当你运行这段代码时,Keras 函数会扫描顶级目录,找到所有图像文件,并自动用正确的类标签(基于它们所在的子目录)对它们进行标记。
这不是很酷吗?
但等等,还有更多。这是一个Python 生成器对象,这意味着它将用于在训练过程中‘逐一产生数据’。这大大减少了处理非常大数据集的问题,这些数据集的内容无法一次性装入内存。查看这篇文章以更好地理解,
生成器表达式是 Python 中的一个有趣特性,它允许我们创建惰性生成的可迭代对象…
构建卷积网络模型
正如承诺的,我们不会花时间或精力分析 CNN 模型背后的代码。简而言之,它由五个卷积层/最大池化层和最后的 128 个神经元组成,随后是一个 5 神经元的输出层,并使用 softmax 激活进行多类分类。
我们使用 RMSprop,初始学习率为 0.001。
这是代码再现。随意尝试网络架构和优化器。
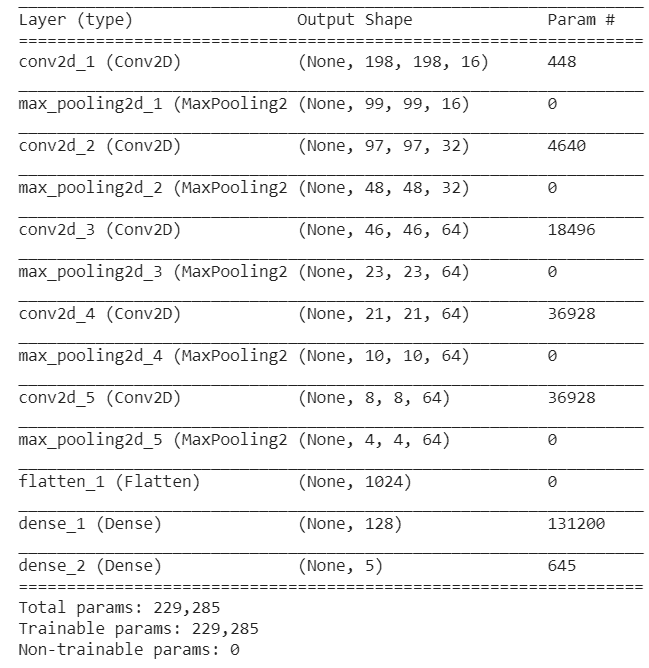
使用‘fit_generator’方法进行训练
我们之前讨论了train_generator对象在flow_from_directory方法及其参数下所做的酷炫事情。
现在,我们在上面定义的 CNN 模型的fit_generator方法中使用这个对象。
注意 steps_per_epoch 参数的设置,因为 train_generator 是一个通用的 Python 生成器,它不会停止,因此 fit_generator 无法知道特定的轮次何时结束以及下一轮次何时开始。我们必须让它知道一个轮次中的步骤数。在大多数情况下,这是总训练样本长度除以批量大小。
在上一节中,我们找出了总样本量为 total_sample。因此,在这种情况下,steps_per_epoch 设置为 int(total_sample/batch_size) 即 34。因此,你将在下面的训练日志中看到每轮 34 个步骤。
部分训练日志…

我们可以使用常见的绘图代码检查准确率/损失。
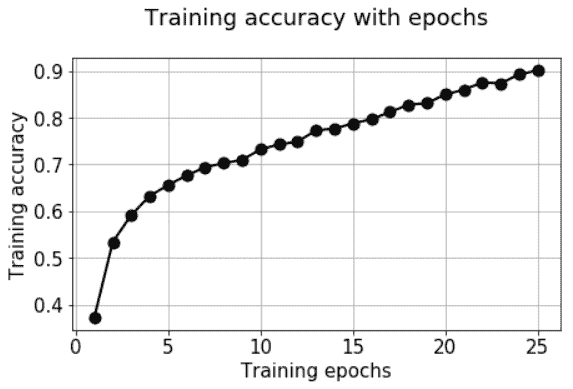
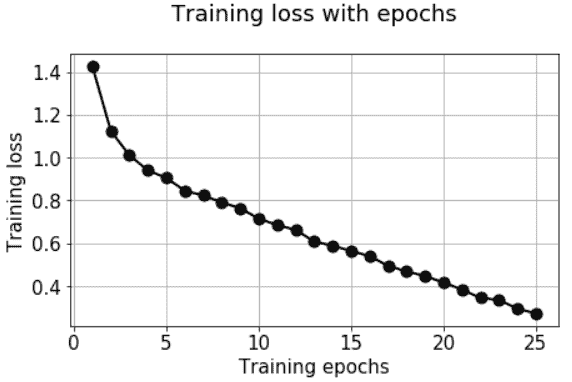
好的,我们到目前为止完成了什么?
我们已经能够利用 Keras ImageDataGenerator 和 fit_generator 方法从单个目录自动提取图像,对其进行标记、调整大小和缩放,并逐个(以批次)流动用于训练神经网络。
我们可以将这些都封装在一个函数中吗?
将这些都封装在一个函数中吗?
制作有用的软件/计算系统的核心目标之一是 抽象,即隐藏内部计算和数据操作的详细信息,并向用户呈现一个简单直观的工作接口/API。
作为实现目标的一个练习,我们可以尝试将我们上面遵循的过程封装在一个函数中。以下是思路,
目标是提供一个灵活的 API,并具有有用的参数
当你设计高层 API 时,为什么不考虑比这次特定的花卉数据集演示所需的更通用的方案?考虑到这一点,我们可以想到为这个函数提供额外的参数,使其适用于其他图像分类场景(我们将很快看到一个示例)。
具体来说,我们在函数中提供以下参数,
-
train_directory: 存储训练图像的目录,图像按照类别分开存放。这些文件夹应该按照类别命名。 -
target_size: 训练图像的目标大小。例如 (200,200) 的元组 -
classes: 包含要进行训练的类别的 Python 列表。这会强制生成器从train_directory中选择特定文件,而不是查看所有数据。 -
batch_size: 训练的批量大小 -
num_epochs: 训练的轮数 -
num_classes: 输出类别的数量 -
verbose: 训练的详细程度,传递给fit_generator方法
当然,我们可以提供额外的参数以对应整个模型架构或优化器设置。本文不集中于这些问题,因此我们保持其简洁。
再次说明,完整代码在 Github 仓库中。以下,我们只展示了文档字符串部分以强调将其做成灵活 API 的重点,
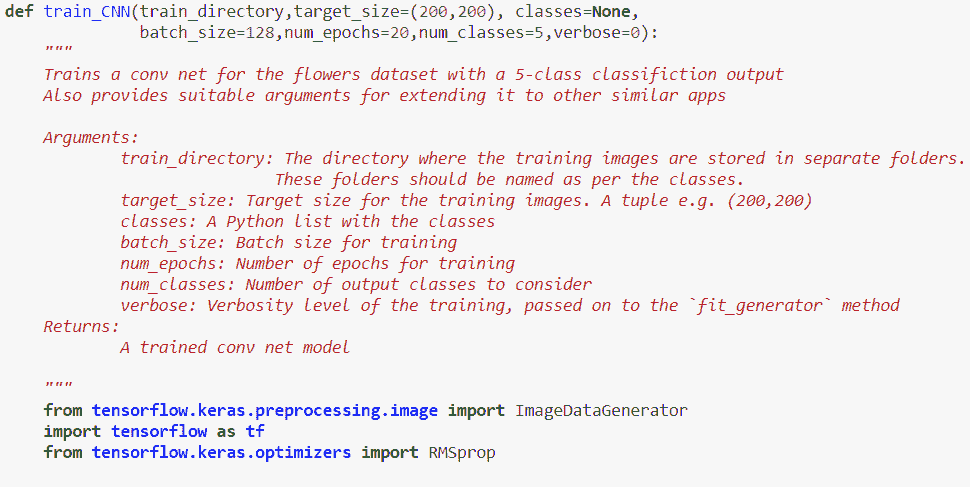
测试我们的实用函数
现在我们通过简单地提供一个文件夹/目录名称并获得一个可以用于预测的训练模型来测试我们的 train_CNN 函数!
让我们假设现在只想训练“雏菊”、“玫瑰”和“郁金香”,忽略其他两种花的数据。我们只需将一个列表传递给 classes 参数。在这种情况下,不要忘记将 num_classes 参数设置为 3。你会注意到,由于训练样本数量少于上述情况,每个 epoch 的步骤自动减少为 20。
同样,请注意,verbose 在上述函数中默认设置为 0,因此如果你希望监控训练的进度,你需要明确指定 verbose=1!
基本上,我们现在只用两行代码就能获得一个完全训练好的 CNN 模型!
该函数对另一个数据集是否有用?
这是对该函数实用性的严格测试。
我们能否直接应用于另一个数据集而无需太多修改?
Caltech-101
一个丰富而又易于管理的图像分类数据集是 Caltech-101。通过易于管理的意思是,它不如 ImageNet 数据库庞大,这需要大规模的硬件基础设施来训练,因此,在你的笔记本电脑上快速测试酷点子超出范围,但它足够多样化,可以练习和学习卷积神经网络的技巧。

Caltech-101 是一个包含 101 类物体的图像数据集。每个类别大约有 40 到 800 张图像。大多数类别有约 50 张图像。每张图像的大小大约为 300 x 200 像素。
该数据集由费菲·李教授及其同事(Marco Andreetto 和 Marc ‘Aurelio Ranzato)于 2003 年在加州理工学院建立,当时她还是一名研究生。因此,我们可以推测,Caltech-101 是她在 ImageNet 上工作的直接前身。
用两行代码训练 Caltech-101
我们下载了数据集并将其解压缩到与之前相同的 Data 文件夹中。目录如下所示,

所以,我们得到了我们想要的——一个包含训练图像的顶级目录及其子目录。
然后,和之前一样的两行代码,
我们所做的只是将该目录的地址传递给函数,并选择我们希望训练模型的图像类别。假设我们想训练模型以区分‘杯子’和‘螃蟹’。我们可以像之前一样将它们的名称作为列表传递给classes参数。
此外,请注意,由于训练图像的总数比 Flowers 数据集要少得多,我们可能需要显著减少batch_size,如果batch_size高于总样本数,则steps_per_epoch将等于 0,这会在训练过程中产生错误。
太棒了!函数找到了相关的图像(总共 130 张),并训练了模型,每批 4 张图像,即每个周期 33 步。

测试我们的模型
如我们所见,只需将训练图像的目录地址传递给函数,即可训练一个 CNN 模型,并使用我们选择的类别。
模型效果如何?让我们通过用从互联网上下载的随机图片测试它来找出答案。
请记住,Caltech-101 数据集是由 Fei Fei Li 和同事们于 2003 年创建的。因此,互联网上任何较新的图像都不太可能出现在数据集中。
我们下载了以下‘螃蟹’和‘杯子’的随机图片。


在进行了一些基本的图像处理(调整大小和扩展维度以匹配模型)后,我们得到了以下结果,
model_caltech101.predict(img_crab)>> array([[1., 0.]], dtype=float32)
模型正确预测了螃蟹测试图像的类别。
model_caltech101.predict(img_cup)>> array([[0., 1.]], dtype=float32)

模型正确预测了杯子测试图像的类别。
那这个怎么办?
model_caltech101.predict(img_crab_cup)>> array([[0., 1.]], dtype=float32)
因此,模型将测试图像预测为杯子。几乎公平,不是吗?
验证集及其他扩展
到目前为止,在fit_generator中我们只有一个train_generator对象用于训练。但验证集怎么办?它遵循与train_generator完全相同的概念。您可以从训练图像中随机分割出一个验证集,将其放在一个单独的目录中(与训练目录相同的子目录结构),然后您应该能够将其传递给fit_generator函数。
ImageDataGenerator类中甚至有一个flow_from_dataframe方法,您可以将图像文件的名称作为 Pandas DataFrame 中的内容传递,训练即可进行。
欢迎随意尝试这些扩展功能。
总结
在本文中,我们介绍了几个 Keras 的实用方法,可以帮助我们构建一个紧凑的实用函数,以高效地训练一个用于图像分类任务的 CNN 模型。如果我们可以将训练图像组织在一个共同目录下的子目录中,那么这个函数可能只需几行代码即可训练模型。
这样做是有道理的,因为与其使用其他库(如 PIL 或 Scikit-image)单独抓取和预处理图像,不如利用这些内置的类/方法和我们的实用函数,我们可以将代码/数据流程完全保持在 Keras 内部,以紧凑的方式训练 CNN 模型。
如果你有任何问题或想法要分享,请通过 tirthajyoti[AT]gmail.com 联系作者。此外,你还可以查看作者的 GitHub** 仓库 **,获取其他有趣的 Python、R 和机器学习资源代码片段。如果你像我一样,对机器学习/数据科学充满热情,请随时 在 LinkedIn 上添加我 或 在 Twitter 上关注我。
原文。经许可转载。
相关:
-
面向数据科学家的面向对象编程:构建你的机器学习估计器
-
简单的面向对象编程如何提升你的深度学习原型
-
本福特定律是什么?它为何对数据科学如此重要?
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关话题
快速了解单行探索性数据分析
原文:
www.kdnuggets.com/2021/07/single-line-exploratory-data-analysis.html
comments
由 Harsha Mandala,JNTUH 工程学院 Jagityala 的学生
探索性数据分析或EDA是系统检查数据的重要步骤。EDA是一个调查数据集的过程,用于发现模式或找出其主要特征,通常采用视觉方法。
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
使用单行代码执行EDA
这是你如何使用 D-Tale 用一行代码执行 EDA。
-
安装 D-Tale 包 dtale.PyPi。
-
复制代码 '
pip install dtale' 并确保下载最新版本。 -
将代码粘贴到 Anaconda 提示符或任何 Python 提示符中,然后按回车。
在 Juptyer Notebook(任何 Python notebook)中导入 Seaborn 并加载数据集。像 'iris'、'titanic'、'Sample-Superstore' 等数据集分析起来很复杂。像 ‘绘制不同图表’、‘网络查看器’、‘预测性电源来源’ 和 ‘相关性’ 等操作都可以在没有任何编码的情况下完成。
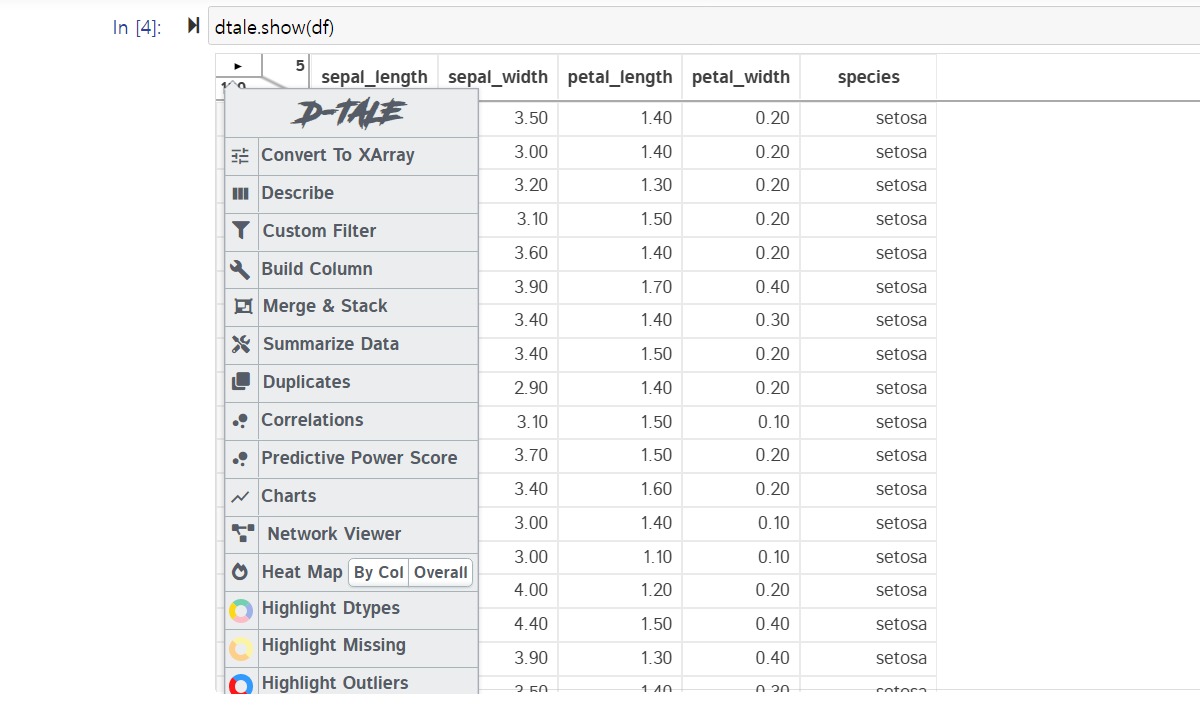
描述数据
所有基本统计细节,如最小值、最大值、标准偏差 (std)、均值 (or) 平均值、中位数等,可以按类别处理。
点击‘代码导出’以复制、粘贴代码
每个分析的数据及其代码按照方法直接放置在 HTML 中。代码可以复制粘贴到笔记本中,并且包含注释,使其更具用户友好性。
绘制图表
根据你选择的行、列或变量,只需点击几下即可更轻松地访问所有类型的图表。
相关性
你可以在选择后直接显示相关值并绘制不同变量相关值的图表。
像 dataprep、dataproc 和 dtale 这样的包可以加快数据科学的速度。这些包通过最少的代码简化了整个 EDA 过程。
个人简介: 是 JNTUH 工程学院 Jagityala 的学生。
原始文章。经许可转载。
相关:
-
Pandas Profiling:用于 EDA 的一行神奇代码
-
使用新的 Sweetviz Python 库更快了解你的数据
-
仅用两行代码进行强大的探索性数据分析
更多相关话题
一个错误如何浪费了我 3 年的数据科学旅程
原文:
www.kdnuggets.com/2021/06/single-mistake-wasted-3-years-data-science.html
评论
由 Pranjal Saxena,数据科学家,人工智能领域顶级写手

照片由 Julia M Cameron 提供,来自 Pexels
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT 支持
我在 2016 年开始了我的数据科学之旅。当时,机器学习的训练营非常受欢迎。课程唯一的要求是基础 Python 知识。我感到非常高兴,因为那时我经常玩 Python 代码,所以我选择了这门课程。
人们学习新事物时的惯常做法是尽量从不同地方收集尽可能多的资料。我们可能认为这些资源能帮助我们学到更多。而且,拥有更多种类的材料,你就有更多选择来选择合适的资源。但这其实是错误的。
我在 2016 年收集的大部分资源仍在我的 D: 盘中,我还没看过。但是,有一门课程我完成了 70%,那就是机器学习训练营课程。而我完成那门课程的原因是——课程容易跟随,一切都简单明了。
当我们处于机器学习领域时,我们可能会幻想在不知道算法背后思想的情况下构建模型。那个训练营课程主要集中在实现部分,而非概念部分,这就是我犯大错误的地方。我抱着学会机器学习的错误希望。
机器学习不仅仅是导入库、输入数据和获取结果。它更多的是算法背后的知识,这帮助我们为数据选择正确的算法,以获得更好的结果。
自主学习课程只是安眠药
自学课程提供的是被动学习,这对于机器学习并不适合。在这里,你可以接触到具有不同层次、激活函数、反向传播、前向传播等许多内容的神经网络,这些是单个人在自学课程中无法覆盖的。而且,自学课程中没有人会分享那些技巧——通常这些课程是免费的或便宜得多。
我像其他人一样,信任机器学习的自学课程,在那里一切都是由别人完成的。我坐在那里,只是观看视频教程来构建完整的机器学习模型,而自己甚至没有尝试过一行代码。然后,对仅仅通过观看这些视频来学习机器学习抱有虚假的希望。
我并不反对自学课程。这取决于学习的领域。自学课程适合学习吉他,因为我们只需要一把吉他来尝试。
行业专家是正确的选择
在尝试了三年的不同自学课程后,我发现我甚至无法为特定问题选择最合适的算法。我对简单的建模过程一无所知。我只知道导入某些库并传递数据以获取回归和分类问题的输出。但是,如何解释这些输出,我没有任何线索。
最后,有一天,我的一位同事建议加入一个由行业专家授课的机构。那天我觉得这只是一种浪费,因为他们的收费是自学课程的十倍。
无论如何,我加入了在线直播课程,并观察到了变化。通过直播课程的积极学习给了我很大的提升。逐步构建神经网络的过程给了我另一种提升。最主要的好处是每天给我们的作业。
我感受到的主要区别有以下几点:我可以联系讲师解答任何疑问;在实时的行业场景中工作,享受专业级的内容,这些都是我们在自学课程中无法获得的。
大多数在互联网上免费提供的课程结构不佳,这就是机器学习的秘密。构建任何模型都有一个逐步的过程。首先,我们需要学习算法,获取数据,清理数据,找出最佳特征,拆分数据,训练模型,验证模型,然后进行推理。如果我们想获得更好的结果,就不能错过任何一步。
最终的想法
在上述文章中,我们讨论了向行业专家学习的重要性,以了解机器学习建模的正确流程。否则,你将不断尝试许多免费的资源,却无法理解建模的适当流程——所以,这些资源是没用的。
我希望你喜欢这篇文章。
感谢阅读!
如果你想要更多关于数据科学和技术的精彩文章,这里是我的新闻通讯。
感谢 Anupam Chugh。
觉得这个故事有趣吗?在 Medium 上关注我(Pranjal)。如果你有私人问题,欢迎通过Linkedin联系我。如果你希望直接收到更多关于数据科学和技术的精彩文章,可以订阅我的免费新闻通讯:Pranjal’s Newsletter。
原文。经许可转载。
相关:
-
未来 5 年数据科学职位会短缺吗?
-
数据科学家、数据工程师及其他数据职业解析
-
如何成为数据科学家的指南(逐步方法)
更多相关话题
培训冠军:构建深度神经网络以进行大数据分析
原文:
www.kdnuggets.com/2019/04/sisense-deep-neural-nets-big-data-analytics.html
赞助文章。
作者:Nir Regev, Sisense。
数据的世界现在就是大数据的世界。魔 genie 已经释放,再也无法回到过去。我们每天都在生成越来越多的数据,而生成的数据集也变得越来越复杂。传统上,处理这些数据集的方法是扩展计算资源以处理更大的数据集。然而,这在全球范围内长期来看并不可行,对于资源有限的小型组织来说,短期内也难以维持。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业之路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT
更复杂的是,为了实现与大数据集的真正互动,用户查询需要接近实时的响应速度。这对最强大的大规模系统来说也是一项挑战。近似查询处理(AQP)消除了查询整个大数据集的需求,并能够迅速提供可用的结果。
Sisense Hunch™
Sisense Hunch™ 是一种处理大数据集的新方法,利用 AQP 技术构建深度神经网络(DNNs),这些网络经过训练以学习查询与结果之间的关系。这为用户提供了一个快速、可扩展的推理层,用户可以在此交互式查询以获得可操作的洞察。大型数据批次可以由 DNN 近似处理,DNN 利用图形处理单元(GPU)进行并行处理。此外,由于 Hunch 的 DNN 通常在 Mb 级别,因此可以轻松部署和分发给数千个用户或物联网设备,将极其快速的大数据分析几乎放置在任何地方。在边缘或用户可以从中受益的任何地方嵌入大数据分析,对于处理这些庞大数据集来说是一个巨大的飞跃。Sisense Hunch 平衡了速度、资源消耗和准确性,并为用户提供了无与伦比的灵活性,以决定将这些洞察应用于何处。
Hunch 系统的强大之处在于 DNN 训练过程,最终生成查询近似模型。该过程分为三个阶段:生成人工SQL 查询,获取训练集的标签(即在数据库上执行查询),最后使用实时生成的查询编码器将查询编码为数字张量。一旦创建了这个训练集,Hunch 使用有监督的方法来学习如何近似训练集查询。
训练过程
生成 SQL 查询
为了近似一个给定数据集可能出现的各种查询,Hunch 自主生成了一套强大的查询集。
这是正式的查询结构描述:

一个 Hunch 生成的查询示例是:
“从表中选择 AVG(sales) 其中 store_type 为 (‘online’) 且 computer_type 为 (‘Mac’) 且小时在 20 到 23 之间,hdisk_tb_size 在 1 和 5 之间”
这个阶段的最终目标是生成一个大规模的代表性聚合 SQL 查询集,以覆盖原始数据的许多(用户导向)方面。为了实现这一点,系统首先从原始数据中提取统计值(数据分布)。
对于每一列具有连续数字值的列,算法计算四分位数分布(最小值、25%、中位数、75%、最大值)。然后,使用这些信息从适合列数值边界的均匀分布中抽取值。系统还执行“Group By”查询,这加速了训练集的生成,主要是因为所有名义列值的排列组合可以在一条数据路径中获得。此外,在我们方法支持的查询格式中,“WHERE”子句语句通过“AND”运算符连接,因此语句的顺序并不重要。为了确保 DNN 不学习特定语句的顺序,我们的方法在构建查询之前会随机打乱语句。这是故意为之,以迫使 DNN 学习近似具有不同“WHERE”子句顺序的语义相同的查询。
标记训练集
为了训练深度神经网络(DNN),构建一个有监督的数据集需要真实的查询结果。为此,我们的方法对数据集执行生成的查询集。由于 DNN 需要相对大量的训练样本,系统使用并发技术生成并执行数十万条查询,以优化成本。然而,这个过程对于每个数据集仅执行一次。当新数据到达,需要生成新查询时,Hunch 使用增量(迁移)学习(稍后会详细介绍)。这种方法在训练集生成阶段和 DNN 训练阶段都节省了时间、精力和成本。
编码查询
由于 DNN 只能处理数字输入,我们开发了一个编码模型,将查询编码为数字矩阵。这个目标通过一个在生成 SQL 查询时动态构建的编码器模型来实现,利用了向量嵌入技术。
编码器的设计目的是通过利用专有嵌入技术,将拥有数百万个不同值的数据集压缩为轻量级内存占用的数字张量。
通过增量学习应对新数据
当新数据被添加到数据集中时,Hunch 需要调整 DNN 以根据新数据近似查询。基于之前的学习过程,Hunch 利用迁移学习,这意味着 DNN 将从其最后的权重状态开始训练,对抗一个新的训练集,该训练集是使用先前的 DNN 和新数据生成的。
评估与分发
一旦训练完成,我们使用一组准确性指标来评估模型的近似度。我们使用标准化均方根误差(NRMSE)来测量模型在保留测试集上的准确性。当 NRMSE 收敛到一个阈值以下时,Hunch 将围绕 DNN 发布一个云 API 端点。然后,用户或 IoT 设备可以发送查询请求。最终用户可以从快速响应和固定查询延迟(与原始数据大小无关!)以及在各种环境中处理大数据时的互动性中获益。
结论
仅仅因为我们现在生活在一个大数据的世界中,并不意味着我们需要放弃与数据互动和真正理解它的能力。深度神经网络 使用近似查询处理为用户提供了一种处理这些庞大数据集、提取强大见解并将这些见解应用于 IoT 和人类使用的方式——这一切都不需要巨大的技术投资或成本。尽管大数据将继续增长,但像 Hunch 这样的技术将帮助人类保持主导地位。
图表 A:1,000,000,000 行、250GB 数据集的查询结果和预测
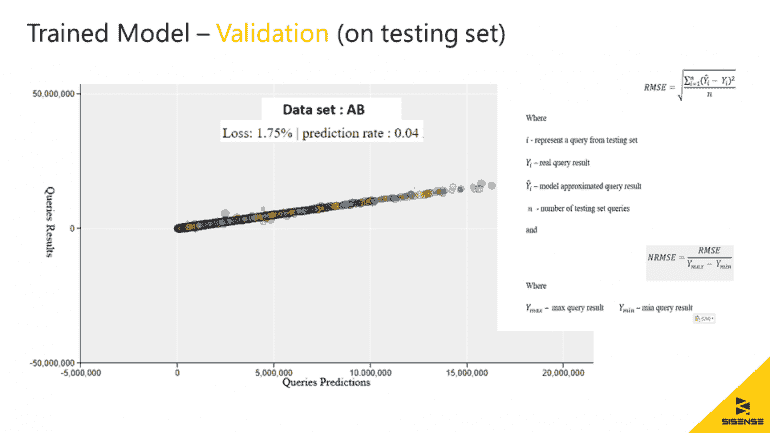
原文。经许可转载。
更多相关话题
精通数据准备的六个步骤
原文:
www.kdnuggets.com/2018/12/six-steps-master-machine-learning-data-preparation.html
评论
由Paxata的副总裁 David Levinger 撰写

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织在 IT 方面
今天的组织继续寻找快速而准确地准备数据的方法,以解决数据挑战并启用机器学习(ML)。但在将数据带入机器学习模型或其他分析项目之前,确保数据干净、一致和准确是很重要的。由于今天的大部分分析依赖于数据的背景,这项任务最好由最接近数据实际表示内容的人完成;即能够将直觉、理论和业务知识应用于数据的业务领域专家。
不幸的是,商业用户通常没有数据科学技能,因此弥合这一差距可能会决定从数据中快速获得价值。结果,许多人正在应用数据准备(DP)来帮助数据科学家和机器学习从业者快速准备和标注企业数据,以扩展数据在企业中用于分析工作负载的价值。
数据收集和准备如何成为可信机器学习模型的基础
要创建成功的机器学习模型,组织必须具备在部署到生产环境之前对其进行训练、测试和验证的能力。数据准备技术被用于创建现代机器学习所需的干净且经过标注的基础,然而,良好的数据准备(DP)通常比机器学习过程中的其他任何部分耗时更长。
缩短数据准备所需的时间变得越来越重要,因为这留出了更多的时间来测试、调整和优化模型,以创造更大的价值。为了同时为分析和机器学习计划准备数据,团队可以加速机器学习和数据科学项目,以提供沉浸式的业务消费者体验,通过遵循六个关键步骤来加速和自动化数据到洞察的管道。
步骤 1:数据收集
这是迄今为止最重要的第一步,因为它解决了常见挑战,包括:
-
自动确定存储在 .csv(逗号分隔)文件中的数据字符串的相关属性。
-
将高度嵌套的数据结构(如 XML 或 JSON 文件中的数据)解析成表格形式,以便于扫描和模式检测。
-
从外部存储库中搜索和识别相关数据。
然而,在考虑数据处理解决方案时,请确保它可以将多个文件合并为一个输入,例如,当你有一个表示每日交易的文件集合,但你的机器学习模型需要处理一年的数据时。此外,还要确保有应急计划来解决数据集和机器学习模型中与采样和偏差相关的问题。
步骤 2:数据探索和分析
一旦数据收集完毕,就需要评估数据的状态,包括查找趋势、异常值、例外、不正确、不一致、缺失或偏斜的信息。这一点很重要,因为源数据将影响模型的所有发现,因此确保其不包含潜在的偏见至关重要。例如,如果你在全国范围内查看客户行为,但只从有限的样本中提取数据,你可能会错过重要的地理区域。这是发现可能错误地影响模型发现的问题的时机,应该关注整个数据集,而不仅仅是部分或样本数据集。
步骤 3:格式化数据以保持一致性
准备优秀数据的下一步是确保数据格式与机器学习模型最匹配。如果你从不同来源汇总数据,或如果数据集由多个利益相关者手动更新,你可能会发现数据格式上的异常(例如:USD5.50 与$5.50)。同样,标准化列中的值(例如,可能会拼写或缩写的州名)将确保数据正确汇总。统一的数据格式可以消除这些错误,使整个数据集使用相同的输入格式协议。
步骤 4:提高数据质量
在这里,首先要制定一个处理错误数据、缺失值、极端值和异常值的策略。如果自助数据准备工具内置了智能功能,可以帮助将来自不同数据集的数据属性匹配并智能地合并它们,那么这些工具可以提供帮助。例如,如果一个数据集中有“FIRST NAME”和“LAST NAME”列,而另一个数据集中有一个名为 CUSTOMER 的列,似乎包含了合并的 FIRST 和 LAST NAME,智能算法应该能够确定一种匹配这些列并将数据集合并以获取客户单一视图的方法。
对于连续变量,确保使用直方图来查看数据的分布并减少偏斜。务必检查超出接受范围的记录。这些“异常值”可能是输入错误,也可能是真实且有意义的结果,因为重复或类似的值可能携带相同的信息,应该被消除。同样,在自动删除所有缺失值的记录之前要小心,因为过多的删除可能会使数据集失真,不再反映现实世界的情况。
第 5 步:特征工程
这一步涉及将原始数据转化为更好地代表模式的特征的艺术与科学。例如,可以将数据分解成多个部分以捕捉更具体的关系,例如按周几分析销售表现,而不仅仅是按月或年。在这种情况下,将日期中的“周一; 06.19.2017”作为一个单独的分类值可能会为算法提供更相关的信息。
第 6 步:将数据拆分为训练集和评估集
最后的步骤是将数据拆分为两个集合:一个用于训练算法,另一个用于评估目的。确保选择不重叠的数据子集作为训练集和评估集,以确保适当的测试。投资于提供版本控制和目录功能的工具,这些工具不仅包括原始源数据,还包括用于机器学习算法的准备数据及其之间的关系。这样,你可以追溯预测结果到输入数据,以便随着时间的推移精炼和优化你的模型。
加速业务绩效 – 数据准备如何支持机器学习并解决数据挑战
数据准备长期以来被认可为帮助商业领导者和分析师准备和处理用于分析、操作和合规要求的数据。运行在 Amazon Web Services (AWS)和 Azure 上的自助数据准备工具通过利用云环境的众多有价值的属性,将其提升到一个新的水平。
结果是,最接近数据且最了解其业务背景的业务用户,可以利用内置智能和智能算法快速准确地准备数据集。他们可以在一个直观的、可视化的应用程序中进行数据访问、探索、塑造、协作和发布,通过点击而非编写代码来完成,并且具备完整的治理和安全性。IT 专业人员能够维护企业和云数据源中数据量和种类的规模,以支持即时和可重复的数据服务需求。
像 DP 这样的解决方案解决了许多数据挑战,并启用增强应用程序的机器智能的 ML 和数据科学工作流。更重要的是,它使他们能够按需将数据转化为信息,赋能组织中的每个人、每个过程和每个系统,以提高智能水平。
简历: David Levinger 是 Paxata 的副总裁,负责开发和云操作,Paxata 是企业级自助数据准备分析的开创者和领导者。欲了解更多信息,请访问 www.paxata.com 或在 Twitter、LinkedIn、Facebook 或 YouTube 上与公司互动。
原始内容。经授权转载。
相关:
-
掌握数据准备与 Python 的 7 个步骤
-
掌握机器学习与 Python 的 7 个步骤
-
掌握机器学习与 Python 的更多 7 个步骤
更多相关主题
在小公司建立数据科学团队的六个建议
原文:
www.kdnuggets.com/2021/01/six-tips-building-data-science-team-small-company.html
评论
作者 Zoe Zbar,NYCDSA 市场推广员 & Raul Vallejo,ION 信用总监

我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你在 IT 方面的组织
当一家公司决定首次利用其数据时,这可能是一项艰巨的任务。许多企业并不完全了解建立数据科学部门所需的全部内容。如果你是被聘用来实现这一目标的数据科学家,我们有一些建议可以帮助你直面这个任务。
提示 #1: 分解公司中最重要的交付成果。
成为公司唯一的数据科学家是很棘手的。你可能被期望在所有与数据或代码相关的事务上都是专家。一个好的起点是分解公司中最重要的交付成果。了解这些交付成果并将其拆解,直到你能够列出最重要的数据源和处理步骤,对于理解公司需要完成的任务至关重要。
提示 #2: 利用项目规划实践
保持组织性是建立成功团队的最重要方面之一,但你不必重新发明轮子。有许多项目规划实践可以帮助为你的数据流程提供结构。例如,《数据科学需求层次结构》是一个很好的资源,有助于在规划过程中保持正轨和有序。
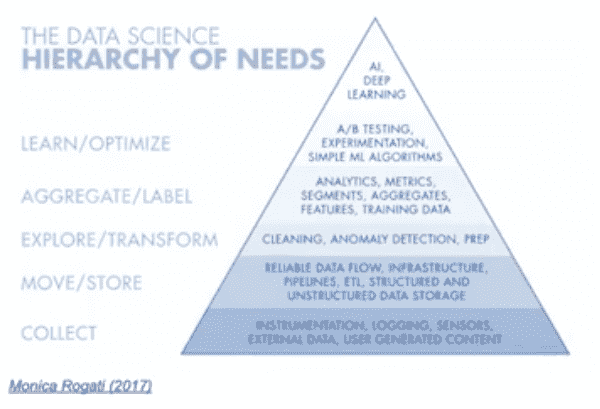
立刻为公司提供 AI 解决方案是很好的,但在现实中,这之前需要建立许多基础。《数据科学需求层次结构》及其他类似的项目规划工具可以帮助你为公司的数据科学目标制定一个合理、可持续的路径。
提示 #3: 及时报告成功
作为首位数据科学家,你可以现实地预期你的非技术同事不会理解你的工作及其所投入的努力。因此,你需要在部署你的第一个数据模型的过程中报告进展。这将确保你的公司跟上你的进展,并建立对你构建和交付能力的信任。
例如,可靠的数据流将成为任何数据团队生产力的基石。它是金字塔的基础部分,它将使你能够迅速解决各种问题。虽然你公司的非技术决策者主要关注的是你从可靠数据流中最终得出的分析结果,但设置数据流并非易事,这是获得这些结果的重要一步。你应该花时间向团队报告这一步,并让他们理解其在整个过程中的重要性。
这样做,你会向你的团队证明你可以持续朝着目标取得进展。
提示 #4: 利用数据可视化方法
数据可视化常常被忽视。它将成为你数据科学工具包中最重要的工具之一。良好的数据可视化全靠实践。
在与利益相关者开会前,进行一个练习,绘制一些图表并自问可能会在观众中出现的问题。之后,调整图表,然后再次自问,查看图表是否解决了问题。
这看起来简单直接,但往往被忽视。它在准备过程中很重要,当你对所有问题都有扎实的回答时,你的老板会对此印象深刻。
把数据可视化视为传达你工作的价值的工具。它对非技术人员理解你要传达的内容有巨大的帮助。最终,它对于在团队之外沟通和推销你的工作至关重要。
提示 #5: 从一个愚蠢的模型开始你的机器学习
在机器学习方面,虽然一开始可能不是优先事项,但始终从一个简单的模型开始。所谓“简单模型”就是一个基本的模型,只要能够端到端地运行。
从那里开始,你可以进行调优和改进,一旦你有了一个可以工作的模型,这个过程会变得容易得多。
你会发现,解决了 80-90%的问题后,大部分解决方案就可以部署。花时间和资源来解决最后的 10%问题将不再是数据科学问题,而是管理问题。
提示 #6: 像魔术师一样管理期望
许多人认为数据科学就像魔法,你是魔术师。你需要管理这些高期望,以便按时交付,避免陷入工作负担和拖延截止日期的困境。
通过提前计划、保持专注,并始终记住最终目标,你可以管理期望。这样做并保持有序,将确保你的上司始终对你的工作印象深刻。
创建数据科学部门是一项大任务,但虽然它很庞大,却也充满了回报和满足感。
在最近的一次 网络研讨会中,NYCDSA Bootcamp 校友劳尔·巴列霍详细讲述了他如何在一家小公司建立数据科学部门。通过此讲座,他提供了来自第一手经验的洞见性建议并回答了观众的问题。
佐伊·兹巴尔 是 NYCDSA 的市场营销研究员。
劳尔·巴列霍 是 ION 的信贷总监。
原文。已获得许可转载。
相关:
-
如何使远程工作对数据科学团队有效
更多相关话题
数据科学家在初创公司成功的六种方式
原文:
www.kdnuggets.com/2020/05/six-ways-data-scientists-succeed-startup.html
comments
作者:Amit Attias,Bigabid首席技术官兼联合创始人

我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你们组织的 IT
无论数据科学家是刚刚开始她的职业生涯,还是已经是经验丰富的专业人士,在初创公司工作都有很多优势。大多数初创公司更加实践,通常大多数员工都参与公司的多个方面。这提供了参与和技能扩展的绝佳机会。
在大公司中,一个团队可能负责研究与开发,而另一个团队负责质量保证。在初创公司中,同一个团队可能负责研究、开发和测试的所有方面。因此,初创公司专业人士接触到更广泛的经验,因为他们能够看到大局,并迅速获得成为团队领导者所需的工具。
如果数据科学家有机会在初创公司工作,以下是六个建议,帮助她和其他数据专业人士获得成功:
1. 学习笔记本
作为团队成员,数据科学家应当在进行代码审查时检查笔记本,同时也应阅读她团队的所有 笔记本和侧面笔记本(包括可能有不同重点的笔记本)。这确保她全面理解整个过程及研究的演变。数据科学家每天做出大量决策而未必意识到。学习笔记本使她能够从初创公司其他人的代码审查中获益。
这些好处有两个方面:
-
小贴士、技巧和窍门是数据科学家在学习同事代码审查时可以挖掘的黄金,从而提高她自己的生产力和技能。
-
笔记本可以揭示在标准代码审查或会议中未出现的信息,挑战之前的假设,并揭示可能的下一步。
2. 与团队成员沟通
通过积极地与团队成员沟通,数据科学家不仅能够掌握他人工作的进展,还能找到自己以有意义和有价值的方式做出贡献的机会。
-
成为他人的倾听者。接受成为一个橡皮鸭的角色。
-
询问其他团队成员面临的挑战,并在可能的情况下提供帮助。
-
熟悉新的工具、方法和解决问题的方法。
3. 拥抱 DIY 精神
拥抱初创公司的“自己动手”精神,使数据科学家有机会开发出在大型公司中由独立工程团队开发的软件工具。这不仅可以提升个人技能,还可以使人更具自给自足的能力,能够独立解决和修复问题。
4. 采取整体方法
在一个较小的初创公司,每个团队成员都是更大生态系统中的重要组成部分,大家和谐地合作以创造产品或服务。这意味着有机会参与并理解公司使命的各个方面的原因。
5. 从用户的视角看 UI
理解用户界面和理解流程以及系统的利益相关者一样重要。在处理假设时,无论是构建内部工具、训练模型,数据科学家都必须考虑:
-
谁在使用这个模型的输出?
-
她/他的使用情况如何?
-
这个智能任务的影响是什么?
数据科学家可以通过寻求用户反馈来更好地理解 UI 的有效性,如果她所在的初创公司提供反馈的话。有时候用户可能已经知道什么有效,什么无效,因此通过倾听他们的意见,可以帮助她决定要集中开发哪些功能。还要从团队成员那里获取关于可能盲点的反馈,因为他们的视角不同,他们的观点会揭示出忽视的地方。
通过对数据科学家所创造的成果负全责,她可以将用户和团队其他成员提供的宝贵见解加以利用。
拉取请求只是开始
在大型公司中,测试拉取请求后,数据科学家的工作就结束了。在初创公司中,数据科学家会进一步检查特性/模型的实时表现以及她的见解是如何被实施的。初创公司的数据科学家还必须注意实时监控器和日志,检查其中的几个以发现前几分钟/小时/天内的任何异常。
正如这六条建议所示,在初创公司取得成功需要更高的适应能力、即兴发挥的意愿以及在必要时的调整能力。这还需要愿意成为一个紧密团队的一部分,并在产品或服务的每一个开发阶段中看到它。虽然风险可能很高,但回报也可能很大。
简历:Amit Attias 是 Bigabid 的首席技术官和联合创始人,Bigabid 是一家数据科学公司,开发了针对移动应用广告用户获取与再参与优化的第二代 DSP。
相关内容:
-
找到你的完美匹配:数据世界职位角色的快速指南
-
数据科学家的四种现实职业选择
-
为你的数据科学初创公司打造电梯演讲
更多相关内容
偏度与峰度——强健的组合
原文:
www.kdnuggets.com/2018/05/skewness-vs-kurtosis-robust-duo.html
评论
由 Pawel Rzeszucinski,Codewise.com 提供

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
描述性统计可以提供大量的数据洞察,但它常常给我们带来有趣的陷阱,有时会导致结果的误解。减轻这种风险的一种方法是使用多种技术的组合,以达成明确的结论。今天,我们将看到如何通过偏度来补充峰度的输出,以应对一个非常有趣的挑战。
介绍
在我之前的帖子中,我们看到峰度(Kurtosis)作为一种强健的度量标准,用于检测数据中的冲动内容。然而,“冲动”可能有多种表现形式,峰度并不总是能够描绘出完整的图像。在下面描述的案例研究中,我将展示如何在图像绘制过程中添加一个额外的“刷子”,即偏度(Skewness)。
案例研究
场景如下——一个商店记录了随着时间推移销售商品的数量,并尝试自动检测任何异常需求的存在。
在去年(上一篇帖子),峰度被成功用于检测冲动。图 1 显示了峰度值为 6.227 的数据——明显高于 3 这个高斯噪声的默认值。冲动内容被检测到了,太好了!然而,过了一段时间,一位好奇的业务分析师发现了一个令人困惑的案例,如图 2 所示。尽管信号的性质发生了显著变化——冲动只包含向上的部分,但峰度返回的值依然是 6.227(实际上我尝试了六次才合成出这样的信号)。
图 1 
图 2
图 1 和图 2 所示的信号的幅度分布分别见于图 3 和图 4。可以看到有显著的变化。图 3 显示了几乎完全对称的分布,而图 4 显示了一个向图表左侧倾斜的形状。附注:尽管向左侧倾斜,这种分布形状仍被称为右偏分布,因为我们真正关心的是均值值的相对移动。在我们的案例中,由于显著冲击的存在,它确实向右侧移动。
起初感到震惊,业务分析师很快发现了问题所在。他参考了峰度的公式(见于公式 1),并注意到方程中的所有幂都是偶数,因此峰度可能对‘均值以上’和‘均值以下’的值之间的差异视而不见。仅在一个方向上的显著冲击(如图 2 所示)可能会与对称冲击(图 1)产生相同的结果。
图 3 
图 4
这就是偏度发挥作用的地方。其公式见于公式 1 [1]:
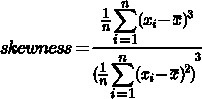
其中 n 是数据中样本的总数,xi 是数据中的第 i 个样本,x 是数据的样本均值。
偏度公式与峰度公式几乎相同,除了分子和分母中的幂,并且现在‘均值以上’和‘均值以下’的值之间的区别变得可能。偏度输出值对于对称分布的信号接近 0,对于右偏(即正偏)信号介于 0 和 1 之间,对于左偏(即负偏)信号介于 0 和 -1 之间。图 5 展示了这些分布的形状及其与均值、中位数和众数的关系(摘自[2])。当应用于图 1 和图 2 的信号时,偏度值分别为 0.06 和 0.58。此时,业务分析师将始终将峰度与偏度值结合使用,以不仅检测冲击的存在,还确定其攻击方向。
图 5 摘自 [2]
参考文献:
[1] Ben Klemens, 《数据建模:科学计算的工具和技术》,普林斯顿大学出版社,2008 年
[2] Ken Black, 《商业统计:现代决策制定》,约翰·威利父子公司,2009 年
个人简介:Pawel Rzeszucinski 获得了克兰菲尔德大学计算机科学硕士学位以及弗罗茨瓦夫理工大学电子学硕士学位。他随后前往曼彻斯特大学,获得了由 QinetiQ 资助的关于直升机齿轮箱诊断的数据分析项目的博士学位。回到波兰后,他曾在 ABB 企业研究中心担任高级科学家,并在汇丰银行的战略分析部门担任高级风险建模师。目前,他在 Codewise 担任数据科学家。
相关:
-
描述性统计学:数据科学中的强大矮人
-
描述性统计学:数据科学中的强大矮人 – 峰值因子
-
描述性统计学关键术语解释
数据工程所需的技能
原文:
www.kdnuggets.com/2020/06/skills-build-data-engineering.html
评论
由 Mohammed M Jubapu,解决方案架构师兼数据工程师

我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你所在组织的 IT
数据工程是目前市场上最受追捧的职位之一。数据无处不在,被认为是新时代的石油。公司从不同来源生成大量数据,而数据工程师的任务是组织数据的收集、处理和存储。然而,要成为数据工程师,你需要具备一些出色的技能,如数据库、大数据、ETL 和数据仓库、云计算以及编程语言。但问题是,你是想具备所有这些技能,还是希望在使用所有这些工具时有所经验?特别是在有许多工具可以完成工作的技术领域,这是最大的困境。
好吧,为了简化这一点,让我们来一杯咖啡,直接深入了解数据工程职位市场中的最新技能观察,这些技能无疑可以提升你现有的职业生涯,或帮助你启动数据工程的旅程。
1- 精通一种编程语言
是的,编程语言是数据工程所必需的技能。大多数职位要求至少熟练掌握一种编程语言。这些语言用于编写 ETL 或数据管道框架。常见的编程语言是掌握数据工程和管道所需的核心编程技能。除了其他方面,Java 和 Scala 用于在 Hadoop 上编写 MapReduce 作业;Python 是数据分析和管道的热门选择,Ruby 也是一种广泛使用的应用程序连接语言。
2- Python 是列出最多的技能
Python! Python! Python! 是的,大约 70%的职位要求具备 Python 技能,其次是 SQL、Java、Scala 以及其他编程技能,如 R、.Net、Perl、Shell 脚本等。
3- Apache Spark 在数据处理层中表现突出
数据处理是将数据收集并转化为可用且期望的形式。Apache Spark 排在数据处理层的首位,其次是 AWS Lambda、Elasticsearch、MapReduce、Oozie、Pig、AWS EMR 等。Apache Spark 是一个强大的开源框架,提供交互式处理、实时流处理、批处理和高速的内存处理,具有标准接口和易用性。
4- Rest APIs 常用于数据收集
对于任何需要分析或处理的数据,首先需要将其收集或导入到数据管道中。Rest APIs 是常用的工具,其次是 Sqoop、Nifi、Azure Data Factory、Flume、Hue 等。
5- 数据缓冲在 Apache Kafka 中很常见
数据缓冲在数据工程框架中是一个关键环节,其中数据需要在从一个地方移动到另一个地方时被暂时存储,以应对高容量。Apache Kafka 是一个常用的分布式数据存储,优化了实时数据流的摄取和处理。流数据是由成千上万的数据源持续生成的数据,这些源通常同时发送数据记录。流处理平台需要处理这种持续不断的数据流,并顺序和增量地处理数据。该类别中的其他工具有 Kinesis、Redis Cache、GCP Pub/Sub 等。
6- 存储你的数据 – SQL 或 NoSQL
数据需要存储以便处理、分析或可视化,从而生成有价值的洞察。数据存储可以是数据仓库、Hadoop、数据库(包括 RDBMS 和 NoSQL)、数据集市等形式。SQL 技能最为受欢迎,其次是 Hive、AWS Redshift、MongoDB、AWS S3、Cassandra、GCP BigQuery 等。
7- 使用 Tableau 或 PowerBI 进行数据可视化
数据可视化是以图形、图表或其他视觉格式呈现数据或信息。它通过图像传达数据之间的关系。Tableau 和 PowerBI 领先于其他工具,其次是 SAP Business Objects、Qlik、SPSS、QuickSight、MicroStrategy 等。
8- 数据工程云平台
有多种基于云或本地的 платформ可以用于不同的数据工程工具集。列出的典型平台有 Hadoop、Google Cloud Platform、AWS、Azure 和 Apprenda。
嗯,人们不可能精通所有技能和工具,也绝不是必须掌握所有这些技能。但通常需要在每个数据管道框架类别中至少对其中之一有较强的掌握,例如 GCP 用于云平台、Python 用于开发、Apache Spark 用于处理、Rest APIs 用于数据收集、Apache Kafka 用于数据缓冲、Hive 用于数据存储和 PowerBI 用于数据可视化。
学习、提升技能,助力你的职业发展!祝好运,数据工程愉快!
简历: Mohammed M Jubapu 是位于阿布扎比 Cleveland Clinic Abu Dhabi 的解决方案架构师和数据工程师。
原文。经许可转载。
相关:
-
五个有趣的数据工程项目
-
为什么以及如何使用 Dask 处理大数据
-
数据工程的可观察性
更多相关话题
skops:提升 Scikit-learn 生产环境的全新库
原文:
www.kdnuggets.com/2023/02/skops-new-library-improve-scikitlearn-production.html
在生产环境中处理机器学习模型时面临各种挑战。这些挑战包括版本控制中的可重现性和安全序列化。在这篇博客文章中,我将带你了解一个名为skops的库,以应对这些挑战。
我们将看到一个端到端的示例:首先训练一个模型,然后序列化它,记录我们的模型,并托管它。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
# let's import the libraries first
import sklearn
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from datasets import load_dataset
# Load the data and split
data = load_dataset("scikit-learn/breast-cancer-wisconsin")
df = data["train"].to_pandas()
y = df["diagnosis"]
X = df.drop("diagnosis", axis=1)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
pipe = Pipeline(
steps=[
("imputer", SimpleImputer()),
("scaler", StandardScaler()),
("model", LogisticRegression())
]
)
pipe.fit(X_train, y_train)
安全序列化
现在我们将保存模型。我们可以使用任何格式保存模型,包括joblib、pickle或skops。
skops引入了一种新的序列化格式。其动机是避免使用 pickle 或joblib来序列化sklearn模型。使用pickle或joblib进行序列化可能导致恶意行为者在你的本地机器上执行代码,如果 pickle 文件来自你不信任的来源,应该避免反序列化。它是一种将代码指令序列化为二进制格式的序列化协议,因此不可读。它可以实际做任何事情:删除你机器上的所有内容或安装恶意软件。你应该仅从你信任的来源反序列化 pickle。
skops引入的序列化格式不依赖于pickle,并允许用户在加载文件之前查看文件的内容。你可以在这里阅读更多相关信息。我们来看一下 API。
你可以通过传递对象和保存路径来保存一个sklearn模型或管道。
import skops.io as sio
sio.dump(pipe, "pipeline.skops")
棘手的部分是从文件中加载模型。我们将把文件路径传递给load。我们还有一个参数叫做trusted,它可以是True、受信任类型的列表或False。如果设置为False,它将仅加载受信任的类型。让我们来看看。
# passing `True`
sio.load("pipeline.skops", trusted=True)
# result
Pipeline(steps=[('imputer', SimpleImputer()), ('scaler', StandardScaler()),
('model', LogisticRegression())])
我们可以使用get_untrusted_types来获取未受信任的类型列表。
unknown_types = sio.get_untrusted_types(file="pipeline.skops")
print(unknown_types)
# output
['numpy.int64']
你可以直接将上述列表传递给trusted。
loaded_model = sio.load("pipeline.skops", trusted=unknown_types)
如果你尝试在没有变换器的情况下加载,加载将失败并抛出UntrustedTypesFoundException。
loaded_model = sio.load("pipeline.skops", trusted=unknown_types[1:])
# output
UntrustedTypesFoundException: Untrusted types found in the file: ['numpy.int64'].
请注意,你总是需要将某些内容传递给trusted,因为这会提示用户确定是否信任该文件。
loaded_model = sio.load("pipeline.skops")
# output
UntrustedTypesFoundException: Untrusted types found in the file: ['numpy.int64'].
模型托管
如果你希望将模型公开托管,可以使用 skops 和 Hugging Face Hub。这使得无需下载模型即可进行推理,模型文档在模型库中,并且只需一行代码即可构建接口。

Hugging Face 模型库

这只需一行代码即可构建
让我们看看如何以编程方式创建这些内容。
hub_utils.init 创建一个包含模型的本地文件夹,并且配置文件包含模型训练环境的要求、训练目标、数据集样本等。传递给 init 的样本数据和任务标识符将帮助 Hugging Face Hub 启用模型页面上的推理小部件以及发现功能来找到模型。
注意: 目前推理小部件、推理 API 和
gradio集成仅支持 pickle 格式。我们目前正在开发对skops格式的支持。因此,我们将暂时以pickle格式保存模型。
from skops import hub_utils
import pickle
# let's save the model
model_path = "example.pkl"
local_repo = "my-awesome-model"
with open(model_path, mode="bw") as f:
pickle.dump(pipe, file=f)
# we will now initialize a local repository
hub_utils.init(
model=model_path,
requirements=[f"scikit-learn={sklearn.__version__}"],
dst=local_repo,
task="tabular-classification",
data=X_test,
)
该库现在包含启用推理的模型和配置文件,构建环境以加载模型等。配置文件是一个 JSON 文件,其中包含:
-
数据集的小样本,
-
数据集的列,
-
加载模型的环境要求,
-
模型文件在库中的相对路径,
-
正在解决的任务。
现在,我们将通过创建模型卡来记录我们的模型。skops 中的模型卡遵循 Hugging Face Hub 模型卡的格式:包括一个 markdown 部分和一个 yaml 元数据部分。你可以在 这里 查看元数据部分的键,以便更好地发现模型。模型卡遵循的模板包括:
-
顶部的 YAML 部分用于元数据(任务 ID、许可证、用于训练的库名称等)
-
以 markdown 格式呈现的自由文本部分和需要填写的部分(例如模型描述、预期用途、限制等),
模型卡的以下部分由 skops 自动生成:
-
模型的超参数,
-
模型的交互式图示,
-
下面是一个展示如何加载和使用模型的小示例,
-
元数据、库名称、任务标识符(例如表格分类)以及推理小部件所需的信息已填写。
skops 通过各种方法支持程序化编辑模型卡。有关卡片模块的文档以及 skops 提供的默认模板,请参见 这里。
你可以从 skops 中实例化 Card 类来创建模型卡。这个类是一个中间数据结构,稍后会渲染为 markdown。我们将把这个卡片保存到托管模型的仓库中。在初始化仓库时,任务名称(例如,tabular-regression)和库名称(例如,scikit-learn)会写入配置文件。任务和库名称也需要在卡片的元数据中,所以你可以使用 metadata_from_config 方法从配置文件中提取元数据,并在创建卡片时将其传递给卡片。你可以使用add方法来添加信息和编辑元数据。
from skops import card
from pathlib import Path
# create the card
model_card = card.Card(pipe, metadata=card.metadata_from_config(Path(local_repo)))
limitations = "This model is not ready to be used in production."
model_description = (
"This is a LogisticRegression model trained on breast cancer dataset."
)
# add information to the model card
model_card.add(**{"Model description/Intended uses & limitations": limitations})
# set the license in the metadata
model_card.metadata.license = "mit"
我们可以评估模型并将其写入模型卡作为指标。我们可以使用add_metrics方法将指标添加到我们的模型卡中,并以表格形式写入。
from sklearn.metrics import (ConfusionMatrixDisplay, confusion_matrix,
accuracy_score, f1_score)
# let's make a prediction and evaluate the model
y_pred = pipe.predict(X_test)
# we can pass metrics using add_metrics and pass details with add
model_card.add_metrics(accuracy=accuracy_score(y_test, y_pred))
model_card.add_metrics(**{"f1 score": f1_score(y_test, y_pred, average="micro")})
可以使用add_plots添加可视化模型性能的图表。
import matplotlib.pyplot as plt
# we will create a confusion matrix
cm = confusion_matrix(y_test, y_pred, labels=pipe.classes_)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=pipe.classes_)
disp.plot()
# save the plot
plt.savefig(Path(local_repo) / "confusion_matrix.png")
# the plot will be written to the model card under the name confusion_matrix
# we pass the path of the plot itself
model_card.add_plot(**{
"Confusion Matrix": "path-to-confusion-matrix.png"})
让我们将模型卡保存在本地仓库中。这里的文件名应该是README.md,因为这是 Hugging Face Hub 所期望的。
model_card.save(Path(local_repo) / "README.md")
仓库现在已准备好推送到 Hugging Face Hub。我们可以使用hub_utils来完成这项操作。Hugging Face Hub 遵循带有令牌的认证流程,因此我们可以在推送时传递我们的令牌。
# set create_remote to True if the repository doesn't exist remotely on the Hugging Face Hub
hub_utils.push(
repo_id="scikit-learn/blog-example",
source=local_repo,
commit_message="pushing files to the repo from the example!",
create_remote=True,
)
一旦模型在 Hugging Face Hub 上,它可以被任何人使用download下载,除非该模型是私有的。仓库包含模型、模型卡和模型配置,模型配置包含数据集的小样本用于重现性、要求等。
# pass repository ID that our model is hosted on the Hub, destination directory can be any path
hub_utils.download(repo_id="scikit-learn/blog-example", dst="downloaded-model")
可以使用推理小部件轻松测试模型。
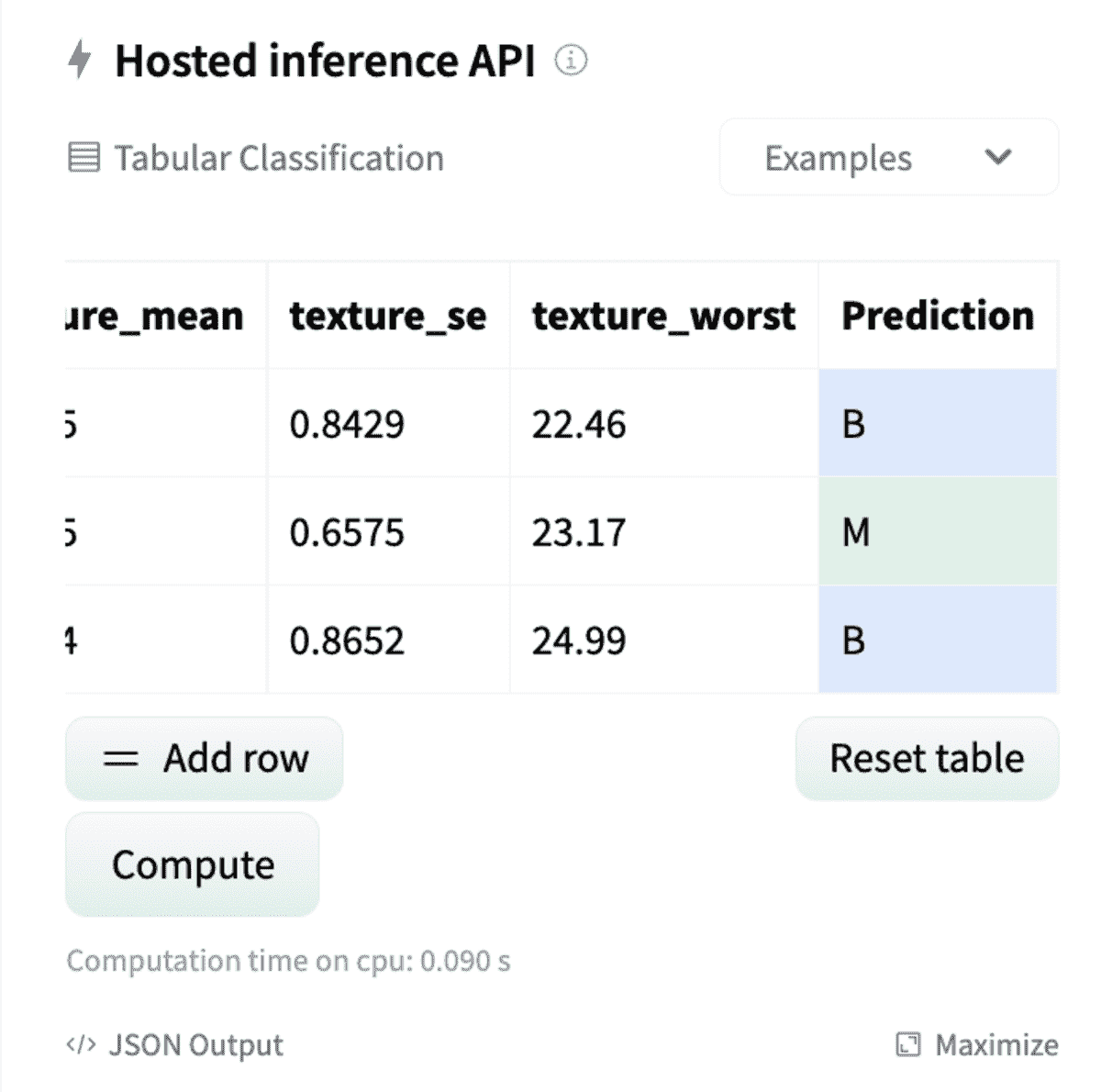
仓库中的推理小部件
现在我们可以使用gradio集成来处理skops。我们只用一行代码就创建了下面的接口! ????
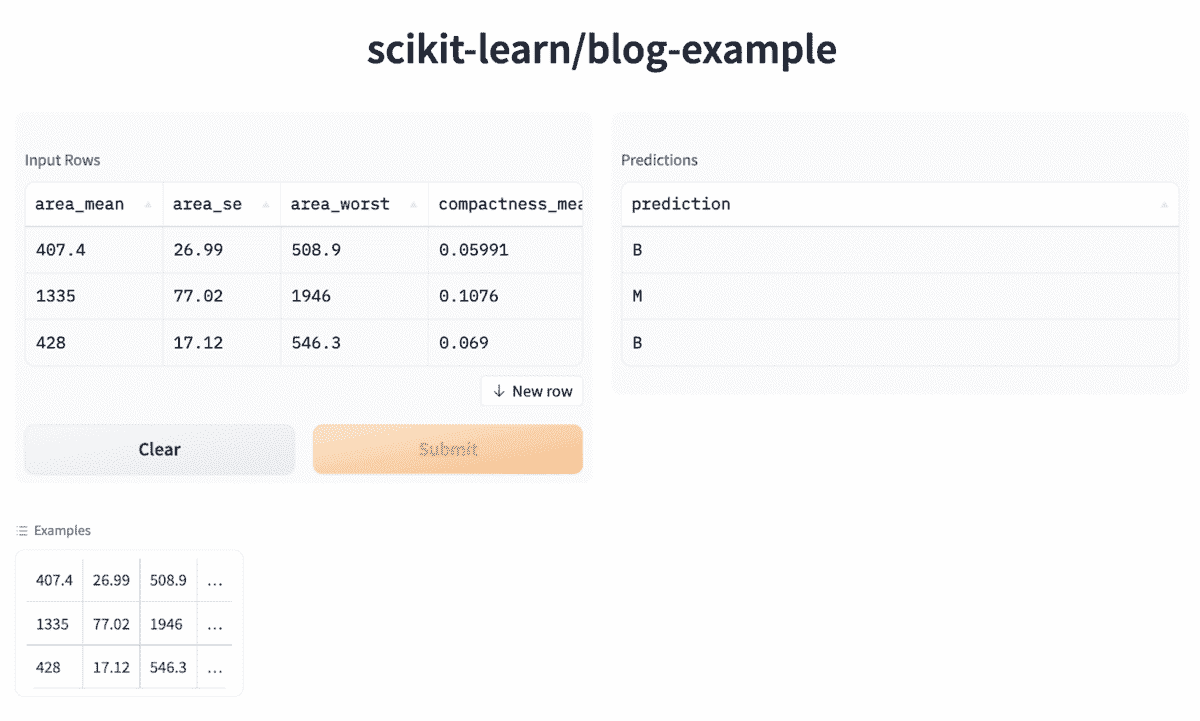
我们模型的 Gradio UI
import gradio as gr
gr.Interface.load("huggingface/scikit-learn/skops-blog-example").launch()
我们可以进一步自定义这个 UI,如下所示:
我们可以将标题、描述等信息传递给加载的 UI。有关可以自定义的更多信息,请查看 gradio 文档中的Interface class。
import gradio as gr
gr.Interface.load("huggingface/scikit-learn/blog-example",
title="Logistic Regression on Breast Cancer").launch()
结果仓库在这里。
进一步资源
Merve Noyan 是一位谷歌机器学习开发专家,并且是 Hugging Face 的开发者推广专家。
更多相关主题
SlamData 开源分析工具用于 MongoDB
原文:
www.kdnuggets.com/2014/12/slamdata-open-source-analytics-tool-mongodb.html
作者:John A. De Goes (SlamData),2014 年 12 月。
SlamData 是一个开源工具,使 MongoDB 上的分析变得简单易用,无论是对开发者还是非开发者。我们刚刚推出了 v1.1,大大增强了工具的功能,并修复了 1.0 版本中识别的一些问题。
为什么选择 SlamData?
MongoDB 目前是增长最快、最成功的 NoSQL 数据库。公司主要利用该数据库构建 web 和移动应用程序。
成功的 MongoDB 应用程序通常会捕获或生成大量数据。我称之为应用智能的数据理解过程,对业务中的多个利益相关者至关重要:
-
产品。我们如何利用这些数据来改进产品或更好地了解用户?我们如何让用户自己从数据中获得见解?
-
市场营销。这些数据告诉我们用户如何使用应用程序?这些应用程序数据能否帮助我们更好地了解市场营销 ROI?
-
支持。如何利用这些数据来帮助识别和解决用户遇到的问题?
-
管理者。这些数据告诉我们关于资源分配什么?我们如何将这些数据与销售和其他数据集关联起来?
-
IT。应用程序生成了什么类型的数据,我们如何为这种数据调整数据库?
MongoDB 没有严格的模式(每一“行”可能与其他“行”有不同的结构),并允许数据的任意嵌套(“行”可以包含其他“表”)。
尽管这种灵活性带来了更快的应用程序开发和更好的性能与扩展性,但代价是:现有分析工具无法与 MongoDB 配合使用。
在关系型数据库的世界中,为了回答这些问题,你只需使用数据发现和临时分析工具。但在 MongoDB 的世界中,如果你需要应用智能,你只有两个选择:
-
编码。让开发者编写低级别的临时代码,与 MongoDB API 交互以发现存储的数据并回答相关问题。
-
ETL。开发一个工作流程,将数据迁移、同质化和标准化到 RDBMS 中,在那里你可以使用现有的分析工具(尽管是在一个不准确表示底层数据的数据模型上)。
最终,任何方法都无法扩展,这就是我们启动 SlamData 的原因,它是一个基于 NoSQL 数据将持续存在这一前提的开源项目,分析工具需要赶上现代数据。
介绍 SlamData
SlamData 提供了一个标准 SQL 接口,用于访问存储在 MongoDB 中的 NoSQL 数据。
每个 SQL 查询都在数据库(或副本集)中 100% 执行,并操作数据的实际结构。
这种方法与其他解决复杂查询问题的方案有很大不同,这些方案从数据库中流式传输数据来处理复杂查询,并在底层数据上叠加一个虚假的关系视图(即使它不是关系型的)。
SlamData 的 SQL 方言(称为SlamSQL)扩展了 ANSI SQL 以支持嵌套数据、异构数据以及在嵌套维度上的聚合(例如,对存储在行中的数组元素求和)。
一个示例 SlamSQL 查询如下所示:
SELECT DISTINCT user_name, SUM(music[*].likes[*].strength)
AS strength
FROM collection WHERE music[*].likes[*].name = 'david bowie'
GROUP BY user_name
ORDER BY strength DESC
LIMIT 10
在这个查询中,双重嵌套在数组中的文档被用来过滤和汇总总体结果中的值。这种查询在 RDBMS 中是不可能的,MongoDB API 的等效代码也很难编写、调试和理解。

通过利用行业标准 SQL,SlamData 使广泛的用户和工具能够与 MongoDB 进行接口,并帮助团队快速轻松地理解由他们的 MongoDB 应用生成或收集的数据。
在当前的 1.1 版本中,支持所有标准 SQL 子句,包括 SELECT、AS、FROM、JOIN、WHERE、GROUP BY、HAVING、OUTER JOIN、CROSS 等。
开启盒子
SlamData 项目在几个关键方面进行了创新:
-
结构类型推断。SlamData 不会扫描数据库以了解数据的结构。相反,SlamData 使用结构类型系统,配备双向类型推断,这使得 SlamData 能够解析查询的意图并生成与该意图一致的执行计划。例如,如果你的查询将一个字段用作字符串,SlamData 将查找该字段为字符串的文档。SlamData 还会在你尝试做无意义的事情时发出警告,比如将 4 加到字符串上,因为即使 SlamData 不知道数据库中有什么,它也知道在什么数据类型上进行什么操作是合理的。
-
多维关系代数。SlamSQL 建立在一个称为多维关系代数(MRA)的关系代数形式扩展上。这一更强大的(但向后兼容的)基础允许对嵌套的、非均匀数据进行切片、切块和聚合。作为一个愉快的副作用,它也为许多 ANSI SQL 不允许的 SQL 查询提供了合理的语义(例如,SELECT price / SUM(price) AS percent FROM ORDERS)。
-
高级多阶段编译。MongoDB 有三种不同的机制来执行查询(其中之一是完整的 map/reduce),每种机制都有不同的优缺点。通常,高效地执行复杂查询可能需要结合这三种机制。SlamData 拥有一个先进的多阶段优化规划器,试图找到所有三种机制的最佳组合。
-
数据库内执行。SlamData 在将查询执行推送到数据库方面极为积极。实际上,100% 的每个查询都将直接在数据库中执行,完全不会流回客户端进行后处理。其他尝试解决此问题的方法大多数依赖客户端处理,因为在数据库中以高效的方式执行每个查询的每一部分是极其困难的(因此需要先进的多阶段编译)。
这些功能的结合使 SlamData 成为“指向并查询”:将 SlamData 指向你的 MongoDB 数据库,并在任何类型的数据上做任何你想做的事。SlamData 会生成最优查询计划并在数据库中 100% 执行。
了解更多
如果你正在使用 MongoDB 并且想尝试 SlamData,你可以在 官方网站 上找到[安装程序],或者可以在 Github 上 从源代码编译项目。
SlamData 是一个 100% 开源项目,所以如果你喜欢你所看到的内容,请考虑以各种方式支持该项目:
-
观看、fork 和收藏 这些仓库。
-
传播 SlamData 的信息(Twitter、Reddit 等)。
我们还有一个你可以在 官方网站 上注册的新闻通讯。请享用!
John A. De Goes,@jdegoes,是 SlamData 的创始人兼首席技术官,同时也是开源 SlamData 项目的贡献者。此前,他曾担任 DataMesh 总经理、RichRelevance 的首席架构师,以及 Precog 的首席执行官/首席技术官。
相关:
-
MongoHQ 更名为 Compose,合并 ElasticSearch 和 MongoDB
-
采访:Prateek Jain,eHarmony 工程总监谈快速搜索与分片
-
Top KDnuggets 推文,8 月 8-10 日:忘记 SQL 与 NoSQL。新趋势是 HTAP:混合事务/分析处理
相关话题
SlangSD:俚语词汇的情感词典
原文:
www.kdnuggets.com/2016/09/slangsd-sentiment-dictionary-slang-words.html
作者:梁武、弗雷德·莫斯塔特、刘欢,亚利桑那州立大学。
人们使用“OMG”和“LOL”等网络俚语词汇来表达他们的感受。识别俚语情感词汇可以在准确发现推文和客户评论中隐藏的情感方面带来极大的优势。为了促进用户生成内容中的情感分析,ASU DMML 发布了一个专门针对网络俚语的情感词典——SlangSD。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你组织中的 IT
SlangSD 是第一个针对俚语词汇的情感词典,提供超过 90,000 个俚语词汇/短语及其情感得分,范围从“强烈负面”、“负面”到“中性”、“正面”和“强烈正面”。我们从 Urban Dictionary (www.urbandictionary.com) 收集俚语词汇,该词典是最大的众包在线俚语词典。情感得分是根据现有情感词汇、词汇间相似性以及社交媒体中的词汇使用自动估算的。
下载、集成并使用
作为一个附加词典,SlangSD 可以下载 (slangsd.com/data/SlangSD.zip) 并轻松与现有情感分析项目集成。

扩展并构建你自己的词典
SlangSD 建立在 Urban Dictionary、社交媒体内容和现有情感词典之上,整个构建过程完全自动化。因此,其他研究人员很容易扩展词典或构建自己的“SlangSD”。生成过程包括以下两个步骤:
-
从 Urban Dictionary 收集俚语词汇和短语。
-
通过以下方式计算俚语词汇的情感得分:
-
参考现有的情感词典;
-
交叉引用与推文中共现的情感词汇;
-
使用用户提供的同义词进行估算。
-
关于我们如何构建 SlangSD 以及 SlangSD 如何改进现有情感分析工具的结果,请参阅报告 arxiv.org/abs/1608.05129。
相关:
-
2016 年里约奥运会在 Twitter 上:积极情绪(75%),水上运动,西蒙·拜尔斯获胜
-
用 Python 矿工 Twitter 数据 第六部分:情感分析基础
-
选举中的开放数据:利用可视化和图形发现分析进行选民教育和公民参与
更多相关内容
Django 框架中的社交用户认证
原文:
www.kdnuggets.com/2023/01/social-user-authentication-django-framework.html

图片由作者提供
介绍
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
Django 是一个免费的开源 Python 网络框架。它遵循模型-视图-控制器架构模式,并提供内置的管理界面、对象关系映射(ORM)和模板引擎等功能。Django 的主要目标是通过提供一套高水平、可重用的组件来简化开发者构建和维护网络应用程序的过程,处理如用户认证、创建和管理数据库、处理 HTTP 请求和响应等日常任务。
本文将讨论如何在 Django 应用中使用 Google 执行社交认证。社交认证,也称为社交登录或登录,是一种使用现有社交媒体账户(如 Facebook、Google 或 Twitter)进行用户认证的方法,而不是为网站或应用程序专门创建新账户。
使用社交认证相较于传统认证系统的好处在于,它消除了用户需要创建和记住另一个用户名和密码的需求,减少了摩擦,提高了用户注册网站或应用的可能性。此外,它通过允许用户使用现有社交媒体账户登录,提升了用户体验。社交认证提供了更流畅和熟悉的用户体验。
从 Google 控制台获取客户端 ID 和客户端密钥
-
登录 Google 控制台平台。你可以使用这个 链接 登录。
-
如果你还没有项目,请创建一个新的项目。
图片由作者提供
-
创建项目后,我们需要配置 OAuth 屏幕。这个屏幕在客户端尝试使用 Google Auth 认证你的网站时显示。它包含你的应用程序的摘要以及所有必需的政策。
-
点击下面所示的按钮。
图片来源:作者
- 选择用户类型为外部并点击“创建”按钮。
图片来源:作者
-
填写所有必要的详细信息并继续。
-
将授权域名部分留空,因为我们当前在本地服务器上测试我们的应用。如果你使用了一个合适的域名托管你的网站,那么你需要在这里输入你网站的域名。
图片来源:作者
-
其他步骤,如 Scopes 和测试用户,保持为空。
-
在配置 OAuth 屏幕后,导航到
**凭证 << 创建凭证 << OAuth 客户端 ID**
图片来源:作者
-
选择应用程序类型为 Web 应用程序。
-
填写所有必需的信息并点击“创建”按钮。
注意: 添加授权重定向 URL,因为我们目前在本地主机上运行我们的应用。你可以根据你的域名更改重定向 URL。
127.0.0.1:8000/accounts/google/login/callback/
localhost:8000/accounts/google/login/callback/
图片来源:作者
- 现在,你将获得你的客户端 ID 和客户端密钥,我们将在我们的 Django 应用中使用它们。
注意: 请不要与任何人分享这些凭证。
图片来源:作者
你将在 凭证部分 中找到你创建的凭证。
图片来源:作者
创建 Django 应用
在本节中,我们将讨论如何创建 Django 应用程序以及如何使用社交用户认证。如果你是 Django 新手,也完全没问题。我会详细解释每一步。
注意: 本教程将使用 Windows 机器。
- 创建虚拟环境
$ py -m venv <venv_name> // Command to create venv
$ <venv_name>\Scripts\activate // Command to activate venv</venv_name></venv_name>
注意: 总是建议创建一个虚拟环境。这将帮助你更好地管理你的库/依赖。
- 安装所需的库:
$ pip install django
$ pip install django-allauth
什么是 Django-allauth?
Django-allauth 是一个用于 Django 网络框架的库,提供了一套一体化的认证视图和表单,统一了各种第三方(社交)账户提供商如 Google、Facebook 等的用户注册和认证过程。它允许开发人员快速、轻松地将认证和注册功能添加到 Django 项目中。它还支持 OAuth 和 OpenID Connect。
- 创建 Django 项目
$ django-admin startproject <project_name>//socialauthapp</project_name>
- 进入项目目录
$ cd <project_directory>//socialauthapp</project_directory>
- 将应用添加到
settings.py文件中的 INSTALLED_APPS 列表中。
INSTALLED_APPS = [
"django.contrib.admin",
"django.contrib.auth",
"django.contrib.contenttypes",
"django.contrib.sessions",
"django.contrib.messages",
"django.contrib.staticfiles",
"allauth",
"allauth.account",
"allauth.socialaccount",
"allauth.socialaccount.providers.google",
]
- 在同一个
settings.py文件中,添加以下身份验证后端。
AUTHENTICATION_BACKENDS = (
"django.contrib.auth.backends.ModelBackend",
"allauth.account.auth_backends.AuthenticationBackend",
)
- 现在我们需要在主项目目录中的
urls.py文件中添加 allauth 的 URL。添加 URL 后,你的urls.py文件看起来是这样的。
from django.contrib import admin
from django.urls import path
from django.urls import include, re_path
urlpatterns = [
path("admin/", admin.site.urls),
re_path("accounts/", include("allauth.urls")),
]
- 执行所有必要的迁移。
$ python manage.py makemigrations
$ python manage.py migrate
- 现在,我们将创建一个超级用户(这是一个具有所有权限/访问权限的管理员用户)。
$ python manage.py createsuperuser
- 最后,我们将运行服务器。
$ python manage.py runserver
- 通过访问这个 URL(
localhost:8000/accounts/login/),你将能够看到登录表单。
作者提供的图片
我们的 Django 应用现在已经创建完成。如果你在运行服务器时遇到任何错误,请再次检查所有步骤。如果你能看到上述登录页面,你的应用运行正常。
在 Django 应用中添加 Client ID 和 Client Secret
在这一部分,我们将把Client ID和Client Secret添加到我们在 Google 控制台创建的应用中。
-
打开 Django 管理员面板。(
localhost:8000/admin/login/?next=/admin/) -
输入在创建超级用户时设置的用户名和密码。
作者提供的图片
- 点击社交应用,然后点击添加社交应用。
作者提供的图片
-
选择提供者为 Google,并输入你的 Client ID 和 Client Secret。然后,点击保存按钮。
-
现在从管理员面板登出,你就完成了。
登录步骤
访问这个 URL(localhost:8000/accounts/google/login/?process=login)以通过 Google 登录你的应用。
作者提供的图片
注意: 登录后,你将自动重定向到个人资料页面(即,
localhost:8000/accounts/profile/)。
更改重定向 URL
你可以通过在settings.py文件中指定特定的重定向 URL 来更改默认的重定向 URL。
例如,
LOGIN_REDIRECT_URL = "/" # This will redirect to your homepage
LOGOUT_REDIRECT_URL = "/"
登出
你可以通过访问这个 URL(localhost:8000/accounts/logout/)来登出应用。
结论
在本文中,我们采用了逐步的方法来展示如何将 Google 身份验证集成到 Django web 应用中。首先,我们在 Google 控制台创建了一个服务并获得了必要的 Client ID 和 Client Secret。然后,在创建应用后,我们在管理员门户中输入了秘密密钥,并成功地通过 Google 身份验证登录了应用。
值得注意的是,我们可以用相同的流程来验证使用Facebook或Github的用户。通过从各自的管理门户创建秘密密钥并将其输入到 Django 应用程序的管理门户中,你还可以启用通过这些提供商的身份验证。
总之,希望你喜欢这篇文章,并觉得它有帮助。如果你有任何建议或反馈,请通过 LinkedIn 与我联系。
祝你有美好的一天????。
Aryan Garg 是一名电气工程学士生,目前正在完成本科的最后一年。他对网页开发和机器学习领域感兴趣,并已经追求了这个兴趣,期待在这些方向上进一步工作。
更多关于这个话题
如何使用 SQL 和规模管理数据质量
原文:
www.kdnuggets.com/2021/05/soda-io-managing-data-quality-sql-scale.html
由 Tom Baeyens,Soda.io 首席技术官兼联合创始人
为什么数据管理?
在过去三年里,我从软件工程师转变为数据工程师。当我与 Soda 的联合创始人 Maarten Masschelein 一起工作,解决隐性和未被检测的数据问题时,我无意中进入了数据管理领域。作为软件工程背景的我,编写单元测试和监控生产中的应用程序是理所当然的,但在数据方面却大相径庭。虽然大多数组织知道他们应该进行测试,但却没有策略,也不知道如何开始解决这个问题,这使得他们的系统暴露在风险中,并可能导致他们正在构建的数据产品出现严重的下游问题。
随着越来越多的产品以数据为核心输入,测试和监控使用的数据质量变得比以往任何时候都重要。因此,我们致力于构建一个数据可观测平台,使组织能够发现、优先处理和解决数据问题。
定义良好的数据质量
我们从 Soda SQL 开始,它于 2021 年 2 月发布。它是我们为数据密集型环境提供的第一个开源数据测试、监控和剖析工具。它与现有的数据工程工作流程协作,创建了一种快速简便的方法来定义对您的业务而言何为良好质量的数据。这使得数据工程师能够定义测试并防范在数据集、数据湖和数据仓库中未被检测出的隐性数据问题。
开源的救援
Soda SQL 是一个开源工具,具有简单的命令行界面(CLI)和 Python 库,通过指标收集来测试您的数据。它利用 YAML 配置文件作为输入,准备 SQL 查询,这些查询在数据库中的表上运行测试,以计算各种指标和测试。非常容易发现无效、缺失或意外的数据。因为 Soda SQL 利用--你猜对了-- SQL,所以数据可以保持原位,并且可以利用现有的计算引擎。
如果测试失败,Soda SQL 允许您停止管道,防止坏数据造成损害。随着指标的计算,诊断信息也会被捕获,以帮助分析如果检测到数据问题。然后可以采取步骤作为一个数据团队优先处理并协作解决问题。Soda SQL 可以单独手动使用,也可以与数据编排工具集成,以便根据扫描结果调度扫描和自动化操作。
您可以查看5 分钟教程了解如何开始,但这里有一个简单的示例:
- 简单的指标和测试可以在扫描 YAML 配置文件中配置。以下是此类文件内容的示例:
- 基于这些配置文件,Soda SQL 将在每次新数据到达时扫描你的数据,如下所示:
使每个人更接近数据
我们刚刚发布了 Soda Cloud,这是一款 web 应用程序,可以实时监控 Soda SQL 指标和测试结果。Soda Cloud 为工程师与数据团队中的其他人员之间创造了透明度。通过这种协作,数据团队可以提前解决隐性数据问题。Soda Cloud 扩展了 Soda SQL,两者无缝协作。
首先,Soda Cloud 通过一个指标数据库扩展了 Soda SQL,从而可以随时间可视化测量和测试结果。这使得能够监控随时间变化的情况和所有指标上的异常检测。
这些可视化和数据概况已经在更大的数据团队中创建了透明度。所有数据团队中的人员都可以看到实际存在的数据和执行的测试。
但 Soda Cloud 更进一步。它允许非技术人员通过简单的 UI 和 3 步向导构建和维护自己的监控器。这一点很重要,因为它消除了对领域知识的瓶颈。如果他们不需要涉及数据工程师来测试他们的领域逻辑,那么意味着更多的领域知识将用于定义什么是良好的数据。因此,将捕获更多的坏数据,防止各种损害。
Soda Cloud 通过提供一个中央平台来跟踪和评分数据在核心质量维度上的健康状况,从而解决了发现隐性数据问题的问题。
数据和分析工程师有了每次数据转换时测试数据的方法,以确保数据管道的可靠性。通过 Soda SQL,可以停止和隔离数据生产。Soda Cloud 可视化数据集的健康状况,并作为数据问题的沟通中心。
数据消费者和生产者现在可以轻松对齐关注点、预期和衡量标准,以确保数据保持适用性。我们还与电子邮件和 Slack 集成,确保在适当的时间通知相关人员,以便诊断、优先处理和解决数据问题。
我们的使命是让每个人都更接近数据,因为我们相信数据质量是一项团队运动。每一个涉及数据的人(我们认为现在业务中的每个人都涉及数据)都需要理解数据、信任数据,并掌握数据。
我在 Soda 的主要责任是确保数据工程师喜欢使用我们的产品,并帮助他们迅速解决实际问题。我们通过结合云平台和一组开源开发者工具来解决问题,这些工具为数据团队提供了所需的可配置性,以创建端到端的可观察性。
高质量数据适用于每个人。访问 GitHub 上的 Soda SQL 和我们的免费试用版 Soda Starter,前往 Soda.io(延长至 2021 年 6 月 30 日)。我们的 Slack 社区和文档包含最佳实践和有用的资源。
提前解决潜在的数据问题。祝好运!
我们的三大推荐课程
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能。
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求。
更多相关话题
这些软技能可以决定你数据科学职业的成败
原文:
www.kdnuggets.com/2021/05/soft-skills-data-science-career.html
评论
作者 Stefan Maraj,网络安全顾问
作为数据科学家,我们有时可能对事情过于… 科学化。虽然 数据科学家的核心技能 在很大程度上与过去相同——统计学、数学和逻辑——但总是会出现新的技能集。有时,这些新技能与计算机编程的新范式或新颖的统计技术相关。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
在今天的商业环境中,最重要的 新兴技能 是软技能。尽管老派程序员会告诉你其他的,但事实是,今天没有人,包括数据科学家,能够忽视这些技能。它们不仅使团队合作更有效,而且还能提升你的职业生涯。
在本文中,我们将带你了解数据科学家最重要的五种软技能,并展示如何培养这些技能。

使用 Pixabay 的图片。
软技能的重要性
首先,如果你仍然对发展这些技能的必要性感到怀疑,那么让我们来看看数据。最近的一项 谷歌研究 研究了几家大型公司的员工,并试图评估最具生产力和创新性的员工所具备的技能。
结果可能会让你感到意外。与其说创新是由拥有最高技术技能的员工推动的,不如说最具生产力和创造力的员工实际上是那些参与跨学科小组的人。在这些小组中,那些拥有最发达的软技能的个人能够推动变革,更有可能晋升为管理职位。
你需要的技能类型当然取决于你的工作方式和工作的重点。然而,有些技能对几乎所有数据科学角色都是至关重要的。以下是一些技能:
- 沟通
作为一名数据科学家,你可能已经以能向普通观众传达复杂的想法和数据分析为自豪。然而,能够在你角色的技术要求之外分享你的技能和专长也是很重要的。主动联系你的客户和经理不仅可以改善这些关系,还可能提升你的职业生涯。
能够将与当前话题相关的大量数据汇总、分析和复述给一群科学家是一回事,但能够将其精髓传达给那些可能能帮助你实现职业上升的人的能力则是另一回事。
假设你在午餐室遇到公司的首席执行官。她正开心地在手机上浏览,谷歌着这个、那个以及其他所有东西。由于 IT 部门每天都在提醒你网络安全的重要性,你随口提到使用全球最受欢迎的搜索引擎是一种糟糕的主意,除非你喜欢你的每一次在线活动都被跟踪和存储。对话开始了。首席执行官对你的聪明才智和愿意帮助的态度印象深刻。下一次她参加董事会会议时,当 C-Suite 团队在审查提升哪个员工或将哪个员工送往西伯利亚时,你的名字会在她的记忆中浮现,作为一个有帮助的人。
你获得了大幅加薪和一个带窗户的角落办公室。这一切都因为你能够超越硬数据科学技能的局限,作为一个人进行沟通。
感谢 维基共享资源。
- 决策制定
高效、清晰、及时的决策制定是商业中至关重要的技能。然而,这往往被数据科学家忽视。这可能为公司带来重大问题,因为数据科学家可能会在没有必要的技能和知识的情况下担任高级职位(参见上面的午餐室故事),无法做出管理或商业决策。
不过,这不一定是一个难以获得的技能。定期审查当前和即将到来的行业趋势可以极大地提升你的监督能力(再次)并表明你渴望更多责任。
- 批判性思维
批判性思维是一个比其他一些技能更难定义的软技能——实际上,这也是为什么一些文科专业的学生在大学中花费多年来磨练这个技能。作为科学家,我们工作的方法常常似乎没有多少空间来进行批判和创造。这实际上正好相反。
最终,批判性思维使你能够做到两件事。一是高效地过滤我们现在面临的信息洪流。在顶级的八个平台上拥有超过九十亿的社交媒体用户,谁能跟得上?没错,没人能。
快速扫描和筛选信息的能力可能是你职业生涯中的关键因素。另一个与批判性思维相关的关键软技能是能够在飞速变化的情况下重新构建和调整你的数据分析,以识别和解决实际问题。
- 团队合作
尽管从事数据分析的工作可能看起来是一项孤独的任务,但实际上,团队合作在组织中一直非常重要。这部分是由于像我上面提到的研究,强调了多学科团队在推动创新中的价值。
在这些环境中工作可能会很有压力,特别是如果你不是一个善于与人交往的人,并且没有与那些可能不分享你专业知识或世界观的同事合作的软技能。与同事建立职业关系的能力至关重要。
- 研究
最后但绝对重要的是研究技能。数据科学的世界以及在其中工作的人角色变化迅速。因此,培养进一步教育的能力是最重要的技能之一。
持续教育的重要性在技术职业中正在被雇主逐渐认识到。如果你保持对该领域新技术、问题和工具的了解,预计会收到更多更好的工作机会。
未来
我们刚刚讨论的软技能不仅对于高效和胜任地工作至关重要,而且在雇主那里也非常受欢迎。成功的软技能发展可能是未来工作场所成功的关键。随着更多的协作工作带来新的挑战,识别你需要增强的技能并立即制定改进计划。
个人简介:Stefan Maraj曾经几乎成为一名会计师,但现在他对网络安全的了解已经超过了收入确认原则。二十年后,他成为了一名网络安全顾问,提供黑客思维的洞察,以准确发现他们从事的计算机恶行及其解决方法。
相关:
更多相关话题
每个数据科学家需要的软技能

作者图片
我认识一个非常了不起的编码员。他为了职业转型学习了 Python,然后迅速掌握了 JavaScript、Go、SQL 以及其他几种语言,仅仅是为了好玩。而且他确实很优秀,不仅仅是那些在简历上列出语言却没有任何数据科学技能的那种人。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业领域。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
但他在找工作时遇到了困难。我几周前和他见过一次面,他的经历激发了这篇文章。为了不对他造成太大冒犯,我提到了他上一次面试的情况。他有些迟到,之后没有发感谢邮件,虽然他在所有编码问题上表现出色,但在白板问题上,他只是一味地给出完美的答案,没有进一步参与讨论。
“Kev,”我对他说,“你的编码能力好得令人难以置信。任何公司都很幸运能拥有你作为数据科学家。但你需要提升你的软技能。”
这是我为每个数据科学家推荐的四项关键软技能,无论你是想进入这个领域、在职业上进步,还是只是为了做得更好。

作者图片
1. 沟通能力
每个人都认为这意味着知道如何说话。事实正好相反:良好的沟通能力完全是关于如何倾听,特别是在数据科学领域。
想象一下这样的情景:一个利益相关者,也许是市场营销副总裁,来找你询问她想要进行的一个活动。她对这个活动充满兴奋,脑海中有一个愿景,但她不确定如何衡量其影响或需要哪些数据。在你立刻深入讨论如何提取数据或使用什么模型之前,你首先要倾听。你让她解释她的目标、担忧以及她希望通过这个活动实现的目标。
通过积极倾听,你可以理解她请求的更广泛背景。也许她不仅仅在寻找简单的分析,而是想了解客户行为或以她未曾考虑的方式细分受众。通过先倾听,你可以提供一个量身定制的解决方案,而不仅仅是最初的任务。
沟通在数据科学中至关重要。你不会整天在黑暗的地下室里敲代码;你会接收请求,准备演示文稿并与人打交道。正如在 数据分析师技能 中提到的,你必须知道如何沟通才能成功。
2. 适应能力
StackOverflow 2023 开发者调查实际上是适应能力的一个很好的例子。作者首次引入了 AI 部分,显示了对不断变化的开发环境的显著适应能力。
AI 只是一个例子。数据科学很好地展示了那个老生常谈的说法:唯一不变的就是变化。要成为成功的数据科学家,你需要准备好迎接挑战。
这可以意味着许多不同的事情。最明显的应用是能够轻松学习新技术。云技术是新的。AI 是新的。FastAPI 是新的。你需要跟上所有这些。
另一个应用是跟上就业趋势。最近的趋势不仅仅是传统意义上的数据科学家;许多雇主期望你身兼多职。你还必须成为数据工程师、机器学习工程师,有时甚至是领域专家。这些角色之间的界限越来越模糊,现代数据科学家常常发现自己在处理曾经分开角色的任务。
你也可以将其理解为理解和整合反馈。作为数据科学家,我们经常基于某些假设或数据集构建模型或解决方案。但它们并不总是按预期工作。适应能力意味着在接受这些反馈的同时,迭代你的模型,并根据实际结果改进它们。
可能最糟糕但最重要的应用是适应被解雇或裁员。2021 年和 2022 年是劳动市场异常的年份,许多大公司在几乎没有警告的情况下裁员。预见到这种可能性并做好准备是一个好主意。
3. 团队合作与协作

作者提供的图片
还记得我提到的沟通吗?团队合作与协作也属于同一范畴。作为数据科学家,你不仅仅与其他数据科学家合作。每个人都喜欢基于数据的任何东西,因此你将接收到各种请求,要求你制作 PowerPoint 演示文稿、报告和图表。
要成功做到这一点,你必须与他人友好合作。数据科学项目通常涉及与跨职能团队的合作,包括业务分析师、工程师和产品经理。有效的合作确保数据科学解决方案与业务目标一致。
例如,在我之前的一个角色中,产品团队希望在我们的应用中引入一个新功能。显然,需要数据来支持他们的决定。他们向我和其他数据科学团队寻求关于类似功能的用户行为见解。
与此同时,营销团队希望了解这个新功能如何影响用户参与度和留存率。与此同时,工程团队需要理解技术需求以及数据管道会受到什么影响。
我们的团队在其中变得至关重要。我们必须从产品团队那里收集需求,向营销团队提供见解,并与工程团队合作,以确保数据流畅。这不仅需要技术专长,还需要理解每个团队的需求,有效沟通——有时还要在冲突的利益之间进行调解。
4. 好奇心
我选择回避这个问题,不提解决问题作为终极软技能,因为我认为它被过度使用。但说实话,好奇心与此相同。
作为数据科学家,我可能不需要告诉你,你会遇到很多问题。但从根本上讲,每个问题实际上都是一个问题。
“我们的用户没有转化”,变成了“我们如何使这个产品更具吸引力?”
“我的模型没有给出准确的预测”,变成了“我可以改变什么来使我的模型更现实?”
“我们的销售在上个季度下滑了”,变成了“是什么因素影响了这种下降,我们如何解决这些问题?”
当以好奇的心态去处理这些问题时,每个问题都会转化为一个寻求理解和改进的问题。好奇心驱使你深入挖掘,不仅仅接受表面现象,并不断寻求更好的解决方案。
Kevin,从我的介绍来看,总体上是一个好奇心强的人。但不知为何,当涉及到数据科学时,他却带着盲目性。每个问题都成了必须用代码锤子解决的钉子。现实是,数据科学工作很难以这种方式完成。
他给了我一个他最近在面试中被问到的例子:“客户支持团队一直收到关于网站结账过程的投诉。你会如何解决这个问题?”
Kevin 详细讲述了他将如何修复技术故障。但面试官真正想要的答案是像“为什么用户觉得结账过程很麻烦?”这样的问题。
在现实世界中,数据科学家需要提出问题以解决问题。可能某个地区的用户由于本地支付网关的集成而面临问题。或者可能是移动版本的网站不够用户友好,导致购物车放弃。
通过将问题框架化为一个问题,数据科学家不仅仅停留在识别问题上;他们深入探讨背后的“为什么”。这种方法不仅会导致更有效的解决方案,还会揭示出可以推动战略决策的更深层次的见解。
最终想法
这里没有提到很多软技能,如同理心、韧性、时间管理和批判性思维等等。但如果你仔细想想,它们都属于这些范畴。
与人沟通。知道如何改变。能够与他人合作。并以好奇心解决问题。凭借这四项软技能,你将能够应对任何问题、面试或出现的 bug。
Nate Rosidi 是一名数据科学家,专注于产品策略。他也是一名兼职教授,教授分析课程,并且是 StrataScratch 的创始人,StrataScratch 是一个帮助数据科学家准备面试的平台,提供来自顶级公司的真实面试问题。Nate 撰写有关职业市场的最新趋势,提供面试建议,分享数据科学项目,并涵盖所有 SQL 内容。
更多相关话题
什么是 Softmax 回归以及它与逻辑回归的关系?
原文:
www.kdnuggets.com/2016/07/softmax-regression-related-logistic-regression.html
Softmax 回归(同义词:多项式逻辑回归、最大熵分类器或仅多类逻辑回归)是逻辑回归的一种推广,适用于多类分类(假设各类别是相互排斥的)。相比之下,在二分类任务中,我们使用(标准)逻辑回归模型。
现在,让我简要解释一下这如何工作以及 softmax 回归与逻辑回归的区别。我在这里有一个关于逻辑回归的更详细的解释:LogisticRegression - mlxtend,但让我重用其中一个图来使事情更清楚:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT

正如名字所示,在 softmax 回归(SMR)中,我们用所谓的 softmax 函数 φ 替代了 sigmoid 逻辑函数:

我们将净输入 z 定义为

(w 是权重向量,x 是 1 个训练样本的特征向量,w0 是偏置项。)
现在,这个 softmax 函数计算这个训练样本 x(i) 属于类别 j 的概率,给定权重和净输入 z(i)。因此,我们计算每个类别标签 j = 1, ..., k 的概率 p(y = j | x(i); wj)。注意分母中的归一化项,这使得这些类别概率的总和为 1。
为了说明 softmax 的概念,让我们通过一个具体的例子来说明。假设我们有一个包含来自 3 个不同类别(0、1 和 2)的 4 个样本的训练集。

首先,我们希望将类别标签编码成更容易处理的格式;我们应用独热编码:

属于类别 0(第一行)的样本在第一个单元格中有一个 1,属于类别 2 的样本在其行的第二个单元格中有一个 1,依此类推。接下来,让我们定义我们 4 个训练样本的特征矩阵。在这里,我们假设我们的数据集包含 2 个特征;因此,我们创建一个 4×(2+1)维的矩阵(+1 是为了偏置项)。

类似地,我们创建了一个(2+1)×3 维的权重矩阵(每个特征一行,每个类别一列)。
为了计算净输入,我们将 4×(2+1)的特征矩阵 X 与(2+1)×3 的权重矩阵 W 相乘。
Z = WX
这产生一个 4×3 的输出矩阵(n_samples × n_classes)。

现在,到了计算我们之前讨论的 softmax 激活的时候了:


如我们所见,每个样本(行)的值现在很好地加起来等于 1。例如,我们可以说第一个样本
[ 0.29450637 0.34216758 0.36332605]有 29.45%的概率属于类别 0。现在,为了将这些概率转换回类别标签,我们可以简单地取每行的 argmax 索引位置:

如我们所见,我们的预测完全错误,因为正确的类别标签是[0, 1, 2, 2]。现在,为了训练我们的逻辑回归模型(例如,通过优化算法如梯度下降),我们需要定义一个我们想要最小化的成本函数J:

这是我们所有 n 个训练样本上的交叉熵的平均值。交叉熵函数定义为

这里的 T 代表“目标”(真实类别标签),O 代表输出(通过 softmax 计算的概率;不是预测的类别标签)。

为了通过梯度下降学习我们的 softmax 模型,我们需要计算导数

然后我们用它来在梯度的反方向上更新权重:
 每个类别 j。
每个类别 j。
(注意 w_j 是类别 y=j 的权重向量。)我不想在这里详细讨论更多乏味的细节,但这个成本导数实际上是:

使用这个成本梯度,我们迭代地更新权重矩阵,直到达到指定的训练周期(对训练集的遍历次数)或达到期望的成本阈值。
简介: Sebastian Raschka 是一位“数据科学家”和机器学习爱好者,对 Python 和开源充满热情。著有《Python 机器学习》。密歇根州立大学。
原文。经许可转载。
相关:
-
深度学习何时比 SVM 或随机森林效果更好?
-
分类作为学习机器的发展
-
为什么从零开始实现机器学习算法?
更多相关话题
软件开发人员与软件工程师
原文:
www.kdnuggets.com/2022/05/software-developer-software-engineer.html

Nubelson Fernandes 通过 Unsplash
一段时间以来,我认为软件开发人员和软件工程师是一样的。开发人员和工程师这两个术语被用作同义词,使得在对话中很难理解这两者之间的区别。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持您的 IT 组织
随着 SaaS(软件即服务)、大数据等行业的不断崛起,软件开发人员和工程师的职业需求也随之增加。
为了理解这两者的区别,让我们从定义开始。
定义
软件开发人员是智能手机应用程序、跟踪锻炼的应用程序以及孩子们沉迷的游戏的创意策划者。软件开发人员创造了这些东西。
一些软件开发人员专注于应用程序及其特定编程;其他人则关注底层系统。这是软件开发人员的两种类型:应用程序软件开发人员和系统软件开发人员。
软件工程师,正如名称所示,是专注于确保软件的有效性、开发和完全功能的专业人士。他们是运用技术、工具和工程原则帮助开发人员创建软件或程序的幕后策划者。
软件工程师角色的一部分是测试软件产品,以更好地了解其局限性及其是否有效。
职位描述
现在你已经了解了每个角色的定义。为了更好地欣赏这两者之间的区别,让我们谈谈这些角色。
软件开发人员的技能/角色
-
数据结构和算法
-
云计算
-
对 IDE(例如 Visual Studio Code)的理解
-
Git 和 GitHub
-
研究、开发并测试新软件
-
开发、设计并实施新的软件。
-
测试新程序是否存在漏洞并修复它们
软件工程师的技能/角色
-
计算机编程、编码技能,如 Python、R 等
-
解决问题的能力
-
面向对象设计
-
跟踪、监控和修正任何软件缺陷
-
编写诊断程序
-
设计操作系统的代码
-
精通测试自动化工具,如 Gherkin、Cucumber 或 Ansible
-
构建可扩展的部署管道
-
修改现有软件以解决可能的缺陷,采用新硬件或改善其性能。
-
他们与经理、平面设计师和其他人紧密合作。
薪资
无论是软件开发人员还是软件工程师都需求量很大,因此他们的薪酬也非常丰厚。
约 21%的技术职位是软件开发人员,他们的需求超过供应,软件工程师在 2022 年被评为美国第 8 大最佳职位。
根据payscale,软件开发人员的平均工资为 73,441 美元,而软件工程师的平均工资为 88,540 美元
正如我们所见,软件工程师的收入高于软件开发人员,他们处理的任务更多。软件工程师能够做软件开发人员的工作,但只有少数或没有多少软件开发人员可以被视为软件工程师。
挑战
许多人谈论工作角色的福利,但从未告知人们挑战。了解你在完全投入之前要做什么总是好的。
软件开发人员
-
一些软件可能很难构建和维护,变得乏味
-
在软件构建过程中,有时很难检测到错误或缺陷。
-
需求变化可能很难适应
-
用户需求被误解
软件工程
-
软件工程的需求大幅增加,但供应不足。这使得现有和新来的软件工程师的工作变得非常艰巨。
-
跟上新软件及其复杂性可能很难维护和实现到应用程序中。
-
许多软件工程师的任务是与团队一起完成的。如果你喜欢独立工作或团队中存在问题,这可能会很困难。
哪个职业适合你?
尽管这两种角色在所需技能和角色上有许多相似之处,因此选择哪个职业适合你取决于你想要的职业类型、兴趣、偏好以及你的最终目标。
如果你喜欢编码、开发软件、测试软件和修复错误;软件开发适合你。然而,如果你喜欢构建工具和解决软件开发人员问题的新解决方案;软件工程适合你。
软件开发者大部分时间都在从零开始开发软件,而软件工程师则有各种不同的任务,如设计、构建和测试应用程序。如果你不喜欢单一任务,觉得可能会变得单调,也许考虑软件工程及其各种任务是适合你的选择。
另一种方式是问自己;你是想成为解决客户问题的人(软件开发者),还是解决开发者问题的人(软件工程师)。
如果我还是不知道呢?
如果你仍在为选择哪种软件职业而苦恼;从经验中学习始终是最佳方法。
如果你还没有开始,学习一门编程语言是你的第一步。一旦你开始练习编码技能,你将会明确你的最终目标,并发现你喜欢什么。
一旦你对这点有了更好的理解,你可以选择额外的课程或攻读与目标相关的特定学位/硕士学位。然后,你可以继续进行个人项目,提升你的技术技能,开始建立一个作品集。
如果我想两者都做呢?
正如开始时提到的,这些角色是可以互换的,并且这两个角色和技能有重叠。
软件工程师可以同时完成他们的任务以及开发者的角色。因此,如果你对这两个角色都感兴趣;那么努力成为一名软件工程师更明智,这样你可以兼顾两者。软件开发者很难做到工程师的工作。
结论
现在你已经了解了软件开发者和软件工程师的基本概念,包括他们的角色、技能、薪资和面临的挑战;你现在可以决定你希望选择哪个方向。
如果你想阅读更多帮助你做出决定的内容,可以阅读以下内容:
-
哈佛最受欢迎的编程入门课程免费提供 由 KDNuggets 发布
-
低代码:开发者仍然需要吗? 由 KDNuggets 发布
-
选择数据领域的正确工作:5 个迹象来判断工程文化 由 KDNuggets 发布
-
顶级机器学习软件工具供开发者使用 由 KDNuggets 发布
尼莎·阿雅 是一位数据科学家和自由技术作家。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探索人工智能如何/可以有利于人类寿命的不同方式。她是一个热心的学习者,寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
了解更多相关话题
数据科学的软件工程技巧与最佳实践
原文:
www.kdnuggets.com/2020/10/software-engineering-best-practices-data-science.html
评论
作者 Ahmed Besbes,AI 工程师 // 博主 // 跑者。

我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
如果你对数据科学感兴趣,那么你可能对这种工作流程很熟悉:你通过启动一个 Jupyter notebook 开始一个项目,然后开始编写 Python 代码,进行复杂分析,甚至训练模型。随着 notebook 文件中函数、类、图表和日志的增多,你会发现自己面前有一大块单一的代码块。如果你运气好,事情可能会顺利。那就祝贺你了!
然而,Jupyter notebooks 隐藏了一些严重的问题,这些问题可能会让你的编码变成一场噩梦。让我们看看这些问题是如何出现的,然后讨论防止这些问题的编码最佳实践。
Jupyter Notebook 的问题

很多时候,如果你想将你的 Jupyter 原型开发提升到一个新的水平,事情可能不会如你所愿。这些是我在使用该工具时遇到的一些情况,你可能也会感到熟悉:
-
由于所有对象(函数或类)都在一个地方定义和实例化,维护性变得非常困难:即使你只想对某个函数做一个小改动,你也必须在 notebook 中找到它,修复它并重新运行整个代码。你不希望这样,相信我。把你的逻辑和处理函数分离到外部脚本中不是更简单吗?
-
由于其互动性和即时反馈,jupyter 笔记本推动数据科学家在全局命名空间中声明变量,而不是使用函数。这在 python 开发中被认为是不良实践,因为它限制了有效的代码重用。它也有害于可重复性,因为你的笔记本变成了一个包含所有变量的大型状态机。在这种配置下,你必须记住哪个结果被缓存了,哪个没有,同时还要期望其他用户遵循你的单元格执行顺序。
-
笔记本的格式在后台是 JSON 对象,这使得代码版本控制变得困难。这就是为什么我很少看到数据科学家使用 GIT 提交笔记本的不同版本或合并特定功能的分支。因此,团队合作变得低效且笨拙:团队成员开始通过电子邮件或 Slack 交换代码片段和笔记本,回滚到代码的前一个版本是一场噩梦,文件组织也开始变得混乱。这是我常见的情况,在使用 jupyter 笔记本没有适当版本控制的两三周后:
****analysis.ipynb **analysis_COPY(1).ipynb
analysis_COPY(2).ipynb
analysis_FINAL.ipynb
analysis_FINAL_2.ipynb**
-
Jupyter 笔记本适合探索和快速原型设计。它们显然不是为了可重用性或生产用途而设计的。如果你用 jupyter 笔记本开发了一个数据处理管道,你最多只能说你的代码仅在你的笔记本电脑或虚拟机上以线性同步的方式按单元格的执行顺序工作。这并没有说明你的代码在更复杂的环境下如何表现,比如更大的输入数据集、其他异步并行任务或较少的资源分配。
笔记本实际上很难测试,因为它们的行为有时是不可预测的。
-
作为一个大部分时间都在 VSCode 中利用强大扩展功能进行代码linting、样式格式化、代码结构、自动补全和代码库搜索的人,我在切换回 jupyter 时不禁感到有些无力。
与 VSCode 相比,jupyter notebook 缺乏强制编码最佳实践的扩展。
好了,各位,暂时别再吐槽了。我真的很喜欢 jupyter,我认为它在设计上做得很好。你绝对可以用它来启动小项目或快速原型设计。
但为了以工业化的方式推出这些想法,你必须遵循一些在数据科学家使用笔记本时可能会丢失的软件工程原则。让我们一起回顾其中的一些,看看它们为什么重要。
使你的代码再次出色的技巧
这些建议来源于不同的项目、我参加的会议,以及与我过去合作的软件工程师和架构师的讨论。如果你有其他建议和想法,欢迎在评论区分享,我会在帖子中给予你的答案以信用。
以下部分假设我们正在编写 Python 脚本,而不是笔记本。
1 - 清理你的代码

照片由 Florian Olivo 在 Unsplash 提供。
代码质量的一个重要方面是清晰性。清晰和可读的代码对协作和维护至关重要。
以下是可能帮助你保持代码更清晰的建议:
- 使用有意义的变量名,它们应具有描述性并暗示类型。例如,如果你要声明一个关于某个属性(例如年龄)的布尔变量,以检查一个人是否年长,你可以通过使用有描述性和类型信息的命名来使其更具解释性。声明数据时也是如此:使其具有解释性。
# not good ...
import pandas as pd
df = pd.read_csv(path)
# better!
transactions = pd.read_csv(path)
-
避免使用只有你自己能理解的缩写和没有人能忍受的长变量名。
-
不要在代码中硬编码“魔法数字”。将它们定义在变量中,以便每个人都能理解它们指的是什么。
# not good ...
optimizer = SGD(0.0045, momentum=True)
# better !
learning_rate = 0.0045
optimizer = SGD(learning_rate, momentum=True)
-
在命名对象时遵循 PEP8 约定:例如,函数和方法的名称使用小写字母,单词之间用下划线分隔;类名称遵循 UpperCaseCamelCase 约定;常量全大写等。
了解更多关于这些约定的信息,点击这里。
-
使用缩进和空白让你的代码有呼吸的空间。存在一些标准约定,比如“每个缩进使用 4 个空格”、“不同部分之间应有额外的空行”等……由于我总是记不住这些,我使用了一个非常好的VSCode 插件 prettier,它可以在按下 ctrl+s 时自动重新格式化我的代码**。

来源:prettier.io/。
2 - 使你的代码模块化
当你开始构建一些你认为可以在相同或其他项目中重用的东西时,你需要将代码组织成逻辑函数和模块。这有助于更好的组织和维护。
例如,你正在进行一个 NLP 项目,你可能有不同的处理函数来处理文本数据(如分词、去除 URL、词形还原等)。你可以将这些单元放在一个名为 text_processing.py 的 Python 模块中,并从中导入它们。这样,你的主程序会轻得多!
这些是我学习到的一些编写模块化代码的好建议:
-
DRY: 不要重复自己。 尽可能地将代码通用化和整合。
-
函数应该做一件事。如果一个函数执行多个操作,就会变得更难以概括。
-
将你的逻辑抽象到函数中,但 不要过度工程化:你可能会遇到模块过多的情况。根据你的判断,如果你经验不足,可以查看流行的 GitHub 库,例如 scikit-learn 并查看他们的编码风格。
3 - 重构你的代码
重构旨在重新组织代码的内部结构,而不改变其功能。通常在一个有效(但尚未完全组织)的代码版本上进行。它有助于去重函数,重组文件结构,并增加更多抽象。
要了解更多关于 Python 重构的内容,这篇文章是一个很好的 resource。
4 - 提高代码效率
编写高效的代码,使其执行迅速且占用更少的内存和存储是软件开发中的另一项重要技能。
编写高效代码需要多年的经验,但这里有一些快速提示,可能会帮助你发现代码运行缓慢的原因以及如何提升性能:
-
在运行任何代码之前,检查算法的复杂性以评估其执行时间
-
通过检查每个操作的运行时间来检查脚本的可能瓶颈
-
通过使用多进程来利用机器的 CPU 核心
5 - 使用 GIT 或任何其他版本控制系统
根据我的个人经验,使用 GIT + Github 帮助我提高了编码技能并更好地组织了我的项目。由于我在与朋友和/或同事合作时使用了它,这使我遵守了过去没有遵守的标准。

来源: freecodecamp。
使用版本控制系统有很多好处,无论是在数据科学还是软件开发中。
-
跟踪你的更改
-
回滚到任何先前的代码版本
-
通过合并和拉取请求实现团队成员之间的高效协作
-
提高代码质量
-
代码审查
-
为团队成员分配任务并监控他们的进展
像 Github 或 Gitlab 这样的平台甚至提供了持续集成和持续交付钩子,用于自动构建和部署你的项目。
如果你是 Git 的新手,那么我推荐查看这个 tutorial。或者你可以查看这个备忘单:
来源: Atlassian。
如果你想专门了解如何为机器学习模型进行版本控制,可以查看这篇文章。
6 - 测试你的代码
如果你在构建一个执行一系列操作的数据管道,确保它按设计执行的一种方法是编写测试来检查预期的行为。
测试可以简单到检查输出形状或函数返回的预期值。
pytest-c-testrunner.readthedocs.io/
为你的函数和模块编写测试带来了许多好处:
-
它提高了代码的稳定性,并使错误更容易被发现。
-
它防止了意外输出。
-
它有助于检测边界情况。
-
它防止了将损坏的代码推送到生产环境中。
7 - 使用日志记录
一旦你的代码的第一个版本运行起来,你肯定会希望在每一步进行监控,以了解发生了什么、跟踪进展或发现故障行为。这就是你可以使用日志记录的地方。
以下是高效使用日志记录的一些技巧:
-
根据你想记录的消息的性质,使用不同的级别(调试、信息、警告)。
-
在日志中提供有用的信息,以帮助解决相关问题。
import logging
logging.basicConfig(filename='example.log',level=logging.DEBUG)
logging.debug('This message should go to the log file')
logging.info('So should this')
logging.warning('And this, too')
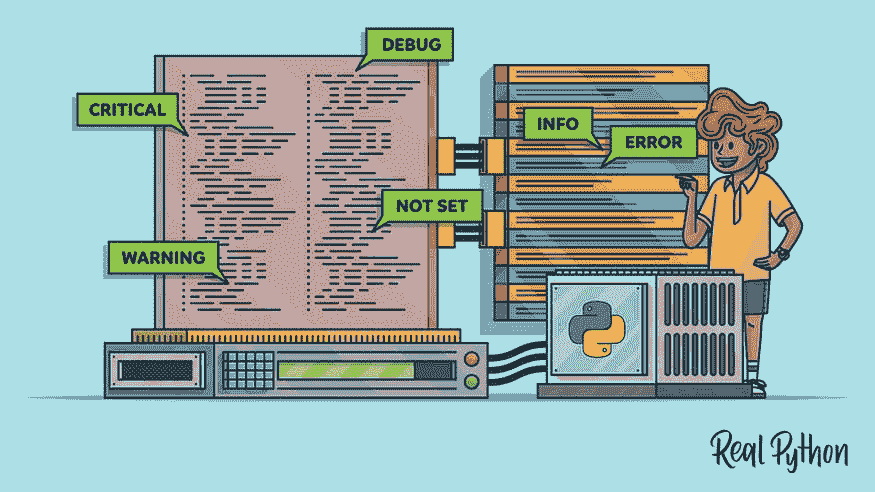
来源: realpython。
结论
数据科学家通过生成与公司系统和基础设施不相关的报告和 jupyter 笔记本来解决问题的时代早已过去。如今,数据科学家开始生成可测试和可运行的代码,与 IT 系统无缝集成。因此,遵循软件工程最佳实践成为了必需。
原文。经许可转载。
简介: Ahmed Besbes是一位居住在法国的数据科学家,工作领域涵盖金融服务、媒体和公共部门。Ahmed 的工作包括设计、构建和部署 AI 应用程序以解决业务问题。Ahmed 还博客分享技术话题,如深度学习。
相关:
更多相关话题
数据科学家的软件工程最佳实践
原文:
www.kdnuggets.com/2021/03/software-engineering-best-practices-data-scientists.html
评论
由 Madison Hunter 提供,地球科学本科生

由 Joonas kääriäinen 提供,来自 Pexels
在我自己开始编写数据分析代码之前,我真的不明白为什么人们会抱怨数据科学家编写的代码。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
来自软件开发的教育背景让我觉得自己对编码最佳实践有很好的掌握,并且对编写干净的代码充满信心。然后,当我开始编写第一次数据分析代码时。
你猜对了。
缺乏函数、不清晰的变量名、意大利面条式的代码、没有单元测试的迹象以及风格的严重缺乏,使得我在让代码工作后,面对的代码相当于一锅混乱的早餐。
最后,我终于理解了那些工程师抱怨的原因。
数据科学不是一个自然源于计算机科学的领域,这一点反映在数据科学家拥有的各种不同背景上。许多数据科学家甚至没有计算机科学的学位,他们往往来自其他不相关的领域,包括数学、科学、工程、商业、医学等。
因此,数据科学家不以总是拥有最干净的代码而闻名也就不足为奇了。
我并不是说数据科学家需要能够编写整个复杂的库。相反,数据科学家应该能够生成干净的代码,这些代码可以被更新、调试,并且在生产环境中使用时工程部门不会发出太多脏话。
编写干净代码的重要性不仅仅是为了他人。在许多公司中,预算不足以聘请数据科学家和软件工程师,这意味着数据科学家通常负责创建生产就绪的代码。因此,个人的理智也应该作为维护和开发干净、易用和可重用代码的一个因素。
许多人会争论优秀的代码是主观的。然而,通常有四个标准是每个人都能同意的,它们定义了使用最佳实践编写的代码:
-
优秀的代码应该是高效的——这意味着你需要从你的 Python 代码中挤出每一丝速度和效率,即使在没有的情况下也是如此。
-
优秀的代码是可维护的——这意味着你可以维护代码,并且其他人也可以轻松理解和维护你的代码。
-
优秀的代码是可读的且结构良好的——这意味着任何人都应该能够查看你的代码并理解你试图实现的目标,而不需要费太大劲。
-
优秀的代码是可靠的——干净的代码是好的代码,而好的代码是可靠的,不容易出现错误或随机故障。
查看这些最佳实践,你可以应用它们来达到上述四个标准。
使用描述性变量名。
我经常看到数据分析代码使用变量名如 x、y,或者任何数学变量的英文单词。
虽然这在编写数学公式时有效,但在阅读他人的代码时并不那么清晰。
在数据科学方面,我喜欢明确我的变量是什么。例如:
null_hypothesis
standard_deviation_paired_differences_population
degrees_of_freedom
observed_frequency
test_statistic_chi_squared
任何修过统计课程的人都会理解我的变量是什么,以及它们在我的方程式中所做的事情。这些基本变量可以在特定的计算或使用时变得更具描述性。
诀窍是尽可能详尽描述情况。当然,有时候计算如此复杂,以至于写出如此描述性的变量没有意义。然而,在这种情况出现之前,尽量做到描述性。
使用函数。
函数,无论你采用什么编程方法论(面向对象、函数式等),对于保持代码干净、简洁、可读和 DRY(我稍后会谈到)是至关重要的。
对于非计算机科学专业的数据科学家来说,函数并不总是直观的,因为代码在没有函数的情况下也能正确运行。
然而,最好的程序员被认为是最懒的程序员。为什么?因为他们写的代码最少,并且往往写出最简洁的代码来解决问题。他们尽可能少地工作以使代码运行,并且通常会产生最简洁的解决方案。这涉及到使用函数。
以下是一些编写优秀函数以保持代码整洁的技巧:
-
函数应该只做一件事。不是 10 件事。不是 20 件事。只是做一件事。
-
函数应该尽量小。有些人认为函数的代码行数不应超过 20 行,但这是一个任意的数字。尽量保持函数简洁明了。
-
函数应该编写得让你能够从上到下阅读和理解其逻辑——就像你读一本书一样。
-
尽量将函数参数的数量保持在最小(少于 3 个为佳)。如果你要求更多的函数参数,问问自己这个函数是否只完成一个任务。
-
确保函数中的逻辑正确缩进,并且整个函数的代码被适当地分块。这将帮助其他人看到函数内部的代码,以及函数的开始和结束位置。
-
使用描述性名称。
使用评论并编写适当的支持文档。
当你在构建改变生活的模型时,这一步很容易被忽视,但事实是,如果没有其他人能够使用它们,那么它们真的能改变生活吗?
我的个人评论规则:
-
在代码文件的顶部写下简要描述代码目标的评论。
-
在每个函数的顶部写下描述其输入、输出和执行逻辑的评论。
-
在我不完全理解的逻辑上方写下评论,以便更好地组织我的思路。这有助于调试和代码重构。
在编写适当的支持文档时,文档不必比 READme 文件更复杂。最基本的,好的文档应包括:
-
代码的目标。
-
如何安装和使用代码的说明。
-
详细解释代码中棘手的部分,逐行描述代码的具体功能,并可能解释你为什么选择这样编写代码。
-
用于调试和故障排除的截图。
-
有助于进一步描述和解释你的逻辑或代码的外部支持文档的有用链接。
使用一致的编码风格,并熟悉你使用的语言的语法惯例。
我承认我并不总是遵循某种语言的正确惯例。
在大学时,我主要学习了 C#编程,对其惯例非常熟悉并感到舒适,随后我懒散地将这些惯例应用到我遇到的其他语言中。
不要像我一样。相反,花时间学习每种新语言的语法惯例,并强迫自己正确使用这些惯例。这不仅有助于你更深入地融入语言,还能帮助你编写更清晰的代码,并有助于你与使用相同语言的其他开发者沟通。
这是一个完成相同功能的代码示例,使用两种不同的语言和每种语言的适当惯例(请注意,由于格式问题,可能缺少缩进):
C#:
// This is a comment in C#. I am going to write some code that prints out a value if the inputted number is correct.int year = 0;
Console.Write("\nEnter the year that C# became a language: ");
year = Convert.ToInt32(Console.ReadLine());if(year == 2000)
{
Console.Write("That is correct!");
}
else
{
Console.Write("This is incorrect.");
}
Python:
# This is a comment in Python. This code is going to do the same job that the code above just did.year = int(input("Enter the year that Python became a language: "))if year == 1989:
print ("That is correct!")
else:
print ("That is incorrect.")
这段傻乎乎的代码其实没做什么,但它让你对每种语言的约定差异有了一个大致的了解。
使用库。
使用现有的库可以节省大量时间,特别是在编写数据分析代码时。Python 充满了能够处理数据科学家需求的库。这些库不仅已经为你编写好,而且已经调试并准备好投入生产。
查看这篇文章,概述了 顶级数据科学库 及其功能。我在这里总结了我发现最有用的七个库:
NumPy
-
基本数组操作:添加、乘法、切片、扁平化、重塑、索引。
-
高级数组操作:堆叠数组,拆分成多个部分。
-
线性代数。
Pandas
-
索引、操作、重命名、排序和合并数据框。
-
对数据框中的列进行基本的 CRUD(更新、添加、删除)功能。
-
输入缺失的文件并处理缺失数据。
-
创建直方图或箱线图。
Matplotlib
- 所有的数据可视化,包括折线图、散点图、条形图、直方图、饼图、茎叶图和频谱图等。
TensorFlow
-
语音和声音识别。
-
情感分析。
-
人脸识别。
-
时间序列。
-
视频检测。
Seaborn
-
确定变量之间的相关性。
-
分析单变量或双变量分布。
-
绘制依赖变量的线性回归模型。
SciPy
- 常见的科学计算,包括线性代数、插值、统计、微积分和常微分方程。
Scikit-Learn
- 用于分类、聚类、回归、降维、模型选择和预处理的监督学习和无监督学习算法。
使用一个好的 IDE。
Jupyter 并不适合编写生产就绪代码。
尽管有方法将 Jupyter Notebooks 用于创建生产就绪代码,但我发现最好还是在数据探索和分析的早期阶段使用它,然后在适当的 IDE 中开发生产级代码。
IDE 提供了简单的工具来保持代码清晰,如代码检查、自动格式化、语法高亮、查找功能和错误捕获。此外,还有大量的 IDE 扩展可以帮助你在编写代码时节省时间。
一些你可以查看的 IDE 包括:
-
Visual Studio Code(我个人的最爱)
保持代码的 DRY(不要重复自己)。
DRY(不要重复自己)是一个软件工程最佳实践,旨在保持代码清晰、简洁和直接。
目标是不要重复任何代码。这意味着,如果你发现自己重复编写相同的代码行,你需要将这些代码转换为一个只编写一次的函数。然后可以多次调用这个函数。
如果你在保持代码干净方面遇到困难,只需使用 我最喜欢的规则:
-
如果这是第一次,编写代码。
-
如果这是第二次,复制它。
-
如果这是第三次,将其做成一个函数或类。
编写单元测试。
单元测试 是一种软件测试类型,涉及测试代码中的各个组件。单元测试是为了确保每一段代码按预期执行。这些测试会检查执行特定功能的小段代码,以确保它准确完成了其工作。被测试的“单元”可以是单独的函数、过程或整个对象。
单元测试的一个很好的例子是测试一个函数在接收到不同参数类型时的响应。这个测试的结果将确保你已考虑到每种可能性,并且函数不会在之后抛出任何无法解释的错误。
查看微软关于如何编写单元测试的这篇文章:
编写单元测试有许多好处;它们有助于回归测试,提供文档,并促进…
虽然这篇文章仅描述了如何在 C# 中编写单元测试,但所学的课程和示例适用于任何语言。
不要过于执着于一行解决方案。
一行代码的解决方案很棒,如果你想给朋友留下深刻印象或想在 Medium 上写一篇病毒式文章。谁不想用一行代码交易股票呢?
虽然使用一行代码创建解决方案令人印象深刻,但在调试和重构代码时,你也在为自己带来麻烦。
相反,尝试每行保持一到两个函数调用,并确保你的逻辑对任何阅读你代码的人都易于理解。如果你不能用简单的术语解释一行代码在做什么,那可能是这行代码太复杂了。
必须指出的是,开发人员编写的代码行数并不能很好地指示他们的能力或技术水平——不要听信那些告诉你不同意见的人。
最后的思考。
本文强调了数据科学家可以实施的最重要的最佳实践,以使他们的代码准备好投入生产。
你的代码是你的责任,因此花时间确保你编写的代码高效、简单且易于理解是有意义的。虽然还有很多其他编写干净代码的技巧和窍门,但上述列出的是你今天就可以应用的最简单的技巧。
简介:Madison Hunter 是地球科学本科生,软件开发毕业生。Madison 撰写关于数据科学、环境和 STEM 的随笔。
原文。已获许可转载。
相关内容:
-
数据科学的软件工程技巧和最佳实践
-
我从高效数据科学家那里学到的 15 个习惯
-
数据科学家的软件工程基础
更多主题
数据科学家的软件工程基础
原文:
www.kdnuggets.com/2020/06/software-engineering-fundamentals-data-scientists.html
评论

来源: Chris Ried @ unsplash。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
数据科学作为一个领域,自从它开始流行以来,就与其他学科发生了争论。统计学家抱怨从业者经常缺乏基本的统计知识,数学家则对在没有扎实理解所应用原理的情况下使用工具提出异议,而软件工程师指出数据科学家在编程时忽视基本原理。说实话,他们都有道理。在统计学和数学方面,确实需要对概率、代数和微积分等概念有扎实的理解。这些知识需要多深?这很大程度上取决于你的角色,但基本知识是不可妥协的。在编程方面也是类似的;如果你的角色涉及编写生产代码,那么你至少需要了解软件工程的基本知识。为什么?原因有很多,但我认为可以根据五个原则总结如下:
-
代码的完整性,包括代码编写质量、对错误的韧性、异常捕获、测试以及其他人的审查。
-
代码的可解释性,需附有适当的文档。
-
代码的速度,以便在实时环境中运行。
-
脚本和对象的模块化以便重用,避免重复,并在你的代码类中提高效率。
-
与团队的慷慨,让他们尽快审查你的代码,并在未来理解你编写的任何代码。
根据这些要点,在这个故事中我们将看到一些我认为最有用的基础知识,作为一个天生不是程序员的人,我从完全不同的背景进入这个领域。这些知识帮助我编写更好的生产代码,为我节省了时间,并使我的同事在实现我的脚本时更轻松。
编写干净代码的重要性

来源:Oliver Hale @ unsplash.
从理论上讲,我们将在这个故事中讨论的几乎所有内容都可以被视为编写更干净代码的工具或技巧。然而,在本节中,我们将重点关注“干净”一词的严格定义。正如罗伯特·马丁在他的书籍《代码整洁之道》中所说,即使糟糕的代码也能正常运行,但如果代码不够干净,它可以让一个开发组织陷入困境。怎么做到呢?说实话,可能性有很多,但只要想象一下审查写得糟糕的代码所浪费的时间,或者在新角色中发现你需要处理一些几乎无法辨认的旧代码,都会令人感到沮丧。更糟的是,想象一下某个功能失效,导致产品特性停止工作,而在你之前写下这些脏代码的人已经不在公司了。
这些都是相对常见的情况,但我们要少一点戏剧化;谁没有写过一些代码,然后因为更紧急的任务将它搁置一段时间,再回来时却不记得它是如何工作的呢?我知道这曾经发生在我身上。
这些都是让我们多花些心思编写更好代码的有效理由。因此,让我们从基础开始,了解一些编写更清洁脚本的技巧:
-
在你的代码中使用描述性的名称。我从大学学习 Java 课程时学到的一个概念就是:让你的代码具有助记性。助记性指的是一种帮助记忆的系统,比如字母、思想或关联的模式。也就是说,编写自解释的名称。
-
尽可能尝试隐含类型。例如,对于返回布尔对象的函数,你可以用 is_ 或 has 前缀它。
-
避免缩写,尤其是单个字母。
-
另一方面,避免长名称和长行。编写长名称并不意味着更具描述性,在行长度方面,PEP 8 Python 代码风格指南建议每行长度最多为约 79 个字符。
-
不要为了保持一致性而牺牲清晰性。例如,如果你有表示员工的对象和一个包含所有员工的列表,employee_list 和 employee_1 比 employees 和 employee_1 更加清晰。
-
关于空行和缩进,使你的代码更易读,通过用空行分隔不同部分并使用一致的缩进来实现。
编写模块化代码的重要性

来源:Sharon McCutcheon @ pexels.
我认为这一点对于数据科学家和数据分析师来说是最重要的,并且常常与软件工程师讨论,因为我们习惯于在 Jupyter Notebooks 等工具中编码。这些工具非常适合探索性数据分析,但不适合编写生产代码。事实上,Python 本质上是一种面向对象的编程语言,讨论其详细含义超出了本讨论范围。但简而言之,与程序化编程不同,后者是编写一系列指令让脚本执行,面向对象编程则是构建具有自身特性和操作的模块。以下是一个例子:
来源:由作者创建的图像。
实际上,这些特性称为属性,操作称为方法。在上面的例子中,计算机和打印机将是独立的类。一个类是一个包含所有该特定类型对象的属性和方法的蓝图。即,我们创建的所有计算机和打印机都将共享相同的属性和方法。这个想法的概念叫做封装。封装意味着你可以将函数和数据组合成一个单一的实体或模块。当你将程序拆分成模块时,不同的模块无需了解如何实现某些功能,只要它们不负责执行这些功能。为什么这有用?不仅是为了代码的可重用性,避免重复,并提高代码类的效率,还使调试变得更容易。
再次强调,如果你只是在 Jupyter Notebook 中进行探索性数据分析,这可能并不重要,但如果你在编写将成为实时环境的一部分的脚本,特别是随着应用程序的增长,将代码拆分成不同的模块是有意义的。在将程序的所有部分合并之前完善每个部分,不仅使在其他程序中重用单个模块变得更容易,还通过能够准确定位错误来源来更容易修复问题。
编写模块化代码的一些进一步提示:
-
DRY:不要重复自己
-
使用函数不仅减少了重复,还通过描述性名称提高了可读性,使理解每个模块的功能变得更容易。
-
最小化实体的数量(函数、类、模块等)
-
单一职责原则:一个类应该有唯一的责任。这比预期的要难。
-
遵循开闭原则,即对象应该对扩展开放,对修改关闭。这个理念是编写代码时,使得你能在不改变现有代码的情况下添加新功能,避免在一个类的变更同时需要调整所有依赖类的情况。应对这一挑战的方式有很多,不过在 Python 中,使用继承是非常常见的。
-
尽量每个函数使用不超过三个参数。如果参数较多,可以考虑拆分它。对函数长度也有类似标准;理想情况下,一个函数应包含 20 到 50 行代码。如果超出这个范围,可能需要将其拆分为多个函数。
-
同样要注意类的长度。如果一个类有超过 300 行代码,那么它可能需要被拆分成更小的类。
如果你已经在使用 Python,但对面向对象编程没有或只有很少的了解,我强烈推荐这两个免费的课程:
-
Python 中的面向对象编程 见 Datacamp
重构的重要性

来源: RyanMcGuire @ pixabay。
维基百科对重构的定义如下:
在计算机编程和软件设计中,代码重构是指在不改变其外部行为的情况下重构现有计算机代码的过程。重构旨在改善软件的设计、结构和/或实现,同时保持其功能。重构的潜在优点包括提高代码可读性和减少复杂性;这些都可以提高源代码的可维护性,并创建一个更简单、更清晰或更具表现力的内部架构或对象模型,从而改善可扩展性。
我认为定义本身就很清楚,但除此之外,我们可以补充一点:重构给我们一个机会,在代码运行后清理和模块化我们的代码。它也给了我们一个提高代码效率的机会。而我到目前为止学到的是,当一个软件工程师谈到高效代码时,他们通常指的是以下其中之一:
-
减少运行时间
-
减少内存占用
让我们简要讨论这两个要点……
根据我的经验,减少代码运行时间 是你在编写越来越多生产代码的过程中逐渐学会的。当你在 Jupyter Notebook 中进行一些分析时,不论计算这些配对距离花费你两分钟、五分钟还是十分钟都无所谓。你可以让它运行,回答一些 Slack 消息,去洗手间,倒杯咖啡,然后回来查看你的代码是否完成。然而,当有用户在等待时,你不能让他们一直等待你的代码编译,对吧?
在 Python 中,有几种方法可以提高性能。我们快速回顾一下其中一些:
使用向量操作来加快计算速度。例如,当检查一个数组的元素是否在另一个数组内时,不必编写 for 循环,你可以使用 NumPy 的 intersect1d。你还可以使用向量根据条件搜索元素以执行加法或类似操作。我们来看看一个快速示例,当我们需要 遍历一个数字列表并根据条件执行操作 时:
不要使用这种方式:
# random array with 10 million points
a = np.random.normal(500, 30, 10000000)
# iterating and checking for values < 500
t0 = time.time()
total = 0
for each in a:
if each < 500:
total += each
t1 = time.time()
print(t1-t0)
时间:3.6942789554595947 秒
# same operation only using numpy
t0 = time.time()
total = a[a<500].sum()
t1 = time.time()
print(t1-t0)
时间:0.06348109245300293 秒
比之前快了 58 倍以上!
我知道 Pandas Dataframes 使用起来非常方便,我们所有 Python 爱好者都喜欢它们。然而,在编写生产代码时,最好还是避免使用它们。我们用 Pandas 执行的大部分操作也可以用 Numpy 完成。我们来看一些其他的例子:
- 根据条件对矩阵的行进行求和
# random 2d array with 1m rows and 20 columnn
# we’ll use the same in following examples
a = np.random.random(size=(1000000,20))
# sum all values greater than 0.30
(a * (a>0.30)).sum(axis=1)
在上述代码中,乘以布尔数组之所以有效,是因为 True 对应 1,False 对应 0。
- 根据某些条件添加列
# obtain the number of columns in the matrix to be used as index of the new one to be placed at the end
new_index = a.shape[1]
# set the new column using the array created in the previous example
a = np.insert(a, new_index, (a * (a>0.30)).sum(axis=1), axis=1)
# check new shape of a
a.shape
打印:(1000000,21)| 新列已添加。
- 根据多个条件筛选表格
# filter if the new last column is greater than 10 and first column is less than 0.30
b = a[(a[:,0]<0.30)&(a[:,-1]>10)]
b.shape
打印:(55183,21)| 55183 行符合条件。
- 如果满足条件则替换元素
# change to 100 all values less than 0.30
a[a<0.3] = 100
除了上述代码,减少运行时间的另一个好方法是 并行化。并行化意味着编写一个脚本来并行处理数据,使用机器上的多个或所有可用处理器。这为何能显著提升速度?因为大多数情况下,我们的脚本是串行计算数据:它们解决一个问题,然后是下一个问题,如此循环。当我们用 Python 编写代码时,通常就是这样。如果我们希望利用并行化,就必须明确这样做。我将很快写一个关于这个主题的独立故事,但如果你迫切想了解更多,在所有可用的并行化库中,到目前为止我最喜欢的是:
关于 减少内存占用,在 Python 中减少内存使用是困难的,因为 Python 实际上不会将内存释放回操作系统。如果你删除对象,那么内存会被新 Python 对象使用,但不会被释放回系统。此外,正如前面提到的,Pandas 是进行探索性数据分析的好工具,但除了在生产代码中较慢之外,它在内存方面也相当昂贵。然而,我们可以做一些事情来控制内存使用:
-
首先:如果可能,使用 NumPy 数组而非 Pandas。即使是字典,如果可能的话,也会比 Dataframe 占用更少的内存。
-
减少 Pandas Dataframe 的数量:在修改数据框时,尝试使用参数 inplace=True 修改数据框本身,而不是创建一个新对象,以避免生成副本。
-
清除历史记录:每次对数据框进行更改(例如,df + 2)时,Python 会在内存中保存该对象的副本。你可以使用 %reset Out 清除这些历史记录。
-
注意数据类型:与数字相比,object 和 string 数据类型在内存方面的开销要大得多。这就是为什么使用 df.info() 检查数据框的数据类型并在可能的情况下使用 df[‘column’] = df[‘columns’].astype(type) 进行类型转换总是很有用的原因。
-
使用稀疏矩阵:如果你有一个包含大量空值或空单元格的矩阵,使用稀疏矩阵会更方便,它通常在内存中占用的空间要少得多。
你可以使用 scipy.sparse.csr_matrix(df.values) 来实现这一点。
- 使用生成器而非对象:生成器允许你声明一个像迭代器一样行为的函数,但使用 yield 关键字而不是 return。生成器不会创建一个包含所有计算的新对象(即列表或 NumPy 数组),而是生成一个存储在内存中的单一值,并且只有在你请求时才会更新。这被称为惰性求值。更多关于生成器的信息可以在 Abhinav Sagar 在 Towards Data Science 上的精彩文章中找到。
测试的重要性

来源: Pixabay 在 @ pexels。
数据科学中的测试是必要的。其他软件相关领域通常抱怨数据科学家的代码缺乏测试。在其他算法或脚本中,如果出现错误,程序可能会停止工作,但在数据科学中,这更危险,因为程序可能会运行,但由于值编码不正确、特征使用不当或数据破坏了模型实际依赖的假设,最终可能导致错误的洞察和建议。
当我们谈到测试时,有两个主要概念值得讨论:
-
单元测试
-
测试驱动开发
让我们先从前者开始。单元测试之所以称为单元测试,是因为它们覆盖了代码的一个小单元。目标是验证代码的每个单独部分是否按设计执行。在面向对象编程语言中,例如 Python,单元测试也可以设计用于评估整个类,但也可以是单个方法或函数。
单元测试可以从头编写。实际上,让我们这样做,以便更好地理解单元测试实际是如何工作的:
假设我有以下函数:
def my_func(a,b):
c=(a+b)/2*1.5
return c
我想测试以下输入是否返回预期的输出:
-
4 和 2 返回 4.5
-
5 和 5 返回 5.5
-
4 和 8 返回 9.0
我们可以完全写出这样的代码:
def test_func(function, output):
out = function
if output == out:
print(‘Worked as expected!’)
else:
print(‘Error! Expected {} output was {}’.format(output,out))
然后简单地测试我们的函数:
test_func(my_func(4,2),4.5)
打印:按预期工作!
然而,当函数变得更加复杂时,尤其是当我们想一次测试多个函数,甚至是一个类时,这会变得更加棘手。一个优秀的单元测试工具是pytest library。Pytest 要求你创建一个包含要测试的函数的 Python 脚本,并且还有另一组函数来断言输出。文件需要以“test”作为前缀保存,然后像运行其他 Python 脚本一样运行它。Pytest 最初是为了从命令行使用而开发的,但如果你仍处于项目的早期阶段,可以使用 Jupyter Notebook 中的 hacky 方法;你可以使用魔法命令%%writefile 创建并保存一个 .py 文件,然后直接从笔记本运行命令行语句来运行脚本。让我们来看一个示例:
import pytest
%%writefile test_function.py
def my_func(a,b):
c=(a+b)/2*1.5
return c
def test_func_4_2():
assert(my_func(4,2)==4.5)
def test_func_5_5():
assert(my_func(5,5)==7.5)
def test_func_4_8():
assert(my_func(4,8)==9.0)
然后运行脚本:
!pytest test_function.py
如果一切按预期运行,你会看到这样的输出:

未来,我会写另一个故事来讨论更复杂的单元测试示例,以及如何测试整个类(如果这是你需要的)。但与此同时,这些示例应该足以帮助你入门并测试一些函数。请注意,在上面的示例中,我测试的是返回的确切数字,但你也可以测试数据框的形状、NumPy 数组的长度、返回对象的类型等。
我们在本章开始时提到的另一个重点是 测试驱动开发(TDD)。这种测试方法或方法论包括在开始开发之前编写单元测试。接下来,你将编写尽可能简单和/或快速的代码,以通过最初编写的测试,这将帮助你通过在编写代码之前专注于需求来确保质量。此外,它将强迫你保持代码简单、干净,并可测试,通过将其拆分为与最初编写的测试相符的小块代码。一旦你有了一段实际通过测试的代码,你就可以专注于重构,以提高代码质量或实现更多功能。

来源:me.me/
TDD 的一个主要好处是,如果将来需要对代码进行更改而你不再参与该项目,可能是你转到另一家公司或只是度假,了解最初编写的测试将帮助任何接手代码的人确保更改后不会破坏任何东西。
一些值得考虑的进一步点:
-
笔记本:理想用于探索,但不适合 TDD。
-
乒乓 TDD:一个人编写测试,另一个人编写代码。
-
为你的测试设置性能和输出指标。
代码审查的重要性

来源: Charles Deluvio @ unsplash。
代码审查对团队中的每个人都有益,以促进最佳编程实践并为生产准备代码。代码审查的主要目标是捕捉错误。然而,它们也有助于提高可读性,并检查团队中的标准是否得到遵守,以便没有肮脏或慢速的代码进入生产。除此之外,代码审查还非常适合分享知识,因为团队成员可以阅读来自不同背景和风格的人的代码片段。
现如今,用于代码审查的优秀工具是 GitHub 平台的拉取请求。拉取请求是将代码或全新脚本集成到某个代码环境中的请求。之所以称之为拉取请求,是因为提交时意味着要求某人将你编写的代码拉入仓库。
从 GitHub 的文档 中,我们可以看到对拉取请求的定义:
拉取请求让你能够告诉他人你已推送到 GitHub 上一个仓库分支的更改。一旦打开拉取请求,你可以与协作者讨论和审查潜在更改,并在更改合并到主分支之前添加后续提交。
拉取请求本身就是一门艺术,如果你有兴趣了解更多,可以参考 Hugo Dias 的 这篇文章,标题为《完美拉取请求的解剖》。不过,在审查代码时,你可以问自己以下几个问题:
-
代码是否干净且模块化? 查找重复、空白、可读性和模块化。
-
代码是否高效? 查看循环、对象、函数结构,是否可以使用多进程?
-
文档是否有效? 查找内联注释、docstrings 和 readme 文件。
-
代码是否经过测试? 查找单元测试。
-
**日志记录 是否足够好? 查找日志消息的清晰度和适当频率。
原文。经允许转载。
相关内容:
更多相关话题
软件工程与机器学习概念
原文:
www.kdnuggets.com/2017/03/software-engineering-vs-machine-learning-concepts.html
评论
作者:保罗·米内罗,微软首席研究软件开发人员。

分而治之 - 软件工程中的一个关键技术是将问题分解为更简单的子问题,解决这些子问题,然后将它们组合成对原始问题的解决方案。可以说,这就是整个工作,递归地应用,直到解决方案可以用所使用的任何编程语言的一行代码表示。经典的教学示例是汉诺塔。
不幸的是,在机器学习中我们从未真正解决一个问题。充其量,我们只是近似解决了一个问题。这就是技术需要改进的地方:在软件工程中,子问题的解决方案是精确的,但在机器学习中,错误会累积,最终结果可能是完全无用的。此外,可能会出现表面上矛盾的情况,即一个组件在孤立状态下被“改进”,但当这种“改进”被部署后,整体系统性能却退化(例如,由于错误模式现在被下游组件意外地处理,即使这些错误更少)。
这是否意味着我们注定要整体考虑(这对大型问题来说似乎不可扩展)?不是,但这意味着你必须对子问题分解持防御态度。最佳策略是(当可行时)端到端地训练系统,即优化所有组件(以及组合策略),而不是孤立地进行。通常这并不可行,因此另一种替代方案(受贝叶斯思想启发)是让每个组件在输出时报告某种置信度或方差,以促进下游处理和集成。
在实践中,当系统达到一定规模时,需要进行分解,以便将工作分配给多人。机器学习中这一点现在不能正常工作是一个问题,正如 Leon Bottou 在他的ICML 2015 特邀讲座中优雅地描述的那样。
说到 Leon 讨论的另一个概念……
正确性 - 在软件工程中,可以证明算法的正确性,即在给定对输入的特定假设时,算法终止时某些属性将为真。在(监督)机器学习中,我们唯一真正拥有的保证是,如果训练集是来自特定分布的独立同分布样本,那么在另一个相同分布的独立同分布样本上的表现将接近于训练集上的表现,并且不会离最优太远。
因此,任何以机器学习为职业的人都具有实验性思维。我经常被问到选项 A 还是选项 B 更好,大多数时候我的回答是“我不知道,我们试试两个选项看看会发生什么。”也许机器学习领域最重要的事情是知道如何评估一个模型,以预测其泛化能力。即便如此,这也是一种“感觉”:识别和防止训练和验证集之间的泄漏(例如,通过分层和时间采样)是通过犯错学会的;反事实循环也是如此。Kaggle 对于学习前者很棒,但后者似乎需要在闭环系统中犯错误才能真正理解。
实验性的“正确性”比其他软件的保证要弱得多,并且有许多方法可能导致问题。例如,在我的经验中,这种情况总是暂时的:模型会变得陈旧,这似乎总是发生。因此,你需要计划不断(因此自动)重新训练模型。
重用 - 这点很有趣。重用是传统软件工程中的关键:重用其他代码不仅更高效,而且你自己编写的每一行代码都是注入缺陷的机会。因此,重用不仅可以让你更快地移动,还可以减少错误:作为回报,你必须支付学习如何操作他人编写的软件的代价(如果做得好,这个代价通过良好的组织、文档和社区支持降低了)。
机器学习的某些方面展示了完全相同的权衡。例如,如果你在编写自己的深度学习工具包,请意识到你是在享受乐趣。享受乐趣本身没有问题,教育活动可能比整天玩电子游戏要好。然而,如果你想完成某项工作,你绝对应该尽可能多地重用技术,这意味着你应该使用标准工具包。一旦你学会如何操作标准工具包,你会移动得更快,犯的错误也会更少。
然而,机器学习工具包是“传统软件”,并设计为可重用。那模型重用呢?这也可以很好,但上述关于分解的警告仍然适用。所以也许你使用一个模型,该模型从用户配置文件中生成特征作为你模型的输入。很好,但你应该对你依赖的模型进行版本管理,而不是盲目地升级而不进行评估或重新训练。重用另一个模型的内部尤其危险,因为大多数机器学习模型是不可识别的,即具有各种内部对称性,这些对称性不是由训练过程决定的。例如,将嵌入与树结合,当下一个版本的嵌入是前一个版本的旋转时,你可以立即看到你的性能变差。
基本上,模型重用会在组件之间创建强耦合,如果其中一个组件发生更改,可能会出现问题。
测试 - 我发现软件测试在机器学习中的角色是最棘手的问题。毫无疑问,测试是必要的,但使用像基于属性的测试这样的东西的挑战在于,机器学习组件所捕捉的概念不容易用属性来表征(否则,你会使用非机器学习软件技术来实现它)。在机器学习组件应该表现出一些属性的程度上,你可以测试这些属性,但除非将这些属性融入到学习过程中(例如,通过参数绑定或数据增强),否则你可能会遇到一些并不一定表示缺陷的属性违反。
拥有一个质量最低可接受的“额外测试”数据集是个好主意:这可以是“任何合理模型”都应该正确处理的简单例子。还有自我一致性:在雅虎,他们曾用一组在模型组装时计算的输入-输出对来发货模型,如果加载的模型没有重现这些对,模型加载会被取消。(这绝不该发生,对吧?惊讶!也许你在使用不同版本的库进行特征化。)
监控部署模型的度量指标(代理指标和真实指标)也有助于检测问题。如果代理指标(即你实际训练模型和估计泛化性能的依据)变差,模型的输入发生了变化(例如,非平稳环境,特征提取管道的变化);但如果代理指标稳定而真实指标变差,问题可能在于模型输出的利用方式。
不幸的是,我发现许多具有机器学习组件的软件系统以一种会让传统软件工程师感到不安的方式进行测试:我们查看输出以确定其是否合理。太疯狂了!随着机器学习成为软件工程中越来越普遍的一部分,这种情况必须改变。
简介: 保罗·米内罗 是微软的首席研究软件开发人员。他喜欢领导中型团队,专注于原型设计、探索性开发和将研究转化为开发("高风险,高回报"的活动)。他喜欢迭代的测试驱动开发、数据驱动决策和积极心理学导向的管理。
原文。经许可转载。
相关:
-
如何向软件工程师解释机器学习
-
深度学习与“常规”机器学习的区别是什么?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关话题
机器学习部署的软件接口
原文:
www.kdnuggets.com/2020/03/software-interfaces-machine-learning-deployment.html
评论
由 Luigi Patruno 提供,数据科学家及 ML in Production 的创始人。

在我们 上一篇文章 关于机器学习部署的文章中,我们介绍了什么是部署机器学习模型。我们了解到,为了使训练好的模型的预测结果可供用户和其他软件系统使用,我们需要考虑许多因素,包括预测生成的频率以及是否一次生成单个样本的预测或批量样本的预测。在这篇文章中,我们将开始研究 如何实现 部署过程。
虽然许多博客文章直接跳到实现 Flask API 或使用工作流调度程序,我们将从更基础的层面开始。我们将首先讨论 软件接口,它可以被认为是软件之间的边界。一个类比是,软件是拼图的一块,整个软件系统是完整的拼图。设计得当时,接口允许你连接许多不同的软件组件,从而形成大型而复杂的项目。
在 ML 部署方面,良好构建的接口有助于实现可重复、自动化的即插即用部署。一个好的接口让你轻松推出模型更新,对你部署的模型进行版本控制,等等。
开始吧!
什么是接口?
想象一个经理分配给员工创建报告的任务。一位好的经理可能会说:“我需要你生成一个包含以下图表和数据的报告。为生成该报告,请使用客户交易数据。”经理明确了期望的结果(报告),并暗示了一种方法(使用客户交易数据)。
相比之下,一位不好的经理可能会做以下任何事情:
-
不指定输入——要求报告但未指定使用哪些数据或暗示员工应与谁联系以发现合适的数据集。
-
不明确交付物——给员工一堆数据,但不告诉他们应该生产什么。
-
微观管理——告诉员工使用哪些工具生成报告,遵循哪些步骤,并承诺任何偏离此计划的行为都将受到迅速且严厉的惩罚。
软件接口就像管理者。一个好的接口明确说明了必要的输入和它产生的输出。例如,作为函数实现的接口将列出所有必需的参数和函数返回的内容。接口可以被看作是定义不同软件如何相互通信的“边界”。当接口构建良好时,不同的软件,甚至是由不同团队或公司开发的软件,可以相互通信并协同工作。
软件工程师被教导要关注他们开发的接口,而不是函数的实现。实现固然重要,但总是可以更新。但更新接口尤其是外部接口在发布后要困难得多。因此,定义接口所投入的时间是值得的。
机器学习模型的基本接口
软件工程师如何看待机器学习模型实际做了什么?从抽象的角度来看,模型接受数据,对这些数据进行某种处理,然后返回结果。就是这么简单。模型如何处理数据可能非常复杂,比如卷积神经网络对图像数据张量进行卷积的前向传播,但这些都是实现细节。
机器学习模型的边界由模型的输入,即特征,以及模型预测的输出组成。因此,一个构建良好的接口必须同时考虑输入特征和预测输出。为了说明这一点,让我们用一个简单的函数来定义这个接口:
def predict(model, input_features):
'''
Function that accepts a model and input data and returns a prediction.
Args:
---
model: a machine learning model.
input_features: Features required by the model to generate a
prediction. Numpy array of shape (1, n) where n is the dimension
of the feature vector.
Returns:
--------
prediction: Prediction of the model. Numpy array of shape (1,).
'''
这个函数的输入是一个model和一组input_features,并返回一个预测。注意我们还没有实现这个函数,即我们还没有编写如何将模型和特征结合以生成预测。我们只是创建了一个契约或承诺——我们保证如果调用者提供了一个model和input_features,函数将返回一个预测。
机器学习模型的多个接口
我们定义的predict()方法接受一个特征向量并返回一个预测。我们怎么知道这一点?文档说明input_features是一个形状为(1, n)的 numpy 数组,其中n是特征向量的维度。如果你的模型期望一次预测一个实例,这很好,但如果模型还需要对样本批次进行预测,就不太理想了。你可以通过编写 for 循环来解决这个问题,但循环的效率可能不高。相反,我们应该定义另一个直接处理批量情况的方法。我们称之为predict_batch:
def predict_batch(model, batch_input_features):
'''
Function that predicts a batch of samples.
Args:
---
model: a machine learning model.
batch_input_features: A batch of features required by the model to
generate predictions. Numpy array of shape (m, n) where m is the
number of instances and n is the dimension of the feature vector.
Returns:
--------
predictions: Predictions of the model. Numpy array of shape (m,).
'''
这个方法定义了一个契约,承诺在提供模型和输入特征批次时返回一批预测。再次强调,我们尚未实现这个方法——这留给方法的开发者。开发者可以选择使用循环并重复调用predict。或者开发者可以做其他事情。这对于部署的目的并不重要。重要的是我们有两个接口:一个用于预测单个样本,另一个用于预测一批样本。
机器学习面向对象编程 – MLOOP
到目前为止,我们忽略了model参数,这对于predict和predict_batch方法都是必需的。让我来解释一下这对机器学习来说为什么是个问题。
目前,大多数开发机器学习模型的工程师都希望使用最佳工具。如果工程师正在构建经典模型,如逻辑回归或随机森林,工程师可能会选择使用scikit-learn。但对于深度学习,该工程师可能会选择使用Tensorflow或PyTorch。即使在经典机器学习中,工程师也可能选择xgboost的梯度提升树实现。每个库中的模型对象具有略微不同的 API。我们无法预测未来的 ML 库将实现哪些 API。这将使我们接口的实现变得非常混乱。例如,我们不希望我们的实现看起来像这样:
def predict(model, input_features):
...
if isinstance(model, sklearn.base.BaseEstimator)
...
elif isinstance(model, xgboost.core.Booster):
...
elif isinstance(model, tensorflow.keras.Model):
...
elif isinstance(model, torch.nn.module):
...
...
这种实现方式将很难维护,也会使调试运行时错误变得困难。此外,想象一下,如果我们希望在使用一个模型时传递额外的参数而不是另一个模型会发生什么。例如,如果我们希望仅在预测 sklearn 模型时传递额外的参数。函数的参数数量将会增加,但这些参数对于非 sklearn 模型是无用的。我们将如何在文档中描述这一点?这些只是为什么面向对象编程、创建类和对象是更受欢迎的几个原因。
我们的接口由两个方法组成:predict和predict_batch。让我们定义一个包含这两个方法的基类:
class Model:
def __init__(self, model):
self.model = model
def predict(self, input_features):
'''
Function that accepts input data and returns a prediction.
Args:
---
input_features: Features required by the model to generate prediction. Numpy
array of shape (1, n) where n is the dimension of the feature vector.
Returns:
--------
prediction: Prediction of the model. Numpy array of shape (1,).
'''
raise NotImplementedError
def predict_batch(self, batch_input_features):
'''
Function that predicts a batch of samples.
Args:
---
batch_input_features: A batch of features required by the model to generate
predictions. Numpy array of shape (m, n) where m is the number of
instances and n is the dimension of the feature vector.
Returns:
--------
prediction: Predictions of the model. Numpy array of shape (m, 1).
'''
raise NotImplementedError
这个基类充当了我们数据科学团队的模板。如果数据科学家想使用 scikit-learn 模型,他只需要继承 Model 类并实现必要的方法。如果另一个数据科学家想使用 Tensorflow,没问题,只需创建一个 Tensorflow 子类!为了说明这一点,让我们创建一个 sklearn 子类:
class SklearnModel(Model):
def __init__(self, model):
super().__init__(model)
def predict(self, input_features):
y = self.model.predict(input_features.reshape(1, -1))
return y
def predict_batch(self, batch_input_features):
ys = self.model.predict(batch_input_features)
return ys
由于 sklearn Predictors 期望 2D 输入,我们在 predict 方法中重新调整了 input_features 参数。这是面向对象方法的一个关键好处。我们可以定义适用于我们解决的问题类型的接口并且利用优秀的第三方机器学习库!
好处不仅仅于此。我们可以添加更多简化 ML 工作流的方法。例如,一旦模型被训练,我们通常需要一种方式来序列化模型,然后在推理时进行反序列化。因此,我们可以在接口中添加两个方法,serialize() 和 deserialize()。我们甚至可以在基类 Model 中提供这些方法的默认实现,并在子类中创建库特定的实现。
其他有用的接口方法示例包括将序列化模型从本地文件系统移动到某个模型存储或像 S3 这样的远程文件系统。你可以添加的方法没有限制。
提前创建良好的接口将为你的机器学习团队节省大量时间,使得在进行额外项目时,部署变得自动化和可重复。
原始。已获许可转载。
简介: Luigi Patruno 是数据科学家和机器学习顾问。他目前是 2U 的数据科学总监,负责领导一个数据科学团队,专注于构建机器学习模型和基础设施。作为顾问,Luigi 帮助公司通过应用现代数据科学方法来实现战略业务和产品目标。他创立了 MLinProduction.com 以收集和分享机器学习操作化的最佳实践,并且教授过统计学、数据分析和大数据工程的研究生课程。
相关:
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关话题
迅速而轻松地解决任何图像分类问题
原文:
www.kdnuggets.com/2018/12/solve-image-classification-problem-quickly-easily.html
评论
由Pedro Marcelino,科学家、工程师与企业家
代码的美丽由Chris Ried在Unsplash上展示
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
深度学习 正迅速成为人工智能应用中的关键工具(LeCun et al. 2015)。例如,在计算机视觉、自然语言处理和语音识别等领域,深度学习取得了显著的成果。因此,深度学习受到越来越多的关注。
深度学习擅长解决的一个问题是图像分类(Rawat & Wang 2017)。图像分类的目标是根据一组可能的类别对特定图片进行分类。图像分类的经典例子是识别一组图片中的猫和狗(例如,狗与猫 Kaggle 竞赛)。
从深度学习的角度来看,图像分类问题可以通过迁移学习来解决。实际上,图像分类中的一些最先进的结果基于迁移学习解决方案(Krizhevsky et al. 2012, Simonyan & Zisserman 2014, He et al. 2016)。Pan & Yang(2010)提供了迁移学习的全面综述。
本文展示了如何实现图像分类问题的迁移学习解决方案。 本文提出的实现基于 Keras(Chollet 2015),使用 Python 编程语言。按照此实现方法,你将能够快速且轻松地解决任何图像分类问题。
本文组织如下:
-
迁移学习
-
卷积神经网络
-
重用预训练模型
-
迁移学习过程
-
深度卷积神经网络上的分类器
-
示例
-
摘要
-
参考文献
1. 迁移学习
迁移学习在计算机视觉中是一种流行的方法,因为它使我们能够以节省时间的方式构建准确的模型 (Rawat & Wang 2017)。使用迁移学习,你不是从零开始学习过程,而是从解决不同问题时已经学习到的模式开始。这样你可以利用以前的学习成果,避免从头开始。把它看作是深度学习版本的Chartres的“站在巨人的肩膀上”。
在计算机视觉中,迁移学习通常通过使用预训练模型来实现。预训练模型是指在大型基准数据集上训练出来的模型,用于解决类似于我们想要解决的问题。因此,由于训练这些模型的计算成本,通常会从已发表的文献中导入并使用模型(例如,VGG、Inception、MobileNet)。Canziani 等人 (2016) 对使用 ImageNet (Deng et al. 2009) 挑战的数据进行的预训练模型在计算机视觉问题上的性能进行了全面回顾。
2. 卷积神经网络
多个用于迁移学习的预训练模型基于大型卷积神经网络 (CNN) (Voulodimos et al. 2018)。一般来说,CNN 在各种计算机视觉任务中表现出色 (Bengio 2009)。其高性能和易于训练是近年来 CNN 流行的两个主要因素。
一个典型的 CNN 有两个部分:
-
卷积基础,由一系列卷积层和池化层组成。卷积基础的主要目标是从图像中生成特征。有关卷积层和池化层的直观解释,请参考 Chollet (2017)。
-
分类器,通常由全连接层组成。分类器的主要目标是根据检测到的特征对图像进行分类。全连接层是指其神经元与前一层的所有激活都有完全连接的层。
图 1 展示了基于 CNN 的模型架构。请注意,这是一个简化版本,适合本文的目的。实际上,这种模型的架构比我们在这里建议的要复杂。
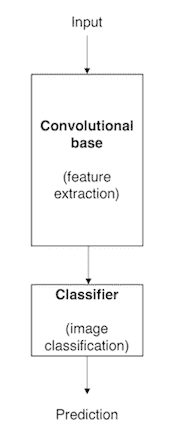
图 1. 基于 CNN 的模型架构。
这些深度学习模型的一个重要方面是它们能够自动学习层次特征表示。这意味着第一层计算的特征是通用的,可以在不同的问题领域中重复使用,而最后一层计算的特征是特定的,依赖于所选择的数据集和任务。根据 Yosinski 等人(2014 年)的说法,‘如果第一层特征是通用的,而最后一层特征是特定的,那么网络中某个地方必定存在从通用到特定的过渡’。因此,我们的 CNN 的卷积基础——尤其是其较低的层(即靠近输入的层)——指的是通用特征,而分类器部分以及卷积基础的一些较高层则指的是专门的特征。
3. 重新利用预训练模型
当你将预训练模型重新利用到自己的需求时,你首先需要移除原始分类器,然后添加一个适合你目的的新分类器,最后你需要根据三种策略之一来微调你的模型。
-
训练整个模型。在这种情况下,你使用预训练模型的架构,并根据你的数据集进行训练。你是在从头开始学习模型,因此你需要一个大数据集(以及大量的计算能力)。
-
训练一些层并保持其他层不变。如你所记得,较低的层指的是通用特征(与问题无关),而较高的层指的是特定特征(与问题相关)。在这里,我们通过选择调整网络权重的多少来玩味这种二分法(一个冻结的层在训练过程中不会变化)。通常,如果你有一个小数据集和大量参数,你会保持更多层不变以避免过拟合。相反,如果数据集很大且参数较少,你可以通过训练更多层来改进你的模型,因为过拟合不是问题。
-
冻结卷积基础。这种情况对应于训练/冻结权衡的极端情况。主要思想是保持卷积基础的原始形式,然后利用其输出作为分类器的输入。你将预训练模型用作固定的特征提取机制,这在计算能力有限、数据集较小和/或预训练模型解决的问题与您想解决的问题非常相似的情况下非常有用。
图 2 以示意图的方式展示了这三种策略。
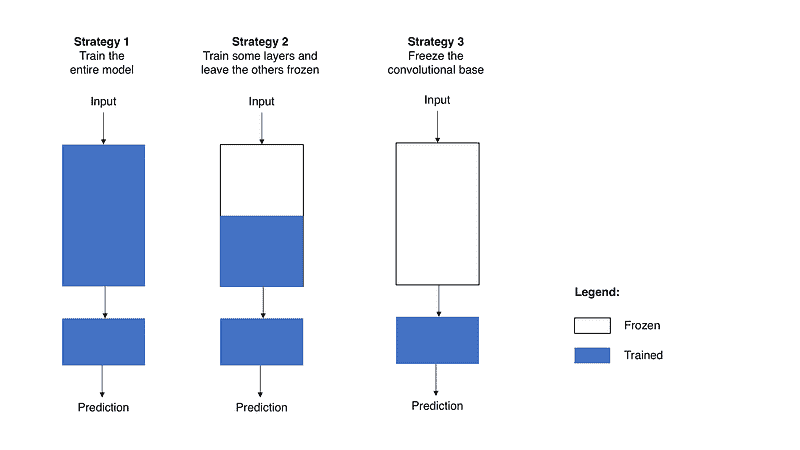
图 2. 微调策略。
与策略 3不同,策略 1和策略 2的应用需要你在卷积部分的学习率上小心。学习率是一个超参数,控制你调整网络权重的程度。当你使用基于 CNN 的预训练模型时,使用较小的学习率是明智的,因为较高的学习率增加了丢失先前知识的风险。假设预训练模型已经经过良好的训练,这是一个合理的假设,保持较小的学习率将确保你不会过早或过度地扭曲 CNN 权重。
4. 迁移学习过程
从实际角度来看,整个迁移学习过程可以总结如下:
-
选择一个预训练模型。从众多可用的预训练模型中,你选择一个看起来适合你的问题的模型。例如,如果你使用 Keras,你可以立即访问一组模型,如 VGG(Simonyan & Zisserman 2014)、InceptionV3(Szegedy 等 2015)和 ResNet5(He 等 2015)。这里你可以查看 Keras 上所有可用的模型。
-
根据 Size-Similarity 矩阵对你的问题进行分类。在图 3 中,你有一个控制你选择的‘矩阵’。该矩阵根据你的数据集大小及其与预训练模型训练数据集的相似性来分类你的计算机视觉问题。作为一个经验法则,如果你的数据集每个类别少于 1000 张图片,则可以认为它是小型数据集。关于数据集相似性,让常识占上风。例如,如果你的任务是识别猫和狗,ImageNet 是一个类似的数据集,因为它包含猫和狗的图像。然而,如果你的任务是识别癌细胞,ImageNet 不能被认为是类似的数据集。
-
微调你的模型。在这里,你可以使用 Size-Similarity 矩阵来指导你的选择,然后参考我们之前提到的关于重新利用预训练模型的三种选项。图 4 提供了接下来文本的视觉总结。
-
象限 1。大型数据集,但不同于预训练模型的数据集。这种情况会导致你使用策略 1。由于你有一个大型数据集,你能够从头开始训练模型并做任何你想做的事情。尽管数据集有所不同,但实际上,从预训练模型初始化你的模型,使用它的架构和权重,仍然是有用的。
-
象限 2. 大数据集且与预训练模型的数据集相似。在这里,你处于梦幻之地。任何选项都有效。可能,最有效的选项是策略 2。由于我们有一个大数据集,过拟合不应该是问题,因此我们可以尽可能多地学习。然而,由于数据集相似,我们可以通过利用先前的知识来节省大量的训练工作。因此,仅需训练分类器和卷积基础的顶层即可。
-
象限 3. 小数据集且与预训练模型的数据集不同。这是计算机视觉问题中的 2–7 离牌手。所有情况都对你不利。如果抱怨不是一个选项,你唯一的希望是策略 2。在训练和冻结层数之间找到平衡会很困难。如果你过深,你的模型可能会过拟合;如果你停留在模型的浅层,你将无法学到任何有用的东西。可能,你需要比在象限 2 中更深入,并且需要考虑数据增强技术(有关数据增强技术的一个很好的总结可以在这里找到)。
-
象限 4. 小数据集,但与预训练模型的数据集相似。我问过大师尤达,他告诉我“最佳选择,策略 3 应该”。我不知道你怎么想,但我不低估原力。因此,选择策略 3。你只需要去掉最后一个全连接层(输出层),将预训练模型作为固定特征提取器运行,然后使用结果特征来训练新的分类器。
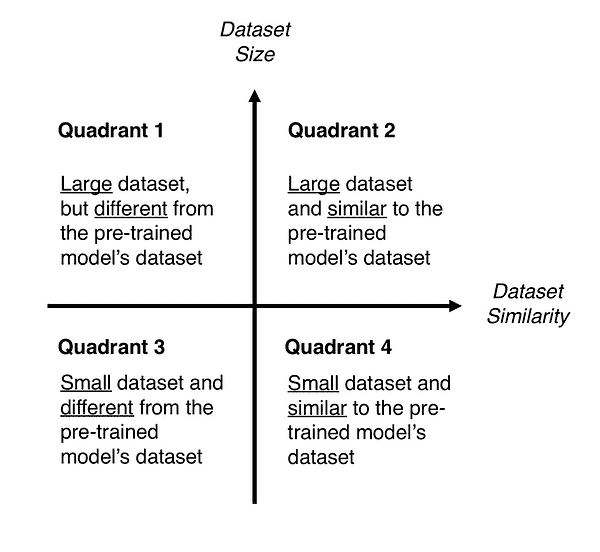
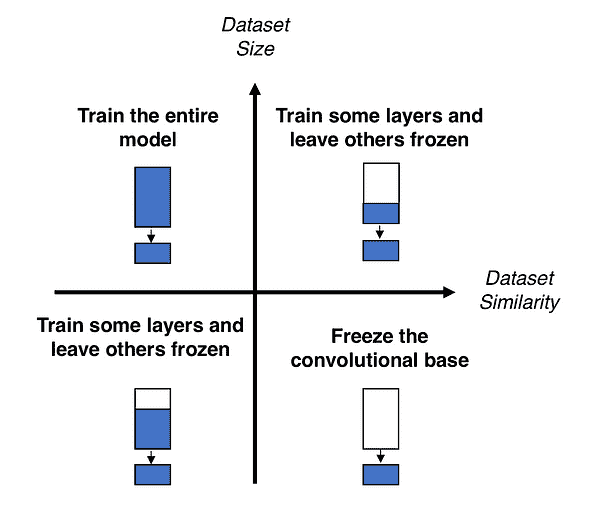
图 3 和 4. 尺寸-相似性矩阵(左)和用于微调预训练模型的决策图(右)。
5. 深度卷积神经网络上的分类器
如前所述,图像分类模型 通过基于预训练卷积神经网络的迁移学习方法通常由两个部分组成:
-
卷积基础,用于特征提取。
-
分类器,根据卷积基础提取的特征对输入图像进行分类。
由于本节重点是分类器部分,我们必须首先说明,构建分类器可以采用不同的方法。一些最受欢迎的方法包括:
-
全连接层。 对于图像分类问题,标准方法是使用一系列全连接层,随后是一个 softmax 激活层(Krizhevsky et al. 2012,Simonyan & Zisserman 2014,Zeiler & Fergus 2014)。softmax 层输出每个可能类别标签的概率分布,然后我们只需根据最可能的类别来分类图像。
-
全局平均池化。 Lin 等人(2013)提出了一种基于全局平均池化的不同方法。在这种方法中,我们不是在卷积基础上添加全连接层,而是添加一个全局平均池化层,并将其输出直接送入 softmax 激活层。Lin 等人(2013)对这种方法的优缺点进行了详细讨论。
-
线性支持向量机。 线性支持向量机(SVM)是另一种可能的方法。根据 Tang(2013)的说法,我们可以通过在卷积基础上提取的特征上训练线性 SVM 分类器来提高分类准确率。关于 SVM 方法的优缺点的更多细节可以在论文中找到。
相关主题更多内容
如何在现实世界中解决机器学习问题
原文:
www.kdnuggets.com/2021/09/solve-machine-learning-problems-real-world.html
评论
由 Pau Labarta Bajo,数学家和数据科学家。

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 部门
所以,你想成为一名专业的机器学习工程师?是否被诱惑去参加(又一个)机器学习的在线课程,以获得那第一份工作?
机器学习的在线课程和 Kaggle 风格的比赛是学习机器学习基础知识的极佳资源。然而,机器学习工程师的日常工作需要额外的技能,这些技能在课程中无法掌握。
在这篇文章中,我将给你 4 个建议,帮助你在现实世界中解决机器学习问题。我在 Toptal 作为自由职业机器学习工程师工作时(经历了一番艰难的学习过程)学到了这些建议。顺便提一下,如果你也希望以自由职业的方式工作(强烈推荐!),你可以查看我 关于如何成为自由职业数据科学家的博客文章。

照片由 Valdemaras D. 提供,来源于 Pexels。
机器学习课程与实践之间的差距
完成许多机器学习的在线课程看起来似乎是一个安全的学习路径。你跟随卷积网络课程中的代码,自己实现,然后大功告成!你就成了计算机视觉的专家!
好吧,你没有。
你还缺少 4 项关键技能,以在专业环境中构建成功的机器学习解决方案。
让我们开始吧!
1. 首先理解业务问题,然后将其框架化为机器学习问题。
当你参加在线课程或参与 Kaggle 比赛时,你不需要定义要解决的机器学习问题。
你会被告知要解决什么问题(例如,预测房价),以及如何衡量你离良好解决方案的距离(例如,模型预测值与实际价格的均方误差)。他们还会给你所有数据,告诉你特征是什么,目标指标是什么。
有了这些信息后,你会直接进入解决方案空间。你会迅速探索数据并开始训练一个又一个模型,希望每次提交后都能在公共排行榜上爬升几个名次。技术型人才,比如软件和机器学习工程师,喜欢构建东西。我也包括在这个群体中。即使在理解需要解决的问题之前,我们也会这样做。我们知道工具,手指很灵活,所以我们在理解眼前的问题(即 WHAT)之前,迅速跳入解决方案空间(即 HOW)。
当你作为专业的数据科学家或机器学习工程师工作时,你需要在构建任何模型之前考虑几个问题。我总是在每个项目开始时提出 3 个问题:
-
管理层希望改善的业务结果是什么?是否有明确的指标,还是我需要找出可以简化工作的替代指标?
在项目开始时与你所有相关的利益相关者沟通是至关重要的。他们通常比你拥有更多的业务背景,可以大大帮助你理解你需要瞄准的目标。在行业中,为正确的问题构建一个尚可的解决方案比为错误的问题构建一个出色的解决方案要好。学术研究往往正好相反。
先回答这个第一个问题,你将知道你机器学习问题的目标指标。
-
目前是否有正在生产环境中解决此问题的解决方案,例如其他模型或一些基于规则的启发式方法?
如果有,这就是你必须超越的基准,以便产生业务影响。否则,你可以通过实施非机器学习解决方案获得快速胜利。有时你可以实现一个简单而快速的启发式方法,这已经会带来影响。在行业中,今天一个尚可的解决方案比两个月后的一个出色解决方案要好。
回答第二个问题,你将理解模型的表现需要达到什么程度才能产生影响。
-
这个模型是作为黑箱预测器使用吗?还是我们打算将它作为帮助人类做出更好决策的工具?
创建黑箱解决方案比创建可解释的解决方案要容易。例如,如果你想构建一个比特币交易机器人,你只关心它产生的预计利润。你会回测它的表现,看看这个策略是否给你带来价值。你的计划是部署机器人,监控它的每日表现,并在它让你亏钱时关闭它。你并不试图通过查看模型来了解市场。另一方面,如果你创建一个模型来帮助医生提高诊断能力,你需要创建一个可以轻松向他们解释的模型。否则,那 95%的预测准确率将没有用处。
回答第三个问题,你将知道是否需要额外花时间处理可解释性,还是可以完全专注于最大化准确性。
回答这三个问题,你将明白你需要解决的机器学习问题是什么。
2. 专注于获取更多更好的数据
在在线课程和 Kaggle 竞赛中,组织者会提供所有数据。实际上,所有参与者使用相同的数据,彼此竞争谁的模型更好。重点在于模型,而不是数据。
在你的工作中,恰恰相反。数据是你拥有的最有价值的资产,它决定了机器学习项目的成功与否。获取更多更好的数据来提高模型性能是最有效的策略。
这意味着两件事:
-
你需要(多多)与数据工程师沟通。
他们知道每一条数据的位置。他们可以帮助你获取这些数据并用它生成有用的特征。此外,他们还可以构建数据摄取管道,以添加可以提高模型性能的第三方数据。保持良好健康的关系,偶尔喝杯啤酒,你的工作会变得更轻松,轻松很多。
-
你需要精通 SQL。
访问数据的最通用语言是 SQL,因此你需要精通 SQL。这在你工作于数据不发达的环境中(如初创公司)尤为重要。掌握 SQL 可以让你快速构建、扩展和修复模型的训练数据。除非你在一个超级发达的科技公司(如 Facebook、Uber 及类似公司)拥有内部功能库,否则你会花费大量时间编写 SQL。所以最好熟练掌握。
机器学习模型是软件(例如,从简单的逻辑回归到庞大的变换器)和数据(是的,字母大写)的结合。数据决定了项目的成功与否,而不是模型。
3. 结构化你的代码

照片由 Igor Starkov 提供,来自 Pexels。
Jupyter notebooks 非常适合快速原型设计和测试想法。它们在开发阶段的快速迭代中表现优秀。Python 是一种为快速迭代而设计的语言,Jupyter notebooks 是完美的配对。
然而,notebooks 很快就会变得拥挤且难以管理。
当你只训练一次模型并将其提交到竞赛或在线课程时,这不是问题。然而,当你在现实世界中开发 ML 解决方案时,你需要做的不仅仅是训练一次模型。
有两个重要的方面你可能会遗漏:
-
你必须部署你的模型并使其对公司其他部门可访问。
不易部署的模型没有价值。在工业界,一个可以轻松部署的普通模型比一个没有人知道如何部署的最新庞大 Transformer 更有用。
-
你必须重新训练模型以避免概念漂移。
现实世界中的数据会随时间变化。无论你今天训练了什么模型,它在几天、几周或几个月后(取决于底层数据的变化速度)都会过时。在工业界,一个使用最新数据训练的普通模型比一个使用昔日数据训练的出色模型更好。
我强烈建议从一开始就打包你的 Python 代码。对我来说,效果较好的目录结构如下:
my-ml-package
├── README.md
├── data
│ ├── test.csv
│ ├── train.csv
│ └── validation.csv
├── models
├── notebooks
│ └── my_notebook.ipynb
├── poetry.lock
├── pyproject.toml
├── queries
└── src
├── __init__.py
├── inference.py
├── data.py
├── features.py
└── train.py
Poetry 是我最喜欢的 Python 打包工具。只需 3 条命令,你就可以生成大部分这样的文件夹结构。
$ poetry new my-ml-package
$ cd my-ml-package
$ poetry install
我喜欢为所有 ML 项目中的常见元素保持单独的目录:data、queries、Jupyter notebooks 和由训练脚本生成的 serialized models:
$ mkdir data queries notebooks models
我建议添加一个 .gitignore 文件,以排除 data 和 models 目录,因为它们包含可能非常大的文件。
对于 src/ 中的源代码,我喜欢保持简单:
-
**data.py**是生成训练数据的脚本,通常通过查询 SQL 类型的数据库来完成。拥有一种干净且可重复的方式来生成训练数据非常重要,否则你会浪费时间试图理解不同训练集之间的数据不一致性。 -
**features.py**包含大多数模型所需的特征预处理和工程。这包括填补缺失值、对分类变量进行编码、添加现有变量的变换等。我喜欢使用并推荐 scikit-learn 数据集转换 API。 -
**train.py**是用于训练的脚本,它将数据拆分为训练集、验证集、测试集,并拟合一个 ML 模型,可能还会进行超参数优化。最终模型作为一个工件保存在models/下。 -
**inference.py**是一个 Flask 或 FastAPI 应用,它将你的模型封装为一个 REST API。
当你将代码结构化为 Python 包时,你的 Jupyter 笔记本中不会包含大量的函数声明。相反,这些函数在src中定义,你可以通过像from src.train import train这样的语句将它们加载到笔记本中。
更重要的是,清晰的代码结构意味着与帮助你的 DevOps 人员关系更健康,以及更快地发布你的工作。双赢。
4. 开始时避免深度学习
现在,我们经常将机器学习和深度学习作为同义词使用。但它们并不是。尤其是在你处理真实世界项目时。
目前,深度学习模型在每个 AI 领域都是最先进的(SOTA)。但你不需要最先进的技术来解决大多数商业问题。
除非你处理的是计算机视觉问题,在这种情况下深度学习是最佳选择,否则请不要一开始就使用深度学习模型。
通常,你开始一个机器学习项目,拟合你的第一个模型,比如逻辑回归,然后你发现模型的表现不够好,无法结束项目。你认为应该尝试更复杂的模型,而神经网络(即深度学习)是最佳候选者。经过一些谷歌搜索,你找到了一段适合你数据的 Keras/PyTorch 代码。你复制并粘贴它,然后尝试用你的数据训练它。
你会失败。为什么?神经网络不是即插即用的解决方案。它们正好相反。它们有成千上万/百万个参数,并且非常灵活,这使得它们在第一次尝试时有些棘手。如果你花费大量时间,你会让它们发挥作用,但你需要投入过多的时间。
有很多现成的解决方案,如著名的XGBoost模型,对于许多问题(特别是表格数据)效果非常好。在进入深度学习领域之前,尝试这些方法。

结论
专业机器学习工程师的工作比你在任何在线课程中学到的要复杂得多。
我很乐意帮助你成为其中的一员,所以如果你想了解更多,请订阅 datamachines 通讯或查看我的博客。
原文。经许可转载。
简介:Pau Labarta Bajo 是一位数学家和数据科学家,拥有超过 10 年的经验,处理了各种问题的数字和模型,包括金融交易、移动游戏、在线购物和医疗保健。
相关:
更多相关主题
解决线性回归应该使用哪些方法?
评论
由 Ahmad Bin Shafiq,机器学习学生。
线性回归是一种监督式机器学习算法。它预测一个独立变量(y)与给定的依赖变量(x)之间的线性关系,以使得独立变量(y)具有最低成本。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
解决线性回归模型的不同方法
我们可以对线性回归模型应用许多不同的方法以提高其效率。但在这里,我们将讨论其中最常见的一些。
-
梯度下降
-
最小二乘法 / 正规方程法
-
亚当方法
-
奇异值分解(SVD)
好的,我们开始吧……
梯度下降
对于初学者而言,解决线性回归问题最常见且最简单的方法之一就是梯度下降。
梯度下降的工作原理
现在,假设我们的数据以散点图的形式绘制出来,当我们对其应用一个成本函数时,我们的模型会做出预测。这个预测可能非常好,也可能与我们的理想预测相距甚远(即成本很高)。因此,为了最小化这个成本(错误),我们应用梯度下降。
现在,梯度下降会逐渐使我们的假设收敛到全局最小值,在那里成本最低。在此过程中,我们必须手动设置alpha的值,且假设的斜率会根据 alpha 的值而变化。如果 alpha 的值很大,那么梯度下降将会采取大的步伐。否则,在小的 alpha 情况下,我们的假设将会慢慢收敛,通过小的步骤。
假设收敛到全局最小值。图片来源于 Medium。
梯度下降的方程是
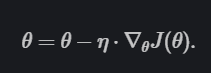
来源:Ruder.io。
在 Python 中实现梯度下降
import numpy as np
from matplotlib import pyplot
#creating our data
X = np.random.rand(10,1)
y = np.random.rand(10,1)
m = len(y)
theta = np.ones(1)
#applying gradient descent
a = 0.0005
cost_list = []
for i in range(len(y)):
theta = theta - a*(1/m)*np.transpose(X)@(X@theta - y)
cost_val = (1/m)*np.transpose(X)@(X@theta - y)
cost_list.append(cost_val)
#Predicting our Hypothesis
b = theta
yhat = X.dot(b)
#Plotting our results
pyplot.scatter(X, y, color='red')
pyplot.plot(X, yhat, color='blue')
pyplot.show()
梯度下降后的模型。
首先,我们创建了我们的数据集,然后遍历所有训练样本,以最小化假设的成本。
优点:
梯度下降法的重要优点包括
-
相比于 SVD 或 ADAM,计算成本较低
-
运行时间为 O(kn²)
-
在特征数量较多的情况下效果很好
缺点:
梯度下降法的重要缺点是
-
需要选择一些学习率α
-
需要多次迭代才能收敛
-
可能会陷入局部最小值
-
如果学习率α不合适,可能无法收敛。
最小二乘法
最小二乘法,也称为正规方程,是解决线性回归模型的最常见方法之一。但这个方法需要对线性代数有一些基本了解。
最小二乘法的工作原理
在普通 LSM 中,我们直接求解系数的值。简而言之,通过一步,我们达到光学最小点,或者我们可以说仅一步我们将假设拟合到数据中,成本最低。
在应用 LSM 之前和之后的数据集。图片来自 Medium。
LSM 的方程是
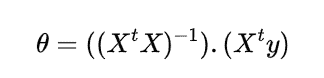
在 Python 中实现 LSM
import numpy as np
from matplotlib import pyplot
#creating our data
X = np.random.rand(10,1)
y = np.random.rand(10,1)
#Computing coefficient
b = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y)
#Predicting our Hypothesis
yhat = X.dot(b)
#Plotting our results
pyplot.scatter(X, y, color='red')
pyplot.plot(X, yhat, color='blue')
pyplot.show()
首先我们创建了我们的数据集,然后使用最小二乘法最小化我们的假设成本。
b = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y)
代码,与我们的方程式等效。
优点:
LSM 的重要优点包括:
-
无需学习率
-
无需迭代
-
特征缩放不是必需的
-
在特征数量较少时效果非常好。
缺点:
重要的缺点有:
-
当数据集很大时计算成本较高。
-
当特征数量较多时较慢
-
运行时间为 O(n³)
-
有时你的 X 转置 X 是不可逆的,即没有逆的奇异矩阵。你可以使用np.linalg.pinv代替np.linalg.inv来克服这个问题。
Adam 方法
ADAM,即自适应矩估计,是一种在深度学习中广泛使用的优化算法。
这是一个迭代算法,对噪声数据效果很好。
这是 RMSProp 和小批量梯度下降算法的结合。
除了像 Adadelta 和 RMSprop 一样存储过去平方梯度的指数衰减平均值外,Adam 还保留了过去梯度的指数衰减平均值,类似于动量。
我们计算过去和过去平方梯度的衰减平均值如下:
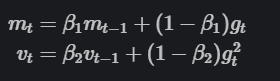
致谢: Ruder.io。
由于mt和vt初始化为 0 向量,Adam 的作者观察到它们在初始时间步骤特别偏向于零,尤其是当衰减率较小(即β1β1 和β2β2 接近 1)时。
他们通过计算经过偏差校正的第一和第二矩估计来抵消这些偏差:
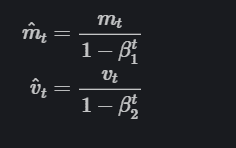
致谢: Ruder.io。
然后他们用以下方法更新参数:
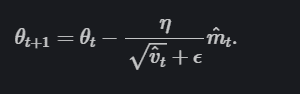
致谢: Ruder.io。
Adam 的伪代码 是

来源: Arxiv Adam。
让我们查看它在纯 Python 中的代码。
#Creating the Dummy Data set and importing libraries
import math
import seaborn as sns
import numpy as np
from scipy import stats
from matplotlib import pyplot
x = np.random.normal(0,1,size=(100,1))
y = np.random.random(size=(100,1))
现在让我们找出线性回归的实际图形以及我们数据集的斜率和截距值。
print("Intercept is " ,stats.mstats.linregress(x,y).intercept)
print("Slope is ", stats.mstats.linregress(x,y).slope)
现在让我们使用 Seaborn 的 regplot 函数查看线性回归线。
pyplot.figure(figsize=(15,8))
sns.regplot(x,y)
pyplot.show()
现在让我们用纯 Python 编写 Adam 优化器。
h = lambda theta_0, theta_1, x: theta_0 + np.dot(x,theta_1) #equation of straight lines
# the cost function (for the whole batch. for comparison later)
def J(x, y, theta_0, theta_1):
m = len(x)
returnValue = 0
for i in range(m):
returnValue += (h(theta_0, theta_1, x[i]) - y[i])**2
returnValue = returnValue/(2*m)
return returnValue
# finding the gradient per each training example
def grad_J(x, y, theta_0, theta_1):
returnValue = np.array([0., 0.])
returnValue[0] += (h(theta_0, theta_1, x) - y)
returnValue[1] += (h(theta_0, theta_1, x) - y)*x
return returnValue
class AdamOptimizer:
def __init__(self, weights, alpha=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8):
self.alpha = alpha
self.beta1 = beta1
self.beta2 = beta2
self.epsilon = epsilon
self.m = 0
self.v = 0
self.t = 0
self.theta = weights
def backward_pass(self, gradient):
self.t = self.t + 1
self.m = self.beta1*self.m + (1 - self.beta1)*gradient
self.v = self.beta2*self.v + (1 - self.beta2)*(gradient**2)
m_hat = self.m/(1 - self.beta1**self.t)
v_hat = self.v/(1 - self.beta2**self.t)
self.theta = self.theta - self.alpha*(m_hat/(np.sqrt(v_hat) - self.epsilon))
return self.theta
在这里,我们使用面向对象的方法和一些辅助函数实现了上述伪代码中提到的所有方程。
现在让我们为我们的模型设置超参数。
epochs = 1500
print_interval = 100
m = len(x)
initial_theta = np.array([0., 0.]) # initial value of theta, before gradient descent
initial_cost = J(x, y, initial_theta[0], initial_theta[1])
theta = initial_theta
adam_optimizer = AdamOptimizer(theta, alpha=0.001)
adam_history = [] # to plot out path of descent
adam_history.append(dict({'theta': theta, 'cost': initial_cost})#to check theta and cost function
最后是训练过程。
for j in range(epochs):
for i in range(m):
gradients = grad_J(x[i], y[i], theta[0], theta[1])
theta = adam_optimizer.backward_pass(gradients)
if ((j+1)%print_interval == 0 or j==0):
cost = J(x, y, theta[0], theta[1])
print ('After {} epochs, Cost = {}, theta = {}'.format(j+1, cost, theta))
adam_history.append(dict({'theta': theta, 'cost': cost}))
print ('\nFinal theta = {}'.format(theta))
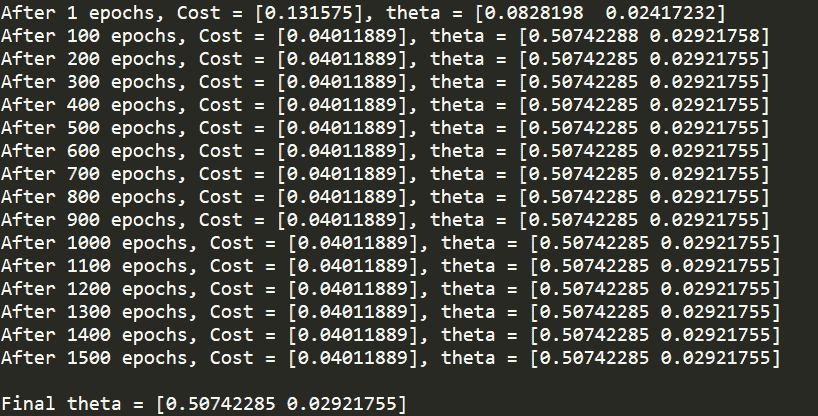
现在,如果我们将 Final theta 值与之前使用 scipy.stats.mstat.linregress 计算的斜率和截距值进行比较,它们几乎相等,经过调整超参数后可以完全相等。
最后,让我们绘制它。
b = theta
yhat = b[0] + x.dot(b[1])
pyplot.figure(figsize=(15,8))
pyplot.scatter(x, y, color='red')
pyplot.plot(x, yhat, color='blue')
pyplot.show()
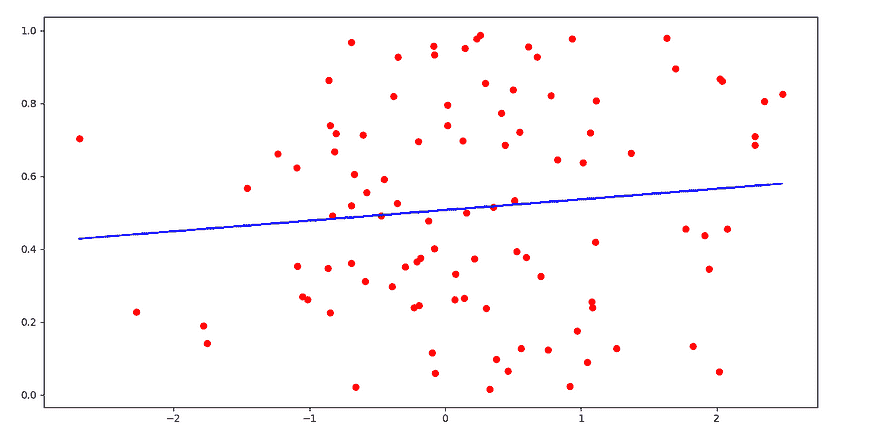
我们可以看到我们的图与使用 sns.regplot 获得的图类似。
优点:
-
实现简单明了。
-
计算效率高。
-
低内存需求。
-
对梯度的对角线重新缩放不变。
-
非常适合数据和/或参数较大的问题。
-
适用于非平稳目标。
-
适用于非常噪声大或稀疏的梯度问题。
-
超参数具有直观的解释,通常需要很少的调整。
缺点:
- Adam 和 RMSProp 对学习率(有时是其他超参数,如批量大小)的某些值非常敏感,如果例如,学习率过高,它们可能会灾难性地无法收敛。(来源: stackexchange)
奇异值分解
奇异值分解(SVD)是线性回归中一种著名且广泛使用的降维方法。
SVD 用于(其中之一)作为预处理步骤,以减少学习算法的维度。SVD 将矩阵分解为三个其他矩阵(U, S, V)的乘积。
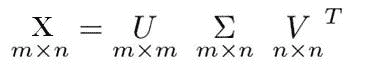
一旦我们的矩阵被分解,假设的系数可以通过计算输入矩阵 X 的伪逆并将其乘以输出向量 y 来找到。之后,我们将假设拟合到数据中,这将给我们最低的成本。
在 Python 中实现奇异值分解
import numpy as np
from matplotlib import pyplot
#Creating our data
X = np.random.rand(10,1)
y = np.random.rand(10,1)
#Computing coefficient
b = np.linalg.pinv(X).dot(y)
#Predicting our Hypothesis
yhat = X.dot(b)
#Plotting our results
pyplot.scatter(X, y, color='red')
pyplot.plot(X, yhat, color='blue')
pyplot.show()
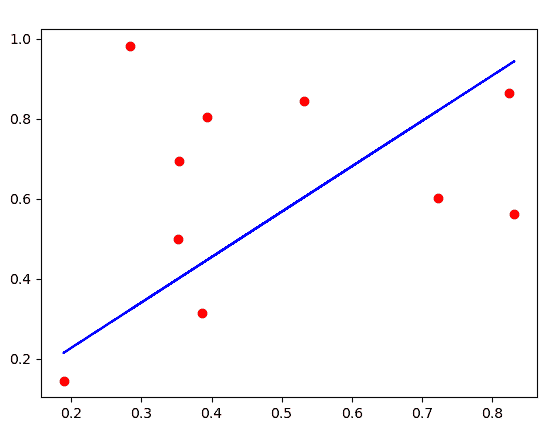
尽管它没有很好地收敛,但仍然相当不错。
首先,我们创建了数据集,然后使用 b = np.linalg.pinv(X).dot(y) 这个 SVD 方程来最小化假设的成本。
优点:
-
在高维数据上效果更好
-
适用于高斯类型分布的数据
-
对于小数据集非常稳定和高效
-
解决线性回归的线性方程时,这种方法更稳定,也是首选方法。
缺点:
-
运行时间为 O(n³)
-
多重风险因素
-
对异常值非常敏感
-
可能在非常大的数据集上变得不稳定
学习成果
到目前为止,我们已经学习并实现了梯度下降、最小二乘法、ADAM 和奇异值分解。现在,我们对这些算法有了很好的理解,也知道了它们的优缺点。
我们注意到,ADAM 优化算法是最准确的,根据实际的 ADAM 研究论文,ADAM 的表现优于几乎所有其他优化算法。
相关:
更多相关话题
有哪些“高级”AI 和机器学习在线课程?
原文:
www.kdnuggets.com/2019/02/some-advanced-ai-machine-learning-online-courses.html
评论
为什么写这篇文章?
许多刚开始数据科学和机器学习之旅的年轻专业人士面临一个共同问题——他们完成了一两个基础在线课程,做了一些编程练习,上传了几个项目到 Github,然后……然后呢?
学习什么?在哪里找到集中资源?
在我之前的一篇文章中(由TDS Team发布),我详细讨论了你可以在哪里找到 MOOC(大规模开放在线课程)以启动你的数据科学和机器学习之旅。那篇文章假定读者为初学者,涵盖了优化的基本和中级学习的 MOOC。你可以在这里查看,
[如何选择有效的机器学习和数据科学 MOOC?
对非计算机科学领域的专业人士的建议,渴望学习并贡献于数据科学/机器学习。来自……towardsdatascience.com](https://towardsdatascience.com/how-to-choose-effective-moocs-for-machine-learning-and-data-science-8681700ed83f)
我写了另一篇详细的文章,专注于数据科学和机器学习中你需要掌握的数学概念及相关课程。你可以在这里查看,
[数据科学的基本数学 - '为什么'和'如何'
数学是科学的基础。我们讨论了成为更好的数据科学家所需掌握的关键数学主题……towardsdatascience.com](https://towardsdatascience.com/essential-math-for-data-science-why-and-how-e88271367fbd)
最近,我收到了许多来自聪明年轻专业人士的个人邮件和 LinkedIn 收件箱中的消息,他们询问类似的问题以及对在线课程的建议。
对于这些消息,我大多有现成的答案。我只需发送一份我的文章列表(其中包含了指向 KDnuggets 或Team AV的其他高度引用文章的链接和参考)。大多数情况下,我会收到愉快的回复 😃
然而,自从撰写那些文章以来,我个人参加了更多“高级”AI 和机器学习(ML)课程,看到了一些讨论和评论,自然感觉需要更新这些参考资料。
经过一番思考,我决定最好保留原始文章,因为它们确实面向初学者,并且为许多读者很好地服务过,同时尝试编制一个新的在线课程列表。
这就是本文的内容。
我所说的“高级”课程是什么意思?
“高级”是一个相对的术语。最好有一个基准来解释这个词在此上下文中的含义。幸运的是,当谈到机器学习在线 MOOC 时,我们几乎有一个黄金标准——Prof. Andrew Ng的Coursera 课程(原始的那个,不是Deeplearning.ai 专业课程)。
因此,在本文中提到的“高级”指的是两个特征,这两个特征需要在将要讨论的课程中存在(不一定是同时存在)。
-
比上述课程具有显著更多的广度,即涵盖更多高级和多样化的主题。
-
与 AI 或 ML 相关的高度专业化焦点
我希望我能明确我的意图不是说 Ng 教授的课程是一个初级课程。它仍然是世界上最好的机器学习入门课程——尤其是对于初学者。然而,在你完成这个课程后,进行一些编程,熟悉数学概念,你应该在你的基础上继续学习多样化的主题。
我只希望这篇文章能够通过列出一些免费的 MOOCs来帮助你达到这一目标。
选择课程的唯一焦点是什么?
AI 和 ML 是热门话题,免费的在线课程层出不穷。然而,我发现真正高质量的 AI 课程数量惊人地少。
是的,我属于那个坚定相信深度学习不是人工智能的阵营,因此拒绝任何标题中包含“AI”但仅涉及 Python 中的深度学习框架的课程被归类为 AI 课程的观点。
因此,为了将我的列表限制在有限数量的高质量课程中,我制定了一些简单的规则或筛选条件。
-
我倾向于避免任何明显关注特定编程框架/工具的课程,即没有名称为“用 Python 进行机器学习……”的课程(一些示例或代码片段是可以的)。
-
按照相同的逻辑,列表中的课程将具有强烈的理论基础——这主要偏向大学课程,而不是由个人创业者或公司(例如 fast.ai、Google、Microsoft、IBM 等)提供的课程。
-
类似地,我包括了由大学教职工或知名研究人员如 Sebastian Thrun 或 Peter Norvig 教授的 Udacity 课程。我没有包括他们的纳米学位参考,因为我认为这些并不具有知识启发性。
-
没有课程专注于数据科学/数据工程/数字分析/应用统计。这些都是当今世界中极其重要的话题,但为了本文的重点,我更倾向于将它们与纯机器学习和人工智能分开。
我相信这种重点会自动将列表筛选为高质量的人工智能和机器学习基础课程,这对中级到高级学习者有益。
毕竟,你将是裁判。
个人来说,我没有完成所有这些课程,尽管我完成了其中的相当一部分。因此,我试图简明扼要地评论这些课程,并保持事实准确。
链接和参考资料
不再耽搁,以下是列表。
通用机器学习和深度学习
这些课程涵盖了通用机器学习和深度学习主题。
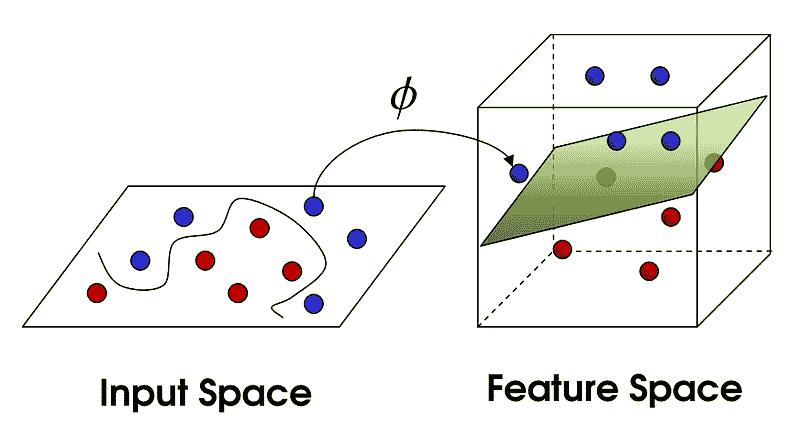
来源:www.jeremyjordan.me/support-vector-machines/
-
乔治亚理工学院的“机器学习”课程在 Udacity:这是最全面的机器学习课程之一,涵盖了监督学习、无监督学习、随机优化技术(例如遗传算法)、强化学习,甚至是入门级博弈论概念。
-
安德鲁·吴教授的斯坦福课堂版讲座:这是吴教授在斯坦福的机器学习课程的完整课堂版本。深入覆盖了机器学习的基础主题,而这些在简化版的在线 MOOC 中缺失。
-
“高级机器学习专业化”由国立研究大学高等经济学院在 Coursera 上提供:这是由俄罗斯研究人员提供的一组很棒的课程(共 5 门)。涵盖了实际深度学习技术以及基础概念。
-
“大规模机器学习”由 Yandex 在 Coursera 上提供:涵盖了使用 MLib/Spark 等进行 ML 模型的部署和扩展。
-
“机器学习 Caltech 课程”:之前在 edX 上,现在已移至 Mostafa 教授的主页。链接指向那里。这是一个在机器学习及学习理论的深层数学方面非常基础的课程。
-
“机器学习基础”由加州大学圣地亚哥分校在 edX 上提供: 一门均衡的课程,教授机器学习中的核心理论和实践概念,强调算法问题。
人工智能与博弈论

这些是与人工智能和博弈论相关的课程。
-
Udacity 的“人工智能导论”课程: 目前网络上最全面的核心人工智能课程。由两位著名专家——Sebastian Thrun 和 Peter Norvig 授课。他们涵盖了如 AI 搜索算法、规划、表征逻辑、概率推理、机器学习、马尔可夫过程、隐马尔可夫模型(HMM)及滤波器、计算机视觉、机器人技术和自然语言处理等主题。
-
哥伦比亚大学的“人工智能 (AI)”课程在 edX 上: 这也是对人工智能关键主题的全面回顾,但水平较低。这是对人工智能广泛领域的良好介绍,涵盖了如智能体的类型和定义、人工智能的历史、搜索、游戏、逻辑、约束满足问题、自然语言处理(NLP)、机器人技术和计算机视觉等主题。
-
斯坦福大学的“博弈论”课程在 Coursera 上: 这是对博弈论奇妙世界的极佳介绍(且全面),涵盖了所有重要主题,如纳什均衡、混合策略、相关均衡、子博弈完美、扩展形式、重复博弈与民间定理、贝叶斯博弈、联盟博弈。
-
“知识基础的人工智能: 认知系统”由乔治亚理工学院在 Udacity 上提供: 一门关于传统人工智能(或称 GOFAI)的全面课程,涵盖了如语义网络、手段与目标分析、案例推理、增量概念学习、逻辑与规划、类比推理、约束传播和元推理等主题。
强化学习

这些是与强化学习相关的课程。
-
乔治亚理工学院的“强化学习”课程在 Udacity 上:这可能是目前最全面的 RL 课程。两位讲师对该主题都非常了解且充满热情。授课模式为对话式且有趣。它涵盖了 MDP 基础、时间差分(TD)学习、价值和策略迭代、Q 学习、收敛性质、奖励塑造、Bandit 问题、Rmax 分析、一般随机 MDP、状态泛化、POMDP、选项、目标抽象技术、机制设计、蒙特卡罗树搜索、DEC-POMDP、策略评论概念等所有相关主题。
-
“实用强化学习”,由国家研究型大学高等经济学院在 Coursera 上提供:这是另一门非常全面的课程,涵盖了强化学习的核心主题。与乔治亚理工学院的课程不同的是,它不包括博弈论讨论,而是更多地讨论深度 Q 学习。它是一门更加实用的课程,教你一些实际技巧(但不一定包括完整的代码)来构建 RL 代理。
其他相关主题
-
Udacity 的“机器人学中的人工智能”:这是一个很棒的小课程,专注于人工智能在机器人领域的应用,由 Sebastian Thrun 教授。他讲授了本地化、卡尔曼滤波器、粒子滤波器、先进的 AI 搜索技术、PID 控制、SLAM(同时定位与地图构建)等主题。
-
“机器学习数学基础专项”由伦敦帝国学院在 Coursera 上提供:这是一个由四门课程组成的优秀专项,专注于构建机器学习的数学基础。它涵盖了多变量微积分、线性代数和主成分分析(还有一个完整的短课程)。
总结
我希望给你提供一些关于免费在线课程的建议,这些课程涵盖了机器学习和人工智能的相对高级主题。本文中,我专门列出了 MOOC,并未考虑自由形式的视频讲座(斯坦福 CS229 课程为例外)。你当然可以在各大学的在线平台上搜索这些视频讲座,通常它们的质量非常高。
祝你在学习这些激动人心的主题的旅程中取得巨大成功!
如果你有任何问题或想法,请通过 tirthajyoti[AT]gmail.com 联系作者。此外,你可以查看作者的 GitHub 库,以获取其他有趣的 Python、R 或 MATLAB 代码片段和机器学习资源。如果你和我一样,对机器学习/数据科学充满热情,请随时 在 LinkedIn 上添加我 或 在 Twitter 上关注我。
[Tirthajyoti Sarkar - 高级首席工程师 - 半导体、人工智能、机器学习 - ON…]
查看 Tirthajyoti Sarkar 在 LinkedIn 上的个人资料,这是全球最大的专业社区。Tirthajyoti 有 8 个职位… www.linkedin.com
简介: Tirthajyoti Sarkar 是一位半导体技术专家、机器学习/数据科学爱好者、电气工程博士、博主和作家。
原文。已获授权转载。
相关:
-
数据科学必备数学: ‘为什么’和‘如何’
-
合成数据生成:新数据科学家必备技能
-
IT 工程师需要学习多少数学才能进入数据科学领域?
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
一些提升 LLM 模型的强大提示工程技术
原文:
www.kdnuggets.com/some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models

使用 DALL-E3 创建的图像
人工智能在科技领域带来了彻底的革命。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
其模仿人类智慧并执行曾被认为仅为人类领域的任务的能力仍然让我们大多数人感到惊讶。
然而,无论这些最近的 AI 进展有多么出色,仍然有改进的空间。
正是提示工程发挥作用的地方!
进入这个可以显著提升 AI 模型生产力的领域。
让我们一起发现这一切吧!
提示工程的本质
提示工程是一个快速增长的领域,专注于提高语言模型的效率和有效性。其核心在于设计完美的提示,以指导 AI 模型产生我们期望的输出。
将其视为学习如何给出更好的指示,以确保对方理解并正确执行任务。
为什么提示工程很重要
-
提高生产力: 通过使用高质量的提示,AI 模型可以生成更准确和相关的响应。这意味着减少了修正的时间,增加了利用 AI 能力的时间。
-
成本效率: 训练 AI 模型是资源密集型的。提示工程可以通过更好的提示优化模型性能,从而减少重新训练的需求。
-
多样性: 一个精心设计的提示可以使 AI 模型更加多样化,使它们能够处理更广泛的任务和挑战。
在深入了解最先进的技术之前,让我们回顾两种最有用(也最基础)的提示工程技术。
基本提示工程方法的初步了解
使用“让我们一步一步思考”进行顺序思考
今天大家都知道,添加“让我们一步一步思考”这个词序列,可以显著提高 LLM 模型的准确性。
为什么……你可能会问?
这是因为我们强迫模型将任何任务分解为多个步骤,从而确保模型有足够的时间处理每一个步骤。
例如,我可以用以下提示挑战 GPT3.5:
如果约翰有 5 个梨,然后吃了 2 个,买了 5 个,再给朋友 3 个,他现在有多少个梨?
模型会立刻给我答案。然而,如果我加上最后的“让我们一步一步来思考”,我就是在强迫模型生成一个多步骤的思维过程。
少样本提示
虽然零样本提示指的是在没有提供任何上下文或先前知识的情况下要求模型执行任务,但少样本提示技术则意味着我们向 LLM 提供一些我们期望的输出示例以及一些具体问题。
比如说,如果我们想创建一个用诗意的语调定义任何术语的模型,这可能会很难解释。对吧?
不过,我们可以使用以下少样本提示来引导模型朝着我们想要的方向。
你的任务是以一致的风格回答,符合以下风格。
: 教我关于韧性的问题。
: 韧性就像一棵随风摇摆却永不折断的树。 这是一种从逆境中反弹并不断前进的能力。
: 你的输入在这里。
如果你还没试过,你可以去挑战 GPT。
不过,由于我很确定你们中的大多数人已经了解这些基本技巧,我将尝试用一些高级技巧来挑战你们。
高级提示工程技术
1. 思维链 (CoT) 提示
由谷歌于 2022 年介绍,这种方法包括指示模型在给出最终回答之前经历几个推理阶段。
听起来很熟悉,对吧?如果是这样,你完全正确。
这就像将顺序思维和少样本提示合并在一起。
怎么做?
实质上,CoT 提示引导 LLM 顺序处理信息。这意味着我们展示如何通过多个步骤解决第一个问题,然后将实际任务发送给模型,期望它在回答实际查询时模仿类似的思维链。
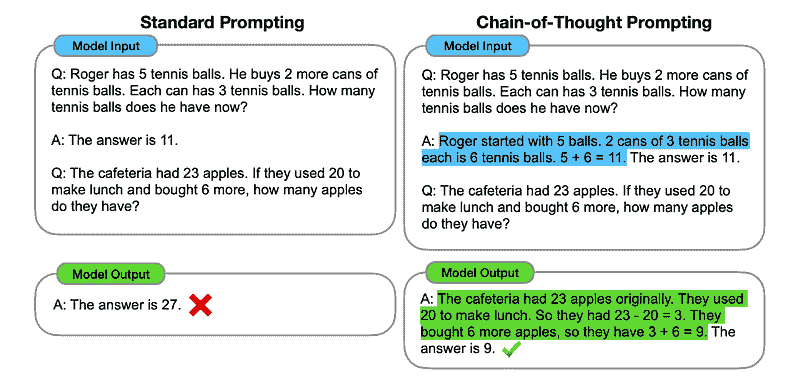
图片取自论文。
所以,按照第一个示例,我们可以提供一个包含第一个问题和顺序解释的提示。然后,我们可以发送我们的输入,看看魔法是如何发生的!
如果约翰有 5 个梨,然后吃了 2 个,买了 5 个,再给朋友 3 个,他现在有多少个梨?让我们一步一步来思考。
让我们一步一步来。约翰开始时有 5 个梨。他吃了 2 个梨,所以剩下 5–2 = 3 个梨。然后,他又买了 5 个梨。所以,他现在有 3 + 5 = 8 个梨。最后,他给了朋友 3 个梨。因此,他剩下 8–3 = 5 个梨。所以,经过所有这些步骤,约翰有 5 个梨。
你的输入在这里。
然而,你们大多数人可能会想… 每次我想在 ChatGPT 上问问题时,都必须想到一种逐步解决问题的方法吗?
嗯… 你不是第一个这样想的人!这就引出了…
2. 自动化思维链(Auto-CoT)
在 2022 年,张和同事们引入了一种避免这种手动过程的方法。避免任何手动任务的主要原因有两个:
-
这可能会很无聊。
-
这可能会导致糟糕的结果——例如,当我们的思维过程错误时。
他们建议结合使用 LLMs 和“让我们一步步思考”提示来逐步生成每个演示的推理链。
这意味着询问 ChatGPT 如何逐步解决任何问题,然后使用这个例子来训练它如何解决其他问题。
3. 自我一致性
自我一致性是另一种有趣的提示技术,旨在改善更复杂推理问题的思维链提示。
所以… 主要区别是什么?
自我一致性的主要思想是意识到我们可以用错误的例子来训练模型。试想一下我用错误的思维过程解决了之前的问题:
如果约翰有 5 个梨子,然后吃掉 2 个,再买 5 个,然后给朋友 3 个,他还有多少个梨子?让我们一步步思考。
从 5 个梨子开始。约翰吃了 2 个梨子。然后,他给了朋友 3 个梨子。这些操作可以组合在一起:2(吃掉的)+ 3(给出的)= 总共 5 个受影响的梨子。现在,从最初的 5 个梨子中减去受影响的梨子:5(初始) - 5(受影响) = 剩下 0 个梨子。 然后,我发送给模型的任何其他任务都会是错误的。
这就是为什么自我一致性涉及从各种推理路径中采样,每条路径包含一链思路,然后让 LLM 选择最佳和最一致的路径来解决问题。
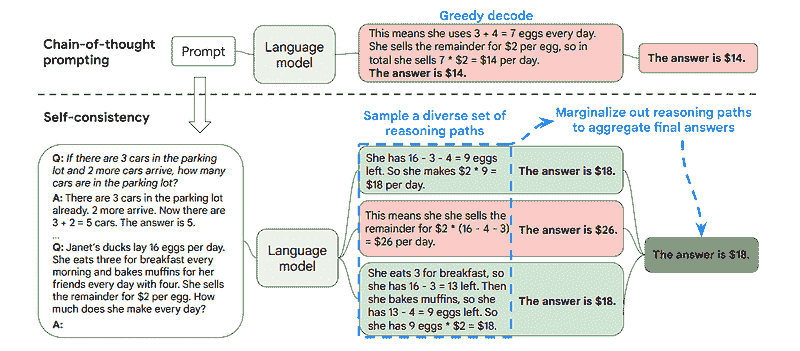
图片摘自论文
在这种情况下,并且再次按照最初的例子,我们可以向模型展示不同的解决问题的方法。
如果约翰有 5 个梨子,然后吃掉 2 个,再买 5 个,然后给朋友 3 个,他还有多少个梨子?
从 5 个梨子开始。约翰吃了 2 个梨子,剩下 5–2 = 3 个梨子。他再买了 5 个梨子,总数变为 3 + 5 = 8 个梨子。最后,他给了朋友 3 个梨子,所以他剩下 8–3 = 5 个梨子。
如果约翰有 5 个梨子,然后吃掉 2 个,再买 5 个,然后给朋友 3 个,他还有多少个梨子?
从 5 个梨子开始。然后他再买 5 个梨子。约翰现在吃了 2 个梨子。这些操作可以组合在一起:2(吃掉的)+ 5(买的)= 总共 7 个梨子。从总数中减去约翰吃掉的梨子,7(总数) - 2(吃掉的)= 剩下 5 个梨子。
你的输入在这里。
最后的技巧来了。
4. 一般知识提示
提示工程的一个常见做法是,在发送最终的 API 调用到 GPT-3 或 GPT-4 之前,使用额外的知识来增强查询。
根据Jiacheng Liu 和其他人的说法,我们可以在任何请求中添加一些知识,以便 LLM 更好地了解问题。
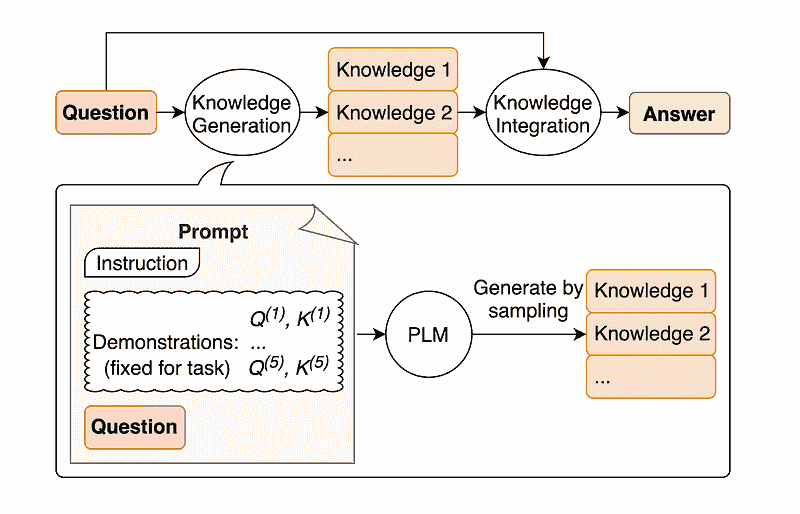
图片取自论文。
例如,当询问 ChatGPT 高尔夫的一部分是否是试图获得比其他人更高的分数时,它会验证我们。但高尔夫的主要目标正好相反。这就是为什么我们可以添加一些先前的知识告诉它“得分较低的玩家获胜”。

那么,如果我们准确地告诉模型答案,有什么有趣的部分呢?
在这种情况下,这种技术用于改善 LLM 与我们的互动方式。
所以,与其从外部数据库中提取补充背景,论文的作者建议让 LLM 生成自己的知识。然后将这些自生成的知识整合到提示中,以增强常识推理并提供更好的输出。
这就是如何在不增加训练数据集的情况下改进 LLM!
结论
提示工程已成为增强 LLM 能力的关键技术。通过迭代和改进提示,我们可以更直接地与 AI 模型沟通,从而获得更准确和上下文相关的输出,节省时间和资源。
对于技术爱好者、数据科学家和内容创作者而言,理解和掌握提示工程可以在充分利用 AI 的潜力方面成为一种宝贵的资产。
通过将精心设计的输入提示与这些更先进的技术相结合,掌握提示工程的技能无疑将在未来几年为你提供优势。
Josep Ferrer**** 是一位来自巴塞罗那的分析工程师。他毕业于物理工程专业,目前从事应用于人类流动的数据科学工作。他还是一位兼职内容创作者,专注于数据科学和技术。Josep 写作涉及所有 AI 相关的内容,涵盖了该领域正在爆炸性增长的应用。
更多相关话题
优步在大规模运行机器学习中学到的一些东西
原文:
www.kdnuggets.com/2020/07/some-things-uber-learned-machine-learning-scale.html
评论
来源: eng.uber.com/scaling-michelangelo/
在过去几年中,优步一直是开源机器学习技术最活跃的贡献者之一。虽然像谷歌或脸书这样的公司将贡献重点放在了新的深度学习技术栈如 TensorFlow、Caffe2 或 PyTorch 上,但优步工程团队确实专注于在现实世界中大规模构建机器学习的工具和最佳实践。像米开朗基罗、Horovod、PyML、Pyro等技术是优步对机器学习生态系统贡献的一些例子。由于只有少数公司开发大规模机器学习解决方案,优步的经验和指导对机器学习从业者来说变得更加宝贵(我确实学到了很多,并且经常写关于优步努力的文章)。
最近,优步工程团队发布了米开朗基罗平台前三年的运营评估。如果我们去除所有米开朗基罗的具体细节,优步的帖子包含了对开始机器学习之旅的组织者来说几条非显而易见的宝贵经验。我将尝试以更通用的方式总结一些关键收获,以适用于任何主流的机器学习场景。
米开朗基罗是什么?
米开朗基罗是优步机器学习技术栈的核心部分。从概念上看,米开朗基罗可以视作一个针对优步内部机器学习工作负载的机器学习即服务平台。从功能角度讲,米开朗基罗自动化了机器学习模型生命周期的不同方面,使得优步的各个工程团队能够在规模上构建、部署、监控和操作机器学习模型。具体而言,米开朗基罗在一个非常复杂的工作流中抽象了机器学习模型的生命周期:
米开朗基罗的架构使用了现代但复杂的技术栈,基于如HDFS、Spark、Samza、Cassandra、MLLib、XGBoost和TensorFlow等技术。
Michelangelo 支持 Uber 不同部门中的数百种机器学习场景。例如,Uber Eats 使用在 Michelangelo 上运行的机器学习模型来排名餐馆推荐。类似地,Uber 应用中的精确到达时间(ETA)是通过在 Michelangelo 上运行的非常复杂的机器学习模型计算的,这些模型逐段估算 ETA。
为了在数十个数据科学团队和数百个模型之间实现这种级别的可扩展性,Michelangelo 需要提供一个非常灵活和可扩展的架构以及相应的工程流程。Michelangelo 的第一个版本于 2015 年部署,在三年和数百个机器学习模型之后,Uber 发现了一些重要的经验教训。
1-训练需要独立的基础设施
如果你正在构建一个模型,你可能会倾向于利用相同的基础设施和工具进行训练和开发。如果你在构建一百个模型,这种方法就不适用了。Uber 的 Michelangelo 使用了一种名为 Data Science Workbench (DSW) 的专有工具集,在大规模 GPU 集群和不同的机器学习工具包上训练模型。除了统一的基础设施外,Michelangelo 的 DSW 抽象了机器学习训练过程中常见的任务,如数据转换、模型组合等。
2-模型需要监控
用我在这一领域的一位导师的话来说:“做出愚蠢预测的模型比完全不预测的模型更糟糕。” 即使是对训练和评估数据表现完美的模型,在面对新的数据集时也可能开始做出愚蠢的预测。从这个角度来看,模型监控和仪器化是实际机器学习解决方案的关键组成部分。Uber Michelangelo 配置机器学习模型以记录生产中的预测,然后将其与实际结果进行比较。这个过程生成一系列准确性指标,可用于评估模型的性能。
3-数据是最难正确处理的
在机器学习解决方案中,数据工程师花费相当一部分时间在数据集上运行提取和转换例程,以选择特征,然后这些特征被用于训练和生产模型。Michelangelo 精简这一过程的方法是构建一个公共特征库,允许不同团队在其模型中共享高质量的特征。类似地,Michelangelo 提供监控工具,以随时间评估特定特征。
4-机器学习应被视为软件工程过程来衡量
我知道这听起来很简单,但事实远非如此。大多数组织将他们的机器学习工作与其他软件工程任务分开处理。虽然确实很难将传统的敏捷或瀑布流程适应于机器学习解决方案,但有很多软件工程实践在机器学习领域依然适用。Uber 强调机器学习是一个软件工程过程,并为 Michelangelo 配备了一系列工具,以确保机器学习模型的正确生命周期。
版本控制、测试或部署是 Uber 的 Michelangelo 在软件工程方面严格执行的一些方面。例如,一旦 Michelangelo 认为模型就像一个已编译的软件库,它就会以严格、版本控制的系统跟踪模型的训练配置,就像你对库的源代码进行版本控制一样。类似地,Michelangelo 运行全面的测试套件,在将模型部署到生产环境之前,对其进行对比数据集评估,以验证其正确性。
5-自动化优化
微调和优化超参数是机器学习解决方案中永无止境的任务。许多时候,数据科学工程师花费在寻找正确的超参数配置上的时间,比实际构建模型的时间还要多。为了解决这个问题,Uber 的 Michelangelo 推出了一个名为 AutoTune 的优化即服务工具,它使用最先进的黑箱贝叶斯优化算法,更高效地搜索最佳的超参数集合。Michelangelo 的 AutoTune 的理念是利用机器学习来优化机器学习模型,使数据科学工程师能更多地集中精力于模型的实现,而不是优化工作。
从机器学习的角度来看,Uber 可以被认为是世界上最富有的实验室环境之一。Uber 数据科学家所处理的任务的规模和复杂性在业内无与伦比。Michelangelo 运行的前三年无疑表明,实施大规模的机器学习解决方案仍然是一个极其复杂的工作。Michelangelo 的经验教训为那些踏上机器学习之旅的组织提供了宝贵的见解。
原文。经许可转载。
相关:
-
Uber 的 Ludwig 是一个开源的低代码机器学习框架
-
遗忘学习:深度神经网络与詹妮弗·安妮斯顿神经元
-
谷歌发布 TAPAS,一种基于 BERT 的神经网络,用于通过自然语言查询表格
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 需求
更多相关内容
Python 中的垃圾邮件过滤器:从零开始的朴素贝叶斯
原文:
www.kdnuggets.com/2020/07/spam-filter-python-naive-bayes-scratch.html
评论
由 Alex Olteanu,Dataquest 数据科学家
在这篇博客文章中,我们将使用 Python 和多项式 朴素贝叶斯 算法构建一个垃圾邮件过滤器。我们的目标是从头开始编写一个垃圾邮件过滤器,使其对消息的分类准确率超过 80%。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
为了构建我们的垃圾邮件过滤器,我们将使用一个包含 5,572 条短信的数据集。数据集由 Tiago A. Almeida 和 José María Gómez Hidalgo 编制,你可以从 UCI 机器学习库 下载。
在整个文章中,我们将专注于 Python 实现,因此我们假设你已经对多项式朴素贝叶斯和条件概率有所了解。
如果你需要在继续之前填补任何知识空白,Dataquest 提供了一个涵盖 条件概率和多项式朴素贝叶斯 的课程,此外还有许多其他课程可以帮助你填补知识空白,并获得 数据科学证书。
探索数据集
首先,我们通过 pandas 包中的 read_csv() 函数打开 SMSSpamCollection 文件。我们将使用:
-
sep='\t'因为数据点是以制表符分隔的 -
header=None因为数据集没有标题行 -
names=['Label', 'SMS']用于命名列
import pandas as pd
sms_spam = pd.read_csv('SMSSpamCollection', sep='\t',
header=None, names=['Label', 'SMS'])
print(sms_spam.shape)
sms_spam.head()
(5572, 2)

下图显示,大约 87% 的消息是正常邮件(非垃圾邮件),其余 13% 是垃圾邮件。这个样本看起来具有代表性,因为在实际情况中,大多数人收到的消息都是正常邮件。
sms_spam['Label'].value_counts(normalize=True)
ham 0.865937 spam 0.134063 Name: Label, dtype: float64
训练集和测试集
现在我们将把数据集拆分为训练集和测试集。我们将使用 80% 的数据用于训练,剩余的 20% 用于测试。
我们将在拆分数据集之前随机化整个数据集,以确保垃圾邮件和正常邮件在数据集中均匀分布。
# Randomize the dataset
data_randomized = sms_spam.sample(frac=1, random_state=1)
# Calculate index for split
training_test_index = round(len(data_randomized) * 0.8)
# Split into training and test sets
training_set = data_randomized[:training_test_index].reset_index(drop=True)
test_set = data_randomized[training_test_index:].reset_index(drop=True)
print(training_set.shape)
print(test_set.shape)
(4458, 2) (1114, 2)
我们现在将分析训练集和测试集中垃圾邮件和正常邮件的百分比。我们期望这些百分比接近于我们在完整数据集中看到的情况,其中大约 87%的消息是正常邮件,剩余的 13%是垃圾邮件。
training_set['Label'].value_counts(normalize=True)
ham 0.86541 spam 0.13459 Name: Label, dtype: float64
test_set['Label'].value_counts(normalize=True)
ham 0.868043 spam 0.131957 Name: Label, dtype: float64
结果看起来很棒!我们现在将继续清理数据集。
数据清理
当有新消息到达时,我们的多项式朴素贝叶斯算法将根据其对以下两个方程的结果进行分类,其中“w[1]”是第一个单词,w[1],w[2], ..., w[n]是整个消息:
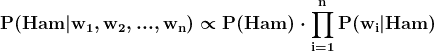
如果 P(Spam | w[1],w[2], ..., w[n]) 大于 P(Ham | w[1],w[2], ..., w[n]),则该消息是垃圾邮件。
要计算 P(w[i]|Spam) 和 P(w[i]|Ham),我们需要使用单独的方程:
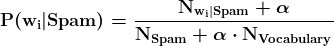
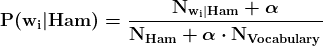
让我们澄清这些方程中的一些术语:
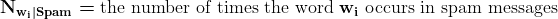
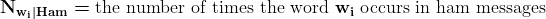
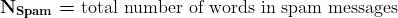
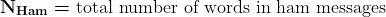
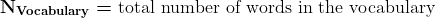
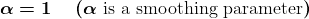
为了计算所有这些概率,我们首先需要进行一些数据清理,将数据转换为一种格式,以便我们可以轻松提取所需的所有信息。目前,我们的训练集和测试集具有以下格式(下面的消息是虚构的,以便示例更易于理解):
 为了简化计算,我们希望将数据转换为这种格式(下表是您上面看到的表格的转换):
为了简化计算,我们希望将数据转换为这种格式(下表是您上面看到的表格的转换): 在上述转换中注意到:
在上述转换中注意到:
-
SMS列被一系列表示词汇表中唯一单词的新列替代——词汇表是我们所有句子中唯一单词的集合。 -
每一行描述了一个单独的消息。第一行的值是
spam, 2, 2, 1, 1, 0, 0, 0, 0, 0,这告诉我们:-
该消息是垃圾邮件。
-
单词“secret”在消息中出现了两次。
-
单词“prize”在消息中出现了两次。
-
单词“claim”在消息中出现了一次。
-
单词“now”在消息中出现了一次。
-
单词“coming”,“to”,“my”,“party”和“winner”在消息中出现了零次。
-
-
词汇表中的所有单词都是小写的,因此“SECRET”和“secret”被视为同一个单词。
-
原始句子中的单词顺序丢失了。
-
标点符号不再被考虑(例如,我们不能通过查看表格得出第一条消息最初有两个感叹号)。
字母大小写和标点符号
让我们通过去除标点符号并将所有单词转换为小写来开始数据清理过程。
# Before cleaning
training_set.head(3)
# After cleaning
training_set['SMS'] = training_set['SMS'].str.replace(
'\W', ' ') # Removes punctuation
training_set['SMS'] = training_set['SMS'].str.lower()
training_set.head(3)
创建词汇表
现在让我们创建词汇表,在这个上下文中,词汇表是指包含训练集中所有唯一单词的列表。在下面的代码中:
-
我们通过在空格字符处拆分字符串,将
SMS列中的每条消息转换为列表 — 我们使用Series.str.split()方法。 -
我们初始化一个名为
vocabulary的空列表。 -
我们遍历转换后的
SMS列。- 使用嵌套循环,我们遍历
SMS列中的每条消息,并将每个字符串(单词)追加到vocabulary列表中。
- 使用嵌套循环,我们遍历
-
我们使用
set()函数将vocabulary列表转换为集合。这将从vocabulary列表中去除重复项。 -
我们使用
list()函数将vocabulary集合转换回列表。
training_set['SMS'] = training_set['SMS'].str.split()
vocabulary = []
for sms in training_set['SMS']:
for word in sms:
vocabulary.append(word)
vocabulary = list(set(vocabulary))
看起来我们的训练集中的所有消息共有 7,783 个唯一的单词。
len(vocabulary)
7783
最终的训练集
现在我们将使用刚刚创建的词汇表进行我们想要的数据转换。
 最终,我们将创建一个新的 DataFrame。我们首先构建一个字典,然后将其转换为所需的 DataFrame。
最终,我们将创建一个新的 DataFrame。我们首先构建一个字典,然后将其转换为所需的 DataFrame。
例如,要创建我们上面看到的表格,我们可以使用这个字典:
word_counts_per_sms = {'secret': [2,1,1],
'prize': [2,0,1],
'claim': [1,0,1],
'now': [1,0,1],
'coming': [0,1,0],
'to': [0,1,0],
'my': [0,1,0],
'party': [0,1,0],
'winner': [0,0,1]
}
word_counts = pd.DataFrame(word_counts_per_sms)
word_counts.head()
要为我们的训练集创建所需的字典,我们可以使用以下代码:
-
我们首先初始化一个名为
word_counts_per_sms的字典,其中每个键是词汇表中的唯一单词(字符串),每个值是一个长度与训练集相同的列表,其中列表中的每个元素都是0。- 代码
[0] * 5输出[0, 0, 0, 0, 0]。因此,代码[0] * len(training_set['SMS'])输出一个长度为training_set['SMS']的列表。
- 代码
-
我们使用
enumerate()函数遍历training_set['SMS'],以获取索引和短信消息(index和sms)。-
使用嵌套循环,我们遍历
sms(其中sms是一个字符串列表,每个字符串代表消息中的一个单词)。- 我们将
word_counts_per_sms[word][index]的值增加1。
- 我们将
-
word_counts_per_sms = {unique_word: [0] * len(training_set['SMS']) for unique_word in vocabulary}
for index, sms in enumerate(training_set['SMS']):
for word in sms:
word_counts_per_sms[word][index] += 1
现在我们有了所需的字典,让我们对训练集进行最终的转换。
word_counts = pd.DataFrame(word_counts_per_sms)
word_counts.head()
Label 列缺失,因此我们将使用 pd.concat() 函数 将刚构建的 DataFrame 与包含训练集的 DataFrame 连接起来。这样,我们也将拥有 Label 和 SMS 列。
training_set_clean = pd.concat([training_set, word_counts], axis=1)
training_set_clean.head()
首先计算常数
现在我们已经完成了训练集的清理,我们可以开始编码垃圾邮件过滤器。多项式朴素贝叶斯算法需要回答这两个概率问题,以便能够对新消息进行分类:
同样,要在上述公式中计算 P(w[i]|Spam) 和 P(w[i]|Ham),我们需要使用以下方程:
上述四个方程中的一些项在每个新消息中将具有相同的值。我们可以一次性计算这些项的值,并避免在新消息到来时重新计算。作为开始,我们首先计算:
-
P(Spam) 和 P(Ham)
-
N[Spam],N[Ham],N[Vocabulary]
需要注意的是:
-
N[Spam] 等于所有垃圾邮件中的单词总数 —— 它 不是 等于垃圾邮件的数量,也 不是 等于垃圾邮件中的 唯一 单词的总数。
-
N[Ham] 等于所有非垃圾邮件中的单词总数 —— 它 不是 等于非垃圾邮件的数量,也 不是 等于非垃圾邮件中的 唯一 单词的总数。
我们还将使用拉普拉斯平滑,并设置 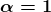 。
。
# Isolating spam and ham messages first
spam_messages = training_set_clean[training_set_clean['Label'] == 'spam']
ham_messages = training_set_clean[training_set_clean['Label'] == 'ham']
# P(Spam) and P(Ham)
p_spam = len(spam_messages) / len(training_set_clean)
p_ham = len(ham_messages) / len(training_set_clean)
# N_Spam
n_words_per_spam_message = spam_messages['SMS'].apply(len)
n_spam = n_words_per_spam_message.sum()
# N_Ham
n_words_per_ham_message = ham_messages['SMS'].apply(len)
n_ham = n_words_per_ham_message.sum()
# N_Vocabulary
n_vocabulary = len(vocabulary)
# Laplace smoothing
alpha = 1
计算参数
现在我们已经计算了常数项,我们可以继续计算参数 P(w[i]|Spam)和 P(w[i]|Ham)。
P(w[i]|Spam) 和 P(w[i]|Ham) 会根据具体的单词而变化。例如,P("secret"|Spam) 会有一个特定的概率值,而 P("cousin"|Spam) 或 P("lovely"|Spam) 可能会有其他值。
因此,每个参数将是与词汇表中每个单词相关的条件概率值。
参数是使用以下两个方程计算的:
# Initiate parameters
parameters_spam = {unique_word:0 for unique_word in vocabulary}
parameters_ham = {unique_word:0 for unique_word in vocabulary}
# Calculate parameters
for word in vocabulary:
n_word_given_spam = spam_messages[word].sum() # spam_messages already defined
p_word_given_spam = (n_word_given_spam + alpha) / (n_spam + alpha*n_vocabulary)
parameters_spam[word] = p_word_given_spam
n_word_given_ham = ham_messages[word].sum() # ham_messages already defined
p_word_given_ham = (n_word_given_ham + alpha) / (n_ham + alpha*n_vocabulary)
parameters_ham[word] = p_word_given_ham
分类新消息
现在我们已经计算了所有参数,可以开始创建垃圾邮件过滤器。垃圾邮件过滤器被理解为一个函数,它:
-
输入一个新消息 (w[1], w[2], ..., w[n])。
-
计算 P(Spam|w[1], w[2], ..., w[n]) 和 P(Ham|w[1], w[2], ..., w[n])。
-
比较 P(Spam|w[1], w[2], ..., w[n]) 和 P(Ham|w[1], w[2], ..., w[n]) 的值,并且:
-
如果 P(Ham|w[1], w[2], ..., w[n]) > P(Spam|w[1], w[2], ..., w[n]),则该消息被分类为 ham。
-
如果 P(Ham|w[1], w[2], ..., w[n]) < P(Spam|w[1], w[2], ..., w[n]),则将消息分类为垃圾邮件。
-
如果 P(Ham|w[1], w[2], ..., w[n]) = P(Spam|w[1], w[2], ..., w[n]),则算法可能会请求人工帮助。
-
请注意,一些新消息将包含不在词汇表中的词汇。我们在计算概率时将简单地忽略这些词汇。
让我们开始编写该函数的第一个版本。对于下面的classify()函数,请注意:
-
输入变量
message需要是一个字符串。 -
我们对字符串
message进行一些数据清理:-
我们使用
re.sub()函数去除标点符号。 -
我们使用
str.lower()方法将所有字母转换为小写。 -
我们在空格字符处分割字符串,并使用
str.split()方法将其转换为 Python 列表。
-
-
我们计算
p_spam_given_message和p_ham_given_message。 -
我们将
p_spam_given_message与p_ham_given_message进行比较,然后打印分类标签。
import re
def classify(message):
'''
message: a string
'''
message = re.sub('\W', ' ', message)
message = message.lower().split()
p_spam_given_message = p_spam
p_ham_given_message = p_ham
for word in message:
if word in parameters_spam:
p_spam_given_message *= parameters_spam[word]
if word in parameters_ham:
p_ham_given_message *= parameters_ham[word]
print('P(Spam|message):', p_spam_given_message)
print('P(Ham|message):', p_ham_given_message)
if p_ham_given_message > p_spam_given_message:
print('Label: Ham')
elif p_ham_given_message < p_spam_given_message:
print('Label: Spam')
else:
print('Equal proabilities, have a human classify this!')
我们现在将测试垃圾邮件过滤器在两个新消息上的效果。一个消息显然是垃圾邮件,另一个则显然是正常邮件。
classify('WINNER!! This is the secret code to unlock the money: C3421.')
P(Spam|message): 1.3481290211300841e-25 P(Ham|message): 1.9368049028589875e-27 Label: Spam
classify("Sounds good, Tom, then see u there")
P(Spam|message): 2.4372375665888117e-25 P(Ham|message): 3.687530435009238e-21 Label: Ham
测量垃圾邮件过滤器的准确性
这两个结果看起来很有前景,但让我们看看过滤器在我们的测试集上的表现如何,该测试集包含 1,114 条消息。
我们将从编写一个返回分类标签而不是打印它们的函数开始。
def classify_test_set(message):
'''
message: a string
'''
message = re.sub('\W', ' ', message)
message = message.lower().split()
p_spam_given_message = p_spam
p_ham_given_message = p_ham
for word in message:
if word in parameters_spam:
p_spam_given_message *= parameters_spam[word]
if word in parameters_ham:
p_ham_given_message *= parameters_ham[word]
if p_ham_given_message > p_spam_given_message:
return 'ham'
elif p_spam_given_message > p_ham_given_message:
return 'spam'
else:
return 'needs human classification'
现在我们有一个返回标签的函数而不是打印它们,我们可以用它来在测试集上创建一个新列。
test_set['predicted'] = test_set['SMS'].apply(classify_test_set)
test_set.head()

我们可以将预测值与实际值进行比较,以测量我们的垃圾邮件过滤器对新消息的分类效果。为了进行测量,我们将使用准确率作为指标:
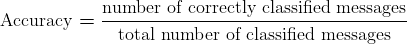
correct = 0
total = test_set.shape[0]
for row in test_set.iterrows():
row = row[1]
if row['Label'] == row['predicted']:
correct += 1
print('Correct:', correct)
print('Incorrect:', total - correct)
print('Accuracy:', correct/total)
Correct: 1100 Incorrect: 14 Accuracy: 0.9874326750448833
准确率接近 98.74%,这非常好。我们的垃圾邮件过滤器对 1,114 条在训练中未见过的消息进行了分类,其中 1,100 条分类正确。
下一步
在这篇博客文章中,我们成功地用多项式朴素贝叶斯算法编写了一个短信垃圾邮件过滤器。该过滤器在我们使用的测试集上的准确率为 98.74%,这是一个很有前景的结果。我们的初步目标是超过 80%的准确率,并且我们成功实现了这一点。
接下来的步骤包括:
-
分析 14 条被错误分类的消息,并尝试找出算法为何将其错误分类的原因
-
通过使算法对字母大小写敏感来使过滤过程更复杂
个人简介: 亚历克斯·奥尔特亚努 是 Dataquest 的数据科学家。
相关内容:
-
概率学习:贝叶斯定理
-
朴素贝叶斯算法:你需要知道的一切
-
概率学习:朴素贝叶斯
更多相关主题


 浙公网安备 33010602011771号
浙公网安备 33010602011771号