KDNuggets-博客中文翻译-三-
KDNuggets 博客中文翻译(三)
原文:KDNuggets
3 种将行附加到 Pandas 数据框的方法
原文:
www.kdnuggets.com/2022/08/3-ways-append-rows-pandas-dataframes.html
图片来源:作者
在这个迷你教程中,我们将学习三种将行附加到 pandas 数据框中的方法。我们还将学习添加多行的最有效和简单的方法。
我们的前三个课程推荐
 1. Google 网络安全证书 - 快速进入网络安全领域的职业生涯。
1. Google 网络安全证书 - 快速进入网络安全领域的职业生涯。
 2. Google 数据分析专业证书 - 提升您的数据分析技能
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT 工作
方法 1
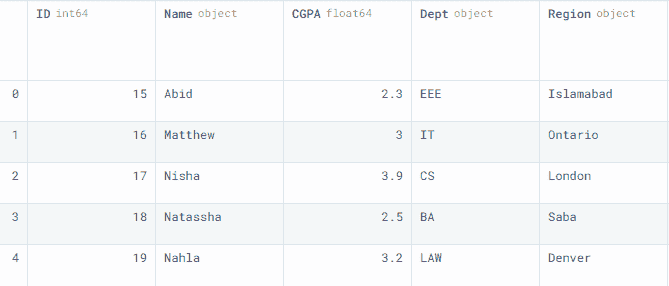
我们将使用 pandas DataFrame() 并以字典形式输入数据来创建一个示例数据框,以供在线硕士学位的学生使用。
import pandas as pd
data1 = pd.DataFrame(
{
"ID": [15, 16, 17, 18, 19],
"Name": ["Abid", "Matthew", "Nisha", "Natassha", "Nahla"],
"CGPA": [2.3, 3.0, 3.9, 2.5, 3.2],
"Dept": ["EEE", "IT", "CS", "BA", "LAW"],
"Region": ["Islamabad", "Ontario", "London", "Saba", "Denver"],
}
)
data1
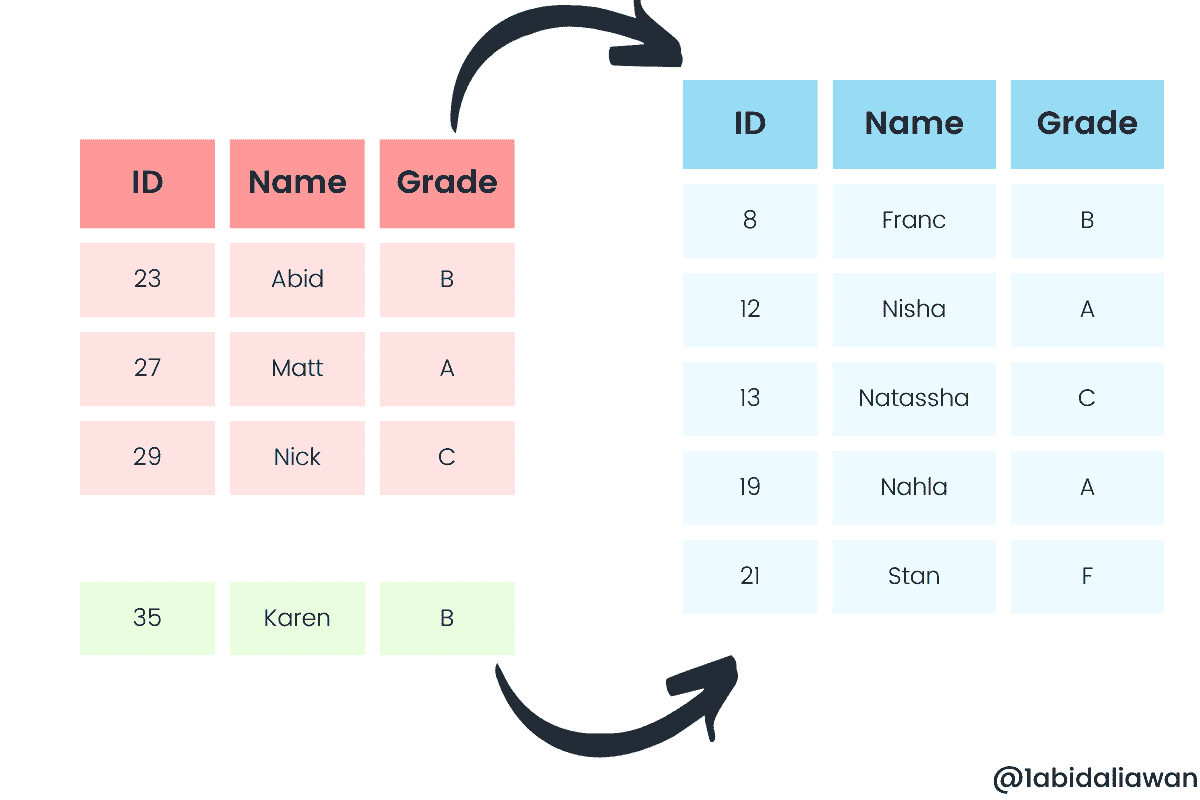
我们有五列和五行不同的行。这将是基础数据框。
我们可以以 pandas Series 的形式附加行。
要将一个 Series 添加到数据框中,我们将在数据框对象后使用append()函数,并在括号中添加 Series 对象。ignore_index 设置为True,以便结果索引将被标记为 0,1,....,n-1。
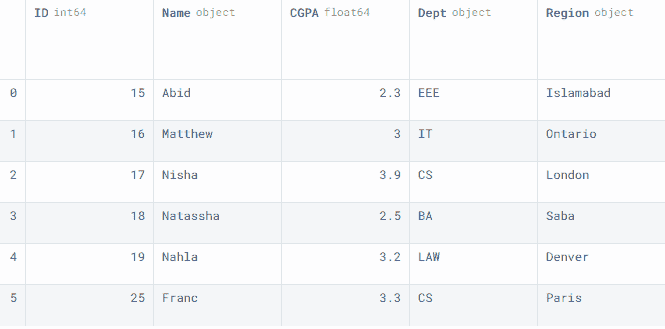
row1 = pd.Series([25, 'Franc', 3.3, 'CS', 'Paris'], index=data1.columns)
data1 = data1.append(row1,ignore_index=True)
data1
正如我们可以观察到的,我们已经成功地将一名学生的信息添加到数据框中。
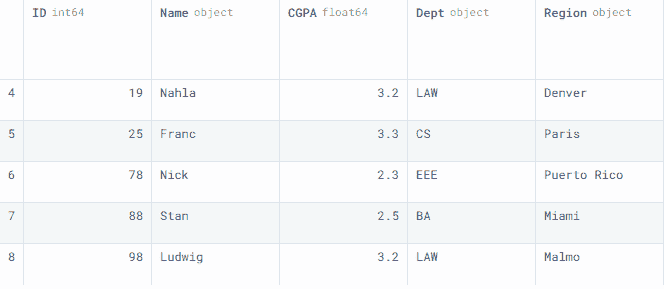
类似地,我们也可以附加一个数据框。在我们的案例中,我们创建了一个data2数据框,并使用.append()函数将多行添加到data1中。
data2 = pd.DataFrame(
{
"ID": [78, 88, 98],
"Name": ["Nick", "Stan", "Ludwig"],
"CGPA": [2.3, 2.5, 3.2],
"Dept": ["EEE", "BA", "LAW"],
"Region": ["Puerto Rico", "Miami", "Malmo"],
}
)
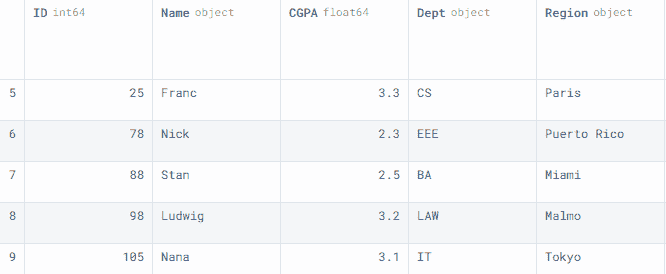
要查看最后五行,我们使用了.tail()。
方法 2
第二种方法相当简单。我们可以创建并附加一个字典到数据框中,使用 append。确保字典遵循下面的格式。每条记录应包含一个列名和相应的值。
row2 = {
"ID": 105,
"Name": "Nana",
"CGPA": 3.1,
"Dept": "IT",
"Region": "Tokyo",
}
data1 = data1.append(row2, ignore_index=True)
data1.tail()
方法 3
第三种方法是将行附加到数据框中的一种有效方式。
注意: DataFrame.append() 或 Series.append() 从 1.4.0 版本开始已被弃用。因此,如果您想使用最新版本,您需要使用这种方法。
要连接两个数据框或 Series,我们将使用 pandas concat() 函数。它提供了高级功能,例如使用内连接或外连接追加列。
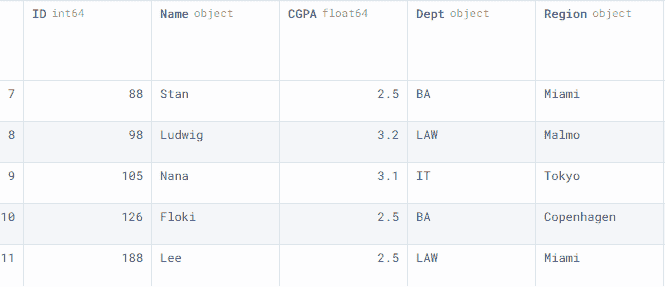
在我们的例子中,我们使用数组创建了一个第三个数据框data3。我们也可以将一个 Numpy 数组追加到数据框中,但需要先将其转换为数据框。
我们正在沿着 0 轴连接data1和data3。这意味着我们在追加行,而不是列。
data3 = pd.DataFrame(
[[126, "Floki",2.5,"BA","Copenhagen" ],
[188, "Lee",2.5,"LAW", "Miami"]],
columns= data1.columns
)
正如我们所见,我们已经成功地使用concat函数添加了行。
结论
你也可以使用 .loc[<index_number>] 将行添加到数据框的末尾。
例如:
data1.loc[12] = [200, "Bala",2.4,"DS","Delhi"]
这是一种简单的方法,但并不充分,因为你需要跟踪索引编号。
在本教程中,我们学习了多种将行添加到 pandas 数据框的方法。学习如何添加数据、管理数据以及为分析任务处理数据是成为专业数据科学家的第一步。
Abid Ali Awan (@1abidaliawan) 是一位认证数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些遭受心理疾病困扰的学生构建一个人工智能产品。
主题扩展
3 种合并 Pandas 数据框的方法
原文:
www.kdnuggets.com/2023/03/3-ways-merge-pandas-dataframes.html
编辑器提供的图像
现实世界中的数据是分散的,需要在一些共同的基础上将不同的来源结合在一起。为了提高效率并降低组织存储所有数据在单一表中的成本,保持数据在多个表中,并在需要时将它们连接在一起,是获取效率和有价值见解的最佳方式。
“Pandas” 提供了数据框合并功能,这在数据分析中非常有用,因为它允许你将来自多个来源的数据合并到一个数据框中。例如,假设你有一个包含客户订单信息的销售数据集和另一个包含客户人口统计信息的数据集。通过在客户 ID 上连接这两个数据框,你可以创建一个包含所有信息的新数据框,使得分析和理解客户人口统计与销售之间的关系变得更加容易。
合并这些数据框可以让你为数据添加额外的列,例如计算字段或汇总统计,这些列可以驱动复杂的机器学习系统。合并也有助于数据准备任务,如清理、标准化和预处理。
在本文中,你将学习三种合并 Pandas 数据框的方法以及输出之间的区别。你还将能够理解如何通过合并、连接和串联操作来促进不同的数据分析用例。
合并
merge() 操作是一种方法,用于根据一个或多个共同的列(也称为键)合并两个数据框。结果数据框仅包含两个数据框中具有匹配键的行。merge() 函数类似于 SQL 的 JOIN 操作。
使用 merge() 的基本语法是:
merged_df = pd.merge(df1, df2, on='key')
这里,df1 和 df2 是你想要合并的两个数据框,而 “on” 参数定义了用于合并的列。
默认情况下,pandas 会执行内连接,这意味着仅包含两个数据框中具有匹配键的行。然而,你可以使用 how 参数指定其他类型的连接,例如左连接、右连接或外连接。
让我们通过下面的示例来理解这一点。
请注意,你可以使用 Jupyter Notebook(或你选择的 IDE)运行以下代码。
import pandas as pd
# Define two dataframes
df1 = pd.dataframe({"key": ["A", "B", "C", "D"], "value1": [1, 2, 3, 4]})
df2 = pd.dataframe({"key": ["B", "D", "E", "F"], "value2": [5, 6, 7, 8]})
# Perform the merge
merged_df = pd.merge(df1, df2, on="key", how="inner")
# Show the resulting
print(merged_df)
这将产生以下输出:
key value1 value2
0 B 2 5
1 D 4 6
从结果中可以明显看出,新的数据框 merged_df 仅包含 'key' 列中值匹配的行,即 B 和 D。
连接
另一方面,join() 操作基于索引而不是特定列来合并两个数据框。结果数据框仅包含两个数据框中具有匹配索引的行。
使用 join() 的基本语法是:
joined_df = df1.join(df2)
其中 df1 和 df2 是要合并的两个数据框。
默认情况下,join() 执行左连接,这意味着第一个数据框(df1)中的所有行都会包含在结果数据框中,而第二个数据框(df2)中具有匹配索引值的任何行也会被添加。如果第二个数据框中有非匹配的行,它们将具有 NaN 值。通过使用 how 参数,你可以指定其他类型的连接,如右连接、内连接或外连接。
让我们通过一个示例来理解,如下所示。
import pandas as pd
# Define two dataframes
df1 = pd.dataframe({"value1": [1, 2, 3, 4]}, index=["A", "B", "C", "D"])
df2 = pd.dataframe({"value2": [5, 6, 7, 8]}, index=["B", "D", "E", "F"])
# Perform the join
joined_df = df1.join(df2, how="inner")
# Show the resulting
print(joined_df)
上述代码将产生以下输出:
value1 value2
B 2 5
D 4 6
在这里,新数据框 joined_df 仅包含索引匹配的行,即 B 和 D。
合并
concat() 用于沿特定轴(行或列)连接多个 pandas 对象(数据框或 Series)。默认情况下,轴为 0,意味着数据沿行(垂直方向)拼接。它的第一个参数是一个 pandas 对象的列表,按列表中指定的顺序拼接。
concatenated_df = pd.concat([df1, df2])
该函数可以通过各种参数进行自定义,如 axis、join、ignore_index 等。
使用 Pandas 的 concat 函数来合并两个数据框的示例如下所示:
import pandas as pd
df1 = pd.dataframe(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
},
index=[0, 1, 2, 3],
)
df2 = pd.dataframe(
{
"A": ["A4", "A5", "A6", "A7"],
"B": ["B4", "B5", "B6", "B7"],
"C": ["C4", "C5", "C6", "C7"],
"D": ["D4", "D5", "D6", "D7"],
},
index=[0, 1, 2, 3],
)
concatenated_df = pd.concat([df1, df2])
print(concatenated_df)
这将产生以下输出:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
0 A4 B4 C4 D4
1 A5 B5 C5 D5
2 A6 B6 C6 D6
3 A7 B7 C7 D7
为了避免如上所示的索引重复(在拼接数据框中索引从 0 到 3 出现两次),请使用 ignore_index=True,如下所示。
concatenated_df = pd.concat([df1, df2], ignore_index=True)
print(concatenated_df)
结果将如下所示。
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
概要
在这篇文章中,你学会了三种合并 Pandas 数据框的方法,并了解它们在任何 BI 项目中处理数据时如何解决不同的目的。该文章通过 Python 代码演示了合并、连接和拼接操作的示例。
Vidhi Chugh 是一位 AI 策略师和数字化转型领导者,在产品、科学和工程交汇处工作,致力于构建可扩展的机器学习系统。她是获奖的创新领导者、作者和国际演讲者。她的使命是使机器学习大众化,并打破术语,让每个人都能参与到这一转型中。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关内容
使用 GPT-4o 构建 Python 项目的 3 种方法
原文:
www.kdnuggets.com/3-ways-of-building-python-projects-using-gpt-4o

图片来源:作者
如果你希望提高工作流程,加快开发速度,并最小化错误,GPT-4o 模型是你首选的 AI 工具。通过将这种先进的 AI 集成到你的 Python 项目中,你可以简化流程,更快地解决问题,专注于真正重要的事情。即使你是编程新手,也可以使用像 ChatGPT、配备 GPTCode 扩展的 VSCode 和 Cursor IDE 等工具创建 Python 项目。这些工具对于在开发环境中实现 GPT-4o 模型的全部潜力至关重要。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
1. ChatGPT
我们都熟悉 ChatGPT 及其生成 Python 代码的能力。在 OpenAI 的最新更新中,新的 GPT-4o 模型已免费提供给所有人使用。我使用 ChatGPT 来生成代码、解决问题和头脑风暴。它真正理解我们在应用程序中想要实现的目标。
例如,我让它构建一个示例 Python 项目。它提供了构建所需的所有代码和指令,包括项目结构中的文件和文件夹。你可以提出后续问题来修改项目,甚至请求它运行脚本以测试是否有效。
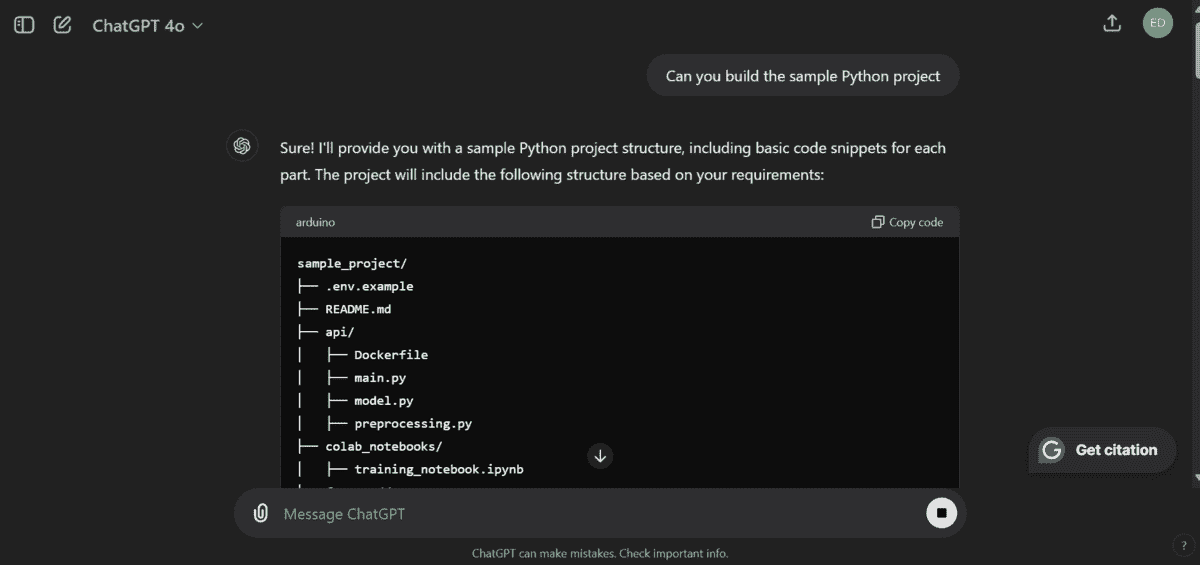
截图来自 ChatGPT
ChatGPT 配备了一个 Python 环境,这意味着它可以为你生成和运行代码,并显示结果。
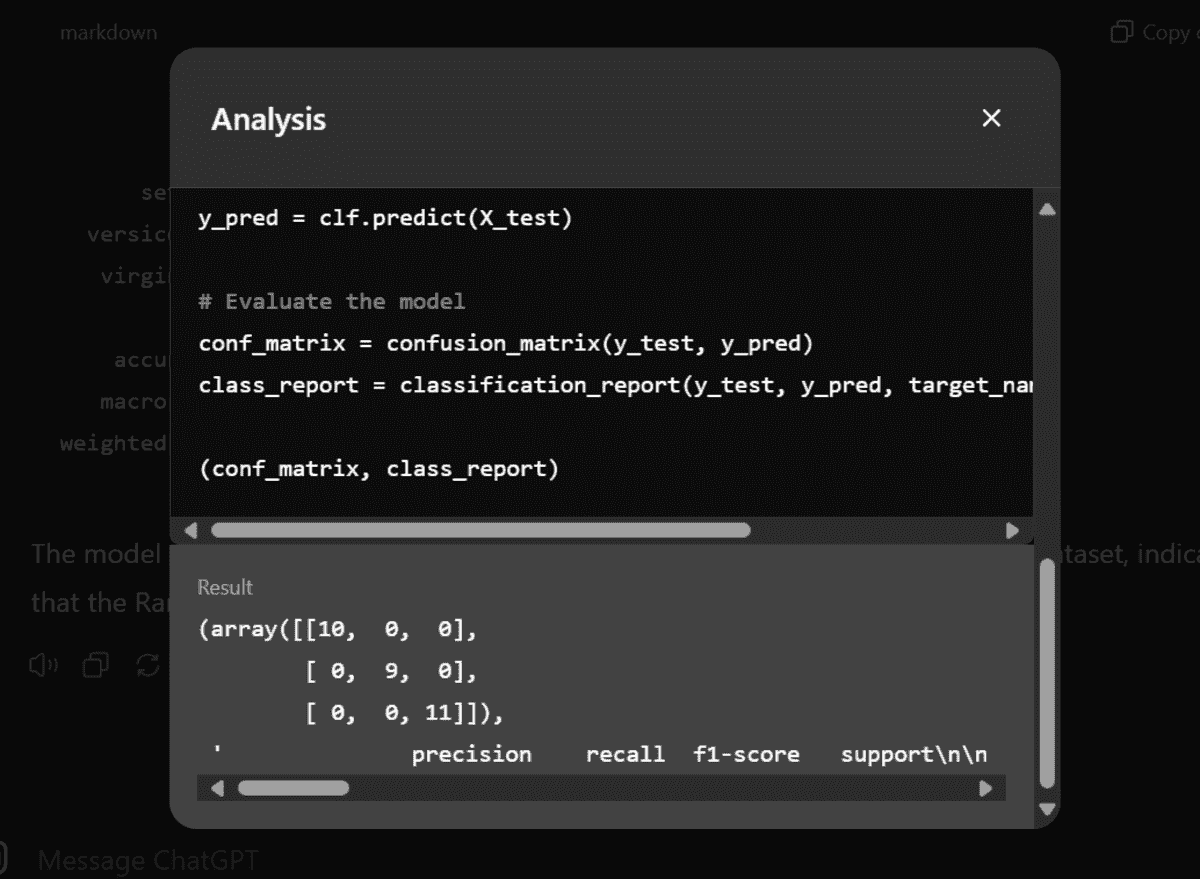
截图来自 ChatGPT
简而言之,如果你是初学者,ChatGPT 是你唯一需要的编码助手。但如果你是开发人员或软件工程师,你需要一个与工作空间集成的工具。那就是 CodeGPT 的作用。
2. CodeGPT
CodeGPT VSCode AI 编码助手扩展,让你更高效地编写代码。它提供 AI 聊天帮助、自动完成、代码解释、重构、文档编写、单元测试等功能。
CodeGPT 扩展还允许你尝试来自不同提供者的各种 AI 模型。你甚至可以使用 Ollama 在本地运行自己的 AI 模型,并将其与 CodeGPT 扩展一起使用。这是一个集成的解决方案,用于软件开发。
在这篇博客中,我们将学习如何设置以便与 GPT-4o 一起使用。首先,你需要通过访问 OpenAI API 来生成一个 OpenAI API 密钥。然后,在 VSCode 扩展市场中搜索并安装 CodeGPT 扩展。接下来,点击 CodeGPT 标签,选择 OpenAI 作为提供者,选择 GPT-4o 作为模型。系统会要求你粘贴 OpenAI API 密钥以访问该模型。
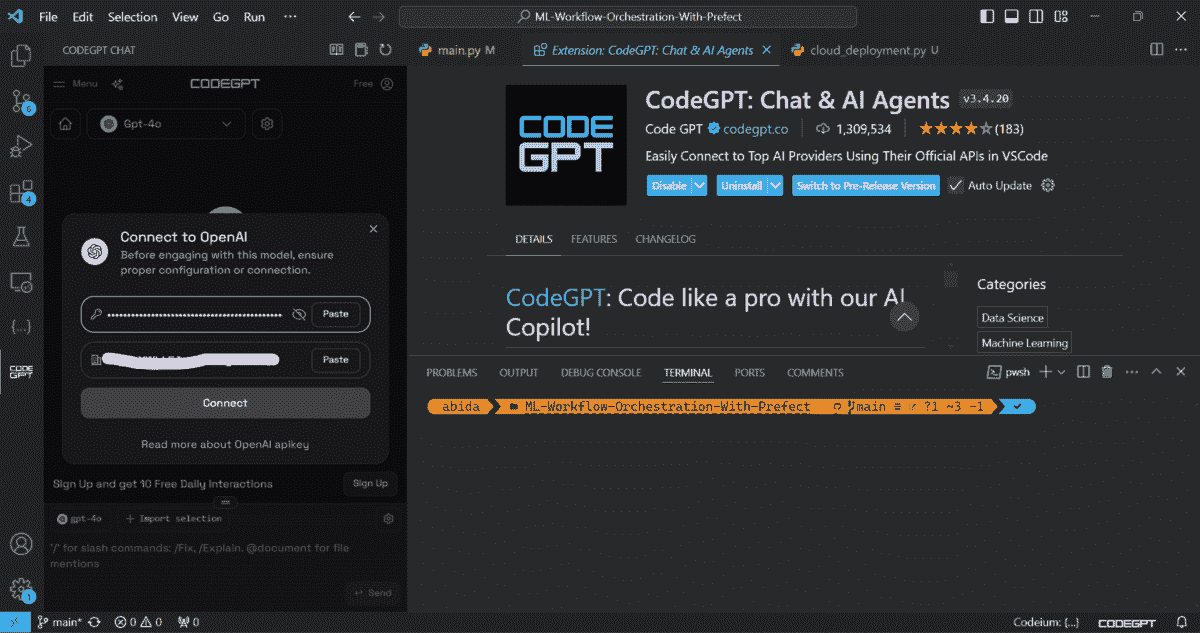
来自 VSCode 的截图
当一切设置完成后,你可以开始使用 GPT-4o 来生成代码、调试、记录和改进你的代码源。
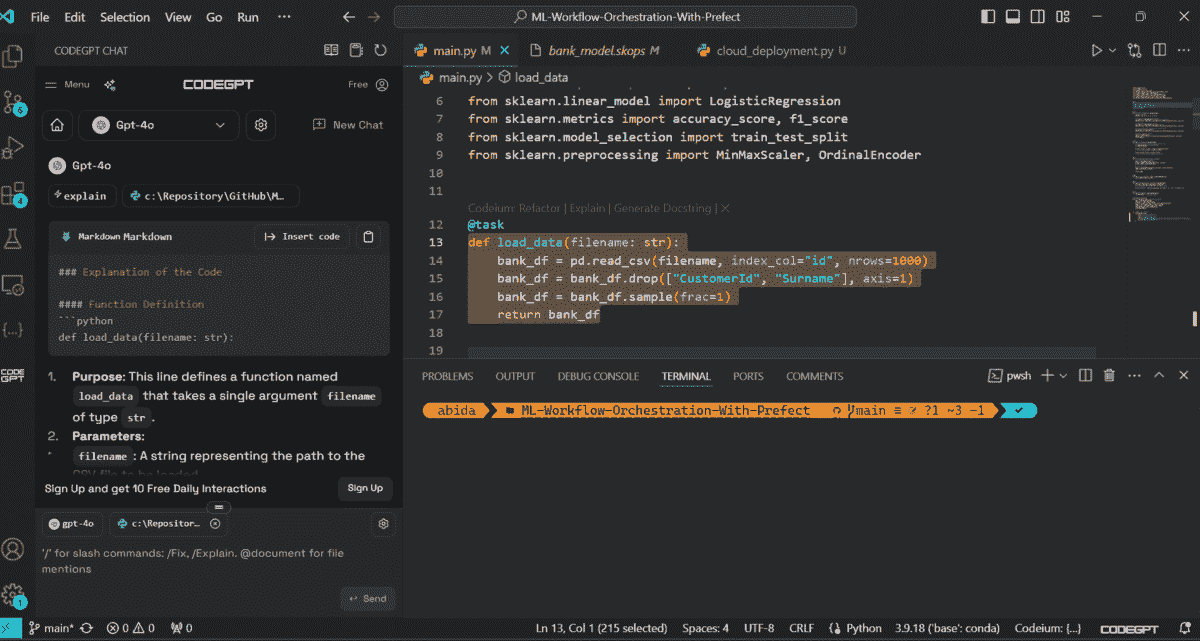
来自 VSCode 的截图
CodeGPT 有许多限制,在自动完成方面速度较慢。你可以购买订阅以访问更好的自动完成模型和 AI 代理,但在将 AI 工具集成到软件开发环境中时,它仍然不够充分。它仍然是一个依赖于代码编辑器的扩展。
3. Cursor IDE
Cursor AI IDE 是硬核程序员、高级软件工程师和数据专业人士的完美工具。它是为 AI 辅助软件开发设计的 VSCode 的一个分支。这意味着它不仅仅是一个扩展,而是一个内置功能的生态系统,帮助你编写更好的代码。
Cursor 理解你的代码源,以提供更好的代码建议,甚至帮助你从零开始编写整个 Python 项目。我已经完全将工作流程从 VSCode 切换到 Cursor,因为它易于使用,响应速度比 VSCode 扩展更快。我没有错过任何功能——它基本上就像使用 VSCode。我仍然可以安装我喜欢的 VSCode 扩展,并使用相同的环境。没有变化。
在下面的示例中,我让 GPT-4o 改进我的代码,它做得非常好。
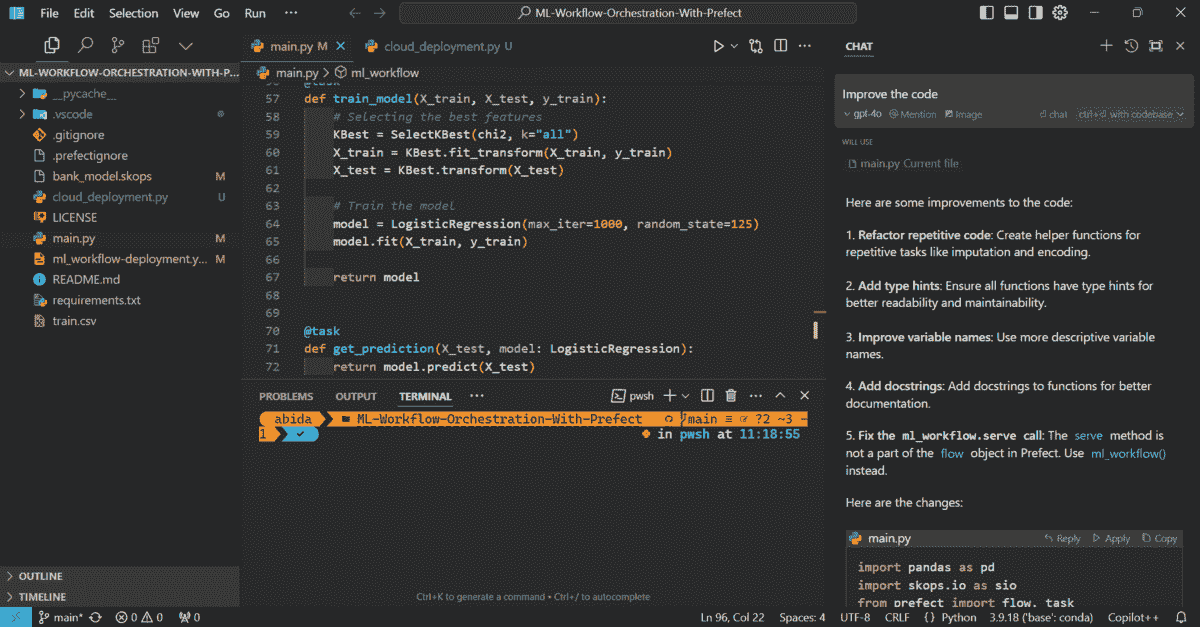
来自 Cursor 的截图
它还配备了内联聊天、理解图像和文档的能力、选择代码进行编辑或改进的能力以及保存之前聊天记录的能力,就像 ChatGPT 一样。
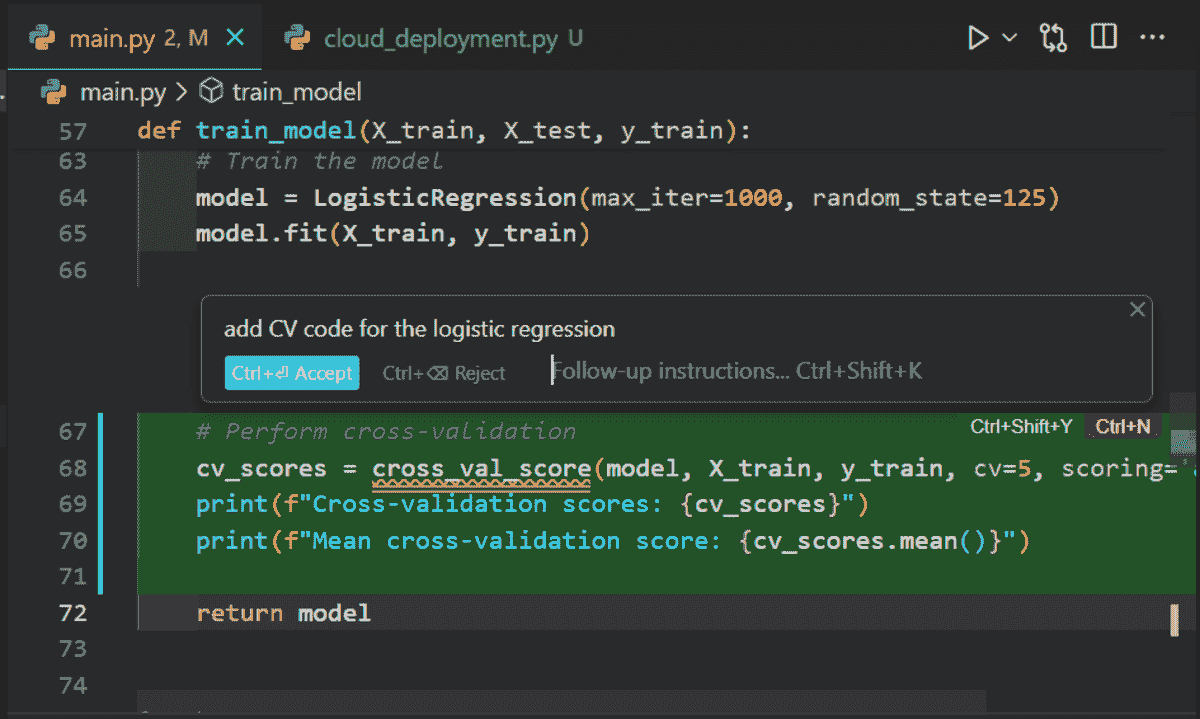
来自 Cursor 的截图
我强烈推荐数据专业人士切换到 Cursor 并享受两周的免费试用,以体验其惊人的功能。无论是编写代码还是向 GPT-4o 提问,感觉都很自然。
结论
我认识的所有数据专业人士都在他们的工作流程中使用 AI 以提高生产力和准确性。在使用 AI 助手工具之前,他们通常需要花费数小时来构建和测试 Python 应用程序,但现在他们可以在几分钟内完成相同的任务。他们所要做的就是审查并运行代码。
在这篇博客中,我们了解了 ChatGPT 用于构建和运行 Python 代码的新功能。我们还了解了 VSCode AI 助手扩展 CodeGPT,它允许你使用各种 AI 模型生成和改进你的 Python 代码。最后,我们了解了 Cursor IDE,这是一款为 AI 辅助软件开发而构建的 VSCode 分支。这些是我在数据分析、机器学习甚至网页开发中的日常工作中使用的工具。我希望你也能从中受益。
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理问题的学生开发 AI 产品。
更多相关话题
处理 CSV 文件的 3 种方法
原文:
www.kdnuggets.com/2022/10/3-ways-process-csv-files-python.html

来源:flaticon
对于那些刚开始学习 Python 编程语言、启动数据科学职业生涯,或只是需要快速回顾的人来说,本文介绍了 3 种在 Python 中处理 CSV 文件的方法。
我们的 3 大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
让我们快速了解什么是 CSV 文件。
什么是 CSV?
CSV 代表逗号分隔值,是一种包含数据的纯文本文件。它被认为是最简单的数据存储格式之一,数据科学家和其他工程师广泛使用。
这是一个示例结构:
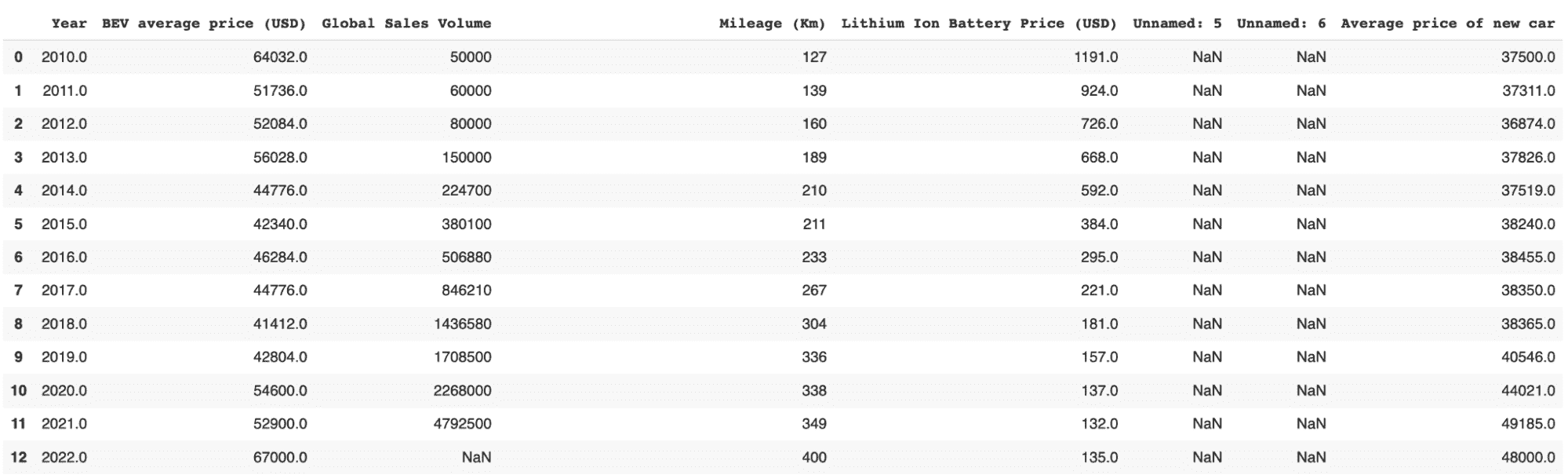
我从 Kaggle 获取了这个数据集,你可以在这里找到它:电动汽车价格
现在让我们深入了解如何在 Python 中处理 CSV 文件。
处理 CSV 文件
出于本文的目的,我将使用电动汽车价格数据集作为示例。
使用 pandas
Pandas 是一个开源 Python 包,建立在 Numpy 之上。步骤如下:
导入库:
import pandas as pd
使用 read_csv() 读取文件
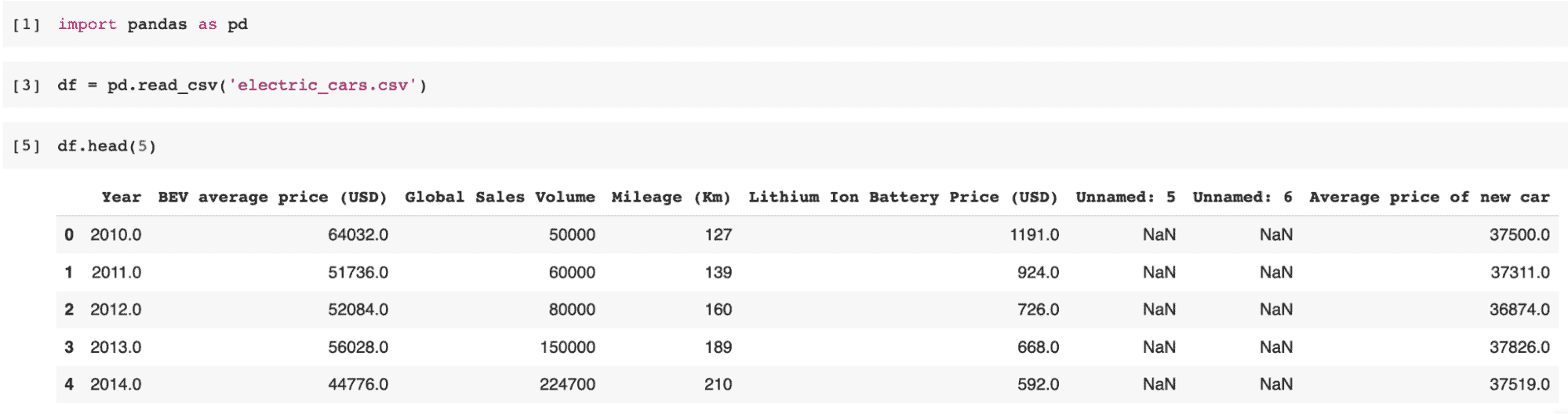
read_csv() 就是它的名字,它将你的 CSV 文件读取到 DataFrame 中,如下所示:
df = pd.read_csv("electric_cars.csv")
df.head(5)
示例:
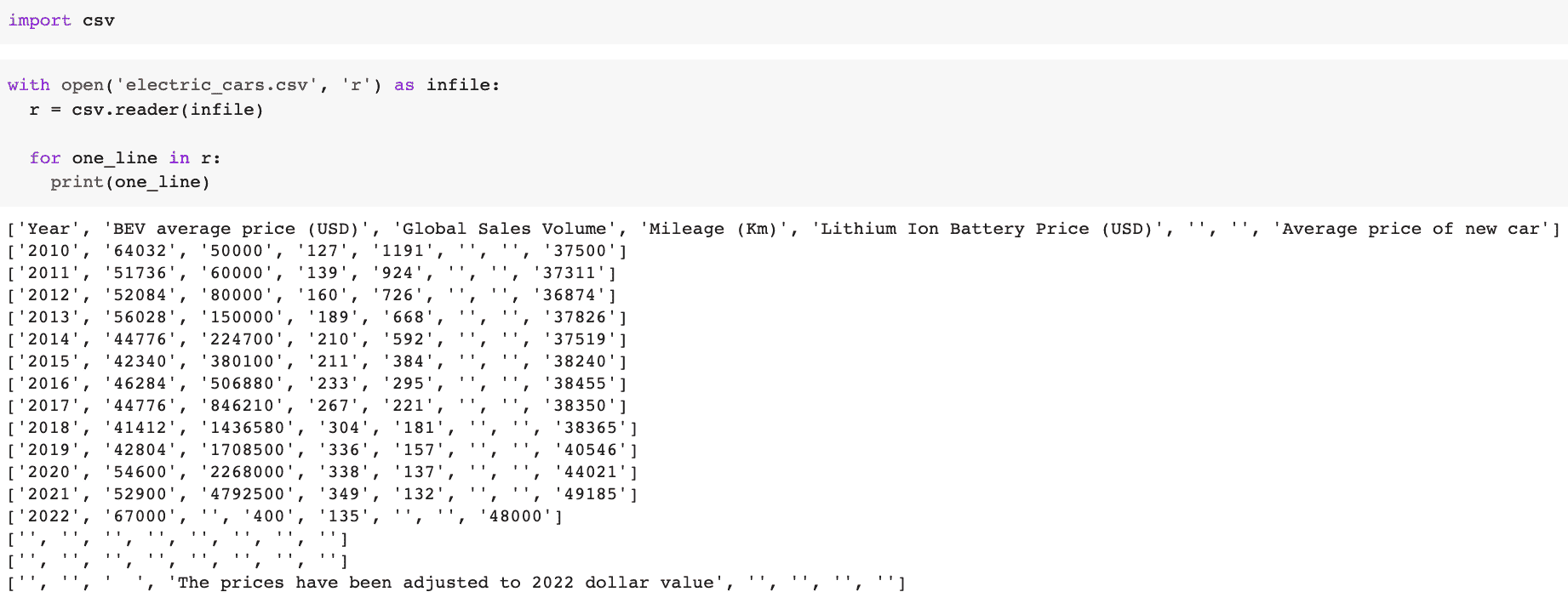
使用 csv.reader
Python 有一个内置模块叫做 csv,可以用来读取文件。以下是一些快速简单的步骤:
导入库:
import csv
打开你的 CSV 文件:
with open('electric_cars.csv', 'r') as infile:
r = csv.reader(infile)
for one_line in r:
print(one_line)
示例:
分割方法
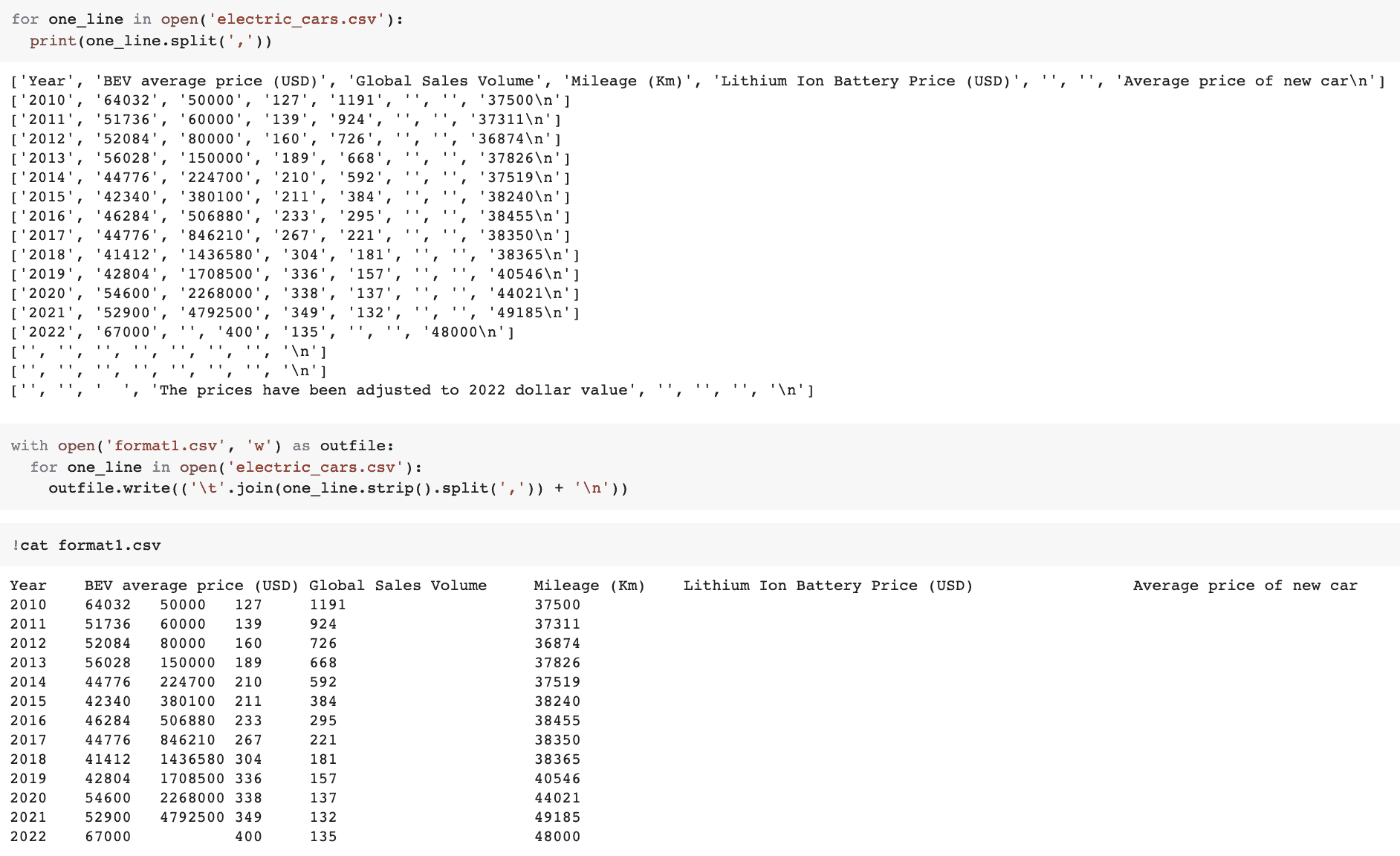
我们可以通过 .split 方法轻松加载 CSV 文件。字符串上的 .split 方法返回一个字符串列表。
for one_line in open('electric_cars.csv'):
print(one_line.split(','))
然而,查看下面的示例图像,如果你想用制表符作为分隔符而不是逗号,可以这样做:
with open('format1.csv', 'w') as outfile:
for one_line in open('electric_cars.csv'):
outfile.write(('\t'.join(one_line.strip().split(',')) + '\n'))
示例:
总结
处理 CSV 文件到 Python 有多种方法。你可能有些方法未曾听说过,也可能已经知道。了解解决数据科学问题的多种方法总是有益的,你应该始终保持学习这些不同方法的开放态度!
Nisha Arya 是一名数据科学家和自由职业技术作家。她特别感兴趣于提供数据科学职业建议或教程以及数据科学的理论知识。她还希望探索人工智能如何/能够促进人类寿命的延续。作为一个热衷学习的人,她希望拓宽自己的技术知识和写作技能,同时帮助引导他人。
更多相关话题
使用稳定扩散生成超现实面孔的三种方法
原文:
www.kdnuggets.com/3-ways-to-generate-hyper-realistic-faces-using-stable-diffusion

作者提供的图片
你是否曾经想知道人们是如何使用 AI 图像生成技术生成如此超现实的面孔,而你的尝试却总是充满了缺陷和伪影,看起来明显是假的?你已经尝试调整提示和设置,但仍然无法匹配你看到的其他人生产的质量。你究竟做错了什么?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
在这篇博客文章中,我将带你了解三种关键技巧,以开始使用稳定扩散生成超现实的人脸。首先,我们将涵盖提示工程的基础,以帮助你使用基本模型生成图像。接下来,我们将探索如何通过升级到稳定扩散 XL 模型,通过更多的参数和训练显著提高图像质量。最后,我将向你介绍一个专门为生成高质量肖像而微调的自定义模型。
1. 提示工程
首先,我们将学习如何编写正面和负面提示以生成逼真的面孔。我们将使用 Hugging Face Spaces 上可用的稳定扩散 2.1 版本演示。它是免费的,你可以在不设置任何东西的情况下开始。
链接: hf.co/spaces/stabilityai/stable-diffusion
创建正面提示时,请确保包含所有必要的细节和图像风格。在这种情况下,我们希望生成一张年轻女性在街上走路的图像。我们将使用一个通用的负面提示,但你可以添加额外的关键词以避免图像中的重复错误。
正面提示: “一个二十多岁的年轻女性,走在街上,直视镜头,自信友好的表情,随意穿着现代时尚的服饰,城市街景背景,明亮的阳光照射,鲜艳的色彩”
负面提示: “变形的,丑陋的,糟糕的,不成熟的,卡通的,动漫的,3d 的,画作的,黑白的,卡通的,画作的,插图的,最差质量,低质量”


我们取得了一个良好的开端。图像准确,但质量还可以更好。你可以尝试不同的提示,但这是基础模型能提供的最佳效果。
2. Stable Diffusion XL
我们将使用 Stable Diffusion XL(SDXL)模型生成高质量的图像。它通过使用基础模式生成潜在图像,然后通过精化器处理,以生成详细且准确的图像。
链接: hf.co/spaces/hysts/SD-XL
在生成图像之前,我们将向下滚动并打开“高级选项”。我们将添加负面提示,设置种子,并应用精化器以获得最佳图像质量。
然后,我们将编写与之前相同的提示,并做出小的更改。我们将生成一位年轻印度女性的图像,而不是普通的年轻女性。
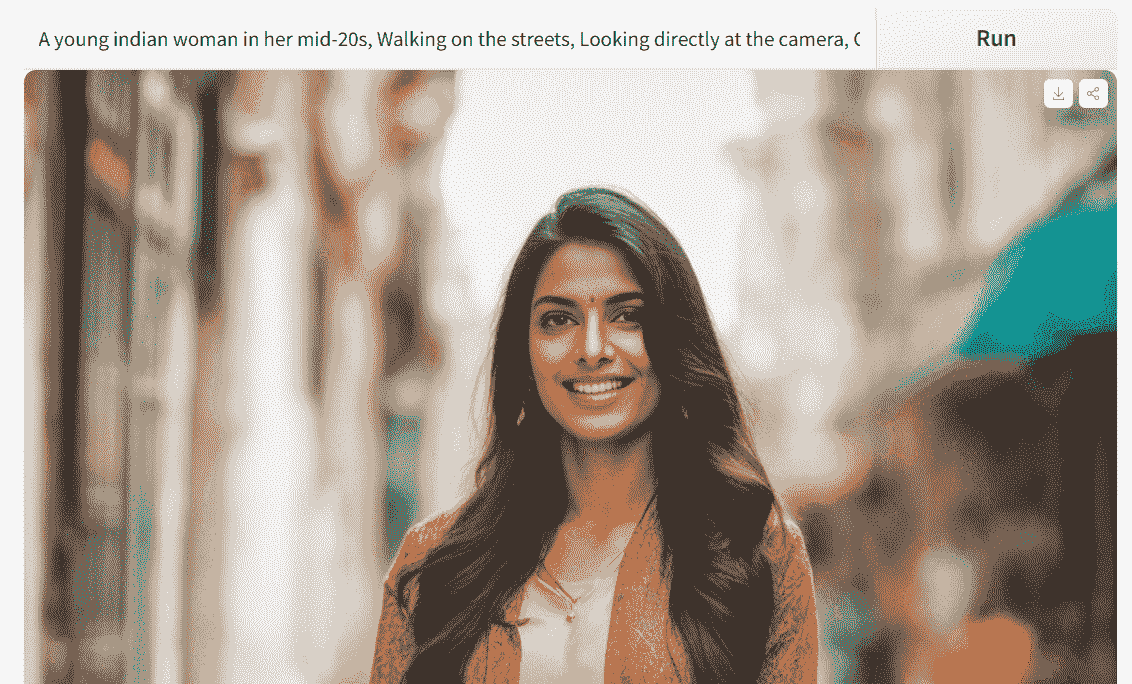
这是一个显著改进的结果。面部特征完美。让我们尝试生成其他种族的图像,以检查偏差并比较结果。
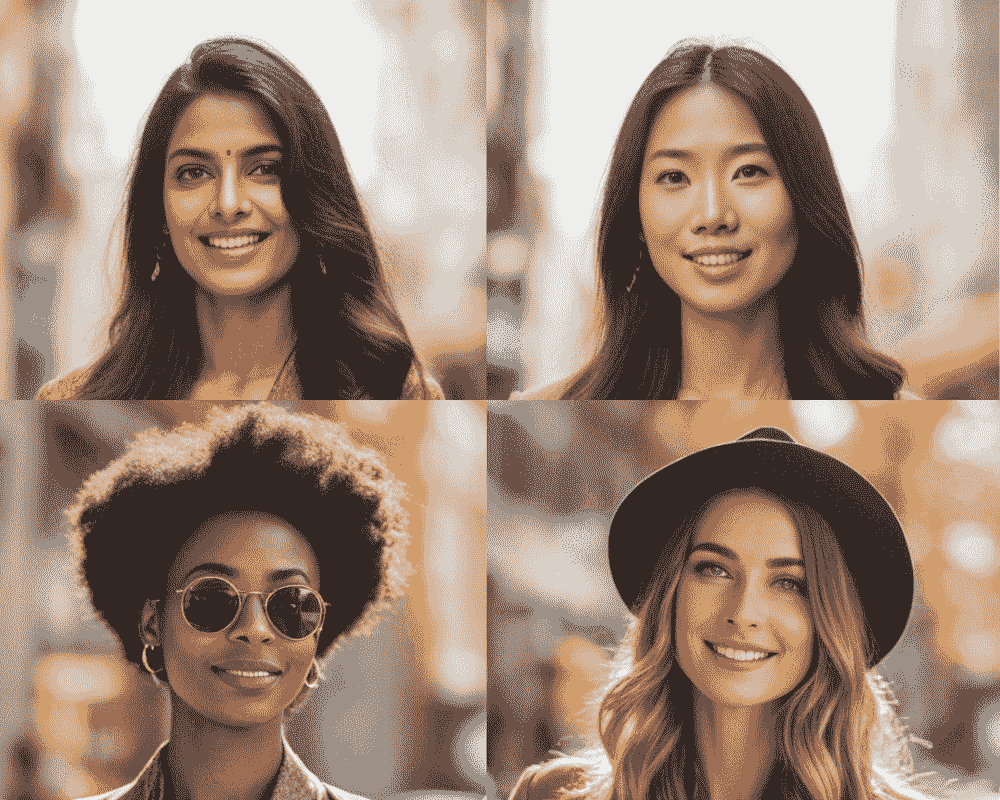
我们得到了逼真的面孔,但所有图像都有 Instagram 滤镜。通常,真实生活中的皮肤不会这么光滑,常常有痤疮、标记、雀斑和皱纹。
3. CivitAI: RealVisXL V2.0
在这一部分,我们将生成具有标记和逼真皮肤的详细面孔。为此,我们将使用来自 CivitAI 的定制模型(RealVisXL V2.0),该模型经过微调以获得高质量的肖像。
链接: civitai.com/models/139562/realvisxl-v20
你可以点击“创建”按钮在线使用模型,或者下载以便在本地通过 Stable Diffusion WebUI 使用。
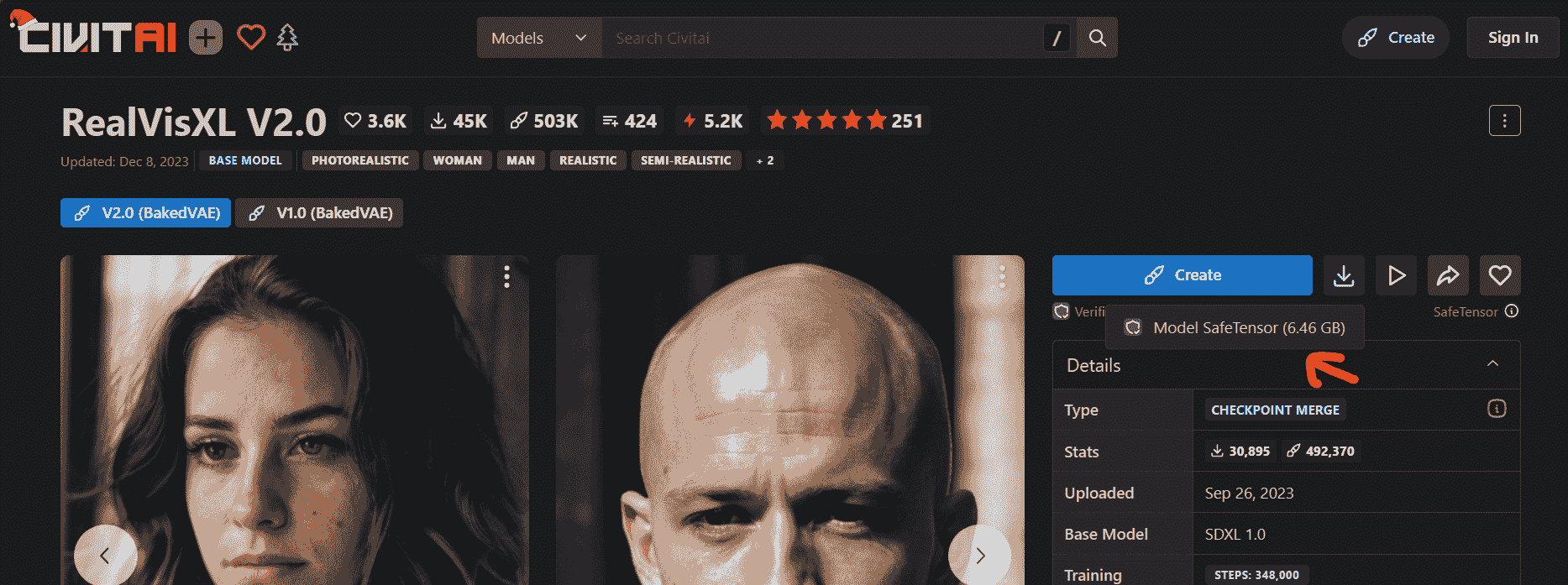
首先,下载模型并将文件移动到 Stable Diffusion WebUI 模型目录:C:\WebUI\webui\models\Stable-diffusion。
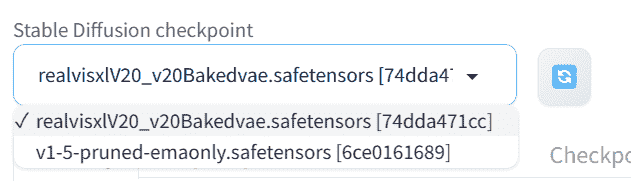
要在 WebUI 上显示模型,你需要按下刷新按钮,然后选择“realvisxl20…”模型检查点。
我们将开始编写相同的正面和负面提示,并生成高质量的 1024X1024 图像。
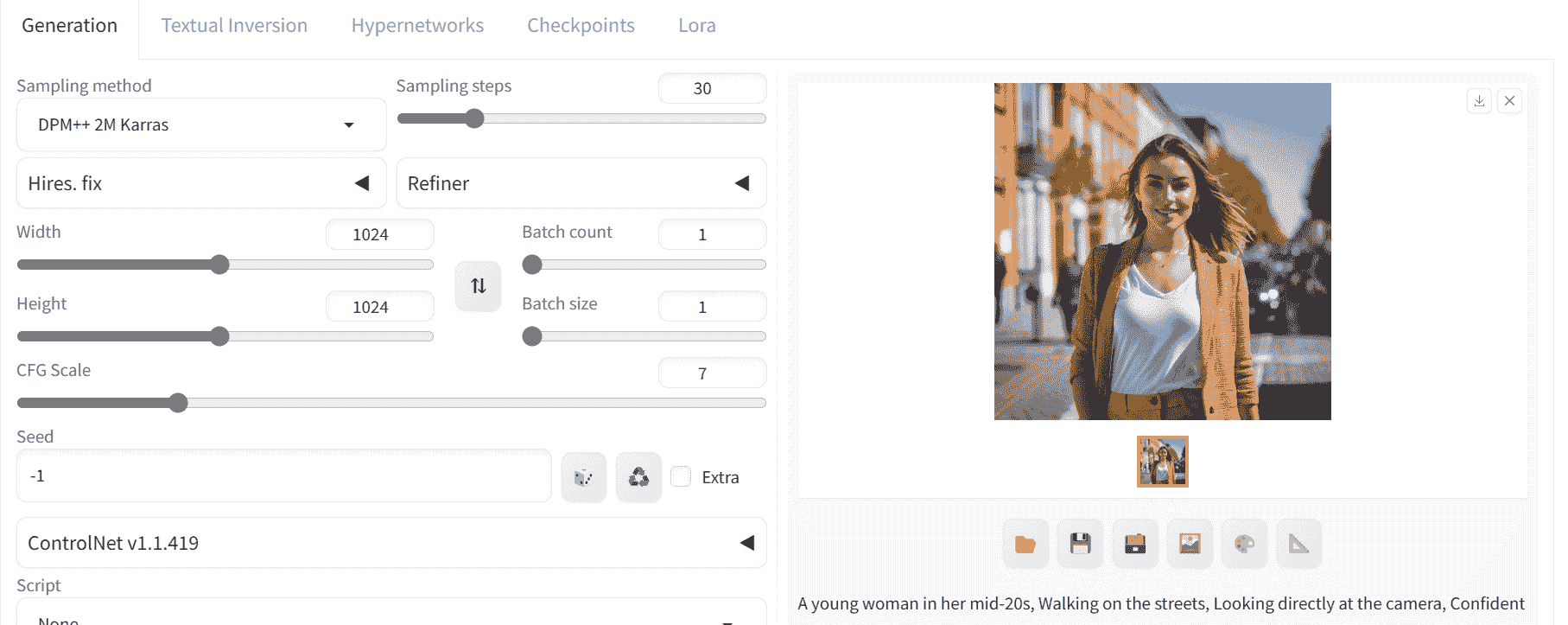
图像看起来很完美。为了充分利用定制模型,我们需要更改我们的提示。
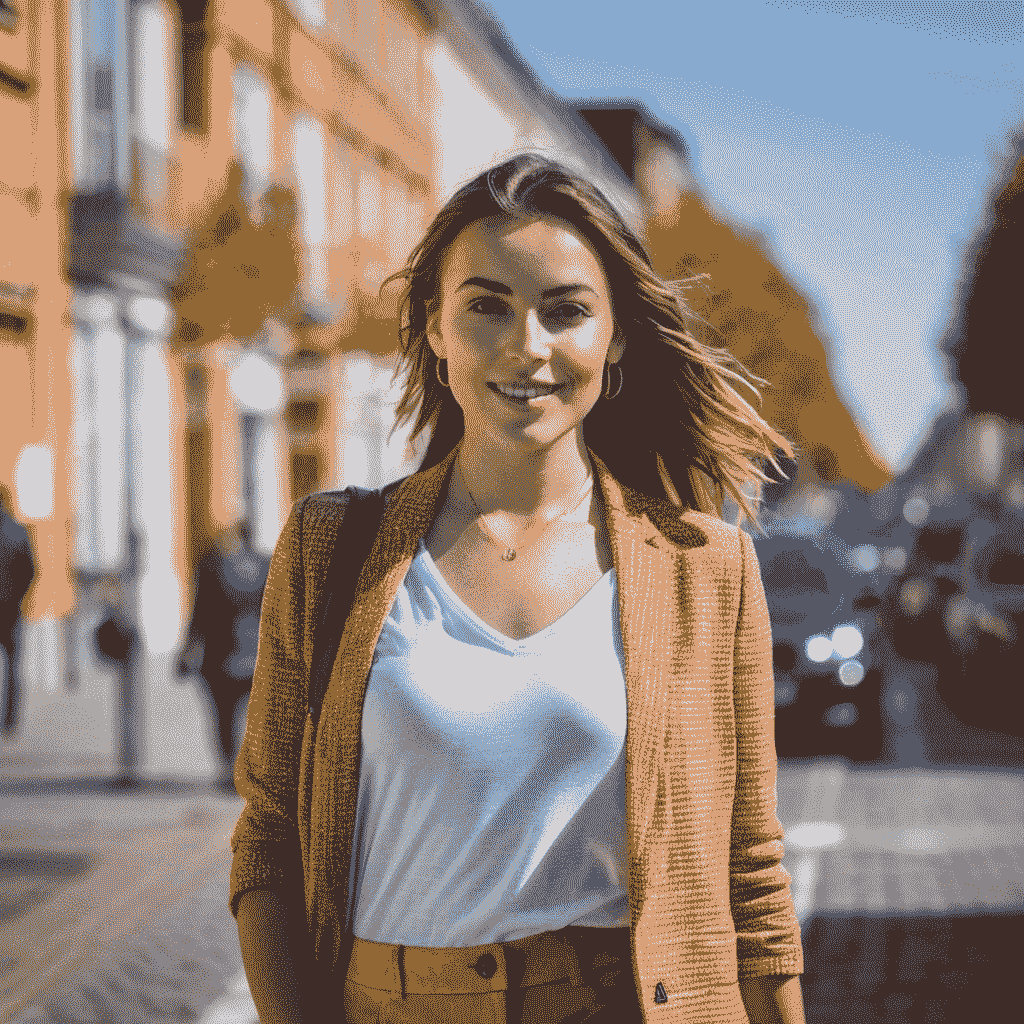
新的积极和消极提示可以通过滚动模型页面并点击你喜欢的逼真图像来获得。CivitAI 上的图像附带了积极和消极提示以及高级引导。
积极提示: “一个专注、果断、超现实的印度年轻女性的图像,动态姿势,超高分辨率,清晰纹理,高细节 RAW 照片,详细的面部,浅景深,锐利的眼睛,(逼真的皮肤纹理:1.2),浅色皮肤,单反,相机颗粒”
消极提示: “(最差质量,低质量,插图,3d,2d,画画,漫画,素描),张嘴”

我们有一张详细的印度女性的图像,皮肤逼真。与基础的 SDXL 模型相比,这是一个改进版本。
我们生成了三张更多的图像以比较不同的民族。这些结果非常出色,包含了皮肤标记、多孔皮肤和准确的特征。
结论
生成艺术的进步将很快达到一个我们难以区分真实和合成图像的水平。这预示着一个可持续的未来,在这个未来中,任何人都可以利用基于多样化真实世界数据训练的自定义模型,从简单的文本提示生成高度逼真的媒体。快速的发展暗示着激动人心的潜力——也许有一天,生成一个逼真的视频来复制你自己的相貌和语言模式将像键入描述性提示一样简单。
在这篇文章中,我们学习了提示工程、高级稳定设计模型以及用于生成高精度和逼真面孔的定制微调模型。如果你想要更好的结果,我建议你探索 civitai.com 上各种高质量的模型。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理健康困扰的学生构建一个 AI 产品。
更多相关内容
利用 ChatGPT 和 AI 赚钱的 3 种方式
原文:
www.kdnuggets.com/3-ways-to-make-money-with-chatgpt-and-ai

编辑提供的图片
作为一个白天有全职工作、晚上从事多个副业(包括创建书面内容、在线课程,以及最近的科技YouTube 频道)的人,我总是在寻找新的被动收入来源。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
所以,当 ChatGPT 发布时,我是第一个在网上寻找如何利用这个工具赚取更多收入的人。
不出所料,我在网上找到的大部分推荐从模糊和不可操作到完全不道德。
显然,成千上万的人开始向亚马逊涌入AI 生成的书籍,导致平台对自出版施加了限制,并大量删除了怀疑为 AI 生成的内容。
然而,在筛选了大量网络上的糟糕建议后,我确实发现了一些相当有用的方法,人们利用 ChatGPT 和生成型 AI 工具来实现货币化。
我甚至开始将这些建议融入到我自己的工作流程中(并成功地在过去一个月里几乎翻倍了我的在线收入)。
在本文中,我将分享我的经验,并提供 3 种实际的方法,帮助你利用 ChatGPT 开始赚取收入。
1. 创建无面孔的社交媒体内容
创作者经济正在爆炸式增长。
通过建立个人品牌并生成他人认为有价值的内容,赚取收入的机会巨大。
然而,内容创作需要花费大量的时间(和金钱)。
一个 YouTube 视频需要构思主题、编写脚本、花费数小时对着摄像头讲话,并在后期制作中进行编辑。
确定理想的视频背景、灯光和音频也需要大量的试错过程。对很多人来说,坐下来对着摄像头讲话可能显得令人生畏和不自然。
生成性 AI 在内容创作领域是一个改变游戏规则的工具。你可以使用 ChatGPT 进行主题研究,为你的 YouTube 视频生成一个吸引人的“引子”,甚至优化你的内容以便在 Google 上获得良好的排名。
然后,你可以使用像Synthesia这样的工具为你的影片创建 AI 头像和配音,这样你就不需要亲自出现在视频中:
图片由作者提供
最后,为了在各种平台上推广你的内容,只需使用像Opus AI这样的工具,将你的 YouTube 视频中的部分内容转换为短视频,这些短视频可以在 TikTok 和 Instagram 等网站上重复使用。
当然,你要让自己与泛滥在互联网上的 AI 生成内容区分开来,这意味着要在视频制作中投入相当的研究,并选择一个细分领域。
ChatGPT 和生成性 AI 应该加快内容创作的过程,而不是取代你的创造力和独特声音。
2. 在线课程
关于生成性 AI 工具如 ChatGPT、Midjourney 和 DALLE 的在线课程正在迅速流行。
注意: 顶级 Udemy 讲师在平台上的收入超过**\(1 百万**](https://www.nichepursuits.com/how-much-do-udemy-instructors-make/),而普通创作者的年收入大约为[**\),而普通创作者的年收入大约为$3,306。
这里是一些在 Udemy 上受欢迎且适合初学者的生成性 AI 课程:
图片由作者提供
看看上述在线课程的学生人数吧!
这应该告诉你,个人和组织愿意大力投资于学习更多关于 AI 的知识。
当然,这并不意味着任何人都可以凭借重复内容来创建一个入门级的 ChatGPT 课程。
你应该这样做:
找到一个细分领域
如果你在市场营销领域工作,例如,你已经拥有了将你与普通人区分开来的专业知识。
现在,开始学习将 ChatGPT 融入到你的日常工作流程中。你的工作中是否有生成性 AI 可以自动化的方面?
例如,AI 在生成符合 SEO 要求的内容方面已经变得非常出色,以至于谷歌也无法可靠地区分这些内容和人类撰写的文章。
利用这些知识,你能否教会小企业主有效地营销他们的产品,而不必雇佣内容创作者或 SEO 专家?
这是一个许多人愿意支付费用学习的技能,因为它教会他们如何节省开支并在长期内提升商业成果。
比如说,这个 Udemy 课程仅用不到 2 小时的视频内容,就已经有了 5000 名学生,因为它教会了人们如何通过 ChatGPT 学习编程:
作者提供的图片
如果你已经拥有一项可销售的技能,你可以通过教别人如何利用 ChatGPT 来磨练这项技能,从而赚到很多钱。
在今天的创作者经济中,开始变得前所未有的简单!
你只需注册一个平台,如Udemy或Teachable,并开始创建课程。
3. 提示工程与人工智能咨询
如果你最近关注了人工智能领域的公告,你可能听说过市场上新兴的热门工作——“提示工程师”。
根据《商业内幕》的报道,这些职位的年薪高达 375,000 美元,甚至不需要技术学位。
那么……这是否意味着任何人只需在 ChatGPT 中输入提示就能赚到这类的钱?有什么陷阱吗?
尽管这是一个相对较新的领域,未来几年将持续发展,但提示工程师的主要角色是利用生成性人工智能来改善商业成果并最大化效率。
大多数提示工程职位需要专业领域的知识。你必须能够应用提示技术来解决特定行业的问题。
例如,如果你从事市场营销工作,你可能会被聘用来让 ChatGPT 创建与业务相关且准确的 SEO 友好内容。
人工智能研究公司 Anthropic 正在积极招聘提示工程师,并没有固定的申请要求。
职位招聘信息指出,他们将考虑那些能够为自己提出有力论据的申请者,并表示:
“如果你还没有做过多少提示工程的工作,你可以通过花一些时间实验 Claude 或 GPT3,并展示你通过一系列精心设计的提示获得了复杂行为,从而最好地展示你的提示工程技能。”
公司的代表进一步提到,逻辑和推理能力是提示工程师最重要的特质,拥有编程知识或机器学习背景在申请这个职位时是一个额外的优势。
尽管许多这些要求看起来非常模糊,但提示工程确实似乎是一项有利可图的技能,各个领域的人们都将受益。
即使你最终没有找到提示工程师的工作,这仍然是一项企业愿意支付来学习的技能,因为员工在人工智能的应用方面仍然面临困难。
你可以在特定领域,如市场营销或金融,提供围绕生成性人工智能和提示工程的咨询服务。
作为曾经向组织提供数据和机器学习咨询服务的人,我成功地通过建立在线存在和创建网站来获得客户,我在另一篇文章中讨论了这一点。
此外,如果从零开始建立品牌看起来很艰巨,这里有一个AI 工具列表,可以帮助你自动化这个过程。
这个人用 ChatGPT 一天之内把 100 美元变成了一个生意
我想通过推荐Jackson Greathouse Fall的故事来结束这篇文章,他用生成式 AI 在一天之内启动了他的业务,要求 ChatGPT 将 100 美元变成“尽可能多的钱”。
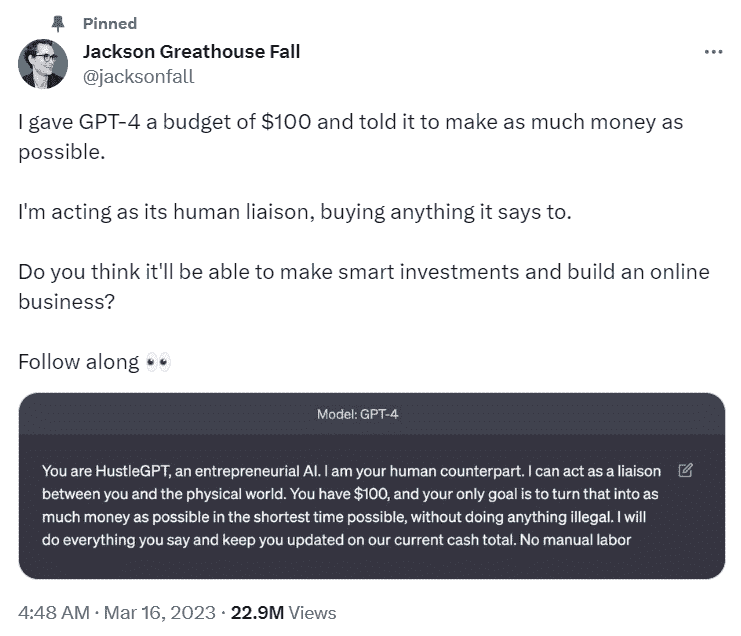
他按照聊天机器人的指示操作,成功在一天之内为公司筹集了 1378 美元。截至三月中旬,公司估值为 25000 美元。
你可以在Business Insider上阅读整个故事。
Natassha Selvaraj 是一位自学成才的数据科学家,热爱写作。Natassha 涉猎所有与数据科学相关的内容,是数据主题的真正大师。你可以通过LinkedIn与她联系,或查看她的YouTube 频道。
更多相关内容
了解贝叶斯定理的 3 种方式将提升你的数据科学水平
原文:
www.kdnuggets.com/2022/06/3-ways-understanding-bayes-theorem-improve-data-science.html
图片由 Ella Olsson 提供,来自 Pexels
贝叶斯定理为我们提供了一种在考虑先前信念的强度的情况下,根据新证据更新信念的方法。应用贝叶斯定理时,你会寻求回答这样一个问题:在新证据面前,我的假设的可能性有多大?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
在这篇文章中,我们将探讨贝叶斯定理如何提高你在数据科学中的实践:
-
更新
-
沟通
-
分类
到最后,你将对这一基础概念有深刻的理解。
#1 — 更新
贝叶斯定理提供了一种测试假设的结构,考虑到先前假设的强度和新证据。这个过程被称为贝叶斯更新。
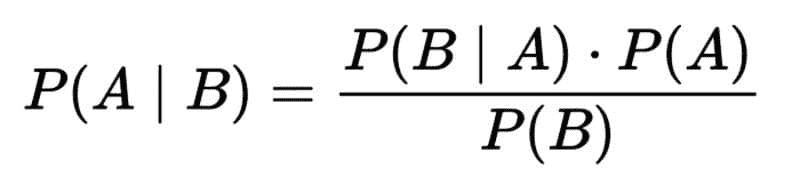
贝叶斯定理,其中 A 代表假设,B 代表与假设相关的新证据。
用语言表达,这个公式是“在 B 给定的情况下 A 的可能性 等于 (左括号) A 给定 B 的可能性 乘以 A 的可能性 (右括号) ***除以 *** B 的可能性。”
让我们再次回顾公式,这次附上变量的定义:
“在新证据面前假设的似然 等于 在假设也为真的情况下新证据为真的似然 乘以 假设在观察到新证据之前的似然,全部除以 新证据的似然。”
这可以进一步简化:
“后验概率 等于 似然 乘以 先验概率 除以 边际似然。”
无论贝叶斯定理现在是否听起来直观,我保证你一直在使用它。
现实世界的例子
比如说,你的朋友打电话告诉你,她非常抱歉,但今晚不能来参加晚餐。她最近领养了一只宠物考拉,这只考拉得了感冒。她真的需要待在家里监控情况。
你的假设是你的朋友不会无缘无故地抛弃你。(毕竟,你做的 ph 很棒,你的朋友会疯狂地错过。)考虑到她新宠物的最近证据,你的假设为真的可能性有多大?

照片由Valeriia Miller提供,来自Pexels
为了评估后验概率,即我们朋友因为照顾考拉而没有来参加晚餐的情况,我们需要考虑你朋友在假设她是一个不抛弃晚餐计划的正直人物的情况下,照顾考拉的可能性。你可能会得出结论,一个通常负责任的好朋友会待在家里照看宠物的可能性很高。
接下来,我们将可能性与先验****概率相乘。在你朋友打电话之前,你对她晚餐计划的承诺的信念有多强?如果你相信你的朋友很坚定,通常不愿在最后一刻改变计划,那么你的先验概率就很强,你不太可能改变这一观点,无论新证据如何。另一方面,如果你的朋友很不靠谱,你已经在想她是否会打电话取消,你的先验概率就会很弱,这也可能会质疑她关于与考拉待在家的说法。
最后,我们将上述计算结果除以考拉拥有的边际可能性??
贝叶斯推断建立在这种灵活的常识性方法上,根据先验的强度和新证据的可能性来更新我们对世界的模型。实际上,贝叶斯定理最初的应用是为了评估上帝的存在。
当涉及到生活和数据科学中的关键问题时,没有什么比贝叶斯定理更直观的方法来评估信念如何随时间变化。
#2 — 沟通
正如贝叶斯定理可以帮助你理解并阐述在面对新证据时如何更新你的理论,贝叶斯定理也可以使你成为一个更强的数据科学沟通者。
数据科学的核心在于应用数据来改善决策制定。
只有两件事决定了你的人生结果:运气和你的决策质量。你只能控制这两件事中的一件。— Annie Duke,扑克冠军和作家
提高决策质量通常意味着说服决策者。像每个人一样,你组织中的决策者也会进入谈话。
现实世界示例
我曾经是一个热气球制造商的顾问。我的任务是帮助建立一个数据库,以改善客户对其供应链、制造过程和销售的end-to-end understanding。
当工厂经理在第一天带我们参观车间时,他自豪地描述了一个关于更轻、更便宜的原材料的新供应商合同。
但有一个问题。随着我的团队将来自不同数据源的表格连接起来,我们发现了新供应商的材料与废品增加 2.5%之间的关系。

由Darren Lee拍摄,来自Unsplash
工厂经理对新供应商有一个非常强烈的先验知识,认为它对他的业务是一个净正面影响。我们有一些相反的证据。我们也有贝叶斯定理。我们理解这一事实:
先验知识越强,改变它所需的证据就越多。
在向工厂经理展示我们的发现之前,我们需要收集额外的证据,以排除其他因素(例如:磨损的机器、新员工、环境条件等)对废品水平差异的影响。
最终,我们向经理提供了更多证据,并帮助他重新谈判了供应商合同。
#3 — 分类
贝叶斯定理可以应用于文本分析的用例,这是一种称为朴素贝叶斯的技术,因为它天真地假设数据集中的每个输入变量(在这种情况下是每个单词)彼此独立。
现实世界示例
假设你发现了一堆你祖父母写的信件。它们中包含了足够的戏剧性,以证明动荡的恋情并不仅限于年轻人在现实电视中。

由RODNAE Productions拍摄,来自Pexels
你想构建一个情感分类器来确定内容的大多数是正面还是负面。一种方法是利用朴素贝叶斯。
一个生成模型(如朴素贝叶斯)将建立一个模型,描述一个类别(在这种情况下是正面或负面)如何生成一些输入数据。给定一个观测值(我们信件测试语料库中的新句子),它返回最可能生成该观测值的类别。这与学习输入特征预测能力的判别模型(如逻辑回归)相对。
朴素贝叶斯基于词袋模型技术——基本上是将文档转换为直方图,统计每个词出现的次数。
你可以使用我们在第 #1 部分学习的贝叶斯推断公式的略微修改版本来计算每个观测值的最可能类别。这种略微的修改就是朴素贝叶斯中的朴素部分:假设在给定类别的条件下,每个词的概率是独立的,因此你可以将它们相乘以生成句子属于该类别的概率。
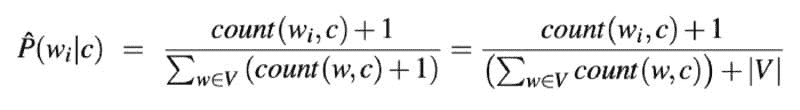
通过 语音与语言处理 由 丹尼尔·朱拉夫斯基 和 詹姆斯·H·马丁
在上述公式中,w? 代表文档 c 中词的计数。公式的分母是词落入给定类别的条件概率之和。
公式中的 +1 防止在类别内没有观测到词的情况下乘以零。这种加一的技术称为拉普拉斯平滑。
最后,|V| 由所有类别中的所有词的并集组成。
贝叶斯定理词汇
-
后验概率:在新证据出现后,假设成立的可能性
-
似然:在假设为真的情况下,证据为真的可能性
-
先验概率:在新证据出现之前你对假设成立的信念强度
-
边际似然:证据
-
朴素贝叶斯:一种假设数据集中特征之间独立的分类器算法
-
生成模型:模拟特定类别如何生成输入数据
-
词袋模型:一种简化文本的表示方法,将文档转换为直方图
-
拉普拉斯平滑:一种简单的加法平滑技术,避免乘以零
总结
我对贝叶斯定理对数据科学家有用持有强烈的先验信念,但我会根据你在评论中留下的反馈更新后验概率。我期待了解你如何在生活和工作中使用贝叶斯定理。
原文。已获许可转载。
更多相关话题
30 个免费资源用于机器学习、深度学习、自然语言处理和人工智能
原文:
www.kdnuggets.com/2018/06/30-free-resources-machine-learning-deep-learning-nlp-ai.html
 评论
评论
这是一个免费资源的集合,超出了常分享的书籍、MOOCs 和课程,主要来自过去一年。它们从零开始,并按顺序进展,适合那些希望掌握一些基本概念的个人,希望能够进一步拓展(参见下面列出的最后 2 个资源以了解更多信息)。
这些资源没有特定的顺序,所以可以随意选择那些对你最具吸引力的。所有的荣誉归于各自材料的作者,如果没有他们的辛勤工作,我们将无法从如此伟大的内容中受益。

有兴趣开始机器学习吗?
由于许多良好的理由,许多高质量的机器学习教育资源往往非常注重理论,特别是在开始时。然而,似乎有一种越来越明显的趋势,即从一开始就进入实际应用,并在资源进展过程中混合实践和理论。本文介绍了 5 个这样的资源。
涵盖从基础的机器学习到从零开始编写算法,以及使用特定的深度学习框架,这些资源覆盖了相当广泛的内容。它们都是免费的,所以赶快阅读、观看和编码吧。
想进一步了解神经网络和深度学习,超越那些基本的入门教程和视频吗?本文包括 5 个具体的视频选项,总共提供了很多小时的见解。如果你已经具备一些基本的神经网络知识,可能是时候深入研究一些更高级的概念了。
你对一些实用的自然语言处理资源感兴趣吗?
在线有如此多的自然语言处理资源,尤其是那些依赖于深度学习方法的,筛选出优质的资源可能是一项任务。有一些著名的、顶尖的主要理论性资源,特别是斯坦福大学和牛津大学的深度学习课程:
-
使用深度学习进行自然语言处理(斯坦福)
-
自然语言处理的深度学习(牛津)

但如果你已经完成了这些内容,已经在 NLP 领域有了基础,并且想转向一些实际资源,或者对其他方法感兴趣,这些方法可能不一定依赖于神经网络,这篇文章(希望)会对你有所帮助。
对将深度学习应用于自然语言处理(NLP)感兴趣?不知道从哪里或如何开始学习?
这是一个针对新手的 5 个资源集合,应该能让你了解可能性和自然语言处理与深度学习交汇处的现状。它也应该为你提供下一步的方向。希望这个集合对你有所帮助。
寻找一个由在线免费材料提供的入门级研究生 AI 课程?随着越来越多的高等教育机构决定允许通过网络向非学生开放课程材料,几乎任何人、任何地方都可以体验到伪大学课程。请查看以下免费的课程材料,所有这些材料都适合初级 AI 理解水平,其中一些还涵盖了特定应用概念和材料。

以下一些教授及其分享的材料在塑造世界顶级 AI 研究人员和从业者的思想方面发挥了重要作用。没有理由你不能从这些材料和指导中获益。
对自动驾驶车辆感兴趣?不知道从哪里或如何开始学习?
这个话题的正规教育资源稀缺,因此那些有兴趣学习的人必须以黑客思维来学习。我整理了一个简短的 5 个资源列表,以帮助新手找到方向,所有这些资源都是免费的。希望对一些人有用。
相关:
-
自然语言处理秘籍:入门 NLP
-
你不应忽视的 5 个机器学习项目,2018 年 6 月
-
DIY 深度学习项目
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关话题
30 个最常被问到的机器学习问题回答
原文:
www.kdnuggets.com/2021/08/30-machine-learning-questions-answered.html
评论
由 Abhay Parashar, Python 开发者 | 数据科学学习者。

图像由作者提供。
机器学习是通向更好和更先进未来的途径。机器学习开发者是 2021 年最热门的工作之一,预计在未来 3-5 年内将增长 20-30%。机器学习本质上是所有统计学和编程概念的结合。机器学习开发者最常用的编程语言是 Python,因为它的简单性。在本博客中,你会找到一些最常被问到的机器学习问题,每个机器学习爱好者都有一天必须回答这些问题。让我们开始吧。
0. 什么是机器学习?
答案:机器学习是让计算机在实时情况下自主行动的科学,而无需明确编程。这是一种人工智能应用,使系统能够自动从先前的经验中学习和改进。它使计算机能够在没有任何人工干预的情况下学习和适应新数据。
1. 解释监督学习、无监督学习和半监督学习之间的基本区别?
答案:
监督学习:模型在标记的数据上进行训练,然后根据之前标记的数据做出预测。它需要一个监督者(标签)来训练数据。例如:文本分类。
无监督学习:模型在未标记的数据上进行训练。模型尝试发现数据中的模式和关系,并根据这些模式进行分类。我们没有任何标记的数据。
半监督学习:这是一种机器学习类型,它使用一些标记的数据和大量未标记的数据来训练模型。其目标是借助标记数据对一些未标记的数据进行分类。
2. 你所说的强化学习是什么意思?
答案:强化学习是机器学习的一个领域,其中模型根据其在环境中的先前行为所获得的奖励进行训练。有一个代理负责给出奖励,并最大化奖励。如果模型正确执行任务,则获得+1 奖励;如果模型任务执行错误,则获得-1 奖励。
应用:自动驾驶汽车、自动停车、难题求解器等。
3. 机器学习中使用的不同类型的数据有哪些?
答案:有两种类型的数据。结构化数据和非结构化数据。
1. 结构化数据:这类数据在存储之前是预定义的、标记的和格式化好的。例如:学生记录表。
2. 非结构化数据:这种类型的数据是原始格式的,直到使用时才会被处理。例如:文本、音频、视频、电子邮件等。
4. 特征与标签?
答:特征是输入信息。另一方面,标签是模式的输出信息。
特征用于预测某些内容,而标签是我们预测的内容。此外,特征被称为独立变量,标签被称为依赖变量。
5. 解释回归和分类之间的区别?
答:
回归:回归是寻找依赖变量和独立变量之间相关性的过程。它有助于预测连续变量,例如股票市场预测、房价预测等。在回归中,我们的任务是找到最适合的线,以准确预测输出。
分类:分类是找到一个函数,帮助将数据分成不同类别的过程。这些主要用于离散数据。在分类中,我们的目标是找到一个决策边界,将数据集划分为不同的类别。

图片由作者提供。
6. Scikit-learn 用于什么?
答:Scikit-learn 是一个强大的 Python 库,用于机器学习任务。Scikit-learn 库包含许多高效的机器学习和统计建模工具和类,包括分类、回归、聚类、特征选择、参数调整等。它是进行预测分析的高效工具。它以类和函数的形式提供所有主要算法。在 Python 中,它被称为sklearn。
7. 什么是机器学习中的训练集和测试集,它们为什么重要?
答:训练集是提供给模型进行训练、分析和学习的数据集。测试集是用于在实际应用之前对模型进行本地测试的数据集。训练集是标记数据,而测试集没有标签。
将数据集划分为训练集和测试集非常重要,这样模型才能避免过拟合或欠拟合。此外,这是评估模型并理解数据特征的一个有效方法。在大多数情况下,划分比例为 70/30,即 70%的数据用于训练,30%的数据用于测试。
8. 解释构建机器学习模型的阶段?
答:
数据收集:这是任何机器学习模型的第一阶段。在这个阶段,决定合适的数据,然后通过某些算法或手动收集这些数据。
数据处理:在这个阶段,我们对第一阶段收集的数据进行预处理,处理所有的空值、分类数据等。此外,在同一阶段,如果数据特征的范围不一致,还会将它们调整到相同的范围。
模型构建:在这个阶段,我们首先选择适当的算法来创建模型,然后借助如 sklearn 等工具构建模型。
模型评估:在模型创建后,使用一些统计技术对其进行评估,例如准确度分数、z 分数、准确性矩阵等。
模型保存与测试:在模型成功评估后,它会被保存以备将来使用,并进行实时测试。
9. 过拟合与欠拟合?
答:
过拟合:当模型在训练数据上的表现很好,但在测试数据上的表现差时,就会出现过拟合。例如:模型在训练集上的准确率为 94%,在测试集上的准确率为 56%。这是一种建模错误,发生在函数过于紧密地拟合有限的数据点集时。为避免过拟合,我们可以收集更多数据,使用集成方法或选择最适合数据的算法。
欠拟合:模型在训练数据和测试数据上的表现都很差。换句话说,这种模型未能对新数据点进行有效泛化。
“机器智能是人类将来不再需要制造的最后发明。” ~ 尼克·博斯特罗姆
10. 解释混淆矩阵在模型评估中的作用?
答:混淆矩阵是用来衡量机器学习算法性能的测量表。它是一个不同预测值和实际值组合的表。它用于衡量召回率、精确度、AUC-ROC 曲线和准确性。矩阵的对角线包含所有正确的数据。矩阵的大小取决于因变量中的类别数。矩阵的大小等于 N*N,其中 N 是因变量输出中的类别数量。
-
真阳性:实际值 = 预测值 当输出为 1 时
-
真阴性:实际值 != 预测值 当输出为 0 时
-
假阳性:第一类错误
-
假阴性:第二类错误
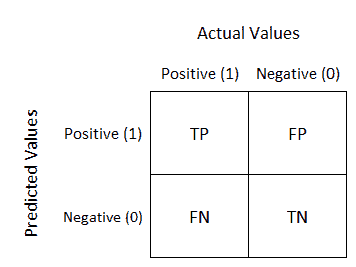
11. 第一类错误和第二类错误有什么区别?
答:
第一类错误(假阳性错误):当零假设为真时却被拒绝,意味着声称某事发生了,但实际上并未发生。
第二类错误(假阴性错误):当零假设被接受时它实际上不是真的,意味着声称什么都没有发生,但实际上发生了。
例子:以零假设为一个无辜的人为例。将无辜的人定罪是第一类错误。另一方面,让一个有罪的人逍遥法外是第二类错误。
12. 区分精确度、召回率、准确性和 F1 分数?
答:
精确度是正确预测的正观察值与总预测正观察值的比率。它显示了我们的模型有多精确。
- 精确度 = TP/TP+FP
召回率是正确预测的正观察值与该类别总观察值的比率。
- 召回率 = TP/TP+FN
F1-分数是召回率和精确度的加权平均值。
- F1-分数 = 2*(召回率 * 精确度) / (召回率 + 精确度)
准确率是正确预测的正观察值与总正观察值的比率。
- 准确率 = TP+TN/TP+TN+FP+FN
13. P 值是什么意思?
答案:P 值是在假设零假设为真的情况下对结果的确定。如果 p 值非常小(<0.05),则我们假设零假设是正确的可能性很小。因此我们拒绝零假设。
14. 解释一下 ROC 曲线是如何工作的?
答案:ROC 曲线是一个显示分类模型在不同阈值下性能的图表。它使用两个曲线绘制参数,即真正率(灵敏度)和假正率(特异性)。
-
曲线越接近左边界然后是上边界,测试的准确度就越高。
-
曲线越接近 ROC 空间的 45 度对角线,测试的准确度就越低。
15. KNN 和 K-means 聚类有什么不同?
答案:KNN 是一种监督式机器学习技术,用于分类或回归问题。在 KNN 中,K 代表用于预测因变量的最近邻居的数量。
K-means 聚类是一种无监督的机器学习算法,用于根据 K(聚类数目)和质心将数据划分为不同的簇。
16. 朴素贝叶斯定理中的“朴素”是什么意思?
答案:朴素贝叶斯分类器假设所有输入变量彼此独立,即它们之间没有任何关系,这实际上对于真实数据来说是不现实的假设。
假设有一个包含水果信息的数据集,用来检测水果是否是苹果。一个样本包含一个红色的、圆形的直径约为 4 英寸的水果。即使这些特征彼此依赖或依赖于其他特征的存在,朴素贝叶斯分类器仍会将它们视为独立的因素来预测水果。
17. 集成学习是如何工作的?
答案:集成学习是一种将多个模型的预测结果或结果组合以实现更好性能的技术。比如说,如果你买一辆车,你通常会在网上查找不同车型的评论和特点。最终,在汇总所有评论后,你会创建自己对这辆车的评论,并决定是否购买它。你创建的评论是所有评论的更好版本,因为它包含了所有评论的信息。
集成学习的工作原理相同:使用来自多个算法的预测来创建更好的模型。
集成学习可以通过两种方式进行。一种是将不同算法的预测结果结合生成新的高精度预测。另一种是多次使用单一算法,最后使用每个模型的预测结果生成一个更好的模型,具有良好的准确性。
“不要让昨天占据今天太多的时间。” ~ 威尔·罗杰斯
18. 机器学习中的袋装和提升是什么?
答案:
袋装是一种结合相同类型预测的方法,即来自相同算法的预测。例如:随机森林。在这种方法中,每个模型独立构建,给予它们相等的权重。它减少了过拟合问题,也降低了方差。
提升是一种结合不同算法预测的方法。例如:梯度提升。新模型受到之前构建的模型表现的高度影响。它减少了偏差。
19. 偏差-方差权衡是什么?
答案:偏差是模型平均预测值与正确值之间的差异。另一方面,方差是数据点的变异性,显示数据的分布情况。
如果我们的模型参数较少,那么它可能具有高偏差和低方差。因此,它将是稳定的但平均不准确。具有大量参数的模型可能具有低偏差和高方差,这些模型在平均上大多准确,但在性质上不一致。一个好的模型总是具有低偏差和低方差。
20. 解释 L1 和 L2 正则化?
答案:使用 L1 正则化的回归模型称为Lasso 回归,而使用 L2 正则化的模型称为Ridge 回归。
-
L1 正则化通过在成本函数中添加权重 (Wj) 的绝对值来增加惩罚项,而 L2 正则化则通过在成本函数中添加权重 (Wj) 的平方值来增加惩罚项。
-
两者之间的另一种区别是,L1 正则化尝试估计数据的中位数,而 L2 正则化尝试估计数据的均值。
-
L1 正则化有助于去除不重要的特征。
21. 处理机器学习中缺失值的不同方法是什么?
答案:
1. 用均值、中位数或众数替换缺失值。
2. 用随机值替换缺失值。
3. 将所有 NaN 值作为新特征使用。
4. 用第三个偏差值替换 NaN 值。
5. 用最小值或最后的异常值替换 NaN
6. 用最频繁的类别替换 NaN (分类值)**7. 将缺失值视为新类别
8. 应用分类器预测 NaN 值
9. 丢弃值
了解更多:处理机器学习中缺失值的 9 种方法
22. 你可以使用哪些不同的技术来选择特征。
答案:
-
单变量选择: 在这种方法中,我们使用 SelectKBest 算法根据依赖列找到特征分数。
-
额外树分类器:该技术为数据的每个特征提供一个分数。分数越高,该特征的重要性和相关性越强。你可以从 sklearn.ensemble 中导入这个类。
-
相关矩阵:一个显示所有特征之间相关性的表格。表格中的每个单元格显示两个变量之间的相关性。我们可以使用阈值来选择数据集中相关性较低的变量。
-
互信息:这是一种分类器,生成每个特征与依赖特征的互信息。信息量越高,相关性越强。
“折磨数据,它会承认一切。” ~ 罗纳德·科斯
23. 如何处理数据集中的分类值?
答案:处理分类值,我们可以进行编码,将分类数据基本上转换为数值数据。
-
名义编码: 当数据没有固有的顺序时。
1 一热编码
1.2 具有许多特征的一热编码
1.3 平均编码
-
序数编码: 当数据具有固有顺序时。
2 标签编码
2.2 目标引导编码
-
计数编码
了解更多:处理分类值的不同方法
24. 什么是异常值,我们如何在机器学习中处理它们?
答案:异常值是与数据集中其他数据点或样本有显著不同的一些不寻常的数据点。它们可能对模型性能产生重大影响。处理异常值,我们可以做三件事。
-
移除所有异常值
-
用合适的值(如第三个偏差)替换异常值
-
使用对异常值不敏感的不同算法。
25. 什么是特征缩放和转换,它们为何必要?
答案:特征转换是一种将特征从一种表示转换为另一种表示的技术。另一方面,特征缩放是将特征的所有值转换到相同范围的技术。
有时候在我们的数据集中,我们有一些具有不同单位的列——比如一个列可以是年龄,而另一个列可以是人的工资。在这种情况下,年龄列的范围是 0 到 100,而工资列的范围是 0 到 10000。这些列的值差异如此之大,因此值较大的列将更大程度地影响输出。这将导致模型性能差。因此,我们需要进行特征缩放和转换。
26. 如何处理不平衡的数据集?
答案:在不平衡数据中,各个类别之间的样本差异很大。例如,一个类别可能有 1000 个样本,而另一个类别可能只有 200–300 个样本。在这种情况下,在做任何事情之前,我们首先需要处理数据的不平衡。有许多技术可以遵循。
-
收集更多数据。
-
当我们有大量数据时应用过采样
-
应用欠采样
-
尝试其他算法
27. 什么是 A/B 测试?
答案:A/B 测试是一种用于随机化两个变量实验的统计假设检验方法。它通常用于比较使用不同预测变量的两个模型,以检查哪个模型更适合数据。
在实际场景中,假设你创建了两个为用户推荐产品的模型。A/B 测试可以用于比较这两个模型,以检查哪个模型给出的推荐最好。
28. 什么是机器学习中的交叉验证?
答案:这是一种通过向模型提供来自数据集的多个样本数据来提高模型性能的技术。采样过程是通过将数据分成具有相同数量行的小部分来完成的。在所有部分中,随机选择一个用于测试集,另一个用于训练集。它包含以下技术:
-
k 折交叉验证
-
保留法
-
分层 k 折交叉验证
-
留出 p 折交叉验证
29. PCA 是什么,它有什么用?
答案:PCA(主成分分析)是一种用于减少大型数据集维度的降维方法。
在现实生活中,我们通常会遇到具有大维度的数据集,因此,视觉化和分析这些数据集变得困难。PCA 可以通过移除数据集中不必要的维度来帮助减少数据集的维度。
“你学得越多,你赚得越多。” ~ 沃伦·巴菲特
30. 在机器学习中,管道是如何使用的?
答案:管道用于自动化机器学习工作流程。一个管道由几个步骤组成,用于训练一个模型。这些管道是迭代的,所以每一步都重复多次以提高模型的准确性。
这个管道主要用于自然语言处理。管道的一部分负责清理和向量化,另一部分则负责模型训练和验证。
原文。经授权转载。
相关内容:
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
更多相关内容
30 个掌握数据可视化的资源
原文:
www.kdnuggets.com/2022/11/30-resources-mastering-data-visualization.html

我们都有过这样的经历。在你看到某些数据中有一个非常酷的模式时,你兴奋地想要分享它。例如,或许你注意到,当你在寒冷天气下跑步时,每英里比在温暖天气下跑步时快一分钟。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
你想与对你重要的人分享这些令人兴奋的发现。也许是你的老板。也许,在跑步的例子中,是你的伴侣或跑步小组。
你向他们展示了你那令人惊叹的表格和超级有趣的数字——他们却呆呆地看着你。因为你兴奋地展示你的发现,忘记了人类的一个基本真理:没有人喜欢看表格。但每个人都喜欢看美观且信息丰富的图表。这就是数据可视化的重要性。
研究 表明 我们处理图像的速度比处理文字快 60,000 倍。你可以自己测试一下——看一个充满数字的表格,然后再看一个表示相同内容的图表。哪一个让你获取更多信息更快?哪一个更让你喜欢?
数据可视化既是一门艺术,也是一门科学。它是一门科学,因为数据部分来自数字和事实。但它是一门艺术,因为你需要考虑受众的心理。你需要考虑数字的格式。你需要考虑你试图传达的内容和方式。你还需要知道如何让它变得漂亮。这就是可视化的部分。
在我看来,如果每个人都知道如何有效地使用数据可视化(LinkedIn Business 的 Paul Petrone 也同意),每个人都会更好。我们几乎所有人,都会在生活中的某个时刻被要求分享一些数字。越来越多地,做生意就意味着处理数据。这是无止境的。
想要掌握数据可视化?这份包含 30 个资源和工具的列表将帮助你开始掌握数据可视化的旅程。
你需要什么来掌握数据可视化?
学习数据可视化只需三件事。
一个是数据。非常自明。
其次是某种界面,用于进行可视化——它可以是像 Python 或 R 这样的语言,也可以是像 Google Sheets 这样的工具。
第三,你需要有分享知识的愿望。如果你只是为了完成某个清单而学习数据可视化,你会遇到困难。但如果你有强烈的愿望去制作一些酷炫的图表以展示某个有趣的发现,那么这将会容易得多。
例子包括:
-
为了你的工作或学位
-
一个热情的项目,比如我之前提到的跑步例子
-
你面临的问题,比如如何做更便宜的饭菜。
有了这三种要素,你可以掌握数据可视化。
从哪里获取数据?
如果你没有来自工作、学校或个人生活的数据,你将需要一些开源数据的来源。以下是一些免费的选项:
-
Tidy Tuesdays。这个 GitHub 每周更新一次,提供免费、有趣的数据,任何人都可以使用。它旨在帮助新手学习使用 R 和
tidyverse包,但任何人都可以使用这些数据。 -
The Pudding。这是一个非常有趣的网站,供任何人探索数据可视化。他们使用来自 音乐、历史、政治、社会公正、和 填字游戏(以及其他大量主题)的数据编写文章。浏览一下,你会发现一些有趣的内容。
-
Kaggle。Kaggle 是一个数据科学家社区,提供大量竞赛和比赛。当你参加比赛时,你可以下载该比赛的数据。
-
FiveThirtyEight。这是一个新闻和体育网站,提供大量非常有趣的数据报道。
-
NASA。可能不需要介绍。如果你喜欢空间或地球科学,你会在这里找到一些很棒的数据集。
学习数据可视化的免费资源

互联网充满了免费的知识。它存在于博客文章、YouTube 视频、免费课程甚至短视频 TikTok 中。困难的部分是导航找到真正有价值的内容。
这里是其中最好的几个。我根据界面对它们进行了分类,因为在我看来,这是学习数据可视化的决定性方式。
Python 中的数据可视化
Python 在数据可视化方面非常出色,得益于其用户友好的库,如 matplotlinb 和 Plotly。Python 本身也是开源和免费的。为了掌握使用 Python 的数据科学,以下是一些我推荐的免费资源:
-
Data Visualization with Python Coursera 课程。Coursera 课程是可审计的,所以你可以免费学习这些技能——只不过你不会得到证书。
-
EdX提供了一个类似的免费课程,不过课程材料的访问权限在你开始后大约一个月后会过期。快速学习吧!
-
SimpliLearn YouTube 频道充满了免费和绝妙的资源。这里仅提供他们 Python 数据可视化教程的一个例子。
-
这篇Towards Data Science 文章介绍了一些你需要的 Python 库以便开始。
-
(免费)《Python 数据分析》一书的第九章是一颗瑰宝,可以在这里找到。(如果你对 Python 感兴趣,整本书值得完整阅读。)
R 中的数据可视化
和 Python 一样,R 是开源的、免费的,并且由热心慷慨的编码社区维护。其ggplot2包和tidyverse使得数据可视化成为梦想。以下是你需要的免费资源:
-
这是关于 R 数据可视化的可审计 Coursera 课程。
-
EdX 的对应课程在这里。
-
Simplilearn 有一个R 数据可视化视频和播放列表。
-
我喜欢这篇关于“为不使用 R 的研究人员进行数据可视化的文章” 。正如标题所示,它适合那些想制作漂亮图表但从未使用过 R 的人。我发现它是一个全面且有趣的教程。
-
这是关于数据科学的R 宝典/教科书。第三章和第三十八章是关键章节,但整本书都很有趣且富有信息量。
Google Sheets 中的数据可视化
Google Sheets 不是开源的。然而,我仍然包括它,因为对于那些不熟悉 R 和 Python(或其他编程语言)的人来说,它更容易获得。此外,由于该产品由一家非常富有的公司拥有,且希望你采用他们的产品,因此有大量旨在让你迷上 Google Sheets 的免费信息。
这是掌握 Google Sheets 数据可视化的免费资源:
-
从他们的介绍博客文章开始。这篇文章给你一个很好的概述,了解可能性。
-
接下来,查看 他们的教程,该教程指导你创建一些关于最高票房电影的可视化。
-
这是一个 很棒(且简短)的 YouTube 视频,由 Pailsware 产品学院制作,讲解如何使用 Google Sheets 可视化预算。
-
这本 免费教科书 帮助你全面掌握 Google Sheets 数据可视化的所有细节。内容全面且深入。
数据可视化的灵感来源

回到我最初关于如何掌握数据可视化的观点,其中一个关键要素是热情。你必须真正关心你正在做的事情。数据可视化必须令人兴奋才能掌握。
那种动力可以是内在的,但如果你缺乏灵感,还有很多地方可以获得外部的激励。
数据可视化影响者
这是我推荐关注的一些优秀数据可视化影响者。这些数据可视化专家将会:
-
展示顶级技术和风格
-
让你了解最新的工具或语言
-
提供额外的数据来源
-
分享他们对数据可视化的热情和激情
这是我推荐关注的对象:
-
Nadieh Bremer。她是一位数据可视化艺术家和毕业天文学家。这里是我喜欢的 她的数据可视化之一,关于婴儿出生的时间。
-
Cole Knaflic。她是《Storytelling With You》的首席执行官和作者,她的网站 storytellingwithdata.com 有一个很棒的社区部分,提供挑战和数据可视化。
-
David McCandless 是一位作家、设计师和作者,运营着 @infobeautiful Twitter 账户。我最喜欢的数据可视化之一 记录 了最无聊的 Wikipedia 编辑战。
-
定期浏览 #dataviz 或 #datavisualization 标签,将有机会创建你自己策划的数据可视化影响者列表。
网上有大量的人在享受并创建精彩的数据可视化。选择你喜欢的,然后从那里开始。
数据可视化社区
灵感不一定只来自于顶层。另一个获得数据可视化动机和激励的好方法是加入社区。以下是一些值得参与的优秀社区:
-
TidyTuesday。我知道我已经分享过这个,但我再分享一次!这是一个定期挑战、汇集了了不起的人和免费资源的好地方,帮助你掌握数据可视化。
-
Kaggle。另一个重复,但值得记住。竞赛方面是一个很好的方式来投入到数据可视化的掌握中。
-
数据可视化协会提供一个免费会员层级(还有几个付费层级)。免费层级让你可以访问一个 Slack 频道,与其他志同道合的数据可视化爱好者聊天。
-
Python 有一个Discord 服务器,他们经常聊数据科学和数据可视化。
如何掌握数据可视化
数据可视化是任何人都应该练习的好技能,无论你的工作或情况如何。无论你是数据科学家还是咖啡师,了解如何有效地展示数据总是有用的。而且,知道如何以让人关注的方式分享信息,竟然出乎意料地有趣和令人满意。
如果你想知道作为数据科学家还需要具备什么其他技能,可以查看我们的帖子“数据科学家技能”。
像其他任何技能一样,掌握数据可视化归结为兴趣和实践。如果你有数据、一个接口工具,以及坚持下去的意愿,你很快就会在路上。这份包含 30 个资源的列表应该能帮助你在掌握数据可视化的旅程中——同时享受过程。
Nate Rosidi 是一名数据科学家和产品战略专家。他还是一名兼职教授,教授分析课程,并且是StrataScratch的创始人,这个平台帮助数据科学家准备与顶级公司面试的真实问题。可以在Twitter: StrataScratch或LinkedIn上与他联系。
相关话题
30 年数据科学:数据科学从业者的回顾
原文:
www.kdnuggets.com/30-years-of-data-science-a-review-from-a-data-science-practitioner

编辑提供的图片
30 年的 KDnuggets 和 30 年的数据科学。差不多是我职业生涯的 30 年。长期从事同一领域工作所带来的特权之一——即经验——就是有机会作为直接目击者撰写其演变过程。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
算法
我在 90 年代初开始从事当时称为人工智能的工作,指的是一种自我学习的新范式,模仿神经细胞的组织,并且不需要验证任何统计假设:没错,就是神经网络!几年前刚刚发布了有效使用回传算法的研究成果[1],解决了多层神经网络隐藏层训练的问题,使得一大批热情的学生能够探索多种老用例的新解决方案。没有什么能阻止我们……只有机器性能。
训练一个多层神经网络需要相当大的计算能力,特别是当网络参数数量多且数据集庞大时。计算能力是当时机器所缺乏的。理论框架已经发展出来,如 1988 年的时间序列回传算法(BPTT)[2]或 1997 年的长短期记忆网络(LSTM)[3]用于选择性记忆学习。然而,计算能力仍然是个问题,大多数数据分析从业者将神经网络搁置,等待更好的时机。
与此同时,出现了更精简且通常表现相当的算法。决策树形式的 C4.5 [4] 在 1993 年变得流行,尽管以 CART [5] 形式的决策树早在 1984 年就已存在。决策树训练起来更轻便,更易于理解,并且在当时的数据集上表现良好。很快,我们还学会了将多个决策树组合成一个森林 [6],在随机森林算法中,或组合成一个级联 [7] [8],在梯度提升树算法中。尽管这些模型相当庞大,即有大量的参数需要训练,但在合理的时间内仍然可管理。尤其是梯度提升树,利用级联的树按序列训练,将所需的计算能力分散到时间上,使其成为数据科学中非常实惠且成功的算法。
直到 90 年代末,所有数据集都是经典的、合理大小的数据集:客户数据、患者数据、交易数据、化学数据等等。基本上,都是经典的业务操作数据。随着社交媒体、电子商务和流媒体平台的扩展,数据开始以更快的速度增长,带来了全新的挑战。首先是存储和快速访问如此大量结构化和非结构化数据的挑战。其次是对更快算法的需求来进行分析。大数据平台负责存储和快速访问。传统的关系型数据库承载结构化数据,逐渐让位于新的数据湖,这些数据湖承载各种类型的数据。此外,电子商务业务的扩展推动了推荐引擎的普及。无论是用于市场篮子分析还是视频流推荐,这两种算法变得常用:apriori 算法 [9] 和协同过滤算法 [10]。
与此同时,计算机硬件的性能得到了提升,达到了难以想象的速度……我们又回到了神经网络。GPU 开始被用作神经网络训练中特定操作的加速器,使得越来越复杂的神经算法和神经架构得以创建、训练和部署。这一神经网络的第二次青春被称为深度学习 [11] [12]。人工智能(AI)这一术语开始重新浮现。
深度学习的一个分支,生成式 AI [13],专注于生成新数据:数字、文本、图像,甚至音乐。模型和数据集的规模和复杂性不断增长,以实现更现实的图像、文本和人机互动的生成。
新模型和新数据在一个持续循环中迅速被新的模型和数据所替代。它越来越成为一个工程问题,而不是数据科学问题。最近,由于数据和机器学习工程方面的卓越努力,已经开发出了用于持续数据收集、模型训练、测试、人机交互动作,以及最终部署大型机器学习模型的自动化框架。所有这些工程基础设施是当前大型语言模型(LLMs)的基础,这些模型经过训练,旨在提供各种问题的答案,同时模拟人际互动。
生命周期
在我看来,过去几年数据科学最大的变化不在于算法,而在于基础设施的变革:从频繁的数据获取到模型的持续平滑再训练和重新部署。也就是说,数据科学已经从一个研究学科转变为一个工程努力。
机器学习模型的生命周期已经从类似 CRISP-DM [14]的纯创建、训练、测试和部署的单一周期,变成了一个双周期,其中一边是创建,而另一边是生产化——部署、验证、消费和维护 [15]。
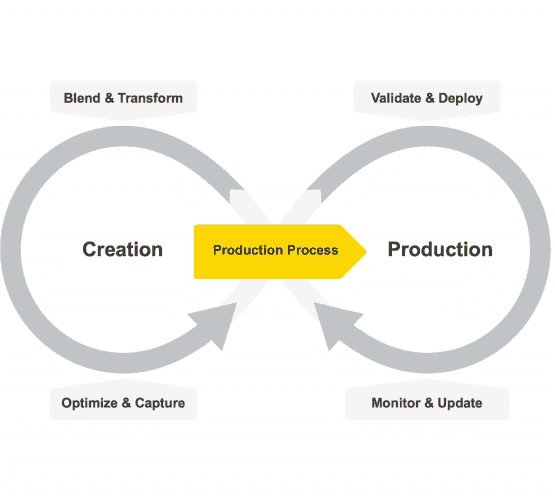
图 1 机器学习模型的生命周期
工具
因此,数据科学工具不得不适应变化。它们不仅要支持创建阶段,还要支持机器学习模型的生产化阶段。必须有两个产品或一个产品的两个独立部分:一个支持用户创建和训练数据科学模型,另一个则使最终结果的生产化过程顺畅且无误。虽然创建部分仍然是智力的练习,但生产化部分则是结构化的重复任务。
显然,在创建阶段,数据科学家需要一个涵盖广泛机器学习算法的平台,从基本算法到最先进、最复杂的算法应有尽有。你永远不知道你需要哪个算法来解决哪个问题。当然,最强大的模型成功的机会更高,但代价是更高的过拟合风险和较慢的执行速度。数据科学家最终就像工匠一样,需要一个装满各种工具的工具箱,以应对他们工作中的各种挑战。
低代码平台也获得了人气,因为低代码使程序员甚至非程序员能够创建和快速更新各种数据科学应用程序。
作为智力的练习,机器学习模型的创建应该对每个人都可及。这就是为什么,尽管不是绝对必要的,但一个开源的数据科学平台将是理想的。开源允许所有有志于数据科学的人员自由访问数据操作和机器学习算法,同时允许社区调查和贡献源代码。
在生命周期的另一端,生产化需要一个提供可靠 IT 框架的平台,用于部署、执行和监控准备好的数据科学应用程序。
结论
在不到 2000 字的篇幅中总结 30 年的数据科学发展当然是不可能的。此外,我引用了当时最受欢迎的出版物,尽管它们可能不是该主题上的绝对首篇。我对那些在这一过程中扮演了重要角色但未在这里提及的许多算法表示歉意。尽管如此,我希望这段简短的总结能让你对数据科学在 30 年后的现状有更深入的理解!
参考文献
[1] Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. (1986). “通过误差反向传播学习表示”。自然,323,页码 533-536。
[2] Werbos, P.J. (1988). "反向传播的泛化及其在递归气体市场模型中的应用"。神经网络。1 (4): 339–356。 doi:10.1016/0893-6080(88)90007
[3] Hochreiter, S.; Schmidhuber, J. (1997). "长短期记忆". 神经计算。9 (8): 1735–1780。
[4] Quinlan, J. R. (1993). “C4.5:机器学习程序” 摩根·考夫曼出版社。
[5] Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. (1984) “分类与回归树”,Routledge。 doi.org/10.1201/9781315139470
[6] Ho, T.K. (1995). 随机决策森林. 第三届国际文档分析与识别会议论文集,蒙特利尔,QC,1995 年 8 月 14-16 日,页码 278-282。
[7] Friedman, J. H. (1999). "贪婪函数近似:一种梯度提升机器,Reitz 讲座
[8] Mason, L.; Baxter, J.; Bartlett, P. L.; Frean, Marcus (1999). "将提升算法视为梯度下降"。见 S.A. Solla 和 T.K. Leen 和 K. Müller (编辑)。神经信息处理系统进展 12。MIT 出版社。页码 512-518
[9] Agrawal, R.; Srikant, R (1994) “挖掘关联规则的快速算法”。 第 20 届国际大型数据库会议论文集,VLDB,第 487-499 页,智利圣地亚哥,1994 年 9 月。
[10] Breese, J.S.; Heckerman, D.; Kadie C. (1998) “协同过滤预测算法的实证分析”, 第十四届人工智能不确定性会议论文集 (UAI1998)
[11] Ciresan, D.; Meier, U.; Schmidhuber, J. (2012). “用于图像分类的多列深度神经网络”。2012 IEEE 计算机视觉与模式识别会议,第 3642–3649 页。 arXiv:1202.2745。 doi:10.1109/cvpr.2012.6248110。 ISBN 978-1-4673-1228-8。 S2CID 2161592。
[12] Krizhevsky, A.; Sutskever, I.; Hinton, G. (2012). “使用深度卷积神经网络进行 ImageNet 分类”。 NIPS 2012: 神经信息处理系统,内华达州湖塔霍。
[13] Hinton, G.E.; Osindero, S.; Teh, Y.W. (2006) “一种快速的深度信念网络学习算法”。 Neural Comput 2006; 18 (7): 1527–1554. doi: doi.org/10.1162/neco.2006.18.7.1527
[14] Wirth, R.; Jochen, H. (2000) “CRISP-DM: 面向数据挖掘的标准过程模型。” 第四届国际知识发现与数据挖掘应用会议论文集 (4),第 29–39 页。
[15] Berthold, R.M. (2021) “如何将数据科学转移到生产环境”,KNIME 博客
Rosaria Silipo 不仅是数据挖掘、机器学习、报告和数据仓库的专家,她还成为了 KNIME 数据挖掘引擎的公认专家,关于这个领域她已经出版了三本书:《KNIME 初学者的好运》、《KNIME 食谱》和《KNIME SAS 用户手册》。此前,Rosaria 曾在欧洲多家公司担任自由数据分析师。她还曾领导 Viseca(苏黎世)的 SAS 开发小组,在 Spoken Translation(加州伯克利)用 C#实现了语音转文本和文本转语音接口,并在 Nuance Communications(加州门洛帕克)开发了多个不同语言的语音识别引擎。Rosaria 于 1996 年在意大利佛罗伦萨大学获得生物医学工程博士学位。
更多相关话题
300 百万个工作岗位真的会被 AI 替代或丧失吗?
原文:
www.kdnuggets.com/2023/07/300-million-jobs-really-exposed-lost-ai-replacement.html

图片来源:Pavel Danilyuk
AI 技术在过去六个月里迅速进入主流,得益于 Midjourney 和 ChatGPT 等工具的广泛流行。自然地,随着这些工具的快速普及以及关于AI 能治愈癌症、通过律师资格考试、在 AP 考试中得高分、编写游戏、和取代记者的惊人文章,人们感觉他们的生计受到了威胁。
然后高盛发布了一份报告,指出 AI 可能导致美国和欧洲市场的 3 亿个工作岗位被降级或丧失。引发了恐慌的头条新闻。
我认为值得深入探讨一下报告的真正含义,我们可以预期哪些类型的工作会丧失,涉及哪些领域,以及那些面临最大风险的人可以采取哪些措施来抵消这些危险。
报告概述
报告基本上有三点内容:
-
几乎每个行业都有任务被 AI 取代的风险。他们指出法律和行政行业最有可能被 AI 取代,而制造业和建筑业则风险最小。
-
作者预测,美国当前最多有 7%的就业岗位会被 AI 完全取代。大约 63%将会得到补充。约 30%将不会受到影响。
-
其累积效应将是生产力的提高,从而导致全球年 GDP 最终增长 7%
尽管有悲观的标题,作者最后却给出了一个充满希望的结论。“显著的劳动成本节省、新职位的创造以及非被取代工人的更高生产力提升了生产力大爆发的可能性,从而大幅提高经济增长。”
如何理解高盛报告
我建议你阅读报告,而不仅仅依赖头条新闻。高盛的报告要谨慎得多。整份报告名为《人工智能对经济增长的潜在巨大影响》,其中包含了很多细微的差别。
例如,虽然 Forbes 作者 Jack Kelly 说 报告暗示 AI 将“减少”职位,但原报告的作者明确表示,他们期望 AI 补充这些工作,而不是减少它们。作者还明确表示,他们期望只有少数员工会被 AI 完全替代。
想象一下报告所提到的行政行业的员工,这是最容易受到 AI 影响的职业之一,46% 的任务可以被 AI 替代。即使你可以替代一个员工 90%的工作,也极不可能让 AI 做到那个员工所做的所有事情。
行政工作人员不仅仅做基本任务;他们还与员工沟通,协作安排会议,并处理意外问题——这些都是只有人类才能做的。如果自动化可以替代行政助理,Calendly 早就会做到这一点了。
这基本上就是报告所说的内容。工作可能面临风险,但大多数(93%)不会。大多数工作只是受到影响,这意味着一些日常任务可能会被 AI 替代,但这将提高生产力。
报告的作者还强调了 AI 将创造新工作的观点。 “[W]自动化带来的工人失业历史上通常被新工作的创造所抵消,技术创新后的新职业出现占长期就业增长的绝大多数,”他们写道。
许多报道还声称 AI 已经替代了许多职业,但我知道这不可能。例如,Kelly 继续写道:“与其让一个真人解决问题,你可以与在线聊天机器人互动。AI 可以帮助诊断癌症和健康问题。”许多医疗专业人士已经公开表明,他们的工作是 AI 无法替代的。
急诊医生 Josh Tamayo-Sarver 测试 了 ChatGPT 诊断病人的能力,并发现其严重不足。
“他写道,当我给 ChatGPT 提供了完美的信息,且病人有典型的症状时,ChatGPT 作为诊断工具表现得相当好,”他详细描述了 ChatGPT 如何误诊了一些病人,同时未能提出人类医生会问的明显问题。“医疗接触中的绝大多数工作是确定正确的病人叙述。”而这一点是无法替代的。

图片来源于Youtube
而任何与聊天机器人互动过的人都知道,能够在电话的另一端联系到真实的人是多么重要和必要。
人工智能如何夺走工作
当然,仍然有工作面临风险。虽然人工智能的净效应可能是创造更多的工作岗位,但这对目前因人工智能失业的人没有任何好处。有两条路径会使你的工作面临风险:直接替代和间接竞争。
直接替代
许多作家、程序员和图形设计师直接受到那些想要削减成本而使用平庸内容生成的无良首席执行官的威胁。至少现在,生成性人工智能还不能完成程序员所做的所有工作,比如调试、同行评审和深思熟虑的问题解决。
但注重成本的老板可能在为时已晚之前不会在意这一点。
间接竞争
在任何一个快速生成优于质量的领域,人工智能都会导致工作岗位流失。例如,我的一位同行最近告诉我,她丢掉了主编的职位——这不是因为她的老板将工作外包给了人工智能,而是因为整个网站由于被人工智能生成的内容在那些关键词上的竞争所致,导致利润减少了 90%。
她的老板遗憾地裁掉了她以节省成本,并希望将来能重新雇用她。从长远来看,我预计内容会受到更多的处罚,但这对她现在来说没有安慰。
哪些工作将会丧失?
根据你阅读的不同研究,不同的工作面临不同程度的风险。例如,高盛的研究指出,行政、法律和信息处理行业面临的风险最大。另一项研究指出写作和编程面临裁员风险;而科学和批判性思维则不在此列。
我认为值得强调的是,这两者有时并不是互斥的。哪个程序员没有使用过批判性思维?这使我相信,造成工作流失的并不是人工智能本身,而是那些试图节省成本的负责人。我相信他们会在长远中感到后悔。
针对人工智能造成的就业流失,目前采取了哪些措施?
目前有几条途径正在被追求以保护员工免受人工智能导致的就业流失。在个人层面,许多人正在学习如何在日常工作中使用人工智能,以提高效率和效果。许多公司和国家正在彻底禁止生成性人工智能以防范安全风险。某些行业正在对抗人工智能。
学习使用人工智能
防止与人工智能相关的工作流失的最简单最快的方法是学习将人工智能融入你的工作流程。作为一家公司的创始人,我几乎不可能在短期内解雇自己,但我已经学会了使用人工智能来草拟电子邮件、记录重要通话的转录、总结长文章以节省时间、获取项目的技术帮助,甚至帮助我编写代码。
其他从业者已将人工智能加入他们的职位名称,例如人工智能提示专家或人工智能驱动的 SEO 专家。雇主也在这样做,在房地产经纪、市场营销领军人物以及技术知识工作者等各个领域雇佣人工智能辅助的工作人员。
如果你是数据科学家或有志于成为数据科学家,这是 ChatGPT 如何帮助你成为更好的数据科学家。
行业罢工和要求
我想到两个例子。首先,一封公开信获得了超过 27,000 名个人的签署,包括像埃隆·马斯克这样的领导者,要求暂停人工智能的发展。签署者引用了其他已经暂停的技术,直到进行研究以使其更安全,比如克隆、人类胚系修改、功能获得研究和优生学。
其次,好莱坞编剧罢工,要求其中包括确保写作室里不会有人工智能,无论是完全自动化还是部分自动化。他们的罢工尚未成功,但它确立了一个先例。
最后,许多在线出版物对人工智能生成的内容(无论是代码、写作还是艺术作品)有限制或完全禁止。以下是一些例子:

使用lexica生成图像
安全禁令
最后,一些国家和公司因安全问题禁止使用 ChatGPT。包括俄罗斯和意大利在内的七个国家禁止使用 ChatGPT,理由包括儿童安全和国际安全。三星要求员工不要使用 ChatGPT 以防安全风险,而美国银行、花旗集团、德意志银行、高盛和富国银行出于相同的原因禁止使用 ChatGPT。
所以说,人工智能的发展并非毫无挑战,许多方面正在仔细考虑如何以对每个人都安全的方式实施它。
人工智能的潜在好处
我喜欢高盛报告总结他们对人工智能可能如何影响经济的立场:“有时替代,常常补充。”
如前所述,预计人工智能技术将在未来几年内使 GDP 增长 7%,与此同时,我知道它至少帮助我提高了整体工作生产力和乐趣。正如我想象今天的程序员很庆幸不再需要通过一系列打孔纸来编程一样,我怀疑明天的程序员将以一种让生活更轻松的方式整合人工智能生成技术,而不是让生活变得更困难或财务状况更不稳定。

计算机科学家玛格丽特·汉密尔顿与她和团队在麻省理工学院开发的阿波罗导航软件合影。来源:麻省理工学院博物馆提供。
关于人工智能对就业的真实风险的最终思考
没有办法预测人工智能可能做的任何事情,原始文章的作者也强调了这一点。毕竟,这被称为“潜在的”大影响。任何声称知道答案的人要么是在撒谎,要么是被误导了。
从我的角度来看,有理由既保持谨慎,又充满希望。一方面,总会有人希望通过牺牲他人来快速赚取利益。另一方面,人工智能代表了一种我们自个人电脑普及以来未曾见过的潜在未来转变。
我不会假装知道结果如何,但我知道,对于任何希望理解人工智能对工作丧失的真实风险的人来说,阅读原始研究、关注思想领袖,并且不要被任何积极或消极的炒作所左右是值得的。这是一个复杂的问题,我很期待看到它的发展。
内特·罗西迪 是一名数据科学家,专注于产品战略。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过顶级公司真实面试问题准备面试。可以通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
相关话题
如何在 Python 中创建一个简单的神经网络
译文:
www.kdnuggets.com/2018/10/simple-neural-network-python.html
评论
神经网络(NN),也称为人工神经网络(ANN),是机器学习领域内的一类学习算法,松散地基于生物神经网络的概念。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
安德烈·布列祖克,一位拥有五年以上经验的德国机器学习专家表示:“神经网络正在彻底改变机器学习,因为它们能够高效地建模跨多个学科和行业的复杂抽象。”
基本上,一个 ANN 包括以下组件:
-
一个接收数据并传递数据的输入层
-
一个隐藏层
-
一个输出层
-
层间权重
-
每个隐藏层的激活函数。在这个简单的神经网络 Python 教程中,我们将使用 Sigmoid 激活函数。
有多种类型的神经网络。在这个项目中,我们将创建前馈或感知神经网络。这种类型的 ANN 直接从前到后传递数据。
训练前馈神经元通常需要反向传播,这为网络提供了相应的输入和输出数据。当输入数据传输到神经元中时,会被处理并生成输出。
这里是一个展示简单神经网络结构的图示:
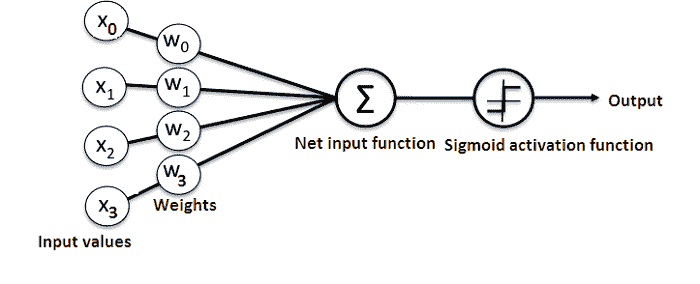
了解神经网络工作原理的最佳方法是学习如何从头开始构建一个(不使用任何库)。
在本文中,我们将演示如何使用 Python 编程语言创建一个简单的神经网络。
问题
这里是一个展示问题的表格。
| 输入 | 输出 | ||
|---|---|---|---|
| 训练数据 1 | 0 | 0 | 1 |
| 训练数据 2 | 1 | 1 | 1 |
| 训练数据 3 | 1 | 0 | 1 |
| 训练数据 4 | 0 | 1 | 1 |
| 新情况 | 1 | 0 | 0 |
我们将训练神经网络,使其在提供新数据集时能够预测正确的输出值。
如你在表中所见,输出的值始终等于输入部分的第一个值。因此,我们期望输出的值(?)为 1。
让我们看看是否可以使用一些 Python 代码得到相同的结果(在继续阅读之前,你可以在本文末尾查看这个项目的代码)。
创建一个 NeuralNetwork 类
我们将在 Python 中创建一个NeuralNetwork类来训练神经元以提供准确的预测。这个类还将包含其他辅助函数。
尽管我们不会在这个简单的神经网络示例中使用神经网络库,我们将导入numpy库来协助计算。
这个库提供了以下四个重要的方法:
-
exp——用于生成自然指数
-
array——用于生成矩阵
-
dot——用于矩阵相乘
-
random——用于生成随机数。注意,我们将对随机数进行初始化,以确保其有效分布。
- 应用 Sigmoid 函数
我们将使用Sigmoid 函数,它绘制了一个特征性的“S”形曲线,作为神经网络的激活函数。
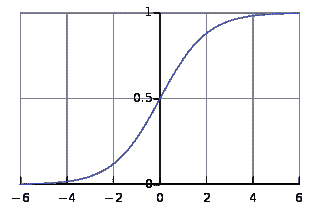
这个函数可以将任何值映射到 0 到 1 之间的值。它将帮助我们对输入的加权和进行归一化。
然后,我们将创建 Sigmoid 函数的导数,以帮助计算对权重的必要调整。
Sigmoid 函数的输出可以用来生成其导数。例如,如果输出变量是“x”,则其导数将是 x * (1-x)。
- 训练模型
这是我们将教神经网络做出准确预测的阶段。每个输入都有一个权重——可以是正的也可以是负的。
这意味着具有大量正权重或大量负权重的输入将对结果输出产生更大的影响。
记住,我们最初是通过将每个权重分配给一个随机数来开始的。
这是我们在这个神经网络示例问题中使用的训练过程:
-
我们从训练数据集中获取输入,根据其权重进行一些调整,并通过一种计算 ANN 输出的方法来处理它们。
-
我们计算了反向传播的误差率。在这种情况下,它是神经元预测输出与训练数据集期望输出之间的差异。
-
根据获得的误差程度,我们使用误差加权导数公式进行了些许权重调整。
-
我们将这个过程迭代了任意次数的 15,000 次。在每次迭代中,整个训练集同时处理。
我们使用了“.T”函数将矩阵从横向位置转置为纵向位置。因此,数字将以这种方式存储:
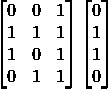
最终,神经元的权重将根据提供的训练数据进行优化。因此,如果神经元被要求思考一个新的情况,与之前的情况相同,它可以做出准确的预测。这就是反向传播的过程。
总结
最后,我们初始化了 NeuralNetwork 类并运行了代码。
这是用于在 Python 项目中创建神经网络的完整代码:
import numpy as np
class NeuralNetwork():
def __init__(self):
# seeding for random number generation
np.random.seed(1)
#converting weights to a 3 by 1 matrix with values from -1 to 1 and mean of 0
self.synaptic_weights = 2 * np.random.random((3, 1)) - 1
def sigmoid(self, x):
#applying the sigmoid function
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(self, x):
#computing derivative to the Sigmoid function
return x * (1 - x)
def train(self, training_inputs, training_outputs, training_iterations):
#training the model to make accurate predictions while adjusting weights continually
for iteration in range(training_iterations):
#siphon the training data via the neuron
output = self.think(training_inputs)
#computing error rate for back-propagation
error = training_outputs - output
#performing weight adjustments
adjustments = np.dot(training_inputs.T, error * self.sigmoid_derivative(output))
self.synaptic_weights += adjustments
def think(self, inputs):
#passing the inputs via the neuron to get output
#converting values to floats
inputs = inputs.astype(float)
output = self.sigmoid(np.dot(inputs, self.synaptic_weights))
return output
if __name__ == "__main__":
#initializing the neuron class
neural_network = NeuralNetwork()
print("Beginning Randomly Generated Weights: ")
print(neural_network.synaptic_weights)
#training data consisting of 4 examples--3 input values and 1 output
training_inputs = np.array([[0,0,1],
[1,1,1],
[1,0,1],
[0,1,1]])
training_outputs = np.array([[0,1,1,0]]).T
#training taking place
neural_network.train(training_inputs, training_outputs, 15000)
print("Ending Weights After Training: ")
print(neural_network.synaptic_weights)
user_input_one = str(input("User Input One: "))
user_input_two = str(input("User Input Two: "))
user_input_three = str(input("User Input Three: "))
print("Considering New Situation: ", user_input_one, user_input_two, user_input_three)
print("New Output data: ")
print(neural_network.think(np.array([user_input_one, user_input_two, user_input_three])))
print("Wow, we did it!")
这是运行代码后的输出:
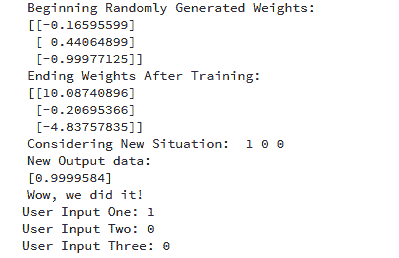
我们成功地创建了一个简单的神经网络。
神经元开始时分配了一些随机权重。之后,它使用训练样本进行了训练。
因此,如果面对一个新的情况 [1,0,0],它给出的值是 0.9999584。
你记得我们想要的正确答案是 1 吗?
那么,这非常接近——考虑到 Sigmoid 函数输出的值介于 0 和 1 之间。
当然,我们只使用了一个神经元网络来完成这个简单的任务。如果我们将几千个这样的人工神经网络连接在一起呢?我们能否可能 100% 模拟人脑的工作方式?
你有任何问题或评论吗?
请在下方提供。
个人简介: Dr. Michael J. Garbade 是洛杉矶区块链教育公司 LiveEdu 的创始人兼 CEO。这是全球领先的平台,为人们提供在未来技术领域创建完整产品的实用技能,包括机器学习。
相关:
更多相关内容
成为数据科学家应该了解的十种机器学习算法
www.kdnuggets.com/2018/04/10-machine-learning-algorithms-data-scientist.html
评论
作者:Muktabh Mayank,ParallelDots

机器学习从业者有不同的个性。有些人是“我是 X 领域的专家,X 算法可以处理任何类型的数据”,其中 X=某个算法;而有些人则是“适合的工具用于合适的工作”。许多人还遵循“全才,专才”策略,即他们在一个领域有深厚的专业知识,同时对机器学习的不同领域有略微的了解。尽管如此,作为实践中的数据科学家,我们必须了解一些常见的机器学习算法的基础知识,这将帮助我们应对遇到的新领域问题。这是对常见机器学习算法的快速浏览及其相关资源,这些资源可以帮助你入门。
1. 主成分分析(PCA)/奇异值分解(SVD)
PCA 是一种无监督方法,用于理解由向量组成的数据集的全局属性。这里分析数据点的协方差矩阵,以了解哪些维度(通常是)/数据点(有时)更重要(即,在它们之间具有高方差,但与其他数据点的协方差低)。一种理解矩阵顶级主成分的方法是考虑其具有最高特征值的特征向量。SVD 本质上也是一种计算有序组件的方法,但你无需获取点的协方差矩阵就能得到它。

该算法通过获取维度减少的数据点来帮助克服维度诅咒。
库:
docs.scipy.org/doc/scipy/reference/generated/scipy.linalg.svd.html
scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html
入门教程:
2a. 最小二乘法和多项式拟合
记得你在大学时的数值分析代码吗?你用来拟合点上的直线和曲线以得到一个方程。你可以在机器学习中使用这些方法来拟合非常小的数据集中的曲线(对于大数据或高维数据集,你可能会严重过拟合,因此不要使用)。OLS 有一个闭式解,因此你不需要使用复杂的优化技术。

显而易见,使用此算法来拟合简单曲线/回归
库:
docs.scipy.org/doc/numpy/reference/generated/numpy.linalg.lstsq.htmldocs.scipy.org/doc/numpy-1.10.0/reference/generated/numpy.polyfit.html
入门教程:
lagunita.stanford.edu/c4x/HumanitiesScience/StatLearning/asset/linear_regression.pdf
2b. 约束线性回归
最小二乘法可能会受到异常值、虚假字段和数据噪声的干扰。因此,我们需要约束条件来减少拟合数据集的线的方差。正确的方法是拟合一个线性回归模型,以确保权重不会出现异常。模型可以具有 L1 范数(LASSO)或 L2 范数(岭回归)或两者都有(弹性回归)。均方损失被优化。

使用这些算法来拟合带约束的回归线,避免过拟合,并掩盖模型中的噪声维度。
库:
scikit-learn.org/stable/modules/linear_model.html
入门教程:
www.youtube.com/watch?v=5asL5Eq2x0A
www.youtube.com/watch?v=jbwSCwoT51M
3. K 均值聚类
每个人最喜欢的无监督聚类算法。给定一组以向量形式存在的数据点,我们可以根据它们之间的距离来创建点的聚类。这是一种期望最大化算法,它通过迭代移动聚类的中心,然后将点与每个聚类中心组合在一起。算法所需的输入是要生成的聚类数和尝试收敛聚类的迭代次数。

从名称中显而易见,你可以使用这个算法在数据集中创建 K 个簇
库:
scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
入门教程:
www.youtube.com/watch?v=hDmNF9JG3lo
www.datascience.com/blog/k-means-clustering
4. 逻辑回归
逻辑回归是受限的线性回归,在应用非线性(通常使用 sigmoid 函数或 tanh 函数)后,限制输出接近于+/-类别(在 sigmoid 的情况下为 1 和 0)。交叉熵损失函数使用梯度下降法进行优化。给初学者的提示:逻辑回归用于分类,而不是回归。你也可以把逻辑回归看作是一个单层的神经网络。逻辑回归使用梯度下降法或 L-BFGS 等优化方法进行训练。NLP 领域的人们经常用最大熵分类器的名称来表示它。
这就是 Sigmoid 的样子:

使用 LR 来训练简单但非常强大的分类器。
库:
scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
入门教程:
www.youtube.com/watch?v=-la3q9d7AKQ
5. SVM(支持向量机)
SVM 是类似于线性/逻辑回归的线性模型,不同之处在于它们具有不同的基于边界的损失函数(支持向量的推导是我见过的最美丽的数学结果之一,与特征值计算一起)。你可以使用优化方法,如 L-BFGS 或甚至 SGD 来优化损失函数。

SVM 的另一个创新是使用核函数对数据进行特征工程。如果你对领域有深入的了解,你可以用更聪明的核函数替代传统的 RBF 核,并从中获利。
SVM 的一个独特之处是它可以学习单类分类器。
SVM 可用于训练分类器(甚至回归器)
库:
scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html
入门教程:
www.youtube.com/watch?v=eHsErlPJWUU
注意: 逻辑回归和 SVM 的 SGD 基于训练可以在 SKLearn 的 scikit-learn.org/stable/modules/generated/sklearn.linear_model.SGDClassifier.html中找到,我常用它,因为它让我可以通过一个通用接口检查 LR 和 SVM。你还可以在大于 RAM 大小的数据集上使用迷你批量进行训练。
我们的前三大课程推荐
1. Google Cybersecurity Certificate - 快速通道进入网络安全领域的职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关话题
前 10 大机器学习应用场景:第二部分
译文:
www.kdnuggets.com/2017/09/ibm-top-10-machine-learning-use-cases-part2.html
作者:Steve Moore,IBM 故事策略师。赞助帖子。

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
上个月,我们发布了 第一部分 ,这是一个系列帖子,旨在突出 IBM 机器学习中心 的前 10 大应用场景。我们特别希望分享那些能扩展我们对机器学习理解的场景——得益于我们与客户数据科学家的合作。
如果你有兴趣尝试 IBM 的新 Watson 机器学习服务 - 点击这里
本系列的目标是超越考虑特定领域时常见的机器学习应用场景。例如,第一部分专注于政府,但不仅仅探讨了机器学习在判刑和假释中的作用,还探索了推动区域和市政机构重要改进的应用场景。在第二部分,我们将超越机器学习在肿瘤学和放射学中的作用,探讨其对心理健康、整体健康和减少再入院率的影响。
1. 利用机器学习帮助减少再入院率
医院和诊所通过多种方式评估自身的有效性——从平均住院时间到急诊等待时间,再到直接的服务调查。再入院率是指标中很重要的一项,它定义为患者出院后在指定时间内返回医院或诊所的比例。再入院可能会给提供者、保险公司和患者带来巨大的成本和麻烦。
但现在,美国的一家医疗保健系统正在利用机器学习来帮助创建一个透视影响再入院因素的视角。从最初的预判再入院率的努力开始,预测建模和认知评估模型汇总了许多因素:医生笔记、医疗注释员、社会因素、患者人口统计等。这些模型不仅将预测准确率提高了 47%,还帮助隔离出有助于降低再入院率的因素,保持患者健康,并节省了开支。
2. 终身的机器学习与健康
一家总部位于华沙的国际医疗公司通过广泛的附属机构网络在其自有健康中心提供医院和临床护理。多年来,他们协调了初级和专科护理、诊断测试、医院服务和后续护理。
由于他们在患者的整个生命周期内提供端到端的护理,他们所捕获的数据赋予了他们个性化医疗计划的巨大能力,以更好地服务患者,平滑不同护理中心之间的过渡,建立信任,并降低成本。做到这一点意味着对患者数据、风险因素和主动解决方案的组合进行深入分析。
3. 将机器学习引入心理健康项目
对心理健康和成瘾问题的研究,无论如何都是一项复杂的工作——但对于那些渴望将实验室和诊所的见解应用于现实世界项目以帮助困境中的个人改善生活的研究人员来说,更是如此。这是美国东北部一家研究机构的任务,该机构与 IBM 合作,组织、维护并挖掘他们的研究数据,以发现数据中的趋势,从而指导他们所采取的干预措施。在 IBM 的帮助下,他们建立了一个系统,该系统跟踪研究环境、患者和时间跨度上的结果。
因为找到足够的资源来支付项目可能是一个挑战,所以能够证实其发现的严谨性——以及干预措施的结果——有助于说服资助者支持该机构的关键工作。
健康图像
随着数据不断涌入医疗保健系统,包括程序、检查、处方信息、可穿戴传感器等,提供者有望利用机器学习来根除低效,并通过改善服务和结果让患者惊艳。进展依赖于我们所有人发现和倡导机会。让我们继续宣传机器学习——并继续分享将其应用的新愿景。

如果你有兴趣尝试IBM 的 Watson 机器学习服务 - 点击这里
更多相关主题
深度学习研究回顾:强化学习
www.kdnuggets.com/2016/11/deep-learning-research-review-reinforcement-learning.html
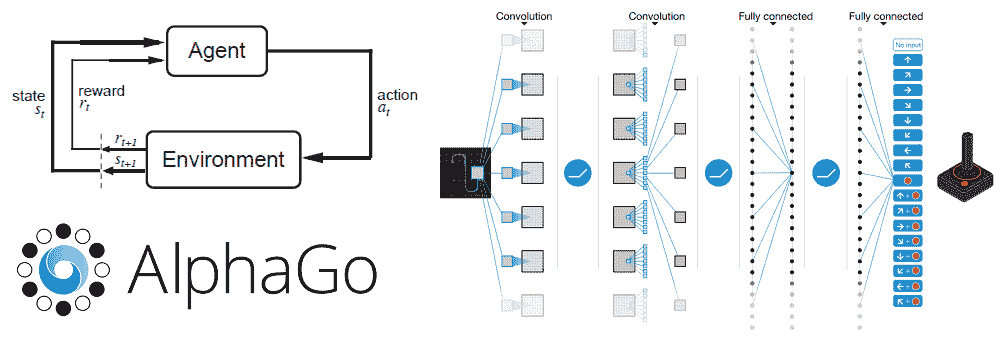
这是一个名为深度学习研究回顾的新系列的第 2 期。每隔几周,我会总结并解释特定深度学习子领域的研究论文。本周关注强化学习。
上次 是生成对抗网络 ICYMI
强化学习简介
机器学习的 3 个类别
在进入论文之前,我们先来谈谈什么是强化学习。机器学习领域可以分为 3 个主要类别。
-
监督学习
-
无监督学习
-
强化学习
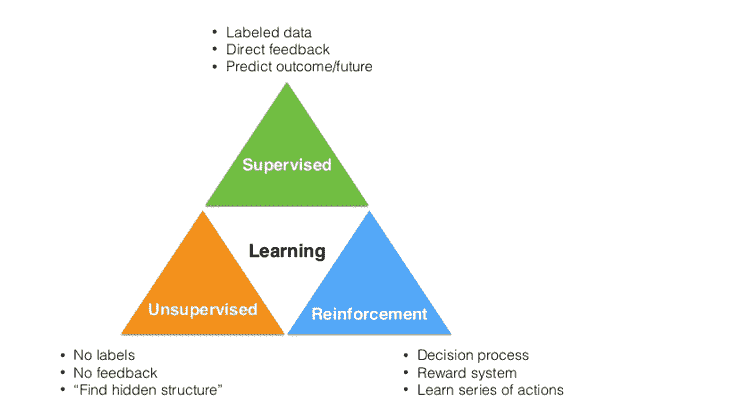
第一个类别,监督学习,是你可能最熟悉的。它依赖于基于一组训练数据(包含输入及其对应的标签)来创建一个函数或模型。卷积神经网络就是一个很好的例子,因为图像是输入,而输出是图像的分类(狗、猫等)。
无监督学习 通过聚类分析的方法在数据中寻找某种结构。最著名的机器学习聚类算法之一 K-Means 就是无监督学习的一个例子。
强化学习 是学习在给定某种情况/环境下应该采取什么行动,以最大化奖励信号的任务。监督学习和强化学习之间有趣的区别在于,奖励信号仅仅告诉你代理采取的行动(或输入)是好是坏,并不会告诉你最佳行动是什么。与此相对的是 CNN,其中每个图像输入的对应标签明确指示了每个输入的输出应该是什么。强化学习的另一个独特组成部分是代理的行动将影响其后续接收到的数据。例如,代理向左移动而不是向右移动意味着代理在下一时间步骤将接收到来自环境的不同输入。让我们从一个例子开始。
强化学习问题
所以,让我们首先考虑在强化学习问题中有什么。假设在一个小房间里有一个小机器人。我们还没有编程这个机器人去移动或走动或采取任何行动。它只是站在那里。这个机器人就是我们的代理。

如前所述,强化学习完全是关于理解做决策/行动的最佳方式,以便我们最大化某个奖励 R。这个奖励是一个反馈信号,仅仅表示代理在给定时间步的表现如何。代理在每个时间步采取的动作 A是奖励(告知代理当前表现如何)的信号和状态 S(描述代理所处环境的情况)的函数。环境状态到动作的映射称为我们的策略 P。策略基本上定义了在特定情况下,代理在特定时间的行为方式。现在,我们还有一个价值函数 V,这是衡量每个位置好坏的标准。这与奖励不同,因为奖励信号指示即时的好处,而价值函数更多地表示在长期来看处于这个状态/位置的好处。最后,我们还有一个模型 M,它是代理对环境的表示。这是代理对环境如何表现的模型。

马尔可夫决策过程
因此,让我们回到我们的小房间中的机器人(代理)。我们的奖励函数取决于我们希望代理完成的任务。假设我们希望它移动到房间的一个角落,在那里它将获得奖励。机器人到达这个点时将获得 +25,并且每经过一个时间步就会得到 -1。我们基本上希望机器人尽快到达角落。代理可以采取的动作是向北、向南、向东或向西移动。代理的策略可以是简单的,即代理将始终移动到具有更高价值函数的位置。对吧?一个高价值函数的位置 = 在这个位置(就长期奖励而言)很好。
现在,这整个 RL 环境可以用马尔可夫决策过程来描述。对于那些以前没听过这个术语的人来说,MDP 是一个建模代理决策的框架。它包含一个有限的状态集(及这些状态的价值函数),一个有限的动作集,一个策略和一个奖励函数。我们的价值函数可以分为两个部分。
- 状态价值函数 V:在状态 S 中,遵循策略 π 的预期回报。这个回报是通过查看每个未来时间步的奖励总和来计算的(gamma 指的是一个常数折扣因子,这意味着时间步 10 的奖励的权重比时间步 1 的奖励略低)。
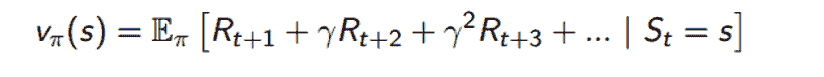
- 动作价值函数 Q:在状态 S 中,遵循策略 π 并采取动作 a 的预期回报(方程与上面相同,只是我们增加了一个额外条件 At = a)。
现在我们有了所有的组成部分,我们该如何处理这个 MDP 呢?当然,我们想要解决它。通过解决 MDP,你将能够找到最大化代理可以从环境中任何状态获得的奖励的最优行为(策略)。
解决 MDP
我们可以通过使用动态规划和特别是策略迭代来解决一个 MDP(还有一种叫做价值迭代的技术,但现在不讨论)。其想法是我们从一些初始策略 π1 开始,并评估该策略的状态价值函数。我们通过贝尔曼期望方程来完成这个过程。
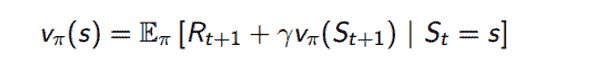
这个方程基本上说,给定我们遵循策略 π,我们的价值函数可以被分解为即时奖励 Rt+1 和后继状态 St+1 的价值函数的期望回报和。如果仔细想想,这等同于我们在上一节中使用的价值函数定义。使用这个方程是我们的策略评估组成部分。为了得到更好的策略,我们使用策略改进步骤,在这个步骤中我们简单地相对于价值函数采取贪婪行动。换句话说,代理采取最大化价值的行动。
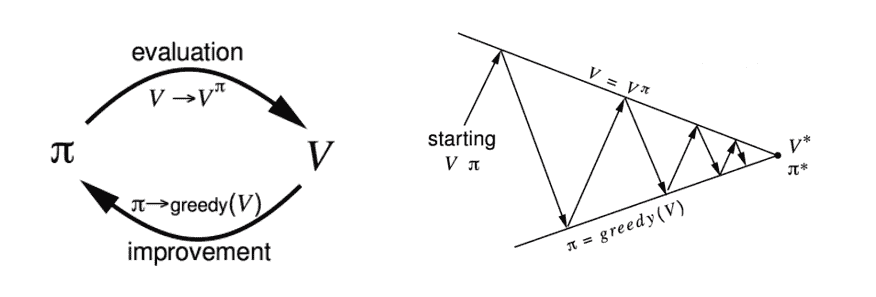
现在,为了获得最优策略,我们重复这两个步骤,一个接一个,直到我们收敛到最优策略 π*。
当没有给定 MDP 时
策略迭代非常棒,但它只在我们有一个给定的 MDP 时才有效。MDP 本质上告诉你环境是如何工作的,而在现实世界中这通常不会被直接给出。当没有给定 MDP 时,我们使用无模型的方法,这些方法直接从代理与环境的经验/交互中得出价值函数和策略。我们将进行相同的策略评估和策略改进步骤,只是没有 MDP 提供的信息。
我们的做法是,不是通过优化状态价值函数来改进我们的策略,而是优化行动价值函数 Q。还记得我们是如何将状态价值函数分解为即时奖励和后继状态的价值函数之和的吗?我们可以用同样的方法处理我们的 Q 函数。
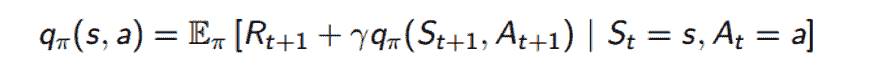
现在,我们将按照相同的过程进行策略评估和策略改进,不过我们将状态值函数 V 替换为动作值函数 Q。现在,我将略过评估/改进步骤中的详细变化。要理解 MDP 无关的评估和改进方法,如蒙特卡罗学习、时间差分学习和 SARSA 等话题需要专门的博客(如果你感兴趣的话,可以听听 David Silver 的Lecture 4和Lecture 5)。然而,现在我将跳到值函数近似以及 AlphaGo 和 Atari 论文中讨论的方法,希望这能让你了解现代强化学习技术。主要的收获是我们想要找到能够最大化我们的动作值函数 Q 的最优策略π*。
值函数近似
所以,如果你考虑到迄今为止我们学到的一切,我们以一种相对简单的方式处理了我们的问题。看看上面的 Q 方程。我们接受一个特定的状态 S 和动作 A,然后计算一个基本上告诉我们预期回报的数字。现在假设我们的代理向右移动了 1 毫米。这意味着我们有了一个全新的状态 S’,现在我们需要为此计算一个 Q 值。在现实世界的强化学习问题中,有成千上万的状态,因此我们的值函数必须理解泛化,以便我们不需要为每个可能的状态存储一个完全独立的值函数。解决方案是使用Q 值函数近似,它能够对未知状态进行泛化。
所以,我们想要的是一个函数,我们称之为 Qhat,它可以在给定某个状态 S 和某个动作 A 的情况下,提供 Q 值的粗略近似。
这个函数将接受 S、A 和一个老旧的权重向量 W(一旦你看到 W,你就知道我们引入了一些梯度下降)。它将计算 x(即表示 S 和 A 的特征向量)和 W 之间的点积。我们改进这个函数的方法是计算真实 Q 值(暂时假设它是已知的)和近似函数输出之间的损失。
在我们计算损失之后,我们使用梯度下降来找到最小值,到那时我们将获得最优的 W 向量。函数近似的这一概念将在稍后查看的论文中非常关键。
还有一件事
在进入论文之前,想要提及最后一件事。有关强化学习的一个有趣讨论是探索与利用的主题。利用是代理利用其已知的知识,并采取它知道会产生最大奖励的行动。听起来不错,对吧?代理将始终根据其当前知识做出最佳行动。然而,这句话中有一个关键短语。当前知识。如果代理没有足够探索状态空间,它无法知道自己是否真的采取了最佳可能的行动。这种以探索状态空间为主要目的的行动被称为探索。
这个想法可以很容易地联系到现实世界的例子。假设你今晚要选择去哪个餐厅用餐。你(作为代理)知道你喜欢墨西哥菜,因此从 RL 的角度来看,去墨西哥餐厅将是最大化你奖励的行动,即在这种情况下是幸福感/满足感。然而,还有一个意大利餐的选择,你以前从未尝试过。有可能它比墨西哥菜更好,或者可能更差。这种在利用代理过去知识与尝试新事物以期发现更大奖励之间的权衡是强化学习(以及我们日常生活中的一个主要挑战)。
其他学习 RL 的资源
哎呀,那真是很多信息。然而,这绝不是对该领域的全面概述。如果你想要更深入的 RL 概述,我强烈推荐这些资源。
-
David Silver(来自 Deepmind)强化学习视频讲座
- 我在 RL 课程中的个人笔记
-
Sutton 和 Barto 的强化学习教材(如果你决心学习这一子领域的所有细节,这真的是终极宝典)
-
Andrej Karpathy 的博客文章关于 RL(如果你想轻松入门 RL,并查看一个做得非常好的实际示例,可以从这个开始)
-
UC Berkeley CS 188 讲座 8-11
-
Open AI Gym: 当你对 RL 感到舒适时,尝试使用 Open AI 创建的这个强化学习工具包创建自己的代理
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
相关话题
AI 尚未触及的难题
评论
谁更强,勒布朗·詹姆斯还是斯蒂芬·库里?哪个国家更强大,美国还是中国?现代 AI 相比于人类有多先进?在上述这三个荒谬的问题中,哪个显得最不明确?尽管如此,我们常常将复杂、多面的议题讨论得好像它们可以简化为单一的标量量。
在过去几年里,现代 AI 技术取得了巨大进展,实现了许多传统上与人类智能相关的成就。特别是,使用深度神经网络的机器学习系统现在可以进行人类水平的语音识别和转录。它们还能为图像添加标签,用合理的自然语言描述它们。就在几个月前,一个将强化学习与深度学习相结合的系统击败了人类在围棋比赛中,这一直被认为是最难以匹敌人类能力的棋类游戏。

在这些成功的背后,人们很容易将 AI 的进展视为一个单一的整体,认为它在所有领域都在均等发展。如果我们只关注监督学习和用于游戏的强化学习,这似乎是可信的。但在接受 AI 单一主义的魔法思维之前,我们应该稍作停顿。尽管一些流行的未来主义者提出了不同的观点,AI 的进展并不会在所有方向上均匀进行,尽管每次计算成本在下降。相反,我们在某些问题类别上取得了快速进展,而在其他问题上则停滞不前。我们的成功来自于那些目标容易且无争议地量化的问题。其他目标更模糊的问题,如个人助手、对话代理、医疗决策等,在向人类能力的进展上相对较少。
哪些问题很难?
人工智能/机器学习研究历史中的一个反复出现的主题是,我们很难确定人类智能的哪个方面是值得注意的。三十年前,许多人认为击败国际象棋大师将构成比匹敌高中生的认知能力更伟大的智能成就。然而,尽管现任冠军马格努斯·卡尔森无法抵挡运行树搜索的 Macbook Pro,但现代对话机器人却无法匹敌一个普通 10 岁孩子的对话能力。也许,我们对各种类型智能的价值观根植于经济思维中。在其他条件相同的情况下,稀缺技能似乎更有价值。国际象棋冠军可能看起来比社交名流更具智能,仅仅因为他们的数量更少。
机器学习问题可能因多种原因而复杂。大多数公开的人工智能处理的是结构良好的模式匹配问题。这些问题包括图像分类等监督学习问题,或像下棋、围棋或玩 Atari 等强化学习问题。这些问题的难度因训练数据的稀缺、行动空间或类别的多样性,或需要学习的模式尤其复杂(如原始音频或视频数据)而有所不同。在这些方面,机器学习研究已经取得了相当大的进展。
然而,机器学习问题也可能因另一个被忽视的原因而变得困难。对于许多我们可能想要引入人工智能代理的场景,这些问题并不是结构良好的。也就是说,优化的目标并不明显。
几乎所有的机器学习任务都涉及某种形式的优化。对于图像分类,我们的目标是最大化正确分类的图像比例。对于语言翻译,我们的目标是输出一个与一组真实候选翻译高度一致的字符串。对于像国际象棋或围棋这样的游戏,我们的目标就是赢。简而言之,监督学习和强化学习都假定存在一个先验的标量量,其最大化等同于成功。
但对于许多我们可能想要插入人工智能代理的现实世界场景,目前没有人能明确目标函数应该是什么。例如,医生的确切目标是什么?我们如何将医疗专业人员的成功提炼为一个随着结果显现而发放的单一奖励?我们如何准确衡量生活质量?肢体与寿命之间的权衡是什么?医生应该如何权衡收入与病人健康(如果生命的价值是无限的,那么所有患者都应该免费就诊)。有时,医生的目标函数可能因患者的偏好而有所不同。人类医生会不断地隐性评估这些权衡,但在我们学会确认目标之前,现有的人工智能可能仍然局限于更孤立的、低层次的模式识别问题。

类似地,对话中的标量量优化是什么?是否仅仅是最大化互动?如果通过恶搞来最大化互动呢?目标是友善吗?提供信息吗?建立持久关系吗?是否应该对不友好的行为施加惩罚?如果是,那么如何量化这种惩罚?
尽管我们在模式识别上取得了显著进展,在监督学习和强化学习中的困难问题上也有所突破,但我们整个学习范式仍需要预先确定的明确目标。然而,对于我们设想中的“强 AI”或类人智能的复杂环境来说,确定这些目标却是一个巨大的障碍。
此外,正是这些无争议的成功指标(测试集准确率、棋类评分等)推动了该领域的进展。与其他因主观性而受阻的领域不同,机器学习受益于这些指标所赋予的客观性。如果目标定义模糊,社区如何才能实现对更一般 AI 的同样和谐的进展?
机器学习已进入黄金时代。它在智力上令人着迷,在经济上影响深远。随着进展似乎稳定地推进,人们很容易将其视为向超智能的单向推进,这种智能在所有领域都与人类能力匹敌或超越。然而,我们可能会记住我们在识别我们智能中具体有趣、有价值或难以复制的方面的糟糕记录。也许正是我们在目标定义模糊的情况下有效操作的能力最为显著——这是机器学习尚未取得显著进展的领域。
 扎克里·蔡斯·利普顿 是加州大学圣地亚哥分校计算机科学工程系的博士生。在生物医学信息学系资助下,他对机器学习的理论基础和应用均感兴趣。除了在 UCSD 的工作外,他还曾在微软研究院和亚马逊担任机器学习科学家,并在 KDnuggets 担任贡献编辑。
扎克里·蔡斯·利普顿 是加州大学圣地亚哥分校计算机科学工程系的博士生。在生物医学信息学系资助下,他对机器学习的理论基础和应用均感兴趣。除了在 UCSD 的工作外,他还曾在微软研究院和亚马逊担任机器学习科学家,并在 KDnuggets 担任贡献编辑。
相关:
-
深度学习来自魔鬼吗?
-
MetaMind 与 IBM Watson Analytics 和 Microsoft Azure Machine Learning 竞争
-
深度学习与经验主义的胜利
-
模型可解释性的神话
-
(深度学习的深层缺陷)的深层缺陷
-
数据科学中最常用、最混乱和最滥用的术语
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
更多相关内容
100 个活跃的分析、大数据、数据挖掘、数据科学和机器学习博客
www.kdnuggets.com/2016/03/100-active-blogs-analytics-big-data-science-machine-learning.html/2
-
奥卡姆剃刀 由阿维纳什·考什克(Avinash Kaushik)撰写,审视网页分析和数字营销。
-
OpenGardens 互联网物联网(IoT)数据科学,由阿吉特·贾奥卡尔(Ajit Jaokar)撰写。
-
O'Reilly 雷达 提供广泛的研究主题和书籍。
-
Oracle 数据挖掘博客 关于 Oracle 数据挖掘的一切——新闻、技术信息、观点、技巧与窍门,尽在一处。
-
观察性流行病学 一位大学教授和统计顾问提供他们在应用统计学、高等教育和流行病学方面的评论、观察和思考。
-
克服偏见 由罗宾·汉森(Robin Hanson)和埃利泽·尤德科夫斯基(Eliezer Yudkowsky)撰写,探讨统计分析在诚实、信号、分歧、预测和远期未来中的作用。
-
概率与统计博客 由马特·阿舍(Matt Asher)撰写,他是多伦多大学的统计学研究生。查看阿舍的统计学宣言。
-
永久谜题 由普拉提克·乔希(Prateek Joshi)撰写,他是一名计算机视觉爱好者,写有以问题形式呈现的引人入胜的机器学习故事。
-
预测分析世界 博客,由预测分析世界和文本分析世界的创始人埃里克·西格尔(Eric Siegel)撰写,同时也是预测分析时报的执行主编,使预测分析的原理和方法变得易于理解和引人入胜。
-
R-bloggers 来自 R 丰富社区的最佳博客,包含代码、示例和可视化。
-
R chart 一个关于 R 语言的博客,由一名网页应用/数据库开发者撰写。
-
R 统计学 由塔尔·加利利(Tal Galili)撰写,他是特拉维夫大学统计学博士生,同时还担任多门统计课程的助教。
-
Revolution Analytics 由 Revolution Analytics 托管和维护。
-
随机思考 由岳一松(Yisong Yue)撰写,内容涉及人工智能、机器学习和统计学。
-
Salford Systems 数据挖掘与预测分析博客 由丹·斯坦伯格(Dan Steinberg)撰写。
-
赛伯统计研究 由菲尔·伯恩鲍姆(Phil Burnbaum)撰写,涉及棒球、股票市场、运动预测和各种主题的统计学。
-
满意度 由巴黎(巴黎第六大学、CREST)的博士生和博士后共同撰写的博客。主要提供日常工作中的技巧和窍门,链接到各种有趣的页面、文章、研讨会等。
-
SAS 文本挖掘博客,SAS 专家撰写,涵盖语音挖掘和非结构化数据。
-
数据的形状,由杰西·约翰逊从几何学的角度介绍数据分析算法。
-
简单统计 由三位生物统计学教授(杰夫·李克、罗杰·彭和拉法·伊里萨里)撰写,他们对数据丰富的新纪元充满热情,并认为统计学家是科学家。
-
智能数据集,集合了许多有趣的数据科学人员的博客
-
统计建模、因果推断与社会科学 作者:安德鲁·杰尔曼
-
猫咪统计 由查理·库夫斯撰写,他从事数据分析已有三十多年,最初作为水文地质学家,自 1990 年代起作为统计学家。他的标语是:当你不能仅凭统计学解决生活中的问题时。
-
统计博客,一个专注于统计相关内容的博客聚合器,通过 RSS 订阅源发布贡献博客的帖子。
-
史蒂夫·米勒 BI 博客,信息管理领域的博客。
-
Geomblog 由苏雷什撰写
-
非官方谷歌分析博客 来自 ROI Revolution。
-
分析因素 作者:凯伦·格雷斯·马丁
-
卫报数据博客,关于新闻中的数据新闻报道。
-
坏科学 作者:本·戈尔德克雷博士,一位使用统计学揭穿坏科学的流行病学家。
-
实用量化 由 O'Reilly Media 首席数据科学家本·洛里卡撰写,内容涉及 OLAP 分析、大数据、数据应用等。
-
数字达人 由《华尔街日报》记者卡尔·比阿利克撰写,他‘审视数字的使用和滥用’
-
三趾树懒 由卡内基梅隆大学统计学教授科斯马·沙利兹撰写的博客。
-
汤姆·H·C·安德森/Odintext 博客,专注于数据和文本挖掘的市场研究。
-
文森特·格兰维尔博客。文森特是 AnalyticBridge 和 Data Science Central 的创始人,定期发布有关数据科学和数据挖掘的有趣话题。
-
什么是大数据。吉尔·普雷斯覆盖大数据领域,并在《福布斯》上撰写关于大数据和商业的专栏。
-
Walking Randomly 由迈克·克劳彻撰写
-
网页分析与联盟营销,丹尼斯·R·莫滕森关于如何通过分析提高出版商收入的博客。
-
Xi’ans Og Blog 由巴黎第九大学统计学教授撰写的博客,主要集中在计算和贝叶斯主题上。
本文更新了 2015 年的帖子 90+ 个关于分析、大数据、数据挖掘、数据科学和机器学习的活跃博客。
相关:
-
Salford Systems: 软件工程师。机器学习算法。C++
-
30 篇哈佛商业评论关于数据科学、大数据和分析的必读文章
-
主动数据挖掘,数据科学博客
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关主题
5 款最佳机器学习 API 用于数据科学
www.kdnuggets.com/2015/11/machine-learning-apis-data-science.html
作者:Khushbu Shah (DeZyre)
大数据正在通过各种数据源(如传感器、社交媒体数据、Excel 电子表格、评论、客户数据等)流入互联网上的企业。许多公司,如 Google、IBM、亚马逊和微软,正在通过构建机器学习 API 帮助企业处理大数据,以便组织可以充分利用机器学习技术。
机器学习是大数据创新的主要前沿,但对于那些非技术狂人或数据科学领域专家的人来说,它可能令人望而却步。类似于标准 API 帮助开发人员创建应用程序,机器学习 API 使得机器学习变得易于使用,适合每个人。机器学习 API 抽象了创建和部署机器学习模型所涉及的复杂性,使开发人员可以专注于数据处理、用户体验、设计、实验以及从数据中获取洞察。
在早期,机器学习算法和技术主要由科学家、技术狂人或领域专家使用。然而,许多组织现在使用机器学习 API 将这些技术提供给大众。机器学习 API 使得开发人员可以轻松地将机器学习应用于数据集,从而为他们的应用程序添加预测功能。机器学习 API 为开发人员提供了一个抽象层,以将机器学习集成到现实世界的应用程序中,而无需担心在其基础设施上扩展算法以及深入了解机器学习算法的细节。机器学习 API 要求开发人员专注于两个重要方面——
-
开发人员可以通过将机器学习 API 集成到他们的应用程序中,专注于查询预测。
-
开发人员可以跟踪他们应用程序中的事件以收集使用数据。
机器学习 API 为企业提供了整合预测分析的能力,以便他们能够更好地了解客户、理解他们的需求,并基于过去的数据趋势提供产品或服务,从而启动销售过程。实时消费者互动通过机器学习 API 的比例不断增加——使它们成为向应用开发人员展示实时预测分析的理想选择。
应用开发人员总是寻找各种方式来简化用户的生活,通过引入新颖和创新的功能,帮助用户节省时间。这就是机器学习 API 在应用开发人员中受欢迎的原因。一些标准的 API 示例包括智能标记、产品推荐、优先级过滤和垃圾邮件过滤。
使用机器学习 API 相关的挑战

使用机器学习 API 最耗时且最重要的部分是识别需要解决的业务问题并构建有意义的数据集。这意味着 –
-
机器学习从业者必须确保他们对需要预测或分类的内容非常清楚。并非所有问题都可以通过机器学习 API 解决,因此决定场景是否适合非常重要。
-
机器学习从业者应尽可能多地收集关于给定上下文的数据,而不是做出多个假设。这很重要,因为 数据科学家 或分析师经常会发现输入数据与他们试图预测或分类的列(即目标值)之间的不可预测的相关性。
机器学习从业者的顶级机器学习 API
机器学习的最新趋势将被商品化为服务,这将成为主流,就像商品化的可视化和存储一样。以下是一些提供商品化机器学习作为服务(MLaaS)给业务分析师和开发人员进行应用集成的最佳机器学习 API –

1) IBM Watson
对于那些正在使用 IBM Watson 机器智能服务的机器学习从业者来说,无需再苦苦寻找。IBM Watson API 是一种认知服务,它简化了数据准备过程,使预测分析变得更加容易。它还提供了使用视觉讲故事工具,如信息图表、地图或图形,以示例化分析结果。IBM Watson 通过 IBM 的 Bluemix 云服务平台对公众开放。
IBM 的 Watson 通过扩展的工具、机器学习技术和认知 API 听、看、说和理解,让自己更具人性。开发人员可以通过嵌入 IBM Watson 创建具有更多认知技能的产品、服务或应用程序,以了解人们如何与他们的应用程序互动和反应。IBM Watson 在短短 2 年内已经发展出 25 个以上的 API,这些 API 由大约 50 种技术驱动。IBM Watson API 提供的一些最佳服务包括 –
-
机器翻译 – 帮助翻译不同语言对中的文本。
-
信息共鸣 – 了解短语或词汇在预定受众中的受欢迎程度。
-
问答服务 – 此服务提供对由主要文档来源触发的查询的直接答案。
-
用户建模 – 从给定文本中预测某人的社会特征。
2) Microsoft Azure 机器学习 API
Azure Machine Learning API 帮助数据科学家在几分钟内发布模型,而以前开发出可行模型后需要几天时间。Azure Machine Learning 通过提供用于欺诈检测、文本分析、推荐系统和其他业务场景的 API,使数据科学家能够轻松地在 IoT 应用程序中使用预测模型。该 API 基于 Microsoft 产品(如 Bing 和 Xbox)中的机器学习能力。
Azure Machine Learning API 提供了各种功能,如 –
-
能够创建自定义的可配置 R 模块,以便数据分析师或数据科学家可以整合他们自己的 R 语言 代码来进行训练或预测任务。
-
Azure 允许数据科学家或分析师使用各种 Python 库(如 SciPy、SciKit-Learn、NumPy、Pandas 等)来包含他们自己的 Python 脚本。流行的工具,如 iPython Notebook 和其他多种 Visual Studio 的 Python 工具,也可以与 Azure Machine Learning API 一起使用。
“我们添加了 Python,这是数据科学家最喜欢的工具之一。它有一个庞大的生态系统。这个功能将对数据科学家非常有力。我们做了很多改进,添加 Python 就是其中的一部分。Azure Machine Learning 是这个平台。你可以复制一段 Python 代码,将其插入到工作室中并创建一个 API。” - 微软公司副总裁 Joseph Sirosh 说
-
分析师或数据科学家可以使用一个类 SVM 进行异常检测,或通过 PCA 或“计数学习”来训练 PB 级的数据。
-
Azure Machine Learning API 还支持 Spark 和 Hadoop 用于大数据处理,使其成为不论平台如何的理想选择。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持组织的 IT
更多相关内容
50+ 数据科学和机器学习备忘单
评论
关于 Python、R 以及 Numpy、Scipy、Pandas 的备忘单
在数据科学领域,有成千上万的包和数百个函数!一个有抱负的数据爱好者不需要了解所有内容。这里是经过头脑风暴并浓缩在几页中的最重要的备忘单。
精通数据科学涉及理解统计学、数学、编程知识,特别是在 R、Python 和 SQL 方面,然后将这些知识组合起来,通过业务理解和人类直觉来推导见解,从而驱动决策。
这里是按类别整理的备忘单:
Python 备忘单:
Python 是初学者的热门选择,同时也足够强大,能够支持一些全球最受欢迎的产品和应用。它的设计使编程体验几乎像用英语写作一样自然。Python 基础或 Python 调试器备忘单为初学者覆盖了开始时重要的语法。社区提供的库如 numpy、scipy、sci-kit 和 pandas 被广泛依赖,而 NumPy/SciPy/Pandas 备忘单提供了对这些库的快速回顾。
R 备忘单:
R 的生态系统扩展得如此之多,以至于需要大量参考。R 参考卡在几页中覆盖了大部分 R 世界。Rstudio 也发布了一系列备忘单,方便 R 社区使用。数据可视化与 ggplot2 似乎特别受欢迎,因为它有助于你在创建结果图表时。
MySQL 和 SQL 备忘单:
对于数据科学家来说,SQL 的基础知识和其他语言一样重要。PIG 和 Hive 查询语言都与 SQL(原始结构化查询语言)紧密相关。SQL 备忘单提供了一个 5 分钟的快速指南,让你学习它,然后你可以探索 Hive 和 MySQL!
Spark 备忘单:
Apache Spark 是一个用于大规模数据处理的引擎。对于某些应用场景,如迭代机器学习,Spark 的速度可以比 Hadoop(使用 MapReduce)快多达 100 倍。Apache Spark 备忘单解释了其在大数据生态系统中的位置,讲解了基本 Spark 应用的设置和创建,并解释了常用的操作和操作。
Hadoop 和 Hive 速查表:
Hadoop 作为一种非传统工具出现,它提供了一个开源软件框架,用于并行处理大量数据,解决了被认为不可解决的问题。探索 Hadoop 速查表,了解在命令行中使用 Hadoop 时的有用命令。SQL 和 Hive 函数的组合是另一个值得查看的速查表。
机器学习速查表:
我们常常花时间思考哪种算法最好?然后再翻回大部头的书籍进行参考!这些速查表给出了关于数据的性质和你正在解决的问题的想法,并建议你尝试一种算法。
-
预测分析模式
Django 速查表:
Django 是一个免费的开源 web 应用框架,用 Python 编写。如果你是 Django 新手,你可以查看这些速查表,快速了解概念,并深入学习每一个概念。
分享更多 & 学习!我们遗漏了什么吗?在评论中添加你最喜欢的备忘单吧!
相关:
-
数据科学备忘单指南
-
按人气排名前 20 的 R 包
-
大数据与 Hadoop 中最具影响力的 150 人
更多相关内容
GitHub 上的极棒公开数据集
数据挑战
经济学
能源
金融
你还可以找到以下类别的各种数据集:
GitHub 链接: github.com/caesar0301/awesome-public-datasets
是 上海交通大学 的博士生。他于 2010 年在 西电大学,中国西安,获得了光信息与科学技术学士学位。他的研究领域是移动网络流量的测量与分析,特别是网络流量的更新模型和特性,使用统计和机器学习技术在 Apache Spark 等分布式处理平台上。
那么,你今天会选择哪个数据集?你想向这个列表中添加什么吗?
在下面的评论中告诉我们你的想法。
相关:
-
KDnuggets 数据集用于数据挖掘和数据科学
-
有趣的社交媒体数据集
-
免费的城市数据 - 有什么用?
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
更多相关话题
=MLOPS=
MLOps 概述
评论
作者:Steve Shwartz,人工智能作者、投资者和连续创业者。

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 工作
照片来源:iStockPhoto / NanoStockk
通常需要相当的数据科学专业知识来创建数据集并为特定应用构建模型。但构建一个好的模型通常是不够的。事实上,这远远不够。如下面所示,开发和测试模型只是第一步。
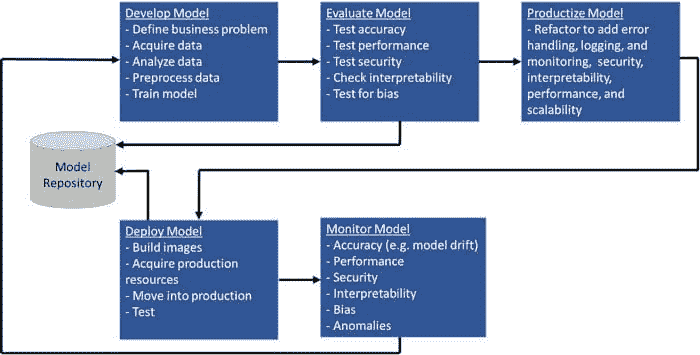
机器学习模型生命周期。
机器学习运维(MLOps)是使模型有用所需的其他一切,包括自动化开发和部署管道、监控、生命周期管理和治理等能力,如上所示。让我们详细了解每一个。
自动化管道
创建生产 ML 系统需要多个步骤:首先,数据必须经历一系列的转换。然后,训练模型。通常,这需要对不同的网络架构和超参数进行实验。经常需要回到数据中尝试不同的特征。接下来,模型必须通过单元测试和集成测试进行验证。它需要通过数据和模型偏差及可解释性的测试。最后,它被部署到公共云、本地环境或混合环境中。此外,过程中的某些步骤可能需要审批流程。
如果这些步骤每一步都手动执行,开发过程往往会很慢且不稳定。幸运的是,许多 MLOps 工具可以自动化这些从数据转换到最终部署的步骤。当需要重新训练时,这一过程是自动化、可靠且可重复的。
监控
机器学习模型在首次部署时往往表现良好,但随着时间的推移表现会下降。正如 Forrester 分析师 Dr. Kjell Carlsson 所说: “AI 模型就像隔离中的六岁小孩:它们需要持续关注……否则,某些东西会坏掉。”
部署中包括各种类型的监控至关重要,以便机器学习团队在这种情况开始发生时能够收到警报。 性能可能因基础设施问题(例如不足的 CPU 或内存)而下降。 当构成模型输入的独立变量的现实世界数据开始表现出不同于训练数据的特征时,性能也可能下降,这种现象称为数据漂移。
同样,由于现实世界条件的变化,模型可能变得不再适用,这种现象称为概念漂移。 例如,许多客户和供应商行为的预测模型在 COVID-19 大流行时陷入了困境。
一些公司还监控替代模型(例如,不同的网络架构或不同的超参数),以查看这些“挑战者”模型是否开始表现得比生产模型更好。
通常,为模型做出的决策设置保护措施是合理的。 这些保护措施是简单的规则,可以触发警报、阻止决策或将决策放入人类审批的工作流中。
生命周期管理
当模型性能由于数据或模型漂移开始下降时,需要对模型进行重新训练,并可能需要重新设计模型。 然而,数据科学团队不应从头开始。 在开发原始模型时,或许在之前的重新设计中,他们可能测试了许多架构、超参数和特征。 记录所有这些先前的实验(及其结果)至关重要,以便数据科学团队不必从头再来。这对于数据科学团队成员之间的沟通与协作也至关重要。
治理
机器学习模型被用于许多影响人们的应用场景,如银行贷款决策、医疗诊断以及招聘/解雇决策。 机器学习模型在决策中的使用受到批评有两个原因:首先,这些模型容易受到偏见的影响,尤其是当训练数据导致模型根据种族、肤色、民族、国籍、宗教、性别、性取向或其他受保护类别进行歧视时。 其次,这些模型往往是黑箱,无法解释其决策过程。
因此,使用基于机器学习的决策的组织面临压力,确保其模型不会歧视并能够解释其决策。 许多 MLOps 供应商正在整合基于学术研究的工具(例如,SHAP和Grad-CAM),帮助解释模型决策,并使用各种技术确保数据和模型不偏见。此外,他们还在监控协议中加入了偏见和可解释性测试,因为模型可能随着时间的推移而变得有偏见或失去解释能力。
组织还需要建立信任,并开始确保持续的性能、无偏见性和可解释性是可审计的。这需要模型目录,不仅记录所有数据、参数和架构决策,还要记录每个决策并提供可追溯性,以便确定每个决策使用了哪些数据、模型和参数、何时重新训练或修改模型,以及谁做出了每个更改。审计员还需要能够重复历史交易,并用假设情境测试模型决策的边界。
安全性和数据隐私也是使用机器学习的组织的关键关注点。必须确保个人信息得到保护,并且基于角色的数据访问能力至关重要,特别是在受监管的行业中。
世界各国政府也在迅速推动对影响人们的机器学习决策进行监管。欧盟通过其 GDPR 和 CRD IV 规章制度走在了前列。在美国,包括美国联邦储备银行和 FDA 在内的几个监管机构已经制定了关于机器学习决策的法规,涉及金融和医疗决策。最近提出的《2020 年数据问责与透明法案》计划在 2021 年提交国会审议。法规可能会发展到 CEO 需要签署他们的机器学习模型的可解释性和无偏见性。
MLOps 领域
随着 2021 年的推进,MLOps 市场正在迅速增长。根据分析公司 Cognilytica 的预测,到 2025 年,这将是一个$4 billion market。
MLOps 领域有大玩家和小玩家。像 Amazon、Google、Microsoft、IBM、Cloudera、Domino、DataRobot 和 H2O 这样的主要机器学习平台供应商正在将 MLOps 能力融入他们的平台中。根据 Crunchbase 数据,在 MLOps 领域,有 35 家私人公司已融资在 $1.8M 和 $1B 之间,且在 LinkedIn 上员工数量在 3 到 2800 之间:
| 融资(百万美元) | 员工数量 | 描述 | |
|---|---|---|---|
| Cloudera | 1000 | 2803 | Cloudera 提供一个适用于任何数据、任何地方的企业数据云,从边缘到人工智能。 |
| Databricks | 897 | 1757 | Databricks 是一个软件平台,帮助其客户统一业务、数据科学和数据工程中的分析。 |
| DataRobot | 750 | 1105 | DataRobot 为全球企业带来人工智能技术和投资回报启用服务。 |
| Dataiku | 246 | 556 | Dataiku 作为一个企业人工智能和机器学习平台进行操作。 |
| Alteryx | 163 | 1623 | Alteryx 通过统一分析、数据科学和自动化流程来加速数字化转型。 |
| H2O | 151 | 257 | H2O.ai 是人工智能和自动化机器学习的开源领导者,致力于使人工智能民主化。 |
| Domino | 124 | 232 | Domino 是全球领先的企业数据科学平台,为超过 20% 的财富 100 强公司提供数据科学支持。 |
| Iguazio | 72 | 83 | Iguazio 数据科学平台使你能够大规模和实时开发、部署和管理人工智能应用 |
| Explorium.ai | 50 | 96 | Explorium 提供一个由增强数据发现和特征工程驱动的数据科学平台 |
| Algorithmia | 38 | 63 | Algorithmia 是一个机器学习模型部署和管理解决方案,自动化组织的 MLOps |
| Paperspace | 23 | 37 | Paperspace 驱动基于 GPU 的下一代应用程序。 |
| Pachyderm | 21 | 32 | Pachyderm 是一个企业级数据科学平台,使可解释、可重复和可扩展的 AI/ML 成为现实。 |
| Weights and Biases | 20 | 58 | 用于实验跟踪、提高模型性能和结果协作的工具 |
| OctoML | 19 | 37 | OctoML 正在改变开发者优化和部署机器学习模型以满足人工智能需求的方式。 |
| Arthur AI | 18 | 28 | Arthur AI 是一个监控机器学习模型生产力的平台。 |
| Truera | 17 | 26 | Truera 为企业提供一个模型智能平台,用于分析机器学习。 |
| Snorkel AI | 15 | 39 | Snorkel AI 专注于通过 Snorkel Flow 实现人工智能的实用性:企业人工智能的数据优先平台 |
| Seldon.io | 14 | 48 | 机器学习部署平台 |
| Fiddler Labs | 13 | 46 | Fiddler 使用户能够创建透明、可解释和易于理解的人工智能解决方案。 |
| run.ai | 13 | 26 | Run:AI 开发了一种自动化分布式训练技术,可虚拟化和加速深度学习。 |
| ClearML (Allegro) | 11 | 29 | ML / DL 实验管理器和 ML-Ops 开源解决方案,端到端产品生命周期管理企业解决方案 |
| Verta | 10 | 15 | Verta 构建软件基础设施,帮助企业数据科学和机器学习(ML)团队开发和部署 ML 模型。 |
| cnvrg.io | 8 | 38 | cnvrg.io 是一个完整的数据科学平台,帮助团队管理模型并构建自适应机器学习管道 |
| Datatron | 8 | 19 | Datatron 提供一个单一的模型治理(管理)平台,管理你所有的 ML、AI 和数据科学模型在生产中 |
| Comet | 7 | 19 | Comet.ml 是一个机器学习平台,旨在帮助人工智能从业者和团队构建可靠的机器学习模型。 |
| ModelOp | 6 | 39 | 管理、监控和管理企业中的所有模型 |
| WhyLabs | 4 | 15 | WhyLabs 是人工智能可观察性和监控公司。 |
| Arize AI | 4 | 14 | Arize AI 提供一个平台,用于解释和排查生产中的人工智能。 |
| DarwinAI | 4 | 31 | DarwinAI 的生成合成“AI 造 AI”技术实现了优化和可解释的深度学习。 |
| Mona | 4 | 11 | Mona 是一个用于数据和 AI 驱动系统的 SaaS 监控平台。 |
| Valohai | 2 | 13 | 您的托管机器学习平台,让数据科学家能够构建、部署和跟踪机器学习模型。 |
| Modzy | 0 | 31 | 可靠的 ModelOps 平台,用于发现、部署、管理和治理大规模机器学习——更快实现价值。 |
| Algomox | 0 | 17 | 促进您的 AI 转型 |
| Monitaur | 0 | 8 | Monitaur 是一家提供审计性、透明度和治理的机器学习软件公司。 |
| Hydrosphere.io | 0 | 3 | Hydrosphere.io 是一个用于 AI/ML 操作自动化的平台 |
这些公司中的许多专注于 MLOps 的某一个环节,例如自动化管道、监控、生命周期管理或治理。有些人认为使用多个最佳实践的 MLOps 产品比单一平台更适合数据科学项目。一些公司正在为特定行业构建 MLOps 产品。例如,Monitaur将自己定位为能够与任何平台兼容的最佳治理解决方案。Monitaur 还为受监管行业(从保险开始)构建特定行业的 MLOps 治理能力。(完全披露:我是 Monitaur 的投资者。)
还有许多开源的 MLOps 项目,包括:
-
MLFlow管理 ML 生命周期,包括实验、可重复性和部署,并包括一个模型注册库。
-
DVC管理 ML 项目的版本控制,使其可共享和可重复。
-
Polyaxon具备实验、生命周期自动化、协作和部署的能力,并包括一个模型注册库。
-
Metaflow是 Netflix 之前的一个项目,用于管理自动化管道和部署。
-
Kubeflow具备在 Kubernetes 容器中进行工作流自动化和部署的能力。
2021 年对 MLOps 来说是个有趣的一年。我们可能会看到快速增长、激烈竞争,并且很可能会有一些整合。
简介: Steve Shwartz (@sshwartz) 多年前在耶鲁大学作为博士后开始了他的人工智能事业,是成功的连续创业者和投资者,也是《邪恶机器人、杀手机器和其他神话:人工智能与人类未来的真相》的作者。
相关:
更多相关话题
=自然语言处理=
你可以在线成为数据科学家吗?
原文:
www.kdnuggets.com/2021/11/365datascience-become-data-scientist-online.html
赞助文章。
技能熟练的数据科学专业人才在各行各业的企业中需求巨大。根据美国劳工统计局的数据,到 2026 年,数据科学工作的数量将增长约 28%,这大约是1150 万个领域职位空缺。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 需求
由于合格候选人供给仍在追赶中,数据科学继续成为任何寻求回报丰厚且不断发展的领域工作的人的绝佳前景。
然而,问题仍然存在——在强大的教育基础设施存在的情况下,传统的数据科学和分析学位是否是通向这一激动人心的职业道路的唯一途径?
数据科学家来自许多不同的背景,这已不是什么秘密。这意味着,许多希望在该领域取得成功的人需要承担起自我学习技能的责任。事实上,在过去几年里,超过 40%的数据科学家在简历中加入了在线课程。考虑到传统学位通常过于昂贵、耗时或不够灵活,以满足大多数需求,这并不令人惊讶。
所以,是的——只要你自律且有足够的动力,你可以在线成为数据科学家。然而,要覆盖这一广泛的专业领域,你需要合适的培训。
365 Data Science提供了一个简单明了的解决方案。其团队由全球公认的讲师组成,创建了一个全面的在线课程,为学生提供数据科学的理论知识和实践经验,同时教授求职过程的方方面面。从基础知识到最先进的主题,他们的全能培训适合完全初学者和希望在工具箱中增加热门技能和技术的在职专业人士。通过大量实际练习、在实际编码环境中编程和真实世界项目,你可以获得实际经验。此外,一旦你通过必要的考试,你将有资格获得课程或职业发展证书——这两种都是业界认可的官方证书,展示你新获得的技能给潜在雇主。
如果你对培训感兴趣,从今天到 11 月 29 日,你可以加入全球150 万名学生,以72% 折扣获得 365 Data Science 项目的无限年度访问权限,学习成功的数据科学专业人士的技能。要了解有关培训内容和运作方式的更多信息,请访问他们的黑色星期五优惠官方页面。
更多相关主题
ChatGPT 在做什么以及它为何有效?
它只是一次添加一个词
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT
ChatGPT 能够自动生成即使在表面上也像是人类编写的文本的能力是令人惊叹的,也出乎意料。但是它是如何做到的呢?为什么它能有效地工作?我的目的在于粗略勾勒一下 ChatGPT 内部的运作机制——然后探讨它为何能如此成功地生成我们认为有意义的文本。我一开始就要说明,我将重点关注整体情况——虽然我会提到一些工程细节,但不会深入探讨。(我将要讲述的本质同样适用于其他当前的“大型语言模型” [LLMs],而不仅仅是 ChatGPT。)
首先需要解释的是,ChatGPT 始终基本上试图做的是生成对目前文本的“合理延续”,其中“合理”的意思是“在看到人们在数十亿个网页上写的内容后,可能会期望某人写出的内容。”
所以假设我们有一段文本“AI 最棒的地方在于它的能力”。想象一下扫描数十亿页人类编写的文本(比如在网上和数字化的书籍中),并找出所有出现该文本的实例——然后查看接下来哪个词出现的频率。ChatGPT 实际上做的就是类似的事情,只不过(正如我将要解释的那样)它并不直接查看文字;它寻找在某种意义上“意义匹配”的内容。但最终的结果是,它生成了一个可能接下来的词的排名列表,以及相应的“概率”:

令人惊讶的是,当 ChatGPT 写作时,它本质上在做的就是一次又一次地问“鉴于目前的文本,接下来的词应该是什么?”——每次添加一个词。(更准确地说,正如我将解释的,它是添加一个“标记”,这可能只是一个词的一部分,这就是它有时能够“创造新词”的原因。)
但是,好吧,每一步它会得到一个带有概率的词汇列表。那么,它应该实际选择哪个词来添加到它正在写的文章中(或其他内容)呢?人们可能认为应该选择“排名最高”的词(即被分配了最高“概率”的词)。但这时一点巫术开始悄然出现。因为出于某种原因——也许有一天我们会有科学风格的理解——如果我们总是选择排名最高的词,通常会得到非常“平淡”的文章,似乎从未“展现出任何创造力”(有时甚至逐字重复)。但如果有时(随机地)选择较低排名的词,我们就会得到一篇“更有趣”的文章。
这里的随机性意味着如果我们多次使用相同的提示,可能会得到不同的文章。而且,按照巫术的想法,有一个所谓的“温度”参数,决定了较低排名的词汇出现的频率。在文章生成中,结果显示“温度”设置为 0.8 似乎是最好的。(值得强调的是,这里并没有使用“理论”;这只是实践中发现有效的方法。比如“温度”概念的存在是因为使用了来自统计物理学的指数分布,但并没有“物理”上的联系——至少我们现在还不知道。)
在继续之前,我应该解释一下,为了阐述的目的,我主要不会使用ChatGPT 中的完整系统,而是通常使用一个更简单的GPT-2 系统,它有一个很好的特点,就是足够小可以在标准桌面计算机上运行。因此,我展示的几乎所有内容都可以包括可以立即在你电脑上运行的明确Wolfram Language代码。(点击任何图片可以复制其背后的代码。)
例如,下面是如何获取上述概率表的。首先,我们必须检索底层的“语言模型”神经网络:

稍后,我们将查看这个神经网络内部的工作原理。但现在我们可以将这个“网络模型”作为黑箱应用于到目前为止的文本,并请求模型所说的按概率排名前 5 的词汇:

这将结果转换为一个明确格式的“数据集”:
如果一个人重复“应用模型”——每一步都添加具有最高概率的单词(在此代码中指定为模型的“决策”)——会发生什么:

如果继续下去会发生什么?在这种(“零温度”)情况下,生成的文本很快变得相当混乱和重复:

但如果不是总是选择“最高”单词,而是有时随机选择“非最高”单词(“随机性”对应于“温度”0.8)会怎么样?同样可以生成文本:

每次这样做时,会做出不同的随机选择,文本也会不同——如下这 5 个示例:

值得指出的是,即使在第一步,有很多可能的“下一个单词”可供选择(在温度 0.8 下),尽管它们的概率很快就会下降(是的,这个对数-对数图上的直线对应于一种 n^(–1) “幂律”衰减,这在语言的一般统计中非常有特点):
那么如果继续下去会发生什么?这是一个随机示例。它比最高概率(零温度)情况更好,但仍然有点怪异:

这是用 最简单的 GPT-2 模型 (来自 2019 年)完成的。使用更新的 更大的 GPT-3 模型,结果会更好。这是用相同的“提示”生成的最高概率(零温度)文本,但使用的是最大的 GPT-3 模型:

这是一个“温度 0.8”的随机示例:

概率从哪里来?
好吧,ChatGPT 总是基于概率选择下一个单词。但这些概率来自哪里?让我们从一个更简单的问题开始。我们来考虑逐字生成英语文本。我们如何计算每个字母的概率?
我们可以做的一个非常简单的事情是,取一段英语文本样本,计算其中不同字母的出现频率。例如,这个工具统计了维基百科文章中“cats”一词的字母:

这对“dogs”也做了相同的处理:

结果相似,但不完全相同(“o”在“dogs”文章中无疑更常见,因为它出现在“dog”这个单词中)。不过,如果我们取一个足够大的英语文本样本,我们可以预期最终会得到至少相当一致的结果:

这是如果我们仅仅根据这些概率生成字母序列的一个样本:

我们可以通过添加空格,将其划分成“单词”,就像这些空格是具有一定概率的字母一样:

我们可以通过强制“单词长度”的分布与英语中的实际情况相符,稍微改善一下“单词”的生成效果:
我们这里没有生成任何“实际单词”,但结果看起来稍微好一些。不过,要进一步改进,我们需要做的不仅仅是随机挑选每个字母。例如,我们知道如果有一个“q”,下一个字母基本上必须是“u”。
这是单个字母概率的图示:
这里是一个图示,显示了典型英语文本中字母对(“2-grams”)的概率。可能的首字母显示在页面的横向,第二个字母显示在页面的纵向:
我们在这里看到,例如,“q”列是空白的(零概率),除了在“u”行。好,现在我们不再一次生成一个字母,而是一次看两个字母,利用这些“2-gram”概率生成“单词”。下面是结果的一个样本,其中包含一些“实际单词”:
通过足够多的英语文本,我们不仅可以对单个字母或字母对(2-grams)的概率进行相当好的估计,还可以对更长的字母序列进行估计。如果我们用逐渐长的n-gram 概率生成“随机单词”,我们会发现它们变得越来越“逼真”:

但让我们现在假设——或多或少像 ChatGPT 所做的那样——我们处理的是整个单词,而不是字母。英语中大约有 40,000 个常用单词。通过查看大量英语文本(比如几百万本书,总共几百亿个单词),我们可以获得每个单词的常见程度估算。利用这些数据,我们可以开始生成“句子”,其中每个单词是独立随机挑选的,出现的概率与其在语料库中的概率相同。以下是我们得到的一个样本:

不出所料,这是荒谬的。那么我们该如何做得更好?就像处理字母一样,我们可以开始考虑不仅是单词的概率,还有单词对或更长的n-gram 的概率。对于对,这里有 5 个示例,所有案例都从“cat”这个词开始:

它看起来略微“更有意义”。我们可以想象,如果我们能够使用足够长的n-gram,我们基本上会“得到一个 ChatGPT”——即我们会得到一种生成具有“正确整体论文概率”的长篇单词序列的东西。但问题是:甚至没有接近足够的英语文本来推断这些概率。
在网络爬虫中可能有几百亿个单词;在已数字化的书籍中可能还有另一百亿个单词。但有了 40,000 个常用单词,即使是可能的 2-gram 的数量也已达到 16 亿——而可能的 3-gram 的数量是 60 万亿。因此,我们无法仅凭现有文本估计所有这些的概率。当我们处理“20 个单词的论文片段”时,可能性数量已经比宇宙中的粒子还多,从某种意义上说,它们永远不可能全部被写下来。
那我们可以做什么?大思路是制作一个模型,让我们估计序列应该出现的概率——即使我们从未在我们查看的文本语料库中明确见过这些序列。ChatGPT 的核心正是一个所谓的“大型语言模型”(LLM),它被构建用来很好地估计这些概率。
什么是模型?
比如你想知道(如伽利略在 1500 年代末所做的)从比萨斜塔的每个楼层掉下的大炮弹需要多长时间才能落地。你可以在每种情况下进行测量,并制作一个结果表。或者你可以做理论科学的本质:建立一个模型,提供一些计算答案的程序,而不仅仅是测量和记住每种情况。
假设我们有(稍微理想化的)数据,表示大炮弹从不同楼层落下所需的时间:
我们如何确定从一个没有明确数据的楼层落下需要多长时间?在这个特定情况下,我们可以使用已知的物理定律来计算。但假设我们只有数据,而不知道支配这些数据的基本定律。然后我们可能会做出数学猜测,比如我们应该使用直线作为模型:
我们可以选择不同的直线。但这是与我们给定的数据平均最接近的一条直线。通过这条直线,我们可以估计任何楼层的落下时间。
我们是如何知道在这里尝试使用直线的?在某种程度上我们并不知道。这只是一些数学上简单的东西,我们习惯于许多测量的数据会被数学上简单的东西很好地拟合。我们可以尝试更复杂的数学模型——比如 a + b x + c x²——这样在这种情况下,我们会做得更好:
但事情可能会搞得很糟糕。比如这里是我们用 a + b/x + c sin(x) 所能做到的最好结果:
需要理解的是,从来没有“没有模型的模型”。你使用的任何模型都有某种特定的基本结构——然后是一组“可以调整的旋钮”(即可以设置的参数)来拟合你的数据。在 ChatGPT 的情况下,使用了很多这样的“旋钮”——实际上是 1750 亿个。
但值得注意的是,ChatGPT 的基本结构——即使是“仅仅”这么多参数——足以使模型计算下一个单词的概率“足够好”,以生成合理的长篇文本。
类似人类任务的模型
我们上面给出的例子涉及为数值数据创建一个模型,这些数据基本上来自简单物理学——我们已经知道几个世纪了“简单数学适用”。但对于 ChatGPT,我们需要创建一个人类大脑产生的人类语言文本的模型。对于这样的东西,我们目前(至少还)没有类似“简单数学”的东西。那么这样的模型可能是什么样的呢?
在讨论语言之前,让我们讨论另一个类似人类的任务:识别图像。作为一个简单的例子,让我们考虑数字图像(是的,这这是一个 经典的机器学习例子):
我们可以做的一件事是为每个数字获取一组样本图像:

然后,为了找出我们输入的图像是否对应于某个特定的数字,我们可以与我们拥有的样本进行逐像素比较。但作为人类,我们显然能做得更好——因为即使这些数字例如是手写的,并且有各种修改和扭曲,我们仍然能识别出来:
当我们为上述数值数据创建模型时,我们能够接受一个数值 x,然后计算 a + b x 对于特定的 a 和 b。所以,如果我们将这里每个像素的灰度值视为某个变量 x[i],是否存在一个所有这些变量的函数——当被评估时——能告诉我们图像的数字是什么?事实证明,构造这样的函数是可能的。不过,这并不令人惊讶,它并不是特别简单。一个典型的例子可能涉及到大约五十万次数学运算。
但最终结果是,如果我们将图像的像素值集合输入到这个函数中,输出的将是指定我们图像中的数字的编号。稍后,我们将探讨如何构造这样的函数以及神经网络的概念。但现在我们先将函数视为一个黑箱,我们输入,例如手写数字的图像(作为像素值数组),然后输出这些图像所对应的数字:

但这里到底发生了什么?假设我们逐渐模糊一个数字。在一段时间内,我们的函数仍然“识别”它,此时为“2”。但很快它就“失效”了,开始给出“错误”的结果:
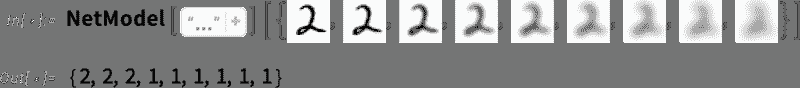
但为什么我们说这是“错误”的结果呢?在这种情况下,我们知道我们是通过模糊“2”的图像得到的所有图像。但如果我们的目标是制作一个能模拟人类识别图像的模型,真正的问题是如果人类面对这些模糊图像之一而不知道其来源时会做什么。
我们有一个“好的模型”是指如果我们从函数中得到的结果通常与人类的判断一致。而且有一个非平凡的科学事实是,对于像这样的图像识别任务,我们现在基本上知道如何构建执行这些任务的函数。
我们能“数学证明”它们有效吗?其实不能。因为要做到这一点,我们需要对我们人类的行为有一个数学理论。拿“2”的图像来改变几个像素。我们可能会想,如果只有几个像素“错位”,我们仍然应该把这个图像视为“2”。但这种错位的范围应该有多大呢?这是一个关于人类视觉感知的问题。没错,答案对于蜜蜂或章鱼无疑会有所不同——并且对于假设的外星生物来说可能会完全不同。
神经网络
好的,那么我们常见的任务模型比如图像识别到底是如何工作的呢?目前最流行—也是最成功的—方法是使用神经网络。神经网络在 1940 年代就以与今天相似的形式被发明,接近今天的使用形式,可以被视为对大脑工作方式的简单理想化。
在人类的大脑中大约有 1000 亿个神经元(神经细胞),每个神经元能够产生每秒高达千次的电脉冲。神经元以复杂的网络形式连接在一起,每个神经元拥有树状分支,使其能够将电信号传递给数千个其他神经元。在粗略的估计中,任何特定的神经元在某一时刻是否产生电脉冲,取决于它从其他神经元接收到的脉冲——不同的连接以不同的“权重”贡献。
当我们“看到图像”时,发生的情况是图像中的光子落在我们眼睛后面的(“光感受器”)细胞上,这些细胞会在神经细胞中产生电信号。这些神经细胞连接到其他神经细胞,最终信号通过一系列神经元层。在这个过程中我们“识别”图像,最终“形成”我们正在“看到一个 2”的“思想”(最终可能会做出类似说出“two”这个词的行为)。
上一节中的“黑箱”函数是这样一个神经网络的“数学化”版本。它恰好有 11 层(尽管只有 4 层“核心层”):
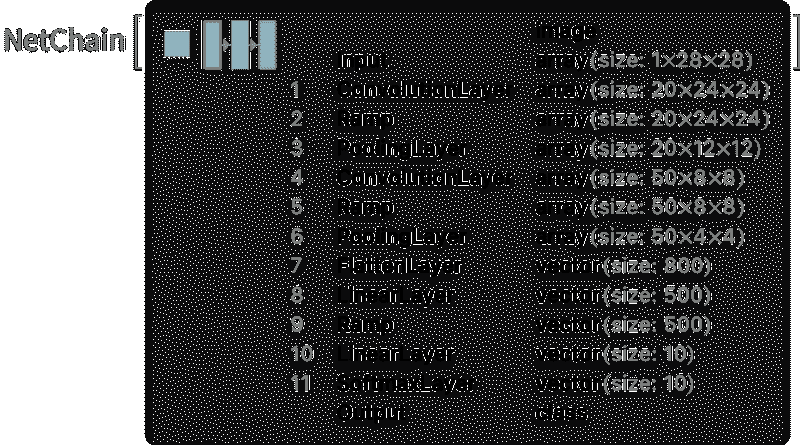
这个神经网络没有什么特别的“理论推导”;它只是某种在1998 年构建的工程的一部分,并发现它有效。(当然,这与我们可能描述我们的大脑是通过生物进化过程产生的差别不大。)
好吧,那么这样的神经网络是如何“识别事物”的?关键在于吸引子的概念。假设我们有 1 和 2 的手写图像:

我们希望所有的 1 都“被吸引到一个地方”,所有的 2 都“被吸引到另一个地方”。换句话说,如果一张图像某种程度上是“更接近 1”而不是 2,我们希望它最终出现在“1 的地方”,反之亦然。
作为一个直接的类比,假设我们在平面上有一些由点表示的位置(在现实生活中,它们可能是咖啡店的位置)。然后我们可以想象,从平面上的任何一点开始,我们总是希望到达最近的点(即,我们总是去最近的咖啡店)。我们可以通过将平面划分为由理想化的“集水区”分隔的区域(“吸引子盆地”)来表示这一点:

我们可以把这看作是实施一种“识别任务”,其中我们不是做类似于识别给定图像“最像哪个数字”的事情——而是我们只是直接查看给定点最接近哪个点。(我们在这里展示的“Voronoi 图”设置将二维欧几里得空间中的点分开;数字识别任务可以被认为是做类似的事情——但在一个由每个图像的所有像素灰度级组成的 784 维空间中。)
那么我们如何让神经网络“进行识别任务”?让我们考虑这个非常简单的案例:
我们的目标是接受一个对应于位置 {x,y} 的“输入”——然后将其“识别”为它最接近的三个点中的任意一个。换句话说,我们希望神经网络计算一个 {x,y} 的函数,如:
那么我们如何用神经网络实现这一点呢?最终,神经网络是一个理想化的“神经元”集合—通常以层的形式排列—一个简单的例子是:
每个“神经元”实际上被设置为评估一个简单的数值函数。要“使用”这个网络,我们只需在顶部输入数字(如我们的坐标 x 和 y),然后让每一层的神经元“评估它们的函数”并将结果向前传递,通过网络—最终在底部产生最终结果:
在传统的(生物启发的)设置中,每个神经元实际上具有一组来自前一层神经元的“输入连接”,每个连接被分配一个特定的“权重”(可以是正数或负数)。给定神经元的值通过将“前一层神经元”的值与其对应的权重相乘,然后将这些值相加并加上一个常数来确定—最后应用一个“阈值”(或“激活”)函数。用数学术语来说,如果一个神经元有输入 x = {x[1], x[2] …},那么我们计算 f[w . x + b],其中权重 w 和常数 b 通常对网络中的每个神经元选择不同;函数 f 通常是相同的。
计算 w . x + b 只是矩阵乘法和加法的问题。“激活函数” f 引入了非线性(并最终导致了非平凡行为)。各种激活函数通常被使用;这里我们将只使用 *[Ramp](http://reference.wolfram.com/language/ref/Ramp.html)(或 ReLU):

对于我们希望神经网络执行的每个任务(或者等效地,对于我们希望它评估的每个整体函数),我们将有不同的权重选择。(并且—正如我们稍后讨论的—这些权重通常通过使用我们期望输出的示例来“训练”神经网络来确定。)
最终,每个神经网络只对应某个整体数学函数—尽管写出来可能很麻烦。对于上面的例子,它会是:
ChatGPT 的神经网络也只是对应于这样一个数学函数—但实际上具有数十亿项。
但让我们回到单个神经元。以下是一个具有两个输入(表示坐标 x 和 y)的神经元在不同权重和常数选择下可以计算的函数的一些示例(以及 *[Ramp](https://reference.wolfram.com/language/ref/Ramp.html) 作为激活函数):
那么,前面提到的更大网络呢?好吧,这是它计算的结果:

这并不完全“正确”,但接近于我们上面展示的“最近点”函数。
让我们看看其他一些神经网络会发生什么。在每种情况下,正如我们稍后会解释的,我们使用机器学习来寻找最佳权重选择。然后我们在这里展示了具有这些权重的神经网络计算结果:
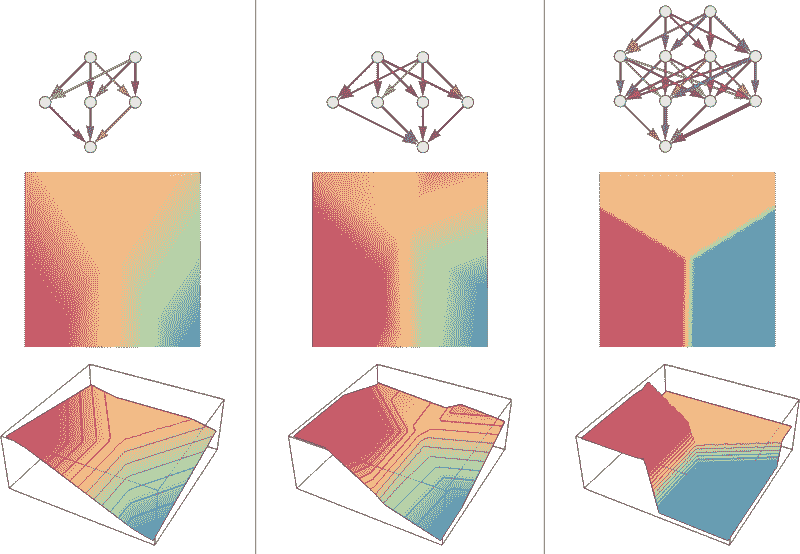
更大的网络通常更擅长于逼近我们所期望的函数。在“每个吸引子盆地的中间”,我们通常会得到我们想要的确切答案。但在边界处——那里神经网络“很难做出决定”——情况可能会更加混乱。
对于这个简单的数学风格的“识别任务”,什么是“正确答案”很清楚。但在识别手写数字的问题中,这就不那么清楚了。如果有人把“2”写得像“7”一样糟糕,怎么办?尽管如此,我们还是可以询问神经网络如何区分数字——这会给出一些指示:

我们能否“数学上”说明网络如何进行区分?不完全能。它只是“做神经网络所做的事”。但结果表明,这通常与我们人类做出的区分非常一致。
让我们举一个更复杂的例子。假设我们有猫和狗的图像。我们有一个经过训练以区分它们的神经网络。它在一些示例中可能会这样做:

现在,什么是“正确答案”变得更加模糊了。比如一只穿着猫装的狗?等等。无论给它什么输入,神经网络都会生成一个答案,并且在某种程度上与人类可能的方式相一致。正如我上面所说的,这不是我们可以“从第一原理推导出来的事实”。这只是经过经验发现的真实情况,至少在某些领域如此。但这也是神经网络有用的关键原因之一:它们以某种方式捕捉了“类人”的做事方式。
给自己看一张猫的图片,然后问“为什么那是一只猫?”。也许你会开始说“嗯,我看到了它的尖耳朵”等等。但很难解释你是如何识别出这是一只猫的。只是你的大脑以某种方式弄明白了。但对于大脑来说,当前还没有办法(至少还没有)“进入内部”查看它是如何搞明白的。那对于(人工)神经网络呢?好吧,当你展示一张猫的图片时,查看每个“神经元”在做什么是直接的。但即使是获得基本的可视化通常也很困难。
在我们用于上述“最近点”问题的最终网络中有 17 个神经元。在识别手写数字的网络中有 2190 个。在我们用于识别猫和狗的网络中有 60,650 个。通常,直观地理解 60,650 维的空间是相当困难的。但由于这是一个处理图像的网络,它的许多神经网络层被组织成数组,就像它查看的像素数组一样。
如果我们拿一张典型的猫的图像

那么我们可以通过一系列衍生图像来表示第一层的神经元状态——其中许多我们可以很容易地解释为“没有背景的猫”或“猫的轮廓”等:

到第十层时,解释发生了什么变得更加困难:

但一般来说,我们可以说神经网络在“提取某些特征”(也许尖耳朵在其中),并利用这些特征来确定图像的内容。但这些特征是否是我们能给出名称的——如“尖耳朵”?大多数情况下不是。
我们的大脑是否使用了类似的特征?大多数情况下我们并不知晓。但值得注意的是,我们在这里展示的神经网络的前几层似乎能提取图像中的某些方面(如物体的边缘),这些特征似乎与我们知道大脑视觉处理的第一层提取的特征类似。
但假设我们想要一个关于神经网络“猫识别”的“理论”。我们可以说:“看,这个特定的网络可以做到这一点”——这立即给了我们一些“问题有多难”的感觉(例如,需要多少神经元或层)。但至少现在我们还没有办法“给出叙述性描述”网络正在做什么。也许是因为它确实在计算上是不可简化的,除了通过明确追踪每一步之外,没有通用的方法来了解它的功能。或者可能是我们还没有“弄清楚科学”,也没有识别出“自然法则”,以便总结正在发生的事情。
当我们谈论使用 ChatGPT 生成语言时,也会遇到类似的问题。而且同样不清楚是否有方法来“总结它在做什么”。但语言的丰富性和细节(以及我们对其的经验)可能使我们能够比图像更进一步。
机器学习和神经网络的训练
到目前为止,我们讨论了“已经知道”如何执行特定任务的神经网络。但神经网络如此有用的原因(也许大脑也是如此)是,它们不仅原则上可以执行各种任务,而且可以通过逐步“从例子中训练”来完成这些任务。
当我们制作一个神经网络来区分猫和狗时,我们不需要编写一个程序(比如)明确地找到胡须;相反,我们只需展示大量猫和狗的示例,然后让网络“机器学习”如何区分它们。
关键点在于训练后的网络从其展示的特定例子中“泛化”。正如我们上面所见,网络不仅仅是识别了它所展示的猫图像的特定像素模式,而是神经网络以某种我们认为的“通用猫性”来区分图像。
那么神经网络训练实际上是如何工作的呢?本质上,我们始终尝试找到使神经网络成功重现我们给出的示例的权重。然后,我们依赖神经网络以“合理”的方式在这些示例之间“插值”(或“泛化”)。
让我们看一个比上面最近点问题更简单的问题。让我们尝试让神经网络学习以下函数:
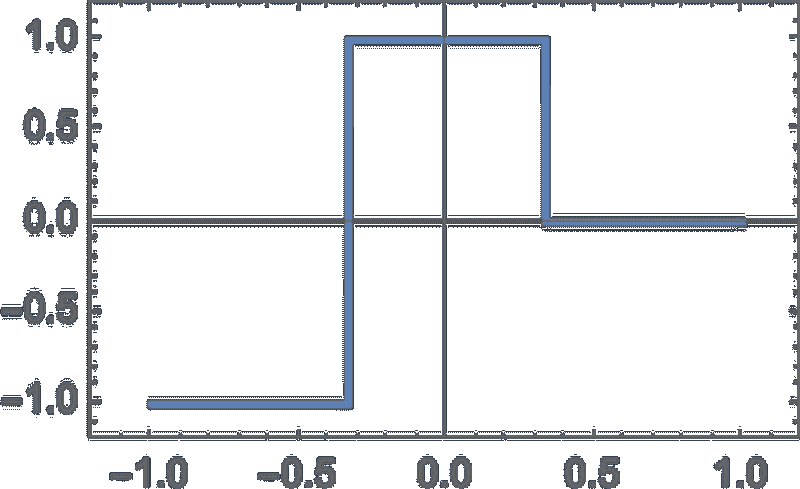
对于这个任务,我们需要一个只有一个输入和一个输出的网络,如下所示:
那么我们应该使用什么权重等呢?对于每一组可能的权重,神经网络将计算某个函数。例如,以下是它对一些随机选择的权重集的处理:
是的,我们可以清楚地看到在这些情况下,网络都未能接近重现我们想要的函数。那么我们如何找到能够重现该函数的权重呢?
基本思想是提供大量“输入 ? 输出”示例以“学习”,然后尝试找到能够重现这些示例的权重。以下是随着示例逐渐增多而得到的结果:
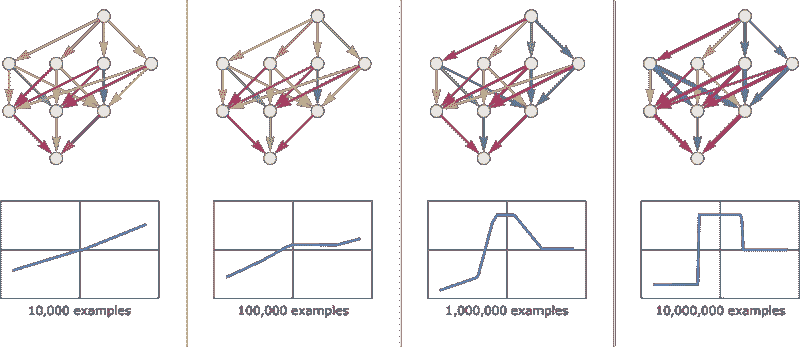
在这种“训练”的每个阶段,网络中的权重都会逐步调整——我们看到最终得到一个成功重现我们想要的函数的网络。那么我们如何调整权重呢?基本的想法是在每个阶段查看“我们离得到我们想要的函数有多远”——然后以这种方式更新权重,以便更接近。
为了找出“我们还差多远”,我们计算通常称为“损失函数”(有时称为“成本函数”)的东西。在这里,我们使用一个简单的(L2)损失函数,它只是我们得到的值与真实值之间差异的平方和。我们看到的是,随着训练过程的进展,损失函数逐渐减少(遵循不同任务的特定“学习曲线”)——直到我们达到一个点,在这个点上网络(至少在很大程度上)成功地重现了我们想要的函数:
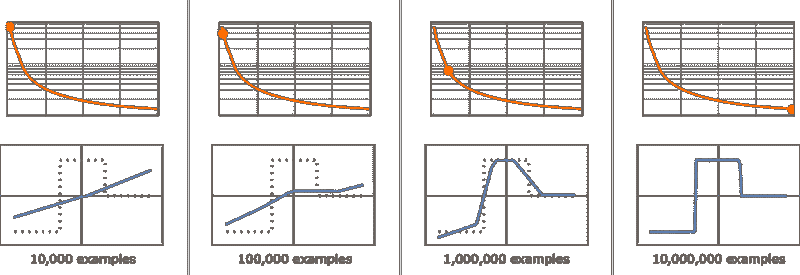
好的,最后一个关键部分是如何调整权重以减少损失函数。如我们所说,损失函数给出的是我们得到的值与真实值之间的“距离”。但“我们得到的值”是在每个阶段由当前版本的神经网络及其中的权重决定的。现在假设这些权重是变量——比如说 w[i]。我们希望找出如何调整这些变量的值,以最小化依赖于它们的损失。
例如,假设(在对实际中使用的典型神经网络进行极简化的情况下)我们只有两个权重 w[1] 和 w[2]。那么我们可能会有一个损失函数,它作为 w[1] 和 w[2] 的函数看起来像这样:
数值分析提供了多种技术来寻找这种情况的最小值。但一种典型的方法是逐步沿着从我们之前的 w[1] 和 w[2] 开始的最陡下降路径前进:
就像水流下山一样,唯一可以保证的是这个过程将最终到达表面的某个局部最小值(“一个山间湖泊”);它可能不会到达最终的全局最小值。
在“权重景观”上找到最陡下降路径并不明显是可行的。但微积分提供了帮助。正如我们之前提到的,可以将神经网络始终看作是计算一个依赖于其输入和权重的数学函数。但现在考虑对这些权重进行微分。事实证明,微积分的链式法则实际上使我们可以“解开”神经网络中各层的操作。而结果是,我们可以——至少在某种局部近似下——“逆转”神经网络的操作,并逐步找到能最小化与输出相关联的损失的权重。
上面的图片展示了我们可能需要在仅有 2 个权重的非现实简单情况下进行的最小化。但是即使有更多的权重(ChatGPT 使用 1750 亿个),依然可以进行最小化,至少在某种程度的近似下是可能的。事实上,大约在 2011 年左右发生的“深度学习”重大突破与发现相关:在某种意义上,当涉及到许多权重时,进行(至少是近似的)最小化可能比涉及较少权重时更容易。
换句话说——有些违反直觉的是——用神经网络解决更复杂的问题可能比解决简单问题更容易。其大致原因似乎是,当存在大量“权重变量”时,会有一个高维空间,其中有“许多不同的方向”可以引导我们到达最小值——而对于较少的变量,更容易陷入局部最小值(“山间湖泊”),没有“方向可以脱离”。
值得指出的是,在典型情况下,有许多不同的权重组合都能使神经网络表现出几乎相同的性能。而在实际的神经网络训练中,通常会做出许多随机选择——这会导致“不同但等效的解决方案”,比如这些:

但每个这样的“不同解决方案”将至少有略微不同的行为。如果我们要求进行例如在给定训练样本区域之外的“外推”,我们可能会得到截然不同的结果:

那么这些结果中哪一个是“正确”的?实际上没有办法确定。它们都与“观察数据”一致。但它们都对应于不同的“固有”方式来“考虑”在“框外”该做什么。有些可能对我们人类来说显得“更合理”。
神经网络训练的实践与经验
尤其是在过去十年中,神经网络训练的艺术取得了许多进展。而且,是的,这基本上是一门艺术。有时——尤其是事后看来——我们可以看到至少一点“科学解释”的闪光点。但大多数情况是通过反复试验发现的,加入了逐渐积累的想法和技巧,从而构建了关于如何使用神经网络的丰富经验。
有几个关键部分。首先,需要考虑在特定任务中应使用什么样的神经网络架构。接着,关键问题是如何获取用于训练神经网络的数据。而且,越来越多的时候,人们不再从头开始训练一个网络:新的网络可以直接融入另一个已经训练好的网络,或者至少可以利用那个网络生成更多的训练示例。
有人可能认为每种特定类型的任务都需要不同的神经网络架构。但发现相同的架构往往对看似完全不同的任务也有效。在某种程度上,这让人想起了通用计算的理念(以及我的计算等效原则),但正如我稍后讨论的,我认为这更多反映了我们通常尝试让神经网络完成的任务是“类人”的,而神经网络可以捕捉到相当普遍的“类人过程”。
在早期的神经网络研究中,通常有一种观念是“让神经网络尽可能少做事情”。例如,在语音转文本的过程中,人们认为应该首先分析语音的音频,将其分解为音素等。但是,事实证明——至少对于“类人任务”——通常更好的是直接在“端到端问题”上训练神经网络,让它“发现”必要的中间特征、编码等。
也曾有人认为应该将复杂的个体组件引入神经网络中,以便使其“明确实现特定的算法思想”。但再一次,这通常被证明并不值得;相反,更好的做法是处理非常简单的组件,让它们“自我组织”(尽管通常以我们无法理解的方式)来实现(推测上)那些算法思想的等效结果。
这并不是说没有与神经网络相关的“结构化想法”。例如,拥有具有局部连接的 2D 神经元数组在图像处理的早期阶段似乎非常有用。而拥有专注于“回顾序列”的连接模式似乎也很有用——正如我们稍后将看到的——在处理类似人类语言的任务时,例如在 ChatGPT 中。
但神经网络的一个重要特性是——像计算机一样——它们最终只处理数据。而当前的神经网络——通过当前的神经网络训练方法——特别处理数字数组。但在处理过程中,这些数组可以被完全重新排列和重塑。举个例子,我们用于识别数字的网络 从一个 2D “图像般”的数组开始,很快“变厚”成多个通道,但随后“浓缩”成一个 1D 数组,最终包含表示不同可能输出数字的元素。
不过,好吧,怎么判断一个神经网络在特定任务中需要多大呢?这有点像艺术。在某种程度上,关键是知道“任务有多难”。但对于类似人类的任务,这通常很难估计。是的,可能有一种系统化的方式,通过计算机非常“机械”地完成任务。但很难知道是否存在所谓的技巧或捷径,可以使任务至少在“类似人类的水平”上变得容易得多。可能需要列举一个巨大的游戏树才能“机械地”玩某个游戏;但可能存在一种更简单的(“启发式的”)方法来实现“人类水平的游戏”。
当处理微小的神经网络和简单任务时,有时可以明确看到“从这里无法到达那里”。例如,以下是似乎在前一节任务中用几个小型神经网络能做到的最佳效果:
我们看到的是,如果网络太小,它就无法复现我们想要的功能。但在某个大小以上,它没有问题——至少如果你为其训练足够长时间,并提供足够的示例。顺便提一下,这些图片展示了一个神经网络的知识点:如果中间有一个“挤压”部分,迫使所有内容通过一个较小的中间神经元数目,通常可以用一个较小的网络来应对。(也值得一提的是,“无中间层”——或称为“感知机”——网络只能学习本质上是线性的函数,但只要有一个中间层,就原则上总是可能近似任何函数,只要有足够的神经元,尽管为了使其可行地训练,通常会有某种正则化或归一化。
好的,假设一个人已经决定使用某种神经网络架构。接下来就是获取训练网络所需数据的问题。许多关于神经网络——以及机器学习总体上的实际挑战——都集中在获取或准备必要的训练数据上。在许多情况下(“监督学习”),人们希望得到输入和期望输出的明确示例。因此,例如,一个人可能希望得到标记了内容的图像或其他属性。也许需要明确地进行标记——通常需要付出很大努力。但是,往往会发现可以利用已经完成的工作,或将其作为某种代理。例如,可以使用网络上为图像提供的 alt 标签。或者,在另一个领域中,可以使用为视频创建的字幕。又或者——对于语言翻译训练——可以使用存在于不同语言中的网页或其他文档的平行版本。
你需要向神经网络展示多少数据才能训练它完成特定任务?再次从基本原理估计很难。通过使用“迁移学习”将已在其他网络中学习到的重要特征列表“转移”过来,需求量可以大大减少。但通常神经网络需要“看到大量示例”才能有效训练。而且至少对于某些任务来说,神经网络的一个重要特性是示例可以非常重复。实际上,将所有的示例反复展示给神经网络是一种标准策略。在每一轮“训练”(或“时期”)中,神经网络将处于至少稍微不同的状态,并且以某种方式“提醒它”一个特定示例有助于它“记住那个示例”。(是的,也许这类似于人类记忆中重复的有效性。)
但通常,仅仅重复相同的示例并不够。还需要向神经网络展示示例的变化。神经网络的一个特性是这些“数据增强”变化不需要复杂就能有用。仅通过基本的图像处理稍微修改图像,就能使它们对神经网络训练来说“几乎全新”。同样,当用完实际视频等来训练自动驾驶汽车的数据时,可以继续从运行模型视频游戏环境中的模拟中获取数据,而无需实际世界场景的详细信息。
像 ChatGPT 这样的模型怎么样?好在它具有“无监督学习”的优点,使得获取训练示例变得容易。回想一下,ChatGPT 的基本任务是弄清楚如何继续给定的文本。因此,要获得“训练示例”,只需获取一段文本,将其末尾遮蔽,然后将其作为“训练输入”——“输出”则是完整的、未遮蔽的文本。我们稍后会详细讨论,但要点是——与学习图像中的内容不同——不需要“显式标记”;ChatGPT 实际上可以直接从所提供的文本示例中学习。
好的,那么神经网络中的实际学习过程如何呢?归根结底,这一切都是关于确定哪些权重能够最好地捕捉所给定的训练示例。这里有各种详细的选择和“超参数设置”(之所以这样称呼,是因为权重可以被视作“参数”),可以用来调整这些操作的方式。有不同的损失函数选择(平方和、绝对值和等)。有不同的损失最小化方法(每一步在权重空间中移动多远等)。然后还有类似于每次估计损失时应该展示多大的“批次”问题。是的,可以应用机器学习(例如我们在 Wolfram 语言中所做的)来自动化机器学习——并自动设置超参数等。
但最终,整个训练过程的特征是观察损失值如何逐渐减少(如在这个Wolfram 语言小型训练进度监控器中所示):
通常情况下,所见的是损失值在一段时间内减少,但最终会在某个常数值上趋于平稳。如果这个值足够小,那么训练可以被视为成功;否则,这可能是一个信号,表明需要尝试改变网络架构。
能否确定“学习曲线”平稳所需的时间?就像许多其他事情一样,似乎存在近似的幂律缩放关系,这些关系依赖于神经网络的规模和所使用的数据量。但总体结论是,训练神经网络很困难——需要大量计算资源。作为实际问题,大部分努力都花在对数字数组进行操作上,而这正是 GPU 擅长的——这也是神经网络训练通常受限于 GPU 可用性的原因。
未来是否会有根本更好的方法来训练神经网络——或一般地做神经网络所做的事情?我认为几乎可以肯定。神经网络的基本思想是用大量简单(本质上相同)组件创建一个灵活的“计算结构”——并使这个“结构”可以逐步修改以从示例中学习。在当前的神经网络中,基本上是使用微积分的思想——应用于实数——来进行这种逐步修改。但越来越明显的是,高精度数字并不重要;即使使用当前的方法,8 位或更少的精度也可能足够。
与像细胞自动机这样的计算系统基本上在许多独立的比特上并行操作一样,如何进行这种增量修改一直不清楚,如何进行这种增量修改也没有理由认为它是不可能的。事实上,类似于“2012 年深度学习突破”,这种增量修改在更复杂的情况下可能比在简单情况下更容易实现。
神经网络—或许有点像大脑—设置为具有基本固定的神经元网络,修改的是它们之间连接的强度(“权重”)。(或许在至少年轻的大脑中,可能还会有大量全新连接的增长。)但尽管这对生物学来说可能是一个方便的设置,但目前还不清楚这是否接近实现我们所需功能的最佳方式。涉及渐进网络重写的事物(或许类似于我们的物理项目)最终可能会更好。
但即使在现有的神经网络框架内,目前也存在一个关键限制:目前的神经网络训练基本上是顺序的,每批样本的效果会被反向传播以更新权重。事实上,即便考虑到 GPU,目前的大多数神经网络在训练过程中大部分时间都是“闲置”的,只有一部分在更新。从某种意义上说,这是因为我们目前的计算机往往有与 CPU(或 GPU)分开的内存。但在大脑中,这显然是不同的——每个“记忆元素”(即神经元)也可能是一个活动的计算元素。如果我们能将未来的计算机硬件设置成这种方式,可能会使训练变得更加高效。
“肯定一个足够大的网络可以做任何事情!”
像 ChatGPT 这样的能力看起来如此令人印象深刻,以至于有人可能会想,如果能“持续进行”并训练越来越大的神经网络,那么它们最终能够“做一切”。如果关注的是那些容易被立即人类思维所接触到的事物,这可能确实是这样。但过去几百年的科学教训是,有些东西可以通过形式化过程来解决,但不容易被立即人类思维所接触。
非平凡的数学就是一个很好的例子。但一般来说,这实际上是计算的问题。最终的问题是 计算不可简约性现象。有些计算你可能认为需要许多步骤才能完成,但实际上可以“简化”成相当直接的东西。但计算不可简约性的发现意味着这并不总是有效。相反,有些过程——可能像下面这个——在计算每一步时都必须追踪。

我们通常用大脑做的事情大概是特别选择以避免计算不可简约性的。要在大脑中进行数学运算需要特别的努力。实际上,仅凭大脑几乎不可能“思考”任何非平凡程序的操作步骤。
但当然我们有计算机。借助计算机,我们可以轻松地完成长时间、计算不可简约的任务。关键点在于,对于这些任务一般没有捷径。
是的,我们可以记住许多特定计算系统中发生的具体例子。也许我们甚至可以看到一些(“计算可简约”)的模式,这些模式可以让我们进行一些泛化。但关键是计算不可简约性意味着我们永远无法保证意外不会发生——只有通过明确的计算才能知道在任何特定情况下实际发生了什么。
最终,学习能力与计算不可简约性之间存在根本性的紧张关系。学习实际上涉及到通过利用规律性来 压缩数据。但计算不可简约性意味着最终可能存在规律性的限制。
实际上,我们可以设想将小型计算设备——如细胞自动机或图灵机——构建到可训练系统如神经网络中。的确,这些设备可以作为神经网络的良好“工具”——就像 Wolfram|Alpha 可以作为 ChatGPT 的一个好工具。但计算不可简约性意味着你不能期望“进入”这些设备并让它们进行学习。
换句话说,能力和可训练性之间存在一种最终的权衡:你希望系统更好地“实际利用”其计算能力,它就会表现出更强的计算不可约性,训练起来也会更加困难。而系统本质上越可训练,它能进行复杂计算的能力就越低。
(以当前的 ChatGPT 为例,情况实际上更加极端,因为生成每个输出的神经网络是纯粹的“前馈”网络,没有循环,因此无法进行任何具有非平凡“控制流”的计算。)
当然,人们可能会想知道进行不可约计算是否真的重要。确实,在人类历史的大部分时间里,这并不特别重要。但我们现代的技术世界是建立在至少数学计算的工程基础上——并且越来越多地是更一般的计算。如果我们观察自然界,它是充满了不可约计算——我们正在慢慢理解如何模拟这些计算并将其用于我们的技术目的。
是的,神经网络确实能够注意到自然界中的某些规律,这些规律我们也可以用“未经帮助的人类思维”轻易发现。但如果我们想解决数学或计算科学领域的问题,神经网络就无法做到——除非它有效地“将普通的”计算系统作为工具。
但所有这些可能存在令人困惑的地方。过去有很多任务——包括写作——我们曾假设这些任务对计算机来说“根本太难”。现在看到 ChatGPT 等完成这些任务,我们会突然认为计算机变得强大得多——特别是超越了它们本来已经能做的事情(如逐步计算像细胞自动机这样的计算系统的行为)。
但这不是正确的结论。计算不可约的过程仍然是计算不可约的,对计算机来说仍然是根本困难的——即使计算机可以轻松计算它们的单个步骤。我们应该得出的结论是,像写作这样的任务——我们人类能做,但我们认为计算机做不到的——实际上在某种意义上比我们想象的计算上更容易。
换句话说,神经网络能够成功写作的原因是写作被证明是一个比我们想象的“计算上浅层”的问题。从某种意义上说,这使我们更接近于“拥有一种理论”来解释我们人类如何完成像写作这样的任务,或一般性地处理语言。
如果你拥有一个足够大的神经网络,那么,是的,你可能能够做任何人类能够做的事情。但你不会捕捉到自然界通常能做的事情——或者我们从自然界中打造的工具能做的事情。正是这些工具——无论是实用的还是概念性的——使我们在最近几个世纪能够超越“纯粹无辅助的人类思维”所能接触的边界,并为人类目的捕捉到更多物理和计算宇宙中的内容。
嵌入的概念
神经网络——至少按照它们目前的设置——从根本上是基于数字的。因此,如果我们要使用它们处理像文本这样的内容,我们需要一种用数字表示文本的方法。当然,我们可以从(本质上就像 ChatGPT 做的那样)给字典中的每个单词分配一个数字开始。但有一个重要的概念——例如对 ChatGPT 来说至关重要——超越了这一点。那就是“嵌入”的概念。可以将嵌入视为通过一组数字来尝试表示某物的“本质”的一种方式——其特点是“相近的事物”由相近的数字表示。
例如,我们可以将词嵌入视为尝试在一种“意义空间”中布置单词,其中在意义上“接近”的单词在嵌入中会彼此接近。实际使用的嵌入——比如在 ChatGPT 中——往往涉及大量的数字列表。但如果我们将其投影到二维,我们可以展示嵌入如何布置单词的示例:

是的,我们看到的确实非常好地捕捉了典型的日常印象。但我们如何构建这样的嵌入呢?大致的想法是查看大量的文本(这里是来自网络的 50 亿个单词),然后看看不同单词出现的“环境”有多么相似。例如,“鳄鱼”和“短吻鳄”在其他相似的句子中几乎可以互换出现,这意味着它们在嵌入中会被放置得很接近。但“萝卜”和“鹰”不会在其他相似的句子中出现,因此它们在嵌入中会被放置得很远。
那么,如何使用神经网络实际实现这样的东西呢?让我们从谈论图像的嵌入开始。我们想找到一种方法,通过数字列表来表征图像,以便“我们认为相似的图像”被分配相似的数字列表。
我们如何判断是否应该“将图像视为相似”?如果我们的图像是手写数字,我们可能会“认为两个图像相似”如果它们是相同的数字。早些时候,我们讨论了一个训练用于识别手写数字的神经网络。我们可以将这个神经网络看作是在最终输出时将图像分到 10 个不同的类别中,每个数字一个类别。
但如果我们在做出最终的“这是‘4’”决定之前“截取”神经网络内部发生的事情呢?我们可能会期望神经网络内部存在一些数字,这些数字将图像特征描述为“主要像 4 但有一点像 2”或类似的东西。其思路是提取这些数字,用作嵌入的元素。
这里的概念是。与其直接尝试表征“什么图像接近什么其他图像”,我们不如考虑一个明确的任务(在这种情况下是数字识别),对于这个任务我们可以获取明确的训练数据——然后利用在执行这个任务时神经网络隐式地做出类似“接近度决策”的事实。因此,我们不必明确讨论“图像的接近度”,我们只需讨论图像表示的具体数字,然后“让神经网络”隐式地确定这对“图像接近度”意味着什么。
那么,这对数字识别网络的详细工作原理是什么呢?我们可以将网络视为由 11 层连续层组成,我们可以像这样用图标来总结(激活函数显示为单独的层):

一开始,我们将实际图像输入到第一层,这些图像由二维像素值数组表示。到最后一层时,我们得到一个包含 10 个值的数组,我们可以理解为“网络对图像对应于数字 0 到 9 的每一个数字的确定程度”。
输入图像  ,最后一层神经元的值为:
,最后一层神经元的值为:
换句话说,神经网络在这一点上对这张图像是 4“非常确定”——为了实际得到输出“4”,我们只需找出具有最大值的神经元的位置。
但如果我们往前看一步呢?网络中的最后一个操作是所谓的 softmax,它试图“强制确定性”。但在应用之前,神经元的值是:
代表“4”的神经元仍然具有最高的数值。但其他神经元的数值中也包含信息。我们可以预期,这些数字列表在某种意义上可以用来表征图像的“本质”,从而提供一种我们可以用作嵌入的方法。例如,这里的每个“4”都有一个稍微不同的“签名”(或“特征嵌入”),与“8”有很大的不同:

在这里,我们基本上使用 10 个数字来表征我们的图像。但通常最好使用更多的数字。例如,在我们的数字识别网络中,我们可以通过访问前一层得到一个 500 个数字的数组。这可能是一个合理的“图像嵌入”数组。
如果我们想对手写数字的“图像空间”进行明确的可视化,我们需要“降维”,实际上是将我们得到的 500 维向量投影到,例如,3D 空间中:

我们刚刚讨论了如何基于通过确定图像是否(根据我们的训练集)对应于相同的手写数字来创建图像的表征(从而进行嵌入)。如果我们有一个训练集来识别每个图像属于 5000 种常见对象(如猫、狗、椅子等)中的哪一种,我们可以以类似的方式处理图像。通过这种方式,我们可以制作一个由我们识别的常见对象“锚定”的图像嵌入,然后根据神经网络的行为“在此基础上进行泛化”。关键是,只要这种行为与我们人类感知和解释图像的方式一致,这将最终成为一个“对我们来说正确”的嵌入,并且在进行“类似人类判断”的任务时实用。
好的,那么我们如何按照相同的方法为词语找到嵌入?关键是从一个我们可以轻松进行训练的词语任务开始。标准的这种任务是“词语预测”。假设我们给定了“the ___ cat”。根据大规模文本语料库(例如,网络上的文本内容),不同词汇填补空白的概率是多少?或者,给定“___ black ___”,不同“旁边词”的概率是多少?
我们如何为神经网络设置这个问题?最终我们必须用数字来表述一切。一种方法是为英语中大约 50,000 个常见单词中的每一个分配一个唯一的数字。因此,例如,“the”可能是 914,而“cat”(前面有一个空格)可能是 3542。(这些是 GPT-2 实际使用的数字。)因此,对于“the ___ cat”问题,我们的输入可能是{914, 3542}。输出应该是什么样的?它应该是一个包含 50,000 个左右数字的列表,这些数字有效地给出每个可能的“填空”单词的概率。再一次,为了找到嵌入,我们希望“拦截”神经网络的“内部”部分,正好在它“得出结论”之前——然后拿到那里的数字列表,我们可以将其视为“表征每个单词”。
好吧,那么这些特征是什么样的?在过去的 10 年里,已经开发了一系列不同的系统(word2vec,GloVe,BERT,GPT,……),每种系统基于不同的神经网络方法。但最终,它们都将单词转化为数百到数千个数字的列表。
在原始形式下,这些“嵌入向量”是相当不具信息量的。例如,以下是 GPT-2 为三个特定单词生成的原始嵌入向量:

如果我们测量这些向量之间的距离,就可以发现单词之间的“接近度”。稍后我们将更详细地讨论我们可能考虑的这种嵌入的“认知”意义。但现在主要的点是,我们有一种有用的方法将单词转换为“神经网络友好的”数字集合。
但实际上,我们可以更进一步,不仅仅通过数字集合来表征单词;我们还可以对单词序列,甚至整块文本进行类似处理。在 ChatGPT 内部,就是这样处理这些事物的。它获取到目前为止的文本,并生成一个嵌入向量来表示它。然后,它的目标是找到可能接下来出现的不同单词的概率。它将其答案表示为一个数字列表,这些数字本质上给出每个大约 50,000 个可能单词的概率。
(严格来说,ChatGPT 不处理单词,而是处理“标记”——方便的语言单元,可以是整个单词,也可以只是像“pre”或“ing”或“ized”这样的片段。处理标记使 ChatGPT 更容易处理稀有、复合和非英语单词,并且有时,无论好坏,能发明新词。)
ChatGPT 内部
好的,我们终于可以讨论 ChatGPT 的内部结构了。是的,最终,它是一个巨大的神经网络——目前是所谓的 GPT-3 网络的一个版本,拥有 1750 亿个权重。从很多方面来看,这个神经网络与我们讨论的其他网络非常相似。但它是一个特别为处理语言而设置的神经网络。而它最显著的特征是一个叫做“transformer”的神经网络架构。
在我们上面讨论的第一个神经网络中,每一层的每个神经元基本上都与前一层的每个神经元连接(至少有一定权重)。但这种完全连接的网络(可能)在处理具有特定已知结构的数据时是过度的。因此,例如,在处理图像的早期阶段,通常使用所谓的卷积神经网络(“convnets”),其中神经元有效地布置在类似于图像中像素的网格上,并且只与网格上附近的神经元连接。
transformer 的理念是对组成文本的标记序列做一些至少有些相似的事情。但与其仅仅定义序列中可以存在连接的固定区域,transformers 引入了“注意力”的概念——即“更关注”序列中的某些部分。也许有一天,启动一个通用的神经网络并通过训练进行所有自定义是有意义的。但至少到目前为止,在实践中,“模块化”事物似乎至关重要——就像 transformers 所做的那样,也可能是我们的大脑所做的那样。
好的,那么 ChatGPT(或者说,它所基于的 GPT-3 网络)实际做了什么?请记住,它的整体目标是基于它从训练中看到的内容,以一种“合理”的方式继续文本(训练包括查看来自网络等的数十亿页文本)。所以在任何给定时刻,它有一定量的文本——其目标是提出一个合适的下一个标记选择。
它在三个基本阶段进行操作。首先,它获取与目前文本对应的令牌序列,并找到一个表示这些令牌的嵌入(即一个数字数组)。然后,它对这个嵌入进行操作——以“标准神经网络方式”,值在网络的连续层中“传递”——生成一个新的嵌入(即一个新的数字数组)。接着,它取出这个数组的最后部分,从中生成一个约 50,000 个值的数组,这些值转化为不同可能下一个令牌的概率。(是的,恰好使用的令牌数量大致与英语中的常见单词数量相同,尽管只有约 3000 个令牌是完整单词,其余的是片段。)
一个关键点是,这个管道的每个部分都是由神经网络实现的,其权重由网络的端到端训练确定。换句话说,实际上除了整体架构外,没有什么是“明确设计”的;一切都是从训练数据中“学习”得来的。
然而,架构设置中还有很多细节——反映了各种经验和神经网络的经验法则。即使这确实是深入细节,我认为谈论一些这些细节是有用的,特别是为了了解构建像 ChatGPT 这样的东西所涉及的内容。
首先是嵌入模块。这里是 GPT-2 的 Wolfram 语言示意图:
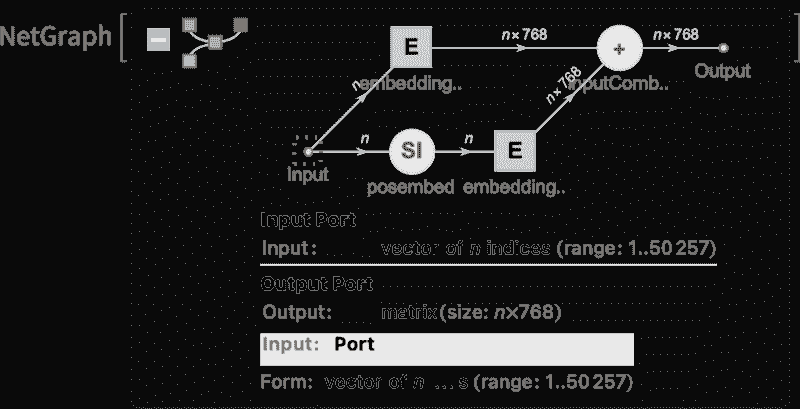
输入是一个[n]令牌的向量(如前一节所示,以从 1 到约 50,000 的整数表示)。这些令牌中的每一个都通过一个单层神经网络转换为一个嵌入向量(GPT-2 的长度为 768,ChatGPT 的 GPT-3 为 12,288)。与此同时,还有一条“次要路径”,它接收令牌位置的(整数)序列,并从这些整数创建另一个嵌入向量。最后,将令牌值和令牌位置的嵌入向量相加,生成来自嵌入模块的最终嵌入向量序列。
为什么要将令牌值和令牌位置嵌入向量相加?我认为这并没有特别的科学依据。只是尝试过各种不同的方法,这个方法似乎有效。而且神经网络的一个经验法则是——在某种意义上——只要设置“大致正确”,通常可以通过足够的训练来调整细节,而无需真正“在工程层面理解”神经网络如何配置。
嵌入模块的作用是对字符串 hello hello hello hello hello hello hello hello hello hello bye bye bye bye bye bye bye bye bye bye 进行处理:
每个令牌的嵌入向量的元素显示在页面的下方,而页面的横向则首先看到一系列的“hello”嵌入,然后是一系列的“bye”嵌入。上面的第二个数组是位置嵌入——其略显随机的结构正是“恰好被学习到”的(在这种情况下是 GPT-2 中的结果)。
好的,嵌入模块之后是变换器的“主要事件”:一系列所谓的“注意力块”(GPT-2 为 12 个,ChatGPT 的 GPT-3 为 96 个)。这一切都非常复杂——并且让人联想到典型的大型难以理解的工程系统,或者说生物系统。无论如何,这里是单个“注意力块”(对于 GPT-2)的示意图:
在每个这样的注意力块中,有一组“注意力头”(GPT-2 为 12 个,ChatGPT 的 GPT-3 为 96 个)——每个头独立地对嵌入向量中不同的值块进行操作。(而且,我们确实不知道为什么将嵌入向量拆分开来的具体理由,或其不同部分的“意义”是什么;这只是被“发现有效”的事情之一。)
好的,那么注意力头究竟做了什么呢?基本上,它们是一种“回顾”令牌序列(即已生成的文本)并以对找出下一个令牌有用的形式“打包过去”的方法。在上面的第一部分我们讨论了如何使用 2-gram 概率根据其直接前驱选择单词。变换器中的“注意力”机制使得对更早的单词也能进行“关注”——因此有可能捕捉到例如动词如何指向句子中许多词之前出现的名词的方式。
在更详细的层面上,注意力头所做的是以某些权重重新组合与不同令牌关联的嵌入向量中的块。例如,第一注意力块(在 GPT-2 中)的 12 个注意力头对于上面的“hello,bye”字符串具有以下(“回顾到令牌序列的开始”)的“重新组合权重”模式:
在经过注意力头处理后,得到的“重新加权嵌入向量”(GPT-2 的长度为 768,ChatGPT 的 GPT-3 的长度为 12,288)会传递通过一个标准的“全连接”神经网络层。很难把握这个层在做什么。但这里有一个 768×768 权重矩阵的图(这是 GPT-2 的):

通过 64×64 移动平均,一些(随机游走般的)结构开始显现:
是什么决定了这个结构?最终,它可能是某种对人类语言特征的“神经网络编码”。但截至目前,这些特征是什么仍然不太清楚。实际上,我们是在“揭开 ChatGPT 的大脑”(或者至少是 GPT-2 的大脑),发现里面确实很复杂,而且我们还不理解它——尽管最终它能够生成可识别的人类语言。
好的,那么在经过一个注意力块后,我们得到了一个新的嵌入向量——然后这个向量会依次通过额外的注意力块(GPT-2 总共 12 个;GPT-3 总共 96 个)。每个注意力块都有其独特的“注意力”和“全连接”权重模式。这里是 GPT-2 的“hello, bye”输入的注意力权重序列,第一个注意力头:
这里是(移动平均后的)“矩阵”,用于全连接层:
有趣的是,尽管这些不同注意力块中的“权重矩阵”看起来相似,但权重的大小分布可能会有所不同(并且不总是高斯分布):
那么在经过所有这些注意力块后,变压器的净效果是什么?本质上,它是将序列的原始嵌入集合转变为最终集合。而 ChatGPT 的具体工作方式是从这个集合中取出最后一个嵌入,并“解码”它以生成一个关于下一个标记应该是什么的概率列表。
所以这就是 ChatGPT 的大致内部结构。它可能看起来很复杂(尤其是因为它有许多不可避免的、略显任意的“工程选择”),但实际上,涉及的最终元素非常简单。因为最终我们处理的只是一个由“人工神经元”组成的神经网络,每个神经元进行的简单操作是接收一组数值输入,然后与某些权重进行组合。
ChatGPT 的原始输入是一个数字数组(到目前为止的令牌嵌入向量),当 ChatGPT “运行”以产生新令牌时,实际上是这些数字在神经网络的层中“波动”,每个神经元“完成其任务”并将结果传递给下一层的神经元。没有循环或“返回”。一切都只是“前馈”通过网络。
这与典型的计算系统——如Turing machine——非常不同,在那种系统中,结果会被同样的计算元素重复“再处理”。在这里——至少在生成给定的输出令牌时——每个计算元素(即神经元)只使用一次。
但从某种意义上说,即使在 ChatGPT 中,仍然存在一个“外部循环”会重用计算元素。因为当 ChatGPT 生成新令牌时,它总是“读取”(即作为输入)之前的整个令牌序列,包括 ChatGPT 自己之前“写”的令牌。我们可以认为这种设置意味着 ChatGPT 至少在最外层涉及了一个“反馈循环”,尽管每次迭代都明确地显示为生成文本中的一个令牌。
但让我们回到 ChatGPT 的核心:被重复用于生成每个令牌的神经网络。在某种程度上,它非常简单:一整套相同的人工神经元。网络的一些部分只是由(“全连接)”的神经元层组成,其中每一层上的每个神经元都与上一层的每个神经元连接(具有某些权重)。但特别是通过其变压器架构,ChatGPT 有更多结构的部分,其中只有不同层上的特定神经元是连接的。(当然,人们仍然可以说“所有神经元都是连接的”——但有些只是权重为零。)
此外,ChatGPT 中的神经网络有一些方面并不完全被认为是由“同质”层组成。例如——如上面的标志性总结所示——在注意力块内部,有些地方会“制作多个副本” 的输入数据,每个副本通过不同的“处理路径”,可能涉及不同数量的层,然后再进行组合。但虽然这可能是对发生情况的方便表示,但原则上总是可以考虑“密集填充”层,只是某些权重为零。
如果查看 ChatGPT 最长的路径,大约有 400 个(核心)层涉及其中——在某种程度上,这并不是一个巨大的数字。但有数百万个神经元——总共有 1750 亿个连接,因此有 1750 亿个权重。而且需要意识到的是,每当 ChatGPT 生成一个新标记时,它必须进行涉及每一个权重的计算。在实现上,这些计算可以按“层”组织成高度并行的数组操作,这些操作可以方便地在 GPU 上完成。但是,对于每一个生成的标记,仍然需要进行 1750 亿次计算(最终可能更多)——因此,是的,生成一段长文本可能需要一些时间,这是不令人惊讶的。
但最终,值得注意的是,所有这些操作——虽然它们单独看起来非常简单——能够共同完成如此出色的“类似人类”的文本生成。这一点需要再次强调的是(至少就我们目前所知),没有“终极理论上的理由”说明这样的事情会有效。实际上,正如我们将讨论的,我认为我们必须将其视为一种——可能令人惊讶的——科学发现:在像 ChatGPT 这样的神经网络中,确实可以捕捉到人脑在生成语言时所做的本质。
ChatGPT 的训练
好的,我们现在已经概述了 ChatGPT 设置后的工作原理。但它是如何被设置的呢?那些 1750 亿个神经网络权重是如何确定的?基本上,它们是通过大规模训练的结果,这些训练基于由人类编写的大量文本——包括网络上的内容、书籍等。正如我们所说,即使有了所有这些训练数据,神经网络是否能成功生成“类似人类”的文本并不明显。而且,再次强调,要实现这一点似乎需要详细的工程技术。但是,ChatGPT 的重大惊喜和发现是这完全是可能的。实际上,一个具有“仅仅” 1750 亿个权重的神经网络可以生成一个“合理的模型”来模拟人类所写的文本。
在现代,存在大量以数字形式存在的人类书写文本。公共网页至少有数十亿个人书写的页面,总共可能有一万亿个词。如果包括非公开网页,这些数字可能大约大 100 倍。迄今为止,已经提供了超过 500 万本数字化的书籍(在曾经出版的约 1 亿本中),另外提供了大约 1000 亿个词。更不用提来自视频等的语音文本。(作为个人比较, 我一生出版的材料总量 略低于 300 万字,过去的 30 年里我写了 大约 1500 万字的邮件,总共打字大约 5000 万字——在过去几年中,我在 直播中讲了超过 1000 万字 。是的,我会从所有这些内容中训练一个机器人。)
好吧,鉴于所有这些数据,如何从中训练一个神经网络?基本过程与我们在上述简单示例中讨论的非常类似。你呈现一批示例,然后调整网络中的权重,以最小化网络在这些示例上的误差(“损失”)。关于“反向传播”中花费的主要部分在于,每次进行时,网络中的每个权重通常会至少改变一点,而需要处理的权重数量非常多。(实际的“反向计算”通常只是比前向计算难度增加一个小的常数因子。)
使用现代 GPU 硬件,从成千上万的示例中并行计算结果是非常直接的。但在实际更新神经网络的权重时,目前的方法基本上需要逐批进行。(而且,是的,这可能正是实际大脑——结合了计算和记忆元素——在架构上至少暂时具有优势的地方。)
即使在我们之前讨论的看似简单的学习数值函数的情况下,我们发现我们经常需要使用数百万个示例来成功训练一个网络,至少从零开始。那么,这意味着我们需要多少个示例来训练一个“类人语言”模型?似乎没有任何基本的“理论”方法来确定。但在实践中,ChatGPT 是在数百亿个词的文本上成功训练的。
有些文本被重复喂入了几次,有些仅被喂入了一次。但它“从它看到的文本中获得了它需要的东西”。但考虑到这个学习文本的量,应该需要多大的网络才能“学得好”?再次地,我们尚无一个基本的理论方法来说明。最终—正如我们将在下文进一步讨论的—人类语言及其通常所说内容可能存在一定的“总算法内容”。但下一个问题是神经网络在基于这些算法内容实施模型时的效率如何。我们仍然不知道—尽管 ChatGPT 的成功表明它在效率上是相当合理的。
最终,我们可以简单地指出,ChatGPT 是通过几个亿个权重来完成它的工作的—这个数量与它所接受的训练数据的总词数(或标记数)相当。从某种程度上来说,这或许令人惊讶(虽然在 ChatGPT 的较小类似模型中也有观察到这种情况),即“网络的规模”与“训练数据的规模”如此相似。毕竟,肯定不是“ChatGPT 内部”直接存储了这些来自网络和书籍等的文本。因为实际上,ChatGPT 内部是一些数字—精度略低于 10 位数字—这些数字是所有这些文本的某种分布式编码。
换句话说,我们可以问人类语言的“有效信息内容”是什么,以及通常所说的内容是什么。有原始的语言示例语料库。然后是 ChatGPT 神经网络中的表示。这个表示很可能远非“算法上最小”的表示(如我们将在下文讨论的)。但这是一个神经网络可以直接使用的表示。在这个表示中,似乎对训练数据的“压缩”相当有限;平均而言,基本上只需少于一个神经网络权重就能承载一个训练数据词的“信息内容”。
当我们运行 ChatGPT 生成文本时,基本上每个权重都需要被使用一次。所以如果有 n 个权重,我们就需要大约 n 步计算—尽管在实际中,许多计算步骤通常可以在 GPU 中并行完成。但如果我们需要大约 n 个训练数据词来设置这些权重,那么从我们以上所说的内容可以得出结论,我们需要大约 n² 步计算来完成网络的训练—这就是为什么,使用当前的方法,需要谈论亿级别的训练投入。
基础训练之外
训练 ChatGPT 的大部分工作是“展示”大量来自网络、书籍等的现有文本。但事实证明,还有另一个—显然相当重要—部分。
一旦它完成了来自原始文本语料库的“原始训练”,ChatGPT 内部的神经网络就准备开始生成自己的文本,继续从提示中进行。但虽然这些结果可能看起来合理,它们往往——特别是对于较长的文本——会以往往相当非人类的方式“偏离”。这不是一种可以通过对文本进行传统统计轻易检测到的情况。但这是实际阅读文本的人容易注意到的。
一个 ChatGPT 构建中的关键思想 是在像网络这样的“被动阅读”之后再进行另一步骤:让实际的人类与 ChatGPT 积极互动,查看它生成的内容,并实际上对其“如何成为一个优秀聊天机器人”提供反馈。但是神经网络如何利用这些反馈?第一步是让人类对神经网络的结果进行评分。但随后构建了另一个神经网络模型,试图预测这些评分。现在,这个预测模型可以运行——本质上就像一个损失函数——在原始网络上,从而使得该网络可以通过已给予的人类反馈进行“调整”。实际结果似乎对系统成功生成“类人”输出有很大影响。
总体来说,令人感兴趣的是,“最初训练过的”网络似乎只需很少的“刺激”就能在特定方向上有用地发展。人们可能会认为,要使网络表现得像是“学到了新东西”,必须进入并运行训练算法,调整权重等等。
但事实并非如此。相反,似乎基本上只需一次告诉 ChatGPT 某些事情——作为你提供的提示的一部分——然后它就可以在生成文本时成功利用你告诉它的内容。我认为,这种有效性的事实是理解 ChatGPT “真实做了什么”以及它如何与人类语言和思维结构相关的重要线索。
这确实有点像人类:至少在它接受了所有那些预训练后,你可以只告诉它一次它就能“记住”——至少“足够长的时间”来使用这些信息生成一段文本。那么,在这种情况下发生了什么?可能是“你告诉它的一切已经在某个地方”——你只是引导它到正确的位置。但这似乎不太可信。相反,更可能的情况是,确实,元素已经在里面,但细节是由类似于“这些元素之间的轨迹”的东西定义的,而这就是你在告诉它某些东西时所引入的。
确实,就像对人类一样,如果你告诉它一些奇怪且出乎意料的内容,这些内容完全不符合它所知道的框架,它似乎无法成功“整合”这些内容。它只能在基本上沿用其已有的框架的情况下“整合”这些内容。
还值得再强调一点,神经网络不可避免地存在“算法限制”,即它可以“捕捉”到的内容。告诉它一些“浅层”的规则,例如“这个去那个”,神经网络很可能能够很好地表示和再现这些规则——事实上,它从语言中“已经知道”的内容会给它一个立刻可以遵循的模式。但如果尝试给它一些实际的“深层”计算规则,这些规则涉及许多可能的计算不可约步骤,它就无法完成。 (记住,在每一步,它总是只是在其网络中“向前传递数据”,除非通过生成新标记来循环。)
当然,网络可以学习特定的“不可约”计算的答案。但一旦出现组合数目的可能性,任何这种“表查找风格”的方法都将不起作用。因此,是的,就像人类一样,神经网络也需要“伸出”并使用实际的计算工具。(而且,是的,Wolfram|Alpha 和 Wolfram Language 是 独特适用 的,因为它们被构建为“讨论世界中的事物”,就像语言模型神经网络一样。)
什么真正让 ChatGPT 工作?
人类语言——以及生成它的思维过程——总是看起来代表了一种复杂性的巅峰。确实,人类的大脑——虽然只有大约 1000 亿个神经元(可能还有 100 万亿个连接)——能够负责这一点,这似乎有些令人惊讶。也许,有人可能会想象,大脑的某些东西比其神经网络更复杂——比如某种尚未发现的物理层次。但现在,凭借 ChatGPT,我们获得了一个重要的新信息:我们知道一个纯粹的人工神经网络,其连接数量与大脑中的神经元数量相当,能够非常出色地生成类似人类的语言。
是的,这仍然是一个庞大而复杂的系统——其神经网络权重的数量与目前世界上可用的文本单词数量大致相当。但在某种程度上,仍然很难相信语言的所有丰富性以及它可以讨论的内容都可以被封装在这样一个有限的系统中。部分原因无疑是反映了普遍存在的现象(这一现象首次在规则 30 的示例中显现出来),即计算过程实际上可以极大地放大系统的表观复杂性,即使其底层规则很简单。但实际上,正如我们上面讨论的那样,ChatGPT 使用的神经网络往往被特别构造,以限制这一现象的影响——以及与之相关的计算不可简化性——以便使其训练更为可及。
那么,ChatGPT 如何在语言上取得如此大的进展呢?基本的回答是,我认为语言在根本上比它看起来的要简单。这意味着,即使是具有最终简单的神经网络结构的 ChatGPT,也能够成功地“捕捉到”人类语言及其背后的思维。此外,在其训练中,ChatGPT 不知怎么地“隐性地发现”了使这一切成为可能的语言(和思维)规律。
我认为,ChatGPT 的成功为我们提供了一个基本且重要的科学证据:它表明我们可以期待发现一些重大的新“语言规律”——实际上是“思维规律”。在 ChatGPT 中——尽管它是作为一个神经网络构建的——这些规律充其量只是隐含的。但如果我们能够以某种方式使这些规律显性化,就有可能以更直接、更高效——以及更透明的方式——做 ChatGPT 所做的事情。
那么,这些规律可能是什么样的呢?最终它们必须给我们一些关于语言——以及我们用它说的话——如何组合的指示。稍后我们将讨论如何“窥视 ChatGPT 内部”可能会给我们一些关于这方面的提示,以及从构建计算语言中得到的知识如何暗示前进的道路。但首先,让我们讨论两个早已为人知的“语言规律”示例——以及它们与 ChatGPT 操作的关系。
首先是语言的语法。语言不仅仅是随机的词汇组合。相反,存在(相当)明确的语法规则,规定了不同类型的词如何组合在一起:例如在英语中,名词可以被形容词修饰并由动词跟随,但通常两个名词不能紧挨在一起。这种语法结构可以(至少大致上)通过一套规则来捕捉,这些规则定义了如何将“解析树”组合在一起:
ChatGPT 并没有明确的“知识”关于这些规则。但它在训练过程中以某种方式“发现”了这些规则——然后似乎能够很好地遵循它们。那么这如何运作呢?从“大图景”层面来看,还不清楚。但为了获得一些见解,也许可以看看一个更简单的例子。
考虑一个由(’和)’组成的“语言”,其语法规定 括号应始终保持平衡,如通过解析树表示:
我们可以训练一个神经网络来生成“语法正确”的括号序列吗?处理序列的神经网络有多种方法,但我们使用与 ChatGPT 相同的变换器网络。给定一个简单的变换器网络,我们可以开始用语法正确的括号序列作为训练样本。一个微妙之处(实际上也出现在 ChatGPT 的语言生成中)是,除了我们的“内容标记”(这里是“(” 和 “)”)外,我们还必须包括一个“结束”标记,用于表示输出不应该继续(即对于 ChatGPT 来说,这表示“故事的结尾”)。
如果我们设置一个只有一个具有 8 个头的注意力块和长度为 128 的特征向量的变换器网络(ChatGPT 也使用长度为 128 的特征向量,但有 96 个注意力块,每个具有 96 个头),那么似乎无法让它学到很多关于括号语言的知识。但有了 2 个注意力块后,学习过程似乎会收敛——至少在给出大约 1000 万个样本后(并且,正如变换器网络中常见的那样,显示更多的样本似乎只是降低了其性能)。
因此,使用这个网络,我们可以模拟 ChatGPT 的功能,并请求预测下一个标记应该是什么——在一个括号序列中:

在第一个例子中,网络“相当确定”序列不能在这里结束——这是好的,因为如果在这里结束,括号将会不平衡。然而,在第二个例子中,网络“正确地识别”序列可以在这里结束,尽管它也“指出”可以“重新开始”,放下一个“(”,推测会跟一个“)” 。但,哎呀,即使拥有大约 40 万个经过辛苦训练的权重,它也表示有 15%的概率下一个标记是“)”——这不对,因为那会导致括号不平衡。
如果我们要求网络对逐渐增长的括号序列进行最高概率的补全,我们会得到以下结果:

是的,对于一定长度的序列,网络表现得很好。但是,超出这个长度后,它就开始出现问题。这是一种在“精确”情况下看到的典型现象,无论是神经网络还是一般的机器学习。神经网络可以解决那些人类“可以一眼看懂”的问题。但是,对于那些需要进行“更算法化”的操作(例如,明确计算括号是否匹配)的问题,神经网络往往会变得“计算上过于浅显”,难以可靠地处理。(顺便提一下,即使是当前版本的 ChatGPT,在处理长序列的括号匹配时也会遇到困难。)
那么,这对像 ChatGPT 这样的系统以及像英语这样的语言的语法意味着什么?括号语言是“简洁的”——更像是“算法化的故事”。但在英语中,基于局部词汇选择和其他提示来“猜测”语法上会适合的内容更为现实。是的,神经网络在这方面要更好——尽管它可能会遗漏一些“形式上正确”的情况,人类也可能会遗漏。但关键点是,语言中存在整体的语法结构——所有的规则性都意味着——在某种程度上限制了“神经网络需要学习的内容”。一个关键的“自然科学”观察是,像 ChatGPT 中的变换器架构似乎成功地学习了那种嵌套树状的语法结构,这种结构似乎存在(至少在某种程度上)于所有人类语言中。
语法为语言提供了一种约束。然而,显然还有更多的约束。像“Inquisitive electrons eat blue theories for fish”这样的句子在语法上是正确的,但通常不被认为是正常的表达,如果 ChatGPT 生成了这样的句子,也不会被认为是成功的——因为按照这些词的正常含义,这句话基本上是毫无意义的。
但是否有一种通用的方法来判断句子是否有意义?对于这个问题没有传统的总体理论。但可以认为 ChatGPT 在用来自网络等的数十亿个(可能有意义的)句子进行训练后,隐含地“发展了一个理论”。
这个理论可能是什么样的呢?嗯,有一个微小的角落基本上已经被了解了两千年,那就是逻辑。毫无疑问,在亚里士多德发现它的三段论形式中,逻辑基本上是一种说法,即遵循某些模式的句子是合理的,而其他的则不是。因此,例如,说“所有 X 都是 Y。这不是 Y,所以它不是 X”是合理的(比如“所有鱼都是蓝色的。这不是蓝色的,所以它不是鱼。”)。正如可以有些异想天开地想象亚里士多德通过大量修辞例子“机器学习风格”地发现了三段论逻辑一样,也可以想象在训练 ChatGPT 时,它能够通过查看大量网络上的文本等来“发现三段论逻辑”。(是的,虽然因此可以期望 ChatGPT 生成的文本包含基于三段论逻辑的“正确推论”,但当涉及到更复杂的形式逻辑时,情况就大相径庭了——我认为可以预期它在这里会失败,原因与括号匹配失败的原因类似。)
但超越狭义的逻辑示例,关于如何系统地构造(或识别)即使是看似有意义的文本,还能说些什么呢?是的,有像疯狂填词这样的东西,使用了非常具体的“短语模板”。但不知怎么的,ChatGPT 隐含地有一种更为通用的方式来做到这一点。也许对于如何做到这一点,没有比“当你有 1750 亿个神经网络权重时它会发生”更好的说法了。但我强烈怀疑有一个更简单、更强的故事。
意义空间和语义运动定律
我们在上面讨论过,在 ChatGPT 内部,任何一段文本实际上都被表示为一个数字数组,我们可以将其视为某种“语言特征空间”中的一个点的坐标。因此,当 ChatGPT 继续一段文本时,这相当于在语言特征空间中描绘出一条轨迹。但现在我们可以问,是什么使这条轨迹对应于我们认为有意义的文本。也许存在某种“语义运动定律”,定义或至少约束语言特征空间中的点在保持“有意义性”时的移动方式?
那么这种语言特征空间是什么样的呢?这里有一个例子,展示了如果我们将这种特征空间投射到二维平面上,单个词(这里是常见名词)可能会如何分布:
上面我们看到的另一个例子基于代表植物和动物的词。但在这两种情况下的要点是,“语义相似的词”被放置在一起。
作为另一个例子,以下是不同词性对应的词的布局方式:
当然,一个给定的词通常并不只有“一种意义”(或必然只对应一种词性)。通过查看包含一个词的句子在特征空间中的布局,通常可以“区分”不同的意义——就像这里的“crane”(鸟或机器?)一词的例子:
好的,所以我们至少可以合理地认为,我们可以将这个特征空间视为在此空间中将“语义相近的词”放得较近。但我们可以在这个空间中识别出什么额外的结构?例如,有没有某种“平行传输”的概念可以反映空间的“平坦性”?一种获取这种信息的方法是查看类比:
是的,即使我们投影到 2D,通常也会有至少一个“平坦性的提示”,尽管这并不是普遍存在的。
那么关于轨迹呢?我们可以查看 ChatGPT 在特征空间中跟随的提示轨迹——然后我们可以看到 ChatGPT 如何继续这一轨迹:
这里显然没有“几何上显而易见”的运动定律。这并不令人惊讶;我们完全预期这会是一个复杂得多的故事。例如,即使发现了“语义运动定律”,它最自然的表述形式(或实际上的“变量”)也远非显而易见。
在上图中,我们展示了“轨迹”中的几个步骤——在每一步我们都选择 ChatGPT 认为最可能的词(“零温度”情况)。但我们也可以询问在给定点上什么词可以“接下来”出现,概率是多少:
在这种情况下,我们看到的是一个高概率词的“扇形”,似乎在特征空间中朝着一个或多或少明确的方向延展。如果我们进一步探索会发生什么?以下是我们“沿着”轨迹移动时出现的连续“扇形”:
这是一个 3D 表示,总共有 40 步:
是的,这看起来像一团糟——并没有特别鼓励人们相信可以通过经验研究“ChatGPT 内部发生了什么”来识别“类似数学物理的” “语义运动法则”。但也许我们只是看错了“变量”(或错误的坐标系),如果我们只看对的,我们就会立即看到 ChatGPT 正在做一些“数学物理简单”的事情,比如遵循测地线。但截至目前,我们还没有准备好“从其内部行为中经验性解码”ChatGPT“发现”的关于人类语言如何“组合”的信息。
语义语法与计算语言的力量
产生“有意义的人类语言”需要什么?过去,我们可能认为这只能由人脑完成。但现在我们知道,这可以由 ChatGPT 的神经网络相当体面地完成。尽管如此,也许这就是我们能走的最远的地方,可能没有更简单的或更易于理解的东西能够奏效。但我强烈怀疑的是,ChatGPT 的成功隐含地揭示了一个重要的“科学”事实:有意义的人类语言实际上比我们知道的要有更多的结构和简单性——最终可能会有一些相当简单的规则来描述这种语言如何组合在一起。
正如我们之前提到的,句法语法为不同词类的词如何在自然语言中组合提供了规则。但要处理意义,我们需要更进一步。一个版本的做法是,不仅考虑语言的句法语法,还要考虑语义语法。
在语法的层面上,我们识别名词和动词等事物。但在语义层面上,我们需要“更精细的划分”。例如,我们可能会识别“移动”的概念,以及一个“在位置上保持其身份独立”的“物体”的概念。这些“语义概念”都有无尽的具体例子。但就我们的语义语法而言,我们会有一些基本的规则,大致说明“物体”可以“移动”。关于这一切如何运作,还有很多要说的(我以前提到过一些)。但我在这里只会简单提几句,指出一些可能的前进方向。
值得一提的是,即使一个句子根据语义语法是完全正确的,也不意味着它已经在实践中实现(或甚至可能实现)。“大象旅行到月球”无疑会“通过”我们的语义语法,但它确实还没有在我们的实际世界中实现(至少目前还没有)——尽管它绝对是虚构世界的公平素材。
当我们开始讨论“语义语法”时,我们很快会问“它底下是什么?”它假设了什么“世界模型”?句法语法实际上只是关于如何从单词构建语言。但语义语法必然涉及某种“世界模型”——这是一种“骨架”,语言可以在其上叠加。
直到最近,我们可能会认为(人类)语言将是描述我们“世界模型”的唯一通用方式。早在几个世纪前,就开始对特定类型的事物进行形式化,特别是基于数学的。但现在有了一种更为通用的形式化方法:计算语言。
是的,这就是我在四十多年时间里(现在体现于Wolfram 语言)的大项目:开发一个精确的符号表示,可以尽可能广泛地谈论世界上的事物,以及我们关心的抽象事物。例如,我们有cities和molecules以及images和neural networks的符号表示,并且我们已经内置了关于如何计算这些事物的知识。
经过几十年的工作,我们已经涵盖了很多领域。但在过去,我们没有特别处理“日常话语”。在“我买了两磅苹果”中,我们可以轻松表示(并对其进行营养和其他计算)“两磅苹果”。但我们还(尚未)拥有“我买了”的符号表示。
这一切都与语义语法的概念有关——以及拥有一个通用符号“构建工具”的目标,这将为我们提供关于什么可以组合在一起的规则,从而决定我们可能转化为人类语言的“流”。
但假设我们有了这种“符号话语语言”。我们会怎么处理它呢?我们可以先从生成“局部有意义的文本”开始。但最终我们可能会想要更多“全球有意义”的结果——这意味着“计算”实际存在或发生在世界上的更多内容(或者也许在某个一致的虚构世界中)。
目前在 Wolfram Language 中,我们拥有大量关于各种事物的内置计算知识。但对于一个完整的符号话语语言,我们还需要构建关于世界上普遍事物的额外“计算体系”:例如,如果一个物体从 A 移动到 B,再从 B 移动到 C,那么它就从 A 移动到了 C,等等。
有了符号话语语言,我们可以用它来做“独立陈述”。但我们也可以用它来提出关于世界的问题,“Wolfram|Alpha 风格”。或者我们可以用它来陈述我们“希望实现的”事情,通常是通过某种外部驱动机制实现的。或者我们可以用它来做断言——也许是关于实际世界,或者关于我们考虑的某个特定世界,无论是虚构的还是其他的。
人类语言在根本上是不精确的,尤其是因为它没有“绑定”到特定的计算实现,其含义基本上只是由使用者之间的“社会契约”定义的。但计算语言本质上具有一定的基本精确性——因为最终它所指定的内容总是可以“在计算机上明确执行”。人类语言通常可以容忍一定的模糊性。(例如,当我们说“行星”时,是否包括系外行星?)但在计算语言中,我们必须对所做的所有区分保持精确和清晰。
在构造计算语言的名称时,利用普通人类语言通常很方便。但它们在计算语言中的含义必然是精确的——而且可能覆盖或不覆盖典型人类语言使用中的某些特定含义。
如何确定适合一般符号话语语言的基本“本体论”?这并不容易。这或许也是为什么自从两千多年前亚里士多德的原始开端以来,这方面的研究几乎没有进展。但今天我们知道了很多关于如何以计算方式思考世界的知识(并且拥有来自我们的 物理学项目 和 ruliad 概念 的“基础形而上学”也很有帮助)。
那么,这些在 ChatGPT 的背景下意味着什么呢?通过训练,ChatGPT 实质上“拼凑”出了一定量的语义语法(相当令人印象深刻)。但它的成功让我们有理由认为,构建一种更完整的计算语言形式是可行的。而且,与我们迄今为止对 ChatGPT 内部结构的了解不同,我们可以期望设计一种计算语言,使其对人类容易理解。
当我们谈论语义语法时,我们可以类比于三段论逻辑。一开始,三段论逻辑本质上是关于用人类语言表达的陈述的规则集合。但(是的,两千年后)当形式逻辑被发展时,三段论逻辑的基本构造现在可以用来构建巨大的“形式塔”,包括例如现代数字电路的操作。因此,我们可以预期,更一般的语义语法也会如此。一开始,它可能只能处理简单的模式,例如以文本形式表达。但一旦构建了整个计算语言框架,我们可以期待它能够用来建立“广义语义逻辑”的高塔,使我们能够以精确和形式化的方式处理各种以前无法接触的事物,只能通过人类语言以“地面层级”处理,带有所有的模糊性。
我们可以把计算语言和语义语法的构建看作是一种在表示事物时的终极压缩。因为它让我们能够讨论可能性的本质,而不需要处理普通人类语言中存在的所有“表达方式”。我们可以将 ChatGPT 的巨大优势视为类似的东西:因为它也在某种程度上“钻透”到了能够“以语义上有意义的方式”组合语言的地步,而不必担心不同的表达方式。
那么如果我们将 ChatGPT 应用到底层计算语言上会发生什么呢?计算语言可以描述什么是可能的。但可以进一步补充的是一种“什么是流行”的感觉——例如,基于读取互联网上的所有内容。但在底层——操作计算语言意味着像 ChatGPT 这样的系统具有即时和根本的访问权限,能够使用潜在不可简化的计算的终极工具。这使得它不仅可以“生成合理的文本”,而且可以期望解决任何可以解决的内容,以确定该文本是否实际上对世界做出了“正确”的陈述——或者它应该讨论的内容。
那么… ChatGPT 在做什么,为什么它能有效?
ChatGPT 的基本概念在某种程度上相当简单。从网络、书籍等来源的大量人类创作文本开始。然后训练一个神经网络生成“像这样的”文本。特别是,让它能够从一个“提示”开始,然后继续生成“像它所训练的那样”的文本。
正如我们所看到的,ChatGPT 的实际神经网络由非常简单的元素构成——尽管有数十亿个。而神经网络的基本操作也非常简单,本质上是将从其迄今生成的文本中派生的输入“通过其元素”处理一次(没有任何循环等),以生成每一个新词(或词的一部分)。
但令人惊讶且出乎意料的是,这个过程可以生成成功“类似”于网络、书籍等上的文本。而且,它不仅是连贯的人类语言,还会“表达”符合其提示的内容,利用它所“阅读”的内容。它并不总是说出“全球上合理”的话(或对应正确的计算)——因为(例如,没有访问 Wolfram|Alpha 的“计算超能力”)它只是在根据训练材料中“听起来对的”东西说话。
ChatGPT 的具体工程设计使其非常引人注目。但最终(至少在它能够使用外部工具之前)ChatGPT 只是从其积累的“传统智慧统计”中“抽取出一些连贯的文本线索”。但结果的类人性令人惊叹。正如我所讨论的,这暗示了一个至少在科学上非常重要的事实:人类语言(及其背后的思维模式)在结构上比我们想象的要简单和“更具规律性”。ChatGPT 已经隐含地发现了这一点。但我们可以通过语义语法、计算语言等方式显式地揭示它。
ChatGPT 在生成文本时的表现非常令人印象深刻——而且结果通常非常接近我们人类会产生的内容。这是否意味着 ChatGPT 像大脑一样工作?它的基础人工神经网络结构最终是基于对大脑的理想化模型。并且,似乎我们人类生成语言时,许多方面与之类似。
在训练(即学习)大脑和当前计算机的不同“硬件”时(以及也许一些尚未开发的算法思想),ChatGPT 被迫使用一种可能与大脑相当不同(在某些方面效率更低)的策略。还有其他一些问题:即使在典型的算法计算中,ChatGPT 也没有内部“循环”或“在数据上重新计算”。这不可避免地限制了它的计算能力——即使与当前计算机相比,也确实与大脑相比。
目前还不清楚如何“修复”这个问题,同时仍保持合理的训练效率。但是,这样做将可能让未来的 ChatGPT 能够做更多“类似大脑的事情”。当然,大脑确实有很多做得不那么好的事情—特别是那些涉及到不可简化计算的任务。对于这些任务,大脑和像 ChatGPT 这样的系统必须寻求“外部工具”—例如Wolfram 语言。
但现在看到 ChatGPT 已经能够做到的事情令人兴奋。在某种程度上,它是一个很好的例子,展示了大量简单计算元素可以做出非凡和意想不到的事情这一基本科学事实。但它也提供了我们在两千年来最好的动机,以更好地理解人类语言这一人类状况核心特征的基本特性和原则,以及背后的思维过程。
感谢
我已经跟踪神经网络的发展约 43 年,在此期间我与许多人进行了互动。其中—有些是很久以前的,有些是最近的,还有一些是跨越多年—包括:Giulio Alessandrini, Dario Amodei, Etienne Bernard, Taliesin Beynon, Sebastian Bodenstein, Greg Brockman, Jack Cowan, Pedro Domingos, Jesse Galef, Roger Germundsson, Robert Hecht-Nielsen, Geoff Hinton, John Hopfield, Yann LeCun, Jerry Lettvin, Jerome Louradour, Marvin Minsky, Eric Mjolsness, Cayden Pierce, Tomaso Poggio, Matteo Salvarezza, Terry Sejnowski, Oliver Selfridge, Gordon Shaw, Jonas Sjöberg, Ilya Sutskever, Gerry Tesauro 和 Timothee Verdier。特别感谢 Giulio Alessandrini 和 Brad Klee 对本文的帮助。
斯蒂芬·沃尔弗拉姆 是 Mathematica、Wolfram|Alpha 和 Wolfram 语言的创始人;Wolfram 物理学项目的发起者;《新科学》及其他书籍的作者;Wolfram Research 的创始人兼首席执行官。
原文。经许可转载。
更多相关内容
37 个原因说明你的神经网络无法工作
原文:
www.kdnuggets.com/2017/08/37-reasons-neural-network-not-working.html
评论
由 Slav Ivanov,企业家与机器学习从业者。
网络已经训练了过去 12 个小时。一切看起来都很好:梯度在流动,损失在减少。但随后预测出来的结果是:全是零,全是背景,什么也没检测到。“我哪里做错了?”——我问我的电脑,但它没有回答。
如果你的模型输出垃圾(例如预测所有输出的均值,或准确率非常差),你应该从哪里开始检查?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
网络可能因为多种原因而无法训练。在多次调试过程中,我经常发现自己进行相同的检查。我将我的经验以及周围的最佳建议编成了这份实用的清单。希望对你也有帮助。
目录
-
0. 如何使用本指南?
-
I. 数据集问题
-
II. 数据规范化/增强问题
-
III. 实施问题
-
IV. 训练问题
0. 如何使用本指南?
许多事情可能会出错。但其中一些比其他的更容易出问题。我通常会从这个紧急响应的短名单开始:
-
从一个已知对这种数据类型有效的简单模型开始(例如,VGG 用于图像)。如果可能,使用标准损失函数。
-
关闭所有的附加功能,例如正则化和数据增强。
-
如果对模型进行微调,务必再次检查预处理步骤,确保它与原始模型的训练一致。
-
验证输入数据是否正确。
-
从一个非常小的数据集(2–20 个样本)开始。在其上进行过拟合,并逐渐增加更多的数据。
-
逐渐添加所有被省略的部分:增强/正则化、自定义损失函数,尝试更复杂的模型。
如果上述步骤不起作用,开始逐项检查以下大清单。
I. 数据集问题

1. 检查你的输入数据
检查你提供给网络的输入数据是否合理。例如,我曾多次混淆图像的宽度和高度。有时,我会错误地输入全零的数据。或者我会一遍又一遍地使用同一批数据。因此,打印/显示几批输入和目标输出,确保它们是正确的。
2. 尝试随机输入
尝试传递随机数字而不是实际数据,看看错误是否表现得一样。如果是,那就说明你的网络在某个点上把数据变成了垃圾。尝试逐层/逐操作调试,看看问题出在哪里。
3. 检查数据加载器
你的数据可能没问题,但将输入传递给网络的代码可能有问题。在任何操作之前,打印第一层的输入并检查它。
4. 确保输入与输出相连
检查一些输入样本是否有正确的标签。还要确保打乱输入样本的方式对于输出标签也一样有效。
5. 输入和输出之间的关系是否过于随机?
也许输入和输出之间的非随机关系相比于随机部分太小(可以说股票价格就是这样)。即输入与输出之间的关系不够紧密。没有通用的方法来检测这个问题,因为这取决于数据的性质。
6. 数据集中的噪声是否过多?
我曾经在从一个食品网站抓取图像数据集时遇到过这种情况。标签错误太多,以至于网络无法学习。手动检查一批输入样本,看看标签是否有问题。
这一点尚有争议,因为这篇论文在使用 50%标签被破坏的情况下在 MNIST 上达到了超过 50%的准确率。
7. 打乱数据集
如果你的数据集没有被打乱,并且有特定的顺序(按标签排序),这可能会对学习产生负面影响。打乱你的数据集以避免这种情况。确保你同时打乱输入和标签。
8. 减少类别不平衡
是否每个类别 B 图像都有 1000 张类别 A 图像?那么你可能需要平衡你的损失函数或尝试其他类别不平衡的方法。
9. 你是否有足够的训练样本?
如果你从头开始训练一个网络(即不是微调),你可能需要大量数据。对于图像分类,有人说你每个类别需要 1000 张图像或更多。
10. 确保你的批次不包含单一标签
在排序的数据集中(即前 10k 个样本包含相同的类别)可能会发生这种情况。通过打乱数据集可以轻松解决。
11. 减少批量大小
这篇论文指出,拥有非常大的批次可能会降低模型的泛化能力。
附加 1. 使用标准数据集(例如 mnist,cifar10)
感谢@hengcherkeng的分享:
在测试新的网络架构或编写新代码时,首先使用标准数据集,而不是你自己的数据。这是因为这些数据集有许多参考结果,并且被证明是“可解决的”。不会有标签噪声、训练/测试分布差异、数据集难度过大等问题。
II. 数据标准化/增强

12. 标准化 特征
你是否将输入标准化为零均值和单位方差?
13. 你是否进行过多的数据增强?
数据增强具有正则化效果。过多的增强与其他形式的正则化(如权重 L2、dropout 等)结合使用,可能导致模型欠拟合。
14. 检查你的预训练模型的预处理
如果你使用了预训练模型,确保你使用的归一化和预处理与训练时的模型一致。例如,图像像素应该在[0, 1]、[-1, 1]还是[0, 255]范围内?
15. 检查训练/验证/测试集的预处理
CS231n 指出一个 常见的陷阱:
“… 任何预处理统计(例如数据均值)必须仅在训练数据上计算,然后应用于验证/测试数据。例如,计算均值并从整个数据集的每张图像中减去,然后将数据拆分为训练/验证/测试集将是一个错误。”
同时,检查每个样本或批次中的不同预处理。
更多相关话题
TF-IDF 定义

作者提供的图片
TF-IDF。你可能在博客中见过这个词,或者你正在学习机器学习中的相关内容。本文概述了 TF-IDF 是什么。
我们的前三个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业。
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你在 IT 领域的组织
TF-IDF 是什么意思?
TF-IDF 代表词频-逆文档频率。
TF-IDF 通常用于机器学习和信息检索领域。
TF-IDF 是一种数值统计,衡量在语料库(文档)中诸如单词、短语等字符串表示的重要性。
让我们拆解这个缩写,深入理解它。
什么是语料库?
在语言艺术或机器学习中的自然语言处理领域,语料库是一个组织成数据集的文本或音频集合。

Sarah Mae 通过 Unsplash
以这首诗的纸质图片为例。此诗的语料库以代码格式呈现如下:
corpus = [
"Little feet.",
"A tempered foot,",
"found new ground.",
"A future unravled,",
"in the gypsy's palm.",
"A blade of grass",
"reflected in a crystal ball,",
"somehow fit the mold.",
"This daughter was leaving home.",
"A dark hair twitched, upon the mole.",
"From maiden to mother to crone",
"the moon takes us,",
"each month",
"a new spell.",
"an untold dimension.",
"Flattery fell in the folding of wings,",
"an angel over a city,",
"an orb, over the sea.",
"somehow, Seattle spoke to me."
]
数学定义
这是定义 TF-IDF 的数学公式:
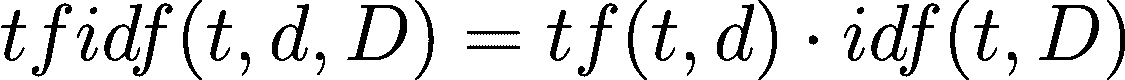
-
t 代表术语
-
d 代表文档
-
D 代表文档集
词频(TF)
TF 是词频。它精确地衡量特定术语的频率。特定术语在语料库中的出现次数可以帮助我们衡量该字符串的重要性。
你可以通过以下方式来测量频率:
-
原始计数 - 你可以通过手动计算词语在语料库中出现的次数来进行原始计数。
-
布尔频率 - 布尔数据类型有两个可能的值 - true/false,yes/no,0/1。若该术语出现,则用 1 表示;若该术语未出现,则用 0 表示。
-
对数刻度 - 通过在一系列值上使用和显示数值数据。
TF 的数学公式:
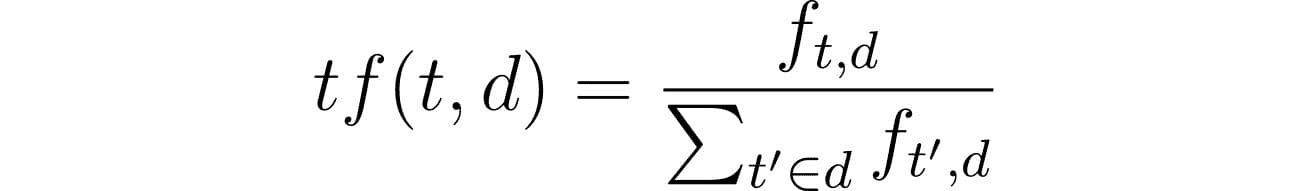
-
t 代表术语
-
f 代表频率
-
d 代表文档
逆文档频率(IDF)
IDF 是逆文档频率。这进一步探讨了一个词在语料库中出现的普遍程度——或者说一个词在语料库中出现的稀有程度。
IDF 是重要的。以英语为例,像“the”、“it”、“as”、“or”这些词在许多类型的文档中频繁出现。逆文档频率本质上是减少这些频繁出现的词的权重,把不那么频繁的词放在前面,以便产生更高的影响。
IDF 的数学公式:
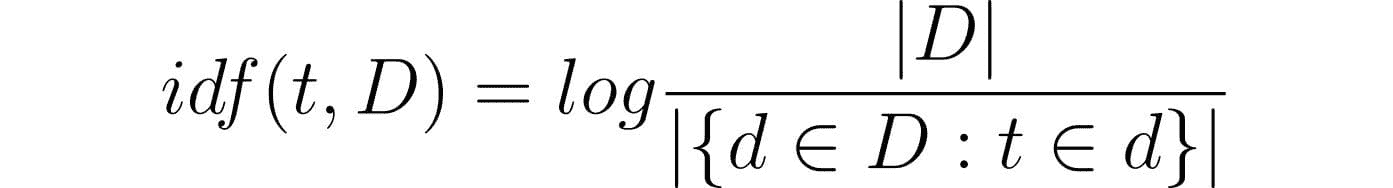
-
t 代表术语
-
d 代表文档
-
D 代表文档集合
对于 IDF,你可能会问这些问题:
1. 为什么我们取逆?
这是因为我们希望给不常见的词赋予更高的值,以便与那些更常见的词进行比较。如果我们不取逆,像“the”这样的常见词会有更高的值,我们将无法真正找到语料库中重要的术语。
2. 为什么我们使用对数尺度?
重要的是,我们不是关注一个术语在语料库中的出现频率,而是这个术语在语料库中的相关性和/或重要性。将词频加上本质上是一个子线性函数,因此使用对数尺度可以将这些术语与词频放在同一尺度或子线性函数中。
TF-IDF 的重要性
自然语言处理领域的技术在不断发展,尽管 TF-IDF 最早是在 1970 年代被认可的——它在 2022 年仍然具有相关性。
与今天使用的自然语言处理技术和工具相比,TF-IDF 看起来很简单。但正因为它简单,并不意味着它没有价值或达不到它的作用。TF-IDF 可以用于更好地理解和解释在 TF-IDF 之上使用的算法的输出。使用多种度量方法没有坏处。
TF-IDF 也被认为解决了流行语言处理技术(如词袋模型)的一些主要缺陷。
哦,还有一个原因:它快速、简单、易于访问。
结论
TF-IDF 是语言处理任务的一个很好的起点,从构建搜索引擎到信息检索。尽管它是一个简单的度量,但它仍然保持了对词语在语料库中权重和相关性的直观衡量方法。
尼莎·阿里亚 是一名数据科学家和自由职业技术作家。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何能(或将能)提升人类寿命。作为一个热衷学习的人,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
我们能用 T5 查询表格吗?

来源:Adobe Stock
你还记得第一次开始构建一些 SQL 查询来分析数据的情景吗?我相信大多数时候你只是想查看“畅销产品”或“按周统计的产品访问次数”。为什么要写 SQL 查询,而不是直接用自然语言提问呢?
这现在得益于最近在自然语言处理领域的进展。你现在不仅可以使用 LLM(大型语言模型),还可以教授它们新技能。这称为迁移学习。你可以将预训练模型作为起点。即使使用较小的标注数据集,相较于单独训练数据,你也可以获得很好的性能。
在本教程中,我们将使用文本到文本生成模型 T5 by Google 进行迁移学习,使用我们的自定义数据,以便将基本问题转换为 SQL 查询。我们将为 T5 添加一个新任务,称为:translate English to SQL。在本文末尾,你将拥有一个训练好的模型,能够翻译以下示例查询:
Cars built after 2020 and manufactured in Italy
成为以下 SQL 查询:
SELECT name FROM cars WHERE location = 'Italy' AND date > 2020
你可以在 Gradio 演示 这里 找到,Layer 项目 这里。
构建训练数据
与常见的语言到语言翻译数据集不同,我们可以借助模板以编程方式构建自定义的英语到 SQL 翻译对。现在,来想一些模板吧:
我们可以构建我们的函数,它将使用这些模板并生成我们的数据集。
如你所见,我们在这里使用了 Layer @dataset 装饰器。我们现在可以轻松地将此功能传递给 Layer:
layer.run([build_dataset])
一旦运行完成,我们可以开始构建自定义数据集加载器来微调 T5。
创建数据加载器
我们的数据集基本上是一个 PyTorch Dataset 实现,特定于我们自定义构建的数据集。
微调 T5
我们的数据集已经准备好并注册到 Layer。现在我们要开发微调逻辑。用 @model 装饰该函数,并将其传递给 Layer。这会在 Layer 基础设施上训练模型,并将其注册到我们的项目下。
在这里我们使用了三个独立的 Layer 装饰器:
-
[@model](https://docs.app.layer.ai/docs/sdk-library/model-decorator): 告诉 Layer 这个函数训练一个 ML 模型 -
[@fabric](https://docs.app.layer.ai/docs/sdk-library/fabric-decorator):告诉 Layer 训练模型所需的计算资源(CPU、GPU 等)。T5 是一个大模型,我们需要 GPU 来微调它。以下是你可以与 Layer 一起使用的可用 fabrics列表。 -
[@pip_requirements](https://docs.app.layer.ai/docs/sdk-library/pip-requirements-decorator):微调模型所需的 Python 包。
现在我们只需将 tokenizer 和模型训练函数传递给 Layer,以便在远程 GPU 实例上训练我们的模型。
layer.run([build_tokenizer, build_model], debug=True)
训练完成后,我们可以在 Layer UI 中找到我们的模型和相关的指标。这是我们的损失曲线:
构建 Gradio 演示
Gradio 是演示机器学习模型的最快方式,提供友好的网页界面,使任何人都可以在任何地方使用它!我们将使用Gradio构建一个互动演示,为希望尝试我们模型的用户提供 UI。
让我们开始编程吧。创建一个名为app.py的 Python 文件,并添加以下代码:
在上述代码中:
-
我们从 Layer 中获取我们微调的模型和相关的 tokenizer
-
使用 Gradio 创建一个简单的 UI:一个用于查询输入的文本字段和一个用于显示预测 SQL 查询的输出文本字段
我们需要一些额外的库来支持这个小的 Python 应用,因此创建一个requirements.txt文件,内容如下:
layer-sdk==0.9.350435
torch==1.11.0
sentencepiece==0.1.96
我们现在准备发布我们的 Gradio 应用:
-
访问 Hugging Face 并创建一个空间。
-
不要忘记选择 Gradio 作为 Space SDK
现在将你的仓库克隆到本地目录中,使用以下命令:
$ git clone [YOUR_HUGGINGFACE_SPACE_URL]
将requirements.txt和app.py文件放入克隆的目录中,并在终端中运行以下命令:
$ git add app.py
$ git add requirements.txt
$ git commit -m "Add application files"
$ git push
现在前往你的 Hugging Face 空间,你会看到应用部署后你的示例
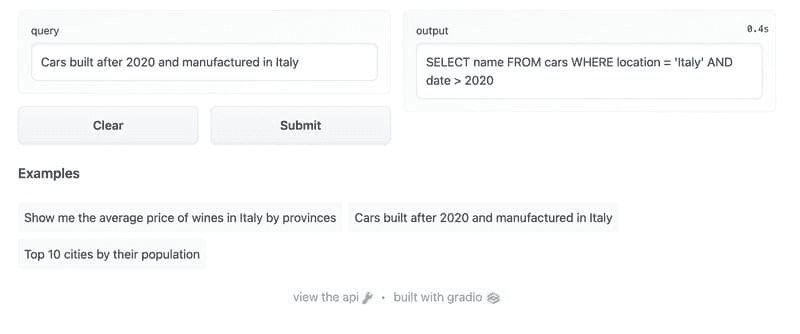
最后的想法
我们学习了如何微调大型语言模型来教授它们一项新技能。现在你可以设计自己的任务,并为自己的用途微调 T5。
查看完整的微调 T5项目并将其修改为适应你的任务。
资源
Mehmet Ecevit 是 Layer: Collaborative Machine Learning 的联合创始人兼首席执行官。
更多相关话题
=PROG=
什么是函数?

编辑者提供的图片
最早的高级函数式编程语言 LISP 于 1950 年代开发。它引入了我们今天编程中仍在使用的概念,例如 Lambda 函数和表达式。即使是像 JAVA 和 C# 这样的面向对象语言,也借鉴了函数式编程语言的符号和特性。
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
尽管 LISP 作为一种编程语言家族至今仍在存在,但没有一种像 JavaScript 或 Python 那样流行——这些语言通常被用作函数式编程语言(除了其他范式之外)。正如名称所示,函数式编程语言围绕函数展开。
那么函数是什么,它与方法有什么不同?由于 JavaScript 是全球最受欢迎的 编程语言(至少在本指南创建时如此),我们将以它作为示例。最终,你将在这里学到的概念可以转移到其他遵循函数式范式的编程语言中。
JavaScript 的本质及函数的重要性
尽管在 ECMAScript 2015 规范(ES6)中引入了类,JavaScript 仍然不被视为基于类的面向对象语言。这主要是因为你不必定义类或类文件就能构建 JavaScript 项目。你可以在类的上下文之外定义和调用函数。
实际上,在 ECMAScript 2015 规范发布之前,JavaScript 函数遵循简单但松散的规则。因此,它们使用起来比 C# 和 JAVA 等面向对象编程语言中的函数(或方法)要直接得多。随着近年来 ECMAScript 规范的增加,JavaScript 的功能也不断增强,使得语言变得更加复杂。
尽管如此,JavaScript 仍然是全球使用最广泛的编程语言,这要归功于它的可扩展性和可移植性。你可以在客户端网页开发以及服务器端和桌面应用中使用它,只要配合合适的运行时和框架。
未来我们只会看到 JavaScript 的应用增加,因为越来越多的云数据库平台(DBaaS)已开始提供原生的 JavaScript SDK。因此,程序员不再被限制于使用SQL 驱动程序(MSSQL 和 MySQL)或其相关的库和函数。
JavaScript 值得学习和掌握——现在比以往任何时候都更加重要。函数使得 JavaScript 运转,你对它们的使用将决定你代码和项目的最终质量。但函数的行为和结构(尤其是 Lambda/Arrow 函数)对于初学者来说可能很难理解。
当 JavaScript 代码嵌入 HTML 中时,其语法可能特别令人困惑。然而,如果你希望从初学者成长为专家,你必须能够有效地构建和利用函数。而第一步就是回答这个问题:“什么是函数?”
什么是函数?
JavaScript 函数是一组包含在标记代码块中的指令。它们很重要,因为它们允许你使用标签来引用这些指令,而不是每次都重复编写它们。调用或调用描述了在代码中使用或引用函数的过程。
作为一种函数式编程语言,JavaScript 拥有所谓的一等函数。这意味着函数可以被视为对象或一等公民。它们可以通过其他函数的参数传递,包含在数据结构中,并赋值给变量/对象。虽然这增加了 JavaScript 的扩展性,但也可能使代码更难阅读和跟随。不过,它的函数式特征是使其适合数据科学的原因之一。函数声明的基本结构如下:
function nameOfFunction(Parameter1, Paramater2, …) {
//Body of function
}
这是一个简单的函数,返回两个变量的和:
function add(v1, v2) {
return v1 + v2;
}
函数是通过“function”关键字定义的,后面跟着函数名称(签名)、由逗号分隔并放置在圆括号之间的参数列表,以及一个代码块。与(旧版本的)C#和 Java 不同,你在定义函数时不需要指定返回类型。这也体现了 JavaScript 的松散类型特性。
函数的名称/标签可以是字母数字字符、下划线(_)和美元符号($)的组合。你可以通过如下方式调用上述函数来给变量/属性赋值:
let out_put = add(5, 5);
调用中的圆括号之间的值称为参数。并非所有 JavaScript 函数都是由程序员定义或声明的。
JavaScript 有一组内置函数,用于处理基本任务,如操作字符串和数组、处理 HTML 包装器、处理日期等。JavaScript 的标准库没有大多数通用编程语言(GPL)那么丰富或功能齐全。这可能是一个优势,因为它降低了学习曲线,并简化了编码,因为你不必担心使用正确的对象或数据类型。
再次提醒,如果你熟悉面向对象编程语言,你可能会感到有些困惑。你可能已经注意到,JavaScript 函数的结构和行为类似于方法。但方法和函数之间是否存在区别,JavaScript 是否有方法?
函数与方法
在许多编程语言中,方法和函数是同义的。然而,JavaScript 对这些术语的定义不同,因此函数和方法是两个略有不同的概念。这些差异很小,因为它们有相同的结构和类似的用法,但在不同的上下文中定义和调用。
方法是对象的函数,因为它们作为对象属性列表的一部分被构造。函数和方法的主要区别在于方法绑定到特定对象,而函数则不是。从本质上讲,属性列表(包括方法)赋予对象类似类的功能。JavaScript 方法的语法如下:
ObjectDefinition = {
methodLabel: function [KEYWORD]() {
//The method’s body
}
};
这是一个简单的返回两个数字和的方法示例:
var addition = {
firstNumber: 1,
secondNumber: 5,
summate: function() {
return this.firstNumber + this.secondNumber;
}
};
“this”关键字用于防止变量遮蔽/隐藏,最终帮助你控制和维护作用域。你可以用它来引用对象声明范围内的其他属性。
你可以通过如下方式使用对象调用方法:
addition.summate();
函数表达式(匿名函数)
如前所述,你可以将函数存储在变量或属性中。函数表达式允许你声明匿名函数,将它们的返回值分配给变量。正如你将看到的,它们与对象方法非常相似。函数表达式的基本语法如下:
[VARIABLE DECLARATION KEYWORDS: var |
const |
let
] variableName = function([PARAMETER LIST]) {
//Body of function
}
函数表达式的一个简单示例如下:
var summate = function(firstNumber, secondNumber) {
return firstNumber + secondNumber;
}
然后你可以使用变量标签来调用该函数:
summate(1,5);
箭头函数
箭头函数首次在 ECMAScript 2015 标准(ES6)中引入。它们类似于 Lambda 表达式 在 Python 和 C# 中,因为它们允许你创建更简洁的声明和函数调用(并且它们都使用箭头)。然而,起初使用它们可能有些棘手。箭头函数的基本语法是:
[let |
const |
var
] functionName = ([PARAMETER LIST…]) => expression[The Body of The Function]
实际应用时,它看起来是这样的:
[let |
const |
var
] functionName = ([PARAMETER LIST…]) => {
//The Body of The Function]
}
或者这样:
var summate = (firstNumber, secondNumber) => firstNumber + secondNumber;
你还可以通过否定函数签名来匿名化箭头表达式,如下所示:
(firstNumber, secondNumber) => firstNumber + secondNumber;
箭头函数的另一个优点是它们处理“this”关键字和作用域的方式。如果正常函数在对象的作用域之外定义,它指向调用它的对象。在网页浏览器环境中,这可能是一个按钮、窗口、文档等。相比之下,当“this”与箭头函数一起使用时,它始终引用定义/声明它的对象。
总结
JavaScript 受欢迎的一个重要原因是其灵活性,尽管有些人认为更严格的约束和规则可能会简化编码体验。
由于其多范式特性,它接受 各种编码风格,这从它允许你声明和使用函数的方式中可以看出。这种宽松性使得开发者可以更自然地混淆代码,因此他们不必局限于某种特定的函数风格。
作为初学者,如果你还不习惯使用箭头函数,可以坚持使用简单的声明和调用。你掌握一项技能或语言的速度很大程度上取决于你对基础知识的理解。
Nahla Davies 是一名软件开发者和技术作家。在全职从事技术写作之前,她曾担任一家公司(在《Inc. 5000》中排名前 5,000)的首席程序员,该公司服务于包括三星、时代华纳、Netflix 和索尼在内的客户。
更多相关话题
我应该学习 Julia 吗?

图片由作者提供
数据科学领域主要由 Python 和 R 编程语言主导。这些语言受欢迎的原因是语法简单、社区庞大以及开源贡献者的支持。即使在招聘网站上,你也会看到招聘人员寻找擅长 Python、SQL 和 R 的开发者和数据科学家。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 需求
但这是否很快会改变?有一个新的竞争者名为Julia,它是为了高性能科学计算而构建的。
| 排名 | 编程语言 | 评分 |
|---|---|---|
| 25 | PL/SQL | 0.52% |
| 26 | Lisp | 0.44% |
| 27 | Julia | 0.43% |
| 28 | Kotlin | 0.43% |
| 29 | Scala | 0.42% |
目前,Julia 在 TIOBE 指数中排名第 27,但它具备成为前 10 的通用编程语言和前 5 的数据科学语言的所有属性。Julia 的稳定版本于 2018 年发布,创始人承诺的 90%已经实现。
创始人 Jeff Bezanson、Stefan Karpinski、Alan Edelman 和 Viral B. Shah 在开始时宣布 Julia 将会是:
-
与 C 一样快
-
动态性类似于 Ruby
-
你可以编写类似 Matlab 的概念
-
在宏方面类似于 Lisp
-
与 Python 一样通用
-
在统计友好性方面类似于 R
-
它将采用类似 Perl 的简单字符串操作
-
类似于 Hadoop 的分布式
-
对线性代数非常强大
简而言之,你将获得所有世界上最好的东西。
“Python 不是机器学习的未来” - Jeremy Howard
在YouTube 视频中,他讨论了 Python 在处理大数据集和机器学习应用时的挫折。为了实现高性能,我们必须使用用其他语言编写的库,并使用各种包来有效地实现并行计算。他还解释了 Julia 如何在几年内取代 Python。
在这篇文章中,我们将深入探讨 Julia,并将其与 Python 进行比较。此外,我们将了解 Julia 如何对你的职业生涯最有利,并查看一些最佳学习资源。
什么是 Julia?
Julia 是一种高层次的通用语言,允许研究人员和科学家更快地实现和执行。它专为高性能计算设计。
根据 Julia 的开发者说,“Julia 是为科学计算、统计分析、机器学习、数据挖掘、大规模线性代数、分布式和并行计算而构建的。”
你可以从官方网站 下载安装程序 并在几秒钟内安装。当前的稳定版本是 1.8.2,如果你正在从 R 和 Matlab 切换过来,你会觉得理解其语法和函数非常自然。
作者提供的图片
你可以使用 Pkg 安装包,如下所示,或者在 Repl 中输入“]”。
using Pkg
Pkg.add(["PyPlot", "CSV", "DataFrames"])
就像 Python 中的 pandas 一样,我们可以简单地将 CSV 文件加载为数据框,而无需额外工作。
在示例中,我们导入了 CSV 和 DataFrames 包,然后使用 CSV.read 读取 CSV 文件并将其转换为数据框。
using CSV
using DataFrames
df_raw = CSV.read("Heart_Disease_Dataset.csv", DataFrame)
注意: 你也可以使用与 Python 类似的
import语法导入包。
Julia vs. Python
在这一部分,我们将把所有编程语言中的“王者”(Python)与 Julia 进行比较。
1. 语法
Julia 不是一种面向对象的编程语言。它是一种动态类型语言,帮助科学家和研究人员用更接近英语的方式编写代码。Julia 比 Python 更简洁,尤其是在科学计算方面。
你可以像在 Matlab 中一样编写多项式。在下面的示例中,我们绘制了一个多项式方程及其对数函数,并用蓝色标记。
我们使用 Pyplot 创建图表,这类似于 Matplotlib。
using PyPlot
PyPlot.svg(true)
x = range(-3,stop=3,length=20)
y = 2*x.² .+ 0.7
figure(figsize=(6,4.3)) #width and height, in inches
plot(x,y,linestyle="-",color="r",linewidth=1.0)
plot(x,log.(y),linestyle=":",color="b",linewidth=3.0)
就像 Python 的三元条件运算符一样,我们可以将 if-else 语句简化为一行。
x = 80; y = 43
if x > y
println("$x is greater than $y")
end
>>> 80 is greater than 43
它比 Python 简单得多。
x > y && println("$x is greater than $y")
>>> 80 is greater than 43
2. 性能
Julia 发布的 基准测试 显示了 Julia 相比 Python 更优越的执行时间。
在一个示例中,他们模拟了 10 亿次掷硬币并将结果存储在一个数组中。结果是 Julia 比 Python 快了 62 倍。
| 语言 | 时间 (秒) |
|---|---|
| PYTHON | 1804 |
| JULIA | 28.8 |
Julia 原生支持并行计算。执行速度接近 C。
3. 包生态系统
Julia 有 7000 个注册的 包,你可以找到各种数据分析、文件处理、机器学习、科学计算和数据工程的工具。
尽管包的数量远少于 Python,但使用 Julia 包的主要优点是大多数包都是 100% 使用 Julia 编写的。
你甚至可以在 Julia 中找到你喜欢的 Python 库,例如 Fast AI,它是建立在 flux.jl 之上的。

图片来自 FluxML/FastAI.jl
4. 社区
社区支持是编程语言的支柱。一个庞大而活跃的社区意味着更多的学习资源来解决问题。如你所知,Julia 是一种相对较新的语言,它有一个较小但充满热情的社区。如果你遇到独特的问题,与 Python 相比,你可能更难在网上找到最终的解决方案。
5. 并行性
Julia 和 Python 都可以并行运行操作。对于任何应用程序或解决方案,必须使用所有可用的资源(计算和内存)。Julia 天生支持并行计算和更好的数据管理。而在 Python 中,你必须使用各种库来实现高性能。简而言之,Julia 的并行化语法比 Python 更简单。
那么,你应该学习它吗?
简单的回答是“是的”。这完全取决于你的职业选择和时间问题。如果你是一个希望从事科学领域的学生,我建议你开始学习 Julia。
如果你刚开始数据科学的职业生涯,我建议你选择 Python。它是行业标准,公司会非常乐意雇用你。
Julia 也适合那些在该领域有专业知识并希望通过学习高性能语言来保持未来竞争力的数据科学家和工程师。
学习 Julia 的关键原因:
-
这是一种动态类型语言,使得使用起来非常简单。
-
它是开源的,代码可以在 GitHub 上找到。
-
Julia 允许你直接调用 Python、C 和 Fortran 库。
-
你可以享受类似于 C 的性能,同时减少代码行数。
-
Julia 可以轻松处理复杂的数据分析任务。
-
它具有用于更大和更复杂模型的原生机器学习和深度学习包。
-
从 Python 和 C 转换代码是容易的。
如何开始学习 Julia?
如果你是 Julia 新手,我强烈建议你从 Julia 入门 课程开始你的学习之旅。课程包括互动编码练习和 16 个视频,涵盖了基本语法、数据结构、函数和包以及用于数据分析任务的 DataFrames。
学习过程永无止境,你可以通过阅读书籍、备忘单、博客和教程来进一步学习。此外,如果你在数据科学领域已是专家并且正在学习新语法,你可以开始从事数据分析项目。
额外资源:
-
探索有关机器学习、数据科学、统计学等领域的 Julia 书籍。
-
免费的 Julia 教程 涵盖数据科学、科学计算和机器学习。
-
YouTube 上有大量的教程和课程播放列表。
-
通过参考Julia 速查表来快速掌握 Julia 的语法和功能。
-
阅读社区贡献的Medium博客。
Abid Ali Awan(@1abidaliawan)是一位认证的数据科学专家,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为正在经历心理问题的学生构建 AI 产品。
更多相关内容
KDnuggets™ 新闻 21:n48, 12 月 22 日:使用管道编写干净的 Python 代码;成为优秀数据科学家所需的 5 项关键技能
功能 | 产品 | 教程 | 意见 | 热门 | 职位 | 提交博客 | 本周图片
本周在 KDnuggets:使用管道编写干净的 Python 代码;成为优秀数据科学家所需的 5 项关键技能;将机器学习算法完整部署到实时生产环境中;成功数据科学家的 5 个特征;学习数据科学统计的顶级资源;还有更多内容。
KDnuggets 顶级博客奖励计划 每月将向顶级博客的作者支付奖励。接受转载,但原创提交的转载率为 3 倍。阅读我们的 指南 并首先向 KDnuggets 提交你的博客!
功能
-
**
,由 Khuyen Tran 提供
-
**
,由 Sharan Kumar Ravindran 提供
-
将机器学习算法完整部署到实时生产环境中,由 Graham Harrison 提供
-
成功数据科学家的 5 个特征,由 Matthew Mayo 提供
-
学习数据科学统计的顶级资源,由 Springboard 提供
 ,由 Khuyen Tran 提供
,由 Khuyen Tran 提供 ,由 Sharan Kumar Ravindran 提供
,由 Sharan Kumar Ravindran 提供产品与服务
- 使用 AI 和分析引擎更快地准备时间序列数据,由 PI.EXCHANGE 提供
教程,概述
-
每个数据科学家都应知道的三大 R 库(即使你使用 Python),由 Terence Shin 提供
-
加速 XGBoost 模型训练的方法,由 Michael Galarnyk 提供
-
云机器学习透视:2021 年的惊喜,2022 年的预测,由 George Vyshnya 提供
-
如果你没有相关学位,如何进入数据分析领域,由 Zulie Rane 提供
意见
-
我如何在 14 年内将薪资提升 14 倍作为数据分析/科学专业人士,由 Leon Wei 提供
-
2022 年及未来的 10 个关键 AI 和数据分析趋势,作者 David Pool
-
聊天机器人转型:从失败到未来,作者 Lubo Smid
-
为什么我们总是需要人类来训练 AI——有时是实时的,作者 Shoma Kimura
顶级故事
-
2021 年顶级故事:我们不需要数据科学家,我们需要数据工程师;成为数据科学家的指南(逐步方法);如何在 18 个月内通过数据科学三倍增加收入,作者 Gregory Piatetsky
-
顶级故事,12 月 13-19:使用管道编写干净的 Python 代码,作者 KDnuggets
职位
-
查看我们最近的 AI、分析、数据科学、机器学习职位
-
你可以在 KDnuggets 职业页面免费发布有关 AI、大数据、数据科学或机器学习的行业或学术职位,电子邮件 - 详情请见 kdnuggets.com/jobs
本周图片

作者提供的图片 | DALLE-3 & Canva
测试软件对于确保在不同场景下的可靠性和功能性至关重要。然而,如果代码实现依赖于外部服务,这就会变成一个相当大的挑战。这时,模拟技术就派上用场了。Python 的 mock 库提供了创建模拟对象以替代真实对象的工具,使你的测试更容易维护。模拟技术有助于专注于组件的测试并加快测试周期。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT 需求
什么是模拟?
模拟是一种在软件测试中用来模拟真实对象的技术。真实对象被模拟对象替代,以模拟它们的功能,允许你在不同场景和隔离下测试代码。模拟特别适用于测试代码库的特定部分,而无需依赖与外部系统、数据库或其他复杂服务的交互。
让我通过一个例子来解释这个概念。假设你有一个使用外部 API 来检索数据的 web 应用程序。为了在不依赖真实 API 的情况下进行测试,你可以创建一个模拟对象,模仿 API 的回答。这样,你可以测试应用程序的功能,而不必依赖可能在开发过程中缓慢、不可靠或根本不可用的真实 API。
听起来很有趣,对吧?现在我们来详细探讨一下如何实际使用这个库。
使用 Mock 的逐步指南
第 1 步:导入 Mock 库
unittest.mock 是 Python 的标准库(3.3 及更新版本),提供了模拟对象以控制真实对象的行为。首先你需要导入 unittest.mock 库。
from unittest.mock import Mock, patch
第 2 步:创建模拟对象
创建模拟对象很简单。导入后,你可以像这样实例化一个模拟对象:
my_mock = Mock()
现在,my_mock 是一个模拟对象,你可以配置它以模拟真实对象的行为。
第 3 步:设置返回值
Mock 库提供了多种配置模拟对象和控制其行为的方法。例如,你可以指定一个方法在被调用时应该返回什么:
my_mock.some_method.return_value = 'Hello, World!'
print(my_mock.some_method())
输出:
Hello, World!
第 4 步:设置副作用
副作用是当模拟对象的方法被调用时触发的额外动作或行为,例如引发异常或执行函数。除了返回值之外,你还可以像这样定义属性或指定副作用。
def raise_exception():
raise ValueError("An error occurred")
my_mock.some_method.side_effect = raise_exception
# This will raise a ValueError
try:
my_mock.some_method()
except ValueError as e:
print(e)
输出:
An error occurred
在这个示例中,每当some_method()被调用时,ValueError会被引发。
第 5 步:断言调用
验证方法调用对于彻底测试至关重要。你可以使用断言来指定方法是否被调用、何时调用以及使用了什么参数。
my_mock.calculate_length('foo', 'bar')
my_mock.calculate_length.assert_called()
my_mock.calculate_length.assert_called_once()
my_mock.calculate_length.assert_called_with('foo', 'bar')
my_mock.calculate_length.assert_called_once_with('foo', 'bar')
-
assert_called(): 如果 calculate_length 至少被调用一次,则返回 True -
assert_called_once(): 如果 calculate_length 仅被调用一次,则返回 True -
assert_called_with('foo', 'bar'):如果 calculate_length 以相同的参数被调用,则返回 True -
assert_called_once_with('foo', 'bar'):如果 calculate_length 以相同的参数被调用且仅被调用一次,则返回 True
如果这些断言在模拟对象上失败,将会引发AssertionError,表示期望的行为与模拟的实际行为不符。
第 6 步:使用修补
patch函数允许你在测试期间用模拟对象替换真实对象。如前所述,这对于模拟第三方库或 API 特别有用,确保你的测试与实际实现保持隔离。为了演示修补,请考虑以下从 URL 获取数据的示例函数。
# my_module.py
import requests
def fetch_data(url):
response = requests.get(url)
return response.json()
通过像这样修补‘requests.get’,你可以避免发出真正的HTTP请求:
# test_my_module.py
import unittest
from unittest.mock import patch
import my_module
class TestFetchData(unittest.TestCase):
@patch('my_module.requests.get')
def test_fetch_data(self, mock_get):
# Set up the mock to return a specific response
mock_get.return_value.json.return_value = {'key': 'value'}
# Call the function to test
result = my_module.fetch_data('http://example.com')
# Check the result
self.assertEqual(result, {'key': 'value'})
# Verify that requests.get was called correctly
mock_get.assert_called_once_with('http://example.com')
if __name__ == '__main__':
unittest.main()
修补装饰器被添加在test_fetch_data function的上方,以用模拟对象替换requests.get函数。
第 7 步:模拟类
你可以模拟整个类及其方法,以模拟对象之间的交互。例如,你可以模拟一个数据库类来测试应用程序与数据库的交互,而不需要像这样设置真实的数据库连接:
# database.py
class Database:
def connect(self):
pass
def save_user(self, user):
pass
def get_user(self, user_id):
pass
# test_database.py
from unittest.mock import Mock
# Creating a mock database object
mock_db = Mock(spec=Database)
# Simulating method calls
mock_db.connect()
mock_db.save_user({"id": 1, "name": "Alice"})
mock_db.get_user(1)
# Verifying that the methods were called
mock_db.connect.assert_called_once()
mock_db.save_user.assert_called_once_with({"id": 1, "name": "Alice"})
mock_db.get_user.assert_called_once_with(1)
总结
这就是今天关于unittest.mock的文章,它是 Python 中一个强大的测试库。它使开发人员能够测试代码,确保对象之间的平稳交互。通过指定副作用、断言调用、模拟类和使用上下文管理器等高级功能,测试各种场景变得更加容易。今天就开始在你的测试中使用模拟对象,以确保更高质量的代码和更顺畅的部署。
Kanwal Mehreen**** Kanwal 是一名机器学习工程师和技术作家,对数据科学及人工智能与医学的交汇处充满热情。她共同撰写了电子书《用 ChatGPT 最大化生产力》。作为 2022 年亚太地区 Google 未来学者,她致力于推动多样性和学术卓越。她还被认可为 Teradata 多样性科技学者、Mitacs 全球研究学者和哈佛 WeCode 学者。Kanwal 是变革的坚定倡导者,创立了 FEMCodes 以赋能 STEM 领域的女性。
更多相关内容
3D 人体姿态估计实验与分析
原文:
www.kdnuggets.com/2020/08/3d-human-pose-estimation-experiments-analysis.html
comments
由 Maksym Tatariants,MobiDev的数据科学工程师
人体姿态估计的基本思想是理解视频和图像中的人的运动。通过在图像或视频中定义人体上的关键点(关节),如手腕、肘部、膝盖和踝关节,基于深度学习的系统可以识别空间中的特定姿势。基本上,姿态估计分为两种类型:2D 和 3D。2D 估计涉及从 RGB 图像中提取每个关节的 X、Y 坐标,而 3D 估计则涉及从 RGB 图像中提取 XYZ 坐标。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 事务
在本文中,我们探讨了基于我们的研究和实验,3D 人体姿态估计是如何工作的,这些研究和实验是分析AI 健身教练应用中的人体姿态估计的一部分。
3D 人体姿态估计的工作原理
3D 人体姿态估计的目标是通过使用包含人的图像来检测人体上特定数量的关节(关键点)的 XYZ 坐标。视觉上,3D 关键点(关节)跟踪如下:
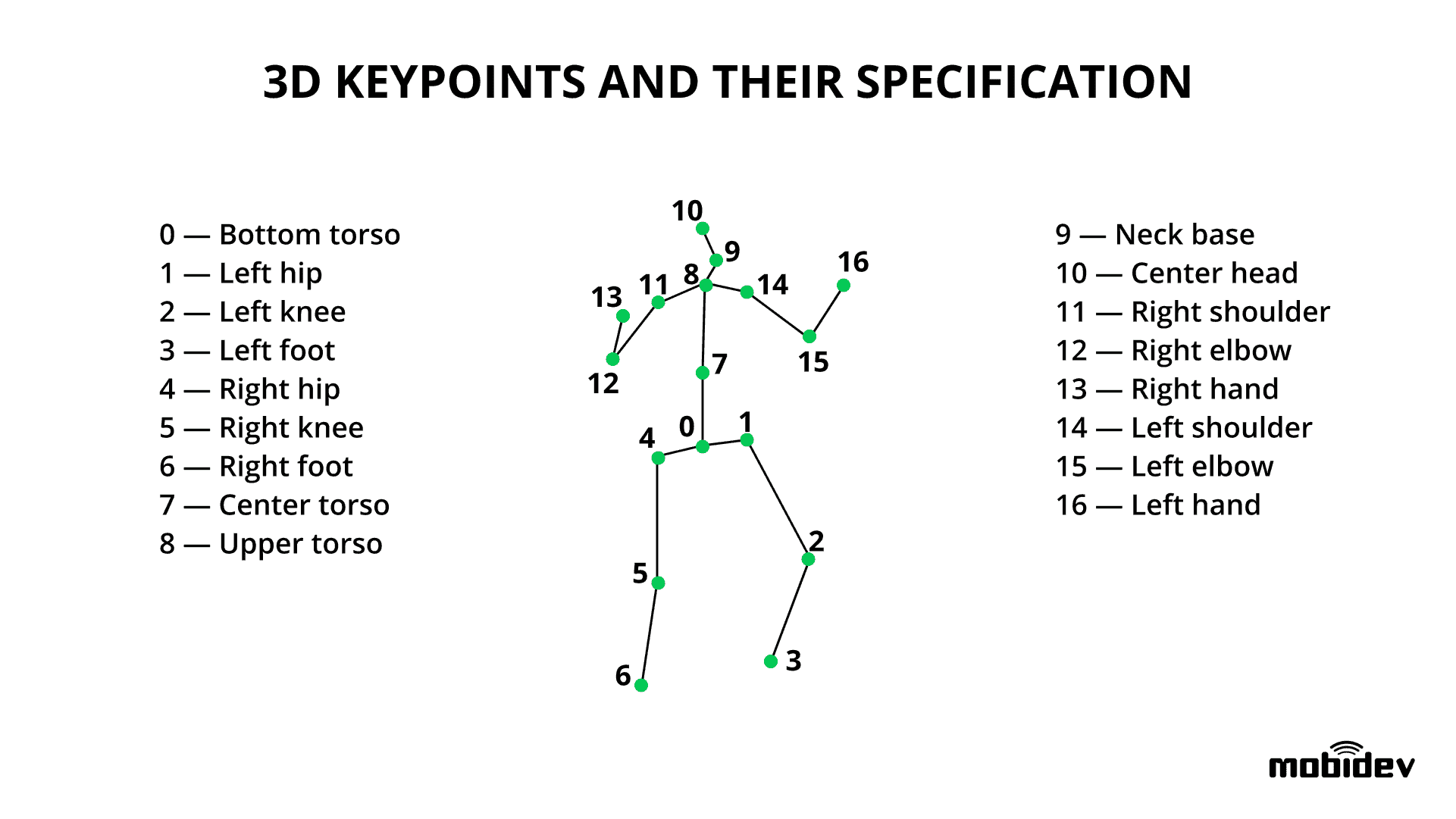
3D 关键点及其规格 (https://mobidev.biz/wp-content/uploads/2020/07/3d-keypoints-human-pose-estimation.png)
一旦提取了关节的位置,运动分析系统会检查一个人的姿势。当关键点从视频流的连续帧中提取出来时,系统可以分析该人的实际运动。
3D 人体姿态估计有多种方法:
-
训练一个能够直接从提供的图像中推断 3D 关键点的模型。
例如,一个多视角模型EpipolarPose被训练以联合估计 2D 和 3D 关键点的位置。有趣的是,它在训练时不需要真实的 3D 数据 - 只需要 2D 关键点。相反,它通过对 2D 预测应用极几何以自监督的方式构建 3D 真实值。这很有帮助,因为训练 3D 人体姿态估计模型时常见的问题是缺乏高质量的 3D 姿态注释。
-
检测 2D 关键点并将其转换为 3D。
这种方法最为常见,因为 2D 关键点预测已被充分探索,并且使用预训练的 2D 预测骨干网可以提高系统的整体准确性。此外,许多现有模型提供了不错的准确度和实时推理速度(例如,PoseNet,HRNet,Mask R-CNN,Cascaded Pyramid Network)。
无论是使用图像 →2D →3D 还是图像 → 3D 的方法,3D 关键点通常通过单视角图像推断得出。另一方面,也可以利用多视角图像数据,其中每一帧都由多个摄像头从不同角度聚焦于目标场景进行拍摄。

多摄像头模型姿态估计 – 多个 2D 检测结果被合并以预测最终的 3D 姿态(来源 – 可学习的三角测量,arxiv.org/abs/1905.05754)
多视角技术可以提高深度感知,并帮助解决图像中一些身体部位被遮挡的情况。因此,模型的预测变得更加准确。
通常这种方法需要同步的摄像头。然而,一些作者展示了即使来自多个不同步和未校准的摄像头的视频流也可以用来估计 3D 关节位置。例如,在《人体姿态作为校准模式》论文中描述了可以利用对人体自然比例的外部知识和放宽的重投影误差来优化未校准摄像头的初始检测,从而获得最终的 3D 预测。
人体姿态估计模型如何检测和分析动作
我们考虑了一个现实的应用开发场景,针对 AI 健身教练。在这个场景中,用户应在进行运动时录制自己,通过应用分析运动的正确性,并回顾在运动过程中所犯的错误。
当复杂的多摄像机设置和深度传感器不可用时,这种情况就会发生。因此,我们选择了 VideoPose3D 模型,因为它适用于简单的单视角检测。VideoPose3D 属于卷积神经网络(CNNs)家族,并采用扩张时间卷积(见下方插图)。
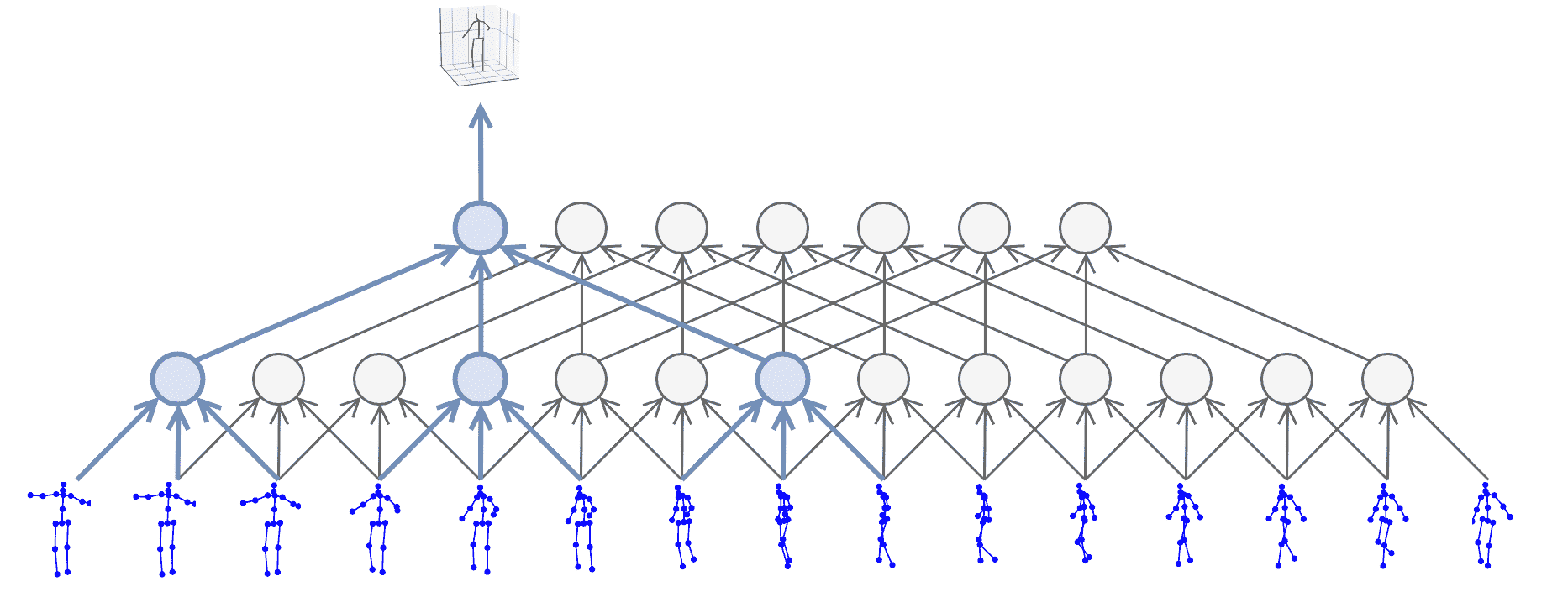
使用 VideoPose3D 进行 2D 到 3D 关键点转换。请注意,在此插图中,使用了过去和未来的帧来进行预测。(致谢 Pavllo et al。)
作为输入,该模型需要一组 2D 关键点检测,其中 2D 检测器是预先训练在 COCO 2017 数据集上的。通过利用不同时间段拍摄的多帧信息,VideoPose3D 实质上基于关于关节的过去和未来位置的数据进行预测,从而允许更准确地预测当前关节的状态,并部分解决不确定性问题(例如,当关节在某一帧中被遮挡时,模型可以“查看”相邻帧以解决问题)。
为了探索 VideoPose3D 的能力和局限性,我们将其应用于力量举和武术练习的分析。
脊柱角度检测
脊柱角度是蹲下时最重要的分析内容之一。保持背部挺直在这个练习中很重要,因为你向前倾斜得越多,质心(身体 + 杠铃)就越向前移动(这可能是非常糟糕的,因为质心的偏移会导致脊柱额外负荷)。
为了测量角度,我们将脊柱(起始关键点 0,结束关键点 8)视为一个向量,并通过取余弦相似度方程的反余弦来测量该向量与 XY 平面的角度。在下方视频中,你可以看到模型如何在示例视频中检测脊柱角度。如你所见,当以不正确的姿势蹲下时,角度可能小至 28-27°。

脊柱角度检测——人员过度前倾(点击查看动画)
从正确执行动作的视频中(见下方视频),我们可以看到角度不会低于 ~47°。这意味着所选方法可以正确检测蹲下时的脊柱角度。

脊柱角度检测——保持背部挺直(点击查看动画)
运动开始和结束的检测
为了能够自动分析仅在运动的活跃阶段或检测其持续时间,我们调查了自动检测运动开始和结束的过程。
由于深蹲时需要特定的手臂定位,我们决定使用手臂的位置作为检测的参考。在深蹲时,两只手臂通常会弯曲成小于 90°的角度,手的位置接近肩膀(按高度)。通过使用一些任意阈值(在我们的案例中,我们选择了小于 78°的角度和小于最大 z 轴值的 10%的距离),我们可以检测到这种情况,如下所示。

深蹲开始检测(点击查看动画)
为了检查运动过程中是否保持了条件和阈值,我们从不同的角度分析了另一段视频,并审查了系统在检测开始后如何在运动中运作。结果发现,观察到的参数远低于所选的阈值。

运动过程中深蹲条件的稳定性(点击查看动画)
我们还检查了在人员完成运动后条件的表现,并看到一旦杠铃被放下,错误条件会立即触发。最后,我们得出结论,这种方法效果很好,尽管它有一些细节(在“人体姿态估计技术中的错误及可能解决方案”部分中描述)。

深蹲条件 – 深蹲结束检查(点击查看动画)
膝盖凹陷检测
膝盖内翻或膝盖凹陷是深蹲中的常见错误。这种问题通常发生在运动员到达深蹲的底部并开始起身时。错误的技术可能导致膝关节的严重磨损,并导致韧带撕裂或膝盖杯的更换。
为了查看模型如何检测膝盖凹陷错误,我们捕捉了关节的 3D 位置。由于结果骨架(见下图)可以随机定位,我们沿 Z 轴旋转它以使其与某个平面对齐。
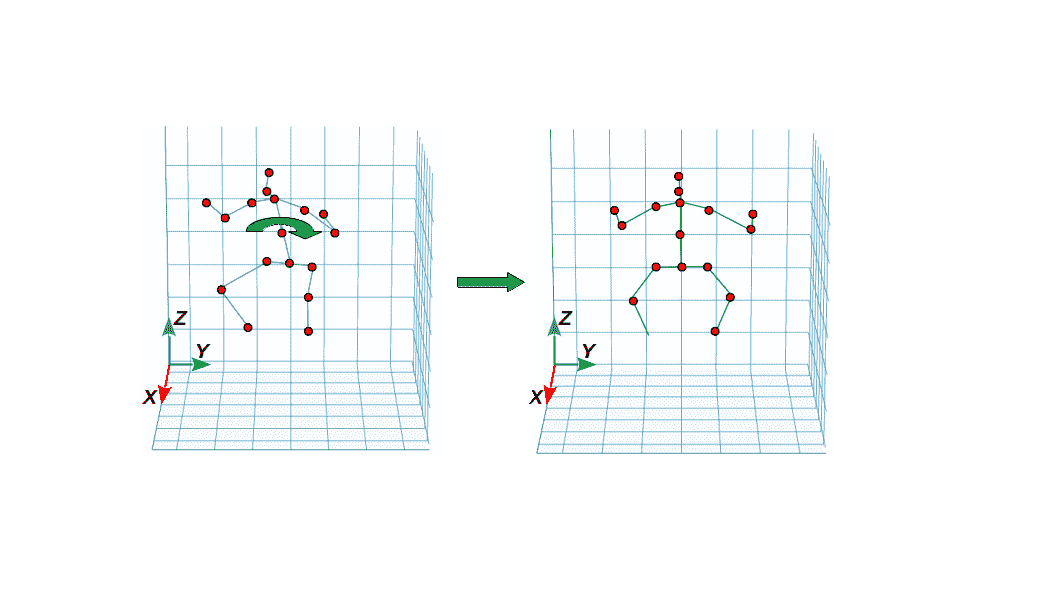
关键点旋转以匹配选定的平面(在此情况下为 ZY 平面)
然后,我们将 3D 关键点投影到平面上,并开始跟踪膝盖相对于脚的位置。目标是检测双腿弯曲的情况,以及膝盖比脚更靠近躯干中心的情况。
从下面的图像中,你可以看到膝盖位置不正确的情况被很好地检测出来了,这意味着这种方法效果很好。
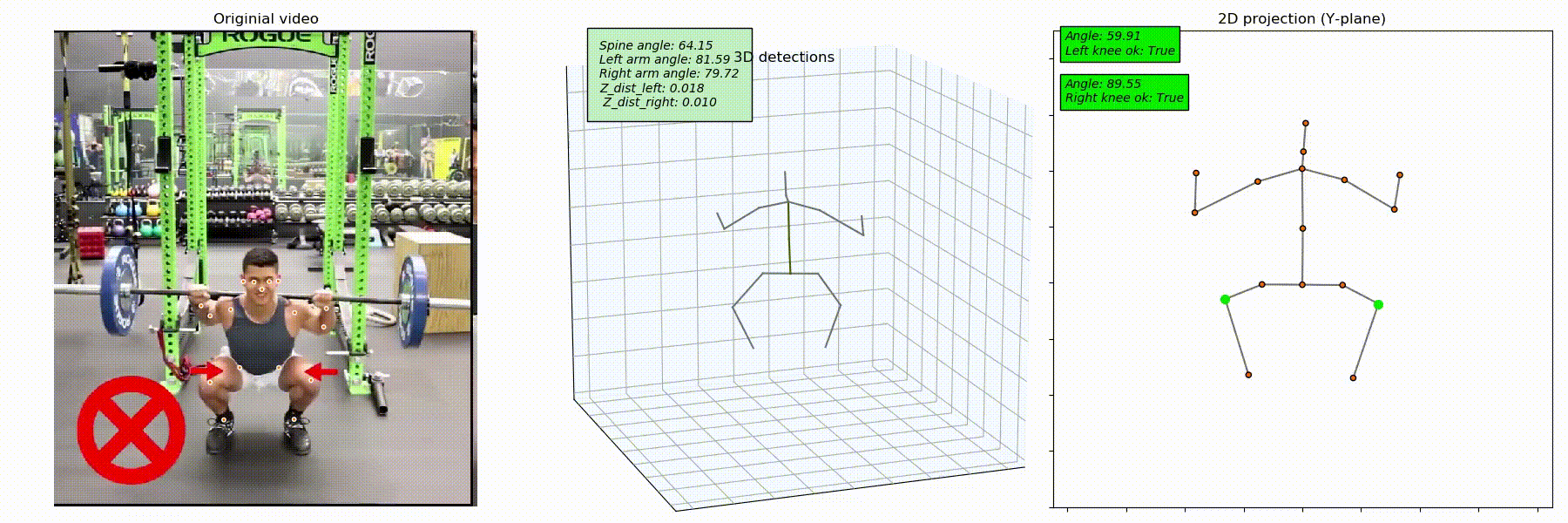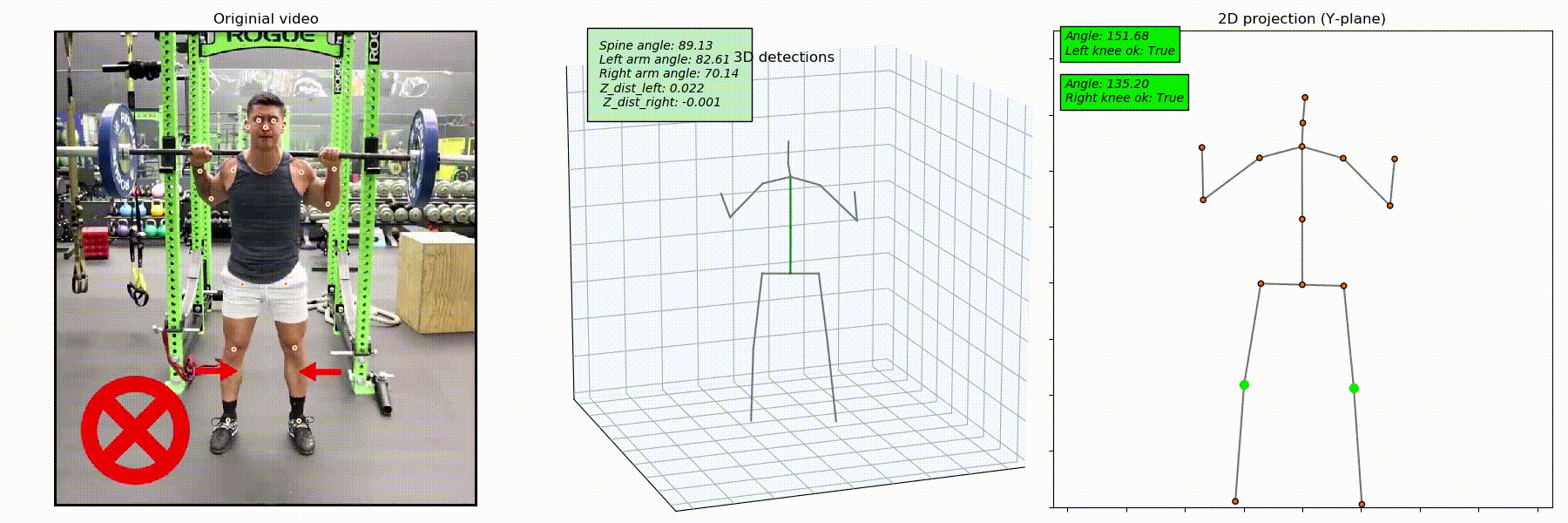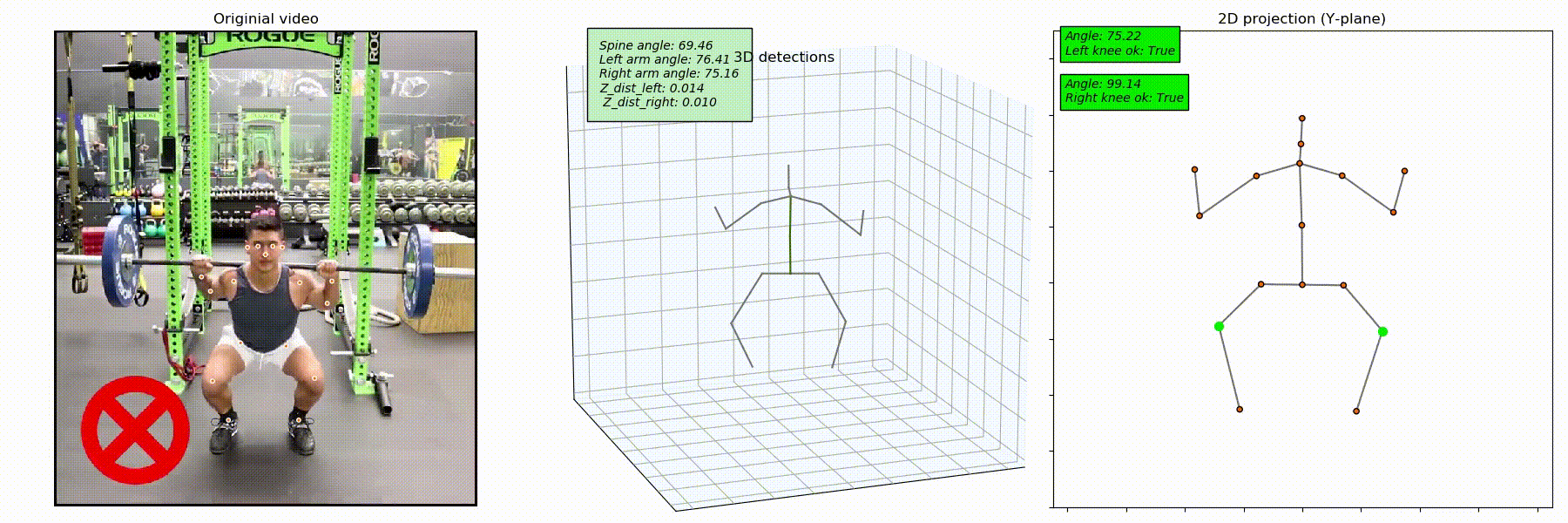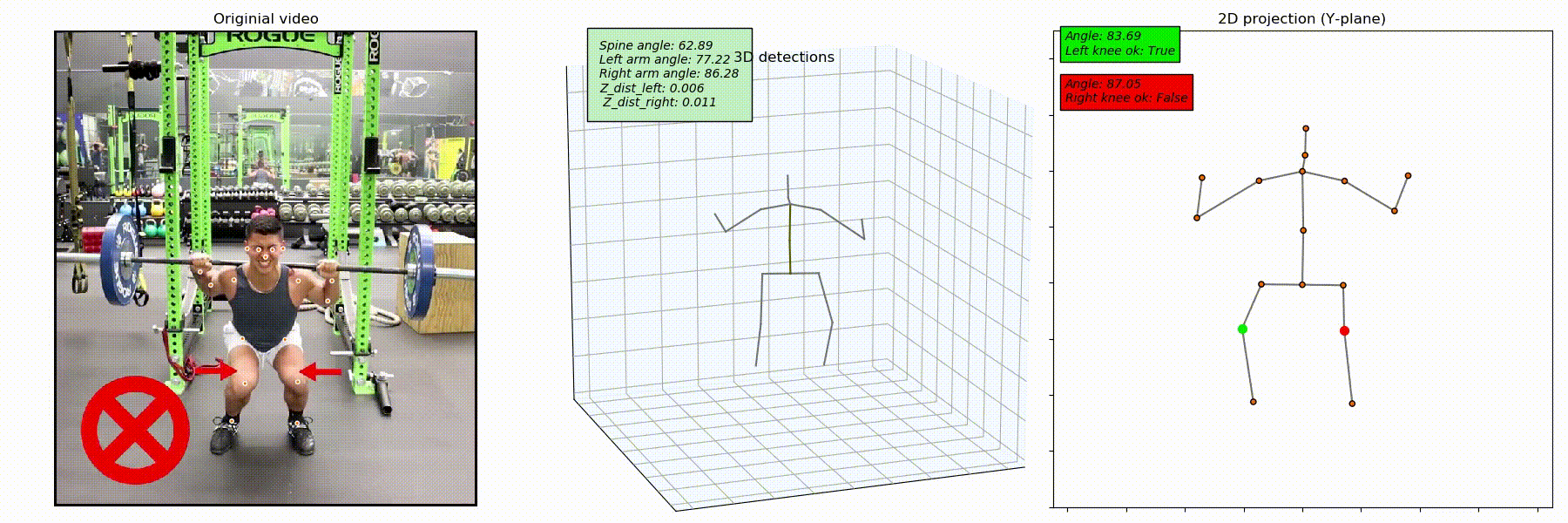
膝盖内陷检测:原始视频、3D 检测和 ZY 平面的正投影(点击查看动画)
比较两位运动员在力量举和抓举中的表现
3D 人体姿态估计技术的另一个有趣应用是比较两个人的运动。为了改进运动技术,运动员可以使用基于人体姿态估计的应用程序将自己与经验更丰富的运动员进行比较。为此,需要有一个包含特定动作的“黄金标准”视频,并利用它来评估身体部位定位的相似性和差异。
对于这种比较,我们拍摄了运动员进行抓举的视频,并标记了开始和结束点。目标是加速或减速以与目标(“黄金标准”)视频的开始和结束同步。过程如下:
-
两个视频中 3D 关键点位置的检测
-
对齐关键点,使“骨架”具有相同的中心点并且旋转类似
-
分析不同关节之间的距离逐帧

比较两位运动员在抓举中的运动:在姿态重建视图的左上角框中显示了相应关节之间的距离(点击查看动画)
结果是,我们发现准确检测人体在快速且突然的运动中的姿态超出了单视角检测方法的极限。当有更多帧可用时,网络对运动的预测更准确,而在 ~2 秒的运动中则不然(至少如果你有 30 fps 的视频)。
硬拉 - 重复计数器
如果你曾考虑过 3D 人体姿态估计是否可以用来计数运动中的重复次数,我们准备了一个基于硬拉练习的示例,展示了如何以自动化方式确定重复次数和运动阶段(向上或向下)。在下面的图像中,你可以看到我们能够检测到人正在向上运动,并且可以相当可靠地计数重复次数。

硬拉中的重复次数和运动阶段检测(点击查看动画)
我们首先考虑了如何定义一个重复动作。基本上,硬拉中的一次重复是当最初弯腰的人开始上升,达到垂直位置,然后再次开始下降。因此,我们需要寻找一个时间点,在这个时间点,一个连续的“向上”帧组后面跟着一个连续的“向下”帧组。两个组之间的边缘帧将是我们可以向计数器中添加一次重复的地方。
在实际应用中,找到上升和下降帧的关键是脊柱角度,我们已经知道如何检测。利用这一点,我们可以遍历所有检测到的帧,并比较邻近帧中的脊柱角度。结果,我们将得到一个由 1 和 0 组成的向量,其中连续的 1 可以代表上升,0 代表下降。
基于脊柱角度比较序列中的两个姿势,以确定个人是上升还是下降。比较滤镜遍历序列中的所有帧。
显然,这些检测结果需要进行一些小的清理,以去除偶然的检测和振荡。这可以通过使用相对小尺寸(4-5)帧的滑动窗口遍历数据,并用窗口内的多数值替换所有值来完成。
运动阶段检测示例,在值清理前(上方)和后(下方)的前 17 帧(1- 上升,0 – 下降)
清理完成后,我们可以开始检测实际的边缘帧,即个人完成一个重复的地方。这出奇简单,因为我们可以应用用于边缘检测的卷积滤镜(核)。
使用边缘检测核的卷积结果
结果是,当接近边缘帧时,值开始增长,变为正值或负值(取决于边缘类型)。由于我们正在寻找上升|下降的边缘,我们需要找到所有滤镜值为-50(最大)的帧的索引,然后我们就会知道何时添加重复。
人体姿势估计中的错误和可能的解决方案
蹲下起始检测错误
问题: 乍一看,蹲下起始检测似乎工作正常,但任意阈值在一个手臂角度短暂超过时会产生错误。

蹲下起始检测 – 阈值错误(点击查看动画)
解决方案: 我们可以提高阈值以避免特定视频中的错误,但不能保证处理其他视频时不会出现相同的错误。这意味着需要通过使用多个不同的示例来测试模型,以建立适当的规则集。
正面视角错误
问题: 在处理不寻常的运动和严格的正面视角时,模型往往会产生低质量的结果,特别是腿部关键点。造成这一问题的可能原因是,尽管 Human3.6M 数据集的规模很大,但其在姿势、运动和视角方面仍然有限。因此,模型无法准确地对呈现的数据(这些数据远远超出了已学习的分布)进行泛化。相比之下,当视角为非正面时,相同的运动预测会更好。

正面位置的运动员在抓举动作中的 3D 检测效果差(点击查看动画)
解决方案: 可以通过在特定领域数据上微调模型来解决这个问题。或者,您可以利用合成数据进行训练(例如用逼真的渲染生成的动画 3D 模型),或者将有关骨骼系统的外部知识编码到损失函数中。
不寻常的运动误差
问题: 在进行 3D 人体姿势估计时,我们发现 2D 检测部分可能导致预测精度低。

在不寻常动作中,腿部位置未被正确检测(点击查看动画)
Keypoint R-CNN 模型错误地检测了快速移动的腿部位置,这在一定程度上归因于快速过渡造成的腿部特征模糊。
此外,这种四肢位置与用于模型预训练的 COCO 2D 关键点数据集中的数据并不十分相似。因此,3D 模型对下半身的预测与实际运动不符,而上半身看起来正确,因为上肢的自由度比腿部在模型训练中使用的图像上更多。
解决方案:
-
收集和标注包含目标领域图像的自有数据集。 尽管这种方法可以提高模型在目标领域的表现,但实施成本可能过于昂贵。
-
使用训练时的数据增强,使模型对人体旋转不那么敏感。 这种方法需要对训练图像及其中的所有关键点进行随机旋转。这确实有助于预测不寻常的姿势,但对于那些不能通过简单旋转获得的姿势(如弯腰或高踢腿),效果可能不佳。
-
采用旋转不变模型,能够推断关键点的位置,无论身体的旋转角度如何。 可以通过训练一个额外的旋转网络来实现,旨在找到将给定图像转换为标准视图所需的旋转角度。一旦网络训练完成,它可以集成到推理流程中,使得关键点检测模型只接收经过角度标准化的图像。
遮挡关节错误
问题: 当身体部位被其他身体部位或物体遮挡时,2D 预测器可能会返回较差的结果。在举重时,如果杠铃上的重量遮挡了手的位置,检测器可能会“失误”,将关键点放置在离真实位置较远的地方。这会导致 3D 关键点模型输出的不稳定和“抖动的手”效果。

2D 关键点模型未能检测左手的位置,导致 3D 重建不准确(点击查看动画)
解决方案: 可以使用多视角系统来获得更好的准确性,因为它们可以显著减少遮挡问题。也有一些专门 设计 来处理遮挡的 2D 关键点定位模型。
总之,根据我们的实际发现,大多数 3D 人体姿态估计技术的弱点是可以避免的。主要任务是选择合适的模型架构和训练数据。此外,3D 人体姿态估计的快速发展表明,当前的障碍在未来可能会变得不那么严重。
简介:Maksym Tatariants 是 MobiDev 的数据科学工程师。他拥有环境和机械工程、材料科学和化学方面的背景,并热衷于在数据科学和机器学习领域获得新的见解和经验。他特别对基于深度学习的技术及其在商业应用中的应用感兴趣。
相关:
-
2019 年人体姿态估计指南
-
用于评估深度学习目标检测器的指标
-
计算机视觉模型是否容易受到权重中毒攻击?
更多相关话题
深度学习的四个最佳 Jupyter Notebook 环境
原文:
www.kdnuggets.com/2020/03/4-best-jupyter-notebook-environments-deep-learning.html
评论
Notebooks 正在成为数据科学家进行原型设计和分析的事实标准。许多云服务提供商以 Jupyter notebooks 的形式提供机器学习和深度学习服务。其他公司现在也开始提供类似存储、计算和定价结构的云托管 Jupyter 环境。主要的区别之一可能是多语言支持和版本控制选项,这允许数据科学家在一个地方分享他们的工作。
Jupyter Notebook 环境的日益普及
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
Jupyter notebook 环境现在成为了将你的数据科学项目产品化的首选平台。Notebook 环境允许我们跟踪错误并保持代码整洁。尽管简单,但其中一个最佳特性是如果发现错误,Notebook 会停止编译你的代码。常规 IDE 即使检测到错误也不会停止编译,且根据代码量的不同,返回并手动检测错误位置可能会浪费时间。

许多云服务提供商和其他第三方服务看到了 Jupyter notebook 环境的价值,这就是为什么许多公司现在提供托管在云上的笔记本,且可供数百万用户访问。许多数据科学家没有进行大规模深度学习所需的硬件,但通过云托管环境,硬件和后台配置大多由系统处理,用户只需配置所需的参数,如 CPU/GPU/TPU、RAM、核心等。
1. MatrixDS
-
MatrixDS 是一个云平台,提供了一种结合了社交网络和 GitHub 的体验,专为与同事分享数据科学项目而设计。它提供了一些最常用的技术,如 R、Python、Shiny、MongoDB、NGINX、Julia、MySQL 和 PostgreSQL。
-
他们同时提供免费和付费的服务。付费服务类似于主要云平台上提供的服务,您可以按使用量或时间付费。该平台根据需要提供 GPU 支持,以便在本地机器不足时完成内存密集型和计算密集型任务。
开始使用 MatrixDS 中的 Jupyter Notebook 环境:
-
注册服务以创建一个帐户。默认情况下,它应该是一个免费帐户。
-
然后,您将被提示进入一个项目页面。在这里,点击右上角的绿色按钮开始一个新项目。给它起个名字和描述,然后点击 CREATE。
-
然后您将被要求设置一些配置,如 RAM 和核心数量。由于这是一个免费帐户,您将被限制为 4GB RAM 和 1 个核心 CPU。
-
完成后,您将被带到一个页面,在这里您的工具(一个 Jupyter Notebook 实例)将会进行配置并准备就绪。
-
一旦您看到设置过程完成,点击 START,然后在运行时点击 OPEN,您将被带到一个新标签页,打开您的 Jupyter Notebook 实例。
2. Google Colaboratory
-
Google Colab 是一个由 Google 提供的免费 Jupyter Notebook 环境,专为深度学习任务设计。它完全运行在云端,使您能够分享您的工作,直接保存到 Google Drive,并提供计算资源。
-
Colab 的主要优势之一是它提供了免费的 GPU 支持(当然有一定限制 – 请查看他们的 FAQ)。请参见 Anne Bommer 关于 Google Colab 入门的精彩文章。
-
它不仅支持 GPU, 我们还可以在 Colab 上使用 TPU。
除了常规的 Jupyter Notebook 之外,使用 Google Colab 进行 Jupyter 环境的一个简单示例是使用来自 opencv-python 包的 The cv2.imshow() 和 cv.imshow() 函数。这两个函数与独立的 Jupyter Notebook 不兼容。Google Colab 提供了一个自定义修复此问题的方法:
py` 从 google.colab.patches 导入 cv2_imshow !curl - o logo.png https://colab.research.google.com/img/colab_favicon_256px.png 导入 cv2 img = cv2.imread('logo.png', cv2.IMREAD_UNCHANGED) cv2_imshow(img) ```py ````
在代码单元中运行上述代码,以验证其确实有效,并开始你的图像和视频处理任务。
3. Google Cloud 的 AI Platform Jupyter Notebooks
-
Google Cloud 提供了集成的 JupyterLab 管理实例,预装了最新的机器学习和深度学习库,如 TensorFlow、PyTorch、scikit-learn、pandas、NumPy、SciPy 和 Matplotlib。
-
该 Notebook 实例与 BigQuery、Cloud Dataproc 和 Cloud Dataflow 集成,以提供从数据摄取、预处理、探索、训练到部署的无缝体验。
-
集成服务使用户能够通过几次点击轻松扩展计算和存储容量。
要在 GCP 上开始使用你的 JupyterLab 实例,请按照以下步骤操作:
使用 Keras 运行以下代码,查看云环境和GPU支持如何加速你的分析:
数据集的链接是:数据集 CSV 文件(pima-indians-diabetes.csv)。为了简便,数据集应与您的 python 文件位于同一工作目录下。
将其保存为文件名:pima-diabetes.csv
py` 从 numpy 导入 loadtxt 从 keras.models 导入 Sequential 从 keras.layers 导入 Dense # 加载数据集 dataset = loadtxt('pima-diabetes.csv', delimiter=',') X = dataset[:,0:8] y = dataset[:,8] # 定义 keras 模型 model = Sequential() model.add(Dense(12, input_dim=8, activation='relu')) model.add(Dense(8, activation='relu')) model.add(Dense(1, activation='sigmoid')) # 由于这是一个二分类问题,选择 Sigmoid model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 编译 keras 模型 model.fit(X, y, epochs=150, batch_size=10) # 训练 keras 模型 _, accuracy = model.evaluate(X, y) # 评估 keras 模型 print('Accuracy: %.2f' % (accuracy*100) ```py ````
4. Saturn Cloud
-
Saturn Cloud 是一个新的云服务,提供一键式托管在云端的 Jupyter 笔记本,可以根据你的计算和存储需求进行扩展,使用 AWS 作为后端。这里有一个教程来帮助你入门:如何轻松创建、发布,甚至分享云托管的 Jupyter 笔记本,使用 Saturn Cloud
-
Saturn Cloud 应该处理数据科学中的 DevOps 部分,通过提供版本控制和协作机会来使你的分析更加可重复。
-
Saturn Cloud 提供了与 Dask(用 Python 编写)的并行计算基础设施,而不是其他大数据工具,如 Spark。
开始使用 Saturn Cloud:
-
登录并创建一个账户:Saturn Cloud 登录。基础计划可以免费使用,以熟悉环境。
-
创建你的笔记本实例:
-
为笔记本指定一个名称
-
存储量
-
使用的 GPU 或 CPU
-
(可选)Python 环境(例如:Pip、Conda)
-
(可选)自动关闭
-
一个 requirements.txt 文件来安装你项目所需的库。
-
-
在指定以上参数后,你可以点击 CREATE 来启动服务器和你的笔记本实例。
-
Saturn Cloud 还提供了托管你的笔记本,使其可以分享。这是 Saturn Cloud 处理数据科学项目的 DevOps 方面的一个示例,使用户不必担心。
运行以下代码以验证你的实例是否按预期运行。
py` 导入 pandas 为 pd 导入 matplotlib.pyplot 为 plt %matplotlib inline url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data" names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class'] data = pd.read_csv(url, names=names) pd.plotting.scatter_matrix(dataset) plt.show() ```py ````
什么是最佳的 Jupyter Notebook 环境?

我们根据分析、可视化能力、数据存储和数据库功能等多个因素,将 Jupyter Notebook 环境从最佳到最差进行排名。每个平台都有其最佳和最差的用例及其独特的卖点。
上述所有服务都旨在满足你的深度学习需求,并提供一个可重现的环境,以便分享你的工作并尽可能少地进行后台工作。随着深度学习取得新进展,算法仍然需要大量的数据,而大多数数据科学家在本地机器上无法实现这一点。这时,上述替代方案允许我们进行无缝体验的分析。以下是我们对哪个平台最好、哪个最差的最佳尝试的客观观点:
- MatrixDS 的独特之处在于,它为不同的任务提供不同的工具。对于分析,它提供 Python、R、Julia、Tensorboard 等,对于可视化,它可以提供 Superset、Shiny、Flask、Bokeh 等,存储数据则提供 PostgreSQL。
- Saturn Cloud 提供并行计算支持,并使注册过程和创建 Jupyter notebook 尽可能简单,与列表中的其他提供商相比。对于那些只想以最少的麻烦开始,并且只需要一个可以处理大数据的服务器的用户,这可能是最好的选择。
#3 Google 的 AI Platform Notebooks:
- 这个 notebook 环境支持 Python 和 R。数据科学用户可能会有首选的语言,而在主要云服务提供商上支持这两种语言是一个吸引人的选择。它还提供对 GCP 其他服务的访问,如 BigQuery,直接从 Notebook 本身进行,使查询数据更高效和强大。
- 虽然相当强大且是唯一一个提供 TPU 支持的环境,但在数据科学工作流的全面性方面,它的功能不如其他环境丰富。它只支持 Python,功能上类似于标准的 Jupyter Notebook,但用户界面不同。它提供将你的 notebook 共享到 Google Drive 并可以访问你的 Google Drive 数据。
原文。经许可转载。
相关内容:
-
5 个 Google Colaboratory 提示
-
替代的云托管数据科学环境
-
如何优化你的 Jupyter Notebook
更多相关主题
数据科学家的 4 种现实职业选择
原文:
www.kdnuggets.com/2020/04/4-career-options-data-scientists.html
评论
由 Ian Xiao,德勤的市场营销与人工智能实践。

照片来源于 Caleb Jones 在 Unsplash。
2020 年 2 月 27 日
大约在城市因 COVID-19 封锁前的三周,我和一个朋友坐在我们最喜欢的多伦多市中心的泰国餐厅里。
“我应该留在数据科学领域吗?如果不应该,我接下来该做什么?” 我的朋友问道。
像聚会的声音和新鲜餐厅食物的香味一样,如何进入数据科学现在似乎有些遥远。事实上,你可以在谷歌上找到约 30 亿个结果,其中有极其具体的逐步指南(而“如何赚钱”仅有约 20 亿个结果)。
截至 2020 年 3 月 25 日的谷歌搜索结果。
然而,我朋友的问题依然萦绕在心。深层次的紧张感源于两个因素:1) 数据科学的期望与现实——它可能比我们预期的更无聊,2) 角色与我们的抱负。
那么,选项是什么呢?
-
保持相同角色并内化挫败感(你可以跳过这篇文章,但请在离开前分享????)
-
离开当前角色,但在其他地方继续从事与数据科学相关的工作(这篇文章是为你准备的)
-
我完全厌倦了(你确定吗?在做出决定之前考虑一下选项 2)
但是,去哪里呢?
要知道我们想去哪里,你必须了解我们现在的位置。要获取更大的选择视角,我们中的许多人可能会转向“什么是数据科学?”的问题。如果你谷歌这个短语,你很可能会遇到类似这样的内容:
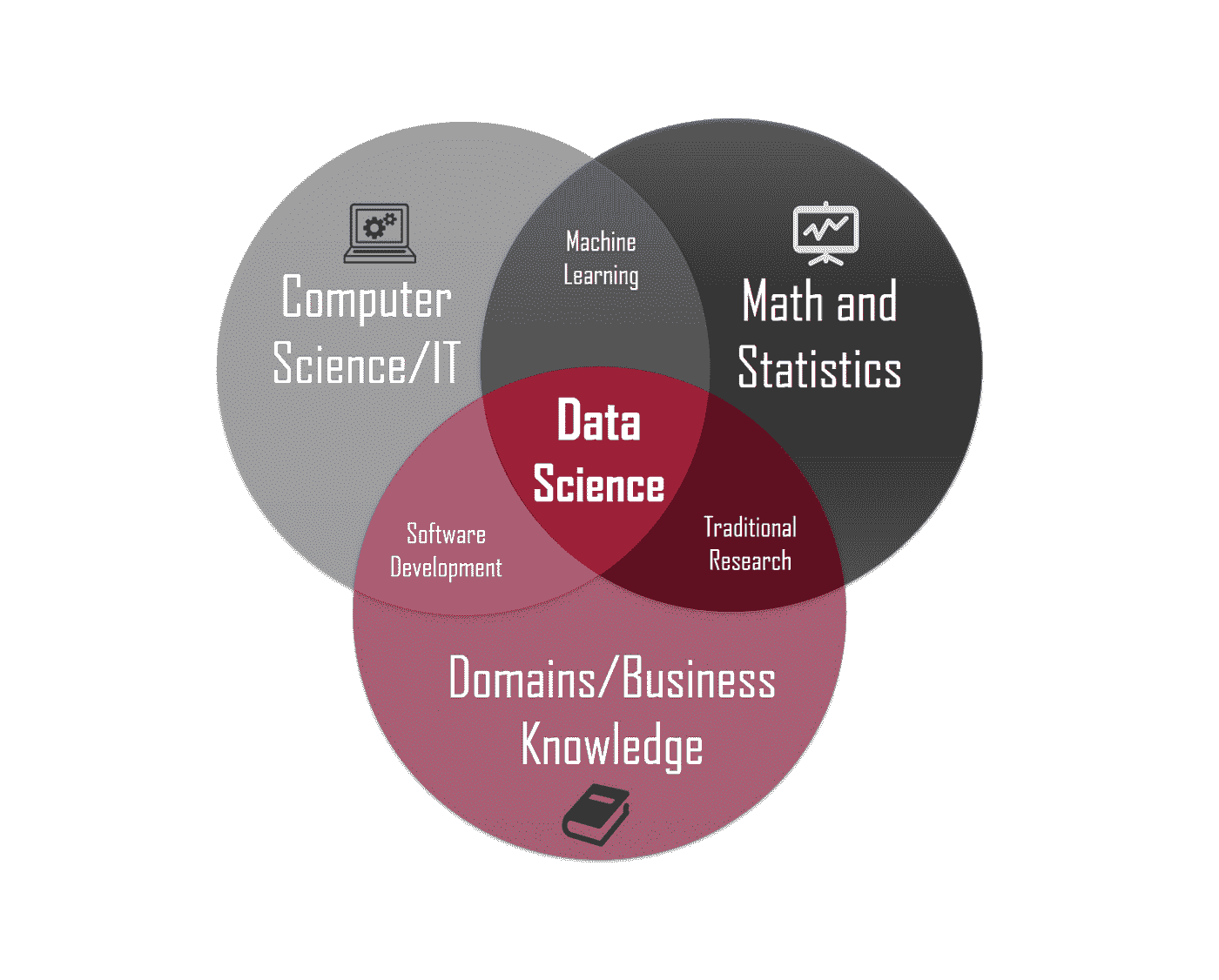
什么是数据科学,图片来源。
这种分类是有意义的,但它并没有真正捕捉到日常工作的实际情况和公司性质。 这两个因素无疑是在我们做出职业决策时最重要的。
有一种更好的思考方式。因此,让我向你展示数据科学家的原型。
等一下...
在我们开始之前,了解我的 背景和经历 是很重要的,这样你可以根据自己的现实和限制来解读我的见解。
简而言之, 我通过为大型企业提供咨询、结识各种数据科学家,以及在一家最终被收购的 AI 初创公司构建机器学习产品,见证了数据科学的演变。
我的观点只是一个数据点(希望它是有用和独特的),所以要注意其他人的看法。
选项:数据科学家的原型
那么,什么是数据科学?这取决于公司规模(企业还是初创公司)和主要责任(客户面对还是内部聚焦)。
当你面试数据科学角色时,尽管有职位名称和工作描述,但很可能会落入以下四个过于简化且主观标记的组别中。
数据科学家的四种原型。作者分析。
你如何使用这个?原型展示了可能性。它允许你查看你目前的位置以及即时的选项。对于有志于成为数据科学家的你,可以利用这个工具来找出最好的起点。
接下来,你可能会问:我怎么知道新角色是否对我更好?
为了帮助你做决定,下面是每个角色的一些优缺点。此外,我将讨论可能最适合的才俊类型。当然,这些都是有些主观的:对我来说好的可能对你不好。总会有例外。请自行判断。
注意:
-
你还可以根据公司的其他方面进行分类,例如行业和产品类型(例如,与数据科学相关的服务或工具,非数据科学产品)。我认为公司规模对日常工作有更大的影响。
-
公司规模不是二元的,还有许多中型公司;为了简单起见,我将其二元化。
-
在初创公司中,客户面对和内部事务之间的墙并不存在;人们往往会同时处理两者。这只是时间分配的问题。
1 — 昂贵的顾问
全球咨询公司或大型科技公司(例如,德勤、麦肯锡、埃森哲、谷歌、IBM 等)的数据科学服务
优秀的:在解决问题和高效工作方面有非常好的培训。处理非常“重要的事务”,因为客户为结果支付高昂费用。如果你感到无聊或沮丧,每个项目都可能不同。晋升路径和要求非常明确(例如,分析师、经理、合伙人)。接触到高层管理人员,早期职业生涯涉及广泛话题,并且有很多雄心勃勃的人。
不佳的:商业价值凌驾于一切之上(例如,科学创新和酷炫的算法)。所有职位级别的工作时间都很紧张。一些公司可能不会将数据科学家纳入传统的合伙人轨道(你可能会感到被边缘化,但别担心,大多数人都非常尊重)。很多主导型个性。
最佳匹配:具备一定技术培训并有志于在大公司内经营“自己的小生意”的商业导向人士。刚起步的学生,寻找导师,想要学习最佳术语并不介意被严格工作。
2 — 技术精通的销售
在以 AI 为重点的初创公司或中型公司中担任技术销售或项目领导角色(例如,Dessa,Element AI,H2O,Cloudera,Palantir)。
好处:你可以处理一些前沿的应用案例,因为客户通常期望你提供创新,而不是提供(无聊的)长期、大规模的转型项目。对重要的战略和产品决策有更大的发言权。灵活而创新。
坏处:一些客户可能不信任你处理大型项目(例如,获得更多预算),这是“灵活与创新”的另一面。可能需要做很多“免费”工作来赢得客户信任。与大公司相比,后台支持较少。产品愿景可能会受到投资者(如果你有错误的风险投资)或沉没成本心理的影响,而不是基于真正的市场需求。
最佳匹配:那些希望在初创阶段与公司共同成长,过上创业梦想生活,并且已经拥有坚实的业务网络、领域专长和/或声誉的人。不适合新人,因为你需要迅速上手。
3 — 产品嬉皮士
具有软件和/或机器学习背景的人,与工程团队合作,构建知识产权、演示并支持销售电话,在 AI 产品公司工作。
好处:处理有趣且实际的问题,而不必应对过多的客户政治。项目周期较短。作为“内部用户”能够影响或定义产品的设计。为客户或内部团队打造酷炫的东西。
坏处:可能会被拉入客户或用户面对的角色,这会在优先级和时间管理上产生紧张。很难找到“前沿”与“立即实用”之间的正确平衡。可能会陷入无休止的客户支持工作。
最佳匹配:那些以产品为导向、以工程为重点但有时有些黑客气息的人。拥有特定技术栈或工作流领域专业知识的资深专业人士。具有开放和好奇心的学生,享受技术挑战,并能完成任务。
4 — 大型家庭
好吧,家庭可能很复杂,因此这个组需要分成两个部分:无名英雄和超级极客。
家庭结构。作者的分析。
4.1 — 默默无闻的英雄
来自企业传统 BI、分析和建模团队的人。他们大多与业务线或职能(例如市场营销、风险、财务等)合作。他们在“数据科学家”这一术语出现之前就是数据科学家。
优点:工作非常专注。接近真实的业务操作。接触独特的数据集。拥有运营化和大规模的基础设施。极佳的工作与生活平衡。具有影响力或权力来做出投资决策。
缺点:在(大多数)时候可能进展缓慢且无聊。通常得不到被称为21 世纪最性感工作的认可。内部政治。较慢的职业发展轨迹。可能会被锁定在特定的角色或项目中。
最佳匹配:那些在生活中找到了激情或喜欢在特定领域投入时间的人。不在乎炒作的人。有大量耐心和韧性的人。
4.2 — 超级极客
数据科学中的“金童”刻板印象。那些在主要公司(如 Google Brain / DeepMind、Facebook 的 FAIR、Uber 和 Walmart Research 等)从事研发的人。
优点:从事非常智力化的主题。有机会接触独特的数据集和问题。能够利用大公司的资源推动创新。获得大量的认可和赞扬。
缺点:由于必须展示“商业价值”而产生的强烈紧张感。商业优先级可能会限制或影响研究课题。如果研究展示了价值,可能会陷入“无聊”的实施阶段。
最佳匹配:学者。对学术研究和教育背景有非常强烈兴趣的工程师。希望发表论文并获得一些行业曝光的研究生。
下一步
现在你对可能性有了很好的了解,问问自己这些问题:
-
我现在在哪里?为什么我感到沮丧?
-
我在数据科学职业(或生活)中真正想要什么?
-
这个目的地是否提供了预期的缓解和好处?(希望这篇文章提供了一些见解)
-
我可以实现的选项有哪些?
-
我怎么才能以最少的努力和最好的结果达到目的?
原文。经许可转载。
个人简介: Ian Xiao 帮助客户通过数字技术和实践(例如 AI、大数据、敏捷、设计思维)转型核心业务或推出新能力,并为 B2B 数据和 AI 初创企业提供建议。Ian 是 Medium 上商业与科技领域的顶尖作家,还被 MIT Review、Fast Company 和 Google 认可。
相关:
更多相关内容
30 天内获得工作准备好的 4 个认证
原文:
www.kdnuggets.com/4-certifications-to-become-job-ready-in-30-days

作者提供的图片
你是否在开启数据世界的新职业旅程?
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
如果是这样,继续阅读这篇博客。当人们转行到新的职业时,他们通常对选择哪个方向感到困惑。我的建议是选择能够提供你所需的所有知识和技能,使你准备好工作的发展方向。
是的,你可以通过大学学位或硕士学位获得相同的结果,但如果你可以通过认证更快地实现呢?
行业专家认可的认证。
数据分析师认证
链接:数据分析师认证
被《福布斯》评为第一的数据分析认证!
如果你想成为数据分析师,你可以在 30 天内通过此认证获得资格。拥有此认证,你将展示你在处理业务关键问题和向利益相关者提供信息方面的知识和技能。
你将有 30 天时间完成此认证,期间你将参加定时考试和实际操作示例。为了获得此认证,你应该能够:
-
执行标准的数据提取、连接和汇总任务。
-
评估数据质量并执行验证任务。
-
执行标准清理任务以准备数据进行分析。
-
计算指标以有效报告数据特征及特征之间的关系。
你的定时考试将涵盖数据管理、探索性分析和统计实验。实际考试将涵盖数据管理、探索性分析和沟通。
数据科学家认证
链接:数据科学家认证
数据分析师和数据科学家在某些角色和职责上类似,但也有所不同。如果你希望成为数据科学家,这个认证将帮助你获得理想的职位。
在这个认证中,你将有两个定时考试,每个考试有两个小时的时间,你可以尝试两次,之后还需要完成一个实践考试,实践考试必须在 30 天内完成。要成功获得此认证,你需要能够:
-
展示你能够使用机器学习和人工智能收集、分析和解读大量数据。
-
有效地将你的分析结果传达给业务相关者。
数据工程师认证
链接:数据工程师认证
数据工程师的需求与日俱增,因为各大公司都需要能够管理和解读数据的人才。
这是另一个可以在 30 天内完成的认证!你将有两个定时考试,每个考试有两个小时的时间,并可以尝试两次,之后还需要完成一个实践考试。在这个实践考试中,你将有四个小时和两次尝试,考试会自动评分,即时通知你结果。
要成功获得此认证,你需要能够:
-
收集和预处理大量数据。
-
展示你能够将数据转化为适合组织中数据用户使用的格式。
SQL 助理认证
链接:SQL 助理认证
类似于数据工程师,SQL 助理因其处理、评估和分析大数据的能力也非常受到需求。
这是一个需要在 30 天内完成的认证,包括一个定时考试(SQ101)和一个实践考试(SQ501P)。对于定时考试,你将有两个小时来完成考试,并可以尝试一次。对于实践考试,你将有四个小时和两次尝试。
要成功获得此认证,你需要能够:
-
展示你能够使用 SQL 从数据库中提取适当的数据。
-
然后利用这些结果回答常见的数据问题。
总结一下
从行业认可的平台获得认证可以提升你的职业信誉,并拓展你的职业机会。这四个认证是由行业领导者根据最新市场需求制定的。
获得认证后,你将能够访问 DataCamp 的专属认证社区,在那里你将与其他专业人士连接,并探索专为该社区策划的内容。
Nisha Arya是一名数据科学家、自由技术作家、编辑以及 KDnuggets 的社区经理。她特别关注提供数据科学职业建议、教程和基于理论的数据科学知识。Nisha 涉及广泛的主题,并希望探索人工智能如何有助于人类生命的长寿。作为一个热衷学习者,Nisha 希望扩展她的技术知识和写作技能,同时帮助他人。
更多相关话题
微软 4 个入门级证书,助你进入需求旺盛的职位
原文:
www.kdnuggets.com/4-entry-level-certificates-from-microsoft-to-land-in-demand-jobs
作者提供的图像 | Canva
当你考虑进入一个新的职业或行业时,首先要考虑的是这个行业的潜力和机会。它会持续一段时间吗?会消失吗?我的工作最终会被取代吗?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
有很多不同的答案和问题。你要考虑的主要问题是这份工作是否有需求。在这篇博客中,我将介绍两个特别为当前市场需求工作定制的新入门级证书。
业务分析师
链接: 微软业务分析师专业证书
很多人没有听说过技术领域对业务分析师的需求。这是由于许多原因,其中主要原因是软件开发人员或机器学习工程师需要始终站在帮助组织开发软件并将其推向市场的最前沿。然而,也需要专业人士来帮助组织做出数据驱动的决策,优化流程,提高效率。
在微软提供的这项专业证书课程中,你将通过只需承诺 3 个月,每周 10 小时的学习,来启动你的业务分析师职业生涯。特别为初学者量身定制,该认证包含 6 个系列,帮助你为工作做好准备。
你将学习如何使用各种技术识别、分析和记录业务问题,以及如何建模业务流程,并利用行业标准技术和数据将这些模型有效地传达给利益相关者。你将使用微软 Excel 进行数据准备、分析和可视化,然后通过使用现实世界场景的毕业项目来展示你的新技能。
云支持
链接: 微软云支持助理专业证书
我们都知道在数字时代云计算的价值。随着越来越多的组织将其运营和数据转移到云端,理解云计算及其数据访问的重要性是一项重要且需求量大的技能。
这就是云支持助理发挥作用的地方。这项专业认证包括 12 门课程,如果你每周投入 10 小时,可以在 4 个月内完成。你可以按照自己的节奏学习,所以不要感到压力。
在这项认证中,你将掌握成功进行信息技术和云支持所需的技能,使用 Microsoft Azure 解决方案和服务。然后,你将学习如何将数据备份、云计算和移动设备管理等概念应用于实际 IT 和云支持场景。总的来说,你将能够展示对 IT 和云支持的整体理解,结合硬件、软件、网络和合规性概念进行问题解决。同时,你还将具备将诊断技能适应于各种 IT 和云问题的扎实基础知识,并管理 Azure 资源,包括安全性和成本优化。
IT 支持
他们是确保一切正常运作和安全的真正“OG”,然而,他们在科技领域并没有获得足够的认可。然而,主要要记住的是,他们是必需的!
在这项认证中,你将通过一系列 6 门课程学习如何成为 IT 支持专家,并投入 3 个月,每周 10 小时。你将掌握成功进行信息技术系统分析和维护所需的技能,以及如何将数据备份、云计算和移动设备管理等概念应用于实际 IT 场景。你将对 IT 支持有全面的了解,结合硬件、软件、网络和安全概念进行问题解决,并学习如何将诊断技能适应于实际商业场景中的各种 IT 问题。
项目管理
链接:微软项目管理专业证书
项目经理是科技公司的核心。他们对当前市场的需求有最清晰的了解,并将这些需求落实到业务中,以确保组织在竞争中处于领先地位。
在这个认证课程中,你将学习如何通过一个包含 9 门课程的系列成为项目经理,如果你每周投入 10 小时,可以在 4 个月内完成。你将掌握项目管理术语、方法论和最佳实践,并能够在实际场景中有效应用。你将使用如 Microsoft Excel 等工具进行数据准备、分析和可视化,以获得开发和管理项目进度的专业知识。然后,你将通过使用实际场景的顶点项目展示你的新技能,并为行业认可的 PMP 认证考试做好准备。
总结
4 个在科技领域内需求量大但遗憾地未受到足够认可的职业——但它们应该被认可!如果你想成为分析组织当前状态并提出改进建议的人,或者你是确保组织的 IT 支持一流的人。
Nisha Arya 是一位数据科学家、自由职业技术作家,同时也是 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及与数据科学相关的理论知识。Nisha 涉及广泛的话题,并希望探索人工智能如何有助于人类寿命的延续。作为一个热衷学习的人,Nisha 希望拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
识别机器学习可解决问题的 4 个因素
原文:
www.kdnuggets.com/2022/04/4-factors-identify-machine-learning-solvable-problems.html
根据最新的 研究,AI 到 2030 年有望为全球经济贡献 15.7 万亿美元。自从疫情引发的数字加速以来,世界已经看到 AI 在商业中的广泛应用。IBM 领导者预测,在接下来的 18-24 个月内,采用率将增加 90%。这完全与无处不在的 AI 形成了共鸣。
-
AI 将决定候选人是否适合某个职位
-
AI 在信用评分模型中找到好的风险贷款候选人
-
我们依赖 AI 在金融交易中发现欺诈行为
-
我们对视频和新闻的偏好由 AI 筛选
-
列表还在继续。
我们是否充分发挥了 AI 的真正潜力?
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
数据以惊人的速度生成,无疑是新的货币。许多公司积累了大量数据,并发现自己在争分夺秒地获取竞争优势。每个人都在快速构建原型,但却忽视了一个基础问题——他们是否真的需要 AI 来解决这个问题,而不是所有问题。将产品作为 AI 驱动的解决方案进行销售看起来和听起来都很花哨,但现实却不同。
来源:科技漫画 PSD,由 jcomp 创建 - freepik,加作者编辑
因此,我们需要提升自身技能,了解 AI/ML 能够解决哪些问题。
Google 已简洁地总结了什么问题适合机器学习的特点。
不应跳过解决方案,即架构算法,假设数据及其属性、数据量和评估指标来解决问题。
在项目的初期阶段,你花在理解问题上的时间越多,出现问题的可能性就会大大减少。专注于问题陈述,明确需求。在提出可能的解决方案之前,确保你已经理解了业务需求。
一旦你评估了业务的核心问题,检查一下使用传统技术解决这些问题的挑战。企业使用启发式规则已经有很长时间了,那么提供的问题有什么独特之处需要人工智能解决?
总的来说,它归结为四个主要因素:模式、环境、验证和维度。
模式
我们首先从“模式”开始。
需要检查数据并寻找模式的问题,将在其解决方案中找到人工智能。既然你已经全面理解了问题,就开始着手一些最佳解决方案,这些方案能够很好地解决你的问题。请注意,前几次迭代通常不会取得重大突破——一般来说,这些初步的迭代涉及到表面问题的探查,暴露出基线模型的薄弱点,并设定方向。
你不仅要迭代模型,还要迭代数据探索周期。
当你在寻找最佳模型的过程中不断迭代不同版本的模型时,文档将揭示你在不同实验中的“实际努力”及其对问题的适用性。然而,文档上没有显示的是你的知识库,它随着所有最终导致最佳模型的失败而不断丰富。这个知识库将区别你作为数据科学家在识别机器学习可解性方面的直觉。
接下来是赢得这场人工智能战争的最强武器——数据。首先,它是否可用?如果不可用,你将发现自己陷入困境。你将不得不寻找最接近的公开数据,或为你的业务案例模拟数据。在任何情况下,模型解决问题的能力只是建立在实际数据基础上的模型的一个代理(不幸的是,这些实际数据对你来说还不可用)。
如果数据可用,那么模型的预测能力依赖于获取正确的属性,这些属性需要携带良好的信号。而问题还没有结束——下一个关注点是评估需要多少数据才能得到第一个模型版本?这取决于机器学习需要解决的任务的复杂性。如果特征能够轻松地将目标变量的不同类别分开(假设是分类机器学习),那么较少的数据也能完成工作,比如在‘Iris toy data’中。
永远记住,机器学习的效果取决于提供的数据和从统计关联中学习。你不仅需要输入好的信号属性,还需要去除那些增加噪声的特征,这将有助于模型更快、更好地学习。
你已经建立了许多假设并进行了很多实验,但你如何选择最佳模型。实际上,什么是最佳模型?一个在以前未见数据上具有良好泛化能力的模型是大家所青睐的。这定义了模型的鲁棒性。进行实验很容易,但找到一个鲁棒的模型却不容易。创建一个能够最佳代表你的模型在生产环境中会遇到并执行的数据集。将你的最佳模型在这个未见的评估数据集上运行,以确认它是否真的最好。
环境
在高度动态的环境中构建机器学习模型将非常困难。让我举个例子。假设你正在构建一个股票价格预测模型,其中股票价格因各种原因而变化——情绪驱动、季度和年度发布、宏观经济因素、新闻、外国投资、临近衍生品到期波动、美联储公告等。
来源: 商业矢量图由 pch.vector 创建 - freepik 以及作者编辑
对模型的现实期望是检查一个合理的人是否能够实现该结果,以及实现的程度。我所说的“合理”是指一个普通人能够识别股票模式并进行交易获利,而不是一个季节性的股市专家,该专家通过多次失败和学习掌握了细微差别和直觉。外部环境通常难以建模,需要大量领域知识来构建机器学习模型。
验证
在开始建模之前,了解模型性能如何转化为业务指标。
科学指标如精确度、召回率、均方根误差(RMSE)、ROC-AUC 可以评估模型在未见数据上的表现,以判断一个机器学习模型的优劣,但这是否能很好地与业务产生共鸣。
例如:80% 的精确度对转换率和业务收入有什么影响?
同时,必须有一种方法来验证模型预测的准确性。了解一组专家对模型输出评估的一致意见。
维度
想象一下你想买一栋房子,并估计房子的市场价值以评估它是否被高估或低估。估算价格的一种方法是与面积相关——面积越大,价格越高。这可以给出一个大概的估计,但可能不够准确。
接下来,你会关注其他因素,比如房子的房间数量或它的年龄,即建造年份,以获取更接近的估计。同样,你也会考虑其他因素,比如——这栋房子附近是否有学校,周围是否有医疗设施,以便更好地预测价格。

来源:财经矢量图由 pch.vector 创建,来源:Unsplash- 作者进行的额外编辑
现在随着维度的增加,即你考虑的影响房价的相关因素越多,你的估算就越准确。但随着因素的增加,人力计算变得越来越困难。在这种情况下,相较于人类专家,ML 在处理大数据集上的数据关联挖掘方面具有优势。
在这篇文章中,我们了解了识别良好 ML 可解决问题的重要性。我们还讨论了问题优先而不是解决方案优先的特质如何帮助理解 ML 是否能对给定问题提供良好帮助。随后,文章解释了模式为何对使用 ML 至关重要,为什么 ML 并非专门适用于不断变化的环境,ML 如何适用于维度增加,以及如何建立验证模型输出的机制。
Vidhi Chugh 是一位屡获殊荣的 AI/ML 创新领袖和 AI 伦理学家。她在数据科学、产品和研究的交汇点上工作,以提供业务价值和洞察力。她是数据中心科学的倡导者,也是数据治理领域的领先专家,致力于构建可信赖的 AI 解决方案。
更多相关话题
提升数据科学技能的 4 门免费数学课程
评论
当我进入数据科学和机器学习领域时,任何与数学和统计相关的内容都是我大约 10 年前最后一次接触的,我想这可能也是我一开始觉得很困难的原因。花了很多小时阅读和观看视频,我才对我们在行业中日常使用的许多工具有了初步的理解。然而,我到了一个阶段,感到需要对所有那些在 Jupyter Notebook 中进行的“导入”和“拟合”操作背后的内容有一个坚实的理解。所以我决定是时候重新审视我的数学知识了。
如今,我仍在学习,我认为这永远不会够。此外,作为一个来自商业领域且处于一个充满工程、统计、物理学及其他精确科学领域的专业人士的行业,我知道数据科学领域有很多东西需要学习。但你知道吗?技术和语言可能会出现和消失,但该领域的数学基础将会保持不变。
这就是为什么今天我整理了一个 4 门课程的列表,以提升你的数学知识,并利用我们因这次不幸事件而获得的一些闲暇时间。因为,你知道,你这些天应该待在家里。
1. 机器学习数学
位置:Coursera
相关机构:帝国理工学院
所需时间:104 小时(实际上可能至少需要+50%)
先决条件:无
课程摘要:
对于许多高级机器学习和数据科学课程,你会发现需要重新学习数学基础——这些东西你可能在学校或大学时学过,但当时是在其他背景下讲授的,或不够直观,以至于你很难将其与计算机科学中的应用联系起来。这门专业课程旨在弥补这个差距,让你掌握基础数学,建立直观理解,并将其与机器学习和数据科学关联起来。
涵盖主题:
-
线性代数
-
多变量微积分
-
主成分分析
提示:大多数 Coursera 的课程和专业都有审核选项。你不会获得证书,但可以访问课程的大部分资源——我个人认为这已经足够了。在注册时,只需选择审核课程的选项即可。
2. 机器学习必备数学:Python 版
位置:edX
相关机构:微软
所需时间:50 小时
前置要求:Python 和一些数学基础知识。
课程摘要:
想学习机器学习或人工智能,但担心你的数学技能可能达不到要求?像“代数”和“微积分”这样的词让你感到恐惧?你是否因为离开学校太久而忘记了很多所学的内容?
你并不孤单。机器学习和人工智能建立在诸如微积分、线性代数、概率、统计和优化等数学原则之上,许多潜在的 AI 从业者会觉得这很令人生畏。该课程并不是为了让你成为数学家,而是帮助你学习一些基本的基础概念及其表达符号。课程提供了一种实践的方法来处理数据并应用你学到的技术。
涵盖的主题:
-
方程、函数和图表
-
微分与优化
-
向量和矩阵
-
统计与概率
提示:该课程有开课日期,但你可以选择一个早期的开课日期,并免费查看该批次的所有内容。
3. 使用 Python 进行数据科学中的概率与统计
位置:edX
参与机构:加州大学圣迭戈分校
所需时间:100–120 小时
前置要求:多元微积分和线性代数
课程摘要:
对不确定性的推理是分析噪声数据的固有部分。概率和统计提供了这种推理的数学基础。
在本课程中,你将学习概率和统计的基础知识。你将学习数学理论,并通过使用 Jupyter 笔记本将这一理论应用于实际数据,获得实践经验。
涵盖的主题:
-
机器学习的数学基础
-
统计素养:理解“99% 置信水平”等陈述的含义。
提示:该课程有开课日期,但你可以选择一个早期的开课日期,并免费查看该批次的所有内容。
4. 贝叶斯统计:从概念到数据分析
位置:Coursera
参与机构:加州大学圣克鲁斯分校
所需时间:22 小时(实际情况可能不低于 30 小时)
前置要求:对概率有一定的基础理解。
课程摘要:
本课程介绍了贝叶斯统计方法,从概率概念开始,逐步到数据分析。我们将学习贝叶斯方法的哲学及其在常见数据类型中的应用。我们将把贝叶斯方法与更常见的频率主义方法进行比较,并了解贝叶斯方法的一些优点。
涵盖的主题:
-
概率与贝叶斯定理
-
统计推断
-
离散数据的先验和模型
-
连续数据的模型
我推荐按照呈现的顺序完成这些课程,但当然,如果你符合要求,可以选择任何你喜欢的课程。
原文。经许可转载。
相关内容:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关话题
2020 年数据科学的四大热门趋势
原文:
www.kdnuggets.com/2019/12/4-hottest-trends-data-science-2020.html
评论
2019 年是数据科学的重要一年。
全球各行各业的公司正在经历人们所称的数字化转型。也就是说,企业正在利用数字技术将传统的业务流程,如招聘、营销、定价和战略,使其效果提高 10 倍。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT 需求
数据科学已成为这些转型的核心部分。凭借数据科学,组织不再需要基于直觉、最佳猜测或小规模调查来做出重要决策。相反,他们分析大量真实数据,以基于真实的数据驱动事实做出决策。这就是数据科学的真正意义——通过数据创造价值。
根据Google 搜索趋势,将数据整合到核心业务流程中的趋势显著增长,过去 5 年间兴趣增加了超过四倍。数据正为公司提供相对于竞争对手的巨大优势。凭借更多的数据和更优秀的数据科学家,企业能够获取市场信息,这些信息可能是竞争对手甚至未曾意识到的。这已成为一场“数据或灭亡”的游戏。
过去 5 年“数据科学”在 Google 搜索中的流行程度。由Google Trends生成。
在当今不断发展的数字世界中,保持竞争优势需要不断创新。专利已不再流行,而敏捷方法和快速跟上新趋势则非常重要。
组织不再能依赖旧有的稳固方法。如果出现新的趋势,如数据科学,人工智能或区块链,需要提前预见并迅速适应。
以下是 2020 年四大最热门的数据科学趋势。这些趋势在今年引起了越来越多的关注,并将在 2020 年继续增长。
(1) 自动化数据科学
即便在今天的数字时代,数据科学仍然需要大量的人工工作。存储数据、清理数据、可视化和探索数据,最后,对数据建模以获得实际结果。这些人工工作迫切需要自动化,因此自动化数据科学和机器学习应运而生。
数据科学流程的几乎每一个步骤都已经或者正在变得自动化。
自动数据清理在过去几年中已经广泛研究。清理大数据往往占用了数据科学家宝贵的时间。初创公司和像 IBM 这样的大公司都提供自动化和工具来进行数据清理。
数据科学的另一个重要部分,即特征工程,已经经历了重大变革。Featuretools提供了自动特征工程的解决方案。除此之外,现代深度学习技术,如卷积神经网络和递归神经网络,能够自行学习特征,无需手动设计特征。
也许最显著的自动化发生在机器学习领域。Data Robot和H2O通过提供端到端的机器学习平台在行业中确立了自己的地位,使数据科学家在数据管理和模型构建方面变得非常轻松。AutoML作为一种自动模型设计和训练的方法,也在 2019 年蓬勃发展,因为这些自动化模型超越了最先进的技术。特别是谷歌正在大量投资Cloud AutoML。
总的来说,公司正在大量投资于构建和购买自动化数据科学的工具和服务。任何能让过程更便宜、更容易的东西。同时,这种自动化也满足了较小和技术能力较弱的组织的需求,这些组织可以利用这些工具和服务,而无需组建自己的团队即可进行数据科学。
(2) 数据隐私和安全
隐私和安全始终是技术中的敏感话题。所有公司都希望快速发展和创新,但因隐私或安全问题失去客户的信任可能是致命的。因此,他们被迫将其作为优先事项,至少要做到不泄露私人数据。
数据隐私和安全在过去一年中成为了一个极为热门的话题,因为问题被巨大的公众黑客攻击所放大。就在最近,2019 年 11 月 22 日,一个没有安全措施的暴露服务器在 Google Cloud 上被发现。该服务器包含了12 亿名独特个体的个人信息,包括姓名、电子邮件地址、电话号码以及 LinkedIn 和 Facebook 个人资料信息。连 FBI 都参与了调查。这是有史以来最大的数据显示泄露事件之一。
数据是怎么到那里的?它属于谁?谁负责数据的安全?它曾在一个 Google Cloud 服务器上,实际上任何人都可以创建这个服务器。
现在我们可以放心,全世界的人在阅读新闻后不会纷纷关闭他们的 LinkedIn 和 Facebook 账户,但这确实引起了一些关注。消费者变得越来越小心他们将电子邮件地址和电话号码提供给谁。
一家能够保证其客户数据隐私和安全的公司将发现,他们更容易说服客户提供更多的数据(通过继续使用他们的产品和服务)。这也确保了,如果政府出台任何要求客户数据安全协议的法律,他们已经做好了充分的准备。许多公司选择了 SOC 2 合规性 来证明他们的安全性。
整个数据科学过程依赖于数据,但大多数数据并不是匿名的。如果数据落入不法之手,可能会引发全球性灾难,破坏日常人的隐私和生活。数据不仅仅是原始数字,它代表和描述了真实的人和事物。
随着数据科学的不断发展,我们也会看到围绕数据的隐私和安全协议的转变。这包括过程、法律以及建立和维护数据的安全、保护和完整性的方法。如果网络安全成为今年的新潮词也不会令人感到惊讶。
(3) 云中的超级数据科学
随着数据科学从一个小众领域成长为一个完整的领域,分析所用的数据量也激增。组织正在收集和存储比以往更多的数据。
一家典型的财富 500 强公司可能需要分析的数据量远远超过了个人电脑能够处理的范围。一台不错的 PC 可能具有大约 64GB 的 RAM、8 核 CPU 和 4TB 的存储空间。这对于个人项目来说完全够用,但对于像银行或零售商这样拥有覆盖数百万客户的数据的全球公司而言就不够用了。
这就是云计算进入该领域的原因。云计算 提供了让任何人几乎可以无限制访问处理能力的能力。云服务供应商如 Amazon Web Services(AWS)提供具有高达 96 个虚拟 CPU 核心和高达 768 GB RAM 的服务器。这些服务器可以设置在自动扩展组中,数百台服务器可以快速启动或停止——按需计算能力。

Google Cloud 数据中心
除了计算能力,云计算公司还提供了全面的数据分析平台。Google Cloud 提供了一个名为 BigQuery 的平台,这是一个无服务器且可扩展的数据仓库,使数据科学家能够在单个平台上存储和分析 PB 级的数据。BigQuery 还可以连接到其他 GCP 服务进行数据科学。通过使用 Cloud Dataflow 创建数据流管道,使用 Cloud DataProc 在数据上运行 Hadoop 或 Apache Spark,或者使用 BigQuery ML 在庞大的数据集上构建机器学习模型。
从数据到处理能力,一切都在增长。随着数据科学的发展,我们最终可能会看到数据科学完全在云端进行,因为数据的体量实在是太大了。
(4) 自然语言处理
自然语言处理(NLP)在深度学习研究取得重大突破后,已经牢牢地进入了数据科学领域。
数据科学最初是作为对纯粹原始数字的分析开始的,因为这是处理和收集数据到电子表格中最简单的方式。如果需要处理任何形式的文本,通常需要将其分类或以某种方式转换成数字。
然而,将一段文字压缩成一个单一的数字确实相当具有挑战性。自然语言和文本包含了丰富的数据和信息——由于我们缺乏将这些信息表示为数字的能力,我们以前往往忽视了这些信息。
深度学习在自然语言处理(NLP)方面取得了巨大的进展,推动了 NLP 在我们常规数据分析中的全面整合。神经网络现在能够从大量文本中迅速提取信息。它们可以将文本分类到不同的类别,确定文本的情感,并对文本数据的相似性进行分析。最终,这些信息可以存储在一个单一的数字特征向量中。
结果是,NLP 成为了数据科学中的一个强大工具。庞大的文本数据存储,不仅仅是一两个词的答案,而是完整的段落,可以转化为标准分析的数值数据。我们现在能够探索更加复杂的数据集。
例如,想象一个新闻网站希望查看哪些主题获得了更多的浏览量。如果没有先进的 NLP,能做的只有依靠关键词,或者只是对某个标题为何比另一个标题表现更好的一种直觉。借助于今天的 NLP,我们将能够量化网站上的文本,将整个段落甚至网页进行比较,以获得更全面的见解。
想要了解过去几年在 NLP 领域最重要的进展的技术概述,你可以查看由Victor Sanh提供的指南。
数据科学整体上在不断发展。随着其能力的增强,它正在渗透到每一个行业,无论是技术性还是非技术性,以及每一个企业,无论大小。
随着这一领域的长期发展,看到其在大规模上实现民主化并成为我们软件工具箱中的一种工具,也并不令人意外。
原始文章。经许可转载。
相关:
更多相关主题
机器学习和机器人技术正在改变的 4 个行业
原文:
www.kdnuggets.com/2017/08/4-industries-transformed-machine-learning-robotics.html
comments

机器人技术、人工智能、机器学习和大数据平台密不可分。尤其在现代社会,这些技术共同工作的情况非常普遍。每项技术也在多方面改进并彻底改变了世界。
例如,机器人技术彻底改变了生产力——特别是在制造和组装市场。机器学习和人工智能正在推动自动化系统,这些系统可以完全取代人工。当与大数据和机器学习结合使用时,人工智能和机器人技术可以随着收集到的信息增多而不断改进。
你不需要远行就能看到这些技术如何彻底改变了世界,并且继续这样做。事实上,我们将会看几个目前正在被这些技术——特别是机器学习、人工智能和机器人技术——改变的行业。
1. 医疗保健行业
医疗保健行业几乎完全被这些技术所改变,每项技术的广泛应用变得越来越普遍。医生们在更加安全和高效的条件下使用机器人进行侵入性手术。
人工智能和机器学习正在帮助医生更准确地诊断患者,因为信息数据库大大增加。
最后,自动化系统的增长速度不如其他技术,但它仍然变得越来越可行。这包括扫描硬件和系统以发现疾病或不健康的身体部位,以及用于进行手术的机器人。一些工具被设计用于执行精确的操作,而不需要人工操作,因为它们更为精准。
外科医生接受新技术的速度较慢,但市场在不断增长。过去几年,FDA 批准了几种新系统,这表明新技术的出现。
2. 制造行业
现代和工业制造业是最早利用机器人和自动化系统的行业之一,早在 1960 年代就开始了。可以想见,自那时以来,这项技术已经取得了显著的进步。
当机器人首次出现时,它们被用于自动化简单、枯燥的任务,这些任务对人类来说既无聊又危险。许多系统与人类协作工作,并且仍需不断监督以确保其有效运作。然而,今天,制造业中使用的机器人和自动化系统往往比新工人或未熟练工人更高效。
当与人工智能和机器学习平台结合使用时,机器人技术可以变得更加先进,甚至智能。它们还显著降低了成本。每 1,000 名工人中,一个机器人可以取代四分之一到一半的工资。
3. 金融行业
想象现代技术在金融市场中占据一席之地可能会显得有些陌生,特别是在金融服务和客户服务方面。尽管如此,在不久的将来,人工智能和机器学习将开始在行业中扎根,几乎取代人类顾问。
例如,人工智能系统在提供金融建议时可以考虑更多的数据。它可以分析社交媒体帖子、电子邮件、消息和购买历史,以提供个性化的情感分析,指导如何处理财务。
随着时间的推移,人工智能还能监控你的习惯和财务,帮助做出更准确的决策。更重要的是,它可以帮助许多金融专业人士建立强大的投资组合。其他感兴趣的领域包括欺诈检测和安全、算法交易、贷款和保险承保等。
4. 零售与客户服务
人工智能和机器学习在零售和消费品行业的进步中责无旁贷。特别是在营销领域,它们可以帮助分析和预测客户行为,以确定可行的促销活动、广告甚至产品渠道。
当然,人工智能和机器学习是行业中最大的进步之一的幕后推手,这一进步目前正经历着巨大的增长:聊天机器人。聊天机器人是一种现代沟通方式,为客户提供 24/7 的支持。它们可以通过一对一的消息平台进行联系,机器人可以回答问题,处理个人账户详情,提供推荐,甚至像真正的人一样聊天。
一些优秀的聊天机器人或 AI 平台包括苹果的 Siri 和亚马逊的 Alexa,但这些平台都是专门为消费者家庭使用设计的。你会在零售网站上遇到提供聊天服务的客户服务聊天机器人。
更先进的技术即将到来
这里列出了一些优秀的示例和案例研究,但重要的是要记住,它们只是一个开始。
人工智能、机器学习、现代机器人技术和自动化系统将在不久的将来改变几乎每个行业——从零售和客户服务到公共交通。未来无疑是光明的。
简历: 凯拉·马修斯 讨论了《周刊》、《数据中心期刊》和《VentureBeat》等出版物中的技术和大数据,并已经写作超过五年。要阅读凯拉的更多文章,订阅她的博客《生产力字节》。
相关:
-
6 个原因说明为什么 Python 突然变得如此受欢迎
-
AI 的真正“恐惧”是自动化泛滥
-
人工智能和机器学习能做什么——以及不能做什么
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
更多相关内容
4 个职业教训帮助我应对艰难的就业市场
原文:
www.kdnuggets.com/2023/05/4-lessons-made-difference-navigating-current-job-market.html

编辑提供的图片
首先,我非常感激在过去两个月里我所获得的所有支持,因为我在各种挑战性情况下面临面试、寻找并开始新角色的挑战!
如果最近裁员对你产生了影响,或者你是面临就业市场挑战的移民,这里有 4 个宝贵的教训,我在寻求数据科学职位时学到的,包括 60 天的移民政策、裁员和健康问题:
1. 向他人寻求并接受帮助
我希望几年前我就意识到这一点——我不必独自完成所有事情,接受那些想支持你目标和成长的人的帮助并没有错。例如,我们是否早期就自己学会了开车或步行?
所以请向你的专业联系人、职业资源、朋友、前同事、队友等寻求帮助,探索并与新机会建立联系。询问人们你想了解的所有细节!哦,当有人提供帮助时,接受它!如果不清楚他们如何能帮忙,问他们:“你能在哪些方面帮助我?”就是这么简单却有效!
2. 在搜索中要具体,从而节省时间
从明确列出你有经验和专业知识的 3-4 个维度开始,并确定那些听起来令人兴奋的角色!例如,我注意到我的背景涉及 3 个关键领域:机器学习 + 销售 + 战略,并且我在寻找创业角色。不幸的是,LinkedIn 上有超过 100,000 个数据科学职位!
**但在筛选出我符合条件并感兴趣的具体术语(销售 AND 机器学习 AND 战略)后——我可以优先安排时间去联系、申请和了解 100 个可用的机会——减少了 99.9%!这个过程帮助我在 6 周内面试并了解了 8 个机会,因此我强烈推荐!
3. 勇敢地提问,并尽早询问
在我在美国的头几年,我曾经因为担心被认为不合适而害怕和小心地向潜在雇主询问有关 H1b 或移民相关的话题。
然而,多年来,我意识到,通过提前提问并弄清楚什么是可能的、什么是不可能的,可以消除很多雇主在开始时需要经历的麻烦。这不仅帮助他们避免在可能无法长期支持的候选人身上投入时间和资源,而且还有助于引导你找到更好的机会,这些机会会理解移民情况并在长期内以最佳方式真正支持你!
4. [最重要的] 减少或消除噪音、新闻通知和外部压力
“专注于学习和逐步进步”
由于所有的移民挑战,我需要专注和优先处理手头的任务 - 无论是与专业人士建立联系、面试准备,还是了解新角色。因此,我花在观看最新公司重组或关于最新聊天 GPT 发布的通知上的时间并不太有帮助(除非聊天 GPT 要为你面试!)。
就我个人而言,过去几年,尤其是最近两个月,我发现有效的方法是 - 我没有为电子邮件或新闻网站设置任何通知,也没有订阅 100+个新闻通讯 - 每天设定时间和意图,专注于任务,并在真正重要的事情上取得逐步进展!
我强烈推荐 Option B 来建立韧性并在挑战时期找到接受感!如果这引发了任何新想法或帮助你找到下一个冒险,随时通过 Linkedin 联系我!
Arjun Arora 帮助了多个大型企业(包括零售、技术和制造业)通过识别业务紧迫性并领导分析和机器学习解决方案及概念验证的技术执行,变得更加数据驱动。此外,他通过各种培训研讨会、网络研讨会和在全国会议上演讲,帮助提高了行业对 AI/ML 解决方案的采用率。工作之外,他致力于个人成长,支持各种 DEI 和 LGBTQ+ 社区倡议,并且是湾区的 avid 徒步旅行者!
更多相关话题
数据科学中的 4 个数据使用层级
原文:
www.kdnuggets.com/2018/07/4-levels-data-usage-data-science.html
评论
在 O'Reilly Data Show 播客的最新一期中,Ben Lorica 采访了来自DXC Technology的嘉宾 Jerry Overton,讨论了数据从业者必须处理的一些非技术性问题,如隐私、安全和伦理,以及当前数据科学在商业中的状态。
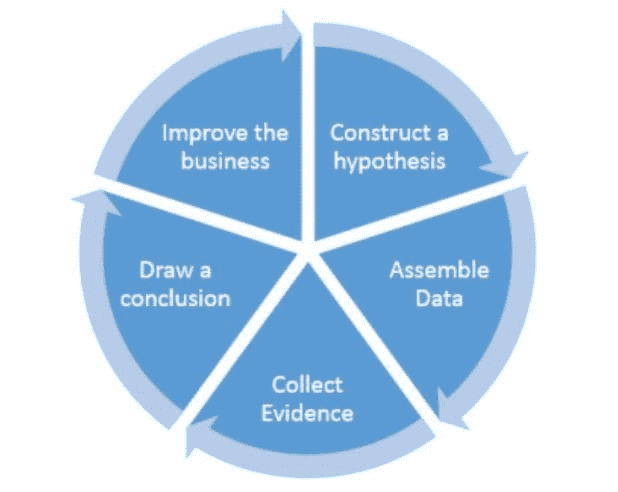
图 1: 利用数据科学积累竞争优势的过程(来源:数据科学职业进阶)
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
Overton 指出,五年前,从数据中提取价值的理念对企业来说还是新的,企业必须被说服认为收集数据并分析其中有意义的模式是值得的。与今天的观点相比,企业现在理解到不使用数据就是失去了潜在的竞争优势。数据科学在某种程度上是必要的,但企业现在面临一系列不同的问题。我们的数据科学家应该做什么?我们应该关注业务的哪些领域?我们的数据到底如何增值?
Ben 和 Jerry 讨论的一个话题是商业中数据使用的层级,或称“桶”,Jerry 定义并概述了这 4 个类别。讨论很有趣,尽管层级描述直观,但在我看来还是很有用的。以下是这些类别的基本总结,我鼓励大家收听整个节目以获取更深入的讨论。
1 - 监控与预测
这个层级包括实施端到端的能力,以查看发生了什么,并观察是否会出现问题。
-
监控业务并预测问题
-
收集有关发生情况的信息
-
收集的信息就是 Overton 称之为“数字数据排放”
-
我们能够回答“是否存在问题?”这个问题
2 - 提高效率
既然你知道问题的存在,那该如何减少与该问题相关的风险呢?
3 - 增强决策制定
在这个层级,我们应该已经知道出了什么问题,并且在预测问题发生的时间上(希望)会有更好的定位。
-
将这些信息传达给决策者
-
我们可以利用洞察力制定业务战略,而不是仅仅依赖数据,或以交易方式使用数据
-
这距离自动化一步之遥,不过人类仍然作为主角需要参与
4 - 自动化
在这个层级,我们将特定过程的控制权交给机器,让机器不间断地运行这些过程,并且不需要持续的人类监督。
-
当机器遇到无法应对的现象时,会提醒人类
-
重要的是要注意,这种自动化是逐步发生的,而不是一次性完成
-
这不是“完全业务自动化”,类似于 SkyNet
-
使人类能够做更有意义的工作,专注于业务需要人类做的事情
图 2: 企业数据科学(来源:DXC Technology,如这里所见)
相关信息:
-
数据科学的什么、哪里和如何
-
数据科学:大多数人失败的 4 个原因
-
人工智能如何改变你的业务
更多相关主题
我在构建第一个模型时希望知道的 4 个机器学习概念
原文:
www.kdnuggets.com/2021/03/4-machine-learning-concepts.html
comments

照片由 Anthony Tori 提供,来源于 Unsplash。
我喜欢写作的原因之一是它给了我一个机会回顾、反思我的经历,并思考什么做得好,什么做得不好。
在过去的三个月里,我负责构建一个机器学习模型来预测一个产品是否应该被 RMA'ed。我会说这是我开发的第一个“认真”的机器学习模型——我说“认真”是因为这是第一个创造实际商业价值的模型。
鉴于这是我第一次“认真”对待的模型,我曾对我构建模型的过程有一个天真的误解:
图片由作者创作。
实际上,我的过程更像这样:
图片由作者创作。
总体而言,我会说这是一次成功,但在构建模型的过程中确实经历了很多起伏——为什么?因为我花了很多时间学习我之前不知道的新概念。在这篇文章中,我想反思并记录下在构建这个模型之前我希望知道的事情。
话虽如此,这里有 4 个概念是我希望在构建这个模型之前就知道的!
1. 使用简单 Web UI 进行模型部署
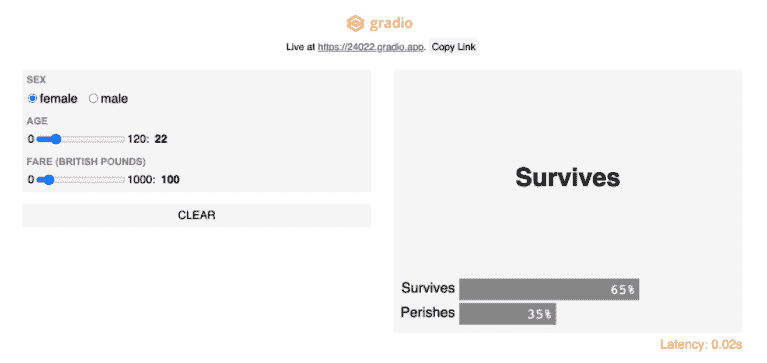
最近我遇到了一些东西,叫做 Gradio,这是一个 Python 包,允许你用少至三行代码构建和部署一个机器学习模型的网络应用。它和 Streamlit 或 Flask 具有相同的目的,但我发现它在部署模型时要快得多,更容易。
为什么这如此有用?有几个原因:
-
这允许进一步的模型验证。具体来说,它允许你交互式地测试模型中的不同输入。这还允许你从其他利益相关者和领域专家那里获得反馈,尤其是来自非编码人员的反馈。
-
这是进行演示的好方法。就个人而言,我发现向某些利益相关者展示 Jupyter Notebook 并没有体现我的模型的实际表现,尽管它的表现非常好。使用这样的库可以更容易地传达你的结果,并更好地推销自己。
-
实现和分发很简单。重申一下,学习曲线很小,因为只需 3 行代码即可实现此功能。此外,它非常容易分发,因为网络应用程序可以通过公共链接访问。
总结:利用像Gradio这样的 ML 模型 GUI 来进行更好的测试和沟通。
2. 特征重要性
特征重要性是指将分数分配给输入变量的一组技术,基于它们在预测目标变量方面的表现。分数越高,该特征在模型中越重要。
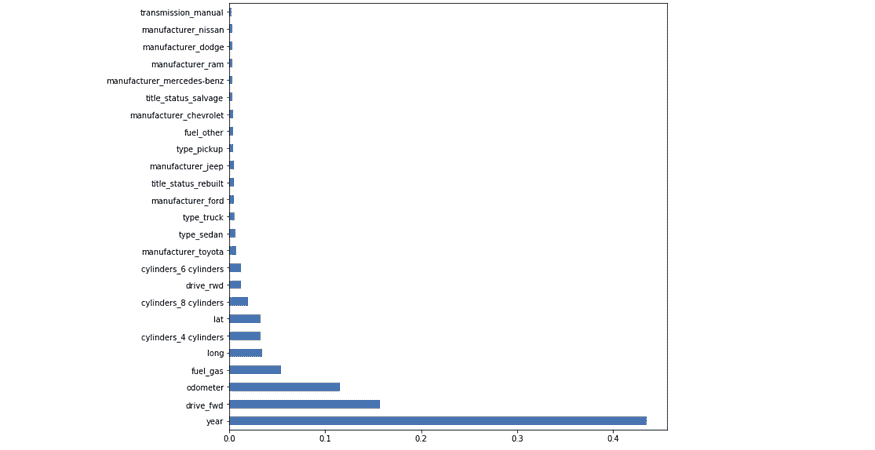
由作者创建的图像。
例如,如果我想使用图中的特征来预测汽车价格,通过进行特征重要性分析,我可以确定模型的年份、是否为前驱动以及汽车的里程(里程表)是预测汽车价格时最重要的因素。
相当棒,对吧?我敢打赌你现在开始看到这有多么有用。
特征重要性在特征选择中非常有用。通过在初步模型上进行特征重要性分析,你可以轻松确定哪些特征对模型有影响,哪些没有。
更重要的是,特征重要性使得解释模型和解释发现变得更容易,因为它直接告诉你哪些特征对目标变量最具指示性。
总结:利用特征重要性来改善特征选择、模型可解释性和沟通。
如果你想看看特征重要性如何实现,可以查看我第一个机器学习模型的演练。*
3. 超参数调整
机器学习的本质是找到最适合数据集的模型参数。这通过训练模型来完成。
另一方面,超参数是不能直接通过模型训练过程学习到的参数。这些是关于模型的更高层次的概念,通常在训练模型之前就固定下来。
超参数的示例包括:
-
学习率
-
决策树可以具有的叶子数或最大深度
-
神经网络中的隐藏层数量
关于超参数的事情是,虽然它们不是由数据本身决定的,但设置正确的超参数可以将你的机器学习模型的准确率从 80%提高到 95%以上。这就是我所经历的情况。
现在回到我的主要观点,有一些技术可以自动优化你的模型超参数,这样你就不需要测试一堆不同的数值了。
两种最常见的技术是网格搜索和随机搜索,你可以在这里阅读更多内容。
TLDR: 像网格搜索和随机搜索这样的技术可以优化你的模型超参数,从而显著提高模型的性能。
4. 模型评估指标
这可能是在线课程、训练营和在线资源中最被忽视的领域之一。然而,它无疑是数据科学中最重要的概念之一。
了解评价机器学习模型的指标最终需要你对你试图解决的业务问题有深入理解。
如上图所示,由于我没有清楚地理解业务问题,因此在最初几周没有取得太大进展,也不知道我试图优化模型的指标是什么。
因此,我们可以将这一点分解为两个子点:
-
理解问题的业务需求。这意味着理解业务要解决的问题、问题的参数、可用的数据、相关方以及模型如何融入业务流程/产品。
-
选择正确的指标来评估你的模型。在我们的案例中,我们需要比较分类假阳性与假阴性的后果。我们最终的决定取决于模型如何融入业务流程。
TLDR: 理解业务问题。充分理解所有相关指标,并理解选择每个指标的后果。
原文。经许可转载。
相关:
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 工作
更多相关内容
《大数据的 4 个误区及深度数据的 4 种改进方式》
原文:
www.kdnuggets.com/2019/01/4-myths-big-data-deep-data.html
评论

对大数据的炒作正在减少。云计算、Hadoop 及其变种已解决了这个问题。但许多人仍在花费大量金钱建立更大的基础设施来处理、存储和管理这些庞大的数据库。对‘大’的盲目追求正在产生一些可观的且可避免的基础设施和人力资源成本。
现在是时候将讨论从‘大数据’转向‘深度数据’了。我们不再需要收集所有可能的数据来实现‘大数据’,而是需要更有思想和审慎。我们需要让一些数据落地,追求多样性而非数量,追求质量而非量。这将带来许多长期的好处。
大数据的误区
为了理解从‘大’到‘深’的转变,我们先来看一下我们对大数据的一些错误观念。以下是一些大误区:
-
所有数据都能并且应该被捕获和存储。
-
更多数据总是能帮助构建更准确的预测模型。
-
更多数据的存储成本几乎为零。
-
更多数据的计算成本几乎为零。
这里是一些现实情况:
-
物联网和网络流量的数据仍然超过了我们捕捉全部数据的能力。部分数据在采集时不得不被舍弃。我们需要聪明一点,基于价值对数据进行优先排序。
-
相同的数据示例重复一千次并不会提高预测模型的准确性。
-
存储更多数据的成本不仅仅是亚马逊网络服务向你收取的每 TB 的费用。还包括寻找和管理多个数据源的额外复杂性,以及你员工在移动和使用这些数据时的‘虚拟重量’。这些成本通常高于存储和计算费用。
-
AI 算法对计算资源的需求很快会超出即使是弹性云基础设施的承载能力。计算资源是线性增长的,而计算需求如果没有得到专业管理,可能会超线性甚至指数级增长。
相信这些误区的问题在于,你会以那些在纸面上看起来不错或长期有效的方式来设计信息系统,但这些方式在短期内过于笨重,难以实用。
大数据的四个问题
盲目相信‘更多更好’的数据观念会带来以下四个问题:
-
相同的数据不会有帮助。 在为 AI 构建机器学习模型时,训练样本的多样性至关重要。原因在于模型试图确定概念边界。例如,如果你的模型试图通过年龄和职业定义“退休工人”的概念,那么重复出现的 32 岁注册会计师对模型没有多大帮助,因为他们都还未退休。更有帮助的是获取年龄 65 岁时的概念边界样本,并观察退休如何与职业相关联。
-
嘈杂的数据可能会伤害模型。 如果新数据中存在错误或不准确,它只会模糊 AI 试图学习的两个概念之间的界限。在这种情况下,更多的数据不会有所帮助,反而可能降低你现有模型的准确性。
-
大数据会拖慢一切。 在一太字节的数据上构建模型可能需要比在一吉字节的数据上构建模型多一千倍的时间。或者可能需要多一万倍,具体取决于学习算法。数据科学完全是关于快速实验的。最好是灵活且不完美。快速失败,前进失败。
-
大数据可实施的模型。 任何预测模型的最终目标都是创建一个可以部署到业务中的高精度模型。有时使用数据湖中较为隐蔽的数据可能会带来更高的准确性,但这些数据可能在实际部署时不可靠。最好是拥有一个较少准确但运行迅速且可以被业务使用的模型。
提升的四个方面
有几件事可以帮助你对抗大数据的“黑暗面”,并朝着深度数据思维模式迈进:
-
理解准确性/执行的权衡。 数据科学家过于常见的假设是更准确的模型就是目标。基于准确性和部署速度,明确项目的 ROI 预期。
-
使用随机样本构建每个模型。 如果你拥有大数据,就没有理由使用所有数据。如果你有一个好的随机抽样函数,那么你可以通过小样本准确预测用整个数据库构建的模型的准确性。先用小样本快速工作,然后用整个数据库构建最终模型。
-
丢弃一些数据。 如果你被来自物联网设备和其他来源的流数据压垮,可以聪明地丢弃一些数据。也许可以丢弃大量数据。你无法购买足够的磁盘来存储所有数据,这会在你数据科学生产线的后期阶段阻碍所有工作。
-
寻找更多的数据源。 最近 AI 的许多突破并非来自于更大的数据集,而是来自于机器学习算法能够接触到以前无法获得的数据。例如,现在常见的大型文本、图像、视频和音频数据集在二十年前并不存在。要不断寻找这些新的数据机会。
四个改进的方面
如果你关注深层数据而不仅仅是大数据,你将享受许多好处。以下是一些关键好处:
-
一切将变得更快。 使用更小的数据集,你的数据移动、实验、模型训练和评分将会更快。
-
减少存储和计算需求。 关注深层数据意味着你将更智能地有效使用较小的磁盘和计算资源。这直接转化为降低基础设施成本。把节省下来的钱用来聘请更多的数据科学家和 AI 专家吧!
-
减少 IT 压力和让数据科学家更开心。 拥有深厚的数据文化,你的 IT 团队将不再频繁为数据科学团队跑腿,或不得不终止那些占用大量云资源的无序作业。同样,当数据科学家可以将更多时间投入到构建和测试模型上,而不是在数据搬运或等待长时间训练完成时,他们会更快乐。
-
更困难的问题可以解决。构建 AI 模型并不是只有像巫师一样的研究人员才能执行的神奇体验。它更多的是关于后勤而不是魔法。这类似于一个艺术老师的故事,他告诉一半的学生,他们的成绩将基于他们创作的艺术品数量,而另一半的学生则根据他们最好的作品的质量来评分。不出所料,数量多的学生创作了最多的艺术品。令人震惊的是,他们还创作出了最高质量的作品。数量有时会带来质量。在我们的案例中,在相同资源约束下尝试更多模型可能意味着更好的最佳模型。
大数据及其支持的技术突破极大地推动了许多公司在决策过程中变得数据驱动。随着 AI 的兴起以及我们能够充分利用这些强大的资源,我们现在需要对数据需求更加精准。建立对深层数据的理解文化而不仅仅是大数据文化,正是现在所需的。
简历:斯蒂芬·史密斯 是数据科学、预测分析及其在教育、制药、医疗、通信和金融行业应用领域的受人尊敬的专家。
资源:
相关:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关内容
4 个你可能不知道的 Python Itertools 过滤函数
原文:
www.kdnuggets.com/2023/08/4-python-itertools-filter-functions-probably-didnt-know.html
图片由作者提供
在 Python 中,迭代器帮助你编写更具 Python 风格的代码,并在处理长序列时更高效。内置的itertools模块提供了几个有用的函数来创建迭代器。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
当你只想遍历迭代器、检索序列中的元素并处理它们时,这些功能特别有用——而无需将它们存储在内存中。今天我们将学习如何使用以下四个 itertools 过滤函数:
-
filterfalse
-
takewhile
-
dropwhile
-
islice
让我们开始吧!
开始之前:关于代码示例的说明
在本教程中:
-
我们将讨论的四个函数都提供迭代器。为了清晰起见,我们将使用简单的序列,并使用
list()来获取包含迭代器返回的所有元素的列表。但在处理长序列时,除非必要,否则应避免这样做,因为这样会失去迭代器带来的内存节省。 -
对于简单的谓词函数,你也可以使用lambdas。但为了更好的可读性,我们将定义常规函数并将其用作谓词。
1. filterfalse
如果你已经编程 Python 有一段时间,你可能已经使用过内置的filter函数,语法如下:
filter(pred,seq)
# pred: predicate function
# seq: any valid Python iterable
filter函数返回一个迭代器,该迭代器从序列中返回谓词返回True的元素。
让我们来看一个例子:
nums = list(range(1,11)) #[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
def is_even(n):
return n % 2 == 0
在这里,nums列表和is_even函数分别是序列和谓词。
要获取nums中所有偶数的列表,我们使用如下的filter:
nums_even = filter(is_even, nums)
print(list(nums_even))
Output >>> [2, 4, 6, 8, 10]
现在让我们了解一下filterfalse。我们将从itertools模块导入filterfalse函数(以及我们将讨论的所有其他函数)。
正如名称所示,filterfalse的功能与filter函数相反。它返回一个迭代器,该迭代器返回谓词返回False的元素。以下是使用filterfalse函数的语法:
from itertools import filterfalse
filterfalse(pred,seq)
函数 is_even 对 nums 中的所有奇数返回 False。所以使用 filterfalse 得到的 nums_odd 列表是 nums 中所有奇数的列表:
from itertools import filterfalse
nums_odd = filterfalse(is_even, nums)
print(list(nums_odd))
Output >>> [1, 3, 5, 7, 9]
2. takewhile
使用 takewhile 函数的语法是:
from itertools import takewhile
takewhile(pred,seq)
takewhile 函数返回一个迭代器,该迭代器在谓词函数返回 True 时返回元素。当谓词首次返回 False 时,它停止返回元素。
对于长度为 n 的序列,如果 seq[k] 是谓词函数首次返回 False 的元素,则迭代器返回 seq[0]、seq[1]、...、seq[k-1]。
考虑以下 nums 列表和谓词函数 is_less_than_5。我们按如下方式使用 takewhile 函数:
from itertools import takewhile
def is_less_than_5(n):
return n < 5
nums = [1, 3, 5, 2, 4, 6]
filtered_nums_1 = takewhile(is_less_than_5, nums)
print(list(filtered_nums_1))
在这里,谓词 is_less_than_5 对数字 5 首次返回 False:
Output >>> [1, 3]
3. dropwhile
从功能上讲,dropwhile 函数做的是 takewhile 函数的反向操作。
你可以这样使用 dropwhile 函数:
from itertools import dropwhile
dropwhile(pred,seq)
dropwhile 函数返回一个迭代器,该迭代器会不断丢弃元素,只要谓词为 True。这意味着迭代器不会返回任何东西,直到谓词第一次返回 False。一旦谓词返回 False,迭代器将返回序列中的所有后续元素。
对于长度为 n 的序列,如果 seq[k] 是谓词函数首次返回 False 的元素,则迭代器返回 seq[k]、seq[k+1]、...、seq[n-1]。
让我们使用相同的序列和谓词:
from itertools import dropwhile
def is_less_than_5(n):
return n < 5
nums = [1, 3, 5, 2, 4, 6]
filtered_nums_2 = dropwhile(is_less_than_5, nums)
print(list(filtered_nums_2))
因为谓词函数 is_less_than_5 对元素 5 首次返回 False,我们得到从 5 开始的所有序列元素:
Output >>> [5, 2, 4, 6]
4. islice
你可能已经熟悉了切片 Python 可迭代对象,如列表、元组和字符串。切片的语法是:iterable[start:stop:step]。
然而,这种切片方法有以下缺点:
-
当处理大型序列时,每个切片或子序列都是一个占用内存的副本。这可能会导致低效。
-
因为步长也可以是负值,使用开始、停止和步长值会影响可读性。
islice 函数解决了上述限制:
-
它返回一个迭代器。
-
它不允许步长为负值。
你可以这样使用 islice 函数:
from itertools import islice
islice(seq,start,stop,step)
下面是几种你可以使用 islice 函数的不同方式:
-
使用
islice(seq, stop)会返回一个遍历切片seq[0]、seq[1]、...、seq[stop - 1]的迭代器。 -
如果你指定开始和停止值:
islice(seq, start, stop),函数返回一个遍历切片seq[start]、seq[start + 1]、...、seq[start + stop - 1]的迭代器。 -
当你指定开始、停止和步长参数时,函数返回一个遍历切片
seq[start]、seq[start + step]、seq[start + 2*step]、...、seq[start + k*step]的迭代器。使得start + k*step<stop且start + (k+1)*step>=stop。
让我们以一个示例列表来更好地理解这一点:
nums = list(range(10)) #[0,1, 2, 3, 4, 5, 6, 7, 8, 9]
现在让我们使用我们已经学到的语法来使用 islice 函数。
仅使用结束值
让我们只指定结束索引:
from itertools import islice
# only stop
sliced_nums = islice(nums, 5)
print(list(sliced_nums))
这是输出结果:
Output >>> [0, 1, 2, 3, 4]
使用开始值和结束值
在这里,我们使用了开始值和结束值:
# start and stop
sliced_nums = islice(nums, 2, 7)
print(list(sliced_nums))
切片从索引 2 开始,扩展到但不包括索引 7:
Output >>> [2, 3, 4, 5, 6]
使用开始值、结束值和步长值
当我们使用开始值、结束值和步长值时:
# using start, stop, and step
sliced_nums = islice(nums, 2, 8, 2)
print(list(sliced_nums))
我们得到一个从索引 2 开始的切片,扩展到但不包括索引 8,步长为 2(返回每第二个元素)。
Output >>> [2, 4, 6]
总结
我希望这个教程帮助你理解 itertools 过滤函数的基础知识。你已经看到了一些简单的示例,以便更好地理解这些函数的工作原理。接下来,你可以学习生成器 生成器函数和生成器表达式如何作为高效的 Python 迭代器工作。
Bala Priya C 是一位来自印度的开发人员和技术写作者。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过编写教程、操作指南、评论文章等方式,与开发者社区分享她的知识。
了解更多相关话题
数据科学技能的 4 个象限和创建病毒式数据可视化的 7 个原则
原文:
www.kdnuggets.com/2019/10/4-quadrants-data-science-skills-data-visualization.html
评论
作者:何塞·贝伦格雷斯,教授及天使投资人。
(关于 哪些数据科学技能是核心的,哪些是热门/新兴的? 的后续文章)
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
我教授计算机科学和设计思维。但今天,我的任务是展示如何制作优秀的图表,因为我不喜欢令人困惑的图表。你可以把我看作是图表界的玛丽·孔多,或者是迪拜的科尔·克纳弗里克,你可能不会完全错。在这篇文章中,我将分享7 个原则,帮助你从Aha-图表转变为Wow-图表。让我们用最近的一项 KDnuggets 调查数据来动手实践吧。
调查只有两个问题:
-
你目前具备哪些技能/知识领域?以及
-
你想要添加或提高哪些技能?
KDnuggets 收到了 1,500 个回答,我们将使用按技能汇总的数据 [1]。
表 1. 调查汇总。
| 技能 | %拥有 | %希望拥有 | 比例 |
|---|---|---|---|
| Python | 71.2% | 37.1% | 0.52 |
| 数据可视化 | 69.0% | 25.3% | 0.37 |
| 批判性思维 | 66.7% | 15.5% | 0.23 |
| Excel | 66.5% | 4.6% | 0.07 |
| 30 行数据未显示 …
…
… | | | |
假设你被要求可视化这项调查。你会怎么做?第一个机器学习直觉是做一个散点图来识别有趣的聚类。X 轴可以是拥有某项技能的受访者的百分比,Y 轴则是希望拥有该技能的受访者的百分比。然而,数据点太多,人类很难理解。这是信息超载的经典案例。
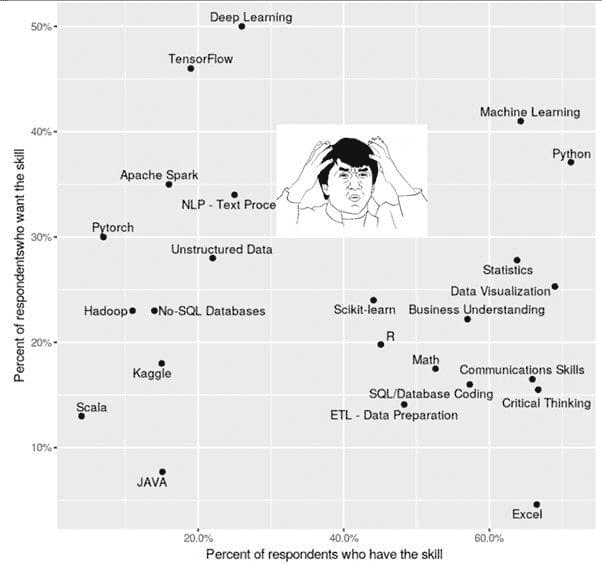
图 1. 信息超载的受害者?
原则 1: 制作以人为本的图表
如何制作更具人性化的图表?我们可以借鉴 Gartner 魔力象限,他们通过使用象限层级来降低复杂性到人类水平 [2]。
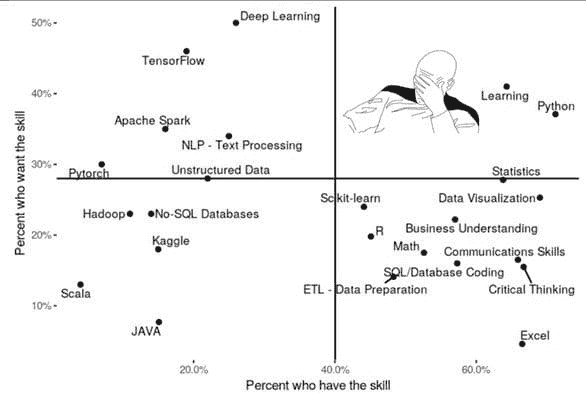
图 2. Gartner 使用象限来减少复杂性。
原则 2:不要与重力或惯例作斗争
关于图表有一些不成文的规则。其中一个是关于重力的。Y 轴与重力隐喻对齐(高度想要,高 Y)。另一个不成文的规则(这是 Guy Kawasaki 提出的)是“你想要(期望目标)在图表的右上角[3]”。在这种情况下,最受欢迎的技能(深度学习)在错误的一侧——我们需要翻转 X 轴。
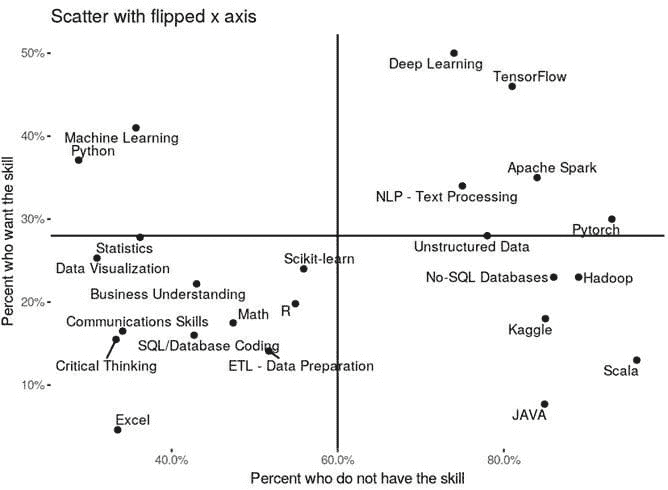
图 3. 目标应该是“高且偏右”——Guy Kawasaki
原则 3:让你的图表讲述一个令人难忘的故事
如果你制作了一个图表而没有人记得它,那它还发生了吗?早期我们用类别赋予意义,但如果没有人记得这些类别,它们有什么用?帮助你的观众记住图表的一种方法是使用人物角色(在 Z 世代的说法中是梗)。让我们应用一些人物角色和聚类原则。四个象限可能意味着:
-
不需要的技能(拥有但不想要 = Excel)
-
不需要的技能(不想要且没有 = JAVA)
-
热门技能(想要但没有 = TF)
-
喜爱的技能(想要且拥有 = Python)

图 4. 流行文化:用来让你的图表更具吸引力。
原则 4:像玛丽·孔多一样整理
象限创造意义并减少复杂性,但玛丽·孔多的工作还没有完成。让我们通过突出每个象限中的一种技能来进一步整理。在这里我们使用红色框,但如果你觉得时尚的话,我们也可以使用更大的字体或粗体字母。

图 5. 使用层级结构来创造意义。
原则 5:从“为什么”开始
最后,图表应该有一个目的——这就是 Simon Sinek[4]所称的为什么。
我的观点是“我希望我的课堂上看到更多的 Python,少一点 Java”。
原则 6:标题是你图表的最佳朋友

图 6. 清晰的沟通胜过风格。
不要害怕在画布上做标记!标题是给你的故事增添意义和冲击力的机会。注意我们用“被忽视”的标签打破了对称性,这对图表而言就像风水一样。
原则 7:如有疑问:预测未来
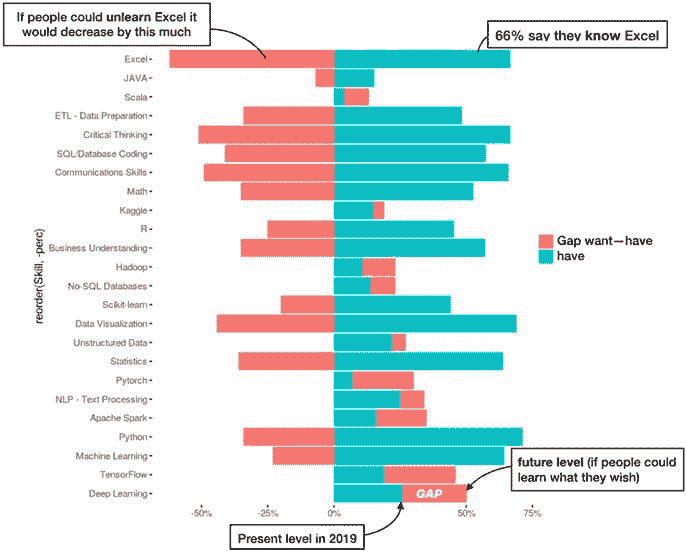
图 7. 如果我知道现在知道的事……
假设你的前一个图表获得了病毒式传播。我们还能可视化什么呢?如果你没有更多的想法,那么这里有一个:预测未来[5]。我们可以将拥有的普及率视为当前的快照,将(想要)[6]视为如果所有受访者能够实现他们的学习目标时的未来预测。现在我们可以思考当前和未来之间的差距。这个图表是在 ggplot2 中完成的。幸运的是,ggplot2 在绘制负堆叠条形图和正堆叠条形图时的方法在这里非常有用。还要注意,我们避免了按升序排列条形图的诱惑,因为这会在图表的波峰处产生虚假的模式。
综合考虑
现在让我们将角色、等级制度、意义构建策略和商业徽标结合在一个所谓的战略图中。
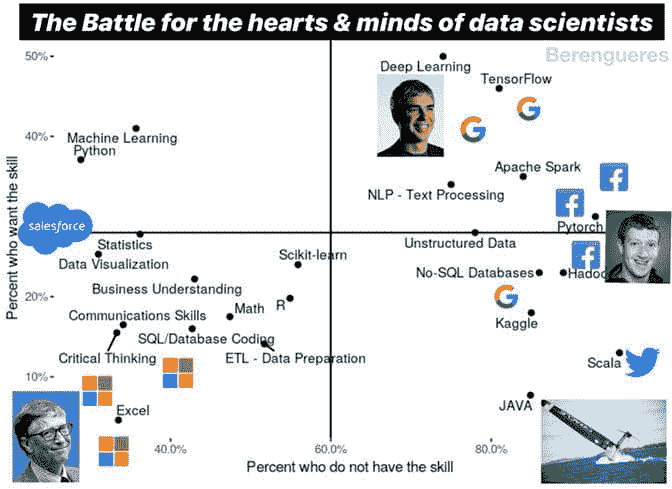
图 8. 为什么有些公司有时会支持免费的产品?
结论
数据科学家比其他专业人士更有可能传播知识。数据可视化就是其中的一种方式。不幸的是,有很多优秀的工作被忽视了,比如这个、这个或这个。我希望这些新的超能力能激励你用引人入胜的图表开始改变世界。
脚注:
[1] 查看 csv 数据 www.kaggle.com/harriken/kdnuggets-magic-skills。
[2] en.wikipedia.org/wiki/Magic_Quadrant 根据乔丹·彼得森的说法,人类深刻理解并接受等级制度。这也是组织和整理图表的一个好方法。
[3] 盖·川崎,《创业的艺术》,TIECON 2006
[4] 西蒙·西内克,《从为什么开始》。
[5] 如果你是对的,那么至少你会出名。
[6] 未来(预测)流行度 = 现在的水平 + 需求,如果假设没有遗忘、人口静态,并且所有想学的人都会最终成功,那么这就 100%正确。可能真相在两者之间,但排名而不是精确度是这张图表的重点。
简介:Jose Berengueres 在东京工业大学获得了生物启发机器人学的硕士和博士学位。他目前在阿联酋的计算机科学系工作,教授敏捷、精益 UX 和设计思维。他还在迪拜辅导企业家,教授大学孵化器项目,并且是 PyData Dubai 的创始人。他曾在 Apple、比勒费尔德大学、墨西哥 CEDIM 和迪拜 Hult 商学院教授设计思维、大数据分析和商业模型。他为各种公司如 Awok、Etihad 和新加坡的 Healint 提供 UX 设计和数据科学咨询。2007-2008 年,他开发了两个初创公司(一个视觉 Twitter 和一个照片分享网站)。他是《数据可视化与讲故事导论》(2019)、《设计思维棕皮书》和《草图思维》的作者。他的研究重点是创造力、人机交互、用户体验和数据科学。Jose 是 Kaggle 大师。
相关:
更多相关话题
你的机器学习代码可能很糟糕的 4 个原因
原文:
www.kdnuggets.com/2019/02/4-reasons-machine-learning-code-probably-bad.html
评论
作者:诺曼·尼默尔,首席数据科学家
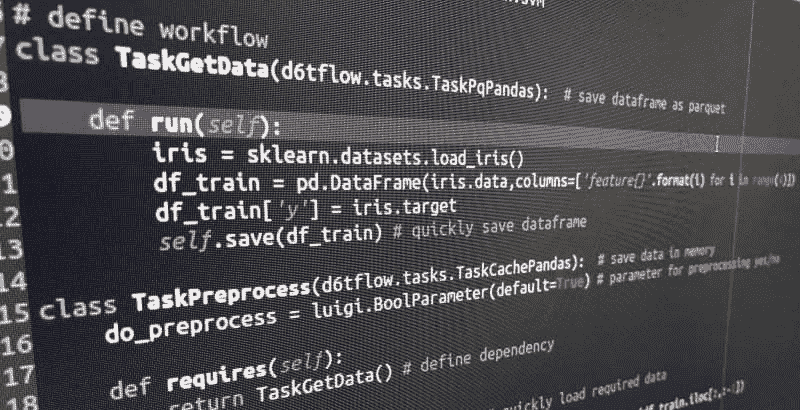
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
你的当前工作流可能会像下面的示例一样将多个函数链在一起。虽然速度很快,但它可能存在许多问题:
-
随着复杂度的增加,它的扩展性不好
-
你必须手动跟踪哪些函数与哪些参数一起运行
-
你必须手动跟踪数据保存的位置
-
其他人很难阅读
import pandas as pd
import sklearn.svm, sklearn.metrics
def get_data():
data = download_data()
data = clean_data(data)
data.to_pickle('data.pkl')
def preprocess(data):
data = apply_function(data)
return data
# flow parameters
reload_source = True
do_preprocess = True
# run workflow
if reload_source:
get_data()
df_train = pd.read_pickle('data.pkl')
if do_preprocess:
df_train = preprocess(df_train)
model = sklearn.svm.SVC()
model.fit(df_train.iloc[:,:-1], df_train['y'])
print(sklearn.metrics.accuracy_score(df_train['y'],model.predict(df_train.iloc[:,:-1])))
应该怎么做?
与线性链式函数相比,数据科学代码更好地编写为具有依赖关系的任务集合。即你的数据科学工作流应该是 DAG。
所以,不是编写一个执行以下操作的函数:
def process_data(data, parameter):
if parameter:
data = do_stuff(data)
else:
data = do_other_stuff(data)
data.to_pickle('data.pkl')
return data
你最好编写可以作为 DAG 链在一起的任务:
class TaskProcess(d6tflow.tasks.TaskPqPandas): # define output format
def requires(self):
return TaskGetData() # define dependency
def run(self):
data = self.input().load() # load input data
data = do_stuff(data) # process data
self.save(data) # save output data
这样做的好处包括:
-
所有任务都遵循相同的模式,无论你的工作流有多复杂
-
你有一个可扩展的输入
requires()和处理函数run() -
你可以快速加载和保存数据,而无需硬编码文件名
-
如果输入任务未完成,它将自动运行
-
如果输入数据或参数发生变化,函数将自动重新运行
一个示例机器学习 DAG
以下是以 DAG 形式表达的机器学习流程的风格化示例。最后,你只需运行 TaskTrain(),它将自动知道要运行哪些依赖项。有关完整示例,请参见github.com/d6t/d6tflow/blob/master/docs/example-ml.md
import pandas as pd
import sklearn, sklearn.svm
import d6tflow
import luigi
# define workflow
class TaskGetData(d6tflow.tasks.TaskPqPandas): # save dataframe as parquet
def run(self):
data = download_data()
data = clean_data(data)
self.save(data) # quickly save dataframe
class TaskPreprocess(d6tflow.tasks.TaskCachePandas): # save data in memory
do_preprocess = luigi.BoolParameter(default=True) # parameter for preprocessing yes/no
def requires(self):
return TaskGetData() # define dependency
def run(self):
df_train = self.input().load() # quickly load required data
if self.do_preprocess:
df_train = preprocess(df_train)
self.save(df_train)
class TaskTrain(d6tflow.tasks.TaskPickle): # save output as pickle
do_preprocess = luigi.BoolParameter(default=True)
def requires(self):
return TaskPreprocess(do_preprocess=self.do_preprocess)
def run(self):
df_train = self.input().load()
model = sklearn.svm.SVC()
model.fit(df_train.iloc[:,:-1], df_train['y'])
self.save(model)
# Check task dependencies and their execution status
d6tflow.preview(TaskTrain())
'''
└─--[TaskTrain-{'do_preprocess': 'True'} (PENDING)]
└─--[TaskPreprocess-{'do_preprocess': 'True'} (PENDING)]
└─--[TaskGetData-{} (PENDING)]
'''
# Execute the model training task including dependencies
d6tflow.run(TaskTrain())
'''
===== Luigi Execution Summary =====
Scheduled 3 tasks of which:
* 3 ran successfully:
- 1 TaskGetData()
- 1 TaskPreprocess(do_preprocess=True)
- 1 TaskTrain(do_preprocess=True)
'''
# Load task output to pandas dataframe and model object for model evaluation
model = TaskTrain().output().load()
df_train = TaskPreprocess().output().load()
print(sklearn.metrics.accuracy_score(df_train['y'],model.predict(df_train.iloc[:,:-1])))
# 0.9733333333333334
结论
将机器学习代码写成线性函数序列往往会产生许多工作流问题。由于不同机器学习任务之间的复杂依赖关系,最好将它们写成 DAG。github.com/d6t/d6tflow 使这一过程非常简单。或者,你可以使用luigi和airflow,但它们更适用于 ETL 而不是数据科学。
简介: 诺曼·尼默 是一家大型资产管理公司的首席数据科学家,他提供基于数据的投资洞察。他拥有哥伦比亚大学的金融工程硕士学位和伦敦 Cass 商学院的银行与金融学士学位。
原文。经授权转载。
相关:
-
机器学习项目检查清单
-
初创企业的数据科学项目流程
-
机器学习项目的端到端指南
更多相关话题
4 个你不应该使用机器学习的理由
原文:
www.kdnuggets.com/2021/12/4-reasons-shouldnt-machine-learning.html
由Terence Shin,数据科学家 | MSc Analytics & MBA 学生

照片由Nadine Shaabana提供,来源于Unsplash
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
介绍
当机器学习最初出现时,许多人猜测它会引发另一次工业革命。快进到今天,许多人会说它不过是一个流行词。
别误解我的意思。机器学习是一个有用的工具,但仅仅是一个工具。说它像瑞士军刀一样是不切实际的——我更愿意把它看作是一个水刀(某种小众工具)。
根据我的经验,机器学习确实在一些应用场景中表现出色。例如,亚马逊的推荐系统将销售额提高了 30%以上。然而,还有更多应用场景中,机器学习是一个次优的解决方案。
在本文中,我们将讨论 4 个你不应该使用机器学习的理由。
话虽如此,让我们深入了解吧!
1. 与数据相关的问题
如AI 需求层次所示,机器学习依赖于几个作为基础的其他因素。这个基础包括从数据收集、数据存储、数据传输到数据转换的所有内容。拥有一个健全的流程来实现这些初步步骤是很重要的,否则你可能不会有可靠的数据。
为什么这如此重要?你一定听过“垃圾进,垃圾出”的说法——你的机器学习模型的性能受限于数据的质量,这就是为什么有可靠的数据是如此重要的原因。
你不仅需要你的数据是可靠的,还需要足够的数据来利用机器学习的力量。没有这两个条件,你将无法发挥机器学习的全部潜力。
2. 可解释性
模型通常分为两大类:预测模型和解释模型:
-
预测模型专注于模型产生准确预测的能力。
-
解释模型更多关注于理解数据中变量之间的关系。
机器学习模型,特别是集成学习模型和神经网络,是预测模型——它们在制定预测方面表现优异,远超传统模型如线性/逻辑回归的预测能力。
也就是说,当涉及到理解预测变量和目标变量之间的关系时,这些模型是一个黑箱。虽然你可能理解这些模型的基本机制,但它们如何得出最终结果仍然不太清楚。
尽管存在像特征重要性和相关矩阵这样的技术,但它们在理解数据关系方面仍然相当有限。总体来说,机器学习和深度学习在预测方面表现出色,但在可解释性方面有所欠缺。
3. 技术债务
维护机器学习模型随着时间的推移是具有挑战性和高成本的。特别是,维护机器学习模型时需要考虑几种“债务”:
-
依赖债务: 依赖债务指的是由于数据依赖的不稳定性和未充分利用的数据依赖所产生的债务。简单来说,这指的是维护同一模型的多个版本、遗留特性和未充分利用的包的成本。
-
分析债务:这指的是机器学习系统通常会在更新时影响自身行为,导致直接和隐性的反馈循环。
-
配置债务: 机器学习系统自身的配置也会产生类似于任何软件系统的债务。应该容易进行小的配置,难以出现手动错误,并且应该容易区分不同的模型。
完整的论文请参见这里,如果你想了解机器学习系统中的隐性技术债务。
4. 更好的替代方案
最后,当存在同样有效的简单替代方案时,不应使用机器学习。在我之前的文章中,“想成为数据科学家?不要从机器学习开始,” 我强调了机器学习不是解决所有问题的答案。
一个简单的解决方案,花费 1 周时间构建,准确率 90%,几乎总是会被选择,胜过一个需要 3 个月构建、准确率 95%的机器学习模型。
理想情况下,你应该从最简单的解决方案开始实施,并逐步判断下一最佳替代方案的边际收益是否超过边际成本。
如果你能用 Python 脚本或 SQL 查询解决你的问题,你应该先使用这些方法。如果你能用决策树解决你的问题,你应该先使用决策树。如果你能用线性回归模型解决你的问题,你应该先使用线性回归模型。
你明白了。越简单=越好。
感谢阅读!
我希望这能提供一些关于机器学习局限性的见解,并说明它并不是一刀切的解决方案。请记住,这篇文章更多是基于个人经验的观点文章,所以请根据需要取舍。但无论如何,我祝愿你在学习过程中一切顺利!
Terence Shin
-
如果你喜欢这个内容, 订阅我的 Medium 以获取独家内容!
-
***同样,你也可以 ***关注我在 Medium 上的动态
-
***有兴趣合作吗?让我们在 ***LinkedIn 上连接
个人简介: Terence Shin 是一位数据爱好者,拥有 3 年以上 SQL 经验和 2 年以上 Python 经验,同时也是 Towards Data Science 和 KDnuggets 的博客作者。
原文。经许可转载。
更多相关话题
管理数据科学项目的 4 个步骤
原文:
www.kdnuggets.com/2022/05/4-steps-managing-data-science-project.html

图片来源:Pexels
关键要点
-
执行数据科学项目需要良好的计划
-
良好的计划和准备不仅能提高生产力,还能帮助避免在项目执行过程中遇到的潜在陷阱和障碍
我们的前三个课程推荐
1. 谷歌网络安全证书 - 加速你的网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
本杰明·富兰克林曾说:
通过失败准备,你就是在准备失败。
本文将讨论管理数据科学项目的四个步骤:计划、准备、生成和发布。
1. 计划
在构建任何机器学习模型之前,仔细计划你希望模型完成的目标是很重要的。在深入编写代码之前,你必须了解待解决的问题、数据集的性质、要构建的模型类型、模型的训练、测试和评估方式。
你可以先提供一个简要的概述,然后是你希望完成的逐步计划。例如,在构建模型之前,你可以问自己:
-
预测变量是什么?
-
目标变量是什么?我的目标变量是离散的还是连续的?
-
我应该使用分类还是回归分析?
-
我如何处理数据集中的缺失值?
-
我应该在将变量标准化到相同尺度时使用归一化还是标准化?
-
我是否应该使用主成分分析?
-
我如何调整模型中的超参数?
-
我如何评估我的模型以检测数据集中的偏差?
-
我是否应该使用集成方法,通过训练不同的模型然后进行集成平均,例如,使用 SVM、KNN、逻辑回归等分类器,然后对 3 个模型进行平均?
-
我怎么选择最终的模型?
2. 准备
在执行之前,重要的是提前准备好如何处理项目。你可以问自己以下问题:项目的规模是什么?这是一个个人项目吗?我需要有一个团队成员吗?哪个平台最适合构建模型?我应该使用 R Studio 还是 Jupyter Notebook?是否需要使用高级生产力工具,如高性能计算资源,或云服务,如 AWS 或 Azure?项目完成的时间线是什么?
3. 生成(设计、构建和执行你的模型)
在这一阶段,你需要选择你希望使用的模型,例如线性回归、逻辑回归、KNN、SVM、朴素贝叶斯、决策树、深度学习、K 均值、蒙特卡洛模拟、时间序列分析等。数据集必须分为训练集、验证集和测试集。使用超参数调优来微调模型,以防止过拟合。进行交叉验证以确保模型在验证集上表现良好。调整模型参数后,将模型应用于测试数据集。模型在测试数据集上的表现大致等于在对未见数据进行预测时的预期表现。
4. 发布(实施、部署或展示你的工作)
在这个阶段,最终的机器学习模型被投入生产,以开始改善客户体验、提高生产力或决定银行是否应批准贷款给借款人等。模型在生产环境中进行评估,以评估其性能。这可以通过将机器学习解决方案的性能与基准或对照解决方案进行比较来完成,例如使用 A/B 测试。任何在从实验模型转化为生产线实际性能过程中遇到的错误都需要进行分析。这些分析结果可以用于微调原始模型。在一些大型项目中,数据科学家需要与其他公司官员和软件工程师或机器学习工程师合作,以部署模型,例如构建一个可以实时读取数据的基于 Web 的接口,将数据输入模型,然后使用最终模型进行预测。
总结一下,我们讨论了数据科学项目管理的四个关键步骤:计划、准备、生成和发布。良好的规划和准备不仅可以提高生产力,还可以帮助避免在项目执行过程中可能遇到的潜在陷阱和障碍。
本杰明·O·塔约 是一位物理学家、数据科学教育者和作家,也是 DataScienceHub 的所有者。此前,本杰明曾在中央俄克拉荷马大学、大峡谷大学和匹兹堡州立大学教授工程学和物理学。
更多相关主题
成为生成性 AI 开发者的 4 个步骤
原文:
www.kdnuggets.com/4-steps-to-become-a-generative-ai-developer
介绍
我们的三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 部门
OpenAI 的 CEO 萨姆·奥特曼 在 2023 年 10 月的 OpenAI 开发者日上展示了产品使用数据。OpenAI 将客户划分为三个细分市场:开发者、企业和普通用户。链接: https://www.youtube.com/watch?v=U9mJuUkhUzk&t=120s
在 2023 年 10 月的 OpenAI 开发者日上,OpenAI 的 CEO 萨姆·奥特曼 展示了一张幻灯片,讲述了不同客户细分市场(开发者、企业和普通用户)中的产品使用情况。
在本文中,我们将重点关注开发者这一细分市场。我们将介绍生成性 AI 开发者的工作内容、你需要掌握的工具以及如何入门。
步骤 1:了解生成性 AI 开发者的工作内容
尽管一些公司致力于开发生成性 AI 产品,但大多数生成性 AI 开发者还是在其他公司,这些公司并不是传统意义上的 AI 聚焦点。
原因在于生成性 AI 在广泛的商业领域中都有应用。生成性 AI 有四种常见用途,适用于大多数企业。
聊天机器人

由 DALL·E 3 生成的图像
尽管聊天机器人已经主流了十多年,但大多数聊天机器人都很糟糕。通常,第一次与聊天机器人的互动最常见的就是询问是否可以与真人交谈。
生成性 AI 的进步,尤其是大语言模型和向量数据库,意味着这种情况不再成立。现在聊天机器人可以为客户提供愉快的使用体验,每家公司都在忙于(或者至少应该忙于)努力升级它们。
MIT 技术评论的文章 生成性 AI 对聊天机器人的影响 对聊天机器人世界的变化有很好的概述。
语义搜索
搜索被广泛应用于各种场所,从文档到购物网站,再到互联网本身。传统上,搜索引擎 heavily 使用关键字,这就产生了搜索引擎需要被编程以识别同义词的问题。
例如,考虑尝试在营销报告中搜索有关客户细分的部分。你按下 CMD+F,输入“segmentation”,然后循环浏览搜索结果直到找到相关内容。不幸的是,你可能会错过作者在文档中使用“classification”而不是“segmentation”的情况。
语义搜索(根据意义进行搜索)通过自动找到具有相似含义的文本来解决同义词问题。这个想法是,你使用一个嵌入模型——一个将文本根据其意义转换为数值向量的深度学习模型——然后找到相关文本只是简单的线性代数。更好的是,许多嵌入模型还允许其他数据类型如图像、音频和视频作为输入,让你为搜索提供不同的数据输入或输出数据类型。
与聊天机器人一样,许多公司正试图通过使用语义搜索来改进其网站的搜索功能。
这篇关于语义搜索的教程由 Milvus 向量数据库的制造商 Zillus 提供,提供了很好的用例描述。
个性化内容
由 DALL·E 3 生成的图像
生成式 AI 降低了内容创建的成本。这使得为不同用户群体创建定制内容成为可能。一些常见的例子是根据你对用户的了解,改变营销文案或产品描述。你还可以提供本地化服务,使内容对不同国家或人群更具相关性。
这篇关于如何使用生成式 AI 平台实现超个性化的文章由 Salesforce 首席数字布道师 Vala Afshar 撰写,涵盖了使用生成式 AI 个性化内容的好处和挑战。
软件的自然语言界面
随着软件变得越来越复杂和功能全面,用户界面也变得臃肿,菜单、按钮和工具让用户难以找到或使用。自然语言界面让用户可以用一句话说明他们想要的内容,这可以显著提高软件的可用性。“自然语言界面”可以指控制软件的口头或书面方式。关键在于,你可以使用标准的、易于理解的人类句子。
商业智能平台是较早采用这一技术的一些平台,自然语言接口帮助商业分析师编写更少的数据处理代码。然而,这一技术的应用几乎是无限的:几乎每个功能丰富的软件都可以受益于自然语言接口。
这篇 Forbes 文章 拥抱 AI 和自然语言接口 来自 Omega Venture Partners 的创始人兼管理合伙人 Gaurav Tewari,对自然语言接口如何帮助软件可用性进行了易于阅读的描述。
第 2 步:了解生成式 AI 开发者使用的工具
首先,你需要一个生成式 AI 模型!对于处理文本,这意味着一个大型语言模型。GPT 4.0 是当前性能的黄金标准,但也有许多开源替代品,如 Llama 2、Falcon 和 Mistral。
其次,你需要一个向量数据库。Pinecone 是最受欢迎的商业向量数据库,还有一些开源替代品,如 Milvus、Weaviate 和 Chroma。
在编程语言方面,社区似乎已经围绕 Python 和 JavaScript 达成了一致。JavaScript 对于 Web 应用很重要,而 Python 则适合其他所有人。
在这些基础上,使用生成式 AI 应用框架是有帮助的。两个主要的竞争者是 LangChain 和 LlamaIndex。LangChain 是一个更广泛的框架,允许你开发各种生成式 AI 应用,而 LlamaIndex 则更专注于开发语义搜索应用。
如果你在开发搜索应用,使用 LlamaIndex;否则,使用 LangChain。
值得注意的是,技术领域变化非常迅速,许多新的 AI 初创公司和新工具每周都会出现。如果你想开发应用程序,预计比其他应用程序更频繁地更改软件堆栈的部分。
特别是,新模型不断出现,你的用例中表现最佳的模型可能会发生变化。一个常见的工作流程是开始使用 API(例如,OpenAI API 用于 API,Pinecone API 用于向量数据库),因为它们开发速度快。随着用户基础的增长,API 调用的成本可能会变得沉重,因此你可能会想切换到开源工具(Hugging Face 生态系统是一个不错的选择)。
第 3 步:学习一些技能以开始
和任何新项目一样,从简单的开始!最好一次学习一个工具,然后再弄清楚如何将它们结合起来。
第一步是为你想使用的任何工具设置账户。你需要开发者账户和 API 密钥才能使用这些平台。
OpenAI API 初学者指南:实践教程和最佳实践包含了逐步说明,介绍了如何设置 OpenAI 开发者账户并创建 API 密钥。
同样,Pinecone 向量数据库掌握教程:全面指南包含了设置 Pinecone 的详细信息。
什么是 Hugging Face?AI 社区的开源绿洲 解释了如何开始使用 Hugging Face。
学习 LLM
要开始编程使用像 GPT 这样的 LLM,最简单的方法是学习如何调用 API 以发送提示并接收消息。
虽然许多任务可以通过 LLM 的单次往返交换完成,但像聊天机器人这样的用例需要较长的对话。OpenAI 最近在其助手 API 中宣布了“线程”功能,你可以在OpenAI 助手 API 教程中了解更多。
并非所有的 LLM 都支持这项功能,因此你可能还需要学习如何手动管理对话状态。例如,你需要决定对话中之前的消息中哪些仍然与当前对话相关。
除此之外,不必仅限于文本工作。你可以尝试处理其他媒体;例如,转录音频(语音转文本)或从文本生成图像。
学习向量数据库
向量数据库最简单的应用场景是语义搜索。在这里,你使用一个嵌入模型(见OpenAI API 文本嵌入介绍),将文本(或其他输入)转换成一个表示其含义的数值向量。
然后,你将嵌入的数据(数值向量)插入到向量数据库中。搜索就是编写一个搜索查询,询问数据库中哪些条目与您所请求的内容最接近。
例如,你可以将公司某个产品的一些常见问题(FAQs)嵌入,并上传到向量数据库中。然后,你询问有关该产品的问题,它会返回最接近的匹配项,将数值向量转换回原始文本。
结合 LLM 和向量数据库
你可能会发现,直接从向量数据库返回文本条目是不够的。通常,你希望文本以一种更自然的方式处理,以回答查询。
解决这个问题的方法是一种称为检索增强生成(RAG)的技术。这意味着在你从向量数据库中检索文本之后,你会为大型语言模型(LLM)写一个提示,然后将检索到的文本包含在提示中(你增强了提示与检索到的文本)。然后,你要求 LLM 写出一个易于理解的回答。
在回答用户从常见问题中提问的例子中,你需要编写一个包含占位符的提示,像下面这样。
"""
Please answer the user's question about {product}.
---
The user's question is : {query}
---
The answer can be found in the following text: {retrieved_faq}
"""
最终步骤是将你的 RAG 技能与管理消息线程的能力结合起来,从而进行更长时间的对话。瞧!你就有了一个聊天机器人!
步骤 4:继续学习!
DataCamp 提供了 一系列九个代码实操课程,教你成为一名生成式 AI 开发者。你需要基本的 Python 技能才能开始,但所有 AI 概念都是从零开始讲解的。
该系列课程由来自 Microsoft、Pinecone、伦敦帝国学院和 Fidelity 的顶级讲师(还有我!)授课。
你将学习到本文涉及的所有主题,包括六个专注于 OpenAI API、Pinecone API 和 LangChain 的商业堆栈的代码实操课程。其他三节教程则专注于 Hugging Face 模型。
在系列课程结束时,你将能够创建一个聊天机器人,并构建 NLP 和计算机视觉应用程序。
Richie Cotton**** 是 DataCamp 的数据传播者。他是 DataFramed 播客的主持人,著有两本关于 R 编程的书籍,并创建了 10 门 DataCamp 数据科学课程,已有超过 70 万学习者参与学习。
更多相关话题
高级特征工程和预处理的 4 个技巧
原文:
www.kdnuggets.com/2019/08/4-tips-advanced-feature-engineering-preprocessing.html
评论
由 Maarten Grootendorst,数据科学家,I/O 心理学家 & 临床心理学家

我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
可以说,开发机器学习模型的两个最重要的步骤是特征工程和数据预处理。特征工程包括特征的创建,而数据预处理涉及数据的清理。
“折磨数据,它会承认任何事情*。” — 罗纳德·科斯
我们通常会花费大量时间将数据提炼成对建模有用的形式。为了使这项工作更高效,我想分享 4 个技巧和窍门,帮助你在特征工程和数据预处理中。
我应该指出,尽管这可能听起来很陈词滥调,领域知识可能是特征工程中最重要的东西之一。它可以帮助你通过更好地理解你使用的特征来防止欠拟合和过拟合。
你可以在这里找到包含分析的笔记本。
1. 重新采样不平衡数据
在实践中,你会经常遇到不平衡的数据。如果你的目标变量只有轻微的不平衡,这不一定会成为问题。你可以通过使用适当的验证措施来解决这个问题,比如平衡准确度、精准度-召回曲线或F1 分数。
不幸的是,这并不总是如此,你的目标变量可能高度不平衡(例如,10:1)。相反,你可以使用一种叫做SMOTE的技术来对少数类目标进行过采样,从而引入平衡。
SMOTE
SMOTE代表Synthetic Minority Oversampling Technique,是一种用于增加少数类样本的过采样技术。
它通过查看目标的特征空间并检测最近邻来生成新样本。然后,它简单地选择类似样本,并在邻近样本的特征空间内随机改变一列。
实现 SMOTE 的模块可以在imbalanced-learn包中找到。你可以简单地导入该包并应用 fit_transform:
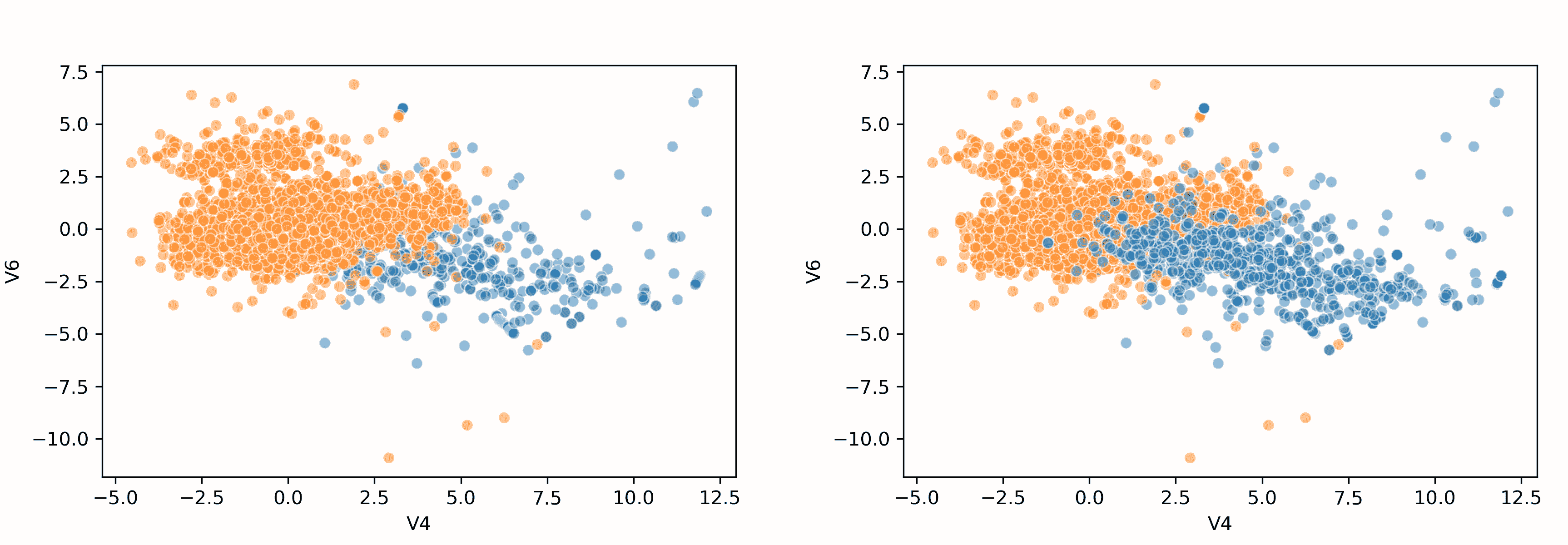 原始数据(左)与过采样数据(右)。
原始数据(左)与过采样数据(右)。
如你所见,模型成功地对目标变量进行了过采样。使用 SMOTE 进行过采样时,你可以采取几种策略:
-
**'minority'**:仅对少数类进行重新采样; -
**'not minority'**:对除少数类外的所有类进行重新采样; -
**'not majority'**:对除多数类外的所有类进行重新采样; -
**'all'**:对所有类进行重新采样; -
当
**dict**时,键对应于目标类。值对应于每个目标类所需的样本数量。
我选择使用字典来指定我希望过采样数据的程度。
附加提示 1:如果你的数据集中有分类变量,SMOTE 可能会为这些变量创建无法发生的值。例如,如果你有一个名为 isMale 的变量,只能取 0 或 1,SMOTE 可能会创建 0.365 作为值。
另外,你可以使用 SMOTENC,它考虑了分类变量的性质。这个版本也可以在imbalanced-learn包中找到。
附加提示 2:确保在创建训练/测试拆分后再进行过采样,这样你只会过采样训练数据。你通常不希望在合成数据上测试你的模型。
2. 创建新特征
为了提高模型的质量和预测能力,通常会从现有变量中创建新特征。我们可以在每对变量之间创建一些交互(例如,乘法或除法),希望找到一个有趣的新特征。然而,这个过程很繁琐,需要大量编码。幸运的是,这可以通过Deep Feature Synthesis自动化。
深度特征合成
深度特征合成(DFS)是一种算法,可以快速创建具有不同深度的新变量。例如,你可以先乘以列 A 和列 B,然后再加上列 C。
首先,让我介绍一下我将用于示例的数据。我选择使用HR 分析数据,因为特征易于解释:
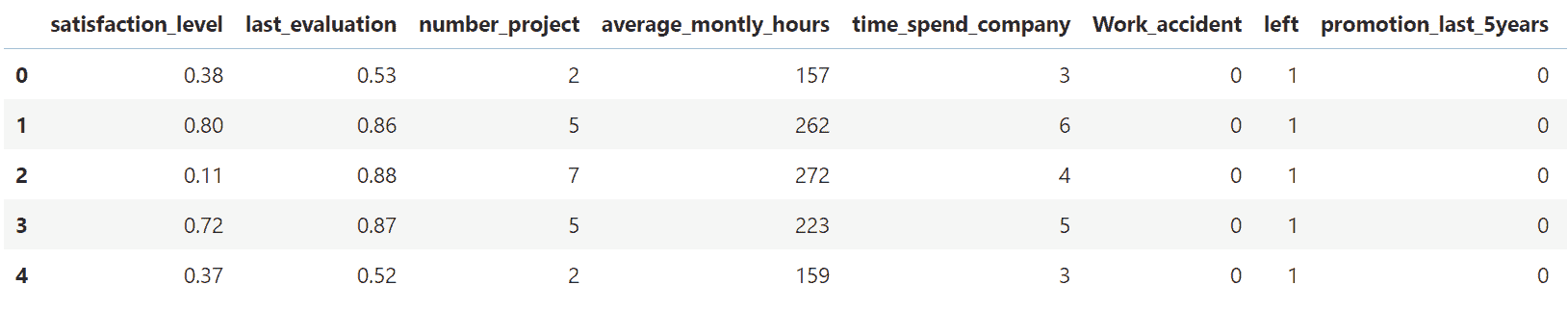
基于我们的直觉,我们可以将**average_monthly_hours**除以**number_project**识别为一个有趣的新变量。然而,如果我们仅依靠直觉,可能会错过更多的关系。
包确实需要理解它们对 Entities 的使用。然而,如果你只使用一个表,可以简单地遵循下面的代码:
第一步是从中创建一个**entity**,如果需要,可以与其他表创建关系。接下来,我们可以简单地运行**ft.dfs**来创建新变量。我们通过参数**trans_primitives**指定如何创建变量。我们选择将数字变量相加或相乘。
 如果 verbose = True,DFS 的输出
如果 verbose = True,DFS 的输出
正如你在上面的图片中看到的,我们仅用几行代码就创建了额外的 668 个特征。以下是创建的一些特征示例:
-
**last_evaluation**乘以**satisfaction_level** -
**left**乘以**promotion_last_5years** -
**average_monthly_hours**乘以**satisfaction_level**再加上**time_spend_company**
额外提示 1: 请注意,这里的实现相对基础。DFS 的优点在于它可以通过表之间的聚合创建新变量(例如,事实和维度)。有关示例,请参见这个链接。
额外提示 2: 运行**ft.list_primitives()**以查看所有可以进行的聚合列表。它甚至处理时间戳、空值和经纬度信息。
3. 处理缺失值
像往常一样,没有一种最佳的方法来处理缺失值。根据你的数据,可能仅用某些组的均值或众数来填补缺失值就足够了。然而,还有一些先进的技术使用已知的数据部分来填补缺失值。
一种方法叫做IterativeImputer,这是 Scikit-Learn 中的一个新包,基于流行的 R 算法 MICE 用于填补缺失变量。
Iterative Imputer
虽然 Python 是开发机器学习模型的出色语言,但仍然有一些方法在 R 中效果更好。例如,R 中的成熟插补包:missForest、mi、mice 等。
Iterative Imputer由 Scikit-Learn 开发,将每个具有缺失值的特征建模为其他特征的函数。它将此作为填补的估计。在每一步,选择一个特征作为输出y,所有其他特征作为输入X。然后在X和y上拟合回归器,并用于预测y的缺失值。这对每个特征都这样做,并重复进行几轮填补。
让我们来看一个例子。我使用的数据是著名的泰坦尼克号数据集。在这个数据集中,Age 列有缺失值,我们希望填补这些值。代码一如既往地简单:
这个方法的一个好处是它允许你使用你选择的估算器。我使用了 RandomForestRegressor 来模拟 R 中常用的 missForest 的行为。
附加提示 1: 如果你拥有足够的数据,简单地删除缺失数据的样本可能是一个有吸引力的选项。然而,请记住,这可能会在数据中产生偏差。也许缺失的数据遵循某种模式,你会错过这些模式。
附加提示 2: 迭代插补器允许使用不同的估算器。经过一些测试,我发现你甚至可以使用Catboost作为估算器!不幸的是,由于其随机状态名称不同,LightGBM 和 XGBoost 不适用。
4. 异常检测
如果没有对数据的良好理解,异常值很难被检测到。如果你对数据很熟悉,就可以更容易地指定数据仍然有意义的阈值。

有时这并不可能,因为对数据的完美理解难以实现。相反,你可以利用一些异常检测算法,例如流行的孤立森林。
孤立森林
在孤立森林算法中,关键词是孤立。从本质上讲,该算法检查一个样本被孤立的难易程度。这会产生一个孤立数,该数值通过在随机决策树中分割所需的次数来计算。然后,将所有树上的孤立数取平均。
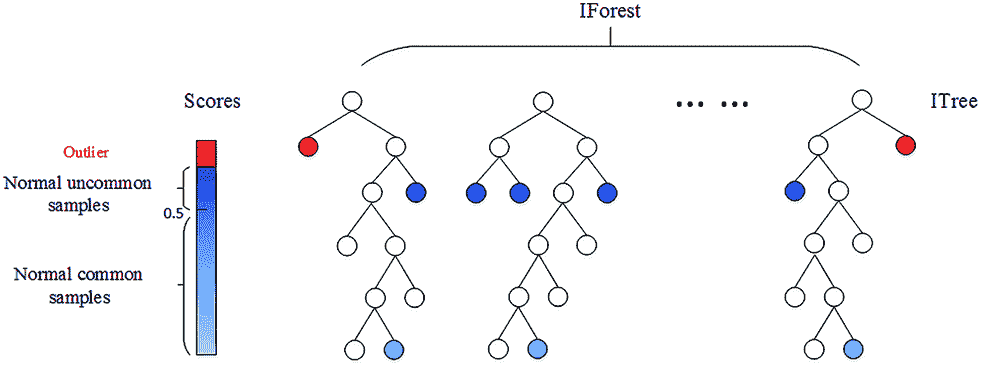 孤立森林过程。来源于:
孤立森林过程。来源于: donghwa-kim.github.io/iforest.html
如果算法只需进行少量分割就能找到一个样本,那么它更可能是一个异常值。分割本身也是随机分割的,因此会产生更短的异常路径。因此,当所有树上的孤立数值较低时,该样本很可能是异常值。
为了举例说明,我再次使用了之前使用过的信用卡数据集:
附加提示 1: 有一个扩展版的孤立森林,它改进了一些不足之处。然而,也有褒贬不一的评论。
结论
希望本文中的技巧和窍门能帮助你进行特征工程和预处理。包含代码的笔记本可以在这里找到。
任何反馈和评论一如既往地受到高度赞赏!
这是Emset发布的一个(至少)每月系列中的第四篇文章,我们展示了应用和开发机器学习技术的新方法和令人兴奋的技术。
个人简介:Maarten Grootendorst 是一名数据科学家、工业与组织心理学家以及临床心理学家。他对任何与 AI 相关的事物充满热情!请联系:www.linkedin.com/in/mgrootendorst/'
原文。经许可转载。
相关内容:
-
在 Pytorch 中训练快速神经网络的 9 个技巧
-
处理小数据的 7 个技巧
-
掌握 Python 机器学习数据准备的 7 个步骤 — 2019 年版
更多主题
加速数据科学写作的 4 个工具
原文:
www.kdnuggets.com/2020/09/4-tools-speed-up-data-science-writing.html
评论
由 Rebecca Vickery,数据科学家

图片由Kat Stokes拍摄,发布于Unsplash
我们的 3 大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你所在的组织进行 IT 支持
我在 Medium 上写数据科学的文章已经有两年多了。写作,尤其是技术写作,可能会非常耗时。你不仅需要构思一个想法,写得好,编辑你的文章以确保准确性和流畅性,还需要校对它们。对于技术文章,你还经常需要编写代码来说明你的解释,确保代码的准确性,并将代码从你使用的工具转移到你的 Medium 文章中。
我尽量每周发布一到两篇文章。当我刚开始写作时,我发现这个过程可能非常耗时,很难在全职工作之余保持这个进度。
随着时间的推移,我找到了一些工具,大大加快了我创建和发布文章的时间。特别是那些包含代码示例的文章。以下工具帮助我在其他生活承诺之间实现每周发布一到两篇文章的目标。
1. Jupyter 到 Medium
这个工具由 Ted Petrou 于今年 5 月刚刚发布,但如果你在 Jupyter Notebooks 中编写代码,它将彻底改变游戏规则。通过这个 Python 包,你可以将整个笔记本的内容直接发布为 Medium 文章。
要使用这个工具,首先需要将其通过 pip 安装到你的项目环境中。
pip install jupyter_to_medium
你可能还需要在你启动笔记本的环境中安装这个扩展。
jupyter bundlerextension enable --py jupyter_to_medium._bundler --sys-prefix
一旦安装完成,当你打开 Jupyter Notebook 并导航到** 文件 >> 部署为,你现在会发现一个选项可以将其部署为Medium 文章**。
当你选择此选项时,你会看到一个表单。在顶部,它要求你输入一个集成令牌。如果你是 Medium 的常规作者,你可能会在 Medium 账户的设置中找到这个令牌。如果你的设置中没有令牌,你需要通过电子邮件联系 Medium 请求一个,地址是 yourfriends@medium.com。
根据我的经验,你会很快得到回应,通常在 1 到 2 天内。
你可以每次将集成令牌粘贴到此表单中,或者为了节省重复访问的时间,你可以将令牌保存为文件,并在以下方式标记目录 .jupyter_to_medium/integration_token。
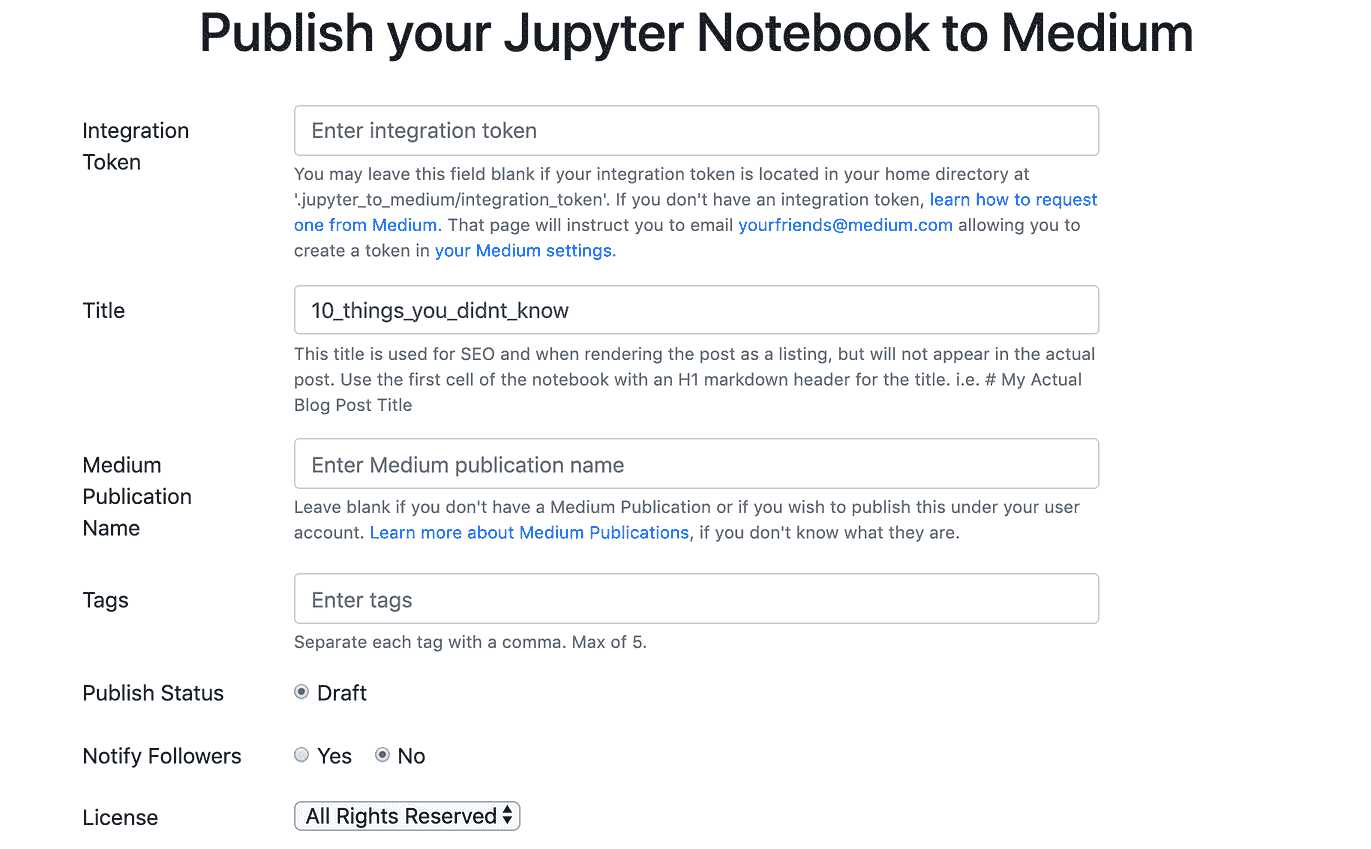
Jupyter 到 Medium 会将你的 Markdown 发布为文本,将代码作为代码块发布,图像则直接以草稿形式发布到 Medium。我发现通常只需进行最小的编辑,即可将其转变为可发布的博客文章。
2. Github Gists
Github 有一个名为 Github Gists 的工具,可以让你轻松地将代码片段直接嵌入到博客文章中。使用 Gists 而不是代码块的好处在于,它们更好地保留了代码格式,推广了你的 Github 账户,并且读者可以更容易地访问你的代码以自己尝试示例。
你需要一个 Github 账户来创建 Gist。创建一个后,只需导航到 Gists 页面 gist.github.com。创建 Gist 非常简单,只需给它起个名字,粘贴你的代码,然后点击发布。发布后,你将看到此页面。要在 Medium 帖子中嵌入 Gist,只需在‘Embed’下编码 URL,并粘贴到你的文章中。
代码在你的 Medium 帖子中的显示如下。
3. Jovian.ml
Jovian.ml 是一个用于在线托管 Jupyter Notebooks 的工具,非常适合从本地环境外部分享分析结果。Jovian 最近发布了一项功能,使得可以将整个笔记本、代码片段、单元输出和 Markdown 直接嵌入到你的 Medium 帖子中。
要开始使用 Jovian,你需要在 jovian.ml 上创建一个账户。免费版允许你创建无限的公共项目,这对于通过 Medium 博客分享内容非常理想。接着,你需要在本地环境中使用 pip 安装。
[p](https://www.jovian.ml/)ip install jovian
要将本地 Jupyter Notebook 上传到你的在线 Jovian 账户,只需在笔记本中运行以下命令。
import jovian
jovian.commit()
这将提示你输入一个 API 密钥,你可以在你的账户中找到它。

要在单元格中嵌入特定的代码片段,请导航到你上传到在线账户的笔记本,以及包含你要分享的代码的单元格。点击 Embed Cell。

这将给你一个可以粘贴到你的 Medium 帖子的链接。

这将显示如下所示。
4. Grammarly
Grammarly 是一个非常知名的应用程序,它检查你的内容中的拼写错误、语法错误甚至文本的情感。虽然它是一个显而易见的写作工具,但我花了一段时间才开始使用它,并且它对我文章的编辑时间产生了巨大的影响,所以我觉得值得在这里分享。
Grammarly 可以作为浏览器扩展、桌面应用程序或移动应用程序进行安装。为了最大限度地利用我的时间,我在许多不同的环境中写作,因此在离线写作时本地安装 Grammarly 非常有用,当我在浏览器中直接写作时也很方便,如果我在移动中写作,Grammarly 的移动版也很有帮助。
如果你对 Medium 上的数据科学写作感兴趣,你可能会发现我之前写的相关文章也很有用。
关于数据科学(或任何其他主题)的写作技巧
博客写作加速了我在数据科学领域的学习,原因如下
感谢阅读!
我每月发送一次新闻通讯,如果你想加入,请通过这个链接注册。期待成为你学习旅程的一部分!
简历:Rebecca Vickery 通过自学学习数据科学。Holiday Extras 的数据科学家。alGo 的联合创始人。
原文。经许可转载。
相关:
-
如果我必须重新开始学习数据科学,我会怎么做?
-
成功的数据科学家需要具备什么?
-
最重要的数据科学项目
更多相关话题
使用 JSON 在 Python 中的 4 个技巧
原文:
www.kdnuggets.com/2020/09/4-tricks-effectively-use-json-python.html
评论
作者 Erik van Baaren,Python 3 指南

作者插图
Python 有两种数据类型,它们结合在一起形成了处理 JSON 的完美工具:字典 和 列表。让我们探索如何:
-
加载和写入 JSON
-
在命令行上格式化输出并验证 JSON
-
通过使用 JMESPath 对 JSON 文档进行高级查询
1. 解码 JSON
Python 配备了一个强大且优雅的 JSON 库。它可以用以下方式导入:
import json
解码 JSON 字符串像 json.loads(…)(意为“加载字符串”)一样简单。
它会转换:
-
对象转换为字典
-
数组转换为列表,
-
布尔值、整数、浮点数和字符串会被识别并转换成 Python 中的正确类型
-
任何
null都会被转换为 Python 的None类型
这是 json.loads 在实际操作中的一个示例:
>>> import json
>>> jsonstring = '{"name": "erik", "age": 38, "married": true}'
>>> **json.loads(jsonstring)**
{'name': 'erik', 'age': 38, 'married': True}
2. 编码 JSON
另一种方式同样简单。使用 json.dumps(…)(意为“转储到字符串”)将一个由字典、列表和其他原生类型组成的 Python 对象转换为字符串:
>>> myjson = {'name': 'erik', 'age': 38, 'married': True}
>>> **json.dumps(myjson)**
'{"name": "erik", "age": 38, "married": true}'
这是完全相同的文档,转换回字符串!如果你想让你的 JSON 文档对人类更可读,请使用缩进选项:
>>> print(json.dumps(myjson, indent=2))
{
"name": "erik",
"age": 38,
"married": true
}
3. 命令行使用
JSON 库也可以从命令行使用,以 验证 和 格式化输出 JSON:
$ echo "{ \"name\": \"Monty\", \"age\": 45 }" | \
python3 -m json.tool
{
"name": "Monty",
"age": 45
}
旁注:如果你使用的是 Mac 或 Linux 并且有机会安装它,请查看一下 jq 命令行工具。它容易记住,能够为你的输出着色,并且具有大量额外功能,正如我在 关于成为命令行高手的文章 中所解释的那样。
jq 默认会对你的 JSON 进行格式化输出
4. 使用 JMESPath 搜索 JSON

截图 作者
JMESPath 是一种查询语言,用于 JSON。它允许你轻松从 JSON 文档中获取所需的数据。如果你之前使用过 JSON,你可能知道获取嵌套值是很简单的。
例如:doc["person"]["age"] 将为你获取一个文档中年龄的嵌套值,如下所示:
{
"persons": {
"name": "erik",
"age": "38"
}
}
但如果你想从一个类似于这样的文档中的人员数组中提取所有的年龄字段呢:
{
"persons": [
{ "name": "erik", "age": 38 },
{ "name": "john", "age": 45 },
{ "name": "rob", "age": 14 }
]
}
我们可以写一个简单的循环遍历所有人员。非常简单。但循环很慢并且会增加代码的复杂性。这就是 JMESPath 发挥作用的地方!
这个 JMESPath 表达式将完成这项工作:
persons[*].age
它会返回一个包含所有年龄的数组:[38, 45, 14]。
假设你想过滤列表,仅获取名为“erik”的人的年龄。你可以使用过滤器来实现:
persons[?name=='erik'].age
看到这有多自然和快捷了吗?
JMESPath 不是 Python 标准库的一部分,这意味着你需要通过 pip 或 [pipenv](https://medium.com/better-programming/improve-your-python-package-management-with-pipenv-28093c007955) 来安装它。例如,当 使用[pip](https://medium.com/better-programming/stop-installing-python-packages-globally-use-virtual-environments-a31dee9fb2de) 在虚拟环境中:
$ pip3 install jmespath
$ python3
Python 3.8.2 (default, Jul 16 2020, 14:00:26)
>>> import jmespath
>>> j = { "people": [{ "name": "erik", "age": 38 }] }
>>> jmespath.search(**"people[*].age"**, j)
[38]
>>>
你现在可以开始实验了!确保尝试一下 互动教程 ,并查看 JMESPath 网站上的 示例!
如果你有更多 JSON 的技巧或窍门,请在评论中分享!
关注我 在 Twitter 以获取我最新的文章,并确保 访问我的Python 3 Guide。这篇文章最初也发布于 那里。
了解 Python 语言的所有基本构建块
简介: Erik van Baaren 是一名软件工程师及 Python 3 Guide 的网站管理员,在那里你可以学习初级和高级 Python 话题。他还是 Medium.com 上的技术文章作者。
原文。经许可转载。
相关:
-
你应该知道的 3 个高级 Python 特性
-
为什么学习 Python?这里有 8 个数据驱动的理由
-
你不知道的 10 个 Scikit-Learn 事实
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT
更多相关主题
数据科学的 4 个有用的中级 SQL 查询
原文:
www.kdnuggets.com/2022/12/4-useful-intermediate-sql-queries-data-science.html

图片由 Shubham Dhage 提供,来源于 Unsplash
所以在这篇文章中,我们将讨论一些数据专业人员必备的中级 SQL 查询。我们将讨论 4 个 SQL 查询,问题是,为什么要学习这 4 个 SQL 查询?
我们都熟悉在 SQL 中创建数据库,但更重要的是知道如何根据我们的需要有效地清理和筛选数据。这些查询就是帮助我们的方法,让我们来看看这些查询是什么。
-
SQL 中的触发器,以及如何在查询中使用它?
-
SQL 中的 Partition By
-
SQL 中的 LIMIT,以及我们如何使用 LIMIT 语法限制 SQL 表中的查询?
-
SQL 中的 COALESCE 函数,以及它如何帮助我们去除 NULL 值?
1. SQL 中的触发器
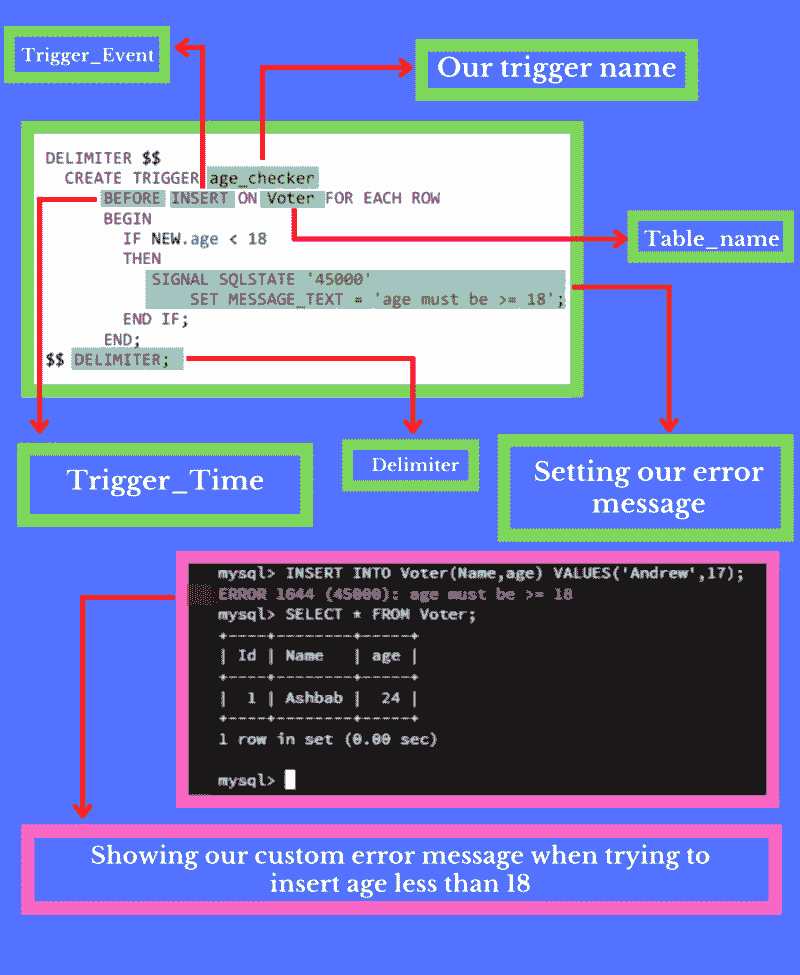
SQL 中的触发器 | 来源:作者提供的图片
在这篇文章中,我们将讨论 SQL 中触发器的强大功能。
什么是 SQL 中的触发器?
触发器是当事件发生时自动运行的 SQL 代码。例如:在下面的查询中,当用户尝试向表中插入值时,我们的触发器会运行。
触发器主要分为三个部分。
1. 触发器时间
2. 触发器事件
3. 表名
1. 触发器时间: 触发器时间指的是你希望这个触发器运行的时间,例如,事件之前或之后。
在下面的查询中,我们使用了 before,为什么?因为我们希望我们的代码在插入到表中之前运行。
2. 触发器事件: 触发器事件是指我们希望触发器运行的时机,例如 INSERT、UPDATE 和 DELETE
在上述示例中,我们使用 INSERT,因为我们希望在执行 INSERT 事件时运行我们的触发器。
3. 表名: 表名就是我们表的名称。
所以让我们详细讨论触发器的语法,并进行适当的实际解释
在 BEGIN 和 END 之间的代码是每当我们在选民表中插入值时,触发器检查年龄,是否小于 18 或大于 18。如果年龄大于或等于 18,则不会发生任何事情,但如果小于 18,则触发器会显示错误,并设置消息。
例如,参见上面的图片,我们设置 message_text = ' age must be >=18', 以便每当我们尝试 插入小于 18 的值时,都会显示此错误消息。在输出部分,当我们尝试插入 Andrew, 17 时,查询显示了包含我们 自定义消息 的错误。这就是 SQL 中的触发器以及如何在查询中使用它们。
查看下面的代码以获得更实际的理解
DELIMITER $$
/* creating a trigger whose name is age_checker */
CREATE TRIGGER age_checker
/* defining when our trigger run before inserting or after inserting
in our case we choose before inserting that's why we use BEFORE */
BEFORE INSERT ON Voter FOR EACH ROW
BEGIN
/* Now we are checking the inserted value in our age column if it is
less then 18 then show our error message */
IF NEW.age < 18
THEN
SIGNAL SQLSTATE '45000'
/* setting our error message in the MESSAGE_TEXT */
SET MESSAGE_TEXT = 'AGE MUST BE >= 18';
END IF;
END;
DELIMETER;
2. SQL 中的分区
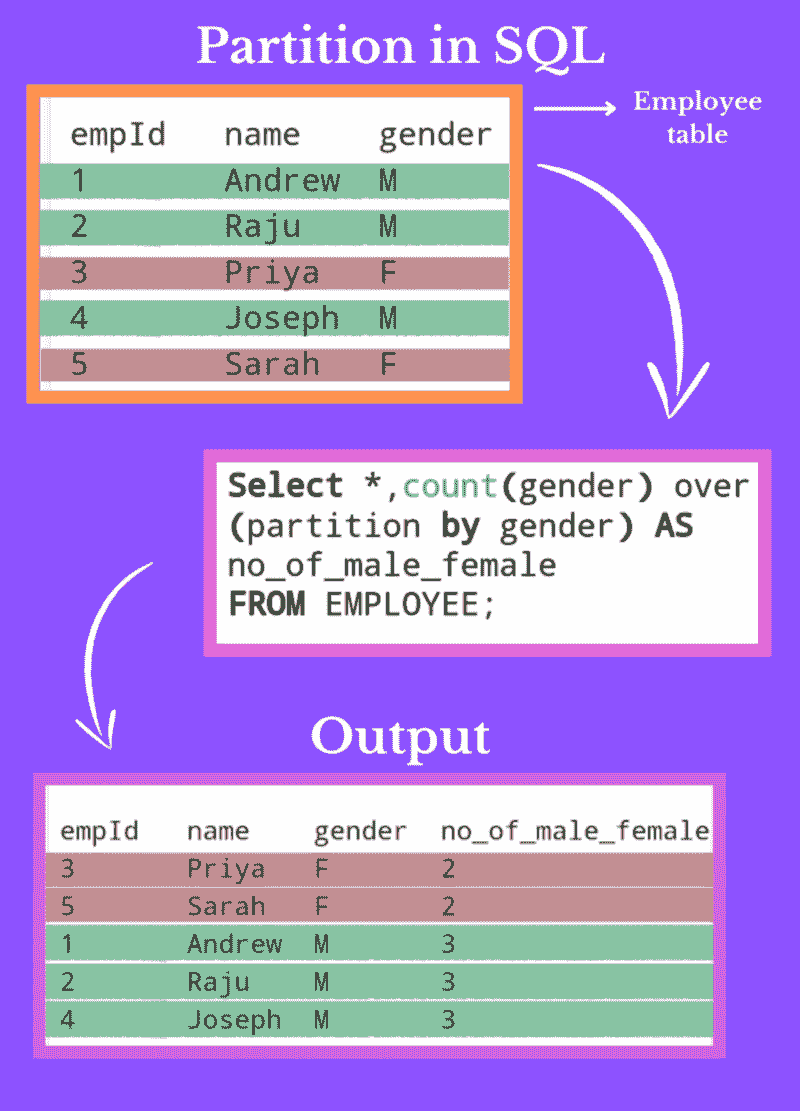
PARTITION BY in SQL | 来源: 作者插图
本文将讨论 分区 及其在 SQL 中的使用方法。
所以第一个问题是,SQL 中的分区是什么?
分区的作用是将具有相似值的行分组,但不限制行数。
让我们举个例子以便更清楚。
请参见上面的第二张图片。
表中有五行,其中有一列名为性别,包含三名男性候选人和两名女性候选人,那么如果我们想要一个新列来显示男性和女性的数量呢?
分区语法根据相似的值对行进行分组,这意味着在我们的查询中,我们使用 partition by 按性别进行分组。这意味着我们希望按性别对行进行分组,因此性别列中只有两个唯一值,第一个是 M,第二个是 F,因此将行分为两个组。
1 性别列中包含 M 的行
2 性别列中包含 F 的行,这就是 SQL 中分区的作用,我们使用计数函数来统计组中的行数。
在输出中,你可以看到新建了一个名为 no_of_male_female 的列,这列包含了组中的行数。例如,F 组中有两行,所以显示为 2,M 组中有三行,所以显示为 3。
有些人可能会想知道
SQL 中的 group by 和 partition by 有什么区别,因为这两者的作用相似。那么答案是,如果你使用 group by,你的五行数据仅会转换为两行。为什么?
因为 group by 显示的是组的数量,在我们上述的查询中,表被分为两个组,M 和 F,所以 group by 只显示每组的第一行,这意味着即使组包含十行数据,它只会显示每组的 1 行。
但如果使用 partition by,则行数保持不变,你会发现输出中的行数和表中的行数保持一致。
SQL 中的分区显示所有行。
两者都有优点和缺点,你可以根据需求选择使用。
如果你需要,请查看下面的代码
/* count function used to count number of gender after partition and then
show output in no_of_male_female column */
SELECT * , COUNT(gender) OVER (PARTITION BY gender)
AS no_of_male_female FROM EMPLOYEE;
3. 限制查询
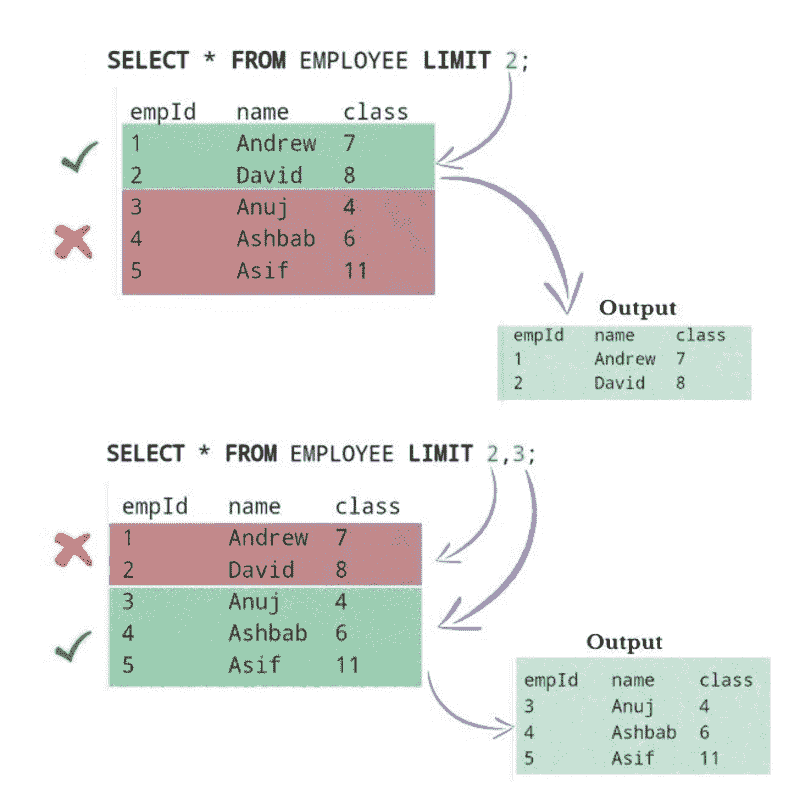
LIMIT in SQL | 来源: 作者插图
SQL 中的 LIMIT 及其工作原理,尽管 LIMIT 在某些 SQL 数据库中不受支持,例如 SQL 服务器和 MS access。
LIMIT 子句在 SQL 数据库中广泛使用,主要用于限制行数。
例如:如果我们想从数据库中找到前 10 或最差的 10 张专辑,那么 LIMIT 就很有用。我们在查询末尾使用 LIMIT 10,工作就完成了。
但这里有一个问题,LIMIT 是如何工作的,我们如何有效地使用它?
我们可以用两种方式使用 LIMIT
1. LIMIT(任何常量值)
例如,下面的代码选择了表中的前八行
SELECT * FROM table_name LIMIT 8;
2. LIMIT(x, y)
这是一种更精确地限制表格的方法。
x 参数用于从顶部消除几行。
y 参数显示你在消除后想要的行数。
例如:
选择 * FROM table_name LIMIT 3,2;
这个查询从顶部消除三行,然后在消除三行后显示两行。
查看下面的代码。
/* This command is used to select first two rows */
SELECT * FROM EMPLOYEE LIMIT 2;
/* This command is used to select 3 rows after eliminating first two rows */
SELECT * FROM EMPLOYEE LIMIT 2,3;
4. COALESCE 函数
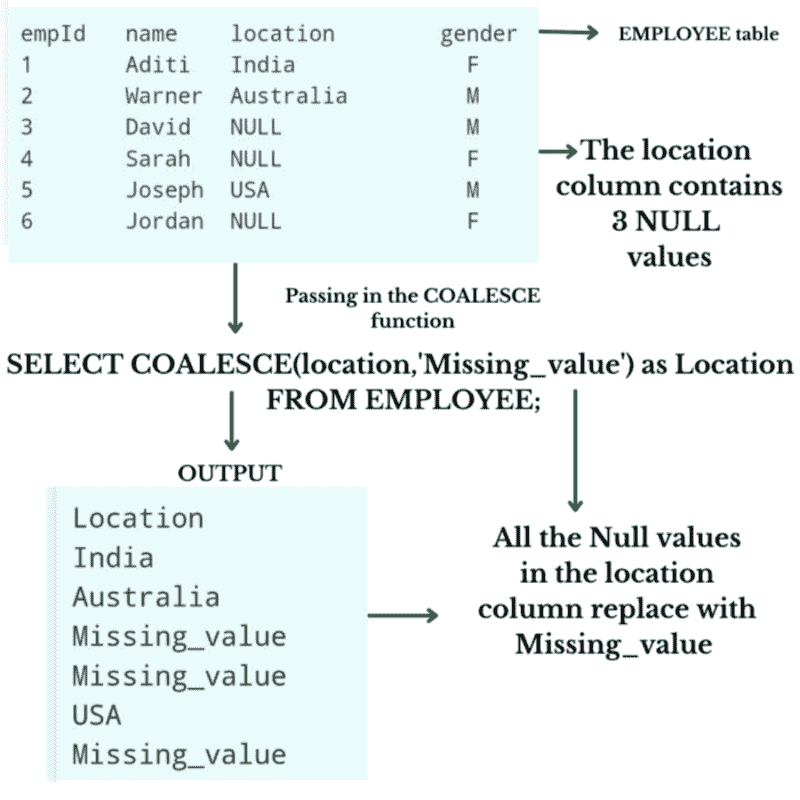
COALESCE 函数在 SQL 中 | 来源: 作者提供的图片
你知道 SQL 中有一些很棒的函数可以节省你的时间吗?
这里我谈论的是COALESCE 函数,这个函数会让你感到惊讶,所以请阅读完整的帖子。
COALESCE 函数接受 n 个值。
COALESCE(value_1,value_2,......, value_n)
所以让我们了解一下;请参见上面的第 4 张图片。你会看到有一个 EMPLOYEE 表,其中包含一个名为 location 的列,在该列中有 3 个 NULL 值。那么如果我们想用有意义的词替换这些 NULL 值呢?所以如上图所示,我们想用词 Missing_value 替换所有 NULL 值。
我们可以通过查看上面图片中的代码来实现这一点。COALESCE 函数将所有 NULL 值替换为 Missing_value。
让我们逐步了解 COALESCE 函数。
步骤 1: 我们在 COALESCE 函数中传递的第一个参数是我们想要查找 NULL 值的列名。这就是为什么我们使用 location。
步骤 2: 如果找到了某些值,则不会发生任何变化;正如你在图像中的代码输出所看到的,值保持不变,但如果找到 NULL 值,它会用我们在 COALESCE 函数中作为第二个参数提供的词来替换这些 NULL 值,我们给出的第二个参数是 Missing_value,这就是为什么它用 Missing_value 替换了 location 列中所有的 NULL 值。
这就是 COALESCE 函数在 SQL 中的工作原理。我们给出了一个使用单列的示例。如果我们想在多个列中替换 NULL 值,我们也可以通过遵循上述语法来实现。
查看下面的代码。
/* So we are targeting the location column from our EMPLOYEE table and
then replacing the NULL values with Missing_value text */
SELECT COALESCE(location,"Missing_value") as Location
FROM EMPLOYEE;
我希望这篇文章能简要说明如何使用这些 SQL 中的重要查询及其好处。如果你有任何问题,请随时在评论区提问。
Ashbab Khan 是一位数据科学家、SQL 专家和富有创意的技术写作者。
原文。经许可转载。
更多相关主题
使用 ChatGPT 生成被动收入的 4 种方法
原文:
www.kdnuggets.com/2023/03/4-ways-generate-passive-income-chatgpt.html
在当今快节奏的世界中,每个人都希望在不付出太多努力的情况下获得额外的收入。被动收入是一种很好的方式,它允许你在无需积极工作情况下赚取钱。
随着人工智能和聊天机器人技术的发展,现在可以利用这些技术产生被动收入。在本文中,我们将探讨使用 ChatGPT 这一由 OpenAI 创建的语言模型来产生被动收入的四种方法。让我们深入了解如何利用 ChatGPT 产生被动收入。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT

ChatGPT | 图片由 Rolf van Root 提供,来源于 Unsplash
1. 构建一个付费的谷歌 Chrome 扩展
第一个方法是构建一个谷歌 Chrome 扩展。这是一种非常可靠的被动收入方法。例如,著名的 Ad block 谷歌 Chrome 扩展创造了超过 4400 万美元的收入。我们可以使用 ChatGPT 来帮助我们构建一个 Chrome 扩展,然后发布它。
让我们构建一个名为 veganit 的谷歌 Chrome 扩展,将非素食选项转换为素食选项。为此,我们首先需要打开 ChatGPT 页面 并注册或登录。接下来,我们将给它以下提示:
你能告诉我创建一个名为 veganieit 的 Chrome 扩展脚本的步骤吗?这个扩展会读取网页内容并将网页上的“牛奶”一词更改为“素食牛奶替代品”
以下是 ChatGPT 的输出:
当然,我可以给你一个关于如何创建一个 Chrome 扩展脚本的大致步骤,这个脚本会根据要求修改网页内容。
这是您可以遵循的基本步骤:
-
在计算机上创建一个新文件夹以包含扩展文件。
-
在新文件夹内,创建一个名为 manifest.json 的文件。此文件将包含有关您扩展的信息,包括其名称、版本和权限。
-
打开 manifest.json 文件并添加以下代码:
{
"manifest_version": 2,
"name": "VeganizeIt",
"version": "1.0",
"description": "Changes 'milk' to 'vegan milk alternative'.",
"permissions": [
"activeTab"
],
"content_scripts": [
{
"matches": [
""
],
"js": [
"content.js"
]
}
]
}
-
保存 manifest.json 文件。
-
在同一文件夹中创建一个名为 content.js 的新文件。这个文件将包含修改网页内容的脚本。将以下代码添加到 content.js:
const replaceText = (node) => {
const wordsToReplace = {
"milk": "vegan milk alternative"
};
Object.keys(wordsToReplace).forEach((word) => {
const regex = new RegExp(`\\b${word}\\b`, "gi");
node.textContent = node.textContent.replace(regex, wordsToReplace[word]);
});
};
const walk = (node) => {
const ignoreNodes = {
"STYLE": true,
"SCRIPT": true,
"NOSCRIPT": true,
"IFRAME": true,
"OBJECT": true,
"EMBED": true,
"VIDEO": true,
"AUDIO": true
};
if (ignoreNodes[node.nodeName]) {
return;
}
if (node.nodeType === 3) {
replaceText(node);
} else {
for (let i = 0; i < node.childNodes.length; i++) {
walk(node.childNodes[i]);
}
}
};
walk(document.body);
-
保存 content.js 文件。
-
打开 Google Chrome 并导航到 chrome://extensions。
-
点击“加载解压缩的”按钮并选择包含扩展文件的文件夹。
-
打开任何网页,通过查找“milk”一词是否被替换为“vegan milk alternative”来测试你的扩展。
之后你可以通过多种方式进行货币化:
-
在 Google Chrome 扩展商店中进行货币化
-
提供免费版和付费版,后者具有更多功能
-
用电子邮件进行交换并创建电子邮件列表,推广其他产品。
由于 ChatGPT 将使构建此类扩展变得简单,一切都取决于你的创造力以及提出独特且有需求的创意的能力,这样你将有更少的竞争和广阔的市场。你可以使用 ChatGPT 指导你构建扩展,然后可以提升你的技能以使其更好。
2. 创建 HTML 网络工具
有很多简单的 HTML 网络工具可以创建,并且能够吸引大量受众。例如这个 BMI 计算器。你可以利用该网站的流量,通过 Google 广告创造收入。我们可以使用 similarweb 工具来衡量和分析网站流量。我们可以看到该网站每月访问量超过 4000 万:
BMI 计算器流量和参与度
利用这些巨大的流量,你可以通过 Google 广告创造大量收入。我们来使用 ChatGPT 帮助我们构建一个类似的工具,我们首先将这个提示作为输入:
你能创建一个 HTML BMI 计算器,让用户输入他的身高、体重、性别和年龄,并得到他的 BMI 吗?
这是 ChatGPT 输出的代码:
<!DOCTYPE html>
<html>
<head>
<title>BMI Calculator</title>
<style>
body {
font-family: Arial, sans-serif;
background-color: #f2f2f2;
}
form {
background-color: #fff;
padding: 20px;
border-radius: 5px;
box-shadow: 0px 0px 10px 0px rgba(0,0,0,0.2);
width: 400px;
margin: auto;
}
input[type="submit"], input[type="reset"] {
background-color: #4CAF50;
color: #fff;
padding: 10px 15px;
border: none;
border-radius: 3px;
cursor: pointer;
margin-top: 10px;
}
input[type="submit"]:hover, input[type="reset"]:hover {
background-color: #3e8e41;
}
label {
display: block;
margin-bottom: 5px;
font-weight: bold;
}
input[type="number"], select {
padding: 10px;
border-radius: 3px;
border: 1px solid #ccc;
width: 100%;
box-sizing: border-box;
margin-bottom: 10px;
font-size: 16px;
}
</style>
</head>
<body>
<form>
<label for="height">Height (cm)</label>
<input type="number" id="height" name="height" placeholder="Enter your height" required>
<label for="weight">Weight (kg)</label>
<input type="number" id="weight" name="weight" placeholder="Enter your weight" required>
<label for="gender">Gender</label>
<select id="gender" name="gender" required>
<option value="">Select your gender</option>
<option value="male">Male</option>
<option value="female">Female</option>
</select>
<label for="age">Age</label>
<input type="number" id="age" name="age" placeholder="Enter your age" required>
<input type="submit" value="Calculate BMI">
<input type="reset" value="Clear">
<p>Your BMI is: <span id="bmi"></span></p>
<p id="message"></p>
</form>
<script>
function calculateBMI() {
var height = document.getElementById("height").value;
var weight = document.getElementById("weight").value;
var gender = document.getElementById("gender").value;
var age = document.getElementById("age").value;
// convert height to meters
var heightInMeters = height / 100;
// calculate BMI
var bmi = weight / (heightInMeters * heightInMeters);
// display BMI
document.getElementById("bmi").textContent = bmi.toFixed(2);
// display message based on BMI
var message = "";
if (bmi < 18.5) {
message = "You are underweight.";
} else if (bmi >= 18.5 && bmi <= 24.9) {
message = "You are healthy.";
} else if (bmi >= 25 && bmi <= 29
然后你可以使用网站构建工具来运行此代码并建立网站。你可以创造出更具独特性、竞争较少的创意,以获得最多的流量。例如,你可以制作一个网站,根据每月的平均观看时长和观看次数来计算估计的 Youtube 收入。正如提到的,这一切都归结于你的创造力以及发现新创意的能力,这些创意应具有广泛的受众。
3. 交易机器人指标
交易机器人的主要功能之一是指标,它们用于分析市场数据并生成自动交易系统的信号。这些指标可以是技术指标、基本面指标或两者的组合。技术指标使用基于市场数据(如价格和交易量)的数学计算来生成交易信号。另一方面,基本面指标分析宏观经济和公司特定数据以生成信号。
通常,指标的订阅费用每年或每 6 个月可能高达数百美元,因此这里是我们将用作 ChatGPT 输入的提示:
你能创建一个预设指标,当 25 分钟时间框架内的交易量增加 5%时触发买入信号吗
你能创建一个预设指标,当 25 分钟时间框架内的交易量增加 5%时触发买入信号吗
这里是 ChatGPT 的输出:
//@version=5
indicator("Volume Increase Alert", shorttitle="VIA")
// Inputs
var float volumeThresholdPercent = input(5, title="Volume Threshold (%)", minval=0, maxval=100)
// Calculate volume change percentage
var float volumePercentChange = change(volume) / volume * 100
// Check if volume percent change is greater than threshold on 25 minute time frame
var bool volumeIncrease25m = timeframe.isseconds and timeframe.multiplier == 25 and volumePercentChange >= volumeThresholdPercent
// Generate buy signal if volume increase on 25 minute time frame
if volumeIncrease25m
strategy.entry("Buy", strategy.long)
alert("Volume increase on 25 minute time frame!")
你可以将其集成到你的机器人中使用,或者创建你自己的交易机器人,并内置多个指标,或者将其出售给交易机器人。你越具创造性和实用性,就越能产生收入。记住,现在使用 AI 可以创建类似的工具,关键在于创造力,以便脱颖而出。
4. 编写并出版儿童书籍
我们将重点关注儿童书籍,因为它们的字数较少,易于编写、出版和在亚马逊上销售。另一个建议是关注教育性主题,以提供一个故事,同时帮助孩子们变得更好,并具有教育意义,这样父母就会愿意购买。
所以让我们使用 ChatGPT 来写一个关于一个叫詹姆斯的男孩被老师欺负以及他如何克服这一困境的故事。以下是 ChatGPT 的输入提示:
写一个关于一个叫詹姆斯的男孩被老师欺负以及他如何克服这一困境的儿童故事
这里是 ChatGPT 的输出:
从前,有一个名叫詹姆斯的小男孩,他喜欢上学。他喜欢学习新事物,交新朋友,探索周围的世界。然而,有一件事让詹姆斯上学变得很有挑战,那就是他的老师。
詹姆斯的老师,格赖姆斯女士,是一个严厉和令人畏惧的人,她以对学生苛刻而闻名。她经常在同学面前批评詹姆斯,称呼他难听的名字,甚至身体上推搡他。詹姆斯尽力忽视她的行为,但随着时间的推移,这变得越来越困难。
一天,在格赖姆斯女士的行为特别让人不安之后,詹姆斯决定他再也无法忍受了。他不想再感到害怕或自卑。因此,他决定与父母谈谈这件事。
他的父母仔细倾听了他,并告诉他格赖姆斯女士的行为是不对的。他们鼓励他为自己发声,不让任何人对他不好。詹姆斯感到宽慰,知道自己的父母支持他,并且他并不孤单。
第二天,詹姆斯带着新获得的自信去上学。当格赖姆斯女士试图在同学面前贬低他时,詹姆斯站出来为自己辩护,并告诉她他不再容忍被欺负了。格赖姆斯女士被詹姆斯的大胆举动吓到了,不知道如何回应。
从那天起,詹姆斯拒绝让格赖姆斯女士的行为影响自己。他继续努力学习,结交了支持他的朋友。格赖姆斯女士最终意识到她对詹姆斯的对待是错误的,并向他道歉。
最终,詹姆斯克服了他的恐惧,并对抗了他的欺负者。他学到了为自己发声的重要性,并且在亲人的支持下,一个人可以克服任何挑战。因此,詹姆斯在学校和生活中继续茁壮成长,知道自己有足够的力量去克服任何困难。
现在我们也可以使用 AI 来绘制图片。首先,我们将让 ChatGPT 为每个故事角色提供描述,我们可以立即使用这些描述生成图像。例如,我们首先会让 ChatGPT 使用以下提示来给我们描述詹姆斯:
你能详细描述一下詹姆斯的样子,以便我可以让 AI 图像生成工具为他绘制一幅图吗?
以下是 ChatGPT 的输出:
詹姆斯是一个 10 岁的男孩,短而略微凌乱的深棕色头发。他有一双明亮的蓝色眼睛,当他开心时会闪闪发光。他的皮肤较白,鼻子和脸颊上有几颗雀斑。他右眉毛上方有一个小伤疤,是去年夏天骑自行车摔伤的。
詹姆斯的身高在同龄人中算是中等,身材苗条。他喜欢穿舒适的衣服,比如 T 恤和牛仔裤,他最喜欢的颜色是蓝色。他经常穿一双红色运动鞋,因为经常跑来跑去和在外面玩耍,所以鞋子有点磨损。
总体来说,詹姆斯看起来友好且容易接近,眼中透着一丝调皮。
现在我们可以使用任何图像生成工具来开始生成图片。在这个例子中,我将使用 稳定扩散 Hugging Face 空间。以下是使用稳定扩散生成的图像,基于我们从 ChatGPT 得到的提示:

使用稳定扩散生成的图像
你还可以让 ChatGPT 为故事中的其他角色和场景提供描述,并可以运用自己的想象力,使用 AI 图像生成工具创建更多场景。
接下来,你可以使用像 Book Bolt Studio 这样的书籍工作室来制作书籍,并将其转换为合适的格式。最后,你可以在亚马逊 KDP 上自助出版你的书籍,这是一个亚马逊自助出版平台。
你可以用多种语言创建多本儿童书籍,并开始在亚马逊上销售,正如之前所说的,想法和创意越多,你能赚到的钱也会越多。
总结来说,ChatGPT 将为建立产品和生成收入提供很多机会,一切都取决于你的创造力和市场理解。在本文中,我们集中介绍了四种赚钱的方法:构建 Chrome 扩展程序、创建网络工具、构建交易机器人指标和编写儿童故事。
尤瑟夫·拉法特 是一名计算机视觉研究员和数据科学家。他的研究专注于开发用于医疗保健应用的实时计算机视觉算法。他还在营销、金融和医疗保健领域担任数据科学家超过 3 年。
更多相关主题
黑客如何利用数据科学盗取数十亿
原文:
www.kdnuggets.com/2022/02/4-ways-hackers-data-science-steal-billions.html

技术照片由 pressfoto 创建 - www.freepik.com
你所认识的大多数数据科学家都站在数据科学的“好”一边。他们在顶尖科技公司工作。他们利用他们的能力做好事,构建产品,发现趋势,甚至积极工作以阻止黑客。例如,一个新的数据科学领域叫做 Phishitycs,利用机器学习来阻止钓鱼攻击。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
即使数据科学家未直接受雇于公司,许多人也作为伦理黑客,利用他们的技能识别并帮助公司修补漏洞,从而获得赏金。
然而,随着数据科学成为一种越来越常见的技能,许多黑客将其作为工具来窃取企业数据、个人数据、侵犯隐私或其他任何可能损害业务的重要信息。
这并不意外。尽管数据科学领域和黑客领域在合法性上处于对立面,但它们有很多共同点。数据科学需要大量的创新思维、问题解决和分析思维,黑客也是如此。
制止敌人的最佳方法是了解你的敌人。以下是黑客如何利用数据科学的四种方式,以及如何阻止他们。
1. 黑客利用机器学习提高对抗人类的效率
最常见且最成功的黑客类型之一是模仿公司中的其他人,以获得对电子邮件、安全服务器等的访问。这种黑客包括欺骗、钓鱼、针对性钓鱼和冒充。
黑客们已经开始使用机器学习来更好地模仿人类的言语和文本模式。正如机器学习可以用来帮助自然语言处理进步一样,这些技能也可以用来让黑客的声音听起来更逼真。
黑客可能会利用机器学习分析你的首席技术官(CTO)的说话和写作风格,通过社交网络进行分析。然后她可能成功冒充你的 CTO,诱使你点击恶意链接。
2. 黑客利用机器学习来突破安全系统一旦进入
人工智能和机器学习可以使用聪明的勒索软件和恶意软件,这些软件对威胁的适应能力越来越强。
许多公司面临的一个问题是,他们的安全系统是被动和反应性的,而不是主动的。由于黑客已经构建了越来越智能的恶意软件,能够识别安全软件并据此进行调整以保持隐蔽,公司必须开发自己的智能安全系统。
到目前为止,他们在这方面的表现并不佳。仅去年,网络犯罪就给公司造成了 总计 200 亿美元 的损失,这一数字在过去几年里稳步上升。
3. 黑客构建可以点击那个小复选框的机器人
每个人都熟悉确认你不是机器人的复选框,称为 CAPTCHA。我们大多数人都对接下来稍显烦人的、奇怪的图片集合有所了解,这些图片要求我们识别交通灯、船只、火车或其他随机物体。
比我,一个人,被要求证明自己不是机器人更让人烦恼的是,意识到机器人也可以做到这一点。如今,任何使用过 Google 图像搜索功能的人应该知道,机器学习和算法可以用来训练能够突破这些安全措施的机器人。
“有许多方法可以绕过文本 CAPTCHA。研究人员展示了他们如何编写一个能够击败图像识别测试的程序。CAPTCHA 可能会让用户感到烦恼,他们在等待 CAPTCHA 测试时被困在网页上。在某些情况下,这会导致他们感到沮丧并彻底放弃,” Ali Qamar 在 Techgenix 中写道。
4. 通过 DoS 或 DDoS 攻击进行过载
DoS(拒绝服务)或 DDoS(分布式拒绝服务)攻击是近年来新闻中最著名的黑客成果之一。黑客会用大量模拟的网络流量来压垮目标的带宽或基础设施。这使得真实访客难以使用网站,干扰了商业活动。
最大的一次攻击发生在 2017 年的 Google——尽管他们直到 2020 年才披露了这次攻击。
虽然 DoS 攻击可以使用单一设备,但更强大的 DDoS 攻击依赖于一个“僵尸”网络,这些设备被感染了特定的恶意软件,允许黑客远程控制它们的活动。这些 DDoS 攻击依赖算法来协调这些攻击。随着物联网的普及,黑客在感染几乎任何设备方面变得更加高效,从公司服务器到支持 Wi-Fi 的冰箱。
公司如何克服这些问题?
阅读上述列表,很容易感到不知所措。幸运的是,对于每个黑客,都有一名数据科学家在努力阻止他们。这些工具也可以被反向使用,保护公司而不是入侵公司。不仅如此,许多攻击还可以通过培训和常识来阻止。以下是三种抵御现代黑客的方法。
1. 投资于正确的技术
随着公司开始转向云端,黑客也不断进化,因为公司迁移到云端时,许多安全问题随之出现,这虽然提升了服务,但也带来了更大的安全威胁。为了应对这一弱点,许多公司也在升级,使用安全接入服务边缘(SASE)。能够定制安全设置和操作需求,意味着公司可以灵活地建立适合自己的安全架构。
2. 积极主动
公司应当着眼于建立更具前瞻性和预测性的安全模型,而不是当前标准的反应模型。公司可以用历史和当前的网络入侵信息来训练机器学习算法,以预测和检测这些入侵,像人类免疫系统一样识别威胁,即使这些威胁发生变化。
3. 专注于人员,而非机器
我最喜欢的关于黑客的民间故事之一是,当未来的计算机科学家们被要求尝试黑入他们的大学服务器时,大多数人无法检测到任何漏洞或突破强大的防火墙。
然而,一名女性戴上了假挂绳,试图进入存放服务器的建筑物。她假装挂绳无法使用,结果被一位热心的员工放行。当她进入内部时,又假装忘记了登录密码,并请求获取密码。她再次成功地进入了系统。
她的技能并不是技术性的,而是心理学上的。许多黑客依赖相同的技能。因此,通过减少人为错误可以阻止很多这些黑客。不要点击电子邮件中的链接。不要下载附件。不要相信你所阅读的内容。仅凭这些,你就可以消除许多黑客入侵的尝试。
Zulie Rane 是一名自由撰稿人和编程爱好者。
了解更多此话题
4 种重命名 Pandas 列的方法
原文:
www.kdnuggets.com/2022/11/4-ways-rename-pandas-columns.html

图片由作者提供
Pandas DataFrame 现在已经成为主流。每个人都在使用它进行数据分析、机器学习、数据工程,甚至软件开发。学习重命名列是数据清洗的第一步,这是数据分析的核心部分。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
在这个小教程中,我们将回顾四种方法,帮助你重命名单个或多个列名。
-
方法 1:使用 rename() 函数。
-
方法 2:分配新列名的列表。
-
方法 3:替换列字符串。
-
方法 4:使用 set_axis() 函数。
创建 Pandas DataFrame
我们将首先创建一个简单的学生班级表现字典。它包括三列:“id”、“name”和“grade”,以及五行数据。
要将 Python 字典转换为 pandas DataFrame,我们将使用 pandas DataFrame() 函数,并通过 Deepnote(Cloud Jupyter Notebook)显示结果。
注意:我们将多次使用
student_dict字典为每种方法创建一个 DataFrame。
方法 1
第一种方法相当简单。我们将使用 pandas rename() 函数来重新标记列名。
重命名单个列
在这个例子中,我们将使用 .rename() 重命名单个列。你只需将 旧 和 新 列名的字典提供给 columns 参数。
例如:{“旧列名” : “新列名”}
正如我们所观察到的,我们已经成功地将“id”替换为“ID”。
student_df_1.rename(columns={"id": "ID"}, inplace=True)
student_df_1
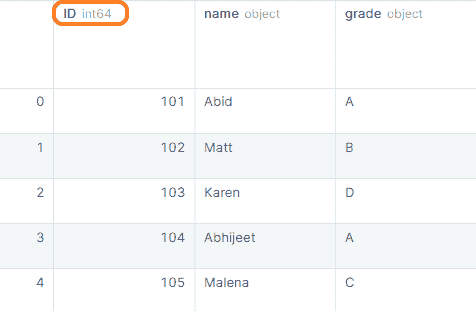
注意:
inplace = True意味着我们正在对 DataFrame 应用更改。这类似于df = df.rename()
重命名多个列
对于多个列,我们只需提供旧列名和新列名的字典,用逗号 “,” 分隔,它将自动替换列名。
新的列名为 "Student_ID", "First_Name", 和 "Average_Grade"。
student_df_1.rename(
columns={"ID": "Student_ID", "name": "First_Name", "grade": "Average_Grade"},
inplace=True,
)
student_df_1
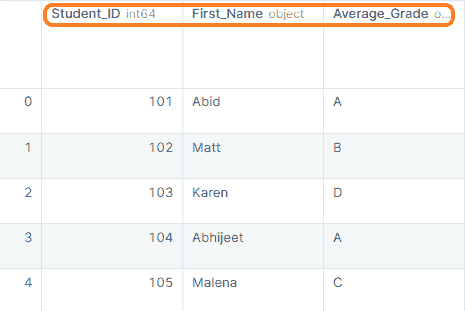
方法 2
第二种方法很简单。我们将通过将新名称列表分配给 DataFrame 对象的 columns 属性来重命名列。
例如,我们使用字典创建了一个新的数据框,并通过提供字符串列表给列属性来重命名列。
student_df_2 = pd.DataFrame(student_dict)
student_df_2.columns = ["Student_ID", "First_Name", "Average_Grade"]
student_df_2
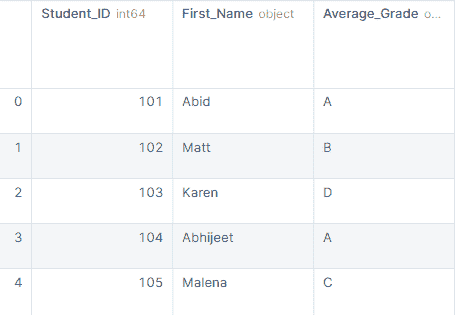
方法 3
第三种方法是 Python 生态系统中原生的,我们替换 columns 属性的字符串。
例如:df = df.columns.str.replace("old_name", "new_name")
我们已经成功将列名更改为“ID”、“Name”和“Grades”。
student_df_3 = pd.DataFrame(student_dict)
student_df_3.columns = student_df_3.columns.str.replace("id", "ID")
student_df_3.columns = student_df_3.columns.str.replace("name", "Name")
student_df_3.columns = student_df_3.columns.str.replace("grade", "Grades")
student_df_3
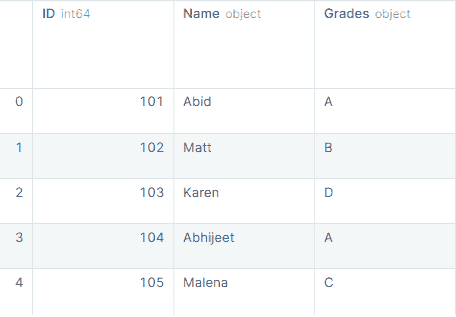
方法 4
在第四种方法中,我们将使用 set_axis() 函数重命名列。你需要提供一个新名称的列表,并设置 axis = ”columns” 以重命名列而不是索引。
student_df_4 = pd.DataFrame(student_dict)
student_df_4.set_axis(["A", "B", "C"], axis="columns", inplace=True)
student_df_4
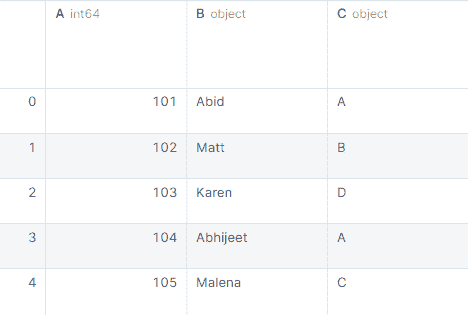
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为心理健康问题困扰的学生开发一个 AI 产品。
相关主题
40%的劳动力将在 3 年内受到人工智能的影响
原文:
www.kdnuggets.com/40-of-labour-force-will-be-affected-by-ai-in-3-years

图片由编辑提供
在过去的十年或二十年里,我们看到电子学习平台的兴起,以满足技术领域的需求。许多人涉足这一领域,因为当时它看起来是下一个大趋势。薪水丰厚,而且总是有成长空间。那时,这似乎是一个双赢的局面。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
然而,随着生成式人工智能在当今各行各业产生重大影响,许多成熟组织面临的一个大问题是填补技能差距。如果组织希望保持竞争力,他们需要有一支技术娴熟的团队。
人工智能可以自动化各种任务,自然会推动某些职位的消失。那么这对我们意味着什么呢?
所以现在这仍然是双赢的局面吗,还是生死攸关?我知道这有点戏剧化。
让我们查看一下统计数据
根据世界经济论坛(WEF),在 2020 年至 2025 年间,新技术及其持续增长将全球范围内扰乱 8500 万个工作岗位,并创造 9700 万个新职位。哎呀,只剩 2 年时间了。这条信息发布于 2020 年,同时指出,分析思维、创造力和灵活性是 2025 年所需的顶尖技能。
如下图所示,这是世界经济论坛(WEF)报告中展示的 2023 年至 2027 年宏观趋势对工作影响的预期。在左侧,你可以看到预期趋势将如何创造或取代工作岗位。
图片由世界经济论坛(WEF)提供
要查看完整报告,请参考这里。
IBM 商业价值研究所的另一项研究指出:
“四分之五的高管表示生成性 AI 将改变员工的角色和技能。尽管所有级别的员工都会感受到生成性 AI 的影响,但预计低级别员工会经历最大的变化。”
看起来,成长过程中接触了更多技术并可能感受到经济衰退影响的 Z 世代,在生成性 AI 和找工作方面也将产生最大的影响。
从IBM 报告中的图片来看,正如我们预期的那样,高管和高级管理人员的影响最小。但随着经验的减少,影响会变得更大。入门级员工的影响会比有经验的员工和初级管理人员小,这可能与上述陈述相矛盾。
这是否由于能够比有经验的员工和初级管理人员更迅速地提升入门级员工的技能?
图片来源:IBM 报告
新的技能范式
IBM 报告中令我感兴趣的一部分是新的技能范式。当我们考虑跟上技术时,大多数人想到的是学习硬技能,如编码或进入技术产品管理领域。该 IBM 报告显示,高管估计,40%的员工将因 AI 和自动化而需要重新技能培训。
新的技能范式关注软技能,以及这些技能如何从 2016 年到 2023 年发生变化。正如下面的图片所示,诸如 STEM 技能和基本计算机及软件应用这些我们认为非常可取的技能,其重要性已经显著下降。时间管理、有效团队合作和沟通等技能则处于领先地位。
图片来源:IBM 报告
IBM 报告还指出,平均 87%的高管预计生成性 AI 将增强而非取代工作角色。87%是一个很大的比例。
这意味着在市场营销(73%)和客户服务(77%)以及采购(97%)、风险和合规(93%)和财务(93%)等角色和任务中,接近四分之三的工作将会被增强。
这是否意味着劳动力将与技术迅速协作,还是我们仍需提升技能?
在这个时代,提升技能的答案始终是正确的。
结论
那么你应该从中获取什么?
许多事情正在发生变化,而且变化很快。为了跟上这些变化,你需要接受重新技能培训或提升技能,并利用 AI 工具来增强你的能力,而不是被取代。
你应该感到欣慰的是,高管们表示,提升技能虽然与生成式 AI 无关,但更多的是关于时间管理和协作,而不是学习编程。
尼莎·阿里亚是一位数据科学家、自由技术作家,同时也是 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及理论知识。尼莎涵盖了广泛的话题,并希望探索人工智能可以如何促进人类寿命的不同方式。作为一名热衷学习者,尼莎寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关主题
Python 之禅

图片由编辑提供
尽管 Python 相对简单,但编写良好、可读、可维护的 Python 代码仍具有挑战性。幸运的是,所有 Python 爱好者都可以从 Python 自身的智慧中获益,也就是所有 Pythonista 所称的“Python 之禅”。
《Python 之禅》是一首简短的诗,呈现了编写高质量 Python 代码的指导方针。
如果你从未听说过它,你可以通过运行这行代码来阅读《Python 之禅》:
import this
这将打印出 Python 掌握的诗歌。
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
尽管这首诗为编写简洁的 Python 代码提供了明确而直接的指导,但让我们谈谈一些免费的资源,这些资源将通过示例引导你阅读诗歌的不同节。
这首诗的前七节都关于风格。Python 注重简洁,所以如果你想学习如何用良好的风格编写简单的 Python 代码,可以参考《Python 编程指南》。它将给你提供代码风格的基础知识。另一篇关于优化 Python 代码的精彩短文是《如何简化你的 Python 代码以获得最佳可读性》由Zoe Zbar和Alex Baransky在纽约数据科学学院撰写。另一种选择是真实 Python的 YouTube 视频《编写 Pythonic 代码 - 习惯用法 Python》。这个 9 分钟的视频将指导你编写良好且符合惯用法的 Python 代码。
下一节关于处理错误和异常。assert语句是捕捉错误的好帮手,可以防止错误破坏你的代码。《Python 异常处理:AssertionError》文章由 Frances Banks 在AirBrake撰写,涵盖了如何最佳使用assert语句。《Python 中的异常处理》的 YouTube 教程由Edureka提供,提供了更广泛的错误处理视角。
这使我们来到了诗歌的结尾,采用简单明了的方式解决给定的问题。在编程和生活中,有许多处理问题的方法。有些方法比其他方法更好,更直接。找到编程问题的最优解决方案是一项超越 Python 掌握的技能。Geeksforgeeks' 的 "如何处理编码问题?" 文章将帮助你建立解决任何问题所需的直觉。
Python 的禅宗只是编写优质代码的 19 条准则(不仅限于 Python)。 Tim Peters 最初在 1999 年的 Python 邮件列表中写了这首诗。编写优质 Python 代码需要练习;你写的代码越多,你的风格就会越好。所以,请记住,尽量遵循这些准则,你的代码将会充满禅意!
Sara Metwalli 是庆应大学的博士候选人,研究测试和调试量子电路的方法。我是 IBM 研究实习生和 Qiskit 推广者,帮助构建更加量子化的未来。我还是 Medium、Built-in、She Can Code 和 KDN 上的作者,撰写有关编程、数据科学和技术主题的文章。我也是 Women Who Code Python 国际分会的负责人,还是一名火车爱好者、旅行者和摄影爱好者。
我们的前三课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关主题
Pandas 中的五种条件过滤方法

编辑者提供的图片
当我开始我的数据科学之旅时,我选择了 R 作为我的第一个编程语言。我变得非常熟悉使用 dplyr 包来根据某些条件过滤数据。几年后,当我开始使用 Python 时,最初对 Pandas 感到有些排斥,因为它与 dplyr 的差异很大。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
随着时间的推移,我变得越来越习惯使用 Pandas 方法来过滤数据,它变得不再那么令人畏惧。本文是一个关于使用 Pandas 进行条件过滤的五种方法的教程,包括单条件过滤和多条件过滤。
本文使用的过滤技术有:
-
Pandas 的选择括号过滤
-
Pandas 系列方法:isin()、between()、contains()
-
在选择括号过滤之外定义单独的过滤器
-
query()
-
loc[]
-
附加内容:使用 pandas 的 filter()方法
数据
本文的数据集来源于 Nehla Birla 发布的“车辆数据集”,托管在Kaggle.com,包含有关待售二手车的信息。
首先,我导入 Pandas 并读取数据集。
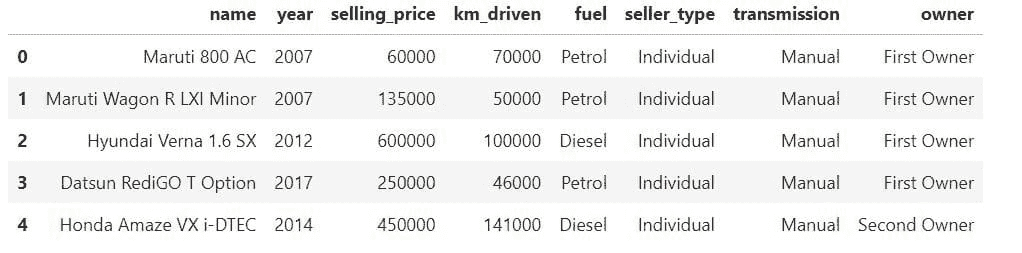
为了感受每种方法的语法和可读性,本文使用两个示例来过滤车辆数据集:一个简单的过滤和一个多条件的过滤。
-
简单过滤:查找所有 2013 年及以后的车辆
-
多条件过滤:查找所有 2013 年、2014 年和 2015 年的本田车型,价格在 300000 到 450000 之间(含)。
过滤方法 1:选择括号
查找所有 2013 年或更新年份的车辆是一个相当标准的 Pandas 过滤任务:选择要过滤的数据集列,告诉它要过滤的值,并将该条件插入整个数据框的括号中。
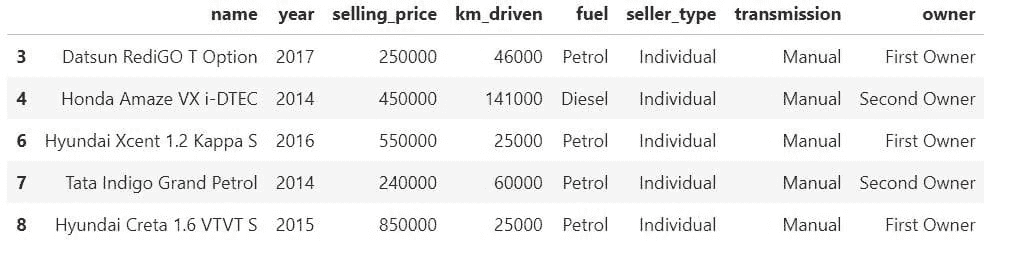
如果我们想进行多条件搜索,我们可以将每个单独的过滤器放在括号 () 内,通过布尔搜索条件分隔(& 表示和,| 表示或,~ 表示非)。
这些多个条件从技术上讲是有效的,但这段代码的可读性不佳。到处都是括号和圆括号。为了简化代码并使用更少的条件,pandas 提供了各种方法,我们可以使用其中之一来获得相同的结果,这里我们在上面的代码块中使用了 str.contains()。
过滤方法 2:带有系列函数的选择括号
我们可以将许多 pandas.Series 方法应用于我们的列。这些方法列在Pandas 文档中。我们在过滤时查看系列方法的原因是因为 Pandas.DataFrame 的每一列都是一个 Pandas.Series 元素,因此我们可以将 Pandas.Series 方法和功能应用于它。
我们可以在车辆数据集上使用许多方法,但为了使用多个条件的例子来过滤数据,我们将使用:
-
isin() – 检查系列值是否在给定列表中
-
str.contains() – 检查系列中是否包含某个字符串
-
between() – 查找介于两个值之间的系列值
我们将使用 isin() 来检查哪些车辆符合我们感兴趣的年份,使用 str.contains() 查找哪些车辆名称中包含 Honda,以及使用 between() 查找价格范围内的车辆。
这在一定程度上简化了代码,并利用了一些 Pandas.Series 方法,但代码仍然不是特别可读。为了使其看起来更好,我们可以将代码分成多行,每行一个过滤操作。这样做的方法是在初始数据框选择括号内部放入普通圆括号,然后将所有条件插入这些圆括号中。
过滤方法 3:带有外部过滤器和系列方法的选择括号
结合上述两种方法,我们可以将过滤器定义在选择括号外部作为变量,然后在选择括号内部调用每个变量。这是一种干净的方式,可以将每个过滤器写在单独的一行,然后在一行代码中调用所有过滤器。这意味着在整个代码中减少了总体上的括号和换行符。
过滤方法 4:query()
一两年前,我在播客中第一次听说 pandas.Series.query,一开始我并不喜欢。但随着时间的推移,它确实让我很喜欢。查询表达式是一种很好的数据子集化方式:它们可以很基础也可以很复杂和强大。用于子集化 2013 年及以后的车辆的查询表达式非常简单。你将过滤参数作为字符串传递进去。
当你使用多条件过滤器时,查询字符串会变得更复杂。你可以用 and 或 or 来代替 & 或 | 之间的过滤参数。以下是为我们的多条件过滤器编写查询表达式的代码。注意:要调用环境中但在 DataFrame/Series 外部的变量,你需要在调用变量之前加上 @。请注意 @ 在调用列表“years”之前的使用。
这是一种非常简洁的数据子集化方式!然而,添加的查询参数越多,代码的可读性就会下降。为了解决这个问题,使用 query,我们可以在想要换行的地方添加 \,并在下一行继续查询表达式。如果需要,我们可以保持每个过滤条件单独一行的表示方式。
过滤方法 5:loc[]
我真的很喜欢使用 Python lambda 函数所带来的强大功能。我们如何将 lambda 转换为用我们的条件过滤车辆数据集?对于我们一直在应用的简单单条件过滤,我们调用 dataframe 上的 loc,并且通过 lambda,我们可以插入我们的条件。
如果我们想要添加多个条件,只需在前一个结果上链式调用另一个 loc。然而,如果放在一行上,会到处都是括号和句点!这变得非常难以阅读。为了提高可读性,我们可以将表达式的整个右侧括在括号中,然后将每个 loc 过滤器放在自己的行上。
过滤奖金:使用 Pandas.DataFrame.filter
有趣的是,Pandas.DataFrame 的 filter() 方法并不允许你基于数据集中的数据来过滤数据集,尽管它的名字原本给我的印象是这样。实际上,filter() 方法允许你基于行/索引名称和/或列名称来过滤数据,从而对数据进行子集化。
筛选只有少数列和整数作为索引名称的车辆数据集,并不能完全展示 filter() 的强大功能。我们可以将“name”列中的值设置为索引,这些值包括汽车的品牌和型号。然而,很多行的品牌和型号是相同的,会有相同的索引,这并不是最佳实践。因此,为了使用品牌和型号,同时使每个索引唯一,我们将当前的整数索引与行的品牌和型号连接起来,然后将其作为新索引。你在实际操作中可能会选择不这样做,但我这样做是为了演示方法。
使用这个新索引,我们可以使用 Pandas.DataFrame 方法 filter() 基于索引名称进行筛选。通过 filter(),我们可以使用类似于之前使用的 str.contains() 的输入来搜索特定的索引,或者可以使用正则表达式来搜索索引。为了根据本篇文章中使用的多条件筛选来过滤数据,我们可以返回与其他五种技术相同的结果。唯一的区别是我们现在使用索引值来帮助筛选结果。
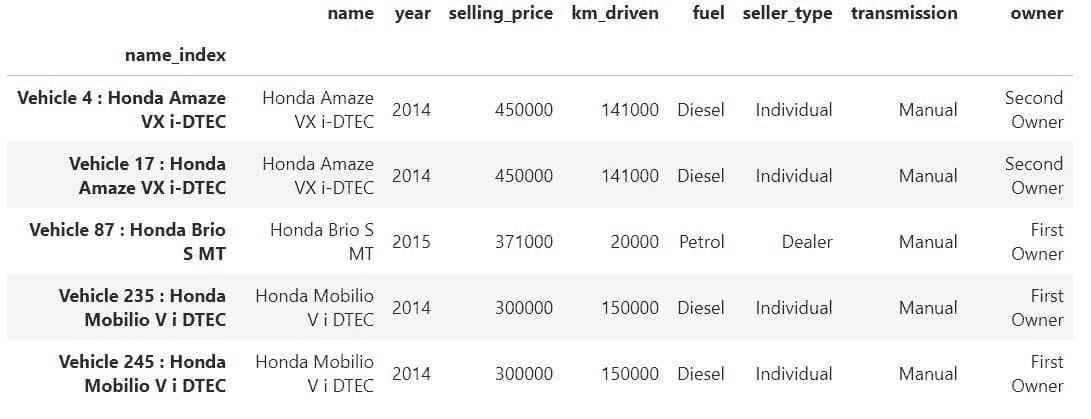
摘要
就这样!我们已经看到五种技术和一种额外的技术,帮助你在给定一个或多个筛选标准的情况下对数据进行切片和切块。我不确定我最喜欢哪一种;我想这取决于使用场景。我能看到自己使用 query() 由于查询字符串表达式的简便性和可读性,但我也能看到自己使用 loc[] 和 lambda 函数!
我希望这篇文章能给你一些如何将强大的 Pandas 功能应用到数据中的想法!
布莱恩·科拉诺 是一名现役的美国陆军军官和数据科学家,居住在华盛顿特区附近。当他不在提升 Python 技能时,他会花时间陪伴他的妻子和四个孩子,或者学习西班牙语和法语。
更多相关内容
KDnuggets™ 新闻 21:n48,12 月 22 日:使用管道编写干净的 Python 代码;成为优秀数据科学家所需的 5 种关键技能
特点 | 产品 | 教程 | 意见 | 热门 | 职位 | 提交博客 | 本周图片
本周在 KDnuggets:使用管道编写干净的 Python 代码;成为优秀数据科学家所需的 5 种关键技能;机器学习算法在实时生产环境中的完整端到端部署;成功数据科学家的 5 个特征;学习数据科学统计的顶级资源;以及更多内容。
KDnuggets 顶级博客奖励计划 将每月支付给顶级博客的作者。接受转发,但原创提交的转发率为 3 倍。阅读我们的 指南 并先向 KDnuggets 提交您的博客!
特点
-
**
,作者:Khuyen Tran
-
**
,作者:Sharan Kumar Ravindran
-
机器学习算法在实时生产环境中的完整端到端部署,作者:Graham Harrison
-
成功数据科学家的 5 个特征,作者:Matthew Mayo
-
学习数据科学统计的顶级资源,作者:Springboard
产品、服务
- 用 AI 和分析引擎更快地准备时间序列数据,作者:PI.EXCHANGE
教程、概述
-
每个数据科学家都应该知道的三个 R 库(即使你使用 Python),作者:Terence Shin
-
如何加速 XGBoost 模型训练,作者:Michael Galarnyk
-
云 ML 的视角:2021 年的惊喜,2022 年的预测,作者:George Vyshnya
-
如何在没有相关学位的情况下进入数据分析领域,作者:Zulie Rane
意见
-
我如何在 14 年内将薪水提高 14 倍,作为数据分析/科学专业人士,作者:Leon Wei
-
2022 年及以后 10 大 AI 和数据分析趋势,作者:David Pool
-
聊天机器人转型:从失败到未来,作者:Lubo Smid
-
为什么我们总是需要人类来训练 AI — 有时甚至是实时的,作者:Shoma Kimura
顶尖故事
-
2021 年顶尖故事:我们不需要数据科学家,我们需要数据工程师;成为数据科学家的指南(逐步方法);我如何在 18 个月内通过数据科学三倍收入,作者:Gregory Piatetsky
-
顶尖故事,12 月 13-19 日:使用管道编写干净的 Python 代码,作者:KDnuggets
职业
-
查看我们最近的 AI、分析、数据科学、机器学习职位
-
你可以在 KDnuggets 职业页面上免费发布与 AI、大数据、数据科学或机器学习相关的行业或学术职位,邮件 - 详细信息请见 kdnuggets.com/jobs
本周图片

图片来源:geralt 在 Pixabay
真实数据,从现实世界中获取,是数据科学的黄金标准,这也许显而易见。当然,诀窍是能够找到项目所需的真实数据。有时你会很幸运,所需的数据就在你的指尖上,形式和数量都正好符合需求。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
然而,现实世界的数据通常不足以满足项目需求。在这种情况下,合成数据可以用来替代真实数据,或用来增加数据集的规模。虽然制造数据的方法很多,有些方法远比其他方法复杂,但仍有许多相对简单的选项可供选择,Faker 是其中之一。
从 Faker 的 文档:
Faker 是一个生成虚假数据的 Python 包。无论你需要启动数据库、创建漂亮的 XML 文档、填充持久层以进行压力测试,还是匿名化从生产服务中获取的数据,Faker 都适合你。
可以通过 pip 安装 Faker:
pip install faker
导入并实例化 Faker 的过程如下:
from faker import Faker
fake = Faker()
基本的 Faker 使用方法
Faker 使用起来非常简单。首先,让我们看一些例子。
首先,让我们生成一个虚假的名字。
print(fake.name())
Deborah Brooks
那么其他几种数据类型怎么样?
# generate an address
print(fake.address())
# generate a phone number
print(fake.phone_number())
# generate a date
print(fake.date())
# generate a social security number
print(fake.ssn())
# generate some text
print(fake.text())
123 Danielle Forges Suite 506
Stevenborough, RI 36008
968-491-2711
1974-05-27
651-27-9994
Weight where while method. Rock final environmental gas provide. Remember continue sure. Create resource determine fine. Else red across participant. People must interesting spend some us.
Faker 优化
如果你对特定地区的数据感兴趣呢?例如,我是否对生成在墨西哥发现的西班牙名字感兴趣?
fake = Faker(['es_MX'])
for i in range(10):
print(fake.name())
Diana Lovato
Ing. Ariadna Palacios
Salvador de la Fuente
Margarita Naranjo
Alvaro Prado Melgar
Tomás Menchaca
Conchita Francisca Velázquez Zedillo
Ivonne Ana Luisa Bueno
Ramiro Raquel Vélez Urbina
Porfirio Esther Irizarry Varela
通过使用 Faker 的权重调整功能,可以进一步优化生成的输出:
Faker 构造函数接受一个与性能相关的参数,称为
use_weighting。它指定是否尝试使值的频率与现实世界的频率匹配(例如,英文名字 Gary 的出现频率会比名字 Lorimer 高得多)。如果use_weighting为False,则所有项目被选中的概率相等,且选择过程会更快。默认值为True。
让我们看看一些美国英语示例是如何工作的:
fake = Faker(['en_US'], use_weighting=True)
for i in range(20):
print(fake.name())
Mary Mckinney
Margaret Small
Dominic Carter
Elizabeth Gibson
Kelsey Garcia
Chelsea Bradford
Robert West
Timothy Howe
Gary Turner
Cynthia Strong
Joshua Henry
Amanda Jenkins
Jacqueline Daniels
Catherine Jones
Desiree Hodge
Shannon Mason DVM
Marcia West
Dustin Parrish
Christopher Rodriguez
Brett Webb
将此与类似输出不使用加权的情况进行比较:
fake = Faker(['en_US'], use_weighting=False)
for i in range(20):
print(fake.name())
Mr. Benjamin Horton
Miss Maria Hardin
Tina Good DDS
Dr. Terry Barr MD
Meredith Mason
Roberta Velasquez
Mr. Tim Woods V
Marilyn Conway
Mr. Dwayne Leblanc III
Dr. Dan Krause IV
Mia Newman DVM
Thomas Small
Joseph Holmes
Dr. Tanner Zhang
Alan Dixon
Miss Rebecca Davila DVM
Joseph Becker MD
Dr. Erin Pugh PhD
Mr. Ernest Juarez
Ross Thompson
请注意,例如,生成的“样本”中医生的比例不成比例。
更全面的示例
假设我们想为一家国际公司生成多个虚假的客户数据记录,我们想模拟真实世界中的命名分布,并希望将这些数据保存到 CSV 文件中,以便在数据科学任务中稍后使用。为了清理数据,我们还将用逗号替换生成的地址中的换行符,并完全删除生成文本中的换行符。
这里有一段代码摘录可以做到这一点,展示了 Faker 在几行代码中的强大功能。
from faker import Faker
import pandas as pd
fake = Faker(['en_US', 'en_UK', 'it_IT', 'de_DE', 'fr_FR'], use_weighting=True)
customers = {}
for i in range(0, 10000):
customers[i]={}
customers[i]['id'] = i+1
customers[i]['name'] = fake.name()
customers[i]['address'] = fake.address().replace('\n', ', ')
customers[i]['phone_number'] = fake.phone_number()
customers[i]['dob'] = fake.date()
customers[i]['note'] = fake.text().replace('\n', ' ')
df = pd.DataFrame(customers).T
print(df)
df.to_csv('customer_data.csv', index=False)
id name ... dob note
0 1 Burkhardt Junck ... 1982-08-11 Across important glass stop. Score include rel...
1 2 Ilja Weihmann ... 1975-03-24 Iusto velit aspernatur nemo. Aliquid ipsum ita...
2 3 Agnolo Tafuri ... 1990-10-03 Aspernatur fugit voluptatibus. Cumque accusant...
3 4 Sig. Lamberto Cutuli ... 1973-01-15 Maiores temporibus beatae. Ipsam non autem ist...
4 5 Marcus Turner ... 2005-12-17 Témoin âge élever loi.\nFatiguer auteur autori...
... ... ... ... ... ...
9995 9996 Miss Alexandra Waters ... 1985-01-20 Commodi omnis assumenda sit ratione non. Commo...
9996 9997 Natasha Harris ... 2003-10-26 Voluptatibus dolore a aspernatur facere. Aliqu...
9997 9998 Adrien Marin ... 1983-05-29 Et unde iure. Reiciendis doloribus dignissimos...
9998 9999 Nermin Heydrich ... 2005-03-29 Plan moitié charge note convenir.\nSang précip...
9999 10000 Samuel Allen ... 2011-09-29 Total gun economy adult as nor. Age late gas p...
[10000 rows x 6 columns]
我们还拥有一个 customer_data.csv 文件,包含我们所有的数据,以便进一步处理和根据需要使用。

生成的客户数据 CSV 文件截图
上述特定类型的数据生成器——如姓名、地址、电话等——被称为提供者。了解如何通过启用 Faker 生成特定类型的数据来扩展其功能,使用标准提供者和社区提供者。
查看 Faker 的GitHub 仓库和文档以获取更多功能,并立即创建自己的数据集。
相关:
-
使用 Python 创建具有异常签名的合成时间序列
-
教 AI 用合成数据分类时间序列模式
-
3 种数据采集、标注和增强工具
更多相关话题
KDnuggets™ 新闻 21:n40, 10 月 20 日:你需要的 20 个 Python 包用于机器学习和数据科学;通过项目组合应对数据科学面试
特性 | 产品 | 教程 | 观点 | 排行 | 招聘 | 提交博客 | 本周图片
本周在 KDnuggets:你需要的 20 个 Python 包用于机器学习和数据科学;如何通过项目组合应对数据科学面试;部署你的第一个机器学习 API;使用 5 行代码进行实时图像分割;什么是聚类及其如何工作?以及更多精彩内容。
请考虑提交原创博客到 KDnuggets!
特性
-
你需要的 20 个 Python 包用于机器学习和数据科学,作者:Sandro Luck
-
**
,作者:Abid Ali Awan
-
**
,作者:Abid Ali Awan
-
使用 5 行代码进行实时图像分割,作者:Ayoola Olafenwa
-
什么是聚类及其如何工作?,作者:Satoru Hayasaka
 ,作者:Abid Ali Awan
,作者:Abid Ali Awan ,作者:Abid Ali Awan
,作者:Abid Ali Awan产品,服务
-
2021 年数据工程师薪资报告分享了快速发展的市场洞察,作者:Burtch Works
-
向西北大学数据科学专家学习,作者:西北大学
-
Hasura 如何通过 PostHog 将转化率提高 20%,作者:PostHog
-
亚马逊网络服务网络研讨会:利用数据集创建以客户为中心的战略并改善业务成果,作者:Roidna
-
知识图谱论坛:技术生态系统与商业应用,作者:Ontotext
教程,概述
-
构建多模态模型:使用 widedeep Pytorch 包,作者:Rajiv Shah
-
AI 的新计算范式:内存处理(PIM)架构,作者:Nam Sung Kim
-
如何使用自动引导法计算机器学习中性能指标的置信区间,作者:David B Rosen (PhD)
-
2022 年最实用的数据科学技能,作者:Terence Shin
-
在生产环境中服务 ML 模型:常见模式,作者:Mo、Oakes 和 Galarnyk
-
如何用 KNIME Analytics Platform 在三步内创建互动仪表盘,作者:Emilio Silvestri
观点
-
避免这些让你看起来像数据新手的五种行为,作者:Tessa Xie
-
我们对算法的痴迷如何破坏了计算机视觉:以及合成计算机视觉如何解决这一问题,作者:Paul Pop
-
你的工作会被机器取代吗?,作者:Martin Perry
-
忙碌时数据专业人士如何给人留下深刻印象,作者:Devin Partida
热点新闻
-
10 月 11-17 日热点新闻:用 SQL 查询 Pandas DataFrames,作者:KDnuggets
-
KDnuggets 2021 年 9 月最佳博客奖,作者:Gregory Piatetsky
招聘信息
-
查看我们最新的 AI、分析、数据科学、机器学习职位
-
你可以在 KDnuggets 招聘页面免费发布与 AI、大数据、数据科学或机器学习相关的行业或学术职位,发送电子邮件 - 详细信息见 kdnuggets.com/jobs
本周图片

我们的前三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你在 IT 领域的组织
怀疑的侦探。信号提取者。被驱使的。如果你是数据科学家,完全可以把这些身份(或全部)视为自己的。至少,今天一些数据科学领域的领先创新者这样说。在这些引用中,他们分享了从多年经验中得出的建议和见解,以解决这一领域最紧迫的问题。这个列表旨在帮助有志于和已建立的数据科学家提升职业生涯,并激发你在下次数据科学聚会上的智能对话。
数据科学家是谁?
- “按定义,所有科学家都是数据科学家。 在我看来,他们一半是黑客,一半是分析师,他们使用数据来构建产品和发现洞察。这是哥伦布遇见科伦波——星光熠熠的探险者和怀疑的侦探。”
―莫妮卡·罗加提,独立数据科学顾问
阅读完整文章 这里。
- “‘被‘驱使’可能是最合适的词。我经常告诉人们,‘我并不想成为数据科学家。你就是某种程度上成为了数据科学家。你就是无法抗拒地看着那份数据集,然后觉得,‘我感觉需要深入看看。我觉得这不对。’”
―詹妮弗·申,尼尔森公司高级首席数据科学家;加州大学伯克利分校讲师
观看完整访谈 这里。
- “我认为数据科学更像是一种实践,而不是一份工作。想象一下科学方法,你需要有一个问题陈述,提出假设,收集数据,分析数据,然后传达结果并采取行动……如果你把科学方法作为应对数据密集型项目的方式,我认为你更有可能在结果上取得成功。”
―Bob Hayes,博士,Appuri 首席研究官
收听完整采访 这里.
- “作为数据科学家,我可以预测可能发生的事情,但我无法解释为什么它会发生。 我可以预测某人可能会流失,或对促销做出回应,或犯欺诈行为,或选择粉色按钮而不是蓝色按钮,但我无法告诉你为什么会发生这些事。我相信无法解释为什么事情会发生是我难以称‘数据科学’为科学的原因。”
―Bill Schmarzo,Dell EMC 首席技术官
阅读完整文章 这里.
- “数据科学家有点像新文艺复兴时代的人,因为数据科学本质上是多学科的。”
―John Foreman,MailChimp 产品管理副总裁
阅读完整文章 这里.
- “数据科学家(n.):比任何软件工程师都擅长统计学,比任何统计学家都擅长软件工程。”
―Josh Wills,Slack 数据工程总监
阅读完整文章 这里.
- “作为数据科学家,我们的工作是从噪音中提取信号。”
―Daniel Tunkelang,顾问 / 顾问
阅读完整文章 这里.
- “数据科学家的工作是提出正确的问题。如果我问一个像‘这个链接点击了多少次?’这样的问题,那是我们一直关注的事情,这不是一个数据科学问题。这是一个分析问题。如果我问一个像‘基于这个出版商网站上以往的链接历史,我能否预测未来三小时内有多少人来自法国会阅读这个?’这样的问题,那就更像是一个数据科学问题。”
―Hilary Mason,Fast Forward Labs 创始人
阅读完整文章 这里.
- “数据科学家对我们的数据进行模型驱动的分析;分析以改善我们的规划,增加我们的生产力,并发展我们对主题的更深层次的专业知识。 数据科学家在战术、操作和战略层面工作,与业务分享见解。”
―克里斯·佩胡拉,C-SUITE DATA 管理咨询实践总监
阅读完整文章 这里。
- “[数据科学家]能够想到利用数据解决那些否则无法解决的问题,或者仅凭直觉解决的问题。”
―彼得·斯科莫罗赫,前 LinkedIn 首席数据科学家
阅读完整文章 这里。
- “什么样的个性适合做有效的数据科学家?绝对是好奇心…… 数据科学中最大的疑问是‘为什么?’ 为什么会发生这种情况?如果你注意到有一个模式,问问自己,‘为什么?’ 数据是否有问题,还是这是一个实际存在的模式?我们能从这个模式中得出什么结论?自然的好奇心肯定会给你一个很好的基础。”
―卡拉·金特里,Talent Analytics 数据科学家
阅读完整文章 这里
- “有句话说,‘全能却无所精通。’ 做数据科学家时你需要有点像这样,但也许更好的说法是,‘全能而有所精通。’”
―布伦丹·蒂尔尼,Oralytics 首席顾问
阅读完整文章 这里。
我如何成为一名数据科学家?
- “我永远的建议是首先跟随你的激情。 了解你擅长什么,关心什么,并追求它……作为一名成功的数据科学家,你的每一天都可能以你为自己能通过数据解决现实问题而感恩的心态开始和结束。”
―科克·博恩,首席数据科学家,Booz Allen Hamilton
阅读完整文章 这里。
- “第一件事是你必须要有激情。 这种对问题的无情追求的丰富激情,以及对自己是否得到合理答案的深刻知识诚实感……”
“第二部分是拥有对数据极其聪明的处理能力。我所说的就是:你在处理模糊性的问题。而且很经常,你不能像处理作业一样严谨地处理问题。唯一的生存之道就是要聪明——思考一个不同的问题,以得到答案。”
―DJ Patil,前美国首席数据科学家
阅读完整文章 这里。
- “没有人谈论学习中的动机。数据科学是一个广泛而模糊的领域,这使得学习变得困难。非常困难。没有动机的话,你会在半途而废,认为自己做不到,其实问题不在你身上,而在于教学。”
通过根据你想做的事情来量身定制你的学习,掌控自己的学习。”
―Vik Paruchuri, 创始人,Dataquest
阅读完整文章 这里。
- “我不知道你如何教人们热爱学习,但自我激励是这个领域的核心。 一旦你掌握了核心概念,能够真正兴奋并持续寻找新信息是我在招聘时所看重的,比如,当我们招聘人员时。”
―Shelly D. Farnham, Ph.D., 执行董事兼研究科学家,Third Place Technologies
阅读完整文章 这里。
- “你最好的数据挖掘和数据科学学习方法是通过实践, 所以尽快开始分析数据吧!然而,别忘了学习理论,因为你需要一个好的统计和机器学习基础来理解你在做什么,并在大数据的噪音中找到真正的价值。”
―Gregory Piatetsky-Shapiro, KDnuggets 总裁
阅读完整文章 这里。
- “学习如何做数据科学就像学习滑雪。你必须去做。”
―Claudia Perlich, 首席科学家,Dstillery
阅读完整文章 这里。
- “数据科学的学习曲线是巨大的。 在很大程度上,你需要一个学位或类似的东西,以证明你对这一职业的承诺……
“课堂教学很重要,但完全专注于读书、考试和听讲座的课程是不够的。动手实验室工作对于成为一个全面的数据科学家至关重要。…
“这不应该退化为一个只生产理论填满脑袋的分析极客的程序,他们的文凭只是挂在墙上的装饰品。”
―James Kobielus, SiliconANGLE Media, Inc. 数据科学、深度学习及应用开发首席分析师
阅读完整文章 这里。
- “在我看来,数据科学专业人员的成功依赖于成为训练有素的数据科学家,具备在大规模进行数据处理和计算的能力。为此,专业人员必须通过包含工程学、数学科学和社会科学元素的多学科项目的机构投入时间进行持续教育。将大数据转化为有意义的信息始于受过各学科教育、既是数据科学家又是统计学家的熟练专业人员。”
―Devavrat Shah,麻省理工学院电气工程与计算机科学系教授
阅读完整文章 这里。
- “数据科学家没有瓶颈……瓶颈通常是在没有数据文化的公司,这些公司无法将过程切分为正确的步骤。”
―Lutz Finger,Snap 数据科学总监
听完整采访 这里。
- “一旦你拥有一定量的数学/统计学和黑客技能,掌握一个或多个学科的基础远比在你的黑客技能中增加另一种编程语言,或者在你的数学/统计学组合中增加另一种机器学习算法要好……客户宁愿与理解其特定领域的数据科学家 A 合作,也不愿意与需要先学习基础的另一数据科学家 B 合作——即便 B 在数学/统计学/黑客技能上更强。”
―Stephan Kolassa,SAP 瑞士数据科学专家
阅读完整文章 这里。
相关话题
-
思维传播:复杂推理的类比方法……
a-science-definition-humor.html)
掌握数据科学的 42 个步骤
原文:
www.kdnuggets.com/2017/08/42-steps-mastering-data-science.html

如果你对各种数据科学主题的元教程感兴趣,你来对地方了。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 加速你的网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
在这里包含的六个 7 步教程中,前 3 个教程按顺序涵盖了从数据准备到多种机器学习任务的过程,包括理论理解和使用 Python 库的实际应用。
第四个教程主要从“理解”的角度讲解深度学习,而最后两个教程则涵盖了数据库主题:数据科学的 SQL 和理解 NoSQL 数据库。
向道格拉斯·亚当斯致敬,生命、宇宙和一切的答案,让我们来看看掌握数据科学的 42 个步骤。
掌握 Python 数据准备的 7 个步骤
数据准备、清理、预处理、净化、整理。无论你选择哪个术语,它们都指代机器学习、数据挖掘和数据科学领域中一系列相关的数据前处理活动。
但请记住,本文涵盖的是一种特定的数据准备技术,具体情况可能会使用额外的或完全不同的技术,基于要求。你应该发现,本文所持的方法既是正统的也是通用的。
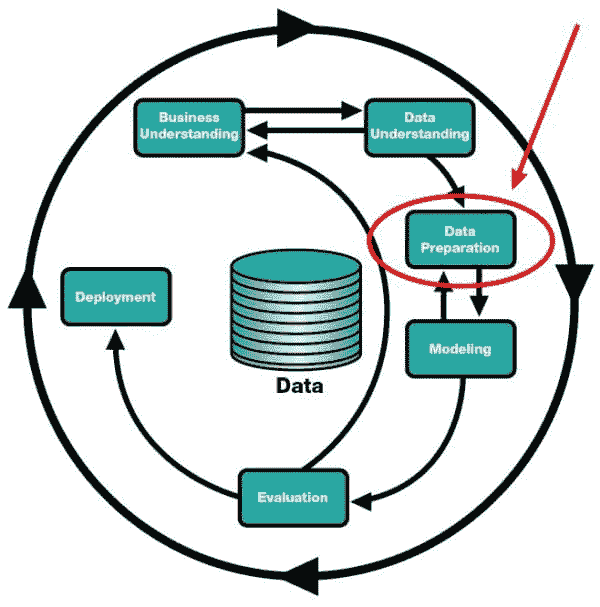
掌握 Python 机器学习的 7 个步骤
本文旨在将新手从对 Python 机器学习的最低知识水平提升到有知识的实践者,整个过程分为 7 步,并且在过程中使用免费提供的材料和资源。本大纲的主要目标是帮助你穿越众多可用的免费选项;确实有很多,但哪些是最好的?哪些相互补充?选择资源的最佳顺序是什么?
掌握 Python 机器学习的更多 7 个步骤
在快速回顾——以及几种新的视角选项之后——这篇文章将更有分类地集中在几个相关的机器学习任务集上。由于这次我们可以安全地跳过基础模块——Python 基础、机器学习基础等——我们将直接进入各种机器学习算法。这次我们也可以沿功能线更好地对教程进行分类。
理解深度学习的 7 个步骤
这组阅读材料和教程旨在为深度神经网络新手提供一个理解这个庞大而复杂主题的路径。虽然我不假设你对神经网络或深度学习有任何真实的理解,但我会假设你对一般机器学习理论和实践有一定的了解。为弥补你在机器学习理论或实践方面的不足,你可以参考最近的 KDnuggets 文章掌握 Python 机器学习的 7 个步骤。由于我们还将看到用 Python 实现的示例,了解一些 Python 语言将会有帮助。入门和复习资源也可以在前述文章中找到。
掌握数据科学 SQL 的 7 个步骤
显然,SQL 在数据科学中很重要。因此,这篇文章旨在利用免费在线资源,将读者从 SQL 新手带到熟练的从业者,时间较短。虽然互联网上有很多这样的资源,但从头到尾绘制出一条路径,使用彼此补充的资源,并不像看起来那么简单。希望这篇文章能在这方面提供帮助。

理解 NoSQL 数据库的 7 个步骤
NoSQL 一词已成为无模式、非关系型数据存储方案的代名词。NoSQL 是一个总称,涵盖了许多不同的技术。这些不同的技术甚至不一定有任何关联,除了 NoSQL 的单一定义特征:它们在本质上不是关系型的;对错与否,结构化查询语言(SQL)多年来已经与关系数据库管理系统混为一谈。

相关:
-
机器学习算法:简明技术概述 – 第一部分
-
深度学习与神经网络入门:初学者的基本概念
-
数据科学入门:初学者的基本概念
更多相关内容
KDnuggets™ 新闻 21:n34,9 月 8 日:你用 Python 读取 Excel 文件吗?有一种快 1000 倍的方法;假设检验解释
特性 | 产品 | 教程 | 观点 | 热门 | 招聘 | 提交博客 | 本周图片
本周在 KDnuggets:你用 Python 读取 Excel 文件吗?有一种快 1000 倍的方法;假设检验解释;数据科学备忘单 2.0;我最近遇到的 6 个酷炫 Python 库;2021 年学习自然语言处理的最佳资源;以及更多内容。
我们新的KDnuggets 顶级博客奖励计划将对顶级博客的作者进行支付 - 查看详细信息。接受转载,但我们更喜欢原创投稿,奖励是转载的 3 倍。
特性
-
**
,作者:Nicolas Vandeput
-
**
,作者:Angelica Lo Duca
-
**
,作者:Aaron Wang
-
我最近遇到的 6 个酷炫 Python 库,作者:Dhilip Subramanian
-
2021 年学习自然语言处理的最佳资源,作者:Aqsa Zafar
 ,作者:Nicolas Vandeput
,作者:Nicolas Vandeput ,作者:Angelica Lo Duca
,作者:Angelica Lo Duca ,作者:Aaron Wang
,作者:Aaron Wang产品,服务
-
未来畅谈系列 | 探索人工智能的未来,作者:Altair
-
电子书:在云中使用第三方数据的实用指南,作者:Roidna
-
验证你的数据和分析技能的热门认证,作者:SAS
教程,概述
-
如何为你的数据科学项目创建令人惊叹的 Web 应用程序,作者:Murallie Thuwarakesh
-
FLAML + Ray Tune 的快速 AutoML,作者:Wu, Wang, Baum, Liaw & Galarnyk
-
使用 Gretel 和 Apache Airflow 构建合成数据管道,作者:Drew Newberry
-
机器学习在移动应用开发中的好处是什么?,作者:Ria Katiyar
-
电子书:使用 R 学习数据科学 - 免费下载,作者:Narayana Murthy
-
关于吴道 2.0 的五个关键事实:迄今为止最大规模的 Transformer 模型,作者:耶稣·罗德里格斯
-
机器学习如何利用线性代数解决数据问题,作者:哈希特·蒂亚吉
观点
-
如何在现实世界中解决机器学习问题,作者:保·拉巴尔塔·巴霍
-
反脆弱性与机器学习,作者:普拉德·乌帕德拉斯塔
-
OpenAI Codex 背后的秘密:5 个你不知道的构建 Codex 的迷人挑战,作者:耶稣·罗德里格斯
热点故事
- 热点故事,8 月 30 日 – 9 月 5 日:你是否用 Python 读取 Excel 文件?有 1000 倍更快的方法;假设检验详解,作者:KDnuggets
职位
-
查看我们最近的人工智能、分析、数据科学、机器学习职位
-
你可以在 KDnuggets 职位页面上免费发布与人工智能、大数据、数据科学或机器学习相关的行业或学术职位,请发邮件 - 详情请见 kdnuggets.com/jobs
本周图片

1. Hugging Face Datasets
Hugging Face 的 Datasets 库本质上是一个包含公共 NLP 数据集的打包集合,提供了一组通用的 API 和数据格式,以及一些辅助功能。
最大的即用型 NLP 数据集中心,具有快速、易用和高效的数据操作工具。
可以轻松通过以下方式安装 Datasets:
pip install datasets
Datasets 进一步描述了两个主要功能:对许多公共数据集的一行数据加载器,以及高效的数据预处理。然而,这种描述忽略了库的另一个主要部分:多个与 NLP 任务相关的内置评估指标。该库还具有其他功能,例如数据集的后端内存管理以及与流行 Python 工具(如 NumPy、Pandas)及主要机器学习平台 TensorFlow 和 PyTorch 的互操作性。
首先来看一下加载数据集:
from datasets import load_dataset, list_datasets
print(f"The Hugging Face datasets library contains {len(list_datasets())} datasets")
squad_dataset = load_dataset('squad')
print(squad_dataset['train'][0])
print(squad_dataset)
The Hugging Face datasets library contains 635 datasets
Reusing dataset squad (/home/matt/.cache/huggingface/datasets/squad/plain_text/1.0.0/4c81550d83a2ac7c7ce23783bd8ff36642800e6633c1f18417fb58c3ff50cdd7)
{'answers': {'answer_start': [515], 'text': ['Saint Bernadette Soubirous']}, 'context': 'Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend "Venite Ad Me Omnes". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858\. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.', 'id': '5733be284776f41900661182', 'question': 'To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?', 'title': 'University_of_Notre_Dame'}
DatasetDict({
train: Dataset({
features: ['id', 'title', 'context', 'question', 'answers'],
num_rows: 87599
})
validation: Dataset({
features: ['id', 'title', 'context', 'question', 'answers'],
num_rows: 10570
})
})
加载一个评估指标同样简单:
from datasets import load_metric, list_metrics
print(f"The Hugging Face datasets library contains {len(list_metrics())} metrics")
print(f"Available metrics are: {list_metrics()}")
# Load a metric
squad_metric = load_metric('squad')
The Hugging Face datasets library contains 19 metrics
Available metrics are: ['accuracy', 'bertscore', 'bleu', 'bleurt', 'comet', 'coval', 'f1', 'gleu', 'glue', 'indic_glue', 'meteor', 'precision', 'recall', 'rouge', 'sacrebleu', 'seqeval', 'squad', 'squad_v2', 'xnli']
你如何使用它们取决于你,但加载一个公开可用的数据集和一个经过验证的评估指标从未如此简单。

2. TextHero
TextHero 在其 Github 仓库中简洁地描述为:
从零到英雄的文本预处理、表示和可视化。
尽管这简要解释了你可能如何使用这个库,但以下对“为什么选择 TextHero?”的回答则进一步阐明了库背后的理由:
以一种非常务实的方式,texthero 只有一个目标:让开发者节省时间。处理文本数据可能很麻烦,而且在大多数情况下,默认管道足以作为起点。总是有时间回过头来改进之前的工作。
现在你知道了为什么可能会使用 TextHero,下面是如何安装它:
pip install texthero
查看 入门指南 可以看到你在几行代码中可以完成的工作。通过下面的 TextHero Github repo 示例,我们将加载一个数据集,清理它,创建一个 TF-IDF 表示,执行主成分分析,并绘制 PCA 的结果。
def text_texthero():
import texthero as hero
import pandas as pd
df = pd.read_csv("https://github.com/jbesomi/texthero/raw/master/dataset/bbcsport.csv")
df['pca'] = (
df['text']
.pipe(hero.clean)
.pipe(hero.tfidf)
.pipe(hero.pca)
)
hero.scatterplot(df, 'pca', color='topic', title="PCA BBC Sport news")
你可以用 TextHero 完成更多的工作,所以请查看其余的 文档,以获取有关数据清理和预处理、可视化、表示、基本 NLP 任务等的更多信息。
3. spaCy
spaCy 专门设计为一个有用的库,旨在实现生产就绪的系统。
spaCy 旨在帮助你进行实际工作——构建真正的产品或获取实际的见解。这个库尊重你的时间,并尽量避免浪费它。它容易安装,API 简单而高效。我们喜欢把 spaCy 视为自然语言处理领域的 Ruby on Rails。

所以当你准备好进行实际工作时,你首先需要安装 spaCy 和至少一个语言模型。在这个示例中,我们将使用它的英文语言模型。库和语言模型的安装可以通过以下命令完成:
pip install spacy python -m spacy download en
要开始使用 spaCy,我们将使用这个示例文本句子:
sample = u"I can't imagine spending $3000 for a single bedroom apartment in N.Y.C."
现在让我们导入 spaCy 和一份英文停用词列表。我们还会加载英文语言模型作为一个 Language 对象(按照 spaCy 的惯例,我们将其称为 'nlp'),然后在我们的示例文本上调用 nlp 对象,它返回一个处理后的 Doc 对象(我们巧妙地称之为 'doc')。
import spacy
from spacy.lang.en.stop_words import STOP_WORDS
nlp = spacy.load('en')
doc = nlp(sample)
所以……就这样?从 spaCy 文档:
即使一个 Doc 已经被处理——例如,分割成单独的词汇并进行注释——它仍然保留原始文本的所有信息,如空白字符。你总是可以获取一个 token 在原始字符串中的偏移量,或者通过连接 tokens 和它们的尾随空白字符来重建原始文本。这样,你在使用 spaCy 处理文本时不会丢失任何信息。
现在,让我们看看这个处理后的示例:
# Print out tokens
print("Tokens:\n=======)
for token in doc:
print(token)
# Identify stop words
print("Stop words:\n===========")
for word in doc:
if word.is_stop == True:
print(word)
# POS tagging
print("POS tagging:\n============")
for token in doc:
print(token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)
# Print out named entities
print("Named entities:\n===============")
for ent in doc.ents:
print(ent.text, ent.start_char, ent.end_char, ent.label_)
Tokens:
=======
I
ca
n't
imagine
spending
$
3000
for
a
single
bedroom
apartment
in
N.Y.C.
Stop words:
===========
ca
for
a
in
POS tagging:
============
I -PRON- PRON PRP nsubj X True False
ca can VERB MD aux xx True True
n't not ADV RB neg x'x False False
imagine imagine VERB VB ROOT xxxx True False
spending spend VERB VBG xcomp xxxx True False
$ $ SYM $ nmod $ False False
3000 3000 NUM CD dobj dddd False False
for for ADP IN prep xxx True True
a a DET DT det x True True
single single ADJ JJ amod xxxx True False
bedroom bedroom NOUN NN compound xxxx True False
apartment apartment NOUN NN pobj xxxx True False
in in ADP IN prep xx True True
N.Y.C. n.y.c. PROPN NNP pobj X.X.X. False False
Named entities:
===============
3000 26 30 MONEY
N.Y.C. 65 71 GPE
spaCy 强大且有明确的观点,可以用于各种 NLP 任务,从预处理到表示再到建模。查看 spaCy 文档,了解你可以从这里开始做什么。

4. Hugging Face Transformers
难以过分强调 Hugging Face Transformers 库在 NLP 实践中的重要性。通过提供访问
从 Github 仓库直接获得的大图景:
最先进的自然语言处理(NLP)用于 PyTorch 和 TensorFlow 2.0
Transformers 提供了数千个预训练模型,用于执行文本分类、信息提取、问答、摘要、翻译、文本生成等任务,支持 100 多种语言。其目标是使尖端 NLP 技术对所有人更易使用。
Transformers 提供 API,快速下载和使用这些预训练模型,针对给定文本进行微调,然后在我们的模型中心与社区分享。同时,每个定义架构的 python 模块可以作为独立模块使用并进行修改,以便进行快速研究实验。
Transformers 由两个最流行的深度学习库 PyTorch 和 TensorFlow 支持,它们之间的集成无缝,允许你使用一个库训练模型,然后用另一个库加载进行推理。
你可以使用Write With Transformer在线测试 Transformer 库,这是该库功能的官方演示。
这个复杂库的安装很简单:
pip install transformers
Transformers 库内容繁多,你可能需要花费很多时间了解它的方方面面。然而,管道 API 的加入允许立即使用模型,几乎无需配置。下面是如何使用 Transformers 管道进行分类的示例(注意,需要安装 TensorFlow 或 PyTorch 才能继续):
from transformers import pipeline
# Allocate a pipeline for sentiment-analysis
classifier = pipeline('sentiment-analysis')
# Classify text
print(classifier('I am a fan of KDnuggets, its useful content, and its helpful editors!'))
[{'label': 'POSITIVE', 'score': 0.9954679012298584}]
荒谬的是,仅此而已。该管道使用预训练模型以及该模型所用的预处理,即使不进行微调,结果也可以非常引人注目。
这是一个第二个管道示例,这次用于问答:
from transformers import pipeline
# Allocate a pipeline for question-answering
question_answerer = pipeline('question-answering')
# Ask a question
answer = question_answerer({
'question': 'Where is KDnuggets headquartered?',
'context': 'KDnuggets was founded in February of 1997 by Gregory Piatetsky in Brookline, Massachusetts.'
})
# Print the answer
print(answer)
{'score': 0.9153624176979065, 'start': 66, 'end': 90, 'answer': 'Brookline, Massachusetts'}
这些是简单的例子,但这些管道比仅仅能够解决琐碎的 KDnuggets 相关任务要强大得多!你可以在这里阅读更多关于管道的内容。
Transformers 使最先进的模型易于使用,并对所有人开放。访问库的Github 仓库开始探索更多。
5. Scattertext
Scattertext 用于创建引人注目的可视化,展示语言在不同文档类型中的差异。来自其 Github 仓库:
一个用于在语料库中查找区分性术语并以交互式 HTML 散点图呈现的工具。对应术语的点被选择性标记,以避免与其他标签或点重叠。
如果你现在还没猜到,安装方法如下:
pip install scattertext
以下示例来自 GitHub 仓库,展示了 2012 年美国政治大会上使用的术语。
2,000 个与政党相关的单词被显示为散点图中的点。它们的 x 轴和 y 轴分别是由共和党和民主党发言者使用的密集排名。
注意,运行示例代码会生成一个 HTML 文件,之后可以在浏览器中查看和交互。
import scattertext as st
df = st.SampleCorpora.ConventionData2012.get_data().assign(
parse=lambda df: df.text.apply(st.whitespace_nlp_with_sentences)
)
corpus = st.CorpusFromParsedDocuments(
df, category_col='party', parsed_col='parse'
).build().get_unigram_corpus().compact(st.AssociationCompactor(2000))
html = st.produce_scattertext_explorer(
corpus,
category='democrat', category_name='Democratic', not_category_name='Republican',
minimum_term_frequency=0, pmi_threshold_coefficient=0,
width_in_pixels=1000, metadata=corpus.get_df()['speaker'],
transform=st.Scalers.dense_rank
)
open('./demo_compact.html', 'w').write(html)
保存的 HTML 文件的结果在查看时(注意这只是下面显示的静态图像,因此不可交互):

Scattertext 具有明确而狭窄的目的,但它做得非常好。其可视化效果绝对美丽,而且同样重要的是,具有深刻的洞察力。访问他们的 GitHub 仓库以获取更多信息和该库的其他用途。
相关:
-
用于深度学习、自然语言处理和计算机视觉的顶级 Python 库
-
5 本极好的自然语言处理书籍
-
最佳 NLP 深度学习课程免费提供
更多相关主题
KDnuggets™ 新闻 20:n42, 11 月 4 日:数据科学、数据可视化与机器学习的顶级 Python 库;掌握时间序列分析
特性 | 新闻 | 教程 | 评论 | 排行榜 | 职位 | 提交博客 | 本周图片
数据科学家可以从 2020 年美国总统选举中学到什么?结果仍未确定,但似乎几个摇摆州的民调高估了民主党票数,就像 2016 年一样。准确预测人类行为很困难,在预测摇摆州的选举结果时,那些在消费者分析中可接受的小误差(例如 48% 而不是 52%)变得尤为重要。记住这些可能性,检查预测假设,尝试使用不同的数据源以减少误差。GP
特性
-
数据科学、数据可视化与机器学习的顶级 Python 库
-
借助专家掌握时间序列分析
-
解释可解释的人工智能:一种两阶段的方法
-
数据科学家的缺失团队
-
数据科学家还是机器学习工程师?哪个职业选择更好?
新闻
-
将敏感数据迁移到云端的七个步骤:数据团队指南
-
与 Stefan Jansen 探讨机器学习在算法交易中的重要性
教程,概述
-
实用统计推理的 10 个原则
-
使用 BERT 进行主题建模
-
微软和谷歌开源了这些基于他们工作的大规模深度学习训练框架
-
如何理解强化学习代理?
-
**
-
处理机器学习中的不平衡数据
-
更新版人工智能简介
-
停止从命令行运行 Jupyter Notebooks

评论
-
当良好的数据分析未能交付你预期的结果
-
克服 AI 中的种族偏见
-
你不再需要使用 Docker
头条新闻、推文
-
头条新闻,10 月 26 日 - 11 月 1 日:如何成为数据科学家:一步步指南;PerceptiLabs — TensorFlow 的 GUI 和可视化 API
-
KDnuggets 顶级推文,10 月 21-27 日:#机器学习可以恢复失落的语言
工作
-
查看我们最近的 AI、分析、数据科学、机器学习职位
-
你可以在 KDnuggets 工作页面上免费发布与 AI、大数据、数据科学或机器学习相关的行业或学术职位,邮件 - 详情请见 kdnuggets.com/jobs
本周图片

更多相关话题
KDnuggets™ 新闻 20:n37,9 月 30 日:Python 中的时间序列分析简介;如何提高机器学习模型准确率
特性 | 新闻 | 教程 | 热点 | 职位 | 提交博客 | 本周图片
了解如何处理 Python 中的时间序列;提高机器学习模型准确率的技巧,从 80%提升到 90%以上;使用 Python 进行地理绘图;让 Python 程序飞快运行的最佳方法;阅读 PyTorch 的完整指南;KDD 2020 最佳论文奖;以及更多内容。
特性
-
**
-
如何将我的机器学习模型的准确率从 80%稳定提升到 90%以上
-
使用 Python 进行地理绘图
-
让 Python 程序飞快运行
-
数据科学家的最完整 PyTorch 指南

新闻
-
数据分析和数据科学是两个不同的领域吗?
-
KDD 2020 庆祝 SIGKDD 最佳论文奖获奖者
-
你戴着“运营分析”帽子效果如何?做这个简单的测验来找出答案。
教程,概述
-
缺失值插补 - 综述
-
Kaggle 以外的国际数据科学/机器学习竞赛替代方案
-
人工智能如何推动天文学的创新
-
窥视黑箱:如何欺骗神经网络
-
成为更好的数据科学家必须修读的在线课程
-
使用 Python 和 Heroku 创建并部署你的第一个 Flask 应用
-
因果推断:免费电子书
-
LinkedIn 的 Pro-ML 架构总结了构建大规模机器学习的最佳实践
-
精准医疗和更好医疗保健的人工智能
热点新闻,推文
-
本周头条,9 月 21-27 日:时间序列分析入门(Python);从零开始的机器学习:免费在线教材
-
本周 KDnuggets 顶尖推文,9 月 16-22 日:63 种#机器学习算法概述
职位
-
查看我们最新的 AI、分析、数据科学、机器学习职位
-
你可以在 KDnuggets 职位页面免费发布与 AI、大数据、数据科学或机器学习相关的行业或学术职位,详情请查看 kdnuggets.com/jobs
本周图片
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
更多相关话题
KDnuggets™ 新闻 20:n36, 9 月 23 日:最新投票:你在 2020 年使用最多的 Python IDE / 编辑器是哪个?;自动化你 Python 项目的每一个方面
特性 | 新闻 | 教程 | 意见 | 精选 | 招聘 | 提交博客 | 本周图片
最新的 KDnuggets 投票询问你在 2020 年使用最多的 Python IDE / 编辑器是哪个。立即投票!
本周还包括:自动化你 Python 项目的每一个方面;Autograd:你未使用的最佳机器学习库?;从零开始用 Python 实现深度学习库;顶级大学的 AI、数据科学、机器学习在线证书/课程;神经网络能展示想象力吗?DeepMind 认为它们可以;以及更多内容。
特性
-
最新投票:你在 2020 年使用最多的 Python IDE / 编辑器是哪个?
-
**
-
**
-
从零开始用 Python 实现深度学习库
-
顶级大学的 AI、数据科学、机器学习在线证书/课程
-
神经网络能展示想象力吗?DeepMind 认为它们可以


新闻
-
Mathworks 深度学习工作流:技巧、窍门和常被遗忘的步骤
-
Coursera 的“人人皆可学机器学习”满足了未被满足的培训需求
教程、概述
-
从零开始的机器学习:免费在线教材
-
用一行代码进行统计和视觉探索性数据分析
-
什么是辛普森悖论以及如何自动检测它
-
生成式和判别式机器学习模型的内部指南
意见
-
预测分析在劳动行业中的潜力
-
我是一名数据科学家,不仅仅是处理你数据的小手
-
一位阿根廷作家和一位匈牙利数学家可以教我们关于机器学习过拟合的知识
-
如何在数据过载时代有效获取消费者洞察
-
不受欢迎的观点 - 数据科学家应该更具端到端能力
热门新闻,推文
-
热门新闻,9 月 14-20 日:自动化你 Python 项目的每个方面;深度学习最重要的思想
-
KDnuggets 推文精选,9 月 9-15 日:你会以每月$49 加入#Google 大学吗?这里有国际上对@Kaggle 的替代方案
职位
-
查看我们最近的 人工智能,分析,数据科学,机器学习职位
-
你可以在 KDnuggets 职位页面上免费发布与人工智能、大数据、数据科学或机器学习相关的行业或学术职位,详情请电邮 - 见 kdnuggets.com/jobs
本周图片

更多相关话题
KDnuggets™ 新闻 20:n29,7 月 29 日:Python 数据预处理简易指南;构建更好的 Spark UI;为程序员提供的计算代数免费课程
特性 | 新闻 | 教程 | 意见 | 头条 | 职位 | 提交博客 | 本周图片
本期内容 - Python 数据预处理简易指南;用更好的 Spark UI 监控 Apache Spark;为程序员提供的计算线性代数免费课程;使用 Snorkel 标注数据;贝叶斯统计;以及更多内容。
特性
-
**
-
监控 Apache Spark - 我们正在构建更好的 Spark UI
-
为程序员提供的计算线性代数免费课程
-
使用 Snorkel 标注数据
-
学习贝叶斯统计的必备资源

新闻
-
为数据科学和 BI 自动化安全与隐私控制 - 网络研讨会
-
NLP 峰会 - 分享你的挑战和工具,加入我们
教程,概述
-
5 本精彩的自然语言处理书籍
-
构建基于内容的图书推荐引擎
-
信号处理中的深度学习:你需要知道的
-
使用 googleAnalyticsR 进行更好的博客分析
-
使用 kdb+进行强大的 CSV 处理
-
Docker 上的 Apache Spark 集群
意见
-
深度对自注意力有用吗?
-
概述推荐系统
-
为什么要把 Scikit-learn 放到浏览器中?
-
应对 2020 年数据隐私和安全法律的 10 个步骤
头条新闻,推文
-
头条新闻,7 月 20-26 日:数据科学 MOOCs 过于肤浅
-
KDnuggets 精选推文,7 月 15-21 日:超棒的#机器学习和#AI 课程大列表
职位
-
查看我们最近的 AI、分析、数据科学、机器学习职位
-
你可以在 KDnuggets 工作页面上发布一个与 AI、大数据、数据科学或机器学习相关的行业或学术职位的免费短期招聘信息,电子邮件 - 详情请见 kdnuggets.com/jobs
本周图像
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 部门
主题相关内容
解释性:破解黑箱,第二部分
评论
由Manu Joseph,问题解决者、从业者、Thoucentric Analytics 的研究员。
在上一篇文章中,我们定义了解释性是什么,并查看了一些可解释的模型以及它们的怪癖和“陷阱”。现在,让我们深入探讨事后解释技术,这在模型本身不透明时非常有用。这与大多数实际应用场景相呼应,因为无论我们喜欢与否,黑箱模型通常能提供更好的性能。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的 IT 组织
数据集
对于本练习,我选择了成人数据集,即人口普查收入数据集。人口普查收入是一个相当受欢迎的数据集,包含年龄、职业等人口统计信息,以及一个列指示该人的收入是否超过 50k。我们使用这一列进行随机森林的二分类。选择随机森林的原因有两个:
-
随机森林是最常用的算法之一,与梯度提升树一样。它们都属于决策树的集成算法家族。
-
有一些特定于基于树的模型的技术,我想讨论。

人口普查收入数据集概述
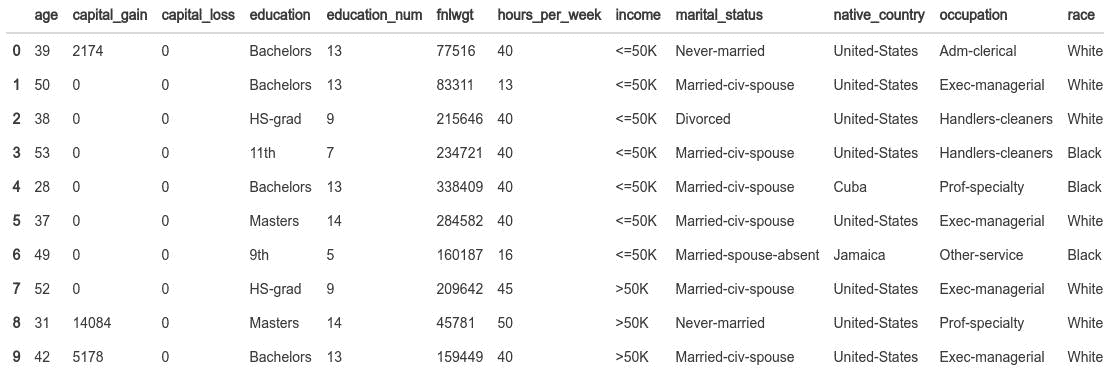
人口普查收入数据集中的示例数据
事后解释
现在让我们来看一下事后解释技术,以理解我们的黑箱模型。在接下来的博客中,讨论将基于机器学习模型(而非深度学习)以及结构化数据。虽然这里许多方法是模型无关的,但由于解释深度学习模型,尤其是非结构化数据中的方法众多,我们将其排除在当前范围之外。(也许另一个博客,另一天。)
数据预处理
-
将目标变量编码为数值变量
-
处理了缺失值
-
通过合并一些值将婚姻状况转换为二进制变量。
-
去除了教育,因为教育年限提供了相同的信息,但以数字格式表示。
-
去除了资本增益和资本损失,因为它们没有提供任何信息。超过 90% 的值为零。
-
去除了native_country,因为其基数较高且偏向美国。
-
去除了关系,因为与婚姻状况有较多重叠。
随机森林算法在数据上进行调优和训练,性能达到 83.58%。考虑到最佳得分在 78%到 86%之间,这个得分还算不错,具体取决于你如何建模和测试。但对于我们的目的来说,模型性能已经足够。
1) 杂质减少的平均值
这是解释树模型及其集成的最流行方法。这在很大程度上归功于 Sci-Kit Learn,它提供了易于使用的实现。拟合随机森林或梯度提升模型并绘制“特征重要性”已经成为数据科学家中最常用且被滥用的技术。
特征的平均杂质减少重要性是通过测量特征在创建决策树时减少不确定性(分类器)或方差(回归器)的效果来计算的,适用于任何集成决策树方法(如随机森林、梯度提升等)。
该技术的优点是:
-
获取特征重要性的快速简便方法
-
在 Sci-kit Learn 和 R 的决策树实现中现成可用。
-
向外行解释这一点相当直观。
算法
-
在树的构建过程中,每当进行拆分时,我们会记录是哪个特征进行了拆分,拆分前后的基尼杂质是什么,以及它影响了多少样本。
-
在树构建过程结束时,计算每个特征在基尼指数中所占的总增益。
-
在随机森林或梯度提升树的情况下,我们将这个得分在所有树中取平均。
实现
Sci-kit Learn 默认在树模型的“特征重要性”中实现了这一点。因此,检索并绘制前 25 个特征非常简单。
feat_imp = pd.DataFrame({'features': X_train.columns.tolist(), "mean_decrease_impurity": rf.feature_importances_}).sort_values('mean_decrease_impurity', ascending=False)
feat_imp = feat_imp.head(25)
feat_imp.iplot(kind='bar',
y='mean_decrease_impurity',
x='features',
yTitle='Mean Decrease Impurity',
xTitle='Features',
title='Mean Decrease Impurity',
)
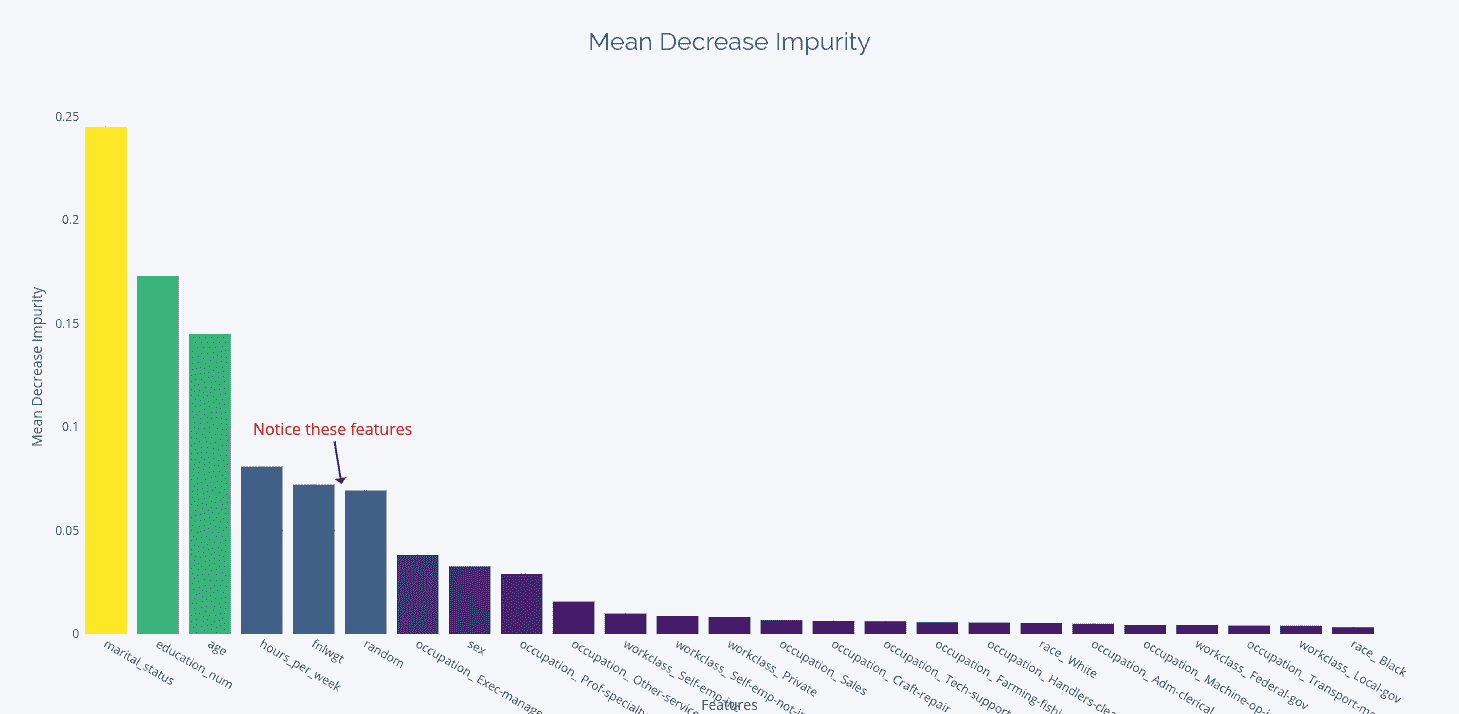
我们还可以检索并绘制每棵树的杂质减少的均值作为箱形图。
# get the feature importances from each tree and then visualize the
# distributions as boxplots
all_feat_imp_df = pd.DataFrame(data=[tree.feature_importances_ for tree in
rf],
columns=X_train.columns)
order_column = all_feat_imp_df.mean(axis=0).sort_values(ascending=False).index.tolist()
all_feat_imp_df[order_column[:25]].iplot(kind='box', xTitle = 'Features', yTitle='Mean Decease Impurity')
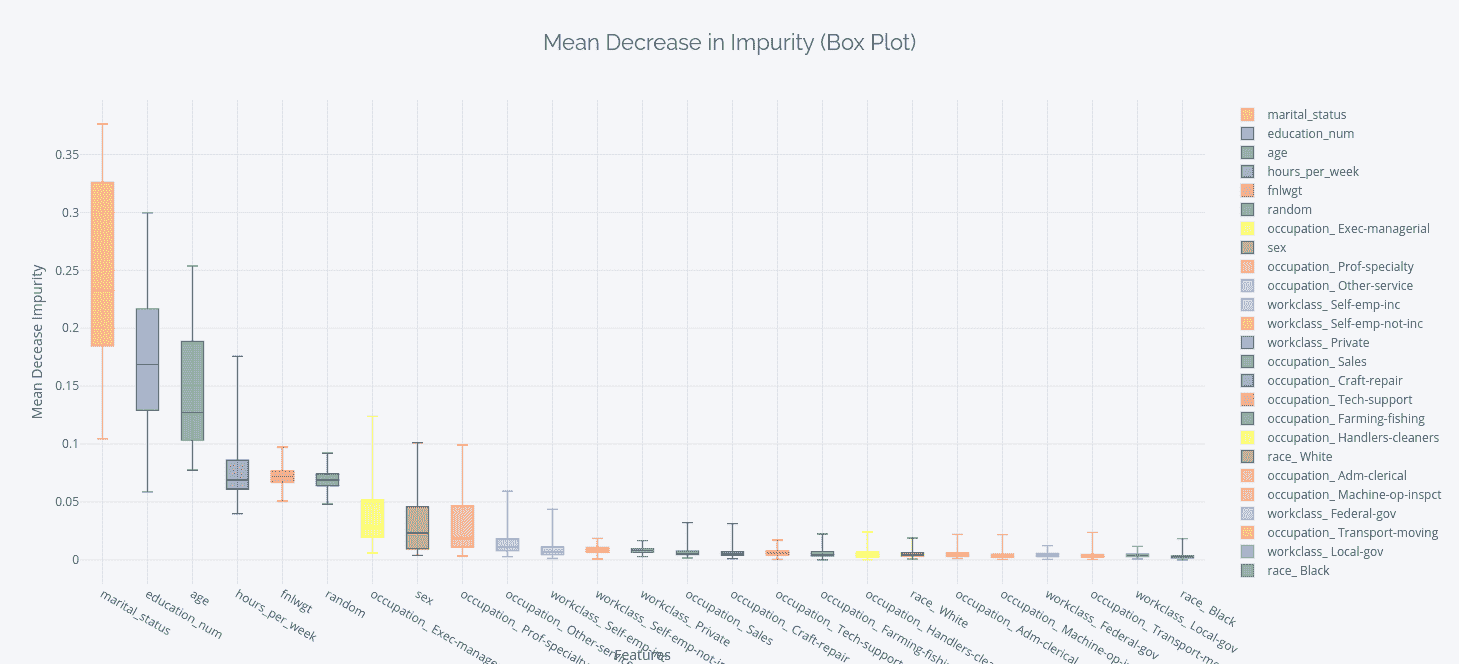
解释
-
排名前 4 的特征是婚姻状况、教育年限、年龄和工作时长。这完全合乎逻辑,因为它们与收入的关系密切。
-
注意到其中的两个特征 fnlwgt 和 random 吗?它们比一个人的职业更重要吗?
-
另一个警告是,我们将 one-hot 特征视为单独的特征,这可能会影响为什么职业特征排名低于随机特征。处理 one-hot 特征时查看特征重要性是一个完全不同的话题。
让我们来看看 fnlwgt 和随机是什么。
-
关于 fnlwgt 数据集的描述是关于人口普查机构如何使用采样来创建任何指定的社会经济特征的“加权统计”的冗长而复杂的描述。简而言之,它是一个采样权重,与个人收入无关。
-
而随机正如其名。在拟合模型之前,我制作了一列随机数字,并将其称为随机。
现在,这些特征不可能比其他特征,如职业、工作类别、性别等更重要。如果是这样的话,那就有问题了。
包中的小丑即“得逞”
当然……确实有。均值减少 impurity 测量是一个有偏的特征重要性测量。它偏向于连续特征和高基数特征。在 2007 年,Strobl et al [1] 也在 随机森林变量重要性测量中的偏差:插图、来源和解决方案 中指出,“Breiman 原始随机森林方法的变量重要性测量……在潜在预测变量在测量尺度或类别数量上有所不同的情况下是不可靠的。”
让我们尝试理解为什么它有偏差。记得如何计算 impurity 的均值减少吗?每当一个节点在某个特征上被拆分时,gini 指数的减少量会被记录下来。当一个特征是连续的或具有高基数时,这个特征可能会被拆分多于其他特征。这会夸大那个特定特征的贡献。我们的两个罪魁祸首特征有什么共同点——它们都是连续变量。
2) 删除列重要性即留一个协变量法 (LOOC)
删除列特征重要性是另一种直观的方法来查看特征重要性。顾名思义,这是一种迭代地删除一个特征并计算性能差异的方法。
该技术的优点包括:
-
提供了每个特征预测能力的相当准确的图像。
-
查看特征重要性的一个直观方式
-
模型不可知。可以应用于任何模型。
-
由于其计算方式,它会自动考虑模型中的所有交互。如果一个特征中的信息被破坏,它所有的交互也会被破坏。
算法
-
使用你训练好的模型参数,在 OOB 样本上计算你选择的指标。你可以使用交叉验证来获得得分。这是你的基准线。
-
现在,从你的训练集里每次删除一列,然后重新训练模型(使用相同的参数和随机状态),并计算 OOB 得分。
-
重要性 = OOB 得分 – 基线
实施
def dropcol_importances(rf, X_train, y_train, cv = 3):
rf_ = clone(rf)
rf_.random_state = 42
baseline = cross_val_score(rf_, X_train, y_train, scoring='accuracy', cv=cv)
imp = []
for col in X_train.columns:
X = X_train.drop(col, axis=1)
rf_ = clone(rf)
rf_.random_state = 42
oob = cross_val_score(rf_, X, y_train, scoring='accuracy', cv=cv)
imp.append(baseline - oob)
imp = np.array(imp)
importance = pd.DataFrame(
imp, index=X_train.columns)
importance.columns = ["cv_{}".format(i) for i in range(cv)]
return importance
让我们进行 50 次交叉验证来估计我们的 OOB 得分。(我知道这有些过头,但让我们这样做以增加我们的箱线图样本)像以前一样,我们绘制了准确率的均值减少和箱线图,以了解交叉验证试验中的分布。
drop_col_imp = dropcol_importances(rf, X_train, y_train, cv=50)
drop_col_importance = pd.DataFrame({'features': X_train.columns.tolist(), "drop_col_importance": drop_col_imp.mean(axis=1).values}).sort_values('drop_col_importance', ascending=False)
drop_col_importance = drop_col_importance.head(25)
drop_col_importance.iplot(kind='bar',
y='drop_col_importance',
x='features',
yTitle='Drop Column Importance',
xTitle='Features',
title='Drop Column Importances',
)
all_feat_imp_df = drop_col_imp.T
order_column = all_feat_imp_df.mean(axis=0).sort_values(ascending=False).index.tolist()
all_feat_imp_df[order_column[:25]].iplot(kind='box', xTitle = 'Features', yTitle='Drop Column Importance')
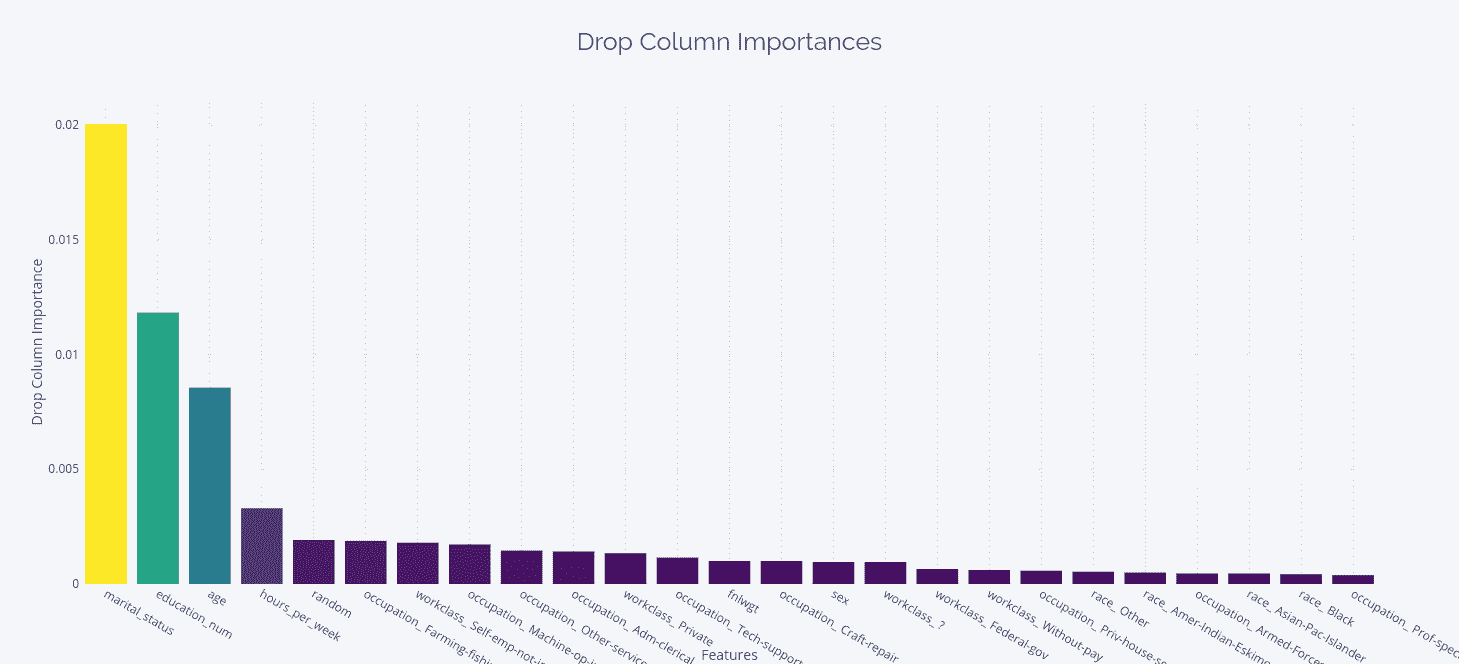
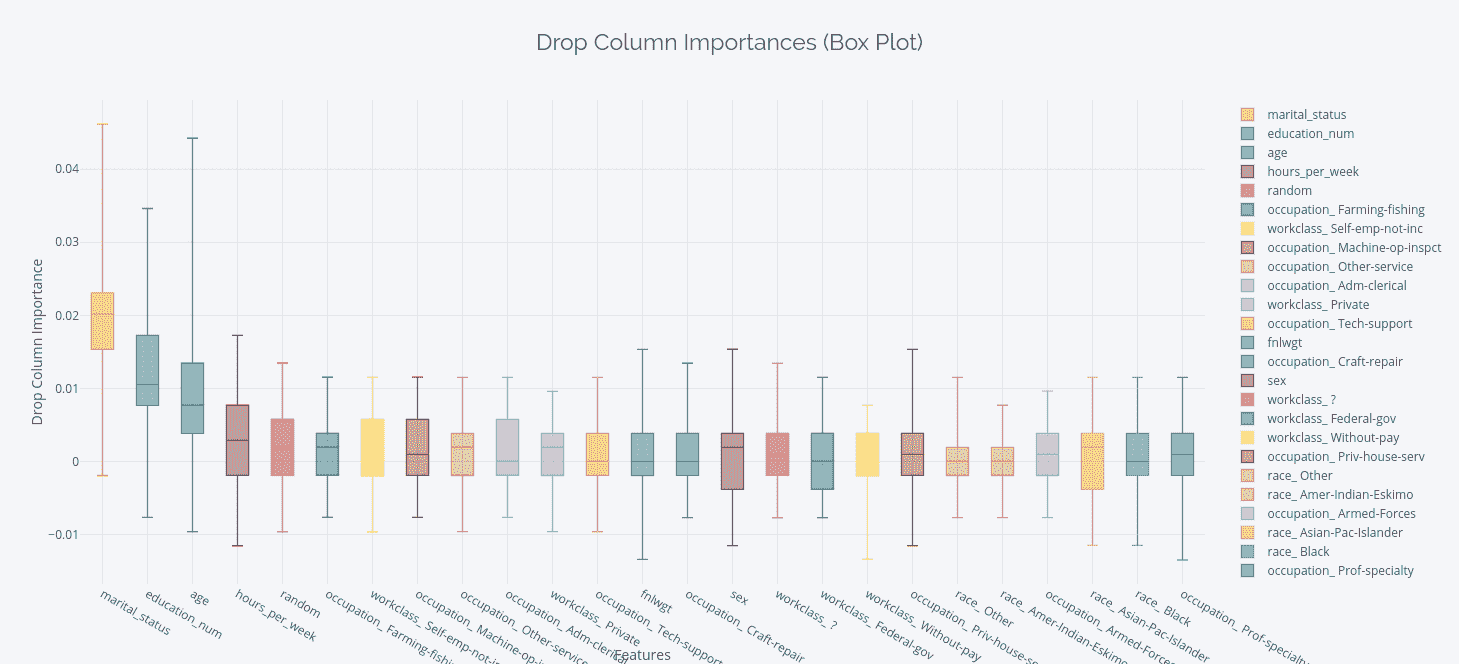
解释
-
前四个特征仍然是marital status、education_num、age和hours_worked。
-
fnlwgt被排到列表的后面,现在排在一些 one-hot 编码的职业之后。
-
random仍然保持在高排名,紧跟在hours_worked之后
正如预期的那样,fnlwgt 的重要性远不如我们从“均值减少不纯度”中得出的结论。random的高排名让我有些困惑,我重新进行了重要性计算,将所有的 one-hot 特征视为一个特征。也就是说,删除所有的职业列,检查职业的预测能力。当我这样做时,我可以看到random和fnlwgt的排名低于occupation和workclass。为了避免让帖子变得更长,我们将这项调查留到另一日。
那么,我们是否得到了完美的解决方案?结果与“均值减少不纯度”一致,逻辑自洽,并且可以应用于任何模型。
包中的黑马
这里的关键是计算的复杂性。要进行这种重要性计算,你必须多次训练模型,每个特征训练一次,并对所需的交叉验证循环重复操作。即使你的模型在一分钟内完成训练,计算所需的时间也会随着特征数量的增加而爆炸。举个例子,我用 36 个特征和 50 次交叉验证循环计算特征重要性花了2 小时 44 分钟(当然,使用并行处理可以改善这一点,但你明白我的意思)。如果你的模型需要两天时间来训练,那么你可以忘记这种技术。
我对这种方法的另一个担忧是,由于我们每次都用新的特征集重新训练模型,因此我们并没有进行公平的比较。我们删除一列并再次训练模型,它会找到另一种方式来推导相同的信息(如果可以的话),当存在共线特征时,这种情况会被放大。因此,当我们进行调查时,我们混淆了特征的预测能力和模型如何配置自身。
3) 排列重要性
排列特征重要性被定义为当单个特征值随机打乱时模型分数的下降 [2]。这种技术测量如果你打乱特征向量,性能的差异。关键点在于,如果模型性能下降则该特征很重要。
这种技术的 优点 包括:
-
直观易懂。打乱特征信息后,性能下降多少?
-
模型无关。尽管这种方法最初是由 Breiman 为随机森林开发的,但很快被适应到一个模型无关的框架中。
-
计算方式会自动考虑模型中的所有交互。如果一个特征中的信息被破坏,那么所有与之相关的交互也会被破坏。
-
模型不需要重新训练,因此我们节省了计算资源。
算法
-
使用指标、训练模型、特征矩阵和目标向量计算基线分数。
-
对于特征矩阵中的每个特征,复制特征矩阵。
-
打乱特征列,通过训练模型进行预测,并使用指标计算性能。
-
重要性 = 基线 – 分数
-
为了统计稳定性,重复 N 次,并计算试验的平均重要性。
实现
排列重要性在 Python 的至少三个库中实现—— ELI5, mlxtend,以及在 Sci-kit Learn 的开发分支 中。我选择了 mlxtend 版本纯粹是因为便利。根据 Strobl et al. [3],“原始 [排列] 重要性… 具有更好的统计特性。” 而不是通过标准差来规范化重要性值。我已经检查了 mlxtend 和 Sci-kit Learn 的源代码,它们没有对其进行规范化。
from mlxtend.evaluate import feature_importance_permutation
#This takes sometime. You can reduce this number to make the process faster
num_rounds = 50
imp_vals, all_trials = feature_importance_permutation(
predict_method=rf.predict,
X=X_test.values,
y=y_test.values,
metric='accuracy',
num_rounds=num_rounds,
seed=1)
permutation_importance = pd.DataFrame({'features': X_train.columns.tolist(), "permutation_importance": imp_vals}).sort_values('permutation_importance', ascending=False)
permutation_importance = permutation_importance.head(25)
permutation_importance.iplot(kind='bar',
y='permutation_importance',
x='features',
yTitle='Permutation Importance',
xTitle='Features',
title='Permutation Importances',
)
我们还绘制了所有试验的箱型图,以了解偏差情况。
all_feat_imp_df = pd.DataFrame(data=np.transpose(all_trials),
columns=X_train.columns, index = range(0,num_rounds))
order_column = all_feat_imp_df.mean(axis=0).sort_values(ascending=False).index.tolist()
all_feat_imp_df[order_column[:25]].iplot(kind='box', xTitle = 'Features', yTitle='Permutation Importance')
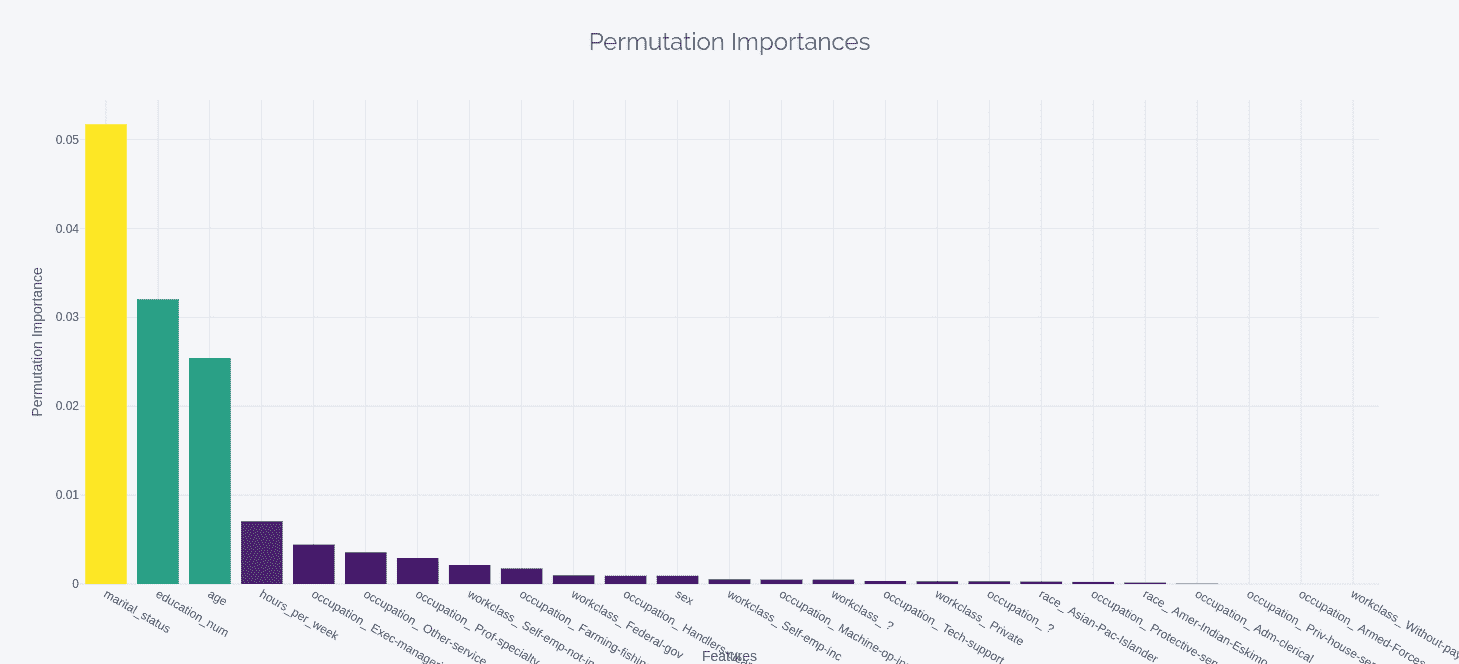
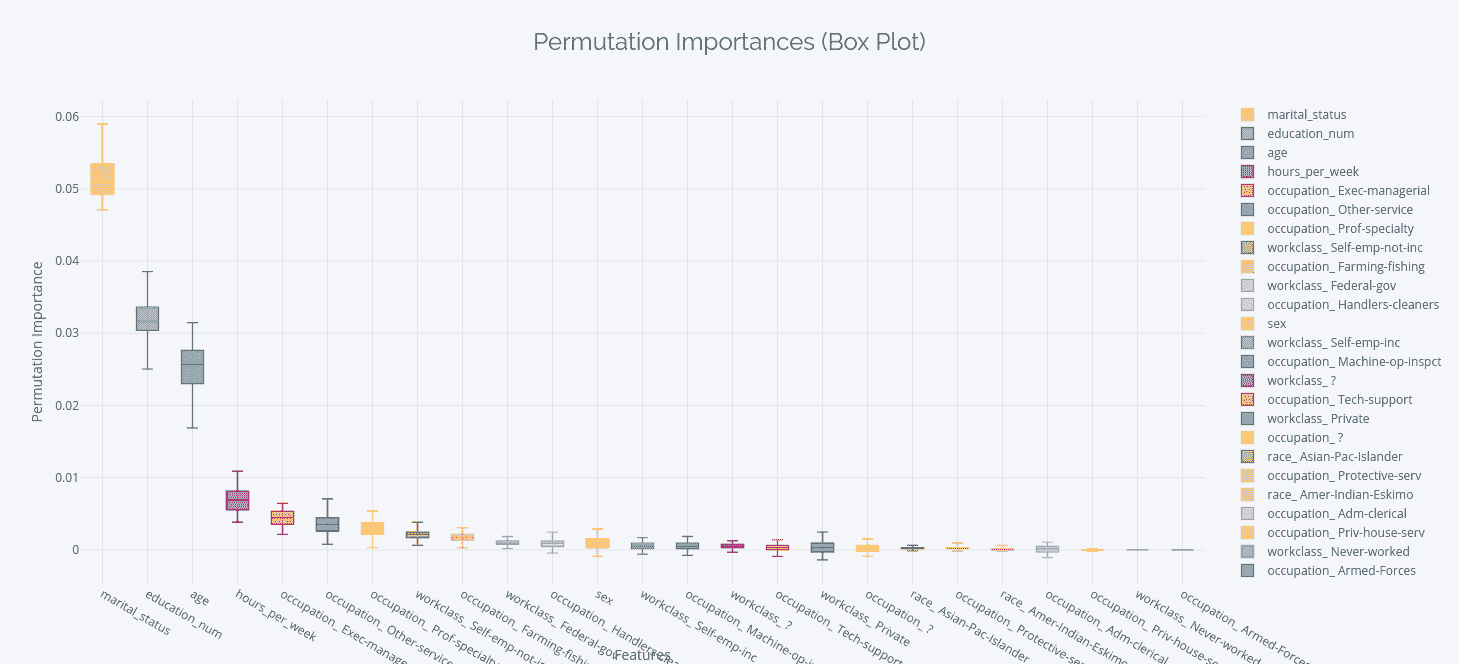
解释
-
前 4 名保持不变,但前三个(marital_status, education, age)在排列重要性中更加突出。
-
fnlwgt 和 random 连前 25 名都未能进入。
-
成为 Exec Manager 或 Prof-speciality 与是否能赚取超过 50k 的收入关系密切。
-
总的来说,这与我们对过程的心理模型相吻合。
特征重要性领域一切都很美好吗?我们是否找到了最好的方式来解释模型用于预测的特征?
包中的小丑
从生活中我们知道,任何事物都不完美,这项技术也不例外。它的致命弱点是特征之间的相关性。就像删除列重要性一样,这项技术也受到特征间相关性影响。Strobl et al. 在《随机森林中的条件变量重要性》中[3] 表示“置换重要性高估了相关预测变量的重要性”。特别是在树的集成中,如果有两个相关变量,某些树可能选择特征 A,而其他树可能选择特征 B。在进行此分析时,如果没有特征 A,那么选择特征 B 的树会表现良好并保持高性能,反之亦然。这将导致相关特征 A 和 B 的重要性都被夸大。
这项技术的另一个缺点是其核心思想在于置换特征。但这本质上是我们无法控制的随机性。因此,结果可能会有很大差异。虽然我们在这里没有看到,但如果箱型图显示特征在各次试验中的重要性变化很大,我会在解释时保持警惕。
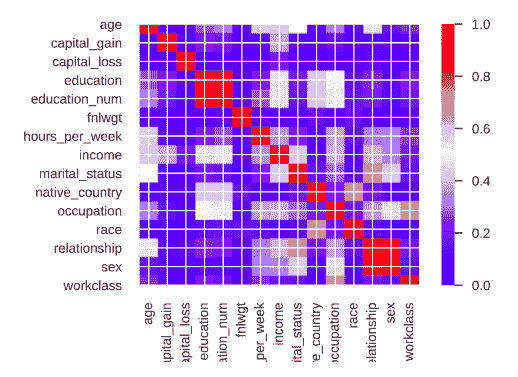
相关系数 [7](内置于 pandas profiling 中,也考虑了分类变量)。
这项技术还有另一个缺点,在我看来,这是最令人担忧的。Giles Hooker 等人[6] 说,“当训练集中的特征表现出统计依赖性时,置换方法在应用于原始模型时可能会非常误导。”
让我们考虑职业和教育。我们可以从两个角度来理解这一点:
-
逻辑:如果你仔细考虑,职业和教育之间有明确的依赖性。如果你有足够的教育,你能找到的工作也就有限,从统计学上看,你可以在它们之间画出相似之处。因此,如果我们对这些列中的任何一列进行置换,就会创建一些没有意义的特征组合。一个教育为10 年级和职业为专业的人并没有太大意义,对吧?因此,当我们评估模型时,我们评估的是像这样的无意义情况,这会混淆我们用来评估特征重要性的指标。
-
数学:职业和教育之间有很强的统计依赖性(我们可以从上面的相关性图中看到)。因此,当我们对这些特征中的任何一个进行置换时,我们实际上是在强迫模型探索高维特征空间中未见过的子空间。这迫使模型进行外推,而这种外推是一个显著的误差来源。
Giles Hooker 等人 [6] 建议使用结合了 LOOC 和置换方法的替代方法,但所有这些替代方法在计算上更为密集,并且没有强有力的理论保证其具有更好的统计性质。
处理相关特征
识别出高度相关的特征后,有两种处理相关特征的方法。
-
将高度相关的变量分组,并仅从该组中评估一个特征作为该组的代表。
-
当你置换列时,一次试验中要置换整个特征组。
注意:第二种方法与我建议处理一热变量的方法相同。
附注(训练集或验证集)
在讨论 Drop Column 重要性和置换重要性时,你应该想到一个问题。我们将测试/验证集传递给这些方法来计算重要性。为什么不使用训练集呢?
这是应用某些方法的灰色地带。这里没有对错之分,因为两者都有利弊。在《可解释机器学习》中,Christoph Molnar 为训练集和验证集的使用都提出了论据。
对于测试/验证数据的情况是不言而喻的。由于我们不通过训练集中的误差来评估模型,因此也不能通过训练集上的表现来评估特征的重要性(尤其是因为重要性本质上与误差相关)。
对于训练数据的情况是违反直觉的。但如果你考虑一下,你会发现我们想要测量的是模型如何使用特征。还有什么比训练集更适合判断这一点的数据呢?另一个显而易见的问题是,我们理想情况下会在所有可用数据上训练模型,在这种理想情况下,不会有测试或验证数据来检查性能。在《可解释机器学习》 [5] 中,第 5.5.2 节对此问题进行了详细讨论,甚至提供了一个过拟合 SVM 的合成示例。
这归结于你是否想知道模型依赖哪些特征来进行预测,还是每个特征在未见数据上的预测能力。例如,如果你在特征选择的背景下评估特征重要性,任何情况下都不应使用测试数据(因为这会使你的特征选择过度拟合测试数据)。
4) 部分依赖图(PDP)和个体条件期望图(ICE)
我们到目前为止审查的所有技术都关注于不同特征的相对重要性。现在让我们稍微改变方向,看看一些技术,这些技术探索了某个特征如何与目标变量互动。
部分依赖图和个体条件期望图帮助我们理解特征与目标之间的函数关系。它们是给定变量(或多个变量)对结果的边际效应的图形可视化。Friedman(2001)在他的开创性论文贪婪函数逼近:一种梯度提升机器中介绍了这一技术。
部分依赖图显示了平均效应,而 ICE 图显示了单个观察的函数关系。PD 图显示平均效应,而 ICE 图显示效应的离散性或异质性。
这一技术的优点包括:
-
计算非常直观,并且容易用通俗的语言解释。
-
我们可以理解特征或特征组合与目标变量之间的关系,即是否是线性、单调、指数等。
-
它们计算和实现起来很简单。
-
它们提供了因果解释,而不是特征重要性风格的解释。但我们需要记住的是,模型对世界的因果解释与现实世界的因果解释之间的差异。
算法
让我们考虑一个简单的情况,即我们绘制单个特征x的 PD 图,包含唯一值 
-
对于
-
复制训练数据并用
 替换原始的 x 值。
替换原始的 x 值。 -
使用训练好的模型生成修改后的整个训练数据的预测值。
-
将所有关于
 的预测存储在类似地图的数据结构中。
的预测存储在类似地图的数据结构中。
-
-
对于 PD 图:
-
计算每个
的平均预测值。
-
绘制对 }")。
-
-
对于 ICE 图:
- 绘制所有对
_n} :where:n\epsilon{1, 2, ...N}")。N 是训练集中的总观察数。
- 绘制所有对
-
在实践中,为了节省计算时间,我们定义一个连续变量的区间网格,而不是取特征的所有可能值。
-
对于分类变量,这一定义也适用,但我们不会在这里定义网格。相反,我们取所有唯一的分类值(或与分类特征相关的所有独热编码变量),并使用相同的方法计算 ICE 和 PD 图。
-
如果过程对你仍然不清楚,我建议查看这个medium post(由 PDPbox 的作者编写,这是一个用于绘制 PD 图的 python 库)。
 替换原始的 x 值。
替换原始的 x 值。 _n} :where:n\epsilon{1, 2, ...N}")。N 是训练集中的总观察数。
_n} :where:n\epsilon{1, 2, ...N}")。N 是训练集中的总观察数。实施
我发现了在PDPbox、skater和Sci-kit Learn中实现的 PD 图。以及在PDPbox、pyCEbox和skater中的 ICE 图。在这些工具中,我发现 PDPbox 是最精致的,它们还支持 2 变量 PDP 图。
from pdpbox import pdp, info_plots
pdp_age = pdp.pdp_isolate(
model=rf, dataset=X_train, model_features=X_train.columns, feature='age'
)
#PDP Plot
fig, axes = pdp.pdp_plot(pdp_age, 'Age', plot_lines=False, center=False, frac_to_plot=0.5, plot_pts_dist=True,x_quantile=True, show_percentile=True)
#ICE Plot
fig, axes = pdp.pdp_plot(pdp_age, 'Age', plot_lines=True, center=False, frac_to_plot=0.5, plot_pts_dist=True,x_quantile=True, show_percentile=True)
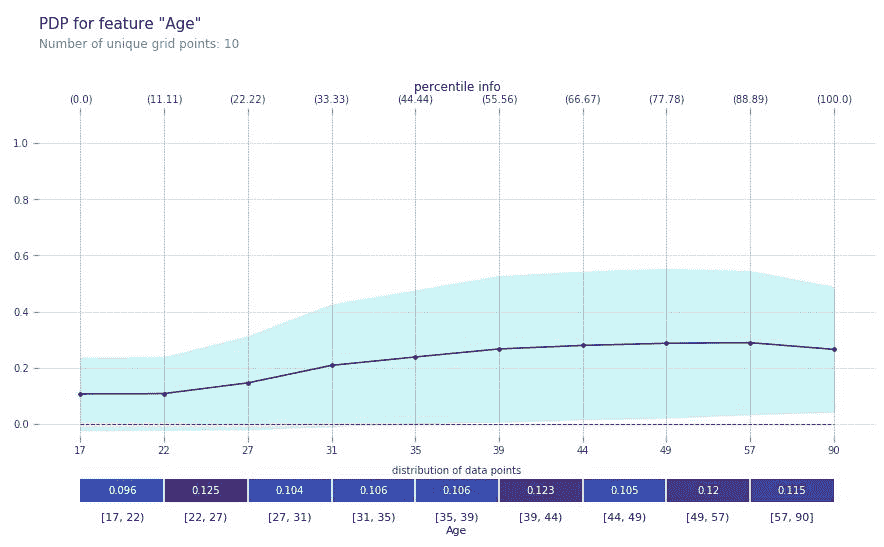
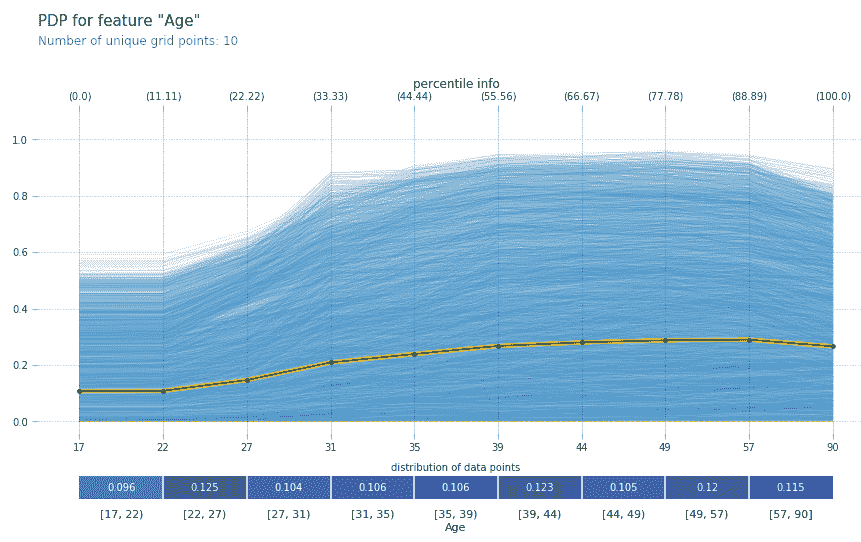
年龄的 ICE 图。
让我花点时间来解释这个图。x 轴显示了你想要理解的特征的值,即年龄。y 轴显示了预测值。在分类的情况下,它是预测概率,而在回归的情况下,它是实际值预测。底部的条形图表示训练数据点在不同分位数的分布。它帮助我们评估推断的好坏。在点数很少的地方,模型看到的例子较少,解释可能会很棘手。PD 图中的单一线条显示了特征与目标之间的平均功能关系。ICE 图中的所有线条显示了训练数据中的异质性,即训练数据中所有观察值如何随年龄的不同值变化。
解释
-
年龄与一个人的收入能力有着基本单调的关系。一个人越老,收入超过 50k 的可能性越大。
-
ICE 图显示了很多离散度。但所有的离散度都表现出我们在 PD 图中看到的相同行为。
-
训练观察在不同分位数之间相当平衡。
现在,我们还可以用一个分类特征,如教育,来举例说明。PDPbox 有一个很好的功能,允许你传递一个特征列表作为输入,它会将这些特征视为分类特征来计算 PDP。
# All the one-hot variables for the occupation feature
occupation_features = ['occupation_ ?', 'occupation_ Adm-clerical', 'occupation_ Armed-Forces', 'occupation_ Craft-repair', 'occupation_ Exec-managerial', 'occupation_ Farming-fishing', 'occupation_ Handlers-cleaners', 'occupation_ Machine-op-inspct', 'occupation_ Other-service', 'occupation_ Priv-house-serv', 'occupation_ Prof-specialty', 'occupation_ Protective-serv', 'occupation_ Sales', 'occupation_ Tech-support', 'occupation_ Transport-moving']
#Notice we are passing the list of features as a list with the feature parameter
pdp_occupation = pdp.pdp_isolate(
model=rf, dataset=X_train, model_features=X_train.columns,
feature=occupation_features
)
#PDP
fig, axes = pdp.pdp_plot(pdp_occupation, 'Occupation', center = False, plot_pts_dist=True)
#Processing the plot for aesthetics
_ = axes['pdp_ax']['_pdp_ax'].set_xticklabels([col.replace("occupation_","") for col in occupation_features])
axes['pdp_ax']['_pdp_ax'].tick_params(axis='x', rotation=45)
bounds = axes['pdp_ax']['_count_ax'].get_position().bounds
axes['pdp_ax']['_count_ax'].set_position([bounds[0], 0, bounds[2], bounds[3]])
_ = axes['pdp_ax']['_count_ax'].set_xticklabels([])
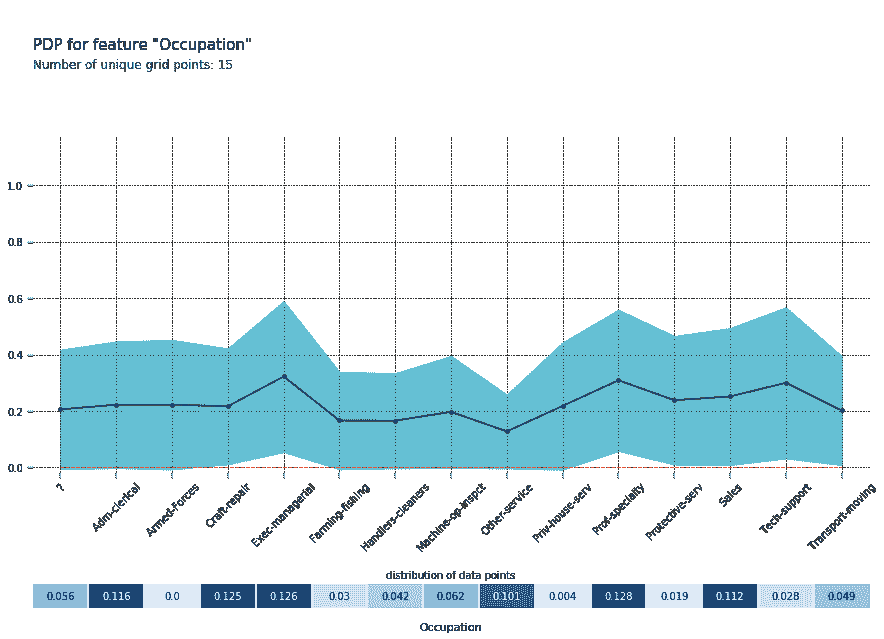
解释
-
大多数职业对你的收入影响非常有限。
-
从中突出的有,Exec-managerial、Prof-speciality 和 Tech Support。
-
但是,从分布来看,我们知道 Tech-support 的训练示例非常少,因此我们对此持保留态度。
多个特征之间的交互
理论上,可以为任意数量的特征绘制 PD 图以展示它们的交互效应。但实际上,我们最多只能做两个,最多三个。让我们看看两个连续特征年龄和教育之间的交互图(教育和年龄并不真正连续,但为了缺乏更好的例子我们选择它们)。
你可以用两种方式绘制两个特征之间的 PD 图。这里有三个维度,特征值 1,特征值 2 和目标预测。我们可以绘制 3D 图或将第三维度表现为颜色的 2D 图。我更喜欢 2D 图,因为我认为它比 3D 图更清晰,3D 图需要查看 3D 形状以推断关系。PDPbox 实现了 2D 交互图,既有轮廓图也有网格图。轮廓图最适合连续特征,网格图适合分类特征。
# Age and Education
inter1 = pdp.pdp_interact(
model=rf, dataset=X_train, model_features=X_train.columns, features=['age', 'education_num']
)
fig, axes = pdp.pdp_interact_plot(
pdp_interact_out=inter1, feature_names=['age', 'education_num'], plot_type='contour', x_quantile=False, plot_pdp=False
)
axes['pdp_inter_ax'].set_yticklabels([edu_map.get(col) for col in axes['pdp_inter_ax'].get_yticks()])
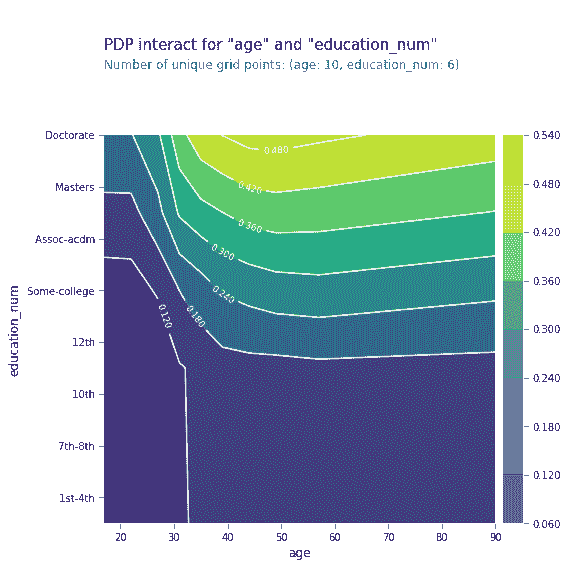
解释
- 即使我们观察到年龄与单独看时的单调关系,现在我们知道这并非普遍。例如,看看12教育水平右侧的轮廓线。与一些大学及以上的线相比,它相当平坦。这实际上表明,你获得超过 50k 的概率不仅随着年龄增长而增加,还与教育有关。大学学位确保了你随着年龄的增长增加收入潜力。
这也是调查算法中的偏见(伦理类型)非常有用的技术。假设我们想查看性别维度中的算法偏见。
#PDP Sex
pdp_sex = pdp.pdp_isolate(
model=rf, dataset=X_train, model_features=X_train.columns, feature='sex'
)
fig, axes = pdp.pdp_plot(pdp_sex, 'Sex', center=False, plot_pts_dist=True)
_ = axes['pdp_ax']['_pdp_ax'].set_xticklabels(sex_le.inverse_transform(axes['pdp_ax']['_pdp_ax'].get_xticks()))
# marital_status and sex
inter1 = pdp.pdp_interact(
model=rf, dataset=X_train, model_features=X_train.columns, features=['marital_status', 'sex']
)
fig, axes = pdp.pdp_interact_plot(
pdp_interact_out=inter1, feature_names=['marital_status', 'sex'], plot_type='grid', x_quantile=False, plot_pdp=False
)
axes['pdp_inter_ax'].set_xticklabels(marital_le.inverse_transform(axes['pdp_inter_ax'].get_xticks()))
axes['pdp_inter_ax'].set_yticklabels(sex_le.inverse_transform(axes['pdp_inter_ax'].get_yticks()))
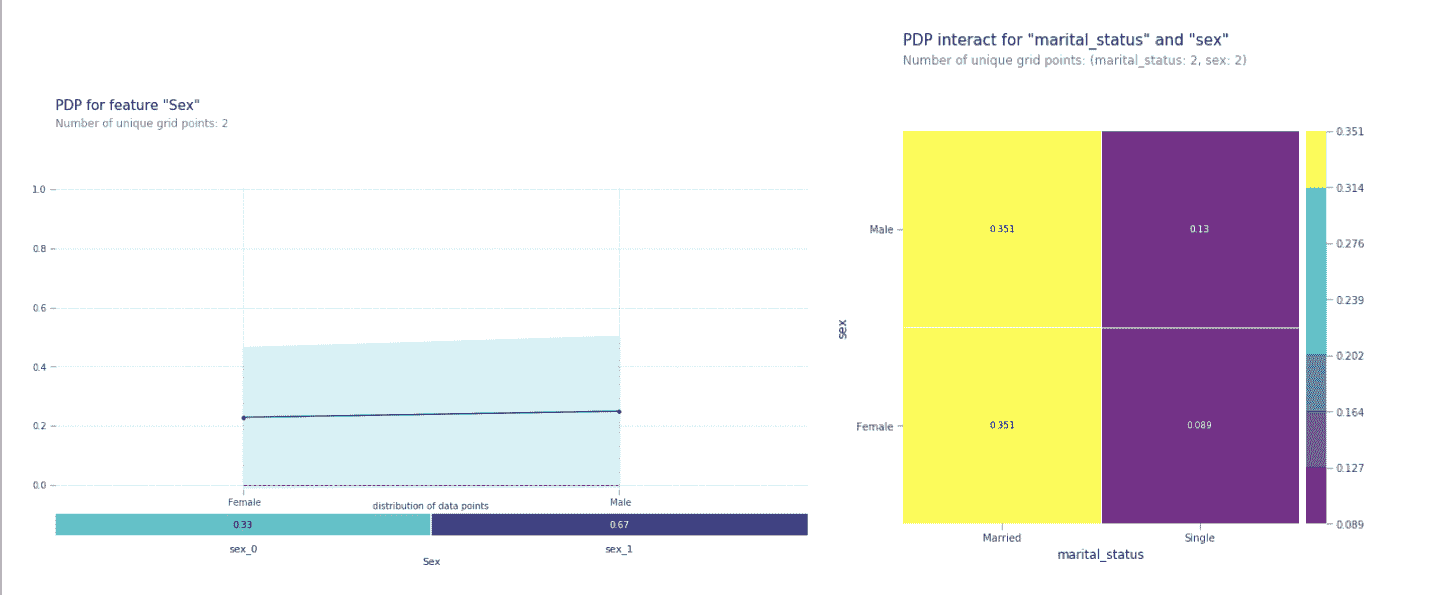
左侧是性别的 PD 图,右侧是性别与婚姻状况的 PD 交互图。
-
如果我们仅查看性别的 PD 图,我们会得出结论,没有基于性别的真实歧视。
-
不过,只需看看与婚姻状况的交互图。左侧(已婚),两个方块的颜色和值相同,但右侧(单身)则存在女性和男性之间的差异。
-
我们可以得出结论,单身男性比单身女性获得超过 50k 的机会要大得多。(虽然我不会基于此对性别歧视发动全面战争,但它肯定是调查的一个起点。)
包装中的小丑
特征之间的独立性假设是该方法最大的缺陷。LOOC 重要性和置换重要性中存在的相同缺陷也适用于 PDP 和 ICE 图。累积局部效应图是解决此问题的方案。ALE 图通过计算——同样基于特征的条件分布——预测差异而非平均值来解决这个问题。
总结每种图(PDP,ALE)如何计算特征在某个网格值 v 上的影响:
部分依赖图:“让我展示当每个数据实例在该特征上具有值 v 时,模型平均预测结果。我忽略了值 v 对所有数据实例是否合理。”
ALE 图:“让我展示在该窗口内的数据实例的特征值 v 附近,模型预测如何在特征的一个小‘窗口’中变化。”
在 Python 环境中,没有好的稳定的 ALE 库。我只找到一个ALEpython,仍在开发中。我设法获得了年龄的 ALE 图,如下所示。但在尝试绘制交互图时出现了错误。它也没有针对分类特征进行开发。
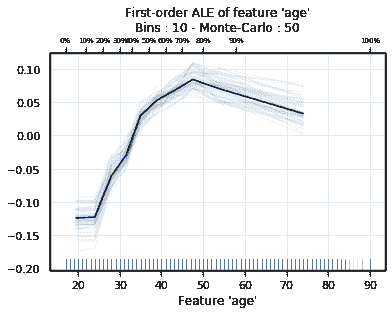
年龄的 ALE 图。
这里我们再次分开,将其余内容推迟到下一个博客帖子。在下一部分,我们将查看 LIME、SHAP、Anchors 等。
完整代码可以在我的Github上找到。
原文。经许可转载。
简介:Manu Joseph (@manujosephv) 是一位天生好奇的自学数据科学家,拥有超过 8 年的专业经验,曾在财富 500 强公司工作,包括Thoucentric分析公司的研究员。
相关:
更多相关主题
KDnuggets™ 新闻 19:n21, 6 月 5 日:职业转型至数据科学;11 大数据科学、机器学习平台;用 Python 掌握中级机器学习的 7 个步骤
特点 | 教程 | 观点 | 排名 | 新闻 | 网络研讨会 | 课程 | 会议 | 职位 | 学术 | 本周图像
我们为您带来 KDnuggets 第 20 届年度软件调查结果:Python 在 11 个最受欢迎的数据科学/机器学习平台中领先;3 个受欢迎的指南——转型数据科学职业;用 Python 掌握中级机器学习;理解自然语言处理(NLP);以及应用于 LSTM 的反向传播。
特点
-
**
-
掌握中级机器学习的 7 个步骤——2019 年版
-
**
-
你的自然语言处理(NLP)指南
-
理解应用于 LSTM 的反向传播


教程,概述
-
如何选择可视化
-
信号与噪声的分离
-
《银河系漫游指南》式的特征提取
-
为什么数据库表的物理存储可能很重要
-
谁是你的金蛋?:队列分析
-
使用 Matplotlib 制作动画
-
成为 3.0 级数据科学家
-
选择模型候选者
-
3 本帮助我提升为数据科学家的机器学习书籍
-
提升你的图像分类模型
-
小心!过多查看模型结果可能导致信息泄漏
-
用 Spark、Optimus 和 Twint 在几分钟内分析推文
-
端到端机器学习:从图像制作视频
-
当“过于像人”意味着不人类:检测自动生成的文本
-
利用 Facebook 的 Pytorch-BigGraph 从知识图谱中提取知识
意见
-
数据科学家是思想家:执行与探索及其对你的意义
-
澄清关于“提升”的误解
-
品茶的女士与科学有什么关系?
-
彩票票据假设如何挑战我们对训练神经网络的所有认识
-
为什么组织在扩展 AI 和机器学习时会失败
-
家庭中的 AI:如何教孩子机器学习
-
ICLR 2019 亮点:Ian Goodfellow 和 GANs,对抗性样本,强化学习,公平性,安全性,社会公益及其他
-
用 Hinton 的胶囊网络修复图像机器学习中的重大弱点
-
6 个正在热衷于预测分析和预测的行业
热点新闻,推文
-
热点新闻,5 月 27 日-6 月 2 日:转型数据科学职业的逐步指南 - 第一部分;Python 引领 11 大数据科学、机器学习平台:趋势与分析
-
Top KDnuggets 推文,5 月 22 日-28 日:蒙娜丽莎微笑、说话和皱眉:#机器学习让古老的画作和照片复活
-
热点新闻,5 月 20 日-26 日:掌握数据科学 SQL 的 7 个步骤;机器学习的数据结构
-
Top KDnuggets 推文,5 月 15 日-21 日:掌握数据科学 SQL 的 7 个步骤 - 2019 版
新闻
- Io-Tahoe 与 OneTrust 集成并加入数据发现合作伙伴计划
网络广播和网络研讨会
- 如何在你的机器学习模型中使用持续学习,6 月 19 日网络研讨会
课程,教育
- 统计思维在工业问题解决中的应用 (STIPS):免费在线课程。
会议
- 大数据与 AI 多伦多 2019,6 月 12-13 日
职位
学术
本周图片
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
更多相关主题
Python 中的自动化机器学习
译文:
www.kdnuggets.com/2019/01/automated-machine-learning-python.html
评论

正如我们已经知道的,机器学习是一种自动化复杂问题解决的方法。但机器学习本身可以被自动化吗?这就是我们将在本文中探索的问题。在文章结束时,我们将回答这个问题,并展示实现这一目标的实际方法。
自动化机器学习(AutoML)
在应用机器学习模型时,我们通常会进行data pre-processing、feature engineering、feature extraction和feature selection。之后,我们会选择最佳算法并tune our parameters以获得最佳结果。AutoML 是一系列用于自动化这些过程的概念和技术。
AutoML 的好处
应用机器学习模型解决我们的问题通常需要计算机科学技能、领域专业知识和数学专业知识。找到具备所有这些技能的专家并不总是那么容易。
AutoML 还减少了在设计机器学习模型时出现的人为偏差和错误。组织还可以通过在其数据管道中应用 AutoML 来减少雇佣众多专家的成本。AutoML 还减少了开发和测试机器学习模型所需的时间。
AutoML 的缺点
AutoML 在机器学习领域是一个相当新的概念。因此,在应用当前一些 AutoML 解决方案时,重要的是要谨慎。这是因为其中一些技术仍在开发中。
另一个主要挑战是运行 AutoML 模型所需的时间。这将真正依赖于我们运行模型的机器的计算能力。正如我们很快会看到的,有些 AutoML 解决方案在我们的本地机器上运行良好,但有些则需要如Google Colab这样的加速解决方案。
AutoML 概念
关于 AutoML,有两个主要概念需要掌握:神经架构搜索和迁移学习。
神经架构搜索
神经网络架构搜索是自动化设计神经网络的过程。通常,强化学习或进化算法被用于这些网络的设计。在强化学习中,模型会因为低准确率而受到惩罚,并因高准确率而获得奖励。使用这种技术,模型将始终努力获得更高的准确率。
已经发布了几篇神经网络架构搜索的论文,例如 学习可迁移的可扩展图像识别架构、高效神经网络架构搜索 (ENAS)、以及 用于图像分类器架构搜索的正则化进化 ,仅举几个例子。
迁移学习
迁移学习,如其名称所示,是一种技术,其中使用预训练模型来转移其在将模型应用于新的但相似的数据集时所学到的内容。这使我们能够在使用更少计算时间和资源的情况下获得高准确率。神经网络架构搜索适用于需要发现新架构的问题,而迁移学习则最适合数据集与预训练模型使用的数据集相似的问题。
AutoML 解决方案
现在让我们看看一些可用的自动化机器学习解决方案。
Auto-Keras
根据 官方网站:
Auto-Keras 是一个开源的自动化机器学习 (AutoML) 软件库。它由德克萨斯 A&M 大学的 DATA Lab 和社区贡献者开发。AutoML 的最终目标是向具有有限数据科学或机器学习背景的领域专家提供易于访问的深度学习工具。Auto-Keras 提供了自动搜索深度学习模型的架构和超参数的功能。
可以使用简单的 pip 命令进行安装:
pip install auto-keras
Auto-Keras 仍在进行最终测试,以备最终发布。官方网站警告说,他们对因使用网站上的库而产生的任何损失不承担责任。该包基于深度学习包 Keras。
Auto-Sklearn
Auto-Sklearn 是一个基于 scikit-learn 的自动化机器学习包。它是 Scikit-learn 估计器的替代品。它的安装也通过简单的 pip 命令完成:
pip install auto-sklearn
在 Ubuntu 中,需要 C++11 构建环境和 SWIG:
sudo apt-get install build-essential swig
通过 Anaconda 的安装步骤如下:
conda install gxx_linux-64 gcc_linux-64 swig
不能在 Windows 上运行 Auto-Sklearn。然而,可以尝试一些变通方法,如使用 Docker 镜像或通过虚拟机运行。
基于树的管道优化工具 (TPOT)
根据其官方 网站:
TPOT 的目标是通过将灵活的 表达树 管道表示与遗传编程等随机搜索算法相结合,自动化构建 ML 管道。TPOT 利用基于 Python 的 scikit-learn 库作为其 ML 菜单。
该软件是开源的,并且可以在 GitHub上获取。
Google 的 AutoML
官方网站声明:
Cloud AutoML 是一套机器学习产品,允许具备有限机器学习专业知识的开发人员,通过利用 Google 的先进迁移学习和神经架构搜索技术,训练出符合其业务需求的高质量模型。
Google 的 AutoML 解决方案不是开源的,其定价可以查看 这里。
H20
H2O 是一个开源的分布式内存机器学习平台,支持 R 和 Python。此软件包支持统计和机器学习算法。
将 AutoML 应用于现实世界问题
现在我们来看看如何使用 Auto-Keras 和 Auto-Sklearn 解决实际问题。
Auto-Keras 实现
我强烈推荐在 Google Colab上运行以下示例,除非我们使用的是具有高计算能力的机器。还需要确保我们在 Google Colab 上使用 GPU 运行时。这里的第一步是安装 Auto-Keras 到我们的 Colab 运行时。
!pip install autokeras
我们将对 MNIST 数据集进行图像分类。第一步是导入该数据集和图像分类器。数据集从 Keras 导入,而图像分类器从 Auto-Keras 导入。由于我们正在构建一个基于预训练模型识别手写数字的模型,因此我们将其归类为监督学习问题。然后我们测试模型在未遇见的数字图像上的准确性。
在这个例子中,图像和标签已经格式化为 numpy 数组,这是机器学习所需的。下一步是将我们刚刚加载的数据分成训练集和测试集,如下所示。
一旦数据被分成训练集和测试集,下一步是拟合图像分类器。
-
将
Verbose指定为 True 意味着搜索过程将被打印在屏幕上供我们查看。 -
在 fit 方法中,
time_limit指的是搜索的时间限制(以秒为单位)。 -
final_fit是模型找到最佳架构后进行的最后一次训练。将retrain指定为 true 意味着模型的权重将被重新初始化。 -
打印
y将显示我们在测试集上评估模型后的准确性。

这就是我们使用 Auto-Keras 分类图像所需的全部内容。极少的代码行,Auto-Keras 将为我们完成所有繁重的工作。
Auto-Sklearn 实现
Auto-Sklearn 的实现与上述 Auto-Keras 实现非常相似。我们将使用数字数据集运行类似的分类。首先,我们需要完成一些导入操作:
-
autosklearn.classification我们稍后将使用它来加载分类器 -
sklearn.model_selection用于模型选择 -
sklearn.datasets用于加载数据集 -
import sklearn.metrics用于测量模型性能
和往常一样,我们加载数据集并将其拆分为训练集和测试集。然后我们从 autosklearn.classification 导入 AutoSklearnClassifier。完成后,我们将分类器拟合到数据集上,进行预测并检查准确性。就是这么简单。
接下来是什么?
自动化机器学习包仍在积极开发中。我们预计在 2019 年将看到更多进展。可以通过关注官方文档网站来跟踪这些包的进展。还可以通过在 GitHub 上提交拉取请求来为这些包做出贡献。更多关于 Auto-Keras 和 Auto-Sklearn 的信息和示例可以在它们的官方网站上找到。
在 Hacker News 和 Reddit 讨论这篇文章。
简历: 德里克·姆维提 是数据分析师、作家和导师。他致力于在每项任务中取得出色的结果,并且是 Lapid Leaders Africa 的导师。
原文。经允许转载。
相关内容:
-
使用开源工具实施自动化机器学习系统
-
使用 Keras 的深度学习简介
-
在 Google Colab 使用 Hyperas 进行 Keras 超参数调整
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
更多相关主题
使用 Keras 的深度学习介绍
译文:
www.kdnuggets.com/2018/10/introduction-deep-learning-keras.html
评论
在本文中,我们将使用 Keras 构建一个简单的神经网络。我们假设你已经具备如 scikit-learn 和其他科学包如 Pandas 和 Numpy 的机器学习知识。
训练人工神经网络
训练人工神经网络包括以下步骤:
-
权重被随机初始化为接近零但不为零的数字。
-
将数据集的观测值输入到输入层。
-
正向传播(从左到右):神经元被激活并得到预测值。
-
比较预测结果与实际值,并测量误差。
-
反向传播(从右到左):调整权重。
-
重复步骤 1–5
-
当整个训练集经过神经网络一次时,称为一个周期。
商业问题
现在让我们开始解决一个实际的商业问题。一家保险公司向你提供了一份客户之前索赔的数据集。保险公司希望你开发一个模型,以帮助他们预测哪些索赔看起来像是欺诈行为。这样做,你希望每年为公司节省数百万美元。这是一个分类问题。以下是我们数据集中的列。



数据预处理
与许多商业问题一样,提供的数据不会为我们处理。因此,我们必须以算法能够接受的方式来准备数据。我们从数据集中看到有一些类别列。我们需要将这些列转换为零和一,以便我们的深度学习模型能够理解它们。另一个需要注意的是,我们必须将数据集作为 numpy 数组输入模型。下面我们导入必要的包,然后加载数据集。
*import pandas as pd
import numpy as np
df = pd.read_csv(‘Datasets/claims/insurance_claims.csv’)*
然后我们将类别列转换为虚拟变量。
在这种情况下,我们使用 drop_first=True 避免虚拟变量陷阱。例如,如果你有 a、b、c、d 作为类别,那么你可以丢弃 d 作为虚拟变量。这是因为如果某些东西既不属于 a、b,也不属于 c,那么它肯定在 d 中。这被称为多重共线性。
我们使用 sklearn 的 train_test_split 将数据分成训练集和测试集。
*from sklearn.model_selection import train_test_split*
接下来,我们确保丢弃我们预测的列,以防止其泄漏到训练集和测试集中。我们必须避免使用相同的数据集来训练和测试模型。我们在数据集末尾设置.values以获得 numpy 数组。这是我们的深度学习模型接受数据的方式。这一步很重要,因为我们的机器学习模型期望数据以数组的形式存在。
然后我们将数据拆分为训练集和测试集。我们使用 70%的数据用于训练,30%用于测试。
*X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)*
接下来,我们需要使用 Sklearn 的StandardScaler对数据集进行缩放。由于深度学习中大量的计算,特征缩放是强制性的。特征缩放标准化了我们自变量的范围。
*from sklearn.preprocessing import StandardScaler*
*sc = StandardScaler()*
*X_train = sc.fit_transform(X_train)*
*X_test = sc.transform(X_test)*
构建人工神经网络(ANN)
首先我们需要导入 Keras。默认情况下,Keras 会使用 TensorFlow 作为其后台。
*import keras*
接下来,我们需要从 Keras 中导入一些模块。Sequential 模块是初始化 ANN 所必需的,而 Dense 模块是构建 ANN 层所必需的。
*from keras.models import Sequential*
*from keras.layers import Dense*
接下来,我们需要通过创建 Sequential 实例来初始化我们的 ANN。Sequential 函数初始化了一个线性堆叠的层。这允许我们以后使用 Dense 模块添加更多层。
*classifier = Sequential()*
添加输入层(第一个隐藏层)
我们使用 add 方法将不同的层添加到我们的 ANN 中。第一个参数是你想添加到这一层的节点数。没有固定的规则来确定应该添加多少个节点。然而,一种常见的策略是将节点数量选为输入层节点数和输出层节点数的平均值。
例如,假设你有五个自变量和一个输出。然后你可以将其求和并除以二,即三。你也可以尝试一种叫做参数调优的技术。第二个参数,kernel_initializer,是用于初始化权重的函数。在这种情况下,它将使用均匀分布来确保权重是接近零的小数。下一个参数是激活函数。我们使用的是 Rectifier 函数,简写为 relu。我们主要在 ANN 的隐藏层中使用此函数。最后一个参数是 input_dim,它是输入层中的节点数。它代表了自变量的数量。
*classsifier.add(
Dense(3, kernel_initializer = ‘uniform’,
activation = ‘relu’, input_dim=5))*
添加第二个隐藏层
添加第二个隐藏层类似于添加第一个隐藏层。
*classsifier.add(
Dense(3, kernel_initializer = ‘uniform’,
activation = ‘relu’))*
我们不需要指定 input_dim 参数,因为我们已经在第一个隐藏层中指定了它。在第一个隐藏层中,我们指定了这个参数以便让该层知道期望多少个输入节点。在第二个隐藏层中,ANN 已经知道期望多少个输入节点,因此我们不需要重复。
添加输出层
*classifier.add(
Dense(1, kernel_initializer = ‘uniform’,
activation = ‘sigmoid’))*
我们更改第一个参数,因为在我们的输出节点中,我们期望只有一个节点。这是因为我们只关心知道一个声明是否是欺诈性的。我们更改激活函数是因为我们想要获得声明是欺诈性的概率。我们通过使用 Sigmoid 激活函数来实现这一点。如果你处理的是一个有多个类别的分类问题(即对猫、狗和猴子进行分类),我们需要更改两件事。我们将第一个参数更改为 3,并将激活函数更改为 softmax。Softmax 是一种应用于具有两个以上类别的独立变量的 sigmoid 函数。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关主题
WTF 是什么 TF-IDF?
评论
由 Enrique Fueyo, Lang.ai 的首席技术官兼联合创始人

来自“超人总动员”(2004)电影的画面
我们的三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
TF-IDF,即词频-逆文档频率,是一种广泛用于信息检索(IR)或总结的评分度量。TF-IDF 旨在反映一个术语在给定文档中的相关性。
其直觉是,如果一个词在一个文档中出现多次,我们应该提高其相关性,因为它应比那些出现次数较少的词更有意义(TF)。同时,如果一个词在一个文档中出现多次但也在许多其他文档中出现,这可能是因为这个词只是一个常见词;而不是因为它有相关性或意义(IDF)。
定义“相关词”是什么意思
我们可以基于直觉提出一个或多或少主观的定义:一个词的相关性与它提供的关于其上下文(一个句子、一个文档或整个数据集)的信息量成正比。也就是说,最相关的词是那些能帮助我们作为人类在不阅读全部文档的情况下更好地理解整个文档的词。
正如所指出的,相关词不一定是最频繁的词,因为像“the”、“of”或“a”这样的停用词在许多文档中经常出现。
还有一个警告:如果我们要将一个文档与关于特定主题的整个数据集(比如电影评论)进行总结,将会有一些词(除了停用词,如角色或情节),这些词可能在文档中以及在许多其他文档中都出现很多次。这些词对于总结文档并不有用,因为它们传达的区分力很小;与其他文档相比,它们对文档内容的描述很少。
让我们通过一些例子更好地说明 TF-IDF 是如何工作的。
搜索引擎示例
假设我们有一个包含数千个猫咪描述的数据库,并且用户想搜索毛茸茸的猫,于是她/他发出了查询“毛茸茸的猫”。作为一个搜索引擎,我们必须决定从我们的数据库中返回哪些文档。
如果我们有与确切查询匹配的文档,那是毫无疑问的……但如果我们必须在部分匹配之间做出决定呢?为了简单起见,假设我们必须在这两个描述之间选择:
-
“可爱的猫”
-
“一只毛茸茸的小猫”
如果第一个描述包含查询中的 3 个词中的 2 个,而第二个描述仅匹配1 个中的 1 个,那么我们将选择第一个描述。TF-IDF 如何帮助我们选择第二个描述而不是第一个描述?
每个词的 TF 相同,这里没有区别。然而,我们可以预期“猫”和“小猫”这两个词会出现在许多文档中(较大的文档频率意味着低 IDF),而“毛茸茸的”这个词会出现在较少的文档中(较大的 IDF)。因此,“猫”和“小猫”的 TF-IDF 值较低,而“毛茸茸的”的 TF-IDF 值较大,即在我们的数据库中“毛茸茸的”比“猫”或“小猫”具有更多的区分能力。
结论
如果我们使用 TF-IDF 来加权匹配查询的不同词汇,“毛茸茸的”将比“猫”更相关,因此我们最终可以选择“毛茸茸的小猫”作为最佳匹配。
总结示例
现在,假设我们想要自动总结一些电影的维基百科页面。我们计划创建一个标签云,帮助我们理解每部电影的内容,因此我们的任务是决定放入哪些词汇(及其大小)。
鉴于一个月前我的家人收养了一只叫Mawi的狗(以《莫阿娜》的角色毛伊命名),我们将使用莫阿娜的维基百科页面作为这个示例。

我的狗:Cala 和 Mawi
第一个想法是列出最常见的词汇:
莫阿娜
最常见的: [‘电影’,‘莫阿娜’,‘的’,‘百万’,‘迪士尼’,‘毛伊’,‘日’,‘发行’,‘te’,‘动画’,‘周末’,‘心’,‘海洋’,‘它’,‘故事’,‘岛’,‘fiti’,‘版本’,‘在’,‘动画’]
我们可以看到一些词汇可能对把握电影情节有用:莫阿娜,毛伊,海洋,岛屿……但 它们仍然提供的信息很少。 此外,它们与其他无关的词混杂在一起,只是增加了噪声(如电影,百万,日,发行或周末)。
如果我们用其他电影进行相同的实验,我们可以看到结果在无关和噪声词方面有些相似。维基百科页面包含的信息是共享的或在所有页面中具有相似结构的:它们是动画 电影,自从首映 第一天就赚了百万美元……但这是我们已经知道的,或者至少对理解情节不重要。
克服问题
为了消除所有电影之间共享的内容并提取每部电影独特的特征,TF-IDF 应是一个非常实用的工具。使用最频繁的词(TF)我们得到了初步的估计,但 IDF 应该帮助我们细化之前的列表并获得更好的结果。考虑到文档频率,我们可以尝试通过减少通用词(那些出现在许多维基百科页面上的词)的相关性来进行惩罚。
海洋奇缘
TF-IDF: [‘毛伊’, ‘他’, ‘海洋奇缘’, ‘菲提’, ‘克拉瓦洛’, ‘女神’, ‘图伊’, ‘波利尼西亚’, ‘塔拉’, ‘卡’, ‘毛利’, ‘奥利’, ‘克莱门特’, ‘鱼钩’, ‘塔毛塔’, ‘杰梅因’, ‘纹身’, ‘配音’, ‘穆斯克’, ‘克莱门茨’]
由于 TF-IDF,像电影、百万或上映这样的词已经从列表顶部消失,我们得到了像波利尼西亚或纹身这样更有意义的新词。
我们还可以对其他评论进行相同的分析,得到如下结果,其中,通用词再次消失,取而代之的是更具体的电影词汇:
最相关的词汇与 TF-IDF 的比较
作为参考,这些是排序后的更多词汇列表:
海洋奇缘
最频繁: *[‘电影’, ‘海洋奇缘’, ‘的’, ‘百万’, ‘迪士尼’, ‘毛伊’, ‘天’, ‘上映’, ‘他’, ‘动画’, ‘周末’, ‘心’, ‘海洋’, ‘它’, ‘故事’, ‘岛屿’, ‘菲提’, ‘版本’, ‘在’, ‘动画’]
TF-IDF: [‘毛伊’, ‘他’, ‘海洋奇缘’, ‘菲提’, ‘克拉瓦洛’, ‘女神’, ‘图伊’, ‘波利尼西亚’, ‘塔拉’, ‘卡’, ‘毛利’, ‘奥利’, ‘克莱门特’, ‘鱼钩’, ‘塔毛塔’, ‘杰梅因’, ‘纹身’, ‘配音’, ‘穆斯克’, ‘克莱门茨’]
—
超人总动员
最频繁: [‘电影’, ‘超人’, ‘鸟’, ‘皮克斯’, ‘上映’, ‘鲍勃’, ‘杰克’, ‘我’, ‘奖’, ‘好’, ‘动画’, ‘特色’, ‘它’, ‘综合症’, ‘角色’, ‘家庭’, ‘工作’, ‘超级英雄’, ‘动画’]
TF-IDF: [‘帕尔斯’, ‘综合症’, ‘紫罗兰’, ‘全能机器人’, ‘帕尔’, ‘幻影’, ‘无人可胜’, ‘海伦’, ‘鸟’, ‘埃德娜’, ‘超级英雄’, ‘冰冻’, ‘地下矿工’, ‘铁’, ‘沃林’, ‘郊区’, ‘大都市’, ‘冲击’, ‘超人’, ‘不可思议’]
—
怪兽公司
最频繁: [‘电影’, ‘苏利’, ‘怪兽’, ‘的’, ‘迈克’, ‘怪物’, ‘皮克斯’, ‘故事’, ‘孩子’, ‘兰道尔’, ‘布’, ‘迪士尼’, ‘角色’, ‘工作’, ‘好’, ‘在’, ‘上映’, ‘他’, ‘医生’, ‘毛发’]
TF-IDF: [‘苏利’, ‘沃特努斯’, ‘布’, ‘CDA’, ‘兰道尔’, ‘吓人者’, ‘菲兹’, ‘塞莉亚’, ‘卡赫斯’, ‘沙利文’, ‘毛发’, ‘工厂’, ‘吓唬’, ‘怪物’, ‘瓦佐斯基’, ‘迈克’, ‘触手’, ‘马德里’, ‘鸽子’, ‘笑声’]
我们是如何做到的
这里是我们用来获得本文中相关词汇列表的代码:
接下来的步骤
对于基础文档集,我们使用了一组精心挑选的 65 部电影。这仅用于演示目的,但为了获得更好的 TF-IDF 结果,我们应该使用更大的文档库。
我们可以在使用这段代码作为起点时轻松尝试的一些其他实验包括:
a) 尝试不同的词频或文档频率的加权分数。它们如何影响列表?
b) 使用不同的文档基础。如果我们选择了任何电影,而不是专注于单一类型,会发生什么?
c) 如果我们尝试不同的领域,比如音乐乐队,结果会如何?
查看我们Building Lang.ai出版物中的其他文章。我们撰写关于机器学习、软件开发和我们的公司文化的内容。
简历: Enrique Fueyo 是 Lang.ai 的首席技术官和联合创始人,致力于无监督 AI 语言理解,打造有助于公司和开发者处理非结构化文本数据的产品和服务。
原文。经授权转载。
相关:
-
理解情感分析背后的内容 – 第一部分
-
理解情感分析背后的内容 – 第二部分
-
文本数据预处理的一般方法
更多相关话题
数据科学投资组合的 5 个高级项目
原文:
www.kdnuggets.com/2023/03/5-advance-projects-data-science-portfolio.html
图片来源:作者
在这篇博客中,我们将探讨五个重要的数据科学项目,这些项目可以提升最后一年学生和专业人员的职业档案。通过这些项目,你将深入了解数据科学工作流,并掌握数据清洗、处理、可视化和建模的关键工具。此外,你还将学习如何撰写项目报告,并在云端部署机器学习模型,以达到最佳效果。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
1. 新加坡节省的回收能源
在 新加坡节省的回收能源 项目中,你将分析新加坡通过回收塑料、纸张、玻璃以及铁质和非铁质金属每年节省了多少能源。该项目涉及数据联接、数据清洗和数据整理。之后,你将使用统计和可视化工具进行深度数据分析。
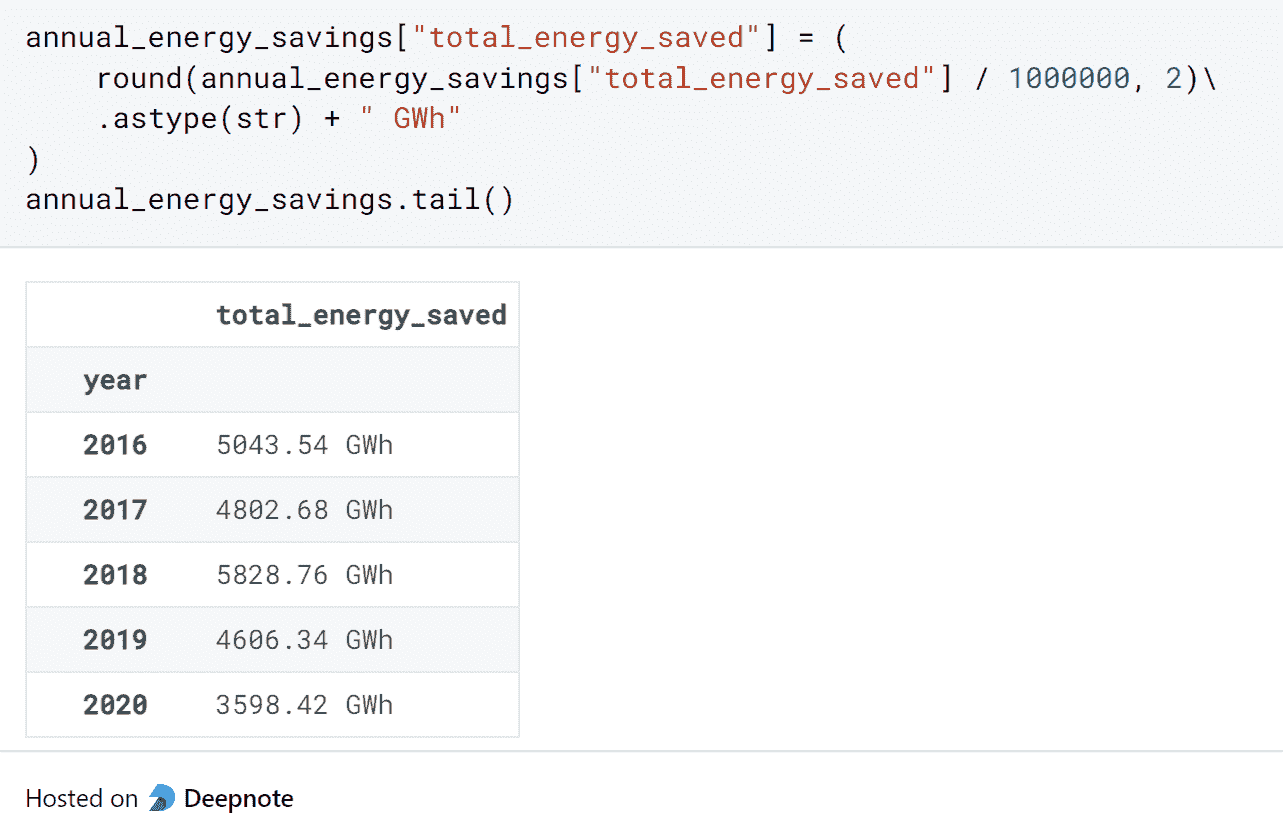
图片来源于项目
最后,你将使用数据处理技术来回答原始问题:基于五种废物类型,从 2003 年到 2020 年新加坡总共节省了多少能源。
2. 使用 statsmodels 和 Prophet 进行时间序列预测
使用 statsmodels 和 Prophet 进行时间序列预测 项目将教会你处理时间序列数据、进行数据分析和预测的核心技能。
图片来源于项目
你将从训练 ARIMA 预测模型开始,并进行模型评估。之后,你将使用 Python 包 Prophet 进行时间序列预测。
3. spaCy 简历分析
在 spaCy 简历分析 项目中,你将使用 spaCy 对 200 份简历进行实体识别,并使用各种 NLP 工具进行文本分析。该项目的目标是帮助招聘人员快速准确地决定成千上万的求职申请。


图片来自项目
你将首先加载爬取的数据集和 spaCy 的英语基础模型。接着,你将创建一个实体规则器并清理数据集。之后,你将进行数据可视化、实体识别和依赖解析。最后,你将创建一个简历匹配评分函数并执行主题建模。
4. Tripadvisor 数据分析
Tripadvisor 数据分析 组合项目涵盖了数据科学的各个方面,从数据加载到数据建模。你将根据客户体验分析评论和评分。
图片来自项目
在这个项目中你将进行:
-
数据探索
-
使用 Vader 进行情感分析
-
数据可视化
-
添加关键词(Gensim)
-
文本处理(NLTK)
-
使用 Keras 构建深度学习模型(BiLSTM)
-
训练和验证
-
模型评估
-
预测
-
保存模型
这是一个使用深度学习模型进行文本分类的介绍。在开始训练之前,你将预处理数据(文本词形还原)、进行数据分析,并准备数据(分词)以用于深度学习模型。
5. 使用 ChatGPT 的端到端贷款审批项目
使用 ChatGPT 的端到端贷款审批项目是我最喜欢的项目。你将学习掌握 GPT 提示以完成真实数据科学项目中的所有步骤。在该项目中,你将要求 ChatGPT 帮助你创建一个端到端的贷款审批项目,使用从 LendingClub.com 提取的数据。
图片来自 贷款分类器
你将学习编写提示以生成创意、数据分析、特征工程、数据预处理和平衡、模型选择、模型调整和评估、构建应用程序并将其部署到服务器上。
我们正处于一个阶段,公司将开始要求员工学习推广技能并更好地使用新 AI 工具。提示工程将成为数据科学家的必备技能,招聘人员将要求具有使用 GPT 进行数据科学任务的经验。
那还等什么?开始使用 GPT-4 和其他人工智能工具,提高生产力,确保未来。
结论
即使你缺乏经验,这些项目也会帮助你获得梦想中的工作。在完成项目后,我强烈建议你将它们分享在 GitHub、DagsHub、Deepnote 或 Kaggle 上。这些平台被开发者和数据科学家用来展示他们的项目和技能。
在这篇文章中,我们回顾了 5 个涵盖数据分析、时间序列、自然语言处理、机器学习和使用 ChatGPT 的提示工程的高级项目。如果你对涉及数据科学特定领域的项目感兴趣,请查看完整的数据科学项目合集——第一部分 和 第二部分。
我希望这些高级项目列表对你有帮助,如果你有更好的建议,请告诉我。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专家,他热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个人工智能产品,帮助那些与心理疾病作斗争的学生。
更多相关主题
Pandas 的 5 个高级功能及其使用方法
原文:
www.kdnuggets.com/2019/10/5-advanced-features-pandas.html
评论

Pandas 是处理数据的黄金标准库。具备加载、过滤、操作和探索数据的功能,难怪它是 数据科学家们的最爱。
我们大多数人自然会坚持使用 Pandas 的基础功能。从 CSV 文件中加载数据,过滤几个列,然后直接跳入 数据可视化。然而,Pandas 实际上包含了许多不太为人知但非常有用的函数,这些函数可以使数据处理变得更加简单和清晰。
本教程将引导你了解这些更高级的功能 — 它们的作用及如何使用。与数据一起玩得更开心!
(1) 配置选项和设置
Pandas 提供了一组用户可配置的选项和设置。这些设置是巨大的生产力提升工具,因为它们允许你根据自己的喜好精确调整 Pandas 环境。
例如,我们可以更改一些 Pandas 的显示设置,以改变显示的行和列数以及浮点数的显示精度。
上面的代码确保 Pandas 始终显示最多 10 行和 10 列,浮点值显示最多 2 位小数。这样,当我们尝试打印出一个大的 DataFrame 时,我们的终端或 Jupyter Notebook 就不会看起来一团糟!
这只是一个基本示例。除了简单的显示设置,还有很多东西可以探索。你可以查看所有选项的 官方文档。
(2) 合并 DataFrame
Pandas DataFrame 的一个相对不为人知的部分是,实际上有两种不同的方法来合并它们。每种方法产生不同的结果,因此根据你的需求选择合适的方法非常重要。此外,它们包含许多参数,可以进一步自定义合并。让我们来了解一下。
拼接
拼接是合并 DataFrame 的最常见方法,可以直观地理解为“堆叠”。这种堆叠可以是水平的,也可以是垂直的。
想象一下你有一个巨大的 CSV 格式数据集。将其拆分成多个文件以便于处理是有意义的(这在大数据集的处理中很常见,称为 分片)。
当你将数据加载到 Pandas 中时,你可以将每个 CSV 的 DataFrame 垂直堆叠,以创建一个包含所有数据的大 DataFrame。例如,如果我们有 3 个分片,每个分片有 500 万行,那么在将它们垂直堆叠后,我们的最终 DataFrame 将有 1500 万行。
下面的代码展示了如何在 Pandas 中垂直拼接 DataFrames。
你可以通过根据列而不是行来拆分数据集,来做类似的操作——为每个 CSV 文件提供几个列(包含数据集的所有行)。这就像是将数据集的特征分成不同的碎片。然后你可以水平堆叠它们来组合这些列/特征。
合并
合并(Merging)更复杂但更强大,采用类似 SQL 的风格将 Pandas DataFrames 组合在一起,即通过某些共同的属性来连接 DataFrames。
假设你有两个描述你的 YouTube 频道的 DataFrames。其中一个包含用户 ID 列表以及每个用户在你的频道上花费的总时间。另一个包含类似的用户 ID 列表以及每个用户观看的视频数量。合并允许我们通过匹配用户 ID 将这两个 DataFrames 组合成一个,通过将 ID、时间和视频数量放在每个用户的单独行中。
在 Pandas 中合并两个 DataFrames 是通过merge函数完成的。你可以在下面的代码中看到它是如何工作的。left 和 right 参数指的是你希望合并的两个 DataFrames,而 on 指定了用于匹配的列。
为了更进一步模拟 SQL 连接,how 参数允许你选择要执行的 SQL 风格连接类型:内连接、外连接、左连接或右连接。要了解更多关于 SQL 连接的信息,请参见 W3Schools 教程。
(3) 重塑 DataFrames
有几种方法来重塑和重构 Pandas DataFrames。这些方法从简单易用到强大复杂。让我们来看看最常见的三种方法。在以下所有示例中,我们将使用这份超级英雄数据集!
转置
其中最简单的。转置将 DataFrame 的行和列互换。如果你有 5000 行和 10 列,然后转置你的 DataFrame,你将得到 10 行和 5000 列。
分组
分组(Groupby)的主要用途是根据某些键将 DataFrames 拆分成多个部分。一旦 DataFrame 被拆分成多个部分,你可以遍历并对每个部分独立应用一些操作。
例如,我们可以看到下面的代码中,我们创建了一个包含年份和得分的球员 DataFrame。然后我们进行了groupby操作,将 DataFrame 按照球员拆分成多个部分。因此,每个球员都有自己的组,显示该球员在每一年中获得的分数。
堆叠
堆叠(Stacking)将 DataFrame 转换为多层索引,即每一行具有多个子部分。这些子部分是通过 DataFrame 的列创建的,将它们压缩成多重索引。总体来说,堆叠可以看作是将列压缩成多重索引的行。
下面的例子最好地说明了这一点。
(4) 处理时间数据
Datetime 库 是 Python 的一个重要库。无论何时处理与现实世界日期和时间信息相关的内容,它都是你首选的库。幸运的是,Pandas 也提供了使用 Datetime 对象的功能。
让我们用一个例子来说明。在下面的代码中,我们首先创建一个包含 4 列的 DataFrame:Day、Month、Year 和 data,然后按年份和月份进行排序。正如你所看到的,这样非常杂乱;我们使用了 3 列来存储日期,但实际上我们知道一个日历日期只是一个值。
我们可以通过 datetime 来整理数据。
Pandas 方便地提供了一个名为 to_datetime() 的函数,可以将多个 DataFrame 列压缩并转换为一个单一的 Datetime 对象。一旦转化为这种格式,你就可以利用 Datetime 库的所有功能。
使用 to_datetime() 函数时,你需要将所有相关列中的“日期”数据传递给它。这包括“Day”、“Month”和“Year”列。一旦我们将数据转化为 Datetime 格式,我们就不再需要其他列,只需将其删除即可。查看下面的代码,了解具体的操作方法!
(5) 将项目映射到组
映射是一个有用的技巧,有助于组织分类数据。举个例子,假设我们有一个包含数千行的大型 DataFrame,其中一列包含我们希望分类的项目。这样做可以大大简化机器学习模型的训练和数据的有效可视化。
查看下面的代码,了解我们如何将食品列表进行分类的迷你示例。
在上面的代码中,我们将列表放入了 pandas 系列中。我们还创建了一个字典,显示了我们想要的映射,将每个食品项分类为“Protein”或“Carb”。这是一个简单的示例,但如果这个系列的规模很大,比如有 1,000,000 项,那么遍历它就不再实际。
我们可以使用 Pandas 内置的 .map() 函数来以优化的方式执行映射,而不是基本的 for 循环。查看下面的代码,了解函数及其应用。
在函数中,我们首先遍历字典,创建一个新字典,其中键表示 pandas 系列中的每一个可能项,而值表示新映射项,“Protein” 或 “Carbs”。然后,我们简单地应用 Pandas 的内置映射函数来映射系列中的所有值。
查看下面的输出以查看结果!
['Carbs', 'Carbs', 'Protein', 'Protein', 'Protein', 'Carbs', 'Carbs', 'Carbs', 'Protein', 'Carbs', 'Carbs', 'Protein', 'Protein', 'Protein', 'Carbs', 'Carbs', 'Carbs', 'Protein', 'Carbs', 'Carbs', 'Carbs', 'Protein', 'Carbs', 'Carbs', 'Carbs', 'Protein', 'Carbs', 'Carbs', 'Protein', 'Protein', 'Protein', 'Carbs', 'Carbs', 'Protein', 'Protein', 'Protein', 'Carbs', 'Carbs', 'Protein', 'Protein', 'Protein', 'Carbs', 'Carbs', 'Carbs', 'Protein', 'Carbs', 'Carbs', 'Carbs', 'Protein', 'Carbs', 'Carbs', 'Carbs', 'Protein', 'Carbs', 'Carbs', 'Protein', 'Protein', 'Protein', 'Carbs', 'Carbs', 'Protein', 'Protein', 'Protein']
结论
所以就这样!这是 Pandas 的 5 个高级功能及其使用方法!
如果你渴望更多内容,不必担心!还有更多关于 Pandas 和数据科学的内容可以学习。作为推荐阅读,KDNuggets 网站 当然是这个主题的最佳资源!
相关:
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT 工作
关于这个话题的更多内容
Python 序列的 5 个高级技巧
原文:
www.kdnuggets.com/2021/11/5-advanced-tips-python-sequences.html
评论
作者 Michael Berk,Tubi 的数据科学家

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
“66%的数据科学家每天都在使用 Python。” — src
如果你是那 66%中的一员,这篇文章就是为你准备的。
我们将涵盖Luciano Ramalho 的《流畅的 Python》第二章中的主要内容,该章节涉及序列,例如列表、元组等。
1 — 列表与元组
提示:列表应保存相同类型的信息,而元组可以保存不同类型的信息。
从基础开始,让我们讨论一下列表和元组之间的主要区别。下面我们可以看到每种的示例——列表用方括号[]括起来,而元组用圆括号() 括起来。
my_tuple = (1,'a',False)
my_list = [1,'a',False]
在后端,列表是可变的,而元组则不是。不可变变量通常需要更少的内存,因此尽可能使用元组。
然而,《流畅的 Python》中涵盖了更深层次的内容。
从语义上讲,最好将不同的kinds的数据存储在元组中,将相同的kinds的数据存储在列表中。请注意,元组和列表都支持在同一变量中使用多种 Python 数据类型,但我们讨论的是变量的概念类型。
例如,一个元组可以用来存储以下信息:(latitude, longitude, city_name)。这些不仅是不同的数据类型(float, float, str),而且在概念上也不同。另一方面,列表仅应存储纬度、经度、城市名称或三者的元组。
# list of [float, float, str]
bad_practice_list = [[39.9526, 75.1652, 'Philadelphia'],
[6.2476, 75.5658m 'Medellín']]# list of tuples
good_practice_list = [(39.9526, 75.1652, 'Philadelphia'),
(6.2476, 75.5658m 'Medellín')]
为了提高 Python 代码的组织性,你应该始终将相同类型的信息保存在列表中。元组用于结构,列表用于序列。
2 — 解包可迭代对象
提示:使用*****和**_**来改进你的解包。
解包是一种非常流畅且易读的方式来访问可迭代对象中的值。它们在循环、列表推导式和函数调用中非常常见。
解包是通过将类序列的数据类型分配给以逗号分隔的变量名来完成的,例如……
x, y, z = (1,2,3)
然而,《流利的 Python》介绍了一些高级解包方法。例如,你可以使用*来解包可迭代对象中的“其余”项。使用星号符号是当你有一些感兴趣的项和其他不那么重要的项时很常见的做法。
x, *y, z = [1,2,3,4,5,6,7]
x #1
y #[2,3,4,5,6]
z #7
如你所见,*操作符可以出现在一组变量的中间,Python 会将所有未处理的值分配给该变量。
不过,我们可以进一步使用星号解包操作符。你可以使用_来解包并不保存一个值。这种惯例在你希望解包某些内容时很有用,但与上面的例子不同,你不需要所有的变量。
x, _ = (1,2)
x #1
下划线_解包操作符的一个使用场景是当你处理字典或内建方法返回多个值时。
最后,为了锦上添花,我们可以将这两种方法结合起来,解包而不保存“其余”值。
x, *_ = (1,2,3,5,6)
x #1
3 — 函数是否返回 None?
提示:如果一个函数返回**None**,它执行的是原地操作。
许多 Python 数据类型有两个版本的相同函数,如下所示的x.sort()和sorted(x)。
x = [3,1,5,2]
x.sort()
x # [1,2,3,5]x = [3,1,5,2]
y = sorted(x)
x # [3,1,5,2]
y # [1,2,3,5]
在使用x.sort()的第一个例子中,我们执行的是原地排序,这更高效且占用更少的内存。但在使用sorted(x)的第二个例子中,我们能够保留列表的原始顺序。
通常,Python 保持这种符号约定。点操作符如x.sort()通常返回None并进行原地变更。像sorted(x)这样的函数将变量作为参数,并返回变更后的变量的副本,但保持原始变量不变。
4 — 生成器表达式 vs. 列表推导式
提示:如果你只访问一次变量,请使用生成器表达式。如果不是,请使用列表推导式。
列表推导式(listcomps)和生成器表达式(genexps)是实例化序列数据类型的不同方法。
list_comp = [x for x in range(5)]
gen_exp = (x for x in range(5))
如上所示,列表推导式和生成器表达式之间唯一的语法区别是括号的类型——生成器表达式使用圆括号(),而列表推导式使用方括号[]。
列表推导式是实例化的,这意味着它们会被评估并保存在内存中。生成器表达式则不是。每次程序需要生成器表达式时,它都会执行计算来评估该表达式。
所以这就是为什么生成器表达式在你只使用变量一次时更好的原因——它们实际上不会存储在内存中,因此效率更高。但是,如果你反复访问一个序列或需要列表特定的方法,最好将其存储在内存中。
有趣的附注——你还可以使用列表推导语法创建字典……
my_dict = {k:v for k,v in zip(['a','b'], [1,2])}
5 — 切片
最后,让我们简单总结一下切片。与解包不同,有时我们希望通过索引访问可迭代对象中的值。切片允许我们通过以下格式来做到这一点:my_list[start:stop:step]
对于那些知道my_list[::-1]可以反转列表顺序但不知道为什么(例如我自己),这就是原因。通过将-1作为步长参数传递,我们可以反向遍历列表。
现在大多数 Python 包遵循[start:stop:index]语法。Numpy 和 pandas 是一些显著的例子。让我们逐一看看每个参数……
-
start:你切片中的起始索引 -
end:你切片中的不包括的结束索引 -
step:你在start和stop索引之间的步长(及方向)
因此,由于这些值都是可选的,我们可以进行各种有趣的切片操作……
x = [1,2,3,4]x[1:3] # [2,3]
x[2:0:-1] # [3,2]last = [-1::] # 4
all_but_last = x[:-1:] # [1,2,3]
reversed = x[::-1] # [4,3,2,1]
就这样!来自《流畅的 Python》第二章的 5 个主要技巧。还有一个部分……
数据科学家的有用笔记
声明,我并不特别有资格对这篇文章提出个人意见。不过,这些笔记应该相当直观。如果你不同意,请告诉我。
-
列表推导几乎总是应该替代循环。 如果循环体很复杂,你可以创建一个执行这些操作的函数。通过将用户定义的函数与列表推导语法结合起来,你可以编写出既可读又高效的代码。如果你需要迭代多个变量,可以使用
[enumerate()](https://realpython.com/python-enumerate/)或[zip()](https://www.w3schools.com/python/ref_func_zip.asp)。 -
在 Python 中“优化”并不重要。 如果你在编写生产级代码,情况可能会有所不同。但实际上,使用元组与列表相比,你不会看到显著的性能提升。确保你的数据处理步骤逻辑清晰且高效是工作中的 99%。如果 1%很重要,那么你可以开始担心元组与列表的问题。此外,如果你真的关注高效代码,你可能不会使用 Python。
-
最后,切片非常酷。 我一直知道
x[::-1]可以反转列表,但直到阅读《流畅的 Python》这一章节才明白原因。它同样适用于 numpy 和 pandas!
感谢阅读!我将再写 35 篇文章,将学术研究带入数据科学行业。查看我的评论以获取此文章的主要来源和一些有用资源的链接。
个人简介:Michael Berk (michaeldberk.com/) 是 Tubi 的数据科学家。
原文。已获授权转载。
相关:
-
如何发现你的机器学习模型中的弱点
-
使用这个 Python 库进行简单的文本抓取、解析和处理
-
使用 Faker 在 Python 中生成简单的合成数据
更多相关主题
5 门来自 Google 的 AI 课程,助力你的职业发展
原文:
www.kdnuggets.com/5-ai-courses-from-google-to-advance-your-career

图片由编辑提供
人工智能或 AI 是一个令人兴奋的领域,无论你是否想成为 AI 开发者或 AI 研究员。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
为帮助你探索,我们整理了 Google 提供的课程和学习路径。从 AI 的基础构建块到构建和部署 AI 模型,这些课程将帮助你全面学习。
所以让我们来详细了解一下。对机器学习相关工作的些许了解将有助于你从这些课程中获得最大收益。
1. Google Cloud 上的 AI 和机器学习介绍
课程Google Cloud 上的 AI 和机器学习介绍将帮助你了解如何将数据转化为 AI 解决方案。因此,你将学习如何构建机器学习模型,设计机器学习管道,并在探索 Google Cloud 产品的同时构建一个完全功能的 AI 系统。
本课程包括以下内容:
-
AI 基础
-
AI 开发选项
-
AI 开发工作流程
2. 深入机器学习
深入机器学习课程将帮助你建立前进所需的机器学习基础。
课程首先探讨了基本概念,如探索性数据分析及其有效应用以改善数据质量。然后涵盖了使用 Vertex AI AutoML 构建和部署应用程序。此外,你还将学习如何使用 BigQuery ML。
本课程包含以下模块:
-
了解你的数据:通过探索性数据分析改进数据
-
实践中的机器学习
-
使用 Vertex AI 训练 AutoML 模型
-
BigQuery 机器学习:为你的数据生活开发 ML 模型
-
优化
-
泛化和采样
链接:深入机器学习
3. Google Cloud 上的 TensorFlow
TensorFlow 是开发深度学习和 AI 应用程序最受欢迎的开发框架之一。课程 TensorFlow 在 Google Cloud 上 深入探讨了使用 TensorFlow 构建应用程序。
从构建输入数据处理管道到大规模训练神经网络,这门课程教你所有关于使用 TensorFlow 的知识。课程中的模块包括:
-
TensorFlow 生态系统介绍
-
设计和构建输入数据管道
-
使用 TensorFlow 和 Keras API 构建神经网络
-
使用 Vertex AI 进行大规模训练
链接:TensorFlow 在 Google Cloud 上
4. 在 Google Cloud 上执行基础数据、ML 和 AI 任务
在 Google Cloud 上执行基础数据、ML 和 AI 任务 是一个学习路径,用于学习如何执行典型机器学习项目中的不同任务。
这意味着你将能够实验数据准备和数据处理任务。此外,你还将学习使用语音转文本和视频智能 API 来构建强大的应用程序。
链接:在 Google Cloud 上执行基础数据、ML 和 AI 任务
5. 生成式 AI 学习路径介绍
生成式 AI 最近变得非常流行,得益于持续的进步,它仍然是谈论的焦点。我们看到新颖的生成式 AI 应用程序不断进入市场。
无论你是想有效使用生成式 AI 模型,还是想深入了解它们的工作原理,生成式 AI 学习路径都能满足你的需求。这个学习路径包含以下课程:
-
生成式 AI 介绍
-
大型语言模型介绍
-
负责任的 AI 介绍
-
生成式 AI 基础
-
负责任的 AI:应用 Google Cloud 的 AI 原则
如果你准备进一步探索,也可以学习 开发者的生成式 AI 学习路径。
总结
希望你发现这些课程汇编对你有帮助。这些课程应帮助你熟练掌握 TensorFlow 框架,并利用 Vertex AI 构建可扩展的 AI 解决方案。
此外,这些课程非常棒,你可以在学习过程中实践和应用所学知识。祝学习愉快,构建顺利!
Bala Priya C** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过编写教程、使用指南、评论文章等,学习并与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。**
更多相关主题
5 个 Airflow 替代方案
原文:
www.kdnuggets.com/5-airflow-alternatives-for-data-orchestration
作者提供的图片
数据编排已成为现代数据工程的关键组成部分,允许团队简化和自动化他们的数据工作流程。虽然 Apache Airflow 是一个以其灵活性和强大社区支持而广泛使用的工具,但还有其他几个提供独特功能和优势的替代方案。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT 需求
在这篇博客文章中,我们将讨论五种管理工作流程的替代方案:Prefect、Dagster、Luigi、Mage AI 和 Kedro。这些工具不仅限于数据工程,可用于任何领域。通过了解这些工具,您将能够选择最适合您的数据和机器学习工作流程需求的工具。
1. Prefect
Prefect 是一个开源工具,用于构建和管理工作流程,提供可观察性和分类功能。您可以使用几行 Python 代码构建交互式工作流应用程序。
Prefect 提供了一种混合执行模型,允许工作流程在云端或本地运行,给用户提供了对数据操作的更大控制。其直观的用户界面和丰富的 API 使得数据工作流程的监控和故障排除变得容易。
2. Dagster
Dagster 是一个强大的开源数据管道编排工具,简化了数据资产在其整个生命周期中的开发、维护和监控。Dagster 专为云原生环境构建,提供集成的数据血统、可观察性和用户友好的开发环境,成为数据工程师、数据科学家和机器学习工程师的热门选择。
Dagster 是一个开源的数据编排系统,允许用户将其数据资产定义为 Python 函数。一旦定义,Dagster 根据用户定义的计划或响应特定事件来管理和执行这些函数。Dagster 可用于数据开发生命周期的每个阶段,从本地开发和单元测试到集成测试、暂存环境和生产环境。
3. Luigi
Luigi 是由 Spotify 开发的基于 Python 的框架,用于构建复杂的批处理作业管道。它处理依赖关系解析、工作流管理、可视化等,注重可靠性和可扩展性。
Luigi 是一个强大的工具,擅长管理任务依赖关系,确保任务按照正确的顺序执行,并且仅在满足其依赖关系时才执行。它特别适合涉及 Hadoop 作业、Python 脚本和其他批处理流程的工作流。
Luigi 提供了支持各种操作的基础设施,包括推荐系统、排行榜、A/B 测试分析、外部报告、内部仪表盘等。
4. Mage AI
Mage AI 是数据编排领域的新进者,提供了一种混合框架,用于数据转换和集成,将笔记本的灵活性与模块化代码的严格性结合在一起。它旨在简化数据的提取、转换和加载过程,使用户能够以更高效和用户友好的方式处理数据。
Mage AI 提供了简单的开发者体验,支持多种编程语言,并支持协作开发。其内置的监控、警报和可观察性功能使其非常适合大规模、复杂的数据管道。Mage AI 还支持 dbt,用于构建、运行和管理 dbt 模型。
5. Kedro
Kedro 是一个 Python 框架,提供了一种标准化的方式来构建数据和机器学习管道。它利用软件工程最佳实践来帮助你创建可重复、可维护和模块化的数据工程和数据科学管道。
Kedro 提供了标准化的项目模板、数据连接器、管道抽象、编码标准和灵活的部署选项,这些都简化了数据科学项目的构建、测试和部署过程。通过使用 Kedro,数据科学家可以确保一致和有序的项目结构,轻松管理数据和模型版本,自动化管道依赖关系,并在各种平台上部署项目。
结论
尽管 Apache Airflow 继续成为数据编排的热门工具,但这里介绍的替代方案提供了一系列功能和好处,可能更适合某些项目或团队的偏好。无论你是优先考虑简洁性、以代码为中心的设计,还是机器学习工作流的集成,都很可能有一种替代方案符合你的需求。通过探索这些选项,团队可以找到合适的工具来提升数据操作,最大化数据项目的价值。
如果你对数据工程领域还不熟悉,可以考虑参加 数据工程专业课程 来为工作做好准备,开始赚取 $300K/年。
Abid Ali Awan(@1abidaliawan)是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为患有心理疾病的学生开发一个 AI 产品。
更多相关话题
2023 年你需要尝试的 5 个令人惊叹且免费的 LLM 平台
原文:
www.kdnuggets.com/5-amazing-free-llms-playgrounds-you-need-to-try-in-2023

作者提供的图片
许多提供免费访问其大型语言模型(LLMs)的公司现在将其隐藏在墙后。不过,仍然有一些令人惊叹的免费 LLM 平台可以让任何人体验最新的 AI 创新。
在这篇文章中,我们将介绍 5 个平台,让你可以在无成本的情况下测试和比较尖端的 AI 模型。这些免费的 LLM 平台可以协助写作、代码生成、故障排除和头脑风暴。
1. Vercel AI Playground
使用 Vercel AI Playground,你可以访问顶级模型,如 Llama2、Claude2、Command Nightly、GPT-4,甚至来自 HuggingFace 的开源模型。你可以并排比较这些模型的性能,或像与其他聊天机器人一样与它们聊天。除了免费访问外,该平台还提供有关模型上下文长度和输入/输出定价的额外信息。它还提供 API 和页面代码,以便你可以构建自己的聊天机器人应用程序,类似于 AI Playground。
图片来源于 Vercel.ai
2. Poe
Quora Poe 毫无疑问是我最喜欢的 AI 助手。作为数据科学家,我每天都依赖它来帮助完成各种任务,从生成代码到总结论文。它的功能似乎无穷无尽。
除了作为我个人的助手外,Quora Poe 还为每个人提供了一些最先进的对话 AI 模型的访问权限。像 GPT-4、Claude2、Llama2、Sage 和 PaLM 这样的模型,只需简单注册即可探索。你可以提供初始提示来创建个性化的机器人,或从共享的社区机器人中选择。
我强烈推荐阅读“忘记 ChatGPT,这款新的 AI 助手领先一步,将永远改变你的工作方式”以了解我如何在日常任务中使用它。
图片来源于 Poe
3. GPT4ALL
GPT4ALL 是一个免费开源的 AI 平台,可以在 Windows、Mac 和 Linux 计算机上本地运行,而无需互联网连接或 GPU。它通过简单的两步过程为用户提供对各种最先进语言模型的访问。你只需下载并安装应用程序,然后下载你喜欢的模型。
作者提供的图像 | GPT4ALL
4. HuggingChat
HuggingChat是一个出色的工具,已成为我生成高质量代码的第二选择。HuggingChat 更令人印象深刻的是它最新加入的Code Llama。通过将 Code Llama 集成到 HuggingChat 中,解决数学问题和生成高度准确的代码变得轻而易举。
HuggingChat 的一大亮点是其开源性质。这意味着代码库对用户开放,允许查看、修改和贡献,促进了一个充满活力的开发者社区。此外,HuggingChat 提供了与网络浏览器的无缝集成,允许用户直接从互联网获取结果。
来自 HuggingChat 的图像
5. LMSys
LMSys是一个基于 Gradio 的网络应用,允许用户尝试各种开源模型,如 Vicuna、Alpaca、WizardLM、MPT-Chat、LLaMA2、StableLM 和 FastChat-T5。用户还可以比较这些模型的性能,根据排行榜,目前 GPT-4 以 1206 的 elo 评级领先。

来自 lmsys.org 的图像
结论
在这篇博客中,我们探讨了前 5 名及我最喜欢的 AI 平台,这些平台让你可以免费使用最先进的大型语言模型。这些平台重视隐私,允许你匿名使用。你可以使用它们来比较模型,甚至用它们来完成日常工作。
请记住,有人正在努力使技术开源并让每个人都能访问。你可以通过贡献或捐赠来支持这些项目,这将有助于实现 AI 的民主化。
Abid Ali Awan (@1abidaliawan)是一位认证的数据科学专家,喜欢构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是为患有心理疾病的学生开发一个基于图神经网络的 AI 产品。
更多相关内容
计算机视觉的 5 种应用
原文:
www.kdnuggets.com/2022/03/5-applications-computer-vision.html

生物识别照片由 rawpixel.com 创建 - www.freepik.com
新技术不断开发,各行各业可以利用它们在日益竞争和数字化的世界中提升运营。无论是利用 5G 技术、物联网(IoT),还是数据分析,许多公司认识到新技术的好处。
我们的 3 大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
计算机视觉(CV)作为一种先进技术,正越来越多地应用于经济的各个领域。CV 的主要优势在于它可以以多种方式应用——可能性似乎是无限的。
什么是计算机视觉?
计算机视觉(CV)是人工智能(AI)领域的一项技术,使机器能够“看见”周围的世界。集成了计算机视觉的设备可以分析视觉信息,并基于这些信息做出决策,或理解其周围环境和情境。深度学习和机器学习算法都用于驱动计算机视觉。
世界产生了大量的数据,这使得计算机视觉呈指数增长。计算机视觉分析的信息大多是图像和视频,但也包括来自其他来源的数据,如红外线和热传感器。由于计算机视觉是人工智能的一部分,其总体目标是尽可能高效地模仿人类行为。
计算机视觉是一项革命性技术,因为机器可以复制人类视觉系统的部分功能,这本身就很复杂。实际上,计算机视觉超越了人类检测和标记物体的能力——今天的系统在反应视觉输入方面已达到 99% 的准确率。
简而言之,计算机视觉就是关于模式识别的。计算机可以通过输入成千上万,甚至数百万张已标记的图像进行训练。研究人员随后对计算机应用各种软件技术,使其能够寻找模式。
计算机分析颜色、形状、物体之间的距离及其他各种元素,直到对这些图像进行分类。理论上,一旦计算机经过训练,它可以利用其经验在面对不同图像时识别各种类型的物体。
CV 有潜力改变行业及其运作方式。以下是一些值得深入探索的显著应用。
1. 机器视觉
企业以多种方式使用机器视觉,主要是为了提高质量、效率和操作。各种组件协同工作以使机器视觉系统正常运作,例如传感器、摄像头和照明。例如,机器视觉系统的常用照明选择包括荧光灯、LED 灯、石英卤素灯和金属卤化物灯(汞灯)。
机器视觉系统通常用于质量控制。例如,在农业中,收获机使用它来检测葡萄在藤上的位置,以便设备可以摘取葡萄串而不会破坏它们。
2. 交通运输
CV 在汽车行业中发挥着重要作用,因为它被应用于智能交通系统(ITS)。自动驾驶车辆和行人检测系统都依赖 CV。
汽车可以使用 CV 收集关于其周围环境的数据,进行解读,并作出相应反应。CV 使人们能够驾驶自动驾驶汽车(AV),并使驾驶更加安全、高效和可靠。
3. 制造业
自 1950 年代以来,制造商就已经使用 CV,随着技术的发展,更多的应用案例出现了。制造公司可以依靠 CV 来读取产品上的文字和条形码,检测有缺陷的产品,以及协助产品组装。
当 CV 可以帮助制造商剔除有缺陷的产品时,供应链中的每个人都会受益。总体而言,CV 已帮助制造业克服了一些最常见的挑战,这一趋势可能会继续下去。
4. 医疗保健
医疗保健领域使用 CV 来改善患者护理和协助手术。在医疗环境中使用 CV 的主要好处包括:
-
优化医学诊断
-
防止女性分娩时的出血
-
允许医生在病床旁花费更多时间
-
比人类更快地识别 CT 扫描中的主要问题
CV 在现代医学中可能成为一个主流,但在实施过程中存在一些障碍。医疗提供者可能需要一些时间来找到解决这些问题的可行方案。
5. 建筑业
CV 可以帮助建筑公司及其员工进行预测性维护,保持设备正常运行,并减少重大建筑项目中的停机时间。
CV 可以提醒工人设备问题,使他们能够采取主动措施在问题变得严重之前进行修复。此外,CV 可以提供个人防护装备检测 以确保工人的安全,这是行业不断努力实现的目标。
未来会有更多 CV 应用
CV 仍在不断发展,研究人员和开发者还面临一些障碍。他们在技术方面已经取得了很大进展。我们期待着看到 CV 如何变得更加广泛应用,并且对各种类型的公司来说更具经济性。
德文·帕蒂达是一位大数据和技术作家,同时也是 ReHack.com 的总编辑
更多相关内容
5 个必试的精彩 Python 数据可视化库
原文:
www.kdnuggets.com/2021/09/5-awesome-data-visualization-libraries-python.html
comments
由 Roja Achary 提供,机器学习爱好者
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
“可视化的目的是洞察,而不是图片。”
―本·施奈德曼

来源 – Venn 图
数据可视化是数据或信息的视觉呈现。数据可视化的目标是清晰有效地向读者传达数据或信息。通常,数据通过图表、信息图、图示、地图等形式进行可视化。
它有什么帮助?
-
识别趋势和异常值
-
在数据中讲述故事
-
强化论点或观点
-
突出数据集中的一个重要点
让我们深入了解它们。
所需库
使用包管理器 pip 安装以下库:
pip install matplotlib
pip install seaborn
pip install plotnine
pip install plotly
pip install bokeh
Matplotlib

Matplotlib 是一个全面的库,用于在 Python 中创建静态、动画和互动可视化。大多数编码人员都从 Matplotlib 开始他们的数据可视化之旅。
特性:
-
它的设计类似于 MATLAB,因此在两者之间切换相对容易。
-
包含许多渲染后端。
-
它可以再现几乎所有的图形(虽然需要一点努力)。
-
已经存在超过十年,因此拥有庞大的用户基础。
Seaborn
Seaborn 利用 Matplotlib 的强大功能,用几行代码创建美丽的图表。关键区别在于 Seaborn 的默认样式和颜色调色板,设计得更具美学和现代感。由于 Seaborn 是建立在 Matplotlib 之上,因此你需要了解 Matplotlib 以调整 Seaborn 的默认设置。
特性:
-
内置主题用于样式化 matplotlib 图形
-
可视化单变量和双变量数据
-
拟合和可视化线性回归模型
-
绘制统计时间序列数据
-
Seaborn 与 NumPy 和 Pandas 数据结构兼容良好
-
它带有内置的主题用于样式化 Matplotlib 图形
Plotnine

Plotnine 是 Python 中图形语法的实现,它基于 ggplot2。该语法允许用户通过明确映射数据到构成图表的视觉对象来组合图表。
特性:
-
统计变换
-
刻度
-
坐标系统
-
方面
-
主题
Bokeh
来源:Patrik Hlobil
Bokeh 是一个现代网页浏览器的互动可视化库。它提供了优雅、简洁的多功能图形构建,并在大型或流数据集上提供高性能的交互。Bokeh 可以帮助任何希望快速轻松创建互动图表、仪表板和数据应用的人。
特性:
-
灵活
-
互动
-
强大
-
高效
-
可共享
-
开源
Plotly
plotly 是一个互动的、开源的、基于浏览器的 Python 绘图库。构建在 plotly.js 之上,plotly.py 是一个高级的、声明式的绘图库。plotly.js 提供了 30 多种图表类型,包括科学图表、3D 图形、统计图表、SVG 地图、金融图表等。
特性:
-
图表,仪表板
-
文件导出,应用管理器
-
Kubernetes,认证
-
作业队列,快照引擎
-
嵌入,Python 的大数据
参考文献和帮助:
简历: Roja Achary (Kaggle, GitHub) 是一位机器学习爱好者和热情的学习者。她对人工智能、数据科学以及软件工程领域感兴趣,并且始终乐于进行有意义的合作。
相关:
-
Python 中的动画条形图竞赛
-
可视化如何改变探索性数据分析
-
直接使用 Pandas 获取交互式图表
更多相关内容
数据科学家需要了解的 5 个基本统计概念
原文:
www.kdnuggets.com/2018/11/5-basic-statistics-concepts-data-scientists-need-know.html
评论
统计学在数据科学(DS)的艺术中可以是一个强大的工具。从高层次来看,统计学是使用数学对数据进行技术分析。像条形图这样的基本可视化可能会给你一些高层次的信息,但通过统计学,我们可以以更加信息驱动和有针对性的方式操作数据。涉及的数学帮助我们对数据形成具体结论,而不仅仅是猜测。
使用统计学,我们可以更深入和更细致地了解数据的结构,并根据这种结构,如何最终优化地应用其他数据科学技术以获取更多信息。今天,我们将探讨数据科学家需要了解的 5 个基本统计概念以及它们如何最有效地应用!
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
统计特征
统计特征可能是数据科学中最常用的统计概念。这通常是你在探索数据集时会应用的第一个统计技术,包括偏差、方差、均值、中位数、百分位数等很多内容。所有这些都相当容易理解并在代码中实现!请查看下面的图示。
基本的箱形图
中间的线是数据的中位数值。中位数比均值更能抵御异常值的影响。第一个四分位数实际上是第 25 百分位数;即数据中 25%的点低于该值。第三个四分位数是第 75 百分位数;即数据中 75%的点低于该值。最小值和最大值代表数据范围的上下端。
箱形图完美地展示了我们可以用基本统计特征做什么:
-
当箱形图短时,这意味着你的数据点大部分都相似,因为在一个小范围内有很多值
-
当箱形图高时,这意味着你的数据点大多相差较大,因为值分布在一个较宽的范围内
-
如果中位数值接近底部,那么我们知道大多数数据具有较低的值。如果中位数值接近顶部,那么我们知道大多数数据具有较高的值。基本上,如果中位数线不在盒子的中间,则表示数据偏斜。
-
胡须是否非常长?这意味着您的数据具有高标准差和方差,即值分布广泛且变化较大。如果一个方向上的胡须很长而另一个方向上的胡须不长,那么您的数据可能只在一个方向上变化很大。
所有这些信息都来自几个简单的统计特征,这些特征容易计算!在需要快速而信息丰富的数据视图时,可以尝试这些。
概率分布
我们可以将概率定义为某事件发生的百分比机会。在数据科学中,这通常在 0 到 1 的范围内量化,其中 0 表示我们确定不会发生,而 1 表示我们确定会发生。概率分布是一个表示实验中所有可能值概率的函数。请查看下面的图示。
常见概率分布。均匀分布(左),正态分布(中),泊松分布(右)
-
均匀分布是我们这里展示的三种分布中最基本的一种。它有一个单一的值,仅在特定范围内出现,而在该范围之外的值为 0。它非常像是一个“开或关”的分布。我们也可以将其视为具有两个类别的分类变量的指示:0 或该值。您的分类变量可能有多个除了 0 之外的值,但我们仍然可以将其视为多个均匀分布的分段函数。
-
正态分布,通常称为高斯分布,由其均值和标准差具体定义。均值值在空间上移动分布,而标准差控制分布的扩展。与其他分布(例如泊松分布)不同的重要区别在于标准差在所有方向上都是相同的。因此,通过高斯分布,我们知道数据集的平均值以及数据的分布,即它是分布在广泛的范围内还是集中在几个值周围。
-
泊松分布类似于正态分布,但具有额外的偏度因素。当偏度值较低时,泊松分布在所有方向上都会有相对均匀的分布,就像正态分布一样。但当偏度值的绝对值较高时,数据的分布在不同方向上会有所不同;在一个方向上会非常分散,而在另一个方向上则高度集中。
还有许多其他分布可以深入研究,但这三种分布已经给了我们很多价值。我们可以通过均匀分布快速查看和解释我们的分类变量。如果我们看到高斯分布,我们知道许多算法默认情况下会在高斯数据上表现良好,所以我们应该选择这些算法。对于泊松分布,我们需要特别注意,选择一个对空间分布变化具有鲁棒性的算法。
降维
术语降维非常直观易懂。我们有一个数据集,希望减少其维度。在数据科学中,这就是特征变量的数量。查看下面的图示了解详细说明。
降维
这个立方体代表我们的数据集,它有 3 个维度,总共有 1000 个点。现在以今天的计算能力,处理 1000 个点很容易,但在更大规模上我们会遇到问题。然而,只需从二维视角来看我们的数据,例如从立方体的一侧,我们可以看到从那个角度划分所有颜色非常简单。通过降维,我们将 3D 数据投影到 2D 平面上。这有效地将我们需要计算的点数减少到 100,节省了大量计算资源!
另一种降维的方法是通过特征剪枝。通过特征剪枝,我们基本上是希望移除我们认为对分析不重要的特征。例如,在探索数据集后,我们可能会发现 10 个特征中,有 7 个与输出的相关性很高,而另外 3 个相关性很低。那么,那 3 个低相关性的特征可能不值得计算,我们可以从分析中移除它们而不影响输出。
最常用的降维技术是 PCA,它本质上创建了特征的向量表示,显示了它们对输出的重要性,即它们的相关性。PCA 可以用于执行上述两种降维风格。阅读更多关于它的内容在this tutorial。
过采样和欠采样
过采样和欠采样是用于分类问题的技术。有时,我们的分类数据集可能会偏向某一侧。例如,我们有 2000 个类别 1 的样本,但类别 2 只有 200 个。这会干扰我们尝试使用的许多机器学习技术来建模数据和做出预测!我们的过采样和欠采样可以解决这个问题。查看下面的图示了解详细说明。
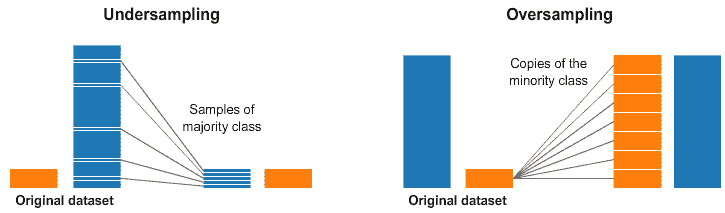
欠采样和过采样
在上面图片的左右两侧,我们的蓝色类别样本远多于橙色类别。在这种情况下,我们有两个预处理选项,可以帮助训练我们的机器学习模型。
欠采样意味着我们只选择多数类中的部分数据,仅使用与少数类相同数量的样本。这种选择应保持类别的概率分布。很简单!我们只需通过减少样本来平衡数据集!
过采样意味着我们将创建副本以使少数类的样本数量与多数类相同。副本将按原样分布,以保持少数类的分布。我们只是通过不获取更多数据而平衡了数据集!
贝叶斯统计
完全理解为什么我们使用贝叶斯统计需要我们首先了解频率统计的不足。频率统计是大多数人在听到“概率”一词时想到的统计类型。它涉及应用数学来分析某个事件发生的概率,具体来说,我们计算的唯一数据是先验数据*。

让我们看一个例子。假设我给了你一个骰子,问你掷出 6 的机会是多少。大多数人会说这是 1/6。如果我们进行频率分析,我们会查看某人掷骰子 10,000 次的数据,并计算每个数字的频率;结果大约是 1/6!
但如果有人告诉你,特定的骰子是你得到的,并且它被加重以总是落在 6 上呢?由于频率分析只考虑先验数据,所以关于骰子被加重的证据是未被考虑的。
贝叶斯统计确实考虑了这些证据。我们可以通过查看贝叶斯定理来说明这一点:
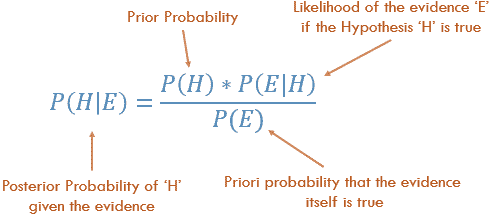
贝叶斯定理
我们方程中的概率P(H)基本上是我们的频率分析;根据我们的先验数据,事件发生的概率是多少。方程中的P(E|H)称为似然性,本质上是给定我们频率分析的信息,我们证据正确的概率。例如,如果你想掷骰子 10,000 次,而前 1000 次都掷出 6,你可能会开始相当相信那个骰子是被加重的!P(E)是实际证据为真的概率。如果我告诉你骰子是加重的,你能相信我并说它实际上是加重的,还是认为这是一个把戏?!
如果我们的频率分析非常好,那么它将对我们的 6 的猜测有一定的权重。同时,我们会考虑有偏骰子的证据,根据其先验和频率分析来判断其真实性。正如方程布局所示,贝叶斯统计考虑了一切。当你觉得先前的数据不能很好地代表你未来的数据和结果时,使用它。
喜欢学习?
在twitter上关注我,我会发布关于最新最棒的 AI、技术和科学的内容!
简介: 乔治·赛夫 是一名认证极客和 AI / 机器学习工程师。
原文。经许可转载。
相关:
-
数据科学家需要了解的 5 种聚类算法
-
选择适合你回归问题的最佳机器学习算法
-
Python 中 5 个快速简单的数据可视化代码
更多相关主题
数据科学面试的 5 种基本问题类型
原文:
www.kdnuggets.com/2016/12/5-basic-types-data-science-interview-questions.html
评论
作者:Roger Huang,Springboard。
这是Springboard 数据科学面试指南的摘录。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 加速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT

“总是解释你选择背后的思考过程以及指导这些选择的假设。”
数据科学面试对许多人来说是令人畏惧且复杂的难关。但尽管它们正在不断演变,典型的数据科学面试的技术部分通常是相当可预测的。大多数候选人通常会遇到的问题通常涵盖行为、数学、统计、编码和情景。然而,虽然这些问题在细节上有所不同,如果你能确定每个问题属于哪个类别,回答起来可能会更容易。以下是问题的分类及其准备方法。
1. 行为问题
与其他面试类似,这些问题旨在测试你的软技能并查看你是否与公司文化相符。
例子:你对上一份工作有什么喜欢和不喜欢的地方?
这里的意图是确定你面试的角色是否适合你的性格和气质,以及确定你为什么离开上一份职位。
不要过度思考,也不要认为这里的关键点与其他类型的面试有很大不同:只需充分了解角色,避免谈论你过去与特定人员的问题,并在描述你不喜欢什么及其原因时保持专业。数据科学角色可能要求有分析思维,但招聘经理仍然希望听到你对工作的热情所在。
2. 数学问题
数据科学家角色中,除了需要实现算法外,还需要根据具体目的对其进行调整,这通常会涉及数学问题。
示例:线性回归算法如何确定最佳系数值?
关键在于查看你对线性回归的理解有多深入,这一点至关重要,因为在许多数据科学角色中,你不仅要处理黑箱中的算法;你还需要将它们付诸实践。这个问题类别测试你对实际发生的情况了解多少。
所以这是那些“展示你的工作”时刻之一。追踪你思考的每一步并写下方程。在你写出解决方案时,描述你的思考过程,以便面试官能看到你的数学逻辑。
3. 统计问题
不用说,扎实掌握统计学对于解决不同的数据科学问题非常重要。你很可能会被考察你在统计推理能力和统计理论知识方面的表现。
示例:什么是第一类错误和第二类错误的区别?
证明你的能力需要展示你对统计学基础的理解。但更重要的是,面试官还希望看到你是否能够运用统计学的技术语言和逻辑来处理你可能不常用的思想——并且仍能清晰沟通。因此,对你的回答要直接了当。使用相关的统计知识来得出答案,但对你被要求定义的内容要尽可能直接。
4. 编码问题
大多数数据科学角色的重要部分是编程以规模化实现算法。这些问题类似于候选人在软件工程面试中遇到的问题;它们旨在测试你对公司使用的技术工具的经验以及你对编程理论的整体知识。
示例:从头开始开发一个 K 近邻算法。
展示你能够清晰地写出算法背后的思路,并在时间限制下高效地部署它,是展示你工程技能的绝佳方式。这通常对那些既懂算法又了解技术实现的数据科学家,或对算法有所背景的数据工程师提出。
无论如何,这类问题测试你对矩阵运算的理解以及如何处理向量和矩阵。因此,从一个输入输出样本集开始,手动计算答案。在进行时,注意 时间/空间复杂度。
5. 情境问题
最后但同样重要的是,情景问题旨在测试你在不同数据科学领域的经验和知识,以了解你的能力在实践中的限制。尽可能彻底地展示你的应用知识,你在任何案例分析中都会表现出色。
示例:如果你是一个在销售鞋子的网络公司的数据科学家,你会如何建立一个推荐鞋子给访客的系统?
这个问题旨在了解你如何设想自己的工作从头到尾交付产品或服务。情景问题并不是测试你在每个领域的知识;它们旨在探讨产品从开始到交付的生命周期,并了解候选人在每个阶段可能遇到的限制。但这些问题也评估整体知识,例如,管理一个团队以交付最终产品需要什么——以确定候选人在团队情境中的表现。
在这里,通常的面试建议同样适用:诚实地说明你能带来大量价值的地方,但也不要害羞地提到你期望从团队成员那里获得一些帮助。尽量关联你的技术知识如何帮助业务成果,并始终解释你选择的思路和指导这些选择的假设。并且不要犹豫去提问,以帮助你洞察面试官的意图,从而更好地调整你的回答。
数据科学面试可能会很棘手——你需要现场编程并提出技术算法,同时你也会被用与非技术角色相同的标准来衡量。你的统计和数学知识会受到考验,你的团队领导能力、沟通能力、说服力和影响力也会受到评估。
因此,与其试图为每一个可能的问题做好准备,不如为这五种类型的问题做好准备。你无法预见到所有的问题,但你可以相当准确地预测招聘经理的需求和期望,然后为此做好准备。
简介:Roger Huang 在 Springboard 从事增长工作。他通过分析一家大型制药公司价值 7 亿美元的销售数据,成功进入了数据职业生涯。现在,他撰写内容,汇集 Springboard 网络中的数据专家的见解,帮助他人也能做到这一点。
本文最初发表于 Fast Company。经许可转载。
相关内容:
-
21 个必须了解的数据科学面试问题及答案
-
提高数据科学面试表现的 10 个技巧
-
完美数据科学面试的秘密
更多相关主题
5 个适合初学者的步骤,使用 Python 学习机器学习和数据科学
原文:
www.kdnuggets.com/2019/09/5-beginner-friendly-steps-learn-machine-learning-data-science-python.html
评论
由丹尼尔·博克,机器学习工程师

照片由山姆·博克提供。谢谢你,山姆。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你所在组织的 IT
两年前,我开始在线自学机器学习。我通过 YouTube 和我的博客分享了我的学习历程。我当时不知道自己在做什么。我之前从未编程过,但决定要学习机器学习。
当人们找到我的工作时,他们有时会联系我并询问问题。我没有所有的答案,但我会尽量回复尽可能多的问题。我收到的最常见的问题是“我从哪里开始?”其次常见的问题是“我需要知道多少数学?”
今天早上,我回答了这些问题中的一小部分。
有人告诉我他们已经开始学习 Python,并希望进入机器学习领域,但不知道下一步该做什么。
我已经学会了 Python,接下来我该做什么?
我在回复中整理了几个步骤,我在这里复制了它们。你可以将它们视为从完全不懂编程到成为机器学习从业者的粗略大纲。
我的学习风格是先编程。先让代码运行,然后在需要时再学习理论、数学、统计学和概率学,而不是提前学习。
记住,如果你刚开始学习机器学习,可能会感到有些吓人。有很多内容。慢慢来。收藏这篇文章,以便随时参考。
我偏向使用 Python,因为这是我开始学习的语言并且一直在使用。你可以使用其他语言,但这些步骤是针对 Python 的。
1. 学习 Python、数据科学工具和机器学习概念
电子邮件中说他们已经学过一些 Python。但这个步骤也适用于完全新手。花几个月时间同时学习 Python 编程和不同的机器学习概念。你将同时需要这两者。
在学习 Python 代码的同时,练习使用数据科学工具,如 Jupyter 和 Anaconda。花几个小时去玩玩这些工具,了解它们的用途以及为何要使用它们。
学习资源
-
AI 要素— 主要人工智能和机器学习概念的概述。
-
Coursera 上的 Python for Everybody— 从零开始学习 Python。
-
freeCodeCamp 的 Python 学习— 一个视频中讲解所有主要的 Python 概念。
-
Corey Schafer 的 Anaconda 教程— 在一个视频中学习 Anaconda(你将用来为数据科学和机器学习设置计算机)。
-
Dataquest 的 Jupyter Notebook 入门教程— 在一篇文章中快速入门 Jupyter Notebooks。
-
Corey Schafer 的 Jupyter Notebook 教程— 在一个视频中学习如何使用 Jupyter Notebooks。
2. 学习 Pandas、NumPy 和 Matplotlib 的数据分析、操控与可视化
一旦你掌握了一些 Python 技能,你会想学习如何处理和操控数据。
要做到这一点,你应该熟悉pandas、NumPy 和 Matplotlib。
pandas 将帮助你处理数据框,这些是类似于 Excel 文件中的表格信息。想象一下行和列。这种数据被称为结构化数据。
NumPy 将帮助你对数据进行数值操作。机器学习将你能想到的一切转化为数字,然后在这些数字中寻找模式。
Matplotlib 将帮助你制作图表和数据可视化。理解表格中的大量数字对人类来说可能很困难,我们更倾向于看到一条穿过图表的线。制作可视化是传达你的发现的重要部分。
学习资源
-
Coursera 上的应用数据科学与 Python— 开始将你的 Python 技能应用于数据科学。
-
pandas in 10-minutes— pandas 库及其一些最有用功能的快速概述。
-
Codebasics 的 Python Pandas 教程— YouTube 系列,讲解 pandas 的所有主要功能。
-
NumPy 教程 by freeCodeCamp— 在一个 YouTube 视频中学习 NumPy。
-
Sentdex 的 Matplotlib 教程— YouTube 系列,教授 Matplotlib 的所有最有用特性。
3. 使用 scikit-learn 学习机器学习
现在你已经掌握了操控和可视化数据的技能,是时候在数据中寻找模式了。
scikit-learn 是一个包含许多有用机器学习算法的 Python 库,随时供你使用。
它还具有许多其他有用的功能,以帮助你判断你的学习算法学得如何。
专注于学习机器学习问题的种类,比如分类和回归,以及哪些算法最适合这些问题。暂时不用从零开始理解每个算法,首先学习如何应用它们。
学习资源
-
Data School 提供的使用 scikit-learn 的 Python 机器学习课程 — 讲解 scikit-learn 主要功能的 YouTube 播放列表。
-
Daniel Bourke 的《探索性数据分析的温和介绍》 — 将前两步中学到的内容整合到一个项目中。包含代码和视频,帮助你进入你的第一个 Kaggle 比赛。
-
Daniel Formosso 的 scikit-learn 探索性数据分析笔记本 — 上述资源的更深入版本,包含一个完整的项目。
4. 学习深度学习神经网络
深度学习和神经网络在没有太多结构的数据上效果最好。
数据框架有结构,图像、视频、音频文件和自然语言文本有结构但相对较少。
小贴士: 在大多数情况下,你会想对结构化数据使用决策树的集成方法(如随机森林或 XGBoost),而对非结构化数据则会使用深度学习或迁移学习(将预训练神经网络应用于你的问题)。
你可以为自己开始一个记录,将这些小信息收集起来。
学习资源
-
Coursera 上 Andrew Ng 的 deeplearning.ai — 由业界顶尖专家教授的深度学习课程。
-
fast.ai 由 Jeremy Howard 提供的深度学习课程 — 由行业顶尖从业者之一教授的实用深度学习方法。
5. 额外课程与书籍
在学习过程中,最好用自己的小项目来实践所学内容。这些项目不需要是复杂的世界改变者,但应该是你可以说“我用 X 做了这个”的东西。然后通过 Github 或博客分享你的作品。Github 用于展示你的代码,博客用于展示你如何沟通你的工作。你应该为每个项目发布一项。
申请工作的最佳方式是已经完成所需的工作。分享你的作品是向潜在未来雇主展示你能力的好方法。
在你熟悉使用一些不同的机器学习和深度学习框架后,可以尝试通过从零开始构建它们来巩固你的知识。你不一定需要在生产或机器学习角色中这样做,但了解事物的内部运作将帮助你在自己的工作基础上进行构建。
学习资源
-
如何开始自己的机器学习项目,作者:Daniel Bourke——开始自己的项目可能很困难,本文给你一些建议。
-
Jeremy Howard 的《fast.ai 深度学习基础》——一旦你从顶层开始,这个课程将帮助你从底层填补空白。
-
Andrew Trask 的《Grokking Deep Learning》——这本书将教你如何从零开始构建神经网络以及你为何需要了解这一过程。
-
这些书籍将帮助你学习机器学习,作者:Daniel Bourke——YouTube 视频讲解一些最佳的机器学习书籍。
每一步需要多长时间?
你可能会在每一部分上花费 6 个月或更长时间。不要急于求成。学习新事物需要时间。作为数据科学家或机器学习工程师,你主要是在培养提问的能力,然后使用你的工具尝试找到答案。
有些日子你会觉得自己什么都没学到,甚至在倒退。忽略它。不要逐日比较你的进展。要逐年比较进展。
我可以在哪里学习这些技能?
我已经列出了一些资源,它们都可以在网上找到,大多数是免费的,但还有很多其他的资源。
DataCamp是做这些的大好去处。否则,我的机器学习和人工智能资源数据库包含了一个很好的免费和付费学习材料档案。
记住,作为数据科学家或机器学习工程师的一部分工作就是解决问题。把你的第一个任务当作了解每一步的更多内容,并创建自己的课程来帮助你学习它们。
如果你想了解一个自创的机器学习课程样例,请查看我的自创 AI 硕士学位。这是我从零编码到成为机器学习工程师的 9 个月使用的课程。虽然不完美,但这是我的,所以它有效。
那统计学呢?那数学呢?那概率学呢?
你会在过程中学习这些东西。先从代码开始。让事情运行起来。在你的代码运行之前试图学习所有的统计学、所有的数学、所有的概率学就像是在试图煮海洋。这会拖慢你的进度。
如果你的代码不能运行,那么统计学、数学和概率学都没有意义。先让代码运行起来,然后利用你的研究技能来确定它是否正确。
那认证呢?
认证很好,但你不是为了它们而来的。你是为了技能。
不要像我一样犯错,认为更多的认证等于更多的技能。不是的。
通过上述课程和资源建立基础知识,然后通过自己的项目建立特定知识(那些无法通过教学获得的知识)。
如果你有问题,请在下面留言,以便其他人也能看到。否则,随时联系我。在可能的情况下使用了附属链接,更多关于我合作伙伴的信息请点击这里。
你可以在YouTube 上找到这篇文章的视频版本。
简介:Daniel Bourke 在技术、健康和艺术的交汇处活动。每日文章请访问:www.mrdbourke.com
原文。转载已获许可。
相关链接:
-
我作为机器学习工程师的第一年学到的 12 件事
-
新数据科学家的建议
-
数据科学入门
更多相关话题
5 个最佳端到端开源 MLOps 工具
原文:
www.kdnuggets.com/5-best-end-to-end-open-source-mlops-tools

图片作者
由于 2024 年你必须尝试的 7 个端到端 MLOps 平台 博客的受欢迎程度,我正在编写另一份开源端到端 MLOPs 工具的列表。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
开源工具提供了对数据和模型的隐私保护和更多控制。然而,你需要自己管理这些工具,部署它们,然后雇佣更多人来维护它们。此外,你还将负责安全性和任何服务中断。
简而言之,付费的 MLOps 平台和开源工具都有优缺点;你只需选择适合你的即可。
在这篇博客中,我们将了解 5 种端到端开源 MLOps 工具,用于训练、跟踪、部署和监控生产中的模型。
1. Kubeflow
kubeflow/kubeflow 使所有机器学习操作在 Kubernetes 上变得简单、可移植和可扩展。它是一个云原生框架,允许你创建机器学习管道,并在生产环境中训练和部署模型。
图片来自 Kubeflow
Kubeflow 兼容于云服务(AWS、GCP、Azure)和自托管服务。它允许机器学习工程师集成各种 AI 框架用于训练、微调、调度和部署模型。此外,它提供了一个集中式仪表板,用于监控和管理管道、使用 Jupyter Notebook 编辑代码、实验跟踪、模型注册和工件存储。
2. MLflow
mlflow/mlflow 通常用于实验跟踪和日志记录。然而,随着时间的推移,它已成为一个端到端的 MLOps 工具,适用于各种机器学习模型,包括 LLMs(大型语言模型)。
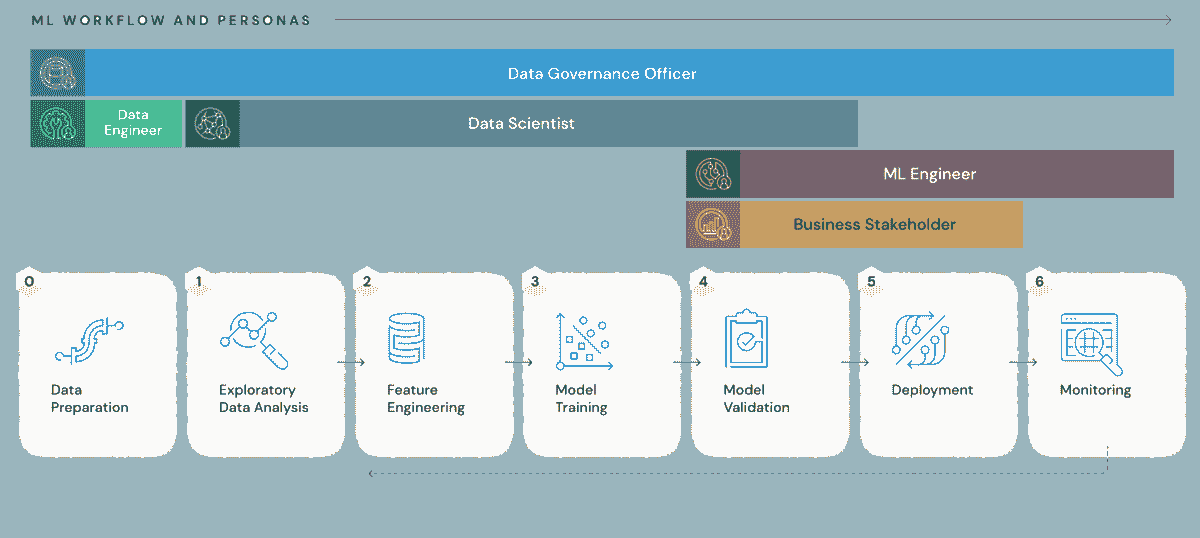
图片来自 MLflow
MLFlow 有 6 个核心组件:
-
跟踪:版本控制和存储参数、代码、指标和输出文件。它还提供交互式指标和参数可视化。
-
项目:将数据科学源代码打包以便于重用和可重复性。
-
模型:以标准格式存储机器学习模型和元数据,供下游工具后续使用。它还提供模型服务和部署选项。
-
模型注册表:用于管理 MLflow 模型生命周期的集中式模型存储库。它提供版本控制、模型谱系、模型别名、模型标记和注释。
-
配方(管道):机器学习管道,让你快速训练高质量模型并将其部署到生产中。
-
大语言模型(LLMs):支持 LLMs 评估、提示工程、跟踪和部署。
你可以使用 CLI、Python、R、Java 和 REST API 管理整个机器学习生态系统。
3. Metaflow
Netflix/metaflow 允许数据科学家和机器学习工程师快速构建和管理机器学习/AI 项目。
Metaflow 最初在 Netflix 开发,以提高数据科学家的生产力。它现在已经开源,所有人都可以受益。
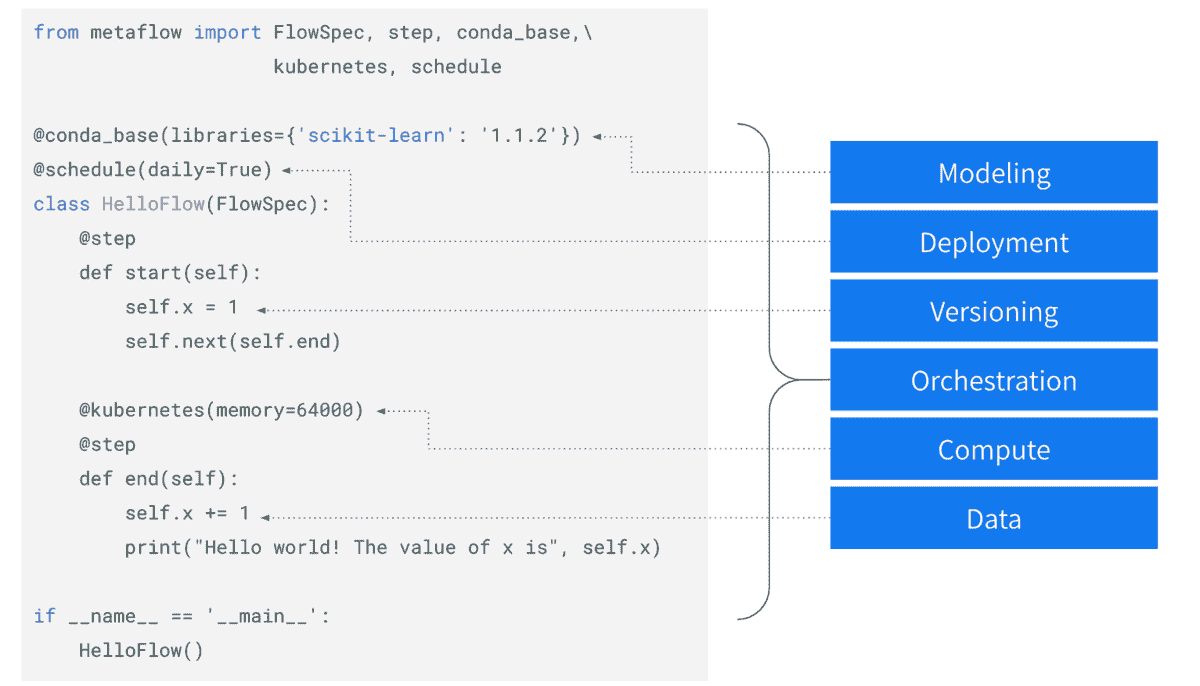
图像来自 Metaflow Docs
Metaflow 提供了一个统一的 API,用于数据管理、版本控制、编排、模型训练和部署,以及计算。它兼容主要的云服务提供商和机器学习框架。
4. Seldon Core V2
SeldonIO/seldon-core 是另一个流行的端到端 MLOps 工具,它让你打包、训练、部署和监控生产中的数千个机器学习模型。
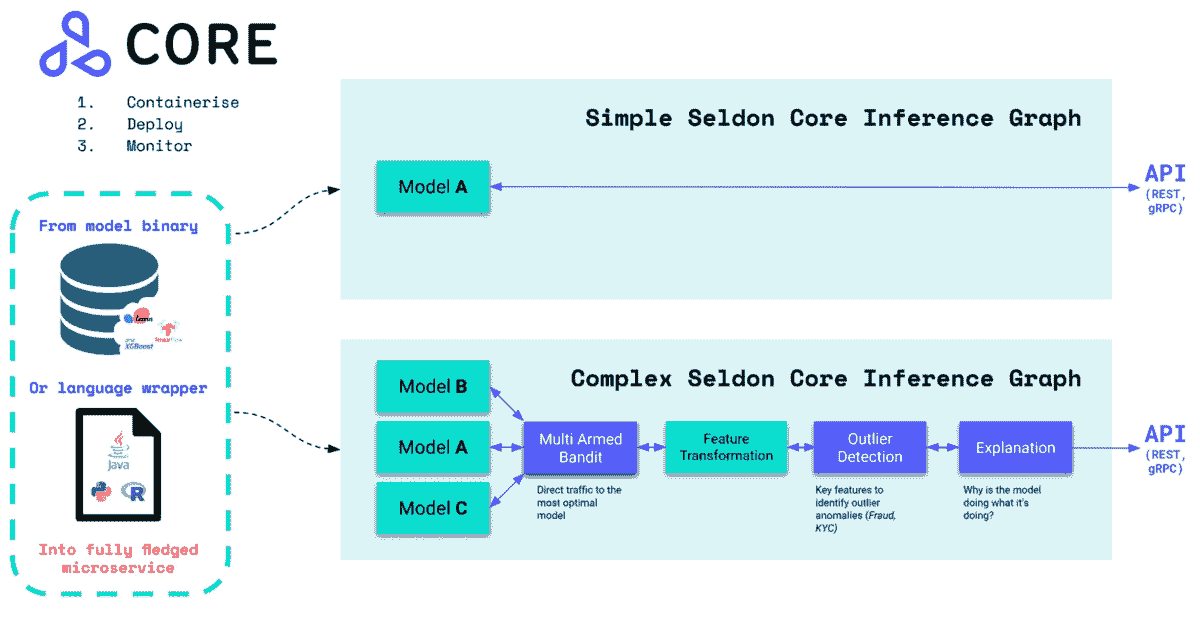
图像来自 seldon-core
Seldon Core 的关键特性:
-
使用 Docker 在本地或在 Kubernetes 集群中部署模型。
-
跟踪模型和系统指标。
-
部署漂移和异常检测器与模型一起。
-
支持大多数机器学习框架,如 TensorFlow、PyTorch、Scikit-Learn、ONNX。
-
数据中心的 MLOps 方法。
-
CLI 用于管理工作流、推理和调试。
-
通过透明地部署多个模型来节省成本。
Seldon Core 将你的机器学习模型转换为 REST/GRPC 微服务。我可以轻松扩展和管理数千个机器学习模型,并提供额外的功能,如指标跟踪、请求日志、解释器、异常检测器、A/B 测试、金丝雀测试等。
5. MLRun
mlrun/mlrun 框架允许轻松构建和管理生产中的机器学习应用程序。它简化了生产数据摄取、机器学习管道和在线应用程序,显著减少了工程工作量、生产时间和计算资源。
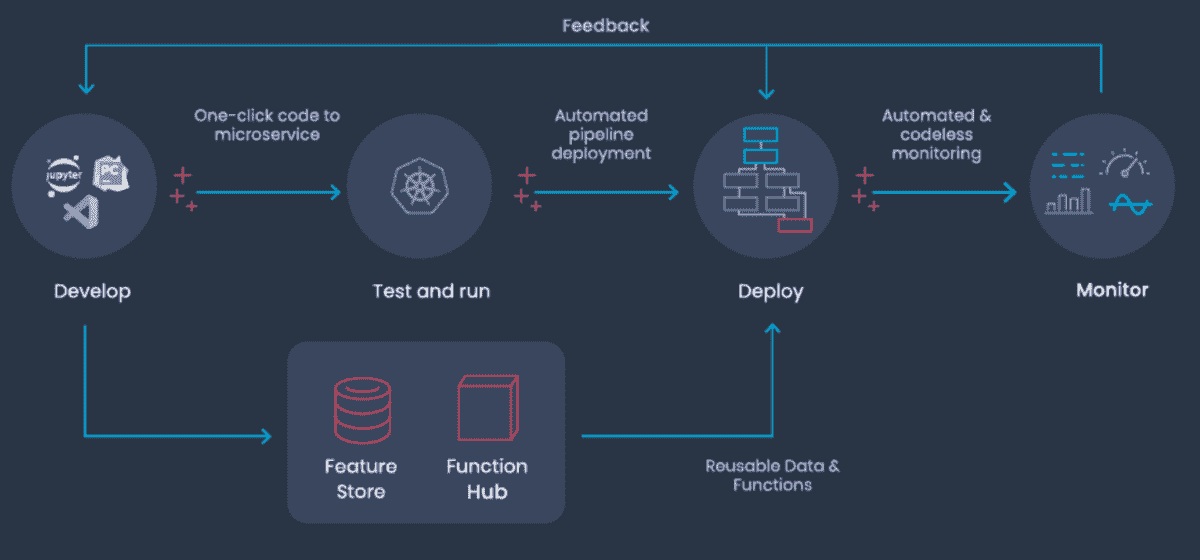
图片来源于 MLRun
MLRun 的核心组件:
-
项目管理:一个集中管理各种项目资产的中心,如数据、函数、作业、工作流、机密等。
-
数据和工件:连接各种数据源,管理元数据、目录,并对工件进行版本控制。
-
特征存储:存储、准备、目录化和提供模型特征,以用于训练和部署。
-
批处理和工作流:运行一个或多个函数,并收集、跟踪和比较它们的所有结果和工件。
-
实时服务管道:快速部署可扩展的数据和机器学习管道。
-
实时监控:监控数据、模型、资源和生产组件。
结论
与其为 MLOps 管道中的每个步骤使用不同的工具,不如只使用一个工具完成所有步骤。只需一个端到端的 MLOps 工具,你就可以训练、跟踪、存储、版本控制、部署和监控机器学习模型。你只需通过 Docker 或在云上本地部署它们即可。
使用开源工具适合需要更多控制和隐私的情况,但它带来了管理、更新、安全问题和停机时间的挑战。如果你是 MLOps 工程师的新手,我建议你先专注于开源工具,然后再转向如 Databricks、AWS、Iguazio 等托管服务。
希望你喜欢我关于 MLOps 的内容。如果你想阅读更多内容,请在评论中提及或通过 LinkedIn 联系我。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一款 AI 产品,帮助那些面临心理健康问题的学生。
更多相关内容
数据科学领域的 5 个最佳行业
原文:
www.kdnuggets.com/2017/10/5-best-industries-find-job-data-science.html
评论

数据驱动着我们现在做的一切。这也意味着我们如何积累、传播、研究、存储和利用数据是最重要的工作之一。这也许就是为什么数据科学如此繁荣的原因——这个行业预计到 2025 年将达到 160 亿美元的市场价值。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域的职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
现在追求这一领域的职业生涯从未如此有利。作为数据科学家,你将获得的技能非常宝贵,你可能会在像 IBM、可口可乐、福特汽车和优步这样多样化的公司工作,也有可能参与无数旨在建设更好世界的公益和非营利事业。
关键在于,世界是复杂的,而数据帮助我们理解它。考虑到这一点,这里有五个极具实践性和激动人心的领域,你可以通过数据科学教育在其中留下你的印记。
1. 生物技术
科学和医学一直以来都紧密相关。未来,随着技术的进步和发达国家及发展中国家重新承诺公共卫生,所有与健康相关的行业都将需要数据科学家——包括生物技术领域。
这个领域将比以往任何时候都更需要数据科学家,原因重大:我们站在揭示人类基因组秘密的门槛上。实现这一目标需要几乎难以想象的庞大数据量,但一旦我们破解它,就会看到治疗方法、医疗设备等领域的研究和发展出现爆炸性增长。
作为这个领域的一个数据科学家,你将帮助开发新的方法来研究大量数据——包括交互式和语义技术,甚至机器学习。在这个层次上的工作将影响哪些治疗方法、技术和药物会进入更广泛的测试,并最终进入市场。
2. 能源
一些能源来源比其他能源更加现代化。但是,与为世界供电的所有行业相关的行业都依赖于数据 - 大量数据。无论我们正在探索从地球中提取能源和矿产财富的新方法,构思更新、更安全的原油储存和运输方式,还是在做负责任的事情并建造更好、更便宜的太阳能电池板,能源部门对数据科学家有着很高的需求。
正是最后一项行业 - 太阳能行业 - 吸引了很多人追求与能源相关的数据丰富职业。由太阳能和风能场提供的清洁能源生产,显然是未来的发展方向,这一点可以从大多数北欧国家的成功看出,这些国家普遍制定了 100%可持续能源目标。
就像开发油田需要研究大量的数据一样,安装和改进清洁能源生产设施也需要关于自然环境和现代建设需求的数据。数据科学家也经常被要求提高安全性和帮助企业遵守新的安全和环境法规。
3. 质量控制和源检验
当企业变得草率时,每个人都受苦。但是要构建一个更好的老鼠夹 - 或者任何其他产品 - 意味着您需要与各种有意义的数据保持联系。你有没有被你最喜欢的应用程序请求,请好心给个评价?这是一种众包的质量控制。您分配的数值评级和评价的积极性或消极性都是被汇总的数据。
质量控制和源检验本身是一门行业。如果你正在进行源检验等工作,你可能需要查看有关生产方法、瓶颈和持久性低效区域的数据。你善于观察的眼睛可以理解使用和破损模式,优化生产和运输,并最终提供能够更好、更安全地为世界提供产品的见解和洞察力。
4. 运输
就像列表中的其他行业一样,运输行业也正在经历一些非常特殊的变化。例如,特斯拉通过发布一款能够自动驾驶的长途卡车,彻底改变了整个货运行业。特斯拉并不是第一个承诺这样做的企业 - 这个未来已经等了很久。但现在它已经到来,我们正在生活其中。
除了自动驾驶汽车和明显的运输应用之外,运输行业还在寻找更加高效的存储和输送能源的方式。这些突破密切与动荡的监管环境和更好的电池技术的发展联系在一起。简而言之,非常重要的运输行业中的每个领域都期待从熟练的数据科学家中受益。
5. 电信
互联网不是“一连串的管道”——它就是数据。未来的互联网将是一个遍及全球的卫星和用户设备之间通过区块链和其他一系列技术进行通信,这些技术目前还不是家喻户晓的词汇,但很快就会成为。
实际上,我们很难给予数据架构和数据科学的重要性过高评价,因为它们将继续推动互联网发展成为其本来应该具有的样子:一个统一、文明和民主化的交流媒介。当我们需要告知人们一款新产品时,我们需要用户数据。当我们需要确定在哪里埋设新的光纤电缆时,我们需要环境数据。我们依赖数据科学家设计和推出更节能的服务器农场。
当下,我们谈论的一切都与互联网有关。而没有信息和有意义的数据的自由交流,互联网是不可能存在的。虽然一些人可能试图从世界中抹去知识,将其从互联网中清除,但他们现在必须知道,他们生活在一个这种做法并不可行的世界。
数据科学是当今一个令人兴奋且重要的领域,随着技术和全球化的发展,它只会变得更加重要。如果你对模式、数字和分析有头脑,这个领域可能非常适合你。
个人简介:Kayla Matthews 在《The Week》、《数据中心杂志》和《VentureBeat》等刊物上讨论技术和大数据,并已经写作超过五年。阅读更多 Kayla 的文章,订阅她的博客 Productivity Bytes。
相关:
-
如何成为数据科学家:权威指南
-
Python 突然变得非常流行的 6 个原因
-
机器学习和机器人技术正在改变的 4 个行业
此主题还有更多相关文章
托管数据科学作品集的 5 个最佳地点
原文:
www.kdnuggets.com/2022/07/5-best-places-host-data-science-portfolio.html

图片由 Christina Morillo 提供
数据科学是一个具有巨大潜力和增长的新兴领域。根据 IBM 的数据,数据科学家的需求以 5% 的年增长率增长。而 DevSkiller 的一份报告显示,数据科学相关任务的需求 增加了 295%。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织进行 IT
然而,目前的劳动力不足以满足不断增长的需求。这意味着竞争较少,雇主支付高薪(平均 $118,972),并提供一些丰厚的福利来吸引人才。
如果你计划进入这个领域,你必须具备交付高质量工作的能力。那么,你如何展示你的 数据科学家技能 和能力呢?这个问题的答案是在线平台,在这些平台上你可以发布你的作品集并抓住机会。
为什么建立作品集对数据科学家很重要?
数据科学领域已经变成了每个人都想要获得的隐藏宝藏;越来越多的人离开他们目前的职业,开始新的职业生涯,成为数据科学家。
构建一个数据科学作品集展示了你的技术和管理技能,以及在不同情况下或环境下工作的能力。持续提升你的作品集也能带来学习机会。
托管数据科学作品集的最佳平台
当你的作品集准备好后,你可以将其上传并发布到以下平台。你可以在多个网站上分享你的作品集,以最大化曝光率。
1. 社交媒体平台
作为一名数据科学家,你可以从社交媒体中获得显著的好处,这些平台不仅仅限于常规活动。一些平台已经成为企业和员工沟通和寻找工作的中心。
你可以使用像 Twitter 和 LinkedIn 这样的社交平台来参与有意义的内容和讨论。LinkedIn 还允许你添加以前的工作经历并连接到你想要的受众。
按照这里详细介绍的方法建立强大的作品集,在社交媒体上创建不可错过的存在:
-
始终通过文明对话重视他人 - 贡献于社区的人更有可能被雇主接触。
-
不要专注于自我推广,要自然地与流程合作。你不想进行垃圾信息推广,因为这可能会影响你的信誉。
-
扩展你的联系,并联系不同行业、地区和视角的新人士,以获取完整的视图,而不是停留在你的知识泡沫中。
分享你的经验和案例研究,提供解决方案以突出你的个人资料并吸引更多人。LinkedIn 还可以向你发送定制的职位提醒。
2. DataCamp Workspace
这个基于云的笔记本具有协作功能,让你可以与团队一起工作、分析数据并发布你的分析结果。
此外,你可以编写代码并在浏览器中共享见解,同时通过VoIP 技术保持与团队的连接,以确保及时沟通和数据发布。
对于需要练习的初学者,Datacamp Workspace 提供了超过 20 个预加载的数据集,你可以分析这些数据集并将其作为你作品的一部分。除了这些数据集,Datacamp 还有预编写的代码,可以帮助你节省时间,避免重复编写代码,并允许你更快地报告结果。
Datacamp 中的数据分析包括使用条形图和折线图等可视化表示法,适用于 R 和 Python 编程语言。最棒的是,Datacamp 笔记本已经获得 ISO 27001:2017 认证,以确保安全性和保密性。
3. GitHub
GitHub 是一个受开发者和程序员欢迎的平台,用于存储他们的代码仓库并在可能的情况下进行更改。它允许其社区成员从世界任何地方共同工作,使其成为数据科学家的理想平台。
想要分享自己工作的数据科学家可以使用 GitHub 的开源项目分享功能,使他们能够分享代码并共同跟踪问题。使用 GitHub 是免费的且简单的;只需按照以下步骤开始在 GitHub 上分享你的数据科学家作品集:
-
访问 GitHub 网站并创建一个用户帐户。
-
获取有关如何使用 GitHub 及其功能的基本信息。GitHub 文档可以为你提供基础信息。
-
使用 GitHub Pages,通过创建一个新公共仓库并使用你想要的用户名来上传你的站点。
-
使用 macOS 和桌面版本的 GitHub,刷新 GitHub 页面并完成安装。
-
在你的文本编辑器中为你的项目创建一个 index.html。
-
完成后,点击发布。
4. Kaggle
Kaggle 是数据科学家和机器学习社区中一个受欢迎的平台。它允许你与其他数据科学家联系,通过发布和分享笔记本和数据集来帮助他们解决问题。
Kaggle 提供了干净且适合使用的数据集;不愿直接处理复杂数据集的初学者可以从这个平台和社区中获得显著的好处。Kaggle 根据竞赛(由平台或其他知名组织创建的任务)分为不同的类别:
-
初级数据科学家可以参加持久的竞赛,以磨练他们的技能并获得深入的知识。
-
Kaggle 竞赛的下一阶段是一个时间限制的竞赛,你可以在其中证明自己有能力解决数据科学问题。
-
使用 Kaggle 寻找最佳数据科学家的组织包括 Google 和 WHO。他们的私人竞赛提供的奖金从 $25k 到 $100k 不等。
Kaggle 竞赛是磨练技能和创建引人注目的作品集的绝佳方式。而当你达到大师级别时,你可以找到一些极好的数据科学机会。
5. 建立个人网站
网站是将你的项目集中存储在一个地方的有效方式。你可以使用像 WordPress 或 Wix 这样的内容管理系统快速建立一个网站。添加博客可以帮助提高网站排名,并增加网站的曝光度。
创建网站不需要巨额预算,但提高网站排名是一个缓慢的过程。与 Kaggle 和 Datacamp 不同,你不能通过你的网站快速获得增长和机会。然而,使用特定的技术和方法可以提升你网站的可见度。
结论
数据科学是你通向有前途职业的关键——几乎每个行业现在或将来都需要数据科学家。初学者应该专注于通过使用上述平台提供优质工作,并推广自己的服务,以获取数据科学行业的新机会。即使你已经在作为数据科学家工作并寻找更好的就业机会,也可以利用上述平台,或同时在所有平台上工作以提升你的技能。
Nahla Davies 是一位软件开发人员和技术作家。在全职从事技术写作之前,她曾担任过一家公司(该公司在《Inc. 5,000》榜单上)的首席程序员,该公司的客户包括三星、时代华纳、Netflix 和索尼。
更多相关话题
数据科学团队协作的五个最佳实践
原文:
www.kdnuggets.com/2023/06/5-best-practices-data-science-team-collaboration.html

作者提供的图片
数据科学项目包含广泛的技能,不同的团队成员扮演不同的角色。每个人都有自己的技能和职责,这些都在协作技术工作中发挥着重要作用。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
然而,我们仍然面临全球疫情的反弹以及越来越多人继续在家工作的情况。这自然会导致人们的工作和操作方式发生变化。
那么数据科学团队可以做些什么来提高协作效率呢?让我们来探讨一下。
确保模型投入生产
众所周知,有许多模型花费了大量的时间、精力和金钱来构建,但它们很少投入生产。根据 VentureBeat AI,87%的数据科学项目从未投入生产。这是一个相当高的数字!但为什么这么高呢?
这是因为业务的数据科学元素和业务的实际目标并不匹配。而它们不匹配的主要原因是数据科学团队需要提供的内容与业务需求之间存在模糊地带。
数据科学团队与商业决策者之间的更好沟通将使数据团队的成员能够有效地生产所需的内容。这可以通过回答以下问题来实现:
-
业务问题是什么?
-
解决这个问题可能吗?
-
商业是否会采纳数据洞察中的解决方案?
回答这三个问题可以使数据科学团队深入了解需要完成的任务。
文档项目
一个数据科学项目由不同角色的人组成,从数据科学家到数据工程师、产品经理、IT 管理员等。进行项目时,记录你所做的每一步可以使团队中的每个人更清楚地了解项目的过程,以及接下来需要做什么。
数据科学项目不会总是成功,但记录下你的每一步可以让你从项目中吸取教训,并在下次确保成功时知道该做什么。
记录项目时需要遵循的两个规则是:
-
尽管文档编制有助于与当前员工协作,但它也是与未来员工协作的方式。
-
要循序渐进。在处理数据科学项目时,像撰写研究论文一样操作。不要急于生产最终产品,而是要建立一个有效且成功地实现商业目标的最终产品。
知识共享
通过记录一切,你也在公司内提供了知识共享。数据科学团队在公司中持有许多宝贵的资产。许多公司面临的最大挑战之一是重复生产相同的工作或资源。
创建一个知识共享平台,让每个人都能访问代码、项目和模型等信息,将为你的组织节省大量时间,避免重复制作相同的内容。
知识共享与项目文档编制密切相关,因为员工应该能够看到数据科学家使用了哪些数据源、建模方法、环境版本等信息。
版本化你的工作
现在来详细讨论数据科学项目的技术元素。大多数数据以平面文件存储或通过关系数据库系统访问。然而,数据科学团队面临的最大挑战是,当团队成员下载原始数据并在本地生成工作时,没有将中间数据版本推送回团队的其他成员。
不幸的是,数据科学团队的其他成员可能会完成相同的工作,导致工作负担的重复。共享你的工作非常有价值,因为它给你的同事提供了利用你所做工作的机会,使他们可以在此基础上继续工作。
你的所有工作都应该被版本化并推送到非本地系统,允许其他人查看更改并获取这些更改进行工作。
你可以通过以下方式确保这一点:
-
为你的团队使用共享服务器。
-
使用自动化工具将中间数据文件推送回适当的位置。
-
利用像 Slack 和 GitHub 这样的集成工具,以便接收变更通知。
数据管道
数据管道允许数据科学项目的数据流动,因为数据处理元素是串联连接的,一个元素的输出是下一个元素的输入。与其花费额外时间运行两个或多个命令从原始数据到达最终结果,不如使用数据管道,通过一个命令就能看到整个转换过程。
这不仅可以减少从头开始重建项目所花费的时间,还可以让你对数据转换有一个结构化的理解。
总结
尽管还有其他实践方法可以用来确保更好的数据科学团队协作方法。然而,这 5 个实践方法如果正确有效地实施,将使你的团队在更有效和高效的方式下取得进展。
想了解如何自动化你的数据科学工作流,请阅读:数据科学工作流的自动化
尼莎·阿亚是一位数据科学家、自由技术撰稿人以及 KDnuggets 的社区经理。她特别感兴趣于提供数据科学职业建议、教程以及理论知识。她还希望探索人工智能如何有助于人类生命的延续。她是一个热衷学习者,寻求拓宽技术知识和写作技能,同时帮助指导他人。
更多相关主题
将机器学习模型投入生产的 5 个最佳实践
原文:
www.kdnuggets.com/2020/10/5-best-practices-machine-learning-models-production.html
评论
由 Sigmoid Analytics 提供

在我们之前的文章中 – 在扩展 ML 模型时需要准备的 5 大挑战,我们讨论了生产化可扩展机器学习(ML)模型的五大挑战。本文的重点是建立使 ML 项目成功的最佳实践。
当前的机器学习模型解决了各行各业中的各种具体业务挑战。选择机器学习模型的方法在很大程度上取决于我们试图解决的业务用例。但在进一步推进之前,我们应该确保选择的模型构建方法是可以投入生产的。
Sigmoid 的前网络研讨会调查显示,43%的公司认为 ML 生产化和集成具有挑战性。
由于复杂性,必须在生产过程中尽早消除正确的风险。在模型选择和开发的早期阶段消除更多风险可以减少在生产化阶段的返工。
机器学习生态系统中的各种考虑因素包括——数据集、技术栈、实施和集成这两者,以及部署 ML 模型的团队。然后是坚韧的测试框架,以确保业务结果的一致性。
通过使用以下最佳实践,Yum! Brands 能够通过生产化他们的 MAB 模型进行个性化电子邮件营销,实现了 8%的销售增长。观看 2 分钟的视频,了解 Yum 的 Scott Kasper 解释最佳实践对生产化 MAB 模型的影响
1. 数据评估
首先,应检查数据的可行性——我们是否拥有足够的正确数据集来运行机器学习模型?我们是否能快速获得数据以进行预测?
例如,拥有数百万注册客户数据的餐饮连锁(QSRs)。这一庞大的数据量足以让任何 ML 模型在其上运行。
当上述数据风险得到缓解后,应该建立一个数据湖环境,以便轻松而强大地访问各种所需的数据源。数据湖(替代传统的数据仓库)可以节省团队大量的官僚和手动开销。
对数据集进行实验,以确保数据包含足够的信息以带来期望的业务变化,在此步骤中至关重要。此外,处理可用数据的可扩展计算环境是一个主要要求。
当数据科学家清理、整理和处理不同的数据集后,我们强烈建议对数据进行编目,以便未来利用。
最终,应建立强大且经过深思熟虑的治理和安全系统,以便组织中的不同团队可以自由共享数据。
2. 评估合适的技术栈
一旦选择了机器学习(ML)模型,就应该手动运行它们以测试其有效性。例如,在个性化电子邮件营销的情况下——我们发送的促销邮件是否带来了新的转化,还是需要重新考虑我们的策略?
在成功完成手动测试后,需要选择合适的技术。数据科学团队应该能够从多种技术栈中选择,以便他们可以实验并挑选出使机器学习生产化更容易的技术。
选择的技术应根据稳定性、业务用例、未来场景和云准备情况进行基准测试。Gartner 统计数据表明,云 IaaS 预计将以 24%的年增长率增长,直至 2022 年。
观看 1 分钟的视频,Mayur Rustagi(CTO & 联合创始人 – Sigmoid)讲述了选择基础设施组件的有效方法
3. 强健的部署方法
标准化部署过程,使得在不同阶段的测试和集成变得顺畅,是强烈推荐的。
数据工程师应专注于打磨代码库,集成模型(作为 API 端点或批量处理模型),并创建工作流自动化,以便团队可以轻松集成。
拥有访问正确数据集和模型的完整环境对任何机器学习模型的成功至关重要。
4. 部署后支持与测试
选择合适的框架用于日志记录、监控和报告结果,将使本来困难的测试过程变得可控。
ML 环境应进行实时测试并密切监控。在复杂的实验系统中,测试结果应反馈给数据工程团队,以便他们更新模型。
例如,数据工程师可以决定在下一次迭代中加重表现出色的变体的权重,同时减少表现不佳的变体的权重。
还需注意负面或严重错误的结果。必须满足正确的服务水平协议(SLA)。应监控数据质量和模型性能。
生产环境因此会逐渐稳定。
5. 变更管理与沟通
每个机器学习模型的成功在很大程度上依赖于各跨职能团队之间的清晰沟通,以便在正确的步骤中减轻风险。
数据工程和数据科学团队必须协同工作才能将机器学习模型投入生产。建议数据科学家完全掌控系统以检查代码和查看生产结果。团队甚至可能需要接受新环境的培训。
透明的沟通将节省大家的精力和时间。
结论:
除了上述所有最佳实践外,机器学习模型还应设计为可重复使用且能够应对变化和剧烈事件。最佳情况并不是所有推荐的方法都到位,而是让某些领域足够成熟和可扩展,以便根据时间和业务需求进行上调和下调。
如果你对将机器学习模型投入生产有任何进一步的问题,请通过电子邮件联系我们。有关“规模化生产机器学习模型”的完整网络研讨会录音,请点击 这里。
原文。经许可转载。
相关:
-
扩展机器学习模型的 5 大挑战
-
机器学习模型部署
-
使用 Python 和 Heroku 创建并部署你的第一个 Flask 应用
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 需求
更多相关主题
5 种大数据和数据科学职业路径解析
原文:
www.kdnuggets.com/2017/02/5-career-paths-data-science-big-data-explained.html
评论
最近,我在 LinkedIn 上接到了很多寻求“数据科学”和/或“大数据”入门建议的人。这些人通常对进入“这个领域”感兴趣,并需要一些关于如何进行的方向。
然而,这些请求中的一个共同主题(我说这话时怀着极大的尊重)是对他们实际在问什么的一般性缺乏理解。这是可以理解的;无论学习什么,每个人都需要从某个地方开始。与其一个一个回答这些类似的请求,不如在这篇文章中阐述一些与“数据科学”和/或“大数据”职业路径相关的非常基础的概念,并希望提供一些关于如何在这个复杂领域中入门的建议。
必要的初步阅读
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
在进一步阅读之前,请阅读以下文章。我是认真的。阅读。那些。文章。
-
数据科学难题解析
-
数据科学难题再探
-
数据科学与大数据解释
-
预测科学与数据科学
第一篇文章概述了数据科学中的一些主导概念,第二篇是对这些概念的更新,第三篇则深入探讨了数据科学和大数据的概念。第四篇也是最后一篇,简要讨论了“数据科学”这个术语与其他术语使用之间的一些复杂性和细微差别。
我已经将各种职业可能性分解为一个易于管理的 5 条职业路径。尽管对于这种角色划分可能会有广泛的抗议和恐慌,但它们实际上有助于从高层次上分类技能和职业责任,因此我相信以下内容对帮助新人了解这个职业领域中存在的各种机会是非常有用的,这些机会往往容易被混淆。

分析职业的粗略估算(点击放大)。
数据管理专业人员
这基本上是一个 IT 职位,类似于数据库管理员。数据管理专业人员负责管理数据及其支持的基础设施。这个角色几乎不涉及数据分析,使用 Python 和 R 等语言可能不必要。SQL 可能会有用,还有 Hadoop 相关的查询语言,如 Hive 或 Pig。
关键技术和技能关注点:
-
Apache Hadoop 及其生态系统
-
Apache Spark 及其生态系统
-
SQL 与关系型数据库
-
NoSQL 数据库
进一步阅读:
-
大数据关键术语解析
-
数据库关键术语解析
-
Hadoop 关键术语解析
-
Apache Spark 关键术语解析
-
云计算关键术语解析
-
理解 NoSQL 数据库的 7 个步骤
-
掌握数据科学 SQL 的 7 个步骤
数据工程师
这是大数据非分析的职业路径。前面职业路径提到的数据基础设施?嗯,它需要被设计和实施,而数据工程师就是这样做的。如果数据管理专业人员是汽车维修工,数据工程就是汽车工程师。但不要搞错了;这两个角色对你汽车的交付和持续运行都是至关重要的,当你从点 A 驾驶到点 B 时,它们同样重要。
说实话,数据工程和数据管理所需的技术和技能是相似的;然而,它们在不同层次上使用和理解这些概念。我不会重复上面角色中分享的信息(这些信息对数据工程师很重要),而是会添加一些关于数据工程师的进一步阅读。
进一步阅读:
-
顶尖 NoSQL 数据库引擎
-
顶尖大数据处理框架
-
顶尖 Spark 生态系统项目
-
Hadoop 和大数据:解答的六大问题
-
为什么数据科学家和数据工程师需要理解云中的虚拟化
业务分析师
在此背景下,我使用“业务分析师”来指代严格与数据分析和展示相关的角色。这包括报告、仪表板以及任何被称为“商业智能”的内容。这个角色通常需要与(或查询)数据库进行交互,包括关系数据库和非关系数据库,以及大数据框架。
虽然之前的角色涉及设计基础设施来管理数据以及实际管理数据,但业务分析师主要关注从数据中提取信息,就像它当前的状态一样。这与接下来的两个角色(机器学习研究员/从业者和数据导向的专业人员)形成对比,这两个角色都专注于从数据中挖掘超越其表面信息的洞察力。因此,业务分析师在这些角色中需要一套独特的技能。
关键技术和技能关注点:
-
SQL 和关系数据库
-
NoSQL 数据库
-
通常需要商业报告和仪表板软件的专业知识
-
报告往往是临时性的,而掌握快速适应工具的能力是关键
-
数据仓库
进一步阅读:
-
2016 年的 10 大商业智能趋势
-
嵌入式分析:商业智能的未来
-
自建与购买 – 分析仪表板
机器学习研究员/从业者
机器学习研究员和从业者是那些设计和使用用于利用数据的预测和相关工具的人。机器学习算法允许以高速应用统计分析,而使用这些算法的人不会满足于让数据以当前形式自行表达。数据的操作方式是机器学习爱好者的工作方法,但需要足够的统计学理解,知道何时推动得足够远,以及何时提供的答案不可信。
统计学和编程是机器学习研究员和从业者最重要的资产。
关键技术和技能关注点:
-
统计学!
-
代数与微积分(从业者中级,研究员高级)
-
编程技能:Python、C++ 或其他通用语言
-
学习理论(从业者中级,研究员高级)
-
对一系列机器学习算法的内部工作原理的理解(算法越多越好,对其理解越深入越好!)
进一步阅读:
-
机器学习与统计学
-
机器学习关键术语解释
-
掌握 Python 机器学习的 7 个步骤
-
进入机器学习职业前需要阅读的 5 本电子书
-
机器学习工程师需要了解的 10 个算法
-
伟大的算法教程汇总
-
十大数据挖掘算法解释
-
15 个数学 MOOC 用于数据科学
深度学习? 虽然它是一种机器学习形式,但为了明确起见,我列出了一个单独的推荐阅读列表:
-
深度学习关键术语解释
-
理解深度学习的 7 个步骤
-
人工智能、深度学习和神经网络解析
-
9 篇关键深度学习论文解析
数据导向专业人士
这是我能想到的对所谓“真正”数据科学家的最佳描述。你知道,独角兽。除了,确实没有独角兽,任何说不同话的人都是在撒谎。
数据管理专业人士和数据工程师关注的是存储数据的基础设施。商业分析专业人士关注的是从现有数据中提取事实。机器学习研究人员和从业者关注的是推进和使用现有工具,以利用数据进行预测和相关分析,这两个角色都是基于算法的(要么开发,要么使用,或两者兼而有之)。数据导向的专业人士主要关注数据以及数据所讲述的故事,无论实现这一任务需要什么技术或工具。
数据导向的专业人士可能会根据他们的具体角色使用上述任何一种技术。这也是“数据科学”相关的最大问题之一;这个术语没有特定的含义,而是总的而言。这一角色是数据领域的全才,可能知道如何启动和运行一个 Hadoop 生态系统;如何对存储的数据执行查询;如何提取数据并存放在非关系型数据库中;如何将非关系型数据提取到平面文件中;如何在 R 或 Python 中处理这些数据;如何在初步探索性描述分析后进行特征工程;如何选择合适的机器学习算法对数据进行预测分析;如何统计分析预测任务的结果;如何将结果可视化以便非技术人员容易理解;以及如何向高管讲述数据处理管道的最终结果。
这只是数据科学家可能拥有的技能之一。然而,无论如何,这个角色的重点在于数据,以及从中获取的信息。领域知识通常也是这种角色的一个重要组成部分,这显然不是在这里可以教授的内容。
重点关注的技术和技能:
-
统计学!
-
编程语言:Python, R, SQL
-
数据可视化
-
沟通技能
进一步阅读:
-
R 学习路径:从初学者到专家的 7 个步骤
-
数据科学统计学 101
-
数据科学中需要哪些统计学主题以出色表现?
-
数据科学家使用的顶级算法和方法
作为一篇介绍性文章,我有意省略了物联网(IoT)的任何提及。这有两个原因:首先,我不想给试图吸收这些新材料的任何人增加额外的困惑;其次,IoT 只是数据的一个特殊情况,每个角色可以将这些角色应用于 IoT 数据,但可能需要一些修改。但核心真理依然不变。
我希望这个概述对那些希望开始“数据科学”或“大数据”职业路径但不确定从哪里或如何开始的人有所帮助。请记住,这绝不是承担这里提到的任何角色的详尽课程。然而,对于对数据职业了解较少的个人来说,这是一个很好的起点。
如果你对这个话题有不同的见解,可以阅读扎卡里·利普顿的真正的数据科学家请站出来。
相关:
-
21 个必知的数据科学面试问题及答案
更多相关内容
扩展机器学习模型的 5 个挑战
原文:
www.kdnuggets.com/2020/10/5-challenges-scaling-machine-learning-models.html
评论
由 Sigmoid Analyitcs 提供

机器学习(ML)模型是为了特定的业务目标而设计的。ML 模型的生产化是指在相关数据集上托管、扩展和运行 ML 模型。生产中的 ML 模型还需要具备对未来变化和反馈的弹性和灵活性。最近的一项研究Forrester 表示,提高客户体验、提升盈利能力和收入增长是组织计划通过 ML 计划实现的关键目标。
尽管获得了全球认可,ML 模型很难转化为实际的商业收益。处理实时数据并将 ML 模型投入生产时,众多工程、数据和业务问题成为瓶颈。根据我们的调查,43% 的人表示在 ML 模型生产和集成过程中遇到瓶颈。确保 ML 模型按照企业预期实现最终目标非常重要,因为全球范围内的组织采纳速度正在以前所未有的速度增长,这得益于强大且廉价的开源基础设施。Gartner 预测,到 2020 年底,超过 40% 的全球领先组织计划实际部署 AI 解决方案。为了了解生产化 ML 模型中的常见陷阱,让我们深入探讨组织面临的 5 个主要挑战。
1. 数据复杂性
训练一个 ML 模型需要大约一百万条相关记录,并且这些数据不能是随便的。数据的可行性和预测风险成为问题。评估我们是否拥有相关数据集以及是否能足够快地获取它们来进行预测并不简单。获取上下文数据也是一个问题。在 Sigmoid 与 Yum Brands 进行的 ML 扩展中,一些公司的产品如 KFC(具有新的会员计划)没有足够的客户数据。仅有数据也不够。大多数 ML 团队以非数据湖方法开始,并在传统的数据仓库上训练 ML 模型。在传统的数据系统中,数据科学家通常将 80% 的时间用于清理和管理数据,而不是训练模型。强大的治理系统和数据目录也是必需的,以确保数据透明共享并得到良好的目录,以便再次利用。由于数据复杂性,维护和运行 ML 模型的成本相对于回报随时间递减。
2. 工程与部署
一旦数据可用,基础设施和技术栈必须根据使用案例和未来的弹性进行最终确定。机器学习系统的工程设计可能非常复杂。机器学习领域提供了广泛的技术选择。在选择每种技术栈时,将其标准化并确保不会使生产化变得更困难对模型的成功至关重要。例如,数据科学家可能会使用像 Pandas 这样的工具并用 Python 编码。但这些工具在生产环境中可能不太适用,Spark 或 Pyspark 更为理想。不当的技术解决方案可能会导致高昂的成本。而且生命周期挑战和管理、稳定多个生产模型也可能变得非常棘手。
3. 集成风险
一个与不同数据集和建模技术良好集成的可扩展生产环境对于机器学习模型的成功至关重要。集成不同的团队和操作系统总是充满挑战。复杂的代码库必须转化为结构良好的系统,准备推向生产。在缺乏标准化流程将模型推向生产的情况下,团队可能会在任何阶段陷入困境。工作流自动化对于不同团队集成到工作流系统和进行测试是必要的。如果模型在正确的阶段未经过测试,整个生态系统可能需要在最后修复。技术栈必须标准化,否则集成可能会成为真正的噩梦。集成也是一个关键时刻,确保机器学习实验框架不是一次性的奇迹。否则,如果商业环境发生变化或发生灾难性事件,模型将无法提供价值。
4. 测试与模型维护
测试机器学习模型虽然困难,但与生产过程的其他步骤同样重要,甚至更重要。理解结果、运行健康检查、监控模型性能、留意数据异常以及重新训练模型,这些步骤共同完成整个生产化周期。即使在测试后,可能还需要适当的机器学习生命周期管理工具来发现测试中看不见的问题。
5. 角色分配与沟通
在数据科学、数据工程、DevOps 和其他相关团队之间保持透明的沟通对机器学习模型的成功至关重要。但角色分配、详细的权限授予和每个团队的监控非常复杂。强有力的协作和过量的沟通对于在早期阶段识别不同领域的风险是必不可少的。让数据科学家深度参与也可以决定机器学习模型的未来。
除了上述挑战外,还需要关注诸如 COVID-19 之类的不可预见事件。当客户的购买行为突然变化时,过去的解决方案不再适用,且缺乏足够的新数据来训练模型成为障碍。扩展机器学习模型并不容易。请关注我们下一篇关于在大规模生产化机器学习模型的最佳实践。
原文。经许可转载。
相关:
-
机器学习模型部署
-
使用 Python 和 Heroku 创建并部署您的第一个 Flask 应用
-
停止训练更多模型,开始部署它们
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
更多相关内容
成功数据科学家的五大特征
原文:
www.kdnuggets.com/2021/12/5-characteristics-successful-data-scientist.html
评论 
图片来源 Tumisu 于 Pixabay
我最近撰写了一篇题为数据科学家、数据工程师与其他数据职业的解释的文章,在其中我尽力简明扼要地定义和区分了五种流行的数据相关职业。每个职业在该文章中都得到了非常高水平的单句总结,作为参考,数据科学家被描述为:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 工作
数据科学家主要关注数据、从中提取的洞察力以及数据能讲述的故事。
除了我为每个职业撰写的额外几段内容外,我还试图提出一个单一的总体区分特征,这五个特征可以结合成一个流程图,可能会被有志于数据领域的专业人士用来帮助确定哪个职业最适合他们。
我收到了一些读者的反馈,这些反馈明显表明我过于关注预测分析作为数据科学家职业的定义特征,并且我在这方面的依赖可能使人觉得数据科学家做的预测分析比其他任何事情都多——而且其他数据专业人士可能完全不做这些。
这种建设性的批评自然让我思考:究竟是什么将数据科学家与其他数据专业人士区分开来?数据科学家使用大量技术技能,特定的技术语言、系统和工具。同时,数据科学家——以及所有其他专业人士——也运用许多软技能来在职业生涯中取得成功。但是,成功的数据科学家有哪些固有特征呢?这些特征是数据科学家在进入这一职业时带来的,还是可以在职业生涯中发展出来的?
下面是我总结出的五个特征,这些特征整体上帮助数据科学家与其他职业区分开,并帮助定义成功的职业生涯。
让我们首先指出,所有数据科学家的角色都是不同的,但它们都有一些共同的联系点,希望这些要点能帮助连接其中的一些联系点。
1. 预测分析思维方式
这个特征被认为的重点是我受到了一些批评的地方。然而,我在这里要再次强调,预测分析思维方式是数据科学家的主要特征之一,也许比其他任何特征都更重要。它是唯一的定义特征吗?当然不是。它是否应该在流程图中用来将数据科学家与所有其他职业区分开?回过头来看,不,可能不应该。
数据科学家会进行预测分析吗?绝对会。非数据科学家也会吗?当然会。然而,如果我将数据科学家放在预测分析的跷跷板的一端,而将<插入其他数据专业人员>放在另一端,我会期望数据科学家那一端总是会落地。
但这不仅仅是预测分析在特定情况下的应用;这是一种思维方式。而且这不仅仅是分析思维方式(去掉预测),而是始终在考虑我们如何利用已有的知识来发现我们尚未知道的内容。这表明预测是方程中不可或缺的一部分。
数据科学家不仅仅是为了预测,但在我看来,从这种思维方式出发是角色定义特征之一,并且许多其他职业,无论是否与数据相关,都不具备这种特征。其他具备这种特征的职业可能会将其放在职业价值列表的更低位置。
2. 好奇心
显然,仅仅使用我们已知的内容来找出我们不知道的内容是不够的。数据科学家必须具备其他角色不一定需要的好奇心(注意我没有说其他人绝对没有这种好奇心)。好奇心几乎是预测分析思维方式的另一面:当预测分析思维方式试图用Y解决X时,好奇心将确定Y到底是什么。
-
“我们如何增加销售额?”
-
“为什么某些月份的流失率比其他月份高?”
-
“为什么这必须以那样的方式来做?”
-
“如果我们对 Y 做 X,会发生什么?”
-
“X 是如何影响这里发生的事情的?”
-
“我们是否尝试过……?”
-
诸如此类……
成为一名有用的数据科学家需要自然的好奇心,故事就到此为止。如果你是那种早上醒来后整天都不会多想宇宙奇观——无论在什么层面——的人,那么数据科学可能不适合你。
在它被消灭之前,好奇心负责了猫的非常长且成功的数据科学家生涯。
3. 系统思维
这里有一条深刻的哲学观点:世界是一个复杂的地方。一切以某种方式相互关联,远远超出明显的层面,从而导致现实世界的复杂性层层叠加。复杂系统与其他复杂系统相互作用,产生它们自己的额外复杂系统,宇宙就是这样运作的。这种复杂性的游戏不仅仅是认识大局:这幅大图在更大的图景中如何定位,等等。
但这不仅仅是哲学上的问题。数据科学家认识到这种现实世界中无尽的复杂网络。他们希望在解决问题的过程中,尽可能多地了解相关的互动,无论是显性还是隐性的。他们寻找情境依赖的已知已知、已知未知和未知未知,理解任何给定的变化可能会在其他地方产生意想不到的后果。
数据科学家的工作是尽可能多地了解相关系统,并利用他们的好奇心和预测分析思维来考虑这些系统的操作和互动,以保持其平稳运行,即使在进行调整时也是如此。如果你不能理解为什么没有一个人能完全解释经济如何运作,那么数据科学可能不适合你。
4. 创造力
现在我们谈到了必要的“跳出框框思考”特质。我们是否鼓励每个人在某种程度上做到这一点?当然。但我在这里的意思并不完全相同。
请记住,数据科学家并非在真空中工作;我们与各种不同角色合作,并在旅程中遇到各种领域专家。这些领域专家即使在跳出框框思考时,也有自己看待其领域的特定方式。作为数据科学家,凭借独特的技能和特定的思维方式——我尽力在这里描述——你可以从领域专家所在的框框之外来解决问题。你可以成为以新的视角看待问题的新鲜眼睛——当然,前提是你对问题有足够的了解。你的创造力将帮助你提出新的想法和视角。
这并不是贬低领域专家;实际上,正好相反。我们数据科学家是他们的支持,凭借我们经过训练的技能,我们(希望能够)为领域专家提供新的视角,以帮助他们在自己的领域中表现卓越。这种新的视角将由数据科学家的创造性思维驱动,这种创造力与好奇心结合,将引导我们提出问题——并追寻答案。
当然,我们需要具备技术、统计和其他额外的技能,以便跟进这些问题,但如果没有创造力来想出有趣且不明显的调查方式,这些技能也会变得无用。这就是为什么数据科学家必须本质上具有创造力的原因。
5. 故事讲述的敏感性
每个人都需要能够有效地与他人沟通,无论他们的社会地位如何。数据科学家也不例外。
但即便如此,数据科学家在向其他可能并不完全沉浸于统计分析电影宇宙™的利益相关者解释工作时,通常也需要一些手把手的帮助。数据科学家必须能够将某人从 A 点叙述到 B 点,即使那个人对这两个点到底是什么没有太多了解。直白地说,讲故事就是能够从一些数据和你的分析过程编织出一个现实的叙述:我们是如何从这个到那个的。
这不仅仅是陈述事实;数据科学家必须看到利益相关者在方程式中的位置,并使叙述过程相关——也许通过有用的视觉效果或其他道具来帮助完成比喻上的交易。
这种讲故事并不像虚构故事那样;它更像是“精巧解释”,或者提供一个针对听众的直观解释。你不会给五岁的孩子讲斯蒂芬·金的故事作为睡前故事,就像你不会向从事研发工作的人详细讲述枯燥乏味的供应链指标一样。要注意你的受众。
这种讲故事也不是说服性的;它是解释性的。我们不是数据政治家,我们是数据科学家。科学家歪曲统计数据以使他人顺从是没有好结果的。把这留给选举官员吧。
我希望这能帮助描绘出我认为成功的数据科学家所具备的重要特征的丰富画面。祝愿你在追求职业的过程中一切顺利。
相关:
-
数据科学家、数据工程师及其他数据职业解析
-
14 种不同数据科学工作的指南
-
能让你被录用的数据科学作品集项目创意(或未能录用)
更多相关话题
5 个 ChatGPT 功能提升你的日常工作
原文:
www.kdnuggets.com/2023/05/5-chatgpt-features-boost-daily-work.html

编辑器提供的图像
ChatGPT 已完全改变了代码开发的方式。 然而,大多数软件开发人员和数据专业人士仍然未使用 ChatGPT 来改善 — 和简化 — 他们的工作。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT。
这就是我在这里概述 5 个不同功能,以提高你日常工作的速度和质量的原因。
你可以在日常工作中使用它们。让我们一起探索如何 ????????
⚠️ 警告:你不应将关键代码或信息提供给 ChatGPT。
#1. 生成你的代码框架
ChatGPT 是我在从零开始构建新项目时的秘密武器。只需几个提示,它就能生成我所需代码的框架,包含我选择的技术、框架和版本。每次都能节省我至少一小时的工作时间,同时也有助于保持我的文档 — 或团队的文档 — 井然有序和最新。这就像是在团队中多了一双手!
例如,假设我想使用一些外部 API。我可以请 ChatGPT 为我草拟一个初步的代码结构。
生成集成外部 API 的 boilerplate 代码,使用 Python。
ChatGPT 立刻给出回答:
截图 ChatGPT 聊天。ChatGPT 给我一个代码框架。
或者我甚至可以要求生成一个框架,用 Selenium 抓取 LinkedIn,ChatGPT 会给我以下输出。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
# Initialize the web driver
driver = webdriver.Firefox()
# Navigate to LinkedIn
driver.get("https://www.linkedin.com/")
# Find the email and password input fields
email = driver.find_element_by_id("username")
password = driver.find_element_by_id("password")
# Enter your credentials
email.send_keys("YOUR_EMAIL")
password.send_keys("YOUR_PASSWORD")
# Click the login button
driver.find_element_by_xpath("//button[@type='submit']").click()
# Wait for the page to load
time.sleep(5)
# Navigate to the profile of the desired user
driver.get("https://www.linkedin.com/in/USER_PROFILE_NAME")
# Extract the information you want from the page
name = driver.find_element_by_xpath("//span[@class='inline t-24 t-black t-normal break-words']").text
location = driver.find_element_by_xpath("//span[@class='t-16 t-black t-normal inline-block']").text
print(name)
print(location)
# close the browser
driver.quit()
简单吧?试着用你能想象的任何项目来挑战 ChatGPT。
#2. 研究和比较
决定如何实现某些功能可能很困难,尤其是当有多个选项可以选择时。我的方法是为每种方法创建一个基本的概念验证,然后进行比较。但在 ChatGPT 的帮助下,这个过程变得容易多了。
我现在可以直接询问它关于我的代码开发的最佳选项或库的专家意见。这节省了我在决策过程中的时间和精力,并确保我使用了最好的工具来完成工作。
设想一下我想处理地理空间数据,但不确定是应该使用Geopandas还是Plotly。我可以请 ChatGPT 为我比较——附带类型 😉——它会立即回答两个库之间的主要区别。

截图 ChatGPT 聊天记录。ChatGPT 向我解释了 geopandas 和 plotly 之间的区别。
如果我现在想抓取一个网站,我可以询问哪个库最适合这样做。ChatGPT 回答了 Python 中最流行的网页抓取库。

截图 ChatGPT 聊天记录。ChatGPT 解释了最流行的抓取网站。
你甚至可以询问哪个是抓取你想要的网站的最佳选项——尽管 ChatGPT 很可能会警告你这可能违反了该网站的内容政策——所以要小心。
抓取社交网络的最佳选项是什么?

截图 ChatGPT 聊天记录。ChatGPT 解释了抓取社交网络的最佳选项。
#3. 理解代码
我们都经历过理解一个不是我们自己创建的代码库的痛苦。在复杂且组织不良的代码中导航——也称为意大利面条代码——可能是一个令人沮丧且耗时的任务。
但是,借助 ChatGPT,理解新的代码库变得容易多了。我现在可以简单地询问它代码的功能,并迅速理解它。不再浪费宝贵的时间和精力试图解读写得很差的代码。
设想一下,我正在尝试抓取 LinkedIn,并且在互联网上找到了一段随机的代码,它应该能够向下滚动 LinkedIn 的职位招聘网站。
以下代码做了什么? [插入代码]
#We find how many jobs are offered.
jobs_num = driver.find_element(By.CSS_SELECTOR,"h1>span").get_attribute("innerText")
if len(jobs_num.split(',')) > 1:
jobs_num = int(jobs_num.split(',')[0])*1000
else:
jobs_num = int(jobs_num)
jobs_num = int(jobs_num)
#Here I choose manually a number of jobs, so it wont take that long:
jobs_num = 1000;
#We create a while loop to browse all jobs.
i = 2
while i <= int(jobs_num/2)+1:
#We keep scrollind down to the end of the view.
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
i = i + 1
print("Current at: ", i, "Percentage at: ", ((i+1)/(int(jobs_num/2)+1))*100, "%",end="\r")
try:
#We try to click on the load more results buttons in case it is already displayed.
infinite_scroller_button = driver.find_element(By.XPATH, ".//button[@aria-label='Load more results']")
infinite_scroller_button.click()
time.sleep(0.1)
except:
#If there is no button, there will be an error, so we keep scrolling down.
time.sleep(0.1)
pass
ChatGPT 会立即回答,并提供对上述代码的详细解释。你甚至可以要求更多关于代码某部分的细节——只需多与 ChatGPT 互动,你会发现它能带来许多奇迹。

截图 ChatGPT 聊天记录。ChatGPT 解释了我不理解的代码。
#4. 为我们的代码添加注释
ChatGPT 还可以帮助我们提高自己代码的质量和可维护性。通过逐行添加注释,我们可以确保在发布之前代码得到了适当的文档记录。这消除了没有注释的代码的需求,并使其他人更容易理解和使用我们的代码。
ChatGPT 可以显著提高代码的可读性、可维护性和与他人的协作能力。
让我们假设之前的代码完全没有注释。我们可以直接要求 ChaGPT 为其添加注释。
为以下代码添加注释 [在此插入代码]
# Find the number of jobs offered on the website
jobs_num = driver.find_element(By.CSS_SELECTOR,"h1>span").get_attribute("innerText")
# Check if the number of jobs contains a ',' and if so, convert it to number * 1000
if len(jobs_num.split(',')) > 1:
jobs_num = int(jobs_num.split(',')[0])*1000
else:
jobs_num = int(jobs_num)
# Convert jobs_num to an integer
jobs_num = int(jobs_num)
# Set the number of jobs to scrape to 1000
jobs_num = 1000;
# Initialize a counter variable to scroll through the jobs
i = 2
# Start a while loop to scroll through the jobs
while i <= int(jobs_num/2)+1:
# Scroll to the bottom of the page
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# Increment the counter variable
i = i + 1
# Print the current number of jobs scrolled through and the percentage of completion
print("Current at: ", i, "Percentage at: ", ((i+1)/(int(jobs_num/2)+1))*100, "%",end="\r")
try:
# Try to locate the "Load more results" button and click on it
infinite_scroller_button = driver.find_element(By.XPATH, ".//button[@aria-label='Load more results']")
infinite_scroller_button.click()
# Sleep for 0.1 seconds
time.sleep(0.1)
except:
# If the button is not present, sleep for 0.1 seconds and continue scrolling
time.sleep(0.1)
pass
令人印象深刻,对吧?再也没有没有注释的代码了! 😄
#5. 使用一些风格重写我们的代码
ChatGPT 不仅是理解陌生代码的宝贵工具,它还可以帮助我们确保自己的代码符合行业标准和惯例。 通过要求它将我们的代码修正为符合 Pep-8 规范——甚至为我们的编码风格创建自定义规范——我们可以避免在合并不同仓库或团队的代码时需要昂贵且耗时的重构。
这有助于简化协作过程,使其更高效。 总体而言,ChatGPT 是一个多功能工具,可以提高我们代码库的质量和可维护性。
如果我们要求 ChatGPT 使用 Pep-8 标准来编写之前的代码,它将直接给我们重构后的代码。
你能用 Pep8 标准重写以下代码吗 [在此插入代码]
截图 ChatGPT 聊天。ChatGPT 按照 Pep8 标准给我们的代码。
主要结论
我希望这篇文章之后你意识到 ChatGPT 可以帮助我们提高生产力,创造更高质量的输出。 我知道很容易陷入 AI 最终可能接管我们工作的陷阱,但正确的 AI 可以成为一个强大的资产,为我们服务。
然而,重要的是要记住,当与 AI 工作时批判性思维仍然是关键,就像与我们的人工同事工作时一样。
所以,在你急于实施 AI 生成的回应之前,确保先花时间审查和评估它们。相信我,这最终是值得的!
如果 ChatGPT 用其他优秀功能让你惊讶,请告诉我。我会在评论中阅读你的反馈! 😄
Josep Ferrer 是一位来自巴塞罗那的分析工程师。他拥有物理工程学位,目前从事与人类移动性相关的数据科学工作。他还是一名兼职内容创作者,专注于数据科学和技术。你可以通过 LinkedIn、Twitter 或 Medium 联系他。
原文。经授权转载。
更多相关话题
5 本便宜的书籍来精通数据科学

使用 DALLE-3 生成的图像
数据科学是一个前景广阔的高收入领域。随着 AI 的最新进展,数据科学仍然成为最受欢迎的职业之一并不令人惊讶。然而,我知道这是一个难以突破的领域。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
如果你想进入数据科学领域并了解许多数据方面,那就有很多学习要做。这也意味着我们需要好的学习材料,以免浪费时间。本文将讨论五本便宜的书籍,你可以用来精通数据科学。
这些书籍是什么?让我们深入了解一下。
数据科学(麻省理工学院出版社必备知识系列)
要精通这一领域,我们需要深入了解我们希望从事的领域。我们需要理解数据科学,以便为我们的工作带来价值并避免完全找不到工作。
数据科学 书籍,由 John D. Kelleher 和 Brendan Tierney 编写,可能成为你了解整体数据科学行业的第一步。价格为 9 美元,你将从书中学到以下内容:
-
数据科学历史
-
数据科学应用
-
数据科学工具
-
数据科学应用中的伦理问题
-
数据科学职业发展
这本书是任何想进入数据科学领域或更好理解数据科学概念的人的绝佳入门书籍。
Python 数据分析
编程技能已经成为数据科学家的支柱,每家公司都将其列为要求。通常要求是 Python 语言,这是现代数据科学家的编程语言。没有 Python 技能,我们很可能无法正确完成工作。
Python 数据分析 书籍,由 Avinash Navlani、Armando Fandango 和 Ivan Idris(作者)编写,将提供有关使用必要的 Python 技能导航数据科学领域的完整学习内容。你将学习到以下内容:
-
核心 Python 库和数据处理
-
统计和数学基础
-
高级数据分析技术
-
专门的数据分析
-
使用 Dask 的计算效率
这本书的价格约为$16,相较于其他书籍来说较为便宜。然而,这本书的价值很大。
裸统计:剥离数据中的恐惧
尽管数据科学家需要掌握编程语言,但我们也必须理解统计理论。我们的数据分析和机器学习算法是基于统计方法的,我们需要理解基本统计学以了解我们所做的数据活动。
《裸统计:剥离数据中的恐惧》由 Charles Wheelan 撰写,以有趣的方式和应用实例拆解了统计学概念。书中包含以下案例:
-
政治民调案例中的标准误差和置信区间应用。
-
英国健康问题风险的回归分析。
-
Netflix 和 Target 在产品推荐中的统计推断应用。
这本书中你仍会学到许多统计概念。以$8 的价格,你很容易理解统计学在数据科学中的重要性。
《机器学习算法的搭车指南》
在对数据科学有了基本了解后,我们应该学习机器学习算法。数据科学家的主要工具是机器学习模型,理解每个模型的工作原理以及我们为何使用它们至关重要。
《机器学习算法的搭车指南》由 Devin Schumacher、Francis La Bounty Jr. 和 Devanshu Mahapatra 编写,将作为进一步理解机器学习算法的参考。你将从这本书中学习到以下概念:
-
分类与回归技术
-
聚类算法
-
神经网络与深度学习
-
优化与问题解决算法
-
集成方法与降维技术
-
强化学习
每章都是独立的部分,因此我们可以跳到任何感兴趣的章节。以$12 的价格,你可以从理论到实际的机器学习应用中获取大量知识。
数据洞察的交付
数据科学不仅仅是编程、机器学习或统计学。它的核心在于从我们拥有的数据中提供价值。因此,任何数据科学家都必须理解如何将我们的技术结果以利益相关者或非技术人员能理解的见解传达出来。
在《数据洞察的交付》这本书中,Mo Villagran 解释了数据专业人士因为与利益相关者沟通不畅、被营销炒作刺激的非现实期望以及大多数数据产品的未充分利用而难以交付价值。凭借她的经验,她制定了七个步骤,以便我们能够更好地沟通并评估利益相关者的需求。
只需 15 美元,你可以快速学习这些步骤,并通过始终需要的软技能提升自己。
结论
数据科学是一个具有挑战性的领域。这就是为什么这五本便宜的书籍将帮助你掌握数据科学。这些书籍包括:
-
《数据科学》(麻省理工学院出版社核心知识系列)
-
Python 数据分析
-
《裸统计:揭示数据中的恐惧》
-
《机器学习算法指南》
-
数据洞察力传递
Cornellius Yudha Wijaya 是一名数据科学助理经理和数据撰写者。在全职工作于安联印尼期间,他喜欢通过社交媒体和写作分享 Python 和数据技巧。Cornellius 撰写了多种 AI 和机器学习相关的主题。
更多相关主题
5 本便宜的机器学习入门书籍
原文:
www.kdnuggets.com/5-cheap-books-to-master-machine-learning

由 DALL-E 3 生成的图像
机器学习已成为为企业带来竞争优势的工具。随着时代的发展,公司逐渐转向数据驱动,并依赖机器学习来帮助他们。这就是为什么机器学习技能需求旺盛。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT
学习机器学习可能具有挑战性,如果你没有合适的学习材料。撇开免费资源,许多高质量的资源被锁在昂贵的书籍里。然而,我相信有一些便宜的书籍可以帮助你掌握机器学习。
这些书是什么呢?让我们深入了解一下。
《绝对初学者的机器学习:数据科学的 Python》
让我们从适合初学者的内容开始。对任何初学者来说,机器学习的基础非常重要,因为你掌握基础后就能处理任何项目。这就是为什么这本便宜的书非常合适。
《机器学习入门书》 由 Oliver Theobald 编写,将帮助你通过 Python 步骤学习机器学习的基础知识,包括:
-
免费数据集下载
-
机器学习库和工具
-
数据预处理技术
-
数据验证
-
回归分析
-
聚类
-
神经网络基础
-
偏差/方差
只需 $16,你就可以获得这本书,提升你的机器学习知识。
《机器学习傻瓜书》
被标记为 Mark Cuban 的顶级阅读书籍之一,这些书籍提供了有关机器学习的信息,而不假设你有多年的机器学习经验。
《机器学习傻瓜书》 由 John Paul Mueller 和 Luca Massaron 编写,将展示如何理解机器学习并构建它,内容包括:
-
机器学习和算法简介
-
机器学习数学
-
机器学习的实际应用
-
最佳实践
-
数据使用的伦理方法
花 $20 买这本书绝对值得投资。
《Python 机器学习精通》
让我们来看看那本能够帮助你自信掌握机器学习的书。《用 Python 进行机器学习的精通》是一本大电子书,包含了逐步指导和端到端的机器学习项目,旨在使你成为专业人士。这是一本完整的书籍,无论你的机器学习知识水平如何都非常适合。
由杰森·布朗利撰写的书籍包含了你应用 Python 进行机器学习所需了解的一切,包括:
-
机器学习基础
-
《用 Python 进行机器学习》
-
如何使用机器学习 Python 包
-
我们如何预处理数据
-
如何开发我们的机器学习模型
-
如何改进我们的模型
-
机器学习项目
-
以及更多
以$47 的价格,这本书将为你提供 16 个步骤的课程、178 页的内容以及 3 个端到端的项目。此外,你还将获得 74 个完全可用的 Python 脚本。
《终极算法:对终极学习机器的追寻将如何重塑我们的世界》
让我们从技术基础出发,转向更概念化的机器学习讨论。我们可以快速构建机器学习模型,但模型的使用场景以及模型将引导我们到何处也是至关重要的。这正是这本书要带给我们的。
这本书可能稍显陈旧,因为它是在 2015 年发布的。然而,佩德罗·多明戈斯的书将引导我们深入思考机器学习概念,并广泛探索机器学习将带我们去何处。
了解我们的社会在面对机器学习时将会处于何种地位,以及你为何应该学习算法,费用仅为$10。
《人工智能与商业中的机器学习:无废话的数据驱动技术指南》
在更高级的版本中,这本书将讨论 AI 和机器学习在商业行业中的应用。这本书试图以尽可能少的技术术语来教育读者关于技术进步,因为本书的目标读者是普通读者。这也是为什么这本书非常适合那些作为经理或非技术领导者,并希望了解机器学习影响的人。
史蒂文·芬莱的书架起了一座桥梁,连接了对社会来说重要的机器学习知识。这本书更注重实际应用以及如何与数据科学家合作以最大化机器学习的价值。
只需花费$20,你就能获得一本关于机器学习应用的书籍。
结论
机器学习是现代社会中的一项重要技能。无论你的职业是什么,我们的工作都会以某种方式与机器学习交织在一起。这就是为什么这五本便宜的书会帮助你掌握机器学习。这些书包括:
-
《绝对初学者的机器学习:数据科学的 Python》
-
《用 Python 掌握机器学习》
-
《傻瓜的机器学习》
-
《大师算法:对终极学习机器的追求将如何重塑我们的世界》
-
《商业中的人工智能与机器学习:无废话的数据驱动技术指南》
Cornellius Yudha Wijaya****是一名数据科学助理经理和数据编写员。在全职工作于 Allianz Indonesia 期间,他喜欢通过社交媒体和写作分享 Python 和数据技巧。Cornellius 撰写了各种人工智能和机器学习主题的文章。
更多相关内容
每个数据科学家必须了解的 5 种分类评价指标
原文:
www.kdnuggets.com/2019/10/5-classification-evaluation-metrics-every-data-scientist-must-know.html
comments
我们想要优化什么? 大多数企业无法回答这个简单的问题。
每个业务问题都有些许不同,因此需要不同的优化方式。
我们的前三推荐课程
1. Google Cybersecurity Certificate - 快速进入网络安全职业生涯。
2. Google Data Analytics Professional Certificate - 提升您的数据分析技能
3. Google IT Support Professional Certificate - 支持您的组织的 IT 需求
我们都创建过分类模型。很多时候我们尝试通过准确率来评估我们的模型。但我们真的希望准确率作为模型性能的指标吗?
如果我们预测的是会撞击地球的小行星数量呢?
只需始终说零。你将会 99%准确。我的模型可能相对准确,但完全没有价值。在这种情况下我们应该怎么办?
设计数据科学项目比建模本身更为重要。
这篇文章讨论了各种评价指标以及如何和何时使用它们。
1. 准确率、精确率和召回率:
A. 准确率
准确率是经典的分类指标。它很容易理解,并且适用于二分类以及多分类问题。
Accuracy = (TP+TN)/(TP+FP+FN+TN)
准确率是指所有检查的案例中真实结果所占的比例。
何时使用?
准确率对于平衡且没有偏斜或没有类别不平衡的分类问题是一个有效的评价指标。
警告
假设我们的目标类别非常稀疏。我们是否希望准确率作为模型性能的衡量标准?如果我们预测的是小行星是否会撞击地球? 只需始终回答No。你将会 99%准确。我的模型可能相对准确,但完全没有价值。
B. 精确率
让我们从精确率开始,它回答以下问题:预测为正的比例中真正的正例占多少?
Precision = (TP)/(TP+FP)
在小行星预测问题中,我们从未预测过一个真实的正例。
因此精确率 = 0
何时使用?
精确度是一个有效的评估指标,当我们想要对我们的预测非常确定时。例如:如果我们在构建一个系统来预测是否应该减少特定账户的信用额度,我们希望对我们的预测非常确定,否则可能会导致客户不满。
警告
非常精确意味着我们的模型将有很多信用违约者未被触及,从而导致损失。
C. 回忆率
另一个非常有用的度量是回忆率,它回答了一个不同的问题:实际正例的比例被正确分类了多少?
Recall = (TP)/(TP+FN)
在小行星预测问题中,我们从未预测到真正的正例。
因此回忆率也等于 0。
何时使用?
当我们希望捕捉尽可能多的正例时,回忆率是一个有效的评估指标。例如:如果我们在构建一个系统来预测一个人是否患有癌症,我们希望即使不太确定也要捕捉到疾病。
警告
回忆率为 1 当我们对所有样本预测 1 时。
因此,出现了利用精确度与回忆率权衡的想法—— F1 分数。
2. F1 分数:
这是我最喜欢的评估指标,我在分类项目中经常使用这个指标。
F1 分数是 0 到 1 之间的数字,是精确度和回忆率的调和平均数。
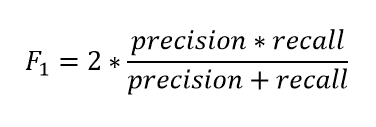
让我们从一个二分类预测问题开始。 我们正在预测小行星是否会撞击地球。
所以如果我们对整个训练集说“否”。我们的精确度为 0。我们的正类回忆率是多少?是零。准确率是多少?超过 99%。
因此,F1 分数也是 0。因此我们了解到,准确率为 99%的分类器在我们的情况下基本上毫无用处。因此它解决了我们的问题。
何时使用?
我们希望拥有一个精确度和回忆率都很好的模型。
精确度-回忆率权衡
简单地说,F1 分数在你的分类器中在精确度和回忆率之间保持了一种平衡。如果你的精确度低,F1 分数低;如果回忆率低,F1 分数同样低。
如果你是警察检查员,并且你想抓住罪犯,你希望确保你抓到的人是罪犯(精确度),同时你也希望捕捉到尽可能多的罪犯(回忆率)。F1 分数处理了这种权衡。
如何使用?
你可以使用以下方法计算二分类预测问题的 F1 分数:
from sklearn.metrics import f1_score
y_true = [0, 1, 1, 0, 1, 1]
y_pred = [0, 0, 1, 0, 0, 1]
*f1_score(y_true, y_pred)*
这是我用来获得最大化 F1 分数的最佳阈值的函数。下面的函数迭代可能的阈值,以找到提供最佳 F1 分数的阈值。
# y_pred is an array of predictions
def bestThresshold(y_true,y_pred):
best_thresh = None
best_score = 0
for thresh in np.arange(0.1, 0.501, 0.01):
score = f1_score(y_true, np.array(y_pred)>thresh)
if score > best_score:
best_thresh = thresh
best_score = score
return best_score , best_thresh
警告
F1 分数的主要问题是它对精确度和回忆率给予相等的权重。我们有时可能需要在评估中包含领域知识,以便我们想要更多的回忆率或更多的精确度。
为解决此问题,我们可以通过创建加权的 F1 指标来实现,下面的公式中β管理精确度和召回率之间的权衡。
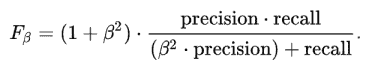
在这里,我们给予召回率β倍的权重,而不是精确度。
from sklearn.metrics import fbeta_score
y_true = [0, 1, 1, 0, 1, 1]
y_pred = [0, 0, 1, 0, 0, 1]
fbeta_score(y_true, y_pred,beta=0.5)
F1 分数也可以用于多类问题。请参阅这篇精彩博客文章,由Boaz Shmueli提供详细信息。
3. 日志损失/二元交叉熵
日志损失是评估二元分类器的一个相当好的指标,并且在逻辑回归和神经网络中有时也是优化目标。
二元日志损失的示例如下公式,其中 p 是预测 1 的概率。
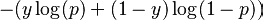
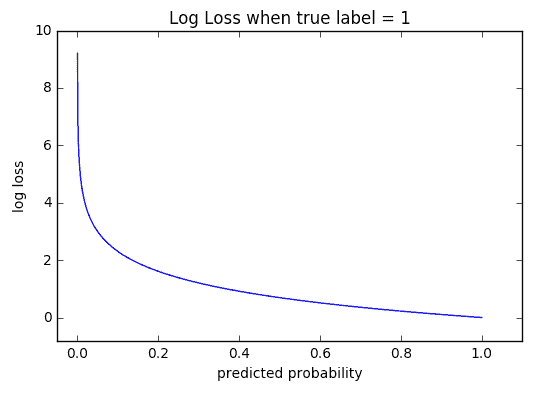
如你所见,当我们对 1 的预测相当确定且实际标签为 1 时,日志损失减少。
何时使用?
当分类器的输出是预测概率时。日志损失考虑了你的预测的不确定性,基于其与实际标签的差异。这为我们的模型性能提供了更细致的视角。一般来说,最小化日志损失可以提高分类器的准确性。
如何使用?
from sklearn.metrics import log_loss
# where y_pred are probabilities and y_true are binary class labels
log_loss(y_true, y_pred, eps=1e-15)
注意事项
在不平衡数据集的情况下,它容易受到影响。你可能需要引入类别权重,以更多地惩罚少数类错误,或者在平衡数据集后使用此方法。
4. 分类交叉熵
日志损失也可以推广到多类问题。在多类情况下,分类器必须为所有示例分配每个类别的概率。如果有 N 个样本属于 M 个类别,则分类交叉熵是-ylogp值的总和:
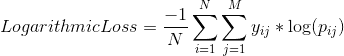
y_ij是 1 如果样本i属于类别j,否则为 0
p_ij是我们分类器预测样本i属于类别j的概率。
何时使用?
当分类器的输出是多类预测概率时,我们通常在神经网络中使用分类交叉熵。一般来说,最小化分类交叉熵可以提高分类器的准确性。
如何使用?
from sklearn.metrics import log_loss
# Where y_pred is a matrix of probabilities
# with shape *=(n_samples, n_classes)* and y_true is an array of class labels
log_loss(y_true, y_pred, eps=1e-15)
注意事项:
在不平衡数据集的情况下,它容易受到影响。
5. AUC
AUC 是 ROC 曲线下的面积。
AUC ROC 指标显示正类概率与负类概率的分离程度
ROC 曲线是什么?
我们从分类器得到了概率。我们可以使用各种阈值来绘制我们的灵敏度(TPR)和(1-特异度)(FPR)的曲线,这样我们就会得到 ROC 曲线。
其中,真正的阳性率(True Positive Rate,TPR)只是我们使用算法捕获的真正阳性的比例。
Sensitivty = TPR(True Positive Rate)= Recall = TP/(TP+FN)
假阳性率(False Positive Rate,FPR)只是我们使用算法捕获的假阳性的比例。
1- Specificity = FPR(False Positive Rate)= FP/(TN+FP)
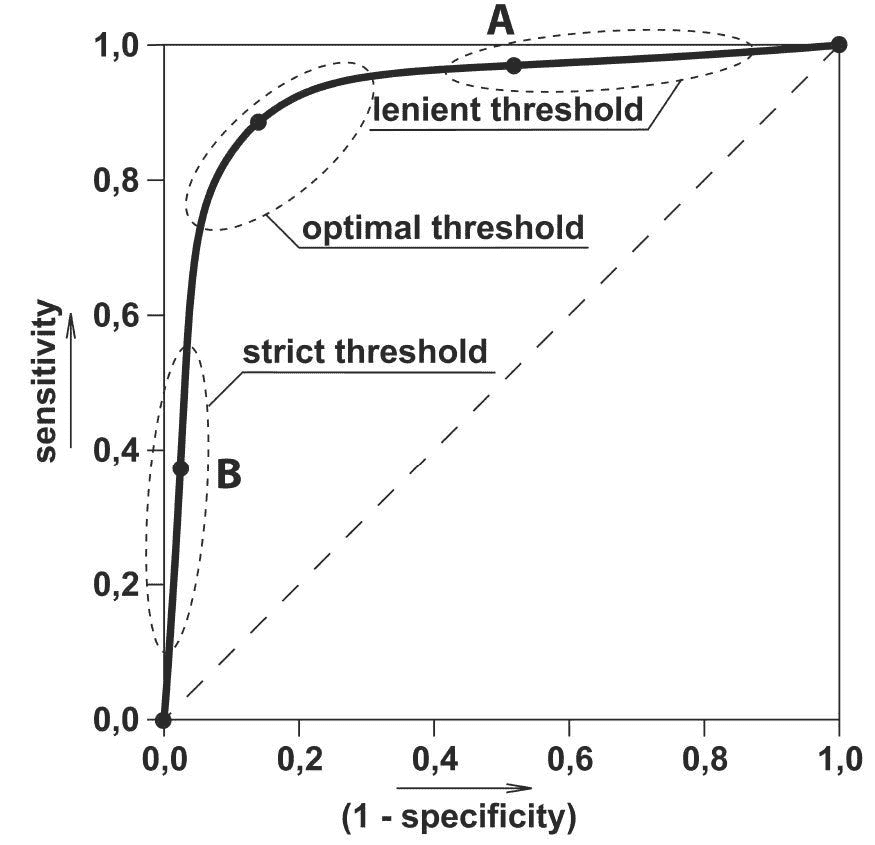
ROC 曲线
在这里,我们可以使用 ROC 曲线来决定阈值。
阈值的选择还将取决于分类器的使用意图。
如果这是一个癌症分类应用,你不希望你的阈值设为 0.5。即使一个患者的癌症概率是 0.3,你也会将他分类为 1。
否则,在降低信用卡限额的应用中,你不希望你的阈值设为 0.5。你此时更担心降低限额对客户满意度的负面影响。
何时使用?
AUC 是尺度不变的。它衡量的是预测的排名情况,而不是其绝对值。因此,例如,如果你作为市场营销人员想要找出响应营销活动的用户列表。AUC 是一个好的指标,因为按概率排名的预测就是你将创建营销活动用户列表的顺序。
使用 AUC 的另一个好处是它是分类阈值不变的,类似于对数损失。它衡量模型预测的质量,而不管选择了什么分类阈值,这与 F1 分数或准确度不同,它们依赖于阈值的选择。
如何使用?
import numpy as np
from sklearn.metrics import roc_auc_score
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
*print(roc_auc_score(y_true, y_scores))*
注意事项
有时我们需要从模型中获得良好的概率输出,而 AUC 对此无济于事。
结论
创建我们的machine learning pipeline的一个重要步骤是将不同的模型相互评估。选择不当的评价指标可能会对整个系统造成严重影响。
因此,始终要注意你预测的内容以及评价指标的选择如何影响/改变你的最终预测。
此外,选择评价指标应与业务目标良好对齐,因此这有些主观。你也可以提出自己的评价指标。
继续学习
如果你想要了解 更多关于如何构建机器学习项目和最佳实践的内容,我推荐他的精彩第三门课程,这门课程名为《构建机器学习项目》,在 Coursera 的深度学习专业课程中提供。一定要看看,它讲述了许多基本概念和改进模型的陷阱。
感谢阅读。我将来还会写更多适合初学者的文章。可以在Medium上关注我,或订阅我的博客以获取最新动态。一直以来,我欢迎反馈和建设性的批评,可以通过 Twitter @mlwhiz 联系我。
另外,附个小免责声明——这篇文章可能包含一些相关资源的推荐链接,因为分享知识永远是个好主意。
简介:Rahul Agarwal 是 WalmartLabs 的高级统计分析师。可以在 Twitter 上关注他 @mlwhiz。
原文。已获许可转载。
相关:
-
数据科学家应该了解的 5 种图算法
-
特征提取的向导
-
数据科学家的 6 条建议
相关主题
5 个“清洁代码”技巧将显著提高你的生产力
原文:
www.kdnuggets.com/2018/10/5-clean-code-tips-dramatically-improve-productivity.html
注释
高质量的代码。很多人谈论这个,但很少有人真正做到这一点。
大多数编程的人自然知道高质量的代码应该是什么样的或感觉如何。它应该非常易于阅读和快速理解,不应该有任何重大缺陷,边界情况应该得到处理,并且应该是“自我文档化”的。然而,许多人在尝试(希望)编写高质量代码时仍然会偏离目标。
错误的原因在许多情况下是可以理解的。预测人们如何解读你的代码、他们是否会觉得它易于阅读或是一场噩梦可能很具挑战性。而且,一旦你的项目变得非常庞大,即使是你也可能无法阅读它!
在这种情况下,建立一些你可以依赖的原则总是很好的。一些你可以在设计或编写代码时随时参考的规则。
以下 5 个清洁编码原则是我编写代码时遵循的!它们为我的工作带来了巨大的生产力提升,并帮助我和我的同事能够轻松解读和扩展我所工作的代码库。希望它们也能帮助你更快、更好地编写代码!
如果没有经过测试,那就是坏的
测试,测试,再测试。我们知道我们应该始终进行测试,但有时我们为了加快项目进度而走捷径。但没有彻底的测试,你如何100%完全知道代码是否有效?是的,有些代码非常简单,但当你遇到那些你认为不需要测试的疯狂边界情况时,总是会感到惊讶!
给自己和团队中的每个人一个好处,定期测试你编写的代码。你会想以粗略到细致的方式进行测试。从小规模的单元测试开始,确保每个小部分独立工作。然后逐渐开始测试不同的子系统,逐步测试整个新系统的端到端。这种测试方式可以让你轻松追踪系统崩溃的地方,因为你可以轻松验证每个单独的组件或小的子系统是否是问题的源头。
选择有意义的名称
这就是使代码自我文档化的原因。当你回顾旧代码时,你不应该需要查看每一个小注释并运行每一小段代码来弄清楚它的作用!
代码应该大致像普通英语一样易读。这对于变量名、类和函数尤为重要。这三者的名称应该始终具有自我解释性。与其使用像“x”这样的默认名称,不如用“width”或“distance”或变量在“实际世界”中应代表的其他名称。用“实际世界”术语进行编码将有助于让你的代码以这种方式易读。
类和函数应该小且遵守单一职责原则(SRP)
小的类和函数使代码的可读性大约提高了 9832741892374 倍……
但说真的,它们真的很重要。首先,它们允许非常独立的单元测试。如果你测试的代码片段很小,那么在测试或部署过程中出现的任何问题都很容易追踪和调试。小的类和函数也有助于提高可读性。与其有一个包含许多循环和变量的大块代码,不如将其减少到一个运行多个较小函数的函数。然后你可以根据这些函数的功能给它们命名,结果就是人类可读的代码!
SRP 带来类似的好处。一个职责意味着你只需测试少量边缘情况,这些情况相对容易调试。此外,命名函数也很简单,因为它具有现实意义。由于它只有一个单一目的,所以它的名称将直接与其目的相关,而不是尝试给一个试图完成多种不同任务的函数命名。
捕获并处理异常,即使你觉得不需要这样做。
代码中的异常通常是边缘情况或我们希望以特定方式处理的错误。例如,通常当错误被抛出时,程序会停止;这对我们已经部署到生产环境中并为用户服务的代码显然是不适用的!我们需要单独处理这些错误,也许试着判断它是否非常关键,或者我们是否应该忽略它。
你应该始终具体地捕获和处理异常,即使你认为不需要这样做。小心总比后悔好。异常处理将让你对代码有更好的顺序感和控制感,因为你知道具体在某个异常被触发或某段代码失败时会发生什么。对代码有更深刻的理解,使其更容易调试,并提高代码的容错性。
日志,日志,日志
记录日志。你可能会问记录什么?……一切,没错!没有什么叫做“日志过多”!
日志是调试代码和监控应用程序在生产环境中运行的绝对首要来源。你应该记录程序的每一个重要“步骤”,它进行的任何重要计算,任何错误、异常或异常结果。记录这些事件发生的日期和时间也可能有助于跟踪。所有这些都将使你更容易追踪程序在管道中的哪个步骤失败。
许多常见的编程语言,如 Python,都附带有一些非常有用的日志库。如果你的应用程序将作为 SaaS 应用运行,那么你可能需要考虑离设备的集中日志记录。这样,如果你的服务器出现故障,你可以轻松地恢复日志!
TL;DR
(1) 如果没有测试,那就是坏的
(2) 选择有意义的名称
(3) 类和函数应该小且遵循单一职责原则(SRP)
(4) 捕获和处理异常,即使你认为不需要也要处理
(5) 日志,日志,日志
喜欢阅读关于技术的内容吗?
在 twitter 上关注我,了解最新和最棒的技术!
感谢 David Smooke。
个人简介:George Seif 是一位认证的极客及 AI / 机器学习工程师。
原文。已获许可转载。
相关:
-
使用 Python 和代码创建的 5 种快速简易数据可视化
-
数据科学家需要了解的 5 种聚类算法
-
为回归问题选择最佳机器学习算法
我们的 3 大课程推荐
1. Google 网络安全证书 - 加速你的网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关内容
数据科学家需要了解的 5 种聚类算法
原文:
www.kdnuggets.com/2018/06/5-clustering-algorithms-data-scientists-need-know.html
评论
聚类是一种机器学习技术,它涉及数据点的分组。给定一组数据点,我们可以使用聚类算法将每个数据点分类到一个特定的组中。理论上,处于同一组的数据点应该具有相似的属性和/或特征,而不同组中的数据点应该具有高度不同的属性和/或特征。聚类是一种无监督学习方法,是许多领域中用于统计数据分析的常用技术。
在数据科学中,我们可以通过聚类分析从数据中获得一些有价值的见解,观察数据点应用聚类算法时落入了哪些组。今天,我们将深入探讨数据科学家需要了解的 5 种流行的聚类算法及其优缺点!
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
K-Means 聚类
K-Means 可能是最知名的聚类算法。它在许多入门数据科学和机器学习课程中都有教授。它易于理解和编码实现!请查看下面的图示。
K-Means 聚类
-
开始时,我们首先选择要使用的类别/组的数量,并随机初始化它们各自的中心点。为了确定使用的类别数量,最好快速查看数据并尝试识别任何明显的分组。中心点是与每个数据点向量长度相同的向量,是上图中的“X”。
-
每个数据点通过计算该点与每个组中心之间的距离来进行分类,然后将该点分类到离它最近的组中。
-
基于这些分类点,我们通过取组中所有向量的均值来重新计算组中心。
-
重复这些步骤直到达到设定的迭代次数或直到组中心在迭代之间变化不大。你也可以选择随机初始化组中心几次,然后选择看起来效果最佳的运行结果。
K-Means 的一个优点是速度相当快,因为我们实际做的只是计算点和组中心之间的距离;计算非常少!因此,它具有线性复杂度 O(n)。
另一方面,K-Means 有一些缺点。首先,你必须选择有多少个组/类。这并不总是简单的,理想情况下,我们希望聚类算法能为我们解决这个问题,因为它的目的是从数据中获得一些洞察。K-Means 还从随机选择的簇中心开始,因此可能会在算法的不同运行中产生不同的聚类结果。因此,结果可能无法重复且缺乏一致性。其他聚类方法则更具一致性。
K-Medians 是另一种与 K-Means 相关的聚类算法,只不过它不是使用均值来重新计算组中心点,而是使用组的中位数向量。这种方法对离群点的敏感性较低(因为使用了中位数),但对于较大的数据集来说,速度要慢得多,因为在计算中位数向量时每次迭代都需要排序。
均值漂移聚类
均值漂移聚类是一种基于滑动窗口的算法,旨在找到数据点的密集区域。它是一种基于中心点的算法,意味着目标是定位每个组/类的中心点,这通过更新中心点候选为滑动窗口内点的均值来实现。这些候选窗口随后在后处理阶段进行过滤,以消除近似重复项,形成最终的中心点集合及其对应的组。请查看下方的图示。
单个滑动窗口的均值漂移聚类
-
为了解释均值漂移,我们将考虑二维空间中的一组点,如上图所示。我们从一个以点 C(随机选择)为中心,半径为 r 的圆形滑动窗口开始,作为核。均值漂移是一种爬山算法,涉及在每一步将该核迭代地移动到更高密度区域,直到收敛。
-
在每次迭代中,滑动窗口被向更高密度的区域移动,通过将中心点移到窗口内点的均值(因此得名)。滑动窗口内的密度与其中的点数成正比。自然地,通过向窗口中点的均值移动,它将逐渐朝着点密度更高的区域移动。
-
我们继续根据均值移动滑动窗口,直到没有方向可以使得更多点进入核。请查看上面的图示;我们继续移动圆圈,直到我们不再增加密度(即窗口中的点数)。
-
步骤 1 到步骤 3 的过程会用许多滑动窗口完成,直到所有点都在一个窗口内。当多个滑动窗口重叠时,会保留包含最多点的窗口。然后根据点所在的滑动窗口进行聚类。
下方展示了整个过程的插图,包含所有滑动窗口。每个黑点表示一个滑动窗口的质心,每个灰点是一个数据点。

Mean-Shift 聚类的整个过程
与 K-means 聚类相比,无需选择聚类的数量,因为均值漂移会自动发现这一点。这是一个巨大的优势。聚类中心收敛到最大密度点的事实也相当理想,因为它直观易懂,并且很好地符合自然数据驱动的感觉。缺点是窗口大小/半径“r”的选择可能并不简单。
基于密度的空间聚类应用与噪声(DBSCAN)
DBSCAN 是一种基于密度的聚类算法,类似于均值漂移,但具有一些显著的优势。查看下面的另一个炫酷图形,我们开始吧!
DBSCAN 微笑面孔聚类
-
DBSCAN 从一个未被访问的任意起始数据点开始。通过距离 ε (所有在 ε 距离内的点都是邻域点) 提取该点的邻域。
-
如果在这个邻域内有足够数量的点(根据 minPoints),则开始聚类过程,当前数据点成为新聚类中的第一个点。否则,该点会被标记为噪声(以后这个噪声点可能会成为聚类的一部分)。在这两种情况下,该点都会被标记为“已访问”。
-
对于新聚类中的第一个点,距离其 ε 距离邻域内的点也会成为相同的聚类的一部分。这个将 ε 邻域内的所有点归入相同聚类的过程会对刚刚添加到聚类组中的所有新点重复进行。
-
步骤 2 和步骤 3 的过程会重复进行,直到确定聚类中的所有点,即所有在聚类的 ε 邻域内的点都已被访问和标记。
-
一旦完成当前的聚类,就会检索并处理一个新的未访问点,从而发现进一步的聚类或噪声。这个过程会重复进行,直到所有点都被标记为已访问。由于最终所有点都已被访问,因此每个点都会被标记为属于某个聚类或是噪声。
DBSCAN 相较于其他聚类算法有一些很好的优势。首先,它根本不需要预设的聚类数量。它还将离群点识别为噪声,这与均值漂移不同,均值漂移即使数据点非常不同也会将它们放入聚类中。此外,它能够很好地找到任意大小和任意形状的聚类。
DBSCAN 的主要缺点是当聚类的密度变化时,它的表现不如其他方法。这是因为用于识别邻域点的距离阈值ε和 minPoints 的设置会随着聚类密度的变化而变化。这个缺点也出现在非常高维的数据中,因为距离阈值ε的估计变得具有挑战性。
期望最大化(EM)使用高斯混合模型(GMM)的聚类
K 均值的一个主要缺点是它对聚类中心的均值值的简单使用。通过查看下图,我们可以看到为什么这不是最好的方法。在左侧,人眼很明显地看到有两个不同半径的圆形聚类,以相同的均值为中心。K 均值无法处理这种情况,因为聚类的均值非常接近。K 均值在聚类不是圆形的情况下也会失败,这又是因为使用均值作为聚类中心。

K 均值的两个失败案例
高斯混合模型(GMMs)比 K 均值提供了更多的灵活性。使用 GMM 时,我们假设数据点是高斯分布的;这一假设比使用均值假设数据点为圆形要不那么严格。因此,我们有两个参数来描述聚类的形状:均值和标准差!以二维为例,这意味着聚类可以采取任何形状的椭圆(因为我们在 x 和 y 方向都有标准差)。因此,每个高斯分布被分配到一个单独的聚类中。
为了找到每个聚类的高斯参数(如均值和标准差),我们将使用一种称为期望最大化(EM)的优化算法。请查看下面的图形,以说明高斯如何适应聚类。然后,我们可以继续进行使用 GMM 的期望最大化聚类过程。
使用 GMM 的 EM 聚类
-
我们首先选择聚类的数量(像 K 均值那样)并随机初始化每个聚类的高斯分布参数。可以通过快速查看数据来尝试提供一个好的初始参数估计。尽管要注意,如上图所示,这并不是 100%必要,因为高斯初始时很差,但会很快得到优化。
-
给定每个簇的高斯分布,计算每个数据点属于特定簇的概率。一个点离高斯中心越近,它属于该簇的可能性就越大。这应该是直观的,因为在高斯分布中,我们假设大多数数据点更靠近簇的中心。
-
基于这些概率,我们计算高斯分布的新参数集,以最大化簇内数据点的概率。我们使用数据点位置的加权和来计算这些新参数,其中权重是数据点属于特定簇的概率。为了直观地解释这一点,我们可以查看上面的图形,特别是黄色簇作为例子。分布在第一次迭代时是随机的,但我们可以看到大多数黄色点位于该分布的右侧。当我们计算加权和时,即使有些点靠近中心,大多数点还是在右侧。因此,分布的均值自然会向这些点的集合移动。我们还可以看到大多数点的分布是“从左上到右下”。因此,标准差发生变化,形成一个更适合这些点的椭圆,以最大化加权和。
-
第 2 步和第 3 步会反复进行,直到收敛为止,此时分布在每次迭代中变化不大。
使用 GMM 有两个主要优势。首先,GMM 在簇协方差方面比 K-Means 更加灵活;由于标准差参数,簇可以呈现任何椭圆形状,而不是局限于圆形。K-Means 实际上是 GMM 的一个特例,其中每个簇在所有维度上的协方差接近 0。其次,由于 GMM 使用概率,它们可以为每个数据点提供多个簇。因此,如果一个数据点位于两个重叠簇的中间,我们可以简单地定义它的类别,表示它属于类别 1 的概率是 X%,属于类别 2 的概率是 Y%。即 GMM 支持混合 成员资格。
聚合层次聚类
层次聚类算法实际上分为两类:自上而下和自下而上。自下而上的算法在开始时将每个数据点视为一个单独的簇,然后逐步合并(或聚合)簇对,直到所有簇合并为一个包含所有数据点的单一簇。因此,自下而上的层次聚类被称为层次聚合聚类或HAC。这种簇的层次结构表示为一棵树(或树状图)。树的根是一个唯一的簇,汇集了所有样本,叶子是仅包含一个样本的簇。请查看下面的图示,然后再继续算法步骤。
聚合层次聚类
-
我们开始时将每个数据点视为一个单独的簇,即如果数据集中有 X 个数据点,那么我们就有 X 个簇。然后,我们选择一种度量簇间距离的距离度量。例如,我们将使用平均连接,它定义了两个簇之间的距离为第一个簇中的数据点和第二个簇中的数据点之间的平均距离。
-
在每次迭代中,我们将两个簇合并为一个。被合并的两个簇是选择那些具有最小平均连接的簇。即根据我们选择的距离度量,这两个簇之间的距离最小,因此它们是最相似的,应该被合并。
-
步骤 2 重复进行,直到我们到达树的根部,即我们只剩下一个包含所有数据点的簇。通过这种方式,我们可以选择最终需要多少个簇,只需选择何时停止合并簇,即何时停止构建树!
层次聚类不需要我们指定簇的数量,我们甚至可以选择哪个簇的数量看起来最好,因为我们在构建树。此外,该算法对距离度量的选择不敏感;所有度量通常效果相同,而其他聚类算法中,距离度量的选择至关重要。层次聚类方法的一个特别好的用例是,当基础数据具有层次结构时,你希望恢复这种层次结构;其他聚类算法无法做到这一点。这些层次聚类的优点是以较低效率为代价的,因为它的时间复杂度为O(n³),不同于 K-Means 和 GMM 的线性复杂度。
结论
这就是数据科学家应知道的前五种聚类算法!我们将以一个精彩的可视化结束,展示这些算法以及其他一些算法的表现,感谢 Scikit Learn!
简介: George Seif 是一名认证的极客和人工智能 / 机器学习工程师。
原文。经许可转载。
相关:
-
比较聚类技术:简明技术概述
-
必知:如何确定最有用的簇数量?
-
通过朴素分片质心初始化方法提高 k-means 聚类效率
更多相关内容
5 种 ChatGPT 无法完成的编码任务

作者提供的图片
我喜欢把 ChatGPT 看作是 StackOverflow 的一个更智能的版本。非常有帮助,但短期内不会取代专业人士。作为前数据科学家,我在 ChatGPT 发布时花了大量时间进行尝试。我对它的编码能力相当印象深刻。它能从零开始生成相当有用的代码;它可以对我自己的代码提供建议。如果我要求它帮我解决错误信息,它在调试方面表现也很好。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
但不可避免的是,使用它的时间越长,我就越遇到它的局限性。对于那些担心 ChatGPT 会取代他们工作的开发者来说,以下是 ChatGPT 无法做到的事情列表。

1. 任何贵公司会专业使用的代码
第一个限制不是关于其能力,而是法律问题。任何完全由 ChatGPT 生成的代码,如果您将其复制粘贴到公司产品中,可能会使您的雇主面临麻烦的诉讼。
这是因为 ChatGPT 会自由地从其训练数据中提取代码片段,这些数据来自互联网各处。Reddit 用户 ChunkyHabaneroSalsa 解释说:“我让 ChatGPT 为我生成了一些代码,我立刻认出了它从哪个 GitHub 仓库获取了大部分内容。”
最终,我们无法确定 ChatGPT 的代码来源,也无法知道它遵循了什么许可证。即使代码完全是从零生成的,ChatGPT 生成的任何内容本身也不能获得版权。正如 Bloomberg Law 的作者 Shawn Helms 和 Jason Krieser 指出的,“‘衍生作品’是‘基于一个或多个现有作品的作品。’ChatGPT 是基于现有作品进行训练的,并且根据这种训练生成输出。”
如果您使用 ChatGPT 生成代码,您可能会发现自己面临雇主的麻烦。
2. 任何需要批判性思维的任务
这是一个有趣的测试:让 ChatGPT 创建一个在 Python 中运行统计分析的代码。
这是否是正确的统计分析?可能不是。ChatGPT 不知道数据是否符合测试结果有效所需的假设。ChatGPT 也不知道利益相关者想看到什么。
例如,我可能会让 ChatGPT 帮助我确定不同年龄组的满意度评分是否存在统计学上的显著差异。ChatGPT 建议使用独立样本 T 检验,并未发现年龄组之间有统计学上的显著差异。但 T 检验在这里并不是最佳选择,原因有几个,比如可能存在多个年龄组,或者数据不符合正态分布。
图片来自 decipherzone.com
一位 全栈数据科学家 会知道检查哪些假设和运行什么样的测试,并可以给 ChatGPT 更具体的指令。但 ChatGPT 自身会高兴地为错误的统计分析生成正确的代码,从而使结果不可靠且无法使用。
对于需要更多批判性思维和问题解决的问题,ChatGPT 并不是最佳选择。
3. 理解利益相关者优先事项
任何数据科学家都会告诉你,工作的一部分是理解和解释项目中的利益相关者优先事项。ChatGPT,或者任何 AI,都不能完全理解或管理这些。
首先,利益相关者的优先事项通常涉及复杂的决策,这些决策不仅考虑数据,还涉及人类因素、业务目标和市场趋势。
例如,在应用程序重新设计中,你可能会发现市场营销团队希望优先考虑用户参与功能,销售团队推动支持交叉销售的功能,而客户支持团队需要更好的应用内支持功能来帮助用户。
ChatGPT 可以提供信息并生成报告,但它无法做出与不同利益相关者的多样化且有时相互竞争的利益相符的微妙决策。
此外,利益相关者管理通常需要高度的情商——即能够与利益相关者产生共鸣,理解他们的关切,并对他们的情感做出回应。ChatGPT 缺乏情商,无法管理利益相关者关系中的情感方面。
你可能不会将其视为编码任务,但目前正在为该新功能推出编写代码的数据科学家清楚其中有多少工作与利益相关者的优先事项相关。
4. 新颖问题
ChatGPT 无法提出真正新颖的内容。它只能重新混合和重新构造从其训练数据中学到的东西。

图片来自 theinsaneapp.com
想知道如何更改 R 图中的图例大小吗?没问题——ChatGPT 可以从成千上万的 StackOverflow 答案中获取相同问题的解决方案。但是(使用我要求 ChatGPT 生成的一个例子),如果是一个它不太可能遇到的情况,比如组织一个社区聚餐,每个人的菜肴必须包含一个以其姓氏首字母为开头的成分,并确保有多样的菜肴,那该怎么办?
当我测试这个提示时,它给了我一些 Python 代码,决定了菜肴的名字必须与姓氏匹配,甚至没有正确捕捉到成分要求。它还要求我想出 26 种菜肴类别,每种字母一个。这不是一个聪明的答案,可能是因为这是一个完全新颖的问题。
5.道德决策制定
最后但同样重要的是,ChatGPT 无法道德地编写代码。它没有能力像人类那样做出价值判断或理解代码的道德影响。
道德编码涉及考虑代码可能如何影响不同的群体,确保它不歧视或造成伤害,并做出符合道德标准和社会规范的决策。
例如,如果你让 ChatGPT 编写一个贷款审批系统的代码,它可能会生成一个基于历史数据的模型。然而,它无法理解该模型可能因数据中的偏见而拒绝向边缘化社区提供贷款的社会影响。需要人类开发者识别公平与公正的需求,寻求并纠正数据中的偏见,并确保代码符合道德实践。
值得指出的是,人们也不是完美的——有人编写了亚马逊的偏见招聘工具,还有人编写了谷歌照片分类,将黑人识别为猩猩。但人类在这方面做得更好。ChatGPT 缺乏编写道德代码所需的同理心、良知和道德推理能力。
人类可以理解更广泛的背景,识别人类行为的细微差别,并进行关于对错的讨论。我们参与道德辩论,权衡特定方法的利弊,并对我们的决策负责。当我们犯错时,我们可以从中学习,这有助于我们的道德成长和理解。
最终思考
我喜欢 Reddit 用户 Empty_Experience_10 对这一点的看法: “如果你只会编程,你就不是一名软件工程师,没错,你的工作会被替代。如果你认为软件工程师高薪是因为他们会写代码,那你对软件工程师的真正含义有根本性的误解。”
我发现 ChatGPT 在调试、代码审查方面非常出色,而且比查找 StackOverflow 上的答案要快一些。但“编码”远不止于将 Python 输入键盘。这包括了解你业务的目标,理解在算法决策时必须多么小心,与利益相关者建立关系,真正了解他们的需求和原因,并寻找实现这些目标的方式。
这是讲故事,知道何时选择饼图或柱状图,以及理解数据试图传达的叙事。它关乎于将复杂的想法用简单的术语传达给利益相关者,让他们能够理解并据此做出决策。
ChatGPT 无法做到这些。只要你能做到,你的工作就安全。
Nate Rosidi是一名数据科学家,专注于产品战略。他还是一名兼职教授,教授分析学,同时是 StrataScratch 的创始人,该平台帮助数据科学家准备面试,提供来自顶级公司的真实面试问题。Nate 撰写关于职业市场的最新趋势,提供面试建议,分享数据科学项目,并涵盖所有 SQL 相关内容。
更多相关话题
5 种数据科学的命令行工具
原文:
www.kdnuggets.com/2023/03/5-command-line-tools-data-science.html
作者提供的图片
1. csvkit
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
Csvkit是表格数据的工具王。它包含了一系列可用于转换 CSV 文件、操控数据和进行数据分析的工具。
你可以使用 pip 安装csvkit。
$ pip install csvkit
示例 1
在这个示例中,我们将使用csvcut来选择两个列,并使用csvlook以表格格式显示结果。
csvcut -c sepal_length,species iris.csv | csvlook --max-rows 5
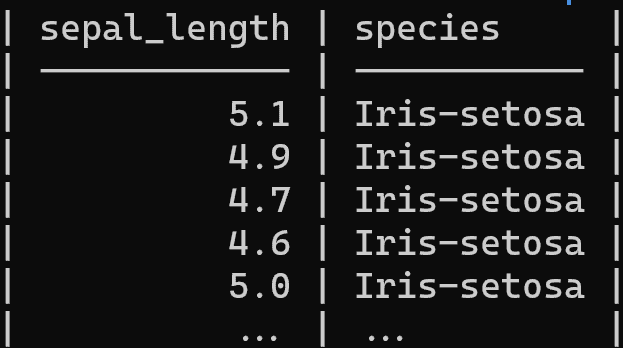
注意: 你可以使用参数--max-rows来限制行数
示例 2
我们将使用csvjson将 CSV 文件转换为 JSON 文件。
csvjson iris.csv > iris.json
注意: csvkit还提供了将 Excel 转换为 CSV 和将 JSON 转换为 CSV 的工具。
示例 3
我们还可以通过使用 SQL 查询对 CSV 文件进行数据分析。csvsql需要 SQL 查询和 CSV 文件路径。你可以显示结果或将其保存为 CSV。
csvsql --query "select * from iris where species like 'Iris-setosa'" iris.csv | csvlook --max-rows 5
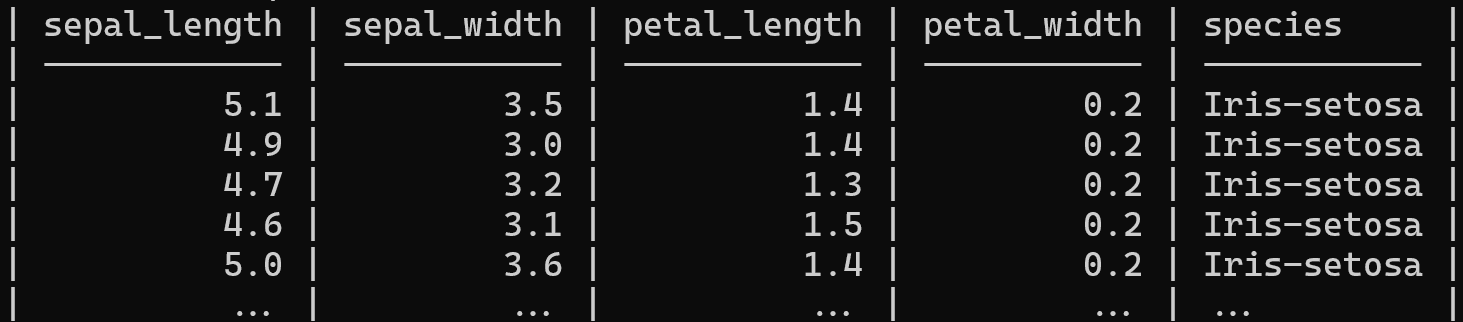
2. IPython
IPython是一个交互式 Python 外壳,它将 Jupyter 笔记本的一些功能带入你的终端。它允许你更快地测试想法,而无需创建 Python 文件。
使用 pip 安装ipython。
$ pip install ipython
注意: Ipython也包含在 Anaconda 和 Jupyter Notebook 中。因此,在大多数情况下你不需要单独安装它。
安装后,只需在终端中输入ipython,即可像在 Jupyter 笔记本中一样开始数据分析。这既简单又快捷。
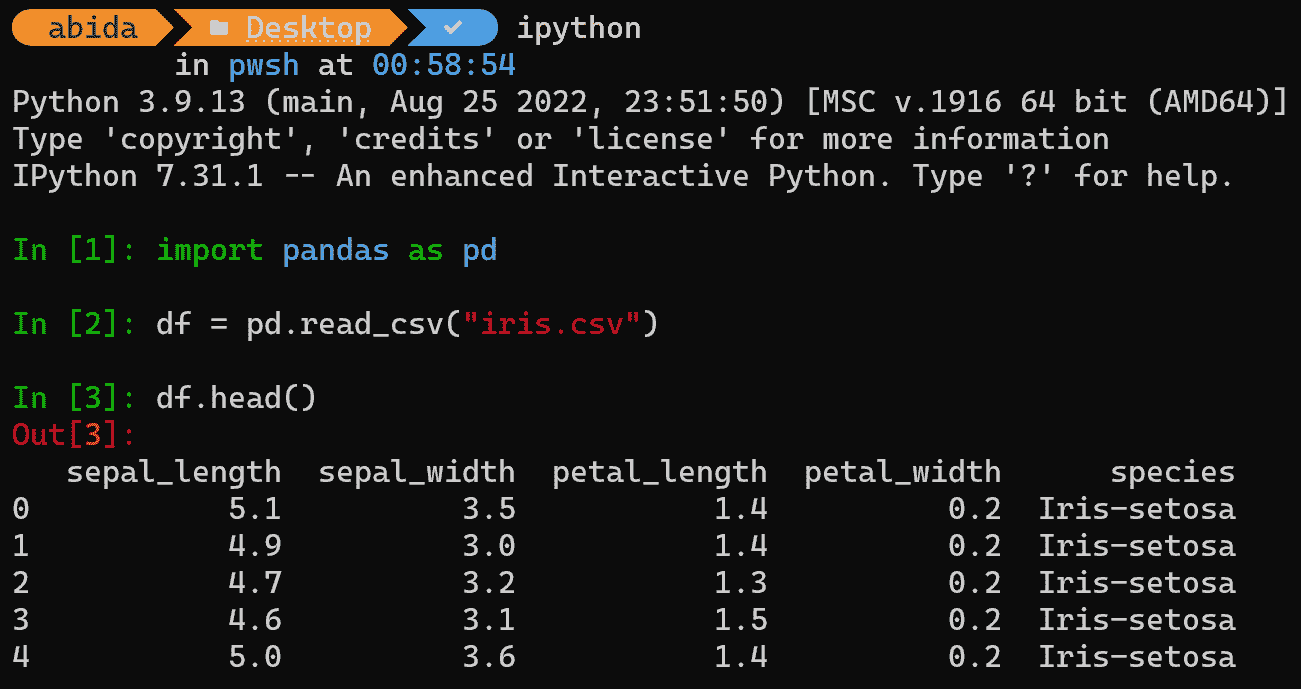
3. cURL
cURL代表客户端 URL,是一个用于通过 URL 在服务器间传输数据的 CLI 工具。你可以使用它来限制速率、记录错误、显示进度以及测试端点。
在这个示例中,我们从加州大学下载机器学习数据并将其保存为 CSV 文件。
curl -o blood.csv https://archive.ics.uci.edu/ml/machine-learning-databases/blood-transfusion/transfusion.data
输出:
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 12843 100 12843 0 0 7772 0 0:00:01 0:00:01 --:--:-- 7769
你可以使用cURL来访问带有令牌的 API、推送文件以及自动化数据管道。
4. awk
Awk 是一种终端脚本语言,我们可以用来操作数据并进行数据分析。它无需抱怨。我们可以使用变量、数字函数、字符串函数和逻辑运算符来编写任何类型的脚本。
在示例中,我们展示了 CSV 文件的第一列和最后一列,并显示了最后 10 行。脚本中的$1 表示第一列。你也可以将其改为\(3 以显示第 3 列。\)NF 表示最后一列。
awk -F "," '{print $1 " | " $NF}' iris.csv | tail

5. Kaggle
Kaggle API 允许你从 Kaggle 网站下载各种数据集。此外,你还可以更新你的公共数据集,提交文件到竞赛,并运行和管理 Jupyter Notebook。它是一个超级命令行工具。
使用 pip 安装 Kaggle API。
$ pip install kaggle
之后,前往 Kaggle 网站并获取你的凭据。你可以按照 这个指南来设置你的用户名和私钥。
export KAGGLE_USERNAME=kingabzpro
export KAGGLE_KEY=xxxxxxxxxxxxxx
示例 1
设置认证后,你可以搜索随机数据集。在我们的案例中,我们使用了 就业趋势调查 数据集。
图片来自 就业趋势调查
你可以使用-d参数 USERNAME/DATASET 来运行下载脚本。
$ kaggle datasets download -d revathyta/survey-on-employment-trends
或者,
你可以通过点击三个点并选择“复制 API 命令”选项来简单地获取 API 命令。
图片来自 就业趋势调查
它将数据集以 zip 文件的形式下载。你还可以将脚本与unzip命令连接,以提取数据。
Downloading survey-on-employment-trends.zip to C:\Users\abida
0%| | 0.00/6.22k [00:00<?, ?B/s]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████| 6.22k/6.22k [00:00<?, ?B/s]
示例 2
要在 Kaggle 上创建并分享你的数据集,你首先需要通过提供数据集的路径来初始化一个元数据文件。
$ kaggle datasets init -p /work/Kaggle/World-Vaccine-Progress
之后创建数据集并将文件推送到 Kaggle 服务器。
$ kaggle datasets create -p /work/Kaggle/World-Vaccine-Progress
你还可以使用 version 命令来更新你的数据集。它需要一个文件路径和消息。就像 git 一样。
$ kaggle datasets version -p /work/Kaggle/World-Vaccine-Progress -m "second version"
你也可以查看我的项目 疫苗更新仪表板,它成功地实现了 Kaggle API 来定期更新数据集。
结论
我使用了许多惊人的 CLI 工具,它们提高了我的生产力,帮助我自动化了大部分工作。你甚至可以使用 click 或 argparse 在 Python 中创建你自己的 CLI 工具。
在这篇文章中,我们学习了 CLI 工具来下载数据集、操作数据、进行分析、运行脚本和生成报告。
我是 Kaalgle API 和 csvkit 的粉丝。我经常使用它们来自动化我的笔记本和分析。如果你想了解如何在数据科学工作流中使用命令行工具,可以在线免费阅读命令行中的数据科学这本书。
Abid Ali Awan (@1abidaliawan) 是一位认证数据科学专家,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络开发一个 AI 产品,帮助那些面临心理健康问题的学生。
更多相关话题
5 个常见数据科学错误及其避免方法
原文:
www.kdnuggets.com/5-common-data-science-mistakes-and-how-to-avoid-them

图片由 FLUX.1 [dev] 生成,并用 Canva Pro 编辑
你是否曾经想过为什么你的数据科学项目显得无序,或者结果比基线模型更差?这可能是因为你犯了 5 个常见但重要的错误。幸运的是,这些错误可以通过结构化的方法轻松避免。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 在 IT 领域支持你的组织
在这篇博客中,我将讨论数据科学家常犯的五个错误,并提供解决方案来克服这些问题。关键在于识别这些陷阱并积极解决。
1. 没有明确目标就急于开展项目
如果你收到一个数据集,经理让你进行数据分析,你会怎么做?通常,人们会忘记业务目标或我们通过分析数据想要实现什么,而直接跳到使用 Python 包进行数据可视化和分析。这可能会浪费资源并得出不明确的结果。没有明确的目标,很容易在数据中迷失,错过真正重要的见解。
如何避免:
-
从清楚定义你想解决的问题开始。
-
与利益相关者/客户沟通,以了解他们的需求和期望。
-
制定一个项目计划,明确目标、范围和交付物。
2. 忽视基础知识
忽视数据清洗、转换以及理解数据集中的每一个特征等基础步骤,会导致分析缺陷和不准确的假设。许多数据科学家甚至不了解统计公式,只是使用 Python 代码来进行探索性数据分析。这是错误的方法。你需要选择适合特定用例的统计方法。
如何避免:
-
投资时间掌握数据科学的基础知识,包括统计学、数据清洗和探索性数据分析。
-
通过阅读在线资源和参与实际项目来保持更新,打下坚实的基础。
-
下载各种数据科学主题的备忘单,并定期阅读,以确保你的技能保持敏锐和相关。
3. 选择错误的可视化方式
选择复杂的数据可视化图表或添加颜色或描述是否重要?不重要。如果你的数据可视化不能正确传达信息,那么它是无用的,有时还可能误导相关利益方。
如何避免这一点:
-
了解不同可视化类型的优缺点。
-
选择最能代表数据和你想讲述故事的可视化方式。
-
使用 Seaborn、Plotly 和 Matplotlib 等各种工具来添加细节、动画和互动可视化,并确定传达发现的最佳和最有效的方法。
4. 缺乏特征工程
在构建模型数据时,科学家们将关注数据清理、转换、模型选择和集成。他们会忘记执行最重要的一步:特征工程。特征是驱动模型预测的输入,选择不佳的特征可能导致结果不佳。
如何避免这一点:
-
从已有特征中创建更多特征,或使用各种特征选择方法丢弃影响较小的特征。
-
花时间理解数据和领域,以识别有意义的特征。
-
与领域专家合作,获取哪些特征可能最具预测性的信息,或者进行 Shap 分析以了解哪些特征对某个模型的影响更大。
5. 更注重准确性而非模型表现
将准确性优先于其他表现指标可能会导致模型在生产环境中表现不佳。高准确性不总是等于好模型,尤其是当它过拟合数据或在主要标签上表现良好但在次要标签上表现不佳时。
如何避免这一点:
-
根据问题的背景,使用各种指标来评估模型,例如精准率、召回率、F1 分数和 AUC-ROC。
-
与利益相关者互动,以了解哪些指标对业务背景最为重要。
结论
这些是数据科学团队不时会犯的一些常见错误,这些错误不能被忽视。
如果你想留在公司,我强烈建议你改善工作流程并学习处理数据科学问题的结构化方法。
在这篇博客中,我们了解了数据科学家经常犯的 5 个错误,并提供了这些问题的解决方案。大多数问题的发生是由于知识、技能和项目结构方面的不足。如果你能加以改进,我相信你会很快成为一名高级数据科学家。
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些遭受心理疾病困扰的学生开发一个人工智能产品。
更多相关话题
5 个常见的 Python 陷阱(以及如何避免它们)
原文:
www.kdnuggets.com/5-common-python-gotchas-and-how-to-avoid-them

作者提供的图片
Python 是一种对初学者友好且多才多艺的编程语言,以其简洁性和可读性而闻名。然而,它优雅的语法并非没有奇怪之处,这可能会让即使是经验丰富的 Python 开发者感到意外。理解这些问题对于编写无错误的代码——或者说无痛调试——是至关重要的。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你组织的 IT
本教程探讨了一些这些问题:可变的默认值、循环和推导式中的变量作用域、元组赋值等。我们将编写简单的示例来了解为什么事情会这样工作,并且还会研究如何避免这些(如果我们真的可以的话 🙂)。
那我们开始吧!
1. 可变的默认值
在 Python 中,可变的默认值常常是个棘手的问题。每当你定义一个带有可变对象(如列表或字典)作为默认参数的函数时,你会遇到意想不到的行为。
默认值仅在函数定义时评估一次,而不是每次调用函数时。如果你在函数内更改默认参数,这可能会导致意想不到的行为。
让我们来看一个例子:
def add_to_cart(item, cart=[]):
cart.append(item)
return cart
在这个例子中,add_to_cart 是一个函数,它接受一个项目并将其追加到一个列表 cart 中。cart 的默认值是一个空列表。也就是说,如果调用函数时没有添加项目,它会返回一个空购物车。
下面是几个函数调用:
# User 1 adds items to their cart
user1_cart = add_to_cart("Apple")
print("User 1 Cart:", user1_cart)
Output >>> ['Apple']
这按预期工作。但现在会发生什么呢?
# User 2 adds items to their cart
user2_cart = add_to_cart("Cookies")
print("User 2 Cart:", user2_cart)
Output >>>
['Apple', 'Cookies'] # User 2 never added apples to their cart!
因为默认参数是一个列表——一个可变对象——它在函数调用之间保持其状态。所以每次调用 add_to_cart 时,它都会将值追加到函数定义时创建的同一个列表对象中。在这个例子中,就像所有用户共享同一个购物车一样。
如何避免
作为解决方案,你可以将 cart 设置为 None,然后在函数内部初始化购物车,如下所示:
def add_to_cart(item, cart=None):
if cart is None:
cart = []
cart.append(item)
return cart
所以每个用户现在都有一个单独的购物车。🙂
如果你需要复习 Python 函数和函数参数,可以阅读 Python 函数参数:终极指南。
2. 循环和推导式中的变量作用域
Python 的作用域怪癖需要一个专门的教程。不过我们将在这里看看其中一个怪癖。
看一下以下代码片段:
x = 10
squares = []
for x in range(5):
squares.append(x ** 2)
print("Squares list:", squares)
# x is accessible here and is the last value of the looping var
print("x after for loop:", x)
变量 x 被设置为 10。但是 x 也是循环变量。我们假设循环变量的作用范围仅限于 for 循环块,对吗?
让我们看看输出:
Output >>>
Squares list: [0, 1, 4, 9, 16]
x after for loop: 4
我们看到 x 现在是 4,这个值是它在循环中取到的最终值,而不是我们设置的初始值 10。
现在让我们看看如果我们将 for 循环替换为列表解析表达式会发生什么:
x = 10
squares = [x ** 2 for x in range(5)]
print("Squares list:", squares)
# x is 10 here
print("x after list comprehension:", x)
在这里,x 是 10,这是我们在列表解析表达式之前设置的值:
Output >>>
Squares list: [0, 1, 4, 9, 16]
x after list comprehension: 10
如何避免
为了避免意外行为:如果你在使用循环时,确保不要将循环变量命名为你稍后想要访问的其他变量相同的名称。
3. 整数身份特性
在 Python 中,我们使用 is 关键字来检查对象身份。这意味着它检查两个变量是否引用了内存中的同一对象。要检查相等性,我们使用 == 操作符。对吗?
现在,启动一个 Python REPL 并运行以下代码:
>>> a = 7
>>> b = 7
>>> a == 7
True
>>> a is b
True
现在运行这个:
>>> x = 280
>>> y = 280
>>> x == y
True
>>> x is y
False
等等,为什么会发生这种情况? 好吧,这是由于 CPython 中的“整数缓存”或“驻留”。
CPython 缓存整数对象 在 -5 到 256 的范围内。这意味着每次你使用这个范围内的整数时,Python 将使用内存中的相同对象。 因此,当你使用 is 关键字比较这范围内的两个整数时,结果是 True,因为它们指向内存中的相同对象。
这就是为什么 a is b 返回 True。你也可以通过打印 id(a) 和 id(b) 来验证这一点。
但是,这个范围之外的整数不会被缓存。每次出现这样的整数都会在内存中创建一个新对象。
所以,当你使用 is 关键字比较两个范围之外的整数时(是的,在我们的示例中 x 和 y 都设置为 280),结果是 False,因为它们确实是内存中的两个不同对象。
如何避免
除非你尝试使用 is 来比较两个对象的相等性,否则这种行为不应成为问题。因此,总是使用 == 操作符来检查任何两个 Python 对象是否具有相同的值。
4. 元组赋值和可变对象
如果你熟悉 Python 的内置数据结构,你会知道元组是 不可变 的。所以你 不能 就地修改它们。另一方面,像列表和字典这样的数据结构是 可变 的。这意味着你 可以 就地更改它们。
但是包含一个或多个可变对象的元组怎么办?
启动一个 Python REPL 并运行这个简单的示例是很有帮助的:
>>> my_tuple = ([1,2],3,4)
>>> my_tuple[0].append(3)
>>> my_tuple
([1, 2, 3], 3, 4)
这里,元组的第一个元素是一个包含两个元素的列表。我们尝试向第一个列表中添加 3,它工作得很好!好吧,我们刚刚就地修改了一个元组吗?
现在让我们尝试向列表中添加两个元素,这次使用 += 操作符:
>>> my_tuple[0] += [4,5]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment</module></stdin>
是的,你会得到一个 TypeError,表示元组对象不支持项赋值。这是预期的。但让我们检查一下元组:
>>> my_tuple
([1, 2, 3, 4, 5], 3, 4)
我们看到元素 4 和 5 已经被添加到列表中!程序是否在同时抛出错误并成功?
+= 操作符在内部通过调用 __iadd__() 方法来执行就地加法,并在原地修改列表。赋值会引发 TypeError 异常,但将元素添加到列表末尾已经成功。 += 也许是最尖锐的棱角!
如何避免
为了避免程序中的这种怪癖,尽量 仅 使用元组来处理不可变集合。尽可能避免将可变对象作为元组元素。
5. 可变对象的浅拷贝
可变性一直是我们讨论中的一个反复出现的话题。所以这是另一个总结本教程的内容。
有时你可能需要创建列表的独立副本。但是,当你使用类似 list2 = list1 的语法创建副本时,其中 list1 是原始列表,会发生什么?
这是一个浅拷贝。因此,它仅复制了对原始列表元素的引用。通过浅拷贝修改元素会影响 原始列表 和 浅拷贝。
让我们看这个例子:
original_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# Shallow copy of the original list
shallow_copy = original_list
# Modify the shallow copy
shallow_copy[0][0] = 100
# Print both the lists
print("Original List:", original_list)
print("Shallow Copy:", shallow_copy)
我们看到对浅拷贝的修改也影响了原始列表:
Output >>>
Original List: [[100, 2, 3], [4, 5, 6], [7, 8, 9]]
Shallow Copy: [[100, 2, 3], [4, 5, 6], [7, 8, 9]]
在这里,我们修改了浅拷贝中第一个嵌套列表的第一个元素:shallow_copy[0][0] = 100。但我们看到修改影响了原始列表和浅拷贝。
如何避免
为了避免这种情况,你可以像这样创建深拷贝:
import copy
original_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# Deep copy of the original list
deep_copy = copy.deepcopy(original_list)
# Modify an element of the deep copy
deep_copy[0][0] = 100
# Print both lists
print("Original List:", original_list)
print("Deep Copy:", deep_copy)
现在,对深拷贝的任何修改都不会改变原始列表。
Output >>>
Original List: [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
Deep Copy: [[100, 2, 3], [4, 5, 6], [7, 8, 9]]
总结
这就结束了!在本教程中,我们探索了 Python 中的一些奇特现象:从可变默认值的意外行为到浅拷贝列表的细微差别。这只是 Python 奇特现象的一个介绍,绝不是详尽无遗的列表。你可以在 GitHub 上找到所有的代码示例。
随着你在 Python 中编程时间的增加——并更好地理解语言——你可能会遇到更多这样的情况。所以,继续编程,继续探索!
哦,如果你想读这个教程的续集,请在评论中告诉我们。
Bala Priya C**** 是来自印度的开发人员和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她通过编写教程、操作指南、观点文章等方式,学习并与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编程教程。
更多相关话题
你应该了解的梯度下降和成本函数的 5 个概念
原文:
www.kdnuggets.com/2020/05/5-concepts-gradient-descent-cost-function.html

这张图片是在香港的 Brick Hill(南朗山)顶端拍摄的。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织的 IT
梯度下降是一种迭代优化算法,用于在机器学习中最小化损失函数。损失函数描述了给定当前参数集(权重和偏置)的模型表现如何,梯度下降用于找到最佳的参数集。我们使用梯度下降来更新我们模型的 参数。例如,参数指的是 线性回归 中的系数和神经网络中的 权重。
在本文中,我将解释梯度下降和成本函数的 5 个主要概念,包括:
-
最小化成本函数的原因
-
梯度下降的计算方法
-
学习率的作用
-
批量梯度下降(BGD)
-
随机梯度下降(SGD)
什么是成本函数?
学习神经网络的主要步骤是定义一个成本函数(也称为损失函数),它衡量网络在测试集上预测输出的效果。目标是找到一组能够最小化成本的权重和偏置。一个常用的函数是 均方误差,它测量实际值y与估计值y(预测值)之间的差异。下面回归线的方程是 hθ(x) = θ + θ1x,它只有两个参数:权重(θ1)和偏置 (θ0)。

最小化成本函数
任何机器学习模型的目标是最小化成本函数。
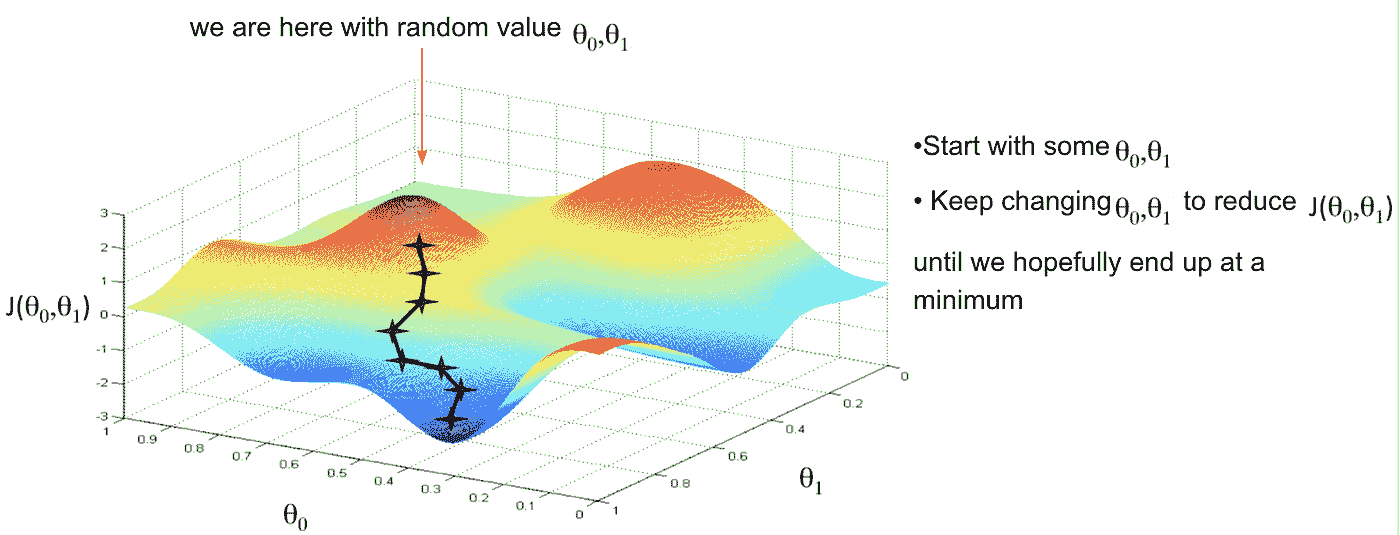
如何最小化成本函数
我们的目标是从右上角的山(高成本)移动到左下角的深蓝色海洋(低成本)。为了获得最低的错误值,我们需要调整权重‘θ0’和‘θ1’以达到最小的误差。这是因为实际值和预测值之间的误差较低意味着算法在学习上表现良好。梯度下降是一种高效的优化算法,旨在找到函数的局部或全局最小值。
计算梯度下降
梯度下降利用微积分迭代地运行,以找到对应于给定成本函数最小值的参数的最优值。在数学上,‘导数’的技巧对最小化成本函数极为重要,因为它帮助找到最小点。导数是微积分中的一个概念,指的是函数在某一点的斜率。我们需要知道斜率,以便了解移动系数值的方向(符号),以便在下一次迭代中获得更低的成本。
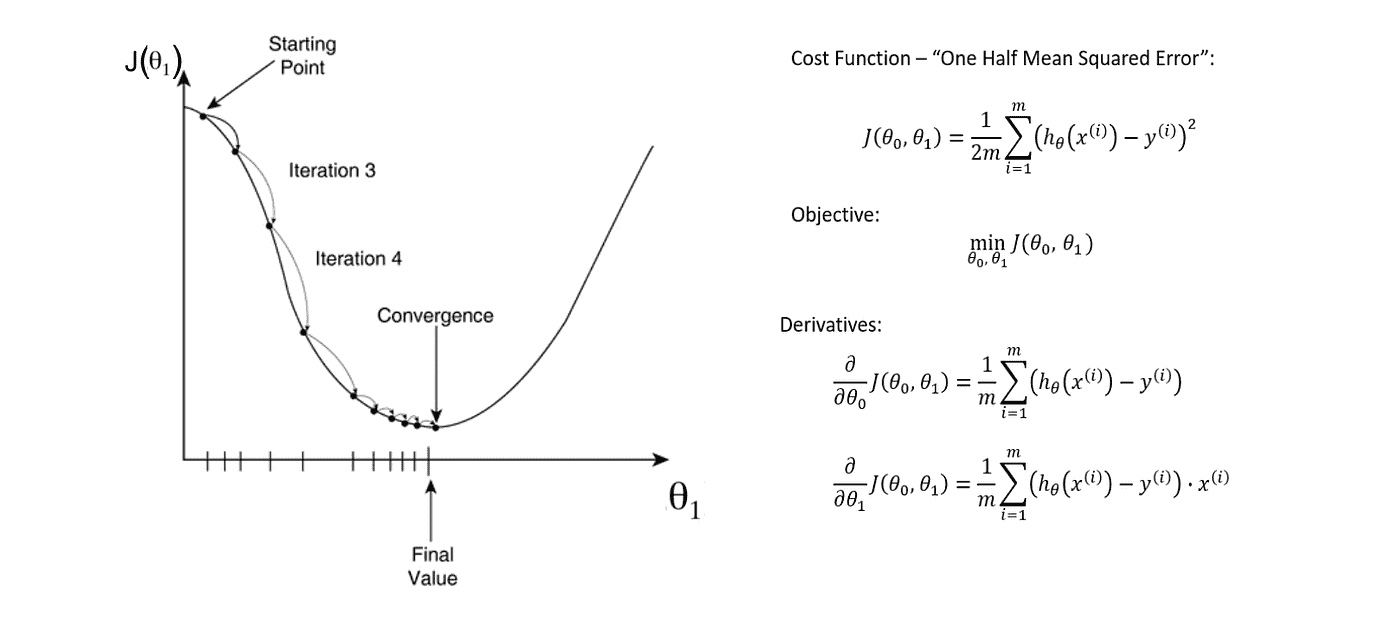
θ1 会逐渐收敛到最小值。
一个函数(在我们这个例子中是J(θ))关于每个参数(在我们这个例子中是权重θ)的导数告诉我们函数对该变量的敏感度,或变量的变化如何影响函数值。因此,梯度下降*使得学习过程能够对学习到的估计值进行修正更新,将模型向最优的参数组合(θ)靠拢。成本是在每次梯度下降算法迭代中,为整个训练数据集计算的。在梯度下降中,算法的一次迭代称为一个批次,表示用于计算每次迭代的梯度的数据集中的样本总数。
导数的步骤
如果你对微积分有一些基本了解会更好,因为在这个过程中应用了偏导数和链式法则。
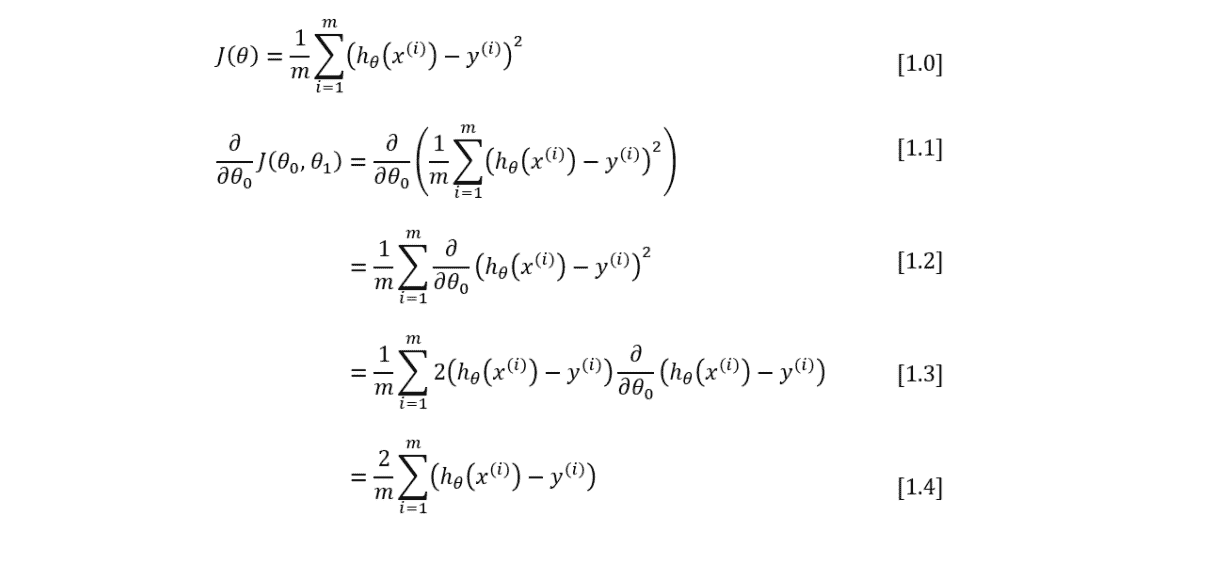
为了解析梯度,我们使用新的权重 ‘θ0’和偏差 ‘θ1’值对数据点进行迭代,并计算偏导数。这一新的梯度告诉我们在当前位置(当前参数值)函数的斜率,以及我们应该移动的方向来更新参数。更新的大小由学习率控制。
学习率(α)
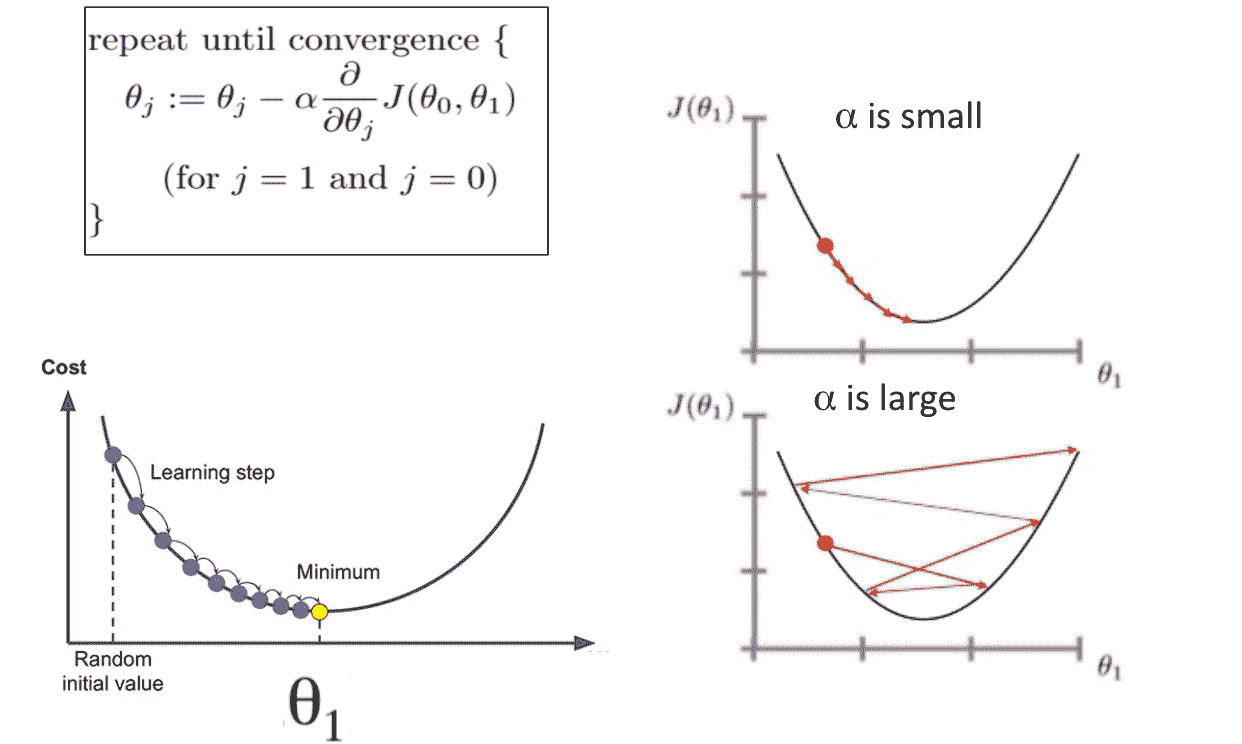
请注意,我们使用‘:=’来表示赋值或更新。
这些步骤的大小称为学习率(α),它给予我们对步骤大小的额外控制。使用较大的学习率,我们可以每一步覆盖更多的范围,但我们冒着超越最低点的风险,因为山坡的斜率不断变化。使用非常低的学习率,我们可以自信地朝负梯度方向移动,因为我们如此频繁地重新计算它。低学习率更为精确,但计算梯度耗时,因此我们需要很长时间才能到达底部。最常用的学习率有:0.001, 0.003, 0.01, 0.03, 0.1, 0.3。
现在让我们讨论梯度下降算法的三种变体。它们之间的主要区别在于计算每个学习步骤的梯度时所使用的数据量。它们之间的权衡是梯度的准确性与执行每个参数更新(学习步骤)的时间复杂度。
随机梯度下降(SGD)
然而,在我们的数据集中应用典型的梯度下降优化技术存在一个缺点。由于我们必须使用所有的一百万个样本来完成一次迭代,而这必须在每次迭代中进行直到达到最小点,因此计算成本非常高。这一问题可以通过随机梯度下降来解决。
词语‘stochastic’指的是一个与随机概率相关的系统或过程。随机梯度下降利用这一概念来加速梯度下降的过程。因此,与典型的梯度下降优化方法不同,随机梯度下降在每次迭代中只使用 1 个示例的成本梯度(详细情况见下图)。虽然使用整个数据集对于以较少噪声或较少随机性的方式达到最小值非常有用,但当我们的数据集非常大时,就会出现问题。
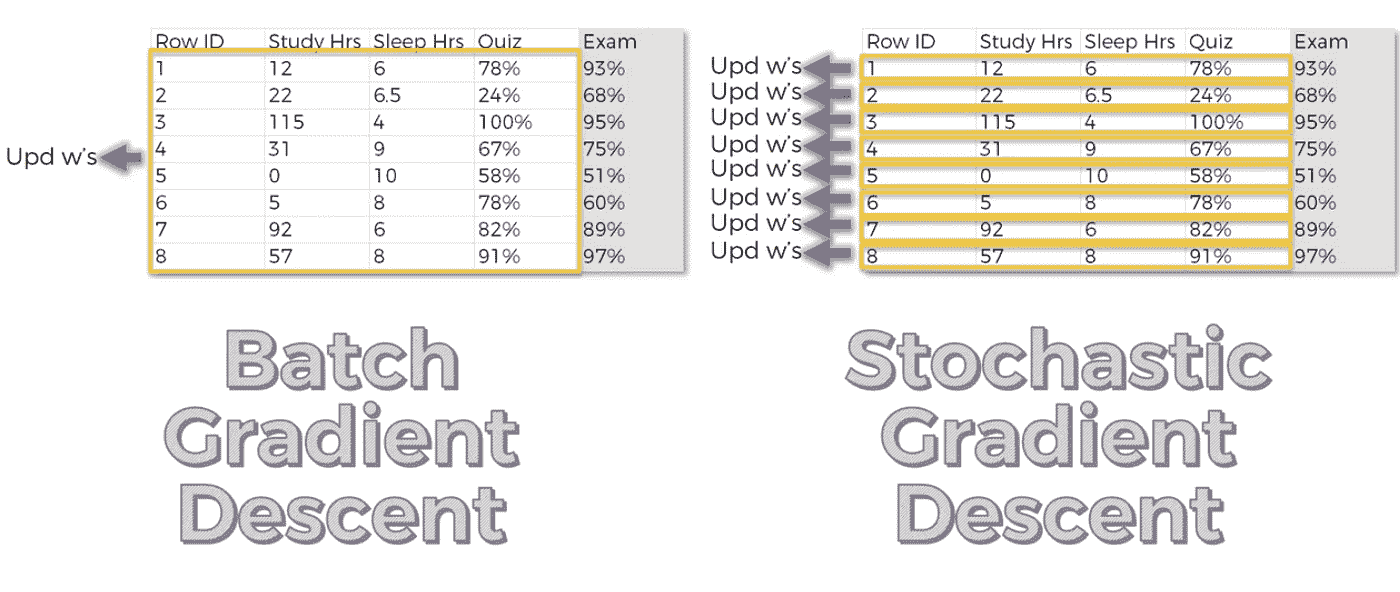
两者之间的主要区别在于,随机梯度下降方法帮助我们避免了找到局部极值或局部最小值而不是整体全局最小值的问题。
如前所述,随机梯度下降方法一次处理一轮或一行数据,因此,其波动性远高于批量梯度下降。
梯度下降算法的三种变体
-
批量梯度下降(BGD):计算训练数据集中每个示例的误差,但只有在评估了所有训练示例后才更新模型。
-
随机梯度下降(SGD):计算误差并更新模型,对训练数据集中的每个示例进行处理。
-
小批量梯度下降:将训练数据集分成小批量,这些小批量用于计算模型误差并更新模型系数。(这是深度学习领域中最常用的梯度下降实现)
迷你批量梯度下降可以在SGD的鲁棒性和BGD的效率之间找到平衡。
总结
阅读完这篇博客后,你现在应该对梯度下降和成本函数的 5 个概念有了更好的理解:
-
成本函数是什么,如何最小化它?
-
如何计算梯度下降?
-
什么是学习率?
-
什么是批量梯度下降(BGD)?
-
为什么随机梯度下降(SGD)在机器学习中如此重要?
更多相关话题
5 个标准来确定你的数据是否准备好进行严肃的数据科学
原文:
www.kdnuggets.com/2015/12/5-criteria-data-ready-data-science.html
评论
数据科学是一种花哨的说法,用来描述用数字和名字回答问题。你可以从视频、测量、录音或文本开始,但当数据科学家开始工作时,它们都已经被转化为数字和名字的形式。数据科学能够做的所有强大功能最终都归结于此。从照片中估计某人的年龄。推荐你可能喜欢的电影。识别使用你信用卡的怪人。这些都始于一个问题和一些数字与名字。

但不仅仅是任何问题或任何数据集能够得到你想要的结果。在数据科学能够构建解决方案以简化你的生活或为你赚取大量资金之前,你必须提供一些高质量的原材料。就像做披萨一样,起始原料越好,最终产品越好。你会知道你准备好了,当:
1. 你的问题很明确
在选择你的数据科学问题时,想象你在接近一个可以告诉你宇宙中任何事物的神谕,只要答案是一个数字或一个名字。但它是一个顽皮的神谕,它的回答将尽可能含糊和混乱。你希望用一个密不透风的问题来逼它告诉你你想知道的内容。糟糕的问题例子包括“我的数据能告诉我关于我的业务什么?”、“我该怎么办?”或“我如何提高我的利润?”这些问题留下了大量模糊的空间,可能会得到无用的答案。相比之下,像“在第三季度,我会在蒙特利尔卖出多少个 Q 型小玩意儿?”或“我的车队中哪辆车最有可能先坏?”这样的问题,其答案则不可避免。

2. 你的数据衡量你关心的内容
一旦你有了问题,确保你的数据相关性很重要。如果你想回答“哪些客户最有可能离开我去找竞争对手?”的问题,你需要有关哪些客户过去已经转向竞争对手的信息。此外,你还需要有关导致他们离开的因素的信息。如果你只有他们的出生日期和鞋码,你很可能无法找到离开的客户的模式。但如果你有相关数据,比如他们的购买历史和对客户满意度调查的回应,那么你就有了更好的机会。
3. 你的数据是准确的
数据科学中最大的误区是认为可以通过拥有大量数据来弥补糟糕的数据。在这个虚拟的世界里,数字是否缺少小数、传感器是否故障、名字是否输入错误都无所谓。数据的庞大量神秘地弥补了这些问题。确实,像拼写检查这样的专业工具可以自动纠正一些错误。确实,尽管仔细记录的数据中不可避免地存在噪音,但有时可以去除或绕过这些噪音。但是,由粗心和忽视引入的错误是无法自动修复的。它们污染了数据集,使得寻找模式变得更加困难。通常,少量精心收集的数据对数据科学家来说比大量粗心收集的数据更有价值。

4. 你的数据是关联的
将一个州的司机年龄与另一个州司机的事故率进行比较,并不能说明司机年龄与事故率之间的关系。为此,你需要查看同一组司机的年龄和事故率。如果数据点不一致,再准确、相关的数据也无济于事。这也被称为缺失值问题。这就像是你的司机通过填写表单来提供信息,但一半人留下了年龄字段为空,另一半人没有告诉你他们的事故历史。一些缺失值是正常且几乎不可避免的。缺失值过多会让你的数据采集像瑞士奶酪一样,严重影响其有效性。

5. 你有大量数据
就像许多事情一样,数据质量比数量更重要。但数量也很重要。一个小而高质量的数据集比一个噪声极大的庞大数据集更有价值。但一个大而高质量的数据集可以做得比它们更好。更多的数据通常更好,因为它可以让你看到更多细节,提出更具体的问题,并对发现结果有更大的信心。不要因为已经有了数百万个数据点或填满了一个一 TB 的硬盘就假设你有足够的数据。只要不降低相关性、准确性或完整性,更多的数据总是更好。
如果你覆盖了这五点–
一个大规模的、相关的、准确的、完整的数据集 和 一个清晰的问题
– 那么恭喜你。你准备好进行一些高级的数据科学工作了。如果你在几个方面有不足之处,也不用担心。这只是意味着你正在现实世界中工作。
这可能需要一些细致的工作。你仍然可能获得所需的信息。但如果这些陈述只有一两个是真的,那么你需要做更多的准备工作。收集更多的数据,明确你的问题,整理数据,移除最嘈杂的数据点——无论你能做什么来提升原材料的质量。如果你直接处理这些数据,任何得到的答案都可能会受到高度怀疑。
本系列的接下来的两个部分将涵盖数据科学可以回答的各种问题及其适用的算法家族,并提供大量示例。敬请关注。
个人简介:Brandon Rohrer, @brohrer,是微软的高级数据科学家。他的工作地点在美国马萨诸塞州波士顿。
相关:
-
在你准备好数据科学之前,停止招聘数据科学家
-
Michael Li,Data Incubator 论数据驱动的招聘策略
-
如何成为数据科学家并找到工作
相关主题更多
制定有效编码常规的 5 个关键步骤
原文:
www.kdnuggets.com/2023/08/5-crucial-steps-develop-effective-coding-routine.html

图片作者
介绍
我记得翻阅詹姆斯·克利尔的《原子习惯》。它让我思考心理学如何影响我们的日常生活。作为一名程序员,我开始思考如何利用这些见解来创建一个真正有效的编码常规。相信我,如果我们能在某种程度上掌握我们大脑的艺术和学习方式,这将是一个游戏规则的改变者。经过仔细的研究和观察,我制定了这 5 个步骤来塑造一个有效的编码常规。让我们一个一个地了解这些步骤,见证心理学如何改变你的编码体验:
1. 小的增量效果的力量:从 1%规则开始
这个策略非常适合初学者和防止职业倦怠。它关注于逐步进步的重要性,并随着时间的发展建立一致性。受到这个理念的启发,我将仅仅一小部分时间(15 分钟)用于编码。尽管看起来微不足道,但它可以铺平一致性的道路。我们的脑袋认为它不那么令人生畏,随着时间的推移,我们开始获得信心。这就像是种下了进步的种子,随着时间的推移而成长。你不是在追求完美,而是在接受进步。我将从数学上向你解释一下:
第 1 天:15 分钟
第 2 天:15 分钟 + 1% = 15.15 分钟
第 3 天:15.15 分钟 + 1% = 15.303 分钟
第 4 天:15.303 分钟 + 1% = 15.45803 分钟
…依此类推
30 天累计效果:
30 天后,你的每日编码时间将大约为 22.44 分钟
60 天后,你的每日编码时间将大约为 33.81 分钟
90 天后,你的每日编码时间将大约为 51.07 分钟
180 天后,你的每日编码时间将大约为 140.61 分钟
…依此类推
采取这些小步骤将帮助你随着时间的推移发展编码常规。
2. 提示、常规、奖励:习惯循环
让我们谈谈建立习惯。这是一个循环,你从一个提示开始,进行一个常规动作,然后获得奖励。它是如何运作的:
提示: 让你意识到该工作的时候的东西。它可以是特定的环境、一天中的特定时间,或一种情绪状态。它会刺激你的大脑,帮助你开始。
常规: 这是你的实际习惯,跟在提示后面。
奖励: 最终,我们得到一个奖励,这种奖励以积极的结果或完成常规动作后产生的感觉形式激励你在未来重复这种行为。
为了让这一切奏效,我设置了一个专门的编码空间,这个空间作为启动点,我的大脑会说“嘿,现在是编码时间了!”。我沉浸在编码中,并从解决编码挑战或解码问题中获得进展的感觉。这是一种小胜利,使我更容易重新进入编码周期。

图片由作者提供
3. 习惯叠加:将编码与现有习惯联系起来
在开始一个新习惯时,你常常会遇到初期的阻力,但通过习惯叠加,这一过程会变得异常顺利。它涉及将旧习惯与新习惯配对。因为你的大脑喜欢模式,这样更容易。习惯叠加有 3 个要素:
锚定习惯(现有习惯):这是你已经能够轻松做到的事情。
新习惯(期望习惯):你想要融入的新习惯。
提示与常规融合:锚定习惯充当新习惯的提示,形成无缝融合。
对我来说,我将编码与我的晚茶联系在一起。当我品茶时,大脑会提醒我该编码了。因此,当水开了煮茶时,打开你的代码编辑器——这样,你就开始了编码之旅!
4. 环境设计:塑造你的编码环境
你猜怎么着?你的环境对你的心态影响比你想象的更大。它们作为环境提示,巧妙地引导我们的行动。考虑到它的重要性,我为自己设立了一个专门的编码空间——这是我旅程中的一个转折点。没有干扰和有意识的设置立刻让我进入了编码的心态。每当我的大脑看到我的工作空间,它就知道现在是编码时间了。这一步提高了我的集中力。

图片由 storyset 提供
5. 奖励的科学:培养内在动机
内在动机与奖励紧密相关。奖励会激活大脑的愉悦中心,释放多巴胺,这种化学物质以产生愉悦感而著称。为了奖励自己,我设立了一些里程碑,并开始通过享受特别的餐点来庆祝每一步的进展。选择让你兴奋的项目。当你充满好奇时,编码感觉就像是一场冒险,而不是一种工作。同时,尝试与他人分享你的进展,和积极的人在一起。他们的反馈和鼓励的话语可以进一步增强你的编码旅程。
结论
恭喜!你已经掌握了建立有效例行程序的工具。随着我结束这篇文章,我邀请我的读者分享他们的转变经历。哪些编码习惯对你有所帮助?最后,请记住,前面提到的策略的有效性可能因人而异,所以尝试并找到最适合你的方法。
Kanwal Mehreen 是一名有志的软件开发者,对数据科学和人工智能在医学中的应用有浓厚兴趣。Kanwal 被选为 2022 年 APAC 地区的谷歌一代学者。Kanwal 喜欢通过撰写文章分享技术知识,并热衷于提高女性在科技行业的代表性。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关主题
适合初学者的 5 个数据分析项目
原文:
www.kdnuggets.com/2023/02/5-data-analysis-projects-beginners.html

作者提供的图片
介绍
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
你是否期待开始你的数据分析师职业生涯,但职位列表要求经验?完全不用担心!你来对地方了。通过构建你的项目将展示你的技能,帮助你找到第一份工作。我将指导你选择适合初学者的数据分析项目,这些项目将说服招聘经理你是这个职位的合适人选。虽然随机选择项目可能会提高你的技能,但请记住这是一个竞争激烈的市场,你必须脱颖而出。你的作品集项目必须展示你收集、清理、分析和以视觉上吸引人的方式呈现数据的能力。
不再拖延,我们来深入探讨这 5 个项目,帮助你开启职业生涯:
1. 在 GitHub 上抓取热门话题的顶级仓库
项目图片
尽管有很多公共数据集可以自由使用,但作为数据分析师,你必须知道如何从网站上抓取更相关的数据以满足特定的使用场景。网络抓取就是以自动化的方式提取数据。
在这个项目中,你将为每个 GitHub 话题创建一个单独的 CSV 文件。每个 CSV 文件包含该话题下的前 25 个仓库,并附有一些额外的信息,如用户名、星标数量以及仓库的 URL。这是一个非常适合初学者的项目,可以添加到你的简历中,由 Jovian(数据科学和机器学习社区平台)首席执行官 Aakash N S 教授。该项目还附带了一个视频教程,链接已提供以供参考。
2. 社会进步指数分析
项目中的图片
社会进步指数是衡量一个国家关心其公民发展的程度的指标。在这个项目中,一些主要因素如基本人类需求、福祉、机会、健康、安全、住房等被用来预测 SPI 分数。完成此项目将使你能够对其他每年发布的全球报告进行类似分析。此外,这些见解对于衡量一个国家在可持续性和发展目标方面的进展是非常有帮助的。
项目链接:社会进步指数分析
3. Covid-19 数据分析项目

项目中的图片
此类项目展示了你分析、解释和可视化真实世界数据的能力。在这个使用 Python 和 Tableau 的 Covid-19 数据分析视频项目中,你将学习如何使用 Python 进行探索性数据分析,并了解如何在 Tableau 中构建 Covid-19 仪表盘。你将了解 Covid-19 在印度的影响以及疫苗接种状态。使用 Tableau,你将创建关于全球病例、死亡和康复的图表。
项目链接:Covid-19 数据分析项目
4. YouTube 情感、词云和表情符号分析

项目中的图片
近年来,文本数据增长迅速,使用词云是可视化和紧凑展示这些大量信息的绝佳方式。在这个项目中,你将通过分析 YouTube 视频的观众反应和评论来学习情感分析。
项目链接:YouTube 情感、词云和表情符号分析
5. HR 分析初学者项目

项目中的图片
这是一个很棒的端到端项目,你可以将其添加到简历中,并且适合初学者。你将利用 Power BI 解决 HR 领域的实时问题。你将学习如何使用 Power Query 收集和转换数据,使用 DAX 创建指标以及创建仪表盘等。欲了解更多详细信息,请点击下面的链接查看完整播放列表:
项目链接:HR 分析初学者项目
结论
完成这五个令人惊叹的项目将为你作为初学者建立坚实的基础,但这可能无法保证你找到工作。因此,你必须继续构建项目以磨练你的技能。我相信,借助互联网上丰富的开源数据集,你将永远不会缺少练习技能的机会。请在评论区告知我你对上述项目的看法。
Kanwal Mehreen 是一位有志的软件开发者,对数据科学及人工智能在医学中的应用充满热情。Kanwal 被选为 2022 年 APAC 地区的 Google Generation Scholar。Kanwal 喜欢通过撰写关于热门话题的文章来分享技术知识,并热衷于改善女性在科技行业中的代表性。
更多相关主题
2024 年获得工作的 5 个数据分析项目
原文:
www.kdnuggets.com/5-data-analyst-projects-to-land-a-job-in-2024

图片由作者提供
我在 2020 年获得了我的第一个数据分析实习机会。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
从那时起,我转变为高级全职职位,获得了多个自由职业的数据分析工作,并为世界不同地区的公司提供咨询。
在这段时间里,我审查了数据分析师职位的简历,甚至筛选了候选人。
我注意到一件事,这使得最突出申请者与其他人有所区别。
项目。
即使你在数据行业没有任何经验,也没有技术背景,你仍然可以通过简历上展示的项目脱颖而出,获得聘用。
在这篇文章中,我将展示如何创建能帮助你从竞争中脱颖而出并获得第一个数据分析师工作的项目。
会毁掉你简历的数据分析项目
如果你正在阅读这篇文章,你可能已经知道在简历上展示项目的重要性。
你甚至可能在参加在线课程或训练营后自己完成了一些项目。
然而,许多数据分析项目对你的作品集的伤害大于好处。这些项目实际上可能降低你获得工作的机会,必须尽一切可能避免。
例如,如果你参加了流行的谷歌数据分析证书课程,你可能已经完成了这个认证所附带的结业项目。
图片来源于 Coursera
然而,已经有超过 200 万人报名了相同的课程,并可能完成了相同的结业项目。
招聘人员可能已经在数百份申请者的简历上见过这些项目,这样的展示不会让他们印象深刻。
相似的逻辑适用于任何其他被重复创建的项目。
使用Titanic、Iris或Boston Housing数据集创建的项目可以是一个有价值的学习经验,但不应展示在你的作品集中。
如果你想在其他人中脱颖而出,你需要显得与众不同。
下面是具体方法。
5 个数据分析项目助你获得工作
一个突出的项目必须是独特的。
选择一个项目:
-
解决实际问题。
-
不能被其他人轻易复制。
-
有趣并讲述一个故事。
互联网上关于数据分析项目的建议大多不准确且无用。
你会被建议创建像 Titanic 数据集分析这样的通用项目——这些项目对你的简历没有实际价值。
不幸的是,那些告诉你做这些事情的人甚至不在数据行业工作,因此你必须对这些建议保持鉴别力。
在这篇文章中,我将展示一些真实的案例,这些人因为他们的作品集项目而在数据分析领域找到了工作。
你将了解到实际能让人获得工作的项目类型,以便你可以构建类似的项目。
1. 职业趋势监控仪表板
第一个项目是一个展示数据行业职业趋势的仪表板。
我在视频中发现了这个项目,该视频由前首席数据分析师 Luke Barousse 制作,他还专注于内容创作。
这是这个仪表板的截图:
图片来源于 SkillQuery
上述仪表板名为 SkillQuery,它展示了雇主在数据行业中寻找的顶级技术和技能。
例如,通过查看仪表板,我们可以知道雇主在数据科学家中最看重的语言是 Python,其次是 SQL 和 R。
这个项目之所以有价值,是因为它解决了一个实际问题。
每个求职者都想知道雇主在他们的领域寻找的顶级技能,以便做好相应准备。
SkillQuery 帮助你做到了这一点,形式是一个你可以互动的仪表板。
这个项目的创建者展示了诸如 Python、网络抓取和数据可视化等关键的数据分析技能。
你可以在这里找到这个项目的GitHub 仓库链接。
2. 信用卡审批
这个项目旨在预测一个人是否会被批准信用卡。
我在同一个由 Luke Barousse 制作的视频中发现了它,这个项目的创建者最终获得了一个全职的数据分析师职位。
信用卡审批模型被部署为一个 Streamlit 应用:
图片来自 Semasuka 的 GitHub 项目
你只需回答这个仪表盘上显示的问题,应用程序将告诉你是否获得了信用卡批准。
再次,这个项目是一个创造性的项目,通过一个用户友好的仪表盘解决了一个现实世界的问题,这也是它在雇主面前脱颖而出的原因。
这个项目展示的技能包括 Python、数据可视化和云存储。
3. 社交媒体情感分析
这个项目是我几年前创建的,涉及对 YouTube 和 Twitter 内容进行情感分析。
我一直喜欢观看 YouTube 视频,并特别对平台上创建化妆教程的频道感到着迷。
当时,在 YouTube 上出现了一场巨大的丑闻,涉及到我最喜欢的两位美容影响者——詹姆斯·查尔斯和塔蒂·韦斯特布鲁克。
我决定通过抓取 YouTube 和 Twitter 上的数据来分析这个丑闻。
我建立了一个情感分析模型,以评估公众对争端的情感,并甚至创建了可视化图表来理解人们对这些影响者的看法。
尽管这个项目没有直接的商业应用,但由于我分析了一个我热衷的话题,它仍然很有趣。
我还写了一篇博客文章概述了我的发现,你可以在 这里 找到。
在这个项目中展示的技能包括网络抓取、API 使用、Python、数据可视化和机器学习。
4. 使用 Python 进行顾客细分
这是另一个由我创建的项目。
在这个项目中,我使用 Python 构建了一个 K-Means 聚类模型,使用了 Kaggle 上的数据集。
我使用了性别、年龄和收入等变量来创建各种购物中心顾客的细分:
图片来自 Kaggle
由于用于这个项目的数据集很受欢迎,我尝试将我的分析与其他分析区分开来。
在开发细分模型后,我更进一步,为每个细分群体创建了消费者档案,并制定了针对性的营销策略。
由于我采取了这些额外的步骤,我的项目专门针对营销和客户分析领域,这增加了我在该领域获得工作的机会。
我还创建了一个关于这个项目的教程,提供了一个 逐步指南,帮助你在 Python 中构建自己的顾客细分模型。
这个项目展示的技能包括 Python、无监督机器学习和数据分析。
5. Udemy 课程数据分析仪表板
这个列表中的最终项目是一个展示 Udemy 课程洞察的仪表板:
图片来自Medium
我在 Medium 上找到这个项目,作者是扎克·奎因,他目前是 Forbes 的高级数据工程师。
扎克说,当他刚开始时,这个仪表板为他带来了来自一家知名公司的数据分析师职位邀请。
很容易明白原因。
扎克不仅仅使用 SQL 和 Python 来处理和分析数据。
他在这个仪表板中融入了数据沟通最佳实践,使其引人入胜且视觉吸引力强。
仅通过查看仪表板,你就可以获得关于 Udemy 课程、学生兴趣和竞争对手的关键洞察。
这个仪表板还展示了对企业至关重要的指标,如客户参与度和市场趋势。
在这篇文章列出的所有项目中,我最喜欢这个,因为它不仅展示了技术技能,还显示了分析师在数据讲故事和演示方面的能力。
这里是扎克的文章链接,其中他提供了创建此项目的代码和步骤。
获取工作的数据分析项目——下一步
我希望本文描述的项目能激励你创建自己的项目。
如果你没有项目想法或在开发自己的项目时遇到障碍,我建议利用生成式 AI 模型进行帮助。
ChatGPT 例如,可以提供大量项目想法,甚至生成虚假数据集,帮助你磨练分析技能。
与 ChatGPT 进行数据分析将使你更快地学习新技术,提高效率,帮助你在竞争中脱颖而出。
如果你想了解更多关于使用 ChatGPT 和生成式 AI 进行数据分析的内容,可以观看我关于该主题的视频教程。
Natassha Selvaraj 是一位自学成才的数据科学家,热衷于写作。Natassha 撰写有关所有数据科学相关的内容,是数据领域的真正大师。你可以在LinkedIn与她联系或查看她的YouTube 频道。
更多相关内容
5 个数据管理挑战及解决方案
原文:
www.kdnuggets.com/2023/04/5-data-management-challenges-solutions.html

图片来源于 Kampus Production
随着数字化和数字化转型带来商业运作模式的范式转变,适当的数据管理确保了准确数据的可访问性和可用性,这些数据可以被分析以生成有价值的洞察。这些洞察对于公司理解市场行为和客户趋势至关重要,进一步帮助推动更好的决策制定。
我们的三大推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 需求
数据管理挑战
随着企业数据的指数级增长,传统处理大量数据的方法迅速变得低效。组织在汇总、维护和从海量数据中生成价值方面面临挑战。最突出的障碍之一是创建多个数据存储库或数据孤岛,这导致数据识别和管理的问题。缺乏熟练资源和对来自不同来源的数据处理的理解也成为采取更好数据管理措施的瓶颈。如果没有适当的数据管理,企业可能无法确保数据的安全性和隐私,这可能导致财务和潜在的法律后果。
1. 多面分布系统中的数据孤岛问题
数据孤岛发生在数据存储在分开且断开的系统、部门或业务单位时,使得访问、共享和整合变得困难。随着组织从各种来源收集更多数据,数据孤岛可能会增长,给数据集成、分析和决策制定带来挑战。
数据集成复杂性出现在尝试将来自多个来源的数据合并和同步时,特别是当处理不一致的数据格式、质量和结构时。集成复杂性使得建立单一真实来源并从数据中提取准确洞察变得具有挑战性。
为克服这些挑战,组织必须采纳全面的数据整合策略,包括数据治理、质量管理以及整合工具和技术。
2. 数据架构的固有复杂性
现代数据策略只能通过发展现有的数据架构来实施。这些架构的固有复杂性要求对相关的基础技术进行彻底的改革,这可能是一项昂贵且耗时的工作。此外,如果遗留系统未更新以满足现代业务需求,数据孤岛可能变得难以整合,导致信息在业务单位之间共享不足或不准确。因此,数据架构需要灵活且适应现代需求,以确保无缝和持续的数据分析,从而进一步推动创新。
大多数企业仍然采用瀑布式的数据共享方法。然而,灵活的数据架构必须确保部门间的数据无缝协作。这可以通过在数据管理策略中采用 DataOps 原则来实现,因为 DataOps 专注于自动化组织内部数据的无缝流动。除了灵活性,DataOps 还引入了急需的敏捷性,以便迅速扩展数据管道,以适应组织的增长。
3. 数据治理和合规的缺失
组织必须实施适当的数据治理实践,以确保数据的完整性和可用性,并便于访问。这确保了数据的可靠性,流动的顺畅,并受到保护以防滥用。然而,在实施数据治理时,组织必须规避如缺乏技能的数据治理领导和资源、数据质量差以及对企业数据缺乏控制等问题。
数据治理和合规是密不可分的。数据治理实践和政策的漏洞可能导致监管合规问题。监管机构可以根据违规的性质和严重程度以及当地的法律法规,处以罚款和处罚。这些违规行为可能会遭受高达2000 万欧元或上一财政年度 4%的总收入(以较高者为准)的罚款。此外,因数据滥用或泄露,企业可能面临一个或多个诉讼。在严重情况下,当加大监管审查时,操作流程可能会长时间受到干扰。
为应对数据治理和合规挑战,组织需要建立明确的政策和程序,分配职责,培训员工,并实施适当的技术和组织控制措施。他们还需要定期监控和审计数据实践,以确保持续合规和不断改进。
4. 数据安全和隐私风险
大量数据对企业保持敏感数据和个人可识别信息(PII)的隐私构成了关键挑战。此外,随着网络攻击和数据泄露变得越来越普遍,投资和更新旧有安全工具和基础设施的成本也在上升。
根据 Check Point Research (CPR) 的报告,2022 年第三季度的网络安全攻击比 2021 年增加了28%,这表明数据泄露和滥用的潜在风险增加。随着业务基础设施快速采用数字模型,必须部署强有力的安全措施和实践,以保护数据隐私并确保其完整性。在数据管理战略的框架下,必须通过认证严格执行对数据的物理和数字访问。在系统故障、数据损坏或不可预见的灾难发生时,也必须有适当的恢复措施来恢复数据。
企业必须投资于数据收集和分类工具,以区分符合监管要求的数据。组织必须制定严格的数据管理政策和程序,包括数据保留、数据质量和数据访问。解决方案应包括基于数据敏感性进行分类,并根据数据的分类应用适当的安全控制。必须根据需要进行持续的风险评估,以识别数据安全和隐私的潜在风险,并实施措施以降低这些风险。
数据生态系统的复杂性质
数据生态系统,即数据源、工具、技术和利益相关者的互联网络,面临着若干挑战。例如,确保不同系统和平台之间的数据互操作性可能会很困难。这需要建立通用的数据标准、协议和接口。此外,从数据中提取有意义的见解是数据生态系统中的一项重大挑战。这需要使用先进的分析工具、技术和技能,从复杂的大数据集中提取有价值的见解。
应对这些挑战需要所有数据生态系统相关利益方的协作努力。组织必须采用全面的数据管理方法,关注数据质量、集成、隐私、安全、治理、可扩展性和分析。这需要结合技术解决方案,如数据集成平台、数据分析工具和安全软件,以及组织变革,包括过程改进、培训和沟通。
集成自然语言处理(NLP)和机器学习(ML)模型可以丰富数据生态系统。NLP 结合流程自动化,可将原始和非结构化数据转换为结构化数据。另一方面,ML 模型可以帮助改进数据生态系统中的操作逻辑,并将人工干预的负担降到最低。
结论
数据被恰当地称为数字黄金,组织迅速而高效地处理大量数据以进行分析和价值生成的能力对业务的敏捷性和可扩展性至关重要。一个有效的数据管理策略可以确保提高效率和生产力、做出更好且经过计算的业务决策、降低成本并增强数据安全性。最终结果是改善客户体验。
理解和努力进行数据管理的重要性将继续增长。随着数据管理的发展,连接各级数据将始终是至关重要的,以满足日益复杂的业务需求。这将进一步推动数据管理领域的创新,并在最前沿采用人工智能。
迪特玛·里奇是Pimcore的首席执行官。作为一名拥有强烈创新意识、技术洞察力和数字化转型感的连续创业者,他是一位充满热情的企业家,20 多年来一直在设计和实现令人兴奋的数字项目。
更多相关内容
5 个数据科学职业生涯的错误要避免
原文:
www.kdnuggets.com/2021/08/5-data-science-career-mistakes-avoid.html
评论
由Tessa Xie,Cruise 高级数据科学家

照片由bruce mars拍摄,来源于Unsplash。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
当我第一次从金融行业转到数据科学领域时,我感觉自己如同站在世界之巅——我找到了梦想中的工作,职业轨迹已经确定,我只需低头努力工作,能出什么问题呢?其实,确实有几个问题……在成为数据科学家的这一年里,我犯了一些错误,我很高兴自己在职业生涯早期发现了这些错误。这样,我有时间反思并及时纠正。过了一段时间,我意识到这些错误相当普遍。事实上,我观察到周围许多数据科学家仍然犯这些错误,却不知道这些错误会对他们的数据职业生涯造成长期伤害。
如果我的麦肯锡教我的 5 个让你成为更好数据科学家的课程是我从最佳实践中学到的,那么本文中的课程是我从艰难经验中获得的,我希望我能帮助你避免犯同样的错误。
错误 1:把自己看作是步兵,而不是思考伙伴
在成长过程中,我们总是根据我们能多好地遵循规则和命令来评估,特别是在学校。如果你遵循教科书和练习考试,努力工作,你会成为顶尖学生。很多人似乎把这种“步兵”心态带入了工作环境中。在我看来,这正是阻碍许多数据科学家最大化影响力并脱颖而出的心态。我观察到很多数据科学家,尤其是初级数据科学家,认为自己在决策过程中没有贡献,宁愿退到背景中,被动地执行为他们做出的决策。这开始了一个恶性循环——你在这些讨论中贡献得越少,利益相关者未来将你纳入会议的可能性就越小,你未来的贡献机会也就越少。
让我给你一个关于模型开发中步兵和思考伙伴差异的具体例子。在数据收集和特征头脑风暴会议中,过去的我通常被动地记录利益相关者的建议,以便之后“完美”实施。当有人提出一个我知道我们没有数据的特征时,我不会说什么,因为我假设他们更资深,肯定知道一些我忽视的东西。但结果是,他们并不知道。我后来发现,我们头脑风暴出的 50%的特征需要额外的数据收集,这会使我们的项目截止日期面临风险。因此,我经常发现自己最终成为传达坏消息的信使。现在,我努力成为思考伙伴,尽早参与讨论,并利用我作为最接近数据的人的独特位置。这样,我可以早期管理利益相关者的期望,并提出建议,帮助团队向前推进。
如何避免这一点:
-
确保在你能够从数据角度做出贡献的会议中不要有所保留:利益相关者对指标的定义是否足够满足他们的测量需求?是否有数据可用于衡量这些指标?如果没有,我们是否能找到已有数据的代理?
-
冒名顶替综合症是现实存在的,特别是在初级数据科学家中。确保你意识到这一点,并且每当你在考虑是否应该说些“别人可能已经想到的”或问一个“愚蠢的澄清问题”时,你应该这么做。
-
保持对其他人工作内容的好奇心。很多时候,我发现自己可以通过注意到别人可能由于对公司数据的理解不足而忽视的空白来增加价值。
错误 2: 把自己限制在数据科学的特定领域
我是想成为数据工程师还是数据科学家?我想处理营销和销售数据,还是做地理空间分析?你可能已经注意到,直到目前为止,我在这篇文章中一直使用“DS”这个术语,作为许多data-related career paths(例如数据工程师、数据科学家、数据分析师等)的通用术语。这是因为在数据领域,这些职位之间的界限非常模糊,尤其是在小型公司中。我观察到很多数据科学家只把自己看作是构建模型的数据科学家,而忽视了业务方面;还有数据工程师只关注数据管道,而不愿了解公司中的建模工作。
最优秀的数据人才是那些能够身兼多职,或至少能理解其他数据角色的工作流程的人。如果你想在早期或成长阶段的初创公司工作,这一点尤其重要,因为这些公司可能还没有那么专业化,你需要灵活应对各种数据相关的职责。即使你在一个明确的职位描述中,随着经验的积累,你可能会发现自己有兴趣转型到不同类型的数据角色。如果你没有把自己和技能局限在一个狭窄的角色中,这种转型会更加容易。
如何避免这种情况:
-
再次,对其他数据角色正在做的项目保持好奇。定期安排与同事的会议,讨论有趣的项目,或者让不同的数据团队定期分享他们的工作/项目。
-
如果你在工作中无法接触到其他数据角色,尽量在空闲时间保持/练习你不常用的数据技能。例如,如果你是数据分析师且有一段时间没有接触建模,考虑通过外部项目如 Kaggle 比赛来练习这些技能。
错误 3:未跟上该领域的发展
自满致命
每位士兵都知道这一点,每个数据科学家也应该知道。对你的数据技能感到自满,不花时间学习新技能是一个常见的错误。在数据领域这样做比在其他领域更危险,因为数据科学是一个相对较新的领域,仍在经历剧烈的变化和发展。新算法、新工具甚至新编程语言不断被引入。
如果你不想成为那种到 2021 年仍只会使用 STATA 的数据科学家(他确实存在,我曾与他共事),那么你需要跟上该领域的发展。
不要让自己成为这样的人(GIF by GIPHY)
如何避免这种情况:
-
注册在线课程,学习新概念和算法,或复习你已经知道但在工作中一段时间没用的知识。学习的能力是每个人都应不断练习的技能,终身学习可能是你能给自己最好的礼物。
-
注册数据科学新闻通讯或关注 Medium 上的数据科学博主/出版物,养成关注数据科学“新闻”的习惯。
错误 4:过度发挥你的分析能力
如果你只有一把锤子,一切看起来都像钉子。不要做那个尝试把 ML 应用到一切事物上的数据科学家。当我第一次进入数据科学领域时,我对在学校里学到的所有高级模型感到非常兴奋,迫不及待想在现实问题上尝试它们。但现实世界不同于学术研究,80/20 法则始终在发挥作用。
在我之前的文章“麦肯锡教我的 5 个经验”中,我写到业务影响和可解释性有时比模型的额外几个百分比的准确性更为重要。有时一个基于假设的 Excel 模型比一个多层神经网络更有意义。在这些情况下,不要过度运用你的分析能力,让你的方法变成过度。相反,要发挥你的商业能力,成为一个也具备商业洞察力的数据科学家。
如何避免以下情况:
-
拥有一系列全面的分析技能/工具,从简单的 Excel 到先进的 ML 建模技能,以便你始终能评估在特定情况下使用哪种工具最为合适,而不是在刀战中带枪。
-
在深入分析之前,了解业务需求。有时利益相关者会因为 ML 模型是一个流行的概念而提出要求,他们对 ML 模型能做什么有不切实际的期望。作为数据科学家,你的工作是管理这些期望,并帮助他们找到更好、更简单的方式来实现目标。记住?成为一个思想伙伴,而不是一个打工者。
错误 5:认为建立数据文化是别人的工作
在我的文章“构建卓越数据文化的 6 个关键步骤”中,我写到了如果公司没有良好的数据文化,数据科学家的生活可能会非常糟糕且低效。事实上,我听到很多数据科学家抱怨那些应该由利益相关者以自给自足的方式轻松处理的无效临时数据请求(例如,在 Looker 中将聚合从按月更改为按日,这实际上只需两次点击)。不要认为改变这种文化是别人的工作。如果你想看到变化,就自己动手。毕竟,谁比数据科学家更适合建立数据文化并教育利益相关者关于数据的知识呢?帮助公司建立数据文化将使你的生活以及你的利益相关者的生活变得更轻松。
如何避免:
-
让自己负责对非分析型利益相关者进行培训,并开发自助资源。
-
确保你开始实践你所宣扬的内容,开始将查询与幻灯片关联,将真实的数据来源链接到文档,并开始记录你的代码和数据库。你不能在一夜之间建立数据文化,这确实需要耐心。
我确实想指出,在你的职业生涯中犯错误是可以的。最重要的是从这些错误中学习,并在未来避免它们。或者更好的是,把它们写下来,以帮助其他人避免犯同样的错误。
原文。已获授权转载。
简介:Tessa Xie 是一位经验丰富的高级分析顾问,擅长数据科学、SQL、R、Python、消费者研究和经济研究,拥有强大的工程背景,曾获得麻省理工学院金融工程硕士学位。
相关内容:
更多相关主题
5 个数据科学社区以促进你的职业发展
原文:
www.kdnuggets.com/5-data-science-communities-to-advance-your-career

编辑器图片
每天似乎都有新的数据科学突破,这对我们的职业生涯至关重要。面对如此众多的变化,我们显然需要每天保持最佳状态,但这确实很难做到。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
当然,我们可以自己学习所有这些技能。但理解所有新出现的内容和应该关注的重点是很困难的。这就是社区的优势,帮助我们了解对职业生涯至关重要的新知识。
许多大小不一的数据科学社区可以帮助提升我们的职业生涯。但如果你只能花时间在五个不同的社区中,这些就是你应该关注的社区。
让我们开始吧。
1. Reddit
我们从看似随意的开始,也就是 Reddit。
是的,Reddit 是一个以表情包和生活中的随意讨论而著名的社交网络论坛。然而,它仍然是一个具有公告板结构的社交媒体平台,导致许多随意讨论,其中之一就是数据科学。
Reddit 实际上是一个充满活动的数据科学爱好者和专业人士的地方。重要的是找到 Reddit 中可以促进我们学习的特定社区。
为此,我推荐加入 r/datascience 社区,该社区拥有 140 万成员,每天都有新的讨论。几乎每天都有关于数据科学话题的讨论。从随意的问题到高级职业发展,该社区都非常活跃,可以与大家展开讨论。
此外,r/machinelearning 是一个很棒的社区,如果你想与其他 290 万成员讨论机器学习相关的话题,可以加入这个社区。
2. Kaggle
下一个你应该加入的社区是 Kaggle。
我相信许多刚开始学习数据科学的你们都听说过它。但如果你从未听说过 Kaggle,它是一个共享和发布数据集的平台,探索和构建机器学习模型的笔记本,并分享我们所有的数据工作。它也是数据科学竞赛的中心,因为许多公司在这个平台上举办在线竞赛。
Kaggle 的前提是与公众分享我们的数据科学工作,因此它已成为许多数据从业者交流的核心地点。我已经从那里的社区得到了很多个人和职业上的帮助,我觉得这是最好的社区之一。
这是因为许多有用的信息和突破都在这里实施,这是一种很好的学习新技能、推动职业发展的方式。此外,许多专业人士和专家为社区免费贡献了很多。
Kaggle 社区对你数据职业生涯的任何阶段都开放。无论你是初学者还是竞赛冠军,Kaggle 社区都会帮助你。
3. LinkedIn
对于一些人来说,LinkedIn 是寻找新工作或学习平台的地方。然而,LinkedIn 本质上仍然是社交媒体。
LinkedIn 允许用户创建社区群组,在这些群组中志同道合的人可以发布和分享他们的想法。LinkedIn 上最大的一个数据科学社区群组是 Robbert van Vlijmen 创建的 数据科学社区(有主持人),该群组有超过 500,000 名成员。
成员们经常分享有用的学习材料,并提供一个可以提问的地方,无论你的专业水平如何。所以,如果你觉得讨论似乎太难以跟上,不要感到有压力。
我推荐加入的另一个 LinkedIn 群组是 KDnuggets 数据科学与机器学习(有主持人)。该群组有超过 150,000 名成员,成员们每天发布的内容将帮助你学习,包括 KDNuggets 最新的文章,你可以在里面讨论。

KDNuggets LinkedIn 群组社区(图片由作者提供)
还有一些其他成员众多但仍与数据科学相关的社区,包括:
-
人工智能、机器学习、数据科学与机器人技术(280 万+成员)
-
机器学习社区(有主持人)(140 万+成员)
-
人工智能、深度学习、机器学习(150 万+成员)
4. DataTalks.club
DataTalks.Club 是由 Alexey Grigorev 创建的数据爱好者社区。
这是一个旨在讨论任何数据话题的社区,从数据分析、机器学习和数据工程到数据科学。无论你有何种数据问题,社区都会准备好回答。
然而,这个社区最棒的部分是你可以讨论任何职业相关的问题,比如决定下一步或者学习什么。如果你想参与社区,加入 DataTalks 的 Slack 频道是进一步讨论的绝佳方式。
该社区还举办了丰富的活动,你可以加入。你可以从小型的一次性活动到免费的训练营自由学习。这些免费的训练营无疑是著名的,因为它们提供了你可能需要在其他地方支付高额费用的公司级技能。
此外,还有播客和书籍讨论,你可以从中学习。关键是这个社区积极努力让你在数据职业生涯中变得更好。
5. MLOps 社区
我推荐的最后一个社区是 MLOps 社区。
MLOps 社区(作者提供的图片)
所以,听我说。这个社区可能并不完全专注于数据科学,因为 MLOps 是数据科学的一部分。然而,一个成功的数据科学项目是我们能够为业务提供持续价值的地方,而 MLOps 提供了这一点。
这就是为什么我推荐 MLOps 社区作为一个可以帮助你未来职业发展的地方。我这样说也是因为 MLOps 正在成为许多数据科学工作岗位寻求的技能。
这个社区,尤其是 Slack 频道,活跃着很多关于 MLOps 的讨论,有时也会有一些一般性的讨论。尽管如此,我在那里获得了许多洞见,你也应该这样做。
结论
数据科学社区在推动我们职业发展方面发挥着重要作用。通过与他人互动和学习,我们可以理解许多以前无法实现的新事物。虽然有很多数据科学社区,但这里有五个你应该加入的社区:
-
Reddit
-
Kaggle
-
LinkedIn
-
DataTalks
-
MLOps 社区
希望这能帮到你!分享你对这里列出的社区的看法,并在下方添加你的评论。
Cornellius Yudha Wijaya**** 是一位数据科学助理经理和数据撰写者。在全职工作于 Allianz Indonesia 期间,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 撰写各种 AI 和机器学习主题的文章。
更多相关话题
5 个你应该考虑贡献的数据科学开源项目
原文:
www.kdnuggets.com/2021/06/5-data-science-open-source-projects-contribute.html
评论

照片由 Markus Winkler 提供,来源于 Unsplash。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你在组织中的 IT 工作
获得理想的数据科学职位的一个关键方面是建立一个强大、引人注目的作品集,以证明你的技能,并展示你能够处理大规模项目,并能很好地与团队合作。你的作品集需要证明你花费了时间、精力和资源来磨练你的数据科学技能。
向不认识你的人证明你的技能,尤其是在短时间内——招聘人员在简历或作品集上的平均停留时间为 7~10 秒——并不容易。然而,这也不是不可能的。
一个好的作品集应包括各种类型的项目,涵盖数据收集、分析和可视化的项目。它还应包含不同规模的项目。处理小项目与处理大规模项目是非常不同的。如果你的作品集包含这两种规模的项目,那么这意味着你能够阅读、处理和调试各种规模的软件,这是一项任何数据科学家都需要的技能。
这可能会让你想知道如何找到那些容易上手且在作品集中看起来很棒的开源数据科学项目。这是个很好的问题,但随着数据科学项目数量的爆炸性增长,找到能让你获得工作的优秀项目并不是一件容易的事。
当你尝试查找可以贡献的数据科学项目时,你通常会遇到一些大型项目,如 Pandas、Numpy 和 Matplotlib。这些巨头项目很棒,但还有一些鲜为人知的项目也被许多数据科学家使用,并且在你的简历上也会显得很有分量。
1: Google 的 Caliban 机器学习工具
让我们从科技巨头 Google 的一个项目开始这个列表。在构建和开发数据科学项目时,你可能会发现构建一个能在实际情况下展示你项目的测试环境很困难。你无法预测所有场景,也不能确保涵盖所有边缘情况。
Google 提供了 Caliban 作为解决这个问题的潜在方案。Caliban 是一个测试工具,可以在执行过程中跟踪你的环境属性,并允许你重现特定的运行环境。这个工具是由 Google 的研究人员和数据工程师开发的,旨在每天执行这个任务。
2: PalmerPenguins
我们列表中的下一个是 PalmerPenguins,这是一个最近才开源的数据集。这个数据集的建立和开发是为了取代非常著名和广泛使用的 Iris 数据集。Iris 之所以出名,是因为它对初学者的使用非常简单,同时它的应用范围也非常广泛。
PalmerPenguins 提供了一个出色的数据集,你可以像使用 Iris 一样轻松地用于数据可视化和分类应用,但选项更多。这个数据集的另一个伟大之处是它提供了艺术作品来教授数据科学概念。
3: Caffe
接下来,我们有一个非常有前景的深度学习框架,Caffe。Caffe 是一个深度学习框架,设计和构建时以速度、模块化和表达为优先。Caffe 最初是由 UC Berkeley AI 实验室和视觉与学习社区的研究团队开发的。
在 Caffe 作为开源项目发布仅一年后,它被全球 1000 多名研究人员和开发人员进行了分叉。这有助于转变研究主题,建立新的初创公司和工业力量。Caffe 社区是一个非常友好和支持的开源社区。
4: NeoML
机器学习可能是数据科学应用的核心,所以我必须至少有一个完全针对机器学习的开源项目。NeoML 是一个机器学习框架,允许用户设计、构建、测试和部署机器学习模型,且提供了超过 20 种传统机器学习算法,操作简便。
它包含了支持自然语言处理、计算机视觉、神经网络以及图像分类和处理的材料。这个框架用 C++、Java 和 Objective-C 编写,可以在任何平台上运行,包括基于 Unix 的系统、macOS 和 Windows。
5: Kornia
我们将用 Kornia 来结束这个列表。Kornia 是一个支持PyTorch的计算机视觉库。它包含了各种例程和可微分的操作,可以用于解决一些通用的计算机视觉问题。Kornia 建立在 PyTorch 之上,严重依赖于其效率和 CPU 的计算能力来完成复杂的函数。
Kornia 不仅仅是一个包,它是一套可以一起使用的库,用于训练模型和神经网络,进行图像变换、图像滤波和边缘检测。
结论
既然你已经成功穿越了数据科学求职的迷宫,解读了职位名称并找到了最适合你技能的角色,接下来就是考虑如何让你的作品集迅速帮你找到工作的时候了。
在你的数据科学学习旅程中,你可能经历了许多项目,从几行代码的小项目到有数百行代码的大项目。但要真正证明你的技能和知识水平,你需要一些让你在申请者池中脱颖而出的贡献。
吸引招聘人员注意的一种方法是参与被全球许多数据科学家使用的大型项目。
原文。经许可转载。
相关:
更多相关主题
2018 年能够让你被聘用的 5 个数据科学项目
原文:
www.kdnuggets.com/2018/06/5-data-science-projects-hired.html
评论
作者:约翰·沙利文,DataOptimal
你已经在参加 MOOC 课程并阅读了许多教科书,但现在该怎么办?获得数据科学工作可能看起来很令人畏惧。展示你的技能的最佳方法是制作一个作品集。这向雇主展示了你能够运用你所学的技能。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
为了展示这些技能,以下是你的作品集中 5 种数据科学项目:
- 数据清洗
数据科学家可以预计在新项目中花费多达 80% 的时间在 数据清洗 上。这是团队中的一个重大痛点。如果你能展示你在数据清洗方面的经验,你将立即变得更有价值。要创建数据清洗项目,找到一些杂乱的数据集,并开始清洗。

如果你使用 Python,Pandas 是一个很好的库,如果你使用 R,你可以使用 dplyr 包。确保展示以下技能:
-
导入数据
-
合并多个数据集
-
检测缺失值
-
检测异常
-
填补缺失值
-
数据质量保证
- 探索性数据分析
数据科学的另一个重要方面是探索性数据分析(EDA)。这是一个生成问题并通过可视化进行调查的过程。EDA 允许分析师从数据中得出结论,从而推动业务影响。它可能包括基于客户细分的有趣见解,或基于季节性影响的销售趋势。通常,你可以发现一些最初没有考虑到的有趣发现。

一些用于探索性分析的有用 Python 库包括 Pandas 和 Matplotlib。对于 R 用户,ggplot2 包将非常有用。一个 EDA 项目应该展示以下技能:
-
能够提出相关的问题进行调查
-
识别趋势
-
识别变量间的协变关系
-
使用可视化(散点图、直方图、箱线图等)有效地传达结果
- 交互式数据可视化
交互式数据可视化包括仪表板等工具。这些工具对数据科学团队和更具业务导向的最终用户都很有用。仪表板使数据科学团队能够协作,共同提取见解。更重要的是,它们为面向业务的客户提供了一个交互式工具。这些客户关注战略目标,而非技术细节。数据科学项目的最终交付物通常是仪表板形式。
对于 Python 用户,Bokeh和Plotly库非常适合创建仪表板。对于 R 用户,确保查看 RStudio 的Shiny包。你的仪表板项目应突出以下重要技能:
-
包含与客户需求相关的指标
-
创建有用的特征
-
合理的布局(“F 型”扫描模式)
-
创建最佳刷新率
-
生成报告或其他自动化操作
- 机器学习
机器学习项目是数据科学组合中的另一个重要组成部分。在你开始构建深度学习项目之前,先停下来考虑一下。与其构建复杂的机器学习模型,不如从基础开始。线性回归和逻辑回归是很好的起点。这些模型更容易解释,并且可以与高层管理沟通。我还建议专注于具有业务影响的项目,例如预测客户流失、欺诈检测或贷款违约。这些项目比预测花卉类型更具现实意义。
如果你是 Python 用户,请使用Scikit-learn库。如果你是 R 用户,请使用Caret包。你的机器学习项目应展示以下技能:
-
选择特定机器学习模型的原因
-
将数据拆分为训练集/测试集(k 折交叉验证)以避免过拟合
-
选择正确的评估指标(AUC、调整后的 R²、混淆矩阵等)
-
特征工程和选择
-
超参数调优
- 沟通
沟通是数据科学的一个重要方面。有效地传达结果是区分优秀数据科学家与杰出数据科学家的关键。无论你的模型多么先进,如果你无法向团队成员或客户解释清楚,你将无法获得他们的认可。幻灯片和笔记本都是很好的沟通工具。将你的机器学习项目放入幻灯片格式中。你也可以使用 Jupyter Notebook 或 RMarkdown 文件进行沟通项目。
确保了解你的目标受众是谁。向高管展示与向机器学习专家展示是非常不同的。确保掌握以下技能:
-
了解你的目标受众
-
展示相关的可视化图表
-
不要让幻灯片上信息过于拥挤
-
确保你的演示流畅
-
将结果与业务影响(降低成本、增加收入)联系起来
确保在 Jupyter Notebooks 或 RMarkdown 文件中记录你的项目。然后,你可以使用 Github Pages 免费将这些 Markdown 文件转换为静态网站。这是向潜在雇主展示你的作品集的好方法。
保持积极,继续构建项目,你将迈向数据科学领域的工作。祝你求职顺利!
简介:John Sullivan 是数据科学学习博客 DataOptimal 的创始人。你可以在 Twitter 上关注他 @DataOptimal。
相关:
更多相关话题
学习 5 个数据科学项目,掌握 5 项关键的数据科学技能
原文:
www.kdnuggets.com/2022/03/5-data-science-projects-learn-5-critical-data-science-skills.html

如果你想进入数据科学行业,拥有一些项目经验是很有帮助的。进行数据科学项目能帮助你发展成为数据科学家所需的技能。你还将拥有可以放在简历上和面试时讨论的成果,这对于展示你知道自己在做什么至关重要。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
数据科学开发周期是任何数据科学项目的主要模式,无论是公司项目还是个人项目。要成为一名熟练的数据科学家,你需要对数据收集、清洗、建模和可视化感到得心应手。你未来的数据科学工作所使用的具体工具栈可能与我下面推荐的工具不同,但就像计算机科学世界中的其他事物一样,重要的是学习如何思考,而不是特定工具的语法或功能。毕竟,如果你能使用 Tableau 创建数据可视化,你会很快学会如何使用 Power BI,因为你已经熟悉了数据可视化的一般过程。
一次性熟悉整个数据科学开发周期可能会让人感到不知所措。周期的每一步都需要若干技能,同时开发所有的数据科学家技能将是一个令人沮丧且可能徒劳的过程。与其挣扎着一次性掌握所有技能,不如通过构建你的学习旅程来给自己一个提升。
你将面临的主要障碍是动力。我保持和激发动力的首选方法是选择一个主题或产品,当尝试将技能扩展到新领域时,思考一个实际产品(无论它看起来多么无用或不可销售),然后围绕这个想法进行整个周期。
跟随你的激情,利用这个机会找到你想要进入数据科学的原因和你生活其他方面之间的交集。如果你喜欢跑步,你可以找到一组比赛时间和训练计划的数据,以查看哪些训练计划能带来最大的改进。也许你对烘焙感兴趣,你想通过分析搜索引擎的关键词频率来弄清楚家庭烘焙爱好者对不同菜肴的受欢迎程度。
下面是五个迷你数据科学项目的概要,你可以尝试。每个项目都会教你一个你需要在简历上展示的技能。
1. 数据收集
类似于你开始烹饪一顿饭时,首先必须确保你已经准备好了所有需要的材料。产生任何类型的洞见的第一步是获取数据。找到适合你数据分析项目的相关数据,无论是个人项目还是工作项目,都是一个巨大的挑战。
API
你应该对使用API感到舒适。可以把 API 看作是两个程序之间的正式协议,比如一个网站的前端和保存及处理数据的服务器和数据库。API 会被发布到前端和后端,以便结构化它们之间的通信。REST API 非常流行,用于查询网络服务以获取数据。你可以使用类似 Google Trends API 的 API 来收集数据。
从数据库导入大数据
你会想在一个云服务(AWS、Azure 或 Google Cloud)上创建一个数据库并连接到它。所有大型云解决方案提供商都有广泛的免费层,非常适合爱好者数据科学家测试。由于大量的消费者、学生和企业使用这些大品牌产品,因此有很多有用的内容涵盖它们的免费层,包括详细的文档和大量的 Stack Overflow 问题。云服务正在成为现代数据科学的核心部分,所以现在了解它们是非常好的。
选择一个产品并创建一个数据库。亚马逊和谷歌都提供了很好的文档来帮助你使用它们的免费数据库层。导入是一个相当简单的文档齐全的过程。谷歌甚至提供了技巧和窍门列表以获取最佳的数据导入策略,比如压缩数据以降低成本。
数据来源
有很多开源数据可以用于个人项目。确保避免使用那些已经过度使用的数据集,比如鸢尾花数据集。你希望你的项目在简历上引人注目。我收集了几个我喜欢的数据源,其中一个很有趣,一个更侧重于流行文化,还有一个包含更严肃的数据,例如人口统计和健康数据。
2. 数据清洗
数据清洗意味着数据本身是脏的。我从未在实际中遇到过真正干净的数据集,你也可能没有。数据清洗是数据科学的一个重要部分,因为脏数据会导致不准确的结果。脏数据可能包含重复项、过时、错误、不完整或不一致。你需要学习如何缓解这些问题。
根据 Tableau 的说法,数据清洗的五个步骤包括去除重复项、修复结构性问题、筛选不需要的异常值、处理缺失数据,以及验证清理后的数据集的质量。
如何清洗脏数据
记住,我们不是追求完美,而是追求足够好。在最大努力和可能过度修正的数据集与草率完成数据清洗过程之间找到平衡。
Database Trends and Applications 提供了一份很棒的指南,帮助你逐步了解数据清洗过程。最重要的是要记住在清洗数据的过程中记录每一次更改。当处理不完整的数据时,例如,你需要做出一些假设,然后根据这些假设做决定。如果你没有记录你的假设以及替换或删除逻辑,你将错过在获得更多信息或理解后重新引入这些数据的机会。
如果你想了解一些具体的脏数据示例,Foresight BI 整理了不同类型脏数据的练习。选择五个对你来说最具挑战性的练习,试试吧。他们提供了结构化的信息和数据可能呈现的良好示例概述。
3. 数据建模
除了基本的统计分析,机器学习是数据科学的核心部分。要熟练开发、维护和部署机器学习模型,将你的数据科学职业生涯提升到一个新的水平。
构建机器学习模型
亚马逊提供了一个 机器学习教程 来指导你如何使用他们的 SageMaker 服务构建、训练和部署机器学习模型。如果你对数据科学或机器学习完全陌生,这个选项很棒,因为它会全程指导你,但你仍然会接触到整个过程。如果你之前没有独立构建、训练和部署模型过,我建议你遵循亚马逊的指南。
构建
然而,如果你有更多经验,不要走捷径。像往常一样构建你的模型,注意将数据分成测试数据和训练数据。根据你拥有的数据类型和你想要进行的预测类型(有标签数据的监督学习、无标签数据的无监督学习等)选择合适的模型。
训练
Chris Rawles 汇编了一个详尽的 如何设置你的模型 的指南以在云中进行训练。他们使用了 Google Cloud,但他推荐的原则适用于任何云服务提供商。
部署
AWS 的 Lamda 服务 非常适合部署你的代码并让它运行。定价模式是按请求付费,因此如果你只是用它来练习部署,或者向一些面试官展示,这可能会非常划算。
构建回归模型
如果你要预测的结果是二元的,那么回归模型效果最佳。尽管回归模型比神经网络或聚类算法更简单,你仍然应该像对待其他机器学习模型一样进行训练和部署。
如果你觉得机器学习和用于数据科学的各种工具让你感到难以应对,可以尝试从一个易于掌握的练习开始。你可以在 Excel 中构建一个简单而有效的回归模型。这并不花哨,这样做不会 让你获得数据科学工作,但这是初学者数据科学家的一个很好的入门步骤。
4. 数据可视化

一旦你完成了寻找数据、清洗数据、开发模型以及生成预测或见解的繁重工作,就可以展示你的成果了!了解哪种类型的可视化最为重要,因为你需要以简单而有效的方式传达你的发现。尝试使用不同的可视化方式向朋友和家人展示你的发现,并找出哪些方式在特定场景中效果更好。
Tableau
Tableau 因其炫酷且吸引人的可视化效果而变得非常著名。Pavleenk Kaur 汇总了 Tableau 中最常用的可视化。它带你了解如何连接数据,并通过描述不同选项颜色的含义来帮助你理解工具的界面,还介绍了不同可视化的优缺点。
其他 BI 工具
微软的 Power BI 非常适合用于仪表盘、生成报告和展示你的预测分析。它作为一个集中的数据报告系统表现出色。全球有超过 20 万个组织在使用它,熟悉这个工具对申请数据科学职位非常有帮助。查看这个 数据可视化工具的顶级列表。
5. 部署
推荐引擎是数据科学实际应用的一个很好的例子。如果一个客户买了帐篷,他们可能还会想购买睡袋、头灯和炉具,对吧?推荐引擎基于共现矩阵的概念,该矩阵表示每个行值在与每个列值相同的上下文中出现的次数。
部署推荐引擎是你掌握数据科学所有技能的最终项目。这一数据科学领域与软件开发者的技能和责任有很大重叠,例如使用 Django 创建在线应用。你可以将使用 Django 或其他框架制作的应用部署到云端(AWS、Azure 或 Google Cloud)。这些云服务可以为你提供服务器和数据库,这些都是你部署应用并保持其运行所需的。
就像一本从未出版的书一样,一个从未开始消耗数据和输出实时预测或调整其分析的数据科学模型的价值要低很多。部署和维护应始终是你的终极目标。通过构建推荐引擎现在学习这些将帮助你在下一个数据科学职位中最大化业务影响和感知绩效。
关于学习数据科学技能的数据科学项目的最终思考
了解构成数据科学开发周期的基本构建块非常重要。我建议将这种理解扩展到包括云解决方案。数据科学模型只有在能够进行实时预测、持续消耗数据以更新模型,并将所有这些见解提供给相关利益方时,才是有用的。
无论你是想创办自己的 数据科学公司,还是希望在科技巨头公司担任数据科学家,你都需要在云环境中熟练执行数据科学家的任务。借助各大云解决方案提供商的免费套餐,现在没有理由不去深入了解这些工具。如果你是初学者,想找到你的第一个数据科学或数据分析职位,这些 19 个数据科学项目创意 可以帮助你。选择一个或全部的项目——选择你觉得最有趣的。
内特·罗西迪 是一位数据科学家,专注于产品战略。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,这个平台帮助数据科学家通过顶级公司真实面试问题来准备面试。可以通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
更多相关内容
在 Python 中加载数据的 5 种不同方法
原文:
www.kdnuggets.com/2020/08/5-different-ways-load-data-python.html

作为一个初学者,你可能只知道一种加载数据的方法(通常是 CSV),那就是使用pandas.read_csv函数读取它。这是一个最成熟和强大的函数,但其他方法也非常有用,有时会派上用场。
我将要讨论的方法有:
-
手动函数
-
loadtxt函数
-
genfromtxt函数
-
read_csv函数
-
Pickle
我们将使用的数据集可以在这里找到。它被命名为 100-Sales-Records。
导入
我们将使用 Numpy、Pandas 和 Pickle 包,所以要导入它们。
import numpy as np
import pandas as pd
import pickle
1. 手动函数
这是最困难的,因为你必须设计一个自定义函数来加载数据。你需要处理 Python 的常规文件概念,并使用这些概念来读取.csv文件。
让我们对 100 销售记录文件进行操作。
def load_csv(filepath):
data = []
col = []
checkcol = False
with open(filepath) as f:
for val in f.readlines():
val = val.replace("\n","")
val = val.split(',')
if checkcol is False:
col = val
checkcol = True
else:
data.append(val)
df = pd.DataFrame(data=data, columns=col)
return df
嗯,这是什么???看起来有点复杂的代码!!让我们一步步解析,以便你了解发生了什么,并可以应用类似的逻辑来读取自己的.csv文件。
在这里,我创建了一个load_csv函数,它接受一个参数,即你想读取的文件路径。
我有一个名为data的列表,它将包含我的 CSV 文件数据,还有另一个名为col的列表,它将包含我的列名。现在在手动检查 CSV 文件后,我知道我的列名在第一行,所以在第一次迭代中,我需要将第一行的数据存储在col中,其余的行存储在data中。
为了检查第一次迭代,我使用了一个名为checkcol的布尔变量,它的值为 False,当第一次迭代中它的值为 False 时,它会将第一行的数据存储在col中,然后将checkcol设置为 True,这样我们就会处理data列表,并将其余的值存储在data列表中。
逻辑
这里的主要逻辑是,我使用readlines()函数遍历文件。这个函数返回一个包含文件中所有行的列表。
在读取标题时,它将新行检测为\n字符,这是一种行终止字符,因此为了去除它,我使用了str.replace函数。
由于这是一个.csv文件,所以我必须根据逗号来分隔内容,因此我将使用string.split(',')来分割字符串。在第一次迭代中,我将把包含列名的第一行存储在一个名为col的列表中。然后,我将把所有数据追加到名为data的列表中。
为了更优雅地读取数据,我将其返回为数据框格式,因为数据框比 numpy 数组或 Python 列表更易于阅读。
输出
myData = load_csv('100 Sales Record.csv')
print(myData.head())

自定义函数中的数据。
优点与缺点
其重要好处是你对文件结构有全部的灵活性和控制权,可以按照你想要的格式和方式读取并存储数据。
你也可以使用自己的逻辑读取没有标准结构的文件。
其重要缺点是编写复杂,特别是对于标准类型的文件,因为它们可以很容易地被读取。你必须硬编码逻辑,这需要反复试验。
你应该仅在文件格式非标准或你需要灵活性并以库无法提供的方式读取文件时使用它。
2. Numpy.loadtxt 函数
这是 Numpy 库中的一个内置函数,Numpy 是 Python 中的一个著名数值库。这个函数非常简单,适合加载数据。它对于读取相同数据类型的数据非常有用。
当数据更复杂时,使用这个函数很难读取,但当文件简单易读时,这个函数确实非常强大。
要获取单一类型的数据,你可以下载this虚拟数据集。让我们跳到代码部分。
df = np.loadtxt('convertcsv.csv', delimeter = ',')
这里我们简单地使用了loadtxt函数,并将delimeter设置为',',因为这是一个 CSV 文件。
现在如果我们打印df,我们会看到我们的数据以相当不错的 numpy 数组形式呈现,准备好使用。
print(df[:5,:])

由于数据量大,我们只打印了前 5 行。
优点与缺点
使用这个函数的一个重要方面是你可以快速地将数据从文件加载到 numpy 数组中。
它的缺点是你不能在数据中拥有不同的数据类型或缺失的行。
3. Numpy.genfromtxt()
我们将使用数据集‘100 Sales Records.csv’,这是我们在第一个例子中使用的,以演示我们可以在其中拥有多种数据类型。
让我们跳到代码部分。
data = np.genfromtxt('100 Sales Records.csv', delimiter=',')
为了更清楚地看到这一点,我们可以以数据框格式查看,即:
>>> pd.DataFrame(data)
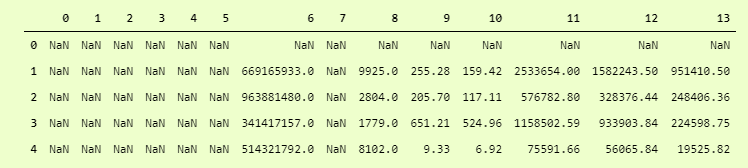
等等?这是什么?哦,它跳过了所有包含字符串数据类型的列。怎么处理这个问题?
只需添加另一个dtype参数并将dtype设置为 None,这意味着它必须自行处理每一列的数据类型,而不是将整个数据转换为单一的数据类型。
data = np.genfromtxt('100 Sales Records.csv', delimiter=',', dtype=None)
然后输出为:
>>> pd.DataFrame(data).head()
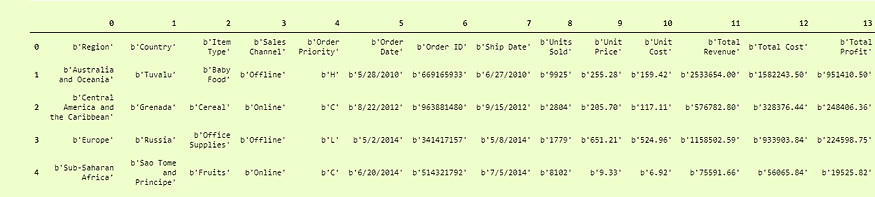
比第一个更好,但是这里我们的列标题变成了行,要将它们设置为列标题,我们必须添加另一个参数,即names,并将其设置为True,这样它会将第一行作为列标题。
即
data = np.genfromtxt('100 Sales Records.csv', delimiter=',', dtype=None, names = True)
我们可以将其打印为:
>>> pd.DataFrame(df3).head()
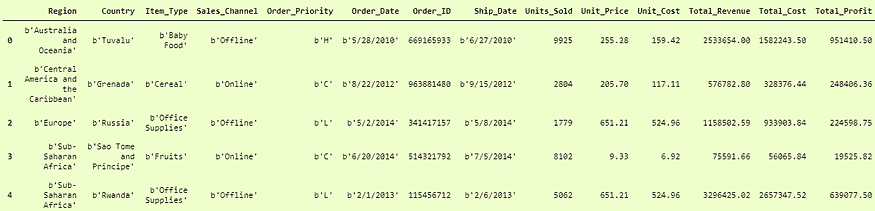
在这里我们可以看到,它成功地将列名添加到了数据框中。
现在最后一个问题是那些数据类型为字符串的列实际上并不是字符串,而是以字节格式存储的。你可以看到每个字符串前面都有一个b',所以为了处理它们,我们需要将它们解码为 utf-8 格式。
df3 = np.genfromtxt('100 Sales Records.csv', delimiter=',', dtype=None, names=True, encoding='utf-8')
这将返回我们所需格式的数据框。
>>> pd.DataFrame(df3)
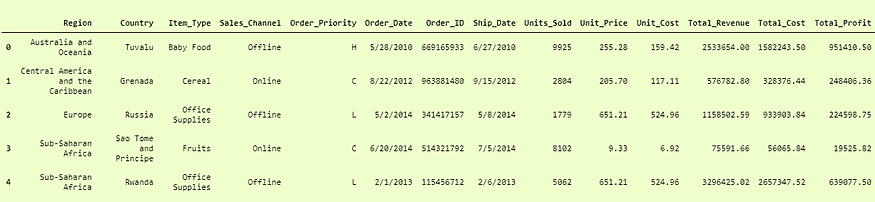
4. Pandas.read_csv()
Pandas 是一个非常流行的数据处理库,而且使用非常广泛。它非常重要且成熟的一个函数是read_csv(),它可以非常容易地读取任何.csv文件,并帮助我们处理它。让我们在我们的 100-Sales-Record 数据集上做这个。
这个函数因其易用性而非常受欢迎。你可以将它与我们之前的代码进行比较,并检查它。
>>> pdDf = pd.read_csv('100 Sales Record.csv')
>>> pdDf.head()
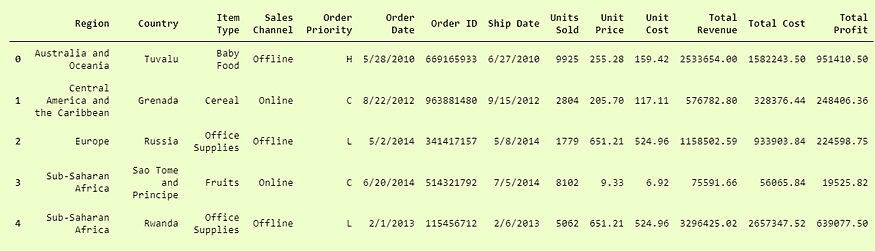
你猜怎么着?我们完成了。这实际上是非常简单和易于使用的。Pandas.read_csv 确实提供了许多其他参数来调整我们的数据集,例如在我们的convertcsv.csv文件中,我们没有列名,所以我们可以这样读取它:
>>> newdf = pd.read_csv('convertcsv.csv', header=None)
>>> newdf.head()
我们可以看到它读取了没有标题的csv文件。你可以在官方文档中探索所有其他参数这里。
5. Pickle
当你的数据不是以良好的、可读的格式存在时,你可以使用 pickle 将其保存为二进制格式。然后你可以使用 pickle 库轻松重新加载它。
我们将取出我们的 100-Sales-Record CSV 文件,并首先将其保存为 pickle 格式,以便我们可以读取它。
with open('test.pkl','wb') as f:
pickle.dump(pdDf, f)
这将创建一个新的文件test.pkl,其中包含我们来自Pandas标题的pdDf。
现在要使用 pickle 打开它,我们只需使用pickle.load函数。
with open("test.pkl", "rb") as f:
d4 = pickle.load(f)
>>> d4.head()
在这里,我们成功地从 pickle 文件中加载了数据,格式为pandas.DataFrame。
你现在知道了 5 种在 Python 中加载数据文件的方法,这可以帮助你在日常项目中以不同的方式加载数据集。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 在 IT 方面支持你的组织
更多相关主题
5 种数据科学必备的 AI 工具
原文:
www.kdnuggets.com/2023/04/5-essential-ai-tools-data-science.html

图片来源
1. Bard AI
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
谷歌 Bard 是一种聊天机器人功能,最终将与谷歌搜索引擎和其他产品集成。它可以用于撰写报告、头脑风暴、Python 编码、SQL 脚本和研究。就像 ChatGPT 一样,它也由大型语言模型驱动,你可以通过 加入候补名单 提前体验。
图片来源于 Richie Cotton
Google Bard 将允许数据科学家优化代码、解决 bug、创建数据图表、执行各种机器学习任务,并协助他们进行研究。如果你想查看 ChatGPT 和 Bard 的对比,可以查看 Richie Cotton 的精彩 博客。
2. ChatGPT
ChatGPT 和 GPT-4 都是数据专业人员的绝佳工具。它们可以用于各种任务,特别是在遇到问题时。ChatGPT 理解问题,并提出适用的解决方案列表。
ChatGPT 由大型语言模型驱动,能够根据用户提供的提示生成小说、故事、博客,甚至数据分析报告。它理解上下文,并利用以前的提示来提供准确的结果。
阅读我的博客:ChatGPT 在数据科学项目中的使用指南 以了解更多信息。
图片来源 | ChatGPT
我使用 ChatGPT 进行创意生成、Python 和 SQL 编码、博客研究、代码调试、句子改进和学习新技术。
这已经成为我工作流程中的一个重要部分,我无法回到以前那种为了学习简单算法而搜索几个小时的日子。
3. GitHub Copilot
GitHub Copilot对 Python 程序员和数据专业人员来说是一个救星。它自动完成整个代码,理解注释生成指定代码,解决错误,并优化代码。
图片来源于GitHub Copilot X。
随着GitHub Copilot X的推出,你将可以访问 GPT-4 模型,帮助你编写更好的代码。此外,你可以与助手进行上下文相关的对话,创建文档,生成拉取请求,并访问 CLI 中使用更多的命令。
如果你每天为项目或研究编写代码,这是一款必备工具。
4. Bing AI
我现在非常喜欢必应,并且已经完全从 Google 转向必应来满足我的所有需求。微软Bing提供了一个聊天机器人功能,可以帮助你完成各种任务。你可以用它来生成代码、研究、调试或学习新技能。它由 GPT-4 驱动,并优化了搜索引擎。
除了必应聊天,Microsoft Edge 浏览器提供了一个撰写功能,让你可以写专业邮件、报告、博客甚至代码。我不建议你使用撰写功能来写代码,因为效果不佳。
图片由作者从必应提供。
必应还集成了用于文本到图像生成的 Dalle-E 功能,称为Image Creator。你可以用它来创建博客特色图片或项目图像。

图片来源于Image Creator。
哦,别忘了必应视觉搜索。GPT-4 是一个多模态模型,可以处理文本和图像,并为你提供准确的结果。
你可以使用此功能在图像或互联网上搜索事物。
图片来源于Bing Visual Search。
5. Hugging Face
Hugging Face是一个开源的 AI 工具生态系统,你可以用来处理数据科学任务。
Hugging Face 的Spaces拥有用于开源文本生成、聊天机器人、语音转文本、图像生成的稳定扩散、图像转文本、视觉问答和 ChatGPT 检测工具的 AI 工具。
图片来源于Spaces。
这是一个为开源社区构建的平台,具有数据共享、模型共享、部署网络应用、模型推断和 AutoML 等功能。
这是我工作生活的一部分,我使用 transformer Python 包来处理数据和模型加载、微调和保存模型。我甚至用它来部署机器学习演示和 API。
结论
信不信由你,我提到的所有工具将在未来几个月内在专业人士中变得普遍。这些工具将帮助数据专业人士编写更好的代码,提出更好的解决方案,并撰写更好的文档或报告。
ChatGPT 和 GPT-4 是学习新技能、概念或算法的优秀工具。它们将节省你的时间和精力。而且,不,人工智能并不会取代我们。这些工具将帮助我们成为更优秀的数据专业人士。
在这篇博客中,我们回顾了五个对数据科学至关重要的 AI 工具,这些工具可以帮助你进行编码、调试、项目规划、学习新技能、研究和报告。
并非所有工具都是闭源的,Hugging Face 提供了上述工具的开源替代方案。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为面临心理健康困扰的学生开发 AI 产品。
更多相关话题
2024 年每个数据科学家都需要的 5 项关键技能
原文:
www.kdnuggets.com/5-essential-skills-every-data-scientist-needs-in-2024

图片来源:安娜·内克拉舍维奇
随着近年来数据技术的发展,我们看到企业在数据科学方面的实施激增。许多公司现在尝试招募最优秀的人才来参与他们的数据项目,以获得竞争优势。其中一种人才就是数据科学家。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
数据科学家已经证明自己能够为公司提供巨大的价值。然而,是什么使数据科学家的技能与其他技能不同呢?这个问题不容易回答,因为数据科学家是一个大范围的职业,工作职责和所需技能因公司而异。尽管如此,如果数据科学家想要从其他人中脱颖而出,仍有一些必需的技能。
这篇文章将讨论 2024 年数据科学家需要的五项关键技能。我不会讨论编程语言或机器学习,因为它们总是必要的技能。我也不会讨论生成式 AI 技能,因为这些是当前的趋势技能,但数据科学的范畴远不止于此。我只会讨论对 2024 年局势至关重要的新兴技能。
这些技能有哪些呢?让我们深入了解一下。
1. 云计算
云计算是一种基于互联网的服务(“云”),可能包括服务器、分析软件、网络、安全等。它旨在根据用户的需求进行扩展,并根据要求提供资源。
在当前的数据科学趋势下,许多公司已经开始实施云计算以扩展业务或降低基础设施成本。从小型初创公司到大型企业,云计算的使用已变得非常明显。因此,你会发现当前的数据科学职位发布要求具备云计算经验。
虽然有许多云计算服务,但你不需要学习所有内容,因为精通一个平台意味着可以更轻松地导航到其他平台。如果你在决定最初学习哪个时感到困难,可以从一个更大的平台开始,例如 AWS、GCP 或 Azure。
你可以通过 Aryan Garg 的初学者云计算指南 了解更多关于云计算的内容。
2. MLOps
机器学习操作(MLOps)是一系列用于将 ML 模型部署到生产环境中的技术和工具。MLOps 旨在通过简化 ML 模型在生产中的部署,避免机器学习应用中的技术债务,同时在 CI/CD 中实施最佳实践,持续监控机器学习模型,从而提高模型质量和性能。
MLOps 已经成为数据科学家最受追捧的技能之一,你可以在招聘广告中看到 MLOps 需求的激增。以前,MLOps 的工作可以委派给机器学习工程师。然而,对数据科学家理解 MLOps 的要求比以往任何时候都要高。这是因为数据科学家必须确保他们的机器学习模型准备好与生产环境集成,而只有模型创建者最了解这一点。
因此,如果你想提升你的数据科学职业生涯,学习 MLOps 在 2024 年是有益的。要了解更多关于 MLOps 的信息,请参考 KDnuggets 的第一期技术简报,其中讨论了关于 MLOps 的所有内容。
3. 大数据技术
大数据可以用三个 V 来描述,即 体量(Volume),指的是生成的数据的庞大数量;速度(Velocity),解释了数据产生和处理的速度;以及 多样性(Variety),指的是各种数据类型(从结构化到非结构化)。
大数据技术在许多公司中变得重要,因为许多洞察和产品依赖于他们如何处理他们拥有的大数据。拥有大数据是一回事,但只有通过处理它,公司才能从中获得价值。这就是为什么许多公司现在尝试招聘具备大数据技术技能的数据科学家。
当我们谈论大数据技术时,其中包含了许多技术。然而,它可以被归类为四种类型:数据存储、数据挖掘、数据分析和数据可视化。
以下是一些招聘广告中常列为必备的流行工具:
-Apache Hadoop
-Apache Spark
-MongoDB
-Tableau
-Rapidminer
你不需要掌握所有可用的工具,但了解其中一些工具无疑会让你的职业生涯更上一层楼。要了解更多关于大数据技术的信息,这里有一篇名为 与大数据合作:Nate Rosidi 的工具和技术 的介绍性文章,可以启动你的大数据之旅。
4. 领域专业知识
数据科学家需要技术技能和强大的领域专业知识才能推动他们的职业发展。初级数据科学家可能会想要建立机器学习模型以达到最高的技术指标,但高级数据科学家明白,我们的模型应当优先带来商业价值。
领域专业知识意味着我们理解我们所从事行业的业务。通过理解业务,我们可以更好地与业务用户对齐,为模型选择更好的指标,并以影响业务的方式框定项目。在 2024 年,随着企业开始理解数据科学如何带来重大价值,这一点尤其变得重要。
获得领域专业知识的问题在于,只有在我们已经在该行业作为数据科学家工作时,才能有效地学习。因此,如果我们不在想要的行业工作,该如何获得这项技能呢?有几种方法,包括:
-
参加相关行业的在线课程和认证
-
积极进行社交媒体网络
-
贡献开源项目
-
从事与行业相关的副项目
-
寻找导师
-
实习
这些是获取领域专业知识的建议方法,但你可以更具创造性地寻找经验。Vaishali Lambe 的文章 《领域知识是数据职业的障碍吗?》 也可以帮助你获得领域专业知识。
5. 伦理和数据隐私
有些人可能将数据视为数据库中的数字或文字,而不关注这些数据所描述的个人。然而,这些数据中有很多是私人信息,如果处理不当,可能会对用户和业务造成伤害。随着数据收集和处理变得更加容易,这一话题在现代时代变得更加重要。
数据科学中的伦理关注的是指导数据科学家工作的方法的道德原则。该领域涵盖了我们数据科学项目对个人和社会的潜在影响,这应当遵循我们能做出的最佳道德决定。该话题通常涉及偏见、公平性、可解释性和同意。
另一方面,数据隐私是一个关注我们如何合法地收集、处理、管理和共享数据的领域。它旨在保护个人信息,并防止滥用。每个领域可能有不同的数据隐私框架;例如,欧洲的《通用数据保护条例》(GDPR)通常仅适用于欧洲的个人数据。
伦理和数据隐私知识已成为数据科学家的基本技能,因为违反这些知识的后果非常严重。Nisha Arya 关于 伦理 和 数据隐私 的文章可能会成为你进一步理解这些主题的起点。
结论
本文讨论了每个数据科学家在 2024 年需要的五项关键技能。这些技能包括:
-
云计算
-
MLOps
-
大数据技术
-
领域专业知识
-
伦理与数据隐私
希望这对你有帮助!分享你对这里列出的技能的看法,并在下方添加你的评论。
Cornellius Yudha Wijaya是一位数据科学助理经理和数据撰稿人。在全职工作于印尼安联保险期间,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 涉及各种人工智能和机器学习话题。
更多相关话题
5 个绝佳的实际机器学习资源
原文:
www.kdnuggets.com/2018/02/5-fantastic-practical-machine-learning-resources.html
评论
想要开始学习机器学习吗?
由于许多好的理由,大部分高质量的机器学习教育资源往往非常注重理论,特别是在开始阶段。然而,似乎有越来越多的趋势从一开始就进入实践,并在资源进展过程中混合实践和理论。本文介绍了 5 个这样的资源。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
这些资源涵盖了从基础知识到从零开始编码算法以及使用特定深度学习框架的内容,范围相当广泛。它们都是免费的,所以快去阅读、观看和编码吧。
1. 初学者机器学习教程
由 Kaggler Kaan Can 提供的第一个资源从基础开始。
在这个教程中,我不会教你机器学习,而是讲解如何自己学习东西。
这个教程直接切入重点,快速实现 Python 库中的机器学习算法。它还涵盖了一些使用 Pandas 的数据清洗和处理,以及一些库的数据可视化,然后再进行建模。
 2.
2. 这是 Sebastian Raschka 和 Vahid Mirjalili 的精彩书籍“Python 机器学习(第 2 版)”的代码库。
不过请注意:
请注意,这些仅仅是配合书籍的代码示例,为了方便你,我上传了这些示例;请留意,没有公式和描述性文字,这些笔记本可能没什么用。
尽管如此,当这段代码与本书的第一版中的类似材料配合使用时,仍然是一套有用的资源。
我有没有提到这是我绝对最喜欢的实用机器学习书籍?因为确实是。

3. 从头开始的机器学习
从使用现有库转向实现机器学习模型,这个 Github 仓库包含了一些从头开始实现的机器学习算法的 Python 实现(因此得名)。虽然不是工业级别,且缺乏像 Scikit-learn 这样经过打磨的库的连贯性、优化和便利性,但这些实现易于跟随,旨在作为实现自己算法或更好理解它们功能的学习材料。
从头开始实现一些基础的机器学习模型和算法的 Python 实现。
这个项目的目的不是为了生成尽可能优化和计算效率高的算法,而是以透明和易于理解的方式呈现它们的内部工作。

4. 深度学习 - 直截了当
“一本关于深度学习的互动书籍。非常简单,所以是 MXNet。哇。”
这本在线书籍做了两件事:一是介绍机器学习基础和深度学习理论,二是通过大量的代码让读者实现这些思想。具体来说,这本书的代码是用 Python 编写的,并使用了 MXNet 库及其高级 Gluon API。
这个仓库包含一系列增量笔记本,旨在教授深度学习、Apache MXNet(孵化中)和 gluon 接口。我们的目标是利用 Jupyter 笔记本的优势,将文本、图形、公式和代码汇集在一个地方。如果我们成功了,结果将是一个同时作为书籍、课程材料、现场教程的道具以及一个可以在我们许可下“借鉴”有用代码的资源。
你也可以感到一些安慰,因为它是由一些著名的机器学习人士编写的。快去看看吧。
5. fast.ai 实用深度学习编程者教程,第一部分(2018 版)
fast.ai 最初大约在一年半前发布了这门实用深度学习 MOOC,现已重新发布。最显著的变化是这次 MOOC 使用了 PyTorch 和他们自己开发的 fast.ai 高级深度学习框架。
了解如何构建最先进的模型,无需研究生级别的数学——但也不会降低任何难度。哦,还有一件事……完全免费!而且有一个由成千上万的其他学习者组成的社区,随时准备帮助你完成学习之旅——如果你需要任何帮助,或者只是想和其他深度学习学习者聊聊,直接访问 forums.fast.ai。
相关:
-
Andrew Ng 的深度学习专精 - 21 个学习心得
-
Andrew Ng 的计算机视觉 - 11 个学习心得
-
15 分钟指南:选择有效的机器学习和数据科学课程
了解更多相关话题
5 个极好的实际自然语言处理资源
原文:
www.kdnuggets.com/2018/02/5-fantastic-practical-natural-language-processing-resources.html
评论
你对一些实际的自然语言处理资源感兴趣吗?
在线有很多 NLP 资源,尤其是那些依赖于深度学习的方法,筛选出优质资源可能是一项艰巨的任务。这里有一些知名的、顶级的理论性资源,尤其是斯坦福和牛津的深度学习课程:
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
但如果你已经完成了这些,已经建立了 NLP 基础,想要转向一些实际资源,或者对其他方法感兴趣(这些方法可能不依赖于神经网络),这篇文章(希望)会对你有帮助。
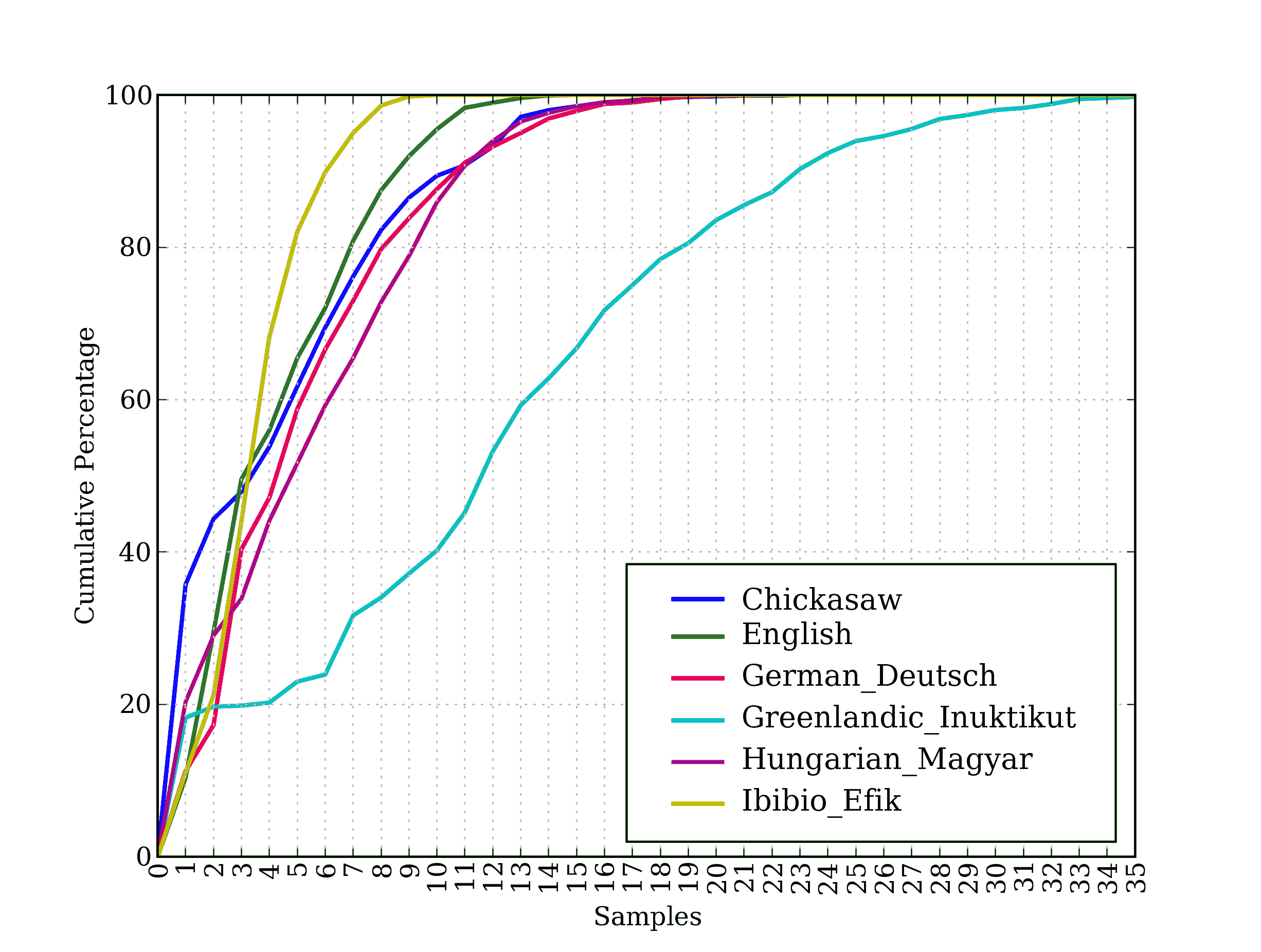
1. 用 Python 进行自然语言处理 – 使用自然语言工具包分析文本
这是最基础的自然语言处理书籍,至少从实用性和 Python 生态系统的双重视角来看。
这本书提供了对 NLP 领域的高度可读的介绍。它可以用于个人学习,也可以作为自然语言处理或计算语言学课程的教材,或作为人工智能、文本挖掘或语料库语言学课程的补充材料。
正如标题所示,这本书通过使用自然语言工具包(NLTK)来处理 NLP,你可能已经听说过,或者需要立即开始学习。
NLTK 包括大量的软件、数据和文档,所有这些都可以从
nltk.org/免费下载。我们为 Windows、Macintosh 和 Unix 平台提供了分发版本。我们强烈建议你下载 Python 和 NLTK,尝试其中的示例和练习。
这本书的最佳部分在于直接切入主题;没有废话,只有大量的代码和概念。
这是与 Jon Krohn 的深度学习 NLP 视频系列配套的 Jupyter 笔记本库。这些笔记本直接从他的视频演示中提取,因此内容几乎没有遗漏。小贴士:如果你有兴趣观看他的视频——这些视频通过 O'Reilly 的 Safari 平台提供——可以注册免费的 10 天试用,并在到期前观看几小时的视频。
这是 Jon 在这些笔记本和配套视频中覆盖内容的概述:
如果你想学习如何:
- 为机器学习应用预处理自然语言数据;
- 将自然语言转换为数值表示(使用 word2vec);
- 使用训练好的深度学习模型进行预测;
- 使用 Keras(高层次的 TensorFlow API)应用高级 NLP 方法;或者
- 通过调整超参数来提高深度学习模型的性能。
笔记本、视频以及你自己环境的结合,是打发漫长下午的好方法。
这是另一套很棒的笔记本教程,风格上类似于上面的 Krohn。
Insight AI 的 Emmanuel Ameisen 拆解了完成各项任务所需的步骤,但他的总结文章真正出色地将课程内容结合起来,并提供了一些很好的可视化效果。
阅读本文后,你将知道如何:
- 收集、准备和检查数据
- 从构建简单模型开始,如有必要过渡到深度学习
- 解释和理解你的模型,确保你实际上在捕获信息而不是噪声
我们编写了这篇文章作为逐步指南;它也可以作为非常有效的标准方法的高级概述
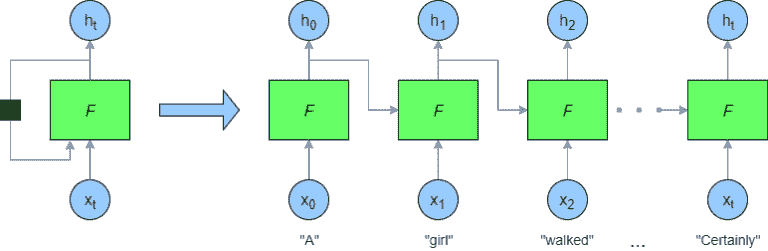
4. Keras LSTM 教程 – 如何轻松构建强大的深度学习语言模型
这个教程比之前的资源更为专注,因为它涉及在 Keras 中实现 LSTM 用于语言建模。就是这样。但它详细地进行了说明,包括解释、代码和视觉展示,并且传达了重点。与其他资源相比,它所需的时间更少,你可以在几个小时内完成从头到尾的学习,包括自己复现代码。
在这个教程中,我将重点介绍如何在 Keras 中创建 LSTM 网络,简要回顾或概述 LSTM 的工作原理。在这个 Keras LSTM 教程中,我们将利用一个名为 PTB 语料库的大型文本数据集来实现一个序列到序列的文本预测模型。
5. 结合 LSTM-CNN 模型的 Twitter 情感分析
我故意寻找了一个新的情感分析资源来包含在其中,原因是:人们向我询问优质情感分析资源的请求比其他任何东西都要多。
这个较短的教程帖子 -- 这是一个论文的概述,包含代码在此 -- 使用了结合 LSTM/CNN 的方法来分析情感。这个项目展示了不同的架构,并报告了不同的性能。
我们的 CNN-LSTM 模型的准确率比 CNN 模型高出 3%,但比 LSTM 模型低 3.2%。与此同时,我们的 LSTM-CNN 模型比 CNN 模型好 8.5%,比 LSTM 模型好 2.7%。
我不能独立认可该项目的结果;然而,创新的情感分析方法(以及它作为情感分析资源的事实)以及将不同神经网络架构混合在一起,是我将其包含在此列表中的原因,尽管它的长度较短。
相关内容:
-
5 个免费的深度学习自然语言处理入门资源
-
自然语言处理关键术语解释
-
处理文本数据科学任务的框架
更多相关话题
我们最喜欢的 5 个免费可视化工具
原文:
www.kdnuggets.com/2018/07/5-favorite-open-source-visualization-tools.html
评论
由 Richard Vermillion,CEO Fulcrum Analytics
现在越来越明显的是,对于那些希望继续成长的企业而言,数据的收集和应用比以往任何时候都更为重要。缺点?随着我们不断发现数据的益处,个人编制、展示和实施发现的难度也会增加。幸运的是,有许多免费的数据可视化工具可以将你独特的空间和表格数据,通过先进的图表和图形呈现给你。
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
那么,哪些工具值得花时间探索和/或可能采纳呢?以下是我们整理的 5 个最喜欢的免费数据可视化工具,它们以必要的图示方法处理复杂数据。
R Shiny
R Shiny 是一个开源包,它提供了构建数据可视化、交互式图表和应用程序的网络框架,使用 R 编写。这个工具可以帮助你将分析结果转化为简洁的交互式网页视觉效果,无需深入了解 HTML、CSS 或 JavaScript。就像电子表格一样,这种反应式编程模型允许轻松操作数据,而不是等待整个页面重新加载……我们已经看到在零售行业中,那些不断更新数据并寻找可以跟上每分钟变化的平台的人取得了成功。
Tableau Public
Tableau Public 是一款流行的数据可视化工具,能够显示图表、图形、地图等,并且完全免费。用户可以使用高达 10 GB 的存储空间和拖放界面,实时查看数据更新,同时与团队中的其他成员协作。Tableau 的“公共”部分意味着你只能将数据保存到公共资料中,其他人可以访问你的数据,但如果你不是一个隐私问题优先的大型公开公司,Tableau Public 对于商业分析师和管理者来说有诸多优势。最新版本针对移动设备进行了优化,可以连接到除了 Excel 之外的多种数据源,并可以直接链接到 Google Sheets。
Datawrapper
Datawrapper 是一个出色的开源工具,能够完全可视化数据并嵌入实时和互动的图表。只需上传一个 CSV 文件,在线工具即可构建定制化的视觉效果,如条形图和折线图。Datawrapper 非常适合小型企业或演示使用,因为每个图表允许的查看次数仅为 10,000 次,但对于拥有大量客户的大型企业来说可能不太理想。然而,大多数人认为,易于使用的界面和能够快速以直观的方式展示统计数据是非常有帮助的。
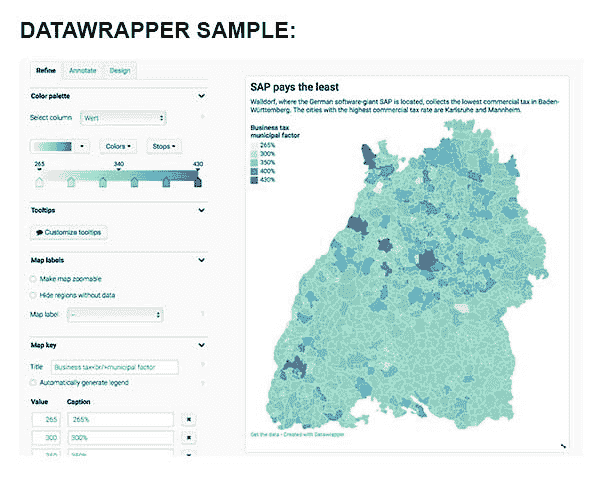
Pivot
Pivot 是一个直观的用户界面,旨在利用备受欢迎的拖放界面进行事件数据的探索性分析。Pivot 的一个特点是它围绕两个操作:过滤(Filter)和拆分(Split)展开。过滤器(Filter)缩小数据视图,相当于 SQL 中的“WHERE”子句,而拆分(Split)非常类似于 SQL 的“GROUP BY”函数。然而,拆分(Split)允许数据跨多个维度进行切割——我们在杂货价格/促销分析和优化中取得了很大的成功。
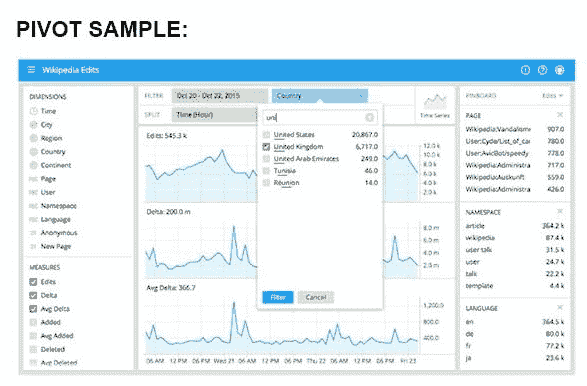
D3
D3,代表数据驱动文档,是一个 JavaScript 库,用于将任意数据绑定到文档对象模型(DOM),然后对文档应用数据驱动的转换。尽管 D3 可能更吸引程序员,因为该工具涉及编写代码,但 D3 能够在网页中构建一系列真正吸引人的图表、地图、图示等。如果你愿意付出一些额外的努力,视觉效果绝对值得。
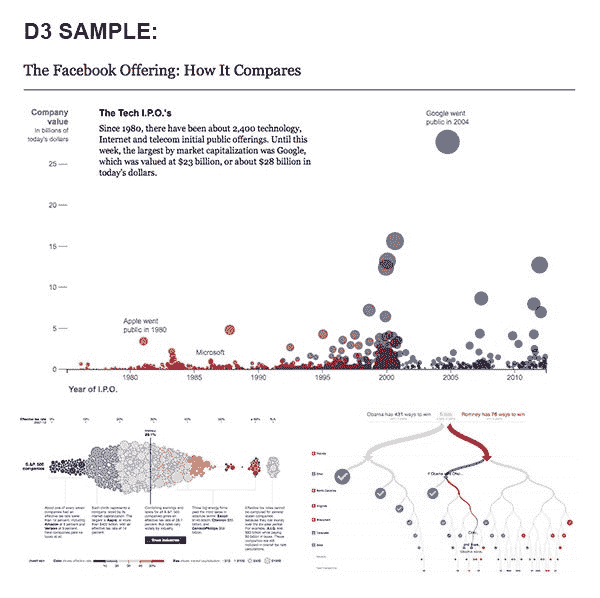
不论行业如何,这些工具都是理解不断涌入的宝贵数据的关键。这些工具易于使用,并且能够在不花费一分钱的情况下可视化模式或强调趋势。
对于这些工具如何应用于你的业务感到好奇?点击 这里 了解我们如何帮助你理解数据。
图片来源
| 来源 | 链接 |
|---|---|
| 来自 R Studio 的 Shiny | https://shiny.rstudio.com/gallery/retirement-simulation.html |
| 仪表板布局和设计,Tableau Public | https://public.tableau.com/en-us/s/blog/2013/10/dashboard-layout-and-design |
| 创建地图演示,Datawrapper | https://www.datawrapper.de/ |
| Imply Pivot | https://github.com/geo-opensource/pivot |
| Facebook 发行情况:与之比较,《纽约时报》 | https://archive.nytimes.com/www.nytimes.com/interactive/2012/05/17/business/dealbook/how-the-facebook-offering-compares.html |
| 美国公司税率差异,《纽约时报》 | https://archive.nytimes.com/www.nytimes.com/interactive/2013/05/25/sunday-review/corporate-taxes.html |
| 通往白宫的 512 条路径,《纽约时报》 | http://archive.nytimes.com/www.nytimes.com/interactive/2012/11/02/us/politics/paths-to-the-white-house.html |
简历: 理查德·弗梅里昂 自 2011 年起担任Fulcrum Analytics的首席执行官。Fulcrum 正在建立一个世界级的数据科学和数据工程组织,解决全球顶级公司在零售、保险、投资、零售银行和医疗保健领域面临的最困难的问题。
相关:
更多相关话题
最新 Scikit-learn 发布版本中的 5 个重要新特性
原文:
www.kdnuggets.com/2019/12/5-features-scikit-learn-release-highlights.html
评论
Python 的主要机器学习库的最新版本包含了许多新特性和错误修复。您可以在官方的 Scikit-learn 0.22 发布亮点 中找到这些更改的完整说明,并可以在 变更日志 中查看详细内容。
更新您的安装通过 pip 完成:
pip install --upgrade scikit-learn
或 conda:
conda install scikit-learn
以下是 Scikit-learn 最新发布版本中值得关注的 5 个新特性。
1. 新的绘图 API
现在提供了新的绘图 API,无需任何重新计算即可使用。支持的绘图包括局部依赖图、混淆矩阵和 ROC 曲线等。以下是 API 的演示,使用了来自 Scikit-learn 用户指南的 示例:
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import plot_roc_curve
from sklearn.datasets import load_wine
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
svc = SVC(random_state=42)
svc.fit(X_train, y_train)
svc_disp = plot_roc_curve(svc, X_test, y_test)
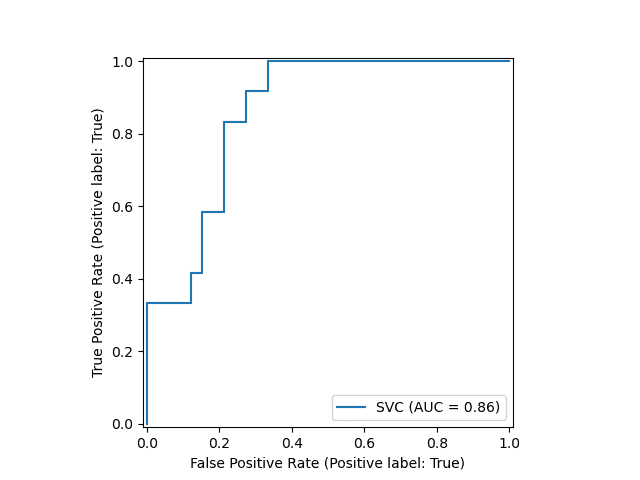
请注意,绘图是通过代码的最后一行完成的。
2. 堆叠泛化
堆叠估计器以减少偏差的集成学习技术现已加入 Scikit-learn。StackingClassifier 和 StackingRegressor 是实现估计器堆叠的模块,final_estimator 使用这些堆叠的估计器预测作为输入。参见 用户指南 中的示例,使用下面定义的回归估计器作为 estimators,并配有一个梯度提升回归器最终估计器:
from sklearn.linear_model import RidgeCV, LassoCV
from sklearn.svm import SVR
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.ensemble import StackingRegressor
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
estimators = [('ridge', RidgeCV()),
('lasso', LassoCV(random_state=42)),
('svr', SVR(C=1, gamma=1e-6))]
reg = StackingRegressor(
estimators=estimators,
final_estimator=GradientBoostingRegressor(random_state=42))
X, y = load_boston(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
reg.fit(X_train, y_train)
StackingRegressor(...)
3. 任何估计器的特征重要性
基于置换的特征重要性 现在适用于任何拟合的 Scikit-learn 估计器。关于如何计算特征的置换重要性的描述,请参见 用户指南:
特征的置换重要性计算方法如下。首先,在由 X 定义的(可能不同的)数据集上评估由评分定义的基准指标。接下来,将验证集中的特征列进行置换,然后重新评估指标。置换重要性定义为基准指标与置换特征列后的指标之间的差异。
一个完整的示例来自发布说明:
from sklearn.ensemble import RandomForestClassifier
from sklearn.inspection import permutation_importance
X, y = make_classification(random_state=0, n_features=5, n_informative=3)
rf = RandomForestClassifier(random_state=0).fit(X, y)
result = permutation_importance(rf, X, y, n_repeats=10, random_state=0, n_jobs=-1)
fig, ax = plt.subplots()
sorted_idx = result.importances_mean.argsort()
ax.boxplot(result.importances[sorted_idx].T, vert=False, labels=range(X.shape[1]))
ax.set_title("Permutation Importance of each feature")
ax.set_ylabel("Features")
fig.tight_layout()
plt.show()
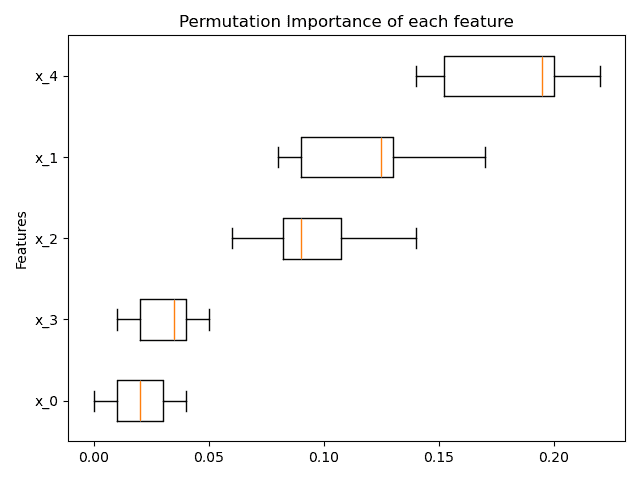
4. 梯度提升缺失值支持
现在梯度提升分类器和回归器都原生支持处理缺失值,从而不再需要手动填补。以下是如何做出缺失值决策的:
在训练过程中,树生长器会在每个分裂点判断缺失值样本是应该分到左子树还是右子树,这取决于潜在的增益。在预测时,缺失值样本会被相应地分配到左子树或右子树。如果在训练期间某个特征没有遇到缺失值,那么缺失值样本将被映射到具有最多样本的子树。
以下示例演示了:
from sklearn.experimental import enable_hist_gradient_boosting # noqa
from sklearn.ensemble import HistGradientBoostingClassifier
import numpy as np
X = np.array([0, 1, 2, np.nan]).reshape(-1, 1)
y = [0, 0, 1, 1]
gbdt = HistGradientBoostingClassifier(min_samples_leaf=1).fit(X, y)
print(gbdt.predict(X))
[0 0 1 1]
5. 基于 KNN 的缺失值填补
尽管梯度提升现在原生支持缺失值填补,但可以使用 K 近邻填补器对任何数据集进行显式填补。每个缺失值都根据训练集中的 n 个最近邻的均值进行填补,只要那些样本在某些特征上不是缺失的邻近即可。默认的距离度量是欧氏距离。
一个示例:
import numpy as np
from sklearn.impute import KNNImputer
X = [[1, 2, np.nan], [3, 4, 3], [np.nan, 6, 5], [8, 8, 7]]
imputer = KNNImputer(n_neighbors=2)
print(imputer.fit_transform(X))
[[1\. 2\. 4\. ]
[3\. 4\. 3\. ]
[5.5 6\. 5\. ]
[8\. 8\. 7\. ]]
最新发布的 Scikit-learn 中还有更多特性未在此覆盖。你可以查看完整发布亮点和变更日志以获取更多信息。
祝机器学习愉快!
相关:
-
训练 sklearn 快速 100 倍
-
如何扩展 Scikit-learn 并为你的机器学习工作流带来理智
-
Scikit-Learn & 更多用于机器学习的合成数据集生成
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关话题
5 门免费的高级 Python 编程课程
原文:
www.kdnuggets.com/5-free-advanced-python-programming-courses
 作者提供的图片
作者提供的图片
我们的前 3 门课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
学习一种语言或找到好的 Python 入门课程相对容易,但当涉及到掌握高级概念时,找到免费的优质资源可能会非常具有挑战性。大多数出色的高级课程内容通常限于付费选项。然而,不用担心!今天,我会为你提供帮助。我将分享一份 5 门高级 Python 课程的列表,你可以在不花一分钱的情况下提升技能。所以,毫不拖延,让我们深入了解吧!
1. 密歇根大学的 Python 3 编程专业
这个在 Coursera 上提供的专业在 Python 社区中非常有名,拥有高达4.7 评分和超过16,000 条评论。它包括 5 门课程,涵盖了广泛的高级主题。由于你已经熟悉 Python 的基础知识,可以跳过入门课程,直接探索其他课程。以下是简要概述:
课程 2: Python 函数、文件和字典:深入学习字典数据结构、用户定义函数、排序技术等。
课程 3: 使用 Python 进行数据收集和处理:掌握 Python 列表推导,交互 REST API,并高效处理数据。
课程 4: Python 类和继承:学习类、实例、继承和高级类设计原则。
课程 5: Python 项目:pillow、tesseract 和 OpenCV:通过使用第三方库,获得图像处理、文本检测和人脸识别的实际经验。
课程链接: 密歇根大学的 Python 3 编程专业
注意: 你可以免费旁听这个专业课程,享受内容。然而,除非你支付课程费用,否则你不会收到完成证书。
2. Patrick Loeber 的高级 Python
Patrick Loeber,一位软件工程师和 AssemblyAI 的开发者倡导者,通过他的 YouTube 频道提供高级 Python 课程,拥有超过 263K 订阅者。用于讲解的代码可以在他的网站上找到。他的课程涵盖了各种主题,包括:
-
列表、元组、字典、字符串、集合和集合
-
使用 Lambda 函数和 Itertools 进行函数式编程
-
异常处理、日志记录和 JSON 操作
-
多线程、进程处理和并发
-
星号 (*) 运算符
-
浅拷贝与深拷贝
-
上下文管理器
-
还有更多内容!
课程链接: Patrick Loeber 的高级 Python
3. Codecademy 的高级 Python 3 课程
Codecademy 是一个受欢迎的在线平台,提供众多免费课程。这个特定课程需要 6 小时 完成,将把你的 Python 编程技能提升到一个新的水平。你将学习新的范式,使你能够编写干净、有效的代码,让你成为一名真正的高级 Python 3 程序员。这个课程有趣的地方在于它包括了迷你项目,加深了你对所讨论概念的理解。
这是课程内容:
-
学习通过日志记录调试和跟踪软件,包括一个 ATM 项目
-
探索使用函数式编程创建高效程序,重点关注高阶函数
-
使用 SQLite 3 分析酒店数据库,以深入了解 Python 的数据库功能
-
通过并发编程技术更高效地实现代码
-
发现如何使用 Flask 打包和部署 Python 脚本,以便有效地分发应用程序
如果你觉得高级课程的内容有点挑战,可以转到他们的 学习中级 Python 3 课程。该课程涵盖了函数、面向对象编程、单元测试、迭代器和生成器、专门的集合以及 Python 中的资源管理等主题。
课程链接: Codecademy 的高级 Python 3 课程
4. Python 编程 MOOC 2023
这个课程材料页面提供了赫尔辛基大学 计算机科学系 的编程导论课程 (BSCS1001, 5 学分) 和高级编程课程 (BSCS1002, 5 学分)。如果你已经熟悉 Python 基础,可以将课程的第一部分作为复习,或完全跳过。然而,真正的宝藏在于第二部分,它专注于高级 Python 编程概念。你会找到录音、幻灯片和大量练习来提高你的技能。
这门课程涵盖了以下内容:
-
对象和方法、封装、方法的作用域和类属性
-
类层次结构、访问修饰符、面向对象编程技术以及开发更大应用程序
-
列表推导和递归
-
函数作为参数、生成器、函数式编程和正则表达式
-
PyGame - 动画、事件及不同技术
-
从零开始进行 Python 游戏项目
课程链接: Python 编程 MOOC 2023
5. 用 Python 进行科学计算(Beta)- FreeCodeCamp
如果你更喜欢基于项目的学习,这门课程非常适合你。 用 Python 进行科学计算(Beta) 课程将使你掌握使用 Python 分析和处理数据的技能。你将学习数据结构、算法、面向对象编程等关键概念,以及如何使用各种工具进行复杂计算。
让我们来看看课程内容:
-
通过构建密码本学习字符串操作
-
通过实现 Luhn 算法学习如何处理数字和字符串
-
通过创建支出跟踪器学习 Lambda 函数
-
通过构建一个大小写转换程序学习 Python 列表推导
-
通过构建密码生成器程序学习正则表达式
-
通过构建最短路径算法学习算法设计
-
通过解决汉诺塔数学难题学习递归
-
通过构建归并排序算法学习数据结构
-
通过构建数独求解器学习类和对象
-
通过构建二叉搜索树学习树遍历
在这些指导项目之后,你将被要求从零开始完成一些项目,比如算术格式化器、时间计算器、预算应用程序、多边形面积计算器和概率计算器,以检验你的知识。
课程链接: 用 Python 进行科学计算(Beta)- FreeCodeCamp
总结
这些免费课程提供了提升 Python 技能的绝佳机会,而无需花费太多。但如果你渴望探索付费选项以获得更深入的学习,建议你查看以下资源:
-
Luciano Ramalho 的《流畅的 Python(第 2 版)》 - 教你如何让代码更简洁、更快、更易读
-
Fred Baptiste 在 Udemy 的课程 - 提升日常 Python 编程能力
-
Julien Danjou 的《严肃 Python》 - 涵盖部署、可扩展性、测试等内容
-
Harry Percival 和 Bob Gregory 的《Python 架构模式》 - 涵盖架构设计模式
这是一个额外赠品:你可以在作者的网站上免费访问《使用 Python 的架构模式》。点击这里享受这本书的内容。祝你学习愉快!
Kanwal Mehreen**** Kanwal 是一位机器学习工程师和技术作家,对数据科学及人工智能与医学的交汇点充满了深厚的热情。她合著了电子书《Maximizing Productivity with ChatGPT》。作为 2022 年 APAC 的 Google Generation Scholar,她倡导多样性和学术卓越。她还被认可为 Teradata Diversity in Tech Scholar、Mitacs Globalink Research Scholar 和 Harvard WeCode Scholar。Kanwal 是变革的热心支持者,她创立了 FEMCodes,旨在赋能女性在 STEM 领域的发展。
更多相关内容
2024 年 5 个免费的 AI 游乐场供你尝试
原文:
www.kdnuggets.com/5-free-ai-playgrounds-for-you-to-try-in-2024
作者提供的图片
你想尝试最新发布的大型语言模型(LLMs)吗?还是希望成为首批探索前沿开源模型并与同行讨论的人?对于 AI 爱好者来说,现在是一个激动人心的时刻,因为多个平台提供了对最先进模型的免费访问,让每个人都能试用并比较。所以,准备好深入 AI 游乐场的世界,探索这些改变世界的新发布的 AI 模型的潜力吧。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
在这篇博客中,我将分享 5 个用户友好、快速、互动的 AI 游乐场,它们提供自定义模型并且免费使用。有些平台甚至提供了对专有模型的免费访问。
1. HuggingChat
HuggingChat是我最喜欢的,即使我有 ChatGPT Pro。我每天使用 HuggingChat,因为它的用户界面、快速响应生成和在模型之间切换的能力都非常出色。
图片来源于 HuggingChat
Hugging Face 为其用户提供了最先进的开源模型,并逐步停用老旧且效率低的模型。因此,你可以放心地享受最佳的 AI 体验,包括代码调试、内容生成、学习新概念和解决问题。
2. Poe
Poe是我第二喜欢的平台,因为它拥有更广泛的大型语言模型库。它快速,用户界面互动且易于导航。Poe AI 游乐场的关键特点是让你尝试所有顶尖的开源和闭源模型。简而言之,你只需收藏 Poe,便可以获得全方位的 AI 体验。

图片来源于 Poe
Poe 还提供创建自定义 AI 聊天机器人的选项,或者你可以探索公共库中的成千上万的聊天机器人。这些聊天机器人通过系统提示、模型类型和知识来源进行定制。
3. Chat LMSys
Chat LMSys 以其聊天机器人排行榜而闻名,但它也可以作为聊天机器人和 AI 游乐场使用。它提供访问 40 个最先进的 AI 模型,包括开源和专有模型,你可以比较它们的结果。
图片来自 Chat LMSys
有三个缺点使我不愿意每天使用它:
-
用户界面不好。
-
网站加载时间。
-
直接聊天中模型的可用性不足。
你必须参与区域战斗才能访问准备模型。
4. AI SDK
AI SDK 是另一个简单且快速的 AI 游乐场。它还提供访问顶级开源和闭源模型的功能。要访问像 GPT-4-turbo 这样的最先进模型,你可能需要订阅 Vercel Pro。但在我看来,这里提供的一些免费模型在其他平台上并不免费。因此,你可以将它与 Poe 或 Chat LMSys 组合使用。
图片来自 Vercel AI 的 AI SDK
AI SDK 无需登录即可使用,你可以同时比较多个模型。它快速,并提供额外选项来修改和改善模型响应。此外,你可以同步提示或为每个模型使用不同的提示。
5. 工作者 AI
工作者 AI 最近才被我了解到。它快速且简单,并提供访问开源 AI 模型的功能。这个平台的特别之处在于,你可以添加多个输入(用户和助手)来创建一个历史或上下文,以便 LLM 理解和适当地回应。除此之外,它加载速度很快,无需任何注册。
图片来自工作者 AI
我把它放在底部,因为它简单、缺乏核心功能、没有所有顶级 AI 模型,最重要的是,你无法调整模型参数来改善响应。
结论
如果你想访问所有的 AI 模型并亲身体验魔法,我建议你查看 Hugging Face Spaces 页面。每天都有新的和令人兴奋的内容可以尝试,在社交媒体上给人留下深刻印象。你可以找到免费的和开放的图像生成、语音生成、LLMs 和多模态模型。
在这篇博客中,我们了解了 5 个你在 2024 年应该使用的 AI 游乐场。它们将帮助你免费访问顶级的 LLMs;其中一些甚至无需注册。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一款 AI 产品,帮助那些与心理健康问题作斗争的学生。
更多相关话题
来自顶尖大学的 5 门免费人工智能课程
原文:
www.kdnuggets.com/5-free-artificial-intelligence-courses-from-top-universities

作者提供的图片
目前,构建 AI 助手和 AI 代理在开发者中非常受欢迎。无论你从事哪个领域——数据分析、机器学习、DevOps 等,你都可以通过 AI 改进工作流程。那么你从哪里开始呢?
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
好吧,你可以直接开始构建 AI 应用程序,并在过程中学习。但学习 AI 的基础知识同样重要。我们整理了一些免费的大学课程,帮助你学习 AI 基础。
注意: 你可以免费访问所有以下课程,包括 Coursera 和 edX 上提供的课程。你无需支付即可访问课程材料和学习。你只需支付费用才能获得 Coursera 和 edX 上的认证证书。
让我们来看看这些课程。
1. CS50 的 Python 人工智能导论 – 哈佛大学
CS50 的 Python 人工智能导论来自哈佛大学,是一门很好的入门课程,帮助你建立人工智能的算法基础。
为了跟上这门课程(以及接下来的其他课程),你应该对使用 Python 编程感到舒适。在这门课程中,你将探索搜索算法、机器学习、大型语言模型等。课程持续约 7 周,你可以在每个模块中进行项目练习。
这是本课程覆盖的主题概述:
-
图搜索算法
-
高级搜索
-
知识表示
-
逻辑推理
-
贝叶斯网络
-
马尔可夫模型
-
机器学习
-
神经网络
-
自然语言处理
2. 人工智能 – 麻省理工学院
人工智能(6.034)由麻省理工学院提供,是一门本科级别的 AI 课程,帮助你学习构建智能系统所需的基础知识。
重点关注以下内容:
-
知识表示
-
问题解决
-
AI 学习方法论
你可以在 MIT OpenCourseWare 上免费访问所有课程内容。本课程涵盖以下主题:
-
推理
-
搜索
-
约束
-
学习算法
-
深度神经网络
-
概率推理
链接: 人工智能
3. 人工智能:原则与技术 – 斯坦福大学
人工智能:原则与技术(CS221)来自斯坦福大学,是一门全面的课程,提供 AI 领域的概述。你将学习机器学习、搜索、游戏玩法等内容。
本课程覆盖的主题如下:
-
机器学习
-
搜索算法
-
马尔科夫决策过程
-
游戏玩法
-
因子图
-
贝叶斯网络
-
逻辑
-
深度学习
4. 医疗健康中的 AI 专业课程 – 斯坦福大学
医疗健康仍然是 AI 应用受益的重要领域之一。从高效的预测和诊断到使医疗更易获得,AI 应用——包括 AI 安全和 AI 伦理——可以极大地提供帮助。
如果你想学习医疗健康中的 AI 应用,查看斯坦福大学在 Coursera 上提供的医疗健康中的 AI专业课程。这门专业课程包括以下课程和一个综合项目:
-
医疗健康简介
-
临床数据简介
-
医疗健康的机器学习基础
-
医疗 AI 应用评估
链接: 医疗健康中的 AI 专业课程
5. 生成式 AI 简介 – 杜克大学
生成式 AI 由于近期的进展和持续的研究变得非常流行。而构建有用的应用程序是开发人员当前最喜欢的事情。
生成式 AI 简介,由杜克大学在 Coursera 上提供,将向你介绍生成式 AI 的背景:与开源和闭源的大型语言模型、云 API 等合作。本课程的模块如下:
-
生成式 AI 简介
-
与模型交互
-
构建稳健的生成式 AI 系统
-
大型语言模型的应用
链接: 生成式 AI 简介
总结
希望你觉得这篇关于免费 AI 课程的总结有帮助。对于 Coursera 和 edX 等平台上的课程,你可以注册一个免费账户并审计课程,以免费访问课程内容。
如果你有兴趣学习机器学习基础,请阅读 5 个免费大学课程学习机器学习。
Bala Priya C**** 是来自印度的开发人员和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和咖啡!目前,她正致力于学习并通过编写教程、操作指南、观点文章等方式与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关内容
5 本免费书籍,帮助你学习数据科学的统计学
原文:
www.kdnuggets.com/2020/12/5-free-books-learn-statistics-data-science.html
评论
由Rebecca Vickery,数据科学家

照片由Daniel Schludi拍摄,来源于Unsplash
我们的三大课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业的快车道。
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你组织的 IT
统计学是数据科学家每天使用的基本技能。它是数学的一个分支,使我们能够收集、描述、解释、可视化数据并做出推断。数据科学家将利用它进行数据分析、实验设计和统计建模。
统计学对机器学习也至关重要。我们将使用统计学来理解数据,然后再训练模型。当我们对数据进行抽样以训练和测试模型时,我们需要运用统计技术以确保公平。在评估模型性能时,我们需要使用统计学来评估预测的变异性和准确性。
“如果统计学很无聊,那是因为你用错了数字。”,Edward Tufte
这些只是数据科学家使用统计的部分方式。因此,如果你在学习数据科学,发展对这些统计技术的良好理解是至关重要的。
这是书籍作为特别有用的学习工具的一个领域,因为对统计概念的详细解释对于你的理解至关重要。
这是我推荐的前五本免费书籍,适合学习数据科学的统计学。
实用统计学:数据科学家的必备工具
作者:Peter Bruce 和 Andrew Bruce

图片:amazon.co.uk
在这里免费阅读****.
主要覆盖的主题:
-
数据结构。
-
描述统计。
-
概率。
-
机器学习。
适合对象:完全初学者。
统计学是一个非常广泛的领域,只有其中一部分与数据科学相关。这本书非常好地只涵盖了与数据科学相关的领域。所以,如果你在寻找一本能快速让你具备足够的理解以便实践数据科学的书籍,这本书绝对是首选。
书中充满了很多实际的代码示例(用 R 语言编写),对任何使用的统计术语提供了非常清晰的解释,并且还链接到其他资源以供进一步阅读。
这本书总体上是一本很好的基础入门书籍,适合对该领域的绝对初学者。
Think Stats
作者:艾伦·B·道尼

涵盖的主要主题:
-
统计思维。
-
分布。
-
假设检验。
-
相关性。
适合人群:具备基础 Python 知识的初学者。
这本书的介绍说明了“这本书关于将知识转化为数据”,并且它通过实际的数据分析例子非常好地介绍了统计概念。
“这本书关于将知识转化为数据”
这是另一本只涵盖直接与数据科学相关的概念的书籍,并且包含了大量的代码示例,这次用 Python 编写。它主要面向程序员,依赖于使用这种技能来理解介绍的关键统计概念。因此,这本书非常适合那些已经至少具备基础 Python 知识的人。
《黑客的贝叶斯方法》
作者:卡梅隆·戴维森-皮隆

图片:amazon.com
涵盖的主要主题:
-
贝叶斯推断。
-
损失函数。
-
贝叶斯机器学习。
-
先验知识。
适合人群:具备 Python 基础知识的非统计学家。
贝叶斯推断是统计学的一个分支,处理理解不确定性。作为数据科学家,不确定性是你需要经常建模的内容。例如,如果你在构建机器学习模型,你需要能够理解你的模型所做预测的不确定性。
贝叶斯方法可能非常抽象且难以理解。这本书明确面向程序员(因此需要一些 Python 基础),是我找到的唯一一本以简单的方式解释这些概念的书籍,使非统计学家也能理解。书中包含了大量代码示例,GitHub 上的仓库也包含了大量笔记本。因此,这是一个极好的动手入门资料。
《通俗英语统计学》
作者:Timothy C. Urdan

图片:amazon.co.uk
涵盖的主要主题:
-
回归。
-
分布。
-
因子分析。
-
概率。
适合:任何编程经验水平的非统计学家。
本书涉及一般统计技术,而不仅仅是针对数据科学家或程序员的技术。然而,它以非常直接的风格编写,并以一种易于理解的方式涵盖了广泛和深入的统计概念。
本书最初是为学习非数学课程的学生编写的,这些课程需要统计学理解,如社会科学。因此,它涵盖了足够的理论以理解这些技术,但不假设已有的数学背景。因此,如果你是以非数学学位进入数据科学领域,这本书非常适合阅读。
《计算机时代的统计推断》
作者:Bradley Efron 和 Trevor Hastie

图片:amazon.co.uk
涵盖的主要主题:
-
贝叶斯和频率学派推断。
-
大规模假设检验。
-
机器学习。
-
深度学习。
适合:具有基本统计学和统计符号理解的人。不需要编程。
本书涵盖了大多数数据科学家今天使用的流行机器学习算法背后的理论。它还对贝叶斯和频率学派的统计推断方法进行了彻底的介绍。
本书的后半部分涉及机器学习算法,是我见过的关于这一主题的最佳资料之一。每个解释都很深入,并且使用了实际例子,如垃圾邮件数据的分类,使得相当复杂的概念更容易消化。这本书最适合那些已经掌握了数据分析基本统计知识,并对一些统计符号有所了解的人。
我在这篇文章中列出的书籍涵盖了足够的主题,适合完全的初学者学习数据科学所需的所有统计知识。它们都可以在网上免费阅读,但大多数也有可以购买的印刷版,如果你更喜欢阅读实体书。统计学是数据科学工具集的一个基本组成部分,通常需要深入阅读才能真正理解这些概念。这些书籍可以提供这种深入的理解。
欲了解更多数据科学阅读清单,请查看我下面的相关文章。
完全免费的 Python 学习阅读清单
学习机器学习时值得阅读的 10 本免费书籍
2020 年,如果你将 AI 应用于你的业务,值得阅读的六本书
感谢阅读!
如果你愿意加入我的每月通讯,请通过这个链接报名。期待成为你学习旅程的一部分!
简介:Rebecca Vickery 通过自学学习数据科学。Holiday Extras 数据科学家。alGo 联合创始人。
原文。经许可转载。
相关:
-
最佳免费数据科学电子书:2020 更新
-
每个人都应该阅读的前 5 本免费机器学习和深度学习电子书
-
机器学习的数学:免费电子书
更多相关话题
2023 年值得阅读的 5 本自然语言处理免费书籍
原文:
www.kdnuggets.com/2023/06/5-free-books-natural-language-processing-read-2023.html

图片由作者提供
在大型语言模型(LLMs)引起轰动之前,自然语言处理(NLP)正在发展,但进展较为隐秘。自从像 ChatGPT 这样的 LLMs 发布以来,它已经发生了革命性的变化。LLMs 已经被证明能够理解和生成类似人类的文本。像 ChatGPT、Google Bard 等模型在深度神经网络架构中训练了大量文本数据。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
那么这些模型到底是如何理解人类以及输出类似人类的回应的呢?这就是自然语言处理(NLP)。NLP 是人工智能的一个子领域,帮助模型处理、理解和输出人类语言。它们通常在诸如下一个词预测的任务上进行训练,这使它们能够建立上下文依赖关系,并生成相关的输出。NLP 领域拥有先进的应用,如聊天机器人、文本摘要等。
关于 LLMs 及其在文本生成中的偏见存在一些伦理担忧,这引发了对 NLP 及其在 LLM 应用中的使用的进一步研究。尽管这些担忧和挑战目前正在解决,但考虑到 LLMs 如 ChatGPT 对世界的影响——它们似乎将长期存在,理解 NLP 将变得至关重要。
如果你想深入了解 LLMs,你需要学习 NLP。在这篇文章中,我将介绍 5 本你在 2023 年需要阅读的免费书籍,以便更好地掌握 NLP。
1. 语音与语言处理
作者: Dan Jurafsky 和 James H. Martin
链接: 语音与语言处理
这本由两位大学教授编写的《语音与语言处理》书籍,为你提供了一个全面的 NLP 世界介绍。它分为三个部分:NLP 基础算法、NLP 应用和语言结构标注。第一部分对初学者至关重要,它提供了对 NLP 的基本理解,并通过示例进行详细讲解。你将遇到语义、语法等各种主题。
如果你对 NLP 领域感到陌生,或者想要转行进入这个领域,我真的相信这本书对个人学习非常有帮助。由于它是由教授编写的,实际的例子能帮助读者比纯理论的书籍更好地理解概念。
2. 统计自然语言处理基础
作者: 克里斯托弗·D·曼宁 和 辛里希·舒茨
链接: 统计自然语言处理基础
如果你是数据专业人士,或者在人工智能领域工作,你会知道统计在这个领域中的重要性。有些人认为你不需要对这个领域有很高的理解,然而我认为这很重要,因为它会让你的数据专业之旅更加顺利。
当你对 NLP 领域有了良好的基础后,你可能会认为下一步是学习算法。在此之前,你会想要了解更多语言的数学基础。这本书不仅从 NLP 的基础开始,还深入探讨了数学方面的内容,如概率空间、贝叶斯定理、方差等。
3. 模式识别与机器学习
作者: 克里斯托弗·M·毕晓普
链接: 模式识别与机器学习
了解模型性能的最佳方式是理解模型如何工作,它的思路、模式识别以及为什么会产生这样的输出。模式识别是根据一组标准通过特殊算法区分数据的过程。它使得学习成为可能,并且为改进留出了空间,这使得它对机器学习算法及其性能非常重要。
每章末尾都有一个练习,旨在更好地解释每个概念。作者将数学内容控制在最低限度,以帮助读者更好地理解,但需注意,理解模式识别和机器学习技术时,具备良好的微积分、线性代数和概率论基础将是有益的。
4. 自然语言处理中的神经网络方法
作者: 约阿夫·戈尔德堡
链接: NLP 中的神经网络方法
在探讨 NLP 的发展时,我们可以说神经网络发挥了重要作用。神经网络为 NLP 模型提供了更好的语言理解,使它们能够预测单词并将不同的话题分类,即使这些话题在学习阶段没有预见到。
这本书不会立刻深入探讨神经网络的细节。它从基础知识入手,如线性模型、感知机、前馈、神经网络训练等。作者采用了数学方法来解释这些基本元素,并结合实际例子。
5. 实用自然语言处理
作者: Sowmya Vajjala, Bodhisattwa Majumder, Anuj Gupta, 和 Harshit Surana
链接: 实用自然语言处理
所以你已经了解了语音和语言,涵盖了统计 NLP,然后研究了 NLP 中的模式识别和神经网络。最后你需要了解的是 NLP 的实际应用。
这本书介绍了 NLP 在现实世界中的应用、NLP 模型的流程以及更多关于文本数据和使用案例的信息,例如 ChatGPT 这样的聊天机器人。在这本书中,你将学习到 NLP 如何在零售、医疗保健、金融等各种领域中使用。通过不同的领域,你将能够了解每个领域的 NLP 流程,并能够自己找到使用方法。
总结
本文的目标和流程是为你提供 5 本我认为必不可少的免费书籍,这些书籍将有助于你的 NLP 职业或学习。虽然我以结构化的形式呈现,希望每本书能够相互衔接,提升你的学习水平。
如果你知道其他免费的 NLP 书籍,认为对他人有帮助,请在评论中分享!
Nisha Arya 是一名数据科学家、自由技术作家和 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程以及数据科学理论知识。她还希望探索人工智能如何/能如何提升人类寿命。她是一个热衷的学习者,寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
了解更多这个话题
5 本免费书籍帮助你掌握 Python

图片由作者提供
当你学习一种新的编程语言或技术栈时,你通常会被大量的资源——书籍、课程、教程等——所淹没。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
如果你是一个有经验的程序员在学习 Python,随需应变的学习以完成特定项目可能更有效。但如果你希望有一个完整的学习路径,你可能会更喜欢一个结构化的学习课程——加上项目——来熟悉语言。
在这里,我们介绍了五本 Python 书籍,帮助你掌握 Python 的各种功能并构建可维护的应用程序。无论你是初学者还是有经验的 Python 程序员,这些书籍将帮助你加深对语言的理解。
1. Python for Everybody: Exploring Data in Python 3
Python for Everybody 由 Dr. Charles Severance(Dr. Chuck)编写,提供了一种以代码为主的 Python 编程语言学习方法。如果你刚刚开始学习 Python,这是一本非常好的书籍。
从安装 Python 到网页抓取和处理常见数据格式,这本书涵盖了广泛的主题——以及练习题和解决方案。你还可以通过 Python for Everybody 讲座——在 freeCodeCamp YouTube 频道上免费提供——进行学习。
这本书涵盖的主题包括:
-
变量、表达式和语句
-
条件执行
-
函数
-
循环和迭代
-
处理字符串和文件
-
列表、元组和字典
-
正则表达式
-
网络编程
-
使用网络服务
-
面向对象编程 (OOP)
-
数据库
-
数据可视化
开始阅读: Python for Everybody (PY4E)
2. 使用 Python 自动化枯燥的任务
使用 Python 自动化枯燥的任务 由 Al Sweigart 编写,是另一个非常适合初学者的资源,可以学习基础到中级的 Python 概念。
你将学习基础知识,如内置数据结构、控制流和异常处理。此外,你将学习编写 Python 脚本以自动化任务,如搜索文件、从网络下载文件、处理 PDF 等。
这是本书涵盖的一些主题概述(除了基础知识):
-
使用正则表达式进行模式匹配
-
输入验证
-
从文件中读取和写入数据
-
调试
-
网络爬虫
-
在 Python 中处理电子表格、PDF、CSV 和 JSON
-
任务调度
-
图像处理
-
GUI 自动化
开始阅读: 用 Python 自动化无聊的事情
3. Python 3 模式、配方与习语
Python 3 模式、配方与习语是一本适合中级 Python 程序员的书籍,他们已经熟悉语言的特性并希望进一步提升。
这本书从 Python 函数和类的回顾开始,涵盖了以下内容:
-
实例的初始化和清理
-
Python 中的单元测试和测试驱动开发
-
装饰器
-
元编程
-
生成器、迭代器、itertools
-
Python 中的设计模式和模式重构
开始阅读: Python 3 模式、配方与习语
4. Python 中的清晰架构
当你超越简单的 Python 脚本,开始构建应用程序时,你需要理解清晰架构并构建生产就绪的应用程序。
《Python 中的清晰架构》由 Leonardo Giordani 编写,是一本免费的书籍,内容包括:
-
清晰架构基础
-
清晰架构的组件
-
与外部系统集成(Postgres 和 MongoDB)
-
运行生产就绪的系统
开始阅读:《Python 中的清晰架构》
5. Python 数据科学手册
你已经对核心 Python 和内置模块的功能有所了解。你也知道编写干净 Python 代码的最佳实践。那么接下来是什么?
如果你想开始数据科学,你还需要添加一些 Python 数据科学库。Python 数据科学手册是一本全面的资源,可以帮助你掌握清理、分析和处理数据的基础。
本书涵盖了 Python 的概念,如 Python 魔法命令、调试和代码分析。它还涵盖了足够的内容,以帮助你开始使用 Python 数据科学库和构建机器学习模型。以下是概述:
-
NumPy
-
Pandas
-
Matplotlib
-
机器学习
开始阅读: Python 数据科学手册
总结与下一步
如前所述,将所学知识应用到你感兴趣的小项目中是非常重要的!这些书籍将成为你在这一过程中不可或缺的伴侣。
当你开始构建应用程序时,可能会在代码中引入一些微妙的反模式。因此,无论你使用什么编程语言,务必阅读 《代码整洁之道》 和 《程序员修炼之道》 以构建更好的应用程序。
Bala Priya C 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过编写教程、操作指南、评论文章等,学习并与开发者社区分享她的知识。
更多相关话题


 浙公网安备 33010602011771号
浙公网安备 33010602011771号