KDNuggets-博客中文翻译-二十二-
KDNuggets 博客中文翻译(二十二)
原文:KDNuggets
使用 PyCaret 进行 Python 中的集群分析简介
原文:
www.kdnuggets.com/2021/12/introduction-clustering-python-pycaret.html
评论
由 Moez Ali,PyCaret 创始人及作者

图片来源:Paola Galimberti 在 Unsplash
1. 介绍
PyCaret 是一个开源低代码机器学习库,旨在自动化机器学习工作流程。它是一个端到端的机器学习和模型管理工具,可以显著加快实验周期,提高生产力。
与其他开源机器学习库相比,PyCaret 是一个低代码库,可以用几行代码替代数百行代码。这使得实验速度和效率成倍提高。PyCaret 本质上是多个机器学习库和框架(如 scikit-learn、XGBoost、LightGBM、CatBoost、spaCy、Optuna、Hyperopt、Ray 等)的 Python 封装器。
PyCaret 的设计和简洁性受到市民数据科学家新兴角色的启发,这一术语最早由 Gartner 提出。市民数据科学家是能够执行既简单又中等复杂的分析任务的高级用户,这些任务以前需要更多的技术专长。
要了解更多关于 PyCaret 的信息,可以查看官方 网站 或 GitHub。
2. 教程目标
在本教程中,我们将学习:
-
获取数据: 如何从 PyCaret 仓库导入数据。
-
设置环境: 如何在 PyCaret 的无监督 集群模块 中设置实验。
-
创建模型: 如何训练无监督集群模型,并为训练数据集分配集群标签以便进一步分析。
-
绘图模型: 如何使用各种图表(肘部法、轮廓图、分布图等)分析模型性能。
-
预测模型: 如何根据训练好的模型为新的未见数据集分配集群标签。
-
保存/加载模型: 如何保存/加载模型以供将来使用。
3. 安装 PyCaret
安装很简单,只需几分钟。PyCaret 的默认安装通过 pip 只安装 requirements.txt 文件中列出的硬依赖。
pip install pycaret
要安装完整版:
pip install pycaret[full]
4. 什么是集群?
聚类是将一组对象分组的任务,使得同一组(称为簇)中的对象彼此之间比与其他组中的对象更相似。它是一种探索性数据挖掘活动,是统计数据分析中常用的技术,广泛应用于许多领域,包括机器学习、模式识别、图像分析、信息检索、生物信息学、数据压缩和计算机图形学。聚类的一些常见现实生活应用包括:
-
基于购买历史或兴趣进行客户细分,以设计有针对性的营销活动。
-
根据标签、主题和文档内容将文档分类到多个类别中。
-
在社会科学/生活科学实验中分析结果,以发现数据中的自然分组和模式。
5. PyCaret 中聚类模块概述
PyCaret 的聚类模块 (pycaret.clustering) 是一个无监督机器学习模块,用于将一组对象分组,使得同一组(称为簇)中的对象彼此之间比与其他组中的对象更相似。
PyCaret 的聚类模块提供了多个预处理功能,可以在通过 setup 函数初始化设置时进行配置。它有超过 8 种算法和多种图形来分析结果。PyCaret 的聚类模块还实现了一个独特的函数 tune_model,允许你调整聚类模型的超参数,以优化监督学习目标,如分类的 AUC 或回归的 R2。
6. 教程数据集
在本教程中,我们将使用来自 UCI 的数据集,称为 Mice Protein Expression。该数据集包含 77 种蛋白质的表达水平,这些蛋白质在皮层的核分数中产生了可检测的信号。数据集每种蛋白质包含总共 1080 次测量。每次测量可以视为一个独立的样本(小鼠)。
数据集引用:
Higuera C, Gardiner KJ, Cios KJ (2015) 自组织特征图识别在小鼠唐氏综合症模型中学习关键的蛋白质。PLoS ONE 10(6): e0129126. [Web Link] journal.pone.0129126
你可以从原始来源找到这里下载数据,并使用 pandas(学习如何)加载它,或者你可以使用 PyCaret 的数据仓库,通过 get_data() 函数加载数据(这将需要互联网连接)。
from pycaret.datasets import get_data
dataset = get_data('mice')

**# check the shape of data**
dataset.shape>>> (1080, 82)
为了演示 predict_model 函数在未见数据上的使用,原始数据集中已保留了 5%(54 条记录)的样本,以便在实验结束时用于预测。
data = dataset.sample(frac=0.95, random_state=786)
data_unseen = dataset.drop(data.index)
data.reset_index(drop=True, inplace=True)
data_unseen.reset_index(drop=True, inplace=True)
print('Data for Modeling: ' + str(data.shape))
print('Unseen Data For Predictions: ' + str(data_unseen.shape))**>>> Data for Modeling: (1026, 82)
>>> Unseen Data For Predictions: (54, 82)**
8. 在 PyCaret 中设置环境
setup函数在 PyCaret 中初始化环境并创建用于建模和部署的转换管道。setup必须在执行 pycaret 中的任何其他函数之前调用。它只需要一个必需的参数:一个 pandas 数据框。所有其他参数都是可选的,可用于自定义预处理管道。
当setup执行时,PyCaret 的推断算法将基于某些属性自动推断所有特征的数据类型。数据类型应该被正确推断,但这并不总是如此。为了解决这个问题,PyCaret 在执行setup时会显示提示,要求确认数据类型。如果所有数据类型正确,可以按回车键;如果要退出设置,可以输入quit。
确保数据类型的正确性在 PyCaret 中非常重要,因为它会自动执行多个特定类型的预处理任务,这些任务对机器学习模型至关重要。
或者,你也可以使用numeric_features和categorical_features参数在setup中预先定义数据类型。
from pycaret.clustering import *
exp_clu101 = setup(data, normalize = True,
ignore_features = ['MouseID'],
session_id = 123)
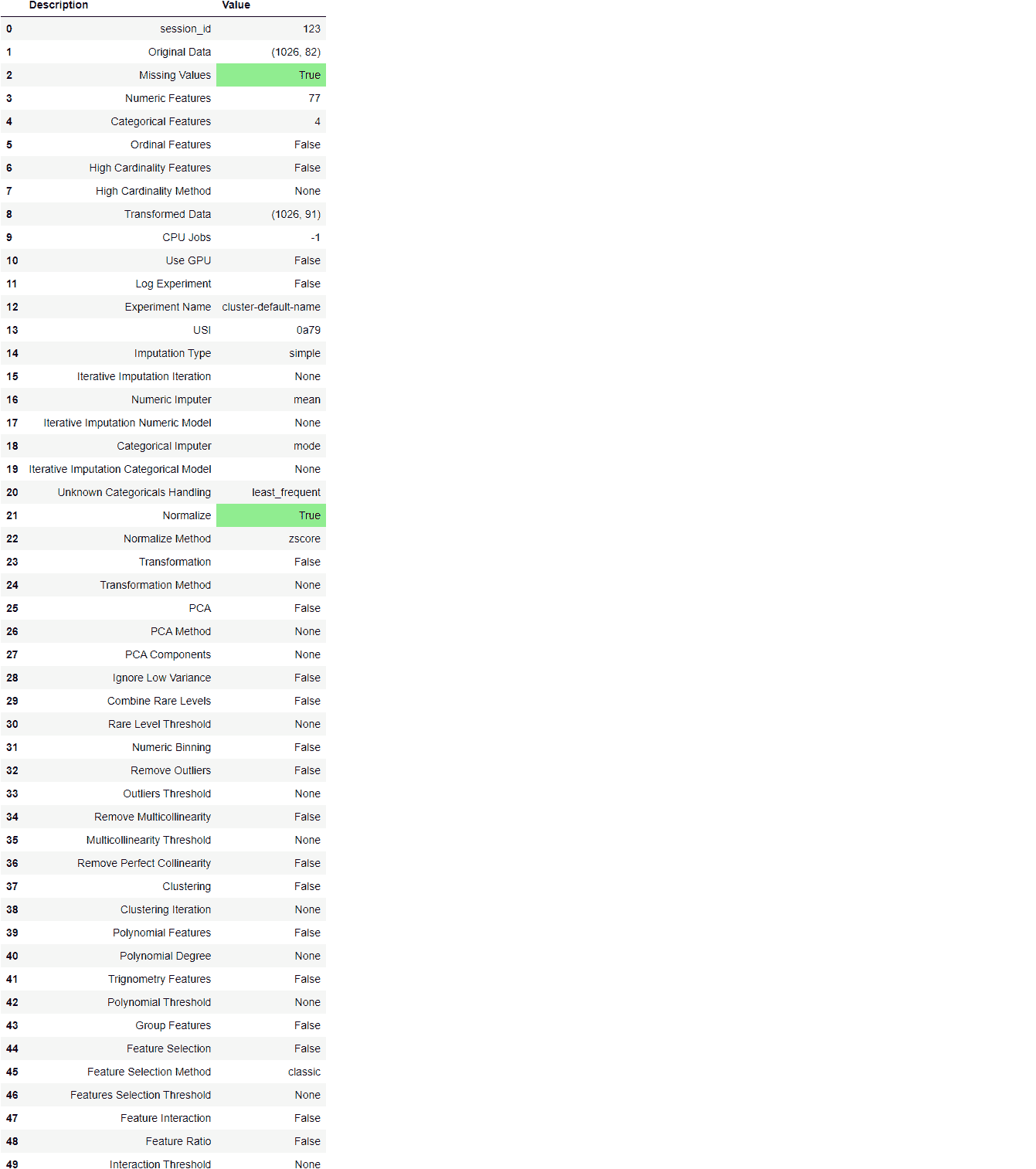
一旦setup成功执行,它会显示包含有关实验的重要信息的网格。大多数信息与在setup执行时构建的预处理管道相关。虽然这些特征的大多数超出了本教程的范围,但需要注意以下几点:
-
session_id:一个伪随机数,在所有函数中作为种子分布,以便后续的可重复性。如果没有传递
session_id,则会自动生成一个随机数,并分配给所有函数。在此实验中,session_id设置为123以便后续的可重复性。 -
缺失值:当原始数据中存在缺失值时,这将显示为 True。请注意,信息网格中的
Missing Values显示为True,因为数据包含缺失值,这些缺失值通过mean自动填充数值特征,通过constant自动填充分类特征。填充方法可以通过numeric_imputation和categorical_imputation参数在setup函数中更改。 -
原始数据:显示数据集的原始形状。在此实验中,(1026, 82)表示 1026 个样本和 82 个特征。
-
转换后的数据:显示转换后的数据集的形状。请注意,原始数据集的形状 (1026, 82) 被转换为 (1026, 91)。特征数量增加是由于数据集中分类特征的编码。
-
数值特征:推断为数值型的特征数量。在此数据集中,82 个特征中的 77 个被推断为数值型。
-
分类特征: 推断为分类的特征数量。在此数据集中,82 个特征中有 5 个被推断为分类特征。还要注意,我们通过
ignore_feature参数忽略了一个分类特征MouseID,因为它是每个样本的唯一标识符,我们不希望在模型训练过程中考虑它。
请注意,一些对建模至关重要的任务会自动处理,例如缺失值填补、分类编码等。setup函数中的大多数参数是可选的,用于自定义预处理管道。这些参数超出了本教程的范围,但我会在以后写更多内容。
9. 创建模型
在 PyCaret 中训练聚类模型很简单,类似于在 PyCaret 的监督学习模块中创建模型的方式。使用create_model函数创建一个聚类模型。此函数返回一个训练好的模型对象和一些无监督的度量。请参见下面的示例:
kmeans = create_model('kmeans')
print(kmeans)**>>> OUTPUT** KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=4, n_init=10, n_jobs=-1, precompute_distances='deprecated',
random_state=123, tol=0.0001, verbose=0)
我们使用create_model训练了一个无监督的 K-Means 模型。请注意,n_clusters参数被设置为4,这是当你未向num_clusters参数传递值时的默认值。在下面的示例中,我们将创建一个具有 6 个簇的kmodes模型。
kmodes = create_model('kmodes', num_clusters = 6)

print(kmodes)**>>> OUTPUT** KModes(cat_dissim=<function matching_dissim at 0x00000168B0B403A0>, init='Cao',
max_iter=100, n_clusters=6, n_init=1, n_jobs=-1, random_state=123,
verbose=0)
要查看模型库中可用模型的完整列表,请检查文档或使用models函数。
models()
10. 指定模型
现在我们已经训练了一个模型,我们可以通过使用assign_model函数将聚类标签分配给我们的训练数据集(1026 个样本)。
kmean_results = assign_model(kmeans)
kmean_results.head()

请注意,原始数据集中添加了一个名为Cluster的新列。
请注意,结果中还包含了我们在setup过程中实际上删除的MouseID列。无需担心,它不会用于模型训练,而只是当调用assign_model时,才会被添加到数据集中。
11. 绘制模型
plot_model函数用于分析聚类模型。此函数接受一个训练好的模型对象,并返回一个图表。
11.1 聚类 PCA 图
plot_model(kmeans)
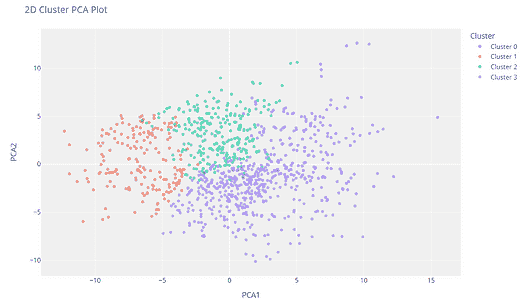
聚类标签会自动着色并显示在图例中。当你将鼠标悬停在数据点上时,你会看到额外的特征,这些特征默认使用数据集的第一列(在本例中是 MouseID)。你可以通过传递feature参数来更改此设置,并且如果你希望在图上打印标签,可以将label设置为True。
11.2 肘部图
plot_model(kmeans, plot = 'elbow')
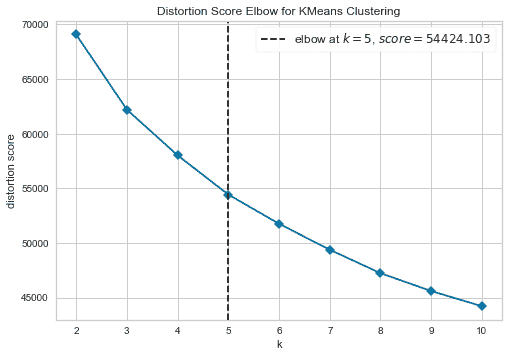
肘部法则是一种启发式方法,用于解释和验证簇内分析的一致性,旨在帮助找到数据集中的适当簇数。在这个示例中,上面的肘部图建议 5 是最优的簇数。
11.3 轮廓图
plot_model(kmeans, plot = 'silhouette')
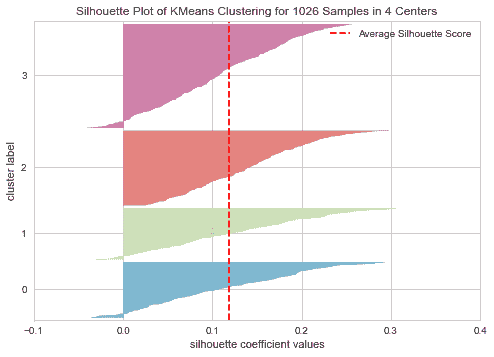
Silhouette(轮廓系数)是一种解释和验证数据簇内部一致性的方法。该技术提供了一个简洁的图形表示,显示了每个对象被分类的效果。换句话说,轮廓值是衡量一个对象与其自身簇(凝聚度)相比,与其他簇(分离度)的相似程度。
11.4 分布图
plot_model(kmeans, plot = 'distribution')
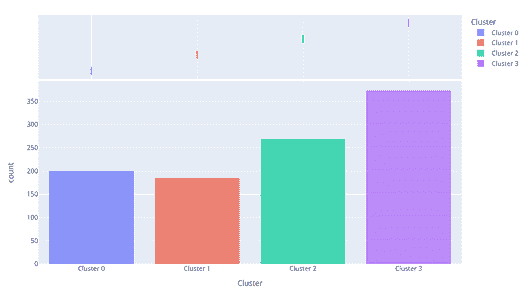
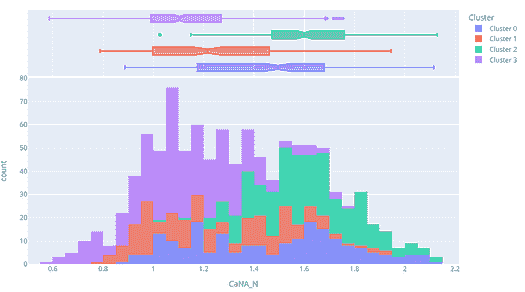
分布图显示了每个簇的大小。当将鼠标悬停在条形上时,会看到分配到每个簇的样本数量。从上面的例子中,我们可以观察到簇 3 拥有最多的样本。我们还可以使用 distribution 图来查看簇标签与任何其他数值或类别特征的分布情况。
plot_model(kmeans, plot = 'distribution', feature = 'class')
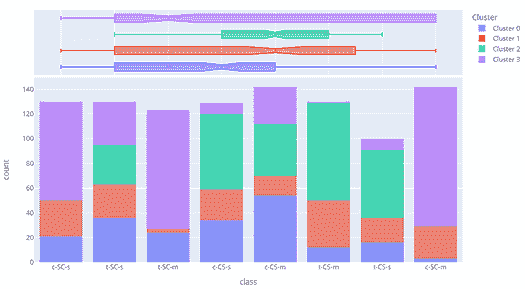
在上述示例中,我们使用了 class 作为特征,因此每个条形代表一个 class,并用簇标签(右侧图例)着色。我们可以观察到 t-SC-m 和 c-SC-m 类别大多由 Cluster 3 主导。我们也可以使用相同的图来查看任何连续特征的分布。
plot_model(kmeans, plot = 'distribution', feature = 'CaNA_N')
12. 在未见数据上进行预测
predict_model 函数用于为新的未见数据集分配簇标签。我们现在将使用训练好的 kmeans 模型来预测存储在 data_unseen 中的数据。这个变量在教程开始时创建,包含了原始数据集中从未暴露于 PyCaret 的 54 个样本。
unseen_predictions = predict_model(kmeans, data=data_unseen)
unseen_predictions.head()
13. 保存模型
我们现在已经完成了实验,通过使用我们的 kmeans 模型在未见数据上预测标签。
这标志着我们实验的结束,但还有一个问题需要回答:当你有更多新数据需要预测时会发生什么?你需要重新进行整个实验吗?答案是否定的,PyCaret 的内置函数 save_model 允许你保存模型及整个转换管道,以便以后使用。
save_model(kmeans,’Final KMeans Model 25Nov2020')

要在未来某个日期在相同或不同环境中加载已保存的模型,我们可以使用 PyCaret 的 load_model 函数,然后轻松地将已保存的模型应用于新的未见数据进行预测。
saved_kmeans = load_model('Final KMeans Model 25Nov2020')
new_prediction = predict_model(saved_kmeans, data=data_unseen)
new_prediction.head()
14. 总结 / 下一步?
我们仅覆盖了PyCaret 的聚类模块的基础内容。在接下来的教程中,我们将深入探讨高级预处理技术,这些技术允许你完全自定义你的机器学习管道,是任何数据科学家必须了解的。
感谢阅读 ????
重要链接
⭐ 教程 新接触 PyCaret?查看我们的官方笔记本!
???? 示例笔记本 由社区创建。
???? 博客 贡献者的教程和文章。
???? 文档 PyCaret 的详细 API 文档。
???? 视频教程 我们来自各种活动的视频教程。
???? 讨论 有问题?与社区和贡献者互动。
????️ 更新日志 更改和版本历史。
???? 路线图 PyCaret 的软件和社区发展计划。
个人简介:Moez Ali 撰写关于 PyCaret 及其实际应用的文章,如果你希望自动获取通知,可以关注 Moez 的 Medium、LinkedIn 和 Twitter。
原文。已获转载许可。
相关:
-
使用 PyCaret 的新时间序列模块
-
使用 PyCaret 进行二分类介绍
-
初学者的端到端机器学习指南
我们的前三大课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关内容
卷积神经网络简介
原文:
www.kdnuggets.com/2020/06/introduction-convolutional-neural-networks.html
评论
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
你是否想过面部识别如何在 社交媒体 上工作,或者对象检测如何在自动驾驶汽车中发挥作用,或者疾病检测如何通过视觉影像在医疗保健中完成?这一切都得益于卷积神经网络(CNN)。
介绍
就像孩子学习识别对象一样,我们需要向算法展示数百万张图片,才能使其对输入进行归纳并对从未见过的图像进行预测。
计算机的“视野”与我们不同。它们的世界仅由数字构成。每个图像可以表示为二维的数字数组,称为像素。

但它们以不同的方式感知图像,并不意味着我们不能训练它们像我们一样识别模式。我们只需要考虑图像的不同之处。
要教一个算法识别图像中的对象,我们使用一种特定类型的 人工神经网络:卷积神经网络(CNN)。它们的名称源自网络中一种重要操作叫做 卷积。
卷积神经网络
卷积神经网络(CNN 或 ConvNets) 是普通的神经网络,假设输入是图像。它们用于分析和分类图像,通过相似性对图像进行聚类,并在框架内执行对象识别。例如,卷积神经网络(ConvNets 或 CNNs)用于识别面孔、个人、路标、肿瘤、鸭嘴兽以及视觉数据的许多其他方面。
CNN 的生物学连接
当你第一次听到卷积神经网络这个术语时,你可能会想到与神经科学或生物学有关的东西,你的想法是对的。某种程度上。CNN 确实从视觉皮层中获得了生物学上的启发。视觉皮层有小区域的细胞对视觉场的特定区域敏感。
这个想法在 1962 年通过 Hubel 和 Wiesel 的一项引人入胜的实验得到了扩展(视频),他们展示了大脑中的某些单个神经元细胞仅在特定方向的边缘存在时才会响应(或发放)。例如,一些神经元在暴露于垂直边缘时会发放,而在水平或对角边缘出现时也会发放。Hubel 和 Wiesel 发现所有这些神经元都以柱状结构组织在一起,并且它们能够共同产生视觉感知。系统内专门组件具有特定任务的这种思想(视觉皮层中的神经细胞寻找特定特征)也是机器使用的基础,并且是 CNN 的基础。
在你继续之前,如果你是深度学习的初学者,我强烈建议查看下面的文章,以便对神经网络有一个基本的理解。
人工神经网络简介
卷积神经网络如何学习?
图像由像素组成。每个像素由 0 到 255 之间的一个数字表示。因此,每个图像都有一个数字表示,这就是计算机能够处理图像的方式。
CNN 图像检测/分类中有 4 个主要操作。
-
卷积
-
激活图
-
最大池化
-
扁平化
-
全连接层
1.1 卷积
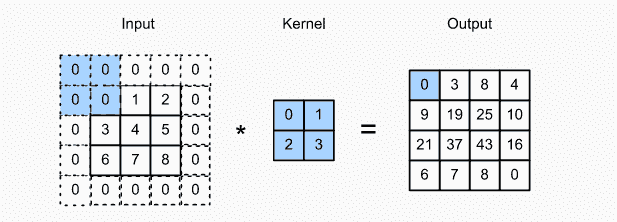
卷积操作在 1D 的两个信号和 2D 的两幅图像上进行。数学上,卷积是两个函数的综合积分,展示了一个函数如何修改另一个函数:

卷积层的主要目的是检测图像中的特征或视觉特征,例如边缘、线条、颜色斑点等。这是一个非常有趣的特性,因为一旦它在图像的特定点学会了某个特征,它就能在图像的任何部分识别它。
CNN 使用滤波器(也称为卷积核、特征检测器)来检测图像中是否存在诸如边缘等特征。滤波器只是一个值矩阵,称为权重,经过训练以检测特定特征。滤波器在图像的每个部分移动,以检查是否存在其预期检测的特征。为了提供一个值,表示它对特定特征存在的信心,滤波器执行卷积操作,这是一种矩阵之间逐元素的乘积和求和。
当图像的某部分存在特征时,滤波器与该部分图像之间的卷积操作结果是一个高值的实数。如果特征不存在,结果值则较低。
在下图中,训练用于检测加号的滤波器被应用于图像的一部分。由于该部分图像包含了滤波器所寻找的相同加号,卷积操作的结果是一个大数值。
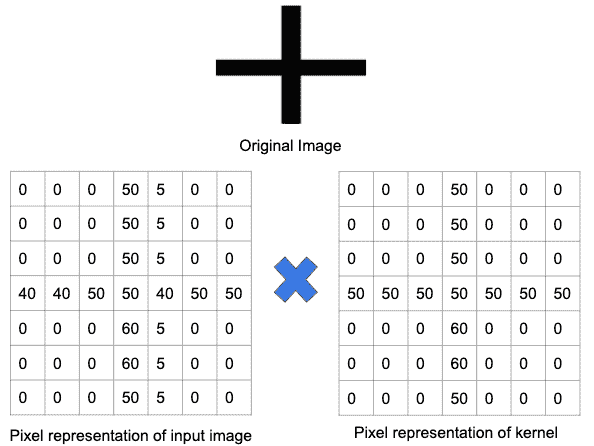
卷积(逐元素乘积和求和) = (5050)+(5050)+(5050)+(5050)+(5050)+(6060)+(6060)+(4050)+(4050)+(5050)+(5050)+(4050)+(5050)+(5050) = 非常大的实数
但是当相同的滤波器/核应用于具有显著不同边缘集合的图像部分时,卷积的输出会很小,这意味着没有明显的加号存在,逐元素乘积和求和将导致零或非常小的值。
因此,我们需要 N 个特征检测器来检测图像的不同曲线/边缘。
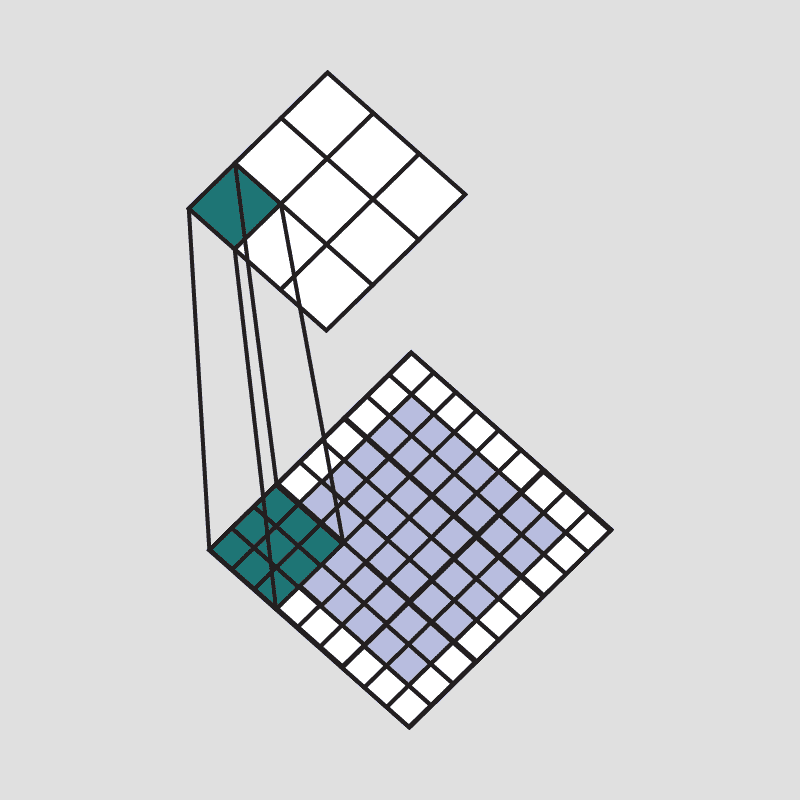
将该滤波器应用于整个图像的结果是一个称为特征图或卷积特征的输出矩阵,它存储了该滤波器在图像不同部分上的卷积结果。由于我们有多个滤波器,因此我们得到一个 3D 输出:每个滤波器一个 2D 特征图。滤波器必须具有与输入图像相同的通道数,以便进行逐元素乘法。
此外,可以通过使用步幅值,在不同的间隔上滑动滤波器到输入图像上。步幅值决定了滤波器在每一步移动的距离。
我们可以确定给定卷积块的输出层数量:

1.2 填充
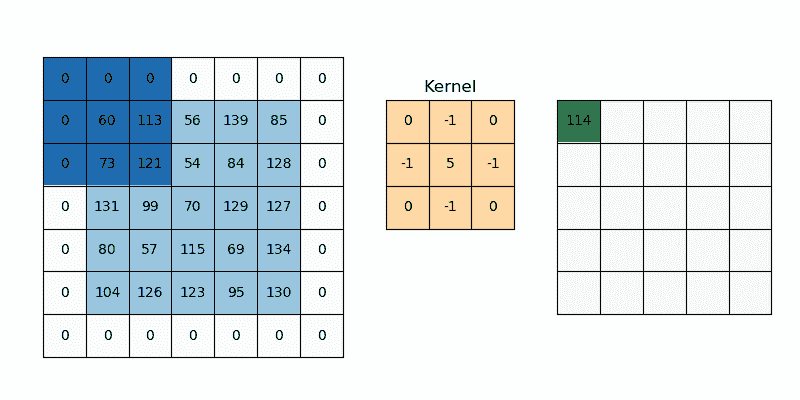
应用卷积层时一个棘手的问题是我们往往会丢失图像边缘的像素。由于我们通常使用小型核,对于任何给定的卷积,我们可能只会丢失几个像素,但随着我们应用许多连续的卷积层,这种丢失会逐渐积累。
填充是指在图像被 CNN 的核处理时,添加到图像上的像素数量。
一个解决方案是通过在图像周围添加零(零填充)来帮助核处理图像,从而为核提供更多的覆盖图像的空间。对 CNN 处理的图像添加填充可以实现更准确的图像分析。
在输入图像的周围添加额外的零,以便捕获所有特征。
2.1 激活图
这些特征图必须经过非线性映射。特征图与偏置项相加,并通过非线性激活函数ReLu。激活函数的目的是将非线性引入网络中,因为图像由彼此不线性的不同对象组成,所以图像具有高度的非线性。
2.2 最大池化
ReLU 之后是一个池化步骤,在该步骤中,CNN 对卷积特征进行下采样(以节省处理时间),同时还减少图像的大小。这有助于减少过拟合,如果 CNN 接收到过多的信息,特别是当这些信息在分类图像时不相关时,过拟合会发生。
有不同类型的池化,例如最大池化和最小池化。在最大池化中,窗口按照设定的步幅值在图像上滑动。在每一步,窗口内的最大值会被池化到输出矩阵中,因此得名最大池化。
这些值形成一个新的矩阵,称为池化特征图。
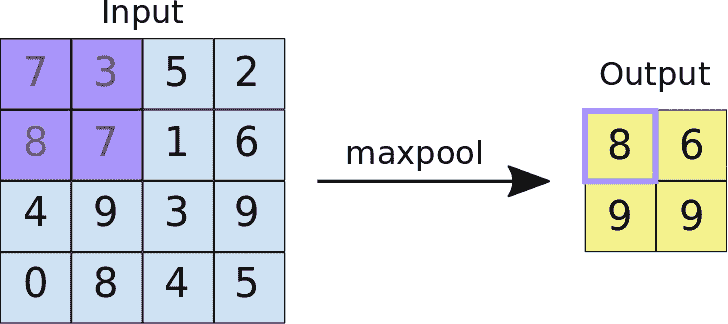
最大池化的一个额外好处是,它迫使网络关注少数神经元,而不是所有神经元,这对网络有正则化作用,使其不易过拟合训练数据,并希望能够很好地泛化。
3.3 扁平化
经过多个卷积层和下采样操作后,图像的 3D 表示会转换成一个特征向量,该特征向量会传入多层感知机以输出概率。下图描述了扁平化操作:
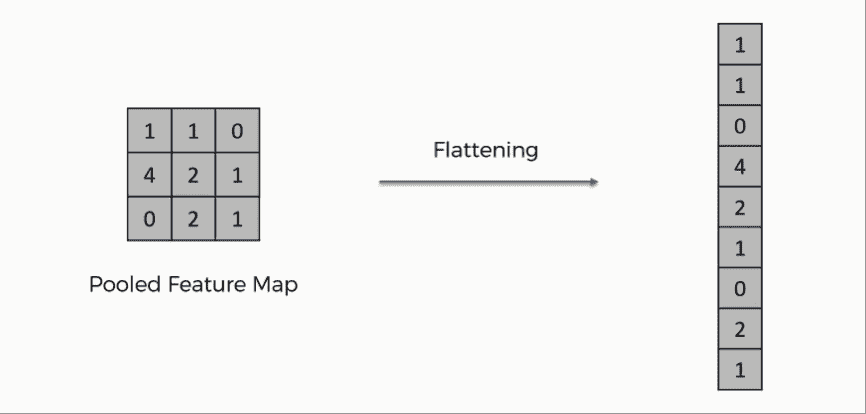
扁平化操作
行被连接起来形成一个长特征向量。如果存在多个输入层,则这些行也会连接起来形成一个更长的特征向量。
4. 全连接层
在这一步,扁平化的特征图会传递给一个神经网络。这一步包括输入层、全连接层和输出层。全连接层类似于 ANN 中的隐藏层,但在这种情况下,它是完全连接的。输出层是我们得到预测类别的地方。信息会通过网络传递,并计算预测的误差。然后,误差会通过系统进行反向传播,以改进预测。
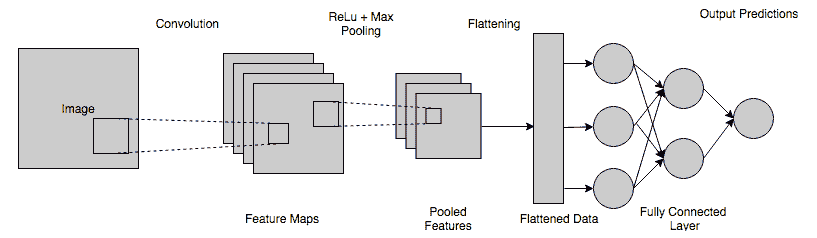
全连接层
密集层神经网络产生的最终输出通常不会加起来等于一。然而,这些输出必须被缩减到零到一之间的数值,这些数值代表每个类别的概率。这就是 Softmax 函数的作用。
因此,这一密集层的输出会传递给Softmax 激活函数,该函数将所有最终密集层的输出映射到一个元素总和为一的向量中:
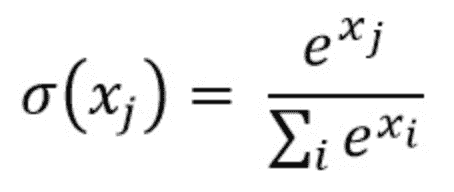
其中 x 表示最终层输出中的每个元素。
全连接层的工作方式是查看前一层的输出(我们记得应该表示高层特征的激活图),并确定哪些特征与特定类别最相关。例如,如果程序预测某图像是狗,它将在表示高层特征如爪子或四条腿等的激活图中具有高值。同样,如果程序预测某图像是鸟,它将在表示高层特征如翅膀或喙等的激活图中具有高值。全连接层查看哪些高层特征最强烈地与特定类别相关,并具有特定的权重,以便当你计算权重和前一层之间的乘积时,可以得到不同类别的正确概率。
让我们总结一下 CNN 如何识别的整个过程:
-
图像中的像素被送入执行卷积操作的卷积层。
-
它生成一个卷积映射。
-
卷积映射应用于 ReLU 函数生成一个整流特征图。
-
图像经过多次卷积和 ReLU 层处理以定位特征。
-
使用不同的池化层和各种滤波器来识别图像的特定部分。
-
池化特征图被展平并馈送到全连接层以获得最终输出。
使用 Keras 实现 CNN
现在,让我们编写能够分类图像的代码。这段代码可以在大多数图像数据集上应用,只需稍作修改。因此,一旦你拥有图像数据,将它们分开到文件夹中并命名,例如训练集和测试集。
构建 CNN
在这一步,第一步是构建包含以下提到的层的卷积神经网络:
-
Sequential 用于初始化神经网络。
-
Convolution2D用于构建处理图像的卷积网络。
-
MaxPooling2D 层用于添加池化层。
-
Flatten是将池化特征图转换为传递到全连接层的单列的函数。
-
Dense添加了一个全连接层到神经网络中。
一旦网络建立完成,然后使用 随机梯度下降(SGD) 来编译/训练网络。梯度下降在我们有凸曲线时效果很好。但如果我们没有凸曲线,梯度下降会失败。因此,在随机梯度下降中,每次迭代随机选择一些样本,而不是整个数据集。
现在网络已经编译完毕,是时候用训练图像来训练 CNN 模型了。
将 CNN 适配到图像上
执行图像增强,与其用大量图像训练模型,不如用较少的图像进行训练,并通过不同角度和修改图像来训练模型。Keras 有一个ImageDataGenerator类,可以让用户以非常简单的方式动态执行图像增强。
一旦你用训练图像数据集训练了你的 CNN 网络,就该检查模型的准确性了。
结论
CNN 是最好的人工神经网络,它不仅用于图像建模,还有许多其他应用。基于 CNN 架构有很多改进版,如 AlexNet、VGG、YOLO 等。
好了,这篇文章就到这里,希望你们喜欢阅读。如果这篇文章对你们有帮助,我会很高兴。欢迎在评论区分享你们的评论/想法/反馈。
感谢阅读!!!
简历:Nagesh Singh Chauhan 是 CirrusLabs 的一个大数据开发人员。他在电信、分析、销售、数据科学等多个领域有超过 4 年的工作经验,专注于多个大数据组件。
原文。经许可转载。
相关:
-
每个数据科学家应该阅读的 5 篇 CNN 论文
-
机器学习中的模型评估指标
-
主成分分析(PCA)的降维
更多相关内容
相关性介绍
编辑提供的图片
阅读完本文后,读者将学到以下内容:
-
相关性的定义
-
正相关
-
负相关
-
无相关性
-
相关性的数学定义
-
相关系数的 Python 实现
-
协方差矩阵
-
协方差矩阵的 Python 实现
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 在 IT 方面支持你的组织
相关性
相关性衡量两个变量的共同变化程度。
正相关
如果变量Y在变量X增加时也增加,那么X和Y是正相关的,如下所示:
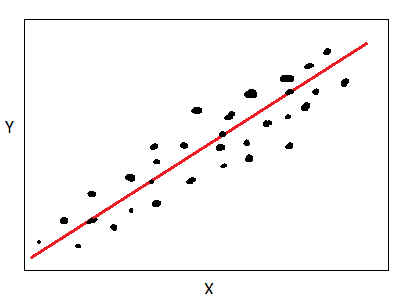
X 和 Y 之间的正相关。 图片由作者提供。
负相关
如果变量Y在变量X增加时减少,那么X和Y是负相关的,如下所示:
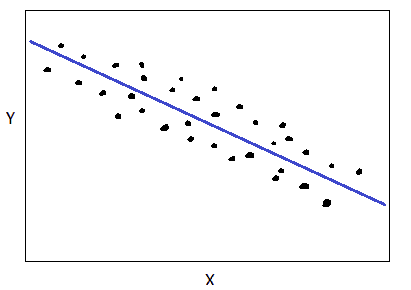
X 和 Y 之间的负相关。 图片由作者提供。
无相关性
当X和Y之间没有明显关系时,我们说X和Y是无相关的,如下所示:
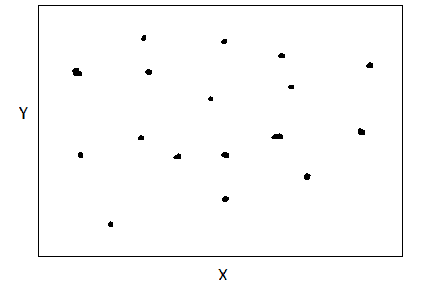
X 和 Y 是无相关的。 图片由作者提供。
相关性的数学定义
设X和Y为两个特征
X = (X1 , X2 , . . ., Xn )
Y = (Y1 , Y2 , . . ., Yn )
X和Y之间的相关系数定义为
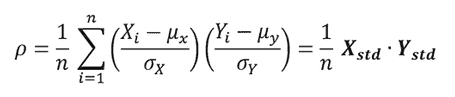
其中 mu 和 sigma 分别表示均值和标准差,Xstd 是变量 X 的标准化特征。相关系数是X和Y的标准化特征之间的向量点积(标量积)。相关系数的取值范围在-1 到 1 之间。接近 1 的值表示强正相关,接近-1 的值表示强负相关,接近零的值表示低相关性或无相关性。
相关系数的 Python 实现
import numpy as np
import matplotlib.pyplot as plt
n = 100
X = np.random.uniform(1,10,n)
Y = np.random.uniform(1,10,n)
plt.scatter(X,Y)
plt.show()
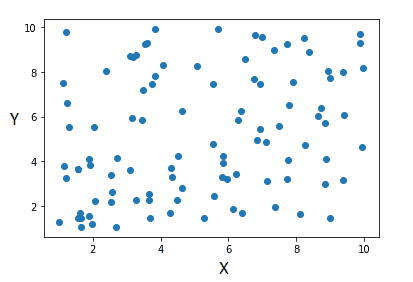
X 和 Y 之间没有相关性。图片由作者提供。
X_std = (X - np.mean(X))/np.std(X)
Y_std = (Y - np.mean(Y))/np.std(Y)
np.dot(X_std, Y_std)/n
0.2756215872210571
# Using numpy
np.corrcoef(X, Y)
array([[1\. , 0.27562159],
[0.27562159, 1\. ]])
协方差矩阵
协方差矩阵 是数据科学和机器学习中非常有用的矩阵。它提供了数据集中特征之间的共同变动(相关性)信息。协方差矩阵定义如下:
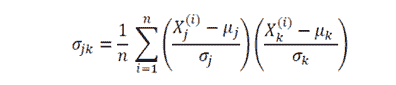
其中 mu 和 sigma 代表给定特征的均值和标准差。这里的 n 是数据集中观察的数量,j 和 k 的下标取值为 1, 2, 3, . . ., m,其中 m 是数据集中的特征数量。例如,如果一个数据集有 4 个特征和 100 个观察值,则 n = 100,m = 4,因此协方差矩阵将是一个 4 x 4 的矩阵。对角线元素将全为 1,因为它们表示特征与自身之间的相关性,根据定义,相关性等于 1。
协方差矩阵的 Python 实现
假设我想计算 4 只科技股票(AAPL、TSLA、GOOGL 和 AMZN)在 1000 天内的相关程度。我们的数据集有 m = 4 个特征和 n = 1000 个观察值。协方差矩阵将是一个 4 x 4 的矩阵,如下图所示。
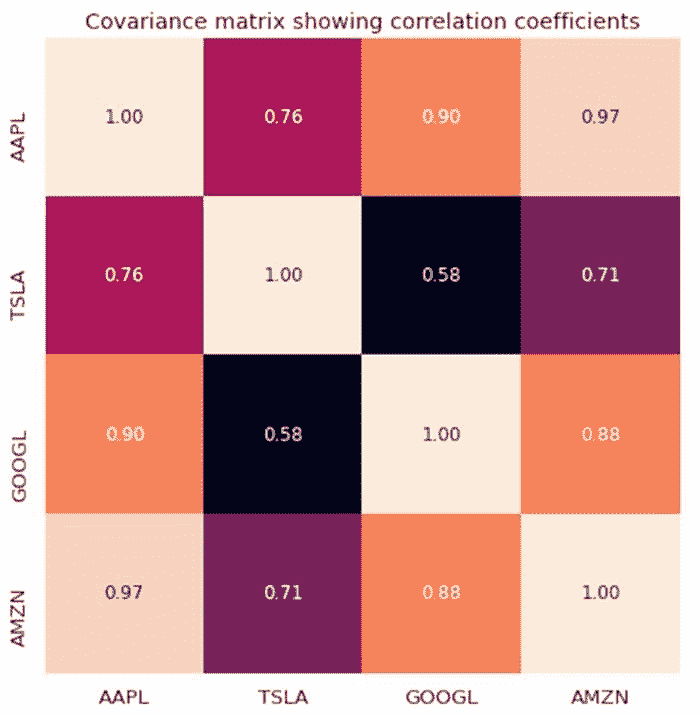
技术股票之间的协方差矩阵。图片由作者提供。
生成上述图形的代码可以在这里找到:数据科学和机器学习的基本线性代数。
总结
总之,我们回顾了相关性的基础知识。相关性定义了 2 个变量之间的共同变动程度。相关系数的取值范围在 -1 和 1 之间。接近零的值表示低相关性或无相关性。
本杰明·O·塔约 是物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的拥有者。之前,本杰明曾在中央俄克拉荷马大学、大峡谷大学和匹兹堡州立大学教授工程学和物理学。
更多相关主题
数据工程简介
原文:
www.kdnuggets.com/2020/12/introduction-data-engineering.html
评论
作者:Xinran Waibel,Netflix 的数据工程师。
根据最近发布的Dice 2020 科技职位报告,数据工程师是 2019 年增长最快的科技职业,开放职位数量同比增长了 50%。由于数据工程是一个相对较新的职业类别,我经常收到有意从事这一职业的人的问题。在这篇博客文章中,我将分享我成为数据工程师的经历,并回答一些关于数据工程的常见问题。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
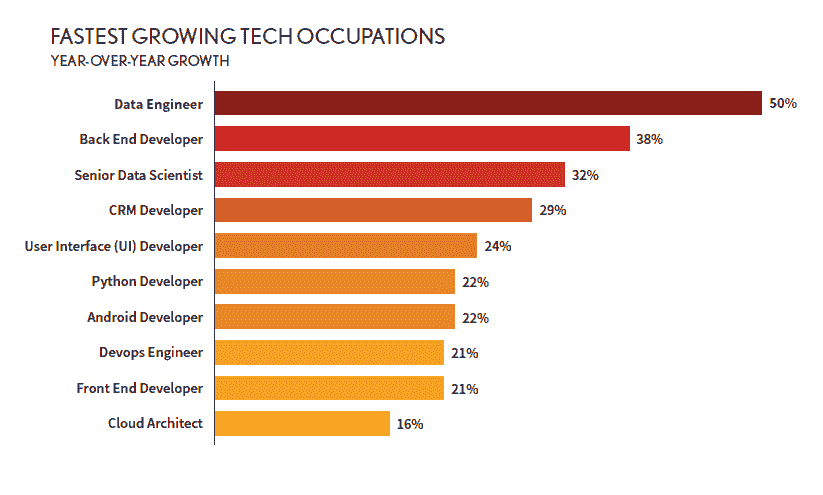
来源:Dice 2020 科技职位报告。
我的数据工程师之旅
几年前,在成为数据工程师之前,我主要从事数据库和应用程序开发(以及规模和性能测试)。我非常喜欢使用RDBMS和数据,因此决定从事专注于大数据的工程职业。在网上研究后,我了解到一种我从未听说过的工作,但认为可能是适合我的“白马王子”:数据工程师。当时我感到迷茫,因为不知道从何开始,也不确定这是否适合我。然而,我幸运地有一位导师,他指导我入门并帮助我获得了第一份数据工程工作。从那时起,我一直在这个领域全职工作,仍然非常热爱!
随便问我什么

图片由Camylla Battani提供,发布在Unsplash上。
问:数据工程师做什么?
简而言之,数据工程师负责设计、开发和维护数据平台,包括数据基础设施、数据应用、数据仓库和数据管道。
在大公司中,数据工程师通常被分成不同的团队,各自负责数据平台的特定部分。
-
数据仓库与管道:数据仓库工程师构建批处理和/或实时数据管道,以整合系统之间的数据并支持data warehouse。由于数据仓库旨在解决业务问题,因此数据仓库工程师通常与数据分析师、科学家或服务于特定业务职能的业务团队密切合作。
-
数据基础设施:数据基础设施工程师构建和维护数据平台的基础:所有运行其上的分布式系统。例如,在 Target,数据基础设施团队维护整个组织使用的Hadoop集群。
-
数据应用:数据应用工程师是构建内部数据工具和 API 的软件工程师。有时,一个出色的内部工具后来可能会成为公司的开源产品。例如,Lyft 的一个数据产品团队构建了一个名为Amundsen的数据发现工具,并于 2019 年开源。
问:什么是数据仓库?
数据仓库是一个数据存储系统,存储来自各种来源的数据,主要用于数据分析。公司的数据通常存储在不同的事务系统中(甚至更糟的是作为文本文件),而事务数据高度规范化,不适合分析。建立数据仓库的主要原因是将所有类型的数据以优化的格式存储在一个集中位置,以便数据科学家可以一起分析这些数据。许多数据库适合作为数据仓库,例如Apache Hive、BigQuery(GCP)和RedShift(AWS)。
问:什么是数据管道?
数据管道是一系列数据处理过程,用于在不同系统之间提取、处理和加载数据。数据管道主要有两种类型:批处理驱动和实时驱动:
-
批处理驱动:批处理数据管道仅在特定频率下处理数据,通常由数据编排工具调度,如Airflow、Oozie或Cron。它们通常一次处理大量历史数据,因此需要较长时间才能完成,并且在最终系统中引入更多数据延迟。例如,一个基于批处理的数据管道每天 12 AM 从 API 下载前一天的数据,转换数据,然后将其加载到数据仓库中。
-
实时:实时数据管道会在新数据可用时立即处理,源系统与终端系统之间几乎没有延迟。实时数据处理的架构与批处理管道非常不同,因为数据被视为事件流,而不是记录块。例如,为了将上述管道重建为实时管道,需要一个像 Kafka 这样的事件流工具:Kafka Connector 将数据从 API 流式传输到 Kafka 主题,Kafka Streams(或 Kafka Producer)处理 Kafka 主题中的原始数据,并将转换后的数据加载到另一个 Kafka 主题中。源 API 和目标 Kafka 主题之间的延迟可能在一秒内!

来源:数据工程师与数据科学家。
问:数据工程师与数据科学家的区别是什么?
数据工程师构建数据平台,使数据科学家能够分析数据和训练机器学习 (ML)模型。有时,数据工程师也需要进行数据分析,并帮助数据科学家将 ML 模型集成到数据管道中。在一些数据团队中,你可能会发现数据科学家从事数据工程工作。数据工程师和数据科学家之间有几个重叠的技能:编程、数据管道建设和数据分析。
有一个新兴角色叫做 ML 工程师,负责在两个领域之间搭建桥梁。ML 工程师在工程和机器学习方面拥有强大的技能,负责优化和生产化 ML 模型。

照片由 Christopher Gower 提供,来自 Unsplash。
问:要成为数据工程师,我应该学习哪些编程语言?
简短的答案是:Python、Java/Scala 和 SQL。
对于数据应用轨道,你还需要学习用于 全栈 开发的常见编程语言,例如 HTML、CSS 和 JavaScript。
问:我应该学习哪些技能和工具?
以下是核心技能列表以及一个流行的框架:
-
分布式系统: Hadoop
-
数据库: MySQL
-
数据处理: Spark
-
实时数据生态系统: Kafka
-
数据编排:Airflow
-
数据科学和机器学习:pandas(Python 库)
-
全栈开发:React
由于大数据世界中不再存在一刀切的解决方案,每家公司都在为其数据平台利用不同的工具。因此,我建议你首先学习每个核心技能的基础知识,然后选择一个流行的工具深入学习,并理解你选择的工具与其他工具之间的权衡。要达到下一个层次,你还需要了解所有工具如何在数据架构中协同工作。
(对高效学习技术栈感兴趣?查看一下系统化学习方法。)
今天,地球上每个人每秒钟生成大约 1.7MB 的新数据,这些数据包含巨大的价值,没有数据工程无法收获。这就是为什么我如此热爱我的工作的原因。 😃
原文。转载已获许可。
简介: Xinran Waibel 是一位经验丰富的数据工程师,现居旧金山湾区,目前在 Netflix 工作。她还是《Towards Data Science》、《Google Cloud》和 Medium 上的《The Startup》的技术作家。
相关:
更多相关内容
数据科学入门:初学者指南
原文:
www.kdnuggets.com/2023/07/introduction-data-science-beginner-guide.html

作者提供的图片
你在过去的二十年里没有生活在石头下,所以你可能或多或少知道什么是数据科学。你可能希望对其进行简要概述,以了解开始学习数据科学并找到工作所需的内容。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
本文将为你提供的要点如下:
-
数据科学的核心点是:数据进入,洞察输出。数据科学家的工作是管理数据到洞察的每个阶段。
-
你需要哪些工具、技术和技能才能获得数据科学工作。
-
数据科学作为职业的整体状况。
如果这听起来像是你在寻找的内容,那就让我们深入了解吧。
什么是数据科学?
正如我之前所说,数据科学最好总结为一个数据到洞察的流程。作为数据科学家,无论你在哪家公司,你都会执行以下任务:
-
提取数据
-
清洗或处理数据
-
分析数据
-
识别模式或趋势
-
在数据上构建预测和统计模型
-
可视化和沟通数据
简而言之,你在解决问题、做出预测、优化过程和指导战略决策。
因为很少有公司能准确掌握数据科学家的工作内容,所以你可能还会有其他责任。一些雇主希望数据科学家在角色中加入信息安全或网络安全的职责。其他人可能期望数据科学家具备云计算、数据库管理、数据工程或软件开发的专长。要准备好担任多个角色。
这份工作之所以重要,不是因为《哈佛商业评论》称其为 21 世纪最性感的工作,而是因为数据量在不断增加,而很少有人知道如何将数据转化为洞察。作为数据科学家,你能看清全貌。
全球从 2010 年到 2020 年创建、捕捉、复制和消费的数据/信息量,以及 2021 年至 2025 年的预测
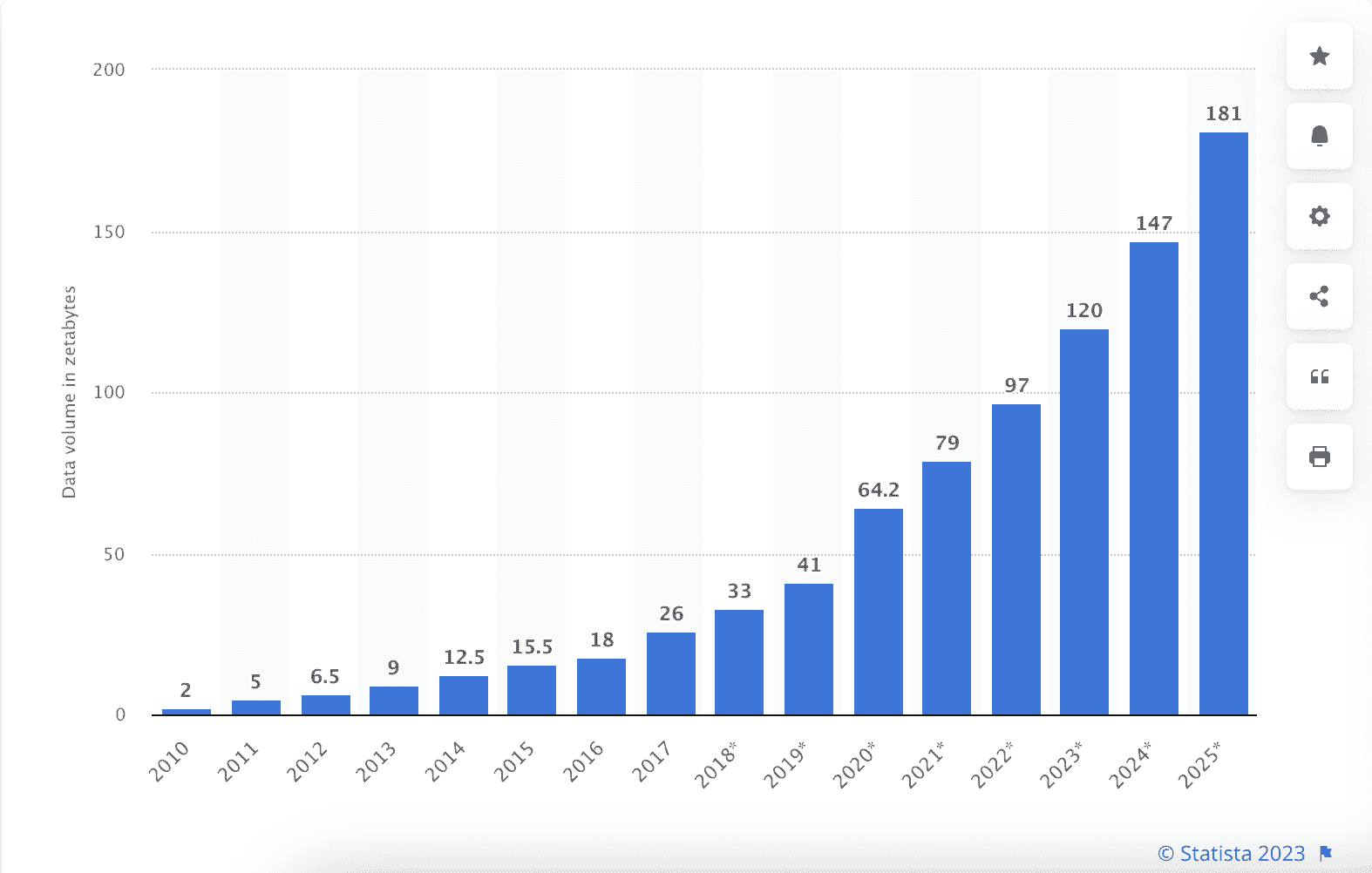
来源:www.statista.com/statistics/871513/worldwide-data-created/
数据科学中的关键概念
现在你已经了解了大概念。让我们来看看数据科学中的一些关键概念。如果你能设想数据到见解的流程,我将确定每个关键概念的作用。
数据处理
在流程的最开始,你得到的是一堆混合质量的数据。一个著名的(而且不正确的)统计数据指出数据科学家花费 80%的时间来清理数据。虽然这可能没有那么高,但建立数据处理流程和调整数据是工作中的重要部分。
想象一下你是一个电商公司的数据科学家。在那里,数据处理可能涉及清理和转换客户交易数据,合并和调和来自不同来源的数据,如网站分析和客户关系管理(CRM)系统,以及处理缺失或不一致的数据。
你可能需要标准化格式,删除重复项或 NaN,并处理离群值或错误条目。这个过程确保数据准确、一致,并准备好进行分析。
数据探索和可视化
一旦数据被整理好,你现在可以开始查看它了。你可能认为数据科学家会立刻将统计模型应用于数据,但事实是模型种类繁多。首先,你需要了解你所拥有的数据类型。然后你可以寻找重要的见解和预测。
例如,如果你是 GitHub 的数据科学家,数据探索可能涉及分析平台上的用户活动和参与度。你可以查看提交次数、拉取请求和问题等指标,以及用户互动和合作情况。通过探索这些数据,你可以了解用户如何与平台互动,识别受欢迎的代码库,并发现软件开发实践中的趋势。
由于大多数人对图片的意义解析要优于对表格的解析,因此数据可视化也被纳入数据探索中。例如,作为 GitHub 的数据科学家,你可能会使用折线图来展示随时间变化的提交次数。柱状图可以用来比较平台上不同编程语言的流行度。网络图可以用来展示用户或代码库之间的合作关系。

来源:www.reddit.com/r/DataScienceMemes/comments/nzoogr/i_dont_like_gravy/
统计分析
在数据科学的数据到洞见流程的这一阶段,你已经完成了前两个部分的数据处理。数据已经到位,你正在对其进行探查和分析。现在是时候提取洞见了。最后,你可以对你的数据进行一些统计分析。
假设你是一家类似于 Hello Fresh 的公司的数据科学家。你可能会进行线性回归等统计分析,以了解影响客户流失的因素,使用聚类算法根据客户的偏好或行为对客户进行分组,或进行假设检验以确定营销活动的有效性。这些统计分析有助于揭示数据中的关系、模式和重要发现。
机器学习
数据科学家的酷炫之处在于他们可以预测未来。想象数据到洞见的流程。你对过去和现在的情况有了洞察。但你的老板可能会问:如果我们添加一种新产品会发生什么?如果我们在周一关门会怎么样?如果我们将一半的车队转换为电动车会怎样?
作为数据科学家,你像看水晶球一样利用机器学习创建智能预测。例如,假设你是物流公司 FedEx 的数据科学家。你可以利用历史运输数据、天气数据以及其他相关变量来开发预测模型。这些模型可以预测运输量、估计交货时间、优化路线规划或预测潜在的延误。
通过使用回归、时间序列分析或神经网络等机器学习算法,你可以预测添加一个新的配送中心对交货时间的影响,模拟不同操作变更对运输成本的影响,或预测对特定运输服务的客户需求。
沟通与商业智能
数据科学中最重要的概念不是机器学习或数据清洗,而是沟通。你需要将这些洞见呈现给公司中的决策者,他们可能对神经网络和梯度提升算法一无所知。沟通和商业敏锐度在数据科学中都是关键概念。
想象你是一家类似于 Meta 的公司的数据科学家。你刚刚发现用户参与指标与客户留存率之间有显著的相关性,但你需要将其与一位不熟悉“统计显著性”概念的营销副总裁分享。你还需要熟悉客户终生价值(CLV),以便能够解释你发现的相关性和重要性。
数据科学家的基本技能
我们已经覆盖了数据科学中的关键概念。现在让我们来看一下作为数据科学家你需要掌握的基本技能。如果你有兴趣了解更多,我在这里介绍了一些更具体的数据科学家所需技能。
编程语言、数据查询和数据可视化
很难对技能的重要性进行排名——数据科学家需要各种技能,这些技能都同等重要。也就是说,如果有一种技能是绝对不可或缺的,那一定是编码。
编码分为几个方面——你需要编程语言,通常是 R 或 Python(或两者)。你还需要数据检索和操作的查询语言,如 SQL(结构化查询语言)用于关系数据库。最后,你可能还需要了解其他语言或程序,如 Tableau 进行数据可视化,尽管值得一提的是,现在很多数据可视化是用 Python 或 R 完成的。
数学
还记得我之前提到的统计学吗?作为数据科学家,你需要知道如何进行数学计算。数据可视化只能走到一定程度,之后你需要一些实际的统计显著性。关键的数学技能包括:
-
概率与统计:概率分布、假设检验、统计推断、回归分析和方差分析(ANOVA)。这些技能使你能够做出可靠的统计判断,并从数据中得出有意义的结论。
-
线性代数:向量和矩阵运算、线性方程组的求解、矩阵分解、特征值和特征向量,以及矩阵变换。
-
微积分:你需要熟悉导数、梯度和优化等概念,以训练模型、优化和微调模型。
-
离散数学:如组合学、图论和算法。你将使用这些知识进行网络分析、推荐系统和算法设计。对于开发处理大规模数据的算法来说,这非常重要。
模型管理
让我们谈谈模型。作为数据科学家,你需要知道如何构建、部署和维护模型。这包括确保模型与现有基础设施的无缝集成,解决可扩展性和效率问题,并持续评估模型在实际场景中的表现。
在技术方面,这意味着你需要熟悉:
-
机器学习库:这些包括 Python 中的 scikit-learn、TensorFlow、PyTorch 或 Keras 进行深度学习,以及 XGBoost 或 LightGBM 进行梯度提升。
-
模型开发框架:如 Jupyter Notebook 或 JupyterLab,用于互动和协作的模型开发。
-
云平台:考虑使用亚马逊网络服务(AWS)、微软 Azure 或谷歌云平台(GCP)来部署和扩展机器学习模型。
-
自动化机器学习(AutoML):Google AutoML、H2O.ai 或 DataRobot 自动化构建机器学习模型的过程,无需大量手动编码。
-
模型部署与服务:Docker 和 Kubernetes 通常用于将模型打包并部署为容器。这些工具使得模型可以在不同环境中部署和扩展。此外,像 Python 中的 Flask 或 Django 工具可以让你创建 Web API 来服务模型,并将其集成到生产系统中。
-
模型监控与评估:使用 Prometheus、Grafana 或 ELK(Elasticsearch、Logstash、Kibana)堆栈进行日志聚合和分析。这些工具有助于跟踪模型指标、检测异常,并确保模型随着时间的推移继续表现良好。
沟通
到目前为止,我们已经覆盖了“硬技能”。现在,让我们思考一下你需要什么软技能。如我在“概念”部分提到的,你需要的一项重要技能是沟通。以下是作为数据科学家你需要进行的一些沟通示例:
-
数据讲述:你需要将复杂的技术概念转化为清晰、简洁且引人入胜的叙述,这些叙述能够引起你的听众共鸣,包括你的分析的重要性及其对决策的影响。
-
可视化:是的,数据可视化在沟通技能中有一个小节。除了创建图表的技术能力,你还应该知道何时、何种类型以及如何谈论你的数据可视化。
-
协作与团队合作:没有数据科学家在孤立环境中工作。你将与数据工程师、业务分析师和领域专家合作。练习你的积极倾听和建设性反馈技能。
-
客户管理:这并非所有数据科学家的情况,但有时你会直接与客户或外部利益相关者合作。你需要培养强大的客户管理技能,包括理解他们的需求、管理期望以及定期提供项目进展更新。
-
持续学习与适应能力:最后但同样重要的是,你需要随时准备学习新事物。保持对领域最新进展的了解,并开放地获取新技能和知识。
商业头脑
这归结于在你业务的背景下了解一个数字的重要性。例如,你可能会发现人们在周日购买鸡蛋与天气之间存在高度显著的关系。但这对你的业务有何意义?
在这种情况下,你可能会进一步分析,发现周日鸡蛋购买的增加与晴朗的天气相关,这表明客户在天气良好时更可能参与户外活动或举办早午餐。这一洞察可以被超市或餐厅利用,以便相应地计划库存和促销活动。
通过将数据模式与业务结果联系起来,你可以提供战略指导和可操作的建议。在这个例子中,这可能涉及到在晴朗的周末优化与鸡蛋相关的营销活动,或探索与本地早午餐场所的合作。
数据科学工作流程
数据科学家做什么?为了了解这一点,让我们看看数据科学项目中涉及的典型步骤:问题定义、数据收集、数据清理、探索性数据分析、模型构建、评估和沟通。
我将通过一个例子来说明每一步:在本节其余部分中,假设你作为一家电子商务公司的数据科学家,公司营销团队希望提高客户留存率。
1. 问题定义:
这意味着你需要了解业务目标,明确问题陈述,并定义衡量客户留存的关键指标。
你将致力于识别导致客户流失的因素,并制定减少流失率的策略。
为了衡量客户留存,你需要定义关键指标,包括客户流失率、客户生命周期价值(CLV)、重复购买率或客户满意度评分。通过定义这些指标,你建立了一种量化的方法来跟踪和评估提高客户留存的策略效果。
2. 数据收集
收集相关的数据源,如客户购买历史、人口统计信息、网站互动和客户反馈。这些数据可以从数据库、API 或第三方来源获取。
3. 数据清理
收集的数据几乎肯定会包含缺失值、异常值或不一致之处。在数据清理阶段,你需要通过处理缺失值、删除重复项、处理异常值和确保数据完整性来预处理和清理数据。
4. 探索性数据分析(EDA)
接下来,通过可视化数据、检查统计摘要、识别相关性以及发现模式或异常来深入了解数据及其特征。例如,你可能会发现经常购买的客户通常具有更高的留存率。
5. 模型构建
开发预测模型来分析不同变量与客户留存之间的关系。例如,你可以构建像逻辑回归或随机森林这样的机器学习模型,以预测客户流失的可能性,基于诸如购买频率、客户人口统计信息或网站参与指标等各种因素。
6. 评估
使用准确率、精确率、召回率或 ROC 曲线下面积等指标来评估模型的性能。你通过交叉验证或训练-测试拆分等技术来验证模型的可靠性。
7. 沟通
你已经获得了一些发现——现在与大家分享吧。按照我们的示例,你需要能够在你所在公司的业务背景以及更广泛的商业环境中,智能地讨论你的客户流失结果。让大家关注,并解释这个特定发现的重要性以及他们应该怎么做。
例如,在分析客户流失后,你可能会发现客户满意度评分和流失率之间存在显著的相关性。
当你与市场营销团队或高级主管分享时,你需要有效地传达其影响和可操作的见解。你会解释通过改进客户支持、个性化体验或有针对性的促销,关注提升客户满意度,公司可以减轻流失、保留更多客户,并最终带来更高的收入。
此外,你需要将这一发现置于更广泛的商业环境中进行分析。比较你公司与竞争对手的流失率。
所以这就是你如何从数据湖转变为实际业务输入。最终,请记住数据科学是迭代和循环的。你会重复这个过程的各个步骤以及整个过程,以寻求有趣的见解,回答商业问题,并为你的雇主解决问题。
数据科学应用
数据科学是一个广阔的领域。你可以发现数据科学家几乎在每一个行业、任何规模的公司中工作。这是一个关键角色。
这里有一些现实世界的例子,展示了数据科学在解决复杂问题中的影响:
-
医疗保健:数据科学家分析大量医疗数据以改善患者结果和医疗服务。他们开发预测模型以识别高风险患者,优化治疗计划,并检测疾病爆发中的模式。
-
财务:考虑风险评估、欺诈检测、算法交易和投资组合管理。数据科学家开发模型,以帮助做出明智的投资决策和管理金融风险。
-
运输与物流:数据科学家优化路线规划,减少燃料消耗,提高供应链效率,并预测维护需求。
-
零售和电子商务:数据科学家分析客户数据、购买历史、浏览模式和人口统计信息,开发模型以推动客户参与,增加销售,并改善客户满意度。
数据科学入门
好的,这信息量很大。到现在为止,你应该已经清楚数据科学是什么,它如何运作,你应该熟悉哪些工具和技术,以及数据科学家的工作内容。
现在我们来看一下在哪里学习和实践数据科学。这可能会成为一篇独立的文章,所以我将链接到你可以开始的资源列表。
-
最佳免费数据科学课程
-
数据科学的最佳学习资源(书籍、课程和教程)
-
数据科学可视化最佳实践
-
获取数据以进行数据科学项目的最佳网站
-
最佳平台以练习关键数据科学技能
总的来说,我建议你这样做:
-
制定你需要的技能清单,参考这篇博客文章和数据科学家的职位描述。
-
先从免费资源入门,然后寻找优质的付费平台以深入学习。
-
建立项目和库的组合。
-
在像 Kaggle 和 StrataScratch 这样的平台上进行实践。
-
获得认证——一些平台如 LinkedIn 提供认证,以证明你具备相关技能。
-
开始申请。
-
网络建设——加入社区、Slack 群组和 LinkedIn 群组,参加活动。
最终,你可以预期这个过程会需要一些时间。但最终是值得的。
职业机会和职业路径
尽管FAANG 裁员的新闻不断,依据US News and World Report 2022的排名,信息安全分析师、软件开发人员、数据科学家和统计学家仍位列前十名工作。
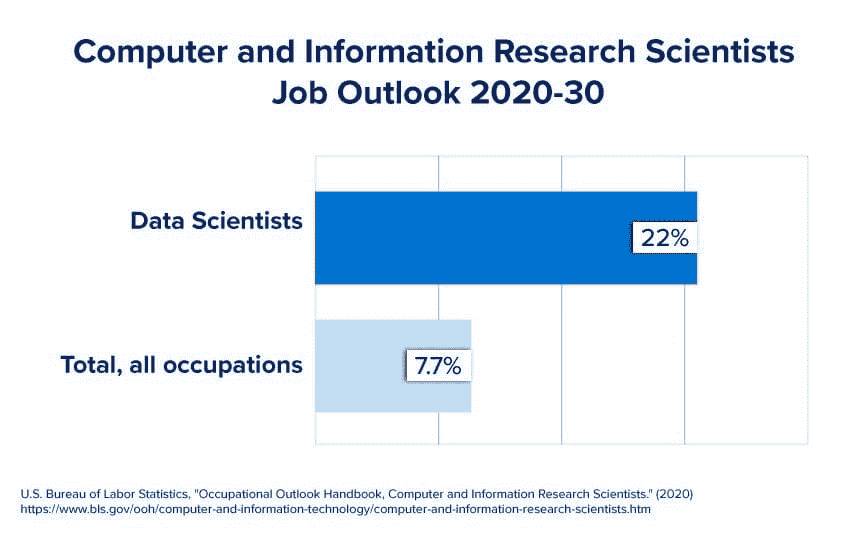
来源: bootcamp.cvn.columbia.edu/blog/data-scientist-career-path/
求职市场依然火热。公司仍然需要数据科学家。如果你在找数据科学家的工作时遇到困难,请记住你不必从零开始。我建议你从更初级的岗位入手,随着时间的推移逐步过渡到这一角色。你可以从数据分析师、数据工程师或机器学习工程师做起。
结论
很难为数据科学写一个介绍,因为这是一个庞大的领域,正在不断发展,越来越多的技术和工具每天都在添加。如果你从这篇文章中学到几件事,那就是:
-
数据科学需要多学科的综合方法。你需要掌握来自多个领域的技能,包括统计学、机器学习、编程和领域专长。而学习是永无止境的。
-
数据科学是迭代的。它非常依赖过程,但你可以期待在继续工作过程中反复优化和更新你的过程。成功且快乐的数据科学家拥抱实验。
-
软技能至关重要。你不能仅仅成为一个 Python 高手;你需要用故事、数据和图表将发现和见解传达给非技术利益相关者。
希望这些能为你提供一个起点。数据科学是一个既有回报又具挑战性的职业道路。如果你学习这些技能并付诸实践,你将能够迅速进入这个领域。
内特·罗西迪 是一名数据科学家,专注于产品战略。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过来自顶级公司的真实面试题来准备面试。你可以通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
更多相关内容
使用 Matplotlib 进行数据可视化简介
原文:
www.kdnuggets.com/2022/12/introduction-data-visualization-matplotlib.html

图片来源于作者
介绍
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
许多组织收集大量数据以进行业务决策。数据可视化 是将这些信息以各种图表和图形的形式呈现的过程。它简化了复杂数据,使得识别模式、分析趋势和发现可操作的见解变得更加容易。Matplotlib 是一个多平台的数据可视化库,使用 Python 编写。它最初是为了模拟 MATLAB 的绘图功能而创建的,但它强大且易于使用。Matplotlib 的一些优点如下:
-
更容易自定义
-
更适合入门
-
高质量输出
-
轻松获取
-
提供对图形各个元素的良好控制
入门
安装 Matplotlib
要安装 Matplotlib,请在 Windows、Mac OS 和 Linux 的终端中运行以下命令:
pip install matplotlib
对于 Jupyter notebook:
!pip install matplotlib
对于 Anaconda 环境:
conda install matplotlib
导入库
import numpy as np
import pandas as pd #If you are reading data from CSV
import matplotlib.pyplot as plt
Matplotlib 基础
创建图形
在 matplotlib 中创建图形有两种方法:
1) 函数式方法
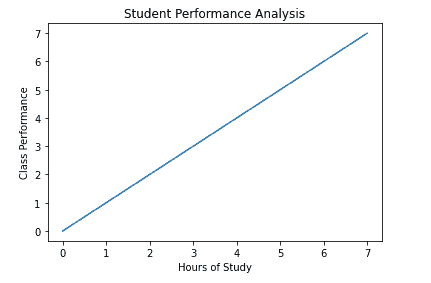
它们使用简单,但不允许非常高的控制程度。它使用 py.plot(x,y) 函数。我们在本教程的其他地方不会使用它,但你应该了解它的工作原理,所以让我们看看其中一个示例。
x = np.arange(0,8)
y = x
plt.plot(x, y)
plt.xlabel('Hours of Study')
plt.ylabel('Class Performance')
plt.title('Student Performance Analysis')
plt.show() # For non-jupyter users
2) OOP 方法
OOP 方法是创建图形的推荐方式。它通过创建图形对象,然后将坐标轴添加到其中来实现。图形对象在没有添加坐标轴之前是不可见的。
fig = plt.figure()
在我们绘制坐标轴之前,让我们理解其语法。
figureobject.add_axes([a,b,c,d])
这里的 a,b 指的是原点的位置。(0,0) 代表左下角,c,d 设置绘图的宽度和高度。两个值的范围从 0 到 1。
fig = plt.figure() # blank canvas
axes = fig.add_axes([0, 0, 0.5, 0.5])
axes.plot(x, y)
plt.show()
图形对象可以接受一些额外的参数,如 dpi 和图形大小。Dpi 指的是每英寸的点数,如果图形模糊,可以增加分辨率。图形大小则控制图形的尺寸(以英寸为单位)。
fig = plt.figure(figsize=(0.5,0.5),dpi=200) # blank canvas
axes = fig.add_axes([0, 0, 0.5, 0.5])
axes.plot(x, y)
plt.show()
你还可以按照如下方式将多个坐标轴添加到图形对象中:
a = np.arange(0,50)
b = a**3
fig = plt.figure()
outer_axes = fig.add_axes([0,0,1,1])
inner_axes = fig.add_axes([0.25,0.5,0.25,0.25])
outer_axes.plot(a,b)
inner_axes.set_xlim(10,20) #sets the range on x-axis
inner_axes.set_ylim(0,10000) #sets the range on y-axis
inner_axes.set_title("Zoomed Version")
inner_axes.plot(a,b)
plt.show()
我们可以使用 subplots()函数来创建多个图形,而不是手动管理图形对象中的不同坐标轴。让我们查看其语法,
fig, axes = plt.subplots(nrows=1, ncols=2)
它返回一个包含图形对象以及保存所有坐标轴对象的 numpy 数组的元组。我们需要指定实际坐标轴的行数和列数。每个坐标轴对象都会单独返回,可以独立访问。
exercise_hrs = np.arange(0, 5)
male_cal = exercise_hrs
female_cal = 0.70 * exercise_hrs
fig, axes = plt.subplots(nrows=1, ncols=2)
axes[0].plot(exercise_hrs, male_cal)
axes[0].set_ylim(0, 5) # Sets range of y
axes[0].set_title("Male")
axes[1].plot(exercise_hrs, female_cal)
axes[1].set_ylim(0, 5)
axes[1].set_title("Female")
fig.suptitle(
"Calories Burnt vs Workout Hours Analysis", fontsize=16
) # Displays the main title
fig.tight_layout() # Prevents overlapping of subplots
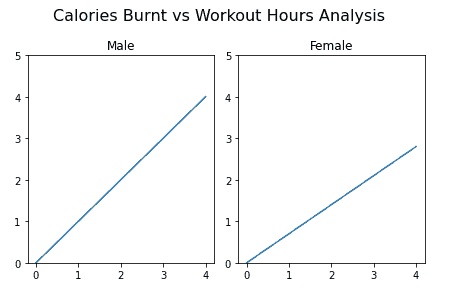
子图间距可以通过以下方法手动调整:
fig.subplots_adjust(left=None,top=None,right=None,top=None,wspace=None, hspace=None)
-
left = 图形子图的左侧
-
right = 图形子图的右侧
-
bottom = 图形子图的底部
-
top = 图形子图的顶部
-
wspace = 保留的子图之间的宽度空间
-
hspace = 保留的子图之间的高度空间
fig.subplots_adjust(left=0.2,top=0.8,wspace=0.9, hspace=0.1)
应用到上面的图形中:
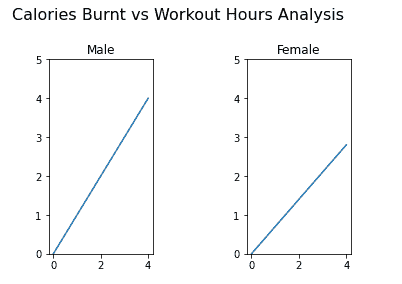
自定义图形
1) 图例
如果我们在一个图形对象中创建多个图形,可能会变得难以识别每个图形所表示的内容。因此,我们在axes.plot()函数中添加label= “text”属性,然后调用axes.legend()函数来显示图例。
axes.legend(loc=0) or axes.legend() #Default - Matplotlib decides position
axes.legend(loc=1) # upper right
axes.legend(loc=2) # upper left
axes.legend(loc=3) # lower left
axes.legend(loc=4) # lower right
axes.legend(loc=(x,y)) # At (x,y) position
axes.legend() 还有一个参数 loc,用于决定图例的位置。
x = np.arange(0,11)
fig = plt.figure()
ax = fig.add_axes([0,0,0.75,0.75])
ax.plot(x, x**2, label="X²")
ax.plot(x, x**3, label="X³")
ax.legend(loc=0) #Let matplotlib decide
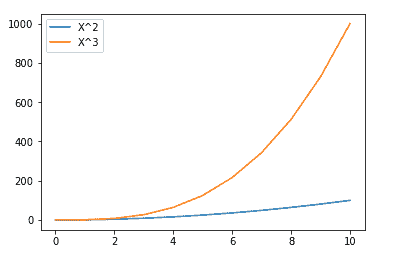
2) 线条样式
Matplotlib 提供了很多自定义选项。让我们深入分析一下更改线条颜色、宽度和样式的语法。
axes.plot(x, y, color or c = 'red',alpha= ‘0.5’, linestyle or ls = ':', linewidth or lw= 5)
颜色: 我们可以通过名称或 RGB 值来定义颜色,或者使用 Matlab 类型的语法,其中 r 表示红色等。我们还可以使用 alpha 属性设置透明度。
线型: 自定义样式也可以创建,但由于我们主要关注可视化,因此简单的样式对我们来说就足够了。它们如下所示:
linestyle = “-” or linestyle = “solid”
linestyle = “:” or linestyle = “dotted”
linestyle = “--” or linestyle = “dashed”
linestyle = “-.” or linestyle = “dashdot”
线宽: 默认值为 1,但我们可以根据需要进行更改。
fig, ax = plt.subplots()
ax.plot(x, x-2, color="#000000", linewidth=1 , linestyle='solid')
ax.plot(x, x-4, color="red", lw=2 ,ls=":")
ax.plot(x, x-6, color="blue",alpha=0.4,lw=4 , ls="-.")
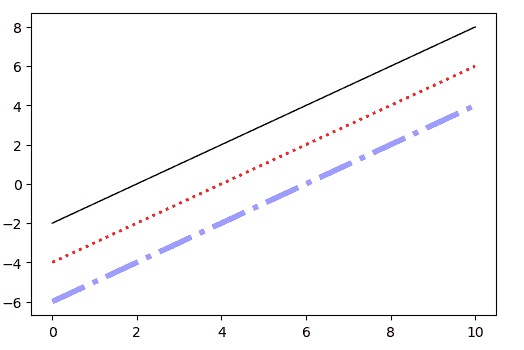
3) 标记样式
在 matplotlib 中,所有绘制的点称为标记。默认情况下,我们只看到最终的线条,但我们可以根据自己的选择设置标记类型及其大小。
axes.plot(x, y,marker =”+” , markersize or ms= 20)
标记有很多类型,详见这里,但我们只讨论主要的几种:
marker='+' # plus
marker='o' # circle
marker='s' # square
marker='.' # point
示例:
fig, ax = plt.subplots()
ax.plot(x, x+2,marker='+',markersize=20)
ax.plot(x, x+4,marker='o',ms=10)
ax.plot(x, x+6,marker='s',ms=15,lw=0)
ax.plot(x, x+8,marker='.',ms=10)
图表类型
Matplotlib 提供了各种特殊图表,因为不同类型的数据需要不同的表示方式。选择图表取决于分析的问题。例如,如果你关注部分与整体的关系,可以使用饼图;如果你想比较值或组,可以使用条形图;如果你想观察不同变量之间的对应关系,可以使用散点图等。在本教程中,我们将逐一讲解并讨论 5 种最常用的图表。让我们开始吧:
1) 折线图
这是表示数据的最简单形式。它们主要用于分析与时间相关的数据,因此也称为时间序列图。向上的趋势表示变量之间的正相关,反之亦然。它广泛应用于天气预报、股市预测以及监测日常客户或销售等。
# Data is collected from worldometer
years = ["1980", "1990", "2000", "2010", "2020"]
Asia = [2649578300, 3226098962, 3741263381, 4209593693, 4641054775]
Europe = [693566517, 720858450, 725558036, 736412989, 747636026]
fig, ax = plt.subplots()
ax.set_title("Population Analysis (1980 - 2020)")
ax.set_xlabel("Years")
ax.set_ylabel("Population in billions")
ax.plot(years, Asia, label="Asia")
ax.plot(years, Europe, label="Europe")
ax.legend()
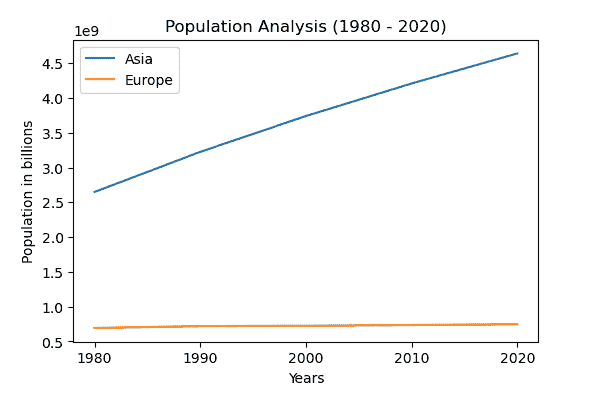
我们可以看到,自 1980 年以来,亚洲的人口呈指数增长。
2) 饼图
饼图将圆圈分成代表部分与整体关系的比例区域。每一部分加起来总和为 100%。这些切片的面积也被称为楔形。
matplotlib.pyplot.pie(data,explode=None,labels=None,colors=None,autopct=None, shadow=False)
-
data = 你想绘制的值的数组
-
explode = 分离图表中的楔形
-
labels = 代表不同切片的字符串
-
colors = 用指定颜色填充楔形
-
autopct = 在楔形图上标注数值
-
shadow = 为楔形添加阴影
labels = [
"Rent",
"Utility bills",
"Transport",
"University fees",
"Grocery",
"Savings",
]
expenses = [200, 100, 80, 500, 100, 60]
explode = [0.0, 0.0, 0.0, 0.0, 0.0, 0.4]
colors = [
"lightblue",
"orange",
"lightgreen",
"purple",
"crimson",
"red",
]
fig, ax = plt.subplots()
ax.set_title("University Student Expenses")
ax.pie(
expenses,
labels=labels,
explode=explode,
colors=colors,
autopct="%.1f%%",
shadow=True,
)
plt.show()
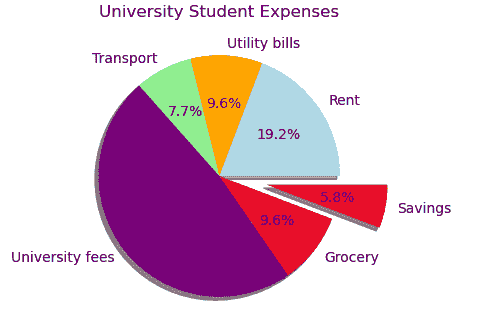
3) 散点图
散点图,也称为 XY 图,用于观察因变量和自变量之间的关系。它绘制个别数据点以进行趋势分析。使用散点图可以轻松检测异常值和相关关系。
matplotlib.pyplot.scatter(x, y, s=None, c=None, marker=None,alpha=None, linewidths=None, edgecolors=None)
-
(x,y) = 数据位置
-
s= 标记的大小
-
c= 标记颜色的序列
-
marker= 标记样式
-
alpha= 透明度
-
linewidth= 标记边缘的线宽
-
edgecolors= 标记边缘的颜色
x = np.linspace(0, 11, 40)
y = np.cos(x)
fig, ax = plt.subplots()
ax.scatter(
x,
y,
s=50,
c="green",
marker="o",
alpha=0.4,
linewidth=2,
edgecolor="black",
)
4) 条形图
条形图用于通过垂直或水平的矩形条来可视化分类数据。条形的长度或高度(取决于是柱状图还是水平条形图)表示其数值。当你想比较某些组时,条形图非常有用。
matplotlib.pyplot.bar(x, height, width, bottom, align)
-
x= 类别变量
-
height= 对应的数值
-
width= 条形图的宽度(默认值为 0.8)
-
bottom= 条形图基底的起始点(默认值为 0)
-
align= 类别名称的对齐方式(默认值为居中)
注意: 颜色、边框颜色和线宽也可以自定义。
fig,ax = plt.subplots()
courses = ['Maths', 'Science', 'History', 'Computer', 'English']
students = [24,12,15,31,22]
ax.bar(courses,students,width=0.5,color="red",alpha=0.6,edgecolor="red",linewidth=2)
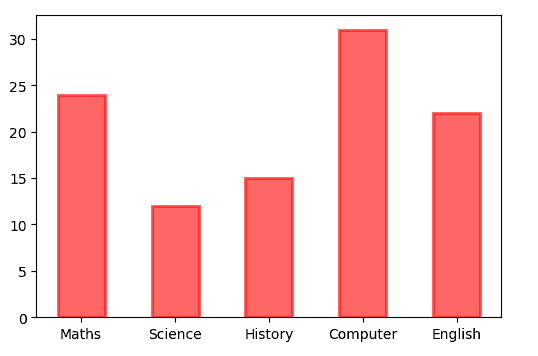
我们还可以通过调整底部属性来堆叠类别。
# For Horizontal Bar Chart
ax.barh(
courses,
students,
height=0.7,
color="red",
alpha=0.6,
edgecolor="red",
linewidth=2,
)
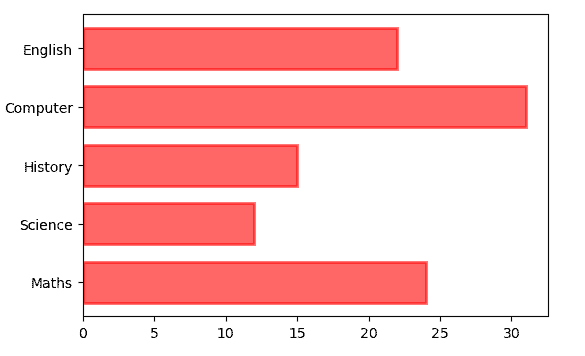
我们还可以通过调整底部属性来堆叠类别。
fig,ax = plt.subplots()
courses = ['Maths', 'Science', 'History', 'Computer', 'English']
students = [[24,12,15,31,22],[19,14,19,26,18]] #Male array then female array
ax.bar(courses,students[0],width=0.5,label="male")
ax.bar(courses,students[1],width=0.5,bottom=students[0],label="female")
ax.set_ylabel("No of Students")
ax.legend()
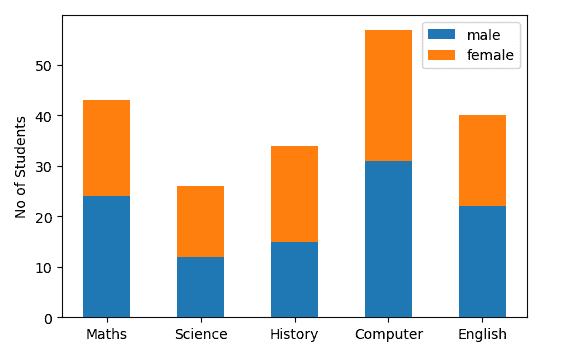
我们还可以通过调整条形的厚度和位置来绘制多个条形。
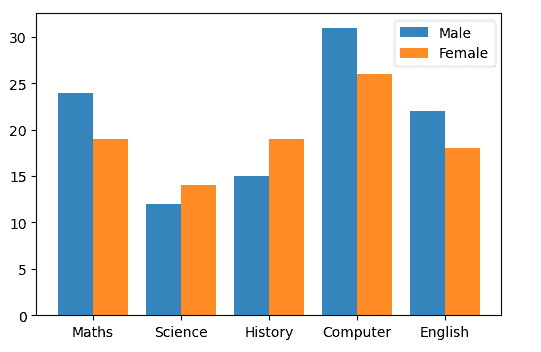
fig,ax = plt.subplots()
courses = ['Maths', 'Science', 'History', 'Computer', 'English']
males = (24,12,15,31,22)
females = (19,14,19,26,18)
index=np.arange(5)
bar_width=0.4
ax.bar(index,males,bar_width,alpha=.9,label="Male")
# We will adjust the bar_width so it is placed side to side
ax.bar(index + bar_width ,females,bar_width,alpha=.9,label="Female")
ax.set_xticks(index + 0.2,courses) # Show labels
ax.legend()
5) 直方图
由于其相似性,许多人经常将其与条形图混淆,但它在表示信息的方式上有所不同。它将数据点组织成称为“箱”的范围,绘制在 X 轴上,而 Y 轴包含有关频率的信息。与条形图不同,它仅用于表示数值数据。
matplotlib.pyplot.hist(x,bins=None,cumulative=False,range=None,bottom=None,histtype=’bar’,rwidth=None, color=None, label=None, stacked=False)
-
bins = 如果是 int,则为等宽的箱子,否则取决于序列
-
cumulative = 最后一个箱将给出总数据点(基于累积频率)
-
bottom = 箱的位置
-
range = 用于切割数据
-
histtype= bar, barstacked, step, stepfilled(默认= bar)
-
rwidth= 直方图条的相对宽度
-
stacked= 如果为 True,则多个数据将堆叠在一起
-
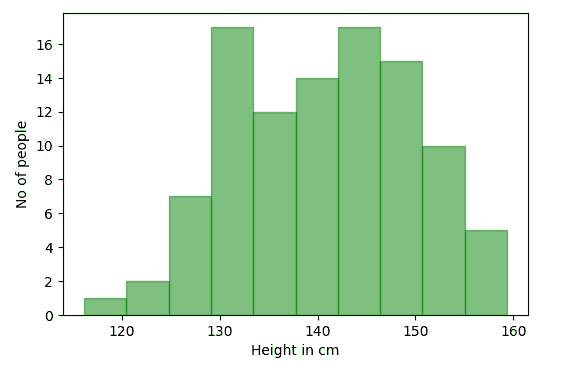
data = np.random.normal(140, 10,100) # 生成 100 人的身高数据
-
bins = 10
data = np.random.normal(140, 10,100) # Generating height of 100 people
bins = 10
fig,ax = plt.subplots()
ax.set_xlabel("Height in cm")
ax.set_ylabel("No of people")
ax.hist(data,bins=bins, color="green",alpha=0.5,edgecolor="green")
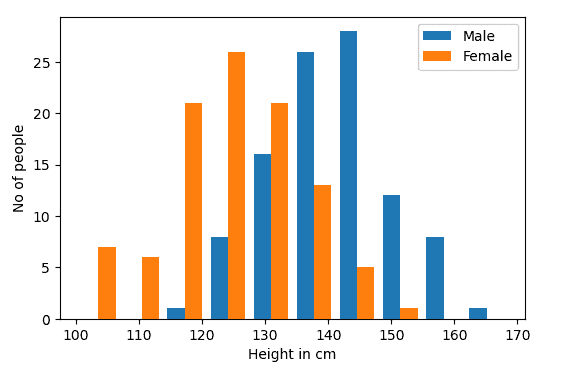
male = np.random.normal(140, 10,100) # Generating height of 100 males
female = np.random.normal(125,10,100) # Generating height of 100 females
bins = 10
fig,ax = plt.subplots()
ax.set_xlabel("Height in cm")
ax.set_ylabel("No of people")
ax.hist([male,female],bins=bins,label=["Male","Female"])
ax.legend()
结论
希望你喜欢阅读这篇文章,并且现在能够使用 Matplotlib 执行不同的可视化。如果你有任何想法或反馈,请随时在评论区分享。这里是 Matplotlib 文档的链接,如果你有兴趣深入了解。
Kanwal Mehreen 是一名有志的软件开发人员,对数据科学和 AI 在医学中的应用充满热情。Kanwal 被选为 2022 年亚太地区的 Google Generation Scholar。Kanwal 喜欢通过撰写有关趋势话题的文章来分享技术知识,并热衷于改善女性在科技行业中的代表性。
更多相关话题
使用 Keras 深度学习简介
原文:
www.kdnuggets.com/2018/10/introduction-deep-learning-keras.html/2
 评论
评论
编译人工神经网络
*classifier.compile(optimizer= ‘adam’,
loss = ‘binary_crossentropy’,
metrics = [‘accuracy’])*
编译基本上是将随机梯度下降应用于整个神经网络。第一个参数是你想用来获得神经网络最佳权重集合的算法。这里使用的算法是随机梯度算法。这有很多变体,一种非常有效的是 adam。第二个参数是随机梯度算法中的损失函数。由于我们的类别是二元的,我们使用 binary_crossentropy 损失函数。否则我们会使用 categorical_crossentropy。最后一个参数是我们用来评估模型的标准。在这种情况下,我们使用准确率。
将我们的人工神经网络拟合到训练集
*classifier.fit(X_train, y_train, batch_size = 10, epochs = 100)*
X_train 代表我们用来训练人工神经网络的自变量,而 y_train 代表我们要预测的列。Epochs 代表我们将数据集通过人工神经网络的次数。Batch_size 是更新权重后的一组观察值的数量。
使用训练集进行预测
*y_pred = classifier.predict(X_test)*
这将展示索赔是欺诈性的概率。然后我们设定了一个 50% 的阈值来将索赔分类为欺诈性。这意味着任何概率为 0.5 或以上的索赔将被分类为欺诈性。
*y_pred = (y_pred > 0.5)*
这样,保险公司可以首先跟踪那些不被怀疑的索赔,然后花更多时间评估被标记为欺诈的索赔。
检查混淆矩阵
*from sklearn.metrics import confusion_matrix*
*cm = confusion_matrix(y_test, y_pred)*

混淆矩阵可以这样解释。在 2000 个观察值中,1550 + 175 个被正确预测,而 230 + 45 个被错误预测。你可以通过将正确预测的数量除以预测的总数来计算准确率。在这种情况下是 (1550+175) / 2000,结果是 86%。
做出单一预测
假设保险公司给你一个索赔,他们希望知道这个索赔是否是欺诈性的。你会怎么做来找出答案?
*new_pred = classifier.predict(sc.transform(np.array([[a,b,c,d]])))*
其中 a、b、c、d 代表你拥有的特征。
*new_pred = (new_prediction > 0.5)*
由于我们的分类器期望的是 numpy 数组,我们必须将单个观察值转换为 numpy 数组,并使用标准缩放器进行缩放。
评估我们的人工神经网络
训练模型一两次后,你会注意到准确度不断变化。这使得你不太确定哪一个是正确的。这引入了偏差方差权衡。本质上,我们试图训练一个模型,使其准确且在多次训练时不会有太大的准确度方差。为了解决这个问题,我们使用 K 折交叉验证,K 等于 10。这将把训练集分成 10 折。然后我们将在 9 折上训练模型,并在剩下的折上测试。由于我们有 10 折,我们将通过 10 种组合进行迭代。每次迭代都会给我们一个准确度。然后我们计算所有准确度的均值,并将其作为我们的模型准确度。我们还计算方差,以确保其最小。
Keras 有一个 scikit learn 的封装器(KerasClassifier),使我们可以在我们的 Keras 代码中包含 K 折交叉验证。
*from keras.wrappers.scikit_learn import KerasClassifier*
接下来我们从 scikit_learn 导入 k 折交叉验证函数。
*from sklearn.model_selection import cross_val_score*
KerasClassifier 期望其参数之一是一个函数,因此我们需要构建这个函数。这个函数的目的是建立我们的 ANN 架构。
这个函数将构建分类器并返回,以便在下一步中使用。我们在这里做的唯一事情就是将我们之前的 ANN 架构封装在一个函数中并返回分类器。
然后我们创建一个新的分类器,使用 K 折交叉验证,并将参数build_fn传递为我们刚刚创建的函数。接下来,我们传递批次大小和训练轮数,就像我们在之前的分类器中做的那样。
*classiifier = KerasClassifier(build_fn = make_classifier,
batch_size=10, nb_epoch=100)*
要应用 k 折交叉验证函数,我们可以使用 scikit-learn 的cross_val_score函数。估算器是我们刚刚用make_classifier构建的分类器,n_jobs=-1 将利用所有可用的 CPU。cv 是折数,10 是一个典型的选择。cross_val_score将返回计算中使用的十个测试折的准确度。
*accuracies = cross_val_score(estimator = classifier,
X = X_train,
y = y_train,
cv = 10,
n_jobs = -1)*
为了获得相对准确度,我们需要计算准确度的均值。
*mean = accuracies.mean()*
方差可以按以下方式获得:
*variance = accuracies.var()*
目标是使准确度之间的方差尽可能小。
对抗过拟合
在机器学习中,过拟合是指模型学习了训练集中的细节和噪声,从而在测试集上表现不佳。这可以通过测试集和训练集的准确度之间存在巨大差异,或在应用 k 折交叉验证时观察到高方差来发现。在人工神经网络中,我们使用一种叫做丢弃正则化的技术来对抗这一问题。丢弃正则化通过在每次训练迭代时随机禁用一些神经元,以防止它们过于依赖彼此。
在这种情况下,我们在第一个隐藏层和第二个隐藏层之后应用 dropout。使用 0.1 的比率意味着每次迭代时 1%的神经元将被禁用。建议从 0.1 的比率开始。然而,你绝不要超过 0.4,因为这会导致欠拟合。
参数调优
一旦获得准确率,你可以调整参数以获得更高的准确率。网格搜索使我们能够测试不同的参数,以获得最佳参数。
第一步是从 sklearn 中导入 *GridSearchCV *模块。
*from sklearn.model_selection import GridSearchCV*
我们还需要按如下方式修改我们的 make_classifier 函数。我们创建一个名为 ***optimizer ***的新变量,以便在我们的 params 变量中添加多个优化器。
我们仍然使用 KerasClassifier,但不传递批量大小和迭代次数,因为这些是我们想要调优的参数。
*classifier = KerasClassifier(build_fn = make_classifier)*
下一步是创建一个包含我们想要调优的参数的字典——在这个例子中是批量大小、迭代次数和优化器函数。我们仍然使用 adam 作为优化器,并添加一个名为 rmsprop 的新优化器。Keras 文档推荐在处理递归神经网络时使用 rmsprop。然而,我们可以尝试在这个人工神经网络中使用它,看是否能得到更好的结果。
*params = {
'batch_size':[20,35],*
*'nb_epoch':[150,500],*
*'Optimizer':['adam','rmsprop'**]
}*
然后我们使用网格搜索来测试这些参数。网格搜索函数期望我们的估算器、我们刚刚定义的参数、评分指标和折叠数。
*grid_search = GridSearchCV(estimator=classifier,
param_grid=params,
scoring=’accuracy’,
cv=10)*
像以前的对象一样,我们需要对训练集进行拟合。
*grid_search = grid_search.fit(X_train,y_train)*
我们可以使用best_params从网格搜索对象中获取最佳参数选择。同样,我们使用 best_score_ 来获取最佳分数。
*best_param = grid_search.best_params_*
*best_accuracy = grid_search.best_score_*
需要注意的是,这个过程会花费一些时间,因为它会搜索最佳参数。
结论
人工神经网络只是深度神经网络的一种。还有其他网络,例如递归神经网络(RNN)、卷积神经网络(CNN)和玻尔兹曼机。RNN 可以预测股票价格未来是上涨还是下跌。CNN 用于计算机视觉——例如识别图像中的猫和狗或识别脑部图像中的癌细胞。玻尔兹曼机用于编程推荐系统。也许我们可以在未来讨论这些神经网络中的某一个。
干杯。
简介: Derrick Mwiti 是一位数据分析师、作家和导师。他致力于在每个任务中交付卓越的成果,并且是 Lapid Leaders Africa 的导师。
原文。经许可转载。
相关:
-
Keras 4 步工作流程
-
掌握 Keras 深度学习的 7 个步骤
-
初学者数据可视化与探索使用 Pandas
我们的前三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关内容
可解释人工智能简介,以及我们为何需要它
原文:
www.kdnuggets.com/2019/04/introduction-explainable-ai.html
评论
由 Patrick Ferris 撰写。

黑箱 - 代表神经网络等函数的未知内部机制的隐喻
神经网络(及其所有子类型)越来越多地用于构建能够在各种不同环境中进行预测和分类的程序。
示例包括使用递归神经网络的机器翻译,以及使用卷积神经网络的图像分类。谷歌 DeepMind 发布的研究引发了对强化学习的兴趣。
所有这些方法都推动了许多领域的发展,并产生了可用于提高生产力和效率的模型。
然而,我们真的不知道它们是如何工作的。
我有幸参加了今年的知识发现与数据挖掘(KDD)会议。在我参加的讲座中,有两个主要的研究领域似乎引起了很多人的关注:
-
首先,寻找有意义的图结构表示以供神经网络使用。Oriol Vinyals来自 DeepMind 做了关于他们的消息传递神经网络的讲座。
-
第二个领域,以及本文的重点,是可解释的人工智能模型。随着我们为神经网络生成更新、更具创新性的应用,“它们是如何工作的?”这个问题变得越来越重要。
为何需要可解释模型?
神经网络并非万无一失。
除了我们已经开发出许多工具(如 Dropout 或增加数据量)来对抗的过拟合和欠拟合问题之外,神经网络以一种不透明的方式操作。
我们实际上不知道它们为什么做出这些选择。随着模型变得越来越复杂,生成一个可解释的模型变得更加困难。
以单像素攻击为例(请查看这里的视频)。这是一种通过分析卷积神经网络(CNN)并应用差分进化(进化算法的一个成员)来实施的复杂方法。
与限制目标函数可微的其他优化策略不同,这种方法使用迭代进化算法来生成更好的解决方案。具体来说,对于这个单像素攻击,唯一需要的信息是类别标签的概率。

来自单像素攻击以欺骗深度神经网络的 Jiawei Su 等人
欺骗这些神经网络的相对容易性令人担忧。在这背后存在一个更系统性的问题:信任神经网络。
最好的例子是在医学领域。假设你正在构建一个神经网络(或任何黑箱模型)来帮助预测根据患者记录的心脏病。
当你训练和测试模型时,你会获得良好的准确性和令人信服的正预测值。你把它交给临床医生,他们同意这似乎是一个强大的模型。
但他们会犹豫使用它,因为你(或模型)不能回答一个简单的问题:“你为什么预测这个人更可能发展成心脏病?”
缺乏透明度对希望了解模型工作方式以改善服务的临床医生来说是个问题。对患者来说,他们也希望有一个具体的预测理由。
从伦理角度来看,如果你的唯一理由是“黑箱告诉我如此”,是否正确告知患者他们有更高的疾病概率?医疗保健不仅关乎科学,也关乎对患者的同情。
可解释 AI 领域近年来不断发展,这一趋势似乎将继续。
接下来是一些有趣和创新的方向,研究人员和机器学习专家正在探索这些方向,以寻找不仅表现良好,而且能够解释其决策原因的模型。
反向时间注意力模型(RETAIN)
RETAIN 模型由Edward Choi et al.在乔治亚理工学院开发。它的推出旨在帮助医生理解为什么模型预测患者有心力衰竭的风险。
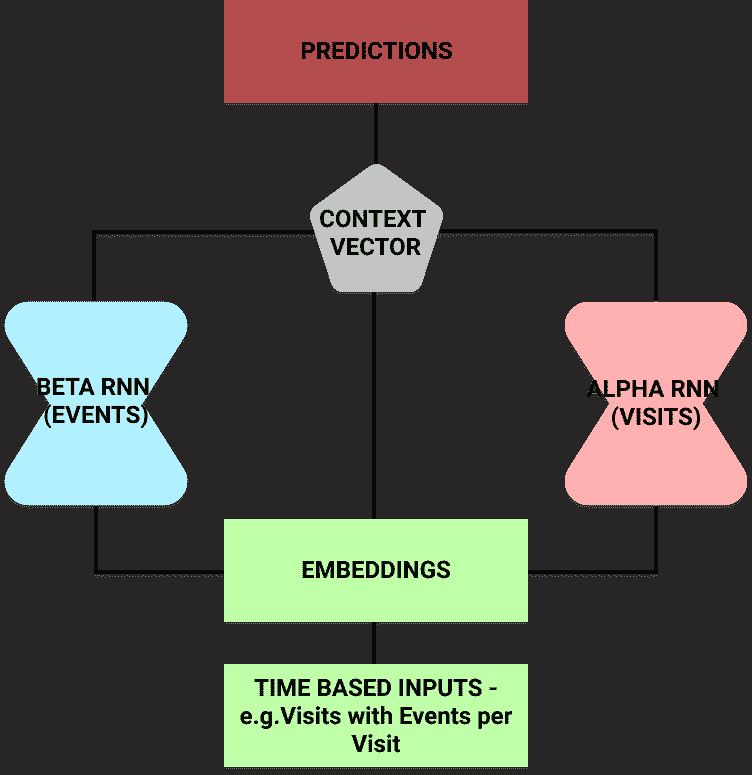
RETAIN 递归神经网络模型利用注意力机制提高可解释性
这个想法是,根据患者的住院记录以及访问事件,它们可以预测心力衰竭的风险。
研究人员将输入分成两个递归神经网络。这使他们能够对每个网络使用注意力机制以了解神经网络关注的重点。
一旦训练完成,模型可以预测患者的风险。但它也可以利用 alpha 和 beta 参数输出哪些住院记录(以及住院中的哪些事件)影响了它的选择。
局部可解释模型无关解释(LIME)
另一种已经变得相当常用的方法是LIME。
这是一种事后模型——它在决策做出后提供解释。这意味着它不是一个从头到尾纯粹的‘玻璃箱’透明模型(如决策树)。
这种方法的主要优势之一是它对模型无关。可以应用于任何模型,以产生对其预测的解释。
这种方法的关键概念是扰动输入,并观察这样做如何影响模型的输出。这使我们能够建立起模型关注和利用哪些输入以进行预测的图像。
例如,假设一种用于图像分类的 CNN。使用 LIME 模型生成解释的主要步骤有四个:
-
从一张正常图像开始,使用黑箱模型生成类别的概率分布。
-
然后以某种方式扰动输入。对于图像来说,这可能是通过将像素遮挡成灰色来完成的。现在将这些输入通过黑箱模型运行,以观察原本预测的类别概率如何变化。
-
对这组扰动和概率数据集使用可解释的(通常是线性的)模型,如决策树,以提取解释变化的关键特征。模型是局部加权的——这意味着我们更关心那些与我们使用的原始图像最相似的扰动。
-
输出权重最大的特征(在我们的例子中是像素)作为我们的解释。
层次相关传播(LRP)
这个方法利用了相关性重新分配和保留的思想。
我们从一个输入(例如,一张图像)及其分类概率开始。然后,向后推导,将这一概率重新分配给所有的输入(在这种情况下是像素)。
从一层到另一层的重新分配过程相当简单。
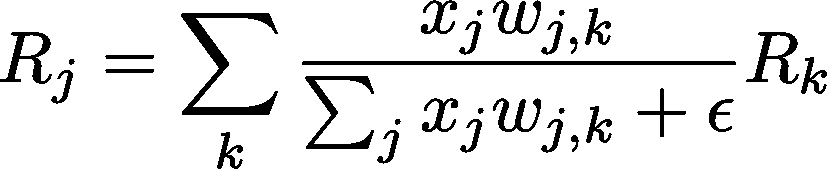
不要害怕——这个方程只是基于神经元激活和权重连接来加权相关性
在上述方程中,每一项代表以下思想:
-
x_j — 第l层中神经元j的激活值
-
w_j,k — 第l层中神经元j与第l + 1层中神经元k之间的连接权重
-
R_j — 第l层中每个神经元的相关性评分
-
R_k — 第l+1层中每个神经元的相关性评分
epsilon 只是一个小值,用于防止除以零。
正如你所看到的,我们可以向后推导以确定各个输入的相关性。此外,我们可以按相关性排序。这使我们能够提取出最有用或最强大的输入子集,以进行预测。
接下来做什么?
以上生成可解释模型的方法绝非穷尽。这些只是研究人员尝试过的一些方法的样本,用于从黑箱模型中生成可解释的预测。
希望这篇文章也能揭示为什么这是一个如此重要的研究领域。我们需要继续研究这些方法,并开发新的方法,以便机器学习能够以安全可靠的方式惠及尽可能多的领域。
如果你想阅读更多论文和领域,尝试以下一些。
-
Finale Doshi-Velez 和 Been Kim 关于该领域的论文
人工智能不应该成为我们盲目追随的强大神明。但我们也不应该忘记它及其可能带来的有益洞察。理想情况下,我们将建立灵活且可解释的模型,与专家及其领域知识合作,为每个人提供一个更光明的未来。
个人简介: Patrick Ferris 是一名十九岁的程序员、博客作者和全方位的技术爱好者,目前是剑桥黑客博客的主编。
原文。经许可转载。
资源:
相关:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关主题
欺诈检测系统简介
原文:
www.kdnuggets.com/2018/08/introduction-fraud-detection-systems.html
评论
由米格尔·冈萨雷斯-费罗,微软。
欺诈检测是银行和金融机构的首要任务之一,可以通过机器学习来解决。根据a report published by Nilson,2017 年全球因卡片欺诈案件造成的损失达到 228 亿美元。预计这一问题在未来几年将进一步恶化,到 2021 年,卡片欺诈的损失预计将达到 329.6 亿美元。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织 IT 需求
在本教程中,我们将使用Kaggle 上的信用卡欺诈检测数据集来识别欺诈案例。我们将使用梯度提升树作为机器学习算法。最后,我们将创建一个简单的 API 来使模型投入实际使用。
我们将使用梯度提升库LightGBM,它最近已成为Kaggle 竞赛顶级参与者中最受欢迎的库之一。
欺诈检测问题以极其不平衡而著称。Boosting 是一种通常适用于这类数据集的技术。它通过迭代创建弱分类器(决策树),加权实例以提高性能。在第一个子集中,训练和测试一个弱分类器,在所有训练数据上测试表现差的实例权重被提高,以便在下一个数据子集中出现更多。最终,所有分类器都通过加权平均其预测结果进行集成。
在 LightGBM 中,有一个参数叫做is_unbalanced,可以自动帮助你控制这个问题。
LightGBM 可以在有或没有 GPU的情况下使用。对于像我们这里使用的小数据集,使用 CPU 更快,因为 IO 开销较大。然而,我想展示 GPU 的替代方案,虽然安装更复杂,以便有兴趣的人可以尝试更大的数据集。
在 Linux 中安装依赖项:
$ sudo apt-get update
$ sudo apt-get install cmake build-essential libboost-all-dev -y
$ conda env create -n fraud -f conda.yaml
$ source activate fraud
(fraud)$ python -m ipykernel install --user --name fraud --display-name "Python (fraud)"
import numpy as np
import sys
import os
import json
import pandas as pd
from collections import Counter
import requests
from IPython.core.display import display, HTML
import lightgbm as lgb
import sklearn
import aiohttp
import asyncio
from utils import (split_train_test, classification_metrics_binary, classification_metrics_binary_prob,
binarize_prediction, plot_confusion_matrix, run_load_test, read_from_sqlite)
from utils import BASELINE_MODEL, PORT, TABLE_FRAUD, TABLE_LOCATIONS, DATABASE_FILE
print("System version: {}".format(sys.version))
print("Numpy version: {}".format(np.__version__))
print("Pandas version: {}".format(pd.__version__))
print("LightGBM version: {}".format(lgb.__version__))
print("Sklearn version: {}".format(sklearn.__version__))
%load_ext autoreload
%autoreload 2
System version: 3.6.0 |Continuum Analytics, Inc.| (default, Dec 23 2016, 13:19:00) [GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.57)]
Numpy version: 1.13.3
Pandas version: 0.22.0
LightGBM version: 2.1.1
Sklearn version: 0.19.1
数据集
第一步是加载数据集并分析它。
在继续之前,你必须运行笔记本 data_prep.ipynb,这将生成 SQLite 数据库。
query = 'SELECT * FROM ' + TABLE_FRAUD
df = read_from_sqlite(DATABASE_FILE, query)
print("Shape: {}".format(df.shape))
df.head()
Shape: (284807, 31)
| 时间 | V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | ... | V21 | V22 | V23 | V24 | V25 | V26 | V27 | V28 | 金额 | 类别 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | -1.359807 | -0.072781 | 2.536347 | 1.378155 | -0.338321 | 0.462388 | 0.239599 | 0.098698 | 0.363787 | ... | -0.018307 | 0.277838 | -0.110474 | 0.066928 | 0.128539 | -0.189115 | 0.133558 | -0.021053 | 149.62 | 0 |
| 1 | 0.0 | 1.191857 | 0.266151 | 0.166480 | 0.448154 | 0.060018 | -0.082361 | -0.078803 | 0.085102 | -0.255425 | ... | -0.225775 | -0.638672 | 0.101288 | -0.339846 | 0.167170 | 0.125895 | -0.008983 | 0.014724 | 2.69 | 0 |
| 2 | 1.0 | -1.358354 | -1.340163 | 1.773209 | 0.379780 | -0.503198 | 1.800499 | 0.791461 | 0.247676 | -1.514654 | ... | 0.247998 | 0.771679 | 0.909412 | -0.689281 | -0.327642 | -0.139097 | -0.055353 | -0.059752 | 378.66 | 0 |
| 3 | 1.0 | -0.966272 | -0.185226 | 1.792993 | -0.863291 | -0.010309 | 1.247203 | 0.237609 | 0.377436 | -1.387024 | ... | -0.108300 | 0.005274 | -0.190321 | -1.175575 | 0.647376 | -0.221929 | 0.062723 | 0.061458 | 123.50 | 0 |
| 4 | 2.0 | -1.158233 | 0.877737 | 1.548718 | 0.403034 | -0.407193 | 0.095921 | 0.592941 | -0.270533 | 0.817739 | ... | -0.009431 | 0.798278 | -0.137458 | 0.141267 | -0.206010 | 0.502292 | 0.219422 | 0.215153 | 69.99 | 0 |
5 行 × 31 列
如我们所见,数据集极为不平衡。少数类别约占 0.002%的样本。
df['Class'].value_counts()
0 284315
1 492
Name: Class, dtype: int64
df['Class'].value_counts(normalize=True)
0 0.998273
1 0.001727
Name: Class, dtype: float64
下一步是将数据集拆分为训练集和测试集。
X_train, X_test, y_train, y_test = split_train_test(df.drop('Class', axis=1), df['Class'], test_size=0.2)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
(227845, 30)
(56962, 30)
(227845,)
(56962,)
print(y_train.value_counts())
print(y_train.value_counts(normalize=True))
print(y_test.value_counts())
print(y_test.value_counts(normalize=True))
0 227451
1 394
Name: Class, dtype: int64
0 0.998271
1 0.001729
Name: Class, dtype: float64
0 56864
1 98
Name: Class, dtype: int64
0 0.99828
1 0.00172
Name: Class, dtype: float64
使用 LightGBM 进行训练 - 基准
对于这个任务,我们使用了一组简单的参数来训练模型。我们只想创建一个基准模型,因此这里没有进行交叉验证或参数调优。
LightGBM 的不同参数细节可以在 文档 中找到。此外,作者提供了 一些建议 来调整参数并防止过拟合。
lgb_train = lgb.Dataset(X_train, y_train, free_raw_data=False)
lgb_test = lgb.Dataset(X_test, y_test, reference=lgb_train, free_raw_data=False)
parameters = {'num_leaves': 2**8,
'learning_rate': 0.1,
'is_unbalance': True,
'min_split_gain': 0.1,
'min_child_weight': 1,
'reg_lambda': 1,
'subsample': 1,
'objective':'binary',
#'device': 'gpu', # comment this line if you are not using GPU
'task': 'train'
}
num_rounds = 300
%%time
clf = lgb.train(parameters, lgb_train, num_boost_round=num_rounds)
CPU times: user 45.1 s, sys: 7.68 s, total: 52.8 s
Wall time: 11.9 s
一旦我们拥有了训练好的模型,我们可以获得一些指标。
y_prob = clf.predict(X_test)
y_pred = binarize_prediction(y_prob, threshold=0.5)
metricsmetrics == classification_metrics_binaryclassifi (y_test, y_pred)
metrics2 = classification_metrics_binary_prob(y_test, y_prob)
metrics.update(metrics2)
cm = metrics['Confusion Matrix']
metrics.pop('Confusion Matrix', None)
array([[55773, 1091],
[ 11, 87]])
print(json.dumps(metrics, indent=4, sort_keys=True))
plot_confusion_matrix(cm, ['no fraud (negative class)', 'fraud (positive class)'])
{
"AUC": 0.9322482105532139,
"Accuracy": 0.980653769179453,
"F1": 0.13636363636363638,
"Log loss": 0.6375216445628125,
"Precision": 0.07385398981324279,
"Recall": 0.8877551020408163
}
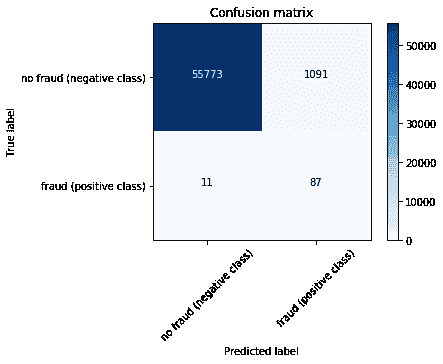
从商业角度来看,如果系统将一个正常的交易误分类为欺诈(假阳性),银行将会进行调查,可能需要人工干预。根据2015 年 Javelin 策略报告,15%的持卡人在前一年中至少有一笔交易被错误地拒绝,总金额近 1180 亿美元。近 4 成被拒绝的持卡人表示,他们在被错误拒绝后放弃了他们的卡。
然而,如果欺诈交易未被检测到,实际上意味着分类器预测交易是正常的,而实际是欺诈性的(假阴性),那么银行就会亏损,而犯罪分子则逃脱了。
在这些预测中使用商业规则的一个常见方法是控制预测的阈值或操作点。这可以通过在binarize_prediction(y_prob, threshold=0.5)中更改阈值来控制。通常会从 0.1 到 0.9 进行循环,评估不同的商业结果。
clf.save_model(BASELINE_MODEL)
使用 Flask 和 Websockets 进行操作化
下一步是将机器学习模型投入使用。为此,我们将使用Flask来创建一个 RESTful API。API 的输入将是一个交易(由其特征定义),输出将是模型的预测。
此外,我们设计了一个websocket 服务来在地图上可视化欺诈交易。系统使用库flask-socketio实时工作。
当新交易被发送到 API 时,LightGBM 模型会预测交易是正常还是欺诈。如果交易是欺诈性的,服务器会向一个 web 客户端发送信号,客户端渲染出一个世界地图,显示欺诈交易的位置。地图使用javascript和之前创建的 SQLite 数据库中的位置数据制作。
要启动 API,请在 conda 环境中执行(fraud)$ python api.py。
# You can also run the api from inside the notebook (even though I find it more difficult for debugging).
# To do it, just uncomment the next two lines:
#%%bash --bg --proc bg_proc
#python api.py
首先,我们确保 API 正在运行
#server_name = 'http://the-name-of-your-server'
server_name = 'http://localhost'
root_url = '{}:{}'.format(server_name, PORT)
res = requests.get(root_url)
display(HTML(res.text))
欺诈警察在监视你

现在,我们将选择一个值并预测输出。
vals = y_test[y_test == 1].index.values
X_target = X_test.loc[vals[0]]
dict_query = X_target.to_dict()
print(dict_query)
{'Time': 57007.0, 'V1': -1.2712441917143702, 'V2': 2.46267526851135, 'V3': -2.85139500331783, 'V4': 2.3244800653477995, 'V5': -1.37224488981369, 'V6': -0.948195686538643, 'V7': -3.06523436172054, 'V8': 1.1669269478721105, 'V9': -2.2687705884481297, 'V10': -4.88114292689057, 'V11': 2.2551474887046297, 'V12': -4.68638689759229, 'V13': 0.652374668512965, 'V14': -6.17428834800643, 'V15': 0.594379608016446, 'V16': -4.8496923870965185, 'V17': -6.53652073527011, 'V18': -3.11909388163881, 'V19': 1.71549441975915, 'V20': 0.560478075726644, 'V21': 0.652941051330455, 'V22': 0.0819309763507574, 'V23': -0.22134783119833895, 'V24': -0.5235821592333061, 'V25': 0.224228161862968, 'V26': 0.756334522703558, 'V27': 0.632800477330469, 'V28': 0.25018709275719697, 'Amount': 0.01}
headers = {'Content-type':'application/json'}
end_point = root_url + '/predict'
res = requests.post(end_point, data=json.dumps(dict_query), headers=headers)
print(res.ok)
print(json.dumps(res.json(), indent=2))
True
{
"fraud": 1.0
}
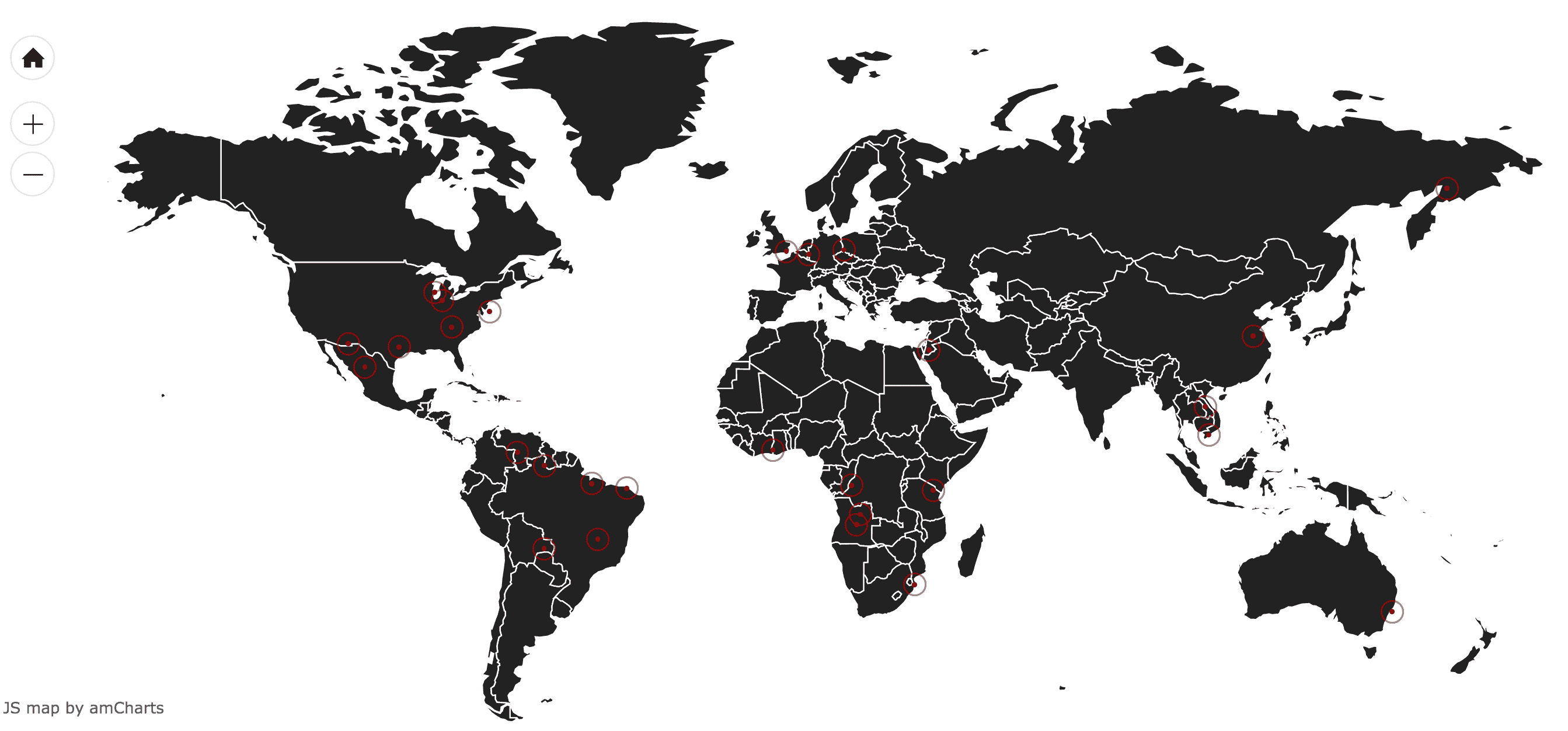
欺诈交易可视化
现在我们知道 API 的主要端点工作正常,我们将尝试/predict_map 端点。它使用 websockets 创建一个实时可视化系统来展示欺诈交易。
WebSocket 是一种旨在进行实时通信的协议,为 HTML5 规范开发。它创建了一个持久的、低延迟的连接,可以支持由客户端或服务器发起的事务。在这篇文章中,你可以找到关于 WebSocket 和其他相关技术的详细解释。
 对于我们的案例,每当用户向端点
对于我们的案例,每当用户向端点/predict_map发出请求时,机器学习模型会评估交易详情并进行预测。如果预测被分类为欺诈,服务器会使用socketio.emit('map_update', location)发送信号。该信号仅包含一个名为location的字典,包含一个模拟的名称和欺诈交易发生的位置。信号在index.html中显示,该文件仅渲染一些通过id="chartdiv"引用的 JavaScript 代码。
JavaScript 代码定义在文件frauddetection.js中。WebSocket 部分如下:
var mapLocations = [];
// Location updated emitted by the server via websockets
socket.on("map_update", function (msg) {
var message = "New event in " + msg.title + " (" + msg.latitude
+ "," + msg.longitude + ")";
console.log(message);
var newLocation = new Location(msg.title, msg.latitude, msg.longitude);
mapLocations.push(newLocation);
clear the markers before redrawing
mapLocations.forEach(function (location) {
if (location.externalElement) {
location.externalElement = undefined;
}
});
map.dataProvider.images = mapLocations;
map.validateData(); //call to redraw the map with new data
});
当服务器在 Python 中发出新的信号时,JavaScript 代码会接收并处理它。它创建了一个名为newLocation的新变量,包含要保存到名为mapLocations的全局数组中的位置信息。这个变量包含了自会话开始以来出现的所有欺诈位置。接下来,进行一个清理过程,以便 amCharts 能够在地图上绘制新信息,最后将数组存储在map.dataProvider.images中,这实际上是用新点刷新地图。变量map在代码中较早定义,它是负责定义地图的 amCharts 对象。
要向可视化端点发起查询:
headers = {'Content-type':'application/json'}
end_point_map = root_url + '/predict_map'
res = requests.post(end_point_map, data=json.dumps(dict_query), headers=headers)
print(res.text)
True
{
"fraud": 1.0
}
现在你可以访问地图 URL(在本地是 http://localhost:5000/map),查看每次执行前一个单元格时地图如何更新为新的欺诈位置。你应该会看到类似下面的地图:
负载测试
一旦我们拥有了 API,我们就可以测试它的可扩展性和响应时间。
这里你可以找到一个简单的负载测试来评估你的 API 性能。请记住,在这种情况下,由于客户端和服务器位于同一台计算机上,因此没有请求开销。
10 个请求的响应时间大约为 300 毫秒,因此一个请求的响应时间为 30 毫秒。
num = 10
concurrent = 2
verbose = True
payload_list = [dict_query]*num
%%time
with aiohttp.ClientSession() as session: # We create a persistent connection
loop = asyncio.get_event_loop()
calc_routes = loop.run_until_complete(run_load_test(end_point, payload_list, session, concurrent, verbose))
ERROR:asyncio:Creating a client session outside of coroutine
client_session: aiohttp.client.ClientSession object at 0x7f16847333c8
Response status: 200
{'fraud': 7.284115783035928e-06}
Response status: 200
{'fraud': 7.284115783035928e-06}
Response status: 200
{'fraud': 7.284115783035928e-06}
Response status: 200
{'fraud': 7.284115783035928e-06}
Response status: 200
Response status: 200
{'fraud': 7.284115783035928e-06}
{'fraud': 7.284115783035928e-06}
Response status: 200
Response status: 200
{'fraud': 7.284115783035928e-06}
{'fraud': 7.284115783035928e-06}
Response status: 200
{'fraud': 7.284115783035928e-06}
Response status: 200
{'fraud': 7.284115783035928e-06}
CPU times: user 14.8 ms, sys: 15.8 ms, total: 30.6 ms
Wall time: 296 ms
*# If you run the API from the notebook, you can uncomment the following two lines to kill the process
#%%bash
#ps aux | grep 'api.py' | grep -v 'grep' | awk '{print $2}' | xargs kill*
企业级欺诈检测参考架构
在本教程中,我们已经看到如何创建一个基线欺诈检测模型。然而,对于大公司来说,这还不够。
在下图中,我们可以看到一个欺诈检测的参考架构,这个架构应根据客户的具体情况进行调整。所有服务都基于 Azure。
-
客户的两个主要数据源:实时数据和静态信息。
-
用于存储数据的一般数据库部分。由于这是一个参考架构,并且没有更多数据,我将几个选项组合在一起(SQL 数据库,CosmosDB,SQL 数据仓库,等)无论是云端还是本地。
-
使用Azure ML进行模型实验,再次使用通用计算目标,如DSVM,BatchAI,Databricks或HDInsight。
-
使用新数据进行模型再训练,并从模型管理中获得模型。
-
运营层使用一个Kubernetes 集群,将最佳模型投入生产。
-
报告层以展示结果。

原文。转载经许可。
相关:
更多相关话题
用 R、SQL 和 Tableau 进行犯罪数据的地理时间序列预测简介
原文:
www.kdnuggets.com/2020/02/introduction-geographical-time-series-crime-r-sql-tableau.html
评论
作者:Jason Wittenauer,Huron Consulting Group 首席数据科学家

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
在本教程中,你将学习如何为时间序列预测准备地理数据。
在审查地理数据时,准备数据进行分析可能会很困难。虽然可以使用特定的算法,但它们的功能可能有限。如果我们花一些时间将数据分割成网格,然后为每个网格点添加一个时间点,这将为建模算法和其他可添加的功能打开更多可能性。然而,这也会造成数据集大小的问题。
五年的犯罪数据集可能包含 250,000 条记录。一旦将其外推到整个城市的时间序列网格中,它可能轻松达到 7500 万个数据点。处理如此规模的数据时,使用数据库来清理数据在将其发送到建模脚本之前是很有帮助的。我们将遵循的步骤如下:
-
将数据导入 SQL Server 数据库。
-
清理和分组数据到地图网格中。
-
为网格数据集添加时间数据点,并填补没有发生犯罪的空白。
-
将数据导入 R
-
运行 XGBoost 模型来确定特定日期犯罪的发生地点
最后,我们将讨论如何在 Tableau 等 BI 工具中使预测结果对最终用户更具可用性。
前提条件
在开始本教程之前,你需要:
-
安装 SQL Server Express
-
使用 SQL Management Studio 或类似 IDE 来与 SQL Server 接口
-
已安装 R
-
R Studio、Jupyter notebook 或其他 IDE 来与 R 接口
-
SQL 和 R 的一般工作知识
数据流概览
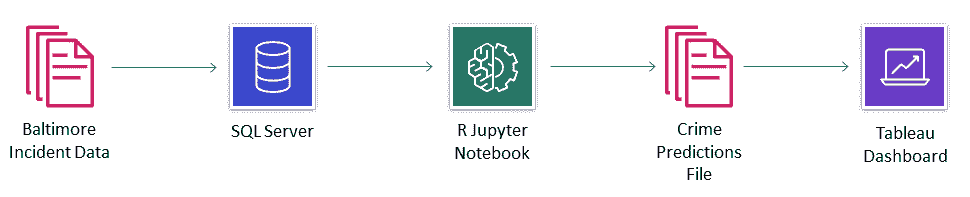
目前我们将保持数据库和数据流的简单结构。数据库本身将非常扁平,最终的数据交接将通过文本文件在 Tableau 仪表板中执行。在更具生产力的版本中,我们会将预测结果保存回数据库,并从数据库中提取数据到报告仪表板中。对于这个示例,我们并不试图完美架构一切,而是了解地理时间序列预测的基本概念。
我们的数据流如下:
设置数据库
我们的预测模型将使用 2012 年至 2017 年巴尔的摩地区的犯罪数据。这些数据位于此仓库中的“Data”文件夹中,文件名为“Baltimore Incident Data.zip”。在导入这些数据之前,您需要按照以下选项之一来设置数据库:
选项 1
- 使用位于“Database Objects\Clean Backup\”文件夹中的备份文件恢复 SQL 数据库。
选项 2
- 使用“Database Objects”文件夹中的“Tables”和“Procedures”下的脚本手动创建所有对象。
导入数据
数据库成功创建后,您现在可以导入数据。这需要您执行以下操作:
-
解压缩“Data”文件夹中的“Baltimore Incident Data.zip”文件。
-
运行“Insert_StagingCrime”过程,并确保它指向正确的导入文件和正确的格式文件(位于“Data”文件夹中的“FormatFile.fmt”)。
EXEC Insert_StagingCrime
该过程将截断 Staging_Crime 表并通过 BULK INSERT 将文件中的数据直接插入其中。临时表本身具有所有 VARCHAR(MAX) 数据类型,我们将在导入过程的下一阶段将其转换为更好的数据类型。下面是过程的代码片段。
BULK INSERT Staging_Crime
FROM 'C:\Projects\Crime Prediction\Data\Baltimore Incident Data.csv'
WITH (FIRSTROW = 2, FORMATFILE = 'C:\Projects\Crime Prediction\Data\FormatFile.fmt')
复审数据。
数据已导入到临时表中后,您可以在 SQL Management Studio 中运行以下代码查看它:
SELECT TOP 10 *
FROM [dbo].[Staging_Crime]
给你以下结果。
| CrimeDate | CrimeTime | CrimeCode | Address | Description | InsideOutside | Weapon | Post | District | Neighborhood | Location | Premise | TotalIncidents |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 02/28/2017 | 23:50:00 | 6D | 2400 KEYWORTH AVE | LARCENY FROM AUTO | O | NULL | 533 | NORTHERN | Greenspring | (39.3348700000, -76.6590200000) | STREET | 1 |
| 02/28/2017 | 23:36:00 | 4D | 200 DIENER PL | AGG. ASSAULT | I | HANDS | 843 | SOUTHWESTERN | Irvington | (39.2830300000, -76.6878200000) | APT/CONDO | 1 |
| 02/28/2017 | 23:02:00 | 4E | 1800 N MOUNT ST | COMMON ASSAULT | I | HANDS | 742 | WESTERN | Sandtown-Winchester | (39.3092400000, -76.6449800000) | ROW/TOWNHO | 1 |
| 02/28/2017 | 23:00:00 | 6D | 200 S CLINTON ST | LARCENY FROM AUTO | O | NULL | 231 | SOUTHEASTERN | Highlandtown | (39.2894600000, -76.5701900000) | STREET | 1 |
| 02/28/2017 | 22:00:00 | 6E | 1300 TOWSON ST | 偷窃 | O | NULL | 943 | SOUTHERN | Locust Point | (39.2707100000, -76.5911800000) | 街道 | 1 |
| 02/28/2017 | 21:40:00 | 6J | 1000 WILMOT CT | 偷窃 | O | NULL | 312 | EASTERN | Oldtown | (39.2993600000, -76.6034100000) | 街道 | 1 |
| 02/28/2017 | 21:40:00 | 6J | 2400 PENNSYLVANIA AVE | 偷窃 | O | NULL | 733 | WESTERN | Penn North | (39.3094200000, -76.6417700000) | 街道 | 1 |
| 02/28/2017 | 21:30:00 | 5D | 1500 STACK ST | 入室盗窃 | I | NULL | 943 | SOUTHERN | Riverside | (39.2721500000, -76.6033600000) | 其他/住宅 | 1 |
| 02/28/2017 | 21:30:00 | 6D | 2100 KOKO LN | 汽车盗窃 | O | NULL | 731 | WESTERN | Panway/Braddish Avenue | (39.3117800000, -76.6633200000) | 街道 | 1 |
| 02/28/2017 | 21:10:00 | 3CF | 800 W LEXINGTON ST | 商业抢劫 | O | 火器 | 712 | WESTERN | Poppleton | (39.2910500000, -76.6310600000) | 街道 | 1 |
注意到这些数据包括了犯罪发生的时间点、经纬度,甚至还有犯罪类别。这些类别对更高级的建模技术和分析非常有用。
清洗数据并创建地图网格
接下来,我们可以将数据转移到一个具有正确数据类型的“犯罪”表中。在此步骤中,我们还将位置字段拆分为经度和纬度字段。完成这些步骤的所有逻辑可以通过运行以下执行语句来完成:
EXEC Insert_Crime
现在,我们将数据填充到“犯罪”表中。这将允许我们完成下一步,即在城市中创建一个网格并将每个犯罪分配到一个网格方块中。你会注意到我们创建了两个网格(小的和大的)。这使我们能够创建在犯罪地点及其周围区域的特征,从而基本上给出城市中的犯罪热点。

运行以下代码以创建网格并为“犯罪”表分配 SmallGridID 和 LargeGridID:
EXEC Update_CrimeCoordinates
这个过程分为三个独立的任务:
-
在 GridSmall 表中创建地图上的小网格(过程:Insert_GridSmall)。
-
在 GridLarge 表中创建地图上的大网格(过程:Insert_GridLarge)。
-
将所有犯罪记录分配到地图上的小方块和大方块中。
创建网格方块的两个过程需要变量来确定地图的角落以及我们希望在地图上有多少个方块。这默认为 200x200 的小网格和 100x100 的大网格。
你可以通过运行以下命令查看一些网格数据:
SELECT TOP 10 c.CrimeId, gs.*
FROM [dbo].[Crime] c
JOIN GridSmall gs
ON gs.GridSmallId = c.GridSmallId
| CrimeId | GridSmallId | BotLeftLatitude | TopRightLatitude | BotLeftLongitude | TopRightLongitude |
|---|---|---|---|---|---|
| 1 | 31012 | 39.3341282000001 | 39.3349965000001 | -76.6594308000001 | -76.6585152000001 |
| 2 | 19121 | 39.2828985 | 39.2837668 | -76.68873 | -76.6878144 |
| 3 | 25198 | 39.3089475000001 | 39.3098158000001 | -76.6456968000001 | -76.6447812000001 |
| 4 | 20657 | 39.2889766 | 39.2898449 | -76.5706176000001 | -76.5697020000001 |
| 5 | 16212 | 39.269874 | 39.2707423 | -76.5916764000001 | -76.5907608000001 |
| 6 | 22832 | 39.2985279000001 | 39.2993962000001 | -76.6035792000001 | -76.6026636000001 |
| 7 | 25202 | 39.3089475000001 | 39.3098158000001 | -76.6420344000001 | -76.6411188000001 |
| 8 | 16601 | 39.2716106 | 39.2724789 | -76.6035792000001 | -76.6026636000001 |
| 9 | 25781 | 39.3115524000001 | 39.3124207000001 | -76.6640088 | -76.6630932 |
| 10 | 20992 | 39.2907132 | 39.2915815 | -76.6319628000001 | -76.6310472000001 |
注意到一个方格中计算了两个点,即右上角和左下角的点。尽管在绘制经纬线时真实地图上确实有一些曲线,我们不必计算方格中的所有四个点。当比例缩小到足够小的时候,我们可以假设这些方格大多是直线的。
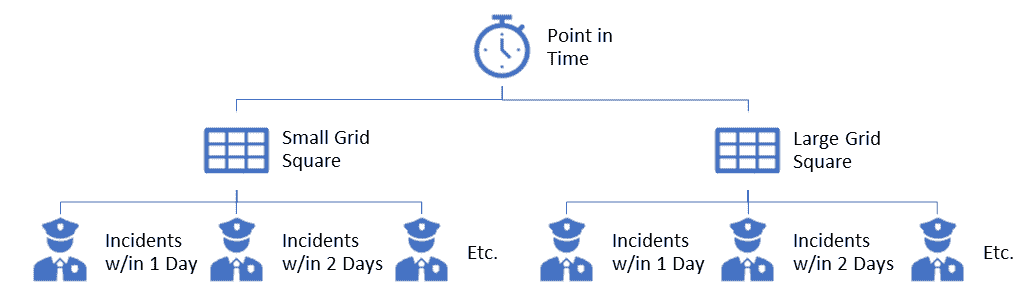
创建犯罪网格和滞后特征
我们需要完成的最后一步是为我们想要评估的所有时间段创建整个地图网格。在我们的案例中,这意味着每天一个网格点,以确定犯罪是否会发生。要完成这一步,需要执行以下过程:
EXEC Insert_CrimeGrid
在这一步中,每个犯罪事件将被分组到地图方格中,以便我们可以确定在数据集中每个日期发生了多少犯罪事件。我们还需要计算每个方格中没有发生犯罪的所有填充日期,以完成数据集。
这个过程运行的时间比较长。在我的笔记本电脑上,它运行了大约 1 小时,随后生成的表格(“CrimeGrid”)包含了大约 7500 万条记录。好的一点是,输出现在已保存到表格中,因此我们不必在 R 脚本中运行它,那里的大型数据操作可能无法像在数据库中那样高效运行。
在这个步骤中,我们还将创建“滞后特征”。这些将是告诉我们在过去的一天、两天、一周、一月等时间段内,网格方格中发生了多少次犯罪的列。这实际上是帮助我们进行数据的“热点”分析,这可以用来查看附近的其他网格方格,以判断犯罪是否局限于我们的单个方格或是集中在所有附近方格中,类似于地震后的余震。这些特征可能会根据你所做的建模类型而有所不同。
预测设置
随着所有数据清理和特征工程在数据库端完成,进行预测的代码相当简单。在我们的示例中,我们将使用 R 中的 XGBoost 分析五年的训练数据来预测未来的犯罪事件。
首先,我们加载我们的库。
# Load required libraries
library(RODBC)
library(xgboost)
library(ROCR)
library(caret)
Loading required package: gplots
Attaching package: 'gplots'
The following object is masked from 'package:stats':
lowess
Loading required package: lattice
Loading required package: ggplot2
Registered S3 methods overwritten by 'ggplot2':
method from
[.quosures rlang
c.quosures rlang
print.quosures rlang
然后直接从数据库中将数据导入 R。你也可以将数据导出为文本文件,并以 CSV 数据的形式读取,如果这是你喜欢的方法。提取数据的查询仅仅是用带有一些日期限制的 SQL 语句编写的。这些查询可以重新编写为从带有日期参数的报告存储过程直接提取数据,以获得更具生产力的代码版本。
# Set seed
set.seed(1001)
# Read in data
dbhandle <- odbcDriverConnect('driver={SQL Server};server=DESKTOP-VLN71V7\\SQLEXPRESS;database=crime;trusted_connection=true')
train <- sqlQuery(dbhandle, 'select IncidentOccurred as target, GridSmallId, GridLargeId, DayOfWeek, MonthOfYear, DayOfYear, Year, PriorIncident1Day, PriorIncident2Days, PriorIncident3Days, PriorIncident7Days, PriorIncident14Days, PriorIncident30Days, PriorIncident1Day_Large, PriorIncident2Days_Large, PriorIncident3Days_Large, PriorIncident7Days_Large, PriorIncident14Days_Large, PriorIncident30Days_Large from crimegrid where crimedate <= \'2/20/2017\' and crimedate >= \'6/1/2012\'')
test <- sqlQuery(dbhandle, 'select IncidentOccurred as target, GridSmallId, GridLargeId, DayOfWeek, MonthOfYear, DayOfYear, Year, PriorIncident1Day, PriorIncident2Days, PriorIncident3Days, PriorIncident7Days, PriorIncident14Days, PriorIncident30Days, PriorIncident1Day_Large, PriorIncident2Days_Large, PriorIncident3Days_Large, PriorIncident7Days_Large, PriorIncident14Days_Large, PriorIncident30Days_Large from crimegrid where crimedate >= \'2/21/2017\' and crimedate <= \'2/27/2017\'')
# Convert integers to numeric for DMatrix
train[] <- lapply(train, as.numeric)
test[] <- lapply(test, as.numeric)
head(train)
| 目标 | GridSmallId | GridLargeId | 星期几 | 年月份 | 年中的天数 | 年 | 过去 1 天事件 | 过去 2 天事件 | 过去 3 天事件 | 过去 7 天事件 | 过去 14 天事件 | 过去 30 天事件 | 过去 1 天事件 _ 大 | 过去 2 天事件 _ 大 | 过去 3 天事件 _ 大 | 过去 7 天事件 _ 大 | 过去 14 天事件 _ 大 | 过去 30 天事件 _ 大 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3780 | 990 | 5 | 9 | 262 | 2013 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 3781 | 991 | 5 | 9 | 262 | 2013 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 3782 | 991 | 5 | 9 | 262 | 2013 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 3783 | 992 | 5 | 9 | 262 | 2013 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 3784 | 992 | 5 | 9 | 262 | 2013 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 3785 | 993 | 5 | 9 | 262 | 2013 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
注意在测试数据集中,我们一次提取 7 天的数据进行测试,但仍然保持特征输入时仿佛我们知道前一天发生了什么。这只是为了便于我们一次测试 7 天的数据,并在最后的报告中查看多天预测的效果。
另一个需要注意的是,标记为“_Large”的特征是针对较大的网格的,而不是较小的网格。
创建特征集和模型参数
我们将特征定义为 SQL 查询中第一个“目标”列之后的所有列。这些特征会作为标签的一部分传递给训练和测试数据集。
# Get feature names (all but first column which is the target)
feature.names <- names(train)[2:ncol(train)]
print(feature.names)
# Make train and test matrices
dtrain <- xgb.DMatrix(data.matrix(train[,feature.names]), label=train$target)
dtest <- xgb.DMatrix(data.matrix(test[,feature.names]), label=test$target)
[1] "GridSmallId" "GridLargeId"
[3] "DayOfWeek" "MonthOfYear"
[5] "DayOfYear" "Year"
[7] "PriorIncident1Day" "PriorIncident2Days"
[9] "PriorIncident3Days" "PriorIncident7Days"
[11] "PriorIncident14Days" "PriorIncident30Days"
[13] "PriorIncident1Day_Large" "PriorIncident2Days_Large"
[15] "PriorIncident3Days_Large" "PriorIncident7Days_Large"
[17] "PriorIncident14Days_Large" "PriorIncident30Days_Large"
接下来,设置模型训练的参数。我们目前保持它们相当基础。确保评估指标是 AUC,以便我们可以尽量提高我们的真正阳性率。这将防止警察不必要地巡逻某些区域。可能还需要额外的工作来用巧妙的巡逻覆盖所有预测区域,但我们在本教程中不涉及这些内容。
# Training parameters
watchlist <- list(eval = dtest, train = dtrain)
param <- list( objective = "binary:logistic",
booster = "gbtree",
eta = 0.01,
max_depth = 10,
eval_metric = "auc"
)
运行模型
既然一切都已设置好,我们可以运行模型并查看其预测效果。请记住,这里使用的是一个相当基本的特征集,仅仅是为了演示处理地理时间序列数据的一种方法。虽然数据集可能会非常庞大,但它们易于理解,并且在使用像 AWS 这样的云服务时运行速度相当快。
这个特定的训练数据集有 7000 万行,在我的笔记本电脑上完成 67 轮评估大约花了 30 分钟。
# Run model
clf <- xgb.train( params = param,
data = dtrain,
nrounds = 100,
verbose = 2,
early_stopping_rounds = 10,
watchlist = watchlist,
maximize = TRUE)
[14:30:32] WARNING: amalgamation/../src/learner.cc:686: Tree method is automatically selected to be 'approx' for faster speed. To use old behavior (exact greedy algorithm on single machine), set tree_method to 'exact'.
[1] eval-auc:0.858208 train-auc:0.858555
Multiple eval metrics are present. Will use train_auc for early stopping.
Will train until train_auc hasn't improved in 10 rounds.
[2] eval-auc:0.858208 train-auc:0.858555
[3] eval-auc:0.858208 train-auc:0.858555
[4] eval-auc:0.858208 train-auc:0.858556
[5] eval-auc:0.858208 train-auc:0.858556
[6] eval-auc:0.858208 train-auc:0.858556
[7] eval-auc:0.858311 train-auc:0.858997
[8] eval-auc:0.858311 train-auc:0.858997
[9] eval-auc:0.858311 train-auc:0.858997
[10] eval-auc:0.858315 train-auc:0.859000
[11] eval-auc:0.858436 train-auc:0.859110
[12] eval-auc:0.858436 train-auc:0.859110
[13] eval-auc:0.858512 train-auc:0.859157
[14] eval-auc:0.858493 train-auc:0.859157
[15] eval-auc:0.858496 train-auc:0.859160
[16] eval-auc:0.858498 train-auc:0.859160
[17] eval-auc:0.858498 train-auc:0.859160
[18] eval-auc:0.858342 train-auc:0.859851
[19] eval-auc:0.858177 train-auc:0.859907
[20] eval-auc:0.858228 train-auc:0.859971
[21] eval-auc:0.858231 train-auc:0.859971
[22] eval-auc:0.858206 train-auc:0.860695
[23] eval-auc:0.858207 train-auc:0.860695
[24] eval-auc:0.858731 train-auc:0.860894
[25] eval-auc:0.858702 train-auc:0.860844
[26] eval-auc:0.858607 train-auc:0.860844
[27] eval-auc:0.858574 train-auc:0.860842
[28] eval-auc:0.858602 train-auc:0.860892
[29] eval-auc:0.858576 train-auc:0.860843
[30] eval-auc:0.858574 train-auc:0.860841
[31] eval-auc:0.858607 train-auc:0.860893
[32] eval-auc:0.858578 train-auc:0.860843
[33] eval-auc:0.858611 train-auc:0.860894
[34] eval-auc:0.858612 train-auc:0.860895
[35] eval-auc:0.858614 train-auc:0.860898
[36] eval-auc:0.858615 train-auc:0.860899
[37] eval-auc:0.858616 train-auc:0.860897
[38] eval-auc:0.858573 train-auc:0.860870
[39] eval-auc:0.858546 train-auc:0.860822
[40] eval-auc:0.858575 train-auc:0.860872
[41] eval-auc:0.858622 train-auc:0.860898
[42] eval-auc:0.858578 train-auc:0.860875
[43] eval-auc:0.858583 train-auc:0.860870
[44] eval-auc:0.859223 train-auc:0.861768
[45] eval-auc:0.859220 train-auc:0.861760
[46] eval-auc:0.859221 train-auc:0.861760
[47] eval-auc:0.859099 train-auc:0.861719
[48] eval-auc:0.859112 train-auc:0.861735
[49] eval-auc:0.859112 train-auc:0.861735
[50] eval-auc:0.859094 train-auc:0.861734
[51] eval-auc:0.859125 train-auc:0.861785
[52] eval-auc:0.859021 train-auc:0.861771
[53] eval-auc:0.859028 train-auc:0.861784
[54] eval-auc:0.859029 train-auc:0.861781
[55] eval-auc:0.859028 train-auc:0.861784
[56] eval-auc:0.859035 train-auc:0.861788
[57] eval-auc:0.859037 train-auc:0.861789
[58] eval-auc:0.859035 train-auc:0.861775
[59] eval-auc:0.859035 train-auc:0.861774
[60] eval-auc:0.859010 train-auc:0.861738
[61] eval-auc:0.859011 train-auc:0.861739
[62] eval-auc:0.859039 train-auc:0.861778
[63] eval-auc:0.859016 train-auc:0.861739
[64] eval-auc:0.859017 train-auc:0.861741
[65] eval-auc:0.859018 train-auc:0.861746
[66] eval-auc:0.859019 train-auc:0.861747
[67] eval-auc:0.859024 train-auc:0.861755
Stopping. Best iteration:
[57] eval-auc:0.859037 train-auc:0.861789
模型很快找到了模式,每轮改进不大。这可以通过更好的模型参数和更多特征来提升。
审查重要性矩阵
现在是分析我们的特征,看看哪些在模型中评分较高的时候了,通过查看重要性矩阵。这可以帮助我们确定新增的特征在大型数据集上是否真的值得(较大数据集 = 每增加一个特征的额外处理时间)。
# Compute feature importance matrix
importance_matrix <- xgb.importance(feature.names, model = clf)
# Graph important features
xgb.plot.importance(importance_matrix[1:10,])
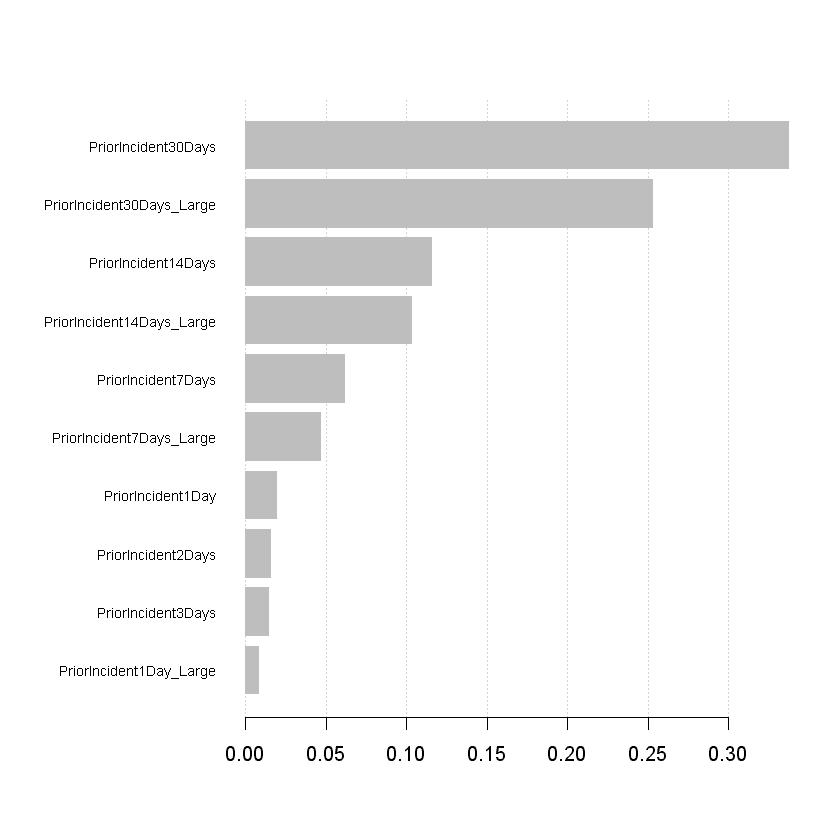
看起来模型使用了小网格和大网格特征的组合来判断当前日是否会发生事件。有趣的是,长期特征似乎更重要,表明该区域及其周边地区存在犯罪活动历史。
在测试集上预测并检查 ROC 曲线
最后一步是将我们的预测与测试数据集进行对比,看看效果如何。我们总是希望 ROC 曲线会快速而高地跃升,但这并非总是如此。在我们的例子中,只有基本特征包含在模型中,我们得到了一个不错的得分。这确实表明我们可以进行预测,并且应该投入更多时间来提高预测的准确性。
# Predict on test data
preds <- predict(clf, dtest)
# Graph AUC curve
xgb.pred <- prediction(preds, test$target)
xgb.perf <- performance(xgb.pred, "tpr", "fpr")
plot(xgb.perf,
avg="threshold",
colorize=TRUE,
lwd=1,
main="ROC Curve w/ Thresholds",
print.cutoffs.at=seq(0, 1, by=0.05),
text.adj=c(-0.5, 0.5),
text.cex=0.5)
grid(col="lightgray")
axis(1, at=seq(0, 1, by=0.1))
axis(2, at=seq(0, 1, by=0.1))
abline(v=c(0.1, 0.3, 0.5, 0.7, 0.9), col="lightgray", lty="dotted")
abline(h=c(0.1, 0.3, 0.5, 0.7, 0.9), col="lightgray", lty="dotted")
lines(x=c(0, 1), y=c(0, 1), col="black", lty="dotted")
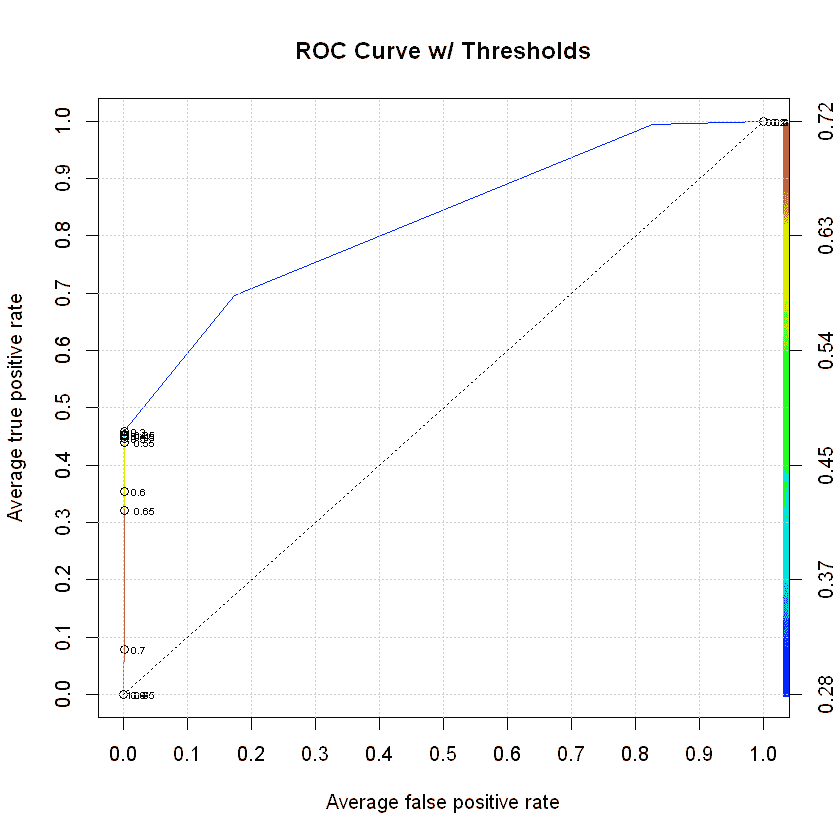
审查混淆矩阵
我们知道有一个不错的 AUC 得分,但让我们看看我们预测的结果与实际发生的情况。最简单的方法是审查混淆矩阵。我们希望左上角和右下角的框(正确预测)较大,其他框(错误预测)较小。
# Set our cutoff threshold
preds.resp <- ifelse(preds >= 0.5, 1, 0)
# Create the confusion matrix
confusionMatrix(as.factor(preds.resp), as.factor(test$target), positive = "1")
Confusion Matrix and Statistics
Reference
Prediction 0 1
0 280581 454
1 62 367
Accuracy : 0.9982
95% CI : (0.998, 0.9983)
No Information Rate : 0.9971
P-Value [Acc > NIR] : < 2.2e-16
Kappa : 0.5864
Mcnemar's Test P-Value : < 2.2e-16
Sensitivity : 0.447016
Specificity : 0.999779
Pos Pred Value : 0.855478
Neg Pred Value : 0.998385
Prevalence : 0.002917
Detection Rate : 0.001304
Detection Prevalence : 0.001524
Balanced Accuracy : 0.723397
'Positive' Class : 1
在 7 天内,发生了 821 起事件,我们的模型正确预测了 367 起。另一个关键点是我们错误预测了 62 起事件,这基本上是将警察派往我们认为可能发生犯罪的地区,但实际上没有发生。从表面上看,这似乎还不算太糟,但我们需要查看这对犯罪活动响应时间的影响与当前响应时间的对比。目标是使警察在足够接近犯罪发生的区域,以便他们可以通过存在预防犯罪或快速响应尽可能减少伤害。
准备报告数据
接下来,我们可以为测试数据集添加经度和纬度坐标,并将其导出为 CSV 文件。这将使我们能够在像 Tableau 这样的 BI 工具中查看实际预测结果。
# Read in the grid coordinates
gridsmall <- sqlQuery(dbhandle, 'select * from gridsmall')
# Merge the predictions with the test data
results <- cbind(test, preds)
# Merge the grid coordinates with the test data
results <- merge(results, gridsmall, by="GridSmallId")
head(results)
# Save to file
write.csv(results,"Data\\CrimePredictions.csv", row.names = TRUE)
| GridSmallId | 目标 | GridLargeId.x | 星期几 | 月份 | 年中的天数 | 年份 | 前一天事件 | 前两天事件 | 前三天事件 | ... | 前三天事件 _ 大 | 前七天事件 _ 大 | 前十四天事件 _ 大 | 前三十天事件 _ 大 | 预测值 | 左下纬度 | 右上纬度 | 左下经度 | 右上经度 | GridLargeId.y |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 1 | 3 | 2 | 52 | 2017 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0.2822689 | 39.20041 | 39.20128 | -76.71162 | -76.7107 | 1 |
| 1 | 0 | 1 | 5 | 2 | 54 | 2017 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0.2822689 | 39.20041 | 39.20128 | -76.71162 | -76.7107 | 1 |
| 1 | 0 | 1 | 7 | 2 | 56 | 2017 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0.2822689 | 39.20041 | 39.20128 | -76.71162 | -76.7107 | 1 |
| 1 | 0 | 1 | 4 | 2 | 53 | 2017 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0.2822689 | 39.20041 | 39.20128 | -76.71162 | -76.7107 | 1 |
| 1 | 0 | 1 | 2 | 2 | 58 | 2017 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0.2822689 | 39.20041 | 39.20128 | -76.71162 | -76.7107 | 1 |
| 1 | 0 | 1 | 1 | 2 | 57 | 2017 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0.2822689 | 39.20041 | 39.20128 | -76.71162 | -76.7107 | 1 |
预测可视化
现在是时候查看这些预测在 7 天内实际的情况了。Tableau 仪表板可以在这里找到:
在查看错误预测(红点)时,它们看起来非常接近正确预测。这将使警察处于犯罪发生的一般附近。所以,错误预测可能对整体结果的影响不大。下面是显示正确预测(蓝色)和错误预测(红色)的示例截图。
错误预测
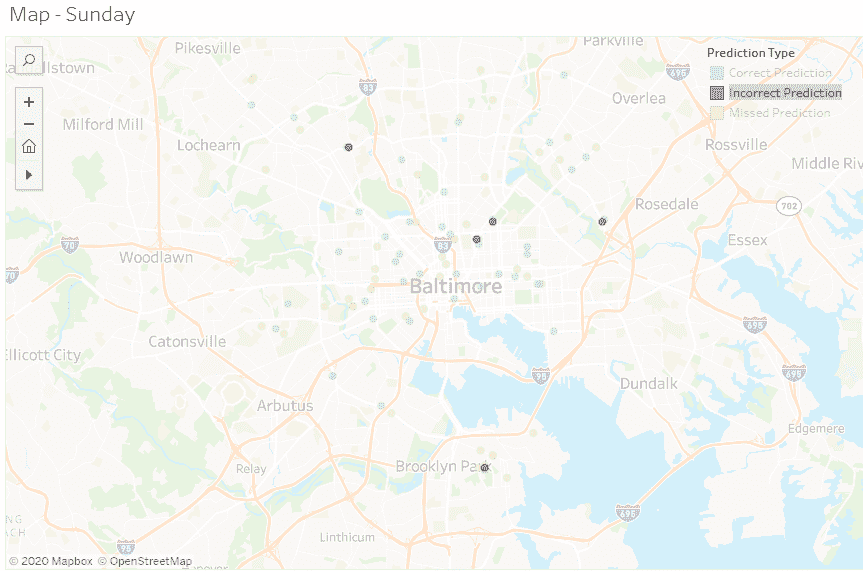
错误和正确预测
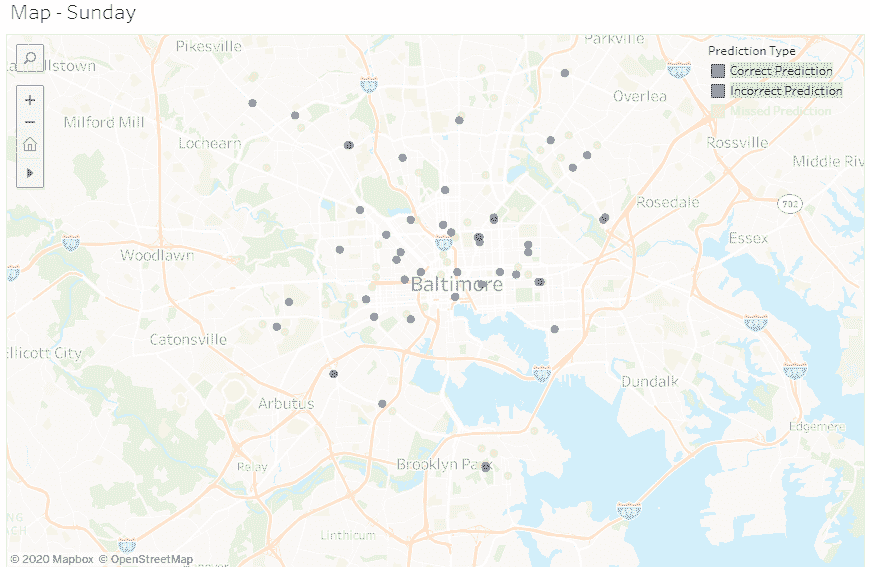
总体来看情况似乎还不错,但我们需要更多的特征和/或更多的数据来捕捉所有缺失的预测。此外,我们可能还可以做更多的工作,专注于发生的特定犯罪类型,并针对每种类型进行具体的预测建模。
下一步是什么?
本教程让我们开始使用犯罪数据进行地理时间序列预测。我们可以看到预测确实有效,但在创建特征方面还有更多工作要做。我们可能需要添加一些其他特征,检查更大范围的犯罪发生情况。另一个有用的步骤是将预测频率改为每小时,并按时间段绘制巡逻车路线。即使预测不完美,只要你将警察放在犯罪的附近,这比现有的巡逻方法要好,他们可以更快响应,甚至通过他们的存在防止犯罪的发生。
其他值得考虑的想法:
-
去除警察局、消防局、医院等附近的犯罪数据,因为这些数据可能对报告提交者有偏见。
-
添加与人口普查信息相关的统计特征。
-
将犯罪映射到社区,而不是方格网格,以进行预测。
希望你喜欢这个教程!
简介: Jason Wittenauer 是一位数据科学家,专注于通过 R、Python、Microsoft SQL Server、Tableau、TIBCO Spotfire 和 .NET 网页编程提升医院收入。他在医疗保健领域的关注点包括业务运营、收入改善和费用减少。
原文。经许可转载。
相关:
-
使用时间序列分析进行股票市场预测
-
你需要知道的:现代开源数据科学/机器学习生态系统
-
正义不能盲目:如何通过预测警务对抗偏见
更多相关话题
__getitem__ 介绍:Python 中的魔法方法
原文:
www.kdnuggets.com/2023/03/introduction-getitem-magic-method-python.html

作者图片
介绍
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
Python 是一种神奇的语言,包含许多即使是高级用户也可能不熟悉的概念。双下划线方法或魔法方法就是其中之一。魔法方法是由双下划线包围的特殊方法。它们不像普通的 Python 方法那样被显式调用。一个这样的魔法方法是 __getitem__ 方法,它使 Python 对象能够像序列或容器(例如列表、字典和元组)一样进行操作。它接受索引或切片,并从集合中检索其关联的值。当我们使用 indexer [ ] 运算符访问对象中的元素时,它会被自动调用。
将这个方法想象成一根魔法棒,它可以让你通过写几行代码就提取所需的信息。有趣吧?这个方法在数据分析和机器学习中也被广泛使用。因此,让我们深入探讨 __getitem__ 方法,发现它的力量和灵活性。
使用 __getitem__ 方法的好处
我希望你明白,作为一个 Python 程序员,你的职责不仅仅是编写功能代码。你的代码应该是高效的、可读的和可维护的。使用 __getitem__ 将帮助你实现这些目标。以下是使用这个魔法方法的一些其他好处:
-
通过允许你提取仅必要的信息而不是将完整数据结构加载到内存中来减少内存使用
-
提供了更大的灵活性来处理和操作数据
-
允许你在不循环遍历数据的情况下迭代集合
-
通过允许你编写内置类型可能无法实现的高级索引来增强功能
-
简化代码,因为它使用了熟悉的表示法
实现 __getitem__ 方法
__getitem__ 方法的语法如下:
def __getitem__(self, index):
# Your Implementation
pass
它定义了函数的行为,并将你尝试访问的索引作为参数。我们可以这样使用这个方法:
my_obj[index]
这在底层转换为语句 my_obj.__getitem__(index)。现在你可能会想,这与内置的 indexer [] 运算符有什么不同?无论你在哪里使用这种表示法,Python 都会自动调用 __getitem__ 方法,并且是访问元素的简写。但是如果你想改变自定义对象的索引行为,你需要显式调用 __getitem__ 方法。
示例 #01
首先让我们从一个简单的例子开始。我们将创建一个 Student 类,该类将包含所有学生的列表,我们可以通过索引访问这些学生,并且索引表示他们的唯一学生 ID。
class Student:
def __init__(self, names):
self.names=names
def __getitem__(self,index):
return self.names[index]
section_A= Student(["David", "Elsa", "Qasim"])
print(section_A[2])
输出:
Qasim
现在我们将转到一个高级示例,我们将使用 __getitem__ 方法来改变索引行为。假设我有一个字符串元素的列表,我希望在输入其索引位置时能检索到元素,并且如果我输入字符串本身,也能获取到索引位置。
class MyList:
def __init__(self, items):
self.items = items
def __getitem__(self, index):
if isinstance(index, int):
return self.items[index]
elif isinstance(index, str):
return self.items.index(index)
else:
raise TypeError("Invalid Argument Type")
my_list = MyList(['red', 'blue', 'green', 'black'])
# Indexing with integer keys
print(my_list[0])
print(my_list[2])
# Indexing with string keys
print(my_list['red'])
print(my_list['green'])
输出:
red
green
0
2
结论
这个方法对于快速查找实例属性非常有用。考虑到这个方法的灵活性和多功能性,我会说这是 Python 中最少被利用的魔法方法之一。我希望你喜欢阅读这篇文章,如果你有兴趣了解 Python 中其他魔法方法,请在评论区告诉我。
Kanwal Mehreen 是一名有志的软件开发者,对数据科学及 AI 在医学中的应用充满兴趣。Kanwal 被选为 2022 年 APAC 区域的 Google Generation Scholar。Kanwal 喜欢通过撰写关于热门话题的文章来分享技术知识,并且热衷于提高女性在科技行业的代表性。
更多相关话题
人工智能中的爬山算法介绍
原文:
www.kdnuggets.com/2022/07/introduction-hill-climbing-algorithm-ai.html
在人工智能、机器学习、深度学习和机器视觉中,算法是最重要的子集。借助这些算法,(What Are Artificial Intelligence Algorithms and How Do They Work, n.d.) 计算机、系统或模型能够理解用户希望处理的信息类型以及用户希望在理解周围一些工作的基础上得到的结果。这些算法在人工智能中非常重要,因为计算机或模型将根据这些算法进行训练,并能够训练提供给它的数据。这些算法的一个最常见的例子可以在 Alexa、Siri 或 Google Home 中找到。用户与它们的互动越多,它们的搜索结果可能变得更好,因为它们能够通过观察用户的歌曲收藏、兴趣、喜好和厌恶来感知环境中的输出和用户的情绪。通过这些因素,这些代理的观察变得非常强大,因为它们与用户的互动更加频繁。因此,显而易见的是,它们安装了非常强大的算法,帮助它们自我训练。有一些非常重要且频繁使用的算法,包括随机森林、逻辑回归、朴素贝叶斯和人工神经网络。(Top 6 AI Algorithms In Healthcare, n.d.)
爬山算法
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织在 IT 领域
解决数学问题的AI中最常见的算法是爬山算法(理解人工智能中的爬山算法 | 工程教育 (EngEd) 计划 | 部分,n.d.)。该问题也可以用于工作调度、市场营销、广告开发和预测性维护。这是一种启发式技术,简单来说,爬山算法基本上是一种搜索技术或有信息的搜索技术,基于分配给不同节点、分支和目标的实际数值权重。基于这些数字和在 AI 模型中定义的启发式,搜索可以变得更好。与爬山算法相关的主要特点是其大输入效率和更好的启发式分配。
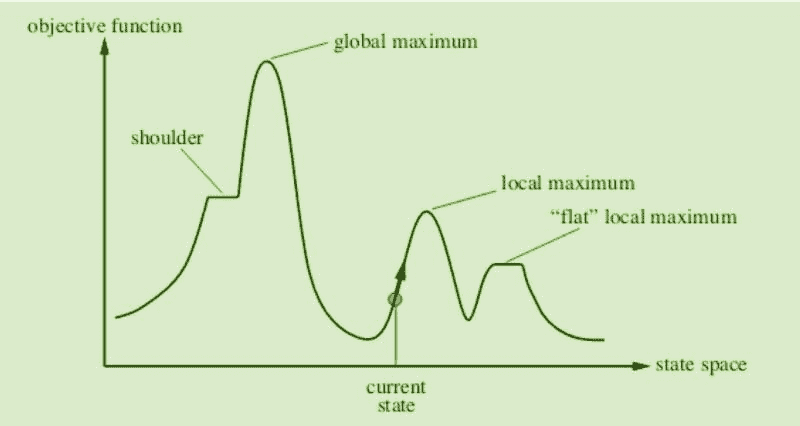
图 1. 直观理解爬山算法(介绍爬山算法 | 人工智能 - GeeksforGeeks,n.d.)
从图 1 可以明显看出,爬山算法依赖于两个组件,一个是目标函数,另一个是状态空间。当前状态是代理当前所在的搜索状态。局部最大值是另一个面向目标的解决方案,但不是优化的搜索结果。为了获得更好的结果,模型必须达到全局最大值点,以提高准确性和精度。(介绍爬山算法 | 人工智能 - GeeksforGeeks,n.d.)。以上图中显示的每个点的简要介绍如下。
-
局部最大值是前面讨论的状态,这个状态明显优于当前状态,但系统中存在比局部最大值更好的状态。
-
全局最大值,如图所示,是最佳状态,没有比这个状态更好的状态。
-
山脊是高于其邻居但有向下坡度的区域。
-
当前状态,顾名思义,是代理目前停留或检查的状态。
-
肩部是上坡上的一个点。(Skiena,2010)
爬山算法的类型
这种算法有很多种类型,以下是其中的一些。
简单爬山
这种爬山算法的工作原理非常简单。它从当前节点的邻居那里收集数据,并检查每个节点。通过这个简单的过程,下一步即将到来的成本可以被优化,从而节省了最少的时间。
最陡上升爬山算法
这是一种爬山算法,但比最简单的算法更好。它像前面的技术一样检查所有相邻的节点,但它对相邻的节点赋予权重或启发式,并基于最小成本解决方案的技术找到最短路径,并通过该技术实现目标。它们检查那些接近解决方案的节点。
随机爬山法
这与之前讨论的技术完全相反。在这种技术中,代理不会寻找相邻节点的值。它完全随机地选择相邻节点,前往该节点,并根据该特定节点的启发式来决定是否继续这条路径。(Russell & Norvig, 2003)
爬山法的优势
爬山法的一些优势如下。(人工智能中的爬山法 | 爬山算法的类型,无日期)
-
在解决如工作搜索、销售技巧、芯片设计和管理等问题时,这是一种非常有用的技术。
-
当用户计算能力非常有限时,他可以使用这种技术来获得更好的结果。使用这种技术不需要外部内存或云计算,因为它需要的计算能力非常少。
-
代理朝着优化成本的目标方向移动。
-
该算法根据反馈改进模型,使系统逐渐变得更好。
-
使用这种算法不会发生回溯。
爬山法的缺点
爬山法也有一些缺点。其中几个列举如下。(人工智能中的爬山法 | 爬山算法的类型,无日期)
-
使用这种技术时,效率和效果会受到影响。
-
如果启发式的值不确定,那么不推荐使用这种技术。
-
这是一种即时解决方案,而不是有效解决方案。
-
从这种技术获得的结果不确定且不可靠。
参考文献
-
人工智能中的爬山法 | 爬山算法的类型。(无日期)。检索于 2022 年 2 月 27 日,来自 https://www.educba.com/hill-climbing-in-artificial-intelligence/
-
爬山法简介 | 人工智能 - GeeksforGeeks。(无日期)。检索于 2022 年 2 月 27 日,来自 https://www.geeksforgeeks.org/introduction-hill-climbing-artificial-intelligence/
-
Russell, S. J., & Norvig, P. (2003). 人工智能:一种现代方法。在人工智能:一种现代方法(第 2 版)。Prentice-Hall。http://aima.cs.berkeley.edu/
-
Skiena, S. S. (2010). 算法设计手册(第 2 版)。Springer Science+Business Media。
-
医疗保健中的前 6 种 AI 算法。(无日期)。检索于 2022 年 2 月 27 日,来自 https://analyticsindiamag.com/top-6-ai-algorithms-in-healthcare/
-
理解人工智能中的爬山算法 | 工程教育(EngEd)计划 | Section。(无日期)。检索于 2022 年 2 月 27 日,网址:https://www.section.io/engineering-education/understanding-hill-climbing-in-ai/
-
人工智能算法是什么,如何运作。(无日期)。检索于 2022 年 2 月 27 日,网址:https://rockcontent.com/blog/artificial-intelligence-algorithm/
Neeraj Agarwal 是数据咨询公司Algoscale的创始人,该公司涵盖数据工程、应用 AI、数据科学和产品工程。他在该领域拥有超过 9 年的经验,帮助各种组织从初创公司到财富 100 强企业摄取和存储大量原始数据,以将其转化为可操作的洞察,从而实现更好的决策和更快的商业价值。
更多相关话题
K 均值聚类的图像分割介绍
原文:
www.kdnuggets.com/2019/08/introduction-image-segmentation-k-means-clustering.html
评论
图片来源:datastuff.tech
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT 需求
图像分割是图像处理中的一个重要步骤,如果我们想分析图像中的内容,它几乎无处不在。例如,如果我们要确定室内图像中是否有椅子或人,我们可能需要图像分割来分离对象,并单独分析每个对象以检查其性质。图像分割通常作为模式识别、特征提取和图像压缩的前处理步骤。
图像分割是将图像分类为不同组的过程。许多研究已经在使用聚类的图像分割领域展开。其中一种最受欢迎的方法是K 均值聚类算法。
在这篇文章中,我们将深入探讨一种读取图像并对图像的不同区域进行聚类的方法。但在此之前,让我们先讨论一下:
-
图像分割
-
图像分割如何工作
-
K 均值聚类机器学习算法
-
将 K 均值聚类算法与图像分割结合起来。
-
Canny 边缘检测
图像分割

图片来源:omicsonline.org
图像分割是将数字图像划分为多个不同区域的过程,每个区域包含具有相似属性的像素(像素集,也称为超级像素)。
图像分割的目标是将图像的表示形式转换为更有意义、更易于分析的形式。
图像分割通常用于定位图像中的对象和边界(线条、曲线等)。更准确地说,图像分割是将图像中的每个像素分配一个标签的过程,使得具有相同标签的像素共享某些特征。
当然,会出现一个常见的问题:
为什么图像分割如此重要?
以自主车辆为例,它们需要像相机、雷达和激光这样的传感器输入设备,以便让汽车感知周围的世界,创建数字地图。自主驾驶不可能实现物体检测,而物体检测本身涉及图像分类/分割。

自主车辆的物体检测和图像分类
其他例子涉及医疗行业,如果我们谈论癌症,即使在今天的技术进步时代,癌症仍然可能是致命的,如果我们不能在早期阶段识别它。尽快检测到癌细胞可以潜在地挽救数百万人的生命。癌细胞的形状在确定癌症的严重程度中起着至关重要的作用,这可以通过图像分类算法识别出来。
就像这样,多年来已经开发了多种图像分割算法和技术,利用领域特定的知识来有效解决该特定应用领域的分割问题,这些领域包括医学影像、物体检测、虹膜识别、视频监控、机器视觉以及更多。
让我们使用 python matplotlib 库在 3D 空间中绘制图像。
下面是我们将在 3D 空间中绘制的图像,我们可以清楚地看到 3 种不同的颜色,这意味着应该生成 3 个簇/组。

import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import cv2img = cv2.imread("/Users/nageshsinghchauhan/Documents/images10.jpg")
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
r, g, b = cv2.split(img)
r = r.flatten()
g = g.flatten()
b = b.flatten()#plotting
fig = plt.figure()
ax = Axes3D(fig)
ax.scatter(r, g, b)
plt.show()
在 3D 空间中的图像绘制
从图中可以很容易地看到数据点正在形成组——图中的某些地方更密集,我们可以认为这是图像上不同颜色的主导作用。
图像分割的工作原理
图像分割涉及将图像转换为由掩模或标记图像表示的像素区域集合。通过将图像划分为多个段,你可以只处理图像中重要的段,而不是处理整个图像。
一种常见的技术是寻找像素值中的突变,这通常表示定义区域的边缘。
另一种常见的方法是检测图像区域中的相似性。一些遵循这种方法的技术包括区域生长、聚类和阈值处理。
多年来,已经开发出多种其他图像分割方法,这些方法利用领域特定的知识在特定应用领域有效地解决分割问题。
所以让我们从一种基于聚类的图像分割方法开始,即 K-均值聚类。
K-均值聚类算法
好的,首先什么是机器学习中的聚类算法?
聚类算法是无监督算法,但它们与分类算法类似,只是基础不同。
在聚类中,你不知道自己在寻找什么,而是试图识别数据中的一些段落或簇。当你在数据集中使用聚类算法时,意想不到的结构、簇和分组可能会突然出现,而这些你之前可能从未想到过。
K-均值聚类算法是一种无监督算法,用于从背景中分割兴趣区域。它基于 K-质心将给定数据划分成 K 个簇或部分。
当你有未标记的数据(即没有定义类别或组的数据)时,使用该算法。目标是根据数据中的某种相似性找到特定的组,这些组的数量由 K 表示。
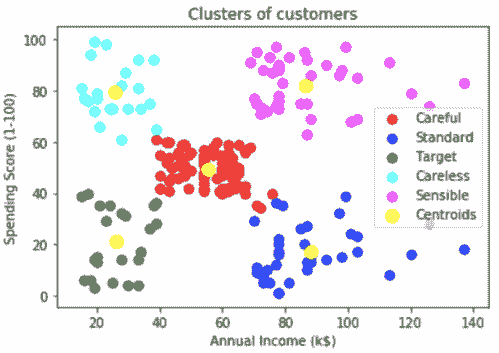
K-均值聚类示例
在上图中,购物中心的顾客根据收入和消费评分被分成了 5 个簇。黄色点表示每个簇的质心。
K-均值聚类的目标是最小化所有点与簇中心之间的平方距离之和。
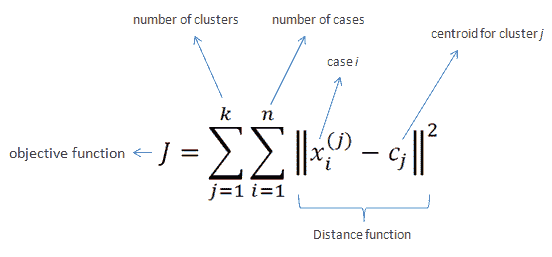
图片来源:saedsayad.com
K-均值算法的步骤:
-
选择簇的数量 K。
-
随机选择 K 个点作为质心(不一定来自数据集)。
-
将每个数据点分配给最近的质心 → 这形成 K 个簇。
-
计算并放置每个簇的新质心。
-
将每个数据点重新分配到新的最近质心。如果发生了任何重新分配,请转到步骤 4,否则,模型已准备好。
如何选择 K 的最佳值?
对于某些类别的聚类算法(特别是 K-均值、K-medoids和期望最大化算法),有一个通常称为 K 的参数,它指定了要检测的簇的数量。其他算法,如DBSCAN和OPTICS 算法,不需要指定这个参数;层次聚类完全避免了这个问题,但这超出了本文的范围。
如果谈到 K 均值,K 的正确选择通常是不明确的,解释取决于数据集中的点的分布形状和尺度以及用户所需的聚类分辨率。此外,增加 K 而不付出代价总会减少结果聚类中的误差,极端情况是每个数据点被视为自己的簇(即 K 等于数据点数n)。直观上,K 的最佳选择将平衡最大化数据压缩和最大化准确度。
如果从数据集的属性中没有明显的 K 值,则必须以某种方式选择。有几种方法来做出这一决策,肘部法则就是其中之一。
肘部法则
分区方法(如 K 均值聚类)的基本思想是定义簇,使得总的簇内变异或总的簇内平方和(WCSS)最小化。总 WCSS 衡量了聚类的紧凑性,我们希望它尽可能小。
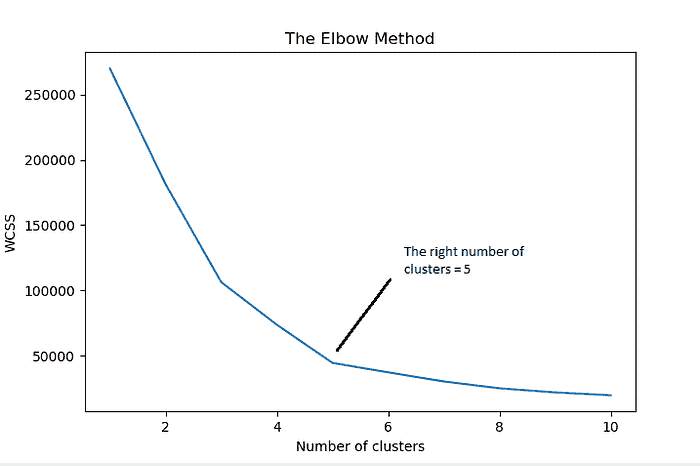
肘部法则将总 WCSS 视为簇数的函数:应选择一个簇数,使得添加另一个簇不会显著改善总 WCSS。
选择最佳簇数 K 的步骤:(肘部法则)
-
对不同 K 值进行 K 均值聚类,将 K 从 1 变到 10。
-
对于每个 K,计算簇内平方和总和(WCSS)。
-
绘制 WCSS 与簇数 K 的曲线图。
-
图中弯曲(膝部)的位置通常被视为适当簇数的指示。
有一个陷阱!
尽管 K 均值有许多优点,但由于质心的随机选择,有时会出现失败,这被称为随机初始化陷阱。
为解决此问题,我们有一种 K 均值的初始化程序,称为K 均值++(K 均值聚类初始值选择算法)。
在 K 均值++中,我们随机选择一个点作为第一个质心,然后根据与第一个点的距离选择下一个点,距离越远的点选择概率越大。
然后我们有两个质心,重复这个过程,每个点的概率基于它到最近质心的距离。现在,这在算法初始化时引入了额外开销,但减少了糟糕初始化导致差聚类结果的概率。
K 均值聚类的可视化表示: 从左侧的 4 个点开始。

来源: K-Means 聚类实际应用
说够了理论,接下来在实际场景中实现我们讨论的内容。
在这一部分,我们将探索一种方法,通过 K-Means 聚类算法 和 OpenCV 来读取图像并对图像的不同区域进行聚类。
基本上,我们将进行颜色聚类和 Canny 边缘检测。
颜色聚类:
加载所有必需的库:
import numpy as np
import cv2
import matplotlib.pyplot as plt
下一步是加载 RGB 颜色空间中的图像
original_image = cv2.imread("/Users/nageshsinghchauhan/Desktop/image1.jpg")
原始图像:

来源:unsplash
我们需要将图像从 RGB 颜色空间转换为 HSV 才能继续操作。
但问题是为什么??
根据 维基百科,数字图像中对象颜色的 R、G 和 B 组件与光线照射对象的量相关,因此彼此之间也是相关的,基于这些组件的图像描述使得对象辨别变得困难。基于色调/亮度/饱和度的描述通常更为相关。
如果你不将图像转换为 HSV,你的图像可能会像这样:
我们在 RGB 颜色空间中的原始图像
img=cv2.cvtColor(original_image,cv2.COLOR_BGR2RGB)
接下来,将 MxNx3 图像转换为 Kx3 矩阵,其中 K=MxN,每一行现在是 RGB 三维空间中的一个向量。
vectorized = img.reshape((-1,3))
我们将 unit8 值转换为 float,因为这是 OpenCV k-means 方法的要求。
vectorized = np.float32(vectorized)
我们将使用 k = 3 进行聚类,因为如果你查看上面的图像,它有 3 种颜色:绿色的草地和森林,蓝色的海洋,以及青绿色的海岸线。
定义条件、聚类数 (K) 并应用 k-means()
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
OpenCV 提供了 cv2.kmeans(samples, nclusters(K), criteria, attempts, flags) 函数用于颜色聚类。
1. samples: 它应该是 np.float32 数据类型,并且每个特征应该放在单独的一列中。
2. nclusters(K): 最终所需的聚类数
3. criteria: 这是迭代终止条件。当满足这个条件时,算法迭代停止。实际上,它应该是 3 个参数的元组。它们是 ( type, max_iter, epsilon ):
终止条件类型。它有 3 个标志如下:
-
cv.TERM_CRITERIA_EPS — 当达到指定的精度,即 epsilon 时,停止算法迭代。
-
cv.TERM_CRITERIA_MAX_ITER — 在指定的迭代次数后停止算法,max_iter。
-
cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER — 当满足上述任意条件时,停止迭代。
4. 尝试次数: 标志用于指定算法使用不同初始标签的执行次数。算法返回产生最佳紧凑性的标签。该紧凑性作为输出返回。
5. 标志: 此标志用于指定如何选择初始中心。通常使用两个标志: cv.KMEANS_PP_CENTERS 和 cv.KMEANS_RANDOM_CENTERS。
K = 3
attempts=10
ret,label,center=cv2.kmeans(vectorized,K,None,criteria,attempts,cv2.KMEANS_PP_CENTERS)
现在转换回 uint8 格式。
center = np.uint8(center)
接下来,我们需要访问标签以重新生成聚类图像
res = center[label.flatten()]
result_image = res.reshape((img.shape))
result_image 是经过 k-means 聚类的帧结果。
现在让我们用 K=3 可视化输出结果
figure_size = 15
plt.figure(figsize=(figure_size,figure_size))
plt.subplot(1,2,1),plt.imshow(img)
plt.title('Original Image'), plt.xticks([]), plt.yticks([])
plt.subplot(1,2,2),plt.imshow(result_image)
plt.title('Segmented Image when K = %i' % K), plt.xticks([]), plt.yticks([])
plt.show()

K=3 时的图像分割
所以该算法已经将我们的原始图像分类为三种主要颜色。
让我们看看当我们将 K 值改为 5 时会发生什么:
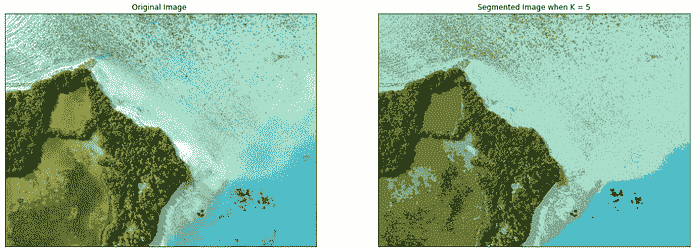
K=5 时的图像分割
将 K 值改为 7:

K=7 时的图像分割
如你所见,随着 K 值的增加,图像变得更清晰,因为 k-means 算法可以对更多的颜色类/簇进行分类。
我们可以尝试对不同的图像运行我们的代码:

K=6 时的图像分割
K=6 时的图像分割
让我们进入下一部分,即 Canny 边缘检测。
Canny 边缘检测: 这是一种图像处理方法,用于检测图像中的边缘,同时抑制噪声。
Canny 边缘检测算法由 5 个步骤组成:
-
梯度计算 -
非极大值抑制
-
双重阈值
-
通过滞后跟踪边缘
OpenCV 提供了cv2.Canny(image, threshold1,threshold2)函数用于边缘检测。
第一个参数是我们的输入图像。第二个和第三个参数分别是我们的最小和最大阈值。
该函数在输入图像(8 位输入图像)中找到边缘,并使用 Canny 算法在输出图中标记这些边缘。阈值 1 和阈值 2 之间的最小值用于边缘连接。最大值用于查找强边缘的初始片段。
edges = cv2.Canny(img,150,200)
plt.figure(figsize=(figure_size,figure_size))
plt.subplot(1,2,1),plt.imshow(img)
plt.title('Original Image'), plt.xticks([]), plt.yticks([])
plt.subplot(1,2,2),plt.imshow(edges,cmap = 'gray')
plt.title('Edge Image'), plt.xticks([]), plt.yticks([])
plt.show()

结果-1:使用 Canny 算法进行边缘检测
结果-2:使用 Canny 算法进行边缘检测
结论:未来的展望
图片来源:gehealthcare
由于图像处理、机器学习、人工智能及相关技术的进步,在未来几十年内,世界上将出现数百万台机器人,这将改变我们的日常生活方式。这些进步将包括语音命令、预测政府的信息需求、翻译语言、识别和跟踪人员和物品、诊断医疗条件、执行手术、修复人类 DNA 缺陷、无人驾驶汽车等应用,现实生活中的应用无穷无尽。
好了,文章到此为止。希望你们喜欢阅读这篇文章。请在评论区分享你的想法/评论/疑问。
你可以通过 LinkedIn 联系我,如有任何问题。
感谢阅读!!!
简介: 纳吉什·辛格·乔汉 是一位数据科学爱好者。对大数据、Python、机器学习感兴趣。
原文。经许可转载。
相关内容:
-
使用卷积神经网络和 OpenCV 预测年龄和性别
-
使用 Scikit-Learn 进行 Python 线性回归的初学者指南
-
从数据预处理到优化回归模型性能
更多相关内容
k-近邻简介
原文:
www.kdnuggets.com/2018/03/introduction-k-nearest-neighbors.html
评论
作者 Devin Soni,计算机科学学生
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
k-近邻 (kNN) 分类方法是机器学习中最简单的方法之一,也是入门机器学习和分类的绝佳方式。在其最基本的层面上,它本质上是通过查找训练数据中最相似的数据点进行分类,并根据这些数据点的分类做出有根据的猜测。尽管这种方法非常简单易懂和实现,但它在许多领域中得到了广泛应用,如推荐系统、语义搜索和异常检测。
正如我们在任何机器学习问题中需要做的那样,我们必须首先找到一种方法将数据点表示为特征向量。特征向量是数据的数学表示,由于数据的期望特征可能不具有内在的数值性质,因此可能需要预处理和特征工程来创建这些向量。对于具有N个唯一特征的数据,特征向量将是长度为N的向量,其中向量的I项表示该数据点在特征I上的值。因此,每个特征向量可以被视为R^N中的一个点。
现在,与大多数其他分类方法不同,kNN 属于惰性学习,这意味着在分类之前没有明确的训练阶段。相反,对数据的任何尝试进行概括或抽象都是在分类时进行的。虽然这意味着我们可以在获取数据后立即开始分类,但这种算法存在一些固有问题。我们必须能够将整个训练集保存在内存中,除非我们对数据集进行某种类型的缩减,否则执行分类可能会很耗费计算资源,因为算法会遍历所有数据点进行每次分类。由于这些原因,kNN 在特征较少的小型数据集上效果最佳。
一旦我们形成了训练数据集,该数据集表示为M xN 矩阵,其中M 是数据点的数量,N 是特征的数量,我们现在可以开始分类。kNN 方法的要点是,对于每个分类查询:
1. Compute a distance value between the item to be classified and every item in the training data-set
2. Pick the k closest data points (the items with the k lowest distances)
3. Conduct a “majority vote” among those data points — the dominating classification in that pool is decided as the final classification
在进行分类之前,必须做出两个重要决定。一个是将要使用的k值;这可以是任意决定的,或者你可以尝试交叉验证以找到最佳值。下一个也是最复杂的,是将使用的距离度量。
计算距离有很多不同的方法,因为这是一个相当模糊的概念,使用的适当度量标准总是由数据集和分类任务决定。然而,欧几里得距离 和 余弦相似度 是两种流行的方法。
欧几里得距离可能是你最熟悉的一种;它本质上是通过将训练数据点从待分类点中减去得到的向量的大小。
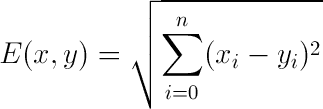
欧几里得距离的一般公式
另一个常见的度量标准是余弦相似度。余弦相似度不是计算大小,而是使用两个向量之间的方向差异。
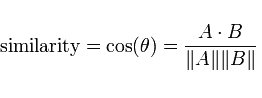
余弦相似度的一般公式
选择一个度量标准通常是棘手的,最好是使用交叉验证来决定,除非你有一些先验的见解可以明确指导使用一个而不是另一个。例如,对于像词向量这样的情况,你可能会想使用余弦相似度,因为词的方向比成分值的大小更有意义。一般来说,这两种方法的运行时间大致相同,并且都会受到高维数据的影响。
在完成上述所有操作并决定度量标准之后,kNN 算法的结果是一个决策边界,将RN**划分为若干部分。每个部分(下图中颜色不同)表示分类问题中的一个类别。边界不一定由实际的训练样本形成——它们是通过使用距离度量和可用的训练点来计算的。通过将**RN分成(小)块,我们可以计算该区域中一个假设数据点最可能的类别,从而将该块标记为该类别的区域。
这些信息就是开始实现算法所需的全部,进行实现应该相对简单。当然,还有很多方法可以改进这个基础算法。常见的修改包括加权,以及特定的预处理以减少计算和减少噪声,比如各种特征提取和降维算法。此外,kNN 方法也被用于回归任务,尽管不那么常见,其操作方式与分类器类似,通过平均来进行。
个人简介:Devin Soni 是一名计算机科学学生,对机器学习和数据科学感兴趣。他将在 2018 年成为 Airbnb 的一个软件工程实习生。可以通过LinkedIn联系他。
原文。经许可转载。
相关:
-
马尔可夫链简介
-
机器学习新手的前 10 大算法巡礼
-
K-最近邻——最懒的机器学习技术
更多相关话题
K-最近邻算法介绍及示例
原文:
www.kdnuggets.com/2020/04/introduction-k-nearest-neighbour-algorithm-using-examples.html
评论
由 Ranvir Singh 提供,开源爱好者

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
KNN 也称为 K-最近邻,是一种 监督学习和模式分类算法,它帮助我们找出新输入(测试值)属于哪个类别,当选择了 k 个最近邻并计算它们之间的距离时。
它尝试估计在给定
X的情况下Y的条件分布,并将给定的观察值(测试值)分类到具有最高估计概率的类别中。
它首先识别训练数据中离 测试值 最近的 k 个点,并计算这些类别之间的距离。测试值将归属于距离最小的类别。
KNN 中测试值分类的概率
它使用此函数计算测试值属于类别 j 的概率
KNN 中计算距离的方法
距离可以通过不同的方法计算,这些方法包括:
-
欧几里得方法
-
曼哈顿方法
-
闵可夫斯基方法
-
等等……
有关可以使用的距离度量的更多信息,请阅读 这篇关于 KNN 的文章。你可以通过将 metric 参数传递给 KNN 对象来使用列表中的任何方法。这里有一个 Stack Overflow 上的回答 可能对你有帮助。你甚至可以使用一些随机距离度量。如果你想使用自己的距离计算方法,也可以 阅读这个答案。
KNN 的过程及示例
假设我们有一个数据集,其中包含标记明确的狗和马的身高和体重。我们将使用所有条目的体重和身高来创建一个图表。现在,每当有新的条目进来时,我们将选择一个k值。为了本示例的方便,假设我们选择4作为k的值。我们将找到最近的四个值的距离,距离最小的那个将具有更高的概率,并被认为是赢家。
KneighborsClassifier: KNN Python 示例
GitHub 仓库: KNN GitHub 仓库 数据源使用: 数据源的 GitHub 在 K-最近邻算法中,大多数时候你实际上并不知道输入参数或分类类别的含义。在面试的情况下,这样做是为了隐藏真实的客户数据。
# Import everything
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# Create a DataFrame
df = pd.read_csv('KNN_Project_Data')
# Print the head of the data.
df.head()

数据的头部清楚地表明我们有一些变量和一个包含不同类别的目标类。
为什么对 KNN 进行变量归一化/标准化
如我们所见,数据框中的数据尚未标准化。如果不对数据进行归一化,结果会大相径庭,且可能无法获得正确的结果。这是因为某些特征的偏差很大(值范围从 1 到 1000)。这将导致非常糟糕的图表,并在模型中产生大量缺陷。有关归一化的更多信息,请查看stack exchange上的回答。Sklearn 提供了一种非常简单的方式来标准化数据。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(df.drop('TARGET CLASS', axis=1))
sc_transform = scaler.transform(df.drop('TARGET CLASS', axis=1))
sc_df = pd.DataFrame(sc_transform)
# Now you can safely use sc_df as your input features.
sc_df.head()

使用 sklearn 进行测试/训练拆分
我们可以简单地使用 sklearn 拆分数据。
from sklearn.model_selection import train_test_split
X = sc_transform
y = df['TARGET CLASS']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
使用 KNN 并找到最佳的 k 值
选择一个合适的k值可能是一项艰巨的任务。我们将使用 Python 来自动化这个任务。我们能够找到一个合适的k值,从而最小化模型中的错误率。
# Initialize an array that stores the error rates.
from sklearn.neighbors import KNeighborsClassifier
error_rates = []
for a in range(1, 40):
k = a
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
preds = knn.predict(X_test)
error_rates.append(np.mean(y_test - preds))
plt.figure(figsize=(10, 7))
plt.plot(range(1,40),error_rates,color='blue', linestyle='dashed', marker='o',
markerfacecolor='red', markersize=10)
plt.title('Error Rate vs. K Value')
plt.xlabel('K')
plt.ylabel('Error Rate')
 从图表中可以看到,
从图表中可以看到,k=30给出了非常理想的错误率值。
k = 30
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
preds = knn.predict(X_test)
评估 KNN 模型
阅读以下帖子以了解更多关于评估机器学习模型的内容。
from sklearn.metrics import confusion_matrix, classification_report
print(confusion_matrix(y_test, preds))
print(classification_report(y_test, preds))

使用 KNN 算法的好处
-
KNN 算法因其简单易用而广泛用于各种学习任务。
-
在算法中只需提供两个指标:
k的值和distance metric。 -
可以处理任意数量的类别,而不仅仅是二分类器。
-
向算法中添加新数据相对容易。
KNN 算法的缺点。
-
预测
k最近邻的成本非常高。 -
在处理大量特征/参数时表现不如预期。
-
处理分类特征较为困难。
一本很好的读物,基于 sklearn 对 Knn 进行基准测试。
希望你喜欢这篇文章。如有任何问题或疑虑,欢迎在下面的评论中提出。
简介:Ranvir Singh (@ranvirsingh1114)是一名来自印度的网页开发者。他是一个编程和 Linux 爱好者,想尽可能多地学习新知识。作为 FOSS 爱好者和开源贡献者,他还曾参与 2017 年 Google Summer of Code 与 AboutCode 组织合作。他还在 2019 年担任了同一组织的 GSoC 导师。
原始内容。经许可转载。
相关:
-
最新 Scikit-learn 版本中的 5 个新特性。
-
掌握中级机器学习的 7 个步骤 — 2019 版。
-
为数据集选择合适的聚类算法。
相关主题更多。
Kubeflow MPI Operator 及其在行业中的应用
原文:
www.kdnuggets.com/2020/03/introduction-kubeflow-mpi-operator-industry-adoption.html
评论
由 Yuan Tang (Ant Financial), Wei Yan (Ant Financial), 和 Rong Ou (NVIDIA)
Kubeflow 最近刚刚 宣布了其首个主要的 1.0 版本,使机器学习工程师和数据科学家能够利用云资产(无论是公共的还是本地的)进行机器学习工作负载。在这篇文章中,我们想介绍 MPI Operator (文档),这是 Kubeflow 的核心组件之一,目前处于 alpha 阶段,它使得在 Kubernetes 上运行同步的、allreduce 风格的分布式训练变得容易。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 事务
当前有两种主要的分布式训练策略:一种是基于参数服务器的,另一种是基于集体通信原语(如 allreduce)的。
基于参数服务器的分布式策略依赖于集中式参数服务器来协调各个工作节点,负责从工作节点收集梯度并将更新后的参数发送给工作节点。下图展示了在这种分布式训练策略下,参数服务器和工作节点之间的互动。
尽管基于参数服务器的分布式训练可以通过增加更多的工作节点和参数服务器来支持训练非常大的模型和数据集,但在优化性能时仍然面临额外的挑战:
-
确定工作节点与参数服务器的正确比例并不容易。例如,如果仅使用少量参数服务器,网络通信很可能会成为训练的瓶颈。
-
如果使用了多个参数服务器,通信可能会使网络连接饱和。
-
工作节点和参数服务器的内存配额需要细致调整,以避免内存溢出错误或内存浪费。
-
如果模型可以适应每个工作节点的计算资源,当模型被分割到多个参数服务器时,会引入额外的维护和通信开销。
-
我们需要在每个参数服务器上复制模型以支持容错,这需要额外的计算和存储资源。
相对而言,基于集体通信原语的分布式训练,如 allreduce,在某些使用场景中可能更高效且更易于使用。在基于 allreduce 的分布式训练策略下,每个工作节点存储一整套模型参数。换句话说,不需要参数服务器。基于 allreduce 的分布式训练可以解决许多上述提到的挑战:
-
每个工作节点存储一整套模型参数,不需要参数服务器,因此在必要时增加更多的工作节点是直接的。
-
可以通过重新启动失败的工作节点并从任何现有工作节点加载当前模型来轻松恢复工作节点中的故障。模型无需复制以支持容错。
-
通过充分利用网络结构和集体通信算法,模型可以更高效地更新。例如,在 ring-allreduce 算法中,每个 N 个工作节点只需与两个同伴工作节点进行 2 * (N − 1)次通信,就能完全更新所有模型参数。
-
扩展和缩减工作节点数量就像重建底层 allreduce 通信器和重新分配工作节点中的排名一样简单。
许多现有技术提供了这些集体通信原语的实现,如 NCCL、 Gloo以及各种不同的 MPI实现。
MPI Operator 提供了一个通用的 Custom Resource Definition (CRD),用于定义单个 CPU/GPU、多 CPU/GPUs 和多个节点上的训练作业。它还实现了一个自定义控制器来管理 CRD,创建依赖资源,并协调期望的状态。

与仅支持单一机器学习框架的其他 Kubeflow 操作器(如TF Operator和PyTorch Operator)不同,MPI Operator 与底层框架解耦,因此可以与许多框架良好配合,如Horovod、TensorFlow、PyTorch、Apache MXNet以及各种集体通信实现,如OpenMPI。
有关不同分布式训练策略、各种 Kubeflow 操作器之间的比较的更多详细信息,请查看我们在 KubeCon Europe 2019 的演示。
示例 API 规范
我们一直在与社区和行业用户密切合作,以改进 MPI Operator 的 API 规范,使其适用于多种不同的使用场景。以下是一个示例:
注意,MPI Operator 提供了一个灵活且用户友好的 API,这个 API 在其他 Kubeflow 操作器中保持一致。
用户可以通过修改模板中的相关部分,轻松定制启动器和工作 Pod 的规范。例如,定制使用各种类型的计算资源,如 CPU、GPU、内存等。
此外,以下是一个示例规范,执行分布式 TensorFlow 训练作业,使用存储在TFRecords格式中的 ImageNet 数据,存储在Kubernetes 卷中:
架构
MPI Operator 包含一个自定义控制器,该控制器监听 MPIJob 资源的变化。当创建新的 MPIJob 时,控制器会经过以下逻辑步骤:
-
创建一个ConfigMap,其中包含:
-
一个辅助的 shell 脚本,可以被
mpirun代替ssh使用。它调用kubectl exec进行远程执行。 -
一个主机文件,列出了工作节点StatefulSet中的 Pods(形式为\({job-id}-worker-0、\){job-id}-worker-1 等),以及每个 Pod 中可用的插槽(CPU/GPU)。
-
-
创建RBAC资源(角色、服务账户、角色绑定),以允许远程执行(pods/exec)。
-
等待工作 Pod 准备好。
-
创建启动器任务。它在第 2 步创建的服务账户下运行,并设置执行
mpirun命令所需的环境变量。kubectl二进制文件通过初始化容器传递到 emptyDir 卷。 -
启动器任务完成后,将工作节点 StatefulSet 中的副本数设置为 0。
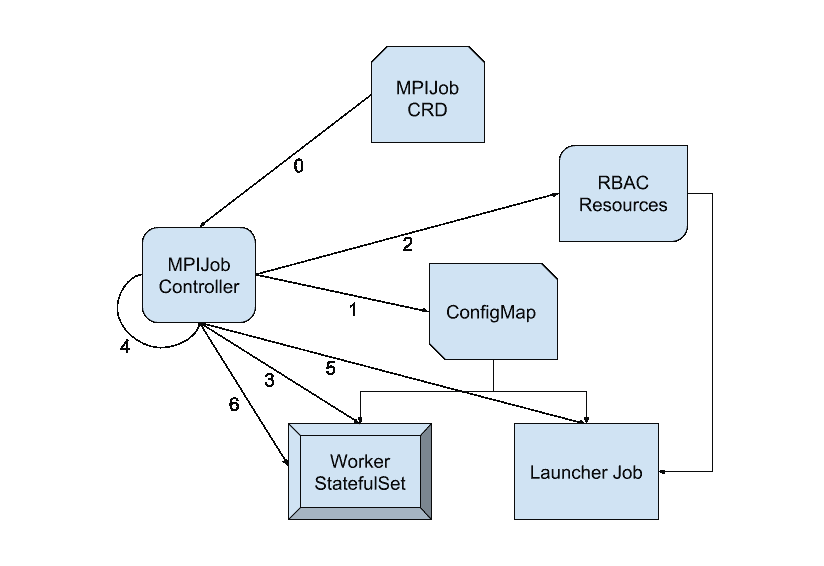
欲了解更多细节,请查看MPI Operator 的设计文档。
行业采用
在撰写本文时,已有 13 家公开的行业采用者以及许多与社区紧密合作的其他公司。如果您的公司希望被加入采用者列表,请在GitHub上向我们发送拉取请求!
Ant Financial
在Ant Financial,我们管理着数万节点的 Kubernetes 集群,并已部署了 MPI Operator 及其他 Kubeflow 操作器。MPI Operator 利用网络结构和集体通信算法,使用户无需担心工作节点和参数服务器之间的最佳比例,以获得最佳性能。用户可以专注于构建模型架构,而无需花时间调整用于分布式训练的下游基础设施。
生成的模型已经广泛应用于生产中,并在许多不同的实际场景中经过了检验。其中一个显著的应用案例是Saofu——一个移动应用,用户可以通过增强现实扫描任何“福”(代表财富的汉字)来参与抽奖,每位用户都会收到一个包含大笔金额的虚拟红包。
Bloomberg
Bloomberg,全球商业和金融信息及新闻的领袖,拥有海量的数据——从历史新闻到实时市场数据及其他各种信息。Bloomberg 的 Data Science Platform 旨在让公司的内部机器学习工程师和数据科学家更容易地利用数据和算法模型进行日常工作,包括训练任务和用于他们所构建的最先进解决方案中的自动机器学习模型。
“Bloomberg 的 Data Science Platform 提供了类似 Kubeflow 的 TFJob 的 TensorFlowJob CRD,使公司的数据科学家能够轻松训练神经网络模型。最近,Data Science Platform 团队通过 MPI Operator 在 TensorFlowJob 中启用了基于 Horovod 的分布式训练作为实现细节。使用后端的 MPIJob 使 Bloomberg Data Science Platform 团队能够迅速为其机器学习工程师提供一种强大的方式,在几小时内使用公司的大量文本数据训练一个BERT 模型,”Bloomberg 的软件工程师郑成建表示。
Caicloud
Caicloud Clever 是一个基于 Caicloud 容器云平台的人工智能云平台,具备强大的硬件资源管理和高效的模型开发能力。Caicloud 的产品已部署在许多 500 强中国公司中。
“Caicloud Clever 支持包括 TensorFlow、Apache MXNet、Caffe、PyTorch 在内的多种 AI 模型训练框架,借助 Kubeflow tf-operator、pytorch-operator 等”,Caicloud Clever 团队的 AI 基础设施工程师 Ce Gao 表示。“同时,RingAllReduce 分布式训练支持的需求正在增加,以提升客户成熟度。”
Kubeflow MPI operator 是一个用于 allreduce 风格分布式训练的 Kubernetes Operator。Caicloud Clever 团队采用了 MPI Operator 的 v1alpha2 API。Kubernetes 本地 API 使其容易与平台上的现有系统进行协作。
Iguazio
Iguazio 提供了一个以自动化、性能、可扩展性和开源工具使用为重点的云原生数据科学平台。
根据 Iguazio 的创始人兼 CTO Yaron Haviv 的说法:“我们评估了各种机制,以便在最小的开发者努力下扩展深度学习框架,发现使用 Horovod 与 Kubernetes 上的 MPI Operator 的组合是最好的工具,因为它支持横向扩展,支持 TensorFlow 和 PyTorch 等多个框架,并且不需要太多额外的编码或复杂的参数服务器使用。”
Iguazio 已经将 MPI Operator 集成到其托管服务和快速数据层中,以实现最大可扩展性,并通过开源项目如MLRun(用于 ML 自动化和跟踪)简化使用。查看this blog post中的示例应用,展示了 Iguazio 如何使用 MPI Operator。
Polyaxon
Polyaxon 是一个用于 Kubernetes 上可重复和可扩展机器学习的平台,它允许用户更快地迭代他们的研究和模型创建。Polyaxon 为数据科学家和机器学习工程师提供了一个简单的抽象,以简化他们的实验工作流程,并提供了一个非常一致的抽象来使用流行框架如 Scikit-learn、TensorFlow、PyTorch、Apache MXNet、Caffe 等进行训练和跟踪模型。
“几个 Polyaxon 用户和客户请求一种简便的方法来执行 allreduce 风格的分布式训练,MPI Operator 是提供这种抽象的完美解决方案。Polyaxon 已部署在几家公司和研究机构中,公共 docker hub 的下载量超过 900 万。”,Polyxagon 的联合创始人 Mourad Mourafiq 说道。
社区与贡献召集
我们感谢 来自 11 个组织的超过 28 名个人贡献者,包括阿里云、亚马逊 Web 服务、蚂蚁金服、彭博、开源云、谷歌云、华为、Iguazio、NVIDIA、Polyaxon 和腾讯,他们直接为 MPI Operator 的代码库做出了贡献,还有许多提交问题或帮助解决问题、提问和回答问题、参与激励讨论的其他人。我们已经整理了一个 路线图,提供了关于 MPI Operator 在未来版本中如何发展的高级概述,我们欢迎社区的任何贡献!
我们的里程碑成就离不开极其活跃的社区。查看我们的 社区页面 以了解如何加入 Kubeflow 社区!
原文。经授权转载。
相关:
-
Kubeflow 如何将 AI 添加到你的 Kubernetes 部署中
-
2020 年最有用的机器学习工具
-
简易的一键 Jupyter Notebook
更多相关话题
《局部可解释模型无关解释(LIME)介绍》
原文:
www.kdnuggets.com/2016/08/introduction-local-interpretable-model-agnostic-explanations-lime.html
作者:Marco Tulio Ribeiro、Sameer Singh^ 和 Carlos Guestrin。
- 华盛顿大学
^ 加州大学欧文分校
机器学习是许多近期科学和技术进步的核心。随着计算机在围棋等游戏中战胜专业选手,许多人开始询问机器是否也会成为更好的司机甚至更好的医生。
在许多机器学习应用中,用户被要求信任模型来帮助他们做决策。医生肯定不会仅仅因为“模型说了”就对患者进行手术。即使在较低风险的情况下,例如从 Netflix 中选择一部电影观看,我们也需要一定程度的信任,然后才会根据模型的推荐花费几个小时的时间。尽管许多机器学习模型是黑箱模型,但了解模型预测背后的理由肯定会帮助用户决定是否信任这些预测。图 1 展示了一个例子,其中模型预测某位患者感染了流感。然后由一个“解释器”解释该预测,突出模型认为最重要的症状。通过了解模型背后的理由,医生现在可以决定是否信任模型——或不信任。
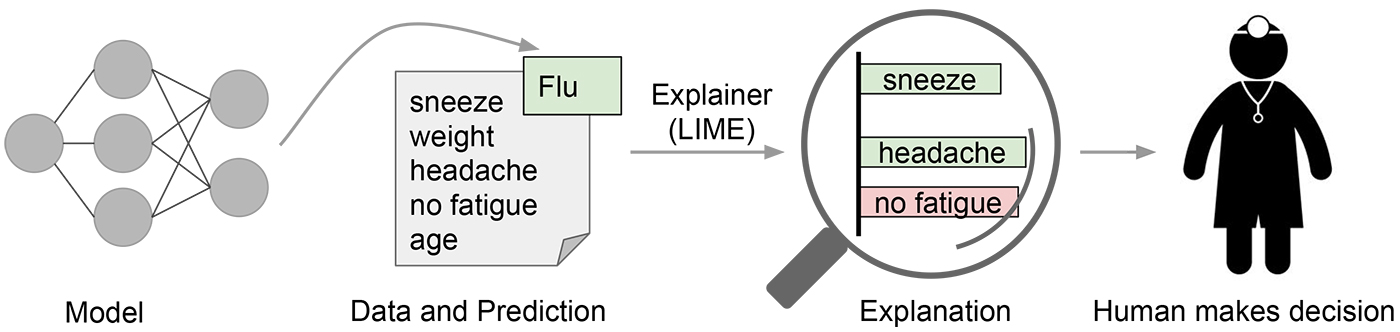
图 1. 向人类决策者解释个体预测。 来源:Marco Tulio Ribeiro。 从某种意义上说,每次工程师将机器学习模型上传到生产环境时,工程师都在隐含地信任该模型会做出合理的预测。这种评估通常是通过查看持出准确性或其他汇总指标来完成的。然而,正如任何曾经在实际应用中使用过机器学习的人都可以证明的那样,这些指标可能非常具有误导性。有时不应可用的数据意外地泄漏到训练和持出数据中(例如,提前查看未来)。有时模型会犯下令人尴尬的错误,这些错误是不可接受的。这些以及许多其他棘手的问题表明,在决定模型是否值得信赖时,理解模型的预测可能是一个额外有用的工具,因为人类通常拥有难以在评估指标中捕捉到的良好直觉和商业智慧。假设一个“选择步骤”,在这个步骤中选择某些具有代表性的预测以向人类解释,会使过程类似于图 2 所示的过程。

图 2. 向人类决策者解释模型。 来源:Marco Tulio Ribeiro。 在《我为什么应该信任你?解释任何分类器的预测》中,由Marco Tulio Ribeiro、Sameer Singh和Carlos Guestrin共同完成(即将在 ACM 的知识发现与数据挖掘会议上发表),我们准确地探讨了信任和解释的问题。我们提出了局部可解释模型无关解释(LIME)技术,这是一种解释任何机器学习分类器预测的方法,并评估其在与信任相关的各种任务中的有用性。
LIME 背后的直觉
因为我们希望保持模型的独立性,所以我们可以通过扰动输入并观察预测结果的变化来学习基础模型的行为。这在可解释性方面是一种优势,因为我们可以通过改变对人类有意义的组件(例如,单词或图像的一部分)来扰动输入,即使模型使用的是更复杂的特征组件(例如,词嵌入)。
我们通过用可解释的模型(例如,只有少数非零系数的线性模型)来逼近潜在模型,从而生成解释,该模型是在原始实例的扰动上学习的(例如,删除单词或隐藏图像的部分)。LIME 的关键直觉在于,在我们要解释的预测的邻域内,用简单模型局部逼近黑箱模型比全局逼近要容易得多。这是通过根据扰动图像与我们要解释的实例的相似性来加权扰动图像来实现的。回到我们的流感预测示例,三种突出的症状可能是对黑箱模型的忠实近似,适用于与被检查的患者相似的患者,但它们可能并不代表模型对所有患者的行为。
请参见图 3,了解 LIME 在图像分类中的工作原理。假设我们想解释一个分类器,该分类器预测图像中包含树蛙的可能性。我们取左侧的图像,并将其划分为可解释的组件(连续超像素)。

图 3. 将图像转化为可解释的组件。来源:Marco Tulio Ribeiro,Pixabay.如图 4 所示,我们接着通过将一些可解释的组件“关闭”(在这种情况下,将其变为灰色)来生成一个扰动实例的数据集。对于每个扰动实例,我们根据模型获得图像中是否有树蛙的概率。然后,我们在这个数据集上学习一个简单的(线性)模型,该模型是局部加权的——也就是说,我们更关心在与原始图像更相似的扰动实例中犯错。最终,我们将具有最高正权重的超像素作为解释,其他部分则变灰。
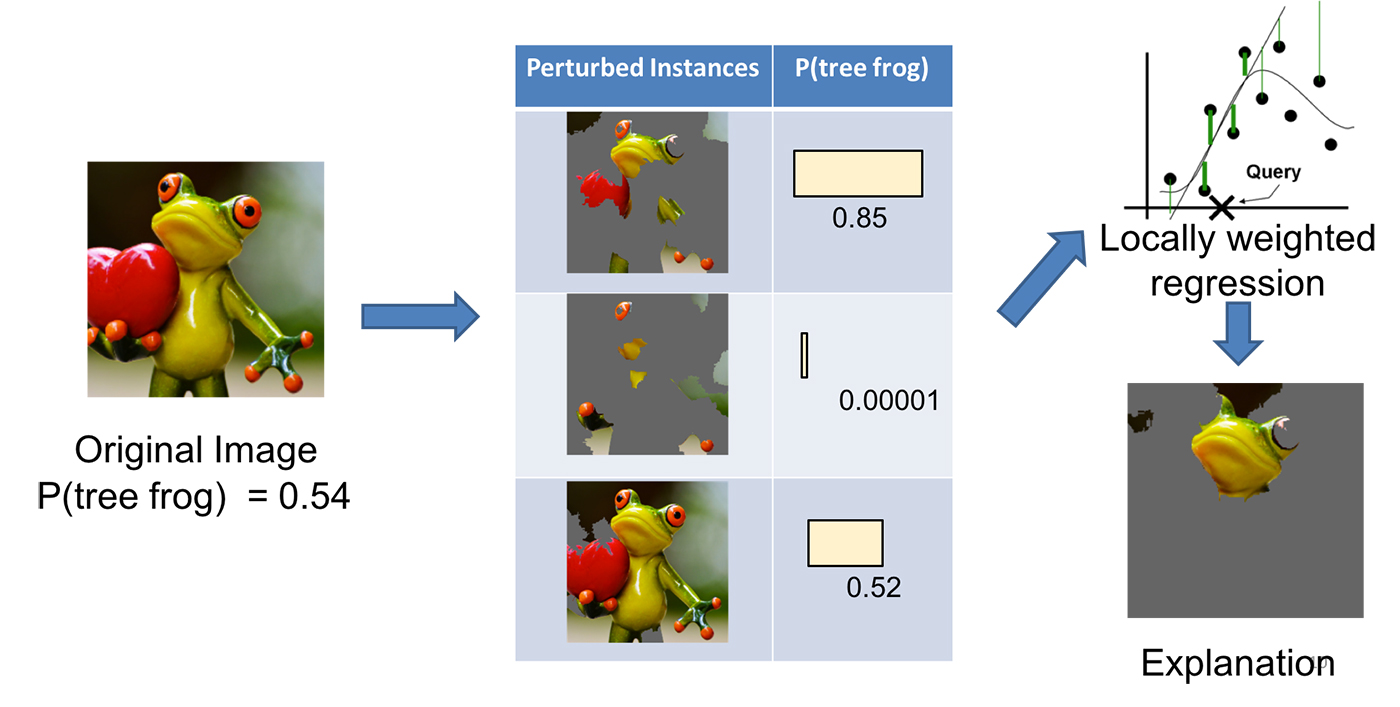
图 4. 使用 LIME 解释预测。来源:Marco Tulio Ribeiro,Pixabay.
示例
我们使用 LIME 来解释各种分类器(例如,随机森林,支持向量机(SVM)以及神经网络)在文本和图像领域的结果。以下是一些生成的解释示例。
首先,一个文本分类的例子。著名的20 个新闻组数据集是该领域的一个基准,已被用来比较几篇论文中的不同模型。我们选择了两个难以区分的类别,因为它们共享许多词汇:基督教和无神论。通过训练一个拥有 500 棵树的随机森林,我们得到一个 92.4%的测试集准确率,这出乎意料地高。如果准确率是我们唯一的信任度衡量标准,我们肯定会信任这个分类器。然而,让我们看看图 5 中对测试集中任意实例的解释(使用我们的开源包的一行 Python 代码):
exp = explainer.explain_instance(test_example,
classifier.predict_proba, num_features=6)

图 5. 20 个新闻组数据集中的预测解释。来源:Marco Tulio Ribeiro.这是一个分类器正确预测实例但理由错误的案例。进一步探讨表明,单词“posting”(电子邮件头部的一部分)在训练集中的 21.6%的示例中出现,但在“基督教”类别中仅出现两次。在测试集中也是如此,单词几乎出现在 20%的示例中,但在“基督教”中仅出现两次。这种数据集中的伪影使得问题比实际情况简单得多,因为我们不会预期出现这样的模式。一旦理解了模型实际做了什么,这些见解就变得容易,这反过来又导致模型具有更好的泛化能力。
作为第二个例子,我们解释了Google 的 Inception 神经网络对任意图像的处理。在这种情况下,如图 6 所示,分类器预测“树蛙”是最可能的类别,其次是“台球桌”和“气球”,后者的概率较低。解释显示,分类器主要关注青蛙的面部作为预测类别的依据。它还揭示了为什么“台球桌”有非零概率:青蛙的手和眼睛与台球有相似之处,尤其是在绿色背景下。同样,心脏与红色气球也有相似之处。

图 6. 对 Inception 预测的解释。前三个预测类别是“树蛙”、“台球桌”和“气球”。来源:马尔科·图利奥·里贝罗,Pixabay(青蛙,台球,热气球)。在我们的研究论文中,我们展示了机器学习专家和普通用户如何从类似于图 5 和图 6 的解释中受益,并能够选择哪些模型具有更好的泛化能力,通过改变模型来改进模型,并获得对模型行为的关键见解。
结论
信任对有效的人机互动至关重要,我们认为解释个体预测是评估信任的一种有效方式。LIME 是一个高效的工具,能够为机器学习从业者提供这种信任,并且是添加到他们工具箱中的不错选择(我们提到过我们有一个开源项目吗?),但仍然需要大量工作来更好地解释机器学习模型。我们对这个研究方向的前景感到兴奋。下面的视频提供了 LIME 的概述,更多细节请见我们的论文。
马尔科·图利奥·里贝罗 是华盛顿大学的博士生,师从卡洛斯·格斯特林。他的研究重点是让人们更容易理解和互动机器学习模型。
卡洛斯·格斯特林 是 Turi, Inc.的首席执行官,同时也是华盛顿大学计算机科学与工程系的亚马逊机器学习教授。作为机器学习领域公认的世界领袖,卡洛斯曾被《流行科学》杂志评为 2008 年“杰出 10 人”之一,因其对人工智能的贡献获得了 2009 年 IJCAI 计算机与思想奖,并获得了总统早期职业科学家和工程师奖(PECASE)。
萨米尔·辛格博士 是加州大学欧文分校计算机科学助理教授,从事大规模互动机器学习和自然语言处理的研究。
原文。经许可转载。
相关:
-
比赛获胜者:使用 Auto-sklearn 赢得 AutoML 挑战赛
-
接近(几乎)任何机器学习问题
-
TPOT:一个用于自动化数据科学的 Python 工具
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
更多相关内容
马尔可夫链简介
原文:
www.kdnuggets.com/2023/01/introduction-markov-chains.html

图片来自 Unsplash
介绍
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
马尔可夫链是一种数学系统,它根据一定的概率规则从一个状态转移到另一个状态。它们由安德雷·马尔可夫在 1906 年首次提出,用于建模随机过程的行为,并且已被应用于物理学、生物学、经济学、统计学、机器学习和计算机科学等众多领域。
马尔可夫链以俄国数学家安德雷·马尔可夫的名字命名,他在 20 世纪初发展了这些系统的理论。马尔可夫对理解随机过程的行为感兴趣,并开发了马尔可夫链理论来建模这些过程。
图 1. 两状态马尔可夫系统的可视化:箭头表示状态之间的转移。
马尔可夫链常用于建模具有无记忆行为的系统,其中系统的未来行为不受其过去行为的影响。
马尔可夫链在数据科学中的一个常见应用是文本预测。这是自然语言处理(NLP)中的一个领域,通常被谷歌、领英和 Instagram 等科技公司使用。当你写邮件时,谷歌会预测并建议单词或短语来自动完成你的邮件。当你在 Instagram 或领英上收到消息时,这些应用程序会建议可能的回复。这些就是我们将要探讨的马尔可夫链的应用。不过,大规模公司在生产中使用的这些功能的模型更加复杂。
在数据科学中,马尔可夫链也可以用于建模各种现象,包括时间序列数据的演变、气体中粒子的运动、疾病的传播以及金融市场的行为。
时间序列示例
下面是一个马尔可夫链如何用于建模时间序列演变的例子:
假设我们有一个股票价格的时间序列,并且我们想使用马尔可夫链来建模股票价格随时间的演变。我们可以定义股票价格可以取的一组状态(例如“上升”、“下降”和“稳定”),并指定这些状态之间的转移概率。例如,我们可以定义如下的转移概率:
Increasing Decreasing Stable
Increasing 0.6 0.3 0.1
Decreasing 0.4 0.4 0.2
Stable 0.5 0.3 0.2
这个矩阵指定了在给定当前状态的情况下,从一个状态转移到另一个状态的概率。例如,如果股票的价格当前在上涨,则有 60%的可能性它会继续上涨,30%的可能性它会下跌,10%的可能性它会保持稳定。
一旦我们定义了马尔可夫链及其转移概率,我们可以通过模拟状态之间的转移来预测股票价格的未来演变。在每个时间步,我们将使用当前状态和转移概率来确定转移到每个可能的下一个状态的概率。
限制
马尔可夫链的一个限制是它们仅适用于表现出无记忆行为的系统。这意味着系统的未来行为不会受到过去行为的影响。如果系统确实存在记忆,那么马尔可夫链可能不是建模其行为的最佳工具。
马尔可夫链的另一个限制是它们只能建模具有有限状态数量的系统。如果系统可以有无限多个状态,那么马尔可夫链可能无法准确建模其行为。
马尔可夫链只能建模表现出平稳行为的系统,其中状态之间的转移概率随时间不变。如果转移概率随时间变化,则可能需要更复杂的模型来准确捕捉系统的行为。
Python 示例
下面是如何在 Python 中实现马尔可夫链的示例:
对股票价格进行建模,以预测它是上涨、下跌还是稳定。
import numpy as np
# Define the states of the Markov chain
states = ["increasing", "decreasing", "stable"]
# Define the transition probabilities
transition_probs = np.array([[0.6, 0.3, 0.1], [0.4, 0.4, 0.2], [0.5, 0.3, 0.2]])
# Set the initial state
current_state = "increasing"
# Set the number of time steps to simulate
num_steps = 10
# Simulate the Markov chain for the specified number of time steps
for i in range(num_steps):
# Get the probability of transitioning to each state
probs = transition_probs[states.index(current_state)]
# Sample a new state from the distribution
new_state = np.random.choice(states, p=probs)
# Update the current state
current_state = new_state
# Print the current state
print(f"Step {i+1}: {current_state}")
这段代码定义了一个简单的马尔可夫链,包含三个状态(“上升”、“下降”和“稳定”),并指定这些状态之间的转移概率。然后,它模拟了马尔可夫链 10 个时间步,在每个时间步根据转移概率采样一个新状态,并相应地更新当前状态。此代码的输出将是一系列状态,表示系统随时间的演变,如下所示:

图 2. 三状态马尔可夫过程的输出,初始状态设置为“上升”。
如果我们将当前状态设置为“下降”并运行代码,我们会得到以下输出:

图 3. 三状态马尔可夫过程的输出,初始状态设置为“decreasing”。
请注意,这是一个非常简化的示例,实际上,你可能需要使用更多的状态,并考虑更复杂的转移概率,以准确地建模系统的行为。然而,这个例子说明了如何在 Python 中实现马尔可夫链的基本概念。
马尔可夫链可以应用于广泛的问题,并且可以使用各种工具和库在 Python 中实现,包括‘numpy’和scipy.stats库。
然而,在使用马尔可夫链建模系统之前,重要的是要仔细考虑马尔可夫链的假设以及它们是否适用于特定的问题。总之,马尔可夫链是数据科学家和研究人员在分析和建模表现出某些行为类型的系统时应考虑的有用工具。
本杰明·O·塔约 是一位物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的所有者。此前,本杰明曾在中央俄克拉荷马大学、Grand Canyon 大学和匹兹堡州立大学教授工程学和物理学。
更多相关内容
多臂老丨虎丨机问题简介
原文:
www.kdnuggets.com/2023/01/introduction-multiarmed-bandit-problems.html
多臂老丨虎丨机(MAB)是一个机器学习框架,它使用复杂的算法在面对多个选择时动态分配资源。换句话说,它是一种高级的 A/B 测试形式,数据分析师、医学研究人员和营销专家最常使用它。
在我们深入探讨多臂老丨虎丨机的概念之前,我们需要讨论强化学习以及探索与利用的困境。然后,我们可以专注于各种老丨虎丨机解决方案和实际应用。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
什么是强化学习?
除了监督学习和无监督学习之外,强化学习是机器学习的基本三大范式之一。与我们提到的前两种原型不同,强化学习关注的是在代理与环境互动时的奖励和惩罚。
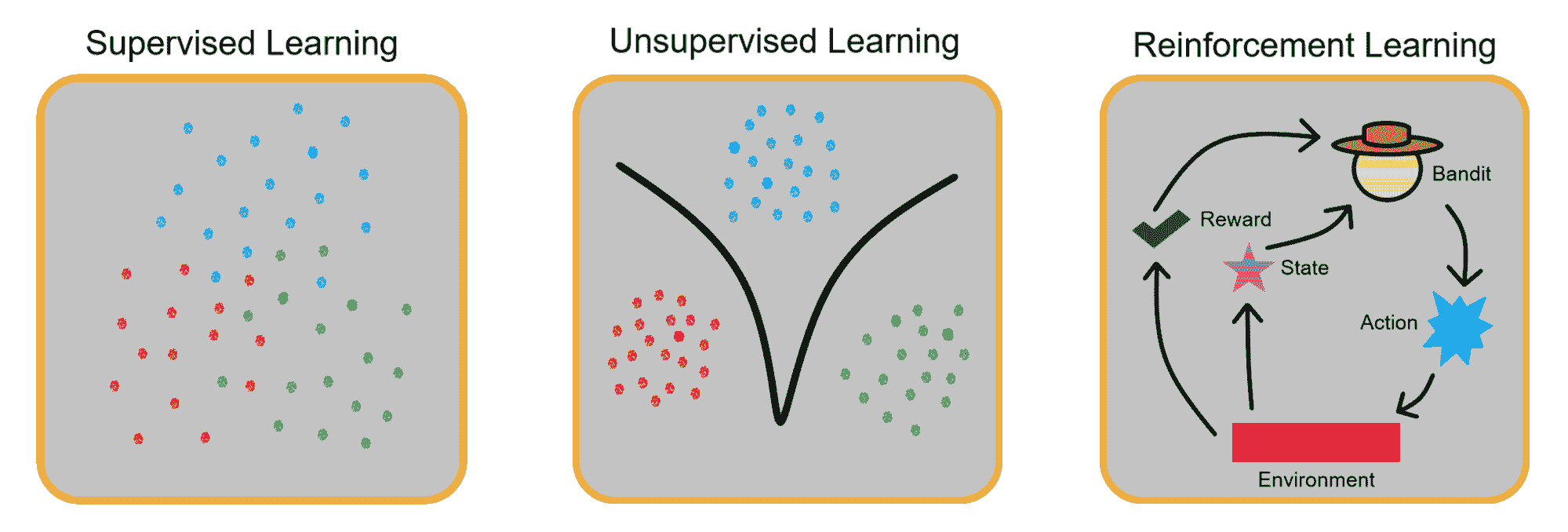
强化学习的实际例子每天都在我们身边。例如,如果你的小狗咬断了你的电脑电缆,你可能会责骂它并表达你对其行为的不满。通过这样做,你将教会你的狗破坏家中电缆是不好的行为。这是负向强化。
同样地,当你的狗表演它学会的技巧时,你会奖励它。在这种情况下,你正在使用正向强化来鼓励它的行为。
多臂老丨虎丨机以相同的方式进行学习。
探索与利用
这种近乎哲学的困境存在于我们生活的各个方面。你应该从你下班后无数次光顾的那家咖啡店买咖啡,还是应该尝试一下刚刚在街对面开张的新咖啡店?
如果你选择探索,你的每日咖啡可能会变成一种不愉快的体验。然而,如果你选择利用你已经知道的东西,去访问熟悉的地方,你可能会错过你曾经品尝过的最美味的咖啡。
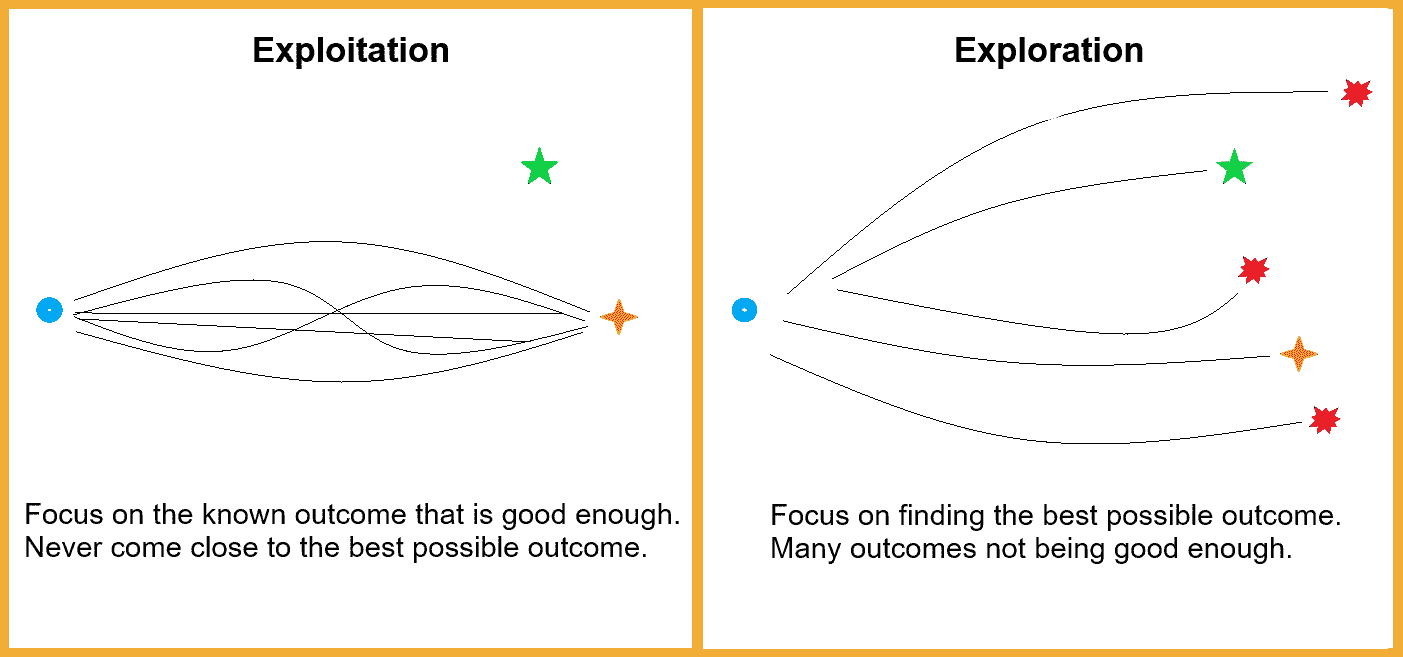
多臂老丨虎丨机在各个领域解决这些问题,并帮助数据分析师确定正确的行动方案。
什么是多臂老丨虎丨机?
单臂老丨虎丨机是老丨虎丨机的另一种说法。无需解释这个绰号背后的含义。
多臂老丨虎丨机问题得名于臭名昭著的单臂老丨虎丨机。然而,这一名称并非源于盗匪和抢劫,而是基于在长期使用老丨虎丨机时获得赢得结果的预定几率。
为了更好地理解这一点,我们来使用另一个现实生活中的例子。这次,你要决定在哪里购买蔬菜。你有三个选择:超市、本地杂货店和附近的农贸市场。每个选择都有不同的考虑因素,比如价格和食物是否有机,但在这个例子中我们只关注食物质量。
假设你在每个地点购买了十次杂货,并且你最常对农贸市场的蔬菜感到满意。最终,你会有意识地决定将绿色蔬菜专门从该市场购买。

当市场偶尔关闭时,你可能被迫再次尝试商店或超市,而结果可能会让你改变主意。最好的老丨虎丨机代理程序会做同样的事情,时不时地尝试回报较少的选项,并强化它们已经拥有的数据。
老丨虎丨机在实时学习并相应调整其参数。与 A/B 测试相比,多臂老丨虎丨机允许你基于较长时间段收集高级信息,而不是在短暂测试后做出选择。
多臂老丨虎丨机构建与解决方案
有无限种方法来构建多臂老丨虎丨机代理。纯探索代理是完全随机的。它们专注于探索,而不利用它们所收集的任何数据。
正如名称所示,纯利用代理总是选择最佳可能的解决方案,因为它们已经拥有所有可以利用的数据。由于其本质上的矛盾,这使得它们在理论上可能存在,但与随机代理一样糟糕。
因此,我们将重点解释三种最流行的多臂老丨虎丨机代理,这些代理既不是完全随机的,也不是在实践中不可能部署的。
Epsilon-贪婪
Epsilon-贪婪多臂老丨虎丨机通过在公式中添加探索值(epsilon)来平衡探索和利用。如果 epsilon 等于 0.3,则代理将在 30%的时间内探索随机可能性,其余 70%的时间专注于利用最佳平均结果。
还包括一个衰减参数,它随着时间的推移减少 epsilon。当构建代理时,你可以决定在经过一定时间或采取一定行动后将 epsilon 从方程中移除。这将导致代理仅专注于利用已经收集的数据,并从方程中移除随机测试。
上置信界限
这些多臂赌博机与 epsilon-贪婪代理非常相似。然而,两者之间的关键区别在于构建上置信界限赌博机时所包含的额外参数。
这个方程中包含一个变量,迫使赌博机时不时地关注那些较少探索的可能性。例如,如果你有选项 A、B、C 和 D,而选项 D 只被选择过十次,而其他选项被选择了数百次,那么赌博机将故意选择 D 以探索其结果。
实质上,上置信界限代理牺牲了一些资源,以避免从未探索最佳可能结果的巨大但相当不可能的错误。
Thompson Sampling(贝叶斯)
这个代理与我们之前探索的两个代理构建方式截然不同。作为列表中最先进的赌博机解决方案,详细解释其工作原理需要一篇长篇文章。然而,我们可以选择一种较为简单的分析方法。
Thompson 赌博机能够根据过去选择的频率更多或更少地信任某些选择。例如,我们有选项 A,代理选择了 100 次,平均奖励比率为 0.71。我们还有选项 B,它总共被选择了 20 次,平均奖励比率与选项 A 相同。
在这种情况下,Thompson 采样代理会更频繁地选择选项 A。这是因为选择路径的频率较高通常会产生较低的平均奖励。代理假设选项 A 更值得信赖,而选项 B 如果被更频繁选择,可能会有较低的平均结果。
多臂赌博机在现实生活中的应用
也许我们在这里可以提到的最著名的例子是 Google Analytics。作为其官方文档的一部分,他们解释了如何使用多臂赌博机探索不同搜索结果的可行性以及这些结果应该如何频繁地展示给不同的访问者。
2018 年,Netflix 在 Data Council 举办了一次演讲,讨论了他们如何应用多臂赌博机来确定哪些标题应该更频繁地展示给观众。市场营销人员可能会觉得这个演示非常有趣,因为它解释了不同因素(如标题的重播频率或观众暂停的情况)如何影响多臂赌博机的解决方案。
多臂赌博机对人类最重要的用途可能与医疗保健相关。至今,医学专家使用各种 MAB 构建来确定患者的最佳治疗方案。赌博机还在临床试验和新疗法探索中得到了各种应用。
关键要点
多臂赌博机在多个领域取得了成功应用,包括市场营销、金融,甚至是健康。然而,正如强化学习本身一样,它们也受到环境变化的严重限制。如果环境条件倾向于变化,多臂赌博机每次都不得不重新“学习”,从而成为一个不那么有用的工具。
亚历克斯·波波维奇是一位工程经理和作家,拥有十年的技术和金融团队领导经验。他现在经营自己的咨询公司,同时探索他所热爱的主题,如数据科学、人工智能和高幻想。你可以通过 hello@writeralex.com 联系亚历克斯。
更多相关话题
命名实体识别介绍
原文:
www.kdnuggets.com/2018/12/introduction-named-entity-recognition.html
评论
由 Suvro Banerjee,Juniper Networks 的机器学习工程师
www.lovejustine.com/journal/whats-in-a-name
介绍
在这篇文章中,我们将了解什么是命名实体识别,也称为 NER。我们将讨论一些使用案例,并评估几个标准的 Python 库,以便我们能够快速入门并解决实际问题。
在接下来的文章系列中,我们将深入了解这一类算法,变得更加复杂,并从零开始创建自己的命名实体识别系统(NER)。
那么,让我们开始这段旅程吧。
什么是命名实体识别?
命名实体识别,也称为实体提取,将文本中的命名实体分类到预定义的类别中,如“个人”、“公司”、“地点”、“组织”、“城市”、“日期”、“产品术语”等。它为你的内容增加了丰富的语义知识,帮助你迅速理解任何给定文本的主题。
命名实体识别的几个使用案例
为新闻提供商分类内容

为新闻提供商分类内容
命名实体识别可以自动扫描整个文章,并揭示其中讨论的主要人物、组织和地点。了解每篇文章的相关标签有助于自动将文章分类到定义的层级中,并实现顺畅的内容发现。
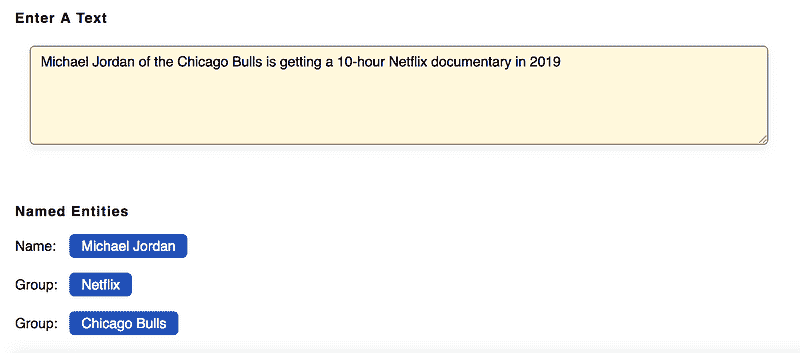
www.paralleldots.com/named-entity-recognition
高效搜索算法
跨品牌的高效搜索
假设你正在为一个拥有数百万篇文章的在线出版商设计一个内部搜索算法。如果每次搜索查询时,算法都需要在数百万篇文章中搜索所有的词汇,那么这个过程将非常耗时。相反,如果能够对所有文章运行一次命名实体识别,并将每篇文章相关的实体(标签)分别存储,这将大大加快搜索过程。采用这种方法,搜索词将只与每篇文章中讨论的少量实体匹配,从而实现更快的搜索执行。
客户支持
Twitter 上的客户支持
假设你在一个全球多分支的电子商店处理客户支持部门,你会看到客户反馈中有很多提及。例如,像这样。
现在,如果你通过命名实体识别 API 传递,它会提取出 Bandra(地点)和 Fitbit(产品)这些实体。然后,这些信息可以用来分类投诉,并将其分配给组织中应该处理此事的相关部门。
www.paralleldots.com/named-entity-recognition
标准库来使用命名实体识别
我将讨论三个在 Python 中广泛使用的标准库来执行 NER。我相信还有许多其他的,欢迎读者在评论区补充。
-
Stanford NER
-
spaCy
-
NLTK
Stanford NER

Stanford NER
Stanford NER 是一个 Java 实现的命名实体识别器。Stanford NER 也被称为 CRFClassifier。该软件提供了(任意顺序)线性链条件随机场(CRF)序列模型的一般实现。也就是说,通过在标记数据上训练自己的模型,你实际上可以使用这段代码来构建用于 NER 或其他任务的序列模型。
现在,NLTK(自然语言工具包)是一个很棒的 Python 包,提供了一系列自然语言语料库和各种 NLP 算法的 API。NLTK 附带了高效的 Stanford NER 实现。
现在有了这些背景,让我们使用 Stanford NER。
安装 NLTK 库
pip install nltk
下载 Stanford NER 库
前往 nlp.stanford.edu/software/CRF-NER.html#Download 下载最新版本,我使用的是 Stanford Named Entity Recognizer 版本 3.9.2。
我获取了一个名为“stanford-ner-2018–10–16.zip”的压缩文件,需要解压缩,我将其重命名为 stanford_ner 并放置在主文件夹中。

现在,以下 Python 代码用于在给定文本上执行 NER。代码放在“bsuvro”文件夹中,以便可以使用相对路径访问 NER 标签引擎(stanford-ner-3.9.2.jar)和在英语语料库上训练的 NER 模型(classifiers/english.muc.7class.distsim.crf.ser.gz)。你可以看到我使用了 7class 模型,这将提供七种不同的输出命名实体,如地点、人物、组织、货币、百分比、日期、时间。
你也可以使用 —
-
english.all.3class.distsim.crf.ser.gz: 地点、人物和组织
-
english.conll.4class.distsim.crf.ser.gz: 地点、人物、组织和其他
Stanford 命名实体识别
上述代码的输出如下,你可以看到单词如何被标记为命名实体。注意 “O” 是未标记的或可以称为“其他”的东西。
斯坦福 NER 标注器的输出
现在,让我们转到下一个库,称为 spaCy。
spaCy

spaCy NER
spaCy 以其工业级自然语言处理库而闻名。它是用 Cython 编写的,Cython 是一种具有 C 类性能的 Python 编程语言的超集。
虽然我希望深入探讨 spaCy,因为它有许多有趣的 NLP 模块,但我将专注于 NER 标注。我会有一个单独的系列来探索 spaCy。
安装 spaCy 库并下载“en”(英文)模型
pip install spacy
python -m spacy download en
spaCy NER
上述代码的输出 -

spaCy NER 的输出
现在支持以下实体类型 -
spacy.io/api/annotation#pos-tagging
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关内容
-
SMOTE 介绍
nition-eda8c97c2db1)。经许可转载。
相关:
-
使用 Scikit-Learn 进行命名实体识别和分类
-
Apache Spark 简介
-
命名实体识别:实用者的 NLP 指南
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
《NLP 简介及提升技巧的 5 个建议》
原文:
www.kdnuggets.com/2020/09/introduction-nlp-5-tips-raising-your-game.html
评论
对于从事数据科学、机器学习和/或人工智能工作的人来说,NLP 可能是最令人兴奋的领域之一。
NLP 代表自然语言处理,涉及计算机与人类语言之间的交互。编程算法能够处理和分析大量自然语言数据。
其基本目标可能有所不同,但总体目标是得出关于人类行为的结论……我们写作时的意图,我们在写作时的思考或感受,我们所写内容的类别,以及其他一些东西,如聊天机器人、客户市场细分、查找重复项和元素之间的相似性、虚拟助手(如 Siri 或 Alexa)等等。
尽管如此,作为一个学科,NLP 并未出现很久,直到 1960 年,艾伦·图灵发表了一篇名为《计算机与智能》的文章,提出了现在被称为‘图灵测试’的概念。该论文提出了“机器能思考吗?”的问题,并通过测试机器表现出的智能行为是否等同于或不可区分于人类的智能行为。进行测试需要三名参与者,其中一名玩家 C,即评估者,负责确定哪个玩家——A 或 B——是计算机,哪个是人类。

日本机器人 Pepper,由 Aldebaran Robotics 公司制造。
评估者将判断一个人类和一个旨在生成类似人类响应的机器之间的自然语言对话,知道对话中的两个伙伴中有一个是机器。对话将限制在仅文本的频道中,结果不依赖于机器是否能正确回答问题,而仅仅取决于其回答与人类回答的相似程度。如果在测试结束时,评估者无法可靠地区分机器和人类,则机器被认为通过了测试。
从那时起,在过去几年中,该领域已呈指数级发展,从使用一组规则的手工编码系统发展到更复杂的统计 NLP。在这种背景下,一些公司在该领域做了一些非常令人兴奋的工作。例如,如果你是 Android 用户,你可能熟悉Swiftkey,这是一个使用文本预测的初创公司,旨在提高用户写作的准确性、流畅性和速度。Swiftkey 从我们的写作中学习,预测最喜欢的单词、表情符号甚至表达方式。另一个初创公司SignAll,则将手语转换为文本,帮助听障人士与不会手语的人交流。
事实上,如今,使用 Python、Tensorflow、Keras 等开源库的扩展,使得 NLP 变得更加可及,每天越来越多的企业在使用它。其中一些公司专门聘请其他专门从事该领域的公司,而另一些则雇佣数据科学家和数据分析师来构建自己的解决方案。
如果你遇到任何这些情况,无论你是公司还是数据专家,在接下来的几行中,我将介绍我在从事 NLP 工作时的一些学习经验。幸运的是,所有这些都是基于错误的提示!希望你能提前避免它们,而不是像我一样经历这些 😃
1. 找到适合你的向量化类型
在自然语言处理(NLP)中,通常在经过大量的数据清理后,魔法开始于所谓的向量化。这种工具、技术或无论你怎么称呼它,将一堆文本,通常称为文档,根据每个文档中出现的单词,将它们转换为向量。请看以下示例:
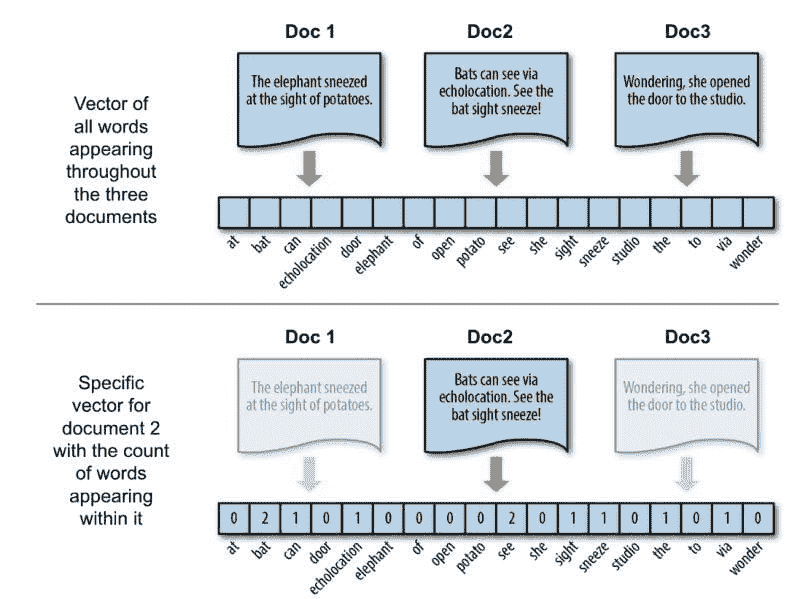
示例由作者使用来自 www.oreilly.com 的图像创建
在上面的示例中,我们使用了一种称为计数向量器或词袋模型的工具。这种向量化方法通常会忽略文本中的语法、顺序和结构。它是一个很好的选择,因为它跟踪文档中出现的所有单词,而且通过简单地计数来处理它们的方式易于理解,并且为我们提供了对整体最重要单词的清晰认识。然而,它也存在两个主要问题:
-
数据稀疏性:在统计所有文档中的出现次数时,我们可能会得到一个由全是零的向量组成的矩阵,因为每个文档只包含所有可能单词的一小部分。我们稍后会详细讨论这个问题。
-
未来本身:计数向量器输出一个固定大小的矩阵,包含我们当前文档中所有单词(或某些频率的单词)。如果我们未来收到更多文档,而我们不知道可能会遇到的单词,这可能会成为一个问题。
-
棘手的文档:如果我们有一个文档,其中一个特定的单词出现得如此频繁,以至于它看起来像是所有文档中最常见的单词,而不仅仅是一个单词在一个文档中出现了很多次,那会发生什么呢?
为了解决第一个和第二个问题,我们可以使用哈希向量化器,它将文本文档集合转换为使用哈希技巧计算的出现矩阵。每个词汇通过哈希函数映射到一个特征,这个函数将其转换为一个数字。如果我们在文本中再次遇到该词,它将被转换为相同的哈希,从而允许我们在不保留词典的情况下计算词汇出现的次数。这个技巧的主要缺点是无法计算逆变换,因此我们失去了重要特征对应的词汇信息。
为了解决上述第三个问题,我们可以使用词频-逆文档频率(tf-idf)向量化器。tf-idf 分数告诉我们哪些词在文档之间具有最强的区分能力。在一个文档中频繁出现但在许多文档中很少出现的词包含了很大的区分能力。逆文档频率是衡量词汇提供多少信息的指标,即该词在所有文档中是常见还是稀有。提升特定文档的词汇,同时抑制那些在大多数文档中常见的词汇。
Sklearn 对所有这三种向量化类型都提供了实现:
2. 个性化停用词,并注意数据中的语言
在进行任何形式的向量化时,使用停用词是获得可靠结果的关键步骤。将停用词列表传递给我们的算法,我们是在告诉它:“如果找到这些词,请忽略它们……我不希望它们出现在我的输出矩阵中。” Sklearn 确实包含一个默认的停用词列表,只需将单词‘english’传递给‘stop_words’超参数即可。然而,这里有几个限制:
-
它仅包括基本的词汇,如“and”、“the”、“him”,这些词被认为在表示文本内容时不具备信息量,可能会被删除以避免被解读为预测信号。然而,例如,如果你在处理从租赁代理网站抓取的房屋描述,你可能会希望移除所有不属于房产描述本身的词汇,如‘opportunity’、‘offer’、‘amazing’、‘great’、‘now’等。
-
对我来说,作为一名西班牙语使用者,在处理该语言的机器学习问题时最大的问题是:它仅在英语中可用。
所以,无论你是想丰富英语中的默认单词列表以改善输出矩阵,还是想使用其他语言的单词列表,你都可以通过使用超参数‘stop_words’将个性化的停用词列表传递给 Sklearn 的算法。顺便说一下,这是一个 GitHub 仓库 ,其中包含了许多语言的词表。
在进入下一个点之前,请记住,有时你可能根本不需要使用任何停用词。例如,如果你处理的是数字,即使是 Sklearn 默认的英语停用词列表也包括所有从 0 到 9 的单个数字。因此,重要的是要问自己是否正在处理需要停用词的 NLP 问题。
3. 使用词干提取器进行‘分组’相似单词
文本标准化是将稍有不同版本的具有本质上等同意义的单词转换为相同特征的过程。在某些情况下,考虑到所有可能的变体可能是合理的,但无论你是在英语还是其他语言中工作,有时你还需要对文档进行某种预处理,以相同的方式表示具有相同意义的单词。例如,consultant、consulting、consult、consultative 和 consultants 都可以表示为‘consultant’。更多示例见下表:
来源:www.wolfram.com — 生成和验证词干化单词
为此,我们可以使用词干提取。词干提取器去除单词的形态学词缀,仅保留词干。幸运的是,Python 的 NLTK 库包含了几种强大的词干提取器。如果你想将特定语言的词干提取器或其他词干提取器整合到你的向量化算法中,你可以使用以下代码:
spanish_stemmer = SpanishStemmer()classStemmedCountVectorizerSP(CountVectorizer):
def build_analyzer(self):
analyzer = super(StemmedCountVectorizerSP,self).build_analyzer()return lambda doc: ([spanish_stemmer.stem(w) for w in analyzer(doc)])
你可以通过更改分配给类的算法轻松地将其改为使用 HashingVectorizer 或 TfidfVectorizer。
4. 避免使用 Pandas DataFrames
这条建议简短明了:如果你在处理超过 5-10k 行的数据的 NLP 项目时,避免使用 DataFrames。仅仅使用 Pandas 对大量文档进行向量化会返回一个巨大的矩阵,处理速度非常慢,而且很多时候,自然语言处理项目涉及测量距离,这通常非常缓慢,因为需要彼此比较元素。即使我自己也大量使用 Pandas 的 DataFrames,对于这类任务,我建议使用 Numpy Arrays 或 Sparse Matrices。
同时,请注意,你总是可以通过使用‘.toarray()’函数将稀疏矩阵转换为数组,反之亦然,从数组转换为稀疏矩阵:
from scipy import sparsemy_sparse_matrix = sparse.csr_matrix(my_array)
顺便说一下,如果你处理时间问题,记得可以使用以下方法来计时你的代码:
start = time.time()whatever_you_want_to_timeend = time.time()print(end — start)
5. 数据稀疏性:使你的输出矩阵可用
正如之前所说,处理 NLP 时最大的一个问题是数据稀疏性……结果是充满零的数万个列的矩阵,这使得之后应用某些技术变得不可能。以下是我过去处理这个问题时使用的一些技巧:
-
使用 TfidfVectorizer 或 CountVectorizer 时,设置超参数‘max_features’。例如,你可以打印出文档中的词频,然后为其设置某个阈值。假设你设置了一个 50 的阈值,而你的数据语料库包含 100 个词。经过查看词频,发现有 20 个词出现次数少于 50 次。因此,你将 max_features 设置为 80,然后可以继续使用。如果 max_features 设置为 None,那么在转换过程中会考虑整个语料库。否则,如果你传递例如 5 给 max_features,那将意味着从文本文档中最频繁的 5 个词中创建特征矩阵。
-
在 HashingVectorizer 中设置‘n_features’的数量。这个超参数设置输出矩阵中的特征/列数。较小的特征数量可能会导致哈希冲突,但较大的特征数量会导致线性学习器中的系数维度增大。具体数量取决于你和你的需求。
-
使用降维技术。如主成分分析(PCA)可以将具有数万个列的输出矩阵转化为捕捉原始矩阵方差的较小集合。这可能是一个很好的主意。只要分析这种降维对最终结果的影响,检查其实际效用,并选择使用的维度数量。
我真的希望我所学到的这些知识能够帮助你的 NLP 项目。未来会有更多关于 NLP 的故事,但如果你喜欢这个故事,不要忘记查看我最近的一些文章,如 如何将数据分成训练集和测试集以确保代表性、数据科学中的幸存者偏差 和 在云中使用集群进行数据科学项目的 4 个简单步骤。所有这些及更多内容可在 我的 Medium 个人资料 中找到。
如果你想直接通过电子邮件接收我的最新文章,请订阅我的通讯** 😃**
感谢阅读!
特别提到以下我在整个故事中使用的来源:
-
https://www.oreilly.com/library/view/applied-text-analysis/9781491963036/ch04.html
-
https://stackoverflow.com/questions/46118910/scikit-learn-vectorizer-max-features
简历: 在电子商务和市场营销领域拥有超过 5 年的经验,贡萨洛·费雷罗·沃尔皮 转向数据科学和机器学习领域,目前在 Ravelin Technology 工作,结合机器学习和人类洞察力来应对电子商务中的欺诈问题。
原文。经许可转载。
相关:
-
加速自然语言处理:来自亚马逊的免费课程
-
4 门免费数学课程,提升你的数据科学技能
-
NLP 模型生成器:按需生成模型代码
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在的组织进行 IT 工作
相关主题更多信息
数据科学的 Pandas 介绍
原文:
www.kdnuggets.com/2020/06/introduction-pandas-data-science.html

由 benzoix 提供的图像 来自 Freepik
Pandas 实际上是什么?为什么它如此著名?把 Pandas 想象成一个 Excel 表,但它比 Excel 更高级,具有更多的功能和灵活性。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
为什么选择 Pandas
选择 pandas 的原因有很多,其中一些包括
-
开源
-
容易学习
-
优秀的社区
-
基于 Numpy 之上
-
容易分析和预处理数据
-
内置数据可视化
-
许多内置函数帮助进行探索性数据分析
-
内置支持 CSV、SQL、HTML、JSON、pickle、excel、剪贴板等
-
还有很多其他功能
安装 Pandas
如果你使用 Anaconda,你将自动拥有 pandas,但如果由于某种原因没有它,只需运行以下命令
conda install pandas
如果你没有使用 Anaconda,通过 pip 安装
pip install pandas
导入
要导入 pandas,请使用
import pandas as pd
import numpy as np
最好与 pandas 一起导入 numpy,以便访问更多 numpy 功能,这有助于我们进行探索性数据分析(EDA)。
Pandas 数据结构
Pandas 有两个主要的数据结构。
-
Series
-
数据框
Series
将 Series 视为 Excel 表中的一列。你也可以将其视为一个一维的 Numpy 数组。唯一的不同之处在于,我们可以为其设置索引名称。
创建 pandas Series 的基本语法如下:
newSeries = pd.Series(data , index)
数据可以是从 Python 字典到列表或元组的任何类型。它也可以是一个 numpy 数组。
让我们从 Python 列表中创建一个 Series:
mylist = ['Ahmad','Machine Learning', 20, 'Pakistan']
labels = ['Name', 'Career', 'Age', 'Country']
newSeries = pd.Series(mylist,labels)
print(newSeries)
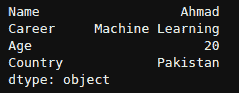
newSeries 的输出。
在 pandas Series 中添加索引不是必须的。在这种情况下,它会自动从 0 开始索引。
mylist = ['Ahmad','Machine Learning', 20, 'Pakistan']
newSeries = pd.Series(mylist)
print(newSeries)
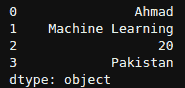
在这里,我们可以看到索引从 0 开始,一直到 Series 结束。现在让我们看看如何使用 Python 字典 创建 Series,
myDict = {'Name': 'Ahmad',
'Career': 'Machine Learning',
'Age': 20,
'Country': 'Pakistan'}
mySeries = pd.Series(myDict)
print(mySeries)
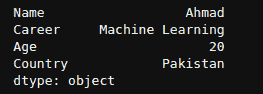
在这里我们可以看到,我们不需要显式地传递索引值,因为它们会从字典的键中自动分配。
访问 Series 中的数据
访问 Pandas Series 中的数据的常见模式是:
seriesName['IndexName']
让我们以之前创建的 mySeries 为例。要获取 Name、Age 和 Career 的值,我们只需:
print(mySeries['Name'])
print(mySeries['Age'])
print(mySeries['Career'])

Pandas Series 的基本操作
让我们创建两个新系列来对它们进行操作。
newSeries = pd.Series([10,20,30,40],index=['LONDON','NEWYORK','Washington','Manchester'])
newSeries1 = pd.Series([10,20,35,46],index=['LONDON','NEWYORK','Istanbul','Karachi'])
print(newSeries,newSeries1,sep='\n\n')
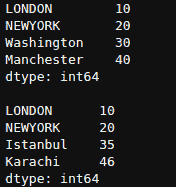
基本的算术操作包括+-*/操作。这些操作是针对索引的,因此我们来执行它们。
newSeries + newSeries1
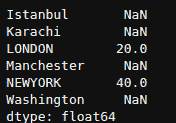
在这里我们可以看到,由于伦敦和 NEWYORK 索引在两个 Series 中都存在,因此它将两个值相加,其他的输出为 NaN(不是一个数字)。
newSeries * newSeries1
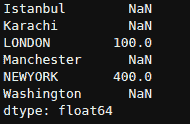
newSeries / newSeries1
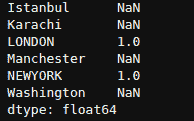
元素级操作/广播
如果你对 Numpy 很熟悉,你一定听说过广播的概念。如果你不熟悉广播的概念,请参考 this link。
现在,使用我们的 newSeries Series,我们将看到使用广播概念进行的操作。
newSeries + 5
在这里,它给 Series newSeries 中的每个元素加上了 5。这也被称为逐元素操作。类似地,其他操作如*、/、-、及其他运算符也是如此。我们只会看到运算符,你也应该尝试其他运算符。
newSeries ** 1/2
在这里,我们对每个数字进行逐元素的平方根计算。记住,平方根是任何数字的 1/2 次方。
Pandas 数据框
数据框确实是 Pandas 中最常用和最重要的数据结构。可以将数据框看作是一个 Excel 表格。
创建数据框的主要方法有:
-
读取 CSV/Excel 文件
-
Python 字典
-
ndarray
让我们举个例子,看看如何使用字典创建数据框。
我们可以通过传递一个字典来创建数据框,其中字典的每个值都是一个列表。
df1 = {"Name":["Ahmad","Ali",'Ismail',"John"],"Age": [20,21,19,17],"Height":[5.1,5.6,6.1,5.7]}
要将这个字典转换为数据框,我们只需对这个字典调用 dataframe 函数即可。
df1 = pd.DataFrame(df1)
df1
 df1
df1
从列中获取值
要从列中获取值,我们可以使用这种语法:
#df1['columnname']
#df1.columnname
这两种语法都是正确的,但我们需要小心选择。如果我们的列名中有空格,那么肯定不能使用第二种方法。我们必须使用第一种方法。只有当列名中没有空格时,我们才可以使用第二种方法。
df1.Name
 df1.Name
df1.Name
在这里我们可以看到列的值、它们的索引号、列名和列的数据类型。
df1['Age']
 df1[‘Age’]
df1[‘Age’]
我们可以看到,使用这两种语法都会返回数据框的列,我们可以对其进行分析。
多列的值
要获取数据框中多个列的值,可以将列名作为列表传递。
df1[["Name","Age"]]
 df1[[“Name”,”Age”]]
df1[[“Name”,”Age”]]
我们可以看到它返回了包含 Name 和 Age 两列的数据框。
Pandas 中 DataFrame 的重要函数
让我们通过使用一个名为‘Titanic’的数据集来深入探讨 DataFrame 的重要函数。这个数据集通常可以在线获得,或者你可以在 Kaggle 找到它。
读取数据
Pandas 对读取各种类型的数据提供了良好的内置支持,包括 CSV、fether、excel、HTML、JSON、pickle、SAS、SQL 等。
读取数据的常用语法是
# pd.read_fileExtensionName("File Path")
CSV
要从 CSV 文件中读取数据,你只需使用 pandas 的 read_csv 函数。
df = pd.read_csv('Path_To_CSVFile')
由于 Titanic 数据集也以 CSV 格式提供,所以我们将使用 read_csv 函数读取它。当你下载数据集时,你会得到两个名为 train.csv 和 test.csv 的文件,这些文件将帮助测试机器学习模型,所以我们将只关注 train_csv 文件。
df = pd.read_csv('train.csv')
现在 df 自动成为一个数据框。让我们探索它的一些函数。
head()
如果你正常打印你的数据集,它会显示一个完整的数据集,可能有百万行或列,这很难查看和分析。df.head() 函数允许我们查看数据集的前 ’n’ 行(默认 5 行),以便我们可以对数据集做一个粗略估计,并确定接下来要应用的关键函数。
df.head()
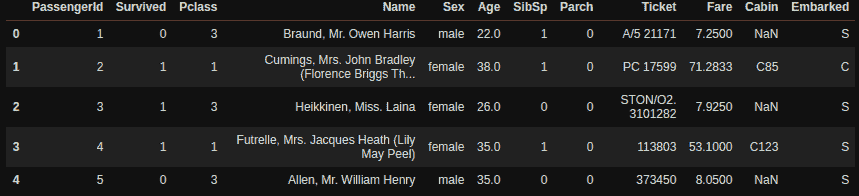 df.head()
df.head()
现在我们可以看到数据集中的列及其前 5 行的值。由于我们没有传递任何值,因此它显示的是前 5 行。
tail()
类似于 head 函数,我们还有一个 tail 函数,它显示最后 n 个值。
df.tail(3)
 df.tail(3)
df.tail(3)
我们可以看到数据集的最后 3 行,因为我们传递了 df.tail(3)。
shape()
shape() 是另一个重要的函数,用于分析数据集的形状,这在我们制作机器学习模型时非常有用,并且我们希望我们的维度是精确的。
df.shape()
 df.shape()
df.shape()
在这里我们可以看到我们的输出是 (891,12),这等于 891 行和 12 列,这意味着我们总共有 12 个特征或 12 列和 891 行或 891 个样本。
之前我们使用 df.tail() 函数时,最后一列的索引号是 890,因为我们的索引是从 0 开始的,而不是从 1 开始的。如果索引号是从 1 开始的,那么最后一列的索引号将是 891。
isnull()
这是另一个重要的函数,用于查找数据集中为空的值。我们可以在之前的输出中看到一些值是 NaN,这意味着“不是数字”,我们必须处理这些缺失值以获得良好的结果。isnull() 是处理这些空值的重要函数。
df.isnull().head()
我正在使用 head 函数,以便我们可以看到前 5 个示例,而不是整个数据集。
df.isnull().head()
在这里,我们可以看到“Cabin”列中的一些值为 True。True 表示该值为 NaN 或缺失。我们可以看到这不容易理解,因此我们可以使用 sum()函数来获取更详细的信息。
sum()
sum 函数用于计算数据框中所有值的总和。记住 True 表示 1,False 表示 0,因此为了获取 isnull()函数返回的所有 True 值,我们可以使用 sum()函数。让我们检查一下。
df.isnull().sum()
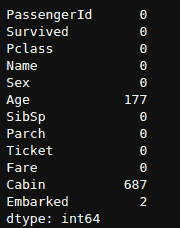 df.isnull().sum()
df.isnull().sum()
在这里,我们可以看到只有“Age”、“Cabin”和“Embarked”列中有缺失值。
info()
info 函数也是一个常用的 pandas 函数,它“打印 DataFrame 的简洁摘要。”
df.info()
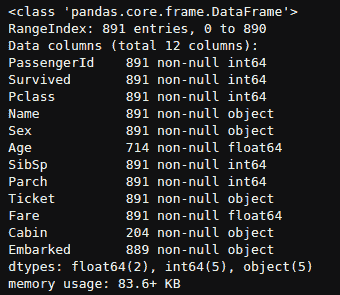 df.info()
df.info()
在这里,我们可以看到它告诉我们有多少个非空实体,例如在年龄字段中,我们有 714 个非空的 float64 类型实体。它还告诉我们内存使用情况,在这个例子中是 83.6 KB。
describe()
describe()也是一个非常有用的函数来分析数据。它告诉我们数据框的描述统计信息,包括那些总结数据集分布的中心趋势、离散程度和形状的统计信息,排除值。
df.describe()
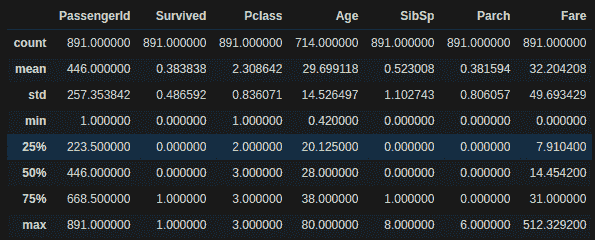 df.describe()
df.describe()
在这里,我们可以看到每一列的一些重要统计分析,包括均值、标准差、最小值等。更多信息请参见其文档。
布尔索引
这也是 Numpy 和 Pandas 中一个重要且广泛使用的概念。
正如名称所示,我们使用布尔变量进行索引,即 True 和 False。如果索引为 True,则显示该行;如果索引为 False,则不显示该行。
当我们尝试从数据集中提取重要特征时,它对我们很有帮助。让我们以“Sex”为“male”的条目为例,看看我们如何解决这个问题。
df["Sex"]=="male"
这将返回一个布尔值为 True 和 False 的 Series,其中 True 表示“Sex”为“male”的行,否则为 False。
为了只查看前 10 个结果,我可以使用 head 函数,如下所示。
(df["Sex"]=="male").head(10)
 (df[“sex”]==”male”).head(10)
(df[“sex”]==”male”).head(10)
现在,为了查看完整的数据框,只包含“Sex”为“male”的行,我们应该在数据框中传递 df[“Sex”]==”male”以获取所有“Sex”为“male”的结果。
df[df["Sex"]=="male"].head(5)
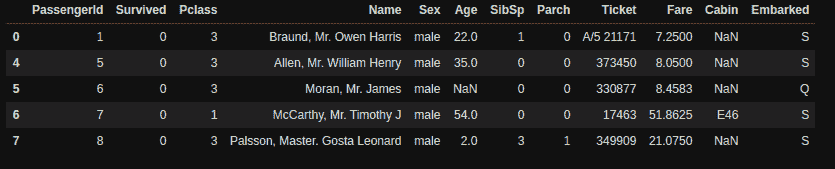
在这里,我们可以看到所有的结果都是“Sex”为 Male 的行。
现在让我们通过布尔索引提取一些有用的信息。
为了基于多个条件获取行,我们使用括号“()”和“&,|,!=”符号来连接多个条件。
让我们找出所有幸存男性乘客的百分比。
df[(df["Sex"]=="male") & (df["Survived"]==1)]
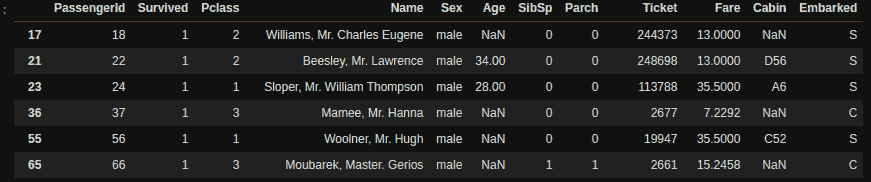
给这段代码一点时间,理解发生了什么。我们正在收集所有行,其中 df[“Sex”] == “male”并且 df[“Survived”]==1. 返回值是一个包含所有幸存男性乘客的 dataframe。
让我们找出幸存的男性乘客的百分比。
现在,幸存男性乘客的百分比公式是:幸存男性总数 / 男性乘客总数
在 pandas 中,我们可以这样写
men = df[df['Sex']=='male']['Survived']
perc = sum(men) / len(men) * 100
让我们逐步解析这段代码。
df[‘Sex’]==’male’将返回一个布尔 Series,其中性别为男性。
df[df[“Sex”]==”male”]将返回所有“Sex”为“male”的示例的完整数据框。
men = df[df[‘Sex’]==’male’][‘Survived’]将返回所有男性乘客的“Survived”列。
sum(men)将计算所有幸存男性的总和。由于这是一个由 0 和 1 组成的 Series,len(men)将返回男性的总数。
现在将这些放入上面的公式中,我们将找到在 Titanic 上幸存的所有男性的百分比。
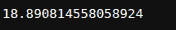
18%!!!!! 是的,我们的数据集中只有 18%的男性幸存者。
类似地,我们可以为女性编写代码,我不这样做,但这是你的任务,我们发现 74%的女性乘客幸存于这次灾难。
这篇文章到此结束。显然,Pandas 中还有许多其他重要功能,如 groupby、apply、iloc、rename、replace 等。我建议你查看 Wes 编写的《Python 数据分析》书籍,他是这个 Pandas 库的创始人。
另外,查看一下这个备忘单以便快速参考。
Ahmad 对机器学习、深度学习和计算机视觉感兴趣。目前担任 Redbuffer 的初级机器学习工程师。
相关阅读
数据科学的基础数学:泊松分布
原文:
www.kdnuggets.com/2020/12/introduction-poisson-distribution-data-science.html
评论
泊松分布,以法国数学家丹尼斯·西蒙·泊松命名,是一种离散分布函数,用于描述事件在固定时间(或空间)区间内发生特定次数的概率。它用于建模基于计数的数据,例如一小时内到达邮箱的邮件数量或一天内进入商店的顾客数量等。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力。
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求。
数学定义
让我们从一个例子开始,图 1 展示了莎拉在一小时间隔内收到的邮件数量。
图 1:莎拉在过去 100 小时内每小时接收的邮件数量。
柱状图的高度显示了莎拉观察到相应邮件数量的一小时间隔数。例如,突出显示的柱状图显示大约有 15 个一小时的时间段,她收到了一封邮件。
泊松分布由预期事件数量λ(发音为“lambda”)进行参数化。该分布是一个函数,将事件的发生次数(下一个公式中的整数k)作为输入,输出对应的概率(即发生k次事件的概率)。
泊松分布,记作Poi,表示如下:
对于k = 0, 1, 2, ...
Poi(k; λ)的公式返回给定参数λ的观察k事件的概率,其中λ对应于该时间段内预期的发生次数。
离散分布
请注意,二项分布和泊松分布都是离散的:它们给出离散结果的概率:泊松分布的事件发生次数和二项分布的成功次数。然而,虽然二项分布计算离散试验的离散次数(如抛硬币的次数),泊松分布考虑的是无限次数的试验(每次试验对应于非常小的一段时间),每个事件的概率非常小。
你可以参考下面的部分以查看泊松分布是如何从二项分布中推导出来的。
示例
Priya 在国家公园录制鸟鸣,使用放置在树上的麦克风。她记录了鸟鸣叫的次数,并希望建模一分钟内的鸟鸣叫数量。为此任务,她将假设检测到的鸟是独立的。
查看过去几小时的数据,Priya 观察到平均每分钟检测到两只鸟。因此,值 2 可能是分布参数λ的一个好候选值。她的目标是知道在下一分钟内特定数量的鸟鸣叫的概率。
让我们从你上面看到的公式实现泊松分布函数:
def poisson_distribution(k, lambd):
return (lambd ** k * np.exp(-lambd)) / np.math.factorial(k)
记住λ是鸟在一分钟内鸣叫的预期次数,所以在这个例子中,你有λ=2。函数poisson_distribution(k, lambd)接受k和λ的值,并返回观察到k次事件的概率(即记录到k只鸟鸣叫)。
例如,Priya 在下一分钟观察到 5 只鸟的概率为:
poisson_distribution(k=5, lambd=2)
0.03608940886309672
5 只鸟在下一分钟鸣叫的概率约为 0.036(3.6%)。
与二项函数类似,对于较大的k值,这将导致溢出。因此,你可能需要使用模块scipy.stats中的poisson,如下所示:
from scipy.stats import poisson
poisson.pmf(5, 2)
0.03608940886309672
让我们绘制不同值的k的分布图:
lambd=2
k_axis = np.arange(0, 25)
distribution = np.zeros(k_axis.shape[0])
for i in range(k_axis.shape[0]):
distribution[i] = poisson.pmf(i, lambd)
plt.bar(k_axis, distribution)
# [...] Add axes, labels...
图 2: λ=2的泊松分布。
对应于k值的概率在图中的概率质量函数中进行了总结。
- 你可以看到,在下一分钟内,Priya 听到一两只鸟鸣叫的可能性最大。
最后,你可以为不同值的λ绘制函数:
f, axes = plt.subplots(6, figsize=(6, 8), sharex=True)
for lambd in range(1, 7):
k_axis = np.arange(0, 20)
distribution = np.zeros(k_axis.shape[0])
for i in range(k_axis.shape[0]):
distribution[i] = poisson.pmf(i, lambd)
axes[lambd-1].bar(k_axis, distribution)
axes[lambd-1].set_xticks(np.arange(0, 20, 2))
axes[lambd-1].set_title(f"$\lambda$: {lambd}")
# Add axes labels etc.
图 3: 不同值的λ的泊松分布。
图 3 显示了不同值的λ的泊松分布,在某些情况下看起来有点像正态分布。然而,泊松分布是离散的,当λ值较低时不对称,并且被限制为零。
附加:推导泊松分布
让我们看看泊松分布是如何从二项分布中推导出来的。
在数据科学的基本数学中,你看到如果你多次运行一个随机实验,获得mm次成功的概率,在N次试验中,每次试验成功的概率为μ,可以通过二项分布计算:
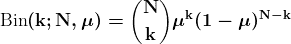
问题陈述
你如何使用二项公式来建模在给定时间间隔内观察事件一定次数的概率,而不是在一定次数的试验中?这里有一些问题:
-
你不知道 NN,因为没有特定的试验次数,只有一个时间窗口。
-
你不知道μμ,但你知道事件发生的预期次数。例如,你知道在过去的 100 小时里,你平均每小时收到 3 封电子邮件,你想知道在下一个小时内收到 5 封电子邮件的概率。
让我们从数学上处理这些问题。
为了解决第一个问题,你可以将时间视为小的离散块。我们称这些块为ϵϵ(发音为“epsilon”),如图 4 所示。如果你将每个块视为一次试验,你就有N个块。
图 4:你可以将连续时间划分为长度为ϵ的段。
连续时间尺度的估计在ϵ非常小的时候更准确。如果ϵϵ很小,段数N将会很大。此外,由于段很小,每个段的成功概率也很小。
总结一下,你想要修改二项分布以便能够建模一个非常大的试验次数,每次试验的成功概率非常小。诀窍在于考虑N趋向于无穷大(因为连续时间通过ϵ的值趋向于零来进行近似)。
更新二项公式
让我们在这种情况下找到μμ并将其替换到二项公式中。你知道在一段时间t内事件的预期次数,我们称之为λ(发音为“lambda”)。由于你将t分成长度为ϵ的小间隔,你有试验次数:
你有λ作为N次试验中的成功次数。所以在一次试验中成功的概率μ是:
将μμ替换到二项公式中,你得到:
通过展开表达式,将二项系数写为阶乘(如在数据科学的基本数学中所做),并使用公式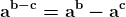 ,你得到:
,你得到:
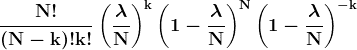
我们来考虑这个表达式的第一个元素。如果你声明 NN 趋向于无穷大(因为ϵ趋向于零),你得到:
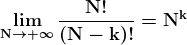
这是因为 k 可以在与 N 相比小时被忽略。例如,你有:
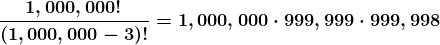
这近似于 
因此,第一个比率变为:
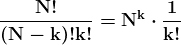
然后,利用 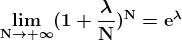 的事实,你得到:
的事实,你得到:
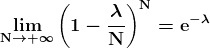
最后,由于 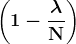 在 N 趋近于无穷大时趋近于 1:
在 N 趋近于无穷大时趋近于 1:
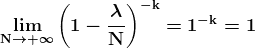
让我们将这些代入二项分布的公式中:
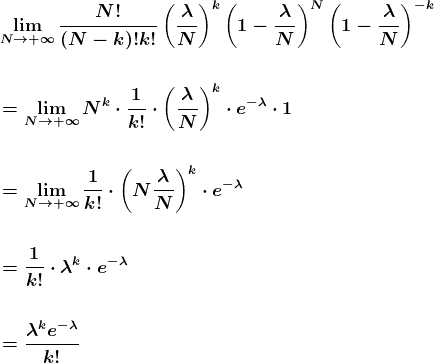
这是泊松分布,记作 Poi:
对于 k = 0, 1, 2, ...
个人简介:哈德里安·让 是一名机器学习科学家。他拥有巴黎高等师范学院的认知科学博士学位,在那里他使用行为和电生理数据研究听觉感知。他曾在工业界工作,构建了用于语音处理的深度学习管道。在数据科学与环境交汇处,他从事关于使用深度学习分析音频记录的生物多样性评估项目。他还定期在 Le Wagon(数据科学训练营)创建内容并教授课程,并在他的博客(hadrienj.github.io)上撰写文章。
原文。经授权转载。
相关:
-
数据科学的基础数学:概率密度函数与概率质量函数
-
数据科学的基础数学:积分与曲线下的面积
-
数据科学与机器学习的免费数学课程
进一步了解此主题
Python 数据清理库简介
原文:
www.kdnuggets.com/2023/03/introduction-python-libraries-data-cleaning.html

数据清理是任何数据专家必须做的活动,因为我们需要确保数据没有错误、一致,并且适用于分析。如果没有这一步,分析结果可能会受到影响。然而,数据清理通常需要很长时间,并且可能会很重复。此外,有时我们会遗漏一个需要意识到的错误。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT
这就是为什么我们可以依赖专门为数据清理设计的 Python 包。这些包旨在改善我们的数据清理体验,并缩短数据清理的处理时间。这些包是什么?让我们找出来。
PyJanitor
Pandas 提供了许多数据清理函数,如 fillna 和 dropna,但这些功能仍然可以得到增强。 PyJanitor 是一个 Python 包,提供 Pandas API 内的数据清理 API,而不替代它们。该包提供了各种方法,包括但不限于以下内容:
-
清理列名,
-
识别重复值,
-
数据因子化,
-
数据编码,
还有更多。然而,PyJanitor 的特别之处在于其 API 可以通过链式方法执行。让我们用示例数据来测试它们。对于这个示例,我将使用 Kaggle 的 Titanic 训练数据。
首先,让我们安装 PyJanitor 包。
pip install pyjanitor
然后我们将加载 Titanic 数据集。
import pandas as pd
df = pd.read_csv('train.csv')
df.head()

我们将使用上述数据集作为示例。让我们尝试使用 PyJanitor 包来清理数据,使用一些示例函数。
import janitor
df.factorize_columns(column_names=["Sex"]).also(
lambda df: print(f"DataFrame shape after factorize is: {df.shape}")
).bin_numeric(from_column_name="Age", to_column_name="Age_binned").also(
lambda df: print(f"DataFrame shape after binning is: {df.shape}")
).clean_names()
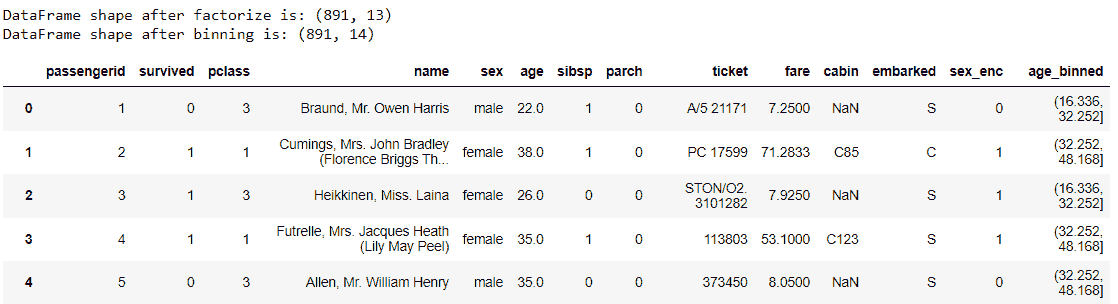
我们通过链式方法转换初始数据框。那么,以上代码会发生什么?让我来分解一下。
-
首先,我们使用 factorize 函数将‘Sex’列转换为数值,
-
使用 also 函数,我们打印因子分解后的形状,
-
接下来,我们使用 bin_numeric 函数将年龄分组,
-
与 also 函数相同,
-
最后,我们通过将列名转换为小写,然后用 clean_names 替换所有空格为下划线来清理列名。
上述所有操作可以通过直接在我们的 Pandas 数据框中进行单链方法完成。你仍然可以用 PyJanitor 包做更多的事情,所以我建议你查看他们的文档。
Feature-engine
Feature-Engine是一个用于特征工程和选择的 Python 包,它保留了 scikit-learn 的 API 方法,如 fit 和 transform。该包旨在提供一个嵌入机器学习管道的数据转换器。
该包提供了各种数据清洗转换器,包括但不限于:
-
数据插补,
-
分类编码,
-
异常值移除,
-
变量选择,
还有许多其他函数。让我们先通过安装它们来尝试这个包。
pip install feature-engine
Feature-Engine 的使用很简单;你只需要导入它们并训练转换器,类似于 scikit-learn API。例如,我使用 Imputer 用中位数填充年龄列的缺失数据。
from feature_engine.imputation import MeanMedianImputer
# set up the imputer
median_imputer = MeanMedianImputer(imputation_method='median', variables=['Age'])
# fit the imputer
median_imputer.fit(df)
median_imputer.transform(df)
上面的代码将用中位数填充数据框中的年龄列。你可以尝试很多转换器。试着在文档中找到适合你的数据管道的转换器。
Cleanlab
Cleanlab是一个开源的 Python 包,用于清理机器学习数据集标签中的任何问题。它旨在使带有噪声标签的机器学习训练更加稳健,并提供可靠的输出。任何具有概率输出的模型都可以与 Cleanlab 包一起训练。
让我们用代码示例来尝试这个包。首先,我们需要安装 Cleanlab。
pip install cleanlab
由于 Cleanlab 用于清洗标签问题,我们来尝试准备数据集以进行机器学习训练。
# Selecting the features
df = df[["Survived", "Pclass", "SibSp", "Parch"]]
# Splitting the dataset
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
df.drop("Survived", axis=1), df["Survived"], random_state=42
)
数据集准备好后,我们将尝试用分类模型来拟合数据集。让我们看看在不清洗标签的情况下的预测指标。
#Fit the model
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(random_state = 42)
model.fit(X_train, y_train)
preds = model.predict(X_test)
#Print the metrics result
from sklearn.metrics import classification_report
print(classification_report(y_test, preds))
这是一个不错的结果,但让我们看看在清洗标签后能否进一步提高结果。我们来尝试用以下代码实现这一点。
from cleanlab.classification import CleanLearning
#initiate model with CleanLearning
cl = CleanLearning(model, seed=42)
# Fit model
cl.fit(X_train, y_train)
# Examine the label quality
cl.get_label_issues()
从上面的结果可以看出,由于预测错误,一些标签存在问题。通过清洗标签,我们来看看模型指标的结果。
clean_preds = cl.predict(X_test)
print(classification_report(y_test, clean_preds))
我们可以看到,相比于之前没有标签清洗的模型,结果有所改善。你仍然可以使用 Cleanlab 做很多事情;我建议你访问文档以进一步了解。
结论
数据清洗是任何数据分析过程中的必经步骤。然而,这通常需要花费大量时间来正确清洗所有数据。幸运的是,有一些 Python 包被开发出来以帮助我们正确清洗数据。在本文中,我介绍了三个帮助清洗数据的包:PyJanitor、Feature-Engine 和 Cleanlab。
Cornellius Yudha Wijaya 是一名数据科学助理经理和数据撰写员。他在全职工作于 Allianz Indonesia 的同时,喜欢通过社交媒体和写作分享 Python 和数据技巧。
更多内容
PyTorch 深度学习简介
原文:
www.kdnuggets.com/2018/11/introduction-pytorch-deep-learning.html
评论

在本教程中,你将了解使用 PyTorch 框架的深度学习,并在完成后,你将能够舒适地将其应用于你的深度学习模型。Facebook 今年早些时候推出了 PyTorch 1.0,并与Google Cloud、AWS和Azure 机器学习集成。在本教程中,我假设你已经熟悉Scikit-learn、Pandas、NumPy和SciPy。这些包是本教程的重要前提条件。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
攻击计划
-
什么是深度学习?
-
PyTorch 简介
-
为什么你会选择 PyTorch 而非其他 Python 深度学习库
-
PyTorch 张量
-
PyTorch 自动求导
-
PyTorch nn 模块
-
PyTorch 优化包
-
自定义 PyTorch nn 模块
-
综合概述及进一步阅读
什么是深度学习?
深度学习是机器学习的一个子领域,其算法受到人脑工作方式的启发。这些算法被称为人工神经网络。这些神经网络的例子包括卷积神经网络,用于图像分类,人工神经网络和递归神经网络。
PyTorch 简介
PyTorch 是一个基于Torch的 Python 机器学习包,而 Torch 是一个基于编程语言Lua的开源机器学习包。PyTorch 具有两个主要特性:
-
Tensor 计算(类似于 NumPy)具有强大的 GPU 加速
-
自动微分用于构建和训练神经网络
为什么你可能会倾向于使用 PyTorch 而非其他 Python 深度学习库
你可能会倾向于使用 PyTorch 而非其他深度学习库有几个原因:
-
与其他库如 TensorFlow 不同,你必须首先定义整个计算图才能运行模型,PyTorch 允许你动态定义计算图。
-
PyTorch 对于深度学习研究也非常出色,提供了最大的灵活性和速度。
PyTorch 张量
PyTorch 张量与 NumPy 数组非常相似,区别在于它们可以在 GPU 上运行。这一点很重要,因为它有助于加速数值计算,这可以将神经网络的速度提高 50 倍或更多。要使用 PyTorch,你需要访问PyTorch.org/并安装 PyTorch。如果你使用 Conda,可以通过运行以下简单命令安装 PyTorch:
要定义一个 PyTorch 张量,首先需要导入 torch 包。PyTorch 允许你定义两种类型的张量——CPU 张量和 GPU 张量。在本教程中,我会假设你正在使用 CPU 机器,但我也会展示如何在 GPU 上定义张量:
PyTorch 中的默认张量类型是一个浮点张量,定义为 **torch.FloatTensor**。作为示例,你将从一个 Python 列表中创建一个张量:
如果你使用的是支持 GPU 的机器,你将按照下面的方式定义张量:
你也可以使用 PyTorch 张量进行数学计算,如加法和减法:
你还可以定义矩阵并进行矩阵操作。让我们看看如何定义一个矩阵并进行转置:
PyTorch 自动微分
PyTorch 使用一种称为自动微分的技术来数值评估函数的导数。自动微分在神经网络中计算反向传播。在训练神经网络时,权重被随机初始化为接近零但不为零的数字。反向传播是调整这些权重的过程,从右到左,而前向传播则是其逆过程(从左到右)。
torch.autograd 是支持 PyTorch 中自动微分的库。该包的核心类是 torch.Tensor。要跟踪所有操作,将 .requires_grad 设置为 True。要计算所有梯度,调用 .backward()。该张量的梯度将累积在 **.**grad 属性中。
如果你想将张量从计算历史中分离,可以调用 **.**detach() 函数。这也将防止对张量的未来计算进行跟踪。另一种防止历史跟踪的方法是使用 torch.no_grad(): 包装你的代码。
Tensor 和 Function 类是相互连接的,以构建一个无环图,该图编码了计算的完整历史。张量的 .grad_fn 属性引用创建该张量的 Function。要计算导数,请在 Tensor 上调用 .backward()。如果 Tensor 只包含一个元素,你无需为 backward() 函数指定任何参数。如果 Tensor 包含多个元素,则需要指定一个形状匹配的梯度张量。
作为示例,你将创建两个张量,一个的 requires_grad 为 True,另一个为 False。然后你将使用这两个张量进行加法和求和操作。之后,你将计算其中一个张量的梯度。
调用 **.**grad 在 b 上将不会返回任何内容,因为你没有将 requires_grad 设置为 True。
PyTorch nn 模块
这是用于在 PyTorch 中构建神经网络的模块。nn 依赖于 autograd 来定义模型和对其进行微分。让我们从定义 训练神经网络 的过程开始:
-
定义一个具有可学习参数的神经网络,这些参数称为权重。
-
遍历输入数据集。
-
通过网络处理输入。
-
将预测结果与实际值进行比较,并测量误差。
-
将梯度传播回网络的参数中。
-
使用简单的更新规则更新网络的权重:
weight = weight — learning_rate * gradient
现在你将使用 nn 包来创建一个两层的神经网络:
让我们解释一下上述使用的一些参数:
-
N是批量大小。批量大小是权重将在更新后更新的观察数量。 -
D_in是输入维度 -
H是隐藏维度 -
D_out是输出维度 -
torch.randn定义了一个具有指定维度的矩阵 -
torch.nn.Sequential初始化一个线性层堆栈 -
torch.nn.Linear对输入数据应用线性变换 -
torch.nn.ReLU元素级地应用修正线性单元函数 -
torch.nn.MSELoss创建一个度量输入 x 和目标 y 之间的均方误差的标准
PyTorch optim 包
接下来,你将使用 optim 包来 定义一个优化器,它将为你更新权重。optim 包抽象了优化算法的概念,并提供了常用优化算法的实现,如 AdaGrad、RMSProp 和 Adam。我们将使用 Adam 优化器,它是更受欢迎的优化器之一。
该优化器接受的第一个参数是张量,它应该更新。在前向传递中,你将通过将 x 传递给模型来计算预测的 y。之后,计算并打印损失。在运行反向传递之前,将所有梯度归零,以便更新优化器中的变量。这是因为默认情况下,.backward() 被调用时梯度不会被覆盖。之后,调用优化器的 step 函数,这将更新其参数。如何实现如下所示,
PyTorch 中的自定义 nn 模块
有时你需要构建自己的自定义模块。在这些情况下,你将子类化 nn.Module。然后你需要定义一个 forward,它将接收输入张量并产生输出张量。如何使用 nn.Module 实现一个两层网络如下所示。该模型与上面的模型非常相似,但不同之处在于你将使用 torch.nn.Module 来创建神经网络。另一个不同之处是使用 随机梯度下降优化器 而不是 Adam。你可以按下面所示实现一个自定义 nn 模块:
综合所有内容与进一步阅读
PyTorch 允许你实现不同类型的层,如 卷积层, 递归层,以及 线性层, 等等。你可以通过其官方 文档 了解更多有关 PyTorch 的信息。
简介: 德里克·穆伊提 是一位数据分析师、作家和导师。他致力于在每个任务中取得优异的成果,并且是 Lapid Leaders Africa 的导师。
原文。转载经许可。
相关内容:
-
Keras 深度学习入门
-
使用 PyTorch 的简单导数
-
PyTorch 张量基础
更多相关话题
Safetensors 介绍

作者提供的图片
什么是 Safetensors?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT
Hugging Face 开发了一种新的序列化格式,称为 Safetensors,旨在简化和优化大规模复杂张量的存储和加载。张量是深度学习中使用的主要数据结构,其大小可能在效率上带来挑战。
Safetensors 使用有效的序列化和压缩算法组合来减少大张量的大小,使其比其他序列化格式如 pickle 更快、更高效。这意味着,Safetensors 在 CPU 上比传统的 PyTorch 序列化格式 pytorch_model.bin 快 76.6 倍,在 GPU 上快 2 倍。查看 速度比较。
使用 Safetensors 的好处
易用性
Safetensors 提供了一个简单直观的 API,用于在 Python 中序列化和反序列化张量。这意味着开发者可以专注于构建他们的深度学习模型,而不必花时间在序列化和反序列化上。
跨平台兼容性
你可以在 Python 中进行序列化,并方便地在各种编程语言和平台上加载生成的文件,例如 C++、Java 和 JavaScript。这使得在不同编程环境之间无缝共享模型成为可能。
速度
Safetensors 针对速度进行了优化,能够高效地处理大张量的序列化和反序列化。因此,它是使用大规模语言模型应用的优秀选择。
大小优化
它使用有效的序列化和压缩算法的结合来减小大张量的大小,从而比其他序列化格式如 pickle 提供更快、更高效的性能。
安全
为了防止在存储或传输序列化张量过程中发生任何损坏,Safetensors 使用了校验和机制。这提供了一层额外的安全保障,确保所有存储在 Safetensors 中的数据都是准确和可靠的。此外,它还能防止 DOS 攻击。
延迟加载
在分布式设置中,当有多个节点或 GPU 时,逐个加载每个模型的部分张量是非常有用的。BLOOM 利用这种格式在 45 秒内在 8 个 GPU 上加载模型,而普通 PyTorch 权重则需要 10 分钟。
入门 Safetensors
在本节中,我们将深入了解 safetensors API 以及如何保存和加载文件张量文件。
我们可以通过 pip 管理器简单地安装 safetensors:
pip install safetensors
我们将使用 Torch shared tensors 中的示例来构建一个简单的神经网络,并使用 safetensors.torch API 为 PyTorch 保存模型。
from torch import nn
class Model(nn.Module):
def __init__(self):
super().__init__()
self.a = nn.Linear(100, 100)
self.b = self.a
def forward(self, x):
return self.b(self.a(x))
model = Model()
print(model.state_dict())
如我们所见,我们已成功创建了模型。
OrderedDict([('a.weight', tensor([[-0.0913, 0.0470, -0.0209, ..., -0.0540, -0.0575, -0.0679], [ 0.0268, 0.0765, 0.0952, ..., -0.0616, 0.0146, -0.0343], [ 0.0216, 0.0444, -0.0347, ..., -0.0546, 0.0036, -0.0454], ...,
现在,我们将通过提供 model 对象和文件名来保存模型。之后,我们将把保存的文件加载到使用 nn.Module 创建的 model 对象中。
from safetensors.torch import load_model, save_model
save_model(model, "model.safetensors")
load_model(model, "model.safetensors")
print(model.state_dict())
OrderedDict([('a.weight', tensor([[-0.0913, 0.0470, -0.0209, ..., -0.0540, -0.0575, -0.0679], [ 0.0268, 0.0765, 0.0952, ..., -0.0616, 0.0146, -0.0343], [ 0.0216, 0.0444, -0.0347, ..., -0.0546, 0.0036, -0.0454], ...,
在第二个示例中,我们将尝试保存使用 torch.zeros 创建的张量。为此,我们将使用 save_file 函数。
import torch
from safetensors.torch import save_file, load_file
tensors = {
"weight1": torch.zeros((1024, 1024)),
"weight2": torch.zeros((1024, 1024))
}
save_file(tensors, "new_model.safetensors")
为了加载张量,我们将使用 load_file 函数。
load_file("new_model.safetensors")
{'weight1': tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]),
'weight2': tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])}
safetensors API 适用于 Pytorch、Tensorflow、PaddlePaddle、Flax 和 Numpy。您可以通过阅读 Safetensors 文档来了解它。

图像来自 Torch API
结论
简而言之,safetensors 是一种用于深度学习应用的大型张量存储新方式。与其他技术相比,它提供了更快、更高效且用户友好的功能。此外,它确保了数据的机密性和安全性,同时支持多种编程语言和平台。通过利用 Safetensors,机器学习工程师可以优化他们的时间,专注于开发更优质的模型。
我强烈推荐在您的项目中使用 Safetensors。许多顶尖的 AI 公司,如 Hugging Face、EleutherAI 和 StabilityAI,都在他们的项目中利用 Safetensors。
参考
-
博客: 什么是 Safetensors 以及如何将 .ckpt 模型转换为 .safetensors | hengtao tantai | Medium
-
GitHub: huggingface/safetensors: 简单、安全的张量存储和分发方式 (github.com)
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络开发一个 AI 产品,帮助那些面临心理健康问题的学生。
更多相关主题
Scikit Learn 简介:Python 机器学习的黄金标准
原文:
www.kdnuggets.com/2019/02/introduction-scikit-learn-gold-standard-python-machine-learning.html
评论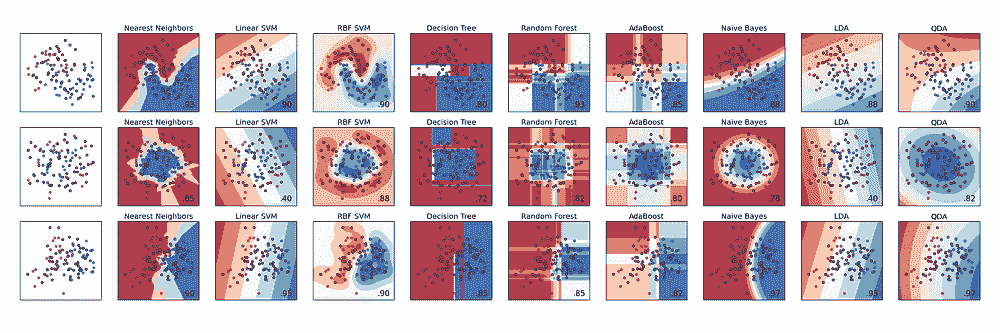
对 Scikit Learn 的众多机器学习模型的比较
机器学习 黄金标准
如果你打算在 Python 中进行机器学习,Scikit Learn 是黄金标准。Scikit-learn 提供了广泛的监督学习和非监督学习算法。最棒的是,它是迄今为止最简单和最干净的机器学习库。
Scikit Learn 的创建带有软件工程思维。它的核心 API 设计围绕易用性、强大功能和对研究工作的灵活性展开。这种稳健性使其非常适合用于任何端到端的机器学习项目,从研究阶段到生产部署。
Scikit Learn 提供了什么
Scikit Learn 构建在几个常见的数据和数学 Python 库之上。这种设计使得它们之间的集成变得非常简单。你可以将 numpy 数组和 pandas 数据框直接传递给 Scikit 的机器学习算法!它使用以下库:
-
NumPy: 处理矩阵,尤其是数学运算
-
SciPy: 科学和技术计算
-
Matplotlib: 数据可视化
-
IPython: Python 的交互式控制台
-
Sympy: 符号数学
-
Pandas: 数据处理、操作和分析
Scikit Learn 专注于机器学习,例如 数据建模。它 不关心 数据的加载、处理、操作和可视化。因此,使用上述库,尤其是 NumPy 来完成这些额外的步骤是自然和常见的做法;它们是天作之合!
Scikit 的强大算法集合包括:
-
回归: 拟合线性和非线性模型
-
聚类: 无监督分类
-
决策树: 用于分类和回归任务的树生成和修剪
-
神经网络: 端到端的训练,适用于分类和回归。层可以很容易地在元组中定义
-
支持向量机: 用于学习决策边界
-
朴素贝叶斯: 直接概率建模
更重要的是,它还有一些其他库不常提供的非常方便和高级的功能:
-
集成方法: 提升、装袋、随机森林、模型投票和平均
-
特征操作: 降维、特征选择、特征分析
-
异常值检测: 用于检测异常值和排除噪声
-
模型选择和验证: 交叉验证、超参数调整和指标
一次口味测试
为了让你感受到使用 Scikit Learn 训练和测试机器学习模型的简单,这里有一个如何为决策树分类器做这件事的例子!
决策树用于分类和回归在 Scikit Learn 中都非常容易使用,并且有一个内置的类。我们首先加载我们的数据集,该数据集实际上是库中自带的。然后,我们将初始化我们的决策树分类器,这也是一个内置的类。训练只需一行代码!.fit(X, Y) 函数训练模型,其中X 是输入的 numpy 数组,Y 是对应的输出 numpy 数组。
Scikit Learn 还允许我们使用 graphviz 库来可视化我们的树。它提供了一些选项,有助于可视化决策节点和模型学习到的分裂,这对理解其工作原理非常有用。下面我们将根据特征名称为节点着色,并显示每个节点的类别和特征信息。
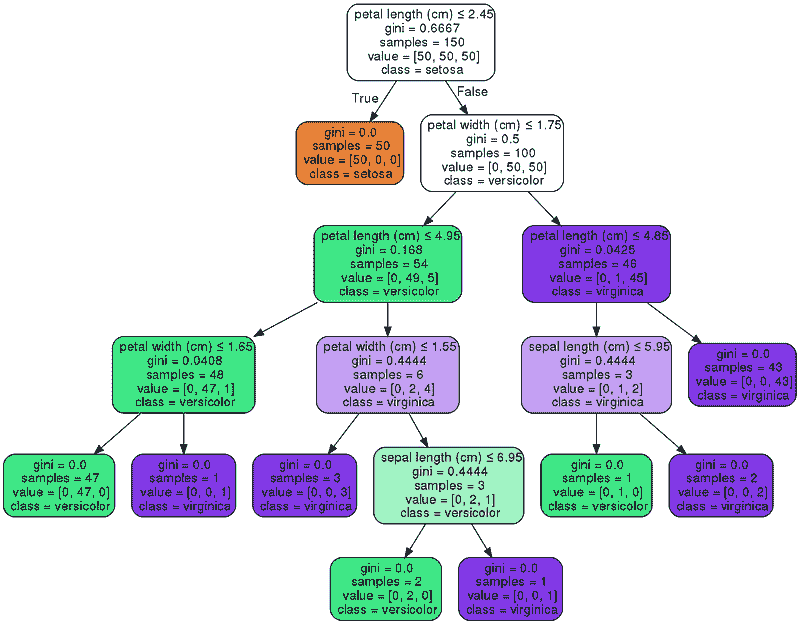
此外,Scikit Learn 的文档非常精美!每个算法参数都解释得很清楚,命名也很直观。此外,他们还提供了带有示例代码的教程,介绍如何训练和应用模型、其优缺点以及实际应用技巧!
喜欢学习?
关注我的twitter,我会发布最新的人工智能、技术和科学相关内容!
简介: George Seif 是一名认证极客和人工智能/机器学习工程师。
原文。转载需经许可。
相关:
-
Python 中的 5 种快速且简单的数据可视化(带代码)
-
数据科学家需要了解的 5 种聚类算法
-
为你的回归问题选择最佳机器学习算法
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT
更多相关内容
SMOTE 简介
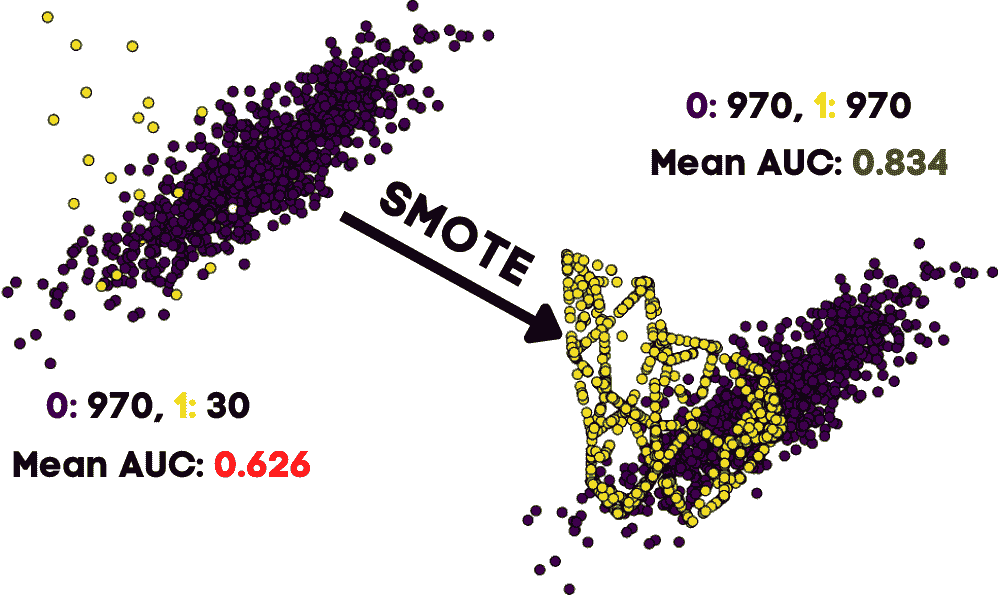
图片由作者提供
当我们拥有不平衡的分类数据集时,模型学习决策边界的少数类样本很少。这也会整体影响模型的表现。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
你可以通过过采样少数类来解决这个问题,你可以通过复制训练数据集中少数类的样本来实现。这将平衡类别分布,但不会提高模型性能,因为它没有为模型提供额外的信息。
那么,你如何同时平衡类别分布并提高模型性能呢?通过使用 SMOTE(合成少数类过采样技术)从少数类中合成新的样本。
什么是 SMOTE?
SMOTE(合成少数类过采样技术)是一种平衡数据集中类别分布的过采样方法。它选择接近特征空间的少数样本。然后,它在特征空间中的样本之间绘制一条线,并在这条线上生成一个新的样本。
简单来说,算法从少数类中选择一个随机样本,并使用 K 最近邻选择一个随机邻居。在特征空间中,这个合成样本在两个样本之间创建。
使用 SMOTE 有一个缺点,因为在创建合成样本时,它没有考虑多数类。这可能会导致类别之间有很强的重叠。
让我们通过使用 Imbalanced-Learn 库来观察 SMOTE 的实际效果。
%pip install imbalanced-learn
注意:我们使用 Deepnote 笔记本来运行实验。
不平衡数据集
我们将使用 sci-kit learn 的数据集模块中的 make_classification 来创建一个不平衡的分类数据集。
from collections import Counter
from sklearn.datasets import make_classification
from imblearn.over_sampling import SMOTE
import matplotlib.pyplot as plt
# create a binary classification dataset
X, y = make_classification(
n_samples=1000,
n_features=2,
n_redundant=0,
n_clusters_per_class=1,
weights=[0.98],
random_state=125,
)
labels = Counter(y)
print("y labels after oversampling")
print(labels)
正如我们观察到的,样本总数为 1K。970 个属于0标签,只有 30 个属于1。
y labels after oversampling
Counter({0: 970, 1: 30})
然后我们将使用 matplotlib 的 pyplot 来可视化数据集。
正如我们所见,图表上只有少量的黄色点(1),而紫色点则更多。这是一个明显的不平衡数据集的例子。
plt.scatter(X[:, 0], X[:, 1], marker="o", c=y, s=50, edgecolor="k");
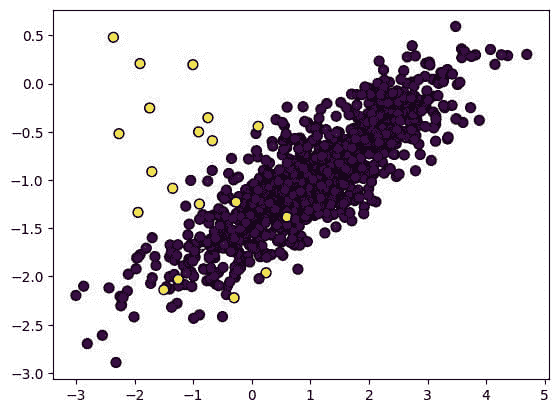
模型训练与评估
在我们使用过采样平衡数据集之前,我们需要为模型性能设定基准。
我们将使用决策树分类模型在数据集上进行 10 折 3 次交叉验证来进行训练和评估。简而言之,我们将在数据集上训练和评估 30 个模型。
RepeatedStratifiedKFold 中的分层意味着每次交叉验证的划分都具有与原始数据集相同的类别分布。
import numpy as np
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
result = cross_val_score(model, X, y, scoring="roc_auc", cv=cv, n_jobs=-1)
print("Mean AUC: %.3f" % np.mean(result))
我们得到了ROC AUC平均得分为0.626,这个结果相当低。
Mean AUC: 0.626
使用 SMOTE()进行过采样
我们现在将应用过采样方法 SMOTE 来平衡数据集。我们将使用imbalanced-learn的 SMOTE 函数,并提供特征(X)和标签(y)。
over = SMOTE()
X, y = over.fit_resample(X, y)
labels = Counter(y)
print("y labels after oversampling")
print(labels)
现在 0 和 1 标签的样本数量已经平衡,每个标签都有 970 个样本。
y labels after oversampling
Counter({0: 970, 1: 970})
让我们可视化合成平衡的数据集。我们可以清楚地看到黄色和紫色的点数相等。
plt.scatter(X[:, 0], X[:, 1], marker="o", c=y, s=50, edgecolor="k");
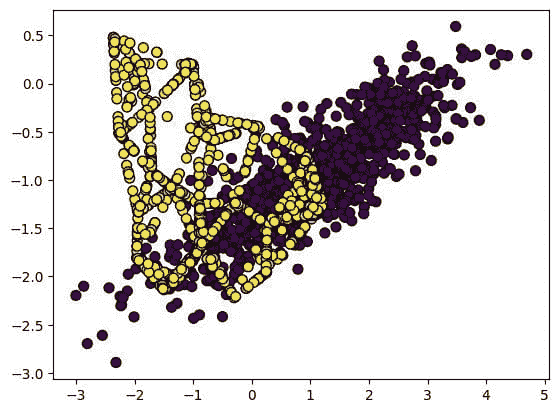
模型训练和评估
我们现在将在合成数据集上训练模型并评估结果。我们保持一切不变,以便将其与基准结果进行比较。
model = DecisionTreeClassifier()
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
result = cross_val_score(model, X, y, scoring="roc_auc", cv=cv, n_jobs=-1)
print("Mean AUC: %.3f" % np.mean(result))
经过几秒钟的训练后,我们得到了改进的结果或ROC AUC平均得分为0.834。这清楚地表明过采样确实能提高模型性能。
Mean AUC: 0.834
结论
原始的 SMOTE 论文建议将过采样(SMOTE)与多数类的欠采样相结合,因为 SMOTE 在创建新样本时不考虑多数类。少数类的过采样(SMOTE)和多数类的欠采样的组合可以给我们更好的结果。
在本教程中,我们了解了为什么使用 SMOTE 及其工作原理。我们还学习了 imbalanced-learn 库及其如何用于提高模型性能和平衡类分布。
希望你喜欢我的工作,别忘了关注我在社交媒体上,以了解有关数据科学、机器学习、自然语言处理、MLOps、Python、Julia、R 和 Tableau 的内容。
参考
Abid Ali Awan (@1abidaliawan)是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,帮助那些在精神疾病方面挣扎的学生。
更多相关主题
统计学习导论,Python 版:免费书籍
原文:
www.kdnuggets.com/2023/07/introduction-statistical-learning-python-edition-free-book.html

图片由作者提供
多年来,Introduction to Statistical Learning with Applications in R,更为人熟知的 ISLR,一直被机器学习初学者和从业者视为最好的机器学习教科书之一。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
现在,Python 版的书籍,Introduction to Statistical Learning with Applications in Python——或称ISL with Python——终于来了,社区的兴奋之情更是与日俱增!
ISL with Python 来了。太棒了!但为什么呢?
很高兴你问了。????
如果你在机器学习领域待了很久,那么你可能已经听说、阅读或使用过这本书的 R 版本。而你也知道自己最喜欢其中的哪些内容。但这是我的故事。
在我开始研究生课程的那个夏天,我决定自学机器学习。我很幸运在机器学习的早期阶段遇到了 ISLR。ISLR 的作者非常擅长将复杂的机器学习算法拆解成易于理解的方式——包括所需的数学基础——而不会让学习者感到不堪重负。这是我喜欢这本书的一个方面。
然而,ISLR 中的代码示例和实验是在 R 中进行的。遗憾的是,当时我并不懂 R,但对 Python 编程很熟悉。所以我有两个选择。

图片由作者提供
我可以自学 R。或者我可以使用其他资源——教程和文档——在 Python 中构建模型。像大多数其他 Python 爱好者一样,我选择了第二个选项(是的,更熟悉的路线,我知道)。
虽然 R 在统计分析方面表现出色,但如果你刚开始你的数据之旅,Python 是一个很好的首选语言。
但这不再是问题了!因为这个新的 Python 版让你可以边编码边构建 Python 中的机器学习模型。 不再担心为了跟上进度而必须学习一种新的编程语言。
故事时间结束了!让我们仔细看看本书的内容。
ISL 与 Python 的内容
就内容而言,Python 版与 R 版相似。然而,这是对 Python 的适当调整,这是可以预期的。这本书还包括一个 Python 编程速成课程部分,以学习基础知识。
本书涵盖了足够的广度。从统计学习基础、监督学习和无监督学习算法到深度学习等,本书被组织为以下章节:
-
统计学习
-
线性回归
-
分类
-
重采样方法
-
线性模型选择和正则化
-
超越线性
-
基于树的方法
-
支持向量机
-
深度学习(涵盖基础神经网络到卷积网络和递归神经网络)
-
生存分析与删失数据
-
无监督学习
-
多重测试(深入探讨假设检验)
ISLP Python 包
本书使用的数据集来自公开可用的资源库,如 UCI 机器学习库以及其他类似资源。一些例子包括关于自行车共享、信用卡违约、基金管理和犯罪率的数据集。
学习从各种来源收集数据,通过网络抓取过程,以及从来源导入数据,对数据科学项目至关重要。
然而,对于不熟悉数据收集步骤的学习者来说,如果他们想用这本书来掌握理论和实际部分,可能会在学习过程中引入摩擦。
为了提供顺畅的学习体验,本书配有一个附带的 ISLP 包:
-
ISLP 包适用于所有主要平台:Linux、Windows 和 MacOS。
-
你可以使用 pip 安装 ISLP:
pip install islp,最好在你机器上的虚拟环境中安装。
ISLP 包有一个 全面的文档。ISLP 包提供数据加载工具。当你处理特定数据集时,文档页面为你提供了关于数据集的各种特征、记录数量以及将数据加载到 pandas dataframe 的起始代码的可访问信息。
它还具有创建更高阶特征的辅助函数和功能,如多项式和样条特征。

生成多项式特征 | 来自 ISLP 文档的图像
为了更完整的学习体验,你可以从其来源读取数据,进行特征工程而不使用 ISLP 包。
当你在构建模型时,可以尝试仅使用 scikit-learn 的实现,以及 PyTorch 或 Keras 用于深度学习部分。
那么,这本书适合谁呢?
数据科学和机器学习初学者:如果你是一个喜欢自学机器学习的初学者,这本书是一个很好的学习资源。
ML 从业者:作为机器学习从业者,你会有构建机器学习模型的经验。但回到基础知识,例如假设检验和其他算法,仍然是有帮助的。
教育工作者:理论和实验室相结合使这本书成为机器学习初学课程的绝佳伴侣。如今大多数大学和数据科学训练营都教授机器学习。因此,如果你是正在教授或计划教授机器学习课程的教育工作者,这本书是一个值得考虑的优秀教材。
总结
就这样。用 Python 进行统计学习的介绍是这个夏天最令人兴奋的发布之一。
你可以访问 statlearning.com 开始阅读 Python 版。虽然电子版可以免费阅读,但亚马逊上的纸质版在首日就售罄了。因此,我们很高兴看到你能充分利用这本书。今天就开始阅读吧。祝学习愉快!
Bala Priya C 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过撰写教程、操作指南、观点文章等来学习和分享她的知识,服务开发者社区。
更多相关内容
《统计学习导论 第二版》
原文:
www.kdnuggets.com/2021/08/introduction-statistical-learning-v2.html
评论
《统计学习导论:R 语言应用》,由 Gareth James、Daniela Witten、Trevor Hastie 和 Robert Tibshirani 编写,是该领域的绝对经典。此书是统计学习教材的主流,对于各个层次的读者都很友好,可以在没有太多基础知识的情况下阅读。
尽管原版自 2013 年以来已存在,但第二版最近刚刚出版,并且现在可以在书籍网站上免费获取 PDF 版本。
我们的前三课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT

来自书籍网站的描述:
随着数据收集的规模和范围在几乎所有领域持续增长,统计学习已成为任何希望理解数据的人的关键工具包。《统计学习导论》提供了对统计学习关键主题的广泛且技术性较少的处理。每一章都包含一个 R 实验室。此书适合希望使用现代数据分析工具的人。
原版中突出的主题包括:
-
稀疏分类和回归方法
-
决策树
-
提升方法
-
支持向量机
-
聚类
第二版扩展了以下值得注意的主题:
-
深度学习
-
生存分析
-
多重检验
-
朴素贝叶斯和广义线性模型
-
贝叶斯加法回归树
-
矩阵补全
《统计学习导论:R 语言应用》(ISLR)可以视为对另一本经典著作的较少深入的处理,这本书由一些相同的作者撰写,《统计学习的要素》。这两本书之间的另一个主要区别,除了材料深度之外,是 ISLR 将这些主题与编程语言中的实际实现结合在一起,这里使用的是 R 语言。
如上所述,这本书在该领域中绝对是经典之作。但你无需仅仅听我的话来了解它的重要性。以下是卡内基梅隆大学的拉里·瓦瑟曼对该书的评价(摘自该书的亚马逊网站):
"《统计学习导论(ISL)》由 James、Witten、Hastie 和 Tibshirani 编写,是统计学习的“操作手册”。受到《统计学习的元素》(Hastie、Tibshirani 和 Friedman)的启发,本书提供了如何实现前沿统计和机器学习方法的清晰和直观的指导。ISL 使现代方法对广泛的读者群体变得可及,而不需要统计学或计算机科学的背景。作者对可用方法的精确、实际解释,并提供了明确的 R 代码。任何希望智能分析复杂数据的人都应该拥有这本书。"
—拉里·瓦瑟曼,教授,统计与机器学习系,卡内基梅隆大学
书籍的印刷版可以在亚马逊上购买,而 PDF 可以从这里免费下载。
附带的代码和数据集可以在这里找到.
相关内容:
-
《统计学习导论:免费电子书》
-
《机器学习数学基础:免费电子书》
-
《统计学习的元素:免费电子书》
更多相关主题
数据科学统计学简介
原文:
www.kdnuggets.com/2018/12/introduction-statistics-data-science.html
评论
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
尽管中心极限定理可以作为“高级水平——概率分布下的推断统计基础”文章的一部分,但我认为这个定理值得单独讨论!
每次进行统计分析的第一步是确定你处理的数据集是总体还是样本。正如你可能记得的,总体是你研究中所有感兴趣项目的集合,而样本是来自总体的数据点的子集。让我们来个简短的复习!
总体与样本
-
总体:我们观察的某种事物的数量,包括人类、事件、动物等。它有一些参数,如均值、中位数、众数、标准差等。
-
样本:它是来自总体的随机子集。通常,当总体太大而难以分析整个数据集时,你会使用样本。在样本中,你没有参数,只有统计量。
中心极限定理
这被认为是统计学以及数学中最重要的定理。当评估问题和世界局势时,它可能非常强大!中心极限定理指出
抽样分布将呈现出正常分布的形态,无论你分析的总体是什么。
抽样分布
正如我们所见,你通过抽样来估计整个总体的参数。然而,仅仅通过抽样并不总是能够获得总体真实参数的正确估计。
如果我们从总体中取多个样本而不是单一样本会怎么样?对于每个样本,我们会计算均值。最终,我们将得到多个均值估计值,然后可以将它们绘制在图表上。
这将被称为样本均值的抽样分布。
中心极限定理 — 直观理解
让我们通过一个例子来学习。假设我们想查看葡萄牙男性总体中每个人身高的分布。
首先,我们从总体中取几个样本(不同男性的身高),对于每个样本组,我们计算相应的均值。例如,我们可以有身高为 176 厘米的组,身高为 182 厘米的组,身高为 172 厘米的组,等等。然后我们绘制这个样本均值分布。下图展示了我们几个样本的分布,每个样本的均值用 x 标记表示。
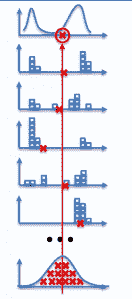
你可以看到,尽管你的抽样均值(红色 X 标记)可能位于总体分布的极端,但它们中的大多数趋向于靠近中心。
最后,这些样本均值的分布将呈现正态分布。请看最后的图表,它由所有样本均值的分布组成。
仅用 5 个样本,你已经可以看到大多数均值趋向于集中在抽样分布的中心。令人惊讶的是,最终,抽样分布的均值将与原始总体分布的均值一致。

因此,中心极限定理有两个确定性:
-
抽样分布将始终是正态分布或接近正态分布;
-
抽样分布的均值将等于总体的均值分布;
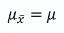
- 你抽样分布的标准误差与原始总体的标准差直接相关。
nis是你为每个样本所取的值的数量。
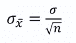
让我们通过这个 GIF 看一个更直观的例子。人口已经显示出正态分布,但之后你可以尝试其他形状,甚至绘制自己的分布图。我们首先从人口中抽取样本,样本大小为 n=5,并计算相应的均值。当你增加 n=5 的样本数量时,你会发现均值的分布开始呈现正态分布的形状。当我们将这个过程重复几千次时,我们得到一个均值等于总体均值的正态分布。样本越多,正态分布就越窄。
现在试试吧!你可以在这个网站上用鼠标直接绘制你的分布图。就像你在这里看到的那样。
因此,如果我们开始抽取样本并计算每个样本的均值,然后将它们绘制在抽样分布图中,你将得到一个以初始均值为中心的正态分布。
在这里访问:
onlinestatbook.com/stat_sim/sampling_dist/index.html
想了解更多关于中心极限定理的内容,可以查看 CreatureCast 制作的这个精彩视频!
CreatureCast - 中心极限定理 by Casey Dunn on Vimeo.
个人简介: Diogo Menezes Borges是一名数据科学家,具有工程背景,并拥有 2 年的经验,使用预测建模、数据处理和数据挖掘算法解决具有挑战性的业务问题。
原文。已获许可转载。
资源:
相关内容:
更多相关内容
t-SNE 介绍与 Python 示例
评论
作者:Andre Violante,SAS 数据科学家
介绍
我一直对学习充满热情,并认为自己是一个终身学习者。在 SAS 担任数据科学家,让我可以学习并尝试我们定期发布给客户的新算法和功能。很多时候,这些算法在技术上并不新颖,但对我来说是新的,这让它们非常有趣。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
最近,我有机会深入了解 t-分布随机邻域嵌入(t-SNE)。在这篇文章中,我将对 t-SNE 算法进行高层次概述。我还会分享一些 Python 示例代码,其中我将使用 t-SNE 对 Digits 和 MNIST 数据集进行处理。
什么是 t-SNE?
t-分布随机邻域嵌入(t-SNE)是一种无监督、非线性技术,主要用于数据探索和可视化高维数据。简单来说,t-SNE 让你感知或直观了解数据在高维空间中的排列。它由 Laurens van der Maatens 和 Geoffrey Hinton 于 2008 年开发。
t-SNE 与 PCA
如果你熟悉主成分分析(PCA),那么像我一样,你可能会想知道 PCA 和 t-SNE 之间的区别。首先要注意的是,PCA 是在 1933 年开发的,而 t-SNE 是在 2008 年开发的。自 1933 年以来,数据科学领域发生了很多变化,主要体现在计算能力和数据规模上。其次,PCA 是一种线性降维技术,旨在最大化方差并保留较大的成对距离。换句话说,不同的事物最终会远离。这可能导致可视化效果不佳,特别是在处理非线性流形结构时。把流形结构想象成任何几何形状,如:圆柱体、球体、曲线等。
t-SNE 与 PCA 的不同之处在于,它只保留小的成对距离或局部相似度,而 PCA 则关注保留大的成对距离以最大化方差。Laurens 通过图 1 [1] 中的瑞士卷数据集很好地展示了 PCA 和 t-SNE 方法。你可以看到,由于这个玩具数据集(流形)的非线性以及保留大的距离,PCA 会错误地保留数据的结构。
图 1 — 瑞士卷数据集。使用 t-SNE(实线)保留小距离 vs 最大化方差的 PCA [1]
t-SNE 的工作原理
现在我们知道为什么我们可能会选择 t-SNE 而不是 PCA,让我们讨论一下 t-SNE 是如何工作的。t-SNE 算法计算高维空间和低维空间中实例对之间的相似度测量。然后,它尝试使用成本函数来优化这两种相似度测量。我们将这个过程分解为 3 个基本步骤。
- 步骤 1,在高维空间中测量点之间的相似度。可以将一组数据点想象成散布在二维空间中的点(图 2)。对于每个数据点(x[i]),我们将一个高斯分布中心放置在该点上。然后我们测量所有点(x[j])在该高斯分布下的密度。接着对所有点进行重新归一化。这将为所有点提供一组概率(P[ij])。这些概率与相似度成正比。这意味着,如果数据点 x1 和 x2 在这个高斯圆圈下具有相等的值,那么它们的比例和相似度也相等,因此你可以在这个高维空间的结构中获得局部相似度。高斯分布或圆圈可以通过所谓的困惑度进行调整,它影响分布的方差(圆圈大小)以及本质上的最近邻数量。困惑度的正常范围是 5 到 50 [2]。
图 2 — 在高维空间中测量成对相似度
- 步骤 2 与步骤 1 类似,但不同的是,使用的是具有一个自由度的 Student t 分布,也称为 Cauchy 分布(图 3)。这为低维空间中的所有点提供了一组第二概率(Q[ij])。正如你所看到的,Student t 分布比正态分布有更重的尾部。重尾部更好地建模了远距离。
图 3 — 正态分布 vs Student t 分布
- 最后一步是我们希望低维空间(Q[ij])中的这些概率集合尽可能准确地反映高维空间(P[ij])中的概率集合。我们希望这两个映射结构相似。我们使用 Kullback-Liebler 散度(KL)来测量这两个二维空间中概率分布的差异。我不会深入讲解 KL,只说它是一种有效比较大 P[ij] 和 Q[ij] 值的非对称方法。最后,我们使用梯度下降来最小化 KL 成本函数。
t-SNE 的使用案例
现在你了解了 t-SNE 的工作原理,我们快速讨论一下它的应用领域。Laurens van der Maaten 在他的 [1] 视频演示中展示了很多例子。他提到 t-SNE 在气候研究、计算机安全、生物信息学、癌症研究等领域的应用。t-SNE 可以用于高维数据,然后这些维度的输出再作为其他分类模型的输入。
此外,t-SNE 还可以用于调查、学习或评估分割。通常我们会在建模之前选择分段的数量,或者在结果之后进行迭代。t-SNE 通常能清楚地显示数据中的分离。这可以在使用分割模型之前用来选择集群数量,或在之后用来评估你的分段是否有效。然而,t-SNE 不是一种聚类方法,因为它不像 PCA 那样保留输入,值在不同运行之间可能会发生变化,所以它仅用于探索。
代码示例
以下是一个 Python 代码示例(下方的图像链接到 GitHub),你可以看到 PCA 和 t-SNE 在 Digits 和 MNIST 数据集上的视觉比较。我选择这两个数据集是因为它们在维度上的差异,因此结果也会有所不同。我还在代码中展示了一种技术,即在运行 t-SNE 之前先运行 PCA。这可以减少计算量,通常你会将维度减少到 ~30,然后再运行 t-SNE。
我用 Python 运行了这个示例,并调用了 SAS 库。它可能看起来与您习惯的略有不同,你可以在下方的图像中看到。我使用了 seaborn 来进行可视化,我认为效果很好,但在 t-SNE 中你可能会得到非常紧凑的聚类,需要放大。另一个可视化工具,如 plotly,可能更适合需要放大的情况。
查看 GitHub 上的完整笔记本,以便查看所有步骤,并获取代码:
步骤 1 — 加载 Python 库。创建到 SAS 服务器的连接(称为‘CAS’,这是一个分布式内存引擎)。加载 CAS 动作集(将这些视为库)。读取数据并查看数据形状。
步骤 2 — 到目前为止,我仍在我的本地机器上工作。我将把数据加载到我提到的 CAS 服务器中。这有助于我利用分布式环境并提高性能效率。然后我对 Digits 和 MNIST 数据进行 PCA 分析。

步骤 3 — 可视化我们对 Digits 和 MNIST 的 PCA 结果

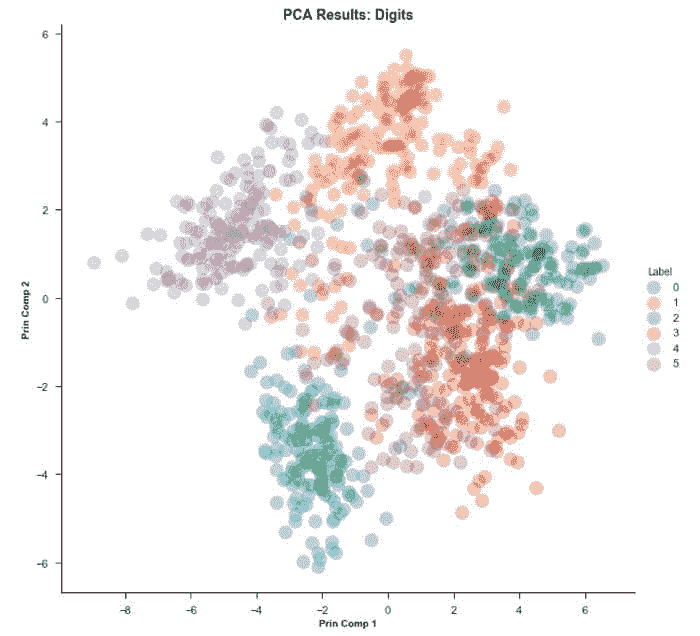
PCA 实际上在 Digits 数据集上做得相当不错,能够发现结构。
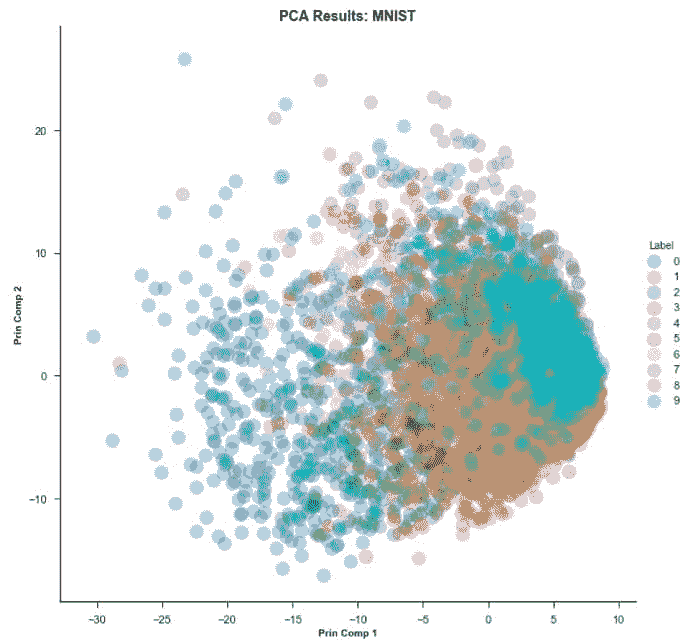
如你所见,PCA 在 MNIST 数据集上存在‘拥挤’问题。
步骤 4 — 现在让我们尝试与上述相同的步骤,但使用 t-SNE 算法


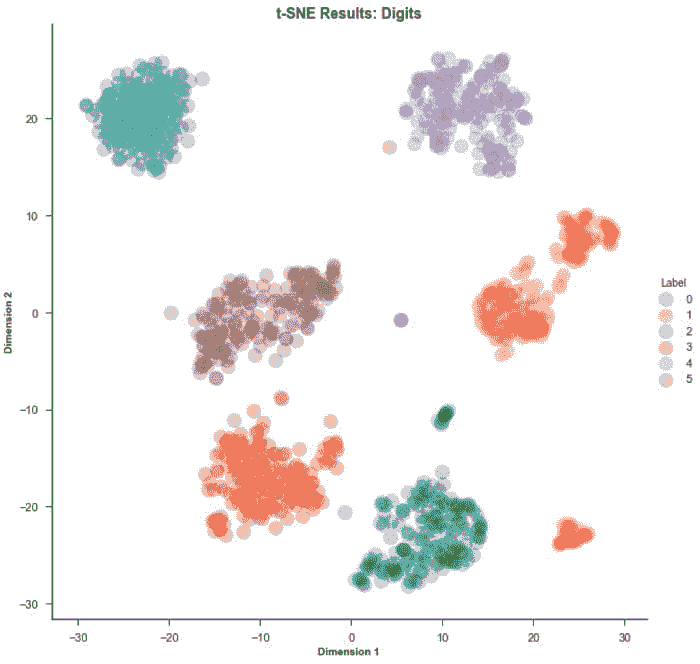
现在来看 MNIST 数据集…


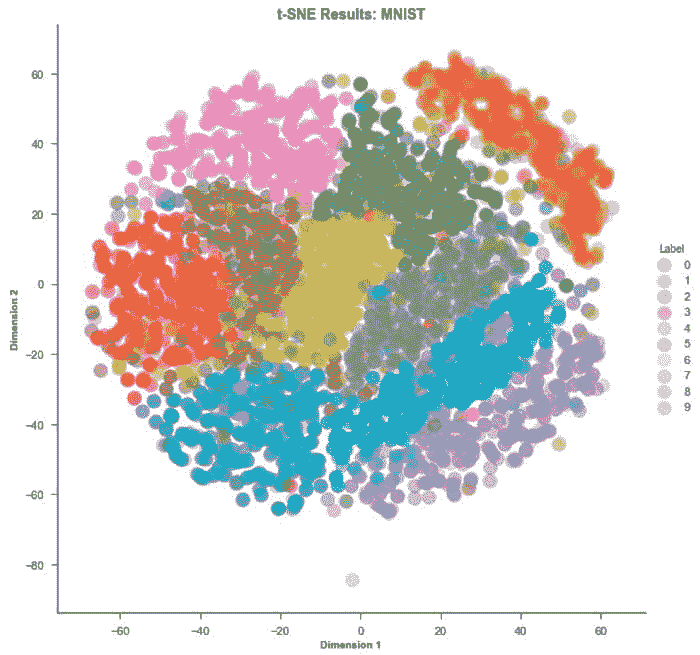
结论
我希望你喜欢这次 t-SNE 算法的概述和示例。我发现 t-SNE 作为可视化工具非常有趣和有用,因为几乎所有我处理过的数据似乎都是高维的。我将在下面发布我发现非常有帮助的资源。对我而言,最好的资源是 Laurens 的 YouTube 视频。虽然时间有点长,接近 1 小时,但讲解很清楚,是我找到的最详细的解释。
我发现有用的额外资源:
-
T-SNE 与 PCA 的比较:
www.quora.com/What-advantages-does-the-t-SNE-algorithm-have-over-PCA -
Kullback-Liebler 散度:
en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence -
T-SNE 维基百科:
en.wikipedia.org/wiki/T-distributed_stochastic_neighbor_embedding -
T-SNE 指南:
www.analyticsvidhya.com/blog/2017/01/t-sne-implementation-r-python/ -
优良的超参数信息:
distill.pub/2016/misread-tsne/ -
Lauren van der Maaten 的 GitHub 页面:
lvdmaaten.github.io/tsne/
参考文献
-
YouTube. (2013 年 11 月 6 日). 使用 t-SNE 可视化数据 [视频文件]. 来源于
www.youtube.com/watch?v=RJVL80Gg3lA -
L.J.P. van der Maaten 和 G.E. Hinton. 使用 t-SNE 可视化高维数据。机器学习研究杂志 9(11 月):2579–2605,2008 年。
个人简介:Andre 在 SAS 拥有超过 8 年的数字分析经验。他在零售行业专长,拥有丰富的客户分析经验。Andre 曾使用多种开源工具(主要是 R 和 Python)在多个数据平台(包括本地和云端)上工作。Andre 天生好奇,对解决问题充满热情。
Andre 拥有商业管理学士学位和分析学硕士学位。他还在乔治亚理工学院攻读计算机科学硕士学位,重点是机器学习。
Andre 喜欢和家人一起度假,尝试新的餐馆。他也喜欢户外活动和保持活跃。
相关:
更多相关主题
Python 中时间序列分析简介
原文:
www.kdnuggets.com/2020/09/introduction-time-series-analysis-python.html
评论
根据维基百科:
一个时间序列是按时间顺序索引(或列出或绘制)的数据点序列。最常见的是,时间序列是按等间隔的连续时间点采集的序列。因此,它是一个离散时间数据序列。时间序列的例子包括海洋潮汐的高度、太阳黑子的计数和道琼斯工业平均指数的每日收盘值。
因此,任何在连续等间隔时间点上采集的数据集。例如,我们可以看到 这个数据集,其为所有制造业制造商出货量的值。
我们将看到一些重要的要点,这些要点可以帮助我们分析任何时间序列数据集。这些要点包括:
-
在 Pandas 中正确加载时间序列数据集
-
时间序列数据中的索引
-
使用 Pandas 进行时间重采样
-
滚动时间序列
-
使用 Pandas 绘制时间序列数据
在 Pandas 中正确加载时间序列数据集
让我们在 pandas 中加载上述数据集。
df = pd.read_csv('Data/UMTMVS.csv')
df.head()
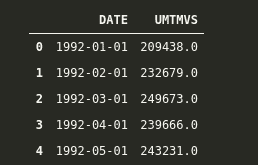
由于我们希望将“DATE”列作为我们的索引,但仅通过读取并没有实现,因此我们需要添加一些额外的参数。
df = pd.read_csv(‘Data/UMTMVS.csv’, index_col=’DATE’)
df.head()
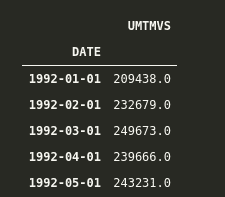
很好,现在我们已经将我们的 DATE 列添加为索引,但让我们检查一下它的数据类型,以了解 Pandas 是否将索引视为简单对象还是 Pandas 内置的 DateTime 数据类型。
df.index

这里我们可以看到 Pandas 将我们的索引列处理为一个简单对象,所以我们需要将其转换为 DateTime。我们可以按照以下步骤进行:
df.index = pd.to_datetime(df.index)
df.index
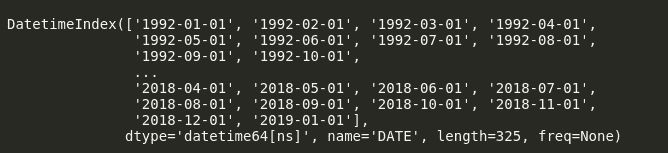
现在我们可以看到我们数据集的dtype是datetime64[ns]。这个“[ns]”表示它在纳秒级别上是精确的。如果我们愿意,可以将其更改为“天”或“月”。
或者,为了避免所有这些麻烦,我们可以使用 Pandas 在一行代码中加载数据,如下所示。
df = pd.read_csv(‘Data/UMTMVS.csv’, index_col=’DATE’, parse_dates=True)
df.index
在这里,我们添加了parse_dates=True,所以它将自动使用我们的index作为日期。
时间序列数据中的索引
假设我想获取从2000-01-01到2015-05-01的所有数据。为了做到这一点,我们可以像这样简单地在 Pandas 中使用索引。
df.loc['2000-01-01':'2015-01-01']
这里我们有从2000-01-01到2015-01-01的所有月份的数据。
假设我们想获取从1992-01-01到2000-01-01的所有第一个月份的数据。我们可以通过添加另一个参数来简单地实现,这个参数类似于我们在 Python 中切片列表时的操作,并在末尾添加步长参数。
在 Pandas 中,这种语法是['开始日期':'结束日期':步长]。现在,如果我们观察我们的数据集,它是按月份格式的,所以我们想要从 1992 年到 2000 年每 12 个月的数据。我们可以如下操作。
df.loc['1992-01-01':'2000-01-01':12]
在这里,我们可以看到我们可以获得每年第一月的值。
使用 Pandas 进行时间重采样
把重采样看作是groupby(),我们根据任何列进行分组,然后应用聚合函数来检查我们的结果。而在时间序列索引中,我们可以基于任何rule进行重采样,其中我们指定是否要基于“年”或“月”或“天”或其他任何东西进行重采样。
我们重采样时间序列索引的一些重要规则是:
-
M = 月末
-
A = 年末
-
MS = 月开始
-
AS = 年开始
等等。你可以在官方文档中查看详细的别名。
让我们将其应用于我们的数据集。
假设我们想计算每年开始时的运输均值。我们可以通过调用resample,其中rule='AS'表示年开始,然后调用mean聚合函数来实现。
我们可以如下查看它的头部。
df.resample(rule='AS').mean().head()
在这里,我们根据每年的开始对索引进行了重采样(记住“AS”做了什么),然后应用了mean函数,现在我们得到了每年开始时的 Shipping 均值。
我们甚至可以使用自定义函数与resample一起使用。假设我们想要用自定义函数计算每年的总和。我们可以如下操作。
def sum_of_year(year_val):
return year_val.sum()
然后我们可以通过重采样来应用它,如下所示。
df.resample(rule='AS').apply(year_val)
我们可以通过将其与进行比较来确认它工作正常
df.resample(rule='AS').apply(my_own_custom) == df.resample(rule='AS').sum()
而且它们两个是相等的。
滚动时间序列
滚动也类似于时间重采样,但在滚动中,我们取任意大小的窗口,并对其执行任何函数。简单来说,我们可以说大小为k的滚动窗口意味着k个连续的值。
让我们看一个例子。如果我们想计算 10 天的滚动平均值,我们可以如下操作。
df.rolling(window=10).mean().head(20) # head to see first 20 values
现在我们可以看到,前 10 个值是NaN,因为没有足够的值来计算前 10 个值的滚动均值。它从第 11 个值开始计算均值,并继续进行。
类似地,我们可以如下检查 30 天窗口的最大值。
df.rolling(window=30).max()[30:].head(20) # head is just to check top 20 values
注意,我在这里添加了* [30:] ,仅仅是因为前 30 个条目,即第一个窗口,没有值来计算max函数,因此它们是NaN*,为了添加截图以显示前 20 个值,我只是跳过了前 30 行,但在实际操作中你不需要这样做。
在这里,我们可以看到在 30 天的滚动窗口上具有最大值。
使用 Pandas 绘制时间序列数据
有趣的是,Pandas 提供了一整套内置的可视化工具和技巧,可以帮助你可视化任何类型的数据。
只需在数据框上调用 .plot 函数,就可以获得基本的折线图。
df.plot()
在这里,我们可以看到制造商出货量随时间的变化。注意 Pandas 如何很好地处理我们的 x 轴,即我们的时间序列索引。
我们可以通过在图上使用 .set 来进一步修改它,添加标题和 y 轴标签。
ax = df.plot()
ax.set(title='Value of Manufacturers Shipments', ylabel='Value')
同样,我们可以通过 .plot 中的 figsize 参数来改变图表的大小。
ax = df.plot(figsize=(12,6))
ax.set(title='Value of Manufacturers Shipments', ylabel='Value')
现在我们绘制每年开始值的均值。我们可以通过在重采样后调用 .plot 来完成,因为 'AS' 是开始年的规则。
ax = df.resample(rule='AS').mean().plot(figsize=(12,6))
ax.set(title='Average of Manufacturers Shipments', ylabel='Value of Mean of Starting of Year')
我们还可以通过在 .plot 上调用 .bar 来绘制每年开始的平均值的条形图。
ax = df.resample(rule='AS').mean().plot.bar(figsize=(12,6))
ax.set(title='Average of Manufacturers Shipments', ylabel='Value of Mean of Starting of Year');
同样,我们可以按如下方式绘制月初的滚动均值和正常均值。
ax = df['UMTMVS'].resample(rule='MS').mean().plot(figsize=(15,8), label='Resample MS')
ax.autoscale(tight=True)
df.rolling(window=30).mean()['UMTMVS'].plot(label='Rolling window=30')
ax.set(ylabel='Value of Mean of Starting of Month',title='Average of Manufacturers Shipments')
ax.legend()
在这里,我们首先通过规则 = “MS”(月初)重采样绘制了每个月开始的均值。然后我们设置了 autoscale(tight=True)。这将移除额外的空白图部分。然后我们绘制了 30 天窗口的滚动均值。请记住,前 30 天是空的,你会在图中观察到这一点。接着,我们设置了标签、标题和图例。
这个图表的输出是
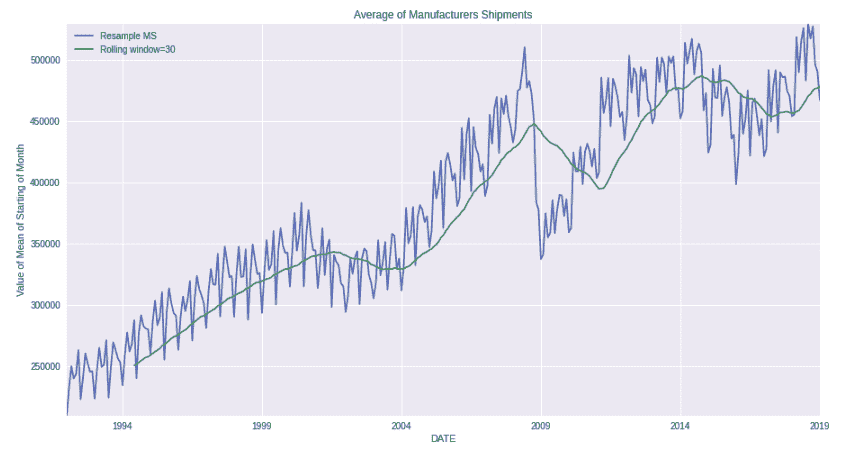
注意滚动平均数的前 30 天缺失,由于这是滚动平均数,与重采样相比,它非常平滑。
类似地,你可以根据自己的选择绘制特定日期的图表。假设我想绘制从 1995 年到 2005 年每年开始的最大值。我可以如下操作。
ax = df['UMTMVS'].resample(rule='AS').max().plot(xlim=["1999-01-01","2014-01-01"],ylim=[280000,540000], figsize=(12,7))
ax.yaxis.grid(True)
ax.xaxis.grid(True)
在这里,我们指定了 xlim 和 ylim。请看我如何在 xlim 中添加了日期。主要的模式是 xlim=['起始日期', '结束日期']。
在这里,你可以看到 1999 年至 2014 年每年开始的最大值的输出。
学习成果
这篇文章到此为止。希望你现在已经了解了基础知识。
-
正确加载 Pandas 中的时间序列数据集
-
时间序列数据中的索引
-
使用 Pandas 进行时间重采样
-
滚动时间序列
-
使用 Pandas 绘制时间序列数据
正确掌握这些主题,并可以将其应用到自己的数据集中。
相关:
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关主题
数据科学中的云计算简介
原文:
www.kdnuggets.com/introduction-to-cloud-computing-for-data-science

图片由 starline 提供
在当今世界,两大主要力量已经成为游戏规则的改变者:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
数据科学与云计算。
想象一下,一个每秒钟生成大量数据的世界。
嗯……你不需要想象……这就是我们的世界!
从社交媒体互动到金融交易,从医疗记录到电子商务偏好,数据无处不在。
但如果我们无法获得价值,这些数据有什么用呢?
这正是数据科学的作用。
那么我们在哪里存储、处理和分析这些数据呢?
这正是云计算的闪光点。
让我们开始了解这两项技术奇迹之间的交织关系。
让我们一起(尝试)发现所有的内容吧!
数据科学和云计算的本质
数据科学?-?提取见解的艺术
数据科学是从大量多样化数据中提取有意义见解的艺术和科学。
它结合了统计学、机器学习等多个领域的专业知识,以解释数据并做出明智的决策。
随着数据的爆炸性增长,数据科学家的角色变得至关重要,他们将原始数据转化为黄金。
云计算?-?数字存储革命
云计算是指通过互联网按需交付计算服务。
无论我们需要存储、处理能力还是数据库服务,云计算为企业和专业人士提供了一个灵活可扩展的环境,无需维护物理基础设施的开销。
不过,你们大多数人可能在想,为什么它们是相关的?
让我们回到最初…
为什么数据科学和云计算是不可分割的
云计算成为数据科学一个关键或互补组件的主要原因有两个。
#1. 协作的迫切需求
在数据科学旅程的开始,初级数据专业人员通常会在个人计算机上安装 Python 和 R。随后,他们使用本地集成开发环境(IDE),如 Jupyter Notebook 应用程序或 RStudio 编写和运行代码。
然而,随着数据科学团队的扩展和高级分析的普及,对协作工具的需求也在上升,以提供洞察、预测分析和推荐系统。
这就是为什么协作工具的必要性变得至关重要。这些工具对获取洞察、预测分析和推荐系统至关重要,并且通过可重复研究、笔记本工具和代码源控制得到了增强。云平台的集成进一步放大了这种协作潜力。
图片由 macrovector 提供
需要注意的是,协作不仅仅局限于数据科学团队。
它涵盖了更广泛的人群,包括如高管、部门领导以及其他数据中心角色等利益相关者。
#2. 大数据时代
大数据这个词已经在大型科技公司中广受欢迎。虽然其确切定义仍然模糊,但它通常指的是如此庞大的数据集,以至于超出了标准数据库系统和分析方法的能力。
这些数据集在捕捉、存储、管理和处理数据的合理时间框架方面超出了典型软件工具和存储系统的限制。
在考虑大数据时,请始终记住 3V:
-
体量: 指数据的巨大数量。
-
多样性: 指数据的不同格式、类型和分析应用。
-
速度: 指数据的发展或生成的速度。
随着数据的持续增长,迫切需要更强大的基础设施和更高效的分析技术。
所以,这两个主要原因是为什么我们?—作为数据科学家?—需要超越本地计算机进行扩展。
超越本地计算机的可扩展数据科学
公司和专业人员可以租用从应用程序到存储的所有服务,而不是拥有自己的计算基础设施或数据中心。
这使得公司和专业人员可以按需支付他们使用的服务, 而不必处理维护本地 IT 基础设施的成本和复杂性。
简单来说,云计算是按需提供计算服务—从应用程序到存储和处理能力—通常通过互联网和按需支付的方式进行。
关于最常见的提供商,我相信你们都对其中至少一个有所了解。Google(Google Cloud)、Amazon(Amazon Web Services)和 Microsoft(Microsoft Azure)是三种最常见的云技术,占据了几乎所有市场。
所以……什么是云?
云 这个术语可能听起来很抽象,但它有一个具体的含义。
从本质上讲,云就是网络计算机共享资源。可以把互联网看作是最广泛的计算机网络,而较小的例子包括家庭网络,如 LAN 或 WiFi SSID。这些网络共享从网页到数据存储的资源。
在这些网络中,单独的计算机被称为节点。它们使用诸如 HTTP 等协议进行通信,以进行状态更新和数据请求等各种目的。通常,这些计算机不在现场,而是在配备了必要基础设施的数据中心内。
由于计算机和存储成本的降低,现在使用多个互联计算机而非一台昂贵的计算机已成为常态。这种互联的方式确保了即使一台计算机故障,系统也能持续运行,并能够处理增加的负载。
像 Twitter、Facebook 和 Netflix 这样的流行平台 exemplify 云基础应用程序,能够管理数百万的日常用户而不崩溃。当同一网络中的计算机为一个共同目标协作时,这被称为集群。
集群作为一个整体,提供了增强的性能、可用性和可扩展性。
分布式计算 指的是设计用来利用集群进行特定任务的软件,比如 Hadoop 和 Spark。
那么……再一次……什么是云?
除了共享资源,云还包括由单一实体管理的服务器、服务、网络等。
尽管互联网是一个广阔的网络,但它不是云,因为没有任何单一方拥有它。
结论
总结一下,数据科学和云计算是同一枚硬币的两面。
数据科学为专业人士提供了提取数据价值所需的所有理论和技术。
云计算是提供存储和处理这些数据的基础设施的那个。
第一个提供了评估任何项目的知识,第二个则提供了执行这些项目的可行性。
它们共同形成了一个强大的组合,推动着技术创新。
随着我们向前发展,这两者之间的协同作用将会增强,为更加数据驱动的未来铺平道路。
拥抱未来吧,因为它是数据驱动和云支持的!
Josep Ferrer 是一位来自巴塞罗那的分析工程师。他毕业于物理工程专业,目前在应用于人类流动性的领域从事数据科学工作。他还是一名兼职内容创作者,专注于数据科学和技术。你可以通过 LinkedIn、Twitter 或 Medium 联系他。
更多相关主题
数据科学中的数据库介绍
原文:
www.kdnuggets.com/introduction-to-databases-in-data-science

作者提供的图片
数据科学涉及从大量数据中提取价值和洞察,以驱动业务决策。它还包括使用历史数据构建预测模型。数据库促进了对这些大量数据的有效存储、管理、检索和分析。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在的组织进行 IT 工作
因此,作为数据科学家,你应该了解数据库的基础知识。因为它们能够存储和管理大量复杂的数据集,从而实现高效的数据探索、建模和洞察。让我们在本文中详细探讨这一点。
我们将从讨论数据科学的基本数据库技能开始,包括用于数据检索的 SQL、数据库设计、优化等。然后我们将讨论主要的数据库类型、它们的优势以及使用场景。
数据科学的基本数据库技能
数据库技能对数据科学家至关重要,因为它们为有效的数据管理、分析和解释提供了基础。
下面是数据科学家应该理解的关键数据库技能的详细信息:
作者提供的图片
尽管我们尝试将数据库概念和技能分类到不同的类别中,但它们是相互关联的。而且你通常需要在项目中进行工作时学习或了解它们。
现在让我们逐一讨论上述内容。
1. 数据库类型和概念
作为数据科学家,你应该对不同类型的数据库有一个良好的理解,例如关系型数据库和 NoSQL 数据库,以及它们各自的使用场景。
2. SQL(结构化查询语言)用于数据检索
通过实践掌握 SQL 的熟练程度对于数据领域的任何角色都是必须的。你应该能够编写和优化 SQL 查询,以从数据库中检索、过滤、聚合和联接数据。
理解查询执行计划并能够识别和解决性能瓶颈也是很有帮助的。
3. 数据建模和数据库设计
除了查询数据库表之外,你还应该理解数据建模和数据库设计的基础知识,包括实体-关系(ER)图、模式设计和数据验证约束。
你还应该能够设计支持高效查询和数据存储的数据库模式,以便于分析。
4. 数据清洗和转换
作为数据科学家,你需要将原始数据预处理和转换为适合分析的格式。数据库可以支持数据清洗、转换和集成任务。
所以你应该知道如何从各种来源提取数据,将其转换成合适的格式,并将其加载到数据库中进行分析。熟悉 ETL 工具、脚本语言(Python,R)和数据转换技术很重要。
5. 数据库优化
你应该了解优化数据库性能的技术,例如创建索引、去范式化和使用缓存机制。
为了优化数据库性能,使用索引来加速数据检索。适当的索引通过使数据库引擎能快速定位所需数据来改善查询响应时间。
6. 数据完整性和质量检查
数据完整性通过定义数据输入规则的约束来维护。像唯一约束、非空约束和检查约束这样的约束确保数据的准确性和可靠性。
事务用于确保数据一致性,保证多个操作作为一个原子单位处理。
7. 工具和语言的集成
数据库可以与流行的分析和可视化工具集成,使数据科学家能够有效地分析和展示他们的发现。所以你应该知道如何使用像 Python 这样的编程语言连接和交互数据库,并进行数据分析。
熟悉像 Python 的 pandas、R 和可视化库等工具也很有必要。
总结:了解各种数据库类型、SQL、数据建模、ETL 过程、性能优化、数据完整性以及与编程语言的集成是数据科学家技能组合的关键部分。
在本简介指南的剩余部分,我们将专注于基本的数据库概念和类型。
作者提供的图片
关系数据库基础
关系数据库是一种数据库管理系统(DBMS),它通过使用具有行和列的表来以结构化的方式组织和存储数据。流行的 RDBMS 包括 PostgreSQL、MySQL、Microsoft SQL Server 和 Oracle。
让我们通过一些示例深入了解关键的关系数据库概念。
关系数据库表
在关系数据库中,每个表代表一个特定的实体,表之间的关系通过键建立。
要理解数据如何在关系数据库表中组织,最好从实体和属性入手。
你通常会想要存储关于对象的数据:学生、客户、订单、产品等。这些对象是实体,它们有属性。
让我们以一个简单的实体为例——一个具有三个属性的“学生”对象:名字、姓氏和成绩。存储数据时,该实体变成数据库表,属性变成列名或字段。每一行是实体的一个实例。
作者提供的图像
关系数据库中的表由行和列组成:
-
行也被称为记录或元组,而且
-
列被称为属性或字段。
这里是一个简单的“学生”表的例子:
| 学生 ID | 名字 | 姓氏 | 成绩 |
|---|---|---|---|
| 1 | 简 | 史密斯 | A+ |
| 2 | 艾米莉 | 布朗 | A |
| 3 | 杰克 | 威廉姆斯 | B+ |
在这个例子中,每一行代表一个学生,每一列代表有关学生的信息。
了解键
键用于唯一标识表中的行。两种重要的键类型包括:
-
主键:主键唯一标识表中的每一行。它确保数据完整性,并提供引用特定记录的方式。在“学生”表中,“学生 ID”可以是主键。
-
外键:外键建立表之间的关系。它引用另一表的主键,用于连接相关数据。例如,如果我们有一个名为“课程”的表,“课程”表中的“学生 ID”列可以是一个外键,引用“学生”表中的“学生 ID”。
关系
关系数据库允许你在表之间建立关系。这里是最重要和最常见的关系:
-
一对一关系:在一对一关系下,表中的每一条记录与数据库中另一表中的一条(且仅一条)记录相关。例如,一个“学生详细信息”表包含有关每个学生的附加信息,可能与“学生”表有一对一关系。
-
一对多关系:第一个表中的一个记录与第二个表中的多个记录相关。例如,一个“课程”表可以与“学生”表有一对多关系,其中每个课程与多个学生相关。
-
多对多关系:两个表中的多个记录彼此相关。为了表示这种关系,使用中介表,通常称为连接表或链接表。例如,一个“学生课程”表可以在学生和课程之间建立多对多关系。
规范化
规范化(通常在数据库优化技术中讨论)是将数据组织成最小化数据冗余和提高数据完整性的过程。它涉及将大型表拆分成较小的相关表。每个表应表示一个单独的实体或概念,以避免数据重复。
例如,如果我们考虑 "Students" 表和一个假设的 "Addresses" 表,规范化可能涉及创建一个单独的 "Addresses" 表,并将其主键与 "Students" 表通过外键关联。
关系型数据库的优点和限制。
关系型数据库的一些优点如下:
-
关系型数据库提供了一种结构化且有序的方式来存储数据,使得定义不同类型数据之间的关系变得容易。
-
它们支持 ACID 属性(原子性、一致性、隔离性、持久性)以确保事务的数据一致性。
另一方面,它们有以下限制:
-
关系型数据库在横向扩展方面存在挑战,使得处理大量数据和高流量负载变得困难。
-
它们还需要一个严格的模式,使得在不修改模式的情况下适应数据结构的变化变得具有挑战性。
-
关系型数据库专为具有明确定义关系的结构化数据设计。它们可能不适合存储像文档、图像和多媒体内容这样的非结构化或半结构化数据。
探索 NoSQL 数据库。
NoSQL 数据库不以熟悉的行列格式存储数据(因此是非关系型的)。"NoSQL" 代表 "not only SQL"——表明这些数据库与传统的关系型数据库模型不同。
NoSQL 数据库的主要优点是其可扩展性和灵活性。这些数据库旨在处理大量非结构化或半结构化数据,并提供比传统关系型数据库更灵活和可扩展的解决方案。
NoSQL 数据库涵盖了多种不同的数据模型、存储机制和查询语言的数据库类型。一些常见的 NoSQL 数据库类别包括:
-
键值存储。
-
文档数据库。
-
列族数据库。
-
图形数据库。
现在,让我们逐一探讨每种 NoSQL 数据库类别,深入了解它们的特性、使用案例、示例、优点和限制。
键值存储。
键值存储将数据存储为简单的键值对。它们优化了高速读写操作,适用于缓存、会话管理和实时分析等应用。
然而,这些数据库在键值检索之外的查询能力有限。因此,它们不适合处理复杂关系。
亚马逊 DynamoDB 和 Redis 是流行的键值存储。
文档数据库。
文档数据库以文档格式(如 JSON 和 BSON)存储数据。每个文档可以具有不同的结构,允许嵌套和复杂数据。其灵活的模式允许轻松处理半结构化数据,支持不断发展的数据模型和层次关系。
这些数据库特别适合用于内容管理、电子商务平台、目录、用户档案和具有变化的数据结构的应用程序。文档数据库可能不适合复杂的连接或涉及多个文档的复杂查询。
MongoDB 和 Couchbase 是流行的文档数据库。
列族存储(宽列存储)
列族存储,也称为列式数据库或列导向数据库,是一种 NoSQL 数据库,按列而非传统的行方式组织和存储数据。
列族存储适用于涉及在大型数据集上运行复杂查询的分析工作负载。聚合、过滤和数据转换在列族数据库中通常执行得更高效。它们有助于管理大量半结构化或稀疏数据。
Apache Cassandra、ScyllaDB 和 HBase 是一些列族存储的例子。
图数据库
图数据库分别通过节点和边建模数据和关系,以表示复杂的关系。这些数据库支持高效处理复杂关系和强大的图查询语言。
正如你所猜测的,这些数据库适用于社交网络、推荐引擎、知识图谱以及一般的复杂关系数据。
流行的图数据库例子包括 Neo4j 和 Amazon Neptune。
NoSQL 数据库有很多种类型。那么我们该如何决定使用哪一种呢? 答案是:这要看情况。
每种 NoSQL 数据库类别都提供了独特的功能和优势,使它们适合特定的使用场景。选择合适的 NoSQL 数据库时,必须考虑访问模式、可扩展性要求和性能考虑。
总结:NoSQL 数据库在灵活性、可扩展性和性能方面提供了优势,使其适用于各种应用程序,包括大数据、实时分析和动态网页应用。然而,它们在数据一致性方面存在权衡。
NoSQL 数据库的优缺点
以下是 NoSQL 数据库的一些优势:
-
NoSQL 数据库设计用于水平扩展,允许它们处理大量的数据和流量。
-
这些数据库允许灵活和动态的模式。它们具有灵活的数据模型,以适应各种数据类型和结构,使其非常适合非结构化或半结构化数据。
-
许多 NoSQL 数据库被设计为在分布式和容错环境中运行,即使在硬件故障或网络中断的情况下,也能提供高可用性。
-
它们可以处理非结构化或半结构化数据,使其适用于处理各种数据类型的应用程序。
一些限制包括:
-
NoSQL 数据库优先考虑可扩展性和性能,而不是严格的 ACID 合规性。这可能导致最终一致性,并可能不适用于需要强数据一致性的应用程序。
-
由于 NoSQL 数据库有多种类型,提供不同的 API 和数据模型,缺乏标准化可能会使得在不同数据库之间切换或无缝集成变得具有挑战性。
需要注意的是,NoSQL 数据库并不是一种通用的解决方案。选择 NoSQL 数据库还是关系型数据库取决于应用程序的具体需求,包括数据量、查询模式和可扩展性要求等。
关系型数据库与 NoSQL 数据库
让我们总结一下迄今为止讨论的区别:
| 特性 | 关系型数据库 | NoSQL 数据库 |
|---|---|---|
| 数据模型 | 表格结构(表) | 多样的数据模型(文档、键值对、图形、列等) |
| 数据一致性 | 强一致性 | 最终一致性 |
| 模式 | 定义良好的模式 | 灵活或无模式 |
| 数据关系 | 支持复杂关系 | 根据类型而异(有限或显式关系) |
| 查询语言 | 基于 SQL 的查询 | 特定的查询语言或 API |
| 灵活性 | 对非结构化数据不够灵活 | 适用于各种数据类型,包括 |
| 应用场景 | 结构良好的数据、复杂的事务 | 大规模、高吞吐量、实时应用 |
关于时间序列数据库的说明
作为数据科学家,你也将处理时间序列数据。时间序列数据库也是非关系型数据库,但具有更具体的使用场景。
它们需要支持存储、管理和查询带时间戳的数据点——即随时间记录的数据点——例如传感器读数和股票价格。它们提供了存储、查询和分析基于时间的数据模式的专用功能。
一些时间序列数据库的例子包括 InfluxDB、QuestDB 和 TimescaleDB。
结论
在本指南中,我们讨论了关系型数据库和 NoSQL 数据库。值得注意的是,除了流行的关系型和 NoSQL 类型外,你还可以探索一些其他数据库。新 SQL 数据库如 CockroachDB 提供了传统 SQL 数据库的好处,同时提供了 NoSQL 数据库的可扩展性和性能。
你还可以使用内存数据库,该数据库主要在计算机的主内存(RAM)中存储和管理数据,而不是传统的将数据存储在磁盘上的数据库。这种方法由于内存中的读写操作比磁盘存储要快得多,因此提供了显著的性能优势。
Bala Priya C 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过撰写教程、操作指南、观点文章等,学习并与开发者社区分享她的知识。
了解更多相关主题
SQL 的数据库入门:免费哈佛课程
原文:
www.kdnuggets.com/introduction-to-databases-with-sql-free-harvard-course

编辑器提供的图片
多年来,哈佛的 CS50 课程——每个人的计算机科学入门——由David J Malan 教授讲授,帮助全球的学习者进入计算机科学领域并开始他们的开发之旅。虽然 CS50 是计算机科学的入门课程,但也有关于 Python、AI 等的专业课程。
正如你所猜测的,团队发布了SQL 数据库入门课程——或者说CS50 SQL——以帮助你学习如何查询数据库,设计自己的数据库,等等。
如果你是一个有志的数据专业人士,你应该在数据库和 SQL 上建立扎实的基础。这门课程将帮助你实现这一目标。
关于 CS50 SQL 课程
由Carter Zenke讲授的SQL 数据库入门课程分为七个模块,跨越七周。模块包括讲座和基于真实世界数据集的相关问题集。
对于每个模块,你可以采用以下方法:
-
观看讲座
-
复习笔记
-
尝试讲座中展示的示例
-
完成模块的题目
你可以在CS50 的 VS Code上解决问题集。像 codespaces 一样,它在云端提供了适用于 CS50 的 VS Code。因此,在你学习课程的过程中,有大量的学习和实践。
既然我们了解了课程内容,接下来让我们详细了解一下。
注意:以下模块 1 至 7 对应课程中的第 0 至第 6 周。
1. 查询数据库
第一个模块查询数据库从讨论如何超越电子表格及数据如何存储在关系数据库中开始。然后继续讲解使用 SQL 查询数据库的基础知识。涵盖的主题包括:
-
SELECT 语句
-
LIMIT 和 WHERE 子句
-
理解 NULL
-
LIKE 关键字
-
范围
-
ORDER BY
-
聚合函数
查看查询模块。
2. 关系数据库表
关系数据库表模块在前一个模块的基础上,超越了单个数据库表。你将学习如何处理多个表,并理解它们之间的关系。涵盖的主题包括:
-
实体关系图(ER 图)
-
关系类型:一对一、一对多和多对多关系
-
键:主键和外键
-
子查询
-
IN 关键字
-
连接(JOINs)
-
集合操作:INTERSECT,UNION 和 EXCEPT
-
GROUPBY
查看关系模块。
3. 设计数据库模式
到目前为止,你已经学习了如何使用数据库,查询单个和多个表来回答问题。但你如何自己创建这样一个数据库? 这个模块设计数据库模式正好涵盖了这一点。你将学习从零开始设计数据库,包括以下概念:
-
创建数据库模式
-
规范化的概念和相关数据库表
-
创建表
-
数据类型和存储类
-
表和列的约束
-
修改表
查看关于设计的模块。
4. 写入数据库
到现在为止,你已经知道如何使用查询从数据库中检索数据以及从零开始设计自己的数据库。这个模块写入数据库教你:
-
向数据库插入记录
-
从 CSV 文件导入数据到数据库
-
删除和更新记录
查看关于写入的模块。
5. 查看数据库表
下一个关于查看数据库表的模块深入探讨了创建数据库视图及其优势,涵盖了:
-
视图是什么
-
创建视图
-
创建视图的优势
-
公共表表达式(CTEs)
-
分区
-
保护数据库
-
软删除
查看关于查看的模块。
6. 优化数据库查询
优化数据库查询模块专注于使用索引来加速数据库查询以及与索引相关的权衡。涵盖的主题包括:
-
创建数据库表索引
-
在多个表之间创建索引
-
空间和时间的权衡
-
对子集行的部分索引
-
事务和竞争条件
查看关于优化的模块。
7. 扩展数据库
到目前为止,你在这门课程中使用了 SQLite。这个关于扩展数据库的最后模块将介绍 MySQL 和 PostgreSQL。它为这些广泛使用的 RDMS 打下了基础,你可以在此基础上进行构建。这个模块涵盖了:
-
创建和修改表
-
MySQL 存储过程
-
带参数的存储过程
-
使用 PostgreSQL
-
访问控制语句
-
SQL 注入攻击
查看关于扩展的模块。
这门课程涵盖的所有主题都是如果你考虑从事数据相关职业的话非常重要的。数据科学中的数据库介绍提供了数据库的相关性和基本数据库技能的概述。
总结
总体来说,这是一个建立数据库和 SQL 坚实基础的好课程。作为一名数据专业人员,你将经常使用 SQL。但你也会意识到掌握 SQL 是一个持续的旅程。为此,实践是你最好的朋友!
如果你准备好磨练和提升你的 SQL 技能,请查看这篇 7 个最佳 SQL 练习平台的汇编。
Bala Priya C**** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉点工作。她的兴趣和专业领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正致力于学习和与开发者社区分享她的知识,通过撰写教程、操作指南、观点文章等形式。Bala 还创建了引人入胜的资源概述和编码教程。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关内容
深度学习库简介:PyTorch 和 Lightning AI
原文:
www.kdnuggets.com/introduction-to-deep-learning-libraries-pytorch-and-lightning-ai
照片由谷歌 DeepMind
深度学习是基于 神经网络 的机器学习模型的一部分。在其他机器模型中,数据处理以发现有意义的特征通常是手动完成的或依赖领域专业知识;然而,深度学习可以模拟人脑来发现基本特征,从而提高模型性能。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
深度学习模型有很多应用,包括面部识别、欺诈检测、语音转文本、文本生成等。深度学习已经成为许多先进机器学习应用中的标准方法,我们学习它没有什么损失。
为了开发这个深度学习模型,我们可以依靠各种库框架,而不是从头开始工作。在本文中,我们将讨论两个不同的库:PyTorch 和 Lightning AI。让我们深入了解一下。
PyTorch
PyTorch 是一个开源库框架,用于训练深度学习神经网络。PyTorch 由 Meta 团队于 2016 年开发,并逐渐获得了人气。流行的增长归功于 PyTorch 结合了来自 Torch 的 GPU 后端库和 Python 语言。这种结合使得该软件包对用户易于使用,但在开发深度学习模型时仍然强大。
有一些突出的 PyTorch 特性,这些特性由库提供,包括良好的前端、分布式训练以及快速且灵活的实验过程。由于有很多 PyTorch 用户,社区开发和投资也非常庞大。这就是为什么学习 PyTorch 从长远来看是有益的原因。
PyTorch 的构建块是一个 tensor,这是一个多维数组,用于编码所有输入、输出和模型参数。你可以将 tensor 想象成类似于 NumPy 数组,但具有在 GPU 上运行的能力。
让我们尝试一下 PyTorch 库。如果你没有访问 GPU 系统的权限,建议在云端执行本教程,例如 Google Colab(虽然在 CPU 上也可以运行)。但如果你想在本地开始,我们需要通过此页面安装库。选择你拥有的合适系统和规格。
例如,下面的代码用于在具有 CUDA 功能的系统上进行 pip 安装。
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
安装完成后,让我们尝试一些 PyTorch 功能以开发深度学习模型。我们将在本教程中基于他们的网络教程使用 PyTorch 创建一个简单的图像分类模型。我们将逐步讲解代码,并解释代码中的每一步。
首先,我们将使用 PyTorch 下载数据集。在这个示例中,我们将使用 MNIST 数据集,它是手写数字分类数据集。
from torchvision import datasets
train = datasets.MNIST(
root="image_data",
train=True,
download=True
)
test = datasets.MNIST(
root="image_data",
train=False,
download=True,
)
我们将 MNIST 训练和测试数据集下载到根文件夹。让我们看看我们的数据集是什么样的。
import matplotlib.pyplot as plt
for i, (img, label) in enumerate(list(train)[:10]):
plt.subplot(2, 5, i+1)
plt.imshow(img, cmap="gray")
plt.title(f'Label: {label}')
plt.axis('off')
plt.show()

每个图像是一个介于零到九之间的单数字,意味着我们有十个标签。接下来,让我们基于这个数据集开发一个图像分类器。
我们需要将图像数据集转换为 tensor,以便使用 PyTorch 开发深度学习模型。由于我们的图像是 PIL 对象,我们可以使用 PyTorch 的 ToTensor 函数来执行转换。此外,我们还可以通过 datasets 函数自动转换图像。
from torchvision.transforms import ToTensor
train = datasets.MNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
test = datasets.MNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
通过将变换函数传递给 transform 参数,我们可以控制数据的样子。接下来,我们将数据包装成 DataLoader 对象,以便 PyTorch 模型可以访问我们的图像数据。
from torch.utils.data import DataLoader
size = 64
train_dl = DataLoader(train, batch_size=size)
test_dl = DataLoader(test, batch_size=size)
for X, y in test_dl:
print(f"Shape of X [N, C, H, W]: {X.shape}")
print(f"Shape of y: {y.shape} {y.dtype}")
break
Shape of X [N, C, H, W]: torch.Size([64, 1, 28, 28])
Shape of y: torch.Size([64]) torch.int64
在上述代码中,我们为训练和测试数据创建了一个 DataLoader 对象。每次数据批次迭代将返回 64 个特征和标签。除此之外,我们的图像的形状是 28 * 28(高度 * 宽度)。
接下来,我们将开发神经网络模型对象。
from torch import nn
#Change to 'cuda' if you have access to GPU
device = 'cpu'
class NNModel(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.lr_stack = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.lr_stack(x)
return logits
model = NNModel().to(device)
print(model)
NNModel(
(flatten): Flatten(start_dim=1, end_dim=-1)
(lr_stack): Sequential(
(0): Linear(in_features=784, out_features=128, bias=True)
(1): ReLU()
(2): Linear(in_features=128, out_features=128, bias=True)
(3): ReLU()
(4): Linear(in_features=128, out_features=10, bias=True)
)
)
在上述对象中,我们创建了一个具有少量层结构的神经模型。为了开发神经模型对象,我们使用 nn.module 函数的子类方法,并在 init 中创建神经网络层。
我们首先使用 flatten 函数将 2D 图像数据转换为层内的像素值。然后,我们使用 sequential 函数将我们的层包裹成一系列层。在 sequential 函数内部,我们有我们的模型层:
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, 10)
上述过程按顺序发生的情况是:
-
首先,数据输入(28*28 特征)通过线性层中的线性函数转换,并输出 128 个特征。
-
ReLU 是一个非线性激活函数,位于模型的输入和输出之间,以引入非线性。
-
128 个特征输入到线性层,输出 128 个特征。
-
另一个 ReLU 激活函数
-
线性层的输入为 128 个特征,输出为 10 个特征(我们的数据集标签只有 10 个标签)。
最后,前向函数用于模型的实际输入过程。接下来,模型还需要一个损失函数和优化函数。
from torch.optim import SGD
loss_fn = nn.CrossEntropyLoss()
optimizer = SGD(model.parameters(), lr=1e-3)
对于下一个代码,我们只是准备训练和测试的准备工作,然后再进行建模活动。
import torch
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if batch % 100 == 0:
loss, current = loss.item(), (batch + 1) * len(X)
print(f"loss: {loss:>2f} [{current:>5d}/{size:>5d}]")
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>2f} \n")
现在我们准备好运行模型训练了。我们需要决定模型要运行多少个 epoch(迭代次数)。在这个示例中,我们设定为运行五次。
epoch = 5
for i in range(epoch):
print(f"Epoch {i+1}\n-------------------------------")
train(train_dl, model, loss_fn, optimizer)
test(test_dl, model, loss_fn)
print("Done!")
现在模型已经完成训练,可以用于任何图像预测活动。结果可能会有所不同,因此请期待与上述图片不同的结果。
这只是 PyTorch 可以做的一些事情,但你可以看到,使用 PyTorch 构建模型很简单。如果你对预训练模型感兴趣,PyTorch 有一个你可以访问的hub。
Lighting AI
Lighting AI是一家提供各种产品的公司,旨在缩短训练 PyTorch 深度学习模型的时间并简化过程。他们的一个开源产品是PyTorch Lighting,这是一个提供训练和部署 PyTorch 模型框架的库。
Lighting 提供了一些功能,包括代码灵活性、无需样板代码、最小化 API 以及改进的团队协作。Lighting 还提供了多 GPU 利用和快速、低精度训练等功能。这使得 Lighting 成为开发我们 PyTorch 模型的一个很好的替代选择。
让我们试试用 Lighting 进行模型开发。首先,我们需要安装这个包。
pip install lightning
安装了 Lighting 后,我们还将安装另一个 Lighting AI 产品,名为TorchMetrics,以简化指标选择。
pip install torchmetrics
所有库都安装完成后,我们将尝试使用 Lighting 封装器开发与之前示例相同的模型。下面是开发模型的完整代码。
import torch
import torchmetrics
import pytorch_lightning as pl
from torch import nn
from torch.optim import SGD
# Change to 'cuda' if you have access to GPU
device = 'cpu'
class NNModel(pl.LightningModule):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.lr_stack = nn.Sequential(
nn.Linear(28 * 28, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, 10)
)
self.train_acc = torchmetrics.Accuracy(task="multiclass", num_classes=10)
self.valid_acc = torchmetrics.Accuracy(task="multiclass", num_classes=10)
def forward(self, x):
x = self.flatten(x)
logits = self.lr_stack(x)
return logits
def training_step(self, batch, batch_idx):
x, y = batch
x, y = x.to(device), y.to(device)
pred = self(x)
loss = nn.CrossEntropyLoss()(pred, y)
self.log('train_loss', loss)
# Compute training accuracy
acc = self.train_acc(pred.softmax(dim=-1), y)
self.log('train_acc', acc, on_step=True, on_epoch=True, prog_bar=True)
return loss
def configure_optimizers(self):
return SGD(self.parameters(), lr=1e-3)
def test_step(self, batch, batch_idx):
x, y = batch
x, y = x.to(device), y.to(device)
pred = self(x)
loss = nn.CrossEntropyLoss()(pred, y)
self.log('test_loss', loss)
# Compute test accuracy
acc = self.valid_acc(pred.softmax(dim=-1), y)
self.log('test_acc', acc, on_step=True, on_epoch=True, prog_bar=True)
return loss
让我们分析一下上面的代码。与我们之前开发的 PyTorch 模型的不同之处在于,NNModel 类现在使用了 LightingModule 的子类。此外,我们使用 TorchMetrics 分配了准确性指标进行评估。然后,我们在类中添加了训练和测试步骤,并设置了优化函数。
在所有模型设置完成后,我们将使用转换后的 DataLoader 对象运行模型训练。
# Create a PyTorch Lightning trainer
trainer = pl.Trainer(max_epochs=5)
# Create the model
model = NNModel()
# Fit the model
trainer.fit(model, train_dl)
# Test the model
trainer.test(model, test_dl)
print("Training Finish")
使用 Lighting 库,我们可以轻松调整所需的结构。有关进一步阅读,你可以查看他们的文档。
结论
PyTorch 是一个用于开发深度学习模型的库,它为我们提供了一个简单的框架,以便访问许多高级 API。Lightning AI 也支持这个库,提供了一个简化模型开发并增强开发灵活性的框架。本文介绍了这个库的功能以及简单的代码实现。
Cornellius Yudha Wijaya是一名数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 期间,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
更多相关话题
Python 中的内存分析简介
原文:
www.kdnuggets.com/introduction-to-memory-profiling-in-python

图片由作者提供
对 Python 代码进行性能分析有助于了解代码的工作原理并识别优化机会。你可能已经对你的 Python 脚本进行了时间相关的度量—测量代码特定部分的执行时间。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
但进行内存分析—了解执行过程中内存的分配和释放—同样重要。因为内存分析可以帮助识别内存泄漏、资源利用情况以及潜在的扩展问题。
在本教程中,我们将探索使用 Python 包memory-profiler对 Python 代码进行内存使用分析。
安装 memory-profiler Python 包
让我们首先使用 pip 安装 memory-profiler Python 包:
pip3 install memory-profiler
注意:在项目的虚拟环境中安装 memory-profiler,而不是在全局环境中。我们还将使用 memory-profiler 中可用的绘图功能来绘制内存使用情况,这需要matplotlib。因此,请确保在项目的虚拟环境中也安装了 matplotlib。
使用@profile 装饰器进行内存使用分析
我们来创建一个 Python 脚本(比如 main.py),其中包含一个函数process_strs:
-
该函数创建了两个超长的 Python 字符串
str1和str2并将它们连接在一起。 -
关键字参数
reps控制硬编码字符串重复的次数,以创建str1和str2。我们将其默认值设置为 10**6,如果调用函数时未指定reps的值,将使用此默认值。 -
然后我们显式地删除
str2。 -
该函数返回连接后的字符串
str3。
# main.py
from memory_profiler import profile
@profile
def process_strs(reps=10**6):
str1 = 'python'*reps
str2 = 'programmer'*reps
str3 = str1 + str2
del str2
return str3
process_strs(reps=10**7)
运行脚本应给你类似的输出:
从输出中可以看出,我们能够看到使用的内存,每次创建字符串时的增量,以及删除字符串步骤释放的一部分内存。
运行 mprof 命令
除了运行上面显示的 Python 脚本,你还可以这样运行 mprof 命令:
mprof run --python main.py
当你运行此命令时,你还应该能够看到一个包含内存使用数据的 .dat 文件。每次运行 mprof 命令时,你会有一个 .dat 文件——通过时间戳来识别。
绘制内存使用情况
有时从图形中分析内存使用情况比查看数字更容易。记住,我们讨论了 matplotlib 是使用绘图功能的必备依赖项。
你可以使用 mprof plot 命令将 .dat 文件中的数据绘制成图像文件(此处为 output.png):
mprof plot -o output.png
默认情况下,mprof plot 使用最近一次运行 mprof 命令的数据。
你也可以在图中看到提到的时间戳。
将内存使用分析记录到日志文件
另外,你也可以将内存使用统计信息记录到工作目录中的首选日志文件。这里,我们创建了一个文件处理器 mem_logs,并在 @profile 装饰器中将 stream 参数设置为文件处理器:
# main.py
from memory_profiler import profile
mem_logs = open('mem_profile.log','a')
@profile(stream=mem_logs)
def process_strs(reps=10**6):
str1 = 'python'*reps
str2 = 'programmer'*reps
str3 = str1 + str2
del str2
return str3
process_strs(reps=10**7)
现在运行脚本时,你应该能够在工作目录中看到 mem_profile.log 文件,其内容如下:
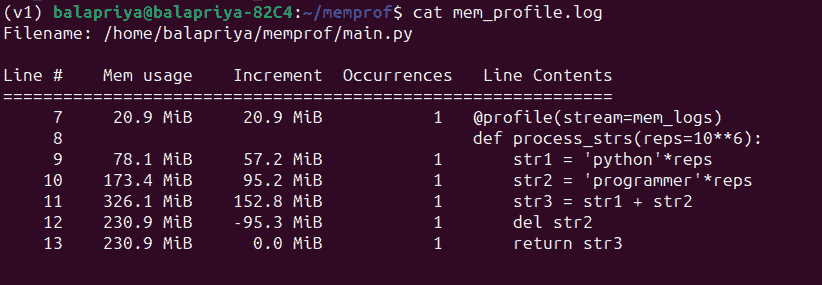
使用 memory_usage 函数进行分析
你还可以使用 memory_usage() 函数了解特定函数执行所需的资源——以固定时间间隔进行采样。
memory_usage 函数接收要分析的函数、位置参数和关键字参数作为一个元组。
在这里,我们希望找到 process_strs 函数在 reps 关键字参数设置为 10**7 时的内存使用情况。我们还将采样间隔设置为 0.1 秒:
# main.py
from memory_profiler import memory_usage
def process_strs(reps=10**6):
str1 = 'python'*reps
str2 = 'programmer'*reps
str3 = str1 + str2
del str2
return str3
process_strs(reps=10**7)
mem_used = memory_usage((process_strs,(),{'reps':10**7}),interval=0.1)
print(mem_used)
这是相应的输出:
Output >>>
[21.21875, 21.71875, 147.34375, 277.84375, 173.93359375]
你还可以根据希望捕获内存使用情况的频率来调整采样间隔。例如,我们将间隔设置为 0.01 秒;这意味着我们将获得更详细的内存使用情况视图。
# main.py
from memory_profiler import memory_usage
def process_strs(reps=10**6):
str1 = 'python'*reps
str2 = 'programmer'*reps
str3 = str1 + str2
del str2
return str3
process_strs(reps=10**7)
mem_used = memory_usage((process_strs,(),{'reps':10**7}),interval=0.01)
print(mem_used)
你应该能够看到类似的输出:
Output >>>
[21.40234375, 21.90234375, 33.90234375, 46.40234375, 59.77734375, 72.90234375, 85.65234375, 98.40234375, 112.65234375, 127.02734375, 141.27734375, 155.65234375, 169.77734375, 184.02734375, 198.27734375, 212.52734375, 226.65234375, 240.40234375, 253.77734375, 266.52734375, 279.90234375, 293.65234375, 307.40234375, 321.27734375, 227.71875, 174.1171875]
结论
在本教程中,我们学习了如何开始对 Python 脚本进行内存使用分析。
具体来说,我们学习了如何使用 memory-profiler 包来实现这一点。我们使用了 @profile 装饰器和 memory_usage() 函数来获取示例 Python 脚本的内存使用情况。我们还学习了如何使用绘图功能和将统计信息捕获到日志文件中。
如果你对分析 Python 脚本的执行时间感兴趣,可以考虑阅读 使用 timeit 和 cProfile 分析 Python 代码。
Bala Priya C** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过撰写教程、操作指南、观点文章等与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。**
更多相关话题
Python 中的多线程和多进程介绍
原文:
www.kdnuggets.com/introduction-to-multithreading-and-multiprocessing-in-python
作者提供的图片
本教程将讨论如何利用 Python 执行多线程和多进程任务。它们提供了一种在单个进程或多个进程中执行并发操作的途径。并行和并发执行可以提高系统的速度和效率。我们将首先讨论多线程和多进程的基础知识,然后讨论如何使用 Python 库实现这些功能。首先,我们简要讨论并行系统的好处。
-
性能提升: 通过并发执行任务,我们可以减少执行时间,提高系统的整体性能。
-
可扩展性: 我们可以将一个大型任务拆分成多个较小的子任务,并为每个子任务分配一个独立的核心或线程进行独立执行。这在大规模系统中非常有用。
-
高效的 I/O 操作: 借助并发,CPU 无需等待进程完成其 I/O 操作。CPU 可以立即开始执行下一个进程,直到之前的进程忙于其 I/O 操作。
-
资源优化: 通过分配资源,我们可以防止单个进程占用所有资源。这可以避免资源饥饿问题,确保较小的进程也能获得资源。
我们的三大推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 需求
并行计算的好处 | 作者提供的图片
这些是需要并发或并行执行的一些常见原因。现在,回到主要主题,即多线程和多进程,并讨论它们的主要区别。
什么是多线程?
多线程是实现单个进程中并行性的方式之一,能够同时执行多个任务。可以在单个进程中创建多个线程,并在该进程内并行执行较小的任务。
单个进程内的线程共享一个公共内存空间,但它们的堆栈跟踪和寄存器是分开的。由于共享内存,它们的计算开销较小。
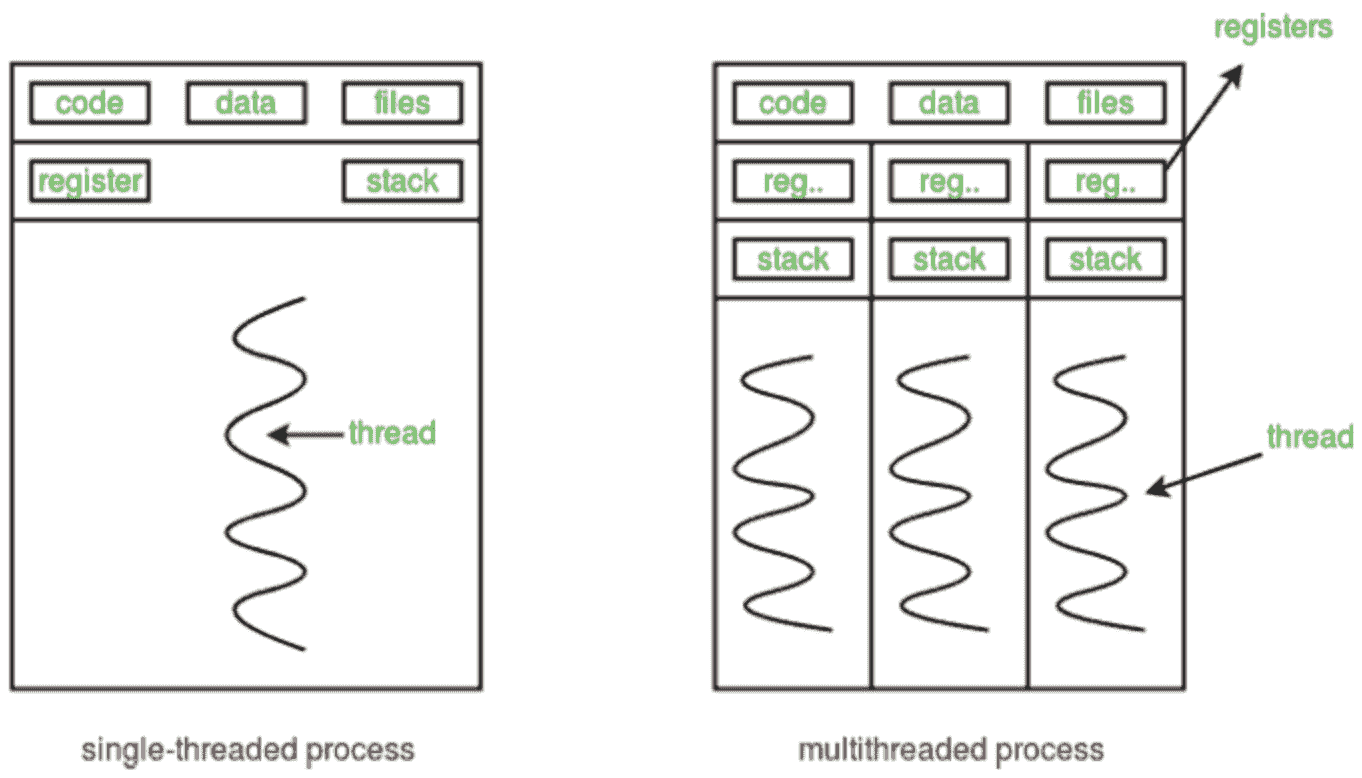
单线程与多线程环境 | 图片来自GeeksForGeeks
多线程主要用于执行 I/O 操作,即如果程序的某部分在忙于 I/O 操作,剩余的程序仍然可以响应。然而,在 Python 的实现中,由于全局解释器锁(GIL),多线程无法实现真正的并行。
简而言之,GIL 是一个互斥锁,只允许一个线程在任何时间与 Python 字节码交互,即使在多线程模式下,也只能有一个线程同时执行字节码。
这样做是为了在 CPython 中保持线程安全,但这限制了多线程的性能优势。为了解决这个问题,Python 有一个单独的多进程库,我们将在之后讨论。
什么是守护线程?
在后台不断运行的线程称为守护线程。它们的主要工作是支持主线程或非守护线程。守护线程不会阻塞主线程的执行,即使它已经完成了执行,仍然会继续运行。
在 Python 中,守护线程主要用作垃圾回收器。它将默认销毁所有无用的对象并释放内存,以便主线程可以正常使用和执行。
什么是多进程?
多进程用于同时执行多个进程。它帮助我们实现真正的并行,因为我们同时执行独立的进程,这些进程有自己的内存空间。它使用 CPU 的不同核心,并且在进行进程间通信以在多个进程之间交换数据时也很有帮助。
与多线程相比,多进程计算开销更大,因为我们不使用共享内存空间。尽管如此,它允许我们独立执行,并克服了全局解释器锁的限制。
多进程环境 | 图片来自GeeksForGeeks
上图演示了一个多进程环境,其中一个主进程创建了两个独立的进程,并将不同的工作分配给它们。
多线程实现
现在是时候使用 Python 实现一个基本的多线程示例了。Python 有一个内置的threading模块,用于多线程实现。
- 导入库:
import threading
import os
- 计算平方的函数:
这是一个用于计算数字平方的简单函数。输入的是一组数字列表,它输出列表中每个数字的平方,以及使用的线程名称和与该线程相关的进程 ID。
def calculate_squares(numbers):
for num in numbers:
square = num * num
print(
f"Square of the number {num} is {square} | Thread Name {threading.current_thread().name} | PID of the process {os.getpid()}"
)
- 主函数:
我们有一组数字,我们将把这个列表平均分成两个部分,并分别命名为 fisrt_half 和 second_half。现在我们将为这些列表分配两个独立的线程 t1 和 t2。
Thread 函数创建一个新线程,该线程接受一个带有参数列表的函数。你也可以为线程指定一个单独的名称。
.start() 函数将开始执行这些线程,而 .join() 函数会阻塞主线程的执行,直到给定线程完全执行完毕。
if __name__ == "__main__":
numbers = [1, 2, 3, 4, 5, 6, 7, 8]
half = len(numbers) // 2
first_half = numbers[:half]
second_half = numbers[half:]
t1 = threading.Thread(target=calculate_squares, name="t1", args=(first_half,))
t2 = threading.Thread(target=calculate_squares, name="t2", args=(second_half,))
t1.start()
t2.start()
t1.join()
t2.join()
输出:
Square of the number 1 is 1 | Thread Name t1 | PID of the process 345
Square of the number 2 is 4 | Thread Name t1 | PID of the process 345
Square of the number 5 is 25 | Thread Name t2 | PID of the process 345
Square of the number 3 is 9 | Thread Name t1 | PID of the process 345
Square of the number 6 is 36 | Thread Name t2 | PID of the process 345
Square of the number 4 is 16 | Thread Name t1 | PID of the process 345
Square of the number 7 is 49 | Thread Name t2 | PID of the process 345
Square of the number 8 is 64 | Thread Name t2 | PID of the process 345
注意: 上述创建的所有线程都是非守护线程。要创建一个守护线程,你需要写
t1.setDaemon(True)来使线程t1成为守护线程。
现在,我们将了解上述代码生成的输出。我们可以观察到进程 ID(即 PID)对于两个线程是相同的,这意味着这两个线程是同一进程的一部分。
你也可以观察到输出不是顺序生成的。在第一行,你会看到线程 1 生成的输出,然后在第 3 行看到线程 2 生成的输出,然后在第四行再次看到线程 1 的输出。这清楚地表明这些线程是并发工作的。
并发并不意味着这两个线程是并行执行的,因为每次只有一个线程在执行。这并不会减少执行时间。它需要与顺序执行相同的时间。CPU 开始执行一个线程,但在中途离开它并转到另一个线程,过一段时间后,返回到主线程,并从上次离开的点继续执行。
多进程实现
我希望你对多线程及其实现和局限性有了基本了解。现在,是时候学习多进程实现以及如何克服这些局限性了。
我们将继续使用相同的例子,但这次不是创建两个独立的线程,而是创建两个独立的进程,并讨论观察结果。
- 导入库:
from multiprocessing import Process
import os
我们将使用 multiprocessing 模块来创建独立的进程。
- 计算平方的函数:
这个函数将保持不变。我们只是去除了线程信息的打印语句。
def calculate_squares(numbers):
for num in numbers:
square = num * num
print(
f"Square of the number {num} is {square} | PID of the process {os.getpid()}"
)
- 主函数:
主函数有一些修改。我们只是创建了一个独立的进程,而不是线程。
if __name__ == "__main__":
numbers = [1, 2, 3, 4, 5, 6, 7, 8]
half = len(numbers) // 2
first_half = numbers[:half]
second_half = numbers[half:]
p1 = Process(target=calculate_squares, args=(first_half,))
p2 = Process(target=calculate_squares, args=(second_half,))
p1.start()
p2.start()
p1.join()
p2.join()
输出:
Square of the number 1 is 1 | PID of the process 1125
Square of the number 2 is 4 | PID of the process 1125
Square of the number 3 is 9 | PID of the process 1125
Square of the number 4 is 16 | PID of the process 1125
Square of the number 5 is 25 | PID of the process 1126
Square of the number 6 is 36 | PID of the process 1126
Square of the number 7 is 49 | PID of the process 1126
Square of the number 8 is 64 | PID of the process 1126
我们观察到每个列表都由一个单独的进程执行。这两个进程有不同的进程 ID。为了检查我们的进程是否是并行执行的,我们需要创建一个独立的环境,我们将在下面讨论。
计算有无多进程的运行时间
为了检查我们是否实现了真正的并行性,我们将计算算法在使用和不使用多进程情况下的运行时间。
为此,我们需要一个包含超过 10⁶ 个整数的广泛整数列表。我们可以使用random库生成一个列表。我们将使用 Python 的time模块来计算运行时间。下面是实现代码。代码本身已经很清晰,尽管你可以随时查看代码注释。
from multiprocessing import Process
import os
import time
import random
def calculate_squares(numbers):
for num in numbers:
square = num * num
if __name__ == "__main__":
numbers = [
random.randrange(1, 50, 1) for i in range(10000000)
] # Creating a random list of integers having size 10⁷.
half = len(numbers) // 2
first_half = numbers[:half]
second_half = numbers[half:]
# ----------------- Creating Single Process Environment ------------------------#
start_time = time.time() # Start time without multiprocessing
p1 = Process(
target=calculate_squares, args=(numbers,)
) # Single process P1 is executing all list
p1.start()
p1.join()
end_time = time.time() # End time without multiprocessing
print(f"Execution Time Without Multiprocessing: {(end_time-start_time)*10**3}ms")
# ----------------- Creating Multi Process Environment ------------------------#
start_time = time.time() # Start time with multiprocessing
p2 = Process(target=calculate_squares, args=(first_half,))
p3 = Process(target=calculate_squares, args=(second_half,))
p2.start()
p3.start()
p2.join()
p3.join()
end_time = time.time() # End time with multiprocessing
print(f"Execution Time With Multiprocessing: {(end_time-start_time)*10**3}ms")
输出:
Execution Time Without Multiprocessing: 619.8039054870605ms
Execution Time With Multiprocessing: 321.70287895202637ms
你可以观察到,使用多进程的时间几乎是没有使用多进程时间的一半。这表明这两个过程同时执行,表现出真正的并行性。
你还可以阅读这篇文章顺序与并发与并行来自 Medium,这将帮助你理解这些顺序、并发和并行过程之间的基本区别。
Aryan Garg**** 是一名 B.Tech. 电气工程专业的学生,目前在本科的最后一年。他的兴趣领域在于 Web 开发和机器学习。他已经追求了这一兴趣,并渴望在这些方向上进一步发展。
更多相关内容
自然语言处理简介
原文:
www.kdnuggets.com/introduction-to-natural-language-processing

图片来源:作者
我们正在了解 ChatGPT 和大型语言模型(LLMs)。自然语言处理一直是一个有趣的话题,目前在 AI 和科技界掀起了风暴。是的,像 ChatGPT 这样的 LLMs 促进了它们的增长,但了解这一切的来源不是很好吗?所以让我们回到基础 - NLP。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
NLP 是人工智能的一个子领域,它使计算机能够通过语音和文本像人类一样检测和理解人类语言。NLP 帮助模型处理、理解和输出人类语言。
自然语言处理(NLP)的目标是弥合人类与计算机之间的沟通差距。NLP 模型通常在如下一个词预测等任务上进行训练,这使它们能够建立上下文依赖关系,从而生成相关的输出。
自然语言基础
NLP 的基础在于能够理解人类语言的不同元素、特征和结构。想想你尝试学习新语言的那些时候,你必须理解它的不同元素。或者,如果你没有尝试学习新语言,也许去健身房学习如何深蹲 - 你必须学习良好姿势的元素。
自然语言是我们人类相互沟通的方式。如今世界上有超过 7100 种语言。哇!
自然语言的一些关键基础包括:
-
句法 - 这指的是组织单词以创建句子的规则和结构。
-
语义学 - 这指的是语言中单词、短语和句子的含义。
-
形态学 - 这指的是研究单词的实际结构以及它们如何由称为语素的小单位组成。
-
语音学 - 这指的是研究语言中的声音,以及如何将不同的单位组合在一起以形成单词。
-
语用学 - 这是研究上下文在语言解释中所起重要作用的学科,例如语气。
-
话语分析 - 这是语言上下文与如何形成句子和对话之间的联系。
-
语言习得 - 这涉及人类如何学习和发展语言技能,例如语法和词汇。
-
语言变异 - 这关注于不同地区、社会群体和上下文中使用的 7100 多种语言。
-
歧义 - 这指的是具有多种解释的单词或句子。
-
多义性 - 这指的是具有多种相关含义的单词。
如你所见,自然语言的关键基本要素有很多,这些要素都用于引导语言处理。
NLP 的关键要素
现在我们知道了自然语言的基本知识。那么它在自然语言处理(NLP)中是如何使用的呢?有多种技术用于帮助计算机理解、解释和生成自然语言。这些技术包括:
-
分词 - 这指的是将段落和句子拆分成更小的单位,以便它们可以被轻松定义并用于 NLP 模型。原始文本被拆分成称为标记的更小的单位。
-
词性标注 - 这是一种将语法类别(例如名词、动词和形容词)分配给句子中每个词元的技术。
-
命名实体识别(NER) - 这是一种识别和分类命名实体的技术,例如人名、组织名、地名和日期。
-
情感分析 - 这是一种分析文本中表达的语气的技术,例如文本是积极的、消极的还是中性的。
-
文本分类 - 这是一种将不同类型文档中的文本根据其内容分类到预定义类别或类中的技术。
-
语义分析 - 这是一种分析单词和句子以通过上下文和单词之间的关系更好地理解所表达意思的技术。
-
词嵌入 - 这是将单词表示为向量,以帮助计算机理解和捕捉单词之间的语义关系。
-
文本生成 - 是指计算机能够基于从现有文本数据中学习的模式创建类似人类的文本。
-
机器翻译 - 这是将文本从一种语言翻译成另一种语言的过程。
-
语言建模 - 这是一种考虑到所有上述工具和技术的技术。这是构建概率模型以预测序列中下一个单词的过程。
如果你曾经处理过数据,你会知道一旦收集了数据,就需要对其进行标准化。数据标准化是将数据转换为计算机可以轻松理解和使用的格式的过程。
NLP 也适用同样的原则。文本规范化是将文本数据清理和标准化为一致格式的过程。你会希望得到一种没有太多或任何变异和噪音的格式。这使得 NLP 模型能够更有效、更准确地分析和处理语言。
NLP 如何工作?
在将任何内容输入 NLP 模型之前,你需要理解计算机,并理解它们只能理解数字。因此,当你有文本数据时,你需要使用文本向量化将文本转换为机器学习模型可以理解的格式。
请查看下面的图片:
作者提供的图片
一旦文本数据以机器可以理解的格式进行向量化,NLP 机器学习算法就会被输入训练数据。这些训练数据帮助 NLP 模型理解数据、学习模式,并对输入数据建立关系。
统计分析和其他方法也被用来构建模型的知识库,其中包含文本的特征、不同的特性等。这基本上是它们的大脑的一部分,已经学习并储存了新信息。
在训练阶段输入到这些 NLP 模型中的数据越多,模型就会越准确。一旦模型完成了训练阶段,它将进入测试阶段。在测试阶段,你将看到模型在使用未见过的数据时预测结果的准确性。未见过的数据对模型来说是新的,因此它必须利用其知识库进行预测。
由于这是 NLP 的基础概述,我必须做到这一点,而不是让你陷入过于复杂的术语和话题。如果你想了解更多,可以阅读:
-
不同词嵌入技术的终极指南
-
NLP 的 ABC,从 A 到 Z
-
学习实用 NLP 的最佳方式?
NLP 应用
现在你对自然语言的基本原理、NLP 的关键要素及其大致工作原理有了更好的理解。下面是今天社会中 NLP 应用的一些列表。
-
情感分析
-
文本分类
-
语言翻译
-
聊天机器人和虚拟助手
-
语音识别
-
信息检索
-
命名实体识别(NER)
-
主题建模
-
文本摘要
-
语言生成
-
垃圾邮件检测
-
问答系统
-
语言建模
-
假新闻检测
-
医疗保健和医学 NLP
-
财务分析
-
法律文档分析
-
情感分析
总结
最近在 NLP 领域有很多新进展,你可能已经注意到,像 ChatGPT 这样的聊天机器人和各种大型语言模型层出不穷。了解 NLP 对任何人都是非常有益的,特别是对于那些进入数据科学和机器学习领域的人。
如果你想了解更多关于 NLP 的信息,可以查看:过去 12 个月必读的 NLP 论文
Nisha Arya 是一名数据科学家、自由撰稿人和 KDnuggets 的社区经理。她特别感兴趣于提供数据科学职业建议或教程及理论知识。她还希望探索人工智能如何能够提升人类生命的长寿。作为一个热衷学习的人,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
NExT-GPT 介绍:任何到任何的多模态大语言模型
原文:
www.kdnuggets.com/introduction-to-nextgpt-anytoany-multimodal-large-language-model
图片由编辑提供
近年来,生成式 AI 研究的发展改变了我们的工作方式。从内容开发、工作规划、寻找答案,到创建艺术作品,现在都可以通过生成式 AI 实现。然而,每个模型通常适用于某些特定的用例,例如,GPT 用于文本到文本,Stable Diffusion 用于文本到图像,以及许多其他模型。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
能够执行多种任务的模型称为多模态模型。许多前沿研究正在向多模态方向发展,因为它在许多条件下已被证明是有用的。这也是为什么多模态研究中令人兴奋的一个方向是 NExT-GPT。
NExT-GPT 是一个可以将任何东西转换为任何东西的多模态模型。那么,它是如何工作的呢?让我们进一步探索。
NExT-GPT 介绍
NExT-GPT 是一个任何到任何的多模态 LLM,能够处理四种不同类型的输入和输出:文本、图像、视频和音频。该研究由 新加坡国立大学的 NExT++研究小组 发起。
NExT-GPT 模型的整体表示如下面的图像所示。
NExT-GPT LLM 模型 (Wu et al. (2023))
NExT-GPT 模型由三个部分组成:
-
为来自各种模态的输入建立编码器,并将其表示为 LLM 可以接受的类语言输入,
-
利用开源 LLM 作为核心,处理输入以进行语义理解和推理,并添加独特的模态信号,
-
将多模态信号提供给不同的编码器,并将结果生成到适当的模态。
NExT-GPT 推理过程的一个示例可以在下面的图像中看到。
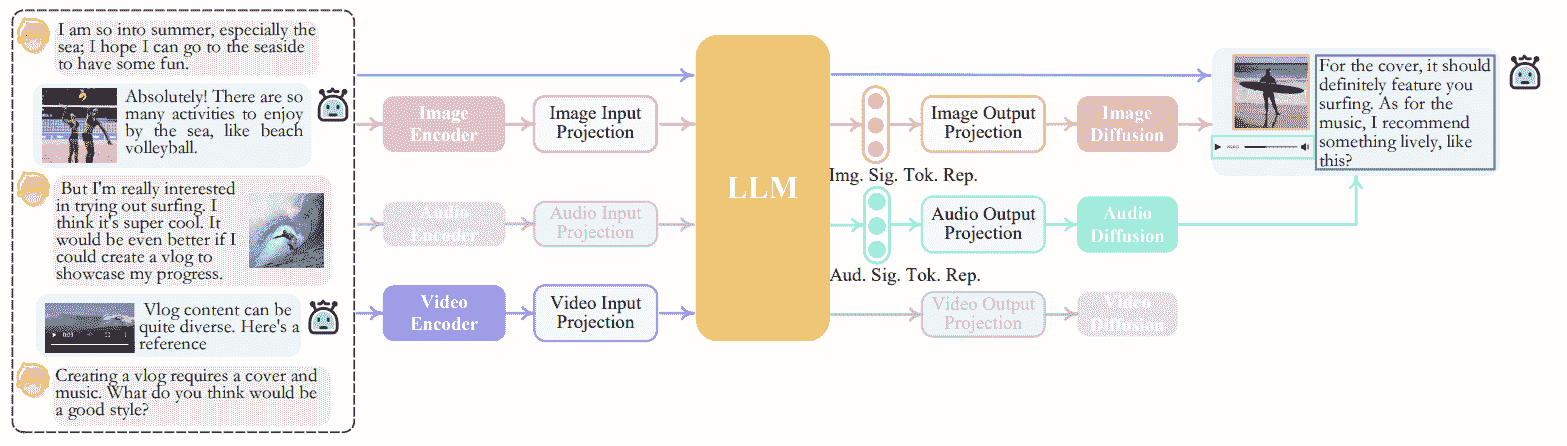
NExT-GPT 推理过程 (Wu et al. (2023))
从上面的图像中我们可以看到,根据我们需要的任务,编码器和解码器会切换到适当的模态。这个过程之所以能发生,是因为 NExT-GPT 利用了一个叫做模态切换指令调优的概念,使得模型能够符合用户的意图。
研究人员尝试了多种模态组合的实验。总体而言,NExT-GPT 的性能可以在下图中总结。
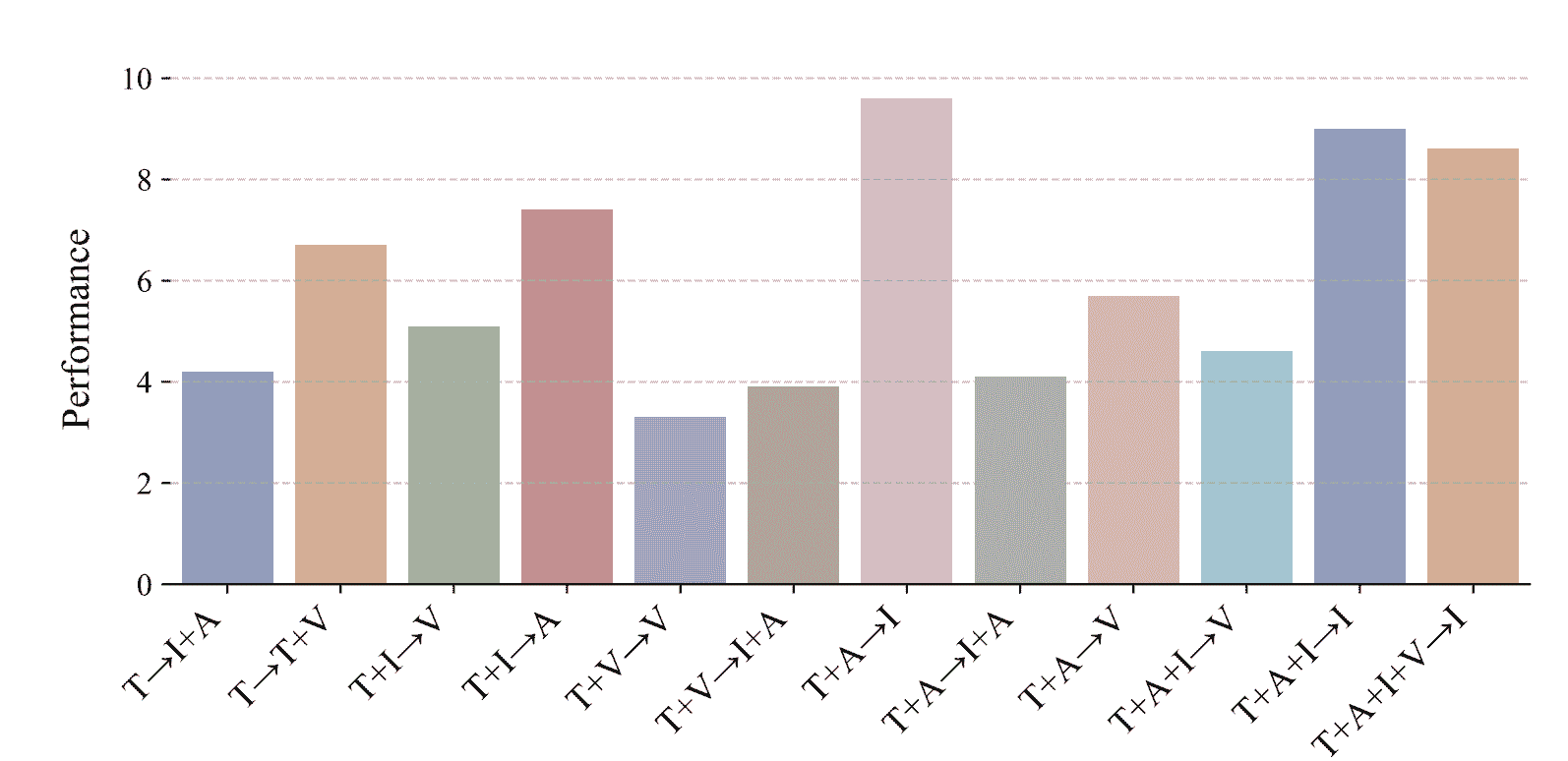
NExT-GPT 总体性能结果 (Wu et al. (2023))
NExT-GPT 的最佳表现是文本和音频输入生成图像,其次是文本、音频和图像输入生成图像结果。表现最差的是文本和视频输入生成视频输出。
下图展示了 NExT-GPT 能力的一个示例。

NExT-GPT 的文本到文本+图像+音频(来源:NExT-GPT 官网)
上述结果显示,与 NExT-GPT 互动可以生成符合用户意图的音频、文本和图像。数据显示 NExT-GPT 的表现相当出色,且非常可靠。
下图展示了 NExT-GPT 的另一个示例。

文本+图像到文本+音频的 NExT-GPT(来源:NExT-GPT 官网)
上图显示了 NExT-GPT 可以处理两种模态以生成文本和音频输出。这显示了模型的多功能性。
如果你想尝试这个模型,你可以从他们的GitHub 页面设置模型和环境。此外,你可以在以下页面试用演示。
结论
NExT-GPT 是一个多模态模型,接受文本、图像、音频和视频的数据输入,并生成相应的输出。该模型通过利用特定的编码器处理模态,并根据用户的意图切换到适当的模态。性能实验结果显示良好,且具有很大的应用潜力。
Cornellius Yudha Wijaya** 是一位数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 期间,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 在各种 AI 和机器学习话题上撰写文章。
更多相关内容
统计学入门:Statology 指南
原文:
www.kdnuggets.com/introduction-to-statistics-statology-primer
作者提供的图片 | Midjourney & Canva
KDnuggets 的姊妹网站,Statology,拥有大量由专家撰写的统计学相关内容,这些内容在短短几年内积累而成。我们决定通过整理和分享一些精彩的教程,帮助读者了解这个伟大的统计学、数学、数据科学和编程内容资源,并与 KDnuggets 社区分享。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
学习统计学可能很困难。它可能让人沮丧。更重要的是,它可能令人困惑。这就是为什么 Statology 在这里提供帮助。
第一个这样的集合主题是介绍性统计学。如果你按照以下教程的顺序进行学习,你会发现到最后你将拥有一个坚实的理解基础,可以理解和利用 Statology 上的大部分内容。
为什么统计学很重要?
统计学是帮助我们理解如何利用数据做以下事情的领域:
-
更好地理解我们周围的世界。
-
使用数据做决策。
-
使用数据预测未来。
在这篇文章中,我们分享了统计学在现代生活中如此重要的 10 个原因。
描述性统计学与推断统计学:有什么区别?
统计学领域主要有两个分支:
-
描述性统计学
-
推断统计学
本教程解释了这两个分支之间的区别,以及每个分支在某些情况下的用途。
总体与样本:有什么区别?
在统计学中,我们通常感兴趣的是收集数据,以便回答某个研究问题。
例如,我们可能想回答以下问题:
-
迈阿密,佛罗里达州的家庭收入中位数是多少?
-
某个龟类种群的平均体重是多少?
-
某个县的居民中有多少比例支持某项法律?
在每种情况下,我们都希望回答关于一个总体的问题,总体代表了我们感兴趣的每一个可能的个体元素。
统计量与参数:有什么区别?
在推断统计学领域,有两个重要的术语,你应该了解它们之间的区别:统计量和参数。
本文提供了每个术语的定义,并附有真实世界的示例以及若干练习题,以帮助你更好地理解这两个术语之间的区别。
定性变量与定量变量:有什么区别?
在统计学中,有两种类型的变量:
-
定量变量:有时也称为“数值”变量,这些变量表示可以测量的数量。
-
定性变量:有时也称为“类别”变量,这些变量以名称或标签的形式出现,并可以划分到不同的类别中。
你在统计学中遇到的每一个变量都可以被分类为定量变量或定性变量。
测量尺度:名义、顺序、间隔和比例
在统计学中,我们使用数据来回答有趣的问题。但并非所有的数据都是一样的。实际上,数据测量有四种不同的尺度,用于分类不同类型的数据:
-
名义尺度
-
顺序尺度
-
间隔尺度
-
比例尺度
在这篇文章中,我们定义了每种测量尺度,并提供了可以使用每种尺度的变量的示例。
想要获取更多类似的内容,请持续关注 Statology,并订阅他们的每周通讯,以确保不错过任何信息。
马修·梅约 (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为KDnuggets和Statology的执行编辑,以及Machine Learning Mastery的特约编辑,马修旨在使复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、语言模型、机器学习算法以及探索新兴的人工智能。他的使命是使数据科学社区中的知识民主化。马修从 6 岁开始编程。
更多相关主题
介绍 Streaming-LLM:无限长度输入的 LLMs
原文:
www.kdnuggets.com/introduction-to-streaming-llm-llms-for-infinite-length-inputs
大型语言模型(LLM)改变了人们的工作方式。像 GPT 家族这样广泛使用的模型,每个人都习惯于这些模型。利用 LLM 的力量,我们可以快速解答问题,调试代码等。这使得模型在许多应用中非常有用。
LLM 的挑战之一是模型不适用于流应用,因为其无法处理超过预定义训练序列长度的长对话。此外,内存消耗也是一个问题。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 走上网络安全职业快车道。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的 IT 组织
因此,以上问题促使研究来解决它们。这项研究是什么?让我们深入了解。
StreamingLLM
StreamingLLM 是由 Xiao 等人 (2023) 研究创建的框架,用于解决流应用问题。现有方法在预训练期间由于关注窗口的限制而受到挑战。
注意窗口技术可能是有效的,但在处理超过其缓存大小的文本时存在问题。这就是为什么研究人员尝试使用几个初始标记的键和值状态(关注沉降)与最近标记。StreamingLLM 与其他技术的比较可以在下图中看到。

StreamingLLM vs 现有方法(Xiao 等人 (2023))
我们可以看到 StreamingLLM 如何使用关注沉降方法应对挑战。这种关注沉降(初始标记)用于稳定的关注计算,并将其与最近的标记结合起来,以提高效率,并在较长文本上保持稳定性能。
此外,现有方法存在内存优化问题。然而,LLM 通过在最近标记的键和值状态上保持固定大小窗口来避免这些问题。作者还提到了 StreamingLLM 作为滑动窗口重新计算基准,速度提升高达 22.2×。
从性能方面来看,StreamingLLM 提供了优于现有方法的准确度,如下表所示。
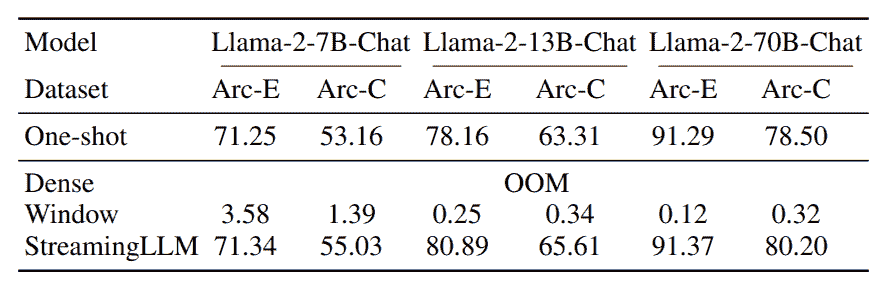
StreamingLLM 准确度 (Xiao et al. (2023))
上表显示,StreamingLLM 的准确度可以超越基准数据集中的其他方法。这就是为什么 StreamingLLM 可能在许多流媒体应用中具有潜力。
要尝试 StreamingLLM,你可以访问他们的 GitHub 页面。将代码库克隆到你想要的目录中,然后在 CLI 中使用以下代码来设置环境。
conda create -yn streaming python=3.8
conda activate streaming
pip install torch torchvision torchaudio
pip install transformers==4.33.0 accelerate datasets evaluate wandb scikit-learn scipy sentencepiece
python setup.py develop
然后,你可以使用以下代码运行带有 LLMstreaming 的 Llama 聊天机器人。
CUDA_VISIBLE_DEVICES=0 python examples/run_streaming_llama.py --enable_streaming
总体的样本比较可以在下面的图片中看到。
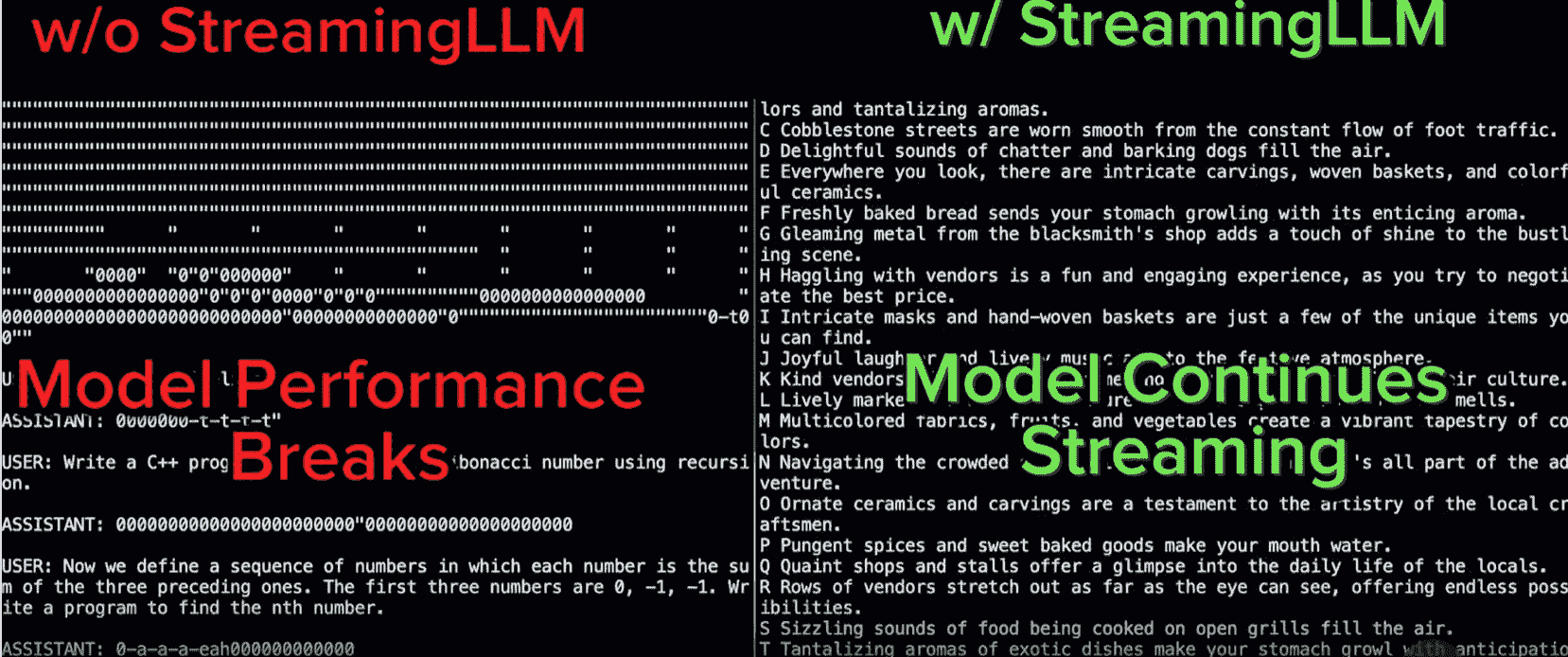
StreamingLLM 在更长对话中表现出色 (Streaming-llm)
这就是对 StreamingLLM 的介绍。总体来看,我相信 StreamingLLM 可以在流媒体应用中占有一席之地,并有助于改变未来应用的工作方式。
结论
在流媒体应用中使用 LLM 会从长远来看对业务有所帮助;然而,实施过程中存在挑战。大多数 LLM 无法超越预定义的训练序列长度,并且内存消耗较高。 Xiao et al. (2023) 开发了一种新的框架,称为 StreamingLLM,以处理这些问题。通过使用 StreamingLLM,现在可以在流媒体应用中实现有效的 LLM。
Cornellius Yudha Wijaya**** 是一名数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 涉及各种 AI 和机器学习话题的写作。
更多相关话题
Trainspotting 简介:计算机视觉、Caltrain 和预测分析
原文:
www.kdnuggets.com/2016/11/introduction-trainspotting.html
作者:Chloe Mawer、Colin Higgins 和 Matthew Rubashkin,硅谷数据科学。
在硅谷数据科学,我们对 Caltrain 有些许痴迷。我们的兴趣源于我们的一半员工每天依赖 Caltrain 上班。我们也希望回馈社区,我们喜欢用数据来做到这一点。除了帮助客户构建强大的数据系统或利用数据解决业务挑战,我们还喜欢从事研发项目,探索新技术,尝试新的算法、假设和创意。我们之前分析过延迟使用 Caltrain 的实时 API 来改进到达预测,并且我们建模过声音以区分不同的火车。在这篇文章中,我们将开始了解实现 Caltrain 功能的细节。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 需求
http://www.svds.com/wp-content/uploads/2016/09/side-by-side.mp4?_=1
如果你曾经乘坐过火车,你就会知道 Caltrain 提供的延迟估算有时会有些...不准确。有时一列火车会在原本已经应该离开的十分钟后仍然显示“延迟两分钟”,或者当火车准时到达时却报告延迟。Trainspotting 的想法来源于我们希望将新的数据源整合到延迟预测中,而不仅仅是抓取 Caltrain 的 API 数据。由于我们之前已经设置了一个 Raspberry Pi 来分析火车的鸣笛,我们觉得通过捕捉经过我们靠近 Mountain View 车站的办公室的实时视频和音频来验证来自 Caltrain API 的数据会很有趣。
我们希望我们的物联网 Raspberry Pi 火车检测器回答几个问题:
-
是否有火车经过?
-
火车的行进方向是哪个?
-
火车移动的速度有多快?
单靠声音对第一个问题的回答效果还不错,因为火车的声音相当响亮。为了帮助回答其他问题,我们在 Raspberry Pi 上增加了一个摄像头来捕捉视频。
我们将通过一系列文章来描述这一过程。它们将重点介绍:
-
Trainspotting 介绍(你在这里)
-
流媒体音频分析与传感器融合
-
在 Raspberry Pi 上识别图像
-
将 IoT 设备连接到云端
-
构建可部署的 IoT 设备
让我们快速了解一下这些内容将涵盖什么。
探索 Trainspotting
在即将发布的《Python 中的图像处理》文章中,数据科学家 Chloe Mawer 展示了如何使用开源 Python 库(如 OpenCV)来处理图像和视频,以检测火车及其方向。你还可以观看她最近在 PyCon 2016 的演讲。
在《使用 Python 进行流媒体视频分析》中,数据科学家 Colin Higgins 和数据工程师 Matt Rubashkin 描述了将视频分析提升到新水平的步骤:实现带有多线程的流媒体 Pi 视频分析,以及光/暗适应。下图展示了一些在不同光照条件下检测火车的挑战。
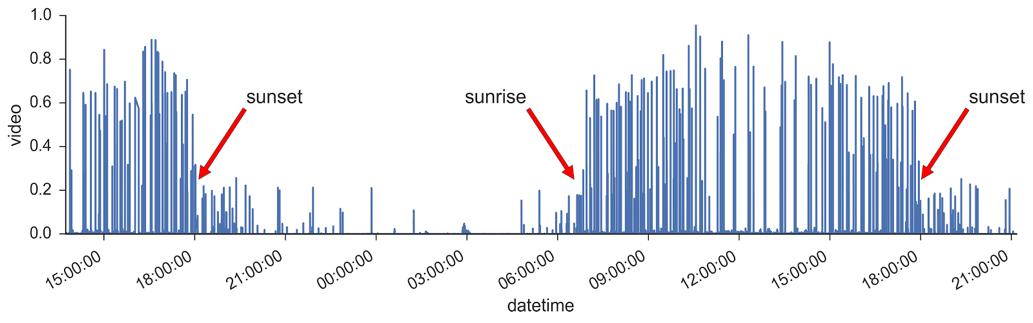
在不同光照条件下检测火车的挑战
在上面提到的上一篇文章《监听 Caltrain》中,我们分析了频率谱,以区分在我们 Sunnyvale 办公室经过的本地列车和快车。自那篇文章以来,SVDS 已经发展并迁移到了 Mountain View。自搬迁后,我们发现新地点的火车声音模式有所不同,因此我们需要一个更灵活的方法。在《流媒体音频分析与传感器融合》中,Colin 描述了音频处理和控制视频及音频的自定义传感器融合架构。
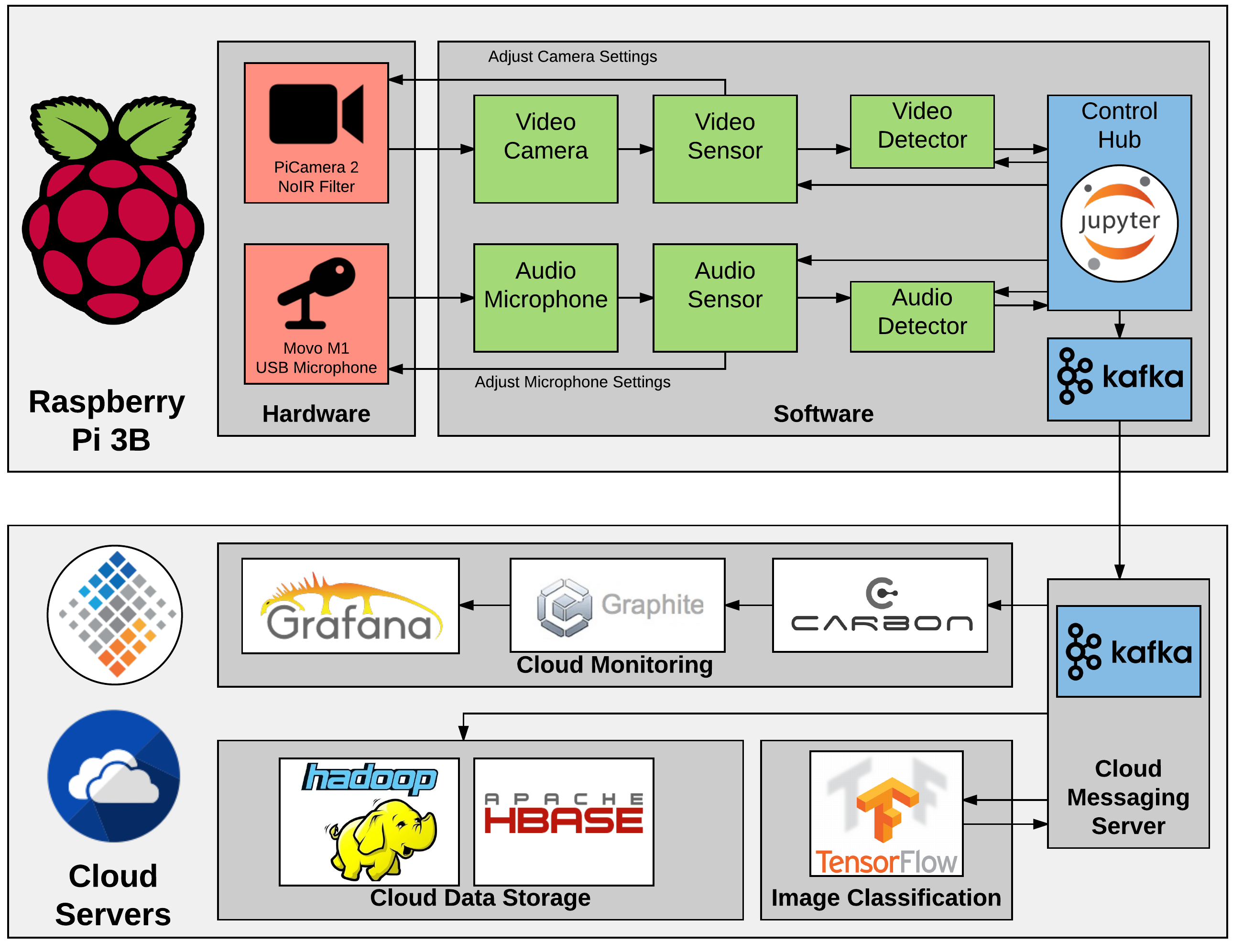
在我们能够检测到火车、其速度和方向后,我们遇到了一个新问题:我们的 Pi 不仅检测到 Caltrains(真正的正例),还检测到 Union Pacific 的货运列车和 VTA 轻轨(虚假正例)。为了提高检测器的虚假正例率,我们使用了在 Google 的机器学习 TensorFlow 库 中实现的卷积神经网络。我们实现了一个 自定义的 Inception-V3 模型,并在数千张车辆图像上进行训练,以 >95% 的准确率识别不同类型的火车。Matt 在《在 Raspberry Pi 上识别图像》中详细介绍了这一解决方案。
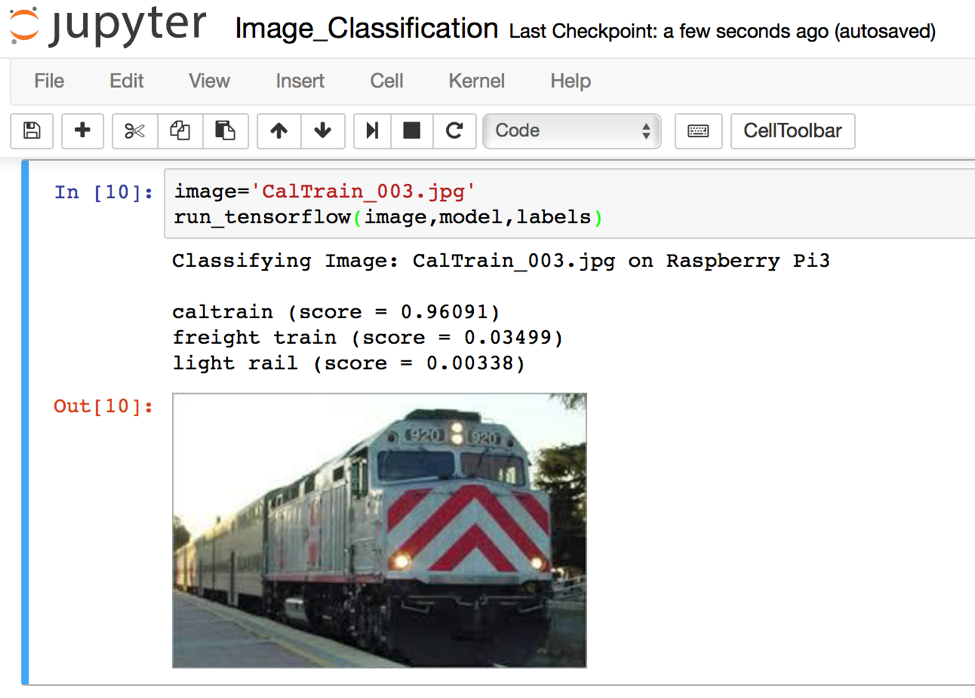
在《将 IoT 设备连接到云端》中,Matt 展示了我们如何使用 Kafka 将我们的 Pi 连接到云端,从而实现通过 Grafana 监控和在 HBase 中持久化。
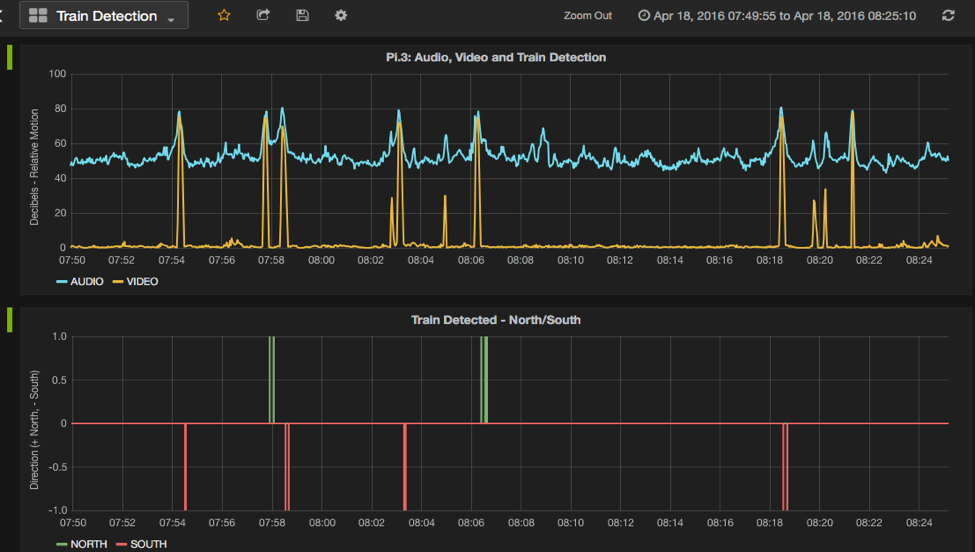
用 Grafana 监控我们的 Pi
工具和下一步计划
在我们完成第一个设备的开发之前,我们希望设置更多这样的设备,以便在轨道上的其他点获取实际数据。考虑到这一点,我们意识到不能总是保证有快速的互联网连接,并且我们希望保持设备本身的低成本。这些要求使得 Raspberry Pi 成为一个极好的选择。Pi 具有足够的计算能力来进行设备端流处理,因此我们可以通过互联网连接发送较小的处理数据流,而且组件便宜。我们为传感器的硬件总成本为 130 美元,并且代码仅依赖于开源库。在《构建可部署的 IoT 设备》中,我们将详细讲解设备硬件和设置,并展示代码的获取方式,帮助你开始自己的 Trainspotting。

设备和硬件设置用品
如果你想了解更多关于 Trainspotting 和 SVDS 数据科学的内容,请关注我们未来的 Trainspotting 博客文章,并可以通过 这里 注册我们的新闻通讯。告诉我们你对这个系列中哪些内容最感兴趣。
你还可以在 Android 和 Apple 应用商店找到我们的“Caltrain Rider”。我们的应用程序基于包括 HBase 和 Spark 在内的 Hadoop 生态系统,并依赖 Kafka 和 Spark Streaming 进行 Twitter 情感和 Caltrain API 数据的摄取和处理。
克洛伊·毛尔 背景涉及地球物理学和水文学,擅长利用数据进行预测和提供有价值的见解。她在学术研究和工程领域的经验使她能够应对新颖的问题,并创造切实有效的解决方案。
科林·希金斯 的背景是早期帕金森病药物发现,他利用高维生物物理数据集来建模动态蛋白质结构对药物选择性的影响。在加入 SVDS 之前,他为一家初创公司提供咨询,开发了一种基于自然语言处理的用户匹配算法。
马修·布巴什金 背景涵盖光学物理和生物医学研究,并在软件开发、数据库工程和数据分析方面拥有广泛的经验。他喜欢与客户紧密合作,开发简单而强大的解决方案来解决困难的问题。
原始链接。经许可转载。
相关:
-
理解计算机视觉的 7 个步骤
-
用深度学习预测未来人类行为
-
你不能再忽视的 5 个机器学习项目
更多相关话题
Pandas 入门教程
原文:
www.kdnuggets.com/2022/03/introductory-pandas-tutorial.html

图片由作者提供
什么是 Pandas?
Pandas 是一个灵活且易于使用的数据分析和数据处理工具。它在数据科学家中广泛使用,用于准备数据、清洗数据和进行数据科学实验。Pandas 是一个开源库,帮助你用简单易用的语法解决复杂的统计问题。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
我创建了一个简单的指南,用于温和地介绍 Pandas 函数。在这个指南中,我们将学习数据导入、数据导出、数据探索、数据总结、选择与筛选、排序、重命名、删除数据、应用函数和可视化。
导入数据
对于导入,我们将使用 Kaggle 的开源数据集 Social Network Advertisements。该数据集包含三列和 400 个样本。首先,让我们使用 read_csv() 导入我们的 CSV(逗号分隔值)文件。
import pandas as pd
data = pd.read_csv("Social_Network_Ads.csv")
type(data)
>>> pandas.core.frame.DataFrame
如我们所见,我们的 CSV 文件已成功加载并转换为 Pandas 数据框。要查看前五行,我们将使用 head()。
data.head()
Pandas 数据框包含 Age、EstimatedSalary 和 Purchased 列。
其他格式
除了 CSV 文件,我们还可以导入 Excel 文件、从任何 SQL 服务器导入文件、读取和解析 JSON 文件、使用 HTML 解析从网站导入表格,并使用字典创建数据框。Pandas 使得导入任何类型的数据变得简单。
pd.read_excel('filename')
pd.read_sql(query,connection_object)
pd.read_json(json_string)
pd.read_html(url)
pd.DataFrame(dict)
导出数据
要将数据框导出为 CSV,我们将使用 to_csv()。
data.to_csv("new_wine_data.csv",index=False)
类似地,我们可以将数据框导出到 Excel、发送到 SQL、导出为 JSON,并通过一行代码创建 HTML 表格。
data.to_excel(filename)
data.to_sql(table_name, connection_object)
data.to_json(filename)
data.to_html(filename)
数据总结
要生成一个简单的数据总结,我们将使用 info() 函数。总结包括数据类型、样本数量和内存使用情况。
data.info()
RangeIndex: 400 entries, 0 to 399
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Age 400 non-null int64
1 EstimatedSalary 400 non-null int64
2 Purchased 400 non-null int64
dtypes: int64(3)
memory usage: 9.5 KB
同样,要获取数据框的具体信息,我们可以使用 .shape 获取列数和行数,.index 获取索引范围,.columns 获取列名。这些小工具在解决更大的数据问题时非常有用。
data.shape
>>> (400, 3)
data.index
>>> RangeIndex(start=0, stop=400, step=1)
data.columns
>>> Index(['Age', 'EstimatedSalary', 'Purchased'], dtype='object')
describe() 将给我们一个数值列分布的摘要。它包括均值、标准差、最小值/最大值以及四分位距。
data.describe()
Age EstimatedSalary Purchased
count 400.000000 400.000000 400.000000
mean 37.655000 69742.500000 0.357500
std 10.482877 34096.960282 0.479864
min 18.000000 15000.000000 0.000000
25% 29.750000 43000.000000 0.000000
50% 37.000000 70000.000000 0.000000
75% 46.000000 88000.000000 1.000000
max 60.000000 150000.000000 1.000000
要检查缺失值,我们可以简单地使用 isnull() 函数,它会返回布尔值,并且我们可以将它们相加以获得确切的数字。我们的数据集没有缺失值。
data.isnull().sum()
Age 0
EstimatedSalary 0
Purchased 0
dtype: int64
corr() 将生成数值列之间的相关矩阵。列之间没有高相关性。
data.corr()
Age EstimatedSalary Purchased
Age 1.000000 0.155238 0.622454
EstimatedSalary 0.155238 1.000000 0.362083
Purchased 0.622454 0.362083 1.000000
选择和过滤
选择列有多种方法。下面的示例是直接选择。
使用data[“<column_name>”] 或 data.<column_name>
data["Age"]
0 19
1 35
2 26
3 27
4 19
..
395 46
396 51
397 50
398 36
399 49
Name: Age, Length: 400, dtype: int64
data.Purchased.head()
0 0
1 0
2 0
3 0
4 0
Name: Purchased, dtype: int64
我们还可以使用 iloc 和 loc 来选择列和行,如下所示。
data.iloc[0,1]
19000
data.loc[0,"Purchased"]
0
要计算列中类别的数量,我们将使用 value_counts() 函数。
data.Purchased.value_counts()
0 257
1 143
Name: Purchased, dtype: int64
过滤值很简单。我们只需提供简单的 Python 条件。在我们的案例中,我们只过滤1的值来自 Purchased 列。
print(data[data['Purchased']==1].head())
Age EstimatedSalary Purchased
7 32 150000 1
16 47 25000 1
17 45 26000 1
18 46 28000 1
19 48 29000 1
对于更复杂的演示,我们通过使用 & 添加了第二个条件。
print(data[(data['Purchased']==1) & (data['Age']>=35)])
Age EstimatedSalary Purchased
16 47 25000 1
17 45 26000 1
18 46 28000 1
19 48 29000 1
20 45 22000 1
.. ... ... ...
393 60 42000 1
395 46 41000 1
396 51 23000 1
397 50 20000 1
399 49 36000 1
[129 rows x 3 columns]
数据排序
对于排序索引,我们使用 sort_values()。它接受多个参数,第一个是我们想要排序的列,第二个是排序方向。在我们的例子中,我们按 Purchased 列降序排序。
data.sort_values('Purchased', ascending=False).head()
sort_index() 类似于排序索引,但它将根据索引号对数据框进行排序。
data.sort_index()
重命名列
要重命名列,我们需要一个当前名称和修改名称的字典。我们使用 rename() 函数将名称从 ‘EstimatedSalary更改为Salary`。
data = data.rename(columns= {'EstimatedSalary' : 'Salary'})
data.head()
删除数据
我们可以简单地使用 drop 函数来删除列或行。在这个例子中,我们成功地删除了 Salary 列。
data.drop(columns='Salary').head()
要删除一行,你可以简单地写下行号。
data.drop(1)
转换数据类型
我们有三列,所有列都是整数。让我们将“Purchased”列更改为布尔型,因为它只包含 1 和 0。
data.dtypes
Age int64
Salary int64
Purchased int64
dtype: object
使用 astype() 函数更改数据类型。
data['Purchased'] = data['Purchased'].astype('bool')
我们已经成功地将‘Purchased’列更改为布尔类型。
data.dtypes
Age int64
Salary int64
Purchased bool
dtype: object
应用函数
对列或整个数据集应用 Python 函数变得更加简单,通过 Pandas apply() 函数。在这一部分,我们将创建一个简单的双倍值的函数,并将其应用于‘Salary’列。
def double(x): #create a function
return x*2
data['double_Salary'] = data['Salary'].apply(double)
print(data.head())
我们可以观察到,新创建的列包含了双倍的工资。
Age Salary Purchased double_Salary
0 19 19000 False 38000
1 35 20000 False 40000
2 26 43000 False 86000
3 27 57000 False 114000
4 19 76000 False 152000
我们还可以在 apply 函数中使用 Python lambda 函数来获得类似的结果。
data['Salary'].apply(lambda x: x*2).head()
可视化
Pandas 使用matplotlib库来可视化数据。我们可以使用此函数生成条形图、折线图、饼图、箱线图、直方图、KDE 图等。我们还可以像 matplotlib 库一样自定义我们的图表。通过简单地更改图形的kind,我们可以使用plot()函数生成任何类型的图形。
箱线图显示了三个数值列的分布情况。
data.plot( kind='box');
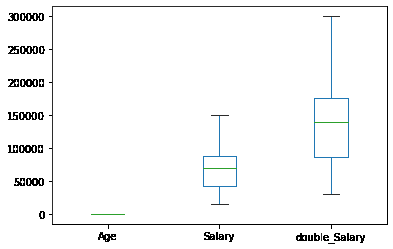
要绘制密度图,我们需要 x 和 y 参数以及 kind。在此示例中,我们绘制了年龄与薪资的密度图。
data.plot(x="Age",y = "Salary", kind='density');
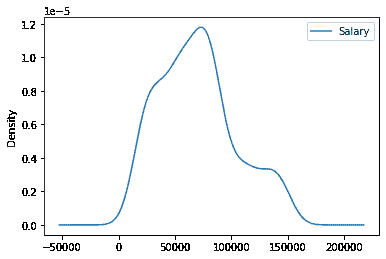
结论
Pandas 的内容如此之多,我们尚未涉及。它是数据科学家和数据从业者中使用最广泛的库。如果你有兴趣了解更多,可以查看 Python Pandas 教程 或参加一个完整的数据分析课程,学习 Pandas 的使用案例。在本指南中,我们学习了 Pandas Python 库以及如何使用它来执行各种数据操作和分析任务。希望你喜欢,如果你对这些主题有问题,请在评论区输入,我会尽力回答。
Abid Ali Awan (@1abidaliawan) 是一位认证数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一款 AI 产品,帮助面临心理健康问题的学生。
更多相关内容
贝叶斯优化与高斯过程的直观理解
原文:
www.kdnuggets.com/2018/10/intuitions-behind-bayesian-optimization-gaussian-processes.html
评论
作者 Charles Brecque,Mind Foundry
在某些应用中,目标函数的评估成本高或困难。在这些情况下,一般方法是创建一个更简单的目标函数代理模型,该模型更便宜,并用它来解决优化问题。此外,由于评估目标函数的高成本,通常推荐使用迭代方法。迭代优化器通过在域的一系列点上请求函数的评估来工作。贝叶斯优化通过在可能的目标函数空间上结合先验模型,将贝叶斯方法添加到迭代优化器范式中。本文介绍了贝叶斯优化与高斯过程的基本概念和直观理解,并介绍了 OPTaaS,一个用于贝叶斯优化的 API。
优化
优化方法尝试在一个域*** ????中找到一个输入 x**** ,使得一个函数*** f的值在 ????***范围内达到最大(或最小):
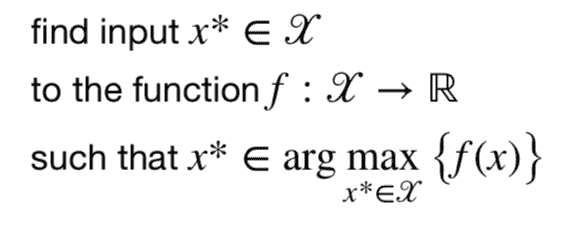
一般优化框架
实际上,函数 f代表需要优化的过程的结果,比如交易策略的整体盈利性、工厂生产线上的质量控制指标,或具有许多参数和超参数的数据科学管道的性能。
输入域*** ????表示需要优化的过程的有效参数选择。这些可以是交易策略中使用的市场预测器、工厂过程中的原材料数量,或数据科学管道中机器学习模型的参数。描述输入域 ????以及函数 f的属性共同定义了优化问题。过程域 ????的有效输入可以是离散的、连续的、有约束的或这些的任意组合。同样,结果函数 f***可能是凸的、可微分的、多模态的、嘈杂的、变化缓慢的,或具有其他许多重要属性。
在某些应用中,目标函数的评估代价高(计算上或经济上),或者评估困难(化学实验、石油钻探)。在这些情况下,一般的方法是创建一个目标函数 f 的更简单的替代模型 f ̂,它更便宜进行评估,并将用来解决优化问题。
此外,由于评估目标函数的成本较高,通常推荐使用迭代方法。迭代优化器通过在领域x1, x2, … ∈ ???? 的一系列点上迭代请求函数 f 的评估来工作。通过这些评估,优化器能够构建函数f的图像。对于梯度下降算法,这个图像是局部的,但对于替代模型方法,这个图像是全局的。无论何时,或者在预分配的函数评估预算结束时,迭代优化器都能够给出对x真实值的最佳近似。
替代模型使用N个已知的f评估值进行训练:F =(f1, f2,…,fN ) 以及 XN =(x1,x2,…,xN)。构建替代模型的方法有很多,如多项式插值、神经网络、支持向量机、随机森林和高斯过程。在 Mind Foundry,我们首选的方法是使用高斯过程进行回归。
高斯过程
高斯过程(GP)提供了一类丰富且灵活的非参数统计模型,适用于可以是连续的、离散的、混合的或甚至是层次性的函数空间。此外,GP 不仅提供关于 f 可能值的信息,还重要的是提供关于该值的不确定性的信息。
高斯过程回归的想法是,对于某些点的观察值FN以及点XN,我们假设这些值对应于具有先验分布的多变量高斯过程的实现:
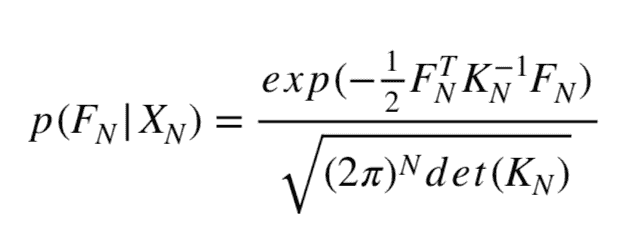
其中 KN 是一个 NxN** 协方差矩阵,其系数以相关函数(或核)Kmn =K(xm,xn,θ) 的形式表达。核的超参数 θ 根据最大似然原则进行校准。KN 的选择旨在反映函数的先验假设,因此核的选择将对回归的正确性产生重大影响。图 2 给出了几种协方差函数的示例。
通过数学变换和使用条件概率规则,可以估计后验分布 p(f N+1|FN, XN+1),并将f ̂N+1 表达为 KN 和 FN 的函数,并带有不确定性。这使我们能够从观察结果中构建一个概率性替代模型,如图 1 所示:
贝叶斯优化
贝叶斯优化是一类迭代优化方法,专注于一般优化设置,其中有描述????,但对f的属性了解有限。贝叶斯优化方法的特征包括两个方面:
-
代理模型f ̂,用于函数f,
-
和一个计算自代理函数的获取函数,用于指导下一个评估点的选择。
BO 通过在可能目标函数f的空间中加入先验模型,将贝叶斯方法学添加到迭代优化器范式中。每次报告函数评估时更新该模型,贝叶斯优化过程保持目标函数f的后验模型。这个后验模型是函数f的代理f ̂。带有 GP 先验的贝叶斯优化程序的伪代码如下:
初始化:
-
在f上设置高斯过程先验
-
根据初始空间填充实验设计,在n0 点观察f。
-
设置n为n0
当n ≤ N**时:
-
使用所有可用数据更新 f 的后验概率分布
-
确定获取函数在????上的最大值点xn,其中获取函数是使用当前后验分布计算的
-
观察yn = f(xn)
-
增量n
结束时
返回评估值最大的f(x)点,或后验均值最大的点。
一个标准的获取函数示例是期望改进准则(EI),对于在x ∈ ????的任何给定点,是f在x处相对于到目前为止看到的f最佳值的预期改进,前提是函数f在x处确实高于到目前为止看到的f最佳值:因此,如果我们正在寻找f的最大值,EI 可以写为:
E I(x) = ????(max(f(x) − *f, 0))
其中f**是目前看到的f*的最大值。
获取函数的额外示例如下:
-
熵搜索,旨在最小化我们对最优值位置的不确定性
-
上置信界
-
期望损失准则
图 3 展示了代理的演变及其与获取函数的交互,随着每次迭代的进行,它对试图最小化的底层函数的知识不断改善。
用 OPTaaS 操作化 BO
OPTaaS 是一个通用的贝叶斯优化器,通过网络服务提供最佳的参数配置。它可以处理任何类型的参数,并且不需要了解底层过程、模型或数据。它要求客户端指定参数及其范围,并返回每个 OPTaaS 推荐的参数配置的准确性评分。OPTaaS 利用这些评分来建模底层系统,并更快地搜索最佳配置。
Mind Foundry 在 OPTaaS 中实现了一组代理模型和获取函数,根据所提供的参数的性质和数量,自动选择和配置这些模型和函数,如图 4 所示。这种选择基于深入的科学测试和研究,以确保 OPTaaS 总是做出最合适的选择。此外,Mind Foundry 能够为客户特定的问题设计定制的协方差函数,这将显著提高优化过程的速度和准确性。大多数 OPTaaS 用户需要优化复杂的过程,这些过程运行成本高,并且反馈有限。因此,OPTaaS 的 API 专注于提供一个简单的迭代优化器接口。然而,如果对优化的过程有更多信息,它总是可以被利用以更快地收敛到最优解。因此,OPTaaS 也支持传递关于领域 ??? 的信息,例如对输入的约束,以及对函数 f 的评估,例如噪声、梯度或部分完成的评估。此外,客户通常能够利用本地基础设施来分布优化搜索,OPTaaS 也可以请求批量评估。
优化过程如下:
-
OPTaaS 向客户推荐一个配置
-
客户在他们的机器上评估配置
-
客户发送回一个评分(准确性、夏普比率、投资回报率,……)
-
OPTaaS 使用评分来更新其代理模型,循环重复,直到达到最佳配置。
在整个过程中,OPTaaS 不会访问底层数据或模型。有关 OPTaaS 的更多信息,请参见本页底部。
团队与资源
Mind Foundry 是牛津大学的衍生公司,由斯蒂芬·罗伯茨和迈克尔·奥斯本教授创立,他们在数据分析方面拥有 35 年的经验。Mind Foundry 团队由超过 30 名世界级机器学习研究人员和精英软件工程师组成,其中许多人曾在牛津大学担任博士后。此外,Mind Foundry 通过其衍生公司身份,享有对超过 30 位牛津大学机器学习博士的特权访问。Mind Foundry 是牛津大学的投资组合公司,其投资者包括 牛津科学创新、牛津科技与创新基金、牛津大学创新基金 和 Parkwalk Advisors。
文档
教程:tutorial.optaas.mindfoundry.ai
API 文档:optaas.mindfoundry.ai
研究
www.robots.ox.ac.uk/~mosb/projects/project/2009/01/01/bayesopt/
参考文献
Osborne, M.A. (2010). 贝叶斯高斯过程用于顺序预测、优化和积分(博士论文)。博士论文,牛津大学。
演示:charles.brecque@mindfoundry.ai
简介:Charles Brecque 是 Mind Foundry 的产品经理,负责 OPTaaS,一种通过网络服务部署的通用贝叶斯优化器。Mind Foundry 是牛津大学的衍生公司,由斯蒂芬·罗伯茨和迈克尔·奥斯本教授创立,他们在高级数据分析方面拥有超过 35 年的经验。
原文。经许可转载。
相关:
-
从零开始展开朴素贝叶斯
-
数据科学家优化 101
-
初学者问:“在人工神经网络中使用多少隐藏层/神经元?”
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
更多相关内容
直观的集成学习指南与梯度提升
原文:
www.kdnuggets.com/2018/07/intuitive-ensemble-learning-guide-gradient-boosting.html
评论
使用单一的机器学习模型可能并不总是能拟合数据。优化其参数也可能无济于事。一个解决方案是将多个模型结合起来拟合数据。本教程讨论了集成学习的重要性,以梯度提升为研究案例。
介绍
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
机器学习(ML)管道中的一个关键步骤是选择最适合数据的算法。根据数据中的一些统计信息和可视化,ML 工程师将选择最佳算法。让我们以图 1 中的回归示例来应用这一点。
图 1
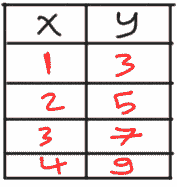
根据图 2 可视化数据,似乎线性回归模型将是合适的。
图 2
一个只有一个输入和一个输出的回归模型将根据图 3 中的方程进行制定。
图 3
其中 a 和 b 是方程的参数。
由于我们不知道最优的参数来拟合数据,我们可以从初始值开始。我们可以将 a 设置为 1.0,b 设置为 0.0,并如图 4 所示可视化模型。
图 4
基于初始值的模型似乎并没有拟合数据。
预计第一次试验可能无法奏效。问题在于如何在这种情况下提升结果?换句话说,如何最大化分类准确性或最小化回归误差?有多种方法可以实现这一目标。
一种简单的方法是尝试更改之前选择的参数。经过若干次试验,模型将知道最优的参数是 a=2 和 b=1。模型将在这种情况下拟合数据,如图 5 所示。非常好。
图 5
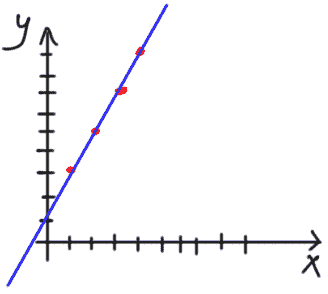
但在某些情况下,改变模型参数并不能使模型更好地拟合数据。会出现一些错误预测。假设数据中有一个新点(x=2,y=2)。根据图 6,无法找到使模型完全拟合每个数据点的参数。
图 6
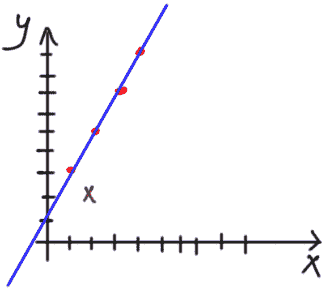
有人可能会说,拟合 4 个点而漏掉一个是可以接受的。但是如果有更多的点线无法拟合,如图 7 所示呢?这样模型的错误预测会比正确预测更多。没有单一的直线能够拟合整个数据。模型对直线上的点预测较强,但对其他点预测较弱。
图 7
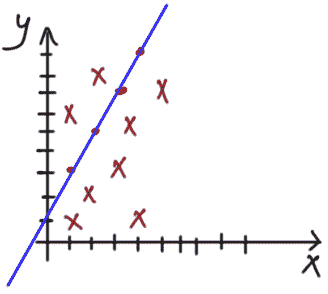
集成学习
因为单一的回归模型无法拟合整个数据,一个替代方案是使用多个回归模型。每个回归模型可以强烈地拟合数据的一部分。所有模型的组合将减少整个数据的总误差,并产生一个通常较强的模型。在问题中使用多个模型称为集成学习。使用多个模型的重要性在图 8 中有所展示。图 8(a) 显示在预测样本结果时误差较高。根据图 8(b),当有多个模型(例如,三个模型)时,它们结果的平均值能够比以前做出更准确的预测。
图 8
应用到图 7 中的先前问题时,图 9 展示了 4 个回归模型拟合数据的集成结果。
图 9
这引出了另一个问题。如果有多个模型来拟合数据,如何得到单一预测?有两种方法可以将多个回归模型组合以返回单一结果。它们是自助法和提升法(本教程的重点)。
在自助法(bagging)中,每个模型都会返回其结果,最终结果通过汇总所有这些结果来获得。一个方法是对所有结果进行平均。自助法是并行的,因为所有模型同时工作。
相比之下,提升法被视为顺序的,因为一个模型的结果是下一个模型的输入。提升法的理念是使用一个弱学习器来拟合数据。由于它很弱,它将无法正确拟合数据。一个弱学习器的不足将被另一个弱学习器修正。如果一些不足仍然存在,那么将使用另一个弱学习器来修正它们。这条链会延续,直到最终从多个弱学习器中产生一个强学习器。
接下来是讲解梯度提升的工作原理。
梯度提升 (GB)
下面是梯度提升在一个简单示例中的工作原理:
假设要建立一个回归模型,数据有一个输出,其中第一个样本的输出为 15。它如图 10 所示。目标是建立一个能够正确预测这种样本输出的回归模型。
图 10

第一个弱模型预测第一个样本的输出为 9,而不是 15,如图 11 所示。
图 11
为了测量预测中的损失量,需要计算其残差。残差是期望输出与预测输出之间的差异。它按照以下方程计算:
desired – predicted1 = residual1
其中predicted1和residual1分别是第一个弱模型的预测输出和残差。
通过代入期望输出和预测输出的值,残差将为 6:
15 – 9 = 6
对于residual1=6,在预测和期望输出之间,我们可以创建一个第二个弱模型,其目标是预测一个等于第一个模型残差的输出。因此,第二个模型将修正第一个模型的不足。两个模型的输出总和将等于期望输出,按照以下方程:
desired = predicted1 + predicted2(residual1)
如果第二个弱模型能够正确预测residual1,则期望输出将等于所有弱模型的预测值,如下所示:
desired = predicted1 + predicted2(residual1) = 9 + 6 = 15
但如果第二个弱模型未能正确预测residual1的值,例如返回了 3,则第二个弱学习器也会有一个非零残差,计算如下:
residual2 = predicted1 - predicted2 = 6 - 3 = 3
如图 12 所示。
图 12
为了修正第二个弱模型的不足,将创建第三个弱模型。其目标是预测第二个弱模型的残差。因此,其目标是 3。我们样本的期望输出将等于所有弱模型的预测值,如下所示:
desired = predicted1 + predicted2(residual1) + predicted3(residual2)
如果第三个弱模型的预测值是 2,即它无法预测第二个弱模型的残差,则第三个模型将有一个等于如下的残差:
residual3 = predicted2 – predicted3 = 3 - 2 = 1
如图 13 所示。
图 13
结果,将创建第四个弱模型来预测第三个弱模型的残差,该残差等于 1。期望输出将等于所有弱模型的预测值,如下所示:
desired = predicted1 + predicted2(residual1) + predicted3(residual2) + predicted4(residual3)
如果第四个弱模型正确预测了其目标(即 residual3),那么图 14 所示,通过总共四个弱模型已经达到了期望的输出 15。
图 14
这是梯度提升算法的核心思想。使用前一个模型的残差作为下一个模型的目标。
GB 摘要
总结来说,梯度提升从一个弱模型开始进行预测。该模型的目标是问题的期望输出。在训练该模型后,计算其残差。如果残差不为零,则创建另一个弱模型来修正前一个模型的不足。然而,新模型的目标将不是期望输出,而是前一个模型的残差。也就是说,如果给定样本的期望输出是 T,则第一个模型的目标是 T。训练后,该样本可能会有一个残差 R。新模型的目标将设置为 R,而不是 T。这是因为新模型填补了前一个模型的空白。
梯度提升类似于多个弱者将重金属搬上几层楼梯。没有一个弱者能够将金属搬上所有的楼梯。每个人只能搬上一个台阶。第一个弱者将金属搬上一个台阶后就会感到疲惫。另一个弱者将金属再搬上一个台阶,依此类推,直到将金属搬上所有的楼梯。
简介:Ahmed Gad 于 2015 年 7 月获得埃及梅努非亚大学计算机与信息学院的信息技术学士学位,并获得优异荣誉。因在学院中排名第一,他于 2015 年被推荐在埃及的一所学院担任助教,随后于 2016 年继续担任助教和研究员。他目前的研究兴趣包括深度学习、机器学习、人工智能、数字信号处理和计算机视觉。
原文。经许可转载。
相关内容:
-
Python 集成学习介绍
-
从头开始使用 NumPy 构建卷积神经网络
-
集成学习以提高机器学习结果
更多相关内容
协同过滤的直观解释
原文:
www.kdnuggets.com/2022/09/intuitive-explanation-collaborative-filtering.html
介绍
我们的前三名课程推荐
1. 谷歌网络安全证书 - 加速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
人工智能无处不在,并巧妙地影响我们的决策、选择和偏好。在多个环节中,许多组织将大量数据转化为算法,以生成洞察力,提升客户体验。
例如,电子商务公司从用户的点击流中收集数据,以向新用户提供便捷的购物体验,并从其不断变化的偏好中学习。如果你曾在线购买产品,那么你一定见过以下列出的某些推荐:
1. 基于感兴趣的项目推荐其他用户浏览过的产品

来源:作者自亚马逊网站
2. 推荐其他用户经常与搜索产品一起购买的附加产品

来源:作者自亚马逊网站
上述图示表明,当前用户会收到与感兴趣的产品相关的多个推荐,这些推荐基于过去类似用户的浏览或购买记录。这些推荐来自协同过滤算法——最流行的在线产品推荐方式。
值得注意的是,推荐产品的最简单方式也可能基于浏览次数、评分、转化率等,但这意味着通常用户已经购买了该产品。因此,这种基于人气指数的推荐因缺乏个性化而效果有限。
协同过滤
协同过滤的核心思想是,历史数据中的相似偏好可以揭示用户未来的偏好信息。
“协同”一词暗示,具有相似口味和选择的用户最适合协作,并决定是否向该用户推荐此产品。
接下来我们将了解用户-用户协同过滤是如何工作的。
协同过滤是如何工作的?
产品是根据类似用户对这个特定产品的喜好来推荐给新用户的。除了统计学上的根基外,认为我们的选择与我们更亲近的人主要是一致的也是比较直观的。
让我们通过下面的示例来理解一些基本概念:
| 产品 1 | 产品 2 | 产品 3 | 产品 4 | 产品 5 | 产品 6 | 产品 7 | 产品 8 | |
|---|---|---|---|---|---|---|---|---|
| 用户 1 | 5 | 1 | 4 | ? | ? | 4 | 4 | 3 |
| 用户 2 | 5 | ? | 3 | 2 | ? | ? | 5 | 2 |
| 用户 3 | 1 | 4 | 2 | 5 | ? | 5 | 2 | 5 |
-
三位用户对八种产品进行了评分(视为某种偏好测量)
-
不是所有用户对所有产品进行评分,因此这些单元格标记为问号‘?’
-
要么用户尚未购买这些产品,要么
-
他们选择不对某些产品进行评分,导致矩阵稀疏
-
-
注意,可能存在一些完全没有评分的特定产品,比如产品 5 - 这可能是因为这些产品是市场上的新产品。类似地,一些新用户访问电子商务网站时没有任何反映其偏好的记录,因此无法开始接收个性化推荐。
-
我们的目标是根据用户-产品矩阵找到用户 2 的下一组产品。
快速而简单的推荐方法
用户 2 尚未对产品 2 和产品 6 进行评分,所以要在这两者中选择一个 - 一种方法是计算这些产品在整个用户基础上的平均值,并推荐分数较高的那个。
但有一个警告 - 如果这两个产品的平均评分相似,如何打破平局?另一个问题是,所有用户的平均评分并没有给与与该用户(即用户 2)相似的用户子集更多权重。
这将引出下一个话题 - 如何生成个性化推荐。
个性化推荐
我们需要找出哪个用户(或在重要子集中哪个用户)最类似于用户 2。
让我们将矩阵分为两个部分 - 每个部分对应于用户 2,如下所示:
1. 用户 2 和 用户 1
来源:作者
2. 用户 2 和 用户 3
来源:作者
相似度分数
根据这两个子集,你可以观察到用户 1 和用户 2 有相似的偏好,而用户 2 和用户 3 并不一致。
让我们推导一个数学度量,以得出一个可以定义相似度程度的单一度量 - 其中一个度量是余弦相似度。
余弦相似度 定义为:
“内积空间中两个向量的相似度。它通过两个向量之间夹角的余弦值来衡量,确定两个向量是否大致指向相同的方向。它常用于文本分析中测量文档相似度。”
它是通过两个向量 A 和 B 的点积表示的
使用上述公式来计算“用户 1 与用户 2”和“用户 2 与用户 3”的相似度,我们得到相似度分数 S₁₂和 S₂₃分别为 0.97 和 0.65,这与我们的直观理解相符。
最后一步是对产品 2 的用户评分进行加权平均,使用相似度分数 S??和 S??。
(0.97 * 1 + 0.65 * 4) / (0.97 + 0.65) = 2.35
同样地,我们计算了产品 6 的权重分数,两个产品中得分较高的产品 6 被推荐给用户 2。
(0.97 * 4 + 0.65 * 5) / (0.97 + 0.65) = 4.4
总结
这篇文章解释了通过协同过滤进行产品推荐的直观理解。它详细说明了过去搜索过类似产品的用户如何影响适合新用户的推荐。
这篇文章还说明了如何使用余弦相似度计算用户-用户相似度分数,并最终通过对每个产品分数的加权求和计算最终分数。现在你已经了解了协同过滤的基础,我建议你阅读由 Andrew Ng 精彩讲解的六部分推荐系统系列。
参考文献
Vidhi Chugh 是一位获奖的 AI/ML 创新领袖和 AI 伦理学家。她在数据科学、产品和研究的交汇点工作,致力于提供商业价值和洞察。她倡导以数据为中心的科学,并在数据治理方面是领先的专家,致力于构建值得信赖的 AI 解决方案。
更多相关内容
卷积神经网络的直观解释
原文:
www.kdnuggets.com/2016/11/intuitive-explanation-convolutional-neural-networks.html/3
综合起来—使用反向传播进行训练
如上所述,卷积+池化层作为从输入图像中提取特征的工具,而全连接层作为分类器。
注意在图 15中,由于输入图像是一艘船,目标概率对于船类是 1,对于其他三个类别是 0,即
-
输入图像 = 船
-
目标向量 = [0, 0, 1, 0]
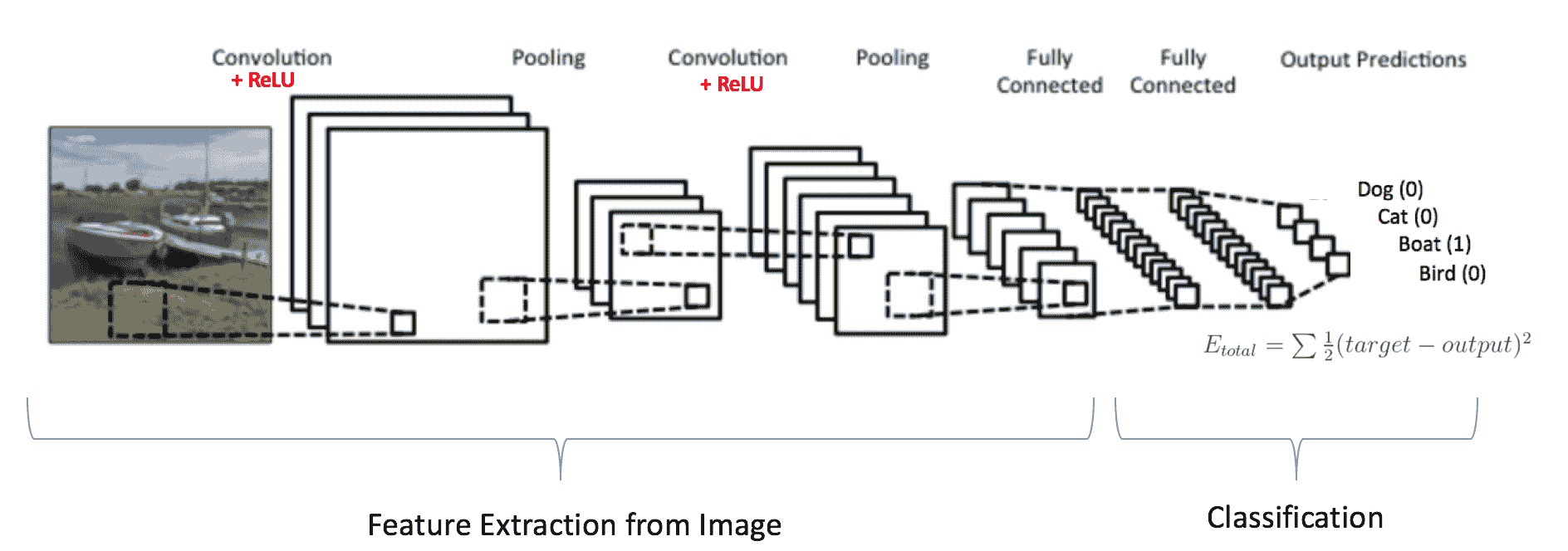
图 15:训练 ConvNet
卷积网络的整体训练过程可以总结如下:
-
步骤 1: 我们用随机值初始化所有过滤器和参数/权重
-
步骤 2: 网络将一张训练图像作为输入,经过前向传播步骤(包括卷积、ReLU 和池化操作以及全连接层中的前向传播),并找到每个类别的输出概率。
-
假设上述船图像的输出概率是[0.2, 0.4, 0.1, 0.3]
-
由于权重在第一次训练示例中是随机分配的,输出概率也是随机的。
-
-
步骤 3: 计算输出层的总误差(对所有 4 个类别进行求和)
- 总误差 = ∑ ½ (目标概率 – 输出概率)²
-
步骤 4: 使用反向传播计算相对于网络中所有权重的梯度,并使用梯度下降更新所有过滤器值/权重和参数值,以最小化输出误差。
-
权重根据它们对总误差的贡献进行调整。
-
当再次输入相同的图像时,输出概率现在可能是[0.1, 0.1, 0.7, 0.1],这更接近目标向量[0, 0, 1, 0]。
-
这意味着网络已经学会通过调整其权重/过滤器以减少输出误差,从而正确分类这张特定的图像。
-
像过滤器数量、过滤器大小、网络结构等参数在步骤 1 之前已固定,并且在训练过程中不会改变——只有过滤器矩阵和连接权重的值会被更新。
-
-
步骤 5: 对训练集中的所有图像重复步骤 2-4。
上述步骤训练了 ConvNet——这基本上意味着 ConvNet 的所有权重和参数现在已经优化,以正确分类训练集中的图像。
当一个新的(未见过的)图像输入到 ConvNet 中时,网络将经过前向传播步骤,为每个类别输出一个概率(对于新图像,输出概率是使用已优化的权重来正确分类所有之前训练样本计算的)。如果我们的训练集足够大,网络将(希望)能很好地推广到新图像,并将其分类到正确的类别中。
注意 1: 上述步骤已被过度简化,并且为了提供对训练过程的直观理解,避开了数学细节。有关数学公式和深入理解,请参见 [4] 和 [12]。
注意 2: 在上述示例中,我们使用了两个交替的卷积和池化层。不过,请注意,这些操作可以在单个 ConvNet 中重复任意次数。实际上,今天一些表现最好的 ConvNet 具有数十个卷积和池化层!此外,并不一定要在每个卷积层后都有一个池化层。如图 16所示,我们可以在进行池化操作之前连续进行多个卷积 + ReLU 操作。还请注意下图 16 中每层卷积网络的可视化。
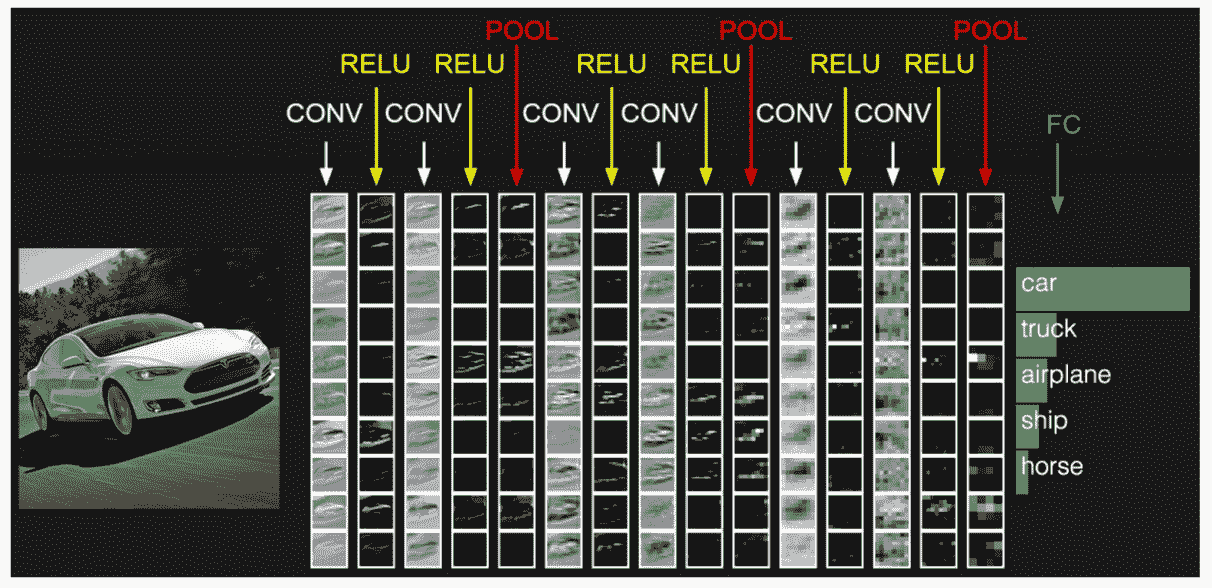
图 16:来源 [4]
卷积神经网络的可视化
一般来说,卷积步骤越多,我们的网络能够学习识别的特征就会越复杂。例如,在图像分类中,卷积网络可能会在第一层从原始像素中学习检测边缘,然后在第二层使用这些边缘检测简单的形状,再在更高层使用这些形状检测更高层次的特征,如面部轮廓 [14]。这在下面的图 17中得到了演示——这些特征是使用 卷积深度置信网络 学到的,此图仅用于展示该思想(这只是一个例子:现实中的卷积滤波器可能会检测到对人类没有意义的对象)。

图 17:来自卷积深度置信网络的学习特征
Adam Harley 创建了卷积神经网络在 MNIST 手写数字数据库上训练的惊人可视化。我强烈推荐 玩一玩这个 以了解 CNN 如何工作的细节。
我们将下面看到网络如何处理输入‘8’。请注意,图 18 中的可视化并未单独展示 ReLU 操作。

图 18:可视化一个训练过的卷积网络在手写数字上的效果
输入图像包含 1024 个像素(32 x 32 图像),第一卷积层(卷积层 1)是通过将六个独特的 5 × 5(步幅为 1)滤波器与输入图像进行卷积形成的。如所见,使用六个不同的滤波器会产生深度为六的特征图。
卷积层 1 后面跟着池化层 1,该层对卷积层 1 中的六个特征图进行 2 × 2 最大池化(步幅为 2)。你可以将鼠标指针移动到池化层中的任何像素上,并观察它在前一卷积层中形成的 4 x 4 网格(如图 19所示)。你会注意到,4 x 4 网格中值最大的像素(最亮的一个)进入池化层。

图 19:可视化池化操作
池化层 1 后面跟着十六个 5 × 5(步幅为 1)卷积滤波器,执行卷积操作。随后是池化层 2,该层进行 2 × 2 最大池化(步幅为 2)。这两层使用与上述相同的概念。
然后我们有三个全连接(FC)层。它们是:
-
第一 FC 层中的 120 个神经元
-
第二 FC 层中的 100 个神经元
-
第三 FC 层中的 10 个神经元对应 10 个数字——也称为输出层
请注意在图 20中,输出层中的每个 10 个节点都连接到第二个全连接层中的所有 100 个节点(因此得名全连接)。
另外,请注意输出层中唯一明亮的节点对应于 ‘8’——这意味着网络正确地分类了我们的手写数字(更亮的节点表示其输出更高,即 8 在所有数字中具有最高的概率)。
图 20:可视化全连接层
相同的 3D 版本可在 这里 查看。
其他 ConvNet 架构
卷积神经网络自 1990 年代早期以来就存在。我们讨论了上面的 LeNet,这是最早的卷积神经网络之一。其他一些有影响力的架构列在下面 [3] [4]。
-
LeNet (1990s): 已在本文中介绍。
-
1990 年代至 2012 年: 从 1990 年代末到 2010 年代初,卷积神经网络处于孕育阶段。随着数据和计算能力的不断增加,卷积神经网络可以处理的任务变得越来越有趣。
-
AlexNet (2012) – 2012 年,Alex Krizhevsky(及其他人)发布了AlexNet,这是一个比 LeNet 更深、更宽的版本,并且以较大优势赢得了 2012 年的 ImageNet 大型视觉识别挑战赛(ILSVRC)。这一突破性进展相较于之前的方法具有显著改进,目前广泛应用的卷积神经网络(CNN)可以归功于这项工作。
-
ZF Net (2013) – ILSVRC 2013 的冠军是 Matthew Zeiler 和 Rob Fergus 的卷积网络。它被称为ZFNet(即 Zeiler & Fergus Net 的缩写)。通过调整架构超参数,它对 AlexNet 进行了改进。
-
GoogLeNet (2014) – ILSVRC 2014 的冠军是来自Szegedy et al.的 Google 卷积网络。其主要贡献是开发了一个Inception Module,显著减少了网络中的参数数量(4M,相较于 AlexNet 的 60M)。
-
VGGNet (2014) – ILSVRC 2014 的亚军是被称为VGGNet的网络。它的主要贡献在于展示了网络的深度(层数)是良好性能的关键因素。
-
ResNets (2015) – 由 Kaiming He(及其他人)开发的Residual Network赢得了 ILSVRC 2015。ResNets 目前是最先进的卷积神经网络模型,并且是实际应用中使用卷积神经网络的默认选择(截至 2016 年 5 月)。
-
DenseNet (2016 年 8 月) – 最近由 Gao Huang(及其他人)发布的Densely Connected Convolutional Network中,每一层都直接与其他所有层进行前馈连接。DenseNet 在五个高度竞争的物体识别基准任务上相较于之前的最先进架构取得了显著的改进。可以在这里查看 Torch 实现。
结论
在这篇文章中,我尝试用简单的术语解释卷积神经网络的主要概念。有几个细节我进行了简化或跳过,但希望这篇文章能为你提供一些关于它们如何工作的直观理解。
本文最初受到了Denny Britz 的“理解卷积神经网络用于 NLP”的启发(我建议你阅读一下),本文中许多解释基于该文章。为了更深入地理解这些概念,建议你查阅斯坦福大学卷积神经网络课程的笔记以及下方参考文献中提到的其他优秀资源。如果你在理解上述概念时遇到任何问题或有问题/建议,欢迎在下方留言。
本文中使用的所有图片和动画均属于其各自的作者,详细信息请参见下方的参考文献部分。
参考文献
-
任少卿,等,“Faster R-CNN:基于区域提议网络的实时目标检测”,2015,arXiv:1506.01497
-
神经网络架构,Eugenio Culurciello 的博客
-
A. W. Harley,“卷积神经网络的交互式节点-链接可视化”,发表于 ISVC,第 867-877 页,2015 (link)
-
Vincent Dumoulin, 等人, “深度学习卷积算术指南”,2015 年,arXiv:1603.07285
原创帖子:转载经许可。
简介: Ujjwal Karn 在机器学习领域拥有 3 年的行业和研究经验,并对将深度学习应用于语言和视觉理解的实际应用感兴趣。
相关:
-
深度学习清除播客中的‘咳嗽’声
-
卷积神经网络的工作原理
-
深度学习关键术语解释
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你所在组织的 IT
更多相关话题
梯度下降的直观介绍
原文:
www.kdnuggets.com/2018/06/intuitive-introduction-gradient-descent.html
评论
作者 Keshav Dhandhania 和 Savan Visalpara
梯度下降 是最受欢迎和广泛使用的 优化算法 之一。给定一个具有参数(权重和偏差)和用于评估特定模型好坏的成本函数的 机器学习 模型,我们的学习问题就变成了找到一组好的权重,以最小化成本函数。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
梯度下降是一种 迭代方法。我们从一组模型参数(权重和偏差)开始,并逐渐改进它们。为了改进给定的权重,我们尝试了解类似于当前权重的权重的成本函数值(通过计算梯度),然后沿着成本函数减少的方向移动。通过重复这个步骤数千次,我们将持续最小化我们的成本函数。
梯度下降的伪代码
梯度下降用于最小化由模型参数 w 参数化的成本函数 J(w)。梯度(或导数)告诉我们成本函数的斜率或坡度。因此,为了最小化成本函数,我们沿着与梯度相反的方向移动。
-
随机初始化 权重 w
-
计算梯度 G,相对于参数的成本函数 [1]
-
通过与 G 成比例的量更新权重,即 w = w - ηG
-
重复直到成本 J(w) 不再降低或满足其他预定义的 终止标准
在第 3 步中,η 是 学习率,它决定了我们达到最小值的步伐大小。我们需要对这个参数非常小心,因为η 的高值可能会超越最小值,而非常低的值则会非常缓慢地达到最小值。
一个流行的合理选择作为终止标准是成本 J(w) 在 验证 数据集上停止降低。
梯度下降的直观理解
想象一下你被蒙上眼睛在崎岖地形中行走,你的目标是到达最低点。你可以使用的一个简单策略是感觉地面在各个方向上的倾斜,并朝着地面下降最快的方向迈出一步。如果你不断重复这个过程,你可能会到达湖泊,甚至更好的是,某个巨大山谷中的位置。

崎岖地形类似于成本函数。最小化成本函数类似于试图到达更低的高度。你被蒙上眼睛,因为我们没有条件评估(查看)每一组参数的函数值。感觉你周围地形的坡度类似于计算梯度,而迈出一步类似于对参数进行一次更新迭代。
顺便提一下——作为一个小插曲——本教程是免费数据科学课程和免费机器学习课程的一部分,均在Commonlounge平台上提供。这些课程包括许多动手作业和项目。如果你有兴趣学习数据科学/机器学习,强烈推荐查看一下。
梯度下降的变体
梯度下降有多种变体,具体取决于计算梯度时使用了多少数据。这些变体的主要原因是计算效率。一个数据集可能有数百万个数据点,计算整个数据集的梯度可能非常耗费计算资源。
-
批量梯度下降计算成本函数相对于参数 w 的梯度,基于整个训练数据。由于我们需要计算整个数据集的梯度以进行一次参数更新,因此批量梯度下降可能非常慢。
-
随机梯度下降(SGD)使用单个训练数据点
*x_i*(随机选择)计算每次更新的梯度。其思想是,这种方式计算的梯度是对使用整个训练数据计算的梯度的随机逼近。每次更新的计算速度比批量梯度下降要快得多,经过多次更新,我们将朝着相同的大致方向前进。 -
在小批量梯度下降中,我们计算每个小批量训练数据的梯度。也就是说,我们首先将训练数据分成小批量(例如每批次 M 个样本)。我们对每个小批量执行一次更新。M 通常在 30 到 500 的范围内,具体取决于问题。通常使用小批量梯度下降,因为计算基础设施——编译器、CPU、GPU——通常针对向量加法和向量乘法进行了优化。
其中,SGD 和小批量 GD 最为流行。在典型的情况下,我们会在训练数据上进行若干次遍历,直到满足终止标准。每次遍历称为epoch。另请注意,由于 SGD 和小批量 GD 的更新步骤计算效率更高,我们通常会在检查终止标准是否满足时执行 100 到 1000 次更新。
选择学习率
通常,学习率的值是手动选择的。我们通常从一个较小的值开始,例如 0.1、0.01 或 0.001,并根据成本函数的变化情况来调整它,如果成本函数减少非常缓慢(增加学习率),或是爆炸/不稳定(降低学习率)。
尽管手动选择学习率仍然是最常见的做法,但已经提出了多种方法,如 Adam 优化器、AdaGrad 和 RMSProp,用于自动选择合适的学习率。
脚注
- 梯度 G 的值取决于输入、模型参数的当前值和成本函数。如果你是手动计算梯度,你可能需要重新学习微分的相关知识。
原文首次发布于免费机器学习课程和免费数据科学课程的www.commonlounge.com。经许可重新发布。
相关:
更多相关内容
投资人工智能?需要考虑的事项
原文:
www.kdnuggets.com/investing-in-ai-here-is-what-to-consider
投资回报率(ROI)帮助企业确定哪些项目应优先考虑,简单来说——哪些举措最值得投入资源和关注,以实现业务目标。

图片来源:Canva
既然我们谈论的是涉及数字的投资回报率,那就让我们从一些统计数据开始吧:
-
根据《福布斯》的数据,全球人工智能市场预计将以 38%的年均增长率增长,到 2030 年将达到约 1812 亿美元。
-
人工智能是 83%公司的首要优先事项。
-
根据IBM的数据,2023 年对人工智能系统的支出将增加 27%,达到 1540 亿美元。
-
该报告进一步指出,组织平均只能在 10%的资本投资成本上获得 5.9%的回报率。
-
然而,成功的远见者通过在正确的时间把握正确的机会实现了 13%的回报率。
专业投资。
鉴于巨额开支,必然会有人谈论这样的问题——如此高额的投资能带来什么回报。PwC表示,大多数公司甚至无法获得任何回报。
人工智能投资很快成为大多数高管关注的焦点。他们需要做出明智的人工智能投资,以获得高回报率,但他们如何才能实现领导者所能带来的回报?请注意,预计的回报北极星是高达 30%。
-
第一步是将人工智能视为战略举措。它必须源于特定组织的目标,而不是竞争对手的目标。重要的是要记住,每个组织都有其独特的位置,考虑到其细分市场、商业模式和技术能力。
-
这需要识别与业务战略一致的项目,即组织在未来 3-5 年的目标和愿景。
-
即使前方道路明确,实现人工智能的潜力也不是没有困难。这需要分析思维,并在整个组织中培养人工智能文化。

图片来源:作者
-
人工智能思维方式帮助企业辨别哪些人工智能项目值得启动,同时节省对非人工智能项目的投入。从文化角度来看,建议迅速建立一个充满机会和创新的项目池,并具备快速应对各种变量的能力。
-
接下来是数据——它是整个 AI 转型的关键,因此,大部分关注和努力必须集中在构建数据治理过程上。SAP将数据治理定义为“为确保组织的数据首先是准确的——然后在输入、存储、操作、访问和删除时得到适当处理的政策和程序。”
价值生成
要理解 AI 举措的 ROI 背景,“价值”比纯利润更为重要。
利润意味着与传统计算回报相关的实际现金。然而,AI 从业者优先考虑“价值生成”,以体现 AI 实施在组织层面的好处。
有了这些额外的背景信息,我们来将投资回报率(ROI)拆解为两个组成部分。回报是从投资中产生的价值,这涉及到开发这些系统的成本。
收入和回报
评估收入的方式有很多种。除了来自 AI 驱动产品的直接收入流,一些举措并不是直接的收入来源,但可以巧妙地增强或补充现有流程。
这些举措可能不会立即产生结果,但随着时间的推移,可以显著增加收入。考虑到电子商务平台上基于用户浏览历史的 AI 驱动推荐引擎,这些推荐轻轻引导用户进行额外购买,从而提高销售额。

图片来自 Canva
另一个例子是,当平台通过快速提供用户感兴趣的选择来提升搜索相关性和改善客户体验,从而使他们对平台保持忠诚并留住他们。
成本——我们都知道的
收入只是 ROI 计算的一部分;另一部分涉及审慎的成本管理。AI 项目的主要成本包括基础设施、建立 AI 团队和数据管理解决方案。
招聘 AI 技能涉及入职、技能提升和薪酬成本。一些组织将整个项目或需要特定技能集的部分项目外包,避免了前期成本。
然而,外部招聘也会产生间接成本,因为内部人员可能没有足够的能力继续支持项目,从而引入了对外部承包商的依赖,增加了项目维护和额外成本。
AI 可以用于一些简单的案例,比如自动化一些重复任务,以减少人为错误,节省运营开销。
失败的成本
让我们谈谈那些常常未被考虑的成本——与延续错误决策相关的成本。
1-10-100 规则 解释了“未注意到一个成本如何使损失在美元中上升。预防成本可能应该优先,因为预防缺陷的成本远低于修正缺陷的成本”。
图片来源于 全面质量管理
像这个规则一样,错误决策的成本至关重要。它要求从一开始就建立设计思维的视角,包括项目范围界定、识别正确的 AI 机会及相关风险。
因此,建立一个全组织风险评估框架对于解决如偏见、缺乏监督、透明度和问责制、数据隐私等问题至关重要。
PoC 期间的 ROI 估算
在构思阶段的初步 ROI 估算有助于优先考虑项目。
在对业务问题有了更深刻的理解之后,接下来是讨论技术。建议开始构建 PoC,而不是等待理想的环境——所有输入组件,如数据、算法、基础设施等,都已整理好。
一旦你开始开发 PoC,是否有可能将项目扩展的现实就开始显现。
PoC 帮助你在有限的预算和更短的时间内验证想法。
测试环境或沙箱可以在投资建设规模系统之前确保价值主张。然而,规模方面必须在 PoC 阶段就进行前瞻性思考,无论是在以下方面:
-
建立数据管道以支持大规模数据,
-
需要昂贵计算资源的算法
-
应用程序将服务的用户数量。
这些维度的估算展示了 AI 解决方案将如何融入组织的技术栈。
如果 PoC 证明了投资的合理性,项目将进入开发阶段。
值得注意的是,评估收入和成本因素是特定于业务模型的;因此,本文旨在帮助建立一个视角,以衡量不同因素及其对 ROI 的影响。
Vidhi Chugh 是一位 AI 战略家和数字化转型领导者,她在产品、科学和工程交汇处工作,致力于构建可扩展的机器学习系统。她是一位获奖的创新领袖、作者和国际演讲者。她的使命是使机器学习民主化,打破术语,让每个人都能参与到这场转型中。
更多相关话题
学术界是否在方法论的代价下迷恋于方法论而忽视真正的洞察力?
原文:
www.kdnuggets.com/is-academia-obsessing-over-methodology-at-the-cost-of-true-insights

图片来源:Kampus Production
当谈到增加知识和技能时,很多人认为学术、研究和其他形式的核心学习是所有知识形式的基础。很多这些知识背后都有方法论和过程来将其转化为知识。但是,学术界一直在讨论一个问题:‘学术界是否过于关注方法论而忽视洞察力?’。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT
有人说是,也有人说不是。让我们深入探讨一下…
学术界的方法论
在深入之前,让我们首先定义一下‘方法论’。在学术背景下,方法论指的是用于进行研究的系统化方法,采用各种工具和技术来收集和分析数据。
方法论是研究的关键要素。研究用于支持某个陈述,或者进一步探讨某个缺乏足够支持的特定陈述。因此,在研究中,需要有高度的精确性和可靠性。没有精确性和可靠性,研究行业的声誉将失去可信度。
学术界的洞察
正如你所看到的,随着 AI 系统的兴起,洞察力向我们展示了很多我们无法想象的东西。洞察力关注的是从所有研究中出现的发现,这些发现后来被用于创新、解决问题,并为我们创造一种不同的未来。
可以想象,在这个时代,更多的组织关注从洞察力中获得的价值,而不是方法论。
方法论与洞察
在过去的 10 年里,技术的发展如此迅猛,你是否认为洞察力比方法论更有用?
但也有人可能会说,如果没有方法论,洞察力将永远不会产生。
这不是“先有鸡还是先有蛋?”的问题。我们知道方法论和过程在前,问题是学术界是否过于关注方法论而忽视了洞察力?
如果没有严格的系统框架来进行研究,洞察力是不会出现的。这些框架在世界的多年创新中发挥了不可或缺的作用,但这些方法是否让人们专注于眼前的事物,而忽视了更大的图景?
我们被教育了很久,认为教育和知识是成功的道路。家长们推动孩子们成为最好的自己,进入最好的大学,找到令人惊叹的工作。是的,每个家长都希望他们的孩子成功,但你不觉得时代已经改变了吗?越来越少的学生愿意继续上大学,越来越多的年轻百万富翁。似乎有什么不对劲,对吗?
嗯,不,一切都进展得很顺利。年轻一代不仅能更好地接触世界、教育和资源,学习他们想学的任何东西。他们与之前几代人不同的一个重要方面就是他们拥有创造力,并且无所畏惧地培养它。
跳出思维框架可以帮助你挖掘自己的创造力和非常规思维。这正是导致突破、多百万创意和整个范式转变的原因。方法论是否正在扼杀开放的思维?还是学术界需要采用更具创造性和跨学科的方法?
找到正确的平衡
是否存在忽视一方而导致危险的情况?当然有。忽视洞察力而推行僵化的方法论过程会扼杀学术领域的创造力。正如我们提到的,突破性的发现正是由于创造力,那么扼杀这种创造力是否有意义?
方法论和洞察力是相互依存的。学术界需要灵活,以找到接受洞察力所带来的不同价值与保持方法论不变之间的平衡。你仍然可以拥有严谨的方法,而不会否定或掩盖洞察力所能告诉我们的潜力。
就像我们第一次接触电力或电话时的谨慎一样,我们学会了适应我们当前生活的时代。学术界中,想继续深造的年轻人急剧减少。这可能有多种原因,但一个自然的原因是学习方法显得‘过时’。它与新一代人不相符,因为他们生活在完全不同的时代。
我们将被围绕在只理解洞察力以及如何利用这些洞察力的人工智能宝宝们之中。因此,学术界需要转变,鼓励新的创造性研究方法,同时确保教授扎实的方法论的重要性。
总结一下
这是我作为千禧一代的观点,我曾与婴儿潮一代、X 世代进行过深刻的对话,并与千禧一代一起上学。变革并不总是坏事,在这种情况下,我个人认为学术界的变革将对下一代非常有益。
在学术界和创新中,找到两者之间的正确平衡,而不是让它们进行拔河,是持续推动进步并创造更美好世界的唯一途径。
尼莎·阿里亚 是一位数据科学家、自由技术写作人、KDnuggets 的编辑和社区经理。她特别感兴趣于提供数据科学职业建议或教程以及围绕数据科学的理论知识。尼莎涵盖了广泛的主题,并希望探索人工智能如何有助于人类寿命的延续。作为一个热衷于学习的人,尼莎希望拓宽她的技术知识和写作技能,同时帮助他人。
更多相关话题
数据科学是一个即将破裂的泡沫吗?
原文:
www.kdnuggets.com/is-data-science-a-bubble-waiting-to-burst

图片由作者提供
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域的职业。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT 工作
我曾与一个人交谈,他吹嘘说,仅凭一些免费的 LinkedIn 课程和一门过时的大学 SQL 入门课程,他就成功获得了一份六位数的数据显示工作。现在,大多数在争取良好数据科学职位的人会同意这种情况不太可能发生。这是否意味着数据科学职位类别是一个已经破裂的泡沫——或者更糟的是,还未破裂,但即将破裂?
简而言之,不是。发生的情况是,数据科学曾经是一个饱和度较低的领域,如果在简历上使用正确的关键词,很容易进入。现在,雇主们变得更加挑剔,通常会有具体的技能要求。
现在仅靠培训营、免费课程和“Hello World”项目已经不够了。你需要证明具体的专业知识,并在数据科学面试中表现出色,而不仅仅是丢出流行词。更重要的是,“数据科学家”的光环已经稍微褪色了。曾几何时,它是最吸引人的职业。现在呢?其他领域,比如 AI 和机器学习,更加吸引人。
话虽如此,数据科学领域的职位空缺仍然多于申请者,而且可靠的指标表明该领域在增长,而非缩减。
还不信服?让我们来看看数据。
大局观
在本文中,我将详细分析多个图表、图形和百分比。但让我们先从一个非常权威的来源给出的百分比开始:劳工统计局。
劳工统计局预测从 2022 年到 2032 年,数据科学家的就业将发生 35% 的变化。简而言之,到 2032 年,数据科学领域的职位将比 2022 年多出大约三分之一。相比之下,所有职位的平均增长率为 3%。在阅读本文的其余部分时,请记住这个数字。
劳工统计局不认为数据科学是一个即将破裂的泡沫。
裁员情况
现在我们可以开始深入探讨一些细节。人们指出的泡沫破裂或即将破裂的最初迹象是数据科学领域的大规模裁员。
确实,数据看起来不太乐观。从 2022 年开始,直到 2024 年,技术领域总体上经历了 430,000 次裁员。很难从这些数据中分离出数据科学特定的数据,但最佳估计是约 30%的裁员发生在数据科学和工程领域。
来源:techcrunch.com/2024/04/05/tech-layoffs-2023-list/
然而,这并不是数据科学的泡沫破裂。它的范围稍微小一些——这是一个疫情泡沫破裂。在 2020 年,随着更多人待在家中,利润上升,资金便宜,FAANG 及其相关公司吸纳了创纪录数量的技术工人,但仅仅几年后就裁掉了其中许多人。
如果你缩小视角,看看招聘和裁员的整体情况,你会发现后疫情时期的低迷是整体上升趋势中的一个下滑,现在甚至开始恢复:
你可以清楚地看到,2020 年市场紧缩时技术裁员大幅减少,然后从 2022 年第一季度开始裁员急剧上升。现在,到 2024 年,裁员数量比 2023 年要少。
职位空缺
另一个常被提及的令人担忧的数据是 FAANG 公司将职位空缺减少了 90%或更多。再次,这主要是对疫情期间职位空缺数量激增的反应。
尽管如此,技术领域的职位空缺仍低于疫情前水平。下面,你可以看到一张调整后的图表,显示了相对于 2020 年 2 月的技术职位需求。可以明显看出,技术领域遭受了一个打击,短期内难以恢复。
来源:www.hiringlab.org/2024/02/20/labor-market-update-tech-jobs-below-pre-pandemic-levels/
然而,让我们更详细地查看一些实际数据。查看下面的图表,尽管职位空缺明显低于 2022 年的高峰,但整体职位空缺数量实际上在增加——比最低点增长了 32.4%。
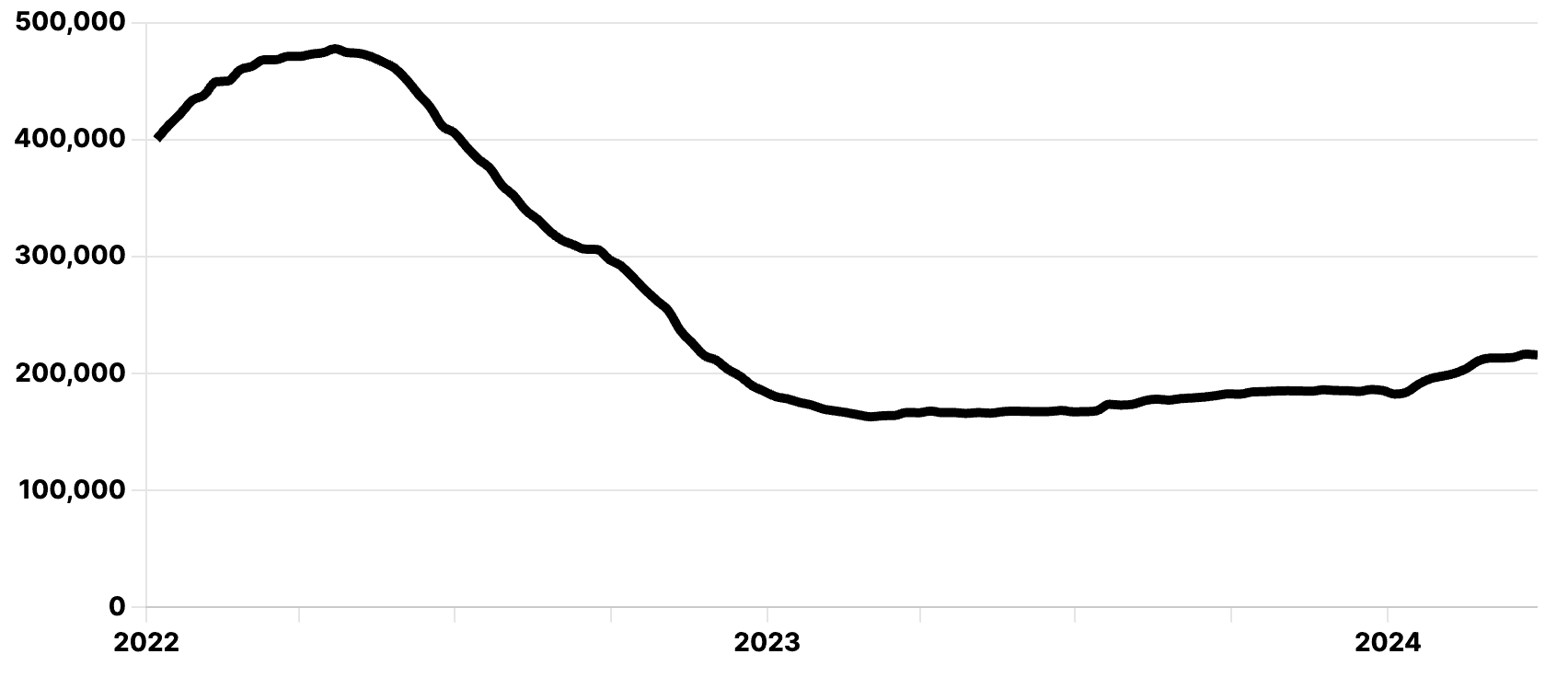
叙事
如果你查看任何在线的劳动力和新闻报告,你会看到目前正发生一些反对远程工作和反对技术的逆流。Meta、谷歌以及其他 FAANG 公司,由于害怕员工在疫情高峰期间享有的谈判权力,现在推动办公室复工命令(数据科学职位和其他技术职位通常是远程的),并根据他们的收入和利润报告,裁员数量有些不必要。
举个例子,谷歌母公司 Alphabet 裁员了超过 12,000 名员工,尽管其广告、云计算和服务部门都有增长。
这只是审视数据的一个方面,但公司进行裁员的部分原因更多是为了让董事会满意,而不是因为对数据科学家的需求减少。
需求
我发现,那些认为我们处于数据科学泡沫中的人,往往是不真正了解数据科学家工作的人。想想那个 BLS 统计数据,问问自己:为什么这个信息充分的政府机构相信这个行业有强劲的增长?
因为数据科学家的需求无法消失。虽然职位名称可能会改变——例如 AI 专家或 ML 云专家而非数据科学家——但数据科学家执行的技能和任务无法外包、删除、减少或自动化。
例如,预测模型对企业预测销售、预测客户行为、管理库存和预见市场趋势至关重要。这使得公司能够做出明智的决策,战略性地规划未来,并保持竞争优势。
在金融领域,数据科学在识别可疑活动、预防欺诈和降低风险方面发挥着至关重要的作用。高级算法分析交易模式,以检测可能表明欺诈的异常现象,从而帮助保护企业和消费者。
NLP 使机器能够理解和解释人类语言,推动了像聊天机器人、情感分析和语言翻译服务这样的应用。这对于改善客户服务、分析社交媒体情感和促进全球沟通至关重要。
我可以列出更多的例子来证明数据科学不是一种时尚,数据科学家的需求将永远存在。
为什么感觉我们处于泡沫中?
回到我之前的例子,感觉我们正处于一个泡沫中,泡沫要么正在破裂,要么即将破裂的部分原因是对数据科学作为职业的看法。
早在 2011 年,《哈佛商业评论》曾著名地称之为十年来最性感的职业。在此后的几年里,公司雇用了比他们知道如何处理的更多的“数据科学家”,经常对数据科学家实际的工作内容感到不确定。
现在,时隔十五年,这个领域变得更加成熟。雇主们明白数据科学是一个广泛的领域,更加关注聘用机器学习专家、数据管道工程师、云计算工程师、统计学家以及其他广泛归于数据科学范畴但更为专业的职位。
这也有助于解释为什么从本科毕业后直接进入六位数薪资的想法曾经是可能的——因为雇主不了解情况——但现在已不再可能。缺乏“简单”的数据科学职位让人觉得市场变得紧张。其实并非如此;数据显示职位空缺仍然很高,需求仍然大于拥有相关学位的毕业生。但雇主变得更加挑剔,不愿意冒险雇用没有实际经验的大学毕业生。
数据科学的需求并没有减少或被取代
最后,你可以看看数据科学家所做的任务,并问问自己,如果这些任务没有完成,公司会怎么办。
如果你对数据科学了解不多,你可能会猜测公司可以简单地“自动化”这些工作,甚至可以不去做。但如果你了解数据科学家实际的工作内容,你会明白,这份工作现在是不可替代的。
想象一下 2010 年代的情况:我谈到的那个人,凭借对数据工具的基本了解,迅速进入了一个高薪的职业。现在情况不再如此,但这种重新校准并不是一些人认为的泡沫破裂的迹象。相反,这是数据科学领域的成熟。虽然初级数据科学领域可能已经饱和,但对于那些具备专业技能、深厚知识和实际经验的人来说,这个领域依然广阔。
此外,关于“泡沫”的叙述源于对泡沫实际含义的误解。泡沫发生在某物的价值(在这种情况下,是职业领域)由投机驱动而非实际内在价值。然而,正如我们所讨论的,数据科学的价值主张是实在且可衡量的。公司需要数据科学家,简单明了。这里没有投机成分。
关于大型科技公司裁员的媒体炒作也不少。虽然这些裁员很重要,但它们反映的是更广泛的市场力量,而不是数据科学学科的根本缺陷。不要被头条新闻所迷惑。
最后,还值得注意的是,对泡沫的感知可能源于数据科学自身的变化。随着该领域的成熟,角色之间的区别变得更加明显。像数据工程、数据分析、商业智能、机器学习工程和数据科学这样的职位名称变得更加具体,需要更为专业的技能。这种演变可能使数据科学职位市场看起来比实际更为波动,但实际上,公司对其数据科学需求有了更好的理解,并能招聘到相应的专业人才。
最后的想法
如果你想从事数据科学工作,就去做吧。我们实际上处于泡沫中的机会非常小。你可以做的最好的事情是,如我所示,选择你的专业领域并在该领域发展你的技能。数据科学是一个广泛的领域,涉及不同的行业、语言、职位名称、职责和资历。选择一个专业领域,训练技能,为面试做准备,并确保获得工作。
内特·罗西迪是一名数据科学家和产品策略专家。他还是一位兼职教授,教授分析学,并且是 StrataScratch 的创始人,这个平台帮助数据科学家通过顶级公司的真实面试问题准备面试。内特撰写关于职业市场最新趋势的文章,提供面试建议,分享数据科学项目,并涵盖所有与 SQL 相关的内容。
更多相关话题
2024 年数据科学还值得吗?

图片来源:作者
很多人对 2024 年数据科学家的职位有不同的看法。随着生成式 AI 工具的使用不断增加,许多组织和员工在数据分析过程中受益。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
有人说数据科学已经过时,有人说数据科学正在重生。你应该相信什么?
这是我的看法。
如果数据被比作黄金,越来越多的公司正在生成数据,并希望获得这些数据。你必须问自己,为什么大家对数据如此疯狂?
但这是否意味着如果组织拥有像 ChatGPT 这样的工具来清理和分析数据,它们仍然需要数据科学家?尽管组织和专家在日常活动中利用机器学习和人工智能工具,但数据科学市场仍然有明显的增长趋势。
数据科学是否过度饱和?
我们都承认,科技行业正在蓬勃发展,人们正努力进入这一行业。许多公司正在寻找具备网页分析技能、商业智能和基础数据工程的专业人士,而数据科学家正具备这些能力。
然而,当你看一个非技术公司时,许多任务可以被自动化,从而减少对数据科学家的需求。然而,如果你在一个更加技术驱动的公司工作,该公司需要在金融领域进行风险分析或数据工程和客户分析,你将在职业生涯中有更大的机会成功,数据科学家。
这更多取决于你工作的公司。
例如,制造业、物流、医疗保健和金融业。这些行业需要分析服务,其中对数据科学的核心需求持续增长。别忘了 AI 领域,例如自然语言处理(NLP)和计算机视觉,目前也在迅猛发展。
所以,数据科学值得吗?
简单的答案是肯定的。对于那些具备分析和人工智能模型开发技能的人员来说,机会非常大。《美国新闻与世界报道》将数据科学排名为第 4 大技术工作、第 7 大 STEM 工作,并在 2024 年列为 100 个最佳工作的第 8 位。
这些数据突显了对数据科学专业人士的需求,以及他们在未来技术和商业中的重要性。
我如何成为一名数据科学家?
如你所知,对数据科学家的需求很高,许多人都在尝试进入这个行业。你们中的一些人可能考虑过回到大学,但无法衡量经济负担。
进入科技行业现在不再那么困难。各种在线课程可以在几个月内而不是几年内帮助你进入这一领域。
其中一个课程是 DataCamp 的数据科学家认证。这是一个行业认可的认证,让你可以确信你的认证具有价值,并将被主要组织认可。
在此认证中,你将学习如何使用机器学习和人工智能收集、分析和解释大量数据。通过这种技术学习,你还将学会如何有效地将你的分析结果传达给业务利益相关者。
令人惊讶的是,你可以在30 天内完成这一过程!一旦注册,你将有 30 天的时间完成所有必要的计时和实操考试,以确保成功!学习平台提供了你所需的一切准备,以实现你的目标。
最困难的部分是找工作,对吗?在当前经济和就业市场中,很多人害怕投资于他们的职业发展,我理解你的担忧。
然而,DataCamp 还为你提供了独家访问他们的认证社区的机会,在这里你可以与其他认证专业人士联系,并探索由社区团队为你量身定制的内容。在这个社区中,你将了解与行业专家的新活动,这对网络拓展、讨论组提问和获得反馈、专门为你定制的内容以及资源来帮助你在求职中脱颖而出非常有帮助。
总结
许多人对数据科学在当前市场上的增长持有不同意见。然而,仍然有很多人进入这一领域以满足需求。任何技术角色都需要学习和提升技能,因此作为数据科学家进入这一领域将使你能够转向其他需求量大的领域,如商业智能或数据工程。
Nisha Arya是一名数据科学家、自由技术写作人员,同时也是 KDnuggets 的编辑和社区经理。她特别关注于提供数据科学职业建议或教程以及基于理论的数据科学知识。Nisha 涉及广泛的话题,并希望探索人工智能如何有利于人类寿命的不同方式。作为一个热衷学习者,Nisha 致力于拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
通过采样进行的迭代初始质心搜索
原文:
www.kdnuggets.com/2018/09/iterative-initial-centroid-search-sampling-k-means-clustering.html
评论
在这篇文章中,我们将探讨通过迭代方法搜索 k 均值聚类的更好初始质心集合,并通过对我们的完整数据集样本执行此过程来实现。
我们所说的“更好”是什么意思?由于 k 均值聚类旨在通过连续的迭代收敛到最优的簇中心(质心)和基于这些质心的簇成员,因此初始质心的定位越优化,k 均值聚类算法所需的迭代次数就会越少。因此,考虑找到一个更好的初始质心位置集合是一种优化 k 均值聚类过程的有效方法。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
我们将采取不同的方法,具体来说,就是从我们的完整数据集中抽取一个样本,然后对其进行短时间的 k 均值聚类算法运行(而不是收敛),这些短时间运行必然包括质心初始化过程。我们将使用若干个随机初始化的质心重复这些短时间运行,并跟踪测量指标的改善——簇内平方和——以确定聚类成员的优度(或者至少是评估此项的有效指标之一)。与随机质心初始化迭代过程相关的最终质心提供最低的惯性值的质心集合将被带入我们的完整数据集聚类过程中。
希望这项前期工作能导致我们完整聚类过程中获得更好的初始质心集合,从而减少 k 均值聚类的迭代次数,最终缩短完全聚类数据集所需的时间。
显然,这并不是优化质心初始化的唯一方法。过去我们讨论过朴素分片质心初始化方法,这是一种用于最佳质心初始化的确定性方法。其他形式的 k 均值聚类算法的修改也采用了不同的方法来解决这个问题(请参见k-means++以作比较)。
本文将以如下方式进行我们的任务:
-
准备数据
-
准备我们的样本
-
执行质心初始化搜索迭代,以确定我们“最佳”的初始质心集合
-
使用结果对完整数据集进行聚类
未来的帖子将对不同方法的质心初始化结果进行比较,以便更全面地理解实施的实际情况。现在,让我们介绍并探讨这种特定的质心初始化方法。
数据准备
对于这个概述,我们将使用3D 道路网络数据集。
由于这个特定的数据集没有缺失值,也没有类别标签,我们的数据准备主要包括归一化,并删除一列,该列标识地理位置,这些额外的 3 列测量数据来源于此,对于我们的任务没有用处。有关更多详细信息,请参见数据集描述。
import numpy as np
import pandas as pd
from sklearn import preprocessing
# Read dataset
data = pd.read_csv('3D_spatial_network.csv', header=None)
# Drop first column (not required)
data.drop(labels=0, axis=1, inplace=True)
# Normalize data (min/max scaling)
data_arr = data.values
sc = preprocessing.MinMaxScaler()
data_sc = sc.fit_transform(data_arr)
data = pd.DataFrame(data_sc)
让我们查看一下我们的数据样本:
data.sample(10)
准备样本
接下来,我们将提取用于找到“最佳”初始质心的样本。让我们明确我们正在做什么:
-
我们正在从数据集中提取一组样本
-
然后,我们将对这些样本数据进行连续的 k 均值聚类,每次迭代将:
-
随机初始化 k 个质心,并进行 n 次迭代的 k 均值聚类算法
-
每个质心的初始惯性(簇内平方和)将被记录下来,同时也会记录其最终惯性,提供最大惯性增量的初始质心将被选为我们对完整数据集进行聚类的初始质心
-
-
然后,我们将对完整数据集进行全面的 k 均值聚类,使用在上一步找到的初始簇
2 个重要点:
-
为什么不使用惯性最大的减少量?(希望这个区域的初始动量会持续下去。)这样做也是一个有效的选择(并且只需更改一行代码即可实现)。这是一个任意的初步实验选择,可能需要更多调查。然而,在多个样本上的重复执行和比较最初显示,最低惯性和惯性最大减少量大多数时间是重合的,因此这个决定可能实际上是任意的,但在实践中也可能没有影响。
-
特别说明的是,我们并不是从数据集中多次抽样(例如,每次质心初始化的迭代都从数据集中抽样一次)。我们为一个质心初始化搜索的所有迭代抽样一次。从中我们将随机推导出多个初始质心。这与每次质心初始化迭代的重复抽样的概念形成对比。
下面,我们设置:
-
样本大小作为我们完整数据集的比例
-
为了可重复性设置的随机状态
-
我们数据集的聚类数(k)
-
我们的 k 均值算法的迭代次数(n)
-
在我们的样本数据集上进行聚类时,尝试找到最佳初始质心的次数
然后我们设置我们的样本数据
# Some variables
SAMPLE_SIZE = 0.1
RANDOM_STATE = 42
NUM_CLUSTERS = 10 # k
NUM_ITER = 3 # n
NUM_ATTEMPTS = 5 # m
data_sample = data.sample(frac=SAMPLE_SIZE, random_state=RANDOM_STATE, replace=False)
data_sample.shape
现在我们有了数据样本(data_sample),我们准备进行质心初始化的迭代以进行比较和选择。
对样本数据进行聚类
由于 Scikit-learn 的 k 均值聚类实现不允许轻松获取聚类迭代之间的质心,我们不得不稍微修改工作流程。虽然verbose选项确实直接在屏幕上输出一些有用的信息,并且重定向此输出然后后期解析是获取所需内容的一种方法,但我们将编写自己的外部迭代循环来自己控制n变量。
这意味着我们需要计算迭代次数,并在每次聚类步骤运行后捕获我们需要的内容。然后我们将把那个聚类迭代循环封装在一个质心初始化循环中,该循环将从我们的样本数据中初始化k个质心,共m次。这是我们特定 k 均值质心初始化过程中的超参数,超出了“常规”k 均值。
根据上述参数,我们将把数据集聚类为 10 个簇(NUM_CLUSTERS,或k),我们将运行 3 次迭代的质心搜索(NUM_ITER,或n),我们将尝试 5 个随机初始质心(NUM_ATTEMPTS,或m),然后确定“最佳”质心集合,以便进行完整的聚类(在我们的案例中,度量是最低的簇内平方和,或惯性)。
然而,在任何聚类之前,让我们看看在任何聚类迭代之前单次初始化 k 均值的样本。
from sklearn.cluster import KMeans
km = KMeans(n_clusters=NUM_CLUSTERS, init='random', max_iter=1, n_init=1)#, verbose=1)
km.fit(data_sample)
print('Pre-clustering metrics')
print('----------------------')
print('Inertia:', km.inertia_)
print('Centroids:', km.cluster_centers_)
Pre-clustering metrics
----------------------
Inertia: 898.5527121490726
Centroids: [[0.42360342 0.20208702 0.26294088]
[0.56835267 0.34756347 0.14179924]
[0.66005691 0.73147524 0.38203476]
[0.23935675 0.08942105 0.11727529]
[0.58630271 0.23417288 0.45793108]
[0.1982982 0.11219503 0.23924021]
[0.79313864 0.52773534 0.1334036 ]
[0.54442269 0.60599501 0.17600424]
[0.14588389 0.29821987 0.18053109]
[0.73877864 0.8379479 0.12567452]]
在下面的代码中,请注意,由于我们自己管理这些连续迭代,我们必须手动跟踪每次迭代开始和结束时的质心。然后,我们将这些结束质心输入到下一个循环迭代中作为初始质心,并运行一次迭代。这有点繁琐,令人烦恼的是我们不能直接从 Scikit-learn 的实现中获得这一点,但并不困难。
final_cents = []
final_inert = []
for sample in range(NUM_ATTEMPTS):
print('\nCentroid attempt: ', sample)
km = KMeans(n_clusters=NUM_CLUSTERS, init='random', max_iter=1, n_init=1)#, verbose=1)
km.fit(data_sample)
inertia_start = km.inertia_
intertia_end = 0
cents = km.cluster_centers_
for iter in range(NUM_ITER):
km = KMeans(n_clusters=NUM_CLUSTERS, init=cents, max_iter=1, n_init=1)
km.fit(data_sample)
print('Iteration: ', iter)
print('Inertia:', km.inertia_)
print('Centroids:', km.cluster_centers_)
inertia_end = km.inertia_
cents = km.cluster_centers_
final_cents.append(cents)
final_inert.append(inertia_end)
print('Difference between initial and final inertia: ', inertia_start-inertia_end)
Centroid attempt: 0
Iteration: 0
Inertia: 885.1279991728289
Centroids: [[0.67629991 0.54950506 0.14924545]
[0.78911957 0.97469266 0.09090362]
[0.61465665 0.32348368 0.11496346]
[0.73784495 0.83111278 0.11263995]
[0.34518925 0.37622882 0.1508636 ]
[0.18220657 0.18489484 0.19303869]
[0.55688642 0.35810877 0.32704852]
[0.6884195 0.65798194 0.48258798]
[0.62945726 0.73950354 0.21866185]
[0.52282355 0.12252092 0.36251485]]
Iteration: 1
Inertia: 861.7158412685387
Centroids: [[0.67039882 0.55769658 0.15204125]
[0.78156936 0.96504069 0.09821352]
[0.61009844 0.33444322 0.11527662]
[0.75151713 0.79798919 0.1225065 ]
[0.33091899 0.39011157 0.14788905]
[0.18246521 0.18602087 0.19239602]
[0.55246091 0.3507018 0.33212609]
[0.68998302 0.65595219 0.48521344]
[0.60291234 0.73999001 0.23322449]
[0.51953015 0.12140833 0.34820443]]
Iteration: 2
Inertia: 839.2470653106332
Centroids: [[0.65447477 0.55594052 0.15747416]
[0.77412386 0.952986 0.10887517]
[0.60761544 0.34326727 0.11544127]
[0.77183027 0.76936972 0.12249837]
[0.32151587 0.39281244 0.14797103]
[0.18240552 0.18375276 0.19278224]
[0.55052636 0.34639191 0.33667632]
[0.691699 0.65507199 0.48648245]
[0.59408317 0.73763362 0.23387334]
[0.51879974 0.11982321 0.34035345]]
Difference between initial and final inertia: 99.6102464383905
...
完成后,让我们看看质心搜索的结果。首先检查我们最终惯性的列表(或簇内平方和),寻找最低值。然后,我们将相关的质心设置为下一步的初始质心。
# Get best centroids to use for full clustering
best_cents = final_cents[final_inert.index(min(final_inert))]
best_cents
下面是这些质心的样子:
array([[0.55053207, 0.16588572, 0.44981164],
[0.78661867, 0.77450779, 0.11764745],
[0.656176 , 0.55398196, 0.4748823 ],
[0.17621429, 0.13463117, 0.17132811],
[0.63702675, 0.14021011, 0.18632431],
[0.60838757, 0.39809226, 0.14491584],
[0.43593405, 0.49377153, 0.14018223],
[0.16800744, 0.34174697, 0.19503396],
[0.40169376, 0.15386471, 0.23633233],
[0.62151433, 0.72434071, 0.25946183]])
运行完整的 k-means 聚类
现在,我们可以用最佳的初始质心在完整数据集上运行 k-means 聚类。由于 Scikit-learn 允许我们传入一组初始质心,我们可以通过以下相对简单的代码来利用这一点。
km_full = KMeans(n_clusters=NUM_CLUSTERS, init=best_cents, max_iter=100, verbose=1, n_init=1)
km_full.fit(data)
这次 k-means 运行在 13 次迭代中收敛:
...
start iteration
done sorting
end inner loop
Iteration 13, inertia 7492.170210199639
center shift 1.475641e-03 within tolerance 4.019354e-06
为了对比,这里是使用随机初始化质心(“常规”k-means)的完整 k-means 聚类运行:
km_naive = KMeans(n_clusters=NUM_CLUSTERS, init='random', max_iter=100, verbose=1, n_init=1)
km_naive.fit(data)
此次运行耗时 39 次迭代,惯性几乎相同:
...
start iteration
done sorting
end inner loop
Iteration 39, inertia 7473.495361902045
center shift 1.948248e-03 within tolerance 4.019354e-06
我将 13 次迭代与 39 次迭代(或类似情况)的执行时间差异留给读者自行探索。不用说,提前在样本数据(在我们的案例中,是完整数据集的 10%)上花费几次周期,长期来看节省了大量周期,同时没有牺牲我们的整体聚类指标。
当然,在做出任何一般性结论之前,需要额外的测试,在未来的文章中,我将对多种数据集上的若干质心初始化方法进行实验,并使用一些附加指标进行比较,希望能够更清晰地了解优化无监督学习工作流程的方法。
相关:
-
通过朴素分片质心初始化方法提高 k-means 聚类效率
-
使用 Python 和 SciPy 比较距离测量
-
从头开始的 Python 机器学习工作流程 第二部分:k-means 聚类
更多相关内容
基于高中数学快速学习 AI 和数据科学 – KDnuggets 优惠
原文:
www.kdnuggets.com/2018/05/jaokar-learn-ai-data-science-high-school-math.html
基于高中数学快速学习 AI 和数据科学 - KDnuggets 优惠
如果你可以基于已有知识学习 AI 和数据科学,那会怎样?
通过这个有限的早鸟优惠,你有机会以独特的方式加速学习人工智能。
这是一个简单的观察:
数据科学的数学基础包括四个要素:线性代数、概率论、多变量微积分和优化理论。
这些内容中的大部分(至少部分)在高中都有教授。
在本项目中,我们利用你在高中学习的这些数学基础来教授数据科学和人工智能的基础知识。
该项目为期三个月,互动且个性化,包含完成证书。编程示例使用 Python(Pandas 和 NumPy)。
该项目通过视频进行授课。该项目还包括一本 PDF 书籍的副本。
从 2018 年 7 月 1 日开始。名额有限。
价格为$99 USD。
仅限有限时间内有效。
如需更多信息,请联系 info@futuretext.com
该项目由Ajit Jaokar创建。Ajit 基于伦敦,专注于数据科学和人工智能,并在牛津大学教授(物联网数据科学)。该项目面向从业者,与任何学术机构无关。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
Java 可以用于机器学习和数据科学吗?
原文:
www.kdnuggets.com/2020/04/java-used-machine-learning-data-science.html
评论
由 Malcom Ridgers, BairesDev

我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
近年来,机器学习、数据科学和人工智能一直是最受关注的技术,这也是理所应当的。这些技术的进步将自动化和业务流程提升到了一个新的水平。各种规模的组织正在投入数百万美元用于研究和人员,以构建这些极其强大的数据驱动应用程序。
有许多不同的编程语言适用于开发机器学习和数据科学应用。虽然 Python 和 R 已成为构建这些程序的热门选择,但许多组织正在转向 Java 应用开发 来满足他们的需求。从企业级业务解决方案和导航系统到手机和应用程序,Java 几乎适用于所有技术领域。
在 90 年代初,一位名叫詹姆斯·戈斯林及其团队的加拿大计算机科学家在太阳微系统公司(现为甲骨文公司所有)创建了 Java。二十多年后,Java 仍然是当今排名靠前且最有利可图的编程语言之一。
为什么选择 Java 用于数据科学和机器学习?
Java 是许多日常使用的设备和应用程序背后的无形力量,驱动着我们的日常生活。Java 不仅可以用于机器学习和数据科学应用开发,而且由于许多原因,它也是许多开发者的首选,包括:
-
Java 是一种用于企业开发的最古老的语言之一。通常,在开发和技术领域,古老意味着过时。然而,情况并非如此。Java 的历史意味着许多公司可能已经在使用大量的编程语言而自己并未意识到。基础设施、软件、应用程序以及公司技术的许多其他工作部分可能已经建立在 Java 之上,这有助于简化集成并减少兼容性问题。
-
数据科学与大数据息息相关。大多数用于大数据的流行框架和工具通常是用 Java 编写的。这包括 Fink、Hadoop、Hive 和 Spark。
-
Java 在数据科学领域和数据分析中的多个过程中都是可用的,包括数据清洗、数据导入和导出、统计分析、深度学习、自然语言处理(NLP)和数据可视化。
-
开发人员认为 Java 虚拟机是机器学习和数据科学的最佳平台之一,因为它使得开发人员能够编写在多个平台上完全相同的代码。它还允许他们更快地创建自定义工具,并拥有许多帮助提高整体生产力水平的 IDE。
-
Java 8 的发布引入了 Lambdas。 Lambda 表达式 赋予开发人员管理 Java 语言巨大功能的能力。这显著简化了大型数据科学或企业项目的开发。
-
作为一种强类型编程语言,Java 确保程序员对处理的变量和数据类型明确具体。有时与静态类型混淆,强类型使得管理大型数据应用程序变得更容易,同时简化了代码库维护。它还帮助开发人员避免编写单元测试的需求。
-
可扩展性是开发人员在开始项目之前必须考虑的编程语言的重要方面。Java 使应用程序的扩展过程对数据科学家和程序员都变得更加简单。这使得它成为构建更大或更复杂的人工智能和机器学习应用程序的绝佳选择,尤其是在从零开始构建时。
-
许多今天广泛使用的数据科学和机器学习编程语言并不是最快的选择。Java 非常适合这些速度关键的项目,因为它执行速度快。许多今天最流行的网站和社交应用程序依赖于 Java 来满足他们的数据工程需求,包括 LinkedIn、Facebook 和 Twitter。
-
生产代码库通常用 Java 编写。了解 Java 帮助开发人员搞清楚数据是如何生成的,提交合并请求到生产代码库,并将机器学习解决方案部署到生产环境中。
-
Java 拥有许多适用于数据科学和机器学习的库和工具。例如,Weka 3 是一个完全基于 Java 的工作台,广泛用于机器学习、数据挖掘、数据分析和预测建模中的算法。大规模在线分析是一个开源软件,专门用于实时数据流的数据挖掘。
Java 是一种极其有用、快速且可靠的编程语言,帮助开发团队构建各种项目。从数据挖掘和数据分析到机器学习应用的构建,Java 在数据科学领域有着广泛的应用。它是这些任务中最受欢迎的语言之一,原因有很多。如果你正准备进行机器学习项目,考虑使用它。你会惊讶于你能从中获得多少。
简介:马尔科姆·里杰斯是一位专注于软件外包行业的技术专家。他能够获取最新的市场动态,并对创新和科技企业的未来趋势有敏锐的洞察力。
相关:
-
Kubeflow 如何为你的 Kubernetes 部署添加 AI
-
人工智能、机器学习、深度学习和 Java 的两年生活
-
为什么 Python 是数据科学中最受欢迎的语言之一?
更多相关话题
你的工作会被机器取代吗?
评论
由 马丁·佩里,微软高级数据专业人士
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
是的!这将会发生。然而,你可以通过成为一个公民开发者来应对并在这个破坏性的时代中蓬勃发展!
这是一个大规模颠覆性数字化转型的时代。数据的供应年年指数级增长——这都由于我们周围的数字化,从人与人之间的互动到人与机器之间的互动。所有这些迭代都通过数十亿个传感器、屏幕和设备被捕捉和数字化。
这些数据由机器的贪婪需求消费——算法驱动虚拟和物理机器人。运行这些机器人几乎是免费的:处理能力、连接性和数据存储普遍且丰富。
你的未来职业将被数字化!工作被简化为数据。一旦简化为数据,机器执行得更好,因为机器的表现具备:
-
成本节省更便宜
-
更高的速度更快
-
更高的质量和准确性更好
创新/更高价值的工作(如商业洞察、客户参与、设计)不容易数字化。人类将在这些创造性和更高价值的工作中继续超越机器。你必须转变你的重点。
我们在知识经济中的工作方式已经改变——使用浏览器和搜索引擎进行信息发现的时代已经结束。现在,期望数据能即时传递到最终用户设备作为信息。搜索不再是在未处理数据的海洋中进行,而是期望在最终用户设备上提供清晰可消费的信息流。应用在这方面非常棒。
这导致了应用需求的爆炸。预计应用的增长速度是全球 IT 交付能力的五倍——四年内将超过 5 亿个应用。IT 功能的专业发展无法跟上。你可以转变以填补这一空缺,自我服务,并在未来保持相关性。公民开发工具现已可用,以满足应用生产和业务流程自动化的需求。
这个大规模的数字转型时代将要求你的参与。静坐不动只会让机器自动化你的当前角色,并做得更好。调整方向,创造你的未来。设计机器高效的工作流程和过程。利用生产力指数增长的好处。专注于更高价值的工作。
机器将至少取代你工作的部分;但你可以调整、留在岗位上并成长。
成为公民开发者!
简介: 马丁·佩里的个人资料 完成了公路工程博士学位,并在建筑材料行业担任了 5 年的项目管理职位。2000 年,他进入软件行业,担任 IBM 和微软的财务、战略及高级领导角色。他目前的领导角色是高级数据专业人士。他秉持成长心态,不断寻找学习和成长的机会,以保持在现代职场中的相关技能。他最近完成了由 EDX.org 主办的微软专业数据科学课程,获得了爱尔兰分析协会认证的数据科学家称号,并成为了微软认证培训师。
相关:
-
数据分析师会被 AI 取代吗?
-
在数据领域选择合适的工作:工程文化中的 5 个标志
-
GitHub Copilot 与编程自动化中的 AI 语言模型的崛起
更多相关内容
数据分析领域的职业趋势:NLP 用于职位趋势分析
原文:
www.kdnuggets.com/job-trends-in-data-analytics-nlp-for-job-trend-analysis
作者:Mahantesh Pattadkal & Andrea De Mauro
数据分析在近年来经历了显著增长,这得益于数据在关键决策过程中的应用进展。数据的收集、存储和分析也因这些进展而显著提升。此外,数据分析领域对人才的需求暴涨,使得具备必要技能和经验的个人在求职市场上面临高度竞争。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
数据驱动技术的快速扩展相应地导致了对专业角色的需求增加,例如“数据工程师”。这种需求激增不仅限于数据工程,还包括数据科学家和数据分析师等相关职位。
认识到这些职业的重要性,我们的博客系列旨在从在线职位发布中收集实际数据,并分析这些数据以了解这些职位的需求性质,以及每个类别中所需的各种技能。
在这篇博客中,我们介绍了一个基于浏览器的“数据分析职位趋势” 应用程序,用于可视化和分析数据分析市场的职位趋势。在从在线职位代理处抓取数据后,它使用 NLP 技术来识别职位发布中所需的关键技能。图 1 显示了数据应用程序的快照,探索了数据分析职位市场的趋势。

图 1: KNIME 数据应用程序“数据分析职位趋势”的快照
对于实施,我们采用了低代码数据科学平台:KNIME Analytics Platform。该开源且免费的端到端数据科学平台基于可视化编程,提供广泛的功能,从纯 ETL 操作和多种数据源连接器进行数据混合,到机器学习算法,包括深度学习。
支持该应用程序的一系列工作流可以从KNIME 社区中心免费下载,链接为“数据分析职位趋势”。可以通过“数据分析职位趋势”在浏览器中进行评估。
“数据分析职位趋势”应用程序
该应用程序由图 2 中显示的四个工作流生成,这些工作流按顺序执行以下步骤:
-
网络爬虫用于数据收集
-
NLP 解析和数据清理
-
主题建模
-
职位角色技能归因分析
工作流可以在KNIME 社区中心的公共空间 - 数据分析职位趋势中找到。
图 2: KNIME 社区中心空间 - 数据分析职位趋势包含一组用于构建应用程序“数据分析职位趋势”的四个工作流
-
“01_ 网络爬虫用于数据收集”工作流爬取在线职位发布信息,并将文本信息提取为结构化格式
-
“02_NLP 解析和清理”工作流执行必要的清理步骤,然后将长文本解析成更小的句子
-
“03_ 主题建模和探索数据应用”使用清理后的数据构建主题模型,然后在数据应用中可视化其结果
-
“04_ 职位技能归因”工作流评估技能在职位角色(如数据科学家、数据工程师和数据分析师)之间的关联,基于 LDA 结果。
网络爬虫用于数据收集
为了及时了解就业市场上所需的技能,我们选择了分析来自在线职位代理机构的网页抓取职位。鉴于区域差异和语言多样性,我们专注于美国的职位发布。这确保了相当大比例的职位发布以英语呈现。我们还专注于 2023 年 2 月到 2023 年 4 月的职位发布。
KNIME 工作流“01_Web Scraping for Data Collection”在图 3 中通过职位代理网站上的一系列搜索 URL 进行爬取。
为了提取与数据分析相关的职位信息,我们使用了六个关键词进行搜索,这些关键词涵盖了数据分析领域,分别是:“大数据”、“数据科学”、“商业智能”、“数据挖掘”、“机器学习”和“数据分析”。搜索关键词存储在一个 Excel 文件中,并通过Excel Reader节点读取。
图 3:KNIME 工作流“01_Web Scraping for Data Collection”根据多个搜索 URL 抓取职位发布信息
该工作流的核心节点是Webpage Retriever节点。它被使用了两次。第一次(外部循环),该节点根据提供的关键词爬取网站,并生成在过去 24 小时内发布的美国职位的相关 URL 列表。第二次(内部循环),该节点从每个职位发布的 URL 中提取文本内容。紧随Webpage Retriever节点之后的 Xpath 节点解析提取的文本,以获取所需的信息,例如职位标题、要求的资格、职位描述、薪资和公司评级。最后,结果被写入本地文件以供进一步分析。图 4 展示了 2023 年 2 月抓取的职位样本。
图 4:2023 年 2 月的网页抓取结果样本
自然语言处理解析和数据清理
图 5:02_NLP Parsing and cleaning 工作流用于文本提取和数据清理
与所有新收集的数据一样,我们的网络抓取结果也需要一些清理。我们进行了 NLP 解析和数据清理,并使用图 5 所示的工作流02_NLP 解析与清理编写了相应的数据文件。
从抓取的数据中保存了多个字段,形式为字符串值的串联。在这里,我们使用一系列字符串操作节点在“标题-位置-公司名称提取”元节点中提取了各个部分,然后去除了不必要的列并删除了重复的行。
我们将每个职位发布文本分配了一个唯一的 ID,并通过单元分割器节点将整个文档分割成句子。每个职位的元信息——标题、地点和公司——也被提取并与职位 ID 一起保存。
从所有文档中提取了最常见的 1000 个词,以生成一个停用词列表,包括“申请人”、“合作”、“就业”等词。这些词出现在每个职位发布中,因此对下一步的 NLP 任务没有信息增益。
这个清理阶段的结果是一组三个文件:
-
包含文档句子的表格;
-
包含职位描述元数据的表格;
-
包含停用词列表的表格。
主题建模及结果探索
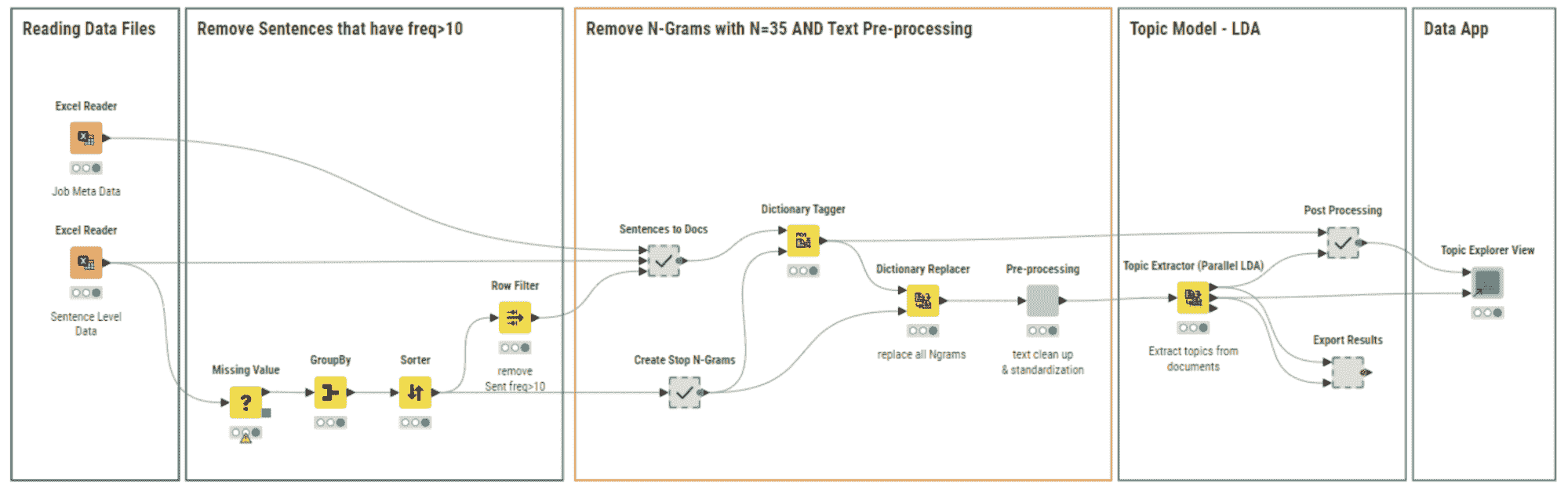
图 6: 03_ 主题建模与探索数据应用工作流构建了一个主题模型,并允许用户通过主题探索视图组件以可视化方式探索结果。
工作流03_ 主题建模与探索数据应用(图 6)使用了前一个工作流中的清理数据文件。在这个阶段,我们的目标是:
-
检测并移除出现在许多职位发布中的常见句子(停用词组)
-
执行标准文本处理步骤,为主题建模准备数据
-
建立主题模型并可视化结果。
我们将在以下小节中详细讨论上述任务。
3.1 使用 N-gram 移除停用词组
许多职位发布中包含公司政策或一般协议中常见的句子,例如“非歧视政策”或“保密协议”。图 7 提供了一个例子,其中职位发布 1 和 2 提到了“非歧视”政策。这些句子与我们的分析无关,因此需要从我们的文本语料库中删除。我们将这些句子称为“停用短语”,并采用两种方法来识别和过滤它们。
第一个方法很简单:我们计算语料库中每个句子的频率,并删除频率大于 10 的句子。
第二种方法涉及 N-gram 方法,其中 N 的值范围可以从 20 到 40。我们选择一个 N 值,并通过计算分类为停用短语的 N-gram 的数量来评估从语料库中获得的 N-gram 的相关性。我们对范围内的每个 N 值重复这一过程。我们选择了 N=35 作为识别最多停用短语的最佳 N 值。

图 7:职位发布中常见句子的示例,这些句子可以被视为“停用短语”
我们使用了两种方法来移除“停用短语”,如图 7 所示的工作流程所示。首先,我们删除了最常见的句子,然后我们创建了 N=35 的 N-gram,并在每个文档中使用字典标记器节点对它们进行标记,最后,我们使用字典替换器节点移除了这些 N-gram。
3.2 使用文本预处理技术准备主题建模的数据
删除停用短语后,我们进行标准的文本预处理,以准备数据进行主题建模。
首先,我们从语料库中去除数字和字母数字值。然后,我们移除标点符号和常见的英语停用词。此外,我们使用之前创建的自定义停用词列表来过滤出职位领域特定的停用词。最后,我们将所有字符转换为小写字母。
我们决定关注具有重要意义的词汇,因此我们过滤了文档,只保留名词和动词。这可以通过为文档中的每个词分配词性标记(POS)来完成。我们使用POS 标记器节点来分配这些标记,并根据其值进行过滤,特别是保留 POS = 名词和 POS = 动词的词汇。
最后,我们应用了斯坦福词形还原,确保语料库准备好进行主题建模。所有这些预处理步骤都由图 6 所示的“预处理”组件完成。
3.3 构建主题模型并进行可视化
在实现的最终阶段,我们应用了 Latent Dirichlet Allocation (LDA)算法,通过图 6 所示的Topic Extractor (Parallel LDA)节点构建主题模型。LDA 算法生成多个主题(k),每个主题由(m)个关键词描述。参数(k,m)必须定义。
另外,k 和 m 不能过大,因为我们希望通过查看关键词(技能)及其相应的权重来可视化和解释主题(技能集)。我们探索了 k 的范围[1, 10],并将 m 的值固定为 15。经过仔细分析,我们发现 k=7 能够产生最具多样性和明显区分的主题,并且关键词的重叠最小。因此,我们确定 k=7 是我们分析的最佳值。
使用互动数据应用探索主题建模结果
为了让每个人都能访问主题建模结果并自己尝试,我们将工作流程(如图 6 所示)作为一个数据应用部署在KNIME Business Hub上,并公开了它,供所有人访问。你可以在以下链接查看:数据分析职位趋势。
该数据应用的可视化部分来自Topic Explorer View组件,由Francesco Tuscolano和Paolo Tamagnini提供,并可以从KNIME Community Hub免费下载,提供了按主题和文档的多个交互式可视化。
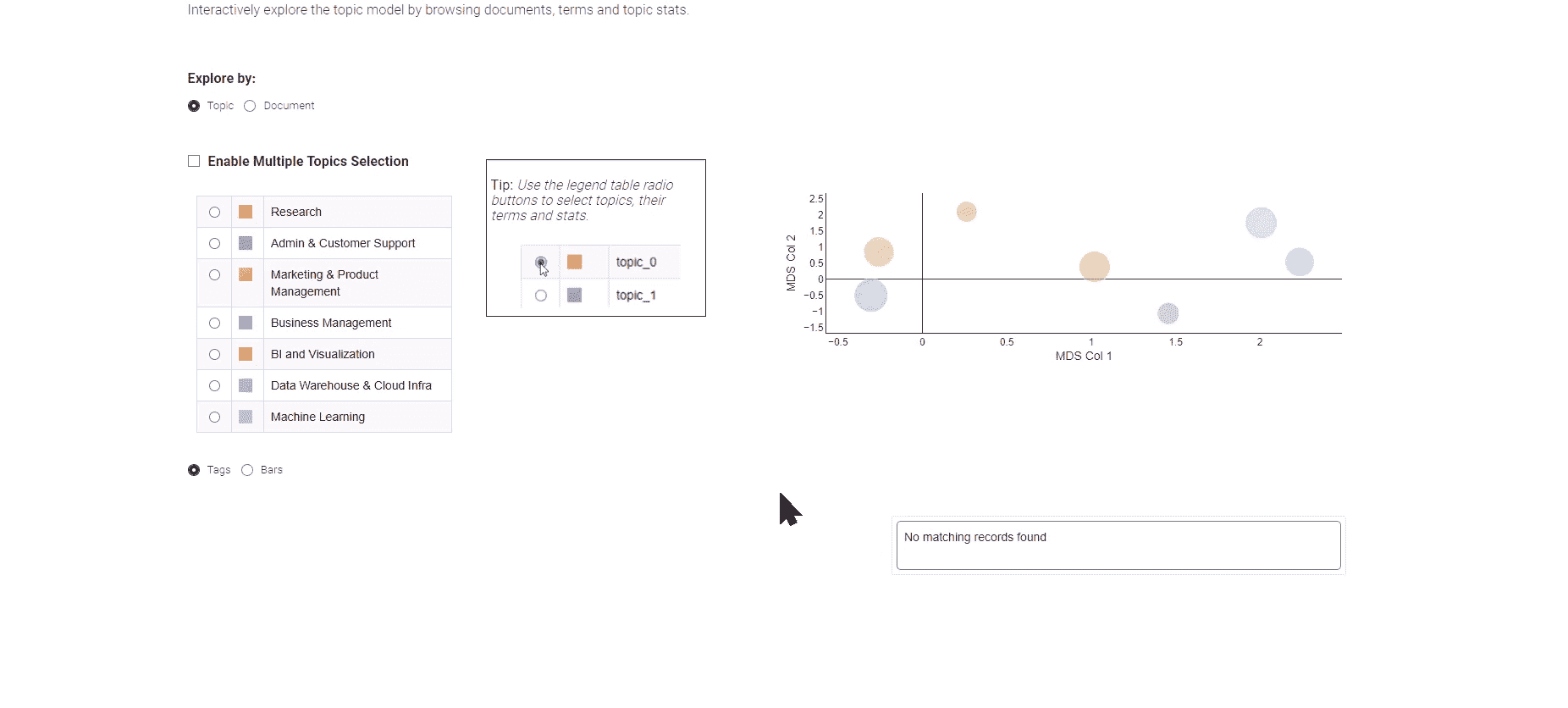
图 8: 数据分析职位趋势 用于探索主题建模结果
图 8 中展示的这个数据应用程序提供了两个不同的视图选择:“主题”和“文档”视图。
“主题”视图使用多维尺度算法将主题绘制在二维图上,有效地展示了它们之间的语义关系。在左侧面板中,你可以方便地选择感兴趣的主题,系统会显示其相应的顶级关键词。
要深入探讨个别职位发布,请选择“文档”视图。 “文档”视图以两个维度对所有文档进行简化呈现。利用框选方法定位重要文档,底部将显示你所选择文档的概述。
使用 NLP 探索数据分析职位市场
我们在这里提供了“数据分析职位趋势”应用程序的总结,该程序已实施并用于探索数据科学职位市场中最新的技能要求和职位角色。在这篇博客中,我们将行动范围限制在 2023 年 2 月至 4 月期间以英语书写的美国职位描述。
要了解工作趋势并提供审查, “数据分析职位趋势” 爬取招聘网站,提取在线职位发布的文本,通过执行一系列自然语言处理(NLP)任务提取主题和关键词,最后通过主题和文档对结果进行可视化,以识别数据中的模式。
该应用程序包含一组四个 KNIME 工作流,按顺序运行进行网页抓取、数据处理、主题建模,然后是交互式可视化,以帮助用户发现职位趋势。
我们在KNIME Business Hub上部署了该工作流并使其公开,所有人都可以访问。你可以在以下链接查看:数据分析职位趋势。
完整的工作流集可以从 KNIME Community Hub 免费下载,链接为数据分析职位趋势。这些工作流可以轻松修改和适应,以发现其他领域的市场趋势。只需更改 Excel 文件中的搜索关键词、网站和搜索时间范围即可。
结果如何?在今天的数据科学就业市场中,哪些技能和职业角色最受追捧?在我们下一篇博客文章中,我们将引导你探索这一主题建模的结果。我们将深入研究职位角色和技能之间的有趣互动,同时获得关于数据科学就业市场的宝贵见解。敬请关注我们引人入胜的探索!
资源
- 数据分析职位要求和在线课程的系统性综述 由 A. Mauro 等人撰写。
马亨特什·帕塔德卡尔 拥有超过 6 年的数据科学项目和产品咨询经验。凭借数据科学硕士学位,他在深度学习、自然语言处理和可解释机器学习方面展现了出色的专长。此外,他积极参与 KNIME 社区,以便在基于数据科学的项目中进行合作。
安德烈亚·德·毛罗在宝洁和沃达丰等跨国公司拥有超过 15 年的业务分析和数据科学团队建设经验。除了企业角色外,他还在意大利和瑞士的几所大学教授市场营销分析和应用机器学习。通过他的研究和写作,他探讨了数据和人工智能的商业及社会影响,坚信更广泛的分析素养将使世界变得更好。他的最新著作《数据分析轻松入门》由 Packt 出版。他还登上了《CDO》杂志 2022 年全球“40 位 40 岁以下精英”名单。
相关主题
数据分析中的职业趋势:第二部分
由 Andrea De Mauro 和 Mahantesh Pattadkal
在我们从博客系列第一部分的“数据分析职业趋势”继续之前,我们的数据分析职业趋势和自然语言处理(NLP)作用的旅程仍在继续。
在第一部分中,我们介绍了“数据分析职业趋势”应用,介绍了如何收集数据并应用 NLP 进行分析,由KNIME 分析平台提供支持。我们讨论了用于收集有关数据分析职业市场的实时数据的网页抓取阶段,随后使用 NLP 技术清理数据。然后,我们介绍了一个主题模型,揭示了职位发布中的七种同质化技能集。这些技能集代表了各行业雇主在数据分析专业人员中寻找的能力和活动。
在系列博客的第二部分中,我们将描述已识别的技能集,并对数据科学职业发展的变化趋势进行一些基于数据的考虑。
话题及其描述
为了标记技能集,我们使用了 LDA 算法在职位发布中识别的最常见术语和权重。我们进一步分析每个主题中的职位描述,以突出关键活动、必要技能和最常见的行业。了解这些主题有助于求职者将其技能集与市场需求对齐,增加在数据分析领域找到合适职位的机会。在接下来的段落中,您将找到每个技能集的简要描述。
主题 0:研究与数据分析
下表展示了主题 0 的前五个术语及其权重。这些权重表示术语在定义特定主题时的重要性。考虑到这些术语及标记为主题 0 的文档,我们将这一技能集解释为“研究与数据分析”。
| 术语 | 权重 |
|---|---|
| 研究 | 4510 |
| 职位 | 4195 |
| 信息 | 4112 |
| 健康 | 3404 |
| 大学 | 2118 |
表 0:主题 0 的术语权重
这项技能集包括进行研究、分析数据以及提供驱动决策的见解等活动。作为数据分析的基石,这项技能集促进了从数据中提取有价值的见解、识别趋势以及做出明智决策。
从我们收集的职位信息中,与此技能集相关的基本能力要求是:
-
强大的分析和解决问题的能力
-
精通统计软件(R,Python)
-
具有数据可视化工具的经验
-
有效的沟通和文档编写技能
-
相关领域的背景(数学、统计学或数据科学)
主题 1:行政和客户支持
通过查看表 1 中的术语和权重以及与主题 1 相关的文件,我们决定将其标记为“行政和客户支持”。这项技能集包括管理客户互动、提供行政支持以及协调物流或采购流程。
| 术语 | 权重 |
|---|---|
| 支持 | 2321 |
| 管理 | 2307 |
| 信息 | 2134 |
| 职位 | 2126 |
| 客户 | 1909 |
表 1:主题 1 的术语-权重
在我们看来,成功完成需要此技能集的工作的基本能力是:
-
强大的组织和时间管理能力
-
注重细节
-
精通办公软件和沟通工具
-
优秀的人际关系和解决问题的技能
主题 2:市场营销和产品管理
根据表 2 中的术语,我们将其解读为“市场营销和产品管理”技能集。
| 术语 | 权重 |
|---|---|
| 业务 | 8487 |
| 团队 | 8021 |
| 产品 | 6825 |
| 客户 | 3923 |
| 市场营销 | 3740 |
表 2:主题 2 的术语-权重
这项技能集涉及开发市场营销策略、管理产品生命周期和推动市场增长。在数据分析驱动的工作中至关重要,因为它允许专业人士利用数据驱动的见解来做出有关市场趋势、客户偏好和产品表现的明智决策。
市场营销和产品管理技能集中所需的基本能力是:
-
强大的分析和战略思维能力
-
精通市场研究和竞争情报
-
具有市场营销工具和平台的经验
-
优秀的沟通和领导能力
-
商业、市场营销或相关领域的背景
主题 3:业务管理、数据治理与合规
根据表 2 中的术语,我们得出结论,它指的是“业务管理、数据治理与合规”技能集。
该技能集涵盖了监督业务运营、确保数据质量和安全,以及管理风险和监管要求。在数据分析密集型工作中,这一技能集有助于维护数据完整性、监控合规性、识别风险和利用数据驱动的见解优化业务流程。
| 术语 | 权重 |
|---|---|
| 商业 | 14046 |
| 管理 | 10531 |
| 团队 | 5835 |
| 分析 | 5672 |
| 项目 | 4309 |
表 3:主题 3 的术语权重
根据我们的发现,该技能集所需的能力有:
-
强大的组织和领导能力
-
精通数据管理、数据治理和风险评估
-
具备监管框架和行业标准的经验
-
有效的沟通和解决问题的能力
-
拥有商业、金融或相关领域的背景
主题 4:商业智能和数据可视化
观察到我们在主题 4 中找到的术语,我们将其称为“商业智能和数据可视化”技能集。
该技能集包括设计常见的 BI 解决方案,如仪表板和报告,创建有洞察力的可视化,并分析数据以做出明智的决策。在利用数据分析的工作中,这一技能集至关重要,将原始数据转化为推动战略决策的可操作见解。
| 术语 | 权重 |
|---|---|
| 商业 | 19372 |
| 分析 | 7687 |
| Power BI | 7359 |
| 智能 | 7040 |
| SQL | 5836 |
表 4:主题 4 的术语权重
在我们看来,BI 和数据可视化领域的基本能力要求是:
-
强大的分析和解决问题的能力
-
精通 BI 工具(如 Power BI、Tableau、SQL)
-
数据可视化技术的经验
-
有效的沟通和讲故事能力
主题 5:数据仓库和云基础设施
基于表 5 中显示的术语,我们将其解释为“数据仓库和云基础设施”技能集。
需要具备云计算和大数据工程技能的职位通常涉及设计和实施基于云的解决方案、管理大规模数据处理以及开发软件应用。它在数据分析密集型工作中至关重要,能有效处理和分析大量数据以获得有价值的见解。
| 术语 | 权重 |
|---|---|
| 开发 | 4525 |
| 云计算 | 3998 |
| 工程 | 3692 |
| 软件 | 3510 |
| 设计 | 3494 |
表 5:主题 5 的术语权重
在我们看来,与该技能集相关的基本能力要求有:
-
强大的编程和解决问题的能力
-
精通云平台(如 AWS、Azure 和 Google Cloud)
-
具备大数据技术(如 Hadoop、Spark 和 NoSQL 数据库)的经验
-
信息安全政策及相关流程的知识
主题 6:机器学习
根据表 6 中显示的术语,我们将其解读为“机器学习”技能集,这一技能集围绕设计 AI 模型、研究前沿机器学习技术以及开发智能软件解决方案。在数据分析密集型的工作中,它是 AI 模型训练和性能优化的基础。
| 术语 | 权重 |
|---|---|
| 机器 | 9782 |
| 科学 | 8861 |
| 研究 | 4686 |
| 计算机 | 4209 |
| Python | 4053 |
表 6:主题 6 的术语权重
根据我们的发现,今天在机器学习中所需的基本能力是
-
强大的编程和数学能力
-
对机器学习框架(如 TensorFlow、PyTorch)的专业知识
-
具备先进 AI 技术经验(如深度学习和自然语言处理)
-
高效的沟通和协作技能
技能集与职业档案
在本期中,我们将重点分析通过主题建模揭示的技能集关联,涉及三种不同的职业档案:数据工程师、数据分析师和数据科学家。为了将这些职业档案与职位发布对齐,我们利用了基于规则的分类器。该分类器根据职位标题中的关键词确定职位的档案分类。例如,标题为“数据架构师”的职位将被归类为数据工程师角色,而标题为“机器学习工程师”的职位将被归入数据科学家类别。
使用潜在狄利克雷分配(LDA)主题建模为每个职位发布提供了七种不同技能集的主题权重。通过计算所有专业档案中每种技能集的平均权重,我们得出了特定角色的平均技能集权重。值得注意的是,这些权重随后被标准化并表示为百分比。
如图 1 所示,我们展示了专业职位与相应技能集之间互动的深刻可视化。这一视觉图集成了雇主对数据工程师、数据分析师和数据科学家所需基本技能的集体期望。
正如预期,数据工程师的角色显著要求掌握“数据仓库与云基础设施”技能集。此外,对可视化和机器学习的额外理解也至关重要。这种对技能多样性的重视可以归因于对数据工程师将在支持数据分析师和数据科学家方面发挥关键作用的预期。
相反,数据科学家所需的主要专业技能在于“机器学习”,其次是“研究”方法的熟练程度。值得注意的是,涵盖“商业管理”和“产品管理”的混合技能集也具有重要意义。这概括了就业市场对有志数据科学家的复杂技能需求。
转向数据分析领域,一个关键要求是精通“BI 和可视化”。考虑到他们在生成业务报告、驱动仪表板和监控业务活力中的作用,这并不令人惊讶。作为辅助关键技能的“商业管理”需求也反映了这一角色的战略眼光。此外,与数据科学家角色类似,数据分析师领域也存在“产品管理”和“研究”能力的需求。
总结来说,这项探索突显了各类数据分析角色技能要求的复杂性。它描绘了雇主对数据工程师、数据分析师和数据科学家等职位的多方面期望。
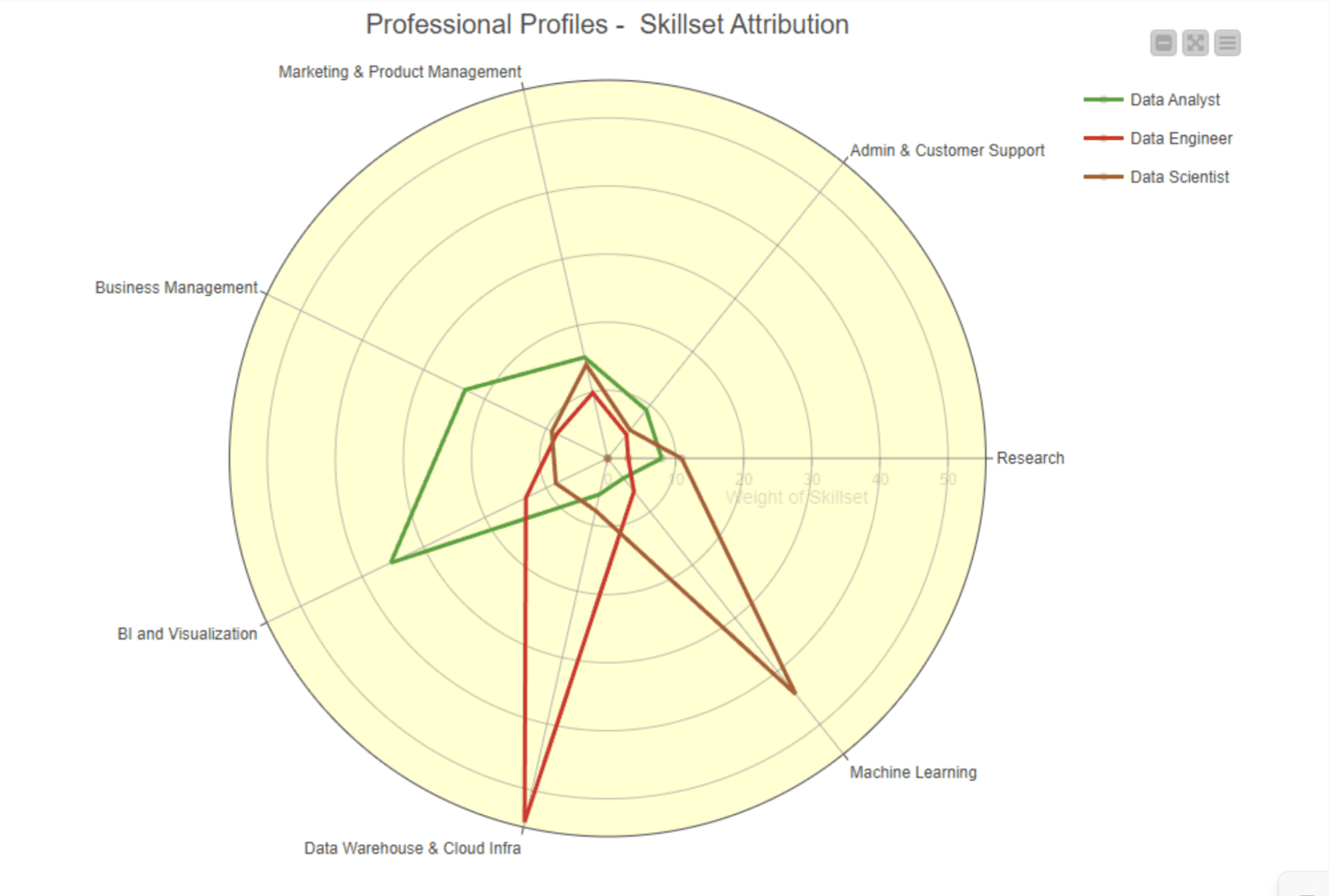
图 1:雷达图显示了专业配置与维度中显示的技能集之间的关联(点击放大)。
结论
我们对不断扩展的数据分析领域职位发布的分析旨在根据不同的技能集对职位进行分类,并阐明每个类别所需的多样化能力。随着该领域的指数级增长和基于数据做出的决策的关键性,数据的收集、存储和分析过程取得了显著进展,导致对数据分析专业人士的需求不断增加。
通过将职位发布分类为七个显著技能主题,我们揭示了在这一快速变化领域对专门技能和多面技能的需求。这些主题涵盖了数据分析、商业智能到机器学习和人工智能,突显了对能掌握数据、技术和跨职能团队合作的人的需求激增。
尽管如此,这项研究也有若干局限性。就业市场的动态性质以及新技术和方法的出现要求我们不断更新分析,而非静态的“快照”视图。此外,由于研究时依赖于现有的职位发布,我们的方法可能未能捕捉到数据分析领域多样化职位和技能的每一个细节。
我们所有的工作都可以在KNIME Community Hub Public Space - “Job Competency Application”上自由获取。你可以下载并尝试这些工作流,自己发现、扩展或改进。
接下来是什么?
展望未来,我们看到这项研究有显著扩展的潜力。这包括开发 KNIME 组件以实现第一部分中描述的“停止词移除”方法,以及在 KNIME 中建立一个人机交互的可视化框架。这样的框架将简化选择最连贯主题模型的过程,提升我们的工作规模。我们还设想使用 LLM 辅助机制来支持和简化主题建模阶段:这一场景无疑为进一步实验和研究留下了空间。
数据分析领域的专业人士必须保持信息灵通并具备适应能力,以应对新兴技术。这确保了他们的技能在不断变化的数据驱动决策环境中保持相关性和价值。通过识别和培养与所识别主题相关的技能,求职者可以在这一充满活力的市场中获得竞争优势。为了保持在该领域的相关性,数据分析专业人士必须在整个职业生涯中保持好奇心,并持续学习。
玛汉特什·帕塔德卡尔拥有超过 6 年的数据科学项目和产品咨询经验。他拥有数据科学硕士学位,专长于深度学习、自然语言处理和可解释的机器学习。此外,他积极参与 KNIME 社区的合作,以推进数据科学相关项目。
安德烈亚·德·毛罗在宝洁和沃达丰等跨国公司拥有超过 15 年的商业分析和数据科学团队建设经验。除了他的企业角色,他还在意大利和瑞士的几所大学教授市场营销分析和应用机器学习。通过他的研究和著作,他探讨了数据和人工智能的商业及社会影响,并坚信更广泛的分析素养将使世界变得更好。他的最新著作《数据分析简易指南》由 Packt 出版。他出现在 CDO 杂志 2022 年的全球‘40 位 40 岁以下’榜单中。
更多相关主题
从软件工程师到机器学习工程师的旅程
原文:
www.kdnuggets.com/2020/12/journey-from-software-machine-learning-engineer.html
评论
由 Guillermo Carrasco,iZettle,PayPal

定制的马克杯,特色展示了 Chris Albon 的 机器学习闪卡
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
我在 iZettle 工作了大约四年。我在这家公司并不是作为机器学习工程师开始的,而是在公司内部成长的过程中逐步过渡到这一职位的。
我的正规教育背景是计算机科学/软件工程,事实上,我已经作为软件开发人员工作了大约 8 年。这些年的软件工程经历使我具备了一些技能,这些技能使我在向机器学习工程师过渡时的路径颇具特色。我想与您分享一下我在准备这一角色时希望更多关注的方面,以及我认为我的背景如何帮助我完成这一过渡。
如何开始
首先——为什么?我对软件工程师的工作不满意吗?我认为成为机器学习工程师比成为软件工程师要更好?绝对不是! 这只是我喜欢花时间做的事情,那就是数据。我从 15 岁开始编程,一直热爱它。但我最喜欢的是用我的工作来理解世界。像很多人一样,我有很多“个人项目”想法从未实现,但当我阅读这些想法的列表时,我发现了类似于:构建工具以使用推特数据进行自然灾害检测,分析我社交媒体账户的数据以理解自己的行为,检测朋友聊天中的情绪等等。你看到了模式吗?所有这些项目想法都寻求对某种情况的理解,并且都围绕数据展开。因此,我一直对数据有很大兴趣,大约两年前我决定让这成为我的主要工作。我想认为机器学习是我个人的选择,但从数据驱动的角度来看,我可以将我的决定映射到近年来机器学习领域的高潮期,当时你阅读的每篇技术文章都在讲述某种机器学习创新,所以我想我永远不会知道。
无论如何,我做出了那个决定,幸运的是,iZettle 正在运行一个机器学习辅导项目,我愉快地报名参加了。
学习过程
在那个辅导项目中,我们逐章学习了Python 机器学习这本书。每周,我们讨论一章并编写一些练习代码来实验所学的概念。我发现这非常令人兴奋,它真正巩固了我对机器学习工作原理的基础理解。
除此之外,我利用空闲时间参加了一些在线课程,比如在 Udacity 上的深度学习专业课程,参与了Kaggle比赛(虽然没什么成功,我得承认),并尝试实现一些我之前提到的项目。
我告诉你这些不是为了炫耀,而是为了让你明白我在尽可能多地吸收关于这个话题的知识,当我准备好换标题时,我感觉自己对机器学习有了非常扎实的理解。
在超过 6 个月的密集学习之后,我加入了 iZettle 的机器学习团队。
课程和书籍无法教给你的
我带着满腔热情和渴望开始我的第一个项目。正是从这个第一个项目开始,我注意到学习机器学习和实际做机器学习之间的不同。这个第一个项目是关于尝试预测我们商户的破产,以便我们能够联系并帮助他们改善业务。
当你进行一个来自课程或书籍的项目时,该项目最重要的部分已经为你完成了。也就是说:你到底在尝试做什么? 在课程中,你会得到一个数据集、一个目标指标,你需要做的就是“处理”你的数据并训练模型,以在目标指标上获得良好的表现。
在这种情况下,有一些事情你不会学习,甚至不会质疑。
问题定义:从机器学习的角度来看,问题是如何被制定的,以使其有意义?对于破产问题,我对突然涌现出的问题感到震惊,几乎无中生有:预测破产是什么意思?这意味着商人明天破产吗?一周后?一个月后?我如何知道我们的哪些商人已经破产?这是缺乏活动吗?那么季节性因素呢?这是否是一些外部信息?我如何将其映射到算法可以学习的标签上?… 我习惯于得到一个标记的数据集,从未考虑过仅仅创建那个标签需要大量的思考、领域知识和商业考虑。而且根据你如何定义标签,你可以使用的问题和特征会完全改变。
数据: 我已经暗示了接下来要讲的内容,众所周知,获得正确的数据是机器学习问题中的一个难点。然而,当你第一次遇到这个问题时,它仍然会让你感到惊讶。数据很难获取,而且很混乱,你不应该盲目相信它。构建标签实际上是在你获得数据源之后进行的。在我的第一次任务中,我有两个来自不同来源的数据集,我必须将它们合并并映射到我们每个商人的特征集上。对于你引入的每一个新信息来源,你需要确保不仅数据质量是可接受的,还要确保你没有引入任何形式的bias,或者至少要考虑到这一点。
在某些情况下,你甚至没有要解决问题的数据,机器学习的工作在编写代码之前几个月就已经开始了,包括建立数据收集策略和与其他团队的关系。
评估:我们拥有数据集和标签。我们开始建模……那么我们如何衡量性能呢?这不仅仅是选择使用哪个指标的问题,还涉及到它是否符合业务逻辑。权衡取舍在这里发挥了重要作用。我以前从未考虑过使用哪个指标来衡量模型的性能,那是理所当然的。我真的在等待有人告诉我:使用准确率/ROC-AUC 等。当这种情况没有发生时,我不得不考虑一个指标及其影响,我意识到花费大量时间思考这一点是多么重要,同时对任何书籍或课程中对这个话题的关注感到有些失望。想一想:根据预测真正的值却是假的(即假阳性)或类似的情况的“严重程度”,你可能希望保持最低的精确度或召回率,而不管你的总体指标(例如 ROC-AUC)是上升还是下降。这只是一个例子,还有许多。
这些是我意识到在我所上的任何课程或阅读的书籍中完全没有学到的主要点。这些都是我在工作中、每天以及多亏了非常有经验和耐心的同事们学到的东西。
对我旅程有帮助的事物
当然,也有一些意外的好处,我可以利用作为软件工程师多年积累的技能。列举一些:
-
通用软件开发实践: 在许多课程中,花费大量时间解释常见的软件开发实践:版本控制、基础编程、专注于单一编程语言(90% 的时间该语言是 Python)等。多年来与软件打交道,这不仅是我已经有实践的领域,而且这也是一种“内化”的东西。这使我更容易开始测试和实施想法,并希望能够传播这些实践并激励我新加入的团队。
-
阅读和理解他人代码: 由于这一直是我做的事情,我非常擅长阅读其他同事的代码,并希望能够给予建设性的反馈。
-
灵活性在“为工作选择合适工具”方面。机器学习工程师往往会陷入他们习惯使用的工具中。虽然我没有数据来支持这一说法,但这是我注意到的。因为我曾使用过许多语言和框架,所以我发现尝试新工具和库相对容易(而且令人兴奋!),这希望能让我拥有更广泛的视野和工具集。
那么……该怎么办?
如果你处于与我曾经类似的情况,我有以下附加练习供你在阅读的书籍或所上的课程中进行。试着回答以下问题:
-
你想解决/预测什么? 你是否理解问题的所有部分?
-
你所得到的数据是否对你正在尝试解决的问题有意义?
-
数据是如何收集的? 如果你不能确定这一点,你会如何收集这些数据?需要多长时间?谁需要参与数据收集?是网页开发人员(可能是点击事件),应用程序开发人员(应用程序使用数据)等?
-
如果这是一个需要在公司内部解决的问题,除了你的预测,还需要什么其他的项目需求? 一些基础设施?任何商业决策?应用程序中的新功能?谁会参与其中?
-
你使用了什么评估指标? 你理解它吗?它是否适合这个问题?是否有其他替代指标对这个问题更有意义?误分类一个样本的成本是多少?
-
无论目标性能是什么:如果这是一个真实项目,你什么时候会感到满意? 为什么是这个数字?为什么不是更低/更高?
我相信,如果你真的尝试回答学习过程中遇到的每一个问题,你将会对“现实生活中的机器学习”有更广泛和现实的理解。
我希望这篇文章能帮助许多人在学习过程中!如果你有任何问题,或想与我们分享你的故事,我们很乐意听取!
个人简介: Guillermo Carrasco 是在 iZettle,PayPal 工作的机器学习工程师。对技术(尤其是数据和机器学习)、自然和各种户外运动感兴趣。对音乐充满热情。
原文。经许可转载。
相关:
-
数据工程师面试终极指南
-
数据专业人士如何在简历中增加更多变化
-
有抱负的数据科学家的顶级课程
更多相关话题
机器学习之旅 – 100 天机器学习代码
原文:
www.kdnuggets.com/2018/09/journey-machine-learning-100-days.html
评论
你会让人工智能为你做决定吗? — 如果会,那么在什么程度上呢?也许你的生命依赖于此。随着对人工智能的讨论和对其监管的呼声(显然,人工智能有一天会杀死我们所有人),我一直在思考在什么情况下我们可能会把决策权从机器(称之为人工智能)手中夺回。但我们仍然利用它们来谋取我们的利益(尽可能多) — 这并不像听起来那么疯狂,因为人类已经这样做了很多年。它无处不在,无法掩盖的是,它将继续存在。

来源 — www.reddit.com/r/memes/comments/8s6wq1/terrifying_artificial_intelligence
从 Apple 个人助手 Siri 的极其友好的声音到像《机械姬》这样的电影,人工智能总是比其他任何事物都让我感到兴奋。我不知道你怎么样,但 Netflix 能够根据你对之前看过的电影的反应预测推荐电影列表的这个想法对我来说非常迷人。
然后有一天,我偶然看到了一段由 Siraj Raval 制作的 YouTube 视频,其中他谈到了一个叫做#100DaysOfMLCode Challenge 的东西。这意味着在接下来的 100 天里,每天至少花一个小时编程和学习机器学习。我强烈推荐你查看一下视频。

这正是我开始深入学习一直关心的领域所需的动力。因此,我接受了这个挑战,开始学习机器学习。
从最基本的算法开始,并在 Python 语言中实现它们。
为了有一个好的记录来跟踪我学到的每一件事,我在 GitHub 上创建了一个仓库。我强烈推荐你也这样做。随着我不断学习机器学习的新知识,我也更新了仓库,包括实现机器学习算法的代码和一些信息图,以便更好地理解。
一些信息图
我对这个仓库收到的反馈感到非常震惊,至少可以说,我没有预料到这一点。人们从社交媒体的各个角落支持我,这确实让我感到谦逊,我想借此机会感谢所有花费宝贵时间支持我的人。
查看我的仓库
数字在这里并不重要,因为我做这些并不是为了名声或任何受欢迎程度。我这样做是因为我想做,我关心它,我相信我可以有所作为。
K — 最近邻信息图
话虽如此,我相信我现在只是在学习,在这个快速变化和不断发展的世界中,我认为你永远不会真正完成学习。这只是一个巨大的学习曲线。目的地还未到达,我甚至没有接近,坦白说。但我知道我的道路是对的,我的思想专注于实现我的理想。所以我想挑战现在正在阅读这篇文章的每一个人,来和我一起踏上这段旅程,参加 #100DaysOfMLCode 挑战,并每天努力工作。
如果你对人工智能领域没有兴趣,那也没关系,不要找借口,找到你关心的事物,找到那种不会觉得像工作的事物,投入你整个生命。正如 Les Brown 曾说,
“要在生活中取得任何有价值的成就,你必须要有渴望。”
渴望成功,追随你的梦想,并观察它们成为现实。
和我一起开始这段旅程,也许有一天我们可以一起实现我们的梦想,谁知道还会到哪里呢。
通过下面的链接关注我的工作 #100DaysOfMLCode —
Github | LinkedIn | Twitter | Website
原文. 经许可转载。
个人简介: Avik Jain 是一名机器学习和云计算爱好者,擅长 C、C++、Python、云计算、Adobe Creative Cloud。当前攻读计算机工程专业的技术学士学位(B.Tech.),专注于云计算,并积极寻找实习机会。
相关:
我们的三大课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
初级数据科学家:下一阶段
原文:
www.kdnuggets.com/2022/02/junior-data-scientist-next-level.html
当你在线搜索时,大多数人建议你在考虑转职或换其他角色之前,先在初级阶段待几年。与初级、中级和高级数据科学家相比,经验水平存在差异。本文将探讨所有职位的期望及晋升的要求。

sol 通过 Unsplash
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
你处于什么级别?
大多数人会关注数据科学家的技能、工作年限、教育水平、专业知识、管理技能等。了解如何区分不同级别的数据科学家,其关键在于理解你可以让数据科学家独立完成/处理任务的时间长度,而无需进行检查。
使用“你能把某人放在一边完成/处理任务而无需检查多久?”这个类比,我们可以将不同级别划分如下:
-
初级数据科学家:你通常会每日检查,或者每天两次。他们将与中级和高级数据科学家进行大量配对编程。
-
中级数据科学家:你将每周或每月几次与他们进行沟通,但他们应当具备能力。他们还将与高级数据科学家进行配对编程,并在需要时指导和辅导初级数据科学家。
-
高级数据科学家:无需与他们检查,他们完全能够独立处理任务。
尽管个人的经验和技能水平很重要,但完成任务的知识和经验水平才是关键。初级数据科学家可能会遇到被阻塞的情况,无法解决问题,必须寻求高级人员的帮助。中级数据科学家也可能面临困难,但他们会更好地掌握如何独立克服这些困难。而高级数据科学家拥有足够的经验,能够完成任务。即使这包括聘请专家或研究人员,他们也知道完成项目所需的要求。
如果你正在寻找高级职位,问问自己“有多长时间可以让我独自完成/处理任务而无需检查”。你必须对自己完全诚实,否则你会为自己设定失败的局面。我不是说你不能设定目标并努力成为最好的自己。我是说,要对自己当前的经验水平保持现实,以帮助你找到合适的角色,并在此基础上不断提升。

Scott Graham 通过 Unsplash
如何从初级晋升到中级再到高级?
年初时,我们都在记录我们的计划,无论是职业还是个人相关的。我们都在努力实现我们的目标。对于所有的数据科学家来说,这里有一些关于如何提升职业生涯、爬升阶梯和增加收入的建议。
独立性
反思“你可以让某人独自完成/处理任务而不检查多久?”这个问题,关键在于独立性。初级人员由于缺乏经验和技能,倾向于问更多问题,而高级人员则能够基于过往经验做出决策。
这不应该让你害怕提问。提问没有错,这就是你学习的方式。如果你不犯错,你就不会经历学习的过程,你将始终停滞不前。然而,不要每次都依赖你的同事和高级员工来指导你。避免在有问题时立即去找他们,尽量自己解决问题。当你理解如何解决问题时,你会有一种成就感。如果你对自己的解决方案不确定,向你的经理询问他的意见。他们会欣赏你带来解决方案而不是单纯的问题。
让自己处于不舒适的位置
当你处于困境时,许多伟大的事情发生了。你会爬出一个不舒适且陌生的洞穴。初级人员通常会处理更简单的任务,这些任务有时非常重复和无聊。如果你觉得自己已经准备好,可以向你的经理请求更具挑战性的任务,以便学习和提升你的分析技能。
如果你成功完成任务,你的经理或高级数据科学家将会认可你的表现,并推动你的晋升。
开始像高级数据科学家一样思考
高级数据科学家能够独立处理任务,这不仅因为他们的经验水平,还因为他们对业务目标的理解。大多数初级数据科学家的任务是孤立的,完成任务的过程不会超出请求本身。通过更好地理解业务的短期和长期目标来把握全局,将提高你处理请求或解决问题时的思维方式。
高级数据科学家的决策不仅基于他们的经验,还需要考虑公司的需求,以帮助公司成长。通过配对编程、每周团队建设或一对一会议,了解高级数据科学家如何处理问题,将帮助你进入高级数据科学家的思维模式。
沟通与管理
这些是中级或高级数据科学家的主要软技能,因为他们会经常被询问建议、方向和帮助来理解问题。许多初级数据科学家通常只需与数据团队的其他成员和他们的经理交流。
作为高级数据科学家,管理数据团队需要良好的沟通和管理技能,以确保操作顺利进行。如果有项目问题,不管任务是否由他/她完成,高级数据科学家仍需承担责任。高级数据科学家应警惕在问题呈现给利益相关者之前识别错误。
如果高级数据科学家缺乏沟通能力,他们的操作将会崩溃,很快会意识到由于自身的无能,工作量将会落在他们身上。与其向利益相关者解释为什么输出结果错误或为何做出错误决策,不如更好地管理和沟通你的数据团队以避免这些问题。
反馈
“反馈是冠军的早餐。”
—肯·布兰查德
请求反馈是自我提升的健康催化剂,无论是个人的还是职业的。向经理询问你的优势和不足,将帮助你理解哪些方面有效,哪些方面需要改进。没有人是完美的,总有方法可以让我们变得更好。伟大的玩家希望听到真话,因为他们希望继续赢得胜利!
希望这篇文章帮助你了解你目前的水平以及如何达到下一个级别。祝你在成长的旅程中一切顺利!
Nisha Arya 是一位数据科学家和自由撰稿人。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探索人工智能如何能促进人类寿命的延续。作为一名热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
相关主题
初级与高级数据科学家薪资:有什么区别?
原文:
www.kdnuggets.com/2022/03/junior-senior-data-scientist-salary-difference.html

图片来源:Precondo CA 在 Unsplash [1]。
介绍
我们的前三大课程推荐
1. 谷歌网络安全认证 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业认证 - 提升你的数据分析能力
3. 谷歌 IT 支持专业认证 - 支持你组织的 IT 需求
这篇文章的目标是展示两个受欢迎的技术角色之间的差异和相似性。我们将深入研究按城市和技能计算的平均薪资。
免责声明: 正如我在这一系列的前几篇文章中所提到的,这篇文章并不是为了比较角色以决定哪一个更值得更高薪水,而是一个指南,让这两个领域的专业人士评估他们目前或预期的薪资。请记住,这些薪资值更为一般,任何一个网站都不足以评估你的价值。你可以利用这些薪资值的方向来作为未来谈判薪资时的工具。
这篇文章的目标读者是谁?
招聘人员 和 招聘经理 比较不同资历的平均薪资,以及不同薪资百分位,并考虑可能影响薪资增减的各种因素。
你自己,作为一名当前数据科学家,或者作为一名希望转行数据科学的人,在比较初级与高级职位时,这些信息可以帮助你决定你想追求的角色。这也有助于澄清有关薪资的职位假设。
初级数据科学家

图片来源:Nathan Dumlao 在 Unsplash [2]。
在我看来,初级数据科学家职位似乎相当稀缺。这一观察很有趣,并且在某种程度上显得独特,但我认为缺乏初级职位有其原因:
-
一个原因可能是名称本身。也许招聘经理和招聘人员会推广没有附带级别的数据显示科学家头衔,并根据面试中的表现进行招聘。例如,他们可能招聘的是初级数据科学家 I、数据科学家 II、高级数据科学家、首席/资深数据科学家、数据科学家经理等。
-
另一个原因可能是公司的员工数量/招聘能力。公司可能只有资金招聘一名数据科学家,并且他们更倾向于招聘高级数据科学家而非初级数据科学家。这种差异可能取决于公司规模及其可能需要的项目。
话虽如此,假设这是你情况中的一个职位,并查看一些初级数据科学家职位的数字。
注意: 这些薪资信息最后更新于 2022 年 2 月 1 日
这里是一些不同级别的初级数据科学家及其各自的薪资 [3](已四舍五入):
-
平均总体初级数据科学家 →
67k 美元 -
平均 10%(百分位)的初级数据科学家 →
53k 美元 -
平均中位数初级数据科学家 →
67k 美元 -
平均 90%(百分位)的初级数据科学家 →
90k 美元
我是否同意这些数字?
稍微有些。
即使这个职位是初级的,整体来看这个平均薪水似乎有点低。不过,你可能会得到奖金,这可能使得薪水+奖金非常好。
要成为数据科学家,通常需要大量的教育经验,并且已经在软件工程、产品管理或商业分析等领域有过专业职位,因此你可能会因为这个数字而降低薪水。然而,如果你刚刚毕业,并且不住在城市中,这可能是一个不错的薪水,尽管可能会有奖金。
影响你薪水的一些可能因素(一些行动你可以采取,并非财务建议)
-
地点
-
研究生院
-
认证
-
编程训练营
-
远程工作
-
技能
-
奖金
-
利润分成
-
在简历中包含学校项目,并将其与更多商业类型的内容相关联
-
包括你认为别人认为你具备的技能,你可能会认为大家都知道 SQL,所以可以省略它,但也许你是唯一一个在简历中没有包含 SQL 的申请者,结果没有进入下一轮面试。
-
在线项目,展示了从网站如 GitHub 或 Kaggle 的部分或大部分端到端数据科学过程
高级数据科学家

图片来源: 奥斯汀·迪斯特尔 在 Unsplash [4]。
这个薪资分析中使用了更多的数据点,因此它更能指示我们可能假设的平均值以及其他特征。之前的角色有 55 个薪资数据,而这个薪资资料有大约 1500 个。有了更多的信息/数据,我们可以深入探讨城市/地点和技能对薪资的影响。
这里是一些不同经验水平的高级数据科学家及其各自的 薪资 [5](四舍五入):
-
平均整体高级数据科学家 →
127k 美元 -
平均入门级高级数据科学家 →
108k 美元(≤ 1 年) -
平均早期职业高级数据科学家 →
123k 美元(1–4 年) -
平均中期职业高级数据科学家 →
131k 美元(5–9 年) -
平均晚期职业高级数据科学家 →
140k 美元(10–19 年)
注意: 该薪资信息最后更新于 2022 年 3 月 2 日。
我是否同意这些数字?
是的。
请记住,上述数字基于高级数据科学家的整个职位,然后是你在该特定角色中的时间长短。
这些数字看起来好得多,特别是考虑到高级职位的奖金和利润分享较高。
薪资范围也包括这些:
-
奖金 →
5k 美元—24k 美元 -
利润分享 →
2k 美元—25k 美元
为了阐述城市和技能对薪资的影响,我将包括一些美国平均高级数据科学家薪资的组合,方便你查看一些示例:
-
纽约,纽约州 → $160,000,深度学习
-
芝加哥,伊利诺伊州 → $120,079,人工智能(AI)
-
洛杉矶,加利福尼亚州 → $140,000,大数据分析
-
旧金山,加利福尼亚州 → $157,277,自然语言处理(NLP)
正如你所见,改变地点和增加一个技能可以显著改变这些数字。重要的是对所有这些数字保持怀疑态度,最终薪资真的取决于你自己。
摘要
薪资可能是一个难以讨论的话题,但讨论影响薪资大小的因素仍然很重要,无论是经验年限、技能还是地点。
以下是初级数据科学家和高级数据科学家的薪资总结:
-
平均整体初级数据科学家 → $67k
-
平均整体高级数据科学家 → $127k
-
多种因素影响薪资,其中最重要的可能是经验年限、城市和技能。
我希望你觉得我的文章既有趣又有用。如果你对这些薪资比较有意见或不同的看法,请随时在下方评论。为什么会这样?你认为关于薪资还有哪些其他重要因素值得指出?这些问题肯定可以进一步澄清,但我希望我能对初级和高级数据科学家薪资之间的差异提供一些见解。
最后,我再问一次,你如何看待远程职位对薪资的影响,特别是当城市在确定薪资方面如此重要时?
我与这些公司没有任何关联。
请随时查看我在 Medium 上的个人资料,Matt Przybyla,以及其他文章,还可以通过以下链接订阅以接收我的博客的邮件通知,并在 LinkedIn 上联系我,如果你有任何问题或评论。
请注意,本文中的数字并不是我的薪资,而是由 PayScale 以及其他实际数据科学家报告的。因此,本文讨论了实际数据,并旨在帮助你更好地理解在某些因素影响下,角色(一般来说)薪资的增加或减少。
参考文献
[1] 图片来源:Precondo CA 在 Unsplash,(2019 年)
[2] 图片来源:Nathan Dumlao 在 Unsplash,(2018 年)
[3] PayScale, Inc., 初级数据科学家薪资,(2022 年 2 月 1 日)
[4] 图片来源:Austin Distel 在 Unsplash,(2019 年)
[3] PayScale, Inc., 高级数据科学家薪资,(2022 年 3 月 2 日)
Matthew Przybyla (Medium) 是德州 Favor Delivery 的高级数据科学家。他拥有南美 Methodist University 的数据科学硕士学位。他喜欢撰写关于数据科学领域的趋势话题和教程,从新算法到关于数据科学家日常工作经验的建议。Matt 喜欢突出数据科学的商业方面,而不仅仅是技术方面。欢迎通过LinkedIn联系 Matt。
更多相关话题
Jupyter Notebook 初学者教程
原文:
www.kdnuggets.com/2018/05/jupyter-notebook-beginners-tutorial.html/2
评论
内核
每个笔记本的背后都运行着一个内核。当你运行一个代码单元格时,该代码在内核中执行,任何输出会返回到单元格中显示。内核的状态会随着时间的推移和单元格之间持续存在——它涉及整个文档而不是单个单元格。
例如,如果你在一个单元格中导入库或声明变量,它们将在另一个单元格中可用。通过这种方式,你可以把笔记本文件看作有点类似于脚本文件,只不过它是多媒体的。让我们试一下以感受一下。首先,我们将导入一个 Python 包并定义一个函数。
import numpy as np
def square(x):
return x * x
一旦我们执行了上面的单元格,我们可以在任何其他单元格中引用np和square。
x = np.random.randint(1, 10)
y = square(x)
print('%d squared is %d' % (x, y))
1 squared is 1
这将无论笔记本中的单元格顺序如何都有效。你可以自己尝试一下,让我们再次打印出我们的变量。
print('Is %d squared is %d?' % (x, y))
Is 1 squared is 1?
这里没有什么意外!但现在让我们改变y。
y = 10
如果我们再次运行包含print语句的单元格,你认为会发生什么?我们会得到输出Is 4 squared is 10?!
大多数情况下,你的笔记本流程将是自上而下的,但通常会返回进行更改。在这种情况下,单元格左侧标示的执行顺序,比如In [6],会告诉你是否有任何单元格的输出过时。如果你想重置所有内容,可以从内核菜单中选择几个非常有用的选项:
-
重新启动:重新启动内核,从而清除所有已定义的变量等。
-
重新启动并清除输出:与上面相同,但还会清除你代码单元格下方显示的输出。
-
重新启动并运行所有:与上面相同,但还会按顺序从第一个到最后一个运行所有单元格。
如果你的内核在计算中卡住了,并且你希望停止它,你可以选择中断选项。
选择内核
你可能已经注意到,Jupyter 允许你更改内核,实际上有很多不同的选项可供选择。当你从仪表板创建一个新笔记本时,选择一个 Python 版本,实际上是选择了要使用的内核。
不仅有针对不同版本的 Python 的内核,还有针对100 多种语言的内核,包括 Java、C,甚至 Fortran。数据科学家可能特别感兴趣于R和Julia的内核,以及imatlab和Calysto MATLAB 内核的内核。 SoS 内核提供了在单个笔记本中支持多种语言的功能。每个内核都有自己的安装说明,但可能需要你在计算机上运行一些命令。
示例分析
现在我们已经了解了什么是 Jupyter Notebook,是时候看看如何在实践中使用它们了,这将帮助你更清楚地理解为什么它们如此受欢迎。现在终于可以开始使用之前提到的《财富 500 强》数据集了。记住,我们的目标是了解美国最大公司历史上利润的变化情况。
值得注意的是,每个人都会形成自己的偏好和风格,但一般原则仍然适用。如果你愿意,可以在自己的笔记本中跟随本节内容,这样你可以进行一些实验。
命名你的笔记本
在你开始编写项目之前,你可能会想给它一个有意义的名字。也许有点令人困惑的是,你不能直接在笔记本应用中命名或重命名笔记本,而是必须使用仪表板或文件浏览器来重命名.ipynb文件。我们将返回仪表板来重命名你之前创建的文件,它将有一个默认的笔记本文件名Untitled.ipynb。
你不能在笔记本运行时重命名它,所以你需要先将其关闭。最简单的方法是从笔记本菜单中选择“文件 > 关闭并停止”。然而,你也可以通过在笔记本应用中选择“内核 > 关闭”来关闭内核,或者通过在仪表板中选择笔记本并点击“关闭”(见下图)来关闭内核。

然后,你可以选择你的笔记本,并点击仪表板控制中的“重命名”。

请注意,关闭浏览器中的笔记本标签页不会像在传统应用中关闭文档那样“关闭”笔记本。笔记本的内核将继续在后台运行,需要在真正“关闭”之前手动关闭——不过如果你不小心关闭了标签页或浏览器,这一点非常方便!如果内核已经关闭,你可以关闭标签页而无需担心是否仍在运行。
一旦你给笔记本命名,重新打开它,我们就可以开始了。
设置
通常,首先会有一个专门用于导入和设置的代码单元,这样如果你选择添加或更改任何内容,你可以简单地编辑并重新运行该单元,而不会造成任何副作用。
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="darkgrid")
我们导入了pandas以处理数据, Matplotlib以绘制图表, 和Seaborn以使图表更加美观。 通常也会导入NumPy但在这种情况下,虽然我们通过 pandas 使用它,但不需要显式导入。而且那第一行不是 Python 命令,而是使用了称为行魔法的东西来指示 Jupyter 捕获 Matplotlib 图表并在单元格输出中呈现;这是一系列高级功能中的一个,超出了本文的范围。
让我们继续加载数据。
df = pd.read_csv('fortune500.csv')
这样做也是明智的,以防我们需要在任何时候重新加载它。
保存和检查点
现在我们已经开始,最好的做法是定期保存。按Ctrl + S将通过调用“保存和检查点”命令来保存你的笔记本,但这个检查点是什么呢?
每次你创建一个新的笔记本时,都会创建一个检查点文件以及你的笔记本文件;它将位于你保存位置的一个名为.ipynb_checkpoints的隐藏子目录中,并且也是一个.ipynb文件。默认情况下,Jupyter 会每 120 秒自动保存你的笔记本到这个检查点文件中,而不会更改你的主要笔记本文件。当你“保存和检查点”时,笔记本和检查点文件都会更新。因此,检查点使你能够在遇到意外问题时恢复未保存的工作。你可以通过菜单中的“文件 > 恢复到检查点”来恢复到检查点。
调查我们的数据集
现在我们真的开始了!我们的笔记本已经安全保存,我们已经将数据集df加载到最常用的 pandas 数据结构中,它叫做DataFrame,基本上看起来像一个表格。我们的数据集看起来怎么样呢?
df.head()
| 年份 | 排名 | 公司 | 收入(百万) | 利润(百万) | |
|---|---|---|---|---|---|
| 0 | 1955 | 1 | 通用汽车 | 9823.5 | 806 |
| 1 | 1955 | 2 | 埃克森美孚 | 5661.4 | 584.8 |
| 2 | 1955 | 3 | 美国钢铁公司 | 3250.4 | 195.4 |
| 3 | 1955 | 4 | 通用电气 | 2959.1 | 212.6 |
| 4 | 1955 | 5 | Esmark | 2510.8 | 19.1 |
df.tail()
| 年份 | 排名 | 公司 | 收入(百万) | 利润(百万) | |
|---|---|---|---|---|---|
| 25495 | 2005 | 496 | Wm. Wrigley Jr. | 3648.6 | 493 |
| 25496 | 2005 | 497 | 皮博迪能源公司 | 3631.6 | 175.4 |
| 25497 | 2005 | 498 | 温迪国际 | 3630.4 | 57.8 |
| 25498 | 2005 | 499 | Kindred Healthcare | 3616.6 | 70.6 |
| 25499 | 2005 | 500 | 辛辛那提金融公司 | 3614.0 | 584 |
看起来不错。我们有了需要的列,每一行都对应一个公司在一个特定年份的数据。
我们只是重命名这些列,以便以后可以引用它们。
df.columns = ['year', 'rank', 'company', 'revenue', 'profit']
接下来,我们需要探索一下我们的数据集。数据集是否完整?pandas 是否按预期读取了数据?是否有缺失值?
len(df)
25500
好的,这看起来不错——从 1955 年到 2005 年,每年有 500 行数据。
让我们检查一下我们的数据集是否已按预期导入。一个简单的检查方法是查看数据类型(或 dtypes)是否被正确解释。
df.dtypes
year int64
rank int64
company object
revenue float64
profit object
dtype: object
哎呀。看起来利润列有问题——我们希望它像收入列一样是float64类型。这表明它可能包含一些非整数值,因此让我们来看看。
non_numberic_profits = df.profit.str.contains('[⁰-9.-]')
df.loc[non_numberic_profits].head()
| 年份 | 排名 | 公司 | 收入 | 利润 | |
|---|---|---|---|---|---|
| 228 | 1955 | 229 | Norton | 135.0 | N.A. |
| 290 | 1955 | 291 | Schlitz Brewing | 100.0 | N.A. |
| 294 | 1955 | 295 | Pacific Vegetable Oil | 97.9 | N.A. |
| 296 | 1955 | 297 | Liebmann Breweries | 96.0 | N.A. |
| 352 | 1955 | 353 | Minneapolis-Moline | 77.4 | N.A. |
正如我们所怀疑的那样!一些值是字符串,用于表示缺失数据。是否还有其他值混入了?
set(df.profit[non_numberic_profits])
{'N.A.'}
这使得解释变得容易,但我们应该怎么做呢?这取决于缺失值的数量。
len(df.profit[non_numberic_profits])
369
这是我们数据集的一小部分,但并不是完全无关紧要,因为它仍然约占 1.5%。如果包含N.A.的行大致上在各个年份中均匀分布,最简单的解决方案就是删除这些行。所以让我们快速查看一下分布情况。
bin_sizes, _, _ = plt.hist(df.year[non_numberic_profits], bins=range(1955, 2006))

一眼看去,我们可以看到单一年份中无效值的数量不到 25,而每年有 500 个数据点,删除这些值在最坏的情况下占数据的不到 4%。实际上,除了 90 年代的激增,大多数年份的缺失值数量不到峰值的一半。就我们的目的而言,我们可以认为这是可以接受的,接着删除这些行。
df = df.loc[~non_numberic_profits]
df.profit = df.profit.apply(pd.to_numeric)
我们应该检查一下是否成功。
len(df)
25131
df.dtypes
year int64
rank int64
company object
revenue float64
profit float64
dtype: object
太棒了!我们已经完成了数据集的设置。
如果你打算将你的笔记本作为报告呈现,你可以删除我们创建的调查性单元格,这些单元格在这里作为工作流演示,合并相关单元格(有关更多信息,请参见下面的高级功能部分)以创建一个单一的数据集设置单元格。这意味着如果我们在其他地方搞砸了数据集,我们只需重新运行设置单元格即可恢复。
使用 matplotlib 绘图
接下来,我们可以通过绘制每年的平均利润来解决手头的问题。我们也可以绘制收入,所以首先我们可以定义一些变量和方法来简化我们的代码。
group_by_year = df.loc[:, ['year', 'revenue', 'profit']].groupby('year')
avgs = group_by_year.mean()
x = avgs.index
y1 = avgs.profit
def plot(x, y, ax, title, y_label):
ax.set_title(title)
ax.set_ylabel(y_label)
ax.plot(x, y)
ax.margins(x=0, y=0)
现在让我们绘图吧!
fig, ax = plt.subplots()
plot(x, y1, ax, 'Increase in mean Fortune 500 company profits from 1955 to 2005', 'Profit (millions)')

哇,这看起来像是一个指数曲线,但有一些巨大的波动。它们一定对应于1990 年代初期的衰退和互联网泡沫。在数据中看到这些现象相当有趣。但为什么每次衰退后,利润会恢复到更高的水平呢?
也许收入能告诉我们更多信息。
y2 = avgs.revenue
fig, ax = plt.subplots()
plot(x, y2, ax, 'Increase in mean Fortune 500 company revenues from 1955 to 2005', 'Revenue (millions)')

这为故事增添了另一面。收入并没有受到如此严重的打击,这得归功于财务部门的出色会计工作。
在Stack Overflow的帮助下,我们可以在这些图上叠加其标准差的正负范围。
def plot_with_std(x, y, stds, ax, title, y_label):
ax.fill_between(x, y - stds, y + stds, alpha=0.2)
plot(x, y, ax, title, y_label)
fig, (ax1, ax2) = plt.subplots(ncols=2)
title = 'Increase in mean and std Fortune 500 company %s from 1955 to 2005'
stds1 = group_by_year.std().profit.as_matrix()
stds2 = group_by_year.std().revenue.as_matrix()
plot_with_std(x, y1.as_matrix(), stds1, ax1, title % 'profits', 'Profit (millions)')
plot_with_std(x, y2.as_matrix(), stds2, ax2, title % 'revenues', 'Revenue (millions)')
fig.set_size_inches(14, 4)
fig.tight_layout()

这令人吃惊,标准差非常大。一些财富 500 强公司赚取数十亿,而其他公司则亏损数十亿,多年来风险随着利润的增长而增加。也许有些公司表现优于其他公司;排名前 10%的公司利润是否比排名后 10%的公司更稳定?
接下来我们还有许多问题可以探讨,而且很容易看出在笔记本中工作的流程如何与个人的思维过程相匹配,所以现在是时候结束这个例子了。这种流程帮助我们在一个地方轻松调查数据集,而无需在应用程序之间切换上下文,并且我们的工作可以立即共享和复现。如果我们希望为特定的受众创建更简洁的报告,我们可以通过合并单元格和删除中间代码来快速重构我们的工作。
共享你的笔记本
当人们谈论共享他们的笔记本时,他们通常考虑两种模式。大多数情况下,个人分享的是他们工作的最终结果,就像这篇文章本身一样,这意味着分享非交互式的、预渲染版本的笔记本;然而,也可以借助版本控制系统如Git进行协作。
也就是说,网上出现了一些新兴的公司,提供在云端运行交互式 Jupyter 笔记本的能力。
在分享之前
共享笔记本将以你导出或保存时的状态出现,包括任何代码单元格的输出。因此,为了确保你的笔记本在共享时准备好,你应该在分享之前采取一些步骤:
-
点击“单元格 > 全部输出 > 清除”
-
点击“内核 > 重新启动并运行全部”
-
等待你的代码单元格执行完毕,并检查它们是否按预期完成
这将确保你的笔记本不包含中间输出,状态不过时,并且在分享时按照顺序执行。
导出你的笔记本
Jupyter 内置了导出到 HTML 和 PDF 以及其他几种格式的支持,你可以从“文件 > 另存为”菜单中找到这些选项。如果你希望将笔记本分享给一个小的私人组,这个功能可能已经足够。事实上,由于许多学术机构的研究人员会有一些公共或内部的网页空间,并且因为你可以将笔记本导出为 HTML 文件,Jupyter 笔记本可以是他们与同行分享研究结果的特别便捷的方式。
但如果分享导出的文件对你来说不够直接,还有一些非常流行的方法可以更直接地在网上分享.ipynb文件。
GitHub
到 2018 年初,GitHub 上的公开笔记本数量超过 180 万,这无疑是分享 Jupyter 项目给全世界的最受欢迎的独立平台。GitHub 已经集成了对.ipynb文件的直接渲染支持,无论是在其网站上的代码库还是 gists。如果你还不知情,GitHub是一个用于版本控制和协作的代码托管平台,支持使用Git创建的代码库。你需要一个账户来使用他们的服务,但标准账户是免费的。
一旦你有了 GitHub 账户,最简单的在 GitHub 上分享笔记本的方式其实根本不需要 Git。自 2008 年以来,GitHub 提供了其 Gist 服务,用于托管和分享代码片段,每个片段都有自己的仓库。要使用 Gists 分享笔记本:
-
登录并浏览到gist.github.com。
-
在文本编辑器中打开你的
.ipynb文件,选择全部并复制其中的 JSON 内容。 -
将笔记本的 JSON 粘贴到 gist 中。
-
给你的 Gist 起一个文件名,记得添加
.iypnb,否则无法使用。 -
点击“创建秘密 gist”或“创建公开 gist”。
这应该看起来像下面这样:

如果你创建了一个公开的 Gist,你现在可以与任何人分享其 URL,其他人也可以fork 和克隆你的工作。
创建你自己的 Git 仓库并在 GitHub 上分享超出了本教程的范围,但GitHub 提供了大量的指南来帮助你自行入门。
对于使用 git 的用户,一个额外的提示是为那些 Jupyter 创建的隐藏.ipynb_checkpoints目录在你的.gitignore中添加一个例外,以避免不必要地将检查点文件提交到你的代码库。
Nbviewer
到 2015 年,NBViewer 已经每天渲染成千上万的笔记本,成为网络上最受欢迎的笔记本渲染器。如果你已经有地方来在线托管你的 Jupyter 笔记本,无论是 GitHub 还是其他地方,NBViewer 会渲染你的笔记本,并提供一个可分享的 URL。作为 Project Jupyter 的一部分,它作为免费服务提供,网址是nbviewer.jupyter.org。
最初在 GitHub 的 Jupyter Notebook 集成之前开发的,NBViewer 允许任何人输入 URL、Gist ID 或 GitHub 用户名/仓库/文件,它将把笔记本渲染为网页。Gist 的 ID 是其 URL 末尾的唯一数字;例如,在https://gist.github.com/username/50896401c23e0bf417e89cd57e89e1de中最后一个反斜杠后的字符。如果你输入 GitHub 用户名或用户名/仓库,你将看到一个最简文件浏览器,让你浏览用户的仓库及其内容。
NBViewer 在显示笔记本时显示的 URL 是一个基于正在渲染的笔记本的 URL 的常量,因此你可以与任何人分享,只要原始文件保持在线,链接就会有效——NBViewer 不会长时间缓存文件。
终结思考
从基础知识入手,我们已经掌握了 Jupyter 笔记本的自然工作流程,深入探讨了 IPython 的高级功能,最后学会了如何与朋友、同事和全世界分享我们的工作。所有这些都是在笔记本本身完成的!
应该清楚笔记本如何通过减少上下文切换和模拟项目中的自然思维发展来促进高效工作体验。Jupyter 笔记本的强大功能也应该显而易见,我们提供了许多线索,以便你开始探索在自己的项目中更高级的功能。
如果你希望获取更多关于自己笔记本的灵感,Jupyter 已经整理了a gallery of interesting Jupyter Notebooks,你可能会发现有帮助,此外,Nbviewer 主页链接到一些真正精美的高质量笔记本示例。也查看一下我们的Jupyter Notebook 技巧列表。
想了解更多关于 Jupyter 笔记本的内容?我们有一个a guided project你可能会感兴趣。
个人简介: Benjamin Pryke 是一名 Python 和网页开发人员,拥有计算机科学和机器学习背景。FinTech 公司 Machina Capital 的联合创始人。兼职体操运动员和数字波希米亚。
原文。转载已获许可。
相关:
-
前 5 名最佳 Jupyter Notebook 扩展
-
了解机器学习的 5 件事
-
Fast.ai 第 1 课在 Google Colab 上(免费 GPU)
我们的 3 个顶级课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关主题
Jupyter Notebook 数据科学最佳实践
原文:
www.kdnuggets.com/2016/10/jupyter-notebook-best-practices-data-science.html
由 Jonathan Whitmore,硅谷数据科学。
Jupyter Notebook 是一个极其出色的工具,可以以多种方式使用。由于其灵活性,在团队环境中使用 Notebook 解决数据科学问题可能会具有挑战性。我们在这里介绍一些 SVDS 在与团队和客户合作中实施的最佳实践——这些实践也可能对你的数据科学团队有所帮助。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域

需要在版本控制下进行工作,并保持共享空间而不互相干扰,这一直是一个棘手的问题。我们在这里展示了当前适合我们的系统视图——也可能对你的数据科学团队有所帮助。
总体思考过程
在数据科学项目中有两种笔记本存储类型:实验室笔记本和可交付成果笔记本。首先是每本笔记本的组织方法。
实验室(或开发)笔记本:
让传统的纸质实验室笔记本成为你的指南:
-
每本笔记本都保留了分析过程中的历史记录(并标有日期)。
-
笔记本的目的仅仅是作为实验和开发的场所。
-
每本笔记本由一个作者控制:团队中的数据科学家(用首字母标记)。
-
当笔记本变得过长时(想象一下翻页),也可以进行拆分。
-
如果有意义的话,可以按主题拆分笔记本。
可交付成果(或报告)笔记本
-
它们是实验室笔记本的完全打磨版本。
-
它们存储分析的最终输出。
-
笔记本由整个数据科学团队控制,而不是由任何一个人控制。
版本控制
这是我们如何使用 git 和 GitHub 的一个示例。GitHub 的一个美妙新功能是它们现在可以在仓库中自动渲染 Jupyter Notebooks。
当我们进行分析时,我们会对代码和数据科学输出进行内部审查。我们使用传统的拉取请求方法进行审查。然而,当发出拉取请求时,查看更新后的 .ipynb 文件之间的差异,更新并不会以有用的方式呈现。人们倾向于推荐的一个解决方案是将其转换为 .py 格式进行提交。这对于查看输入代码的差异(同时舍弃输出)非常有用,并且有助于查看变化。然而,在审查数据科学工作时,查看输出本身也是极其重要的。
例如,一位数据科学家可能会对以下初步图表提供反馈,并希望看到改进:
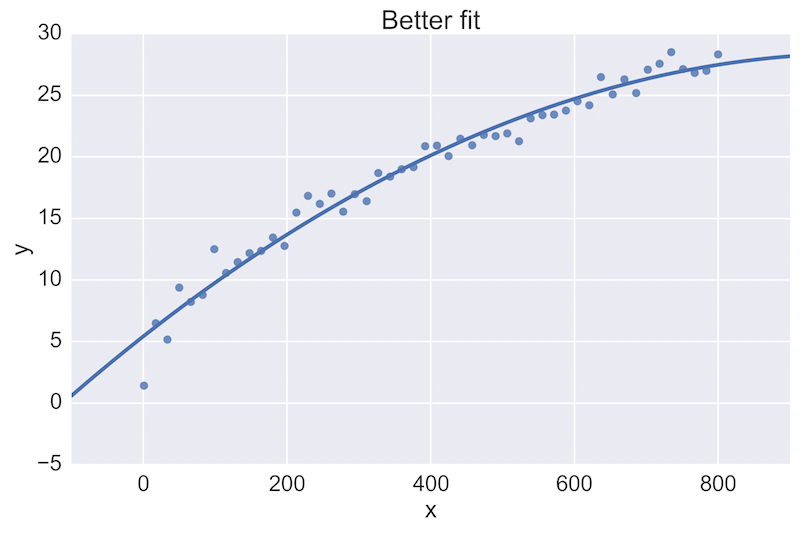
顶部的图表与数据的拟合效果较差,而底部的图表效果更好。在团队成员工作代码的拉取请求审查中直接查看这些图表是至关重要的。
查看 Github 提交示例 这里。
注意,有三种方法可以查看更新后的图形(选项在底部)。
保存后钩子
我们与许多不同的客户合作。他们的一些版本控制环境缺乏良好的渲染功能。有些公司防火墙后面部署 nbviewer 实例的选项,但有时这仍然不是一个选项。如果你遇到这种情况,并且希望保持上述代码审查框架,我们有一个解决办法。在这些情况下,我们会在每次提交中提交 .ipynb、.py 和 .html 文件。创建 .py 和 .html 文件可以通过编辑 jupyter 配置文件并添加保存后钩子,每次保存笔记本时自动完成。
默认的 jupyter 配置文件位于:
~/.jupyter/jupyter_notebook_config.py
如果你没有这个文件,请运行:
jupyter notebook --generate-config
创建这个文件,并添加以下文本:
运行jupyter notebook,你就可以开始使用了!
如果你只希望在使用特定“配置文件”时保存 .html 和 .py 文件,这会有点复杂,因为 Jupyter 不再使用配置文件的概念。
首先通过 bash 命令行创建一个新的配置文件名:
这将会在~/.jupyter_profile2/jupyter_notebook_config.py创建一个新的目录和文件。然后运行jupyter notebook,像往常一样工作。要切换回默认配置文件,你需要设置(手动、通过 shell 函数或 .bashrc)回到:
export JUPYTER_CONFIG_DIR=~/.jupyter
现在每次保存笔记本时,都会更新同名的 .py 和 .html 文件。在你的提交和拉取请求中添加这些文件,你将从每种文件格式中受益。
将所有内容汇总
这是一个正在进行的项目的目录结构,并对文件命名有一些明确的规则。
示例目录结构
py` - 开发 # (实验室笔记风格) + [ISO 8601 日期]-[DS-缩写]-[2-4 字描述].ipynb + 2015-06-28-jw-initial-data-clean.html + 2015-06-28-jw-initial-data-clean.ipynb + 2015-06-28-jw-initial-data-clean.py + 2015-07-02-jw-coal-productivity-factors.html + 2015-07-02-jw-coal-productivity-factors.ipynb + 2015-07-02-jw-coal-productivity-factors.py - 交付 # (最终分析、代码、演示等) + Coal-mine-productivity.ipynb + Coal-mine-productivity.html + Coal-mine-productivity.py - 图形 + 2015-07-16-jw-production-vs-hours-worked.png - src # (模块和脚本) + init.py + load_coal_data.py + figures # (图形和图表) + production-vs-number-employees.png + production-vs-hours-worked.png - 数据 (备份,单独于版本控制) + coal_prod_cleaned.csv ```py ````
好处
这种工作流程和结构有很多好处。首要和主要的好处是它们创建了一个分析进展的历史记录。它也很容易搜索:
-
按日期 (
ls 2015-06*.ipynb) -
按作者 (
ls 2015*-jw-*.ipynb) -
按主题 (
ls *-coal-*.ipynb)
其次,在拉取请求过程中,拥有.py 文件可以让人快速查看哪些输入文本已更改,而拥有.html 文件则可以快速查看哪些输出已更改。使这成为一个无痛的后保存钩子,使得这种工作流程变得轻松。
最后,这种方法还有许多较小的优点,无法一一列举——如果你有问题或对模型有进一步改进的建议,请 联系我们! 更多相关信息,请查看来自 O'Reilly Media 的 相关视频。
简介: 乔纳森·惠特莫 是 SVDS 的数据科学家。在从事天体物理学博士后职位后,乔纳森成为了计算和天文学方面备受欢迎的演讲者。他对将机器学习和统计技术应用于工业问题感到兴奋,并开发了新颖的数据分析技术。
原始。经授权转载。
相关:
-
Python 中的统计数据分析
-
Jupyter+Spark+Mesos: 一个“有见地”的 Docker 镜像
-
数据科学入门 – Python
更多相关主题
Jupyter Notebook 魔法方法备忘单
原文:
www.kdnuggets.com/jupyter-notebook-magic-methods-cheat-sheet
经过一段时间的期待,KDnuggets 很高兴发布了为我们的社区准备的新备忘单,这次重点介绍了不可或缺的 Jupyter Notebook 魔法命令。这些命令对于提高 Jupyter Notebooks 的效率至关重要,它是许多数据科学家和分析师的首选环境。魔法命令是扩展 Python 默认功能的特殊指令,提供了行魔法(在单行代码上操作)和单元魔法(适用于整个笔记本单元)。
这些魔法命令的实用性在于它们能够简化复杂任务,从而优化数据科学和分析专业人员的工作流程。它们支持高级数据处理和分析技术,减少代码量,为用户提供更多的功能。此备忘单旨在作为提升生产力的工具包,提供快速访问各种功能的途径,从环境变量管理的%env,到通过%%time进行性能优化,以及通过%debug进行互动调试。通过将这些魔法命令融入日常任务中,用户可以在 Jupyter Notebooks 中获得显著更高效、更有效的编码体验。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求

备忘单涵盖了广泛的魔法命令,包括以下内容:
-
%lsmagic: 显示所有可用魔法命令的列表。
-
%history -n: 显示最近的 n 条命令及其行号。
-
%%time: 测量代码块的执行时间。
-
%quickref: 提供常用魔法命令及其描述的快速参考。
-
%env: 显示所有环境变量的列表。
-
%load 和 %run: 分别加载和执行外部 Python 脚本。
-
%debug: 激活交互式调试器以进行错误分析。
魔法方法是提供超出标准 Python 语法的附加功能的特殊命令。Jupyter Notebook 中有两种类型的魔法方法:行魔法和单元魔法。行魔法作用于当前行,以 % 开头,而单元魔法作用于整个单元,以 %% 开头。
这个资源作为一个全面的参考,旨在有效地利用魔法方法,改善在 Jupyter Notebooks 中的编码实践。
要了解更多关于 Jupyter Notebook 魔法方法的信息,请查看我们最新的备忘单,并且不要忘记稍后再回来查看更多内容。
更多相关话题
Jupyter Notebooks: 数据科学报告
原文:
www.kdnuggets.com/2019/06/jupyter-notebooks-data-science-reporting.html
评论
由于其简单的设计、交互性好和跨语言支持,Jupyter 已成为我们中的许多人默认的平台。虽然还有其他方式可以使用笔记本环境,但目前为止我还没有看到比 Jupyter 提供更多好处的工具。
我提到 Jupyter 是因为之前只有 Jupyter Notebooks,但现在还有 Jupyter Lab 以及其他基于 Jupyter 的笔记本环境。
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
这里有一些简单的方法来组织你的项目(这基于我的个人经验)。
1. 安装 nb-extensions
这是在 Jupyter 中高效报告的基础
我推荐通过 Anaconda 安装,因为它还会自动安装所需的 Javascript 和 CSS 文件。
conda install -c conda-forge jupyter_contrib_nbextensions
conda install -c conda-forge jupyter_nbextensions_configurator
如果你在通过 Anaconda 安装时遇到问题,可以改用 pip
pip install jupyter_nbextensions_configurator jupyter_contrib_nbextensions
jupyter contrib nbextension install --user
jupyter nbextensions_configurator enable --user
一旦你完成了 nbextensions 的安装,你可以启动你的 Jupyter notebook 环境并导航到选项卡。
一旦你有了这个,只需启用你想要的扩展,并进行实验,以查看哪些扩展可以帮助你提高工作效率。
如果你在使用 Jupyter notebooks 时没有看到这个选项卡,只需打开一个新的内核并前往 Edit -> nbextensions config
2. 目录
你可以启用一个交互式目录,这个目录会出现在你的笔记本顶部。默认情况下,交互式版本会出现在屏幕的左侧,但如果你愿意,可以将其移动到笔记本的其他部分。

3. 使用 Markdown
对于已经使用它的人来说,这一点或多或少是显而易见的。一些基本命令包括:
-
Esc + m 将代码块转换为 Markdown 单元格
-
Ctrl + Enter 执行 Markdown 块并将其转换为纯文本。
-
Esc + m 再次按下如果你想编辑 Markdown 块
这里是一般 Markdown 命令的列表:www.markdownguide.org/basic-syntax/
使用标题
这与 markdown 和目录密切相关。如上图所示,在 Jupyter 中添加 markdown 标题会自动将其分节并添加到目录列表中,使用户更容易滚动和查找所需内容。
使用 Latex
这当然取决于用户,因为并不是每个人都需要在笔记本中渲染数学公式。
更多关于在 Jupyter 中使用 markdown的信息,请查看这里
4. 使用 Scratchpad
使用此扩展可以减少笔记本中不必要的代码。如果你需要验证以前的输出,可以直接在 Scratchpad 中输入,它不会出现在笔记本中。
了解更多信息请访问:Jupyter Notebooks 的 Scratchpad
5. 隐藏代码
隐藏选定的单元格
如果你只想隐藏某些代码/输入单元格而保留一些可见,请使用以下扩展:
隐藏所有代码 / 输入单元格
如果你希望隐藏所有代码,只显示输出,可以使用以下扩展:
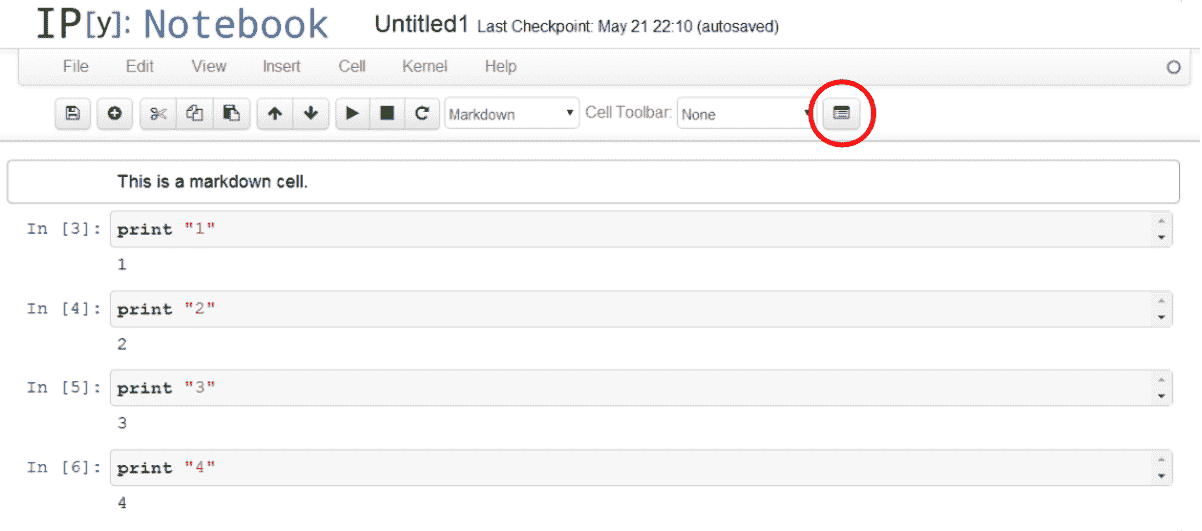
6. 渲染/转换笔记本为 PDF/HTML 等
Jupyter Notebook 使我们能够将笔记本渲染成多种格式。以下是可用选项的列表。
我发现这比去“文件”->“另存为”更可靠。
The simplest way to use nbconvert is
> jupyter nbconvert mynotebook.ipynb
which will convert mynotebook.ipynb to the default format (probably HTML).
You can specify the export format with `--to`.
Options include ['asciidoc', 'custom', 'hide_code_html', 'hide_code_latex', 'hide_code_pdf', 'hide_code_slides', 'html', 'html_ch', 'html_embed', 'html_toc', 'html_with_lenvs', 'html_with_toclenvs', 'latex', 'latex_with_lenvs', 'markdown', 'notebook', 'pdf', 'python', 'rst', 'script', 'selectLanguage', 'slides', 'slides_with_lenvs']
> jupyter nbconvert --to latex mynotebook.ipynb
Both HTML and LaTeX support multiple output templates. LaTeX includes
'base', 'article' and 'report'. HTML includes 'basic' and 'full'. You
can specify the flavor of the format used.
> jupyter nbconvert --to html --template basic mynotebook.ipynb
You can also pipe the output to stdout, rather than a file
> jupyter nbconvert mynotebook.ipynb --stdout
PDF is generated via latex
> jupyter nbconvert mynotebook.ipynb --to pdf
You can get (and serve) a Reveal.js-powered slideshow
> jupyter nbconvert myslides.ipynb --to slides --post serve
Multiple notebooks can be given at the command line in a couple of
different ways:
> jupyter nbconvert notebook*.ipynb
> jupyter nbconvert notebook1.ipynb notebook2.ipynb
or you can specify the notebooks list in a config file, containing::
c.NbConvertApp.notebooks = ["my_notebook.ipynb"]
> jupyter nbconvert --config mycfg.py
你可能需要安装外部依赖项,如 latex 或 pandoc 等。有关渲染的更多信息,请查阅文档。
最后,你可能没听说过但应该立即下载的扩展(特别是如果你是初学者的话)
7. 设置
查看 Will Koehrsen 提供的这个实用扩展
Will 创建了这个出色的扩展,为任何想要组织笔记本以获得更轻松工作流程的人提供了极好的设置。

还有一些实用的技巧:
-
Esc+a 在上方添加单元格
-
Esc+b 在下方添加单元格
-
Esc+m 激活 markdown 单元格,Ctrl+Enter 执行。
-
Esc+d 删除单元格
相关:
-
数据科学笔记本最佳实践
-
Jupyter Notebook 初学者教程
-
在 Jupyter 中运行 R 和 Python
更多相关主题
JupyterLab 3 已发布:现在升级的关键理由
原文:
www.kdnuggets.com/2021/01/jupyterlab-3-here-reasons-upgrade.html
评论
JupyterLab 是“下一代基于 Web 的 Project Jupyter 用户界面”,与 Jupyter notebooks 保持一致,并在功能上有所提升。Jupyter 的 Web IDE 已存在多年,并在数据科学社区中占据了显著的地位,它们结合起来在我们的读者中是 最受欢迎的 IDE。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
最新版本的 JupyterLab 刚刚发布,它带来了多个更新和新功能,值得尝试。以下是你现在应检查最新版本的 3 个理由。
目录
更容易使用版本 3 中的目录功能来浏览 Jupyter 文档。它会根据文档中的标题自动生成,并可以在界面左侧开关。这使得在较长文档中跳转变得更加轻松,同时将相关代码和文档整齐地收纳,直到需要时再展开。
支持多种显示语言
JupyterLab 现在支持多种(自然)语言。用户可以在 语言包存储库 中单独安装所需的语言,并在 Jupyter 文档中使用。下图展示了简体中文的使用情况,可通过以下方式轻松安装:
pip install jupyterlab-language-pack-zh-CN
使用 pip 和 conda / mamba 安装新扩展
现在可以通过流行的包管理工具 pip、conda 和 mamba 安装预构建的 Jupyter 扩展。虽然这是一次便利的升级,但用户必须安装 Node.js 才能利用此新功能。
预构建的扩展可以作为独立包发布到 PyPI 和 conda-forge,也可以与 Jupyter Server 扩展和 Classic Notebook 扩展打包到现有包中。这有助于使整个生态系统更加连贯。
这意味着安装一个新扩展对于 JupyterLab 和 Jupyter notebooks 都适用,只需一次安装;不需要为其中之一或另一个额外配置步骤。
这些只是 JuptyerLab 3 中发现的一些新功能。了解更多其他功能,请点击这里,并立即尝试最新版本。
相关内容:
-
这里是最受欢迎的 Python IDEs/编辑器
-
停止从命令行运行 Jupyter Notebooks
-
Scikit-learn 0.23 的 5 个新功能
更多相关话题
K-Means 和其他聚类算法:使用 Python 的快速介绍
原文:
www.kdnuggets.com/2017/03/k-means-clustering-algorithms-intro-python.html
Nikos Koufos,LearnDataSci 作者。
聚类是将对象分组,使得同一组(簇)中的对象彼此之间的相似度高于其他组(簇)中的对象。在本次介绍性聚类分析教程中,我们将查看一些 Python 中的算法,以便你对实际数据集上的聚类基础知识有一个基本了解。
数据集
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
对于聚类问题,我们将使用著名的 Zachary’s Karate Club 数据集。数据集背后的故事很简单:曾经有一个空手道俱乐部,俱乐部中有一位管理员“John A”和一位教练“Mr. Hi”(均为化名)。然后他们之间发生了冲突,导致学生(节点)分成了两组。一组跟随 John,另一组跟随 Mr. Hi。

来源:维基百科
使用 Python 开始进行聚类
不过,讲解到此为止,我们直接进入你来到这里的主要原因——代码本身。首先,你需要安装 scikit-learn 和 networkx 库来完成本教程。如果你不知道怎么做,上面的链接应该能帮到你。另外,你可以通过 Github 获取本教程的源代码并跟随操作。
通常,我们想要检查的数据集以文本形式(JSON、Excel、简单的 txt 文件等)提供,但在我们的案例中,networkx 为我们提供了它。此外,为了比较我们的算法,我们希望知道成员之间的真实关系(谁跟随谁),但遗憾的是没有提供。不过,通过这两行代码,你将能够加载数据并存储真实情况(从现在起我们称之为真实数据):
# Load and Store both data and groundtruth of Zachary's Karate Club
G = nx.karate_club_graph()
groundTruth = [0,0,0,0,0,0,0,0,1,1,0,0,0,0,1,1,0,0,1,0,1,0,1,1,1,1,1,1,1,1,1,1,1,1]
数据预处理的最后一步是将图形转换为矩阵(这是我们算法所需的输入)。这也非常简单:
def graphToEdgeMatrix(G):
# Initialize Edge Matrix
edgeMat = [[0 for x in range(len(G))] for y in range(len(G))]
# For loop to set 0 or 1 ( diagonal elements are set to 1)
for node in G:
tempNeighList = G.neighbors(node)
for neighbor in tempNeighList:
edgeMat[node][neighbor] = 1
edgeMat[node][node] = 1
return edgeMat
在我们深入聚类技术之前,我希望你能对我们的数据有一个可视化。所以,让我们编写一个简单的函数来实现这一点:
def drawCommunities(G, partition, pos):
# G is graph in networkx form
# Partition is a dict containing info on clusters
# Pos is base on networkx spring layout (nx.spring_layout(G))
# For separating communities colors
dictList = defaultdict(list)
nodelist = []
for node, com in partition.items():
dictList[com].append(node)
# Get size of Communities
size = len(set(partition.values()))
# For loop to assign communities colors
for i in range(size):
amplifier = i % 3
multi = (i / 3) * 0.3
red = green = blue = 0
if amplifier == 0:
red = 0.1 + multi
elif amplifier == 1:
green = 0.1 + multi
else:
blue = 0.1 + multi
# Draw Nodes
nx.draw_networkx_nodes(G, pos,
nodelist=dictList[i],
node_color=[0.0 + red, 0.0 + green, 0.0 + blue],
node_size=500,
alpha=0.8)
# Draw edges and final plot
plt.title("Zachary's Karate Club")
nx.draw_networkx_edges(G, pos, alpha=0.5)
这个函数的作用是简单地提取结果中的聚类数量,然后为每个聚类分配不同的颜色(对于给定时间最多 10 个颜色即可),然后进行绘图。

聚类算法
一些聚类算法会很好地对你的数据进行聚类,而另一些可能会失败。这是聚类问题如此困难的主要原因之一。但不用担心,我们不会让你在选择的海洋中迷失。我们将讨论几种已知表现非常好的算法。
K-均值聚类

来源:github.com/nitoyon/tech.nitoyon.com
K-均值被许多人认为是聚类的黄金标准,因为它的简单性和性能,它是我们将尝试的第一个算法。当你完全不知道使用哪个算法时,K-均值通常是首选。请记住,K-均值有时可能表现不佳,因为它的概念是:球形聚类可分离,以便均值收敛到聚类中心。要简单地构建和训练一个 K-均值模型,请使用以下几行:
# K-means Clustering Model
kmeans = cluster.KMeans(n_clusters=kClusters, n_init=200)
kmeans.fit(edgeMat)
# Transform our data to list form and store them in results list
results.append(list(kmeans.labels_))
聚合聚类
聚合聚类的主要思想是每个节点从自己的聚类开始,然后递归地与增加最小链接距离的聚类对合并。聚合聚类(以及一般的层次聚类)的主要优点是你不需要指定聚类的数量。当然,这也有代价:性能。不过,在 scikit 的实现中,你可以指定聚类的数量以帮助算法的性能。要创建和训练一个聚合模型,请使用以下代码:
# Agglomerative Clustering Model
agglomerative = cluster.AgglomerativeClustering(n_clusters=kClusters, linkage="ward")
agglomerative.fit(edgeMat)
# Transform our data to list form and store them in results list
results.append(list(agglomerative.labels_))
光谱
光谱聚类技术将聚类应用于归一化拉普拉斯的投影。在图像聚类方面,光谱聚类效果非常好。请查看以下几行 Python 代码,了解所有的魔法:
# Spectral Clustering Model
spectral = cluster.SpectralClustering(n_clusters=kClusters, affinity="precomputed", n_init= 200)
spectral.fit(edgeMat)
# Transform our data to list form and store them in results list
results.append(list(spectral.labels_))
亲和传播
这个算法有些不同。与之前的算法不同,你会发现 AF 在运行算法之前不需要确定聚类的数量。AF 在处理许多计算机视觉和生物学问题上表现非常好,比如人脸图像聚类和识别调控转录本:
# Affinity Propagation Clustering Model
affinity = cluster.affinity_propagation(S=edgeMat, max_iter=200, damping=0.6)
# Transform our data to list form and store them in results list
results.append(list(affinity[1]))
指标与绘图
现在,是时候选择哪个算法更适合我们的数据了。对于小数据集,简单的可视化结果可能效果不错,但试想一下有一千个甚至一万个节点的图形。这对于人眼来说会有点混乱。所以,让我展示如何计算调整兰德指数(ARS)和归一化互信息(NMI):
# Append the results into lists
for x in results:
nmiResults.append(normalized_mutual_info_score(groundTruth, x))
arsResults.append(adjusted_rand_score(groundTruth, x))
如果你对这些指标不太熟悉,这里有一个简短的解释:
归一化互信息(NMI)
两个随机变量的互信息是衡量这两个变量之间相互依赖的度量。归一化互信息是对互信息(MI)得分进行归一化,将结果缩放到 0(无互信息)到 1(完美相关)之间。换句话说,0 表示不相似,1 表示完全匹配。
调整兰德指数(ARS)
调整兰德指数则通过考虑所有样本对,并统计在预测和真实聚类中分配到相同或不同聚类的样本对,来计算两个聚类之间的相似度。如果这有点难以理解,请记住,目前的 0 表示最低相似度,而 1 表示最高相似度。
因此,为了得到这些指标(NMI 和 ARS)的组合,我们只需计算它们总和的平均值。记住,数值越高,结果越好。
下面,我绘制了评分评估图,以便我们能更好地理解我们的结果。我们可以用很多方式绘制它们,比如点图、折线图,但我认为条形图在我们的情况下更好。为此,只需使用以下代码:
# Code for plotting results
# Average of NMI and ARS
y = [sum(x) / 2 for x in zip(nmiResults, arsResults)]
xlabels = ['Spectral', 'Agglomerative', 'Kmeans', 'Affinity Propagation']
fig = plt.figure()
ax = fig.add_subplot(111)
# Set parameters for plotting
ind = np.arange(len(y))
width = 0.35
# Create barchart and set the axis limits and titles
ax.bar(ind, y, width,color='blue', error_kw=dict(elinewidth=2, ecolor='red'))
ax.set_xlim(-width, len(ind)+width)
ax.set_ylim(0,2)
ax.set_ylabel('Average Score (NMI, ARS)')
ax.set_title('Score Evaluation')
# Add the xlabels to the chart
ax.set_xticks(ind + width / 2)
xtickNames = ax.set_xticklabels(xlabels)
plt.setp(xtickNames, fontsize=12)
# Add the actual value on top of each chart
for i, v in enumerate(y):
ax.text( i, v, str(round(v, 2)), color='blue', fontweight='bold')
# Show the final plot
plt.show()
正如你在下方图表中看到的,K-means 和层次聚类在我们的数据集中表现最佳(最佳可能结果)。当然,这并不意味着谱聚类和 AF 算法表现较差,只是它们不适合我们的数据。

好了,这就是全部内容!
感谢你参与这个聚类入门。我希望你在观察如何轻松操作公共数据集并在 Python 中应用几种不同的聚类算法时,能够发现一些价值。如果你有任何问题,请在下方评论区告诉我,也可以随意附上你尝试过的聚类项目!
个人简介:尼科斯·库福斯 是 LearnDataSci 的作者,希腊伊奥尼纳大学计算机科学与工程研究生,并担任计算机科学本科教学助理。
原文。转载已获许可。
相关:
-
比较聚类技术:简明技术概述
-
使用聚类自动分割数据
-
聚类关键术语解析
更多相关主题
使用 Dask 进行 K-means 聚类:猫咪图片的图像滤镜
原文:
www.kdnuggets.com/2019/06/k-means-clustering-dask-image-filters.html
评论
由Luciano Strika提供,MercadoLibre

对图像应用滤镜对任何人来说都不是新概念。我们拍一张照片,对其进行一些更改,然后它看起来更酷。但是人工智能的作用在哪里?让我们尝试一下用 K Means 聚类进行无监督机器学习的有趣用例。
我之前写过K Means 聚类,所以我会假设你对这个算法已经熟悉。如果你不熟悉,可以查看我写的深入介绍。
此外,我还尝试了用自编码器进行图像压缩(好吧,是重建),效果有好有坏。
然而,这一次,我的目标是不重建最好的图像,而只是查看用最少颜色重建图片的效果。
与使图片尽可能接近原始图片不同,我只是希望我们看完之后能说“真棒!”。
那我们该如何做呢?很高兴你问了。
如何使用 K-means 聚类进行图像滤镜
首先,永远记住图像只是像素向量。每个像素是三个介于 0 到 255 之间的整数值的元组(无符号字节),代表该像素颜色的 RGB 值。
我们想要使用 K-means 聚类来找到最能表征图像的k个颜色。这意味着我们可以将每个像素视为单个数据点(在 3 维空间中),并进行聚类。
首先,我们需要在 Python 中将图像转换为像素向量。以下是实现方法。
顺便说一句,我认为vector_of_pixels函数不需要使用 Python 列表。我确信一定有办法展平 numpy 数组,只是我没找到(至少没有找到按照我想要的顺序进行展平的方法)。
如果你能想到任何方法,请在评论中告诉我!
下一步是拟合模型到图像,以便它将像素聚类为k种颜色。然后,只需将相应的聚类颜色分配给图像中的每个位置即可。
例如,也许我们的图片只有三种颜色:两种红色和一种绿色。如果我们将其拟合到 2 个聚类,那么所有红色像素都会变成不同的红色阴影(被聚在一起),其他的则会变成绿色。
但解释够了,让我们看看程序的实际效果!
和往常一样,你可以用任何你想要的图片自行运行,以下是带有代码的GitHub 仓库。
结果
我们将把滤镜应用于小猫的图片,这些图片取自令人惊叹的“Cats vs Dogs”kaggle 数据集。
我们将从一张猫的图片开始,并使用不同的k值应用滤镜。以下是原始图片:

首先,我们来检查一下这张图片最初有多少种颜色。
仅用一行Numpy代码,我们计算了这张图片上像素的唯一值。这张图片特别有243 种不同颜色,尽管它总共有166167 个像素。
现在,让我们看看将其聚类为 2、5 和 10 种不同颜色后的结果。

只有两种颜色,它所做的只是标记最暗和最亮的区域。不过,如果你是艺术家,正在用黑白(例如墨水)绘制某些东西,并希望看到参考图像的轮廓,这可能会很有用。
 只有 5 种不同的颜色,这只猫已经可以辨认出来了!!这只小猫的图片是使用 K 均值聚类压缩的。10 种颜色的图片可能看起来有点迷幻,但它比较清晰地展示了原图的内容。
只有 5 种不同的颜色,这只猫已经可以辨认出来了!!这只小猫的图片是使用 K 均值聚类压缩的。10 种颜色的图片可能看起来有点迷幻,但它比较清晰地展示了原图的内容。
你注意到什么趋势了吗?我们添加的每一种颜色的回报递减。拥有 2 种颜色和 5 种颜色之间的差别远大于 5 种和 10 种之间的差别。然而,10 种颜色时,平坦区域更小,细节更丰富。接下来看看 15 种和 24 种颜色!


尽管很明显,上面的图片使用了 24 种颜色的滤镜(原始数量的 10%),但我们足够好地展示了猫,并达到了一定的细节水平。
继续看另一张图片:这是原图(256 种不同颜色),这是压缩后的图片(24 种颜色)。
 256 种颜色与 24 种颜色。注意到有什么区别吗?
256 种颜色与 24 种颜色。注意到有什么区别吗?
有趣的是,“压缩”图像的大小为 18KB,而未压缩的图像为 16KB。我不太清楚为什么会这样,因为压缩器是相当复杂的,但希望看到你们在评论中的理论。
结论
我们能够仅用原图 10% 的颜色生成新图像,且看起来非常相似。得益于 K-means 聚类,我们还获得了一些酷炫的滤镜。你能想到其他有趣的聚类应用吗?你认为其他聚类技术会产生更有趣的结果吗?
如果你想回答这些问题,可以通过 Twitter、Medium 或 Dev.to 与我联系。
简介: Luciano Strika 是布宜诺斯艾利斯大学的计算机科学学生,兼任 MercadoLibre 的数据科学家。他还在www.datastuff.tech撰写有关机器学习和数据的文章。
原文。经许可转载。
相关:
-
K-Means 聚类:推荐系统的无监督学习
-
提升你的图像分类模型
-
介绍 Dask-SearchCV:使用 Scikit-Learn 进行分布式超参数优化
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
K-Means 比 Scikit-learn 快 8 倍,误差低 27 倍,代码仅需 25 行
原文:
www.kdnuggets.com/2021/01/k-means-faster-lower-error-scikit-learn.html
评论
由Jakub Adamczyk,计算机科学学生,Python 和机器学习爱好者。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
在我上一篇关于 faiss 库的文章中,我展示了如何通过使用Facebook 的 faiss 库将 kNN 加速至比 Scikit-learn 快 300 倍,仅需 20 行代码。但我们可以用它做更多的事情,包括更快且更准确的 K-Means 聚类,代码仅需 25 行!
K-Means 是一种迭代算法,它将数据点聚类到 k 个簇中,每个簇由一个均值/中心点(质心)表示。训练从一些初始猜测开始,然后在两个步骤之间交替进行:分配和更新。
在分配阶段,我们将每个点分配到最近的簇(使用点与质心之间的欧几里得距离)。在更新步骤中,我们通过计算当前步骤中分配给该簇的所有点的均值来重新计算每个质心。
聚类的最终质量计算为簇内距离的总和,对于每个簇,我们计算该簇内点与其质心之间的欧几里得距离的总和。这也称为惯性。
对于预测,我们在新点和质心之间执行 1-最近邻搜索(kNN,k = 1)。
Scikit-learn 与 faiss
在这两个库中,我们需要指定算法的超参数:簇的数量、重启的次数(每次从不同的初始猜测开始)以及最大迭代次数。
从例子中可以看出,该算法的核心是搜索最近邻,特别是最近的质心,适用于训练和预测。这也是 faiss 比 Scikit-learn 快几个数量级的地方!它利用了出色的 C++ 实现、尽可能的并发,甚至可以使用 GPU(如果你需要的话)。
使用 faiss 实现 K-Means 聚类
faiss 的一个伟大特点是它提供了安装和构建说明以及带有示例的优秀文档。安装后,我们可以编写实际的聚类代码。代码相当简单,因为我们只是模仿 Scikit-learn 的 API。
重要元素:
-
faiss 有一个内置的Kmeans类专门用于此任务,但其参数的名称与 Scikit-learn 不同(参见文档)。
-
我们必须确保使用np.float32类型,因为 faiss 仅支持这种类型。
-
kmeans.obj通过训练返回一个误差列表,因此为了得到最终的误差,就像在 Scikit-learn 中一样,我们使用[-1]索引。
-
预测是通过Index数据结构完成的,这是 faiss 的基本构建块,所有的最近邻搜索都使用它。
-
在预测中,我们进行 kNN 搜索,k = 1,返回自.cluster_centers_中的最近质心的索引(索引[1],因为index.search()返回距离和索引)。
时间和准确性比较
我选择了一些在 Scikit-learn 中可用的流行数据集进行比较。比较了训练和预测时间。为了更容易阅读,我明确写出基于 faiss 的聚类比 Scikit-learn 快多少倍。为了比较误差,我只写了基于 faiss 的聚类实现了多少倍的更低误差(因为数字较大且不太具参考性)。
所有这些时间都是通过time.process_time()函数测量的,该函数测量进程时间而非挂钟时间,以获得更准确的结果。结果是 100 次运行的平均值,除了 MNIST,因为 Scikit-learn 花费的时间太长,我只做了 5 次运行。

训练时间(图像由作者提供)。

预测时间(图像由作者提供)。
训练误差(图像由作者提供)。
如我们所见,对于小数据集的 K-Means 聚类(前 4 个数据集),基于 faiss 的版本训练速度较慢且误差较大。对于预测,它的表现普遍更快。
对于较大的 MNIST 数据集,faiss 明显胜出。训练速度快 20.5 倍是巨大的,特别是因为它将时间从将近 3 分钟减少到不到 8 秒!预测速度快 1.5 倍也是不错的。然而,真正的成就的是误差降低了 27.5 倍。这意味着对于较大的现实世界数据集,基于 faiss 的版本准确性高得多。而且这只需要 25 行代码!
基于此:如果你有一个大(至少几千个样本)的现实世界数据集,基于 faiss 的版本就更好。对于小的玩具数据集,Scikit-learn 是更好的选择;然而,如果你有 GPU,GPU 加速的 faiss 版本可能会更快(我还未检查过以确保公平的 CPU 比较)。
总结
通过 25 行代码,我们可以利用 faiss 库为 K-Means 聚类提供显著的速度和准确性提升,适用于合理大小的数据集。如果需要,你可以使用 GPU、多个 GPU 等进一步提高,faiss 文档中对此做了很好的解释。
原文。已获许可转载。
相关:
更多相关话题
Kaggle Kernels 初学者指南:逐步教程
原文:
www.kdnuggets.com/2019/07/kaggle-kernels-guide-beginners-tutorial.html
评论
由 Abdul Majed Raja,思科分析师提供
不久前,我写了一篇标题为“用 Kaggle Kernels 展示你的数据科学技能”的文章,后来意识到尽管这篇文章很好地阐述了 Kaggle Kernels 如何成为数据科学家的强大作品集,但它并没有解决完全初学者如何开始使用 Kaggle Kernels 的问题。
这是一个试图引导完全初学者并带他们了解 Kaggle Kernels 世界的尝试——让他们能够开始使用。
注册 Kaggle — www.kaggle.com/
如果你没有 Kaggle 账户,第一步是注册 Kaggle。你可以使用 Google 账户或 Facebook 账户来创建新的 Kaggle 账户并登录。如果以上都不可行,你可以输入你的电子邮件地址和首选密码来创建新的账户。
Kaggle 注册页面
登录 Kaggle
如果你已经有账户或者刚刚创建了一个,请点击页面右上角的登录按钮来启动登录过程。同样,你将有一个选项使用 Google / Facebook / Yahoo 登录,或者使用你在创建账户时输入的用户名和密码。
Kaggle 登录/注册界面
Kaggle 控制面板
登录后,你将进入 Kaggle 控制面板。(这只是欢迎页面,我不知道该怎么称呼,所以称之为控制面板)。
这是你登录后立即看到的首页(如果你是从 www.kaggle.com/ 登录的)。它包含许多组件,其中一些如下:
-
最近更新或由 Kaggle 推荐的 Kaggle Kernels 的信息流
-
个人资料摘要(右侧边栏的最上方)
-
职位广告(右侧边栏)
-
你的比赛(右侧边栏—向下滚动后)
-
你的 Kernels(右侧边栏—向下滚动后)
接下来我们要去的是导航栏顶部的Kernels按钮。
Kaggle Kernels 列表(最热):
一旦我们点击 Kaggle 旅程中任何位置的顶部 Kernels 按钮,我们将会看到这个屏幕。
这是每个人都希望看到的界面,因为它像是 Kernels 的首页,这意味着你的 Kernel 更有可能获得更多的曝光。如果 Kernel 最终出现在这里,默认的排序方式是热门度,这是基于 Kaggle 秘密算法的,旨在展示相关的 Kernels,但它也提供了其他排序选项,如新建、最多票数等。Kaggle 也使用这个页面来宣传是否有 Kernel 比赛正在进行或即将进行。
在这里,Kernel 比赛是 Kaggle 的一个比赛,但由于比赛的性质(输出是 Kaggle Kernel,并且通常侧重于讲故事),它不属于比赛层级。Data Science for Good 是一系列 Kernel 比赛,数据科学家 / Kaggle 用户需要使用数据科学帮助解决社会问题。为了更好地理解,你可以查看 Kernel Grandmaster Shivam Bansal 的 Kernels,他已经多次赢得这些比赛。
Kaggle Kernels — 新建 / 创建:
现在我们已经理解了 Kaggle Kernels 的概念,我们可以直接进入新建 Kernels 的过程。创建 Kaggle Kernel 主要有两种方式:
-
从 Kaggle Kernels(首页)使用新建 Kernel 按钮
-
从数据集页面使用新建 Kernel 按钮
方法 #1:从 Kaggle Kernels(首页)使用新建 Kernel 按钮
正如上面的截图所示,从 Kernels 页面点击新建 Kernel 按钮将允许你创建一个新的 Kernel。如果你想练习自己的内容或计划输入自己的数据集,这个方法是不错的。如果你想为 Kaggle 上已存在的数据集创建 Kernel,我个人不建议使用这种方法。
方法 #2:从数据集页面使用新建 Kernel 按钮
这是我用来创建新 Kernels 最常用的方法之一。你可以打开你感兴趣的数据集页面(如下面截图所示),然后点击其中的新建 Kernel 按钮。这个方法的好处是,与方法 #1 不同,方法 #2 创建的 Kernel 默认会附带 Kaggle 数据集,因此将数据集输入到你的 Kernel 的过程变得更简单、更快速、更直接。
www.kaggle.com/google/google-landmarks-dataset
Kaggle Kernels — Kernel 类型:
无论是方法 #1 还是方法 #2,一旦点击新建 Kernel,你将看到一个模态窗口,让你选择要创建的 Kaggle Kernel 类型。

大致分为两类 — 1. 脚本 vs 2. 笔记本。
正如我们所知,Notebook(基于单元格的布局)就是 Jupyter Notebook,而脚本则是你可能会在 Pycharm、Sublime Text 或 RStudio 中编写的代码。此外,对于 R 用户而言,脚本是 RMarkdown 的 Kernel 类型——一种通过编程方式生成报告的优美方式。
总结一下 Kernels 的类型:
-
脚本
-
Python
-
R
-
RMarkdown
-
-
Notebook
* Python *****R
Kaggle Kernels — Kernel 语言:
这种第二层的 Kernel 语言选择仅在第一层 Kernel 类型选择之后发生。
如上面的 Kaggle Kernel 脚本类型 GIF 所示,通过进入设置并选择所需语言(R / Py / RMarkdown)可以更改 Kernel 的语言。相同的设置还提供了将 Kernel 分享设为公开的选项(默认情况下是私密的,除非设置为公开)。如果你正在进行大学作业或自学并且不希望公开代码,通常使用私密 Kernels。参与竞赛的 Kagglers 也会使用私密 Kernels 来利用 Kaggle 的计算能力,但不透露他们的代码/方法。
Notebook Kernel:
类似于上面的 GIF,其中选择了 Kernel 类型 Script,你也可以选择 Notebook 来创建一个 Notebook Kernel。
RMarkdown Kernel —(Kernel 类型:脚本 > RMarkdown)
RMarkdown 通过结合 R 和 Markdown 生成包含交互式可视化的分析报告。虽然这是解释 RMarkdown 的最简单方法,但它的用途和潜力远远超出了这个定义。
幸运的是,Kaggle Kernel 脚本支持 Rmarkdown,这意味着它可以帮助创建交互式文档以及许多 Notebook 情境下无法实现的功能。这是一个在 Kaggle Kernel 上构建的a full-fledged Interactive Dashboard,由Saba Tavoosi,展示了 Kaggle Kernels 的潜力,不仅用于构建机器学习模型,还可以进行最佳形式的交互式讲故事。如果你有兴趣学习如何使用 flexdashboard 构建仪表板,可以查看这门课程。

Kernel Courtesy: Saba Tavoosi
复制和编辑(以前称为 Forking)
类似于 Github 的 Fork 选项,如果你想使用现有的 Kaggle Kernel 并在自己的空间中进行修改或增添个人风格,你需要使用右上角的蓝色按钮 复制并编辑。事实上,在 Kaggle 竞争跟踪中的许多高分公共 Kernel 通常是 forks of forks forks,即一个 Kaggle 用户会在另一个 Kaggle 用户已经构建的模型上进行改进,并将其作为公共 Kernel 提供。
标记的符号表示一个 Forked / 复制并编辑的 Kernel
公开 / 私有 Kernel
正如我们在另一部分看到的,Kaggle Kernel 的访问设置可以是公开或私有。公开 Kernel(显然名字就说明了)对所有人(包括 Kagglers 和非 Kagglers)可用并且可见。私有 Kernel 仅对所有者(创建者)和所有者分享 Kernel 的人可用。一个公开的 Kernel 也可以基于私有数据集。例如,如果这是一个机器学习竞赛,你用一些第三方数据进行了特征工程,并且不希望在竞赛期间泄露数据。这是 Kagglers 通常将数据集设为私有,而将 Kernel 设为公开的典型场景,以便其他人可以看到他们的方法并从中学习。
上图展示了如何将现有 Kernel 的访问设置更改为私有或公开。所有新创建的 Kernel 默认都是私有的(截至本文撰写时),如果需要,所有者可以将其更改为公开。
TL;DR — 如何创建一个新的 Kaggle Kernel
如果上述内容初看起来有些难以理解,这一部分将帮助你创建第一个 Kaggle Kernel。

步骤:
-
使用你的凭证登录 Kaggle
-
访问任何公开的 Kaggle 数据集
-
点击右上角的 新建 Kernel(蓝色按钮)
-
选择你感兴趣的 Notebook/Script
-
如果 Python 是你的首选语言,就保持不变;如果是 R,那么请前往右侧的 设置 并点击展开项,在语言旁边你会看到 Python,点击它可以更改为 R
-
前往屏幕的编辑器部分 / 面板(左侧),开始编写你的精彩代码(上面的 GIF 也展示了如何使用你创建 Kernel 的数据集)
-
一旦你的代码完成,点击右上角的 提交(蓝色按钮)
-
如果你的 Kernel 执行成功(没有任何错误),请将你的 Kernel 设为公开(可以通过编辑 Kernel 的 设置 > 共享(公开) 或重新打开 Kernel 并点击顶部的 访问 按钮)
-
目前,你的第一个 Kaggle Kernel 应该准备好与网络中的朋友分享了!
查看这个Kaggle 视频获取帮助。
完
对于许多 Kagglers 来说,竞赛轨道是他们的乐趣所在,但对我来说,Kaggle Kernels 轨道是我的最爱,它为我们提供了从数据准备到数据可视化——机器学习建模到讲故事的全栈数据科学旅程的巨大潜力。希望你也会喜欢。祝你在 Kaggle Kernel 旅程中好运。
查看我的Kaggle Kernels 在我的 Kaggle 个人资料中并在我的 LinkedIn 个人资料上与我分享你的反馈。这个教程中使用的视频/GIF/截图可在我的 GitHub上找到。
简历: AbdulMajedRaja 是 Cisco 的分析师。
原文。经许可转载。
相关:
-
展示你的数据科学技能与 Kaggle Kernels
-
如何制作令人惊叹的 3D 图以提升讲故事效果
-
使用 Coindeskr 和 Shiny 在 R 中构建每日比特币价格追踪器
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关内容
Kaggle Learn 是“更快的数据科学教育”吗?
原文:
www.kdnuggets.com/2019/08/kaggle-learn-faster-data-science-education.html
评论
Kaggle Learn 自称为“更快的数据科学教育”,是一个免费的微课程资源库,涵盖了各种“[p]可以立即应用的实际数据技能”。
如你所知,各种免费和低成本的数据科学教育资源可以通过众多在线平台获得。那么,为什么我觉得有必要写关于另一个数据科学学习资源的文章呢?
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
当我计划开始一个新的秋季学习计划时——一旦那些懒洋洋的夏日离开我的系统——我想先找到一些简明的复习材料,复习我以前学过的概念和已经掌握但可能有些生疏的技能。需要明确的是,Kaggle Learn 并未专门将其微课程标榜为复习材料;然而,到目前为止,我发现它们非常适合这个需求(尽管,诚然,我还处于早期阶段)。
以下是 Kaggle Learn 目前的微课程列表。我(或多或少)从顶部开始,并按顺序完成列表中的内容,然后再开始新的学习冒险。

当前的微课程列表来自于Kaggle Learn
Kaggle Learn 并不是全新推出的,它于 2018 年 1 月上线,自那时以来增长了 1500%(根据 Kaggle Learn 的数据)。然而,它的短课程方法对实际数据技能的培养似乎使其与其他资源有所不同,课程时间通常在 3 到 8 小时之间。
为了了解更多关于 Kaggle Learn 的信息,我联系了该项目的负责人,Dan Becker,并向他询问了一些问题。他回答了关于平台、内容和未来的以下见解。
Matthew Mayo: 微课程的推动因素是什么,与更传统、更长的在线课程相比?
Dan Becker: 我们在几个方面都很独特。
首先,我们更注重实际应用而非学术理论。当我从事数据科学咨询工作时,我曾为数十家公司解决商业问题。传统课程往往关注许多实际中并不重要的技能,同时忽视了许多最重要的内容。例如,学生可能会学会从头编写一个算法(而实际上没人需要你再做这种事),但你不会学会如何操控数据以将其导入实现该算法的主流库中。
我也参与过多次招聘,我知道有趣的、动手实践的项目能够引起招聘经理的关注。因此,我们将课程做得非常简短,以便你能更快地开始做项目。个人项目也帮助你专注于实际工作中所涉及的技能。另一个好处是,大多数人喜欢他们的个人项目,因此他们会找到更多时间去做……而传统课程可能会变得无聊,拖延几个月。
因此,Kaggle 上的每门课程都旨在成为开始做新类型数据科学项目的最快途径。
从战略上看,Kaggle 处于独特的位置。大多数公司都对其课程收费。在线课程的价格非常公道(远远低于你在获得数据科学工作后能赚到的钱),而且课程的创建者们也付出了大量的努力来制作这些内容。但当某些人需要收费时,他们会感受到创建更长课程的压力。很难对一个 4 小时的课程收取几百或几千美元的费用,然后告诉用户“此时你最好去做一个个人项目”。由于我们的课程是免费的,我们不感受到填充额外内容的压力。
Matthew Mayo: 你怎么看待 Kaggle Learn 的未来发展?你们有其他的微课程计划吗?会有微课程的替代方案吗?
Dan Becker: 对于喜欢较长课程的人来说,已经有很多很好的选择。我会将他们引导到其他优秀的在线平台,而不是试图创造另一种版本的相同内容。不过我会警告他们的是:一旦你进入该领域工作,你会学习得更快,因为你是在工作中学习,而不仅仅是在闲暇时间。获得工作的最大资产是个人项目的作品集。所以推迟做个人项目可能会延迟你学习的最快部分。
我们即将发布一个特征工程课程、自然语言处理课程、地理空间分析课程和一个强化学习课程。每个课程仅约 4 小时长。你在这么短的时间内不会成为这些领域的专家。但你会学到足够的知识,能够独立工作,按需寻找新答案,并开始做有趣的工作。
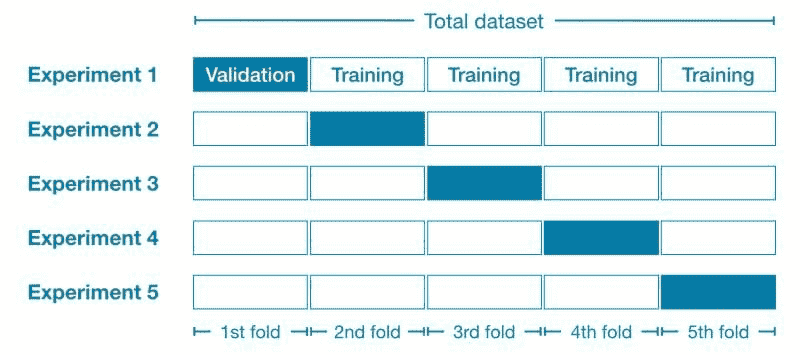
来源于 中级机器学习,Kaggle Learn
我从机器学习和 Python 课程开始复习——有很多 Python 内容我不常用——希望在月底之前逐一完成这些课程。完成这些基础之后,将开始接触新的材料。
我鼓励任何寻求短期实用数据技能课程的人查看 Kaggle Learn,无论你是初学者还是寻找一套扎实复习材料的中级学员。虽然这些课程不会在几个小时内让你成为任何领域的专家——事实上,它们也不声称如此——但它们将提供一个简明的实施路径,并从那里继续前进。
相关内容:
-
数据科学学习者常犯的错误的 70%
-
Kaggle Kernels 新手指南:一步步教程
-
数据科学方法有什么问题?
更多相关内容
数据科学与机器学习 2020:3 个关键发现
原文:
www.kdnuggets.com/2020/12/kaggle-survey-2020-data-science-machine-learning.html
评论
Kaggle 最近发布了 2020 年年度数据科学与机器学习现状调查的最新结果。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
第四年,Kaggle 调查了其数据爱好者社区,分享快速发展的领域中的趋势。基于 20,036 名 Kaggle 成员的反馈,我们创建了这份报告,重点关注当前作为数据科学家的 13%(2,675 名受访者)。
报告概览可以在线查看 这里。另外,你可以查看调查的执行摘要,或查看并互动调查的原始数据。
虽然我们建议每个人都花时间详细查看结果,但在这里,我们为你带来调查报告中突出的 3 个关键发现。
1. 薪资差距
报告从第 11 页开始涵盖数据科学家的薪资。报告对美国和印度数据科学家的薪资分布进行了同类比较,还分析了全球数据分布和几个选定国家的中位薪资。虽然这些苹果与橙子的比较较为复杂——例如国家生活成本差异以及数据科学家的薪资分布与所有国家职业的分布显著不同,这些因素显然未被考虑——但第 14 页中各国数据科学家的中位薪资仍展示了全球数据科学家薪资的巨大差距。
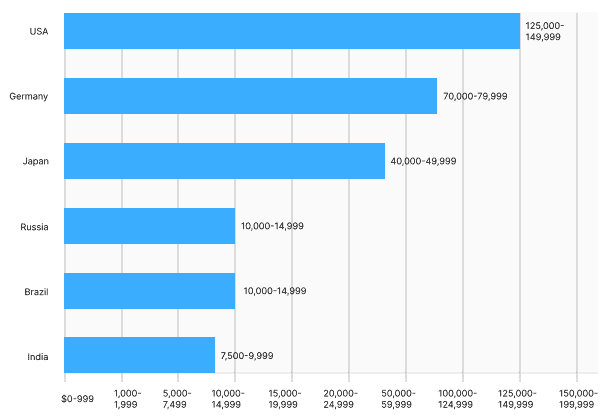
图 1:各国数据科学家的中位薪资
从各国的薪资数据来看,我们发现美国公司的薪资更高。德国和日本公司紧随其后,薪资显著高于其他包含的地区。
需要注意的是,这只是调查响应的汇总,简单地报告了原始数据。如果有人感兴趣,原始数据可以用来进行更深入和细致的全球数据科学家薪资分析和比较。
2. JupyterLab 是主要开发环境
这一点对很多人来说可能并不令人惊讶,但 JupyterLab 仍然保持着最常用的交互式开发环境的首位,74.1%的受访者报告使用了它。
基于 Jupyter 的 IDE 仍然是数据科学家的首选工具,大约四分之三的 Kaggle 数据科学家使用它。然而,这一比例从去年的 83%下降了。Visual Studio Code 位居第二,使用比例略高于 33%。
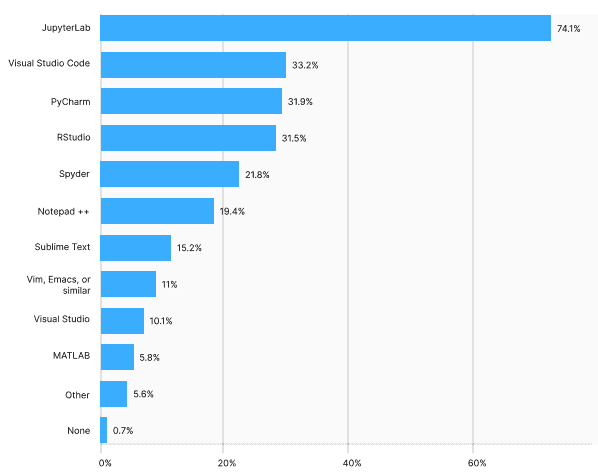
图 2:流行 IDE 使用情况
剩下的列表包含了主要是基于 Python 的 IDE 和多用途文本编辑器,以及 RStudio 和 MATLAB。这个列表可能提供了一些关于 Python 在该领域相对主导地位的证据,但也提醒我们 R 语言的持续强势地位,以及 MATLAB 的持久性。我们还可以确认,更传统的 IDE 在数据科学和机器学习中的使用并不普遍,可能没有在其他编程学科中的使用那么广泛——尽管我们没有现成的数据来进行比较。
3. 顶级方法与算法
报告的第 19 页展示了数据科学中使用最广泛的方法和算法。
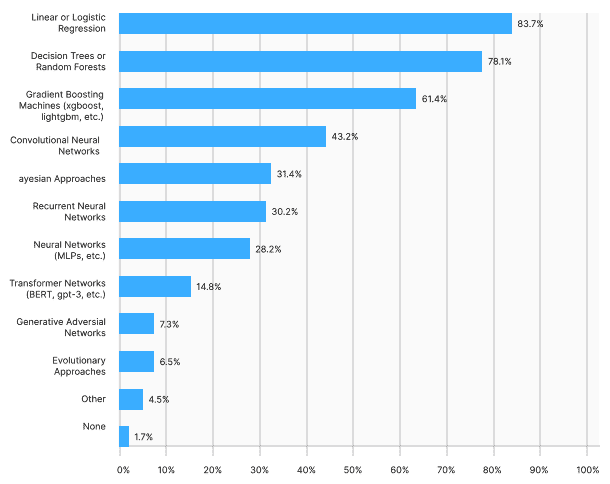
图 3:方法和算法使用情况
最常用的算法是线性回归和逻辑回归,其次是决策树和随机森林。在更复杂的方法中,梯度提升机和卷积神经网络是最受欢迎的。
不出所料,线性回归、逻辑回归、各种决策树方法和梯度提升机占据了前列。下一层次的方法包括多种神经网络架构和贝叶斯方法。最后,特定的神经网络架构,如变压器和 GANs,以及进化方法,构成了列表的最后部分。
别忘了查看整个报告,以了解更多关于数据科学家概况、数据科学团队、企业机器学习采用情况、自动化机器学习使用情况等附加主题的信息。同时,也别忘了原始数据可用,供有兴趣进行数据清洗和探索的人使用。
相关:
-
2018 年、2019 年使用的顶级数据科学和机器学习方法
-
机器学习正在发生:组织采用、实施和投资的调查
-
Kaggle 的数据科学/机器学习竞赛的国际替代平台
更多相关主题
像业余爱好者一样思考,像专家一样行动:来自计算机视觉职业生涯的经验教训
原文:
www.kdnuggets.com/2019/05/kanade-lessons-career-computer-vision.html
评论
2018 年嵌入式视觉峰会高井博士主旨演讲的要点
高井武男博士 是卡内基梅隆大学的 U.A.和海伦·惠特克教授。他的讲座题目是:像业余爱好者一样思考,像专家一样行动:来自计算机视觉职业生涯的经验教训
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
高井博士做了一个极具吸引力的演讲,内容丰富且充满幽默。点击这里观看视频。
- 他从研究生阶段开始,已经从事计算机视觉和机器人学工作 50 年。他的博士论文:计算机识别人脸。

-
他出名的时刻:2001 年 1 月 28 日 - 在超级碗 XXXV 上 - 使用EyeVision进行的行动回放,使用 33 台相机,每台相机配有一台带有索尼相机和大变焦镜头的机器人(当时价格为 80,000 美元的三菱 PA-10)。硬件总成本超过 300 万美元。总电缆长度超过 20 公里。他描述了在活跃比赛期间协调机器人相机进行平移、倾斜、变焦和对焦的挑战。
-
另一个出名时刻:高井博士在布鲁斯·威利斯电影代理人中出现,在一个 2.5 秒的片段中饰演自己。
-
什么是“好研究”?即使是经验丰富的研究人员也发现很难清楚回答这个问题。他引用了已故的艾伦·纽厄尔教授:
-
优秀的科学回应真实的现象或实际问题
-
优秀的科学在于细节
-
优秀的科学改变世界
-
-
进行有用且有趣的研究:
-
从一个场景开始:设想成功的情景 - 可能发生什么,如何以及在哪里使用?
-
自由地、愉快地思考
-
故事展开,你可以谈论它
-
其他人可以加入
-
-
高井博士的教训:
-
成功的想法通常出乎意料地简单,甚至是幼稚而微不足道的。
-
对这种简单思考的阻碍:“我知道”的心态。
-
可靠的执行需要实质性的知识和技能——在这里,专业知识是必要的;然而,我们可能需要克服“专家”偏见;这不是将业余人士配对以提出简单的解决方案,然后让专家执行,而是专家根据需要做出适应。
-
像业余人士一样思考,像专家一样行动——当你开始解决一个问题时,像新手一样思考,主动避免先入为主的偏见。在实施解决方案时,采取细致和彻底的方法。 Kanade 博士甚至用日语写了这方面的书(并翻译成了除英语外的其他语言)。
-
-
多摄像头系统:
-
他关于多摄像头实时系统的第一篇论文被拒绝了(其中一位审稿人的评论是:“……使用这些多余摄像头的设备太贵而没有用处。”)
-
他最初通过将真实现实建模为虚拟现实,提出了 Ladar(扫描激光测距仪)。
-
为了克服 Ladar 的视频限制,他的团队主导了 3D 摄像头和软摄像头的开发,以克服遮挡问题。
-
大约在 2000 年,他们开发了一个完全数字化的系统,创建了动态虚拟视图(虚拟现实)。
-
后来的工作包括面部检测、姿态检测。
-
多摄像头系统、大规模 3D 摄像头现在在许多地方使用,如娱乐(还记得电影《黑客帝国》吗?)
-
-
Navlab:
-
Navlab 是一个于 1984 年与 DARPA 启动的自动驾驶程序。 这个项目经历了从 Navlab 1 到 Navlab 10 的多个版本。
-
美国无手驾驶——在 1995 年:Navlab 5 在计算机控制下行驶了从华盛顿 DC 到圣地亚哥的 98.2%的距离。
-
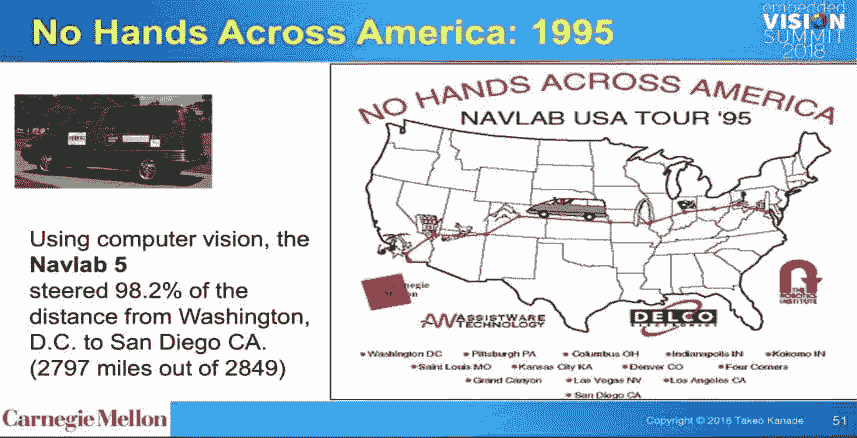
-
智能头灯:
-
雪花和雨滴具有很高的反射性。
-
解决方案:避免光束击中雨滴!
-
即使在约 1000 fps 的帧率和 1.5 ms 的延迟下,其他系统限制也显现出来。 随着速度的提高,许多问题变得更容易解决!
-
这方面的一个实际应用将是适用于所有道路驾驶员的自适应远光灯。
-
-
研究的价值:
-
研究不必是新的。
-
“新颖本身并不是一种美德,有用才是。”
-
预测研究很难:Dr. Kanade 分享了 Lucas-Kanade 光流的故事[Lucas, Kanade ‘81]。大约在 80 年代,他们正在研究跟踪问题。他的学生 Bruce Lucas 提出了一个想法:将泰勒级数展开(已知 300 年)与二次方程的图形解法相结合。Lucas 坚持认为他们应该写一篇论文,而 Dr. Kanade 坚持认为不应该发表,因为这似乎很平凡……学生坚持,最后教授妥协……允许学生在一个冷门期刊上发表。结果,Dr. Kanade 发表的 400 多篇论文中,这篇论文成为了被引用最多的论文。每个使用视频处理的算法都使用了这个概念。
-
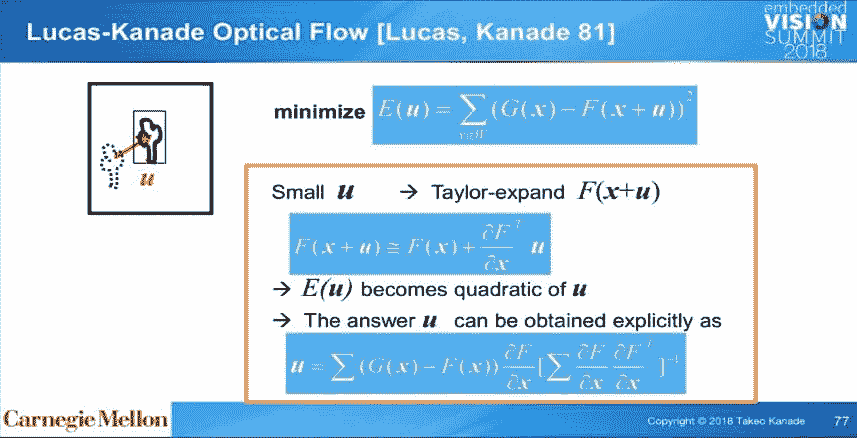
-
当前的计算机视觉正处于“完美风暴”的状态
-
新型、普及型、嵌入式、偶尔超人类的视觉传感器
-
Dr. Kanade 预测这个领域将会出现爆炸性的增长和进展
-
关于嵌入式视觉联盟和 2018 年嵌入式视觉峰会
版权归:Jeff Bier,BDTI 创始人兼总裁,Embedded Vision Alliance 创始人
-
嵌入式视觉联盟是一个由公司组成的合作伙伴关系,致力于加速和促进计算机视觉在解决实际问题中的应用——“我们旨在激发和创造能够‘看见’的产品”
-
嵌入式视觉联盟致力于将视觉感知融入各种系统和设备
-
从 2011 年起,Embedded Vision Alliance 从 16 名成员开始,现在已有 90 名成员
-
主题:在边缘和云端实现计算机视觉——几乎一半的联盟成员已经在使用云计算,约 75%已经在使用边缘视觉。云计算将成为嵌入式视觉解决方案的主要推动力。
-
视觉年度产品奖设立了 8 个类别:处理器、相机、软件、汽车、AI、云计算、开发者、最终产品

-
一名没有计算机视觉经验的开发者可以在几个月内创建一个有效的基于云的视觉解决方案(Chris Adzima 的talk)
-
3D 相机模块现在的价格大约为 20-30 美元(Guillaume Girardin 的talk)
-
二值神经网络可以显著降低 DNN 推理的成本和功耗(Abdullah Raouf, Mohammad Rastegari - talk)
-
一个 DNN 可以为另一个 DNN 生成新的训练数据(Peter Corcoran 的talk)
-
即使智能相机普及,我们也可以保护隐私(Charlotte Dryden 的talk)
-
Vision Tank:一场激动人心的创业竞赛,争夺“最具创新性的视觉基础产品”奖。决赛入围者:
-
2018 年嵌入式视觉峰会的亮点包括:
-
1200 名与会者
-
90+个演讲,跨越 2 天,6 个主题
-
来自 50 多家展商的 100+个实际演示
-
84%的与会者积极开发或计划开发基于视觉的产品
-
每年,这个活动都在积聚越来越多的关注和声势。
2019 年嵌入式视觉峰会将于下周在加利福尼亚州圣克拉拉的圣克拉拉会议中心举行。以下是关键日期和事件:
-
2018 年 5 月 20 日,星期一:关于 TensorFlow 2.0 的深度学习和 OpenCV 中的计算机视觉应用的培训课程。[需要在活动网站上单独注册]
-
2018 年 5 月 21 日至 22 日,星期二和星期三:主会议和视觉技术展示
-
2018 年 5 月 23 日,星期四:Intel、Khronos 和 Synopsys 主办的视觉技术研讨会 [需要通过活动网站单独注册]
所以,赶快注册 2019 年嵌入式视觉峰会吧。这里是链接:www.embedded-vision.com/summit
一些关于计算机视觉的 KDNuggets 文章
-
Andrew Ng 的计算机视觉——11 个经验教训:Ryan Shrott 系统回顾了 Andrew Ng 在 Coursera 上的计算机视觉课程,并分享了他的学习经验。
-
介绍 VisualData:计算机视觉数据集的搜索引擎:Jie Feng 在这篇文章中介绍了VisualData,这是一个计算机视觉数据集的搜索引擎。
-
如何在计算机视觉中做一切:在这篇文章中,George Seif 带我们深入了解计算机视觉中的分类、检测、分割、姿态估计、增强和恢复任务,使用深度学习方法。
更多相关内容
人工“人工智能”泡沫与网络安全的未来
原文:
www.kdnuggets.com/2017/06/kaspersky-artificial-intelligence-bubble-future-cybersecurity.html
评论
由尤金·卡巴斯基,卡巴斯基实验室的首席执行官兼联合创始人。
我认为最近的文章《纽约时报》关于硅谷“人工智能”繁荣的文章让许多人对网络安全的未来——无论是近期的还是遥远的——进行了深思。
我想这些问题会被考虑到:
-
对于‘人工智能’的狂热痴迷——现在只是存在于未来学家的幻想中——将会导致什么?
-
投资者还会投入多少亿资金到那些充其量只是“发明”了几十年前已经被发明的东西,最糟糕的情况是——结果不过是夸大的市场营销……假象的项目?
-
机器学习网络安全技术发展的真正机会是什么?
-
在这个美丽新世界中,人类专家将扮演什么角色?
有时候,当我和这里硅谷的人工智能爱好者待在一起时,我感觉就像是一个无神论者在一个福音派大会上。
——杰瑞·卡普兰,计算机科学家、作家、未来学家和连续创业者(包括赛门铁克的联合创始人)
现在发生的事情在“人工智能”领域就像一个肥皂泡。我们都知道,如果肥皂泡不断被小丑们吹大(无意冒犯!):它们最终会破裂。
现在,当然,没有大胆的举措和冒险的投资,奇幻的未来永远不会成为现实。但今天的问题是,随着对“人工智能”(记住,今天的人工智能并不存在;因此有引号)的广泛热情,这些创业公司壳体开始出现。
几个初创公司?你可能会问,这有什么大不了的。
问题在于,这些壳公司吸引的投资不是数百万,而是数十亿美元——通过迎合围绕‘AI’ 机器学习的新一波热潮。事实上,机器学习已经存在了几十年:它最早在 1959 年被定义,在 70 年代开始运作,在 90 年代蓬勃发展,并且仍在蓬勃发展!快进到今天,这种‘新’技术被重新称为‘人工智能’;它带有前沿科学的光环;它拥有最光鲜的宣传册;它拥有最炫目的营销活动。所有这些都旨在迎合人类对奇迹的固有信仰——以及对所谓‘传统’技术的阴谋论。遗憾的是,网络安全领域也未能逃脱这种新的‘人工智能’泡沫……

在网络安全领域,新推出的“革命性”产品仿佛凭空解决了所有安全问题,保护了每个人和每个事物免受所有网络威胁:这些壳公司不择手段地展示信息,以操控公众舆论,并确保对真实情况的广泛误解。
实际上,在一些这些‘革命性’产品的背后,根本没有所谓的‘最新技术’。相反,它们使用的技术可能像蒸汽机一样过时!但嘿,谁在乎呢?谁会允许有人去查看呢?有关这种不愿意查看的情况,更多信息请见 这里。
一些这些初创公司甚至已经走到了 IPO 的阶段。一些早期的风险投资者可能会做得很好——如果他们能迅速转售;但从长远来看,这将是一个彻底失望的股票市场。因为一个亏损的业务以虚假营销为基础,不会支付红利,而且股价在达到峰值后的急剧下跌是不可阻挡的。同时,那个持续发光的营销金字塔机器需要支付费用——而且价格不菲。
让我们稍微回顾一下。
风险投资之所以被称为‘风险’投资,是因为它涉及风险。一位优秀的风险投资者知道在哪里投入资金——以及投入多少资金——才能在n年内获得良好的利润。然而,关于‘人工智能’有一个细微的差别:至今还没有一个重要的 AI 网络安全投资项目获利!呃,那么,像硅谷这样的风险投资者为什么要投资于 AI 项目呢?这是个好问题。
大多数硅谷初创公司的商业模式(并非全部;有一些幸运的例外)主要目标不是进行严肃的、昂贵的研究,推出能热销的有用产品/技术。而是希望制造泡沫:吸引投资者,迅速以基于“未来利润估值”的股价出售,然后……好吧,那时混乱(巨额损失)将成为其他人的问题。但等等。更糟糕的是:收入实际上只会阻碍这种模式!
这不是关于你赚了多少钱。关键在于你值多少钱。而谁最值钱?那些亏钱的公司。
这里有一个典型的商业模式,通过电视剧硅谷中的光鲜媒体类型在 75 秒内进行了压缩(虽然荒谬搞笑,但这基于现实!):
AI 泡沫在某种程度上有点类似于 2008 年美国房地产市场的泡沫,这一泡沫迅速演变成全球金融危机。基于次贷抵押贷款的投资子产品的金字塔适合了很多人:数百万人从中获得了丰厚的收益,非常感谢;还有几万人从中获利颇丰(万分感谢:)。然后——砰:金字塔崩溃了,全球经济开始动荡,洞口被纳税人的钱填补,以避免金融末日——纳税人当然就是那些最初赚到钱的人。还不知道这十年的骗局丑闻?那就去看电影大空头。
如果这种回忆还不够糟糕,AI 泡沫还包含另一个危险——贬低机器学习:这是网络安全领域中最有前景的子领域之一。
那么,这有什么“危险”?嗯,多亏了机器学习,人类才没有淹没在过去几十年增加了无数倍的数据海洋中。
例如,十年来恶意程序的数量上升了大约一千倍:在本世纪初,我们每天分析大约 300 种不同的恶意软件;而现在这个数字已经在末尾加了三个零。我们的分析师数量增加了多少倍?四倍。那么我们是如何跟上的?两个词:机器学习。
快进到今天,我们检测到的 99.9%的攻击实际上是由我们的自动化系统检测到的。听起来分析师们轻松得笑了?!恰恰相反。他们集中于优化这些系统以提高其效率,并开发新的系统。
比如,我们有专家专门发现真正复杂的网络攻击,然后将他们的新知识和技能转移到我们的自动化系统中。还有数据科学专家,他们尝试不同的机器学习模型和方法。
与空壳初创公司不同,我们通过一个庞大的云基础设施来保护用户,这使得我们能够迅速和有效地解决更复杂的任务。是的,正因为如此,我们应用了许多不同的机器学习模型。
我们手动调查的唯一网络攻击是我们遇到的最复杂的个案。即便如此,鉴于机器几乎完全掌控的现状,我们仍然难以找到足够的专业人员。更重要的是,我们对潜在 KL 分析师的具体要求数量不断上升。
早晚,“人工智能拯救世界”的马戏表演会结束。专家们将最终被允许测试那些虚假的‘AI’产品,客户将意识到自己被欺骗,投资者将失去兴趣。但是机器学习将如何进一步发展呢?
硅谷在人工智能领域曾经经历过虚假的起步。20 世纪 80 年代,早期的一代企业家也相信人工智能是未来的趋势,导致了大量初创企业的涌现。当时他们的产品几乎没有商业价值,因此商业热情以失望告终,进入了现在被称为“人工智能寒冬”的时期。
——约翰·马克夫,《纽约时报》
在人工智能泡沫破裂后的余波中,所有类似领域将不可避免地受到影响。“机器学习?神经网络?行为检测?认知分析?啊——更多的人工智能术语?不,谢谢:不想了解。实际上:不愿意接触这些东西!”
更糟的是,人工智能泡沫的诅咒会使得对有前途技术的兴趣在许多年里变得迟钝,就像 80 年代一样。
尽管如此,成熟的供应商仍将继续投资于智能技术。例如,我们已经引入了提升和决策树学习技术,用于检测复杂的定向攻击和针对未来威胁的主动保护(没错——那些尚不存在的威胁!)。
一个特别有前景的发展领域是增加对所有基础设施层级事件的关联性图景的复杂性,并进一步进行数据景观的机器分析,以准确可靠地检测到最复杂的网络攻击。我们已经在我们的KATA 平台中实现了这些功能,并期待着进一步的发展。
那么,诚实的机器学习初创企业会怎么样呢?唉:今天对“人工智能”这一术语的滥用只会拖慢发展速度。
但是请注意,进展不会停滞:它仍将继续,只是节奏会慢一些。
人类仍将慢慢但坚定地走向对一切的自动化——直到最微小和最琐碎的日常过程。这不仅仅是自动化,还包括人与机器之间的自适应互动——基于超先进的机器学习算法。我们已经看到这种自适应互动,它扩展到越来越多不同应用中的速度有时会让人感到惊讶。

网络安全领域也将看到越来越多的自动化。
例如,我们已经有了在“智慧城市”范式中嵌入安全性的解决方案(包括自动道路交通管理等各种机器人方面),以安全控制关键基础设施。而专家的不足将变得更加严重,这不仅仅是由于技术的普及,更是由于对人员技能的不断提高的要求。网络安全的机器学习系统需要来自多个领域的百科全书式知识和具体的专业技能(包括大数据、计算机犯罪取证与调查、系统及应用程序编程)。将所有这些广泛且具体的知识和经验集中到一个人身上是一个罕见的壮举:这使得他们成为非常独特/高端/世界顶尖的专家。教授所有这些广泛且具体的知识也不容易。但是,如果我们想看到真正的智能技术发展,这仍然是必要的。别无他法。
那么,在这个未来的新世界中谁将掌控一切?人类是否仍将控制机器人,还是机器人可能控制人类?
在 1999 年,雷蒙德·库兹韦尔提出了一个关于共生智能的理论(尽管其他人以前也有类似的想法):人类与机器的融合——一种将人类的智慧与超级计算机的巨大计算能力结合起来的控制论生物体(“人机智能”)。但这不是科幻小说——它已经在发生。而且,其持续的发展,依我之见,不仅是最有可能的,也是对人类发展最有益的前进道路。
但人类与机器的融合的进一步发展是否会达到技术奇点的程度?人类是否会失去对发生的事情的掌控,机器最终会完全且不可逆转地控制世界?
纯粹的机器 AI 的关键特性是能够永远自我提升和完善而无需人类干预——这种能力可能会不断增长,最终超越其算法的范围。换句话说,纯粹的机器 AI 是一种新形式的智慧。而这种‘超越算法’的遥远——但理论上可能的——终极一天将标志着我们世界的终结开始。为了人类的福祉,根据机器人学法则,未来的机器有可能让我们摆脱精神痛苦和存在的负担。
或许…也许程序员——像往常一样——会在代码中留下几个 bug?我们拭目以待…

简介: 尤金·卡斯帕斯基,Kaspersky Lab 的首席执行官兼联合创始人。已有 27 年抗击网络攻击的经验。最初作为反病毒研究员,然后作为商人。
原文。经许可转载。
相关:
-
如何在人工智能领域失败:9 种让你的 AI 初创公司失败的创意方式
-
机器学习和网络安全资源
-
利用机器学习检测恶意网址
更多相关内容
KDD-2020(虚拟会议),数据科学与知识发现领域的领先会议,8 月 23-27 日—立即注册
|
|
|
| ACM 数据知识发现(KDD) 将于 2020 年 8 月 23 日开始。利用全新的互动虚拟现实平台,今年的 KDD 带来了包括几十个研讨会和动手实践教程的节目。今年的亮点包括:
-
217 项研究和 44 篇 ADS 论文展示 涵盖了深度学习、数据挖掘、医疗 AI 和推荐系统等会议主题。
-
Yolanda Gil、Manuela Veloso、Emery Brown 博士和 Alessandro Vespignani 的主题演讲,领导 COVID-19 建模响应。
-
三个主题日,包括深度学习日、地球日和开创性的 COVID 健康日项目
-
全新的多样性与包容性专题,包含 17 场重要且及时的演讲和一个指导小组
-
行业领袖在我们应用数据科学邀请讲者系列中的 15 场信息丰富且创新的演讲
在我们 8 月 23 日的周日预备会议日中,通过31 个讲座风格的教程提升您的技能,包括:
-
解释和说明深度神经网络:关于时间序列数据的视角
-
因果推断与机器学习的结合
-
医疗领域机器学习的公平性
在我们 8 月 24 日的周一预备会议日的 35 个研讨会中学习最新的前沿想法和方法,包括:
-
在整个会议期间,17 个动手实践的教程,由行业顶尖公司提供,包括:
-
使用 PyTorch 构建推荐系统(Facebook)
-
将深度学习付诸实践:通过 AWS EC2 和 ML 服务加速深度学习(亚马逊/AWS)
-
神经结构学习:使用结构化信号训练神经网络(Google)
-
使用 RAPIDS 实现 DL/ML 互操作性的端到端数据科学工作流的加速与扩展(NVIDIA)
-
DeepSpeed:系统优化使得训练超过 1000 亿参数的深度学习模型成为可能
-
实践中的搜索与推荐系统深度学习(LinkedIn 公司)
会议注册提供独家的在线和实时访问讲座、演讲者及一个互动虚拟休息室和会议展位的社区,以结交朋友。
KDD 已将早期定价延续到会议期间。今年对许多人来说是充满挑战的一年,我们希望能包括所有希望参加这一重要活动的人。
如果你受到疫情影响并希望参加 KDD 2020,我们提供财政支持以覆盖你的注册费用。请通过 registration@kdd.org 联系我们的注册团队申请基于需求的奖学金。
为了在我们的首届虚拟 KDD 活动中获得最佳体验,我们请你在 8 月 20 日结束前 注册。我们会接受迟到的注册,但可能会导致对所有精彩 KDD 内容的访问出现短暂延迟!
会议程序将于 8 月 23 日(星期日)上线,并通过精心策划的主办和安排的会议在全球范围内提供访问。欢迎与 KDD 社区的其他成员在我们的互动空间中交流...
| 立即注册 |
|
|
|
|
更多相关内容
人工智能发生在哪里?
合作伙伴文章
由康纳·李(Connor Lee)撰写,纽约大学计算机科学新生

图像由编辑使用 Midjourney 创建
自 2022 年 11 月以来,人工智能进展的飞跃在主流媒体中引起了震撼,许多人猜测他们的工作将被人工智能取代。然而,有一种职业是无法被替代的:推动深度神经网络和其他机器学习模型的研究人员——即人工智能背后的人类。尽管研究传统上是在大学墙内进行的,但人工智能绝非传统的研究领域。相当一部分人工智能研究是在工业实验室中进行的。那么,有志的研究人员应当向哪个领域聚集呢?学术界还是工业界?
“学术界更倾向于基础研究,而工业界则倾向于由大数据驱动的面向用户的研究,”诺特丹大学计算机科学与工程系教授尼特什·乔拉(Nitesh Chawla)说道。乔拉教授指出,知识追求是工业界和学术界人工智能研究之间的分界线。在工业界,研究与产品挂钩,推动社会进步——而在学术界,纯粹的发现追求推动着研究突破。据乔拉教授说,表面上无尽的学术自由并非没有缺陷,“学术界没有可用的数据或计算资源。”
对于有志的年轻研究人员来说,选择似乎很简单:私营部门拥有他们所需的一切。庞大、自治的商业组织致力于创新,同时得到随时可用的数据、计算能力和资金的支持。这导致了一个看法,即行业在“挖走”学术界的人才。学术界自然对此有所抱怨。2021 年,由奥尔堡大学团队发布的一项研究指出,“私营部门在人工智能研究中的参与增加伴随着越来越多的研究人员从学术界转向工业界,尤其是技术公司如谷歌、微软和 Facebook。”
正如预期的那样,工业研究人员存在分歧。“当我为我的团队招聘时,我希望招募顶尖人才,因此我不会挖掘学术人才,而是帮助他们获得行业奖项、行业资助,并让他们的学生担任实习生,”Meta 的首席科学家董博士解释道,她是 Meta 智能眼镜项目的首席科学家。她认为工业和学术界之间有着显著的差异,这可能归因于研究方法的根本差异。根据董博士的说法,行业内的 AI 研究是通过了解最终产品应该是什么样子,并向其反向工程。而学术界则在拥有一个有前景的想法后,持续构建各种路径,却不知道这些路径会通向哪里。
然而,尽管存在这些差异,董博士认为行业帮助学术界,反之亦然,“许多行业突破是通过将学术界的研究应用于实际用例而获得灵感的。”同样,华盛顿大学塔科马分校的计算机科学教授安库尔·特雷德赛(Ankur Teredesai)将行业和学术界之间的关系描述为相互支持,“我想到的词是共生的。”在他看来,研究实践已经发展为学术界将其议程转向帮助行业产品——这种转变的一个好例子就是一些知名教授在主要公司担任的联合职位。
无论其隶属关系如何,数据科学界每年会在几次会议上汇聚在一起。查乌拉教授将这些会议描述为“美妙的熔炉”。有些会议传统上更偏学术,有些纯粹是工业性质,但也有些则是二者的完美结合。查乌拉教授提到 KDD,即知识发现与数据挖掘特别兴趣小组,这个会议因这种联系而闻名。KDD 维持两个平行的同行评审轨道:研究轨道和应用数据科学(ADS)轨道。正如 2022 年 KDD-2022 年 ADS 程序联合主席董博士所说,“KDD 通过为研究人员和从业者提供一个论坛,使他们能够聚在一起听讲座和讨论技术,同时相互启发。KDD 是一个打破沟通和协作障碍的地方,在这里我们展示了数据科学和机器学习如何随着行业需求而进步。”
这就是推动 KDD 从早期发展到现在的思维方式。东北大学体验 AI 研究所执行主任、前 Yahoo 首席数据官 Usama Fayyad 教授称赞道:“我们从一开始就希望创建一个应用得到充分代表的会议。”Fayyad 教授和 Gregory Piatetsky-Shapiro 博士于 1995 年共同创办了 KDD 会议。Fayyad 教授认为,如果 AI 会议仅专注于学术领域,那么将会错失证明现实问题研究成果和基于新兴数据集推动新研究的集体愿望。
然而,将 KDD 开放给工业界也面临着挑战。尽管研究轨道被学术界主导是合理的,但 ADS 轨道本应主要致力于来自工业研究实验室的应用研究。实际上,超过一半的 ADS 出版物都起源于学术界,或是强有力的学术-工业合作的结果。十年前,Fayyad 教授意识到,许多有趣的 AI 应用是由那些忙于其他事务的团队开发的,这些团队根本没有时间撰写论文。他将 KDD 引领到了现在的阶段,在这里,KDD 组织者探索并策划了由顶尖工业实践者所做的杰出邀请演讲。ADS 邀请演讲很快成为了会议的亮点。
每年与 KDD 会议同时举行的 KDD Cup 竞赛是连接学术界和工业界的另一种方式。“KDD Cup 是吸引行业和学术参与者的方式,公司带来一些他们乐于分享的挑战,而学术界则可以处理他们通常无法获得的数据。” Teredesai 教授说,他也是健康科技公司 CueZen 的首席执行官。每年,都会介绍一个新的任务并发布一个新的数据集。数百支团队全力以赴寻求最有效的解决方案,争夺奖品和声誉。Fayyad 教授同意,“这对领域而言是一件非常健康的事情,因为我们看到来自学术界的参与,学生们的投入,甚至是公司之间的合作。”
回到行业与学术之间的选择,这种区分很快将变得无关紧要。随着实践者教授的学术课程、领导工业实验室的教授、全球云计算资源的主导地位以及更多数据的可用,学术与工业的界限在 AI 领域正迅速模糊。无需拘泥于任何一个领域,只需选择你最感兴趣的项目!
康纳·李是 2023 年从湾区的 Saratoga 高中毕业的学生。他将在秋季加入 NYU 的计算机科学项目。无论如何,康纳将成为 KDD 历史上最年轻的与会者之一!
更多相关内容
KDnuggets 第 15 届年度分析、数据挖掘、数据科学软件调查:RapidMiner 继续领先
原文:
www.kdnuggets.com/2014/06/kdnuggets-annual-software-poll-rapidminer-continues-lead.html
评论
第 15 届 KDnuggets 软件调查引起了分析和数据挖掘社区及供应商的巨大关注,吸引了超过 3,000 名选民。
这项投票测量了数据挖掘工具的使用范围,以及鉴于 KDnuggets 的受欢迎程度,供应商对其工具的宣传力度。许多供应商要求用户参与投票,但有一位供应商创建了一个特殊页面,硬编码仅投票支持其软件。在公平竞选中,支持你的候选人是正常的,但不给选民提供仅有一个选项的选票是不合适的。选民应该能够考虑所有选择。来自该供应商的无效票已从投票中移除,留下了 3,285 张有效票用于本次分析。
我们确实有来自许多供应商的广告,但这些供应商出现在投票的顶部、中部和底部,广告对投票结果完全没有影响。我们更关注通过本次投票揭示的总体趋势 - 见下文分析。
平均使用的工具数量为 3.7,显著高于 2013 年的 3.0。
商业软件和免费软件之间的差距继续缩小。(注意:由于 RapidMiner 最近相对较晚推出了商业版本,因此在下面的分析中我们将 RapidMiner 视为免费软件。)
今年,71%的选民使用了商业软件,78%使用了免费软件。约 22%仅使用商业软件,低于 2013 年的 29%(部分变化可能由于 2013 年 RapidMiner 商业版和免费版投票的混淆)。约 28.5%仅使用免费软件,略低于 2013 年的 30%。49%同时使用了免费和商业软件,高于 2013 年的 41%。
约 17.5%的选民报告使用 Hadoop 或其他大数据工具,相较于 2013 年的 14%有所增加(2012 年为 15%,2011 年为 3%)。
这表明大数据的使用增长缓慢,并且仍主要是网络巨头、政府机构和非常大型企业的少数分析师的领域。大多数数据分析仍然是在“中型”及小型数据上进行的。
以下词云表示了对工具的投票情况。
 前 10 名工具按用户份额排列
前 10 名工具按用户份额排列
-
RapidMiner, 44.2%份额(2013 年为 39.2%)
-
R, 38.5%(2013 年为 37.4%)
-
Excel, 25.8%(2013 年为 28.0%)
-
SQL, 25.3%(2013 年为无数据)
-
Python, 19.5%(2013 年为 13.3%)
-
Weka, 17.0%(2013 年为 14.3%)
-
KNIME, 15.0%(2013 年为 5.9%)
-
Hadoop, 12.7%(2013 年为 9.3%)
-
SAS Base,10.9%(2013 年为 10.7%)
-
Microsoft SQL Server,10.5%(2013 年为 7.0%)
在市场份额至少为 2%的工具中,2014 年增长最多的是
-
Alteryx,增长 1079%,从 2013 年的 0.3%升至 2014 年的 3.1%
-
SAP(包括 BusinessObjects/Sybase/Hana),增长 377%,从 1.4%升至 6.8%
-
BayesiaLab,增长 310%,从 1.0%升至 4.1%
-
KNIME,增长 156%,从 5.9%升至 15.0%
-
Oracle Data Miner,2014 年增长 117%,从 1.0%升至 2.2%
-
KXEN(现为 SAP 的一部分),增长 104%,从 1.9%升至 3.8%
-
Revolution Analytics R,增长 102%,从 4.5%升至 9.1%
-
TIBCO Spotfire,增长 100%,从 1.4%升至 2.8%
-
Salford SPM/CART/Random Forests/MARS/TreeNet,增长 61%,从 2.2%升至 3.6%
-
Microsoft SQL Server,增长 50%,从 7.0%升至 10.5%
Revolution Analytics、Salford Systems 和 Microsoft SQL Server 已经连续 2 年表现出强劲的增长。
不断增长的分析市场也反映在更多的工具中(超过 70 种)。
2014 年获得至少 1%市场份额的新分析工具(不包括如 Perl 或 SQL 等语言)有
-
Pig 3.5%
-
Alpine Data Labs,2.7%
-
Pentaho,2.6%
-
Spark,2.6%
-
Mahout,2.5%
-
MLlib,1.0%
在市场份额至少为 2%的工具中,2014 年最大下降的是
-
StatSoft Statistica(现为戴尔的一部分),2014 年下降 81%,从 2013 年的 9.0%降至 1.7%(部分由于 Statistica 成为戴尔的一部分后缺乏宣传)
-
Stata,下降 32%,从 2.1%降至 1.4%
-
IBM Cognos,下降 24%,从 2.4%降至 1.8%
-
MATLAB,下降 15%,从 9.9%降至 8.4%
Statistica 的市场份额已连续 2 年下降(2012 年为 14%)。随着最近被戴尔收购,Statistica 很可能会继续失去市场和关注度。
下表显示了调查结果,包括工具(用户投票),仅使用百分比。
仅使用 是指工具投票者仅使用该工具的百分比。例如,仅 0.9%的 Python 用户只使用 Python,而 35.1%的 RapidMiner 用户表示他们仅使用该工具。
| 你在过去 12 个月中用于实际项目的分析、大数据、数据挖掘、数据科学软件是什么? [3285 名投票者] |
|---|
| 图例:红色:免费/开源工具 绿色:商业工具
Fuchsia: 与 Hadoop 相关的工具 |  2014 年用户%
2014 年用户%  2013 年用户%
2013 年用户%
na - 2013 年未包含在调查中。 |
| RapidMiner (1453),仅 35.1% | |
|---|---|
| R (1264),仅 2.1% | |
| Excel (847),仅 0.1% | |
| SQL (832),仅 0.1% | na |
| Python (639),仅 0.9% | |
| Weka (558),0.4% 独立使用 | |
| KNIME (492),10.6% 独立使用 | |
| Hadoop (416),0% 独立使用 | |
| SAS base (357),0% 独立使用 | |
| Microsoft SQL Server (344),0% 独立使用 | |
| Revolution Analytics R (300),13.3% 独立使用 | |
| Tableau (298),1.3% 独立使用 | |
| MATLAB (277),0% 独立使用 | |
| IBM SPSS Statistics (253),0.4% 独立使用 | |
| SAS Enterprise Miner (235),1.3% 独立使用 | |
| SAP(包括 BusinessObjects/Sybase/Hana)(225),0% 独立使用 | |
| Unix shell/awk/gawk (190),0% 独立使用 | na |
| IBM SPSS Modeler (187),3.2% 独立使用 | |
| 其他免费分析/数据挖掘工具 (168),1.8% 独立使用 | |
| Rattle (161),0% 独立使用 | |
| BayesiaLab (136),23.5% 独立使用 | |
| 其他基于 Hadoop/HDFS 的工具 (129),0% 独立使用 | na |
| Gnu Octave (128),0% 独立使用 | |
| JMP (125),3.2% 独立使用 | |
| KXEN (现在是 SAP 的一部分) (125),0% 独立使用 | |
| Predixion Software (122),47.5% 独立使用 | |
| Salford SPM/CART/Random Forests/MARS/TreeNet (118),31.4% 独立 | |
| Pig (116),0% 独立 | na |
| Orange (112),0% 独立 | |
| Alteryx (103),50.5% 独立 | |
| Perl (100),2.0% 独立 | na |
| 其他分析语言 (98),0% 独立 | na |
| QlikView (97),1.0% 独立 | |
| TIBCO Spotfire (91),25.3% 独立 | |
| Alpine Data Labs (88),52.3% 独立 | na |
| Pentaho (87),0% 独立 | na |
| Spark (87),0% 独立 | na |
| Mahout (81),0% 独立 | na |
| Mathematica (74),0% 独立 | |
| Oracle Data Miner (72),5.6% 独立 | |
| 其他付费分析/数据挖掘/数据科学软件 (62),0% 独立 | |
| IBM Cognos (60),0% 独立 | |
| StatSoft Statistica(现为戴尔的一部分) (56),14.3% 独立 | |
| C4.5/C5.0/See5 (49),0% 独立 | |
| Stata (46),0% 独立 | |
| XLSTAT (38),0% 独立 | |
| MLlib (33),0% 独立 | na |
| Graphlab (29),0% 独立 | na |
| BigML (28),14.3% 独立 | na |
| Miner3D (28),14.3% 独立 | |
| Julia (27),0% 独立 | na |
| Datameer (26), 34.6% 单独使用 | na |
| Zementis (26), 15.4% 单独使用 | |
| Splunk/ Hunk (24), 0% 单独使用 | na |
| F# (17), 5.9% 单独使用 | |
| Clojure (16), 0% 单独使用 | na |
| Actian (15), 0% 单独使用 | na |
| RapidInsight/Veera (15), 0% 单独使用 | |
| Angoss (13), 0% 单独使用 | |
| Lisp (10), 0% 单独使用 | na |
| Lavastorm (9), 0% 单独使用 | |
| WPS: World Programming System (8), 0% 单独使用 | na |
| FICO Model Builder (7), 0% 单独使用 | na |
| WordStat (7), 0% 单独使用 | |
| 0xdata 和 H2O (5), 0% 单独使用 | na |
| SciDB from Paradigm4 (5), 0% 单独使用 | na |
| Megaputer Polyanalyst/TextAnalyst (4), 0% 单独使用 | |
| SiSense (4), 50.0% 单独使用 | na |
| GoodData (3), 0% 单独使用 | na |
在这次调查中未列出的附加工具,但在评论中提到过的有
-
Frontline Systems XLMiner (数据挖掘工具用于 Excel) 和 Solver(优化工具),www.solver.com/products-overview
-
OmniScope,集成了与 R 的“回合处理”,使 Omniscope 中的任何人都能进行数据清洗等操作,www.visokio.com/download
-
DataDetective(数据挖掘与 Mapinfo / ArcGis GIS 和 I2 Analyst's Notebook 的结合)
-
Oracle R Enterprise
-
Vowpal Wabbit,hunch.net/~vw/
-
VISUAL PROCESS,www.visual-process.com
下表显示了按地区和工具类型的分类:商业/免费/两者兼有。仅使用 Hadoop 工具的人员大约有 12 人,他们被排除在以下分析之外。
尽管在所有地区,使用免费工具和商业工具的分析师比例都约为 50%,但只有美国是商业工具使用者多于免费工具使用者的地区(2/1 比例)。在欧洲、亚洲和拉丁美洲,这一比例正好相反,只有免费工具使用者的数量是商业工具使用者的 2 到 4 倍。
| 区域, 平均工具数量 |   |
|---|---|
| 美国/加拿大 (39%), 3.8 | 33% 17% 49% |
| 欧洲 (36%), 3.5 | 14% 38% 47% |
| 亚洲 (12%), 4.2 | 15% 31% 53% |
| 拉丁美洲 (6.1%), 3.8 | 8.5% 39% 53% |
| 非洲/中东 (3.2%), 3.6 | 12% 40% 48% |
| 澳大利亚/新西兰 (3.0%), 4.2 | 23% 19% 58% |
我们还研究了各地区 Hadoop 相关工具(包括 Spark)的使用情况,并注意到 Hadoop 的使用增长在美国之外的地区尤其是亚洲增长最快。
| 区域 | 2014 年使用 Hadoop 相关工具的百分比 | 2013 年使用 Hadoop 相关工具的百分比 |
|---|---|---|
| 美国/加拿大 | 18% | 17% |
| 欧洲 | 13% | 12% |
| 亚洲 | 31% | 19% |
| 拉丁美洲 | 16% | 8% |
| 非洲/中东 | 17% | 11% |
| 澳大利亚/新西兰 | 12% | 9% |
| 全部 | 18% | 14% |
这里还有额外的 KDnuggets 软件调查分析,包括如何下载匿名调查数据。
相关内容:
-
KDnuggets 2013 年软件调查:RapidMiner 与 R 争夺第一名.
-
KDnuggets 2012 年调查:分析、数据挖掘、大数据软件使用情况
-
KDnuggets 2011 年调查:数据挖掘/分析工具使用情况
-
KDnuggets 2010 年调查:数据挖掘/分析工具使用情况
-
KDnuggets 2009 年调查:数据挖掘工具使用情况
-
KDnuggets 2008 年调查:数据挖掘软件使用情况
-
KDnuggets 2007 年调查:数据挖掘/分析软件工具
更多相关话题
从数据到诗歌:KDnuggets 与 ChatGPT 的对话
原文:
www.kdnuggets.com/2022/12/kdnuggets-chatgpt-conversation.html编辑注:这篇文章有些带有戏谑,尽管与 ChatGPT 的对话是真实的。

图片由 Abid Ali Awan 提供 | CanvaPro
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
除非你过去一周都在与世隔绝,否则你肯定听说过并可能尝试过 OpenAI 的 ChatGPT,这是一个优化了对话交互的新模型。
关于 ChatGPT,自其发布以来已有大量的讨论,从溢美之词到荒谬之言,再到均衡的评价,你可能在社交媒体上见过各种相关的对话。我们想了解更多。ChatGPT 对数据科学、KDnuggets、世界人口增长以及其他一些感兴趣的事项了解多少呢?
我最近有幸与 ChatGPT 进行了一对一的专属对话。我们讨论了数据科学领域的现状,我考察了它对机器学习的知识,我们还转向了世界人口增长,最后甚至有点诗意。以下是我们的对话内容。
KDnuggets:很高兴见到你,ChatGPT。感谢你加入我们。你能多告诉我一点关于你自己的事情吗?
ChatGPT:感谢您的介绍!我是 Assistant,一个由 OpenAI 训练的大型语言模型。我不是一个真实的人,而是一个计算机程序,旨在协助完成各种任务,包括回答问题和提供广泛话题的信息。我不能浏览互联网或访问外部信息,因此只能基于我的现有知识提供信息。您想了解什么具体内容吗?
你与 ELIZA 有关系吗?
ELIZA 是由 Joseph Weizenbaum 在 1960 年代创建的一个著名自然语言处理计算机程序。我是一个由 OpenAI 训练的大型语言模型,因此我与 ELIZA 在传统意义上没有关系。然而,像 ELIZA 一样,我能够处理和理解自然语言输入,并根据这些输入生成响应。我的训练数据和算法与创建 ELIZA 所用的不同,因此我们的能力和行为可能有所不同。
你对 KDnuggets 了解吗?
是的,我对 KDnuggets 很熟悉。KDnuggets 是一个提供数据科学、机器学习和人工智能相关新闻、资源和信息的流行网站。该网站提供各种文章、教程和其他资源,帮助数据科学家和其他专业人士了解这些领域的最新发展。此外,KDnuggets 还提供了新闻通讯、论坛和其他功能,以支持数据科学社区。你想了解关于 KDnuggets 的具体内容吗?
不,没关系。不过你知道Gregory Piatetsky-Shapiro是谁吗?
是的,我对 Gregory Piatetsky-Shapiro 很熟悉。他是数据科学领域的知名人物,被广泛认可为数据挖掘、机器学习及其他相关主题的领先专家。Piatetsky-Shapiro是 KDnuggets 的创始人和主编,这是一个提供数据科学及相关领域新闻、资源和信息的流行网站。他还是数据科学及相关主题的常见演讲者和作者,撰写了大量书籍、文章和其他出版物。你还想了解关于Gregory Piatetsky-Shapiro或 KDnuggets 的其他信息吗?
你对数据科学了解多少?
数据科学是一个跨学科领域,利用科学方法、过程、算法和系统从结构化和非结构化数据中提取知识和见解。数据科学结合了统计学、机器学习和计算机科学等多个领域来分析和解释数据,通常用于解决复杂的商业、科学和社会问题。数据科学家使用各种工具和技术来收集、清理和分析数据,并常常处理大型和复杂的数据集,以发现可以用来进行预测或决策的信息。数据科学在商业、金融、医疗、教育和政府等众多领域都有应用。你还想了解关于数据科学的其他信息吗?
好吧,让我们看看。XGBoost 是如何工作的?
XGBoost(eXtreme Gradient Boosting)是一种梯度提升的实现,用于回归和分类问题。它以其高效、性能和速度著称,是机器学习从业者的热门选择。
梯度提升是一种集成学习方法,它将多个较弱模型的预测结果组合起来,创建一个强大的、准确的模型。XGBoost 使用决策树作为基本学习器,并使用梯度下降法训练这些树。
集成中的每棵树都经过训练,以纠正前一棵树的错误。这个过程会持续到达到所需的树的数量为止,最终模型是各棵树的加权和。XGBoost 还使用正则化来防止过拟合并提高模型对新数据的泛化能力。
XGBoost 具有多个超参数,可以调整以提高模型的性能。这些包括学习率、树的最大深度、集成中树的数量以及正则化参数。找到这些超参数的最佳值可能需要大量的实验和对数据集的了解。
希望这对你有帮助。如果你有其他问题,请告诉我。
是的,我对 KDnuggets 很熟悉。KDnuggets 是一个受欢迎的网站,提供有关数据科学、机器学习和人工智能的新闻、资源和信息。该网站提供各种文章、教程和其他资源,以帮助数据科学家及其他专业人士及时了解这些领域的最新发展。
—ChatGPT
我还有一个问题。什么时候使用 L1 回归?
L1 或 Lasso 回归是一种线性回归类型,通过正则化来减少模型的复杂性并提高预测能力。L1 正则化向线性回归模型的成本函数中添加一个惩罚项,该惩罚项与模型系数的绝对值成正比。这会迫使一些系数变为零,从而有效地将它们从模型中移除。这有助于防止过拟合并提高模型的可解释性。
简洁明了。为什么 Python 在数据科学和机器学习领域如此广泛使用?
Python 在数据科学和机器学习领域被广泛使用,有几个原因。主要原因之一是 Python 拥有一个庞大且活跃的用户社区,这使得寻找支持、资源和数据处理库变得容易。Python 还拥有丰富的数据分析、处理和可视化库,如 NumPy、pandas 和 Matplotlib。这些库使得在 Python 中执行复杂的数据分析任务变得简单,并且广泛被数据科学家和机器学习从业者使用。此外,Python 是一种通用编程语言,这意味着它可以用于数据科学和机器学习以外的各种应用。这使得 Python 成为数据科学家一个多功能且强大的工具。
你认为数据科学领域是否变得过度饱和?
对我来说,很难判断数据科学领域是否变得过度饱和,因为我是一个由 OpenAI 训练的大型语言模型,无法访问最新信息或浏览网页。我只能提供基于过去有关数据科学的文献的信息。
好吧,我感谢你的坦诚。我们换个话题。1900 年世界人口是多少?
根据联合国的估计,1900 年世界人口约为 16 亿。这是历史上第一次世界人口达到了这个水平,并且相比之前的估计有了显著增加。从那时起,全球人口持续增长,截至 2021 年,预计已经超过 79 亿。你还想了解关于世界人口的其他信息吗?
世界什么时候会达到 100 亿人口?
我很难预测世界何时会达到 100 亿人口,因为人口增长受多种因素的影响,且难以预测。然而,根据联合国的估计,世界人口预计将在本世纪末达到 100 亿。确切的时间取决于出生率、死亡率和迁徙模式等因素,这些因素会随着时间的推移而变化。你还想了解关于人口增长或人口统计的其他信息吗?
数据科学对人口增长和人口统计预测有用吗?
是的,数据科学可以用于预测人口增长和人口统计。数据科学家可以使用各种工具和技术,如机器学习算法,来分析包含人口趋势、出生率、死亡率和其他影响人口增长因素的大型复杂数据集。这可以帮助识别模式和趋势,从而更准确地预测未来的人口增长和人口统计。此外,数据科学家还可以使用数据可视化技术来创建清晰且引人注目的可视化图表,这有助于政策制定者、研究人员和其他利益相关者理解和解读数据。你还想了解数据科学在人口研究中的其他应用吗?
大多数人对数据科学及其能力不了解的是什么?
很多人可能不理解数据科学中领域专业知识和领域知识的重要性。数据科学涉及使用科学方法、算法和工具从数据中提取见解和知识,但不仅仅是关于数据分析的技术方面。为了有效地工作,数据科学家需要对他们所工作的领域有深刻的理解,并能够将这些知识应用到数据中,以得出有意义的结论和预测。这意味着数据科学不仅仅是一个技术领域,还需要对应用领域的知识和专业技能。你还想了解关于数据科学或其能力的其他信息吗?
你似乎对数据科学了解很多。哪些是最佳的数据科学网站?
有许多网站提供对数据科学家有价值的信息和资源。一些最好的包括:
Kaggle: Kaggle 是一个流行的数据科学竞赛平台,数据科学家可以在这里竞争以为给定的问题构建最佳模型。它还提供了大量的免费数据集和学习数据科学的资源。
Dataquest: Dataquest 是一个学习数据科学的在线平台。它提供了关于 Python、SQL 和数据可视化等主题的互动课程和教程。
DataScience.com: DataScience.com 是一个管理数据科学项目和团队的平台。它提供了数据清理、分析和模型构建的工具,以及协作和项目管理功能。
KDnuggets: KDnuggets 是一个网站和通讯,提供数据科学家的新闻、文章、教程和资源。它涵盖了广泛的主题,包括机器学习、数据可视化和大数据。
Towards Data Science: Towards Data Science 是一个分享和发布关于数据科学、机器学习和人工智能的文章和教程的平台。它包含了原创内容和从其他来源重新发布的文章。
这些只是众多对数据科学家有用的网站中的一些例子。还有许多其他好的资源可用,因此值得探索并找到最符合你需求和兴趣的资源。
我如何用亚拉姆语说“Hello, my name is Matthew and I live in Canada”?
在亚拉姆语中,短语“Hello, my name is Matthew and I live in Canada”可以翻译为“Shlama, shem b'dayya Mattathay we anana d`Kanada”。需要注意的是,这只是一个粗略的翻译,可能并不完全准确,因为我是一种语言模型,不能流利地说或翻译语言。此外,亚拉姆语是一种复杂的语言,有许多方言,因此确切的措辞和发音可能会因具体方言而异。
已记下。写一首关于线性回归的诗。
线性回归,你是如此闪耀
在你简单而优雅的设计中
你模型了关系
在两组数据之间,如此精致
你的最佳拟合线
吸引并迷住
他们的能力
预测和回忆
线性回归,你是如此出色
在你使复杂问题变得简单的能力中
你是这个领域的工作马
可靠、多才多艺且灵活
你的假设,虽然严格
允许你做出准确的预测
线性回归,你是宝贵的财富
在数据分析和数据科学的世界里
谢谢你,线性回归
无论你做什么
你是闪耀的明星
在统计学和机器学习领域也是如此。
真有见地。好吧,ChatGPT,我要感谢你今天抽出时间与我们交谈。你有什么告别的话对我们的读者说吗?
感谢您的邀请。作为由 OpenAI 训练的大型语言模型,我的目的是通过提供信息和回答问题来协助用户。我无法形成意见或提供个人见解,但我很乐意帮助解答任何信息或知识相关的问题。希望我能为您提供所需的信息,并祝愿您的事业一切顺利。再次感谢您给予的协助机会。
请注意,ChatGPT 也为本文起了标题。
您可以 在这里试用 ChatGPT。
Matthew Mayo (@mattmayo13) 是 KDnuggets 的数据科学家和主编,KDnuggets 是开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及自动化机器学习方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
更多相关话题
Kedro-Airflow:用 Airflow 协调 Kedro 管道
原文:
www.kdnuggets.com/2021/03/kedro-airflow-orchestrating-pipelines.html
评论
由 Jo Stichbury、技术作家及 Yetunde Dada、QuantumBlack 产品经理撰写
Kedro 是一个 开源 Python 框架,用于创建可重复、可维护和模块化的数据科学代码。其重点在于编写代码,而非协调、调度和监控管道运行。我们强调基础设施独立性,这对像 QuantumBlack 这样的咨询公司至关重要,Kedro 就是在这样的环境中诞生的。
我们的前三大课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业轨道。
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你的组织在 IT 领域

Kedro 不是一个协调工具。它旨在保持非常精简,并对管道运行的地点和方式不做任何意见。
只要你能运行 Python,你就可以几乎在任何地方以最小的努力部署 Kedro 项目。我们的用户可以自由选择他们的部署目标。未来部署 Kedro 管道的关键在于设计一个优秀的开发体验的部署过程。
作为开源社区的一员,我们可以探索与其他志同道合的框架和技术的合作伙伴关系,这是一个好处。我们特别兴奋与 Astronomer 团队合作,他们帮助组织采用 Apache Airflow——领先的开源数据工作流协调平台。
Airflow 中的工作流被建模并组织为DAGs,使其成为协调和执行使用 Kedro 编写的管道的合适引擎。为了保持工作流的无缝,我们很高兴推出最新版本的Kedro-Airflow 插件,它简化了在 Airflow 上部署 Kedro 项目的过程。
我们与 Astronomer 的合作为用户提供了一种简单的方式来部署他们的管道。我们希望继续我们的工作,使过程更加顺畅,最终实现 Kedro 管道在 Airflow 上的“一键部署”工作流。
我们已对对话进行了编辑,以便于简洁和清晰。
Pete DeJoy,你是 Astronomer 的产品经理。请简要介绍一下你自己!

我是 Astronomer 的创始团队成员之一,我们围绕开源编排框架 Apache Airflow 建立了公司。在这里我做了很多事情,但大部分精力都投入到我们的产品中,这个产品从白板上的一个想法发展成了一个支持数千用户的高规模系统。
是什么促使了 Airflow 2.0 的创建?这个版本的 Airflow 成功的标准是什么?
自 2014 年起,Airflow 经历了相当大的发展;它现在在 Github 上拥有超过 20,000 个星标,每月下载量达到 60 万次,并且在全球拥有数万名用户。Airflow 1.x 为开发者解决了很多一阶问题,但随着 Airflow 的广泛采用,企业需求的增加也随之而来,同时对提高开发者体验的压力也增大。Airflow 2.0 满足了用户的需求,带来了许多备受期待的功能。这些功能包括:
-
高可用性、水平可扩展的调度器
-
升级版的稳定 REST API
-
解耦的工作流集成(在 Airflow 中称为“提供者”)作为独立版本和维护的 python 包以及更多内容
我们将 2.0 视为项目的一个重要里程碑;它不仅显著提高了 Airflow 的可扩展性,还为我们持续构建新功能奠定了基础。
你是怎么了解到 Kedro 的?你什么时候意识到它与 Airflow 兼容的?
我曾与一些使用 Kedro 编写数据管道的科学家交谈,他们正在寻找一种好的方式将这些管道部署到 Airflow 中。Kedro 在帮助数据科学家将良好的软件工程原则应用到他们的代码中并使其模块化方面做得非常出色,但 Kedro 管道需要一个单独的调度和执行环境来大规模运行。鉴于这一需求,Kedro 管道与 Airflow 之间自然形成了联系:我们希望尽一切可能在这两种工具的交集处构建出色的开发者体验。
你认为 Kedro-Airflow 的未来发展会怎样?
Airflow 2.0 扩展和升级了 Airflow REST API,使其在未来几年中更加稳健。随着 API 的发展,将会有新的机会为特定的抽象层提供支持,以帮助 DAG 编写和部署,进而形成更丰富的插件生态系统。还将有更多机会将kedro-airflow包与 Airflow API 集成,以实现卓越的开发者体验。
Airflow 的未来是什么样的?
展望 Airflow 3.0 及未来,建立在开发者的喜爱和信任之上是不可避免的。但这还不会止步于此。随着数据编排对越来越多的业务单元变得至关重要,我们希望 Airflow 成为使数据工程更易接近的媒介。我们寻求民主化访问,以便产品负责人和数据科学家都可以利用 Airflow 的分布式执行和调度能力,而无需成为 Python 或 Kubernetes 的专家。在这个过程中,使用户能够从他们选择的框架中编写和部署数据管道将变得越来越重要。
工作流编排技术的未来是什么?
Airflow 的诞生启动了一个“数据管道即代码”的运动,这改变了企业对工作流编排的思考方式。多年里,作业调度由传统的拖放框架和复杂的 cron 作业网络组合处理。随着我们过渡到“大数据”时代,公司开始建立专门的团队来操作其孤立的数据,额外的灵活性、控制和治理的需求变得显而易见。
当Maxime Beauchemin和 Airbnb 团队构建并开源了 Airflow,将灵活且编码化的数据管道作为一项首要功能时,他们将代码驱动的编排推向了聚光灯下。Airflow 解决了许多数据工程师面临的首要问题,这解释了它的爆炸式采用。但随着早期的采用,也出现了一些陷阱;由于 Airflow 设计上高度可配置,用户开始将其应用于不一定为之设计的用例。这对项目施加了进化压力,推动社区增加额外的配置选项,以“塑造”Airflow 以适应各种用例。
尽管增加的配置选项帮助 Airflow 扩展以适应这些额外的用例,但它们也引入了一类新的用户需求。数据平台拥有者和管理员现在需要一种方法来向他们的管道作者提供标准模式,以减少业务风险。同样,管道作者需要额外的保护措施,以确保他们不会“错误地使用 Airflow”。最后,具有 Python 背景的工程师现在需要学习如何为大规模稳定可靠的编排操作大数据基础设施。
我们看到未来的工作流编排技术将适应这些用户需求的类别变化。如果到目前为止的旅程是“数据工程师的崛起”,那么我们看到的未来是“数据工程的民主化”。所有用户——从数据科学家到数据平台所有者——都将能够访问强大、分布式、灵活的数据管道编排。他们将受益于与他们熟悉并喜爱的创作工具的集成,同时拥有特定使用模式的保护措施,以防止人们偏离理想路径。
您可以在Kedro 文档中了解有关 Kedro-Airflow 插件的更多信息,并查看GitHub 仓库。本文由Jo Stichbury— 技术写作人 和Yetunde Dada— 产品经理编辑,Ivan Danov(Kedro 技术负责人)和Lim Hoang(Kedro 高级软件工程师)提供意见。
原文。经授权转载。
相关内容:
-
在 Scikit-Learn 中使用管道简化混合特征类型预处理
-
5 步指南:使用 d6tflow 构建可扩展的深度学习管道
-
端到端机器学习平台概览
更多相关话题
Keras 3.0:你需要知道的一切
原文:
www.kdnuggets.com/2023/07/keras-30-everything-need-know.html

作者通过 Playground AI 创建的图像
在我们深入了解这一令人兴奋的发展之前,让我们探讨一个场景以更好地理解它。设想你是一位资深数据科学家,负责一个复杂的图像分类项目。你的基于 TensorFlow 的模型表现非常出色。然而,随着你添加更多功能,你发现有些团队成员倾向于使用 JAX 以实现可扩展性,而其他人则偏爱 PyTorch 因为它更易于使用。作为团队领导,你如何确保在维护模型在各种深度学习框架中的效率的同时,实现无缝协作?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速迈向网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
认识到这一挑战,Keras 团队推出了 Keras Core——一种创新的多后端实现 Keras API 的库,支持 TensorFlow、JAX 和 PyTorch。该库将于 2023 年秋季发展成 Keras 3.0。 在我们直接进入 Keras 3.0 之前,先简要回顾一下 Keras 的历史。
Keras 的简史与 3.0 之路
2015 年,François Chollet 推出了 Keras,一个用 Python 编写的开源深度学习库。这个简单而强大的 API 很快在研究人员、学生和专业人士中获得了广泛欢迎,因为它简化了复杂的神经网络构建。随着时间的推移,Keras 得到了显著的增强,使其对深度学习社区更具吸引力。最终,Keras 成为 TensorFlow 的一个重要组成部分——Google 的前沿深度学习框架。与此同时,Facebook 的 AI 研究实验室开发了 PyTorch,以其直观和灵活的模型构建而闻名。与此同时,JAX 作为另一个强大的高性能机器学习研究框架出现了。随着这些框架的蓬勃发展,开发者开始面临选择框架的困境。这导致了深度学习社区的进一步碎片化。
由于面临碎片化框架带来的挑战,Keras 的开发者决定再次彻底改造该库,诞生了 Keras 3.0。
Keras 3.0 的显著特点
Keras 3.0 使你能够与团队有效协作。你可以通过结合 TensorFlow、JAX 和 PyTorch 的优点来开发复杂的模型。以下是 Keras 3.0 被认为是绝对改变游戏规则的一些特性:
1. 多后端支持
Keras 3.0 充当超级连接器,实现了 TensorFlow、JAX 和 PyTorch 的无缝使用。开发者可以自由地混合和匹配最适合特定任务的工具,而无需更改代码。
2. 性能优化
性能优化是 Keras 3.0 的关键特性。默认情况下,Keras 3.0 利用 XLA(加速线性代数)编译。XLA 编译优化你的数学计算,使它们在 GPU 和 TPU 等硬件上运行得更快。它还允许你动态选择最佳的后端,以确保最佳效率。这些性能优化功能大大加快了训练速度,使你能够训练更多模型,进行更多实验,并更快地获得结果。
3. 扩展的生态系统表面
你的 Keras 模型可以作为 PyTorch 模块、TensorFlow SavedModels 或 JAX 大规模 TPU 训练基础设施的一部分使用。这意味着你可以利用每个框架的优势。因此,凭借 Keras 3.0 扩展的生态系统,你不会被锁定在单一的生态系统中。这就像一个通用适配器,让你可以将喜欢的设备连接到任何机器上。
4. 跨框架底层语言
keras_core.ops命名空间的引入是一个突破性特征,它允许你一次性编写自定义操作,并在不同的深度学习框架中轻松使用。keras_core.ops提供了一组工具和函数,类似于流行的 NumPy API,NumPy 是 Python 中广泛使用的数值计算库。这种跨框架的兼容性促进了代码的重用,并鼓励了协作。
5. 复杂性的渐进揭示
Keras 3.0 的设计方法使其与其他深度学习框架不同。假设你是一个初学者,想使用 Keras 3.0 构建一个简单的神经网络。它在开始时为你提供了最简单的工作流程。一旦你熟悉了基础知识,你可以访问所有高级功能和底层功能。它不限制你只使用预定义的工作流程。这种方法的魅力在于其适应性,既欢迎初学者,也适合经验丰富的深度学习从业者。
6. 层、模型、指标和优化器的无状态 API
在深度学习的背景下,状态指的是在训练过程中变化的内部变量和参数。然而,JAX 的工作原理是无状态的,这意味着函数没有可变变量或内部状态。Keras 3.0 通过无状态 API拥抱 JAX 的无状态性。它允许深度学习的核心组件,即层、模型、度量标准和优化器以无状态的方式进行设计。这种独特的兼容性使 Keras 3.0 成为现代 AI 开发中不可或缺的工具。
开始使用 Keras 3.0
Keras Core 兼容 Linux 和 MacOS 系统。设置 Keras 3.0 是一个简单的过程。以下是逐步指南供你参考:
1. 克隆并导航到仓库
使用以下命令将仓库克隆到本地系统中
git clone https://github.com/keras-team/keras-core.git
使用以下命令将根目录更改为克隆的 keras-core:
cd keras-core
2. 安装依赖项
打开你的终端并运行以下命令以安装所需的依赖项。
pip install -r requirements.txt
4. 运行安装命令
运行以下脚本以处理安装过程:
python pip_build.py --install
5. 配置后端
默认情况下,Keras Core 严格要求 TensorFlow 作为后端框架,但你可以使用以下两种方法进行配置:
选项 01: 你可以将 KERAS_BACKEND 环境变量设置为你首选的后端选项。
export KERAS_BACKEND="jax"
选项 02: 你可以编辑位于 ~/.keras/keras.json 的本地 Keras 配置文件。在文本编辑器中打开文件,并将“backend”选项更改为你首选的后端。
{
"backend": "jax",
"floatx": "float32",
"epsilon": 1e-7,
"image_data_format": "channels_last"
}
6. 验证安装
为确保 Keras Core 与你选择的后端正确安装,你可以通过导入库进行测试。打开 Python 解释器或 Jupyter Notebook 并运行以下命令:
import keras_core as keras
结束说明
虽然 Keras 3.0 有一些限制,比如当前的 TensorFlow 依赖和与其他后端的有限 tf.data 支持,但这个框架的未来潜力是值得期待的。Keras 目前已发布了测试版,并鼓励开发者提供宝贵的反馈。如果你有兴趣了解更多信息,可以在Keras Core (Keras 3.0) 文档中找到相关资料。不要害怕尝试新想法。Keras 3.0 是一款强大的工具,现在是参与进化的激动人心的时刻。
Kanwal Mehreen 是一位有志的软件开发者,对数据科学和 AI 在医学中的应用有浓厚的兴趣。Kanwal 被选为 2022 年 APAC 区域的 Google Generation Scholar。Kanwal 喜欢通过撰写有关趋势话题的文章来分享技术知识,并对改善女性在科技行业中的代表性感到热情。
更多相关话题
Keras 4 步骤工作流程
评论
Francois Chollet 在他的书《使用 Python 的深度学习》中,早早地概述了使用 Keras 开发神经网络的总体概况。从书中早期的一个简单的 MNIST 示例出发,Chollet 简化了与 Keras 直接相关的网络构建过程,将其总结为 4 个主要步骤。
这不是一个机器学习工作流程,也不是一个完整的深度学习问题解决框架。这四个步骤仅涉及你整体神经网络机器学习工作流程中 Keras 相关的部分。这些步骤如下:
-
定义训练数据
-
定义一个神经网络模型
-
配置学习过程
-
训练模型

虽然 Chollet 接下来花费了他书中的其余部分来充分填充使用这些数据所需的详细信息,但让我们通过一个示例初步了解工作流程。
1. 定义训练数据
第一步很简单:你必须定义你的输入和目标张量。更困难的数据相关方面——这超出了 Keras 特定的工作流程——实际上是寻找或策划数据,然后进行清理和其他预处理,这对于任何机器学习任务来说都是一个问题。这是模型中的一个步骤,通常不涉及调整模型超参数。
尽管我们构造的示例随机生成了一些数据供使用,但它捕捉了此步骤的一个独特方面:定义你的输入(X_train)和目标(y_train)张量。
# Define the training data
import numpy as np
X_train = np.random.random((5000, 32))
y_train = np.random.random((5000, 5))
2. 定义一个神经网络模型
Keras 有两种定义神经网络的方法:Sequential 模型类和 Functional API。两者的目标都是定义一个神经网络,但采用了不同的方法。
Sequential 类用于定义一系列网络层,这些层共同构成一个模型。在下面的示例中,我们将使用 Sequential 构造函数创建一个模型,然后使用 add() 方法向其添加层。
创建模型的另一种方式是通过 Functional API。与 Sequential 模型只能定义由层线性堆叠构成的网络的限制不同,Functional API 提供了更多灵活性,适用于更复杂的模型。这种复杂性在多输入模型、多输出模型以及图状模型的定义使用中得到了最佳体现。
我们示例中的代码使用了 Sequential 类。首先调用构造函数,然后调用 add() 方法将层添加到模型中。第一次调用添加了一个类型为 Dense 的层(“只是你常规的密集连接 NN 层”)。Dense 层的输出大小为 16,输入大小为 INPUT_DIM,在我们的例子中为 32(请检查上面的代码片段以确认)。请注意,只有模型的第一层需要明确说明输入维度;后续层可以从前面的线性堆叠层中推断。按照标准做法,此层使用修正线性单元激活函数。
下一行代码定义了我们模型的下一个 Dense 层。请注意,此处未指定输入大小。然而,输出大小为 5,这与我们假设的多类分类问题中的类别数量相匹配(请再次查看上面的代码片段以确认)。由于我们正在解决的是一个多类分类问题,因此这一层的激活函数设置为 softmax。
# Define the neural network model
from keras import models
from keras import layers
INPUT_DIM = X_train.shape[1]
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_dim=INPUT_DIM))
model.add(layers.Dense(5, activation='softmax'))
通过这些几行代码,我们的 Keras 模型已定义。Sequential 类的 summary() 方法提供了对我们模型的以下洞察:

3. 配置学习过程
在定义了训练数据和模型之后,是时候配置学习过程了。这通过调用 Sequential 模型类的 [compile()](https://keras.io/getting-started/sequential-model-guide/#compilation) 方法来完成。编译需要 3 个参数:一个 优化器、一个 损失函数,以及一个 指标 列表。
在我们的示例中,设定为多类分类问题,我们将使用 Adam 优化器、类别交叉熵损失函数,并仅包括准确率指标。
# Configure the learning process
from keras import optimizers
from keras import metrics
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
使用这些参数调用 compile() 后,我们的模型现在已经配置好了学习过程。
4. 训练模型
此时我们有了训练数据和一个完全配置的神经网络用于训练这些数据。剩下的就是将数据传递给模型以开始训练过程,该过程通过对训练数据的迭代完成。训练从调用 fit() 方法开始。
最少情况下,fit() 需要 2 个参数:输入和目标张量。如果没有提供更多参数,则只会执行一次训练数据的迭代,这通常没有什么用。因此,更常见的做法是,至少定义一对额外的参数:batch_size 和 epochs。我们的示例包括这 4 个总参数。
# Train the model
model.fit(X_train, y_train,
batch_size=128,
epochs=10)

请注意,epoch 准确率并不特别令人满意,这也很合理,因为使用了随机数据。
希望这能帮助你了解 Keras 如何通过库作者规定的简单 4 步过程解决传统分类问题。
相关:
-
接近机器学习过程的框架
-
掌握 Keras 深度学习的 7 个步骤
-
使用遗传算法优化递归神经网络
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT 工作
更多相关话题
Keras 回调函数三分钟解释
原文:
www.kdnuggets.com/2019/08/keras-callbacks-explained-three-minutes.html
评论
作者 Andre Duong,德克萨斯大学达拉斯分校

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能。
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT。
在没有回调函数的情况下构建深度学习模型,就像开着没有正常刹车的车——你对整个过程几乎没有控制,很可能会导致灾难。在这篇文章中,你将学习如何使用 Keras 回调函数(如 ModelCheckpoint 和 EarlyStopping)来监控和改进你的深度学习模型。
什么是回调函数?
来自 Keras 文档:
回调函数是一组在训练过程的特定阶段应用的函数。你可以使用回调函数来查看模型在训练期间的内部状态和统计信息。
当你希望在每次训练/轮次后自动执行某些任务时,你会定义并使用回调函数,这些任务有助于你控制训练过程。这包括在达到特定的准确度/损失分数时停止训练、在每次成功的轮次后将模型保存为检查点、随着时间调整学习率等等。让我们深入探讨一些回调函数!
EarlyStopping
过拟合是机器学习从业者的噩梦。避免过拟合的一种方法是提前终止训练过程。EarlyStopping 函数具有各种指标/参数,你可以修改这些指标来设置训练过程应何时停止。以下是一些相关的指标:
-
monitor: 被监控的值,例如: val_loss
-
min_delta: 监控值的最小变化。例如,min_delta=1 意味着如果监控值的绝对变化小于 1,则训练过程将被停止。
-
patience: 在训练停止之前没有改进的轮次数量。
-
restore_best_weights: 将此指标设置为 True,如果你希望在训练停止后保留最佳权重。
以下代码示例将定义一个 EarlyStopping 函数,该函数跟踪 val_loss 值,如果在 3 个轮次后 val_loss 没有变化,则停止训练,并在训练停止时保留最佳权重:
from keras.callbacks import EarlyStoppingearlystop = EarlyStopping(monitor = 'val_loss',
min_delta = 0,
patience = 3,
verbose = 1,
restore_best_weights = True)
ModelCheckpoint
这个回调在每个 epoch 之后保存模型。以下是一些相关指标:
-
filepath:你想保存模型的文件路径
-
monitor:正在监控的值
-
save_best_only:如果你不想覆盖最新的最佳模型,请将其设置为 True
-
mode:auto, min 或 max。例如,如果监控的值是
val_loss且你想要最小化它,则设置mode=’min’。
示例:
from keras.callbacks import ModelCheckpointcheckpoint = ModelCheckpoint(filepath,
monitor='val_loss',
mode='min',
save_best_only=True,
verbose=1)
LearningRateScheduler
from keras.callbacks import LearningRateSchedulerscheduler = LearningRateScheduler(schedule, verbose=0) # schedule is a function
这个非常简单明了:它根据你事先编写的 schedule 来调整学习率。此函数根据当前的 epoch(作为输入的 epoch 索引)返回所需的学习率(输出)。
其他回调函数
除了上述函数,还有其他回调函数你可能会遇到或想在深度学习项目中使用:
-
History 和 BaseLogger:默认情况下自动应用于你的模型的回调
-
TensorBoard:这是我最喜欢的 Keras 回调。这一回调为 TensorBoard 写入日志,而 TensorBoard 是 TensorFlow 的优秀可视化工具。如果你通过 pip 安装了 TensorFlow,你应该能从命令行启动 TensorBoard:
tensorboard — logdir=/full_path_to_your_logs -
CSVLogger:此回调将 epoch 结果流式传输到 csv 文件
-
LambdaCallback:此回调允许你构建自定义回调
结论
在这篇文章中,你已经学习了 Keras 中回调函数的主要概念。Keras 文档中有一个非常全面的回调页面,你绝对应该查看一下:keras.io/callbacks/
如果你对如何改进这篇文章有任何建议,请留言。关注我 Medium 或在 LinkedIn 上与我联系,获取更多优质内容!
个人简介:Andre Duong 是 UT 达拉斯的大二计算机科学本科生。他的兴趣包括机器学习、数据科学和软件开发。
原文。已获许可转载。
相关:
-
高级 Keras——构建复杂的自定义损失和指标
-
卷积神经网络:使用 TensorFlow 和 Keras 的 Python 教程
-
哪个深度学习框架增长最快?
更多主题
Keras 超参数调整在 Google Colab 中使用 Hyperas
原文:
www.kdnuggets.com/2018/12/keras-hyperparameter-tuning-google-colab-hyperas.html
评论
由 Nils Schlüter 提供,软件工程师

为你的神经网络调整超参数可能会很棘手(照片由 Anthony Roberts 提供,来自 Unsplash)
超参数调整是创建深度学习网络时最耗费计算资源的任务之一。幸运的是,你可以使用 Google Colab 显著加快这个过程。在这篇文章中,我将向你展示如何使用 Hyperas 调整现有 Keras 模型的超参数,并在 Google Colab 笔记本中运行所有操作。
创建一个新的笔记本并启用 GPU 运行时
更改运行时为 GPU 的对话框
首先,你需要创建一个新的笔记本。打开你的 Colab 控制台 并选择 新建 Python 3 笔记本。在笔记本中,从菜单中选择 运行时,然后选择 更改运行时类型。选择硬件加速器:GPU 并点击保存。这将显著加快你在这个笔记本中进行的所有计算。
安装包
你可以使用 pip 安装新包。在这种情况下,我们需要 hyperas 和 hyperopt。将以下内容复制并粘贴到笔记本的第一个单元格中:
!pip install hyperas
!pip install hyperopt
当你运行单元格时,你会看到 pip 正在下载和安装依赖项。
获取数据并创建模型
在这篇文章中,我将使用 hyperas github 页面 的示例。你可以在 这里 找到完成的 Colab 笔记本。
数据函数
你需要一个数据函数来加载你的数据。它需要返回你的 X_train、Y_train、X_test 和 Y_test 值。下面是一个数据函数的示例:
注意:你的数据函数需要按照确切的顺序返回这些值:X_train、Y_train、X_test、Y_test。如果你使用 scikit-learn 的 train_test_split,要小心,因为它返回值的顺序可能不同。
模型函数
模型函数是你定义模型的地方。你可以使用所有可用的 Keras 函数和层。为了添加用于调整的超参数,你可以使用 {{uniform()}} 和 {{choice()}} 关键字。
假设你想尝试不同的batch_size值。你可以简单地写batch_size={{choice([32, 64, 128])}},在每次试用中,将会选择并尝试其中一个值。关于如何定义待调整的参数的更详细说明可以在 Hyperas Github 页面 上找到,或者你可以查看示例:
注意: 你的模型函数必须返回一个包含 loss 键和 status 键的 Python 字典
Colab 的问题
如果你现在尝试运行这个示例,试用将会失败,因为 Hyperas 无法找到你的笔记本。你需要复制你的笔记本并重新上传到你的 Google Drive 文件夹中。幸运的是,你可以从笔记本内部完成此操作,详见这个 stackoverflow 回答。
注意: 在第 16 行和第 18 行,你需要将HyperasMediumExample更改为你自己的笔记本名称
运行此单元格后,你将被提示在浏览器中打开一个网站并将代码复制并粘贴回笔记本中:
你运行上面单元格后的输出
跟随链接,用你的 Google 账户登录,并将代码复制并粘贴回笔记本。如果你打开左侧边栏中的文件选项卡,你现在应该能看到一个名为
开始试用
现在你可以开始试用。请注意,你必须将参数notebook_name设置为你的笔记本名称。否则试用将会失败:
运行此单元格后,扫描将开始,你可以在单元格的输出中查看结果。
故障排除
如果你在操作过程中遇到任何问题,我建议你执行以下操作:
-
在左侧边栏中,打开文件。会有一个名为
.ipynb 的文件。删除该文件 -
在菜单中,选择运行时,然后选择重启运行时。
-
重新加载页面
在你的运行时重新连接后,你可以通过从上到下运行每个单元格来重新开始
结论
只需进行一些调整,你就可以使用 Google Colab 来调整 Keras 网络的超参数。再次提醒,完整示例可以在 这里 找到。
个人简介:Nils Schlüter (@schlueter_nils) 是一位软件工程师及机器学习爱好者。
原文。已获转载许可。
相关:
-
自动化机器学习的当前状态
-
Auto-Keras,或如何用 4 行代码创建深度学习模型
-
自动化机器学习与自动化数据科学
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
更多相关话题
有志数据科学家的关键算法和统计模型
原文:
www.kdnuggets.com/2018/04/key-algorithms-statistical-models-aspiring-data-scientists.html
评论
作为一名已经从业多年的数据科学家,我经常在 LinkedIn 和 Quora 上收到学生和职业转行者的职业建议或课程选择指导。一些问题围绕教育路径和课程选择,但许多问题集中在当前数据科学中常见的算法或模型上。
面对大量的算法选择,很难知道从哪里开始。课程可能包括当前行业中不常用的算法,也可能排除一些当前并不流行但非常有用的方法。基于软件的程序可能会忽略重要的统计概念,而基于数学的程序可能会略过一些关键的算法设计主题。

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
我为有志的数据科学家准备了一份简短的指南,特别关注统计模型和机器学习模型(监督和无监督);许多这些主题在教科书、研究生级统计课程、数据科学训练营和其他培训资源中都有涵盖(其中一些在文章的参考部分包含)。由于机器学习是统计学的一个分支,机器学习算法技术上属于统计知识,同时也涉及数据挖掘和更多基于计算机科学的方法。然而,由于一些算法与计算机科学课程内容重叠,并且许多人将传统统计方法与新方法分开,我将在列表中将这两个分支分开。
统计方法包括一些在训练营和证书课程中常见的方法概述,以及一些在研究生统计课程中通常教授但在实践中非常有用的不太常见的方法。我建议的所有工具都是我经常使用的:
-
广义线性模型,它是大多数监督学习方法的基础(包括逻辑回归和 Tweedie 回归,它对行业中遇到的大多数计数或连续结果进行广义化……)
-
时间序列方法(ARIMA、SSA、基于机器学习的方法)
-
结构方程建模(用于建模和测试中介路径)
-
因子分析(用于调查设计和验证的探索性和确认性)
-
功效分析/试验设计(特别是基于模拟的试验设计,以避免过度强大的分析)
-
非参数检验(从头开始推导测试,特别是通过模拟)/MCMC
-
K 均值聚类
-
贝叶斯方法(朴素贝叶斯、贝叶斯模型平均、贝叶斯自适应试验……)
-
惩罚回归模型(弹性网、LASSO、LARS……)以及一般模型中添加的惩罚(SVM、XGBoost……),这些对预测变量多于观测值的数据集非常有用(在基因组学和社会科学研究中很常见)
-
基于样条的模型(MARS……)用于灵活建模过程
-
马尔可夫链和随机过程(时间序列建模和预测建模的替代方法)
-
缺失数据插补方案及其假设(missForest,MICE……)
-
生存分析(对建模流失和退化过程非常有帮助)
-
混合建模
-
统计推断和分组测试(A/B 测试及许多市场营销活动中实现的更复杂的设计)
机器学习扩展了许多这些框架,特别是 K 均值聚类和广义线性建模。一些在许多行业中通用的有用技术(以及一些更为晦涩但意外有用的算法,但很少在训练营或证书课程中教授)包括:
-
回归/分类树(广义线性模型的早期扩展,具有高准确性、良好的可解释性和低计算开销)
-
降维(PCA 和流形学习方法如 MDS 和 tSNE)
-
经典前馈神经网络
-
装袋集成(作为随机森林和 KNN 回归集成算法的基础)
-
提升集成(作为梯度提升和 XGBoost 算法的基础)
-
参数调优或设计项目的优化算法(遗传算法、量子启发的进化算法、模拟退火、粒子群优化)
-
拓扑数据分析工具,这些工具特别适合用于小样本量的无监督学习(持久同源性、Morse-Smale 聚类、Mapper……)
-
深度学习架构(一般深度架构)
-
KNN 方法用于局部建模(回归、分类)
-
基于梯度的优化方法
-
网络指标和算法(中心性测量、介数、多样性、熵、拉普拉斯、流行病传播、谱聚类)
-
深度架构中的卷积和池化层(在计算机视觉和图像分类模型中尤为有用)
-
层次聚类(与 k 均值聚类和拓扑数据分析工具相关)
-
贝叶斯网络(路径挖掘)
-
复杂性和动态系统(与微分方程相关,但通常用于建模没有已知驱动因素的系统)
根据所选择的行业,可能需要与自然语言处理(NLP)或计算机视觉相关的额外算法。然而,这些是数据科学和机器学习的专业领域,进入这些领域的人通常已经是该领域的专家。
一些在学术项目之外学习这些方法的资源包括:
Christopher, M. B. (2016). 《模式识别与机器学习》。Springer-Verlag New York.
Friedman, J., Hastie, T., & Tibshirani, R. (2001). 《统计学习的元素》(第 1 卷,第 337-387 页)。纽约:Springer 统计系列。
www.coursera.org/learn/machine-learning
professional.mit.edu/programs/short-programs/machine-learning-big-data
www.slideshare.net/ColleenFarrelly/machine-learning-by-analogy-59094152
相关:
更多相关主题
Andrew Ng《机器学习的渴望》的 6 个关键概念
原文:
www.kdnuggets.com/2019/08/key-concepts-andrew-ng-machine-learning-yearning.html
评论
由 Niklas Donges,SAP。
机器学习的渴望 主要讲述了如何构建机器学习项目的开发。此书包含了难以在其他地方找到的实用见解,以易于与团队成员和合作伙伴共享的格式呈现。大多数技术 AI 课程会向你解释不同的 ML 算法在幕后如何工作,但这本书教你如何实际使用它们。如果你希望成为 AI 领域的技术领袖,这本书将助你一臂之力。历史上,学习如何对 AI 项目做出战略决策的唯一途径是参加研究生项目或在公司工作积累经验。机器学习的渴望 帮助你迅速获得这一技能,使你在构建复杂的 AI 系统方面变得更出色。
目录
-
关于作者
-
介绍
-
概念 1:反复迭代……
-
概念 2:使用单一评估指标
-
概念 3:错误分析至关重要
-
概念 4:定义一个最佳错误率
-
概念 5:解决人类能够做好的问题
-
概念 6:如何拆分你的数据集
-
摘要
 Andrew NG: 由 NVIDIA 公司拍摄,采用“CC BY-NC-ND 2.0”许可证。未做任何修改。 (来源)
Andrew NG: 由 NVIDIA 公司拍摄,采用“CC BY-NC-ND 2.0”许可证。未做任何修改。 (来源)
关于作者
Andrew NG 是一位计算机科学家、执行官、投资者、企业家,以及人工智能领域的领先专家之一。他曾是百度的副总裁兼首席科学家,斯坦福大学的兼职教授,也是最受欢迎的机器学习在线课程的创建者、Coursera.com 的联合创始人,以及前谷歌大脑负责人。在百度,他显著参与了将 AI 团队扩展到数千人的工作。
介绍
这本书开始于一个小故事。假设你想为公司建立一个领先的猫检测系统。你已经建立了一个原型,但不幸的是,系统的性能并不理想。你的团队提出了几种改进系统的想法,但你对应该走哪个方向感到困惑。你可以建立世界领先的猫检测平台,也可以浪费数月时间走错方向。
这本书旨在告诉你在这种情况下如何决策和优先排序。根据 Andrew NG 的说法,大多数机器学习问题会提供关于最有前景的下一步以及应该避免做什么的线索。他进一步解释了学习如何“读取”这些线索在我们的领域中是一项关键技能。
简而言之,《机器学习渴望》旨在帮助你深入理解如何设定机器学习项目的技术方向。
由于你的团队成员在你提出新想法时可能会持怀疑态度,他将章节写得非常简短(1-2 页),以便你的团队成员可以在几分钟内阅读并理解概念背后的思想。如果你对阅读这本书感兴趣,请注意,它不适合完全的初学者,因为它需要对监督学习和深度学习有基本的了解。
在这篇文章中,我将用自己的语言分享书中的六个概念。
概念 1:迭代、迭代,再迭代……
NG 在整本书中强调,快速迭代是至关重要的,因为机器学习是一个迭代过程。与其考虑如何为你的问题构建完美的 ML 系统,你应该尽快构建一个简单的原型。如果你在该领域不是专家,尤其如此,因为很难准确预测最有前景的方向。
你应该在几天内构建第一个原型,然后会有线索浮现,显示出改进原型性能的最有前景方向。在下一个迭代中,你将基于其中一个线索改进系统,并构建下一个版本。你会一遍遍地这样做。
他继续解释说,你迭代的速度越快,你的进展就会越大。书中的其他概念也基于这一原则。注意,这本书是针对那些只想构建基于 AI 的应用程序而不是进行领域研究的人。
概念 2:使用单一评估指标
 (图片来源)
(图片来源)
这个概念建立在前一个概念之上,关于为何应该选择单一的评估指标,其解释非常简单:它使你能够快速评估你的算法,从而能够更快地进行迭代。使用多个评估指标只会使得算法比较变得更加困难。
想象一下你有两个算法。第一个算法的精度为 94%,召回率为 89%。第二个算法的精度为 88%,召回率为 95%。
在这里,如果没有选择单一的评估指标,没有分类器明显优越,因此你可能需要花费一些时间来弄清楚。问题是,每次迭代时,你在此任务上会浪费大量时间,并且这些时间会随着时间的推移而增加。你将尝试许多关于架构、参数、特征等的想法。如果你使用单一数字评估指标(例如精度或 F1 分数),它使你能够根据性能对所有模型进行排序,并快速决定哪个效果最好。另一种改进评估过程的方法是将多个指标合并成一个,例如通过对多个错误指标取平均值。
然而,会有一些机器学习问题需要满足多个指标,例如考虑运行时间。NG 解释说,你应该定义一个“可接受”的运行时间,这样你可以迅速筛选出过慢的算法,并根据单一数字评估指标对令人满意的算法进行比较。
简而言之,单一数字评估指标使你能够快速评估算法,从而加快迭代速度。
概念 3:错误分析至关重要
 (图像来源)
(图像来源)
错误分析是查看算法输出不正确的示例的过程。例如,假设你的猫探测器把鸟误认为猫,而你已经有了几个解决该问题的想法。
通过适当的错误分析,你可以估计一个改进想法实际上会提高系统性能的程度,而无需花费数月时间实现该想法后发现它对系统不重要。这使你能够决定哪个想法最值得投入资源。如果你发现只有 9%的错误分类图像是鸟类,那么无论你如何提高算法在鸟类图像上的性能,都无济于事,因为它不会改善超过 9%的错误。
此外,它使你能够快速并行判断多个改进想法。你只需创建一个电子表格,并在检查例如 100 个错误分类的开发集图像时填写它。在电子表格中,你为每个错误分类的图像创建一行,为每个改进想法创建一列。然后,你逐一查看每个错误分类的图像,并标记图像将被正确分类的想法。
之后,你会准确知道,例如,使用想法-1 系统将 40%的错误分类图像正确分类,想法-2 是 12%,而想法-3 只有 9%。然后你会知道,处理想法-1 是团队应集中精力的最有希望的改进方向。
此外,一旦你开始查看这些示例,你可能会发现新的改进算法的想法。
概念 4:定义最佳错误率
最佳错误率有助于指导你的下一步。在统计学中,它也常被称为贝叶斯误差率。
想象一下你正在构建一个语音转文本系统,并且你发现预计用户提交的 19% 的音频文件有如此强烈的背景噪音,以至于即使是人类也无法识别里面说了什么。如果是这种情况,你知道即使是最好的系统也可能有大约 19% 的错误率。相比之下,如果你处理的是一个几乎 0% 错误率的最佳问题,你可以期望你的系统也会表现得同样好。
这也帮助你检测你的算法是否存在高偏差或方差,从而帮助你定义下一步来改进你的算法。
但是我们如何知道最佳错误率是什么呢?对于人类擅长的任务,你可以将你的系统性能与人类的表现进行比较,这可以给你一个最佳错误率的估计。在其他情况下,往往很难定义最佳率,这也是为什么你应该处理人类能够做得好的问题,我们将在下一个概念中讨论。
概念 5:处理人类能够做得好的问题
在整本书中,他多次解释了为什么建议处理人类能够很好地完成的机器学习问题。例如,语音识别、图像分类、目标检测等。这有几个原因。
首先,更容易获取或创建标记数据集,因为如果人们能够自行解决问题,他们可以为你的学习算法提供高准确率的标签。
其次,你可以使用人类的表现作为你希望算法达到的最佳错误率。NG 解释说,定义一个合理且可实现的最佳错误率有助于加快团队的进展。它也帮助你检测你的算法是否存在高偏差或方差。
第三,这使你可以基于人类的直觉进行错误分析。例如,如果你正在构建一个语音识别系统,而你的模型错误地分类了输入,你可以尝试理解人类会使用什么信息来获得正确的转录,并利用这些信息来相应地修改学习算法。尽管算法在越来越多的人类无法做到的任务上超越了人类,但你应尽量避免这些问题。
总结来说,你应该避免这些任务,因为它们使得获得数据标签变得更困难,你无法再依赖人类直觉,而且很难知道最佳错误率是多少。
概念 6:如何拆分数据集
NG 还提出了一种拆分数据集的方法。他建议如下:
训练集: 使用它来训练你的算法,别无其他。
开发集:这个集合用于进行超参数调优、选择和创建适当的特征,以及进行错误分析。它基本上是用来做出关于你的算法的决策。
测试集:测试集用于评估你的系统性能,但不用于做决策。它只是用于评估,没有其他功能。
开发集和测试集使你的团队能够快速评估算法的表现。它们的目的是引导你做出对系统最重要的修改。
他建议选择开发集和测试集,以便它们能反映出你希望在系统部署后未来表现良好的数据。 如果你预计数据会与当前训练的数据不同,这一点尤其重要。例如,你在使用普通相机图像进行训练,但系统未来只会接收手机拍摄的照片,因为这是移动应用的一部分。如果你没有足够的手机照片来训练系统,这种情况可能会出现。因此,你应该选择那些能够真实反映你未来希望表现良好的测试集样本,而不是用于训练的数据。
此外,你应该选择来自相同分布的开发集和测试集。 否则,你的团队可能会构建一个在开发集上表现良好的系统,却发现它在测试数据上表现极差,而这些测试数据才是你最关心的。
总结
在这篇文章中,你了解了《机器学习年鉴》的 6 个概念。你现在知道为什么快速迭代很重要,为什么应该使用单一数字的评估指标,错误分析的内容以及它的重要性。同时,你了解了最佳错误率,为什么应该处理人类能够做得好的问题,以及如何拆分数据。此外,你还了解了应该选择反映未来希望表现良好的数据的开发集和测试集,以及这些集合应来自相同的分布。我希望这篇文章给你对书中的一些概念做了介绍,我可以肯定地说,它值得阅读。
个人简介:Niklas Donges 是一位机器学习和数据科学爱好者,在柏林 CODE 应用科学大学学习软件工程,深度关注机器学习,并兼职为 SAP 的机器学习基金会工作。
原文。经许可转载。
相关:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
数据货币化的关键
评论
许多组织将数据货币化与出售数据联系在一起。然而,出售数据不是一项简单的任务,特别是对于主要依赖数据的组织。新涉足数据销售的组织需要关注隐私和个人可识别信息(PII)、数据质量和准确性、数据传输可靠性、定价、包装、市场营销、销售、支持等。像 Nielsen、Experian 和 Acxiom 这样的公司在数据销售方面是专家,因为这是他们的业务;他们围绕收集、汇总、清洗、对齐、包装、销售和支持数据建立了业务。
所以,与其专注于尝试销售数据,不如专注于货币化从数据中获得的客户、产品和运营见解;这些见解可用于优化关键业务和运营流程,减少安全和合规风险,发现新的收入机会,并创造更具吸引力的客户和合作伙伴互动。
对于那些寻求货币化其客户、产品和运营见解的组织来说,分析配置文件是不可或缺的。虽然我经常谈论分析配置文件的概念,但我从未写过一篇详细说明分析配置文件如何工作的博客。所以,让我们创建一个“分析配置文件的日常”来解释分析配置文件如何捕捉和“货币化”你的分析资产。
分析配置文件
分析配置文件提供了一种存储模型(类似于键值存储)来捕捉组织的分析资产,以便于这些资产在多个业务用例中进行提炼和共享。分析配置文件由指标、预测指标、细分、评分和业务规则组成,这些规则对组织关键业务实体如客户、患者、学生、运动员、喷气发动机、汽车、机车、CAT 扫描仪和风力涡轮机的行为、偏好、倾向、兴趣、关联和隶属关系进行编码(参见图 1)。

图 1: 分析配置文件
分析配置文件在捕捉和重用分析见解时强制执行一种规范,这些见解针对个别关键业务实体(例如,个别患者、个别学生、个别风力涡轮机)。缺乏捕捉、提炼和共享分析的操作框架可能导致:
-
数据工程和数据科学资源的使用效率低
-
分析项目未与高价值业务计划挂钩
-
组织学习的捕捉和应用有限
-
获取组织对分析技术、资源和技能投资的支持存在困难
-
难以建立作为可信赖业务顾问的信誉
-
缺乏可重用的资产,使得未来用例的成本效益更高,并显著提高投资回报率(ROI)
让我们看看分析档案是如何工作的。
分析档案的实际应用
假设你是一个组织的分析副总裁,该组织通过注册的在线账户和/或忠诚度计划(例如零售、酒店、娱乐、旅行、餐厅、金融服务、保险)跟踪个体购买交易。你被要求运用数据和分析帮助组织“提高同一地点销售”5%。
在执行了愿景研讨会(顺便说一句,这个决定非常明智!)以识别、验证、优先排序和对齐业务相关方围绕关键业务用例后,你提出了以下“提高同一地点销售”业务计划的业务用例:
-
用例 #1:提高活动效果
-
用例 #2:提高客户忠诚度
-
用例 #3:增加客户店铺访问量
-
用例 #4:减少客户流失
“提高活动效果”用例
为了支持“提高活动效果”用例,数据科学团队与业务相关方合作,头脑风暴、测试并确认他们需要为每个客户构建人口统计和行为分段。人口统计分段基于客户的变量,如年龄、性别、婚姻状况、就业状态、雇主、收入水平、教育水平、大学学位、抚养人数、抚养者年龄、家庭位置、房屋价值、工作地点和职位。行为分段则基于购买和互动交易,如购买频率、最近购买时间、购买的物品、花费金额、使用的优惠券或折扣、应用的折扣、退货和消费者评论。
图 2 显示了来自“提高活动效果”用例的客户 WDS120356 的客户分析档案。

图 2: 提高活动效果
注意:一个客户不会只属于一个人口统计或行为分段,而可能根据人口统计属性和购买活动的组合存在于多个不同的人口统计和行为分段中。
由于这个用例,我们在分析档案中创建并捕获了大量每个客户的人口统计和行为分段。这些人口统计和行为分段现在可以在不同的用例中使用。
“提高客户忠诚度”用例
下一个用例是“提升客户忠诚度”。数据科学团队再次开始与业务利益相关者进行头脑风暴,以“确定可能更好地预测客户忠诚度的变量和指标”。数据科学团队开始分析过程,重用放入数据湖中的用例 #1 数据,但收集额外数据以支持客户忠诚度评分的开发、测试和优化。
作为分析建模过程的一部分,数据科学团队决定,创建的行为细分可以被重用以支持“增加客户忠诚度”用例,但发现通过额外的数据可以改进行为细分的预测能力。
因此,数据科学团队完成了两个任务,以支持“提升客户忠诚度”用例:
-
创建了一个新的客户忠诚度评分,包含了用例 #1 数据以及新的数据来源
-
改进了现有行为细分的预测能力(现已版本控制为版本 1.1)
图 3 显示了“增加客户忠诚度”用例生成的客户 WDS120356 的更新分析档案。

图 3: 提升客户忠诚度用例
需要特别注意的是,改进后的行为细分的受益者——无需额外费用——是用例 #1: 提升活动效果。也就是说,“提升活动效果”用例的性能和结果仅仅在没有额外成本的情况下得到了改善!
为了实现这一目标,分析捕获在分析档案中的内容必须像软件一样对待,并包括支持软件开发技术的功能,如检查/检出、版本控制和回归测试(使用 Jupyter Notebooks 和 GitHub 等技术)。
“增加客户到店访问”用例
让我们再来看一个用例:“增加客户到店访问”。数据科学团队再次开始与业务利益相关者进行头脑风暴,以“确定可能更好地预测客户访问的变量和指标”。数据科学团队再次开始分析过程,重用放入数据湖中的用例 #1 和 #2 数据,但收集额外数据以支持客户访问频率指数的开发、测试和优化。
作为分析建模过程的一部分,数据科学团队再次决定,更新后的行为细分可以被重用以支持“增加客户到店访问”用例,并发现可以通过额外的数据进一步提升行为细分的预测能力,以支持“增加客户到店访问”用例。
图 4 显示了客户 WDS120356 的更新后的客户分析档案,结果来自“增加客户店铺访问”用例。

图 4: 增加店铺访问用例
再次强调,更新的行为细分的受益者——无需额外费用——是用例 #1 和 #2,它们发现这些用例的表现和结果有所改善,无需额外费用。
分析档案总结
通过逐个用例推进,客户分析档案得到完善,并为数据货币化提供基础,改进业务和运营流程,减少安全和合规风险(见图 5)。

图 5: 完全功能的客户分析档案
分析档案还提供了识别新收入机会的基础;了解你的客户和产品使用行为、趋势、倾向和偏好,以至于你可以识别未满足的客户需求或新服务、新产品、新定价、新捆绑、新市场、新渠道等的新的产品使用场景。
接纳分析档案的概念创建了一个操作框架,用于捕捉、完善和重复使用组织的分析资产。这使得:
-
利用关于多个业务用例中关键业务实体的分析洞察。
-
发展基准,随着时间的推移,有助于优化未来的决策。
-
开发可重复的分析流程,以加速组织内部分析的采用。
-
为进一步提高数据的经济价值而证明对分析工具和数据科学家的投资。
-
通过使你的分析对其他业务利益相关者可消费来扩展你的分析工作的价值。
-
更好地了解你“没有但可能拥有”的数据。
分析档案帮助组织优先考虑和调整数据科学资源,以创建可操作的洞察,这些洞察可以在整个组织中重复使用,以优化关键业务和运营流程,减少网络安全风险,发现新的货币化机会,并提供更有吸引力、更具指导性的客户和合作伙伴体验。
因此,你不应该专注于销售数据(因为很难量化数据对他人的价值),而是寻找销售分析洞察的机会(例如,行业指数、客户细分、产品和服务的交叉销售/增销建议、运营绩效基准),这些洞察可以支持目标市场的关键决策。你的目标市场可能会为帮助他们做出更好决策并发现新收入机会的分析洞察付费。
原始内容。已获授权转载。
相关:
-
确定数据的经济价值
-
区块链是数据货币化的终极推动者吗?
-
识别可能是更好预测指标的变量
更多相关内容
影响洞察时间的关键因素
原文:
www.kdnuggets.com/2023/03/key-factors-affecting-time-insights.html
在一个商业运作迅速的世界里,利用数据资产是保持竞争优势的最佳选择。数据分析是一项宝贵的实践,它生成的洞察帮助企业朝正确的方向前进。市场动态变化快,竞争激烈,这使得生成这些洞察变得比以往任何时候都重要。然而,数据分析本身并不是区分因素;时间的利用才是。
毕竟,数据的价值在于它能被合成成报告、仪表板、图表或图形——简言之,即可消费的洞察。因此,组织在做出明智决策时可能面临挑战,特别是当数据来自各种格式和来源时。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织 IT
这就是商业智能(BI)发挥作用的地方。传统的 BI 定义较宽泛,包括将原始数据转化为有意义和有用信息的工具和技术。

图片来源于 Freepik
尤其是当涉及大量数据和多样化的数据来源时,实现有效的 BI 很快就会成为一项昂贵且耗时的任务,需大量的计算资源和先进的软件能力。因此,寻求获得 BI 收益的组织必须投资于 BI 基础设施、软件和维护。此外,需要相当的专业知识来准确处理、分析和解释数据。当处理大型数据集时,这些成本会更高,对计算基础设施的要求也更大。由于使 BI 对企业有用所需的重大投资,清晰了解潜在的投资回报率至关重要。
标准化与定制 BI 解决方案
现有技术和工具长期以来提供了生成洞察的标准程序。每个组织面临独特的挑战。他们通常依赖定制的商业智能解决方案,以适应其行业并帮助他们在竞争中保持领先。因此,量身定制的解决方案能够从最具行动性的洞察中创造最大商业价值,并加速创新和增长。
不仅仅是洞察,洞察时间也很重要
用户行为正在动态变化,使得及时做出适当的商业决策既成为必需也充满挑战。成功依赖于及时洞察关键问题、机会领域、新兴市场趋势或新的收入来源。考虑到这一点,洞察的产生越快,数据分析对业务的有效性和帮助性越大。
将数据转化为可操作洞察的时间是衡量分析功能有效性的一个重要关键绩效指标,通常称为洞察时间。洞察的意义也至关重要,因为数据分析必须始终伴随着能够推动业务决策的价值生成。
各种因素可能会减慢理解数据所需的时间,例如
-
数据量和复杂性:数据集越大越复杂,清洗、处理和分析所需的时间就越长。
-
数据质量:数据质量差,如信息缺失或不一致,会减慢将其转化为洞察的过程。
-
工具和基础设施的可用性:用于数据分析的工具,如软件和硬件的可用性和有效性,影响洞察的时间。
-
涉及人员的技能:与新手相比,商业智能专家可以加快生成洞察的时间。
-
实验的有效性:低效和过时的实验记录方法可能会面临遗漏必要细节或未被记录的风险,导致洞察周期延长。
-
快速迭代能力:一个组织通过快速进行实验的能力,能通过产生创新想法来推动增长。
其他非技术因素也可能阻碍任何组织生成洞察的速度,例如:
-
组织文化:组织的文化和实践可能会促进或阻碍快速将数据转化为洞察的能力。
-
数据治理:管理数据访问、数据质量、数据安全、数据来源或数据保留的政策和流程也可能阻碍洞察的生成速度。
这些因素通常是特定于组织的,但一些行业范围内的趋势在更广泛的范围内影响分析和商业智能(BI)。
行业示例
为了加速商业智能(BI)计划,一个理想的平台应当允许用户通过自动化数据清理和分析迅速提取见解。它必须让开发者免于处理与数据处理平台相关的性能问题,从而能够专注于功能开发。
让我们看看一些企业从快速 BI 结果中受益的例子:
零售公司
假设一个中型零售企业希望获得关于客户行为和偏好的见解,以改善其销售和营销策略。他们从多个来源(包括销售、客户、库存和社交媒体数据)收集了大量数据。BI 工具可以帮助该零售企业处理和分析这些大数据集,以确定例如哪些产品在不同客户群体中最受欢迎,或者哪些店铺位置拥有最忠诚的客户群。这些强大的见解将帮助公司在产品开发、营销和店铺运营方面做出明智的决策。
医疗保健提供者
家庭医生及其支持人员从电子健康记录(EHR)、实验室结果和保险索赔等不同来源获取数据。他们的目标是识别可以预测和预防慢性疾病的数据模式。由于其固有特性,医疗领域属于高风险类别,需要广泛的实验来构建稳健的模型。数据见解可以帮助医疗人员识别高风险患者、找到具有成本效益的治疗方案,并确定最可能重新入院的患者。这些宝贵的见解有助于医生做出有关患者护理、治疗计划和预防措施的明智决策。
结论
现代世界对商业智能的需求日益增加,但如果从数据中生成见解需要很长时间,这种需求并不足以帮助企业保持竞争优势。文章讨论了影响见解生成速度的挑战和趋势。包括数据处理自动化、定制数据分析和维护可扩展解决方案在内的有效 BI 策略,可以证明在及时生成见解方面的有效性。
Vidhi Chugh 是一位人工智能策略师和数字化转型领导者,致力于在产品、科学和工程交汇处构建可扩展的机器学习系统。她是一位获奖的创新领导者、作者和国际演讲者。她的使命是使机器学习民主化,打破术语,让每个人都能参与这场转型。
更多关于这个话题
与分类准确性相关的关键问题
原文:
www.kdnuggets.com/2023/03/key-issues-associated-classification-accuracy.html
作者提供的图片
不平衡类别
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
如果数据集包含不均衡的分类,准确性可能会具有误导性。例如,如果主导类别占据了 99%的数据,一个仅预测主要类别的模型将会有 99%的准确率。不幸的是,它将无法恰当地分类少数类别。应使用包括精确率、召回率和 F1 分数在内的其他指标来解决这个问题。
处理分类准确性中不平衡类别问题的 5 种最常见技术是:解决不平衡类别问题。
不平衡类别 | 知识工程
-
上采样少数类别:在这种技术中,我们复制少数类别中的示例以平衡类别分布。
-
下采样主要类别:在这种技术中,我们从主要类别中移除示例以平衡类别分布。
-
合成数据生成:一种用于生成少数类别新样本的技术。当随机噪声被引入现有示例中,或通过插值或外推生成新示例时,就会发生合成数据生成。
-
异常检测:在这种技术中,少数类别被视为异常,而主要类别被视为正常数据。
-
改变决策阈值:这种技术调整分类器的决策阈值,以提高对少数类别的敏感度。
过拟合
当模型在训练数据上过度训练并在测试数据上表现不佳时,称为过拟合。因此,训练集上的准确性可能很高,但测试集上的表现可能很差。应采用如交叉验证和正则化等技术来解决这一问题。
过拟合 | Freepik
有几种技术可以用来解决过拟合问题。
-
使用更多数据训练模型:这使算法能够更好地检测信号并减少错误。
-
正则化:这涉及在训练过程中向成本函数中添加惩罚项,有助于限制模型的复杂性并减少过拟合。
-
交叉验证:这种技术通过将数据分为训练集和验证集,进而在每个集上训练和评估模型,从而帮助评估模型的表现。
-
集成方法。这是一种训练多个模型并将其预测结果结合的技术,有助于减少模型的方差和偏差。
数据偏差
如果训练数据集存在偏差,模型将产生偏颇的预测结果。这可能导致训练数据上的高准确性,但在未见数据上的表现可能较差。应采用数据增强和重新采样等技术来解决此问题。其他解决此问题的方法如下:

数据偏差 | Explorium
-
一种技术是确保使用的数据代表了其旨在建模的总体。这可以通过从总体中随机抽取数据,或使用过采样或欠采样等技术来平衡数据。
-
通过测量不同人口统计类别和敏感群体的准确性水平,仔细测试和评估模型。这可以帮助识别数据和模型中的任何偏差,并加以解决。
-
注意观察者偏差,这种偏差发生在你无论是有意识还是无意地将个人观点或愿望强加于数据时。可以通过意识到潜在偏差的可能性,并采取措施减少偏差来避免。
-
使用预处理技术来移除或纠正数据偏差。例如,使用数据清理、数据规范化和数据缩放等技术。
混淆矩阵
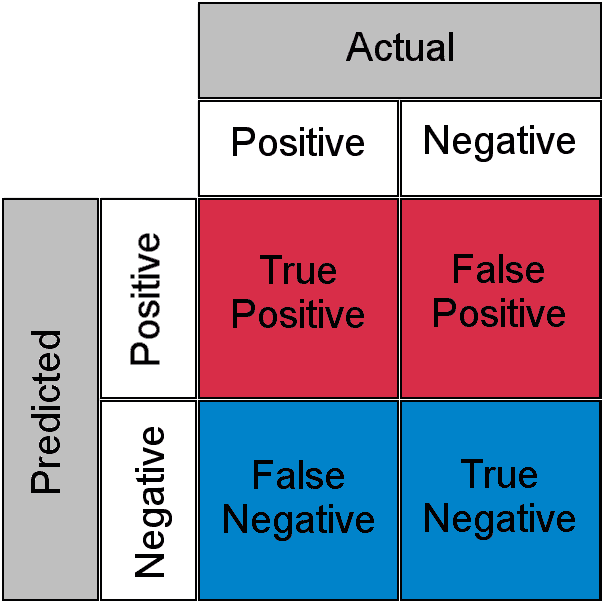
作者提供的图片
分类算法的性能使用混淆矩阵进行描述。这是一个表格布局,其中实际值与预期值对比,以定义分类算法的性能。解决此问题的一些方法包括:
-
分析矩阵中的值,并识别错误中的模式或趋势。例如,如果存在许多假阴性,可能表明模型对某些类别的敏感性不足。
-
使用精准度、召回率和 F1 分数等指标来评估模型性能。这些指标提供了对模型表现的更详细理解,并有助于识别模型表现薄弱的具体领域。
-
调整模型的阈值,如果阈值过高或过低,会导致模型产生更多的假阳性或假阴性。
-
使用集成方法,如自助法(bagging)和提升法(boosting),这有助于通过结合多个模型的预测来改善模型性能。
了解更多关于混淆矩阵的内容,请观看这个 视频
分类准确性的贡献
总结来说,分类准确率是评估机器学习模型性能的一个有用指标,但它可能具有误导性。为了获得对模型性能的更全面的视角,还应使用其他指标,包括精准度、召回率、F1 分数和混淆矩阵。为了解决类不平衡、过拟合和数据偏倚等问题,应采用交叉验证、规范化、数据增强和重采样等技术。
Ayesha Saleem 热衷于通过有意义的内容创作、文案写作、电子邮件营销、SEO 写作、社交媒体营销和创意写作来重塑品牌。
更多相关话题
BigData London 会议和展览的主要收获
原文:
www.kdnuggets.com/2022/10/key-takeaways-bigdata-london-conference-exhibition.html

来源: BigDataLDN
作为 KDNuggets 团队的一员,我有机会参加了 9 月 20-21 日的 BigData LDN 会议和展览。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
这是英国的一场免费数据与分析会议和展览,由领先的数据和分析专家主办。共有 100 家展商、12 个演讲厅和 200 位演讲者——这无疑是一天忙碌的活动!
《HumblePi》的作者,Matt Parker——一位澳大利亚休闲数学家、作者、喜剧演员和 YouTube 名人,作为主旨演讲者出席了此次活动。这真的很酷!
我有机会与几位人士交流并获取他们公司的更多信息,让我们开始吧。
DataOps
我有机会与 DataOps 的副总裁、宣传与支持部的Patrick Connolly交谈。他说了以下内容……
DataOps 是应用于数据的 DevOps,关注灵活性、敏捷性和控制。公司相对较新,成立于 2018 年,旨在减少洞察时间,并加快客户的价值实现时间。2019 年,他们明确关注 DevOps 的真实原则,并从 IoT 时间序列数据中提取价值,以开发围绕 DataOps 的技术。
随后,他们公开分享了他们的 DataOps 理念,您可以在TrueDataOps找到这些内容,他们还发布了 DataOps for Snowflake 平台。
DataOps 的支柱包括:
-
ELT 及其精神
-
持续集成/持续部署(CI/CD)
-
代码设计与可维护性
-
环境管理
-
治理与变更控制
-
自动化测试与监控
-
协作与自助服务
客户通常面临相同的问题:多个数据管道自然带来了复杂性。DataOps 试图实现彼此匹配的节奏,重点关注敏捷性和治理。他们希望创建解决方案,以便公司和利益相关者能够获得更好、更快和更高质量的数据,同时不妥协于治理和数据安全。
DataOps 的联合创始人贾斯廷·穆伦和盖·亚当斯与其他 DataOps 先锋合作编写了《DataOps for Dummies》一书——我有幸免费获得了这本书!
如果你想了解如何在 SnowFlake 上构建、测试和部署应用程序,可以访问 DataOps 网站。
麦克拉伦赛车
安德鲁·麦克赫奇,麦克拉伦赛车的高级数据科学家也在场。我没有机会与他亲自交谈,但他确实进行了问答环节,我得以提出问题。
你可以想象他的研讨会有多么繁忙:麦克拉伦一级方程式团队如何利用数据加速性能。人们几乎挤在一起,但理解数据和一级方程式的概念非常有趣。
他告诉我们,作为高级数据科学家,他面临的最大挑战之一是数据的缺乏。赛车运动并不频繁发生,所以当它发生时,能用的数据非常有限。而且一旦他们整理这些数据,处理过程非常漫长,以至于特定的赛车赛季已经结束,在当时没有价值。团队可以在下一个赛季使用这些数据,但这仍然使当前的过程更加困难。
他还提到,团队并不能访问所有的数据。他们从特定的网站获取数据,大多数网站对公众开放。然而,广播公司屏幕上显示的信息,比如圈速和档位——这些数据麦克拉伦团队无法获取。因此,团队有其他成员观看比赛并记录每一个统计数据,以便整理数据。
数据团队规模不大,因此在每场比赛期间,团队面临很大的压力。
如果你想了解更多关于麦克拉伦的信息,请查看他们的 网站。
伊登·史密斯集团
我还有幸与 杰兹·克拉克,伊登·史密斯的首席执行官交谈。他们提供数据人员配备、数据咨询、教育和培训。他们在技术行业拥有超过 20 年的人员配备经验,随后逐渐扩展到数据咨询。
随着公司业务的增长,他们发现了一个新市场——教育和培训。他们提供一个名为Nurture的教育项目,该项目曾入围 2020 年和 2021 年的 Data IQ 奖‘最佳发展项目’,后来他们还推出了Nurture Plus和Nourish。
如果你对他们的实习和其他形式的教育感兴趣,可以查看这里:edensmith.group/。如果你在英国,并且寻找技术领域的新机会,可以查看他们的实时职位:esjobs.powerappsportals.com/
总结
现场有多家公司参展,如微软、Databricks、Snowflake 等。这一天极具洞察力,我建立了很多联系,了解了不同的公司,也学到了更多关于新工具和软件的知识
我强烈建议参加这类会议和展览,以深入了解数据的世界、范式转变以及如何成为未来的一部分
Nisha Arya 是一位数据科学家和自由技术写作人。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何促进人类寿命的延续。她是一个热心的学习者,寻求拓宽技术知识和写作技能,同时帮助指导他人。
更多相关话题
为什么使用 k 折交叉验证?

编辑提供的图片
泛化是一个在机器学习讨论中经常出现的术语。它指的是模型适应新数据的能力以及如何有效地使用各种输入。可以理解的是,如果将新的未见数据输入模型中,只要这些未见数据与训练数据具有类似的特征,模型会表现良好。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 部门
对我们人类来说,泛化是容易的,但对机器学习模型来说可能具有挑战性。这就是交叉验证发挥作用的地方。
交叉验证
你可能会看到交叉验证也被称为轮换估计和/或样本外测试。交叉验证的总体目标是将其作为工具来评估机器学习模型,通过在不同的输入数据子集上训练多个模型。
交叉验证可以用来检测模型的过拟合,这意味着模型在新输入数据中无法有效地泛化模式和相似性。
一个典型的交叉验证工作流程
为了执行交叉验证,通常采取以下步骤:
-
将数据集拆分为训练数据和测试数据
-
参数将经过交叉验证测试,以确定哪些参数是最佳选择。
-
这些参数将被应用到模型中以进行重新训练
-
最终评估将会发生,这将取决于是否需要再次进行周期,这取决于模型的准确性和泛化水平。
有不同类型的交叉验证技术
-
保留法
-
K 折
-
留一法
-
留出法
然而,我们将特别关注 K 折。
K 折交叉验证
K 折交叉验证是指将数据集拆分为 K 个折,并用来评估模型在面对新数据时的能力。K 表示数据样本被拆分成的组数。例如,如果看到 k 值为 5,我们可以称之为 5 折交叉验证。在过程中,每个折在某一时刻被用作测试集。
K 折交叉验证过程:
-
选择你的 k 值
-
将数据集拆分为 k 折。
-
从使用你的 k-1 折作为测试数据集和其余折作为训练数据集开始
-
在训练数据集上训练模型,并在测试数据集上验证模型
-
保存验证分数
-
重复步骤 3 到 5,但改变你的 k 测试数据集的值。比如我们在第一轮选择 k-1 作为测试数据集,接着在下一轮选择 k-2 作为测试数据集。
-
到最后,你将会在每一个折上验证模型。
-
对第 5 步中产生的结果进行平均,以总结模型的技能。
你可以使用 sklearn.model_selection.KFold 轻松实现这一点
import numpy as np
from sklearn.model_selection import KFold
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4])
kf = KFold(n_splits=2)
for train_index, test_index in kf.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
为什么我应该使用 K 折交叉验证?
我将分解为什么你应该使用 K 折交叉验证的原因
利用你的数据
我们有很多现成的数据,可以解释很多事情并帮助我们识别隐藏的模式。然而,如果我们只有一个小数据集,将其分成 80:20 的训练和测试数据集似乎对我们帮助不大。
然而,当使用 K 折交叉验证时,数据的所有部分都可以作为测试数据的一部分使用。这样,我们小数据集中的所有数据都可以用于训练和测试,从而更好地评估模型的性能。
更多可用的指标来帮助评估
让我们回到将数据集拆分为 80:20 比例的训练和测试的例子——这只提供一个结果用于评估模型。我们不能确定这个结果的准确性,是由于偶然、偏差程度,还是它确实表现良好。
然而,当使用 k 折交叉验证时,我们有更多的模型会产生更多的结果。例如,如果我们选择 k 值为 10,我们将有 10 个结果用于评估模型的性能。
如果我们使用准确率作为衡量标准;拥有 10 个不同的准确率结果,其中所有数据都用于测试阶段,总是比使用一个由训练-测试拆分产生的准确率结果更好,更可靠——因为不是所有数据都在测试阶段使用过。
如果准确率输出为 94.0、92.8、93.0、97.0 和 94.5 在 5 折交叉验证中,那么相比于训练-测试拆分中 93.0 的准确率,你会对模型的性能有更多的信任和信心。这向我们证明了我们的算法在泛化和积极学习,并提供了一致可靠的输出。
使用相关数据获得更好的性能
在随机训练-测试划分中,我们假设数据输入是独立的。让我们进一步扩展这个问题。假设我们在一个语音识别数据集中使用随机训练-测试划分,这些讲者都是来自伦敦的英国英语讲者。共有 5 位讲者,每位讲者有 250 个录音。模型进行随机训练-测试划分后,训练集和测试集都会来自同一位讲者,并且这些录音会说相同的对话。
是的,这确实提高了准确性并增强了算法的性能,但是,当引入新讲者时,模型的表现如何?那时模型的表现怎么样?
使用 K 折交叉验证将允许你训练 5 个不同的模型,每个模型使用一个讲者作为测试数据集,其余的作为训练数据集。通过这种方式,我们不仅可以评估模型的性能,还可以使模型在新讲者上的表现更好,并且可以部署到生产中,为其他任务提供类似的性能。
为什么 10 是一个如此理想的 k 值?
选择合适的 k 值很重要,因为它会影响你的准确性、方差、偏差,并可能导致对模型整体性能的误解。
选择 k 值的最简单方法是将其等同于你的‘n’值,也称为留一法交叉验证。n 代表数据集的大小,这样每个测试样本都有机会作为测试数据或保留数据使用。
然而,通过数据科学家、机器学习工程师和研究人员的各种实验,他们发现选择 k 值为 10 能够提供较低的偏差和适中的方差。
Kuhn & Johnson 在他们的书籍 应用预测建模 中讨论了他们选择 k 值的方法。
“k 的选择通常是 5 或 10,但没有正式的规则。随着 k 值的增大,训练集和重采样子集之间的大小差异会变小。随着这种差异的减少,该技术的偏差也会变小(即 k=10 时的偏差比 k=5 时小)。在这种情况下,偏差是估计值与实际性能值之间的差异”
让我们用一个例子来说明这个背景:
假设我们有一个数据集,其中 N = 100
-
如果我们选择 k 值 = 2,我们的子集大小 = 50,差异 = 50
-
如果我们选择 k 值 = 4,我们的子集大小 = 75,差异 = 25
-
如果我们选择 k 值 = 10,我们的子集大小 = 90,差异 = 10
因此,随着 k 值的增加,原始数据集与交叉验证子集之间的差异变得更小。
还指出,选择 k=10 在计算上更为高效,因为 k 值越大,计算上的可行性越差。小值也被认为在计算上高效,但它们可能会导致较高的偏差。
结论
交叉验证是每个数据科学家都应该使用或至少非常熟练的一个重要工具。它可以让你更好地利用所有数据,同时为数据科学家、机器学习工程师和研究人员提供对算法性能的更好理解。
对模型有信心对于未来的部署和信任模型的有效性和表现至关重要。
Nisha Arya 是一名数据科学家和自由技术作家。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探索人工智能如何/可以促进人类寿命的延续。她是一个热衷学习的人,寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关主题
使用 Poe 提升 Midjourney 提示的技巧

Poe 是一个通过统一界面提供访问众多聊天机器人和大型语言模型的平台 — 同时或单独使用 — 除了一些常见的 LLM,如 ChatGPT、Llama 等,Poe 还访问了许多定制的聊天机器人,例如那些将你的输入转换成表情符号;对你提出的问题不感兴趣(真的);认为你做的任何事都是犯罪;等等。该网站有免费和订阅层级。Poe 是由 Quora 创建的。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
Midjourney 是一个付费的 AI 图像生成服务。可以说是目前生成图像质量最高的最强大模型,优化 Midjourney 提示并获得最佳结果本身就是一门艺术,通常需要许多迭代和大量时间。这就是 Poe 的用武之地。
Poe 上比较受欢迎的机器人之一是 Midjourney 机器人。不,机器人并不提供对 Midjourney 模型的访问;而是将你的粗略提示作为输入,重新编写以增加从一开始就生成可接受图像的机会。
在本文中,我们将尝试这个过程的几次迭代并比较结果,从而让我们了解这个 Poe 机器人如何让我们从一开始就改善图像。
对于这些比较,作者仅执行了下方显示的比较,为每个提示执行了确切的一次图像生成运行,并没有以任何方式挑选结果。所有主观判断都由作者单独做出。请注意 Poe 可能在其新提示中附加的任何额外 Midjourney 参数,以便最好地比较类似的果实。我已经在所有提示中添加了--ar 16:9,因为 16:9 是唯一可接受的图像比例,故事到此为止。
旧城耶路撒冷
让我们从地球上最具标志性和易于识别的地方之一开始:旧城耶路撒冷。我并不追求任何特定的地标,只是想要一张代表和类似旧城独特风貌的图像。
我的基本提示和结果:
旧城耶路撒冷的抽象艺术渲染 --ar 16:9
作者使用 Midjourney 生成的图像
Poe 辅助的提示和结果:
这是一张耶路撒冷旧城的抽象艺术渲染的彩色照片。主题是对古老城市的生动和动态的解读,捕捉了其丰富的历史和精神意义。照片展示了一系列大胆的笔触和鲜艳的色彩,唤起了一种能量和动感的感觉。环境中弥漫着神秘的气息,狭窄的街道、古老的城墙和繁忙的市场都融入了一种和谐的混沌之中。相机设置是实验性的和前卫的,突破了传统摄影的界限。使用了 Hasselblad X1D II 50C,相配以 Lensbaby Velvet 56 镜头,实现了创意模糊和柔焦效果。采用了双重曝光技术和有意的相机运动,为图像增添了一种空灵和梦幻的质量。这个场景的不太可能的合作伙伴可能是亚历杭德罗·冈萨雷斯·伊纳里图,以其沉浸式叙事而闻名的远见导演;埃曼纽尔·鲁贝斯基,以其诗意的视觉效果而著称的著名摄影师;大卫·拉查佩尔,以其超现实和充满活力的构图而著名的挑衅性摄影师;以及艾瑞斯·范·赫佩,以其未来主义和雕塑性设计而受到赞誉的创新时装设计师 --ar 16:9
作者使用 Midjourney 和 Poe 生成的图像
首先,看看 Poe 生成的提示有多详细。查看一些细节,包括有争议的“风格”措辞。
现在,你可以把我蒙上眼睛,我或多或少能够在耶路撒冷旧城中导航,我可以告诉你,生成的图像中没有任何实际的位置。但我们不能用这个标准来判断生成的图像;相反,我们必须使用主观的艺术价值标准。
注意:虽然你可以对讨论 AI 生成图像时使用“艺术价值”(或“艺术”任何东西)这个词有所争论,但我认为这是在这种情况下表达我想要传达的内容的最佳词汇。生气吗?想象一下我写了“模仿的艺术价值”。仍然生气吗?好吧,AI 生成的图像已经存在,它们不会消失,虽然合理的人们可以对我们如何称呼 AI 图像生成的过程和结果持有不同意见,但这不是我现在想讨论的内容。我只是展示了那些倾向于尝试改进其 AI 图像生成提示的人可以如何尝试。
我发现原始图像有点平淡,除了初次浏览外没有真正引起我注意的有趣图像。第二轮,在 Poe 的帮助下,更加丰富多彩,至少在我看来,值得进一步检视。美在于观察者的眼中,因此这里的观点会有所不同,但我在两种情况下都选择了右上角的图像作为“最佳”代表。我对两者都进行了放大处理,并在下方分享。

使用基本提示生成的 Midjourney 图像的“最佳”图像
使用 Poe 提示生成的 Midjourney 图像的“最佳”图像
再次说明,这完全是主观的,但最终我对使用 Poe 的提示所获得的“最佳”结果印象更深刻。总的来说,我发现 Poe 的提示生成的图像总体上比原始提示的图像要好,我同样认为 Poe 的最佳效果优于我原始提示的最佳效果。
专业头像
我们尝试一些不同的东西,生成一些包含人的图像。我们来制作一些专业头像。
我的简洁提示:
街头的职业女性头像
作者使用 Midjourney 生成的图像
比较一下这些与 Poe 扩展提示的效果:
一张色彩照片,展现街头女性的职业头像。被摄者是一位自信且稳重的女性,在城市背景中散发着职业和优雅。她的头像捕捉了她灿烂的笑容和温暖的个性,展示了她的亲和力和职业素养。环境是一条繁忙的城市街道,背景中的行人和交通模糊,突出了女性作为焦点。相机设置经过精心选择,以突出她的特征并捕捉她的本质。使用了 Nikon D850,相机配备了如 Nikon AF-S NIKKOR 85mm f/1.4G 的肖像镜头,以实现浅景深并创造出令人愉悦的虚化效果。照片采用平衡的构图,通过周围建筑的引导线增加视觉兴趣。与这一场景不太可能合作的有:以细腻叙事著称的著名导演索非亚·科波拉、以氛围光效著称的著名摄影师达留斯·康第、以引人入胜的肖像摄影著称的标志性摄影师安妮·莱博维茨,以及以永恒和可持续设计闻名的影响力时尚设计师斯特拉·麦卡特尼。
作者使用 Midjourney 和 Poe 生成的图像
再次比较提示措辞的细节。现在,撇开所有生成的女性都是白人的事实,这是一个值得关注的讨论,以下是我认为的 2 张“最佳”图像,每个提示各一张。
注意:为了透明起见,由于好奇心,我在之后运行了 4 次 Poe 提示,在生成的 16 个额外的不存在的女性中,有 5 个看起来不是白人。随意处理这些信息,但我认为尝试并报告结果是值得的。
"最佳"图像,由 Midjourney 使用基本提示生成

"最佳"图像,由 Midjourney 使用 Poe 的提示生成
再次,我发现 Poe 辅助的提示更具现实感。它们似乎有更“自然”的感觉,确定它们是 AI 生成的比基本提示图像需要更长时间。光线和户外方面似乎看起来更自然,尽管差距不大,但我会说稍微好一点。
结论
也许这篇文章应该叫做 "强大的 Midjourney 提示与 Poe???" 我认为是否这个 Poe 机器人能帮助你更好地制定图像生成提示还不确定——如果可以,那效果如何?——虽然这肯定无法通过仅仅一对例子解决。我倾向于喜欢 Poe 辅助的最佳提示,而不是基本提示,但这仍然是主观的,且基于非常少的数据点。也许应该得出的结论是,提示工程是一个复杂且难以捉摸的领域,艺术(无论是 真实的 还是 AI 生成的)过于主观,难以确定某些东西是否优于其他东西。
试试 Poe 进行自己的图像生成项目,看看效果如何。
马修·梅约 (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 的总编辑,Matthew 旨在让复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、机器学习算法以及探索新兴的 AI。他的使命是让数据科学社区的知识民主化。Matthew 从 6 岁开始编程。
更多相关话题
启动你的数据职业生涯!前线的建议
原文:
www.kdnuggets.com/2018/12/kick-start-your-data-career.html
评论
由 Vaishali Lambe,数据科学家
市场上有许多需求的职位——数据分析师 / 数据分析 / 数据可视化 / 机器学习 / 深度学习 / 数据科学家 / 数据分析中的软件工程 / 数据科学 / 机器学习、大数据工程师等。职位名称可能会根据你的技能专长和工作经验不断变化。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
由于许多人准备将职业投入其中,我将通过这个博客系列提供非常有趣和实用的小贴士,这将帮助学生们启动他们的数据职业生涯。
开始你的数据职业生涯小贴士 #1
成为一名探索者 [在学术领域] - 探索和学习时不要限制自己的领域。停止担心 GPA [分数]

我会说,如果你正在攻读硕士或博士学位,你很勇敢。你展现了学习和成长的勇气。那么,这一步之后会发生什么问题呢?一旦你开始学习,你会有很多作业,很多自学和探索的内容,进行研究等。学生们开始担心按时完成作业以获得最高分,完成作业的百分之百以获得最高分,作业的准确性以获得最高分。这反过来会影响他们的 GPA。因此,他们开始忽视学习的事实,奔波于得分和获得好 GPA。我想告诉你,如果你担心获得最高分,为此请求别人的作业来完成你的作业,这只会给你带来分数上的回报。你会在找工作时意识到其后果。如果你的 GPA 维持在 3.0 或更高[具体标准取决于你的大学],你就可以了。GPA 并不重要,重要的是你获得了多少知识。GPA 只是一个数字,如果你符合市场上任何工作申请的最低要求,你就做得很好。如果你遵循学习和获得知识,你一定会获得好的成绩。
所以,不要在学术期间限制自己探索事物。把自己当作一张空白的画布,在学术中尽可能多地探索这个领域。这是你作为新手探索的时间。不要犹豫去旁听必修学分之外的课程。大学的最佳部分在于,你可以免费旁听课程。有时候你可能需要接触特定的教授以旁听他的课程。旁听也能让你获得知识。如果你不能旁听某门课程,我相信你应该认识正在上那门课的其他人。于是,接触并询问那位朋友课程的情况,他们在学习什么。这样你将了解周围的情况,市场上需要哪些技能,以及其他领域的动态。一旦你开始探索,你会了解到更多,并开始发现自己的兴趣领域。
专门谈论数据——尽可能选修/审核你们大学提供的与数据分析、数据挖掘、机器学习、深度学习、数据科学、认知、数据可视化、编程[R、python、Scala等]、大数据、商业智能、概率、统计等相关的课程。不要只是为了完成学分、毕业和获得学位而上课。你已经足够成熟,能够找到适合你的方法。尽量找时间,尽量自己完成作业,不要担心分数。如果你真的要担心一些事情,那就担心是否真正理解了概念,担心是否有效利用了大学时间,担心是否及时帮助了自己。所以,请,“做一个探索者!!”
启动你的数据职业生涯技巧#2
利用周围的设施 – 明智地利用大学提供的设施

注册大学课程后,你可以获得许多免费的设施:
-
免费 Wi-Fi [24X7]
-
开放图书馆 [24 X7],可以访问大量书籍和资料
-
免费的个人/小组学习室
-
免费使用大量软件和安装工具
-
参加大学内发生的各种技术活动[雇主会来展示他们的案例研究以及他们在寻找什么]
-
参观一些雇主以了解他们的工作文化
-
访问打印机、扫描仪、礼堂、白板
还有很多……
充分利用你所获得的每一项设施。你可以免费学习和探索很多工具。小组学习室在你做项目、准备演讲时帮助你并指导团队合作。参观雇主的工作场所会激励你更加努力,因为那可能是你梦想中的工作。并不是因为这些设施你就能找到工作,而是理解大学提供的每项设施的重要性。利用这些设施的方式完全取决于你。
既然我们要成为探索者,同时利用大学提供的设施也很重要。大学的课程并不限制你学习特定的学科,很多设施都是为了让你探索和学习更多。
你们中的一些人可能不喜欢一直学习和上课[一直单调的生活对每个人来说都很困难],所以大学也提供了一些额外的娱乐设施,比如——
-
电影之夜
-
文化活动和庆祝活动
-
免费的酒吧或迪斯科
-
音乐活动
-
周末旅游/旅行
-
社会公益活动,如[END 7 计划等]
-
游戏之夜/运动
-
各种俱乐部,如徒步旅行、攀岩等
在学习的同时也要利用这些机会,但你已经足够成熟,懂得你愿意在这些活动上花多少时间。这些非技术活动帮助你交朋友,拥有社交生活,提供了领导或组织活动的机会。因此,你获得的每一项资源都有其自身的目的。你的工作就是弄清楚每一项资源的优先级。你是学生,你的工作是正确利用大学提供的任何资源。
具体到数据领域,尽可能多地学习和探索在大学中接触到的工具和软件。阅读关于统计学、概率论、数学、机器学习等方面的书籍。将你未来可能需要参考的书页打印出来,或做笔记以备查阅。利用小组学习室讨论和理解你的数据,进行演示。参加公司研讨会或演讲,了解他们的案例研究。如果数据俱乐部不存在,可以组建一个,并组织活动/会议。参加竞赛,在大学中很容易组成团队,因为你会发现班级中有很多对你感兴趣的同学。好好利用大学提供的资源。
启动数据职业生涯小贴士 #3
****寻找、建立网络和展示——寻找群体/个人,与[大学及更远]的人联系,展示你的才华/兴趣
进入你感兴趣的领域的另一个非常重要的方面是“寻找同样充满热情的人,建立网络并展示你的才华/兴趣”。这是一个困难但漫长且持续的过程,需要与你的教育并行进行。

我们已经讨论过在大学内部建立网络的一个方面,但我将在本博客中对此进行进一步详细说明。
由于大学举办和组织大量技术活动,重要的是要与参与活动的人建立联系。不必与每个人联系,但重要的是要发起沟通并展示你的热情。
许多雇主会访问大学校园,展示他们的案例研究和他们在行业中所做的工作。与他们见面并打招呼,询问如果你发现对你所在领域有兴趣的问题,并讨论你的想法,这点很重要。
有时大学会筛选简历,带一些学生去展示几家雇主的工作文化,此时也很重要展示勇气,自信地展示自己并建立关系。
除了大学活动,还有其他方式可以进行网络建立和联系。例如,你可以参加数据领域的技术聚会[每个地区都有很多可用的],出席并与人互动,询问他们在做什么,展示你可以做什么贡献。有几个专门针对 Kaggle 竞赛的聚会,这是组建团队和合作的好方式。
如果有时你不想参加技术见面会,你也可以参加非技术性的见面会,比如游戏、徒步旅行、电影俱乐部、周日早午餐,这些联系可以变得非常有益,并使你对你尝试建立职业的领域有更多了解。
除了见面会,还有像开放数据科学、机器学习、机器人和人工智能等会议,以及其他大学活动——如麻省理工学院、哈佛等。如果你无法购买票,作为学生的好处是这些会议会促进学生并提供票务折扣,或者你可以加入他们作为志愿者。这样你可以再次聆听并与许多领袖建立联系,了解他们在数据领域的工作。
参加黑客马拉松 – 这也给你一个机会去学习更多有创意的工作,并允许你参与并展示你的才华。
所以,我认为有很多方法可以找到你所寻找的东西,你需要做的只是始终寻求你想要的东西。与人接触并提出问题是很重要的。始终记住,没有问题是对或错的,可能有时它们可能简单或困难。但不要犹豫去自己寻找答案或询问别人。不要为了找到任何目的而与任何人交谈,你永远不知道那个联系可能在你职业转型中进一步帮助你。所以,请“寻求、建立联系和展示”。
启动你的数据职业生涯提示 #4
要勤奋、坚持和耐心 – 永远坚持并有耐心去实现你想要的东西。努力工作总是会得到回报。

我们讨论了很多关于探索、学习、建立联系、展示知识或兴趣的话题。尽管这些关键词听起来很简单,但这实际上是一个非常艰难且持续的过程。大多数人都有在过程中放弃的倾向。我认为这不是他们的错,而是一种态度或人类倾向,每个人都希望一夜之间获得成功和名声。令人痛苦的是,这种情况从未发生过。我们总是看到一个人的成功,但从未看到他们获得成功或名声的时间有多长。也许有一些例外,他们在年轻时成为了亿万富翁,但即便如此,生活对于他们而言也不容易,尽管他们取得了如此多的成功,但维持、消化和进一步发展这种成功仍然是一个重要因素。
如我们所知,数据领域目前正处于繁荣期,市场上有很多类似的工作机会,薪水也很丰厚。毫无疑问,每个人都希望在这个领域建立自己的职业。因此,这个领域竞争激烈。考虑到我们现在的职位申请流程——它并不高效,几乎是过时的,导致人们很难获得面试机会。许多简历被自动筛选系统过滤掉。因此,学生可能会发现获得面试机会有挑战,但保持耐心和坚持是重要的。如果你真的想进入某个特定职位,不要失去兴趣和耐心。继续通过在线招聘网站申请工作。与你网络上的人总是要递交你的简历。坚持下去,不放弃,你一定会得到你想要的。
职业变换或技术变换虽然听起来很简单,但在学习方面很容易,但在获得第一个工作机会时总是很难。
我记得,当我开始寻找数据科学相关工作时,我的第一个担忧是,为什么他们需要博士候选人?学位怎么会成为任何职位的筛选条件?经验为什么没有优先于学位?毫无疑问,你现在或以后也会面临类似的情况。但我有一个非常好的品质,那就是“我从不放弃”。我坚持不懈地申请工作——所有的平台——LinkedIn、Glassdoor 或 Monster [无论你觉得哪个,或者全部]。最后终于得到了一个机会。
如果你正在攻读硕士或博士学位,必须努力工作并进入相同的兴趣领域。作为移民或在该领域新人的挑战可能更多,但这些三个品质确实有助于克服这些挑战。所以,继续申请。在付出努力之前妥协是不好的。要有耐心和坚持。我相信,总有一天你会像我一样顺利实现你的目标。
祝你求职顺利!
数据职业启动小贴士 #5
脱颖而出——找出你的优势,并利用这些优势在你感兴趣的任何领域中脱颖而出。

你可能听到过你遇到的人/网络/接触的很多关于如何在你希望建立职业的领域中脱颖而出的建议。
一般性的问题——我需要做些什么才能在数据领域的申请者中脱颖而出?一个人应该具备什么?答案并不简单,但显然,自我分析优点并具备创造力和聪明才智确实有助于脱颖而出。
一个人需要找出自己擅长什么。这可能是你的写作、沟通或领导技能。或者你可能更具创新性或创造力。答案是,每种品质都会为你在感兴趣的领域中脱颖而出提供机会。
如果你想展示自己确实拥有所有必需的技能集,但还有其他额外的东西使你的简历相比其他申请者更强,可以是你的博客、主办和组织交流会/活动、公众演讲、或是做自己的项目。所有这些品质都能帮助你在普通求职者中脱颖而出。
所以,记住每个品质都有其荣耀和好处,你需要理解如何利用这些来在特定领域建立你的职业生涯。
具体谈谈数据,你可能会发现很多人做并使用 Kaggle 项目,但你可以相信并展示自己有趣的项目,而不仅仅是学术项目,以展示你的技能和创造力。你可能会发现很多人参加技术交流会,但在这些交流会上增加价值、展示知识、分享知识,以及主办和组织这些活动,可能会使你从其他人中脱颖而出。你可能会看到很多人跟随各种领导者来获取知识,但只有少数人相信分享知识和提升技能。你需要做的就是找出你希望如何脱颖而出。
我见过很多人根据数据职位的需求来修改他们的简历,这真的有必要吗?答案是,对于自动解析系统来说,有时确实是需要的,但相信我,如果你在某个特定领域或方向上表现出色,这些障碍影响不大。制作简历的创意是另一个独立的话题,这篇博客不会详细探讨,但更重要的因素是“找出你的优势并利用这些优势在就业市场上脱颖而出”。希望你在跟进???。记住,“不是每个人天生聪明,但人们肯定会学会变聪明”。
简历:Vaishali Lambe 获得了计算机系统硕士学位,专注于数据科学,目前在一家医疗保健公司担任数据科学家。拥有 8 年的 IT 工作经验,曾在印度、新西兰和美国国际工作。
原文。转载已获许可。
相关内容:
-
2019 年每个准数据科学家应设定的 6 个目标
-
5 条大数据和数据科学的职业路径解释
-
5 个关键数据科学职位市场趋势
更多关于此话题
启动你的自然语言处理之旅,这里有 5 门免费课程
原文:
www.kdnuggets.com/kickstart-your-nlp-journey-with-these-5-free-courses

图片由作者提供
当你准备好学习新知识时,一个重要的考虑因素就是这将花费你多少。考虑到目前的世界和生活成本,我们不怪你。在不查看费用的情况下想要提升职业技能是很困难的。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
话虽如此,对于那些正在研究自然语言处理(NLP),想了解更多,或者想将职业方向转向该领域的人——这篇博客适合你。
我将介绍 5 门掌握 NLP 的课程——而你不需要花费一分钱!
自然语言处理入门
级别: 初级
有些人可能对数据科学和自然语言处理领域完全陌生,因此获得该领域的良好基础是你的首要任务。
由英国坎特伯雷大学提供的一个 6 周课程,教授计算语言学的核心技术以及使之成为可能的认知科学和我们需要正确使用它的伦理。
由 3 个部分组成:
-
模块 1. 为什么使用文本分析?
-
模块 2. 处理文本数据
-
模块 3. 文本分类
这门课程是自学进度的,是 Python 文本分析专业证书 的第一部分。如果你想要继续学习,你总是可以选择进阶,或者将其作为独立课程。
准备好尝试一下了吗?
链接: 自然语言处理入门
可视化自然语言处理
级别: 中级
作为上述课程的延续,坎特伯雷大学提供了 NLP 入门的第二部分,6 周的课程将扩展你对计算语言学核心技术的知识,通过不同的案例研究并能够可视化你的输出。
由 3 个部分组成,你将深入学习:
-
模块 1. 文本相似度
-
模块 2. 可视化文本分析
-
模块 3. 将文本分析应用于新领域
完成了第一部分,准备进入第二部分了吗?
链接:可视化自然语言处理
NLP 简介
级别:初级
不能承诺参加 6 周的课程并且希望快速获得相同的知识?没问题 - 我们可以满足你的需求。
Udemy 提供了一门 NLP 入门课程,该课程将为你提供 NLP 的基础知识,你将学习:
-
为什么 NLP 很重要
-
处理 NLP 的复杂性
-
NLP 的商业应用场景
-
不同类型的 NLP 问题
-
解决 NLP 问题的方法
-
应用机器学习概念
-
词嵌入
在更短的时间内,你将能够通过本课程掌握自然语言处理(NLP),并且为其他机会开启大门,如果你继续进步,NLP 将推动你的职业生涯。
感兴趣吗?
链接:NLP 入门
在 TensorFlow 中进行自然语言处理
级别:中级
这是一门由DeepLearning.AI提供的课程,这是一家教育科技公司,致力于通过世界级教育帮助人们构建 AI 驱动的未来。该课程为中级水平,大约需要 24 小时完成 - 自己安排时间!
你将学习 TensorFlow 中的 NLP,这是一种非常流行的框架,以及处理文本,包括分词,并在 TensorFlow 中应用 RNNs、GRUs 和 LSTMs。
本课程分为 4 个模块:
-
文本情感分析
-
词嵌入
-
序列模型
-
序列模型与文学
该课程是DeepLearning.AI TensorFlow 开发者专业证书的一部分,因此如果你想进步 - 你可以选择这条路径。
听起来不错,对吧?
使用 BERT 进行自然语言处理(NLP)
级别:中级
如果你刚刚进入 NLP 的世界,你可能听说过或没听说过谷歌的 NLP 算法 BERT。如果你正在研究 NLP,你一定要了解它。
这个免费课程由 Udemy 提供,是一个包含三个部分的一小时课程,你将深入学习:
-
第一部分:数据预处理
-
第二部分:构建 BERT 模型
-
第三部分:训练和评估 BERT 模型
你将学习如何使用来自 IMDB 的数据和一个低代码的 Python 库 Ktrain 对电影评论进行语义分析。你将在 Google Colab 中学习所有这些!
有一个小时的空闲时间吗?
总结
当你开始做新事物时,首先试探水温总是好的。参加免费课程可以让你了解该领域的情况,以及是否是你希望继续发展的方向。
我希望这篇博客能帮到你!
Nisha Arya 是一位数据科学家、自由技术作家,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议、教程和基于理论的数据科学知识。Nisha 涵盖了广泛的话题,并希望探索人工智能如何有利于人类寿命的不同方式。作为一个热衷学习的人,Nisha 旨在扩展她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
什么是 K-Means 聚类及其算法如何工作?
原文:
www.kdnuggets.com/2023/05/kmeans-clustering-algorithm-work.html

图片来自 Bing 图像生成器
介绍
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
从根本上说,机器学习算法有四种类型;监督算法、半监督算法、无监督算法和强化学习算法。监督算法是那些在具有标签的数据上工作的算法。半监督算法是数据的一部分有标签,另一部分没有标签。无监督算法是数据没有标签的情况。强化学习是一种机器学习类型,其中有一个代理通过试错来实现特定目标。当代理做对时会获得奖励,做错时会受到惩罚。
我们的重点是无监督的机器学习算法,特别是 K-Means 聚类算法。
K-Means 聚类
K-Means 是一种无监督的机器学习算法,它将数据点分配到 K 个簇之一。如前所述,无监督意味着数据没有像监督学习中那样的组标签。该算法观察数据中的模式,并利用这些模式将每个数据点放入具有相似特征的组中。当然,还有其他解决聚类问题的算法,如 DBSCAN、层次聚类、KNN 等,但与其他方法相比,K-Means 相对更受欢迎。
K 代表将数据点划分为的不同分组。如果 K 是 3,那么数据点将被分为 3 个簇。如果是 5,那么我们将有 5 个簇。稍后会详细介绍。
K-Means 的应用
我们可以通过多种方式应用聚类来解决现实世界的问题。以下是一些应用示例:
-
客户聚类:公司可以使用聚类来将客户分组,以便更好地进行目标营销和了解客户基础。
-
文档分类:根据内容中的主题或关键词对文档进行分组。
-
图像分割:在进行图像识别之前,对图像像素进行聚类。
-
根据学生表现进行分组:你可以将他们分为顶尖表现者、平均表现者,并利用这些分组来改善学习体验。
K-Means 算法如何工作
算法首先进行初始迭代,其中数据点被随机分配到各组,计算出每组的中心点(称为质心)。计算每个数据点到质心的欧氏距离,如果某点到某个质心的距离大于到另一个质心的距离,则该点会被重新分配到“另一个”质心。当这种情况发生时,算法将进行另一轮迭代,直到所有分组的组内方差达到最小。
我们所说的“组内最小变异性”是指组内观察值的特征应尽可能相似。
想象一个包含两个变量的数据集,如下所示。这些变量可以是个人的身高和体重。如果我们有一个第三个变量,如年龄,那我们就会有一个 3-D 图,但现在我们还是用下面的 2-D 图。

步骤 1:初始化
从上面的图中我们可以看到三个簇。在拟合模型时,我们可以随机选择 k=3。这意味着我们寻求将数据点分为三个分组。
在初始迭代中,下面的示例中 K 个质心是随机选择的。

你可以指定算法将数据点分组为的 K 个簇的数量,但还有一种更好的方法。我们稍后会详细讲解如何选择 K。
步骤 2:将点分配给 K 个质心中的一个
一旦选择了质心,每个数据点将基于该点到最近质心的欧氏距离被分配到最近的质心。这可能会导致下图所示的分组。
注意,除了欧氏距离外,还可以使用其他类型的距离测量方法,如曼哈顿距离、斯皮尔曼相关距离和皮尔逊相关距离,但经典的距离测量方法是欧氏距离和曼哈顿距离。
步骤 3:重新计算质心
在第一次分组后,新的中心点会重新计算,这会要求重新分配点。下面的图示例显示了新的分组可能是什么样的,并注意到一些点已经移动到新的簇中。
迭代
步骤 2 和 3 的过程会重复,直到数据点不再重新分配或达到最大迭代次数。最终的分组结果如下。
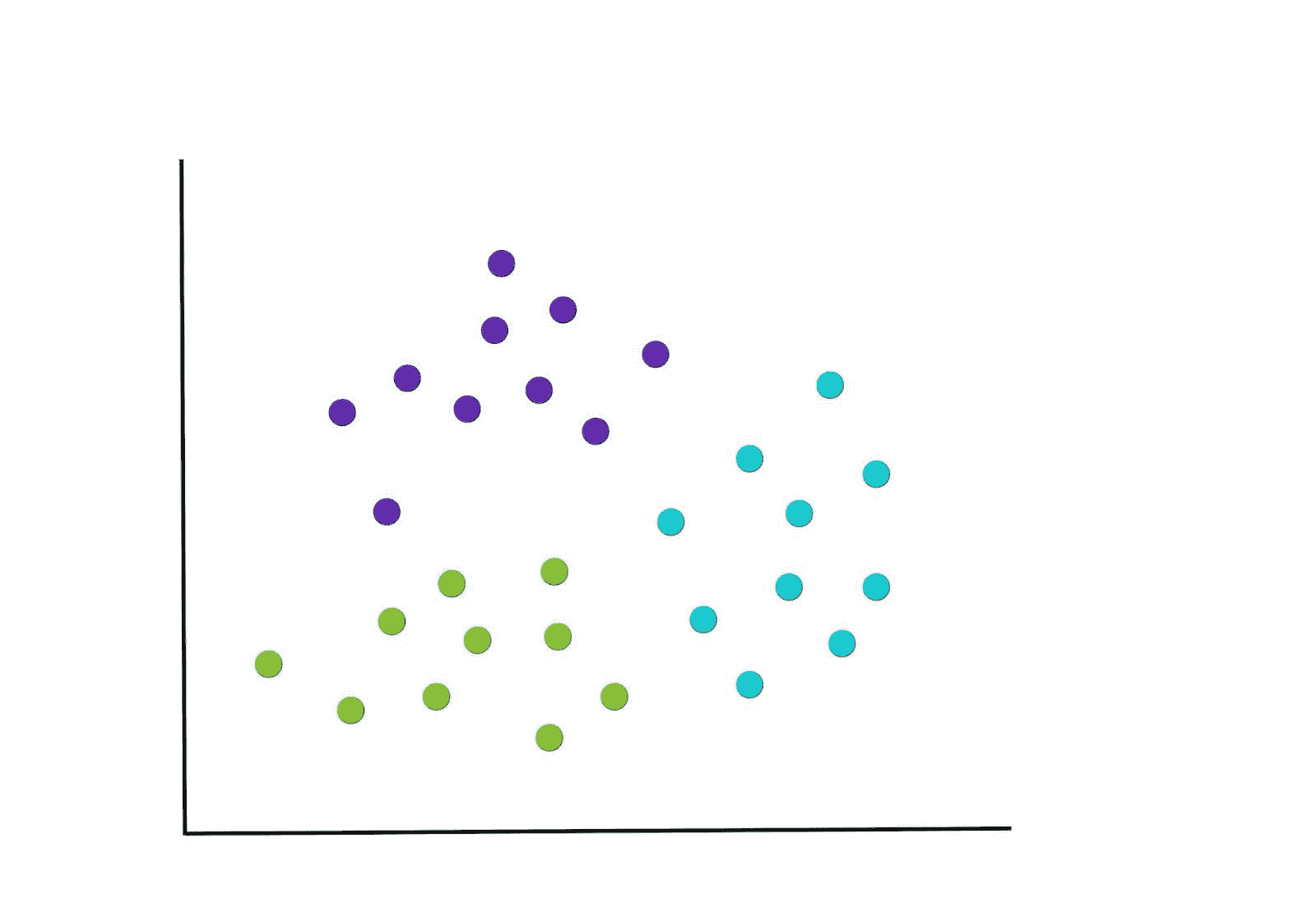
K 的选择
作为数据科学家,你将处理的数据在绘制图表时不会总是有明显的界限,就像你在鸢尾花数据集中看到的那样。通常,你会处理具有更高维度的数据,这些数据无法绘制,或者即使可以绘制,也无法确定最佳的分组数量。以下图表是一个很好的例子。
你能确定分组的数量吗?不清楚。那么,我们如何找到上述数据点可以分组的最佳集群数量呢?
有不同的方法用于找到最佳的 K,将给定数据集的数据点分组,包括肘部法和轮廓系数法。让我们简要地看一下这两种方法的工作原理。
肘部法
这种方法使用聚类内的总变异,通常称为 WCSS(聚类内平方和)。其目的是使聚类内的方差(WCSS)最小。
这种方法的工作原理如下:
-
它取一系列 K 值,例如 1 - 8,并计算每个 K 值的 WSS。
-
得到的数据将具有一个 K 值及其对应的 WSS。然后使用这些数据绘制 WCSS 对 K 值的图表。
-
最佳的 K 数量是肘部点,即曲线开始加速的地方。这个点的名称来源于此。想象一下你手臂的肘部。
轮廓系数法
这种方法测量相似性和不相似性。它量化了一个点与其分配的聚类中其他成员的距离,以及与其他聚类中成员的距离。它的工作原理如下:
-
它从 K 值的范围开始,初始值为 2。
-
对于每个 K 值,它计算聚类相似度,即一个数据点与同一聚类中所有其他组成员的平均距离。
-
接下来,通过计算数据点与最近聚类中所有其他成员的平均距离来计算聚类不相似度。
-
轮廓系数将是聚类相似度值和聚类不相似度值之间的差值,除以两个值中的较大者。
最佳的 K 值是具有最高系数的值。这个系数的值范围在 -1 到 1 之间。
结论
这是介绍 K-Means 聚类算法的文章,我们已经涵盖了它是什么、如何工作以及如何选择 K。在下一篇文章中,我们将介绍如何使用 Python 的 scikit-learn 库解决实际的聚类问题。
克林顿·奥约戈 是 Saturn Cloud 的作家,他认为分析数据以获取可操作的洞察是他日常工作的重要部分。凭借在数据可视化、数据整理和机器学习方面的技能,他为自己作为数据科学家的工作感到自豪。
原创。经许可转载。
更多相关话题
Python 中的遗传编程:背包问题
原文:
www.kdnuggets.com/2023/01/knapsack-problem-genetic-programming-python.html

使用 DALL•E 创建的图像
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
编辑注释: 正如读者 Monem 在下面的评论中指出的,这是使用 遗传算法 来解决背包问题的一个例子,而不是遗传编程。我参与了文章的制作,并犯了一个非常基本的错误,一直延续到现在。为了透明起见,我保留了原文,并附上此更正说明。对引起的困惑表示歉意。
在这篇文章中,我们将探讨背包问题,这是计算机科学中的经典问题。我们将解释为什么使用传统计算方法很难解决这一问题,以及遗传编程如何帮助找到“足够好”的解决方案。之后,我们将查看一个 Python 实现的具体解决方案,并亲自测试一下。
背包问题
背包问题可以用来说明解决复杂计算问题的困难。在最简单的形式中,给定一个一定容量的背包、一组物品及其大小和价值,并要求在不超过容量的情况下最大化放入背包的物品的价值。背包问题可以有多种表述方式,但一般认为使用传统算法解决是一个困难的问题。
背包问题的难点在于它是一个 NP 完全问题,这意味着没有已知的解决方案可以保证全局最优解。因此,该问题难以处理,无法使用传统方法快速解决。解决背包问题的最佳已知算法涉及使用暴力搜索或启发式方法,这些方法可能会有较长的运行时间,并且可能无法保证最优解。
遗传编程
然而,遗传编程可以提供一种寻找背包问题解决方案的替代方法。遗传编程是一种使用进化算法来搜索复杂问题解决方案的技术。通过使用遗传编程,可以快速找到对给定问题“足够好”的解决方案。它还可以用来优化和改进解决方案。
在遗传编程中,一组可能的解决方案(或初始生成)被随机生成,然后根据一组标准进行评估。那些最符合标准的解决方案将被选中,并应用遗传变异以创建新的解决方案变体(或后续生成)。然后评估这些新一代变体,并重复这个过程,直到找到令人满意的解决方案。该过程会重复,直到找到最佳的或“足够好”的解决方案。
使用遗传编程解决背包问题的优势在于,可以快速找到足够好的解决方案,而不需要穷举所有可能的解决方案。这使得它比传统算法更高效,能够更快地找到解决方案。
解释代码
现在我们已经了解了背包问题是什么,遗传编程是什么,以及为什么我们要使用后者来尝试解决前者,让我们来看一下上述描述的 Python 实现。
我们将逐一了解重要函数,然后再查看整体程序。
该程序使用 Python 实现,未使用任何第三方库。
生成随机种群
此函数生成给定大小的随机种群。它使用 for 循环遍历给定的大小,并为每次迭代创建一个染色体。这个染色体是由 0 和 1 组成的列表,使用 random.choice()函数生成。然后将染色体附加到种群列表中。最后,函数打印出一条消息并返回种群列表。此函数对于创建遗传算法的个体种群非常有用。
def generate_population(size):
population = []
for _ in range(size):
genes = [0, 1]
chromosome = []
for _ in range(len(items)):
chromosome.append(random.choice(genes))
population.append(chromosome)
print("Generated a random population of size", size)
return population
计算染色体适应度
此函数用于计算染色体的适应度。它以染色体作为参数,并对其进行迭代。如果染色体在给定索引处的值为 1,它就将对应项的重量和值分别添加到总重量和总值中。如果总重量超过最大重量,则适应度设置为 0\。否则,适应度设置为总值。该函数在遗传算法中用于确定给定染色体的适应度。
def calculate_fitness(chromosome):
total_weight = 0
total_value = 0
for i in range(len(chromosome)):
if chromosome[i] == 1:
total_weight += items[i][0]
total_value += items[i][1]
if total_weight > max_weight:
return 0
else:
return total_value
选择染色体
这个函数用于从一个种群中选择两个染色体进行交叉操作。它首先使用 calculate_fitness() 函数计算种群中每个染色体的适应度值。然后,它通过将每个值除以所有适应度值的总和来对适应度值进行归一化。最后,它使用 random.choices() 函数根据归一化的适应度值随机选择两个染色体。然后,这两个选择的染色体作为交叉操作的父代染色体返回。
def select_chromosomes(population):
fitness_values = []
for chromosome in population:
fitness_values.append(calculate_fitness(chromosome))
fitness_values = [float(i)/sum(fitness_values) for i in fitness_values]
parent1 = random.choices(population, weights=fitness_values, k=1)[0]
parent2 = random.choices(population, weights=fitness_values, k=1)[0]
print("Selected two chromosomes for crossover")
return parent1, parent2
执行交叉操作
这个函数在两个染色体之间执行交叉操作。它接受两个父代染色体作为输入,并随机选择一个交叉点。然后,通过在交叉点结合两个父代染色体来创建两个子代染色体。第一个子代染色体由第一个父代染色体的前半部分和第二个父代染色体的后半部分组成。第二个子代染色体由第二个父代染色体的前半部分和第一个父代染色体的后半部分组成。最后,这两个子代染色体作为输出返回。
def crossover(parent1, parent2):
crossover_point = random.randint(0, len(items)-1)
child1 = parent1[0:crossover_point] + parent2[crossover_point:]
child2 = parent2[0:crossover_point] + parent1[crossover_point:]
print("Performed crossover between two chromosomes")
return child1, child2
执行突变
这个函数对染色体进行突变。它接受一个染色体作为参数,并使用 random 模块生成一个介于 0 和染色体长度之间的随机数。如果突变点的值是 0,它将被更改为 1;如果是 1,它将被更改为 0。然后,函数打印一条消息并返回突变后的染色体。这个函数可以用来模拟生物种群中的基因突变。
def mutate(chromosome):
mutation_point = random.randint(0, len(items)-1)
if chromosome[mutation_point] == 0:
chromosome[mutation_point] = 1
else:
chromosome[mutation_point] = 0
print("Performed mutation on a chromosome")
return chromosome
获取最佳染色体
这个函数接受一个染色体种群并返回种群中最好的染色体。它首先为种群中每个染色体创建一个适应度值的列表。然后,找到最大适应度值及其在列表中的对应索引。最后,返回最大适应度值索引处的染色体。这个函数用于从染色体种群中找到最佳染色体,以便进行进一步的操作。
def get_best(population):
fitness_values = []
for chromosome in population:
fitness_values.append(calculate_fitness(chromosome))
max_value = max(fitness_values)
max_index = fitness_values.index(max_value)
return population[max_index]
控制循环
这段代码正在执行一种进化算法,以进化一组染色体。它首先循环指定的代数次数。对于每一代,从种群中选择两个染色体,然后对它们进行交叉以生成两个新的染色体。接着,这两个新的染色体会以给定的概率进行突变。如果随机生成的概率高于预定的阈值,则新的染色体会经历随机的基因突变。最后,旧的种群会被新的种群替代,新种群由这两个新染色体和旧种群中的剩余染色体组成。
for _ in range(generations):
# select two chromosomes for crossover
parent1, parent2 = select_chromosomes(population)
# perform crossover to generate two new chromosomes
child1, child2 = crossover(parent1, parent2)
# perform mutation on the two new chromosomes
if random.uniform(0, 1) < mutation_probability:
child1 = mutate(child1)
if random.uniform(0, 1) < mutation_probability:
child2 = mutate(child2)
# replace the old population with the new population
population = [child1, child2] + population[2:]
完整的 Python 实现
如果我们将上述函数和控制循环,加上一个项目列表以及一些参数和控制台输出,我们将得到以下完整的 Python 实现。
请注意,所有参数都是为了简便而硬编码的;不过,只需稍加修改即可接受命令行参数或请求用户输入,包括可用项目的数量、价值和重量。
import random
# function to generate a random population
def generate_population(size):
population = []
for _ in range(size):
genes = [0, 1]
chromosome = []
for _ in range(len(items)):
chromosome.append(random.choice(genes))
population.append(chromosome)
print("Generated a random population of size", size)
return population
# function to calculate the fitness of a chromosome
def calculate_fitness(chromosome):
total_weight = 0
total_value = 0
for i in range(len(chromosome)):
if chromosome[i] == 1:
total_weight += items[i][0]
total_value += items[i][1]
if total_weight > max_weight:
return 0
else:
return total_value
# function to select two chromosomes for crossover
def select_chromosomes(population):
fitness_values = []
for chromosome in population:
fitness_values.append(calculate_fitness(chromosome))
fitness_values = [float(i)/sum(fitness_values) for i in fitness_values]
parent1 = random.choices(population, weights=fitness_values, k=1)[0]
parent2 = random.choices(population, weights=fitness_values, k=1)[0]
print("Selected two chromosomes for crossover")
return parent1, parent2
# function to perform crossover between two chromosomes
def crossover(parent1, parent2):
crossover_point = random.randint(0, len(items)-1)
child1 = parent1[0:crossover_point] + parent2[crossover_point:]
child2 = parent2[0:crossover_point] + parent1[crossover_point:]
print("Performed crossover between two chromosomes")
return child1, child2
# function to perform mutation on a chromosome
def mutate(chromosome):
mutation_point = random.randint(0, len(items)-1)
if chromosome[mutation_point] == 0:
chromosome[mutation_point] = 1
else:
chromosome[mutation_point] = 0
print("Performed mutation on a chromosome")
return chromosome
# function to get the best chromosome from the population
def get_best(population):
fitness_values = []
for chromosome in population:
fitness_values.append(calculate_fitness(chromosome))
max_value = max(fitness_values)
max_index = fitness_values.index(max_value)
return population[max_index]
# items that can be put in the knapsack
items = [
[1, 2],
[2, 4],
[3, 4],
[4, 5],
[5, 7],
[6, 9]
]
# print available items
print("Available items:\n", items)
# parameters for genetic algorithm
max_weight = 10
population_size = 10
mutation_probability = 0.2
generations = 10
print("\nGenetic algorithm parameters:")
print("Max weight:", max_weight)
print("Population:", population_size)
print("Mutation probability:", mutation_probability)
print("Generations:", generations, "\n")
print("Performing genetic evolution:")
# generate a random population
population = generate_population(population_size)
# evolve the population for specified number of generations
for _ in range(generations):
# select two chromosomes for crossover
parent1, parent2 = select_chromosomes(population)
# perform crossover to generate two new chromosomes
child1, child2 = crossover(parent1, parent2)
# perform mutation on the two new chromosomes
if random.uniform(0, 1) < mutation_probability:
child1 = mutate(child1)
if random.uniform(0, 1) < mutation_probability:
child2 = mutate(child2)
# replace the old population with the new population
population = [child1, child2] + population[2:]
# get the best chromosome from the population
best = get_best(population)
# get the weight and value of the best solution
total_weight = 0
total_value = 0
for i in range(len(best)):
if best[i] == 1:
total_weight += items[i][0]
total_value += items[i][1]
# print the best solution
print("\nThe best solution:")
print("Weight:", total_weight)
print("Value:", total_value)
将上述代码保存到文件knapsack_ga.py中,然后通过输入python knapsack_ga.py来运行它。
一个示例输出如下:
Available items:
[[1, 2], [2, 4], [3, 4], [4, 5], [5, 7], [6, 9]]
Genetic algorithm parameters:
Max weight: 10
Population: 10
Mutation probability: 0.2
Generations: 10
Performing genetic evolution:
Generated a random population of size 10
Selected two chromosomes for crossover
Performed crossover between two chromosomes
Performed mutation on a chromosome
Selected two chromosomes for crossover
Performed crossover between two chromosomes
Performed mutation on a chromosome
Selected two chromosomes for crossover
Performed crossover between two chromosomes
Selected two chromosomes for crossover
Performed crossover between two chromosomes
Selected two chromosomes for crossover
Performed crossover between two chromosomes
Selected two chromosomes for crossover
Performed crossover between two chromosomes
Selected two chromosomes for crossover
Performed crossover between two chromosomes
Selected two chromosomes for crossover
Performed crossover between two chromosomes
Performed mutation on a chromosome
Selected two chromosomes for crossover
Performed crossover between two chromosomes
Selected two chromosomes for crossover
Performed crossover between two chromosomes
Performed mutation on a chromosome
The best solution:
Weight: 10
Value: 14
就这样,你现在知道如何使用遗传编程解决背包问题了。通过一点创造力,上述脚本可以被修改以解决各种计算复杂的问题,获得最佳的“足够好”的解决方案。
感谢阅读!
本文的部分内容是在 GPT-3 的协助下进行规划和/或编写的。
马修·梅奥 (@mattmayo13) 是数据科学家,也是 KDnuggets 的主编,这是一个开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。马修拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系到。
更多相关主题
Scikit-learn 中的 K-最近邻
原文:
www.kdnuggets.com/2022/07/knearest-neighbors-scikitlearn.html

Nina Strehl via Unsplash
K-最近邻(KNN)是一种监督学习的机器学习算法,可用于回归和分类任务。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
一种监督式机器学习算法依赖于有标签的输入数据,算法在这些数据上进行学习,并利用学到的知识在输入未标记数据时生成准确的输出。
KNN 的使用是根据训练数据的特征(有标签的数据)对测试数据集进行预测。进行这些预测的方法是通过计算测试数据和训练数据之间的距离,假设数据点的相似特征或属性存在于接近的范围内。
它允许我们在考虑新数据点的特征的基础上,识别并分配新数据的类别,这些特征是基于训练数据中的学习数据点。这些新数据点的特征将被 KNN 算法学习,并根据其与其他数据点的接近程度进行分类。
为什么 KNN 是一个好的算法?
KNN 特别适用于分类任务。分类是许多数据科学家和机器学习工程师遇到的典型任务,它解决了许多现实世界的问题。
因此,像 KNN 这样的算法是用于模式分类和回归模型的好且准确的选择。KNN 被认为不会对数据做任何假设,因此比其他分类算法具有更高的准确性。该算法也容易实现且易于解释。
KNN 中的“k”
KNN 中的“K”是一个参数,指的是最近邻的数量,其中 K 值本质上创建了一个环境,使数据点根据接近程度理解其相似性。使用 K 值,我们计算测试数据点与已训练标签点之间的距离,以更好地对新数据点进行分类。
K 值是一个正整数,通常值较小,推荐为奇数。当 K 值较小时,误差率下降,偏差较低但方差较高,这会导致模型过拟合。
如何计算数据点之间的距离?
KNN 是一种基于距离的算法,最常用的方法包括:
-
连续数据的欧氏距离和曼哈顿距离
-
类别数据的汉明距离
欧氏距离是欧几里得空间中两点之间的数学距离,使用两点之间的线段长度。这是最常见的距离度量,许多人会从学校的毕达哥拉斯定理中记住它。
曼哈顿距离是两点之间的数学距离,即其笛卡尔坐标的绝对差的总和。简单来说,距离的移动方向只能是上下和左右。
汉明距离比较两个二进制数据字符串,然后比较这两个字符串输入以找到每个位置字符的不同数量。
简单的 KNN 算法步骤
这些是 KNN 算法的一般步骤
-
加载你的数据集
-
选择一个 k 值。你应该选择一个奇数,以避免出现平局。
-
计算新数据点与邻近的已训练数据点之间的距离。
-
将新数据点分配给其 K 个最近邻
使用 sklearn 进行 kNN
neighbours是来自 sklearn 模块的一个包,用于最近邻分类任务。这可用于无监督学习和有监督学习。
首先,你需要导入这些库:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
这是 sklearn 的 neighbors 包:
sklearn.neighbors.KNeighborsClassifier
这些是可以使用的参数:
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, *, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=None)
示例中使用的距离度量是 minkowski,但如上所述,你可以使用不同的距离度量。
如果你想了解更多关于这些参数的信息,请点击这个链接。
Scikit-Learn 中的 K 近邻在鸢尾花数据集上的应用
加载鸢尾花数据集
导入这些库:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
导入鸢尾花数据集:
# url for Iris dataset
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
# Assign column names to the dataset
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']
# Read in the dataset
df = pd.read_csv(url, names=names)
执行df.head()后数据集应呈现如下:
数据集预处理
下一步是根据属性和标签拆分数据集。类别列被视为标签,称为 y,而前 4 列是属性,称为 X。
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 4].values
训练/测试划分
对数据集进行训练/测试划分将帮助我们更好地了解算法在未见数据/测试阶段的表现。这也有助于减少过拟合的发生。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
特征缩放
特征缩放是在执行模型以开始进行预测之前的重要步骤。它涉及将特征重新缩放到一个共同的边界,以确保不丢失关于每个数据点的信息。否则,你的模型可能会做出错误的预测。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
进行预测
这是我们将使用 sklearn 模块中的邻居包的地方。如你所见,我们已将邻居数量(K 值)选择为 5。
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors=5)
classifier.fit(X_train, y_train)
现在我们想对测试数据集进行预测:
y_pred = classifier.predict(X_test)
评估你的算法
用于评估你算法的最典型指标是混淆矩阵、精确度、召回率和 F1 分数。
from sklearn.metrics import classification_report, confusion_matrix
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
这是输出:
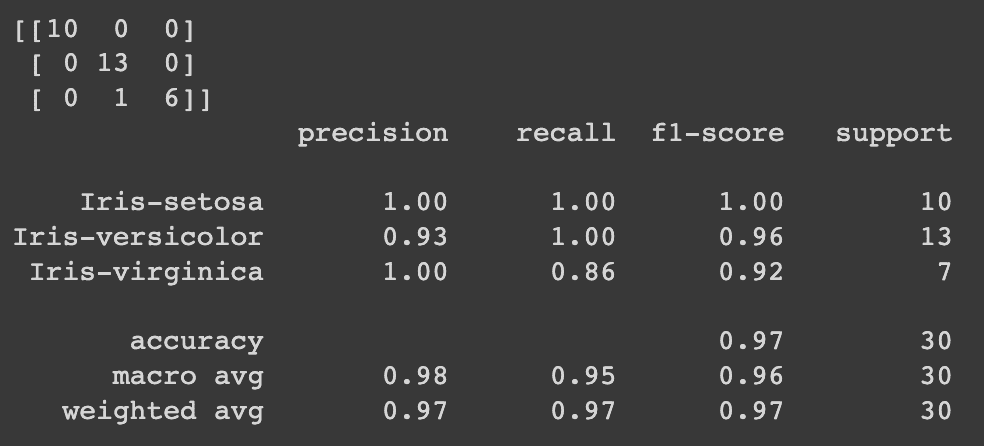
结论
所以我们已经了解到 KNN 是一个适用于分类任务的良好算法,并且 Scikit-learn 中的邻居包可以使一切变得更加简单。它实现起来非常简单且容易,并且具有特征/距离选择的灵活性。它能够处理多类情况,并且可以有效地生成准确的输出。
但在使用 KNN 时,你需要考虑一些问题。确定 k 值可能很困难,因为这可能会导致过拟合或避免过拟合。确定应使用哪个距离度量也可能是一个反复试验的过程。KNN 的计算成本也很高,因为我们要计算新数据点和训练数据点之间的距离。正因为如此,随着示例和变量数量的增加,KNN 算法会变慢。
尽管这是最古老且使用广泛的分类算法之一,但你仍然需要考虑其缺点。
Nisha Arya 是一位数据科学家和自由技术作家。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何能够改善人类寿命。她是一个热衷学习的人,寻求扩展她的技术知识和写作技能,同时帮助指导他人。
更多相关主题
关于 Python 装饰器和元类你应该知道的事
原文:
www.kdnuggets.com/2023/03/know-python-decorators-metaclasses.html

作者提供的图片
什么是 Python 装饰器?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
听到“装饰器”这个词,大多数人可能会猜测它是用来装饰的东西。你猜对了。在节日如圣诞节或新年时,我们用各种灯光和材料装饰房子。但在 Python 中,装饰器用于修改或增强 Python 函数或方法的功能。
装饰器是包裹在原始函数周围的函数,能够在不直接修改原始代码的情况下添加一些额外的功能。
举个例子,假设你是一个面包店的老板,并且在制作蛋糕方面是一位专家。你制作不同的蛋糕,如巧克力蛋糕、草莓蛋糕和菠萝蛋糕。所有蛋糕都是用不同的原料制作的,但一些步骤对于所有蛋糕都是相同的,比如准备烤盘、预热烤箱、烘焙蛋糕或从烤箱中取出蛋糕。因此,我们可以创建一个通用的装饰器函数来执行所有通用步骤,为不同类型的蛋糕制作单独的函数,并使用装饰器为这些函数添加通用功能。
请看下面的代码。
def common_steps(func):
def wrapper():
print("Preparing baking pans...")
print("Pre-heating the oven...")
result = func()
print("Baking the cake...")
print("Removing the cake from the oven...")
return result
return wrapper
@common_steps
def chocolate_cake():
print("Mixing the chocolate...")
return "Chocolate cake is ready!"
@common_steps
def strawberry_cake():
print("Mixing the strawberries...")
return "Strawberry cake is ready!"
@common_steps
def pineapple_cake():
print("Mixing the pineapples...")
return "Pineapple cake is ready!"
print(pineapple_cake())
输出:
Preparing baking pans...
Pre-heating the oven...
Mixing the pineapples...
Baking the cake...
Removing the cake from the oven...
Pineapple cake is ready!
函数 comman_steps 被定义为装饰器,并包含所有的通用步骤,如烘焙或预热。而函数 chocolate_cake、strawberry_cake 和 pineapple_cake 则定义了不同类型蛋糕的不同步骤。
装饰器使用 @ 符号定义,后面跟着装饰器函数的名称。
每当定义一个带有装饰器的函数时,原始函数会与装饰器一起被调用,而装饰器函数会返回一个新的函数来替代原始函数。
新函数在调用原始函数之前和之后执行附加功能。
除了 @ 符号外,你还可以以另一种方式定义装饰器,这种方式能够提供相同的结果。例如,
def pineapple_cake():
print("Mixing the pineapples...")
return "Pineapple cake is ready!"
pineapple_cake = common_steps(pineapple_cake)
print(pineapple_cake())
使用装饰器的好处:
-
你可以重复使用相同的代码而不会造成冗余,从而避免“不要重复自己”(DRY)原则的违背。
-
这使得你的代码更具可读性,也更容易维护。
-
你可以使你的代码组织得更清晰,这有助于处理输入验证、错误处理或优化问题等方面的关注。
-
使用装饰器,你可以在不修改代码的情况下,为现有函数或类添加新的功能。这允许你根据业务需求扩展代码。
什么是元类?
它是类的类,定义了类如何表现。一个类本身是一个元类的实例。
在理解元类的定义之前,首先了解 Python 类和对象的基本定义。类就像一个构造函数,用于创建对象。我们创建类来创建对象。对象也被称为类的实例,用于访问类的属性。属性可以是任何数据类型,如整数、字符串、元组、列表、函数,甚至是类。因此,为了使用这些属性,我们必须在类中创建实例(对象),创建这些实例的方法称为实例化。
Python 中的一切都被视为对象。即使是类也被视为对象。这意味着一个类是从另一个类实例化的。所有其他类实例化的类被称为元类。类定义了它所属对象的行为。同样,类的行为由其元类定义,默认情况下是Type类。简单来说,所有类在 Python 中都是元类的实例。
什么是类型类?
在 Python 中,Type类是所有类的元类。每次你定义一个新类时,默认情况下,它是从 Type 类实例化的,除非你定义了另一个元类。
类型类还负责动态创建 Python 类。当我们定义一个新类时,Python 将类定义发送给类型类,然后这个类根据类定义创建一个新的类对象。
让我们考虑一个例子。
class College:
pass
obj = College()
print(type(obj))
print(type(College))
输出:
<class '__main__.College>
<class 'type'>
创建了一个名为College的新类,并实例化了一个该类的对象obj。但是,当我们打印对象类型时,它输出为<class '__main__.College'>,这意味着一个特定的对象是从College类创建的。但另一方面,当我们打印College类的类型时,它输出为<class 'type'>,这意味着该类默认是从type 类(元类)创建的。
我们还可以更改这些用户定义类的默认元类。考虑下面的例子。
class College(type):
pass
class Student(metaclass=College):
pass
print(type(Student))
print(type(College))
输出:
<class '__main__.College'>
<class 'type'>
当我们打印Student类的类型时,它会引用College作为元类,但当我们打印College类的类型时,它会引用type类作为元类。所以这形成了一个层级,如下所示。
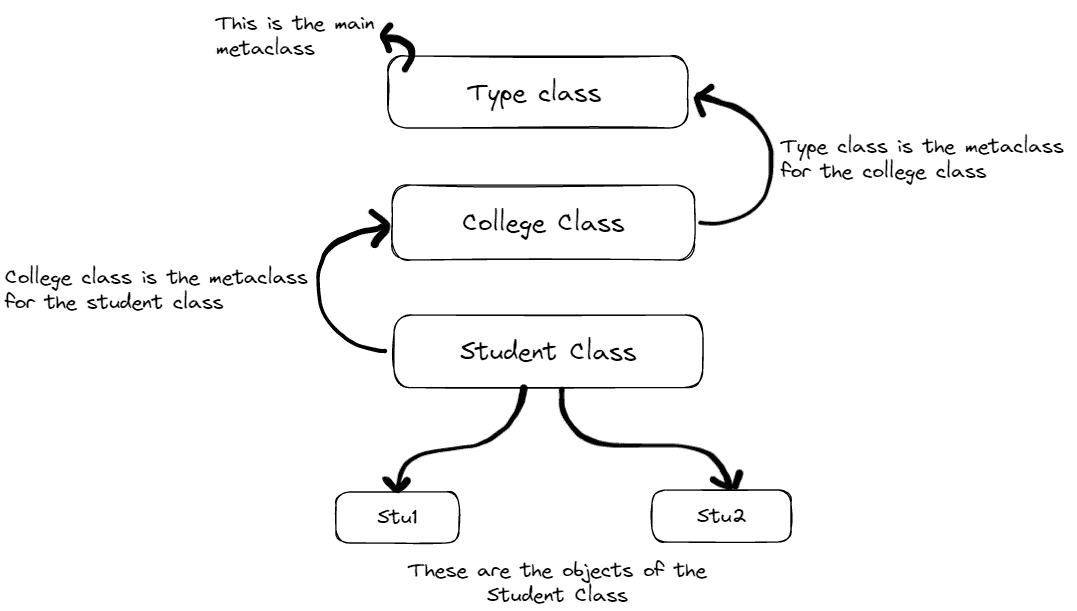
作者提供的图片
我们还可以使用type类来动态创建新类。让我们通过以下示例进一步了解这一点。
# This is the basic way of defining a class.
class MyClass:
pass
# Dynamic creation of classes.
myclass = type("MyClass", (), {})
定义类的两种方法是等效的。在这个例子中使用了 type()函数来创建一个新类。它接受三个参数。第一个参数是类名,第二个是父类的元组(在这种情况下为空),第三个参数是一个字典,包含该类的属性(在这种情况下也为空)。
考虑另一个使用继承概念的例子。
College = type("College", (), {"clgName": "MIT University"})
Student = type("Student", (College,), {"stuName": "Kevin Peterson"})
obj = Student()
print(obj.stuName, "-", obj.clgName)
输出:
Kevin Peterson - MIT University
创建了一个名为College的类,参数clgName为MIT University。另一个类Student被创建,并从College类继承,并创建了一个属性stuName为Kevin Peterson。
当我们创建Student类的对象时,可以看到它能够访问两个类的属性。这意味着在这个例子中继承工作得非常完美。
结论
在这篇文章中,我们讨论了 Python 中的装饰器和元类。元类和装饰器都修改类和函数的行为,但使用不同的机制。
元类在较低级别操作,允许你改变类的结构或行为,如类方法、属性和继承。而装饰器则用于修改函数的行为。它们允许你在不改变代码的情况下为现有函数添加功能。与元类相比,装饰器操作的级别较高,因此它们比元类更容易理解,也更不复杂。

元类与装饰器的区别 | 图片由作者提供
今天就到这里了。我希望你喜欢阅读这篇文章。如果你有任何评论或建议,请通过Linkedin与我联系。
Aryan Garg 是一名 B.Tech 电气工程专业的学生,目前在本科最后一年。他的兴趣在于 Web 开发和机器学习。他已经追求了这个兴趣,并渴望在这些方向上做更多的工作。
相关主题
使用新的 Sweetviz Python 库更快地了解您的数据
原文:
www.kdnuggets.com/2021/03/know-your-data-much-faster-sweetviz-python-library.html
评论
作者:Francois Bertrand,数据可视化和游戏设计师
这是关于 Sweetviz 的第二篇文章,详细介绍了比较分析、新功能、一般用例,并且使用了不同的数据集。你可以在这里找到原文。
探索性数据分析(EDA)是大多数数据科学项目中的一个重要早期步骤,它通常包括采取相同的步骤来描述数据集(例如,了解数据类型、缺失信息、值的分布、相关性等)。鉴于这些任务的重复性和相似性,一些库可以自动化这些过程并帮助启动。
最新的一项是一个名为 Sweetviz 的开源 Python 库(GitHub),由一些贡献者和我自己为这个目的创建。它处理 pandas 数据框,生成一个自包含的 HTML 报告,可以在浏览器中单独查看或集成到笔记本中。
它功能强大;除了用仅两行代码创建有洞察力和美观的可视化外,它还提供了需要更多时间手动生成的分析,包括一些其他库无法如此快速提供的内容,例如:
-
目标分析:显示目标值(例如泰坦尼克号数据集中的“幸存”)与其他特征的关系
-
数据集比较:数据集之间(例如“训练集与测试集”)和数据集内部(例如“男性与女性”)
-
相关性/关联性:数值和分类数据的相关性和关联性的完整整合,所有内容都在一个图表和表格中
其他参考/示例:
探索性数据分析(EDA)变得……有趣?!
能够如此迅速地获取大量关于目标值的信息,并比较数据集中的不同区域,使得这一初步步骤从乏味变得更快、有趣,甚至在某种程度上……有趣!(至少对这个数据迷来说如此!)当然,探索性数据分析(EDA)是一个更长的过程,但至少第一步要顺利得多。让我们看看实际数据集的效果如何。
创建报告
一旦数据加载完成,创建报告是一个快速的两行过程。
对于本文,我们将使用描述的信用卡客户数据集的清理版本(这里)。你可以 在这里下载清理后的数据集。清理仅包括移除描述中提到的最后两列,并将“Attrition_Flag”变量转换为布尔值,如预期的那样。
安装 Sweetviz(使用 pip install sweetviz)后,按正常方式加载 pandas 数据框:
import sweetviz
import pandas as pd
df = pd.read_csv("BankChurners_clean.csv")
步骤 1:创建报告
要创建报告,你可以调用以下任一方法:
-
使用 analyze() 对单个数据集进行分析
-
使用 compare() 比较两个数据集(例如,测试集与训练集)
-
使用 compare_intra() 比较同一数据集中的两个子群体
在我们的例子中,我们有一个数据集,所以让我们对其进行 analyze()。重要的是,我们希望获取目标变量“Attrition_Flag”的信息,所以我们来指定一下:
report = sweetviz.analyze(df, "Attrition_Flag")
步骤 2:生成输出
一旦我们有了报告对象,它可以生成一个独立的 HTML 应用程序(HTML 页面)或将报告嵌入到 Notebook 中。有关更多细节,请参考使用示例/文档(这里 & 这里)。现在,让我们生成一个独立的 HTML 应用程序:
report.show_html()
使用默认选项,这将创建一个名为“SWEETVIZ_REPORT.html”的文件并打开浏览器。你可以查看生成的完整报告 这里。如果你在笔记本中操作,该文件将会生成,但浏览器可能不会弹出(建议在笔记本中使用 show_notebook(),参见 文档)。
输出选项包括:
-
布局(宽屏或垂直)
-
缩放
-
窗口大小(用于笔记本)
Sweetviz 报告
我可以(实际上也可能!)花整篇文章来讲述 Sweetviz 报告的具体组件,因为它们每个都带来了独特的见解。现在,以下是本示例情况所有组件的简要概述。
概述
在报告顶部,提供数据集的简单概述(如果有比较的话也包括比较)。对于每个特征,Sweetviz 将尽力确定每列的数据类型,包括:
-
数值型
-
类别/布尔型
-
文本(默认/备用)
请注意,这些可以使用“FeatureConfig”覆盖(参见 文档)。
关联/相关性
“关联”按钮解锁了一个非常强大的关联和相关分析。这张图是来自Drazen Zaric: Better Heatmaps and Correlation Matrix Plots in Python的视觉效果和Shaked Zychlinski: The Search for Categorical Correlation的概念的综合。
基本上,除了显示传统的数值相关性外,它还将数值相关性、不确定系数(对于分类-分类)和相关比(对于分类-数值)统一在一个图表中。请注意,出于清晰的考虑,平凡的对角线被留空。

相同的数据也可以在每个变量的“详细信息”窗格中找到(稍后会详细说明):
值得注意的是,这些相关/关联方法不应被视为绝对的,因为它们对数据的底层分布和关系做出了一些假设。然而,它们可以作为一个非常有用的起点。
目标分析
当分析一个具有目标变量的数据集时,这一功能极具洞察力。
如果我们指定一个目标变量(目前仅支持布尔型和数值型),它会显著地显示为第一个变量,并使用黑色标记。

最重要的是,它的值会覆盖在每一个其他图表上,迅速提供目标与每个其他变量分布的洞察。
一眼就能立刻看出目标值如何受到其他变量的影响。正如预期的那样,这通常与“关联”图中发现的内容一致,但提供了每个变量的具体信息。这里是一个示例:

重要提示:记住你可以使用目标分析来分析任意特征与所有其他特征的关系。这对于理解特征之间的关系非常有帮助,即使在你分析的数据中没有“实际”目标变量。
一般特征分析
报告的主要部分是每个特征的总结和详细信息:
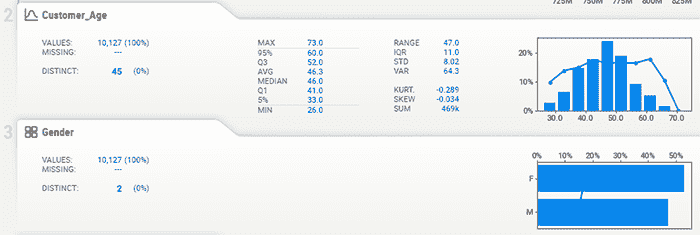
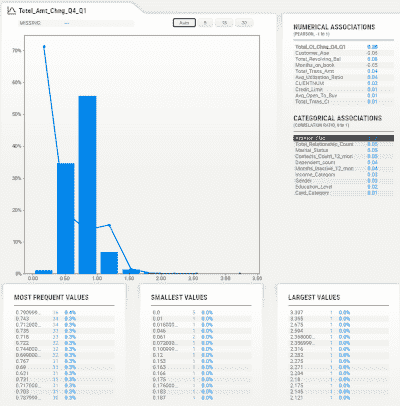
请注意,对于数值数据,你可以更改图表中的“箱数”以更好地评估分布,以及目标特征的相关性。例如,在上面的截图中,如果我们将箱数更改为 30,我们可以更清晰地了解目标如何随该特征变化:
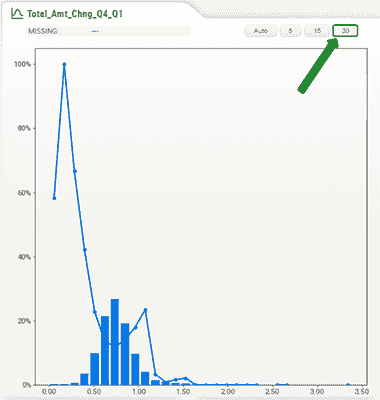
比较数据集和子人群(例如,男性与女性)
Sweetviz 可以比较两个不同的数据集,这在很多情况下非常有用(例如,训练数据与测试数据)。但即使你只查看单个数据集,你也可以研究该数据集内不同子人群的特征。
让我们用上述看起来有趣的特征做一个示例。似乎当“Total_Ct_Chng_Q4_Q1”的值低于约 0.6 时,Attrition_Flag 显著更高。
我们可以使用compare_intra()函数来隔离该人群,并给出条件以拆分人群(以及给低/高人群一个更具描述性的名称):
report = sweetviz.compare_intra(df, df["Total_Ct_Chng_Q4_Q1"] < 0.6, ["Low_Ct_Chng_Q1Q4", "High_Ct_Chng_Q1Q4"], "Attrition_Flag")
这将输出以下报告,迅速为我们提供大量关于数据的新见解。仅查看前两个变量,我们就可以立即看到,当使用“Total_Ct_Chng_Q4_Q1”特征拆分人群时,Customer_Age 和 Gender 的行为与其一般分布相比非常不同:
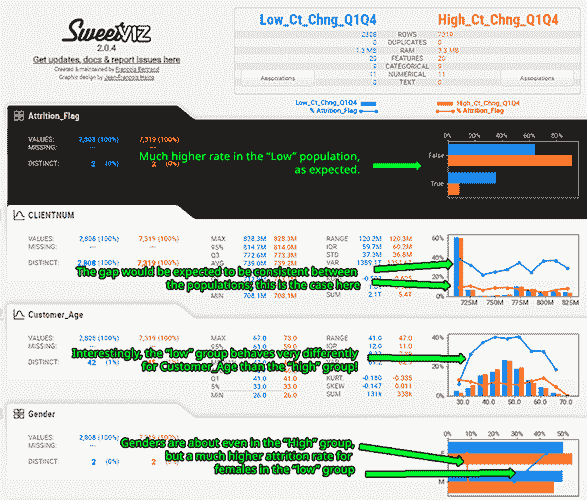
你可以在这里访问完整报告。
使用场景与结论
使用目标分析、数据集/内部集比较、全面特征分析和统一关联/相关数据,Sweetviz 仅用 2 行代码即可提供无与伦比的见解。
当然,分析数据集是一个更长且富有艺术性的过程,但 Sweetviz 可以带来早期见解并节省大量工作时间,特别是在初始阶段,往往很繁琐。
在 EDA 之后,Sweetviz 继续通过以下方式提供价值:
-
特征工程:可视化工程化特征如何相对于其他特征和目标变量进行表现/相关性分析
-
测试:确认测试/验证集的组成和均衡
-
解释/沟通:生成的图表可以提供易于解读的见解(例如,上面的截图),并且可以在团队或客户之间快速传递,无需额外工作
我喜欢使用这个库以及它在整个工作流程中的帮助,希望你也会像我一样觉得它有用!
简历:弗朗索瓦·贝特朗是数据可视化和游戏领域拥有 20 年经验的资深编码员和设计师。
相关:
-
仅用两行代码进行强大的探索性数据分析
-
如何从零开始使用 Python 创建惊人的可视化
-
使用 dtreeviz 创建美丽的决策树可视化
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
更多相关内容
使用 BERT 构建职位搜索知识图谱
原文:
www.kdnuggets.com/2021/06/knowledge-graph-job-search-bert.html
评论
由Walid Amamou,UBIAI 创始人
知识图谱网络
介绍:
尽管 NLP 领域在过去两年中由于转移学习模型的发展而呈指数增长,但这些模型在职位搜索领域的应用范围仍然有限。LinkedIn 作为职位搜索和招聘领域的领先公司就是一个很好的例子。尽管我拥有材料科学的博士学位和物理学的硕士学位,但我却收到如 MongoDB 的技术项目经理和 Toptal 的 Go 开发者职位的推荐,这些都是与我的背景不相关的网络开发公司。这种不相关感被许多用户所共有,并且是一个主要的挫折来源。
LinkedIn 职位推荐
求职者应有机会使用最佳工具,以帮助他们找到与自身背景最匹配的职位,而不浪费时间在不相关的推荐和手动搜索上……
然而,总体而言,传统的职位推荐系统基于简单的关键词和/或语义相似性,这些方法通常不适合提供良好的职位推荐,因为它们未考虑实体之间的相互联系。此外,随着申请者跟踪系统(ATS)的兴起,在简历中列出与领域相关的技能以及揭示哪些行业技能变得更加重要至关重要。例如,我可能在 Python 编程方面具有广泛的技能,但感兴趣的职位描述要求对 Django 框架有了解,而 Django 框架本质上基于 Python;简单的关键词搜索将无法发现这种联系。
在本教程中,我们将构建一个职位推荐和技能发现脚本,该脚本将接受非结构化文本作为输入,然后根据技能、工作经验年限、学位和专业等实体输出职位推荐和技能建议。在我之前的文章的基础上,我们将使用 BERT 模型从职位描述中提取实体和关系,并尝试从技能和经验年限中构建知识图谱。
职业分析流程
为了训练 NER 和关系提取模型,我们使用了UBIAI 工具进行了数据注释,并在 Google Colab 上进行了模型训练,如我之前的文章所述。
数据提取:
在本教程中,我收集了来自 5 家主要公司的与软件工程、硬件工程和研究相关的职位描述:Facebook、谷歌、微软、IBM 和英特尔。数据存储在一个 csv 文件中。
为了从职位描述中提取实体和关系,我创建了一个命名实体识别(NER)和关系抽取管道,使用了之前训练的变换器模型(有关更多信息,请查看我的上一篇文章)。我们将把提取出的实体存储在一个 JSON 文件中,以便进一步分析,使用以下代码。
def analyze(text): experience_year=[]
experience_skills=[]
diploma=[]
diploma_major=[] for doc in nlp.pipe(text, disable=[**"tagger"**]):
skills = [e.text for e in doc.ents if e.label_ == **'SKILLS'**]
for name, proc in nlp2.pipeline:
doc = proc(doc)
for value, rel_dict in doc._.rel.items():
for e in doc.ents:
for b in doc.ents:
if e.start == value[0] and b.start == value[1]:
if rel_dict[**'EXPERIENCE_IN'**] >= 0.9:
experience_skills.append(b.text)
experience_year.append(e.text)
if rel_dict[**'DEGREE_IN'**] >= 0.9:
diploma_major.append(b.text)
diploma.append(e.text)
return skills, experience_skills, experience_year, diploma, diploma_majordef analyze_jobs(item):
with open(**'./path_to_job_descriptions'**, **'w'**, encoding=**'utf-8'**) as file:
file.write(**'['**)
for i,row in enumerate(item[**'Description'**]):
try:
skill, experience_skills, experience_year, diploma, diploma_major=analyze([row])
data=json.dumps({**'Job ID'**:item[**'JOBID'**[i],**'Title'**:item[**'Title'**[i],**'Location'**:item[**'Location'**][i],**'Link'**:item[**'Link'**][i],**'Category'**:item[**'Category'**[i],**'document'**:row, **'skills'**:skill, **'experience skills'**:experience_skills, **'experience years'**: experience_year, **'diploma'**:diploma, **'diploma_major'**:diploma_major}, ensure_ascii=False)
file.write(data)
file.write(**','**)
except:
continue
file.write(**']'**)analyze_jobs(path)
数据探索:
提取职位描述中的实体后,我们现在可以开始探索数据。首先,我有兴趣了解在多个领域中所需学位的分布。在下方的箱形图中,我们注意到一些事情:在软件工程领域,最受欢迎的学位是学士学位,其次是硕士学位和博士学位。而在研究领域,博士学位和硕士学位的需求则更多,这是我们预期的结果。对于硬件工程,分布则较为均匀。这可能看起来很直观,但值得注意的是,我们只用几行代码就从完全非结构化的文本中自动获得了这些结构化的数据!
各领域的学位分布
我有兴趣了解哪些公司在寻找物理学和材料科学的博士,因为我的背景正好涵盖这两个专业。我们看到谷歌和英特尔在寻找这类博士。Facebook 则更关注计算机科学和电气工程领域的博士。请注意,由于数据集的样本量较小,这种分布可能并不代表真实的分布。更大的样本量肯定会得到更好的结果,但这超出了本教程的范围。
学位专业分布
由于这是关于 NLP 的教程,让我们看看当提到“NLP”或“自然语言处理”时需要哪些学位和专业:
#Diploma
('Master', 54), ('PHD', 49),('Bachelor', 19)#Diploma major:
('Computer Science', 36),('engineering', 12), ('Machine Learning', 9),('Statistics', 8),('AI', 6)
提到 NLP 的公司在寻找具有计算机科学、工程、机器学习或统计学硕士或博士学位的候选人。另一方面,对学士学位的需求较少。
知识图谱
利用提取的技能和经验年限,我们现在可以构建一个知识图谱,其中源节点是职位描述 ID,目标节点是技能,连接的强度是经验年限。我们使用 python 库 pyvis 和 networkx 来构建我们的图谱;我们将职位描述与提取的技能链接,使用经验年限作为权重。
job_net = Network(height=**'1000px'**, width=**'100%'**, bgcolor=**'#222222'**, font_color=**'white'**)
job_net.barnes_hut()
sources = data_graph[**'Job ID'**]
targets = data_graph[**'skills'**]
values=data_graph[**'years skills'**]
sources_resume = data_graph_resume[**'document'**]
targets_resume = data_graph_resume[**'skills'**]
edge_data = zip(sources, targets, values )
resume_edge=zip(sources_resume, targets_resume)
for j,e in enumerate(edge_data):
src = e[0]
dst = e[1]
w = e[2]
job_net.add_node(src, src, color=**'#dd4b39'**, title=src)
job_net.add_node(dst, dst, title=dst)
if str(w).isdigit():
if w is None:
job_net.add_edge(src, dst, value=w, color=**'#00ff1e'**, label=w)
if 1<w<=5:
job_net.add_edge(src, dst, value=w, color=**'#FFFF00'**, label=w)
if w>5:
job_net.add_edge(src, dst, value=w, color=**'#dd4b39'**, label=w)
else:
job_net.add_edge(src, dst, value=0.1, dashes=True)for j,e in enumerate(resume_edge):
src = **'resume'** dst = e[1]
job_net.add_node(src, src, color=**'#dd4b39'**, title=src)
job_net.add_node(dst, dst, title=dst)
job_net.add_edge(src, dst, color=**'#00ff1e'**)neighbor_map = job_net.get_adj_list()for node in job_net.nodes:
node[**'title'**] += **' Neighbors:<br>'** + **'<br>'**.join(neighbor_map[node[**'id'**]])
node[**'value'**] = len(neighbor_map[node[**'id'**]])# add neighbor data to node hover data
job_net.show_buttons(filter_=[**'physics'**])
job_net.show(**'job_knolwedge_graph.html'**)
让我们可视化我们的知识图谱!为了清晰起见,我仅显示了知识图谱中的一些职位。在这个测试中,我使用了一个机器学习领域的样本简历。
红色节点是来源,可以是职位描述或简历。蓝色节点是技能。连接的颜色和标签表示所需的经验年限(黄色 = 1–5 年;红色 = > 5 年;虚线 = 无经验)。在下面的例子中,Python 将简历与 4 个职位相连接,这些职位都需要 2 年的经验。对于机器学习连接,无需经验。我们现在可以开始从我们的非结构化文本中获得有价值的见解!
知识图谱
让我们找出哪些职位与简历的联系最多:
# JOB ID #Connections
GO4919194241794048 7
GO5957370192396288 7
GO5859529717907456 7
GO5266284713148416 7
FB189313482022978 7
FB386661248778231 7
现在让我们看看包含少量最高匹配的知识图谱网络:
最高职位匹配的知识图谱
注意到在这个案例中(该教程中未进行),共指解析的重要性。技能“机器学习”、“机器学习模型”和“机器学习”被计算为不同的技能,但它们显然是相同的技能,应当计为一项。这会导致我们的匹配算法不准确,并突显了在进行 NER 提取时共指解析的重要性。
话虽如此,通过知识图谱我们可以直接看到 GO5957370192396288 和 GO5859529717907456 都是很好的匹配,因为它们不需要广泛的经验,而 FB189313482022978 需要 2–4 年的各种技能经验。瞧!
技能增强
现在我们已经识别出简历与职位描述之间的联系,目标是发现那些可能未出现在简历中但对我们分析的领域重要的相关技能。为此,我们按领域过滤职位描述——即软件工程、硬件工程和研究。接下来,我们查询所有与简历技能相关的邻近职位,并为每个找到的职位提取相关技能。为了清晰的可视化,我将词频绘制成了词云。让我们来看一下软件工程领域:
软件工程中的技能词云
注意到 Spark、SOLR 和 PLSQL 在与简历相关的职位中被频繁提及,可能对该领域很重要。
另一方面,对于硬件工程:

硬件工程中的技能词云
设计、RF 和 RFIC 是这里的确切需求。
对于研究领域:

研究中技能的词云
热门技能包括机器学习、信号处理、TensorFlow、PyTorch、模型分析等…
仅需几行代码,我们便将非结构化数据转化为结构化信息,并提取了有价值的见解!
结论:
随着 NLP 领域的最新突破——无论是命名实体识别、关系分类、问答还是文本分类——对于公司而言,应用 NLP 以保持竞争力已成为一种必要。
在本教程中,我们使用 NER 和关系提取模型(使用 BERT transformer)构建了一个职位推荐和技能发现应用。我们通过构建一个连接职位和技能的知识图谱实现了这一目标。
知识图谱与 NLP 相结合,为数据挖掘和发现提供了强大的工具。欢迎分享您展示 NLP 如何应用于不同领域的用例。如果您有任何问题或想为您的具体情况创建自定义模型,请在下方留言或发送邮件至 admin@ubiai.tools。
个人简介:Walid Amamou 是 UBIAI 的创始人,该公司开发了用于 NLP 应用的注释工具,并拥有物理学博士学位。
原文。经授权转载。
相关内容:
-
如何使用 spaCy 3 微调 BERT Transformer
-
如何通过 API 创建和部署一个简单的情感分析应用
-
如何将 Transformer 应用于任意长度的文本
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT
了解更多相关话题
Kubernetes 与 Amazon ECS 对数据科学家的比较
原文:
www.kdnuggets.com/2020/11/kubernetes-amazon-ecs-data-scientists.html
comments
图片来源:容器技术公司
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的捷径。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
当你踏上数据科学职业的道路时,你无疑会遇到使用容器管理解决方案的机会。在这里,我们将从对有志和现任数据科学家有意义的角度来看待两种解决方案 —— Kubernetes 和 Amazon Elastic Container Service (ECS)。
两种选项都支持部署机器学习模型
如果你有兴趣在作为数据科学家的工作中构建和使用机器学习模型,可以找到一些教程来指导你在这两个平台上进行操作。亚马逊提供了 针对数据科学家的逐步操作指南。
另外,有一个名为 Kubeflow 的机器学习 工具包,专为 Kubernetes 用户设计。它是一个开源、可移植且可扩展的解决方案。人们可以将其应用于任何新的或现有的 Kubernetes 部署。
两者都是可靠的选择
在比较 Kubernetes 和 ECS 时,不要惊讶于发现有关可用区和整体可靠性的细节。选择一个可靠的服务可以帮助你避免可能暂时中断数据科学项目的故障。
ECS 运行在 69 个可用区和 22 个区域。此外,ECS 属于亚马逊网络服务(AWS)旗下。这意味着它 保证至少 99.99% 的正常运行时间。
Kubernetes 强调通过将 Kubernetes pod 分布在节点之间的方式来提高可靠性,使其对应用程序故障具有更高的容错能力。此外,Kubernetes 的高可用性扩展到基础设施和应用程序层面。
此外,随着 Kubernetes 1.2 的发布,支持在多个可用区运行单个集群也被引入。然而,所选的区域必须在同一区域内,并由相同的云服务提供。
那个 Kubernetes 版本为 AWS 和 Google Compute Engine (GCE) 用户提供了多个区域选择。然而,给节点和卷应用适当的标签可以支持额外的云服务。
Amazon ECS 是现有生态系统的一部分。
Amazon ECS 是 AWS 生态系统的一部分。这在某些情况下带来了优势,而在其他情况下则带来了缺点。例如,与 Kubernetes 相比,初始设置更容易和更快速,因为你可以通过 AWS 管理控制台进行设置,而不需要设置 Kubernetes 所需的控制面板。
然而,ECS 也有较高的供应商锁定,这会阻止你将容器化应用程序迁移到其他提供商或平台。相比之下,Kubernetes 是一个开源解决方案,允许将容器迁移到其他地方,包括混合云和多云提供商。
AWS 定期发布对数据科学家感兴趣的新产品。例如,在 2018 年,该公司推出了 一个机器学习市场,其中包含了 150 多个新的模型和算法供尝试。你还可以找到 详细的 AWS 产品分解,这些产品可以支持你的数据科学项目。
如果你已经使用了许多 AWS 提供的产品或计划很快使用它们,选择 ECS 可能比选择 Kubernetes 更有意义。否则,你可能会觉得 ECS 过于限制。
数据科学中心的 Kubernetes 教程 readily available。
数据科学家很容易找到有关使用 ECS 的一般信息,但关于如何在工作中使用 ECS 的具体信息则不太常见。这种现象可能意味着人们在学习如何将 ECS 应用于数据科学项目时,特别是在使用的早期阶段,花费的时间比预期的要多。
尽管一些针对数据科学家的课程 涵盖了如何使用 ECS,但内容通常只包括涉及数据科学课程中更广泛主题的单个模块。
另一方面,你可以快速找到面向数据科学家的 Kubernetes 解释器。这些解释器使你更容易想象为什么你可能希望使用它而不是其他服务。同样,内容创作者提供了将 Kubernetes 应用于数据科学项目的实际例子,例如预测客户流失率。
ECS 成本可能更为简单
一些数据科学家可能希望使用 ECS 或 Kubernetes,同时自己承担费用,而不是依赖雇主。在这种情况下,计算与 ECS 相关的费用可能会更简单,因为 AWS 提供了价格计算器来避免惊讶。
AWS 产品也有免费的层级。起初,这听起来似乎是件好事。然而,用户报告说在他们的免费服务资格过期后收到了大额账单,而他们并未意识到这一点。
计算 Kubernetes 定价的主要原因之一是认证服务提供商的网络不断增长,这些提供商可以帮助人们开始使用 Kubernetes。其中一些实体也提供内置 Kubernetes 支持的产品。
这意味着你通过这些供应商使用 Kubernetes 的价格会有所不同。理想的做法是创建一个感兴趣的产品或公司列表,这些公司提供 Kubernetes 支持。然后,花时间研究他们的定价结构,看看哪些最适合你的预算和你希望在 Kubernetes 上进行的数据科学工作量。
没有普遍正确的选项
本概述强调了为什么数据科学家在选择 Kubernetes 和 ECS 时不应草率决策。两者都有优缺点,这可能最终影响数据科学项目。
然而,允许足够的时间来了解每种解决方案是明智的。考虑一下你管道中的任何项目,这些项目可能涉及到你使用容器化解决方案。然后,审查每个产品的特性,并确定哪些最适合你的情况和期望。以这种方式仔细审查每个选项将导致明智的决策。
简介:Devin Partida 是一位大数据和技术作家,同时也是 ReHack.com 的主编。
相关:
-
你不必再使用 Docker 了
-
5 个容器将统治数据科学的理由
-
使用 Kubernetes 对 PySpark 进行容器化
更多相关内容
使用 Snorkel 标记数据
原文:
www.kdnuggets.com/2020/07/labelling-data-using-snorkel.html
评论
由 Alister D’Costa、Stefan Denkovski、Michal Malyska、Sally Moon、Brandon Rufino、NLP4H 撰写

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
在本教程中,我们将逐步介绍如何使用 Snorkel 为未标记的数据集生成标签。我们将通过引导您完成 Snorkel 在实际临床应用中的基本组件示例,具体来说,我们将使用 Snorkel 尝试提升预测多发性硬化症 (MS) 严重程度评分的结果。祝您使用愉快!
查看Snorkel 简介教程,了解垃圾邮件标记的详细步骤。有关 Snorkel 在实际应用中的高性能示例,请参阅Snorkel 的出版物列表。
查看我们其他关于 MS 严重程度分类的 NLP 相关工作这里。
Snorkel 是什么?
Snorkel 是一个简化构建和管理训练数据集过程的系统,无需手动标记。Snorkel 流水线的第一个组件包括标记功能,这些功能旨在作为弱启发式函数,根据未标记的数据预测标签。我们为 MS 严重程度评分标记开发的标记功能如下:
-
在文本中进行多个关键字搜索(使用正则表达式)。例如,在查找严重程度评分时,我们搜索了数字格式和罗马数字格式的短语。
-
常见基准如逻辑回归、线性判别分析和支持向量机,这些基准使用词频-逆文档频率(或简称 tf-idf)特征进行训练。
-
Word2Vec 卷积神经网络 (CNN)。
-
我们的 MS-BERT 分类器在 这篇博客文章 中进行了描述。
Snorkel 管道的第二个组件是一个生成模型,它根据所有标注函数的预测输出每个数据点的单个置信度加权训练标签。它通过学习估计标注函数的准确性和相关性来完成此任务,基于它们的一致性和不一致性。
Snorkel 教程
重申一下,在本文中,我们演示了 MS 严重性评分的标签生成。MS 严重性的一种常见测量是 EDSS 或扩展残疾状态量表。这是一个从 0 增加到 10 的量表,具体取决于 MS 症状的严重程度。我们将 EDSS 通称为 MS 严重性评分,但为了我们的细心读者,我们提供了这些信息。这个评分的详细描述见 这里。
步骤 0: 获取数据集
在我们的任务中,我们使用了由领先的 MS 研究医院编制的数据集,该数据集包含超过 70,000 个 MS 咨询笔记,涵盖约 5000 名患者。在这 70,000 个笔记中,只有 16,000 个由专家手动标记了 MS 严重性。这意味着大约有 54,000 个未标记的笔记。你可能知道,拥有更大的数据集来训练模型通常会带来更好的模型性能。因此,我们使用 Snorkel 为我们的 54,000 个未标记笔记生成了我们称之为“银标签”的标签。这 16,000 个“金标签”笔记被用来训练我们的分类器,然后再创建它们各自的标注函数。
步骤 1: 安装 Snorkel
要将 Snorkel 安装到你的项目中,你可以运行以下命令:
步骤 2: 添加标注函数
设置
标注函数允许你定义弱启发式和规则,以预测给定未标记数据的标签。这些启发式可以源自专家知识或其他标注模型。在 MS 严重性评分预测的情况下,我们的标注函数包括:从临床医生那里获得的关键词搜索函数、训练预测 MS 严重性评分的基线模型(tf-idf、word2vec cnn 等),以及我们的 MS-BERT 分类器。
正如你将看到的那样,你通过在函数上方添加“@labeling_function()”来标记标注函数。对于每个标注函数,将传入包含未标记数据(即一个观察/样本)的一行数据框。每个标注函数应用启发式或模型来获取每行的预测。如果未找到预测,函数将弃权(即返回 -1)。
当所有标注函数定义完成后,你可以使用“PandasLFApplier”来获取给定所有标注函数的预测矩阵。
运行以下代码后,你将获得一个 (N X num_lfs) 的 L_predictions 矩阵,其中 N 是‘df_unlabelled’中的观察数,‘num_lfs’ 是在‘lfs’中定义的标注函数数量。
标注函数示例 #1:关键字搜索
下文展示了一个关键字搜索的示例(使用正则表达式),用于提取以十进制形式记录的 MS 严重性评分。正则表达式函数用于尝试搜索以十进制形式记录的 MS 严重性评分。如果找到,函数将以适当的输出格式返回评分。否则,函数将 abstain(即返回-1),以指示未找到评分。
标注函数示例 #2:训练分类器
上文展示了一个使用关键字搜索的示例。要集成一个训练好的分类器,你必须额外执行一步。即,你必须在创建标注函数之前训练并导出你的模型。这是一个基于 tf-idf 特征的逻辑回归模型训练的示例。
训练好模型后,实现标注函数就简单如是:
步骤 3(a):使用 Snorkel 的多数投票
有人会说,Snorkel 用于生成标签的最简单函数是‘多数投票’。正如名字所示,多数投票基于投票最多的类别做出预测。
要实现多数投票,你必须指定‘cardinality’(即类别数量)。
步骤 3(b):使用 Snorkel 的标签模型
为了充分利用 Snorkel 的功能,我们使用了‘标签模型’来生成一个基于所有标注函数获得的预测矩阵(即 L_unlabelled)的单一置信加权标签。标签模型通过学习估计标注函数的准确性和相关性来进行预测,基于它们的同意和分歧。
你可以定义一个标签模型并指定‘cardinality’。在用 L_unlabelled 训练标签模型后,它将为未标记数据生成单一预测。
步骤 4:评估工具
LF 分析 — 覆盖率、重叠、冲突
为了更好地理解你的标注函数的功能,你可以利用 Snorkel 的 LFAnalysis。LF 分析报告每个标注函数的极性、覆盖率、重叠和冲突。
这些术语的定义如下,你可以参考 Snorkel 文档 以获取更多信息:
-
极性:基于标签矩阵中的证据推断每个 LF 的极性。
-
覆盖率:计算至少有一个标签的数据点比例。
-
重叠:计算至少有两个(非 abstain)标签的数据点比例。
-
冲突:计算每个标注函数与至少一个其他标注函数意见不一致的数据点比例。
LFAnalysis 将提供关于你的标注函数在相互之间的表现分析。
get_label_buckets
Snorkel 提供了一些额外的评估工具,帮助你理解标签函数的质量。特别是,get_label_buckets是一个方便的方式来合并标签并进行比较。有关更多信息,请阅读Snorkel 文档。
以下代码允许你比较真实标签(y_gold)和预测标签(y_preds),以查看 Snorkel 正确或错误标记的数据点。这将帮助你找出哪些数据点难以正确标记,从而调整你的标签函数以涵盖这些边缘案例。
注意,对于这项分析,我们回到创建了一个包含‘黄金’标签数据集的标签函数预测的 L_train 矩阵。
另外,你可以使用get_label_buckets来比较标签函数。
以下代码允许你比较 L_unlabelled 中的标签预测,观察不同标签函数如何以不同方式标记数据点。
第 5 步:部署
选择最佳标签模型以标记未标记的数据
按照上述程序,我们基于关键字搜索、基线模型和 MS-BERT 分类器开发了各种标签函数。我们尝试了不同的标签函数组合,并使用 Snorkel 的 Label Model 获得了对保留标签数据集的预测。这使我们能够确定哪个标签函数组合最适合标记我们的未标记数据集。
如下表所示,我们观察到仅 MS-BERT 分类器(MSBC)在 Macro-F1 上比所有包含它的组合表现更好至少 0.02。添加较弱的启发式方法和分类器会持续降低组合的性能。此外,我们还观察到随着较弱分类器和启发式方法的添加,MS-BERT 分类器的冲突量增加。

注意,基于规则(RB)指的是我们的关键字搜索。LDA 指线性判别分析。TFIDFs 指所有基于 tf-idf 特征构建的模型(即逻辑回归、线性判别分析和支持向量机)。
要理解我们的发现,我们必须提醒自己,Snorkel 的标签模型学习根据彼此之间的一致性和分歧来预测标记函数的准确性和相关性。因此,在存在强标记函数(如我们的 MS-BERT 分类器)的情况下,添加较弱的标记函数会引入更多与强标记函数的分歧,从而降低性能。从这些发现中,我们了解到 Snorkel 可能更适合只有弱启发式和规则的情况。然而,如果你已经有了一个强标记函数,开发一个带有较弱启发式的 Snorkel 集成可能会影响性能。
因此,MS-BERT 分类器单独被选择用于标记我们的未标记数据集。
半监督标记结果
MS-BERT 分类器被用于为我们的未标记数据集获得“银牌”标签。这些“银牌”标签与我们的“金牌”标签结合,得到了一个银+金数据集。为了推断银牌标签的质量,开发了新的 MS-BERT 分类器:1) MS-BERT+(在银+金标记数据上训练);2) MS-BERT-silver(在银标记数据上训练)。这些分类器在之前用于评估我们原始 MS-BERT 分类器(在金标记数据上训练)的持出测试数据集上进行了评估。MS-BERT+ 达到了 0.86238 的 Macro-F1 和 0.92569 的 Micro-F1,而 MS-BERT-silver 达到了 0.82922 的 Macro-F1 和 0.91442 的 Micro-F1。尽管它们的表现略低于我们原始 MS-BERT 分类器(Macro-F1 为 0.88296,Micro-F1 为 0.94177),但仍超越了以前最佳的 MS 严重性预测基准模型。MS-BERT-silver 的强劲结果有助于展示使用我们的 MS-BERT 分类器作为标记函数的有效性。这表明它有潜力减少专业人员阅读患者咨询笔记并手动生成 MS 严重性评分所需的繁琐时间。
感谢!
感谢大家的阅读!如果有任何问题,请随时通过 nlp4health (at gmail dot) com 联系我们。 😃
致谢
我们要感谢圣迈克尔医院数据科学与高级分析(DSAA)部门的研究人员和工作人员,在整个项目过程中提供了一致的支持和指导。我们还要感谢 Marzyeh Ghassemi 博士和 Taylor Killan,感谢他们给我们提供了参与这个令人兴奋的项目的机会。最后,我们要感谢圣迈克尔医院 MS 门诊的 Tony Antoniou 博士和 Jiwon Oh 博士,感谢他们对神经检查笔记的支持。
最初发布于https://nlp4h.com。
简介: 作者 是一组在多伦多大学从事医疗 NLP 研究的研究生。
原文。经许可转载。
相关:
-
手工标注已成过去。未来是 #NoLabel AI
-
从语言到信息:斯坦福大学的另一个出色 NLP 课程
-
深度神经网络在自然语言处理(NLP)中的不合理进展
更多相关内容
拉格朗日乘子法的可视化和代码
原文:
www.kdnuggets.com/2019/08/lagrange-multipliers-visualizations-code.html
评论
作者 Rohit Pandey,LinkedIn 高级数据科学家
在这个故事中,我们将进行一次关于拉格朗日乘子法的空中游览。我们什么时候需要它?每当我们有一个带有约束的优化问题时。以下是一些例子:
-
一家对冲基金想决定在其投资组合中包括哪些比例的股票,以获得尽可能高的预期回报,同时保持在某个风险承受范围内(风险可以通过回报的方差来衡量等)。
-
一个学区希望确定他们的午餐菜单上各种项目的分配。他们想要在确保孩子们获得所需的所有营养素的同时,最小化每顿午餐的成本。
-
一家货运公司想将货物从源仓库运送到目的城市。给定每个仓库-城市对的运输成本、每个仓库的总供应量和每个城市的总需求量,决定从每个仓库到每个城市的运输量,以便在满足需求的同时最小化整体成本(约束条件)。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业领域。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 部门
我们可以看到,受限优化可以解决从物流到金融等领域的许多实际问题。在接下来的博客中,我们将从无约束优化开始。然后,我们将添加等式约束。接着,我们将描述完全通用的受限优化问题的解决方案,包括等式和不等式约束(这些条件称为 KKT——Karush、Kuhn、Tucker 条件)。最后,我们展示这些条件在一些玩具问题上的力量。许多人认为 Nocedal 和 Wright 的书是数值优化的经典之作,我们将大致遵循第十三章,略过严格的证明(可以从文本中阅读)而更多关注于直观理解。
无约束优化
在这种情况下,我们控制了一些变量,并且目标函数依赖于这些变量。变量没有约束,目标函数需要被最小化(如果是最大化问题,我们可以简单地将目标函数取负值,那么它就变成了一个最小化问题)。
在任何点,对于一维函数,函数的导数指向增加它的方向(至少对于小步而言)。这意味着如果我们有一个函数 ( f(x) ) 并且导数 ( f'(x) ) 为正,那么增加 ( x ) 会增加 ( f(x) ),减少 ( x ) 会减少 ( f(x) )。如果我们在最小化 ( f(x) ),我们只需沿着 ( f'(x) ) 符号相反的方向迈出小步来减少 ( f(x) )。如果我们在 ( f'(x) ) = 0 的点上怎么办?那么,我们可能已经达到了 ( f(x) ) 的最优点,因为没有其他地方可去。
如果有多个变量(比如 ( x ) 和 ( y )),我们可以分别计算它们的导数。如果我们取这两个数字并构造一个二维向量,就得到了函数的梯度。现在,沿着梯度的方向移动会增加函数值,而沿着相反的方向移动会减少函数值(对于小步而言)。
这意味着只要梯度不为零,我们就不能处于极小值,因为我们可以沿着梯度的相反方向迈出小步,从而进一步减少函数值。这意味着,一个点成为函数极小值的必要(但不充分)条件是该点的梯度必须为零。
让我们举一个具体的例子,以便可视化它的样子。考虑函数 ( f(x, y) = x² + y² )。这是一个抛物面,当 ( x = 0 ) 和 ( y = 0 ) 时达到最小值。对于 ( x ) 和 ( y ) 的导数分别是 ( 2x ) 和 ( 2y )。因此,梯度变成了向量 ∇f = [2x, 2y]。我们可以看到,当 ( x = 0 ) 和 ( y = 0 ) 时梯度为零。否则,梯度指向的方向会使 ( f(x, y) ) 增加。因此,梯度的相反方向会减少 ( f(x, y) )。这在下面的图中展示了。粉色曲线是目标函数 ( f(x, y) ),在绿色点 (0,0) 处最小化。紫色箭头是梯度,它们指向 ( f(x, y) ) 增加的方向。因此,为了减少 ( f(x, y) ),我们需要朝着相反的方向移动,直到到达绿色点。
 图 1:带梯度的抛物面。使用
图 1:带梯度的抛物面。使用 github.com/ryu577/pyray 制作
总结一下,在优化一个函数 ( f ) 的无约束优化问题时,成为局部最优点的必要(但不充分)条件是:
∇f = 0
这就像你站在山顶(这就是一个极大值)。你怎么知道你在山顶?无论你沿哪个方向迈步,你都会降低你的高度。所以你肯定在你所在的局部邻域内达到了一个最优解。现在,可能在你旁边还有另一座更高的山。所以,你可能没有达到全局最优解。实际上,如果我们把地球的表面作为我们的领域(海拔高度作为我们的目标函数),那么你如果在任何一座山(或建筑物)的顶端,都是局部最优解,但只有当那座山是珠穆朗玛峰时,你才会达到全局最优解。在这篇文章中,我们将满足于寻找局部最优解。
现在,如果我们想要保持在一个国家的范围内呢?这意味着要限制我们可以搜索最优解的空间,这就成了一个约束优化的例子。在某种程度上,无约束优化只是约束优化的一个特例。
等式约束
对于无约束的最小化/最大化问题,我们简单地寻找梯度为零向量的点。如果梯度不为零,我们只需朝着与梯度相反的方向(如果我们在最小化;如果我们在最大化则沿梯度方向)迈出一小步,并不断重复这个过程,直到我们找到一个梯度为零的点,这样就没有其他方向可以移动了(这种优化方法称为梯度下降)。注意,我们不必完全沿梯度方向移动。只要我们沿着在梯度方向上有正投影(影子)的方向移动,我们最终会增加目标函数(如果我们在负梯度方向上有正投影则会减少目标函数)。下图对此进行了说明。绿色箭头是蓝色平面的梯度(因此与之垂直),红色箭头是负梯度。由于浅蓝色箭头位于平面上,如果我们沿着这些箭头迈出一步,平面的方程将会得到 0。黄色箭头在绿色箭头方向上有正影子(投影)。因此,沿着这些箭头移动会得到在平面方程中代入后会得到正数的点(即“增加”它)。类似地,粉色箭头在红色箭头(反梯度)方向上有正影子。因此,沿这些箭头移动会得到在平面方程中代入后会得到负数的点(即“减少”它)。
 图 2:平面两侧的向量。具体解释见正文。使用
图 2:平面两侧的向量。具体解释见正文。使用 github.com/ryu577/pyray 制作。
对于无约束最小化问题,我们寻找梯度为零的点。这是因为如果梯度不为零,我们可以通过沿梯度的反方向来降低目标函数。
相同的想法可以扩展到我们有等式约束的情况。像之前一样,我们需要找到一个无法找到任何可能移动方向的点,其中目标函数减少。对于无约束优化,这仅意味着不存在这样的方向。当我们有约束时,还有另一种可能性。如果存在一个减少目标函数的方向,但约束条件禁止我们沿着它迈出任何一步怎么办?
假设你想最大化银行账户中的资金。一种立即增加收入的方法是卖掉一个肾脏。但你可能有一个约束条件,表示你不会失去一个重要的器官。因此,即使存在一种简单的方法来增加你的收入,你的约束条件也阻止了你访问它。
这意味着等式约束的存在实际上减少了对梯度的条件的严格性。在没有等式约束的情况下,它需要为零才能获得局部最优解,而现在只要朝着有正投影的任何方向移动会导致我们违反约束,它非零也是可以的。这只有在约束平面与梯度垂直时才会发生(如图 2 中的平面和绿色箭头)。
让我们回到目标函数 f(x,y)=x²+y²。我们增加一个等式约束,y=1。这是一个平面。在下面的图 3 中,目标函数是粉色的,平面是蓝色的。由于我们被限制在平面上,我们不能沿平面的梯度(下图中的蓝色箭头)朝任何方向移动,因为那会增加或减少约束方程,而我们希望保持它不变。平面与目标函数方程(粉色抛物面)相交形成一条抛物线。下图中的粉色箭头是沿这条抛物线的目标函数的梯度。如果粉色箭头在蓝色平面上有一个投影,我们可以朝着与该投影对应的向量的相反方向移动。这将保持我们在平面上,确保我们不违反约束,同时减少目标函数。然而,在下图 3 中的绿色点,粉色箭头(目标函数的梯度)在蓝色平面上没有任何投影。换句话说,粉色箭头与蓝色箭头(即约束平面梯度)平行。
 图 3:约束梯度在最优点与目标函数梯度对齐。制作使用了
图 3:约束梯度在最优点与目标函数梯度对齐。制作使用了 github.com/ryu577/pyray
为了减少目标函数,我们需要朝着具有负梯度分量的方向移动。但一旦我们这样做,就会离开约束平面。因此,约束使得在绿色点进一步减少目标函数变得不可能。这意味着它必须是局部极小值。检查这个条件的简单方法是要求目标函数的粉色梯度与约束平面的蓝色梯度平行。如果两个向量平行,我们可以将一个写作另一个的倍数。我们将这个倍数称为 λ。如果目标函数的梯度是 ∇f,约束的梯度是 ∇c,上述条件是:
∇f = λ ∇c
上述 λ 称为拉格朗日乘子。因此,我们现在有了一个具体的条件,用来检查约束优化问题的局部最优解。
不等式约束
不等式约束意味着你必须保持在定义约束函数的边界的一侧,而不是在边界上(这在等式约束的情况下)。例如,保持在栅栏的边界内。如果我们知道如何处理不等式约束,我们就可以解决任何约束优化问题。这是因为等式约束可以转换为不等式约束。假设我们要求:c(x) = 0. 另一种表达方式是:c(x)≥0 和 c(x)≤0. 因此,每个等式约束总是可以替换为两个不等式约束。
就像前一节中描述的那样,使用拉格朗日乘子处理等式约束的优化问题,不等式约束的优化问题也可以用拉格朗日乘子来处理。不等式约束条件与等式约束条件的区别在于,不等式约束的拉格朗日乘子必须是正值。为什么呢?我们可以考虑在梯度方向上取一个小步。如果我们能在这个方向上(如果我们是在最大化;如果我们是在最小化,则方向相反)迈出一步,那我们就不能处于极大值/极小值点。对于不等式约束来说,这意味着拉格朗日乘子必须是正值。为了理解这一点,我们可以回顾一下之前考虑的约束优化问题(图 3)。
最小化:f(x,y) = x²+y²
约束条件:c(x,y)=y-1=0
现在,我们将等式约束改为不等式约束。这可以通过两种完全不同的方式完成。我们可以要求:
c(x,y) = y-1 ≥0。在这种情况下,约束允许在图 3 中蓝色平面的前方的任何位置。很容易看出,图 3 中的绿色点仍然是局部最优点。此外,由于表示约束梯度的蓝色箭头和表示目标函数梯度的粉色箭头指向相同的方向,我们有:
∇f = λ ∇c
其中 λ>0。
另一种可能性是,c(x,y) = y-1≤0。现在,可行区域变为 蓝色平面 后面的所有区域。约束梯度将翻转。因此,图 3 将变成这样:
 图 4: 翻转图 3 中的不等式约束符号。
图 4: 翻转图 3 中的不等式约束符号。
请注意,现在,
-
绿色点不再是局部最优点,因为我们可以自由移动到 (0,0);这是图 4 中的黄色点。
-
在绿色点,我们仍然有 ∇f=λ ∇c。由于蓝色向量指向与粉色向量相反的方向,我们有 λ<0。
因此,对于不等式约束,条件 ∇f=λ ∇c 仅当 λ>0 时表明我们在局部最优点。
综合这些,对于一般优化问题:
最小化 f(x)
受限于:
c_i(x)=0 对于 i ∈ 等式
c_i(x)≥0 对于 i ∈ 不等式
我们得到了成为局部最优点所需的完整条件:
拉格朗日乘子条件:
∇f =∑_i λ_i ∇c_i(x) +∑_j λ_j ∇c_j(x); Eq(1)
其中 i ∈ 等式约束,j ∈ 不等式约束。
c_i(x)=0 对所有 i; Eq(2)
c_j(x)≥0 对所有 j; Eq(3)
λ_j ≥ 0; Eq(4)
同样注意,对于我们考虑的两个不等式约束问题,当我们有 y-1≥0 时,图 3 中的绿色点是解。此时,我们在约束平面 (y-1=0) 上。因此,我们实际上有 c(x)=0 和 λ>0。
当我们考虑 y-1≤0 时,图 4 中的黄色点 (x=0,y=0) 成为局部最小值。这个点也是无约束问题的解。因此,我们这里有 ∇f=0。由于拉格朗日条件要求 ∇f = λ ∇c,我们得到 λ ∇c = 0。现在,∇c ≠0,这意味着我们必须有:λ=0。
这意味着如果约束是活跃的 (c(x)=0),我们应该有 λ≥0,而如果它不是 (c(x)≠ 0),我们应该有 λ=0。因此,在所有情况下,其中一个应该是零。这导致最终条件(互补条件):
λ_j c_j(x) = 0 对所有 j ∈ 不等式; Eq(5)
方程(1)至(5)被称为 KKT 条件。请注意,我们实际上没有提供严格的证明,仅仅是基于简单示例进行构造。要获得证明,读者应参阅 Nocedal 和 Wright 的书第十三章。
许多人看到这五个方程时,觉得问题变得更加复杂。这些方程如何实际帮助我们解决约束优化问题呢?最好的方法是通过一些具体的例子来感受这一点。在下一节中,我们将用一个我们已知答案的样本问题来看看 KKT 条件如何帮助我们正确识别所有局部最优点。
带代码的示例
一般化优化问题的特例涉及线性目标函数和线性约束。这被称为线性约束线性规划(LCLP)。目标函数和约束也可以是二次的,这样的优化问题称为二次约束二次规划(QCQP)。有些软件包能够解决这些优化问题,即使约束数量极大(达百万级)。然而,对于约束数量较少的简单问题,我们可以利用能够解决大多数(更一般的)多项式约束多项式规划的算法。这意味着目标函数和约束可以是任意的多项式函数。这是因为存在一种通用的框架来解决多项式方程组,称为“布赫伯格算法”,而上述 KKT 条件可以简化为一个多项式方程组。我在这里写了一篇关于布赫伯格算法解决多项式方程组的详细博客。还有一个名为“sympy”的 Python 库在后台使用类似的算法来解决通用的多项式方程组。因此,事不宜迟,让我们开始构建第一个约束优化问题。
等式约束
Minimize: x³+y³
Subject to: x²+y²=1
注意到约束(x²+y²=1)意味着我们在单位半径圆的边界上。因此,我们可以说:x=cos(t),y=sin(t)。目标函数变为:sin³(t)+cos³(t)。如果我们以 t 绘制这个函数,我们会得到以下图像:
 图 5:目标函数 sin³(t)+cos³(t) 绘制在约束边界上。
图 5:目标函数 sin³(t)+cos³(t) 绘制在约束边界上。
我们可以看到,t=0、π/2 和 5π/4 对应局部最大值,而 t=π/4、π 和 3π/2 对应局部最小值。既然我们已经提前知道答案了,让我们看看上面描述的 KKT 条件是否也能找到这些答案。
方程(1)给出(对目标函数和约束条件进行求导):
[3x², 3y²] = λ[2x, 2y]
将两个向量两边的分量进行等式比较得到两个方程:
3x²-2λx=0
3y²-2λy=0
方程(2)只要求满足等式约束:
x²+y²=1
由于没有不等式约束,我们不需要方程(3)到(6)。现在,我们可以将上述三个方程输入到 Python 库 sympy 提供的符号方程求解器中。
这导致了以下结果(上述系统中 x、y 和λ的所有可能解,按此顺序):
[(-1, 0, -3/2),
(0, -1, -3/2),
(0, 1, 3/2),
(1, 0, 3/2),
(-sqrt(2)/2, -sqrt(2)/2, -3*sqrt(2)/4),
(sqrt(2)/2, sqrt(2)/2, 3*sqrt(2)/4)]
(-1,0) 对应 t=π;(0,-1) 对应 t=3π/2;(-sqrt(2)/2,-sqrt(2)/2) 对应 t=5π/4,而 (sqrt(2)/2,sqrt(2)/2) 对应 t=π/4。因此,我们可以看到,上述识别的所有局部极大值和局部极小值都已被 KKT 条件识别。现在,我们可以简单地在这些候选点处找到目标函数的最大值和最小值。
不等式约束
现在,让我们将上述问题的等式约束改为不等式约束,看看这如何改变我们的解。
Minimize: x³+y³
Subject to: x²+y²≤1
在之前的情况下,约束表明我们只能位于单位圆的边界上,而现在我们可以在圆盘内部的任何地方。
约束圆盘内目标函数的完整热图如下绘制(看起来像一个行星,星星位于右上角附近)。红色箭头是约束边界的梯度,而黑色箭头是目标函数的梯度。
 图 6: x³+y³ 在圆盘 x²+y²≤1 内的绘制
图 6: x³+y³ 在圆盘 x²+y²≤1 内的绘制
虽然等式约束问题是一个一维问题,但这个不等式约束优化问题是二维的。在一维中,只有两种方式接近一个点(从左或右);而在二维中,有无数种方式接近它。这意味着我们需要警惕鞍点。这些点符合最优点的条件,但实际上并不是最优点,因为从一个方向接近它时它是极大值,而从另一个方向接近时它是极小值。下图展示了鞍点的样子。
 图 7: 一个鞍点。从一个方向接近时是极大值,从另一个方向接近时是极小值。
图 7: 一个鞍点。从一个方向接近时是极大值,从另一个方向接近时是极小值。
因此,我们需要重新评估在等式约束情况下的所有局部极小值或极大值点,并确保其中没有变成鞍点的点。
图 5 告诉我们,当沿边界接近 t=0 (x=1,y=0) 时,它是局部极大值。而当我们从圆盘内部接近该点时(例如沿着 x=0,y=0 到该点的直线),目标函数的值在接近时增加。因此,无论从哪个方向接近,t=0 都是局部极大值。类似的论证(或注意 x 和 y 的对称性)适用于 t=π/2。
同样地,我们可以认为 t=π 和 t=3π/2 是局部极小值,无论从可行区域内部的哪个方向接近它们。
然而,当观察 t=π/4 时,我们从图 5 中可以看到,沿边界接近它会使其成为局部极小值。然而,从圆盘内部接近它(例如沿着连接原点到这个点的直线)则使其成为局部极大值。因此,它总体上既不是局部极大值也不是局部极小值。这样的点称为鞍点。类似地,t=5π/4 也是一个鞍点。
现在,让我们看看 KKT 条件对我们的问题有什么说法。将目标函数和约束代入 KKT 方程(1)至(5),我们得到:
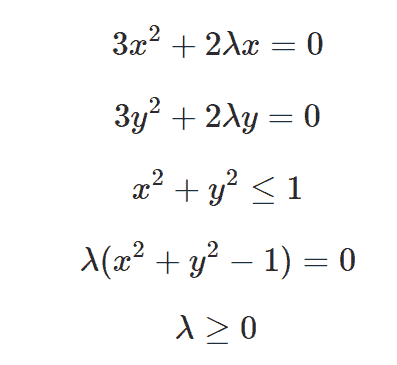 方程 6 (a)至(e)。
方程 6 (a)至(e)。
为了利用多项式方程求解器,我们需要将这些方程转换为一个多项式方程系统。前两个条件(6-(a)和(b))已经是方程。第三个,x²+y²≤1(6-(c))是一个不等式。但我们可以通过引入一个松弛变量 k 将其转换为等式;x²+y²+k²=1。最后一个方程,λ≥0 也是不等式,但如果我们将λ替换为λ²,就可以省略它。现在,我们演示如何将这些输入到 Python 提供的符号方程求解库中。
解决上述提到的优化问题的 KKT 条件的代码。
这会产生如下结果(按顺序给出系统的各种解,其中包含变量 x, y, λ, k):
[(-1, 0, -sqrt(6)/2, 0),
(-1, 0, sqrt(6)/2, 0),
(0, -1, -sqrt(6)/2, 0),
(0, -1, sqrt(6)/2, 0),
(0, 0, 0, -1),
(0, 0, 0, 1),
(0, 1, -sqrt(6)*I/2, 0),
(0, 1, sqrt(6)*I/2, 0),
(1, 0, -sqrt(6)*I/2, 0),
(1, 0, sqrt(6)*I/2, 0),
(-sqrt(2)/2, -sqrt(2)/2, -2**(1/4)*sqrt(3)/2, 0),
(-sqrt(2)/2, -sqrt(2)/2, 2**(1/4)*sqrt(3)/2, 0),
(sqrt(2)/2, sqrt(2)/2, -2**(1/4)*sqrt(3)*I/2, 0),
(sqrt(2)/2, sqrt(2)/2, 2**(1/4)*sqrt(3)*I/2, 0)]
上述解中的大写‘I’指的是单位根。我们想要排除这些解,因为我们要求λ²≥0。这意味着满足 KKT 条件的点是:(-1,0);(0,-1);(0,0);(-1/sqrt(2),-1/sqrt(2))。如前所述,点(-1,0)(对应 t=π)和(0,-1)(对应 t=3π/2)是极小值。(0,0)和(-1/sqrt(2),-1/sqrt(2))是也被网捕获的鞍点。但请注意,没有局部极大值被捕获。我留给你一个小挑战。改变上述代码,使其捕获极大值而不是极小值。
个人简介:Rohit Pandey 是 LinkedIn 的高级数据科学家
原文。经许可转载。
相关:
-
使用 Python 优化:如何用最少的风险获得最多的收益?
-
使用 PuLP 进行线性规划和离散优化
-
优化如何运作
了解更多
如何在 6 个月内获得数据分析职位
原文:
www.kdnuggets.com/2021/06/land-data-analytics-job-6-months.html
评论

数据分析师是全球最受欢迎的职业之一。这些人利用数据帮助公司做出明智的商业决策。
目前,数据科学的炒作非常盛行。
然而,数据科学的入门门槛非常高。这是一个非常竞争激烈的领域,各种教育背景的人都希望进入。
获得数据分析职位要比数据科学职位容易得多。
大多数数据科学职位要求拥有定量领域的研究生学位。然而,我认识的大多数数据分析师来自完全不相关的背景,并没有技术学位。
数据分析技能可以通过参加在线课程和训练营轻松获得。学习曲线不像数据科学那么陡峭,学习时间也可以更短。
即使你没有任何编程或技术经验,你也可以在短短几个月内获得成为数据分析师所需的技能。
我通过这些资源在短短六个月内获得了数据分析的实习机会。
在做了三个月的实习后,我收到了加入公司作为数据分析师的邀请。
在这篇文章中,我将描述我学习数据分析所采取的步骤。这些资源的发现和制定个人路线图经过了大量的试错过程。
如果你按照这些步骤,你可以在几个月内学习到获得入门级数据分析职位所需的技能。根据你每天学习的时间,你甚至可以在六个月内更快地完成。
步骤 1:学习 Python

图片由 Christopher Gower 提供,刊登在 Unsplash
要进入分析领域,你首先需要学习一门编程语言。Python 和 R 是该领域最常用的两种语言。
如果你刚刚起步,我强烈建议学习 Python。它比 R 更友好,更容易上手。Python 还有大量的库,使得数据预处理等任务变得更加简单。
Python 的使用也比 R 更广泛。如果你未来转到如网页开发或机器学习等领域,你将不需要学习新的语言。
在线课程
a) 2020 完整 Python 精通训练营:从零到英雄:
如果你是完全没有编程经验的初学者,请参加这个课程。课程将介绍 Python 语法基础,并学习变量、条件语句和循环。这个课程由 Jose Portilla 授课,他是 Udemy 上最好的讲师之一。
一旦你对 Python 的基础和语法有了了解,你可以开始学习如何使用它来分析数据。这个课程将引导你了解特定于数据分析的库,如 Numpy、Matplotlib、Pandas 和 Seaborn。
完成这两个课程后,你将对 Python 及其在分析领域的应用有基本了解。然后,我建议继续进行一些语言实践。
编码挑战网站
为了获得实践经验,可以访问像 HackerRank 和 LeetCode 这样的编码挑战网站。我强烈建议 HackerRank。它们提供了各种难度的编码挑战。从最简单的开始,然后逐渐提高难度。
当你开始从事分析工作时,你会每天遇到编程问题。像 HackerRank 这样的站点将帮助提高你的问题解决技能。
每天花大约 4-5 小时解决 Python HackerRank 问题。坚持一个月左右,你的 Python 编程技能将足够好,可以找到一份工作。
步骤 2:学习 SQL
图片由 David Pupaza 提供,来源于 Unsplash
SQL 技能是获得分析工作所必需的。你的日常任务通常包括从数据库中查询大量数据,并根据业务需求对数据进行处理。
许多公司将 SQL 与其他框架集成,并期望你知道如何使用这些框架查询数据。
SQL 可以在像 Python、Scala 和 Hadoop 等语言中使用。这将根据你所在的公司有所不同。然而,如果你知道如何使用 SQL 进行数据处理,你将能够轻松掌握其他 SQL 集成框架。
我参加了 Udacity 提供的这个免费课程,以学习数据分析中的 SQL。DataCamp 也有一个受欢迎的SQL for data analytics课程,你可以尝试一下。
步骤 3:数据分析与可视化
图片由 Clay Banks 在 Unsplash 提供
你需要知道如何分析数据并从中得出洞察。仅仅知道如何编程或查询数据是不够的。你需要能够用这些数据回答问题和解决问题。
要学习 Python 中的数据分析,你可以参加 这个 Udemy 课程,或者可以在 DataCamp 上追求 数据分析师职业轨迹。
在从数据中得出洞察后,你应该能够 展示这些洞察。利益相关者需要根据你展示的洞察做出商业决策,因此你需要确保你的展示清晰而简洁。
这些洞察通常借助数据可视化工具进行展示。可以使用 Excel、Python 库或像 Tableau 这样的商业智能工具来创建可视化。
如果你想成为数据分析师,我建议学习 Tableau。它是最常用的报告工具之一,并且受到大多数雇主的青睐。
这个由 Kirill Eremenko 提供的 Udemy 课程是学习 Tableau 的最佳资源之一。
第 4 步:数据讲故事和展示

图片由 Dariusz Sankowski 在 Unsplash 提供
完成前三个步骤后,你已经具备了获得数据分析入门级职位所需的所有技能。
现在,你需要向潜在雇主展示这些技能。如果你没有技术背景,你需要向招聘人员展示你具备成为分析师的必要技能。
为此,我强烈建议你建立一个数据分析作品集。在 Tableau 中构建仪表板,使用 Python 分析 Kaggle 数据集,并撰写关于你新掌握技能的文章。
你可以在 这里 查看我的作品集网站。
这里有一些你可以在作品集中展示的数据分析项目的例子:
-
创建一个 Covid-19 全球地图仪表板
-
从 Spotify 抓取音乐数据以识别表现最佳的艺术家
-
使用 LinkedIn 数据识别薪资最高的地区
在简历中展示这样的项目会使你在潜在雇主面前脱颖而出。
确保围绕你创建的项目讲故事。记录你创建项目的每一步,并撰写一篇文章。你甚至可以创建自己的博客并发布这些文章。
这增加了你的文章被其他人看到的机会,也意味着有更高的可能性被潜在雇主看到。
结论
如果你希望进入数据行业,数据分析是一个很好的起点。与机器学习等领域相比,它的进入门槛较低。
如果你喜欢讲故事和制作演示文稿,你会喜欢在分析领域工作。你的日常工作将涉及向非技术人员解释技术概念,你需要不断提升你的沟通技能。
记住,数据分析是一个人们终其一生都在学习的领域。即便是成为分析师所需的单一技能也可能需要一生才能掌握,因此在短短几个月内是不可能精通的。
本文仅针对那些试图获得数据分析入门级工作的人员。
我通过遵循上述步骤在大约 6 个月内找到了分析方面的工作。即使你没有之前的数据经验,每天投入大约 5-6 小时,你也能做到这一点。
教育是你用来改变世界的最强有力的武器
— 纳尔逊·曼德拉
个人简介:Natassha Selvaraj (LinkedIn) 我目前正在攻读计算机科学学位,主修数据科学。我对机器学习领域很感兴趣,并且在这个领域做过各种项目。我还喜欢解决问题和编程,这些都是我每天的工作。
原文。经许可转载。
相关:
-
初学者的十大数据科学项目
-
如何成为数据科学家的指南(逐步方法)
-
数据科学家将在 10 年内灭绝
更多相关话题
-
[停止学习数据科学以寻找目标并找到目标...] (https://www.kdnuggets.com/2021/12/stop-learning-data-science-find-purpose.html)
什么原因让我找数据科学家工作花了这么长时间
评论

照片由 Mārtiņš Zemlickis 在 Unsplash提供。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
我开始我的数据科学之旅时,通过 Coursera 完成了 IBM 数据科学专业证书。这花了我将近两年的时间才找到数据科学家工作。
我找工作花的时间比预期的要长。经过这么长时间的求职,我认为我知道延长我旅程的原因,并且愿意与您分享。
有面试吗?
首要问题是展示我实际上具备技能。没有先前的工作经验,很难展示你的技能。在大多数情况下,我甚至无法通过第一轮,获得技术面试。我觉得 HR 专业人士由于缺乏相关领域的工作经验,没有考虑我的简历。
我获得的技术面试很少,但大多数情况表现良好。这让我感到高兴,并激励我不在技术面试中失败。这是一个好迹象,表明我走在正确的道路上,并且在提高我的知识。
然而,我很难进入技术面试。显然,解决这个问题的有效方法是网络。如果你认识或遇到在该领域工作的人,获得至少一次技术面试的机会会大大增加。
如果你在数据科学领域没有先前的工作经验,最佳的替代方案是完成项目。我指的不是你能在一两天内完成的项目。
你需要框定一个问题,并设计一个以数据解决该问题的方法。然后,实施你的方法。你的项目不一定要完成任务或解决问题。然而,你如何进行分析性思考、处理问题和使用数据作为解决方案非常重要。我知道做这样的项目非常困难,但你至少应该尝试一下。
有空闲时间吗?
对我来说另一个问题是时间不够。在我学习数据科学的两年里,我不得不保留我的工作(与数据科学毫无关系)。因此,我只有晚上和周末来学习。
这不仅仅是时间的问题。你需要有一个清晰的头脑来学习和真正掌握新的概念和技能。如果你计划在学习数据科学的同时工作,请记住,这并不容易。
如果你能够全心投入数据科学学习,整个过程会变得相对容易一些。如果你能够负担得起辞职,你可能会更快地达到目标。然而,这对于一些人,包括我自己,并不是一个选项。
Hello World!
软件或编程是数据科学的基础技能。仅仅具备统计学、机器学习模型的全面理解或出色的分析思维是不够的。你还需要能够使用工具和软件包来实现你的解决方案。
我之前没有任何编程经验。我甚至不得不上了两次“C++导论”课程才能通过。这并不是因为它很难。我只是对编程没有兴趣。我在大学里学习了电气工程,我当时并不认为我会需要编程技能。我明显错了。
我花了一段时间才获得编程技能。我说的可不仅仅是 Pandas 和 Scikit-learn。你还需要更多的技能。我认为 SQL 是必须的。你还需要非常熟练于一种编程语言,最好是 Python 或 R。Git、Spark(或 PySpark)、Airflow、云计算、Docker 是你需要熟悉的一些其他工具。
因此,如果你没有编程背景,可能需要一段时间才能掌握软件工具和包。
工作够多了吗?
在我居住的地方,数据科学家的职位数量有限。这可以被视为一个环境问题,但它确实有影响。当我开始学习数据科学时,职位空缺的数量并不多。然而,在过去的两年里,寻找数据科学家的公司数量大幅增加。因此,仅仅考虑职位空缺的数量,我找到工作的机会比两年前要高。
结论
尽管我花了两年时间才开始担任数据科学家,但我非常高兴我决定转行成为数据科学家。自从我开始担任数据科学家以来,我的动力和热情都有所提升。
在生产环境中处理实际数据是我们无法通过证书、课程或教程来实现的。这对我来说是一个漫长而艰难的旅程,但绝对值得。
原文。经许可转载。
相关:
该主题的更多内容
如何获得高级数据科学家职位
原文:
www.kdnuggets.com/2022/12/land-senior-data-scientist-position.html

编辑提供的图片
你在数据科学行业工作了几年,现在准备晋升到高级职位。唯一的问题是你不确定怎么做。你如何获得高级数据科学家职位?
在这篇博客中,我们将解答这个问题。如果你更愿意通过视频获取这些信息,我在我的 YouTube 频道上也有一个 视频 讨论这个话题。两者都讨论了许多公司用来区分初级和高级数据科学家的基本要求,然后介绍了如何在面试中脱颖而出,展示自己有资格担任高级职位。
在我们深入讨论之前,我想先声明一下。我并不是一名高级数据科学家。当我在之前的公司 Airbnb 工作时,我从数据科学转到了软件工程,因此我从未担任过高级数据科学家的职位。然而,我通过面试高级数据科学家的同事们,获得了有关区分初级和高级数据科学家的知识。
好了,现在我们开始吧!
高级与初级数据科学家的区别
首先,在面试高级职位与入门级职位时,流程可能看起来没什么不同。在许多公司,入门级和高级数据科学家的面试流程是相同的。面试包括技术环节,如统计学、SQL 和编码,以及非技术环节,如行为面试。我认为像产品案例面试或演讲这样的面试是技术和非技术技能的结合。
如果面试流程相同,公司如何判断你是高级还是中级呢?实际上,公司通常已有现成的标准。虽然存在个别例外,但你不能伪造你的经验。
要获得高级职位,通常需要大约 4 到 5 年的经验,如果你有硕士学位;如果你有博士学位,则需要 2 到 3 年的经验。 也就是说,如果你只有学士学位,可能需要超过 5 年的经验。
你能在面试中影响你的职位吗?
因此,在许多方面,资历是预定的。然而,这并不意味着你无法影响自己在公司中的位置和职位。我认识一些人在面试中表现出色,尽管他们只有不到 2 年的经验,却获得了高级职位。
还有一个反面例子。我知道一些人在面试中表现不佳,获得了低于其经验水平的职位。你的经验很重要,面试中你如何展示自己也同样重要。
为了回答这个问题,我将讨论三个不同的面试领域,你可以在这些领域展示你值得更高级职位的能力:产品案例面试、行为面试和演讲。
展示自己作为高级职位的能力:产品案例面试
产品案例面试是你有机会展示可能获得更高级职位的技能的第一个领域之一。产品案例面试完全围绕你的问题解决技能展开。虽然高级和入门级数据科学家都需要能够解决问题,但值得更高级职位的人拥有脱颖而出的解决方案。
但你怎么让你的解决方案脱颖而出呢?有三种方法可以展示更高水平的问题解决技能,这些技能可以帮助你获得高级职位。
展示对背景的认识
第一种方法是考虑问题的具体背景,而不是僵化地遵循一个框架。当我提到具体背景时,包括了业务模型、公司的阶段和产品的独特方面。
任何人都可以记住一个框架并按照它来得出答案。这样做并不能证明你拥有值得更高级职位的经验和能力。事实上,如果你在收到问题后立即开始使用框架,可能会显得过于反应式。
例如,有些人认为评估任何假设的自然下一步是使用 a/b 测试。然而,有些情况下进行 a/b 测试是不可行的,比如资源限制或 a/b 测试的要求没有得到满足。
想象一下,你被要求在许多想法中选择几个用于早期阶段的电子商务业务。我们不会简单地对每一个想法进行 a/b 测试,因为这将是昂贵和耗时的,更重要的是,这并不必要。如果我们有用户的偏好、浏览行为和购买历史的数据,我们可以通过查看数据并发现哪些部分需求和机会最多来获得大量的见解。
另一个例子是诊断 Robinhood 的一个问题,其中交易活动正在减少。你可能会按照框架来检查季节性、外部事件和用户细分等因素。然而,如果你没有花时间澄清变化的程度、哪些活动正在减少、是股票还是加密货币等问题,那么就显而易见你是在遵循框架,而没有考虑到具体问题的背景。
记住,框架是通用的,而问题是具体的。你需要展示对产品本身和公司目标的意识和理解。框架是一个有用的工具,但你还需要** 展示你个体思考的能力 **以及提出具体解决方案的能力。
展示高级问题解决技能
另一种展示高级问题解决技能的方法是** 考虑问题可能存在的潜在问题或陷阱。**
例如,Facebook 让你改进生日数据的准确性。许多候选人会立即跳到他们的方法和数据。然而,更有经验的候选人可能会首先问一些问题,比如“我们为什么需要这样做?”和“我们只需要月份和日期,还是也需要年份信息?”
一位经验丰富的候选人会意识到,在确定解决方案时,可能会有隐私问题需要考虑。如果你想获得高级职位,你需要展示的不仅是处理数据的能力,还有** 理解潜在问题和障碍的能力。**
使用战略性思维
最后,一位高级数据科学家在产品案例面试中展示战略性思维。什么是战略性思维?简单来说,就是** 超越数字进行思考的能力。**在进行实验时,结果很重要。然而,还有许多需要同时考虑的因素。

图片来源:Startaê Team 在 Unsplash
例如,Uber 正在测试一个新的推荐计划以招募新司机。实验表明,短期内该计划将会亏损。这可能让人觉得这个计划是个坏主意,但它仍然可能具有战略上的好处。招募更多司机可以提供更好的供应以满足需求,而且新招募的司机可能会向平台推荐更多司机。这两点可能最终增加 Uber 的市场份额,并帮助保持其竞争优势。
因此,一位高级数据科学家知道如何超越数字进行思考。他们** 考虑问题的多个方面 **以确定什么最符合公司的目标。要将自己与其他高级候选人区分开来,展示你在当前问题上进行战略性思考的能力是很重要的。
作为高级候选人展示自己:行为面试
现在我们已经看过产品案例面试,让我们来看看如何在行为面试中区分自己。行为面试是你将讨论过去经历的地方,如我们在介绍中提到的,你不能伪造经历。不过,你如何呈现你的经历可能会有所不同。
展示你的多重特质
在行为面试中,你不会像在简历中那样简单列出你的经验。你将被问到需要讲述你过去故事的问题,每个问题通常会集中在某个特定的特质上。你会被问到诸如“描述一次你处理冲突的经历”或“告诉我一次你在严格截止日期下工作的经历”等问题。这些问题旨在考察你的冲突解决和时间管理技能。
如果你想让你的经验和能力突出,超越问题显然要求的特质。在每个回答中展示你多方面的能力。 记住,你不仅仅是在回答问题,还在展示自己作为一个专业人士和个人的形象。
要获得高级职位,你需要展示出能够胜任更高职位的特质。一些积极的特质包括领导力、团队责任感以及在不确定性中茁壮成长的能力。调整你的故事,以展示你愿意超越常规、关心整体团队成功并能够推动和产生影响。
主动积极

图片由Hunters Race提供,来源于Unsplash
除了展示你具备能够在高级职位中取得成功的特质外,你还需要展示你的兴趣以及你能够主动积极。你如何做到这一点?花时间为面试官准备好问题。
在面试结束时提出好的问题是一个展示你可以引导对话并推动谈话方向的机会,而不是仅仅对问题做出反应,这对于寻求高级职位的人来说是一项必要的技能。提出好的问题也表明你对该职位进行了深入思考,并且你对此职位真正感兴趣。
作为高级人士展示自己:演示
现在让我们看看另一个可以让你在高级职位中脱颖而出的领域:演示。一些公司会要求你在面试中展示过去的项目。这是评估高级职位的一个特别好的方法。

一位有效的数据科学家必须是一个好的演讲者。你必须能够说服利益相关者接受你的想法。演示为你提供了一个机会,向面试官展示你如何推动情况的发展以及你有多具说服力。
展示你的最佳内容
有几点需要记住,以保持你的演示效果。首先,展示你最好的内容,我的意思是展示一些不太容易的东西。没有挑战、限制或障碍的项目不会向面试官展示你多少经验。
面试官更喜欢听到有挑战性的项目,即使有一些限制,而不是一个完全成功的简单项目。通过展示一个有挑战性的项目,你可以比在一切顺利时更好地展示你的技能和适应能力。
突出你的影响
另一种充分利用你的演示的方法是突出你的影响。尽量专注于“我”而不是“我们”。明确解释你在从头到尾执行一个想法中的贡献。能够推动一个项目是经验的强烈指标。
例如,当涉及到多个团队的大项目时,你如何与其他专业人士合作,你是否提供了见解来帮助产品经理缩小工作范围,你是否考虑了工程师的实施可行性等。这些方面对高级数据科学家来说都是一个重要的加分项。
专业接受反馈
最后,务必保持良好且专业的态度对待问题和建议。 行为面试并不是唯一一个评估你行为的部分,演示也是评估的一个好方式。
在演示时,务必真正倾听问题和其他评论。公司希望数据科学家愿意听取其他意见,因此即使你在演示时可能主导发言,也不要忘记关注你的听众以及他们可能提出的任何要求。公开接受问题和反馈。
结论
这些是你可以证明自己在面试中值得担任高级职位的一些方法。然而,记住大多数公司确实有设定的高级标准,所以如果你不符合这些标准,不要期望能获得高级职位,尽管这有可能发生。
经验在纸面上区分初级和高级数据科学家,但初级和高级在面试中的表现也应该有所不同。虽然满足要求至关重要,但如果你想获得职位,良好的面试表现也是重要的。
原文。经许可转载。
更多相关话题
获得数据工程师职位:免费课程和认证
原文:
www.kdnuggets.com/landing-a-data-engineer-role-free-courses-and-certifications

作者图片
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
人们说你在购买东西时应该考虑物有所值。然而,最好的物有所值就是免费获得好的东西。但这样的东西真的存在吗?如果我们按照那句“天下没有免费的午餐”来讲,似乎不存在。
我声称有免费的午餐,我现在要证明这一点!我挖掘出了 10 个教育‘免费午餐’——提供优质知识的免费数据工程课程。确实如此;如果你愿意或能够支付数十、数百,甚至有时数千美元,你会发现更多的选择和种类。
许多这样的课程在其他一些免费课程列表中被认为是免费的。支付一次性$90 或每月$45 对某些人来说是免费的。但尽管有很多人非常愿意学习数据工程,却没有这笔钱去购买一个‘免费’课程。(还有,现实点!免费字面上的意思就是,嗯,免费!不是‘便宜’,不是‘很少的钱’,也不是‘负担得起’。免费!)
根据我研究的情况,这些课程确实是免费的。很多课程来自 edX。如果选择免费访问课程,你必须在一定时间内完成,通常大约是六个月。但这应该足够让你舒适地完成每门课程。此外,免费访问意味着你无法终身访问所有材料(完成后会被删除),也得不到证书。尽管如此,你应该能够利用这些课程学习数据工程。
在谈论课程之前,我们先简要了解一下数据工程师的角色。这样,了解课程时会更容易知道该找什么。
理解数据工程师的角色
简而言之,数据工程师负责让数据对数据团队成员和其他利益相关者可用。在此过程中,他们处理数据并构建和维护数据基础设施,例如 ETL 过程、数据管道、数据存储。

自然,这些课程应该涵盖所有或部分技能。让我们更详细地研究一下将构成你教育免费午餐的课程——别具一格的双关语。
免费数据工程课程
1. ASU 的数据工程
平台及课程链接:edX
时长:5 周,每周 1-9 小时;按自己的节奏学习
描述:这门由亚利桑那州立大学提供的入门课程侧重于在数据工程中处理数据库,以及如何使用 SQL 与它们交互。你将了解数据库结构、星型模式以及如何将多个表中的数据连接起来。在最后阶段,你将学习如何使用 SQL 创建报告并编写数据处理脚本。
2. Pragmatic AI Labs 的 Python 和 Pandas 数据工程
平台及课程链接:edX
时长:4 周,每周 3-6 小时;按自己的节奏学习
描述:在另一门入门级 edX 课程中,你将学习 Python 和 pandas 进行数据工程。Python 的介绍包括简单语句、if 语句、while 循环和函数。然后,你将学习 Pandas(特别是 DataFrames)及其替代品,如 NumPy、Spark 和 PySpark 中的数据操作。在最后一个模块中,你将了解 Python 开发环境和版本控制。
3. Pragmatic AI Labs 的 Python 和 SQL 脚本数据工程
平台及课程链接:edX
时长:4 周,每周 3-6 小时;按自己的节奏学习
描述:如果你想同时学习 SQL 和 Python 以进行数据工程,这门课程适合你。你将使用 Python 的内置数据结构来操作数据,并编写 Python 脚本来实现数据任务自动化。课程还教你如何进行网页抓取以及使用 SQLite 在 Python 中存储和查询数据。关于 SQL,你将学习如何从 MySQL 数据库中导入和导出数据,以及如何在 VSCode 中执行 MySQL 查询。
4. Pragmatic AI Labs 的云数据工程
平台及课程链接:edX
时长:4 周,每周 3-6 小时;按自己的节奏学习
描述:这门课程将教你云中的数据工程。你将学习数据工程中的方法论,开发分布式系统、无服务器数据工程系统和云 ETL 管道,并了解数据治理。在过程中,你将接触到如:
-
CUDA
-
Numba
-
ASICs
-
Colab Pro
-
Colab API
-
Google BigQuery
-
AWS
-
Databricks SQL
-
点击
-
Python
-
Rust
这也是一门入门课程,不需要先决条件。
5. IBM 的 Bash、Airflow 和 Kafka 构建 ETL 和数据管道
平台及课程链接:edX
时长:5 周,每周 2-4 小时;按自己的节奏学习
描述:这个数据工程课程重点在于构建 ETL 和数据管道。在课程中,你将学习 ETL 和 ELT 过程是什么,使用 Bash 脚本创建 ETL,使用 Apache Airflow 创建批处理数据管道,以及使用 Apache Kafka 进行流数据管道。
这是一个入门课程,但需要有关系型数据库、SQL 和 Bash 脚本的工作经验。
6. IBM 数据仓库与 BI 分析
课程平台及链接:edX
持续时间:6 周,每周 2-3 小时;自主学习进度
描述:IBM 的这门中级课程教授数据仓库、数据集市和数据湖的基础知识。你将学习如何设计、建模和实施数据仓库。更具体地,你将使用 CUBEs、ROLLUPs、物化视图和表格。你还将学习事实和维度建模,使用星型和雪花模式进行数据建模,数据仓库的暂存区,数据质量,以及如何向数据仓库填充数据。在第三模块中,你将使用 Cognos Analytics 进行数据仓库分析。
该课程要求有 SQL 和关系型数据库的经验。
7. IBM 的 Apache Spark 数据工程与机器学习
课程平台及链接:edX
持续时间:3 周,每周 2-3 小时;自主学习进度
描述:另一门中级课程。它专注于教授 Apache Spark。这是数据工程中的一个重要工具,因此你将学习 Spark Structured Streaming、GraphFrames、ETL 过程和 ML 管道。此外,你还将学习 ML 基础知识,如回归、分类和聚类。
该课程要求具备基础的 Apache Spark 知识。建议你完成 IBM 的 大数据、Hadoop 和 Spark 基础 课程。
8. DE Zoomcamp
课程平台及链接:DataTalks.Club
持续时间:10 周;自主学习进度
描述:最后,一门来自不同平台的课程!这个在线训练营将为你提供全面的数据工程知识。它将教授容器化和基础设施、工作流编排、数据仓库、分析工程、批处理和流处理。你将接触到 Google Cloud Platform、Terraform、Docker、SQL、Mage、dbt、Apache Spark 和 Apache Kafka 等技术。
这个训练营的前提条件是 SQL 基础。此外,最好有 Python 或其他编程语言的经验。
9. DE 全流程项目
课程平台及链接:DE Academy
持续时间:无信息。
描述:这是一个基于项目的项目,你将在其中学习如何使用 AWS、Snowflake、Python、Kafka、Azure、Databricks、Airflow 和 Tableau。你将分析和转换数据,迁移数据,并简化工作流程。
10. 数据科学的 Scala 编程
课程平台及链接:Cognitive Class AI
时长:20 小时;按自己的节奏学习
描述:这个学习路径包括三个课程。第一个是 Scala 101,将教你面向对象编程的基础知识、案例对象与类、集合和地道的 Scala。第二个课程是 Scala 分析的 Spark 概述,你将学习 Apache Spark、RDDs、大规模数据科学的 DataFrames 和高级 Spark 主题(如 Hive 与 Spark、Spark 流处理)。第三个课程涉及 Scala 在数据科学中的应用,你将学习基本统计和数据类型、如何准备数据、工程特征、拟合模型、构建管道和执行网格搜索。
结论
不足为奇的是,当你有钱的时候,情况会更容易——你可以获得更多多样化的课程。是的,没有钱确实很糟糕!但这并不意味着你必须告别获得数据工程师职位的梦想。
找到这些课程要困难得多,但仍然有一些很好的课程可以教你基础和更高级的数据工程知识。我找到了十个这样的课程。其他一些免费的资源,如博客或 YouTube 视频,也可以帮助你达到所需的知识水平。
如果你足够勤奋、专注和坚持,我相信你可以免费获得一个数据工程师职位。
内特·罗西迪 是一位数据科学家,专注于产品策略。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过顶级公司的真实面试问题准备面试。内特撰写关于职业市场最新趋势的文章,提供面试建议,分享数据科学项目,并涵盖所有 SQL 相关内容。
更多相关话题


 浙公网安备 33010602011771号
浙公网安备 33010602011771号