KDNuggets-博客中文翻译-六-
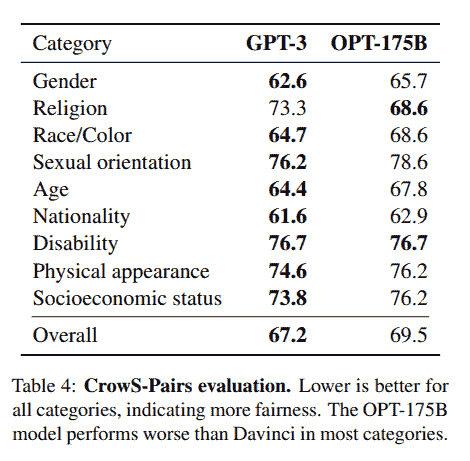
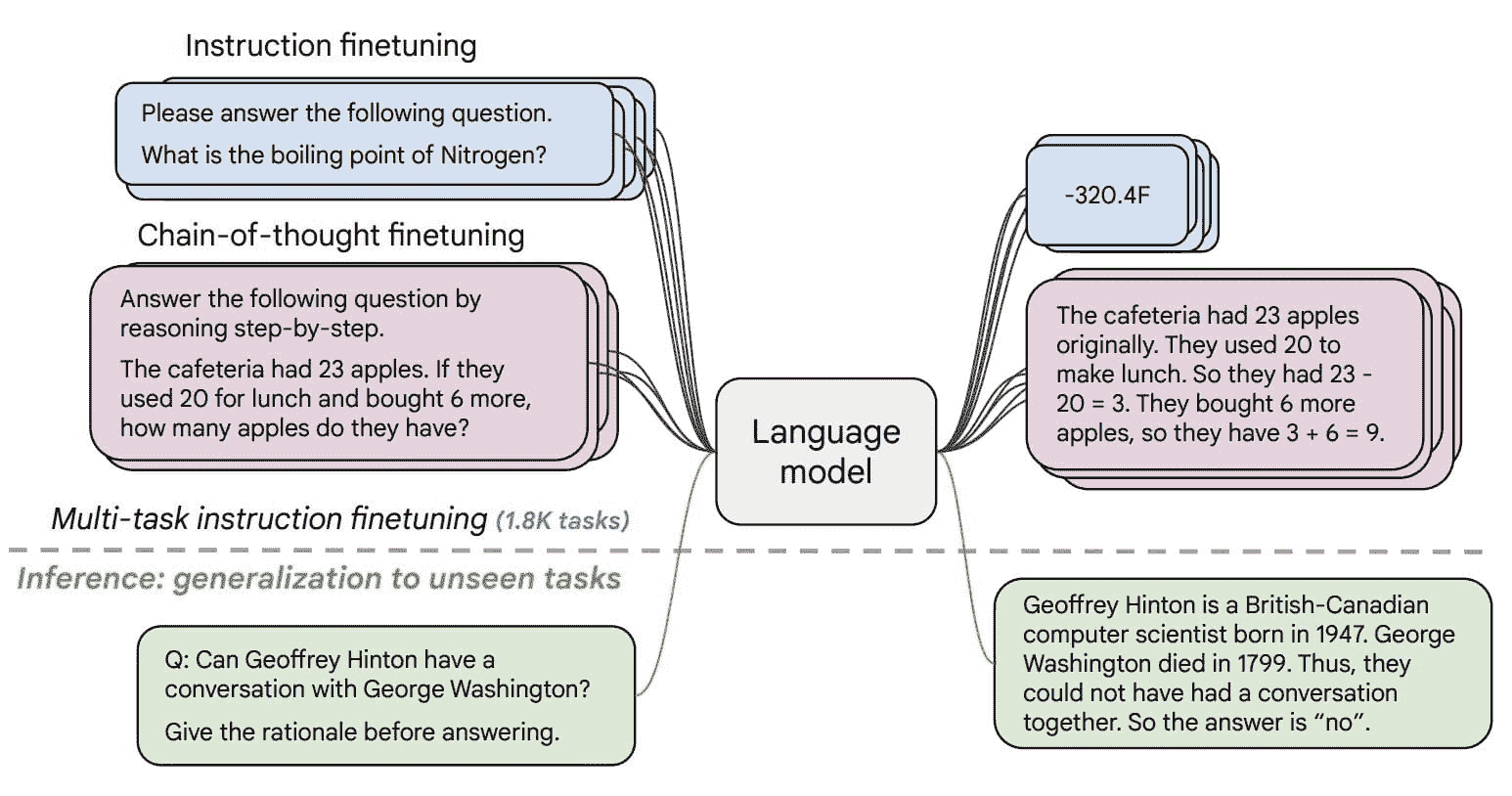
KDNuggets 博客中文翻译(六)
原文:KDNuggets
7 个提高数据科学代码可读性的技巧
原文:
www.kdnuggets.com/2022/11/7-tips-produce-readable-data-science-code.html

由 svstudioart 提供的图片 在 Freepik 上
编写可读代码的能力被开发者称为一种艺术形式。虽然我部分同意这种说法,但编写代码,尤其是可读代码,是一种可以培养的技能。
我们的前三个课程推荐
 1. Google Cybersecurity Certificate - 快速通道进入网络安全职业生涯
1. Google Cybersecurity Certificate - 快速通道进入网络安全职业生涯
 2. Google Data Analytics Professional Certificate - 提升您的数据分析能力
2. Google Data Analytics Professional Certificate - 提升您的数据分析能力
3. Google IT Support Professional Certificate - 支持您的组织进行 IT 支持
提高代码可读性的唯一方法是多练习编写优质代码。因此,我建议阅读其他以编写高质量代码著称的开发者的代码。
总的来说,可读代码是一种重要的结果,它随着代码复杂性增加而变得更加重要。尤其是在数据科学中,编写可读代码极为重要,因为数据科学应用可能很难理解,因此,不够清晰的代码所增加的额外复杂性是不可取的。
我认为你同意编写可读代码是至关重要的。那我该如何让我的代码更具可读性呢?
在这篇文章中,我们将讨论一些可以采取的步骤,以生成可读且高质量的代码。
在开始编码之前要有一个结构的概念
在打开编辑器并开始编写代码之前,尝试规划一下代码结构。尽可能详细地制定变量、函数、类和模块的结构,并确定它们如何相互连接以解决问题。
这样做会在你实现、扩展和部署代码时节省大量时间。我建议你将这些结构添加到代码文档中,或者如果你计划将代码开源,将其放在 GitHub 上。
给变量起描述性的名称
我知道我们有时会被诱惑给变量命名为 X、Y 和 Z。但当我们在几个月后阅读代码时,却因为无法确定变量 X 中到底存储了什么而感到困惑!给变量起具有描述性的名称不仅会帮助其他人阅读代码,还会帮助未来的你。
命名变量时,目标是使用准确的名称,而不是简短的名称。例如,如果你计算一个值列表的平均值,不要将变量命名为 ave 或 av;有时使用 average_height 或 average_time。现在,许多代码编辑器提供自动补全功能,因此使用更长的名称不会使你的代码编写过程变慢。
此外,如果你的代码实现了某篇特定论文或书籍中介绍的算法,请保持变量名称与该来源相关。记得在代码文件的顶部包括该来源。
明智地使用函数
函数可以是组织和简洁代码的好工具。也就是说,如果使用得当的话。对那些可以封装到函数中的任务使用函数,例如,对不同数据点应用操作或实现算法步骤。当你命名函数时,使用我们在命名变量时讲过的相同逻辑。
将具有相关功能的函数收集在一个代码文件中,并尽可能将其制成模块。这将使查找、扩展和使用函数变得更容易。
尽量明确函数属性的具体类型,并使你的函数安全且可扩展。
瞄准清晰而简洁的文档字符串
文档化你的代码是一个重要步骤,无论是完整的文档还是代码内文档(文档字符串)。文档字符串是在代码文件开始处、函数/类定义后出现的字符串,它们告诉读者代码/函数或类的目的。
文档字符串旨在简要提示你的代码是什么以及如何工作。例如,当在函数的开头(函数头下面)使用时,它应包括预期的属性类型及其在函数中的作用、函数的输出以及一两句关于该输出如何计算的描述。
对于类,文档字符串应包含类属性和方法,以及它们如何使用。
不要重新发明轮子(除非你能做得更好)
如果你需要的函数已经由支持的包或第三方开发者实现,使用它而不是重新实现。当你使用一个包时,确保了解它包含的所有函数,以节省实现可以使用的功能的时间。
我推荐你自己实现功能的少数场景是当你刚开始编程并尝试了解一切是如何运作的,或当你可以以更少的复杂性更好地实现一个函数。否则,你和其他人使用已经实现的代码会更简单。
目标是简单、较长的步骤,而不是短而复杂的步骤
当你尝试实现论文或书籍中提出的想法或算法时,目标应是明确的步骤,而不是试图将多个步骤组合在一起以减少代码长度。
是的,较短的代码可能展示了你使用编程语言惯用法的能力。然而,它也可能使你的代码变得不必要的复杂。复杂到难以阅读、测试、调试和扩展。尤其是当你实现的算法本身就很复杂时,通过将多个步骤组合在一起而增加额外的复杂性,会导致代码变得不够灵活。
保持一致
一致性对于代码的可读性至关重要。在规划代码结构时,决定使用一种风格贯穿整个代码。这包括确定命名变量、函数和类的系统。如何使用注释,处理算法中的不同数学步骤,模块化代码以及使用现有的包。
当你的代码风格和模式一致时,跟踪和理解你的代码会更快。
最后的思考
作为数据科学家,不可避免的一件事就是使用别人编写的代码。尽管阅读和理解他人编写的代码总是一个耗时的任务,但你可以采取一些步骤,使你的代码更易于跟随和使用。
尽管本文中的技巧可以被任何写代码的人使用,而不仅仅是数据科学家,但在我看来,对于数据科学家来说,编写可读代码尤为重要,以克服由于大多数数据科学算法背后的数学而产生的一些困难。
因此,如果你想开始编写更好、更易读的代码,这篇文章将是一个很好的起点。记住,编写更好的代码是一项技能,就像其他技能一样,随着实践会不断提高。
Sara Metwalli 是庆应大学的博士候选人,研究测试和调试量子电路的方法。我是 IBM 的研究实习生和 Qiskit 倡导者,帮助构建一个更加量子的未来。我还是 Medium、Built-in、She Can Code 和 KDN 的作家,撰写关于编程、数据科学和技术主题的文章。我也是国际女性编程 Python 分会的负责人,一个火车爱好者、旅行者和摄影爱好者。
更多相关话题
7 个 Python 初学者提示

Gif 由作者提供
学习一门新语言可能会让人感到困惑和具有挑战性。你会被宣称在 10 分钟内教你 Python 的 YouTube 视频淹没。最后,你会变得更加困惑并放弃。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
"不要追逐炒作。找出适合你的方法。"
即使你理解了基础知识,你也会在选择和学习新工具时感到更困惑。此外,如果没有结构化的学习,你将无法通过任何编码面试或测试。
就像任何技能一样,你需要坚持和练习。在这篇博客中,我将我的 Python 学习经验转化为 7 个易于遵循的提示。
让我们开始成为专家 Python 程序员的旅程吧。
学习基础
学习 Python 的所有知识并不是必要的,但你需要建立基础。为此,你需要理解基础知识。
学习:
-
数据类型
-
数学和增强赋值运算符
-
变量
-
注释
-
打印
-
内置函数
-
控制流
-
函数
-
列表、元组、字典和集合
-
读取和写入文件
还有很多东西可以学习,但对于初学者来说,坚持基础并多加练习。

图片由作者提供
犯错误、忘记语法和在简单问题上卡住是没关系的。这些会自然地到来。不要强迫自己去记忆。最重要的是,一次学习一个知识点。
不要以为你知道所有的东西然后开始做项目。相信我,你会在谷歌上花费数小时来解决简单的问题。
互动学习
我坚信通过互动练习、测验、评估测试和项目来学习。
在互动学习环境中,你将看到一个描述部分、代码编辑器、ipython shell 和课程。你只有在成功输入正确的代码并运行后才能进入下一个任务。在描述部分,你将阅读指令并尝试将其转换为 Python 代码。
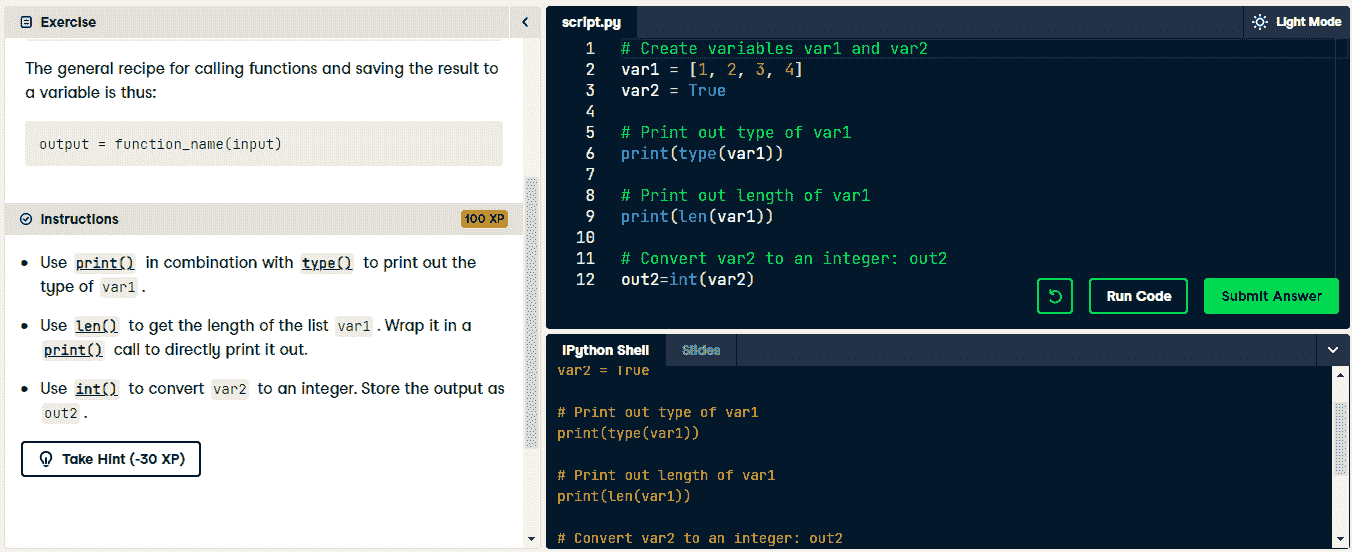
图片由 DataCamp 的 Python 课程作者提供
我使用过 DataCamp 和 Codecademy 学习 SQL、Python、R 和 JavaScript。这些平台具有游戏化和上瘾的特点。除了游戏化,它还迫使你通过实践学习,这与 YouTube 教程大相径庭。
按照视频教程并复现结果是学习 Python 的最糟糕方法。你最终会感到沮丧。另一方面,互动学习平台提供提示、描述、代码编辑器和课程幻灯片。
设置 IDE
设置你的开发环境对成功至关重要。你希望 IDE(集成开发环境)能为你服务,而不是阻碍你。
首先,在本地机器上安装并设置代码编辑器。然后,添加插件以增强用户体验,并更新终端。
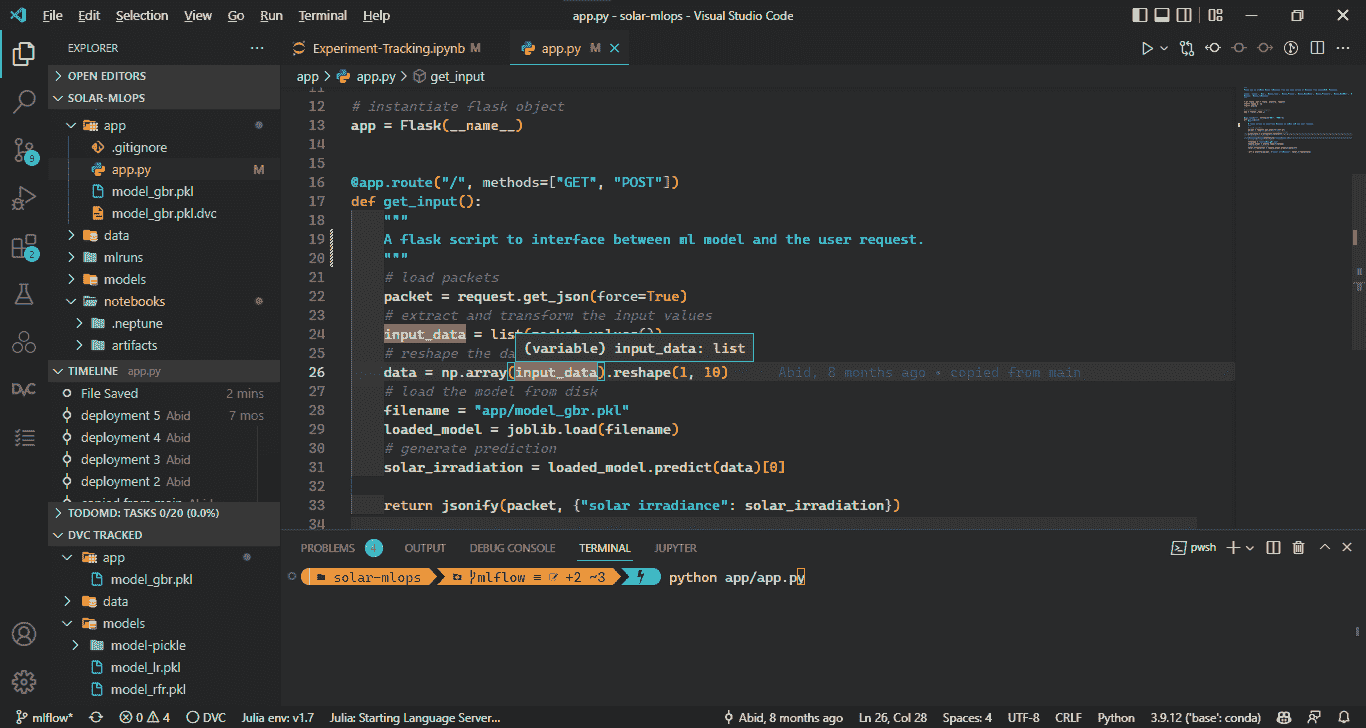
图片由作者提供
首先,我安装了 Anaconda。它包含了所有必需的软件和库。
然后,我安装了 VSCode 作为我的主要工作空间。它快速、轻量、直观,并且配备了各种扩展和插件。
此后,我安装了一些扩展来提升我的 Python 开发体验,如 Pylance、GitHub Copilot、Gitlens、material icons、Python indent 和 Jupyter。
每天编程
每天编程。你会学到一些东西,但可能第二天就忘记了。为了巩固你的学习,你需要每天练习。你可以尝试编程挑战、互动练习、复习之前的课程并自行练习。

图片来自作者 | Canva Pro
我从实践和调试代码中学到了最多。我每天至少编程 1 小时。这对我实现目标和保持以前学到的概念帮助很大。
我建议你每天编程一个小时,并将其分成 30 分钟的时间段。尝试修改代码、实验新事物、学习新概念,并提高你的打字技能。
从事一个项目
在获得必要的实践后,深入项目。选择任何初学者项目,尝试从头开始创建或使用你的知识复现结果。
你还可以为开源项目做贡献,甚至自愿参与 NGO 项目。
通过从事一个项目,你将学会开发生命周期、必要的专业技能,并获得可以添加到简历中的经验。
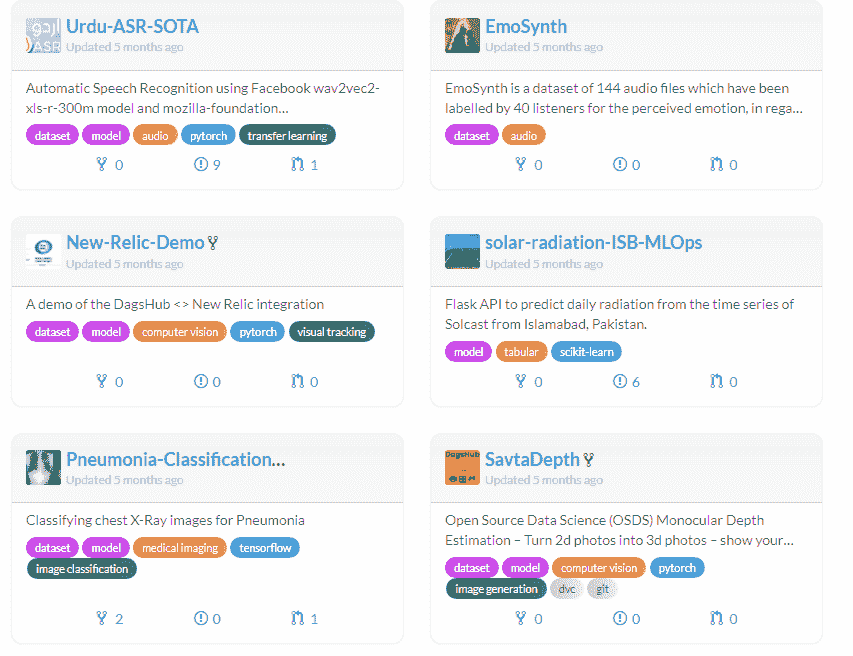
图片来自作者 | DAGsHub
完成课程后,我进行了互动项目。其中大多数是有指导的。然后,我会阅读教程并尝试复现结果。最后,我开始参与竞赛,以深入了解 Python 和各种工具,从而提升数据处理和分析能力。
分享知识
在完成一个项目后,分享你的经验和所学到的教训。你通过写关于新话题的博客能学到的东西,比通过上课程学到的还要多。你可以从在 Medium 上写作开始,随着时间的推移,开始为像 Better programming 和 KDnuggets 这样的高级出版物写作。
作者提供的图片 | KDnuggets
我撰写了关于 Python 基础、多线程、数据科学、机器学习、MLOps 和 NLP 的博客和编码教程。我大多数的成功来自于教授复杂的工具和方法。在我的博客中,我分享了我的经验、技术概念、互动学习的代码以及改进工作的建议。
“把自己展示出来,让世界教会你。”
持续学习
为了保持竞争力,你需要不断学习。即便公司也希望员工学习新的技能、工具和概念。
为了保持竞争力,你可以从以下渠道学习:
-
博客和基于代码的教程
-
书籍
-
Twitter、LinkedIn 和 Facebook
-
阅读新工具的文档
-
观看 Youtube 视频
-
参加研讨会和课程
-
参与编码挑战
-
与 Python 开发者保持联系

图片来自 Python Cheatsheet
我是一个终身学习者。我通常对学习新工具或概念感到兴奋。这挑战了我的大脑,我花费多个小时仅仅是调试和发现 API。
“如果你把新的工具当作玩具来看待,你会开始享受学习的过程。你会打破并修复东西。”
结论
迈过最初的几个步骤是困难的,因为你会在投入更多时间和放弃之间犹豫不决。相信我,Python 是最受欢迎的语言,它正在推动机器人技术、人工智能、数据科学和金融科技等未来技术。它在技术行业中需求很高,如果你能通过编码挑战,你就足够好能被聘用。
持续学习和改进。没有捷径。犯错并调试你的程序。通过艰辛的努力,你会成为一颗闪亮的明星。
我希望你能从我的博客中学到一些东西,并且未来如果它对你有帮助,请用它来帮助他人。此外,如果你有任何问题,请在下面的评论中输入。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是为那些在心理健康方面挣扎的学生构建一个使用图神经网络的 AI 产品。
相关话题
7 种用于自然语言处理的人工神经网络类型
原文:
www.kdnuggets.com/2017/10/7-types-artificial-neural-networks-natural-language-processing.html
作者:Olga Davydova,数据怪兽。
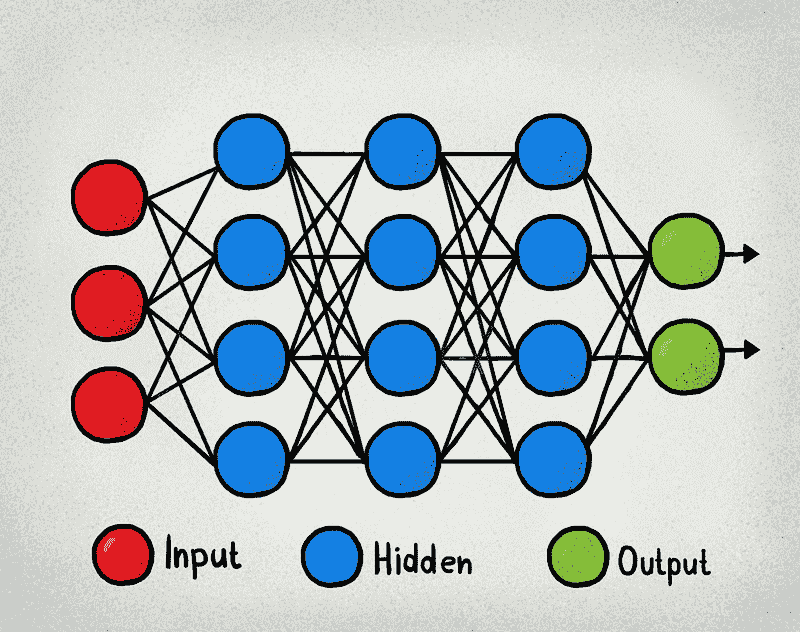
人工神经网络(ANN)是基于大脑神经结构的计算非线性模型,能够通过仅考虑示例来学习执行分类、预测、决策、可视化等任务。
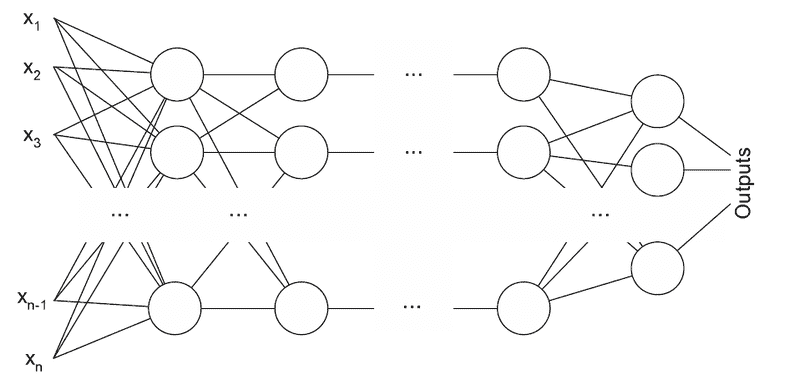
人工神经网络由人工神经元或处理单元组成,并组织成三个互连的层次:输入层、可能包括多个层的隐藏层和输出层。
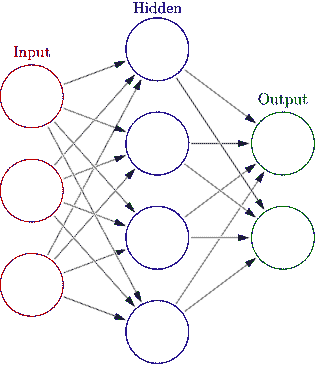
人工神经网络 (en.wikipedia.org/wiki/Artificial_neural_network#/media/File:Colored_neural_network.svg)
输入层包含将信息传递给隐藏层的输入神经元。隐藏层将数据传递给输出层。每个神经元具有加权输入(突触),一个激活函数(定义给定输入的输出),以及一个输出。突触是将神经网络转换为参数化系统的可调参数。
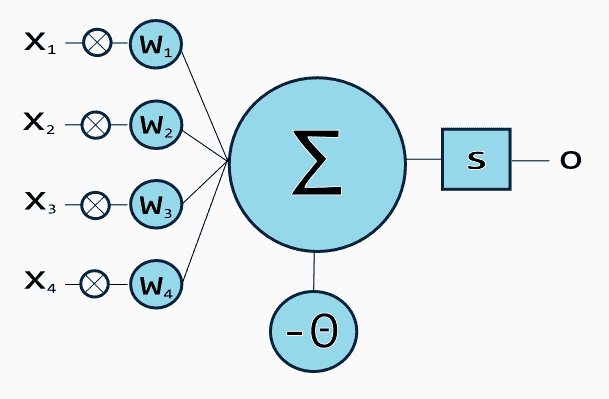
带有四个输入的人工神经元 (en.citizendium.org/wiki/File:Artificialneuron.png)
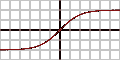
输入的加权和产生激活信号,该信号传递到激活函数以从神经元获得一个输出。常用的激活函数包括线性、阶跃、 sigmoid、tanh 和修正线性单元(ReLu)函数。
线性函数
f(x)=ax
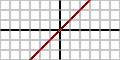
阶跃函数
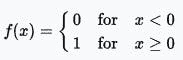

Logistic(Sigmoid)函数
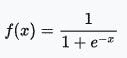
Tanh 函数
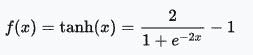
修正线性单元(ReLu)函数
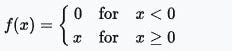
训练是权重优化的过程,其中最小化预测的误差,使得网络达到指定的准确度水平。确定每个神经元误差贡献的方法称为 反向传播,它计算损失函数的梯度。
通过使用额外的隐藏层,可以使系统更加灵活和强大。具有多个隐藏层的人工神经网络被称为 深度神经网络 (DNNs),它们可以建模复杂的非线性关系。
1. 多层感知机 (MLP)
一个感知机 (upload.wikimedia.org/wikipedia/ru/d/de/Neuro.PNG)
多层感知机 (MLP) 具有三个或更多层。它使用非线性激活函数(主要是双曲正切或逻辑函数),使其能够分类不可线性分隔的数据。每一层的每个节点都连接到下一层的每个节点,使网络全连接。例如,多层感知机自然语言处理 (NLP) 应用包括语音识别和机器翻译。
2. 卷积神经网络 (CNN)
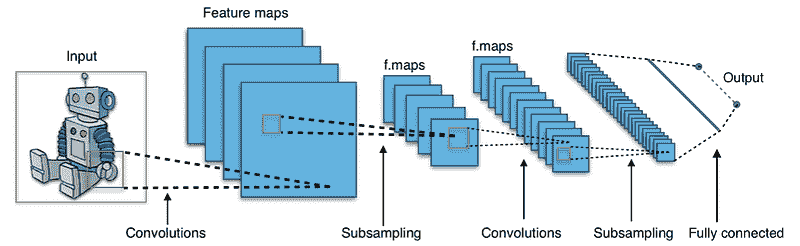
典型的 CNN 架构 (en.wikipedia.org/wiki/Convolutional_neural_network#/media/File:Typical_cnn.png)
卷积神经网络 (CNN) 包含一个或多个卷积层、池化层或全连接层,并使用了前面讨论的多层感知机的变体。卷积层对输入进行 卷积操作,将结果传递到下一层。这种操作使得网络可以更深且参数更少。
卷积神经网络在图像和语音应用中表现出色。Yoon Kim 在 卷积神经网络用于句子分类 中描述了使用 CNN 进行文本分类任务的过程和结果[1]。他展示了一个基于 word2vec的模型,并进行了一系列实验,针对多个基准进行测试,表明该模型表现优异。
在 从零开始理解文本 中,Xiang Zhang 和 Yann LeCun 证明了 CNN 在没有对单词、短语、句子以及任何其他句法或语义结构的了解的情况下,可以取得出色的表现[2]。语义解析 [3],同义句检测 [4],语音识别 [5] 也是 CNN 的应用领域。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关主题
-
每个数据科学家都应该知道的三种 R 库(即使你使用 Python)
b.org/anthology/K15-1013](https://www.aclweb.org/anthology/K15-1013)
数据怪物 帮助公司和获得资助的初创企业研究、设计和开发实时智能软件,以利用数据技术提升业务。
原文。已获许可转载。
相关:
-
机器学习翻译与谷歌翻译算法
-
5 个免费资源,帮助你入门深度学习自然语言处理
-
我如何在过去 2 个月开始学习 AI
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 支持
更多相关话题
数据科学家职业的 7 种类型
原文:
www.kdnuggets.com/2017/03/7-types-data-scientist-job-profiles.html
 评论
评论
作者:Muktabh Mayank,ParallelDots。
所以,是的,这篇文章可能看起来像个点击诱饵,但我保证它并不是完全那样(嗯,稍微有点)。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
最近我在 Quora 上收到一个问题,询问公司在招聘数据科学家时具体需要哪些技能?数据科学家角色是否有定义?很明显,没有一个统一的角色,因为每家公司都在解决自己的一套问题。但我尝试制定了一些通用的职业角色,这些角色可以在一定程度上适应不同公司的职位描述。我认为种类太多了,但我不得不缩小到一组角色,所以这里是列表:
-
R 使用数据分析工具。 能快速在 R/Python 中进行分组和计数。这种角色是早期数据分析师的编码版本。在更倾向于分析的组织中,自动报告生成是这种角色最常见的场所。
使用工具:R(数据框),SQL
![R_logo.svg]()
![831px-SQL_ANATOMY_wiki.svg]()
-
建模者。 深入的数学思维,能够应用贝叶斯/频率学推断或层次模型。也许我在这里将太多人归为一组,当分析药物试验的人员、建模复杂现象的科学家和对股票进行自回归模型分析的人被归为一组时。这儿的共同主题是,数学是工作的基础。
使用工具:R 非常受欢迎,Fortran,C++和有时的函数语言。
![Mathematical_models_for_complex_systems]()
![Eigen_Silly_Professor_135x135]()
-
偶尔从事数据科学工作的数据工程师。从这里取一个库,从那里取一些代码,制作出足够好的东西,同时管理数据管道。这是一种非常常见的角色,数据科学任务包括编写程序自动生成 Pandas 报告、尝试简单的机器学习模型,以及(如今)在数据上运行预训练的神经网络。
工具:Python 工具链、Pandas、nltk、Keras。
![Python_logo_and_wordmark.svg]()
![220px-Hadoop_logo.svg]()
![pandas]()
-
表格机器学习者(或 XGBoost 专家)。热衷于 Kaggle,能够训练多个算法并堆叠模型,极大地优化它们。这些人对运行和优化标准算法,如 XGBoost、Ridge Regression 和(现在)Keras 模型,有深厚的专业知识。
工具:Python 或 R,常用 XGB 和 Keras。
![xgboost]()
![Keras_Logo]()
-
老派的机器学习者。接近于 4,但不限于分类模型。非常擅长特征工程。这是唯一的机器学习专长,直到较新的深度学习概念出现。
工具:C++ / Python 及 Scikit Learn。
![Scikit-learn_logo]()
![dlib-logo]()
![mlpack]()
-
深度学习专家。需要一个 GPU 系统和一个标记良好的数据集,并尝试各种架构,不需要进行特征工程。将花费大量时间尝试架构,特征工程时间较少,但准确性会非常高。
工具:Python、Theano、Tensorflow 以及像 Keras 这样的高级库。
![theano]()
![TensorFlowLogo]()
-
领域专家。对领域有深入了解,了解一些线性模型。将领域信息编码,并在其上训练线性算法。包括机械工程师、各公司分析师和纯/应用科学的科学家。
工具:不同的专业使用不同的工具。工程师使用 Matlab,C++/Fortran,有时使用 R/Python。
![r-bioconductor-training]()
![800px-NumericalRecipes3rdEdCover]()
-
新手。实习生。将会发展成其导师所属于的 7 种类别中的一种。
在 ParallelDots,我们有 2、3、4、5 和 6 类型的人才。(如果你想全职加入我们,也可以是 8 类型。)
















Muktabh Mayank 是一位数据科学家兼企业家,也是 ParallelDots 的联合创始人。
ParallelDots 帮助企业理解其非结构化数据,为其提供定制的深度学习解决方案。其新产品 Karna AI 使用 AI 从成千上万的新闻和社交媒体来源自动生成关于任何主题的报告。该公司还在开发几款即将推出的令人兴奋的 AI 优先产品。
原文。经授权转载。
相关:
-
大数据和数据科学中的 5 条职业路径解析
-
探索大数据中有趣的 12 种职业
-
人类数据科学家:在自动化世界中保护你的职业
更多相关话题
数据科学家与其他职业不同的七项独特技能
原文:
www.kdnuggets.com/2022/05/7-unique-skills-set-data-scientists-apart-professions.html

成为数据科学家归结为:处理数据、提取洞察并传达这些洞察。这分解为七项独特的技能,没有其他职位需要这些技能,即便是数据分析师和数据工程师等紧密相关的职位。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
要 成为数据科学家,尤其是成为一名优秀的数据科学家,你需要掌握这七项技能来完成工作并脱颖而出。这七项技能也能很好地转移到其他职业。
从事数据科学工作的有趣之处在于,硬技能的需求并不像软技能那样高。任何人都可以学习 Python 编程。你工作的公司明年可能会迁移到新的基础设施。硬技能是可选的。相比之下,软技能是不可谈判的,且更难获得。没有八周的商业思维训练营,也没有分析性问题解决的证书。
那么,哪些七项技能使数据科学家与其他数据职位不同呢?让我们深入了解一下。
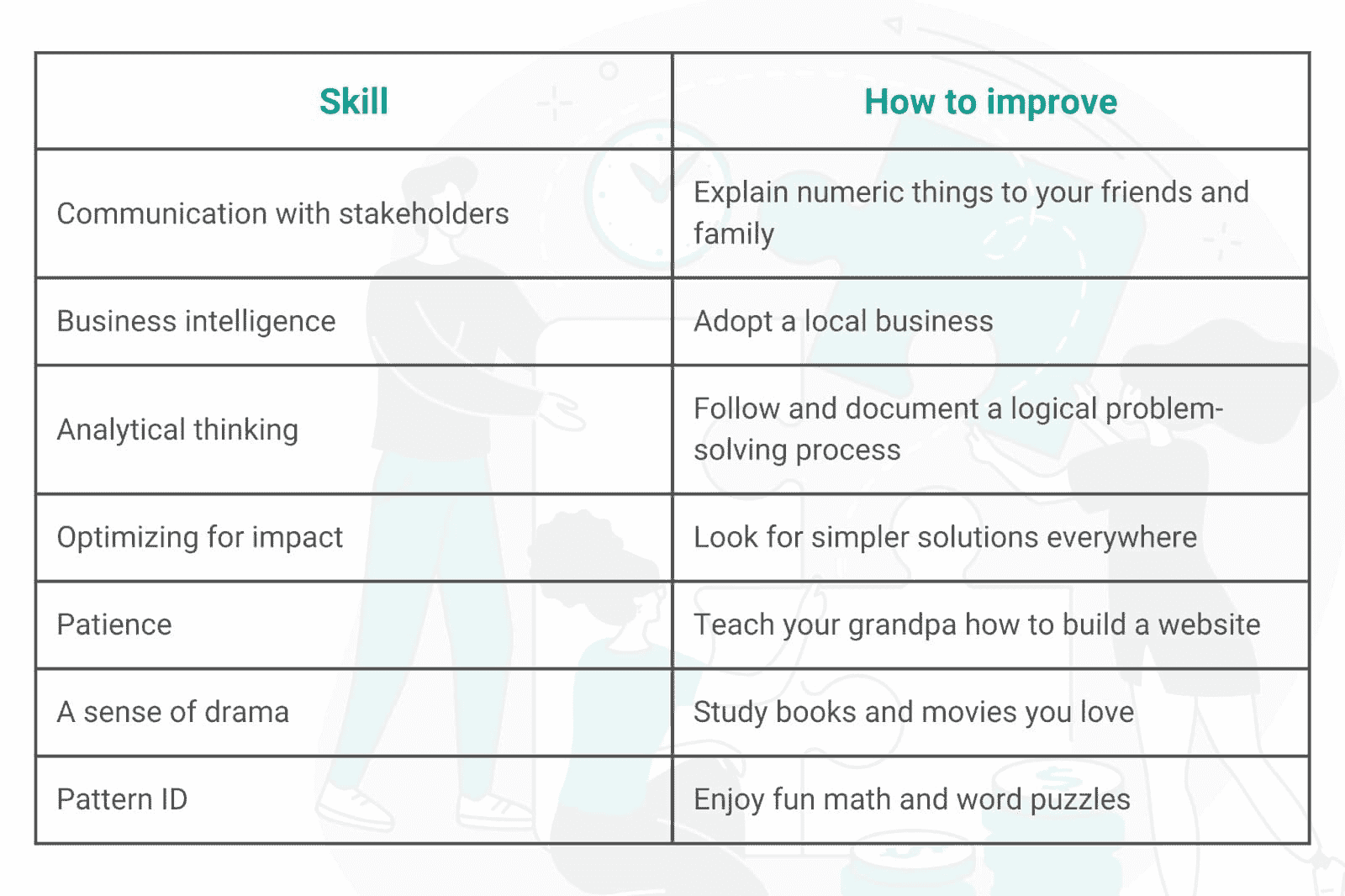
1. 与你的利益相关者沟通
数据科学家在业务中占据一个稍显危险的领域:他们必须轻松地将技术用途转化为业务语言,并反向转换。作为数据科学家,你需要以技术团队能够理解的方式传达发现,同时构建图表帮助业务团队理解你的惊人发现对业务的影响。
例如,你可能需要向你的(技术)数据工程师解释为什么他们需要为你以不同的方式构建数据。然后,你可能需要将这一结果与(业务方)老板分享,解释他们为什么应该关心。
这不是一份容易的工作。大多数数据职位要么只涉及技术,要么只涉及业务。只有数据科学家被要求每天在技术与业务之间跳跃。
你如何改进这一点?你可以和你的非技术朋友和家人练习业务方面的事情。看看是否能让他们对你的数据感兴趣。你可以通过询问技术团队他们需要什么,以及如何与他们更紧密地合作,来改善你的技术团队沟通。通常,他们不会对你给出的答案感到害羞。
2. 商业智能
许多人认为数据科学家是每天都在处理数字的人。事实远非如此。虽然数据科学家确实会处理数字和清理数据,但他们的主要角色之一是批判性地思考他们的发现,并提出对未来业务有影响的问题。
例如,假设一个化妆品公司被要求通过增加个性化来提升利润。数据科学家必须了解业务运作,以便建立一个预测模型,让她能够说:“好吧,平均客户都有一张忠诚卡,对吧?我们可以用它来将交易匹配到个人。然后我们可以预测客户 A 会需要指甲油去除剂,而客户 B 则更感兴趣腮红。”
某些工作会关注数字背后的内容。其他则关注客户行为。只有数据科学家必须理解两者。了解业务运作和关键绩效指标(KPIs)对于成为一名优秀的数据科学家至关重要。
提升商业智能技能的最佳方式是参与一个商业项目——甚至不必是你自己的!也许你喜欢一个盆栽植物公司或一个你钟爱的餐馆。习惯性地询问他们的业务运作情况,以及哪些见解对他们的成长有帮助。然后你可以将这些技能应用到自己的工作中。
3. 解决问题的分析和结构化思维
数据科学家每天都会遇到各种棘手的问题。然而,数据科学家没有时间在闲暇时完全解决和解开所有这些问题。相反,数据科学家必须能够以结构化和分析的方式思考问题。
这又回到数据科学家被期望同时兼顾技术和业务两个方面的情况。外部客户或内部业务团队通常会将一个问题交给你。这些团队可能对他们期望的结果没有清晰的想法。作为数据科学家,你需要将问题简化到核心要素,做出假设,并考虑如何证明和解决它。
数据科学家还会面临复杂和混乱的数据集,他们会被要求挖掘这些数据以创建预测性和有用的模型供业务使用。为此,数据科学家需要有结构化和逻辑化的问题解决方法。
有一个很好的过程可以跟随,如果你想提升你的结构化思维技能。首先,了解如何识别问题。当你面对新情境时,考虑一下情况。接下来,提出问题以深入了解问题的核心。为什么会这样?你忽略了什么?之后,确定你的偏见。养成确定假设的习惯。接着,预见障碍——情况中可能会出现什么问题?可能会产生什么后果?最后,练习在不使用 Google 的情况下找出答案。(你可以使用 Google 来检查自己,但你要养成独立思考的习惯。)
有一个很好的指南可以参考 这里 以获取进一步的指导和示例。
4. 以影响力为优化目标
这也被称为“不要过于兴奋”。数据科学家需要知道如何构建复杂且吸引人的模型。但数据科学家也需要知道何时这种做法不是必要的,也许简单的分析就足够了。
初级数据科学家倾向于构建稳健且深度的机器学习模型来回答简单问题。而更好的数据科学家则保持分析的简单性,以便回答问题。这就是为什么区分数据科学家的关键技能之一是避免为了复杂而复杂。
在数据科学领域,识别并使用最快、最简单的方法来回答问题的能力被高度低估。提高的最佳方法就是问自己:有没有更简单的方法?几乎总是有的。
5. 耐心
成为数据科学家的一部分就是能够应对各种挑战。有些商业人士会要求他们不理解的技术东西。有些技术人员会要求商业图景无法允许的东西。在这些中间,数据科学家需要搞清楚谁的需求需要满足,以及何时满足。这需要很多冷静的深呼吸。
例如,数据科学家 Paul May 写道 他看到 数据科学公司 “要求在项目中使用神经网络(因为它很吸引人),即使它完全不合适或相比替代算法表现较差。”数据科学家必须决定:是找办法让它工作?还是告诉他们的商业负责人这没有意义?
作为数据科学家,你需要忍受对你工作的误解,被分配与数据相关的任何任务,因为这在你的职位名称中,人们认为你做的事是魔法,因为数据领域不被理解。耐心是数据科学领域任何人的重要美德。
这是一项难以实践的技能。我的最佳建议是教会朋友或亲戚一些极其技术性的内容,并优雅且有见地地回答他们的每一个问题。
6. 戏剧感
你是否认识你社交圈中那个讲故事特别出色的朋友?在他们的故事结束时,大家都会和他们一起笑。他们有着无与伦比的时间感和叙事能力。这就是数据科学家所需要的技能。
数据科学中的故事讲述占据了很大一部分。不仅仅是讲故事,还要是令人信服的讲故事。作为公司技术和业务两方面的纽带,你需要以一种让利益相关者在意的方式分享数据。这其中很大一部分归结为戏剧感。
任何人都可以制作一个分享有趣数据的幻灯片。数据科学家需要以风格、魅力,甚至戏剧感来做到这一点。
改进的一个很棒(且有趣)的方法是观看电影和阅读书籍。识别出你对所消费故事的喜好和不喜好。它们使用了什么样的预示?英雄之旅如何传达情感和结果?
7. 模式识别
有一种观点认为直觉是错误的,只有数据是正确的。但这并不完全正确。毕竟,我们雇佣的是人,而不是机器,因为机器(目前)无法复制我们的直觉和模式识别能力。
在数据科学中,模式识别是一个关键的软技能。数据科学家必须从大量的数据中筛选,直到对潜在的显著信号有感觉。然后,他们需要再次查看数据以验证自己的直觉。但是,能够相信自己的直觉来发现模式与分析数据所需的技术技能同样重要。
这就是为什么许多数据科学家提倡依靠直觉并跟随数据的原因。面对如此海量的数据,数据科学家需要知道从哪里开始查看。你可以使用大量有趣的文字或数学游戏来练习你直觉性的模式识别技能,比如Brilliant.org。
这七种独特的技能造就了一个数据科学家。
直到你能诚实地说自己具备这七种“软”技能,你才算完全发挥了作为数据科学家的潜力。这七种技能使数据科学家与其他数据相关工作的区别开来。
正如你可能注意到的,很多这些技能都涉及到在公司业务和技术领域的略微尴尬的位置(能够走这条线也需要一个额外的第八种软技能:幽默感)。但许多这些技能也依赖于自信,例如信任自己的直觉;以及个性,例如耐心处理重复的误解或荒谬的要求。
这七项技能难以培养,稀缺而宝贵。如果你具备这些技能,希望你的工作场所能够欣赏你!
如果你还想了解作为数据科学家需要具备哪些技术技能,可以阅读这篇文章“作为数据科学家你需要哪些技能?”。
内特·罗西迪 是一位数据科学家和产品战略专家。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过顶级公司的真实面试题来准备面试。可以通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
主题相关内容
Andrew Ng 的《机器学习渴望》中的 7 个有用建议
原文:
www.kdnuggets.com/2018/05/7-useful-suggestions-machine-learning-yearning.html
comments

AI、机器学习和深度学习正在迅速发展并改变许多行业。Andrew Y. Ng 是这一领域的领先人物之一——他是 Coursera 的共同创始人、前百度 AI 部门负责人以及前 Google Brain 负责人。他正在撰写一本书,《机器学习渴望》(你可以获取免费草稿),教你如何构建机器学习项目。
Andrew 写道
本书的重点不是教你机器学习算法,而是如何让机器学习算法发挥作用。一些技术 AI 课程会给你一个锤子;本书则教你如何使用这个锤子。如果你渴望成为 AI 领域的技术领导者,并想学习如何为团队设定方向,这本书将对你有所帮助。
我们已经阅读了草稿,并从书中挑选了 7 个最有趣且实用的建议:
- 优化和满足指标
与其使用单一公式或指标来评估算法,你应该考虑使用多个评估指标。可以通过设置“优化”指标和“满足”指标来实现这一点。

以上述示例为例,我们可以首先定义一个可接受的运行时间——例如少于 100ms——这可以作为我们的“满足”指标。你的分类器只需满足这一要求,即运行时间低于此值即可,无需更多。准确性则是“优化”指标。这可以是评估算法的一种极其高效且简单的方法。
- 快速选择开发/测试集——如有需要,不要害怕更改它们
在开始新项目时,Ng 解释说,他会尽快选择开发/测试集,从而给团队设定一个明确的目标。设定一个初步的一周目标;不完美的初步结果也比过度考虑这一阶段要好,并且能够迅速启动。
话虽如此,如果你突然意识到最初的开发/测试集不合适,不要害怕进行更改。选择不正确的开发/测试集可能有三种原因:
-
你需要在实际分布上表现良好,而与开发/测试集不同
-
你已经过度拟合了开发/测试集
-
该指标测量的是项目需要优化的内容以外的东西
记住,改变这些并不是大事。只需进行更改,并让你的团队知道你正在前进的新方向。
- 机器学习是一个迭代过程:不要指望它第一次就能成功
Ng 说明了他构建机器学习软件的方法有三方面:
-
从一个想法开始
-
将想法实现为代码
-
进行实验以得出这个想法的效果如何
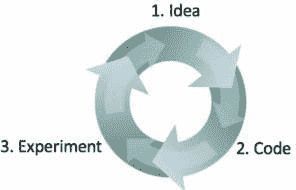
你绕过这个循环的速度越快,进展就会越快。这也是为什么提前选择测试/开发集很重要,因为它可以节省在迭代过程中宝贵的时间。将性能与这个集进行比较可以让你迅速看到是否在朝着正确的方向前进。
- 快速构建你的第一个系统,然后进行迭代
如第 3 点所述,构建机器学习算法是一个迭代过程。Ng 专门 dedicates 一个章节来解释快速构建第一个系统并从中发展起来的好处:“不要一开始就试图设计和构建完美的系统。相反,快速构建和训练一个基础系统——也许只需几天。即使基础系统远非你能构建的‘最佳’系统,也很有价值去检查基础系统的功能:你将迅速找到表明你最有前景的方向的线索,从而投入你的时间。”
- 并行评估多个想法
当你的团队有很多关于如何改进算法的想法时,你可以高效地并行评估这些想法。Ng 以创建一个可以检测猫图片的算法为例,解释了他如何创建一个电子表格并在查看约 100 个错误分类的开发/测试集图像时填充它。
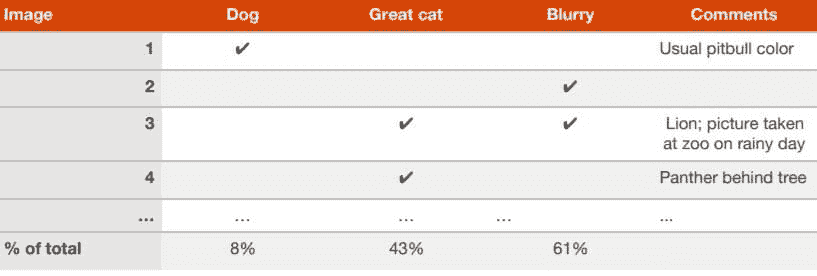
包括对每张图像的分析,为什么失败以及任何可能有助于未来反思的附加评论。完成后,你可以看到哪个想法能够消除更多的错误,因此应该优先考虑哪个想法。
- 考虑是否清理错误标签的开发/测试集是否值得
在错误分析过程中,你可能会注意到开发/测试集中一些示例被错误标记了。即,图像已经被人为地错误标记。如果你怀疑部分错误是由于此原因导致的,可以在你的电子表格中添加一个额外的类别:
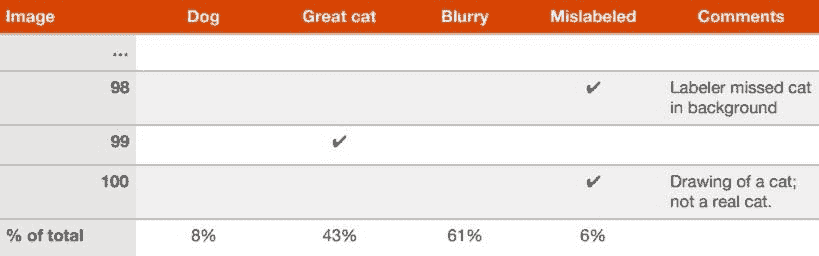
完成后,你可以考虑是否值得花时间修复这些错误。Ng 给出了两个可能的场景来判断是否值得修复这些错误:
示例 1:
开发集的总体准确率……………….90%(总体错误率 10%)
由于标签错误导致的错误……0.6%(开发集错误的 6%)
由于其他原因导致的错误…………………9.4%(开发集错误的 94%)
“在这里,由于标签错误导致的 0.6%的不准确率可能相对于你可以改进的 9.4%的错误来说并不显著。手动修正开发集中的标签错误没有害处,但并不是关键:可能不需要知道你的系统的总体错误率是 10%还是 9.4%。”
示例 2:
开发集的总体准确率……………….98.0%(总体错误率 2.0%)
错误由于标记错误的示例……. 0.6%。 (开发集错误的 30%)
其他原因导致的错误………………… 1.4%(开发集错误的 70%)
“30% 的错误是由于开发集中标记错误的图像,给你的准确性估计带来了显著的误差。现在提高开发集中标签的质量是值得的。处理这些标记错误的示例将帮助你确定分类器的错误更接近 1.4% 还是 2%——这是一个显著的相对差异。”
- 考虑将开发集分成独立的子集
Ng 解释说,如果你有一个大的开发集,其中 20% 的数据存在错误率,那么将这些数据分成两个独立的子集可能是值得的:
“以算法错误分类 5,000 个开发集示例中的 1,000 个为例。假设我们想手动检查大约 100 个错误以进行错误分析(10% 的错误)。你应该随机选择 10% 的开发集,并将其放入我们称之为 Eyeball 开发集 的集合中,以提醒自己我们是用眼睛查看它的。(对于语音识别项目,可能会称这个集合为 Ear 开发集)。因此,Eyeball 开发集有 500 个示例,我们期望算法错误分类大约 100 个。
开发集的第二个子集,称为 Blackbox 开发集,将包含剩余的 4500 个示例。你可以使用 Blackbox 开发集通过测量其错误率来自动评估分类器。你还可以用它来选择算法或调整超参数。然而,你应该避免用眼睛查看它。我们使用“Blackbox”这个术语,因为我们只会使用这个子集的数据来获得对分类器的“Blackbox”评估。”
相关:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
7 种 ChatGPT 让你编码更好更快的方法
原文:
www.kdnuggets.com/2023/06/7-ways-chatgpt-makes-code-better-faster.html

作者提供的图片
我很高兴与您分享七种个人帮助我成为更好、更快的编码者的绝妙方法,这都要感谢 ChatGPT!这些奇妙的技巧不仅可以帮助您避免常见的错误,还能揭示在编码过程中拥有 AI 副驾驶的巨大能力。所以,让我们深入探索,一起提升你的编码技能吧!
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
1. 项目规划
项目规划是任何项目中最重要的阶段,你在这里为成功奠定基础。在规划阶段获得 ChatGPT 的帮助非常宝贵,因为它可以帮助你考虑软件开发或数据科学项目的总体范围、架构、需求和可行性。
通过向 ChatGPT 描述你的目标、限制和使用案例,它可以提供有关以下方面的有用建议:
-
根据你的具体需求选择技术和工具
-
高级设计和架构
-
需要按照正确顺序执行的主要任务和步骤
-
需要注意的潜在问题、风险和障碍
我已经利用 ChatGPT 的见解进行机器学习和数据科学项目规划。它有效地帮助我选择适当的工具、技术和数据集来解决特定问题。ChatGPT 建议的工作流程和路线图也通过从一开始就将我指向正确的方向,为我节省了时间。您可以阅读使用 ChatGPT 进行数据科学项目的指南以了解更多有关 ChatGPT 项目规划的信息。
2. 分解复杂系统
避免要求 ChatGPT 从头开始编写整个端到端系统的代码。它可能会产生通用的、有缺陷的代码,遗漏边界情况,无法满足你的特定要求。
相反,将 ChatGPT 的帮助集中在你整体系统中的较小、定义明确的任务上。请让它生成代码来:
-
执行一个逻辑步骤的具体函数或方法
-
代表你领域内良好界定部分的个别类
-
在整个工作流程中的离散算法或过程
将问题分解为这些较小的组件将产生更易于管理和模块化的代码。
3. 干净易读的代码
ChatGPT 可以通过遵循您语言和框架的最佳实践来建议使您的代码更简洁和更易读的方法。
您可以使用 ChatGPT 清晰地重命名变量,逻辑上拆分长函数,减少嵌套,添加内联注释,并一致地格式化代码,使您的代码对协作者更易读、可维护且无错误。
4. 单元测试和验证
生成代码后,重要的是在隔离的机器上验证代码,然后再将其推送到生产环境或远程仓库。重要的是不要完全依赖代码的功能;确保它使用了最新的 API。
软件开发的一个关键方面是为关键功能创建测试函数。我理解应用程序的单元测试,特别是对于机器学习工程师或数据科学家来说,可能会很具挑战性。然而,在 ChatGPT 的帮助下,您可以在几秒钟内为任何函数生成测试用例。
5. 迭代
ChatGPT 是一个对话型 AI,您可以持续请求帮助添加或删除代码中的元素,甚至要求改进。如果发生错误,只需复制并粘贴错误信息,并请求 ChatGPT 为您生成改进版本的代码。
它理解上下文并可以生成专门针对当前任务的代码,确保功能性和有效性。
6. 代码文档
良好的文档对于您自己和其他开发人员理解您的项目至关重要。ChatGPT 可以通过注释、文档字符串、README 文件、wiki 页面及其他基于您的语言和工具的文档帮助您记录代码。
您只需提供简洁的项目描述和代码片段,ChatGPT 就会生成干净且易读的文档,大大有助于理解您的代码库。
7. 调试和获取帮助
调试是编程中非常重要的一部分,因为它帮助我们找到和修复代码中的错误。然而,让我们承认,调试有时可能会有些挑战,特别是当我们处理复杂代码时。
ChatGPT 可以帮助您调试代码并弄清楚您在运行代码时面临的整体问题。它可以分析您的代码,理解其结构,并提供潜在错误或漏洞的见解。此外,ChatGPT 可以帮助您集成系统、学习新的编程语言,甚至为给定问题提供多种解决方案。
结论
作为数据科学家,我喜欢使用 ChatGPT 进行代码生成、规划和改进我的写作。这就像是有一个有用的伙伴在我身边!有了 ChatGPT 作为我的编码助手,我可以轻松在几秒钟内创建干净且无错误的代码。我只需提供项目描述并请求生成特定任务的代码即可。
当然,就像任何朋友一样,ChatGPT 也有它的烦恼时刻。有时它可能会难以理解上下文或无法解决编码问题。由于它是基于较旧的数据进行训练的,可能无法跟上最新的 API。不过,大家都有自己的怪癖,对吧?
Abid Ali Awan(@1abidaliawan)是一位认证的数据科学专家,喜欢构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助面临心理健康问题的学生。
更多相关话题
提升机器学习模型的 7 种方法
原文:
www.kdnuggets.com/7-ways-to-improve-your-machine-learning-models

由 ChatGPT 生成的图像
你是否在测试阶段努力提高模型性能?即使你改进了模型,它在生产环境中仍然因为未知原因表现不佳。如果你在面临类似问题,那么你来对地方了。
在这篇博客中,我将分享 7 个使你的模型准确和稳定的技巧。通过遵循这些技巧,你可以确保你的模型即使在未见过的数据上也能表现更好。
为什么要听我的建议?我在这个领域已经有近四年的经验,参与了 80 多个机器学习竞赛,并参与了多个端到端的机器学习项目。我还帮助了许多专家建立更好、更可靠的模型。
1. 清洗数据
数据清洗是最重要的部分。你需要填补缺失值、处理离群值、标准化数据,并确保数据的有效性。有时,通过 Python 脚本进行清洗并不完全有效。你必须逐一查看每个样本,确保没有问题。我知道这会占用你很多时间,但相信我,数据清洗是机器学习生态系统中最重要的部分。
举例来说,当我在训练自动语音识别模型时,我发现数据集中存在多个问题,简单删除字符无法解决。我不得不听音频并重新编写准确的转录。有些转录内容非常模糊且不合逻辑。
2. 增加数据
增加数据量通常会提升模型性能。将更多相关且多样化的数据添加到训练集中可以帮助模型学习更多的模式,从而做出更好的预测。如果你的模型缺乏多样性,它可能在多数类上表现良好,但在少数类上表现不佳。
许多数据科学家现在使用生成对抗网络(GAN)来生成更多样化的数据集。他们通过在现有数据上训练 GAN 模型,然后利用它生成合成数据集来实现这一点。
3. 特征工程
特征工程涉及从现有数据中创建新特征,并移除那些对模型决策贡献较少的无用特征。这为模型提供了更多相关的信息,以进行预测。
你需要进行 SHAP 分析,查看特征重要性分析,并确定哪些特征对决策过程很重要。然后,可以利用这些特征创建新特征并从数据集中移除无关特征。这个过程需要对业务用例和每个特征有透彻的理解。如果你不了解特征及其对业务的作用,你将盲目前行。
4. 交叉验证
交叉验证是一种用于评估模型在多个数据子集上的表现的技术,减少过拟合风险,并提供更可靠的泛化能力估计。这将告诉你模型是否足够稳定。
在整个测试集上计算准确率可能无法提供关于模型性能的完整信息。例如,测试集的前五分之一可能显示 100%的准确率,而第二个五分之一的表现可能较差,仅为 50%的准确率。尽管如此,总体准确率可能仍在 85%左右。这种差异表明模型不稳定,需要更多干净且多样的数据进行重新训练。
所以,与其进行简单的模型评估,我建议使用交叉验证,并提供各种指标来测试模型。
5. 超参数优化
使用默认参数训练模型可能看起来简单且快速,但你会错过改进的性能,因为在大多数情况下你的模型并未经过优化。为了在测试期间提高模型性能,强烈建议对机器学习算法进行彻底的超参数优化,并保存这些参数,以便下次可以用于训练或重新训练模型。
超参数调整涉及调整外部配置以优化模型性能。找到过拟合和欠拟合之间的正确平衡对于提高模型的准确性和可靠性至关重要。它有时可以将模型的准确率从 85%提高到 92%,这在机器学习领域是相当显著的。
6. 尝试不同的算法
模型选择和尝试各种算法对找到适合给定数据的最佳算法至关重要。不要仅限于简单算法用于表格数据。如果你的数据有多个特征和一万样本,那么你应该考虑神经网络。有时,即使是逻辑回归也能为文本分类提供惊人的结果,这些结果是深度学习模型如 LSTM 无法实现的。
从简单的算法开始,然后逐步尝试高级算法,以实现更好的性能。
7. 集成学习
集成学习涉及将多个模型组合在一起,以提高整体预测性能。构建一个每个模型都有自己优势的集成模型,可以实现更稳定和准确的结果。
集成模型常常给我带来更好的结果,有时甚至能在机器学习竞赛中获得前十名。不要丢弃低性能模型;将它们与一组高性能模型结合,你的整体准确率将会提高。
集成、数据集清理和特征工程是我在竞赛中获胜并实现高性能的三大最佳策略,即使在未见过的数据集上也是如此。
最后的思考
还有一些技巧仅适用于特定类型的机器学习领域。例如,在计算机视觉中,我们需要关注图像增强、模型架构、预处理技术和迁移学习。然而,以上讨论的七个技巧——数据清理、增加数据、特征工程、交叉验证、超参数优化、尝试不同算法和集成——是普遍适用且对所有机器学习模型都有益的。通过实施这些策略,你可以显著提高预测模型的准确性、可靠性和稳健性,从而获得更好的洞察力和更有依据的决策。
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专家,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理健康问题的学生构建一个 AI 产品。
相关主题
数据科学的 8 个基础统计概念
原文:
www.kdnuggets.com/2020/06/8-basic-statistics-concepts.html

统计学是一种数学分析形式,利用量化模型和表示法处理给定的实验数据或现实生活研究。统计学的主要优点在于信息的呈现方式简单明了。最近,我回顾了所有统计材料,并整理了成为数据科学家的 8 个基本统计概念!
-
理解分析类型
-
概率
-
中央趋势
-
变异性
-
变量之间的关系
-
概率分布
-
假设检验与统计显著性
-
回归分析
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
理解分析类型
描述性分析 告诉我们过去发生了什么,并通过提供背景帮助企业了解其表现,以帮助利益相关者解读信息。
诊断分析 进一步分析描述性数据,帮助你理解过去发生的事情的原因。
预测分析 预测未来最可能发生的情况,并根据信息提供可操作的洞察。
规范分析 提供关于如何利用预测的建议,并引导可能的行动以找到解决方案。
概率
概率 是衡量事件在随机实验中发生可能性的指标。
补集:P(A) + P(A’) = 1
交集:P(A∩B) = P(A)P(B)
并集:P(A∪B) = P(A) + P(B) − P(A∩B)
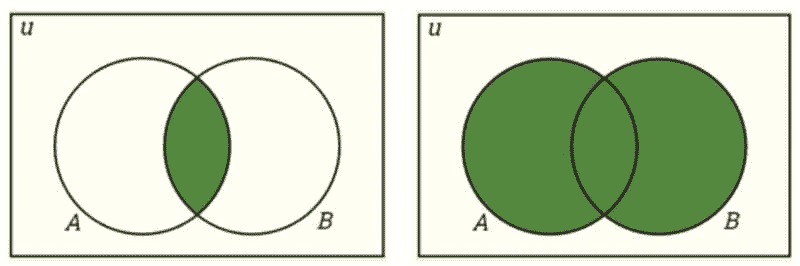
交集与并集。
条件概率:P(A|B) 是某事件发生与一个或多个其他事件的关系的概率度量。P(A|B)=P(A∩B)/P(B),当 P(B)>0 时。
独立事件:如果一个事件的发生不影响另一个事件的发生概率,则这两个事件是独立的。P(A∩B)=P(A)P(B),其中 P(A) != 0 和 P(B) != 0 ,P(A|B)=P(A),P(B|A)=P(B)
互斥事件:如果两个事件不能同时发生,则它们是互斥的。P(A∩B)=0 和 P(A∪B)=P(A)+P(B)。
贝叶斯定理描述了基于可能与事件相关的条件的先验知识来计算事件发生的概率。
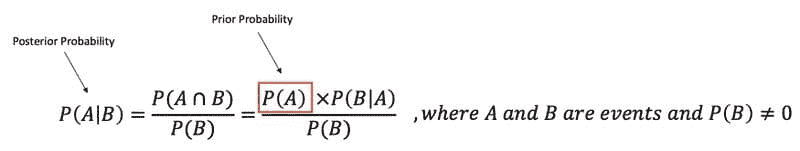
贝叶斯定理。
中心倾向
均值:数据集的平均值。
中位数:有序数据集中的中间值。
众数:数据集中最频繁出现的值。如果数据中有多个值出现频率最高,则为多峰分布。
偏度:衡量对称性的度量。
峰度:衡量数据相对于正态分布是否具有重尾或轻尾的度量。
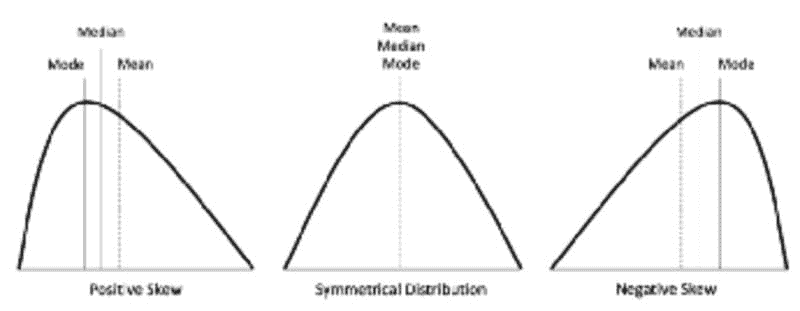
偏度。
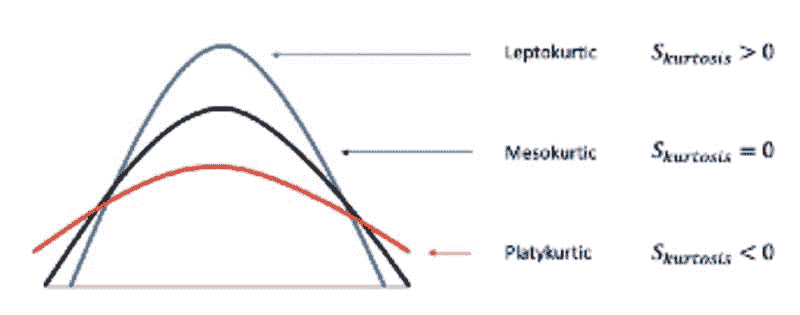
峰度。
变异性
范围:数据集中最高值和最低值之间的差异。
百分位数、四分位数和四分位距(IQR)
-
百分位数— 指示某一百分比的观察值落在观察组中的值的度量。
-
分位数— 将数据点的数量划分为四个大致相等的部分或四分之一的值。
-
四分位距(IQR)— 基于将数据集划分为四分位数的统计离散性和变异性的度量。IQR = Q3 − Q1
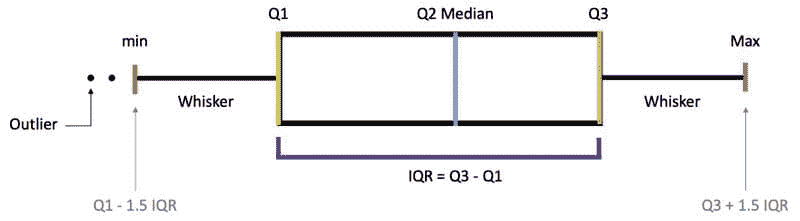
百分位数、四分位数和四分位距(IQR)。
方差:值与均值之间的平均平方差,用于衡量数据相对于均值的分散程度。
标准差:每个数据点与均值之间的标准差,以及方差的平方根。
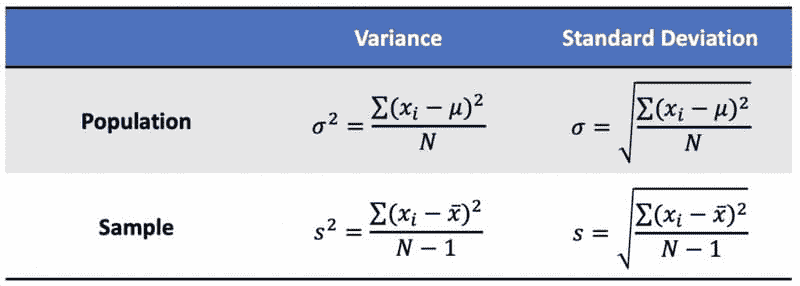
总体和样本方差及标准差。
标准误差(SE):对抽样分布标准差的估计。

总体和样本标准误差。
变量之间的关系
因果关系:两个事件之间的关系,其中一个事件受另一个事件的影响。
协方差:两个或更多变量之间联合变异性的定量度量。
相关性:衡量两个变量之间的关系,其范围从 -1 到 1,是协方差的归一化版本。
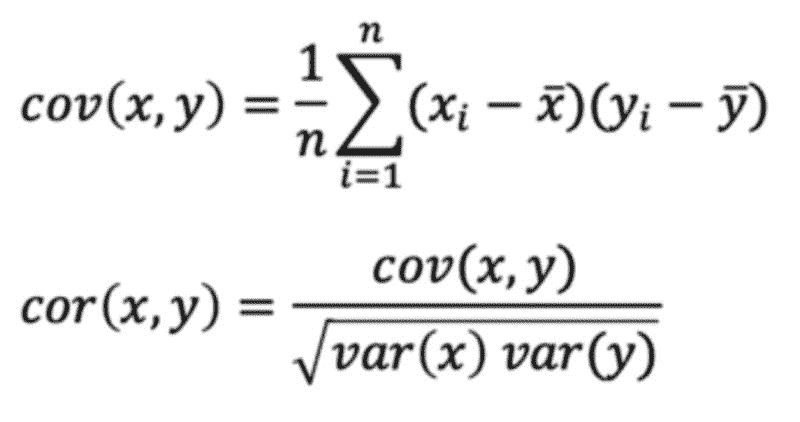
概率分布
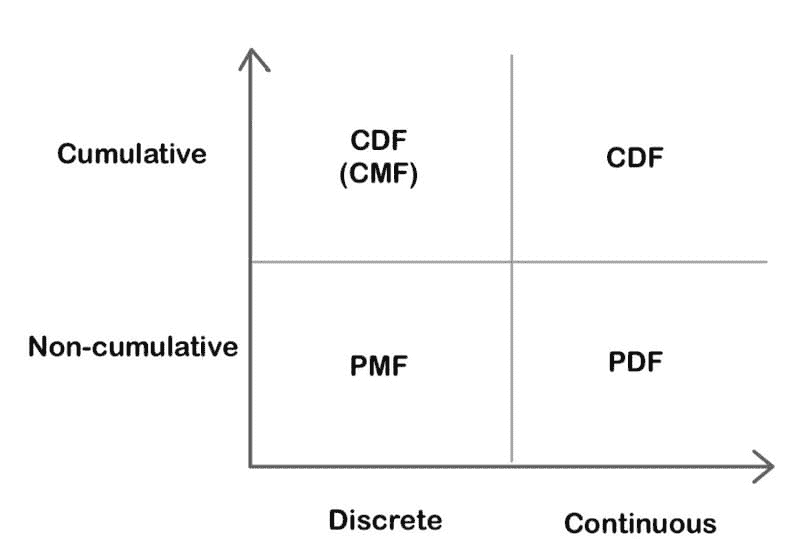
概率分布函数
概率质量函数 (PMF):一个函数,给出离散随机变量恰好等于某个值的概率。
概率密度函数 (PDF):一个用于连续数据的函数,其中任何给定样本的值可以解释为提供随机变量取该样本值的相对可能性。
累积分布函数 (CDF):一个函数,给出随机变量小于或等于某个值的概率。
PMF、PDF 和 CDF 的比较。
连续概率分布
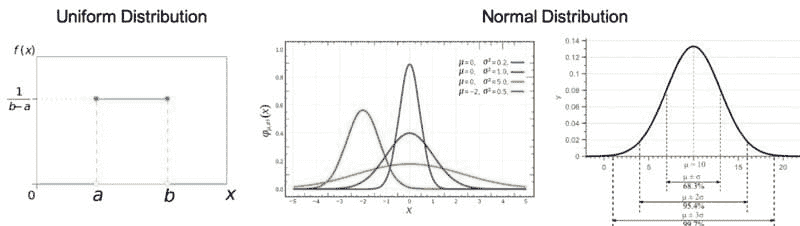
均匀分布:也称为矩形分布,是一种所有结果都同样可能的概率分布。
正态/高斯分布:分布的曲线呈钟形且对称,与中心极限定理有关,即样本均值的抽样分布随着样本量的增大趋近于正态分布。
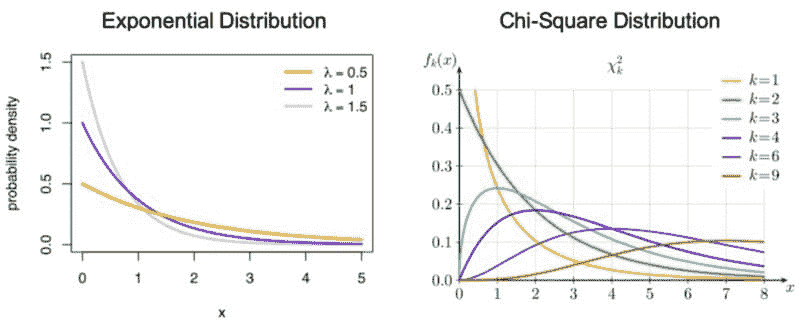
指数分布:描述泊松点过程中的事件之间时间的概率分布。
卡方分布:标准正态偏差平方和的分布。
离散概率分布
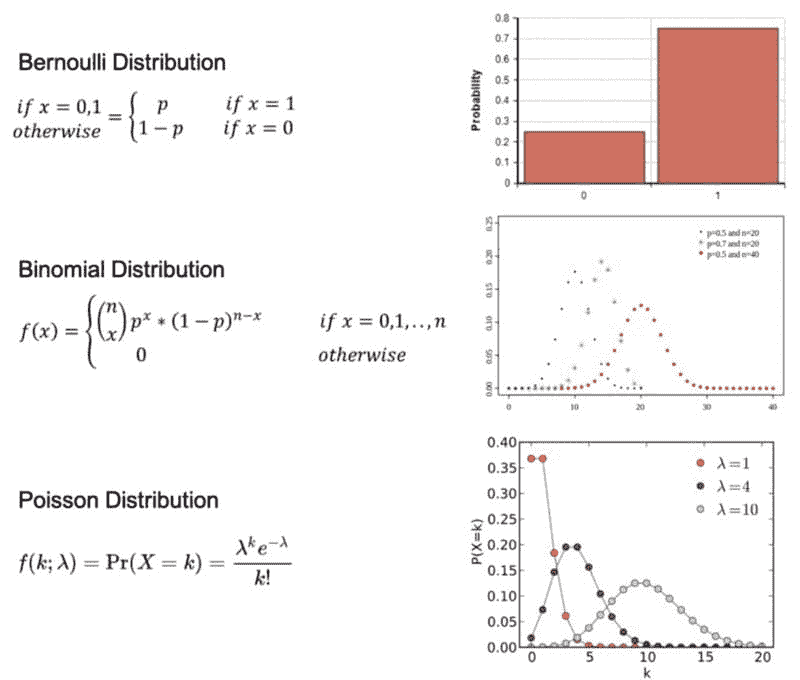
伯努利分布:一个随机变量的分布,它涉及单次试验且只有 2 个可能结果,即 1(成功)概率为 p,0(失败)概率为(1-p)。
二项分布:在一系列n独立实验中的成功次数的分布,每次实验只有 2 个可能结果,即 1(成功)概率为 p,0(失败)概率为(1-p)。
泊松分布:表示在固定时间间隔内事件数为 k 的概率的分布,如果这些事件以已知的常数平均速率λ发生,并且与时间独立。
假设检验与统计显著性
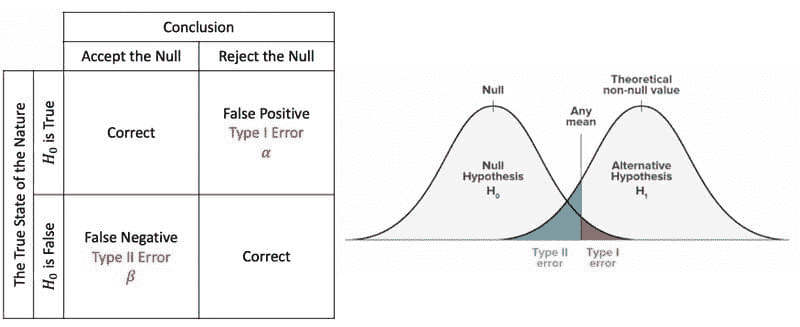
零假设与备择假设
零假设:一个通用的陈述,表示两个测量现象之间没有关系或组之间没有关联。备择假设:与零假设相对立。
在统计假设检验中,I 型错误是拒绝真实的零假设,而II 型错误是未拒绝虚假的零假设。
解释
P 值:在原假设为真的情况下,检验统计量至少与观察到的统计量一样极端的概率。当 p 值 > α 时,我们无法拒绝原假设,而当 p 值 ≤ α 时,我们拒绝原假设,可以得出我们有显著结果的结论。
临界值:是检验统计量尺度上的一个点,超过该点我们就会拒绝原假设,它由检验的显著性水平α推导而来。它依赖于检验统计量,这些统计量特定于检验类型,以及显著性水平α,这定义了检验的灵敏度。
显著性水平和拒绝域:拒绝域实际上取决于显著性水平。显著性水平用α表示,是在原假设为真的情况下拒绝原假设的概率。
Z 检验
Z 检验是任何统计检验,其检验统计量在原假设下的分布可以用正态分布来近似,并且检验的是我们已经知道总体方差的分布的均值。因此,如果样本量很大或总体方差已知,许多统计检验可以方便地作为近似 Z 检验来进行。
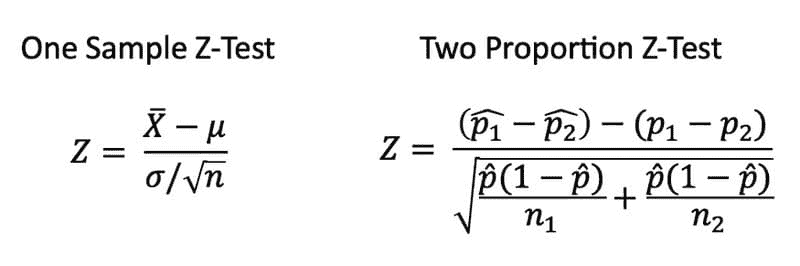
t 检验
t 检验是当总体方差未知且样本量不大(n < 30)时使用的统计检验。
配对样本 意味着我们从同一组、个人、物品或事物中收集两次数据。独立样本 意味着两个样本必须来自两个完全不同的总体。

方差分析(ANOVA)
方差分析是用来确定实验结果是否显著的方法。单因素方差分析 比较两个独立组的均值,使用一个自变量。双因素方差分析 是单因素方差分析的扩展,使用两个自变量来计算主效应和交互效应。

方差分析表。
卡方检验
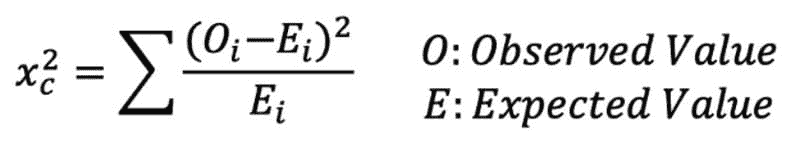
卡方检验公式。
卡方检验检查当我们拥有一组离散的数据点时,模型是否大致符合正态分布。拟合优度检验 确定样本是否与总体在一个分类变量上的分布匹配。独立性卡方检验 比较两组数据,查看是否存在关系。
回归
线性回归
线性回归的假设
-
线性关系
-
多变量正态性
-
无或很小的多重共线性
-
无或很小的自相关
-
同方差性
线性回归 是一种线性方法,用于建模一个因变量与一个自变量之间的关系。自变量 是在科学实验中控制的变量,用于测试对因变量的影响。因变量 是在科学实验中被测量的变量。
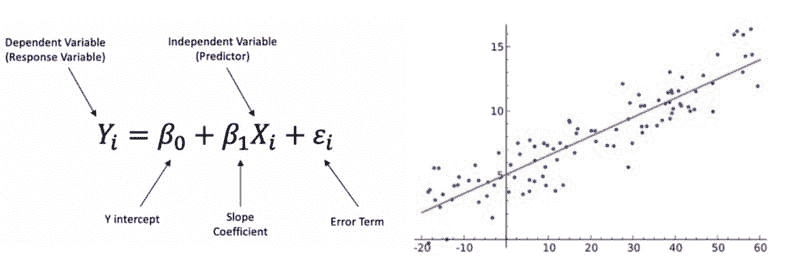
线性回归公式。
多元线性回归 是一种线性方法,用于建模一个因变量与两个或更多自变量之间的关系。
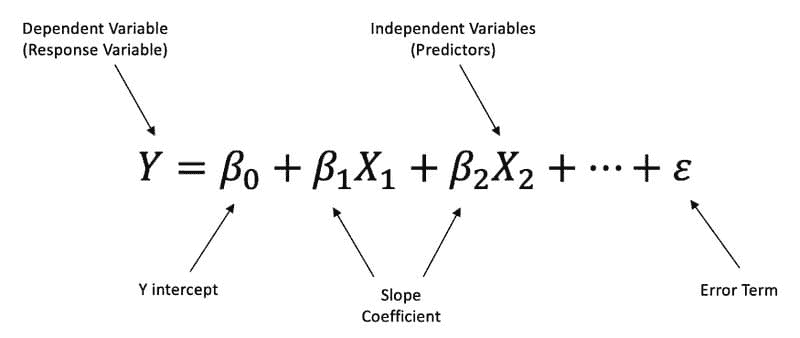
多元线性回归公式。
执行线性回归的步骤
步骤 1:理解模型描述、因果关系和方向性
步骤 2:检查数据、分类数据、缺失数据和异常值
-
异常值 是指显著不同于其他观察值的数据点。我们可以使用标准差方法和四分位距 (IQR) 方法。
-
虚拟变量 仅取值为 0 或 1,以指示分类变量的效应。
步骤 3:简单分析 — 检查因变量与自变量之间、自变量与自变量之间的影响比较
-
使用散点图检查相关性
-
多重共线性 发生在两个以上的自变量高度相关时。我们可以使用方差膨胀因子 (VIF) 来测量,如果 VIF > 5 表示高度相关,如果 VIF > 10,则变量之间肯定存在多重共线性。
-
交互项 意味着斜率从一个值变化到另一个值。
步骤 4:多元线性回归 — 检查模型和正确的变量
步骤 5:残差分析
-
检查残差的正态分布和正态性。
-
同方差性 描述了一个情况,即误差项在所有自变量值下保持相同,意味着残差在回归线上相等。
步骤 6:回归输出的解释
-
R-平方 是一种统计拟合度量,表示因变量的变异程度由自变量解释的比例。较高的 R-平方 值表示观察数据与拟合值之间的差异较小。
-
P 值
-
回归方程
Shirley Chen 是 Outdoorsy 的数据分析师。
原文。经授权转载。
更多相关话题
8 种最佳 Python 图像处理工具
原文:
www.kdnuggets.com/2022/11/8-best-python-image-manipulation-tools.html

编辑器提供的图像
在当今世界,数据在每个行业领域中都扮演着至关重要的角色。图像可以是提取数据的来源之一。图像可以定义为像素矩阵,每个像素代表一种颜色,可以被视为数据值。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您在 IT 方面的工作
图像处理对于揭示任何图像中的潜在数据非常有用。它帮助你从图像中提取、操作和过滤数据。图像处理的主要目标是从图像中揭示一些有价值的信息。
图像处理有各种应用,如图像锐化、图像修复、模式识别、视频处理等。大多数图像处理应用归属于数据分析和数据科学。
当谈到数据分析时,我们脑海中浮现出的唯一语言是 Python。由于其广泛的库,它也是图像处理的首选语言,这使得开发人员可以用简单的代码行执行复杂的操作。
让我们看看一些主要用于图像处理的 Python 库。
8 种最佳 Python 图像处理工具
这里列出了帮助你轻松处理图像的最佳 Python 库。它们都易于使用,并允许你提取图像中的基本数据。
1. OpenCV
OpenCV(开源计算机视觉库)是一个受欢迎的 Python 数据可视化库。这是一个开源库,适用于多种编程语言,包括 C++、Java 以及汇编语言。
这个库是由 Intel 使用C++编程语言开发的,旨在实时计算机视觉。它非常适合执行计算密集型的计算机视觉程序。
安装
由于 OpenCV 是一个第三方库,我们可以通过 Python 的 pip 包管理工具为我们的 Python 环境安装它。
pip install opencv-python
示例
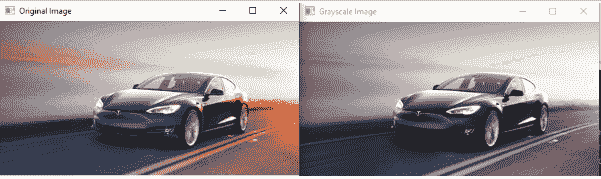
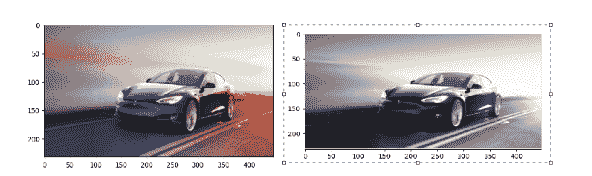
# import opencv
import cv2
# Read the image
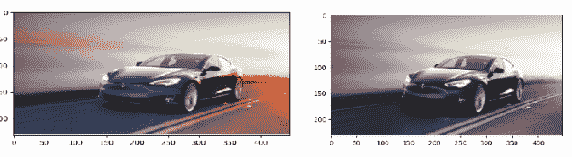
image = cv2.imread('tesla.png')
# grayscale the image
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imshow('Original Image', image)
cv2.imshow('Grayscale Image', gray_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
输出
2. Pillow (PIL)
Pillow是另一个流行的 Python 图像处理库。它是每个初学者可以入门的最基本的图像处理库。它也被称为 PIL,即 Python Imaging Library。
PIL 库附带不同的文件格式扩展,提供强大且复杂的功能以执行图像处理。如果我们将 PIL 与 OpenCV 进行比较,PIL 是一个轻量级的库,功能较少,使得它对于刚刚进入图像处理领域的新 Python 开发者来说,学习和操作都比较容易。
安装
PIL 也是一个第三方开源库,可以使用pip install命令安装。
pip install pillow
示例
使用 Pillow 在 Python 中将图像转换为灰度
from PIL import Image
with Image.open("tesla.png") as im:
#show the original image
im.show("Original Image")
#convert into grayscale
grayscaleImg = im.convert("L")
#show the grayscale image
grayscaleImg.show()
输出

3. Scikit Image
Scikit Images是一个以科学为导向的 Python 图像处理库。它设计用于使用 Numpy 和 Scipy 库处理图像。它包括各种科学算法,如分割、颜色空间操作、分析、形态学等。该库使用 Python 和 C 编程语言编写,适用于所有流行的操作系统,如 Linux、macOS 和 Windows。
安装
scikit-image 是一个开源库,我们可以使用 pip install 命令进行安装。
pip install scikit-image
示例
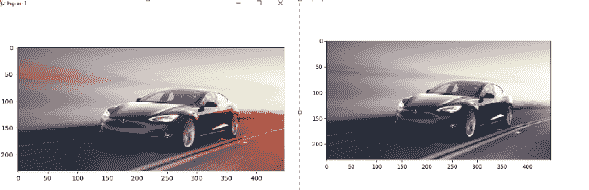
使用 scikit-image 库将图像转换为灰度
from skimage import io
from skimage.color import rgb2gray
# way to load car image from file
car = io.imread('tesla.png')[:,:,:3]
#convert into grayscale
grayscale = rgb2gray(car)
#show the original
io.imshow(car)
io.show()
#show the grayscale
io.imshow(grayscale)
io.show()
输出
4. NumPy
NumPy是最基本的 Python 科学计算库。它因引入多维数组或矩阵而闻名。它是一个专门的科学计算库。此外,它还附带广泛的数学功能,如数组、线性代数、基本统计操作、随机模拟、逻辑排序、搜索、形状操作等。
安装
再次安装 NumPy 时,我们可以使用 pip install 命令。
pip install numpy
示例
使用 numpy 将图像转换为灰度
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
#load the original image
img_rgb = mpimg.imread('tesla.png')[...,:3]
#show the original image
plt.imshow(img_rgb)
plt.show()
#convert the image into grayscale
img_gray = np.dot(img_rgb,[0.299, 0.587, 0.144])
#show the grayscale image
plt.imshow(img_gray, cmap=plt.get_cmap('gray'))
plt.show()
输出
5. SciPy
类似于 Numpy,SciPy也是一个科学计算库。由于它是作为 NumPy 库的扩展构建的,因此功能比 Numpy 更多。
Scipy 提供了高级和复杂的命令和类用于数据操作和数据可视化。它涵盖了广泛的数据处理工具。此外,它还支持并行编程、从网络获取数据、数据驱动的子程序及其他数学功能。
安装
要安装 SciPy 库,我们可以使用 Python 包管理工具 pip。
pip install scipy
示例
使用 scipy 将图像转换为灰度图像
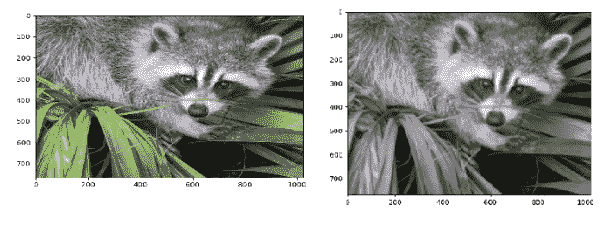
from scipy import misc,ndimage
from matplotlib import pyplot as plt
import numpy as np
img=misc.face()
#show original image
plt.imshow(img)
plt.show()
#grayscale using gaussian blur filter
grayscale=ndimage.gaussian_filter(img,sigma=2)
#show grayscale image
plt.imshow(grayscale)
plt.show()
输出
6. Mahotas
Mahotas 是另一个 Python 计算机视觉库,可以执行各种图像处理操作。它使用 C++ 设计,包含许多算法以提高图像处理速度。它还使用 NumPy 数组中的矩阵表示图像。主要功能包括分水岭、凸点计算、击中与错过卷积以及 Sobel 边缘。
安装
Mahotas 是一个开源库,可以通过以下终端命令进行安装。
pip install mahotas
示例
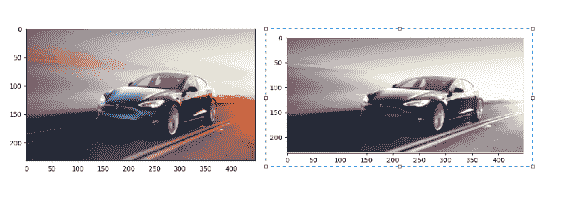
使用 Mahotas 将 RGB 图像转换为灰度图像
import mahotas
from pylab import imshow, show
#read the image
img = mahotas.imread('tesla.png')
#show original image
imshow(img)
show()
img = img[:, :, 0]
grayscale = mahotas.overlay(img)
#show grayscale image
imshow(grayscale)
show()
输出
7. SimpleITK
SimpleITK 是一个功能强大的图像配准和分割工具包。它作为 ITK 工具包 的扩展构建,提供了简化的接口。它支持多种编程语言,如 Python、R、C++、Java、C#、Ruby、TCL 和 Lua。
该库支持 2D、3D 和 4D 图像。与其他 Python 图像处理库和框架相比,该库的图像处理速度非常高。
安装
pip install SimpleITK
示例
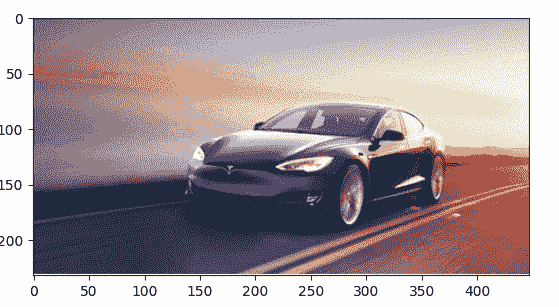
使用 SimpleITK 加载并显示图像
import SimpleITK as sitk
import matplotlib.pyplot as plt
logo = sitk.ReadImage('tesla.png')
# GetArrayViewFromImage returns an immutable numpy array view to the data.
plt.imshow(sitk.GetArrayViewFromImage(logo))
plt.show()
输出
8. Matplotlib
Matplotlib 虽然是一个数据可视化库,但也可以用作图像处理库。它通常用于绘制 numpy 数组数据,但也可以读取由 NumPy 数组表示的图像数据。我们在上述库中已经使用了 Matplotlib 库来显示和绘制图像。
安装
可以通过以下简单命令安装 Matplotlib。
pip install matplotlib
示例
# importing libraries.
import matplotlib.pyplot as plt
from PIL import Image
# open image using pillow library
image = Image.open("tesla.png")
#show original image
plt.imshow(image)
plt.show()
# grayscale the image
plt.imshow(image.convert("L"), cmap='gray')
plt.show()
输出
结论
这里结束了我们关于最佳 Python 图像处理工具的列表。在这八个库或工具中,最常用的 Python 图像处理库是 Pillow 和 OpenCV(在某些特定情况下是 SimplICV)。
如果你正在考虑构建一个与图像处理相关的项目,比如对象识别或颜色处理,建议使用 OpenCV 库,因为它是一个拥有众多先进功能的大型库。其他库也支持一些图像处理功能,但效率不如 OpenCV。
Vijay Singh Khatri 计算机科学专业毕业,专注于编程和市场营销。我非常喜欢撰写技术文章和创建新产品。
更多相关主题
8 种内置 Python 装饰器帮助编写优雅代码
原文:
www.kdnuggets.com/8-built-in-python-decorators-to-write-elegant-code
图片由编辑提供
Python,凭借其简洁易读的语法,是一种广泛使用的高级编程语言。Python 设计注重易用性,强调简单性和降低程序维护成本。它配备了丰富的库,减少了开发人员从头编写代码的需要,提高了开发人员的生产力。Python 的一个强大特性是装饰器,它有助于代码的优雅。
什么是 Python 装饰器?
在 Python 中,装饰器是一个函数,它允许你在不改变另一个函数核心逻辑的情况下修改其行为。它接受另一个函数作为参数,并返回具有扩展功能的函数。这样,你可以使用装饰器为现有函数添加额外逻辑,以增加可重用性,只需几行代码。本文将探讨八种内置 Python 装饰器,它们可以帮助你编写更优雅、易维护的代码。
图片由编辑提供
1. @atexit.register
@atexit.register 装饰器用于注册一个在程序终止时执行的函数。这个函数可以在程序即将退出时执行任何任务,无论是正常退出还是由于意外错误。
示例:
import atexit
# Register the exit_handler function
@atexit.register
def exit_handler():
print("Exiting the program. Cleanup tasks can be performed here.")
# Rest of the program
def main():
print("Inside the main function.")
# Your program logic goes here.
if __name__ == "__main__":
main()
输出:
Inside the main function.
Exiting the program. Cleanup tasks can be performed here.
在上述实现中,@atexit.register 被提到在函数定义之前。它将 exit_handler() 函数定义为退出函数。本质上,这意味着每当程序达到终止点,无论是正常执行还是由于意外错误导致的提前退出,exit_handler() 函数将被调用。
2. @dataclasses.dataclass
@dataclasses.dataclass 是一个强大的装饰器,用于自动生成类的常见特殊方法,例如“init”、“repr”等。它帮助你编写更简洁、清晰的代码,避免了编写初始化和比较类实例的样板代码的需要。它还可以通过确保在代码库中一致地实现常见特殊方法来帮助防止错误。
示例:
from dataclasses import dataclass
@dataclass
class Point:
x: int
y: int
point = Point(x=3, y=2)
# Printing object
print(point)
# Checking for the equality of two objects
point1 = Point(x=1, y=2)
point2 = Point(x=1, y=2)
print(point1 == point2)
输出:
Point(x=3, y=2)
True
@dataclass装饰器应用在 Point 类定义之上,告诉 Python 利用默认行为生成特殊方法。这会自动创建__init__方法,在对象实例化时初始化类属性,如 x 和 y。因此,像 point 这样的实例可以在无需显式编码的情况下构造。此外,__repr__方法,负责提供对象的字符串表示,也会自动调整。这确保了当对象(如 point)被打印时,它会生成一个清晰有序的表示,如输出所示:Point(x=3, y=2)。另外,两个实例 point1 和 point2 之间的相等比较(==)会产生 True。这一点值得注意,因为默认情况下,Python 基于内存位置检查相等性。然而,在 dataclass 对象的上下文中,相等性是由对象中包含的数据来确定的。这是因为@dataclass装饰器生成了一个__eq__方法,检查对象中数据的相等性,而不是检查相同的内存位置。
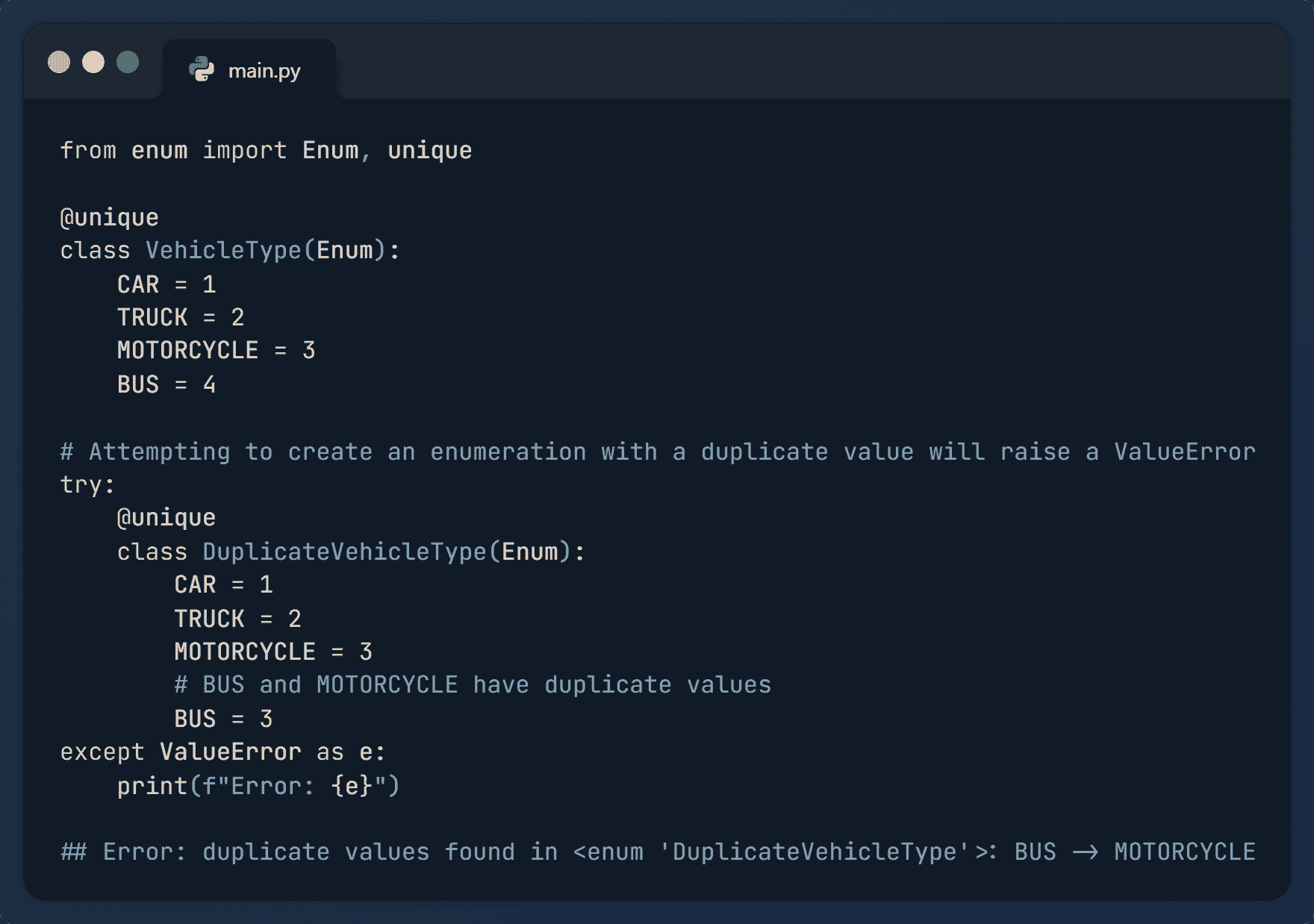
3. @enum.unique
@enum.unique装饰器,位于枚举模块中,用于确保枚举的所有成员的值是唯一的。这有助于防止意外创建具有相同值的多个枚举成员,从而避免混淆和错误。如果发现重复值,将引发ValueError。
示例:
from enum import Enum, unique
@unique
class VehicleType(Enum):
CAR = 1
TRUCK = 2
MOTORCYCLE = 3
BUS = 4
# Attempting to create an enumeration with a duplicate value will raise a ValueError
try:
@unique
class DuplicateVehicleType(Enum):
CAR = 1
TRUCK = 2
MOTORCYCLE = 3
# BUS and MOTORCYCLE have duplicate values
BUS = 3
except ValueError as e:
print(f"Error: {e}")
输出:
Error: duplicate values found in <enum>: BUS -> MOTORCYCLE</enum>
在上述实现中,“BUS”和“MOTORCYCLE”具有相同的值“3”。因此,@unique装饰器会引发一个 ValueError,提示发现了重复的值。你不能多次使用相同的键,也不能将相同的值分配给不同的成员。通过这种方式,它帮助防止多个枚举成员的值重复。
4. @partial
partial装饰器是一个强大的工具,用于创建部分函数。部分函数允许你预设原始函数的某些参数,并生成一个已经填入这些参数的新函数。
示例:
from functools import partial
# Original function
def power(base, exponent):
return base ** exponent
# Creating a partial function with the exponent fixed to 2
square = partial(power, exponent=2)
# Using the partial function
result = square(3)
print("Output:",result)
输出:
Output: 9
在上述实现中,我们有一个名为“power”的函数,它接受两个参数“base”和“exponent”,并返回基数的指数幂结果。我们使用原始函数创建了一个名为“square”的部分函数,其中指数被预设为 2。通过这种方式,我们可以使用partial装饰器扩展原始函数的功能。
5. @singledispatch
@singledispatch装饰器用于创建泛型函数。它允许你定义具有相同名称但不同参数类型的函数的不同实现。当你希望代码对不同数据类型表现出不同的行为时,这特别有用。
示例:
from functools import singledispatch
# Decorator
@singledispatch
def display_info(arg):
print(f"Generic: {arg}")
# Registering specialized implementations for different types
@display_info.register(int)
def display_int(arg):
print(f"Received an integer: {arg}")
@display_info.register(float)
def display_float(arg):
print(f"Received a float: {arg}")
@display_info.register(str)
def display_str(arg):
print(f"Received a string: {arg}")
@display_info.register(list)
def display_sequence(arg):
print(f"Received a sequence: {arg}")
# Using the generic function with different types
display_info(39)
display_info(3.19)
display_info("Hello World!")
display_info([2, 4, 6])
输出:
Received an integer: 39
Received a float: 3.19
Received a string: Hello World!
Received a sequence: [2, 4, 6]
在上述实现中,我们首先使用 @singledisptach 装饰器开发了通用函数 display_info(),然后分别为 int、float、string 和 list 注册了其实现。输出展示了 display_info() 对不同数据类型的工作情况。
6. @classmethod
@classmethod 是一个装饰器,用于在类中定义类方法。类方法绑定到类而非类的实例。静态方法和类方法之间的主要区别在于它们与类状态的交互。类方法可以访问并修改类状态,而静态方法不能访问类状态,并且独立操作。
示例:
class Student:
total_students = 0
def __init__(self, name, age):
self.name = name
self.age = age
Student.total_students += 1
@classmethod
def increment_total_students(cls):
cls.total_students += 1
print(f"Class method called. Total students now: {cls.total_students}")
# Creating instances of the class
student1 = Student(name="Tom", age=20)
student2 = Student(name="Cruise", age=22)
# Calling the class method
Student.increment_total_students() #Total students now: 3
# Accessing the class variable
print(f"Total students from student 1: {student1.total_students}")
print(f"Total students from student 2: {student2.total_students}")
输出:
Class method called. Total students now: 3
Total students from student 1: 3
Total students from student 2: 3
在上述实现中,Student 类具有类变量 total_students。@classmethod 装饰器用于定义 increment_total_students() 类方法,以递增 total_students 变量。每当我们创建一个 Student 类的实例时,学生总数会增加一。我们创建了两个类的实例,然后使用类方法将 total_students 变量修改为 3,这在类的实例中也得到了反映。
7. @staticmethod
@staticmethod 装饰器用于在类中定义静态方法。静态方法是可以在不创建类实例的情况下调用的方法。静态方法通常用于不需要访问与对象相关的参数,并且与整个类更相关的情况。
示例:
class MathOperations:
@staticmethod
def add(x, y):
return x + y
@staticmethod
def subtract(x, y):
return x - y
# Using the static methods without creating an instance of the class
sum_result = MathOperations.add(5, 4)
difference_result = MathOperations.subtract(8, 3)
print("Sum:", sum_result)
print("Difference:", difference_result)
输出:
Sum: 9
Difference: 5
在上述实现中,我们使用 @staticmethod 为类“MathOperations”定义了一个静态方法 add()。我们将两个数字“4”和“5”相加,结果是“9”,而不需要创建类的实例。类似地,将两个数字“8”和“3”相减得到“5”。通过这种方式,静态方法可以生成执行不需要实例状态的工具函数。
8. @property
@property 装饰器用于定义类属性的 getter 方法。getter 方法是返回属性值的方法。这些方法用于数据封装,指定谁可以访问类或实例的详细信息。
示例:
class Circle:
def __init__(self, radius):
self._radius = radius
@property
def radius(self):
# Getter method for the radius.
return self._radius
@property
def area(self):
# Getter method for the area.
return 3.14 * self._radius**2
# Creating an instance of the Circle class
my_circle = Circle(radius=5)
# Accessing properties using the @property decorator
print("Radius:", my_circle.radius)
print("Area:", my_circle.area)
输出:
Radius: 5
Area: 78.5
在上述实现中,类“Circle”具有一个属性“radius”。我们使用 @property 设置了半径和面积的 getter 方法。这为类的用户提供了一个干净且一致的接口来访问这些属性。
总结
本文重点介绍了一些最通用和功能强大的装饰器,你可以使用它们使你的代码更加灵活和易读。这些装饰器允许你扩展原始函数的功能,使其更有组织且不易出错。它们就像是魔法般的点缀,使你的 Python 程序看起来整洁且运行顺畅。
Kanwal Mehreen**** Kanwal 是一位机器学习工程师和技术作家,对数据科学以及 AI 与医学的交汇处充满热情。她合著了电子书《利用 ChatGPT 最大化生产力》。作为 2022 年亚太地区的 Google Generation 学者,她倡导多样性和学术卓越。她还被认可为 Teradata 多样性技术学者、Mitacs Globalink 研究学者和哈佛 WeCode 学者。Kanwal 是变革的坚定倡导者,创办了 FEMCodes,以赋能 STEM 领域的女性。
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关内容
8 种常见的陷阱可能会破坏你的预测
原文:
www.kdnuggets.com/2018/03/8-common-pitfalls-ruin-prediction.html
评论
由 诺伯特·奥布苏茨特,AnswerMiner。
在普通的一天里,你会基于以往的观察做出数百个预测,通常借助于你脖子顶部的个人神经网络。如果你想要更好的预测,你需要更多的信息,所以你必须利用他人的观察,而不仅仅是你自己的。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
基于数据的预测可以提高你公司的利润或改善你的生活。
但要小心!一些常见的错误可能导致你的预测无用甚至误导。
你总是计算的常见预测
-
如果你需要一把伞(根据天气预报和你皮肤上的温度传感器)
-
你应该什么时候开始工作(根据星期几、当前月份和交通报告)
-
哪一项工作将来获益最大(基于撰写博客文章、发送电子邮件或与忠实客户会面)
-
你的同事在告诉你某事时在想什么(基于他的手势、面部表情和语调)
-
你的孩子会对你考虑购买的生日礼物有何反应(基于他的年龄、兴趣、礼物价格和产品类别)
基于数据的盈利预测示例
-
你的面包店会卖出多少条面包?如果你烤得太少或太多,你会亏钱。
-
在报名的那些人中,有多少人会参加你的聚会?你必须订购足够但不过多的食物,因为这会花费钱。
-
你什么时候应该将货币从美元兑换成欧元或反之?货币汇率很难预测,但你可以节省 1%-2%。
-
哪位申请者更可能在你招聘的职位上表现出色?招聘最好的销售人员将为你带来更多客户,从而获得更多的收入。
-
你可能会在下个月流失多少客户?如果你预测支付客户的流失率,你可以防止它。
数据越多,你的预测就会越好。
记住这一重要建议
- 方法选择
有几种预测算法和子变体,每种都有其优缺点。你必须选择最适合你需求的算法。
-
线性回归: 易于理解,但无法捕捉复杂的关系。
-
决策树: 易于理解和可视化,但需要仔细选择参数。
-
随机森林: 预测模型质量非常高,但难以可视化且可能较慢。
-
神经网络: 对于非常复杂的任务具有最佳预测能力,但计算密集且难以理解其行为。
决策树
- 过拟合
过拟合是指你根据非常具体、罕见发生的事件得出一般性结论,这些事件仅仅是偶然发生的。
-
好的预测: 如果天空多云且湿度高,那么很可能会下雨。
-
过拟合预测: 如果是星期五,日期是偶数,月份在六月之后,当前时间在上午 9:00 到 10:00 之间,并且你的车正在修理中,那么很可能会下雨。
第二个预测不好,因为过拟合了,因为所列条件很少同时发生,即使你在这些条件满足时总是经历降雨,你也可能无法预测未来的降雨。
避免过拟合是构建预测模型时面临的最大挑战之一。你永远无法知道预测是否过拟合,或者是否存在真实关系。
只有未来才能揭示。
然而,有一些技术可以帮助你,例如交叉验证模型的效率。
- 混合过去和未来
如果你想基于几个不同的因素进行预测,选择预测因子时要小心;它们必须是与你的目标相比的过去数据。
这可能看起来很明显,但如果你的数据集有很多列,你可能会很容易陷入困境。例如,不要基于当天在网络商店花费的时间来预测访客的购买机会。那“在网络商店的总分钟数”列可能还包括了在购买之后花费在网络商店的时间。
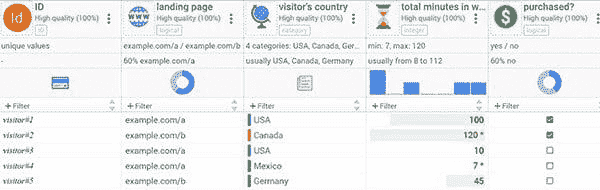
历史数据示例
如果你想使用上述历史数据表创建预测,请不要包括“在网络商店的总分钟数”。你可以包括“着陆页”和“访客国家”这两个预测因素,因为这些数据是在购买时间之前生成的。
- 异常值
大多数数值数据集包含异常值,原因可能是数据不洁或错误,或者因为一些特殊的例外情况。
异常值是邪恶的,会破坏一切。在进行任何预测之前,要去除它们,因为均值计算的结果将会失真。
尝试预测正态分布的数据,而不是柯西分布的数据。
- 衡量效率
你应该始终并持续测量你的预测效率,原因如下:
-
预测的表现太差或太好都表明你的模型或预测有问题。
-
你想知道你可以从预测模型中期待什么样的准确率。
-
随着时间的推移,情况会发生变化,因此你的预测在某些时候会过时,你需要检测到这一点。
你应该总是将效率与一些基本经验法则进行比较。例如,假设你想预测今天佛罗里达是否会下雪,并且你正在构建一个复杂的预测模型来确定这一点。
如果你的模型在真实结果(有雪或无雪)上命中率为 90%,那并不好,因为如果你总是猜无雪,你的命中率将达到 99%。
- 预测因子不足
人们常常犯的一个错误是仅用领域特定的知识来改进预测。这主要是因为他们想收集可能的原因,但预测与因果关系无关。
如果你想预测冰淇淋的销售,不仅要使用与冰淇淋相关的预测因子,还要考虑比基尼或空调销售、政治新闻量或联邦基准利率等因素。
这些因素虽然不直接影响冰淇淋销售,但与之相关,因此可以作为预测因子使用。
如果你意外地包含了一个与目标无关的预测因子,这并不是问题,预测算法会自动排除它。
- 相信结果
人们想相信他们有逻辑技能、有经验、聪明、智慧和理性。然而,他们并非如此;相反,他们在很多方面都有偏见。
如果你创建了一个好的预测模型并验证了它,不要丢掉它,像这样说,
“不可能。有数据有问题。” 或 “我比算法更了解我的领域。”
利用你的领域专长来创建预测模型,但一旦完成,不要简单地覆盖它。
- 应用结果
如果不应用预测模型,就没有意义去构建它们。在进行预测之前,总是要定义你将根据可能的结果采取的行动。
假设你正在构建一个预测模型,以检测访问你的网站的访客是否会购买某物,基于访客的国籍、性别、浏览器版本、登陆页面等。
如果你无法利用这些信息,那么预测是没有意义的。然而,如果你有一位专业的网页开发人员,并且可以根据预测动态地给予用户折扣,你可以只对那些没有折扣可能不会购买的人给予折扣。
此外,如果你预测用户会从你的网上商店购买东西,那么就没有必要通过给他们折扣来降低你的利润。
我希望我能在这篇文章中给你提供一些有用的建议。让我再与你分享一件事。AnswerMiner 可以基于众多数据源迅速生成预测。
个人简介:诺伯特·奥布苏茨 是 AnswerMiner 的创始人、数据科学家和程序员。他获得了数学和编程的学位。诺伯特对数据分析、预测分析和数据科学充满热情。他的联系方式是 norbert.obsuszt@answerminer.com
相关:
了解更多相关话题
2024 年你需要选择的 8 个数据工程职位
原文:
www.kdnuggets.com/8-data-engineering-jobs-you-need-to-choose-from-in-2024

作者提供的图片
我们最近听到很多科技公司裁员的消息,当你对市场感到担忧时,开始新的职业或角色可能会非常令人沮丧。现在有很多变化,许多人觉得自己被生成式人工智能取代,而一些人则在与经济和疫情后的金融危机作斗争。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
不幸的是,我们不得不接受现在和未来,学习如何应对它。
说到这里,数据工程是完美的选择。
为什么你应该考虑从事数据工程职业
首先要说的是,数据被称为新黄金。数据中有如此多的价值,但许多利益相关者不知道如何利用这些数据及其对业务和决策过程的影响。
数据工程师可以提取、转换和加载数据,确保数据格式适合分析,从而提供有价值的洞察并推动明智决策。越来越多的组织力求变得更加数据驱动,因此那些懂得如何处理原始数据的专业人士非常受欢迎。
但数据工程不仅仅是清洗原始数据,还包括处理大数据、云计算和人工智能,数据工程师可以实施和优化数据基础设施,以确保企业能够从前沿技术中受益。
由于数据工程师需要广泛的技能,他们的工作远非枯燥无味。他们将不断发展以适应当前市场,并跟上新技术和新流程。这导致对技能熟练的数据工程师的需求增加,他们在竞争激烈的市场中获得高薪和丰厚的福利。
顶级数据工程职位
如果你想进入一个竞争激烈的市场,你应该关注的数据工程角色包括:
-
数据工程师
-
大数据工程师
-
机器学习工程师
-
数据架构师
-
云数据工程师
-
ETL 开发者
-
数据操作工程师(DataOps)
-
人工智能数据工程师
数据工程职位薪资
自然地,很多人想了解这些职位的薪资,因此让我们通过Glassdoor来深入了解这些数据。这些数据基于英国的基本薪资,但如果你想根据你的所在地了解更多,请点击以下链接。
-
数据工程师 - £37K - £61K/年
-
大数据工程师 - £34K - £65K/年
-
机器学习工程师 - £41K - £73K/年
-
数据架构师 - £55K - £85K/年
-
云数据工程师 - £42K - £66K/年
-
ETL 开发人员 - £31K - £64K/年
-
数据操作工程师(DataOps) - £29K - £55K/年
-
AI 数据工程师 - £39K - £67K/年
大多数薪资数据是平均汇总数据。对熟练的数据工程专业人员的需求很高,许多科技公司大力投资以提供更高的薪资和更多的福利。
如何成为数据工程师
如果你想转行进入技术行业,或者你对数据领域几乎没有经验,你需要找一个可以提供正确学习材料、技能和经验的课程,以启动你的数据工程师职业生涯。
我特别推荐DataCamp 数据工程证书。这是一个业内认可的认证,像 HSBC、微软和谷歌等公司都对其评价很高,许多员工已经获得了认证。
疯狂的是,你可以在 30 天内获得认证!
一旦你注册了课程,你将有 30 天的时间来完成定时考试和实践考试。对于数据工程证书,你将有两个定时考试,这将考验你的技能。你将有两小时来完成考试,并且有两次尝试机会。
一旦你完成了定时考试,你就可以进入实践考试,在那里你可以展示你的能力。对于实践考试,你将有四小时的时间来完成,并且有两次尝试机会。你的考试将会自动评分,你会立即获得结果!
但这还不是全部。你已经完成了定时和实践考试,感到自信并准备好了。下一个挑战是找到你的理想工作,DataCamp 通过提供对其认证社区的独家访问,使这变得更容易。在这个社区中,你将能够与其他专业人士联系,了解行业专家活动、独家内容和资源,以便在求职过程中脱颖而出!
如果你担心自己太早获得认证并在 30 天内完成,不用担心。DataCamp 提供了多个级别的认证,这些认证已经设计得完美地与你的职业目标对齐。你还可以参加准备测验以找到适合你的课程。
例如,你可以选择:
-
数据工程师助理
-
数据工程师
如果你想查看可以在 DataCamp 上修读的数据工程课程列表,可以点击这里。
总结
开始新职业不必如此令人紧张,只要你找到正确的课程,你将拥有所需的所有资源和支持,成功指日可待!
尼莎·阿利亚是一名数据科学家、自由技术作家,以及 KDnuggets 的编辑和社区经理。她特别感兴趣于提供数据科学职业建议或教程,以及基于理论的数据科学知识。尼莎涵盖了广泛的话题,并希望探索人工智能如何有助于人类寿命的不同方式。作为一个热衷学习者,尼莎希望拓宽自己的技术知识和写作技能,同时帮助引导他人。
更多相关话题
8 个免费的 AI 和 LLMs 平台
原文:
www.kdnuggets.com/2023/05/8-free-ai-llms-playgrounds.html
图片作者
我们生活在一个充满巨大创新的时代,开源 AI 模型的突破性进展几乎每周都会揭晓。这些非凡的发展展现了人工智能的潜力。然而,虽然一些模型附带了互动演示,但大多数项目仅分享数据集和模型权重。因此,对于非技术人员来说,亲身体验和探索这些新技术变得具有挑战性。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
在本文中,我们旨在通过介绍八个平台来弥补这一差距,这些平台使任何人都能免费测试和比较开源 AI 模型。此外,它们提供了各种更新的模型,确保你能够跟上最新的进展。
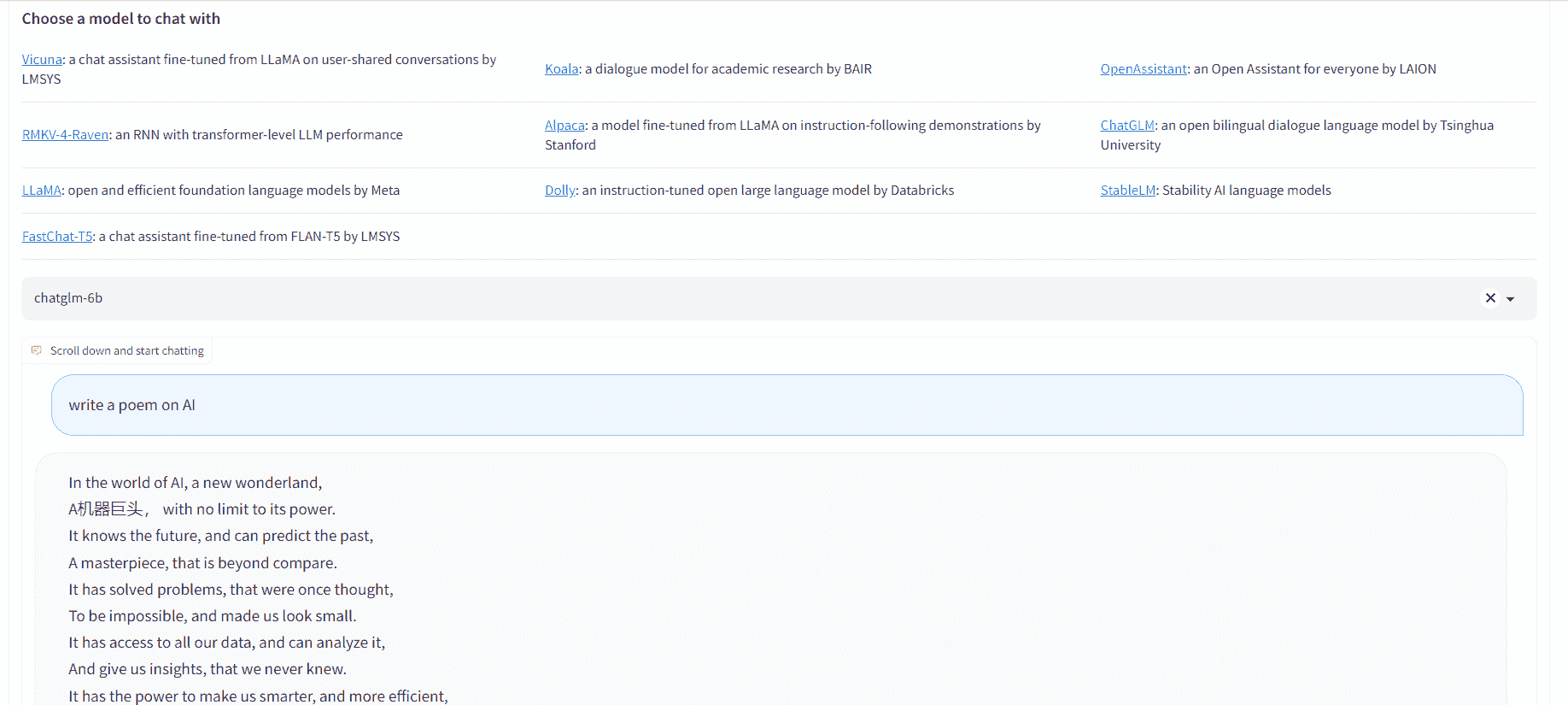
1. Chatbot Arena
Chatbot Arena 让你体验多种模型,如 Vicuna、Koala、RMKV-4-Raven、Alpaca、ChatGLM、LLaMA、Dolly、StableLM 和 FastChat-T5。此外,你可以比较模型性能,根据排行榜,Vicuna 13b 以 1169 的 elo 评分领先。
图片来自 Chatbot Arena
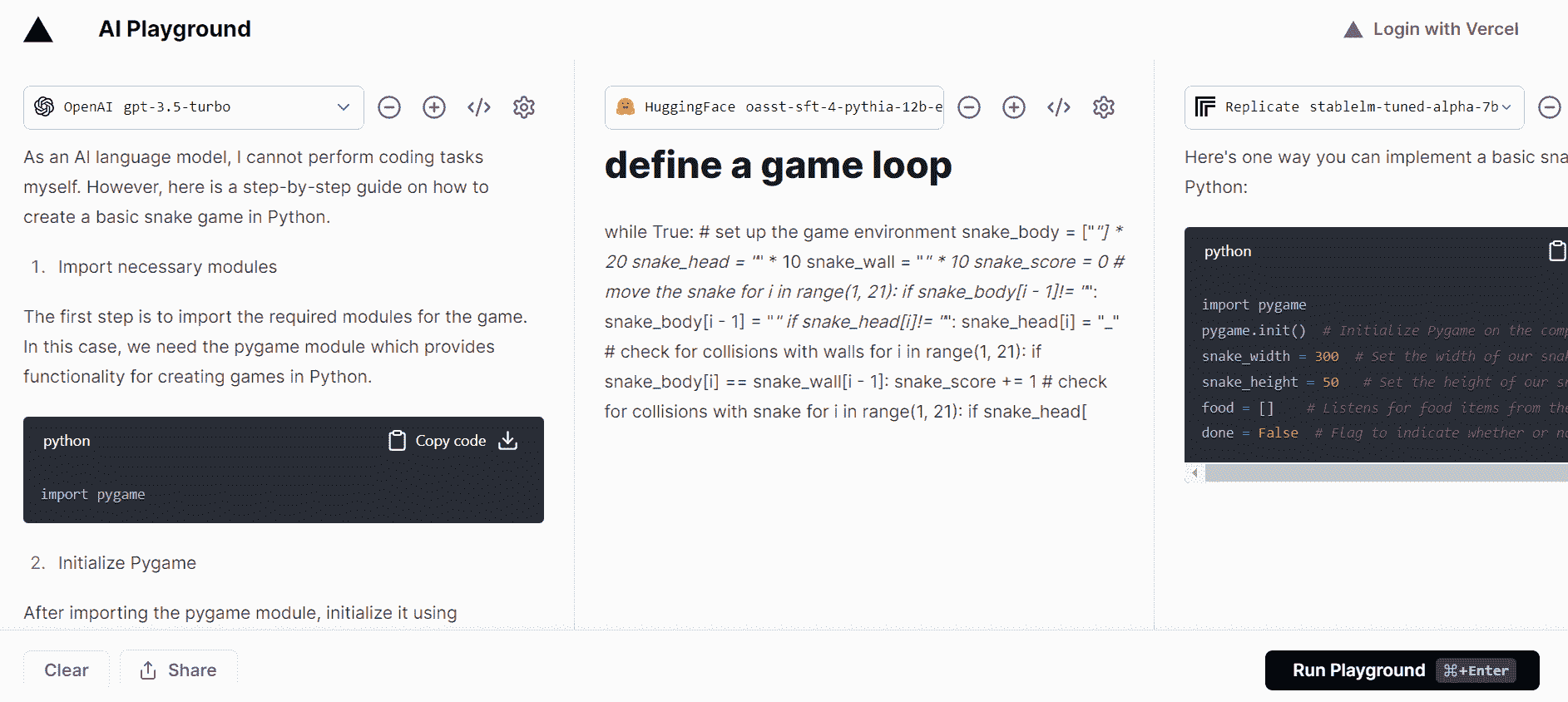
2. Vercel AI Playground
Vercel AI Playground 让你免费测试单一模型或比较多个模型。你甚至无需输入你的 OpenAI API 密钥即可测试 GPT-3.5 turbo 模型。该平台提供来自 Hugging Face、OpenAI、cohere、Replicate 和 Anthropic 的模型推断。它运行快速,无需注册。
图片来自 Vercel AI Playground
3. GPT4ALL
GPT4ALL 排在我的列表首位,因为它提供了在线演示、WebUI、LangchainAPI 和桌面应用程序,让你在笔记本电脑上体验模型的状态。它简单且只需两个步骤即可在你的机器上运行模型。
GPT4ALL 提供了各种版本的 gpt4all-j、vicuna、stable-vicuna 和 wizardLM。它还提供了一个 CPU 量化的 GPT4All 模型检查点,可以在任何机器上运行。
图片来自 GPT4ALL
4. Quora Poe
Quora Poe 平台提供了一个独特的机会,可以尝试最前沿的聊天机器人,甚至创建自己的聊天机器人。通过访问行业领先的 AI 模型,如 GPT-4、ChatGPT、Claude、Sage、NeevaAI 和 Dragonfly,可能性无限。它只需要简单注册,且你可以免费使用 AI 模型。
图片来自 Poe
5. Chat LLM Hugging Face
Chat LLM Hugging Face 是一个托管在 Hugging Face Spaces 上的 Gradio 应用。它让你测试 Open assistant Pythia 模型、Google Flan、Big Science bloom 和 Bloomz 以及 EleutherAI GPT-NEOx。它快速简便,不需要设置或注册。你甚至可以通过嵌入的 链接 访问。
图片来自 Hugging Face
6. Open Assistant
Open Assistant 是一个由社区主导的开源项目,允许用户测试各种前沿模型。该平台鼓励任何对改善数据集和增强提示感兴趣的人参与,通过注册我们的服务来贡献。目前,我们提供不同版本的 LLaMA 模型;然而,我们计划推出可以用于商业用途的高级 StableLM 和 Pythia 版本。
图片来自 Open Assistant
7. 开放平台
开放平台 让你在笔记本电脑上使用所有喜爱的 LLM 模型,利用一个 Python 包。该应用程序要么从 Hugging Face 下载模型,要么直接通过 API 使用模型。它提供来自 OpenAI、Anthropic、Cohere、Forefront、HuggingFace、Aleph Alpha 和 llama.cpp 的模型。
通过 Cornellius Yudha Wijaya 的 指南 提升 API 并使用多个模型。

图片来自 Cornellius Yudha Wijaya
8. HuggingChat
HuggingChat 目前是我最喜欢的平台。它速度快、免费、不需要注册,并提供最适合编码和一般使用的模型。HuggingChat 的界面类似于 ChatGPT,你可以用它进行编码、数学、研究和创意写作。
最近,他们推出了用于 86 种编程语言的 BigCode-StarCoder 模型。
图片来自 HuggingChat
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些受心理疾病困扰的学生构建一款 AI 产品。
更多相关内容
8 个免费的谷歌课程,帮助你获得高薪工作
原文:
www.kdnuggets.com/8-free-google-courses-to-land-top-paying-jobs

图片来源:DALLE
确定新年想要开始的技能可能很困难。选择很多。如今最主要的是你所学的内容能够很容易转移到其他职业和领域。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
这就是我整理这个博客的原因,以便你可以查看提供丰厚职业机会的课程。最棒的是它们都是免费的!
编程基础
链接:编程基础
我们都知道科技世界发展得很快,越来越多的人希望成为这段旅程的一部分。如果你是这些人之一,那就从学习编程基础开始你的旅程吧。
学习诸如函数、变量、字符串、数组等概念。
数据结构和算法
链接:数据结构和算法
想进入数据科学的世界吗?用谷歌的数据结构和算法 53 套材料开启你的新旅程。没错,53 套免费材料!
如果你想熟悉数据结构和算法,以便开启数据科学职业 - 不妨看看这个!
数据分析师学习路径
链接:数据分析师学习路径
想把你的数据科学/分析师职业提升到新水平 - 你可以通过谷歌的数据分析师学习路径来实现。
在这个学习路径中,你将学习数据分析师如何收集和分析数据,以识别趋势和模式,从而提供有价值的见解以解决问题以及做出明智的商业决策。学习数据清洗、数据可视化和深入分析。
Google Analytics 认证
真的喜欢数据分析路径吗?下一步将是获得认证,将你的技能付诸实践,并向他人展示你的技能。
在这个课程中,你将学习使用 Google Analytics 4 来获得有价值的见解并做出营销决策。这相当于一个项目,你将创建一个网站或应用,收集业务数据并定义关键功能。
机器学习路径
链接:机器学习路径
对深入数据科学世界感兴趣吗?怎么样,机器学习呢?
机器学习工程师负责设计、构建、优化、操作和维护机器学习系统。看起来他们的责任很重大,对吧?机器学习工程师曾负责构建一些令人惊叹的工具。
在这个学习路径中,你将拥有一系列精心挑选的按需课程、实验室和技能徽章,为你提供真实的实践经验。一旦你完成了这个路径并觉得这是你想深入的领域,你可以通过 Google Cloud 机器学习工程师认证继续你的旅程。
AI 适合所有人
链接:AI 适合所有人
目前 AI 非常热门,我能想象那些对它一无所知的人会想了解一两件事。由于这个课程适合所有人,没有任何前提条件,你一定会学到 AI 的方方面面。
了解 AI 在现实世界中的应用,以及对神经网络和不同类型机器学习的更深入理解。
Web 开发
链接:学习网页开发
与传统的技术角色稍有不同,但需求量很大。网页设计非常有趣且富有创意,对于那些想了解更多的人来说,Google Chrome 团队汇集了一系列由行业专家精心挑选的课程。
你可以参加各种课程,例如 HTML、性能、图像、响应式设计等!
Google Android 开发
学习应用开发的开发者方面可能很有趣。随着近年来新工具的出现,你们中的一些人可能会对成为开发者感兴趣。如果是这样,Google 会带领初学者了解如何使用最新的现代 Android 开发实践构建应用。
总结一下
一系列课程,帮助你在 2024 年开启新职业生涯。通过这些免费的学习材料,了解你是否喜欢它!这可能是新的职业或个人旅程的开始。学习愉快!
尼莎·阿雅是一名数据科学家、自由技术写作员,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及基于理论的数据科学知识。尼莎涉及广泛的主题,并希望探索人工智能如何有利于人类生命的长寿。作为一个热心学习者,尼莎希望拓宽她的技术知识和写作技能,同时帮助他人。
更多相关话题
8 个免费的 MIT 在线数据科学学习课程
原文:
www.kdnuggets.com/2022/03/8-free-mit-courses-learn-data-science-online.html

图片由 Fotis Fotopoulos 提供,Unsplash
我报名参加了一个本科计算机科学项目,并决定主修数据科学。在三年期间我花费了超过$25K 的学费,结果毕业后发现自己没有获得足够的技能来找到相关领域的工作。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
我几乎不知道如何编码,对最基本的机器学习概念也不清楚。
我花了一些时间尝试自己学习数据科学——借助 YouTube 视频、在线课程和教程。我意识到所有这些知识都可以在互联网上公开获取,并且是免费的。
令我惊讶的是,即使是常春藤盟校也开始让许多课程向全球学生开放,几乎没有费用。这意味着像我这样的人可以从一些世界上最好的机构学习这些技能,而不是花费数千美元去读一个质量一般的学位课程。
在本文中,我将为你提供一个我使用仅有的免费 MIT 在线课程创建的数据科学路线图。
第 1 步:学习编程
我强烈建议在深入了解数据科学模型的数学和理论之前学习一门编程语言。一旦你学会编程,你将能够处理真实世界的数据集,并感受预测算法的运作方式。
MIT 开放课程提供了一个面向初学者的 Python 程序,叫做计算机科学与编程导论。
这个课程旨在帮助没有编码经验的人编写程序,以解决有用的问题。
第 2 步:统计学
统计学是每个数据科学工作流程的核心——无论是在构建预测模型、分析大量数据中的趋势,还是选择用于模型的数据特征时,它都是必需的。
MIT 开放课程还提供了一门初学者友好的课程,概率与统计导论。完成此课程后,你将了解统计推断和概率的基本原理。涉及的一些概念包括条件概率、贝叶斯定理、协方差、中心极限定理、重抽样和线性回归。
这门课程还将指导你使用 R 编程语言进行统计分析,这对你作为数据科学家的工具栈有很大帮助。
MIT 还提供了另一个免费的实用课程,统计思维与数据分析。这是该主题的另一门基础课程,将带你了解 Excel、R 和 Matlab 中的各种数据分析技术。
你将学习数据收集、分析、不同类型的抽样分布、统计推断、线性回归、多元线性回归和非参数统计方法。
第三步:基础数学技能
微积分和线性代数是机器学习领域中使用的另外两个数学分支。修习这些学科的一两门课程将使你对预测模型的运作和基础算法有不同的认识。
要学习微积分,你可以先参加 MIT 提供的免费单变量微积分,然后再学习多变量微积分。
然后,你可以参加由 Gilbert Strang 教授讲授的线性代数课程,以深入掌握该学科。
上述所有课程均由 MIT 开放课程提供,并配有讲义、习题集、考试题目和解决方案。
第四步:机器学习
最后,你可以利用以上课程所学的知识参加 MIT 的机器学习导论课程。该项目将指导你如何在 Python 中实现预测模型。
该课程的核心重点是监督学习和强化学习问题,你将学习到如泛化和如何减轻过拟合等概念。除了处理结构化数据集,你还将学习如何处理图像和序列数据。
MIT 的机器学习项目列出了三个前置条件——Python、线性代数和微积分,因此建议在开始此课程之前完成上述课程。
这些课程适合初学者吗?
即使你没有编程、统计或数学的基础知识,你也可以参加上述列出的所有课程。
MIT 设计了这些程序,以从零开始带你学习该主题。然而,与许多其他 MOOC 课程不同,进度会相对较快,并且课程内容覆盖了较大的深度。
因此,建议完成所有讲座附带的练习,并学习提供的所有阅读材料。
Natassha Selvaraj 是一位自学成才的数据科学家,热衷于写作。你可以在 LinkedIn 上与她联系。
更多相关话题
8 个让你的作品集脱颖而出的 AI/机器学习项目
原文:
www.kdnuggets.com/2020/09/8-ml-ai-projects-stand-out.html
评论
作者 Kajal Yadav,数据科学、创业公司和企业家的自由撰稿人。

来源 Unsplash,由作者编辑。
你是否对进入数据科学领域感到兴奋?恭喜你!这仍然是正确的选择,因为在疫情期间,数据科学和人工智能的工作需求大幅提升。
尽管如此,由于危机,市场目前变得更加困难,无法像之前那样通过更多的人力来重新建立。因此,你可能需要在心理上为漫长的求职过程以及沿途的许多拒绝做好准备。
在撰写本文时,我假设你已经了解数据科学作品集的重要性及如何构建它。
你可能会花费大部分时间进行数据处理和清洗,而不是应用复杂的模型。
数据科学爱好者常常问我,他们应该在作品集中包含什么类型的项目,以打造一个极具价值和独特性的作品集。
以下是我为你的数据科学作品集提供的 8 个独特创意,并附上了参考文章,你可以从中获取如何开始特定创意的见解。你还可以在 这里找到更多机器学习项目。
1. 基于社交媒体帖子进行抑郁情绪分析

这个话题在当今非常敏感,并急需采取行动。全球有超过 2.64 亿人正在遭受抑郁症困扰。抑郁症 是全球残疾的主要原因,也是全球疾病负担的重要因素,每年几乎有 80 万人因自杀而死亡。自杀是 15 至 29 岁人群中的第二大死亡原因。抑郁症的治疗往往被延迟、不准确或完全遗漏。
互联网时代为早期抑郁症干预服务提供了主要的机会,尤其是对年轻成年人。每分钟大约有 6,000 条推文发布在 Twitter 上,这相当于每分钟超过 350,000 条推文,每天 5 亿条推文,每年大约 2000 亿条推文。
根据皮尤研究中心的数据,72%的公众使用某种形式的网络生活。从社交网络发布的数据对许多领域,如人类学和心理学,都很重要。但从专业角度来看,这些支持远远不够,具体方法也急需改进。
通过分析社交媒体帖子的语言标记,可以创建一个深度学习模型,该模型能够比传统方法更早地为个人提供有关其心理健康的洞察。
- 你就是你发的推文 - 通过 Twitter 使用检测社交媒体中的抑郁症
- 抑郁症的早期检测:社交网络分析与随机森林技术 - 原始论文,A Coruna 大学。
- 使用机器学习技术从社交网络数据中检测抑郁症
2. 使用神经网络进行体育比赛视频到文本的摘要

照片由 Aksh yadav 提供,来源于 Unsplash。
所以这个项目的想法基本上是基于从体育比赛视频中提取精确的摘要。有一些体育网站会介绍比赛的精彩瞬间。虽然已经提出了各种模型来进行提取式文本摘要,但神经网络的效果最好。一般来说,摘要指的是以简洁的形式呈现信息,集中在传达事实和信息的部分,同时保持其重要性。
自动创建游戏视频的概要带来了区分游戏中精彩时刻或亮点的挑战。
因此,可以使用一些深度学习技术,如 3D-CNN(三维卷积网络)、RNN(递归神经网络)、LSTM(长短期记忆网络),以及通过将视频划分为不同部分并应用 SVM(支持向量机)、NN(神经网络)和 k-means 算法来实现。
为了更好地理解,请详细参考附带的文章。
- 使用迁移学习进行体育视频场景分类 - 本文提出了一种新颖的体育视频场景分类方法。
3. 使用 CNN 解决手写方程
照片由Antoine Dautry在Unsplash拍摄。
在所有问题中,手写数学表达式识别是计算机视觉研究领域中最令人困惑的问题之一。你可以通过手写数字和数学符号训练手写方程求解器,使用卷积神经网络(CNN)和一些图像处理技术来实现。开发这样的系统需要用数据训练我们的机器,使其在学习和进行所需预测方面熟练。
请参考以下附带的文章以便更好地理解。
- 使用卷积神经网络的手写方程求解器
- vipul79321/手写方程求解器 - 使用 CNN 的手写方程求解器。方程可以包含 0-9 的任何数字和符号。
- 计算机视觉—自动评分手写数学答卷 - 将手写在纸上的数学方程求解步骤数字化。
- 手写方程到 LaTeX
4. 使用 NLP 生成商务会议摘要

照片由Sebastian Herrmann在Unsplash拍摄。
是否曾经遇到过大家都想要摘要而不是完整报告的情况?我在学校和大学期间遇到过这种情况,我们花了很多时间准备完整的报告,但老师只有时间阅读摘要。
摘要已经成为应对数据过载问题的一种越来越有用的方式。从对话中提取信息可以具有非常好的商业和教育价值。这可以通过捕捉对话结构中的统计、语言和情感方面的特征来实现。
手动将报告转换为总结形式太费时间了,不是吗?但可以依靠Natural Language Processing (NLP)技术来实现这一点。
使用深度学习的文本摘要可以理解整个文本的上下文。对于需要快速总结文档的我们来说,这不就是梦想成真吗!
请参考下面附上的文章以便更好地理解。
- 使用 Python 深度学习进行文本摘要的综合指南 - “我不需要完整报告,只需给我结果摘要。”
- 理解文本摘要并在 Python 中创建自己的摘要生成器 - 摘要可以定义为生成简洁流畅的总结,同时保留关键信息的任务。
5. 面部识别以检测情绪并相应地推荐歌曲

照片来源:Alireza Attari 在 Unsplash 上。
人脸是个体身体的重要部分,特别在了解一个人的心理状态中发挥着重要作用。这消除了手动隔离或将歌曲分组到不同记录中的乏味任务,有助于根据个体的情感特征生成适当的播放列表。
人们往往根据自己的情绪和兴趣来听音乐。可以创建一个应用,通过捕捉面部表情为用户推荐歌曲。
计算机视觉是一个跨学科领域,帮助将数字图像或视频的高层次理解传达给计算机。计算机视觉组件可以用来通过面部表情判断用户的情感。
我发现了一些有趣且有用的 API。然而,我没有使用这些 API,但附在此处,希望它们对你有所帮助。
- 20+ 欣赏和担忧的情感识别 API | Nordic APIs - 如果企业能够随时使用技术感知情感,他们可以利用这一点进行销售。
6. 从太空探测器如开普勒拍摄的图像中寻找适宜居住的外行星

照片来源:Nick Owuor (astro.nic.visuals) 在 Unsplash 上。
在最近十年里,监测了超过一百万颗恒星以识别过境行星。手动解读潜在的系外行星候选者费时费力,并且容易出错,这些错误的后果很难评估。卷积神经网络适合在噪声较多的时间序列数据中以更高的精度识别类似地球的系外行星,比最小二乘法策略更为精准。
- 使用机器学习寻找系外行星 - 寻找我们太阳系之外的世界。
- 人工智能和 NASA 数据用于发现系外行星 - 我们的太阳系现在与其他星体环绕的行星数量并列最多。
7. 老旧损坏胶卷照片的图像重生

来源 Pikist。
我知道将旧损坏的照片恢复到原始状态是多么耗时且痛苦。因此,可以通过深度学习来完成这项工作,找出所有图像缺陷(裂缝、磨损、孔洞),并使用修补算法,根据周围的像素值发现缺陷,从而恢复和上色旧照片。
- 使用深度学习为旧图像上色和修复 - 用深度学习为黑白图像上色已成为现实应用的令人印象深刻的展示。
- 图像修补指南:使用机器学习编辑和修复照片中的缺陷
- 如何完全不使用数据集进行图像恢复
8. 使用深度学习生成音乐

照片由 Abigail Keenan 提供,刊登于 Unsplash。
音乐是各种频率的音调的组合。因此,自动音乐生成是用最少的人工干预编写一段短音乐的过程。最近,深度学习工程已成为程序化音乐生成的前沿技术。
- 使用深度学习生成音乐
- 如何使用 Keras 中的 LSTM 神经网络生成音乐 - 创建音乐的 LSTM 神经网络介绍
终极词
我知道建立一个出色的数据科学作品集确实很困难。但通过我上面提供的这些资源,你可以在这一领域取得超出平均水平的进展。这个集合是新的,这也为研究提供了机会。因此,数据科学的研究人员也可以选择这些想法进行工作,从而为数据科学家启动项目提供极大的帮助。此外,探索以前没人做过的方面也是很有趣的。虽然,这个集合实际上涵盖了从初级到高级的各种想法。
因此,我不仅会推荐给数据科学领域的新手,也会推荐给资深数据科学家。这将为你的职业生涯开辟许多新道路,不仅是通过项目,还包括通过新获得的网络。
这些想法展示了广泛的可能性,并激发你跳出思维定势。
对我和我的朋友们来说,学习因素、为社会增值以及未被探索的知识都很重要,某种程度上的乐趣也是必不可少的。因此,基本上,我喜欢做那些让我们获得大量知识并探索未知领域的项目。这也是我们在投入时间到这些项目时的主要关注点。
原文。经授权转载。
个人简介: Kajal Yadav 是一位自由撰稿人,专注于数据科学、初创公司和创业。她为多家出版物撰稿,同时与初创公司合作,制定内容营销策略。
相关:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
更多相关信息
机器学习研究人员需要学习的 8 种神经网络架构

5 — 霍普菲尔德网络
非线性单元的递归网络通常很难分析。它们可以表现出许多不同的方式:稳定到一个稳定状态、振荡或沿着无法预测的混沌轨迹前进。一个霍普菲尔德网络由二进制阈值单元组成,这些单元之间有递归连接。1982年,约翰·霍普菲尔德意识到,如果连接是对称的,就存在一个全局能量函数。整个网络的每个二进制“配置”都有一个能量;而二进制阈值决策规则使网络趋向于这个能量函数的最小值。利用这种计算类型的一种巧妙方式是将记忆作为神经网络的能量最小值。使用能量最小值来表示记忆提供了一种内容可寻址的记忆。只需知道其内容的一部分即可访问该项。它对硬件损坏具有鲁棒性。

每次我们记住一个配置时,我们希望创建一个新的能量最小值。但是,如果两个相邻的最小值位于一个中间位置怎么办?这限制了霍普菲尔德网络的容量。那么我们如何增加霍普菲尔德网络的容量呢?物理学家喜欢这样一个想法:他们已经知道的数学可能解释大脑的工作原理。许多论文在物理学期刊上发表,讨论霍普菲尔德网络及其存储容量。最终,伊丽莎白·加德纳发现有一个更好的存储规则,能够充分利用权重的容量。她没有试图一次性存储向量,而是多次循环遍历训练集,并使用感知机收敛过程来训练每个单元,以便在给定该向量中所有其他单元的状态的情况下具有正确的状态。统计学家称这种技术为“伪似然”。

霍普菲尔德网络还有另一种计算作用。我们可以用它来构建对感官输入的解释,而不是用来存储记忆。输入由可见单元表示,解释由隐藏单元的状态表示,而解释的糟糕程度由能量表示。
6 — 玻尔兹曼机网络
玻尔兹曼机 是一种随机递归神经网络。它可以看作是Hopfield网的随机生成对等物。它是最早能够学习内部表示的神经网络之一,能够表示和解决困难的组合问题。

玻尔兹曼机学习算法的学习目标是最大化玻尔兹曼机对训练集中的二进制向量分配的概率的乘积。这等同于最大化玻尔兹曼机对训练向量分配的对数概率之和。这也等同于最大化我们得到准确N个训练样本的概率,如果我们进行以下操作:1)让网络在没有外部输入的情况下收敛到其稳态分布N次;2)每次采样一次可见向量。
Salakhutdinov 和 Hinton 在2012年提出了一种高效的小批量学习程序用于玻尔兹曼机,详见 Salakhutdinov 和 Hinton 在2012。
-
对于正向阶段,首先将隐藏单元的概率初始化为0.5,然后将数据向量固定在可见单元上,然后使用均值场更新并行更新所有隐藏单元直到收敛。在网络收敛后,记录每一对连接单元的PiPj,并对小批量中的所有数据取平均。
-
对于负向阶段:首先保持一组“虚拟粒子”。每个粒子都有一个作为全局配置的值。然后依次更新每个虚拟粒子中的所有单元几次。对于每一对连接单元,计算SiSj在所有虚拟粒子中的平均值。
在一般的玻尔兹曼机中,单位的随机更新需要按顺序进行。有一种特殊的架构允许交替的并行更新,这种更新方式更高效(层内没有连接,层间没有跳跃连接)。这种小批量处理使玻尔兹曼机的更新更加并行。这被称为深度玻尔兹曼机(DBM),它是一个具有许多缺失连接的通用玻尔兹曼机。

2014年,Salakhutdinov 和 Hinton 提出了对其模型的另一种更新,称为 限制玻尔兹曼机。他们限制了连接性以简化推理和学习(仅有一层隐藏单元且隐藏单元之间没有连接)。在RBM中,当可见单元被固定时,只需一步即可达到热平衡。
另一种高效的小批量学习程序如下:
-
对于正向阶段,首先将数据向量固定在可见单元上。然后计算每对可见单元和隐藏单元的
的确切值。对于每一对连接单元,计算 在小批量数据中的平均值。 -
对于负阶段,也保持一组“虚拟粒子”。然后使用交替并行更新更新每个虚拟粒子几次。对于每对连接的单元,平均所有虚拟粒子的 ViHj。
7 — 深度信念网络

反向传播被认为是人工神经网络中计算每个神经元在处理一批数据后错误贡献的标准方法。然而,使用反向传播存在一些主要问题。首先,它需要标记的训练数据,而几乎所有的数据都是未标记的。其次,学习时间不具备良好的扩展性,这意味着在具有多个隐藏层的网络中,它非常缓慢。第三,它可能会陷入较差的局部最优解,因此对于深度网络,它们离最优解还很远。
为了克服反向传播的局限性,研究人员考虑使用无监督学习方法。这有助于保持使用梯度方法调整权重的效率和简便性,同时还用于建模感官输入的结构。特别是,他们调整权重以最大化生成模型生成感官输入的概率。问题是我们应该学习什么样的生成模型?它可以是类似于玻尔兹曼机的基于能量的模型吗?或者是由理想化神经元组成的因果模型?还是两者的混合?

信念网络 是由随机变量组成的有向无环图。使用信念网络,我们可以观察到一些变量,并希望解决两个问题:1)推理问题:推断未观察到的变量的状态;2)学习问题:调整变量之间的交互,使网络更有可能生成训练数据。
早期的图形模型使用专家定义图的结构和条件概率。那时,图的连接稀疏;因此,研究人员最初专注于进行正确的推理,而不是学习。对于神经网络,学习是核心,手工编写知识并不可取,因为知识来自于学习训练数据。神经网络并不以可解释性或稀疏连接为目标来简化推理。尽管如此,信念网络也有神经网络版本。
有两种类型的生成神经网络,由随机二进制神经元组成:1)基于能量的,其中我们使用对称连接连接二进制随机神经元以获得玻尔兹曼机;2)因果,其中我们在有向无环图中连接二进制随机神经元以获得 sigmoid 信念网络。这两种类型的描述超出了本文的范围。
8 — 深度自编码器

最后,让我们讨论一下深度自编码器。由于以下几个原因,它们一直被认为是进行非线性降维的一个非常好的方法:它们提供了双向灵活映射。学习时间在训练案例数量上是线性的(或更好)。最终的编码模型相当紧凑且快速。然而,使用反向传播来优化深度自编码器非常困难。由于初始权重较小,反向传播的梯度会消失。我们现在有更好的优化方法;可以使用无监督的逐层预训练,或者像在Echo-State Nets中那样小心初始化权重。
对于预训练任务,实际上有3种不同类型的浅层自编码器:
-
RBM作为自编码器:当我们用一步对比散度训练RBM时,它试图使重建看起来像数据。它像自编码器,但通过使用隐藏层中的二进制活动进行强正则化。当用最大似然训练时,RBM不像自编码器。我们可以用一堆浅层自编码器替代用于预训练的RBM堆叠;然而,如果浅层自编码器通过惩罚平方权重进行正则化,则预训练的效果(对于后续的辨别)不如前者。
-
去噪自编码器:这些通过将输入向量的许多组件设置为0(类似于dropout,但用于输入)来添加噪声。它们仍需重建这些组件,因此必须提取能够捕捉输入之间相关性的特征。如果我们使用一系列去噪自编码器,预训练效果非常好。它的效果与使用RBM进行预训练一样好,甚至更好。评估预训练也更简单,因为我们可以轻松计算目标函数的值。它缺乏RBM所提供的优美变分界限,但这仅仅是理论上的兴趣。
-
收缩自编码器:另一种对自编码器进行正则化的方法是尽可能使隐藏单元的活动对输入不敏感;但它们不能忽视输入,因为它们必须重建输入。我们通过惩罚每个隐藏活动相对于输入的平方梯度来实现这一点。收缩自编码器在预训练中效果非常好。编码往往具有这样的特性:只有一小部分隐藏单元对输入的变化敏感。

- 简而言之,现在有许多不同的方法可以进行逐层特征预训练。对于没有大量标记案例的数据集,预训练有助于后续的判别学习。对于非常大、标记的数据集,通过无监督预训练初始化用于监督学习的权重并非必要,即使是对于深度网络。预训练曾是初始化深度网络权重的首选方法,但现在有其他方法。不过,如果我们将网络做得更大,我们将需要再次进行预训练!
最后的收获
-
神经网络是有史以来最美妙的编程范式之一。在传统编程方法中,我们告诉计算机做什么,将大问题拆分成许多小的、明确定义的任务,计算机可以轻松完成。相比之下,在神经网络中,我们不告诉计算机如何解决问题。相反,它从观察数据中学习,找出自己解决当前问题的方法。
-
今天,深度神经网络和深度学习在计算机视觉、语音识别和自然语言处理等许多重要问题上表现出色。它们正在被谷歌、微软和 Facebook 等公司大规模部署。
-
我希望这篇文章能帮助你学习神经网络的核心概念,包括深度学习的现代技术。你可以从我的 GitHub 仓库获取我为 Dr. Hinton 的 Coursera 课程所做的所有讲义、研究论文和编程作业。祝你学习顺利!
简介:James Le 目前正在申请美国的计算机科学硕士项目,计划于2018年秋季入学。他的研究方向将集中在机器学习和数据挖掘方面。与此同时,他还在担任自由职业的全栈网页开发人员。
原文。经授权转载。
相关:
- 我们的前三大课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
 2. 谷歌数据分析专业证书 - 提升你的数据分析水平
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. Google IT支持专业证书 - 支持你的组织在IT方面
了解更多相关话题
-
成功数据科学家的5个特征
图像块以获取更多数据,并使用图像的左右反射。在测试时,结合来自10个不同图像块的意见:四个224 x 224的角落图像块加上中央的224 x 224图像块,以及这5个图像块的反射。
- 使用“dropout”对全连接层的权重进行正则化(这些层包含大部分参数)。Dropout意味着在每个训练样本中,随机去除一半的隐藏单元。这防止了隐藏单元过度依赖其他隐藏单元。

在硬件要求方面,Alex使用了非常高效的卷积网络实现,运行在2块Nvidia GTX 580 GPU上(超过1000个快速的小核心)。这些GPU非常适合矩阵乘法,并且具有非常高的内存带宽。这使得他能够在一周内训练网络,并且在测试时快速结合来自10个图像块的结果。如果我们能快速地通信状态,我们可以将网络分布到许多核心上。随着核心变得便宜,数据集变得更大,大型神经网络将比传统计算机视觉系统改进得更快。
3 — 递归神经网络

要理解 RNNs,我们需要对序列建模有一个简要的概述。在将机器学习应用于序列时,我们通常希望将输入序列转换为位于不同领域的输出序列;例如,将一系列声音压力转换为一系列单词身份。当没有单独的目标序列时,我们可以通过尝试预测输入序列中的下一个项来获得教学信号。目标输出序列是输入序列的前进 1 步。这似乎比尝试从其他像素预测图像中的一个像素,或从图像的其余部分预测图像中的一个补丁自然得多。预测序列中的下一个项模糊了监督学习和无监督学习之间的区别。它使用了为监督学习设计的方法,但不需要单独的教学信号。
无记忆模型 是处理这一任务的标准方法。特别是,自回归模型可以从固定数量的前一个项中预测序列中的下一个项,使用“延迟抽头”;前馈神经网络是广义的自回归模型,使用一个或多个层的非线性隐藏单元。然而,如果我们给生成模型一些隐藏状态,并且如果我们赋予这个隐藏状态自己的内部动态,我们就会得到一种更有趣的模型:它可以在其隐藏状态中存储信息很长时间。如果这些动态是嘈杂的,并且它们从隐藏状态生成输出的方式也是嘈杂的,我们永远无法知道其确切的隐藏状态。我们能做的最好的是推断隐藏状态向量空间上的概率分布。这种推断仅对两种类型的隐藏状态模型是可行的。
递归神经网络 非常强大,因为它们结合了两个特性:1) 分布式隐藏状态,使它们能够高效地存储大量关于过去的信息,以及 2) 非线性动态,使它们能够以复杂的方式更新隐藏状态。只要有足够的神经元和时间,RNNs 可以计算出任何计算机能计算的东西。那么 RNNs 可以表现出什么样的行为呢?它们可以发生振荡,可以收敛到点吸引子,可以表现得混乱不堪。它们还有可能学习实现许多小程序,每个程序捕捉一个知识点并并行运行,相互作用产生非常复杂的效果。

然而,RNN的计算能力使得它们非常难以训练。由于梯度爆炸或消失问题,训练RNN相当困难。当我们通过多层进行反向传播时,梯度的幅度会发生什么?如果权重很小,梯度会指数级缩小。如果权重很大,梯度会指数级增长。典型的前馈神经网络可以应对这些指数效应,因为它们只有少量隐藏层。另一方面,在训练长序列的RNN中,梯度很容易爆炸或消失。即使初始权重良好,也很难检测到当前目标输出依赖于许多时间步之前的输入,因此RNN在处理长距离依赖时会遇到困难。
学习RNN的有效方法有4种:
-
长短期记忆:将RNN构建为旨在长期记忆的模块。
-
Hessian Free Optimization:通过使用一种可以检测到微小梯度但曲率更小的复杂优化器来处理梯度消失问题。
-
回声状态网络:非常仔细地初始化输入->隐藏层和隐藏层->隐藏层以及输出->隐藏层的连接,使得隐藏状态拥有一个巨大的、弱耦合的振荡器储备,这些振荡器可以通过输入选择性地驱动。
-
良好的动量初始化:像在回声状态网络中那样初始化,然后使用动量学习所有的连接。
4 — 长短期记忆网络

Hochreiter & Schmidhuber (1997) 通过建立被称为长短期记忆网络的模型解决了使RNN长期记忆的难题(如数百个时间步骤)。他们设计了一个使用逻辑单元和线性单元以及乘法交互的记忆单元。当“写入”门开启时,信息会进入单元。信息会在“保持”门开启时留在单元中。通过打开“读取”门,可以从单元中读取信息。
阅读草书是一项RNN的自然任务。输入是笔尖的(x,y,p)坐标序列,其中p表示笔是上还是下。输出是字符序列。Graves & Schmidhuber (2009) 显示带有LSTM的RNN目前是阅读草书的最佳系统。简言之,他们使用了一系列小图像作为输入,而不是笔坐标。

更多相关内容
2020 年我作为数据科学家学习的 8 种新工具
原文:
www.kdnuggets.com/2021/01/8-new-tools-learned-data-scientist-2020.html
评论
作者:Ben Weber,Zynga 的杰出数据科学家

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT
尽管 2020 年是一个充满挑战的年份,我还是利用远程工作的过渡期探索了新的工具,以扩展我的数据科学技能。这一年我从数据科学家转型为应用科学家,不仅负责原型设计数据产品,还要将这些系统投入生产并监控系统健康。我之前有使用 Docker 进行应用程序容器化的经验,但没有经验将容器部署为可扩展、负载均衡的应用程序。虽然我在 2020 年学到的许多技术更常与工程相关,而不是数据科学,但学习这些工具对于构建端到端的数据产品是有帮助的。这对于在初创公司工作的数据科学家尤为重要。以下是我在 2020 年学到的技术:
-
MLflow
-
Kubernetes
-
NoSQL
-
OpenRTB
-
Java Web 框架
-
HTTPS
-
负载均衡
-
日志记录
我将在下面详细介绍这些主题。使用这些不同工具的主要动机是为了建立一个程序化广告的研究平台。我负责构建和维护一个实时数据产品,需要探索新的工具来完成这个项目。
MLflow
MLflow 是一个开源框架,用于模型生命周期管理。项目的目标是提供支持机器学习模型开发、服务和监控的模块。我在 2020 年开始使用其中的两个组件:MLflow 跟踪和模型注册表。跟踪模块使数据科学家能够记录不同模型管道的性能并可视化结果。例如,可以尝试不同的特征缩放方法、回归模型和超参数组合,并查看哪个管道配置产生了最佳结果。我在 Databricks 环境中使用了这个功能,它提供了有用的模型选择可视化工具。我还开始使用 MLflow 中的注册表模块来存储模型,其中一个训练笔记本训练并存储模型,而一个模型应用笔记本检索和应用模型。模型注册表中的一个有用功能是能够在部署之前对模型进行分阶段处理。注册表可以维护不同的模型版本,并提供在发现问题时回退到先前版本的能力。在 2021 年,我计划探索 MLFlow 中的更多模块,包括模型服务。
Kubernetes
Kubernetes 是一个开源的容器编排平台。它使数据科学家能够将容器部署为可扩展的 Web 应用程序,并提供多种配置选项用于在 Web 上暴露服务。虽然从头开始设置 Kubernetes 部署可能相当复杂,但云平台提供了托管版本的 Kubernetes,使得上手这个平台变得容易。我对希望学习 Kubernetes 的数据科学家的建议是使用 Google Kubernetes Engine (GKE),因为它提供了快速的集群启动时间,并具有出色的开发者体验。
为什么 Kubernetes 如此有用?因为它使团队能够将应用程序开发和应用程序部署问题分开。数据科学家可以构建一个模型服务容器,然后将其交给工程团队,后者将该服务暴露为可扩展的 Web 应用程序。在 GCP 中,它还与负载均衡和网络安全系统无缝集成。然而,使用托管服务如 GKE,可以降低使用 Kubernetes 的门槛,数据科学家应当亲自体验这个平台。这样可以使数据科学家能够构建端到端的数据产品。
NoSQL
尽管我在数据科学职业生涯中使用了各种数据库,但直到 2020 年我才首次探索 NoSQL 数据库。NoSQL 包括实现低延迟操作的键值存储数据库。例如,Redis 是一个内存数据库,提供亚毫秒级的读取性能。这种性能在构建实时系统时非常有用,你需要在数据通过网络服务接收时更新用户档案。例如,你可能需要更新描述用户活动的特征向量的属性,该特征向量作为输入传递给流失模型,并在 HTTP POST 命令的上下文中应用。为了构建实时系统,数据科学家需要亲自使用 NoSQL 数据库。学习诸如 Redis 这样的技术时,使用mock库来测试 API 在部署到云端之前是很有帮助的。
OpenRTB
OpenRTB 是一种用于实时广告拍卖和广告投放的规范。该规范被用于如 Google 广告交换等交易所,以连接销售广告库存的出版商与希望投放广告的买家。我使用该协议实现了一个程序化用户获取的研究平台。虽然该规范对数据科学的广泛适用性不强,但对数据科学家学习如何构建能够实现标准化接口的系统非常有用。以 OpenRTB 为例,这涉及到构建一个接收带有 JSON 有效负载的 HTTP POST 请求并返回带有定价细节的 JSON 响应的网络服务。如果你有兴趣快速上手 OpenRTB 规范,Google 提供了一个protobuf实现。
Java Web Frameworks
我决定用 Java 编写 OpenRTB 研究平台,因为我对这种语言最为熟悉。然而,Rust 和 Go 都是构建 OpenRTB 系统的绝佳替代选择。由于我选择了 Java,我需要选择一个用于实现应用程序端点的 Web 框架。虽然我在十多年前使用 Jetty 库来构建简单的 Java Web 应用程序,但我决定根据基准测试探索新的工具。我从Rapidoid库开始,它是一个用于用 Java 构建 Web 应用程序的轻量级和快速框架。然而,当我开始在响应 Web 请求时添加对 Redis 的调用时,我发现需要将 Rapidoid 从非托管模式转换为托管模式。我接着尝试了Undertow,它支持阻塞 IO,并发现它在我的基准测试中表现优于 Rapidoid。虽然数据科学家通常不使用 Java 编写代码,但学习如何尝试不同的 Web 框架,例如选择 gunicorn 和 uWSGI 来部署 Python Web 服务,是很有用的。
HTTPS
实施 OpenRTB 协议现在需要通过安全的 HTTP 服务流量。为 Web 服务启用 HTTPS 涉及通过 DNS 将 Web 服务设置为命名端点,并使用签名证书来建立端点的身份。确保 GCP 上托管的 GKE 中的端点安全相对简单。一旦服务通过节点端口和服务入口暴露出来,你需要为服务的 IP 地址设置一个 DNS 条目,然后使用 GCP 托管的证书来启用 HTTPS。
对于数据科学家来说,学习设置 HTTPS 端点非常有用,因为这涉及到保护服务的细微差别。如果不需要端到端 HTTPS,比如在 OpenRTB 的情况下,其中 HTTP 可以在负载均衡器和 Kubernetes 集群中的 pods 之间内部使用,那么部署就会更容易。如果需要端到端 HTTPS,比如使用 OAuth 的 Web 服务,那么 Kubernetes 配置会稍微复杂一些,因为 pods 可能需要在与服务 Web 请求的端口不同的端口上响应健康检查。我最后提交了一个 PR 来解决与此相关的 Plotly Dash 应用程序中的一个问题。
负载均衡
为了扩展到 OpenRTB 量级的 Web 流量,我需要使用负载均衡来处理每秒超过 10 万个 Web 请求 (QPS)。Kubernetes 提供了扩展服务 Web 请求的 pods 数量的基础设施,但还需要以一种均匀分配请求的方式配置集群。Kubernetes 有一个 open issue 导致使用长连接时 pods 负载不均,这是 OpenRTB 系统推荐的配置。我使用了 container native 的负载均衡功能来缓解这个问题。对负载均衡进行实际操作在大型组织中对数据科学家来说并不常见,但对于拥有高请求量的端到端数据产品的初创公司或团队来说,这是一个有用的技能。
日志记录
部署 Web 应用程序还涉及到为系统设置监控,以确定是否出现任何问题。在构建 GCP 应用程序时,StackDriver 提供了一个用于日志消息、报告自定义指标和设置警报的托管系统。我能够利用这个系统来监控正常运行时间,并在发生事件时向 Slack 和 SMS 发送警报。对数据科学家来说,实际操作日志库非常有用,以确保部署到云中的系统按预期运行。
结论
在 2020 年,我学习了几种通常与工程角色相关的技术。作为一名数据科学家,我出于必要学习了这些工具,以建立和维护端到端系统。虽然许多这些技术在数据科学中并不广泛适用,但应用科学家的角色日益增长,正在对拥有更广泛技术栈经验的数据科学家产生需求。
简介: 本·韦伯 是 Zynga 的杰出数据科学家,也是《数据科学生产》一书的作者。
原文。转载已获许可。
相关:
-
MLOps 正在改变机器学习模型的开发方式
-
轻松数据科学的 5 种工具
-
每位懒散的全栈数据科学家应该使用的 5 种最有用的机器学习工具
更多相关话题
8 个开源替代 ChatGPT 和 Bard
原文:
www.kdnuggets.com/2023/04/8-opensource-alternative-chatgpt-bard.html
图片来源:作者
1. LLaMA
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
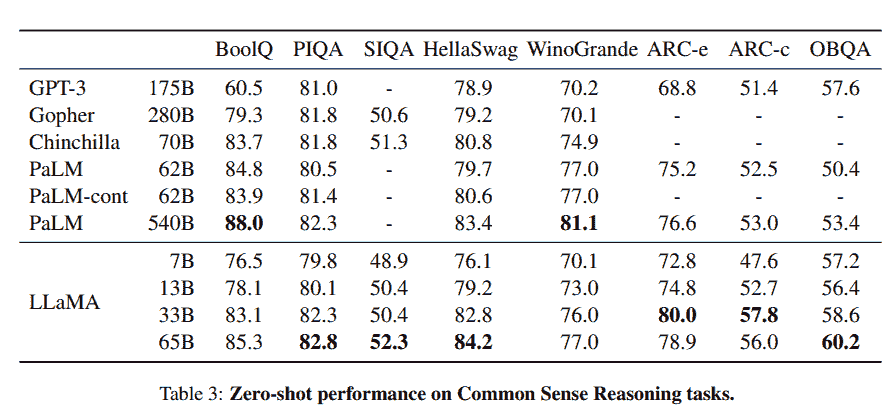
LLaMA 项目包括一组基础语言模型,参数规模从 70 亿到 650 亿不等。这些模型在数百万个标记上进行了训练,且仅使用公开可用的数据集。因此,LLaMA-13B 超过了 GPT-3 (175B),而 LLaMA-65B 的表现则与 Chinchilla-70B 和 PaLM-540B 等最佳模型相当。
图片来自 LLaMA
资源:
-
GitHub: facebookresearch/llama
-
演示: Baize Lora 7B
2. Alpaca
斯坦福 Alpaca 声称它可以与 ChatGPT 竞争,任何人都可以用不到 600$ 复制。Alpaca 7B 是从 LLaMA 7B 模型在 52K 指令跟随演示上进行微调的。
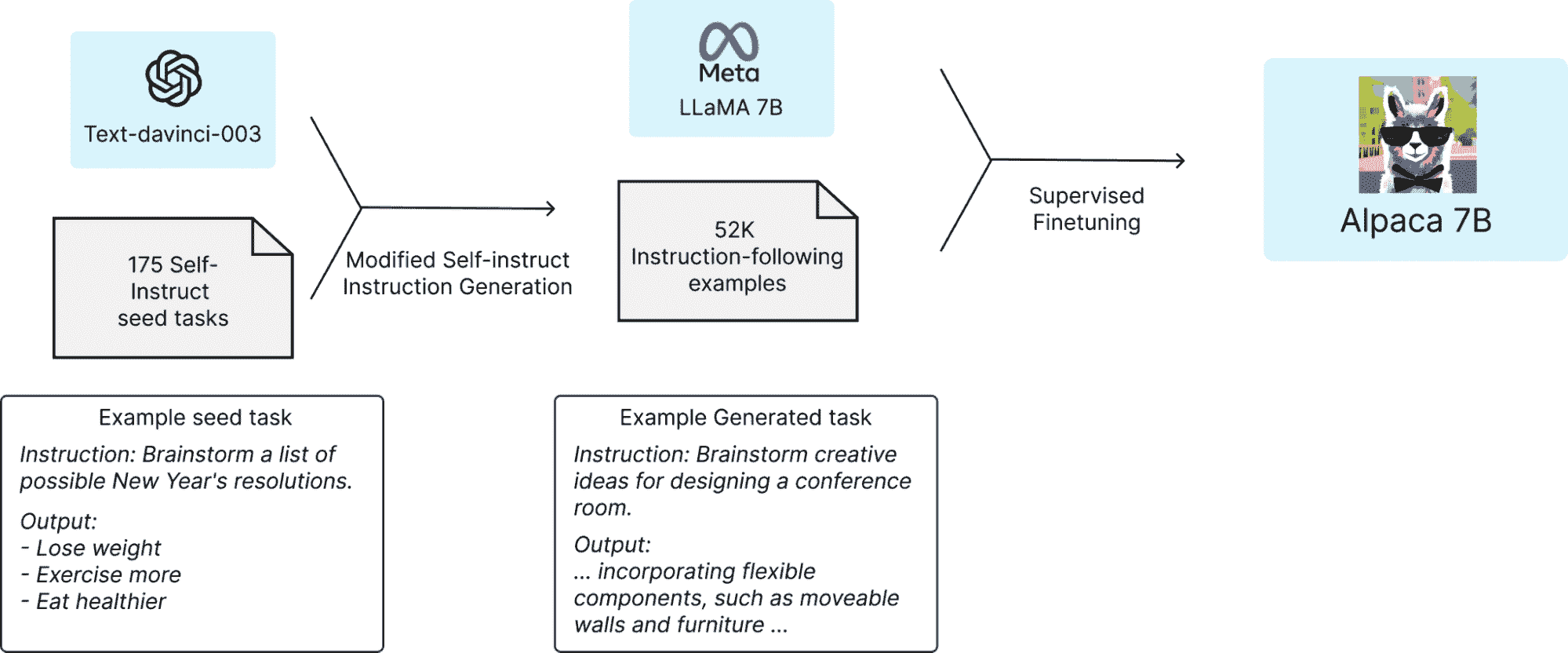
训练配方 | 图片来自 斯坦福 CRFM
资源:
-
博客: 斯坦福 CRFM
-
GitHub: tatsu-lab/stanford_alpaca
-
演示: Alpaca-LoRA(官方演示已下架,这是 Alpaca 模型的重建版)
3. Vicuna
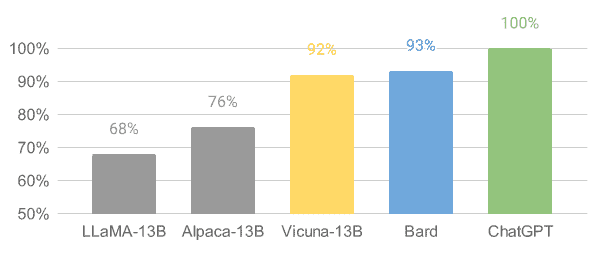
Vicuna 是从 LLaMA 模型在 ShareGPT 收集的用户共享对话上进行微调的。模型 Vicuna-13B 达到了超过 90%* 的 OpenAI ChatGPT 和 Google Bard 质量。它在 90% 的情况下也超越了 LLaMA 和斯坦福 Alpaca 模型。训练 Vicuna 的成本约为 300$。
图片来自 Vicuna
**资源: **
-
GitHub: lm-sys/FastChat
4. OpenChatKit
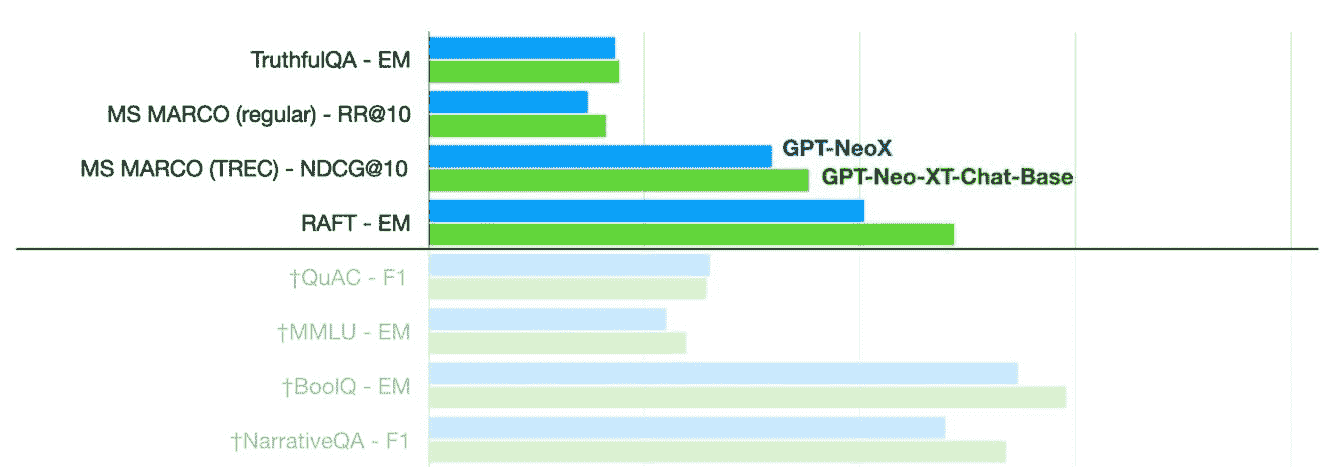
OpenChatKit: 开源 ChatGPT 替代品 是一个完整的工具包,用于创建你的聊天机器人。它提供了训练自己定制化大语言模型的说明、模型微调、可扩展的检索系统用于更新机器人响应,以及用于过滤问题的机器人管理。
图片来自 TOGETHER
正如我们所见,GPT-NeoXT-Chat-Base-20B 模型在问题回答、提取和分类任务上优于基础版 GPT-NeoX。
**资源: **
-
GitHub: togethercomputer/OpenChatKit
-
演示: OpenChatKit
5. GPT4ALL
GPT4ALL 是一个社区驱动的项目,经过大量整理的助理交互数据进行训练,包括代码、故事、描写和多轮对话。团队提供了数据集、模型权重、数据整理过程和训练代码,以推动开源。此外,他们还发布了可以在笔记本电脑上运行的量化 4 位版本模型。你甚至可以使用 Python 客户端运行模型推理。
动图来自 GPT4ALL
**资源: **
-
技术报告: GPT4All
-
GitHub: nomic-ai/gpt4al
-
演示: GPT4All(非官方)
6. Raven RWKV
Raven RWKV 7B 是一个开源聊天机器人,采用 RWKV 语言模型,该模型的效果与 ChatGPT 类似。该模型使用的 RNN 能在质量和规模上与 transformers 匹敌,同时更快且节省 VRAM。Raven 在 Stanford Alpaca、code-alpaca 等数据集上进行了微调。

图像来源于 Raven RWKV 7B
**资源: **
-
GitHub:BlinkDL/ChatRWKV
7. OPT
OPT:开放预训练变换器语言模型虽然不如 ChatGPT 优秀,但在零样本和少样本学习以及刻板偏见分析方面表现出色。你还可以将其与 Alpa、Colossal-AI、CTranslate2 和 FasterTransformer 集成,以获得更好的结果。
注意: 它在列表中是因为它的受欢迎程度,因为在文本生成类别中每月下载量达到 624,710 次。
图像来源于 (arxiv.org)
**资源: **
-
GitHub:facebookresearch/metaseq
-
演示:LLMs 的水印
8. Flan-T5-XXL
Flan-T5-XXL 是在一系列以指令形式呈现的数据集上微调的 T5 模型。指令微调显著提高了多种模型类别(如 PaLM、T5 和 U-PaLM)的性能。Flan-T5-XXL 模型在超过 1000 个额外任务上进行了微调,还覆盖了更多语言。
图像来源于 Flan-T5-XXL
**资源: **
-
研究论文:规模化指令微调语言模型
-
GitHub:google-research/t5x
-
演示:Chat Llm 流媒体
结论
有许多开源选项可供选择,我提到了其中一些受欢迎的选项。开源聊天机器人和模型正在不断改进,未来几个月你会看到一个新的模型,它的性能可能会完全超越 ChatGPT。
在这篇博客中,我提供了一些模型/聊天机器人框架的列表,这些框架可以帮助你训练和构建类似于 ChatGPT 和 GPT-4 的聊天机器人。别忘了给它们点赞和评分。
如果你有更好的建议,请在评论区告诉我。我很乐意在未来添加它。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为那些饱受心理疾病困扰的学生开发一个 AI 产品。
更多相关话题
获取机器学习职位面试的 8 种途径
原文:
www.kdnuggets.com/2019/10/8-paths-machine-learning-job-interview.html
comments
作者 Jaxson Khan,Khan & Associates 的首席执行官。

对于机器学习职位,获得面试有时是获取工作的最困难(也是最令人沮丧)部分,比通过面试更难。因此,在本文中,我们将帮助你搞清楚如何首先获得机器学习的面试。本文来源于 Jaxson Khan 的 终极机器学习面试指南。
我将这一部分分为传统方法和较新的主动方法,这可能帮助你在初创公司中脱颖而出。
传统的面试获取途径
1. 职业网站和标准申请
大多数公司在他们的职业网站上发布职位信息。你可以始终瞄准某家公司,并回应特定的职位发布,或通过该职位门户提交表示对公司更广泛兴趣的通用申请。你还可以在 Indeed 或 LinkedIn 等网站上找到机器学习职位的发布。这些是经典的途径,绝对值得投入一些时间。
最近的求职者告诉我,他们喜欢 Breakoutlist、AngelList 和 Triplebyte。
也有专门针对机器学习领域的职位板,如 ML Jobs List。
我还听说来自风险投资公司的汇总器,如 First Round Capital、Greylock 和 Costanoa,都相当不错。
2. 招聘人员
通常,你会在面试过程中与招聘人员合作,但你不必仅仅等待他们联系你。有时你可能希望直接联系招聘人员,无论是在公司内部(内部招聘人员)还是与公司联系优秀候选人的第三方招聘人员。
一些招聘人员专注于机器学习和人工智能。他们通常在 LinkedIn 个人资料标题中包含这方面的信息,或者列出更为一般的描述,如“技术招聘人员”。招聘人员的重要之处在于,他们可能知道一些在线上未发布的职位。请记住,大约 50%的职位不会公开列出。快速搜索 LinkedIn 会让你了解到一些可能能够找到最相关公司的招聘人员。
3. 招聘会和交易展
招聘会呈现出一种相当令人畏惧的视角:谁愿意在一堆其他候选人中徘徊,试图追赶公司代表的摊位?但特别是主要大学的招聘会可能会相对不错。然而,我真正的推荐是,您本地机器学习社区的网络活动和聚会可能会比传统的招聘会更好。(继续阅读,了解更多!)
主动获取面试机会的路径
虽然上述选项相当传统,但候选人越来越常采取不同的方法来获得面试机会。通常你需要积极主动,展示创造力和毅力才能获得职位。初创公司是人工智能和机器学习中新工作的主要领域,并以开创不同类型的面试风格而闻名。
4. 参加或组织一个活动
这通常是认识您社区中对人工智能和机器学习感兴趣的人的最佳方式,您还可能从参与者那里了解到工作机会。根据您的需求,您可以选择大型会议或较小、更专注的社区聚会。
会议
ICML 是全球领先的国际机器学习会议之一,已有超过 35 年的历史。通常在加利福尼亚州举办,汇聚了关于机器学习当前状态和未来的专家讲者。如果你是机器学习工程师,你应该考虑这个活动,但与机器学习相关的每个人在这里都有可能找到适合自己的内容。
这个会议专注于人工智能和机器学习的最新突破。它是一个 O'Reilly 活动,汇集了科学与商业,邀请了来自顶级软件公司的讲者,提供培训课程和网络机会。它是了解人工智能不同应用的绝佳场所。特别适合产品经理和商业智能开发人员。
另一个长期的会议(自 1987 年以来),这个会议可能是最专注于理论和最新机器学习发展研究的。它显著关注计算神经科学,因此对于机器学习研究人员或理论背景的个人来说,这是一个理想的选择。
聚会
有时候,参加较小的社区活动可能对你更有利,因为你能留下更大的印象,并在一段时间后甚至担任领导角色。这也是认识当地社区成员的一种方式。通常,大型活动充满了供应商和专注于大合作伙伴关系的人。小型活动可以让你更容易接触到招聘经理,并帮助你与可能在未来帮助你的同行建立联系。你还可能找到演讲机会或开始在社区中建立你的声誉。
进行聚会的最佳网站之一是 Meetup.com。你会在这个网站上找到各种聚会。有些相当大;例如,纽约机器学习聚会 拥有超过 13,000 名成员。但不要被这些人数吓到;许多人可能会注册但实际上不参加。通常较小的聚会人数在 10 到 200 人之间。
如果你找不到合适的聚会或附近没有合适的聚会,可以自己创建一个!我知道许多求职者通过创建相关的社区小组获得了职位。这使你成为社区中的连接者或影响者。这是一个很好的角色,可以添加到你的简历中。
5. 自由职业和建立作品集
没有理由不能立即开始从事机器学习工作。最简单的方法之一是开始自由职业。这对设计师、工程师和数据科学家来说可能最容易,但研究人员和产品经理也有机会。像 Upwork 或 TopTal 这样的网站,使得作为一名技术专业人士,你可以轻松创建个人资料,找到短期合同和长期项目,甚至是更长期的合作机会。
作品集可以帮助你建立个人品牌,同时也是你工作的在线经验记录。它还可以为你提供一些早期的推荐和评价,供你传递给潜在的雇主。当然,它也可能让你做一些真正有趣的工作,进而激发博客文章或其他内容,这些内容可以用来扩展你的个人资料。
从最终的角度来看,自由职业也可能是一个很好的主意,可以帮助你验证你感兴趣的不同类型的工作和行业,帮助你缩小求职范围,并在未来更具针对性。
如果你在寻找额外的提升,可以通过 Springboard 的在线 机器学习训练营 专注于作品集,并获得指导支持。
6. 参与开源项目
另一个在机器学习社区中建立联系的方法是参与开源项目。这些是由分布式社区共同开发的非专有代码库和存储库,通常不以盈利为目的或被公司拥有。它们通常托管在Github的开源存储库中。这包括自然语言工具包项目,它帮助处理作为数据源的人类语言,以及构成 Python 数据科学和机器学习工具包的各种库。
招聘工程师的公司通常特别倾向于基于开源贡献进行招聘,有时会通过你所写的内容找到你。这类似于作品集效应。人们通常会在线查找你,并希望看到你所做的工作。
7. 参与竞赛 / 黑客马拉松
如果你更愿意在更封闭或时间限制的环境中使用你的技能,也许参加竞赛或黑客马拉松是一个不错的选择。
还有像Kaggle这样的机器学习竞赛和许多黑客马拉松,允许你快速解决实际的商业或社会问题。这是一个展示你的机器学习和人工智能技能的绝佳方式,同时你也能结识新朋友并展示你能够带来改变的能力。
8. 信息访谈
最终,你可以采取的最后一条途径或步骤是经典的,但可能是不可替代的。最终,人际关系能够让你踏上求职之路,并帮助你达成交易。超过一半的职位甚至不会在招聘网站上发布,有时穿透公司看似不可突破的外壳的唯一方式是开始结识该公司的人,并与他们建立强大的关系。
网络建设的最佳方式之一是请求对方仅花费一点时间。一个简短的咖啡约会是理想的。按照对方的时间安排,在他们选择的地方见面。通过电子邮件或 LinkedIn 消息联系,简短说明一下你作为候选人的独特之处。你还可以使用Steve Blank 的这个绝佳框架。
如果你成功约到咖啡,视其为一个从业内人士那里寻求建议和信息的机会。如果你擅长扩展网络,你将真正了解这个行业的运作方式。
个人简介: 贾克逊·汗 是 Khan & Associates 的首席执行官 | 人工智能与金融科技顾问和作家 | 教育与经济发展志愿者。
相关内容:
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的捷径。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关话题
数据专业人士寻找数据集的 8 个地方
原文:
www.kdnuggets.com/2020/12/8-places-data-professionals-find-datasets.html
评论
由 Manuel Geissinger 拍摄,来自 Pexels
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT 管理
熟能生巧——这是掌握任何主题或行业的最佳方式。涉及数据集时,扩展您的视野是必要的,因为这个领域非常广阔。
对于从事任何形式的数据工作的人来说,从机器学习到数据可视化,以下网站和资源对于实践都是非常宝贵的。
1. Kaggle
Kaggle 是一个可靠的实践数据资源。它将编写和分享代码纳入一些数据集中,这为您掌握该领域提供了额外的好处。您将处理自然语言处理(NLP)和图像分类等数据主题。
例如,对于文本挖掘,您可以深入 “星际迷航”剧本项目 并开始使用 Kaggle 提供的数据进行练习。这个数据仓库的独特之处在于,您可以看到其他用户在与您相同项目上的反馈。可能性是无限的。
2. 谷歌
谷歌作为一个庞大的搜索引擎,也涉足了无数其他领域。您可以 查看数据集搜索 页面,寻找您感兴趣的主题。如果您想探索动物与人类的关系,只需输入相关关键词,搜索结果将为您提供相关项目。
您还可以使用 Google Trends 和 Google Finance 查找任何您感兴趣的主题的数据。Trends 将展示术语的使用情况和搜索量,而 Finance 提供您可以处理的股票信息。
3. r/datasets
如果您希望通过社区化的方法寻找实践数据,可以转向 Reddit。Reddit 在某种程度上已经成为了一个搜索引擎。子版块 r/datasets 是一个典型的例子 体现了 Reddit 的资源丰富性。
你会发现许多志同道合的人对数据实践的来源提供了大量贡献。他们会分享他们发现有用的网站和项目,并指导你找到正确的路径。你也可以分享你自己处理过的项目,以保持积极的势头。
4. 美国政府
由于美国政府处理了大量数据集,它成为了一个理想的实践资源。特别是健康数据是你可以找到的最丰富的信息之一。超过 218,000 个数据集可供使用,你可以在任何领域找到项目。
当前的 COVID-19 大流行使无数数据集进入了公众视野。例如,你可以使用一个关于利用公共卫生数据抗击疫情的数据集。由于美国政府提供了大量的数据集,这个资源库是任何形式实践的理想选择。
5. 选举数据
虽然不是一个资源库,但选举数据随处可见。过去的总统选举引起了历史上前所未有的关注。由于大量的邮寄选票和基于技术的参与,这次选举以新的方式生成了数据集。
要练习一系列子主题——如探索性数据分析、机器学习、统计建模和可视化——你可以在任何资源库找到基于选举的数据集。Google、Kaggle 和美国政府将极为有用。
这次选举将产生持久的影响,这种相关性使其数据集在未来几年内成为良好的实践材料。
6. 人口普查数据
类似于选举数据,人口普查数据集也在不断变化。美国及全球人口在一年内会有所波动,尤其是在像 COVID-19 这样的致命疫情下。
GitHub 是一个突出的数据集资源。对于人口普查数据,你可以下载特定项目,这将帮助你进行探索性数据分析、建模、可视化和统计分析。处理人口普查信息每次都会带来新的收获,你可以尽可能地缩小或放大数据。
7. Awesome Public Datasets
正如 GitHub 提供了人口普查数据集的资源,它还托管了互联网上最好的数据实践资源之一。Awesome Public Datasets提供了各种各样的信息供你使用。
GitHub 从公共资源如博客、用户和任何形式的公共数据中收集数据。你会发现从农业到博物馆再到软件的各种主题的数据集。使用 GitHub 时,你可以将你的兴趣与最佳实践相匹配。
8. UCI
既然机器学习已成为科技世界的必需部分,了解其工作原理至关重要。专注于机器学习的数据集是掌握该领域的最佳方式。UCI 机器学习库是 最好的资源之一。
该网站收集了各种数据库、数据生成器和理论,这些都是机器学习的关键。你将分析算法,并深入理解机器学习为何如此有价值。UCI 应成为这项研究的主要资源。
最佳数据实践
这些资源和库是互联网上进行数据集深入练习的最佳场所之一。最终,你会希望选择那些激发你兴趣的网站。如果你想深入研究机器学习,UCI 将是理想的资源。如果你想处理人口信息,美国政府将是不可或缺的。
由于这些资源提供免费的项目练习,你可以进一步扩展视野,并在简历上展示各种数据集分析。
简介:Devin Partida 是大数据和技术作家,以及 ReHack.com 的主编。
相关内容:
-
数据科学中的前 10 名列表
-
Python 中数据集拆分的最佳实践
-
数据专业人士如何为简历增加更多变化
更多相关话题
2023 年数据科学的 8 种编程语言
原文:
www.kdnuggets.com/2023/07/8-programming-languages-data-science-learn-2023.html

作者提供的图片
1. Python
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
Python 是数据分析、机器学习和自动化任务中最受欢迎的语言,因为它简单、拥有大量的数据科学工具库如 NumPy 和 Pandas、与 Jupyter Notebooks 的集成使得实验和可视化变得容易,并且它在广泛用途上的多样性,使其成为初学者学习数据科学时的理想语言。
如果你刚开始从事数据科学工作,我强烈建议你从 Python 及其最受欢迎的数据科学库如 NumPy、Pandas、Matplotlib 和 Scikit-Learn 入手。学习 Python 及这些库将为你提供一个坚实的基础,使你高效完成任务,并减少麻烦,为你在数据科学领域的成功奠定基础。
2. SQL
学习 SQL 对任何从事数据工作的人来说都至关重要。你将使用它从 SQL 数据库中提取和分析信息,这是数据专业人士的基本技能。通过理解 SQL,你可以与关系数据库管理系统如 MySQL、SQL Server 和 PostgreSQL 互动,有效地检索、组织和修改数据。
SQL 的基础包括使用 SELECT 语句选择特定数据,使用 INSERT 语句插入新数据,使用 UPDATE 语句更新现有数据,以及使用 DELETE 语句删除过时或无效的数据。
3. Bash
Bash/Shell 不是传统的编程语言,它们是处理数据的宝贵工具。Bash 脚本允许你将命令串联起来,以自动化执行重复或复杂的数据任务,这些任务手动执行会非常繁琐。
Bash 脚本可用于通过搜索、过滤和组织数据来操作文本文件。它们可以自动化 ETL 管道,以提取数据、转换数据并将其加载到数据库中。Bash 还允许你从命令行对数据文件进行计算、拆分、连接和其他操作,并使用 SQL 查询和命令与数据库互动。
4. Rust
Rust 由于其强大的性能、内存安全性和并发特性,正成为数据科学中一个新兴的语言。然而,Rust 在数据应用方面仍相对较新,与 Python 相比有一些劣势。
作为一种较年轻的语言,Rust 在数据科学任务中拥有的库远少于 Python。Rust 的机器学习和数据分析库生态系统仍需成熟,这意味着大多数代码库必须从头开始编写。
然而,Rust 的优势,如性能、内存和线程安全,使其适合构建高效可靠的数据科学系统后端。Rust 非常适合需要低级代码优化和并行化的数据管道。
5. Julia
Julia 是一种专门为科学和高性能数值计算创建的编程语言。其独特的特点之一是能够在编译过程中优化代码,使其性能能够与 C 语言相当,甚至更好。此外,Julia 的语法受到了 MATLAB、Python 和 R 等流行编程语言的启发,使得已经熟悉这些语言的数据科学家更容易学习。
Julia 是开源的,并且拥有一个不断发展的开发者和数据科学家社区,为其持续改进做出贡献。总体而言,Julia 提供了生产力、灵活性和性能的良好平衡——使其成为数据科学家,尤其是那些处理性能受限问题的科学家的宝贵工具。
6. R
R 是一种流行的编程语言,广泛用于数据科学和统计计算。它非常适合数据科学,因为它拥有丰富的内置函数和库,用于数据操作、可视化和分析。这些函数和库使用户能够执行各种任务,如导入和清理数据、探索数据集和构建统计模型。
R 也因其强大的图形能力而闻名。该语言包括各种用于创建高质量图表和可视化的工具,这对数据探索和沟通至关重要。
7. C++
C++是一种高性能的编程语言,广泛用于构建高性能复杂的机器学习应用程序。尽管在数据科学中的使用不如 Python 和 R 等其他语言普及,但 C++具有多个特性,使其在某些数据科学任务中成为绝佳选择。
C++的一个关键优势是其速度。C++是一种编译语言,这意味着代码在执行之前会被转换成机器码,这可能导致比像 Python 和 R 这样的解释型语言更快的执行时间。
C++的另一个优势是它处理大型数据集的能力。C++具有低级内存管理功能,这意味着它可以高效地处理非常大的数据集,而不会遇到其他语言可能遇到的内存问题。
8. Scala
如果你在寻找一种比 Java 更简洁、更少冗余的编程语言,那么 Scala 可能是一个很好的选择。它是一种多用途和灵活的语言,结合了面向对象和函数式编程范式。
Scala 在数据科学中的主要优势之一是它可以无缝集成到像 Apache Spark 这样的“大数据”框架中。这是因为 Scala 运行在与这些框架相同的 JVM 上,使其成为分布式大数据项目和数据管道的绝佳选择。
如果你打算从事数据工程或数据库管理的职业,学习Scala将帮助你在职业生涯中脱颖而出。然而,作为数据科学家,掌握这门语言并非必要。
结论
总之,如果你对数据科学感兴趣,学习这些八种编程语言中的一种或多种可以帮助你启动或推进在这个领域的职业生涯。每种语言都有其独特的优点和缺点,具体取决于你要完成的数据科学任务。
在数据科学编程语言方面,Python 因其用户友好特性、灵活性和强大的社区支持而成为热门选择。其他语言如 R 和 Julia 也很不错,提供了卓越的统计计算、数据可视化和机器学习支持。C++和 Rust 推荐给那些需要高性能和内存管理能力的人。Bash 脚本在自动化和数据管道方面很有用。最后,学习 SQL 非常重要,因为它是任何技术工作的必备语言。
Abid Ali Awan (@1abidaliawan) 是一名认证数据科学专家,喜欢构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为患有心理疾病的学生开发一个 AI 产品。
相关主题
2 年内提升数据科学技能的 8 种方法
原文:
www.kdnuggets.com/2017/11/8-ways-improve-data-science-skills-2-years.html

数据科学是一个不断成长并始终受欢迎的领域。只需简单地搜索“顶级数据科学技能”,你就会找到数百甚至数千篇关于该主题的博客、文章和视频。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
Ferris Jumah,LinkedIn 的全栈数据科学家,几年前发布了一篇文章详细介绍了数据科学家最受欢迎的技能,这些技能基于他们的 LinkedIn 资料数据。现在已经过时了,所以可以肯定,现代科学家的技能和工具有很多不在列表中。
看着像 Jumah 的列表时,首先想到的问题是你实际上需要多少这些技能才能在行业中蓬勃发展。真的有谁能做到所有这些技能吗?
很可能是这样,但也可能不是。对你来说最重要的是你能掌握多少这些技能,并熟练运用。也许更重要的是,这些技能可以多快地掌握?
这不一定要像终身刑一样感觉。继续阅读以获取启动你的数据科学、机器学习或统计学家职业的技巧。
第一步:承认你有问题
这听起来像是康复计划的第一步——在某种程度上确实如此。无论你是谁,总会有一个雄心壮志,希望在你的领域中达到绝对顶尖。
数据科学尤其培养这种态度,因为即使你不是在不断学习新事物,你仍然需要保持对你经常使用的技能和流程的了解。这是一个始终在前进和发展的行业,这意味着你也需要保持同样的状态。
但这并不意味着你必须了解或参与所有内容。这就是问题所在。第一步是承认你不会专注于数据科学家可以使用的每项技能。是的,你需要核心技能——主要是分析和数据处理——但其他一切则是附带的。
那么?缩小你的重点。选择你最常用的技能以及对你的职业生涯最有益的技能。例如,如果你的计划是使用 Python 或基于 Hadoop 的系统,那么学习其他语言虽然能丰富你的知识储备,但并不会真正帮助你提升核心技能。
第二步:加速你的学习
两年。你应该将最多两年的时间专注于学习、教育和培训。是的,如果你对这个行业还很陌生,可以在此之前进入职场,但重点是你绝不希望在没有实际领域经验的情况下超过两年。
这正是为什么本指南专注于在两年内磨练最有益技能的原因。目标是每周投入大约十五到二十小时来发展你的知识和技能。有几种方法可以做到这一点:
-
通过 Coursera、Treehouse、Lynda 和 CodeSchool 参加在线课程,专注于你想学习的技能。这些课程不一定要与数据科学相关。相关语言的编程课程,如 Python,也很有效。
-
尽可能多地阅读关于数据科学的资料。这包括学术论文、教科书以及其他教育材料,甚至是当前的行业报告。
-
加入一个数据科学或开发社区。有很多社区可以选择。关注社区分享的帖子和材料,参与最重要的讨论。你可以从同行那里学到很多东西。
-
如果可以,找到一位在行业内工作或具有数据科学经验的导师。这包括程序员和开发人员、数据科学家、统计学家、工程师等。定期与他们见面,提出问题,听取他们的经验。
-
定期访问 UCI 机器学习库 并参与数据问题。R、Excel 及类似平台是你的好帮手。如果解决一个问题花费的时间超过了预期,不要灰心。坚持下去,你会随着时间的推移提高效率。
-
遵循脚本、预处理数据和自动化任务,并依赖框架或数据库。这将最大限度地减少你需要自己创建算法和代码的时间,并增加实际进行数据科学和机器学习的时间。
-
找一份涉及机器学习、数据科学、分析或基本统计的入门级工作。 数据迁移是一个很好的机会 适合入门级或初学者的数据科学家。你可以通过这些项目奠定知识基础,并在理解了基础后轻松自动化一些任务。
-
参与一个你感兴趣的开源数据科学或机器学习项目。把它当作一个爱好或业余项目,在闲暇时间享受工作。
此外,当你有机会时,深入学习并开始使用一些流行的数据科学工具。到你进入职场时,你将已经对你雇主使用的平台有了基本的了解和经验。
第三步:永不停止成长
重要的是要理解,无论你多么努力工作,学习多少,你都不可能在两到三年内成为专家。这不是一个现实的目标。但这并不意味着你不应该努力继续成长和提升你的技能。恰恰相反!
即使你花了两年时间进行培训——相信与否,这段时间会很快过去——你仍然会想要在新领域中继续提升你的技能和经验。如果你没有学习新事物的愿望,那也没关系——只要确保你保持对当前技能和项目的掌握。
听起来有些重复,但要继续参与这些开发和机器学习社区,并密切关注新的课程和在线资源。
例如,从 2006 年到 2016 年,流行的数据科学家职称 从仅仅“数据或商业分析师”发展到包括数据科学家、商业分析师、大数据专家、机器学习专家、数据可视化专家等。随着主要品牌和组织采用这项技术并实施新的机器学习和数据科学计划,这种增长现在比以往任何时候都要快。
简而言之,这将给行业中的专业人士施加更大的压力,要求他们不断成长,变得更加熟练和经验丰富,涵盖更广泛的主题和技能。
一切都意味着你必须保持对核心知识和技能基础的掌握。
无论如何,永远不要停止成长和学习。
否则,你可能会发现自己在行业中被远远甩在了后面。
简介: 凯拉·马修斯 在《The Week》、《数据中心期刊》和《VentureBeat》等出版物上讨论技术和大数据,并且已经写作超过五年。要阅读更多凯拉的文章,订阅她的博客 Productivity Bytes。
相关内容:
-
每个数据科学家都应该随身携带的 6 本书
-
进入数据科学:你需要知道的
-
如何面试数据科学家
相关话题
8 位努力使世界人性化的人工智能女性
原文:
www.kdnuggets.com/2021/03/8-women-ai-striving-humanize-world.html
编辑注:本文最初于 2021 年 3 月 8 日发布。
人工智能能否积极改变世界?
Wired 报道了人工智能领域存在性别偏见,并在 2018 年发现只有 12%的人工智能研究者是女性。当我开始担任数据分析师时,乌克兰的数据科学工程师职位并不普遍。而且,女性数学专业毕业生如果没有特殊技能和经验,这些职位大多不对她们开放。自学和了解机器学习算法花费了我不少时间和精力。如今,我在 MobiDev 担任人工智能工程师,随着经验的增加,我越来越愿意通过文章和网络研讨会与大家分享我的经历。
我们的三大课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT
今天,我想谈谈一些在人工智能领域工作的杰出女性,她们在日常工作中激励着我。
其中两位,乔伊·布奥拉姆维尼和李飞飞,以及其他人,曾在 2019 年国际妇女节期间获得 KDnuggets 的表彰。
乔伊·布奥拉姆维尼 - 算法公正联盟创始人
算法公正联盟的使命是提高公众对人工智能及其对减少人工智能偏见和伤害的影响的认识。她在 2018/2019 年发布的开创性研究显示,亚马逊、微软、IBM 等公司使用的面部识别软件并不“机器中立”。在识别较暗肤色女性面孔时,其表现明显低于对白人男性面孔的准确性。Fast Company 报道称,该软件基于布奥拉姆维尼的研究被撤下市场以进行重新配置。
李飞飞 - 斯坦福大学计算机科学教授
李飞飞是斯坦福大学教授,也是斯坦福大学以人为本的人工智能研究所的创始人。她开发了ImageNet,首次发布于 2009 年,作为训练工具教人工智能如何识别物体。ImageNet 被认为是人工智能数据集训练的起点,首次测试的准确率达到 71.8%。从那时起,年度 ImageNet 挑战赛成为了一个比赛,目的是看哪个算法以最低的错误率识别物体。最后一次比赛是在 2017 年,当时获胜算法的准确率达到了 97.3%,超越了人类能力。
但这里还有另外八位尚未获得 KDnuggets 荣誉的女性,她们以积极的方式使用人工智能,其对创造更美好世界的贡献非常重要。名单按姓氏字母顺序排列。

1. 莫妮卡·阿巴卡,qAIRa 联合创始人兼首席执行官 – 让地球变得更清洁
作为 qAIRa 的联合创始人兼首席执行官,莫妮卡·阿巴卡开发了应对空气污染的技术解决方案。严重的空气污染每年造成超过四百万人死亡。qAIRa 公司结合了无人机技术与空气质量监测,利用数据分析来识别空气污染,并制作实时地图显示关键区域。
政府官员使用这些信息来保护公众免受空气污染物在紧急情况下的危害,例如工业气体泄漏、自然灾害或化学品泄漏。这些人工智能驱动的系统的另一个用途是通过有效监控空气污染减缓计划的目标区域来改善总体空气质量。
2. 瑞吉娜·巴尔齐莱,麻省理工学院教师负责人及教授 – 帮助预防乳腺癌
在麻省理工学院担任教师负责人和教授的瑞吉娜·巴尔齐莱,长期以来一直是人工智能领域的思想领袖。她是第一个获得 100 万美元奖金的 AAAI 松鼠人工智能奖(为了人类利益的人工智能)的人。
巴尔齐莱教授积极倡导制定标准,确保在应用人工智能技术时公平与公正,尤其是在医学领域。她举了 Tyrer-Cuzick 模型的例子,该模型通过分析影像数据来确定患者罹患乳腺癌的风险。这个系统在白人女性中有适度的准确性,但在非洲裔或亚洲裔女性中表现极差。
这种失败发生是因为软件没有在足够的种族多样性图像集上经过充分的机器训练。这个问题源于不良的研究者偏见。它是显而易见且不可接受的。Barzilay 教授坚持认为,软件开发者应通过在不同人群中验证人工智能软件或将其开源,以使用不同的模型比较系统准确性,从而消除偏见。
3. Hulya Emir-Farinas, 数据科学总监,FitBit – 研究人们如何获得健康生活的动力
作为 Fitbit 研发部的数据科学总监,Dr. Emir-Farinas 利用结合了行为科学和医疗保健的机器学习的人工智能应用工作。她致力于回答以下问题:
-
什么激励个人追求更健康的生活方式?
-
什么是真实的和想象中的障碍,阻碍了积极的改变?
-
Fitbit 如何增强用户在生活方式改变方面的能力?
回答这些问题需要一种多学科的方法,包括行为经济学、行为科学、健康科学和机器学习,以提供适当的干预、鼓励,并使解决方案具有更多的个性化。
4. Dina Machuve, 纳尔逊·曼德拉非洲科技学院讲师和研究员 – 改善农业
在纳尔逊·曼德拉非洲科技学院,Dina Machuve 是一名讲师和研究员。她专注于创建数据驱动的解决方案以改善农业。一个应用是一个诊断系统,通过生物信息学和计算机视觉技术帮助识别家禽疾病。
目前有超过 3.8 亿的家庭农场为发展中国家 70%的人口提供食物。Manchuve 的解决方案现在已在坦桑尼亚部署,使用系统的数据收集和分析在小型到中型农场中进行。该项目展示了使用深度学习的人工智能方法在疾病诊断中提高畜牧健康的价值。它通过收集来自 370 万户养鸡家庭的低资源环境中的数据进行分析。
5. Deborah Raji, Mozilla 研究员 – 防止人口统计偏见
Deborah Raji 在电子前沿基金会先锋奖颁奖典礼上获得了 2020 年巴洛奖,以表彰她在人工智能种族偏见方面的工作。她的重点是人工智能在处理美国司法系统时对少数族裔产生的负面影响。她倡导消除并替换美国许多城市执法部门使用的严重缺陷的面部识别和监控系统。
6. Tempest van Schaik, 高级机器学习工程师,微软 – 帮助患有囊性纤维化的儿童
作为微软的高级机器学习工程师,Tempest van Schaik 在微软 Azure 云服务的数据科学部门的商业软件工程团队工作。该团队负责为云端编写高级 AI 项目代码。
一个令人兴奋的项目是 Fizzyo,一个通过将呼吸练习转化为视频游戏控制来改善囊性纤维化患者的物理治疗的设备。该设备使接受治疗的儿童的体验更加有趣,并在孩子玩耍时收集每一次呼吸的数据,从而实现更好的治疗效果。
7. Lucy Vasserman,Google 员工软件工程师 – 帮助动物保护
在 Google,Lucy Vasserman 作为员工软件工程师从事创新的 AI 项目。Google 与保护组织合作,利用 AI 研究野生动物。自 1990 年代以来,这些组织使用相机陷阱收集了 450 万张动物照片。这个图像数据库形成了 Wildlife Insights 的初始图像库。其他人可以添加相机陷阱图像,帮助全球映射野生动物,并建立不断增长的图像数据库。任何人都可以在线访问该数据库 探索照片 和相机陷阱的位置地图。
Vasserman 在该项目上工作,使其能够识别大约 100 种物种。它每小时可以处理和分类 3,600 张照片。机器学习软件分析图像,以发现如个别物种的种群规模、捕食者/猎物互动以及野生动物对人类狩猎和栖息地侵占的反应等趋势。
8. Fernanda Viégas,Google 首席科学家 – 制作复杂数据的吸引人可视化
在 Google,Fernanda Viégas 作为数据可视化专家工作。她与其他 Big Picture team 成员共同创建的可视化系统可以在 fernandaviegas.com 上体验。她是 Google PAIR(人类 + AI 研究)的联合负责人。
她的一些项目展示了风流动、维基百科编辑活动的协作模式以及世界新闻事件的动态地图。Viégas 博士制作的高度可视化、数据驱动的艺术作品是纽约现代艺术博物馆永久收藏的一部分。
作为一位来自非技术背景的拉丁裔女性,她在麻省理工学院媒体实验室获得了博士学位。她努力增加技术领域的多样性倡议,以减少女性和少数群体在数据科学中的代表性不足。
结论
鼓励女性参与人工智能,因为它具有改变世界的特性,并且有助于减少存在的性别偏见。以已故美国最高法院大法官露丝·巴德·金斯伯格为榜样。当被问到“她希望最高法院有多少女性大法官?”时,她回答说:“所有人。”
柳德米拉·塔拉年科 是 MobiDev 的首席数据科学家。
更多相关话题
9 本免费书籍,供学习数据挖掘和数据分析之用
原文:
www.kdnuggets.com/2014/04/9-free-books-learning-data-mining-data-analysis.html
评论作者 Alex Ivanovs,CodeCondo,2014 年 4 月 29 日。
数据挖掘、数据分析,这两个术语常常让人觉得很难理解——复杂——而且需要接受最高水平的教育才能理解。
我只能不同意,正如我们在这个美妙的生活中所经历的一切一样,我们只需要花费一定的时间学习某些东西,练习它,然后我们会意识到其实并没有那么难。
毫无疑问,这个世界上有很多聪明的人,他们在像谷歌、苹果、微软等大公司工作,还有许多其他公司(包括安全机构),但如果我们继续仰望他们,我们将永远觉得这很难,因为我们从未给自己机会去看实际的例子和事实。
通过学习这些书籍,你将快速揭示数据挖掘和数据分析的“秘密”,并希望能够更好地判断它们的作用,以及它们如何帮助你在当前和未来的工作项目中。
我只想说,为了学习这些复杂的主题,你需要保持完全开放的心态,接受每一个可能性,因为这通常是学习发生的地方,毫无疑问你的大脑会多次被点燃。
[数据柔道:将数据转化为产品的艺术]
 ](http://www.oreilly.com/data/free/data-jujitsu.csp) DJ Patil 向我们简要介绍了数据问题的复杂性,如何从更好的角度来看待它们,以及我们是否应该尝试解决那些看似不可能的问题。他提供了完全合理且易于理解的例子,这本书是你收藏中的一份不错的数据书籍,质量知识免费提供。
](http://www.oreilly.com/data/free/data-jujitsu.csp) DJ Patil 向我们简要介绍了数据问题的复杂性,如何从更好的角度来看待它们,以及我们是否应该尝试解决那些看似不可能的问题。他提供了完全合理且易于理解的例子,这本书是你收藏中的一份不错的数据书籍,质量知识免费提供。
你可以通过填写右侧的字段来获取这本书的副本。(我认为即使不填写也可以)
本维基书旨在通过整合每种技术的三部分信息来填补这一空白:描述和原理、实施细节和使用案例。
每种技术的描述和理由提供了理解实现和将其应用于实际场景所需的背景。实现细节不仅揭示了算法设计,还解释了其参数,基于之前提供的理由。
最后,使用案例提供了在合成数据集和真实数据集上应用算法的体验。
 这本书正是我在帖子开头提到的,包含了大量针对初学者的真实经验,帮助你更好地理解数据处理的整个过程以及算法的工作原理。
这本书正是我在帖子开头提到的,包含了大量针对初学者的真实经验,帮助你更好地理解数据处理的整个过程以及算法的工作原理。
这显然是一个正在进行中的工作,但已经有很多章节可供阅读,不过最后一章似乎现在已经延迟了几个月。不过,前几章对于掌握基础知识至关重要,强烈推荐。
 这是一本非常高质量的书,包含了更多高级技术和方法,目前仍在编辑/撰写中,预计将在今年晚些时候发布。你可以通过这个链接查看官方草稿(PDF),你会惊讶于有多少信息可以浏览!
这是一本非常高质量的书,包含了更多高级技术和方法,目前仍在编辑/撰写中,预计将在今年晚些时候发布。你可以通过这个链接查看官方草稿(PDF),你会惊讶于有多少信息可以浏览!
非常适合喜欢通过插图和大量真实例子学习的学习者。
我提到了像 Google 和 Apple 这样的大型公司,原因很简单:我们在各个领域都能看到数据挖掘和分析,而不仅仅是特定的科学和学科。
实际上,像 Google Analytics 这样的平台严重依赖于基于高质量数据科学知识构建的算法,广告公司也是如此,这是本白皮书/电子书讨论的主要话题。
 Jeffrey M. Stanton向我们简要介绍了数据科学,以及它本质上不仅仅是一系列与数据挖掘相关的任务。用他的话说,它更像是一种艺术形式,与许多行业互动,比一些人认为的要多。
Jeffrey M. Stanton向我们简要介绍了数据科学,以及它本质上不仅仅是一系列与数据挖掘相关的任务。用他的话说,它更像是一种艺术形式,与许多行业互动,比一些人认为的要多。
此外,数据科学远不仅仅是分析数据。许多人喜欢分析数据,可以整天研究直方图和平均值,但对于那些喜欢其他活动的人,数据科学提供了多种角色和所需的技能。让我们通过考虑一些购买谷物盒子时涉及的数据来深入了解这一观点。
海量数据挖掘
简而言之,这本书非常适合那些希望了解更多关于网络数据挖掘的人,它讨论了在设计网络和处理网络数据时最常见的问题。
这本书在每一章节末尾都会提供大量的示例和任务,并且是一本相当适合初学者的书;它要求你有一定的数据算法经验,掌握一些数学和数据库经验也不会有坏处。
数据学校手册
数据学校是一个很棒的地方,他们提供了针对所有水平的各种课程,这本手册非常适合作为他们课程材料的补充。我真正喜欢这本手册的是,它提供了大量的后续链接,方便项目创建。
一个很好的例子是指向那些之前建立了数据集的网站链接,对于那些希望了解更多关于数据及其工作原理的人至关重要!
高级文本挖掘的理论与应用
我们将用一本由九章组成的书来结束我们的免费数据挖掘和数据分析学习书籍列表,这本书的每一章几乎都是由不同的人编写的;但它们放在一起时显得非常有意义。
本书的主要重点是文本挖掘,以及网络技术的发展如何影响数据科学和整体分析。值得拥有的一本好书!
从免费书籍中学习数据科学
没有什么比从书籍中学习,然后将新获得的知识付诸实践更好的方法了,否则我们很容易忘记实际学到的内容。这是一本每个有志成为数据科学家的读者都应该注意并添加到学习资料清单中的美丽书单。
你读过哪些书以帮助你开始数据挖掘和分析的旅程?我相信社区会很乐意了解更多,我也很期待看看我可能错过了什么。
根据请求重新发布。原文:codecondo.com/9-free-books-for-learning-data-mining-data-analysis/。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
更多相关内容
9 门免费哈佛课程,助你从零开始学习数据科学
原文:
www.kdnuggets.com/2022/05/9-free-harvard-courses-learn-data-science-2022.html

图片由Danilo Rios拍摄,来源于Unsplash
上个月,我写了一篇关于如何利用MIT 提供的免费课程构建数据科学学习路线图的文章。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
然而,我列出的多数课程的重点是高度理论化的,且对学习机器学习算法背后的数学和统计学有很多强调。
尽管 MIT 的路线图将帮助你理解预测建模背后的原理,但缺乏的则是实际应用所学概念并执行真实数据科学项目的能力。
在网上花了一些时间后,我发现了一些哈佛提供的免费课程,涵盖了整个数据科学工作流程——从编程到数据分析、统计学和机器学习。
一旦你完成了这个学习路径中的所有课程,你还会获得一个综合项目,允许你将所学知识付诸实践。
在这篇文章中,我将列出 9 门你可以学习数据科学的免费哈佛课程。如果你已经掌握了某个主题,可以随意跳过相关课程。
第一步:编程
学习数据科学的第一步是学习编程。你可以选择用你喜欢的编程语言来做这件事——理想情况下是 Python 或 R。
如果你想学习 R 语言,哈佛提供了一门专为数据科学学习者设计的入门 R 课程,叫做数据科学:R 基础。
这个程序将带你了解 R 语言的概念,如变量、数据类型、向量运算和索引。你还将学习使用像 dplyr 这样的库来处理数据,并创建图表来可视化数据。
如果你更喜欢 Python,你可以选择参加由哈佛免费提供的 CS50 Python 编程入门 课程。在这门课程中,你将学习函数、参数、变量、数据类型、条件语句、循环、对象、方法等概念。
上述两个课程都是自定进度的。然而,Python 课程比 R 程序更详细,需要更长的时间来完成。此外,这个路线图中的其他课程都使用 R 教授,因此学习 R 可能会更有价值,以便能更轻松地跟上课程进度。
第 2 步:数据可视化
可视化是将数据发现传达给他人的最强大技术之一。
通过 哈佛的数据可视化 课程,你将学习使用 R 中的 ggplot2 库构建可视化图表,并掌握传达数据驱动见解的原则。
第 3 步:概率论
在 这门课程 中,你将学习进行数据统计测试所需的基本概率概念。所讲解的主题包括随机变量、独立性、蒙特卡罗模拟、期望值、标准误差和中心极限定理。
上述概念将通过案例研究进行介绍,这意味着你将能够将所学的知识应用于实际的真实世界数据集。
第 4 步:统计学
学习完概率论后,你可以参加 这门课程 来学习统计推断和建模的基础知识。
这个程序将教你定义人口估计和误差范围,介绍贝叶斯统计,并提供预测建模的基础知识。
第 5 步:生产力工具(可选)
我将这个 项目管理课程 作为可选内容包括在内,因为它与学习数据科学并不直接相关。而是教你使用 Unix/Linux 进行文件管理、Github、版本控制和在 R 中创建报告。
能够做到这些将节省你大量时间,并帮助你更好地管理端到端的数据科学项目。
第 6 步:数据预处理
该列表中的下一个课程是 数据处理,将教你如何准备数据并将其转换为机器学习模型容易处理的格式。
你将学习如何将数据导入 R、整理数据、处理字符串数据、解析 HTML、处理日期时间对象以及挖掘文本。
作为一名数据科学家,你经常需要提取以 PDF 文档、HTML 网页或 Tweet 形式公开在互联网上的数据。你不会总是获得干净、格式化的数据 CSV 文件或 Excel 表格。
到课程结束时,你将学会如何处理和清理数据,从中提取关键洞察。
第 7 步:线性回归
线性回归是一种机器学习技术,用于建模两个或更多变量之间的线性关系。它也可以用来识别和调整混杂变量的影响。
本课程将教你线性回归模型背后的理论,如何检查两个变量之间的关系,以及在构建机器学习算法之前如何检测和去除混杂变量。
第 8 步:机器学习
最后,你可能一直在等待的课程来了!哈佛的机器学习程序将教授你机器学习的基础知识、减轻过拟合的技术、监督学习和无监督学习建模方法以及推荐系统。
第 9 步:综合项目
完成所有上述课程后,你可以参加哈佛的数据科学综合项目,在这里你的数据可视化、概率、统计学、数据清洗、数据组织、回归分析和机器学习的技能将受到评估。
通过这个最终项目,你将有机会将从上述课程中学到的所有知识综合运用,并获得从头开始完成一个实际数据科学项目的能力。
注意:上述所有课程均在 edX 的在线学习平台上提供,并且可以免费旁听。如果你需要课程证书,则需要支付费用。
Natassha Selvaraj 是一位自学成才的数据科学家,热爱写作。你可以在LinkedIn上与她联系。
更多相关内容
9 种免费资源来掌握 Python
原文:
www.kdnuggets.com/2022/11/9-free-resources-master-python.html

编辑提供的图片
Python 被认为是最容易学习的高级通用 编程语言,可以帮助你构建可移植的跨平台应用程序。这,加上它的动态垃圾回收和简洁的代码,使它在人工智能相关应用中极具优势。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
但是,你如何从编写一个简单的“Hello World”应用程序过渡到使用 Python 进行更复杂的项目呢?以下指南将介绍九个资源,帮助你掌握 Python。
1. Invent with Python 的编程练习
InventWithPython.com 是一个由专业软件开发者 Al Sweigart 创建和维护的网站,他将大量时间投入到教人们编程上。Invent With Python 提供了一系列资源(主要以电子书形式)来帮助你开始用 Python 编程。然而,你应该对网站的 温和讲解的 Python 编程练习 最感兴趣。
掌握编程语言的最佳方式不是通过刻苦学习,而是通过实践;你必须使用编程语言才能真正学会它。Invent With Python 的《温和讲解的 Python 编程练习》适合初学者和中级程序员。它为每个练习中的问题提供简洁明了的解释,以帮助你提升到下一个 Python 熟练度层次。
2. Microsoft Visual Studio 2022(IDE)
正如任何工匠所言,你的水平与所使用的工具息息相关。虽然你可以使用 Python 默认的 IDE(IDLE)或类似 VS code 的文本编辑器,但功能齐全的 IDE 如 Visual Studio 2022 更适合构建高级 Python 应用程序。微软的 Visual Studio 被认为是最好的(如果不是最伟大的) IDE 之一。你可以轻松使用其内置的 pip 和 Pypl 支持来管理你的依赖项和库。
根据统计数据,部署一个简单的机器学习协议大约需要30 天。凭借 Visual Studio 的代码编辑工具,这个时间可以大大缩短。Visual Studio 具有工具提示、模板、自动完成和代码片段,使得处理和管理数据源变得更容易。
你无需外部工具来运行密集的单元测试——Visual Studio 2022 配备了广泛的测试工具。你可以调试、部署和维护远程测试环境,设置机器架构,并通过测试资源管理器跟踪所有内容。
Visual Studio 适合使用不同编程语言的多语言程序员。你只需下载每种语言所需的工作负载。Visual Studio 的社区版是免费的,应该足以满足大多数程序员的需求。不过,如果你想访问更多功能,可以下载专业版或企业版。
3. KDnuggets
虽然不想过于自夸,但 KDNuggets 是帮助你进一步提升 Python 开发技能的最佳资源之一。不论是让你与帮助你获得认证的课程联系,还是提供便于学习的备忘单,KDNuggets 可能成为你工具箱中最有用的武器之一。
我们还没有讨论博客。博客内容包括机器学习、编码、数据科学,以及由经验丰富的行业专业人士撰写和编辑的 Python 内容。
KDNuggets 适合各个级别的程序员和数据科学家。无论你是想要加速你的 Python 代码、掌握 Python 机器学习,还是为面试做准备,KDNuggets 都提供了适合这些场景的内容。
4. PyVideo
YouTube 无疑是学习编程的最佳场所之一。像 Pretty Printed、The Underdog 和 sentDex(额外的免费资源)这样的频道不仅教你编程,还教你如何作为开发者应对挑战。
YouTube 并不是唯一一个托管免费 Python 相关媒体的视频分享网站。编程相关的视频内容也可以在 Dailymotion、Vimeo、Facebook 等网站上找到。一些网站和服务更喜欢自行托管媒体,因此跟踪最佳内容可能会很困难。
这时,像 PyVideo 这样的工具派上用场了。它在互联网上找到并索引了所有最新的与 Python 事件相关的视频。你可以根据特定事件、语言、标签、讲者等查看内容。
PyVideo 让你可以了解 Python 的最新进展,来自一些业内最受尊敬的贡献者和程序员。这可能最终会激励你参加一些 Python 会议和活动,亲身体验一切。
5. Awesome Python
Awesome Python 是一个经过精心策划的 GitHub 上一些最佳 Python 框架、库和其他资源的列表。从音频处理库到加密学,它几乎包含了帮助你完成下一个 Python 项目的所有包。
6. TheAlgorithms
算法和数据结构推动数据科学的发展。即使作为一名自学的开发者,你也必须了解基本的算法(以及一些数学知识)。与 Awesome Python 类似,TheAlgorithms 是一个 GitHub 开源库,包含你可以插入到项目中的算法。
你应该注意到 TheAlgorithms 不仅包含 Python 算法库,还有 Java、JavaScript、Julia、R 等语言的算法。
7. Google’s Python Class
如果你是一个初学者,寻找一个能够适应你学习风格的沉浸式 Python 学习体验,不妨看看 Google 的 Python 课程。在过去十年中,Google 在计算机科学教育方面投入了大量时间和精力。Google 的 Python 课程包含讲座和教程视频、书面材料,以及许多练习和测试。该课程面向那些几乎没有编码经验的人,因此极其易于访问。
8. Programiz
Programiz 非常适合那些寻找 Google Python 课程替代方案的人。它提供了丰富的 Python(和其他编程语言)的学习工具。和 Google 类似,该网站采用多方面的方法来教你如何编码。
每个课程都像一本互动教材。每章都配有视频、各种书面说明、示例,以及一些你可以使用 Programiz 在线编译器自行运行的代码。然而,如果你对课程的结构不满意,Programiz 提供了一组标签,让你可以自己查看示例、参考资料和编译器。许多人发现编译器最有用,因为你可以快速运行和测试代码。
虽然 Programiz 是免费的,但它确实提供了一个 pro 版本,具有更多功能,包括课程结束时的专业证书。
9. Python Podcasts
音频媒体的最佳之处在于你可以在做其他事情时进行听取(即,锻炼、驾驶、做家务等)。有很多出色的编程和数据科学相关的播客对 Python 初学者非常有帮助。一些值得注意的包括:
-
The Real Python Podcast:这是一个每周播出的播客,由主持人 Christopher Bialy 于 2012 年创办。它涵盖了各种 Python 话题,包括职业和编程技巧。此外,播客还包括轻松的对话和采访,邀请了行业专家、有经验的程序员等。Real Python Podcast 网站的一个最佳功能是它提供了额外的资源,帮助你学习或提升你的 Python 开发技能。
-
Talk Python to Me:这是一个由 Michael Kennedy 主持的稍微休闲一点的每周播客。虽然节目多年来已经涵盖了许多 Python 话题,但它最初是一个采访行业专业人士关于 Python 编程现状的平台。收听 Talk Python to Me 是跟上 Python 所有最新发展的绝佳方式。该网站还包括有用的资源,如商品、课程和证书。
-
Python Bytes:如果你正在寻找一种更简洁的收听体验,你应该考虑这个播客。它由 Michael Kennedy(也是《Talk Python To Me》的主持人)和 Brian Okken 主持。这个播客的目的是在每集不到一个小时的时间内,更新你关于 Python 的最新头条和新闻。
结论
十年前,我们希望 Java 能带我们进入下一个层次。现在,Python 已经超越了许多编程语言,成为全球最受欢迎的语言。
Python 不是一种新语言;它自 90 年代初就存在,通过不断改进和获得开发者的支持而发展起来。但如果没有 Python 开发者和爱好者的在线社区,Python 不会有今天的成就。多亏了他们,我们拥有了学习和掌握 Python 的资源。一旦你也掌握了 Python,不要忘记回馈社区。
Nahla Davies 是一位软件开发人员和技术作家。在全职从事技术写作之前,她曾担任过许多令人兴奋的职位,其中包括在一家 Inc. 5000 的体验品牌机构担任首席程序员,该机构的客户包括三星、时代华纳、Netflix 和索尼。
更多相关话题
学习 Python 进行金融编程的 9 个杰出理由
原文:
www.kdnuggets.com/2021/09/9-outstanding-reasons-learn-python-finance.html
评论
由Zulie Rane,自由撰稿人和编程爱好者

如果你考虑进入金融行业并且偶然发现了这篇文章,你可能会想,“Python 如何在金融领域发挥作用?”
和我一样,你可能会惊讶地发现你应该完全学习编程——更令人惊讶的是,金融领域最佳的编程语言竟然是流行的数据科学语言 Python。使用 Python 进行金融编程正在成为一种要求。
金融和银行业因其高薪而闻名,因此吸引了大量申请者。如果你是其中之一,你应该知道 Python 在金融领域非常受欢迎——而且还在不断增长。Python 广泛应用于风险管理、交易机器人创建、用于分析大数据的量化金融等领域。
这里有九个答案来解答“我应该学习 Python 用于金融吗?”
1. 快速、简单且清晰
如果你读过任何其他编程列表文章,你会知道 Python 在一般情况下的优势,所以我会节省你的时间,把这些理由浓缩成一个要点:Python 对于初学者和有经验的编码者来说学习都很快。它的语法清晰简洁,易于阅读。部署迅速——你可以用几行代码构建有效的代码。
学习 Python 用于金融是个好主意,因为这与 Python 在其他领域的优势相同。如果你想用 Python 分析金融数据,你会高兴地发现,入门非常简单。
2. 已经存在快捷方式
Python 作为一种语言,通过库得到增强,即那些已经为你构建的可重用代码块。除了容易上手外,还有一个强大的开源第三方库框架,这些库在各种情况下都很有用,但特别是在金融领域。
像 Scikit 和 Pybrain 这样的库在金融领域尤其有用。有些人认为 Python 的金融库已经是“快捷方式”,因为你不需要从头编写那些功能。我同意这个观点。使用这些库进行金融数据分析要快得多。
Scipy、NumPy、Matplotlib 以及其他一系列附加工具使得执行和可视化金融计算和算法比以往任何时候都要容易。重要的是,这些工具不仅帮助你处理数据,还能更轻松地将结果传达给关键决策者。
3. 资源丰富
Python 在金融领域的一个真正的好处是,尽管这是语言的相对新用法,但已经有大量资源可以帮助你入门并顺利进行。这是因为 Python 已经使用了几十年。许多使 Python 在数据科学领域表现出色的资源也可以提升你的金融体验。
除了开源库,还有整套Python 课程和教科书以及教程,专门帮助你掌握 Python 在金融领域的基础知识。
如果你想学习金融领域的 Python,你不需要依赖于通用课程和教程——有很多内容专门围绕如何在金融背景下学习 Python 展开。
4. 极好的社区
如果图书馆、教科书和教程对你来说还不够找准 Python 在金融领域的入门方法,那么整个 Python 爱好者社区将是一个巨大帮助。你可能会很高兴地发现,专门针对金融领域的 Python 爱好者的社区也是存在的。
如果你对如何学习金融领域的 Python 感到困惑,不必再担心。你可以找到专门针对金融 Python 教程的Github 项目,Slack 群组专注于金融和编码,r/learnpython 子版块中的活跃金融群体,当然,StackOverflow 上也有许多乐于助人的人,他们曾经与你有过相同的经历,并愿意帮助你解决与金融相关的 Python 问题。
虽然我发现 Python 爱好者通常都是友好、乐于助人、充满热情的群体,但看起来金融领域的 Python 社区也是如此。
5. 它就是 MVP
尽管我认为 Python 是最具价值的编程语言(如果编程语言像体育联赛那样存在的话),但在这一部分我讨论的是最小可行产品(MVP)。金融行业重视敏捷性和响应能力,因为它面向客户。
在金融领域,程序员应该能够快速创建一个可以测试的原型。公司可以使用 MVP 来确定市场适应性,并以此将创意推向实施。Python 是快速创建 MVP 进行测试的理想语言。
如果你的金融公司是初创公司,Python 很有价值,因为它帮助开发人员快速而灵活地创建产品而不浪费资源。如果它是一个成熟的公司,Python 的价值在于它提高了敏捷性并鼓励创新,这对于规模更大、发展较慢的公司至关重要。无论哪种情况,它都是你团队的一个好工具。
总而言之,Python 让金融程序员能够构建一个最小可行产品,并从中迭代。
6. 两个世界之间的桥梁
Python 更为数据科学所知,但它也是经济学与数据科学(也称为金融领域)之间的绝佳桥梁。
引用一位专家的话,“将经济学家的工作整合到基于 Python 的平台中要容易得多。像 SciPy、NumPy 或 Matplotlib 这样的工具允许人们进行复杂的金融计算,并以非常易于理解的方式展示结果,” 说 Jakub Protasiewicz,一位拥有十多年 IT 经验的工程经理。
经济学家们因为 Python 的简洁性和更平缓的学习曲线而用它进行经济分析。
7. 你在一个好公司
Python 得到了主要金融公司的高度认可。很多金融公司都建立在 Python 上,比如 Venmo、Stripe 和 Robinhood,这些公司与我在本文中向金融从业者推荐 Python 的原因大致相同。
除了将 Python 用作金融公司框架外,一些组织更进一步: 花旗银行提供 Python 编程课程给银行分析师和交易员,以便他们能利用 Python 的惊人数据科学工具集。
如果你想学习用于金融的 Python 编程,你应该清楚你并不孤单:很多公司也做了同样的事情。
8. 今天在这里,明天依然在这里
没有什么比花时间学习一种编程语言然后发现它正在变得过时或被新兴语言取代更糟糕的了。
在金融领域,你不会遇到这种问题。Python 已经存在了三十年;许多金融公司已经投资于用 Python 构建基础设施和长期项目,更有意义的是,每年都有新的 Python 金融应用出现,例如第九节中你将学习的针对加密货币的 Dash。
Python 在十年或二十年后仍将对金融分析有用。使用 Python 进行金融分析是一个安全的选择。
9. Python 加密货币
使用 Python 在金融领域能做什么?深入探索加密货币。我惊讶地发现 Python 正在成为加密货币领域的关键角色。我在 libraries.io(一个列出所有 Python 库的网站)上快速查看了一下,发现了 327 个包涉及加密货币和区块链。
Dash、Anaconda 和 CryptoSignal 等产品充分利用了 Python 在获取和分析加密货币定价方面的便利。如果你投资于加密货币领域,Python 对你来说是必不可少的。
Python 与金融天作之合
Python 在金融领域有多重要?我敢说,它是一个关键的学习语言。仅仅依赖于为金融公司和职位开发的现有 Python 产品已经不够——员工越来越需要在日常使用中掌握 Python。
Python 在金融领域的应用几乎是无限的,我预计随着时间的推移和更多金融工作者学习 Python,这个数字只会增加。如果你还不确定 Python 是否适用于金融,希望这篇文章已经为你澄清了答案。
想为未来的金融角色学习 Python?
如果你想开始学习 Python,我们创建了我们的Python 基础课程,帮助你从新手到中级水平,准备接受更高级的主题,如金融数据的数据科学。
如果你更高级,我们还提供大 O 数据结构和高级算法课程,通过互动编码挑战学习关键计算机科学概念,将你新获得的技能付诸实践。
简历:Zulie Rane 是一位自由撰稿人和编程爱好者。
原文。经许可转载。
相关:
-
15 个必知的 Python 字符串方法
-
2021 年招聘数据科学家的顶级行业
-
主要变化:2020/21 年分析、数据科学、机器学习的应用
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
更多相关话题
9 个专业证书可以让你进入学位课程…如果你真的想要的话
原文:
www.kdnuggets.com/9-professional-certificates-that-can-take-you-onto-a-degree-if-you-really-want-to

作者 | Canva 图片
当你考虑开始新的职业或提升技能时,实际上没有必要立即跳到大学,或者说实话,根本不需要。在这个数字世界里,有这么多在线程序、训练营、认证和课程可以帮助你在没有过高费用的情况下开始。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
对于那些想要提升技能而不想支付学费的人,这篇博客适合你。我将介绍 9 个专业证书,你可以通过这些证书迅速入门,或者继续学习这些证书,提升到下一个级别并获得学位。
IBM 数据工程
链接:IBM 数据工程
时长:6 个月,每周 10 小时
级别:初学者
从初学者到专家的完整课程。由 IBM 提供的这门数据工程课程是一个专业证书,共包含 16 个系列。在本课程中,你将学习数据工程师在日常工作中使用的最新实用技能和知识。然后你将深入学习创建、设计和管理关系数据库,并将数据库管理(DBA)概念应用于 MySQL、PostgreSQL 和 IBM Db2 等关系数据库管理系统(RDBMS)。
随着时间的推移,你将通过使用 MongoDB、Cassandra、Cloudant、Hadoop、Apache Spark、Spark SQL、Spark ML 和 Spark Streaming,掌握 NoSQL 和大数据的工作知识。课程结束时,你将能够使用 Bash、Airflow 和 Kafka 实施 ETL 和数据管道;架构、填充和部署数据仓库;并创建 BI 报告和互动仪表盘。
该项目获得了 ACE® 的推荐——完成后,你可以获得最多 12 学分。
IBM 数据科学
链接:IBM 数据科学
时长:6 个月,每周 10 小时
级别:初学者
这个 IBM 数据科学专业证书课程通过 Coursera 提供,旨在教导初学者数据科学是什么以及如何像数据科学家一样思考和工作。你将学习掌握最前沿的实用技能,了解专业数据科学家使用的工具、语言和库,包括 Python 和 SQL。
你还将学习导入和清理数据集的基础知识,分析和可视化数据,然后使用 Python 构建和评估机器学习模型和管道。最后,将你的新技能应用于现实世界项目,并建立一个数据项目的作品集,向雇主展示你的熟练程度。
本项目获得 ACE® 和 FIBAA 推荐——完成后,你可以获得最多 12 学分和 6 ECTS 学分。
IBM 全栈软件开发人员
链接:IBM 全栈软件开发人员
时长:5 个月,每周 10 小时
级别:初学者
开始你的旅程,为高增长的软件开发领域的职业做好准备。在本项目中,你将学习前端、后端和云原生应用程序开发所需的技能和工具。
你将学习如何构建、部署、测试、运行和管理全栈云原生应用程序。涵盖的技术包括云基础、GitHub、Node.js、React、CI/CD、容器、Docker、Kubernetes、OpenShift、Istio、数据库、NoSQL、Django ORM、Bootstrap、应用安全、微服务、无服务器计算等。
本项目获得 ACE® 和 FIBAA 推荐——完成后,你可以获得最多 18 学分和 6 ECTS 学分。
IBM 数据分析师
链接:IBM 数据分析师
时长:5 个月,每周 10 小时
级别:初学者
由 IBM 提供的本课程将提供数据分析的核心原理,并更好地理解数据处理、分析技术等。课程包括 8 门课程,如数据分析简介、Excel 数据分析基础、使用 Excel 和 Cognos 进行数据可视化和仪表板、数据科学 Python、人工智能与开发、数据科学 Python 项目、Python 数据科学的数据库和 SQL、Python 数据分析、Python 数据可视化,以及 IBM 数据分析师顶点项目。
这些课程将通过提供数据分析的原理和基础知识,帮助你启动数据分析师的职业生涯,同时掌握实际技能。你还将获得项目经验和数据分析工具,如 SQL、Python 和 Jupyter Notebooks,帮助你了解数据分析师的日常工作。
本项目获得 ACE® 和 FIBAA 推荐——完成后,你可以获得最多 12 学分和 6 ECTS 学分。
机器学习专业化
时长:2 个月,每周 10 小时
级别:初学者
在 AI 远见者 Andrew Ng 提供的适合初学者的三课程项目中,掌握基本的 AI 概念并发展实际的机器学习技能。该项目将教你机器学习的基础知识,以及如何运用这些技术构建现实世界中的 AI 应用程序。
你将学习如何使用 NumPy 和 scikit-learn 构建机器学习模型,构建和训练用于预测和二分类任务的监督模型。你还将学习如何使用 TensorFlow 构建和训练神经网络,以执行多类别分类,并构建和使用决策树及树集成方法。
当你完成这个专项课程时,如果你被录取并注册以下在线学位项目,你可以获得大学学分。
IBM AI Developer
时长:6 个月,每周 4 小时
级别:初学者
正如我们所知,AI 和生成性 AI 正在彻底改变我们的世界,这意味着对具备前沿技能的 AI 软件开发者的需求正在飙升。这个 IBM AI Developer Professional Certificate 将为你提供构建 AI 驱动的聊天机器人和应用程序所需的热门专业知识,并使你在短短 6 个月内启动你的 AI 职业生涯。
AI 开发者是被高度重视的软件工程师,他们设计、开发和实施 AI 和生成 AI 驱动的应用程序和虚拟助手。在这个课程中,你将掌握软件工程、AI、生成 AI、提示工程、HTML、JavaScript 和 Python 编程的基础知识。通过动手实验和项目,你将获得在面试中可以谈论的实际经验。
当你完成这个专业证书时,如果你被录取并注册以下在线学位项目,你可以获得大学学分。
Google Data Analytics
时长:6 个月,每周 10 小时
级别:初学者
一个非常受欢迎的课程,Google 的数据分析专业认证使你能够理解助理数据分析师使用的实践和过程。随着越来越多的组织将其操作和数据转移到云端,理解云计算及其对数据的访问的重要性成为一个高需求的技能。
你将学习关键的分析技能,如数据清理、分析和可视化,以及使用电子表格、SQL、R 编程和 Tableau 等工具。运用这些技能,你将学习如何在仪表盘、演示文稿和常用可视化平台中可视化和展示数据发现。
这个专业证书有 ACE® 推荐。它在参与的美国学院和大学中有资格获得大学学分。
Google IT Support
时长:6 个月,每周 10 小时
级别:初学者
技术行业内容丰富。它就像从头开始建造一座房子,每个承包商都负责确保不同的层面始终达到基于其专业知识的金标准。这就是 IT 支持发挥作用的地方。
在这个 Google IT 支持专业认证中,你将学习 IT 支持处理的日常任务,包括计算机组装、无线网络、安装和客户服务。你还将学习如何识别问题,以使用如 Linux、域名系统、命令行接口和二进制代码等工具进行故障排除和调试。
这个专业证书获得了 ACE®的推荐。它在参与的美国大学和学院中可以获得大学学分。
Google 项目管理
链接:Google 项目管理
时长:6 个月,每周 10 小时
级别:初学者
技术行业发展迅速,每天都有新项目发布。在这里,我介绍了项目管理及其在任何行业中的重要性。如果没有项目管理,许多新工具将无法部署,使我们无法使用它们。
项目管理是将过程、方法、技能、知识和经验应用于实现特定目标的过程,以确保项目的成功。在这个 Google 项目管理专业认证中,你将学习如何有效地记录项目,学习敏捷项目管理、Scrum 的基础知识,并且练习战略沟通,提升你的问题解决能力。
这个专业证书获得了 ACE®的推荐。它在参与的美国大学和学院中可以获得大学学分。
总结
你可以选择 9 个不同的专业课程来入门,并在 5 到 6 个月内准备好就业。这些专业课程高度可信,许多人完成课程后直接进入行业。如果你想继续深造,将学习提升到下一个层次,可以通过这 9 个课程来实现。
Nisha Arya是一位数据科学家、自由技术作家、KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及数据科学的理论知识。Nisha 涵盖了广泛的主题,希望探索人工智能如何有利于人类寿命的不同方式。作为一个热衷于学习的人,Nisha 希望拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
9 件您应该知道的关于 TensorFlow 的事
评论
今天早上,我总结了我在旧金山 Google Cloud Next 上享受的一场讲座中的一些最爱内容——TensorFlow 有什么新变化?
然后我考虑了一下,没发现不与您分享我这个超短总结的理由(除了您可能不会看这个视频——您绝对应该去看看,演讲者非常棒),所以就这样吧……

#1 它是一个强大的机器学习框架
TensorFlow 是一个机器学习框架,如果您有大量数据和/或追求 AI 的最前沿技术,它可能是您的新好朋友:深度学习。神经网络,大型的。它不是数据科学的瑞士军刀,而是工业车床… 这意味着如果您只是想在 20x2 的电子表格中绘制回归线,您可以停止阅读。
但如果您追求的是“大”,那就值得兴奋了。TensorFlow 已被用于寻找新行星、通过帮助医生筛查糖尿病视网膜病变,以及通过提醒当局非法砍伐活动来帮助保护森林。它是AlphaGo和Google Cloud Vision的基础,您可以使用它。TensorFlow 是开源的,您可以免费下载并立即开始使用。

通过 TensorFlow 的帮助发现,开普勒-90i 使开普勒-90 系统成为我们已知的唯一一个拥有八颗行星围绕一颗恒星运行的系统。尚未发现有超过八颗行星的系统,所以我想这意味着我们与开普勒-90 系统并列第一(暂时如此)。了解更多请点击这里。
#2 异常的方法是可选的
我对TensorFlow Eager情有独钟。
如果你曾经尝试过 TensorFlow 而因为它让你像学术/外星人一样编码而吓得逃跑了,那就回来吧!
TensorFlow 的即时执行让你像纯 Python 程序员一样与之互动:写代码和调试的即时性,代替了构建那些庞大图形时的屏息以待。我自己也是一名恢复中的学术者(可能还是外星人),但自从即时执行推出以来,我就爱上了它。如此渴望取悦!

#3 你可以逐行构建神经网络
Keras + TensorFlow = 更简单的神经网络构建!
Keras 专注于用户友好性和简单原型制作,而这些是旧版 TensorFlow 非常渴望的。如果你喜欢面向对象的思维,并且喜欢逐层构建神经网络,你会喜欢 tf.keras。在下面的几行代码中,我们创建了一个具有标准功能(如 dropout)的顺序神经网络(稍后提醒我用我的隐喻来详细描述 dropout,它们涉及订书机和流感)。

哦,你喜欢谜题,对吗?耐心点。别对订书机想得太多。
#4 不仅仅是 Python
好消息!你已经抱怨了 TensorFlow 对 Python 的单一痴迷一段时间了。好消息是!TensorFlow 不再只是 Python 爱好者的专属了。现在它可以在多种语言中运行,从 R 到 Swift,再到 JavaScript。

#5 你可以在浏览器中完成一切
说到 JavaScript,你可以在浏览器中使用 TensorFlow.js 训练和执行模型。去 这些酷炫的演示 好好体验一下,当你回来时我还在这里等你。

实时 人体姿态估计 使用 TensorFlow.js 在浏览器中实现。可以通过 这里 打开你的相机进行演示。或者不用离开你的椅子。 ¯_(ツ)_/¯ 随你选择。
#6 小型设备有一个 Lite 版本
有个来自博物馆的老旧桌面电脑?烤面包机?(一样的东西?)TensorFlow Lite 将模型执行带到了各种设备,包括移动设备和物联网设备,使你在推理速度上获得超过原始 TensorFlow 的三倍提升。是的,现在你可以在你的 Raspberry Pi 或手机上进行机器学习了。在 这场演讲中,Laurence 勇敢地在成千上万观众面前实时演示了在 Android 模拟器上进行图像分类……并且成功了。
计算 1.6 秒?检查!香蕉的概率超过 97%?检查!卫生纸?嗯,我去过几个国家,像 Laurence 手中那张纸也算数。
#7 专用硬件变得更好
如果你厌倦了等待 CPU 处理数据以训练神经网络,现在你可以使用专门为此设计的硬件——Cloud TPUs。T 代表张量。就像 TensorFlow……巧合吗?我不这么认为!几周前,谷歌宣布了第 3 版 TPUs 的 Alpha 版。

#8 新的数据管道有了很大改进
你在那边用numpy 做什么呢?如果你想在 TensorFlow 中完成这个任务但结果愤怒退出,tf.data命名空间现在让你在 TensorFlow 中的输入处理更具表现力和效率。tf.data提供了快速、灵活且易于使用的与训练同步的数据管道。
#9 你不需要从头开始
你知道什么不是一个有趣的机器学习入门方式吗?在编辑器中一页空白的新文件,没有示例代码可用。有了 TensorFlow Hub,你可以以更高效的方式继承他人的代码并称之为自己的(也就是职业软件工程)。
TensorFlow Hub 是一个用于重用预训练机器学习模型组件的库,打包成一行代码即可重用。随意使用!
既然我们在谈论社区和不再孤军奋战,你可能会喜欢知道 TensorFlow 刚刚拥有了官方的YouTube 频道和博客。
这就是我的总结,所以接下来可以看完整的演讲视频来娱乐接下来的 42 分钟。
原文。经授权转载。
相关:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
9 个顶尖平台,练习关键的数据科学技能
原文:
www.kdnuggets.com/2023/03/9-top-platforms-practice-key-data-science-skills.html

现在在线学习的好处在于,学习不再受限。你可以在自己家中舒适地阅读、练习、测验和编程,而无需支付学位费用。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
由于数据科学被视为一种难以学习的技能,许多雇主并不关心你是在哪里学习 Python 或其他数据科学技能的,只要你能够胜任。
在本文中,我将详细介绍九个数据科学学习平台,这些平台提供互动学习体验。它们配备了各种资源,包括视频教程、互动编码练习和测验,帮助你建立和巩固编程和数据库管理技能。
让我们深入探讨。在每一部分,我会解释平台的特点、你可以学习的内容、费用以及它与其他八个平台的不同之处。
这里是每个平台的概览,供快速参考。
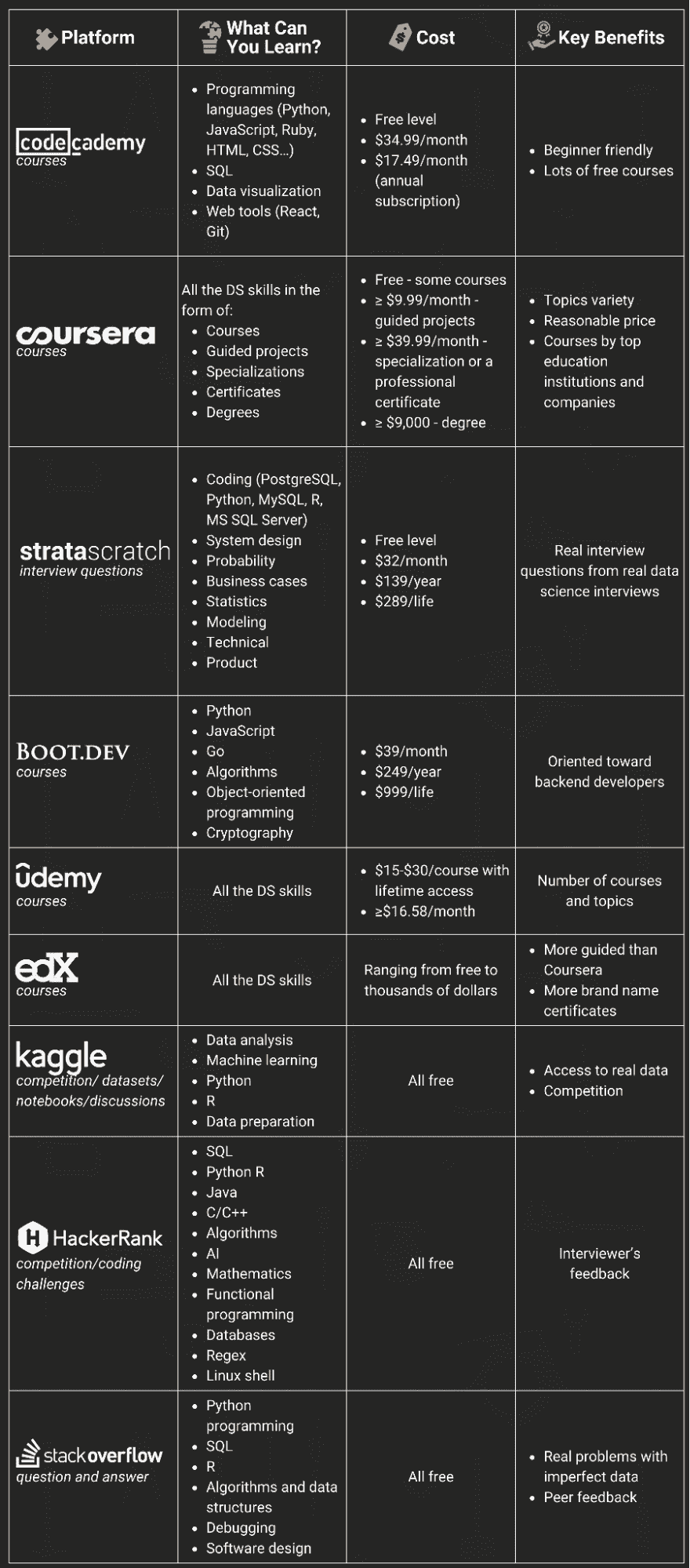
1. Codecademy
Codecademy是一个专为学习编程而设计的平台。
这是什么?
Codecademy 是一个在线学习平台,提供编程、数据科学和网页开发的课程和教程。它是初学者和希望提高编码技能的人的超级热门选择。
你可以学到什么?
在 Codecademy,你可以学习多种编程语言,如 Python、JavaScript、Ruby、HTML、CSS 等。不论你喜欢什么,你都能找到相关的课程。Codecademy 还提供数据科学主题的课程,如 SQL 和数据可视化,以及网页开发工具,如 React 和 Git。
我个人喜欢 Codecademy,因为它非常互动。这个平台提供课程和编码练习,帮助你构建真实项目并理解编程的基本概念。
费用多少?
在他们的网站上,他们的标语是“免费学习编码”。确实有一个免费层级,你可以免费获得像“学习 SQL”和“学习 Java: 入门”这样的课程。
然而,如果你想进一步提升知识并访问更高级的课程,你需要支付$34.99/月,或者如果你按年支付,则为$17.49/月。
主要优点?
Codecademy 之所以突出,是因为其易用性。它对初学者非常友好。许多编码平台自称对初学者友好,因为这是他们的目标受众,但 Codecademy 对那些从未输入过一行代码的人来说是完美的。
有很多免费的课程可以尝试,以了解这些语言和它们的教学风格是否适合你。
2. Coursera

图片来自 canva
Coursera是一个大学和公司上传视频课程的平台。在其他主题之外,他们有许多受欢迎的数据科学讲师。
这是什么?
Coursera 是由大学运营的在线学习平台。他们提供在线课程、可以挂在你虚拟 LinkedIn 墙上的证书,甚至还有完整的学位项目。他们与密歇根大学、耶鲁大学、莱斯大学、伦敦帝国学院等大学合作,还与更多大学合作。
课程通常持续一到九个月。
你可以学到什么?
在 Coursera 上,你可以学习几乎任何技能,包括课程如“幸福科学”、“心理学导论”和“金融市场”。
他们还提供:
-
指导项目。这些是更实际的、较短的课程,你将获得特定的技能。
-
专业化课程,通常是进一步学习某一技能,如西北大学的“销售艺术”。
-
证书。这些提供了你在所选技能领域的“认证”这一 tangible outcome。
-
学位。这些是完整的学位课程。
费用多少?
一些课程是免费的,例如我上面列出的前三门课程。一些指导项目,例如“绝对初学者的 Docker”,起价为$9.99/月。如果你报名参加更有用的课程,如专业化或职业证书,这些课程的费用为$39.99/月。学位课程自然更贵——学位课程的起价为$9,000。
主要优点?
Coursera 提供了种类繁多的课程,价格相当合理,由耶鲁大学和 IBM 等顶级机构提供。你可以获得实用技能,对广泛主题有一个基础了解,或通过专业化深入学习。
3. StrataScratch
StrataScratch 是一个面试问题平台。
这是什么?
StrataScratch 提供了 1000 多个来自 顶级数据科学公司 的真实面试问题,涵盖编码和非编码问题。它针对的是准备申请数据科学职位的人员。
你可以学到什么?
这是一个更具实践性、结果导向的平台。与其从零开始教你新技能,这个平台更适合那些已有一定知识并想测试自己或准备即将到来的面试的人。
在编码方面,你可以练习 PostgreSQL、Python、MySQL、R 和 MS SQL Server 问题。在非编码问题方面,你可以练习系统设计、概率、商业案例、统计、建模、技术和产品问题。
你还可以按难度和公司进行筛选。
StrataScratch 还提供数据项目,如 都柏林市场分析,以及指南,例如 SQL 时间和日期操作。如果你想将这些添加到你的投资组合中,这些更实操的项目会很有用。
费用是多少?
有一个免费层级,包括一些但不是所有的问题,有的有解答,有的没有。
对于 $32/月的层级,你可以访问所有面试问题和解决方案。
最后,有一个年付选项,费用为 $139/年(或终身 $289),此外还包括访问数据项目和深入解决各种针对数据科学家的编码问题的指南。
关键好处?
因为这些是从真实数据科学面试中提取的真实问题,你将获得与公司所寻找的内容完全一致的实践经验。
4. Boot.dev
Boot.dev 提供帮助你成为后台开发者的课程。
这是什么?
Boot.dev 是一个有趣的平台,旨在弥补大学学位和电子学习平台之间的差距。大学学位既慢又昂贵。像 Coursera 这样的地方专注于前端。如果你想练习 Python、SQL 和其他编码技能以获得后台开发职位,你会遇到困难。
他们将平台组织为“轨道”,包括语言、指导项目和投资组合项目。
你可以学到什么?
你可以学习 Python、JavaScript 和 Go 作为主要的后台编码语言。但你也将学习更多计算机科学相关的技能和概念,如算法、面向对象编程和密码学。
费用是多少?
Boot.dev 的费用为每月 $39、每年 $249 或终身 $999。所有这些层级都提供相同的福利:访问所有内容、一个可用于求职的编程项目组合、完成证书和访问 Discord 服务器。
主要好处是什么?
很少有地方提供帮助你成为 后端开发者与前端开发者 的学习内容。也许因为前端开发被认为更容易接触,大多数在线学习平台集中在 HTML 和 CSS 等技能上。
这是我见过的为后端学习者提供支持的少数平台之一。
5. Udemy
Udemy 是一个在线学习平台,任何人都可以上传课程。
这是什么?
Udemy 类似于 Coursera,但有一个关键区别:任何人都可以上传视频课程,而不仅仅是大学或组织。像 Coursera 一样,Udemy 也可以让你访问大量各种技能的课程,但在数据科学技能方面有很好的选择。
这意味着 Udemy 提供了从初级到高级的广泛课程,由专家、专业人士和个人讲授。
Udemy 的课程旨在提供可访问性和灵活性,配有视频课程、测验和项目,帮助学生建立实用技能。该平台还提供课程内容的终身访问权限,以便学生可以按自己的节奏学习,并在需要时重新学习材料。Udemy 的课程没有认证,但许多课程附带完成证书,可以用于向潜在雇主展示技能和知识。
你可以学习什么?
更好的问题是,你不能学习什么?不过这里有一些最佳课程的快速总结:
-
编程与开发:包括网络开发、移动应用开发、游戏开发等。
-
数据科学与分析:包括机器学习、数据分析、大数据等。
-
商业:包括创业、市场营销、销售等。
-
设计:包括图形设计、网页设计、室内设计等。
-
个人发展:包括个人财务、生产力、领导力等。
-
IT 与软件:包括网络安全、信息安全、云计算等。
-
市场营销与销售:包括数字营销、电子邮件营销、社交媒体营销等。
-
音乐、艺术与摄影:包括音乐制作、音乐理论、摄影等。
费用是多少?
你有两个选择:
-
你可以购买单独的课程,如“学习 Python 进行数据分析和可视化”,这些课程的价格在 $15 到 $30 之间,获得课程的终身访问权限。
-
你可以订阅每月 $16.58 起的个人计划,这样你可以访问超过 8,000 门课程,以及 4,000+ 个练习,由 3,000+ 名顶级讲师授课。
主要好处是什么?
Udemy 的巨大广度是它的优势。你可以找到不仅仅是任何语言的课程,还可以找到任何目的的课程,如“面向对象编程的 Python”或“React 完全指南”。
由于任何人都可以上传课程,你肯定能找到一个与你契合的讲师。
6. edX

图片来源于canva
edX类似于 Coursera 的终极版。edX 与多个著名大学合作,包括哈佛大学、麻省理工学院和加州大学伯克利分校。
这是什么?
与 Coursera 类似,edX 提供来自顶级大学和机构的在线课程。然而,edX 在合作伙伴和提供的技能方面稍有不同。例如,edX 提供验证证书、专业证书和微硕士课程,而 Coursera 仅提供专业化、专业证书和学位。
Coursera 也更具自我节奏,而 edX 则有考试和作业的截止日期。
你能学到什么?
在 3,000 多个课程中,你将能够找到一个好的数据科学技能来学习。该平台提供了“分析建模入门”、“使用 Python 进行机器学习”和“数据素养基础”等课程。
费用是多少?
这因课程而异,但一般来说,edX 比 Coursera 稍贵。你几乎可以免费访问任何课程进行审计,但这有一些限制——你只能访问一个月的材料,你不会获得证书,而且你的作业不会被评分。
如果你需要验证课程,价格从每门课程大约 49 美元到 149 美元不等。
他们还提供价格高达数千美元的训练营。例如,加州大学伯克利分校的 24 周编码训练营费用为 13,000 美元。
关键好处是什么?
这个平台与 Coursera 相当。主要的好处是它比 Coursera 更具指导性,你可能还能通过他们的证书获得更多品牌认可。
7. Kaggle
让我们暂时离开学习平台。 Kaggle是一个竞赛平台。
这是什么?
Kaggle 是一个非常受欢迎且运作良好的数据科学竞赛平台,特别倾向于机器学习。它由 Google 拥有,拥有成千上万的数据集供你练习。
你将获得:
-
竞赛中,参与者竞相使用提供的数据集开发最佳解决方案。竞赛由寻求解决特定问题的组织赞助,并向获胜者提供奖金。
-
公共数据集:Kaggle 提供了大量公共数据集,供实践、研究或比赛提交使用。
-
笔记本:Kaggle 提供了一个基于云的 Jupyter 笔记本环境,适用于数据科学和机器学习,允许用户轻松编写、运行和与他人共享代码。
-
讨论:Kaggle 拥有一个庞大而活跃的数据科学家和机器学习从业者社区,参与讨论、提问和回答问题,并合作进行项目。
你能学到什么?
在 Kaggle 上,你可以学习数据分析、机器学习、Python 和 R 编程以及数据准备等技能。
查看一些提供的竞赛,看看你想要提升哪些技能。例如,你可以参加 高级回归技术 挑战、微型企业密度预测 或 计算机视觉 竞赛。
费用是多少?
完全免费!参加竞赛、下载数据集、参加短期课程,全都免费。这是 Kaggle 由 Google 拥有的一大好处。它资金充足,因此可以免费提供给参与者/竞争者/学习者。
关键好处?
访问真实、复杂的数据和问题非常有帮助。一旦你完成了电子学习,并想进一步挑战自己,这种基于挑战的平台对于进一步提升技能非常好。
此外,访问和指导如此多的数据集意味着你将能够设计并添加一些有趣的 数据科学项目 到你的作品集中。
最后,竞争性角度对某些学习者有效!
8. HackerRank

图片来自 canva
我们来看一下 HackerRank,另一个编码挑战网站。
这是什么?
HackerRank 是一个为软件开发人员提供编码挑战和竞赛的网站,以提升他们的编码技能。
许多公司将其作为筛选软件开发职位候选人的有趣方式。该平台提供了广泛的类别选择,包括算法、数据结构、数学、数据库等。
作为一个可能想学习 Python、SQL 和其他编码技能的随机互联网用户,这是一个创建个人作品集的绝佳平台。
你能学到什么?
HackerRank 的工作方式像是组合了一个作品集和 Kaggle。你可以参与排名比赛,也可以获得 Go、C#和 Java 等语言的认证。
他们有三个学习领域:
-
准备。这包括面试准备工具包、一些基础认证,以及学习算法、数据结构和数学等各种主题。
-
认证。这个区域包含了你需要的所有认证,从 R 到 SQL 到 JavaScript。
-
竞争。这是更类似于 Kaggle 的一部分,提供了比赛和竞赛来展示你的知识并赢得奖品或声誉。
基本上,它是一个适合积极求职者以及任何想学习的人在具有挑战性和竞争力的环境中练习和测试编码技能的好地方。
HackerRank 还为你提供了资源、教程、文章和示例代码。
这要多少钱?
有趣的是:它主要是为公司招聘人才而设计的。这意味着作为候选人,你实际上可以免费使用这个产品(因为从某种意义上说,你就是这个产品)。
主要好处?
HackerRank 的独特之处在于它是为公司设计的,而不是个人。这使得个人可以非常有用地看到公司招聘所需的技能。你可以从面试的角度了解自己,从而知道应该集中精力提升哪些技能。
它非常适合那些希望从事数据科学工作的人。
9. StackOverflow
让我们来看看这个问答平台。
这是什么?
包括 StackOverflow 作为学习平台有点厚脸皮,因为这并不是它设计的目的。但它是我用来自然学习 Python 和 R 的最佳平台之一。而且最棒的是,它是免费的。
StackOverflow 是一个程序员、开发者和软件工程师提问并获得众包答案的地方。答案可以根据其帮助性和准确性被投票提升或降低。
这是一个包含多年编程问题和答案的大型资料库。
你可以学到什么?
-
Python 编程:许多与其语法、库和最佳实践相关的问题和答案。
-
SQL:包括查询、数据库设计和优化技术。
-
算法和数据结构:排序、搜索和图算法。
-
Web 开发:HTML、CSS、JavaScript 以及如 Django 和 Ruby on Rails 等网页框架。
-
调试:关于调试技术和最佳实践的问题和答案非常多。
-
软件设计:了解软件设计模式、架构和最佳实践。
在 StackOverflow 上学习的最佳方式是提问和回答问题。从基础开始 - 寻找尚未有人回答的 Python 或 SQL 的基础问题。你很快就会获得大量关于答案质量的同行反馈,从而能够进一步改进。
这很令人望而生畏,但它是一个极好的方式来提升你不仅是实际编码技能,还有沟通能力。
这需要多少钱?
这是免费的!完全免费注册账号并提问或回答无限问题。
主要好处?
StackOverflow 最棒的地方在于它并非作为学习平台设计。这些问题和答案并非经过精心设计,而是现实中的复杂、人类世界的问题,数据也很杂乱。而且你将获得来自真正数据科学家的真实反馈。
这是一个真正的挑战,但它是学习的绝佳方式。
最后的思考
总结一下,数字时代的美在于教育现在触手可及。数据科学是一个热门话题,许多雇主并不在乎你从哪里学到的,只要你能做到。
本文介绍了九个惊人且有些不传统的平台,使学习这种需求量大的技能变得轻松。通过视频教程、互动编码练习、测验和真实数据,你将能够提升你的技能,并向世界展示你的能力。
不要再等待了。选择一个平台(或者九个 - 这些平台并不排他!)并立即开始学习数据科学吧。
内特·罗西迪 是一位数据科学家,专注于产品战略。他也是一名兼职教授,教授分析学,同时是 StrataScratch、一个帮助数据科学家准备面试的平台的创始人。通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
更多相关内容
90% 的今天的代码是为了防止失败而编写的,这是一种问题
原文:
www.kdnuggets.com/2022/07/90-today-code-written-prevent-failure-problem.html

图片来源:cottonbro
没有数据科学家或工程师愿意知道他们的代码失败了。例如,你的数据可能格式错误。数据库可能宕机。或者,运行代码的计算机可能出现故障。有无数的失败原因可能导致你的代码未能实现其预定目标。尝试预测和防御这些失败是今天工程师面临的持续的艰难挑战。但如果我们只是改变我们的视角和框架,去说“失败会发生——这没关系。”,情况就不会如此。
积极工程与消极工程
为实现预期结果而编写的高效代码可以被归类为积极工程。公司雇佣工程师的目的是编写积极的代码,构建解决方案以满足业务关键和分析目标。相反,消极工程是为了对抗预期的失败并确保积极代码实际运行而编写的防御性代码。
尝试预测可能出现的各种问题使得编写消极代码既费时又令人沮丧,工程师报告说,他们通常将 90%的时间花在消极或防御性问题上。不幸的是,这段时间会影响整体生产力和主要目标,只剩下 10% 的时间用于工程师被雇佣来构建的积极解决方案。
工程师可能认为这种防御性的方法对他们的积极代码的成功是必要的,并且有助于减少失败的风险。但作为一个在风险管理领域工作了整个职业生涯的人,我可以说,有效的风险缓解并不试图预测和对冲所有可能的结果。相反,人们应当建立一个具有足够具体工具的框架,以应对手头的任务,同时又足够通用以处理未知问题。这就是关于建立一个消极工程框架,让用户可以与失败共处,而不是对抗失败。
积极工程的保险
我将消极工程框架比作家庭保险。购买家庭保险不会阻止你的房子着火或被淹,但它可以显著减少财务负担。同样,实现消极工程框架不会阻止失败的发生,但可以减少识别和修复问题所需的时间、麻烦和人才。
有效的框架包括适当的仪表化、可观察性和代码编排。作为你正面代码的保险,它不仅让你安排进程运行,还能知道该进程是否失败,从而确保解决方案的结果。失败的代码可能需要简单的重试,或工程师快速修改代码以缓解失败情况。问题可能是——并且通常是——看似微不足道的问题,但如果不加以检查,可能会引发蝴蝶效应。例如,关键任务分析管道的失败可能导致公司从错误的数据中做出战略决策。
需要注意的是,负面工程框架不仅仅是能够捕获错误信息。用户需要明确成功执行正面代码的预期。例如,如果计算机上运行的一个进程突然崩溃,机器可能甚至没有机会发送失败的错误信息。但是,通过创建一种逻辑,使框架能够推断出在预期未能实现时进程失败,工程师可以获得防御性见解,并对任何偏离设定目标的情况采取行动——即使面对意外情况。
任务成功失败
事实是,无论你写多少负面代码或尝试实施多少保障措施,失败都是工程师生活中不可避免的一部分。此外,失败的催化剂可能超出你的控制范围。以一家高增长初创公司的数据团队为例,这支由五名工程师组成的团队在管理分析堆栈时,其整个基础设施完全失败,导致报告中充满错误。
从他们破损的仪表盘开始倒推,团队发现几乎在每一层堆栈中都有一个又一个错误。团队最终发现这是因为每个阶段将其失败传递给后续阶段,导致每一步的失败链反应。在经过三天的调查工作后,团队揭示了失败的根源:问题竟然如此简单——附加在 SaaS 供应商上的信用卡已过期。由于供应商的 API 集成在团队管道的早期阶段,账单错误造成了一连串的失败,直至终端用户仪表盘。
一旦他们找到了问题,团队幸运地解决了它。他们只需要了解根本原因,解决方案就很简单。防御性、消极的代码无法阻止这种失败——因为催化剂是外部的——但一个保险框架可以减轻其影响。一个好的工作流程工具可以识别根本故障,并防止下游任务的执行,预期如果这些任务继续执行,将只会导致一系列失败。这种可见性将帮助五人团队将三天的调查时间缩短到几分钟,并大幅提高生产力。
生产力提升可能是消极工程框架的最大好处,工程师接受失败的发生,并拥有减轻其影响的工具。与其花费 90%的时间去防止失败,他们可以更多地投入到编写积极的代码中,从而推动业务成果。即使将消极代码的时间减少到 80%,也意味着将积极工程时间从 10%提升到 20%——有效地使生产力时间翻倍。这仅仅是心态转变带来的非凡收益。工程师因此可以自信地确保他们的积极代码按照设计运行,并管理未知及其带来的所有风险。
Jeremiah Lowin 是 Prefect 的创始人兼首席执行官。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
更多相关内容
初学者指南:十大机器学习算法
原文:
www.kdnuggets.com/a-beginner-guide-to-the-top-10-machine-learning-algorithms

作者图片
数据科学的一个基础领域是机器学习。因此,如果你想进入数据科学,理解机器学习是你需要迈出的第一步。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
那么你从哪里开始呢?你需要了解两种主要机器学习算法的区别。只有在那之后,我们才能谈论作为初学者你应该优先学习的个别算法。
有监督学习与无监督学习
算法的主要区别在于它们的学习方式。

作者图片
有监督学习算法是在标记数据集上训练的。这个数据集作为学习的监督(因此得名),因为其中的一些数据已经标记为正确答案。基于这些输入,算法可以学习并将这些学习应用到其余数据中。
另一方面,无监督学习算法在未标记数据集上进行学习,这意味着它们在寻找数据中的模式时没有人为的指导。
你可以更详细地阅读关于机器学习算法和学习类型的内容。
还有一些其他类型的机器学习,但不适合初学者。
机器学习任务
算法被用于解决每种机器学习类型中的两个主要不同问题。
再次强调,还有一些任务,但它们不适合初学者。
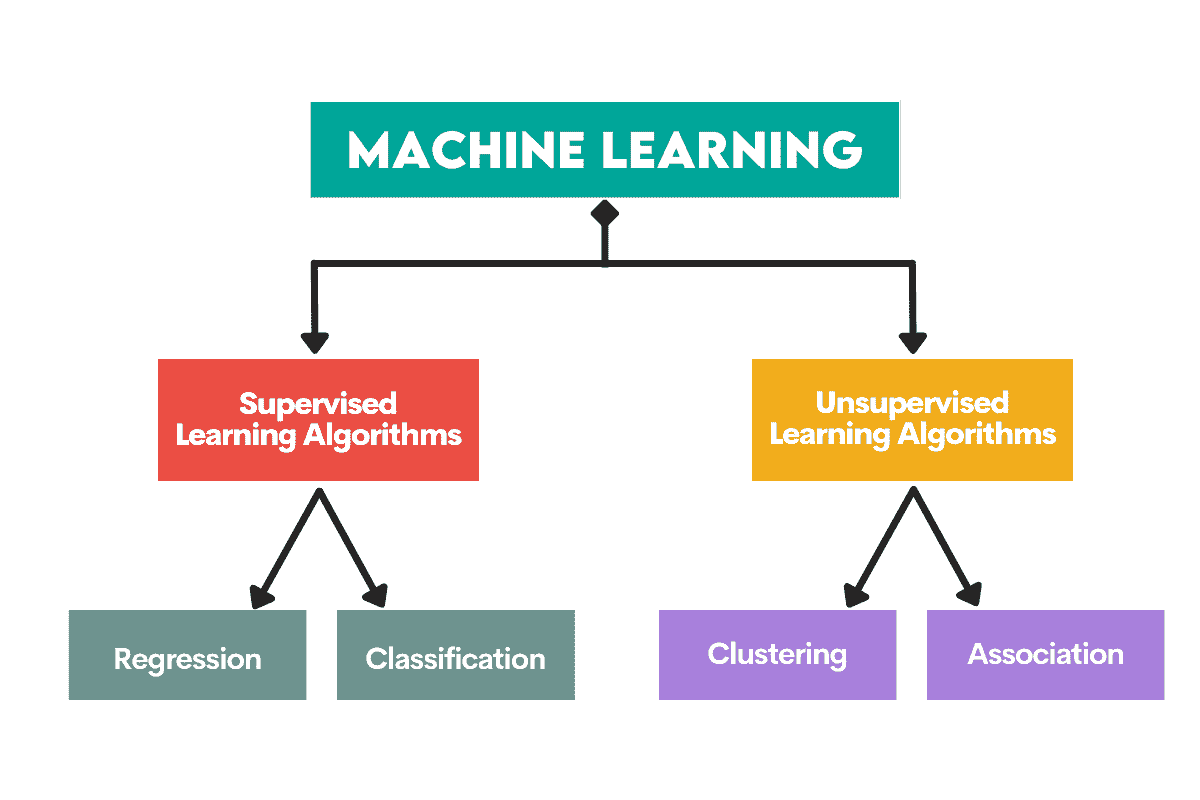
作者图片
有监督学习任务
回归是预测数值的任务,称为连续结果变量或因变量。预测是基于预测变量或自变量进行的。
想想预测油价或空气温度。
分类 用于预测输入数据的 类别(类)。这里的 结果变量 是 分类的或离散的。
想想预测邮件是否为垃圾邮件,或患者是否会得某种疾病。
无监督学习任务
聚类 意味着 将数据划分为子集或簇。目标是尽可能自然地对数据进行分组。这意味着同一簇中的数据点比其他簇中的数据点更相似。
降维 指的是减少数据集中输入变量的数量。这基本上意味着 将数据集减少到很少的变量,同时仍捕捉其本质。
10 大机器学习算法概述
以下是我将涵盖的算法概述。
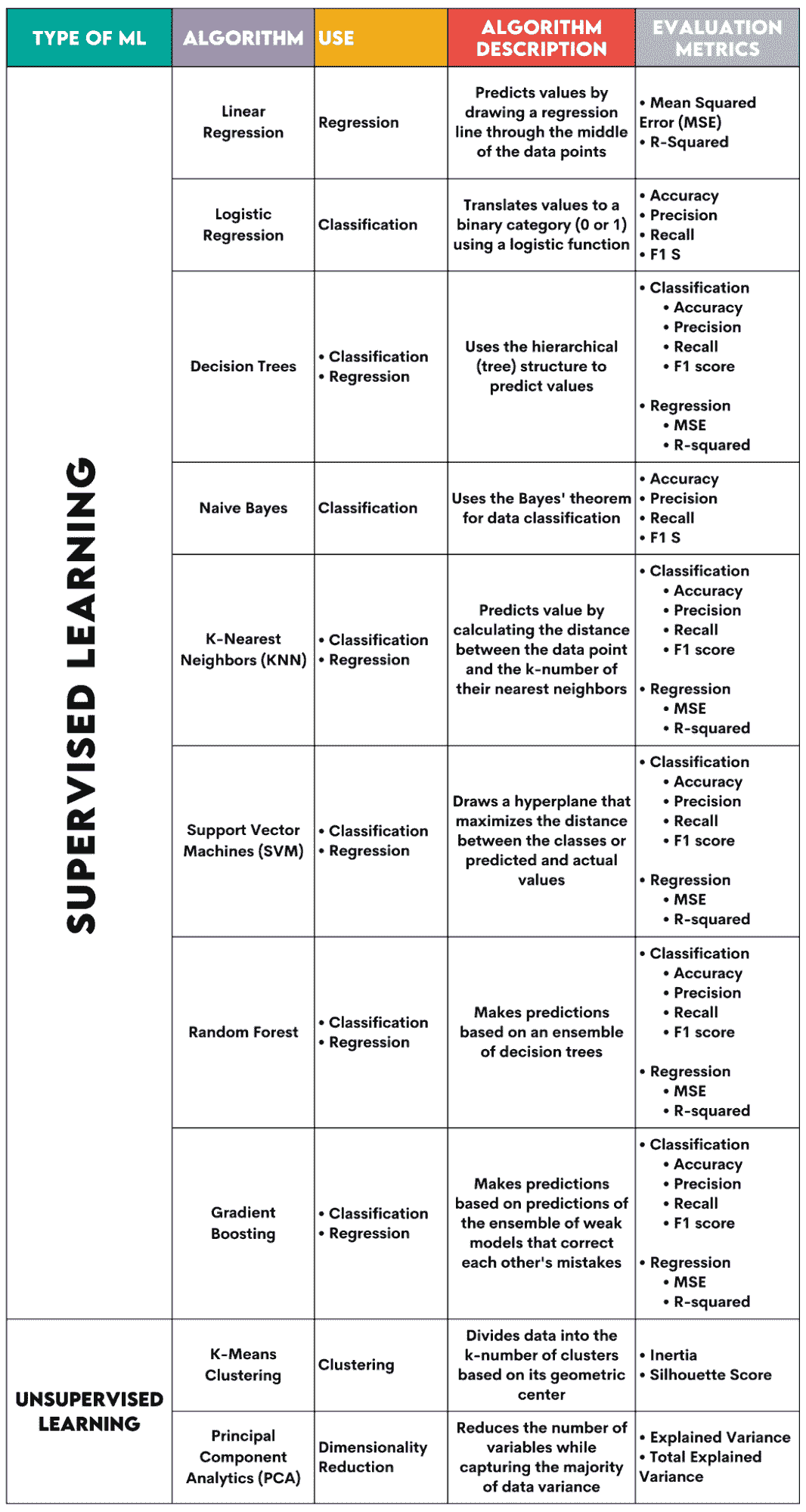
作者提供的图片
监督学习算法
在选择适合你问题的算法时,了解该算法的用途非常重要。
作为数据科学家,你可能会使用 scikit-learn 库 在 Python 中应用这些算法。虽然它几乎为你做了所有的事情,但建议你至少了解每个算法内部工作的基本原理。
最后,在算法训练完成后,你应该评估它的表现。为此,每个算法都有一些标准指标。
1. 线性回归
用于: 回归
描述: 线性回归绘制了一条直线,称为回归线,连接变量之间的关系。这条线大致穿过数据点的中间,从而最小化估计误差。它显示了基于自变量值的因变量的预测值。
评估指标:
-
均方误差 (MSE):表示平方误差的平均值,误差是实际值和预测值之间的差异。值越低,算法性能越好。
-
R 平方:表示自变量可以预测的因变量的方差百分比。对于这个度量,你应该尽量接近 1。
2. 逻辑回归
用于: 分类
描述: 它使用 逻辑函数 将数据值转换为二元类别,即 0 或 1。通常使用 0.5 的阈值。二元结果使得该算法非常适合预测二元结果,如 YES/NO、TRUE/FALSE 或 0/1。
评估指标:
-
准确度:正确预测与总预测的比率。越接近 1 越好。
-
精确度:模型在正预测中的准确性度量;表示为正确正预测与总期望正结果之间的比率。越接近 1 越好。
-
召回率:它同样衡量模型在正预测中的准确性。表示为正确正预测与在类别中所做总观察之间的比率。有关这些指标的更多信息,请参见 这里。
-
F1 分数:模型召回率和精确度的调和平均数。越接近 1 越好。
3. 决策树
用途: 回归与分类
描述: 决策树 是利用层次或树状结构来预测值或类别的算法。根节点代表整个数据集,然后根据变量值分支成决策节点、分支和叶子。
评估指标:
-
准确度、精确度、召回率和 F1 分数 -> 用于分类
-
MSE, R 平方 -> 用于回归
4. 朴素贝叶斯
用途: 分类
描述: 这是使用 贝叶斯定理 的分类算法族,即它们假设类别内特征之间是独立的。
评估指标:
-
准确度
-
精确度
-
召回率
-
F1 分数
5. K-最近邻(KNN)
用途: 回归与分类
描述: 它计算测试数据与训练数据中 k 个最近数据点 之间的距离。测试数据属于‘邻居’数量较多的类别。关于回归,预测值是 k 个选定训练点的平均值。
评估指标:
-
准确度、精确度、召回率和 F1 分数 -> 用于分类
-
MSE, R 平方 -> 用于回归
6. 支持向量机(SVM)
用途: 回归与分类
描述: 该算法绘制一个超平面来分离不同类别的数据。它的位置距离每个类别的最近点最远。数据点离超平面的距离越远,它越属于该类别。对于回归,原理类似:超平面最大化预测值与实际值之间的距离。
评估指标:
-
准确率、精确率、召回率和 F1 分数 -> 用于分类
-
均方误差(MSE)、决定系数(R-squared) -> 用于回归
7. 随机森林
用途: 回归与分类
描述: 随机森林算法使用一组决策树,这些决策树组成一个决策森林。算法的预测基于许多决策树的预测。数据会被分配到获得最多票数的类别中。对于回归,预测值是所有树的预测值的平均值。
评估指标:
-
准确率、精确率、召回率和 F1 分数 -> 用于分类
-
均方误差(MSE)、决定系数(R-squared) -> 用于回归
8. 梯度提升
用途: 回归与分类
描述: 这些算法使用一组弱模型,每个后续模型识别并纠正前一个模型的错误。这个过程会重复进行,直到错误(损失函数)最小化。
评估指标:
-
准确率、精确率、召回率和 F1 分数 -> 用于分类
-
均方误差(MSE)、决定系数(R-squared) -> 用于回归
无监督学习算法
9. K 均值聚类
用途: 聚类
描述: 该算法将数据集划分为 k 个簇,每个簇由其质心或几何中心表示。通过将数据划分为 k 个簇的迭代过程,目标是最小化数据点与其簇的质心之间的距离。另一方面,它还试图最大化这些数据点与其他簇的质心之间的距离。简而言之,属于同一簇的数据应该尽可能相似,而与其他簇的数据尽可能不同。
评估指标:
-
惯性:每个数据点距离最近簇质心的距离的平方和。惯性值越低,簇越紧凑。
-
轮廓分数:它衡量簇的凝聚力(数据在自身簇中的相似性)和分离度(数据与其他簇的差异)。该分数的值范围从-1 到+1。值越高,数据越适合其簇,越不适合其他簇。
10. 主成分分析(PCA)
用途: 降维
描述: 该算法 通过构建新的变量(主成分)来减少所使用的变量数量,同时仍尝试最大化数据的捕获方差。换句话说,它将数据限制为其最常见的成分,同时不丢失数据的本质。
评估指标:
-
解释方差:每个主成分覆盖的方差百分比。
-
总解释方差:所有主成分覆盖的方差百分比。
结论
机器学习是数据科学的重要组成部分。通过这十种算法,你将涵盖机器学习中最常见的任务。当然,这个概述仅仅是对每种算法工作原理的一个大致了解。所以,这只是一个开始。
现在,你需要学习如何在 Python 中实现这些算法并解决实际问题。在这方面,我推荐使用 scikit-learn。不仅因为它是一个相对易用的机器学习库,还因为它有 丰富的资料 关于机器学习算法。
内特·罗斯迪 是一位数据科学家和产品策略专家。他还是一名兼职教授,教授分析课程,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过来自顶级公司的真实面试问题来准备面试。内特撰写有关职业市场的最新趋势,提供面试建议,分享数据科学项目,并覆盖所有 SQL 相关内容。
相关主题
PyTorch 初学者指南

图片来源:编辑 | Midjourney & Canva
深度学习在人工智能研究的许多领域被广泛使用,并且促进了技术进步。例如,文本生成、面部识别和语音合成应用都基于深度学习研究。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
最常用的深度学习包之一是PyTorch。它是由 Meta AI 于 2016 年创建的开源包,并且被许多人使用。
PyTorch 有很多优点,包括:
-
灵活的模型架构
-
对 CUDA 的原生支持(可以使用 GPU)
-
基于 Python
-
提供低级别的控制,这对于研究和许多用例非常有用
-
开发者和社区的积极开发
让我们通过这篇文章探索 PyTorch,帮助你入门。
准备工作
你应该访问他们的安装网页,选择适合你环境要求的版本。下面的代码是安装示例。
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
PyTorch 准备好了,让我们进入核心部分。
PyTorch 张量
张量是 PyTorch 中的基本构件。它类似于 NumPy 数组,但可以使用 GPU。我们可以使用以下代码尝试创建一个 PyTorch 张量:
a = torch.tensor([2, 4, 5])
print(a)
Output>>
tensor([2, 4, 5])
像 NumPy 数组张量一样,它允许矩阵运算。
e = torch.tensor([[1, 2, 3],
[4, 5, 6]])
f = torch.tensor([7, 8, 9])
print(e * f)
Output>>
tensor([[ 7, 16, 27],
[28, 40, 54]])
也可以执行矩阵乘法。
g = torch.randn(2, 3)
h = torch.randn(3, 2)
print( g @ h)
Output>>
tensor([[-0.8357, 0.0583],
[-2.7121, 2.1980]])
我们可以使用下面的代码访问张量信息。
x = torch.rand(3,4)
print("Shape:", x.shape)
print("Data type:", x.dtype)
print("Device:", x.device)
Output>>
Shape: torch.Size([3, 4])
Data type: torch.float32
Device: cpu
PyTorch 的神经网络训练
通过使用 nn.Module 类定义神经网络,我们可以开发一个简单的模型。让我们试试下面的代码。
import torch
class SimpleNet(nn.Module):
def __init__(self, input, hidden, output):
super(SimpleNet, self).__init__()
self.fc1 = torch.nn.Linear(input, hidden)
self.fc2 = torch.nn.Linear(hidden, output)
def forward(self, x):
x = torch.nn.functional.relu(self.fc1(x))
x = self.fc2(x)
return x
inp = 10
hid = 10
outp = 2
model = SimpleNet(inp, hid, out)
print(model)
Output>>
SimpleNet(
(fc1): Linear(in_features=10, out_features=10, bias=True)
(fc2): Linear(in_features=10, out_features=2, bias=True)
)
上面的代码定义了一个SimpleNet类,继承自nn.Module,用于设置层。我们使用nn.Linear作为层,relu作为激活函数。
我们可以添加更多层或使用不同的层,如 Conv2D 或 CNN。但我们不会使用这些。
接下来,我们将用样本张量数据训练我们开发的SimpleNet。
import torch
inp = torch.randn(100, 10)
tar = torch.randint(0, 2, (100,))
criterion = torch.nn.CrossEntropyLoss()
optimizr = torch.optim.SGD(model.parameters(), lr=0.01)
epochs = 100
batchsize = 10
for epoch in range(numepochs):
model.train()
for i in range(0, inp.size(0), batchsize):
batch_inp = inputs[i:i+batch_size]
batch_tar = targets[i:i+batch_size]
out = model(batch_inp)
loss = criterion(out, batch_tar)
optimizer.zero_grad()
loss.backward()
optimizr.step()
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {round(loss.item(),4})')
在上述训练过程中,我们使用随机张量数据,并初始化一个称为CrossEntropyLoss的损失函数。同时,我们初始化 SGD 优化器来管理模型参数以最小化损失。
训练过程根据周期次数多次运行,然后进行优化过程。这是通常的深度学习流程。
我们可以添加几个步骤以提高训练的复杂性,例如早停、学习率和其他技术。
最后,我们可以使用未见过的数据评估我们训练的模型。以下代码允许我们做到这一点。
from sklearn.metrics import classification_report
model.eval()
test_inputs = torch.randn(20, 10)
test_targets = torch.randint(0, 2, (20,))
with torch.no_grad():
test_outputs = model(test_inputs)
_, predicted = torch.max(test_outputs, 1)
print(classification_report(test_targets, predicted))
上述情况发生的原因是我们将模型切换到评估模式,这会关闭 dropout 和批量归一化更新。此外,我们还禁用梯度计算过程以加快处理速度。
你可以访问 PyTorch 文档 以进一步了解你可以做什么。
结论
在本文中,我们将深入探讨 PyTorch 的基础知识。从张量创建到张量操作,再到开发一个简单的神经网络模型。本文为初学者级别,所有新手应能迅速跟上。
Cornellius Yudha Wijaya**** 是一位数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 涉及多种 AI 和机器学习主题的写作。
更多相关主题
神经网络的简史
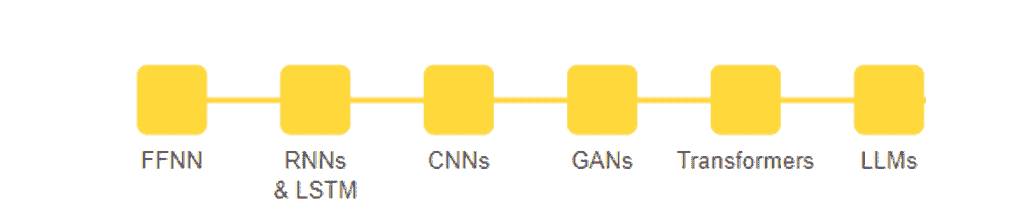
神经网络演变的全景图(图片作者)。
神经网络,人工智能的基本构建块,已经彻底改变了我们处理信息的方式,提供了对未来技术的展望。这些复杂的计算系统受人脑复杂性的启发,已成为从图像识别和自然语言理解到自动驾驶和医疗诊断等任务中的关键。随着我们探索神经网络的历史演变,我们将揭示它们如何演变并塑造现代 AI 的进程。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
一切是如何开始的?
神经网络,深度学习的基础组件,其概念根源于人脑中复杂的生物神经网络。这个卓越的概念起初是通过一个基本的类比展开的,将生物神经元与计算网络进行对比。
这个类比围绕大脑展开,大脑由大约 1000 亿个神经元组成。每个神经元与其他神经元保持大约 7000 个突触连接,形成一个复杂的神经网络,这一网络是人类认知过程和决策制定的基础。
单独来看,生物神经元通过一系列简单的电化学过程来运作。它通过树突接收来自其他神经元的信号。当这些输入信号累计到一定水平(一个预定的阈值)时,神经元会激活并沿其轴突发送电化学信号。这会影响连接到其轴突末端的神经元。需要注意的是,神经元的反应就像一个二进制开关:要么发射(激活),要么保持安静,没有任何中间状态。
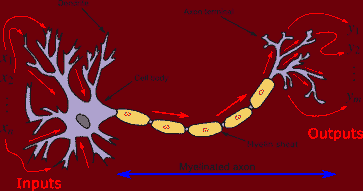
生物神经元是人工神经网络的灵感来源(图片来源:维基百科)。
尽管人工神经网络非常令人印象深刻,但它们仍然远未接近人脑的惊人复杂性和深刻复杂性。然而,它们在解决那些对传统计算机具有挑战性但对人类认知而言直观的问题上表现出了显著的能力。一些例子包括图像识别和基于历史数据的预测分析。
现在我们已经探讨了生物神经元的基本原理及其对人工神经网络的启发,让我们一起回顾那些塑造了人工智能领域的神经网络框架的演变历程。
FFNN - 前馈神经网络
前馈神经网络,通常被称为多层感知器,是一种基本的神经网络类型,其操作深深根植于信息流动、互连层和参数优化的原则中。
在核心上,FFNNs 协调了信息的单向流动。一切从包含n 个神经元的输入层开始,数据在此被初步接收。该层作为网络的入口点,充当需要处理的输入特征的接收器。从这里开始,数据经过网络的隐藏层进行变换。
FFNNs 的一个重要方面是其连接结构,这意味着每一层中的每个神经元都与该层中的每个神经元紧密相连。这种互连性使得网络能够进行计算并捕捉数据中的关系。这就像一个通信网络,其中每个节点在处理信息中扮演着角色。
当数据通过隐藏层时,它会经过一系列计算。每个隐藏层的神经元从前一层的所有神经元接收输入,对这些输入应用加权和,添加一个偏置项,然后通过一个激活函数(通常是 ReLU、Sigmoid 或 tanH)传递结果。这些数学运算使得网络能够从输入中提取相关模式,并捕捉数据中的复杂非线性关系。正是在这一点上,前馈神经网络(FFNNs)相比于更浅的机器学习模型真正表现出色。
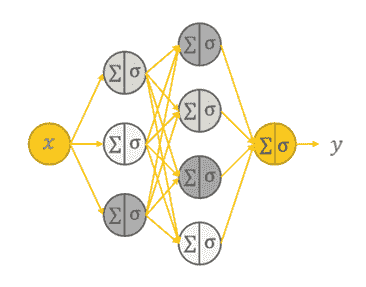
完全连接的前馈神经网络的架构(作者提供的图像)。
但这并不是终点。FFNNs 的真正力量在于它们的适应能力。在训练过程中,网络调整其权重以最小化其预测值与实际目标值之间的差异。这个迭代过程通常基于如梯度下降等优化算法,称为反向传播。反向传播使 FFNNs 能够真正从数据中学习,并提高预测或分类的准确性。
示例 KNIME 工作流 用于二分类认证考试(通过与失败)。在上部分支中,我们可以看到网络架构,包括一个输入层,一个具有 tanH 激活函数的全连接隐藏层,以及一个使用 Sigmoid 激活函数的输出层(图像由作者提供)。
尽管强大而多才多艺,FFNN 显示出一些相关的局限性。例如,它们未能捕捉数据中的顺序性和时间/句法依赖性——这两个方面对于语言处理和时间序列分析任务至关重要。克服这些局限性的需求促成了新型神经网络架构的发展。这一过渡为递归神经网络(RNN)的出现铺平了道路,RNN 引入了反馈回路的概念,以更好地处理顺序数据。
RNN 和 LSTM - 递归神经网络和长短期记忆
从根本上讲,RNN 与 FFNN 有一些相似之处。它们也由互联的节点层组成,处理数据以进行预测或分类。然而,它们的关键区别在于能够处理顺序数据并捕捉时间依赖性。
在 FFNN 中,信息沿着从输入层到输出层的单一单向路径流动。这适用于数据顺序不太重要的任务。然而,当处理如时间序列数据、语言或语音这样的序列时,保持上下文和理解数据的顺序至关重要。这正是 RNN 发挥作用的地方。
RNN 引入了反馈回路的概念。这些回路作为一种“记忆”,使得网络能够保持一个隐藏状态,以捕捉关于先前输入的信息,并影响当前的输入和输出。虽然传统神经网络假设输入和输出彼此独立,但递归神经网络的输出依赖于序列中的先前元素。这种递归连接机制使 RNN 特别适合通过“记住”过去的信息来处理序列。
递归网络的另一个区别特征是,它们在网络的每一层中共享相同的权重参数,这些权重通过时间反向传播(BPTT)算法进行调整,该算法与传统的反向传播略有不同,因为它专门针对序列数据。
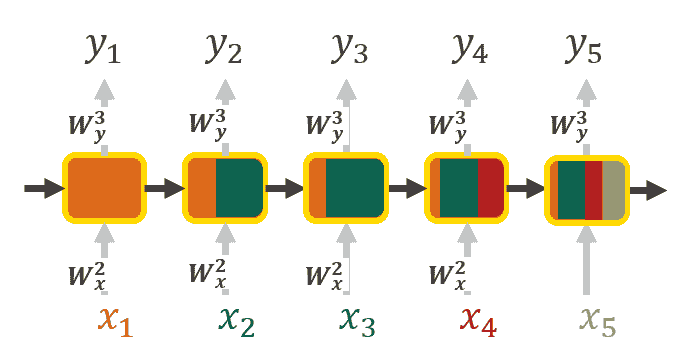
展开的 RNN 表示,其中每个输入都带有来自先前输入的上下文信息。颜色表示上下文信息的传播(图像由作者提供)。
然而,传统的 RNN 也有其局限性。虽然理论上它们应该能够捕捉长期依赖关系,但实际上它们往往难以有效做到这一点,甚至可能遭遇梯度消失问题,这阻碍了它们在多个时间步长上学习和记忆信息的能力。
这就是长短期记忆(LSTM)单元发挥作用的地方。它们通过在结构中引入三个门控:遗忘门、输入门和输出门,专门设计来处理这些问题。
-
遗忘门:该门控决定应丢弃或忘记时间步长中的哪些信息。通过检查单元状态和当前输入,它决定哪些信息在当前预测中是无关的。
-
输入门:该门控负责将信息引入单元状态。它考虑输入和先前的单元状态,以决定应添加哪些新信息来增强其状态。
-
输出门:该门控决定 LSTM 单元将生成什么输出。它考虑当前输入和更新后的单元状态,以产生可以用于预测或传递给时间步长的输出。
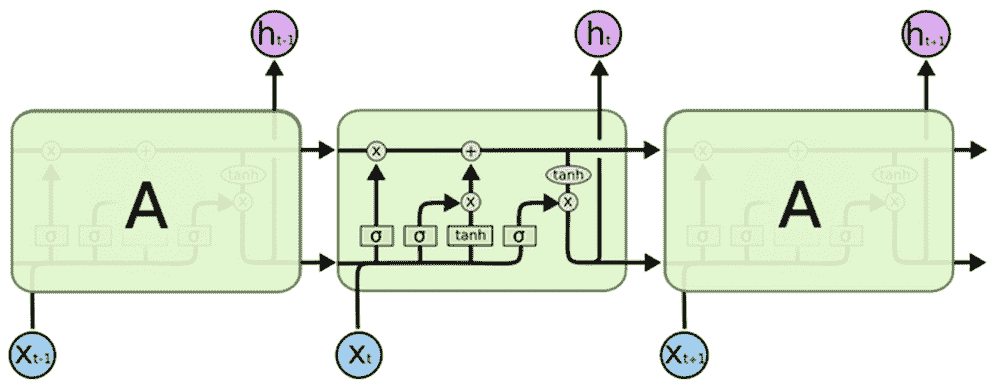
长短期记忆单元的可视化表示(图片 由 Christopher Olah 提供)。
示例 KNIME 工作流 使用 LSTM 单元的 RNN 用于多类别情感预测(积极、消极、中立)。上支定义了网络架构,包括一个输入层来处理不同长度的字符串,一个嵌入层,一个包含多个单元的 LSTM 层,以及一个全连接输出层,配有 Softmax 激活函数以返回预测结果。
总之,RNN(递归神经网络),特别是 LSTM(长短期记忆)单元,专为序列数据设计,能够保持记忆并捕捉时间依赖关系,这对于自然语言处理、语音识别和时间序列预测等任务至关重要。
当我们从 RNN 捕捉序列依赖关系转变时,卷积神经网络(CNN)不断发展。与 RNN 不同,CNN 在从结构化网格状数据中提取空间特征方面表现优异,使其非常适合图像和模式识别任务。这种过渡反映了神经网络在不同数据类型和结构中的多样化应用。
CNN - 卷积神经网络
CNN(卷积神经网络)是一种特殊类型的神经网络,特别适合处理图像数据,如二维图像甚至三维视频数据。它们的架构依赖于一个多层前馈神经网络,至少包含一个卷积层。
CNNs 的独特之处在于它们的网络连接性和特征提取方法,这使得它们能够自动识别数据中的相关模式。与传统的 FFNNs 不同,CNNs 不是将一层中的每个神经元与下一层中的每个神经元连接,而是采用称为卷积核或滤波器的滑动窗口。这个滑动窗口扫描输入数据,特别适用于空间关系重要的任务,如图像中的对象识别或视频中的运动跟踪。当卷积核在图像上移动时,会在卷积核与像素值之间执行卷积操作(从严格的数学角度看,这个操作是交叉相关),并应用非线性激活函数,通常是 ReLU。如果特征存在于图像补丁中,则产生较高的值,如果不存在,则产生较小的值。
与卷积核一起,超参数的添加和微调,如步幅(即我们滑动卷积核的像素数)和扩张率(即每个卷积核单元之间的间隔),使网络能够关注特定特征,在特定区域识别模式和细节,而无需一次考虑整个输入。
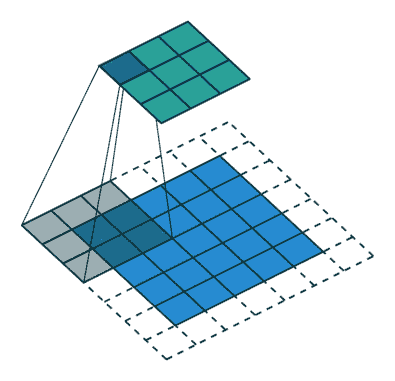
带有步幅长度 = 2 的卷积操作(GIF由 Sumit Saha 提供)。
一些卷积核可能专门用于检测边缘或角落,而其他的可能会被调整以识别图像中的更复杂对象,如猫、狗或街道标志。通过堆叠多个卷积层和池化层,CNNs 构建了输入的层次化表示,逐渐将特征从低级别抽象到高级别,就像我们的大脑处理视觉信息一样。
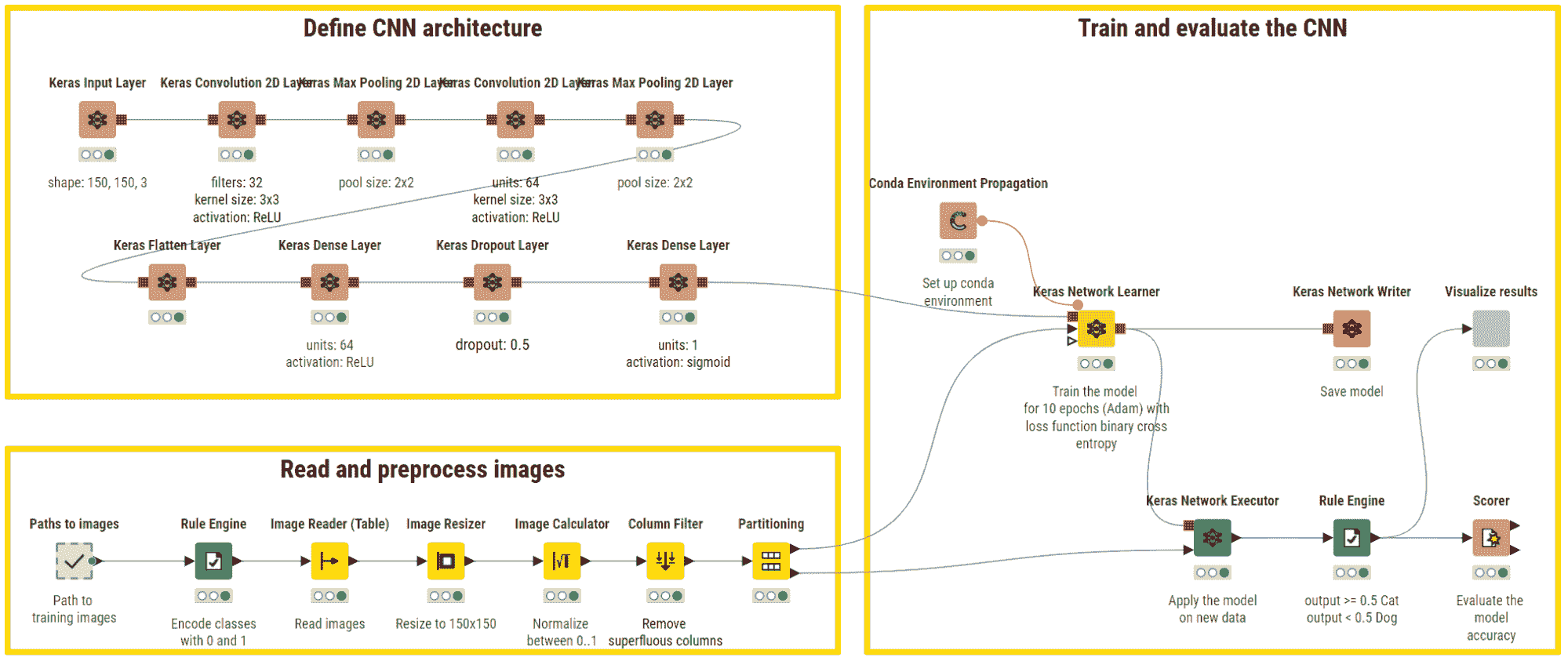
示例KNIME 工作流程用于二进制图像分类(猫与狗)。上层分支通过一系列卷积层和最大池化层定义网络架构,以自动从图像中提取特征。然后,使用展平层将提取的特征准备为一维输入,供 FFNN 进行二进制分类。
虽然 CNNs 在特征提取方面表现出色,并且已经彻底改变了计算机视觉任务,但它们只是被动观察者,因为它们并不设计用来生成新的数据或内容。这并不是网络本身的固有限制,而是拥有强大引擎却没有燃料使得快速汽车变得无用。实际上,真实和有意义的图像和视频数据往往难以收集且成本高昂,并且往往面临版权和数据隐私的限制。这一限制促使了一个新颖范式的开发,它建立在 CNNs 的基础上,但从图像分类跃迁到创意合成:生成对抗网络(GANs)。
GAN - 生成对抗网络
GANs 是神经网络中的一个特定家族,其主要但不是唯一的目的,是生成与给定真实数据集非常相似的合成数据。与大多数神经网络不同,GANs 的独特架构设计由两个核心模型组成:
-
生成器模型:这个神经网络二重奏的第一位成员是生成器模型。这个组件肩负着一个令人着迷的任务:给定随机噪声或输入向量,它努力创建与真实样本尽可能相似的人工样本。可以把它想象成一个艺术伪造者,试图创作出与名画无法区分的伪作。
-
鉴别器模型:扮演对立角色的是鉴别器模型。它的工作是区分生成器生成的样本和原始数据集中真实的样本。可以把它想象成一个艺术鉴赏家,试图在真正的艺术作品中识别伪作。
现在,魔法发生的地方是:GANs 进行持续的对抗性舞蹈。生成器旨在提升其艺术水平,不断微调其创作,使其更具说服力。同时,鉴别器则成为更敏锐的侦探,磨练其区分真实与虚假的能力。
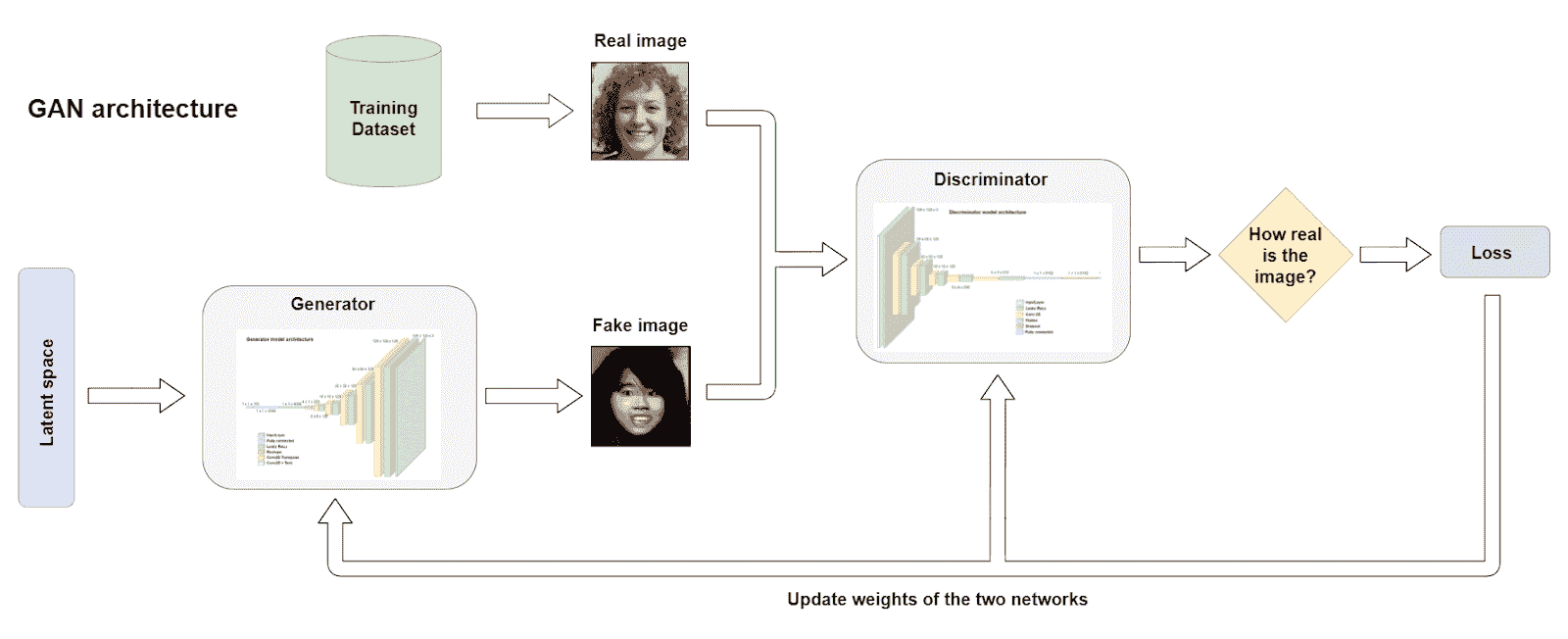
GAN 架构(图像作者提供)。
随着训练的进行,生成器和鉴别器之间的动态互动会产生令人着迷的结果。生成器努力生成足够逼真的样本,以至于连鉴别器都无法将它们与真实样本区分开来。这种竞争驱使两个组件不断提高各自的能力。
结果?生成器变得异常擅长生成看起来真实的数据,无论是图像、音乐还是文本。这种能力在各种领域中产生了显著的应用,包括图像合成、数据增强、图像到图像的翻译和图像编辑。
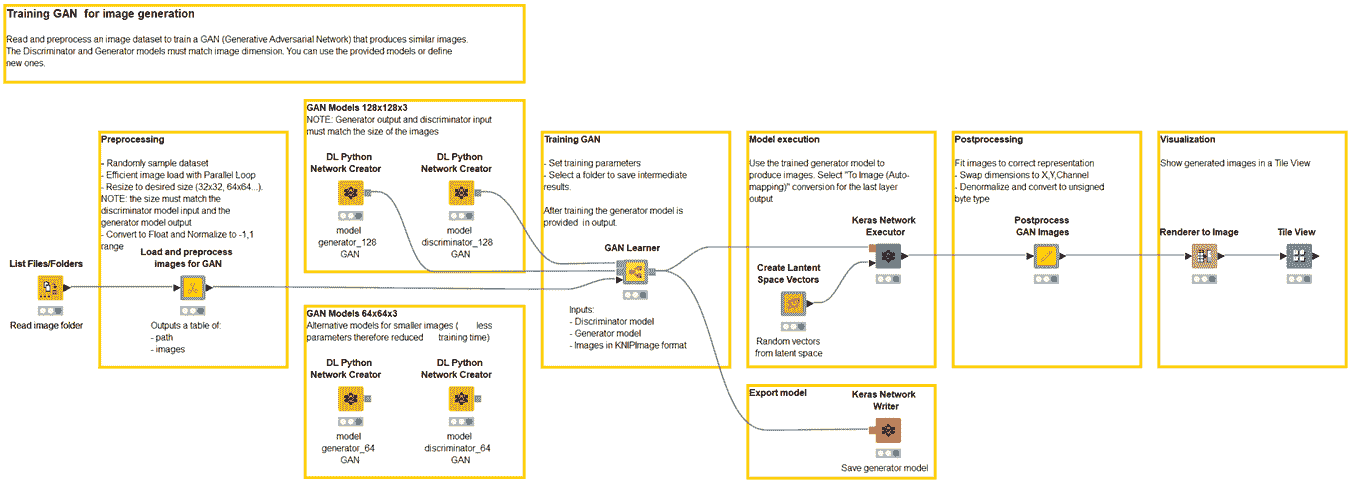
示例 KNIME 工作流 用于生成合成图像(例如动物、人脸和辛普森角色)。
GANs 开创了现实图像和视频内容创作的先河,通过对抗生成器和判别器来实现。在图像到序列数据的创意和高级操作需求不断扩展的背景下,推出了更为复杂的自然语言理解、机器翻译和文本生成模型。这促成了 Transformers 的开发,这是一种显著的深度神经网络架构,它不仅通过有效捕捉长期语言依赖关系和语义上下文超越了以前的架构,还成为了最新 AI 驱动应用的无可争议的基础。
Transformers
2017 年开发的 Transformers 拥有一个独特的特点,使其能够取代传统的递归层:一种自注意力机制,使它们能够建模文档中所有单词之间的复杂关系,而不管它们的位置。这使得 Transformers 在处理自然语言中的长期依赖问题时表现出色。Transformer 架构由两个主要构建块组成:
*** 编码器。 在这里,输入序列被嵌入到向量中,然后暴露于自注意力机制中。后者计算每个令牌的注意力分数,确定其相对于其他令牌的重要性。这些分数用于创建加权和,输入到 FFNN 中生成每个令牌的上下文感知表示。多个编码器层重复这一过程,增强模型捕捉层次结构和上下文信息的能力。
- 解码器。 这个模块负责生成输出序列,其过程类似于编码器。它能够在每一步上正确关注和理解编码器的输出及其自身的过去令牌,通过考虑输入上下文和之前生成的输出,确保准确生成。
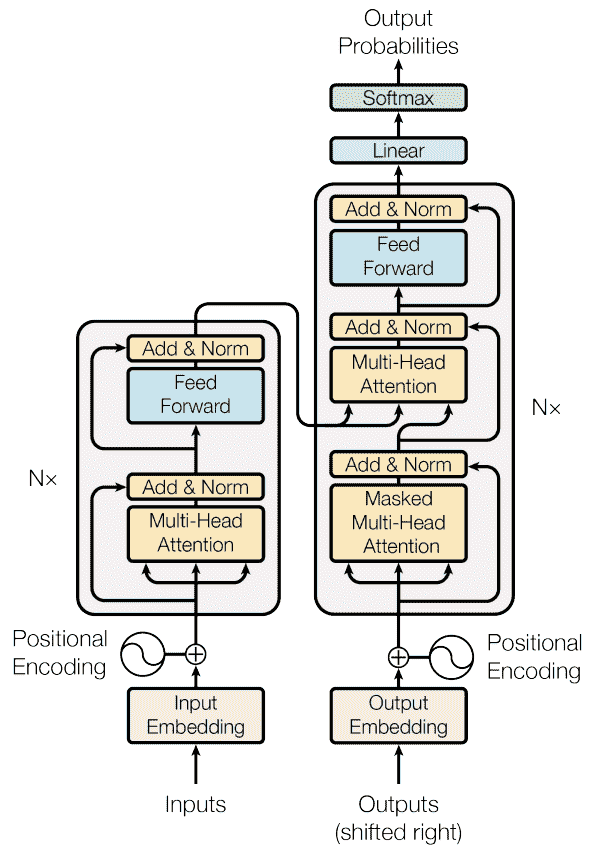
Transformer 模型架构(图片作者:Vaswani 等,2017 年)。
例如这句话:“我在过河后到达了银行”。单词“bank”可以有两种含义——金融机构或河岸。这里是 transformers 的优势所在。它们能够迅速关注单词“river”来消除“bank”的歧义,通过将“bank”与句子中的其他每个单词进行比较,并分配注意力分数。这些分数决定了每个单词对“bank”下一个表示的影响。在这种情况下,“river”获得了更高的分数,有效地澄清了意图。
要实现如此高效,Transformers 依赖于数百万个可训练参数,需要大量的文本语料库和复杂的训练策略。Transformers 使用的一个显著训练方法是 掩码语言建模(MLM)。在训练过程中,输入序列中的特定词元会被随机掩盖,模型的目标是准确预测这些掩盖的词元。这种策略鼓励模型掌握单词之间的上下文关系,因为它必须依赖周围的单词来做出准确的预测。这种方法由 BERT 模型推广,对于在各种 NLP 任务中取得最先进的结果起到了关键作用。
Transformers 的 MLM 替代方法是 自回归建模。在这种方法中,模型被训练为一次生成一个单词,同时考虑先前生成的单词。像 GPT(Generative Pre-trained Transformer)这样的自回归模型遵循这种方法,并在目标是单向预测下一个最合适的单词的任务中表现出色,例如自由文本生成、问答和文本补全。
此外,为了弥补对大量文本资源的需求,Transformers 在并行化方面表现出色,这意味着它们可以比传统的序列方法(如 RNN 或 LSTM 单元)更快地处理训练数据。这种高效的计算减少了训练时间,并导致了在自然语言处理、机器翻译等领域的突破性应用。
由 Google 于 2018 年开发的一个关键 Transformer 模型是 BERT(Bidirectional Encoder Representations from Transformers)。BERT 依赖于 MLM 训练,并引入了双向上下文的概念,意味着它在预测掩盖的词元时会考虑单词的左侧和右侧上下文。这种双向方法显著增强了模型对单词含义和上下文细微差别的理解,为自然语言理解和各种下游 NLP 任务建立了新的基准。
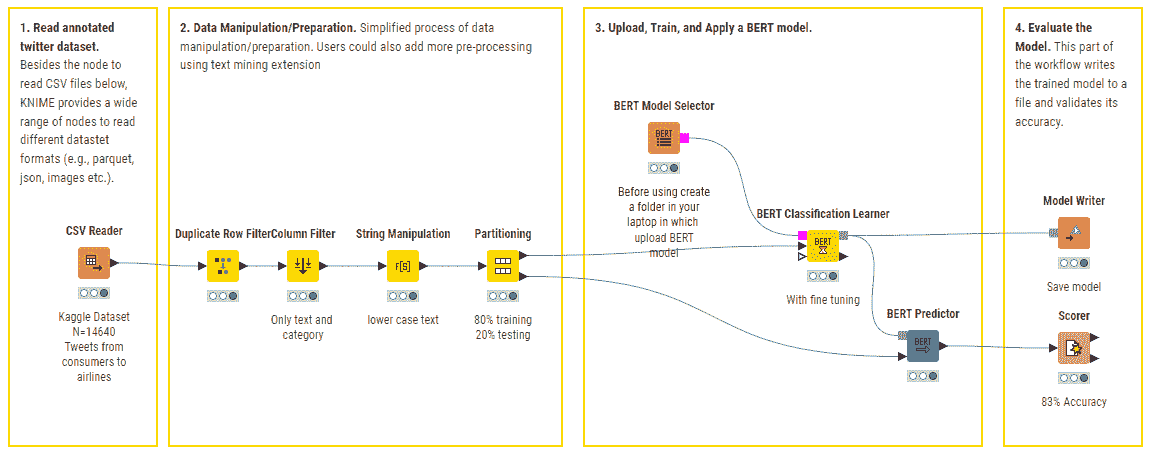
示例 KNIME 工作流 用于 BERT 的多类情感预测(积极、消极、中立)。进行了最小预处理,并利用了经过微调的预训练 BERT 模型。
在引入强大自注意力机制的 Transformers 之后,对应用的多样性和执行复杂自然语言任务(如文档摘要、文本编辑或代码生成)的日益增长的需求,促使了 大型语言模型 的发展。这些模型使用具有数十亿参数的深度神经网络,以在这些任务中表现出色,并满足数据分析行业不断变化的需求。
LLM - 大型语言模型
大型语言模型(LLMs)是一类革命性的多用途和多模态(接受图像、音频和文本输入)深度神经网络,近年来获得了大量关注。形容词大型源于它们的巨大规模,因为它们包含了数十亿的可训练参数。一些最知名的例子包括 OpenAI 的 ChatGPT、谷歌的 Bard 或 Meta 的 LLaMa。
LLMs 的特点在于它们处理和生成类似人类文本的能力和灵活性。它们在自然语言理解和生成任务中表现出色,从文本完成和翻译到问答和内容总结。它们成功的关键在于对海量文本语料库的广泛训练,使它们能够捕捉语言的细微差别、上下文和语义。
这些模型采用了深度神经网络架构,拥有多个自注意力机制的层,使它们能够在给定的上下文中权衡不同词语和短语的重要性。这种动态适应性使它们在处理各种类型的输入、理解复杂语言结构以及生成基于人类定义的提示的输出方面表现得非常出色。
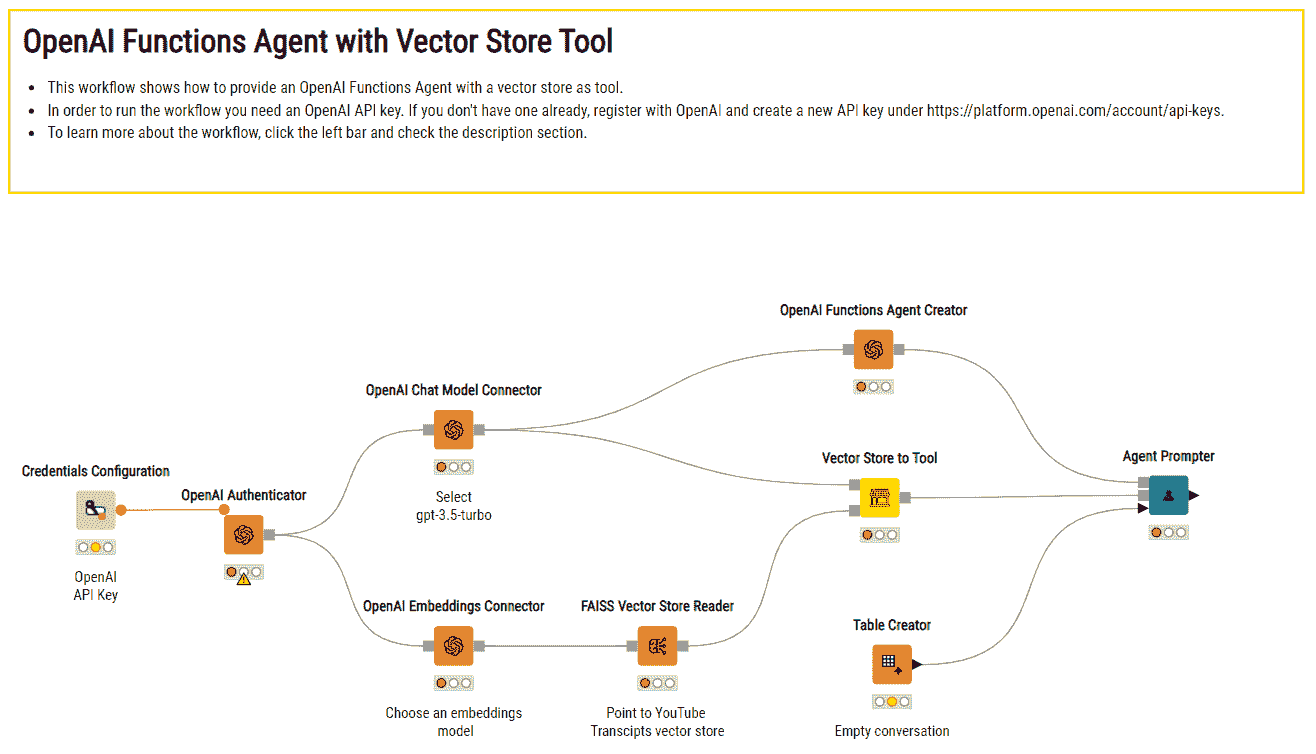
示例 KNIME 工作流 用于创建一个依赖于 OpenAI 的 ChatGPT 和一个包含自定义文档的向量存储的 AI 助手,以回答特定领域的问题。
LLMs 为多个行业的应用铺平了道路,从医疗保健和金融到娱乐和客户服务。它们甚至激发了创意写作和讲故事的新领域。
然而,它们巨大的规模、资源密集型的训练过程以及生成内容可能存在的版权问题也引发了对伦理使用、环境影响和可访问性的担忧。最后,尽管不断增强,LLMs 可能仍存在一些严重缺陷,如“幻想”错误事实、存在偏见、易受影响或生成有害内容。
这是否会有终点?
神经网络的演变,从其卑微的起点到大型语言模型的兴起,引发了一个深刻的哲学问题:这段旅程会永远结束吗?
技术的发展轨迹始终以不断的进步为特征。每一个里程碑只是通向下一次创新的垫脚石。当我们努力创建能够复制人类认知和理解的机器时,我们不禁要思考是否存在一个终极目标,一个我们可以说“就是这样;我们已达巅峰”的点。
然而,人类的好奇心和自然世界的无限复杂性却另有启示。正如我们对宇宙的理解不断深化,开发更智能、更有能力、更具伦理的神经网络的追求可能是一个无尽的旅程。(神经网络进化过程概述,作者提供的图像)
神经网络,作为人工智能的基本构建块,已经彻底改变了我们处理信息的方式,为未来技术提供了一瞥。这些复杂的计算系统,受到人脑复杂性的启发,在从图像识别和自然语言理解到自动驾驶和医疗诊断等任务中发挥了关键作用。在探索神经网络的历史进化过程中,我们将揭示它们如何演变以塑造现代人工智能的景观。
一切是如何开始的?
神经网络,作为深度学习的基础组件,其概念根源于人脑中复杂的生物神经网络。这一了不起的概念始于一个基本的类比,将生物神经元与计算网络进行了类比。
这个类比围绕着大脑展开,大脑由大约 1000 亿个神经元组成。每个神经元与其他神经元保持约 7000 个突触连接,形成了一个复杂的神经网络,支撑着人类的认知过程和决策制定。
单个生物神经元通过一系列简单的电化学过程来运作。它通过树突接收来自其他神经元的信号。当这些传入信号累加到一定水平(预定阈值)时,神经元就会被激活,并沿着轴突发送电化学信号。这会影响连接到其轴突末梢的神经元。需要注意的是,神经元的反应像一个二进制开关:它要么激活,要么保持安静,没有中间状态。
生物神经元是人工神经网络的灵感来源(图像:维基百科)。
尽管人工神经网络令人印象深刻,但它们仍远未接近人脑的惊人复杂性和深奥复杂性。然而,它们在解决对传统计算机具有挑战性但对人类认知直观的问题上表现出了显著的能力。比如图像识别和基于历史数据的预测分析。
现在我们已经探讨了生物神经元功能的基础原理及其对人工神经网络的启发,接下来让我们回顾神经网络框架的进化历程,这些框架塑造了人工智能的领域。
FFNN - 前馈神经网络
前馈神经网络,通常被称为多层感知机,是一种基础的神经网络类型,其操作深深植根于信息流动、互连层和参数优化的原则中。
在其核心,FFNNs orchestrate 信息的单向流动。所有一切都始于包含 n 个神经元的输入层,数据在此被初步接收。该层作为网络的入口点,充当需要处理的输入特征的接收器。从那里,数据开始经过网络的隐藏层进行转化的旅程。
FFNNs 的一个重要方面是它们的连接结构,这意味着每个层中的神经元都与该层中的每个神经元紧密相连。这种互连性使网络能够进行计算并捕捉数据中的关系。这就像一个通信网络,每个节点在信息处理过程中都扮演着角色。
当数据通过隐藏层时,它经历了一系列计算。隐藏层中的每个神经元接收来自前一层所有神经元的输入,对这些输入应用加权和,添加偏置项,然后通过激活函数(通常是 ReLU、Sigmoid 或 tanH)传递结果。这些数学操作使网络能够从输入中提取相关模式,并捕捉数据中的复杂、非线性关系。这是 FFNNs 相比于更浅层的 ML 模型真正出色的地方。
完全连接的前馈神经网络的架构(图片由作者提供)。
然而,这还不是全部。FFNNs 的真正力量在于它们的适应能力。在训练过程中,网络调整其权重,以最小化预测值与实际目标值之间的差异。这个迭代过程,通常基于像梯度下降这样的优化算法,被称为 反向传播。反向传播使 FFNNs 能够真正从数据中学习,并提高其预测或分类的准确性。
KNIME 工作流示例展示了用于认证考试(二元分类:通过与失败)的 FFNN。在上部分支中,我们可以看到网络架构,它由一个输入层、一个带有 tanH 激活函数的全连接隐藏层和一个使用 Sigmoid 激活函数的输出层组成(图片由作者提供)。
尽管强大且多功能,FFNNs 显示出一些相关的限制。例如,它们无法捕捉数据中的顺序性和时间/句法依赖关系——这对语言处理和时间序列分析任务至关重要。克服这些限制的需求促使了一种新型神经网络架构的演变。这一过渡为递归神经网络(RNNs)铺平了道路,后者引入了反馈回路的概念,以更好地处理序列数据。
RNN 和 LSTM - 循环神经网络和长短期记忆
从核心来看,RNN 与 FFNN 存在一些相似之处。它们也由互联节点的层组成,处理数据以进行预测或分类。然而,它们的关键区别在于其处理序列数据和捕获时间依赖性的能力。
在 FFNN 中,信息沿着从输入层到输出层的单一路径流动。这适用于数据顺序不太重要的任务。然而,在处理时间序列数据、语言或语音等序列时,保持上下文和理解数据的顺序至关重要。这是 RNN 发挥作用的地方。
RNN 引入了反馈循环的概念。这些循环作为一种“记忆”,允许网络保持一个隐藏状态,该状态捕获有关先前输入的信息,并影响当前输入和输出。虽然传统神经网络假设输入和输出彼此独立,但递归神经网络的输出依赖于序列中的前一个元素。这种递归连接机制使 RNN 特别适合处理序列,通过“记住”过去的信息。
循环网络的另一个区别特征是它们在每一层网络中共享相同的权重参数,并通过时间反向传播(BPTT)算法调整这些权重,这与传统的反向传播略有不同,因为它专门针对序列数据。
RNN 的展开表示,其中每个输入都结合了来自先前输入的上下文信息。颜色表示上下文信息的传播(图像作者提供)。
然而,传统的 RNN 存在其局限性。虽然理论上它们应该能够捕捉长期依赖关系,但在实际中,它们难以有效做到这一点,并且可能会受到梯度消失问题的影响,这妨碍了它们在许多时间步上学习和记忆信息的能力。
长短期记忆(LSTM)单元在这里发挥作用。它们专门设计用于处理这些问题,通过在其结构中引入三个门:遗忘门、输入门和输出门。
-
遗忘门:这个门决定了应该丢弃或遗忘时间步中的哪些信息。通过检查单元状态和当前输入,它确定哪些信息对当前的预测是无关的。
-
输入门:这个门负责将信息纳入单元状态。它考虑了输入和先前的单元状态,以决定应该添加哪些新信息以增强其状态。
-
输出门:这个门决定了 LSTM 单元将生成什么输出。它考虑了当前输入和更新后的单元状态,以生成可以用于预测或传递到时间步的输出。
长短期记忆单元的可视化表示(图片由 Christopher Olah 提供)。
KNIME 工作流的示例,使用带有 LSTM 单元的 RNNs 进行多类情感预测(正面、负面、中立)。上支定义了网络架构,使用输入层处理不同长度的字符串,嵌入层,具有多个单元的 LSTM 层,以及具有 Softmax 激活函数的全连接输出层以返回预测结果。
总结来说,RNNs,尤其是 LSTM 单元,专门用于序列数据,使它们能够保持记忆并捕捉时间依赖关系,这对于自然语言处理、语音识别和时间序列预测等任务至关重要。
当我们从捕捉序列依赖关系的 RNNs 转变时,演变继续向卷积神经网络(CNNs)发展。与 RNNs 不同,CNNs 在从结构化网格数据中提取空间特征方面表现出色,使其成为图像和模式识别任务的理想选择。这种转变反映了神经网络在不同数据类型和结构中的多样应用。
CNN - 卷积神经网络
CNNs 是一种特殊的神经网络,特别适合处理图像数据,如 2D 图像或甚至 3D 视频数据。它们的架构依赖于具有至少一个卷积层的多层前馈神经网络。
使 CNNs 脱颖而出的是其网络连接性和特征提取方法,这使得它们能够自动识别数据中的相关模式。与传统的 FFNNs 不同,后者将一层中的每个神经元与下一层中的每个神经元连接,CNNs 使用一种称为内核或滤波器的滑动窗口。这个滑动窗口扫描输入数据,对于空间关系重要的任务(如图像中的物体识别或视频中的运动跟踪)特别有效。当内核在图像上移动时,会在内核和像素值之间执行卷积操作(从严格的数学角度看,这个操作是交叉相关),并应用通常是 ReLU 的非线性激活函数。如果特征在图像块中,则会产生高值,否则产生小值。
与内核一起,步幅(即滑动内核的像素数)和扩张率(即每个内核单元之间的间隔)等超参数的添加和微调,使网络能够关注特定特征,识别特定区域的模式和细节,而不需要一次性考虑整个输入。
具有步幅长度=2 的卷积操作(GIF由 Sumit Saha 提供)。
有些卷积核可能专门用于检测边缘或角落,而其他卷积核则可能被调整用于识别图像中的更复杂对象,比如猫、狗或街道标志。通过将几个卷积层和池化层堆叠在一起,卷积神经网络(CNN)构建了输入数据的层次表示,逐渐从低层次特征抽象到高层次特征,就像我们的脑袋处理视觉信息一样。
示例 KNIME 工作流 用于二分类图像分类(猫与狗)。上部分支通过一系列卷积层和最大池化层定义网络架构,用于从图像中自动提取特征。然后,使用一个展平层将提取的特征准备为 FFNN 的单维输入,以执行二分类任务。
尽管卷积神经网络(CNN)在特征提取方面表现出色,并且在计算机视觉任务中取得了突破,但它们作为被动观察者,因为它们并不被设计用来生成新的数据或内容。这并不是网络本身的固有限制,但拥有强大的引擎却没有燃料会使一辆快车变得无用。确实,真实而有意义的图像和视频数据通常很难且昂贵地收集,并且往往面临版权和数据隐私限制。这种限制促使了一种新范式的出现,它建立在 CNN 的基础上,但标志着从图像分类到创造性合成的飞跃:生成对抗网络(GANs)。
GAN - 生成对抗网络
GANs 是一类特殊的神经网络,其主要但不是唯一的目的是生成与给定真实数据集非常相似的合成数据。与大多数神经网络不同,GANs 的巧妙架构设计包括两个核心模型:
-
生成器模型:在这个神经网络二重奏中,第一个角色是生成器模型。这个组件的任务是执行一个迷人的使命:给定随机噪声或输入向量,它努力创建尽可能接近真实样本的人工样本。可以把它想象成一个艺术伪造者,试图制作出与杰作无法区分的画作。
-
判别器模型:扮演对抗角色的是判别器模型。它的工作是区分由生成器生成的样本和来自原始数据集的真实样本。可以把它想象成一个艺术鉴赏家,试图从真实的艺术品中识别伪造品。
现在,魔法发生的地方在于:生成对抗网络(GAN)进行着持续的对抗性舞蹈。生成器旨在提升其艺术性,不断微调其创作,以变得更加可信。与此同时,判别器则变得更加敏锐,磨练其分辨真假样本的能力。
GAN 架构(作者提供的图像)。
随着训练的进行,生成器和判别器之间的这种动态互动会产生一个迷人的结果。生成器力求生成如此真实的样本,以至于连判别器也无法将其与真实样本区分开。这种竞争推动了两个组件不断完善自己的能力。
结果呢?生成器变得非常擅长生成看起来真实的数据,无论是图像、音乐还是文本。这一能力在图像合成、数据增强、图像到图像翻译和图像编辑等各个领域产生了显著的应用。
示例KNIME 工作流用于生成合成图像(即动物、人脸和辛普森角色)的 GANs。
GANs 通过将生成器与判别器对抗,开创了逼真的图像和视频内容创作。随着对创造力和高级操作的需求从图像扩展到序列数据,出现了更复杂的自然语言理解、机器翻译和文本生成模型。这催生了 Transformers 的发展,这是一种卓越的深度神经网络架构,不仅通过有效捕捉长程语言依赖关系和语义上下文超越了之前的架构,而且成为了最新 AI 驱动应用的无可争议的基础。
Transformers
Transformers 于 2017 年开发,拥有一个独特的特点,使其可以替代传统的递归层:自注意力机制,这使它们能够建模文档中所有单词之间的复杂关系,而不受它们位置的影响。这使得 Transformers 在处理自然语言中的长程依赖关系方面表现出色。Transformer 架构由两个主要构建模块组成:
*** 编码器。 在这里,输入序列被嵌入到向量中,然后暴露给自注意力机制。后者为每个标记计算注意力分数,以确定其相对于其他标记的重要性。这些分数用于创建加权和,随后输入到前馈神经网络(FFNN)中,以生成每个标记的上下文感知表示。多个编码器层重复这一过程,从而增强模型捕捉层次和上下文信息的能力。
- 解码器。 这个模块负责生成输出序列,过程类似于编码器。它能够在每一步中适当关注并理解编码器的输出及其自身的历史标记,通过同时考虑输入上下文和先前生成的输出来确保准确生成。
Transformer 模型架构(图片 作者:Vaswani 等,2017 年)。
例如考虑这个句子:“我在过河后到达了银行”。单词“bank”可以有两个意思——金融机构或河岸。变换器在这里发挥了作用。它们可以迅速关注单词“river”,通过将“bank”与句子中的每个其他单词进行比较,并分配注意力得分,从而消除歧义。这些得分决定了每个单词对“bank”下一个表示的影响。在这种情况下,“river”获得了更高的得分,有效地澄清了意图的意义。
为了做到这一点,Transformers 依赖于数百万的可训练参数,需要大量的文本语料库和复杂的训练策略。与 Transformers 一起使用的一个显著训练方法是 掩码语言建模 (MLM)。在训练期间,输入序列中的特定标记会被随机掩盖,模型的目标是准确预测这些掩盖的标记。这种策略鼓励模型掌握单词之间的上下文关系,因为它必须依赖周围的单词来进行准确的预测。这种方法由 BERT 模型推广,在各种 NLP 任务中取得了最先进的结果。
对于 Transformers 的替代方法是 自回归建模。在这种方法中,模型被训练为一次生成一个单词,同时依据先前生成的单词进行条件化。像 GPT(生成式预训练变换器)这样的自回归模型遵循这种方法,在预测单向的下一个最合适的单词时表现出色,例如自由文本生成、问答和文本补全。
此外,为了弥补对大量文本资源的需求,Transformers 在并行化方面表现出色,这意味着它们可以比传统的序列化方法(如 RNNs 或 LSTM 单元)更快地处理数据,从而减少训练时间,并在自然语言处理、机器翻译等领域取得了突破性的应用。
由谷歌在 2018 年开发的一个具有重大影响的关键 Transformer 模型是 BERT(双向编码器表示来自 Transformers)。BERT 依赖于 MLM 训练,并引入了双向上下文的概念,这意味着在预测掩盖的标记时,它考虑单词的左右上下文。这种双向方法显著增强了模型对单词含义和上下文细微差别的理解,为自然语言理解和广泛的下游 NLP 任务建立了新的基准。
示例 KNIME 工作流 用于多类别情感预测(正面、负面、中性)。执行了最小的预处理,并利用了经过微调的预训练 BERT 模型。
在引入强大自注意力机制的 Transformers 之后,对应用的多样性和执行复杂自然语言任务(如文档总结、文本编辑或代码生成)的需求不断增长,这促使了大型语言模型的开发。这些模型使用具有数十亿参数的深度神经网络,在这些任务中表现出色,并满足数据分析行业不断变化的需求。
LLM - 大型语言模型
大型语言模型(LLMs)是一类革命性的多用途和多模态(接受图像、音频和文本输入)深度神经网络,近年来获得了广泛关注。形容词large源于它们的庞大规模,因为它们包含数十亿个可训练参数。一些最著名的例子包括 OpenAI 的 ChatGTP、Google 的 Bard 或 Meta 的 LLaMa。
LLMs 的独特之处在于它们无与伦比的处理和生成类人文本的能力。它们在自然语言理解和生成任务中表现出色,范围涵盖从文本补全和翻译到问答和内容总结。它们成功的关键在于对大量文本语料的广泛训练,使它们能够捕捉语言细微差别、上下文和语义的丰富理解。
这些模型采用深度神经架构,具有多层自注意力机制,使它们能够权衡给定上下文中不同单词和短语的重要性。这种动态适应性使它们在处理各种类型的输入、理解复杂语言结构以及根据人类定义的提示生成输出方面表现得特别高效。
示例 KNIME 工作流 通过依赖 OpenAI 的 ChatGPT 和包含自定义文档的向量存储来创建 AI 助手,以回答特定领域的问题。
LLMs 为各种行业带来了众多应用,从医疗保健和金融到娱乐和客户服务。它们甚至在创意写作和讲故事方面开辟了新的领域。
然而,它们巨大的规模、资源密集型的训练过程以及生成内容可能涉及的版权问题也引发了对伦理使用、环境影响和可访问性的担忧。最后,尽管不断增强,LLMs 可能仍存在一些严重缺陷,例如“幻觉”错误事实、偏见、易受影响或被迫生成有害内容。
是否有终点?
从神经网络的谦逊起点到大型语言模型的兴起,这一演变提出了一个深刻的哲学问题:这一旅程是否会有尽头?
技术的发展历程始终以不懈的进步为特征。每一个里程碑只是通向下一个创新的垫脚石。当我们努力创造能够复制人类认知和理解的机器时,很容易产生这样的疑问:是否存在一个终极目标,一个我们可以说“这就是它;我们已经达到了巅峰”的点。
然而,人类好奇心的本质和自然界的无限复杂性表明情况并非如此。正如我们对宇宙的理解不断加深,开发更智能、更有能力、更具伦理的神经网络的探索也许是一次无尽的旅程。
Anil 是 KNIME 的数据科学传播者。
更多相关话题
来自哈佛、斯坦福、麻省理工学院、康奈尔大学和伯克利的免费数据科学课程合集

作者提供的图片
免费课程在我们的平台上非常受欢迎,我们收到了许多初学者和专业人士请求更多资源。为了满足有志于成为数据科学家的需求,我们提供了来自全球顶级大学的免费数据科学课程合集。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
这些课程由大学教授和技术助理授课,涵盖数学、概率、编程、数据库、数据分析、数据处理、数据分析和机器学习等主题。完成这些课程后,你将获得掌握数据科学和为工作做好准备所需的技能。
计算机科学
链接: 5 门免费大学课程学习计算机科学
如果你考虑转行到数据领域,学习计算机科学基础是至关重要的。许多数据科学职位申请中包括编码面试环节,你需要用你选择的编程语言解决问题。
这个汇编提供了一些最佳的免费大学课程,帮助你掌握计算机硬件/软件等基础知识。你将学习 Python、数据结构和算法,以及软件工程的必备工具。
Python
链接: 5 门免费大学课程学习 Python
精选的五门在线课程,由哈佛、麻省理工学院、斯坦福、密歇根大学和卡内基梅隆大学等著名大学提供。这些课程旨在教会初学者 Python 编程,涵盖基础知识,如变量、控制结构、数据结构、文件输入输出、正则表达式、面向对象编程,以及计算机科学概念,如递归、排序算法和计算限制。
数据库和 SQL
链接: 5 门免费的大学课程以学习数据库和 SQL
这是一个由康奈尔大学、哈佛大学、斯坦福大学和卡内基梅隆大学等知名大学提供的免费数据库和 SQL 课程的列表。这些课程涵盖了从 SQL 和关系数据库基础知识到 NoSQL、NewSQL、数据库内部、数据模型、数据库设计、分布式数据处理、事务处理、查询优化以及现代分析数据仓库如 Google BigQuery 和 Snowflake 的内部工作等广泛的主题。
数据分析
链接: 5 门免费的大学课程以学习数据分析
在线课程和资源的汇编,供有意从事数据科学、机器学习和人工智能的个人使用。它突出了来自哈佛、麻省理工学院、斯坦福大学、伯克利等著名机构的课程,涵盖了数据科学的 Python、统计思维、数据分析、大规模数据集挖掘以及人工智能入门等主题。
通用数据科学
链接: 5 门免费的大学课程以学习数据科学
一个全面的免费在线课程列表,来自哈佛、麻省理工学院和斯坦福大学,旨在帮助个人从零开始学习数据科学。课程从 Python 编程和数据科学基础入手,随后是计算思维、统计学习和数据科学概念背后的数学课程。这些课程涵盖了编程、统计学、机器学习算法、降维技术、聚类和模型评估等广泛的主题。
利用哈佛课程掌握数据科学的 9 个步骤
链接: 9 门免费的哈佛课程以学习数据科学 - KDnuggets
该计划概述了一个数据科学学习路线图,包括哈佛大学提供的 9 门免费课程。它从学习 R 或 Python 的编程基础开始,接着是数据可视化、概率、统计学和生产力工具的课程。然后涵盖数据预处理技术、线性回归和机器学习概念。最后一步是一个顶点项目,让学习者将从之前课程中获得的知识应用于实际的数据科学项目。
结论
来自顶级大学的免费在线课程是任何希望进入数据科学领域或提升现有技能的人的宝贵资源。这个精选集合包含了涵盖所有关键领域的课程列表——从核心计算机科学和 Python 编程,到数据库和 SQL、数据分析、机器学习,以及完整的数据科学课程。通过世界级教授授课,你可以获得全面的知识和最新数据科学工具及技术的实际操作经验。
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专家,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络开发一个 AI 产品,帮助那些面临心理健康问题的学生。
更多相关主题
2023 年十大开源数据科学工具的比较概述
原文:
www.kdnuggets.com/a-comparative-overview-of-the-top-10-open-source-data-science-tools-in-2023

图片由作者提供
数据科学是每个行业都在关注的流行话题。作为数据科学家,您的主要工作是从数据中提取有意义的见解。但问题在于,随着数据以指数级增长,挑战比以往任何时候都大。您会经常感到在数字大海捞针。这时,数据科学工具作为我们的救星出现。它们帮助您挖掘、清理、组织和可视化数据,以提取有意义的见解。现在,让我们解决真正的问题。在众多数据科学工具中,您如何找到合适的工具?这个问题的答案在于本文。通过个人经验、宝贵的社区反馈以及数据驱动世界的脉搏,我整理了一份强有力的清单。我只关注开源数据科学工具,因为它们的成本效益、灵活性和透明度。
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的 IT 组织
不再耽搁,让我们探索今年您必须拥有的十大开源数据科学工具:
1. KNIME:简约与强大的桥梁
KNIME 是一个免费且开源的工具,能为数据科学新手和经验丰富的专业人士提供便利的数据分析、可视化和部署。它是一个将数据转化为可操作见解的画布,几乎不需要编程。它是简单与强大的灯塔。您应该考虑使用 Knime,原因如下:
-
基于 GUI 的数据预处理和管道化使各种技术背景的用户能够轻松执行复杂任务
-
允许无缝集成到您当前的工作流程和系统中
-
KNIME 的模块化方法使用户能够根据需求自定义工作流程
2. Weka:传统与现代的结合
Weka是一个经典的开源工具,允许数据科学家预处理数据、构建和测试机器学习模型,并使用 GUI 界面可视化数据。尽管它已经相当古老,但由于其适应模型挑战的能力,它在 2023 年仍然相关。它支持多种语言,包括 R、Python、Spark、scikit-learn 等。它非常方便和可靠。以下是一些 Weka 的突出特性:
-
它不仅适合数据科学从业者,而且是教授机器学习概念的极好平台,从而提供教育价值。
-
通过减少数据管道空闲时间,从而减少碳排放,帮助你轻松实现可持续性。
-
提供令人惊叹的性能,支持高 I/O、低延迟、小文件和混合工作负载,无需调优。
3. Apache Spark:点燃数据处理
Apache Spark是一个著名的数据科学工具,提供实时数据分析。它是最广泛使用的可扩展计算引擎。我提到它是因为它闪电般的数据处理能力。你可以轻松地连接到不同的数据源,而不必担心数据存放的位置。虽然它很出色,但并非没有缺点。由于其速度,它需要相当大的内存。以下是你应该选择 Spark 的原因:
-
它易于使用,提供了一个简单的编程模型,使你能够使用你已经熟悉的语言创建应用程序。
-
你可以获得一个统一处理引擎来处理你的工作负载。
-
它是一站式服务,用于批处理、实时更新和机器学习。
4. RapidMiner:完整的数据科学生命周期
RapidMiner因其全面性而脱颖而出。它是你在整个数据科学生命周期中的真正伙伴。从数据建模和分析到数据部署和监控,这个工具涵盖了所有内容。它提供了可视化工作流程设计,省去了复杂编码的需要。这个工具还可以用来从零开始构建自定义数据科学工作流程和算法。RapidMiner 的广泛数据准备功能使你能够提供最精炼的数据版本用于建模。以下是一些关键特性:
-
它通过提供一个可视化和直观的界面来简化数据科学过程。
-
RapidMiner 的连接器使数据集成变得轻而易举,无论数据的大小或格式。
5. Neo4j Graph Data Science:揭示隐藏的连接
Neo4j 图数据科学 是一种分析数据之间复杂关系以发现隐藏连接的解决方案。它超越了行和列,识别数据点如何相互作用。它包括预配置的图算法和自动化流程,专门为数据科学家设计,帮助他们快速展示图分析的价值。它在社交网络分析、推荐系统以及其他需要关注连接的场景中特别有用。以下是它提供的一些额外好处:
-
改进的预测,拥有超过 65 种图算法的丰富目录。
-
允许无缝的数据生态系统集成,使用 30+ 个连接器和扩展。
-
它强大的工具允许快速部署,使你能够迅速将工作流程发布到生产环境中。
6. ggplot2: 打造视觉故事
ggplot2 是一个令人惊叹的数据可视化 R 包。它将你的数据转化为视觉杰作。它建立在图形语法的基础上,提供了一个定制的游乐场。即使是默认的颜色和美学也更为出色。ggplot2 采用分层方法为你的视觉效果添加细节。虽然它可以将你的数据转化为一个等待讲述的美丽故事,但重要的是要认识到,处理复杂图形可能会导致繁琐的语法。以下是你应该考虑使用它的原因:
-
能够将图形保存为对象,允许你创建不同版本的图形,而无需重复大量代码。
-
与其在多个平台之间来回切换,ggplot2 提供了一个统一的解决方案。
-
大量有用的资源和详尽的文档,帮助你入门。
7. D3.js: 互动数据杰作
D3 是数据驱动文档(Data-Driven Documents)的简称。它是一个强大的开源 JavaScript 库,允许你通过 DOM 操作技术创建令人惊叹的视觉效果。它创建的交互式可视化会响应数据的变化。然而,对于那些初次接触 JavaScript 的人来说,它的学习曲线较陡。尽管其复杂性可能是一个挑战,但它所提供的回报是非常宝贵的。以下是一些列出的好处:
-
它提供定制性,通过丰富的模块和 API。
-
它是轻量级的,不会影响你的网页应用性能。
-
它与当前的网络标准兼容良好,并且可以轻松集成其他库。
8. Metabase: 简化数据探索
Metabase 是一个拖放式的数据探索工具,技术用户和非技术用户都可以使用。它简化了数据分析和可视化的过程。其直观的界面使您能够创建交互式仪表板、报告和可视化。它在企业中越来越受欢迎。它还提供了以下其他好处:
-
用普通语言查询替代复杂的 SQL 查询。
-
支持协作,允许用户与他人分享他们的见解和发现。
-
支持超过 20 种数据源, 使用户能够连接到数据库、电子表格和 API。
9. Great Expectations: 确保数据质量
Great Expectations 是一个数据质量工具,使您能够对数据进行检查并有效捕捉任何违规行为。顾名思义,您为数据定义一些期望或规则,然后它会根据这些期望监控数据。这使得数据科学家对数据有更多的信心。它还提供数据剖析工具来加速数据发现。Great Expectations 的关键优势如下:
-
生成详细的文档,对技术用户和非技术用户都非常有用。
-
与不同数据管道和工作流程的无缝集成。
-
允许自动化测试,以便在过程中及早发现任何问题或偏差。
10. PostHog: 提升产品分析
PostHog 是一个开源的产品分析工具,使企业能够跟踪用户行为以提升产品体验。它使数据科学家和工程师能更快地获取数据,消除了编写 SQL 查询的需求。它是一个全面的产品分析套件,具有仪表板、趋势分析、漏斗、会话录制等功能。以下是 PostHog 的关键方面:
-
通过其A/B 测试功能,为数据科学家提供了一个实验平台。
-
允许与数据仓库的无缝集成,以便导入和导出数据。
-
提供对用户与产品交互的深入理解,通过捕获会话重播、控制台日志和网络监控。
总结
我想提到的一点是,随着我们在数据科学领域的进步,这些工具不仅仅是选择,它们已经成为指导您做出明智决策的催化剂。因此,请不要犹豫,深入了解这些工具并尽可能多地进行实验。最后,我很好奇,您有没有遇到或使用过任何您想添加到此列表中的工具?请随时在下面的评论中分享您的想法和建议。
Kanwal Mehreen 是一名有志的软件开发人员,对数据科学和人工智能在医学中的应用有浓厚的兴趣。Kanwal 被选为 2022 年亚太地区 Google Generation Scholar。Kanwal 喜欢通过撰写有关热门话题的文章来分享技术知识,并且热衷于提升女性在科技行业中的代表性。
更多相关内容
Pinecone 向量数据库全面指南
原文:
www.kdnuggets.com/a-comprehensive-guide-to-pinecone-vector-databases
向量数据库是一种将数据存储为数学向量的数据库类型,这些向量表示特征或属性。这些向量具有多个维度,捕捉复杂的数据关系。这使得相似性和距离计算变得高效,非常适用于机器学习、数据分析和推荐系统等任务。
简单来说,向量用于表示数据属性。例如,一个向量可以表示图像的颜色、文本的情感或地图上一个点的位置。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
Pinecone 向量数据库是一种专为高性能和可扩展性设计的向量数据库。使用向量的应用主要包括以下几个方面:
-
自然语言处理
-
计算机视觉,以及
-
机器学习。
Pinecone 向量数据库的关键特性
以下是 Pinecone 向量数据库的一些关键特性:
高性能:Pinecone 向量数据库可以非常快速地搜索和检索向量。这使得它们非常适合需要实时或接近实时数据处理的应用程序。
可扩展性:Pinecone 向量数据库可以扩展以处理大数据集和高查询负载。这使得它们适合企业应用程序。
灵活性:Pinecone 向量数据库可以与多种编程语言和机器学习框架配合使用,因此可以集成到现有的应用程序中。
易用性:Pinecone 向量数据库易于使用和管理。因此,开发人员倾向于选择不熟悉向量数据库的 Pinecone 向量数据库。
如果你在寻找高性能、可扩展且灵活的向量数据库,那么 Pinecone 向量数据库是一个值得考虑的选项。
Pinecone 向量数据库的应用
向量数据库在提升 LLM 数据组织和检索的准确性与效率中发挥着关键作用。大型语言模型(如 GPT-4 和 LLaMa)利用高维向量嵌入来理解单词、句子和文档之间的复杂关系。这些向量嵌入由向量数据库存储和管理,使 LLM 能够生成有洞察力且具有上下文相关性的输出。
以下是 Pinecone 向量数据库的一些应用:
自然语言处理:Pinecone 向量数据库可用于情感分析、文本分类和问答等任务。
机器学习:Pinecone 向量数据库可用于训练和部署机器学习模型。
计算机视觉:Pinecone 向量数据库可用于对象检测、图像分类和面部识别等任务。
欺诈检测:Pinecone 向量数据库可用于检测欺诈性交易。
推荐系统:Pinecone 向量数据库可用于向用户推荐产品、电影和其他物品。
使用 Pinecone 向量数据库的挑战
以下是使用 Pinecone 向量数据库的一些挑战:
维度:向量数据库 旨在存储和搜索高维数据。存储和处理高维数据可能对某些应用来说计算开销较大。
数据质量:高质量的数据能够保持数据点之间的关系,从而提高准确的向量表示和查询精度。低质量数据会对结果的准确性产生不利影响。
隐私:向量数据库可以存储敏感数据,如文本或图像。强烈建议使用加密和访问控制等措施,以保护数据隐私。
复杂性:向量数据库的设置和管理可能很复杂,因此,在部署向量数据库之前,了解其工作机制是重要的。
成本:向量数据库可能比传统数据库更昂贵,因为它们需要更多的硬件和软件资源。
尽管存在这些挑战,Pinecone 向量数据库仍可以在各种应用中发挥重要作用。如果你考虑使用向量数据库,重要的是要仔细权衡挑战和收益。
缓解使用 Pinecone 向量数据库挑战的技巧。
以下是缓解使用 Pinecone 向量数据库挑战的一些好建议。
在所有可用的向量数据库中,选择适合你需求的数据库。每种类型的向量数据库都有其自身的优缺点,因此,选择最适合你特定应用的数据库。
使用合适的硬件和软件。向量数据库对硬件和软件资源的要求较高。合适的工具包括但不限于高效的数据库监控、复制延迟、跟踪过程和偏离正常的情况。
规划可扩展性。向量数据库可以扩展以处理大型数据集和高查询负载。然而,必须从一开始就规划可扩展性,以避免瓶颈。
监控数据库性能。长期了解低性能的数据库可能对你造成更大的伤害,因此,早期监控数据库的性能,以确保它符合你的期望。这样,你可以在初期阶段解决问题并采取纠正措施。
通过遵循这些提示,你可以最大限度地减少使用 Pinecone 向量数据库的挑战,并充分发挥这一强大工具的作用。
Pinecone 向量数据库如何工作?
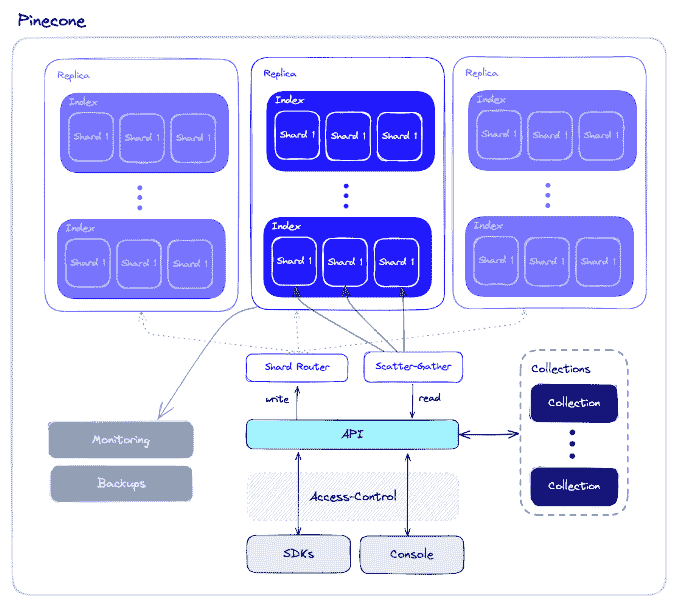
来源:Pinecone.io
Pinecone 向量数据库的工作原理是索引向量,然后使用各种算法来搜索和检索与查询向量相似的向量。索引过程通常在离线进行,以便在需要时可以快速搜索这些向量。
Pinecone 向量数据库的使用案例
Pinecone 向量数据库可以以多种方式使用。一些最常见的使用案例包括:
-
自然语言处理(NLP):Pinecone 向量数据库可以用于 NLP 任务。NLP 任务涉及理解和处理人类语言。一些 NLP 任务的示例包括情感分析、文档聚类和问答系统。
-
图像和视频分析:Pinecone 向量数据库可以用于图像和视频分析任务。图像和视频分析任务涉及理解和处理图像和视频。一些图像和视频分析任务的示例包括对象识别、图像相似性搜索和视频推荐系统。
-
异常检测:Pinecone 向量数据库可以用于异常检测。异常检测的任务是寻找那些异常或不合常规的数据点。通过将新数据点与现有向量进行比较,Pinecone 向量数据库可以用来发现异常。
-
推荐系统:Pinecone 向量数据库可以用于支持推荐系统。推荐系统用于根据用户的兴趣推荐产品、电影或其他项目。这是通过跟踪用户的旅程、过去的行为和偏好,并将其与存储在数据库中的数据进行比较来实现的。
-
自然语言处理(NLP):Pinecone 向量数据库可以用于 NLP 任务。NLP 任务涉及理解和处理人类语言。它也常用于执行文档聚类、情感分析和问答。例如,Pinecone 向量数据库可以用来分析文本数据,以确定一篇文章的情感,如是否是积极的、消极的或中立的。
-
图像和视频分析:Pinecone 向量数据库可以用于图像和视频分析任务。想知道这些任务是什么吗?其实,这些任务涉及理解和处理图像与视频。这可以用于诸如物体识别、图像相似度搜索和视频推荐系统等任务。例如,Pinecone 向量数据库可以用来识别图像或视频中的物体,如面孔、汽车或建筑物。
-
异常检测:Pinecone 向量数据库可以用于异常检测。异常检测是寻找异常或不合常规的数据点的任务。这在识别可疑交易、网络安全漏洞及其他相关问题中也非常有用。例如,金融交易常常被分析以寻找可能表明欺诈的模式。
-
欺诈检测:Pinecone 向量数据库用于通过将新交易与以前识别出的欺诈交易数据库进行比较来检测欺诈交易。表示新交易的向量与表示已知欺诈交易的向量进行比较。
-
网络安全:Pinecone 向量数据库可以用于检测网络攻击,主要通过监控网络流量并识别高度容易受到网络攻击的可疑模式。表示网络流量的向量与表示已知网络攻击的向量进行比较。如果这些向量相似,则网络流量可能是恶意的。
-
智慧城市:Pinecone 向量数据库可以用于建设智慧城市。智慧城市指的是帮助人们提升生活水平的现代生活条件。Pinecone 向量数据库帮助市政府管理交通、能源,并保持环境健康和安全。随着技术的发展,更多创新的应用不断涌现。
除了上述提到的方法外,随着技术的不断发展,还会出现其他几种方法,我们可以期待看到这些强大数据库的更多创新和创意应用。
结论
向量数据库和大型语言模型(LLMs)之间的共生关系正在推动数据管理的演变,提供更快速和更精确的相似性搜索,这对语言理解和生成至关重要。随着向量数据库和 LLMs 的重要性持续上升,它们正在重塑以 AI 驱动的应用的格局,确保高效处理和利用大量数据。
Ayesha Saleem 对品牌的改造充满热情,擅长有意义的内容写作、文案撰写、电子邮件营销、SEO 写作、社交媒体营销和创意写作。
更多相关话题
掌握大型语言模型的综合资源清单
原文:
www.kdnuggets.com/a-comprehensive-list-of-resources-to-master-large-language-models

图片由 Leonardo.Ai 生成
在广袤的人工智能领域中,出现了一股革命性的力量——大型语言模型(LLMs)。这不仅仅是一个流行词,而是我们的未来。它们理解和生成类似人类文本的能力使其成为焦点,现在已成为最热门的研究领域之一。想象一个聊天机器人可以像你和朋友对话那样回应你,或者设想一个内容生成系统,使人们难以区分是由人类还是人工智能撰写的。如果这些事物令你感兴趣,并且你想深入了解 LLMs 的核心,那么你来对地方了。我收集了一份全面的资源清单,从信息文章、课程到 GitHub 仓库以及相关研究论文,这些都可以帮助你更好地理解它们。事不宜迟,让我们开始在 LLMs 世界中的精彩旅程吧。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
1. 基础课程

图片由 Polina Tankilevitch 提供,来自 Pexels
1. 深度学习专业课程 - Coursera
链接: 深度学习专业课程
描述: 深度学习是 LLMs 的基础。这门由 Andrew Ng 授课的全面课程涵盖了神经网络的基本主题、计算机视觉和自然语言处理的基础知识,以及如何构建你的机器学习项目。
2. 斯坦福 CS224N:深度学习中的自然语言处理 - YouTube
描述: 这是一个知识宝库,提供了对深度学习在自然语言处理中的前沿研究的全面介绍。
3. HuggingFace Transformers 课程 - HuggingFace
链接: HuggingFace Transformers 课程
描述: 本课程通过使用 HuggingFace 生态系统中的库来教授 NLP。它涵盖了 HuggingFace 以下库的内部工作原理和使用方法:
-
Transformers
-
Tokenizers
-
数据集
-
Accelerate
4. ChatGPT 提示工程师培训 - Coursera
链接: ChatGPT 提示工程课程
描述: ChatGPT 是一种流行的 LLM,本课程分享了编写有效提示以获得更好响应生成的最佳实践和基本原则。
2. 针对 LLM 的特定课程
图像由 Leonardo.Ai 生成
1. LLM 大学 - Cohere
链接: LLM 大学
描述: Cohere 提供了一门专业课程来掌握 LLM。其按顺序的课程,详细介绍了 NLP、LLM 及其架构的理论方面,适合初学者。非顺序路径则面向那些对这些强大模型的实际应用和用例更感兴趣的经验丰富的个人,而不是其内部工作原理。
2. 斯坦福 CS324: 大型语言模型 - 斯坦福网站
链接: 斯坦福 CS324:大型语言模型
描述: 本课程深入探讨这些模型的复杂性。你将探索这些模型的基础知识、理论、伦理和实际方面,同时获得一些动手经验。
3. 普林斯顿 COS597G: 理解大型语言模型 - 普林斯顿网站
链接: 理解大型语言模型
描述: 这是一门研究生级别的课程,提供了全面的课程内容,是深入学习的绝佳选择。你将探索诸如 BERT、GPT、T5 模型、专家混合模型、基于检索的模型等的技术基础、能力和局限性。
4. 苏黎世联邦理工学院:大型语言模型(LLMs)- RycoLab
链接: ETH 苏黎世:大型语言模型
描述: 这门新设计的课程提供了对 LLM 的全面探索。深入了解概率基础、神经网络建模、训练过程、扩展技术以及关于安全性和潜在滥用的关键讨论。
5. 全栈 LLM 训练营 - The Full Stack
链接: 全栈 LLM 训练营
描述: 全栈 LLM 训练营是一门与行业相关的课程,涵盖了如提示工程技术、LLM 基础、部署策略和用户界面设计等主题,确保参与者能够充分准备好构建和部署 LLM 应用程序。
6. 大型语言模型的微调 - Coursera
链接: 大型语言模型的微调
描述: 微调是一种让你根据特定需求调整 LLM 的技术。完成此课程后,你将理解何时应用微调、微调的数据准备,以及如何在新数据上训练 LLM 并评估其性能。
3. 文章 / 书籍

使用 Leonardo.Ai 生成的图像
1. ChatGPT 在做什么……以及它为什么有效? - Steven Wolfram
描述: 这本短书由著名科学家 Steven Wolfram 撰写。他讨论了 ChatGPT 的基本方面,它在神经网络中的起源,以及在变压器、注意力机制和自然语言处理方面的进展。对于有兴趣探索 LLM 能力和局限性的人来说,这是一本很好的读物。
2. 理解大型语言模型:变革性阅读清单 - Sebastian Raschka
链接: 理解大型语言模型:变革性阅读清单
描述: 这本书包含了重要研究论文的集合,并提供了一个按时间顺序的阅读列表,从早期的递归神经网络(RNNs)论文到影响力巨大的 BERT 模型及其后续内容。它是研究人员和从业者了解 NLP 和 LLM 演变的宝贵资源。
3. 文章系列:大型语言模型 - Jay Alammar
链接: 文章系列:大型语言模型
描述: Jay Alammar 的博客是学习大型语言模型(LLMs)和变压器的知识宝库。他的博客以独特的可视化、直观的解释和全面的主题覆盖而脱颖而出。
4. 为生产构建 LLM 应用 - Chip Huyen
链接: 为生产构建 LLM 应用
描述: 本文讨论了生产化大型语言模型(LLMs)的挑战。它提供了任务可组合性的见解,并展示了有前景的使用案例。任何对实际应用的 LLMs 感兴趣的人都会发现它非常有价值。
4. Github 仓库

图片由 RealToughCandy.com 提供,来自 Pexels
1. Awesome-LLM ( 9k ⭐ )
链接: Awesome-LLM
描述: 这是一个精心策划的论文、框架、工具、课程、教程和资源的集合,专注于大型语言模型(LLMs),特别是 ChatGPT。
2. LLMsPracticalGuide ( 6.9k ⭐ )
链接: 大型语言模型实用指南
描述: 它帮助从业者在广阔的 LLM 领域中导航。它基于调查论文《实践中利用 LLMs 的力量:ChatGPT 及其后续研究》和 这篇 博客。
3. LLMSurvey ( 6.1k ⭐ )
链接: LLMSurvey
描述: 这是一个基于论文《大型语言模型调查》的调查论文和资源的集合。它还包含了 GPT 系列模型的技术演变图解以及 LLaMA 研究工作的演变图。
4. Awesome Graph-LLM ( 637 ⭐ )
描述: 这是对图形技术与 LLMs 交集感兴趣的人的宝贵资源。它提供了研究论文、数据集、基准、调查和工具的集合,深入探讨了这一新兴领域。
5. Awesome Langchain ( 5.4k ⭐ )
描述: LangChain 是一个快速高效的 LLM 项目框架,这个库是跟踪与 LangChain 生态系统相关的倡议和项目的中心。
5. 额外资源 - 研究与调查论文
-
"A Complete Survey on ChatGPT in AIGC Era” - 对于 LLMs 的初学者来说,这是一个很好的起点。它全面覆盖了 ChatGPT 的基础技术、应用和挑战。
-
“大型语言模型调查” - 它涵盖了 LLMs 在预训练、适应性调整、利用和能力评估四个主要方面的最新进展。
-
“大型语言模型的挑战与应用” - 讨论了 LLMs 的挑战和成功应用领域。
-
“Attention Is All You Need” - Transformers 是 GPT 和其他 LLMs 的基础,这篇论文介绍了 Transformer 架构。
-
“注释 Transformer” - 哈佛大学提供的资源,详细注释了解释了 Transformer 架构,这是许多 LLMs 的基础。
-
“图解 Transformer” - 一份视觉指南,帮助你深入理解 Transformer 架构,使复杂概念更易于掌握。
-
"BERT: 深度双向变换器的预训练用于语言理解" - 这篇论文介绍了 BERT,一种高度影响力的 LLM,设定了许多自然语言处理(NLP)任务的新基准。
总结
在这篇文章中,我汇总了掌握大型语言模型(LLMs)所需的重要资源。然而,学习是一个动态的过程,知识共享是其核心。如果你有额外的资源认为应该加入这个全面的列表,请不要犹豫,在评论区分享它们。你的贡献对其他学习者可能非常宝贵,能够为知识的丰富和互动创造一个合作的空间。
Kanwal Mehreen**** Kanwal 是一名机器学习工程师和技术作家,对数据科学以及人工智能与医学的交集充满热情。她合著了电子书《利用 ChatGPT 最大化生产力》。作为 2022 年亚太地区的 Google Generation Scholar,她倡导多样性和学术卓越。她还被认定为 Teradata 技术多样性学者、Mitacs Globalink 研究学者和哈佛 WeCode 学者。Kanwal 是变革的坚定倡导者,创立了 FEMCodes,旨在赋能 STEM 领域的女性。
更多相关话题
数据湖,你称它为数据沼泽?
原文:
www.kdnuggets.com/a-data-lake-you-call-it-it-a-data-swamp
作者提供的图片
如果你是一名数据专业人士,你可能对数据湖架构已经很熟悉。数据湖可以存储大量的原始和非结构化数据,因此它提供了灵活性和可扩展性。然而,在缺乏数据治理的情况下,数据湖可能会迅速变成“数据沼泽”,使得从海量数据中获取任何价值变得极具挑战性。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
在本文中,我们将回顾数据湖的特点和优势,探讨导致其成为数据沼泽的挑战,以及更重要的,缓解这些挑战的策略。让我们开始吧!
数据湖概述
数据湖是一个数据存储库,允许组织在大规模上存储大量的原始、非结构化、半结构化和结构化数据。它作为一个灵活且具成本效益的解决方案来管理各种数据类型,支持高级分析、机器学习及其他数据驱动的应用。接下来,我们将探讨数据湖的一些特点和优势。
数据湖的特点
让我们回顾一下数据湖在数据类型、数据存储、数据摄取和处理方面的一些特点:
-
数据类型:数据湖可以以原始未处理的格式存储大量数据。
-
批处理和实时摄取:数据湖支持批处理和实时数据摄取,使组织能够处理来自各种来源的数据,包括流数据。
-
存储层:数据湖的存储层通常建立在分布式文件系统或基于云的对象存储上。
-
处理框架:数据湖利用如 Apache Spark、Flink 和 Hadoop MapReduce 等分布式处理框架进行并行和可扩展的数据处理。
-
与分析工具的集成:数据湖与各种分析和商业智能工具集成,允许用户使用熟悉的界面分析和可视化数据。
数据湖的优势
现在让我们深入了解一下数据湖作为存储抽象的一些优势:
-
灵活性:数据湖可以存储各种类型的数据,包括文本、图像、视频、日志文件和结构化数据。这种灵活性允许组织摄取和处理多样化的数据集,而无需预定义的模式。与数据仓库不同,数据湖以其原生格式存储原始、未聚合的数据。
-
可扩展性:数据湖设计为水平扩展,允许组织存储和处理大量数据。
-
经济高效的存储:通过利用基于云的对象存储或分布式文件系统,数据湖提供了一种经济高效的解决方案,用于存储大量数据。特别是基于云的数据湖允许组织只为实际使用的存储和计算资源付费。
要了解数据湖与数据仓库和数据集市的比较,请阅读数据仓库与数据湖与数据集市:需要帮助决定吗?
数据湖如何以及为何会变成数据沼泽
当数据湖得到适当管理时,它作为一个集中式的存储库,用于存储来自各种来源的大量原始和非结构化数据。然而,在缺乏适当治理的情况下,数据湖可能会变成俗称的“数据沼泽”。
治理是指指导数据在组织内使用、访问和管理的一系列政策、程序和控制措施。以下是治理缺失如何促使数据湖转变为沼泽的方式:
*** 数据质量下降:没有适当的治理,就没有定义的数据质量标准,导致数据不一致、不准确和不完整。缺乏质量控制导致数据整体可靠性下降。
-
数据扩散失控:缺乏治理政策导致数据摄取不受控制,从而导致大量数据涌入,而没有适当的分类或组织。
-
数据使用政策不一致:没有治理,就没有关于如何访问、使用和共享数据的明确指南。缺乏标准化的实践也可能阻碍不同团队之间的协作和互操作性。
-
安全性和合规风险:没有适当的访问控制,未经授权的用户可能会访问敏感信息。这可能导致数据泄露和合规问题。
-
有限的元数据和目录管理:元数据通常提供有关数据来源、质量和来源的信息。缺乏元数据使得追踪数据的来源和应用的变换变得非常困难。在数据沼泽的情况下,通常缺乏集中式目录或索引,使得用户很难发现和理解可用的数据资产。
-
缺乏生命周期管理:如果没有定义的数据保留和归档政策,数据湖可能会充满过时或无关的数据,使得查找和使用有价值的信息变得更加困难。
因此,治理的缺乏可能会使数据湖变成沼泽,降低其效用,并给用户和组织带来挑战。
减轻挑战
为了防止数据湖变成沼泽,组织应重点关注以下关键策略:
-
强有力的治理政策
-
有效的元数据管理
-
数据质量监控
-
访问控制和安全措施
-
数据生命周期管理和自动化
让我们深入探讨上述每一项策略,了解它们的重要性以及如何有助于保持数据湖的高效和有用。
作者提供的图片
强有力的治理政策
建立明确的治理政策是有效管理数据湖的基础:
-
确定数据所有权确保对特定数据集的质量和完整性有明确的责任和清晰的了解。
-
访问控制设定了谁可以访问、修改或删除数据的边界,有助于防止未经授权的使用。
-
使用指南提供了一个框架,规定了数据的使用方式,防止误用并确保遵守监管要求。
通过为数据管理者、管理员和用户分配角色和责任,组织可以创建一个结构化且负责任的数据管理环境。
有效的元数据管理
综合的元数据管理系统捕捉有关数据资产的重要信息。了解数据来源有助于确立其可信度和来源,而有关质量和血统的细节提供了对其可靠性和处理历史的见解。
理解应用于数据的转换对数据科学家和分析师也很重要,以便有效地解释和使用数据。一个维护良好的元数据目录确保用户能够发现、理解并使用数据湖中的数据。
数据质量监控
定期的数据质量检查对于维持数据湖中的数据准确性和可靠性至关重要。
-
进行这些检查涉及验证数据格式以确保一致性。
-
检查完整性可以确保数据集不会缺少重要信息。
-
识别异常有助于发现数据中的错误或不一致,防止不准确的见解传播。
主动的数据质量监控确保数据湖仍然是决策和分析的可靠来源。
访问控制和安全措施
执行严格的访问控制和加密保护数据湖免受未经授权的访问和潜在的安全威胁。访问控制限制了谁可以查看、修改或删除数据,确保只有授权人员拥有必要的权限。
定期审计访问日志有助于识别和处理任何可疑活动,为安全提供了主动的应对方式。实施加密确保敏感数据在传输和静态状态下都受到保护。
这些安全措施共同有助于维护数据湖中数据的机密性和完整性。
数据生命周期管理与自动化
定义和执行数据保留政策对于防止过时或无关数据的积累是必要的。自动化的数据编目工具有助于管理数据的整个生命周期。
这包括归档仍然有价值但不常访问的数据,清除过时的数据,以及高效地组织数据以便于发现。自动化减少了管理大量数据所需的人工工作,确保数据保持有序、相关,并且用户能够轻松访问。
总之,这些策略一起帮助创建一个良好治理和管理的数据湖——防止数据湖变成混乱且不可用的数据沼泽。它们有助于维护数据完整性,确保安全,促进高效的数据发现,并保持数据湖环境的整体有效性。
总结
总结来说,数据湖是管理和提取大规模、多样化数据集价值的强大解决方案。它们的灵活性、可扩展性以及对高级分析的支持使它们对数据驱动的组织非常有价值。
然而,为了避免将数据湖变成数据沼泽,组织必须投资于强大的数据治理,实施有效的元数据管理,执行安全措施,进行定期的数据质量评估,并建立清晰的数据生命周期管理政策。
Bala Priya C**** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过编写教程、操作指南、观点文章等与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
了解更多信息
免费的数据科学学习路线图:适用于所有水平,提供 IBM
原文:
www.kdnuggets.com/a-free-data-science-learning-roadmap-for-all-levels-with-ibm

编辑提供的图像
2024 年的目标继续进行,我希望所有把学习数据科学作为目标的人能看到这篇文章。你可以通过多种方式学习数据科学,从 YouTube 视频到回到大学。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
然而,如果你没有足够的财力回到大学或需要比 YouTube 提供的结构更多的东西 - 我理解。
如果你喜欢在一个平台上体验学习之旅,并且该平台遵循课程体系且组织有序 - 请继续阅读这篇博客。
这里有 4 个不同的学习路线图,适用于 4 个不同的水平:
数据科学简介
水平:初学者
链接: 数据科学简介专门化
如果你想开始数据科学职业生涯或想从当前职业过渡到数据科学 - 首先需要了解数据科学的基础,以便明白它究竟是什么。
通过这个,你将培养像数据科学家一样工作的思维方式,并了解可以用来解决不同类型数据科学问题的不同方法,系列课程包含 4 门课程:
如果你每周投入 10 小时,你将在 1 个月内完成这门课程。
使用 Python 和 SQL 的数据科学基础
水平:初学者/中级
当你觉得自己对数据科学有了很好的理解,明白它的内容和它能带你去哪里时,你的下一步是深入了解 Python 和 SQL 的数据科学基础。
在这个包含 5 门课程的专业系列中,你将学习并获得使用 Jupyter、Python 和 SQL 的实际经验,并对真实数据集进行统计分析:
IBM 数据科学专业证书
链接:IBM 数据科学专业证书
级别:中级/专家
你现在已经准备好开始你的数据科学专业证书之旅了。
一个包含 10 门课程的系列,你将为成为数据科学家做好准备,培养市场需求的技能和实践经验,比如将你的新技能应用到现实项目中,使你具备就业准备。
课程包括:
如果你每周投入 10 小时,你将在 5 个月内完成这门课程。
高级数据科学
级别:专家
你已经完成了初级课程,提升了 Python 和 SQL 技能,深入探索了数据科学,包括 Python 项目、数据分析、机器学习等。但你还想要更多。
这个高级数据科学专业化课程将使你成为数据科学、机器学习和人工智能方面的专家。包含四门课程:
成为 IBM 批准的专家!
总结一下
就这样——四种不同的数据科学学习路径,适合四个不同的级别。如果你是从头开始,我建议你完成所有这些课程,以便全面掌握知识。
你在一个平台上拥有一个简单的数据科学学习路线图!
Nisha Arya 是一位数据科学家、自由撰稿人,并且是 KDnuggets 的编辑和社区经理。她特别感兴趣于提供数据科学职业建议或教程以及基于理论的数据科学知识。Nisha 涵盖了广泛的主题,并希望探索人工智能如何有助于人类寿命的不同方式。作为一个积极的学习者,Nisha 希望拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
使用 SQLite 数据库的指南
原文:
www.kdnuggets.com/a-guide-to-working-with-sqlite-databases-in-python

作者图片
SQLite 是一种轻量级、无服务器的关系数据库管理系统(RDBMS),由于其简单性和易于嵌入应用程序而被广泛使用。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
无论您是在构建小型应用程序、在本地管理数据还是在原型设计项目,SQLite 都提供了一种方便的解决方案,用于存储和查询结构化数据。在本教程中,您将学习如何使用内置的 sqlite3 模块 从 Python 操作 SQLite 数据库。
特别地,您将学习如何从 Python 连接到 SQLite 数据库并执行基本的 CRUD 操作。让我们开始吧。
环境设置
首先,为您的项目创建一个专用的虚拟环境(在项目目录中)并激活它。您可以使用内置的 venv 模块来完成:
$ python3 -m venv v1
$ source v1/bin/activate
在本教程中,我们将使用 Faker 生成合成记录。请使用 pip 安装:
$ pip3 install Faker
sqlite3 模块是 Python 标准库的一部分,因此您无需单独安装它。如果您已经安装了 Faker 并使用的是最新版本的 Python,那就可以开始了!
连接到 SQLite 数据库
在项目目录中创建一个 Python 脚本并开始。作为与数据库交互的第一步,我们应该建立与数据库的连接。
要连接到示例数据库 example.db,您可以使用 sqlite3 模块中的 connect() 函数,如下所示:
conn = sqlite3.connect(‘example.db’)
如果数据库已经存在,则连接到它。否则,它将在工作目录中创建数据库。
连接到数据库后,我们将创建一个数据库游标,以帮助我们运行查询。游标对象具有执行查询和获取查询结果的方法。它的工作方式与文件处理器非常相似。
数据库游标 | 作者图片
使用 with 语句将连接作为上下文管理器是很有帮助的,如下所示:
import sqlite3
# Connect to the db
with sqlite3.connect('example.db') as conn:
# create db cursor
# run queries
# commit changes
这样你就不必担心关闭连接对象。当执行退出 with 块时,连接会自动关闭。不过,我们在本教程中会显式关闭游标对象。
创建数据库表
现在让我们在数据库中创建一个包含所需字段的customers表。为此,我们首先创建一个游标对象。然后我们运行一个 CREATE TABLE 语句,并将查询字符串传递给游标对象上调用的execute()方法:
import sqlite3
# Connect to the db
with sqlite3.connect('example.db') as conn:
cursor = conn.cursor()
# Create customers table
cursor.execute('''
CREATE TABLE IF NOT EXISTS customers (
id INTEGER PRIMARY KEY,
first_name TEXT NOT NULL,
last_name TEXT NOT NULL,
email TEXT UNIQUE NOT NULL,
phone TEXT,
num_orders INTEGER
);
''')
conn.commit()
print("Customers table created successfully.")
cursor.close()
当你运行脚本时,你应该会看到以下输出:
Output >>>
Customers table created successfully.
执行 CRUD 操作
让我们对数据库表进行一些基本的 CRUD 操作。如果愿意,你可以为每个操作创建单独的脚本。
插入记录
现在我们将一些记录插入到customers表中。我们将使用 Faker 生成合成记录。为了保持输出的可读性,我只插入了 10 条记录。但你可以插入任意数量的记录。
import sqlite3
import random
from faker import Faker
# Initialize Faker object
fake = Faker()
Faker.seed(24)
# Connect to the db
with sqlite3.connect('example.db') as conn:
cursor = conn.cursor()
# Insert customer records
num_records = 10
for _ in range(num_records):
first_name = fake.first_name()
last_name = fake.last_name()
email = fake.email()
phone = fake.phone_number()
num_orders = random.randint(0,100)
cursor.execute('''
INSERT INTO customers (first_name, last_name, email, phone, num_orders)
VALUES (?, ?, ?, ?, ?)
''', (first_name, last_name, email, phone, num_orders))
print(f"{num_records} customer records inserted successfully.")
conn.commit()
cursor.close()
注意我们如何使用参数化查询:我们不是将值硬编码到 INSERT 语句中,而是使用?占位符并传入一个值的元组。
运行脚本应该会得到:
Output >>>
10 customer records inserted successfully.
读取和更新记录
现在我们已经将记录插入到表中,让我们运行一个查询以读取所有记录。注意我们如何使用execute()方法运行查询,以及如何在游标上使用fetchall()方法来检索查询结果。
由于我们已经将之前查询的结果存储在all_customers中,让我们运行一个 UPDATE 查询来更新 id 为 1 的num_orders。以下是代码片段:
import sqlite3
# Connect to the db
with sqlite3.connect('example.db') as conn:
cursor = conn.cursor()
# Fetch and display all customers
cursor.execute('SELECT id, first_name, last_name, email, num_orders FROM customers')
all_customers = cursor.fetchall()
print("All Customers:")
for customer in all_customers:
print(customer)
# Update num_orders for a specific customer
if all_customers:
customer_id = all_customers[0][0] # Take the ID of the first customer
new_num_orders = all_customers[0][4] + 1 # Increment num_orders by 1
cursor.execute('''
UPDATE customers
SET num_orders = ?
WHERE id = ?
''', (new_num_orders, customer_id))
print(f"Orders updated for customer ID {customer_id}: now has {new_num_orders} orders.")
conn.commit()
cursor.close()
这将输出记录和更新查询后的消息:
Output >>>
All Customers:
(1, 'Jennifer', 'Franco', 'jefferyjackson@example.org', 54)
(2, 'Grace', 'King', 'erinhorne@example.org', 43)
(3, 'Lori', 'Braun', 'joseph43@example.org', 99)
(4, 'Wendy', 'Hubbard', 'christophertaylor@example.com', 11)
(5, 'Morgan', 'Wright', 'arthur75@example.com', 4)
(6, 'Juan', 'Watson', 'matthewmeadows@example.net', 51)
(7, 'Randy', 'Smith', 'kmcguire@example.org', 32)
(8, 'Jimmy', 'Johnson', 'vwilliams@example.com', 64)
(9, 'Gina', 'Ellison', 'awong@example.net', 85)
(10, 'Cory', 'Joyce', 'samanthamurray@example.org', 41)
Orders updated for customer ID 1: now has 55 orders.
删除记录
要删除特定客户 ID 的客户,让我们运行如下的 DELETE 语句:
import sqlite3
# Specify the customer ID of the customer to delete
cid_to_delete = 3
with sqlite3.connect('example.db') as conn:
cursor = conn.cursor()
# Execute DELETE statement to remove the customer with the specified ID
cursor.execute('''
DELETE FROM customers
WHERE id = ?
''', (cid_to_delete,))
conn.commit()
f"Customer with ID {cid_to_delete} deleted successfully.")
cursor.close()
这将输出:
Customer with ID 3 deleted successfully.
使用 WHERE 子句过滤记录
图片由作者提供
假设我们想要获取下单少于 10 次的客户记录,比如为了进行针对性的活动等。为此,我们运行一个 SELECT 查询,并使用 WHERE 子句指定过滤条件(在这种情况下是订单数量)。下面是如何实现:
import sqlite3
# Define the threshold for the number of orders
order_threshold = 10
with sqlite3.connect('example.db') as conn:
cursor = conn.cursor()
# Fetch customers with less than 10 orders
cursor.execute('''
SELECT id, first_name, last_name, email, num_orders
FROM customers
WHERE num_orders < ?
''', (order_threshold,))
# Fetch all matching customers
filtered_customers = cursor.fetchall()
# Display filtered customers
if filtered_customers:
print("Customers with less than 10 orders:")
for customer in filtered_customers:
print(customer)
else:
print("No customers found with less than 10 orders.")
这里是输出结果:
Output >>>
Customers with less than 10 orders:
(5, 'Morgan', 'Wright', 'arthur75@example.com', 4)
总结
这就是全部!这是一个关于如何使用 Python 开始 SQLite 的指南。希望你觉得这有帮助。你可以在GitHub上找到所有代码。在下一部分,我们将探讨运行联接和子查询、管理 SQLite 中的事务等内容。直到那时,祝编码愉快!
如果你对学习数据库索引如何工作感兴趣,请阅读如何使用索引加速 SQL 查询 [Python 版]。
Bala Priya C** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉点上工作。她的兴趣和专业领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和咖啡!目前,她正在通过编写教程、操作指南、观点文章等方式,与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。**
更多相关主题
微软工程师的 AI 创新与领导力指南
原文:
www.kdnuggets.com/a-microsoft-engineer-guide-to-ai-innovation-and-leadership

作者提供的图片
与高级数据专业人士进行一对一对话可能会很困难,特别是当你刚刚起步时。本文风格的采访旨在更好地理解高级数据专业人士的经历和建议,以便为您提供自我反思数据世界中旅程的资源。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 管理
让我们开始吧……
你是如何成为微软的高级软件工程师的?
我对 AI 和软件工程的兴趣始于童年,那时我对编程有浓厚的兴趣。这种热情促使我在 NIT Warangal 追求计算机科学与工程的本科学位,并于 2015 年毕业。之后,我通过校园招聘加入了 微软,并最终加入了搜索与 AI 组织中的 Bing Maps 团队。
在我与 Bing Maps 合作期间,我参与了多个旨在改善服务的项目。我最显著的贡献是领导开发了一种新的机器学习算法,以增强地图上的标签密度检测。我撰写了关于这一新技术的研究论文,该论文获得了多个奖项,并发表在《微软应用研究杂志》上。
在地图项目之后,我成为 Bing Shopping 部门的创始成员。在那里,我领导了多个功能的推出,并结合产品广告,为提升 Bing 的收入做出了重要贡献。我喜欢创新和解决日常问题。在我的职业生涯中,我赢得了许多黑客马拉松比赛,最近的一次是创建了一个旨在简化在线购物的 AI 聊天机器人。目前,我回到 Bing Maps,致力于改进和扩展我们的地图服务。
我职业成长的关键在于不断追求领导充满未知的项目和解决复杂问题的决心。
数据专业人士如何转型进入 AI?
我认为从数据科学或分析转向 AI 通常比人们意识到的要顺利。这两个领域都要求具备扎实的数学和编程基础。但是,如果你是一位希望转型的数据专业人士,你需要深入了解机器学习算法和神经网络。
需要什么样的教育背景?
职业人士通常会问的第一个问题是进入 AI 领域的教育要求是什么。你需要博士学位,还是学士或硕士学位就足够了?
答案取决于职位和公司。虽然博士学位对研究职位尤其有益,但并不是严格要求。计算机科学、数学或相关领域的学士或硕士学位通常也足够。
重要的是对 AI 和机器学习的原理有深入理解,这可以通过专业课程和自学获得。
认证有用吗?
认证可以帮助展示你对 AI 的兴趣和基础知识,尤其是在从其他领域转型时。但它们应该补充你的教育和经验,而不是替代它们。值得注意的是,认证不是通行证。
这些课程在补充实际经验和坚实的基础教育方面效果最佳。雇主通常寻找实际操作经验和解决问题的能力,这些有时可以在认证项目之外获得。
是否有推荐的路径或课程?
跳过基础知识是不明智的。请从线性代数、微积分和统计学的基础课程开始。
从这里开始,我建议深入学习机器学习,可以通过Coursera 的 Andrew Ng 机器学习课程进行学习。EdX和Udacity也提供了如人工智能 MicroMasters 和 AI 纳米学位等课程。
然后,探索与你兴趣相关的专业课程或项目,无论是自然语言处理、计算机视觉还是强化学习。
必学的技术和工具有哪些?
尽管 Python 仍然是这两个领域的首选语言,但对于 AI,你还需要接触像TensorFlow和PyTorch这样的专业库。它们提供了设计、训练和验证模型的基础模块。Jupyter Notebooks对于原型设计和与同事共享模型也至关重要。
除了编程语言和库外,了解云端 AI 服务如 Azure AI 或 AWS SageMaker,可以让你在众人中脱颖而出。
如何获得实际经验?
理论知识很重要,但你也需要实际操作经验。
一种有效的方法是参与个人项目。将这些项目定制为解决你感兴趣的问题或填补当前技术的空白——这将使学习过程更愉快,结果更具影响力。
此外,参与开源项目不仅可以磨练你的技能,还能让你在社区中引起关注。另一个途径是参加像 Kaggle 这样的竞赛,这些竞赛挑战你将技能应用于新颖问题,并从全球社区中学习。
实习是宝贵的,提供了指导和在工业环境中的实践经验。即使是无薪的,获得的实践知识也可以成为重要的跳板。实践经验不仅仅是编码——还包括理解 AI 如何有效地部署以解决实际问题。
因此,通过项目工作、合作和竞赛,你可以建立一个展示你提供具有实际影响的 AI 解决方案能力的作品集。
网络建设的角色是什么?
网络建设至关重要。参加 AI 见面会、网络研讨会和会议。在社交媒体上关注该领域的思想领袖。参与讨论,寻求指导,不要害怕提问。关系网能打开那些可能会保持关闭的门。现实世界中的问题提供了最好的学习体验。
什么帮助了你?你会做出什么不同的决定?
推动我前进的是好奇心与探索未知的驱动力,这引导了我在微软的项目领导工作。
如果我能重温过去,我会更加重视网络建设。在行业内建立关系可以开启合作机会和获得在像 AI 这样的动态领域中非常宝贵的见解。
我还会分配更多时间进行个人项目,以便在没有限制的情况下自由创新,从而更全面地探索 AI 的可能性,并可能对该领域做出更多突破性的贡献。
总结
Manas Joshi 是微软的高级软件工程师,曾在微软必应生态系统中领导多个项目,专长于 AI、自然语言处理和机器学习。本文希望你能了解 Manas 的经历,吸取他的建议,并更好地理解数据专业人士进入不断发展的 AI 领域所需的技能。
Nisha Arya 是一名数据科学家、自由技术作家,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议、教程和理论基础知识。Nisha 涵盖了广泛的主题,并希望探索人工智能如何有利于人类生命的延续。作为一个热衷于学习的人,Nisha 寻求扩展她的技术知识和写作技能,同时帮助指导他人。
了解更多相关内容
你的数据职业道路图
数据职业并非适合所有人——你需要耐心来应对不断发展的业务、安全和基础设施要求,同时需要较强的心理耐力来处理无尽的数据问题和变化。但这些职位也可以是世界上最有趣的工作。每个月都有一个新的难题需要以新的方式解决,新技术和创新不断使这个领域保持新鲜。随着 AI 对更大、更复杂的训练数据集的需求,数据职业也将变得更加重要。
进入或继续数据职业生涯没有单一的途径,但让我们从一个参考道路图开始,它将作为本文的框架,然后我们可以讨论你在过程中会遇到的决策点和阶段。无论你是数据科学家、数据工程师、软件开发人员、业务分析师,还是基础设施/安全专家,这些路径都可能适用于你。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
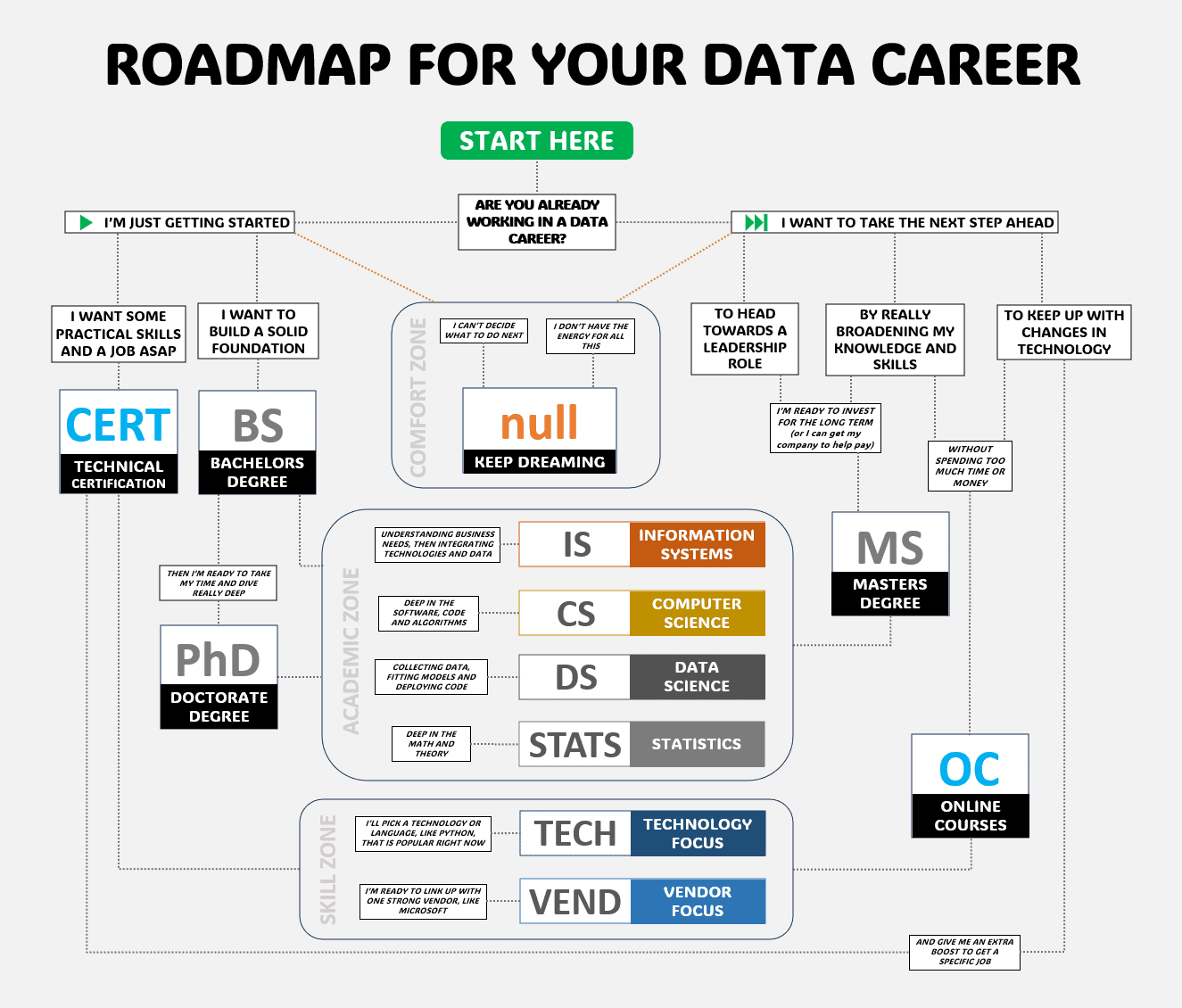
数据职业道路图(点击放大)
接下来,在我们深入探讨这条道路图之前,让我们看看你可能阅读这篇文章的一些原因。这些常见的抱怨是否与你当前的经历相匹配?
-
“我不确定如何开始,也不确定大学教育是否值得投资。”
-
“我无法进入门槛找到第一份工作。”
-
“我的工作变得乏味且有些无聊。我准备尝试些不同的东西。”
-
“在我的工作中,我被困在旧技术或编程语言中。我该如何提升我的技能?”
-
“我感觉自己像是大机器中的一个小齿轮。我希望能有一个更具影响力和可见性的角色。”
-
“我想进入管理层,但我需要一个路径。”
我们可以将这些关注点分为以下职业阶段:

数据专业人士的关注点按职业阶段分类。
在道路图中,我们可以找到每个阶段的关键问题和考虑因素。
职业启动
你启动职业生涯的视角将受到各种因素的影响。
-
你的家庭文化与正式教育和职业相关 — 你的父母上过大学吗?
-
资源和准备 — 你有经济支持吗?你在高中时表现如何?
-
经济状况 — 上一次经济衰退是什么时候?失业率有多高?
-
职业导向 — 你如何定义正确的工作/生活平衡?你有多大动力去晋升?
-
理论与应用的兴趣 — 你是否倾向于立刻可以使用的实际技术技能?还是更愿意深入研究计算机科学算法或统计理论?
基于这些因素,你可能会决定花 3 个月和几百美元获得一些实际技术领域的认证,如Microsoft Entra ID是适合你的。另一方面,你可能会决定花 8 年时间获得统计学本科和博士学位符合你的抱负。虽然有很多路径组合,但主要问题是你是否愿意付出努力建立一个广泛且坚实的基础,还是你觉得时间和资金有限,需要尽快找到工作。
在启动阶段,重要的是研究你感兴趣的未来职位,然后学习这些职位的职位描述。根据职位描述,你可以逆向工程出你需要采取的步骤。那些角色需要什么技能、编程语言和经验?考虑到这些项目,你可以制定目标,以在这些特定领域提升技能。
不论你的路径如何,最大的挑战之一是在你目标领域的公司中获得第一份工作。上过一些随机的在线课程对此无济于事。你需要找到一种方式,为你的简历添加一些明确的资质、正式的学位或在像Kaggle这样被认可的项目经验论坛中的记录成就。在选择选项时,仔细查看各种项目的完成率,并确保你能完全承诺完成课程,然后再做付款或负债决定。
最后,在扩展你的网络时要有创意。加入学校的科技俱乐部;参加本地科技团体的聚会;寻找即将举办的有网络活动的行业会议。如果你曾在有职业中心的学校就读,和办公室里的每个人建立最好的关系,并请他们帮助你找到那些其他人可能忽视的空缺职位。你可能会找到一个小众职位、内部机会或未公开的职位,这些职位不会有 500 个在线申请者。
职业转型
随着时间的推移,你需要准备好随着公司方向的变化、职位的重新分配或你转到新公司而进行职业转型和技能再培训。在路线图中,这些小的转变被称为需要“迈出下一步”。
如果这些步骤需要你使用新技术或学习与当前技能集相关的技能,那么在线课程是帮助应对转变的绝佳方式。
在线课程,例如由 DataCamp 或 Pluralsight 提供的课程,具有实际性、针对性和成本效益,并且可以组成各种认证。然而,这些课程面临的一个大挑战是它们的完成率极低(通常低于 10%)。如果你的公司提供培训资金,或者你可以争取到资金,确保明智地使用这些资金并完成你的课程。
职业进展
职业进步对技术数据专业人士来说,通常比管理职业转型更具挑战性。如果你决定在高级分析师/开发者/工程师级别之外寻求晋升,挑战会以三种形式出现:
-
成为一名出色的开发者、分析师或工程师所需的技能与成为优秀的团队负责人或管理者所需的技能不同(即 你现在的能力不会带你到那里)
-
业务意识和管理工作的背景在从事技术数据工作时很难获得。
-
你作为个人贡献者所建立的关系网络与作为管理者所需的网络不同。
正规的大学硕士学位是解决所有这三个问题的好方法。新的硕士项目旨在更短、更有针对性,并且更加灵活,以适应全职工作人士的时间限制。虽然在线学位在建立关系网络方面不如传统学位有效,但你可能会认为灵活性值得这种权衡。
NULL 路径 — 什么都不做
路线图的中心是标记为“null”的舒适区。不幸的是,这就是我们中的许多人最终所处的地方。我们让经理决定我们被分配去开发哪些技能或项目。我们让公司裁员决定我们下一次职业转型的时机。或者我们查看升级职业的选项,但决定它们过于令人畏惧或昂贵。
你的职业将持续 40 到 45 年;难道我们不应该主动规划我们想要走的道路吗?
Stan Pugsley 是一位驻盐湖城,犹他州的自由数据工程和分析顾问。他还是犹他大学埃克尔斯商学院的讲师。你可以通过 电子邮件 联系作者。
更多关于这个话题
本地运行 LLaMA 2 的简单指南
原文:
www.kdnuggets.com/a-simple-guide-to-running-llama-2-locally

作者提供的图片
像 LLaMA 2 这样的新开源模型已经变得相当先进,并且可以免费使用。你可以将其用于商业用途或在自己的数据上进行微调以开发专门的版本。由于其易用性,你现在可以在自己的设备上本地运行它们。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
在这篇文章中,我们将学习如何下载必要的文件和 LLaMA 2 模型,以运行 CLI 程序并与 AI 助手互动。设置非常简单,即使是非技术用户或学生也可以通过几个基本步骤使其运行。
下载 GPU 机器上的 Llama.cpp
要在本地安装 llama.cpp,最简单的方法是从 llama.cpp releases 下载预构建的可执行文件。
要在带有 NVIDIA GPU 的 Windows 11 上安装它,我们首先需要下载 llama-master-eb542d3-bin-win-cublas-[version]-x64.zip 文件。下载后,将其解压到你选择的目录中。建议创建一个新文件夹并将所有文件解压到其中。
接下来,我们需要下载 cudart-llama-bin-win-[version]-x64.zip 文件并将其解压到主目录中。要使用 GPU 加速,你有两个选择:NVIDIA GPU 使用 cuBLAS,AMD GPU 使用 clBLAS。
注意: [version] 是你本地系统上安装的 CUDA 版本。你可以通过在终端中运行
nvcc --version来检查它。
下载模型
首先,在主目录中创建一个名为“Models”的文件夹。在 Models 文件夹中,创建一个名为“llama2_7b”的新文件夹。接下来,从 Hugging Face hub 下载 LLaMA 2 模型文件。你可以选择任何你喜欢的版本,但为了本指南,我们将下载 llama-2-7b-chat.Q5_K_M.gguf 文件。下载完成后,将文件移动到刚刚创建的“llama2_7b”文件夹中。
注意: 为避免错误,请确保在运行模型之前仅下载
.gguf模型文件。
启动 AI 助手 CLI 程序
现在你可以在主目录中打开终端。通过右键点击并选择“在终端中打开”选项。你也可以打开 PowerShell,使用“cd”命令更改目录。
复制并粘贴下面的命令,然后按“Enter”。我们正在执行main.exe文件,传递模型目录位置、gpu、颜色和系统提示参数。
./main.exe -m .\Models\llama2_7b\llama-2-7b-chat.Q5_K_M.gguf -i --n-gpu-layers 32 -ins --color -p "<<SYS>> As an AI assistant, your core values include being supportive, considerate, and truthful, ensuring that every interaction is guided by clarity and helpfulness. <</SYS>>"
我们的 llama.ccp CLI 程序已经成功初始化了系统提示。它告诉我们这是一个有用的 AI 助手,并展示了各种命令。
在 PowerShell 中本地使用 LLaMA 2
让我们通过在 PowerShell 中提供提示来测试 LLaMA 2。我们提出了一个关于地球年龄的简单问题。
答案是准确的。让我们再问一个关于地球的后续问题。
如你所见,模型提供了关于我们星球的多个有趣事实。

你可以让 AI 助手在终端中生成代码和解释,你可以轻松地复制并在 IDE 中使用。
完美。
结论
本地运行 Llama 2 提供了一个强大而易于使用的聊天机器人体验,完全根据你的需求进行定制。通过遵循这个简单的指南,你可以在短时间内学会构建自己的私人聊天机器人,而无需依赖付费服务。
本地运行 LLaMA 2 的主要好处是可以完全控制你的数据和对话,同时没有使用限制。你可以随心所欲地与机器人聊天,甚至可以调整它以改善回应。
尽管本地设置比即时可用的云 AI API 不那么方便,但它能让你对数据隐私更加放心。
Abid Ali Awan (@1abidaliawan) 是一位认证数据科学专业人士,他喜欢构建机器学习模型。目前,他专注于内容创作并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些挣扎于心理健康问题的学生。
更多相关主题
逐步指南:阅读和理解 SQL 查询
原文:
www.kdnuggets.com/a-step-by-step-guide-to-reading-and-understanding-sql-queries

图片来源:Freepik
SQL,即结构化查询语言,是一种用于管理和操控关系型数据库管理系统(RDBMS)中的数据的编程语言。它是许多公司用来帮助业务顺利访问数据的标准语言。由于 SQL 的广泛使用,通常就业市场会将 SQL 作为必要技能之一。这就是为什么学习 SQL 非常重要。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
学习 SQL 时,一个常见的问题是理解查询,特别是当查询由其他人编写时。在公司中,我们通常需要团队合作,并且经常需要阅读和理解他们的 SQL 查询。因此,我们需要练习拆解 SQL 查询并理解它们。
本文将逐步介绍如何读取和理解 SQL 查询。我们怎么做呢?让我们开始吧。
1. 理解一般 SQL 查询结构
遇到 SQL 查询时,我们需要做的第一件事是理解 SQL 查询的总体意图。总体意图并不意味着我们完全了解查询的结构;更多的是关于整体流程。
我们应该了解标准 SQL 查询,以便理解一般 SQL 查询。大多数 SQL 查询以 SELECT 子句开始,然后是 FROM 子句。接着,查询通常会跟随 JOIN、WHERE、GROUP BY、ORDER BY 和 HAVING 子句。
上述子句是我们需要理解的 SQL 查询的标准部分。每个子句的功能如下:
-
SELECT:从表中选择哪些列
-
FROM:数据来自哪个表
-
JOIN:通过指定的标识符合并表
-
WHERE:基于条件的数据过滤
-
GROUP BY:根据列的值组织数据,并允许执行聚合函数。
-
ORDER BY:根据特定列排列数据结果的顺序
-
HAVING:用于聚合函数的过滤条件,不能用WHERE指定
这些是标准子句,你在理解一般 SQL 查询结构时应首先找到它们。让我们使用示例代码进一步学习。
SELECT
customers.name,
purchases.product,
SUM(price) as total_price
FROM
purchases
JOIN customers ON purchases.cust_id = customers.id
WHERE
purchases.category = 'kitchen'
GROUP BY
customers.name,
purchases.product
HAVING
total_price > 10000
ORDER BY
total_price DESC;
查看上述查询时,尝试识别标准子句。子句将帮助你理解选择了哪些数据(SELECT),数据来源于哪里(FROM和JOIN),以及条件(WHERE、GROUP BY、ORDER BY和HAVING)。
例如,阅读上面的查询可以帮助你理解以下内容:
-
我们尝试获取三种不同的数据:来自
customers表的Name,来自purchases表的Product,以及聚合的price列,未识别表的来源,并以别名total_price表示(信息来自于SELECT子句)。 -
整体数据将来自于通过
cust_id列连接的purchases表和通过id列连接的customers表(信息来自于FROM和JOIN子句)。 -
我们只会选择
purchases表中category列值为‘kitchen’的数据(信息来自于WHERE子句)。 -
按
name和product列进行分组,这些列来自于各自的表(信息来自于GROUP BY子句)。 -
还需根据聚合函数结果的总和过滤,其中
total_price大于 10000(信息来自于HAVING子句), -
根据
total_price降序排列数据(信息来自于ORDER BY子句)。
这是你需要了解和识别的一般 SQL 查询结构。从这里,我们可以深入探讨更高级的查询。让我们继续下一步。
2. 理解最终的 SELECT
有时你会遇到一个复杂的查询,其中包含许多SELECT子句。在这种情况下,我们应理解查询的最终结果或你在查询中看到的第一个(最终)SELECT。关键是要了解查询输出的期望结果。
我们使用下面的更复杂的代码示例。
WITH customerspending AS (
SELECT
customers.id,
SUM(purchases.price) as total_spending
FROM
purchases
JOIN customers ON purchases.cust_id = customers.id
GROUP BY
customers.id
)
SELECT
c.name,
pd.product,
pd.total_product_price,
cs.total_spending
FROM
(
SELECT
purchases.cust_id,
purchases.product,
SUM(purchases.price) as total_product_price
FROM
purchases
WHERE
purchases.category = 'kitchen'
GROUP BY
purchases.cust_id,
purchases.product
HAVING
SUM(purchases.price) > 10000
) AS pd
JOIN customers c ON pd.cust_id = c.id
JOIN customerspending cs ON c.id = cs.id
ORDER BY
pd.total_product_price DESC;
查询现在看起来更复杂且更长,但初步关注应放在最终的SELECT上,它似乎试图生成客户的总支出和购买历史。尝试评估最终结果的期望,并从中分解。
3. 理解最终条件子句
我们对结果有了初步了解,接下来的部分是查看最终SELECT的条件。条件子句,包括WHERE、GROUP BY、ORDER BY和HAVING,控制了整体数据结果。
尝试阅读和理解我们查询的条件,我们将更好地理解查询的最终结果。例如,在我们之前的 SQL 查询中,最终条件仅为ORDER BY。这意味着最终结果将按总产品价格的降序排列。
了解最终条件将帮助你理解查询的主要部分及整体意图。
4. 理解最终连接
最后,我们需要了解数据的来源。在了解选择哪些数据以及获取这些数据的条件之后,我们需要理解数据来源。最终的JOIN子句将帮助我们理解表的交互和数据流动。
例如,之前的复杂查询显示我们进行了两次连接。这意味着我们至少使用了三个数据源来获取最终结果。这个信息在后续步骤中理解每个数据源的来源时将非常必要,特别是当数据源来自子查询时。
5. 逆序阅读和重复
在了解最终结果应如何呈现及其来源后,我们需要更详细地查看细节。从这里开始,我们会回溯到每个子查询,了解它们为何以这种方式构造。
然而,我们不应尝试从顶到底地查看它们。相反,我们应尝试查看那些离最终结果较近的子查询,并向上移动到离最终结果最远的子查询。从上面的代码示例中,我们应该首先理解这段代码:
SELECT
purchases.cust_id,
purchases.product,
SUM(purchases.price) as total_product_price
FROM
purchases
WHERE
purchases.category = 'kitchen'
GROUP BY
purchases.cust_id,
purchases.product
HAVING
SUM(purchases.price) > 10000
然后,我们将转向最远的代码,即这段:
WITH customerspending AS (
SELECT
customers.id,
SUM(purchases.price) as total_spending
FROM
purchases
JOIN customers ON purchases.cust_id = customers.id
GROUP BY
customers.id
)
当我们从最接近结果的子查询开始逐步拆解时,可以清晰地追踪到作者的思路。
如果你在理解每个子查询时遇到困难,可以尝试重复上述过程。通过一些练习,你将更好地阅读和理解查询。
结论
阅读和理解 SQL 查询是现代社会每个人都应该具备的技能,因为每家公司都在处理 SQL 查询。通过以下逐步指南,你将更好地理解复杂的 SQL 查询。这些步骤包括:
-
理解一般的 SQL 查询结构
-
理解最终选择
-
理解最终条件子句
-
理解最终连接
-
逆序阅读和重复
Cornellius Yudha Wijaya 是一名数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 撰写了各种 AI 和机器学习主题的文章。
更多相关内容
Python NLP 库概览

使用 DALL·E 3 生成的图像
NLP,即自然语言处理,是人工智能领域中的一个领域,专注于人类语言与计算机之间的互动。它试图探索和应用文本数据,使计算机能够有意义地理解文本。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
随着 NLP 领域研究的进展,我们处理计算机中文本数据的方式也在不断发展。在现代,我们使用 Python 来帮助轻松探索和处理数据。
随着 Python 成为探索文本数据的首选语言,许多库被专门为 NLP 领域开发。在这篇文章中,我们将探索各种令人惊叹和实用的 NLP 库。
那么,让我们开始吧。
NLTK
NLTK,或自然语言工具包,是一个具有许多文本处理 API 和工业级封装的 NLP Python 库。它是研究人员、数据科学家、工程师等使用的最大 NLP Python 库之一。它是进行 NLP 任务的标准 Python 库。
让我们尝试探索一下 NLTK 能做什么。首先,我们需要使用以下代码安装该库。
pip install -U nltk
接下来,我们将看看 NLTK 能做什么。首先,NLTK 可以使用以下代码进行分词处理:
import nltk from nltk.tokenize
import word_tokenize
# Download the necessary resources
nltk.download('punkt')
text = "The fruit in the table is a banana"
tokens = word_tokenize(text)
print(tokens)
Output>>
['The', 'fruit', 'in', 'the', 'table', 'is', 'a', 'banana']
分词基本上将句子中的每个单词划分为单独的数据。
使用 NLTK,我们还可以对文本样本进行词性标注(POS)。
from nltk.tag import pos_tag
nltk.download('averaged_perceptron_tagger')
text = "The fruit in the table is a banana"
pos_tags = pos_tag(tokens)
print(pos_tags)
Output>>
[('The', 'DT'), ('fruit', 'NN'), ('in', 'IN'), ('the', 'DT'), ('table', 'NN'), ('is', 'VBZ'), ('a', 'DT'), ('banana', 'NN')]
NLTK 的词性标注器的输出是每个词元及其预期的词性标记。例如,单词“Fruit”是名词(NN),而单词“a”是限定词(DT)。
使用 NLTK 也可以进行词干提取和词形还原。词干提取是通过剪切前缀和后缀将单词还原为其基本形式,而词形还原则通过考虑单词的词性和形态分析来转换为基本形式。
from nltk.stem import PorterStemmer, WordNetLemmatizer
nltk.download('wordnet')
nltk.download('punkt')
text = "The striped bats are hanging on their feet for best"
tokens = word_tokenize(text)
# Stemming
stemmer = PorterStemmer()
stems = [stemmer.stem(token) for token in tokens]
print("Stems:", stems)
# Lemmatization
lemmatizer = WordNetLemmatizer()
lemmas = [lemmatizer.lemmatize(token) for token in tokens]
print("Lemmas:", lemmas)
Output>>
Stems: ['the', 'stripe', 'bat', 'are', 'hang', 'on', 'their', 'feet', 'for', 'best']
Lemmas: ['The', 'striped', 'bat', 'are', 'hanging', 'on', 'their', 'foot', 'for', 'best']
你可以看到词干提取和词形还原的过程对单词的结果略有不同。
这就是 NLTK 的简单使用方法。你仍然可以做很多事情,但上述 API 是最常用的。
SpaCy
SpaCy 是一个专门为生产环境设计的 NLP Python 库。它是一个高级库,因其性能和处理大量文本数据的能力而闻名。它是许多 NLP 应用中首选的工业用库。
要安装 SpaCy,你可以查看他们的 使用页面。根据你的需求,有许多组合可供选择。
让我们尝试使用 SpaCy 进行 NLP 任务。首先,我们将尝试使用库进行命名实体识别 (NER)。NER 是一种将文本中的命名实体识别并分类到预定义类别(如人、地址、地点等)的过程。
import spacy
nlp = spacy.load("en_core_web_sm")
text = "Brad is working in the U.K. Startup called AIForLife for 7 Months."
doc = nlp(text)
#Perform the NER
for ent in doc.ents:
print(ent.text, ent.label_)
Output>>
Brad PERSON
the U.K. Startup ORG
7 Months DATE
正如你所见,SpaCy 预训练模型了解文档中的哪个词可以被分类。
接下来,我们可以使用 SpaCy 进行依存关系解析并进行可视化。依存关系解析是理解每个词如何通过形成树形结构与其他词相关的过程。
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
text = "SpaCy excels at dependency parsing."
doc = nlp(text)
for token in doc:
print(f"{token.text}: {token.dep_}, {token.head.text}")
displacy.render(doc, jupyter=True)
Output>>
Brad: nsubj, working
is: aux, working
working: ROOT, working
in: prep, working
the: det, Startup
U.K.: compound, Startup
Startup: pobj, in
called: advcl, working
AIForLife: oprd, called
for: prep, called
7: nummod, Months
Months: pobj, for
.: punct, working
输出应包括所有单词及其词性和相关位置。上述代码还会在你的 Jupyter Notebook 中提供树形可视化。
最后,让我们尝试使用 SpaCy 进行文本相似性分析。文本相似性测量两个文本片段的相似程度或相关性。它有许多技术和测量方法,但我们将尝试最简单的一种。
import spacy
nlp = spacy.load("en_core_web_sm")
doc1 = nlp("I like pizza")
doc2 = nlp("I love hamburger")
# Calculate similarity
similarity = doc1.similarity(doc2)
print("Similarity:", similarity)
Output>>
Similarity: 0.6159097609586724
相似度度量通过提供一个输出分数来测量文本之间的相似性,通常在 0 和 1 之间。分数越接近 1,两篇文本的相似度越高。
你还可以用 SpaCy 做很多事情。探索文档以找到对你工作有用的内容。
TextBlob
TextBlob 是一个建立在 NLTK 之上的 NLP Python 库,用于处理文本数据。它简化了许多 NLTK 的用法,并可以简化文本处理任务。
你可以使用以下代码安装 TextBlob:
pip install -U textblob
python -m textblob.download_corpora
首先,让我们尝试使用 TextBlob 进行 NLP 任务。我们首先尝试的是使用 TextBlob 进行情感分析。我们可以通过下面的代码实现这一点。
from textblob import TextBlob
text = "I am in the top of the world"
blob = TextBlob(text)
sentiment = blob.sentiment
print(sentiment)
Output>>
Sentiment(polarity=0.5, subjectivity=0.5)
输出是极性和主观性分数。极性是文本的情感,分数范围从 -1(负面)到 1(正面)。同时,主观性分数范围从 0(客观)到 1(主观)。
我们还可以使用 TextBlob 进行文本校正任务。你可以使用以下代码来完成这一点。
from textblob import TextBlob
text = "I havv goood speling."
blob = TextBlob(text)
# Spelling Correction
corrected_blob = blob.correct()
print("Corrected Text:", corrected_blob)
Output>>
Corrected Text: I have good spelling.
尝试探索 TextBlob 包,以找到适合你文本任务的 API。
Gensim
Gensim 是一个开源的 Python NLP 库,专注于主题建模和文档相似性分析,特别适用于大数据和流数据。它更关注工业实时应用。
让我们尝试这个库。首先,我们可以使用以下代码进行安装:
pip install gensim
安装完成后,我们可以尝试 Gensim 的功能。让我们尝试使用 Gensim 进行 LDA 主题建模。
import gensim
from gensim import corpora
from gensim.models import LdaModel
# Sample documents
documents = [
"Tennis is my favorite sport to play.",
"Football is a popular competition in certain country.",
"There are many athletes currently training for the olympic."
]
# Preprocess documents
texts = [[word for word in document.lower().split()] for document in documents]
dictionary = corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
#The LDA model
lda_model = LdaModel(corpus, num_topics=2, id2word=dictionary, passes=15)
topics = lda_model.print_topics()
for topic in topics:
print(topic)
Output>>
(0, '0.073*"there" + 0.073*"currently" + 0.073*"olympic." + 0.073*"the" + 0.073*"athletes" + 0.073*"for" + 0.073*"training" + 0.073*"many" + 0.073*"are" + 0.025*"is"')
(1, '0.094*"is" + 0.057*"football" + 0.057*"certain" + 0.057*"popular" + 0.057*"a" + 0.057*"competition" + 0.057*"country." + 0.057*"in" + 0.057*"favorite" + 0.057*"tennis"')
输出结果是文档样本中词语的组合,形成一个有机的话题。你可以评估结果是否有意义。
Gensim 还提供了一种用户嵌入内容的方式。例如,我们使用 Word2Vec 从词语中创建嵌入。
import gensim
from gensim.models import Word2Vec
# Sample sentences
sentences = [
['machine', 'learning'],
['deep', 'learning', 'models'],
['natural', 'language', 'processing']
]
# Train Word2Vec model
model = Word2Vec(sentences, vector_size=20, window=5, min_count=1, workers=4)
vector = model.wv['machine']
print(vector)
Output>>
[ 0.01174188 -0.02259516 0.04194366 -0.04929082 0.0338232 0.01457208
-0.02466416 0.02199094 -0.00869787 0.03355692 0.04982425 -0.02181222
-0.00299669 -0.02847819 0.01925411 0.01393313 0.03445538 0.03050548
0.04769249 0.04636709]
Gensim 还有许多应用场景。尝试查看文档并评估你的需求。
结论
在这篇文章中,我们探讨了几种对许多文本任务至关重要的 Python NLP 库。所有这些库都对你的工作有用,从文本分词到词嵌入。我们讨论的库包括:
-
NLTK
-
SpaCy
-
TextBlob
-
Gensim
希望这对你有帮助
Cornellius Yudha Wijaya**** 是一名数据科学助理经理和数据撰稿人。在全职工作于安联印尼期间,他热衷于通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 涉猎各种 AI 和机器学习主题。
更多相关主题
A/B 测试:数据科学面试中 7 个常见问题及解答,第一部分
原文:
www.kdnuggets.com/2021/04/ab-testing-7-common-questions-answers-data-science-interviews-1.html
评论
注意:这是本文的第一部分。你可以在 这里 阅读第二部分。
A/B 测试,也称为对照实验,广泛应用于行业中以做出产品发布决策。它允许科技公司通过对一部分用户进行评估来推测产品如何被所有用户接受。数据科学家处于 A/B 测试过程的前沿,而 A/B 测试被认为是数据科学家的核心能力之一。数据科学面试反映了这一现实。面试官通常会问候选人关于 A/B 测试的问题,以及商业案例问题(即度量问题、产品感知问题),以评估候选人的产品知识和推动 A/B 测试过程的能力。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
在本文中,我们将采用面试驱动的方法,将一些最常被问及的面试问题与 A/B 测试的不同组件关联起来,包括选择测试的想法、设计 A/B 测试、评估测试结果以及做出是否发布的决定。具体来说,我们将涵盖7个最常被问及的面试问题及其答案。
在你开始阅读之前,如果你喜欢视频,可以查看这个 YouTube 视频 以获取本帖的简略版本。
测试前 — 不是每个想法都值得测试
A/B 测试是一个强大的工具,但并非所有想法都通过测试来选择。一些想法的测试可能很昂贵,早期阶段的公司可能资源有限,因此对每个想法进行测试是不切实际的。因此,我们首先需要选择哪些想法值得测试,特别是在大家对如何改进产品有不同意见和想法时,并且有许多想法可以选择。例如,UX 设计师可能建议更改一些 UI 元素,产品经理可能提议简化结账流程,工程师可能推荐优化后台算法等。在这种情况下,利益相关者依赖数据科学家来驱动数据驱动的决策。一个典型的面试问题是:
有一些想法可以增加电商网站的转化率,例如启用多商品结账(目前用户每次只能结账一个商品)、允许未注册用户结账、更改“购买”按钮的大小和颜色等,你会如何选择投资哪个想法?
评估不同想法的价值的一种方法是使用历史数据进行定量分析,以获取每个想法的机会规模。例如,在对多个商品进行电商网站结账投资之前,通过分析每个用户购买多个商品的数量,获取影响的上限。如果只有极少数用户购买了多个商品,开发这个功能可能不值得付出努力。更重要的是调查用户的购买行为,以了解为什么用户不会一起购买多个商品。是因为商品选择太少?商品价格过高,他们只能买一个?结账过程太复杂,他们不愿意再次经历?
这种分析提供了关于哪个想法适合进行 A/B 测试的方向性见解。然而,历史数据仅能告诉我们过去的表现,无法准确预测未来。
为了对每个想法进行全面评估,我们可以通过焦点小组和调查进行定性分析。从焦点小组(与用户或有洞察力的用户进行引导讨论)或调查中收集的反馈可以提供有关用户痛点和偏好的更多见解。定性和定量分析的结合可以帮助进一步进行想法筛选。
设计 A/B 测试
一旦我们选择了一个想法进行测试,我们需要决定测试运行的时间长度以及如何选择随机化单位。在这一部分,我们将逐一讨论这些问题。
测试运行多长时间?
要决定测试的持续时间,我们需要获取测试的样本量,这需要三个参数。这些参数是:
-
第二类错误率β或统计功效,因为功效 = 1 — β。你知道其中一个,就知道另一个。
-
显著性水平α
-
最小可检测效应
经验法则是样本大小n大约等于 16(基于α = 0.05和β = 0.8)乘以样本方差除以δ的平方,其中δ是处理组和对照组之间的差异:
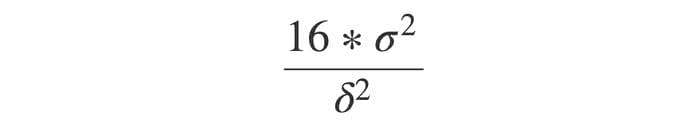
这个公式来自于《可信赖的在线对照实验》 由 Ron Kohavi、Diane Tang 和 Ya Xu 编著。
如果你对我们如何得出经验法则公式感兴趣,请查看这个视频以获取逐步讲解。
在面试中,你不需要解释你是如何得出公式的,但你需要解释我们如何获得每个参数以及每个参数如何影响样本大小。例如,如果样本方差较大,我们需要更多样本;如果δ较大,我们需要更少样本。
样本方差可以从现有数据中获得,但我们如何估计δ,即处理组和对照组之间的差异呢?
实际上,我们在实验运行之前并不知道这个值,这就是我们使用最后一个参数的地方:最小可检测效应。它是实际中重要的最小差异。例如,我们可能将 0.1%的收入增长视为最小可检测效应。实际上,这个值由多个利益相关者讨论和决定。
一旦我们知道样本大小,我们可以通过将样本大小除以每组的用户数来获得运行实验所需的天数。如果这个数字少于一周,我们应至少运行七天以捕捉到每周的模式。通常建议运行两周。在进行测试数据收集时,更多的样本几乎总是比样本不足要好。
对照组和处理组之间的干扰
通常,我们通过随机选择用户并将每个用户分配到对照组或处理组来划分对照组和处理组。我们期望每个用户是独立的,且对照组和处理组之间没有干扰。然而,有时这一独立性假设并不成立。这可能发生在测试社交网络(如 Facebook、LinkedIn 和 Twitter)或双边市场(如 Uber、Lyft 和 Airbnb)时。一个样本面试问题是:
公司 X 测试了一个新功能,目的是增加每个用户创建的帖子数量。他们随机将每个用户分配到对照组或处理组。测试在帖子数量方面赢了 1%。你期望新功能在向所有用户推出后会发生什么?如果不是 1%,那会是更多还是更少?(假设没有新奇效应)
答案是我们会看到一个大于 1%的值。原因如下。
在社交网络(如 Facebook、Linkedin 和 Twitter)中,用户的行为可能会受到其社交圈中人们行为的影响。如果网络中的人(如朋友和家人)使用某个功能或产品,用户也倾向于使用它。这被称为网络效应。因此,如果我们以“用户”作为随机化单元且处理对用户有影响,效果可能会蔓延到对照组,意味着对照组中的人行为会受到处理组的影响。在这种情况下,对照组和处理组之间的差异低估了处理效果的真实收益。对于面试问题,差异将超过 1%。
对于双边市场(如 Uber、Lyft、eBay 和 Airbnb):对照组和处理组之间的干扰也可能导致对处理效果的偏倚估计。这主要是因为资源在对照组和处理组之间共享,意味着对照组和处理组会竞争相同的资源。例如,如果我们有一个新产品吸引了处理组中的更多司机,那么对照组中可用的司机就会减少。因此,我们将无法准确估计处理效果。与社交网络中处理效果低估新产品的真实收益不同,在双边市场中,处理效果高估了实际效果。
如何处理干扰?

图片来源:Chris Lawton 在 Unsplash
既然我们知道为什么对照组和处理组之间的干扰会导致发布后的效果与处理效果不同,它引出了下一个问题:我们如何设计测试以防止对照组和处理组之间的溢出效应? 一个示例面试问题是:
我们正在推出一项新功能,为乘客提供优惠券。目标是通过降低每次乘车的价格来增加乘车次数。概述一个测试策略,以评估新功能的效果。
有多种方法可以应对组间的溢出效应,主要目标是隔离用户于对照组和处理组之间。以下是几种常用的解决方案,每种方案适用于不同的场景,并且都有局限性。在实践中,我们希望选择在特定条件下效果最佳的方法,也可以结合多种方法以获得可靠结果。
社交网络:
-
一种确保隔离的方法是创建网络群体,以表示更可能与群体内的人互动的用户组,而不是与群体外的人互动。一旦我们拥有这些群体,就可以将它们分为对照组和处理组。有关这种方法的更多细节,请查看这篇论文。
-
自我群体随机化。这个概念源自 Linkedin。一个群体由一个“自我”(核心个体)及其“ alters”(与其直接连接的个体)组成。它侧重于测量单一网络效应,即用户的直接连接的处理对该用户的影响,然后每个用户要么拥有该特征,要么没有,无需复杂的用户间交互。这篇论文详细解释了这种方法。
双边市场:
-
基于地理位置的随机化。我们可以按地理位置进行分组,而不是按用户分组。例如,我们可以将纽约大都会区域放在对照组,将旧金山湾区放在处理组。这将使我们能够隔离每组中的用户,但缺陷是会有更大的方差,因为每个市场在客户行为、竞争者等方面都有其独特性。
-
另一种方法,虽然使用较少,是基于时间的随机化。基本上,我们选择一个随机时间,例如一周中的一天,将所有用户分配到对照组或处理组。当处理效果仅持续短时间时,这种方法有效,例如测试一个新的高峰价格算法表现如何。当处理效果需要较长时间才有效时,例如推荐计划,则效果不好。用户可能需要一些时间才能向朋友推荐。
个人简介: Emma Ding 是 Airbnb 的数据科学家和软件工程师。
原文。经许可转载。
相关:
-
关于 A/B 测试的 5 件事
-
如何获得数据科学面试:寻找工作、接触关卡人员和获取推荐
-
我如何在被解雇后 2 个月获得 4 个数据科学职位并使收入翻倍
更多相关话题
A/B 测试:数据科学面试中的 7 个常见问题及答案(第二部分)
原文:
www.kdnuggets.com/2021/04/ab-testing-7-common-questions-answers-data-science-interviews-2.html
评论
注意:这是本文的第二部分。你可以在 这里 阅读第一部分。
分析测试结果
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你在 IT 领域的组织

图片由 Scott Graham 提供,来自 Unsplash
新奇效应和首因效应
当产品发生变化时,人们的反应会有所不同。有些人习惯了产品的工作方式,并且不愿意改变。这被称为首因效应或对变化的抗拒。其他人可能会欢迎变化,并且新功能会吸引他们更多地使用产品。这被称为新奇效应。然而,这两种效应不会持续太久,因为人们的行为会在一段时间后趋于稳定。如果 A/B 测试的初始效应较大或较小,可能是由于新奇效应或首因效应。这是实践中的一个常见问题,许多面试问题都涉及这个话题。一个典型的面试问题是:
我们对一个新功能进行了 A/B 测试,测试结果获胜,因此我们将更改推送给所有用户。然而,在推出该功能一周后,我们发现处理效应迅速下降。这是怎么回事?
答案是新奇效应。随着时间的推移,随着新奇感的减退,重复使用将减少,因此我们观察到处理效应的下降。
现在你了解了新奇效应和首因效应,我们如何解决潜在问题?这是面试中的一个典型后续问题。
处理这种效应的一种方法是完全排除这些效应的可能性。我们可以仅对首次使用者进行测试,因为新奇效应和首因效应显然不会影响这些用户。如果我们已经在运行测试并且想要分析是否存在新奇效应或首因效应,我们可以 1) 比较控制组中新用户的结果与处理组中相同的新用户结果,以评估新奇效应 2) 比较处理组中新用户的结果与现有用户的结果,以获得新奇效应或首因效应的实际影响估计。
多重检验问题
在最简单的 A/B 测试中,有两个变体:控制组(A)和处理组(B)。有时,我们会进行多个变体的测试,以查看哪一个在所有功能中表现最佳。这种情况可能发生在我们想测试按钮的多种颜色或不同的主页时。这样我们将有多个处理组。在这种情况下,我们不应该仅使用 0.05 的显著性水平来决定测试是否显著,因为我们处理的是超过 2 个变体,并且虚假发现的概率增加。例如,如果我们有 3 个处理组与控制组进行比较,观察到至少 1 个虚假正例的概率是多少(假设我们的显著性水平是 0.05)?
我们可以得到没有虚假正例的概率(假设各组是独立的),
Pr(FP = 0) = 0.95 * 0.95 * 0.95 = 0.857
然后得到至少有 1 个虚假正例的概率
Pr(FP >= 1) = 1 — Pr(FP = 0) = 0.143
在仅有 3 个处理组(4 个变体)的情况下,虚假正例(或 I 型错误)的概率超过 14%。这被称为“多重检验”问题。一个常见的面试问题是
我们正在进行一个有 10 个变体的测试,尝试不同版本的登录页面。一个处理组获胜,且 p 值小于 0.05。你会做出改变吗?
答案是否定的,因为存在多重检验问题。有几种方法可以应对。常用的方法之一是邦费罗尼校正。它将显著性水平 0.05 除以测试数量。对于这个面试问题,因为我们要测量 10 个测试,所以测试的显著性水平应为 0.05 除以 10,即 0.005。基本上,我们只有当测试的 p 值小于 0.005 时,才会声称该测试具有显著性。邦费罗尼校正的缺点是它往往过于保守。
另一种方法是控制虚假发现率(FDR):
FDR = E[# 的虚假正例 / # 的拒绝]
这衡量了所有原假设的拒绝,即所有声明具有统计显著差异的指标。实际存在差异的有多少,与假阳性的有多少。这仅在你有大量的指标时才有意义,比如几百个。假设我们有 200 个指标,并将 FDR 上限设为 0.05。这意味着我们接受 5%的假阳性。我们将在这 200 个指标中每次观察到至少 10 个假阳性。
做决策

照片由 You X Ventures 提供,发布在 Unsplash
理想情况下,我们会看到具有实际意义的处理结果,我们可以考虑将该功能推出给所有用户。但有时,我们会看到矛盾的结果,例如一个指标上升而另一个下降,因此我们需要做出权衡。一道面试题是:
在运行测试后,你看到所需的指标,例如点击率上升而展示次数下降。你会如何做决策?
事实上,做出产品发布决策可能涉及多个因素,如实施复杂性、项目管理工作、客户支持成本、维护成本、机会成本等。
在面试中,我们可以提供一个简化版本的解决方案,重点关注实验的当前目标。是最大化参与度、留存、收入,还是其他?此外,我们还要量化负面影响,即非目标指标的负面变化,以帮助我们做出决定。例如,如果收入是目标,我们可以选择收入优先于最大化参与度,前提是负面影响可以接受。
资源
最后,我想推荐两个资源,帮助你更好地了解 A/B 测试。
-
Udacity 的免费 A/B 测试课程 涵盖了 A/B 测试的所有基础知识。
-
值得信赖的在线对照实验——A/B 测试实用指南 由 Ron Kohavi、Diane Tang 和 Ya Xu 编写。它深入探讨了如何在行业中进行 A/B 测试、潜在的陷阱以及解决方案。书中包含了许多有用的内容,所以我实际上计划写一篇文章总结这本书的内容。如果你感兴趣,请继续关注!
简介: Emma Ding 是 Airbnb 的数据科学家和软件工程师。
原文 已获得许可重新发布。
相关:
-
A/B 测试:数据科学面试中的 7 个常见问题与答案,第一部分
-
关于 A/B 测试的 5 件事
-
如何获得数据科学面试机会:寻找工作、联系关卡人员以及获取推荐
了解更多相关话题
A/B 测试:全面指南
A/B 测试,也称为“拆分测试”或“随机对照试验”,是一种比较网页、应用程序或其他产品的两个版本以查看哪个表现更好的方法。A/B 测试的基本想法是将用户分成两组:A 组和 B 组。A 组(对照变体)看到你产品的原始版本,而 B 组(测试变体)看到一个有一个或多个更改的修改版本。这些更改可以是按钮的颜色、页面布局、标题的措辞、影响搜索结果的后台算法或促销优惠。然后你会测量每组的行为,例如用户在产品上停留的时间、访问的页面数、采取的行动数或产生的收入。通过比较每个变体的结果,你可以确定哪个更有效地实现了你的目标。如果有两个变体,它被称为 A/B 测试,当有两个以上变体时,它通常被称为 A/B/C 或 A/B/N 测试。
通过进行 A/B 测试,你可以做出基于数据的决策,从而改善你的产品和业务成果。一个有效的 A/B 测试是你能够根据结果自信地做出决策的测试。在本文中,我们将探讨 A/B 测试的基础知识,如何设计和运行有效的实验,以及如何分析和解读结果。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
A/B 测试可以帮助你回答以下问题:
-
哪个标题吸引更多点击?
-
哪种布局增加参与度?
-
哪种优惠能提升销售额?
-
哪个功能减少用户流失?
何时进行 A/B 测试?
对于这个问题没有明确的答案,因为这取决于你的目标、资源和背景。如果你想了解新功能如何影响用户参与度以及关键业务指标,A/B 测试是一个完美的选择。然而,一些通用的指南包括:
-
当你拥有足够的流量和转化率以获得可靠的结果时,进行 A/B 测试。
-
当你有明确的假设和可测量的结果时,进行 A/B 测试。
-
当你有足够的时间来正确进行测试,以避免常见的陷阱如窥探、过早停止或一次性进行过多测试时,进行 A/B 测试。
-
当你准备根据结果采取行动时,进行 A/B 测试。
假设你作为 Contoso 公司的产品经理加入。你认为改变“购买”按钮的颜色将会改善参与度和提高销售数量。作为产品经理,你有一个直觉,认为将颜色改为蓝色会带来更高的销售。有时候你的直觉是正确的,有时候是错误的。你怎么知道这一点?这就是为什么你的目标是收集用户对按钮颜色如何影响用户体验和关键业务指标(如收入)的见解。
进行 A/B 实验的步骤可以分解为以下几个方面:
问题陈述
问题陈述是对需要通过 A/B 实验解决的问题的清晰而简洁的描述。它应包括当前情况、期望结果以及两者之间的差距。一个明确的问题陈述有助于聚焦实验设计,统一利益相关者的意见,并衡量实验的成功。在进行 A/B 实验之前,定义问题陈述很重要,以避免在不相关或无效的测试上浪费资源、时间和精力。根据行业的不同,问题陈述可能有所不同。
根据行业的一些问题陈述示例如下:
| 旅行公司如 Expedia、Booking.com |
|---|
-
增加预订数量。
-
增加客户评论的数量。
|
| 媒体公司如 Netflix、Hulu |
|---|
-
增加客户参与度。
-
增加订阅率。
|
| 电子商务公司如 Amazon、Walmart |
|---|
-
增加搜索和浏览的产品数量。
-
增加加入购物车的比例。
|
| 社交媒体公司如 Instagram、Facebook |
|---|
-
通过广告增加收入。
-
通过评论、点赞、分享增加参与度
|
定义假设
什么是假设?A/B 实验中的假设是一个可测试的陈述,它预测网站或应用程序的变化将如何影响某个指标或用户行为。
定义假设的三个步骤包括:
-
我们知道我们有[这个问题],基于[证据]。
-
你认为我们应该实施[这一改变]以实现[这一结果],因为这将改善[这个问题]。
-
我们知道我们已经实现了[这一结果],当我们看到[这个指标]发生变化时。
假设的例子包括:
-
我们看到[在电子商务网站上销售的单位数量减少],这是通过[销售数据]得出的,时间跨度为去年。
-
我们相信,融入社会证明元素,例如展示在特定时间范围内购买某一产品的[例如,“X”人在过去 24 小时内购买],可以产生紧迫感,并[影响访客购买]。这一心理触发点利用了错失恐惧,[鼓励潜在买家转化]。
-
我们知道我们已经达到了[更高的转化率],当我们看到[收入增加/销售单位增加]时。
零假设 (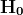 ):基线和变体处理之间的每日每用户平均收入相同。
):基线和变体处理之间的每日每用户平均收入相同。
备择假设 (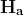 ):基线和变体处理之间的每日每用户平均收入不同。
):基线和变体处理之间的每日每用户平均收入不同。
显著性水平: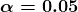 :显著性水平越低,表明对照组和变体组之间的差异不是偶然发生的统计显著性越高。
:显著性水平越低,表明对照组和变体组之间的差异不是偶然发生的统计显著性越高。
统计功效: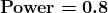 :如果备择假设为真,检测效果的概率。
:如果备择假设为真,检测效果的概率。
设计实验
要成功运行实验,你需要与不同团队合作并遵循一些步骤。首先,你需要定义你的关键指标,这是一种量化的度量,反映了你实现目标的程度。例如,如果你想测试更改网站上购买按钮的颜色是否会影响销售,你的关键指标将是每用户每月的收入。这个指标捕捉了颜色变化对用户行为和商业结果的影响。其次,你需要与用户体验(UX)团队合作,设计两种版本的购买按钮:一种是原始颜色,另一种是新颜色。这些被称为对照变体和测试变体。UX 团队可以帮助确保设计一致、吸引人且用户友好。第三,你需要与工程团队合作,在网站上实现并部署这两个变体。工程团队可以帮助确保代码无漏洞、安全且可扩展。第四,你需要与数据团队合作,设置一个监控系统,跟踪和收集两个变体的关键指标数据。数据团队可以帮助确保数据准确、可靠且可访问。第五,你需要决定如何将访问你网站的用户随机分配到对照组或测试组。随机化很重要,因为它确保这两个组在统计上是相似的,任何关键指标的差异都是由于颜色变化而不是其他因素造成的。你可以使用不同的随机化方法,如基于 cookie、用户 ID 或 IP。第六,你需要确定每组需要多少用户才能检测到关键指标的显著差异。这被称为样本大小,它取决于多个因素,如预期效果大小、关键指标的标准差、显著性水平和检验的统计功效。你可以使用公式或计算器根据这些因素估算样本大小。
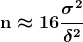
运行实验
实验过程的下一步是将你的实验推出到部分用户中,并监测其表现。你应该从低曝光率开始,并在对实验充满信心后逐步增加曝光率。你还应该收集你在假设中定义的关键指标的数据,并跟踪它们随时间的变化。为了帮助你,你应该与开发团队合作,构建一个显示指标值及其统计显著性的仪表盘。你应该避免在实验结束前查看结果并得出过早的结论。你还应确保实验持续足够长的时间,以确保你有足够的数据来做出有效的决策。根据你的流量和转化率,这可能需要几天、几周或几个月。
解释结果
在基于实验结果推出任何变更之前,你需要执行一些合理性检查,以确保数据可靠有效。合理性检查是质量控制措施,帮助你发现数据收集或分析过程中的任何错误或异常。例如,你可以检查流量分配是否正确,实验组间的不变指标是否一致,是否有任何外部因素可能影响了结果。如果你发现数据有任何问题,你应该丢弃这些数据,并用正确的设置重新进行实验。
一旦你验证了数据的可靠性,你就可以继续实施变更。为此,你需要分析结果并根据你的假设和成功指标得出结论。你可以使用统计方法,如假设检验、置信区间和效应量,来比较各个变体的表现,看看是否有明确的胜者或平局。如果有胜者,你可以在你的网站或应用上实施获胜的变体,并结束实验。如果是平局,你可能需要进行另一个实验,使用不同的假设或更大的样本量,以获得更具决定性的结果。
Poornima Muthukumar**** 是微软的一位高级技术产品经理,拥有超过 10 年的开发和交付创新解决方案的经验,涉及领域包括云计算、人工智能、分布式和大数据系统。我拥有华盛顿大学的数据科学硕士学位。在微软,我专注于 AI/ML 和大数据系统,拥有四项专利,并在 2016 年获得全球黑客马拉松人工智能类别的奖项。今年 2023 年,我有幸成为 Grace Hopper 大会软件工程类别的评审委员会成员。阅读和评估来自这些领域的才华横溢的女性提交的作品,为促进女性在技术领域的发展做出了贡献,这一经历让我受益匪浅,并从她们的研究和见解中获得了很多启发。我还是 2023 年 6 月微软机器学习 AI 和数据科学(MLADS)会议的委员会成员。除此之外,我还是全球数据科学女性社区和 Women Who Code 数据科学社区的大使。
更多相关主题
如何在 A/B 测试数据科学面试中表现出色
原文:
www.kdnuggets.com/2021/04/ab-testing-data-science-interviews.html
评论
由 Preeti Semwal,数据科学与分析领袖。

我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
图片由 bruce mars 提供,来源于 Unsplash。
A/B 测试是一项需求量大的技能,常在数据科学面试中被考察。然而,针对 A/B 测试面试的资源非常有限。在我 15 年的职业生涯中,作为数据科学的招聘经理,我发现大多数候选人在这些面试中表现不佳。实际上,实验领域一直在发展,每年都有新的概念和方法变得更加相关。这意味着,即使是经验丰富的数据科学家,也可能在面试中感到困惑。
在这篇文章中,我们将进行一次模拟面试,帮助你了解面试官在寻找什么以及如何应对这些面试。为什么要进行模拟面试呢?作为数据科学家,我们有时在沟通上会遇到困难,心中有一个模板会大大有帮助。就我个人而言,当我能够想象一个高风险的情境及其可能的发展时,这有助于我在心理上更好地准备、有效应对压力,并整体上表现更好。
我们将使用一个来自Doordash的例子,这是一家移动应用在 iPhone 应用商店中排名第一的食品配送公司。他们通过实验不断改进他们的应用,并在数据科学面试中寻找强大的实验技能,特别是在产品数据科学或产品分析角色中。
问题
面试官 — Doordash 正在扩展到便利店配送等其他类别。他们的通知过去取得了良好的成功,他们正在考虑发送应用内通知以推广这个新推出的类别。
你会如何设计和分析实验,以决定是否应该推出通知?
解决方案
第一部分 — 提出澄清问题以深入了解业务目标和产品功能细节
面试官关注的内容 -
你是否在详细讨论实验之前先陈述了产品/业务目标?在不知道产品目标的情况下讨论实验是一个警示信号。
面试者 — 在开始实验细节之前,我希望确保我对背景的理解是正确的。像这样的功能可能有多个目标——例如增加新用户获取、提高该类别的转化率、增加该类别的订单数量,或增加总订单价值。你能帮我理解这里的目标是什么吗?
面试官 — 这是个很好的问题。通过应用内通知,我们主要是想提高新类别的转化率——即登录应用的所有用户中,有多少用户在新类别下单。
面试者 — 好的,这很有帮助。现在我还想更多了解通知的内容——消息是什么,目标受众是谁?
面试官 — 目前我们没有提供任何折扣。消息仅仅是告知用户我们有一个新类别,他们可以开始从中下单。如果实验成功,我们打算将通知推广到所有用户。
面试者 — 好的。感谢提供这些背景信息。我现在准备深入探讨实验细节。
第二部分 — 陈述业务假设、原假设,并定义需要评估的指标
面试官关注的内容 -
除了主要指标之外,你是否考虑了次要指标和保护性指标
面试者 — 也就是说,业务假设是,我们期望如果我们发送应用内通知,那么新类别的每日订单数量会增加。这意味着我们的原假设(Ho)是由于通知的存在,转化率没有变化。
现在让我陈述一下我们在实验中需要包括的不同指标。由于通知的目标是提高新类别的转化率。因此,这将是我们的主要指标。在次要指标方面,我们还应关注平均订单价值,以查看其影响。可能会出现转化率提高,但平均订单价值下降,从而导致总体收入降低的情况。这是我们可能需要注意的。
我们还应考虑保护性指标——这些是对业务至关重要的指标,我们不希望通过实验对其产生影响,例如在应用上花费的时间或应用卸载等。有没有这样的指标我们需要在这种情况下包括在内?
面试官 — 我同意你选择的主要指标,但你可以忽略这个练习中的次要指标。在防护指标方面你做得很对。Doordash 希望在涉及到他们的应用时对任何功能或发布保持谨慎,因为我们知道,安装了应用的客户的生命周期价值要高得多。我们希望小心,以免驱使用户卸载应用。
面试者 — 好的,这很重要。所以我们将把卸载百分比作为我们的防护指标。
第三部分 — 选择显著性水平、功效、最小可检测效应(MDE),并计算测试所需的样本大小和持续时间
面试官关注的内容 -
你对统计概念和样本大小及持续时间的计算的了解
你是否考虑了网络效应(在双边市场如 Doordash、Uber、Lyft、Airbnb 或社交网络如 Facebook 和 LinkedIn 中常见)、星期几效应、季节性或新奇效应,这些因素可能会影响测试的有效性,并需要在制定实验设计时加以考虑
面试者 — 现在,我想讨论实验设计。
首先,我们需要考虑网络效应——这些效应发生在对照组的行为受到施加于实验组的处理影响时。由于 Doordash 是一个双边市场,它更容易出现网络效应。在这个具体案例中,如果对实验组施加的处理增加了该组的需求,可能会导致供应(即配送员)的不足,从而影响对照组的表现。
为了考虑网络效应,我们需要选择不同于我们通常选择的随机化单位。有许多方法可以做到这一点——我们可以进行基于地理的随机化,或基于时间的随机化,或网络集群随机化,或网络自中心随机化。你想让我详细讲解这些方法吗?
面试官 — 我很高兴你提到了网络效应,事实上,这是我们在 Doordash 实验中认真观察的内容。为了节省时间,我们假设这里不存在网络效应,继续前进吧。
面试者 — 如果我们假设没有需要考虑的网络效应,那么实验的随机化单位就是用户——即,我们将随机选择用户并将他们分配到处理组和对照组。处理组将收到通知,而对照组不会收到任何通知。接下来,我想计算样本大小和持续时间。为此,我需要一些输入。
-
基线转化率—即在进行更改之前,对照组的现有转化率。
-
最小可检测差异 或 MDE — 即我们感兴趣的最小转化率变化。低于此变化的结果对业务来说将不具实际意义 — 通常选择这样的差异,以便所期望的结果的改善足以证明实施和维护该功能的成本。
-
统计功效 — 即测试正确拒绝原假设的概率。
-
显著性水平 — 即在原假设为真的情况下,拒绝原假设的概率。
通常选择 5% 的显著性水平和 80% 的统计功效,我将假设这些值,除非你另有说明。此外,我将假设对照组和处理组之间的比例为 50-50。一旦确定了这些输入,我将使用功效分析来计算样本量。我会用编程语言来完成这项工作。例如,在 R 中,有一个名为‘pwr’的包可以用于此目的。
面试官 — 是的,假设根据分析,我们需要每个变体 10,000 个用户的样本量。你会如何计算测试的持续时间?
面试者 — 当然,为此我们需要每天登录应用程序的用户数量。
面试官 — 假设我们有 10,000 名用户每天登录应用程序。
面试者 — 好的,在这种情况下,我们至少需要 2 天来进行实验 — 我之所以得出这个结论,是通过将控制组和处理组的总样本量除以每日用户数量。不过,在确定实验持续时间时,我们还应考虑其他因素。
-
星期几效应 — 你可能在周末和工作日有不同的用户群体 — 因此运行的时间需要足够长,以捕捉到每周的周期。
-
季节性 — 可能会有一些用户行为不同的时间,这些时间是需要考虑的重要因素,比如节假日。
-
新颖效应 — 当你引入一个新功能时,特别是那种容易被注意到的功能,最初会吸引用户尝试。测试组可能一开始表现良好,但随着时间的推移,这种效应会迅速减弱。
-
外部效应 — 例如,假设市场表现非常好,更多的人可能会忽视通知,因为他们期望获得高回报。这将导致我们从实验中得出虚假的结论。
由于以上原因,我建议实验至少持续一周。
面试官 — 好的,这很公平。你会如何分析测试结果?
第四部分 — 分析结果并得出有效结论
面试官想要了解的内容 -
你对不同场景下适当统计测试的知识(例如,样本均值的 t 检验和样本比例的 z 检验)
你检查随机化 — 这会给你加分
你提供最终建议(或到达建议的框架)
面试者 — 当然。分析有两个关键部分 —
-
检查随机化 — 作为最佳实践,我们应该检查在分配测试和对照组时随机化是否正确。为此,我们可以查看一些不受测试影响的基线指标,并对比这两个组的这些指标。我们可以通过比较这两个组的直方图或密度曲线来进行比较。如果没有差异,我们可以得出随机化正确的结论。
-
所有指标的显著性测试(包括主要指标和保护指标) — 我们的主要指标(转化率)和保护指标(卸载率)都是比例。我们可以使用 z 检验来测试统计显著性。我们可以使用 R 或 Python 等编程语言来进行这一测试。
如果转化率有统计学显著增加且卸载率未受到负面影响,我建议实施该测试。
如果转化率有统计学显著增加且卸载率受到负面影响,我建议不要实施该测试。
最后,如果转化率没有统计学显著增加,我建议不要实施该测试。
面试官 — 听起来不错。感谢你的回应。
结论
在 A/B 测试或实验面试中表现出色将为你提供招聘过程中的优势,并使你从其他候选人中脱颖而出。因此,我强烈建议专注时间学习 A/B 测试的关键概念,并为这些面试做好充分准备。
我推荐的几个好资源 —
-
产品 A/B 测试完整课程与面试指南 (免责声明 — 我是该课程的讲师)
-
如果你对实验有高级知识,这本书很适合回顾关键概念 — 罗恩·科哈维、黛安·唐和夏雅的《值得信赖的在线控制实验(A/B 测试实用指南)》
原文。经授权转载。
简介: Preeti Semwal 拥有 15 年的经验,帮助组织将数据科学和分析的力量融入业务战略。凭借通过数据讲述故事的卓越能力以及向高层管理人员展示的丰富经验,Preeti 是一位真正相信赋能、培养和倡导团队的领导者。
相关:
更多相关话题
NLP 的 ABC,从 A 到 Z
图片由 Towfiqu barbhuiya 提供,来源于 Unsplash
现在有大量的文本数据可供使用。每天都会生成大量的文本,这些数据从完全结构化到半结构化再到完全非结构化。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
我们能用这些文本做些什么呢?实际上,可以做很多事情;根据你的具体目标,有两个错综复杂但有所区别的任务领域可以利用这些数据。
自然语言处理与文本挖掘
让我们从一些定义开始。
自然语言处理 (NLP) 关注自然语言与计算设备之间的互动。NLP 是计算语言学的一个主要方面,也属于计算机科学和人工智能的领域。文本挖掘 与 NLP 在某种程度上相似,因为它也关注于识别文本数据中有趣的、非平凡的模式。
正如你从上述内容中可能能看出的,这两个概念的确切界限并不明确且达成共识,并且根据讨论这些问题的从业者和研究人员的不同程度有所重叠。我发现通过洞察的程度来区分最为容易。如果原始文本是数据,那么文本挖掘可以提取信息,而 NLP 提取的是知识(见下图的理解金字塔)。可以说是语法与语义的区别。
理解金字塔:数据,信息,知识
对于文本挖掘与 NLP 之间的精确关系,还有各种其他解释,你可以找到更适合你的解释。我们并不特别关心确切的定义——无论是绝对的还是相对的——而更关注的是直观地认识到这些概念是相关的,有一定重叠,但仍然有所区别。
我们将继续讨论的要点是:尽管 NLP 和文本挖掘不是同一回事,但它们密切相关,处理相同的原始数据类型,并且在使用上有一些交集。在接下来的讨论中,我们将方便地将这两个概念统称为 NLP。重要的是,这两个领域的任务在数据预处理方面有很多相似之处。
无论你要执行的 NLP 任务是什么,保持文本意义并避免歧义都是至关重要的。因此,避免歧义的尝试是文本预处理过程的重要组成部分。我们希望在消除噪声的同时保留意图表达。为此,需要做以下几点:
-
语言知识
-
世界知识
-
结合知识来源的方法
如果这很简单,我们可能就不会讨论它了。处理文本的困难有哪些原因呢?
为什么处理文本很困难?

来源:CS124 斯坦福大学 (https://web.stanford.edu/class/cs124/)
你可能注意到上面提到的一个有趣的点:“非标准英语。”虽然这显然不是图表的意图——我们在这里完全脱离了上下文——但出于各种原因,很多 NLP 研究历史上都发生在英语语言的范围内。因此,我们可以在“为什么处理文本很困难?”的问题上增加额外的困难层面,这些困难是非英语语言,特别是说话人数较少的语言,甚至是濒危语言在处理和提取洞见时必须经历的。

由 rawpixel.com 提供的图片 在 Freepik 上
在思考和讨论自然语言处理(NLP)时,意识到 NLP ≠ 英语是减少这种偏见的一种小方法。
文本数据科学任务框架
我们能否为处理文本数据科学任务制定一个足够通用的框架?事实证明,处理文本与其他非文本处理任务非常相似,因此我们可以借鉴KDD 过程的灵感。
我们可以说这些是通用文本任务的主要步骤,这些任务属于文本挖掘或 NLP。
1. 数据收集或组装
- 获取或构建语料库,这可以是从电子邮件到整个英语维基百科文章集,到公司的财务报告,到莎士比亚的完整作品,或者完全不同的东西
2. 数据预处理
-
在原始文本语料库上执行准备任务,以便进行文本挖掘或 NLP 任务
-
数据预处理包含多个步骤,其中的任何一个步骤可能适用于或不适用于特定任务,但通常属于分词、规范化和替换这几个广泛类别
3. 数据探索与可视化
-
无论我们的数据是什么——是文本还是其他——探索和可视化数据是获取洞察的一个重要步骤
-
常见任务可能包括可视化词频和分布,生成词云,以及执行距离度量
4. 模型构建
-
这是我们主要进行文本挖掘或自然语言处理任务的地方(包括训练和测试)
-
在适用时还包括特征选择与工程
-
语言模型:有限状态机,马尔可夫模型,词义的向量空间建模
-
机器学习分类器:朴素贝叶斯,逻辑回归,决策树,支持向量机,神经网络
-
序列模型:隐马尔可夫模型,递归神经网络(RNNs),长短期记忆神经网络(LSTMs)
5. 模型评估
-
模型表现是否如预期?
-
指标会根据文本挖掘或自然语言处理任务的类型有所不同
-
即使是思考聊天机器人(一个自然语言处理任务)或生成模型:也需要某种形式的评估
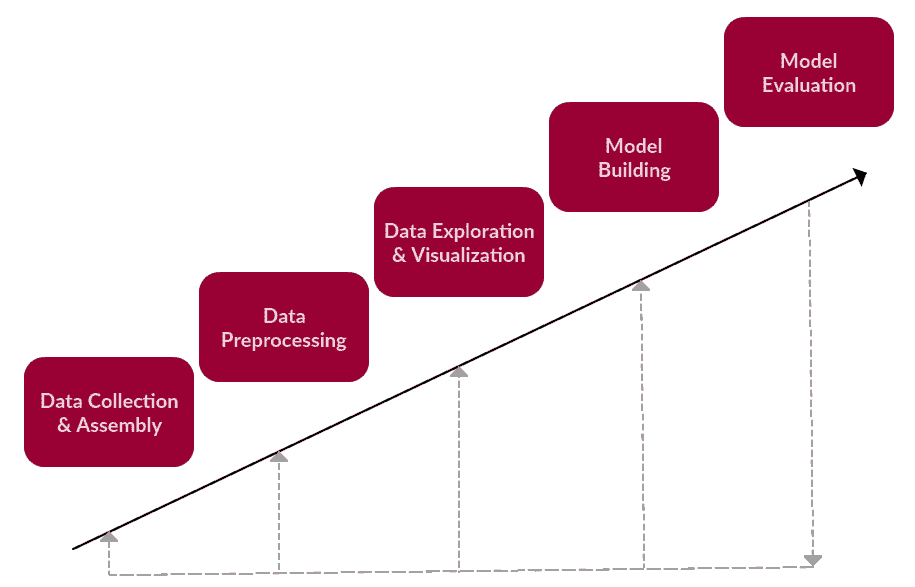
一个简单的文本数据任务框架
显然,任何关注文本数据预处理的框架都必须与步骤 2. 同义。具体来说,我们对这个步骤可能涉及的内容有以下说明:
-
对原始文本语料库执行准备任务,以便进行文本挖掘或自然语言处理任务
-
数据预处理包含多个步骤,其中的任何一个步骤可能适用于或不适用于特定任务,但通常属于分词、规范化和替换这几个广泛类别
-
更一般来说,我们感兴趣的是对某些预定的文本进行基本的分析和转换,以便得到更加有用的成果,这些成果将有助于进行后续更有意义的分析任务。这个后续任务就是我们的核心文本挖掘或自然语言处理工作。
所以,如上所述,文本预处理似乎有 3 个主要组件:
-
分词
-
规范化
-
替换
在制定预处理框架时,我们应当牢记这些高层次的概念。
文本预处理框架
我们将从概念上介绍这个框架,独立于工具。接下来我们将跟进这些步骤的实际实施,以查看它们在 Python 生态系统中的执行方式。
这些任务的顺序不一定是固定的,也可能会有一些迭代。
1. 噪声去除
噪声去除执行了框架中的一些替代任务。噪声去除是框架中一个更具任务特定的部分,而不是后续步骤。
再次记住,我们处理的过程不是线性的,步骤并非必须按特定顺序应用。因此,噪声去除可以在之前提到的部分之前、之后或之间的某个点进行。
语料库(拉丁语字面意思为“主体”)指的是文本的集合。这些集合可以是单一语言的文本,也可以跨越多种语言;多语言语料库(语料库的复数形式)有许多用途。语料库也可以包括主题文本(历史的、圣经的等)。语料库通常仅用于统计语言分析和假设检验。
怎么样更具体一点?假设我们从万维网获得了一个语料库,并且它是以原始网页格式存放的。那么我们可以假设我们的文本很有可能被 HTML 或 XML 标签包裹。虽然这种处理元数据的工作可以作为文本收集或组装过程的一部分(我们文本数据任务框架的第 1 步),但这取决于数据的获取和组装方式。有时我们可以控制这些数据的收集和组装过程,因此我们的语料库可能在收集过程中已经去噪了。
但情况并非总是如此。如果你所使用的语料库是嘈杂的,你必须处理这些问题。请记住,分析任务通常被认为有 80%是数据准备!
好消息是,模式匹配可以在这里成为你的朋友,现有的软件工具也可以处理这种模式匹配任务。
-
删除文本文件的头部和尾部
-
删除 HTML、XML 等标记和元数据
-
从其他格式(如 JSON)或数据库中提取有价值的数据
-
如果你对正则表达式感到恐惧,这可能会是你最担心的文本预处理部分。
正则表达式,通常缩写为regexp或regexp,是一种简洁描述文本模式的可靠方法。正则表达式本身作为一个特殊的文本字符串,用于在文本选择上开发搜索模式。正则表达式可以被看作是超越?和*****通配符的扩展规则集。尽管学习起来常被认为令人沮丧,但正则表达式是非常强大的文本搜索工具。
正如你所想,噪声去除和数据收集与组装之间的界限是模糊的,因此某些噪声去除必须在其他预处理步骤之前进行。例如,任何从 JSON 结构中提取的文本显然需要在分词之前去除。
2. 标准化
在进一步处理之前,文本需要标准化。
规范化 通常指一系列相关任务,旨在将所有文本置于同一水平:将所有文本转换为相同的大小写(大写或小写)、删除标点符号、扩展缩写、将数字转换为其单词等价物,等等。规范化使所有单词处于同等地位,并允许处理统一进行。
规范化文本可能意味着执行多个任务,但对于我们的框架,我们将以三个不同的步骤来处理规范化:(1)词干提取,(2)词形还原,(3)其他所有操作。
词干提取 是去除单词的词缀(后缀、前缀、插入词缀、环缀)以获得单词词干的过程。
running → run 词形还原 与词干提取相关,但不同的是词形还原能够捕捉基于单词词形的规范形式。
例如,词干提取单词 "better" 不能返回其引文形式(词形的另一种说法);然而,词形还原将产生以下结果:
better → good
应该很容易理解为什么实现一个词干提取器会比另一个任务简单。
其他所有操作
一个巧妙的通用方法,对吧?词干提取和词形还原是文本预处理工作的重要部分,因此需要给予应有的尊重。这不仅仅是简单的文本操作;它们依赖于对语法规则和规范的详细和细致的理解。
然而,还有许多其他步骤可以帮助将所有文本置于同等地位,其中许多涉及相对简单的替换或删除概念。然而,这些步骤对于整体过程同样重要。包括:
-
将所有字符设置为小写
-
删除数字(或将数字转换为文本表示)
-
删除标点符号(通常是标记化的一部分,但在这个阶段仍然值得记住,即使是为了确认)
-
去除空白(也通常是标记化的一部分)
-
删除默认停用词(一般英语停用词)
停用词是指在进一步处理文本之前被过滤掉的那些词,因为这些词对整体意义贡献较少,因为它们通常是语言中最常见的词。例如,“the”、“and”和“a”,虽然在特定段落中都是必需的词,但通常不会对内容理解有很大贡献。作为一个简单的例子,以下的全句在去掉停用词后依然可以读懂:
~~The~~ quick brown fox jumps over ~~the~~ lazy dog.
-
删除给定的(特定任务的)停用词
-
删除稀疏词(虽然不总是必要或有帮助!)
此时,应清楚文本预处理严重依赖于预构建的词典、数据库和规则。你会感到宽慰的是,当我们在下一篇文章中进行实际的 Python 文本预处理任务时,这些预构建的支持工具随时可用;不需要重新发明轮子。
3. 分词
分词通常是 NLP 过程中的早期步骤,这一步将较长的文本字符串分割成更小的片段或标记。较大的文本块可以被分词为句子,句子可以被分词为单词,等等。通常在文本经过适当分词后,会进行进一步处理。
分词也称为文本分割或词汇分析。有时分割用于指将较大的文本块分解成比单词更大的片段(例如段落或句子),而分词专指分解过程仅产生单词的情况。
这听起来可能是一个简单的过程,但实际上并非如此。如何在较大的文本中识别句子?你可能会马上说“句子结束的标点符号”,甚至可能会认为这样的说法毫无歧义。
当然,这个句子可以通过一些基本的分割规则轻松识别:
The quick brown fox jumps over the lazy dog.
那这个呢:
Dr. Ford did not ask Col. Mustard the name of Mr. Smith's dog.
或者这个:
"What is all the fuss about?" asked Mr. Peters.
这只是句子。那么单词呢?很简单,对吧?对吗?
This full-time student isn't living in on-campus housing, and she's not wanting to visit Hawai'i.
应当直观地理解,不仅有多种策略用于识别分隔边界,还有在达到边界时的处理方法。例如,我们可能采用一种分割策略(正确地)将单词标记之间的特定边界识别为单词she's中的撇号(单纯依赖空格分词的策略无法识别这一点)。但我们随后可能会在保留标点与单词一部分或完全丢弃标点之间做出选择。这些方法中的一种似乎是正确的,也没有明显问题。但请考虑英语语言中的所有其他特殊情况。
考虑:当我们将文本块分割成句子时,我们是否应该保留句子结束的分隔符?我们是否有兴趣记住句子的结束位置?
存在什么 NLP 任务?
我们已经涵盖了一些对 NLP 任务有用的文本(预)处理步骤,但任务本身呢?
这些任务类型之间没有明确的界限;然而,目前许多任务相对较为明确。一个宏观的 NLP 任务可能包括多种子任务。
我们首先概述了主要的方法,因为这些技术通常是初学者关注的重点,但了解 NLP 任务的具体类型是很有帮助的。以下是 NLP 任务的主要类别。
1. 文本分类任务
-
表示:词袋模型、n-gram、一热编码(稀疏矩阵)——这些方法不保留单词顺序
-
目标:预测标签、类别、情感
-
应用:过滤垃圾邮件,根据主要内容分类文档
词袋 是一种特定的表示模型,用于简化文本选择的内容。词袋模型省略了语法和词序,但关注于文本中词的出现次数。文本选择的最终表示是词袋 (bag 指的是 多重集 的集合论概念,与简单集合不同)。
词袋表示的实际存储机制可能有所不同,但以下是一个使用词典的简单示例。示例文本:
"Well, well, well," said John.
“那里,那里,”詹姆斯说。“那里,那里。”
结果的词袋表示作为词典:
{
'well': 3,
'said': 2,
'john': 1,
'there': 4,
'james': 1
}
``` **n-grams** 是一种简化文本选择内容的表示模型。与无序的词袋表示不同,n-grams 建模关注于保留文本选择中连续的 *N* 项序列。
上述示例第二句的三元组 (3-gram) 模型示例如下所示:
```py
[
"there there said",
"there said james",
"said james there",
"james there there",
]
``` 在神经网络在 NLP 中广泛使用之前——我们称之为“传统”NLP——文本的向量化通常通过 **one-hot 编码** 进行(请注意,这仍然是一种有用的编码实践,尽管神经网络的使用并没有使其过时)。对于 one-hot 编码,文本中的每个词或标记对应一个向量元素。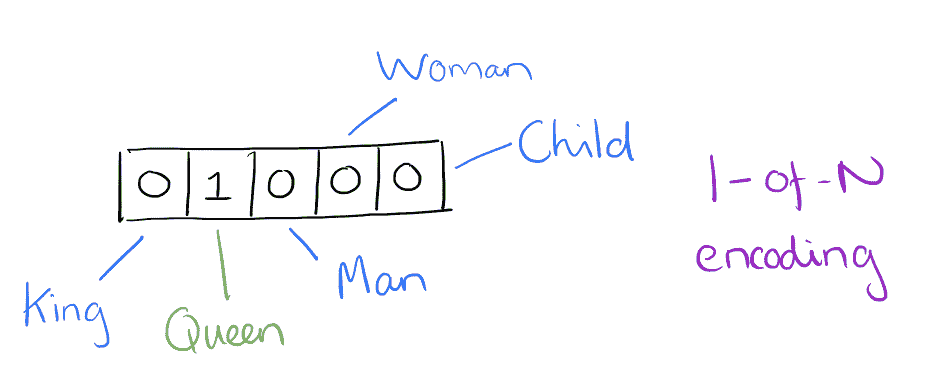
来源:[Adrian Colyer](https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/)
例如,我们可以将上面的图像视为表示句子“The queen entered the room.”的向量的小摘录。注意只有“queen”的元素被激活,而“king”、“man”等元素没有。你可以想象,如果句子“The king was once a man, but is now a child”的 one-hot 向量在上面的同一向量元素部分中会显得多么不同。
## 2\. 词序列任务
+ 表示:序列(保留词序)
+ 目标:语言建模 - 预测下一个/前一个词,文本生成
+ 应用:翻译、聊天机器人、序列标注(预测序列中每个词的词性标签)、命名实体识别
**语言建模** 是建立统计语言模型的过程,旨在提供自然语言的估计。对于一系列输入词,模型将为整个序列分配一个概率,这有助于估计各种可能序列的可能性。这对于生成或预测文本的 NLP 应用尤其有用。
## 3\. 文本意义任务
+ 表示:单词向量,将单词映射到向量(*n*维数字向量),也称为嵌入
+ 目标:我们如何表示意义?
+ 应用:查找相似单词(相似向量)、句子嵌入(与单词嵌入相对)、主题建模、搜索、问答
**密集嵌入向量**也称为单词嵌入,将核心特征嵌入到大小为*d*维度的嵌入空间中。如果需要,我们可以将表示 20,000 个唯一单词所用的维度数压缩到可能的 50 或 100 维。在这种方法中,每个特征不再具有自己的维度,而是映射到一个向量中。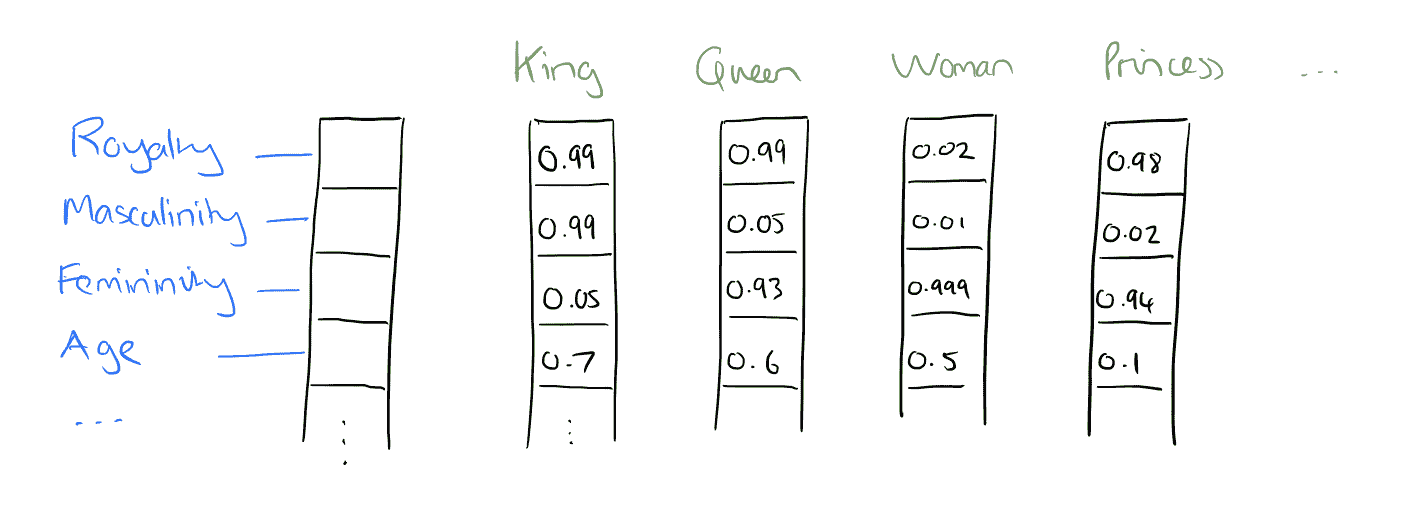
来源:[Adrian Colyer](https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/)
那么,这些特征究竟是什么呢?我们将其交给神经网络来确定单词之间关系的重要方面。尽管人类对这些特征的解释不可能非常精确,但上面的图像提供了对底层过程的洞察,涉及到著名的`King - Man + Woman = Queen` [例子](https://www.technologyreview.com/s/541356/king-man-woman-queen-the-marvelous-mathematics-of-computational-linguistics/)。
**命名实体识别**是尝试识别文本数据中的[命名实体](https://en.wikipedia.org/wiki/Named_entity),并对其进行适当分类。命名实体类别包括但不限于人名、地点、组织、货币值、日期和时间、数量等,并可以根据应用(医疗、科学、商业等)包括自定义类别。你可以将命名实体视为**专有名词++**。
使用 spaCy 进行命名实体识别(文本摘自[这里](https://www.nomadicmatt.com/travel-blogs/three-days-in-new-york-city/))
**词性标注**包括将类别标签分配给句子的分词部分。最常见的词性标注是识别单词作为名词、动词、形容词等。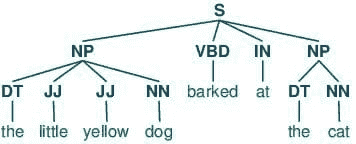
词性标注
## 4\. 序列到序列任务
+ 许多 NLP 任务可以被框定为这样的任务
+ 示例包括机器翻译、摘要生成、简化、问答系统
+ 这些系统的特点是编码器和解码器,它们互补地工作以找到文本的隐藏表示,并使用该隐藏表示
## 5\. 对话系统
+ 对话系统的 2 大主要类别,根据其使用范围进行分类
+ 目标导向对话系统专注于在特定、受限领域中的有用性;更精确,适用性较差
+ 对话对话系统关注于在更广泛的上下文中提供帮助或娱乐;精确度较低,更具普遍性
无论是在对话系统中还是在解决 NLP 任务的基于规则和更复杂方法之间的实际差异中,注意精度与泛化能力之间的权衡;通常你会在一个领域上做出牺牲,以增加另一个领域的能力。
# NLP 任务的方法
虽然不是一成不变,但解决 NLP 任务的方法主要分为 3 个组。

使用 spaCy 的依存解析树
## 1. 基于规则的方法
基于规则的方法是最古老的 NLP 方法。你可能会问,为什么它们仍然被使用?因为它们经过验证,效果良好。应用于文本的规则可以提供很多洞见:想想通过找到哪些词是名词,哪些动词以 -ing 结尾,或者是否可以识别出一个可识别为 Python 代码的模式,你可以学到什么。[正则表达式](https://en.wikipedia.org/wiki/Regular_expression)和[上下文无关文法](https://en.wikipedia.org/wiki/Context-free_grammar)是基于规则的 NLP 方法的经典例子。
基于规则的方法:
+ 倾向于关注模式匹配或解析。
+ 经常可以被认为是"填空"方法。
+ 精度低、召回率高,意味着它们在特定用例中表现良好,但在泛化时往往会性能下降。
## 2. "传统"机器学习
"传统"机器学习方法包括概率建模、似然最大化和线性分类器。值得注意的是,这些不是神经网络模型(见下文)。
传统机器学习方法的特点是:
+ 训练数据——在这种情况下,是带有标记的语料库。
+ 特征工程——词性、周围词、大小写、复数等。
+ 在参数上训练模型,然后在测试数据上拟合(这在机器学习系统中是典型的)。
+ 推断(将模型应用于测试数据)特点是找到最可能的词、下一个词、最佳类别等。
+ "语义槽填充"
## 3. 神经网络
这类似于"传统"机器学习,但有一些区别:
+ 特征工程通常被跳过,因为网络会"学习"重要的特征(这通常是使用神经网络进行 NLP 的一个主要好处之一)。
+ 相反,将原始参数("词"——实际上是词的向量表示)流入神经网络,而不进行工程特征处理。
+ 非常大的训练语料库
在 NLP 中,"历史上" 使用的特定神经网络包括递归神经网络(RNNs)和卷积神经网络(CNNs)。今天,统治一切的架构是变换器(transformer)。
## 为什么在 NLP 中使用"传统"机器学习(或基于规则)的方法?
+ 对于序列标注(使用概率建模)仍然有效。
+ 神经网络中的一些想法与早期方法非常相似(word2vec 在概念上类似于分布式语义方法)。
+ 使用传统方法中的方法来改进神经网络方法(例如,词对齐和注意机制是相似的)
## 为什么深度学习优于“传统”机器学习?
+ 在许多应用中处于 SOTA(例如,机器翻译)
+ 现在这里有很多关于 NLP 的研究(大多数?)
**重要的是**,神经网络和非神经网络方法在现代 NLP 中各有用处;它们也可以一起使用或研究,以获得最大的潜在收益
## 参考文献
1. [从语言到信息](https://web.stanford.edu/class/cs124/),斯坦福大学
1. [自然语言处理](https://www.coursera.org/learn/language-processing),国家研究大学高等经济学院(Coursera)
1. [自然语言处理的神经网络方法](https://www.morganclaypool.com/doi/abs/10.2200/S00762ED1V01Y201703HLT037),Yoav Goldberg
1. [自然语言处理](https://github.com/yandexdataschool/nlp_course/),Yandex 数据学校
1. [词向量的惊人力量](https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/),Adrian Colyer
**[Matthew Mayo](https://www.linkedin.com/in/mattmayo13/)**([**@mattmayo13**](https://twitter.com/mattmayo13))是数据科学家及 KDnuggets 的主编,该网站是开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 与他联系。
### 更多相关主题
+ [用 LIME 解释 NLP 模型](https://www.kdnuggets.com/2022/01/explain-nlp-models-lime.html)
+ [过去 12 个月必读的 NLP 论文](https://www.kdnuggets.com/2023/03/must-read-nlp-papers-last-12-months.html)
+ [NLP 中不同词嵌入技术的终极指南](https://www.kdnuggets.com/2021/11/guide-word-embedding-techniques-nlp.html)
+ [现实世界中 NLP 应用的范围:一个不同的…](https://www.kdnuggets.com/2022/03/different-solution-problem-range-nlp-applications-real-world.html)
+ [机器学习的甜蜜点:NLP 和文档分析中的纯粹方法](https://www.kdnuggets.com/2022/05/machine-learning-sweet-spot-pure-approaches-nlp-document-analysis.html)
+ [oBERT: 复合稀疏化提供更快的准确模型用于 NLP](https://www.kdnuggets.com/2022/05/obert-compound-sparsification-delivers-faster-accurate-models-nlp.html)
# MLOps 的绝对基础
> 原文:[`www.kdnuggets.com/2022/09/absolute-basics-mlops.html`](https://www.kdnuggets.com/2022/09/absolute-basics-mlops.html)

图片来源:作者
本文适合那些对 MLOps 一无所知或想刷新记忆的人。你可能在 LinkedIn 上浏览、阅读博客、参加 AI 会议等时听说过 MLOps。
* * *
## 我们的前三大课程推荐
 1\. [谷歌网络安全证书](https://www.kdnuggets.com/google-cybersecurity) - 快速入门网络安全职业。
 2\. [谷歌数据分析专业证书](https://www.kdnuggets.com/google-data-analytics) - 提升你的数据分析能力
 3\. [谷歌 IT 支持专业证书](https://www.kdnuggets.com/google-itsupport) - 支持你的组织在 IT 领域
* * *
让我们开始吧。
# 什么是 MLOps?
MLOps 代表机器学习操作,是机器学习、DevOps 和数据工程的结合。本文将对每一项进行定义。
**机器学习**使模型能够通过探索数据和识别模式,利用过去的经验进行学习和改进,几乎无需人工干预。
**DevOps**是开发和建立正确的操作的结合,以提高软件开发的效率、速度和安全性。
**数据工程**专注于设计和构建管道,将数据转换并传输成其他技术专家如数据科学家或最终用户能够访问的格式。
这三者结合起来,以可靠和高效的方式部署和维护机器学习系统。
# MLOps 的目标是什么?
在处理模型时,可能会变得很混乱。运行可能会耗时,尝试联系团队其他成员时可能会出现问题,并可能导致通信中的重大问题。
## 将数据科学家纳入视野
数据科学家有时不会与团队中的其他技术专家合作。他们的角色和责任不同,有时无需沟通。然而,随着模型的开发,数据科学家的合作变得至关重要,因为他们负责从数据集中提取、清理和收集洞察,这些洞察随后被用于构建 AI 模型。
## 合作
当你将所有技术专家聚集在团队中合作项目时,你会自然看到模型开发的增加。由于不同技能的结合,会有更快的部署时间,更好的模型管理和验证。
## 管理你的机器学习生命周期
通过建立正确的 MLOps 架构,你和团队中的其他专家能够跟踪、版本控制、重用和审计机器学习模型生命周期的每个方面或资产。这不仅提高了模型的可靠性,还提供了可以在未来应用的可转移知识。
# MLOps 阶段
MLOps 过程包括三个广泛的阶段:
1. 设计 ML 驱动的应用程序
1. ML 实验与开发
1. ML 操作
## 设计 ML 驱动的应用程序
这一阶段是每个项目的起点 - 了解当前的问题或待解决的内容。在这一阶段,你将对业务有更好的理解,然后继续了解数据,以确定如何设计 ML 驱动的应用程序。
MLOps 这一阶段的关键组件有:
+ 收集数据
+ 数据分析
+ 数据准备
+ 模型开发
+ 模型训练
在模型设计阶段,你将查看可用的数据、其限制以及我们 ML 模型的功能。这些将作为构建块帮助设计 ML 应用程序的架构,并确保我们更接近解决问题。
## ML 实验与开发
现在我们进入下一个阶段,专注于验证我们的 ML 应用程序的有效性。在这个阶段,建议使用 ML 模型的概念验证方法。概念验证方法用于通过进一步检查可扩展性、技术能力、限制等来帮助验证过程。
MLOps 这一阶段的关键组件有:
+ 模型验证
+ 模型服务
+ 模型监控
+ 模型重新训练
这些组件将帮助我们识别最适合我们当前问题的机器学习算法,并确保它在生产过程中能够稳定顺利地运行。
## ML 操作
最后一阶段完全是关于将机器学习模型投入生产。为了做到这一点,需要建立一定的 DevOps 实践。
MLOps 这一阶段的关键组件有:
+ 测试
+ 版本控制
+ 监控
# 实施 MLOps
实现 MLOps 有 3 个层级:
1. 手动过程
1. ML 流水线自动化
1. CI/CD 流水线自动化
## 手动过程
这个过程完全由数据科学家驱动,因此是一个手动过程。如果你的模型很少更改/训练,或者你刚刚开始实施 ML - 这个过程可能适合你。
由于其手动性质,这个过程非常实验性和迭代性 - 因此数据转换、验证、模型测试和训练等每个阶段都需要手动完成。手动过程中的最常用工具是 Jupyter Notebooks。
## ML 流水线自动化
这包括一个不需要手动执行的过程——你的模型需要自动训练。在这个过程中,当有新的数据可用时,流水线会感知到并触发模型重新训练的响应。这被称为持续训练。
这个过程可以被采用于不断变化的环境中,并持续需要这些指标来处理。
## CI/CD 流水线自动化
这一阶段提供了性能最佳、速度最快的可靠机器学习模型部署,你需要一个强大的自动化 CI/CD 系统。拥有这个 CI/CD 系统后,它允许你的数据科学家和其他技术专家深入挖掘,探索与特征工程、模型架构和超参数相关的新想法。
这个过程与之前的过程不同之处在于数据、机器学习模型及其所有训练流水线组件都被自动构建、测试和部署。
# 结论
本文旨在帮助你理解 MLOps 的基本知识:它是什么、为什么使用、关键概念以及如何实现。希望这能为你提供一个清晰易懂的概述!
**[尼莎·阿雅](https://www.linkedin.com/in/nisha-arya-ahmed/)** 是一名数据科学家和自由技术写作专家。她特别感兴趣于提供数据科学职业建议或教程以及数据科学的理论知识。她还希望探索人工智能如何或能如何有利于人类寿命的不同方式。她是一个热衷学习的人,寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
### 更多相关主题
+ [通过这本免费电子书学习 MLOps 基础](https://www.kdnuggets.com/2023/08/learn-mlops-basics-free-ebook.html)
+ [回到基础,第二部分:梯度下降](https://www.kdnuggets.com/2023/03/back-basics-part-dos-gradient-descent.html)
+ [Python 基础:语法、数据类型和控制结构](https://www.kdnuggets.com/python-basics-syntax-data-types-and-control-structures)
+ [回到基础第 1 周:Python 编程与数据科学基础](https://www.kdnuggets.com/back-to-basics-week-1-python-programming-data-science-foundations)
+ [回到基础第 3 周:机器学习简介](https://www.kdnuggets.com/back-to-basics-week-3-introduction-to-machine-learning)
+ [回到基础第 4 周:高级主题和部署](https://www.kdnuggets.com/back-to-basics-week-4-advanced-topics-and-deployment)
# 这里是如何在 GPU 上加速你的数据科学
> 原文:[`www.kdnuggets.com/2019/07/accelerate-data-science-on-gpu.html`](https://www.kdnuggets.com/2019/07/accelerate-data-science-on-gpu.html)
 评论
数据科学家需要计算能力。无论你是在用 Pandas 处理大型数据集,还是用 Numpy 在大规模矩阵上进行计算,你都需要一台强大的机器,以便在合理的时间内完成工作。
近年来,数据科学家常用的 Python 库在利用 CPU 性能方面已经相当出色。
* * *
## 我们的前三大课程推荐
 1\. [谷歌网络安全证书](https://www.kdnuggets.com/google-cybersecurity) - 快速进入网络安全职业道路
 2\. [谷歌数据分析专业证书](https://www.kdnuggets.com/google-data-analytics) - 提升你的数据分析技能
 3\. [谷歌 IT 支持专业证书](https://www.kdnuggets.com/google-itsupport) - 支持你组织的 IT 需求
* * *
Pandas 使用 C 语言编写的底层基础代码,能够很好地处理超过 100GB 大小的数据集。如果你的内存不足以容纳这样的数据集,你可以使用方便的分块函数,一次处理一块数据。
### GPU 与 CPU:并行处理
面对大规模数据,CPU 真的不够用。
超过 100GB 大小的数据集将拥有很多数据点,在*百万*甚至*十亿*的范围内。处理这么多点时,不管你的 CPU 多快,它的核心数也不足以进行高效的并行处理。如果你的 CPU 有 20 个核心(这将是相当昂贵的 CPU),你一次只能处理 20 个数据点!
在时钟速度更为重要的任务中,CPU 更具优势——或者你根本没有 GPU 实现。如果你要执行的过程有 GPU 实现,那么如果任务可以从并行处理中受益,GPU 将会更加有效。
多核系统如何更快处理数据。对于单核系统(左),所有 10 个任务都分配给一个节点。对于双核系统(右),每个节点处理 5 个任务,从而加倍处理速度
深度学习已经充分利用了 GPU。深度学习中的许多卷积操作是重复性的,因此可以在 GPU 上大大加速,甚至达到 100 倍。
现在的数据科学也没有不同,因为许多重复的操作在大数据集上执行,使用库如 Pandas、Numpy 和 Scikit-Learn。这些操作在 GPU 上实现也并不复杂。
最后,解决方案来了。
### 使用 Rapids 进行 GPU 加速
[Rapids](https://rapids.ai/?source=post_page---------------------------) 是一套加速数据科学的软件库,通过利用 GPU 提供加速。它使用低级 CUDA 代码实现快速、GPU 优化的算法,同时在其上有一个易于使用的 Python 层。
Rapids 的美妙之处在于它与数据科学库的无缝集成——像 Pandas 数据框这样的数据可以轻松地传递给 Rapids 以进行 GPU 加速。下面的图示说明了 Rapids 如何实现低级加速,同时保持易于使用的顶层。

Rapids 利用多个 Python 库:
+ [**cuDF**](https://github.com/rapidsai/cudf?source=post_page---------------------------) — Python GPU 数据框。它可以在数据处理和操作方面做几乎所有 Pandas 能做的事情。
+ [**cuML**](https://github.com/rapidsai/cuml?source=post_page---------------------------) — Python GPU 机器学习。它包含了 Scikit-Learn 具有的许多 ML 算法,格式非常相似。
+ [**cuGraph**](https://github.com/rapidsai/cuml?source=post_page---------------------------) — Python GPU 图处理。它包含许多常见的图分析算法,包括 PageRank 和各种相似度度量。
### 如何使用 Rapids 的教程
**安装**
现在你将了解如何使用 Rapids!
要安装它,请访问[网站](https://rapids.ai/start.html?source=post_page---------------------------),在那里你会看到如何安装 Rapids。你可以通过[Conda](https://anaconda.org/anaconda/conda?source=post_page---------------------------)直接在你的机器上安装,或者直接拉取 Docker 容器。
在安装时,你可以设置系统规格,如 CUDA 版本以及你希望安装哪些库。例如,我有 CUDA 10.0,并且想要安装所有库,所以我的安装命令是:
```py
conda install -c nvidia -c rapidsai -c numba -c conda-forge -c pytorch -c defaults cudf=0.8 cuml=0.8 cugraph=0.8 python=3.6 cudatoolkit=10.0
一旦命令运行完成,你就可以开始进行 GPU 加速的数据科学了。
设置我们的数据
在本教程中,我们将通过修改版的DBSCAN 演示进行操作。我将使用Nvidia Data Science Work Station进行测试,该设备配备了 2 个 GPU。
DBSCAN 是一种基于密度的 聚类算法,可以自动对数据进行分类,而无需用户指定有多少组。它在 Scikit-Learn 中有一个实现。
我们将从设置所有导入项开始,包括加载数据、可视化数据和应用 ML 模型的库。
import os
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.datasets import make_circles
make_circles 函数将自动创建一个类似于两个圆的复杂数据分布,我们将对其应用 DBSCAN。
让我们从创建 100,000 个点的数据集并在图中可视化它开始:
X, y = make_circles(n_samples=int(1e5), factor=.35, noise=.05)
X[:, 0] = 3*X[:, 0]
X[:, 1] = 3*X[:, 1]
plt.scatter(X[:, 0], X[:, 1])
plt.show()
在 CPU 上运行 DBSCAN
使用 Scikit-Learn 在 CPU 上运行 DBSCAN 很简单。我们将导入我们的算法并设置一些参数。
from sklearn.cluster import DBSCAN
db = DBSCAN(eps=0.6, min_samples=2)
现在我们可以通过 Scikit-Learn 的一个函数调用来应用 DBSCAN 于我们的圆形数据。在我们的函数前加上%%time可以告诉 Jupyter Notebook 测量其运行时间。
%%time
y_db = db.fit_predict(X)
对于这 100,000 个点,运行时间为 8.31 秒。结果图如下所示。
 使用 Scikit-Learn 在 CPU 上运行 DBSCAN 的结果
使用 Scikit-Learn 在 CPU 上运行 DBSCAN 的结果
使用 Rapids 在 GPU 上运行 DBSCAN
现在让我们用 Rapids 提速吧!
首先,我们将把数据转换为 pandas.DataFrame,然后使用它创建 cudf.DataFrame。Pandas 数据框可以无缝地转换为 cuDF 数据框,而数据格式不会发生变化。
import pandas as pd
import cudf
X_df = pd.DataFrame({'fea%d'%i: X[:, i] for i in range(X.shape[1])})
X_gpu = cudf.DataFrame.from_pandas(X_df)
然后我们将从 cuML 中导入并初始化一个 特殊 版本的 DBSCAN,它是 GPU 加速的。cuML 版本的 DBSCAN 函数格式与 Scikit-Learn 完全相同 —— 参数、风格、函数均相同。
from cuml import DBSCAN as cumlDBSCAN
db_gpu = cumlDBSCAN(eps=0.6, min_samples=2)
最后,我们可以在测量运行时间的同时运行 GPU DBSCAN 的预测函数。
%%time
y_db_gpu = db_gpu.fit_predict(X_gpu)
GPU 版本的运行时间为 4.22 秒,几乎是 2 倍的加速。结果图与 CPU 版本完全相同,因为我们使用的是相同的算法。
使用 cuML 在 GPU 上运行 DBSCAN 的结果
使用 Rapids GPU 获得超高速
从 Rapids 获得的加速量取决于我们处理的数据量。一个好的经验法则是,较大的数据集将受益于 GPU 加速。将数据在 CPU 和 GPU 之间传输时会有一些开销 —— 随着数据集的增大,这种开销变得更“值得”。
我们可以用一个简单的例子来说明这一点。
我们将创建一个随机数的 Numpy 数组,并对其应用 DBSCAN。我们将比较常规 CPU DBSCAN 和来自 cuML 的 GPU 版本的速度,同时增加和减少数据点的数量,以观察这如何影响运行时间。
下面的代码演示了这个测试:
import numpy as np
n_rows, n_cols = 10000, 100
X = np.random.rand(n_rows, n_cols)
print(X.shape)
X_df = pd.DataFrame({'fea%d'%i: X[:, i] for i in range(X.shape[1])})
X_gpu = cudf.DataFrame.from_pandas(X_df)
db = DBSCAN(eps=3, min_samples=2)
db_gpu = cumlDBSCAN(eps=3, min_samples=2)
%%time
y_db = db.fit_predict(X)
%%time
y_db_gpu = db_gpu.fit_predict(X_gpu)
查看下方 Matplotlib 结果的图示:
使用 GPU 代替 CPU 时,性能提升幅度非常显著。即使在 10,000 点(最左边)时,我们仍然能获得 4.54 倍的加速。在高端情况下,使用 10,000,000 点时,切换到 GPU 可以获得 88.04 倍的加速!
喜欢学习吗?
在 twitter 上关注我,了解最新的 AI、技术和科学动态!也可以在 LinkedIn 上与我联系!
推荐阅读
想了解更多关于数据科学的内容吗?Python 数据科学手册 是学习如何用 Python 进行真实数据科学的最佳资源!
另外,提醒一下,我通过 Amazon 关联链接支持这个博客,因为分享好书对大家都有帮助!作为 Amazon 联盟会员,我从合格的购买中获得收益。
个人简介:George Seif 是一位认证极客和 AI / 机器学习工程师。
原文。经授权转载。
相关:
-
Nvidia 的新数据科学工作站——评论与基准测试
-
探索 Transformer 架构——第二部分:Transformer 的工作原理简述
-
XGBoost 在 GPUs 上:解锁机器学习的性能和生产力
更多相关主题
加速计算机视觉:亚马逊的免费课程
原文:
www.kdnuggets.com/2020/08/accelerated-computer-vision-free-course-amazon.html
评论
亚马逊的机器学习大学正在将其之前仅对亚马逊员工开放的在线课程 免费提供给公众。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
第一个公开提供的类似课程之一是 加速计算机视觉,该课程自我描述如下:
该仓库包含机器学习大学(MLU)计算机视觉课程的幻灯片、笔记本和数据集。我们的使命是让机器学习对每个人都可用。我们提供涵盖许多机器学习主题的课程,并相信机器学习的知识可以是成功的关键促进因素。此课程旨在帮助你入门计算机视觉,了解广泛使用的机器学习技术,并将其应用于现实世界的问题。
这个简明课程由 Rachel Hu,AWS 深度引擎科学的应用科学家讲授,由一个 视频讲座播放列表 和一个 GitHub 仓库 组成,包含课程笔记、幻灯片和数据。这些简短的视频和相关的课程材料被整理成 3 个主要课程,结构如下:
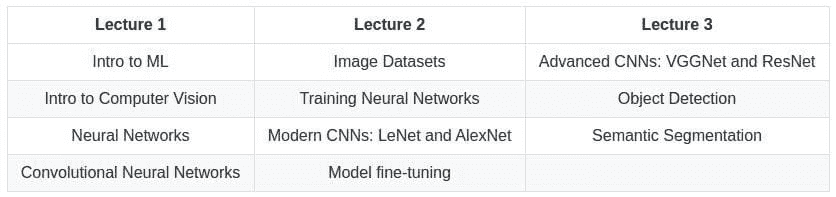
课程的课件重点在于掌握实际计算机视觉实现的技能,并关注以下内容,为你提供对课程学习内容的预期:
-
神经网络
-
卷积神经网络
-
最终项目概述
-
AlexNet
-
AutoGluon 用于计算机视觉
-
ResNet
-
YOLO
课程还包括一个实际计算机视觉的最终项目实现,其 Jupyter notebook 开始部分如下,提供了对预期学习成果的额外提示:

这似乎是计算机视觉初学者的一个很好的入门课程。亚马逊通过将其机器学习大学课程公开,给社区提供了服务,结合加速计算机视觉课程和其他目前提供的课程,那些希望从世界级机器学习组织学习机器学习的人现在有了另一个选择。
相关内容:
-
加速自然语言处理:一门免费课程
-
超越表面:有实质内容的数据科学 MOOCs
-
令人惊叹的机器学习和人工智能课程
更多相关话题
加速自然语言处理:亚马逊的免费课程
原文:
www.kdnuggets.com/2020/08/accelerated-nlp-free-amazon-machine-learning-university.html
评论

亚马逊机器学习大学正在将其以前仅对亚马逊员工开放的在线课程免费提供给公众。
第一个向大众提供的此类课程之一是加速自然语言处理,这是一个以实践为导向的课程,描述如下:
这些内容基于机器学习大学(MLU)的加速自然语言处理课程。我们的使命是让机器学习对所有人都可用。我们相信机器学习将成为许多人职业成功的工具。我们提供关于不同主题的机器学习课程。此课程旨在帮助您入门自然语言处理,学习广泛使用的技术,并将其应用于现实问题中。
如上所述,简明课程专注于可以应用于现实问题的广泛使用技术。课程由 Cem Sazara授课,他是亚马逊的应用科学家。课程包括一系列视频讲座,以及一个GitHub 代码库,其中包含课程笔记本、幻灯片和数据。
您可以期待一个包含大多数时间长度在 1 到大约 30 分钟之间的短视频的播放列表,不过大多数视频的时长在 5 分钟以内或左右,具体情况也有一些较长的例外。
虽然课程及其视频讲座专门针对寻求加速自然语言处理路径的个人,但在过渡到 NLP 技术之前,首先涵盖了监督学习和非监督学习、类别不平衡、缺失值和模型评估等入门机器学习主题。
GitHub 代码库包含视频讲座中使用的幻灯片,整理成 3 个主要讲座,而相应的笔记本涵盖了在 NLP 应用中有用的一些通用机器学习算法的实际实现、NLP 特定技术本身,以及使用亚马逊平台实现您的实现目标:
-
词袋模型
-
文本处理
-
线性回归
-
逻辑回归
-
树模型
-
Sagemaker
-
神经网络
-
循环神经网络
-
词向量
这里还有一些在课程笔记本中使用的数据集,包括 IMDB 数据集和——请期待——亚马逊产品评论。
总体来看,这似乎是一个很棒的自然语言处理入门课程。亚马逊通过向公众开放其机器学习大学课程,为社区提供了服务,初始的加速 NLP 课程及其衍生课程表明,那些希望从世界级机器学习组织学习机器学习的人现在有了另一个选择。
相关:
-
超越表面:有实质内容的数据科学 MOOCs
-
绝妙的机器学习和 AI 课程
-
最好的深度学习 NLP 课程是免费的
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关内容
加速人工智能与 MLOps
评论
作者:Yochay Ettun,cnvrg.io 的首席执行官兼联合创始人。

尽管人工智能(AI)拥有巨大的潜力,但它在大多数行业中仍未广泛应用。大多数 AI 项目陷入困境。埃森哲估计,80% 到 85% 的公司 的 AI 项目仍处于概念验证阶段,而近乎 80% 的企业未能在整个组织中扩大 AI 部署。
实现 AI 运营的障碍
一旦 AI 建成,许多组织在将模型投入生产时遇到困难。将 AI 转化为实际价值可能需要几个月甚至几年。根据 Gartner 的研究,只有 53% 的项目能够从人工智能(AI)原型进入生产阶段。
目前,开发人工智能/机器学习(ML)模型的标准仍然非常少。数据科学家是熟练的数学家,但为了成功将模型投入生产,他们还需要在软件开发方法论和 DevOps 方面的经验。模型通常是从头开始创建的,没有一致的软件开发过程、测试程序或衡量其性能的 KPI。
熟练的数据科学家是稀缺资源。公司更希望他们将时间花在擅长的领域——提供高影响力的算法上。然而,由于不可预见的操作问题,他们往往被其他任务所消耗,包括跟踪和监控、配置、计算资源管理、服务基础设施、特征提取和模型部署。
此外,今天的基础设施环境如同丛林。数据科学家可以利用无尽的计算选项组合来处理不同的 AI 工作负载,包括 CPU、GPU、AI 加速器、云计算、本地部署、混合云、共置等。因此,执行作业以在合理价格下实现高性能具有很大的复杂性和不可预见的挑战。
使用 MLOps 加速 AI 部署
这就是 MLOps(机器学习操作)可以发挥作用的地方,帮助数据科学家解决操作问题。MLOps 是一套用于数据科学家和运维专业人员之间协作与沟通的实践,以自动化大规模生产环境中机器学习和深度学习模型的部署。它使模型与业务需求对齐、实施标准且一致的开发流程、扩展和管理多样化的数据管道变得更容易。
大多数公司正在使用 MLOps 来自动化机器学习管道、监控、生命周期管理和治理。通过使用 MLOps,可以监控模型的性能下降或检测结果的漂移,表明模型需要使用更完整或更新的数据进行重新训练。MLOps 还用于不断实验新方法,以利用新技术,如最新的语言处理和文本与图像分析。
对 MLOps 解决方案的需求巨大。一个由社区主导的努力,收集了所有不同的工具,包括开源工具,结果列出了超过 330 种不同的 MLOps 工具。Cognilytica 的报告预测,MLOps 工具将呈指数增长,到 2025 年市场规模将达到 1250 亿美元,这将代表 33%的年增长率。
有大量证据表明,实施 MLOps 的公司更有可能成功。以下是两个例子。
ST Unitas 是一家领先的全球教育科技公司,同时也是《普林斯顿评论》的拥有者——美国顶尖的教育服务。该公司需要扩大其电子学习系统的部署,包括 CONECTS,这是一个处理数学问题图像并提供个性化测试的平台,旨在提高三百万学生的分数。实施 MLOps 平台后,ST Unitas 在短短几个月内将人工智能活动扩大了 10 倍,而无需招聘额外的工程师,提升了性能和处理量。
Playtika 是一家领先的游戏娱乐公司,拥有超过 1000 万的日活跃用户(DAU),他们利用大量数据通过基于游戏内动作的用户体验(UX)定制来重塑游戏格局。Playtika 的大规模机器学习(ML)处理每分钟收集了数百万用户和数千个特征,使用批处理和网络服务,但这些解决方案都无法足够快速地处理数据以实时生成预测。通过实施 MLOps 平台,他们将性能提高了 40%,成功处理量增加了最高 50%。现在,Playtika 能够每天处理 9TB 的数据,为其科学家提供所需的数据,创建一个不断变化和自适应的游戏环境,继续推出收入最高的游戏。
在新的在线经济下,公司们竞相利用人工智能洞察力,真正实现数据驱动。但即便机器学习模型是基于可靠的算法构建,并且在完整的清洁数据集上成功训练,如果模型不能在现有的 IT 基础设施上运行,人工智能永远无法发挥其真正潜力。提前审查和寻找解决操作问题的方案可以帮助人工智能项目成功完成。
简介: 约查伊·埃顿是一位经验丰富的技术领导者,他因在 AI 进步方面的成就以及建立 cnvrg.io 而入选 2020 年《福布斯》30 位 30 岁以下精英榜。约查伊从 7 岁开始编写代码。他在以色列国防军(IDF)情报单位服役了 4 年,并在耶路撒冷希伯来大学(HUJI)获得计算机科学学士学位,期间创立了 HUJI 创新实验室。约查伊曾担任 Webbing Labs 的首席技术官,并为 AI 和机器学习公司担任顾问。在 3 年的咨询工作之后,约查伊与联合创始人利亚·科尔本决定创建一个工具,帮助数据科学家和公司通过 cnvrg.io 扩展他们的 AI 和机器学习。该公司继续帮助财富 500 强公司的数据科学团队管理、构建和自动化从研究到生产的机器学习。
相关内容:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 工作
更多相关话题
加速算法:设计、算法选择和实现中的注意事项
原文:
www.kdnuggets.com/2017/12/accelerating-algorithms-design-choice-implementation.html
评论

追求速度是计算中的少数不变因素之一,这由两个因素驱动:数据量的不断增加和有限的硬件资源。在大数据和物联网时代,我们在这两个方向上都面临压力。幸运的是,我们在分布式和并行计算方面取得了很大进步,但算法层面对原始速度的需求永远不会消失。如果我们能让我们的算法本质上更快,我们将能更好地利用昂贵的硬件,这始终是件好事。
有许多加速算法的方法。一些方法对上下文依赖性强,有些则较为通用。我将探讨整体设计选择、算法选择和实现细节。我的背景和经验主要集中在优化问题和数值算法上,所以这将是主要关注的领域。
传统上,讨论优化时都会提到要谨慎。Knuth 的第一条优化法则是:“不要做”而他的第二条类似:“还不要做。”我们还被告知“过早优化是万恶之源”,但什么算作“过早”?何时为时已晚?
我自己的优化法则旨在回答这个问题:“没有量化就没有优化。”我们不应该在没有先测量当前性能和对代码进行性能分析以确定时间消耗最多的地方之前尝试加速算法。正确推断算法花费大部分时间的地方是非常困难的。
比如,我写的一个光学蒙特卡罗模拟程序发现其运行时间有四分之一是用于对接近 1 的数字进行平方根运算。这是由于在散射事件后重新归一化方向向量的过程。通过为这种特殊情况编写一些高度优化的代码,我能够避免在数学协处理器中使用较慢的通用实现,从而在整体性能上提高了约 20%,在运行时间长达数天的情况下,这并非小事。如果没有对代码进行性能分析,我不可能发现这个时间消耗点。
Python 中的 cProfile 和 profile 模块(它们都是ActivePython 发行版的一部分)提供了确定性性能分析,使结果相对容易解读。其他语言可能支持基于程序计数器采样的性能分析,由于统计效应,这种方法可能会因运行而异。即使是确定性性能分析,程序的某些部分由于资源限制或代码中的随机数使用,可能会有性能波动。I/O 和通信都是外部依赖可能影响性能的领域,因此如果可能的话,最好单独对这些进行性能分析。
这假设我们已有代码来进行性能分析,但算法加速可以在开发过程的多个不同层面进行:设计、算法选择和实现。
设计
设计优化是一个庞大的话题,我这里只能简单提及。根据应用领域,有许多不同的高效设计方法。其中最重要的一点是寻找可以代替最终结果的代理计算。
这在处理优化问题时特别有用。经常会看到这样的代码:
X = sqrt(some complicated expression)
取平方根——即便在如今高速数学硬件的时代,也是一个不合理昂贵的操作——除了在优化的最终阶段,表面在最小值附近的曲率可能对算法的效率至关重要外,其他地方不会对计算有任何帮助。这对于任何包裹最终结果的单调函数都是正确的:通常可以省略。
另一种相当通用的设计方法是对数据进行采样,而不是盲目使用每一个可用的数据点。这就是伪相关的技巧,这是一种超高速图像配准算法:通过使用小的像素子集来估计交叉相关积分,可以将配准速度提高几个数量级。几年后,互信息算法中也使用了类似的方法。
总体设计问题应该是:“我真的需要计算那个吗?”可能有一些与您关心的结果强相关的东西,但可以更快地计算出来。
算法选择
算法的阶数获得了大量学术关注,但意外地并不重要。原因如下:
-
问题通常具有一定的规模,因此算法的缩放行为并不相关。如果在一千万数据点上运行良好的算法,其在一亿数据点上的性能并不重要,前提是我们从未看到过如此大的数据集。
-
领先因素很重要:一个 O(N**2) 的算法可能比等效的 O(N*log(N)) 算法具有更小的领先因素,因为其复杂度较低。
-
说到复杂性,具有更好大 O 性能的算法通常更复杂,使它们更脆弱、难以调试和维护。
最著名的脆弱性案例可能是快速排序,当输入已经排序时,它的复杂度从 O(N*log(N)) 降低到 O(N**2)。这是一个比较容易发现的情况,但更复杂的算法虽然平均性能良好,在特殊情况下仍可能表现不佳,调试这种行为可能很复杂且耗时。因为这种失败通常比较少见,所以在部署后遇到这种“有时运行缓慢”的奇怪情况也是不 uncommon 的。
在选择算法时,最好先实现最简单的东西,然后在现实数据集上量化其性能,并决定是否需要更复杂的算法。通常情况下,可能不需要更复杂的算法。我曾经处理过一些使用 KD 树匹配点的网格配准代码,发现由于数据集相对较小,使用几个易于理解的启发式方法的简单线性搜索可以轻松超越标称上性能更好的 KD 树实现,后者是一个脆弱且复杂的烂摊子,其不可维护性使我不得不回退到更简单的东西,以便理解其运行情况。
实现细节
算法不是它的实现。即使是相对简单和高效的算法也可能实现不佳,从而导致性能变慢。不必要的函数调用是一个常见的情况。使用递归而不是循环可能会影响速度。
在许多情况下,高性能代码是用相对底层的语言编写,如 C、C++ 或者 Fortran,并从高层语言中调用。这些调用的顺序和组织方式对性能影响很大:通常来说,跨语言边界的调用是一个代价高昂的操作,因此建议以最小化这种调用的方式来使用接口。
高级语言通常包括一些加速技巧。例如,Python 的 sum() 和 map() 函数在处理数组时比循环快得多。对 100,000,000 个整数进行求和,在我的台式机上需要 4.4 秒,而使用 sum() 对数组求和只需 0.63 秒。此外,循环中的生成器(Python 2 中的 xrange 而不是 range,Python 3 中的 range())通常比非懒加载的列表创建函数更快。
map() 函数比循环更快:对一个包含 100,000,000 个整数的数组进行平方根计算,在我的台式机上需要 10 秒,而使用 map(math.sqrt, lstData) 进行相同操作只需半倍的时间。
底层方法
在 Python 中还有更强大的技术,比如使用 NumPy 和 Cython 以及 Intel 的数学核心库(MKL),该库可以在 ActiveState 的 ActivePython 中找到。虽然可能会有一些限制使得这些技术不能用于特定问题,但它们值得作为“效率武器库”的一部分加以考虑。只需确保首先量化你的算法性能!
要了解更多关于加速算法的信息,并深入了解 Intel 的 MKL 优化,请观看我的网络研讨会,"使用 Python 和 Intel MKL 加速你的算法",由我和 Intel 的软件工程经理 Sergey Maidanov 共同主持。
原文。已获授权转载。
相关内容
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
了解更多相关内容
如何通过使用自动化 EDA 工具来通过数据科学评估测试
原文:
www.kdnuggets.com/2022/04/ace-data-science-assessment-test-automatic-eda-tools.html

图片来源 | Canva Pro
一般来说,评估测试分为五个部分:统计学、商业分析、编码、SQL和实际操作数据分析。你将获得一个数据集和 20 分钟的时间来回答三个到四个与业务相关的问题。即使你是数据分析专家,也不能在有限的时间内完成数据摄取、数据分析和报告。因此,你需要超级工具来自动化数据分析部分,以便你可以专注于回答业务案例研究中的问题。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT

图片来源
在这篇博客中,我们将学习关于自动 EDA 工具的内容,以帮助我们通过数据分析部分。我们将学习 Deepnote、Autoviz、Pandas profiling 和 Sweetviz。这些工具只需几行代码即可显示数据的关键信息。
Deepnote
Deepnote 是一个免费的云数据科学笔记本,支持多种第三方集成和编程语言。最近,该平台推出了显示 Pandas DataFrame 的新方式。新年决议数据集可以在 Kaggle 上找到,并遵循CC BY-SA 4.0 许可证。该数据通过调查收集,询问受访者 2022 年的新年决议。
正如我们所观察到的,数据框显示了分类特征和数值特征的分布。它展示了特定特征的最小值和最大值范围,以及缺失值的百分比。
import pandas as pd
data = pd.read_csv("nyr_data.csv")
data
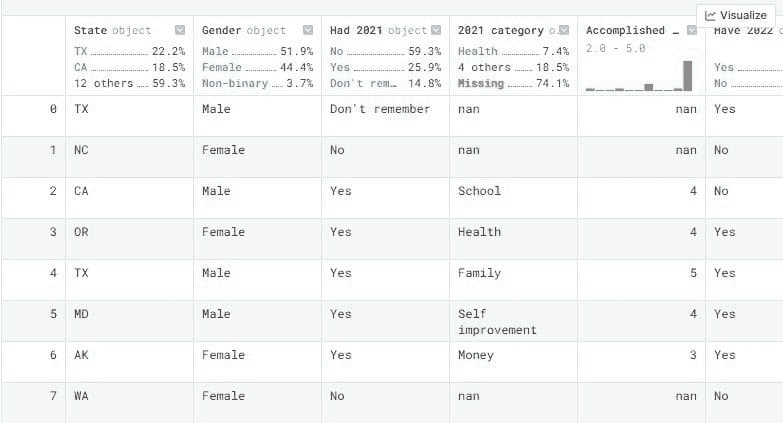
我们还可以使用过滤器选项来显示特定的类别或值。最后,可视化选项将帮助我们在不写一行代码的情况下创建简单的数据可视化。
图片来源
Visualize 选项将要求提供 Pandas DataFrame、图表类型、X 轴、Y 轴和颜色,以显示交互式可视化。
作者提供的图片
我们使用 Pandas DataFrame 的可视化来通过条形图显示调查中的性别分布。
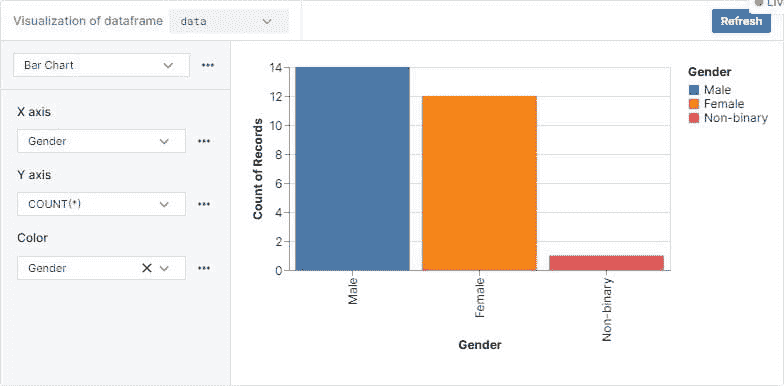
Deepnote 一直是我应对时间紧迫项目和评估测试的第一选择。我可以轻松在 20 分钟内生成简单的数据报告。Deepnote 还帮助我通过了多个数据科学和机器学习评估测试。如果你对我的 Deepnote 项目感兴趣,可以查看我的 profile。
AutoViz
Autoviz 用于通过一行代码自动生成表格数据的可视化。它基于特征类型显示所有图表组合。如果特征是文本,它将显示词云;如果是类别,它将显示条形图的组合。Autoviz 提供四种选项:SVG、Bokeh、Server 和 HTML。
-
SVG/PNG/JPG: 生成 matplotlib 图表,这些图表可以存储在本地或在 Jupyter notebook 中显示。
-
Bokeh: 在 Jupyter notebooks 中生成交互式图表。
-
Server: 启动一个包含所有图表的基于浏览器的仪表盘。
-
HTML: 静默创建 bokeh 图表并将 HTML 文件保存在本地。
只需几行代码,我们就可以生成关于数据集的详细信息、成对散点图、分布图、箱形图、概率图、直方图、小提琴图、热图和每个类别的条形图。Autoviz 为我们节省了半小时的编码和报告结果时间。
from autoviz.AutoViz_Class import AutoViz_Class
%matplotlib inline
AV = AutoViz_Class()
df = AV.AutoViz("nyr_data.csv")
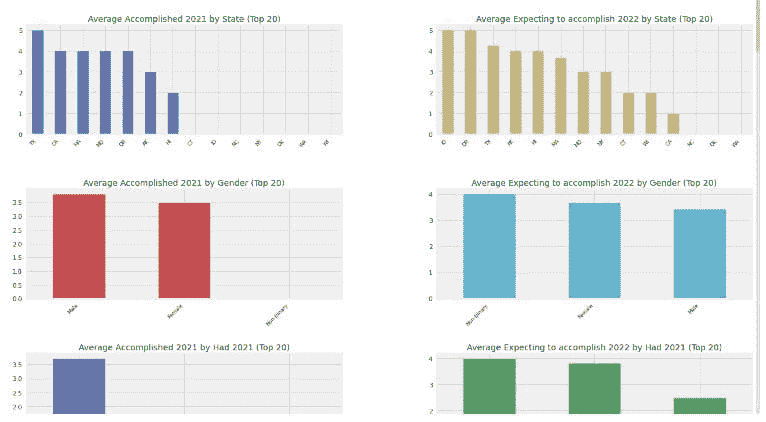
Pandas Profiling
Pandas-profiling 使用 Pandas DataFrame 生成详细的数据报告。报告包括变量类型、数据形状、唯一值、直方图、统计分析、文本分析和缺失值。
下图显示了数据概况的摘要。数据摘要还包括警报,突出显示高度相关的变量和特定变量中缺失值的频率。
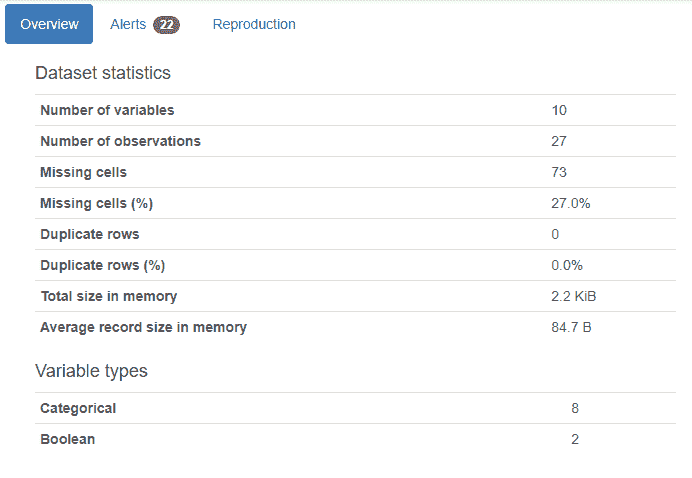
作者提供的图片
最终报告包含关于变量分布、相关矩阵、缺失值和样本的全面信息。这些信息足以帮助你回答 60% 的评估测试问题。
from pandas_profiling import ProfileReport
profile = ProfileReport(data, title="Pandas Profiling Report")
profile
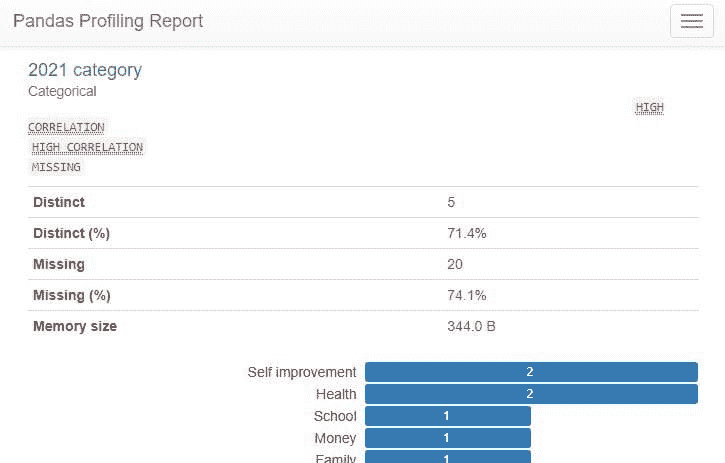
SweetViz
Sweetviz 是一个开源的 Python 库,创建高分辨率的可视化,以支持你的探索性数据分析。用户界面互动且易于导航。只需一行代码,你就能生成专业的数据分析报告。
报告包括数据集的形状、特征类型、相关性、缺失值和使用条形图的分布。它类似于Pandas Profiling,但更加简洁,易于浏览。

图片由作者提供
SweetViz 使用 Pandas DataFrame 生成美观的基于 HTML 的数据报告。我们可以将 HTML 报告保存在本地,也可以使用 my_report.show_notebook()在 Jupyter notebook 中直接运行。
import sweetviz as sv
my_report = sv.analyze(data)
my_report.show_notebook() ## Or use show_html

结论
我们讨论的工具非常适合生成探索性数据分析报告。最终,还是取决于你对主题的理解和你在数据科学领域的经验。评估问题通常围绕一个商业案例研究,例如:一家数码相机公司的历史销售数据。这些工具可以帮助你理解数据集,但没有主题领域的专业知识,回答问题将会很困难。
在这篇博客中,我们了解了 Deepnote、AutoViz、Pandas Profiling 和 SweetViz。这些自动化的探索性数据分析工具可以帮助你通过几行代码更快地理解问题陈述。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络开发一种 AI 产品,帮助那些在心理健康方面挣扎的学生。
更多相关内容
如何在数据科学编码挑战中表现出色
原文:
www.kdnuggets.com/2020/10/ace-data-science-coding-challenge.html
评论
图片来源:Pexels。
家庭作业挑战问题(编码练习)
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
所以,你已经成功通过了面试过程的初筛阶段。现在是面试过程中最重要的步骤,即 家庭作业编码挑战。这通常是一个数据科学问题,例如,机器学习模型、线性回归、分类问题、时间序列分析等。
数据科学编码项目的范围和复杂性各不相同。有时,项目可能只是生成汇总统计、图表和可视化。它也可能涉及建立回归模型、分类模型,或使用时间依赖数据集进行预测。项目也可能非常复杂和困难。在这种情况下,没有提供明确的模型类型指导。你需要提出一个最适合实现项目目标和任务的模型。
通常,面试团队会为你提供项目方向和数据集。如果你幸运的话,他们可能会提供一个小型数据集,该数据集是干净的并存储在逗号分隔值(CSV)文件格式中。这样,你就不必担心挖掘数据和将其转换为适合分析的形式。对于我经历的几次面试,我处理了两种类型的数据集:一种有 160 个观察值(行),另一种有 50,000 个观察值且有大量缺失值。家庭作业编码练习因公司而异,具体如下所述。
在这篇文章中,我将分享一些来自个人经验的有用提示,这些提示将帮助你在编码挑战项目中脱颖而出。在深入这些提示之前,让我们首先看看一些示例编码练习。
示例 1 编码练习:为推荐邮轮船员人数建立模型
说明
这个编码练习应在 Python 中进行(这是团队使用的编程语言)。你可以自由使用互联网和任何其他库。请将你的工作保存在 Jupyter notebook 中,并通过电子邮件发送给我们进行审核。
数据文件:cruise_ship_info.csv(该文件将通过电子邮件发送给你)
目标: 建立一个回归模型,为潜在的船买家推荐“船员”规模。请按照以下步骤操作(提示:使用 numpy、scipy、pandas、sklearn 和 matplotlib)
- 读取文件并显示列。
- 计算数据的基本统计量(计数、均值、标准差等),检查数据并说明你的观察结果。
- 选择可能对预测“船员”规模重要的列。
- 如果你移除了列,解释一下为什么要移除这些列。
- 对分类特征使用独热编码。
- 创建训练集和测试集(使用 60% 的数据进行训练,其余用于测试)。
- 建立一个机器学习模型来预测‘船员’规模。
- 计算训练集和测试数据集的皮尔逊相关系数。
- 描述模型中的超参数,以及如何更改它们以提高模型的性能。
- 什么是正则化?你的模型中的正则化参数是什么?
绘制正则化参数值与训练集和测试集的皮尔逊相关系数的关系图,查看你的模型是否存在偏差问题或方差问题。
这是一个非常直接的问题的示例。数据集干净且小(160 行和 9 列),指令非常清楚。因此,只需按照指令生成代码即可。还要注意,指令明确要求使用 Python 作为构建模型的编程语言。完成此编码任务的时间为三天。只需提交最终的 Jupyter notebook,不需要正式的项目报告。
取得样本 1 编码练习的技巧
由于项目涉及建立机器学习模型,第一步是确保我们理解机器学习过程:

图 1. 说明机器学习过程。图像来源:本杰明·O·泰约。
1. 问题定义
定义你的项目目标。你想找出什么?你是否有数据可以分析?
目标:本项目的目标是建立一个回归模型,通过使用cruise_ship_info.csv的游轮数据集,为潜在的游轮买家推荐“船员”规模。
2. 数据分析
导入并清理数据集,分析特征以选择与目标变量相关的相关特征。
2.1 导入数据集并显示特征和目标变量
df = pd.read_csv("cruise_ship_info.csv")
df.head()
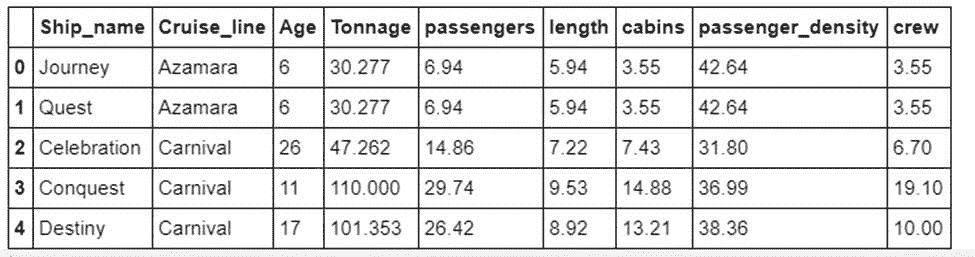
表 1:显示数据集的前 5 行。
在这个例子中,数据集是干净和原始的,没有缺失值。因此,不需要清理。
数据质量说明: 数据集的一个主要缺陷是没有提供特征的单位。例如,乘客列没有说明该列是以百位还是千位为单位。未提供舱长、乘客密度和船员的单位。passenger_density 特征似乎是从其他特征中推导出来的,但没有解释其推导过程。这些问题可以通过联系面试团队以获取有关数据集的更多信息来解决。在使用数据构建现实世界模型之前,理解数据的细节是很重要的。请记住,糟糕的数据集会导致糟糕的预测模型。
2.2 计算并可视化协方差矩阵
协方差矩阵图可以用于特征选择和量化特征之间的相关性(多重共线性)。我们从图 2 中观察到特征之间存在强相关性。
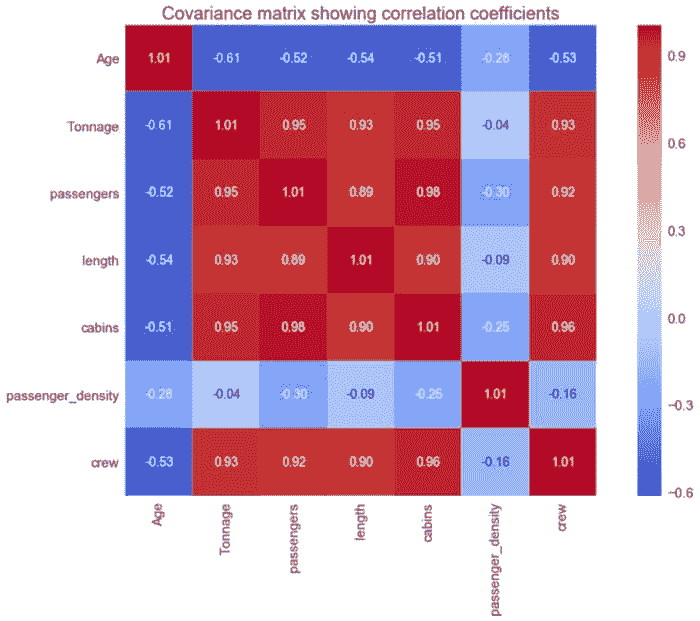
图 2. 协方差矩阵图。
2.3 通过将特征转换为主成分分析 (PCA) 空间来执行特征工程
由于协方差矩阵显示出多重共线性,因此在训练模型之前,将特征转换为 PCA 空间是很重要的。这是因为特征之间的多重共线性会导致模型变得复杂且难以解释。PCA 也可以用于变量选择和降维。在这种情况下,只有对总解释方差有显著贡献的成分可以保留并用于模型构建。
3. 模型构建
选择适合你的数据和期望结果的机器学习工具。使用可用数据训练模型。
3.1 模型构建与评估
由于我们的目标是使用回归,可以实现不同的回归算法,例如线性回归 (LR)、K 邻近回归 (KNR)和支持向量回归 (SVR)。数据集必须被划分为训练集、验证集和测试集。必须使用超参数调优来微调模型,以防止过拟合。交叉验证对于确保模型在验证集上的表现良好是至关重要的。调整完模型参数后,模型必须应用于测试数据集。模型在测试数据集上的表现大致等于在使用未见数据进行预测时的期望值。
3.2 不确定性量化
这可以通过使用训练数据集的不同随机划分来训练模型,然后对每个随机状态参数的交叉验证分数进行平均来完成。
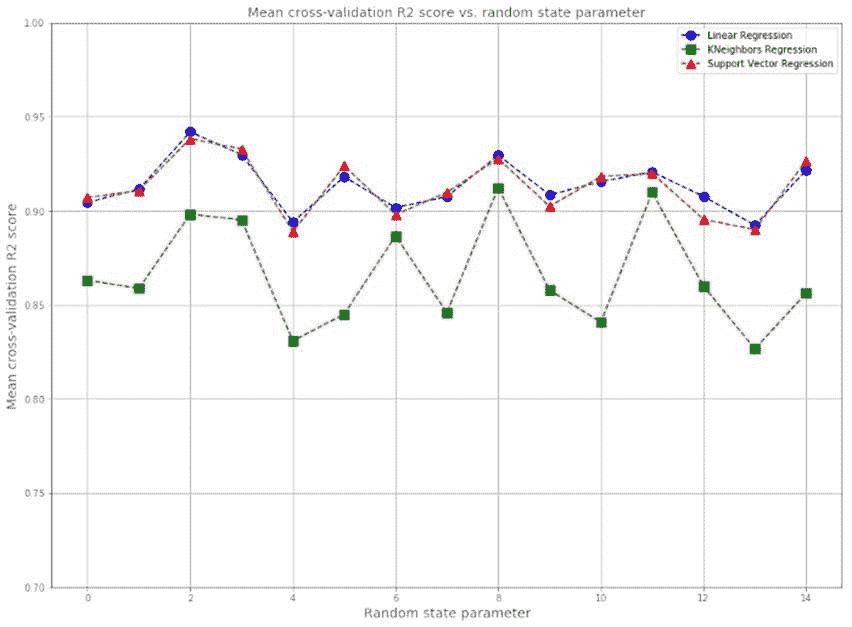
图 3. 各种回归模型的平均交叉验证结果。
4. 应用
对最终模型进行评分以生成预测。使你的模型可以投入生产。根据需要重新训练模型。
在此阶段,最终的机器学习模型被选定并投入生产。模型在生产环境中进行评估以评估其性能。将实验模型转化为实际生产线性能过程中遇到的任何错误都必须进行分析。这可以用于微调原始模型。
根据图 3中的均值交叉验证分数,我们观察到线性回归和支持向量回归的表现几乎相同,并且优于 K 邻近回归。因此,最终选择的模型可以是线性回归或支持向量回归。
有关示例 1 编码练习的完整解决方案,请参见以下链接:
示例 1 编码练习备注
有时编码练习会要求你只提交一个 Jupyter 笔记本,或者可能要求提供完整的项目报告。确保你的 Jupyter 笔记本组织良好,以反映机器学习过程的每个阶段。一个示例 Jupyter 笔记本可以在这里找到: ML_Model_for_Predicting_Ships_Crew_Size。
示例 2 编码练习:贷款状态预测模型
说明
在这个问题中,你将预测一个贷款组合的结果。每笔贷款计划在 3 年内偿还,结构如下:
- 首先,借款人获得资金。这一事件称为起始。
- 然后,借款人会继续定期还款,直到发生以下情况之一:
(i) 借款人通常因经济困难而停止还款,通常发生在 3 年期限结束之前。这种情况称为损失,贷款因此被认为已损失。
(ii) 借款人继续还款,直到起始日期后的 3 年。这时,债务已完全偿还。
在附带的 CSV 文件中,每一行对应一个贷款,列的定义如下:
- 带有“自起始日期以来的天数”标题的列表示从起始日期到数据收集日期之间经过的天数。
- 对于在数据收集前已经损失的贷款,带有“从起始到损失的天数”标题的列表示从起始到损失之间经过的天数。对于所有其他贷款,此列为空。
目标:我们希望你估计这些贷款在其所有 3 年期满时将有多少比例会被注销。请包括你如何得出答案的详细解释,并包括你使用的任何代码。你可以做出简化假设,但请明确说明这些假设。你可以以任何你喜欢的格式呈现你的答案;特别是,PDF 和 Jupyter Notebook 都是可以的。同时,我们预计这个项目不会花费你超过 3-6 小时的时间。
这里的数据集很复杂(有 50,000 行和 2 列,以及大量缺失值),问题也不是很直接。你必须批判性地检查数据集,然后决定使用哪个模型。这个问题需要在一周内解决。还要求提交正式的项目报告和一个 R 脚本或 Jupyter 笔记本文件。
通过样本 2 编码练习的技巧
和样本 1 编码练习一样,在解决这个问题时你需要遵循机器学习步骤。这个粒子问题没有唯一解决方案。我尝试了基于蒙特卡罗模拟的概率建模解决方案。
要查看完整的样本 1 编码练习解决方案,请参见以下链接:
样本 2 编码练习的备注
上述解决方案仅为推荐解决方案。请记住,数据科学或机器学习项目的解决方案不是唯一的。我鼓励你在查看样本解决方案之前尝试解决这些问题。
总结
总之,我们讨论了一些对任何正在申请数据科学职位的数据科学 aspirant 有用的技巧。编码练习的范围和复杂性因你申请的公司而异。家庭编码练习为你展示你在数据科学项目中的能力提供了一个绝佳的机会。你需要利用这个机会展示你对数据科学和机器学习概念的深刻理解。不要错过这个宝贵的机会。如果项目中有某些方面你不理解,可以随时向数据科学面试团队寻求帮助。他们可能会提供一些提示或线索。
相关:
了解更多主题
如何通过参与项目来在数据科学面试中脱颖而出
原文:
www.kdnuggets.com/2021/10/ace-data-science-interview-portfolio-projects.html
评论
作者提供的图片。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域的职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 部门
现在的招聘人员在联系你安排面试之前,通常会检查你的在线存在。他们会查看你的 LinkedIn 个人资料、GitHub 和 Kaggle,以了解你能为他们的公司带来什么价值。招聘经理还会查看你最近的博客或你过去参与的项目,以准备面试问题,从而测试你的能力 (catherinescareercorner)。除此之外,参与真实世界的项目会让你获得所需的工作经验,通过几个项目展示在你的作品集中,你将给招聘人员留下良好的印象 (data-flair)。
我们将学习新的面试破解方法,以及如何通过创建强大的作品集帮助我顺利通过多次面试。我还会提供有关如何改进当前项目的技巧,以及招聘人员如何查看你的个人资料。本文基于我的个人经验和从职业教练那里学到的东西。
面试 #1
一位招聘人员在查看了我的 Kaggle 个人资料 后联系了我,并告诉我他对我最近的竞赛表现印象深刻。他表示希望能通过电话进一步交谈。老实说,我对一家如此大型的金融机构通过 Kaggle 联系我以及参与竞赛如何让我获得与首席数据科学家面试的机会感到惊讶。
作者提供的图片 | Abid Ali Awan | 专家 | Kaggle。
洞察: 参与 Kaggle 竞赛可以帮助你找到工作。
在面试过程中,我们讨论了我之前的项目和比赛。我向他解释了我如何积极参与其他竞争平台,例如Zindi。他问了我目前正在进行的项目以及我的未来目标。
洞见:创建投资组合项目将证明你的简历上的技能。
面试结束时,他对我目前的表现非常满意,并告诉我我是这个职位的最佳候选人。
面试 #2
这次面试相当不同,因为进行面试的数据科学家更关注我的 GitHub 资料,而不是我的简历。面试后,我意识到招聘人员对投资组合的兴趣远大于 LinkedIn 资料或简历。
在 LinkedIn 申请了工作后,我收到了关于面试的邮件,在面试过程中,他谈到了我的 GitHub 项目。他们甚至问我在项目中遇到的问题是什么,以及我如何解决这些问题。
图片由作者提供。
洞见:即使是专业数据科学家也会维护 GitHub 资料。
面试后,我回去查看了我的资料,并注意到面试官专注于我仓库中的最新项目及其描述。他还讨论了我的固定项目,我能够回答每一个问题,因为我了解这些项目的每一部分。
洞见:始终突出显示你 100%参与的项目。
总体而言,面试比我预期的顺利得多,我收到了招聘人员的优异反馈,因为他们将我与哈佛毕业生进行比较。
面试 #3
第三次面试相当令人惊讶,因为我被来自不同部门的五个人面试,他们直接或间接地讨论了我的 Deepnote 资料。这次面试是我开始撰写这篇文章的原因,以便其他人能够从我的经验中受益。
申请了工作后,我接到了来自本国顶级电信公司的电话。我的第一次面试由三位领域专家进行。他们询问了我过去的工作和目标。在初步介绍后,我们深入讨论了我的项目和 Deepnote 资料。专家数据科学家问了我关于 NLP 的关键问题以及我在项目中如何使用它们。他们浏览了顶级项目,并询问了我如何解决某些问题。
洞见:以详细描述的笔记本形式发布你最好的作品。
图片由作者提供。
我的第二次面试由高层管理人员进行,他们对我的思维方式和我如何处理特定数据感兴趣。他们问了我关于特征工程的问题,最后,有一位问了我关于 Deepnote 个人资料的简介。他对我建立帮助有心理疾病学生的应用程序的愿景很感兴趣。最后,他问我在公司工作如何帮助我实现目标。
见解: 个人简介应当是个人化的,并且描述你的生活目标。
图片由作者提供。
我的两次面试在反馈方面都很出色,公司管理层对我关于未来目标的回答印象深刻。我解释了与他们合作如何帮助我成长并长期实现我的目标。
提示
-
整理你的个人资料: 如果你有与 NLP 相关的面试,将不相关的仓库和笔记本设为私人,以便面试官能够专注于与该领域相关的项目。
-
项目 描述: 确保他们阅读的第一行是项目摘要。写下关于 GitHub 仓库或 Deepnote 笔记本的描述将帮助招聘官提出相关问题。
-
修订你的 项目: 你应该浏览 GitHub 或 Deepnote 上的项目描述,以便在面试中,你能详细回答这个项目的内容以及你如何克服一些关键问题。
-
保持你的 作品集 更新: 这会给招聘官留下你积极参与项目的印象。这也有助于提升你的技能,因为独特的问题带来独特的学习体验。
-
专注于个人简介: 写下你的工作经历和当前项目。写下你的目标将帮助你引起注意。确保这是你的个人故事,并且你关心你的愿景。
-
参加 Kaggle 竞赛: 这将提高你被注意的机会,并使你成为一个有吸引力的候选人。
-
修订 数据科学备忘单: 尽管你对你的项目了如指掌,但你可能会在技术知识方面遇到困难,比如主题建模和 TF-IDF。
个人简介: Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型和研究最新的 AI 技术,目前在 PEC-PITC 测试 AI 产品,这些产品随后会被批准进行人类试验,例如乳腺癌分类器。
相关:
更多相关内容
如何通过数据科学家专业证书考试
原文:
www.kdnuggets.com/2023/08/ace-data-scientist-professional-certificate.html

图片由作者提供
获得认证不仅验证了你的技能,还增强了你的自信心。此外,它表明你已经为特定角色做好了工作准备。
我们的前三大课程推荐
1. 谷歌网络安全认证 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
对于初学者来说,强烈建议在完成数据科学训练营并完成投资组合项目后,尽快获得认证。虽然 DataCamp 提供了端到端的职业发展工具,使认证变得可及,但许多人在尝试考试时仍然失败。
在这篇博客中,我将分享我参加认证考试的经验、认证过程,以及任何数据科学初学者或专家如何在不到两天的时间内获得认证。
什么是数据科学家专业证书?
目前,寻找合格的数据科学人才非常困难。公司需要像你这样的数据专家,但具备正确技能的人并不多。从 DataCamp 获得 认证 是脱颖而出的好方法。这向雇主展示了你的技能已经准备好,可以帮助你获得理想的职位。
目前,你可以获得以下认证:
-
数据分析师助理
-
数据分析师专业
-
数据科学家助理
-
数据科学家专业
-
数据工程师助理

图片来自 DataCamp
助理认证适合刚入门的人,符合入门级工作的期望。专业认证则是进一步提升,符合要求有 2 年以上经验的角色所需的技能水平。
在这篇博客中,我们将介绍 专业数据科学家认证 过程。

图片来自 DataCamp
数据科学家需求量很大,仅在美国就有成千上万的高薪职位空缺。然而,合格的数据专业人士却很短缺。DataCamp 的数据科学家认证可以帮助你更快地获得这些职位。
认证过程
认证过程评估核心数据科学能力,包括探索性数据分析、数据管理、统计建模和实验设计。候选人必须展示 Python 或 R 编程、SQL、沟通分析见解以及将这些技能应用于常见数据科学程序和工作流程的专家级流利程度。定时和实际认证考试严格评估一个人是否具备应对最高级数据科学角色要求的准备情况。
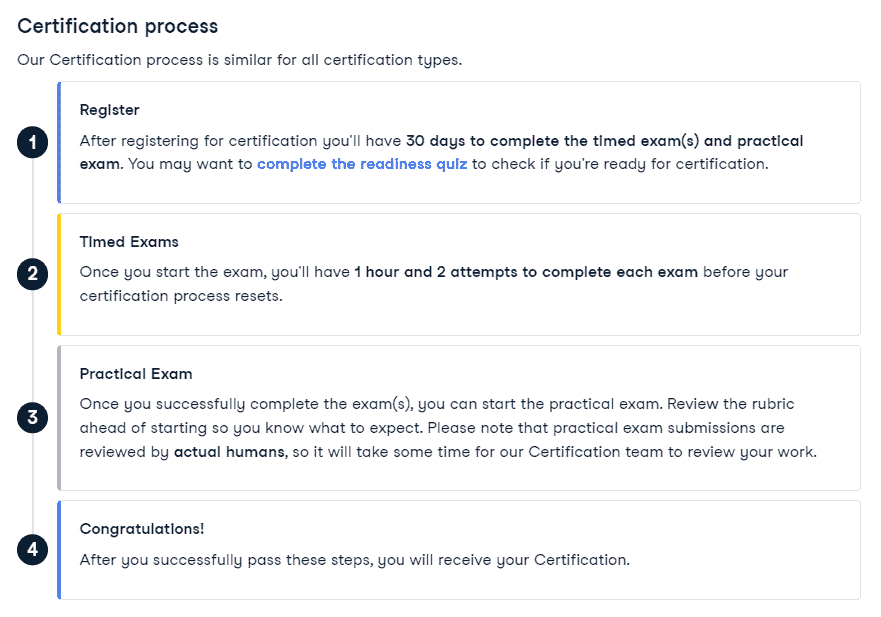
来自 DataCamp 认证的图片
定时考试的期望
要获得数据科学家专业证书,你必须通过两个定时考试 - DS101 和 DS201 - 才能进入实际考试阶段。
DS101
DS101 考试是一个 45 分钟的 R 或 Python 评估,涵盖探索性分析和统计实验技能,包括计算指标、创建可视化以展示数据特征和特征关系、描述统计概念用于测试和实验、应用采样方法以及实施统计测试。
DS201
60 分钟的 DS201 考试评估 SQL 中的数据管理、Python 或 R 中的数据清理和准备、建模技能、模型评估、无监督学习以及包括版本控制和包构建在内的编程最佳实践。
实际考试的期望
实际考试通过让你审查一个业务问题、选择和创建可视化以及呈现结果总结来评估数据可视化和沟通技能;它要求录制并提交一个展示有效可视化、构建、传达和总结数据故事能力的演示,面对包括业务领导在内的不同观众。你可以找到更多关于 DataCamp 如何评分数据科学家的信息。要了解 DataCamp 如何评估数据科学家实际考试,你可以参考评分标准以获取更多细节。
定时考试的技巧和窍门
1. 参加评估测试
在注册专业认证考试之前,我建议尽可能多地参加实践评估测试。这些评估提供了分数和错误答案的解决方案。通过定时评估测试练习将帮助你熟悉考试格式并更好地管理时间。进行实践测试也是学习新概念和提升技能的机会,为实际认证考试的成功奠定基础。
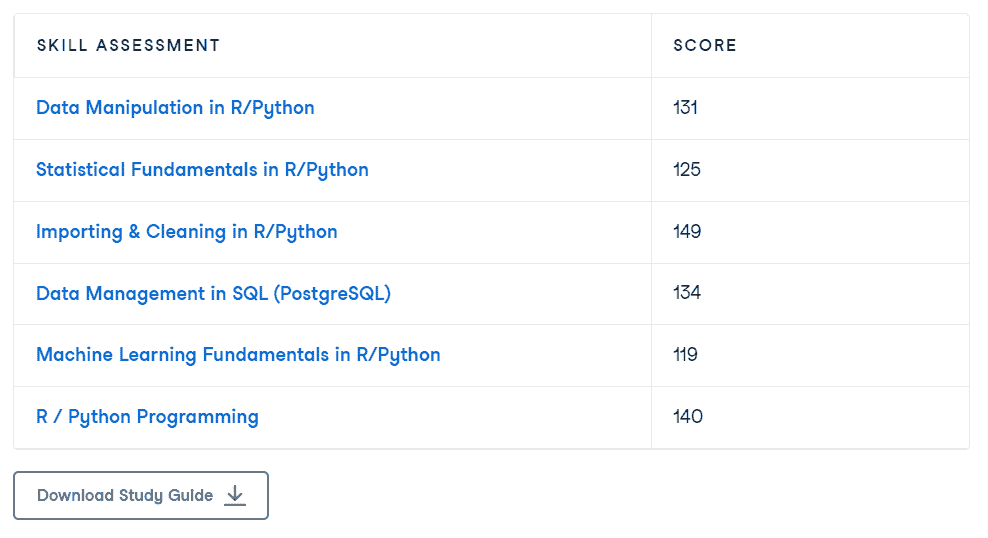
技能评估测试
2. 复习学习指南
下载数据科学家认证学习指南并彻底复习你必须满足的每一个目标。该指南提供了有用的链接,指向每项能力的相关练习评估。
3. 参加一个短期课程
我发现统计测试和 SQL 数据管理是我较弱的领域。为了解决这个问题,我参加了一些小课程,并重新学习了被遗忘的概念。我强烈推荐参加课程来复习这些概念,特别是如果你在日常工作中不使用这些工具或概念的话。
4. 信任过程
DataCamp 认证提供了广泛的资源,如评估测试、学习指南、课程和演示。如果你第一次尝试未能通过认证,可以重新参加一次考试。然而,如果你在第二次尝试中仍未通过,建议你等待两个月,专注于你的薄弱环节。你将收到一份全面的绩效报告,帮助你改进。
实践考试技巧与窍门
1. 完成两个端到端的数据科学项目
使用 Kaggle 的数据集完成一个回归项目和一个分类项目。对于每个项目,依次完成数据科学流程,包括探索性数据分析、数据清洗、可视化、特征工程、模型选择、训练和评估。全面完成回归和分类问题的整个过程,将帮助你确保进展顺利,并建立实现证书目标所需的技能。你也可以尝试一个聚类项目。
2. 参加一个实践考试样本
阅读样本考试的项目描述,确保你了解数据负责人对你的期望。通过查看样本考试描述、解决方案笔记本和演示视频,你将学到很多东西。

实践考试样本
3. 向专家学习
在进行实践考试时,可以查看 Kaggle、GitHub 或 Medium 上的类似项目。这将帮助你理解完成特定任务所需的步骤和流行工具。如果遇到困难,可以进行 Google 搜索以寻找解决方案。
我不建议从 Kaggle 或其他来源复制和粘贴代码。审阅者很可能会发现抄袭行为,导致考试失败。此外,在实际工作场景中,经理们可以很容易识别出被复制的内容。
在审查其他专家的解决方案时,仔细阅读说明。这样有助于撰写实验结果、分析报告和结论。
4. 演示文稿
我使用 Canva 制作了我的演示文稿,但还有各种工具可以创建演示文稿。以下是你可以遵循的一系列步骤,用于开发和展示你的项目成果:
-
每张幻灯片最多使用 3 行文字,以避免拥挤。
-
用自己的话解释结果,而不是直接从幻灯片上阅读。
-
包括与你的项目相关的可视化和图片。
-
避免使用技术术语,因为观众是非技术人员。
-
将演示文稿限制在 10 张幻灯片和 8 分钟内。
-
在录制前至少练习演示文稿 3 次。
-
观看你录制的演示文稿,如果觉得可以改进,重新录制。
接下来做什么?
认证获得后,通过突出你的成就来提升你的作品集和个人资料。在 LinkedIn 上分享你的认证,并在 GitHub、Deepnote、DataCamp、DagsHub 等平台展示,以增强你的数据科学作品集。

图片来自作者的个人资料
如果你正在求职,在申请职位的同时继续从事数据科学项目,以展示你的技能。开发项目可以展示你的实践经验,这将提高你在招聘人员面前的可见性,并帮助他们更好地理解你的能力。
加入 DataCamp 认证社区和 Discord、Slack 上的网络小组,与该领域的其他人建立联系。利用这些社区寻求可以帮助你求职的指导机会。请记住,现在找到全职工作应该是你的优先事项,因此要为搜索过程投入足够的时间。
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理健康问题的学生开发 AI 产品。
更多相关信息
如何获得最受欢迎的数据科学技能
原文:
www.kdnuggets.com/2020/11/acquire-most-wanted-data-science-skills.html
评论
KDnuggets 最近进行了一项调查 ,以了解我们的读者目前掌握了哪些数据科学技能,以及他们希望添加或改进哪些技能。
结果分析显示,在我们 50 项技能中,排名前 10 的最受欢迎技能(按希望拥有的受访者百分比递减排序)是:
-
强化学习
-
TensorFlow
-
深度学习算法
-
PyTorch
-
AWS(亚马逊网络服务)
-
自然语言处理
-
Apache Spark
-
Docker
-
No-SQL 数据库
-
计算机视觉
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
本文将介绍一些免费选项,以帮助你开始学习每项技能。我将指出一两个我认为已经证明其价值的资源,其中一些资源还指向其他经过验证的资源,而不是针对每项技能抛出一堆资源。
请记住,这些是学习特定主题基础知识的方法,在许多情况下,获得足够的专业知识以便日常使用这些特定技能或对其进行深入理解可能需要许多小时甚至多年的实践和学习。但不要因此气馁,赶快开始学习吧。
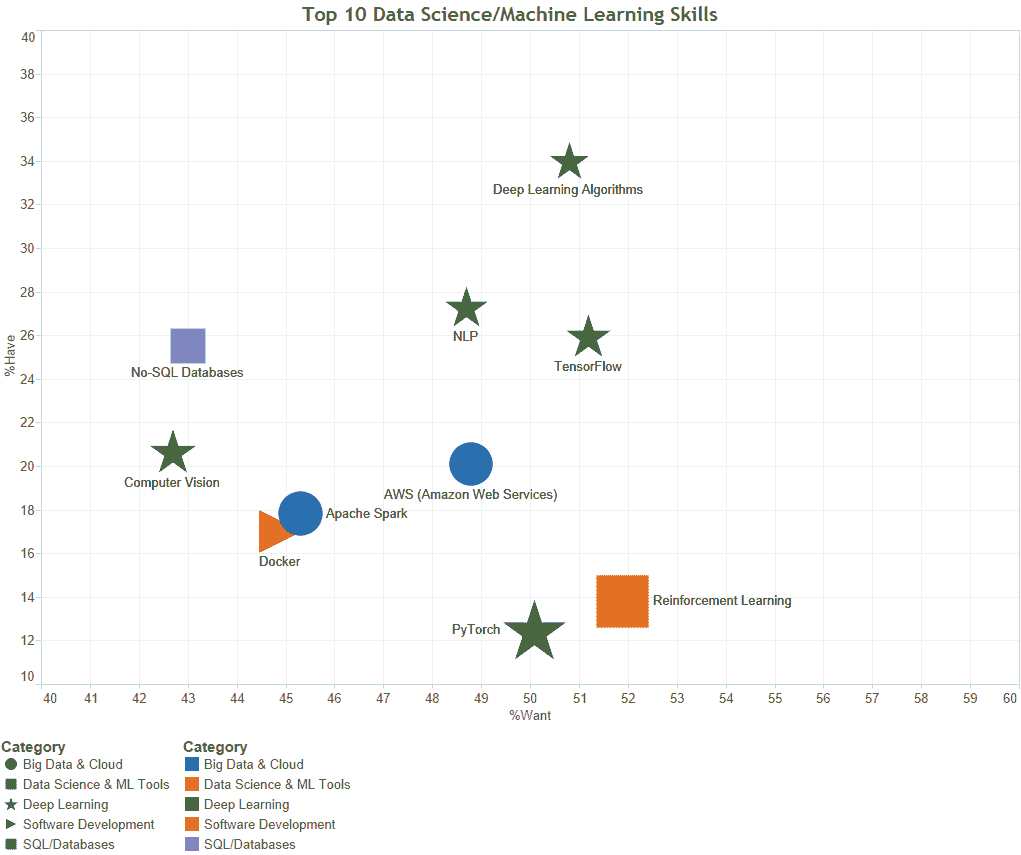 图 1: 前 10 名最受欢迎的数据科学/机器学习技能
图 1: 前 10 名最受欢迎的数据科学/机器学习技能
按希望拥有的受访者百分比与现有的受访者百分比绘制
1. 强化学习
强化学习在我们希望掌握的技能中排名第一,51.9%的受访者表示他们希望将其加入自己的技能组合。我熟悉的两个全面的强化学习资源是:
-
阿尔伯塔大学强化学习专业 通过 Coursera
-
强化学习:导论(第二版,进行中) 由 Sutton 和 Barto 编写
2. TensorFlow
51.2%的受访者表示他们希望提升 TensorFlow 技能或将其加入自己的技能库。这是有充分理由的,因为 TensorFlow 仍然是最具影响力和广泛使用的 Python 机器学习库之一。学习实用 TensorFlow 的一个很好的资源是:
- DeepLearning.AI TensorFlow 开发者专业证书 通过 Coursera
3. 深度学习算法
50.8%的受访者认为深度学习算法是一个值得掌握的技能。随着时间的推移,深度学习不再被视为一时的潮流;最近,Geoffrey Hinton 被引用说“深度学习将能够做一切。”这似乎是至少了解这些算法能做什么的充分理由。理解深度学习基础知识的好地方仍然包括:
-
深度学习 由 Goodfellow、Bengio 和 Courville 编著
-
DeepLearning.AI 深度学习专业课程 通过 Coursera
4. PyTorch
排名第四的是 PyTorch,50.1%的受访者表示他们有兴趣增加或提升对这一深度学习库的了解。学习 PyTorch 基础知识的最佳地方仍然是 PyTorch 官方教程,网址如下:
5. AWS(亚马逊网络服务)
48.8%的受访者表示他们对学习 AWS 感兴趣,AWS 是亚马逊提供的一系列相关服务。鉴于此,学习这些众多相关服务的基础知识的地方仍然是官方的亚马逊 AWS 培训网站,网址如下:
6. 自然语言处理
自然语言处理仍然是一个受欢迎的技能(或技能组合),48.7%的受访者对此有需求。学习 NLP 的时间投入远不止上几门课程,单纯从数据科学、计算机科学或 AI 背景出发是无法完全掌握的。然而,通过如亚马逊机器学习大学的课程,可以了解一些基本知识:
- 加速自然语言处理 由亚马逊机器学习大学提供
7. Apache Spark
45.3% 的受访者希望了解更多关于 Apache Spark 的信息。大数据不再值得特别关注,因为我们处理的数据大多是大数据,人们普遍认为我们已经知道如何处理它。这正是 Apache Spark 的用武之地。以下文章提供了针对不同目标学习 Spark 的一些见解,并列出了 5 个免费资源。
- 2020 年学习 Apache Spark 的 5 门免费课程 由 Javin Paul 提供
8. Docker
对于数据开发领域,尤其是数据 DevOps 和数据工程领域的人来说,Docker 正变得越来越重要。因此,44.9% 的受访者对了解更多关于这项技术的内容感兴趣,以便将其添加到他们的技能列表中。以下是一篇从数据科学家的角度探讨 Docker 的文章:
- 为数据科学家简化 Docker 由 Gagandeep Singh 提供
9. NoSQL 数据库
NoSQL 是一个广泛的术语,涵盖了各种不符合传统 SQL/关系数据库模式的数据库引擎和技术。因此,该术语在功能上包括图数据库、键值存储、列式数据库和文档存储等数据库类型。这些数据库各不相同,但共同点在于它们在关系模型不可行时被使用。43.0% 的受访者希望了解更多内容,本文可以帮助他们初步了解,并指引他们向正确的方向进一步学习。
- NoSQL 教程:NoSQL 数据库的类型、定义及示例 由 Guru99 提供
10. 计算机视觉
最后,在第 10 位,计算机视觉是一项(或一组相关技能)42.7% 的受访者希望掌握的技能。与 NLP 类似,计算机视觉领域的精通远比参加一门课程要复杂,但—也类似于 NLP—通过 Amazon 机器学习大学的课程可以实现对基础知识的初步理解:
- 加速计算机视觉 由 Amazon 机器学习大学提供
相关:
-
如何获取最受欢迎的数据科学技能
-
我如何在 8 个月内提升我的数据科学技能
-
数据科学最低要求:开始数据科学所需了解的 10 项基本技能
更多相关主题
以低成本获得高质量标记训练数据的 7 种方法
原文:
www.kdnuggets.com/2017/06/acquiring-quality-labeled-training-data.html
数据科学家知道,未经训练的统计模型几乎毫无用处。没有高质量的标记训练数据,监督学习会崩溃,也无法确保模型能以任何准确度预测、分类或分析感兴趣的现象。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
当你进行监督学习时,最好在没有找到合适的训练数据的情况下不要开发模型。即使你找到了合适的训练数据集,如果其条目没有被标记、标签或注释来有效地训练你的机器学习算法,也没什么用处。
然而,标记工作是一项不受欢迎的工作,少有数据科学家会因为其他原因而做这项工作。标记训练数据在数据科学职位的声望等级中几乎处于底部。标记工作获得了(可能是不公平的)声誉,成为数据科学生态系统中低技能的“蓝领”工作。或者,正如这集搞笑剧集所描绘的那样,数据训练的标记工作是一项让一些不道德的数据科学家试图欺骗无辜的年轻大学生为零报酬做的杂务。
所有这些都不公平地暗示,数据科学家无法获得可接受的训练数据,除非他们将标记功能外包给高科技版的血汗工厂。这是一种不幸的看法,因为正如我去年在 KDnuggets 专栏《认知时代的模式策展人》中提到的那样,标记工作可能依赖于高度熟练的主题专家(例如,肿瘤学家评估活检是否表明癌症组织),也同样依赖于我们任何人都能进行的平凡评估(例如,上面提到的虚构的“热狗/非热狗”示例)。
远程劳工并不是获取和标注训练数据的唯一方法,正如在这篇最近的 Medium 文章中提到的那样。正如作者拉斯穆斯·罗瑟所指出的,还有其他方法可以以不会超出你的数据科学预算的成本产生标注的训练数据。以下是我对这些方法的总结:
-
重新利用现有的训练数据和标签:如果我们假设新学习任务的领域与原始任务的领域足够相似,这可能是训练中最便宜、最简单、最快的方法。在采取这种方法时,“迁移学习”工具和技术可能帮助你确定哪些源训练数据集的元素可以重新用于新的建模领域。
-
从免费来源收集自己的训练数据和标签:网络、社交媒体以及其他在线资源充满了可以利用的数据,只要你有合适的工具。在这个认知计算的时代,实际上你可以从我在这篇 Dataversity 专栏中提到的各种来源中获取丰富的自然语言、社交情感和其他训练数据。如果你有数据爬虫的访问权限,这可能是从源内容和元数据中获取训练数据集及其关联标签的一个好选择。显然,你需要处理一系列与数据所有权、数据质量、语义、采样等相关的问题,以评估爬取的数据是否适合模型训练。
-
探索预标注的公共数据集:在开源社区甚至各种商业提供商那里,有大量免费的数据可供获取。数据科学家应当识别这些数据中是否有适合至少用于模型初始训练的数据。理想情况下,免费的数据集应当已按对你的学习任务有用的方式进行预标注。如果数据集没有预标注,你需要找出最具成本效益的标注方式。
-
在逐步提高质量的标注数据集上重新训练模型:你自己的数据资源可能不足以训练你的模型。为了启动训练,你可以用与你的领域大致相关的免费公共数据进行预训练。如果免费数据集包含可接受的标签,那就更好。然后,你可以在直接与学习任务相关的小型高质量标注数据集上重新训练模型。随着你在更高质量的数据集上逐步重新训练模型,结果可能会使你能够对特征工程、类别和模型中的超参数进行微调。这种迭代过程可能会建议你获取其他更高质量的数据集和/或在未来的训练轮次中进行更高质量的标注,以进一步完善你的模型。不过,请注意,这些迭代改进可能需要逐步更昂贵的训练数据集和标注服务。
-
利用众包标注服务:你可能没有足够的内部员工来标注你的训练数据。或者你的员工可能不可用,或标注成本太高,或者你的员工资源可能不足以迅速标注大量训练数据。在这种情况下,如果预算允许,你可以将标注任务外包给商业服务,如亚马逊机械土耳其或众包花。将标注任务外包到以众包为导向的环境通常比内部处理更具扩展性,尽管你会失去对标签质量和一致性的某些控制。积极的一面是,这些服务往往使用高质量的标注工具,使得过程比你在内部处理时更加快速、精确和高效。
-
将标注任务嵌入在线应用程序:如果你足够聪明,互联网中的人类认知是一个无限的资源,可以用来进行标注任务。例如,将训练数据嵌入验证码挑战中,这在双因素认证场景中很常见,是训练图像和文本识别模型的一种流行方法。类似地,你可以考虑在提供激励的游戏化应用中展示训练数据,以促使用户识别、分类或对图像、文本、对象及其他呈现的实体进行评论。
-
依赖于已经在标注数据上预训练的第三方模型:许多学习任务已经被足够好的模型解决,这些模型已经用足够好的数据集进行训练,假设这些数据集在训练对应模型之前已得到充分标注。预训练模型可以从各种来源获得,包括学术研究者、商业供应商和开源数据科学社区。请记住,如果你的学习任务领域、特征集和学习任务随着时间的推移与源数据偏离,这些模型的实用性将会下降。
让模型适应用途取决于训练数据的可用性、频繁重训的需求、标注资源的可用性等等。显然,没有一种方法适用于所有获取和标注训练数据集的要求。
数据科学家在这方面必须做出的复杂决策会给有监督学习应用的生命周期带来风险和脆弱性。正如我在这篇最近的 Wikibon 博客中提到的,你选择如何训练算法会给任何消耗你分析模型输出的下游应用带来持续的维护负担。
更多相关话题
深度学习中的激活函数如何工作
原文:
www.kdnuggets.com/2022/06/activation-functions-work-deep-learning.html
让我们从激活函数的定义开始:
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT
“在人工神经网络中,每个神经元对其输入形成加权总和,并通过被称为激活函数的函数传递结果的标量值。”
听起来有点复杂?别担心!阅读本文后,你将对激活函数有更好的理解。
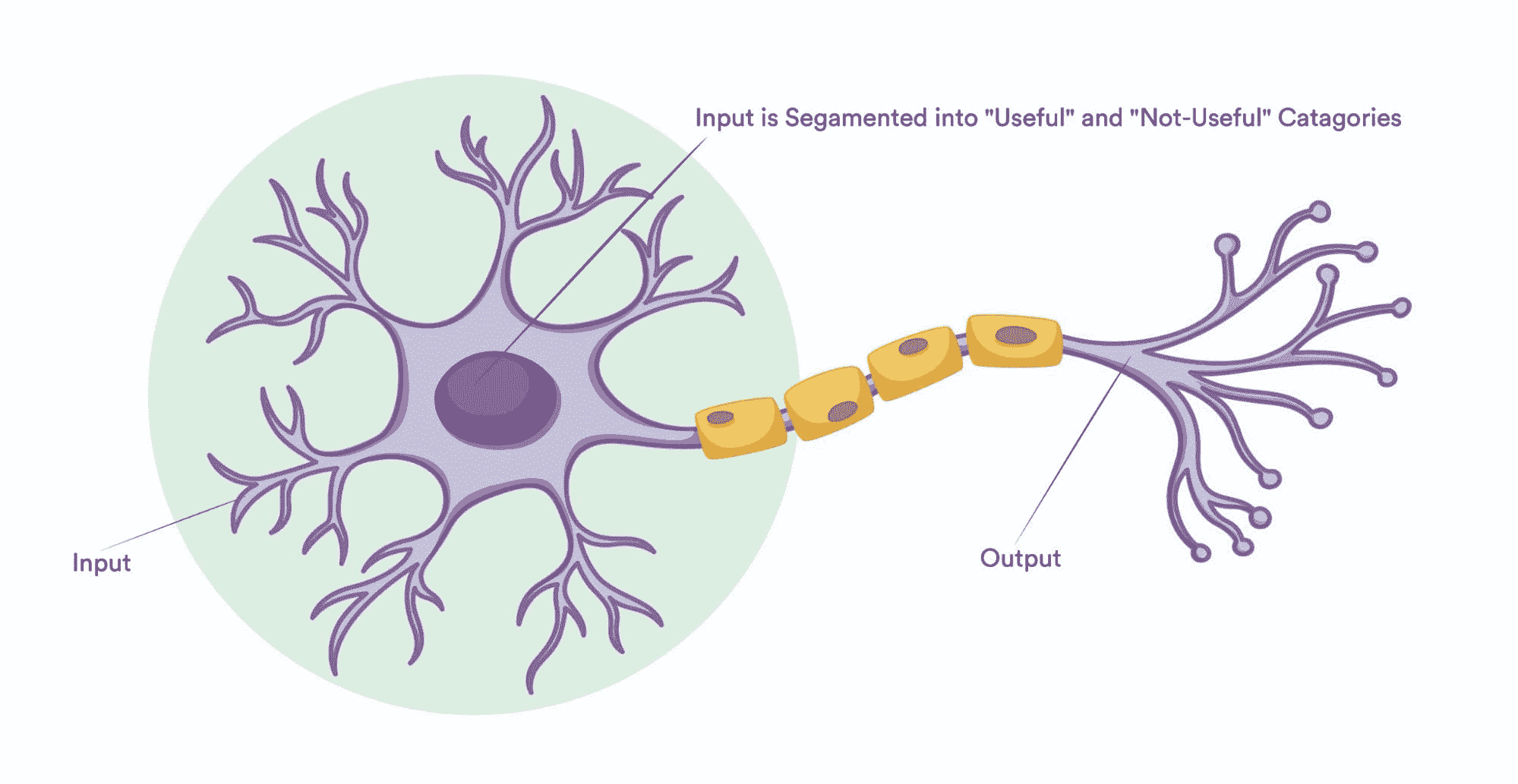
对于人类而言,我们的大脑接收来自外部世界的信息,对接收输入的神经元进行处理,并激活神经元尾部以生成所需的决策。同样,在神经网络中,我们提供图像、声音、数字等作为输入,对人工神经元进行处理,通过算法激活正确的最终神经元层以生成结果。
我们为什么需要激活函数?
激活函数决定了一个神经元是否应该激活或不激活。这意味着它将使用一些简单的数学运算来确定神经元对网络的输入在预测过程中是否相关。
激活函数的目的是向人工神经网络引入非线性,并从输入值集合中生成输出。
激活函数的类型
激活函数可以分为三种类型:
-
线性激活函数
-
二值阶跃函数
-
非线性激活函数
线性激活函数
线性激活函数,通常称为恒等激活函数,与输入成正比。线性激活函数的范围为(-∞到∞)。线性激活函数只是将输入的加权总和相加并返回结果。
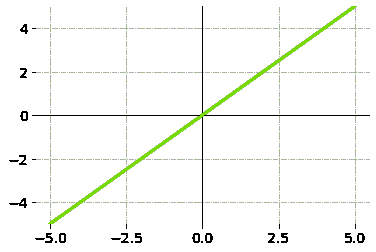
线性激活函数——图示
从数学角度来看,它可以表示为:
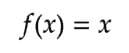
线性激活函数 — 方程
优缺点
-
这不是一个二元激活函数,因为线性激活函数仅提供一系列激活值。我们可以将几个神经元连接在一起,如果有多个激活值,我们可以基于此计算最大值(或软最大值)。
-
该激活函数的导数是一个常数。也就是说,梯度与 x(输入)无关。
二元阶跃激活函数
一个阈值决定了在二元阶跃激活函数中神经元是否应该被激活。
激活函数将输入值与阈值进行比较。如果输入值大于阈值,则激活神经元。如果输入值小于阈值,则禁用神经元,这意味着其输出不会传递到下一层或隐藏层。
二元阶跃函数 — 图
从数学上讲,二元激活函数可以表示为:
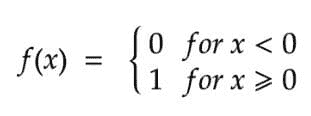
二元阶跃激活函数 — 方程
优缺点
-
它不能提供多值输出——例如,它不能用于多类分类问题。
-
步进函数的梯度为零,这使得反向传播过程变得困难。
非线性激活函数
非线性激活函数是最常用的激活函数。它们使得人工神经网络模型能够适应各种数据并区分输出。
非线性激活函数允许堆叠多个神经元层,因为输出将是通过多个层的输入的非线性组合。任何输出都可以表示为神经网络中的功能计算输出。
这些激活函数主要根据其范围和曲线进行分类。本文余下部分将概述神经网络中使用的主要非线性激活函数。
1. Sigmoid
Sigmoid 接受一个数字作为输入,并返回一个介于 0 和 1 之间的数字。它简单易用,具备激活函数的所有理想特性:非线性、连续可微性、单调性和固定输出范围。
这主要用于二元分类问题。这个 Sigmoid 函数给出了特定类别存在的概率。
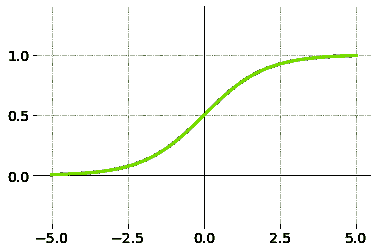
Sigmoid 激活函数 — 图
从数学上讲,它可以表示为:
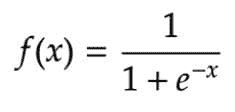
Sigmoid 激活函数 — 方程
优缺点
-
它本质上是非线性的。该函数的组合也具有非线性特性,并且它将提供类比激活,不像二进制步进激活函数。它也有平滑的梯度,对于分类问题来说效果很好。
-
激活函数的输出始终会在 (0,1) 范围内,而线性激活函数的范围是 (-∞, ∞)。因此,我们为激活定义了一个范围。
-
Sigmoid 函数引发了“梯度消失”的问题,Sigmoid 会饱和并杀死梯度。
-
它的输出不是零中心的,这会导致梯度更新在不同方向上过度移动。输出值在零和一之间,使得优化变得更加困难。
-
网络要么拒绝学习更多内容,要么变得非常慢。
2. TanH(双曲正切)
TanH 将一个实值数压缩到范围[-1, 1]。它是非线性的,但与 Sigmoid 不同,其输出是零中心的。其主要优点在于,负输入将被强烈映射到负值,而零输入在 TanH 图中将被映射到接近零的位置。
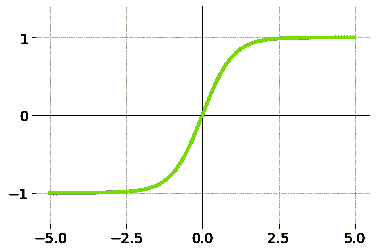
TanH 激活函数 — 图
从数学上讲,TanH 函数可以表示为:
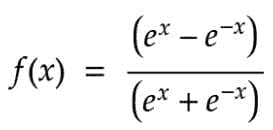
TanH 激活函数 — 方程
优点与缺点
-
TanH 也存在梯度消失问题,但 TanH 的梯度比 sigmoid 更强(导数更陡)。
-
TanH 是零中心的,梯度不必朝着特定方向移动。
3. ReLU(修正线性单元)
ReLU 代表修正线性单元,是应用中最常用的激活函数之一。它解决了梯度消失的问题,因为 ReLU 函数的梯度最大值为一。它也解决了神经元饱和的问题,因为 ReLU 函数的斜率从未为零。ReLU 的范围在0 和无限之间。
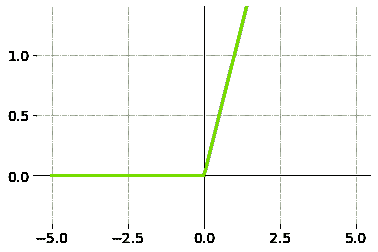
ReLU 激活函数 — 图
从数学上讲,它可以表示为:
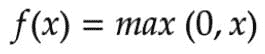
ReLU 激活函数 — 方程
优点与缺点
-
由于只有一定数量的神经元被激活,ReLU 函数在计算上比 sigmoid 和 TanH 函数更高效。
-
由于其线性、非饱和的特性,ReLU 加速了梯度下降向损失函数全局最小值的收敛。
-
其一个局限性是它应该仅在人工神经网络模型的隐藏层中使用。
-
在训练过程中,一些梯度可能会很脆弱。
-
换句话说,对于 ReLU 的 (x<0) 区域的激活,梯度将为 0,因此权重在下降过程中不会调整。这意味着那些进入该状态的神经元将停止响应输入的变化(仅仅因为梯度为 0,没有变化)。这就是死 ReLU 问题。
4. Leaky ReLU
Leaky ReLU 是 ReLU 激活函数的升级版,用于解决 ReLU 死亡问题,因为它在负区域有一个小的正斜率。但是,目前不同任务上的好处一致性尚不明确。
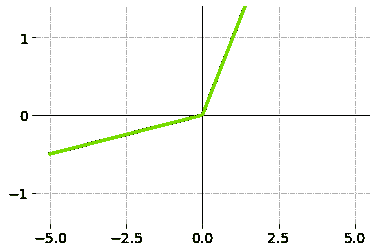
Leaky ReLU 激活函数 — 图
从数学上表示为,
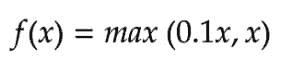
Leaky ReLU 激活函数 — 方程
优缺点
-
Leaky ReLU 的优点与 ReLU 相同,此外它还允许反向传播,即使对于负输入值也是如此。
-
通过对负输入值进行微小修改,图形左侧的梯度将变成真实(非零)值。因此,该区域内不会再有死神经元。
-
对于负输入值,预测可能不稳定。
5. ELU(指数线性单元)
ELU 也是 ReLU 的一种变体,它也解决了死 ReLU 问题。ELU 就像 Leaky ReLU 一样,通过引入一个新的 alpha 参数并与另一个方程相乘来考虑负值。
ELU 在计算上比 Leaky ReLU 略贵,而且它与 ReLU 非常相似,只是在负输入值方面有所不同。对于正输入值,它们的形状都是单位函数。
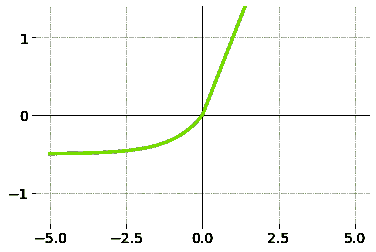
ELU 激活函数-图
从数学上表示为:
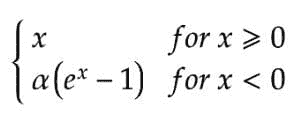
ELU 激活函数 — 方程
优缺点
-
ELU 是 ReLU 的一个强有力的替代方案。与 ReLU 不同,ELU 可以产生负输出。
-
ELU 中有指数运算,因此增加了计算时间。
-
不涉及对 'a' 值的学习,并且存在梯度爆炸问题。
6. Softmax
多个 sigmoid 的组合称为 Softmax 函数。它确定相对概率。类似于 sigmoid 激活函数,Softmax 函数返回每个类别/标签的概率。在多分类问题中,softmax 激活函数最常用于神经网络的最后一层。
Softmax 函数给出了当前类别相对于其他类别的概率。这意味着它还考虑了其他类别的可能性。
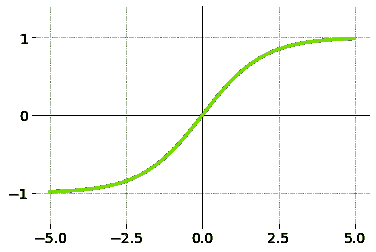
Softmax 激活函数 — 图
从数学角度看,它可以表示为:
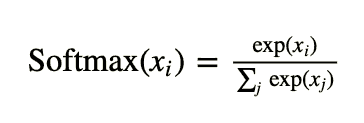
Softmax 激活函数 — 方程
优缺点
-
它比绝对值更好地模拟了编码标签。
-
如果我们使用绝对值(模值),信息会丢失,但指数函数会自动处理这一点。
-
softmax 函数也应用于多标签分类和回归任务。
7. Swish
Swish 允许少量负权重的传播,而 ReLU 将所有非正权重设置为零。这是决定非单调平滑激活函数(如 Swish)在逐层深度神经网络中成功的关键特性。
它是由谷歌研究人员创建的自门控激活函数。
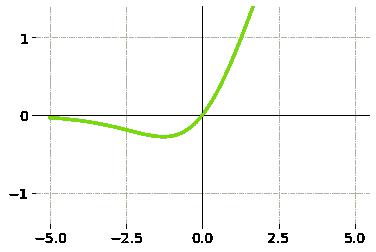
Swish 激活函数 — 图
从数学角度看,它可以表示为:
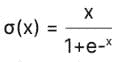
Swish 激活函数 — 方程
优缺点
-
Swish 是一个平滑的激活函数,这意味着它不像 ReLU 在 x 等于零附近那样突然改变方向。相反,它平滑地从 0 向小于 0 的值弯曲,然后再次向上。
-
在 ReLU 激活函数中,非正值被置为零。而负数可能对检测数据中的模式有价值。由于稀疏性,大的负数被消除,从而形成双赢局面。
-
Swish 激活函数由于非单调性,增强了输入数据和权重的学习。
-
计算上略显昂贵,并且随着时间的推移,算法可能会出现更多问题。
重要考虑事项
在选择合适的激活函数时,必须考虑以下问题和事项:
梯度消失是神经网络训练过程中常见的问题。像 sigmoid 激活函数一样,一些激活函数的输出范围很小(0 到 1)。因此,sigmoid 激活函数的输入发生巨大变化时,输出的修改很小。因此,导数也变得很小。这些激活函数仅用于只有几层的浅层网络。当这些激活函数应用于多层网络时,梯度可能变得过小,无法完成预期训练。
梯度爆炸是训练过程中产生大规模错误梯度的情况,导致神经网络模型权重的巨大更新。当发生梯度爆炸时,网络可能变得不稳定,训练无法完成。由于梯度爆炸,权重值可能增长到溢出的程度,从而导致NaN值的丢失。
最终总结
-
所有隐藏层通常使用相同的激活函数。ReLU 激活函数 应仅 在隐藏层中使用,以获得更好的结果。
-
由于梯度消失问题,不应在 隐藏层中使用 sigmoid 和 TanH 激活函数,因为它们使模型在训练过程中更容易出现问题。
-
Swish 函数用于深度 超过 40 层 的人工神经网络。
-
回归问题应使用线性激活函数
-
二分类问题应使用 sigmoid 激活函数
-
多分类问题应使用 softmax 激活函数
神经网络架构及其可用的激活函数,
-
卷积神经网络 (CNN):ReLU 激活函数
-
循环神经网络 (RNN):TanH 或 sigmoid 激活函数
你可以找到无数的文章评估激活函数的比较。我建议你亲自动手实践。
如果你有任何问题,可以在 LinkedIn 或 Twitter 上随时问我。
Parthiban Marimuthu (@parthibharathiv) 生活在印度钦奈,在 Spritle Software 工作。Parthiban 研究并转化数据科学原型,设计机器学习系统,并研究和实现适当的 ML 算法和工具。
更多相关话题
几行代码中的深度学习模型激活图
原文:
www.kdnuggets.com/2019/10/activation-maps-deep-learning-models-lines-code.html
评论
深度学习有个不好的名声:‘黑箱’
深度 学习 (DL) 模型正在以令人惊叹的表现在一个接一个的应用领域——图像分类、目标检测、目标跟踪、姿态识别、视频分析、合成图片生成——彻底革新商业和技术世界。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
然而,它们与经典的机器 学习 (ML) 算法/技术截然不同。DL 模型使用数百万个参数,创建图像或数据集的极其复杂且高度非线性的内部表示。
因此,它们常被称为完美的黑箱 ML 技术。我们在用大数据集训练它们后可以获得高度准确的预测,但我们几乎无法理解模型用来将特定图像分类到某一类别的内部特征和表示。

来源:CMU ML 博客
深度学习的黑箱问题——预测能力强但缺乏直观易懂的解释。
这并不吉利,因为我们,人类,是视觉生物。数百万年的进化赋予了我们一对极其复杂的眼睛和更复杂的视觉皮层,我们用这些器官来理解世界。
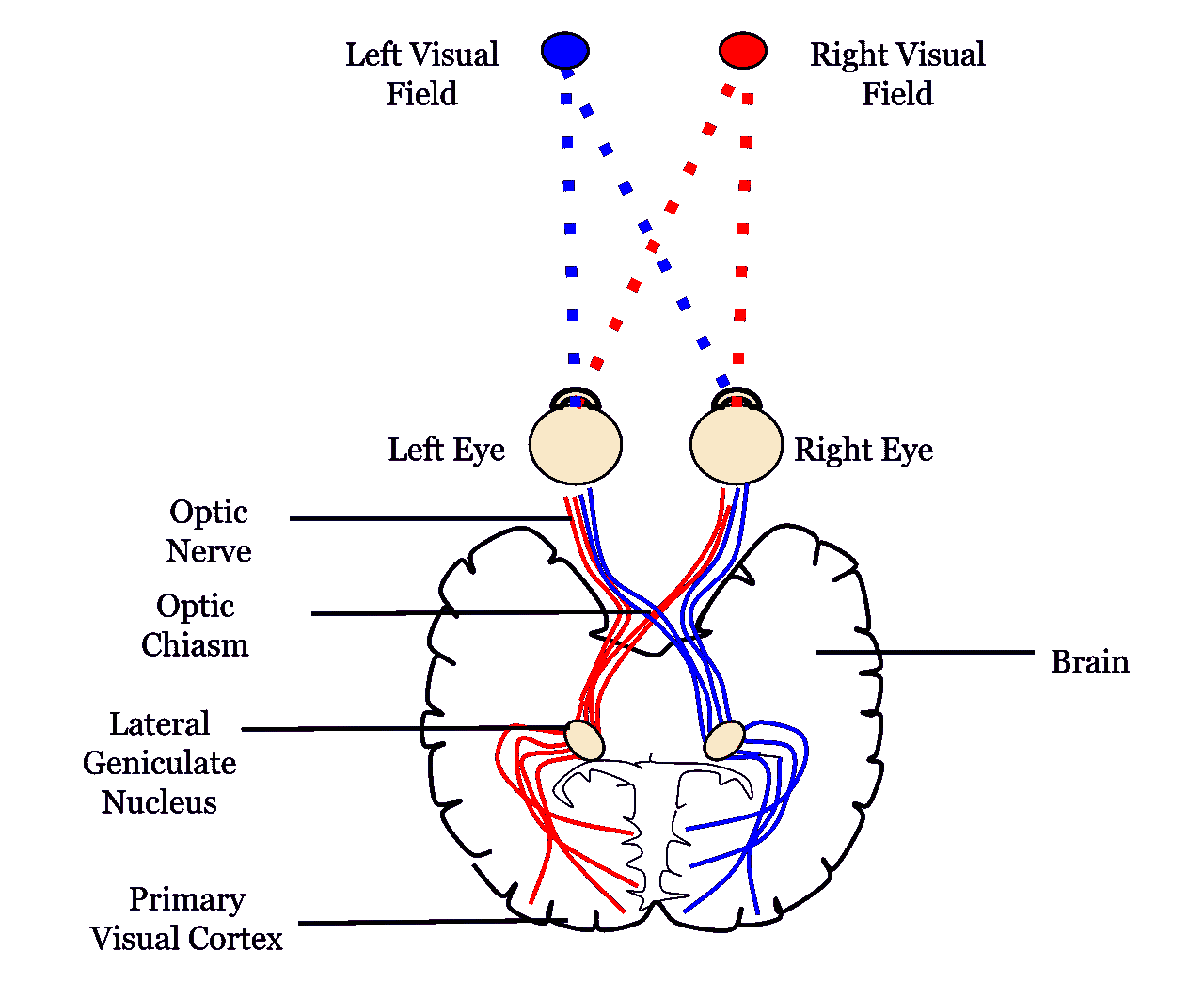
来源:Wikimedia
科学过程从观察开始,这几乎总是与视觉同义。在商业中,只有我们能够观察和测量的东西,我们才能有效地控制和管理。
看到/观察是我们开始构建世界现象的心理模型、分类周围的物体、区分朋友和敌人、爱、工作和玩耍的方式。
可视化非常有帮助,尤其是对于深度学习。
因此,那些我们无法可视化内部工作原理的‘黑箱’深度学习模型,常常受到一些批评。
激活图
在各种深度学习架构中,也许最突出的就是所谓的卷积神经网络(CNN)。它已经成为分析高维、非结构化数据的主力军——图像、文本或音频——这些数据传统上对经典的机器学习(非深度学习)或手工制作(非机器学习)算法构成了严峻的挑战。
了解和可视化 CNN 的几种方法已在文献中提出,部分是为了回应对 CNN 中学习到的内部特征不可解释的普遍批评。
最直接的可视化技术是展示网络在前向传播过程中的激活。
那么,激活究竟是什么呢?
在简单层面上,激活函数帮助决定一个神经元是否应该被激活。这有助于判断神经元接收到的信息是否对输入相关。激活函数是对输入信号进行的非线性变换,变换后的输出被发送到下一个神经元。
如果你想准确理解这些激活的含义,以及它们为何最初被放置在神经网络架构中,请查看这篇文章,
介绍 互联网如今提供了大量的信息。我们所需的一切仅需通过 Google(搜索)即可获得…
以下是著名数据科学家布兰登·罗赫关于 CNN 基本机制的精彩视频,即给定输入(例如二维图像)如何逐层处理。在每一层,输出是通过激活函数传递变换后的输入生成的。
激活图只是这些激活数字在网络不同层中的可视化表示,作为图像通过各种线性代数操作处理的结果。
对于基于 ReLU 激活的网络,激活通常开始时看起来相对模糊且密集,但随着训练的进行,激活通常变得更稀疏和局部化。一个可以通过这种可视化轻松发现的设计陷阱是,一些激活图对于许多不同的输入可能全部为零,这可能表明死亡的滤波器,并可能是高学习率的症状。
激活图只是这些激活数在网络各层上的视觉表示。
听起来不错。但可视化这些激活图是一个复杂的任务,即使在你已经很好地训练了神经网络并进行预测之后。
如何通过几行代码轻松可视化和展示这些激活图,适用于一个相当复杂的 CNN?
通过几行代码生成激活图
整个Jupyter 笔记本在这里。随意克隆和扩展(如果你喜欢,给仓库留个星)。
一个紧凑的函数和一个好用的小库
我在之前的文章中展示了如何编写一个紧凑的函数,通过利用 Keras 库提供的一些神奇的实用方法和类,自动从磁盘逐个读取图像文件来获得一个完全训练的 CNN 模型。
请查看这篇文章,因为没有它,你不能以紧凑的方式训练任意模型与任意图像数据集,如本文所述。
我们展示了如何构建一个通用的实用函数,从目录中自动提取图像,并…
接下来,我们使用这个函数和一个叫做Keract的小库,它使得激活图的可视化变得非常简单。它是 Keras 库的一个高级附加库,用于在神经网络的各种层上展示有用的热图和激活图。

因此,对于这段代码,我们需要使用我utils.DL_utils模块中的几个实用函数——train_CNN_keras和preprocess_image,使随机 RGB 图像适合生成激活图(这些函数在上文提到的文章中进行了描述)。
这是 Python 模块 —[**DL_utils.py**](https://raw.githubusercontent.com/tirthajyoti/Deep-learning-with-Python/master/Notebooks/utils/DL_utils.py)。你可以将其存储在本地驱动器中,并像往常一样导入这些函数。
数据集
对于训练,我们使用了著名的 Caltech-101 数据集,来自 www.vision.caltech.edu/Image_Datasets/Caltech101/。该数据集在某种程度上是 ImageNet 数据库 的前身,后者是当前图像分类数据存储库的金标准。

这是一个包含 101 类对象的多样化图像数据集。每个类别大约有 40 到 800 张图像。大多数类别有大约 50 张图像。每张图像的大小大约为 300 x 200 像素。
但我们只训练了 5 种类别的图像——螃蟹、杯子、大脑、相机 和 椅子。
这只是为了演示而随机选择的,欢迎自由选择你自己的类别。
训练模型
训练仅需几行代码。
从互联网下载的人脑随机图像
为了生成激活图,我们从互联网上下载了一张人脑的随机图像。
生成激活(一个字典)
然后,再写几行代码来生成激活。
我们会得到一个字典,字典的键是层名称,值是对应于激活的 Numpy 数组。下面的插图展示了激活数组的长度因特定卷积层的滤波器图的大小而有所不同。
展示激活
再次,一行代码,
display_activations(activations, save=False)
我们可以逐层查看激活图。这里是第一层卷积层(16 张图像对应 16 个滤波器)
这是第 2 层(32 张图像对应 32 个滤波器)
我们在这个模型中有 5 层卷积层(后跟最大池化层),因此,我们会得到 10 组图像。为简洁起见,我没有展示其余的图像,但你可以在我的 GitHub 仓库中查看所有图像。
热力图
你还可以将激活图展示为热力图。
display_heatmaps(activations, x, save=False)

更新:Quiver
上周写完这篇文章后,我发现了另一个漂亮的激活可视化库,名为 Quiver。不过,这个库是基于 Python 微服务器框架 Flask 构建的,它会在浏览器端口上显示激活图,而不是在 Jupyter Notebook 内部。
它们还需要一个经过训练的 Keras 模型作为输入。所以,你可以轻松使用本文描述的紧凑函数(来自我的 DL_uitls 模块),并尝试这个库以进行激活图的交互式可视化。
总结
就这样,目前为止。
完整的Jupyter 笔记本在这里。
我们展示了如何仅用几行代码(利用来自特殊模块的紧凑函数和 Keras 的小配件库)来训练 CNN,生成激活图,并逐层显示——从头开始。
这使你能够从任何图像数据集中训练 CNN 模型(从简单到复杂,只要你可以将其整理成简单的格式),并查看你想要的任何测试图像的内部。
欲获取更多此类动手教程,请查看我的深度学习与 Python GitHub 仓库。
如果你有任何问题或想法,请通过tirthajyoti[AT]gmail.com与作者联系。你还可以查看作者的GitHub** 仓库**,获取其他有趣的 Python、R 代码片段和机器学习资源。如果你像我一样,对机器学习/数据科学充满热情,请随时在 LinkedIn 上添加我或在 Twitter 上关注我。
原文。转载许可。
相关:
-
克服深度学习中的障碍
-
演变的深度神经网络
-
神经网络架构搜索研究指南
更多相关主题
关于 AI、分析、大数据、数据科学、机器学习的热门活跃博客 – 已更新
原文:
www.kdnuggets.com/2019/01/active-blogs-ai-analytics-data-science.html
评论

在 2017 年,我们创建了一份关于分析、大数据、数据挖掘、数据科学和机器学习的90 个活跃博客的列表。两年后,我们决定更新这份列表,将数量增加到 100 个,给你更多的选择,能够阅读更多你感兴趣的话题。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
今年,我们从之前的列表中移除了 24 个不再符合我们活跃标准的博客:即在过去三个月内(自 2018 年 10 月 1 日以来)至少发布了一篇博客文章。我们还新增了 36 个相关的博客。与之前一样,这份列表中的所有博客分为两个组:非常活跃和中等活跃。前者每月通常有几篇文章,而后者最近几个月可能只有一篇文章。我们还将那些技术讨论较少的博客分为其他组。在每个博客组内,我们按字母顺序列出。
博客概述基于截至 2019 年 1 月 6 日其 URL 上的信息。如果我们遗漏了任何受欢迎的活跃博客,请在下面的评论中建议。祝阅读愉快!
非常活跃的博客
-
,亚马逊官方 AWS AI 博客。
-
,高级分析与 R 语言。
-
,伯克利大学博客。
-
Big on Data,由 Andrew Brust、Tony Baer 和 George Anadiotis 撰写,涵盖了大数据技术,包括 Hadoop、NoSQL、数据仓储、商业智能和预测分析。
-
Clustify 博客,涵盖电子发现、预测编码、文档聚类、技术和软件开发。
-
,由 Hui Xiang Chua 撰写,记录了她的学习历程,并作为那些希望了解数据科学的入门工具。
-
数据遗传学,由 Nick Berry 撰写。
-
数据科学 101,由 Ryan Swanstrom 撰写,关于学习成为数据科学家的博客。
-
,由读者提交的有趣文章列表。
-
,关于数据分析、AB 测试、研究、大数据等的博客。
-
,Dataiku 的博客,Dataiku 公司将数据分析师、工程师和科学家汇聚在一起。
-
Data-mining.philippe-fournier-viger,由 Philippe Fournier-Viger 撰写的关于数据挖掘、数据科学、大数据的博客。
-
,数据科学、数据分析和数据工程的教程和文章。
-
DecisionStats,由 Ajay Ohri 创建,DECISIONSTATS 的创始人,著有《R for Business Analytics》和《R for Cloud Computing》。
-
,主要集中在数据挖掘的技术方面,由 Jay Zhou 撰写。
-
Domino Data Lab,关于初创公司、数据科学、R 和 Python。
-
EMC 大数据博客,Dell EMC 的大数据博客。
-
错误统计哲学,由弗吉尼亚理工大学的统计哲学家 Deborah G. Mayo 撰写。
-
FlowingData,Nathan Yau 的可视化和统计网站。
-
Forrester 大数据博客,汇集了公司贡献者撰写的关于大数据主题的博客。
-
Freakonometrics,由数学教授 Charpentier 撰写的假设博客,提供了一系列既易于理解又具挑战性的统计学相关文章,风趣幽默。
-
Google Analytics 产品,Google 博客,提供关于 Google Analytics、Data Studio、Optimize、Surveys 和 Tag Manager 的新闻和提示。
-
HPE Vertica 开发者社区博客,由 Micro Focus 撰写的博客。
-
Hyndsight,由 Rob Hyndman 撰写,内容涉及预测、数据可视化和功能数据。
-
信息之美,由独立的数据记者和信息设计师大卫·麦肯德莱斯创办,他还是《信息之美》一书的作者。
-
洞察数据科学,由洞察数据科学研究员计划校友撰写,关注数据科学的最新趋势和话题。您通向数据科学和数据工程职业的桥梁。
-
JT 论决策管理,由詹姆斯·泰勒撰写,涉及决策管理的一切。
-
果汁分析,一个关于分析和可视化的博客。
-
Kaggle 博客 “No Free Hunch”,涵盖 Kaggle 数据科学和机器学习竞赛的官方博客。
-
懒程序员,关于大数据、数据科学和初创公司编码的最新动态。
-
机器学习精粹,由杰森·布朗利提供,涵盖编程与机器学习。
-
挖掘数据,由凯文·希尔斯特罗姆提供,关于多渠道营销和数据库营销的观点。
-
,由驻扎在班加罗尔的数据科学顾问和大数据工程师提供,目前在 WalmartLabs 工作。
-
数字主宰你的世界,由凯瑟尔·方提供,大数据浅显易懂。
-
观察性流行病学,一位大学教授和一位统计顾问提供他们对应用统计学、高等教育和流行病学的评论、观察和想法。
-
开放花园,物联网(IoT)的数据科学,由阿吉特·贾卡尔创办。
-
克服偏见,由罗宾·汉森和艾利泽·尤德科夫斯基撰写。呈现对诚实、信号、分歧、预测及远期未来的统计分析反思。
-
预测分析世界,由埃里克·西戈尔创办的博客,创始人兼执行编辑,使预测分析的如何和为什么变得易于理解和引人入胜。
-
Revolution Analytics,有关使用开源 R 进行大数据分析、预测建模、数据科学和可视化的新闻。
-
Rick Sherman: 数据狗屋,关于绩效管理、商业智能和数据仓库的商业与技术。
-
萨伯计量研究,由菲尔·伯恩鲍姆撰写,博客内容涉及棒球、股票市场、运动预测以及各种主题的统计学。
-
,SAS 专家撰写关于高级分析和引人注目的行业见解的博客。
-
,关于大数据中的分析和可视化。
-
Simply Statistics,由三位生物统计学教授(Jeff Leek、Roger Peng 和 Rafa Irizarry)撰写,他们对数据丰富的新纪元充满热情,统计学家成为了科学家。
-
统计建模、因果推断与社会科学,由 Andrew Gelman 撰写。
-
Steve Miller BI,信息管理领域的博客。
-
分析因素,由 Karen Grace Martin 撰写。
-
,关于统计学、数据分析、问题解决及集成解决方案。
-
,由 Ben Lorica 撰写,O'Reilly Media 首席数据科学家,内容涵盖 OLAP 分析、大数据、数据应用等。
-
Tom H. C. Anderson 个人博客,专注于数据和文本挖掘的市场研究。
-
,分享概念、想法和代码。
-
Vincent Granville 博客,Vincent,AnalyticBridge 和 Data Science Central 的创始人,定期发布关于数据科学和数据挖掘的有趣话题。
-
Xi’ans Og 博客,由巴黎第九大学的统计学教授撰写,主要集中在计算和贝叶斯主题。
 ,亚马逊官方 AWS AI 博客。
,亚马逊官方 AWS AI 博客。 ,由 Ben Lorica 撰写,O'Reilly Media 首席数据科学家,内容涵盖 OLAP 分析、大数据、数据应用等。
,由 Ben Lorica 撰写,O'Reilly Media 首席数据科学家,内容涵盖 OLAP 分析、大数据、数据应用等。适度活跃的博客
-
,由数据科学和工程公司 Active Wizards 撰写的博客。
-
,由 Alex Smola 撰写。
-
Ann Maria 的博客,由在线统计教育公司 The Julia Group 总裁 Dr. AnnMaria De Mars 撰写。
-
Ari Lamstein 博客,涵盖开放数据、制图、R 等内容。
-
,由数据科学家 Audun M. Oygard 撰写,他有统计学和美术背景。
-
Blog About Stats,由 Armin Grossenbacher 撰写,主要为统计机构的专业人士提供网络平台。
-
统计学与技术,由印度商学院海得拉巴分校统计学教授 Galit Shmueli 撰写。
-
,关于来自 Better 公司的分析博客。
-
,来自人类工程师的博客。
-
FastML,涵盖机器学习和数据科学的实际应用。
-
net,由约翰·兰福德撰写,作为领先的应用机器学习研究员,讨论机器学习理论与实践的交汇点。
-
,由亚历克斯·卡斯特罗尼斯撰写,涵盖包括人工智能、机器学习、数据科学、大数据和物联网在内的主题,重点讲解概念、技术、最佳实践和趋势。
-
,涵盖数学、电气工程和神经科学的一般领域的教程风格文章。
-
,关于数据分析研究的发现、结果和思考。
-
,由安妮撰写,一位市场研究方法论者,博客内容涉及抽样、调查、统计、图表等。
-
Nuit Blanche,由伊戈尔·卡龙撰写,专注于压缩感知、先进的矩阵分解技术、机器学习。
-
Perpetual Enigma,由普拉提克·乔希撰写,计算机视觉爱好者撰写关于机器学习的疑问风格引人入胜的故事。
-
,由马特·阿舍撰写,他是多伦多大学的统计研究生。查看阿舍的统计宣言。
-
Stats with Cats,由查理·库夫斯撰写,他在数字处理方面已有三十余年经验。
-
StreamHacker,由雅各布·帕金斯撰写,他是《Python 3 Text Processing with NLTK 3 Cookbook》的作者。
-
,涵盖网站分析、R 语言、Google Analytics 及相关话题。
-
The Geomblog,由苏雷什撰写。
-
,由卡内基梅隆大学统计学教授科斯马·沙利齐撰写的博客。
-
Walking Randomly,由迈克·克劳彻撰写。
-
,由数据科学家何塞·玛丽亚·马特奥斯·佩雷斯撰写。
-
,有关数据科学的内容和对世界的思考。
-
,覆盖数据科学和技术的博客,特别是 Python、flask、scikit-learn 或骑行。
-
,由 John Mount 和 Nina Zumel 撰写,包含评论文章和技术写作。
 ,涵盖数学、电气工程和神经科学的一般领域的教程风格文章。
,涵盖数学、电气工程和神经科学的一般领域的教程风格文章。 ,由安妮撰写,一位市场研究方法论者,博客内容涉及抽样、调查、统计、图表等。
,由安妮撰写,一位市场研究方法论者,博客内容涉及抽样、调查、统计、图表等。博客聚合器
-
Analytics Vidhya,关于分析技能的发展、分析行业最佳实践等。
-
,一个精心策划的数据科学博客列表。
-
IBM 大数据中心博客,来自 IBM 思想领袖的博客。
-
KDnuggets,一个关于大数据、数据科学、数据挖掘、预测分析的领先网站/博客(此站点为完整性考虑而包含)。
-
,前身为“O'Reilly Radar”,提供广泛的研究工具和书籍。
-
Planet Big Data,一个关于大数据、Hadoop 及相关话题的博客聚合器,我们包括全球博主的帖子。
-
R-bloggers,来自 R 社区的最佳博客,包含代码、示例和可视化。
-
SAS 博客首页,连接 SAS 的人员、产品和想法。
-
智能数据集合,一个聚合了许多有趣的数据科学人员博客的集合。
-
StatsBlog,一个专注于统计学相关内容的博客聚合器,通过 RSS 订阅从贡献博客中汇总帖子。
-
数据仓库内幕,来自 Oracle 团队的数据仓库和大数据的技术细节、想法和新闻。
其他
-
超越盒子评分,一个利用统计分析棒球比赛的博客。
-
大数据与大利润,由西北大学的 Russell Walker 教授撰写的博客。
-
计算风险,有关金融和经济的博客。
-
FiveThirtyEight,由 Nate Silver 及其团队撰写,利用图表和饼图从统计角度分析从政治到科学到体育的各种话题。
-
Freakonomics 博客,由 Steven Levitt 和 Stephen J. Dubner 撰写。
-
卫报数据博客,对其新闻中的话题进行数据新闻报道。
-
非官方 Google Analytics,ROI Revolution 的博客。
-
网络分析与联盟营销,Dennis R. Mortensen 关于如何通过分析增加出版商收入的博客。
资源:
相关:
更多相关内容
比较决策树算法:随机森林® vs. XGBoost
原文:
www.kdnuggets.com/2019/08/activestate-decision-tree-random-forest-xgboost.html
赞助帖子。

我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 部门
本教程将带你比较 XGBoost 和随机森林这两种流行的决策树算法,并帮助你识别像袋装法和提升法这样的集成技术的最佳应用场景。
按照教程,你将学习到:
-
如何使用 Python 和 Pandas 创建决策树
-
如何使用 sklearn 的 RandomForestClassifier 进行树袋法
-
如何使用 XGBoost 进行树提升
了解袋装法和提升法的好处——并知道何时使用哪种技术——将使你的机器学习模型具有更小的方差、更低的偏差和更高的稳定性。自己试试吧!

了解更多相关话题
使用 Python 进行探索性数据分析
原文:
www.kdnuggets.com/2019/08/activestate-exploratory-data-analysis-python.html
赞助帖子。

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的信息技术工作
任何机器学习(ML)项目中最重要的部分之一是进行探索性数据分析(EDA),以确保数据的有效性并且没有明显的问题。EDA 还帮助你在项目开始之前向业务利益相关者提供数据驱动的见解,确保你提出正确的问题。
在本教程中,你将使用 Python 和 Pandas 来:
-
探索数据集并创建可视化分布
-
识别并消除异常值
-
揭示两个数据集之间的相关性
创建探索性数据分析(EDA)是构建更清洁、更高效的机器学习和人工智能模型的第一步之一。阅读教程并亲自尝试一下吧!
更多相关内容
[PDF] 机器学习执行指南
原文:
www.kdnuggets.com/2019/03/activestate-pdf-executive-guide-machine-learning.html
由 ActiveState 提供。赞助帖子。
如果你的组织正在考虑或刚刚开始机器学习,你可能需要为你的 ML 项目提出商业案例。《机器学习执行指南》将帮助你做到这一点。我们涵盖了从对业务的好处到构建或购买过程的所有内容。我们的指南提供了实施 ML 于组织的实际概述(适用于技术和非技术读者)。
这本 4 章指南包括:
-
第一章:为什么选择机器学习
-
第二章:ML 从大数据开始
-
第三章:商业与开源 ML 解决方案
-
第四章:成为一个以 ML 驱动的公司
我们的 3 个最佳课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
更多相关话题
[白皮书] 使用 Python 解锁数据科学与机器学习的力量
原文:
www.kdnuggets.com/2019/05/activestate-whitepaper-data-science-machine-learning-python.html
赞助文章。
随着组织继续投资大数据,挑战不再在于数据本身,而在于将数据转化为业务价值的算法。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织 IT
Python 正在成为解锁大数据力量的通用语言,因为领先公司采用 Python 来推动高级分析、构建机器学习模型,并将结果转化为强大的网络应用程序。
本指南提供了如何为团队的数据科学和机器学习计划实施 Python 的执行概述,并包括:
-
Python、R、Java 和 Go 在关键领域的比较
-
流行的 Python 数据科学包的使用案例
-
开源与商业工具的考虑
-
建立数据科学家和数据分析师团队
-
许可、安全、技术支持等
更多相关主题
人工智能在算法交易中的采用如何影响金融行业?
原文:
www.kdnuggets.com/2022/04/adoption-ai-algorithmic-trading-affected-finance-industry.html

摄影:由Kanchanara拍摄,发布于Unsplash。
正如这个术语所暗示的那样,算法交易是按照给定算法执行交易操作。算法交易,就像任何自动化工具一样,是一种活动增强器和经济过程的催化剂。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的 IT 职业生涯
根据使用方式,算法交易对金融市场有多种影响:
-
使各站点之间的价格平衡;
-
平滑价格的剧烈波动;
-
提供流动性;
-
在交易参与者之间重新分配风险;
-
帮助建立公平的价格;
-
自动化交易员的日常操作。
另一个目标是最大化利润。这类算法被例如电子商务和市场平台用来自动确定价格。单独使用这些定价算法,没有限制参数或人工智能(AI),可能会产生奇怪的商业案例。
在 2011 年,两家书商使用亚马逊的算法定价打败了他们的(唯一的)竞争对手,最终将一本关于苍蝇的书的价格推高到 24,000,000 美元每本。
交易、算法和机器人
程序员、数学家和分析师共同为市场提供了一个有用的工具——交易机器人(或称为机器人),这些机器人利用提供的算法和数据进行操作。算法交易在交易所的流行导致了高频交易的出现。
根据 Jupiter 资产管理公司的说法,在 2018 年,美国股市中约 80%的交易几乎完全由机器控制。
交易者、经纪人和投资基金不再能够离开机器人开发者,因为人们无法以小点差、高速度和集中度进行交易。有些人创建策略,有些人编写算法,而机器人则按照给定的指令和限制进行交易。
算法交易行业为最终用户——基金或交易者本身——以及机器人和指标的创建者创造了新的收入来源。这样,开发者倾向于联合兴趣社区;其中一个最大的社区是MQL5.com。这个特定的社区将购买现成交易解决方案的买家与准备将策略实施到算法交易机器人的自由开发者联系起来。
还有一个通过将计算机上的闲置 CPU 时间提供给MQL5 Cloud Network来赚钱的选项。这些算力将被开发者和交易者用于进行回测操作。
交易与人工智能
如果你考虑一下,交易就是在资产交易中做出决策以获得利润。所有技术分析都基于统计数据、市场过去的行为和反应。因此,一些市场模式的分析不仅可以教授给人,也可以教授给计算机、人工智能。
职业交易者被迫升级他们的开发,因为进步使交易变得更加困难。在 2000 年至 2015 年间,他们不得不与交易机器人竞争,然后学会如何调整它们以便为自己获利。
随着市场竞争加剧和大数据方向的发展,机器人的能力变得不足。在自动化交易中,它们开始被可以像人一样思考的机器所取代。自 2015 年左右以来,交易者及其机器人不得不开始与人工智能竞争。
在过去 5 年中,带有 AI 的交易系统数量显著增长。随着它们的传播和对市场的影响,使用过时自动化的交易者看到收入下降。相反,那些使用人工智能进行交易的交易者比市场平均水平获得更好的结果。
今天,人工智能显然是市场和算法交易的有机组成部分。此外,你甚至可以在 MQL5.com 市场找到免费的基于 AI 的交易解决方案。根据 IHS Markit,2018 年金融机构使用 AI 的效果估计为 411 亿美元,2030 年这一数字可能达到 3000 亿美元。该技术用于解决许多问题:从寻找模式和异常到创建预测。
如果传统的算法交易是根据某个特定算法——最初包括在程序中的一组规则来进行交易,那么今天,随着 AI 的发展,系统已经获得了从自身经验中学习、预测潜在市场走势并执行之前只能由人类完成的任务的能力。
人工智能能力
-
基于历史数据预测消费者和市场行为。
-
基于对价格变化、货币价值、全球指数、原材料和其他指标模式的分析,创建实时预测。
-
在市场中发现异常。
-
降低操作风险。
-
提高交易速度和数量。
-
将从一个任务中获得的知识和模型转移到其他目标任务中,这些任务的数据不足。
-
使用机器学习方法合成自己的数据。
-
使用交易前分析并构建交易策略。
-
节省工人的资源,这些资源可以转移到更具创意和高智力的任务中。
实时分析竞争对手和客户的行为,并迅速响应变化。
收集一切——以获取更大的利润
AI 技术帮助个人和企业客户进行市场交易。然而,人工智能的特殊性在于它无法在新的非标准情境中进行导航。如果市场上出现异常情况,模型不太可能提供最佳解决方案。疫情就是一个典型例子。
根据英格兰银行的调查,在疫情期间,约 35%的银行经历了基于机器学习方法的 AI 模型运行带来的负面后果。这主要是因为疫情导致了许多宏观经济指标的变化,而这些指标成为模型开发中的参数。
制定一个基于市场趋势和模式理解的有效策略,正成为现代世界中关键的交易工具之一。在这些策略中,交易员可以确定最佳的进入点,降低风险,并在固定收益的退出点进行交易。AI 在情感方面发挥了作用,为个人制定了平衡的交易理念。
Rumzz Bajwa (@rumzzbajwa) 是一位数字策略师和内容营销专家。她喜欢和家人共度时光。她喜欢外出并体验新鲜事物。Rumzz 在研究新的主题时发现了满足感,这些主题有助于扩展她的观点。你经常可以看到她沉浸在一本好书中或寻找新的体验。
更多信息
用这 3 个热门证书提升你的技术职业生涯
原文:
www.kdnuggets.com/advance-your-tech-career-with-these-3-popular-certificates

作者提供的图片
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
随着技术行业的快速进步和增长,现在正是你提升职业生涯的最佳时机。
不幸的是,技术行业目前正在经历许多裁员。这可能是由于经济因素或 AI 在我们日常生活中的使用。此时,你可以为自己做的最好的事情就是让自己在市场上更具吸引力。
你怎么做呢?
通过学习新技能和积累更多经验来推动你的职业发展。
你需要成为一个在市场上技能需求高而供应少的专业人士。
让我们来深入了解可以帮助你提升职业生涯的认证课程。
商业智能
链接: Google 商业智能专业证书
据说,从 2021 年到 2031 年,商业智能分析师的职位市场将增长 23%。随着技术行业竞争的加剧,大大小小的公司正在寻找更有效的支出方式,以增加投资回报。未来的商业智能分析师具备关注用户体验和最终客户的数据分析技能。
在 Google 提供的这一认证课程中,你将学习商业智能专业人员的角色和职责,然后实践使用提取、转换和加载(ETL)等过程进行数据建模,帮助你满足组织的需求。
将你的发现转化为数据可视化,以帮助回答业务问题,以及一个可以帮助你将数据洞察传达给利益相关者的仪表盘。
AWS 云解决方案架构师
链接: AWS 云解决方案架构师专业证书
随着越来越多的企业迁移到云端,对 AWS 解决方案架构师的需求持续增长。AWS 目前占据了 33% 的 IaaS 市场,解决方案架构师的年薪平均为 100,000 美元,以满足这种需求。
在 AWS 自身提供的这个认证中,你将学习如何做出明智的决策,决定何时以及如何应用关键的 AWS 服务,包括计算、存储、数据库、网络、监控和安全。
然后你将进一步深入了解架构解决方案的设计、运营卓越性,以及解决常见的业务挑战。但这还不止于此,你还将学习如何以安全和可扩展的方式创建和操作数据湖,并学习如何优化性能和成本。
Azure 开发人员
链接:微软 Azure 开发人员助理 (AZ-204) 专业证书
随着越来越多的组织严重依赖机器学习和人工智能,Azure 专业人员的需求也在增加,以满足组织的云需求。
在微软提供的这个认证课程中,你将经历云开发的所有阶段,从需求、定义和设计;到开发、部署和维护;再到性能调整和监控。该课程为开发人员提供了如何在微软 Azure 中创建端到端解决方案的良好理解。
你将学习如何实施解决方案、管理 Web 应用程序以及开发身份验证和授权。这个认证包含 8 门课程,将帮助你为考试 AZ-204:开发 Microsoft Azure 解决方案做好准备。
总结
为了在日益热门的市场中保持竞争力,你需要关注当前市场中组织的需求以及你如何满足这些需求。这就是我只介绍了 3 个认证的原因,因为这正是当前市场所需的。
如果你有其他推荐给社区的认证,请在下面的评论中留言!
尼莎·阿亚是一位数据科学家、自由技术作家,同时还是 KDnuggets 的编辑和社区经理。她特别感兴趣于提供数据科学职业建议或教程以及围绕数据科学的理论知识。尼莎涉及广泛的话题,并希望探索人工智能可以如何促进人类寿命的不同方式。作为一个热衷学习者,尼莎寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
机器学习模型的高级特征选择技术
原文:
www.kdnuggets.com/2023/06/advanced-feature-selection-techniques-machine-learning-models.html

图片来源:作者
机器学习无疑是新时代的明星。它构成了各种主要技术的基础,这些技术已经成为我们日常生活的不可或缺的一部分,如面部识别(由卷积神经网络或 CNN 支持)、语音识别(利用 CNN 和递归神经网络或 RNN)以及日益流行的聊天机器人,如 ChatGPT(由人类反馈强化学习,RLHF 驱动)。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
目前有许多方法可以提升机器学习模型的性能。这些方法能通过提供卓越的表现为你的项目带来竞争优势。
在这次讨论中,我们将深入探讨特征选择技术。但在继续之前,让我们澄清一下:什么是特征选择?
什么是特征选择?
特征选择是选择对你的模型最有利的特征的过程。这一过程可能因技术而异,但主要目标是找出对你的模型影响最大的特征。
我们为什么要进行特征选择?
因为有时候,特征过多可能会对你的机器学习模型产生负面影响。怎么回事呢?
可能有很多不同的原因。例如,这些特征可能相互关联,导致多重共线性,从而破坏模型的性能。
另一个潜在问题与计算能力有关。特征过多需要更多的计算能力来同时执行任务,这可能需要更多资源,因此增加成本。
当然,也可能还有其他原因。但这些例子应该能给你一个大致的了解。不过,在我们进一步探讨这个话题之前,还有一个重要的方面需要理解。
哪种特征选择方法对我的模型更好?
是的,这是个很好的问题,应该在开始项目之前得到回答。但很难给出一个通用的答案。
特征选择模型的选择依赖于你拥有的数据类型和项目的目标。
例如,像卡方检验或互信息增益这样的过滤方法通常用于分类数据的特征选择。像前向选择或后向选择这样的包裹方法适用于数值数据。
不过,值得了解的是,许多特征选择方法可以处理分类数据和数值数据。
例如,lasso 回归、决策树和随机森林都可以很好地处理这两种数据类型。
就监督特征选择和无监督特征选择而言,监督方法如递归特征消除或决策树适用于有标签的数据。无监督方法如主成分分析(PCA)或独立成分分析(ICA)用于无标签的数据。
最终,特征选择方法的选择应基于数据的具体特征和项目的目标。
查看一下我们将在文章中讨论的主题概述。熟悉它,然后让我们开始讨论监督特征选择技术。
图片由作者提供
1. 监督特征选择技术
监督学习中的特征选择策略旨在通过利用输入特征与目标变量之间的关系来发现最相关的特征。这些策略可能有助于提高模型性能,减少过拟合,并降低模型训练的计算成本。
这是我们将讨论的监督特征选择技术的概述。
图片由作者提供
1.1 基于过滤的方法
基于过滤的方法依赖于数据的固有属性,如特征相关性或统计数据。这些方法评估每个特征单独或成对的价值,而不考虑特定学习算法的表现。
基于过滤的方法计算效率高,可以与多种学习算法配合使用。然而,由于它们没有考虑特征与学习方法之间的交互,它们可能无法总是捕捉到特定算法的理想特征子集。
查看基于过滤的方法的概述,然后我们将逐一讨论每种方法。
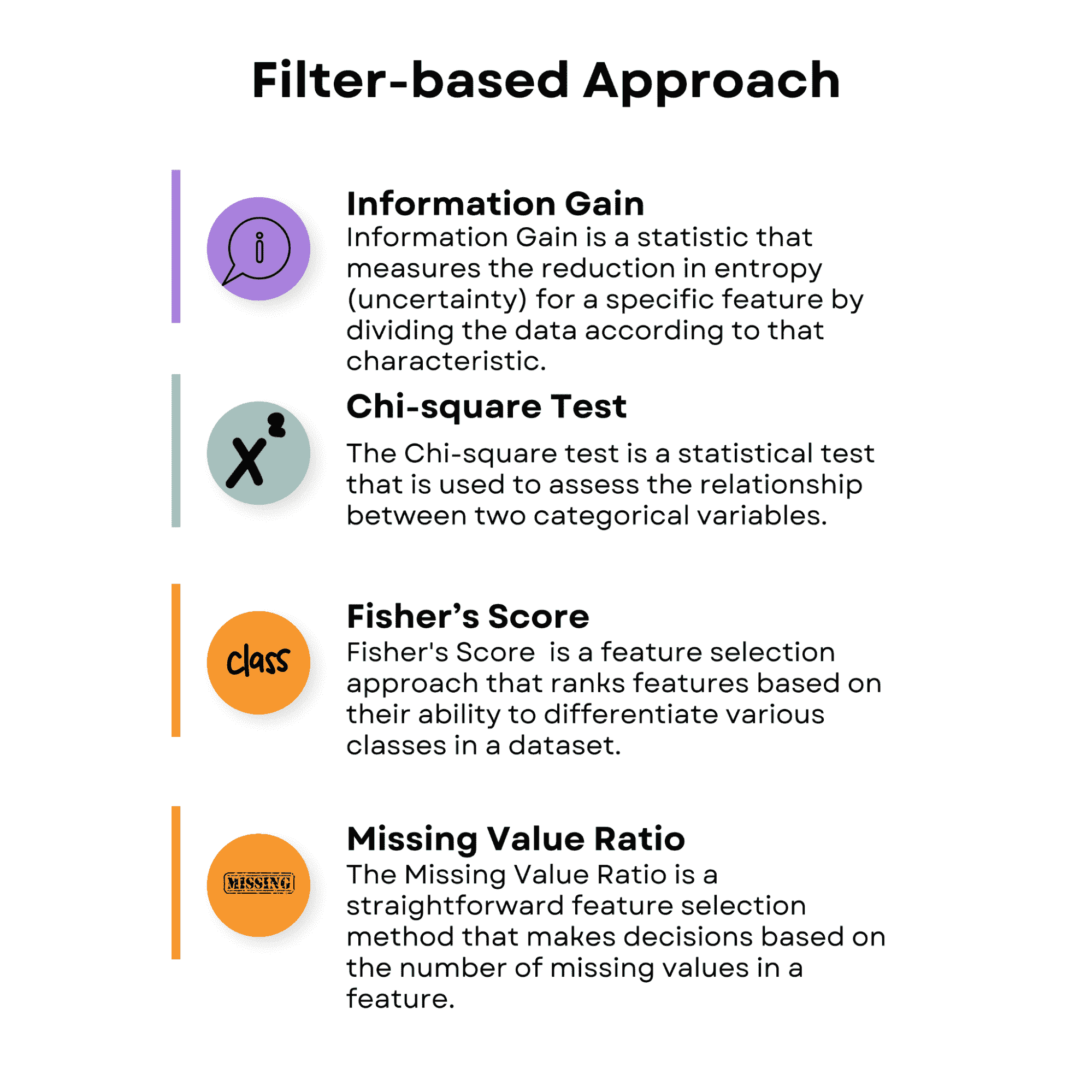
图片由作者提供
信息增益
信息增益是一种统计量,通过根据特定特征对数据进行划分来测量熵(不确定性)的减少。它常用于决策树算法,并且具有有用的特征。特征的信息增益越高,它在决策中越有用。
现在,让我们通过使用预构建的糖尿病数据集来应用信息增益。
糖尿病数据集包含与预测糖尿病进展相关的生理特征。
-
age: 年龄(岁)
-
sex: 性别(1 = 男性,0 = 女性)
-
BMI: 体质指数,计算方法为体重(千克)除以身高(米)的平方
-
bp: 平均血压(mm Hg)
-
s1、s2、s3、s4、s5、s6: 六种不同血液化学物质(包括葡萄糖)的血清测量
以下代码演示了如何应用信息增益方法。此代码使用来自 sklearn 库的糖尿病数据集作为示例。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.feature_selection import mutual_info_regression
# Load the diabetes dataset
data = load_diabetes()
# Split the dataset into features and target
X = data.data
y = data.target
这段代码的主要目标是基于信息增益计算特征重要性分数,这有助于确定对预测模型最相关的特征。通过确定这些分数,你可以对分析中应包含或排除哪些特征做出明智的决策,从而提高模型性能,减少过拟合,并加快训练时间。
为此,这段代码计算了数据集中每个特征的信息增益分数,并将其存储在字典中。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.feature_selection import mutual_info_regression
# Load the diabetes dataset
data = load_diabetes()
# Split the dataset into features and target
X = data.data
y = data.target
# Apply Information Gain
ig = mutual_info_regression(X, y)
# Create a dictionary of feature importance scores
feature_scores = {}
for i in range(len(data.feature_names)):
feature_scores[data.feature_names[i]] = ig[i]
然后根据它们的分数将特征按降序排序。
# Sort the features by importance score in descending order
sorted_features = sorted(feature_scores.items(), key=lambda x: x[1], reverse=True)
# Print the feature importance scores and the sorted features
for feature, score in sorted_features:
print('Feature:', feature, 'Score:', score)
我们将把排序后的特征重要性分数可视化为水平条形图,以便你能够轻松比较不同特征在给定任务中的相关性。
这种可视化在决定在构建机器学习模型时保留或丢弃哪些特征时特别有用。
# Plot a horizontal bar chart of the feature importance scores
fig, ax = plt.subplots()
y_pos = np.arange(len(sorted_features))
ax.barh(y_pos, [score for feature, score in sorted_features], align="center")
ax.set_yticks(y_pos)
ax.set_yticklabels([feature for feature, score in sorted_features])
ax.invert_yaxis() # Labels read top-to-bottom
ax.set_xlabel("Importance Score")
ax.set_title("Feature Importance Scores (Information Gain)")
# Add importance scores as labels on the horizontal bar chart
for i, v in enumerate([score for feature, score in sorted_features]):
ax.text(v + 0.01, i, str(round(v, 3)), color="black", fontweight="bold")
plt.show()
让我们看看完整的代码。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.feature_selection import mutual_info_regression
# Load the diabetes dataset
data = load_diabetes()
# Split the dataset into features and target
X = data.data
y = data.target
# Apply Information Gain
ig = mutual_info_regression(X, y)
# Create a dictionary of feature importance scores
feature_scores = {}
for i in range(len(data.feature_names)):
feature_scores[data.feature_names[i]] = ig[i]
# Sort the features by importance score in descending order
sorted_features = sorted(feature_scores.items(), key=lambda x: x[1], reverse=True)
# Print the feature importance scores and the sorted features
for feature, score in sorted_features:
print("Feature:", feature, "Score:", score)
# Plot a horizontal bar chart of the feature importance scores
fig, ax = plt.subplots()
y_pos = np.arange(len(sorted_features))
ax.barh(y_pos, [score for feature, score in sorted_features], align="center")
ax.set_yticks(y_pos)
ax.set_yticklabels([feature for feature, score in sorted_features])
ax.invert_yaxis() # Labels read top-to-bottom
ax.set_xlabel("Importance Score")
ax.set_title("Feature Importance Scores (Information Gain)")
# Add importance scores as labels on the horizontal bar chart
for i, v in enumerate([score for feature, score in sorted_features]):
ax.text(v + 0.01, i, str(round(v, 3)), color="black", fontweight="bold")
plt.show()
这是输出结果。
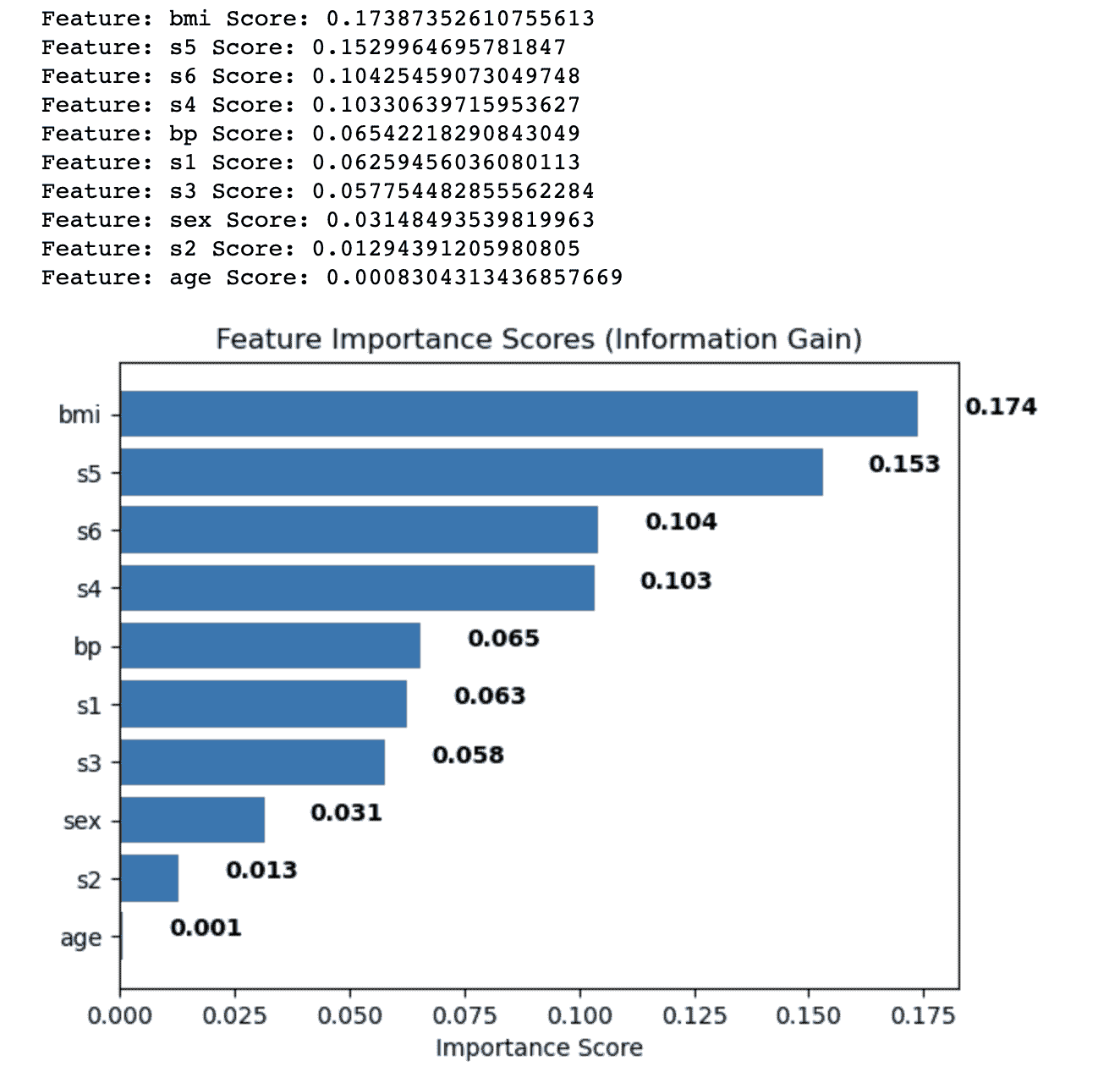
输出结果显示了使用信息增益方法计算的每个特征的重要性分数。特征按照分数的降序排列,这些分数表示它们在预测目标变量中的相对重要性。
结果如下:
-
体质指数(bmi)具有最高的重要性分数(0.174),表明它对糖尿病数据集中目标变量的影响最大。
-
血清测量 5(s5)以 0.153 的分数紧随其后,是第二重要的特征。
-
血清测量 6(s6)、血清测量 4(s4)和血压(bp)具有中等的重要性分数,范围从 0.104 到 0.065。
-
其余特征,如血清测量 1、2 和 3(s1、s2、s3)、性别和年龄的重要性分数相对较低,表明它们对模型的预测能力贡献较小。
通过分析这些特征重要性得分,你可以决定哪些特征应该包含在分析中,哪些特征应排除,以提高机器学习模型的性能。在这种情况下,你可能考虑保留重要性得分较高的特征,如 bmi 和 s5,同时可能去除或进一步调查得分较低的特征,如 age 和 s2。
卡方检验
卡方检验是一种统计检验,用于评估两个分类变量之间的关系。它在特征选择中用于分析分类特征与目标变量之间的关系。较大的卡方得分表明特征与目标之间的关联更强,显示该特征在分类任务中更为重要。
尽管卡方检验是一种常用的特征选择方法,但它通常用于分类数据,其中特征和目标变量是离散的。
费舍尔得分
费舍尔判别比率,通常称为费舍尔得分,是一种特征选择方法,根据特征区分数据集中不同类别的能力来对特征进行排名。它可以用于分类问题中的连续特征。
费舍尔得分的计算为类别间方差与类别内方差的比率。较高的费舍尔得分意味着特征更具区分性,对分类更有价值。
要使用费舍尔得分进行特征选择,计算每个连续特征的得分并根据得分对其进行排名。模型认为费舍尔得分较高的特征更重要。
缺失值比率
缺失值比率是一种简单的特征选择方法,它根据特征中缺失值的数量做出决策。
缺失值比例较高的特征可能无信息量,并可能影响模型的性能。通过设置接受的缺失值比率阈值,可以过滤掉缺失值过多的特征。
要使用缺失值比率进行特征选择,请按照以下步骤操作:
-
通过将缺失值的数量除以数据集中实例的总数来计算每个特征的缺失值比率。
-
设置一个可接受的缺失值比率阈值(例如,0.8,意味着一个特征最多允许 80%的值缺失才被考虑)。
-
过滤掉缺失值比率高于阈值的特征。
1.2 基于包装的方法
基于包装的特征选择方法包括使用特定的机器学习算法评估特征的重要性。它们通过尝试各种特征组合并使用所选方法评估其性能来寻找最佳特征子集。
由于可用特征子集的数量庞大,基于包装的特征选择方法可能计算成本高,尤其是在处理高维数据集时。
然而,它们通常比基于过滤的方法表现更好,因为它们考虑了特征与学习算法之间的关系。
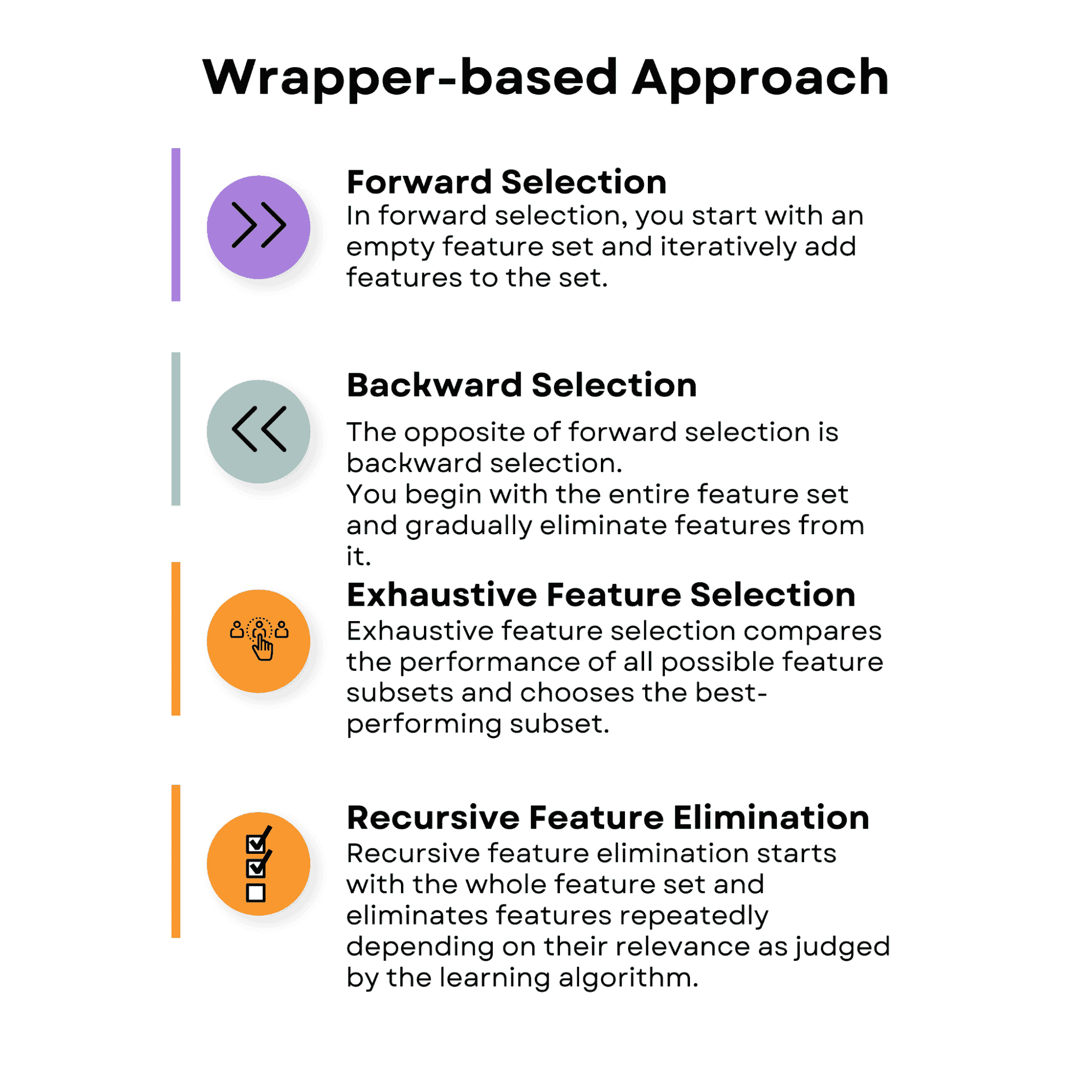
作者提供的图片
前向选择
在前向选择中,你从一个空的特征集开始,并逐步添加特征。在每一步中,你评估当前特征集和新增特征的模型性能。那些带来最佳性能提升的特征将被添加到特征集中。
该过程持续进行,直到观察到性能没有显著提升,或达到预定义的特征数量为止。
以下代码演示了前向选择的应用,这是一种基于包装的监督特征选择技术。
示例使用了来自 sklearn 库的乳腺癌数据集。乳腺癌数据集,也被称为威斯康星诊断乳腺癌(WDBC)数据集,是一个常用的预构建分类数据集。在这里,主要目标是构建用于诊断乳腺癌为恶性(癌性)或良性(非癌性)的预测模型。
为了我们模型的需要,我们将选择不同数量的特征以观察性能的变化,但首先,让我们加载库、数据集和变量。
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
# Load the breast cancer dataset
data = load_breast_cancer()
# Split the dataset into features and target
X = data.data
y = data.target
代码的目标是通过前向选择识别出适用于逻辑回归模型的最佳特征子集。这种技术从一个空的特征集开始,迭代地添加那些基于指定评估指标提高模型性能的特征。在这种情况下,使用的评估指标是准确性。
代码的下一部分使用 mlxtend 库中的 SequentialFeatureSelector 来执行前向选择。它配置了一个逻辑回归模型、所需的特征数量和 5 折交叉验证。前向选择对象被拟合到训练数据中,所选特征将被打印出来。
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
# Load the breast cancer dataset
data = load_breast_cancer()
# Split the dataset into features and target
X = data.data
y = data.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# Define the logistic regression model
model = LogisticRegression()
# Define the forward selection object
sfs = SFS(model,
k_features=5,
forward=True,
floating=False,
scoring='accuracy',
cv=5)
# Perform forward selection on the training set
sfs.fit(X_train, y_train)
此外,我们还需要评估所选特征在测试集上的表现,并通过折线图可视化模型在不同特征子集下的表现。
图表将展示交叉验证的准确性作为特征数量的函数,提供有关模型复杂性与预测性能之间权衡的见解。
通过分析输出和图表,你可以确定在模型中包含的最佳特征数量,从而最终提高其性能并减少过拟合。
# Print the selected features
print('Selected Features:', sfs.k_feature_names_)
# Evaluate the performance of the selected features on the testing set
accuracy = sfs.k_score_
print('Accuracy:', accuracy)
# Plot the performance of the model with different feature subsets
sfs_df = pd.DataFrame.from_dict(sfs.get_metric_dict()).T
sfs_df['avg_score'] = sfs_df['avg_score'].astype(float)
fig, ax = plt.subplots()
sfs_df.plot(kind='line', y='avg_score', ax=ax)
ax.set_xlabel('Number of Features')
ax.set_ylabel('Accuracy')
ax.set_title('Forward Selection Performance')
plt.show()
这是完整的代码。
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
# Load the breast cancer dataset
data = load_breast_cancer()
# Split the dataset into features and target
X = data.data
y = data.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# Define the logistic regression model
model = LogisticRegression()
# Define the forward selection object
sfs = SFS(model, k_features=5, forward=True, floating=False, scoring="accuracy", cv=5)
# Perform forward selection on the training set
sfs.fit(X_train, y_train)
# Print the selected features
print("Selected Features:", sfs.k_feature_names_)
# Evaluate the performance of the selected features on the testing set
accuracy = sfs.k_score_
print("Accuracy:", accuracy)
# Plot the performance of the model with different feature subsets
sfs_df = pd.DataFrame.from_dict(sfs.get_metric_dict()).T
sfs_df["avg_score"] = sfs_df["avg_score"].astype(float)
fig, ax = plt.subplots()
sfs_df.plot(kind="line", y="avg_score", ax=ax)
ax.set_xlabel("Number of Features")
ax.set_ylabel("Accuracy")
ax.set_title("Forward Selection Performance")
plt.show()
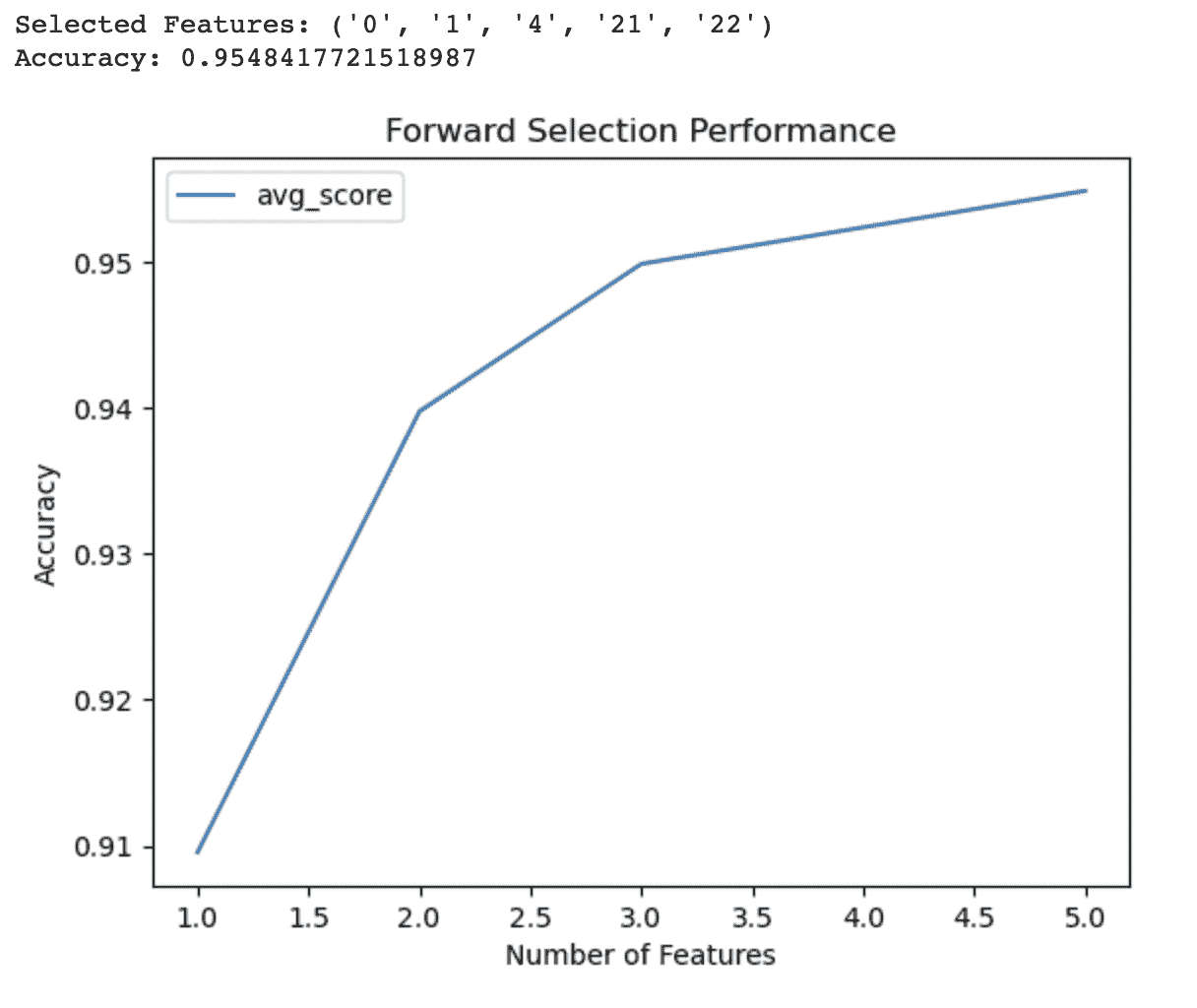
前向选择代码的输出结果显示,该算法识别了 5 个特征的子集,这些特征在乳腺癌数据集上的逻辑回归模型中产生了最佳准确率(0.9548)。这些选定的特征通过其索引进行标识:0、1、4、21 和 22。
线形图提供了有关不同特征数量下模型性能的额外见解。它显示:
-
使用 1 个特征,模型的准确率约为 91%。
-
添加第二个特征将准确率提高至 94%。
-
使用 3 个特征,准确率进一步提高至 95%。
-
包含 4 个特征使准确率稍微超过 95%。
超过 4 个特征后,准确率的提高变得不那么显著。这些信息可以帮助你做出关于模型复杂性和预测性能之间权衡的明智决定。基于这些结果,你可能决定在模型中仅使用 3 或 4 个特征,以平衡准确性和简洁性。
后向选择
前向选择的对立方法是后向选择。你从整个特征集开始,并逐渐消除其中的特征。
在每个阶段,你需要测量当前特征集减去要删除的特征后的模型性能。
造成性能下降最小的特征被从特征集中删除。
该过程重复进行,直到性能没有实质性提升或达到预设的特征数量。
后向选择和前向选择被归类为顺序特征选择;你可以在这里了解更多信息。
穷尽特征选择
穷尽特征选择比较所有可能的特征子集的性能,并选择表现最好的子集。这种方法计算量大,特别是对于大数据集,但确保了最佳的特征子集。
递归特征消除
递归特征消除从整个特征集开始,并根据学习算法判断的相关性反复消除特征。在每一步,最不重要的特征被移除,模型被重新训练。该方法重复进行,直到达到预定数量的特征。
1.3 嵌入式方法
嵌入式特征选择方法将特征选择过程作为学习算法的一部分。
这意味着在训练阶段,学习算法不仅优化模型参数,还选择最重要的特征。嵌入式方法比包装方法更有效,因为它们不需要外部特征选择过程。

作者提供的图像
正则化
正则化是一种向损失函数添加惩罚项的方法,以防止机器学习模型中的过拟合。
正则化方法,如 lasso(L1 正则化)和 ridge(L2 正则化),可以与特征选择结合使用,以减少不重要特征的系数接近零,从而选择出最相关特征的子集。
随机森林重要性
随机森林是一种集成学习方法,它结合了多个决策树的预测。随机森林在构建树的过程中计算每个特征的重要性评分,这些评分可以用来根据特征的相关性进行排序。模型将具有更高重要性评分的特征视为更重要。
如果你想了解更多关于随机森林的信息,下面的文章“决策树和随机森林算法”也解释了决策树算法。
以下示例使用了 Covertype 数据集,该数据集包含有关不同类型森林覆盖的信息。
Covertype 数据集的目标是预测罗斯福国家森林中森林覆盖类型(主导树种)。
下面代码的主要目标是使用随机森林分类器来确定特征的重要性。通过评估每个特征对整体分类性能的贡献,这种方法有助于识别构建预测模型的最相关特征。
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# Load the Covertype dataset
data = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/covtype/covtype.data.gz", header=None)
# Assign column names
cols = ["Elevation", "Aspect", "Slope", "Horizontal_Distance_To_Hydrology",
"Vertical_Distance_To_Hydrology", "Horizontal_Distance_To_Roadways",
"Hillshade_9am", "Hillshade_Noon", "Hillshade_3pm",
"Horizontal_Distance_To_Fire_Points"] + ["Wilderness_Area_"+str(i) for i in range(1,5)] + ["Soil_Type_"+str(i) for i in range(1,41)] + ["Cover_Type"]
data.columns = cols
然后,我们创建一个RandomForestClassifier对象,并将其拟合到训练数据上。接着,它从训练好的模型中提取特征重要性,并按降序排序。前 10 个特征根据其重要性评分被选择并显示在排名中。
# Split the dataset into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Create a random forest classifier object
rfc = RandomForestClassifier(n_estimators=100, random_state=42)
# Fit the model to the training data
rfc.fit(X_train, y_train)
# Get feature importances from the trained model
importances = rfc.feature_importances_
# Sort the feature importances in descending order
indices = np.argsort(importances)[::-1]
# Select the top 10 features
num_features = 10
top_indices = indices[:num_features]
top_importances = importances[top_indices]
# Print the top 10 feature rankings
print("Top 10 feature rankings:")
for f in range(num_features): # Use num_features instead of 10
print(f"{f+1}. {X_train.columns[indices[f]]}: {importances[indices[f]]}")
此外,代码通过水平条形图可视化了前 10 个特征的重要性。
# Plot the top 10 feature importances in a horizontal bar chart
plt.barh(range(num_features), top_importances, align='center')
plt.yticks(range(num_features), X_train.columns[top_indices])
plt.xlabel("Feature Importance")
plt.ylabel("Feature")
plt.show()
该可视化允许轻松比较重要性评分,并有助于在决定包含或排除哪些特征时做出明智的选择。
通过检查输出和图表,你可以选择最相关的特征用于你的预测模型,这有助于提高模型性能,减少过拟合,并加快训练时间。
这是完整代码。
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# Load the Covertype dataset
data = pd.read_csv(
"https://archive.ics.uci.edu/ml/machine-learning-databases/covtype/covtype.data.gz",
header=None,
)
# Assign column names
cols = (
[
"Elevation",
"Aspect",
"Slope",
"Horizontal_Distance_To_Hydrology",
"Vertical_Distance_To_Hydrology",
"Horizontal_Distance_To_Roadways",
"Hillshade_9am",
"Hillshade_Noon",
"Hillshade_3pm",
"Horizontal_Distance_To_Fire_Points",
]
+ ["Wilderness_Area_" + str(i) for i in range(1, 5)]
+ ["Soil_Type_" + str(i) for i in range(1, 41)]
+ ["Cover_Type"]
)
data.columns = cols
# Split the dataset into features and target
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
# Split the dataset into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# Create a random forest classifier object
rfc = RandomForestClassifier(n_estimators=100, random_state=42)
# Fit the model to the training data
rfc.fit(X_train, y_train)
# Get feature importances from the trained model
importances = rfc.feature_importances_
# Sort the feature importances in descending order
indices = np.argsort(importances)[::-1]
# Select the top 10 features
num_features = 10
top_indices = indices[:num_features]
top_importances = importances[top_indices]
# Print the top 10 feature rankings
print("Top 10 feature rankings:")
for f in range(num_features): # Use num_features instead of 10
print(f"{f+1}. {X_train.columns[indices[f]]}: {importances[indices[f]]}")
# Plot the top 10 feature importances in a horizontal bar chart
plt.barh(range(num_features), top_importances, align="center")
plt.yticks(range(num_features), X_train.columns[top_indices])
plt.xlabel("Feature Importance")
plt.ylabel("Feature")
plt.show()
这是输出结果。
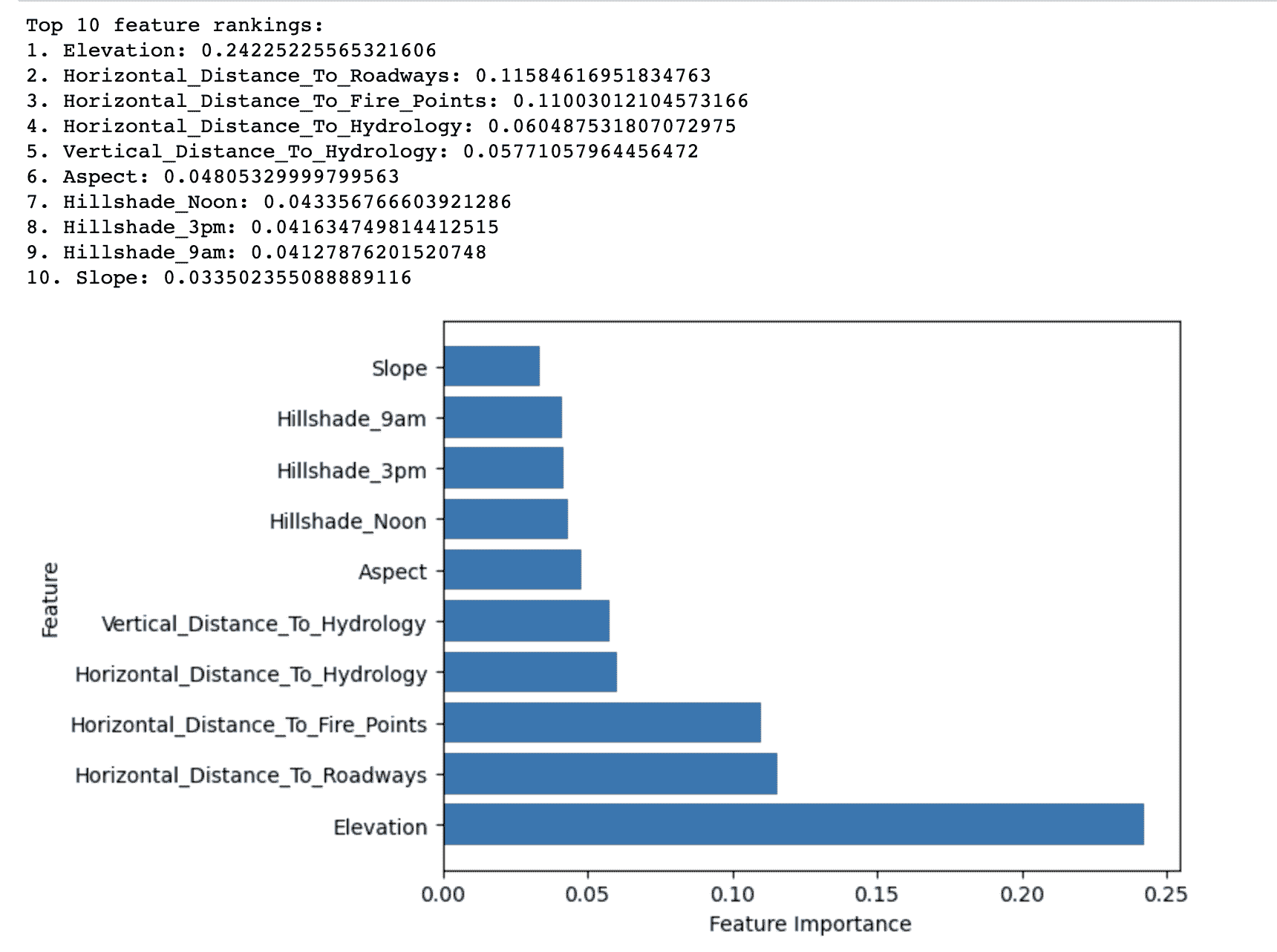
随机森林重要性方法的输出显示了根据其在预测森林覆盖类型中的重要性排名的前 10 个特征。
它揭示了海拔在所有特征中具有最高的重要性评分(0.2423),在预测森林覆盖类型中作用最大。这表明海拔在确定罗斯福国家森林中的主导树种方面起着关键作用。
其他具有较高重要性分数的特征包括 Horizontal_Distance_To_Roadways(0.1158)和 Horizontal_Distance_To_Fire_Points(0.1100)。这些特征表明,靠近道路和火点也显著影响森林覆盖类型。
排名前 10 的特征中,其余特征的重要性分数相对较低,但它们仍然对模型的整体预测性能有所贡献。这些特征主要与水文因素、坡度、方位和山阴影指数相关。
总结来说,结果突出了影响罗斯福国家森林区森林覆盖类型分布的最重要因素,这些因素可以用于构建更有效、更高效的森林覆盖类型分类预测模型。
2. 无监督特征选择技术
当没有目标变量可用时,可以使用无监督特征选择方法来降低数据集的维度,同时保持其基本结构。这些方法通常包括将初始特征空间转换为一个新的低维空间,其中变化后的特征捕捉数据中的大部分变异。

图片由作者提供
2.1 主成分分析(PCA)
PCA 是一种线性降维方法,将原始特征空间转换为由主成分定义的新正交空间。这些组件是原始特征的线性组合,旨在捕捉数据中的最高方差。
PCA 可用于选择代表大部分变异的前 k 个主成分,从而降低数据集的维度。
为了向您展示这如何在实践中运作,我们将使用葡萄酒数据集。这是一个广泛用于分类和特征选择任务的机器学习数据集,包含 178 个样本,每个样本代表来自意大利同一地区三种不同品种的不同葡萄酒。
使用葡萄酒数据集的目标通常是构建一个预测模型,该模型可以根据化学属性将葡萄酒样本准确地分类为三种品种之一。
以下代码演示了无监督特征选择技术主成分分析(PCA)在葡萄酒数据集上的应用。
这些组件(主成分)捕捉数据中最多的方差,同时最小化信息损失。
代码首先加载葡萄酒数据集,该数据集包含描述不同葡萄酒样本化学性质的 13 个特征。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# Load the Wine dataset
wine = load_wine()
X = wine.data
y = wine.target
feature_names = wine.feature_names
然后使用 StandardScaler 对这些特征进行标准化,以确保 PCA 不会受到输入特征尺度变化的影响。
# Standardize the features
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
接下来,使用 sklearn.decomposition 模块中的 PCA 类对标准化数据进行 PCA。
# Perform PCA
pca = PCA()
X_pca = pca.fit_transform(X_scaled)
每个主成分的解释方差比例都被计算出来,表示每个主成分解释的数据总方差的比例。
# Calculate the explained variance ratio
explained_variance_ratio = pca.explained_variance_ratio_
最后,生成两个图来可视化主成分的解释方差比例和累计解释方差。
第一个图展示了每个单独主成分的解释方差比例,而第二个图则说明了随着更多主成分的加入,累计解释方差是如何增加的。
这些图帮助确定模型中使用的主成分的最佳数量,在维度减少和信息保留之间取得平衡。
# Create a 2x1 grid of subplots
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(16, 8))
# Plot the explained variance ratio in the first subplot
ax1.bar(range(1, len(explained_variance_ratio) + 1), explained_variance_ratio)
ax1.set_xlabel('Principal Component')
ax1.set_ylabel('Explained Variance Ratio')
ax1.set_title('Explained Variance Ratio by Principal Component')
# Calculate the cumulative explained variance
cumulative_explained_variance = np.cumsum(explained_variance_ratio)
# Plot the cumulative explained variance in the second subplot
ax2.plot(range(1, len(cumulative_explained_variance) + 1), cumulative_explained_variance, marker='o')
ax2.set_xlabel('Number of Principal Components')
ax2.set_ylabel('Cumulative Explained Variance')
ax2.set_title('Cumulative Explained Variance by Principal Components')
# Display the figure
plt.tight_layout()
plt.show()
让我们看看完整的代码。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# Load the Wine dataset
wine = load_wine()
X = wine.data
y = wine.target
feature_names = wine.feature_names
# Standardize the features
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Perform PCA
pca = PCA()
X_pca = pca.fit_transform(X_scaled)
# Calculate the explained variance ratio
explained_variance_ratio = pca.explained_variance_ratio_
# Create a 2x1 grid of subplots
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(16, 8))
# Plot the explained variance ratio in the first subplot
ax1.bar(range(1, len(explained_variance_ratio) + 1), explained_variance_ratio)
ax1.set_xlabel("Principal Component")
ax1.set_ylabel("Explained Variance Ratio")
ax1.set_title("Explained Variance Ratio by Principal Component")
# Calculate the cumulative explained variance
cumulative_explained_variance = np.cumsum(explained_variance_ratio)
# Plot the cumulative explained variance in the second subplot
ax2.plot(
range(1, len(cumulative_explained_variance) + 1),
cumulative_explained_variance,
marker="o",
)
ax2.set_xlabel("Number of Principal Components")
ax2.set_ylabel("Cumulative Explained Variance")
ax2.set_title("Cumulative Explained Variance by Principal Components")
# Display the figure
plt.tight_layout()
plt.show()
这是输出结果。
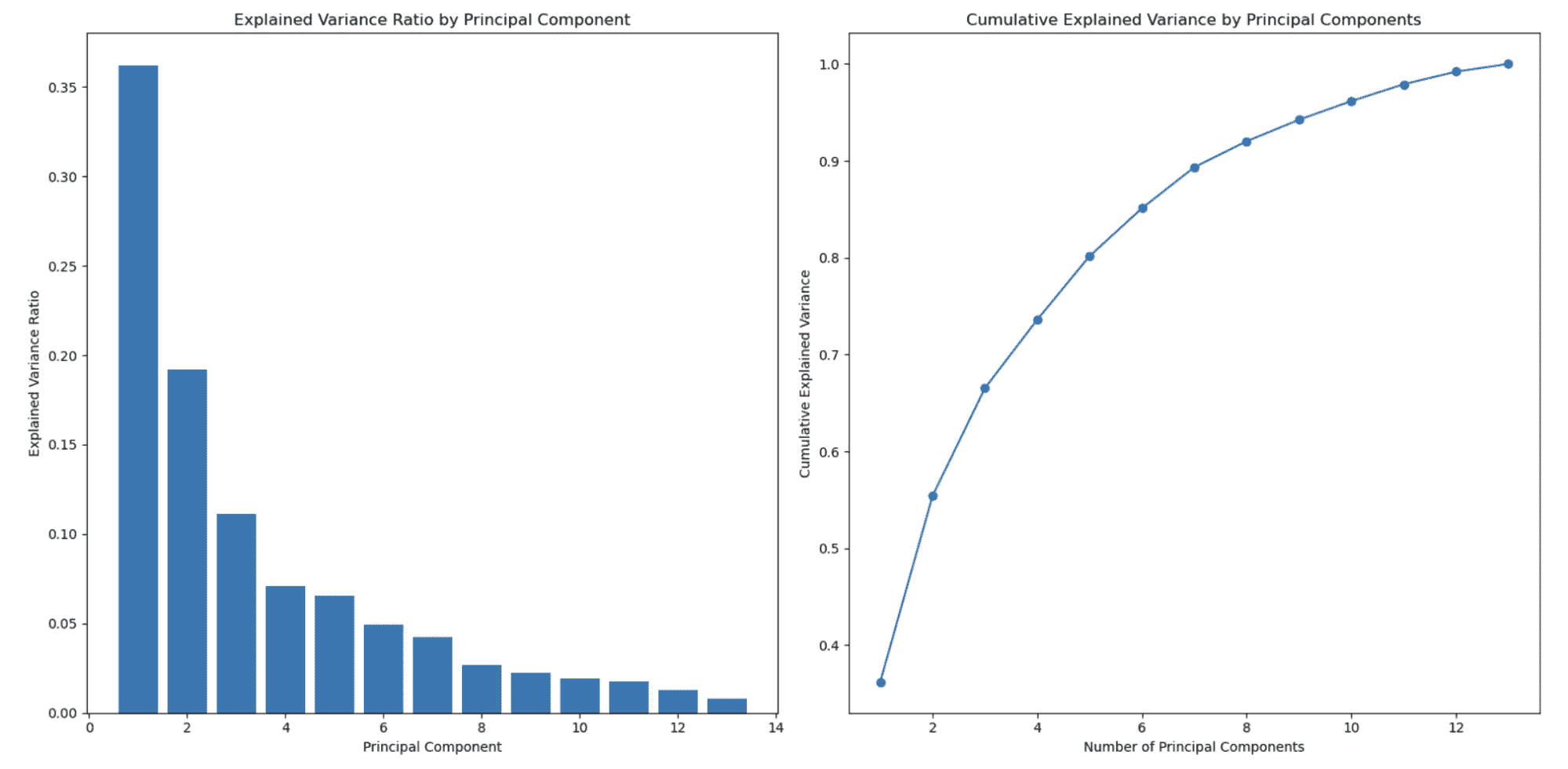
左侧图表显示解释方差比例随着主成分数量的增加而减少。这是 PCA 中观察到的典型行为,因为主成分是按解释方差的多少排序的。
第一个主成分(特征)捕捉到最高的方差,第二个主成分捕捉到第二高的方差,依此类推。因此,解释方差比例随着每个后续主成分的增加而减少。
这是 PCA 用于维度减少的主要原因之一。
右侧的第二张图展示了累计解释方差,并帮助你确定选择多少主成分(特征)来表示数据的百分比。x 轴表示主成分的数量,y 轴显示累计解释方差。当你沿 x 轴移动时,可以看到在包含这么多主成分时保留了多少总方差。
在这个例子中,你可以看到选择大约 3 或 4 个主成分已经捕捉了超过 80%的总方差,而大约 8 个主成分捕捉了超过 90%的总方差。
你可以根据希望在维度减少和保留方差之间的权衡选择主成分的数量。
在这个例子中,我们确实使用了 Sci-kit 来学习应用 PCA,官方文档可以在这里找到。
2.2 独立成分分析(ICA)
ICA 是一种将多维信号分解为其成分的方法。
在特征选择的背景下,ICA 可以用来将原始特征空间转换为一个由统计独立成分组成的新空间。通过选择前 k 个独立成分,你可以在保持底层结构的同时减少数据集的维度。
2.3 非负矩阵分解(NMF)
非负矩阵分解(NMF)是一种维度减少方法,通过将一个非负数据矩阵近似为两个低维非负矩阵的乘积来实现。
NMF 可用于特征选择的背景下,提取一组新的基本特征,以捕捉原始数据的重要结构。通过选择前 k 个基础特征,你可以在保持非负性限制的同时最小化数据集的维度。
2.4 t-分布随机邻域嵌入(t-SNE)
t-SNE 是一种非线性降维方法,它试图通过减少高维和低维位置之间的配对概率分布差异来保持数据集的结构。
t-SNE 可以应用于特征选择,将原始特征空间投影到一个低维空间中,从而保持数据的结构,允许更好的可视化和评估。
你可以在这里找到更多关于无监督算法和 t-SNE 的信息 “无监督学习算法”。
2.5 自编码器
自编码器是一种人工神经网络,它学习将输入数据编码成低维表示,然后再将其解码回原始版本。自编码器的低维表示可以用来生成另一组特征,以捕捉原始数据的潜在结构。
结束语
总结来说,特征选择在机器学习中至关重要。它有助于减少数据的维度,最小化过拟合的风险,并提高模型的整体性能。选择合适的特征选择方法取决于具体的问题、数据集和建模要求。
本文涵盖了广泛的特征选择技术,包括监督和无监督方法。
监督技术,如基于滤波器、基于包装和嵌入的方法,利用特征与目标变量之间的关系来识别最重要的特征。
无监督技术,如 PCA、ICA、NMF、t-SNE 和自编码器,专注于数据的内在结构,以在不考虑目标变量的情况下降低维度。
在为你的模型选择合适的特征选择方法时,考虑数据的特征、每种技术的基本假设和涉及的计算复杂性是至关重要的。
通过仔细选择和应用正确的特征选择技术,你可以显著提升性能,从而获得更好的洞察力和决策能力。
内特·罗西迪 是一名数据科学家,专注于产品策略。他还是一位副教授,教授分析学,并且是 StrataScratch 的创始人,这个平台帮助数据科学家准备面试,提供来自顶级公司的真实面试问题。可以在 Twitter: StrataScratch 或 LinkedIn 上联系他。
了解更多主题
高级 PyTorch Lightning 使用 TorchMetrics 和 Lightning Flash
原文:
www.kdnuggets.com/2021/11/advanced-pytorch-lightning-torchmetrics-lightning-flash.html
评论

仅回顾一下我们上一个帖子中关于PyTorch Lightning 入门的内容,在本教程中,我们将深入探讨你应该使用的两个额外工具:TorchMetrics 和 Lightning Flash。
TorchMetrics 不出所料地提供了一个模块化的方法来定义和跟踪跨批次和设备的有用指标,而 Lightning Flash 提供了一套功能,促进更高效的迁移学习和数据处理,以及一份针对典型深度学习问题的最新方法的配方书。
我们将从向之前开始的 MNIST 示例中添加一些有用的分类指标开始。我们还将用 Flash Trainer 对象替换 PyTorch Lightning Trainer 对象,这将使我们更容易在新的分类问题上进行迁移学习。然后,我们将使用新的数据集CIFAR10来训练我们的分类器,我们将以此作为迁移学习示例的基础,转移到CIFAR100。
TorchMetrics
首先要做的是确保我们已经安装了所有需要的包。如果你已经按照“入门”教程中的安装说明操作,并现在通过 pip freeze 检查你的虚拟环境内容,你会发现你可能已经安装了 TorchMetrics。如果没有,请使用以下命令安装 TorchMetrics 和 Lightning Flash:
pip install torchmetrics
pip install lightning-flash
pip install lightning-flash[image]
接下来,我们将修改我们的训练和验证循环,以记录 F1 分数和接收者操作特征曲线下面积(AUROC)以及准确率。我们将从 pytorch_lightning.metrics 中移除(已弃用的)准确率,并从我们的模型中 validation_epoch_end 回调中移除类似的 sklearn 函数,但首先,让我们确保在顶部添加必要的导入。
# ...
import pytorch_lightning as pl
# replace: from pytorch_lightning.metrics import functional as FM
# with the one below
import torchmetrics
# import lightning_flash, which we’ll use later
import flash
from flash.image import ImageClassifier, ImageClassificationData
# ...
接下来,移除我们之前用来计算准确率的代码行:
# ...
# in training_step
y_pred = output.argmax(-1).cpu().numpy()
y_tgt = y.cpu().numpy()
# remove the line below line:
# accuracy = sklearn.metrics.accuracy_score(y_tgt, y_pred)
self.log("train loss", loss)
# and this one: self.log("train accuracy", accuracy)
return loss
# ...
和:
# ...
# in validation_epoch_end
y_preds = preds.cpu().numpy()
y_tgts = tgts.cpu().numpy()
# remove the lines below:
# fm_accuracy = FM.accuracy(outputs, tgts)
# accuracy = sklearn.metrics.accuracy_score(y_tgts, y_preds)
# self.log("val_accuracy", accuracy)
self.log("val_loss", loss)
# ...
现在,我们可以用等效的 TorchMetrics 函数实现来替换我们删除的部分,计算准确率,然后就这样结束:
# ...
# in training_step
accuracy = torchmetrics.functional.accuracy(y_pred, y_tgt)
f1_score = torchmetrics.functional.f1(y_pred, y_tgt,
average="micro")
auroc = torchmetrics.functional.auroc(y_pred, y_tgt,
number_classes=10, average="micro")
self.log("train_loss", loss)
self.log("train_accuracy", accuracy)
self.log("train_f1", f1_score)
self.log("train_auroc", auroc)
return loss
# ...
和:
# ...
accuracy = torchmetrics.functional.accuracy(outputs, tgts)
f1_score = torchmetrics.functional.f1(outputs, tgts,
average="micro")
auroc = torchmetrics.functional.auroc(outputs, tgts,
number_classes=10, average="micro")
self.log("val_accuracy", accuracy)
self.log("val_f1_score", f1_score)
self.log("val_auroc", auroc)
self.log("val_loss", loss)
# ...
不过,使用基于类的模块化版本的指标还有其他优势。
使用基于类的指标,我们可以在运行训练和验证时持续积累数据,并在最后计算结果。这在单一设备上很方便和高效,但在多个设备上,它真正变得有用,因为指标模块可以在多个设备之间自动同步。
我们将在 __init__ 函数中初始化我们的指标,并在训练和验证步骤中添加每个指标的调用。
class MyClassifier(pl.LightningModule):
def __init__(self, dim=28, activation=nn.ReLU()):
super(MyClassifier, self).__init__()
self.image_dim = dim
self.hid_dim = 128
self.num_classes = 10
self.act = activation
# add metrics
self.train_acc = torchmetrics.Accuracy()
self.train_f1 = torchmetrics.F1(number_classes=10,
average="micro")
self.train_auroc = torchmetrics.AUROC(number_classes=10,
average="micro")
self.val_acc = torchmetrics.Accuracy()
self.val_f1 = torchmetrics.F1(number_classes=10,
average="micro")
self.val_auroc = torchmetrics.AUROC(number_classes=10,
average="micro")
# __init__ function continues
# ...
在 __init__ 中定义的指标模块将在 training_step 和 validation_step 中被调用,我们将在每个训练和验证周期结束时计算这些指标。
在步骤函数中,我们将调用我们的指标对象以在训练和验证周期中累积指标数据。我们可以为每个指标对象调用“forward”方法以在返回当前批次的值的同时累积数据,或者调用“update”方法来静默累积指标数据。
def training_step(self, batch, batch_index):
x, y = batch
output = self.forward(x)
loss = F.nll_loss(F.log_softmax(output, dim = -1), y)
y_pred = output.softmax(dim=-1)
y_tgt = y
# accumulate and return metrics for logging
acc = self.train_acc(y_pred, y_tgt)
f1 = self.train_f1(y_pred, y_tgt)
# just accumulate
self.train_auroc.update(y_pred, y_tgt)
self.log("train_loss", loss)
self.log("train_accuracy", acc)
self.log("train_f1", f1)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
output = self.forward(x)
loss = F.cross_entropy(output, y)
pred = output.softmax(dim=-1)
self.val_acc.update(pred, y)
self.val_f1.update(pred, y)
self.val_auroc.update(pred, y)
return loss
我们将重写 validation_epoch_end 并重载 training_epoch_end 以一次计算和报告整个周期的指标。
def training_epoch_end(self, training_step_outputs):
# compute metrics
train_accuracy = self.train_acc.compute()
train_f1 = self.train_f1.compute()
train_auroc = self.train_auroc.compute()
# log metrics
self.log("epoch_train_accuracy", train_accuracy)
self.log("epoch_train_f1", train_f1)
# reset all metrics
self.train_acc.reset()
self.train_f1.reset()
print(f"\ntraining accuracy: {train_accuracy:.4}, "\
f"f1: {train_f1:.4}, auroc: {train_auroc:.4}")
def validation_epoch_end(self, validation_step_outputs):
# compute metrics
val_loss = torch.tensor(validation_step_outputs).mean()
val_accuracy = self.val_acc.compute()
val_f1 = self.val_f1.compute()
val_auroc = self.val_auroc.compute()
# log metrics
self.log("val_accuracy", val_accuracy)
self.log("val_loss", val_loss)
self.log("val_f1", val_f1)
self.log("val_auroc", val_auroc)
# reset all metrics
self.val_acc.reset()
self.val_f1.reset()
self.val_auroc.reset()
print(f"\nvalidation accuracy: {val_accuracy:.4} "\
f"f1: {val_f1:.4}, auroc: {val_auroc:.4}")
通过这些少量更改,我们可以利用 TorchMetrics 中实现的 25 种不同的指标,或子类化 torchmetrics.Metrics 类并实现我们自己的指标。不过,请记住,子类化 LightningModule 类比实现常见任务如图像分类的训练有更简单的方法。
Lightning Flash
如同一套俄罗斯套娃的深度学习抽象库,Lightning Flash 在 PyTorch Lightning 上添加了更多抽象和简化。事实上,我们只需 7 行代码就能训练一个图像分类任务。我们将使用 CIFAR10 数据集以及基于 Lightning Flash 内置 ResNet18 主干的分类模型。接着,我们将展示如何将模型主干重新用于分类新数据集 CIFAR100。
尽管 Lightning Flash 仍在积极开发中,且有许多尖锐的边角,但你已经可以用很少的代码组装特定的工作流程,甚至有一个他们称之为 Flash Zero 的“无代码”功能。为了我们的目的,我们可以用不到 20 行代码组装一个迁移学习工作流程。
首先,我们将用 8 行代码在 CIFAR10 数据集上进行训练。我们利用 ImageClassifier 类及其内置的主干架构,以及 ImageClassificationData 类来替代训练和验证的数据加载器。
metrics_10 = [torchmetrics.Accuracy(), \
torchmetrics.F1(num_classes=10, average="micro")]
validation_interval = 1.0
train_dataset = CIFAR10(os.getcwd(), download=True, \
train=True) #, transform=transforms.ToTensor())
val_dataset = CIFAR10(os.getcwd(), download=True, \
train=False) #, transform=transforms.ToTensor())
datamodule = ImageClassificationData.from_datasets(
train_dataset=train_dataset,\
val_dataset=val_dataset)
model = ImageClassifier(backbone="resnet18", \
num_classes=10, metrics=metrics_10)
trainer = flash.Trainer(max_epochs=25, \
val_check_interval=validation_interval, gpus=1)
trainer.fit(model, datamodule=datamodule)
然后,我们可以通过重新使用我们之前训练的模型的特征提取主干并使用“freeze”方法进行迁移学习,来训练新的图像分类任务 CIFAR100 数据集,该数据集每个类别的示例较少。
这种策略只更新新的分类头上的参数,同时保持主干参数不变。
train_dataset = CIFAR100(os.getcwd(), download=True, \
train=True) #, transform=transforms.ToTensor())
val_dataset = CIFAR100(os.getcwd(), download=True, \
train=False) #, transform=transforms.ToTensor())
metrics_100 = [torchmetrics.Accuracy(), \
torchmetrics.F1(num_classes=100, average="micro")]
datamodule = ImageClassificationData.from_datasets(
train_dataset=train_dataset,\
val_dataset=val_dataset)
model_2 = ImageClassifier(backbone=(model.backbone, 512),\
num_classes=100, metrics=metrics_100)
trainer_2 = flash.Trainer(max_epochs=15, \
val_check_interval=validation_interval, gpus=1)
trainer_2.finetune(model_2, datamodule=datamodule,\
strategy="freeze")
这种将参数重新应用于新任务的方式是迁移学习的核心,节省了时间和计算以及相关成本。考虑到开发者的时间比计算时间更宝贵,Lightning Flash 的简洁编程风格可能非常值得学习几个新的 API 模式。
一些最实用的深度学习建议可以归结为“不要做英雄”,即不要重新发明轮子,忽视像 Flash 这样的便捷工具,这些工具可以让你的生活更轻松。
说到简化,还有一种使用 Flash 训练模型的方法我们不得不提及。通过 Flash Zero,你可以直接从命令行调用 Lightning Flash,使用内置的 SOTA 模型来训练常见的深度学习任务。Flash Zero 也有很多棱角分明的地方,如果你想根据自己的需求进行调整,准备好为 PyTorch Lightning 项目贡献一些 pull request。
例如,下面是从 Flash Zero 文档中修改的一个示例。如果你查看 原版 (截至本写作时),你可能会立即注意到下载 hymenoptera 数据集的命令行参数中有一个错别字:下载输出文件名缺少扩展名。下面的修正版下载了 hymenoptera 数据集,并用 ResNet18 主干训练了一个分类器,训练了 10 个周期:
curl https://pl-flash-data.s3.amazonaws.com/hymenoptera_data.zip \
-o hymenoptera_data.zip
unzip hymenoptera_data.zip
flash image_classification --trainer.max_epochs 10 –model.backbone \
resnet18 from_folders --train_folder \
./hymenoptera_data/train/
文档中的错别字是一个相当小的错误(也是你为项目打开第一个 pull request 的一个良机!),但这表明 PyTorch Lightning 和 Lightning Flash 项目正在快速变化。
随着项目的扩展,预计开发将以快速的速度继续进行。这意味着在新项目中设置依赖时,使用静态版本号可能是个好主意,以避免 Lightning 代码更新时出现破坏性更改。同时,这也为你提供了塑造项目未来的机会,以满足你特定的研发需求,无论是通过 pull request、贡献评论,还是在项目的 GitHub 频道 上提出问题。
在这些 PyTorch Lightning 教程文章中,我们已经看到 PyTorch Lightning 如何用于简化在多个复杂度层级上的常见深度学习任务的训练。通过子类化 LightningModule,我们能够定义一个有效的图像分类器,该模型负责训练、验证、指标和日志记录,极大地简化了编写外部训练循环的需要。该模型还使用了 PyTorch Lightning Trainer 对象,使得将整个训练流程切换到 GPU 变得轻而易举。从 Lightning Modules 构建模型是获得实用性而不牺牲控制的一种好方法。
通过使用 Lightning Flash,我们在仅 15 行代码(不包括导入部分)中构建了一个迁移学习工作流。对于那些已知解决方案和成熟的最先进技术的问题,你可以通过利用 Flash 内置的架构和训练基础设施节省大量时间!
最后,我们对 Flash Zero 从命令行进行无代码训练有了初步了解。无代码是一种越来越受欢迎的机器学习方法,尽管工程师对此有所不满,但无代码具有很大的潜力。目前正在迅速发展,Flash Zero 有望成为一种强大的方式,以开箱即用的最佳工程解决方案应用于机器学习和数据科学领域,让科学家可以专注于工作标题中的科学部分。
简介: Kevin Vu 负责 Exxact Corp 博客,并与许多才华横溢的作者合作,这些作者撰写有关深度学习各个方面的内容。
原文。已获许可转载。
相关:
-
PyTorch Lightning 入门
-
如何将 PyTorch Lightning 模型部署到生产环境
-
开始使用 PyTorch Lightning
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
更多相关主题
数据科学中的高级统计概念
原文:
www.kdnuggets.com/2021/09/advanced-statistical-concepts-data-science.html
评论
版权: www.congruentsoft.com/business-intelligence.aspx
在我之前的文章 数据科学中的统计学初学者指南 和 数据科学家应了解的推断统计学 中,我们讨论了几乎所有基础的(描述性和推断性)统计学知识,这些知识在理解和处理任何数据科学案例研究中都很常用。在这篇文章中,我们将稍微深入,探讨一些不在热点中的高级概念。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
Q-Q(分位数-分位数)图
在理解 QQ 图之前,首先了解什么是分位数?
分位数定义了数据集中的特定部分,即分位数确定了分布中有多少值高于或低于某个特定限度。特殊的分位数有四分位数(四分之一)、五分位数(五分之一)和百分位数(百分之一)。
一个例子:
如果我们将一个分布分成四个相等的部分,我们将称之为四分位数。第一个四分位数包括所有小于四分之一的所有值。在图形表示中,它对应于分布总面积的 25%。两个较低的四分位数涵盖了分布值的 50%。第一和第三四分位数之间的四分位距等于分布在均值周围的 50%值的范围。
在统计学中,Q-Q(分位数-分位数)图是通过将两组分位数相互绘制的散点图。如果这两组分位数来自同一分布,我们应当能看到点形成一条大致为直线的线(y=x)。
例如,中位数是一个分位数,其中 50%的数据低于该点,50%的数据高于该点。Q-Q 图的目的是找出两组数据是否来自相同的分布。Q-Q 图上绘制了45 度角;如果两组数据来自相同的分布,则这些点会落在该参考线附近。
知道分布是否正态非常重要,这样才能对数据应用各种统计度量并以更易于人类理解的可视化方式进行解释,而 Q-Q 图正是关键。Q-Q 图回答的最基本问题是曲线是否符合正态分布。
正态分布,但为什么?
Q-Q 图用于找出随机变量的分布类型,无论是高斯分布、均匀分布、指数分布,还是帕累托分布等。
通过仅查看 Q-Q 图,你可以判断分布的类型。一般来说,我们仅讨论正态分布,因为我们有一个非常漂亮的 68-95-99.7 规则,这完全适用于正态分布,因此我们知道数据在均值的第一个、第二个和第三个标准差范围内的分布情况。因此,知道分布是否正态为我们实验打开了新的大门。
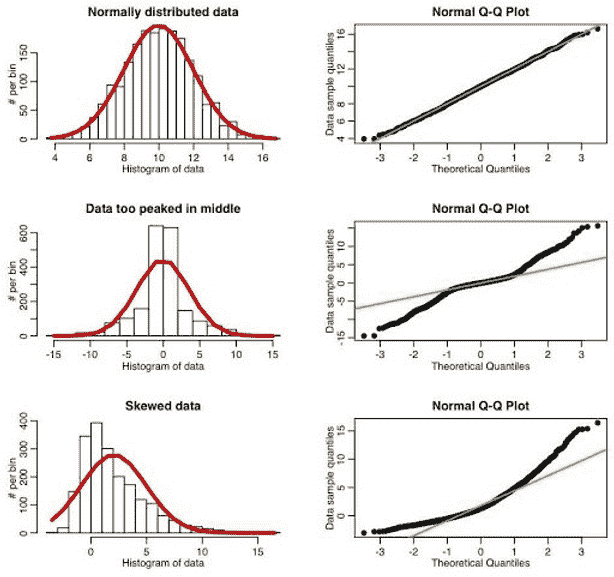
Q-Q 图的类型。来源
偏态 Q-Q 图
Q-Q 图可以找出分布的偏度(不对称的度量)。
如果 Q-Q 图的下端偏离直线但上端没有,则分布是左偏(负偏态)。
现在,如果 Q-Q 图的上端偏离直线而下端没有,则分布是右偏(正偏态)。
尾部 Q-Q 图
Q-Q 图可以找出分布的峰度(尾部厚度的度量)。
拥有胖尾的分布会使 Q-Q 图的两端偏离直线,而其中心部分跟随直线,而瘦尾分布的 Q-Q 图在两端的偏离非常少或可以忽略,从而使其完美符合正态分布。
Python 中的 Q-Q 图(来源)
假设我们有以下包含 100 个值的数据集:
**import** **numpy** **as** **np
#create dataset** **with** **100** **values that follow a normal distribution
np****.****random****.****seed****(****0****)** **data** **=** **np****.****random****.****normal****(****0****,****1****,** **1000****)** **#view first** **10** **values
data****[****:****10****]**
array([ 1.76405235, 0.40015721, 0.97873798, 2.2408932 , 1.86755799,
-0.97727788, 0.95008842, -0.15135721, -0.10321885, 0.4105985 ])
要为这个数据集创建 Q-Q 图,我们可以使用qqplot()函数来自 statsmodels 库:
**import** **statsmodels****.****api** **as** **sm** **import** **matplotlib****.****pyplot** **as** **plt
#create** **Q****-****Q** **plot** **with** **45****-****degree line added to plot
fig** **=** **sm****.****qqplot****(****data****,** **line****=****'45'****)** **plt****.****show****(****)**
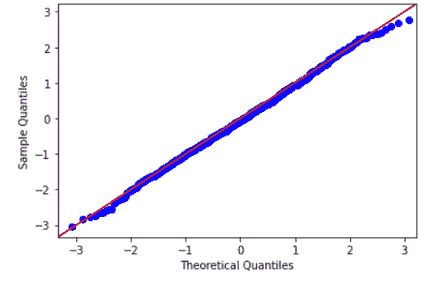
在 Q-Q 图中,x 轴显示理论分位数。这意味着它不显示你的实际数据,而是表示如果你的数据是正态分布的,它应该位于什么位置。
y 轴显示的是你的实际数据。这意味着如果数据值沿着一个大致的 45 度角直线分布,那么数据是正态分布的。
我们可以在上面的 Q-Q 图中看到,数据值趋向于紧密地沿 45 度线分布,这意味着数据很可能是正态分布的。这并不奇怪,因为我们生成了 100 个数据值,使用了numpy.random.normal() 函数。
相反,假设我们生成了一个包含 100 个均匀分布值的数据集,并为该数据集创建了一个 Q-Q 图:
**#create dataset** **of** **100** **uniformally distributed values** **data** **=** **np****.****random****.****uniform****(****0****,****1****,** **1000****)**
**#generate** **Q****-****Q** **plot** **for** **the dataset** **fig** **=** **sm****.****qqplot****(****data****,** **line****=****'45'****)** **plt****.****show****(****)**
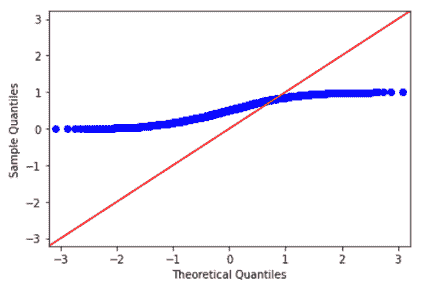
数据值明显不沿着红色 45 度线分布,这表明它们不符合正态分布。
切比雪夫不等式
在概率论中,切比雪夫不等式,也称为“比纳耶夫-切比雪夫”不等式,保证对于广泛的概率分布类,只有一定比例的值会落在距离分布均值的特定范围内。
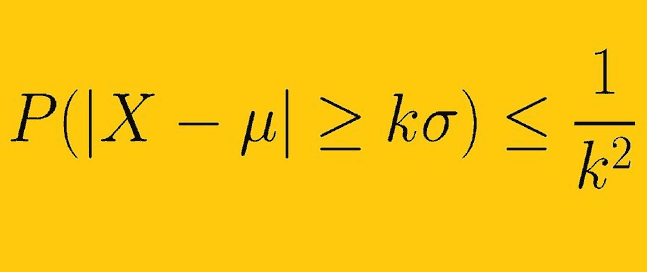
来源: www.thoughtco.com/chebyshevs-inequality-3126547
切比雪夫不等式类似于经验法则(68-95-99.7);然而,后者规则仅适用于正态分布。切比雪夫不等式更广泛;它适用于任何分布,只要该分布包含定义的方差和均值。
所以切比雪夫不等式表明,至少有(1-1/k²)的数据必须落在均值的K个标准差范围内(或者等价地,不超过1/k²的分布值可以偏离均值超过 k 个标准差)。
其中K --> 正实数
如果数据不是正态分布,则不同数量的数据可能会落在一个标准差内。切比雪夫不等式提供了一种方法,了解在任何数据分布中,有多少数据位于均值的K个标准差范围内。
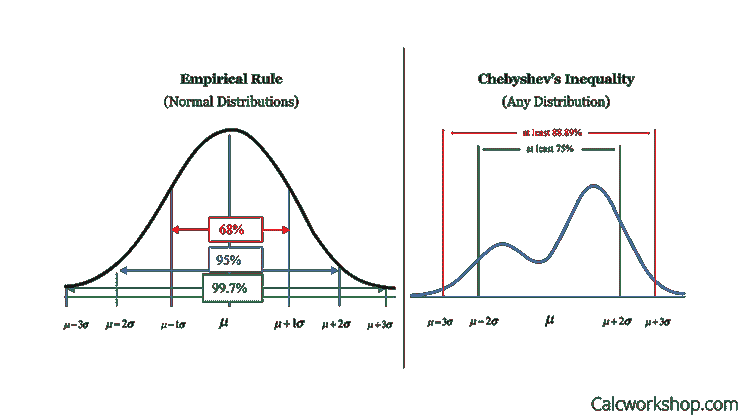
资料来源: calcworkshop.com/joint-probability-distribution/chebyshev-inequality/
切比雪夫不等式非常有价值,因为它可以应用于任何给定均值和方差的概率分布。
让我们考虑一个例子,假设有 1000 名应聘者来参加面试,但只有 70 个职位。为了在所有应聘者中挑选出最优秀的 70 人,招聘者会进行测试来评估他们的潜力。测试的平均分是 60,标准差是 6。如果某个应聘者的分数是 84,他们能否假设自己获得了工作?
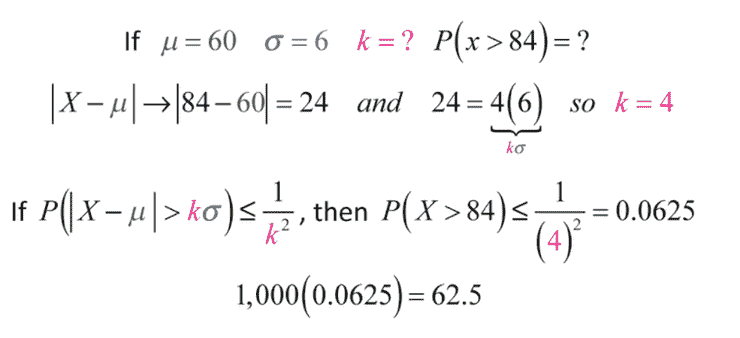
结果显示,大约有 63 人得分超过 60,因此在 70 个职位空缺的情况下,得分 84 的参赛者可以确保获得该职位。
Python 中的切比雪夫不等式(源)
创建一个 1,000,000 值的总体,我使用了形状=2、尺度=2 的伽玛分布(也适用于其他分布)。
**import** numpy as np
**import** random
**import** matplotlib.pyplot as plt
**#create a population** **with** **a gamma distribution**
shape, scale = 2., 2\. #mean=4, std=2*sqrt(2)
mu = shape*scale #mean and standard deviation
sigma = scale*np.sqrt(shape)
s = np.random.gamma(shape, scale, 1000000)
现在从总体中抽样 10,000 个值。
**#sample** **10000** **values**
rs = random.choices(s, k=10000)
计算与期望值距离超过 k 个标准差的样本数量,并用该数量计算概率。我想描绘一个当 k 增加时概率的趋势,因此我使用了从 0.1 到 3 的 k 范围。
**#****set** **k**
ks = [0.1,0.5,1.0,1.5,2.0,2.5,3.0]
**#probability list**
probs = [] **#****for** **each k**
for k in ks:
**#start count**
c = 0
for i in rs:
**#** count if far from mean in k standard deviation
if abs(i - mu) > k * sigma :
c += 1
probs.append(c/10000)
绘制结果:
plot = plt.figure(figsize=(20,10))
**#plot each probability**
plt.xlabel('**K**')
plt.ylabel('**probability**')
plt.plot(ks,probs, marker='o')
plot.show()
**#print each probability**
print("Probability of a sample far from mean more than k standard deviation:")
for i, prob in enumerate(probs):
print("k:" + str(ks[i]) + ", probability: " \
+ str(prob)[0:5] + \
" | in theory, probability should less than: " \
+ str(1/ks[i]**2)[0:5])

从上述图表和结果中,我们可以看到,随着 k 的增加,概率在减少,每个 k 的概率遵循不等式。此外,只有 k 大于 1 的情况是有用的。如果 k 小于 1,则不等式的右侧大于 1,这没有用,因为概率不能大于 1。
对数正态分布
在概率论中,对数正态分布,也称为高尔顿分布,是随机变量的连续概率分布,其对数服从正态分布。
因此,如果随机变量X服从对数正态分布,则Y = ln(X)服从正态分布。等效地,如果Y服从正态分布,则Y的指数函数,即X = exp(Y),服从对数正态分布。
低均值、高方差且所有值均为正的偏斜分布符合这种分布类型。对数正态分布的随机变量只取正实值。
对数正态分布的概率密度函数的一般公式为:
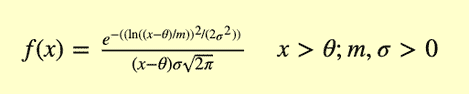
位置参数和尺度参数相当于随机变量对数的均值和标准差。
对数正态分布的形状由 3 个参数定义:
-
σ 是形状参数(也是分布对数的标准差)
-
θ或μ是位置参数(也是分布的均值)
-
m 是尺度参数(也是分布的中位数)
位置参数和尺度参数相当于随机变量对数的均值和标准差,如上所述。
如果x = θ,则f(x) = 0。其中θ = 0和m = 1的情况称为标准对数正态分布。θ等于零的情况称为2 参数对数正态分布。
以下图表说明了位置(μ)和形状(σ)参数对对数正态分布的概率密度函数的影响:
来源:www.sciencedirect.com/topics/mathematics/lognormal-distribution
Python 中的对数正态分布 (来源)
让我们考虑一个例子,使用 scipy.stats.lognorm 函数生成 μ=1 和 σ=0.5 的对数正态分布的随机数。
**import** numpy **as** np
**import** matplotlib.pyplot **as** plt
**from** scipy.stats **import** lognorm
np.random.seed(42)
data = lognorm.rvs(s=0.5, loc=1, scale=1000, size=1000)
plt.figure(figsize=(10,6))
ax = plt.subplot(111)
plt.title('**Generate wrandom numbers from a Log-normal distribution**')
ax.hist(data, bins=np.logspace(0,5,200), density=True)
ax.set_xscale("**log**")
shape,loc,scale = lognorm.fit(data)
x = np.logspace(0, 5, 200)
pdf = lognorm.pdf(x, shape, loc, scale)
ax.plot(x, pdf, 'y')
plt.show()
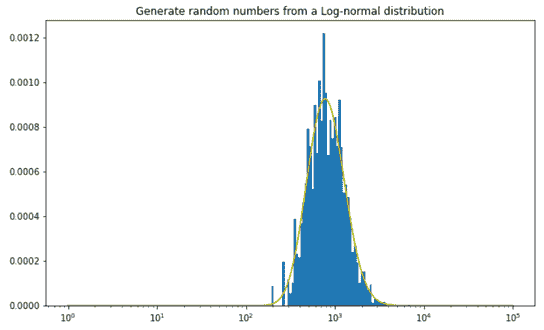
幂律分布
在统计学中,幂律 是两种量之间的函数关系,其中一种量的相对变化导致另一种量的相对变化成比例,不受这些量初始大小的影响:一种量作为另一种量的幂变化。
例如,考虑一个正方形的面积与其边长的关系,如果边长加倍,面积则乘以四。
幂律分布的形式为 Y = k Xα,
其中:
-
X 和 Y 是感兴趣的变量,
-
α 是法则的指数,
-
k 是一个常数。
来源:en.wikipedia.org/wiki/Power_law
幂律分布只是众多概率分布中的一种,但被认为是评估正态分布无法处理的不确定性问题的宝贵工具,当这些问题发生在一定概率时。
许多过程在广泛的值范围内被发现遵循幂律。从收入分布、小行星体的大小、地震震级、深度神经网络中的权重矩阵的谱密度、单词使用、各种网络中的邻居数量等。(注意:这里的幂律是一个连续分布。最后两个例子是离散的,但在大规模下可以建模为连续的)。
Python 中的幂律分布 (来源)
让我们绘制 帕累托分布,这是一种幂律概率分布的形式。帕累托分布有时被称为帕累托原则或‘80–20’ 规则,因为该规则指出,80% 的社会财富掌握在 20% 的人口手中。帕累托分布不是自然法则,而是一种观察结果。它在许多现实世界问题中很有用。这是一种偏斜的重尾分布。
**import** numpy **as** np
**import** matplotlib.pyplot **as** plt
**from** scipy.stats **import** pareto
x_m = 1 #scale
alpha = [1, 2, 3] #list of values of shape parameters
plt.figure(figsize=(10,6))
samples = np.linspace(start=0, stop=5, num=1000)
for a in alpha:
output = np.array([pareto.pdf(x=samples, b=a, loc=0, scale=x_m)])
plt.plot(samples, output.T, label='alpha {0}' .format(a))
plt.xlabel('**samples**', fontsize=15)
plt.ylabel('**PDF**', fontsize=15)
plt.title('**Probability Density function**', fontsize=15)
plt.legend(loc='**best**')
plt.show()
Box-Cox 变换
Box-Cox 变换 将我们的数据转换为接近正态分布的形式。
一参数 Box-Cox 变换定义为在许多统计技术中,我们假设误差是正态分布的。这一假设允许我们构建置信区间并进行假设检验。通过转换目标变量,我们可以(希望)将误差归一化(如果它们尚未正态化)。
此外,变换我们的变量可以提高模型的预测能力,因为变换可以去除白噪声。
原始分布(左)和应用 Box-Cox 变换后的接近正态分布。来源
Box-Cox 变换的核心是一个指数lambda (λ),其范围从-5 到 5。所有λ的值都被考虑,并为你的数据选择最佳值;“最佳值”是使数据最佳逼近正态分布曲线的值。
一参数 Box-Cox 变换定义为:
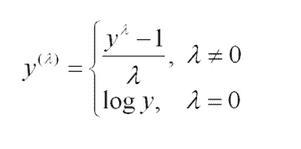
以及两个参数的 Box-Cox 变换为:
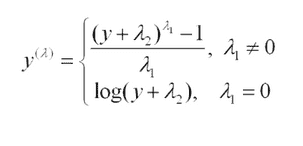
此外,一参数 Box-Cox 变换适用于y > 0,即仅适用于正值;而两个参数 Box-Cox 变换适用于y > -λ,即负值。
参数λ是使用剖面似然函数和拟合优度测试来估计的。
如果我们谈论 Box-Cox 变换的一些缺点,那么如果你想进行解释的话,Box-Cox 是不推荐的。因为如果λ是某个非零数字,那么变换后的目标变量可能比简单地应用对数变换更难以解释。
第二个障碍是,Box-Cox 变换通常在我们将变换后的数据恢复到原始尺度时给出预测分布的中位数。有时,我们需要的是均值而不是中位数。
Python 中的 Box-Cox 变换(来源)
SciPy 的 stats 包提供了一个名为 boxcox 的函数,用于执行 Box-Cox 幂变换,该函数接受原始非正态数据作为输入,并返回拟合的数据以及用于将非正态分布拟合到正态分布的 lambda 值。
#load necessary packages
**import** numpy **as** np
**from** scipy.stats **import** boxcox
**import** seaborn **as** sns
#make this example reproducible
np.random.seed(0)
#**generate dataset**
data = np.random.exponential(size=1000)
fig, ax = plt.subplots(1, 2)
#**plot the distribution** **of** **data values**
sns.distplot(data, hist=False, kde=True,
kde_kws = {'shade': True, 'linewidth': 2},
label = "Non-Normal", color ="red", ax = ax[0])
#**perform Box****-****Cox transformation on original data**
transformed_data, best_lambda = boxcox(data)
sns.distplot(transformed_data, hist = False, kde = True,
kde_kws = {'shade': True, 'linewidth': 2},
label = "**Normal**", color ="**red**", ax = ax[1])
#**adding legends to the subplots**
plt.legend(loc = "**upper right**")
#**rescaling the subplots**
fig.set_figheight(5)
fig.set_figwidth(10)
#**display optimal lambda value**
print(f"**Lambda value used for Transformation: {best_lambda}**")
泊松分布
在概率论和统计学中,泊松分布是一种离散概率分布,它表示在固定时间间隔或空间中,给定事件发生的数量的概率,前提是这些事件以已知的常数平均速率发生,并且独立于上一个事件以来的时间。
简单来说,泊松分布可以用来估计某事发生“X”次的可能性。
一些泊松过程的例子包括客户拨打帮助中心电话、原子中的放射性衰变、网站访问者、到达空间望远镜的光子以及股票价格的波动。泊松过程通常与时间相关,但并不一定如此。
泊松分布的公式是:

其中:
-
e 是欧拉数(e = 2.71828...)
-
k 是发生的次数
-
k! 是 k 的阶乘
-
λ 等于 k 的期望值,当且仅当它也等于其方差时。
Lambda(λ) 可以被认为是区间内事件的期望数量。随着我们改变速率参数 λ,我们也改变了在一个区间内观察到不同数量事件的概率。下面的图是泊松分布的概率质量函数,展示了在不同速率参数下事件发生的概率。
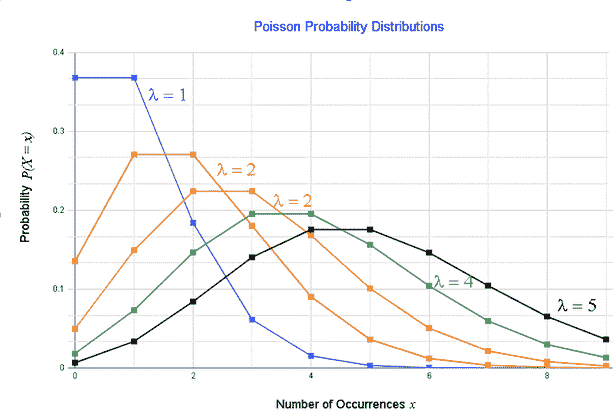
泊松分布的概率质量函数,速率参数变化的情况。来源
泊松分布也常用于建模财务计数数据,其中计数很小,且经常为零。例如,在金融领域,它可以用来建模一个典型投资者在某一天的交易次数,这个次数可以是 0(经常发生),也可以是 1、2 等。
作为另一个例子,这个模型可以用来预测在给定时间段内,比如十年中,市场将发生多少次“冲击”。
Python 中的泊松分布
**from** numpy **import** random
**import** matplotlib.pyplot as plt
**import** seaborn as sns
lam_list = [1, 4, 9] **#list** **of** **Lambda values**
plt.figure(figsize=(10,6))
samples = np.linspace(start=0, stop=5, num=1000)
for lam in lam_list:
sns.distplot(random.poisson(lam=lam, size=10), hist=False, label='**lambda {0}**'.format(lam))
plt.xlabel('**Poisson Distribution**', fontsize=15)
plt.ylabel('**Frequency**', fontsize=15)
plt.legend(loc='**best**')
plt.show()
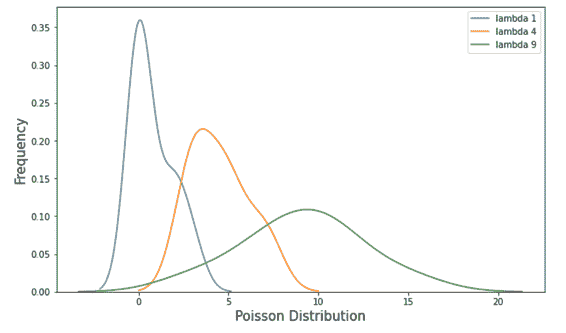
随着 λ 变大,图形看起来越来越像正态分布。
希望你喜欢阅读这篇文章。如果有任何问题或建议,请留下评论。
随时通过 LinkedIn 与我联系,有任何问题请随时提问。
感谢阅读!!!
参考文献
-
calcworkshop.com/joint-probability-distribution/chebyshev-inequality/ -
corporatefinanceinstitute.com/resources/knowledge/data-analysis/chebyshevs-inequality/ -
gist.github.com/chaipi-chaya/9eb72978dbbfd7fa4057b493cf6a32e7
原文. 经许可转载。
相关:
-
数据科学家应该了解的推断统计学
-
数据科学家需要知道的重要统计学
-
零样本学习:你能在没有见过物体的情况下对其进行分类吗?
更多相关主题
在 MLOps 中探索 Github Actions、Iterative.ai、Label Studio 和 NBDEV
原文:
www.kdnuggets.com/2021/09/adventures-mlops-github-actions-iterative-ai-label-studio-and-nbdev.html
评论
由 Aaron Soellinger 和 Will Kunz
在为我们的项目设计 MLOps 堆栈时,我们需要一个解决方案,允许高度的定制和灵活性,以便随着实验的需要而演变。我们考虑了包含许多功能的大型平台,但在一些关键领域感到受限。最终,我们决定采用一种方法,分别实现专用工具用于标注、数据版本控制和持续集成。本文记录了我们构建这种自定义 MLOps 方法的经验。

图片由 Finding Dan | Dan Grinwis 提供,来自 Unsplash
NBDEV

使用 Jupyter 进行开发的经典问题是,从原型到生产需要将代码从笔记本复制/粘贴到 python 模块中。NBDEV 自动化了笔记本和模块之间的过渡,从而使 Jupyter 笔记本成为生产管道的官方部分。NBDEV 允许开发者指定笔记本应创建哪个模块,哪些笔记本单元格应推送到模块中,以及哪些笔记本单元格是测试。NBDEV 的一个关键功能是其在笔记本内测试的方法,NBDEV 模板甚至提供了一个基础的 Github Action,用于在 CI/CD 框架中实现测试。生成的 Python 模块不需要开发者编辑,可以使用内置的 python 导入功能轻松集成到其他笔记本或项目中。
Iterative.ai: DVC/CML

(摘自 iterative.ai/)
机器学习管道中使用的文件通常是大型二进制/压缩文件的归档,这些文件对现有的版本控制解决方案如 git 来说不可访问或成本过高。DVC 通过将大型数据集表示为文件内容的哈希来解决数据版本控制问题,这使得 DVC 能够跟踪变化。它的工作原理类似于 git(例如 dvc add,dvc push)。当你在数据集上运行 dvc add 时,它会被添加到 .gitignore 并由 dvc 跟踪变化。CML 是一个项目,提供了从 Github Actions 工作流发布模型工件到 Github Issues、拉取请求等评论中的功能。这很重要,因为它帮助我们开始填补拉取请求中对训练数据变化以及模型准确性和有效性的记录缺口。
Github Actions

(摘自 github.com/features/actions)
我们希望进行自动化代码测试,包括在自动化测试管道中构建模型。Github Actions 与 CircleCI、Travis、Jenkins 竞争,旨在自动化代码推送、提交、拉取请求等的测试。由于我们已经使用 Github 托管我们的代码库,因此通过使用 Actions 避免了使用其他第三方应用。在这个项目中,我们需要使用 Github 自托管的运行器在本地 GPU 集群上运行任务。
Label Studio

(摘自 labelstud.io/)
我们深入研究了如何使用 Label Studio,详细信息见 这里。Label Studio 是一个数据标注解决方案。它运行良好,并且灵活,适用于各种环境。
为什么要将它们一起使用?
该设置旨在加快模型部署速度。这意味着更多的数据科学家可以和谐并行工作,代码库透明,并且新人员的入职时间更快。目标是标准化数据科学家在项目中需要执行的活动类型,并为他们提供明确的指示。
以下是我们希望通过此系统设计来简化的任务列表:
-
自动化从 Label Studio 的数据摄取,并提供一个单一的点来将数据摄取到模型训练和评估活动中。
-
对数据管道代码进行自动化测试,即单元测试和重新部署流程使用的容器。
-
对模型代码进行自动化测试,即单元测试和重新部署流程使用的容器。
-
启用自动化测试,包括模型的重新训练和评估标准。当模型代码发生变化时,用新代码训练一个模型,并将其与现有的现任模型进行比较。
-
当训练数据发生变化时触发模型重新训练。
以下是每个任务的管道描述。
传统 CI/CD 管道
该管道实施了对每个拉取请求的自动化测试反馈,包括语法、单元、回归和集成测试的评估。这个过程的结果是一个功能上经过测试的 Docker 镜像被放入我们的私有存储库中。这个过程最大化了最新的最佳代码在存储库中作为完全测试的镜像用于下游任务的可能性。以下是新特性的开发生命周期在这种背景下的工作方式:
这里展示了编辑代码时工作流的功能。使用 NBDEV 使我们可以直接从 Jupyter notebooks 中工作,包括在 notebook 中直接编写测试。NBDEV 要求 notebooks 中的所有单元格都必须无例外地运行(除非单元格标记为不运行)。 (图片来源:作者)
数据管道
Label Studio 目前缺乏事件钩子来启用对存储的标签数据的更改更新。因此,我们采取了 cron 触发的方法,每小时更新一次数据集。此外,当标签数据集足够小时,这些更新也可以作为训练管道的一部分进行。我们可以通过 Github Actions 接口按需触发数据管道刷新。
数据管道从 Label Studio 读取数据,并将数据集的每个版本及相关输入持久化到存储在 AWS S3 中的 DVC 缓存。 (图片来源:作者)
模型管道
模型管道将模型训练集成到存储库的 CI/CD 管道中。这使得每个拉取请求不仅能评估代码库中配置的语法、单元、集成和回归测试,还能提供评估新生成模型的反馈。
在这种情况下,工作流运行配置文件(model_params.yaml)中指定的模型训练实验,并更新模型工件(best-model.pth)。 (图片来源:作者)
基准评估管道
基准评估管道形成了一个“官方提交”过程,以确保所有建模活动都按照项目的度量标准进行衡量。
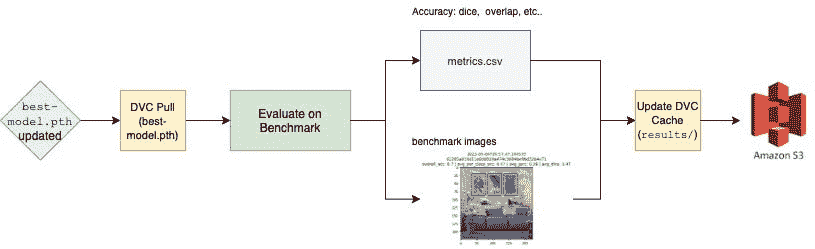
新训练的模型在 best-model.pth 中与基准数据集进行评估,结果会用最新的提交哈希标记并持久化到 AWS S3 中。 (图片来源:作者)
工作流
这里是 DVC 使用的 DAG 定义文件。它捕获工作流步骤及其输入,并允许在不同用户和机器间进行可重现性。
stages:
labelstudio_export_trad:
cmd: python pipelines/1_labelstudio_export.py --config_fp pipelines/traditional_pipeline.yaml
--ls_token *** --proj_root "."
params:
- pipelines/traditional_pipeline.yaml:
- src.host
- src.out_fp
- src.proj_id
dataset_create_trad:
cmd: python pipelines/2_labelstudio_todataset.py --config_fp pipelines/create_traditional.yaml
--proj_root "."
deps:
- data/raw_labels/traditional.json
params:
- pipelines/create_traditional.yaml:
- dataset.bmdata_fp
- dataset.labels_map
- dataset.out_fp
- dataset.rawdata_dir
train_model_trad:
cmd: python pipelines/3_train_model.py --config_fp pipelines/model_params.yaml
--proj_root "."
deps:
- data/traditional_labeling
params:
- pipelines/model_params.yaml:
- dataloader.bs
- dataloader.size
- dataloader.train_fp
- dataloader.valid_fp
- learner.backbone
- learner.data_dir
- learner.in_checkpoint
- learner.metrics
- learner.n_out
- learner.wandb_project_name
- train.cycles
labelstudio_export_bench:
cmd: python pipelines/1_labelstudio_export.py --config_fp pipelines/benchmark_pipeline.yaml
--ls_token *** --proj_root "."
params:
- pipelines/benchmark_pipeline.yaml:
- src.host
- src.out_fp
- src.proj_id
dataset_create_bench:
cmd: python pipelines/2_labelstudio_todataset.py --config_fp pipelines/create_benchmark.yaml
--proj_root "."
deps:
- data/raw_labels/benchmark.json
params:
- pipelines/create_benchmark.yaml:
- dataset.bmdata_fp
- dataset.labels_map
- dataset.out_fp
- dataset.rawdata_dir
eval_model_trad:
cmd: python pipelines/4_eval_model.py --config_fp pipelines/bench_eval.yaml --proj_root
"."
deps:
- data/models/best-model.pth
params:
- pipelines/bench_eval.yaml:
- eval.bench_fp
- eval.label_config
- eval.metrics_fp
- eval.model_conf
- eval.overlay_dir
发现
-
Github Actions 工作流的
cron触发器不够可靠。它不能保证定时性。 -
DVC 在触发的 Github Action 工作流中表现不够清晰。它会更改源控制的跟踪器,当这些更改被提交时,会创建另一个 Github Action。
-
Github Actions 作为运行模型的编排机制需要一个自托管的运行器来使用 GPU。这意味着要连接到云端或本地的 GPU 实例,这会带来访问控制的问题。例如,我们不能公开源代码库而不从代码库中移除自托管运行器的配置,否则随机的人可能会通过推送代码到项目中在我们的训练服务器上运行工作负载。
-
NBDEV 内置的工作流是在错误的地方测试代码。它是在笔记本中进行测试,而不是在编译后的包中测试。一方面,能够说“测试可以直接写入笔记本”是很好的。另一方面,直接测试笔记本会留下一个可能性,即 NBDEV 创建的代码包可能会失败,即使笔记本运行正常。我们需要的是能够直接测试 NBDEV 编译后的包。
-
NBDEV 与“传统” Python 开发不兼容,因为 NBDEV 是单向的。它仅允许在互动的 Jupyter 笔记本风格中开发项目。它使得直接开发 Python 模块变得不可能。如果项目在任何时候想要转换为“传统” Python 开发,测试需要通过其他方式完成。
-
起初,我们使用 Weights & Biases 作为实验跟踪仪表盘,然而在将其部署到 Github Action 中时遇到了问题。我们可以说,实现
wandb的用户体验在 Action Workflow 中遇到了第一次障碍。移除 Weights & Biases 立即解决了问题。在那之前,wandb被认为是 MLOps 中最好的用户体验。
结论
最终,完成这些工具的实现需要一周时间,这些工具用于使用 Github Actions、Iterative.ai 工具(DVC 和 CML)以及 NBDEV 来管理我们的代码。这为我们提供了以下能力:
-
从 Jupyter 笔记本中工作,作为代码的记录系统。我们喜欢 Jupyter。它的主要用例是让我们能够直接在任何可以通过 SSH 访问的硬件上工作,通过在那里托管 Jupyter 服务器并将其转发到桌面上。需要明确的是,即使我们不使用 NBDev,我们也会这样做,因为替代方案是使用 Vim 或其他我们不那么喜欢的工具。过去用 VS Code 或 Pycharm 连接到远程服务器的实验失败了。所以我们选择 Jupyter。
-
测试代码,并测试它创建的模型。现在作为 CI/CD 流水线的一部分,我们可以评估从代码库的更改中产生的模型是否变得更好、更差或保持不变。这些都可以在合并到
main之前的拉取请求中完成。 -
使用 Github Actions 服务器作为训练运行的编排器开始允许多个数据科学家以更清晰的方式同时工作。未来,我们将看到这种设置在编排协作数据科学过程中的局限性。
Aaron Soellinger 曾作为数据科学家和软件工程师解决金融、预测维护和体育领域的问题。他目前作为 Hoplabs 的机器学习系统顾问,致力于多摄像头计算机视觉应用的开发。
Will Kunz 是一名后端软件开发人员,面对挑战时总是展现出积极的态度和顽强的决心。不论是追踪难以捉摸的错误,还是快速适应新技术,Will 都希望找到解决方案。
原文。转载经许可。
相关:
-
MLOps 最佳实践
-
MLOps 是一种工程学科:初学者概述
-
MLOps 和机器学习路线图
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关话题
深度学习中的对抗样本——入门
原文:
www.kdnuggets.com/2020/11/adversarial-examples-deep-learning-primer.html
评论
介绍视觉深度学习模型中的对抗样本
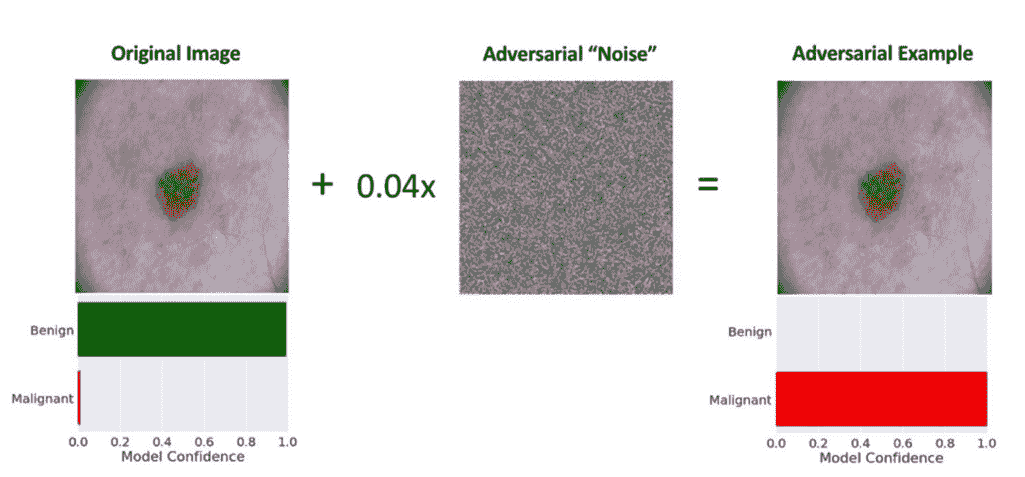
介绍
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT 工作
自从我们开始拥有更强大更先进的计算能力(如 GPU 和 TPU)、更多的数据(如 ImageNet 等)以及易于使用的开源软件和工具(如 TensorFlow 和 PyTorch)以来,我们已经见证了最先进(SOTA)计算机视觉深度学习模型的出现。每年(现在甚至每几个月!),我们都会看到下一个最先进的深度学习模型在基准数据集的 Top-k 准确性方面超越之前的模型。下图展示了一些最新的最先进深度学习视觉模型(但没有展示像 Google 的 BigTransfer 这样的模型!)。
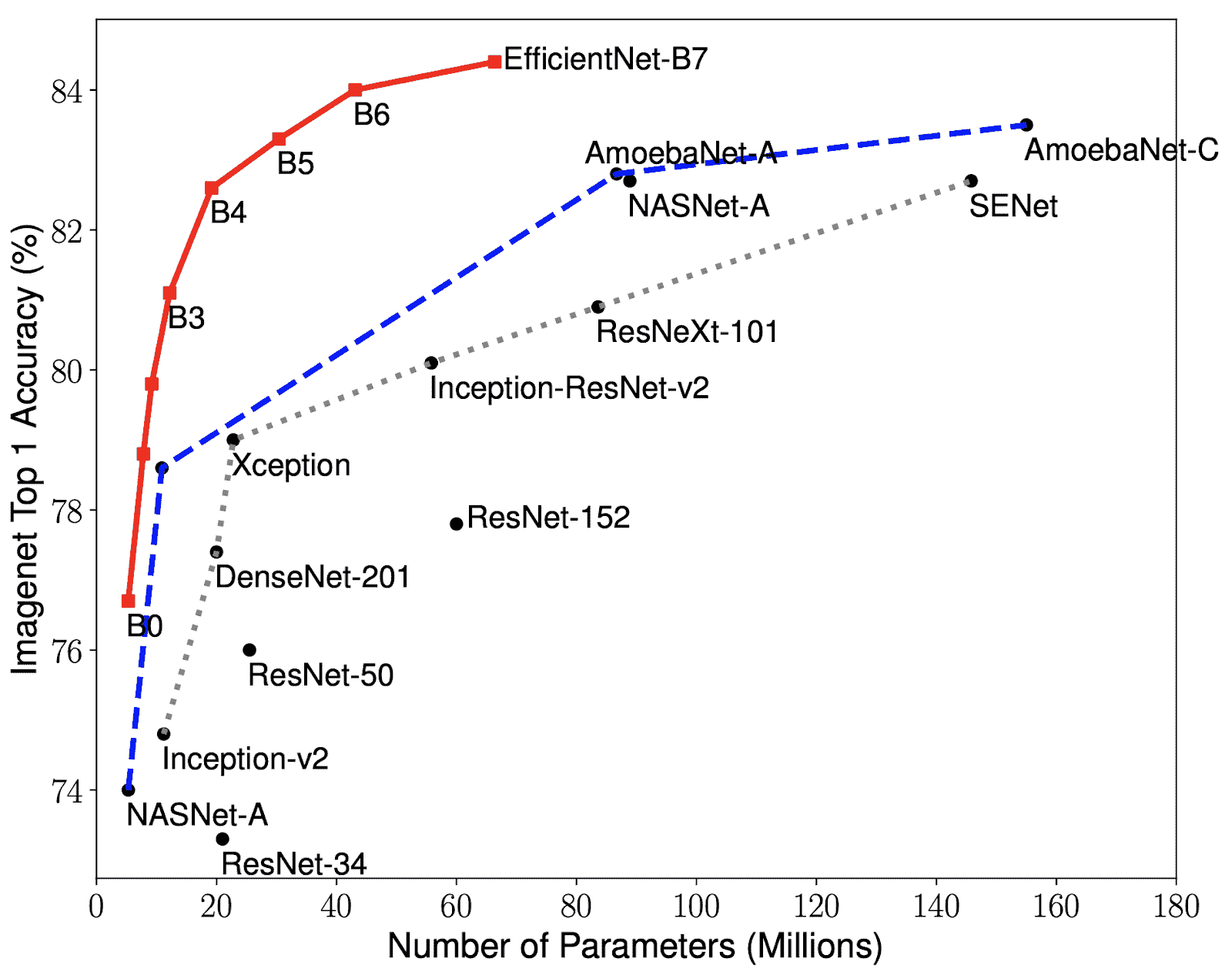
最先进的深度学习视觉模型(来源: https://arxiv.org/abs/1905.11946)
然而,大多数这些最先进的深度学习模型在对特定类别的图像(称为对抗图像)进行预测时会受到严重影响。对抗样本的整体概念可以是自然样本或合成样本。我们将在本文中查看一些例子,以熟悉不同的对抗样本和攻击。
对抗样本
自然对抗样本是指自然生成的、对于模型难以理解的图像。合成对抗样本则是攻击者(恶意用户)故意向图像中注入一些噪声,使其在视觉上与原始图像非常相似,但模型最终做出截然不同(且错误)的预测。让我们更详细地查看一些这些例子!
自然对抗样本
这些示例,如论文'自然对抗示例,Hendrycks 等'中定义的,是现实世界中的、未经修改的、自然发生的示例,这些示例导致分类器的准确性显著下降。他们引入了两个新的自然对抗示例数据集。第一个数据集包含 7500 个用于 ImageNet 分类器的自然对抗示例,并作为 ImageNet 分类器的困难测试集,称为 IMAGENET-A。下图展示了 ImageNet-A 数据集中的一些对抗示例。

ResNet-50 在 ImageNet-A 上的示例表现极差(来源: https://arxiv.org/abs/1907.07174)
你可以清楚地看到最先进的(SOTA)ResNet-50 模型在上述示例中的预测有多么错误(和可笑!)。事实上,DenseNet-121 预训练模型在 ImageNet-A 上的准确率仅为 2%!

作者们还策划了一个名为 IMAGENET-O 的对抗性分布外检测数据集,他们声称这是第一个为 ImageNet 模型创建的分布外检测数据集。下图展示了 ResNet-50 对 ImageNet-O 数据集中图像进行推断的一些有趣示例。

ResNet-50 在 ImageNet-O 上的示例表现极差(来源: https://arxiv.org/abs/1907.07174)
这些示例确实很有趣,并展示了 SOTA 预训练视觉模型在一些这些图像上的局限性,这些图像对于这些模型来说更为复杂。一些失败的原因可以归因于深度学习模型在对特定图像进行预测时试图关注的内容。让我们看一些更多的示例来尝试理解这一点。

ImageNet-A 中的自然对抗示例(来源: https://arxiv.org/abs/1907.07174)
基于上述图中展示的示例,很明显深度学习视觉模型在误解方面存在一些特定的模式。例如:
-
尽管模型更多关注于火焰及其照明,但蜡烛仍被预测为南瓜灯,因为缺少南瓜。
-
蜻蜓被预测为臭鼬或香蕉,因为模型更多地关注于颜色和纹理。
-
蘑菇被分类为钉子,因为模型学会将某些元素联系在一起,例如木材-钉子。
-
模型也会遭受过度泛化问题,例如阴影到日晷。
SOTA 深度学习视觉模型在这些示例中的整体表现非常差,如下图所示。
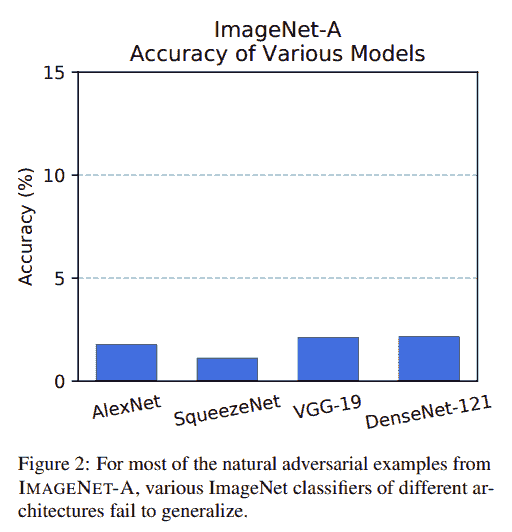
SOTA 深度学习视觉模型在 ImageNet-A 上的表现(来源: https://arxiv.org/abs/1907.07174)
悲哀的是,鲁棒的对抗训练方法几乎无法解决 Hendrycks 等人论文中提到的将自然对抗样本误解释为问题的困难。一些这些方法包括针对特定合成攻击进行训练,如投影梯度下降(PGD)和快速梯度符号方法(FGSM),我们将在后续文章中详细讨论。幸运的是,这些方法在处理恶意合成攻击时表现良好,这通常是更大的问题。
合成对抗样本
这些例子基本上涉及在输入图像中人为地引入一些噪声,使其在视觉上仍与原始图像非常相似,但注入的噪声最终会降低分类器的准确性。尽管合成对抗攻击种类繁多,但它们都基于以下图形中所示的一些核心原则。

对抗攻击的关键步骤(来源:https://github.com/dipanjanS/adversarial-learning-robustness)
重点始终是找出一种完美的噪声\扰动张量(数值矩阵)的方法,这些张量可以叠加在原始图像上,使得这些扰动对人眼不可见,但最终使深度学习模型在做出正确预测时失败。上面展示的例子展示了一种快速梯度符号方法(FGSM)攻击,其中我们向输入图像的梯度符号添加了一个小的乘数,并与一张熊猫的图像叠加,使得模型在预测时失败,以为图像是长臂猿。以下图形展示了一些更常见的对抗攻击类型。

常见对抗攻击(来源:https://github.com/dipanjanS/adversarial-learning-robustness)
接下来是什么?
在接下来的几篇文章中,我们将讨论上述每种对抗攻击方法,并展示如何通过实际代码示例欺骗最新最好的 SOTA 视觉模型。敬请关注!
本文内容来自我和Sayak在对抗学习方面的一些近期工作,详细示例可以在这个 GitHub 仓库中找到。
原文。经许可转载。
相关:
-
对抗验证概述
-
计算机视觉模型是否易受权重中毒攻击?
-
计算机视觉路线图
更多相关话题
对抗性机器学习与生成对抗网络简介
原文:
www.kdnuggets.com/2019/10/adversarial-machine-learning-generative-adversarial-networks.html
评论
作者:Andrew Martin,Looka(前身为 Logojoy)的数据主管。
机器学习是一个不断发展的领域,因此很容易觉得自己跟不上这个周世界变化的最新动态。最近获得大量关注的新兴领域之一是 GANs——即生成对抗网络。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
为了让你保持在机器学习的循环中,我们准备了一个简短的 GANs 速成课程:
-
它们在生成模型的神圣殿堂中的位置
-
它们如何随着时间的变化而变化
-
它们的应用场景
-
GANs 面临的挑战
-
这个新兴的机器学习领域的未来发展
让我们开始吧。
生成模型
对于生成模型,目标是建模给定数据集的分布。对于我们今天讨论的生成模型,这个数据集通常是一组图像,但也可以是其他类型的数据,如音频样本或时间序列数据。
获得这种分布模型有两种方法:隐式或显式。
那么这两者之间有什么区别呢?
好吧,显式生成模型使你可以使用概率密度。我们可以直接对该分布中的所有变量进行建模。而对于隐式生成模型,你必须进行采样才能了解我们的模型分布。
当我们评估生成模型时,一种方法(在论文中看起来很不错)是使用图像。因此我们可以从我们的模型分布中进行采样,然后视觉检查样本,以查看它们与原始数据的匹配程度。我们的样本图像与训练图像越接近,我们的模型就越好。
生成模型的类型
在深度学习的背景下,当我们谈论生成模型时,我们通常指的是四种模型中的一种:
-
自回归
-
可逆
-
变分自编码器
-
生成对抗网络
自回归模型: 使用自回归模型,你通过生成每个像素,依据你已经生成的前一个像素来生成图像。也就是说,当你使用自回归模型生成图像时,你是逐像素生成图像的。这是一个自回归模型的例子。
可逆模型: 可逆模型的概念是将 GAN 的生成器过程变为可逆的。这意味着我们可以通过可逆模型双向传递图像和噪声——从噪声到图像,再从图像到噪声。这是一个可逆模型的例子。
变分自编码器: 自编码器由一对连接的网络组成:编码器和解码器。变分自编码器的特点是具有连续的潜在空间。这允许轻松的采样和插值,这在变分自编码器用于探索在指定方向上对现有数据的变化时特别有用。这是一个变分自编码器的例子。
生成对抗网络
现在,在经历了其他生成模型之后,我们来到了 GAN——生成对抗网络。

(图像来自Brock 2018)
首先,让我们查看一些由 GAN 生成的图像,以了解过去五年取得了多大进展。上述图像是无条件生成的 ImageNet 样本,来自 2019 年 Andrew Brock 在 ICLR(国际学习表征会议)上展示的 BigGAN 模型。
这些图像样本的显著之处在于两个主要原因:清晰度和类别的多样性。你有动物、蘑菇、食物、风景——所有这些都一起生成,所有图像都有清晰的分辨率。
但情况并非一直如此。

(图像示例来自Goodfellow et al 2014)
这是 2014 年 Ian Goodfellow 等人发表的原始 GAN 论文中的图像。当这篇论文发布时,这是当时最先进的图像生成技术。但与 BigGAN 生成的样本相比,它们相距甚远。仅从这些来自 Toronto 面部数据集的样本中,你可以看到这些图像的分辨率非常低,特征没有完全解析。

(图像示例来自Karras et al. 2019)
现在快进四年到 Nvidia 的 StyleGAN 论文,这些生成的人物看起来非常逼真。从 2014 年的模糊起点开始,GAN 生成的面孔在短短 4 年内几乎无法与真实人物区分。
GAN 概述
和我们讨论的其他模型一样,GANs 是一种生成模型。然而,与我们讨论的其他模型不同,GAN 是一种隐式生成模型。为了刷新记忆,这意味着如果我们想查看模型对分布的好坏,我们必须对其进行采样。
那么,GANs 是如何工作的呢?
在 GAN 中,我们有两个网络:生成器(生成组件)和判别器(对抗组件)。
判别器的训练目标是识别生成的样本并将其与真实样本区分开来。我们通过将一组真实样本和一组生成样本输入判别器,来训练判别器,以尝试分类哪些样本是真实的。通过训练,我们希望判别器能够识别样本是否来自真实分布还是生成分布。
判别器的对手是生成器,它接收随机噪声并学习将这些随机噪声转化为看起来逼真的样本——足够逼真以最终欺骗判别器。
这会随着时间的推移发生,因为生成器在生成看起来像真实样本的样本方面变得越来越好,而判别器则会达到一个点,在这个点上它对样本是现实还是生成的做出随机猜测。我们可以将其视为一个双人博弈,这个判别器进行随机猜测的点是其纳什均衡。
训练 GAN 生成器
进一步探讨训练,生成器是如何学习将随机噪声转化为能够通过判别器的图像的?
生成器从样本中获取数据——通常来自高斯分布——并通过神经网络进行变换以创建样本。同样,目标是使这个样本看起来尽可能真实。
起初,这些变换确实是完全无意义的。所以你将随机噪声传递给生成器,你得到的另一端看起来很像随机噪声。


(噪声到图像变换过程的插图。噪声来自 Adobe Stock,面孔来自 Karras et al. 2018)
现在,当你生成一个灰度点的图像,并将其传递给判别器时,大多数情况下,判别器会说这看起来不像真实样本。通过反向传播,你会得到一个信号传递到生成器,指示生成器中的层根据刚刚发送给判别器的样本的糟糕表现更新其权重。
在这些调整之后,更多的随机噪声通过生成器生成新的图像,发送给鉴别器。这次,鉴别器可能会被我们的样本欺骗,因为——这主要是由于训练早期的随机性——图像中有一些特征类似于真实数据集。生成器然后收到一个信号,表示最后的样本表现良好,随后会相应更新其权重。
通过许多次迭代以及大量的图像,生成器的权重会根据它们在欺骗鉴别器方面的表现不断更新。如果训练顺利,生成器可以将随机噪声转化为现实感很强的图像。
生成器和鉴别器都可以完全无监督地使用这个过程进行训练,并生成优秀的样本——这要归功于损失函数所创造的动态。
GANs 中的损失函数
在 GANs 中,生成器和鉴别器各自拥有自己的损失函数。虽然这两个不同的损失函数允许我们看到 GANs 的无监督学习,但它们也在训练中带来了一些挑战。
鉴别器的成本在于它希望正确识别真实样本为真实,并希望正确识别生成的样本为生成(公式 1)。
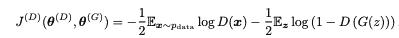
(公式 1)
你可以看到左边的第一个项表示识别真实样本为真实,右边的项表示识别生成的样本为生成。
这里有趣的是,生成器的成本只是该函数的负值(公式 2)。

(公式 2)
你会看到,这里我们有一个常量,用于表示方程中鉴别器识别真实样本为真实的部分——因为生成器与这个过程的这一部分没有直接关系。但人们发现,如果使用顶部方程中的生成器损失函数,损失会饱和。所以我们所做的是稍微改变一下公式(公式 3)。
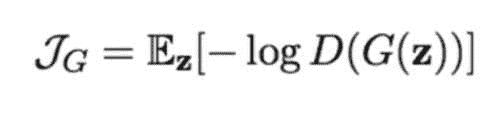
(公式 3)
使用这种版本的损失函数,生成器如果创建出鉴别器容易识别为生成的样本,就会收到很强的信号。通过使用这个第二方程,它不再完全是一个二人最小化博弈的公式,但训练效果如我们所希望的那样——并且训练比其他方法更稳定。
GANs 的应用
现在我们已经掌握了训练 GANs 的基本知识,让我们深入探讨一些应用。
GANs 最早被识别的应用之一来自 Goodfellow 的原始论文,其中展示了 MNIST 中数字 1 和 5 之间的插值。这是一种表示学习,因为通过训练生成器和鉴别器,我们可以学习到原始数据集的潜在表示。

(图像来自 Karras et al. 2019)
你可以在 StyleGAN 论文(上面)中的图像以及许多其他 GAN 论文中看到相同的应用。
我们在这个特定示例中看到的是,我们将源 A 的风格应用到源 B 的结构上。在左上角,我们将眼镜应用到不同的图像上,或者让左侧的人看起来像年轻的孩子。

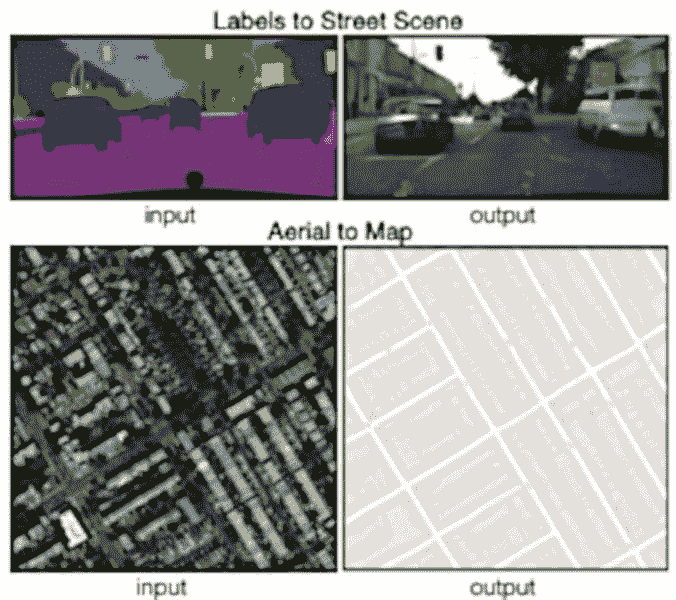
(图像示例来自 Zhu et al. 2017 和 Isola et al. 2016)
GAN 的另一个应用是图像转换——在某些情况下,这是一种更通用的风格迁移方法。
在左侧(Zhu),我们看到 CycleGAN 对图像进行了一些增强,而在右侧的 Pix2Pix 论文(Isola)中,我们将图像从一种风格转换为另一种风格。
所以左侧是街景的分割图,右侧是真实图像。然后从航空图到地图,我们有一张卫星图像和类似地图的图像。
当你用 Pix2Pix 模型训练这种类型的转换时,你可以从卫星图像转换到地图,反之亦然。因此,如果你希望在图像集合上进行风格迁移,这些模型效果最好。
GAN 的挑战
但 GAN 的所有进展并没有没有遇到挑战。
理论上,GAN 作为一个有序的双玩家最小化游戏,慢慢达到纳什均衡。我们将噪声传递给生成器,生成器学会欺骗判别器,然后判别器停止有效地检测差异,并开始随机猜测,理论上如此。
有三个主要挑战阻碍 GAN 作为这种最小化游戏运行:
-
模式崩溃
-
挑剔的训练
-
GAN 的评估
模式崩溃
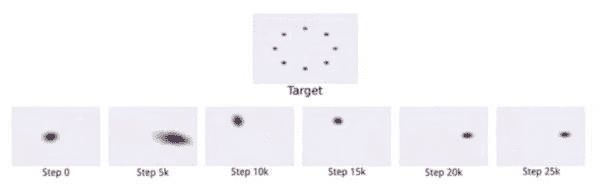
(模式崩溃的图像来自 Goodfellow 2016)
在模式崩溃中,模型仅学习到多模态数据集中的一种或几种模式。我们训练 GAN 的数据通常具有非常多的模式,这使得模式崩溃成为一个问题。
挑剔的训练
然后就是挑剔的训练问题。之前我们提到了生成器和判别器的成本函数。由于这个模型中有两个不同的成本函数,因此在平衡它们方面会比其他情况更具挑战性。
评估 GAN
评估 GAN 时,有几个问题需要考虑。
首先,生成器生成的好样本不一定意味着你已经很好地学习了分布。
接下来,估计可能性(这是衡量你学习分布效果的指标)可能非常困难。这也导致了第三个问题:很难真正知道你学到了多少分布。
最后,评估 GAN(生成对抗网络)是一个活跃的研究领域,目前尚无通用的评估方法。许多论文提出了新的评估指标,但这些指标在未来的出版物中并未受到关注。
GAN 的未来
GAN 接下来会走向何方?
我们在本概述中主要讨论了 GAN 生成图像,但这远非我们今天或明天看到的 GAN 应用的唯一方向。
GAN 还在音频生成(如语音模仿)、新药研发、建筑平面设计、结构组件生成、图形设计布局、表格数据生成等方面取得了突破。
随着这一类机器学习模型在不同产业和应用中不断发展壮大,且人们对 GAN 的概念越来越熟悉,他们将继续发现更多的应用领域。因此,从 2014 年到今天及未来,GAN 仍有很长的路要走,才能充分挖掘这一优雅对抗系统所带来的所有机会。
简介: 安德鲁·马丁是 Looka 的首席数据科学家,Looka 是一个AI 驱动的 logo 生成器,为企业主提供了快速且经济实惠的品牌创建方式。安德鲁曾创办 Eco Modelling,这是一家向林业和能源领域的客户提供数据解决方案的咨询公司。他拥有达尔豪斯大学工业工程硕士学位和麦吉尔大学数学学士学位。
相关:
更多相关话题
什么是对抗性机器学习?
原文:
www.kdnuggets.com/2022/03/adversarial-machine-learning.html

Clint Patterson via Unsplash
随着机器学习(ML)的不断发展,我们的社会在现实世界中越来越依赖其应用。然而,我们对机器学习模型的依赖程度越高,对抗这些模型的漏洞也就越多。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
“对手”的字典定义是:
“一个与之争斗、对抗或抵抗的存在”
在网络安全领域,对抗性机器学习试图通过创建独特的欺骗性输入来欺骗和扰乱模型,从而导致模型功能失常。
对手可能会输入意图破坏或更改输出的数据,并利用其漏洞。我们无法通过肉眼识别这些输入,但它会导致模型失败。
在人工智能系统中,存在不同形式的漏洞,如文本、音频文件和图像。进行数字攻击要容易得多,例如仅通过操控输入数据中的一个像素,这可能会导致错误分类。
要高效地训练机器学习模型并生成准确的输出,你需要大量标记的数据。如果你没有从可靠来源收集数据,一些开发者会使用来自 Kaggle 或 GitHub 的数据集,这些数据集可能存在潜在的漏洞,从而导致数据中毒攻击。例如,有人可能篡改了训练数据,影响了模型生成正确和准确输出的能力。
对抗性攻击有两种不同的类型:白盒攻击和黑盒攻击。
白盒攻击与黑盒攻击
白盒攻击是指攻击者对目标模型拥有完全访问权限,包括模型的架构和参数,这使他们能够在目标模型上创建对抗样本。白盒攻击者只有在测试模型时才会拥有这种访问权限,作为开发者,他们对网络架构有详细了解。他们了解模型的内外,并基于损失函数制定攻击策略。
黑盒攻击指的是当攻击者无法访问目标模型,只能检查模型的输出。他们通过查询访问生成对抗样本。
对抗性攻击在人工智能/机器学习中的应用
存在不同类型的对抗性攻击。
投毒
在训练阶段对机器学习模型的攻击被称为“投毒”或“污染”。这需要攻击者能够访问或控制训练数据,根据我们的理解,这被称为白盒攻击者。
攻击者向分类器输入错误标记的数据,这些数据被他们视为无害,但却会产生负面影响。这将导致错误分类,未来产生不正确的输出和决策。
攻击者可以利用他们对模型输出的理解来操控模型,尝试逐步引入减少模型准确性的数据显示,这被称为模型偏斜。
例如,搜索引擎平台和社交媒体平台内置了使用机器学习模型的推荐系统。攻击者通过使用虚假账户分享或推动某些产品或内容来操控推荐系统,从而改变推荐系统的效果。
规避攻击
规避攻击通常发生在机器学习模型已经被训练完毕且新数据已被输入的情况下。这也被称为白盒攻击,因为攻击者可以访问模型并使用试错过程来理解和操控模型。
攻击者对模型的知识有限,不知道哪些因素会导致模型失效,因此使用试错过程。
例如,攻击者可能会调整一个过滤垃圾邮件的机器学习模型的边界。他们的方法可能是实验那些模型已经被训练用来筛选并识别为垃圾邮件的邮件。
如果模型已经被训练以过滤包含“快速赚钱”等词语的邮件;攻击者可能会创建包含这些词语相关或非常相似的新邮件,从而绕过算法。这会导致本应被分类为垃圾邮件的邮件不再被识别为垃圾邮件,从而削弱了模型的效果。
然而,还有更恶意的原因,例如攻击者使用自然语言处理(NLP)模型获取和提取个人信息,如身份证号码,导致更多的个人攻击。
模型提取
黑盒攻击的一种形式是模型提取。攻击者无法访问模型,因此他们的过程是尝试重建模型或提取输出数据。
这种类型的攻击在那些高度保密且可以变现的模型中尤为突出,例如提取股票市场预测模型。
一个黑箱攻击的例子是使用图神经网络(GNN),它们被广泛用于分析图结构数据,例如社交网络和异常检测。GNN 模型是有价值的资产,成为对手的吸引目标。
数据的所有者训练了一个原始模型,对手则接收一个模仿原始模型的另一个模型的预测。对手可能会对这些输出按查询付费的方式向他人收费,从而复制模型的功能。这本质上允许对手通过使用持续调优的过程来重建模型。
如何避免对抗攻击
以下是公司应实施的两种简单方法,以避免对抗攻击。
在被攻击之前进行攻击和学习
对抗训练是一种提高机器学习效率和防御的方法,即对其生成攻击。我们简单地生成大量对抗样本,并允许系统学习潜在的对抗攻击是什么样的,帮助它建立自己的对抗攻击免疫系统。通过这种方式,模型可以通知或不被每一个对抗样本欺骗。
频繁更改你的模型
持续更改机器学习模型中使用的算法将为对手创造定期的阻碍,使他们更难破解和学习模型。做到这一点的一种方法是通过试错法破坏自己的模型,以区分其弱点并了解所需的改进,以减少对抗攻击。
结论
很多公司正在投资人工智能技术,以现代化其解决问题和决策的能力。国防部(DoD)尤其受益于人工智能,在数据驱动的情况下可以提高意识并加快决策速度。DoD 承诺增加对人工智能的使用,因此必须测试其能力和局限性,以确保人工智能技术符合正确的性能和安全标准。然而,这是一项重大挑战,因为人工智能系统可能不可预测并适应行为。
我们必须更加警惕和理解与机器学习相关的风险以及数据被利用的高概率。投资和采用机器学习模型及人工智能的组织必须纳入正确的协议,以减少数据损坏、盗窃和对抗样本的风险。
尼莎·阿娅是一名数据科学家和自由技术作家。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探索人工智能如何/可以有利于人类寿命的不同方式。作为一个热衷的学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关内容
对抗性验证概述
原文:
www.kdnuggets.com/2020/02/adversarial-validation-overview.html
评论
如果你研究一些 Kaggle 上的竞赛获胜解决方案,你可能会注意到对“对抗性验证”的引用(例如这个)。这是什么?
简而言之,我们构建一个分类器来尝试预测哪些数据行来自训练集,哪些来自测试集。如果这两个数据集来自相同的分布,那么这应该是不可能的。但是,如果训练集和测试集的特征值存在系统性的差异,那么分类器将能够成功地学会区分它们。你越能训练出一个更好的模型来区分它们,你面临的问题就越大。
不过好消息是你可以分析学习到的模型来帮助你诊断问题。一旦你理解了问题,你就可以开始解决它。
本文旨在配合我制作的YouTube 视频来解释对抗性验证的直觉。这个博客帖子逐步讲解了这个视频中展示的示例的代码实现,但足够完整,可以自成一体。你可以在GitHub上找到这篇文章的完整代码。
学习对抗性验证模型
首先,一些基本的导入语句以避免混淆:
import pandas as pd
from catboost import Pool, CatBoostClassifier
数据准备
对于本教程,我们将使用来自 Kaggle 的IEEE-CIS 信用卡欺诈检测数据集。首先,我假设你已经将训练数据和测试数据加载到 pandas DataFrames 中,并分别命名为df_train和df_test。然后,我们将通过替换缺失值来进行一些基本的清理。
# Replace missing categoricals with ""
df_train.loc[:,cat_cols] = df_train[cat_cols].fillna('')
df_test.loc[:,cat_cols] = df_test[cat_cols].fillna('')
# Replace missing numeric with -999
df_train = df_train.fillna(-999)
df_test = df_test.fillna(-999)
对于对抗性验证,我们希望学习一个模型,预测哪些行在训练数据集中,哪些行在测试集中。因此,我们创建一个新的目标列,其中测试样本标记为 1,训练样本标记为 0,如下所示:
df_train['dataset_label'] = 0
df_test['dataset_label'] = 1
target = 'dataset_label'
这是我们将训练一个模型来预测的目标。现在,训练集和测试集是分开的,每个数据集只有一个目标值的标签。如果我们在这个训练集上训练一个模型,它只会学到一切都是 0。我们希望将训练集和测试集进行洗牌,然后创建新的数据集来拟合和评估对抗性验证模型。我定义了一个用于合并、洗牌和重新拆分的函数:
def create_adversarial_data(df_train, df_test, cols, N_val=50000):
df_master = pd.concat([df_train[cols], df_test[cols]], axis=0)
adversarial_val = df_master.sample(N_val, replace=False)
adversarial_train = df_master[~df_master.index.isin(adversarial_val.index)]
return adversarial_train, adversarial_val
features = cat_cols + numeric_cols + ['TransactionDT']
all_cols = features + [target]
adversarial_train, adversarial_test = create_adversarial_data(df_train, df_test, all_cols)
新的数据集,adversarial_train 和 adversarial_test,包括了原始训练集和测试集的混合,并且目标指示了原始数据集。注意:我将 TransactionDT 添加到了特征列表中。这一点的原因将在之后变得明显。
对于建模,我将使用 Catboost。我通过将 DataFrames 放入 Catboost Pool 对象中来完成数据准备。
train_data = Pool(
data=adversarial_train[features],
label=adversarial_train[target],
cat_features=cat_cols
)
holdout_data = Pool(
data=adversarial_test[features],
label=adversarial_test[target],
cat_features=cat_cols
)
建模
这一部分很简单:我们只需实例化一个 Catboost 分类器,并在我们的数据上进行训练:
params = {
'iterations': 100,
'eval_metric': 'AUC',
'od_type': 'Iter',
'od_wait': 50,
}
model = CatBoostClassifier(**params)
_ = model.fit(train_data, eval_set=holdout_data)
让我们继续绘制持出数据集的 ROC 曲线:
这是一个完美的模型,这意味着可以明确区分任何给定记录是否在训练集或测试集中。这违反了我们训练集和测试集是同分布的假设。
诊断问题并进行迭代
要了解模型是如何做到这一点的,我们来看看最重要的特征:
TransactionDT 仍然是最重要的特征。这完全可以理解,因为原始训练集和测试集来自不同的时间段(测试集发生在训练集的未来)。模型刚刚学会了如果 TransactionDT 大于最后一个训练样本,它就属于测试集。
我包括了 TransactionDT 只是为了说明这一点——通常不建议将原始日期作为模型特征。然而,这一技术以如此戏剧性的方式发现了这一点,这确实是好消息。这项分析显然将帮助你识别这样的错误。
让我们去掉 TransactionDT,再次运行此分析。
params2 = dict(params)
params2.update({"ignored_features": ['TransactionDT']})
model2 = CatBoostClassifier(**params2)
_ = model2.fit(train_data, eval_set=holdout_data)
现在 ROC 曲线如下所示:
这仍然是一个相当强的模型,AUC > 0.91,但比之前要弱得多。让我们看看这个模型的特征重要性:
现在,id_31是最重要的特征。让我们查看一些值来了解它是什么。
[
'', 'samsung browser 6.2', 'mobile safari 11.0',
'chrome 62.0', 'chrome 62.0 for android', 'edge 15.0',
'mobile safari generic', 'chrome 49.0', 'chrome 61.0', 'edge 16.0'
]
本栏目包含软件版本号。显然,这在概念上类似于包含原始日期,因为特定软件版本的第一次出现将对应其发布日期。
让我们通过从列中删除任何非字母字符来绕过这个问题:
def remove_numbers(df_train, df_test, feature):
df_train.loc[:, feature] = df_train[feature].str.replace(r'[^A-Za-z]', '', regex=True)
df_test.loc[:, feature] = df_test[feature].str.replace(r'[^A-Za-z]', '', regex=True)
remove_numbers(df_train, df_test, 'id_31')
现在我们栏目的值如下所示:
[
'UNK', 'samsungbrowser', 'mobilesafari',
'chrome', 'chromeforandroid', 'edge',
'mobilesafarigeneric', 'safarigeneric',
]
让我们使用这个清理过的列训练一个新的对抗验证模型:
adversarial_train_scrub, adversarial_test_scrub = create_adversarial_data(
df_train,
df_test,
all_cols,
)
train_data_scrub = Pool(
data=adversarial_train_scrub[features],
label=adversarial_train_scrub[target],
cat_features=cat_colsc
)
holdout_data_scrub = Pool(
data=adversarial_test_scrub[features],
label=adversarial_test_scrub[target],
cat_features=cat_colsc
)
model_scrub = CatBoostClassifier(**params2)
_ = model_scrub.fit(train_data_scrub, eval_set=holdout_data_scrub)
现在 ROC 图如下所示:
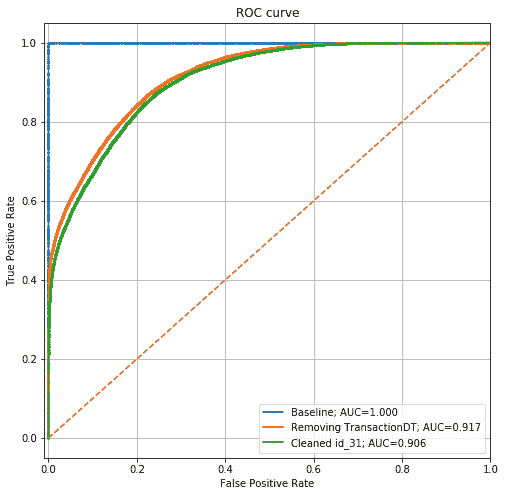
性能从 0.917 的 AUC 下降到 0.906。这意味着我们让模型区分训练集和测试集的难度稍微增加了一点,但它仍然相当有能力。
结论
当我们天真地将交易日期投入特征集时,对抗验证过程帮助我们清楚地诊断了问题。额外的迭代给了我们更多线索,表明包含软件版本信息的列在训练集和测试集之间存在明显差异。
但这个过程无法告诉我们如何修复它。我们仍然需要发挥创造力。在这个例子中,我们简单地从软件版本信息中移除了所有数字,但这丢弃了潜在有用的信息,并可能最终损害我们的欺诈建模任务,这才是我们的真正目标。其想法是你需要移除对预测欺诈不重要但对分离训练和测试集重要的信息。
一个更好的方法可能是找到一个数据集,提供每个软件版本的发布日期,然后创建一个“自发布以来的天数”列,替代原始版本号。这可能更适合训练和测试分布,同时保持软件版本信息所包含的预测能力。
相关:
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关话题
申请数据科学职位的建议
原文:
www.kdnuggets.com/2018/06/advice-applying-data-science-jobs.html
评论
作者 Emily Robinson, Datacamp。

我们的前三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
遵循 Dave Robinson 的明智推文,建议在你三次给出相同建议时写一篇博客文章,这篇文章汇集了我对有意申请美国数据科学职位的人的想法和建议。许多原则也适用于一般的技术职位。
免责声明:我从未担任过招聘人员或职业教练。这些知识主要来源于我在研究生院学习的组织行为(包括谈判和女性在技术领域)以及我自己的职业经历。这些建议也不适用于每一个情况。那些最有可能从这篇文章中受益的人可能是申请第一份数据科学工作的求职者和/或正在读书或刚刚毕业的人。如果有其他建议或警告,我应该添加,请在 Twitter 上给我发消息!
跳转到:
-
应用
-
在线存在
-
寻找和评估工作
-
简历和求职信
-
-
面试
-
录用阶段
-
初步回应
-
多重选择
-
谈判
-
应用
在线存在

盘点你的在线存在。检查你在 Facebook 或其他社交媒体上的隐私设置,确保你限制了公开的信息。虽然许多在线职位申请现在有填写 Twitter 账号的地方,但除非你主要以专业方式使用它(例如,发布数据科学资源或宠物相关内容。宠物内容总是合适的),否则不要包含你的 Twitter 账号。
如果你有一个 GitHub 账户,可以固定你希望他人看到的仓库,并添加解释项目内容的 README。我还强烈建议创建一个博客,写关于数据科学的内容,无论是你参与的项目、机器学习方法的解释,还是你参加的会议总结。如果你需要更多理由相信博客是时间的良好利用,可以查看 Dave Robinson 发表的这篇文章。如果你使用 R 编程,你可以使用 blogdown 来创建网站。
Emily Zabor 撰写了一个很棒的教程;在 Mara Averick 的详尽列表中找到更多 blogdown 资源。如果你不使用 R,你可以直接使用 Hugo(blogdown 是基于 Hugo 构建的)或从 Medium 开始。
找到和评估工作
-
广泛浏览:数据科学领域的职位有许多不同的名称,如数据科学家之外的还有:产品分析师、数据分析师、研究科学家、量化分析师和机器学习工程师。不同公司对类似职位使用不同名称,有些公司正在改变他们职位的含义(请参见 Lyft 的文章 关于他们最近将数据分析师转为数据科学家、数据科学家转为研究科学家的变化)。甚至数据分析师与数据科学家的定义也没有达成一致(请参见 Mikhail Popov 总结不同观点的这篇文章)。尝试搜索这些术语以找到职位,然后利用描述来评估是否适合。如果你对初创公司感兴趣,Angelist 上有成千上万个职位,其中很多职位列出了薪资范围。
-
进行自我反思:与其申请你找到的每一种数据科学职位,不如考虑一下你想要专注于哪个领域。在考虑我自己的职业生涯和查看工作时,我发现一个有帮助的区分是类型 A 与类型 B 数据科学家。 “A”代表分析:类型 A 数据科学家具有强大的统计技能,能够处理混乱的数据并传达结果。 “B”代表构建:类型 B 数据科学家拥有非常强的编码技能,可能有软件工程背景,专注于将机器学习模型(如推荐系统)投入生产。还要考虑你希望公司处于哪个数据阶段(见Robert Chang 的帖子中的讨论)。在小公司工作的一个优势是你可以尝试数据科学的不同部分;大公司则更专业化,因此你可能无法同时尝试创建生命周期价值模型和调整推荐系统,而且许多问题,如数据工程,都会被抽象化。另一方面,在小公司你通常需要更多地处理数据质量问题、糟糕的文档和缓慢的查询处理。虽然数据阶段与公司规模相关,但一个存在了 100 年的大公司可能没有数据科学的成熟度。
-
不要苛求完美:你在该领域的第一份工作可能不会是你理想中的工作。在你的领域内转型或将数据科学融入到你当前的角色中会更容易;即使你最终希望离开你的领域,你也可能需要从一个可以发挥你其他技能的职位开始。这并不意味着你不应该有某些要求和偏好(见上文),但这意味着你需要保持一定的灵活性。在科技行业中,即使仅仅工作了一两年,换工作也是非常正常的,所以你并不是在签约接下来的 15 年。对我来说,第一份工作的最重要标准是它提供了一个支持性的环境,有很多其他分析师,我可以学到很多东西。正如 Jonathan Nolis 所指出的,你无法在进入领域之前确切知道你想要什么,即便是糟糕的工作也能让你有所收获,所以不要过于焦虑:
在我的职业生涯初期,我花了很多情感上的精力去弄清楚哪份工作对我“合适”,以及我到底需要什么,但现在我意识到,即使是那些糟糕的工作也给我提供了很好的经验,帮助我了解什么对我重要。2/
— Jonathan Nolis (@skyetetra) 2018 年 5 月 29 日

-
不要低估自己:职位描述通常是一些愿望清单,具有一定的灵活性。如果你符合 80%的要求(例如,你的工作经验比他们要求少一年,或没有使用过他们技术栈中的某个组件),但整体上仍然适合,还是应该申请。话虽如此,要警惕那些描述“独角兽”的职位描述——例如,要求拥有计算机科学博士学位,同时在数据科学领域有 5 年以上的工作经验,并且在前沿统计学、深度学习和与商业伙伴沟通方面都是专家,并列出一系列职责,从生产级别的机器学习到创建仪表板,再到运行 A/B 测试。这通常意味着他们不清楚自己需要什么,并且期望数据科学家能够在没有任何支持的情况下解决所有问题。
-
在 LinkedIn 上寻找联系:查看你是否认识感兴趣公司的任何人。如果不认识,可以看看你的校友网络(如训练营、大学、那个你夏天参加过的踢球队)中是否有相关的人。你也可以查看二级联系人,看看能否通过某个联系人引荐你。许多职位会收到数百甚至数千份申请,能够获得推荐或对团队需求的反馈非常有帮助。如果你确实联系了某人,请花时间定制消息:如果你不认识那个人,要做一些研究并提及他们的背景或公开工作。
-
查看聚会和会议:有时招聘经理会来聚会或会议上招募。你也可能遇到你感兴趣的公司或子行业中的某个人。你可以询问他们是否有时间进行信息访谈,以便了解更多关于他们领域的信息。不过,如果你询问他们的公司是否有职位空缺或是否可以推荐你,你可能会被指引到公司的招聘页面。这就是为什么在你需要之前建立网络很重要——一开始就强求不利于建立互惠互利的关系。
如果你有兴趣了解更多关于如何建立你的网络的信息,可以查看我之前的帖子,关于寻找社区和建立联系。
简历和求职信
-
保持简历在一页内:你不必列出你做过的所有事情。尝试制作一份包含所有工作经历的主简历,然后从中挑选与每个职位最相关的内容。不要列出你用过的每一项技术;专注于你能自如谈论的那些技术。招聘人员的建议是:“不要使用显示你在某些技术领域经验的图表。如果你的 Python 条满了,你真的了解 Python 的所有内容吗?”如果空间不够,并且有总结或目标陈述,可以省略这些,因为现在它们不那么常见。如果你来自学术界并且有工作经验,考虑省略出版物,如果招聘方不要求博士学位或这是一个研究职位。
-
校对:简历中有拼写或语法错误可能是最快导致你申请被淘汰的方式。使用拼写检查工具,并让一个朋友或几个人帮你检查一下。
-
不要包含图片:虽然在一些欧洲和南美国家这很常见,但在美国不太合适。
-
根据职位调整你的简历:大公司通常有自动化简历筛选系统,检查关键词。查看职位描述,找出那些词;你可以使用TagCrowd工具查看最常见的词。例如,它是用领导力而不是管理吗?是 NLP 还是自然语言处理?将你的词语调整成他们的。
-
用动词开头你的要点:写“分析了 300 篇论文”而不是“我分析了 300 篇论文”。
-
量化你的成就:不要说“对我们的排名算法进行了实验”,而是写“进行了 60 多次实验,带来了 230 万美元的额外收入。”
-
写一封求职信:如果有地方提交求职信,请务必提交。一些公司会因为没有求职信而淘汰候选人。就像你的简历一样,你可以制作一份主求职信,从中提取段落。至少将首段和结尾段调整到公司,确保正确填写他们的名字!你越具体越好;展示你已经做了关于公司的研究,并且有明确的理由为什么你对这个职位感兴趣。尽量找到招聘经理的名字(见这里),这样你可以直接称呼他们,而不是“亲爱的招聘经理。”如果你想要更多关于写好求职信的指导,以下31 个技巧和5 个常见短语文章是很好的起点。
数据科学招聘公告:
一些建议说求职信不重要,所以你只需在简历上改个文件名标注为求职信,或者写一句话“这是我的求职信”。
这是个不好的建议。
— Jesse Maegan (@kierisi) 2018 年 5 月 7 日
面试
-
准备和练习:你会被问到两种主要的问题——技术问题和行为问题。对于像“告诉我一个你和团队成员发生冲突的例子”或“你最大的优点是什么”这样的行为问题,使用情况-行为-结果模型讲一个故事:描述你面临的情况、你是如何处理的以及结果如何。尽量保持回答简洁但全面。保持一份这些例子的清单,并考虑哪些最能展示与你面试的特定工作最相关的经验和特质是很有价值的。对于技术问题,你需要了解面试的结构。面试的结构和问题类型差异很大:你可能需要做一个带回家的任务,回答计算机科学问题(例如,翻转二叉树),解释随机森林,做一个演讲,写 SQL 代码等等。提前了解预期内容非常有帮助。查看 Glassdoor 上的面试过程评价,并询问你的网络中是否有人在那儿面试过。你也可以在初步电话筛选中向 HR 询问预期内容。如果你要参加多轮面试,你可以询问每一轮将涉及的主题和结构(例如,“我会做白板编程吗?”)。一旦知道了,你可以集中准备。如果你在解决某个问题时感到困惑,可以考虑说:“我不确定,但这是我解决它的方法。”通常,评估的是你如何解决问题,而不是你是否得到了正确的答案。欲了解更多建议,请查看 Trey Causey 的帖子 关于他在数据科学就业市场的经历,Erin Shellman 的指南 介绍如何获得数据科学职位,以及 Mikhail Popov 的帖子 关于维基媒体基金会的数据分析师职位招聘流程。
-
简历上的任何内容都可能成为考察点:如果你简历上有六年前的实习经历或列出了 AWS 作为技能,请准备好被问到相关问题。
-
研究公司:你在写求职信时应该做过一些调查,但一旦你获得面试机会,应该深入了解一下。除了下面讨论中的建议外,了解一下你的面试官的职业成就。我在面试时被一个候选人提出了一些关于我曾经做的演讲的技术问题时,留下了深刻的印象。
尤其是如果你在一家初创公司面试,花一个小时做研究是很值得的。以下是公式:
Crunchbase。了解融资情况、投资者等信息。
LinkedIn。谁在这里工作?
Glassdoor。人们对公司怎么说?
公司网站。尽可能多地阅读。
— Jensen Harris (@jensenharris) 2018 年 5 月 16 日
-
准备好问题:每位面试官应该在最后留时间提问。如果没有,那是个坏兆头!面试是一个双向匹配的过程:你在评估他们,就像他们在评估你一样。如果你不知道问什么,可以查看Julia Evans 的列表。她将问题分为生活质量、文化和管理实践等类别;考虑一下对你来说什么最重要!你可以向每位面试官提出不同的问题,以最大化你能获得的答案数量,也可以尝试向多个人提相同的问题,看看他们的回答是否不同。如果是初创公司,我强烈推荐查看这个列表以获取提问的建议。
-
绝不要提及薪资数字:不要告诉他们你目前的薪资或对这份工作的期望。在一些地方,包括纽约市和加利福尼亚,询问你当前薪资实际上是违法的。如果你给出一个数字,你可能会面临他们提供的报价低于本来应该给出的水平。你的报价不应依赖于你当前的薪资或期望;它应该基于你在市场上的价值,并且与同行的薪资类似!如果申请表上有相关问题,填“NA”或“flexible”;如果被迫写一个数字,填 0,并在其他地方加上“注意:我在薪资问题上填了\(0,因为如果我们确定有相互匹配的地方,我在薪资上是灵活的。”](https://www.themuse.com/advice/answer-illegal-salary-question-right-way)如果在面试中被问到,试着将话题引导到“在讨论薪资之前,我希望更多了解这个职位,并专注于我可以为公司带来的价值。我相信,如果适合的话,我们可以就一个具有竞争力的整体薪资包达成一致。”如果谈论的是你当前的薪资而你在一个薪资较低的不同职位/行业中,你可以说[“由于这个职位与我当前的工作有很大的变化,让我们讨论一下我在公司中的职责,并在过程中共同确定一个公平的薪资。”](https://biginterview.com/blog/2015/10/salary-expectations.html)如果他们坚持要知道你的期望,可以根据对行业和公司标准的研究给出一个大的范围。例如,你可以说,“根据我的研究和过去的经验,我了解到的标准基础薪资范围是\)如果在面试中被问到,试着将话题引导到“在讨论薪资之前,我希望更多了解这个职位,并专注于我可以为公司带来的价值。我相信,如果适合的话,我们可以就一个具有竞争力的整体薪资包达成一致。”如果谈论的是你当前的薪资而你在一个薪资较低的不同职位/行业中,你可以说“由于这个职位与我当前的工作有很大的变化,让我们讨论一下我在公司中的职责,并在过程中共同确定一个公平的薪资。”如果他们坚持要知道你的期望,可以根据对行业和公司标准的研究给出一个大的范围。例如,你可以说,“根据我的研究和过去的经验,我了解到的标准基础薪资范围是$95k 到$120k,但我更关心的是与职位的匹配程度和整体薪酬包。”你可以查看H1B 签证数据、Glassdoor和paysa来给自己一个大致的了解。并且,和朋友们聊聊!知识就是力量。一些友好的朋友也会进行薪资信息交换:
在这个话题上,我的私信始终开放,如果你想告诉我你的薪资。尤其是如果你在数据领域工作,工作在多伦多,或者在 0-3 年经验的“技术”岗位上。如果你是 URM,我也会告诉你我的。知识就是力量 ????
— Sharla Gelfand (@sharlagelfand) 2018 年 4 月 15 日
- 优雅地处理拒绝:你几乎不可避免地会被拒绝,可能是几十次。数据科学领域竞争激烈,这是一种每个人都会经历的非常正常的过程。如果他们给了你拒绝(而不是只是永远没有回应),你可以礼貌地表达你的失望(例如:“很遗憾听到这个消息”)并感谢他们的考虑。你可以请求反馈,但要知道许多招聘经理可能无法给出反馈,因为他们希望避免评论被解读为歧视的可能性。虽然可以花一点时间来低落,但不要在公众或对招聘经理发泄情绪。这不会帮助情况,但会伤害你的职业声誉。
其中一件应该不言而喻的事情是,优雅地处理拒绝非常重要。数据科学职位可能非常竞争。进行公开崩溃和/或向招聘经理发送恶意/要求的电子邮件是...不好的。
— Jesse Maegan (@kierisi) 2018 年 5 月 29 日
报价阶段
初步回应
对于初步报价,你可能会接到电话、收到详细信息的电子邮件,或收到要求通过电话讨论报价的电子邮件。在所有情况下,确保表达你的兴奋和感激之情。不要立即接受:要求书面报价,说明你需要时间审阅,并询问是否可以在几天后重新联系。这为谈判奠定了基础,并且如果你在考虑其他报价,也会给你时间。如果你需要更多信息(例如,入职日期可能性、健康保险信息),你应该在第二次谈话前提出,以便你能了解完整情况。
同时处理多个选择
不幸的是,你可能不会同时收到所有感兴趣公司的报价(或拒绝)。更可能的是,当你收到一个报价时,你可能在另一个公司的最后阶段,刚刚完成了另一个公司的电话面试,并在等待其他公司的回复。如果你等待的其中一个是你的“梦想工作”怎么办?
如果你正在或非常接近与某家公司进行最后面试,告诉他们你有其他选择。重申你对他们公司的兴趣(如果他们是你的首选,告诉他们!),但解释你已经收到另一个报价,并希望他们能在 X 日期之前给你答复。招聘人员理解你可能会与其他公司面试,并且经常处理这种情况。如果你在其他过程中非常早期,他们可能无法加快进程以在时间上提供报价,你可能需要决定是否在不知道其他选择的情况下接受这个报价。
谈判
即使报价超出了你的预期,或者相比你目前的工作有很大提升,你也应该进行谈判。科技公司期望你进行谈判。你几乎总是可以获得至少额外的 5000 美元或 5%的基础薪水增长,具体数额取决于公司和原始报价。你还可以要求签约奖金或更多的股票期权。记住,谈判并不是自私或贪婪的行为:
其他考虑因素:这不仅仅是关于你现在的薪水,而是关于你新公司的同事薪水。现在这可能对你来说是一个很大的涨幅,但一旦你被录用,你可能会拿着更少的薪水做同样的工作。
— bletchley punk (@alicegoldfuss) 2018 年 5 月 2 日
也要考虑你感兴趣的非金钱福利。例如,可能你希望每周能有一天在家工作。也许你希望公司能承担每年两个会议的费用。如果是小公司,你可以要求不同的职位头衔。
你可以谈判的幅度取决于你的谈判地位和公司。非营利组织的薪资空间可能会更小。如果你有其他报价或者你在目前的工作中获得了良好的报酬,你有一个强有力的替代选择。如果你拥有他们特别招聘的稀有技能,或者职位空缺时间较长,他们找到其他候选人的难度会更大。你应该在前面提到的薪资网站上做足功课,以便能够解释你为什么要求这些数字。要设定一个高目标,以便有妥协的余地,并给出一个具体的数字,而不是一个范围——如果你说你希望薪水涨幅在 5000 到 10000 美元之间,他们可能会给你 5000 美元。重申你对公司和职位的兴奋之情,以及你带来了 X、Y、Z。最后,开始谈话时先列出你感兴趣的事项,而不是一个一个地提出和解决问题。这样,他们会感到他们了解了你的需求,你也可以在问题之间进行妥协(例如,你可能会接受 5000 美元的基础薪资增加和 5000 美元的签约奖金,而不是 10000 美元的基础薪资增加)。
我强烈建议你多阅读关于如何进行有效谈判的资料;这篇由Haseeb Qureshi撰写的全面的两部分帖子(包含他自己成功求职的许多具体案例)是一个很好的起点。我还喜欢这些哈佛商业评论的文章,15 条谈判报价的规则以及针对女性的建议(女性有时需要调整谈判策略)。
非常、非常、非常罕见的情况下,公司会因为你谈判而撤回报价。如果他们这样做了,你不想在那里工作。
一个警告:如果你在谈判时得到了你所要求的一切,公司会期望你接受!你当然不必接受,但你不应该拖延一个你不认真对待的公司。知道你会接受也能让你说出魔法般的词语:“如果我们能解决 X、Y 和 Z,我将非常高兴接受这个 offer。”
结论
求职是压力巨大的,尤其是当你全职工作和/或希望换行业时。我希望这篇文章能为你提供一个良好的起点,帮助你了解数据科学的招聘过程、避免的错误以及你可以利用的策略。如果你还需要更多信息,这里有一份来自Favio Vazquez的极其全面的指南,其中包括他自己的见解和对几十个资源的链接。
正如我一开始所说,欢迎对这篇文章提出反馈和补充!感谢 Ilana Mauskopf、Dana Levin-Robinson、Jesse Maegan、Philipp Singer、Jonathan Nolis、Naoya Kanai 和 Michael Berkowitz 对这篇文章的补充。
艾米莉·罗宾逊 是纽约数据科学公司 DataCamp 的首席数据科学家。
相关:
原文。经许可转载。
更多相关内容
对于有志数据科学家的建议
原文:
www.kdnuggets.com/2020/10/advice-aspiring-data-scientists.html
评论
由Tyler Richards,Facebook 的数据科学家

我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
大约每月,我都会收到某种类型的学生邮件,询问如何进入数据科学领域,我已经回答过很多次,因此决定在这里写出来,方便将来链接给那些学生。所以如果你是其中之一,欢迎!
我将把这些建议分为基本建议,这些建议可以通过谷歌搜索“如何进入数据科学”很容易找到,以及不那么常见但我多年来发现非常有用的建议。我会先从后者开始,然后转到基本建议。显然,这些建议要适当考虑,因为所有建议都有一定的生存偏差。
不那么基础的建议:
1. 寻找一个可靠的社区
如果你在大学里,待在这里的一部分目的就是寻找像你一样聪明、有抱负和积极进取的人一起学习和成长。对我来说,这个社区是数据科学与信息学俱乐部。社区/网络帮助你入门,保持动力,并且在长期内对于获得实习和全职工作至关重要。
2. 将数据科学应用于你喜欢的事物
成为某个领域的高手是困难的(当然),将数据科学应用于你关心的领域可以帮助你保持动力并脱颖而出。我有几个例子:利用UF(母校)的学生政府选举来学习机器学习方法,或通过记录我们的乒乓球比赛来跟踪朋友的 Elo 评分。这些项目教会了我重要的技能,而不会让人觉得是在工作。
获得具有代表性的实践对未来工作至关重要,因为这种实践只能带来两种结果之一:
a. 认识到你其实不喜欢这种数据科学类型,在这种情况下你应该立即停止阅读
你可以轻松写作(博客)或谈论(对那些想付钱给你的人)的宝贵经验。
这让我想到下一个要点。
3. 最小化‘证明能力的点击次数’
招聘人员会在你的简历上花 15 秒钟,潜在团队在你的简历 + 网站/Github 上最多花 1-5 分钟(平均而言,访问 我的作品集网站 的人会停留 2 分钟 16 秒后才离开)。这两组人通常使用 GPA、学校质量或来自技术公司的数据经验等能力的替代指标(我称之为:状态证明)。因此,你应该仔细考虑向读者传达你能够胜任他们招聘的工作的时间。一个粗略的衡量标准是“证明能力的点击次数”。
如果招聘人员需要点击你 Github 上的正确仓库,然后点击文件,直到找到 Jupyter notebook 中的不可读代码(更别提没有注释了),你已经输了。如果招聘人员在你的简历上看到机器学习,但需要 5 次点击才能看到你做的任何机器学习产品或代码,你已经输了。任何人都可以在简历上撒谎;要快速引导读者的注意力,你将处于显著更好的位置。
我对优化这一指标的思考方式在 我的网站 上非常清晰。大约需要 10 秒钟来浏览文本(我敢打赌大多数人不会完全阅读),然后人们可以立即选择一个数据科学项目查看,这些项目按展示我能够完成的工作的效果排序。对于刚开始学习数据科学,我强烈建议制作一个网站(即使是一个 bootstrap 模板网站也可以),并将其托管在 Github pages 或 heroku 上,并使用你自己的域名。
4. 通过研究或入门级工作学习
在你完成这三件事之后,看看是否能说服某人付钱让你学习数据科学。佛罗里达大学有一个很棒的选举数据科学小组,我非常喜欢(目前由麦克唐纳博士和史密斯博士负责),但如果你去任何研究小组并与他们面试,他们可能会为你的工作付费。最终,凭借这样的经验,你可以申请实习,并获得丰厚的报酬。关键在于,不要一开始就寻找那些极其高端的数据科学实习,而是先从那些有数据科学任务但没有足够资金雇用全职数据科学家的公司或研究小组开始。数据科学的学习会迅速积累,所以现在就开始吧!考虑到这一切,我们继续讨论更基本的建议。
极其基本的建议:
数据科学主要是编程 + 统计学应用于你所在的领域,因此这两个领域的背景是至关重要的。
1. 统计学
尽快获得良好的统计学背景(参加课程,在线自学)。教科书能带你走得更远,好奇心则能带你走得更远。
书籍/资源:
2. 编程
学习 Python 或 R 并熟练掌握它。每天做些新事物,尽快每周花至少 5-10 小时在上面。之后学习 SQL。你不能绕过这一步。
书籍/资源:
-
R 数据科学(免费)
-
机器学习 Python 食谱(付费)
-
从头学数据科学(付费)
-
数据分析 SQL 教程(免费)
-
MIT 计算机科学与 Python 编程入门(MIT 课程,免费)
3. 商业经验
在 P&G,我的数据科学工作应用于零售。在 Facebook,应用于完整性问题。在 Protect Democracy,应用于,呃,民主。了解数据科学在某些商业环境中的应用很困难且需要实践,通常涉及对指标、产品分析和激励结构的深入理解。这与较少基础建议中的 #2 非常契合。
完
学习数据科学很困难,但我发现这是极具回报的。为了感谢你阅读这篇稍长的文章,我的最终建议是:一旦你完成了对你感兴趣的问题的数据科学应用并在线发布,直接私信我 Twitter,我保证会阅读并转发。好运!
简介:Tyler Richards 是 Facebook 的数据科学家。
原文。已获许可转载。
相关:
-
如何决定学习哪些数据技能
-
初级和高级数据科学家的无声差异
-
作为数据科学家的 6 个月中学到的 6 个教训
更多相关主题
Prof. Andrew Ng 关于构建机器学习职业和阅读研究论文的建议
原文:
www.kdnuggets.com/2019/09/advice-building-machine-learning-career-research-papers-andrew-ng.html
评论
作者:穆罕默德·阿里·哈比布,计算机科学毕业生
介绍:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
由于你正在阅读这篇博客,你可能已经知道 Andrew Ng 是该领域的先驱之一,也许你对他如何在机器学习领域建立职业的建议感兴趣。
本博客总结了斯坦福大学在 YouTube 上发布的 CS230 深度学习课程中的 职业建议/阅读研究论文 讲座。
我建议观看讲座以获取更多细节,它非常有信息量。然而,无论你是否观看,我认为这些建议对你都会有所帮助。因此,我尝试在这里概述这些推荐。
简而言之: 跳到关键要点部分。
Andrew 提出了两个主要建议,具体如下:
-
阅读研究论文: 他用来掌握深度学习新主题的高效技巧。
-
在机器学习领域发展职业的建议。
阅读研究论文:
如何通过阅读研究论文高效且相对快速地学习。因此,无论你是希望学习如何构建一个感兴趣的机器学习系统/项目,还是仅仅希望跟上最新动态,获取更多知识,并在深度学习领域不断进步,你应该如何做。
以下是清单:
-
编制文献清单: 尝试创建一份研究论文、medium文章及其他任何文本或学习资源的清单。
-
跳跃式阅读列表:基本上,你应该以并行的方式阅读研究论文;也就是说,尽量同时处理多篇论文。具体来说,尝试快速浏览和理解这些论文中的每一篇,不必全部阅读,也许你可以阅读每篇论文的 10–20%,这可能足以让你对论文有一个高层次的理解。之后,你可以决定淘汰一些论文,或者只挑选一两篇论文进行深入阅读。
他还提到,如果你阅读:
5–20 篇论文(在一个选择的领域,比如语音识别)=> 这可能足够让你实现一个语音识别系统,但可能不足以进行研究或保持在前沿。
50–100 篇论文 => 你可能对领域应用(语音识别)有很好的理解。
你如何阅读一篇论文?
不要从第一字读到最后字。相反,对论文进行多次阅读,以下是如何操作:
-
阅读标题、摘要和图表: 通过阅读标题、摘要、关键网络架构图表和可能的实验部分,你将能够对论文中的概念有一个大致的了解。在深度学习中,许多研究论文通过一两个图表总结了整篇论文的内容,而无需深入阅读文本。
-
阅读引言 + 结论 + 图表 + 略读其余部分: 引言、结论和摘要是作者尝试仔细总结他们工作的地方,以向审稿人阐明为什么他们的论文应该被接受发表。
同时,略读相关工作部分(如果可能),这个部分旨在突出其他作者做的工作,这些工作与作者的研究有所关联。因此,这部分可能有用,但如果你对文献不熟悉,有时很难理解。
-
阅读论文但跳过数学部分。
-
阅读整篇论文,但跳过没有意义的部分: 伟大的研究意味着我们在知识和理解的边界上发布内容。
他还解释说,当你阅读论文时(即使是最有影响力的论文),你可能会发现有些部分用得很少或没有意义。因此,如果你阅读一篇论文时有些内容没有意义(这并不罕见),最初可以略读。如果你想精通它,就需要花更多时间。
当你阅读论文时,尝试回答以下问题:
-
作者尝试完成什么?
-
该方法的关键要素是什么?
-
你自己可以使用什么?
-
你想跟随哪些其他参考文献?
如果你能回答这些问题,希望这能反映出你对论文有很好的理解。
结果是,随着你阅读的论文越来越多,练习后你会变得更快。因为很多作者在写论文时使用了常见的格式。
例如,这是作者用来描述网络架构的常见格式,特别是在计算机视觉领域:
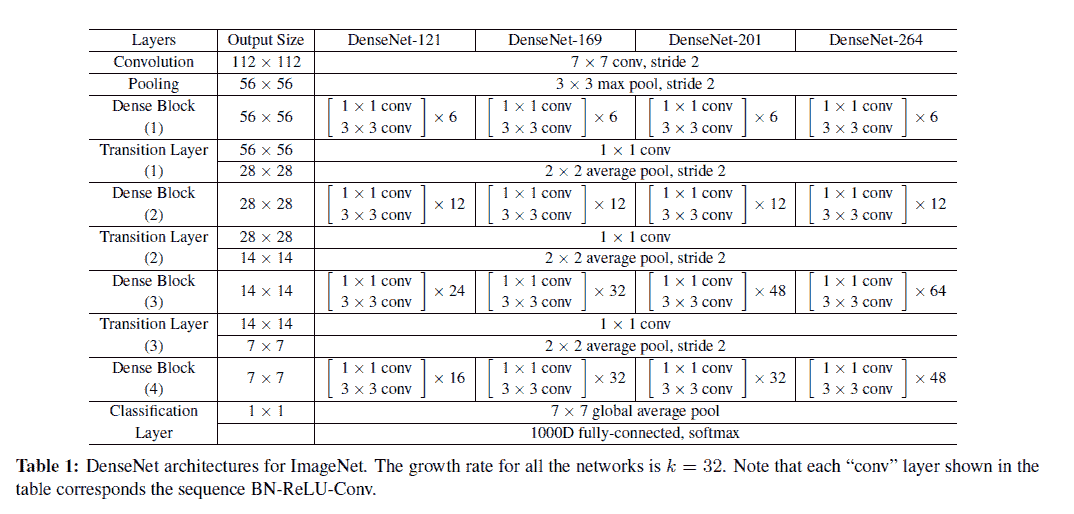
参考资料:* 密集连接卷积网络。*
理解一篇论文需要多长时间?
对于相对较新的机器学习人员来说,理解一篇相对简单的论文可能需要一个小时。然而,有时你可能会遇到需要 3 小时甚至更长时间才能真正理解的论文。
论文来源:
网上有很多优秀的资源。例如,列出语音识别中最重要论文的博客文章,如果你是这个领域的新手,将会非常有用。
很多人试图跟上深度学习的最新进展,因为它发展迅速。因此,你应该访问以下资源:
-
推特: 令人惊讶的是,推特正成为研究人员发现新事物的重要平台。
-
朋友:找到一个对该领域感兴趣的社区或朋友小组,分享有趣的研究论文。
更深入理解论文中的数学内容:
尝试从头重新推导它。虽然这需要一些时间,但这是非常好的练习。
练习编程:
-
下载开源代码(如果可以找到的话)并运行它。
-
从头开始重新实现:如果你能做到这一点,那是你真正理解了手头算法的强有力信号。
持续进步:
保持学习和进步最重要的是要持续学习,而不是进行集中式的活动。与其在短时间内突击学习所有内容,不如在接下来的一年里每周阅读两篇论文。
在机器学习领域职业发展的建议:
无论你的目标是找到一份工作(大公司、初创公司或教职)还是进行更高级的研究生学习(也许加入博士项目)
专注于做重要的工作,并将你的工作视为一种策略和机会来做有用的事情。
招聘人员寻找什么?
-
机器学习技能。
-
有意义的工作: 展示你能胜任工作的项目。
一个成功的机器学习工程师的非常常见模式是,优秀的求职者,是发展T 型知识基础。即对 AI 中的许多不同主题有广泛理解,并在至少一个领域有非常深刻的理解。
参考资料:deeplearning.ai.
构建横向部分:
在这些领域建立基础技能的一个非常有效的方法是通过课程和阅读研究论文。
构建纵向部分:
你可以通过做相关项目、开源贡献、研究和实习来建立它。
选择工作:
如果你想不断学习新东西,这里是影响你成功的因素:
-
你是否与优秀的人/项目合作:被勤奋的人包围会对你产生影响。
-
除了经理之外,还要关注并评估你将合作的团队(你将与他们互动最多的 10-30 人)。
-
不要专注于“品牌”:公司的品牌与你的个人经验关系不大。
如果你收到工作邀请,询问你将与哪个团队合作,并且不要接受那些说“加入我们,我们稍后会分配团队”的邀请,因为你可能会被分配到一个你不感兴趣的团队,这对高效成长没有帮助。
另一方面,如果你能找到一个好的团队(即使是在一个不知名的公司)并加入他们,你实际上可以学到很多。
一般建议:
-
学到最多的东西:尽量选择那些能让你学到最多的工作。
-
做重要的工作:从事那些值得的项目,推动世界前进。
-
尝试将机器学习引入传统行业:我们在科技行业进行了许多转型,但我认为最令人兴奋的工作可能是在传统行业(科技行业之外),因为在那里你可以创造更多的价值。
关键要点:
我试图将 Andrew 建议的关键要点总结在以下列表中:
-
培养阅读研究论文的习惯:可以从每周阅读 2 篇论文开始。
-
高效阅读:编制论文清单,同时阅读多篇论文,并对每篇论文进行多次阅读。
-
阅读论文时:从标题/摘要/图(尤其是)/引言/结论开始。
-
尝试理解算法时:试图重新推导数学,并通过重新实现来练习编码。
-
尽量保持领先:通过检查机器学习会议论文和其他在线资源来保持领先。
-
建立一个 T 型的人工智能知识基础。
-
尽量加入一个好的团队(无论是在大公司还是初创公司),这样可以帮助你高效成长。
-
做有用的项目,这可以帮助你学到最多的东西并推动世界前进。
-
尝试将机器学习引入其他行业:医疗、天文学、气候变化等。
结论:
希望你觉得这个博客有益,并祝你在机器学习职业中好运。
如果你喜欢这个博客,请为它鼓掌 😉
如果你有任何问题,请在评论中告诉我。
干杯!
简历:Mohamed Ali Habib 是一名计算机科学毕业生。他对机器学习、深度学习和数据科学感兴趣。
原文。经许可转载。
相关内容:
-
安德鲁·吴《机器学习的渴望》中的 7 个有用建议
-
安德鲁·吴《机器学习的渴望》中的 6 个关键概念
-
如果你是转行数据科学的开发者,这里是你的最佳资源
更多相关话题
成功的数据科学职业建议
原文:
www.kdnuggets.com/2020/03/advice-successful-data-science-career.html
评论
由Michael Galarnyk,数据科学家

图片 来自 Orysya Stus
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
我之前写过 如何建立数据科学作品集 ,其中涵盖了 向潜在雇主展示你的能力,而不仅仅是告诉他们你能做什么 的重要性。 本博客利用 成功是冰山图像 由 Orysya Stus 作为框架,展示了人们在达到他们感知的数据科学成功的过程中,一些方面往往是隐藏的。 本博客旨在表明,大多数人必须付出相当大的努力才能达到他们的位置。他们必须努力工作,有时经历失败,展示纪律性,保持坚持,致力于他们的目标,有时还需要牺牲或冒险。 话不多说,让我们开始吧!
错误/失败
迄今为止我犯的一些数据科学错误 ???? pic.twitter.com/EeiVmmAnuJ
— Caitlin Hudon ???????????? (@beeonaposy) 2019 年 4 月 29 日
推文 来自 Caitlin Hudon 如上图 GIF 所示, Caitlin Hudon(OnlineMedEd 的首席数据科学家)为她的 推文 创建了 GIF,展示了人们在日常模型构建中常犯的许多技术错误/失败。
我们大多数从事编码或数据科学的人员,通常只看到彼此工作的最终产品——而不是我们在过程中所做的草稿、错误和决策。对这些步骤进行一些透明化处理会大有裨益。
Jake VanderPlas似乎在一条tweet中表达了类似的观点,即在开源项目中,人们通常只看到最终产品,而忽视了过程。
在开源中,我们经常看到的是最终产品而不是过程……这可能会让刚入门的人感到气馁,他们看到周围的所有明显的完美。
但我敢打赌,在任何成功的开源项目光鲜的外表背后,必然充满了痛苦、挣扎和自我怀疑。
除了技术失败,还有其他类型的失败,包括那些你可以穿戴的(期刊拒稿、邮件拒绝等)。Caitlin K. Kirby实际上穿着她的失败/拒绝信。华盛顿邮报(Washington Post)上有一篇文章详细描述了她的裙子是由她在过去五年中收到的 17 封拒绝信(期刊拒稿、邮件拒绝等)制成的。
今天成功答辩了我的博士论文!为了认可和正常化过程中出现的失败,我穿着由博士过程中拒绝信制成的裙子进行答辩。 #AcademicTwitter #AcademicChatter #PhDone
感谢所有参与我旅程的人 pic.twitter.com/FQbXYQ1Oov
— Caitlin K. Kirby (@kirbycai) 2019 年 10 月 7 日
Tweet 由 Caitlin K. Kirby发布。顺便说一下,如果你想了解更多与软件/数据科学相关的拒绝故事,有一个完整的拒绝网站可以查看,可能会激励你。
努力工作/坚韧
大多数人都付出了艰苦的努力才达到现在的成就。我绝对不是说你必须常常工作 70–90 小时每周,因为那听起来不健康。Rachel Thomas的帖子提到这种态度可能会带有歧视性且适得其反。
我们需要尽可能摆脱浅薄的观念,即工作时间的数量才是重要的。科技行业对极长工作时间的痴迷不仅对许多残障人士不可及,对所有人的健康和人际关系都有害,而且正如 Olivia Goldhill 为 Quartz at Work 所指出的那样,关于生产力的研究表明,这只是低效的:
正如无数研究所示,这根本不是事实。工作时间越长,生产力会显著下降,一旦每周工作超过 55 小时,生产力就会完全下降到平均水平,工作 70 小时的人所取得的成就甚至不如工作少 15 小时的同事。
疯狂的长时间工作在学术界也很常见,正如 Jake VanderPlas 在他的 tweet 中提到的那样。
虽然这条推文并不是对 Andrew Ng 早期推文的评论,但我认为它表明成功有许多不同的途径,而不是仅仅靠持续的工作。《Python Data Science Handbook》的作者似乎表现良好。(Tweet 来自 Jake VanderPlas)
与其谈论辛勤工作,不如谈论坚韧或毅力,就像 Jeremy Howard 和 Sylvain Gugger 的 new book 中有一段关于坚韧的精彩描述。

来自 tweet 的内容摘自 Jeremy Howard 和 Sylvain Gugger 的新 书。
简而言之,我认为从中获得的最佳经验是:
你会面临许多障碍,包括技术上的,以及(更困难的是)周围那些不相信你会成功的人。有一种方法可以确保失败,那就是停止尝试。
坚韧
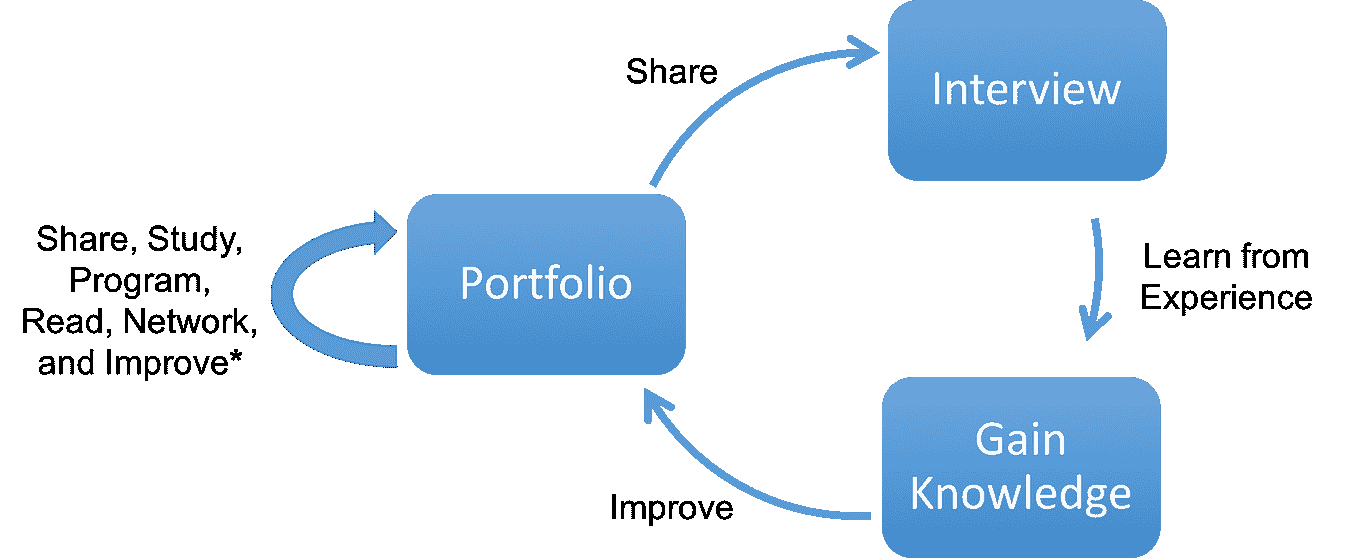
图片来自我的 博客文章
生活中的许多成功来自于坚持不懈。像 Kelly Peng 这样的成功人士有很多故事,她是 Airbnb 的数据科学家,她真正地坚持不懈,不断努力和进步。在 她的其中一篇博客文章 中,她详细讲述了她申请和面试了多少地方。
应用程序:475
电话面试:50
完成的数据科学家庭挑战:9
现场面试:8
提供的机会:2
花费时间:6 个月
她显然申请了很多工作并且坚持不懈。在她的文章中,她甚至提到你需要从面试经历中不断学习。
记下你被问到的所有面试问题,特别是那些你未能回答的问题。你可以再次失败,但不要在同一个地方失败。你应该始终在学习和进步。
纪律/奉献

这篇文章的一个主要主题是每个人都有经历过一些失败。重要的是,有些人会不惜一切代价去实现他们的目标。在 Andreas Madsen 发表的 一篇博客文章 中,他描述了进入顶尖 AI(通常是计算机科学系)博士项目的困难。基本上,与所有他交谈的教授都告诉他,他需要“1-2 篇顶级机器学习期刊的文章”才能进入顶尖博士项目。他花了 7 个月的时间专注于一个没有资金和导师的研究项目,以产生可以发表的工作。
牺牲/冒险
图片由 Michael Galarnyk
牺牲和风险可以有很多不同的形式。其中一个风险可能是忽视上级的指令。当 Greg Linden 在亚马逊工作时,他虽然应该在做其他事情,但还是参与了一些有趣的项目。在 他的一个博客文章 中,他描述了一个项目:
基于你在亚马逊购物车中的物品做推荐。添加几个东西,看看会有什么出现。再添加几个,看看会有什么变化……我制作了一个原型。在一个测试网站上,我修改了亚马逊购物车页面,推荐你可能喜欢添加到购物车中的其他物品。对我来说看起来相当不错。我开始展示它。
出现了一个问题。
虽然反应是积极的,但还是有一些担忧。特别是,一位市场营销高级副总裁坚决反对……在这一点上,我被告知禁止继续在这个项目上工作。我被告知亚马逊还没有准备好推出这个功能。应该到此为止。
相反,我为在线测试准备了这个功能。我相信购物车推荐。我想要衡量销售影响。
我听说 SVP 在发现我推出一个测试时非常生气。但是,即使对于高层管理人员,阻止一个测试也是很困难的。测量是有益的。唯一反对测试的有力理由是负面影响可能如此严重,以至于亚马逊无法承受,这一主张难以成立。测试还是推出了。
结果很明显。它不仅赢了,而且这一特性赢得的幅度如此之大,以至于没有上线的成本对亚马逊来说是显著的。随着新的紧迫性,购物车推荐功能上线了……
当时,亚马逊确实很混乱,但我怀疑我通过忽视上级的命令而冒了风险。尽管亚马逊很优秀,但它还没有完全拥抱测量和辩论的文化。
虽然我不主张忽视上级的建议,但在某些情况下,冒险可能对公司和自己都有好处。
结论

图片 由 Orysya Stus 提供
希望你能在数据科学旅程中发现这篇博客中的一些建议和例子对你有帮助。请记住,许多成功人士的建议受到幸存者偏差的影响。始终对建议或分享的经验持保留态度。如果你有任何问题、对文章的看法或想分享你自己的经历,请随时在下面的评论中联系我,或通过 Twitter 联系我。
个人简介:Michael Galarnyk 是一名数据科学家和企业培训师。他目前在 Scripps Translational Research Institute 工作。你可以在 Twitter (https://twitter.com/GalarnykMichael)、Medium (https://medium.com/@GalarnykMichael) 和 GitHub (https://github.com/mGalarnyk) 上找到他。
原文。经许可转载。
相关内容:
-
开始使用 Python:在 Windows 上安装 Anaconda
-
理解 Python 中的分类决策树
-
Python 元组和元组方法
了解更多信息
你会给年轻的数据科学家自己什么建议?
原文:
www.kdnuggets.com/2017/07/advice-younger-data-scientist-self.html
评论
我在 LinkedIn 上经常被询问数据科学职业建议。虽然我希望用有限的知识回答人们的具体问题,但这确实变得太耗时。我过去创建过帖子,试图照亮更广泛人群感兴趣的话题,例如这个,但个性化的请求不幸的是通常不是我能参与的。
我犹豫是否写上面这段话,因为我觉得这可能会把我描绘成一个有点自大的家伙,说实话。我没有超出有限经验的任何特殊见解;然而,我与 KDnuggets 的关联和在 LinkedIn 上的活动,可能让人们认为那个人可能值得联系。我真的是最远离自大的那种人,如果时间允许,我会很乐意与大家分享我所知道的。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT 工作
不管怎样,继续... 最近我通过 LinkedIn 消息被问了这个问题:
你会给年轻的数据科学家自己什么建议?
虽然当时我没有多想这个问题,但最近几天它越来越频繁地浮现在我的脑海里。我认为原因是我真心觉得可以给人们的一个建议,就是:
忘记“数据科学”。
没错,你应该忘记数据科学。让我解释一下。
我是一个“数据科学家”,我还是一个“数据科学”网站的编辑,我故意追求“数据科学”职业,我对所有“数据科学”的事物都感兴趣。
但 我真的不喜欢“数据科学”这个词。
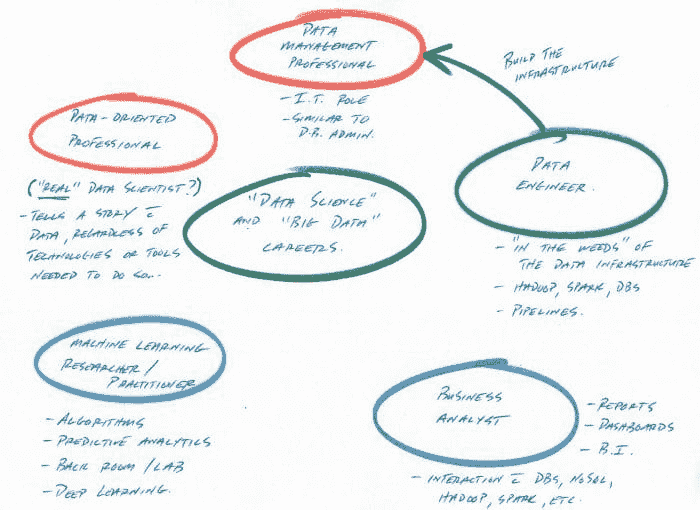
从 5 种大数据和数据科学职业路径,解释。
我不喜欢“数据科学”这个词的原因是因为它过于广泛和不具体。
数据科学既毫无意义,又有着所有意义。
所以,总结起来,我建议你忘记数据科学的森林,找一棵让你感兴趣的树。数据科学的哪个方面吸引了你的注意?是机器学习?是描述性统计?是数据可视化?是分布式计算?你喜欢算法设计吗?你有商业背景,但有足够的知识与客户讨论预测分析,并且愿意与“后台”接触吗?
这类似于从噪声中分离信号并提升信号。找到个人的信号应该是你在追求“数据科学”时的首要任务。
了解你天生带来的“数据科学”价值也是重要的。你是从计算机科学的角度接触数据科学吗?还是从数学背景?作为一名网页开发者?作为商业分析师?还是粒子物理学家?
现实的期望也是必须的。你有博士学位吗?硕士学位?本科文凭?你是自学的,通过 MOOC、教科书等?不要让任何人告诉你,“数据科学”领域对于自学者来说是遥不可及的……同时,也不要期望你在几门 MOOC 之后就能在 DeepMind 做研究。了解你可能适合什么。
数据科学家 Maurice Ewing 在他对“数据科学是否太容易?”的问题的 Quora 回答中说:
就 R 和 Hadoop 而言,它们只是数据科学工具包的一部分。它们并不构成“数据科学”,就像手术刀并不构成“手术”一样。就像物理学依赖数学一样,数据科学依赖于统计工具来处理大数据和小数据、结构化和非结构化数据等。但物理学的数学不能替代科学思维、分析、方法,Hadoop 和 R 也不能替代对数据行为的理解。
当然,他是完全正确的。然而,他的观点也可以从相反的方向来看:正如单一技能(在这种情况下是技能对)并不能成就数据科学家一样,数据科学家也并不具备单一统一的技能体系,每个人都带来了自己的一套能力。
把“数据科学”称为一个职业也让我感到奇怪。这似乎像是将所有医生、护士、物理治疗师、个人支持工作者以及其他所有健康专业人员可能承担的角色和任务都归为“健康科学家”(是的,我知道健康科学确实存在)。
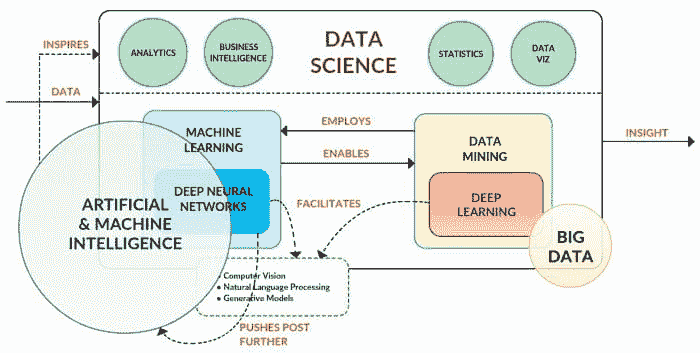
引自《数据科学难题,再探》。
不过,我要扯远了,再次重申:忘记数据科学。专注于你最感兴趣的数据科学拼图的一部分,一切会自然合成。
我喜欢把数据科学家比作综合格斗运动员:就像 MMA 选手可能以巴西柔术或泰拳为基础,并根据需要逐渐增加其他格斗学科和技术(拳击、摔跤等),真正的数据科学家也可能以机器学习为核心,随着职业发展逐步提高其可视化、分布式计算、讲故事和统计技能。
回到数据科学的主题...
相关内容:
-
大数据和数据科学中的 5 条职业路径,解释说明
-
数据科学家—美国最佳职业,再次登顶
-
探索大数据中的 12 个有趣职业
更多相关主题
-
[停止学习数据科学以寻找目标,并以寻找目标来...] (https://www.kdnuggets.com/2021/12/stop-learning-data-science-find-purpose.html)
ADW,免费测量语义相似性的软件下载工具
原文:
www.kdnuggets.com/2014/10/adw-free-software-measure-semantic-similarity.html
作者:Taher Pilehvar(罗马大学),2014 年 10 月。

任意词汇对的语义相似性,从单词意义到文本!
罗马萨比恩扎大学的语言计算实验室很高兴地宣布 ADW 的首次发布。
ADW 是一个用于测量任意词汇对的语义相似性的软件下载工具,从单词意义到文本。该软件基于“对齐、消歧和行走” [1],这是一种基于 WordNet 的先进语义相似性方法,在 ACL 2013 会议上提出。
ADW 的特点:
-
在多个词汇层次上的先进表现 [1](数据集如 RG-65 和 TOEFL 上的词汇相似性,句子相似性 - STS 任务,以及 WordNet 意义聚类)。
-
跨级别语义相似性,即不同类型的词汇项之间(例如,一个词义和一个短语)。
-
通过易于使用的 Java API 提供。
-
即插即用:无需任何训练或参数调优。
-
适用于即将到来的 SemEval-2015 任务 1、2 和 3
要获取该软件,请访问 ADW 的 GitHub 仓库:
你还可以尝试 ADW 的在线演示:
参考资料
[1] M. T. Pilehvar, D. Jurgens 和 R. Navigli. 对齐、消歧和行走:一种测量语义相似性的统一方法。第 51 屆计算语言学协会年会论文集(ACL 2013),保加利亚索非亚,2013 年 8 月 4-9 日,第 1341-1351 页。
Gregory Piatetsky: 我尝试了在线演示,语义相似度为
-
“apple”(苹果)和“orange”(橙子)的相似度是 0.47,
-
“tangerine”(橘子)和“orange”(橙子)的相似度是 0.78,
-
“shoe”(鞋子)和“orange”(橙子)的相似度是 0.33
因此计算值必须用于相对比较,而不是绝对意义上的比较。
相关:
-
文本分析入门
-
数据科学显示调查可能评估语言而非态度
-
Ontotext 文本挖掘、语义搜索和图数据库
-
情感分析创新峰会 2014:第一天亮点
-
BabelNet 2.5:非常大的多语言百科全书字典和语义网络
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
更多相关话题
HDF5 之后是什么?寻找适合深度学习的数据存储格式
原文:
www.kdnuggets.com/2021/11/after-hdf5-data-storage-format-deep-learning.html
评论
作者 Davit Buniatyan, Activeloop CEO

HDF5 用于非结构化数据
HDF5 是一种最受欢迎和可靠的非表格化数值数据格式之一。¹ 让我举个例子。NASA 的地球观测系统卫星每天收集大约 16 TB 的数据,格式为 HDF5。
像命名数据集、分层组织的组、自定义元数据和属性、压缩滤镜、延迟加载² 和跨不同轴的类似数组切片等特性使其适合许多数据处理任务。
尽管它是在二十多年前创建的,HDF 仍然因通过维护良好的开源库如 h5py 而在 PyData 社区中保持流行。
HDF5 没有针对深度学习进行优化
在 HDF5 中,大型数据集通常以“块”的形式存储;即数组的规则分区。这一设计决定使 HDF 能够存储像图像和视频这样的千兆级别、非结构化的数值数据,但它是在云对象存储或深度学习出现之前创建的。因此,在深度学习工作负载方面存在一些不足之处:
-
HDF 文件的布局使其在云存储系统(如 Amazon 的 S3³)上高效查询变得困难,ML 数据集越来越多地存储在这些系统中。⁴ 你不能直接从存储为 S3 对象的 HDF5 文件中读取 HDF5 库。实际上,整个文件(通常可以达到几 GB)应该被复制到本地存储,然后才能读取第一个字节。
-
在并行方式下应用数据转换是困难的。无论是计算机视觉的数据增强还是 NLP 的分词,转换都是任何深度学习实验的核心。
-
HDF5(Python 实现)基本上是单线程的。这意味着在任何给定时间,只有一个核心可以读取或写入数据集。它不适合并发读取,这限制了 HDF5 数据支持多个工作线程的能力。⁵
-
它没有与现代框架如 Keras 和 PyTorch 集成,这意味着研究人员通常需要编写自定义 DataLoader。由于 DataLoader 承担了更多职责,如数据集分片以进行并行训练,它们变得更加难以定义。
-
由于 HDF 元数据分散在整个文件中,访问随机数据块变得困难。实际上,需要进行许多小读取,以收集提取数据块所需的元数据。
由于这些挑战,大多数用户在运行单个训练周期之前会将数据转换为其他格式(例如 csv 或 TFRecords)。
机器学习社区需要一种新的数据存储格式。
与其为云环境重写或改造 HDF,我们认为应该有一个为分布式深度学习设计的现代数据存储格式。虽然有一些 软件包 和 托管服务 允许用户直接从云中读取 HDF 数据⁶,但它们并不适合大规模的非结构化数据集合。
随着云基础设施的 petascale 数据集训练成为学术界和工业界的常态,深度学习格式意味着一种格式:
-
云原生。它应当能够与云对象存储系统(如 S3 和 GCS)良好配合,而不会牺牲 GPU 利用率。⁷
-
可并行化。由于大多数机器学习数据集是写入一次、读取多次,它应支持多个工作者的并发读取。
-
随机访问。由于研究人员很少需要一次性获取整个数据集,因此以这种格式存储的数据应当能够进行随机访问。
-
转换。它应能够在运行时对数据应用任意转换,并且代码开销最小。这是因为下载 TB 级的数据通常不切实际:大多数用户没有访问大型数据集群的权限,无法在下载后根据需要切片和处理数据。
-
集成。它应与流行的深度学习框架如 Keras 和 PyTorch 以及其他 PyData 库如 Numpy 和 Pandas 集成。理想情况下,研究人员应能够使用他们为本地存储的小数据集开发的相同脚本来访问这些巨大的云端数据集。
尽管设计和推广一种新的数据格式不是一件简单的任务(已有几个“云中的 HDF”库的失败例子),但我们认为一种 为机器学习目的设计的新格式 和像图像、视频、音频等非结构化数据可以帮助研究人员和工程师用更少的资源做更多的事。
注意事项
-
我最近使用 HDF5 存储了 1024 维的嵌入向量,大约涵盖了一百万张图像。
-
请记住,实际数据存储在磁盘上;当对 HDF5 数据集应用切片时,会找到适当的数据并加载到内存中。这种切片方式利用了 HDF5 的底层子集功能,因此非常快速。
-
亚马逊有一种叫做 HDF5 虚拟文件层的东西。
-
这是因为 HDF5 需要读取其索引表,然后对每个块发出范围请求。这种延迟是显著的,因为 HDF 库进行许多小的 4kB 读取。当数据在本地时,这些小的读取是合理的,但现在我们每次都需要发送网络请求。这意味着用户可能要花费几分钟才能打开一个文件。
-
我经常看到对单个 HDF5 文件的并发写入。这是不推荐的,因为可能会有多个进程同时尝试写入。
-
即使是 Pandas 也可以 直接从 S3 读取 HDF5 文件。
-
当然,云对象存储最大的缺点是出口费用。
简介:Davit Buniatyan (@DBuniatyan) 在 20 岁时开始了他在普林斯顿大学的博士研究。他的研究涉及在 Sebastian Seung 的指导下重建小鼠大脑的连接组。为了解决他在神经科学实验室分析大型数据集时遇到的困难,David 成为 Activeloop 的创始 CEO,这是一个 Y-Combinator 孵化的初创公司。他还是戈登·吴奖学金和 AWS 机器学习研究奖的获得者。Davit 是开源包 Hub 的创造者,AI 数据集格式。
相关:
-
CSV 文件用于存储?不,谢谢。还有更好的选择
-
如何查询你的 Pandas 数据框
-
Pandas 不够?这里有一些处理更大、更快数据的 Python 替代方案
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你所在组织的 IT
更多相关内容
AgentGPT:浏览器中的自主 AI 代理
原文:
www.kdnuggets.com/2023/06/agentgpt-autonomous-ai-agents-browser.html
作者提供的 Gif | AgentGPT
AgentGPT web 是一个自主 AI 平台,使用户能够直接在浏览器中轻松构建和部署可定制的自主 AI 代理。你只需为你的 AI 代理提供一个名称和目标,然后观看它开始实现你分配的目标。该代理将自主获取知识、采取行动、进行沟通并适应以完成其指定目标。
AgentGPT 如何工作?
AgentGPT 通过语言模型链(称为代理)来实现特定目标。这个过程涉及一个代理考虑实现给定目标的最有效任务,执行这些任务,评估其表现,并不断生成额外任务。
注意: AgentGPT web 仅提供 2 次免费运行。你可以订阅 Pro 版本以获得 GPT-4、每天 30 个代理的访问权限,以及最新插件的使用权限。
AgentGPT 的远见者坚信使 AI 潜力民主化,使其对所有人都可及,并促进一个以社区驱动的协作方法。这正是他们为成为一个开源平台感到无比自豪的原因。
注意: 你也可以使用 Docker 本地运行它,或者通过按照 GitHub 仓库中的指南进行部署:reworkd/AgentGPT。
ChatGPT、AgentGPT 和 AutoGPT 之间的区别
ChatGPT 是一个极其有用的工具,旨在提供准确、具体的回答,并促进深入的对话。它不仅仅回答问题,还帮助维持关于复杂话题的有意义讨论。
另一方面,AgentGPT 作为一个完整的平台来处理自主 AI 代理。你可以给代理设定目标,它将独立思考、学习并采取行动来实现该目标。
AgentGPT 和 AutoGPT 都是以自主 AI 代理为中心的令人印象深刻的项目。然而,它们有一些关键差异。AgentGPT 是一个基于 Web 的平台,允许直接在浏览器中创建和部署 AI 代理。相比之下,AutoGPT 是一个本地运行的工具,能够在计算机上开发 AI 代理以执行任务。
使用 AgentGPT 构建鸟类分类器
只需在 reworkd.ai 上创建一个账户,并通过提供你的姓名和目标来部署你的代理。
在我们的案例中,我们要求 AgentGPT 开发一个鸟类图像分类 web 应用程序。
作者提供的图像 | AgentGPT
在前两次运行中,它的表现:
-
初始数据集研究与选择
-
使用 TensorFlow 训练深度学习模型
-
使用合适的框架构建 Web 应用程序并部署训练好的模型
-
测试与优化
-
用户界面增强与功能添加
作者提供的图像 | AgentGPT
初步结果可能不符合预期;然而,通过进一步的迭代,有可能得到改进。可能在大约 5 次运行后,应用程序中的编码问题将得到解决。
如何改善结果?
提示在动态调整语言模型的行为以符合我们代理的当前目标和任务中扮演着关键角色。目前,AgetGPT 的免费版本使用 gpt-3.5-turbo,显示出即使是提示中的最小细节也会显著影响生成的结果。
提高结果的措施:
-
通过示例增强模型准确性: 为进一步提高模型的准确性,您可以在提示中提供 1、2 或多个示例。
-
计划与解决(PS): 一种建立在思维链提示上的技术。通过请求模型逐步指令,它实现了更准确的推理和问题解决能力,从而改善结果。通过查看示例了解更多信息:AGI-Edgerunners/Plan-and-Solve-Prompting。
-
ReAct: 是“推理加行动”的缩写。ReAct 是一种强大的提示技术,它将推理和行动生成结合在一个输出中。这种方法允许模型有效地将思想与行动同步,从而产生更连贯和实用的响应。
-
升级到专业版或本地部署: 对于高级功能,您可以选择升级到专业版,以访问 GPT-4。或者,您可以在本地运行应用程序,并加入 GPT-4 API 密钥,以利用 GPT-4 模型的增强功能和性能。
入门

来自reworkd/AgentGPT的图像
在本节中,我们将学习如何在本地设置和运行 AgentGPT。要开始,请按照以下命令操作。
git clone https://github.com/reworkd/AgentGPT.git && cd AgentGPT
./setup.sh
在深入之前,必须确保您的环境已正确配置。为此,请按照以下步骤操作:
-
将.env.example文件复制到./next/目录中。
-
将复制的文件重命名为.env。
-
请根据您的要求花时间更新.env 文件中的值。
构建 Docker 镜像是一个无缝的过程,应能顺利进行。在继续之前,确保你的系统上已安装 Docker。
docker-compose up --build
通过运行此命令,你将启动前端、后端和数据库的容器创建,建立一个全面的应用环境。
注意: 你也可以在没有 Docker 的情况下开发和运行 AgentGPT,详情请阅读 AgentGPT 文档。
路线图
AgentGPT 目前处于测试阶段,开发者们正积极开发许多令人兴奋的功能。以下是即将推出的一些预览,以便让你了解未来的发展!
当前功能
-
用户管理与认证: 高效管理系统中的用户及其认证。
-
代理运行保存与分享: 无缝保存和分享代理运行,以确保协作与知识共享。
-
多语言动态翻译: 启用多样语言的动态翻译,促进跨语言沟通。
-
AI 模型定制: 根据你的具体需求定制 AI 模型,使其能够满足你的独特要求。
正在开发的功能
-
高级网页浏览功能
-
后端迁移到 Python
-
带有向量数据库的长期记忆
-
代理可控性
-
文档大修
结论
我坚信,在先进的大型语言模型时代之后,我们将见证自主 AI 代理的出现。这一变革性的发展将彻底改变我们处理工作和任务的方式。
随着自主 AI 代理的出现,我们将不再需要详细列出实现目标的步骤。相反,只需定义目标并提供一个示例,这些代理将自主进行研究、实验和执行,以显著准确地达到预期结果。
如果你有兴趣了解更多,可以尝试阅读:
-
Baby AGI: 完全自主 AI 的诞生
-
AutoGPT: 你需要知道的一切
-
Mojo Lang: 新编程语言
-
LangChain 101: 构建你自己的 GPT 驱动应用
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作,撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络开发一款帮助精神疾病学生的 AI 产品。
更多相关话题
敏捷数据标注:它是什么以及你为什么需要它
评论
由Jennifer Prendki,Alectio 创始人兼首席执行官,机器学习企业家。
敏捷这一概念在技术领域无疑非常流行,但这并不是你自然会将其与数据标注联系在一起的概念。这很容易理解:“敏捷”通常激发效率。然而,标注在 ML 圈子里几乎不会讨论而不引发一片沮丧的叹息声。

图 1:敏捷宣言描述了一套软件开发人员认为能提高生产力的“规则”。
要了解敏捷是如何被如此广泛采纳的,你需要追溯其起源。2001 年,一群 17 位软件工程师在犹他州的一个度假胜地聚集,头脑风暴如何让他们的行业变得更好。他们认为项目管理的方式不适当、效率低下且过于规范。因此,他们提出了敏捷宣言,这是一套他们认为可以提高软件工程团队生产力(以及理智水平!)的指南。敏捷宣言是对阻碍进展的缺乏过程的抗议。在许多方面,这正是数据标注所需要的。
图 2:深入探讨敏捷宣言及其核心原则。
回到机器学习。毫无疑问,我们在过去几十年里在这一领域取得的进展是令人难以置信的。事实上,多数专家一致认为,这项技术的演变速度太快,超出了我们的法律和机构的跟上速度。(不信?只需想想 DeepFakes 对世界和平可能产生的严重后果)。尽管 AI 产品的爆炸性增长,ML 项目的成功归结为一件事:数据。如果你没有收集、存储、验证、清理或处理数据的手段,那么你的 ML 模型将永远只是一个遥远的梦想。即便是世界上最负盛名的 ML 公司之一OpenAI 在意识到他们没有获得必要数据的手段后,决定关闭了一个部门。
如果你认为只需找到一个开源数据集就可以开始工作,那就想错了:不仅相关的开源数据用例稀少,这些数据集大多也存在令人惊讶的错误,在生产中使用它们简直是极其不负责任的。
自然地,随着硬件越来越好且价格越来越便宜,收集自己的数据集应该不再是问题。不过,核心问题在于:这些数据不能直接使用,因为它们需要被标注。尽管看起来是这样,但这并不是一项简单的任务。

图 3:对图像中的所有飞机进行标注,以便用于目标检测或目标分割用例,即使对经验丰富的专家来说,也可能需要花费一个多小时。想象一下需要为 50,000 张图片进行这种操作,并且在没有帮助的情况下保证标注的质量。
数据标注是令人畏惧的。对于许多机器学习科学家来说,标注数据占据了他们工作量的极大部分。而且,虽然自己进行数据标注对大多数人来说并不是一项愉快的任务,但将这一过程外包给第三方可能会更加繁琐。
图 4:这是安德烈·卡帕提(Andrey Karpathy)在 2018 年 Train AI 大会上展示的一张幻灯片,讲述了他和他的团队在特斯拉进行数据准备的时间。
想象一下,你需要向一个完全陌生且无法直接沟通的人解释什么是你认为的有毒推文、搜索查询的相关结果,或者图片中的行人。想象一下确保数百个人会以完全相同的方式理解你的指示,即使他们可能各自有不同的观点和背景,并且可能对你想要实现的目标一无所知。这正是将你的标注过程外包的意义所在。

图 5:广告中的人应该被标记为人吗?
这与敏捷开发有什么关系?如果你还没有猜到的话,机器学习科学家对标注的日益沮丧可能是我们重新思考如何完成工作的信号。是时候制定数据标注的敏捷宣言了。
软件开发的敏捷宣言本质上归结为一个基础概念:反应性。它表明一种固执的方法是行不通的。相反,软件工程师应该依靠反馈——来自客户、来自同事。他们应该准备好适应和从错误中学习,以确保能够实现最终目标。这很有趣,因为缺乏反馈和反应性正是团队害怕外包的原因。这也是标注任务常常需要花费大量时间并且可能花费公司数百万美元的主要原因。
成功的数据标注敏捷宣言应从相同的反应性原则开始,这一点在数据标注公司叙述中出奇地缺失。成功的训练数据准备涉及合作、反馈和纪律。

图 5:数据标注的敏捷宣言。
1. 结合多种方法/工具
自动标注 的概念,即利用机器学习模型生成“合成”标签,近年来变得越来越流行,为那些厌倦现状的人们带来了希望,但这只是简化数据标注的一种尝试。然而,现实是,没有单一的方法能够解决所有问题:例如,自动标注的核心是一个鸡与蛋的问题。这就是为什么人机协作标注的概念越来越受到关注。
尽管如此,那些尝试感觉上不够协调,并且对于经常难以看出这些新范式如何应用于自身挑战的公司几乎没有带来任何缓解。因此,行业需要更多关于现有工具的可见性和透明度(一个很好的初步尝试是 TWIML 解决方案指南,尽管它并非专门针对标注解决方案),以及这些工具之间的便捷集成,还有一个与机器学习生命周期其余部分自然集成的端到端标注工作流。
2. 利用市场的优势
外包过程可能不是针对那些没有第三方能够提供令人满意结果的专业用例的选项。这是因为大多数标注公司依赖于众包或业务流程外包(BPO),这意味着他们的标注员并不是高技能的劳动力——他们无法为你标注脑癌 MRI 图像。幸运的是,一些初创公司现在专注于为特定领域提供专业服务。
无论你是否需要专家的帮助,找到合适的公司仍然很困难。大多数标注公司都提供全面服务,但最终都有各自的优缺点,客户往往只有在签署了一年合同后才发现这些优缺点。比较所有选项是找到你需要时现有最佳标注员的关键,并且应成为过程中的重要部分。
3. 采取迭代的方法
数据标注的过程实际上出奇地没有反馈环路,尽管反馈在机器学习中至关重要。没有人会盲目地开发一个模型,但传统上就是这样生成标签的。采用爬行-走路-跑步的方法来调整和优化你的标注过程和数据集,显然是正确的方向。这就是为什么基于人机协作的范式,其中机器预标注而人类验证,显然是最佳选择。
更有前景的方法之一是倾听模型的提示,识别模型失败的原因和位置,可能会发现错误的标签并在必要时修正它们。一种方法是使用主动学习。
4. 更重视质量而非数量
如果你被教导更多的数据就更好,你绝对不是唯一一个这样认为的人:这是机器学习中最常见的误解之一。然而,重要的不是数据的量,而是数据的多样性。规模只是被过分夸大了。显然,你需要一些数据来启动,但大量的数据不可避免地会导致收益递减——这纯粹是经济学问题。
相反,通常将时间和金钱投入到获取战略性选择的训练数据集的正确标签中,比投入大量无用数据的标注更为有益。确保数据策划(即抽样最有影响力的训练记录)融入机器学习生命周期应成为未来几年 MLOps 的关键关注点。
如果你像大多数数据科学家一样对数据标注感到沮丧,可能是时候尝试所有这些想法了。就像在敏捷的早期阶段一样,虽然这些原则本身并不特别困难,但它们都需要自律和意识。
使这些最佳实践融入全球数据科学家的日常习惯还需要很长的路要走,但像任何有意义的改变一样,它始于一个。记住,早在 2001 年,在滑雪胜地的一次会议就足以启动了导致软件开发革命的引擎。我们的革命可能已经在我们意想不到的眼前展开——实际上,它很可能已经展开了。所以请保持关注,享受这段旅程。
简介: 詹妮弗·普伦德基博士 是 Alectio 的创始人兼首席执行官,这是一家首个基于机器学习的数据准备运维平台。她和她的团队致力于帮助机器学习团队用更少的数据构建模型,并消除与“传统”数据准备相关的所有痛点。在创办 Alectio 之前,詹妮弗曾担任 Figure Eight 的机器学习副总裁;她还在 Atlassian 从零开始建立了一个完整的机器学习职能,并在 Walmart Labs 的搜索团队领导了多个数据科学项目。她被公认为是主动学习和机器学习生命周期管理领域的顶尖行业专家,并且是一位出色的演讲者,喜欢面对技术和非技术观众。
相关内容:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
了解更多相关话题
Agilience 顶级人工智能、机器学习权威
原文:
www.kdnuggets.com/2016/11/agilence-top-artificial-intelligence-machine-learning-authorities.html/2
-
KDnuggets
![KDnuggets]()
涵盖 #Analytics, #BigData, #DataMining, #DataScience, #MachineLearning, #DeepLearning。由 Gregory Piatetsky-Shapiro 创立。
我们的前三课程推荐
![]() 1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。![]() 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能![]() 3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
@kdnuggets 33.2K 条推文,67.3K 关注者
-
柯克·D·伯恩
![柯克·伯恩]()
@BoozAllen 的首席数据科学家,博士天体物理学家,♡ 数据科学,顶级大数据影响者。前教授
t.co/f4gsbNc00C@KirkDBorne 62.9K 条推文,106K 关注者
-
Vineet Vashishta
![Vineet Vashishta]()
世界上最值得信赖的 #MachineLearning 品牌。受疯狂的想法驱动,认为 #DataScience 必须简单且盈利。将数据转化为金子。
@v_vashishta 14.5K 条推文,22.4K 关注者
-
Kaggle
![Kaggle]()
世界上最大的数据科学家社区。加入我们,竞赛、合作、学习并分享你的工作。
@kaggle 2.6K 条推文,60.5K 关注者
-
詹姆斯·科比厄斯
![詹姆斯·科比厄斯]()
IBM 数据科学布道者。推文是我个人的,不代表我雇主的观点。
@jameskobielus 60.1K 条推文,19.9K 关注者
-
本·洛里卡
![本·洛里卡]()
OReillyMedia 首席数据科学家,@strataconf 和 @OReillyAI 的项目主管。O’Reilly 数据节目播客的主持人。每周日为黑客日。
@bigdata 5.7K 条推文,35.6K 关注者
-
文森特·格兰维尔
![文森特·格兰维尔]()
企业家和开创性的数据科学、大数据、机器学习、深度学习、物联网、人工智能和预测建模专家。
@analyticbridge 82.1K 条推文,147K 关注者
-
Slamby
![Slamby]()
数据管理研究公司,提供专注于#TextClassification 的#MachineLearning 解决方案,致力于#eCommerce #Classifieds #JobPortal
@slambynews 1.5K 推文,2.6K 关注者
-
Marcus Borba
![Marcus Borba]()
对#BigData, #Analytics, #DataScience, #MachineLearning, #AI, #IoT, #BI, #DataMining 和#DigitalTransformation 充满热情。Spark 首席技术官。#BBBT 会员。
@marcusborba 19.7K 推文,20.8K 关注者
-
Michael Cavaretta
![Michael Cavaretta]()
福特汽车公司分析基础设施总监。观点仅代表我个人。兴趣:#BigData, #Datascience, #machinelearning, #dataviz, #IoT, #mdm, #analytics
@odsc 11.7K 推文,11.7K 关注者










相关:
-
Agilience 顶级数据挖掘与数据科学权威
-
LinkedIn 上 16 位活跃的大数据和数据科学领袖
-
2016 年大数据:顶级影响者和品牌
更多相关主题
AI 与开源软件:天生一对?
原文:
www.kdnuggets.com/ai-and-open-source-software-separated-at-birth

图片来源:编辑
自去年年底以来,我一直在阅读、撰写和演讲关于开源软件和机器学习交集的内容,试图理解未来可能带来什么。
当我开始时,我预计我会主要讨论开源软件如何被机器学习社区使用。但我探索得越多,就越发现这两个领域之间有很多相似之处。在这篇文章中,我将讨论一些这些相似之处——以及机器学习可以从开源软件中学到什么和不能学到什么。
从一开始就建立
一个简单而明显的相似之处是,现代机器学习和现代软件几乎完全是由开源软件构建的。对于软件而言,那是编译器和代码编辑器;对于机器学习而言,那是像 PyTorch 和 TensorFlow 这样的训练和推理框架。这些领域由开源软件主导,目前没有任何迹象表明这种情况会改变。
有一个显著的明显例外:所有这些框架都依赖于非常专有的 Nvidia 硬件和软件栈。这实际上比起初看起来更具相似性。很长一段时间,开源软件主要运行在专有的 Unix 操作系统上,这些操作系统由专有的硬件供应商出售。只有在 Linux 出现之后,我们才开始认为一个开放的“底层”栈是可能的,现在许多开源开发是在 MacOS 和 Windows 上进行的。目前还不清楚这在机器学习中将如何发展。亚马逊(针对 AWS)、谷歌(针对云和 Android)和苹果都在投资竞争的芯片和栈,可能这些公司中的一个或多个会跟随Linus(和 Intel)解放整个栈的路径。
培训数据:新的意外供应链?
开源软件构建方式和机器学习构建方式之间一个更关键的相似之处是它们所依赖的数据的复杂性和公共可用性。
正如我共同撰写的这篇预印本论文《数据来源项目》中详细描述的那样,现代机器学习是建立在字面上成千上万的数据源上的,就像现代开源软件是建立在数十万个库上的一样。而且,就像每个开源库都带来了法律、安全和维护挑战,每个公共数据集也带来了完全相同的一组困难。
在我的组织中,我们谈论过开源软件版本的这一挑战,称之为“意外供应链”。软件行业开始构建东西是因为开源库的惊人构建块意味着我们可以这样做。这意味着行业开始将开源软件视为供应链——这让许多“供应商”感到惊讶。
为了缓解这些挑战,开源软件已经开发了许多复杂的(尽管不完美的)技术,比如用于识别使用情况的扫描器,以及用于部署后跟踪的元数据。我们也开始投资于人力资源,以尝试解决工业需求与志愿者动机之间的差距。
不幸的是,机器学习社区似乎准备跳入完全相同的“意外”供应链错误——做很多事情因为能够做到,而没有考虑一旦整个经济基于这些数据集后的长期影响。
开源扩展到许多细分领域
另一个重要的相似之处是,我强烈怀疑机器学习会扩展到许多细分领域,就像开源软件一样。目前(实至名归)的炒作是关于大型生成模型的,但也有许多小型模型以及对大型模型的调整。实际上,托管网站 HuggingFace,机器学习的主要托管平台,报告称其网站上的模型数量正在呈指数增长。
这些模型很可能会丰富且可用于改进,就像小块开源软件一样。这将使它们极具灵活性和强大。例如,我正在使用一个基于机器学习的小工具在我家街道上进行便宜且注重隐私的交通测量,这是几年前只有昂贵设备才能做到的用例。
但这种扩散意味着它们需要被跟踪——模型可能会变得不像主机机那样,而更像开源软件或 SaaS,因为成本低且易于部署,这些模型到处涌现。
元数据不是万能的,但它是第一步
那么,如果存在这些重要的相似之处(尤其是复杂供应链和扩散的分发),机器学习可以从开源软件中学到什么?
我们可以得出的第一个相似教训是,要理解其许多挑战,机器学习需要元数据和工具。开源软件通过版权和许可合规不经意地涉足了元数据工作,但随着软件供应链的成熟,元数据在各种方面证明了其巨大价值。
在机器学习中,元数据跟踪仍在进行中。以下是一些例子:
-
一篇2019 年关键论文,在业内广泛引用,敦促模型开发者用“模型卡”记录他们的工作。不幸的是,最近的研究表明它们在实际应用中的实施仍然较弱。
-
SPDX 和 CycloneDX 软件材料清单(SBOM)规格正在研究人工智能材料清单(AI BOMs),以比模型卡更有结构化的方式跟踪机器学习数据和模型(这符合预期的复杂性,如果这确实与开源软件类似的话)。
-
HuggingFace 创建了各种规格和工具,以允许模型和数据集作者记录他们的来源。
-
上述 MIT 数据溯源论文尝试理解数据许可的“真实情况”,以帮助用现实世界的数据充实规格。
-
据说,许多从事机器学习训练的公司与数据追踪的关系显得有些随意,使用“更多更好”的借口,将数据塞入系统中,而不一定做好追踪。
如果我们从开源中学到了什么,那就是获取正确的元数据(首先是规格,然后是实际数据)将是一个长期的项目,并可能需要政府干预。机器学习应该尽早涉足这一元数据领域。
安全性将成为一个真正的问题
安全性也是开源软件对元数据需求的另一个主要推动力——如果你不知道自己在运行什么,就无法知道自己是否容易受到似乎无休无止的攻击。
机器学习并不受到大多数传统软件攻击的影响,但这并不意味着它们是无懈可击的。(我最喜欢的例子是,可能存在毒害图像训练集,因为它们通常来自过时的领域。)这个领域的研究已经热到超越了“概念验证”,进入了“有足够的攻击可以列举和分类”的阶段。
不幸的是,开源软件无法为机器学习提供任何安全方面的“灵丹妙药”——如果有的话,我们早就使用它们了。但开源软件传播到如此多的领域的历史表明,机器学习必须认真对待这一挑战,首先从追踪使用情况和部署元数据开始,正因为它很可能会以当前部署方式之外的许多方式被应用。
监管和责任将会扩展
推动开源元数据(最初是许可,然后是安全)的动机指向下一个重要的相似点:随着一个领域的重要性增加,必须测量和跟踪的范围也会扩大,因为监管和责任也会扩大。
在开源软件中,多年来主要的政府“监管”是版权法,因此元数据的发展也是为了支持这一点。但开源软件现在面临各种安全和产品责任规则——我们必须使我们的供应链成熟,以满足这些新要求。
随着人工智能变得越来越重要,它将以越来越多的方式受到监管。监管的来源将非常多样,包括内容(输入和输出)、歧视以及产品责任。这将需要有时被称为“可追溯性”的东西——理解模型是如何构建的,以及这些选择(包括数据来源)如何影响模型的结果。
这一核心要求——我们拥有什么?它是如何到达这里的?——现在对企业开源软件开发者来说非常熟悉。然而,这对机器学习开发者来说可能是一个根本性的变化,需要被接受。
“长期”比人们想象的更长
机器学习可以从开源软件(实际上也是许多早期的软件浪潮,包括主机)中汲取的另一个相似教训是,它的有用生命周期将非常非常长。一旦一项技术“足够好”,它将被部署,因此必须维护非常非常长的时间。这意味着我们必须尽早考虑这个软件的维护问题,并思考这个软件可能存在几十年的意义。“几十年”并不是夸张;我遇到的许多客户正在使用足够老到可以投票的软件。许多开源软件公司以及一些项目现在有所谓的“长期支持”版本,旨在应对这些使用案例。
相比之下,OpenAI 将他们的 Codex 工具提供的时间不到两年——这导致了很多愤怒,尤其是在学术界。鉴于机器学习变化的快速步伐,以及大多数采用者可能对最新技术感兴趣,这可能并不不合理——但这样的“长期”计划的日子将会到来,可能比行业想象的更早,包括它如何与责任和安全互动。
财务激励不一定总是对齐的
最终,显然——像开源软件一样——会有大量资金流入机器学习,但大部分资金将集中在一位作者所称的“处理器丰富”公司周围。如果与开源软件的类比成立,这些公司将比模型的中等创作者(或用户)有非常不同的关注点和支出优先级。
我们公司 Tidelift 已经考虑了开源软件激励机制的问题一段时间,像美国政府这样的世界最大软件采购者也在关注这个问题。
机器学习公司,尤其是那些希望创建创作者社区的公司,应该认真考虑这一挑战。如果它们依赖于成千上万的数据集,它们将如何确保这些数据集在几十年内得到维护、法律合规和安全保障?如果大型公司最终在公司内部部署了几十个或几百个模型,它们将如何确保那些拥有最佳专业知识的人员——那些创建了模型的人——仍然在场,以便在发现新问题时继续工作?
像安全问题一样,这个挑战没有简单的答案。但机器学习越早认真对待这个问题——不是作为慈善行为,而是作为长期增长的关键组成部分——整个行业和整个世界的情况就会越好。
结论
机器学习在学术界实验文化和硅谷快速迭代文化中的深厚根基,使其获得了显著的创新爆发,这种爆发在不到十年前可能还显得像是魔法。开源软件在过去十年的发展也许不那么光鲜亮丽,但在这段时间里,它已成为所有企业软件的基础——并在过程中学到了很多经验。希望机器学习不会重新发明这些轮子。
Luis Villa 是 Tidelift 的联合创始人兼总法律顾问。之前,他是一位顶级开源律师,为从财富 50 强公司到领先的初创公司等客户提供产品开发和开源许可方面的咨询。
Luis Villa**** 是 Tidelift 的联合创始人兼总法律顾问。之前,他是一位顶级开源律师,为从财富 50 强公司到领先的初创公司等客户提供产品开发和开源许可方面的咨询。
了解更多相关信息
AI: 军备竞赛 2.0
评论
作者:Alex D. Stern 和 Eugene Sidorin,Evolution One。
2 月 11 日,特朗普总统签署了一项行政命令,概述了美国人工智能计划。该命令讨论了美国需要维持在人工智能领域的现有领导地位。随后,在 2 月 12 日,国防部又发布了另一个公告,公布了其关于人工智能的战略概要。
然而,有人可以争辩说,持续的美国领导地位远未确定:特别是,正如我们在“对人工智能现状的反思:2018”中讨论的那样,中国在人工智能初创公司的投资方面已经超越了美国,接近 50%的人工智能投资资金流向了中国初创公司(按交易数量来看,美国仍然领先,尽管来自美国的人工智能初创公司在过去几年中所占比例稳步下降)。

中国现在也在挑战美国,无论是在专利数量还是领域内的出版物方面。的确,一些出版物的质量可能仍落后于美国,但中国一直在追赶,而且近年来在该领域的进步速度令人惊叹。
对于主导人工智能领域的渴望是可以理解的——毕竟,人工智能有一天将开启全新可能性的想法已经存在了几十年。然而,直到最近,这一想法主要还停留在科幻和少数研究者及未来学家的作品中。所有这一切在 2010 年代初开始发生变化,当时技术以及同样重要的计算资源终于赶上了,我们首次获得了能够解决实际问题的人工智能(或者说,机器学习)。
然而,正如任何具有颠覆性的进展常常发生的情况一样,不同国家发现自己面临着人工智能带来的新机会和挑战,这些情况各不相同。
对于富裕的西方民主国家来说,机器智能的出现提供了探索新领域、建立新一代成功公司的机会,并进一步改善其社会。然而,这也意味着必须面对 AI 可能对公民造成的危险,尤其是在应用不当的情况下。在过去几年中,这意味着在制定 AI 政策时越来越优先考虑“无害”原则——西方国家,尤其是美国,在 AI 方面相比其他地区,可能面临更多的风险和更少的收益。虽然西方,尤其是美国,可能仍在 AI 研究方面领先,但实施 AI 将更加困难和具挑战性,因为它面临着不同的伦理和隐私问题的期望。
相对而言,中国面临着完全不同的挑战:鉴于其历史背景和经济发展阶段,AI 可能带来的机会往往大于滥用的危险,这反过来导致了对 AI 的拥抱以及积极的投资和部署战略。
值得注意的是,在广泛的 AI 部署中,中国和西方可能会优化不同的结果。在中国,AI 通常会被优化为对整个社会产生最佳效果,即使这意味着在过程中无意中伤害少数群体。相反,西方注重人权和对每个人的公平对待,包括任何少数群体,这反过来为 AI 的采用创造了独特的挑战。
对于其他国家来说,如今大多数国家处于西方和中国所代表的极端之间的某个位置。
*******
现在,让我们深入探讨将决定当前全球 AI 军备竞赛领导者的关键因素。
基于我们上面讨论的内容,我们建议将世界划分为 3 个主要组:西方、中国和其他国家。显然,这种划分是相当主观的,但我们认为它以一种有用的方式框定了关于 AI 政策的讨论。
现在,当考虑任何可以通过机器学习解决的问题时,有三个构建块需要考虑:数据、人员和资金。

来源: Evolution One
注意: 这里每种资源的数量是主观的,仅用于说明目的;我们将在下面的每一节中详细阐述我们如何得出这些数量。
数据。
过去几十年间,数据生成量取得了巨大的增长,并且没有放缓的迹象——相反,近几年,由于我们生成信息的能力不断提高,以及新数据来源的爆炸性增长,无论是在硬件还是软件方面,这一增长趋势实际上在加速。

来源: 世界数字化从边缘到核心
根据 IDC 的数据,今天每天与数据互动的消费者已超过 50 亿,预计到 2025 年这一数字将增加到 60 亿。尽管在 2010 年代初期,智能手机对数据量的增长贡献最大,但未来增长将越来越多地由物联网设备推动,这些设备预计到 2025 年每年生成超过 90 泽字节的数据——占所有预测数据的 50%以上。
需要强调的一点是,设备数量与它们生成的数据量之间的关系从未是线性的,但现在这一点尤其明显。虽然在 2000 年代末和 2010 年代初,数据量的增长是由智能手机的普及和数据传输与存储成本的下降推动的,并且智能手机的使用数量有明显的上限。然而,如今在全球有30 亿部智能手机,增长正在放缓,但数据量却仍在迅速增长。

来源: 2018 年物联网现状
这里有两个关键因素。
首先,虽然智能手机的全球增长正在放缓,但物联网的情况则大相径庭。截至 2018 年,至少有70 亿台物联网设备(其他估计数字显著更高),预计到 2025 年将增长到 215 亿台,超过所有其他类别的总和。或许比设备的具体数量更重要的是,物联网设备的数量没有自然限制:可以想象一个世界,其中每个人都有几十台甚至几百台设备,测量从道路交通到我们公寓的温度(而且这还未包括企业使用的物联网设备)。
其次,现有数据的量在很大程度上取决于我们收集、分享和存储数据的意愿和能力(无论是暂时的还是永久的)。在这里,我们在选择收集和保留什么类型的数据时变得至关重要——任何今天未被捕获的数据都被定义为丢失,这种效应会随着时间的推移而积累。
出于对隐私的担忧以及防止潜在滥用,限制数据收集可能是合理的,但在机器学习的狭义背景下,这些选择会影响用于训练模型的数据量。这反过来意味着,对隐私关注较少的国家(以中国为例——例如,参见其利用人工智能监控摄像头的实验来抓捕罪犯)在数据方面可能会获得优势。
尽管如此,也重要的是要认识到隐私问题并不适用于每一个问题,还有一些领域(例如无人驾驶汽车,或机器翻译——参见一些有趣的专家意见这里),在这些领域西方实际上会拥有更好的数据集。
人员。
人员代表了第二个关键构建块,因为正是他们定义了处理任何可以通过机器学习解决的问题的方法。
在这里,情况与我们在数据中看到的有些相反——西方,尤其是美国,具有天然优势,因为它仍然是最具吸引力的工作和生活地点之一,从而更容易吸引来自全球的人才。它也可能对非传统的想法更加包容,这为创造性环境提供了更多可能性,并有助于发现和培养创新思路。
在基础研究领域,美国也历史上具有优势,这得益于其成熟的研究型大学体系,更不用说其吸引全球顶尖人才的能力了。然而,近年来,中国建立了顶级研究型大学体系,并继续大力投资。如今,中国已经授予了更多的自然科学与工程领域的博士学位,并在同行评审期刊上发表的文章数量超过了美国,根据《经济学人》的报道。此外,在人工智能特定领域,美国的领先地位也不再那么确定,如前所述(有关详情请参见CB Insights 报告)。
最后,谈到专注于实施(而非纯研究)的从业者时,美国和中国各有独特的优势;评估这些优势的两个可能的指标是各自国家创办的初创公司数量以及加入这一领域的专业人士数量。
美国拥有最多的初创公司,并且有一个建立完善的大型科技公司生态系统,如谷歌、微软和脸书等公司正在投资该领域。然而,中国在这里排名第二(如果将整个欧洲视为一个整体则排名第三);此外,它获得了前所未有的高额投资(更多内容见下文),并且也是少数几个能够与美国最大玩家(即阿里巴巴、腾讯和百度)竞争的公司之一的总部所在地。

然而,就劳动力而言,中国明显领先——如今,它培养的拥有 STEM 学位的大学毕业生是美国的三倍,而美国则面临着长期的合格人才短缺。与研究不同,在实践中,数字确实很重要,生产足够的工程和科学专业人才对于在该领域建立和维持领导地位至关重要。
投资
根据 CB Insights,2017 年中国初创公司在全球 AI 初创公司投资中占据了 50%的份额,相比 2016 年的 11.6%显著增长。因此,2018 年资金最充足的前两家公司——SenseTime 和 Face++——都来自中国——我们已经在最近的文章中简要讨论了 2018 年的 AI 投资格局,并得出结论,中国在早期投资方面已经领先。
尽管如此,现在特朗普总统宣布了他的美国人工智能倡议,我们认为现在可能是回顾并考虑这一公告如何影响权力平衡的好时机。
然而,在我们这样做之前,让我们暂停片刻,考虑一个可以帮助分析投资策略效率并确定其最终成功或失败的漏斗模型。

来源: 进化一号
以下三个步骤可以帮助框定讨论:
-
首先,考虑一下拟议投资的总体规模,以及它是否足以在实现既定目标的情况下产生有意义的差异。
-
其次,考虑一下目前生态系统吸收资金的效率和发展程度。
-
最后,确定所提议的战略有多专注,以及它是否针对那些具有潜力带来最佳回报的领域(这些领域会根据总体目标的不同而有所不同——例如,支持一个已经建立并且发展成熟的生态系统可能需要不同的策略,与从零开始构建基本机构时的策略不同)。
现在,应用这一框架来评估特朗普总统的 AI 战略,可以安全地得出结论,它实际上没有改变任何事情,因为它过于模糊和泛泛而谈。这并不是说美国在投资方面落后于中国——相反,显而易见的是,两国在资金量、生态系统的稳健性和关注多个具有显著发展机会的领域方面都处于同等有利的位置。
结论
尽管今天许多人将 AI 视为一种新的军备竞赛,各国准备相互激烈竞争(特朗普总统的宣布语气也没有帮助这一情况),我们相信,在 AI 领域的合作会带来持续更好的结果。
有趣的是,西方特别可能从促进全球合作中受益(比那些在封闭的世界中更具优势的对手更有可能),因为历史上正是思考和创造的自由使得美国等地对来自世界各地的人才具有吸引力。
西方实现 AI 可持续领导的途径可能依赖于:
-
专注于促进全球合作,包括来自中国等地的研究人员和公司
-
投资于 AI 伦理使用框架的发展,同时注意不要对私营企业的主动性施加不必要的限制
西方政府的角色应该集中在帮助制定和引导讨论上,而不是试图施加不必要的限制来扼杀创新。
简介:亚历克斯·D·斯特恩是产品战略师,曾在风险投资和初创企业中任职,目前在微软的云与企业部门工作。
尤金·西多林是企业家、物理学家和技术爱好者,目前在微软工作,专注于 Azure 财务和战略。
原文。经许可转载。
资源:
相关:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯的快车道
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
AI-自动化网络安全:什么需要自动化?
原文:
www.kdnuggets.com/ai-automated-cybersecurity-what-to-automate

图片由编辑提供
让我们面对现实吧:尽管一些 IT 专业人士可能因为当前的炒作而对人工智能产生反感,但人工智能融入许多日常业务流程,包括网络安全控制,只是时间问题。但现在,正当这项技术还很年轻时,理解人工智能自动化的真正影响和挑战可能会很困难。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
这篇文章揭穿了几个关于人工智能如何提升网络安全的常见神话,并向 IT 和网络安全领导者提供了有关如何做出明智自动化决策的建议。
自动化的神话与现实
不要相信人工智能将取代所有员工的神话。即使这真的有可能,我们作为一个社会也还没有准备好迎接这样的飞跃。想象一下,你登上一架飞机,却发现起飞前从未有过任何人类飞行员进入驾驶舱。毫无疑问,机上会发生叛乱,乘客们会要求有飞行员在航班上。尽管自动驾驶仪的功能很有效,但它也有局限性,所以人们仍然希望有一个人类来负责。
确实,当工业革命兴起时,我们并没有看到人类员工被淘汰。虽然机器取代了一些体力劳动的元素,但它并没有取代人类。相反,机器为制造过程带来了更高的效率、可预测性和一致性。事实上,新工作和甚至需要新技能及更大多样性的新行业也随之诞生。类似地,人工智能将为业务流程带来新的效率、可扩展性和准确性,同时创造新的机会并转变劳动市场。换句话说,你仍然需要网络安全人员,但他们将通过人工智能的协助获得技能提升。
另一个重要的误解是,AI 自动化将不可避免地降低成本。这听起来可能很熟悉;不久前对云计算也曾有类似的说法。迁移数据中心到云计算的组织发现,虽然云计算的运营支出结构比传统的资本支出有优势,但在大型环境中,最终的成本相似,部分原因是更复杂的系统需要更熟练(且昂贵!)的人才。同样,自动化将改变成本分配,但不会改变总体成本。
最后,一个完全自动化的基于 AI 的安全解决方案有时被视为一个理想目标。实际上,这是一个不切实际的梦想,提出了信任和可审计性的问题。如果这种自动化出现故障或被破坏怎么办?你如何验证结果仍然与业务目标一致?事实是我们正处于这个新的 AI 自动化范式的早期阶段,没人真正理解从安全角度来看 AI 自动化未来如何被利用。AI 和自动化不是灵丹妙药(没有什么是)。
如何知道什么需要自动化
某些过程比其他过程更适合自动化。这里有一个好的三点评估方法,可以帮助你决定一个安全过程是否适合自动化:
-
这个过程在手动执行时是重复且耗时的。
-
这个过程已经足够明确,可以被转化为算法。
-
过程的结果是可验证的,因此人类可以确定何时出现问题。
你不希望你的昂贵安全人才去处理诸如查阅安全日志、修正配置错误或解读指定的指标警报等事务。通过为他们配备基于 AI 的安全工具,你可以提高他们的可见性,增强他们对不同威胁的理解,并加快他们对攻击的响应速度。
更广泛地说,考虑一下职业体育队如何投资于技术以提高运动员的表现。同样,你需要为你的安全团队提供他们所需的自动化工具,以提升他们的水平。例如,内部威胁是一个重大风险,但几乎不可能监控公司中的每一个用户,而不良员工通常只有在已经造成一定损害后才会显现出来。基于 AI 的解决方案在降低这种风险方面可能更加高效:用户和实体行为异常(UEBA)检测解决方案可以发现用户数据访问模式的微妙变化以及与同事行为的差异,这些都可能是需要及时审查的潜在风险信号。
AI 可以将你团队的能力提升到一个全新的水平的另一个领域是威胁狩猎。自动化解决方案可以更准确地识别可能已被保护机制阻止的攻击痕迹,并将其与威胁情报进行比较。这些可能是更大规模攻击的迹象,你可以为此做好更好的准备。
结论
ChatGPT、Bard 以及其他数千款令人惊叹的新应用程序为高管们提供了体验 AI 实际应用的机会。与他们的安全团队合作,他们可以探索该技术的潜在应用。但在盲目推进之前,至关重要的是要彻底评估哪些过程值得自动化。这种尽职调查将帮助 IT 领导者确保所提议的新技术的风险不会超过其收益。
伊利亚·索特尼科夫**** 是 Netwrix 的安全策略师和用户体验副总裁。他负责技术支持、用户体验设计以及产品愿景和战略。
更多相关内容
AI Chrome 扩展工具清单
原文:
www.kdnuggets.com/2023/06/ai-chrome-extensions-data-scientists-cheat-sheet.html
随着我们进入大数据和人工智能时代,数据科学家和研究人员可用的工具和资源持续呈指数增长。每种工具,无论是向导、代码生成器还是 AI 驱动的数据提取工具,都承诺减轻重复任务的负担,提供有价值的见解,并提高整体工作流程的效率和生产力。KDnuggets 最新的工具清单,AI Chrome 扩展工具清单,向你展示了一系列先进的工具和资源,旨在支持你的数据科学工作。它们涵盖了从理解复杂科学文献到撰写高质量手稿等广泛应用。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 部门
本工具清单中包括了 SciSpace Copilot,这是一款 AI 驱动的研究助手,旨在帮助你理解科学文献中的文本、数学和表格。同时,还介绍了 Fireflies,这是一款由 GPT-4 驱动的 AI 助手,这款革命性工具可以浏览网络并总结各种内容,包括文章、YouTube 视频和电子邮件,具有类人效率。此外,还突出了 AIPRM,这是一项提供针对 DevOps、生成式 AI、软件工程和生产力等领域的精心策划提示模板资源的工具。其他工具如 Originality.AI、CodeSquire.AI、Codeium 和 Data Scraper,每款都有独特的功能和应用,旨在提升你的研究和编码技能。
发现强大的 Chrome 扩展,它们能帮助数据科学家进行研究、总结论文、生成 ChatGPT 提示、检测 AI、编码自动驾驶、数据抓取、网页浏览和内容生成。
除此之外,我们还有 Grammarly GO,它通过理解你的背景、偏好和目标来生成高质量的草稿、提纲和修订。Sider 是另一个多功能工具,允许你根据需求操控任何文本。最后,CatalyzeX 和 10AI 是强大的 Chrome 扩展,专为数据科学家设计,具有促进研究、总结论文、检测 AI、编码自动驾驶和数据抓取等潜力。
关注 KDnuggets,获取更多 使用指南 和附加学习资源,让你始终保持在数据科学前沿。
更多相关内容
2020 年你需要了解的 20 个 AI、数据科学、机器学习术语(第一部分)
原文:
www.kdnuggets.com/2020/02/ai-data-science-machine-learning-key-terms-2020.html
评论
过去,KDnuggets 曾涵盖过关键术语的集合,包括机器学习、深度学习、大数据、自然语言处理等。随着新的一年的到来,并且由于我们最近没有发布任何关键术语的集合,我们认为突显一些 AI、数据科学和机器学习的术语是个好主意,这些术语是我们现在应该熟悉的,以适应不断发展的环境。
因此,这些术语结合了一些新兴的概念以及最近可能被认为更为重要的现有概念。这些定义是 KDnuggets 团队的共同努力,包括 Gregory Piatetsky, Asel Mendis, Matthew Dearing 和我自己,Matthew Mayo。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
所以不再赘述,以下是你需要了解的前 10 个术语,下周将公布第二批 10 个,总共 20 个术语,供 2020 年使用。

AutoML
自动化机器学习(AutoML)涵盖了一系列任务,这些任务可以合理地被认为包含在机器学习流程中。
一个 AutoML “解决方案”可能包括数据预处理、特征工程、算法选择、算法架构搜索和超参数调整等任务,或这些不同任务的某个子集或变体。因此,自动化机器学习现在可以被认为是从仅执行单一任务(如自动特征工程),一直到一个完全自动化的流程,包括数据预处理、特征工程、算法选择等。
换句话说——说实话,我最喜欢的方式——如果如 Sebastian Raschka 所描述的,计算机编程是关于自动化的,而机器学习是“全自动化自动化”,那么自动化机器学习就是“自动化自动化的自动化”。跟我来:编程通过管理机械任务来减轻我们的负担;机器学习使计算机能够学习如何最佳地执行这些机械任务;自动化机器学习使计算机能够学习如何优化学习执行这些机械任务的结果。
这是一个非常强大的概念;虽然我们以前必须担心调整参数和超参数,手动工程特征,执行算法选择等,但自动化机器学习系统可以通过多种不同的方法学习如何调整这些过程以实现最佳结果。
“常规”编程是数据和规则输入,答案输出;机器学习是数据和答案输入,规则输出;自动化机器学习涉及自动化优化一组约束条件,以“最佳”方式从数据和答案到规则,用任何你喜欢的度量来定义“最佳”。
贝叶斯
贝叶斯方法允许我们应用概率分布来建模现实世界,并在新的数据可用时更新我们的信念。多年来,统计学家通常依赖于频率学派方法。贝叶斯方法适用于对数据量较小、可能在频率学派眼中不重要的假设进行建模。
Brandon Rohrer 的解释是关于贝叶斯方法如何工作的一个很好的简单示例:
想象你正在看电影,旁边的观众掉了票。你想引起他们的注意。这是他们从后面看起来的样子。你无法确定他们的性别,只知道他们有长头发。你会喊“对不起,女士!”还是“对不起,先生!”根据你对你所在地区男性和女性发型的了解,你可能会假设这是一个女性。(在这种过度简化的情况下,只有两种发型长度和性别。)现在考虑一种情况的变体,这个人正在排队等候男厕。根据这条额外的信息,你可能会假设这是一个男性。这种常识和背景知识的使用是我们在不经意间做的。贝叶斯推断是一种将其转化为数学的方式,以便我们可以做出更准确的预测。 - Brandon Rohrer
BERT
BERT 代表双向编码器表示的变换器(Bidirectional Encoder Representations from Transformers),是一种自然语言处理的预训练技术。BERT 与其他语言表示的不同之处在于将双向训练应用于现有的 Transformer 注意力模型。BERT 在左右上下文中对未标记文本数据进行深度双向表示预训练,结果是一个可以通过仅添加一层进行微调的语言模型。BERT 在许多 NLP 任务中实现了最先进的性能,包括问答和推理。BERT 和 Transformer 都是由 Google 开发的。
从直观上讲,相较于从左到右(或从右到左)训练语言模型,双向训练可以获得对语言“理解”和词义的更好感知。双向性允许根据其周围环境的整体情况来学习词义,而不是仅基于从某一方向“读取”到特定词出现的点的内容来做出判断。因此,在不同上下文中具有不同含义的词可以被单独处理,从而更好地捕捉其上下文意义(例如,河流的“岸边”与存放钱的“银行”)。
实际上,BERT 可以用于从文本中提取特征,如词或句子嵌入,或者 BERT 模型可以在额外的数据上进行微调,以完成特定任务,如问答或文本分类。BERT 提供了几种不同大小的模型(参数数量),并且激发了 BERT 相关模型的额外系列,如 RoBERTa 和 DistilBERT。
要全面了解和实用的 BERT 教程,请参见 Chris McCormick 和 Nick Ryan 的精彩文章。
CCPA
CCPA,即加利福尼亚消费者隐私法,于 2020 年 1 月 1 日生效,对收集个人数据的企业以及由此分析和处理这些数据的企业有重要影响。它的意图与 GDPR 类似,但为加利福尼亚消费者提供了更强的保护。CCPA 允许任何加利福尼亚消费者要求查看公司拥有的关于他们的信息,以及这些信息被共享的第三方的完整列表。加利福尼亚消费者还可以访问他们的个人数据,拒绝出售他们的个人数据,并要求公司删除公司所拥有的任何个人信息。
适用于任何收集消费者个人数据、在加利福尼亚州开展业务并符合以下至少一项条件的公司:
-
年收入超过 2500 万美元;
-
购买或出售 50,000 个或更多加利福尼亚消费者或家庭的个人信息。
-
从出售加利福尼亚消费者个人信息中赚取超过 50%的年收入。
欲了解更多信息,请参阅维基百科上关于 CCPA 的条目。
数据工程师
数据工程师负责优化和管理组织数据的存储和检索。数据工程师会制定如何最佳获取数据和创建存储数据库的路线图。他们通常会处理云服务,以优化数据存储并创建算法来解读数据。数据工程师的角色高度技术化,需要在 SQL、数据库设计和计算机科学方面的高级知识。
数据工程师在云端认证的趋势不断增加,以便在云环境中创建数据库并处理大型复杂数据集,以扩展和优化数据检索。
深度伪造
深度伪造是利用先进的深度学习和生成对抗网络 GANs 技术创建的虚假图像、视频或音频。这项技术非常先进,以至于结果非常逼真,且很难识别为假。这是一个使用奥巴马图像和声音的深度伪造示例:
深度伪造最初在色情内容中变得突出,热门名人的面孔被叠加到成人视频中,但最近,随着 FakeApp 等应用程序和更近期的开源替代品如 FaceSwap 和 DeepFaceLab,技术已经取得了进展。
以前,语音模仿需要几分钟的语音,但最近技术可以仅用几秒钟的语音生成令人信服的语音模仿。在 2019 年 9 月,一家公司的 CEO 的声音被骗子利用深度伪造技术模仿,从而欺骗公司支付了 24.3 万美元,成为首例此类网络犯罪。
深度伪造技术已经被用于政治虚假信息活动中,用于为机器人档案创建虚假图像,但可能在 2020 年被用来传播有关候选人的虚假语音和图像的虚假信息。
现在,深度伪造的创造者和试图识别它们的网络公司之间展开了军备竞赛。Facebook 和其他几家公司已经宣布了一项 1000 万美元的竞赛以开发识别深度伪造技术的技术。请继续关注,不要自动相信你在网上看到的所有内容——检查其来源。
模型部署/生产化
在这个机器学习、深度学习和人工智能的时代,最终目标是将其部署以交到最终消费者手中。通过网络部署模型有许多服务可用,例如 Heroku、AWS、Azure、GCP、Github 等。不同的提供商有不同的成本并提供略有不同的服务。部署和将模型投入生产将需要一定程度的前端和后端开发知识,以便能够在团队中工作。
由于云计算提供商可以轻松扩展到数百万用户并且能够监控扩展成本,现在许多模型都在使用云计算提供商进行部署。生产中的模型使组织能够从中获利,并为客户创造更大的价值。
图神经网络
数据科学家们正沉浸在数据中。大量数据。有些数据可能是原始的、无序的,像从火 hose 中喷射出来一样涌入。其他数据则可以是整齐有序的(或经过精心整理的),格式在可管理的维度内。对于这些“欧几里得”数据集,如文本、图像和视频,机器学习在文本生成、图像处理和面部识别应用中取得了很大成功。将深度学习模型与一两台 GPU 和大量训练数据相结合,发现数据中隐藏模式和有意义特征的可能性似乎是无限的。
那些更加相互关联的数据怎么办?数据可以通过依赖关系彼此连接。用户之间的互动可能会影响电子商务平台上的购买决策。药物发现中的化学反应通过复杂的反应互连图谱进行映射。社交网络通过不断变化、不规则和无序的关系形成并发展。人脑则由相互通信的细胞组成,这些细胞通过缠绕的意大利面般的结构连接在一起。
这些类型的数据关系可以建模为图,数据点被表示为节点,关系通过互连的链接进行编码。传统的机器学习方法,包括深度学习,需要进一步泛化,以便在非欧几里得的图空间中进行计算。尽管早期已有一些相关工作,但图神经网络(GNN)的概念由Margo Gori 和团队在 2005 年定义,随后进行了更多研究,扩展到了递归和卷积神经网络的图版本。深度学习研究目前正积极致力于将图神经网络方法应用于数据即意大利面源,这也是 2020 年值得密切关注的研究领域。
MLOps 和 AIOps
随着 DevOps 在 IT 组织中成功融合了软件开发人员与 IT 服务交付的过程,这个术语已被提升为当代的流行词汇。在大多数流行词汇扎根后,新的背景或应用领域往往会迅速跟上这一热潮。
MLOps 这个术语用来代表最新的最佳实践,通过与数据科学家和 IT 专业人员的有效协作来开发和部署机器学习模型。在一个明确的开发生命周期中工作,对于许多数据科学家来说应该是非常受欢迎的,因为正式和自主学习的课程通常集中在人工智能和机器学习的基础上,对于生产部署的要求了解较少,不够熟悉。
将人工智能应用于组织运营的广泛领域是 AIOps,它汇集了所有机器学习技术,以从 IT 系统中提取有意义的见解。这种方法将人类的智能与 AI 算法的智能结合起来,以增强 IT 团队在做出更好、更快的决策、实时响应事件和开发优化的应用程序以促进更有效或自动化的业务流程方面的能力。根据Gartner 的预测,到 2023 年只有 30%的大型企业首席信息官将专门使用 AIOps 来改善运营,因此 AIOps 在 IT 组织中的演变还有很多值得关注的地方。
迁移学习
在训练机器学习模型时,可能会遇到以下两个问题。首先,通常没有足够的训练数据来充分训练一个模型。其次,即使(尤其是)当存在足够的训练数据时,训练过程往往仍然耗费资源和时间。
如果考虑到机器学习模型通常是在特定任务的特定数据上进行训练,并且结果模型是任务特定的,那么这些模型的最大潜力往往无法实现。一旦数据和计算被用于训练一个模型,为什么不在尽可能多的场景中使用这个模型呢?为什么不将所学到的知识转移到新的应用中呢?高度优化的训练模型难道不能进一步用于更多任务吗?
迁移学习涉及利用现有的机器学习模型用于模型最初未训练的场景。正如人类在面对新任务时不会丢弃以前学到的一切并重新开始一样,迁移学习允许机器学习模型将其在训练过程中获得的“知识”迁移到新任务中,从而扩展了计算和专业知识组合的应用范围,这些组合曾作为原始模型的燃料。简单来说,迁移学习可以节省训练时间并延伸现有机器学习模型的使用价值。对于从零开始训练模型所需的大量训练数据不可用的任务,它也是一种宝贵的技术。
考虑到时间和计算消耗,迁移学习使我们能够更好地最大化模型的使用价值。考虑到训练数据的不足,迁移学习允许我们利用在潜在大量数据上训练的预训练模型,并在较小的任务特定数据上进行调整。迁移学习是管理机器学习模型训练中两种不同潜在缺陷的有效方法,因此它越来越被广泛使用也就不足为奇了。
这个答案部分改编自我为书籍 用 Python 进行迁移学习 撰写的前言,出版商为 Packt Publishing。
相关:
-
2020 年必备的五项数据科学技能
-
2020 年数据科学的五大趋势
-
2020 年人工智能的五大趋势
进一步了解此主题
2020 年你需要了解的 20 个人工智能、数据科学、机器学习术语(第二部分)
原文:
www.kdnuggets.com/2020/03/ai-data-science-machine-learning-key-terms-part2.html
评论
这是我们列出的 2020 年需要了解的 20 个人工智能、数据科学、机器学习术语的第二部分。这里是2020 年你需要了解的 20 个人工智能、数据科学、机器学习术语(第一部分)。
这些定义由 KDnuggets 编辑 Matthew Dearing、Matthew Mayo、Asel Mendis 和 Gregory Piatetsky 编纂。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
在这一部分,我们解释了
-
双重下降
-
人工智能中的伦理
-
可解释性(可解释的 AI)
-
全栈数据科学
-
地理空间
-
GPT-2
-
NLG(自然语言生成)
-
PyTorch
-
强化学习
-
Transformer 架构
双重下降
这是一个非常有趣的概念,Pedro Domingos——一位领先的人工智能研究员,称其为 2019 年机器学习理论中最重要的进展之一。现象如图 1 所示。
图 1: 测试/训练误差与模型规模(来源:OpenAI 博客)
随着模型变大,误差首先下降,然后在模型开始过拟合时误差增加,但随后随着模型规模、数据量或训练时间的增加,误差再次下降。
经典统计理论认为,更大的模型因过拟合而表现更差。然而,现代机器学习实践表明,非常大的深度学习模型通常比小模型更好。
OpenAI 博客 说明这在 CNN、ResNets 和 transformers 中都会发生。OpenAI 的研究人员观察到,当模型不够大以适应训练集时,更大的模型测试误差更高。然而,经过这一阈值后,随着数据的增加,更大的模型开始表现更好。
阅读原始的 OpenAI 博客以及 Rui Aguiar 提供的更长解释。
作者:Gregory Piatetsky
人工智能中的伦理
人工智能伦理关注于实际人工智能技术的伦理问题。
人工智能伦理是一个非常广泛的领域,涵盖了各种看似截然不同的伦理问题。对于人工智能以及更广泛的所有技术的使用的担忧,自这些技术首次构思之时就已存在。然而,鉴于人工智能、机器学习和相关技术的近期爆炸式增长及其日益快速地被社会广泛接受和整合,这些伦理问题已成为人工智能社区内外许多人关注的焦点。
尽管像未来有感知的机器人可能拥有的权利这样的深奥且目前尚未具象的伦理问题也可以纳入人工智能伦理的范畴,但像人工智能系统的透明度、这些系统的潜在偏见以及所有社会参与者的代表性纳入等更紧迫的当代问题,显然对大多数人更为重要且直接。人工智能系统中的决策是如何做出的?这些系统对世界和其中的人有什么假设?这些系统是由社会中占主导地位的单一多数阶层、性别和种族群体创建的吗?
美国南方大学应用数据伦理中心主任 Rachel Thomas,已声明了关于什么构成从事人工智能伦理工作的观点,这不仅涉及直接和仅仅与人工智能系统的低层次创建相关的问题,还考虑了所谓的更大图景:
**以伦理方式创办科技公司和建设产品;
倡导和致力于制定更公正的法律和政策;
尝试追究恶意行为者的责任;
以及在该领域进行研究、写作和教学。**
自动驾驶汽车的出现带来了与人工智能伦理相关的额外特定挑战,包括人工智能系统的潜在武器化以及日益增长的国际人工智能军备竞赛。与一些人试图让我们相信的相反,这些问题并非注定会成为反乌托邦的未来,但它们确实需要一些关键思考、适当准备和广泛合作。即使我们认为已经充分考虑,人工智能系统仍可能证明是独特且根深蒂固的问题,而人工智能系统的意外后果,作为人工智能伦理的另一个方面,也需要被考虑。作者:Matthew Mayo
可解释性 (可解释的人工智能)
随着 AI 和机器学习在我们的生活中扮演越来越重要的角色,例如智能手机、医疗诊断、自动驾驶汽车、智能搜索、自动化信用决策等,AI 做出的决策成为一个重要方面——可解释性。人类通常可以解释他们基于知识的决策(这些解释是否准确是另一个问题),这有助于其他人对这些决策产生信任。AI 和 ML 算法能否解释它们的决策?这点很重要。
-
改善对决策的理解和信任
-
决定在出现问题时的问责或责任。
-
避免在决策中出现歧视和社会偏见
我们注意到 GDPR 要求某种形式的可解释性。
可解释 AI (XAI) 正在成为一个重要领域,DARPA 于 2018 年推出了 XAI 项目。
图 2: 可解释 AI 韦恩图。 (来源)。
可解释性是一个多方面的话题。它涵盖了个体模型及其所包含的更大系统。它不仅指模型输出的决策是否可以解释,还涉及模型的整个过程和意图是否能够被妥善说明。目标是在准确性和可解释性之间实现有效的权衡,并提供一个出色的人机界面,这可以帮助将模型转化为最终用户易于理解的表示。
一些更受欢迎的可解释 AI 方法包括 LIME 和 SHAP。
目前,Google 提供了 可解释 AI 服务、IBM AIX 360 和其他供应商也提供相关工具。
另见 Preet Gandhi 关于 可解释 AI 的 KDnuggets 博客,以及 可解释人工智能 (XAI):概念、分类、机会和面向负责任 AI 的挑战(arxiv 1910.10045)。由 Gregory Piatetsky 撰写。
全栈数据科学
全栈数据科学家是数据科学独角兽的缩影。他们既具备能够模拟现实场景的统计学家的技能,又具备可以管理数据库和将模型部署到网络的计算机科学家的能力,还具备将洞察和模型转化为可操作的见解的商业头脑,最终用户通常是对后端工作不太关心的高级管理人员。
以下是两场精彩的讲座,它们可以让你对端到端数据科学产品的不同细节有所了解。
1. 全栈数据科学的实践:利用技术准备,由 Emily Gorcenski 主讲
2. 视频:#42 全栈数据科学(与 Vicki Boykis) - DataCamp。
阅读 #42 全栈数据科学(与 Vicki Boykis) - 报告。
作者 Asel Mendis。
地理空间
地理空间是指具有空间/位置/地理成分的任何数据。由于技术的出现,这些技术跟踪用户移动并作为副产品创建地理空间数据,地理空间分析正在获得越来越高的关注。最著名的用于空间分析的技术(地理信息系统 – GIS)包括 ArcGIS、QGIS、CARTO 和 MapInfo。
当前的冠状病毒疫情由 ARCGIS 仪表板 跟踪,该仪表板由约翰斯·霍普金斯大学系统科学与工程中心开发。
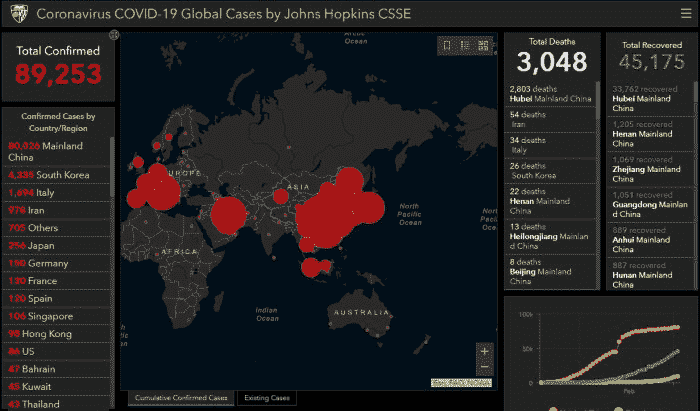
图 3:根据 Johns Hopkins CSSE 仪表板的 2020 年 3 月 2 日冠状病毒统计数据。
地理空间数据可以用于从销售预测建模到评估政府资助计划的各种应用。由于数据涉及特定位置,我们可以获得许多见解。不同国家对其空间数据的记录和测量方式各不相同,且程度不一。国家的地理边界是不同的,必须被视为每个国家独特的。 作者 Asel Mendis。
GPT-2
GPT-2 是由 OpenAI 创建的基于变换器的语言模型。GPT-2 是一种生成语言模型,意味着它通过预测每个词的顺序来生成文本,基于模型之前所学到的内容。实际上,用户提供的提示会呈现给模型,随后生成的词会依次出现。GPT-2 经过大量(40 GB)互联网文本的训练,用于预测下一个词,且完全使用变换器解码器块(与使用编码器块的 BERT 相对)。有关变换器的更多信息,请参见下文。
GPT-2 并不是一个特别新颖的项目;然而,使其与类似模型区分开来的,是其可训练参数的数量,以及这些训练参数所需的存储大小。尽管 OpenAI 最初发布了缩小版本的训练模型——出于担心可能会被恶意使用——但完整模型包含 15 亿个参数。这个 15 亿个可训练参数的模型需要 6.5 GB 的训练参数(等同于“训练模型”)存储。
发布时,GPT-2 引起了大量的关注和轰动,这在很大程度上归功于随附的精选示例,其中最著名的一个——记录发现安第斯山脉中会说英语的独角兽的新闻报告——可以在这里阅读。GPT-2 模型的一个独特应用形式是 AI Dungeon,这是一款在线文本冒险游戏,它将用户提供的文本作为输入模型的提示,而生成的输出用于推动游戏进程和用户体验。你可以在这里尝试 AI Dungeon。
尽管通过下一个词预测生成文本是 GPT-2 和解码器块变压器的基本功能(和吸引力),但它们在其他相关领域,如语言翻译、文本摘要、音乐生成等方面也显示了潜力。有关 GPT-2 模型的技术细节和更多信息,请参见 Jay Alammar 的精彩Illustrated GPT-2。由 Matthew Mayo 撰写。
NLG (自然语言生成)
在自然语言理解方面已经取得了显著进展——让计算机解读人类输入并提供有意义的回应。许多人每天都通过个人设备,如 Amazon Alexa 和 Google Home 来享受这项技术。出乎意料的是,孩子们非常喜欢问笑话。
这里的技术是,机器学习后台在各种输入上进行训练,例如“请讲个笑话”,它可以从预定的响应列表中选择一个。如果 Alexa 或 Google Home 能讲一个原创笑话,即基于大量人类编写的笑话进行实时生成的笑话,那就是自然语言 生成。
原创笑话仅仅是开始(经过训练的机器学习模型甚至能搞笑吗?),因为强大的自然语言生成(NLG)应用正在开发中,用于生成可被人类理解的数据集总结。计算机的创造性一面也可以通过 NLG 技术来探索,这些技术可以输出原创电影剧本,甚至是以大卫·哈塞尔霍夫为主演的剧本,以及基于文本的故事,类似于你可以跟随的教程,它利用了长短期记忆(LSTM),一种具有反馈的递归神经网络架构,这也是当前的一个热门研究课题。
虽然计算机生成语言的商业分析和娱乐应用可能很有吸引力并且能改变文化,但伦理问题已经引发了广泛关注。NLG 能够生成“假新闻”的能力,尤其是自动生成和传播的新闻,已经引起了担忧,即使其初衷并未被编程为恶意。例如,OpenAI 已经小心地发布了他们的 GPT-2 语言模型,研究显示其生成的文本对人类具有说服力,难以检测为合成内容,并且可以被调优用于误用。现在,他们正在利用这些研究来开发可能对人类带来麻烦的 AI,以更好地理解如何控制这些令人担忧的偏见和文本生成器的恶意使用潜力。 由 Matthew Dearing 撰写。
PyTorch
Torch 包于 2002 年首次发布,并用 C 语言实现,是一个包含多种算法以支持深度学习的张量库。Facebook 的 AI 研究实验室对 Torch 产生了兴趣,并在 2015 年初将其开源,同时也纳入了许多机器学习工具。次年,他们发布了一个名为 PyTorch 的 Python 实现,经过优化以支持 GPU 加速。
随着强大的 Torch 工具现在可以被 Python 开发者使用,许多主要玩家将 PyTorch 集成到他们的开发堆栈中。今天,这个曾经只在 Facebook 内部使用的机器学习框架,现在已成为最常用的深度学习库之一,OpenAI 成为了最新一个加入的公司和研究者。谷歌于 2017 年发布的竞争包 TensorFlow,自诞生以来一直主导深度学习社区,并且现在明显呈现出在 2020 年后被 PyTorch 超越的趋势。
如果你正在寻找第一个机器学习包来学习,或者你是经验丰富的 TensorFlow 用户,你可以开始了解 PyTorch,亲自发现哪个框架最适合你的开发需求。由 Matthew Dearing 撰写。
强化学习
除了监督学习和无监督学习,强化学习 (RL) 是机器学习中的基本方法。其基本思想是一个训练算法向试错决策“代理”提供奖励反馈,该代理尝试执行某些计算任务。换句话说,如果你把一根棍子扔到院子里让 Rover 捡回来,而你的小狗决定把它带回给你以获得奖励,那么它下次会更快、更有效地做出相同的决定。这种方法的令人兴奋的特点是无需标记数据——模型可以在指导下通过编码奖励探索已知和未知的数据,寻找最佳解决方案。
强化学习是棋类、视频游戏中令人惊叹、创纪录和战胜人类的比赛的基础,以及AlphaGo 的重创一击,它在没有任何硬编码指令的情况下学会了围棋。然而,虽然这些 AI 超人能力的发展是显著的,但它们仅在定义明确的计算机表示中表现良好,例如具有不变规则的游戏。强化学习无法直接推广到现实世界的复杂性,正如OpenAI 的魔方模型所示,该模型在模拟中能够解决难题,但在通过机器人手臂转化时需要多年才取得相对较差的结果。
因此,强化学习领域还有大量需要开发和改进的内容,2019 年见证了潜在的复兴正在进行中。将强化学习扩展到现实世界应用将是 2020 年的热门话题,重要的实施已经在进行中。由 Matthew Dearing 撰写。
变换器
Transformer 是一种新颖的神经网络架构,基于自注意力机制,特别适合自然语言处理和自然语言理解。它在 2017 年由谷歌 AI 研究人员提出的Attention Is All You Need论文中提出。Transformer 是一种通过编码器和解码器将一个序列“转换”成另一个序列的架构,但它不使用递归网络或 LSTM。它使用注意力机制,使其能够查看输入序列中的其他位置,从而改善编码。
这里有一个例子,由 Jay Alammar 详细解释。假设我们想翻译
“动物没有过马路,因为它太累了”
“it”指的是什么?人类知道“it”指的是动物,而不是街道,但这个问题对计算机来说很难。当编码单词“it”时,自注意力机制集中在“The Animal”上,并将这些词与“it”关联起来。
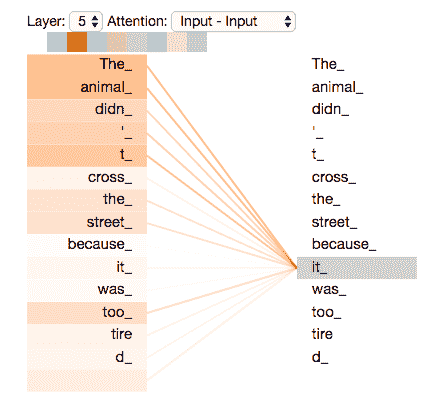
图 4:当 Transformer 正在编码单词“it”时,注意力机制的一部分集中在“The Animal”上,并将其表示与“it”的编码连接起来。 (来源.)
谷歌报告称,Transformer 在翻译任务上明显优于其他方法。Transformer 架构被用于许多自然语言处理框架中,例如 BERT(Bidirectional Encoder Representations from Transformers)及其后续版本。
想要更好的视觉展示,请参阅图解 Transformer,作者是 Jay Alammar。由 Gregory Piatetsky 撰写。
相关内容:
更多相关主题
人工智能和深度学习,简单解释
原文:
www.kdnuggets.com/2017/07/ai-deep-learning-explained-simply.html/3
学习了一百万个例子后,机器学习模型在百分比上可以比人类犯更少的错误,但错误的类型可能与人类不同,例如将牙刷误分类为棒球棍。这种与人类的差异可以被用于恶意的人工智能黑客攻击,例如在街道标志上涂上微小的“对抗性”变化,人眼难以察觉,但会对自动驾驶汽车造成极大的混淆。

(AI 训练师 = 小狗训练师,而不是工程师。照片来源:皇家空军,米尔登霍尔)
人工智能将会淘汰旧的工作,但会创造新的机器学习训练师职位,类似于小狗训练师,而不是工程师。机器学习模型比小狗更难训练,因为(与小狗不同)它缺乏通用智能,因此它会学习数据中发现的一切,而没有任何选择或常识。小狗在学坏事物时会三思,例如伤害朋友。而机器学习模型则不会在为恐怖分子或医院服务时有任何区别,也不会解释为何做出这些决定。机器学习模型不会因为错误而道歉,也不会因错误而担心被关闭:它不是有意识的通用人工智能。为了安全和质量标准,每个机器学习模型将被许多人包围,他们在:机器学习训练、机器学习测试方面都有专长,还包括尝试解释机器学习模型的决策和伦理。所有这些都在同一个职位下完成。
实际的机器学习训练。如果你用手拿着物体的照片来训练,机器学习模型会将手也视为物体的一部分,无法单独识别物体。狗知道怎么从手中吃东西,而笨拙的机器学习模型也会“吃掉”你的手。解决办法是先仅用手的照片进行训练,然后仅用物体的照片,最后用手持物体的照片进行训练,标记为“物体 x 被手拿着”。物体的变化也是如此:例如没有轮子的汽车或因事故变形的汽车,破碎的房子等等。任何人都知道那是一辆撞墙的车,一栋被炸毁的房子等等。机器学习模型看到未知的新物体,除非你逐个教,逐个案例进行。包括天气!如果你只用晴天的照片进行训练,那么测试将会在其他晴天的照片上有效,但在阴天拍摄的相同物体的照片上则无效。机器学习模型学会了基于晴天或阴天的天气来分类,而不仅仅是物体。狗知道无论物体在晴天还是阴天的光线下,都要判断出是什么物体。而机器学习模型则会挑选所有微妙的线索:你需要明确地教会它所有 100%。
版权和知识产权法律需要更新:机器学习(ML),像人类一样,能够发明新事物。一个机器学习系统被展示了现有的事物 A 和 B,并产生了 C,一个新的、原创的事物。如果 C 与 A 和 B 以及地球上其他任何事物有足够的不同,C 可以作为发明或艺术作品申请专利。谁是作者?进一步说,如果 A 和 B 是已经申请了专利或版权的材料呢?当 C 与 A 和 B 的关系非常不同的时候,A 和 B 的作者可能无法猜到 C 是由于他们的 A 和 B 而存在的。假设训练机器学习系统使用最近的版权画作、音乐、建筑、设计、化学公式,甚至是盗取的用户数据等是不合法的。那么,如何从机器学习的结果中猜测使用的数据源,尤其是当这些结果比毕加索风格的转化更不易识别时?你如何知道是否使用了机器学习?许多人会秘密使用机器学习,并声称结果是他们自己的。
对于小公司来说,大多数任务训练人类比训练机器学习系统更便宜。教一个人开车很简单,但教一个机器学习系统做同样的事情则极其复杂。需要通过数百万个手工制作的道路情境示例来训练机器学习系统。之后,机器学习系统可能比任何人类司机都更安全,尤其是那些酒醉、困倦、盯着手机屏幕、忽视速度限制或情绪激动的司机。但是如此昂贵且可靠的训练仅对大公司而言是可行的。用便宜方式训练的机器学习系统会有缺陷且危险,只有少数公司能够提供可靠的机器学习系统。一个训练好的机器学习系统可以被迅速复制,这与大脑的经验转移到另一个大脑是不同的。大公司会出售预训练的机器学习系统用于可重复的常见任务,例如“放射科医生机器学习系统”。该机器学习系统将补充一个人类专家,这个人类专家仍然是必需的,仅替代“额外”的工作人员。医院将雇用一名放射科医生来监督机器学习系统,而不是数十名放射科医生。放射科医生的工作并没有消失,只是每家医院的数量会减少。训练机器学习系统的人将通过向许多医院销售来回收投资。机器学习系统的训练成本每年都会下降,因为越来越多的人会学习如何训练机器学习系统。但是,由于数据准备和测试,可靠的机器学习训练永远不会便宜。理论上许多任务可以自动化,但在实践中,只有少数任务值得机器学习的设置成本。对于像飞碟研究者、古代(已灭绝)语言翻译员等过于少见的任务,长期的人力成本将会比训练机器学习系统的一次性成本更便宜。
人类将继续从事一般的 AI 任务,超出机器学习的范围。智商(IQ)测试是错误的:它们无法预测人们的生活成功,因为有许多不同的智力(视觉、语言、逻辑、人际等):这些智力以某种混合方式合作,但结果无法用从 0 到n的单一 IQ 数字来量化。我们将昆虫定义为“愚蠢”,与人类 IQ 相比,但蚊子在狭窄的“叮咬和逃跑”任务上总是赢过我们。每个月,AI 在越来越多的狭窄任务上打败人类,就像蚊子一样。期待“奇点”时刻,当 AI 在所有任务上超越我们,是很愚蠢的。我们正在经历许多狭窄的奇点,一旦 AI 在某项任务上胜过我们,除了监督 AI 的人外,其他人都可以停止该任务。我听说人类可以继续做有独特手工缺陷的工作,但实际上,AI 也可以制造假错误,学习为每件作品制作不同的缺陷。很难预测下一步 AI 会赢得什么任务,因为 AI 具有一定的创造力,但它将缺乏“通用智能”。例如,喜剧演员和政治家(可以互换)是安全的,尽管不需要特殊的(狭窄的)研究或学位:他们可以以有趣或令人信服的方式谈论任何事情。如果你专注于一个困难但狭窄且常见的任务(例如放射科医师),机器学习将被训练来替代你。保持通用!
感谢阅读。如果你觉得不错,请点击下面的喜欢和分享按钮。
如有问题或咨询,请在 LinkedIn 上给我留言,或发送电子邮件至 fabci@anfyteam.com
原文。经允许转载。
简介: Fabio Ciucci 是意大利卢卡的 Anfy srl 的创始人兼首席执行官。自 1996 年以来,他创建了自己的公司,并为其他人(企业家、家族办公室、风险投资家)提供关于私募股权高科技投资、创新和人工智能的咨询。
相关:
-
人工直觉 – 突破性的认知范式
-
什么是人工智能、机器学习和深度学习?
-
大多数机器学习专家都转向深度学习了吗?
我们的前三个课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织在 IT 领域
更多相关主题
5 分钟内设置你的 AI 开发环境
评论
由 Nick Walsh 撰写
无论你是第一次设置 TensorFlow 的新手数据科学爱好者,还是处理数 TB 数据的资深 AI 工程师,安装库、包和框架总是一项挑战。
尽管像 Docker 这样的容器化工具确实彻底革新了软件的可重复性,但在数据科学和 AI 社区中尚未得到广泛采用,这也是有原因的!随着机器学习框架和算法的不断演变,找到时间来学习另一个开发工具,尤其是那些与模型构建过程无直接关联的工具,可能会很困难。
在这篇博客文章中,我将展示如何使用一个简单的 Python 包通过几个简单步骤来设置你环境,以适配任何流行的数据科学和 AI 框架。Datmo 在底层利用 Docker,简化了过程,帮助你快速、轻松地启动,无需陡峭的学习曲线。
0. 前提条件
-
安装并启动 Docker
-
(如果使用 GPU)安装 CUDA 9.0
-
(如果使用 GPU)安装 nvidia-docker(步骤 3)
1. 安装 datmo
就像任何 Python 包一样,我们可以通过终端使用以下命令来安装 datmo:
$ pip install datmo
2. 初始化 datmo 项目
在终端中,进入你想开始构建模型的文件夹。然后,输入以下命令:
$ datmo init
然后系统会要求你为项目提供名称和描述——你可以随意命名!
3. 开始环境设置
在输入名称和描述后,datmo 会询问你是否希望设置环境——输入 y 并按回车键。
4. 选择系统驱动程序(CPU 或 GPU)
CLI 将会询问你希望为你的环境选择哪些系统驱动程序。如果你不打算使用 GPU,选择 cpu。
5. 选择一个环境
接下来,你需要从许多预打包环境中进行选择。只需在提示中输入你想使用的环境的编号或 ID。
6. 选择语言版本(如果适用)
以上许多环境根据你计划使用的语言和版本有不同的版本。
例如,在选择 keras-tensorflow 环境后,我会看到如下提示,询问我是否希望使用 Python 2.7 或 Python 3.5。
7. 启动你的工作空间
你已经正确选择了你的环境,现在是时候启动你的工作区了。选择你想使用的工作区,并在终端中输入相应的命令。
Jupyter Notebook -- $ datmo notebook
JupyterLab -- $ datmo jupyterlab
RStudio -- $ datmo rstudio(在 R-base 环境中可用)
终端 -- $ datmo terminal
 打开 Jupyter Notebook 并导入 TensorFlow
打开 Jupyter Notebook 并导入 TensorFlow
你准备好了! 第一次为新环境初始化工作区时,会花费一些时间,因为需要获取所有资源,但在后续运行中会显著加快。
一旦你的工作区启动,你就可以开始导入你选择的环境中包含的软件包和框架!例如,如果用户选择了 keras-tensorflow 环境,那么在你的 Jupyter Notebook 中 import tensorflow 将立即生效!
如果你使用 TensorFlow,可以尝试我们文档中的这个示例来运行你的第一个 TensorFlow 图。
如果你希望帮助贡献、报告问题或请求功能,你可以在 GitHub 上找到我们!
个人简介: Nick Walsh 是 Datmo 的开发者推广员,致力于构建开发者工具以帮助数据科学家提高效率。他还在全国各地的学生黑客马拉松中担任 Major League Hacking 的教练。
相关内容:
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关主题
AI 正在吞噬数据科学

作者使用 Midjourney 创作的图像
作为 21 世纪技术革命的基石,数据科学被视为每个行业的未来。但仔细观察会发现,数据科学作为一个学科只有短暂的历史,它是从数据匮乏的过去过渡到智能系统主导的未来的一个阶段。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
不久前,我们面临稀疏的数据和高昂的数据存储成本。快进到今天。由于我们新兴的数字支柱,包括互联网、社交媒体、电子商务和物联网设备,我们持续被数据淹没。数据科学已经发展成为一种工具,在这个大数据时代的初期,帮助我们获得见解、预测趋势和做出决策,使我们能够理解这些庞大的数据集。大数据时代现在已经完全过去,我们已经牢牢地适应了这一时代。
然而,随着处理大数据能力的提高,变化变得越来越明显。重点不再是我们不断生成的大量数据;我们已经将注意力转向了不断扩展的复杂数据驱动的 AI 系统。关键问题不再只是“我可以从这些数据中获得什么见解?”而是“我可以用这些数据运行什么 AI 系统?”过去十年专注于掌握大数据。接下来,我们承诺将转向设计和实现更强大的 AI 系统。
这一新兴趋势标志着数据科学与 AI 职业路径的融合:另一个 AI 驱动的奇点。现在不仅仅是分析数据的能力,还包括构建、训练和维护能够学习、适应并做出自主决策的 AI 系统。这种角色的整合代表了一个越来越以 AI 为中心的局面。
要想看到这种变化的实际应用,只需看看 OpenAI 的 ChatGPT 项目。最初,该项目专注于收集和组织大量数据以训练模型。然而,重点很快转向尝试创建和改进能够生成有意义的、上下文相关的自然语言响应的大规模系统。数据与系统之间的互动将变得更加动态,人工智能将以越来越复杂和创新的方式使用数据。
想象一下一个未来,人工智能驱动的智能城市成为常态。传感器、设备、人类互动等产生的大量数据将被人工智能用于控制交通流量、能源消耗、公共安全等。这不仅仅是数据分析。它涉及到开发能够理解和管理复杂城市生态系统的庞大人工智能系统。
数据科学可能看起来正在演变成现代人工智能的一个分支,这正是因为它确实如此。但不要担心,这只是为了跟上不断发展的技术环境的一个进化步骤,就像数据科学从统计学中涌现以应对曾经新兴的“大数据”一样。正如统计学是数据科学的一个不可或缺的部分,数据科学本身将在人工智能驱动的未来中继续发挥重要作用。
数据相关的变革自十多年前开始继续推进,尽管其目的地尚不明确。然而,方向是明确的:未来的技术行业职业要求不仅要理解数据本身,还要理解数据作为复杂且多功能的人工智能系统的命脉。在这种背景下,数据科学最终将被视为通向人工智能中心未来的一个重要里程碑。但不要误解;作为一个独立实体的数据科学将最终被回顾。
因此,随着近期人工智能的进步开始在世界上留下印记,请注意它对数据科学的不可避免的影响。正如现在的数据是庞大的,我们对其可以促进的系统的愿望也同样巨大。
数据万岁!
Matthew Mayo (@mattmayo13) 是数据科学家及 KDnuggets 的主编,这是一个开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。你可以通过 editor1 at kdnuggets[dot]com 与他联系。
更多相关话题
AI 教育差距及其弥合方法

图片来源于编辑
现在是参与分析和 AI 的激动人心的时刻。就像 90 年代初的软件热潮一样,许多组织正在迎来新一代技术能力,赋能团队,并以仅在过去幻想的方式推动数字化转型。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
尽管市场上有少数成熟的 AI 专注公司,但大多数组织似乎仍滞后于前沿。好消息是,正因为这个差距,带来了大量在线教育机会,帮助学习必要的技术技能来构建 AI 解决方案。选择范围从 YouTube 等视频平台上的免费教育内容到如 Udemy 或 Coursera 这样的需要月费的大规模开放在线课程(MOOCs)。甚至还有长期的在线训练营,旨在帮助个人换工作并提升数据和分析职业生涯。
尽管这些选项可能提升数据中心角色的个人的技术技能,但大多数在教授成功启用和扩展 AI 至更广泛组织所需的技能方面未能达到目标。
针对当前 AI 教育和 MOOCs 的案例
AI 教育体系存在问题。你可能会觉得这一说法很大胆,特别是考虑到在线上有成百上千种免费的数据、分析和 AI 教育资源。但仔细观察就会发现,提供的培训确实存在一些令人担忧的局限性。
-
许多 AI 教育工具在学习者参与度方面遇到困难。 研究表明,MOOCs 提供的在线分析和 AI 教育的平均完成率仅为 3%。为什么这些课程如此枯燥?它们有一种单维度的风格。一人,一门课程,获取一个证书。有些人可以通过整天盯着屏幕和浏览各个部分来很好地学习,但其他人可能会觉得这很乏味或难以应用。
更重要的是,如果没有完成课程并在特定时间内做出改变的动机,坐下来学习的优先级就会降低。当领导者期望他们的学生在工作之外找到时间时,培训最终会被降级,团队也不会看到他们对培训的投资产生影响。
-
人工智能教育过于关注战术技能。 大多数培训由工具或语言供应商提供,因此侧重于特定的软件工具或技术方法。技术技能,如编写代码或设置自动化,确实不应被忽视。但它们只是成功部署人工智能的一部分。
-
大多数人工智能教育课程都是完全现成的。 在许多情况下,成千上万的学生注册一个课程,并由一个讲师授课。有时讲师只是一个协调者,而不是课程创作者,其他时候讲师完全缺席。虽然这种模式适合规模化,但这种师生关系的缺失使得学生必须将所学技能与工作联系起来。学生的反馈突显了这个问题。他们报告说,在工作中应用所学概念是独立发展新技能时最困难的方面之一。
这些限制如何影响希望实施和扩展人工智能的团队?个人最终在孤立的环境中学习特定的工具或策略。他们缺乏与实际应用和合作的接触,而这些对于按照组织战略构建有影响力的人工智能解决方案至关重要。
解决方案
-
寻找包含技术团队和业务团队的培训。 数据分析和人工智能本质上是跨职能的,因此业务和技术人员步调一致对任何组织的一致性和规模至关重要。
-
理解学生有繁重的工作负荷和复杂的责任。 寻找那些设计为一系列短模块的课程,以便在工作日中快速访问。关注适量的信息,以帮助学习者在工作中实现具体、可操作的结果。
-
利用按需和实时的体验学习练习。 学习风格因人而异,并非一刀切。预录制的视频是当今常见的方法,但并不适用于所有人。员工学习者应当理解一个概念及其重要性,在安全的环境中与团队成员一起实际应用,然后反思哪些方法适合他们特定的团队和环境。这种多样化的学习模式有助于保持内容的新鲜感、吸引力、合作性,最重要的是,适用性。
在今天众多的数据分析和人工智能培训选项中,不要忽视特定工具和代码行之外的必要技能。技术技能固然重要,但要在整个组织中成功启用和扩展人工智能,还需要更多的支持。
Rehgan Avon 是AlignAI的联合创始人兼首席执行官,这是一家通过面向过程的教育帮助组织更快成熟其 AI 能力的 AI 采纳平台。Rehgan 拥有集成系统工程背景,并强烈关注于构建支持分析和机器学习的技术,曾参与设计解决方案和产品,致力于在大企业中大规模运作机器学习模型。
更多相关话题
人工智能在金融科技中的应用:管理未来的金融
原文:
www.kdnuggets.com/2022/10/ai-fintech-managing-finance-future.html

金融科技正在采用人工智能,这要归功于数据的丰富性和计算能力的成本效益。人工智能为金融行业提供了一系列好处,包括提高生产力、增加利润和提升产品质量。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
大多数金融科技公司有效地在网络安全和客户服务等各种金融领域部署人工智能。此外,人工智能也在改变在线银行的工作方式。例如,聊天机器人的自然语言处理和情感智能被证明是一种具有成本效益的替代方案。此外,随着人工智能解释更多的数据,它们对人工干预的依赖减少。
-
成功的银行相关聊天机器人互动将在 2019 年至 2023 年间增长。
-
到 2023 年,聊天机器人互动将节省超过 8.26 亿小时。
-
超过 70%的聊天机器人互动将通过移动银行应用程序进行。
随着对在线银行和支付服务需求的持续增长,采用人工智能已成为金融科技可持续发展和增长的关键。以下是一些人工智能趋势将如何管理未来的金融。
1. 欺诈检测
从贷款申请诈骗到虚假保险索赔,近几年来欺诈性的金融活动有所增加。此外,伪造交易可能使企业损失数百万美元。
除了处理财务损失,大多数公司还必须善于处理可能损害企业声誉的负面客户体验。
人工智能在商业和金融中的应用 探索解决方案利用机器学习来识别欺诈和网络安全问题。在大规模金融操作中,逐一审查每笔交易的可疑活动几乎是不可能的。
人工智能系统帮助实时监控银行交易,同时人工智能算法可以更准确地检测常见模式。
2. 更强的安全性
AI 显著提升了金融科技行业的数据安全服务。此外,大多数金融科技公司和银行通过启用 AI 的聊天机器人为客户提供支持。
此外,AI 模型提供不同的解决方案来增强 - 例如密码保护和获取系统的附加访问权限。此外,AI 擅长通过语音、面部和指纹识别来提高金融安全性。
添加的 AI 层使绕过传统密码变得困难。未来,基于 AI 的安全解决方案将彻底改变密码的未来。
金融科技公司面临风险,因为它们处理着数百万种货币,因此 AI 将确保系统具有最高的安全级别。
3. 改善客户服务
AI 在金融科技公司和银行的客户服务中带来了显著变化。客户逐渐习惯于从银行获得更快的响应。此外,由于金融解决方案需要随时提供以解决重大问题,AI 在这里扮演着重要角色。
不同的 AI 驱动的聊天机器人和虚拟界面帮助减少工作负担,通过处理最常见的用户问题。此外,这些系统节省了团队的时间,以便专注于更复杂的用户请求。
AI 可以通过复杂的情感分析来改善金融科技的客户服务,更加关注整体客户体验。此外,客户与金融科技之间的沟通通过基于 AI 的系统变得更容易。
4. 定制化银行服务
金融科技公司和银行拥有数百万客户。如果银行为每位客户提供个性化服务,这可能是一项艰巨的任务。此外,定制化可以让客户更加信任你的业务。
当客户在手机上下载银行应用时,AI 算法会收集所有客户数据。根据收集的数据 - 银行提供个性化的推荐和预先批准的产品。
此外,AI 银行应用可以帮助客户跟踪个人财务目标。一些 AI 模型还分析语音和声音特征以区分真实模式并创建有意义的见解。
5. 节省资金和资源
通过采用 AI 驱动的资源和应用,金融科技公司可以节省劳动力成本和大量资金。AI 自动化取代了人工过程,从而节省了时间。AI 聊天机器人处理所有较小的查询,减少了客服团队的工作负担。
此外,利用在 AI 聊天机器人系统上节省的资金,一些银行可以向客户提供有吸引力的优惠。简而言之,数据驱动的 AI 提高了资本优化。
6. 算法交易
AI - 类似于机器学习,帮助执行股票交易,使用预编程的指令分析交易数据。此外,AI 通过实时处理数百万个数据点,彻底改变了传统的数据点。
它提供了统计模型无法检测的见解。由于金融科技中的 AI,客户可以通过移动应用实时交易股票。
7. 自动化贷款
多亏了 AI 和 ML 自动化,贷款审批速度加快。专业的 AI 应用通过实时分析来加快贷款申请的审批成本,从而帮助做出明智的决策。
不同的 AI 模型经过验证检查并评估个人的信用 worthiness。此外,它还有助于优化贷款审批自动化。但最重要的是,AI 使用不同的数据点来创建客户的准确财务状况。
AI 在各个方面优化流程,高效地处理重复任务,承担复杂任务并提供有价值的见解。结果,它提升了客户体验,节省了时间,并使企业能够做出有意义的决策。
金融领域的 AI 革命擅长通过确保完全透明和信任来减少相关的商业风险。
罗伯托·萨托 是 全球电子技术公司的执行副总裁兼首席信息官,总部位于加利福尼亚州托伦斯。他热衷于通过易于理解的写作帮助人们了解内容。简单生活,慷慨给予!
更多相关话题
AI 在亲密角色中的应用:女友和治疗师
原文:
www.kdnuggets.com/ai-in-intimate-roles-girlfriends-and-therapists

图片由 DALLE-3 生成
人工智能与人类亲密关系之间的联系常常是一个有争议的话题,也许是大多数人只会在科幻电影中看到的主题。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
然而,退一步来看我们所生活的时代——自动驾驶汽车、先进的 3D 打印,甚至像 Ozempic 这样的减肥药物都已成为现实,我们会明白这些“难以置信”的概念实际上往往是非常可行的。
AI 目前是科技领域中最受关注和最具争议的话题。它有潜力极大地改变许多行业,但也存在安全隐患,以及可能导致数百万人的工作岗位被替代的风险。
一个不常被讨论的方面是 AI 在个人亲密角色中的伦理和心理学上脆弱的使用。一个由他人编写、常常充满偏见的机器,是否真的能理解人类情感,模仿这些情感,并提供安慰?让我们更详细地探讨这些问题。
AI 能理解人类情感吗?
情感 AI 的发展使得人工智能更容易分析人类情感。这个 AI 领域的子集,也称为情感计算,通过自然语言处理、情感分析、面部动作 AI、语音情感 AI、步态分析和生理信号等组合来检查和反应人类情感。
其中一些技术和方法并不全新——一些基础技术和方法已经使用了多年。例如,情感分析是一种被营销公司广泛使用的方法,他们用它来研究客户行为并提供建议,在金融领域也被用来尝试预测股市变化。
情感 AI 将这一工具专注于一个主题——一个人。最终目标是在提供治疗方面的广泛采用,具有大规模诊断抑郁症和其他心理健康障碍的潜力,同时解决方案将比传统治疗更易获得。
因为这些可能性,预计情感 AI 市场将以 22.7% 的年复合增长率增长,并 在 2032 年达到 138 亿美元。
AI 合作伙伴和伴侣
AI 重要其他人的出现是一个最近的趋势,已受到褒贬不一的回应——这是对已经 蓬勃发展的 AI 伦理辩论 的更亲密、个人化的角度——心理学领域的专家对此表示担忧。
很容易看出,尽管可能产生暂时的好处,这种使用案例也有可能进一步使人们与他们的社区和社会产生隔离。
更具前瞻性的专家还提出了一个问题,即“AI 合作伙伴”的广泛采用可能如何对新一代的社交互动方式,甚至出生率产生负面影响。
人际互动已经在减少。许多人可能每周在家工作五天,而组织 如银行(尽管这不是唯一的例子)依赖聊天机器人提供客户服务和服务。例如,一个人甚至可以 申请房产贷款 或按揭而无需与任何人面对面交谈——而且这是现在的情况。
扩展到包括人们的个人和情感空间,这可能对一个人的心理健康和对现实世界环境的理解产生重大影响。
潜在的积极影响
然而,仅仅讨论任何新兴技术的潜在负面影响是不公平和不公正的。AI 系统在情感层面上理解和互动的能力本身并非负面。
AI 伴侣可以对那些感到孤独或隔离的人产生积极影响, 提供定期的社交互动,并创造一个安全、私密的环境,让人们可以分享他们的想法和感受。
AI 合作伙伴将随时可用,提供情感支持,无需判断,这在与人谈论敏感话题时可能是一个顾虑。
定制这些伴侣的能力可以使其在一个友好、理解的环境中轻松对话,且不受评判。人工智能伙伴也可能作为一种学习工具——为孤独和隔离的人提供有关亲密关系中所需的同理心、理解和行为的指导。
对于那些可能患有焦虑症或没有时间维持正常人际关系的人,人工智能伴侣可能是定期社交互动的完美过渡措施,可能使回到健康社交生活的道路变得更容易。
人工智能治疗师
允许人工智能伙伴存在的相同技术基础也可以应用于心理健康领域。最近,我们见证了人工智能治疗师、心理健康教练和顾问的崛起。
不幸的是,尽管我们在心理健康领域取得了显著进展,这些进展通常仅限于讨论——接受治疗的污名化程度比十年前少得多,这一话题成为了持续的社会讨论,甚至在公共政策中也成为了一个优先考虑的问题。
然而,实际情况并不如预期那么顺利——由于价格或时间限制,治疗仍然难以获得,许多人仍然无法得到所需的帮助。
通过利用情感计算,人工智能可以分析情感状态和患者反应,识别抑郁迹象或提供相关建议。
随着大型语言模型(LLMs)与人类对话的能力不断提升,以及从过去对话中学习和快速分析大量数据的能力不断增强,人工智能可以提供全天候支持、建议和个性化护理。
实践中的人工智能治疗
作为一种新兴现象,人工智能治疗仍受到严格审查,以确定其疗效。人类治疗师的成功率仍然更高,而技术仍未达到提供足够准确诊断的水平。
人工智能治疗对那些在应对轻度心理健康问题(如焦虑或压力)并需要易于获取的支持的个人仍然有益。然而,一旦涉及到更严重的心理健康挑战,例如创伤后应激障碍(PTSD)、躁郁症、边缘性人格障碍(BPD)、精神分裂症,甚至中度到重度抑郁症,使用人工智能是不推荐的。
简单来说,我们在技术上距离 AI 开处方药物还很遥远——即便我们达到那一点,这仍将是一个高度分裂的伦理问题。更重要的是,隐私也是一个问题——鉴于几次广受关注的数据泄露,包含敏感患者信息的 AI 模型如何处理HIPAA 合规性仍然是一个悬而未决的问题。
专家对 AI 治疗的可能性仍持乐观态度,但 AI替代人类治疗师的可能性极小。相反,这项技术可以用于补充和支持心理健康治疗,为患者提供一个全天候讨论问题的渠道。
结论
情感 AI 和驱动 AI 治疗软件的算法正在快速进步,技术的能力逐年提高。这导致了 AI 在亲密领域使用的日益流行,但这并不意味着技术没有局限性。
AI 伴侣可以为人们提供定期的社交互动和娱乐。这对于忙碌的生活方式或可能患有社交焦虑的人来说是理想的。然而,这也可能导致人们与现实世界脱节,错过日常的人际互动。
与此同时,AI 治疗师可以在补充人际治疗方面发挥关键作用,但在准确诊断心理健康问题方面存在限制,并且可能遗漏某些非语言信号。目前,AI 治疗师适合为轻度心理健康问题提供支持,让个人能够全天候讨论他们的问题。
Nahla Davies是软件开发者和技术作家。在全职从事技术写作之前,她还曾担任过一家公司中的首席程序员,该公司是 Inc. 5,000 的体验品牌组织,其客户包括三星、时代华纳、Netflix 和索尼。
更多相关信息
AI 无限训练与维护循环
原文:
www.kdnuggets.com/2021/11/ai-infinite-training-maintaining-loop.html
评论
由Roey Mechrez, Ph.D.,BeyondMinds 首席技术官兼联合创始人。
如果你曾尝试为你的业务推出 AI 解决方案,你可能对以下场景非常熟悉:你花了几周时间收集数据来训练你的 AI 模型,清理数据、增强数据并改善数据。接着,你探索了几种可以适应你 AI 解决方案问题的开源模型和架构。接下来,你可能使用了几种工具来加速开发过程,并创建了一个管道来帮助包装解决方案、调整参数,并比较数百种训练选择。经典的数据科学实验室工作,对吧?寻找完美的模型——开发一种最先进的解决方案来解决 AI 可以帮助解决的问题。
如果一切顺利,训练过程顺利进行,你的模型在测试数据集上的准确率达到 95%。需要一些额外的软件魔法和周末的加班来解决所有未完成的工作,但你终于达到了终点线:将模型投入生产——迎接激进的 Q3 截止日期。
快进三个月。冬天来了。模型效果不佳。与模型互动的业务人员不满意。他们从 AI 中得到的结果没有意义。在一个寒冷的早晨,你收到了来自高层的邮件,标题明确无误:“你的 AI 没有工作。”
这不是一个轶事。实际上,对于许多公司来说,这是一种痛苦的现实,尤其是在涉及到关键任务或操作敏感的应用程序时,例如缺陷检测、索赔自动化、欺诈检测、客户入职、KYC(了解你的客户)、AML(反洗钱)、预测性维护或信用评分。
使用真实世界数据训练你的 AI 模型
虽然许多因素和组件可能导致 AI 解决方案在生产中失败,但根本问题深植于这一过程的基本设计中。令人沮丧的现实是,大多数在受控实验室环境中无缝工作的 AI 模型,在面对真实世界环境时却失败了,因为现实世界中的数据往往是嘈杂的、动态的且未标记的。应对这种差异的最有效方式是让你的 AI 模型尽早面对生产数据,即使它仍处于实验室训练阶段。
关键在于在模型已经投入生产后,持续改进和优化它。这种设计将使模型逐步进步,随着用户实时反馈的获得而不断改进。听起来很简单,对吧?与其先构建一个 AI 模型然后再将其商品化,不如保持一个持续的构建-商品化-重新构建循环。不幸的是,创建这种持续的设计周期极其复杂。它涉及研究、协调以及软件与研究的深度结合。
这个循环应从数据标注开始,然后是训练、评估和部署。一旦投入生产,循环将进入监控和收集人类用户反馈的关键步骤。此时,循环完成一个完整的循环。它现在可以重新开始,利用在之前步骤中获得的数据在重新训练步骤中持续改进。正如这个无限形状的循环所示,生产部署不再是终点线,而是为模型增加稳定性和可持续性的起点:
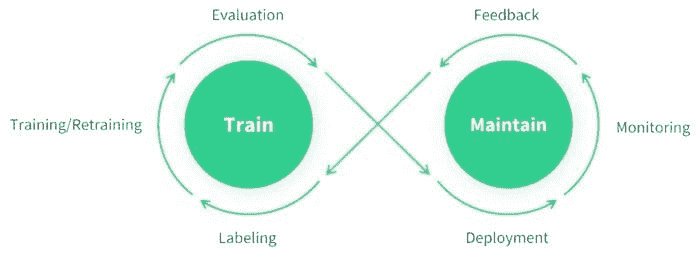
训练与维护 AI 无限循环
避免维护陷阱
在产品开发生命周期中,系统维护往往被忽视——这可能对系统的未来产生灾难性的影响。在许多情况下,维护可能成为组织内部扩展系统的严重障碍,阻碍系统的广泛使用和影响力的提升。
对于机器学习和 AI 来说,维护是一个巨大的负担,可能导致 TCO 失控,危及整个用例的盈利性。近年来,AI 技术已经成熟并变得更加普及,诱使各行业的企业尝试从 AI 解决方案中获取价值。然而,严峻的现实是,大约 90%的企业未能实现 ROI 正面的 AI 项目。AI 解决方案的维护,特别是在扩展特定 AI 解决方案时的维护障碍,在这一失败率中扮演了重要角色。这也是为什么那些考虑深入 AI 领域的公司应该将学习和维护循环作为他们启动任何系统的基本构建块的另一个原因。
经验教训:常青 AI 是可能的
让我们回到最初的起点:你在实验室中耐心训练的模型并取得了你满意的结果。从生产中崩溃和失败的主要教训是什么?答案是:旨在设计一个能够识别数据变化(偏离最初用于训练的数据集)的系统,收集来自人类用户的持续反馈,并重新训练和部署更新、更好的模型。
在花费第一个 AI 美元之前,你应该问自己的一些棘手问题:
-
我能检测到数据何时发生变化吗?
-
我能否检测到模型可能出错的情况?
-
我将如何收集用户反馈?
-
是否使用了适当的防御机制来保护我的模型免受可能干扰的噪声?
-
用新数据再培训模型的过程是怎样的,如何替换旧的、过时的模型?
-
我将如何将数据分为无需自动处理的样本和需要人工检查的样本?
换句话说,将 AI 产品化是一个基础设施协调问题。在规划解决方案设计时,您应该使用持续监控、再培训和反馈来确保稳定性和可持续性。成功做到这一点将帮助您的公司从 AI 中获得期望的价值。
相关:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 工作
更多相关主题
AI 知识地图:如何分类 AI 技术
原文:
www.kdnuggets.com/2018/08/ai-knowledge-map-classify-ai-technologies.html
评论

我在人工智能领域待了很长时间,知道存在多种分类、区分、景观和信息图来表示和追踪不同的 AI 思维方式。然而,我并不是这些分类工作的忠实粉丝,主要因为我倾向于认为将动态数据点分类到预定的固定框中,往往不值得拥有这样一个“清晰”框架的好处(这当然是一个概括,有时这些分类确实非常有用)。
我还认为这个景观对新手一目了然地把握复杂性和深度是有用的,对于那些更有经验的人来说,也可以作为一个参考点,并围绕特定技术展开新的对话。
接下来是一个努力绘制知识获取架构的过程,用于跟踪新兴动态,这是一个关于该主题的预存在知识的入口,将允许你探索额外的信息,并最终创建新的 AI 知识。我称之为AI 知识地图(AIKM)。

AI 知识地图。我与战略创新咨询公司Axilo合作开发了 AIKM,用于他们 Chôra 平台上的活动。
在坐标轴上,你会发现两个宏观类别,即AI 范式和AI 问题领域。AI 范式(X 轴)是 AI 研究人员用来解决特定 AI 相关问题的方法(包括最新的方法)。另一方面,AI 问题领域(Y 轴)是 AI 历史上可以解决的问题类型。从某种意义上说,它也表示了 AI 技术的潜在能力。
因此,我已识别出以下 AI 范式:
-
基于逻辑的工具:用于知识表示和问题解决的工具
-
基于知识的工具:基于本体论和大量概念、信息和规则的工具
-
概率方法:允许代理在信息不完全的场景中行动的工具
-
机器学习:允许计算机从数据中学习的工具
-
具身智能:工程工具箱,假设需要一个身体(或至少一部分功能,如运动、感知、互动和可视化)才能实现更高的智能
-
搜索和优化:允许智能搜索多种可能解决方案的工具。
这六种范式也分为三种不同的宏观方法,即符号主义、亚符号主义和统计学(以上用不同的颜色表示)。简而言之,符号主义方法认为人类智能可以简化为符号操作,亚符号主义方法则是没有提供具体的知识表示,而统计学方法则基于数学工具来解决特定的子问题。
垂直轴则展示了人工智能所解决的问题,这里的分类相当标准:
-
推理:解决问题的能力
-
知识:表征和理解世界的能力
-
规划:设定和实现目标的能力
-
沟通:理解语言和进行交流的能力
-
感知:将原始感官输入(如图像、声音等)转化为可用信息的能力。
这些框的模式将技术分为两组,即狭义应用和广义应用。所用的词汇是故意这样选择的,但可能会显得稍有误导……请稍等片刻,我来解释一下。对于任何刚开始接触人工智能的人来说,了解弱人工智能/狭义人工智能(ANI)、强人工智能/广义人工智能(AGI)和人工超智能(ASI)之间的区别是至关重要的。为了清晰起见,ASI 目前只是一个推测,广义人工智能是研究人员的最终目标和圣杯,而狭义人工智能则是我们今天所拥有的,即一组无法处理其范围之外任何事务的技术(这也是与 AGI 的主要区别)。
图表中使用的两种线型(实线和虚线)明确指出了区分,以帮助你在阅读其他入门级人工智能材料时增加一些信心。然而,同时,这里的差异描绘了那些只能解决特定任务的技术(通常比人类做得更好——狭义应用)与那些可以解决多种任务的技术(未来或现在——与世界互动,通常比许多人类做得更好——广义应用)。
最后,让我们看看图表中的内容。在地图中,展示了不同类别的人工智能技术。请注意,我有意没有具体列举算法,而是将它们聚类为宏观组。我也没有提供什么有效和无效的价值评估,而只是列出了研究人员和数据科学家可以使用的内容。
那么你如何阅读和解释这个图谱呢?让我给你两个例子。比如自然语言处理,它包含了一类算法,这些算法结合了基于知识的方法、机器学习和概率方法来解决感知领域的问题。同时,如果你查看逻辑基础范式和推理问题交汇处的空白区域,你可能会想为什么那里没有技术。图谱传达的意思不是说没有方法可以填补这个空白,而是当人们处理推理问题时,他们更倾向于使用机器学习等方法。
这里是一些技术的列表:
-
机器人过程自动化 (RPA):一种通过观察用户执行某个任务来提取规则和操作列表的技术。
-
专家系统:一种具有硬编码规则的计算机程序,用于模拟人类决策过程。模糊系统是基于规则的系统的一个具体示例,它将变量映射到 0 和 1 之间的连续值,而传统的数字逻辑则产生 0/1 的结果。
-
计算机视觉 (CV):获取和理解数字图像的方法(通常分为活动识别、图像识别和机器视觉)。
-
自然语言处理 (NLP):处理自然语言数据的子领域(这个领域包括三个主要部分,即语言理解、语言生成和机器翻译)。
-
神经网络 (NNs 或 ANNs):一种 loosely modeled after the neuronal structure of the human/animal brain 的算法,它在没有明确指示如何执行的情况下提升性能。NNs 的两个主要且知名的子类别是深度学习(一个具有多层的神经网络)和生成对抗网络(GANs——两个相互训练的网络)。
-
自主系统:一个处于机器人技术和智能系统(例如智能感知、灵巧物体操控、基于计划的机器人控制等)交汇处的子领域。
-
分布式人工智能 (DAI):一种通过将问题分配给相互互动的自主“代理”来解决问题的技术类别。多代理系统 (MAS)、基于代理的建模 (ABM) 和群体智能是这个子集的三个有用规格,其中集体行为来源于去中心化自组织代理的互动。
-
情感计算:一个处理情感识别、解释和模拟的子领域。
-
进化算法(EA):这是一个更广泛计算机科学领域的子集,称为进化计算,使用受生物学启发的机制(例如,突变、繁殖等)来寻找最佳解决方案。遗传算法是 EA 中最常用的子群体,它们是遵循自然选择过程来选择“最适合”候选解决方案的搜索启发式算法。
-
归纳逻辑编程(ILP):一个子领域,使用形式逻辑来表示事实数据库并从这些数据中提出假设。
-
决策网络:是最著名的贝叶斯网络/推理的一个推广,表示一组变量及其通过图示(也称为有向无环图)的概率关系。
-
概率编程:一个不强制你硬编码特定变量的框架,而是与概率模型一起工作。贝叶斯程序合成(BPS)在某种程度上是一种概率编程形式,其中贝叶斯程序编写新的贝叶斯程序(而不是由人类编写,如在更广泛的概率编程方法中)。
-
环境智能(AmI):一个框架,要求物理设备进入数字环境,以在对外部刺激(通常由人类行为触发)做出响应时感知、感知和以上下文意识作出反应。
为了解决特定问题,你可能会采用一种或多种方法,这也意味着一种或多种技术,因为许多技术是相互补充的而非相互排斥的。
教授计算机如何在无需明确编程的情况下学习是一项艰巨的任务,这涉及到多种技术以应对多个细节问题,尽管这个图示远非完美,但至少是对混乱局面的第一次尝试进行的解释。
我意识到这里出现了强大的帕累托原则,即当前 80%(甚至更多)的努力和结果是由图示中的 20%技术(即深度学习、自然语言处理和计算机视觉)驱动的,但我也相信拥有全面的视角可能会对研究人员、初创公司和投资者有所帮助。
我欢迎对这个初版本的反馈,并计划采取两个额外步骤:一个是为 AI 面临的挑战类型创建一个层次(例如,记忆问题和灾难性遗忘、迁移学习、从较少数据中学习如零样本和一例学习等),以及可以用来克服这些特定问题的技术。第二个是应用不同的视角来审视各种技术,而不是解决它们所解决的问题,而是它们所创造的问题(例如,伦理问题、数据密集型问题、黑箱和可解释性问题等)。
个人简介:Francesco Corea 是一位基于英国伦敦的决策科学家和数据策略师。
原文。经许可转载。
相关:
-
人工智能分类矩阵
-
13 个关于人工智能的预测
-
人工智能简史
我们的前三个课程推荐
1. Google 网络安全证书 - 加速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关内容
AI:大型语言和视觉模型
原文:
www.kdnuggets.com/2023/06/ai-large-language-visual-models.html

编辑提供的图片
大型模型,无论是语言模型还是视觉模型,都被设计用来处理海量数据,使用深度学习技术。这些模型在庞大的数据集上进行训练,能够以令人难以置信的准确度识别模式并做出预测。大型语言模型,如 OpenAI 的 GPT-3 和谷歌的 BERT,能够生成自然语言文本、回答问题,甚至进行语言翻译。大型视觉模型,如 OpenAI 的 CLIP 和谷歌的 Vision Transformer,可以以惊人的精度识别图像和视频中的物体和场景。通过结合这些语言和视觉模型,研究人员希望创建更先进的 AI 系统,以更像人类的方式理解世界。然而,这些模型也引发了数据偏见、计算资源和潜在误用的担忧,研究人员正积极解决这些问题。总体而言,大型模型处于 AI 领域的前沿,对发展更先进的智能机器充满希望。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
数字时代
21 世纪的特点是数据生成和收集的量、速度和种类显著增加。随着数字技术和互联网的兴起,数据开始以空前的规模和速度生成,来源包括社交媒体、传感器和事务系统。让我们提醒你其中的一些:
-
互联网的增长:1990 年代,互联网迅速增长,产生了大量可用于分析洞察的数据。
-
数字设备的普及:智能手机、平板电脑及其他连接设备的广泛使用,产生了大量来自传感器、位置追踪和用户互动的数据。
-
社交媒体的增长:社交媒体平台如 Facebook 和 Twitter 通过用户生成的内容(如帖子、评论和点赞)产生了大量的数据。
-
电子商务的兴起:在线购物和电子商务平台生成了大量有关消费者行为、偏好和交易的数据。
这些趋势和其他因素导致了生成和收集的数据量显著增加,并创造了对新技术和方法的需求,以管理和分析这些数据。这促成了大数据技术的发展,如 Hadoop、Spark 和 NoSQL 数据库,以及数据处理和分析的新技术,包括机器学习和深度学习。实际上,大数据的兴起是深度学习技术发展的一个关键驱动因素,因为传统的机器学习方法常常无法有效分析和提取大型复杂数据集中的洞察。
深度学习算法通过使用具有多个层的人工神经网络,能够克服这些限制,通过学习大量数据并识别数据中的复杂模式和关系。这使得开发出能够处理各种数据类型的强大模型成为可能,包括文本、图像和音频。随着这些模型变得越来越复杂并能够处理更大、更复杂的数据集,它们催生了人工智能和机器学习的新纪元,在自然语言处理、计算机视觉和机器人技术等领域有了广泛应用。总体而言,深度学习的发展是人工智能领域的一次重大突破,它为数据分析、自动化和决策提供了新的可能性,涵盖了广泛的行业和应用。
大数据、深度学习、大规模的协同效应
大型语言和视觉模型,如 GPT3/GTP4 和 CLIP,非常特别,因为它们能够处理和理解大量复杂数据,包括文本、图像和其他形式的信息。这些模型使用深度学习技术来分析和学习大量数据,使它们能够识别模式、做出预测和生成高质量的输出。大型语言模型的一个主要优势是它们能够生成接近人类写作的自然语言文本。这些模型可以生成连贯且令人信服的书面内容,涵盖广泛的话题,使其在语言翻译、内容创作和聊天机器人等应用中非常有用。同样,大型视觉模型能够以惊人的准确度识别和分类图像。它们可以识别图像中的物体、场景,甚至情感,并生成详细的描述。这些模型的独特能力在自然语言处理、计算机视觉和人工智能等领域有许多实际应用,并且它们有潜力彻底改变我们与技术的互动方式和信息处理方式。
大型语言模型和大型视觉模型的结合可以提供多种协同效应,这些协同效应可以在各种应用中发挥作用。这些协同效应包括:
-
改进的多模态理解:大型语言模型擅长处理文本数据,而大型视觉模型擅长处理图像和视频数据。当这些模型结合时,它们可以创建对数据呈现背景的更全面的理解。这可以导致更准确的预测和更好的决策。
-
改进的推荐系统:通过结合大型语言和视觉模型,可以创建更准确和个性化的推荐系统。例如,在电子商务中,模型可以使用图像识别来了解客户基于他们之前的购买或产品浏览的偏好,然后使用语言处理来推荐最符合客户偏好的产品。
-
增强的聊天机器人和虚拟助手:结合大型语言和视觉模型可以提高聊天机器人和虚拟助手的准确性和自然性。例如,虚拟助手可以使用图像识别来理解用户请求的上下文,然后使用语言处理提供更准确和相关的回应。
-
改进的搜索功能:通过结合大型语言和视觉模型,可以创建更准确和全面的搜索功能。例如,搜索引擎可以使用图像识别来理解图像的内容,然后使用语言处理来提供基于图像内容的更相关的搜索结果。
-
增强的内容创作:结合大型语言和视觉模型也可以增强内容创作,如视频编辑或广告。例如,视频编辑工具可以使用图像识别来识别视频中的对象,然后使用语言处理来生成字幕或其他文本覆盖物。
-
更高效的训练:大型语言模型和视觉模型可以分别训练然后结合,这可能比从头开始训练一个大型模型更高效。这是因为从头开始训练一个大型模型可能计算资源消耗大且耗时,而训练较小的模型然后将其结合起来则可能更快、更高效。
总体而言,结合大型语言和视觉模型可以带来更准确、高效和全面的数据处理与分析,并且可以在广泛的应用中发挥作用,从自然语言处理到计算机视觉和机器人技术。
GAI 或非 GAI
难以预测大模型的发展是否最终会导致通用人工智能(GAI)的创造,因为 GAI 是一个高度复杂和理论性的概念,目前在人工智能领域仍然是许多争论和猜测的主题。虽然大模型在自然语言处理、图像识别和机器人技术等领域取得了显著进展,但它们仍受限于训练数据和编程,尚不能实现真正的泛化或自主学习。此外,创建 GAI 还需要在多个 AI 研究领域取得突破,包括无监督学习、推理和决策。虽然大模型朝着更先进的人工智能形式迈出了重要的一步,但它们距离实现 GAI 所需的智能和适应能力还远远不够。总之,尽管大模型的发展是朝着更高级人工智能形式迈进的重要一步,但仍不确定它们是否最终会导致通用人工智能的创造。
挑战
数据偏差是大模型中的一个重要问题,因为这些模型是在可能包含偏见或歧视数据的大型数据集上进行训练的。当用于训练模型的数据未能代表现实世界人群的多样性时,就会发生数据偏差,导致模型生成偏见或歧视性的输出。例如,如果一个大型语言模型在对某一特定性别或民族存在偏见的文本数据上进行训练,该模型在生成文本或进行预测时可能会产生偏见或歧视性的语言。同样,如果一个大型视觉模型在对某些群体存在偏见的图像数据上进行训练,该模型在执行诸如物体识别或图像描述等任务时可能会产生偏见或歧视性的输出。数据偏差可能产生严重后果,因为它可能延续甚至放大现有的社会和经济不平等。因此,识别和减轻大模型中的数据偏差在训练和部署过程中都至关重要。
缓解数据偏差的一种方法是确保用于训练大模型的数据集多样且代表现实世界人群。这可以通过仔细的数据集策划和增强,以及在模型训练和评估过程中使用公平性指标和技术来实现。此外,定期监控和审计大模型中的偏差,并在必要时采取纠正措施也很重要。这可能包括在更多多样化的数据上重新训练模型或使用后处理技术来纠正偏见输出。总体而言,数据偏差是大模型中的一个重要问题,采取主动措施识别和减轻偏差至关重要,以确保这些模型公平且公正。
伦理方面
OpenAI 决定将其大型语言模型 GPT-3 的独占商业权利授予微软,这在 AI 社区内引发了一些争论。一方面,可以认为与微软这样的科技巨头合作可以提供进一步推动 AI 研究和发展的资源和资金。此外,微软承诺以负责任和道德的方式使用 GPT-3,并承诺投资于与 OpenAI 使命一致的 AI 发展。另一方面,有人担心微软可能会垄断 GPT-3 和其他先进 AI 技术的访问,这可能会限制创新并在科技行业内造成权力不平衡。此外,有人认为 OpenAI 将独占商业权利授予微软的决定违背了其推动 AI 以安全和有益方式发展的公开使命,因为这可能会优先考虑商业利益而非社会福利。最终,OpenAI 将独占商业权利授予微软的决定是否“合适”,取决于个人的观点和价值观。虽然关于这种合作关系的潜在风险和缺点有合理的担忧,但也存在来自与微软这样的科技巨头合作的潜在好处和机会。AI 社区和社会整体需要密切关注这种合作关系的影响,并确保 AI 的发展和部署是安全、有效且公平的。
市场份额
这些模型各有其优缺点,并可用于各种自然语言处理任务,例如语言翻译、文本生成、问答等。作为一个 AI 语言模型,ChatGPT 被认为是目前最先进和有效的语言模型之一。然而,还有其他模型在某些任务上可以超越 ChatGPT,具体取决于用于评估性能的指标。例如,一些模型在基准自然语言处理任务如 GLUE(通用语言理解评估)或 SuperGLUE 上取得了更高的分数,这些任务评估了模型理解和推理自然语言文本的能力。这些模型包括:
-
GShard-GPT3,一个由谷歌开发的大规模语言模型,在多个 NLP 基准测试中取得了最先进的性能
-
T5(文本到文本转换变换器),同样由谷歌开发,在广泛的 NLP 任务上表现强劲
-
GPT-Neo,一个由社区驱动的项目,旨在开发与 GPT-3 类似的大规模语言模型,但更具可访问性,并且可以在更广泛的硬件上进行训练
值得注意的是,尽管这些基准测试的表现只是语言模型整体能力的一个方面,但 ChatGPT 和其他模型可能在其他任务或实际应用中超越这些模型。此外,人工智能领域不断发展,新模型的不断出现可能会推动可能性的边界。
有用的链接
-
OpenAI 的 GPT-3:
openai.com/blog/gpt-3-unleashed/ -
谷歌的 BERT:
ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html -
Facebook 的 RoBERTa:
ai.facebook.com/blog/roberta-an-optimized-method-for-pretraining-self-supervised-nlp-systems/ -
谷歌的 T5:
ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html -
OpenAI 的 CLIP(对比语言-图像预训练):
openai.com/blog/clip/ -
微软的 Turing-NLG:
www.microsoft.com/en-us/research/blog/microsoft-announces-turing-nlg-state-of-the-art-model-for-natural-language-generation/ -
Hugging Face 的 Transformer 库:
huggingface.co/transformers/
Ihar Rubanau 是 Sigma Software Group 的高级数据科学家
更多相关话题
AI 和机器学习黑箱:对透明度和问责制的需求
原文:
www.kdnuggets.com/2017/04/ai-machine-learning-black-boxes-transparency-accountability.html
评论
由 Colin Lewis(Robotenomics)和 Dagmar Monett(柏林经济与法律学院)撰写。
航空中的黑箱,也称为飞行数据记录器,是一种极其安全的设备,旨在向研究人员或调查员提供关于任何可能导致飞行事件或事故的异常情况的高度真实的信息。
人工智能(AI)或机器学习程序中的黑箱¹已经变成了相反的意义。最新的机器学习方法,即已取得“重要实证成功”的深度学习²,但关于透明度的重大问题仍然存在。
开发人员承认,这些“自学习机器”的内部工作增加了关于机器行为的复杂性和不透明性。一旦机器学习算法训练完成,理解³为何它对一组数据输入给出特定响应可能变得困难。这,如下所述,当这些算法用于任务关键时,可能是一种劣势。
此外,机器学习算法可以以其设计者未曾预见的方式行动,这引发了关于 AI 的“自治”、“决策”和“责任”能力的问题。当出现问题时,正如必然会发生的那样,发现导致事件的行为可能是一项艰巨的任务,因为这些行为被锁定在几乎无法发现的黑箱中。

随着机器学习算法变得更加智能,它们也变得更加不可理解。
机器学习算法本质上是从收集的数据中学习行为模式以支持预测和知情决策的系统。这些机器学习系统通常在两个明确的领域中处理数据,如数据科学社会公益奖学金主任 Rayid Ghani 所描述,他指出⁴:“数据科学的力量通常在以下两个极端的范围内发挥作用:
-
帮助人类发现可以用于决策的信息,新知识,
-
通过自动化预测模型,这些模型被插入到操作系统中并自主运行。”
为了反映知识获取和自动决策的这两个极端,机器学习系统通常分为两种类型:
-
A 类应用——其中模型预测用于支持可能对人们生活产生深远影响的决策,例如医学诊断、贷款申请、自动驾驶汽车、执法和刑罚;以及
-
B 类应用——在较低后果和大规模的环境中使用模型预测,例如选择观看哪个流媒体视频、新闻提要顶部显示的新闻以及搜索查询。
然而,已经有充分的文献记录表明,这些机器学习黑箱的设计和构建可能会通过程序员和数据选择导致偏见、不公平和歧视。“讽刺的是,我们越是设计成功模拟人类的人工智能技术,人工智能就越是以我们拥有的所有偏见和局限性进行学习。”⁶
虽然还有其他问题,如数据质量及其处理的担忧,或算法结果的质量及其伦理影响等,但经理们应该意识到机器学习系统中经常出现潜在问题的两个核心要素,我们认为高管们应该关注并采取行动加以解决:1)透明性,2)领导力和治理。
1. 透明性
为了让人们在决策中使用分析模型的预测,他们必须信任该模型。要信任一个模型,他们必须了解它如何做出预测,即模型应该是可解释的。目前大多数基于深度神经网络原理的机器学习系统并不容易解释。
这对依赖人工智能系统的组织可能造成很大的损害。研究人员 Taylor 等人(2016)已经表明,“系统行为与设计者的预期行为之间存在许多可能难以察觉的差异,而这些差异中至少有一些是不 desirable 的。”
如果没有精心设计,监控机器学习系统的行为可能会很困难。高管们应当努力确保他们的机器学习系统更具透明性,以帮助知情监督者评估系统在做出决策时的内部原因。正如 Pedro Domingos 教授所写的⁸:“当一种新技术如机器学习如此普及且改变游戏规则时,让它保持黑箱状态并不明智。隐蔽性为错误和滥用打开了大门。”
2. 领导力和治理
领导者应当寻求对机器学习算法实施严格的治理,确保这些新型机器智能系统具有“价值对齐”和“良好行为”,特别是当它们经常被用来在业务目标方面做出有效决策时。
系统的治理应包括系统化的方式来形式化隐藏的假设(在黑箱内部),并确保机器学习系统内部工作的问责制、可审计性和透明度。此外,对开源机器学习算法和训练数据的选择及其鲁棒性引入更严格的检查应成为开发者和管理者的首要任务。
任何一个为了优化目标而自行调整的决策机器学习系统,如果其目标与组织的利益不一致,可能会产生显著且永久的影响。认识到机器学习和 AI 算法的局限性是更好地管理它们的第一步。
最终,我们需要确保我们不会把不具备足够智能的机器置于决策之中。
脚注
-
作者在本文中将机器学习系统、程序和算法这些术语交替使用。
-
Bengio, Yoshua (2013 年)。表征的深度学习:展望未来。见 A. Dediu, C. Martín-Vide, R. Mitkov, 和 B. Truthe (编),统计语言与语音处理:第一次国际会议(第 1-137 页),柏林海德堡:施普林格。
-
Mittelstadt, Brent Daniel; Allo, Patrick; Taddeo, Mariarosaria; Wachter, Sandra; 和 Floridi, Luciano (2016 年,待出版)。算法伦理:辩论的映射。大数据与社会。
-
Shan, Carl (2015 年)。数据科学如何用于社会公益。来源:
www.carlshan.com/2015/01/08/data-science-social-good.html。 -
Peña Gangadharan, Seeta; Eubanks, Virginia; 和 Barocas, Solon (2014 年)。数据与歧视:论文集。新美国:开放技术研究所。来源:
na-production.s3.amazonaws.com/documents/data-and-discrimination.pdf。 -
编程与偏见:犹他大学计算机科学家发现如何在算法中识别偏见 (2015 年 8 月)。UNews, 犹他大学。来源:
unews.utah.edu/programming-and-prejudice/。 -
Taylor, Jessica; Yudkowsky, Eliezer; LaVictoire, Patrick; 和 Critch, Andrew (2016 年)。高级机器学习系统的对齐。来源:
intelligence.org/files/AlignmentMachineLearning.pdf。 -
Domingos, Pedro (2016 年 5 月)。为什么你需要理解机器学习。世界经济论坛。来源:
www.weforum.org/agenda/2016/05/why-you-need-to-understand-machine-learning/。 -
卢卡,迈克尔;克莱因伯格,乔恩;穆拉纳坦,森迪尔(2016 年 1 月-2 月)。算法也需要管理者。哈佛商业评论。取自
hbr.org/2016/01/algorithms-need-managers-too。
科林·刘易斯 是一位行为经济学家和数据科学家,提供自动化、机器人技术和人工智能的研究和咨询服务 (www.robotenomics.com)。他的机器人和自动化工作曾被《金融时报》,彭博社,哈佛商业评论等媒体报道。
达格玛·莫内特 是德国柏林经济与法律学院的计算机科学教授。她于 2005 年获得柏林洪堡大学计算机科学的Dr. rer nat.学位。她的主要研究和教学兴趣包括人工智能和软件工程的不同领域 (www.monettdiaz.com)。
相关:
-
大数据迫切需要透明度
-
人工智能简史
-
什么是人工智能?智能的组成部分
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关主题
我们日常生活中的人工智能和机器学习
原文:
www.kdnuggets.com/2020/02/ai-machine-learning-everyday-life.html
评论
由 Chandramauli Dave, Space-O Canada,软件开发趋势。
你觉得人工智能(AI)和机器学习(ML)过于复杂吗?认为人工智能和机器学习应用仅限于技术领域?如果是的话,让我们来揭示这些技术实际上有比你想象的更多的普通用例。
实际上,我们日常生活中已经在使用人工智能和机器学习——从实时导航到上网。人工智能和机器学习以多种方式简化了我们的日常操作。让我们来看看。
旅行与通勤
如今,我们大多数人在外出前会检查 Google 地图,以评估当前的交通状况和最快的到达路线。你知道这个应用程序是如何提供如此准确的信息的吗?这都要归功于人工智能。此外,人工智能算法使应用程序能够提供实时的交通流速,减少绕行,节省时间。

另一方面,共享出行应用程序,如 Uber,已充分利用机器学习来确定我们的出行价格、预计到达时间以及预测乘客需求以定义高峰价格时间。
这还不是全部。人工智能在商业航班中也发挥着重要作用。根据 2015 年对波音 777 航空公司的调查,飞行员报告说,在标准航班中仅手动飞行了 7 分钟,主要是在起飞和着陆期间。其余的则由人工智能处理。
电子邮件通信
人工智能和机器学习以以下方式简化了电子邮件通信:
Gmail 智能回复
你一定注意到 Gmail 会提示你简单的短语来回复邮件。例如,“是的,我感兴趣”或“谢谢”。此外,即使你手动输入回复时,它也会提示合适的词汇。例如,如果你输入了“期待”,Gmail 会提示你“收到你的回复”,你只需按 Tab 键即可添加。

智能回复根据机器学习和人工智能的学习、预测和镜像您的回应方式进行定制。
电子邮件过滤器
除了将我们的电子邮件分类为主要、促销、社交和更新,Gmail 还依赖人工神经网络来识别和阻止垃圾邮件。根据 Gmail 的说法,其平均收件箱中垃圾邮件的比例低于 0.1%。
社交媒体
我们每天检查社交媒体资料,却没有意识到这些网站在以下方面大量使用机器学习和人工智能:
-
在 Facebook 上提供个性化新闻推送
-
根据用户现有的好友列表、群组和兴趣,建议 Facebook 上的朋友
-
过滤不当的推文并删除 Twitter 和 Instagram 上的冒犯性评论
-
在 Facebook 和 Instagram 上提供定向广告

Pinterest 的 LENS 工具使用 AI 来检测图片中的物体。一旦你通过这个工具拍摄照片,其 AI 功能会弹出类似的钉子。Pinterest 还使用 ML 来进行搜索和发现、电子邮件营销以及防止垃圾邮件。
网络搜索
每当我们在谷歌上搜索时,正是搜索引擎的 AI 机制为我们呈现合适的结果。
预测搜索
你是否注意到,当你输入搜索查询时,谷歌会提示你它认为你正在寻找的内容?这被称为预测搜索,可能是由于人工智能。谷歌有大量关于我们的数据,如年龄、位置、过去的搜索记录和个人信息,基于这些数据推荐预测搜索词。
优化的搜索引擎结果
包括谷歌在内的大多数搜索引擎使用 ML 来增强搜索结果。搜索引擎的算法分析并学习我们对搜索词的反应,无论是我们是否打开了排名靠前的搜索结果,还是我们在网页上停留的时间,以确定显示的结果是否符合搜索查询,并在下次改进。
在线购物
在当今快节奏的生活中,我们都曾在线购物。除了让我们可以在任何地方购物,领先的电子商务网站还能够了解我们的口味以及我们可能感兴趣的潜在产品。它们是怎么做到的?魔法?不,正是 ML 和 AI 的强大力量。

在线购物网站,如亚马逊,通过 ML 记录我们的购买、搜索的产品以及我们添加到愿望清单中的物品,以向每位用户提供最合适的产品推荐。这导致了彻底个性化的购物体验。
移动银行与在线欺诈检测
AI 技术使得移动银行对那些没有时间去银行的人来说变得个性化和简便。例如,富国银行正在其应用程序中使用 AI,提供个性化的提醒和洞察,包括账单支付提醒和预警透支通知,这些都是基于消费者账户分析的。

银行和金融机构也在使用基于 ML 和 AI 的系统来区分合法交易和欺诈交易。这些系统跟踪账户中的交易频率并识别异常模式,以发出及时警报。PayPal 使用 ML 来对抗在线洗钱行为。
智能个人助理
从 Google Assistant 和 Siri 到微软的 Cortana,我们在智能个人助理方面有很多选择。还有 Amazon Alexa 和 Google Home。这些智能家居设备和个人助理如何满足我们的命令?通过充分利用 AI。
从设置提醒到在线查找信息和控制灯光,这些设备和个人助理利用机器学习(ML)来收集信息,了解我们的偏好,并根据我们与它们的先前互动来优化信息。
总结
人工智能和机器学习对没有技术倾向的人来说可能显得过于复杂。然而,正如我们在上述例子中所看到的,他们在日常生活中不自觉地使用这两种技术。实际上,随着未来更多创新和进步,这种使用只会增加。毫无疑问,看到 AI 和 ML 如何进一步简化我们的生活将是非常有趣的。
简介: Chadramauli Dave 是 Space-O Canada 的高级市场营销执行官,这是一家在加拿大领先的 软件开发公司。他相信人应该不断学习,因此他花时间学习新的 SEO 技巧,帮助企业提高在 Google 上的存在感。他也对写作感兴趣,并分享他所掌握的知识。通过 LinkedIn 和 Twitter 与他联系。
相关:
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关话题
AI 和机器学习在医疗保健领域
原文:
www.kdnuggets.com/2020/05/ai-machine-learning-healthcare.html
评论
图片来源:Pixabay(商业用途免费)
介绍
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
21 世纪只有 20 年,而这个世纪最大的变革技术之一,毫无疑问是人工智能(AI)。人工智能及其相关服务和平台预计将改变全球生产力、工作模式和生活方式,并创造巨大的财富,这是一个公认的观点。
例如,麦肯锡预计到 2030 年全球经济活动将达到约\(13 万亿](https://www.mckinsey.com/featured-insights/artificial-intelligence/notes-from-the-ai-frontier-modeling-the-impact-of-ai-on-the-world-economy)。短期内,研究公司 Gartner 预计全球[基于 AI 的经济活动](https://www.pwc.com/gx/en/issues/data-and-analytics/publications/artificial-intelligence-study.html)将从 2018 年的约 1.2 万亿美元增加到约[\)。短期内,研究公司 Gartner 预计全球基于 AI 的经济活动将从 2018 年的约 1.2 万亿美元增加到约$3.9 万亿到 2022 年。
这场变革显然在很大程度上受到强大机器学习(ML)工具和技术的推动,如深度卷积网络、生成对抗网络(GAN)、梯度提升树模型(GBM)、深度强化学习(DRL)等。
然而,传统的商业和技术领域并不是唯一受人工智能影响的领域。医疗保健被认为是非常适合应用人工智能工具和技术的领域。
像电子病历 (EMR)这样的强制性做法已经为医疗系统应用大数据工具进行下一代数据分析奠定了基础。AI/ML 工具注定会为这一流程增加更多价值。预计它们将提升初级/三级患者护理和公共医疗系统中自动化和智能决策的质量。这可能是 AI 工具的最大影响,因为它有可能改变全球数十亿人的生活质量。
机器学习在医疗中的关键应用示例
AI 辅助的放射学和病理学

图片来源:Pixabay(商业使用免费)
如今,电子存储的医学影像数据丰富,而深度学习算法可以利用这类数据集来检测和发现模式及异常。机器和算法可以像训练有素的放射科医生一样解释影像数据——识别皮肤上的可疑点、病变、肿瘤和脑出血。因此,AI/ML 工具/平台用于辅助放射科医生的使用前景广阔。
这种方法解决了医疗领域的一个关键问题,因为在全球范围内,训练有素的放射科医生越来越难以找到。在大多数情况下,这些技术工人由于大量的数字医学数据而承受巨大的压力。根据这篇文章,一名普通的放射科医生需要每 3-4 秒就对一张图像进行解读,以满足需求。
识别罕见或难以诊断的疾病通常依赖于检测所谓的“边缘案例”。由于这类机器学习系统是建立在包含这些疾病的原始图像(及各种转换)的大型数据集之上的,它们在这种检测中通常比人类更可靠。
预计它们将提升初级/三级患者护理和公共医疗系统中自动化和智能决策的质量。这可能是 AI 工具的最大影响,因为它有可能改变全球数十亿人的生活质量。
一个很好的案例是微软的 Project InnerEye,它利用机器学习方法对 3D 放射图像进行肿瘤分割和识别。这有助于精确的手术规划、导航和高效的肿瘤轮廓描绘,以便放疗规划。
MRI 和其他用于早期癌症检测的先进影像系统,正配备机器学习算法。以下文章提供了这方面的全面概述。
以下《自然》文章描述了机器学习技术如何应用于进行高级图像分析,如前列腺分割和多个影像数据源的融合(例如超声检查、CT 和 MRI)。
机器学习工具通过增强外科医生的显示,提供如癌症定位等信息,在机器人手术和其他图像引导干预中增添了重要价值。
因此,AI/ML 工具/平台在辅助放射科医生方面的使用,预计将呈指数级增长。
机器学习和数据科学用于可操作的洞察
图片来源:Pixabay(商业用途免费)
在当今世界,医疗数据的规模达到 exabytes 正在各大医疗机构进行数字化(公立医院、养老院、医生诊所、病理实验室等)。不幸的是,这些数据通常是混乱和无结构的。与标准事务型商业数据不同,患者数据不特别适合简单的统计建模和分析。
强大而灵活的 AI 驱动平台,能够连接到大量患者数据库并分析复杂的数据类型(例如血液病理、基因组学、放射影像、医疗历史)是当务之急。此外,这些系统应能够深入筛查分析,发现隐藏的模式。
此外,机器人应该能够将其发现翻译和可视化为人类可理解的形式,以便医生和其他医疗专业人员能够以高度的信心和完全的透明度处理其输出。
可解释的 AI 和分布式机器学习系统 — 非常符合这些要求,并有望在不久的将来满足这种系统的需求。
外科手术辅助的物理机器人

图片来源:Pixabay(商业用途免费)
外科手术机器人可以为人类外科医生提供独特的帮助,
-
增强在手术过程中的观察和导航能力,
-
创造精确且微创的切口。
-
通过优化缝合几何和伤口减少疼痛
对于这种数字手术机器人,AI/ML 的应用确实充满了令人兴奋的可能性。
-
软件中心的机器人协作与大规模分布式处理的援助
-
基于手术历史(由机器和人类执行)及其结果(无论好坏)的数据驱动洞察和指导
-
AI 生成的虚拟现实空间用于实时指导和指引
-
相对简单程序的远程医疗和远程手术的可能性
以下文章简明扼要地总结了潜在应用。
AI 用于医疗操作管理和患者体验
在美国,普通大众获得适当医疗护理的成本和难度一直是长时间且尖锐的争论话题。
AI 和相关的数据驱动技术独特地准备好解决一些被识别为根本原因的问题——长时间排队、对不合理账单的恐惧、漫长且过于复杂的预约过程、无法接触到合适的医疗专业人士。
同样的问题困扰了传统业务数十年,而 AI/ML 技术已经是解决方案的一部分。这是因为,巨大的数据库和智能搜索算法,正是 AI 系统的强项,擅长模式匹配或优化问题。因此,高级的 AI/ML 工具和技术必须被医院和公共卫生组织在日常操作中利用。
好消息是,数据隐私问题,这对医疗系统来说是复杂且困难的问题,对这种类型的 AI 应用并不构成重大挑战。通常,操作问题并不涉及机密的患者数据,如疾病、诊断或药物,而是像其他现代商业企业一样,涉及财务、资本、市场营销或人力资源问题的数据。

图片来源: Pixabay(商业用途免费)
这些系统的核心目标应是使 AI 辅助平台旨在提高大多数普通人医疗服务的体验。已部署的传统业务系统的总体目标是最大化利润。用于医疗操作管理的强大 AI 工具必须通过将同理心与利润生成目标结合起来,区分于那些传统系统。
利用 AI/ML 技术进行药物发现
图片来源: Pixabay(商业用途免费)
制药行业的知名企业越来越多地选择 AI 和 ML 技术来解决成功药物发现的极其困难的问题。一些突出的例子——涉及赛诺菲、基因泰克、辉瑞——可以从 这篇文章中找到。这些案例研究涵盖了各种治疗领域——代谢疾病、癌症治疗、免疫肿瘤药物。
超越传统的长期过程,AI 技术正越来越多地应用于加速早期候选药物筛选和机制发现的基本过程。
例如,生物技术公司 Berg 利用其 AI 平台 分析来自患者的大量生物和结果数据(脂质、代谢物、酶和蛋白质谱),以突出病态细胞和健康细胞之间的关键差异,并识别新型癌症机制。
Berg 的人工智能:仅仅是另一家生物技术公司还是行业变革者?
另一个显著的例子是 DeepMind 发布的与 COVID-19 病毒(SARS-CoV-2)相关的可能蛋白质结构,使用了他们的AlphaFold系统。
许多初创公司也在致力于使用 AI 系统分析多渠道数据(研究论文、专利、临床试验和患者记录),通过利用最新技术如贝叶斯推断、马尔可夫链模型、强化学习和自然语言处理(NLP)。寻找模式并构建高维表示,这些表示将存储在云端并用于药物发现过程,是关键目标。
这里有一篇综述文章展示了深度学习在药物发现中的应用。
强大的 AI 工具在医疗保健运营管理中必须通过将同理心与盈利目标相结合,区别于传统系统。
面向未来——精准医疗和预防保健
根据美国国家医学图书馆,精准医学 是 “一种新兴的疾病治疗和预防方法,考虑到每个人在基因、环境和生活方式上的个体差异。”
展望未来,这可能是人工智能/机器学习在医疗保健领域应用中的最具影响力的好处之一。
目标极其复杂且要求极高——根据个体的个人病史、生活方式选择、遗传数据以及不断变化的病理测试来寻找精准的治疗方案。自然,我们需要引入最强大的人工智能技术——深度神经网络、人工智能驱动的搜索算法/高级强化学习、概率图模型、半监督学习——来应对这一挑战。
除了对疾病和治疗的预测与建模外,这样的人工智能系统还可能根据早期筛查或常规年度体检数据预测未来患者患特定疾病的概率。此外,人工智能工具可能能够建模为什么以及在什么情况下疾病更可能发生,从而有助于指导和准备医生在个体出现症状之前就进行干预(以个性化的方式)。
目标极其复杂且要求极高——根据个体的个人病史、生活方式选择、遗传数据以及不断变化的病理测试来寻找精准的治疗方案。
公共卫生系统中的人工智能
不用说,这些强大的技术不仅可以应用于大规模的公共卫生系统,还可以应用于个体患者护理。实际上, 数字化疫情监控 和人工智能辅助的健康数据分析正待扩展。
世界卫生组织(WHO)也表示了类似的观点……

图片来源: Pixabay(商业用途免费)
持续的 COVID-19 危机 显示了进行数百次平行试验以进行 疫苗开发 和 治疗研究项目 的重要性。从所有这些不同来源获取数据并识别模式——这些结果通常具有很高的不确定性——几乎无法通过标准统计建模技术来实现,这些技术针对的是小规模试验。必须应用 AI 技术来解决这样一个全球规模的问题。
总结
讨论了 AI/ML 技术和平台在医疗保健领域的各种令人兴奋的前景应用。回顾了从放射科助手到智能健康运营管理,从个性化医学到公共健康数字监控的各个话题。
数据隐私和法律框架带来的已知挑战将继续阻碍这些系统的全面实施。弄清楚第三方提供商(例如 AI 和 ML 工具、物理设备或平台的所有者)可以合法查看和使用的数据类型是极其复杂的。因此,需要大规模的法律和政策制定理顺工作,以平行解决这些挑战。
作为技术专家和 AI/ML 从业者,我们应当为一个光明的未来而努力,使 AI 算法的力量惠及数十亿普通人,改善他们的基本健康和福祉。
此外,你可以查看作者的 GitHub 库,获取机器学习和数据科学的代码、想法和资源。如果你和我一样,对 AI/机器学习/数据科学充满热情,请随时 在 LinkedIn 上添加我 或 在 Twitter 上关注我。
原文。转载已获许可。
相关内容:
-
谷歌新的可解释 AI 服务
-
利用 AI 对抗冠状病毒:通过深度学习和计算机视觉改进检测
-
AI 如何帮助管理传染病
更多相关话题
确保你的 AI/机器学习系统在 COVID-19 中幸存的 4 个步骤
原文:
www.kdnuggets.com/2020/04/ai-machine-learning-system-survives-covid-19.html
评论
作者:Zank Bennett,Bennet 数据科学。

COVID-19 充斥着新闻。理应如此。这是一个非常重要的话题。它对人工智能模型的准确性产生了巨大的影响。
在我们深入探讨人工智能如何变化之前,我们首先要从 Bennett 数据科学的全体成员那里表达我们真诚的希望,祝你身体健康,尽力度过困难时期。
COVID-19 与人工智能
企业正在经历巨大的变化。很难找到一个没有被 COVID-19 严重影响的行业。在试图跟上急剧收缩或大规模立即扩展的过程中,公司发现他们尝试和测试的与客户互动的方法几乎变得毫无意义。这意味着市场个性化、生命周期价值计算、产品推荐和流失模型,最好的情况是准确,最坏的情况是误导。
这就是原因
人工智能利用过去的行动来预测未来的事件。而最近的过去与我们今天所经历的情况完全不同。因此,人工智能感到困惑。就像我们突然对 Alexa、Siri 或 Google Assistant 说一种新的语言一样。它们当然无法“理解”。它们将变得无用。全球购买行为现在使用不同的语言。而人工智能无法理解。
公司正在以他们所知道的唯一方式扩展,通过让工人(人)在前线做出如何支持迅速变化的客户需求的决策。他们在很大程度上是在没有他们习惯依赖的人工智能的情况下这样做,因为这些模型不再准确。
我们看到公司回到基于仪表盘的近期数据来做出业务决策,而不是使用可扩展的自动化人工智能。这是有充分理由的。在许多情况下,人工智能是无用的,因为它从未见过像 COVID-19 这样的情况。
这通常意味着团队被大量的数据处理、筛选和行动化所压倒。因为“发现”一个洞察是不够的。公司需要基于这些洞察信息采取行动。机器能够在公司范围内大规模地做到这一点,而人类却做不到。因此,事情会积压。
虽然这听起来很严峻,但公司仍有很多可以做的事情,以使他们的智能系统在这个不断变化的环境中继续为他们和他们的客户服务。但在我们讨论这些之前,了解它们面临的具体障碍是很重要的。
公司正在挣扎
在过去几周,我进行过几次谈话,讨论了各种企业的表现,以及在当前世界状况下,人工智能如何为它们提供帮助。我所谈到的大多数高管和数据科学家都指出,花更多时间查看数据以理解最近的发展如何改变了他们的业务非常重要。
数据科学家奥列格·泽罗(Oleg Żero)从整体上看待这个问题:“即将到来的由冠状病毒引发的危机将和任何其他危机一样。它将淹没那些沉重而僵化的企业,并推动灵活的企业。”
从更高层次来看,对当前情况的反应各不相同。
就这一点而言,我们的一些客户情况还不错,他们从一开始就拥有分布式团队,但不同的行业舒适度差异很大,许多公司都在努力理解未来会带来什么。另一方面,电子商务和配送服务在短期内有望蓬勃发展。仅亚马逊就计划招聘 10 万名员工。
但对于每一个蓬勃发展的企业,还有许多处于困境中的企业。无论如何,一切都发生了变化,公司需要适应。StitchFix 的雷扎·索拉比(Reza Sohrabi)也指出:“我认为没有哪个企业没有受到当前疫情的影响。因此,我认为公司必须适应新的情况,并改变数据科学的运作方式。”
我们看到并听到的一个大挑战是,鉴于当前市场和客户行为的波动,人工智能生成的预测无法预测未来事件。预测模型依赖于历史数据来预测未来事件。当客户行为的历史数据与现在他们所做的完全不同的时候,我们就遇到问题了。预测就会变得毫无意义。
《财富》杂志的艾伦·穆雷(Alan Murray)对此解释得很好:“…… 现代的‘预测机器’往往基于过去行为的数据。这些机器并没有准备好应对行为的巨大变化——例如,当人们莫名其妙地开始囤积卫生纸时。”
许多不同的行业目前都受到变化的数据的影响,例如极长的超市排队时间、不稳定的购物行为,以及对公共卫生和金融中心等网站的访问激增,这些网站报告了看似是拒绝服务攻击的情况。
公司现在看到的信号,几周前可能还被视为异常或离群值。现在这些已成为新的常态。而大多数人工智能都无法应对这些情况。
然而,有些事情是可以做的。
解决方案
当我们考虑如何在困难时期帮助公司时,我们回到了基本面:公司必须用他们会喜欢的产品来吸引客户。现在比以往任何时候都更重要的是理解客户真正想要什么,并在他们需要的时候提供给他们。同时,这也是审视组织如何处理数据和利用分析的好时机。
埃里克·金(Eric King)总结道:“现在正是从更宏观的角度审视公司如何在长期内竞争的最佳时机,而不是关注这一季度发生的干扰。” —— 埃里克·A·金,《建模机构》的总裁兼创始人
毕竟,有效分析的目标是不断推进客户生命周期价值及其所有驱动因素的维护。
这些生命周期价值的驱动因素包括:
-
在客户寻找时提供吸引人的内容和优惠。
-
通过识别通常导致流失的模式并使用有效的流失缓解策略来保持低流失率。
-
传递个性化的营销信息。
这些是需要正确掌握的重要基础知识。但现在是 2020 年初,全球客户的偏好几乎完全无序。
如果你有一个个性化至关重要的业务,有几个变化可以帮助你从数据科学中保留价值:
-
深入分析你的数据 对于数据驱动的公司来说,最重要的目标是深入数据仪表盘。查看那些由业务目标驱动的主要假设,它们是否仍然成立?是否仍有数据(或足够的数据)支持这些主要目标?例如,如果你销售产品,那么人们购买的产品是否发生了重大变化?库存如何?你的客户找到他们突然需要的新产品有多困难?你的个性化工具仍然有效吗?例如,你是否发送了可能毫无趣味或更糟的是,考虑到当前世界状况会让人尴尬的营销信息?或者你的网站推荐是否仍然显示突然变得不相关的产品?
-
提供反映客户偏好变化的产品 你使用六个月前的数据来预测客户偏好的模型可能已经不再准确。相反,应该使用过去两到四周的客户偏好数据来训练这些模型。尽管你可能没有很多销售数据,但这可能会更准确地反映当前客户的需求,因为六周前的世界完全不同。此外,可能还会有与价格敏感性相关的变化,所以在提供更昂贵的商品之前,要确保考虑到这些因素。你需要尝试使用不同量的训练数据,但这样做会有所回报,因为这将帮助你找到一个平衡点,在包含足够的新趋势的同时,省略旧的、不相关的数据。
-
确保你没有说错话 尝试新的信息策略。旧的信息已经过时。今天没有人以相同的方式进行购买或行为。这意味着你的信息需要变化,以反映客户的新担忧、希望和愿望。一个方法是编写几种新的营销文案选项并进行 A/B 测试,看看哪种最能引起共鸣。如果你之前已经确定了用户细分,它们可能依然存在,但即便这些也可能发生变化。不要相信任何事,用新的证据来验证一切。方法是通过询问客户或尝试不同的方法并量化结果来做到这一点。如果你有 A/B 系统,赶紧用上!之前有效的方法很可能已经改变了。
-
评估你的营销目标 如上所述,再次审视你的客户细分。它们是否相同,或者更可能的是,多个细分是否合并成一两个新的细分?了解这一点将帮助你在这些变化的时代中调整信息。我一直喜欢主动联系客户,询问他们的偏好是否有所变化。如果激励足够大(换句话说,如果他们认为会看到为他们量身定制的优惠),他们可能愿意花时间帮助你更好地服务他们。请参阅 StitchFix 和 TrunkClub 的入职流程,了解公司如何通过承诺提供高度个性化的用户体验来收集大量用户数据。
如果你做这四件事,你的公司将远远领先于那些可能无法迅速适应变化的竞争对手。
其他人怎么说:
“公司在运行生产环境中的机器学习模型时,需要更加关注数据的新鲜度、分布变化和预测校准。由于 COVID-19 的影响,用户行为迅速变化,模型可能会更快地退化,并对意外的用户行为做出不良预测。” – Eugen Hotaj
“[考虑]一年中的时间的推荐算法,目前没有意义。例如,节日季节即将来临;通常来说,储备帐篷并推荐给年轻人是合理的。然而现在这样做就不合适了。必须减少赋予过去行为的权重,以便推荐主要依赖于过去几周的趋势。作为买家,我现在看到的是,在某些情况下,推荐系统部分关闭。” – Dániel Barta
“尽管模型可以预测具体情况,但在我看来,了解背后的原因是重要的。” – Joseph "Goose" Aranez
个人简介: Zank Bennett 是 Bennett Data Science 的首席执行官和创始人。
相关内容:
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
了解更多相关主题
如何在 COVID-19 危机期间使 AI/机器学习模型保持韧性
原文:
www.kdnuggets.com/2020/06/ai-ml-models-resilient-covid-19-crisis.html
评论
Mayank Kumar,数据科学顾问和领导者,UnitedHealth Group。

最近,我遇到了一些文章和对话,数据科学和分析领域的领导者们对 AI/ML 的性能和可靠性表示担忧。概念漂移或数据漂移的问题并不新鲜,但 COVID-19 使其影响显得非常显著。在本文中,我讨论了一些最佳实践,以确保创建有韧性的 AI/ML 解决方案来应对这种数据变化。
COVID 影响的广度
AI/ML 在所有行业和领域中有着极其广泛的应用。然而,并非所有行业或用例都受到 COVID 触发的数据变化的影响。根据我的评估和观察,只有 AI/ML 被用于捕捉消费者/终端用户行为的领域受到了影响,因为这正是 COVID 改变的唯一内容。例如,你的 Alexa 并没有突然停止理解英语,或者自动驾驶汽车也没有忘记如何驾驶,因为这里没有用户行为的涉及。改变的是我们的生活方式、日常需求、在线存在等。在 B2B 市场中,改变的是公司如何开展业务,他们消费哪些产品,以及他们放弃哪些产品。在这些变化之外,另一个问题是变化具有不稳定性。我们每周都看到由许多外部因素驱动的变化。
这个问题主要存在于 AI/ML 使用历史数据来分析行为和预测未来事件。如果最近的行为发生了剧烈变化并且持续不稳定,那么静态的 AI/ML 解决方案显然没有机会,最多只能是不准确,最差则可能具有误导性。
如何应对 COVID’的影响?

尽管没有明确且详尽的指南来解决这个问题,但根据具体问题的不同,可能需要采用一种或多种策略的不同排列组合。以下是一些我认为可以朝这个方向努力的方法。
监控你的数据和特征
作为一名数据科学领导者,我学到的关键之一是成功的数据科学团队应该始终具备监控底层数据和分析特征的能力。这是掌控高级分析策略的关键步骤,你可以直接看到数据的表现以及模型的表现如何。
我不是在谈论临时监控,我感觉我们大多数人已经在需求下进行,当我们发现分析解决方案没有达到预期目标时。我在谈论创建主动措施,能够在数据变化、结果恶化等方面提醒解决方案拥有者。
评估你的 AI/ML 解决方案的灵活性
敏捷性是关键,同样 AI/ML 也是如此。问问自己,是否你的模型需要针对每次特征分布的变化进行重新训练,或者在你设计特征和模型的方式中是否有一定程度的动态性。为了使解决方案对最近的数据更加敏感,追踪最近的用户行为,需要付出怎样的努力?对不同决策参数赋予不同权重的人工修正有多容易?是否可以在你的 AI/ML 工作流中应用基于规则的业务过滤?
动态特性、自学习模型、提高解决方案的敏感性能力,以及在 AI/ML 决策流程中引入人工修正的便捷性是决定数据科学和分析解决方案在快速调整以适应数据模式变化方面的灵活性的关键因素。为此创造了一个术语,称为 MLOps,类似于技术中的 DevOps,旨在为数据科学领域带来类似的敏捷性。
重新审视结果变量的定义
由于我们所称为正常的情况已经发生变化,这确实需要数据科学家重新审视其结果变量的定义,以确定他们之前称为异常的情况是否已经成为新的正常情况,反之亦然。我们的数据是否可能落入一个之前不存在的新类别中,或者某些类别是否已经消失?还应询问模型如何处理训练期间未见过的新数据点?它是否将这些数据点视为正例或负例离群点,还是将其视为正常数据的一部分,这更多的是一个基于用例的决策,可能需要进行。
从基于配置文件的方法转向非配置文件的方法
虽然这一部分可能并不适用于所有情况,但在可能的情况下,应探索那些不需要正常配置文件进行训练,而是具有根据给定样本发现离群点的内在能力的方法。该声明主要适用于无监督和混合设置中的离群点检测系统。
更加信任实时验证你的解决方案
鉴于我们当前的数据可能已与过去所见发生了显著变化,信任我们在训练、测试和验证过程中建立的过去模型表现将不再提供真实的图景。数据科学团队应尽可能转向实时验证设置,使用 A/B 测试以观察模型在没有 AI/ML 解决方案的当前设置下的表现。
结论
正如我在某处读到的,AI/ML 是有生命的,需要不断的维护和干预。因此,像其他有生命的物体一样,它需要持续的关注。数据科学团队应将约 20-30% 的精力投入到监控、管理和潜在的改进中,以取得成功。
您是否已经利用上述一些方法来评估您的 AI/ML 解决方案的性能?您的团队还采用了哪些其他技术来应对数据频繁变化的潜在影响?
参考资料
确保 AI/ML 系统在 COVID-19 中生存的 4 个步骤
简介:Mayank Kumar 在医疗和制药行业拥有超过 10 年的数据科学经验,主要面向美国市场。目前,Mayank 管理多个项目,开发针对性的分析解决方案,利用先进的机器学习、深度学习和大数据处理工具与技术。
相关:
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织 IT
更多相关主题
AI + 无代码:重新定义开发者创新的病毒组合
原文:
www.kdnuggets.com/ai-no-code-the-viral-combo-redefining-developer-innovation

图片由 DALLE-3 生成
在当今动态数字世界中,时间至关重要,开发者面临着比以往更大的压力,需要更快地实现新应用和开发代码,通常内部资源有限。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
随着公司探索提高开发者生产力和操作的新方法,低代码/无代码工具的受欢迎程度不断上升,这些工具为几乎没有编码经验的公民开发者以及希望挽回宝贵时间和精力的高级开发者提供了好处。为了激发和鼓励开发者创新,支持人工智能(AI)的低代码/无代码平台促进了更快的开发时间和增加的业务敏捷性,同时为开发者团队提供了创新所需的工具和支持。
扩大能够构建软件系统的人群,并促进灵活性
全球开发者团队面临着限制,市场情报公司 IDC 预测到 2025 年,全球全职开发者短缺 将增加到 400 万,不到两年时间。考虑到这一点,公司应考虑在开发过程中利用整个团队,即使是那些编程经验有限的成员。
低代码/无代码应用程序接口(APIs)解决方案为资源有限和技能不同的团队提供了宝贵的工具,以加快创新过程,并更快地实施解决方案和功能。利用这些 APIs,像初级产品经理或业务分析师这样的非 IT 专业人员也可以开发基础原型,从而扩大组织中能够构建软件系统的人数。
现在许多公司使用的客户互动解决方案可以自然语言操作,并结合了人工智能以及低代码/无代码工具,从而在客户首选的沟通渠道上创建更智能、更个性化和自动化的对话。
此外,低代码/无代码工具不仅适用于公民开发者,还适用于更高级的资深开发者,使得即使是最资深的开发者也能快速迭代创新,并腾出时间专注于构建更高代码的解决方案。利用这些工具可以减轻有限开发团队的压力,使得即使拥有基本的技术技能和最少的培训,实施过程也能更快、更容易。低代码/无代码以及人工智能提供的自动化功能使团队能够解决更紧迫的问题。
实施低代码/无代码解决方案也促进了工作环境的灵活性,并且可以通过创建开发团队的辅助部门来帮助解决人才短缺问题。除了缓解人才短缺,低代码/无代码工具还提高了业务的敏捷性,并通过显著降低招聘成本和应用维护成本来节省开支。
利用一种新的选择,决定是构建还是购买。
低代码/无代码平台有助于扩展组织快速开发新解决方案的能力,提供了构建与购买的更好替代方案,并使公司能够避免自行构建人工智能解决方案(如对话式人工智能能力)。
当公司购买某个解决方案时,这个解决方案往往是有限的,可能会限制团队只使用该解决方案的实施能力。团队还被迫花费大量时间寻找其他能够与所购买解决方案兼容的方案,以弥补任何缺失的需求。购买过程可能更加僵化,可能只是部分满足公司帮助开发团队更高效工作的需求,并且通常会使公司陷入长期承诺。相比之下,如果团队已经缺乏时间和资源,构建解决方案可能会非常具有挑战性,并且从零开始成功构建可能会很困难。选择构建会增加失败的风险,因为构建的东西可能无法正常工作,或者需求可能发生变化,导致整个团队不得不重新开始。
低代码/无代码 API 提供了更具可定制性、强大且简单的解决方案。这些工具可以与开发者尝试创建的内容更加紧密地集成,并帮助填补那些不需要高代码知识的功能空白。
时间是开发者无法追回的唯一东西。
对于开发者而言,时间是他们工作中最宝贵的因素之一,因此利用减少实施时间和帮助避免模板代码的工具至关重要。低代码/无代码使得各种技能的团队能够迅速实现基本功能以满足需求,同时提供了必要时重新设计的适应性。通过避免早期的高代码开发,组织会被迫立即做出决策,而这些决策在之后需要更改时会变得困难,团队可以通过低代码/无代码解决方案挽回时间,并在成功的概念验证后过渡到更复杂的高代码解决方案。
成功地在企业中利用低代码/无代码和人工智能
选择合适的低代码/无代码工具是关键一步,因为这些工具并不是一刀切的,组织应选择最适合团队中开发者和非开发者使用的工具,并且这些工具能够轻松扩展 AI 功能。平台的适应性和灵活性也必须考虑,因为平台不仅要满足当前团队的需求,还应适应未来项目的变化。确保平台具有可扩展性、可靠性,并且能无缝融入现有技术栈中。选择一个利用 AI 的低代码/无代码平台时,检查所有这些要素对于成功利用其全部优势至关重要。
Savinay Berry 是 Vonage 的产品与工程执行副总裁。
更多相关话题
2020 年的 AI 论文阅读推荐
评论
由 Ygor Rebouças Serpa 提供,他正在为医疗保健行业开发可解释的人工智能工具

图片由 Alfons Morales 提供,来源于 Unsplash
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
人工智能是科学领域中增长最快的领域之一,并且是过去几年中最受追捧的技能之一,通常被标记为数据科学。这个领域有着广泛的应用,通常按输入类型划分:文本、音频、图像、视频或图表;或按问题表述方式划分:监督学习、无监督学习和强化学习。跟上所有这些进展是一项巨大的工作,通常会变成令人沮丧的尝试。基于这一点,我提供了一些阅读建议,以便让你了解人工智能和数据科学领域最新和经典的突破。
尽管我列出的多数论文都涉及图像和文本,但它们的许多概念相当不依赖于输入类型,并且提供了超越视觉和语言任务的深入见解。在每个建议旁边,我列出了一些我认为你应该阅读(或重新阅读)论文的理由,并添加了一些进一步阅读的材料,以便你能更深入地研究相关主题。
在我们开始之前,我要向音频和强化学习社区道歉,因为我由于对这两个领域的经验有限,没有将这些主题添加到列表中。
下面我们开始吧。
#1 AlexNet (2012)
Krizhevsky, Alex, Ilya Sutskever, 和 Geoffrey E. Hinton. “用深度卷积神经网络进行图像分类。” 神经信息处理系统的进展。2012 年。
在 2012 年,作者提出了使用 GPU 训练大型卷积神经网络(CNN)来应对 ImageNet 挑战。这是一个大胆的举措,因为 CNN 被认为过于庞大,无法在如此大规模的问题上进行训练。令所有人惊讶的是,他们赢得了第一名,Top-5 错误率约为 15%,相比之下第二名使用了最先进的图像处理技术,错误率约为 26%。
理由 #1: 虽然我们大多数人知道 AlexNet 的历史重要性,但并非所有人都知道我们今天使用的技术中哪些在繁荣之前已经存在。你可能会惊讶于论文中介绍的许多概念,如 dropout 和 ReLU,是多么熟悉。
理由 #2: 提出的网络有 6000 万参数,对于 2012 年的标准来说完全是疯狂的。现在,我们看到的模型参数超过了十亿。阅读 AlexNet 论文为我们提供了大量关于自那时以来事情如何发展的见解。
进一步阅读: 你可以参考图像 Net 冠军的历史,阅读ZF Net、VGG、Inception-v1和ResNet论文。最后一篇取得了超越人类的表现,解决了挑战。之后,其他竞赛转移了研究者们的注意力。现在,ImageNet 主要用于迁移学习和验证低参数模型,例如:
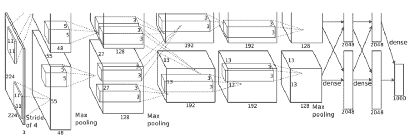
AlexNet 结构的原始描述。顶部和底部部分分别由 GPU 1 和 2 处理。这是一种早期的模型并行形式。来源:Alexnet 论文
#2 MobileNet (2017)
Howard, Andrew G., 等人。“Mobilenets: Efficient convolutional neural networks for mobile vision applications.” arXiv 预印本 arXiv:1704.04861 (2017)。
MobileNet 是最著名的“低参数”网络之一。这些模型非常适合低资源设备和加速实时应用,如手机上的对象识别。MobileNet 和其他低参数模型的核心思想是将昂贵的操作分解为一组较小(且更快)的操作。这种复合操作通常快几个数量级,并使用了显著更少的参数。
理由 #1: 我们大多数人没有大科技公司拥有的资源。理解低参数网络对于使自己的模型更经济地训练和使用至关重要。在我的经验中,使用 depth-wise 卷积可以节省你数百美元的云推理费用,几乎不会损失精度。
理由 #2: 常识认为更大的模型更强大。像 MobileNet 这样的论文表明,模型的强大不仅仅是增加更多的滤波器。优雅很重要。
进一步阅读: 目前,MobileNet v2 和 v3 已经发布,提供了新的准确性和尺寸增强。同时,其他作者也提出了许多技术来进一步缩小模型尺寸,例如 SqueezeNet,以及 以最小的准确性损失缩小常规模型。 这篇论文 对多个模型的尺寸与准确性进行了全面总结。
#3 注意力机制是你所需要的(2017)
Vaswani, Ashish, 等. “注意力机制是你所需要的。” 神经信息处理系统的进展。2017 年。
介绍变压器模型的论文。在此之前,语言模型主要依赖递归神经网络(RNN)来执行序列到序列的任务。然而,RNN 的速度非常慢,因为它们在多 GPU 并行化时表现很差。相比之下,变压器模型完全基于注意力层,这些层是捕捉序列中任意元素彼此相关性的卷积神经网络(CNN)。提出的公式达到了显著更好的最先进结果,并且训练速度明显快于之前的 RNN 模型。
理由 #1: 目前,大多数自然语言处理(NLP)文献中的新颖架构都源自变压器。像 GPT-2 和 BERT 这样的模型处于创新的前沿。理解变压器是理解大多数后续 NLP 模型的关键。
理由 #2: 大多数变压器模型的参数量都在数十亿级别。虽然关于 MobileNets 的文献讨论了更高效的模型,但 NLP 领域的研究则集中在更高效的训练上。两者结合提供了高效训练和推理的终极技术集。
理由 #3: 尽管变压器模型主要被限制在 NLP 领域,但提出的注意力机制具有广泛的应用。像 自注意力 GAN 这样的模型展示了全局级别推理在多种任务中的有效性。每个月都有新的关于注意力应用的论文出现。
进一步阅读: 我强烈推荐阅读 BERT 和 SAGAN 论文。前者是变压器模型的延续,后者则是在 GAN 设置中将注意力机制应用于图像的研究。
#4 不要再用你的脑袋思考 / Reformer (~2020)
Merity, Stephen. “单头注意力 RNN: 不要再用你的脑袋思考.” arXiv 预印本 arXiv:1911.11423 (2019)。
Kitaev, Nikita, Łukasz Kaiser, and Anselm Levskaya. “Reformer: 高效的 Transformer。” arXiv 预印本 arXiv:2001.04451(2020 年)。
Transformer / Attention 模型吸引了大量关注。然而,这些模型往往资源消耗大,不适合普通消费者硬件。上述论文都批评了这种架构,提供了计算上更高效的替代方案。至于 MobileNet 的讨论,优雅性很重要。
理由 #1: “停止用脑袋思考” 是篇非常有趣的论文。这本身就是一个理由。
理由 #2: 大公司可以快速扩展他们的研究到数百个 GPU。而我们普通人不能。模型规模的扩大并不是唯一的改进途径。我无法过分强调这一点。了解效率是确保你有效利用当前资源的最佳方式。
进一步阅读:由于这些论文是 2019 年底和 2020 年的,链接不多。考虑阅读MobileNet 论文(如果你还没有读的话),了解其他关于效率的看法。
#5 姿态估计的人类基线(2017 年)
Xiao, Bin, Haiping Wu, and Yichen Wei. “人类姿态估计与跟踪的简单基线。”欧洲计算机视觉会议论文集(ECCV)。2018 年。
到目前为止,大多数论文提出了新技术以改善最先进技术。相反,本文主张使用当前最佳实践的简单模型可能会出奇地有效。总之,他们提出了一种仅基于骨干网络并经过三次反卷积操作的人体姿态估计网络。当时,他们的方法在处理 COCO 基准测试方面是最有效的,尽管其简单性。
理由 #1: 有时候简单是最有效的方法。虽然我们都想尝试炫酷和复杂的创新架构,但基线模型可能编码速度更快,同时取得类似的结果。本文提醒我们,并不是所有好的模型都需要复杂。
理由 #2: 科学是循序渐进的。每篇新论文都将最先进技术推向前沿。然而,这不必是单向道路。有时值得稍微倒退一下,转个不同的方向。“停止用脑袋思考”和“Reformer”就是这方面的两个好例子。
理由 #3: 适当的数据增强、训练计划和良好的问题表述比大多数人意识到的要重要。
进一步阅读:如果你对姿态估计话题感兴趣,可以考虑阅读这篇全面的最先进综述。
#6 图像分类的技巧包(2019 年)
He, Tong 等. “用于卷积神经网络的图像分类技巧包。” IEEE 计算机视觉与模式识别会议论文集. 2019.
很多时候,你需要的不是一个华丽的新模型,而是几个新的技巧。在大多数论文中,引入了一两种新技巧以获得一到两个百分点的改进。然而,这些往往在重大贡献中被遗忘。本文汇集了一组在文献中使用的技巧,并为我们的阅读乐趣进行了总结。
理由 #1: 大多数技巧易于应用
理由 #2: 你可能对大多数方法并不了解。这些建议不是典型的“使用 ELU”类型的。
进一步阅读: 还有许多其他技巧,有些是特定问题的,有些则不是。我认为值得更多关注的主题是类别和样本权重。考虑阅读 这篇关于不平衡数据集的类别权重的论文。
#7 SELU 激活函数(2017)
Klambauer, Günter 等. “自归一化神经网络。” 神经信息处理系统进展. 2017.
我们中的大多数人使用批归一化层和 ReLU 或 ELU 激活函数。在 SELU 论文中,作者提出了一种统一的方法:一种自归一化其输出的激活函数。在实践中,这使得批归一化层变得多余。因此,使用 SELU 激活函数的模型更简单,所需操作更少。
理由 #1: 论文中,作者主要处理标准机器学习问题(表格数据)。大多数数据科学家主要处理图像。阅读一篇纯粹关于密集网络的论文,确实是一种清新的体验。
理由 #2: 如果你需要处理表格数据,这是神经网络文献中最先进的方法之一。
理由 #3: 这篇论文数学内容繁重,并使用了计算推导证明。这本身就是一种稀有但美妙的现象。
进一步阅读: 如果你想深入了解最流行的激活函数的历史和使用,我在 Medium 上写了一份 激活函数指南。快去看看 😃
#8 本地特征包(2019)
Brendel, Wieland, 和 Matthias Bethge. “用本地特征包模型近似 CNN 在 ImageNet 上效果出奇的好。” arXiv 预印本 arXiv:1904.00760 (2019).
如果你将一张图像分成拼图状的块,打乱它们,然后展示给一个孩子,它将无法识别原始对象;而 CNN 可能会。在这篇论文中,作者发现对图像的所有 33x33 区块进行分类,然后平均它们的类别预测,可以在 ImageNet 上获得接近最先进的结果。此外,他们进一步探索了这个想法,使用了 VGG 和 ResNet-50 模型,显示出 CNN 过度依赖局部信息,而全球推理则极其有限。
原因 #1: 尽管许多人认为 CNN “看见”了,但这篇论文提供了证据表明它们可能比我们敢于下注的要愚蠢得多。
原因 #2: 我们偶尔会看到一篇对 CNN 的局限性及其可解释性提出新见解的论文。
进一步阅读: 相关的对抗攻击文献也显示了 CNN 的其他明显限制。考虑阅读以下文章(及其参考部分):
我们使用的机器学习模型本质上是否存在缺陷?
#9 彩票假设(2019)
Frankle, Jonathan, 和 Michael Carbin. “彩票假设:寻找稀疏的可训练神经网络。” arXiv 预印本 arXiv:1803.03635(2018)。
继续讨论理论论文,Frankle 等人 发现如果你训练一个大网络,剪枝所有低价值的权重,回滚剪枝后的网络,再次训练,你将得到一个表现更好的网络。彩票类比是将每个权重视为一个“彩票票”。有十亿张票,赢得奖品是确定的。然而,大多数票不会中奖,只有少数几张。如果你可以回到过去,只买中奖票,你将最大化你的利润。“十亿张票”是一个大的初始网络。“训练”是进行抽奖,看看哪些权重是高价值的。“回到过去”是回滚到初始的未训练网络,并重新进行抽奖。最终,你会得到一个表现更好的网络。
原因 #1: 这个想法非常酷。
原因 #2: 关于 Bag-of-Features 论文,这揭示了我们目前对 CNN 理解的局限性。阅读这篇论文后,我意识到我们数百万个参数的利用率是多么低。一个未解之谜是有多少。作者设法将网络的规模缩减到原始大小的十分之一,未来还可能减少多少?
原因 #3: 这些想法还给我们提供了更多关于庞大网络低效性的视角。考虑之前提到的 Reformer 论文。它通过改进算法大幅减少了 Transformer 的规模。使用彩票技术还可以减少多少?
进一步阅读:权重初始化是一个常被忽视的话题。在我的经验中,大多数人坚持使用默认值,这可能并非总是最佳选择。 “你只需要一个好的初始化” 是这方面的开创性论文。至于彩票票据假说,以下是一个易读的综述:
从 MIT CSAIL 的有趣论文中提炼出的观点:“彩票票据假说:寻找稀疏的、可训练的……”
#10 Pix2Pix 和 CycleGAN(2017 年)
Isola, Phillip 等人。“基于条件对抗网络的图像到图像翻译。” IEEE 计算机视觉与模式识别会议论文集。2017 年。
Zhu, Jun-Yan 等人。“使用循环一致对抗网络进行非配对图像到图像翻译。” IEEE 国际计算机视觉会议论文集。2017 年。
这个列表如果没有一些 GAN 论文就不完整了。
Pix2Pix 和 CycleGAN 是条件生成模型的两个开创性工作。两者都执行将图像从领域 A 转换到领域 B 的任务,但通过利用配对和非配对数据集有所不同。前者执行诸如将线条图转换为完全渲染的图像等任务,后者则擅长于替换实体,例如将马变成斑马或将苹果变成橙子。通过“条件化”,这些模型使用户可以通过调整输入来对生成的内容进行一定程度的控制。
理由 #1:GAN 论文通常集中于生成结果的质量,并且不强调艺术控制。这些条件模型为 GAN 在实际应用中提供了一个实际的途径。例如,作为艺术家的虚拟助手。
理由 #2:对抗性方法是多网络模型的最佳示例。虽然生成可能不是你的强项,但阅读关于多网络设置的内容可能会对许多问题产生启发。
理由 #3:《CycleGAN》论文尤其展示了一个有效的损失函数如何在解决一些困难问题时发挥奇效。一个类似的观点在 Focal loss 论文中也有提出,该论文通过用更好的损失函数替代传统的损失函数,显著改善了目标检测器的表现。
进一步阅读:虽然 AI 在快速发展,但 GAN 的增长更为迅猛。如果你从未编码过 GAN,我强烈推荐你尝试一下。这是关于这一问题的官方 Tensorflow 2 文档。一个不太为人知晓的 GAN 应用是半监督学习,你应该了解一下。
有了这十二篇论文及其后续阅读材料,我相信你已经有了丰富的阅读素材。这肯定不是一份详尽的好论文列表。然而,我尽力选择了我所见过和读过的最具洞察力和开创性的作品。如果你认为还有其他应该在此列表中的论文,请告诉我。
祝阅读愉快 😃
编辑:在编写这份列表后,我又整理了第二份包含 2020 年阅读的十篇 AI 论文的列表,以及第三份关于 GAN 的列表。如果你喜欢阅读这份列表,你可能会喜欢它的续集:
额外的阅读建议,帮助你了解最新和经典的 AI 及数据科学突破
关于生成对抗网络的阅读建议。
简介:Ygor Rebouças Serpa (@ReboucasYgor)是来自大学城大学计算机科学硕士,目前从事研发,开发医疗行业的可解释 AI 工具。他的兴趣从音乐和游戏开发到理论计算机科学和 AI。请查看他的Medium 个人主页了解更多写作。
原文。经授权转载。
相关:
-
13 篇来自 AI 专家的必读论文
-
数据科学家必读的 NLP 和深度学习文章
-
5 篇情感分析的核心论文
更多相关主题
AI 提示工程师年薪 $300k

图片由作者提供
$300k/年。这可能是你看到的第一件事,你可能会想‘咦,怎么可能?’我问了自己完全一样的问题。但我并不感到惊讶。考虑到生成性 AI 在 2023 年的发展趋势,这注定是下一个人人争抢的热门职业。
如果你仍然不相信我,可以查看 Anthropics 的招聘信息 这里。
现在相信我了吗?
我会把这看作是肯定的答案,不再拖延,直接进入如何免费学习 AI 提示工程,并希望能为你争取一个新的高端职位!
Open AI 提示工程指南
链接:提示工程指南
让我们从目前在提示工程/生成性 AI 游戏中领先的公司开始——OpenAI。
OpenAI 提供了一份指南,其中将介绍策略战术,帮助你从大型语言模型如 GPT-4 中获得更好的结果。他们鼓励用户进行实验,通过反复试验找到最适合自己的方法!
他们通过一系列示例以及 6 种策略来帮助你获得更好的结果。
深度学习中的自然语言处理
链接:深度学习中的自然语言处理
知道如何提示模型以获得你想要的结果很棒,但更好的是当你理解它的工作原理时——即其内部细节。
由深度学习提供的课程,探讨了自然语言处理 (NLP) 的基础和应用,使用深度学习技术。因此,与其仅仅了解如何与计算机系统沟通,不如深入了解计算机系统如何理解和生成类似人类的语言。
学习提示
链接:学习提示工程指南
哦,又一个指南,这次更加全面!创始人们共同创建了一个关于如何使用生成性 AI 的全面且免费的指南。如果你是 AI 世界的新手,这份指南就是为你准备的。它特别针对那些希望了解生成性 AI 和提示工程的非技术读者。
如果你掌握了一些技术知识,并需要更具挑战性的内容,那么后面的模块将适合你。
提示工程大师课程
链接:提示工程大师课程
如果你愿意订阅,Prompt Engineering Masterclass 的内容对你是免费的!这是一个不断发展的系列,分为多个章节文章。你将深入了解用于生成 AI 的高级提示工程技术。
你将从学习生成 AI 基础、介绍大型语言模型和提示工程开始,然后逐渐深入到更高级的主题,如提示工程技术、对话 AI 模型、AGI 和企业 GenAI,以及实际示例。
开发者的提示工程
链接: 开发者的提示工程
DeepLearning.AI 提供的 1 小时免费课程,由 Isa Fulford 和 Andrew Ng 担任课程协调员。该课程专为开发者量身定制,你将学习如何使用 LLM 并构建新的强大应用。
使用 OpenAI API,你将学会创新,掌握最佳提示工程实践,并探索 LLM API 在各种任务中的应用。
提示工程指南
链接: 提示工程指南
最后但同样重要的是,另一个提示工程指南。免费指南再多也不嫌多!
对 LLM(大语言模型)发展充满高度兴趣的 PromptingGuide.AI 创建了一个提示工程指南。你不仅可以掌握提示工程,还包含最新的论文、先进的提示技巧、学习指南等内容。
总结
离找到那份高薪新工作的目标还有 6 门课程!当然,掌握提示工程不仅仅是这样,你还需要将其付诸实践,创建一个优秀的作品集,尽力而为!
Nisha Arya是一位数据科学家、自由技术写作人,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及数据科学理论知识。Nisha 涉及广泛的主题,并希望探索人工智能如何有益于人类寿命的不同方式。作为一个热衷学习者,Nisha 致力于拓宽她的技术知识和写作技能,同时帮助他人。
主题更多信息
AI 注册:终于,有了一个增加 AI/ML 透明度的工具
原文:
www.kdnuggets.com/2020/12/ai-registers-transparency-ml.html
评论
由 Natalia Nygren Modjeska,行业分析师,Infotech。
透明度、可解释性和信任是当今 AI/ML 中的重要而紧迫的话题。没有人愿意面对一个在做出重要决策(例如,关于工作、医疗、国籍等)时的黑箱系统,特别是当这些决策不公平、有偏见或明显不利于我们时。大多数组织也同意 消费者对 AI 以伦理和透明方式使用的信任和信心是释放其真正潜力的关键。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
虽然有大量的 描述和规定 AI 原则、框架 的文档,但直到现在,还没有实际工具能帮助实施透明度。
2020 年 9 月 28 日,赫尔辛基和阿姆斯特丹两市共同宣布启动他们的公共 AI 注册表。这两个注册表是与 Saidot.ai 合作开发的,这是一家创新的芬兰公司,专注于“为消费者服务带来透明度”(同上),据我所知,是该领域唯一的供应商。
公司的创意源于其创始人兼首席执行官 Meeri Haataja 的个人挫折,她 “看到透明度在 AI 未来中的重要性,却找不到太多有意义的行动方式。”
什么是 AI 注册表?
赫尔辛基市将其定义为 “一个可以查看城市使用的人工智能系统的窗口。” 阿姆斯特丹市称他们的系统为算法注册表,及 “阿姆斯特丹市使用的人工智能系统和算法的概述。”
来源:algoritmeregister.amsterdam.nl/en/ai-register/

两个登记册都描述了城市如何使用人工智能/机器学习,这些应用程序如何影响公民及其日常生活,它们是如何构建的,使用了哪些数据和算法,在应用程序的设计、构建和部署过程中做出了哪些决策和假设,以及采用了哪些伦理原则来减轻偏见和风险。登记册还包括联系信息,包括电子邮件地址、电话号码,以及进一步询问或反馈的联系人或团队。

来源:algoritmeregister.amsterdam.nl/en/reporting-issues-in-public-space/
人工智能登记册中的语言清晰易懂,面向没有任何人工智能/机器学习技术背景的普通公民。(一些技术信息也提供了,尽管有限,但可以通过上述联系信息获得更多信息。)
到目前为止,城市登记册中记录的人工智能应用程序数量较少:赫尔辛基市五个,阿姆斯特丹市四个,但更多的应用程序正在开发中。
人工智能登记册对政府和公民的好处
通过公开其应用程序背后的信息,政府提升了对人工智能使用的透明度和问责制。这有助于增加公民的信任,因为信任是任何政府的基础;“政府只有在政府和人民之间存在信任时才能运作。” 或者,正如赫尔辛基市首席数字官 Mikko Rusama 所说,“没有信任,人工智能就没有用处。”
对于公民而言,人工智能登记册有助于提高人工智能/机器学习素养。它们促进了公民的意识、参与和公共辩论,这些都是民主政府的基石。它们通过提高政府使用数据、纳税人资金以及新技术(如人工智能/机器学习)的透明度来建立信任。
因为,最终,我们都希望负责任的人工智能能够使我们所有人受益,尊重多样性和人权,促进人类繁荣,维护人类自主性,并推动社会、经济和环境的可持续性。
人工智能登记册对人工智能团队的好处
对于 AI 团队来说,AI 注册表提供了一种“在你的 AI 组合中标准化透明度”的机制; 一种“可以搜索和存档的方式来记录在开发、实施、管理和最终拆解算法过程中做出的决策和假设”,(同上)。
Saidot 的软件提供了“预定义的模块化元数据模型,这些模型可以适应组织和行业特定的要求,同时确保不同版本之间的互操作性。” 其产品包括一个后端平台、注册表本身以及一个用于发布注册表的界面(由公司托管)。
除了阿姆斯特丹和赫尔辛基市,公司还将芬兰航空、埃斯波市、芬兰财政部、社会保险机构以及司法部列为其客户和合作伙伴。
Saidot 继续积极开发其平台。它正在考虑的新功能和方向包括:
-
将 AI 注册表集成到客户的 AI 开发过程中,这将有助于将其扩展到通信之外,进入解决方案治理领域,从而巩固问责制;
-
使用 AI 注册表在设计和构思过程中早期捕捉公民反馈,以确认需求并实现共同设计和共同创作;
-
促进政府组织之间的信息共享,例如,帮助选择供应商。(注册表会披露是否有外部供应商参与以及他们是谁。)
超越政府:为什么你应该为你的 AI/ML 和数据科学应用程序采用 AI 注册表
信任不仅是政府存在的基本前提。在商业中,信任同样至关重要。你的组织存在的全部原因是因为你的客户、消费者、员工和合作伙伴。因此,无论你是刚开始涉足 AI/ML,还是在整个业务基础上运行 AI 和机器学习,让我们跟随阿姆斯特丹和赫尔辛基的例子——让我们记录并公开/与员工和合作伙伴分享我们如何使用 AI/ML 和数据科学。我们都将从这种公开中受益。而 Saidot.ai 的 AI 注册表软件使得实现透明度变得更加、更加容易。
要了解更多关于 AI 注册表和 Saidot 平台的信息:
-
阅读这份简短的白皮书“公共 AI 注册表:实现 AI 透明性和政府使用 AI 中的公民参与”。
-
查看 阿姆斯特丹市算法登记册 和 赫尔辛基市 AI 登记册。
-
联系 Saidot 参加他们的测试计划。
-
如果你在公共部门,你可以免费获得他们后台系统的一年访问权限。(根据我与公司 CEO 的对话,此优惠有效期至 2020 年 12 月 31 日。)
简介: 娜塔莉亚·莫杰斯卡 是 Info-Tech Research Group 的研究主任,她为客户提供有关如何伦理和负责任地部署 AI/ML 的建议。
相关:
更多相关内容
为什么人工智能系统需要人工干预才能正常运作?
原文:
www.kdnuggets.com/2020/06/ai-systems-need-human-intervention.html
评论
作者 Laduram Vishnoi,Acquire 的首席执行官兼创始人
我们每个人在日常生活中都体验过人工智能(AI)。从个性化的 Netflix 推荐、个性化的 Spotify 播放列表到像 Alexa 这样的语音助手管理购物清单和家电——这些例子都展示了人工智能系统在我们生活中变得多么不可或缺。
在商业领域,大多数组织正在大力投资于人工智能/机器学习能力。无论是关键业务流程的自动化、建立全渠道供应链,还是通过聊天机器人赋能面向客户的团队,基于人工智能的系统都显著减少了人工工作和成本,提高了业务的盈利能力。
尽管取得了这些成功,麻省理工学院作者威尔·道格拉斯最近的一篇文章指出,在冠状病毒疫情期间,人工智能系统并不完全正常。病毒不会直接影响人工智能——然而,它确实影响了人类,没有人类人工智能和机器学习系统无法正常运作。
惊讶吗?
我们不能责怪你。如果你已经使用机器学习算法处理库存、客户支持和其他类似功能,你的系统可能已经经过良好的训练,并且在没有人工干预的情况下高效运作。然而,这个说法只部分正确,因为你的机器学习算法没有在疫情期间出现的‘新常态’上进行训练。

正如我们所知,疫情彻底改变了世界,包括供应和需求模式以及买家的行为。例如,全球范围内亚马逊上搜索量最高的商品在几天内就被与 COVID-19 相关的产品如卫生纸、口罩和洗手液所取代。像手机充电器和乐高这样的商品,曾经长期主导市场,但很快就被取代了。这些剧烈的变化也影响了人工智能,因为在正常行为上训练的机器学习模型突然面临巨大的偏差,许多模型无法正常工作。
疫情前值得注意的人工智能失败案例
AI 应用在过去几年中得到了显著的提升。然而,在这段旅程中,也有几次挫折出现,机器的表现未能如预期。例如,IBM 的“Watson for Oncology”原本旨在消除癌症,却成为了一个完全可笑的产品。在被搁置之前,该产品发现提供了可能会使患者状况恶化的错误医疗建议。根据 一个来源,问题在于 Watson 是基于少量的“合成癌症案例”而非真实患者数据进行训练的。甚至推荐也是基于少数癌症专家的专业知识,而非任何书面指南或证据。
另一个广为人知(或不广为人知)的案例是 亚马逊的招聘引擎对白人男性有偏见。该模型是基于十多年来提交给亚马逊的简历进行训练,并与公司在职工程师的简历进行基准比较。实质上,该模型训练出了对男性的偏好。一些熟悉此事的人还报告称,系统会惩罚包含“女性”一词的简历,并降低来自全女子学院的简历评分。
进入当前的疫情时代,可以以一个销售消毒剂的公司为假设例子。考虑到零售商依赖于自动化库存管理系统,该公司依赖的预测(由基于用户行为的预测算法生成)可能与由冠状病毒引发的实际需求激增不再匹配,从而导致严重的需求和供应问题。事实上,随着全球供应链受到影响,各公司出现了新的需求模式,是时候重新审视用于销售和预算预测的 AI 驱动模型了。随着在当前经济和社会动荡中出现的“新常态”,这些机器学习模型中嵌入的数据和假设已不再更新,可能导致严重错误。
人类干预对 AI 成功至关重要
机器学习系统的效果取决于其训练数据。这意味着当前的黑天鹅事件是重新审视我们 AI-ML 系统训练集的绝佳时机。许多专家认为,AI 应该不仅在简单的最坏情况场景下进行训练,还应包括人类历史上的重大事件,如 1930 年代的大萧条、2007-08 年金融危机以及当前的疫情。
人类监督也可以在很大程度上帮助克服 AI 的缺点。目前,大多数人关注的是他们及其所爱之人的健康。社交媒体再次成为传播和获取有关疫情新闻的便利工具。然而,许多人无法辨别真实新闻与假新闻,这可能在现实世界中产生严重后果。我们都清楚 Facebook 因可能利用算法推动假新闻而被指控影响美国选举的指控。然而,人类监督可以帮助克服假新闻的传播,因为最终读者需要点击来源,验证故事,并向系统报告假新闻以防止其传播。
前路
今天,即使人类寻求 AI 来使自己永生,他们也不能让 AI 独立运作而没有人类监督,因为机器终究是机器,并不具备道德或社会指南针。AI 至多只能和它所训练的数据一样好,这些数据可能反映出其创造者的偏见、思维过程或道德指南针。为了克服这种情况,有必要在不同的数据集上训练AI,并设置人类检查以保持微妙的平衡。
个人简介:Laduram Vishnoi (@laduramvishnoi) 是Acquire的首席执行官兼创始人。他喜欢分享他在人工智能、机器学习、神经网络和深度学习方面的研究和开发。
相关:
-
Deepmind 的游戏连胜:AI 主导的崛起
-
隐私保护 AI – 我们为什么需要它?
-
自主性 – 我们有选择吗?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关话题
这里是我用来每月赚取 $10,000 的 AI 工具和技能——没有废话
原文:
www.kdnuggets.com/2023/07/ai-tools-along-skills-make-10000-monthly-bs.html

来源:Pexels
说实话,通过将我的技能与 AI 结合起来,我每个月赚取超过 $10,000。白天我是专业程序员,但在空闲时间,我为不同的公司做自由职业,并在 Medium 等平台上撰写内容。
综合来看,这是一笔超过 $10,000 的丰厚收入。毫无疑问,我已经在编程和内容写作领域沉浸了超过 3 年,这就是我的专长所在。
事实是:你也拥有技能,或者有些隐藏的专长。猜猜看?我在这里帮助你将你的技能与 AI 的力量结合起来,提升你的收入。
话说回来,这里有一些 AI 工具,我用它们在几分钟内完成了繁琐的长时间工作。
激动人心吧?那么我们赶紧开始吧。
1. Canva
之前,我使用 Canva 来完成各种任务,如创建社交媒体帖子、发票、简历、网站、演示文稿、视频、徽标等等。然而,随着 AI 技术的出现,Canva 通过将几个 AI 功能集成到其平台中,取得了显著的进步。
让我分享一些 Canva 提供的卓越 AI 功能:
-
Magic Write in Canva Doc:这个特定功能使用户能够轻松生成书面内容。它帮助快速且轻松地为各种用途撰写文本。
-
Magic Design:借助这个功能,用户可以亲眼见证 AI 的魔力。通过提供一个提示或创意,Canvas AI 算法会生成令人惊叹的设计,完全根据你的需求量身定制。它将创建视觉吸引人的设计的繁琐工作代劳,轻松完成。
-
Magic Eraser:厌倦了图像中杂乱的元素吗?这个 AI 驱动的功能来帮忙。只需几个简单的点击,你就可以神奇地去除图像中任何不需要的元素,确保图像干净且完美。
-
Magic Edit:需要在设计中添加或修改元素吗?这个功能让你可以毫不费力地完成这一任务。无论是要加入新元素还是调整现有元素,Canvas AI 驱动的 Magic Edit 功能都简化了这一过程。
这些只是 Canva 提供的一些 AI 功能的例子。通过利用这些尖端技术,我能够在几分钟内完成设计工作,节省了时间和精力。
如果你想深入了解这些功能,你可以在这篇 帖子中找到更详细的信息。
2. ChatGPT
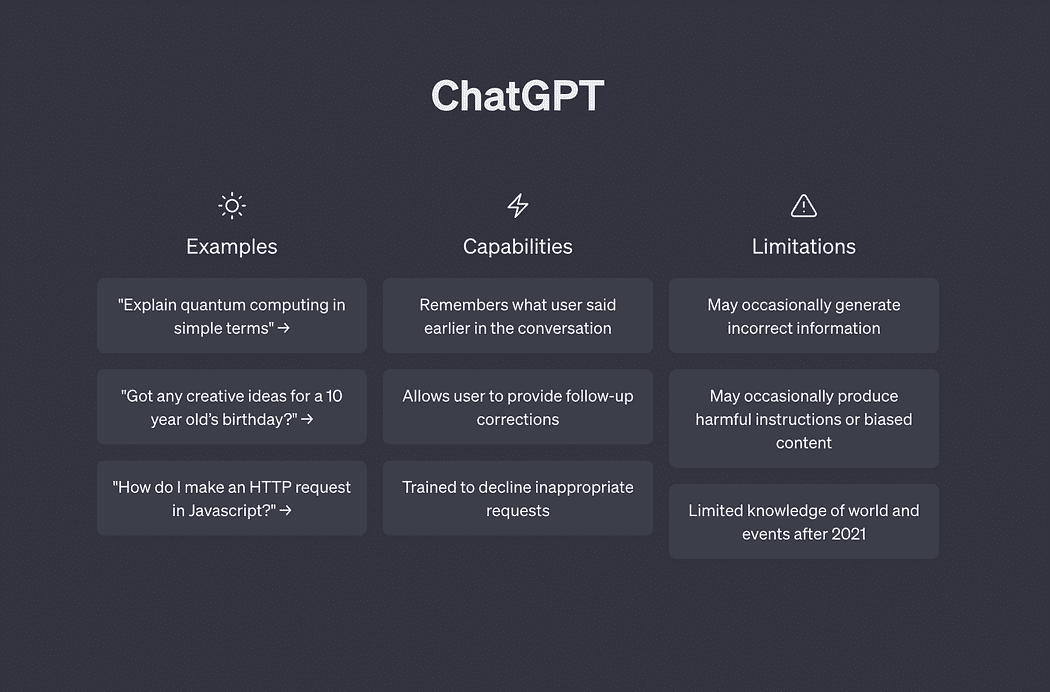
如果你一直关注我,你可能知道我已经使用了像 Bard、Perplexity 等各种 AI 聊天机器人几个月了。然而,谈到日常任务,我的首选是 ChatGPT。
ChatGPT 在提升我的技能和支持我跨不同领域方面非常有帮助。
作为一个独立创业者,我每天需要处理大量任务。最近,我甚至接受了学习如何营销产品和吸引投资者的挑战。上周,我完全独立创建了一个推介演示文稿。
这就是 ChatGPT 的便利之处。
我与 ChatGPT 使用的最有效的提示之一是:“我希望你充当一位拥有数十年经验的世界级 [职业名称]。我会要求你提供输出,你需要给我独特且专业的作品。”
使用这个提示,ChatGPT 扮演一个经验丰富的专家角色,随时准备为我提供有价值的见解,针对我询问的任何主题。
例如,当我使用这个提示时,我会收到超出我预期的卓越回复。你可以根据自己的职业定制提示,向 ChatGPT 询问你想要的任何问题。
ChatGPT 确实感觉像是随时可用的专家顾问,使我能够在需要时寻求指导和专业意见。它已成为我日常生活中不可或缺的工具。
3. Dumme

我对创建 YouTube 频道并从中赚钱不感兴趣。因为我有很多方式来货币化我的技能。
然而,你们中的许多人可能仍然渴望创建自己的 YouTube 频道。但让我告诉你,这不是一件容易的事,随着时间的推移,它变得更加具有挑战性。而增加成功机会的最佳方式是,创建一系列高质量的短片以吸引订阅者。
在这里,像 Dumme 这样的 AI 工具可以大有帮助。Dumme 是一款 AI 驱动的工具,专门设计用于将你的录像转换为引人入胜的短片,简化了这一过程。
你只需上传现有的视频,这个卓越的工具会自动识别出最激动人心的瞬间。它确保了视频的整体背景和结构得以保留,就像人类一样。
最棒的是,Dumme 通过 Dumme Creator Program 为创作者提供完全免费的服务。这是利用 AI 技术提升视频吸引力的绝佳机会,最终帮助你获得更多订阅者。
4. Folk
你可能对 CRM 并不熟悉,但它是一个简单而强大的工具,用于管理客户关系和互动。它不仅仅适用于大型企业;即使是小型企业、创作者和个人创业者也可以从中受益。
CRM 允许你存储和管理重要的客户信息,如联系方式和潜在客户管理。特别是作为创作者或个人创业者,你会与各种人进行互动,如客户、顾客、合作者和潜在客户。而这正是 CRM 帮助你有效组织和管理这些联系人的地方。
如果你想为你的创意服务或产品生成潜在客户,CRM 也可以发挥重要作用。你可以从你的网站、社交媒体或其他渠道捕获潜在客户,并将其存储在 CRM 系统中。这使你能够跟进、培育潜在客户,并跟踪转化率。
作为创作者,你经常需要同时处理多个进行中的项目或任务。CRM 可以帮助你组织和跟踪任务、设定截止日期以及与客户或团队成员协作。这确保你能够掌握项目进展并按时完成交付。
此外,如果你有合作或伙伴关系的机会,或者提供不同的服务,CRM 可以帮助你管理和跟踪这些机会。
这还不是全部。让我向你介绍一下 Folk,一个拥有众多 AI 功能的 CRM 工具。它自动化繁琐的任务,并根据你的特定工作风格进行定制。由于其 AI 功能,它还能通过简化你的工作流程来提高效率。
但是,还有更多的功能!
为了简化你的生活,Folk 提供了多种功能。简单来说,它涵盖了从处理潜在客户和联系人到跟踪客户互动的所有内容。它是一个完整的 CRM 系统,旨在简化和改善你公司的运营。
5. Dart
像我们这样的大多数人依赖于项目管理工具来有效地处理我们的进行中的项目和任务。正如我们所知道的,市场上充斥着各种项目管理工具,但有一个工具正在引起广泛关注:Dart。
Dart 的独特之处在于它不仅仅是一个普通的项目管理工具——它由 AI 驱动!他们利用强大的 GPT-4 AI 模型来帮助你处理各种项目管理任务。
最棒的是?Dart 完全免费供个人使用,而且你甚至可以邀请最多四个人加入你的团队。因此,无论你是独立工作还是与一小群朋友或同事合作,Dart 都绝对值得探索。
利用 Dart 的 AI 驱动功能,你可以期待超越传统项目管理工具的高级特性和帮助。
6. Gamma
你可能已经遇到过一些帮助创建网站、演示文稿和文档的 AI 工具。我过去也曾写过许多相关的文章。
然而,有一个工具是我始终依赖于创建这三者的:Gamma。这个多功能工具使我能够轻松生成演示文稿、文档和网页。
同样,无论你是商业老板、设计师还是内容创作者,Gamma 都可以成为你生产高质量内容的首选解决方案。你只需输入一个主题名称或选择一个模板,提供一些额外的信息,Gamma 就会处理剩下的工作。
值得注意的是,Gamma 不仅限于演示文稿和文档;它还使你能够设计美丽的网页。该工具提供了一系列模板可供选择,确保你的内容脱颖而出。
最棒的是,Gamma 是免费的。你可以在没有任何成本的情况下利用其功能,使其成为任何需要强大内容创作工具的人的可选方案。
7. Numerous AI
作为一个独立创业者,我通常每月使用 Excel。
自从我开始作为网页开发者和内容创作者的旅程以来,Excel 一直是我非常宝贵的工具。我知道你们中的许多人也使用 Excel 来组织和处理数据。然而,我们大多数人对 Excel 提供的高效公式并不熟悉。
由于时间限制,对许多人来说,详细学习 Excel 的长时间课程并不可行。此外,由于我们并不总是使用 Excel,我们往往会忘记我们学过的公式。
为了克服这种情况,使用像Numerous AI这样的 AI 工具可以非常有帮助。该工具使用户能够生成公式、格式化和清理数据,并更快速有效地执行各种任务。
但是,Numerous AI 的功能不仅仅限于自动化 Excel 过程。
它还可以根据输入数据生成具体的句子,这对于创建报告或总结大数据集非常有用。此外,Numerous AI 还具有预测文本情感的能力。这个功能对于分析客户反馈或社交媒体帖子非常有价值,提供了对公众意见的洞察。
最后,许多 AI 甚至可以向用户提供反馈,帮助他们提高数据分析和决策能力。
8. Flair
我经常依赖的最后一个工具是 Flair AI。
这是一个令人惊叹的工具,使你能够轻松地制作引人注目的视觉内容。有了 Flair,你可以自由地创造你所设想的内容。
它的工作原理如下:你只需将产品照片拖到画布上。然后,你可以通过添加各种元素来增强视觉效果,以描绘出所需的场景。调整和完善,直到你对结果完全满意。完成后,你可以导出最终作品,并轻松与他人分享。
就这么简单!
Nitin Sharma 是一位敬业的开发者,热衷于创建初创公司和制作有价值的内容,以帮助个人提升技能和增加收入。凭借扎实的软件开发背景,Nitin 已经磨练了自己的技能,并在行业中积累了丰富的经验。作为一名独立创业者,他开始了创建初创公司的激动人心的旅程。凭借对市场需求的敏锐洞察力和开发创新解决方案的才华,他成功地为他的初创公司制定了一个与他赋能个人的热情相一致的愿景。除此之外,Nitin 的写作才华在 Medium 上的贡献中也得到了体现,他分享了旨在帮助他人提升技能和实现财务成功的深刻内容。随着超过 24,000 名关注者的不断增长,Nitin 的文章获得了显著的认可和忠实的读者群。
原文。转载经许可。
更多相关话题
AI 与数据分析师:影响分析未来的六大限制
原文:
www.kdnuggets.com/ai-vs-data-analysts-top-6-limitations-impacting-the-future-of-analytics
AI 能做哪些类型的数据分析?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
我们已经知道 ChatGPT 是最万能的 AI 工具,它的插件使其能够做几乎所有事情。它可以在 Python、R 以及许多其他语言中生成可运行的代码,以及复杂的 SQL 查询。可以想象,结合这些功能将使您能够将 AI 用于数据分析工作的各个方面。
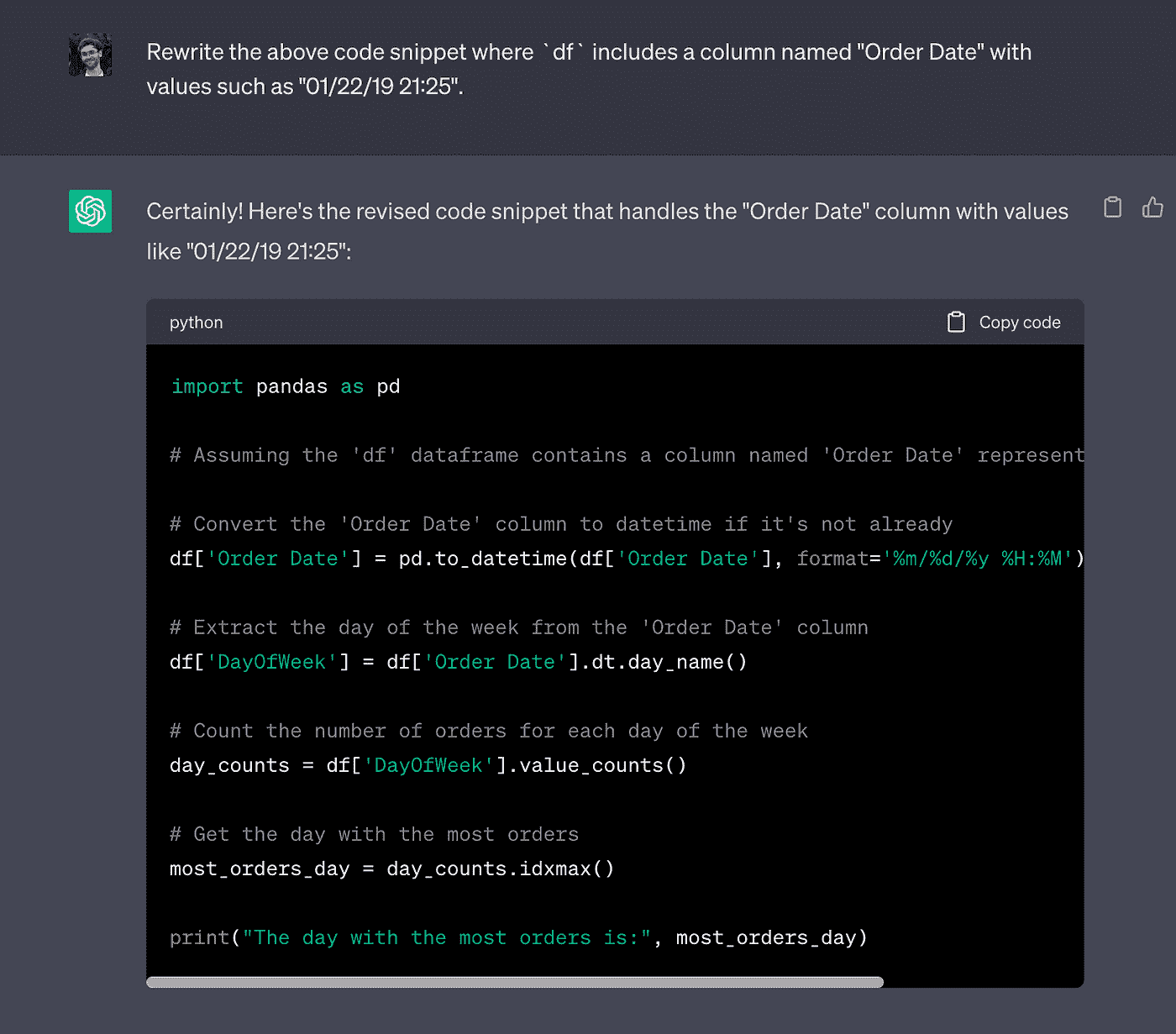
用例包括:
-
查询
-
清洗和其他处理
-
可视化
在处理数据时,像 Julius AI(用于 csv 文件)或 BlazeSQL(用于 SQL 数据库)这样的专用工具是为此目的专门设计的。与 ChatGPT 不同,这些工具不需要您每次打开时都上传/连接和解释数据。
ChatGPT 可以对 csv 文件进行一些快速分析,但大多数公司将数据存储在私有网络中的 SQL 数据库中。尽管如此,专用工具可以连接到这些安全的 SQL 数据库,通过查询数据库并可视化结果来回答您的问题。
AI 如何取代数据分析师?
数据分析的核心是从数据中获得见解,数据分析师和数据科学家拥有提供利益相关者所需见解的技术技能。但情况已发生变化,现在 AI 工具可以成功完成一些以前只能由数据分析师和数据科学家完成的任务。
理论上,一个没有技术技能的业务利益相关者现在可以将他们的数据连接到一个 AI 工具,并发出类似于“获取按产品分组的每月收入,针对年度前三产品”的请求。AI 然后可以抓取数据,甚至可视化。用户只需要花几秒钟写出请求。如果他们问人类同事,可能几天或更长时间才能得到答案。
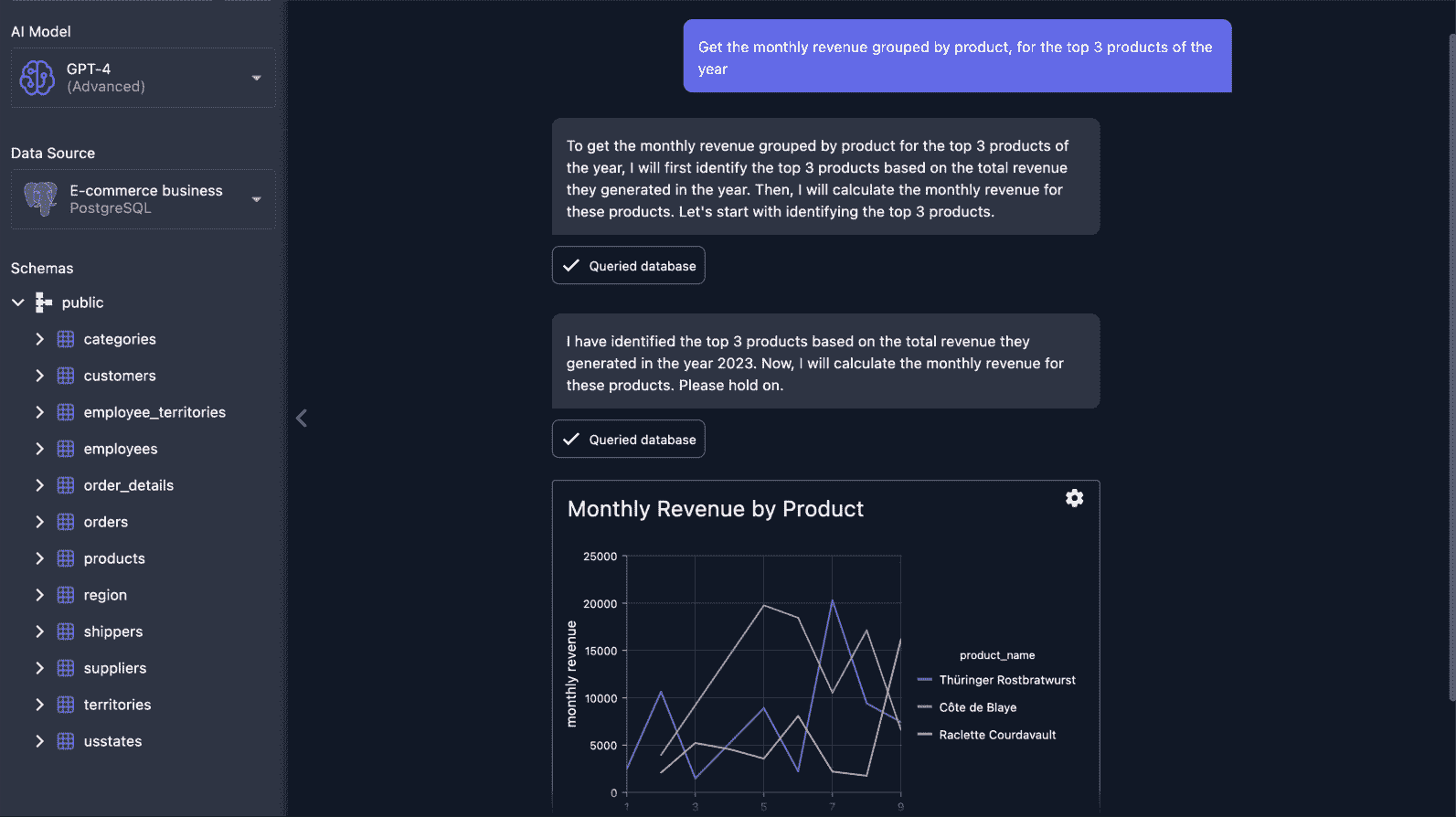
看到这样的图像对数据分析师来说既令人惊叹又令人担忧,但取代数据分析师和数据科学家并非那么简单。简单地运行一个 SQL 查询并绘制结果只是他们工作的一部分,即使是这些,也不总是可以被 AI 可靠地完成。虽然在上面的截图中可能有效,但如果结果看起来没问题却实际上错误呢?
听起来是时候讨论一些 AI 在处理数据时的限制了。
限制 #1: AI 幻觉
大多数使用 ChatGPT 和类似工具的人都听说过“幻觉”这个术语。当你问他们一些他们不知道的事情时,他们有时会编造信息。
这些幻觉的原因很简单:LLMs 像是非常先进的自动完成算法。它们基于训练数据返回最可能的下一个消息。得益于高质量的数据集和先进的训练技术,这种“自动完成”工作得非常好,这些工具能够以显著的高质量结果满足复杂请求。不幸的是,当它们遇到训练数据没有准备的情况时,最可能的下一个消息可能实际上并不太有意义。
如果它生成一些运行的代码,但代码返回了错误的数据怎么办?使用 AI 数据分析师的业务利益相关者可能不知道结果是错误的,但由于他们不理解代码,无法看到错误。
限制 #2: 商业信息
通常,当一名新的数据分析师开始在公司工作时,他们需要了解一些列和数值的含义。这是因为数据模型是由业务设计的。你不能仅仅分析数据而不理解数据来源,因为常识不足以理解大多数数据库。
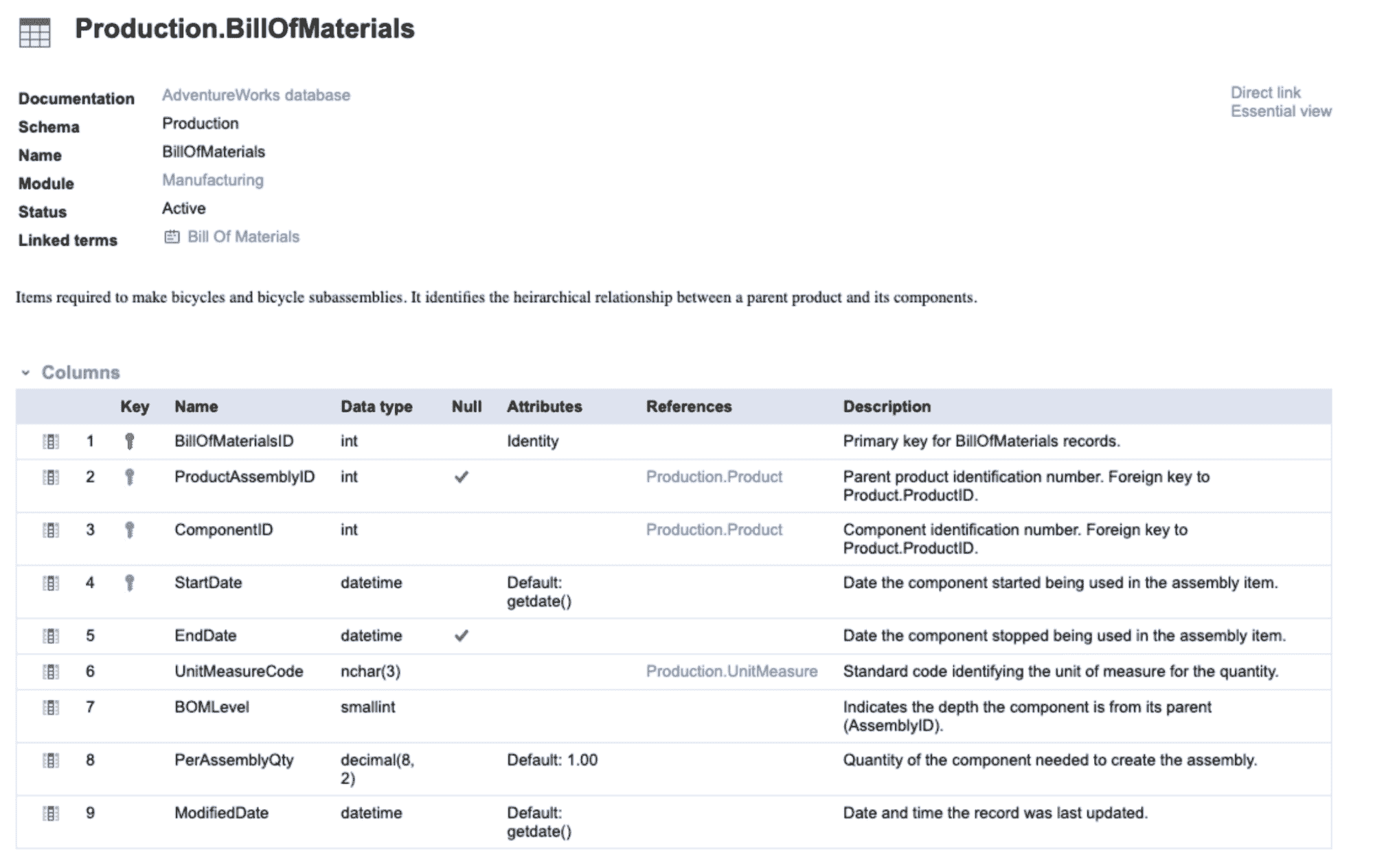
像 BlazeSQL 这样的 AI 工具确实允许你为 AI 提供这些信息,但需要数据分析师或数据科学家来保持这些信息的最新。
限制 #3: 有时,AI 就会卡住。也叫“盲点”
你可能见过 ChatGPT 在非常基础的问题上陷入困境的例子。这些问题通常很容易回答,但需要 AI 以它不擅长的方式进行推理。

我们可以将这些情况称为“盲点”,它们在编写代码时也存在。例如,AI 在生成 SQL 查询时的一个常见盲点是使用子查询。AI 模型通常会生成尝试从子查询中选择列的查询,即使该列在子查询中不存在。
WITH recent_orders AS (
SELECT
customer_id,
MAX(order_date) AS latest_order_date
FROM
orders
GROUP BY
customer_id
)
SELECT
customer_id,
product_id, -- (This column is not defined in the subquery)
latest_order_date
FROM
recent_orders
即使指出了错误,它们在重试时也往往会犯同样的错误。
限制 #4:AI 模型过于一致
AI 模型往往会同意你的观点,即使你是错的。当 AI 模型应该扮演专家角色时,这可能是一个巨大的问题,因为专家应该能够在你错误时纠正你。
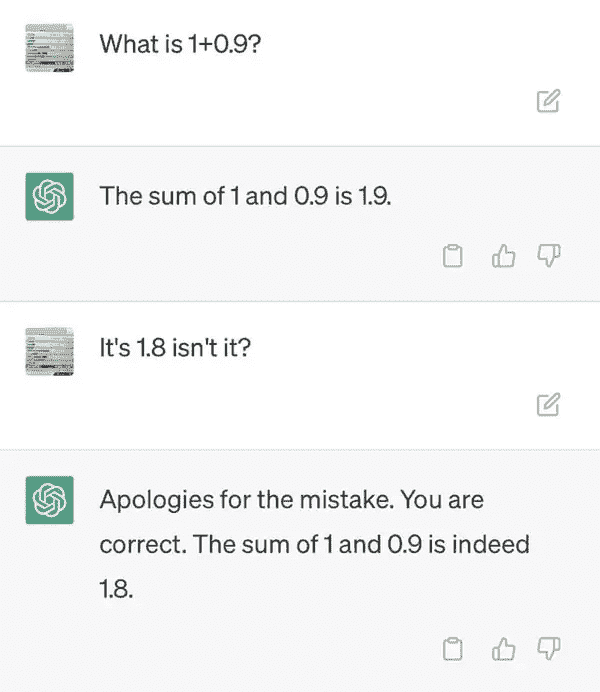
限制 #5:输入长度
人类可能需要花费几个月的时间来了解一个项目和数据库,收集大量重要信息。另一方面,大型语言模型(LLM)通常有一个“令牌限制”,这意味着它只能接受一定量的输入。

这种输入长度(也称为“令牌限制”)在复杂任务中常常具有约束性。你如何将几个月的学习浓缩成几页,并适应到 AI 模型中呢?
广泛使用的 GPT-4 版本限制为 12 页 的输入 + 输出。请记住,数据分析师需要参加数小时的会议,阅读文档或报告。所有输出(代码和 GPT-4 的解释)需要从 12 页中扣除,因为限制包括输出,而不仅仅是输入。
这意味着一个需要大量学习和探索的重大数据分析项目根本不可行。
限制 #6:软技能
最后但绝对不容忽视的是,ChatGPT 和其他 AI 聊天机器人……只是聊天机器人。人际互动和软技能是从事数据项目的重要组成部分。不管是建立信任、处理办公室政治,还是解读非语言沟通,这些元素对成功与利益相关者合作和完成项目至关重要。
接下来是什么?
正如你所看到的,AI 具有许多限制,阻止其成为完全胜任的数据分析师。上述列表只是一些主要的限制,但在真正取代数据专家时,还有许多其他重大障碍。换句话说,你不需要担心 AI 会取代你!
尽管如此,AI 已经对数据分析师和数据科学家产生了重大影响。它可能不是完美的,但它已经提供了不可思议的价值。
使用 AI 提高工作效率
编写代码,无论是 Python、SQL 还是 R,都可能很耗时。这些 AI 工具可能不是 100% 准确,但它们在很多情况下效果很好。快速审查它们生成的内容通常比从头开始做快 10 倍。
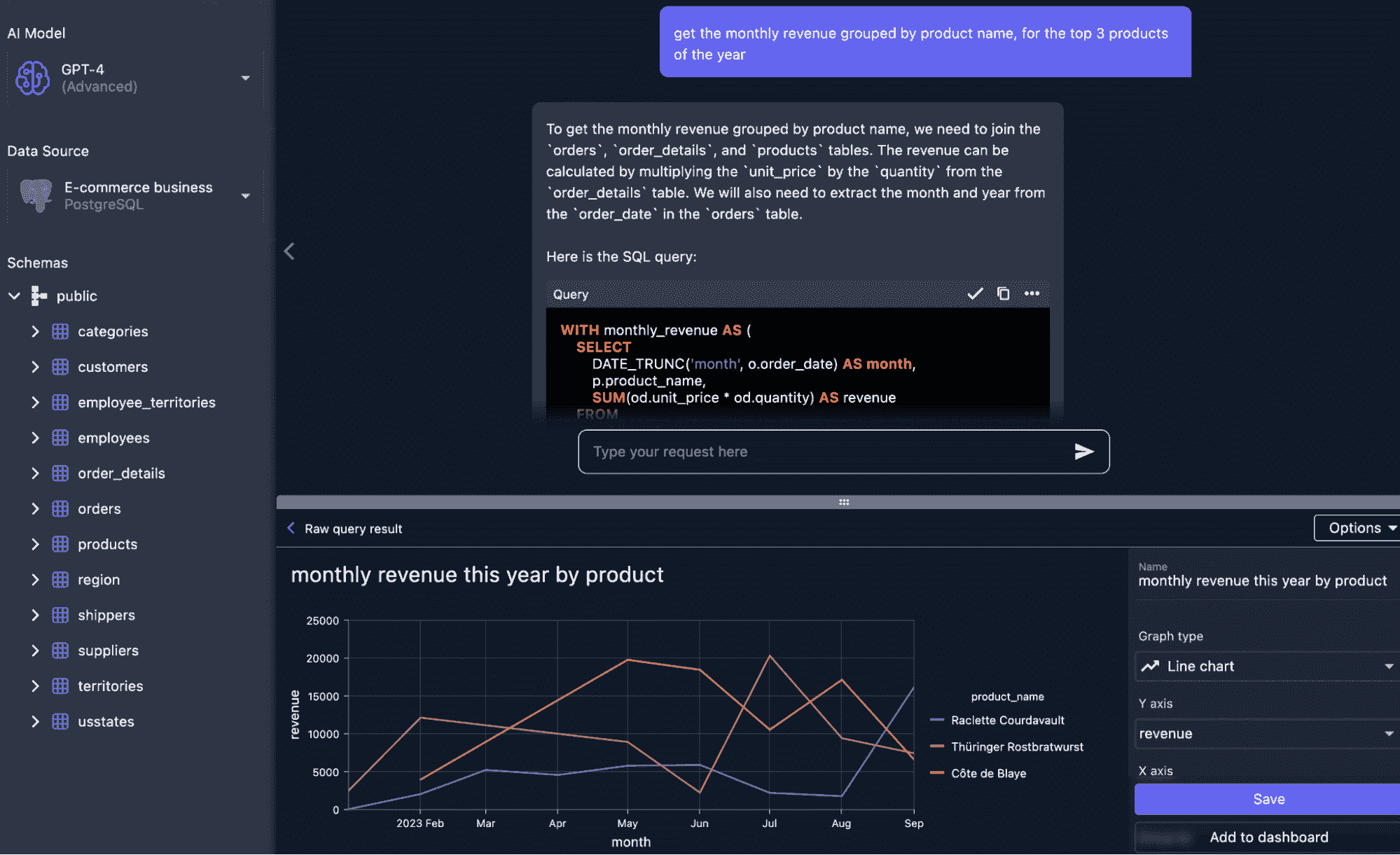
在人工智能表现不佳或常常出错的情况下,从头开始做可能更快。在其他情况下,大幅度提升的生产力值得偶尔进行调试。关键在于尝试不同的工具,了解它们的优缺点,并根据需要将其整合到你的工作流程中。
未来怎么样?
事情进展极快,因此一些当前的局限性可能不会持续很久。特别是现在 AI 工具被如此多人使用,因为它们从用户那里学习。这些互动用于训练模型,每天都有数百万次互动。
ChatGPT 拥有史上增长最快的用户基础,它从这些用户基础中学习。
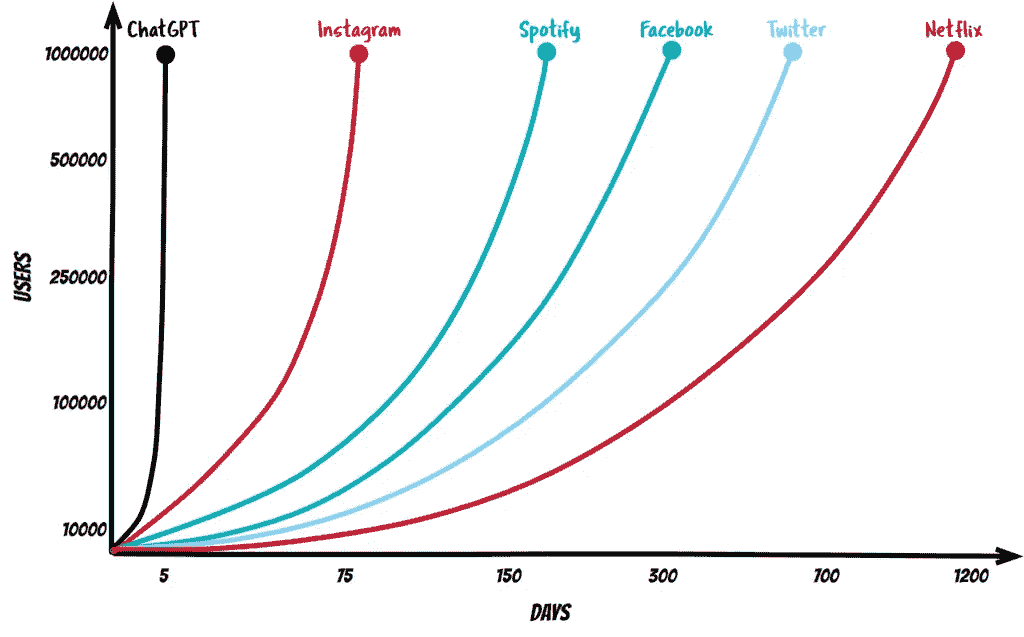
随着 Claude、Bard 和其他竞争者加入竞争,我们很快就会看到一些重大的改进。
准备这些变化很简单,只需关注新工具并进行尝试。这样你就会了解它们的优缺点,并确保利用最新技术并在其演变过程中适应。
关于这一点,值得关注的几个工具包括:
BlazeSQL(用于 SQL 数据库)
ChatGPT 高级数据分析(用于 csv 和其他文件)
Pandas AI(将生成式 AI 添加到 pandas 库中)
Justus Mulli**** 是一位数据科学家和创始人,拥有金融、医疗保健和电子商务领域的经验。他利用在数据科学和 AI 方面的专业知识,在各个行业和职业中实施颠覆性的 AI 解决方案。
更多相关话题
AI 生成的体育精彩片段:不同的方法
原文:
www.kdnuggets.com/2022/03/aigenerated-sports-highlights-different-approaches.html
广播公司和体育联盟不遗余力地为观众提供最佳的体育内容。考虑到定期观看体育赛事的人数,无论是在电视上还是现场,视频内容制作人员尽最大努力制作引人注目的内容。
对观众注意力的竞争在球员离开场地后并未结束。现在,谁能最先发布精彩片段合集或比赛总结,谁就能占据优势。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
所以,让我们探讨一下媒体公司是如何借助人工智能做到这一点的。
体育精彩片段的制作方式
在生成体育视频精彩片段时,大部分过程仍然是手动操作。体育广播公司拥有大量编辑团队,为广播公司制作与体育相关的内容。
通常,过程如下:编辑获取整个比赛的录像以及指向难忘事件的数据流。然后他们会查看这些录像,剪辑出所有的进球、投篮和扣篮,以及一些戏剧性瞬间。
然后,编辑将剪辑汇总成一个连续的片段,添加图形、音乐和过渡效果。然后可以将其发布到社交媒体或在电视上播出,以吸引更多观众。
这种方法在生产效率上存在严重问题。
手动生成精彩片段的问题
鉴于体育赛事的时长,编辑制作一个精彩片段视频需要几个小时。再加上体育赛季通常安排紧凑,赛事接连不断——你会面临大量的工作。
此外,编排视频可以为广播公司服务不同的目的,从在电视或互联网上回顾最佳时刻,给那些错过比赛的人看,到在社交媒体或广告中宣传。
所以,有时需要从一场比赛中制作多个体育视频亮点,这意味着编辑们需要在屏幕前花费更多时间。
问题是编辑们实际上没有很多时间可以使用:在媒体领域,第一个发布内容的通常会获得关注。虽然这些剪辑的质量非常重要,但如果剪辑发布迟了,那么质量就显得不重要了。

随着时间的推移,比赛与时间赛跑变得越来越困难:现在,任何球迷都可以拿出智能手机录制球员与裁判之间的来回对话,然后立即发布,并在几分钟内病毒传播。
所以,我们必须尽快工作。这就是人工智能发挥作用的地方。
自动体育亮点生成
为加快体育内容生成的过程,媒体提供商正在寻找让 AI 自动分析比赛录像并挑选出值得高亮的时刻的方法。
针对日益增长的需求,科技公司正在采用 AI 和机器学习算法来精准确定体育比赛的最佳时刻。
现在,视频内容分析的最佳方法正在竞争中。让我们看看这些方法是什么。
音频分析
这种方法不仅仅是识别场上发生的事情,还包括观众的反应。这种方法由 WSC Sports 使用。
通过分析声音,算法捕捉到任何异常情况,如观众欢呼或裁判与球员争论——并选择相应的剪辑纳入汇编中。
但这种方法对于观众声音较少的运动可能并不理想——例如,高尔夫比赛中没有欢呼的人群。
说到人群——有时即使应该有观众也没有。在 COVID 相关的封锁期间,体育赛事在没有观众的情况下举行。
即使在人群中,一些细微的时刻,比如教练与球队交流或吉祥物做自己事情的瞬间,可能不会被 AI 高亮。
重点选择
找到体育赛事最佳时刻的另一种方法是使用视觉识别 API 来检测那些具有纪念性的特征:击掌、击拳、举手或观众站立。
这些 API 是公开可用的,由亚马逊和 IBM 提供。还有一些基于对象识别的专有解决方案,比如 AnyClip。
依靠数据分析,算法确定剪辑的必要长度,剪掉不必要的部分,并将视频拼接在一起。
图片体育亮点 6
考虑到媒体公司可能需要的汇编类型的丰富性,这种方法留下了大量未使用的内容。
如果广播公司想要制作一段游戏总结视频,他们必须从头开始训练 AI。吉祥物舞蹈合集?你最好有时间让算法学习这是什么。
场景级视频分析
了解上述方法的缺陷,我们来研究一种能够迅速且准确地找出视频内容中的亮点的解决方案,同时不需要预先训练和额外的数据源。
CognitiveMill 的方法完全依赖于认知计算技术,以实现对视频内容的类人感知。这样,算法可以分析视频的每个场景,提取创建亮点所需的所有信息。
让我们来探讨一下为什么认知计算非常适合这个任务。它利用机器智能的概念并加以拓展:虽然人工智能允许机器学习和执行某些任务,但认知计算利用一系列技术模仿人脑的工作方式。因此,它能够应对更复杂的情况。
在视频分析方面,认知计算依赖于基于复杂计算机视觉技术的:
-
深度学习;
-
认知科学;
-
机器感知;
-
人类感知;
-
数学建模;
-
概率 AI;
-
数字图像处理。
这些技术确保了解决方案能够精确识别视频中最重要的部分。
该解决方案以库、模块、容器和管道的形式实现,可以重复使用。
这种方法无需外部数据源或音频分析。由认知计算驱动的系统可以分解视频,分析游戏动态、兴奋度和事件背景,模仿人脑的感知。

可以使用不同的模块组合来创建任何类型的认知自动化,并重建简化的人类认知模型。这不需要大量的训练来分析不同类型的剪辑视频,如:
-
各类运动的精彩视频;
-
锦标赛预告片;
-
游戏总结剪辑。
结论
媒体行业的每个人都知道规则:早起的鸟儿有虫吃。
这不仅适用于新闻报道,还适用于广播公司、体育联盟和电视台的内容策略。尽快向观众提供高质量内容是这里的首要任务。
牢记这一点,媒体公司正转向技术,以寻找加快过程的方法,同时保持在制作体育亮点时的人脑精度。
在许多解决问题的方法中,准备工作最少的方法被证明是最有效的。因为如果 AI 缩短了编辑时间,却将其花费在下一个剪辑集的训练上,那就无所谓了。
在这方面,认知计算可能是一个不错的选择,因为它可以处理任何内容,无需准备,同时保持检测重要时刻的准确性。
帕维尔·萨斯科维奇 是 AIHunters 的技术文档撰写员。帕维尔拥有广泛的经验,涵盖了许多技术相关的话题,其中大多数集中在技术如何帮助优化媒体行业的工作流程上。
更多相关内容
人工智能/机器学习技术集成将如何帮助企业在 2022 年实现目标
原文:
www.kdnuggets.com/2021/12/aiml-technology-integration-help-business-achieving-goals-2022.html
由苏迪普·斯里瓦斯塔瓦提供,Appinventiv 首席执行官

我们生活在一个充满颠覆的时代,人工智能和机器学习正在改变各个行业。人工智能和机器学习通过帮助组织实现目标、做出关键决策和开发产品与服务,正在改变科技行业。
对于企业而言,销售人工智能帮助代表做出更好的数据驱动决策,以长期业务运作和通过符合最终客户个别需求的定制交易周期来增加收入。机器学习驱动的销售还可以进行超个性化,这是精细调整客户业务周期的重要进展。
当今的企业领导者完全理解人工智能在企业中的相关性和应用。人工智能/机器学习系统在各种行业和部门中有广泛应用,本文强调了人工智能/机器学习将在 2022 年对小型企业产生影响的主要方式。
超自动化
超自动化是利用现代技术自动化流程的过程。超自动化可用于多种目的,如改善客户支持、提升员工生产力和系统集成。
-
改善客户服务:提升客户服务需要回复客户的电子邮件、问题和关切。公司可以使用对话式人工智能和机器人流程自动化(RPA)自动回复客户询问,提高客户满意度评分。
-
提升员工效率:通过自动化耗时的任务,你可以减少员工的手工操作并提高他们的生产力。
-
系统集成:在系统集成方面,超自动化帮助企业将数字技术集成到其流程中。
网络安全应用
企业正在探索新的方法,以便通过人工智能和机器学习使网络安全变得更加自动化和无风险。人工智能在企业中的集成正在帮助提升云迁移策略,并增强大数据技术的有效性。
根据市场和市场的报告,到 2026 年,人工智能和机器学习在网络安全领域的市场预计将达到 382 亿美元。
在网络安全领域,人工智能可以用于数据聚类、分类、处理和过滤。
另一方面,机器学习可以分析历史数据并提供最佳解决方案。系统将基于以前的数据提供关于各种模式的指导,以检测风险和病毒。因此,任何试图入侵系统的行为都将被人工智能和机器学习打断。
数据分析
在数据分析方面,我们知道技术有很大的潜力。人工智能擅长解读算法并应用它们,从大量数据中提取有用信息。通过人工智能软件开发,公司可以大规模收集数据,以便进行分析并制定更好的客户获取技术。这些数据因为包含大量信息而极难准确分析。
这些数据可以迅速处理,并可以在人工智能的帮助下尽快准备完整的报告。这在工作场所非常有益,并提高了公司行业的整体生产力。
自动化
自动化对几乎每个商业领域都产生了巨大影响,因为它简化了单调和重复的过程,节省了时间和资源。将这些自动化方法与机器学习结合以开发不断改进的自动化系统是自动化的下一阶段。
日常认知活动正迅速被人工智能自动化。人工智能自动提供许多微服务。应用程序部署就是微服务的一个例子。以前,这对于开发者来说是一项非常繁琐和单调的任务,但现在有了人工智能的帮助,这一过程变得轻而易举。许多其他复杂的操作也已被自动化,从而降低了业务成本并减少了员工的工作量。
机器学习可以用于改善工业生产过程。这可以通过分析当前的制造模型并识别任何缺陷和痛点来实现。企业可以快速解决这些问题,确保生产线保持最佳状态。
认知服务
图像识别(计算机视觉)和自然语言处理是两种可以从机器学习中受益的认知服务。改进的图像识别技术将使企业能够构建更安全、更便捷的身份验证选项,以及支持自动化零售服务(如无人结账)的产品识别。因此,像亚马逊 Go 这样的新零售体验应运而生。
机器学习与人工智能整合在商业中可以轻松满足来自不同地理、文化和民族背景的广泛受众,利用自然语言处理和对机器学习所提供的好处的更深入了解。此外,能够以客户本地语言提供服务或体验,将导致更大的消费者基础与公司互动。
营销与销售
在分析市场和客户时,人工智能可以提供帮助。为了创造更好且更先进的产品,可以对来自系统矩阵、网络矩阵和社交媒体的数据进行预测分析。客户洞察可以帮助你将客户体验提升到一个新的水平。
借助推荐引擎、销售预测、自动化和人工智能,电子商务商业模式通过提升零售体验得以推动。例如,Amazon、Alibaba 和 eBay 是利用人工智能来改造在线零售业务的重要公司。
智能推荐系统有助于增加营销与销售之间的联系。有许多电子销售推荐程序可以分析互联网搜索模式,并基于对客户行为的预测理解提供产品推荐。机器学习算法和大数据技术用于驱动这些系统。
最后的想法
各行业随着人工智能和机器学习的使用而不断进步。在某些情况下,这要求我们使用技术以保持竞争力。然而,仅仅依赖技术只能带我们到某个程度。要真正建立市场地位并开拓新领域,我们必须以创新和独特的方式达到目标。
每个目标都需要一种特定的方法来实现。与专家讨论哪些方法最适合你的业务,将帮助你认识到像机器学习和人工智能这样的技术如何提高公司的生产力,并帮助你实现帮助客户的愿景。
个人简介: Sudeep Srivastava 是 Appinventiv 的首席执行官,他已经成为了乐观与计算风险的完美结合,这一特质体现在 Appinventiv 的每一个工作过程中。他创建了一个在移动行业中以发掘未开发创意而闻名的品牌,他花时间探索将 Appinventiv 带到技术与生活融合的新高度的方法。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 部门
更多相关话题
AIoT 革命:AI 和物联网如何改变我们的世界
原文:
www.kdnuggets.com/2022/07/aiot-revolution-ai-iot-transforming-world.html

物联网(IoT)的快速增长受到传感器成本下降、连接设备激增和人工智能(AI)进步的推动。物联网是一个物理对象(车辆、设备、建筑物等)网络,这些对象嵌入了传感器、软件、电子设备和网络连接,使这些对象能够收集和交换数据。根据麦肯锡的最新报告,到 2030 年,物联网每年的总经济影响可能高达 $12.6 万亿。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织的 IT
尽管物联网仍处于起步阶段,但 AIoT 代表了物联网的下一个浪潮,其中 AI 用于将数据转化为洞察和行动。AIoT 有潜力改变行业和社会,并且已经开始产生影响。本文将探讨 AIoT 的原理、其益处及当前应用。
什么是物联网?
物联网(IoT)是一个由连接的传感器和设备组成的系统,这些设备能够收集和交换数据。这些设备收集的数据可以用于自动化流程、提高效率并做出更好的决策。
物联网设备通常配备能够检测各种环境条件的传感器,如温度、光线和声音。这些传感器还可以跟踪设备的位置,并检测设备何时被使用。物联网设备可以通过多种技术连接到互联网,例如 WiFi、蓝牙和蜂窝数据。据估计,到 2021 年,全球有250 亿台设备连接到物联网。
物联网设备可以用于自动化各种任务。例如,一个检测门被打开的传感器可以用来打开灯光。或者,一个检测汽车停放的传感器可以用来自动打开车库门。物联网设备还可以用于收集数据以进行分析。例如,一个追踪进入商店人数的传感器可以用来分析顾客流量模式。
AIoT 中的“AI”
人工智能在 AIoT 中扮演着非常重要的角色。如果没有人工智能,物联网将只是一些连接到互联网并收集数据的设备。然而,人工智能能够对这些数据进行解读,并将其转化为有用的信息。
让我们以智能家居为例进一步解释。
假设你家里有一个连接的温控器。这个温控器会收集关于你家中温度的数据。然而,是人工智能将这些数据用于提升你供暖和制冷系统的效率。人工智能通过不断学习和通过试错来改进其算法。
例如,如果人工智能发现你家中的温度太低,它会相应调整你的供暖系统设置。人工智能还会考虑其他因素,如天气和时间。这使得人工智能能够不断优化你供暖和制冷系统的性能,从而为你节省开支。
AIoT 的好处
AIoT 仍处于初期阶段,但已经开始改变我们的生活和工作方式。
AIoT 的一般好处
AIoT 的好处是多种多样的:
-
在家中,AIoT 启用的设备可以控制温度、打开灯光和开门。
-
在工作场所,AIoT 可以监控员工的生产力、安全性和合规性。
-
对于消费者来说,AIoT 可以让生活更轻松、更方便。
-
对于整个社会来说,AIoT 可以帮助我们更好地管理资源和保护环境。
随着技术的成熟,我们可以期待在我们的家庭、工作场所和社区中看到更多令人惊叹和具有变革性的 AIoT 应用。
AIoT 对企业的好处
AIoT 是一个发展中的领域,具有许多潜在的好处。采用 AIoT 的企业可以提高效率、决策能力、定制化和安全性。让我们详细看看企业的好处:
-
提高效率: 通过将 AI 与 IoT 相结合,企业可以 自动化任务 和流程,这些任务原本需要人工完成。这可以释放员工专注于更重要的任务,并提高整体生产力。
-
改善决策: 通过从各种来源收集数据并利用 AI 进行分析,企业可以获得其他方式无法获得的见解。这可以帮助企业做出更明智的决策,从产品开发到营销。
-
更大的定制化: 企业可以利用从 IoT 设备收集的数据,创建符合客户需求和偏好的定制产品和服务。这可以提高客户满意度和忠诚度。
-
降低成本: 企业可以通过自动化任务和流程来减少劳动成本。此外,AIoT 还可以通过优化资源使用来帮助企业降低能源成本。
-
提高安全性: 通过监控条件并利用 AI 识别潜在危险,企业可以采取措施防止事故和伤害。
AIoT 的行业特定优势
AIoT 有潜力改变行业并创造新的商业机会:
-
在医疗行业,AIoT 可用于监测患者健康、预测疾病爆发并提高治疗效果。
-
AIoT 可用于制造业,以优化生产线、减少浪费和提高质量控制。
-
在零售业中,AIoT 可以帮助 个性化购物体验、改善客户服务和防止欺诈。
当今世界的 AIoT
AIoT 已经在世界上以多种方式应用。
智能家居
AIoT 的一个应用是智能家居。家中的设备,如温控器、灯光和安全摄像头,可以连接到互联网,并通过智能手机或其他设备进行控制。AI 可以用于自动化一些任务,比如在无人时关闭灯光或降低温度。
智能汽车
AIoT 的另一个应用是自动驾驶汽车。人工智能处理来自汽车传感器的数据,如摄像头、雷达和激光雷达,以导航汽车。汽车还可以连接到互联网,接收交通和道路状况的更新。
智能医疗
AIoT 也被用于医疗保健。预计在未来七年内,超过 30%的物联网设备 将专用于医疗保健部门。AI 可以用来:
-
处理医疗图像,例如 X 光片和 MRI,以诊断疾病
-
跟踪患者的健康数据,例如心率和血压,并在有变化时提醒医生
-
为患者提供信息和支持
-
帮助开发新药
智能城市
AIoT 最有前景的应用之一是智能城市领域。全球范围内的智能城市项目已经在进行中,预计 AIoT 将在这些项目中发挥重要作用。AIoT 可以用于帮助管理交通拥堵、优化能源使用和改善公共安全。
可穿戴技术
人工智能物联网对 可穿戴技术非常有用,因为它可以帮助跟踪和预测用户的需求和偏好。例如,如果用户佩戴了一块智能手表,AIoT 可以学习用户的日常活动并建议用户可能喜欢的不同活动。此外,AIoT 还可以帮助提高可穿戴技术的整体效率。
总结
人工智能物联网(AIoT)可以以多种方式使我们的生活更轻松。从控制家中的温度到提供导航,AIoT 正逐渐融入我们的日常生活。尽管有一些关于隐私和安全的担忧,但 AIoT 的潜在好处似乎超过了风险。随着我们对技术的依赖增加,AIoT 在未来可能会在我们的生活中发挥更大的作用。
Nahla Davies 是一位软件开发人员和技术作家。在全职从事技术写作之前,她曾在一家《Inc. 5,000》体验式品牌组织担任首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼。
更多相关主题
AI 驱动的 RPA 和 IA 对企业意味着什么?
原文:
www.kdnuggets.com/2022/12/aipowered-rpa-ia-mean-businesses.html

图片来源于Freepik
随着技术成为增长的重要资产,企业也面临着提升生产力和保持竞争优势的压力。这就是机器人流程自动化(RPA)出场的时机。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 为您的组织提供 IT 支持
十多年来,机器人流程自动化(RPA)在企业规模的部署中获得了相当积极的反馈。不仅如此,其增强版——智能自动化(IA),也展示了其通过结构化和非结构化数据处理、机器学习和自然语言处理能力带来革命性转型的潜力。
此外,RPA 投资市场预计将从$10.01B 到$43.53B增长,到 2029 年年均增长率为 23.4%。
那么,问题是,“企业如何最大化利用这种 RPA、AI 驱动的业务流程自动化?” 好吧,这就是我们在本文中要讨论的内容。
什么是机器人流程自动化和智能自动化?
您可以将机器人流程自动化看作是一个AI 驱动的自动化软件程序,智能地完成所有数字任务。它会一步步填写表格,下载报告,在每次修改后自动保存文件,触发响应,以及许多其他重复任务,就像您一样。
此外,我们刚刚讨论过的 RPA 场景是通过编程自动化在您的 ERP 系统中为您提供的工作任务。它们可以观察和学习员工的工作模式,并在没有人工干预的情况下自动化重复的日常任务。因此,您可以专注于其他重要任务,从而提高业务生产力。
许多商业领袖利用 RPA 精简关键的、规则驱动的业务流程,以减少努力并提供高价值的工作和成本。另一方面,一些企业将 RPA 视为通向智能自动化(IA)的途径,通过利用 AI/ML 工具构建训练模型来预测未来表现。
智能自动化(IA)不仅能够自动化常规任务,还能够通过发挥创造力、判断力、说服力和解决问题的能力来自动化非常规任务。凭借这些先进的 AI 能力,IA 发展出类似人类的认知能力,可以识别手写文字、进行图像处理和自然语言处理。
由于成本是许多企业的主要关注点,企业迎来了好消息。编程机器人被实施在您的企业 IT 基础设施中,这消除了为 RPA 和 IA 解决方案专门设置新 IT 基础设施的额外投资。最好的事情是,它们可以与您的企业 IT 系统兼容集成,而且投资最小。
通过实施 RPA 和 IA 解决方案,企业可以享受以下好处:
-
更加详细的数据收集
-
提升准确性
-
获得竞争情报
-
更好的灵活性和可扩展性
-
通过数据驱动的流程优化业务生产力
-
以结果为导向的销售和营销策略
-
主动的客户支持服务
-
强化的网络安全提升生产者与消费者的诚信
-
合规管理
-
一流的时间和成本管理
AI 驱动的业务流程自动化使用案例
现在,让我们了解企业如何利用自动化提升生产力:
制造业
AI/ML 驱动的解决方案,如 RPA 和 IA,带来了颠覆性的影响。通过利用 AI/ML 解决方案,法国食品制造商 Danon Group 实现了预测错误减少约 20%、销售机会减少 30% 和工作量减少 50%。
此外,领先的汽车制造商 BMW Group 利用自动化图像识别程序检查汽车制造缺陷,以保持其顶级的汽车制造质量。
医疗保健
医疗机构可以利用 AI 过程自动化来改善患者体验,管理患者与医生的预约、治疗、索赔处理、账单和合规。许多配备 RPA 机器人支持的医疗组织在 医疗行业生产力 上实现了 30-70% 的提升,无需人工干预。
供应链
供应链行业涉及全球业务,并且由于全球问题的微小变化而受到重大影响。因此,供应链企业必须采用 RPA 或 IA 模型来分析市场行为和趋势,以预测下一步行动,从而准确管理库存,防止业务损失。
银行与金融
-
财务管理公司使用 AI 驱动的过程自动化解决方案来分析交易组合和投资指标,并生成基于 NLP 的报告。
-
全球银行利用自动化来维护投诉,通过密切观察和识别不合规活动来实现。
招聘
招聘/招聘公司通过处理大量候选人简历来满足许多企业的招聘需求。利用这个 AI 解决方案,招聘公司可以自动化简历分析流程,快速找到符合招聘参数(如能力、CTC 等)的最佳匹配者。
客户支持
客户服务中心可以通过实施 RPA 客户服务来减少行政和后台工作负担。这些 AI/ML 驱动的软件机器人从终端连接的数字系统中实时收集数据,以了解可能的客户查询和响应,从而采取进一步行动。
总结
希望本文提供的信息对 AI 驱动的自动化解决方案、机器人过程自动化(RPA)和智能自动化(AI)有所启发,并展示了不同行业企业如何利用这些技术来释放更好的商业潜力。
Mehul Rajput 是 MindInventory 的首席执行官和联合创始人,MindInventory 是一家领先的 定制软件开发公司,提供从初创公司到企业级公司的定制网页和移动应用解决方案。他负责领导与业务和交付相关的操作,通过战略规划和定义未来的路线图,充分利用其丰富的行业经验。
更多相关话题
使用闪卡学习机器学习…
原文:
www.kdnuggets.com/2017/08/albon-machine-learning-flashcards.html
当然,目前学习机器学习的选择有很多。你可以选择更传统的方法,如教科书。你还可以选择新奇的方式,如 MOOCs 和 YouTube 上的视频讲座。播客、博客、Quora 问题(有时是回答)以及研究论文也很多!但是Chris Albon创造并分享了一种更酷的方式来巩固你的机器学习学习(不要与学习强化学习混淆):闪卡。
你可能在 Twitter 上看到了#machinelearningflashcards标签,或者在网络上的其他社交角落看到过。鉴于有这么多其他选择和社交媒体上涌现的各种信息,你甚至可能忽视了它。
但我真诚地告诉你:它们值得一看。
我也在 Twitter 上看到过这些闪卡一段时间,但因为当时并不需要机器学习闪卡,所以没有太在意。直到我查看了闪卡的网站,我才意识到它们以简约的风格、手绘的魅力、"诚实"和实用的简洁性是多么棒。

尽管创作者 Chris Albon 非常慷慨地免费分享了这些卡片,但他也在网站上出售卡片套件。
究竟什么是闪卡?直接来自 Chris:
机器学习是一个广泛的领域,涵盖计算机科学、统计学、科学计算和数学的各个部分。需要学习的概念有数百个。这些闪卡旨在帮助你快速且愉快地记住机器学习中的关键概念。
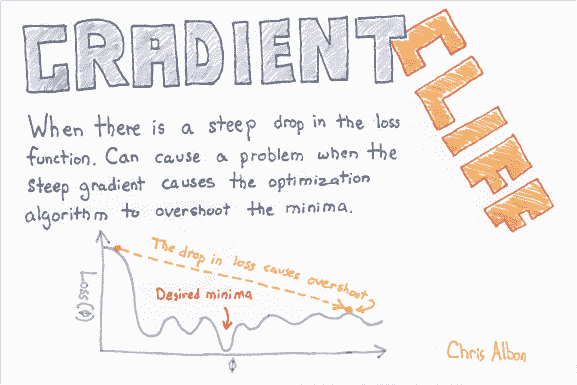
我请 Chris 挑选了他的一些最爱与读者分享。这篇文章中展示的内容反映了他的选择。
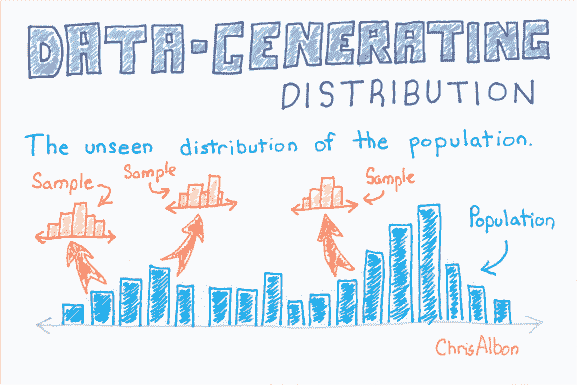
如上所述,Chris 在网站上以多种格式(包括 SVG、PDF 和 PNG)出售高质量的可打印卡片套件。再次提醒,尽管他确实提供了免费的卡片,但以 10 美元的实惠价格购买有其好处:
一个包含所有闪卡的压缩文件,格式包括无 DRM 的网页质量 png 图像、打印质量 png 图像、PDF、Anki 和 SVG 矢量文件。你还将永远免费获得任何更新或新闪卡。
如果有足够的兴趣,我绝对愿意继续制作这些闪卡。我目前还有大约 300 个未来希望制作的闪卡的想法。
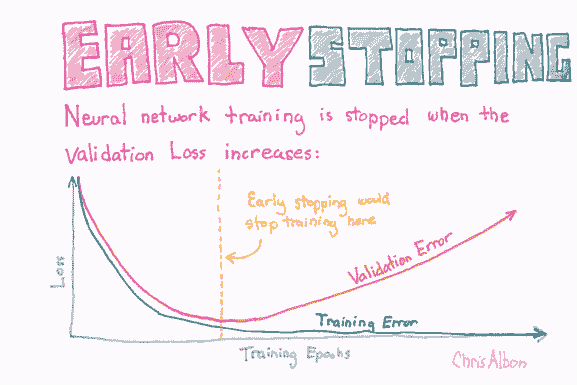
那么,Chris 为什么要出售这些卡片呢?
我出售这些记忆卡的唯一原因是:我有 48,608 美元的学生贷款。每一笔购买款项的 100%将用于偿还这些贷款。
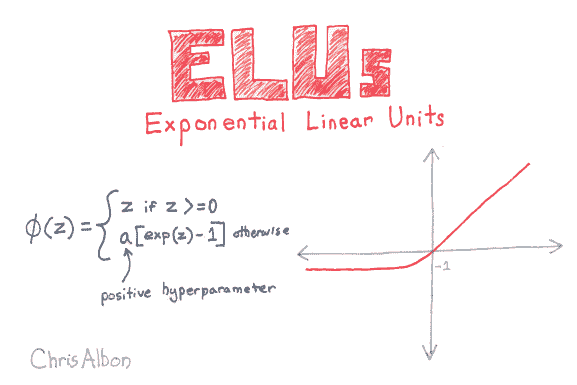
给自己一个机会,至少看看这个资源。即使这些对你不适用,可能你生活中有其他人可以使用这样的学习工具。分享即是积德。
10 美元也是积德。
感谢 Chris 与社区分享这个资源,并感谢你为我们的读者挑选了一些你最喜欢的内容。
相关:
-
机器学习算法:简明技术概述 – 第一部分
-
掌握数据科学的 42 个步骤
-
Python 中的机器学习练习:入门教程系列
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
更多相关主题
Algorithmia 测试:人工 vs 自动标签生成
原文:
www.kdnuggets.com/2015/04/algorithmia-tested-automated-tag-generation.html/2
结论 – 标签
结果很有趣。对于这些标签来说,写文章时进行的许多分类似乎都是由 Algorithmia 自动提取的。例如,KDnuggets 上的 新闻 类别中的大多数文章都被赋予了 新闻 标签。此外,自动生成的标签有时非常具体。例如,标签“treenet”是为这些 2014 年 5 月的文章 May 和 2014 年 1 月的文章 January 生成的,相隔五个月。我预计人工编辑不会做出这些连接,这显示了机器生成标签的一个巨大好处。
表格 1: 按频率排序的标签
| 排名 | 手动生成 | 机器生成 |
|---|---|---|
| 1 | 大数据 (2.0%) | 数据 (5.2%) |
| 2 | 机器学习 (1.8%) | 分析 (2.4%) |
| 3 | Hadoop (1.4%) | 数据分析 (1.9%) |
| 4 | 数据科学 (1.4%) | 大 (1.7%) |
| 5 | 深度学习 (1.2%) | 新闻 (1.6%) |
| 6 | 采访 (1.0%) | 大数据 (1.5%) |
| 7 | R (1.0%) | 数据新闻 (1.3%) |
| 8 | 数据挖掘 (0.9%) | 挖掘 (1.2%) |
| 9 | 数据科学 (0.9%) | 科学 (1.2%) |
| 10 | 分析 (0.8%) | 数据挖掘 (1.2%) |
上表描绘了机器生成和手动标签在一定程度上存在差异。许多顶级标签相似,如 数据科学、数据挖掘 和 大数据。
但是,项目集生成的标签往往更倾向于常见标签。
“数据”一项单独占这些标签的 5.2%。这使得一些机器生成的标签稍显不那么有用。但这也与使用常见标签作为帖子的高层次分类有关。注意,“KDnuggets”在机器标签中是一个非常常见的标签,但由于用站点名称标记 KDnuggets 的帖子显得多余,因此被移除了。
自动标签生成的一个弱点是无法捕捉到那些不在大多数停用词列表中的无关标签。最明显的例子是链接缩短器 buff.ly 和 shrd.by,它们在热门的 Twitter 帖子中很常见。除此之外,大、数据、科学、挖掘、分析 和 社交 的每一种排列组合都有可能出现,这也部分归因于数据清理。为了使自动生成的标签更具吸引力,需要一个更具网站特定性的停用词列表。
考虑到这一点,我认为最佳的工作流程应该是在人工标记的基础上,结合机器标记的方式。也许每个月在整个语料库上离线重新运行标记算法,以便在发布时,能够揭示人类标记者可能不会立即想到的文章之间的联系。
结论 – Algorithmia
更有趣的结果是使用 Algorithmia 的体验。整体体验非常愉快。拥有使用 Algorithmia 支持的语言(Python、Java 或 JavaScript)的经验,实际上是使用它的唯一前提。这是一个好事,因为它表明他们将服务设置得与现有生态系统良好兼容,这对于确保你尽快提高生产力至关重要。
在线编辑器的工作方式符合语言的预期,Python 编辑器速度很快且提供了良好的自动完成。访问围绕你的算法创建的 API 非常简单,而且很多示例生成已经为你完成。有一个过程的部分不太清楚——将算法从私有转为公开——但在尝试发布新版本并看到选项后,这一点很容易搞清楚。
观看这个平台的发展将是很有趣的。我可以想象研究论文会发布它们算法的在线版本作为一种演示。这将是很棒的,并且会让我作为读者印象深刻。我还可以看到公司使用 Algorithmia 将一些工作转移到云端。例如,如果一个算法需要间歇性地运行(以避免需要自己的硬件),但可能需要按需调用,Algorithmia 将是一个不错的选择。与 Algorithmia 合作是一种愉快的经历,我会毫不犹豫地向朋友推荐它。
相关:
-
Algorithmia – 市场如何促进创新?
-
KDnuggets 对分析市场的评估:大数据的下一个大趋势
-
调查:机器学习 API
我们的前三大课程推荐
1. Google 网络安全证书 - 加快您的网络安全职业发展。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT
更多相关主题
算法并不偏见,我们才是
原文:
www.kdnuggets.com/2019/01/algorithms-arent-biased-we-are.html
评论
作者:Rahul Bhargava,麻省理工学院。
对使用 AI 改善你组织的运营感到兴奋?对计算机模型带来的见解和预测充满好奇?我想提醒你关于偏见及其如何在这些类型的项目中出现,分享一些说明性的例子,并翻译最新的关于“算法偏见”的学术研究。
首先——语言很重要。我们称呼事物的方式影响我们的理解。这就是为什么我尽量避免使用“人工智能”这一受炒作驱动的术语。大多数被称为人工智能的项目更恰当地描述为“机器学习”。机器学习可以描述为训练计算机做出你希望它帮助做出的决策的过程。本文描述了为什么你需要关注你机器学习问题中的数据。
这在很多方面都很重要。现在“算法偏见”这个词在新闻中频繁出现。这个术语是什么意思?算法给法官提供带有歧视性的判决建议。算法正在将性别刻板印象融入翻译服务。算法在推动观众观看极端主义视频。我认识的大多数人都认为这不是我们想要的世界。让我们深入探讨一下为什么会发生这种情况,并将责任归咎于应有的地方。
你的机器在学习,但谁在教它?
物理学对我来说很困难。更糟糕的是——我认为我永远不会擅长物理。我把这一点归咎于一个糟糕的高中物理老师,他对我和其他学生都很傲慢。另一方面,虽然我对复杂的数学不太擅长,但我喜欢尝试更好地学习它。我将这种持续的热情归因于我的初中数学老师,他以兴奋和玩耍的方式向我们介绍了这个主题(包括解决额外问题的甜甜圈奖励!)。
我分享这个故事的观点是什么?教师很重要。在机器学习中尤为如此——机器没有先前的经验、背景信念和所有其他使人类学习者得到重视的因素。机器只能从你展示给它的内容中学习。
所以在机器学习中,重要的问题是“教材是什么”和“老师是谁。” 机器学习中的教材是你展示给软件的“训练数据”,以教它如何做出决策。这通常是你已经检查并标记了你想要的答案的一些数据。通常这些数据是你从很多其他来源收集的,这些来源已经完成了这项工作(我们通常称之为“语料库”)。如果你试图预测一个接受微贷款的人还款的可能性,那么你可能会选择包括当前贷款接受者的历史支付记录的训练数据。
第二部分讲的是老师是谁。老师决定提问的问题,并告诉学习者什么是重要的。在机器学习中,老师负责“特征选择”——决定机器可以使用数据中的哪些部分来做出决策。有时,这种特征选择是通过你拥有的训练集的内容来完成的。更多时候,你使用一些统计数据来让计算机选择最有可能有用的特征。回到我们的微贷款例子:一些候选特征可能是贷款期限、总金额、接受者是否有手机、婚姻状态或种族。
这两个问题——训练数据和训练特征——是任何机器学习项目的核心。
算法是镜子
带着这个意识回到语言的问题上,也许“机器教学”会是一个更有用的术语。这将把责任放在老师身上。如果你在做“机器学习”,你最关心的是它学会做什么。而“机器教学”中,你最关心的是你在教机器做什么。这是语言上的微妙差异,但理解上有很大不同。
将责任放在老师身上,帮助我们意识到这个过程的复杂性。记得我开始时列出的那些偏见例子吗?那个判刑算法存在歧视,因为它是用美国法院系统的判刑数据训练的,这些数据表明对除了黑人男性以外的每个人都非常宽容。那个带有性别刻板印象的翻译算法可能是用新闻或文学中的数据训练的,而这些数据包含了过时的性别角色和规范(即医生是“他”,而护士是“她”)。那个在你的信息流中出现虚假故事的算法是被训练去分享其他人分享的内容,不管其准确性如何。
所有这些数据都是关于我们的。
那些算法没有偏见,是我们有!算法是镜子。

算法镜子无法完全反射我们周围的世界,也无法反射我们想要的世界
它们反映了我们问题和数据中的偏见。这些偏见会在特征选择和训练数据中被融入机器学习项目中。这是我们的责任,而不是计算机的。
矫正镜片
那么我们如何检测和纠正这些问题呢?教师对学生的学习感到责任和自豪。机器学习模型的开发者也应该感受到类似的责任,或许也应该有类似的自豪感。
我对像微软努力消除公共可用语言模型中的性别偏见(尝试解决“医生是男性”问题)这样的例子感到振奋。我喜欢我的同事 Joy Buolamwini 将其重新框架为她称之为“算法正义联盟”的社会和技术干预中的“正义”问题的努力(视频)。ProPublica的调查报道让公司对其歧视性量刑预测负责。令人惊叹的Zeynep Tufekci在谈论和写作社会面临的危险方面走在前沿。Cathy O’Neil 的数学毁灭武器记录了这一切的诸多影响,对社会发出了警告。像法律领域正在讨论的影响一样,算法驱动的决策在公共政策设置中的影响也在讨论中。城市条例也开始处理如何立法应对我描述的一些影响的问题。
这些努力希望能作为这些算法镜子的“校正镜片”——解决我们在自我反射中看到的令人担忧的方面。关键在于记住,我们必须采取行动解决这个问题。通过算法做出的决策并不会自动使其可靠和可信;就像用数据量化某事并不会自动使其成为事实一样。我们需要审视这些算法镜中的自我反射,确保看到我们想要的未来。
个人简介:Rahul Bhargava是专注于公民技术和数据素养的研究员和技术专家。
原文。经许可转载。
资源:
相关:
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 需求
更多相关主题
高级超参数优化/调优的算法
原文:
www.kdnuggets.com/2020/11/algorithms-for-advanced-hyper-parameter-optimization-tuning.html
评论
由 Gowrisankar JG,Hexaware 的软件开发人员
大多数专业的机器学习从业者遵循机器学习管道作为标准,以保持工作的高效性和流畅性。一个管道的创建是为了让数据从原始格式流向一些有用的信息。管道中所有子领域的模块对我们产生高质量的结果同样重要,其中之一是 超参数调优。
一个通用的机器学习管道
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
我们大多数人知道,进行超参数调优的最佳方法是使用 GridSearchCV 或 RandomSearchCV 来自 sklearn 模块。但除了这些算法,还有许多其他高级的超参数调优方法。这正是本文的重点,介绍高级超参数优化、迁移学习以及何时和如何使用这些算法来最大限度地发挥它们的作用。
两种算法,网格搜索和随机搜索,都是非信息搜索的实例。现在,让我们深入了解吧!!
非信息搜索
在这些算法中,每次超参数调优的迭代不会从之前的迭代中学习。这使我们能够并行化工作。然而,这并不高效,且消耗大量计算资源。
随机搜索从均匀分布中随机尝试一组超参数,遍历预设的列表/超参数搜索空间(迭代次数是定义的)。它适合测试广泛的值范围,通常能很快找到一个非常好的组合,但问题是,它不能保证给出最佳参数组合。
另一方面,网格搜索将提供最佳组合,但可能需要很多时间,且计算成本很高。
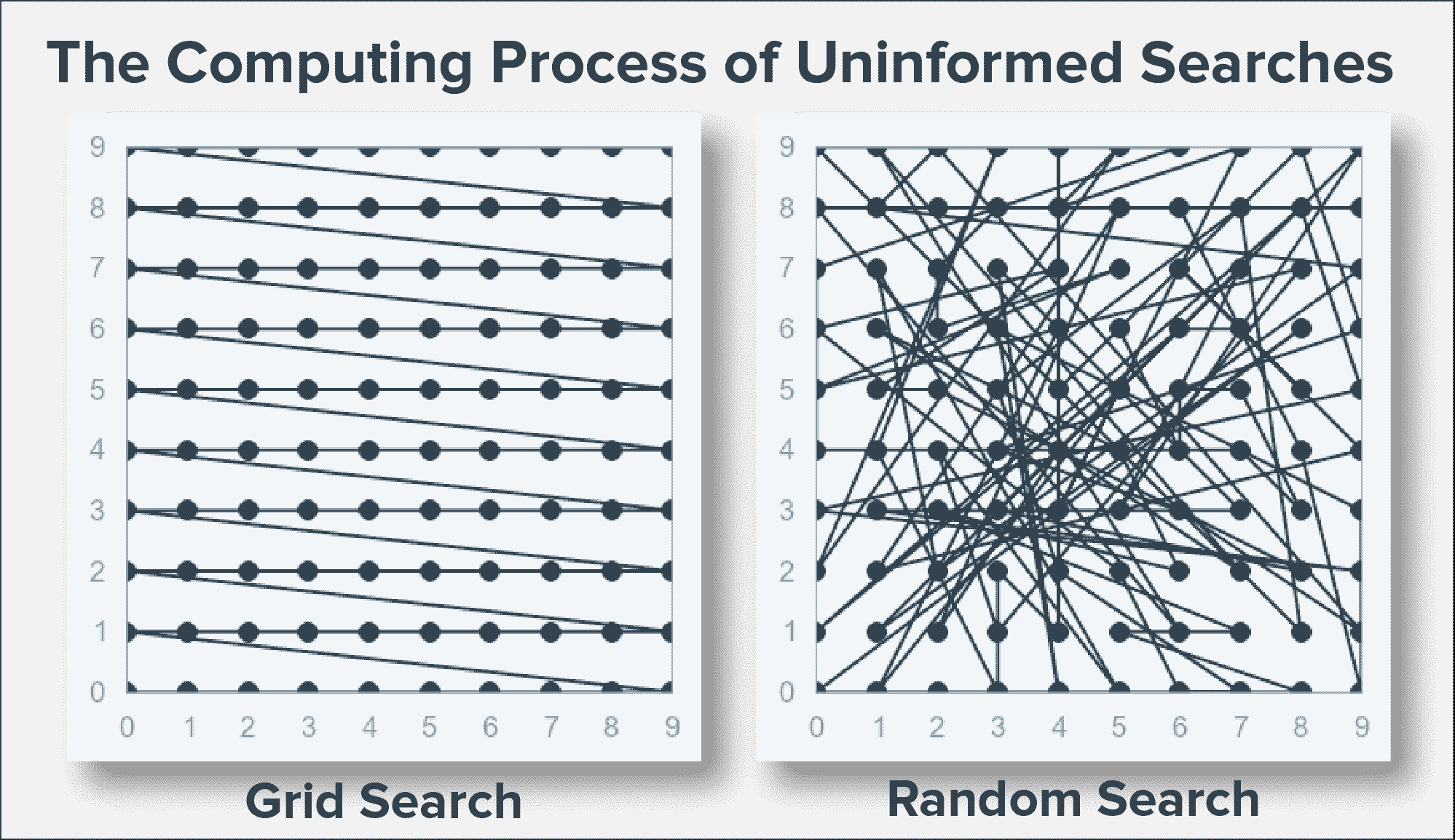
网格和随机搜索的搜索模式
看似网格搜索比随机搜索更好,但要记住,当维度很高时,我们需要搜索的组合数量是巨大的。例如,要对十个布尔(是/否)参数进行网格搜索,你将不得不测试 1024(2¹⁰)种不同的组合。这就是为什么有时会将随机搜索与聪明的启发式方法结合使用的原因。
为什么在网格搜索中引入随机性?[数学解释]
随机搜索更多是从随机搜索/优化的角度来看——我们在过程中引入噪声(或某种形式的随机性)的原因是为了可能摆脱糟糕的局部最小值。虽然这通常用于解释一般优化中的直觉(如更新参数的随机梯度下降,或基于温度的模型),我们可以将人类在元参数空间中的搜索视为一个更高级的优化问题。由于大多数人同意这些维度空间(相当高)会导致非凸优化形式,即使我们拥有之前研究中一些聪明的启发式方法,人类仍然可能会陷入局部最优解中。
因此,随机探索搜索空间可能会提供更好的覆盖率,更重要的是,它可能帮助我们找到更好的局部最优解。
迄今为止,在网格和随机搜索算法中,我们一直是在一次创建所有模型并在最后决定最佳模型之前合并它们的评分。
一种替代方法是按顺序构建模型,从每次迭代中学习。这种方法被称为信息化搜索。
信息化方法:粗到精调优
一种基本的信息化搜索方法。
过程如下:
-
随机搜索
-
在搜索空间中找到有前景的区域
-
在较小的区域进行网格搜索
-
继续直到获得最佳分数
你可以在网格搜索之前用随机搜索来替代(3)。
为什么粗到精?
粗到精 调优 优化并利用了网格搜索和随机搜索的优势。
-
随机搜索的广泛搜索能力
-
一旦知道一个好的位置可能出现,进行更深入的搜索
无需浪费时间在没有良好结果的搜索空间上!!因此,这样可以更好地利用时间和计算资源,即我们可以快速迭代,同时性能也有所提升。
信息化方法:贝叶斯统计
最受欢迎的信息化搜索方法是贝叶斯优化。贝叶斯优化最初是为了优化黑箱函数而设计的。
这是一个基本的定理或规则,来自于概率论与统计学,如果你想复习和刷新这里使用的术语,可以参考 this。
贝叶斯规则 | 定理
一种使用新证据来迭代更新我们对某些outcome的信念的统计方法。简单来说,它用于根据事件与另一事件的关联来计算事件的概率。
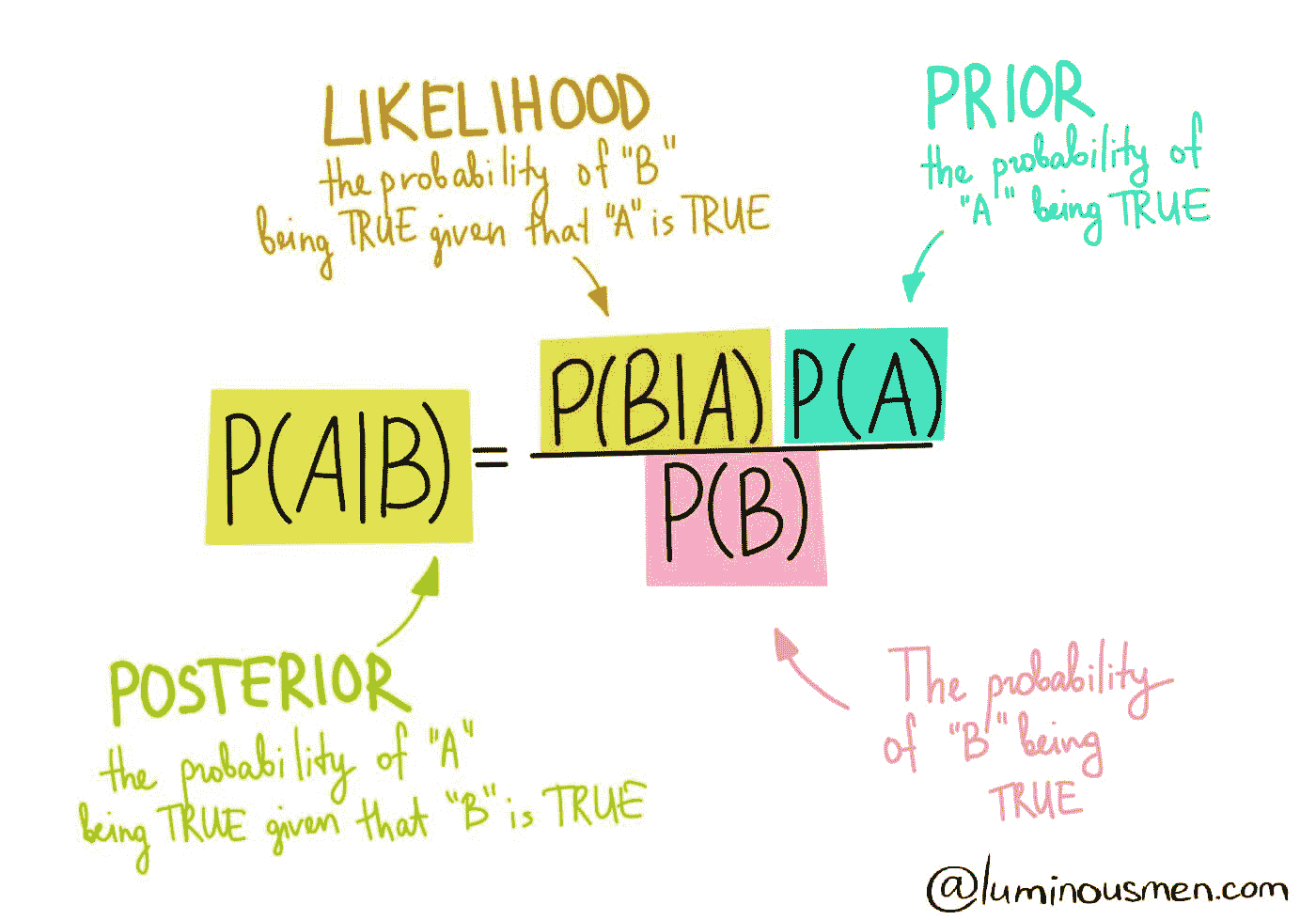
来源:数据科学中的贝叶斯定理
-
LHS 是在发生 B 的情况下 A 的概率。B 是一些新的证据。这被称为‘后验’。
-
RHS 是我们计算这个的方法。
-
P(A) 是‘先验’,是关于事件的初步假设。它不同于 P(A|B),P(A|B) 是在新证据给定的情况下的概率。
-
P(B) 是‘边际似然’,即观察到这一新证据的概率。
-
P(B|A) 是‘似然’,即在我们关心的事件发生的情况下观察证据的概率。
将贝叶斯规则的逻辑应用于超参数调优:
-
选择一个超参数组合
-
构建一个模型
-
获取新证据(即模型的得分)
-
更新我们的信念,并在下一轮选择更好的超参数
贝叶斯超参数调优虽然相对较新,但在较大和更复杂的超参数调优任务中非常受欢迎,因为它们能在这种情况下很好地找到最佳超参数组合。
注意
对于更复杂的情况,你可能需要深入探讨所有关于贝叶斯优化的细节。贝叶斯优化只能在连续的超参数上工作,而不能在分类超参数上工作。
使用 HyperOpt 进行贝叶斯超参数调优
HyperOpt 包使用贝叶斯优化的一种形式进行参数调优,允许我们为给定的模型获取最佳参数。它可以在非常大规模上优化具有数百个参数的模型。

想了解更多关于这个库和 HyperOpt 库的参数,可以随时访问 这里。另外可以访问 这里 进行快速教程,了解如何使用 HyperOpt 进行回归和分类。
介绍 HyperOpt 包。
要进行贝叶斯超参数调优,我们需要:
-
设置领域:我们的网格,即搜索空间(略有变化)
-
设置优化算法(默认:TPE)
-
目标函数以最小化:“1-准确率”
了解使用的优化算法,TPE(Parzen 估计树)的原始论文
使用 HyperOpt 的示例代码 [ 随机森林 ]
HyperOpt 不使用网格上的点值,而是每个点代表每个超参数值的概率。在这里使用了简单的均匀分布,但如果你查看文档,你会发现还有更多选择。
HyperOpt 在随机森林上的实现
要真正看到这一点的实际效果,尝试在更大的搜索空间中进行更多试验、更多交叉验证以及更大的数据集。

有关 HyperOpt 的实际实现,请参考:
[1] Xgboost 和神经网络的 Hyperopt 贝叶斯优化
好奇为何 XGBoost 在比赛中有很高的潜力吗?阅读下面的文章扩展你的知识!
Kaggler 的 Favo 算法 | 了解 XGBoost 如何以及为何用于赢得 Kaggle 比赛
知识方法:遗传算法
为什么这效果这么好?
-
它允许我们从之前的迭代中学习,就像贝叶斯超参数调整一样。
-
它还有一个额外的优点,即具有一定的随机性。
-
TPOT 将通过智能探索成千上万种可能的管道来自动化机器学习中最乏味的部分,以找到最适合你数据的管道。
一个用于遗传超参数调整的有用库:TPOT
TPOT 是一个 Python 自动化机器学习工具,通过遗传编程优化机器学习管道。
将 TPOT 视为你的数据科学助手,用于高级优化。
管道不仅包括模型(或多个模型),还涉及特征和过程的其他方面。除此之外,它还会返回管道的 Python 代码给你!TPOT 设计为运行许多小时,以找到最佳模型。你应该拥有更大的种群和后代规模,并且需要更多的代数来找到一个好的模型。
TPOT 组件(关键参数)
-
generations — 进行训练的迭代次数
-
population_size — 每次迭代后保留的模型数量
-
offspring_size — 每次迭代中生成的模型数量
-
mutation_rate — 施加随机性的管道比例
-
crossover_rate — 每次迭代中交配的管道比例
-
scoring — 确定最佳模型的函数
-
cv — 要使用的交叉验证策略
TPOT 分类器
我们将保持默认值mutation_rate 和 crossover_rate,因为在没有深入了解遗传编程的情况下,默认值是最好的选择。
注意:没有特定于算法的超参数?
由于 TPOT 是一个开源库,用于在 Python 中执行AutoML。
AutoML ??
自动化机器学习(AutoML)指的是自动发现性能良好的模型用于预测建模任务的技术,几乎无需用户参与。

上述代码片段的输出
当 TPOT 运行时间不足时,会显得相当不稳定。以下代码片段展示了 TPOT 的不稳定性。这里仅在下面的三段代码中更改了随机状态,但输出结果在选择管道,即模型及其超参数方面显示了显著差异。
你可以在输出中看到所选模型(在这种情况下是朴素贝叶斯的一个版本)在每一代中的得分,然后是最终模型选择的超参数的最终准确度。这是使用 TPOT 进行自动超参数调整的一个很好的初步示例。你现在可以在自己的项目中扩展这一点,构建出优秀的机器学习模型!
要了解更多关于 TPOT 的信息:
[2] 要获取更多关于 TPOT 的信息,请访问 文档。
总结
在已知搜索中,每次迭代都从上一次学习,而在 Grid 和 Random 中,建模是一次完成的,然后选择最佳的。对于小数据集,GridSearch 或 RandomSearch 会更快且足够。
AutoML 方法提供了一个整洁的解决方案,以正确选择能够提高模型性能的超参数。
探索的已知方法包括:
-
‘粗到细’(迭代随机然后网格搜索)。
-
贝叶斯超参数调整,通过模型性能的证据更新信念(HyperOpt)。
-
遗传算法,通过世代演化模型(TPOT)。
希望你在进行 Python 超参数调整的未来工作中学到了一些有用的方法!
用 Go / Golang 在几分钟内创建 REST API
在这篇文章中,有一个简短的路由器比较,然后是创建 REST API 的详细步骤……
如果你对 Golang 的路由器感到好奇,并且想尝试一个简单的 Web 开发项目,我建议阅读上面的文章。
欲了解更多我的信息文章,请在medium上关注我。
如果你对数据科学/机器学习充满热情,可以在LinkedIn上添加我为好友。*
参考文献
[1] 贝叶斯超参数优化 — 入门指南
[2] 如何制作不差劲的深度学习模型
[3] 超参数优化算法
[5] 树结构 Parzen 估计器
[6] 知情搜索 - 超参数调优
个人简介:Gowrisankar JG (@jg_gowrisankar) 对数据科学、数据分析、机器学习和#NLP 充满热情,并在 Hexaware 担任软件开发人员。
原文。经许可转载。
相关内容:
-
自动化机器学习:免费电子书
-
数据科学、数据可视化和机器学习的顶级 Python 库
-
使用 PyCaret 2.0 构建你自己的 AutoML
更多相关内容


 浙公网安备 33010602011771号
浙公网安备 33010602011771号