KDNuggets-博客中文翻译-二十一-
KDNuggets 博客中文翻译(二十一)
原文:KDNuggets
如何使用 Hugging Face 的数据集库进行高效的数据加载
原文:
www.kdnuggets.com/how-to-use-hugging-faces-datasets-library-for-efficient-data-loading

图片由编辑 | Midjourney 提供
本教程演示如何使用 Hugging Face 的 Datasets 库从不同来源加载数据集,仅需几行代码。
我们的前三个课程推荐
 1. Google 网络安全证书 - 快速进入网络安全职业生涯。
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
 2. Google 数据分析专业证书 - 提升您的数据分析技能
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
Hugging Face Datasets 库简化了数据集的加载和处理过程。它为 Hugging Face 的中心提供了数千个数据集的统一接口。该库还实现了各种性能指标,以评估基于变换器的模型。
初始设置
某些 Python 开发环境可能需要在导入之前安装 Datasets 库。
!pip install datasets
import datasets
通过名称加载 Hugging Face Hub 数据集
Hugging Face 在其中心托管了大量数据集。以下函数按名称输出这些数据集的列表:
from datasets import list_datasets
list_datasets()
让我们加载其中一个,即 情感数据集,以对推文中的情感进行分类,方法是指定其名称:
data = load_dataset("jeffnyman/emotions")
如果您想加载在浏览 Hugging Face 网站时遇到的数据集,并且不确定正确的命名约定是什么,请点击数据集名称旁边的“复制”图标,如下所示:
数据集被加载到一个 DatasetDict 对象中,该对象包含三个子集或折叠:训练集、验证集和测试集。
DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 16000
})
validation: Dataset({
features: ['text', 'label'],
num_rows: 2000
})
test: Dataset({
features: ['text', 'label'],
num_rows: 2000
})
})
每个折叠反过来是一个 Dataset 对象。使用字典操作,我们可以检索训练数据折叠:
train_data = all_data["train"]
这个 Dataset 对象的长度表示训练实例(推文)的数量。
len(train_data)
生成以下输出:
16000
通过索引(例如,第 4 个)获取单个实例就像模仿列表操作一样简单:
train_data[3]
该操作返回一个 Python 字典,其中数据集中的两个属性作为键:输入推文 文本 和 标签,表示它被分类的情感。
{'text': 'i am ever feeling nostalgic about the fireplace i will know that it is still on the property',
'label': 2}
我们还可以通过切片同时获取几个连续的实例:
print(train_ds[:100])
这个操作返回一个单一的字典,如之前一样,但现在每个键都有一个值的列表,而不是单一值。
{'text': ['i didnt feel humiliated', ...],
'label': [0, ...]}
最后,要访问单个属性值,我们指定两个索引:一个用于其位置,另一个用于属性名称或键:
train_data[3]["text"]
加载你自己的数据
如果你不想使用 Hugging Face 数据集中心,而是想使用自己的数据集,Datasets 库也允许你这样做,通过使用相同的 load_dataset() 函数,并传入两个参数:数据集的文件格式(例如“csv”、“text”或“json”)以及其所在的路径或网址。
这个例子从一个公共 GitHub 仓库加载 Palmer Archipelago Penguins 数据集:
url = "https://raw.githubusercontent.com/allisonhorst/palmerpenguins/master/inst/extdata/penguins.csv"
dataset = load_dataset('csv', data_files=url)
将数据集转换为 Pandas DataFrame
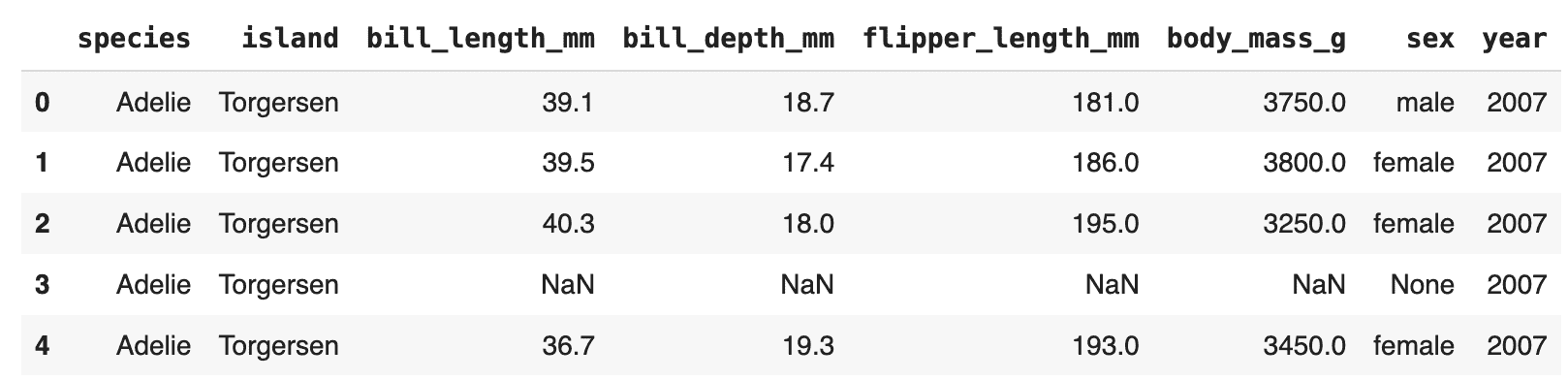
最后但同样重要的是,有时将加载的数据转换为 Pandas DataFrame 对象是方便的,这可以利用 Pandas 库的广泛功能来简化数据处理、分析和可视化。
penguins = dataset["train"].to_pandas()
penguins.head()
现在你已经学会了如何使用 Hugging Face 的专用库高效加载数据集,下一步是通过使用大语言模型(LLMs)来利用它们。
伊万·帕洛马雷斯·卡拉斯科萨 是一位在人工智能、机器学习、深度学习和 LLMs 领域的领袖、作家、演讲者和顾问。他培训和指导他人将 AI 应用于现实世界。
更多相关主题
如何在 Pandas 中使用 MultiIndex 进行层次数据组织
原文:
www.kdnuggets.com/how-to-use-multiindex-for-hierarchical-data-organization-in-pandas

图片由编辑提供 | Midjourney & Canva
让我们学习如何在 Pandas 中使用 MultiIndex 进行层次数据处理。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
准备
我们需要确保安装了 Pandas 包。你可以使用以下代码进行安装:
pip install pandas
然后,让我们学习如何在 Pandas 中处理 MultiIndex 数据。
在 Pandas 中使用 MultiIndex
Pandas 中的 MultiIndex 指的是在 DataFrame 或 Series 上进行多级索引。当我们在二维表格结构中处理更高维的数据时,这个过程很有帮助。通过 MultiIndex,我们可以用多个键来索引数据,并且更好地组织它们。让我们用一个数据集示例来更好地理解它们。
import pandas as pd
index = pd.MultiIndex.from_tuples(
[('A', 1), ('A', 2), ('B', 1), ('B', 2)],
names=['Category', 'Number']
)
df = pd.DataFrame({
'Value': [10, 20, 30, 40]
}, index=index)
print(df)
输出:
Value
Category Number
A 1 10
2 20
B 1 30
2 40
如你所见,上面的 DataFrame 有一个包含类别和编号的两级索引。
也可以使用 DataFrame 中现有的列来设置 MultiIndex。
data = {
'Category': ['A', 'A', 'B', 'B'],
'Number': [1, 2, 1, 2],
'Value': [10, 20, 30, 40]
}
df = pd.DataFrame(data)
df.set_index(['Category', 'Number'], inplace=True)
print(df)
输出:
Value
Category Number
A 1 10
2 20
B 1 30
2 40
即使采用不同的方法,我们也能得到类似的结果。这就是为什么我们可以在 DataFrame 中使用 MultiIndex。
如果你已经有了 MultiIndex DataFrame,可以使用以下代码交换级别。
print(df.swaplevel())
输出:
Value
Number Category
1 A 10
2 A 20
1 B 30
2 B 40
当然,我们可以使用以下代码将 MultiIndex 返回为列:
print(df.reset_index())
输出:
Category Number Value
0 A 1 10
1 A 2 20
2 B 1 30
3 B 2 40
那么,如何在 Pandas DataFrame 中访问 MultiIndex 数据呢?我们可以使用.loc方法。例如,我们访问 MultiIndex DataFrame 的第一级。
print(df.loc['A'])
输出:
Value
Number
1 10
2 20
我们也可以使用元组访问数据值。
print(df.loc[('A', 1)])
输出:
Value 10
Name: (A, 1), dtype: int64
最后,我们可以使用.groupby方法对 MultiIndex 进行统计聚合。
print(df.groupby(level=['Category']).sum())
输出:
Value
Category
A 30
B 70
精通 Pandas 中的 MultiIndex 将帮助你深入了解层次数据。
额外资源
Cornellius Yudha Wijaya 是一名数据科学助理经理和数据撰写者。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 涉猎多种 AI 和机器学习主题。
更多相关内容
如何使用 NumPy 解决非线性方程组
原文:
www.kdnuggets.com/how-to-use-numpy-to-solve-systems-of-nonlinear-equations

作者提供的图片
非线性方程式是数学中非常有趣的一个方面,其应用范围涉及科学、工程和日常生活。在学校时,我花了很长时间才对其概念有了深刻的理解。与形成直线的线性方程式不同,非线性方程式会创建曲线、螺旋或更复杂的形状。这使得它们解决起来有点棘手,但也极具价值,用于建模现实世界的问题。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 工作
简单来说,非线性方程式涉及的变量的指数不为一,或嵌入了更复杂的函数中。以下是几种常见类型:
-
二次方程式:涉及平方项,如 ax² + bx + c = 0。它们的图形形成抛物线,可以向上或向下开口。
-
指数方程式:例如 e^x = 3x,其中变量作为指数出现,导致快速增长或衰减。
-
三角方程式:例如 sin(x) = x/2,其中变量位于三角函数内,形成波浪状模式。
这些方程可以生成各种图形,从抛物线到振荡波,使它们成为建模各种现象的多用途工具。以下是一些非线性方程应用的例子:
-
物理学:建模行星的运动、粒子的行为或混沌系统的动力学。
-
工程学:设计具有反馈回路的系统,如控制系统或电路行为。
-
经济学:分析市场趋势、预测经济增长,或理解不同经济因素之间的复杂互动。
NumPy 可以用来简化解决非线性方程组的过程。它提供了处理复杂计算、找到近似解和可视化结果的工具,使得解决这些挑战性问题变得更容易。
在接下来的部分中,我们将探讨如何利用 NumPy 来解决这些引人入胜的方程,将复杂的数学挑战转化为可管理的任务。
在深入探讨使用 NumPy 求解非线性方程系统的技术细节之前,了解如何有效地制定和设置这些问题是很重要的。要制定一个系统,请遵循以下步骤:
-
识别变量:确定将成为系统一部分的变量。这些是你试图求解的未知数。
-
定义方程:将系统中的每个方程写下来,确保它包含已识别的变量。非线性方程包括 x²、e^x 或 xy 等项。
-
安排方程:清晰地组织方程,将其转换为 NumPy 更易处理的格式。
步骤逐步解决过程
在这一部分中,我们将把非线性方程的求解分解为易于处理的步骤,使问题更加可处理。以下是如何使用NumPy和SciPy系统地解决这些问题。
定义函数
第一步是将你的非线性方程系统转换为 Python 可以处理的格式。这涉及到将方程定义为函数。
在 Python 中,你将每个方程表示为一个函数,该函数在给定一组变量的情况下返回方程的值。对于非线性系统,这些函数通常包括平方项、指数项或变量的乘积。
例如,你有一个由两个非线性方程组成的系统:
-
f[1] (x, y) = x² + y² − 4
-
f[2] (x, y) = x² − y − 1
下面是你如何在 Python 中定义这些函数:
def equations(vars):
x, y = vars
eq1 = x**2 + y**2 - 4
eq2 = x**2 - y - 1
return [eq1, eq2]
在这个函数中,vars 是你希望求解的变量列表。每个方程被定义为这些变量的函数,并返回一个结果列表。
设置初始猜测
在找到解决方案之前,你必须为变量提供初始猜测。这些猜测是必不可少的,因为像 fsolve 使用的迭代方法依赖于这些猜测来开始寻找解决方案。
良好的初始猜测可以帮助我们更有效地收敛到解决方案。差的猜测可能会导致收敛问题或不正确的解决方案。可以把这些猜测看作是寻找方程根的起点。
选择有效初始猜测的提示:
-
领域知识:利用有关问题的先前知识进行有根据的猜测。
-
图形分析:绘制方程图,以便对解决方案可能所在的位置有一个直观的了解。
-
实验:有时,尝试几个不同的猜测并观察结果可能会有所帮助。
对于我们的示例方程,你可以从以下开始:
initial_guesses = [1, 1] # Initial guesses for x and y
求解系统
在定义函数和设置初始猜测后,你现在可以使用 scipy.optimize.fsolve 来找到非线性方程的根。fsolve 旨在通过找到函数为零的地方来处理非线性方程系统。
下面是如何使用 fsolve 来解决系统的方法:
from scipy.optimize import fsolve
# Solve the system
solution = fsolve(equations, initial_guesses)
print("Solution to the system:", solution)
在这段代码中,fsolve 接受两个参数:表示方程系统的函数和初始猜测。它返回满足方程的变量值。
解决之后,你可能想要解释结果:
# Print the results
x, y = solution
print(f"Solved values are x = {x:.2f} and y = {y:.2f}")
# Verify the solution by substituting it back into the equations
print("Verification:")
print(f"f1(x, y) = {x**2 + y**2 - 4:.2f}")
print(f"f2(x, y) = {x**2 - y - 1:.2f}")
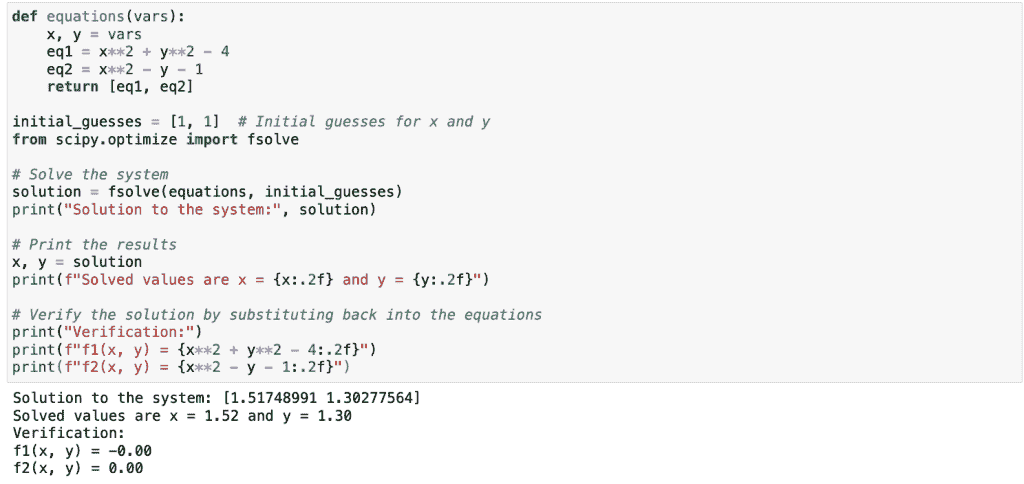
这段代码打印出解,并通过将值代入原始方程来验证,以确保它们接近零。
解决方案可视化
一旦你解出了一个非线性方程组,可视化结果可以帮助你更好地理解和解释这些结果。无论你处理的是两个变量还是三个变量,绘制解提供了这些解在问题背景下的清晰视图。
让我们用几个例子来说明如何可视化这些解:
2D 可视化
假设你已经解出了具有两个变量 x 和 y 的方程。以下是如何在 2D 中绘制这些解:
import numpy as np
import matplotlib.pyplot as plt
# Define the system of equations
def equations(vars):
x, y = vars
eq1 = x**2 + y**2 - 4
eq2 = x**2 - y - 1
return [eq1, eq2]
# Solve the system
from scipy.optimize import fsolve
initial_guesses = [1, 1]
solution = fsolve(equations, initial_guesses)
x_sol, y_sol = solution
# Create a grid of x and y values
x = np.linspace(-3, 3, 400)
y = np.linspace(-3, 3, 400)
X, Y = np.meshgrid(x, y)
# Define the equations for plotting
Z1 = X**2 + Y**2 - 4
Z2 = X**2 - Y - 1
# Plot the contours
plt.figure(figsize=(8, 6))
plt.contour(X, Y, Z1, levels=[0], colors='blue', label='x² + y² - 4')
plt.contour(X, Y, Z2, levels=[0], colors='red', label='x² - y - 1')
plt.plot(x_sol, y_sol, 'go', label='Solution')
plt.xlabel('x')
plt.ylabel('y')
plt.title('2D Visualization of Nonlinear Equations')
plt.legend()
plt.grid(True)
plt.show()
这是输出结果:
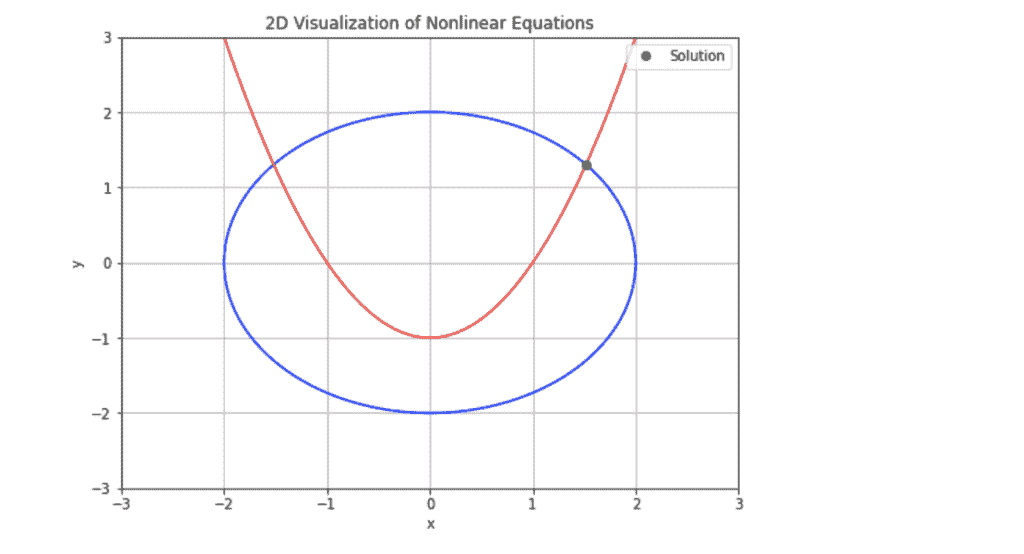
图中的蓝色和红色轮廓表示每个方程为零的曲线。绿色点显示了这些曲线交点的解。
3D 可视化
对于涉及三个变量的系统,3D 图可以提供更多信息。假设你有一个包含 x、y 和 z 变量的系统。以下是如何可视化这个系统:
from mpl_toolkits.mplot3d import Axes3D
# Define the system of equations
def equations(vars):
x, y, z = vars
eq1 = x**2 + y**2 + z**2 - 4
eq2 = x**2 - y - 1
eq3 = z - x * y
return [eq1, eq2, eq3]
# Solve the system
initial_guesses = [1, 1, 1]
solution = fsolve(equations, initial_guesses)
x_sol, y_sol, z_sol = solution
# Create a grid of x, y, and z values
x = np.linspace(-2, 2, 100)
y = np.linspace(-2, 2, 100)
X, Y = np.meshgrid(x, y)
Z = np.sqrt(4 - X**2 - Y**2)
# Plotting the 3D surface
fig = plt.figure(figsize=(10, 7))
ax = fig.add_subplot(111, projection='3d')
ax.plot_surface(X, Y, Z, alpha=0.5, rstride=100, cstride=100, color='blue')
ax.plot_surface(X, Y, -Z, alpha=0.5, rstride=100, cstride=100, color='red')
# Plot the solution
ax.scatter(x_sol, y_sol, z_sol, color='green', s=100, label='Solution')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
ax.set_title('3D Visualization of Nonlinear Equations')
ax.legend()
plt.show()
输出:
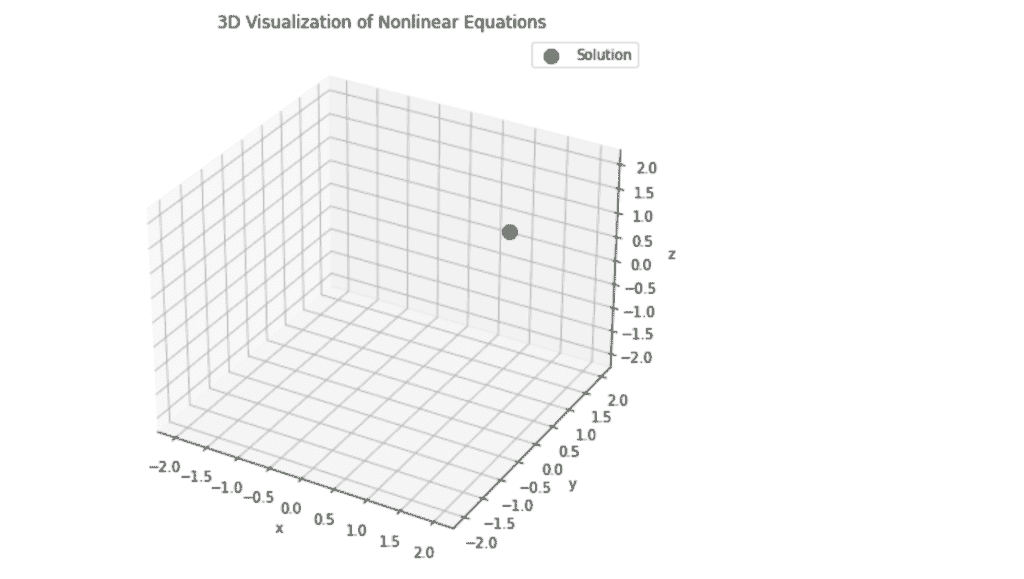
在这个 3D 图中,蓝色和红色表面表示方程的解,而绿色点显示了 3D 空间中的解。
结论
在这篇文章中,我们探讨了使用 NumPy 解决非线性方程组的过程。通过分解步骤,从定义问题到可视化解决方案,我们使复杂的数学概念变得易于接近和实际应用。
我们从在 Python 中公式化和定义非线性方程开始。我们强调了初始猜测的重要性,并提供了选择有效起始点的技巧。接着,我们利用 scipy.optimize.solve 找到方程的根。最后,我们展示了如何使用 matplotlib 可视化这些解,使结果的解释和验证更加容易。
Shittu Olumide 是一位软件工程师和技术写作人员,热衷于利用前沿技术编写引人入胜的叙述,对细节有敏锐的洞察力,并擅长简化复杂概念。你也可以在 Twitter 上找到 Shittu。
更多相关话题
如何使用 Hugging Face Tokenizers 库来预处理文本数据
原文:
www.kdnuggets.com/how-to-use-the-hugging-face-tokenizers-library-to-preprocess-text-data

作者提供的图像
如果你学习过 NLP,你可能听说过“分词”这个术语。这是文本预处理中的一个重要步骤,我们通过将文本数据转换为机器可以理解的形式来完成。这是通过将句子拆分成更小的部分,称为标记。根据使用的分词算法,这些标记可以是单词、子词,甚至是字符。本文将探讨如何使用 Hugging Face Tokenizers 库来预处理我们的文本数据。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
设置 Hugging Face Tokenizers 库
要开始使用 Hugging Face Tokenizers 库,你需要先安装它。你可以使用 pip 来完成这个操作:
pip install tokenizers
Hugging Face 库支持多种分词算法,但主要有三种类型:
-
字节对编码 (BPE): 迭代地合并最频繁的字符或子词对,创建一个紧凑的词汇表。GPT-2 等模型使用了这种方法。
-
WordPiece: 类似于 BPE,但侧重于概率合并(不选择最频繁的对,而是选择合并后能最大化语料库概率的对),通常被 BERT 等模型使用。
-
SentencePiece: 一种更灵活的分词器,可以处理不同语言和脚本,通常与 ALBERT、XLNet 或 Marian 框架等模型一起使用。它将空格视为字符,而不是单词分隔符。
Hugging Face Transformers 库提供了一个AutoTokenizer类,可以自动选择适合给定预训练模型的最佳分词器。这是使用特定模型正确分词器的一种便捷方式,并且可以从transformers库中导入。然而,考虑到我们对 Tokenizers 库的讨论,我们将不采用这种方法。
我们将使用预训练的BERT-base-uncased分词器。这个分词器是基于与BERT-base-uncased模型相同的数据和技术训练的,这意味着它可以用来预处理与 BERT 模型兼容的文本数据:
# Import the necessary components
from tokenizers import Tokenizer
from transformers import BertTokenizer
# Load the pre-trained BERT-base-uncased tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
单句分词
现在,让我们使用这个标记器对一个简单句子进行编码:
# Tokenize a single sentence
encoded_input = tokenizer.encode_plus("This is sample text to test tokenization.")
print(encoded_input)
输出:
{'input_ids': [101, 2023, 2003, 7099, 3793, 2000, 3231, 19204, 3989, 1012, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
为确保准确性,让我们解码标记化的输入:
tokenizer.decode(encoded_input["input_ids"])
输出:
[CLS] this is sample text to test tokenization. [SEP]
在这个输出中,你可以看到两个特殊标记。[CLS] 标记输入序列的开始,[SEP] 标记结束,表示单个文本序列。
批量标记化
现在,让我们使用 batch_encode_plus 对文本语料库进行标记化,而不是单个句子:
corpus = [
"Hello, how are you?",
"I am learning how to use the Hugging Face Tokenizers library.",
"Tokenization is a crucial step in NLP."
]
encoded_corpus = tokenizer.batch_encode_plus(corpus)
print(encoded_corpus)
输出:
{'input_ids': [[101, 7592, 1010, 2129, 2024, 2017, 1029, 102], [101, 1045, 2572, 4083, 2129, 2000, 2224, 1996, 17662, 2227, 19204, 17629, 2015, 3075, 1012, 102], [101, 19204, 3989, 2003, 1037, 10232, 3357, 1999, 17953, 2361, 1012, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
为了更好地理解,让我们像处理单句时那样解码批量编码的语料库。这将提供原始句子,标记化得当。
tokenizer.batch_decode(encoded_corpus["input_ids"])
输出:
['[CLS] hello, how are you? [SEP]',
'[CLS] i am learning how to use the hugging face tokenizers library. [SEP]',
'[CLS] tokenization is a crucial step in nlp. [SEP]']
填充和截断
在为机器学习模型准备数据时,确保所有输入序列具有相同长度通常是必要的。实现这一点的两种方法是:
1. 填充
填充通过在较短序列的末尾添加特殊标记 [PAD],以匹配批次中最长序列的长度或模型支持的最大长度(如果定义了 max_length)。你可以通过以下方式实现:
encoded_corpus_padded = tokenizer.batch_encode_plus(corpus, padding=True)
print(encoded_corpus_padded)
输出:
{'input_ids': [[101, 7592, 1010, 2129, 2024, 2017, 1029, 102, 0, 0, 0, 0, 0, 0, 0, 0], [101, 1045, 2572, 4083, 2129, 2000, 2224, 1996, 17662, 2227, 19204, 17629, 2015, 3075, 1012, 102], [101, 19204, 3989, 2003, 1037, 10232, 3357, 1999, 17953, 2361, 1012, 102, 0, 0, 0, 0]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0]]}
现在,你可以看到额外的 0 被放置,但为了更好地理解,让我们解码以查看标记器放置 [PAD] 标记的位置:
tokenizer.batch_decode(encoded_corpus_padded["input_ids"], skip_special_tokens=False)
输出:
['[CLS] hello, how are you? [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]',
'[CLS] i am learning how to use the hugging face tokenizers library. [SEP]',
'[CLS] tokenization is a crucial step in nlp. [SEP] [PAD] [PAD] [PAD] [PAD]']
2. 截断
许多 NLP 模型有最大输入长度序列,截断通过剪切较长序列的末尾来满足这个最大长度。它减少了内存使用,并防止模型被非常大的输入序列压垮。
encoded_corpus_truncated = tokenizer.batch_encode_plus(corpus, truncation=True, max_length=5)
print(encoded_corpus_truncated)
输出:
{'input_ids': [[101, 7592, 1010, 2129, 102], [101, 1045, 2572, 4083, 102], [101, 19204, 3989, 2003, 102]], 'token_type_ids': [[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1], [1, 1, 1, 1, 1], [1, 1, 1, 1, 1]]}
现在,你还可以使用 batch_decode 方法,但为了更好地理解,让我们以不同的方式打印这些信息:
for i, sentence in enumerate(corpus):
print(f"Original sentence: {sentence}")
print(f"Token IDs: {encoded_corpus_truncated['input_ids'][i]}")
print(f"Tokens: {tokenizer.convert_ids_to_tokens(encoded_corpus_truncated['input_ids'][i])}")
print()
输出:
Original sentence: Hello, how are you?
Token IDs: [101, 7592, 1010, 2129, 102]
Tokens: ['[CLS]', 'hello', ',', 'how', '[SEP]']
Original sentence: I am learning how to use the Hugging Face Tokenizers library.
Token IDs: [101, 1045, 2572, 4083, 102]
Tokens: ['[CLS]', 'i', 'am', 'learning', '[SEP]']
Original sentence: Tokenization is a crucial step in NLP.
Token IDs: [101, 19204, 3989, 2003, 102]
Tokens: ['[CLS]', 'token', '##ization', 'is', '[SEP]']
本文是我们关于 Hugging Face 的精彩系列的一部分。如果你想更深入了解这个话题,这里有一些参考资料可以帮助你:
Kanwal Mehreen**** Kanwal 是一位机器学习工程师和技术作家,对数据科学及人工智能与医学的交叉领域充满热情。她共同撰写了电子书《利用 ChatGPT 最大化生产力》。作为 2022 年亚太地区的 Google Generation 学者,她倡导多样性和学术卓越。她还被认可为 Teradata 多样性科技学者、Mitacs Globalink 研究学者和哈佛 WeCode 学者。Kanwal 是变革的积极倡导者,创立了 FEMCodes 以赋能女性在 STEM 领域的成长。
更多相关话题
如何使用 pivot_table 函数进行高级数据汇总
原文:
www.kdnuggets.com/how-to-use-the-pivot_table-function-for-advanced-data-summarization-in-pandas

图片来源:作者 | Midjourney
让我指导你如何使用 Pandas 的 pivot_table 函数进行数据汇总。
准备工作
让我们开始安装必要的软件包。
pip install pandas seaborn
然后,我们将加载软件包和数据集示例,即 Titanic。
import pandas as pd
import seaborn as sns
titanic = sns.load_dataset('titanic')
在成功安装包并加载数据集后,让我们进入下一部分。
使用 Pandas 创建数据透视表
Pandas 中的数据透视表允许灵活的数据重组和分析。让我们从简单的应用开始探讨一些实际应用。
pivot = pd.pivot_table(titanic, values='age', index='class', columns='sex', aggfunc='mean')
print(pivot)
Output>>>
sex female male
class
First 34.611765 41.281386
Second 28.722973 30.740707
Third 21.750000 26.507589
生成的数据透视表显示了平均年龄,乘客类别在纵轴上,性别类别在顶部。
我们可以更进一步,使用数据透视表来计算票价的均值和总和。
pivot = pd.pivot_table(titanic, values='fare', index='class', columns='sex', aggfunc=['mean', 'sum'])
print(pivot)
Output>>>
mean sum
sex female male female male
class
First 106.125798 67.226127 9975.8250 8201.5875
Second 21.970121 19.741782 1669.7292 2132.1125
Third 16.118810 12.661633 2321.1086 4393.5865
我们可以创建自己的函数。例如,我们创建一个函数,该函数计算数据的最大值和最小值之间的差异,并将其除以二。
def data_div_two(x):
return (x.max() - x.min())/2
pivot = pd.pivot_table(titanic, values='age', index='class', columns='sex', aggfunc=data_div_two)
print(pivot)
Output>>>
sex female male
class
First 30.500 39.540
Second 27.500 34.665
Third 31.125 36.790
最后,你可以添加边际数据,查看总体分组平均值和具体子组之间的差异。
pivot = pd.pivot_table(titanic, values='age', index='class', columns='sex', aggfunc='mean', margins=True)
print(pivot)
Output>>>
sex female male All
class
First 34.611765 41.281386 38.233441
Second 28.722973 30.740707 29.877630
Third 21.750000 26.507589 25.140620
All 27.915709 30.726645 29.699118
掌握 pivot_table 函数将帮助你从数据集中获得洞察。
额外资源
Cornellius Yudha Wijaya**** 是数据科学助理经理和数据撰稿人。在 Allianz 印度尼西亚全职工作时,他喜欢通过社交媒体和写作分享 Python 和数据技巧。Cornellius 涉及多种 AI 和机器学习主题的写作。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
了解更多相关主题
如何编写高效的 Python 代码:初学者教程
原文:
www.kdnuggets.com/how-to-write-efficient-python-code-a-tutorial-for-beginners
图片由作者提供
初学者喜欢使用 Python 编程,因为它的简单性和易读语法。然而,编写高效的 Python 代码比你想象的要复杂。这需要对语言的一些特性有一定理解(不过它们也很容易掌握)。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
如果你来自其他编程语言,如 C++ 或 JavaScript,这个教程是为你提供一些编写高效 Python 代码的技巧。但是如果你是初学者——将 Python 作为你的第一门(编程)语言——那么这个教程将帮助你从一开始就编写 Pythonic 代码。
我们将重点关注以下内容:
-
Pythonic 循环
-
列表和字典推导式
-
上下文管理器
-
生成器
-
集合类
那么让我们开始吧!
1. 编写 Pythonic 循环
理解循环构造无论你编程使用哪种语言都是重要的。如果你来自 C++ 或 JavaScript 这样的语言,学习如何编写 Pythonic 循环会很有帮助。
使用 range 生成数字序列
range()函数生成一个数字序列,通常在循环中作为迭代器使用。
range()函数返回一个范围对象,该对象默认从 0 开始,到指定的数字(但不包括)为止。
这里是一个例子:
for i in range(5):
print(i)
Output >>>
0
1
2
3
4
使用range()函数时,你可以根据需要自定义起始点、终止点和步长。
使用 enumerate 访问索引和项
enumerate()函数在你需要同时获取每个元素的索引和值时非常有用。
在这个例子中,我们使用索引来访问fruits列表:
fruits = ["apple", "banana", "cherry"]
for i in range(len(fruits)):
print(f"Index {i}: {fruits[i]}")
Output >>>
Index 0: apple
Index 1: banana
Index 2: cherry
但使用enumerate()函数,你可以同时访问索引和元素,如下所示:
fruits = ["apple", "banana", "cherry"]
for i, fruit in enumerate(fruits):
print(f"Index {i}: {fruit}")
Output >>>
Index 0: apple
Index 1: banana
Index 2: cherry
使用 zip 在多个可迭代对象中并行遍历
zip()函数用于并行遍历多个可迭代对象。它将不同可迭代对象中的对应元素配对在一起。
考虑以下示例,其中你需要遍历names和scores列表:
names = ["Alice", "Bob", "Charlie"]
scores = [95, 89, 78]
for i in range(len(names)):
print(f"{names[i]} scored {scores[i]} points.")
这输出:
Output >>>
Alice scored 95 points.
Bob scored 89 points.
Charlie scored 78 points.
这里是一个使用zip()函数的更具可读性的循环:
names = ["Alice", "Bob", "Charlie"]
scores = [95, 89, 78]
for name, score in zip(names, scores):
print(f"{name} scored {score} points.")
Output >>>
Alice scored 95 points.
Bob scored 89 points.
Charlie scored 78 points.
使用zip()的 Pythonic 版本更优雅,避免了手动索引的需要,使代码更清晰易读。
2. 使用列表和字典推导
在 Python 中,列表推导和字典推导是用来分别创建列表和字典的简洁单行表达式。它们还可以包含条件语句来根据某些条件过滤项。
我们从循环版本开始,然后转到对列表和字典的推导式。
Python 中的列表推导
假设你有一个numbers列表。你想创建一个squared_numbers列表。你可以使用如下的 for 循环:
numbers = [1, 2, 3, 4, 5]
squared_numbers = []
for num in numbers:
squared_numbers.append(num ** 2)
print(squared_numbers)
Output >>> [1, 4, 9, 16, 25]
但列表推导提供了更清晰和简洁的语法来完成这项工作。它们允许你通过对可迭代对象中的每个项应用表达式来创建一个新列表。

列表推导语法 | 图片作者
这里是使用列表推导式表达式的简洁替代方案:
numbers = [1, 2, 3, 4, 5]
squared_numbers = [num ** 2 for num in numbers]
print(squared_numbers)
Output >>> [1, 4, 9, 16, 25]
在这里,列表推导创建了一个新列表,其中包含numbers列表中每个数字的平方。
带有条件过滤的列表推导
你还可以在列表推导式表达式中添加过滤条件。考虑这个例子:
numbers = [1, 2, 3, 4, 5]
odd_numbers = [num for num in numbers if num % 2 != 0]
print(odd_numbers)
Output >>> [1, 3, 5]
在这个例子中,列表推导创建了一个只包含numbers列表中奇数的新列表。
Python 中的字典推导
使用类似于列表推导的语法,字典推导允许你从现有的可迭代对象创建字典。

字典推导语法 | 图片作者
假设你有一个fruits列表。你想创建一个fruit:len(fruit)键值对的字典。
下面是如何使用 for 循环来实现这一点:
fruits = ["apple", "banana", "cherry", "date"]
fruit_lengths = {}
for fruit in fruits:
fruit_lengths[fruit] = len(fruit)
print(fruit_lengths)
Output >>> {'apple': 5, 'banana': 6, 'cherry': 6, 'date': 4}
现在让我们写出字典推导的等效形式:
fruits = ["apple", "banana", "cherry", "date"]
fruit_lengths = {fruit: len(fruit) for fruit in fruits}
print(fruit_lengths)
Output >>> {'apple': 5, 'banana': 6, 'cherry': 6, 'date': 4}
这个字典推导创建了一个字典,其中键是水果,值是水果名称的长度。
带有条件过滤的字典推导
让我们修改我们的字典推导式表达式以包含一个条件:
fruits = ["apple", "banana", "cherry", "date"]
long_fruit_names = {fruit: len(fruit) for fruit in fruits if len(fruit) > 5}
print(long_fruit_names)
Output >>> {'banana': 6, 'cherry': 6}
在这里,字典推导创建了一个字典,键是水果名称,值是它们的长度,但只对名称长度超过 5 个字符的水果。
3. 使用上下文管理器进行有效的资源处理
Python 中的上下文管理器帮助你有效管理资源。使用上下文管理器,你可以轻松地设置和清理资源。上下文管理器最简单和最常见的例子是在文件处理上。
看下面的代码片段:
filename = 'somefile.txt'
file = open(filename,'w')
file.write('Something')
它没有关闭文件描述符,导致资源泄漏。
print(file.closed)
Output >>> False
你可能会得到以下结果:
filename = 'somefile.txt'
file = open(filename,'w')
file.write('Something')
file.close()
虽然这试图关闭描述符,但它没有考虑到在写操作期间可能出现的错误。
现在,你可以实现异常处理以尝试打开文件并在没有错误的情况下写入内容:
filename = 'somefile.txt'
file = open(filename,'w')
try:
file.write('Something')
finally:
file.close()
但这很冗长。现在看看以下使用 with 语句的版本,它支持作为上下文管理器的 open() 函数:
filename = 'somefile.txt'
with open(filename, 'w') as file:
file.write('Something')
print(file.closed)
Output >>> True
我们使用 with 语句来创建一个上下文,在其中打开文件。这确保了当执行退出 with 块时,文件会被正确关闭——即使在操作过程中引发了异常。
4. 使用生成器进行内存高效处理
生成器提供了一种优雅的方式来处理大数据集或无限序列——提高代码效率并减少内存消耗。
什么是生成器?
生成器是使用 yield 关键字逐个返回值的函数,保留其内部状态以便在调用之间继续。与一次计算所有值并返回完整列表的常规函数不同,生成器按需计算并逐步生成值,使它们适合处理大型序列。
生成器是如何工作的?
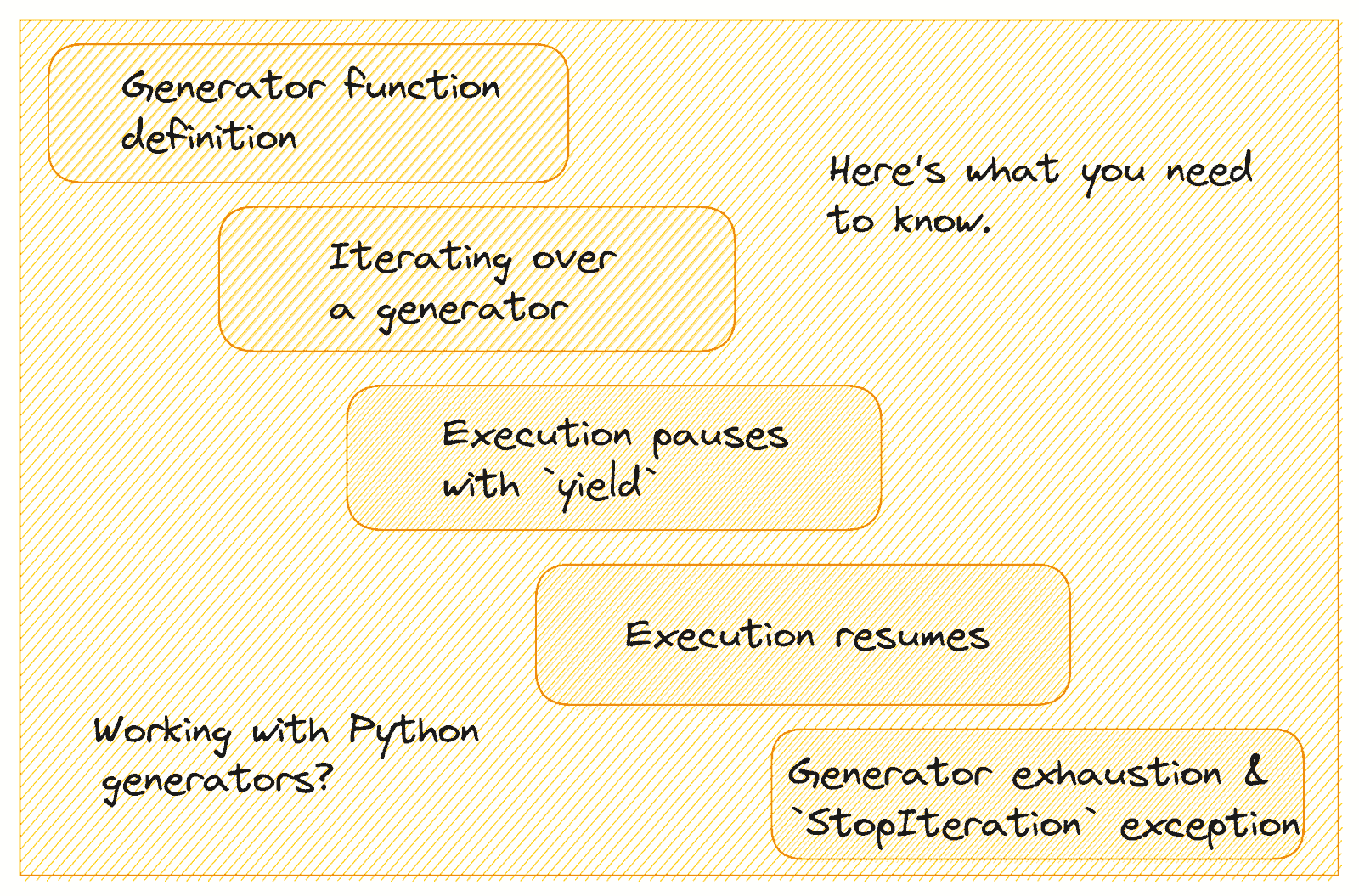
图片由作者提供
让我们了解生成器是如何工作的:
-
生成器函数的定义方式类似于常规函数,但它使用
yield而不是return关键字来返回一个值。 -
当你调用生成器函数时,它会返回一个生成器对象。你可以使用循环或调用
next()来遍历它。 -
当遇到
yield语句时,函数的状态被保存,并且返回的值会传递给调用者。函数的执行会暂停,但它的局部变量和状态会被保留。 -
当生成器的
next()方法再次被调用时,执行将从暂停的地方继续,函数将继续执行直到下一个yield语句。 -
当函数退出或抛出
StopIteration异常时,生成器被认为是耗尽的,进一步调用next()将抛出StopIteration。
创建生成器
你可以使用生成器函数或生成器表达式来创建生成器。
这是一个示例生成器函数:
def countdown(n):
while n > 0:
yield n
n -= 1
# Using the generator function
for num in countdown(5):
print(num)
Output >>>
5
4
3
2
1
生成器表达式类似于列表推导式,但它们创建的是生成器而不是列表。
# Generator expression to create a sequence of squares
squares = (x ** 2 for x in range(1, 6))
# Using the generator expression
for square in squares:
print(square)
Output >>>
1
4
9
16
25
5. 利用集合类
我们将通过了解两个有用的集合类来结束本教程:
-
命名元组
-
计数器
使用 NamedTuple 创建更具可读性的元组
在 Python 中,命名元组 在 collections 模块 中是内置元组类的一个子类。但它提供了命名字段,这使得它比常规元组更具可读性和自解释性。
这是创建一个 3D 空间点的简单元组并访问单个元素的示例:
# 3D point tuple
coordinate = (1, 2, 3)
# Accessing data using tuple unpacking
x, y, z = coordinate
print(f"X-coordinate: {x}, Y-coordinate: {y}, Z-coordinate: {z}")
Output >>> X-coordinate: 1, Y-coordinate: 2, Z-coordinate: 3
这里是 namedtuple 版本:
from collections import namedtuple
# Define a Coordinate3D namedtuple
Coordinate3D = namedtuple("Coordinate3D", ["x", "y", "z"])
# Creating a Coordinate3D object
coordinate = Coordinate3D(1, 2, 3)
print(coordinate)
# Accessing data using named fields
print(f"X-coordinate: {coordinate.x}, Y-coordinate: {coordinate.y}, Z-coordinate: {coordinate.z}")
Output >>>
Coordinate3D(x=1, y=2, z=3)
X-coordinate: 1, Y-coordinate: 2, Z-coordinate: 3
因此,NamedTuples 让你编写比普通元组更清晰、更易维护的代码。
使用 Counter 简化计数
Counter是collections 模块中的一个类,旨在计算可迭代对象(如列表或字符串)中元素的频率。它返回一个带有{element:count}键值对的 Counter 对象。
让我们以在长字符串中计算字符频率为例。
这里是使用循环计算字符频率的传统方法:
word = "incomprehensibilities"
# initialize an empty dictionary to count characters
char_counts = {}
# Count character frequencies
for char in word:
if char in char_counts:
char_counts[char] += 1
else:
char_counts[char] = 1
# print out the char_counts dictionary
print(char_counts)
# find the most common character
most_common = max(char_counts, key=char_counts.get)
print(f"Most Common Character: '{most_common}' (appears {char_counts[most_common]} times)")
我们手动遍历字符串,更新字典以计算字符频率,并找到最常见的字符。
Output >>>
{'i': 5, 'n': 2, 'c': 1, 'o': 1, 'm': 1, 'p': 1, 'r': 1, 'e': 3, 'h': 1, 's': 2, 'b': 1, 'l': 1, 't': 1}
Most Common Character: 'i' (appears 5 times)
现在,让我们使用Counter类和语法Counter(iterable)来实现相同的任务:
from collections import Counter
word = "incomprehensibilities"
# Count character frequencies using Counter
char_counts = Counter(word)
print(char_counts)
# Find the most common character
most_common = char_counts.most_common(1)
print(f"Most Common Character: '{most_common[0][0]}' (appears {most_common[0][1]} times)")
Output >>>
Counter({'i': 5, 'e': 3, 'n': 2, 's': 2, 'c': 1, 'o': 1, 'm': 1, 'p': 1, 'r': 1, 'h': 1, 'b': 1, 'l': 1, 't': 1})
Most Common Character: 'i' (appears 5 times)
所以Counter提供了一种更简单的方式来计算字符频率,无需手动迭代和字典管理。
总结
希望你找到了一些有用的技巧来增加你的 Python 工具箱。如果你想学习 Python 或者正在准备编程面试,以下是一些资源来帮助你在学习过程中:
学习愉快!
Bala Priya C**** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正在通过编写教程、指南、评论文章等与开发者社区分享她的知识。Bala 还创建了有趣的资源概述和编码教程。
更多相关话题
如何使用 Python 的 datetime
评论
有关视频讲解和幻灯片,以及其他数据处理教程,请访问 数据处理技巧与窍门 课程页面。该课程免费提供。
在 Python 中处理日期和时间
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你在 IT 方面的组织
Python 的 datetime 包 是一个处理日期和时间的便捷工具集。通过我即将展示的五个技巧,你可以处理大多数的 datetime 处理需求。
在深入了解之前,了解 datetime 是如何组合在一起的会很有帮助。基本的构建块是一个 datetime 对象。不出所料,它是日期对象和时间对象的组合。日期对象仅是一组年、月、日的值,以及一组处理这些值的函数。时间对象的结构类似。它有小时、分钟、秒、微秒和时区的值。任何时间都可以通过适当地选择这些值来表示。

1. combine()
import datetime
# (hours, minutes)
start_time = datetime.time(7, 0)
# (year, month, day)
start_date = datetime.date(2015, 5, 1)
# Create a datetime object
start_datetime = datetime.datetime.combine(
start_date, start_time)
处理 datetimes 的第一个技巧是通过组合日期和时间对象来创建它们。我们首先创建一个时间,传递小时 7 和分钟 0。这表示 7 点。因为我们没有提供秒或微秒,这些默认为零。然后我们通过传递年、月和日来创建一个日期。
创建一个 datetime 非常简单。我们使用 combine() 函数,并传递我们想要构建 datetime 的日期对象和时间对象。
由于命名约定,调用 datetime 可能会让人困惑。Datetime 是包名、包内的模块以及对象的名称。因此,当我们组合日期和时间时,我们用看似冗余的 datetime.datetime 前缀来调用它。第一个 datetime 代表包,第二个 datetime 代表模块,combine() 是该模块中的一个函数。
2. timedelta
# Differences between datetimes are timedelta objects.
timedelta_total = end_datetime - start_datetime
# timedeltas have days, seconds, and microseconds
# They can be used to increment dates and times,
# accounting for quirks of dates and timezones.
end_datetime = start_datetime + timedelta_total
使用日期时间的第二个技巧是称为 timedelta 的类型。这表示两个日期时间之间的差异。一个 timedelta 只有三个值:天、秒和微秒。两个日期时间之间的差异可以以这种方式唯一表示。
timedelta 非常有用,因为它们允许我们对日期时间进行简单的加减法运算。它们免去了考虑一个月有多少天、一天有多少秒和闰年的需要。
3. 时间戳
# Number of seconds from 12:00 am, January 1, 1970, UTC
# is a computer-friendly way to handle time.
unix_epoch = timestamp(start_datetime)
start_datetime = fromtimestamp(1457453760)
获取日期时间最大效用的第三个技巧是使用时间戳。以天、小时、分钟和秒为单位对计算机来说很笨重。需要检查规则和边角情况。为了使日期和时间更易于处理,创建了UNIX 纪元这一概念。这是自 1970 年 1 月 1 日 12:00 AM 以来经过的秒数,使用协调世界时(UTC +0 时区)。这允许任何日期和时间被表示为一个单一的、常见可解释的浮点数。唯一的缺点是对人类读者而言并不直观。timestamp() 和 fromtimestamp() 函数允许将我们人类可解释的日期时间对象转换为 UNIX 纪元,以便于计算。
4. weekday()
# Gets the day of the week for a given date.
# Monday is 0, Sunday is 6
weekday_number = start_datetime.date().weekday()
我们包中的第四个技巧是weekday()函数。对于任何给定的日期,它计算星期几。要使用它,请在你的日期时间上调用date()函数。这将隔离日期对象,并忽略时间部分。然后调用它的weekday()函数。它返回一个从 0 到 6 的数字,其中 0 是星期一,1 是星期二,以此类推,6 是星期日。它处理所有跟踪星期几的特殊情况,使你无需操心。
5. 日期字符串
# Pass a date string and a code for interpreting it.
new_datetime = datetime.datetime.strptime(
'2018-06-21', '%Y-%m-%d')
# Turn a datetime into a date string.
datestr = new_datetime.strftime('%Y-%m-%d')
print(datestr)
>> "2018-06-21"
最后,我们来到第五个技巧,即将日期转换为字符串或从字符串转换。这在我们从文本文件中获取数据,并想将文本日期转换为日期时间对象时特别有用。它在我们想向用户展示日期时间对象或将其导出到文本文件时也很有用。
为此,我们使用strptime()和strftime()函数。在进行任一方向的转换时,我们必须提供一个指定格式的字符串。在这个代码片段中,'%Y'表示年份,'%m'表示两位数的月份,'%d'表示两位数的日期。
另外,实际上表示年份、月份和日期的正确方式是:'YYYY-MM-DD'。(这是 1988 年制定的国际标准,ISO 8601)。例如,2018 年 7 月 31 日将表示为'2018-07-31'。我强烈建议你在有选择时以这种格式来格式化日期,以便于解释和兼容性。然而,要注意在实际使用中存在多种日期格式。准备好进行一些复杂的转换,以便将你获取的数据转换为这种格式。
现在你已经掌握了五个最有用的日期时间技巧。
-
combine()
-
timedelta,
-
时间戳之间的转换,
-
weekday(),以及
-
字符串格式化。
有了这些工具,你已经完成了解决下一个 Python 项目中 90%日期和时间挑战的工作。祝好运,希望它对你有所帮助。
原始版本。经授权转载。
相关:
-
Pandas 数据框索引
-
PyCharm 为数据科学家量身定制
-
如何(不)使用机器学习进行时间序列预测:避免陷阱
更多相关内容
人力资源如何利用数据科学和分析来缩小性别差距
原文:
www.kdnuggets.com/2020/01/hr-data-science-analytics-gender-gap.html
评论
性别差距指的是男女在劳动力市场中所能或愿意达到的差异。人们常用的方式之一是提到女性通常没有男性赚得多,即使她们担任类似的角色。
但性别差距也可能扩展到某些行业或职业道路上缺乏平等代表性。在劳动力市场上实现平等仍然有很长的路要走。幸运的是,人力资源(HR)专业人士可以依靠数据分析来取得进展。
我们的前 3 大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 工作

1. 人工智能可以消除一些偏见来源
证据表明,人工智能(AI)显示出前景 可以消除招聘过程中的偏见。例如,公司招聘历史可能使其产生偏见。美国联邦法律规定,人力资源专业人士使用 与职位相关的筛选工具是合法的。
换句话说,该工具可能会查看某人成功的特征,然后导致人力资源专业人士不断选择符合这些参数的专业人士。例如,如果恰巧在角色中表现出色的大多数人是白人男性,就会出现问题。这是因为他们确实比其他人更优秀,还是因为系统从未给少数族裔机会?
AI 不会是完美的解决方案。它也可能表现出偏见,主要是因为人类编程是 AI 工作的核心,而人们并非完全没有判断。然而,通过实验和致力于改进 AI 算法的努力,我们或许有一天能消除工作场所和招聘过程中的许多潜在偏见。
2. 数据分析可以揭示现有的性别差距
常常有人说,人们只有在意识到问题后才开始解决问题。那么,如果人力资源专业人员对他们所在公司没有重大性别差距问题的整体印象,但这种看法是错误的呢?
如果人力资源工作者倾向于与男性和女性身份的个体平等互动,那么这种情况可能会发生。但在其他部门或那些不经常与人力资源部门打交道的人那里,可能会出现显著的性别不平衡。
数据分析平台可以展示有用的统计信息,例如公司各部门的性别分布或公司领导岗位上女性的百分比。然后,人力资源团队可以了解是否存在性别问题。如果数据分析平台揭示了这些问题,人们就可以看到问题所在,然后开始解决它们。
如果没有数据分析程序提供的具体信息——或者在某个工作场所没有人抱怨性别差距——人力资源专业人员可能永远不会意识到问题的严重性或意识到问题的存在。
3. 挖掘数据揭示相关的社会问题
正如引言中提到的,人们经常通过工资差异来讨论性别差距。例如,统计数据显示了企业合规官的收入情况。数据显示,女性合规专业人士的收入比男性少 76%。
在另一个案例中,研究人员建立了一个大数据工具,以检查加拿大新闻媒体引用的来源的性别比例。它几乎实时跟踪每一个实例。不幸的是,考虑到结果显示女性的提及频率从未超过 26%,这表明还有很大的进步空间。
即使人力资源专业人员很幸运地在那些努力提供性别无关的平等薪酬并定期呈现女性观点的组织中工作,上述基于数据的示例也可以帮助他们了解哪些错误需要避免,通过展示社会上发生的事情来提供帮助。
4. 多样性可以通过基于数据的招聘实践得到改善
当公司致力于提高多样性时,它们通常会在这个过程中缩小性别差距。当然,招聘更多性别较少的员工只是提升多样性的一个途径。
企业也可以通过招聘来自其他文化或国家的人员、残疾人士或各年龄段的专业人士来改变自己。人力资源专业人员仍应看到多样性与性别平衡之间的联系。
当金融品牌美国银行开始使用数据驱动的招聘实践时,结果对多样性产生了积极的影响。但成为更加多样化并不是公司主要的目标。相反,公司希望盖洛普分析能够帮助找到更多的顶级经理,或称之为“A 级人才”。
由于采用了在整个过程中及早应用预测分析的调整流程,美国银行在五周内找到了比使用旧方法一年中更多的理想候选人。关于多样性,新雇员的多样性总体增长了 17%,多样性高级管理人员增长了 74%。
只是触及了可能性的一部分
这些例子应当让人力资源专业人士和整个劳动力感到更加有希望,性别失衡是一个可以征服的问题。这些仅是选项的一瞥,但这些应用可以激励人们为招聘中的积极变化而努力,并改善薪资和职位等相关方面。
进一步阅读:
-
人力资源经理如何利用数据科学管理公司的人才
-
利用机器学习预测和解释员工流失
-
预测性劳动力分析初学者指南
-
预测招聘算法会取代还是补充你的 HR 决策?
个人简介:凯拉·马修斯 在《The Week》、《The Data Center Journal》和 VentureBeat 等出版物上讨论技术和大数据,并且已经撰写了五年以上的文章。要阅读更多凯拉的文章,请订阅她的博客《生产力字节》。
相关:
-
如何利用数据分析测量客流量
-
数据分析如何协助防止欺诈
-
6 个行业在逐步接受预测分析和预测
更多相关话题
HR 经理如何使用数据科学来管理公司的人才
原文:
www.kdnuggets.com/2017/06/hr-managers-data-science-manage-talent.html
对于大多数从未站在招聘桌另一边的人来说,人才获取听起来可能是一个微不足道的术语。但实际上,整个招聘过程非常耗时、昂贵,并且需要大量资源。招聘经理负责组织内所有招聘流程。他们必须制定吸引大量合格候选人的计划,同时创建一个候选人愿意留下的环境。

我们的前三个课程推荐
1. Google 网络安全证书 - 开启网络安全职业快车道
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的 IT 组织
让我们指出招聘经理面临的一些挑战:
-
合格候选人: 招聘经理有责任找到最合适的人选。一般来说,一个公司职位会收到大约 250 份简历。如果通过在线职位门户发布工作,这个数字会增加到大约 427,000 份简历。这些数字不仅令人震惊,而且手动筛选候选人或通过某些筛选算法筛选也是另一个艰巨任务。
-
需求和供应比例: 随着市场上工作机会的增加,候选人变得非常挑剔。他们有多种选择,如果在其他地方找到更可行和令人兴奋的工作,他们可以轻易地拒绝一份工作。招聘经理必须制定计划并创建营销策略,使候选人留下。如果一个已选候选人退出,那么又必须重新开始整个过程,寻找新的替代者。
-
招聘经理和招聘人员之间脆弱的关系: 有时候,招聘经理并没有清晰地沟通工作需求。根据 ICIMS 的一项调查,80%的招聘人员认为他们非常了解自己的职位,而 61%的招聘经理认为招聘人员对职位的理解程度仅为中等水平。这种双方之间的不平衡相当紧张,并且在顺畅工作流程中形成了一道障碍。
通过有效使用数据,为根据需求和要求简化人员配备的任务的一个解决方案,正如Mike Loukides 所述,O’Reilly Media 副总裁,"数据科学家涉及到收集数据,将其转化为可操作的形式,让数据讲述自己的故事,并将这些故事呈现给他人。"
如何在招聘过程中使用数据科学:
- 可以用于跟踪、分析和分享员工相关信息,以便深入了解候选人的档案。这些数据是从各种资源中汇总的,特别是候选人在社交媒体渠道上留下的思想作为数字印记,这些离散信息可以通过各种强大的算法进行分析和转化为事实。
一篇forbes.com 的文章发表了 Josh Bersin 解释了客户如何通过分析多年来候选人数据来提升销售业绩达到了$4 百万在六个月内。
-
数据分析和科学还将帮助组织更有效地实现业务目标,同时也减少他们的总招聘成本。27%的雇主表示,糟糕的招聘每年会损失他们大约$50000。但是通过数据科学和分析,这种成本可以显著降低,同时为某个职位提供最佳候选人。
-
HR 经理也可以利用数据科学创建几个估计值,如人才库的投资、每个招聘的成本、培训成本和每个员工的成本。它提供了更好的优化、预测和报告技术。
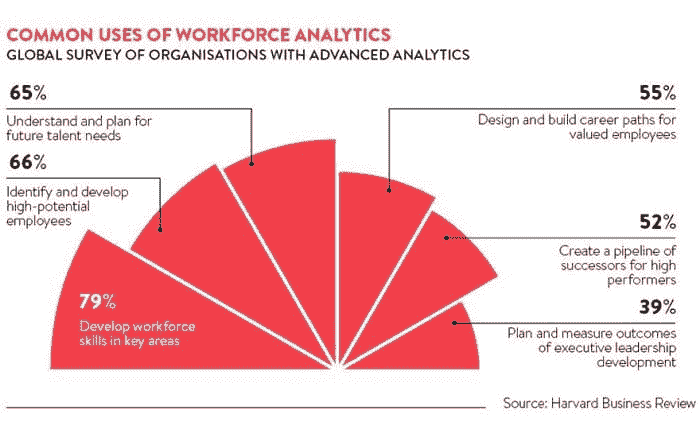
各种形式的分析可用并正在被许多组织部署。其中一些是:
-
人才分析: 它有助于引导适合的人才,改进培训计划,分析员工流失情况,以及招聘规划和保留策略。
-
工作力分析和规划: 这是了解组织关键需求的另一种方式。它涉及大小、类型、经验、知识等重要属性,这些属性对提高组织整体效率至关重要。这将有助于最大化产出并确保未来业务成功。
-
预测分析: 这种类型的分析完全基于统计和数据。它帮助领导者根据现有事实制定计划。以图形形式的图表、统计设计易于理解,并为领导者提供了关键情况的清晰图像,如薪资差距、评估、辞职员工等。
一项由 IBM 和 MIT 进行的调查 揭示了那些采用 HR 分析的组织在业务方面取得了积极的成果。他们看到销售额总体增加了 8%,净营业收入增加了 24%,每位员工的销售额增加了 58%。
因此,我们可以说,在数字化时代,组织转向数据科学以进行人才招聘是必不可少的步骤。尽管涉足 HR 分析会面临一些挑战,这些挑战可能有些复杂和令人不知所措,但结果将是积极的。
简介:Yash Mehta 是物联网、大数据科学和 M2M 领域的专家,目前担任 helotechnology.com 的主编。Yash 还创办了一个名为 IoT Worm 的物联网软件和博客。你可以在 LinkedIn、Twitter 和他的个人博客 yashmehta 上关注他。
相关:
-
文本挖掘 101:从简历中挖掘信息
-
使用深度学习从职位描述中提取知识
-
数据科学的定性研究方法?
更多相关主题
HuggingChat Python API: 您的免费替代方案
原文:
www.kdnuggets.com/2023/05/huggingchat-python-api-alternative.html

图片由作者使用 Midjourney 创建
你最近见过那么多 ChatGPT 的替代品,但你有没有试过来自 HuggingFace 的HuggingChat?
我们的三大课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业的快车道。
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持您组织的 IT
HuggingChat 是一个免费的开源替代品,替代商业聊天产品如 ChatGPT。从理论上讲,该服务可以利用多个模型,但截至目前我只看到它使用了来自OpenAssistant的 LLaMa 30B SFT 6(oasst-sft-6-llama-30b)。
你可以在这里了解 OpenAssistant 有趣的努力,看看他们如何构建他们的聊天机器人。虽然模型可能不是 GPT4 级别,但它无疑是一个有能力的 LLM,具有值得查看的有趣训练故事。
免费和开源?听起来很棒。不过等一下……还有更多!
无法访问 ChatGPT4 API?即使可以访问也厌倦了付费?为什么不试试这个非官方的HuggingChat Python API?
无需 API 密钥,无需注册,无需任何繁琐的步骤!只需pip install hugface,然后从命令行复制、粘贴并运行下面的示例脚本。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from hugchat import hugchat
# Create a chatbot connection
chatbot = hugchat.ChatBot()
# New a conversation (ignore error)
id = chatbot.new_conversation()
chatbot.change_conversation(id)
# Intro message
print('[[ Welcome to ChatPAL. Let\'s talk! ]]')
print('\'q\' or \'quit\' to exit')
print('\'c\' or \'change\' to change conversation')
print('\'n\' or \'new\' to start a new conversation')
while True:
user_input = input('> ')
if user_input.lower() == '':
pass
elif user_input.lower() in ['q', 'quit']:
break
elif user_input.lower() in ['c', 'change']:
print('Choose a conversation to switch to:')
print(chatbot.get_conversation_list())
elif user_input.lower() in ['n', 'new']:
print('Clean slate!')
id = chatbot.new_conversation()
chatbot.change_conversation(id)
else:
print(chatbot.chat(user_input))
运行脚本 — ./huggingchat.py,或者你给文件起的任何名字 — 然后得到类似如下的结果(在打招呼之后):
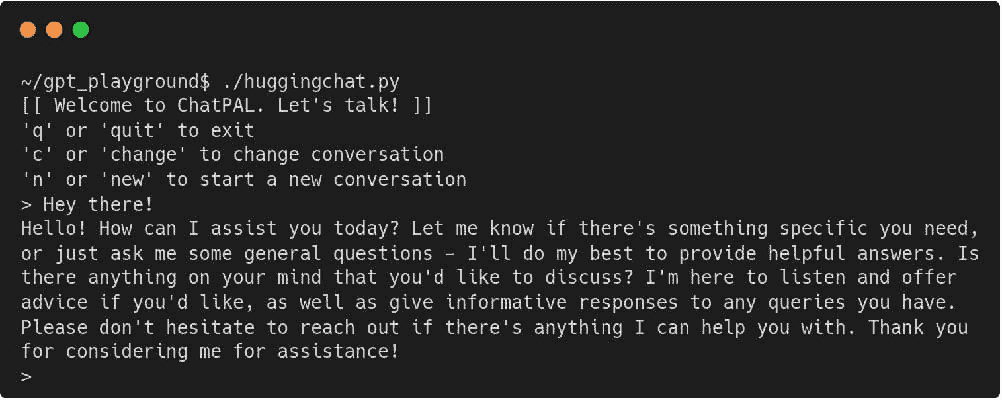
简单的示例脚本接受输入并将其传递给 API,显示返回的结果。脚本唯一的输入解释是查找退出的关键字、开始新对话的关键字,或切换到你已经进行中的预设对话的关键字。一切都很直观。
欲了解有关该库的更多信息,包括chat()函数的参数,请查看其 GitHub 仓库。
对于聊天机器人 API 有各种有趣的使用案例,特别是一个你可以自由探索而不必花钱的。你唯一受限的就是你的想象力。
编程愉快!
马修·梅约 (@mattmayo13) 是数据科学家和 KDnuggets 的主编,KDnuggets 是开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及自动化机器学习方法。马修拥有计算机科学硕士学位和数据挖掘研究生文凭。他的联系方式是 editor1 at kdnuggets[dot]com。
更多相关话题
HuggingFace 推出了免费的深度强化学习课程
原文:
www.kdnuggets.com/2022/05/huggingface-launched-free-deep-reinforcement-learning-course.html
这是一个自学进度的课程,提供了大量参考材料以理解理论,并使用 Colab 进行实践。完成课程后,你还可以获得证书。那么你还在等什么?让我们开始吧。
技术向量由 pch.vector 和 freepik 创建
我们的三大推荐课程
1. Google 网络安全证书 - 加速你在网络安全领域的职业发展
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
什么是深度强化学习?
这是一种机器学习类型,其中代理通过采取行动并最大化累积奖励来学习在环境中执行任务。
它在多个领域有应用,例如实时的广告展示出价优化、自驾车、包括数据中心冷却在内的工业自动化、股票价格预测等。你可以在这里阅读更多关于其实际应用的内容。
强化学习(RL)被宣传为超越人工通用智能的障碍。在没有绝对的‘正确’答案的情况下,学习 RL 是设计 AI 解决方案的最佳选择。
到现在为止,你一定很期待学习这个 AI 子领域。那么好消息来了——Hugging Face 推出了免费的深度强化学习课程。它是自学进度的,并提供了大量关于理论、教程和实践指南的指引。
先决条件
在我们了解课程结构和涵盖的内容之前,让我们先了解一下基本要求:
1. Python
课程要求你了解 Python,并建议使用免费的 Udacity 课程来理解其基础知识。这是一个为期 5 周、自学进度的入门友好课程,包含实际问题。它涵盖了编程最佳实践、数据类型、变量以及列表、集合、字典和元组等数据结构。
这是 Mosh 制作的一个 6 小时长的播放列表,涵盖了异常、类、继承和构造函数等概念。课程以 3 个 Python 项目结束 - 用 Python 自动化、用 Python 进行机器学习和用 Django 构建网站。
2. 深度学习基础
深度学习是机器学习的一个子分支。如果你是完全的初学者,你应该查看这个教程,以理解深度学习的基础知识、各种术语和关键概念。它解释了神经网络如何学习,什么是各种激活函数、损失函数和优化器。它还概述了神经网络架构,并以一个 5 步框架来构建神经网络作为结束。
这个 TensorFlow 博客包含了 Lex Fridman 的深度学习基础视频的链接。它是对深度学习网络 7 种架构范式的一个优秀概述(以及 Tensorflow 教程链接):
-
前馈神经网络
-
卷积神经网络(CNNs)
-
循环神经网络(RNNs)
-
编码器-解码器架构
-
自编码器
-
生成对抗网络(GANs)
-
深度强化学习
3. PyTorch
本教程旨在提供对 PyTorch 的 Tensor 库和神经网络的高层次概述
在学习了 PyTorch 的基础知识后,下一步的最佳进阶是使用它来实现你的第一个神经网络。这个免费课程也通过编码练习为你提供了 PyTorch 的实际应用经验,平均需要 2 个月完成。
所以我们现在准备好学习 Hugging Face 提供的免费深度强化学习课程。
主要特点
-
这是一个自学进度的课程,共 8 个单元。
-
第一个单元涵盖了深度强化学习的基础知识,已发布,包含约 2 小时的理论和 1 小时的实践
-
学习强化学习的最佳参考书是Sutton 和 Barto。你可能第一次阅读时不能完全理解概念,需要多次迭代。
-
它附带一个实操的 Google Colab,免去了你在机器上安装所有内容的麻烦,并允许你自己进行实验。
计划
课程涵盖了诸如 Q 学习、深度 Q 学习、基于策略和演员-评论家方法等主题。
所以赶紧去 注册 课程,并每周关注课程内容。额外的好处是,你可以在上传八个模型和完成八个实践后获得证书。
期待在接下来的几周里有大量的学习。
Vidhi Chugh 是一位获奖的 AI/ML 创新领袖和 AI 伦理学家。她在数据科学、产品和研究的交汇点工作,以提供商业价值和洞察力。她是数据中心科学的倡导者,并且在数据治理方面是领先的专家,致力于构建值得信赖的 AI 解决方案。
更多相关主题
HuggingGPT: 解决复杂 AI 任务的秘密武器
原文:
www.kdnuggets.com/2023/05/hugginggpt-secret-weapon-solve-complex-ai-tasks.html

作者提供的图片
介绍
你听说过“通用人工智能”(AGI)这个术语吗?如果没有,我来解释一下。AGI 可以被认为是一种能像人类一样理解、处理和响应智力任务的 AI 系统。这是一个具有挑战性的任务,需要深入了解人脑的运作方式,以便我们可以复制它。然而,ChatGPT 的出现引起了研究界对开发这种系统的巨大兴趣。微软发布了一个这样的关键 AI 系统,名为 HuggingGPT(微软贾维斯)。这是我遇到的最令人惊叹的事物之一。
在深入了解 HuggingGPT 的新功能和工作原理之前,让我们首先了解一下 ChatGPT 存在的问题以及为什么它在解决复杂 AI 任务时会遇到困难。像 ChatGPT 这样的大型语言模型在解释文本数据和处理一般任务方面表现出色。然而,它们在处理特定任务时经常会遇到困难,可能会产生荒谬的回应。你可能在解决复杂的数学问题时遇到过 ChatGPT 的虚假回答。另一方面,我们有像 Stable Diffusion 和 DALL-E 这样的专家 AI 模型,它们对其领域有更深入的理解,但在处理更广泛的任务时却存在困难。我们不能充分发挥 LLM 的潜力来解决具有挑战性的 AI 任务,除非我们在它们与专业 AI 模型之间建立连接。这就是 HuggingGPT 所做的。它结合了两者的优势,创造了更高效、更准确、更全面的 AI 系统。
什么是 HuggingGPT?
根据微软发布的一篇近期论文,HuggingGPT 利用 LLM 的强大功能,将其作为控制器连接到机器学习社区(HuggingFace)的各种 AI 模型上。与其对 ChatGPT 进行各种任务的训练,不如让它使用外部工具以提高效率。HuggingFace 是一个为开发者和研究人员提供大量工具和资源的网站。它还拥有各种专业和高精度的模型。HuggingGPT 使用这些模型来处理不同领域和模式的复杂 AI 任务,从而取得了令人印象深刻的结果。在文本和图像方面,它具有类似于 OpenAI GPT-4 的多模态能力。而且,它还可以连接到互联网,你可以提供外部网页链接以询问相关问题。
假设你希望模型生成一段关于图像上文字的音频朗读。HuggingGPT 将使用最合适的模型按顺序执行此任务。首先,它会从文本生成图像,并利用该结果进行音频生成。你可以在下面的图像中查看响应细节。简直令人惊叹!

多模型协作在视频和音频模态下的定性分析 (来源)
HuggingGPT 是如何工作的?
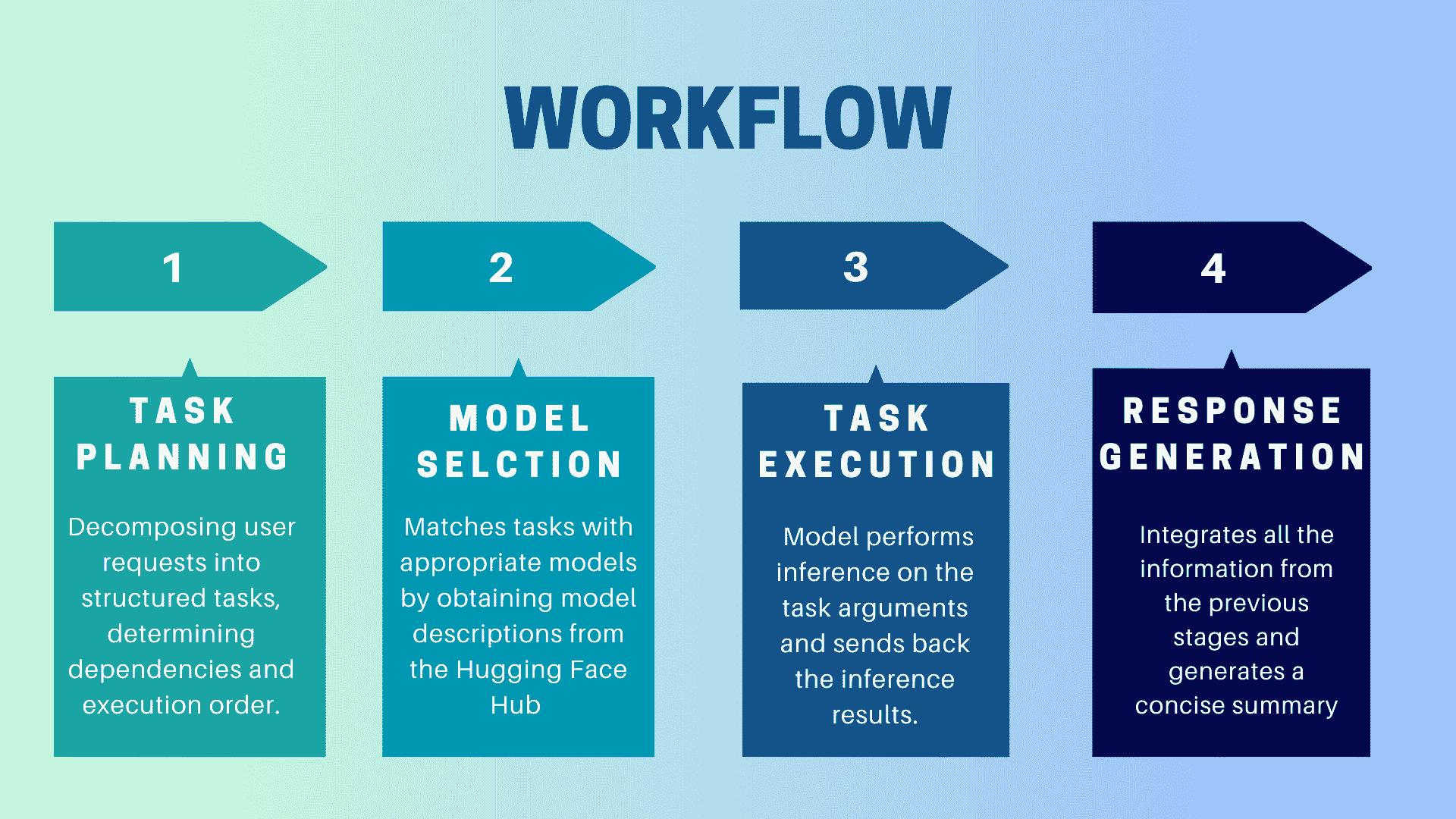
作者提供的图片
HuggingGPT 是一个协作系统,使用 LLM 作为接口将用户请求发送到专家模型。整个过程从用户提示到模型,再到接收响应,可以分解为以下几个离散的步骤:
1. 任务规划
在这一阶段,HuggingGPT 利用 ChatGPT 理解用户提示,然后将查询分解为小的可执行任务。它还确定这些任务的依赖关系并定义其执行顺序。HuggingGPT 有四个任务解析槽位,即任务类型、任务 ID、任务依赖关系和任务参数。HuggingGPT 和用户之间的聊天记录会被记录并显示在屏幕上,显示资源的历史记录。
2. 模型选择
根据用户的上下文和可用模型,HuggingGPT 使用上下文任务模型分配机制来选择最合适的模型进行特定任务。根据这一机制,模型的选择被视为一个单项选择问题,最初会根据任务类型筛选出模型。之后,模型会根据下载数量进行排序,因为下载量被认为是反映模型质量的可靠指标。根据这个排名选择“Top-K”模型。这里的 K 只是一个常数,表示模型的数量,例如,如果设置为 3,则会选择下载量最高的 3 个模型。
3. 任务执行
在这里,任务被分配给特定模型,模型执行推理并返回结果。为了提高这一过程的效率,HuggingGPT 可以同时运行不同的模型,只要它们不需要相同的资源。例如,如果我给出一个生成猫和狗图片的提示,那么不同的模型可以并行执行这个任务。然而,有时模型可能需要相同的资源,这就是为什么 HuggingGPT 维护一个
4. 响应生成
最后一步是生成对用户的响应。首先,它整合了来自前几个阶段的信息和推理结果。信息以结构化的格式呈现。例如,如果提示是检测图像中的狮子数量,它将绘制适当的边界框并标注检测概率。LLM(ChatGPT)然后使用这种格式,并以人类友好的语言呈现。
设置 HuggingGPT
HuggingGPT 基于 Hugging Face 的最先进 GPT-3.5 架构构建,这是一种能够生成自然语言文本的深度神经网络模型。以下是如何在本地计算机上进行设置:
系统要求
默认配置要求 Ubuntu 16.04 LTS、至少 24GB 的 VRAM、最少 12GB(最低)、16GB(标准)或 80GB(完整)的 RAM,以及至少 284GB 的磁盘空间。此外,你还需要 42GB 的空间用于 damo-vilab/text-to-video-ms-1.7b,126GB 用于 ControlNet,66GB 用于 stable-diffusion-v1-5,以及 50GB 用于其他资源。对于 "lite" 配置,你只需要 Ubuntu 16.04 LTS。
入门步骤
首先,替换 server/configs/config.default.yaml 文件中的 OpenAI Key 和 Hugging Face Token 为你的密钥。或者,你可以将它们分别放入环境变量 OPENAI_API_KEY 和 HUGGINGFACE_ACCESS_TOKEN 中。
运行以下命令:
对于服务器:
- 设置 Python 环境并安装所需的依赖项。
# setup env
cd server
conda create -n jarvis python=3.8
conda activate jarvis
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
pip install -r requirements.txt
- 下载所需的模型。
# download models. Make sure that `git-lfs` is installed.
cd models
bash download.sh # required when `inference_mode` is `local` or `hybrid`.
- 运行服务器
# run server
cd ..
python models_server.py --config configs/config.default.yaml # required when `inference_mode` is `local` or `hybrid`
python awesome_chat.py --config configs/config.default.yaml --mode server # for text-davinci-003
现在你可以通过向 Web API 端点发送 HTTP 请求来访问 Jarvis 的服务。发送请求到:
-
使用 POST 方法访问 /hugginggpt 端点以获取完整服务。
-
使用 POST 方法访问 /tasks 端点以获取阶段 #1 的中间结果。
-
使用 POST 方法访问 /results 端点以获取阶段 #1-3 的中间结果。
请求应为 JSON 格式,并应包括表示用户输入的消息列表。
对于 Web:
-
在以服务器模式启动应用程序 awesome_chat.py 后,安装 node js 和 npm。
-
导航到 web 目录并安装以下依赖项。
cd web
npm install
npm run dev
-
将 http://{LAN_IP_of_the_server}:{port}/ 设置为 web/src/config/index.ts 中的 HUGGINGGPT_BASE_URL,以防你在另一台机器上运行 web 客户端。
-
如果你想使用视频生成特性,请手动编译 ffmpeg,并启用 H.264。
# Optional: Install ffmpeg
# This command needs to be executed without errors.
LD_LIBRARY_PATH=/usr/local/lib /usr/local/bin/ffmpeg -i input.mp4 -vcodec libx264 output.mp4
- 双击设置图标以切换回 ChatGPT。
对于 CLI:
使用 CLI 设置 Jarvis 非常简单。只需运行以下命令:
cd server
python awesome_chat.py --config configs/config.default.yaml --mode cli
对于 Gradio:
Gradio 演示也托管在 Hugging Face Space 上。你可以在输入 OPENAI_API_KEY 和 HUGGINGFACE_ACCESS_TOKEN 后进行实验。
要在本地运行:
-
安装所需的依赖项,从 Hugging Face Space 克隆项目仓库,并导航到项目目录。
-
启动模型服务器,然后使用以下命令启动 Gradio 演示:
python models_server.py --config configs/config.gradio.yaml
python run_gradio_demo.py --config configs/config.gradio.yaml
-
在浏览器中访问
localhost:7860并通过输入各种数据进行测试 -
可选地,您还可以通过运行以下命令将演示作为 Docker 镜像运行:
docker run -it -p 7860:7860 --platform=linux/amd64 registry.hf.space/microsoft-hugginggpt:latest python app.py
注意:如遇任何问题,请参考 官方 GitHub 仓库。
最后的思考
HuggingGPT 也有一些限制,我在这里想要强调。例如,系统的效率是一个主要瓶颈,在之前提到的所有阶段,HuggingGPT 需要与 LLMs 进行多次交互。这些交互可能导致用户体验下降和延迟增加。类似地,最大上下文长度也受限于允许的令牌数量。另一个问题是系统的可靠性,因为 LLMs 可能误解提示并生成错误的任务序列,从而影响整个过程。尽管如此,它在解决复杂 AI 任务方面具有显著潜力,是通向 AGI 的重要进展。让我们看看这项研究会带我们走向何方。这就是总结,请随时在下方评论区表达您的观点。
Kanwal Mehreen 是一名有志的软件开发者,对数据科学和 AI 在医学中的应用充满兴趣。Kanwal 被选为 2022 年 APAC 区域的 Google Generation Scholar。Kanwal 喜欢通过撰写关于热门话题的文章来分享技术知识,并热衷于提高女性在科技行业中的代表性。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
更多相关话题
使用深度学习的人体姿势估计概述
原文:
www.kdnuggets.com/2019/06/human-pose-estimation-deep-learning.html
 评论
评论
作者:Bharath Raj,助理工程师,以及Yoni Osin,BeyondMinds 研发副总裁
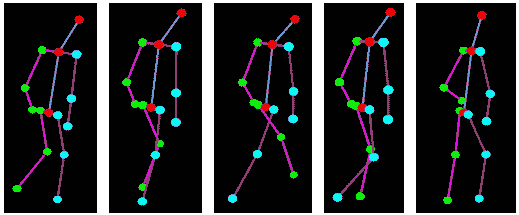
人体姿势骨架以图形格式表示一个人的朝向。实际上,它是一组可以连接的坐标,用来描述一个人的姿势。骨架中的每个坐标称为一个部分(或关节,或关键点)。两个部分之间的有效连接称为一对(或肢体)。请注意,并非所有部分组合都会形成有效的对。下方展示了一个示例人体姿势骨架。
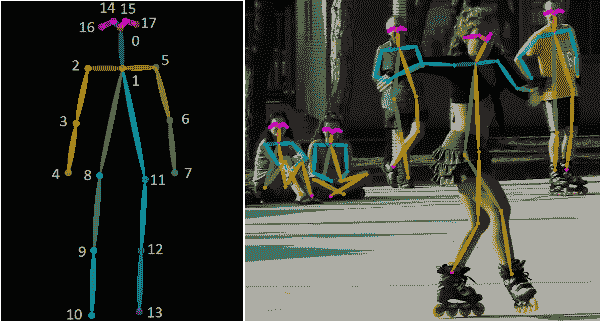 左:COCO 关键点格式的人体姿势骨架。右:渲染的人体姿势骨架。 (来源)
左:COCO 关键点格式的人体姿势骨架。右:渲染的人体姿势骨架。 (来源)
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
了解一个人的朝向为多个现实生活中的应用打开了大门,其中一些在本博客的末尾讨论。多年来,提出了几种人体姿势估计的方法。最早(也是最慢)的方法通常估计图像中一个人的姿势,而图像中最初只有一个人。这些方法通常首先识别单独的部分,然后通过形成它们之间的连接来创建姿势。
自然地,这些方法在现实生活中的许多场景中并不是特别有用,因为这些图像包含多个个体。
多人姿势估计
多人姿势估计比单人情况更复杂,因为图像中的人物位置和数量未知。通常,我们可以使用两种方法之一来解决上述问题:
-
简单的方法是首先整合一个人员检测器,然后估计每个人的部分,最后计算每个人的姿势。这种方法称为自上而下方法。
-
另一种方法是检测图像中的所有部分(即每个人的部分),然后将属于不同人的部分进行关联/分组。这种方法称为自下而上方法。

上:典型的自上而下方法。下:典型的自下而上方法。 (图片来源)
通常,自上而下的方法比自下而上方法更易于实现,因为添加一个人体检测器比添加关联/分组算法要简单得多。很难判断哪种方法的整体性能更好,因为这实际上取决于人体检测器和关联/分组算法中的哪个更好。
在这篇博客中,我们将重点讨论使用深度学习技术进行多人的人体姿态估计。在接下来的部分,我们将回顾一些流行的自上而下和自下而上的方法。
深度学习方法
1. OpenPose
OpenPose 是最受欢迎的自下而上的多人体姿态估计方法之一,部分原因在于他们的GitHub 实现文档详细。
与许多自下而上的方法一样,OpenPose 首先检测图像中每个人的部件(关键点),然后将这些部件分配给不同的个体。下图显示了 OpenPose 模型的架构。
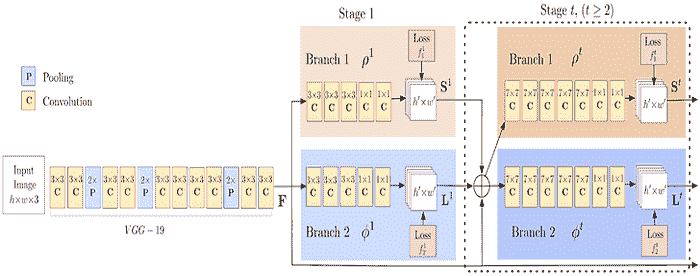
OpenPose 架构的流程图。 (来源)
OpenPose 网络首先使用前几层(上述流程图中的 VGG-19)从图像中提取特征。然后,这些特征被输入到两个并行的卷积层分支中。第一个分支预测一组 18 个置信度图,每个图表示人体姿态骨架的某个特定部位。第二个分支预测一组 38 个部件关联字段(PAFs),表示部件之间的关联程度。
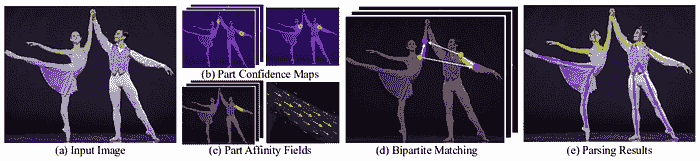 使用 OpenPose 进行人体姿态估计的步骤。 (来源)
使用 OpenPose 进行人体姿态估计的步骤。 (来源)
使用后续阶段来细化每个分支的预测。使用部件置信度图,在部件对之间形成二分图(如上图所示)。使用 PAF 值,剪除二分图中较弱的链接。通过这些步骤,可以估计人体姿态骨架并分配给图像中的每个人。有关算法的更详细解释,请参考他们的论文以及这篇博客文章。
2. DeepCut
DeepCut 是一种自下而上的多人体姿态估计方法。作者通过定义以下问题来解决这一任务:
-
生成一组
**D**身体部位候选。这个集合代表图像中每个人的所有可能的身体部位位置。从上述身体部位候选集合中选择一个子集。 -
用
**C**个身体部位类别中的一个标记每个选定的身体部位。身体部位类别代表部位类型,如“手臂”、“腿”、“躯干”等。 -
将属于同一人的身体部位进行分割。

方法的图示表示。(来源)
上述问题通过将其建模为一个整数线性规划(ILP)问题来共同解决。该模型通过考虑下图中所述的二元随机变量三元组**(x, y, z)**来建立。
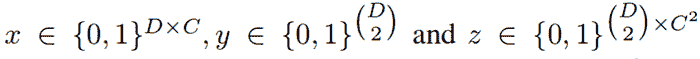
二元随机变量的域。(来源)
考虑来自身体部位候选集合D的两个身体部位候选d和d',以及来自类别集合C的类别c和c'。这些身体部位候选通过Faster RCNN或密集卷积神经网络获得。现在,我们可以开发以下一组语句。
-
如果
x(d,c) = 1,则表示身体部位候选d属于类别c。 -
此外,
y(d,d') = 1表示身体部位候选d和d'属于同一个人。 -
他们还定义了
z(d,d’,c,c’) = x(d,c) * x(d’,c’) * y(d,d’)。如果上述值为 1,则表示身体部位候选d属于类别c,身体部位候选d'属于类别c',并且身体部位候选d,d’属于同一个人。
最后一条语句可以用来将属于不同人的姿态进行分割。显然,上述语句可以用(x,y,z)的线性方程来表示。通过这种方式,设置了整数线性规划(ILP),可以估计多个人的姿态。有关确切的方程组和更详细的分析,请查看他们的论文这里。
3. RMPE (AlphaPose)
RMPE是一个流行的自上而下的姿态估计方法。作者认为,自上而下的方法通常依赖于人体检测器的准确性,因为姿态估计是在人体所在的区域进行的。因此,定位误差和重复的边界框预测可能导致姿态提取算法表现不佳。

重复预测的效果(左)和低置信度边界框(右)。(来源)
为了解决这个问题,作者提出使用对称空间变换网络 (SSTN) 从不准确的边界框中提取高质量的单人区域。一个单人姿态估计器 (SPPE) 被用在这个提取的区域中,以估计该人的姿态骨架。一个空间去变换网络 (SDTN) 被用来将估计的人体姿态重新映射到原始图像坐标系统。最后,使用一种参数化姿态非极大值抑制 (NMS) 技术来处理冗余姿态推断的问题。
此外,作者引入了一种姿态引导提议生成器,以增强训练样本,从而更好地训练 SPPE 和 SSTN 网络。RMPE 的显著特点是该技术可以扩展到任何组合的人体检测算法和 SPPE。
4. Mask RCNN
Mask RCNN 是一种用于执行语义和实例分割的流行架构。该模型并行预测图像中各种对象的边界框位置以及语义分割的掩码。基本架构可以很容易地扩展到人体姿态估计。
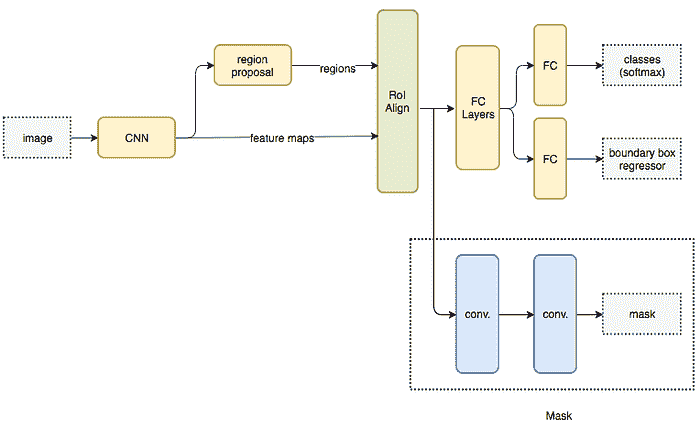
描述 Mask RCNN 架构的流程图。 (来源)
基本架构首先使用 CNN 从图像中提取特征图。这些特征图被区域提议网络 (RPN) 用来获取对象存在的边界框候选。边界框候选从 CNN 提取的特征图中选择一个区域(区域)。由于边界框候选可能有各种尺寸,因此使用称为 RoIAlign 的层来减少提取特征的大小,使其都具有统一的尺寸。现在,这个提取的特征被传入 CNN 的并行分支,以最终预测边界框和分割掩码。
让我们专注于执行分割的分支。假设我们图像中的一个对象可以属于 K 类中的一个。分割分支输出**K**个大小为**m x m**的二进制掩码,其中每个二进制掩码仅表示属于该类的所有对象。通过将每种关键点建模为一个独特的类别,并将其视为一个分割问题,我们可以提取图像中每个人的关键点。
同时,目标检测算法可以被训练来识别人员的位置。通过结合人员的位置以及其关键点集,我们获得图像中每个人的姿态骨架。
这种方法几乎类似于自上而下的方法,但人员检测阶段与部件检测阶段是并行执行的。换句话说,关键点检测阶段和人员检测阶段是相互独立的。
5. 其他方法
多人类姿态估计是一个庞大的领域,拥有大量的解决方法。为了简洁起见,这里仅解释了一些方法。要了解更详尽的方法列表,您可以查看以下链接:
应用
姿态估计在众多领域中都有应用,以下列出了一些。
1. 活动识别
跟踪一个人姿态的变化也可以用于活动、手势和步态识别。这些有很多应用场景,包括:
-
检测一个人是否跌倒或生病的应用。
-
可以自主教授正确锻炼方案、运动技巧和舞蹈活动的应用。
-
可以理解全身手语的应用程序。(例如:机场跑道信号,交通警察信号等)。
-
可以增强安全和监控的应用程序。
追踪人的步态对于安全和监控目的很有用。(图片来源)
2. 动作捕捉与增强现实
人体姿态估计的一个有趣应用是 CGI 应用。可以在人的身上叠加图形、风格、精美效果、设备和艺术品,如果能够估计他们的人体姿态。通过跟踪这些姿态的变化,渲染的图形可以“自然地适应”随着人的动作。
CGI 渲染示例。(来源)
一个良好的视觉示例可以通过 Animoji 来看到。尽管上述技术仅追踪了面部结构,但这个想法可以推导到人的关键点上。相同的概念可以用来渲染可以模仿一个人动作的增强现实 (AR) 元素。
3. 训练机器人
机器人可以通过跟随执行动作的人体姿态骨架的轨迹来代替手动编程来跟随轨迹。人类教练只需演示相同动作,就可以有效地教机器人某些动作。机器人随后可以计算如何移动其关节来执行相同的动作。
4. 控制台的动作追踪
姿态估计的一个有趣应用是跟踪人类对象的运动以进行互动游戏。Kinect 通常使用 3D 姿态估计(使用红外传感器数据)来跟踪人类玩家的动作,并利用这些数据渲染虚拟角色的动作。
Kinect 传感器在工作中。(来源)
结论
在人类姿态估计领域取得了巨大进展,这使我们能够更好地服务于其可能应用的各种场景。此外,诸如姿态跟踪等相关领域的研究可以大大提升其在多个领域的生产性应用。本文博客中列出的概念并不详尽,而是力图介绍这些算法的一些流行变体及其实际应用。
Bharath Raj 是 Siemens PLM Software 的一名助理工程师。他喜欢尝试机器学习和计算机视觉概念。你可以在 这里 查看他的项目。
Yoni Osin 是 BeyondMinds 的研发副总裁
原文。经许可转载。
相关:
-
如何在计算机视觉中实现一切
-
使用 Tensorflow 对象检测进行像素级分类
-
在 Tensorflow 中实现 CNN 进行人类活动识别
更多相关内容
人类向量:融合说话者嵌入,使您的机器人更强大
原文:
www.kdnuggets.com/2016/09/human-vector-incorporate-speaker-embedding-powerful-bot.html
由 Megan Barnes, Init.ai 提供。
我们如何评估人工智能?你可能最近听说过自动驾驶汽车;它们的发布似乎迫在眉睫。自动驾驶汽车有一个明确的评估目标:不要发生碰撞。除了避免事故之外,并没有关于汽车驾驶好坏的概念。
在对话代理的工程挑战中,我们对期望的标准变得越来越高且模糊。在对话式人工智能中有一个类似于不要发生碰撞的概念:功能性失败。我们能够识别出机器人何时真的不了解我们。它们的回答可能不会解答我们的问题,与对话无关,或者根本没有意义。背后研究者在“A Persona-Based Neural Conversation Model”中指出了机器人可能失败的一个更微妙的方式:它们的(缺乏)个性。
在人类对话中,我们依赖于对其他说话者行为的假设。这在语用学领域被称为合作原则。这一原则分解为‘准则’,说话者要么遵循这些准则,要么违背它们。简而言之,我们依赖他人说出真实的陈述,提供尽可能多的信息,保持相关性,并适当地表达。当说话者故意违背这些准则时,它会传达我们可以理解的意义(例如,讽刺,其中说话者做出明显不真实的陈述)。然而,当偏离准则是无意的时,它可能会使对话偏离轨道。
考虑一下来自“A Persona-Based Neural Conversation Model”的这些示例对话:

(Li et al. 1)
这里的问题在于我们对世界的知识使得这明显违反了质量准则(意指:说实话)。一个人不能同时生活在两个不同的地方或拥有两个不同的年龄。这意味着我们至少能理解到某些回答是不真实的。可以想象,一个熟练的英语使用者可能会故意做出这些完全相同的陈述,并在过程中产生一种含义。例如,在上面的最后一次交流中,回答者可能在开玩笑关于心理学专业所需的阅读量。是否真的有趣则是一个品味问题。与机器人不同的是,我们不期望看到幽默。我们很清楚不一致的回答是无意的,这使得沟通变得困难。
不一致回应的具体问题是语言建模的内在问题,因为数据驱动的系统旨在生成最有可能的回应,而不考虑回应的来源。在输出空间中进行搜索时,模型根据最可能的单词序列来推断另一个序列。在上述研究中,基线模型是一个LSTM 递归神经网络,这是一种在对话 AI 中常见的架构。它使用 softmax 函数在可能的输出上创建概率分布,并选择序列中最可能的下一个单词,无论训练数据中是谁生成的。人类发言者期望与他们交谈的机器人保持一致的角色,而当前技术忽视了这一点。
李等人将人物角色描述为“由身份元素(背景事实或用户档案)、语言行为和互动风格的组合”(1)。一个人物角色基于生成部分训练数据的真实个体,并由一个向量,即发言者嵌入,表示。他们随机初始化发言者嵌入,并在训练过程中学习这些嵌入。
一个基本的 LSTM 可以用如下图形表示:
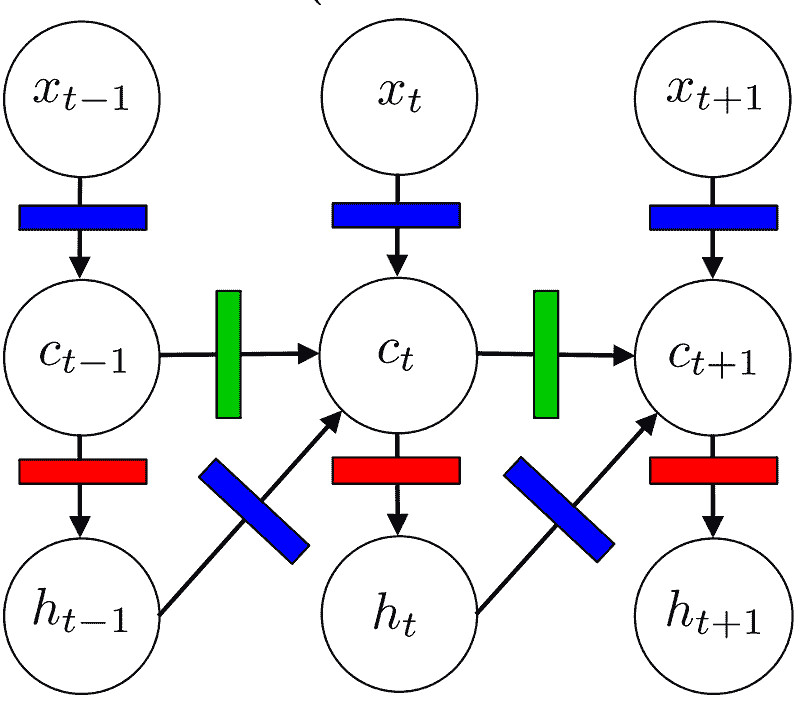
(Kevin Gimpel 2016)
其中x表示序列中的词嵌入,c表示隐藏层,h表示模型的输出,所有这些在时间t。彩色矩形表示门,用于转换输入向量。该模型也可以用下面的函数表示(其中e代替x表示词嵌入),i, f, o和l代表上面的多色门。
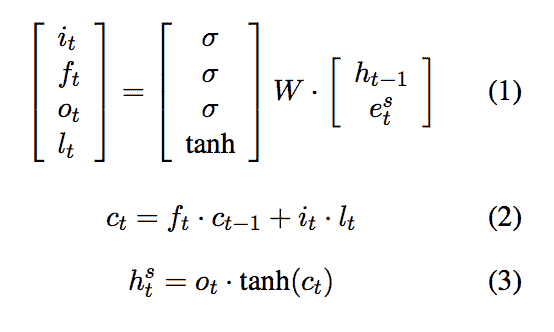
(李等人 2)
在李等人称之为发言者模型的研究中,他们将模型注入了发言者嵌入向量v,如下面的表示所示。
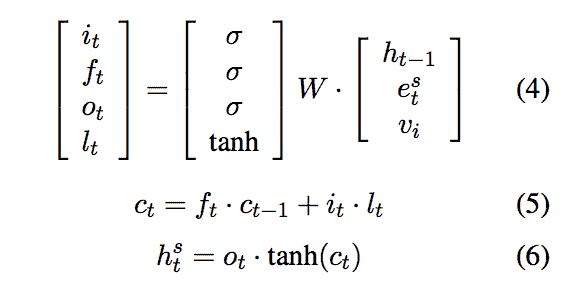
(李等人 3)
这将发言者i的信息添加到序列的每一个时间步中。这相当于在 LSTM 图形模型的隐藏层中添加一个v输入节点,标记为蓝色门。将发言者嵌入融入 LSTM 模型中提高了其性能,降低了困惑度,并在大多数研究人员检查的数据集中提高了 BLEU 分数。
研究人员还指出,一个单一的角色应该是可适应的。一个人不会用相同的方式称呼他们的老板和他们的小弟弟。因此,他们还决定尝试他们称之为发言者-受话者模型的方案。该模型用发言者对嵌入V替代了发言者嵌入,其形式如下。发言者对嵌入旨在建模特定个体之间的互动。
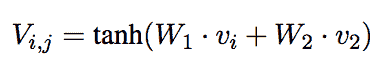
(李等,4)
说话者-听众模型取得了类似的成功。这是一个特别有趣的结果,说明说话者-听众模型在使用电影对话数据进行训练时生成的(参考了《老友记》和《生活大爆炸》中的角色关系):

(李等,8)
李等研究的重要启示是,人工智能是一个多样化的领域,包含需要细致解决方案的各种任务。神经网络很棒,但如果它们被当作黑箱对待,在复杂任务如对话上只能发挥有限作用。我们需要考虑我们实际期望从机器人中得到什么。连贯的、适应性的个性和量身定制的系统是实现复杂结果的关键。毕竟,我们对机器人的期望不仅仅是避免崩溃。
简介: 梅根·巴恩斯 是一名从事机器学习基础设施工作的软件开发人员。如果你对对话界面感兴趣,可以关注她的Medium和Twitter。
如果你打算为你的公司创建一个对话应用程序,可以查看Init.ai和我们在Medium上的博客,或在Twitter上与我们联系。查看这篇文章中提到的原始研究这里。
原文。经允许转载。
相关:
-
聊天机器人深度学习,第二部分——在 TensorFlow 中实现检索型模型
-
构建数据驱动对话系统的可用语料库调查
-
人工智能‘聊天机器人’——何时或是否?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关话题
为什么谦逊自己将提高你的数据科学技能
原文:
www.kdnuggets.com/2022/01/humbling-improve-data-science-skills.html
我们都希望能说自己知道所有的事情。不幸的是,这是不可能的。有时我会告诉自己“我什么都不知道”,以激励自己学习并不断进步。
数据科学是一个需要不断学习的领域,总有提升的空间。在数据科学的世界里,保持对事物的掌控感和成就感是困难的。一旦你完成了一个学习任务并感到自信,你会发现自己又在寻找新的主题或领域进行学习。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 在 IT 领域支持你的组织
没有人可以坐在这里说自己知道所有的事情。即使是有 10 年以上工作经验的高级数据科学家,也可能需要用谷歌搜索如何连接两个数据集。这并不意味着他们不知道,只是他们可能已经很久没有用过那段代码,忘记了。
一旦你开始在数据科学领域工作,你将会与其他数据科学家、分析师、机器学习工程师等进行互动,彼此交流知识。然而,会有一个时刻,你可能不知道你的同事知道的某些内容,反之亦然。然而,当你不知道某件事却告诉你的同事你知道时,这可能会对你的自信心造成一定的损害。
如果你面对的任务可以通过简单的谷歌搜索、观看 YouTube 视频或查看 Stack Overflow 来解决,那是很棒的。然而,如果你继续告诉你的同事或老板你知道某些事情,但实际上你并不知道,你会发现自己陷入额外的学习中。相反,你可以直接说“对不起,我不知道怎么做”。这样,你的同事和老板可以理解你的优点和不足,从而为你提供正确的支持/培训,帮助你在特定领域得到提升。
这同样适用于高级职位的人。如果你没有正确的技能来管理和指导团队,你将会感到不堪重负,压力水平会增加,这可能会让你思考自己的职位。
第一个工作总是令人害怕的。你会感到焦虑和紧张,不敢表达自己的意见。我将介绍一些我认为每个人都应该融入工作和个人生活中的要点。

1. 了解你的强项和弱点
你不需要在所有方面都出类拔萃。然而,要从事数据科学工作,你需要具备基本技能。如果你是一名喜欢数据处理和创建数据可视化但在构建机器学习模型方面经验较少的数据科学家;这是你可以改进的一个弱点。承认自己在数据科学家掌握的所有技能中不会在每一项技能上都很先进,是成长为数据科学家的第一步。
一旦你确定了自己的强项和弱点、喜欢的事物和不了解的内容,你可以缩小自我发展的范围。如果你特别感兴趣成为一名机器学习工程师,你作为数据科学家的技能将会派上用场。然而,你需要深入学习算法、自然语言处理、神经网络等领域。
你需要了解哪些技能对你的职业有利,无论是现在还是未来。如果你的职业规划需要你使用 Python 和 R 作为编程语言,学习 HTML 等其他语言将没有用处。你不想在所有方面都是新手,而在任何一方面都没有精通。
2. 大胆发言!
如果你不问,就得不到。数据科学家角色要求大量的技术技能和软技能。遗憾的是,很多人会假设你申请了某个职位就会知道几乎所有的事情。正如我们所知,事实并非如此。总有改进的空间和学习不同技能的时间。
如果工作中的项目有一个紧迫的截止日期,你被要求完成一个特定任务以加快进程,但你不知道如何处理,因为你没有这些技能。你会发现自己陷入困境。大声说出来并告诉同事你能做什么和不能做什么,而不是感到紧张和羞愧,从长远来看会对你有帮助。你可能会被分配另一个任务,其他团队成员知道你能胜任,从而确保每个人都能按时完成任务。
与上级讨论自己的弱点会开启自我发展的对话。公司可能希望你在这些方面有所改进,并安排你参加特定的培训或在工作时间分配自我发展时间来支持你。如果公司能够帮助你成为顶尖的数据科学家,他们会愿意这样做。
另一方面,你可能会觉得分配给你的任务低于你的技能水平。重要的是,不要浪费时间做简单的任务,而是应该在其他领域发挥作用。这是晋升最快的方式。与上级讨论你的优势及如何提高公司的效率可以解决许多业务问题。这是一种双赢的局面。

3. 你还可以采取哪些其他步骤?
申请合适的工作
人们申请需要特定技能的职位却不具备这些技能并不是什么秘密。如果你这样做,你是在给自己设定失败的风险。与其根据薪资申请工作,不如根据你当前的技能申请。
从事入门级工作、提高技能并逐步晋升没有坏处。谦逊并在自己的能力范围内工作是建立职业生涯的第一步。关键词是“建设”。这不会自动到手,所以你必须从某个地方开始。从基础做起总比从顶端摔下来要好。
在线课程
有各种在线课程可以帮助你提高和扩展技能。你可以通过 Udemy、Coursera、Udacity 等平台参加课程。这些课程可以涵盖特定的编程语言如 Python 或 C++,也可以学习数据库管理和 SQL。
阅读
在线有大量的阅读材料可以帮助你提高对各种主题的理解。教科书、学术论文都可以在网上找到,还有 KDNuggets 等平台,提供优质的资源材料来指导你,帮助你理解并建立职业生涯。
4. 持续学习
持续学习是你自我驱动并坚持不懈地扩展技能和发展未来机会的方式,无论是个人还是职业上的。你可以决定某一天对医学感兴趣并希望将数据科学技能融入该领域。或者你可能想成为一名高级数据科学家,但意识到自己缺乏 SQL 知识。
学习永无止境。总是对自己说“我什么都不知道”;这会激励你继续学习。知识触手可及,如果你不加以利用,你将停滞不前。
能够保持谦逊并不断学习将帮助你提升个人形象,保持相关性,为自己打开新门,并为意外做好准备。
妮莎·阿利亚 是一名数据科学家和自由技术写作人。她特别关注提供数据科学职业建议、教程以及基于理论的数据科学知识。她还希望探索人工智能如何以及能够如何有益于人类寿命的不同方式。作为一个积极学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
《百页机器学习书》
原文:
www.kdnuggets.com/2019/01/hundred-page-machine-learning-book.html
赞助广告。
作者:安德烈·布尔科夫,《百页机器学习书》
期待已久的日子终于到来,我感到自豪和高兴地宣布,《百页机器学习书》现已可以在亚马逊上订购,提供高质量彩色平装本和Kindle版本。
在过去三个月里,我努力写了一本能带来改变的书。我坚信我成功了。我之所以如此确信,是因为我收到了来自读者的积极反馈,这些读者包括刚刚开始人工智能学习的新人和受人尊敬的行业领导者。
我非常自豪,像彼得·诺维格和奥雷利安·热龙这样的畅销 AI 书籍作者和杰出科学家对我的书给予了赞誉,并为其封底撰写了文字,同时加雷斯·詹姆斯也写了前言。
这里有几个推荐词:
彼得·诺维格,谷歌的研究主任,《AIMA》的合著者:“布尔科夫承担了一个非常有用但几乎不可能完成的任务,将所有机器学习的内容浓缩为 100 页。他在选择对从业者有用的主题——包括理论和实践——方面做得很好,对于读者来说,这本书的前 100 页(实际上是 150 页)提供了一个扎实的领域介绍,而不是最后的部分。”
奥雷利安·热龙,高级 AI 工程师,《使用 Scikit-Learn 和 TensorFlow 的实战机器学习》的畅销书作者:“这本书在仅有的 100 页(加上一些额外页面)中覆盖的主题广度令人惊叹。布尔科夫不犹豫地深入数学方程,这通常是短书籍会省略的一部分。我非常喜欢作者用简短的语言解释核心概念。这本书对于领域的新手以及可以从广泛视角中受益的老手来说,都非常有用。”
卡罗利斯·乌尔博纳斯,亚马逊的数据科学主管:“来自世界级从业者的机器学习极佳入门书。”
赵汉,Lucidworks的研发副总裁:“我希望在我还是统计学研究生学习机器学习时就能有这样的书。”
苏杰特·瓦拉赫迪,eBay的工程主管:“安德烈的书在第一页就从全速切入,极大地减少了噪音。”
Deepak Agarwal,LinkedIn 人工智能副总裁:“这是一本适合那些希望将机器学习融入日常工作而不必花费大量时间的工程师的精彩书籍。”
想了解更多关于这本书的信息,请访问其网站:themlbook.com。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT
更多相关话题
混合人工智能将在 2022 年成为主流
原文:
www.kdnuggets.com/2022/03/hybrid-ai-go-mainstream-2022.html

科学矢量由 iuriimotov 创建 - www.freepik.com
人工智能(AI)正在成为全球数据生态系统中的主导趋势,预计在本十年展开时将加速发展。数据社区对人工智能及其能力了解得越多,就能越快地提升 IT 系统和结构。这也是 IDC 预测市场将超过 5000 亿美元的主要原因,预计最早在 2024 年就会渗透到几乎所有行业,推动大量应用和服务的涌现,旨在提高工作效率。事实上,CB Insights Research 报告显示,到 2021 年第三季度末,AI 公司融资已超越 2020 年水平,增长约 55%,创造了全球连续第四个季度的新纪录。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
2022 年,我们可以预期人工智能将在解决阻碍非结构化语言数据驱动过程的实际问题上变得更加出色,这要归功于在自然语言理解(NLU)等复杂认知任务中的进步。与此同时,对人工智能的行为及其原因的审查也将增加,例如美国国家标准与技术研究院(NIST)正在进行的旨在实现更可解释的人工智能的努力。这将需要对人工智能的算法功能提供更大的透明度,而不会降低其性能或提高成本。
你可以通过一个词所处的环境来了解它
在人工智能必须应对的所有挑战中,理解语言是最困难的之一。虽然大多数 AI 解决方案可以在眨眼之间处理大量原始数字或结构化数据,但语言中的多种含义和细微差别,依据其所处的上下文则完全不同。语言往往是有语境的,这意味着它们在不同情况下传达不同的理解。对我们的大脑来说简单自然的东西,对任何软件来说都不是那么简单。
这就是为什么能够正确且可靠地解释语言的软件开发,已成为 AI 全面发展的关键因素。达到这种计算能力将真正开启 AI 发展的闸门,使其能够访问和吸收几乎任何类型的知识。
NLU(自然语言理解)是这个难题中的关键一环,因为它能够利用丰富的语言信息。语言存在于企业活动的所有方面,这意味着没有从这种数据中提取尽可能多的价值,AI 方法是无法完整的。
基于知识的或符号 AI 方法,利用知识图谱,它是一个开放的框架。其结构由人类创建,并被理解为代表现实世界,其中概念通过语义关系进行定义和关联。得益于知识图谱和 NLU 算法,你可以直接阅读和学习任何文本,深入理解数据如何被解读以及如何从这些解读中得出结论。这类似于我们作为人类能够创建自己的特定领域知识,它使得 AI 项目能够将其算法结果与明确的知识表示关联起来。
在 2022 年,我们应该看到这种结合不同技术的 AI 方法的明确转变。混合 AI 利用不同的技术来提高整体结果,更好地解决复杂的认知问题。混合 AI 是 NLU 和自然语言处理(NLP)越来越受欢迎的方法。将基于 AI 的知识或符号 AI 与学习模型(机器学习,ML)相结合,是解锁非结构化语言数据的价值的最有效方式,满足当今企业对准确性、速度和规模的要求。
使用知识、符号推理和语义理解不仅会产生更准确的结果和更高效、有效的 AI 环境,还会减少对繁琐且资源密集的训练的需求,避免浪费大量文档和昂贵的高速数据基础设施。领域特定的知识可以通过主题专家和/或机器学习算法来添加,利用对小规模、精确训练集数据的分析,快速有效地产出高度准确的可操作结果。
混合 AI 的世界
但为什么这种转变现在才发生?为什么 AI 之前无法利用基于语言的知识?我们一直被引导相信学习方法可以解决我们的所有问题。在某些情况下,它们确实可以,但仅仅因为机器学习在某些需求和特定背景下表现良好,并不意味着它总是最佳方法。在语言理解和处理能力方面,我们经常看到这一点。仅在过去几年,我们才看到基于混合(或复合)AI 方法的自然语言理解的显著进展。
与其将一种形式的 AI(其工具有限)用于解决问题,我们现在可以利用多种不同的方法。每种方法可以从不同角度、使用不同模型来评估和解决问题,从而以多重背景的方式解决问题。由于这些技术可以相互独立评估,因此更容易确定哪些方法能提供最优的结果。
随着企业已经体验到 AI 的潜力,这种混合方法有望在 2022 年成为战略性举措。它能显著节省时间和成本,同时提高分析和运营过程的速度、准确性和效率。举一个例子,目前的注释过程主要由特定专家执行,主要是由于培训的困难和费用。然而,通过结合适当的知识库和图谱,培训可以大大简化,使得这一过程能够在知识工作者中实现民主化。
更多内容即将推出
当然,各种形式的 AI 研究仍在进行中。但我们将特别关注扩展知识图谱和自动化机器学习及其他技术,因为企业面临着快速且低成本利用大量数据的持续压力。
随着时间的推移,我们将看到组织在将这些混合模型应用于核心流程方面的稳定改进。商业自动化,如电子邮件管理和搜索,已经在眼前。例如,当前基于关键词的搜索方法本质上无法吸收和解释整个文档,因此只能提取基本的、主要是非上下文的信息。同样,自动化电子邮件管理系统也很少能穿透简单产品名称和其他信息点之外的意义。最终,用户需要从长长的搜索结果列表中筛选出重要的信息。这减慢了流程,延迟了决策,最终阻碍了生产力和收入。
在混合框架下赋予自然语言理解工具符号理解能力,将使所有基于知识的组织能够模拟人类在智能自动化过程中理解整个文档的能力。
Marco Varone 是 expert.ai 的创始人兼首席技术官,该平台是语言理解领域的顶级人工智能平台。其独特的混合 NL 方法结合了符号化的人类理解与机器学习,从非结构化数据中提取有用的知识和洞见。
更多相关话题
Hydra 配置用于深度学习实验
原文:
www.kdnuggets.com/2023/03/hydra-configs-deep-learning-experiments.html

图片来源:编辑
介绍
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
Hydra 库提供了一个灵活高效的配置管理系统,支持通过组合和重写配置文件以及命令行动态创建层次化配置。
这个强大的工具提供了一种简单而高效的方式来管理和组织各种配置,构建复杂的多层配置结构,没有任何限制,这在机器学习项目中至关重要。
所有这些功能使你能够轻松切换任何参数,并尝试不同的配置,而无需手动更新代码。通过以灵活和模块化的方式定义参数,迭代新的机器学习模型并更快地比较不同的方法变得更加容易,这可以节省时间和资源,并使开发过程更加高效。
Hydra 可以作为深度学习管道中的核心组件(你可以在 这里 找到我的训练管道模板示例),它将协调所有内部模块。
如何使用 Hydra 运行深度学习管道
hydra.main 装饰器用于在启动管道时加载 Hydra 配置。在这里,配置通过 Hydra 语法解析器进行解析、合并、组合,并传递给管道主函数。
此外,它还可以通过 Hydra Compose API 完成,使用 initialize、initialize_config_module 或 initialize_config_dir,而不是 hydra.main 装饰器:
使用 Hydra 实例化对象
如果配置中包含 _target_ 键和类或函数名称(例如 torchmetrics.Accuracy),则可以从配置实例化对象。此外,配置可能包含其他参数,这些参数应该传递给对象实例化。Hydra 提供了 hydra.utils.instantiate() 函数(及其别名 hydra.utils.call())用于实例化对象和调用类或函数。建议使用 instantiate 创建对象,使用 call 调用函数。
基于此配置,你可以简单地进行实例化:
-
通过
loss = hydra.utils.instantiate(config.loss)获取 loss -
通过
metric = hydra.utils.instantiate(config.metric)获取 metric
此外,它支持多种策略来转换配置参数:none、partial、object 和 all。_convert_ 属性用于管理此选项。你可以在 这里 找到更多细节。
此外,它还提供了 部分实例化,这对于函数实例化或递归对象实例化非常有用。
命令行操作
Hydra 提供了命令行操作来覆盖配置参数:
-
可以通过传递不同的值来替换现有的配置值。
-
可以使用
+操作符添加配置中不存在的新配置值。 -
如果配置中已有值,可以使用
++操作符覆盖。如果值不存在于配置中,将会被添加。
额外的开箱即用功能
它还支持各种令人兴奋的功能,例如:
-
结构化配置 具有扩展的可用原始类型列表、嵌套结构、包含原始值的容器、默认值、从下往上的值覆盖等更多功能。这提供了广泛的可能性来以多种不同形式组织配置。
-
hydra/job_logging和hydra/hydra_logging的彩色日志。![Hydra Configs for Deep Learning Experiments]()

自定义配置解析器
Hydra 通过 OmegaConf 库提供了扩展其功能的机会。它允许将自定义可执行表达式添加到配置中。OmegaConf.register_new_resolver() 函数用于注册这样的解析器。
默认情况下,OmegaConf 支持以下解析器:
-
oc.env:返回环境变量的值 -
oc.create:可用于动态生成配置节点 -
oc.deprecated:可用于将配置节点标记为已弃用 -
oc.decode:使用给定的编解码器解码字符串 -
oc.select:提供一个默认值,以防主插值键未找到,或选择其他非法插值键或处理缺失值 -
oc.dict.{keys,value}:类似于普通 Python 字典中的 dict.keys 和 dict.values 方法
更多细节请查看这里。
因此,它是一个强大的工具,可以添加任何自定义解析器。例如,在多个地方的配置中重复编写损失或指标名称可能是乏味且耗时的,比如early_stopping配置、model_checkpoint配置、包含调度器参数的配置或其他地方。通过添加自定义解析器,将__loss__和__metric__名称替换为实际的损失或指标名称,可以解决这个问题,这些名称会传递给配置并由 Hydra 实例化。
注意:你需要在hydra.main或Compose API调用之前注册自定义解析器。否则,Hydra 配置解析器将无法应用它。
在我的快速深度学习实验模板中,它被实现为一个装饰器[utils.register_custom_resolvers](https://github.com/gorodnitskiy/yet-another-lightning-hydra-template/blob/936e99fd6c9d033b4f407b96370fd64656566874/src/utils/utils.py#L328),允许在一个地方注册所有自定义解析器。它支持 Hydra 的主要命令行标志,这些标志是覆盖配置路径、名称或目录所必需的。默认情况下,它允许通过以下语法将__loss__替换为loss.__class__.__name__,将__metric__替换为metric.__class__.__name__:${replace:"__metric__/valid"}。在${replace:"..."}中使用引号来定义内部值,以避免与 Hydra 配置解析器的语法问题。
有关utils.register_custom_resolvers的更多细节,请查看这里。你可以轻松扩展它以满足其他需求。
简化复杂模块配置
这个强大的工具显著简化了复杂管道的开发和配置,例如:
-
实例化具有任何自定义逻辑的模块,例如:
-
通过 Hydra 递归地实例化整个模块及其内部所有子模块。
-
主模块和一些内部子模块可以由 Hydra 初始化,其余部分则需手动初始化。
-
手动初始化主模块和所有子模块。
-
-
将动态结构(如数据增强)打包到配置中,你可以轻松设置任何
transforms类、参数或适用顺序。参见基于albumentations库的可能实现示例[TransformsWrapper](https://github.com/gorodnitskiy/yet-another-lightning-hydra-template/blob/main/src/datamodules/components/transforms.py),它可以轻松地为任何额外增强包进行修改。配置示例: -
创建复杂的多层配置结构。这里 是配置组织的概要:

- 还有许多其他功能……它的限制非常少,因此你可以在项目中实现任何自定义逻辑。
最后的想法
Hydra 为可扩展的配置管理系统铺平了道路,使你能够扩展工作流程的效率,同时保持对配置的灵活更改能力。能够轻松切换不同的配置,简单地重新组合并尝试不同的方法,而无需手动更新代码,是解决机器学习问题(尤其是深度学习相关任务)时使用此系统的关键优势,因为在这些任务中,额外的灵活性至关重要。
亚历山大·戈罗德尼茨基 是一位机器学习工程师,具备深厚的机器学习、计算机视觉和分析知识。我拥有超过 3 年的经验,专注于使用机器学习创建和改进产品。
更多相关话题
超参数优化:10 个顶级 Python 库
原文:
www.kdnuggets.com/2023/01/hyperparameter-optimization-10-top-python-libraries.html
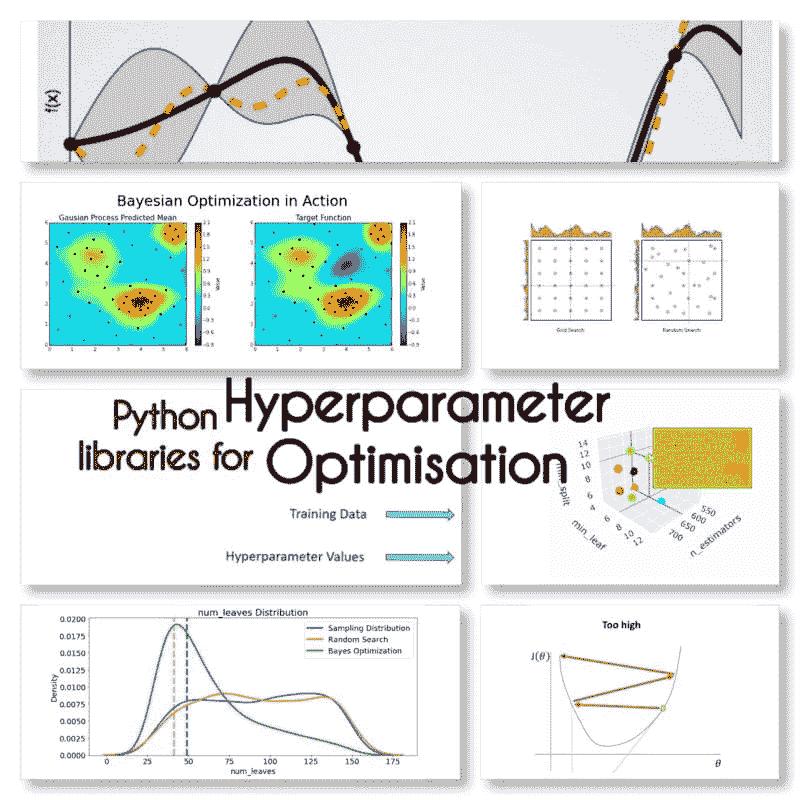
图片由作者提供
超参数优化在确定机器学习模型的性能中起着关键作用。它们是训练的三个组成部分之一。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
模型的 3 个组成部分
训练数据
训练数据是算法利用的内容(可以理解为构建模型的指令),用于识别模式。
参数
算法通过根据训练数据调整参数(如权重)来“学习”,以进行准确预测,这些预测作为最终模型的一部分保存。
超参数
超参数是调节训练过程的变量,在训练过程中保持不变。
不同类型的搜索
网格搜索
用提供的超参数值的所有可能组合训练模型是一个耗时的过程。
随机搜索
训练模型时随机从定义的分布中抽样超参数值,这是一种更有效的搜索方法。
拥有网格搜索
用所有值训练模型,然后通过仅考虑在上轮表现最佳的参数值来重复“对搜索空间进行二分”。
贝叶斯搜索
从初始值开始,利用模型的表现来调整这些值。这就像侦探从嫌疑人列表开始,然后使用新信息来缩小列表。
超参数优化的 Python 库
我找到了这 10 个用于超参数优化的 Python 库。
Optuna
你可以通过名为 optuna-dashboard 的实时 Web 仪表板调节几乎所有的 ML、DL 包/框架的估计器,包括 Sklearn、PyTorch、TensorFlow、Keras、XGBoost、LightGBM、CatBoost 等。
Hyperopt
使用贝叶斯优化进行优化,包括条件维度。
Scikit-learn
不同的搜索方法,如 GridSearchCV 或 HalvingGridSearchCV。
Auto-Sklearn
AutoML 和 scikit-learn 估计器的替代品。
超活跃
非常容易学习但极其多才多艺,提供智能优化。
Optunity
提供了不同的方法以及大量的评分函数。
HyperparameterHunter
自动保存/从实验中学习以进行持续优化
MLJAR
AutoML 从 ML 流水线生成 Markdown 报告
KerasTuner
内置贝叶斯优化、Hyperband 和随机搜索算法
Talos
TensorFlow、Keras 和 PyTorch 的超参数优化。
我是否遗漏了任何库?
来源:
玛丽亚姆·米拉迪 是一名人工智能和数据科学负责人,拥有机器学习和深度学习的博士学位,专注于自然语言处理和计算机视觉。她拥有超过 15 年的成功人工智能解决方案经验,成功交付了 40 多个项目。她曾在 12 个不同的组织中工作,涵盖了金融犯罪检测、能源、银行、零售、电子商务和政府等多个行业。
该主题的更多内容
机器学习模型的超参数优化
原文:
www.kdnuggets.com/2020/05/hyperparameter-optimization-machine-learning-models.html
评论
介绍
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能。
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT。
模型优化是实现机器学习解决方案中的最大挑战之一。整个机器学习和深度学习理论的分支都致力于模型优化。
机器学习中的超参数优化旨在找到给定机器学习算法的超参数,以在验证集上测得最佳性能。与模型参数不同,超参数由机器学习工程师在训练前设定。随机森林中的树木数量是一个超参数,而神经网络中的权重是训练过程中学习到的模型参数。我喜欢把超参数看作是模型设置,需要调整以使模型能够最佳地解决机器学习问题。
一些模型超参数的例子包括:
-
用于训练神经网络的
learning rate。 -
支持向量机中的
**C**和**????**超参数。 -
k-最近邻算法中的
**k**。
超参数优化找到一个超参数组合,以返回一个最优模型,该模型减少了预定义的损失函数,从而提高了给定独立数据上的准确性。
超参数优化方法
超参数对机器学习算法的训练有直接影响。因此,为了实现最佳性能,了解如何优化它们是很重要的。以下是一些常见的超参数优化策略:
1. 手动超参数调整
传统上,超参数是通过试错法手动调整的。这仍然是常见的做法,经验丰富的工程师可以“猜测”出能够为 ML 模型提供非常高准确度的参数值。然而,仍在不断寻找更好、更快、更自动化的优化超参数的方法。
2. 网格搜索
网格搜索可以说是最基本的超参数调优方法。使用这种技术,我们只是为提供的所有超参数值的每个可能组合构建一个模型,评估每个模型,并选择产生最佳结果的架构。
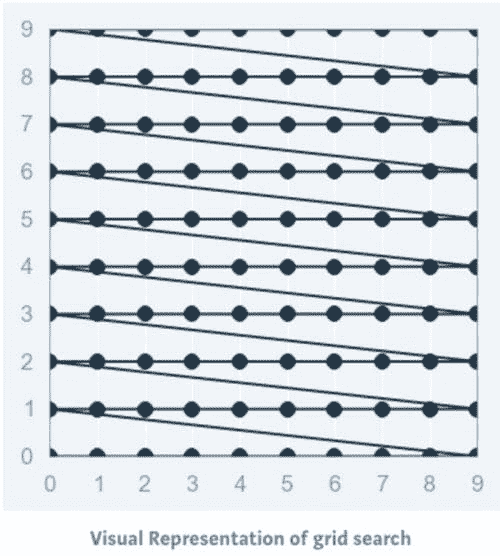
网格搜索不仅适用于一种模型类型,还可以应用于机器学习中的各类模型,以计算用于任何给定模型的最佳参数。
例如,典型的软间隔支持向量机(SVM)分类器配备了 RBF 核函数,它有至少两个超参数需要优化以在未见数据上获得良好性能:正则化常数C和核超参数 γ。两个参数都是连续的,因此为了进行网格搜索,需要为每个参数选择一个有限的“合理”值,比如

网格搜索然后用这两个集合的笛卡尔积中的每一对(C, γ)训练一个 SVM,并在保留的验证集上评估它们的性能(或者通过对训练集的内部交叉验证,在这种情况下,每对会训练多个 SVM)。最后,网格搜索算法输出在验证过程中获得的最高分的设置。
它在 Python 中如何工作?
from sklearn.datasets import load_iris
from sklearn.svm import SVC
iris **=** load_iris()
svc **=** SVR()
这是一个使用[GridSearchCV](https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html)来自sklearn库的网格搜索的 Python 实现。
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVR
grid = GridSearchCV(
estimator=SVR(kernel='rbf'),
param_grid={
'C': [0.1, 1, 100, 1000],
'epsilon': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.05, 0.1, 0.5, 1, 5, 10],
'gamma': [0.0001, 0.001, 0.005, 0.1, 1, 3, 5]
},
cv=5, scoring='neg_mean_squared_error', verbose=0, n_jobs=-1)
网格搜索的实现:
grid.fit(X,y)
网格搜索的方法:
#print the best score throughout the grid search
print grid.best_score_#print the best parameter used for the highest score of the model.
print grid.best_param_
然后,我们使用在网格搜索中选择的最佳超参数值,应用于实际模型,如上所示。
网格搜索的缺点之一是当涉及到维度时,它在评估超参数数量指数增长时表现不佳。然而,没有保证搜索会产生完美的解决方案,因为它通常通过在正确的集合周围徘徊来找到一个。
3. 随机搜索
通常,有些超参数比其他超参数更为重要。进行随机搜索而不是网格搜索可以更精确地发现重要超参数的良好值。
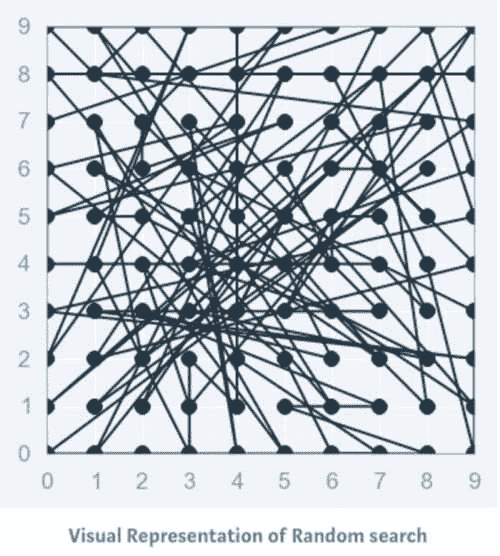
随机搜索设置了一个超参数值的网格,并选择随机组合来训练模型和评分。这允许你明确控制尝试的参数组合的数量。搜索迭代的次数根据时间或资源进行设置。Scikit Learn 提供了RandomizedSearchCV函数来执行这一过程。
尽管RandomizedSearchCV可能找不到像GridSearchCV那么准确的结果,但它往往在比GridSearchCV快得多的时间内选出最佳结果。考虑到相同的资源,随机搜索甚至可能优于网格搜索。这在使用连续参数时可以在下面的图示中看到。
随机搜索的机会相对较高,因为随机搜索模式下,模型可能会在优化参数上进行训练而没有任何别名。由于维度较低,随机搜索在找到合适参数集的时间更短,因此适用于较低维度的数据。对于维度较少的情况,随机搜索是最佳的参数搜索技术。
在深度学习算法的情况下,它优于网格搜索。
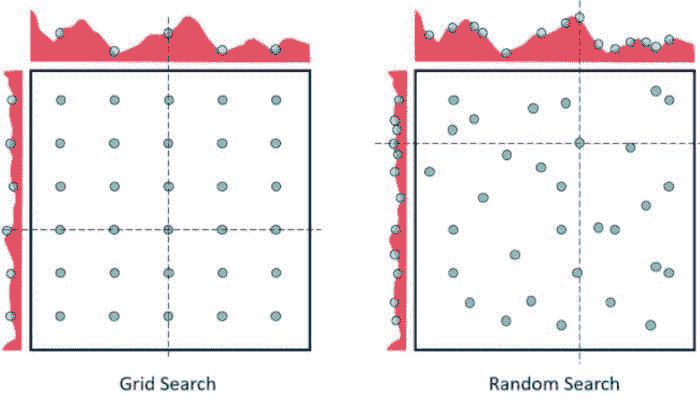
在上图中,恭喜你有两个参数,通过 5x6 网格搜索你只检查每个参数的 5 种不同值(左侧图中的六行五列),而通过随机搜索你检查了每个参数的 14 种不同值。
它在 Python 中如何工作?
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestRegressor
iris **=** load_iris()
rf = RandomForestRegressor(random_state = 42)
下面是使用sklearn库的RandomizedSearchCV进行网格搜索的 Python 实现。
from sklearn.model_selection import RandomizedSearchCV
random_grid = {'n_estimators': n_estimators,
'max_features': max_features,
'max_depth': max_depth,
'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf,
'bootstrap': bootstrap}rf_random = RandomizedSearchCV(estimator = rf, param_distributions = random_grid, n_iter = 100, cv = 3, verbose=2, random_state=42, n_jobs = -1)# Fit the random search model
随机搜索的拟合:
rf_random.fit(X,y)
网格搜索中运行的方法:
#print the best score throughout the grid search
print rf_random.best_score_#print the best parameter used for the highest score of the model.
print rf_random.best_param_Output:
**{'bootstrap': True,
'max_depth': 70,
'max_features': 'auto',
'min_samples_leaf': 4,
'min_samples_split': 10,
'n_estimators': 400}**
4. 贝叶斯优化
之前的两个方法通过各种超参数值进行单独实验,并记录每个模型的表现。由于每个实验都是孤立进行的,因此很容易并行化这个过程。然而,由于每个实验都是孤立进行的,我们无法利用一个实验的信息来改进下一个实验。贝叶斯优化属于基于模型的序列优化(SMBO)算法的一类,允许我们使用先前迭代的结果来改进下一次实验的采样方法。
这反过来限制了模型需要训练的次数,因为只有那些预计会产生更高验证分数的设置才会被传递以供评估。
贝叶斯优化通过构建最能描述你想优化的函数的后验分布(高斯过程)来工作。随着观察数量的增加,后验分布会改进,算法对参数空间中值得探索和不值得探索的区域变得更加确定。
我们可以在下面的图像中看到这一点:
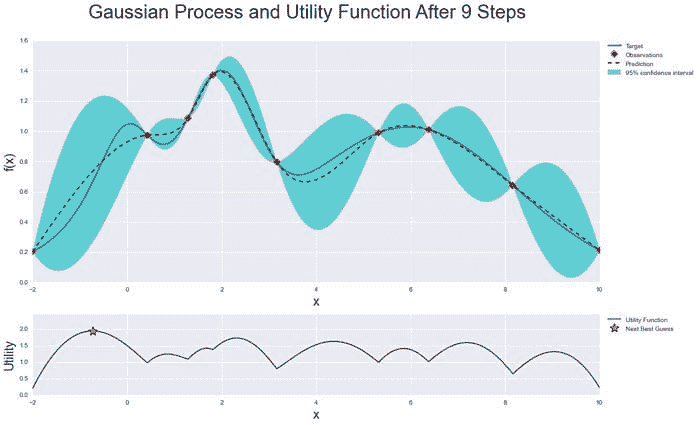
来源:贝叶斯优化
当你一遍遍迭代时,算法会在考虑目标函数已知信息的基础上平衡探索和开发的需求。在每一步中,将为已知样本(之前探索过的点)拟合一个高斯过程,并结合探索策略(如 UCB(上置信界)或 EI(期望改进)),以确定应探索的下一点。
使用贝叶斯优化,我们可以更智能地探索参数空间,从而减少进行此过程所需的时间。
你可以查看下面的贝叶斯优化的 Python 实现:
thuijskens/bayesian-optimization
5. 基于梯度的优化
它特别用于神经网络的情况。它计算关于超参数的梯度,并使用梯度下降算法对其进行优化。
计算梯度问题并不是最难的,至少在高级的自动微分软件出现之后。(当然,为所有 sklearn 分类器以通用方式实现这一点并不容易)
尽管有一些人使用这种想法的工作,但他们只是为一些特定且明确的问题(例如 SVM 调优)做了这件事。此外,这可能有很多假设,因为:
为什么这不是一个好主意?
1. 超参数优化通常是不平滑的
-
GD 真的喜欢平滑函数,因为零梯度没有帮助。
-
每个由某些离散集合定义的超参数(例如 l1 与 l2 惩罚的选择)会引入不平滑的表面。
2. 超参数优化通常是非凸的
-
梯度下降的整个收敛理论假设基础问题是凸的。
-
好的情况:你能获得某个局部最小值(可以非常糟糕)。
-
最坏的情况:梯度下降甚至没有收敛到某个局部最小值。
要获取 Python 实现和更多关于梯度下降优化算法的信息,请点击这里。
6. 进化优化
进化优化遵循一个受生物进化概念启发的过程,由于自然进化是在变化环境中的动态过程,因此它们也非常适合动态优化问题。
进化算法通常用于寻找良好的近似解决方案,这些方案无法通过其他技术轻易解决。优化问题通常没有精确的解决方案,因为找到最优解决方案可能过于耗时和计算密集。然而,在这种情况下,进化算法是理想的,因为它们可以用于找到一个接近最优的解决方案,这通常是足够的。
进化算法的一个优点是它们可以生成没有任何人为误解或偏见的解决方案,这意味着它们可以产生我们可能永远无法自己想出的惊人想法。
你可以在这里了解更多关于进化算法的信息。你也可以在这里查看 Python 实现。
一般来说,每当你想要优化调优超参数时,请考虑网格搜索和随机搜索!
结论
在本文中,我们了解到寻找合适的超参数值可能是一项令人沮丧的任务,可能导致机器学习模型的欠拟合或过拟合。我们看到如何通过使用网格搜索、随机搜索和其他算法来克服这一难题——这些算法优化超参数的调优,以节省时间并消除通过随机猜测导致的过拟合或欠拟合的可能性。
好了,这篇文章到此结束。希望你们喜欢阅读这篇文章,欢迎在评论区分享你的评论/想法/反馈。
感谢阅读 !!!
作者:纳戈什·辛格·乔汉 是一名数据科学爱好者。对大数据、Python 和机器学习感兴趣。
原文。经许可转载。
相关:
-
如何在 3 个简单步骤中对任何 Python 脚本进行超参数调优
-
使用 Biopython 进行冠状病毒 COVID-19 基因组分析
-
实用超参数优化
更多相关内容
使用网格搜索和随机搜索进行超参数调优
原文:
www.kdnuggets.com/2022/10/hyperparameter-tuning-grid-search-random-search-python.html

图片由编辑提供
介绍
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 方面的工作
所有机器学习模型都有一组超参数或参数,这些参数必须由从业者指定。
例如,一个逻辑回归模型有不同的求解器用于找到可以给出最佳输出的系数。每个求解器使用不同的算法来找到最佳结果,并且这些算法没有哪个严格优于其他算法。除非你尝试所有的求解器,否则很难判断哪个求解器在你的数据集上表现最好。
最佳超参数是主观的,并且对于每个数据集都不同。Python 中的 Scikit-Learn 库提供了一组默认的超参数,这些超参数在所有模型上表现都还算不错,但它们不一定适用于每个问题。
找到数据集的最佳超参数的唯一方法是通过试验和错误,这也是 超参数优化 的主要概念。
简单来说,超参数优化是一种技术,涉及在一系列值中搜索,以找到一组能够在给定数据集上实现最佳性能的结果。
有两种流行的技术用于进行超参数优化——网格搜索和随机搜索。
网格搜索
在进行超参数优化时,我们首先需要定义一个 参数空间 或 参数网格,其中包含一组可以用于构建模型的可能超参数值。
网格搜索技术将这些超参数放置在类似矩阵的结构中,然后在每个超参数值的组合上训练模型。
然后选择表现最佳的模型。
随机搜索
虽然网格搜索会查看所有可能的超参数组合以找到最佳模型,但随机搜索只会选择并测试一个随机的超参数组合。
该技术从超参数网格中随机抽样,而不是进行详尽的搜索。
我们可以指定随机搜索应该尝试的总运行次数,然后再返回最佳模型。
现在你对随机搜索和网格搜索的基本原理有了了解,我将向你展示如何使用 Scikit-Learn 库实现这些技术。
使用网格搜索和随机搜索优化随机森林分类器
第 1 步:加载数据集
在 Kaggle 上下载酒质数据集,然后输入以下代码行,使用Pandas库读取数据:
import pandas as pd
df = pd.read_csv('winequality-red.csv')
df.head()
数据框的头部如下所示:

第 2 步:数据预处理
目标变量“quality”包含范围在 1 到 10 之间的值。
我们将通过将所有质量值小于或等于 5 的数据点分配为 0,将其余观察值分配为 1,将其转化为二分类任务:
import numpy as np
df['target'] = np.where(df['quality']>5, 1, 0)
让我们将数据框中的因变量和自变量分开:
df2 = df.drop(['quality'],axis=1)
X = df2.drop(['target'],axis=1)
y = df2[['target']]
第 3 步:构建模型
现在,让我们实例化一个随机森林分类器。我们将调整该模型的超参数,以创建适合我们数据集的最佳算法:
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier()
第 4 步:使用 Scikit-Learn 实现网格搜索
定义超参数空间
我们现在将尝试调整该模型的以下超参数集合:
-
“Max_depth”:该超参数表示随机森林模型中每棵树的最大层级。较深的树可以很好地捕捉训练数据中的大量信息,但对测试数据的泛化能力较差。默认情况下,Scikit-Learn 库中的该值设置为“None”,这意味着树会完全扩展。
-
“Max_features”:随机森林模型在每次分裂时允许尝试的最大特征数量。Scikit-Learn 中的默认值设置为数据集中变量总数的平方根。
-
“N_estimators”:森林中决策树的数量。Scikit-Learn 中的默认估计器数量为 10。
-
“Min_samples_leaf”:每棵树的叶节点所需的最小样本数。Scikit-Learn 中的默认值为 1。
-
“Min_samples_split”:每棵树内部节点分裂所需的最小样本数。Scikit-Learn 中的默认值为 2。
我们现在将创建一个包含所有上述超参数的多个可能值的字典。这也叫做超参数空间,将会通过它来寻找最佳的参数组合:
grid_space={'max_depth':[3,5,10,None],
'n_estimators':[10,100,200],
'max_features':[1,3,5,7],
'min_samples_leaf':[1,2,3],
'min_samples_split':[1,2,3]
}
运行网格搜索
现在,我们需要进行搜索以找到模型的最佳超参数组合:
from sklearn.model_selection import GridSearchCV
grid = GridSearchCV(rf,param_grid=grid_space,cv=3,scoring='accuracy')
model_grid = grid.fit(X,y)
评估模型结果
最后,让我们输出最佳模型的准确性,并附上产生该分数的超参数集合:
print('Best hyperparameters are: '+str(model_grid.best_params_))
print('Best score is: '+str(model_grid.best_score_))
最佳模型的准确率约为 0.74,其超参数如下:

现在,让我们在相同的数据集上使用随机搜索,看看是否能得到类似的结果。
步骤 5:使用 Scikit-Learn 实现随机搜索
定义超参数空间
现在,让我们定义超参数空间以实现随机搜索。这个参数空间可以比我们为网格搜索构建的范围更大,因为随机搜索不会尝试每一种超参数组合。
它随机抽样超参数以找到最佳参数,这意味着与网格搜索不同,随机搜索可以快速浏览大量值。
from scipy.stats import randint
rs_space={'max_depth':list(np.arange(10, 100, step=10)) + [None],
'n_estimators':np.arange(10, 500, step=50),
'max_features':randint(1,7),
'criterion':['gini','entropy'],
'min_samples_leaf':randint(1,4),
'min_samples_split':np.arange(2, 10, step=2)
}
运行随机搜索
运行以下代码行以在模型上执行随机搜索:(注意,我们已指定 n_iter=500,这意味着随机搜索将在选择最佳模型之前运行 500 次。你可以尝试不同的迭代次数以查看哪种给你最优的结果。请记住,较大的迭代次数将带来更好的性能,但也更耗时。)
from sklearn.model_selection import RandomizedSearchCV
rf = RandomForestClassifier()
rf_random = RandomizedSearchCV(rf, space, n_iter=500, scoring='accuracy', n_jobs=-1, cv=3)
model_random = rf_random.fit(X,y)
评估模型结果
现在,运行以下代码行以打印随机搜索找到的最佳超参数及最佳模型的最高准确率:
print('Best hyperparameters are: '+str(model_random.best_params_))
print('Best score is: '+str(model_random.best_score_))
随机搜索找到的最佳超参数如下:

所有构建的模型的最高准确率也大约为 0.74。
观察到网格搜索和随机搜索在数据集上表现都相当不错。请记住,如果你在相同的代码上运行随机搜索,你的结果可能会与我上面展示的结果大相径庭。
这是因为它通过随机初始化搜索非常大的参数网格,这可能导致每次使用该技术时结果变化剧烈。
完整代码
这里是教程中使用的完整代码:
# imports
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from scipy.stats import randint
from sklearn.model_selection import RandomizedSearchCV
# reading the dataset
df = pd.read_csv('winequality-red.csv')
# preprocessing
df['target'] = np.where(df['quality']>5, 1, 0)
df2 = df.drop(['quality'],axis=1)
X = df2.drop(['target'],axis=1)
y = df2[['target']]
# initializing random forest
rf = RandomForestClassifier()
# grid search cv
grid_space={'max_depth':[3,5,10,None],
'n_estimators':[10,100,200],
'max_features':[1,3,5,7],
'min_samples_leaf':[1,2,3],
'min_samples_split':[1,2,3]
}
grid = GridSearchCV(rf,param_grid=grid_space,cv=3,scoring='accuracy')
model_grid = grid.fit(X,y)
# grid search results
print('Best grid search hyperparameters are: '+str(model_grid.best_params_))
print('Best grid search score is: '+str(model_grid.best_score_))
# random search cv
rs_space={'max_depth':list(np.arange(10, 100, step=10)) + [None],
'n_estimators':np.arange(10, 500, step=50),
'max_features':randint(1,7),
'criterion':['gini','entropy'],
'min_samples_leaf':randint(1,4),
'min_samples_split':np.arange(2, 10, step=2)
}
rf = RandomForestClassifier()
rf_random = RandomizedSearchCV(rf, rs_space, n_iter=500, scoring='accuracy', n_jobs=-1, cv=3)
model_random = rf_random.fit(X,y)
# random random search results
print('Best random search hyperparameters are: '+str(model_random.best_params_))
print('Best random search score is: '+str(model_random.best_score_))
网格搜索 vs 随机搜索 - 该使用哪一个?
如果你在选择网格搜索和随机搜索之间犹豫,以下是一些帮助你决定使用哪一个的提示:
-
如果你已经有一个大致的已知超参数值范围,并且这些值表现良好,就使用网格搜索。确保保持参数空间小,因为网格搜索可能非常耗时。
-
如果你还不清楚哪些参数在你的模型上表现良好,可以在广泛的值范围上使用随机搜索。随机搜索比网格搜索更快,并且在参数空间很大时应始终使用。
-
同时使用随机搜索和网格搜索也是一个好主意,以获得最佳结果。
你可以先使用随机搜索,特别是在参数空间很大的情况下,因为它更快。然后,使用随机搜索找到的最佳超参数来缩小参数网格,并将更小范围的值提供给网格搜索。
Natassha Selvaraj 是一位自学成才的数据科学家,对写作充满热情。你可以通过LinkedIn与她联系。
相关主题
超参数调优:GridSearchCV 和 RandomizedSearchCV 的解释
原文:
www.kdnuggets.com/hyperparameter-tuning-gridsearchcv-and-randomizedsearchcv-explained
作者提供的图像
每个你训练的机器学习模型都有一组参数或模型系数。机器学习算法的目标——作为一个优化问题——是学习这些参数的最佳值。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
此外,机器学习模型还有一组超参数。例如,K-最近邻算法中的 K 值,即邻居的数量,或者在训练深度神经网络时的批次大小等等。
这些超参数不是由模型学习的,而是由开发者指定的。它们影响模型性能,并且是可调节的。那么你如何找到这些超参数的最佳值呢?这个过程称为超参数优化或超参数调优。
两种最常见的超参数调优技术包括:
-
网格搜索
-
随机搜索
在本指南中,我们将学习这些技术的工作原理及其在 scikit-learn 中的实现。
训练基线 SVM 分类器
让我们开始在酒类数据集上训练一个简单的 支持向量机 (SVM) 分类器。
首先,导入所需的模块和类:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
酒类数据集是 scikit-learn 中内置数据集的一部分。所以让我们按如下方式读取特征和目标标签:
# Load the Wine dataset
wine = datasets.load_wine()
X = wine.data
y = wine.target
酒类数据集是一个简单的数据集,包含 13 个数值特征和三个输出类别标签。这是一个很好的数据集,用于了解多分类问题。你可以运行wine.DESCR来获取数据集的描述。
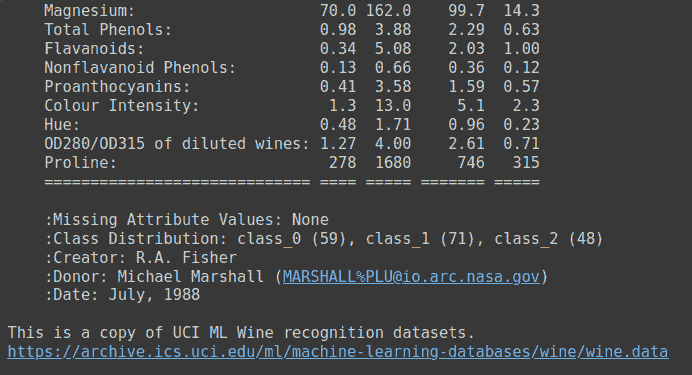
wine.DESCR 的输出
接下来,将数据集分成训练集和测试集。在这里,我们使用了test_size为 0.2。所以 80%的数据进入训练数据集,20%进入测试数据集。
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=24)
现在实例化一个支持向量分类器并将模型拟合到训练数据集。然后评估其在测试集上的性能。
# Create a baseline SVM classifier
baseline_svm = SVC()
baseline_svm.fit(X_train, y_train)
y_pred = baseline_svm.predict(X_test)
因为这是一个简单的多分类问题,我们可以查看模型的准确率。
# Evaluate the baseline model
accuracy = accuracy_score(y_test, y_pred)
print(f"Baseline SVM Accuracy: {accuracy:.2f}")
我们看到这个模型在默认超参数值下的准确率约为 0.78。
Output >>>
Baseline SVM Accuracy: 0.78
这里我们使用了 random_state 为 24。对于不同的随机状态,你将得到不同的训练测试拆分,从而得到不同的准确率分数。
所以我们需要比单一训练-测试拆分更好的方法来评估模型性能。也许,可以在许多这样的拆分上训练模型,并考虑平均准确率,同时尝试不同的超参数组合?是的,这就是我们在模型评估和超参数搜索中使用交叉验证的原因。我们将在接下来的部分中了解更多。
接下来让我们确定可以为这个支持向量机分类器调整的超参数。
SVM 超参数调整
在超参数调优中,我们的目标是找到 SVM 分类器的最佳超参数值组合。支持向量分类器常调的超参数包括:
-
C:正则化参数,控制最大化边界和最小化分类错误之间的权衡。
-
kernel:指定要使用的核函数类型(例如 'linear','rbf','poly')。
-
gamma:'rbf' 和 'poly' 核的核系数。
理解交叉验证的作用
交叉验证 帮助评估模型 对未见数据的泛化能力,并减少对单一训练-测试拆分的过拟合风险。常用的 k 折交叉验证涉及将数据集拆分为 k 个相等大小的折叠。模型被训练 k 次,每个折叠 一次 作为验证集,其余折叠作为训练集。因此,对于每个折叠,我们将获得一个交叉验证准确率。
当我们运行网格和随机搜索以找到最佳超参数时,我们将基于最佳的平均交叉验证得分选择超参数。
什么是网格搜索?
网格搜索 是一种超参数调优技术,通过 对指定的超参数空间进行全面搜索 来找到产生最佳模型性能的超参数组合。
网格搜索如何工作
我们将超参数搜索空间定义为参数网格。参数网格 是一个字典,在其中你指定每个要调整的超参数及其要探索的值列表。
网格搜索系统地探索超参数网格中的每一个可能组合。它使用交叉验证对每个组合进行模型拟合和评估,并选择产生最佳性能的组合。
接下来,让我们在 scikit-learn 中实现网格搜索。
Scikit-Learn 中的 GridSearchCV
首先,从 scikit-learn 的 model_selection 模块中导入 GridSearchCV 类:
from sklearn.model_selection import GridSearchCV
让我们定义 SVM 分类器的参数网格:
# Define the hyperparameter grid
param_grid = {
'C': [0.1, 1, 10],
'kernel': ['linear', 'rbf', 'poly'],
'gamma': [0.1, 1, 'scale', 'auto']
}
网格搜索则系统地探索参数网格中的每一个可能组合。在这个例子中,它使用以下参数评估模型的性能:
-
C设置为 0.1, 1 和 10, -
kernel设置为 'linear', 'rbf' 和 'poly',并且 -
gamma设置为 0.1, 1, 'scale' 和 'auto'。
这将导致总共 36 种不同的组合需要评估。网格搜索对每个组合进行拟合和评估,并使用交叉验证选择出最佳表现的组合。
然后我们实例化GridSearchCV来调整baseline_svm的超参数:
# Create the GridSearchCV object
grid_search = GridSearchCV(estimator=baseline_svm, param_grid=param_grid, cv=5)
# Fit the model with the grid of hyperparameters
grid_search.fit(X_train, y_train)
注意,我们使用了 5 折交叉验证。
最后,我们在测试数据上评估通过网格搜索找到的最佳模型——具有最优超参数的模型的性能:
# Get the best hyperparameters and model
best_params = grid_search.best_params_
best_model = grid_search.best_estimator_
# Evaluate the best model
y_pred_best = best_model.predict(X_test)
accuracy_best = accuracy_score(y_test, y_pred_best)
print(f"Best SVM Accuracy: {accuracy_best:.2f}")
print(f"Best Hyperparameters: {best_params}")
如所见,模型在以下超参数下达到了 0.94 的准确率:
Output >>>
Best SVM Accuracy: 0.94
Best Hyperparameters: {'C': 0.1, 'gamma': 0.1, 'kernel': 'poly'}
网格搜索的优缺点
使用网格搜索进行超参数调整具有以下优点:
-
网格搜索探索所有指定的组合,确保你不会错过定义的搜索空间中的最佳超参数。
-
它适合于探索较小的超参数空间。
然而,另一方面:
- 网格搜索可能计算开销较大,尤其是在处理大量超参数及其值时。对于非常复杂的模型或广泛的超参数搜索,可能不切实际。
现在让我们了解一下随机搜索。
什么是随机搜索?
随机搜索是另一种超参数调整技术,它探索指定分布或范围内的随机超参数组合。当处理较大的超参数搜索空间时,它特别有用。
随机搜索如何工作
在随机搜索中,你可以定义每个超参数的概率分布或范围,而不是指定一个值的网格。这会变成一个更大的超参数搜索空间。
随机搜索然后随机抽样从这些分布中选取固定数量的超参数组合。这使得随机搜索能够高效地探索多样的超参数组合。
Scikit-Learn 中的 RandomizedSearchCV
现在让我们使用随机搜索来调整基线 SVM 分类器的参数。
我们导入RandomizedSearchCV类并定义param_dist,一个更大的超参数搜索空间:
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform
param_dist = {
'C': uniform(0.1, 10), # Uniform distribution between 0.1 and 10
'kernel': ['linear', 'rbf', 'poly'],
'gamma': ['scale', 'auto'] + list(np.logspace(-3, 3, 50))
}
类似于网格搜索,我们实例化随机搜索模型来寻找最佳超参数。在这里,我们将n_iter设置为 20;因此将采样 20 个随机的超参数组合。
# Create the RandomizedSearchCV object
randomized_search = RandomizedSearchCV(estimator=baseline_svm, param_distributions=param_dist, n_iter=20, cv=5)
randomized_search.fit(X_train, y_train)
然后我们评估通过随机搜索找到的最佳超参数的模型性能:
# Get the best hyperparameters and model
best_params_rand = randomized_search.best_params_
best_model_rand = randomized_search.best_estimator_
# Evaluate the best model
y_pred_best_rand = best_model_rand.predict(X_test)
accuracy_best_rand = accuracy_score(y_test, y_pred_best_rand)
print(f"Best SVM Accuracy: {accuracy_best_rand:.2f}")
print(f"Best Hyperparameters: {best_params_rand}")
最佳准确率和最优超参数为:
Output >>>
Best SVM Accuracy: 0.94
Best Hyperparameters: {'C': 9.66495227534876, 'gamma': 6.25055192527397, 'kernel': 'poly'}
通过随机搜索找到的参数与通过网格搜索找到的参数不同。具有这些超参数的模型也达到了 0.94 的准确率。
随机搜索的优缺点
让我们总结一下随机搜索的优点:
-
随机搜索在处理大量超参数或广泛范围的值时效率较高,因为它不需要进行详尽的搜索。
-
它可以处理各种参数类型,包括连续值和离散值。
以下是随机搜索的一些限制:
-
由于其随机特性,它可能不会总是找到最佳的超参数。但它通常能快速找到好的超参数。
-
与网格搜索不同,它不保证所有可能的组合都会被探索。
结论
我们学习了如何使用RandomizedSearchCV和GridSearchCV进行超参数调整。然后,我们用最佳超参数评估了模型的性能。
总结来说,网格搜索详尽地搜索参数网格中的所有可能组合,而随机搜索则是随机抽样超参数组合。
这两种技术都帮助你确定机器学习模型的最佳超参数,同时减少对特定训练-测试划分的过拟合风险。
Bala Priya C**** 是一位来自印度的开发人员和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和咖啡!目前,她正在通过撰写教程、操作指南、观点文章等,与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关话题
实践超参数调整与 Keras Tuner
原文:
www.kdnuggets.com/2020/02/hyperparameter-tuning-keras-tuner.html
评论
作者:Julie Prost,Sicara 的数据科学家
本文将解释如何使用 Keras Tuner 和 Tensorflow 2.0 自动进行超参数调整,以提高计算机视觉问题的准确性。

现在,你的模型正在运行并产生第一组结果。然而,它们远未达到你期望的最佳结果。你错过了一个关键步骤:超参数调整!
在这篇文章中,我们将逐步通过整个超参数调整流程。完整的代码可以在Github上找到。
什么是超参数调整以及为什么你应该关注
机器学习模型有两种类型的参数:
-
可训练参数是在训练过程中由算法学习的。例如,神经网络的权重就是可训练参数。
-
超参数需要在启动学习过程之前设置。学习率或密集层中的单元数量就是超参数。
即使是小型模型,超参数也可能非常多。调整它们可能是一个真正的脑筋急转弯,但值得挑战:一个好的超参数组合可以大幅提高模型的性能。在这里,我们将看到,在一个简单的 CNN 模型中,它可以帮助你在测试集上提高 10%的准确率!
幸运的是,现有的开源库可以自动为你执行这一步骤!
Tensorflow 2.0 和 Keras Tuner
Tensorflow是一个广泛使用的开源机器学习库。2019 年 9 月,Tensorflow 2.0 发布了,带来了重大的改进,特别是在用户友好性方面。随着这个新版本的发布,Keras,一个高级 Python 深度学习 API,成为了 Tensorflow 的主要 API。
不久之后,Keras 团队发布了Keras Tuner,这是一个可以轻松进行超参数调整的库,适用于 Tensorflow 2.0。本文将展示如何在目标分类应用中使用它,并包括对库中不同超参数调整方法的比较。
Keras Tuner 现在已经脱离了 beta 版本!v1 已在 PyPI 发布。
t.co/riqnIr4auA功能全面、可扩展、易于使用的 Keras 及其以外的超参数调整。pic.twitter.com/zUDISXPdBw
— François Chollet (@fchollet) 2019 年 10 月 31 日
使用 Keras Tuner 进行超参数调整
在深入代码之前,先了解一下 Keras Tuner 的理论。它是如何工作的?
使用 Keras Tuner 进行超参数调优过程
首先,定义一个调优器。它的作用是确定应该测试哪些超参数组合。库的搜索功能执行迭代循环,评估一定数量的超参数组合。评估通过计算训练模型在保留的验证集上的准确性来进行。
最后,可以在保留的测试集上测试验证准确性方面最佳的超参数组合。
入门
开始吧!通过这个教程,你将拥有一个端到端的流程来调整一个简单卷积网络的超参数,以进行 CIFAR10 数据集上的物体分类。
安装步骤
首先,从终端安装 Keras Tuner:
pip install keras-tuner
现在,你可以打开你最喜欢的 IDE/文本编辑器,开始编写 Python 脚本以完成剩下的教程!
数据集

CIFAR10 随机样本。 数据集 由 60000 张图像组成,这些图像属于 10 个对象类别中的一个。
本教程使用 CIFAR10 数据集。CIFAR10 是计算机视觉中的常见基准数据集。它包含 10 个类别,并且相对较小,共有 60000 张图像。这个大小允许相对较短的训练时间,我们将利用这一点来进行多次超参数调优迭代。
加载和预处理数据:
调优器期望输入为浮点数,而除以 255 是数据归一化步骤。
模型定义
在这里,我们将尝试一个简单的卷积模型,将每个图像分类为 10 个可用类别中的一个。
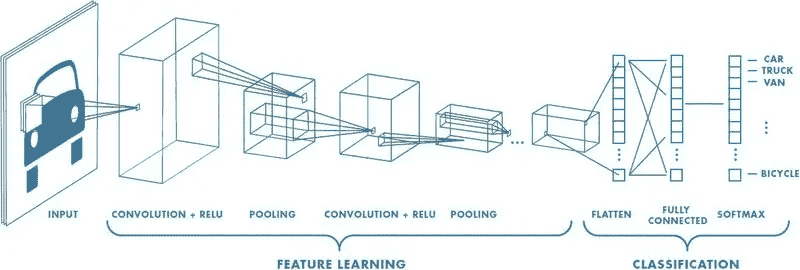
简单 CNN 表示,来自这个优秀的 关于 CNN 的博客文章
每个输入图像将经过两个卷积块(2 个卷积层后跟一个池化层)和一个用于正则化的 dropout 层。最后,每个输出被展平并经过一个密集层,将图像分类为 10 个类别中的一个。
在 Keras 中,这个模型可以如下定义:
搜索空间定义
要进行超参数调优,我们需要定义搜索空间,即哪些超参数需要优化以及在什么范围内。在这里,对于这个相对较小的模型,已经有 6 个超参数可以调整:
-
三个 dropout 层的丢弃率
-
卷积层的滤波器数量
-
密集层的单元数
-
它的激活函数
在 Keras Tuner 中,超参数有类型(可能是 Float、Int、Boolean 和 Choice)和唯一名称。然后,需要设置一组选项来帮助引导搜索:
-
Float 和 Int 类型的最小值、最大值和默认值
-
Choice 类型的可能值集合
-
可选地,可以选择线性、对数或反对数的采样方法。设置此参数允许添加您对调节参数的先验知识。我们将在下一节中看到如何利用它来调整学习率。
-
可选地,设置步长值,即两个超参数值之间的最小步长。
例如,要设置超参数“滤波器数量”,可以使用:
密集层有两个超参数,即单元数和激活函数:
模型编译
然后让我们进入模型编译步骤,在这里还存在其他超参数。编译步骤是定义优化器、损失函数和指标的地方。在这里,我们将使用分类熵作为损失函数,准确率作为指标。对于优化器,有不同的选项可供选择。我们将使用流行的 Adam。
在这里,学习率(表示学习算法的进展速度)通常是一个重要的超参数。通常,学习率是在对数尺度上选择的。这些先验知识可以通过设置采样方法来纳入搜索中:
Keras Tuner Hypermodels
为了将整个超参数搜索空间整合在一起并执行超参数调优,Keras Tuners 使用 HyperModel 实例。Hypermodels 是库中引入的可重用类对象,定义如下:
该库已经提供了两个现成的计算机视觉超模型:HyperResNet 和 HyperXception。
选择调优器
Keras Tuner 提供了主要的超参数调优方法:随机搜索、Hyperband 和贝叶斯优化。
在本教程中,我们将重点关注随机搜索和 Hyperband。我们不会深入理论,但如果您想了解更多关于随机搜索和贝叶斯优化的信息,我写了一篇文章:贝叶斯优化超参数调优。至于 Hyperband,其主要思想是优化随机搜索的搜索时间。
对于每个调优器,可以定义一个种子参数以确保实验的可重复性:SEED = 1。
Random Search
执行超参数调优的最直观方法是随机抽样超参数组合并进行测试。这正是 RandomSearch 调优器所做的!
目标是要优化的函数。调优器根据其值推断这是一个最大化问题还是最小化问题。
然后,max_trials 变量表示调优器将测试的超参数组合的数量,而 execution_per_trial 变量是每次试验中应该构建和拟合的模型数量,以保证鲁棒性。下一节将解释如何设置这些参数。
Hyperband
Hyperband 是随机搜索的优化版本,它使用早停法来加快超参数调整过程。其主要思想是为少量轮数训练大量模型,并仅继续训练在验证集上表现最佳的模型。max_epochs 变量是模型可以训练的最大轮数。
调优器的超参数?

你可能会想知道这个过程的实际效果,因为不同调优器还需要设置多个参数:
但这里的问题与确定超参数稍有不同。实际上,这些设置主要依赖于你的计算时间和资源。你可以进行的试验次数越多,效果越好!关于训练轮数,最好知道你的模型需要多少轮才能收敛。你还可以使用早停法来防止过拟合。
超参数调整
一旦模型和调优器设置好,任务摘要就可以轻松获得:
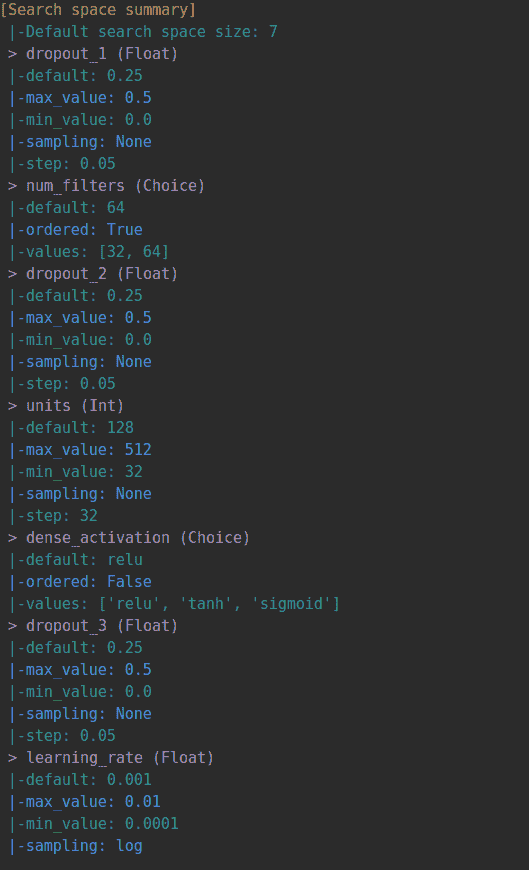
搜索空间摘要输出
调优可以开始了!
搜索功能以训练数据和验证拆分作为输入来执行超参数组合评估。epochs 参数在随机搜索和贝叶斯优化中用于定义每个超参数组合的训练轮数。
最后,搜索结果可以总结并如下使用:
结果
你可以在 Github 上找到这篇文章的代码。以下结果是在 RTX 2080 GPU 上运行后获得的:
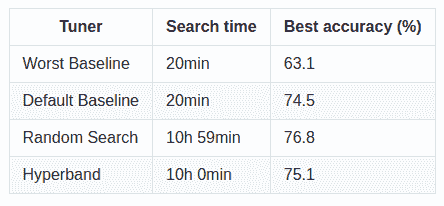
Keras Tuner 结果。最差基准:使用随机搜索的一组超参数中表现最差的模型。默认基准:通过将所有超参数设置为默认值获得。
这些结果远未达到 最先进模型在 CIFAR10 数据集上 达到的 99.3% 准确率,但对于如此简单的网络结构来说也不算太差。你可以看到基准模型和调优模型之间的显著改进,其中随机搜索和第一个基准之间的准确率提升超过 10%。
总的来说,Keras Tuner 库是一个不错且易于学习的选项,用于为你的 Keras 和 TensorFlow 2.0 模型进行超参数调整。你需要工作的主要步骤是将模型调整为适应超模型格式。实际上,库中目前提供的标准超模型较少。
补充文档和教程可以在 Keras Tuner 的网站 和他们的 Github 仓库 上找到!
简介:朱莉·普罗斯特 (@JPro20) 是 Sicara 的数据科学家。
原文。转载经许可。
相关:
-
自动化机器学习项目实施复杂性
-
高级 Keras — 构建复杂的自定义损失和指标
-
卷积神经网络:使用 TensorFlow 和 Keras 的 Python 教程
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
了解更多相关主题
如何在 3 个简单步骤中对任何 Python 脚本进行超参数调优
原文:
www.kdnuggets.com/2020/04/hyperparameter-tuning-python.html
评论
作者:Jakub Czakon,Neptune.ai。

你写了一个训练和评估机器学习模型的 Python 脚本。现在,你希望自动调整超参数以提高其性能吗?
我明白了!
在这篇文章中,我将向你展示如何将你的脚本转换为一个目标函数,该函数可以使用任何超参数优化库进行优化。

只需 3 个步骤,你就可以像没有明天一样调整模型参数。
准备好了吗?
开始吧!
我猜你的 main.py 脚本大致如下:
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import train_test_split
data = pd.read_csv('data/train.csv', nrows=10000)
X = data.drop(['ID_code', 'target'], axis=1)
y = data['target']
(X_train, X_valid,
y_train, y_valid )= train_test_split(X, y, test_size=0.2, random_state=1234)
train_data = lgb.Dataset(X_train, label=y_train)
valid_data = lgb.Dataset(X_valid, label=y_valid, reference=train_data)
params = {'objective': 'binary',
'metric': 'auc',
'learning_rate': 0.4,
'max_depth': 15,
'num_leaves': 20,
'feature_fraction': 0.8,
'subsample': 0.2}
model = lgb.train(params, train_data,
num_boost_round=300,
early_stopping_rounds=30,
valid_sets=[valid_data],
valid_names=['valid'])
score = model.best_score['valid']['auc']
print('validation AUC:', score)
第一步:将搜索参数与代码解耦
将你想要调整的参数放在脚本顶部的一个字典中。通过这样做,你有效地将搜索参数与代码的其余部分解耦。
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import train_test_split
SEARCH_PARAMS = {'learning_rate': 0.4,
'max_depth': 15,
'num_leaves': 20,
'feature_fraction': 0.8,
'subsample': 0.2}
data = pd.read_csv('../data/train.csv', nrows=10000)
X = data.drop(['ID_code', 'target'], axis=1)
y = data['target']
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=1234)
train_data = lgb.Dataset(X_train, label=y_train)
valid_data = lgb.Dataset(X_valid, label=y_valid, reference=train_data)
params = {'objective': 'binary',
'metric': 'auc',
**SEARCH_PARAMS}
model = lgb.train(params, train_data,
num_boost_round=300,
early_stopping_rounds=30,
valid_sets=[valid_data],
valid_names=['valid'])
score = model.best_score['valid']['auc']
print('validation AUC:', score)
第二步:将训练和评估包装成一个函数
现在,你可以将整个训练和评估逻辑放入一个 train_evaluate 函数中。这个函数接受参数作为输入,并输出验证分数。
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import train_test_split
SEARCH_PARAMS = {'learning_rate': 0.4,
'max_depth': 15,
'num_leaves': 20,
'feature_fraction': 0.8,
'subsample': 0.2}
def train_evaluate(search_params):
data = pd.read_csv('../data/train.csv', nrows=10000)
X = data.drop(['ID_code', 'target'], axis=1)
y = data['target']
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=1234)
train_data = lgb.Dataset(X_train, label=y_train)
valid_data = lgb.Dataset(X_valid, label=y_valid, reference=train_data)
params = {'objective': 'binary',
'metric': 'auc',
**search_params}
model = lgb.train(params, train_data,
num_boost_round=300,
early_stopping_rounds=30,
valid_sets=[valid_data],
valid_names=['valid'])
score = model.best_score['valid']['auc']
return score
if __name__ == '__main__':
score = train_evaluate(SEARCH_PARAMS)
print('validation AUC:', score)
第三步:运行超参数调优脚本
我们快到了。
现在你需要做的就是将这个 train_evaluate 函数用作你选择的黑箱优化库的目标。
我将使用 Scikit Optimize,我在另一篇文章中详细描述了它,但你可以使用任何超参数优化库。
简而言之,我:
-
定义搜索 SPACE,
-
创建需要最小化的 objective 函数,
-
通过 forest_minimize 函数运行优化。
在这个例子中,我尝试了 100 种不同的配置,从 10 组随机选择的参数集开始。
import skopt
from script_step2 import train_evaluate
SPACE = [
skopt.space.Real(0.01, 0.5, name='learning_rate', prior='log-uniform'),
skopt.space.Integer(1, 30, name='max_depth'),
skopt.space.Integer(2, 100, name='num_leaves'),
skopt.space.Real(0.1, 1.0, name='feature_fraction', prior='uniform'),
skopt.space.Real(0.1, 1.0, name='subsample', prior='uniform')]
@skopt.utils.use_named_args(SPACE)
def objective(**params):
return -1.0 * train_evaluate(params)
results = skopt.forest_minimize(objective, SPACE, n_calls=30, n_random_starts=10)
best_auc = -1.0 * results.fun
best_params = results.x
print('best result: ', best_auc)
print('best parameters: ', best_params)
就这些了。
results 对象包含关于 最佳分数 和参数 的信息。
注意:
如果你想在训练完成后可视化你的训练并保存诊断图表,那么你可以添加一个回调和一个函数调用,记录每次超参数搜索到 Neptune。只需使用这个 来自 neptune-contrib 的帮助函数 库。
import neptune
import neptunecontrib.monitoring.skopt as sk_utils
import skopt
from script_step2 import train_evaluate
neptune.init('jakub-czakon/blog-hpo')
neptune.create_experiment('hpo-on-any-script', upload_source_files=['*.py'])
SPACE = [
skopt.space.Real(0.01, 0.5, name='learning_rate', prior='log-uniform'),
skopt.space.Integer(1, 30, name='max_depth'),
skopt.space.Integer(2, 100, name='num_leaves'),
skopt.space.Real(0.1, 1.0, name='feature_fraction', prior='uniform'),
skopt.space.Real(0.1, 1.0, name='subsample', prior='uniform')]
@skopt.utils.use_named_args(SPACE)
def objective(**params):
return -1.0 * train_evaluate(params)
monitor = sk_utils.NeptuneMonitor()
results = skopt.forest_minimize(objective, SPACE, n_calls=100, n_random_starts=10, callback=[monitor])
sk_utils.log_results(results)
neptune.stop()
现在,当你运行参数扫描时,你会看到以下内容:

查看 skopt 超参数扫描实验 ,包含所有代码、图表和结果。
最后思考
在这篇文章中,你已经学会了如何在仅仅 3 个步骤中优化几乎任何 Python 脚本的超参数。
希望通过这些知识,您能以更少的努力构建更好的机器学习模型。
祝学习愉快!
原文。转载已获许可。
相关:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 相关工作
更多相关主题
假设检验和 A/B 测试

图片来源:编辑
在数据至上的时代,企业和组织不断寻找利用数据力量的方法。
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析水平
3. Google IT 支持专业证书 - 支持您组织的 IT 工作
从你在亚马逊上推荐的产品到你在社交媒体上看到的内容,这背后都有一套精密的方法。
这些决策的核心是什么?
A/B 测试和假设检验。
但它们是什么?为什么在我们以数据为中心的世界中如此关键?
让我们一起发现一切吧!
屏幕背后的魔法
统计分析的一个重要目标是发现数据中的模式,并将这些模式应用于现实世界。
这就是机器学习发挥关键作用的地方!
机器学习通常被描述为在数据中寻找模式并将其应用于数据集的过程。凭借这一新能力,世界上的许多过程和决策变得极其数据驱动。
每次你浏览亚马逊并获得产品推荐,或者当你在社交媒体动态上看到定制内容时,都没有什么魔法。
这是复杂的数据分析和模式识别的结果。
许多因素可以决定一个人是否喜欢成为购买者。这些因素包括之前的搜索、用户的人口统计信息,甚至是一天中的时间和按钮的颜色。
这正是通过分析数据中的模式所能发现的。
像亚马逊或 Netflix 这样的公司建立了复杂的推荐系统,分析用户行为中的模式,如查看的产品、喜欢的项目和购买记录。
但由于数据通常会受到噪声和随机波动的影响,这些公司如何确保他们看到的模式是真实的呢?
答案在于假设检验。
假设检验:验证数据中的模式
假设检验是一种统计方法,用于确定某一假设成立的可能性。
简单来说,它是一种验证数据中观察到的模式是否真实存在或只是偶然结果的方法。
这个过程通常包括:
#1. 发展假设
这涉及到提出一个零假设,它被假设为真实的,通常是假设观察结果是随机的,还有一个替代假设,这是研究者希望证明的。
作者提供的图片
#2. 选择检验统计量
这是用来确定零假设真值的方法和价值。
#3. 计算 p 值
这是一个检验统计量至少与观察到的统计量一样显著的概率,假设零假设为真。简单来说,就是在相应的检验统计量右侧的概率。
p 值的主要好处在于可以在任何所需的显著性水平 alpha 下进行检验,通过将这个概率直接与 alpha 比较,这也是假设检验的最终步骤。
Alpha 指的是对结果的信心程度。这意味着 alpha 为 5% 意味着有 95% 的置信度。只有当 p 值小于或等于 alpha 时,才保留零假设。
通常,较低的 p 值更受欢迎。
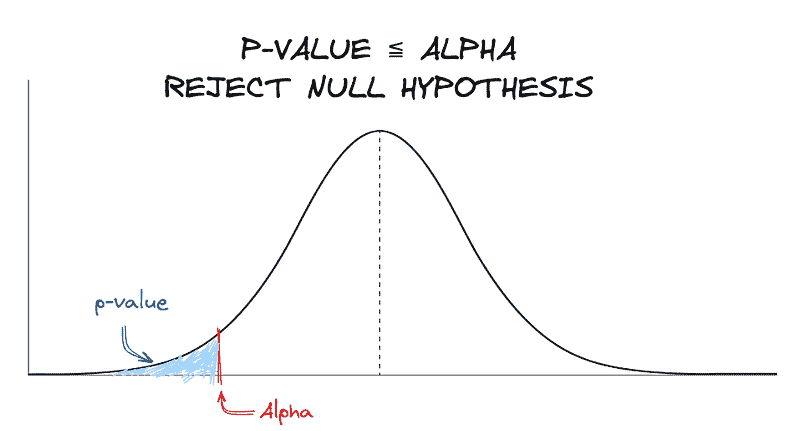
作者提供的图片
#4. 得出结论
根据 p 值和选定的显著性水平 alpha,决定接受或拒绝零假设。
例如,如果一家公司想确定更改购买按钮的颜色是否会影响销售,假设检验可以提供一个结构化的方法来做出明智的决策。
A/B 测试:实际应用
A/B 测试是假设检验的实际应用。这是一种用于比较产品或特性两个版本的方法,以确定哪个版本表现更好。
这涉及到同时向不同用户段展示两个变体,然后使用成功和跟踪指标来确定哪个变体更成功。
每一份用户看到的内容都需要被细化以实现其最大潜力。A/B 测试在这些平台上的过程与假设检验相似。
所以……让我们想象一下,我们是一家社交媒体平台,我们想了解用户在使用绿色或蓝色按钮时是否更容易参与。
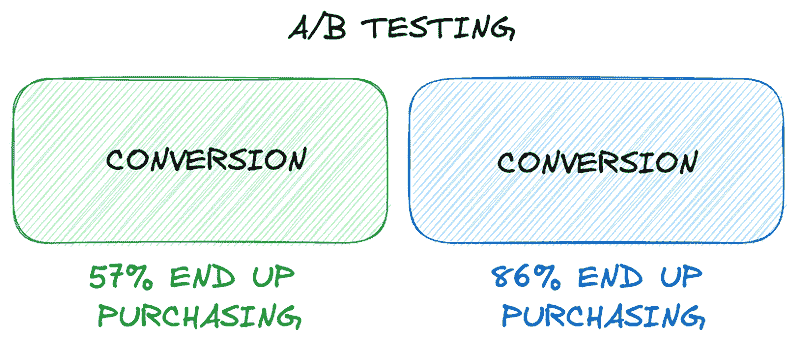
作者提供的图片
这涉及到:
-
初步研究: 了解当前情况并确定需要测试的特性。在我们的案例中是按钮颜色。
-
假设制定: 如果没有这些,测试活动将没有方向。使用蓝色时,用户更有可能参与。
-
随机分配: 测试特性的变体会随机分配给用户。我们将用户分成两个不同的随机组。
-
结果收集与分析: 测试后,收集结果,进行分析,并部署成功的变体。
实际的 A/B 测试商业案例
保持我们是一家社交媒体公司的想法,我们可以尝试描述一个真实案例。
目标: 提高平台上的用户参与度。
衡量指标: 平均在平台上花费的时间。这也可以是其他相关的指标,如分享的帖子数量或点赞数。
#步骤 1:识别变化
社交媒体公司假设,如果他们重新设计分享按钮,使其更突出和更易于找到,更多用户将分享帖子,从而提高参与度。
#步骤 2:创建两个版本
-
版本 A(原始): 平台当前的设计,分享按钮保持不变。
-
版本 B(替代): 相同的平台,但分享按钮经过重新设计,更加突出。
#步骤 3:划分受众
公司随机将其用户基础分成两组:
-
50% 的用户将看到版本 A。
-
50% 的用户将看到版本 B。
#步骤 4:进行测试
公司在预定的时间段内进行测试,例如 30 天。在此期间,他们收集两个组的用户参与指标数据。
#步骤 5:分析结果
测试期结束后,公司分析数据:
- 版本 B 组在平台上花费的平均时间是否增加?
#步骤 6:做出决定
一旦我们收集到所有数据,就有两个主要的选择:
-
如果版本 B 在参与度方面超过了版本 A,公司决定将新的分享按钮设计推广给所有用户。
-
如果没有显著差异或版本 A 表现更好,公司决定保留原始设计并重新思考他们的方法。
#步骤 7:迭代
始终记住,迭代是关键!
公司不会止步于此。他们现在可以测试其他元素,以不断优化参与度。
确保组别随机选择且唯一的区别是正在测试的变更是至关重要的。这可以确保观察到的参与差异确实是由于变更而非其他外部因素。
推断统计学:超越单纯的差异
虽然仅仅比较两组的表现似乎很直接,但推断统计学如假设检验提供了更结构化的方法。
例如,在测试一种新的培训方法是否提高送货司机的表现时,仅仅比较培训前后的表现可能会由于外部因素如天气条件而产生误导。
通过使用 A/B 测试,这些外部因素可以被隔离,从而确保观察到的差异确实是由于处理措施所致。
导航数据驱动的环境
在今天这个决策越来越依赖数据的世界里,像 A/B 测试和假设检验这样的工具是不可或缺的。它们提供了科学的决策方法,确保企业和组织不仅仅依靠直觉,而是基于实证证据。
随着我们生成更多的数据以及技术的发展,这些工具的重要性将只会越来越突出。
请始终记住,在浩瀚的数据海洋中,不仅仅是收集信息,还要学习如何处理这些信息并加以利用。
借助假设检验和 A/B 测试,我们拥有了有效导航这些数据领域的指南针。
欢迎来到数据驱动决策的迷人世界!
Josep Ferrer 是一位来自巴塞罗那的分析工程师。他毕业于物理工程专业,目前从事与人类移动相关的数据科学领域工作。他还是一名兼职内容创作者,专注于数据科学和技术。你可以通过 LinkedIn、Twitter 或 Medium 联系他。
主题扩展
数据科学中的假设检验
原文:
www.kdnuggets.com/2023/02/hypothesis-testing-data-science.html

作者提供的图片
‘假设’一词源自希腊语单词‘hupo’,意思是“下方”,以及‘thesis’,意思是“放置”。利用有限的证据推断出一个可以作为进一步调查的起点的想法。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织进行 IT 工作
所以你可以说‘假设’是一个有根据的猜测,但这并不意味着它不能被证明是真实的。
什么是假设检验?
当我们提到假设检验时,这意味着使用系统化的程序来决定数据和研究是否可以支持我们对人群的特定理论。
我们通过使用两个互斥的假设关于一个人群,并评估这些陈述来决定这些陈述是否得到样本数据的支持。
什么时候在数据科学中使用假设检验?
如果你想根据预测结果进行比较,那么你需要使用假设检验。它将允许你比较发现的前后结果。
它通常用于我们想要比较的情况:
-
一个组与外部标准
-
两个或更多组之间
假设检验与假设生成
在数据科学的世界里,构建假设时有两个方面需要考虑。
假设检验是当团队根据现有数据集构建一个强有力的假设时。这将帮助团队在整个数据科学项目中进行指导和规划。然后使用完整的数据集对假设进行检验,并确定它是否:
-
零假设 - 人群中没有效应
-
替代假设 - 人群中存在某种效应
假设生成是基于各种因素的有根据的猜测,用于解决当前问题。它是将我们的解决问题能力与商业直觉结合的过程。你将关注特定因素如何影响目标变量,然后通过假设检验得出变量之间的关系。
不同类型的假设检验
零假设
统计变量之间没有关系,这种测试称为零假设检验。零假设表示为 H0。零假设的类型有:
-
简单假设
-
复合假设
-
精确假设
-
不精确假设
替代假设
存在两个变量之间的关系,证明它们具有统计关联。替代假设表示为 H1 或 HA。替代假设可以分为:
-
单尾。 这是指你在一个方向上进行测试,忽略与另一个方向上其他变量的关系。样本均值会高于或低于总体均值,但不会同时如此。
-
双尾。 这是指你在两个方向上进行测试,显示样本均值是否高于或低于总体均值。
非方向性假设
这是指假设没有明确方向,但说明一个因素影响另一个因素,或者两个变量之间有相关性。然而,关键点是这两个变量之间没有方向。
方向性假设
这是指使用两个变量之间的特定方向关系构建的假设,并基于现有理论。
它在数据科学中的用途是什么?
在处理数据时,需要在查看、操控或进行任何形式的分析之前先提出问题。提问将帮助你在准备阶段,使分析更加容易。
数据科学家将生成不同的问题,这些问题需要回答以提升业务表现。这些问题将帮助引导数据科学项目,使其在决策过程中更加有效。
例如,当提问并一起形成假设时,数据科学家可以仔细考虑哪些变量会影响他们的项目,以及哪些变量不需要考虑。
假设帮助数据科学家:
-
更好地理解当前的业务问题,并深入挖掘数据集中的变量。
-
使他们能够得出哪些重要因素对于解决问题至关重要,并有效利用时间在不重要的因素上。
-
在准备阶段通过从各种对业务问题至关重要的来源收集数据来提供帮助。
通过使用假设检验来排除可能性,帮助数据科学家得出更好的结论。他们将能更好地集中精力于当前的问题,并做出有效的决策以呈现给高管。
假设检验的其他术语
参数
参数是对目标总体的总结描述。例如,如果你的任务是找出班级的平均身高,你需要询问班级中每个人的身高(总体)。因为每个人都被问到了相同的问题,所以你会得到一个真实的描述,并得到一个参数。
统计量
统计量是对总体(样本)的一个小部分的描述。以同样的例子为例,如果你现在的任务是找出你所在年龄组的平均身高,你可以利用你从班级(样本)中收集的信息。这类信息被称为统计量。
抽样分布
抽样分布是通过从特定总体中选择大量样本得到的概率分布。例如,如果你从 200 家咖啡店的总体中随机抽取 10 家咖啡店作为样本,那么这个随机样本可能是咖啡店编号 4、7、13、76、94、145、11、189、52、165,或其他任何组合。
标准误差
标准误差类似于标准偏差,两者都衡量数据的离散程度。值越高,数据的离散程度越大。然而,区别在于标准误差使用的是样本数据,而标准偏差使用的是总体数据。标准误差告诉你样本统计量与实际总体均值的偏离程度。
Type-I 错误
Type-I 错误,也称为假阳性,发生在团队错误地拒绝一个真实的原假设时。这意味着报告表明你的发现是显著的,但实际上是偶然出现的。
Type-II 错误
Type-II 错误,也称为假阴性,发生在团队未能拒绝一个实际上是错误的原假设时。这意味着报告表明你的发现并不显著,但实际上是显著的。
显著性水平
显著性水平是你愿意接受的做出假阳性结论(Type I 错误)的概率和最大风险。数据科学家、研究人员等会提前设定这个值,并将其作为统计显著性的阈值。
P 值
P 值是指概率值,是与显著性水平比较的一个数值,用于决定是否拒绝原假设。它决定样本数据是否支持反对原假设的观点,并判断原假设是否为真。如果你的 p 值高于显著性水平,那么原假设并没有错或不成立,结果也不具有统计显著性。然而,如果你的 p 值低于显著性水平,结果将被解释为反对原假设并被视为具有统计显著性。
结论
本文介绍了假设检验的基础知识以及数据科学家为何使用它。假设检验是数据科学家工作流程中的一个重要环节。它为他们的假设提供了更多的信心,使他们能够毫不犹豫地向高层展示他们的工作。
如果你想了解更多关于假设检验的知识,一本好的读物是 假设检验:数据驱动决策的直观指南。
尼莎·阿亚 是一位数据科学家和自由职业技术写作员。她特别感兴趣于提供数据科学职业建议或教程以及数据科学相关的理论知识。她还希望探索人工智能如何能够促进人类寿命的不同方式。作为一名热衷于学习的人员,她寻求拓宽技术知识和写作技能,同时帮助指导他人。
了解更多相关话题
假设检验解释
原文:
www.kdnuggets.com/2021/09/hypothesis-testing-explained.html
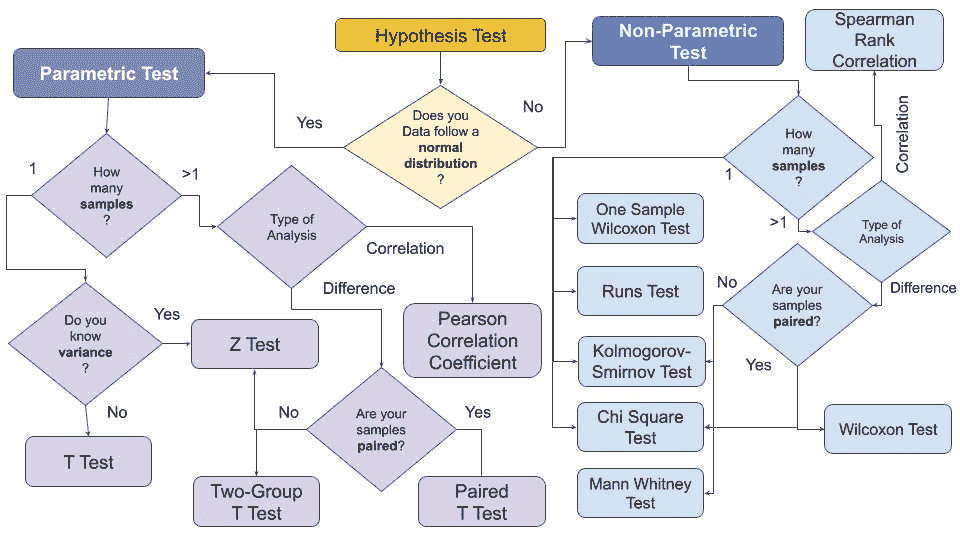
什么是假设检验?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 在 IT 方面支持你的组织
根据吉姆·弗罗斯特的说法,假设检验是一种推论统计形式,使我们能够根据代表性样本对整个总体得出结论 [..] 在大多数情况下,观察整个总体以了解其属性几乎是不可能的。唯一的替代方法是收集一个随机样本,然后使用统计学进行分析 [1]。
在进行假设检验时,首先必须提出一个假设。一个假设的例子是“总体中身高和性别之间存在相关性”,或者“两个总体组之间存在差异”。
通常,待证明的论点称为替代假设(HA),其对立面是原假设(H0)。在实践中,原假设表明总体中没有发生任何新事物。
在之前的示例中,原假设可以被表述为:总体中身高和性别之间没有相关性,并且两个组之间没有差异。假设检验的目的是验证是否可以拒绝原假设。一般来说,拒绝原假设并不自动意味着接受替代假设。 然而,在某些情况下,拒绝原假设可能意味着可以接受替代假设。
在进行假设检验时,可能会发生两种类型的错误:
-
第一类错误:当原假设实际上是正确的时拒绝原假设。
-
第二类错误:当原假设实际上是错误的时接受原假设。
以下表格总结了第一类和第二类错误:

假设检验的类型
假设检验可以分为两个大类 [2]:
-
参数检验,如果样本符合正态分布。一般来说,如果样本的均值为 0,方差为 1,则样本符合正态分布。
-
非参数检验,如果样本不符合正态分布。
根据要比较的样本数量,可以制定两类假设检验:
-
单样本,如果只有一个样本,必须与给定值进行比较。
-
双样本,如果有两个或更多样本需要比较。在这种情况下,可能的检验包括样本之间的相关性和差异。在这两种情况下,样本可以是配对的或不配对的。配对样本也称为依赖样本,而不配对样本也称为独立样本。在配对样本中,发生自然或匹配的配对。
通常,参数检验具有相应的非参数检验,如[3]所述。
本文顶部的图表回顾了如何根据样本选择合适的假设检验。
参数检验
如前所述,参数检验假设数据呈正态分布。下表描述了一些最受欢迎的参数检验及其测量内容。
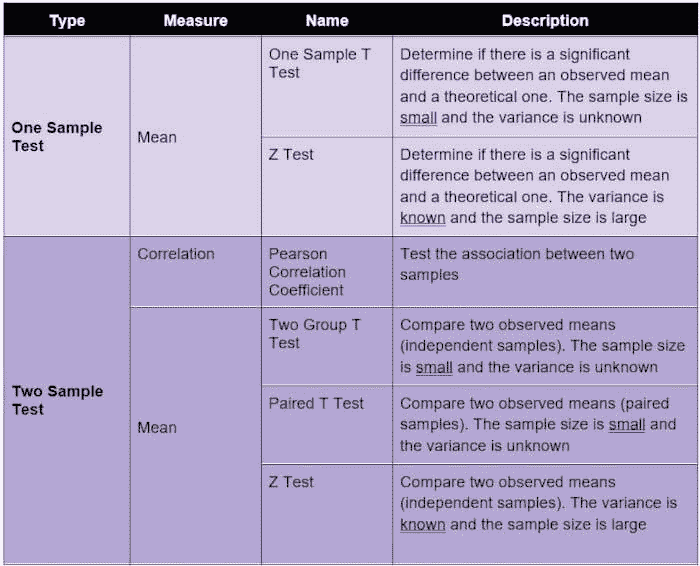
非参数检验
非参数检验不对数据分布做任何假设。下表描述了一些最受欢迎的非参数检验及其测量内容。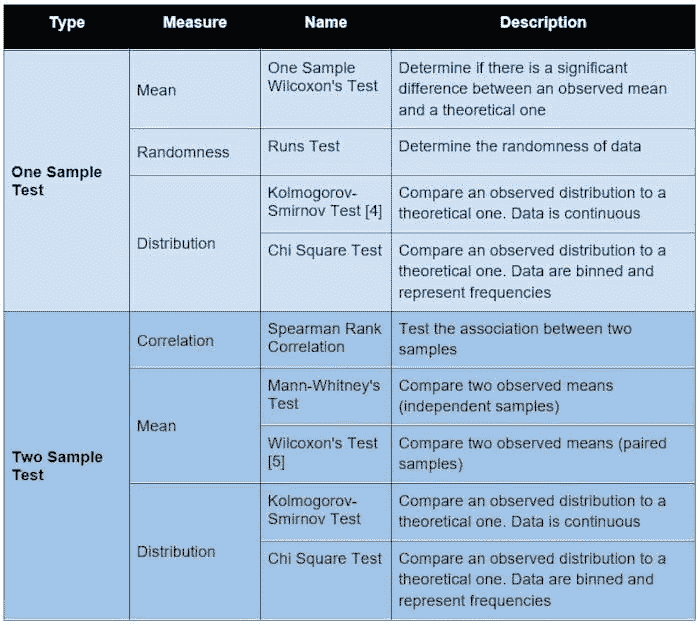
摘要
在这篇简短的文章中,我描述了假设检验的概念,以及最受欢迎的检验及其使用场景。
对于那些仍然难以理解假设检验的人,有一个名为 easy-ht 的 Python 库 [6],它可以在无需统计学知识的情况下运行主要的假设检验。关于如何使用easy-ht的教程可以在此链接找到。
参考文献
[1] 统计假设检验概述 statisticsbyjim.com/hypothesis-testing/statistical-hypothesis-testing-overview/
[2] 参数统计与非参数统计的区别是什么? sourceessay.com/what-is-the-difference-between-parametric-and-non-parametric-statistics/
[3] 你应该使用哪个统计检验? help.xlstat.com/s/article/which-statistical-test-should-you-use?language=en_US
[4] Kolmogorov–Smirnov 检验 en.wikipedia.org/wiki/Kolmogorov%E2%80%93Smirnov_test
[5] Wilcoxon 检验 www.investopedia.com/terms/w/wilcoxon-test.asp
[6] easy-ht pypi.org/project/easy-ht/
安杰利卡·洛·杜卡 (Medium) (@alod83) 在意大利比萨的国家研究委员会(IIT-CNR)信息学与电信研究所担任博士后研究员。她是比萨大学数字人文学科硕士课程中的“数据新闻学”教授。她的研究兴趣包括数据科学、数据分析、文本分析、开放数据、网络应用和数据新闻,应用于社会、旅游和文化遗产。她曾从事数据安全、语义网和链接数据方面的工作。安杰利卡还是一位热情的技术作家。
更多相关内容
假设验证:每个成功的数据科学家都需要的最重要技能
评论
由 AbderRahman Sobh,数据科学家、机器学习工程师、软件开发者、导师
最成功的数据科学项目始于良好的假设构建。一个经过深思熟虑的假设为数据科学项目设定了方向和计划。因此,假设是评估数据科学项目是否成功的最重要项。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT
这种技能不幸的是经常被忽视或以一种随意的方式教授,而倾向于进行功能重要性的实际测试以及在数据上应用模型以查看它们是否能够预测任何东西。虽然确实总是需要特征工程和模型选择,但在对问题没有真正理解的情况下进行这些操作可能是危险且低效的。
通过经验,我总结出了一种系统的方法来处理数据科学问题,这种方法既保证了相关的假设,又能强烈指示数据科学方法是否会成功。在本文中,我概述了用于完成此任务的步骤:定义数据背景、检查可用数据以及形成假设。我还查看了一些 Kaggle 的已完成竞赛,并将它们应用于此过程,以提供实际示例。
制作完美的假设
1. 映射数据背景
就像在物理问题中形成自由体图或在计算机科学中使用面向对象设计一样,描述给定数据背景中的所有有效实体有助于绘制它们之间预期的相互作用。此步骤的目标是完全指定在上下文中可能收集的所有数据,即完美数据集的描述。如果所有这些数据都可用,那么组件之间的相互作用将被完全定义,并且可以使用启发式公式来定义每种类型的因果关系。
2. 检查可用数据与数据背景的重叠
接下来,进行观察以确定可用数据中有多少符合前一步定义的完美数据集。重叠越多,定义实体之间交互的解决方案空间就越好。虽然这不是一个数字指标,但这种观察提供了强烈的直觉信号,表明可用数据是否足够适合和相关。如果有完全的重叠,那么启发式方法可能比拟合数据模型更好。如果重叠很少,那么即使是最好的建模技术也将无法一致地提供准确的预测。请注意,最强的预测信号总是那些直接相关的,因此间接特征关系的重视程度较低,更倾向于真实的信号。主要关注强信号的直觉是,收集具有强信号的更好数据将确保更好的性能和可靠性。相反,使用弱信号进行的预测在获得更好数据后很容易变得过时。
3. 形成假设
完成前两个步骤后,形成假设本身变得简单。假设通常是通过组合一组可用特征来预测另一特征的结果,这些特征可能在未来难以收集或其值可能在结果出现之前就需要。
既然数据背景与可用数据之间的重叠已经明确界定,并且假设相当一部分可用数据是相关的/类别平衡的/etc,那么假设可以简单地表述为:“可用数据可以在给定的数据背景中产生显著的结果,预测____”。请注意,预测标签是开放的,因为它可以被填入许多不同的内容!这是因为,只要符合数据背景且与可用数据有足够的重叠,几乎可以围绕任何给定的特征形成假设。选择特定的预测特征将取决于哪些使用案例最有利。
示例项目
下面,我精心挑选了几个不同的 Kaggle 项目,以使用假设形成技术进行分析。这些示例展示了一些特征设置的假设形成方法,以及每个示例都有一个可以在其数据背景中评估的假设。
项目 1: 预测 PubG 比赛的获胜者 (https://www.kaggle.com/c/pubg-finish-placement-prediction)
选择这个项目是因为数据上下文被简化了,由于预测是在虚拟世界中进行的。模拟的预测预计会表现得更为一致,并沿着非常明确的路径操作,而不是现实生活系统中可能有的不易观察的因素。换句话说,数据上下文可以非常自信地被全面定义。在这个视频游戏中,玩家控制一个可以执行有限动作的单元。数据上下文已在下图中映射出:
数据可以映射到的四个主要实体是:玩家、玩家控制的角色、地图和比赛本身。我选择了这些高层次的实体,是基于它们之间的重要交互以及每个实体的独特性。因此,它们共同定义了这个场景中大部分甚至全部的数据上下文。
接下来,目标是观察比赛提供的数据中有多少符合数据上下文:
-
对于玩家数据,主要提供的是过去比赛的历史记录。关于玩家本身的信息非常有限。
-
关于玩家控制的角色以及比赛的完全重叠,即详尽的数据。
-
没有直接提供关于地图的特征。
利用这些洞察,可以定义出强有力的假设候选。再次强调,这种生成假设的技术忽略了特征相关性或间接关系,而是专注于绝对最强的信号,即直接相关的特征。在这次比赛中,涉及玩家控制的角色和比赛的预测被详细捕捉。相反,虽然我们可能能够根据玩家控制的角色推断出关于玩家的情况,但由于这会使假设变弱,因此避免了这种做法。
一些示例假设在下文中进行了评估,包括比赛中给定的假设:

项目 2:预测哥斯达黎加贫困 (https://www.kaggle.com/c/costa-rican-household-poverty-prediction)
对于第二个示例,我选择了一个具有现实世界元素的项目,但仍保持了相对简单的背景。具体而言,这个比赛的假设是,可以利用给定的数据预测贫困水平。围绕这个假设的数据上下文可以定义为家庭成本与收入,如下图所示:
这个比赛中的数据特征非常详细,所以我将它们大致总结为几个类别:53 个特征用于房屋状况(材料、建筑、质量),6 个特征用于家庭状况,23 个特征用于家庭属性,32 个特征用于个人属性,6 个特征用于租赁状况,8 个特征用于位置。接下来,演示了给定数据与数据背景的重叠情况:

-
主要的导致贫困的成本因素未被收集在数据中。生活中的变化,如家庭成员的最近去世,也没有被包含在内。同样,未提及任何未偿债务。
-
日常成本因素如食品杂货和奢侈品购买不包括在此数据集中。
-
描述家庭收入的唯一一个广泛特征是贫困水平。在图示中,我包括了一些间接特征,这些特征可能会被利用,鉴于直接特征的稀缺。然而,这些特征永远不会像拥有关于工作/薪水/投资的适当数据那样强。
从观察数据重叠中得到的最大洞察是,比赛数据集中没有提供许多与预测贫困相关的方面。提供的信息主要集中在住房和家庭属性上。
以下是一些示例假设的评估,包括比赛给出的假设:

进一步阅读
我写这篇文章的目标是帮助他人获得对数据科学本质的实际理解,并提供一个使用它的起点。数据科学的工作应旨在真正解释我们周围的世界,帮助我们用数字方法填补空白,以便发现。
回到所有这些背后的强大模型和算法,它们本身就是深入的研究,帮助我们从复杂的数据场景中获得更多的理解。如果你对这些算法的工作原理感兴趣,我鼓励你查看我在 Kindle 上的书籍:“Essential Data Science: A Guide to the Applied Machine Learning Toolkit”。
个人简介:AbderRahman Sobh 是一位数据科学家、机器学习工程师、软件开发人员和导师。
原文。经许可转载。
相关内容:
-
如何获得最受欢迎的数据科学技能
-
我在 8 个月内提升数据科学技能的经历
-
数据科学的基本要求:开始数据科学需要掌握的 10 项关键技能
更多相关主题
我参加了谷歌数据分析认证课程,目前已有 2,148,697 人注册
原文:
www.kdnuggets.com/i-took-the-google-data-analytics-certification-where-2148697-have-already-enrolled

作者提供的图片
如果你像我一样,已经到了一个回到大学不再是选择的年纪,或者你准备转行但需要指导——你来对地方了。我当时全职工作,没有选择,只能参加一个灵活的课程,因为我需要维持生活开支。大学完全不在考虑范围内。我需要一个可以让我在不妥协财务和过多时间的情况下获得技能和知识的课程。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 需求
我在看到好评后偶然发现了谷歌数据分析认证。
工作有点慢,所以我决定在没有因工作过度而感到疲惫时尝试一下。
什么是谷歌数据分析认证?
链接: 谷歌数据分析认证
谷歌的数据分析专业认证使你能够理解助理数据分析师使用的实践和流程。
在这项认证中,你将学习关键的分析技能,例如数据清理、分析和可视化,以及 SQL、R 编程和 Tableau 等工具。通过这些技能,你将能够了解如何清理和组织数据以进行分析,并使用电子表格、SQL 和 R 编程完成分析和计算。
到课程结束时,你将学习如何在仪表板、演示文稿和常用可视化平台中可视化和展示数据发现。
该课程面向初学者,如果你每周投入 10 小时,通常可以在 6 个月内完成。课程安排灵活——你可以按照自己的节奏学习!
我对认证的看法
在参加认证之前,我已经在两年前参加过一个训练营。当我进入科技行业并获得我的第一个初级数据科学家职位时,我意识到有些数据科学的元素是训练营没有教给我的。我曾经绕了很多圈子才明白,我需要回到基础,好好学习才能继续我的数据科学之旅。
所以这就是我所做的。我决定参加 Google 的数据分析认证,并设定了在 2 个月内完成它的目标。
所以学习之旅开始了,我想说的第一件事是:内容——令人惊叹!过程——顺利!指导——无可挑剔。
如果你像我一样觉得需要对数据分析或数据科学的学习进行一些复习,或者你是数据领域的新手,需要指导——这个课程正好满足了这些需求。
是的,学习材料很多,但所有这些材料都是学习过程中不可或缺的一部分,并且有助于我的理解。在每一章节之后,多项选择题帮助我理解每一部分,而不是在每个模块结束时才遇到一堆问题。
当涉及到完成各章节的多项选择题和模块测试时——我做得非常出色。是的,我之前的训练营知识在这方面帮了我一些忙,但经历了几年的数据科学空白期——这些内容对我获得认证简直是救星。
这门课程非常好,以至于我推荐给了一些没有技术经验的家人和朋友,他们回来后给予了很好的反馈,说课程的结构和过程对初学者非常友好。
我对这个认证的总体评价和反馈是,我会强烈推荐给那些对科技行业还不太熟悉的人,因为它的课程结构非常适合初学者,也适合那些想要巩固现有知识以确保自己掌握得非常牢固的人!
记住,这个认证是针对初学者的,这意味着你的数据科学学习之旅不应止步于此。持续学习新技能和工具将帮助你成为一名成功的数据科学家!
总结
每个人的学习过程都不同。有些人可能已经完成了认证,并且更喜欢其他学习方式。然而,如果你是一个需要指导并且喜欢循序渐进的人——这个认证强烈推荐!
KDnuggets 的团队希望每个人都能成功,我们希望我们能帮助你的学习之旅!
尼莎·阿里亚是一位数据科学家、自由技术写作员,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议、教程以及基于理论的数据科学知识。尼莎涵盖了广泛的主题,并希望探索人工智能如何有利于人类寿命的延续。作为一名热衷学习者,尼莎致力于拓宽她的技术知识和写作技能,同时帮助指导他人。
相关主题
我参加了 Udacity 的免费 A/B 测试课程:这是我学到的内容
原文:
www.kdnuggets.com/i-took-udacitys-free-a-b-testing-course-by-google-heres-what-i-learned

图片由作者提供
我是一名拥有计算机科学背景的数据科学家。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 部门
当我刚进入这个领域时,由于缺乏对基础数学和统计学概念的了解,我在数据科学面试中苦苦挣扎。
其中一个概念就是 A/B 测试。
尽管我在面试的编码部分表现出色,但当被问及推断统计和实验设计的问题时,我常常会僵住。
为了弥补这一知识差距,我参加了 Udacity 上的免费 A/B 测试课程,该课程由谷歌的高级数据专业人士教授。
在这篇文章中,我将详细解析我在课程中学到的内容,并解释你如何使用这些知识来建立对推断统计的理解。
什么是 A/B 测试,我们为什么需要它?
假设你的公司想要推出一种新类型的糖果,同时继续销售现有的甜点。
假设是新的糖果将吸引更多用户到全球各地的商店,从而导致总销售额的增加。
在将这种新糖果在所有商店推出之前,公司需要了解这样做是否有利可图。
它必须首先在几个商店上测试这一假设,只有在确实有销售增长的情况下,才扩大生产。
这就是 A/B 测试的作用所在。
简而言之,A/B 测试比较两种版本的事物,以找出哪一种更好。
A/B 测试通常包括以下几个组成部分:
-
变体 A:在我们的甜点店例子中,这是不销售新糖果的变体。它也被称为对照组。
-
变体 B:这是应用了变化的变体。在我们的例子中,这包括提供新糖果的商店组。它被称为处理组。
-
假设:这是你期望发生的事情的明确陈述。以下是我们例子中的假设:“销售新糖果的商店将看到比不销售的商店更高的平均销售额。”
假设陈述可以进一步细分为零假设和备择假设,这将在本免费课程中进行讲解。
你将在 Udacity 的免费 A/B 测试课程中学到什么
1. A/B 测试概述
你将了解 Netflix、Amazon 和 Google 等大型公司如何使用 A/B 测试。
我发现这个见解很有价值,因为你可以从在 Google 担任统计学家和工程师的讲师那里学习 A/B 测试的实际应用。
2. 推论统计与实验设计
然后,本课程将涵盖你需要了解的所有实验设计内容——从你想要测量的指标,到置信区间和统计显著性等概念。
你将学习:
-
如何构建置信区间
-
不同的统计分布(正态分布、二项分布)
-
设计零假设和备择假设的最佳实践。
本课程通过一个简单的实际例子来演示如何提高网站点击率,这个例子我觉得很有趣。
3. 实验的政策和伦理
本课将涵盖进行实验时的伦理考量——理解实验参与者是否面临风险以及获取用户同意。
4. 如何确定实验规模
你将学习如何确定实验的适当样本大小,包括统计功效、显著性水平、标准差和最小可检测效果(MDE)等度量。
如果这些概念对你来说很陌生,不用担心!
我开始这门课程时对上述统计主题了解不多,但凭借提供的额外学习材料和笔记,我能够轻松跟上进度。
5. 如何分析实验结果
在这里,你将了解在实验中所有组必须保持不变的指标类型。这些称为不变量。
你还将学习如何分析实验结果是否具有统计学意义——无论是单指标实验还是多指标实验。
6. 将结果转化为可操作的洞察
在这一部分,你将学习如何利用 A/B 测试的结果来做出商业决策。
例如,如果你发现销售新糖果的商店确实有显著的销售提升,那么下一步该怎么做?
你会将这种新糖果的多个批次推出到全球所有商店吗?还是从一个州或国家开始?
也许你会希望根据你收集的数据对实验进行迭代。
本课程的这一部分重点关注 A/B 测试的商业影响,并帮助在测试完成后进行决策。
7. 最终项目
在最终项目中,你将获得 Udacity 实际运行的实验中的真实数据。
使用这些数据,你需要回答一系列关于实验设计的问题——你将被要求计算标准差、实验持续时间和样本大小等指标。
在回答完有关数据集的所有问题后,你需要根据所进行的分析作出是否启动实验的最终建议。
收获
我进入Udacity 的 A/B 测试课程时,期望它会很数学密集且难以理解。
令我惊讶(也是高兴的是),它更加以商业为中心,专注于 A/B 测试的实际实施。
如果你想开始进行 A/B 测试,并且希望了解如何定义假设、选择样本大小以及其他实验参数,这门课程将帮助你快速上手。
我还推荐这门课程给那些希望加深对统计推断和实验设计理解的人,因为了解这些概念将帮助你在数据科学和分析面试中表现出色。
 
 
Natassha Selvaraj是一位自学成才的数据科学家,对写作充满热情。Natassha 写作涉及所有数据科学相关的内容,是所有数据话题的真正大师。你可以通过LinkedIn与她联系,或者查看她的YouTube 频道。
相关话题
前 10 大机器学习用例:第一部分
原文:
www.kdnuggets.com/2017/08/ibm-top-10-machine-learning-use-cases-part1.html
由 IBM 故事战略师 Steve Moore 撰写。赞助帖子。

机器学习已经扩展到日常生活的许多方面,记住一些其对特定行业影响的常用示例对我们来说可能很有帮助。例如,我们可能会把欺诈检测视为机器学习在金融领域的典型示例。或者我们可能会把 Watson 的认知方法在肿瘤学中的应用视为机器学习在医疗领域的典型示例。又或者,我们可能会将 Netflix 和 Amazon 的推荐引擎视为机器学习在零售领域的典型示例。
如果你有兴趣尝试IBM 的 Watson 机器学习服务 - 点击这里
当然,这些都是展示技术力量的巨大示例——综合起来,它们展示了机器学习在我们生活中的普遍存在。但便利的常用示例可能也会带来代价。特别是,引用相同的便捷示例可能会使我们忽视机器学习在各个领域中的广泛应用。
这篇帖子是一个系列的第一篇,旨在颠覆我们对机器学习在特定领域可能实现的认知——超越那些总是浮现在脑海中的用例。
从政府开始...
1. 将机器学习应用于环境保护
像任何商业领域一样,政府也面临着用更少的资源做更多事的压力,更有效和更智能地服务更多的公民。这包括那些负责环境保护的机构,如DCMR Milieudienst Rijnmond,它们在荷兰的鹿特丹周边地区与污染、废物和其他环境威胁作斗争。
通过结合各种IBM Analytics软件、与荷兰安全公司DataExpert的强大合作关系以及一系列远程传感器,团队能够利用机器学习实时识别和评估环境危害——并按严重性和紧急性对这些危害进行排序。通过算法检测和评估环境威胁,系统可以识别关键风险和合规缺失。自动化和改进这一方面的工作可以为 DCMR 节省更多时间和精力,从而提升公共安全。
2. 机器学习与比利时人的就业保障
在欧洲的同一区域,一个名为 VDAB 的就业和职业培训机构正在努力为比利时弗兰德地区的工人提供他们所需的信息和资源,以便找到并保持工作。值得庆幸的是,比利时的失业率正在 下降——从去年 8.2%降至 6.8%——但即使是 6.8%,显然还有很多工作要做。
该机构的一个关键目标是缩短年轻工人的失业时间,同时寻找将有限资源有效分配到真正需要的地方的方法。机器学习解决方案:由 IBM 全球业务服务 制作的一个机器学习模型,通过分析过去的数据预测每位求职者的失业持续时间。通过关注最有风险的年轻比利时人,该机构可以更有效地打断失业模式,并启动自我强化的步骤,以实现就业保障——这将对整体经济带来长期的好处。
3. 机器学习在解决青少年饥饿问题中的作用
在地球另一端,我们找到 哥伦比亚家庭福利研究所,这是一个在哥伦比亚全国范围内开展早期儿童、儿童、青少年保护和家庭福利工作的机构。尽管预算紧张,该组织仍然成功地通过其项目和服务覆盖了超过 800 万哥伦比亚人。
在这 800 万人中,2016 年有 38,730 名营养不良的儿童收到了 29,552 份紧急食品救助和超过五百万份的膳食补充品。这项工作并非偶然。幕后,分析公司 Informese 使用 IBM SPSS Modeler 提供预测分析和微目标能力,以优化援助分配到哥伦比亚最贫困和最偏远的地区。
世界各地的政府及其机构正在使用机器学习,超越处理税务申报或让公交车准时运行的任务。让我们将这三个新的例子加入我们的工具箱中,继续倡导机器学习,并寻找将其能力发挥到极致的新方法。
在这里尝试 IBM Watson 机器学习服务
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关主题
增强现实中的高维数据可视化
原文:
www.kdnuggets.com/2017/09/ibm-visualizing-high-dimensional-data-augmented-reality.html
作者:本杰明·雷斯尼克。赞助帖子。

创意共享许可证
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平。
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT。
如果你有兴趣试用IBM Watson 机器学习服务 - 点击这里。
想象一下,几年后的一个周一早晨,你走进办公室。你给自己倒一杯咖啡,查看新闻,然后戴上一副 AR 眼镜。你发现自己被一片柔和发光的彩色光点包围。这些光点代表了驱动你业务的所有数据。你对这些数据非常熟悉。这些光点的图案和颜色就像指纹一样。但是,漂浮在咖啡机上的数据有些不寻常。你伸手选择那些数据。所有相关细节的摘要出现在附近的电脑屏幕上。
如果某件事对你的业务重要,你的系统会跟踪它。当你想查看所有信息时,你会使用这种沉浸式可视化;突破电脑屏幕的限制,信息密集、高效且美观。
我在 IBM 的团队正在努力实现上述描述的体验。沉浸式洞察是一款增强现实数据可视化应用。请查看下面的视频了解我们的进展:
概述
本文概述了我团队最近一直在研究的一种技术。
我们一直在尝试一种总结和可视化高维数据的方法,使用沉浸式洞察。这种总结复杂数据中重要关系的能力是我们长期愿景的关键部分。
数据可以有很多属性。例如,Instacart 的开源数据集包含了购物记录。数据集中的每个人都可以看作一个数据点。每个数据点可以通过一系列购买的产品来描述。这对每个用户来说超过了 50,000 种可能的产品。
了解这些人彼此之间的关系将非常有用。但我们如何开始理解如此多的数据呢?
通常,当数据科学家首次获得数据集时,他们会使用 2D 散点图矩阵来快速概览内容。2D 散点图显示了属性对之间的关系。但对于具有大量属性的数据,这种分析方法的规模就显得不够。
2D 散点图矩阵,与 Immersive Insights 并置
受 projector.tensorflow.org/ 的启发,我们使用以下技术进行数据分析:
-
将复杂数据简化为总结重要关系的三维(在此案例中通过应用 PCA)
-
使用 IBM Immersive Insights 可视化数据
-
根据对嵌入关系的不断理解,迭代标记和颜色编码数据。
通过使用 Immersive Insights 导航该功能空间,可以更快地验证假设,并对高维数据集中实体之间的关系形成更好的直觉。
Immersive Insights 与 IBM DSX 集成。这使得将沉浸式可视化技术作为典型数据分析工作流的扩展变得可能。在 R、Python 和 Immersive Insights 之间来回切换相对容易。
适用于此技术的数据集通常用于训练机器学习模型。如果数据科学家使用此过程来理解其数据中的嵌入关系,这可能有助于他们改进 ML 特性和模型。这种技术也有助于了解黑箱预测模型在幕后可能在做什么。
短期内,Immersive Insights 团队专注于为熟悉编程的数据专家提供可视化技术。我们正在开发方法,以便这些专家在 AR 中可视化时间序列、地理和网络数据。
从长远来看,我们希望扩大产品的范围,以便业务分析师也能使用 Immersive Insights!
Instacart 分析代码
我们是如何创建附加视频中所示的可视化效果的?
首先,数据是在一个 python notebook 中准备的。查看该代码这里。
Instacart 的用户通过一个描述他们与每个潜在购买产品关系的向量进行建模。这个向量的形式是一个稀疏的 0 和 1 数组。每个 1 对应一个该用户至少购买过一次的产品。每个 0 对应一个未购买的产品。这种技术被称为"独热编码"。然后,对数据执行 PCA(主成分分析),以便用仅仅三个数字或"主成分"来描述每个用户。每个主成分总结了数据中的方差方面。实际上,由于内存限制,我只能分析 120,000 名用户。在执行 PCA 后,处理好的数据被导出到 CSV。
接下来,数据通过一个单独的 R notebook 发送到耳机进行可视化。查看那个代码这里。
R notebook 根据可能影响潜在空间用户分布的各种标准对用户进行颜色编码。用户根据他们最常订购的部门(如冷冻食品、零食、农产品)进行颜色编码。另一种颜色编码方案则表示用户是否购买了任何有机食品。我还参考了 Immersive Insights 中各种用户的 ID,然后在 R notebook 中查找了他们的购买历史。这使我能够直观地了解哪些产品购买会导致用户被放置在潜在空间的不同区域。
分析结果
没有购买任何有机食品的用户在潜在空间中被紧密聚集。这一发现是支持从可视化中得出的定性观察的有力证据:Instacart 购买模式中的大部分方差似乎存在于购买高端商品的用户和喜欢类似商品的低价版本的用户之间。这种对成本敏感与高端购买者的差异对 Instacart 的营销、促销和推荐策略有着重要意义。
我们还发现,Instacart 用户购买的农产品远多于其他类别的商品。有许多不同类型的用户喜欢农产品。几乎每个人都买农产品!
当根据用户购买商品的最常见部门(即模式部门)对用户进行分类时,他们并不是线性可分的。我们发现,虽然这种分类方式有助于理解一些用户购买模式之间的关系,但它似乎错过了数据集三大主成分描述的大部分方差。
结论
本文介绍了一种使用增强现实分析大数据的技术。这种技术最适用于准备创建机器学习模型的数据科学家。
大数据、增强现实和机器学习正成为三种颠覆性技术,它们将塑造未来的商业和社会。如前所述,这些颠覆性技术可以以创造性、有用的方式相互融合。你可以在这里阅读有关这些结合的颠覆性技术的潜在影响:www.weforum.org/agenda/2016/01/the-fourth-industrial-revolution-what-it-means-and-how-to-respond/
本文描述的技术范围有限。但 Immersive Insight 的愿景范围巨大。Immersive Insights 团队很高兴继续构想数据可视化和分析的未来。我们的目标:让数据变得简单。
有用的链接
本文有助于理解如何为 PCA 准备数据
本文帮助展示了为什么高维数据的探索性技术对机器学习从业者如此有用
更多相关话题
如果你想进入科技领域:成为一名软件开发者
原文:
www.kdnuggets.com/if-you-want-to-get-in-the-tech-space-become-a-software-developer
图片由作者提供
尽管我们生活在诸如 ChatGPT 这样的复杂人工智能工具的兴起和裁员的背景下,但关于科技行业是否仍然值得进入存在许多问题和意见。也有很大强调认为软件开发已经死了——但他们错了。
为了使组织成为数字优先,他们将需要软件开发者、分析师和其他相关角色来实现这一目标。
美国新闻与世界报道将软件开发者排名为最佳科技职位的第一位。他们在最佳 STEM 职位中排名第二,在 100 个最佳职位中排名第三,在最佳高薪职位中排名第十九。
如果你在想,为什么在 AI 和机器学习工具占据主导地位时,软件开发者仍然需求如此之高?就像世界上任何其他角色一样,它们也必须随着市场的发展而进化,以提高工作流程和效率,软件开发者将用新发布的工具以同样的方式做出调整。
最好的新技术在推出后仍然需要维护、升级和故障排除。没有什么是完成的产品。因此,像 ChatGPT 这样的工具虽然为很多人提供了更好的工作流程和工作生活平衡,但仍然需要具备正确技能的专家来确保其顺利运行。
这就是软件开发者发挥作用的地方。
为什么我们需要软件开发者?
如前所述,由于裁员对进入科技行业存在很大恐惧。然而,无论你在互联网上看到什么,裁员的数量基本保持不变。
越来越多的组织正在变得依赖技术,如果他们还没有开始的话。数字解决方案是主要的业务目标,因此对熟练的软件开发者的需求几乎没有减缓的迹象。
根据美国劳工统计局,他们预测在未来十年内软件开发者职位的增长率将达到 26%。这意味着到 2030 年,我们将看到 120 万个新的软件开发者职位。
不要害怕科技裁员,这是虚惊一场。虽然 AI 在未来几年会变得更加复杂,但本质上,它仍然需要能够解决问题并为企业提供机会来构建更好解决方案的软件开发者。
如何成为一名软件开发者?
你可能在问自己,那我该怎么做?我如何进入软件工程师的行业?
计算机科学知识
你的第一步将是了解计算机科学的所有基础知识。你可以采取各种措施,例如攻读学位、参加在线课程或自学。
以下是一些推荐:
-
计算机科学学士学位 由伦敦大学提供
-
计算机科学:编程的目的 由普林斯顿大学提供
-
计算机科学:算法、理论与机器 由普林斯顿大学提供
-
学习 R 编程 由 DataCamp 提供
-
应用软件工程基础专门化 由 IBM 提供
获取实践经验
雇主希望聘用能够将知识应用于实践的人。这意味着需要一个实际项目的作品集,雇主通常会对这些项目感兴趣。这表明你已经花时间学习基础知识并能够将其应用到像他们这样的公司中。
以下是一些推荐:
总结
不要被关于技术裁员的头条新闻吓到。对软件开发人员的需求持续上升。
你最好的选择是今天开始学习!
Nisha Arya 是一位数据科学家、自由技术作家,同时也是 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及数据科学相关的理论知识。Nisha 涉及广泛的话题,希望探索人工智能如何有利于人类寿命的不同方式。作为一个热衷学习者,Nisha 寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关主题
如果你想掌握生成式 AI,忽略所有(除了两个)工具
原文:
www.kdnuggets.com/if-you-want-to-master-generative-ai-ignore-all-but-two-tools
现在是 2 月 7 日。外面相当寒冷,但显然还不足以冷却 ChatGPT 在冬季之前引发的兴奋。微软准备宣布 Bing Chat,这是一个基于 OpenAI 下一代模型构建的聊天机器人,能够进行网络搜索——谷歌注定要失败(在三个月内第二次)。每个人都会转向 Bing,微软将吞噬谷歌的搜索收入。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
现在是 3 月 14 日。北半球的花朵羞怯地绽放。我们特别期待一个罕见的,有 8(或者 16?)个花瓣的花朵。它即将绽放(或者可能不会)。GPT-4 发布了;这是语言模型有史以来最神秘的发布。但它比 GPT-3.5 好,不——比 GPT-3.5 好得多。谁不愿意为每月 $20 的 100 倍生产力提升买单?这是个划算的交易。
现在是 3 月 21 日。一段柔和的,可能是幻觉中的旋律唤醒了谷歌的长时间沉睡。Bard 对 Sundar Pichai 耳朵的音乐。但是有些音符不对——是一个匆忙的发布吗?看起来上面的两个夹击策略运作得很顺利。但是 Bard 只是一个测试版——真正的劲爆产品将会在未来带来更强大的模型。谷歌重新回到了竞争中。
现在是 7 月 18 日。史上最热的夏天。太阳高挂;空气炽热;GPU 将再次“嗡嗡作响”。Meta 不再浪费时间在元宇宙上,宣布了一个广受欢迎的 AI 发布:他们流行的 LLaMA 模型的开源第二版,Llama 2. 他们这样做是为了给 OpenAI、微软和谷歌上课,告诉他们如何公开透明地做事。
Alberto,我觉得你还遗漏了一些——你知道的,Anthropic 的 Claude?那 Perplexity 呢?Character 呢?Inflection 的 Pi 呢?AI21 的 Jurassic 呢?Cohere 的 Xlarge 呢?Mosaic 的 MPT 呢?……别忘了每周推出的略显昂贵且被高估的礼品包装纸!
哦天哪,这真是变得荒谬了。
本文摘选自算法桥,这是一个旨在弥合 AI、算法与人类之间差距的教育新闻通讯。它将帮助你理解 AI 对你生活的影响,并开发出更好地驾驭未来的工具。*
或许这已经足够了
我读了作家 Zulie Rane 的一篇文章,谈到社交媒体平台的饱和,灵感来自于在 Threads 上注册的狂热(仅仅是一周后退出。这篇文章时机恰到好处,令人极为贴切。我喜欢开头的风格——我借用了这篇文章的风格。标题结构也借鉴了另一篇文章。
我忍不住了。这种平行性真是令人难以置信:社交媒体上发生的现象与生成式 AI 工具上发生的现象完全相同。也许这就是我们作为一个社会的现状,受到对错过的恐惧、信息的海量、不断加速职业发展的驱动,或者不被抛在后头的绝望所影响。
无论情况如何,我们都无法抗拒。生成式 AI 的狂热让我们无意识地用心理健康换取过度的吸引力。我不需要这么多。你也不需要。我们实际上几乎不需要它。
标题中的“但两个”部分仅仅是个人观点。(我考虑了一个用于写作,一个用于图片。但也许你想要不同的工具用于编程。或者你不编码。或者你对 AI 艺术不感兴趣。但你明白我的意思。)不过它确实反映了一个非常真实的感受,我敢打赌你也有这种感受,自从 ChatGPT 以一种无法解释、意外、前所未有——是的,幸好——的方式变得病毒式传播以来。
世界对于巨大的好处、跨领域的威胁和个人感受到的 — 但集体分享的 — AI 疲劳感准备不足。影响者、营销人员和骗子并不是引发这种恼人感觉的原因。他们只是利用它来获取杠杆;真正的原因早于他们,且很难避免。
所以我决定缩小范围。我专注于我真正想要的,并坚持下去。否则我获得的额外价值是无法弥补心理成本的。
避免生成式 AI 疲劳的三大理由
到目前为止,这只是纯粹的情绪发泄,但我的情感背后有其合理性。
一项技术魔法统治一切
尽管生成型 AI 技术的范围令人惊叹,产品的有效性经过验证,以及资金在不同手中流转(虽然大部分没有离开硅谷),但事实是它们都源于相同的技术基础。
这并不是否认在任何一天我可能想使用 Bing 的搜索框、Claude 的 100,000-token 上下文窗口、GPT-4 的推理能力、Bard 的提示多模态性、Pi 的高情感敏感度或 Character 的多样化个性……但说实话:我真的需要 所有这些 吗?
不久后,它们几乎无法区分。最富有的公司将能够商业化最佳产品,而所有这些产品都将具有相同的基本特征。其余的——风险投资支持的初创公司和较小的语言模型包装项目——将不得不细分市场或消亡。我们使用的工具将归结为个人偏好,但所有这些工具都将来自一小群大公司。还是那一群。
即使是能力上的假定差距(哪些预训练模型更好)和行为(哪些尚未被强化学习调优到无用)对于大多数任务来说也是无关紧要的。GPT-4 的所谓暂时性性能下降仅仅是 OpenAI 在公开迭代的副产品,无论原因是什么,肯定会很快解决。
简而言之:在即将被商品化的生成型 AI 行业中,少即是多。
避免陷阱。
避免工具制造工厂
但也许你确实关心那些微小的差异。
在这种情况下,我鼓励你尝试一些工具,你会发现坚持使用其中几个就足够了。为什么?因为你会发现自己更自然地倾向于某些工具,而不是其他工具。正如Rane 所说: “你的技能和兴趣使你不适合 99% 的平台,但非常适合 1%。”她说的是社交媒体,但这完全可以推断到生成型 AI 工具。我的三个标准是能力(我擅长什么?)、偏好(我喜欢做什么?)和活动(我需要它做什么?)
比如,让我们对工作任务做一个简要的非详尽概述:如果你是作者或创意写作者,也许高温低 RLHF 的基础模型最适合你(例如,GPT-3 或 3.5)。如果你是 SEO 内容营销人员或文案撰写者,也许定制包装是最佳选择(例如,Jasper,尽管现在 ChatGPT、Bard 和 Claude 也很好)。如果你是技术娴熟的作家,也许 Llama 2 更好,以避免依赖。如果你是数字艺术家,那么选择 Midjourney。如果你有编程技能并且想要更高的可操控性,可以选择 Stable Diffusion。作为编码人员,选择 GPT-4 或 GitHub Copilot。数据分析?选择代码解释器。
观察新工具的发布是好的,但如果我坚持使用一两个工具会更高效;每周分析新闻以查看新事物是否比当前工具好 0.1%是令人疲惫的,并且是导致倦怠的主要原因。
用户与公司之间的固有不匹配
还有第三个原因——虽然与其他原因关系较远——说明为何不值得过度关注生成式 AI 的疲劳。
尽管这种局面看起来像是一张由竞争动态、利益冲突和商业紧张构成的网,最终结果是竞争驱动的消费者福祉,但我提到的所有公司都有 紧密的、有利的 和 互利的 关系,其唯一目标是让我们这些用户为他们的产品付费(包括最终可能会变成付费的免费产品)。
这些公司不是为了提供更多的价值而推出越来越多的产品,而是为了获取丰厚的生成式 AI 市场份额。这并没有什么不好。我的意思是,谁不会这样做呢?这是预期中的——没有比社交媒体平台更差——但值得记住的是,万一你以为我们是这些产品的主要受益者——其实我们不是。公司不会犹豫片刻地采取对我们不利的方向。如果有必要,他们会毫不犹豫地切断对产品的访问,并完全关闭他们的服务。
总之,生成式 AI 工具可以是福音,也可以是诅咒。生命太短暂,不值得一直追逐我们真正不需要的东西。
确定重点。保持自由。避免疲劳。
Alberto Romero 是一名专注于科技和 AI 的自由撰稿人。他撰写了 The Algorithmic Bridge,这是一个帮助非技术人员理解 AI 新闻和事件的新闻通讯。他还是 CambrianAI 的技术分析师,专注于大型语言模型。
原文。已获转载许可。
主题相关更多内容
使用卷积神经网络 (CNN) 进行图像分类
原文:
www.kdnuggets.com/2022/05/image-classification-convolutional-neural-networks-cnns.html

什么是卷积神经网络 (CNN)?
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
卷积神经网络是一类特殊的神经网络,具有从图像数据中提取独特特征的能力。例如,它们被用于面部检测和识别,因为它们能够识别图像数据中的复杂特征。
卷积神经网络如何工作?
像其他类型的神经网络一样,CNN 消耗数值数据。
因此,输入这些网络的图像必须转换为数值表示形式。由于图像由像素组成,它们被转换为数值形式,然后传递给 CNN。
然而,正如我们将在下一部分讨论的那样,并非所有的数值表示都传递到网络中。要理解这一点,我们来看看训练 CNN 时涉及的一些步骤。
卷积
通过卷积操作减少传递给 CNN 的数值表示的大小。这一过程至关重要,以便只有在图像分类中重要的特征被传递给神经网络。除了提高网络的准确性,这也确保了在训练网络时使用最少的计算资源。
卷积操作的结果称为特征图、卷积特征或激活图。应用特征检测器会生成特征图。特征检测器也被称为核心或滤波器。
核心通常是一个 3x3 的矩阵。通过对核心与输入图像进行逐元素乘法,并将值求和,得到特征图。这是通过在输入图像上滑动核心来完成的。滑动的步骤被称为步幅。在创建 CNN 时,可以手动设置步幅和核心的大小。
例如,给定一个 5x5 的输入,3x3 的卷积核将输出一个 3x3 的特征图。
填充
在上述操作中,我们已经看到应用卷积操作时特征图的大小会减少。如果你希望特征图的大小与输入图像相同,该如何实现?这可以通过填充来实现。
填充涉及通过用零“填充”图像来增加输入图像的大小。因此,将滤波器应用于图像会导致特征图的大小与输入图像相同。
填充减少了卷积操作中丢失的信息量。它还确保图像的边缘在卷积操作中被更频繁地考虑。
在构建 CNN 时,你将有选项定义所需的填充类型或完全不使用填充。这里常见的选项是 valid 或 same。Valid 表示不应用填充,而 same 表示应用填充,以便特征图的大小与输入图像的大小相同。
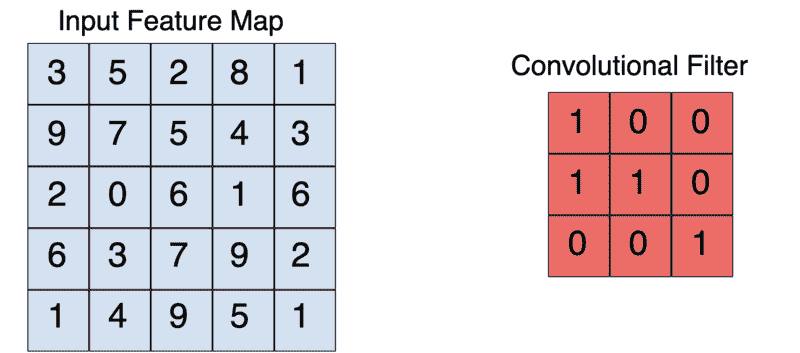
这里是上述特征图和滤波器逐元素乘法的效果。
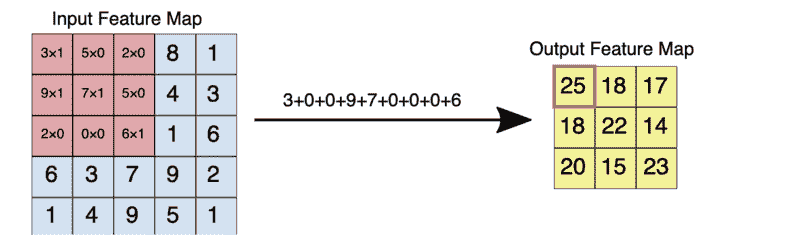
激活函数
在每次卷积操作后应用了一个修正线性单元(ReLU)变换,以确保非线性。ReLU 是最流行的激活函数,但也有其他激活函数可供选择。
在变换之后,所有低于零的值都被返回为零,而其他值保持不变。
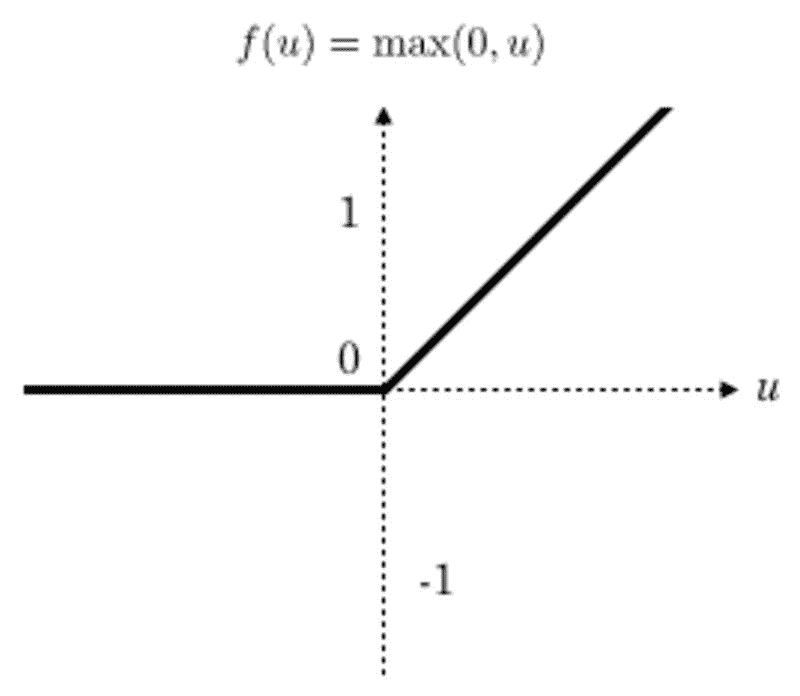
池化
在这个操作中,特征图的大小进一步减少。有各种池化方法。
一种常见的技术是最大池化。池化滤波器的大小通常是一个 2×2 的矩阵。在最大池化中,2×2 的滤波器在特征图上滑动,并在给定的区域中选取最大值。此操作的结果是一个池化特征图。
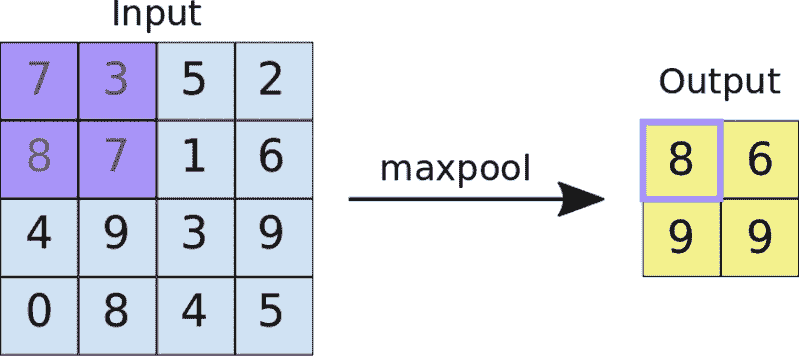
池化迫使网络识别图像中的关键特征,而不考虑其位置。减少的图像大小也使训练网络变得更快。
Dropout 正则化
应用 Dropout 正则化是 CNN 中常见的做法。这涉及到随机丢弃某些层中的节点,使其在反向传播过程中不会被更新。这可以防止过拟合。
扁平化
扁平化涉及将池化特征图转换为一个单列,然后传递给全连接层。这是在从卷积层过渡到全连接层时的常见做法。
全连接层
扁平化后的特征图接着传递给全连接层。根据问题和网络结构,可能会有多个全连接层。最后一个全连接层负责输出预测结果。
最终层使用的激活函数取决于问题的类型。用于二分类的激活函数是 sigmoid 激活函数,而用于多类图像分类的则是 softmax 激活函数。
为什么选择卷积网络而不是前馈神经网络?
在学习了 CNN 之后,你可能会想知道为什么我们不能用普通神经网络处理图像问题。普通神经网络无法像 CNN 一样从图像中提取复杂特征。
CNN 通过应用过滤器从图像中提取特征的能力使其更适合处理图像问题。此外,直接将图像输入到前馈神经网络中计算成本也很高。
卷积神经网络架构
你可以从零开始设计你的 CNN。然而,你也可以利用许多已经开发并公开发布的架构。其中一些网络还提供了预训练模型,你可以轻松地将其适配到你的用例中。一些流行的架构包括:
你可以通过Keras 应用开始使用这些架构。例如,以下是如何使用 VGG19:
from tensorflow.keras.applications.vgg19 import VGG19
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.vgg16 import preprocess_input
import numpy as np
model = VGG19(weights='imagenet', include_top=False)
img_path = 'elephant.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
features = model.predict(x)
TensorFlow 中的卷积神经网络(CNN)示例
现在,让我们使用食物数据集构建一个食物分类 CNN。该数据集包含超过十万张属于 101 个类别的图像。
加载图像
第一步是下载并解压数据。
!wget --no-check-certificate \
http://data.vision.ee.ethz.ch/cvl/food-101.tar.gz \
-O food.tar.gz
!tar xzvf food.tar.gz
让我们看一看数据集中一张图像。
plt.imshow(Image.open("food-101/images/beignets/2802124.jpg"))
plt.axis('off')
plt.show()
生成 tf.data.Dataset
接下来,将图像加载到TensorFlow 数据集中。我们将使用 20%的数据进行测试,其余用于训练。因此,我们需要为训练集和测试集创建一个[ImageDataGenerator](https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/image/ImageDataGenerator?authuser=1)。
训练集生成器还将指定一些图像增强技术,如缩放和翻转图像。增强可以防止网络的过拟合。
base_dir = 'food-101/images'
train_datagen = ImageDataGenerator(rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.1,
validation_split=0.2
)
validation_gen = ImageDataGenerator(rescale=1./255,validation_split=0.2)
有了生成器,下一步是使用它们从基础目录加载食物图像。在加载图像时,我们指定图像的目标大小。所有图像将被调整为指定的大小。
image_size = (200, 200)
training_set = train_datagen.flow_from_directory(base_dir,
seed=101,
target_size=image_size,
batch_size=32,
subset = "training",
class_mode='categorical')
加载图像时,我们还指定:
-
加载图像的目录。
-
批量大小,此处为 32,这意味着图像将以 32 张为一批加载。
-
子集;无论是训练还是验证。
-
类别模式为分类,因为我们有多个类别。如果只有两个类别,则为二进制。
validation_set = validation_gen.flow_from_directory(base_dir,
target_size=image_size,
batch_size=32,
subset = "validation",
class_mode='categorical')
模型定义
下一步是定义 CNN 模型。网络的架构将类似于我们在 CNN 工作原理部分讨论的步骤。我们将使用Keras Sequential API来定义网络。CNN 是通过Conv2D层定义的。
model = Sequential([
Conv2D(filters=32,kernel_size=(3,3), input_shape = (200, 200, 3),activation='relu'),
MaxPooling2D(pool_size=(2,2)),
Conv2D(filters=32,kernel_size=(3,3), activation='relu'),
MaxPooling2D(pool_size=(2,2)),
Dropout(0.25),
Conv2D(filters=64,kernel_size=(3,3), activation='relu'),
MaxPooling2D(pool_size=(2,2)),
Dropout(0.25),
Flatten(),
Dense(128, activation='relu'),
Dropout(0.25),
Dense(101, activation='softmax')
])
Conv2D 层期望:
-
要应用的过滤器数量,此处为 32。
-
卷积核的大小,此处为 3 x 3。
-
输入图像的大小。200 x 200 是图像的大小,3 表示这是一个彩色图像。
-
激活函数;通常是ReLu。
在网络中,我们应用 2 x 2 的池化滤波器,并应用Dropout层以防止过拟合。
最后一层有 101 个单元,因为有 101 个食物类别。激活函数是softmax,因为这是一个多类别图像分类问题。
编译 CNN 模型
我们 编译 网络时使用了类别损失和准确率,因为它涉及多个类别。
model.compile(optimizer='adam',
loss=keras.losses.CategoricalCrossentropy(),
metrics=[keras.metrics.CategoricalAccuracy()])
训练 CNN 模型
现在让我们训练 CNN 模型。我们在训练过程中应用早停回调,以便在模型在一定迭代次数后没有改进时停止训练。在这种情况下是 3 个时期。
callback = EarlyStopping(monitor='loss', patience=3)
history = model.fit(training_set,validation_data=validation_set, epochs=100,callbacks=[callback])
我们在这里使用的图像数据集相当大。因此,我们需要使用 GPU 来训练这个模型。我们可以利用 Layer 提供的免费 GPU 来训练模型。为此,我们需要将上述开发的所有代码打包到一个函数中。该函数应返回一个模型。在这种情况下是一个 TensorFlow 模型。
要使用 GPU 来训练模型,只需将函数装饰为 GPU 环境。这是通过 fabric 装饰器 来指定的。
#pip install layer-sdk -qqq
import layer
from layer.decorators import model, fabric,pip_requirements
# Authenticate a Layer account
# The trained model will be saved there.
layer.login()
# Initialize a project, the trained model will be save under this project.
layer.init("image-classification")
@pip_requirements(packages=["wget","tensorflow","keras"])
@fabric("f-gpu-small")
@model(name="food-vision")
def train():
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense,Conv2D,MaxPooling2D,Flatten,Dropout
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import EarlyStopping
import os
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import pandas as pd
import tarfile
import wget
wget.download("http://data.vision.ee.ethz.ch/cvl/food-101.tar.gz")
food_tar = tarfile.open('food-101.tar.gz')
food_tar.extractall('.')
food_tar.close()
plt.imshow(Image.open("food-101/images/beignets/2802124.jpg"))
plt.axis('off')
layer.log({"Sample image":plt.gcf()})
base_dir = 'food-101/images'
class_names = os.listdir(base_dir)
train_datagen = ImageDataGenerator(rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.1,
validation_split=0.2
)
validation_gen = ImageDataGenerator(rescale=1./255,validation_split=0.2)
image_size = (200, 200)
training_set = train_datagen.flow_from_directory(base_dir,
seed=101,
target_size=image_size,
batch_size=32,
subset = "training",
class_mode='categorical')
validation_set = validation_gen.flow_from_directory(base_dir,
target_size=image_size,
batch_size=32,
subset = "validation",
class_mode='categorical')
model = Sequential([
Conv2D(filters=32,kernel_size=(3,3), input_shape = (200, 200, 3),activation='relu'),
MaxPooling2D(pool_size=(2,2)),
Conv2D(filters=32,kernel_size=(3,3), activation='relu'),
MaxPooling2D(pool_size=(2,2)),
Dropout(0.25),
Conv2D(filters=64,kernel_size=(3,3), activation='relu'),
MaxPooling2D(pool_size=(2,2)),
Dropout(0.25),
Flatten(),
Dense(128, activation='relu'),
Dropout(0.25),
Dense(101, activation='softmax')])
model.compile(optimizer='adam',
loss=keras.losses.CategoricalCrossentropy(),
metrics=[keras.metrics.CategoricalAccuracy()])
callback = EarlyStopping(monitor='loss', patience=3)
epochs=20
history = model.fit(training_set,validation_data=validation_set, epochs=epochs,callbacks=[callback])
metrics_df = pd.DataFrame(history.history)
layer.log({"Metrics":metrics_df})
loss, accuracy = model.evaluate(validation_set)
layer.log({"Accuracy on test dataset":accuracy})
metrics_df[["loss","val_loss"]].plot()
layer.log({"Loss plot":plt.gcf()})
metrics_df[["categorical_accuracy","val_categorical_accuracy"]].plot()
layer.log({"Accuracy plot":plt.gcf()})
return model
通过将训练函数传递给 layer.run 函数来完成模型训练。如果您希望在本地基础设施上训练模型,请正常调用 train() 函数。
layer.run([train])

做出预测
模型准备好后,我们可以对新图像进行预测。可以按照以下步骤进行:
-
从 Layer 获取训练好的模型。
-
加载与训练图像大小相同的图像。
-
将图像转换为数组。
-
通过除以 255,将数组中的数字转换为 0 到 1 之间。训练图像也是这种形式。
-
扩展图像的维度,以添加一个批处理大小为 1,因为我们在对单张图像进行预测。
from keras.preprocessing import image
import numpy as np
image_model = layer.get_model('layer/image-classification/models/food-vision').get_train()
!wget --no-check-certificate \
https://upload.wikimedia.org/wikipedia/commons/b/b1/Buttermilk_Beignets_%284515741642%29.jpg \
-O /tmp/Buttermilk_Beignets_.jpg
test_image = image.load_img('/tmp/Buttermilk_Beignets_.jpg', target_size=(200, 200))
test_image = image.img_to_array(test_image)
test_image = test_image / 255.0
test_image = np.expand_dims(test_image, axis=0)
prediction = image_model.predict(test_image)
prediction[0][0]
由于这是一个多类别网络,我们将使用 softmax 函数 来解释结果。该函数将 logits 转换为每个类别的概率。
class_names = os.listdir(base_dir)
scores = tf.nn.softmax(prediction[0])
scores = scores.numpy()
f"{class_names[np.argmax(scores)]} with a { (100 * np.max(scores)).round(2) } percent confidence."
结论
在本文中,我们详细介绍了 CNN。特别是,我们讨论了:
-
什么是 CNN?
-
CNN 的工作原理。
-
CNN 架构。
-
如何构建一个用于图像分类问题的 CNN。
资源
Derrick Mwiti 在数据科学、机器学习和深度学习方面经验丰富,并且在建立机器学习社区方面具有敏锐的眼光。
相关主题
Python 中的基本图像处理,第二部分
原文:
www.kdnuggets.com/2018/07/image-data-analysis-numpy-opencv-p2.html
评论
本博客是使用 Numpy 和 OpenCV 进行基本图像数据分析 – 第一部分的续篇。
使用逻辑运算符处理像素值
我们可以使用逻辑运算符创建一个相同大小的布尔 ndarray。然而,这不会创建任何新数组,而是简单地将True返回给它的主变量。例如:假设我们想过滤掉一些低值像素或高值像素(或任何条件)在 RGB 图像中,转换 RGB 为灰度图像确实是很好的,但现在我们不会进行这个转换,而是处理彩色图像。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
首先加载一张图像并在屏幕上显示它。
pic=imageio.imread('F:/demo_1.jpg')
plt.figure(figsize=(10,10))
plt.imshow(pic)
plt.show()

好的,让我们考虑这张转储图像。现在,对于任何情况,我们想过滤掉所有低于假设值 20 的像素值。为此,我们将使用逻辑运算符来完成这个任务,并返回所有索引的 True 值。
low_pixel=pic<20
*# to ensure of it let's check if all values
in low_pixel are True or not* iflow_pixel.any()==True:
print(low_pixel.shape)
(1079, 1293, 3)
如前所述,主变量,这个名字传统上并不常用,但我使用它是因为它的行为。它只保存 True 值而无其他内容。因此,如果我们查看 low_pixel 和 pic 的形状,我们会发现它们的形状是相同的。
print(pic.shape)
(1079,1293,3)
print(low_pixel.shape)
(1079,1293,3)
我们使用全局比较运算符生成了低值滤波器,用于所有小于 200 的值。然而,我们可以使用这个 low_pixel 数组作为索引,将这些低值设置为一些特定值,这些值可能高于或低于之前的像素值。
*# randomly choose a value*
importrandom
*# load the original image*
pic=imageio.imread('F:/demo_1.jpg')
*# set value randomly range from 25 to 225 -
these value also randomly chosen*pic[low_pixel]=random.randint(25,225)
*# display the image*
plt.figure(figsize=(10,10))
plt.imshow(pic)plt.show()
遮罩
图像遮罩是一种图像处理技术,用于去除那些边缘模糊、透明或有毛发部分的背景。
现在,我们将创建一个圆盘形状的遮罩。首先,我们将测量图像中心到每个边界像素的距离。然后,我们取一个合适的半径值,使用逻辑运算符创建一个圆盘。操作相当简单,让我们看看代码。
if__name__=='__main__':
*# load the image* pic=imageio.imread('F:/demo_1.jpg')
*# separate the row and column values* total_row,total_col,layers=pic.shape
''' Create vector.
Ogrid is a compact method of creating a multidimensional-
ndarray operations in single lines.
for ex:
>>>ogrid[0:5,0:5]
output:
[array([[0],[1],[2],[3],[4]]),
array([[0, 1, 2, 3, 4]])]
'''
x,y=np.ogrid[:total_row,:total_col]
*# get the center values of the image* cen_x,cen_y=total_row/2,total_col/2
'''
Measure distance value from center to each border pixel.
To make it easy, we can think it's like, we draw a line from center-
to each edge pixel value --> s**2 = (Y-y)**2 + (X-x)**2 '''
distance_from_the_center=np.sqrt((x-cen_x)**2+(y-cen_y)**2)
*# Select convenient radius value* radius=(total_row/2)
*# Using logical operator '>'* ''' logical operator to do this task which will
return as a value of True for all the index according to the
given condition '''
circular_pic=distance_from_the_center>radius
'''
let assign value zero for all pixel value that outside
the circular disc. All the pixel value outside the circular
disc, will be black now.
'''
pic[circular_pic]=0
plt.figure(figsize=(10,10))
plt.imshow(pic)
plt.show()

卫星图像处理
在 edX 的一个 MOOC 课程中,我们介绍了一些卫星图像及其处理系统。这当然非常有用。然而,让我们对它进行一些分析任务。
*# load the image* pic=imageio.imread('F:\satimg.jpg')
plt.figure(figsize=(10,10))
plt.imshow(pic)
plt.show()
让我们来看一下它的一些基本信息。
print(f'Shape of the image {pic.shape}')
print(f'hieght {pic.shape[0]} pixels')
print(f'width {pic.shape[1]} pixels')
Shapeoftheimage(3725,4797,3)
height 3725 pixels
width 4797 pixels
现在,这张图像有些有趣的地方。与许多其他可视化一样,每个 RGB 层中的颜色都有其含义。例如,红色的强度将指示像素中地理数据点的高度。蓝色的强度将指示方位的测量值,而绿色将指示坡度。这些颜色有助于更快速、更有效地传达信息,而不是展示数字。
-
红色像素表示:高度
-
蓝色像素表示:方位
-
绿色像素表示:坡度
仅凭观察这张色彩丰富的图像,经过训练的眼睛已经能分辨出高度、坡度和方位。因此,将更多含义赋予这些颜色,以指示更科学的内容就是这个想法。
检测每个通道的高像素
*# Only Red Pixel value , higher than 180*
pic=imageio.imread('F:\satimg.jpg')
red_mask=pic[:,:,0]<180
pic[red_mask]=0
plt.figure(figsize=(15,15))
plt.imshow(pic)
*# Only Green Pixel value , higher than 180*
pic=imageio.imread('F:\satimg.jpg')
green_mask=pic[:,:,1]<180
pic[green_mask]=0
plt.figure(figsize=(15,15))
plt.imshow(pic)
*# Only Blue Pixel value , higher than 180*
pic=imageio.imread('F:\satimg.jpg')
blue_mask=pic[:,:,2]<180
pic[blue_mask]=0
plt.figure(figsize=(15,15))
plt.imshow(pic)
*# Composite mask using logical_and*
pic=imageio.imread('F:\satimg.jpg')
final_mask=np.logical_and(red_mask,green_mask,blue_mask)
pic[final_mask]=40
plt.figure(figsize=(15,15))
plt.imshow(pic)

简介: Mohammed Innat目前是电子与通信专业的大四本科生。他热衷于将机器学习和数据科学知识应用于医疗保健和犯罪预测领域,在这些领域可以在医疗部门和安全部门工程中找到更好的解决方案。*
相关:
更多相关主题
使用 Python 进行基础图像数据分析 – 第三部分
原文:
www.kdnuggets.com/2018/09/image-data-analysis-python-p3.html
评论
之前我们已经看过一些在 Python 中非常基础的图像分析操作。在这最后一部分基础图像分析中,我们将讨论以下一些内容。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
以下内容是我在上学期完成的学术图像处理课程的反思。因此,我不打算将任何内容投入生产领域。相反,本文的目的是尝试实现一些基础图像处理技术的基本原理。为此,我将主要使用 SciKit-Image 和 numpy 来执行大部分操作,尽管我会偶尔使用其他库,而不是像 OpenCV 这样的最受欢迎的工具。
我原本想将这个系列分成两部分,但由于内容的吸引力和多样性,我不得不将其拆分成太多部分。然而,您可以在我的主页上找到整个系列的两部分,链接如下。
查找完整系列: 第一部分, 第二部分 所有源代码: GitHub-图像处理-Python
如果你不想跳转,请继续在这里阅读。在上一篇文章中,我们讨论了一些基本操作。为了跟上今天的内容,持续阅读是非常重要的。
我很兴奋,让我们开始吧!
强度变换
让我们开始导入图像。
%matplotlibinline
import imageio
import matplotlib.pyplot as plt
import warnings
import matplotlib.cbook
warnings.filterwarnings("ignore",category=matplotlib.cbook.mplDeprecation)
pic=imageio.imread('img/parrot.jpg')
plt.figure(figsize=(6,6))
plt.imshow(pic);
plt.axis('off');

图像负片
强度变换函数在数学上定义为:
S = T(r)
其中 r 是输入图像的像素,s 是输出图像的像素。T 是一个变换函数,将每个 r 值映射到每个 s 值。
负片变换,这是身份变换的反向。在负片变换中,输入图像的每个值从 L−1 中减去,并映射到输出图像上。
在这种情况下,进行了以下转换:
s=(L–1)–r
因此,每个值都减去255。结果是,较亮的像素变暗,较暗的图像变亮。这会导致图像负片。
negative =255- pic # neg = (L-1) - img
plt.figure(figsize= (6,6))
plt.imshow(negative);
plt.axis('off');

对数变换
对数变换可以通过以下公式定义:
s=c∗log(r+1)
其中 s 和 r 是输出图像和输入图像的像素值,c 是常数。对输入图像的每个像素值加上 1,因为如果图像中有像素强度为 0,则log(0)等于无穷大。因此,加 1 使得最小值至少为 1。
在对数变换过程中,图像中的暗像素相对于较高像素值被扩展。较高的像素值在对数变换中被压缩。这会导致以下图像增强效果。
对数变换中的 c 值调整我们所寻求的增强类型。
%matplotlibinline
import imageio
import numpyasnp
import matplotlib.pyplotasplt
pic=imageio.imread('img/parrot.jpg')
gray=lambda rgb : np.dot(rgb[...,:3],[0.299,0.587,0.114])
gray=gray(pic)
'''
log transform
-> s = c*log(1+r)
So, we calculate constant c to estimate s
-> c = (L-1)/log(1+|I_max|)
'''
max_=np.max(gray)
def log_transform():
return(255/np.log(1+max_))*np.log(1+gray)
plt.figure(figsize=(5,5))
plt.imshow(log_transform(),cmap=plt.get_cmap(name='gray'))
plt.axis('off');

伽玛校正
伽玛校正,通常简称为伽玛,是一种非线性操作,用于在视频或静态图像系统中编码和解码亮度或三刺激值。伽玛校正也称为幂律变换。首先,我们的图像像素强度必须从范围0, 255缩放到0, 1.0。然后,通过应用以下公式,我们获得输出的伽玛校正图像:
Vo = V^(1/G)
其中Vi是我们的输入图像,G是我们的伽玛值。输出图像Vo随后被缩放回范围0-255。
伽玛值,G < 1有时称为编码伽玛,使用这种压缩幂律非线性进行编码的过程称为伽玛压缩;伽玛值< 1 会将图像向光谱的较暗端移动。
相反,伽玛值G > 1称为解码伽玛,应用扩展的幂律非线性称为伽玛扩展。伽玛值> 1 会使图像看起来更亮。伽玛值G = 1不会对输入图像产生影响:
import imageio
import matplotlib.pyplotasplt
# Gamma encoding
pic=image io.imread('img/parrot.jpg')
gamma=2.2# Gamma < 1 ~ Dark ; Gamma > 1 ~ Bright
gamma_correction=((pic/255)**(1/gamma))
plt.figure(figsize=(5,5))
plt.imshow(gamma_correction)
plt.axis('off');

伽玛校正的原因
我们应用伽玛校正的原因是我们的眼睛对颜色和亮度的感知与数字相机的传感器不同。当数字相机上的传感器接收到两倍的光子时,信号也会加倍。然而,我们的眼睛并不是这样工作的。相反,我们的眼睛将双倍的光线感知为仅仅亮了一些。因此,虽然数字相机的亮度具有线性关系,而我们的眼睛则具有非线性关系。为了考虑这种关系,我们应用伽玛校正。
还有其他线性变换函数,列举如下:
-
对比度拉伸
-
强度级切片
-
位平面切片
卷积
我们在之前的文章中简要讨论过,当计算机看到图像时,它看到的是像素值的数组。现在,根据图像的分辨率和大小,它会看到一个 32 x 32 x 3 的数字数组,其中 3 代表 RGB 值或通道。为了更好地说明这一点,假设我们有一张 PNG 格式的彩色图像,大小为 480 x 480。代表性的数组将是 480 x 480 x 3。每个这些数字的值从 0 到 255,这描述了该点的像素强度。
正如我们之前提到的,输入是一个 32 x 32 x 3 的像素值数组。现在,解释卷积的最佳方式是想象一个手电筒照在图像的左上角。假设手电筒照射到一个 3 x 3 的区域。现在,让我们想象这个手电筒在输入图像的所有区域上滑动。在机器学习术语中,这个手电筒被称为滤波器或内核,有时也称为权重或掩模,而它照射的区域称为感受野。
现在,这个滤波器也是一个数字数组,其中的数字称为权重或参数。一个非常重要的说明是,这个滤波器的深度必须与输入的深度相同,因此这个滤波器的尺寸是 3 x 3 x 3。
图像内核或滤波器是一个小矩阵,用于应用诸如模糊、锐化、轮廓描边或浮雕等效果,类似于 Photoshop 或 Gimp 中的效果。它们在机器学习中也用于特征提取,这是一种确定图像最重要部分的技术。有关更多信息,请查看 Gimp 的关于使用图像内核的优秀文档。我们可以在这里找到最常见的内核列表。
现在,让我们将过滤器移动到左上角。当过滤器滑动或卷积输入图像时,它会将过滤器中的值与图像的原始像素值相乘(即计算逐元素乘法)。这些乘法结果会被求和。因此我们得到一个单一的数字。请记住,这个数字仅代表过滤器在图像的左上角时的值。现在,我们对输入体积的每个位置重复这个过程。下一步是将过滤器向右移动一个步幅或步长 1 单位,再向右移动一个步幅 1,依此类推。输入体积上的每个唯一位置都会产生一个数字。我们也可以选择步幅或步长为 2 或更多,但必须注意它是否适合输入图像。
在滑动过滤器覆盖所有位置后,我们会发现,剩下的是一个 30 x 30 x 1 的数字数组,我们称之为激活图或特征图。我们得到 30 x 30 数组的原因是 3 x 3 过滤器可以适配在 32 x 32 输入图像的 900 个不同位置。这 900 个数字被映射到 30 x 30 数组。我们可以通过以下步骤计算卷积后的图像:
Convolved: (N−F)/S+1
其中 N 和 F 分别代表输入图像大小和卷积核大小,而 S 代表步幅或步长。因此,在这种情况下,输出将是
32−31+1=30
假设我们有一个 3x3 的过滤器,对 5x5 矩阵进行卷积,根据方程,我们应该得到一个 3x3 矩阵,技术上称为激活图或特征图。
让我们从视觉上看一下,
此外,我们实际上使用了更多的过滤器而不是一个。然后我们的输出体积将是 28x28xn(其中 n 是激活图的数量)。
通过使用更多的过滤器,我们能够更好地保持空间维度。
然而,对于图像矩阵边界上的像素,一些卷积核元素可能会超出图像矩阵,因此没有来自图像矩阵的对应元素。在这种情况下,我们可以消除这些位置的卷积操作,从而得到一个比输入更小的输出矩阵,或者我们可以对输入矩阵应用填充。
现在,我确实意识到这些话题有些复杂,可能会成为独立的完整帖子。为了保持简洁却又不失全面性,我将提供链接到更多详细解释这些话题的资源。
首先,我们将一些自定义均匀窗口应用于图像。这会通过将每个像素与附近的像素平均来“烧录”图像:
%%time
import numpy as np
import imageio
import matplotlib.pyplot as plt
from scipy.signal import convolve2d
def Convolution(image, kernel):
conv_bucket= []
for d in range(image.ndim):
conv_channel= convolve2d(image[:,:,d], kernel,
mode="same", boundary="symm")
conv_bucket.append(conv_channel)
returnnp.stack(conv_bucket, axis=2).astype("uint8")
kernel_sizes= [9,15,30,60]
fig, axs=plt.subplots(nrows=1, ncols=len(kernel_sizes), figsize=(15,15));
pic =imageio.imread('img:/parrot.jpg')
for k, ax in zip(kernel_sizes, axs):
kernel =np.ones((k,k))
kernel /=np.sum(kernel)
ax.imshow(Convolution(pic, kernel));
ax.set_title("Convolved By Kernel: {}".format(k));
ax.set_axis_off();
Wall time: 43.5 s

请查看更多内容这里。我在其中深入讨论了各种类型的内核,并展示了它们的区别。
简介: 穆罕默德·因纳特 目前是一名电子与通信专业的四年级本科生。他热衷于将他的机器学习和数据科学知识应用于医疗保健和犯罪预测领域,以便在医疗和安全部门提供更好的解决方案。
相关:
更多相关内容
如何处理不平衡分类问题,而无需重新平衡数据
原文:
www.kdnuggets.com/2021/09/imbalanced-classification-without-re-balancing-data.html
评论
作者:David B Rosen (PhD),IBM 全球融资自动化信用审批首席数据科学家

照片由Elena Mozhvilo提供,来源于Unsplash
在机器学习中,当用数据构建分类模型时,如果某一类别的实例远多于另一类别,初始默认分类器通常是不令人满意的,因为它几乎将所有情况都分类为多数类。许多文章展示了如何使用过采样(例如SMOTE)或有时是欠采样,或者简单地使用基于类别的样本加权来重新训练模型以“重新平衡”数据,但这并非总是必要的。在这里,我们的目标是展示在不平衡数据或重新训练模型的情况下,你可以做到多少。
我们通过简单地调整“类 1”阈值来实现这一点,当模型预测的“类 1”概率高于该阈值时,而不是天真地使用默认分类规则(即选择预测最可能的类别,概率阈值为 0.5)。我们将看到这如何让你灵活地在假阳性和假阴性分类之间进行所需的权衡,同时避免由于重新平衡数据而产生的问题。
我们将使用来自 Kaggle 的信用卡欺诈识别数据集进行说明。数据集的每一行代表一次信用卡交易,其中目标变量 Class0 表示合法交易,而 Class1 表示交易被认定为欺诈。总共有 284,807 笔交易,其中仅有 492 笔(0.173%)为欺诈——确实非常不平衡。
我们将使用一个梯度提升分类器,因为这些分类器通常能取得较好的结果。具体来说,我们使用 Scikit-Learn 的新 HistGradientBoostingClassifier,因为当数据集较大时,它比原始的 GradientBoostingClassifier 快得多。
首先,让我们导入一些库并读取数据集。
import numpy as np
import pandas as pd
from sklearn import model_selection, metrics
from sklearn.experimental import enable_hist_gradient_boosting
from sklearn.ensemble import HistGradientBoostingClassifier
df=pd.read_csv('creditcard.csv')
df.info()
V1 至 V28(来自主成分分析)和交易金额是特征,这些特征都是数值型的,并且没有缺失数据。因为我们只使用树基分类器,所以我们不需要对特征进行标准化或归一化。
现在我们将数据拆分为训练集和测试集后训练模型。这在我的笔记本电脑上花费了大约半分钟的时间。我们使用 n_iter_no_change 来提前停止训练,如果在验证子集上的表现因过拟合开始恶化。我单独进行了少量超参数调优,以选择 learning_rate 和 max_leaf_nodes,但这不是本文的重点。
Xtrain, Xtest, ytrain, ytest = model_selection.train_test_split(
df.loc[:,'V1':'Amount'], df.Class, stratify=df.Class,
test_size=0.3, random_state=42)
gbc=HistGradientBoostingClassifier(learning_rate=0.01,
max_iter=2000, max_leaf_nodes=6, validation_fraction=0.2,
n_iter_no_change=15, random_state=42).fit(Xtrain,ytrain)
现在我们将此模型应用于测试数据,作为默认的硬分类器,对每个交易进行 0 或 1 的预测。我们实际上将决策阈值 0.5 应用于模型的连续概率预测,作为一个软分类器。当概率预测超过 0.5 时,我们标记为“1”,当低于 0.5 时,我们标记为“0”。
我们还打印了混淆矩阵以显示结果,将第 1 类(欺诈)视为“正类”,这是惯例,因为它是较少见的类别。混淆矩阵显示了真正例、假正例、假负例和真负例的数量。标准化混淆矩阵率(例如 FNR = 假负率)作为百分比包括在括号中。
hardpredtst=gbc.predict(Xtest)
def conf_matrix(y,pred):
((tn, fp), (fn, tp)) = metrics.confusion_matrix(y, pred)
((tnr,fpr),(fnr,tpr))= metrics.confusion_matrix(y, pred,
normalize='true')
return pd.DataFrame([[f'TN = {tn} (TNR = {tnr:1.2%})',
f'FP = {fp} (FPR = {fpr:1.2%})'],
[f'FN = {fn} (FNR = {fnr:1.2%})',
f'TP = {tp} (TPR = {tpr:1.2%})']],
index=['True 0(Legit)', 'True 1(Fraud)'],
columns=['Pred 0(Approve as Legit)',
'Pred 1(Deny as Fraud)'])
conf_matrix(ytest,hardpredtst)

我们看到,第 1 类(即上面显示的敏感性或真正例率TPR)的召回率仅为 71.62%,这意味着 71.62%的真实欺诈行为被正确识别为欺诈并因此被拒绝。因此,28.38%的真实欺诈行为不幸被错误地批准为合法交易。
特别是在数据不平衡的情况下(或一般来说,当假正例和假负例可能有不同后果时),重要的是不要局限于使用默认的隐式分类决策阈值 0.5,如我们上面使用“.predict( )”时所做的那样。我们希望提高第 1 类的召回率(TPR),以减少欺诈损失(减少假负例)。为此,我们可以降低阈值,当我们预测的概率高于该阈值时,我们标记为“第 1 类”。这样,我们可以在更广泛的预测概率范围内标记为“第 1 类”。这种策略称为阈值移动。
最终,决定减少这些假负例的程度是一个商业决策,因为作为权衡,假正例(真正的合法交易被错误地拒绝为欺诈)的数量会随着我们调整模型的概率预测阈值(从“.predict_proba( )”而不是“.predict( )”中获得)而不可避免地增加。
为了阐明这一权衡并帮助我们选择阈值,我们绘制了假正例率和假负例率与阈值的关系图。这是接收者操作特征(ROC)曲线的一种变体,但重点在于阈值。
predtst=gbc.predict_proba(Xtest)[:,1]
fpr, tpr, thresholds = metrics.roc_curve(ytest, predtst)
dfplot=pd.DataFrame({'Threshold':thresholds,
'False Positive Rate':fpr,
'False Negative Rate': 1.-tpr})
ax=dfplot.plot(x='Threshold', y=['False Positive Rate',
'False Negative Rate'], figsize=(10,6))
ax.plot([0.00035,0.00035],[0,0.1]) #mark example thresh.
ax.set_xbound(0,0.0008); ax.set_ybound(0,0.3) #zoom in
尽管存在一些选择最佳阈值的经验法则或建议指标,但最终完全依赖于假阴性与假阳性对业务的成本。例如,查看上面的图,我们可能会选择应用阈值 0.00035(已添加垂直绿色线)如以下所示。
hardpredtst_tuned_thresh = np.where(predtst >= 0.00035, 1, 0)
conf_matrix(ytest, hardpredtst_tuned_thresh)

我们已将假阴性率从 28.38%降低到 9.46%(即识别并拒绝了 90.54%的真实欺诈行为,作为我们新的召回率或敏感度或真正阳性率或 TPR),同时假阳性率(FPR)从 0.01%增加到 5.75%(即仍批准了 94.25%的合法交易)。对于我们来说,拒绝约 6%的合法交易作为仅批准不到 10%的欺诈交易的代价可能是值得的,这一代价相比使用默认硬分类器(隐含分类决策阈值为 0.5)时非常昂贵的 28%的欺诈交易。
不平衡数据的平衡理由
避免“平衡”不平衡训练数据的一个原因是,这些方法会偏向/扭曲训练模型的概率预测,使这些预测变得误校准,通过系统性地提高模型对原始少数类的预测概率,因此被简化为仅仅是相对的序数判别分数或决策函数或置信度分数,而不是在原始(“不平衡”)训练和测试集以及分类器可能对其进行预测的未来数据中潜在准确的预测类别概率。如果确实需要这种训练重新平衡,但仍希望获得数值准确的概率预测,则必须重新校准预测概率至具有原始/不平衡类别比例的数据集。或者,您可以对平衡模型的预测概率应用修正 — 请参见平衡即不平衡和此回复。
通过过采样(与依赖类实例加权不同,这种方法没有这个问题)来平衡数据的另一个问题是它会使天真的交叉验证产生偏差,可能导致在交叉验证中无法检测到的过度拟合。在交叉验证中,每次数据被划分为一个“折”子集时,一个折中的实例可能是另一个折中实例的重复或生成的。因此,折并不完全独立,如交叉验证所假设的——存在数据“泄漏”或“渗漏”。例如,请参见不平衡数据集的交叉验证,该文描述了如何在这种情况下正确地重新实现交叉验证。然而,在 scikit-learn 中,至少对于通过实例复制(不一定是 SMOTE)进行的过采样情况,这可以通过使用model_selection.GroupKFold进行交叉验证来解决,该方法根据一个选定的组标识符对实例进行分组,该标识符对给定实例的所有重复项具有相同的值——请参见我的回复以了解对上述文章的回应。
结论
我们可以尝试使用原始模型(在原始的“失衡”数据集上训练),并简单绘制假阳性和假阴性之间的权衡,来选择一个可能产生理想业务结果的阈值,而不是天真地或隐式地应用默认的 0.5 阈值,或立即使用重新平衡的训练数据进行重新训练。
如果您有任何问题或意见,请留下回复。
编辑:为什么重新平衡训练数据即使唯一的实际“问题”是默认的 0.5 阈值不合适,也能“有效”?
您的模型产生的平均概率预测将近似于训练实例中属于类别 1 的比例,因为这是目标类别变量的实际平均值(其值为 0 和 1)。回归中也是如此:目标变量的平均预测值预计将近似于目标变量的平均实际值。当数据严重失衡且类别 1 是少数类时,这种平均概率预测将远低于 0.5,而且绝大多数类别 1 的概率预测将低于 0.5,因此被归类为类别 0(多数类)。如果您重新平衡训练数据,平均预测概率将增加到 0.5,因此许多实例将会高于默认阈值 0.5,同时也会有许多低于该阈值的预测——预测类别将更为平衡。因此,与其降低阈值以使概率预测更常高于该值并给出类别 1(少数类),重新平衡会增加预测概率,使得概率预测更常高于默认阈值 0.5 并给出类别 1。
如果您想要获得类似(但不完全相同)的结果,而不实际重新平衡或重新加权数据,您可以尝试将阈值设置为模型预测类别 1 的平均值或中位数。但当然,这并不一定是为您的特定业务问题提供最佳假阳性和假阴性平衡的阈值,也不会通过重新平衡数据和使用 0.5 的阈值来实现。
可能存在一些情况和模型,其中重新平衡数据将实质性地改进模型,而不仅仅是将平均预测概率移至默认阈值 0.5。但是,仅仅因为模型在使用默认阈值 0.5 时大多数时间选择了多数类,并不能支持重新平衡数据将实现超出使平均概率预测等于阈值的任何主张。如果您希望平均概率预测等于阈值,您可以简单地将阈值设置为平均概率预测,而不必修改或重新加权训练数据以扭曲概率预测。
编辑:关于置信度评分与概率预测的说明
如果你的分类器没有 predict_proba 方法,例如支持向量分类器,你也可以使用它的 decision_function 方法来代替,生成一个序数判别分数或置信度分数模型输出,即使它不能解释为 0 到 1 之间的概率预测,也可以以相同的方式进行阈值处理。根据特定分类器模型如何计算两个类别的置信度分数,有时可能需要,而不是将阈值直接应用于类别 1 的置信度分数(如上所述,因为类别 0 的预测概率仅为类别 1 的概率减去 1),而是将阈值应用于类别 0 和类别 1 之间的差异,默认阈值为 0,假设假阳性的成本与假阴性的成本相同。本文假设是一个二分类问题。
个人简介: David B Rosen (PhD) 是 IBM 全球融资部门自动化信用审批的首席数据科学家。可以在 dabruro.medium.com 找到更多 David 的文章。
原文。经许可转载。
相关:
-
处理不平衡数据集的 5 种最有用的技术
-
处理机器学习中的不平衡数据
-
重采样不平衡数据及其局限性
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的信息技术
更多相关内容
处理机器学习中的不平衡数据
原文:
www.kdnuggets.com/2020/10/imbalanced-data-machine-learning.html
评论
作为机器学习工程师或数据科学家,有时你不可避免地会遇到一个类别标签有数百条记录而另一个类别标签有数千条记录的情况。
训练模型后,你获得了超过 90% 的准确率。然后你发现模型将所有预测都归入记录较多的类别。欺诈检测问题和流失预测问题就是这样的优秀例子,其中大多数记录都在负类中。在这种情况下你该怎么办?这将是本文的重点。
收集更多数据
最直接明显的做法是收集更多的数据,特别是关于少数类的数据点。这显然会改善模型的性能。然而,这并非总是可能的。除了需要承担的成本,有时收集更多数据并不现实。例如,在流失预测和欺诈检测的情况下,你不能仅仅等待更多事件发生以便收集更多数据。
考虑除准确率之外的指标
准确率不是衡量类别标签不平衡模型性能的好方法。在这种情况下,考虑其他指标是明智的,比如精确率、召回率、曲线下面积(AUC)——仅举几个例子。
精确率 测量了在所有被预测为真正例和假正例的样本中真正例的比例。例如,在我们模型预测的流失人群中,有多少人实际流失了?
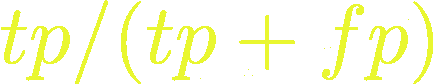
召回率 测量了真正例在真正例和假负例之和中的比例。例如,我们模型预测会流失的人中,实际流失的百分比。
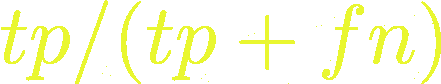
AUC 是通过接收器操作特性(ROC)曲线获得的。该曲线是通过将真正率与假正率绘制在图表上得到的。假正率是通过将假正例除以假正例与真正例之和得到的。
接近 1 的 AUC 更好,因为它表明模型能够找到真正例。
强调少数类
处理不平衡数据的另一种方法是让模型专注于少数类。这可以通过计算类别权重来完成。模型将专注于权重较高的类别。最终,模型将能够平等地从两个类别中学习。这些权重可以通过 scikit-learn 计算。
from sklearn.utils.class_weight import compute_class_weight
weights = compute_class_weight(‘balanced’, y.unique(), y)
array([ 0.51722354, 15.01501502])
然后,你可以在训练模型时传递这些权重。例如,在逻辑回归的情况下:
class_weights = {
0:0.51722354,
1:15.01501502
}lr = LogisticRegression(C=3.0, fit_intercept=True, warm_start = True, class_weight=class_weights)
或者,你可以将类权重设置为balanced,权重将会自动调整。
lr = LogisticRegression(C=3.0, fit_intercept=True, warm_start = True, class_weight=’balanced’)
这是权重调整前的 ROC 曲线。
这是权重调整后的 ROC 曲线。注意 AUC 从 0.69 提高到了 0.87。
尝试不同的算法
当你关注于不平衡数据的正确指标时,你也可以尝试不同的算法。一般来说,基于树的算法在不平衡数据上表现更好。此外,一些算法如LightGBM具有可以调节的超参数,以指示数据不平衡。
生成合成数据
你也可以生成合成数据来增加少数类的记录数量——通常称为过采样。这通常在训练集进行训练-测试拆分后完成。在 Python 中,可以使用Imblearn包来实现。包中的一种策略是Synthetic Minority Over-sampling Technique (SMOTE),该技术基于 k 最近邻算法。
使用 SMOTE 时:
-
第一个参数是
float类型,表示在重新采样完成后,少数类样本与多数类样本的比例。 -
生成合成样本时使用的邻居数量可以通过
k_neighbors参数指定。
from imblearn.over_sampling import SMOTEsmote = SMOTE(0.8)X_resampled,y_resampled = smote.fit_resample(X.values,y.values)pd.Series(y_resampled).value_counts()0 9667
1 7733
dtype: int64
然后,你可以将重新采样的数据拟合到你的模型中。
model = LogisticRegression()model.fit(X_resampled,y_resampled)predictions = model.predict(X_test)
对多数类进行欠采样
你也可以尝试减少多数类的样本数量。可以实现的一种策略是[NearMiss](https://imbalanced-learn.readthedocs.io/en/stable/generated/imblearn.under_sampling.NearMiss.html)方法。你也可以像 SMOTE 一样指定比例,以及通过n_neighbors指定邻居数量。
from imblearn.under_sampling import NearMissunderSample = NearMiss(0.3,random_state=1545)pd.Series(y_resampled).value_counts()0 1110 1 333 dtype: int64
最终思考
其他可用的技术包括使用集成学习将多个弱学习器组合成一个强分类器。对于最重要的正类,精确度-召回曲线和曲线下面积(PR、AUC)也是值得尝试的指标。
一如既往,你应该尝试不同的技术,并选择那些能为你的具体问题提供最佳结果的技术。希望这篇文章能提供一些入门的见解。
个人简介:德里克·姆维蒂是一位数据科学家,热衷于分享知识。他通过诸如 Heartbeat、Towards Data Science、Datacamp、Neptune AI、KDnuggets 等博客积极贡献于数据科学社区,仅这些博客上的内容就已在互联网上被浏览超过一百万次。德里克还是一位作者和在线讲师。他还与各种机构合作,实施数据科学解决方案并提升员工技能。德里克在多媒体大学学习了数学和计算机科学,还曾是梅尔特沃特创业技术学院的校友。如果你对数据科学、机器学习和深度学习感兴趣,可以查看他的Python 完整数据科学与机器学习训练营课程。
原文。经授权转载。
相关:
-
如何修复不平衡的数据集
-
处理不平衡数据集的 5 种最有用技术
-
专家提示:如何处理类别不平衡和缺失标签
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 为你的组织提供 IT 支持
更多相关话题
噪声标签对机器学习模型的影响
原文:
www.kdnuggets.com/2021/04/imerit-noisy-labels-impact-machine-learning.html
赞助文章。
监督式机器学习需要标记的训练数据,而大型机器学习系统需要大量的训练数据。标记训练数据是资源密集型的,虽然众包和网络抓取等技术可以提供帮助,但它们可能容易出错,给训练集添加‘标签噪声’。
位于 iMerit的团队是提供高质量数据的领导者,他们已经审查了关于如何使训练有噪声标签的机器学习系统有效运行的现有研究。如果你希望了解更多关于创建成功机器学习应用所需的训练数据的信息,请联系我们与专家对话。
在某些条件下,使用标签错误的数据训练的机器学习系统可以运行良好。例如,一项 2018 年由 MIT/康奈尔大学进行的研究测试了不同标签噪声水平下的机器学习图像分类系统的准确性。他们发现,在以下条件下,机器学习系统能够在高水平的标签噪声下保持良好的性能:
-
机器学习系统必须具有足够大的参数集来管理图像分类任务的复杂性。例如,四层卷积神经网络(CNN)对手写字符基准任务足够,但对一般对象识别基准任务则需要 18 层残差网络。
-
训练数据集必须非常大——足够大以包含许多正确标记的样本,即使大部分训练数据被标记错误。通过足够好的训练样本,机器学习系统可以通过在标签噪声中找到‘信号’来学习准确的分类。
另一个对研究结果重要的因素是标签噪声的性质。错误标记的样本以足够随机的方式添加到训练集中,以至于不会创建强烈的模式来覆盖由正确标记的样本表示的‘信号’。
尽管这项研究表明机器学习系统有基本的能力处理误标,但许多实际应用中的机器学习面临的复杂情况使得标签噪声成为更大问题。这些复杂情况包括:
-
无法创建非常大的训练集,并且
-
系统性标签错误会混淆机器学习。
其中一个例子是研究,它使用远程感测和机器学习来评估地震损害。
在 2017 年,研究人员分析了误标训练数据对用于分类 2011 年新西兰地震瓦砾的机器学习系统的影响。他们注意到,在这种远程感测应用中,标签噪声并不像 MIT/康奈尔研究中那样遵循随机模式。观察到的标签错误主要是由于地理空间划分不准确,这可能是由于缺乏培训(例如,误解了什么应被包含为瓦砾)或工具不充分(例如,一个粗略绘制的多边形将未受损的步道包括为瓦砾)。
研究人员模拟了他们观察到的地理空间标签噪声类型的训练数据集,以及随机标签噪声。他们比较了机器学习分类在这两种数据集上的表现,发现地理空间误标比随机误标使分类性能下降约五倍。
我们可以从这些研究中获得什么启示?
-
并非所有训练数据标签错误对机器学习系统性能的影响都相同。如果你的标签错误大多是随机的,它们对你的机器学习系统的伤害会较小。错误不会产生足够大的‘信号’来使训练偏离正确方向。
-
如果你的标签错误是结构化的,例如由于标签规则的反复错误应用,它们可能对你的机器学习系统非常有害。系统会将这些错误数据创建的模式当作正确标注来学习。
-
为了减少标签错误的影响:
-
确保你的训练数据向机器学习系统提供强学习‘信号’,并具有足够量的准确标注样本。
-
明确界定标签要求。这是绝对关键的——使用未能充分反映你在应用中所寻找的内容的标签进行训练将会破坏你的机器学习系统。
-
选择一个技术高超的标注合作伙伴。提供满足要求的数据的专业知识与要求本身一样重要。
-
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
三种边缘案例罪魁祸首:偏差、方差和不可预测性
原文:
www.kdnuggets.com/2021/04/imerit2-bias-variance-unpredictability.html
赞助帖子。
iMerit 是提供高质量数据的领先者用于训练数据集。在我们最新的博客帖子中,我们为您带来识别和处理 ML 系统中边缘案例的最新方法。如果您希望与专家交谈并了解更多关于克服边缘案例的信息,请联系我们。
通过训练,机器学习(ML)系统通过将输入(例如,像素值、音频样本、文本)与类别(例如,物体身份、单词、情感)关联来学习识别模式。这种关联可以被认为是将可能输入的多维空间划分为表示类别的区域,这些区域由决策边界定义。当在测试或操作过程中,输入落在分配给其类别的区域边缘之外时,输入会被错误分类。这种情况称为边缘案例。
边缘案例发生的三个基本原因:
-
偏差 – ML 系统过于“简单”
-
方差 – ML 系统过于“经验不足”
-
不可预测性 – ML 系统在充满惊喜的环境中运行。
我们如何识别这些边缘案例情况,以及我们可以做些什么?
偏差
偏差表现为 ML 系统在其训练数据集上的表现不佳。这表明 ML 系统的架构,其模型,无法表示训练数据中的细微差别。下面是一个非常简单的例子:
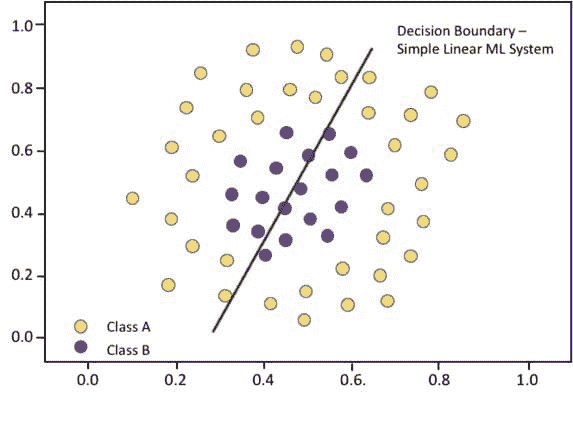
该图表展示了一个具有两个输入、单层、两个神经元的神经网络实现的线性决策边界。由于其简单的线性决策边界不足以分离这些类别,它在尝试区分紫色和黄色点时表现不佳。
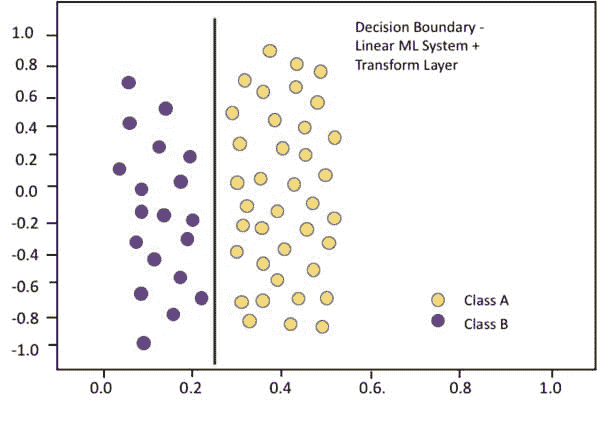
如果我们通过添加一个预处理层,将原始输入转换为极坐标,使机器学习系统变得稍微复杂一点,紫色和黄色的点在呈现给机器学习系统线性部分的新输入空间中对齐方式会有所不同,我们得到的决策边界看起来是这样的。这个更复杂的机器学习系统在训练数据上表现良好。
“层的结构本身也可以产生很大的影响。”
通常,克服机器学习系统偏差所需的额外复杂性可以通过简单地增加处理单元和层来实现。然而,层的结构本身也可以产生很大的影响。自 2010 年以来,ImageNet 视觉数据库已被用来基准测试对象识别机器学习系统的性能。在2012年,最佳性能在这个数据集上跃升了 10.8 个百分点,当时卷积神经网络取代了使用预处理和支持向量机的早期架构,实际上是上述简单机器学习系统的更复杂版本。
方差
当一个机器学习系统在其训练数据上表现良好,但在测试中表现较差时,问题往往在于训练数据集过小,无法充分反映机器学习系统操作环境中的变异范围。

减少由于方差引起的边缘情况的主要方法是收集更多的训练数据。
例如,所示的对象识别 系统 在成人面前表现良好,但显然在儿童方面经验不足。
方差问题引起的边缘情况对于自动面部识别系统是一个大问题。例如,虽然这些系统在识别智能手机用户方面可以非常准确,但在用于执法时可能会产生不准确且令人担忧的结果。在 2018 年的一项 测试 中,28 名美国国会议员被错误地匹配到一个包含 25,000 名罪犯的数据库中的照片。
减少由于方差引起的边缘情况的主要方法是收集更多的训练数据。 研究表明,随着训练数据集大小的增加,即使对于已经非常大的数据集,机器学习系统的性能也会持续改善。
在某些情况下,数据增强 可以通过对原始数据进行小的变化来增加训练数据集的大小,以表示诸如物体旋转、光照或姿态等变异。然而,特别重要的是确保训练数据能够代表操作环境中遇到的重要但可能较少见的情况,例如儿童的出现或极端天气条件。
不可预测性
机器学习依赖于在输入数据中找到规律模式。数据中总是存在统计变异,但通过适当的架构和足够的训练数据,机器学习系统通常可以找到足够的数据规律(实现足够小的偏差和方差),以做出可靠的决策并最小化边缘情况。

然而,自动驾驶是一个例子,它为机器学习系统提供了如此高的变异性,以至于可能的情况几乎是无穷无尽的。训练数据可以通过数百万英里的驾驶收集,但可能无法遇到重要的边缘情况。例如,2018 年一名女性被撞击并且被自驾车撞死,因为机器学习系统从未被训练去识别和应对带自行车的过马路行人。
处理在不可预测的自动驾驶应用中遇到的几乎无限数量的边缘情况是一项特别困难的挑战。为应对这一问题,正在采取两条途径。一种方法是开发专门训练以识别危险或可疑系统并采取覆盖措施以维护安全的“检查员”机器学习系统。
另一种方法是训练自动驾驶车辆的机器学习系统,以更好地处理边缘情况。一个方法是使用虚拟道路训练环境来扩展训练情况的范围。另一种方法使用对抗性训练,这项技术因创建“深度伪造”而闻名,以大幅扩展训练集,使机器学习系统能更好地处理新情况。
克服边缘情况
下表总结了如何识别和处理由于机器学习偏差、方差和不可预测性引起的边缘情况:
| 元凶 | 表现形式 | 解决方法 |
|---|---|---|
| 偏差 | 训练表现差 | 更好的机器学习系统模型 |
| 方差 | 测试表现差 | 更多的训练数据 |
| 不可预测性 | 操作惊喜 | 仿真对抗性训练 |
关键要点
-
确保你的训练和测试数据集足够大且多样化(当然也要准确标记!),以暴露机器学习设计中的弱点,并充分表征操作环境的多样性。
-
对于具有高不可预测性的操作环境,考虑通过仿真和对抗性训练生成的示例来增强训练数据。
-
监控操作并应对新出现的边缘情况。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
更多相关话题
云计算的未来就是现在
赞助帖子。
随着“大数据”的出现,数据从系统的副产品转变为创新和竞争优势的来源。如今,随着普遍的数字化转型以及当前 AI、ML 和云数据平台的兴起,数据被视为一种产品,其使用、价值和意义不断演变。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
如果我们对数据的理解正在改变,那么数据团队和 DataOps 的角色也在更快地现代化和修改。深入理解现代 DataOps 是完全掌握数据当前价值和角色的必要条件。
我们最近对 130 多位顶级数据工程师、数据架构师和高管的调查揭示了数据工程和 DataOps 当前状态的细节和趋势。我们识别出流行的趋势,如云数据平台的采用,并深入了解了成功和新兴平台、数据工程挑战,以及组织如何处理敏感数据。
阅读我们的调查报告 以了解更多关于这些趋势的信息,以及我们对未来障碍的预测和避免它们的建议。
更多相关内容
探索地理信息系统的影响
原文:
www.kdnuggets.com/2020/04/impact-geographic-information-systems.html
评论 来源
来源
地理信息系统(GIS)近年来因 COVID-19 疫情而受到新的关注,疫情促使许多人使用空间分析来展示病毒传播情况。GIS 在机器学习和深度学习等更流行的 buzzwords 背后一直存在。GIS 一直在我们身边,在政府、商业、医疗、房地产、交通、制造业等领域被使用。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
GIS 软件行业有一些主要玩家。以下软件用于创建静态和/或基于网页的互动地图:
其他替代方案包括使用像 R、Python 和 Javascript 这样的语言:
-
Leaflet.js - 开源
-
OpenLayers - 开源
以下服务可用于托管空间图层,这些图层可能过大,无法通过标准个人计算机呈现,这种情况在许多地理空间应用中最为常见:
GIS 开发人员有许多选择可以探索和学习新技能(有些是免费的,有些则不是)。
现在让我们深入了解 GIS 分析对社会的影响。
1. 特许经营
在特许经营的世界里,特许经营者由其特许人分配一个位置和/或领域,以便使用特许人的品牌运营自己的业务。通过 GIS 分析,特许人可以向其特许经营者提供有关其位置的见解,例如人口统计概况、竞争者分析、交通生成器等,以便宣传特许经营位置的吸引力。这些服务可以帮助企业更好地评估其站点进行扩展,同时最小化风险。
2. 教育
教育机构的运作基于人口统计数据。通过使用空间数据,教育机构可以隔离出核心人口(例如:5-19 岁)丰富的区域,以便更接近这些区域进行市场推广并为未来扩展开设新校区。国家按照空间边界划分,这些空间文件可以携带有价值的人口统计信息,帮助这些机构做出决策。
另一个应用是学校招生分析,通过这种方式可以绘制出机构当前和未来的学生,并识别其地理分布。这可以协助市场营销和扩展计划。
3. 智慧城市
智慧城市 GIS 是一个集成的跨部门平台,用于收集、管理、汇编、分析和可视化时空信息,以实现可持续的城市规划、发展和管理。GIS 在智慧城市规划和发展的每个阶段都得到部署。基础框架由信息和通信技术(ICT)提供,而重点则放在“空间”或 GIS 上。这个通用平台贯穿了生命周期的所有阶段——从建模、规划、建设到管理——涵盖了全功能范围。
4. 公共卫生
在 2020 年,公共卫生应用 GIS 可以说是当前最主流的应用。GIS 被用来研究和可视化 COVID-19 在全球的传播,并向公众通报发生了什么。GIS 是政府、企业和公众传播有用信息的催化剂。流行病学家负责研究疾病在社会中的传播,而 GIS 使他们的部分分析能够覆盖到全球数十亿人。
相关
-
地图制作的未来是开放的,由传感器和人工智能驱动
-
使用 R、SQL 和 Tableau 进行地理时间序列预测简介
-
7 种可视化地理空间数据的技术
相关话题
如何实现一个联邦学习项目与医疗数据
原文:
www.kdnuggets.com/2023/02/implement-federated-learning-project-healthcare-data.html
图片由 Nataliya Vaitkevich 提供
联邦学习(FL)是一种机器学习方法,它允许在多个分散的设备或机构上训练模型,而无需将数据集中到单一服务器上。它已被应用于多个行业,从移动设备键盘到自动驾驶车辆再到石油平台。在医疗行业中尤为有用,因为涉及到敏感的患者数据,需要遵循严格的法规来保护个人隐私。在这篇博客中,我们将讨论一些实施医疗数据联邦学习项目的实际步骤。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
首先,理解项目的要求和限制非常重要。这包括了解你将处理的数据类型以及必须遵循的法规,以保护个人隐私。可能还需要获得必要的批准和许可,以便将数据用于你的项目,例如机构审查委员会(IRB)批准。
接下来,你需要准备数据。这包括从不同的临床系统中提取数据,协调不同站点的数据(因为数据可能以不同的方式编码、格式不同,并且每个站点的数据分布也不同),注释数据(有时需要医生审查和注释数据),以及将数据划分为训练、测试和验证的部分。确保数据正确平衡并且能够代表整体人群,以确保结果的准确性是非常重要的。
一旦你的数据准备好后,你需要选择一个联邦学习框架。现有几个可供选择的选项,包括NVIDIA FLARE、TensorFlow Federated、PySyft、OpenFL和Flower。这些框架各有其特性和能力,因此选择最适合你项目需求的框架非常重要。我们发现 NVIDIA FLARE 提供了一个强大的框架,可以与任何底层机器学习框架(如 PyTorch、TensorFlow、sklearn 等)兼容使用。
接下来,你需要为你的联邦学习项目建立基础设施。这包括选择一个云服务器来托管最终模型并协调联邦学习过程,以及在每个参与站点设置服务器,安装所需的软件,使本地数据集对该服务器可用,并确保服务器能够与云服务器通信。根据你选择的联邦学习框架,你可能还需要在每个站点的本地服务器和云服务器之间设置一个安全的通信通道,以确保数据的隐私和安全。
一旦基础设施搭建完毕,你可以开始训练过程。这包括将你的模型架构提供给云服务器,云服务器将协调联邦学习训练——将模型发送到参与的设备或机构,在那里本地数据将用于训练本地模型。本地模型随后被发送回服务器,在服务器上进行汇总并用于更新全局模型。这个过程会重复进行,直到全局模型收敛到一个可接受的准确度水平。
最后,评估模型的性能并确保其符合项目要求是非常重要的。这涉及在一组独立的数据上测试模型或使用其对真实世界数据进行预测。在许多情况下,这还包括对模型架构、底层数据集和/或预处理进行迭代,以优化模型性能。
这些步骤可能看起来很复杂,但幸运的是,有像Rhino Health这样的联邦学习平台,可以使整个过程变得简单而无缝。强大的端到端联邦学习平台将负责基础设施的配置,提供强大的安全功能,并支持从数据预处理到模型训练和结果分析的所有联邦项目步骤,具备最大灵活性——允许数据科学家使用他们选择的数据分析/处理工具和机器学习/联邦学习框架。它们使得联邦项目更像是使用集中式数据的项目。
医疗保健创新的未来依赖于能够访问大量数据以进行分析和模型训练。联邦学习是一种强大的工具,它可以在不冒数据隐私风险的情况下访问数据,使其成为提高患者护理和推动医疗保健领域发展的有前景的方法。通过遵循这些步骤并采取必要的预防措施来保护患者隐私,你可以成功实施联邦学习项目,并在医疗保健行业中产生积极的影响。
Yuval Baror 是 Rhino Health 的首席技术官及联合创始人。他在软件工程、管理和初创公司方面有近 20 年的经验(包括创办了一家成功被收购的初创公司)。在过去十年中,他在 3 家不同的公司从事基于 AI 的生产系统的构建工作。我喜欢人工智能的深度挑战,享受构建对客户产生实质性影响的生产系统的兴奋,以及在实际系统中使 AI 工作的独特交叉点。
更多相关话题
为什么要从头实现机器学习算法?
原文:
www.kdnuggets.com/2016/05/implement-machine-learning-algorithms-scratch.html
评论
从头实现算法有几个不同的原因可能会很有用:
-
它可以帮助我们理解算法的内部工作原理。
-
我们可以尝试更高效地实现一个算法。
-
我们可以为算法添加新特性或实验不同的核心概念变体。
-
我们可以绕过许可问题(例如,Linux vs. Unix)或平台限制。
-
我们想发明新算法或实现尚未实现/分享的算法。
-
我们对现有的 API 不满意,或者我们想将其更“自然”地集成到现有的软件库中。
让我们在上述六点的背景下进一步缩小“从头实现”这个短语的范围。当我们谈论“从头实现”时,我们需要缩小范围,使这个问题真正切实可行。让我们讨论一个具体的算法,简单的逻辑回归,以便用具体的例子来解决不同的点。我认为逻辑回归已经实现了不下于千次。
我们仍然希望从头实现逻辑回归的一个原因可能是我们觉得自己没有完全理解它的工作原理;我们读了一些论文,虽然理解了核心概念。通过编程语言进行原型设计(例如,Python、MATLAB、R 等),我们可以从论文中获取想法,并尝试逐步用代码表达它们。一个成熟的库,如 scikit-learn,可以帮助我们再次检查结果,看看我们的实现——我们对算法如何工作的理解——是否正确。在这里,我们并不真正关心效率;尽管我们花了很多时间实现算法,但如果我们想在研究实验室或公司中进行一些严肃的分析,我们可能还是会想使用成熟的库。成熟的库通常更值得信赖——它们经过了许多人使用的考验,可能已经遇到了一些边界情况,并确保没有奇怪的意外。此外,这些代码也更有可能随着时间的推移被高度优化以提高计算效率。在这里,从头实现的目的仅仅是为了自我评估。阅读一个概念是一回事,但将其付诸实践则是对理解的更高层次——能够向他人解释则是锦上添花。
另一个我们可能希望从头开始重新实现逻辑回归的原因是我们对其他实现的“特性”不满意。让我们天真地假设其他实现没有正则化参数,或者不支持多类设置(即通过一对多、一对一或 softmax)。或者如果计算(或预测)效率是一个问题,也许我们想使用另一种求解器(例如牛顿法与梯度下降法与随机梯度下降法等)来实现它。但是,关于计算效率的改进不一定需要通过算法的修改来实现,我们可以使用更底层的编程语言,例如使用 Scala 代替 Python,或使用 Fortran 代替 Scala……这可能涉及到汇编语言或机器代码,甚至设计一个优化用于运行这种分析的芯片。然而,如果你是一个机器学习(或“数据科学”)从业者或研究人员,这可能是你应该委托给软件工程团队的事情。

回到主要问题:不同的人因各种原因从头实现算法。就个人而言,当我从头实现算法时,是因为学习的体验。
简介: Sebastian Raschka 是一位“数据科学家”和机器学习爱好者,对 Python 和开源有极大热情。《Python 机器学习》的作者。密歇根州立大学。
原文。经许可转载。
相关:
-
深度学习何时优于支持向量机或随机森林?
-
分类发展作为学习机器
-
十大数据挖掘算法解析
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关话题
如何从头开始在 PyTorch 中实现 YOLO (v3) 物体检测器:第一部分
原文:
www.kdnuggets.com/2018/05/implement-yolo-v3-object-detector-pytorch-part-1.html
评论
作者 Ayoosh Kathuria,研究实习生
我们的前三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
物体检测是一个从深度学习的最新发展中获益匪浅的领域。近年来,人们开发了许多物体检测算法,其中包括 YOLO、SSD、Mask RCNN 和 RetinaNet。
在过去的几个月里,我一直在研究实验室中改进物体检测。这段经历最重要的收获之一就是意识到学习物体检测的最佳方式是从零开始自己实现算法。这正是我们在本教程中要做的。
我们将使用 PyTorch 实现基于 YOLO v3 的物体检测器,它是现有的更快的物体检测算法之一。
本教程的代码设计用于 Python 3.5 和 PyTorch 0.4。完整代码可以在这个 Github 仓库 中找到。
本教程分为 5 部分:
-
第一部分(此部分):了解 YOLO 的工作原理
前提条件
-
你应该了解卷积神经网络的工作原理。这还包括对残差块、跳跃连接和上采样的知识。
-
什么是物体检测、边界框回归、IoU 和非极大值抑制。
-
基本的 PyTorch 使用。你应该能够轻松创建简单的神经网络。
我在帖子末尾提供了链接,以防你在任何方面遇到困难。
什么是 YOLO?
YOLO 代表“你只看一次”(You Only Look Once)。它是一个目标检测器,利用深度卷积神经网络学到的特征来检测对象。在我们动手编码之前,我们必须了解 YOLO 是如何工作的。
全卷积神经网络
YOLO 仅使用卷积层,使其成为一个全卷积网络(FCN)。它有 75 层卷积层,配有跳跃连接和上采样层。没有使用池化,使用步幅为 2 的卷积层来对特征图进行降采样。这有助于防止通常归因于池化的低级特征丢失。
作为一个全卷积网络(FCN),YOLO 对输入图像的大小是不变的。然而,实际上,由于各种问题,我们可能希望坚持使用固定的输入大小,这些问题只有在实现算法时才会显现出来。
其中一个主要问题是,如果我们想批量处理图像(批量图像可以通过 GPU 并行处理,从而提高速度),我们需要所有图像具有固定的高度和宽度。这是为了将多个图像合并成一个大批量(将多个 PyTorch 张量合并成一个)。
网络通过一个称为步幅(stride)的因子对图像进行降采样。例如,如果网络的步幅是 32,那么一个 416 x 416 的输入图像将得到一个 13 x 13 的输出。通常,网络中任何层的步幅是指该层的输出比网络输入图像要小的因子。
解读输出结果
通常情况下(如所有目标检测器一样),卷积层学到的特征会传递给一个分类器/回归器,该分类器/回归器进行检测预测(边界框的坐标、类别标签等)。
在 YOLO 中,预测是通过使用 1 x 1 卷积的卷积层完成的。
现在,首先要注意的是我们的输出是一个特征图。由于我们使用了 1 x 1 的卷积,预测图的大小与之前的特征图完全一致。在 YOLO v3(及其后代)中,解释这个预测图的方式是每个单元可以预测固定数量的边界框。
尽管在特征图中描述单位的技术术语是神经元,但在我们的上下文中称之为细胞会更加直观。
在深度方面,特征图中有(B x (5 + C))个条目。 B 代表每个单元格可以预测的边界框数量。根据论文,这些 B 个边界框中的每一个可能专注于检测某种特定类型的对象。每个边界框具有5 + C个属性,描述中心坐标、尺寸、目标分数和每个边界框的C类置信度。YOLO v3 为每个单元格预测 3 个边界框。
你期望特征图的每个单元格通过其边界框中的一个来预测一个对象,如果对象的中心落在该单元格的感受野中。(感受野是单元格可见的输入图像区域。有关卷积神经网络的进一步说明,请参见链接)。
这与 YOLO 的训练方式有关,其中只有一个边界框负责检测任何给定的对象。首先,我们必须确定这个边界框属于哪个单元格。
为此,我们将输入图像划分为与最终特征图大小相同的网格。
让我们考虑下面的一个例子,其中输入图像为 416 x 416,网络的步幅为 32。如前所述,特征图的尺寸将为 13 x 13。然后我们将输入图像划分为 13 x 13 个单元格。
然后,包含对象的真实框中心的单元格(在输入图像上)被选择为负责预测该对象的单元格。在图像中,它是标记为红色的单元格,包含真实框的中心(标记为黄色)。
现在,红色单元格是网格中第 7 行第 7 列的单元格。我们将第 7 行第 7 列的单元格在特征图上(特征图上对应的单元格)分配为负责检测狗的单元格。
现在,这个单元格可以预测三个边界框。哪个将被分配给狗的真实标签?为了理解这一点,我们必须深入了解锚点的概念。
注意,我们在这里讨论的单元格是预测特征图上的单元格。我们将输入图像划分为网格,仅仅是为了确定预测特征图的哪个单元格负责预测。
锚点框
预测边界框的宽度和高度可能是有意义的,但在实践中,这会导致训练期间梯度不稳定。相反,大多数现代目标检测器预测对数空间变换,或简单地说是相对于预定义默认边界框的偏移,称为锚点。
然后,这些变换应用于锚点框以获得预测。YOLO v3 具有三个锚点,这导致每个单元格预测三个边界框。
回到我们之前的问题,负责检测狗的边界框将是与真实框的 IoU 最高的锚点对应的那个。
做出预测
以下公式描述了网络输出如何转化为边界框预测。
bx, by, bw, bh 是我们预测的 x, y 中心坐标、宽度和高度。tx, ty, tw, th 是网络输出的内容。cx 和 cy 是网格的左上角坐标。pw 和 ph 是框的锚点维度。
中心坐标
注意,我们将中心坐标预测通过了一个 sigmoid 函数。这强制输出值在 0 和 1 之间。为什么会这样?请耐心等待。
通常,YOLO 不预测边界框中心的绝对坐标。它预测的是偏移量,这些偏移量是:
-
相对于预测物体的网格单元的左上角。
-
由特征图的单元维度规范化,即 1。
例如,考虑我们的狗图像的情况。如果中心的预测是 (0.4, 0.7),这意味着中心位于 13 x 13 特征图上的 (6.4, 6.7)。(因为红色单元的左上角坐标是 (6,6))。
但等一下,如果预测的 x, y 坐标大于 1,比如 (1.2, 0.7),这意味着中心位于 (7.2, 6.7)。注意到中心现在位于紧邻我们红色单元的单元中,即第 7 行的第 8 个单元。这破坏了 YOLO 背后的理论,因为如果我们假设红色框负责预测狗,则狗的中心必须位于红色单元内,而不是旁边的单元内。
因此,为了弥补这个问题,输出会通过一个 sigmoid 函数,这会将输出压缩到 0 到 1 的范围内,有效地将中心保持在预测的网格中。
边界框的维度
通过对输出应用对数空间变换并与锚点相乘来预测边界框的维度。
检测器输出如何转化为最终预测。图片来源。christopher5106.github.io/
结果预测的 bw 和 bh 由图像的高度和宽度进行规范化(训练标签以这种方式选择)。所以,如果包含狗的框的预测 bx 和 by 是 (0.3, 0.8),那么在 13 x 13 特征图上的实际宽度和高度是 (13 x 0.3, 13 x 0.8)。
物体性得分
物体得分表示物体被包含在边界框中的概率。对于红色和邻近网格,它应该接近 1,而对于例如角落的网格,它几乎应该是 0。
物体性得分也通过一个 sigmoid,因为它需要被解释为概率。
类别置信度
类别置信度表示检测到的物体属于特定类别(如狗、猫、香蕉、汽车等)的概率。在 v3 之前,YOLO 使用 softmax 计算类别得分。
然而,这种设计选择在 v3 中被放弃,作者选择使用 sigmoid。原因是 Softmax 的类别分数假设类别是相互排斥的。简单来说,如果一个对象属于一个类别,那么它就不能属于另一个类别。这对我们将基于其构建检测器的 COCO 数据库来说是成立的。
然而,当我们有像 女人 和 人 这样的类别时,这些假设可能不成立。这就是为什么作者避免使用 Softmax 激活的原因。
不同尺度下的预测
YOLO v3 在 3 个不同的尺度上进行预测。检测层用于在三种不同大小的特征图上进行检测,分别具有 步幅 32、16、8。这意味着,在 416 x 416 的输入下,我们在尺度 13 x 13、26 x 26 和 52 x 52 上进行检测。
网络对输入图像进行下采样,直到第一个检测层,在该层使用步幅为 32 的特征图进行检测。进一步地,层通过 2 的因子进行上采样,并与前一层具有相同特征图大小的特征图连接。然后在步幅为 16 的层上进行另一次检测。相同的上采样过程重复进行,最终在步幅为 8 的层上进行检测。
在每个尺度下,每个单元格使用 3 个锚点预测 3 个边界框,因此总共使用的锚点数量为 9。 (不同尺度下的锚点不同)

作者报告说,这有助于 YOLO v3 更好地检测小物体,这是早期 YOLO 版本的一个常见投诉。上采样可以帮助网络学习细粒度特征,这对于检测小物体至关重要。
输出处理
对于大小为 416 x 416 的图像,YOLO 预测 ((52 x 52) + (26 x 26) + 13 x 13)) x 3 = 10647 个边界框。然而,对于我们的图像,只有一个对象,一只狗。我们如何将检测数量从 10647 减少到 1?
基于对象置信度的阈值处理
首先,我们根据对象分数过滤框。通常,分数低于阈值的框会被忽略。
非最大抑制
NMS 旨在解决同一图像多次检测的问题。例如,红色网格单元格的所有 3 个边界框可能会检测到一个框,或者相邻单元格可能会检测到同一个对象。

如果你对 NMS 不熟悉,我提供了一个解释相同内容的网站链接。
我们的实现
YOLO 仅能检测训练网络所用数据集中存在的类别的对象。我们将使用官方权重文件来进行检测。这些权重是通过在 COCO 数据集上训练网络获得的,因此我们可以检测 80 个对象类别。
第一部分到此为止。这篇文章足以解释 YOLO 算法的基本概念,让你能够实现检测器。然而,如果你想深入了解 YOLO 的工作原理、训练方式以及与其他检测器的性能比较,你可以阅读原始论文,以下是相关链接。
本部分内容到此为止。在下一部分 (第二部分),我们将实现组装检测器所需的各种层。
进一步阅读
简介: Ayoosh Kathuria 目前是印度国防研究与发展组织的实习生,正在致力于改善模糊视频中的目标检测。工作之余,他要么在睡觉,要么在吉他上弹奏 Pink Floyd。你可以在LinkedIn上与他联系,或者在GitHub上查看他更多的工作。
原始文章。已获许可转载。
相关:
-
入门 PyTorch 第一部分:理解自动微分的工作原理
-
PyTorch 张量基础
-
使用 Google Colab、TensorFlow、Keras 和 PyTorch 进行深度学习开发
更多相关内容
从零实现 AdaBoost 算法
原文:
www.kdnuggets.com/2020/12/implementing-adaboost-algorithm-from-scratch.html
评论
由 James Ajeeth J 提供,Praxis 商学院
在本文结束时,你将能够:
-
理解自适应提升 (AdaBoost) 算法的工作原理和数学原理。
-
能够从零开始编写 AdaBoost 的 Python 代码。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
提升介绍:
提升是一种集成技术,旨在通过多个弱分类器创建强分类器。与许多机器学习模型专注于单一模型的高质量预测不同,提升算法通过训练一系列弱模型来改进预测能力,每个模型都弥补其前任的不足。提升赋予机器学习模型提升预测准确性的能力。
AdaBoost:
AdaBoost,简称自适应 提升,是由 Yoav Freund 和 Robert Schapire 提出的 机器学习 算法。AdaBoost 技术遵循深度为一的决策树模型。AdaBoost 实质上是桩森林而非树森林。AdaBoost 通过对难以分类的实例施加更多权重,对已处理良好的实例施加较少权重来工作。AdaBoost 算法旨在解决分类和回归问题。
AdaBoost 的思想:
-
桩模型(一个节点和两个叶子)在进行准确分类时效果并不好,所以它不过是一个弱分类器/弱学习器。许多弱分类器的组合形成了强分类器,这也是 AdaBoost 算法的原理。
-
一些桩模型的表现优于其他模型或分类效果更好。
-
连续的桩模型会考虑之前桩模型的错误。
从零开始的 AdaBoost 算法:
在这里,我使用了 Iris 数据集作为从零开始构建算法的示例,并且为了更好地理解,只考虑了两个类别(Versicolor 和 Virginica)。

步骤 1:对所有观察值分配相等的权重
初始时对数据集中每个记录分配相同的权重。
样本权重 = 1/N
其中 N = 记录数量
步骤 2:使用 stumps 对随机样本进行分类
从原始数据中用替换抽取随机样本,概率等于样本权重,并拟合模型。这里 AdaBoost 中使用的模型(基学习器)是决策树。 决策树是创建深度为 1 的树,只有一个节点和两个叶子,通常称为 stump。将模型拟合到随机样本中,并对原始数据进行分类预测。

‘pred1’ 是新预测的类别。
步骤 3:计算总错误
总错误率即为误分类记录的权重之和。
总错误 = 误分类记录的权重
总错误将始终在 0 和 1 之间。
0 代表完美的 stump(正确分类)
1 代表弱 stump(误分类)

步骤 4:计算 Stump 的性能
使用总错误率来确定基学习器的性能。计算得到的 stump(α) 值用于在连续迭代中更新权重,也用于最终预测计算。
stump 的性能(α) = ½ ln (1 – 总错误/总错误)

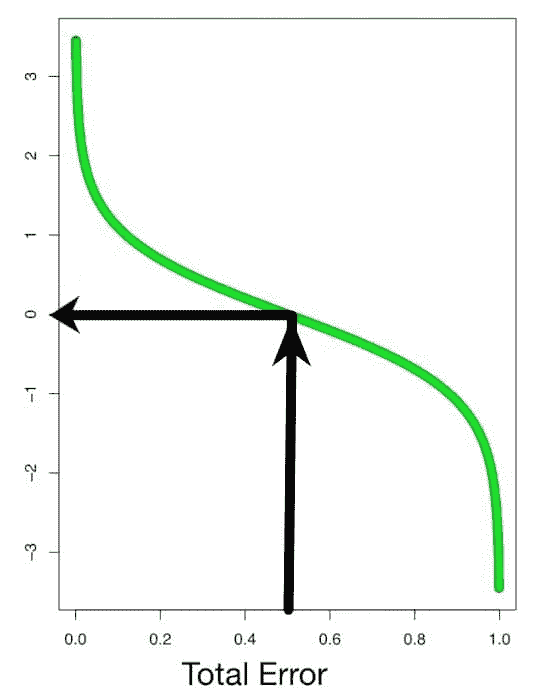
案例:
-
如果总错误率为 0.5,则 stump 的性能为零。
-
如果总错误为 0 或 1,则性能将分别变为无穷大或负无穷大。
当总错误等于 1 或 0 时,上述方程会表现出异常。因此,在实际操作中会加入一个小的误差项来防止这种情况发生。
当性能(α) 相对较大时,stump 在分类记录方面表现良好。当性能(α) 相对较低时,stump 在分类记录方面表现不佳。利用性能参数(α),我们可以增加错误分类记录的权重,并减少正确分类记录的权重。
步骤 5:更新权重
根据 stump(α) 的性能更新权重。我们需要下一个 stump 正确分类误分类记录,通过增加相应的样本权重并减少正确分类记录的样本权重。
新权重 = 权重 * e^((性能)) → 误分类记录
新权重 = 权重 * e^(-(性能)) → 正确分类记录

如果 ‘Label’ 和 ‘pred1’ 相同(即 1 或 -1),那么将值代入上述方程将得到正确分类记录的方程。类似地,如果值不同,将值代入上述方程将得到误分类记录的方程。
关于 e^(性能) 的简短说明,即用于误分类
当性能相对较高时,最后一个决策树在分类记录方面表现良好,现在新样本权重将远大于旧的。当性能相对较低时,最后一个决策树在分类记录方面表现较差,现在新样本权重仅比旧的稍大。
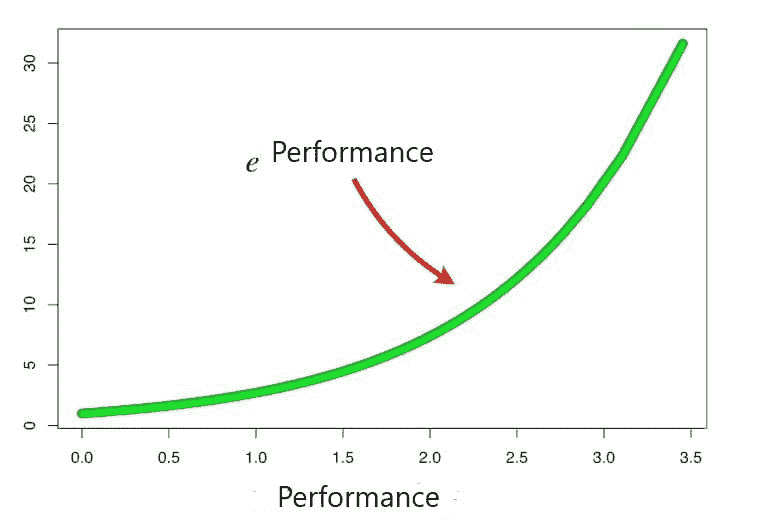
关于 e^-(性能) 的简短说明,即用于没有误分类
当性能相对较高时,最后一个决策树在分类记录方面表现良好,现在新样本权重将比旧的要小得多。当性能相对较低时,最后一个决策树在分类记录方面表现较差,现在新样本权重仅比旧的稍小。
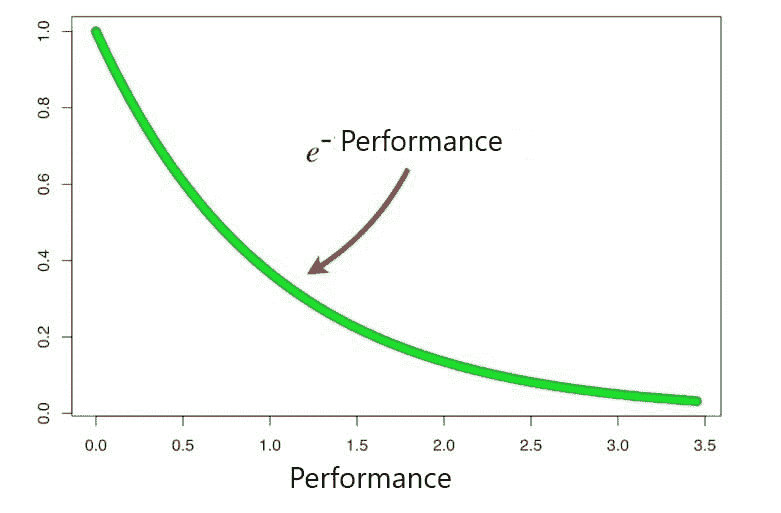
在这里,更新后的权重总和不等于 1,而初始样本权重的总和等于 1。因此,为了实现这一点,我们将除以一个数,这个数就是更新后的权重之和(归一化常数)。
归一化常数 = ∑ 新权重
归一化权重 = 新权重 / 归一化常数
现在归一化权重的总和等于 1。


‘prob2’ 是更新后的权重。
步骤 6:迭代中更新权重
使用归一化权重来生成森林中的第二个决策树。创建一个与原始数据集大小相同的新数据集,根据更新后的样本权重进行重复。这使得误分类的记录有更高的被选中概率。通过更新权重进行特定次数的迭代,重复步骤 2 到 5。

‘prob4’ 是每个观察值的最终权重。
步骤 7:最终预测
通过获取最终预测值加权和的符号来完成最终预测。
最终预测/符号(加权和) = ∑ (α[i]*(每次迭代的预测值))
例如:5 个弱分类器可能预测值为 1.0、1.0、-1.0、1.0、-1.0。通过多数投票,看起来模型会预测为 1.0 或第一类。这 5 个弱分类器的性能(α)值分别为 0.2、0.5、0.8、0.2 和 0.9。计算这些预测的加权和结果为 -0.8,这将是 -1.0 或第二类的集成预测。
计算:
t = 1.00.2 + 1.00.5 - 1.00.8 + 1.00.2 - 1.0*0.9 = -0.8
仅考虑符号的话,最终预测将是 -1.0 或第二类。

AdaBoost 算法的优势:
-
AdaBoost 算法的许多优点之一是它快速、简单且易于编程。
-
Boosting 已被证明对过拟合具有鲁棒性。
-
它已经扩展到二分类问题之外的学习问题(即)可以用于文本或数值数据。
缺点:
-
AdaBoost 对噪声数据和异常值可能很敏感。
-
弱分类器过于薄弱可能会导致低边际和过拟合。
结论:
AdaBoost 帮助为每个新的分类器选择训练集,这些分类器的训练基于前一个分类器的结果。同时,在合并结果时,它确定每个分类器提议答案的权重。它将弱学习器组合成一个强学习器,以纠正分类错误,这也是第一个成功的用于二分类问题的提升算法。
代码文件和数据的 GitHub 链接:
github.com/jamesajeeth/Data-Science/tree/master/Adaboost%20from%20scratch
参考文献:
书籍:
- Hastie, Trevor, Tibshirani, Robert, Friedman, Jerome, 《统计学习的元素:数据挖掘、推断与预测(第二版)》
站点:
个人简介: James Ajeeth J 是印度班加罗尔 Praxis 商学院的研究生。
相关:
-
机器学习的集成方法:AdaBoost
-
探索蛮力 K-近邻算法
-
KNN 中最常用的距离度量及何时使用它们
更多相关话题
在 Scikit-learn 中实现 Adaboost
原文:
www.kdnuggets.com/2022/10/implementing-adaboost-scikitlearn.html
来源:作者图片
什么是 AdaBoost?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域的职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
AdaBoost 算法,简称为自适应提升,是一种用于机器学习中的集成方法的 Boosting 技术。由于权重会重新分配给每个实例,其中更高的权重分配给那些未被正确分类的实例,因此它被称为自适应提升。
如果你想了解更多关于集成方法及其使用时机的信息,请阅读这篇文章: 何时使用集成技术会是一个好选择?
Boosting 是一种集成机器学习算法的方法,用于减少预测数据分析中的错误。它通过结合弱学习者的预测来实现这一点。在成为一个实际概念之前,Boosting 更多是一个理论概念。
如果你想了解更多关于 Boosting 的信息,请阅读这篇文章: Boosting 机器学习算法概述
术语
什么是弱学习者? 弱学习者是指一种简单模型,其技能水平较低,但表现稍微优于随机机会。
什么是 Stump? 在基于树的算法中,一个有两个叶子的节点被称为 Stump。弱学习者几乎总是 Stumps。
AdaBoost 如何工作?
AdaBoost 算法在数据训练期间使用短的决策树。被错误分类的实例会被优先考虑,并作为第二个模型的输入 - 被称为弱学习者。这个过程会一次又一次地重复,直到模型尝试纠正之前模型做出的预测。
AdaBoost 背后的思想:
-
弱学习者的组合用于分类
-
一些 Stumps 在分类中的影响力大于其他 Stumps
-
每个 Stump 考虑到之前 Stumps 的错误
AdaBoost 和 Scikit-Learn
Scikit-Learn 提供了使用 Python 机器学习库实现 AdaBoost 的集成方法。AdaBoost 可用于分类和回归问题,因此让我们看看如何使用 Scikit-Learn 解决这些类型的问题。
分类
sklearn.ensemble.AdaBoostClassifier
AdaBoost 分类器的目标是首先在原始数据集上拟合一个分类器,然后拟合额外的分类器,其中错误分类实例的权重会被调整。
这些是参数:
sklearn.ensemble.AdaBoostClassifier(base_estimator = None, * ,
n_estimators = 50, learning_rate = 1.0, algorithm = 'SAMME.R',
random_state = None)
你可以在 这里 了解更多关于它们及其属性的信息。
让我们来看一个例子:
导入:
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_breast_cancer
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.preprocessing import LabelEncoder
加载数据集:
breast_cancer = load_breast_cancer()
X = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names)
y = pd.Categorical.from_codes(breast_cancer.target, breast_cancer.target_names)
将恶性编码为 1,将良性编码为 0:
encoder = LabelEncoder()
binary_encoded_y = pd.Series(encoder.fit_transform(y))
训练/测试集:
train_X, test_X, train_y, test_y = train_test_split(X,
binary_encoded_y, random_state = 1)
拟合我们的模型:
classifier = AdaBoostClassifier(
DecisionTreeClassifier(max_depth = 1),
n_estimators = 200
)
classifier.fit(train_X, train_y)
进行预测:
predictions = classifier.predict(test_X)
评估模型:
confusion_matrix(test_y, predictions)
输出:
array([[86, 2],
[ 3, 52]])
代码来源:Cory Maklin
回归
sklearn.ensemble.AdaBoostRegressor
AdaBoost 回归器的目标是首先在原始数据集上拟合一个回归器,然后拟合额外的回归器,其中权重根据当前预测误差进行了调整。
这些是参数:
sklearn.ensemble.AdaBoostRegressor(base_estimator = None, * ,
n_estimators = 50, learning_rate = 1.0, loss = 'linear',
random_state = None)
如果你想了解更多关于它们及其属性的信息,请点击 这里。
让我们来看一个例子:
#evaluate adaboost ensemble
for regression
from numpy
import mean
from numpy
import std
from sklearn.datasets
import make_regression
from sklearn.model_selection
import cross_val_score
from sklearn.model_selection
import RepeatedKFold
from sklearn.ensemble
import AdaBoostRegressor
# define dataset
X, y = make_regression(n_samples = 1000, n_features = 20,
n_informative = 15, noise = 0.1, random_state = 6)
# define the model
model = AdaBoostRegressor()
# evaluate the model
cv = RepeatedKFold(n_splits = 10, n_repeats = 3, random_state = 1)
n_scores = cross_val_score(model, X, y, scoring =
'neg_mean_absolute_error', cv = cv, n_jobs = -1, error_score =
'raise')
# report performance
print('MAE: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
总结
如果你想了解更多关于集成方法以及如何使用技术:装袋、提升和堆叠来提高预测准确性的信息,请查看 MachineLearningMastery 书籍:Python 中的集成学习算法
Josh Starmer,统计和机器学习专家,通过这个视频帮助我更好地理解 AdaBoost:AdaBoost 清晰解释
Nisha Arya 是一位数据科学家和自由撰稿人。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探索人工智能如何及如何可以惠及人类寿命的不同方式。她是一个热衷学习者,寻求拓宽技术知识和写作技能,同时帮助指导他人。
更多相关话题
使用开源工具实现自动化机器学习系统
原文:
www.kdnuggets.com/2018/10/implementing-automated-machine-learning-open-source-path.html
评论
我之前写过一些关于自动化机器学习的内容。我不会重复已经涵盖的介绍性材料,但如果有兴趣了解主要点,以及实际操作的尝试,请随意浏览这些文章,然后再继续。
-
自动化机器学习的当前状态
-
自动化机器学习与自动化数据科学
-
使用 AutoML 与 TPOT 生成机器学习管道
在我看来,机器学习的实践归结为两个主要的任务,因此在一个有限的实际定义中,我们可以将自动化机器学习的核心视为:
-
自动化特征工程和/或选择
-
自动化超参数调优和架构搜索
从语义上讲,机器学习模型的训练,虽然这些自动化步骤的结果,但在自动化机器学习过程中是偶然的,而自动化步骤如模型评估和模型选择则是辅助的。见图 1。
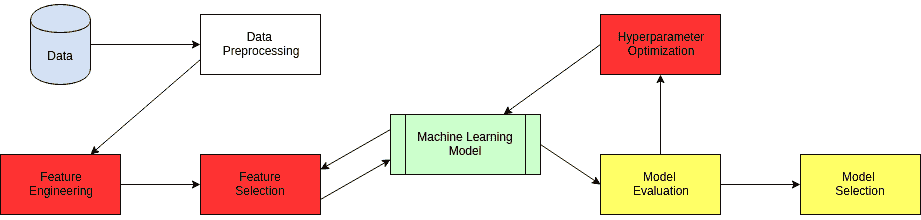
图 1. 自动化机器学习过程(核心自动化过程用红色标出,辅助过程用黄色标出)
理论上讲,这一切都很好。但如果你想实现自己的自动化机器学习管道,或在上述两个主要任务方面自动化机器学习管道的特定方面怎么办?
请放心,不需要重新发明轮子;自动化机器学习作为一个学科,可能尚未完全形成,但也绝非完全未开发。请参见下面的开源工具样本,它们可以帮助你完善自己的自动化机器学习管道。
请记住,下面的第一组(超参数调优和架构搜索)通常被广泛认为是“自动化机器学习工具”。但是,请注意,超参数调优和架构搜索工具可以且经常执行某种类型的特征选择。有一套强大的工具只提供自动化特征工程和/或选择(注意你对自动化的定义在这些特定情况下可能不完全一致),因此也提供了这些工具的样本。
自动化超参数调优与架构搜索
Auto-Keras 是一个用于自动化机器学习(AutoML)的开源软件库。它由德克萨斯 A&M 大学的 DATA Lab 和社区贡献者开发。AutoML 的最终目标是为数据科学或机器学习背景有限的领域专家提供易于访问的深度学习工具。Auto-Keras 提供了自动搜索深度学习模型架构和超参数的功能。
auto-sklearn 是一个自动化机器学习工具包,是 scikit-learn 估计器的直接替代品。auto-sklearn 使机器学习用户摆脱算法选择和超参数调优的困扰。它利用了贝叶斯优化、元学习和集成构建方面的最新优势。通过阅读我们在 NIPS 2015 上发表的论文,可以进一步了解 auto-sklearn 背后的技术。
MLBox 是一个强大的自动化机器学习 Python 库。它提供了以下功能:
- 快速阅读和分布式数据预处理/清理/格式化
- 高度可靠的特征选择和泄漏检测
- 高维空间中准确的超参数优化
- 最先进的分类和回归预测模型(深度学习、堆叠、LightGBM 等)
- 带有模型解释的预测
一个优化机器学习管道的 Python 自动化机器学习工具,使用遗传编程。将 TPOT 视为你的数据科学助手。TPOT 是一个使用遗传编程优化机器学习管道的 Python 自动化机器学习工具。TPOT 通过智能探索数千个可能的管道,来自动化机器学习中最繁琐的部分,以找到最适合你数据的管道。
自动化特征工程/选择
Featuretools 是一个用于自动化特征工程的 Python 库。Featuretools 可以与你已经使用的工具一起工作来构建机器学习管道。你可以加载 pandas 数据框,并在手动操作所需时间的一小部分内自动创建有意义的特征。
一个用于 Python 数据分析和机器学习库的扩展和辅助模块库。
进一步了解:
那么,我们如何在 Python 中执行前向特征选择呢?Sebastian Raschka 的 mlxtend 库包括一个实现(Sequential Feature Selector),因此我们将使用它来演示。无需多言,你应该在继续之前安装 mlxtend(检查 Github 仓库)。
请注意,这仅仅是可用 Python 自动化机器学习工具的一个样本。除了这里列出的开源工具(以及 Python 生态系统之外),还有许多专有和托管选项可供使用,这些可能在不久的将来需要自己独立的调查文章。
相关:
-
自动化机器学习与自动化数据科学
-
使用 AutoML 生成机器学习管道与 TPOT
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关话题
在 Python 中实现 DBSCAN
原文:
www.kdnuggets.com/2022/08/implementing-dbscan-python.html
图片由作者提供
聚类应用于数据集,以将相似的数据点分组。它查找数据点之间的相似性和差异性,并将它们聚集在一起。聚类没有标签。聚类是一种无监督学习,用于发现数据集的潜在结构。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 需求
聚类算法的类型:
-
基于分区的聚类
-
模糊聚类
-
层次聚类
-
基于网格的聚类
-
排他性聚类
-
重叠聚类
-
基于密度的聚类
在这篇博客中,我们将重点关注基于密度的聚类方法,特别是使用 scikit-learn 的 DBSCAN 算法。基于密度的算法擅长发现高密度区域和离群点。它通常用于异常检测和聚类非线性数据集。
什么是 DBSCAN?
DBSCAN(基于密度的空间聚类算法,带噪声)是一种基于密度的无监督学习算法。它计算最近邻图以找到任意形状的簇和离群点。而 K-means 聚类生成的是球形簇。
DBSCAN 最初不需要K个簇。相反,它需要两个参数:eps 和 minPts。
-
eps:这是特定邻域的半径。如果两个点之间的距离小于或等于 eps,它们将被视为邻居。
-
minPts:在给定邻域中形成簇所需的最小数据点数量。
DBSCAN 使用这两个参数来定义核心点、边界点或离群点。
图片来自 维基百科
DBSCAN 聚类算法是如何工作的?
-
随机选择任何点p。如果在邻域中有比minPts更多的数据点,它也被称为核心点。
-
它将使用eps和minPts来识别所有密度可达点。
-
如果p是核心点,它将使用eps和minPts来创建一个簇。
-
如果p是边界点,它将移动到下一个数据点。一个数据点被称为边界点,如果在邻域中有的点少于minPts。
-
算法将继续进行,直到所有点都被访问。
Python 中的 DBSCAN 聚类
我们将使用 Deepnote 笔记本来运行示例。它附带了预装的 Python 包,因此我们只需导入 NumPy、pandas、seaborn、matplotlib 和 sklearn。
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
我们使用的是来自 Kaggle 的 Mall Customer Segmentation Data。它包含客户的年龄、性别、收入和消费评分。我们将使用这些特征来创建各种簇。
首先,我们将使用 pandas read_csv 加载数据集。然后,我们将选择三列(‘Age','Annual Income (k$)','Spending Score (1-100)')来创建X_train数据框。
df = pd.read_csv('Mall_Customers.csv')
X_train = df[['Age', 'Annual Income (k$)', 'Spending Score (1-100)']]
我们将使用eps 12.5 和min_sample 4 来拟合X_train 到 DBSCAN 算法中。之后,我们将从X_train 创建一个DBSCAN_dataset,并使用clustering.labels_ 创建一个‘Cluster’列。
clustering = DBSCAN(eps=12.5, min_samples=4).fit(X_train)
DBSCAN_dataset = X_train.copy()
DBSCAN_dataset.loc[:,'Cluster'] = clustering.labels_
为了可视化簇的分布,我们将使用 value_counts() 并将其转换为数据框。
如你所见,我们有 5 个簇和 1 个离群点。0 簇的大小最大,共有 112 行。
DBSCAN_dataset.Cluster.value_counts().to_frame()
在本节中,我们将使用上述信息并可视化散点图。
有两个图: “年收入与消费评分” 和 “年收入与年龄”。簇通过颜色定义,离群点被定义为小黑点。
可视化清楚地显示了每个客户如何属于 5 个簇中的一个,我们可以利用这些信息向紫色簇的客户提供高端优惠,而向深绿色簇的客户提供便宜的优惠。
outliers = DBSCAN_dataset[DBSCAN_dataset['Cluster']==-1]
fig2, (axes) = plt.subplots(1,2,figsize=(12,5))
sns.scatterplot('Annual Income (k$)', 'Spending Score (1-100)',
data=DBSCAN_dataset[DBSCAN_dataset['Cluster']!=-1],
hue='Cluster', ax=axes[0], palette='Set2', legend='full', s=200)
sns.scatterplot('Age', 'Spending Score (1-100)',
data=DBSCAN_dataset[DBSCAN_dataset['Cluster']!=-1],
hue='Cluster', palette='Set2', ax=axes[1], legend='full', s=200)
axes[0].scatter(outliers['Annual Income (k$)'], outliers['Spending Score (1-100)'], s=10, label='outliers', c="k")
axes[1].scatter(outliers['Age'], outliers['Spending Score (1-100)'], s=10, label='outliers', c="k")
axes[0].legend()
axes[1].legend()
plt.setp(axes[0].get_legend().get_texts(), fontsize='12')
plt.setp(axes[1].get_legend().get_texts(), fontsize='12')
plt.show()
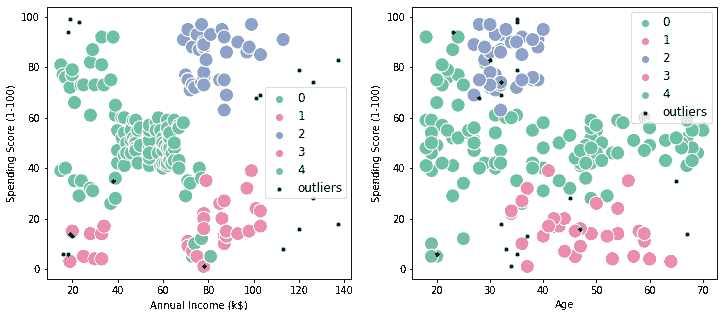
结论
DBSCAN 是用于客户细分的众多算法之一。你可以使用 K-means 或层次聚类来获得更好的结果。这些聚类算法通常用于推荐引擎、市场和客户细分、社交网络分析和文档分析。
在本博客中,我们了解了基于密度的算法 DBSCAN 的基础知识,以及如何使用它通过 scikit-learn 创建客户细分。你可以通过使用silhouette score和热图来寻找最佳的eps和min_samples,从而改进算法。
参考资料
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,帮助那些与心理疾病作斗争的学生。
了解更多主题
从零开始用 Python 实现深度学习库
原文:
www.kdnuggets.com/2020/09/implementing-deep-learning-library-scratch-python.html
评论
由 Parmeet Bhatia,机器学习从业者和深度学习爱好者
深度学习在短时间内从简单的神经网络演变为相当复杂的架构。为了支持这一快速扩展,沿途开发了许多不同的深度学习平台和库。这些库的主要目标之一是提供易于使用的接口来构建和训练深度学习模型,以便用户可以更多地专注于手头的任务。为实现这一目标,可能需要在几个抽象层后隐藏核心实现单元,这使得理解深度学习库所基于的基本原理变得困难。因此,本文的目标是提供对深度学习库构建块的见解。我们首先回顾一下深度学习的背景,以了解功能需求,然后使用 NumPy 在 Python 中实现一个简单而完整的库,该库能够对神经网络模型(非常简单的类型)进行端到端的训练。在这个过程中,我们将学习深度学习框架的各种组件。该库代码不到 100 行,因此应该相对容易跟随。完整的源代码可以在 github.com/parmeet/dll_numpy 找到。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
背景
通常,一个深度学习计算库(如 TensorFlow 和 PyTorch)由下图所示的组件组成。
深度学习框架的组件
操作符
也常与层互换使用,它们是任何神经网络的基本构建块。操作符是将数据转换的向量值函数。一些常用的操作符包括线性层、卷积层、池化层和 ReLU、Sigmoid 等激活函数。
优化器
它们是任何深度学习库的基础。它们提供了使用梯度来更新模型参数的必要配方,以实现优化目标。一些著名的优化器有 SGD、RMSProp 和 Adam。
损失函数
它们是闭式和可微分的数学表达式,用作当前问题优化目标的代理。例如,交叉熵损失和铰链损失是分类任务中常用的损失函数。
初始化器
它们提供了模型参数在训练开始时的初始值。初始化在训练深度神经网络中起着重要作用,因为不良的参数初始化可能导致收敛缓慢或无法收敛。有很多方法可以初始化网络权重,例如,从正态分布中抽取的小随机权重。你可以查看keras.io/initializers/以获取全面的列表。
正则化器
它们提供了必要的控制机制,以避免过拟合并促进泛化。可以通过显式或隐式措施来调节过拟合。显式方法对权重施加结构性约束,例如,通过最小化其 L1-范数和 L2-范数,使权重变得更稀疏或更均匀。隐式措施则是专门的操作符,通过显式归一化(例如,BatchNorm)或通过改变网络连接性(例如,DropOut 和 DropConnect)来对中间表示进行变换。
上述组件基本上属于库的前端部分。前端指的是那些暴露给用户的组件,使他们能够高效地设计神经网络架构。在后端,这些库提供了自动计算模型中各种参数的损失函数梯度的支持。这种技术通常被称为自动微分(AD)。
自动微分(AD)
每个深度学习库都提供了一种 AD 的实现,使用户可以专注于定义模型结构(计算图),并将梯度计算的任务委托给 AD 模块。让我们通过一个例子来看它是如何工作的。假设我们要计算以下函数相对于输入变量X₁和X₂的偏导数:
***Y =* sin(*x₁*)*+X₁*X₂***
以下图表来自en.wikipedia.org/wiki/Automatic_differentiation,展示了计算图及通过链式法则计算导数的过程。
计算图和通过链式法则计算导数
上图展示了反向模式自动微分(AD)的一个示例。众所周知的反向传播算法是上述算法的一个特殊情况,其中顶部的函数是损失函数。AD 利用了每个复合函数由基本算术操作和基本函数组成的事实,因此可以通过递归应用链式法则来计算这些操作的导数。
实现
在前一节中,我们已经介绍了所有必要的组件,以构建第一个可以进行端到端训练的深度学习库。为了简单起见,我将模仿Caffe库的设计模式。在这里我们定义了两个抽象类:“Function”类和“Optimizer”类。此外,还有一个“Tensor”类,它是一个简单的结构,包含两个 NumPy 多维数组,一个用于保存参数的值,另一个用于保存它们的梯度。各种层/运算符中的所有参数将是“Tensor”类型。在我们深入之前,以下图提供了库的高层次概述。
图书馆的 UML 图
在撰写本文时,该库包含线性层、ReLU 激活函数和 SoftMaxLoss 层的实现,以及 SGD 优化器。因此,该库可以用于训练包含全连接层和 ReLU 非线性的分类模型。现在让我们来看看我们拥有的两个抽象类的细节。
“Function”抽象类提供了运算符的接口,其定义如下:
抽象 Function 类
所有的运算符都是通过继承“Function”抽象类来实现的。每个运算符必须提供forward(…)和backward(…)方法的实现,并可选地实现getParams函数以提供对其参数(如果有的话)的访问。forward(…)方法接收输入并返回运算符的变换结果。它还会进行必要的维护,以计算梯度。backward(…)方法接收损失函数相对于运算符输出的偏导数,并实现损失函数相对于运算符输入和参数(如果有的话)的偏导数。请注意,backward(…)函数本质上为我们的库提供了执行自动微分的能力。
为了使事情具体化,让我们看看下面代码片段中线性函数的实现:
线性函数的实现
forward(…)函数实现了形式为Y = X*W+b的转换并返回它。它还存储输入 X,因为在反向函数中计算W的梯度时需要它。backward(…)函数接收损失相对于输出Y的偏导数dY,并实现相对于输入X以及参数W和b的偏导数。此外,它返回相对于输入X的偏导数,这些偏导数将传递给前一层。
抽象的“Optimizer”类提供了优化器的接口,定义如下:
抽象优化器类
所有优化器都是通过继承“Optimizer”基类实现的。具体的优化类必须提供step()函数的实现。该方法使用相对于我们正在优化的损失的偏导数来更新模型参数。各种模型参数的引用在init(…)函数中提供。注意,重置梯度的公共功能是在基类中实现的。
为了使事情具体化,我们来看看具有动量和权重衰减的随机梯度下降(SGD)的实现。
进入实质内容
为此,我们拥有了使用我们的库训练(深度)神经网络模型的所有组成部分。为此,我们需要以下内容:
-
模型: 这是我们的计算图
-
数据和目标: 这是我们的训练数据
-
损失函数: 这是我们优化目标的替代指标
-
优化器: 更新模型参数
以下伪代码描绘了一个典型的训练周期:
**model** *#computation graph*
**data,target** #*training data*
**loss_fn** *#optimization objective*
**optim** *#optimizer to update model parameters to minimize loss***Repeat:**#until convergence or for predefined number of epochs
**optim.zeroGrad()** *#set all gradients to zero*
**output = model.forward(data)** *#get output from model*
**loss = loss_fn(output,target)** *#calculate loss*
**grad = loss.backward()** *#calculate gradient of loss w.r.t output*
**model.backward(grad)** *#calculate gradients for all the parameters*
**optim.step()** *#update model parameters*
虽然这不是深度学习库的必要组成部分,但将上述功能封装在一个类中可能是个好主意,这样我们在训练新模型时就无需重复这些步骤(这与像Keras这样的高层抽象框架的理念是一致的)。为此,我们可以定义一个“Model”类,如以下代码片段所示:
这个类提供了以下功能:
-
计算图: 通过add(…)函数,可以定义一个顺序模型。在内部,该类将所有操作符存储在名为computation_graph的列表中。
-
参数初始化: 该类将在训练开始时自动用从均匀分布中抽取的小随机值初始化模型参数。
-
模型训练: 通过fit(…)函数,该类提供了一个通用接口来训练模型。此函数需要训练数据、优化器和损失函数。
-
模型推断: 通过predict(…)函数,该类提供了一个通用接口来使用训练好的模型进行预测。
由于这个类不作为深度学习的基本构建块,我将其实现放在了一个名为 utilities.py 的单独模块中。请注意,fit(…)函数利用了DataGenerator类,该类的实现也提供在 utilities.py 模块中。这个类只是我们训练数据的一个包装器,为每次训练迭代生成小批量数据。
训练我们的第一个模型
现在让我们来看一下使用所提出的库训练神经网络模型的最终代码。受到Andrej Karapathy的博客文章的启发,我将对螺旋数据训练一个隐藏层神经网络模型。生成数据和可视化的代码可在 utilities.py 文件中找到。
三类螺旋数据
上图展示了三类螺旋数据。数据是非线性可分的。因此,我们希望我们的一个隐藏层神经网络能够学习非线性决策边界。将所有内容汇总,以下代码片段将训练我们的模型。
用于训练神经网络模型的端到端代码
下图展示了相同的螺旋数据及其训练模型的决策边界。
训练模型的螺旋数据及其对应的决策边界
总结性 remarks
随着深度学习模型复杂性的不断增加,这些库的功能和底层实现也以指数级增长。尽管如此,核心功能仍可以用相对少量的代码行实现。虽然该库可以用来训练端到端的神经网络模型(简单类型),但它仍然在许多方面受到限制,这使得深度学习框架可以用于包括(但不限于)视觉、语音和文本等各种领域。尽管如此,我认为这也是一个分支基本实现并添加缺失功能以获得实际操作经验的机会。你可以尝试实现的一些功能包括:
-
运算符:卷积 池化等。
-
优化器:Adam RMSProp 等。
-
正则化器:BatchNorm DropOut 等。
我希望这篇文章能让你了解在使用任何深度学习库训练模型时,背后发生了什么。感谢你的关注,期待你在评论区提出意见或问题。
简历:Parmeet Bhatia 是一位机器学习从业者和深度学习爱好者。他是一位经验丰富的机器学习工程师和研发专业人士,拥有开发和产品化 ML 及数据驱动产品的丰富经验。他对大规模构建端到端智能系统充满热情。
原文。经允许转载。
相关:
-
Autograd:你没在用的最佳机器学习库?
-
你不知道的 10 个关于 Scikit-Learn 的事
-
信号处理中的深度学习:你需要知道的
更多相关内容
实现深度学习方法和文本数据的特征工程:FastText
评论
编辑注释: 这篇文章只是一个更全面、深入的原文的一部分,原文链接,涵盖了比这里更多的内容。
FastText 模型
FastText模型首次由 Facebook 在 2016 年介绍,作为对普通 Word2Vec 模型的扩展和改进。基于原始论文‘Enriching Word Vectors with Subword Information’ by Mikolov et al.,这是深入了解该模型如何工作的绝佳读物。总体来说,FastText 是一个学习词表示以及进行稳健、快速、准确的文本分类的框架。该框架由Facebook在GitHub上开源,并声称具备以下功能。
尽管我还未从头实现该模型,但根据研究论文,以下是我对模型工作的理解。一般来说,像 Word2Vec 这样的预测模型通常将每个词视为一个独立的实体(例如,where)并为该词生成一个密集的嵌入。然而,这对于具有大量词汇和许多稀有词的语言来说是一个严重的限制,这些稀有词在不同语料中可能不会出现很多。Word2Vec 模型通常忽略每个词的形态结构,将词视为一个单一的实体。FastText 模型将每个词视为一个字符 n-gram 的袋子。 这在论文中也称为子词模型。
我们在单词的开头和结尾添加特殊的边界符号 < 和 >。这使我们能够区分前缀和后缀与其他字符序列。我们还将单词 w 本身包含在其 n-gram 集中,以学习每个单词的表示(除了它的字符 n-gram)。以单词 where 和 n=3(三元组)为例,它将由字符 n-gram 表示:<wh, whe, her, ere, re> 以及表示整个单词的特殊序列
实际上,论文建议提取所有的 n-gram,n ≥ 3 和 n ≤ 6。这是一种非常简单的方法,可以考虑不同的 n-gram 集,例如提取所有前缀和后缀。我们通常将每个 n-gram 关联一个向量表示(嵌入)。因此,我们可以通过 n-gram 向量表示的总和或这些 n-gram 嵌入的平均值来表示一个单词。因此,由于这种基于字符的 n-gram 的作用,稀有单词获得良好表示的机会更高,因为它们的基于字符的 n-gram 应该会出现在语料库中的其他单词中。
应用 FastText 特性于机器学习任务
gensim 包提供了很好的封装,给我们提供了接口来利用在 gensim.models.fasttext 模块下可用的 FastText 模型。让我们再次在我们的圣经语料库上应用这个,并查看我们感兴趣的单词及其最相似的单词。

你可以看到,与我们的 Word2Vec 模型相比,结果中存在许多相似之处,每个感兴趣的单词都有相关的相似单词。你注意到有什么有趣的关联和相似之处吗?

摩西、他的兄弟亚伦和摩西的帐幕
注意: 运行这个模型计算开销大,通常比 skip-gram 模型花费更多时间,因为它考虑了每个单词的 n-gram。如果使用 GPU 或较好的 CPU 进行训练效果更好。我在 AWS
***p2.x***实例上进行了训练,花了大约 10 分钟,而在普通系统上则需要超过 2 到 3 小时。
现在让我们使用主成分分析 (PCA)来将单词嵌入维度降至 2D,然后可视化。
在我们的圣经语料库中可视化 FastText 单词嵌入
我们可以看到很多有趣的模式!诺亚、他的儿子Shem和祖父Methuselah彼此接近。我们还看到上帝与Moses和埃及相关,那里经历了包括饥荒和瘟疫在内的圣经灾难。此外,耶稣和一些他的门徒也彼此接近。
要访问任何词嵌入,你可以按如下方式用词索引模型。
ft_model.wv['jesus']
array([-0.23493268, 0.14237943, 0.35635167, 0.34680951,
0.09342121,..., -0.15021783, -0.08518736, -0.28278247,
-0.19060139], dtype=float32)
拥有这些嵌入,我们可以执行一些有趣的自然语言任务。其中之一是找出不同词(实体)之间的相似性。
print(ft_model.wv.similarity(w1='god', w2='satan'))
print(ft_model.wv.similarity(w1='god', w2='jesus'))
Output
------
0.333260876685
0.698824900473
我们可以看到‘god’与‘jesus’的关联比与‘satan’的关联更为紧密,基于我们《圣经》语料库中的文本。相当相关!
考虑到词嵌入的存在,我们甚至可以从一堆词中找出奇异词。
st1 = "god jesus satan john"
print('Odd one out for [',st1, ']:',
ft_model.wv.doesnt_match(st1.split()))
st2 = "john peter james judas"
print('Odd one out for [',st2, ']:',
ft_model.wv.doesnt_match(st2.split()))
Output
------
Odd one out for [ god jesus satan john ]: satan
Odd one out for [ john peter james judas ]: judas
在这两种情况下,奇异实体与其他词汇之间都有有趣且相关的结果!
结论
这些示例应该能让你对利用深度学习语言模型提取文本数据特征以及解决诸如词汇语义、上下文和数据稀疏性等问题的新颖高效策略有一个很好的了解。接下来将详细介绍利用深度学习模型进行图像数据特征工程的策略,敬请期待!
要了解连续数值数据的特征工程策略,请查看本系列的 第一部分!
要了解离散分类数据的特征工程策略,请查看本系列的 第二部分!
要了解非结构化文本数据的传统特征工程策略,请查看本系列的 第三部分!
本文使用的所有代码和数据集可以从我的 GitHub 访问。
代码也可以作为 Jupyter notebook 获取。
除非明确注明,否则架构图属于我的版权。请随意使用,但如果你想在自己的工作中使用它们,请记得注明来源。
如果你对我的文章或数据科学有任何反馈、评论或有趣的见解,欢迎通过我的 LinkedIn 社交媒体渠道联系我。
个人简介: Dipanjan Sarkar 是英特尔的数据科学家、作者、Springboard 的导师、作家以及体育和情景喜剧迷。
原文。经授权转载。
相关内容:
-
文本数据预处理:Python 实践指南
-
预处理文本数据的一般方法
-
处理文本数据科学任务的框架
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 部门
更多相关话题
实现深度学习方法和文本数据特征工程:GloVe 模型
评论
编辑注: 本文仅为更为全面深入原文的一部分,原文在此提供,涵盖了远超本文的内容。
GloVe 模型
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
GloVe 模型代表全球向量,是一种无监督学习模型,可以用来获取类似于 Word2Vec 的稠密词向量。然而,技术上有所不同,训练是在聚合的全球词词共现矩阵上进行的,为我们提供了具有有意义子结构的向量空间。这种方法由 Pennington 等人在斯坦福大学发明,我推荐你阅读原始论文《GloVe: Global Vectors for Word Representation》由 Pennington 等人撰写,这是一篇出色的文章,可以帮助你了解这个模型的工作原理。
我们不会在这里过多详细讲解模型的从零实现,但如果你对实际代码感兴趣,可以查看官方 GloVe 页面。我们在这里保持简单,尝试理解 GloVe 模型背后的基本概念。我们已经讨论过基于计数的矩阵分解方法,如 LSA,以及预测方法,如 Word2Vec。论文声称,目前这两类方法都存在显著缺陷。像 LSA 这样的算法有效地利用了统计信息,但在诸如词语类比任务(比如发现语义相似的词汇)上表现较差。像 skip-gram 这样的方法在类比任务上可能表现更好,但在全局层面上对语料库的统计信息利用不充分。
GloVe 模型的基本方法是首先创建一个巨大的词语-上下文共现矩阵,该矩阵包含(词语,上下文)对,每个元素表示一个词语与上下文(可以是一系列词语)共现的频率。然后,应用矩阵因式分解来近似这个矩阵,如下图所示。
GloVe 模型实现的概念模型
考虑到词语-上下文 (WC) 矩阵、词语-特征 (WF) 矩阵和特征-上下文 (FC) 矩阵,我们尝试因式分解**WC = WF x FC**,以便通过将 WF 和 FC 相乘来重建 WC。为此,我们通常将 WF 和 FC 初始化为一些随机权重,并尝试将它们相乘以得到 WC’(WC 的近似值),并测量其与 WC 的接近程度。我们使用随机梯度下降 (SGD) 多次进行此操作,以最小化误差。最终,词语-特征矩阵 (WF) 为每个词语提供了词语嵌入,其中 F 可以设置为特定的维度。一个非常重要的点是,Word2Vec 和 GloVe 模型在工作方式上非常相似。它们都旨在构建一个向量空间,其中每个词语的位置受到其邻近词语的上下文和语义的影响。Word2Vec 从词语共现对的局部个体示例开始,而 GloVe 从语料库中所有词语的全局聚合共现统计数据开始。
将 GloVe 特征应用于机器学习任务
让我们尝试利用基于 GloVe 的嵌入进行文档聚类任务。非常流行的[**spacy**](https://spacy.io/) 框架具有利用不同语言模型的 GloVe 嵌入的功能。你还可以 获取预训练词向量 并根据需要使用 gensim 或 spacy 加载它们。我们将首先安装 spacy 并使用 en_vectors_web_lg 模型,该模型包含 300 维的词向量,基于 GloVe 在 Common Crawl 上训练。
# Use the following command to install spaCy
> pip install -U spacy
OR
> conda install -c conda-forge spacy
# Download the following language model and store it in disk
https://github.com/explosion/spacy-models/releases/tag/en_vectors_web_lg-2.0.0
# Link the same to spacy
> python -m spacy link ./spacymodels/en_vectors_web_lg-2.0.0/en_vectors_web_lg en_vecs
Linking successful
./spacymodels/en_vectors_web_lg-2.0.0/en_vectors_web_lg --> ./Anaconda3/lib/site-packages/spacy/data/en_vecs
You can now load the model via spacy.load('en_vecs')
在 spacy 中也有自动安装模型的方法,如果需要更多信息,你可以查看他们的 Models & Languages page。我遇到了一些问题,因此必须手动加载模型。现在我们将使用 spacy 加载我们的语言模型。
Total word vectors: 1070971
这验证了所有内容正常工作。现在让我们获取玩具语料库中每个词的 GloVe 嵌入。
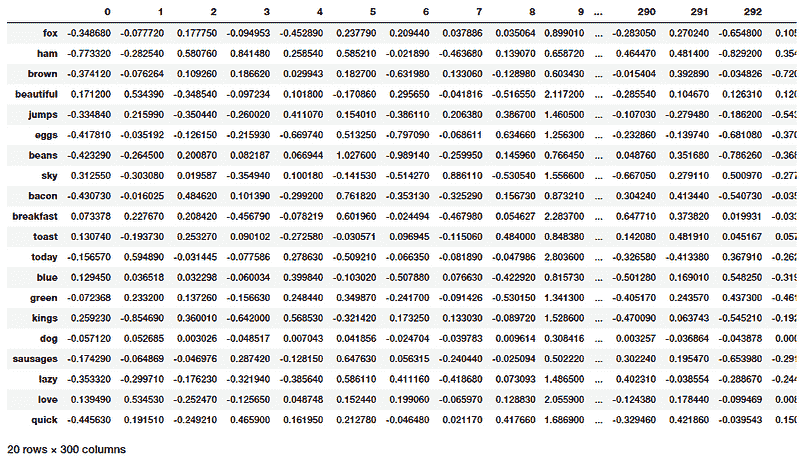
我们玩具语料库中词语的 GloVe 嵌入
现在我们可以使用 t-SNE 来可视化这些嵌入,类似于我们使用 Word2Vec 嵌入时所做的那样。
在我们的玩具语料库上可视化 GloVe 词嵌入
spacy 的美妙之处在于,它会自动为每个文档中的词提供平均嵌入,而无需像我们在 Word2Vec 中实现的那样编写函数。我们将利用这一点来获取我们语料库的文档特征,并使用k-means 聚类来对文档进行分类。

基于我们文档特征的 GloVe 分配的簇
我们观察到一致的簇,类似于我们从 Word2Vec 模型中获得的结果,这很好!GloVe 模型声称在许多场景下性能优于 Word2Vec 模型,如下图所示,来自Pennington 等人的原始论文。
GloVe 与 Word2Vec 性能比较(来源:nlp.stanford.edu/pubs/glove.pdf由 Pennington 等人提供)
上述实验是在相同的 6B 令牌语料库(维基百科 2014 + Gigaword 5)上训练 300 维向量,使用相同的 400,000 词汇表和对称的 10 大小上下文窗口完成的,如果有人对细节感兴趣的话。
个人简介:Dipanjan Sarkar 是一位 @Intel 的数据科学家、作者、@Springboard 的导师、作家以及体育和情景喜剧迷。
原始。已获转载许可。
相关:
-
文本数据预处理:Python 中的逐步指南
-
文本数据预处理的通用方法
-
接近文本数据科学任务的框架
更多相关主题
实现深度学习方法和文本数据的特征工程:跳词模型
评论
编辑注释: 本文只是一个更全面和深入的原始内容的一部分,可以在这里找到,涵盖了比这里包含的内容更多的内容。
跳词模型
跳词模型的架构通常试图实现与 CBOW 模型相反的目标。它试图根据目标词(中心词)预测源上下文词(周围词)。考虑到我们之前的简单句子,“the quick brown fox jumps over the lazy dog”。 如果我们使用 CBOW 模型,我们会得到(context_window, target_word)的配对,例如考虑上下文窗口大小为 2 时,我们会得到类似于([quick, fox], brown), ([the, brown], quick), ([the, dog], lazy)的例子。现在考虑到跳词模型的目标是根据目标词预测上下文,模型通常会反转上下文和目标,并试图从目标词预测每个上下文词。因此,任务变成了预测上下文[quick, fox]给定目标词‘brown’,或[the, brown]给定目标词‘quick’,等等。因此,该模型试图根据目标词预测上下文窗口中的词汇。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织在 IT 领域
跳词模型架构(来源:arxiv.org/pdf/1301.3781.pdf Mikolov 等)
就像我们在 CBOW 模型中讨论的那样,我们现在需要将这个 Skip-gram 架构建模为一个深度学习分类模型,以便我们以 目标词作为输入 并尝试 预测上下文词。这变得稍微复杂,因为我们的上下文中有多个词。我们通过将每个 (目标, 上下文 _ 词) 对 拆分为 (目标, 上下文) 对 来进一步简化这一点,其中每个上下文仅包含一个词。因此,我们之前的数据集被转换为像 (brown, quick), (brown, fox), (quick, the), (quick, brown) 等对。但如何监督或训练模型以了解哪些是上下文相关的,哪些是不相关的呢?
为此,我们将 (X, Y) 对馈入 skip-gram 模型,其中 X 是我们的 输入,Y 是我们的 标签。我们通过使用 [(目标, 上下文), 1] 对作为 正输入样本,其中 目标 是我们感兴趣的词,上下文 是出现在目标词附近的上下文词,而 正标签 1 表示这是一个在上下文中相关的对。我们还将 [(目标, 随机), 0] 对作为 负输入样本,其中 目标 仍然是我们感兴趣的词,但 随机 只是从词汇表中随机选择的一个词,与目标词没有上下文或关联。因此,负标签 0 表示这是一个在上下文中不相关的对。我们这样做是为了让模型学习哪些词对在上下文中是相关的,哪些是不相关的,并为语义相似的词生成相似的嵌入。
实现 Skip-gram 模型
现在让我们尝试从头开始实现这个模型,以了解幕后工作原理,并与我们的 CBOW 模型实现进行比较。我们将像往常一样利用我们的圣经语料库,该语料库包含在 **norm_bible** 变量中用于训练我们的模型。实现将集中于五个部分
-
构建语料库词汇表
-
构建一个 skip-gram [(目标, 上下文), 相关性] 生成器
-
构建 skip-gram 模型架构
-
训练模型
-
获取词嵌入
让我们开始动手构建我们的 skip-gram Word2Vec 模型吧!
构建语料库词汇表
首先,我们将遵循构建语料库词汇表的标准流程,从中提取每个独特的词,并分配一个唯一的标识符,类似于我们在 CBOW 模型中所做的。我们还维护映射关系,以便将词转换为其唯一标识符,反之亦然。
Vocabulary Size: 12425
Vocabulary Sample: [('perceived', 1460), ('flagon', 7287), ('gardener', 11641), ('named', 973), ('remain', 732), ('sticketh', 10622), ('abstinence', 11848), ('rufus', 8190), ('adversary', 2018), ('jehoiachin', 3189)]
正如我们所期望的,语料库中的每个独特词汇现在都是我们词汇表的一部分,并且拥有一个唯一的数字标识符。
构建一个 skip-gram [(目标, 上下文), 相关性] 生成器
现在是时候构建我们的 skip-gram 生成器,它将像我们之前讨论的那样给出词对及其相关性。幸运的是,keras提供了一个方便的skipgrams工具,我们不需要像在 CBOW 中那样手动实现这个生成器。
注意: 函数
[**skipgrams(…)**](https://keras.io/preprocessing/sequence/#skipgrams)存在于[**keras.preprocessing.sequence**](https://keras.io/preprocessing/sequence)这个函数将词索引的序列(整数列表)转换为如下形式的词对:
(词,同一窗口中的词),标签为 1(正样本)。
(词,词汇中的随机词),标签为 0(负样本)。
(james (1154), king (13)) -> 1
(king (13), james (1154)) -> 1
(james (1154), perform (1249)) -> 0
(bible (5766), dismissed (6274)) -> 0
(king (13), alter (5275)) -> 0
(james (1154), bible (5766)) -> 1
(king (13), bible (5766)) -> 1
(bible (5766), king (13)) -> 1
(king (13), compassion (1279)) -> 0
(james (1154), foreskins (4844)) -> 0
因此,你可以看到我们已经成功生成了所需的 skip-grams,并且基于前面输出的样本 skip-grams,你可以清楚地看到基于标签(0 或 1)哪些是相关的,哪些是无关的。
构建 skip-gram 模型架构
我们现在在tensorflow之上利用keras构建 skip-gram 模型的深度学习架构。为此,我们的输入将是目标词和上下文或随机词对。每个输入都会传递到一个自己的嵌入层(初始化时权重随机)。一旦我们获得目标词和上下文词的词嵌入,我们将其传递到一个合并层,在那里计算这两个向量的点积。然后,我们将这个点积值传递到一个密集的 sigmoid 层,该层根据词对的上下文相关性预测 1 或 0(Y’)。我们将其与实际相关性标签(Y)进行匹配,通过利用mean_squared_error损失计算损失,并在每个周期中执行反向传播,以更新嵌入层。以下代码展示了我们的模型架构。
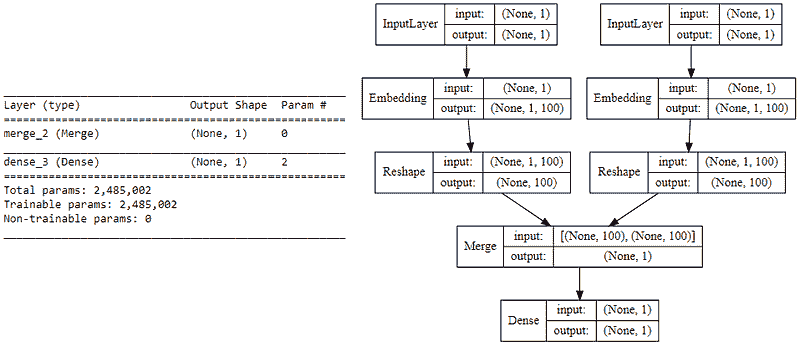
Skip-gram 模型总结和架构
理解上述深度学习模型相当简单。然而,我将尝试用简单的术语总结该模型的核心概念,以便于理解。对于每个训练示例,我们有一对输入词,其中包含一个输入目标词,具有唯一的数字标识符,以及一个上下文词,也具有唯一的数字标识符。如果它是正样本,则该词具有上下文意义,是上下文词,我们的标签 Y=1;如果是负样本,则该词没有上下文意义,仅是随机词,我们的标签 Y=0。我们将每个词传递到各自的嵌入层,其大小为**(vocab_size x embed_size)**,这将为这两个词提供密集词嵌入,**(每个词 1 x embed_size)**。接下来,我们使用合并层来计算这两个嵌入的点积并获得点积值。然后将其发送到密集 sigmoid 层,输出 1 或 0。我们将其与实际标签 Y(1 或 0)进行比较,计算损失,反向传播误差以调整权重(在嵌入层中),并对所有(目标词, 上下文词)对重复此过程多次。下图尝试解释相同内容。
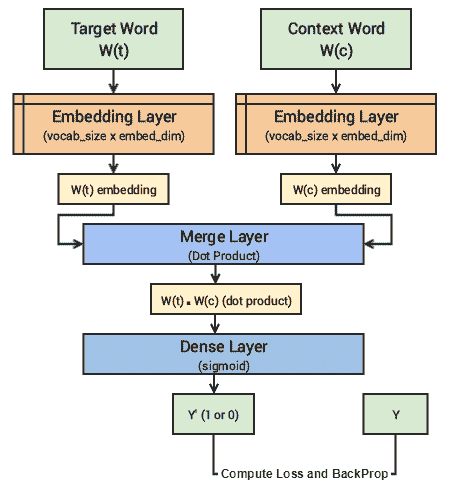
Skip-gram 深度学习模型的视觉表示
现在让我们开始训练我们的 Skip-gram 模型。
训练模型
在完整语料库上运行模型需要相当多的时间,但比 CBOW 模型少。因此,我只运行了 5 个周期。你可以利用以下代码并根据需要增加更多周期。
Epoch: 1 Loss: 4529.63803683
Epoch: 2 Loss: 3750.71884749
Epoch: 3 Loss: 3752.47489296
Epoch: 4 Loss: 3793.9177565
Epoch: 5 Loss: 3716.07605051
一旦训练完成,这个模型中相似的词应该会基于嵌入层具有相似的权重,我们可以进行测试。
获取词嵌入
要获取我们整个词汇表的词嵌入,我们可以通过以下代码从嵌入层中提取相同的内容。请注意,我们仅对目标词嵌入层感兴趣,因此我们将从**word_model**嵌入层中提取嵌入。我们不取位置 0 的嵌入,因为我们词汇中的词没有数字标识符 0,我们将其忽略。
基于 Skip-gram 模型的词汇表词嵌入
因此,你可以清楚地看到每个词都有一个大小为**(1x100)**的密集嵌入,如之前的输出所示,与我们从 CBOW 模型获得的相似。现在,让我们对这些密集嵌入向量应用欧氏距离度量,以生成词汇中每个词的成对距离度量。然后,我们可以根据最短的(欧氏)距离找出每个感兴趣的词的 n 个最近邻,类似于我们在 CBOW 模型的嵌入上所做的。
(12424, 12424)
{'egypt': ['pharaoh', 'mighty', 'houses', 'kept', 'possess'],
'famine': ['rivers', 'foot', 'pestilence', 'wash', 'sabbaths'],
'god': ['evil', 'iniquity', 'none', 'mighty', 'mercy'],
'gospel': ['grace', 'shame', 'believed', 'verily', 'everlasting'],
'jesus': ['christ', 'faith', 'disciples', 'dead', 'say'],
'john': ['ghost', 'knew', 'peter', 'alone', 'master'],
'moses': ['commanded', 'offerings', 'kept', 'presence', 'lamb'],
'noah': ['flood', 'shem', 'peleg', 'abram', 'chose']}
从结果中可以清楚地看到,每个感兴趣的单词的许多相似单词是有意义的,并且我们相比于 CBOW 模型获得了更好的结果。现在让我们使用t-SNE来可视化这些单词嵌入,它代表了t-distributed stochastic neighbor embedding,这是一个流行的降维技术,用于将高维空间可视化到低维空间(例如 2-D)。
使用 t-SNE 可视化 skip-gram word2vec 单词嵌入
我在一些圆圈中标记了红色,这些圆圈似乎显示了在向量空间中彼此靠近的不同上下文相似单词。如果你发现任何其他有趣的模式,请随时告诉我!
个人简介: Dipanjan Sarkar 是 Intel 的数据科学家、作者、Springboard 的导师、作家以及体育和情景喜剧爱好者。
原文。经许可转载。
相关:
-
文本数据预处理:Python 实践指南
-
文本数据预处理的一般方法
-
处理文本数据科学任务的框架
更多相关话题
在边缘设备上实施 MLOps
原文:
www.kdnuggets.com/2020/08/implementing-mlops-edge-device.html
评论
作者:Felix Baum,高通技术公司
传统软件的生命周期可以说相当直接。最简单来说,你开发、测试和部署软件,然后根据需要发布带有新功能、更新和/或修复的新版本。为了便于此,传统软件开发通常依赖于DevOps,它涉及持续集成(CI)、持续交付(CD)和持续测试(CT),以减少开发时间,同时持续交付新版本并维护质量。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
在机器学习(ML)建模中,人们很容易认为 ML 工作流遵循类似的模式。毕竟,这应该只是创建和训练 ML 模型、部署它,并根据需要发布新版本的问题。但 ML 系统运行的环境使事情变得复杂。首先,由于数据驱动的、非确定性的行为,ML 系统本质上与传统软件不同。而且,正如近期全球事件所突显的那样,我们的世界在不断变化,因此 ML 从业者必须预见到生产模型所推断的真实数据也必然会发生变化。
因此,出现了一种特殊的 ML DevOps,称为MLOps(“机器学习与运维”的缩写),以帮助管理这种持续变化和随之而来的模型重新部署需求。MLOps 继承了 DevOps 的持续集成和持续交付,但将持续测试阶段替换为持续训练。这种新模型的持续训练,包括这些新模型的重新部署及其相关的所有技术工作,旨在解决 ML 项目的三个显著方面:
-
对于模型如何以及为什么做出某些预测的“可解释性”的需求。这对审计目的尤其重要,以满足法规和/或某些预测性能水平。
-
模型衰退,即由于模型遇到的新变化的真实世界数据导致生产模型的预测性能随时间下降。
-
模型的持续开发和改进是由业务需求驱动的。
持续训练,实际上,MLOps 一般都接受模型会不断且不可避免地变化的理念,这意味着组织在不同程度上实施 MLOps 策略和战术。
随着 MLOps 的发展,许多组织提出了最佳实践框架。一个突出的例子是 谷歌的 MLOps 指南,它描述了组织采用的三种 MLOps 实现级别:
-
MLOps 级别 0: 手动过程:模型训练和部署的需求被正式认可,但通常是手动执行的,往往通过脚本和交互过程以临时方式进行。这一层级通常缺乏持续集成和持续交付。
-
MLOps 级别 1: ML 流水线自动化:这一层级引入了一个持续训练的流水线。数据和模型验证是自动化的,并且设置了触发器,以便在模型性能下降时用新数据重新训练模型。
-
MLOps 级别 2: CI/CD 流水线自动化:ML 工作流程已经自动化到数据科学家可以在减少开发人员干预的情况下更新模型和流水线的程度。
实施了 MLOps 级别 2 或 MLOps 级别 3 的组织可能还会使用所谓的“影子模型”,这些模型与生产模型并行训练,每个模型使用不同的训练数据集。当需要新的生产模型时,可以快速选择和部署一个影子模型。
图 1 - 不同数据集上影子模型的并行训练的视觉描述。每个模型都是成为新生产模型的潜在候选者。
为了更好地理解这些不同级别的 MLOps 如何以及何时可以实施,考虑以下示例。
示例 1: 包装机器人
一个简单的例子是一个位于装配线末端的机器人,使用由 ML 驱动的计算机视觉来分析和包装产品。ML 模型可能已经被训练来识别有限范围内的方形和矩形箱子。然而,业务现在将引入新的形状和尺寸的包装,因此创建并部署了一个新的 ML 模型。在这种情况下,MLOps 级别 0 的开发团队将手动创建、训练和部署一个新模型,预防性地在新类型的包装开始在装配线上滚动之前。鉴于机器人的能力范围有限,这一层级的 MLOps 可能足够。
示例 2:语音识别
设想一个能够根据人们的说话方式感知或识别上下文(例如语调或情感)的移动应用。随着时间的推移,新短语和俚语出现,人们的说话风格也会发生变化。在这种情况下,机器学习模型可能会在较长时间内表现出模型衰退。
这是一个 MLOps 1 级指南可能有所帮助的示例。在 MLOps 1 级下,系统可以在设备上运行,监控模型的预测性能。如果性能接近或低于某个阈值,系统会触发警报,通知团队应使用新数据训练一个新模型,然后将其部署以替代生产模型。
示例 3:股票市场中的突发异常值
今年早些时候,石油价格进入了负值区域。如果一个机器学习模型是基于石油价格进行预测的,但只用正值价格进行训练,那么当它突然遇到负股票价格时会表现如何?在这种情况下,团队成员需要立即被警告,并且必须能够迅速训练和重新部署一个新的模型。
在这里,MLOps 2 级的实现可能会有所帮助。在这一层级,训练和部署新模型的流程大部分已被自动化,因此数据科学家应该能够处理大部分或所有的流程而无需开发人员的帮助。此外,自动化的程度应该使他们能够尽可能快速且可靠地更新、训练和部署新的模型。
为边缘设备实现 MLOps
许多现代高端边缘设备在 MLOps 方面表现优异。它们不仅能够托管大型模型,而且通常配备了专门优化推理运行的向量处理器。例如,Hexagon 数字信号处理器(DSP)就是 Qualcomm® Snapdragon™ 移动平台系列中的一员,它 为许多现代高端设备提供动力²。此外,这些处理器通常配备丰富的人工智能(AI)SDK 和工具集,开发人员可以利用这些工具优化和加载模型到设备上。正是这些 SDK 和工具可以集成到 MLOps 流程中,以便简化模型部署过程。
在机器学习工作流程的背景下,使用 SDK 的一般过程如下:
-
机器学习模型使用像 TensorFlow 这样的框架进行设计和训练。
-
Qualcomm Neural Processing SDK 中的转换工具用于将该模型转换为专有格式,优化以在 Snapdragon 上执行。
-
从 Qualcomm 神经处理 SDK 的 API 调用被添加到应用程序中,以将数据加载到 Qualcomm® Hexagon™ 处理器并进行推理。
-
一旦加载完成且应用程序运行,模型已被部署到边缘进行真实数据的推理。

图 2 - 在边缘设备上集成和执行 ML 模型的基本工作流。
在 MLOps 的背景下,上述的第 1、2 和 4 步骤会在产品生命周期内重复进行,因为需要进行模型更新。根据实施的 MLOps 级别,开发人员可能会构建额外的实体,如运行在边缘设备上的监控工具,以评估模型的预测性能。他们也可能构建某种警报和/或触发器,以启动 ML 工作流的新迭代。
深入了解 MLOps 管道
进一步来看,有许多工具和阶段需要集成到 MLOps 管道模型部署脚本中。以下展示了一个基于 Qualcomm 神经处理 SDK 的示例管道:
图 3 – 边缘设备 SDK 在 ML 工作流中的作用的更详细视图。
在工作流的上半部分,ML 模型在 ML 框架中进行训练。在工作流的下半部分,SDK 的工具被用来将模型转换为边缘设备的专有格式,并可选择地优化模型以适应边缘设备。在 MLOps 的背景下,这些工具要么是手动调用,要么是自动构建脚本的一部分。
开发人员还可以实施不同的方法将新模型重新加载到运行在边缘设备上的应用程序中。一个方法是在设备上运行服务,自动下载新模型并重新启动应用程序(甚至重新启动整个设备),但这可能会在重新启动过程中中断服务。另一种选择是应用程序本身在运行时监视新模型文件的存在,并重新调用必要的 API 来加载新模型。还有一种选择是使用推送方法,其中服务器发起的空中更新将新模型推送到设备。
根据应用程序的架构,每个选项可能会导致不同程度的停机,因为模型被部署并且应用程序切换到使用它。因此,开发人员需要权衡每种技术的实施复杂性与部署新模型所需的潜在停机时间。
结论
ML 系统本质上不同于传统软件,因为它们是非确定性的,并且在不断变化的数据世界中运行。但多亏了像 MLOps 这样的正式方法论,开发人员拥有了策划和实施稳健 ML 解决方案所需的工具。
随着机器学习在今天许多设备上的边缘计算中越来越重要,看到这些硬件与其 SDK 和工具结合能够支持有效的 MLOps 管道令人兴奋。
-
生产模型 指的是已经部署用于真实数据推断的机器学习模型。
-
www.statista.com/statistics/233415/global-market-share-of-applications-processor-suppliers/
简介:费利克斯·鲍姆 负责管理高通技术公司的数字信号处理器(DSP)软件产品,并在支持 Hexagon DSP 在连接、音频、语音、传感器融合、计算机视觉和机器学习应用中的作用中发挥了重要作用。
原文 已获授权转载。
相关:
-
驾驭 MLOps 中的复杂性
-
揭开 AI 基础设施堆栈的面纱
-
端到端机器学习平台巡礼
相关主题
实现你自己的 k-最近邻算法使用 Python
原文:https://www.kdnuggets.com/2016/01/implementing-your-own-knn-using-python.html
作者:Natasha Latysheva。
编辑注:Natasha 活跃于 剑桥编程学院,该学院将于 2016 年 2 月 20-21 日举办 Python 数据科学训练营,在这里你可以学习针对现实世界问题的最先进机器学习技术。
在机器学习中,你可能经常希望构建分类器,将事物分类到某些类别中,这些类别是基于一组相关值。例如,可以根据来自先前患者的数据为患者提供诊断。分类可能涉及在类别之间构造高度非线性的边界,如下图所示的红色、绿色和蓝色类别 下面:

许多算法已经被开发用于自动分类,常见的算法包括随机森林、支持向量机、朴素贝叶斯分类器和多种类型的神经网络。为了了解分类的工作原理,我们以一个简单的分类算法——k-最近邻(kNN)为例,并在 Python 2 中从头开始构建它。如果你刚刚开始学习 Python,可以使用主要的 命令式编程风格,而不是使用 lambda 函数 和 列表推导式 的声明式/函数式风格,以保持简单。在这里,我们将介绍后一种方法。kNN 通过将新的实例与最相似的案例分组来进行分类。在这里,你将使用 kNN 处理流行的(尽管是理想化的)鸢尾花数据集,该数据集包括三种鸢尾花的花卉测量数据。我们的任务是根据花卉测量数据预测花卉的物种标签。由于你将基于一组已知的正确分类来构建预测器,因此 kNN 是一种监督式机器学习(虽然有些令人困惑的是,在 kNN 中没有显式的训练阶段;请参见 懒惰学习)。kNN 任务可以分解为编写 3 个主要功能:
1. 计算任何两点之间的距离
2. 基于这些成对距离找到最近邻
3. 基于最近邻列表对类别标签进行多数投票
以下图中的步骤提供了你在代码中需要完成任务的高层次概述。

算法
简而言之,你将构建一个脚本,对于每个需要分类的输入,搜索整个训练集中的 k 个最相似的实例。然后,通过多数投票总结最相似实例的类别标签,并将其作为测试案例的预测结果返回。
完整的代码在文章的最后。现在,让我们分别查看不同部分并解释它们的功能。
加载数据并拆分为训练集和测试集。为了快速上手,你将使用一些辅助函数:虽然我们可以自己下载鸢尾花数据并使用csv.reader加载它,你也可以直接从 scikit-learn 快速获取鸢尾花数据。此外,你可以使用 train_test_split 函数进行 60/40 的训练/测试拆分,但你也可以自己随机分配行(请参见此类型的实现)。在机器学习中,训练/测试拆分用于减少过拟合——在完整数据集上训练模型往往会导致模型过拟合数据的噪声和特性,而不是实际的底层趋势。你只在训练集上进行任何类型的模型调整(例如,选择邻居的数量 k)——测试集作为一个独立的、未触及的数据集,用于测试最终模型的性能。
from sklearn.datasets import load_iris
from sklearn import cross_validation
import numpy as np
# load dataset and partition in training and testing sets
iris = load_iris()
X_train, X_test, y_train, y_test = cross_validation.train_test_split(iris.data, iris.target, test_size=0.4, random_state=1)
# reformat train/test datasets for convenience
train = np.array(zip(X_train,y_train))
test = np.array(zip(X_test, y_test))
这是鸢尾花数据集、数据拆分以及索引的简要指南。

更多相关内容
-
使用 ChatGPT 的 GPTs 创建你自己的 GPT
理想情况下,可以通过查看哪个值产生最准确的预测来优化k(参见 交叉验证)。
对kNN的一个很好的概述可以在 这里 阅读。一个更深入的实现,包括加权和搜索树,见 这里。
完整脚本
完整的脚本如下:
from sklearn.datasets import load_iris
from sklearn import cross_validation
from sklearn.metrics import classification_report, accuracy_score
from operator import itemgetter
import numpy as np
import math
from collections import Counter
# 1) given two data points, calculate the euclidean distance between them
def get_distance(data1, data2):
points = zip(data1, data2)
diffs_squared_distance = [pow(a - b, 2) for (a, b) in points]
return math.sqrt(sum(diffs_squared_distance))
# 2) given a training set and a test instance, use getDistance to calculate all pairwise distances
def get_neighbours(training_set, test_instance, k):
distances = [_get_tuple_distance(training_instance, test_instance) for training_instance in training_set]
# index 1 is the calculated distance between training_instance and test_instance
sorted_distances = sorted(distances, key=itemgetter(1))
# extract only training instances
sorted_training_instances = [tuple[0] for tuple in sorted_distances]
# select first k elements
return sorted_training_instances[:k]
def _get_tuple_distance(training_instance, test_instance):
return (training_instance, get_distance(test_instance, training_instance[0]))
# 3) given an array of nearest neighbours for a test case, tally up their classes to vote on test case class
def get_majority_vote(neighbours):
# index 1 is the class
classes = [neighbour[1] for neighbour in neighbours]
count = Counter(classes)
return count.most_common()[0][0]
# setting up main executable method
def main():
# load the data and create the training and test sets
# random_state = 1 is just a seed to permit reproducibility of the train/test split
iris = load_iris()
X_train, X_test, y_train, y_test = cross_validation.train_test_split(iris.data, iris.target, test_size=0.4, random_state=1)
# reformat train/test datasets for convenience
train = np.array(zip(X_train,y_train))
test = np.array(zip(X_test, y_test))
# generate predictions
predictions = []
# let's arbitrarily set k equal to 5, meaning that to predict the class of new instances,
k = 5
# for each instance in the test set, get nearest neighbours and majority vote on predicted class
for x in range(len(X_test)):
print 'Classifying test instance number ' + str(x) + ":",
neighbours = get_neighbours(training_set=train, test_instance=test[x][0], k=5)
majority_vote = get_majority_vote(neighbours)
predictions.append(majority_vote)
print 'Predicted label=' + str(majority_vote) + ', Actual label=' + str(test[x][1])
# summarize performance of the classification
print '\nThe overall accuracy of the model is: ' + str(accuracy_score(y_test, predictions)) + "\n"
report = classification_report(y_test, predictions, target_names = iris.target_names)
print 'A detailed classification report: \n\n' + report
if __name__ == "__main__":
main()
想了解更多?查看我们的两天数据科学训练营:
https://cambridgecoding.com/datascience-bootcamp
简介:Natasha Latysheva 是MRC分子生物学实验室的计算生物学博士生。她的研究集中于癌症基因组学、统计网络分析和蛋白质结构。更广泛地说,她的研究兴趣包括数据密集型分子生物学、机器学习(特别是深度学习)和数据科学。
原文。经允许转载。
相关:
我们的三大课程推荐
 1. Google 网络安全证书 - 快速入门网络安全职业。
1. Google 网络安全证书 - 快速入门网络安全职业。
 2. Google 数据分析专业证书 - 提升你的数据分析技能
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
更多相关话题
数据科学中数据清洗的重要性
原文:
www.kdnuggets.com/2023/08/importance-data-cleaning-data-science.html

编辑者提供的图片
在 数据科学中,预测模型的准确性至关重要,以确保避免任何高昂的错误,并且每个方面都能达到其最佳水平。数据在选择和格式化后,需要进行清洗,这是模型开发过程中的一个关键阶段。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
在这篇文章中,我们将概述数据清洗在数据科学中的重要性,包括它是什么、好处、数据清洗过程以及常用工具。
什么是数据清洗?
在数据科学中,数据清洗是识别错误数据并修复错误的过程,以使最终的数据集准备好使用。错误可能包括重复字段、格式不正确、不完整字段、无关或不准确的数据以及损坏的数据。
在数据科学项目中,清洗阶段 在数据管道中优于验证。在管道中,每个阶段处理输入并生成输出,逐步改进数据。数据管道的好处在于每个步骤都有特定的目的并且自成一体,意味着数据经过彻底检查。
数据科学中数据清洗的重要性
数据很少以易于使用的形式到达;实际上,可以肯定地说数据从未是完美的。当从不同的来源和实际环境中收集数据时,数据必然包含大量错误,并采用不同的格式。因此,数据清洗的重要性便体现出来了——将数据变得无误、相关且易于模型吸收。
在处理来自多个来源的大型数据集时,可能会出现错误,包括重复或错误分类。这些错误严重影响算法的准确性。值得注意的是,数据清理和组织可能会消耗 数据科学家高达 80%的时间,突显了其在数据处理流程中的关键作用。
数据清理的示例
以下是三个数据清理如何修复数据集错误的示例。
数据格式化
数据格式化涉及 将数据转换为特定格式 或修改数据集的结构。确保数据集的一致性和良好的结构对于避免数据分析中的错误至关重要。因此,在清理过程中采用各种技术是必要的,以保证准确的数据格式化。这可能包括将分类数据转换为数值以及将多个数据源整合为统一的数据集。
空值/缺失值
数据清理技术在解决缺失或空值等数据问题中起着至关重要的作用。这些技术包括使用相关信息来估算和填补数据集中的空白。
例如,考虑位置字段。如果字段为空,科学家可以用数据集或类似数据集中的平均位置数据填充该字段。虽然不完美,但拥有最可能的位置总比没有位置信息要好。这种方法确保了数据质量的提升,并增强了数据集的整体可靠性。
识别异常值
在数据集中,某些数据点可能与其他数据点没有实质性的关联(例如,在数值或行为方面)。因此,在数据分析过程中,这些异常值有可能显著扭曲结果,导致误导性的预测和有缺陷的决策。然而,通过实施各种数据清理技术,可以识别并消除这些异常值,从而确保数据集的完整性和相关性。

数据清理的好处
数据清理提供了一系列好处,对数据的准确性、相关性、可用性和分析具有显著影响。
-
准确性 - 使用数据清理工具和技术可以显著减少数据集中的错误和不准确之处。这对于数据分析至关重要,有助于创建能够做出准确预测的模型。
-
可用性 - 一旦数据被清理并正确格式化,它可以应用于多个用例,使其变得更加可访问,从而可以用于各种项目类型。
-
分析 - 清洁的数据使得分析阶段更加有效,允许分析师获得更深入的见解并提供更可靠的结果。
-
高效的数据存储 - 通过移除不必要和重复的数据,可以减少存储成本,因为只需保留相关的、有价值的数据,无论是存储在本地服务器还是云数据仓库。
-
治理 - 数据清理可以帮助组织遵守严格的法规和数据治理,保护个人隐私并避免处罚。最近几个月出台了更多的数据合规法律。例如,最近的德克萨斯州消费者隐私法(TDPSA),禁止某些数据实践,如收集不为收集目的合理必要的个人客户数据。
数据清理过程:8 个步骤
数据管道的数据清理阶段由八个常见步骤组成:
-
重复数据的移除
-
不相关数据的移除
-
大小写标准化
-
数据类型转换
-
异常值的处理
-
错误的修正
-
语言翻译
-
处理任何缺失值
1. 重复数据的移除
利用多个数据源的大型数据集很可能存在错误,包括重复数据,特别是在新条目没有经过质量检查时。重复数据是冗余的,占用不必要的存储空间,需要进行数据清理以提高效率。常见的重复数据包括重复的电子邮件地址和电话号码。
2. 不相关数据的移除
为了优化数据集,移除不相关的数据字段是至关重要的。这将导致模型处理更快,并使得更加专注于实现特定目标。在数据清理阶段,将删除任何与项目范围不符的数据,只保留完成任务所需的必要信息。
3. 大小写标准化
在数据集中文本的标准化对于确保一致性和便于分析至关重要。纠正大小写尤其重要,因为这可以防止创建虚假的类别,从而导致数据混乱和困惑。
4. 数据类型转换
在使用 Python 处理 CSV 数据时,分析师通常依赖于 Pandas 这一数据分析库。然而,有时 Pandas 在有效处理数据类型方面会有所不足。为了保证数据转换的准确性,分析师采用清理技术。这确保了在应用于实际项目时,正确的数据能够被轻松识别。
5. 异常值处理
异常值是缺乏与其他点相关性的数据点,在数据集的整体背景中偏离显著。虽然异常值有时可以提供有趣的见解,但它们通常被视为应该删除的错误。
6. 错误修正
确保模型的有效性至关重要,在数据分析阶段之前纠正错误是关键。这些错误通常源于手动数据输入而没有足够的检查程序。例如,包括数字错误的电话号码、没有“@”符号的电子邮件地址或没有标点的用户反馈。
7. 语言翻译
数据集可以从不同语言的各种来源收集。然而,在使用这些数据进行机器翻译时,评估工具通常依赖于单语自然语言处理(NLP)模型,这些模型一次只能处理一种语言。幸运的是,在数据清理阶段,AI 工具可以通过将所有数据转换为统一语言来提供帮助。这确保了翻译过程中的更大连贯性和兼容性。
8. 处理任何缺失值
数据清理的最后步骤之一涉及处理缺失值。这可以通过删除缺少值的记录或使用统计技术填补空白来实现。全面了解数据集对于做出这些决策至关重要。
总结
数据科学中数据清理的重要性不能被低估,因为它会显著影响数据模型的准确性和整体成功。经过彻底的数据清理,数据分析阶段更有可能输出有缺陷的结果和不正确的预测。
在数据清理阶段需要纠正的常见错误包括重复数据、缺失值、不相关数据、异常值以及将多种数据类型或语言转换为单一形式。
Nahla Davies 是一名软件开发人员和技术作家。在全职从事技术写作之前,她还曾担任过各种有趣的角色,包括在一家 Inc. 5,000 体验品牌机构担任首席程序员,该机构的客户包括三星、时代华纳、Netflix 和索尼。
更多相关主题
数据科学中实验设计的重要性
原文:
www.kdnuggets.com/2022/08/importance-experiment-design-data-science.html
引言
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
我们每个人或多或少都是实验的参与者。要么是某个广告定位机构正在进行实验,以检查展示给用户的广告类型以获取销售,即转化。要么是一些流行机器学习课程提供商的网站上的功能变更,以评估用户对哪些变化最敏感,以及这些变化是否推动了实验组织者希望观察的商业 KPI。这种随机化实验被称为 AB 测试,广泛归类于假设测试的范畴。

来源:图像由 freepik 创建
如果您到目前为止跟上了,那么欢迎来到实验的世界。让我们首先了解什么是实验。
一般来说,实验被定义为:
在一般定义的基础上,实验的科学意义涉及假设测试,以检查所提出的解决方案是否适用于给定的问题陈述。需要注意的一点是,实验是以受控的方式进行的。
在这篇文章中,我们将了解实验设计在数据科学项目中的重要性。因此,让我们再了解一个实验设计的定义:
“实验设计是一个用于组织、实施和解释实验结果的概念,它通过进行少量试验确保获得尽可能多的有用信息。”
数据科学家可以用多种方式设计和实施机器学习项目中的实验。但首先尝试哪些,团队应如何计划和同时进行多个实验,并最终将其分析转化为有意义的见解和成果?这需要熟练的数据科学家才能不被众多可能的优秀想法所压倒。他们会直接排除一些想法和实验,因为他们知道哪些算法和方法适用于哪些数据集,以及所选算法的不足之处。这种技能不是一朝一夕就能培养出来的,需要多年的经验来对实验进行排序,以获得更高的时间和资源回报。
一个例子
数据科学家往往会跳跃性地假设哪种机器学习框架最适合当前问题。理解业务背景是机器学习项目的核心。如何将业务问题映射到统计机器学习问题上,对于业务成果和影响的成功至关重要。让我们通过一个例子来了解典型的机器学习实验:
- 根据这些输入,数据科学家需要缩小范围并决定使用哪个算法。例如,如果这是一个分类问题,那么是使用逻辑回归还是随机森林分类器,构成了实验的一部分。
设计实验时要考虑的因素:
想法是免费的,不花钱。但是,哪些想法可以继续推进和设计实验需要考虑多种因素。
-
假设 - 对于这个实验如何解决给定问题的直观理解。
-
数据可用性 - 你是否有可以开始的数据?
-
所需数据 - 拥有大量数据并不保证项目的成功,需要仔细评估解决业务问题所需的所有属性。与业务领导进行初步的探索性和可行性研讨会有助于将这一要求纳入视野。
-
努力程度(LOE) - 进行这个实验的努力估算是多少?
-
自己动手(DIY)或开源 - 是否存在可以快速利用的现有工具、包、库或代码库,以验证假设?
-
是否独立 - 这个实验是否依赖于某些先前的结果,还是可以独立进行?在多个团队的依赖或基础设施缺乏的情况下,执行实验的速度会受到阻碍。
-
成功标准 - 如何判断实验是否得到了预期的结果?
-
集成测试 - 你的成功实验是否在某些约束条件下有效,并且一旦环境发生变化(这是不可避免的),是否不可靠?它在统计上是否显著?你对结果的可重复性有多大信心?最终结果是否与机器学习生态系统的其他部分良好集成?
实验设计被简要说明为确定一组可能影响过程性能的因素,选择每个因素的合理水平,定义因素水平的组合集,并根据定义的实验设计执行实验。
专业提示 1
一位经验丰富的数据科学家能够利用从以往项目中学到的知识库,审慎地选择已选实验以产生业务价值,而不是朝着所有方向发展。话虽如此,与团队进行健康的技术讨论,征求他们的意见,决定每个实验的利弊,在什么假设下该实验会成功或失败,并将其记录在追踪器中,总是一种好做法。这样的讨论将帮助你对实验进行排序,按其潜在影响和结果进行排序。这个前提源于机器学习中的集成方法,即单个数据科学家可能无法考虑所有的边角情况,除非得到第二双眼睛的帮助(尽可能多的合格眼睛 😃)
专业提示 2
很多时候,实验一开始就被认为是更多的研究导向,数据科学家知道即使这个实验给出了最佳的性能,也不能投入生产。那么你可能会想,我们为什么要尝试这样的实验呢?嗯,建立最佳案例即北极星,即使它只是理论上的,也很重要。这样可以估算当前生产就绪的模型版本距离最佳已知性能还有多远,以及为了达到最佳性能需要进行哪些类型的权衡。
专业提示 3
进行实验是一回事,准确分析实验结果则是另一回事。你可能需要在不同的算法或不同的样本集上进行多次循环来决定最终结果。但如何分析输出才是关键。最终选择的实验不仅仅依赖于单一的评估指标。它还取决于解决方案在基础设施需求方面的可扩展性以及结果的可解释性。
实验管理
到目前为止,我们讨论了实验设计的样子。如果你对如何管理多个实验和工件感兴趣,可以参考这篇优秀文章。它涵盖了 AI/ML 项目中的变量组合,包括但不限于以下内容:
-
预处理、模型训练和后处理模块
-
数据和模型版本管理:用于训练先前模型或生产模型的数据是什么?
-
采样方法:训练数据是如何创建和采样的——是否存在不平衡?是如何处理的?
-
模型评估:模型是如何验证的,使用了哪些数据?它是否代表了将用于生产系统的数据模型?
-
算法:你怎么知道哪个算法用于哪个模型版本?我们还需要理解,即使在新模型版本中算法可能相同,但架构也可能已发生变化。
摘要
在这篇文章中,我们讨论了实验的重要性,特别是在数据科学项目中的重要性。此外,我们谈到了在设计和进行机器学习实验之前需要考虑的各种因素。文章最后强调了实验设计中需要管理的多个实体和工件。
Vidhi Chugh 是一位屡获殊荣的 AI/ML 创新领导者和 AI 伦理学家。她在数据科学、产品和研究交汇的领域工作,以提供商业价值和洞察力。她倡导以数据为中心的科学,并且是数据治理领域的领先专家,致力于构建值得信赖的 AI 解决方案。
相关主题
排列在神经网络预测中的重要性
原文:
www.kdnuggets.com/2022/12/importance-permutation-neural-network-predictions.html
图片由编辑提供
排列表示每一种可能的排列方式,无论是事物还是数字。排列在以数学为中心的学科中很重要,例如统计学,但它也影响神经网络所做的预测。这里是更详细的介绍。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你在 IT 领域的组织
排列可以确定统计学意义
数据科学家经常发现自己需要更多地了解作为信息来源的总体。然而,他们仍然必须确定统计学意义。在处理时间序列数据时,运行排列检验是一个实用的方法。
排列检验估算了总体分布。在获取这些信息后,数据科学家可以确定观察值相对于总体的稀有程度。排列检验提供了所有可能排列的样本,而不替换任何值。
它们在样本量较小的情况下也有很高的有效性。因此,排列检验可以帮助人们确定他们的神经网络模型是否揭示了具有统计学意义的发现。
这些检验还可以帮助人们确定他们可以多大程度上信任模型的结果。评估准确性可能极其重要,这取决于模型的用途。在将模型应用于医疗诊断或财务决策之前,人们必须对模型的表现有高度信心。
排列可以展示哪些数据集特征影响有用的预测
许多神经网络依赖于黑箱模型。它们在广泛的应用中非常准确。然而,通常需要一定的工作来观察预测因素对最终预测的影响。
一种叫做排列特征重要性的选项提供了一种解决这一障碍的方法。它向数据科学家展示哪些数据集特征具有预测能力,无论使用什么模型。
确定模型中特征重要性的技术允许人们根据相对预测能力对预测器进行排名。随机排列通过显示特征的重新排列是否会导致预测准确性下降来发挥作用。
也许质量下降是最小的。这表明与原始预测器相关的信息对生成整体预测没有重大影响。
人们可以继续对模型预测器进行排名,直到得到一个值的集合,显示出哪些特征最重要和最不重要以生成准确预测。数据科学家还可以使用排列特征重要性来调试模型并获得有关整体性能的更好见解。
排列影响模型提供的知识
一个优秀的数据科学家必须始终探索模型提供的细节并质疑相关结论。许多专业人士在小学的 STEM 课程中学会了这种思维方式。排列是神经网络预测的一个必要方面,因为它决定了模型提供或不提供什么信息。对排列的熟悉有助于数据科学家构建和调整他们的雇主或客户所希望和期望的模型。
考虑一个公司需要一个与客户点击网站相关的神经网络模型的情况。决策者可能希望了解有多少客户通过特定路径浏览网站。模型必须计算排列。
另一方面,要求机器学习模型的人可能希望了解访问网站上某些页面组的人员情况。这种洞察与组合有关,而不是排列。准确了解一个人希望从神经网络模型中获得什么信息有助于确定使用何种类型以及排列在其中的作用。
此外,神经网络在训练数据集包含相关信息时将产生最佳结果。谷歌的机器学习工程师还在研究所谓的排列不变神经网络代理。当每个代理的感官神经元接收来自环境的输入时,它会即时理解意义和上下文。
这与假设固定含义相对。研究表明,即使模型包含冗余或噪声信息,排列不变的神经网络代理也能表现良好。
排列对神经网络的准确性和相关性至关重要
这些只是为什么排列在使神经网络展现最佳性能方面发挥着关键作用的一些原因。理解排列的影响可以帮助数据科学家构建和使用模型,从而获得更好的结果。
April Miller 是 ReHack 杂志的消费技术主编。她有创造高质量内容的经验,这些内容能够为我合作的出版物带来流量。
更多相关内容
机器学习中的预处理重要性
原文:
www.kdnuggets.com/2023/02/importance-preprocessing-machine-learning.html

很明显,开发新模型或算法的 ML 团队期望模型在测试数据上的性能是最优的。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您所在组织的 IT。
但很多时候这种情况并不会发生。
原因可能有很多,但主要的罪魁祸首是:
-
数据不足
-
数据质量差
-
过拟合
-
欠拟合
-
算法选择不当
-
超参数调优
-
数据集中的偏差
上述列表并不详尽。
在这篇文章中,我们将讨论可以解决上述多个问题的过程,并且 ML 团队在执行时要非常注意。
这是数据的预处理。
机器学习社区普遍接受预处理数据是 ML 工作流中的重要一步,并且它可以提高模型的性能。
许多研究和文章已经显示了在机器学习中预处理数据的重要性,例如:
“Bezdek 等人(1984 年)的研究发现,预处理数据可以使几种聚类算法的准确性提高多达 50%。”
“Chollet(2018 年)的研究发现,数据预处理技术,如数据归一化和数据增强,可以提高深度学习模型的性能。”
还值得一提的是,预处理技术不仅对提高模型的性能很重要,而且对使模型更具解释性和鲁棒性也很重要。
例如,处理缺失值、去除异常值和缩放数据可以帮助防止过拟合,从而使模型对新数据的泛化能力更强。
无论如何,重要的是要注意,所需的具体预处理技术和预处理的程度将取决于数据的性质和算法的具体要求。
还要记住,在某些情况下,数据预处理可能不是必要的,甚至可能对模型的性能产生负面影响。
在将数据应用于机器学习 (ML) 算法之前的预处理是 ML 工作流程中的一个关键步骤。
这一步有助于确保数据处于算法可以理解的格式,并且没有错误或异常值,这些都可能对模型性能产生负面影响。
在本文中,我们将讨论数据预处理的一些优势,并提供一个如何使用流行的 Python 库 Pandas 预处理数据的代码示例。
数据预处理的优势
数据预处理的主要优势之一是它有助于提高模型的准确性。通过清理和格式化数据,我们可以确保算法仅考虑相关信息,而不受任何无关或不正确数据的影响。
这可以导致一个更准确、更稳健的模型。
数据预处理的另一个优势是,它可以帮助减少训练模型所需的时间和资源。通过移除无关或冗余的数据,我们可以减少算法需要处理的数据量,这可以大大减少训练模型所需的时间和资源。
数据预处理还可以帮助防止过拟合。过拟合发生在模型在一个过于特定的数据集上进行训练,因此在训练数据上表现良好,但在新的、未见过的数据上表现较差。
通过预处理数据并移除无关或冗余的信息,我们可以帮助减少过拟合的风险,并提高模型对新数据的泛化能力。
数据预处理还可以提高模型的可解释性。通过清理和格式化数据,我们可以更容易理解不同变量之间的关系及其如何影响模型的预测。
这可以帮助我们更好地理解模型的行为,并做出更明智的决定来改进它。
示例
现在,让我们看一个使用 Pandas 进行数据预处理的示例。我们将使用一个包含关于葡萄酒质量信息的数据集。该数据集有几个特征,如酒精含量、氯化物、密度等,还有一个目标变量,即葡萄酒的质量。
import pandas as pd
# Load the data
data = pd.read_csv("winequality.csv")
# Check for missing values
print(data.isnull().sum())
# Drop rows with missing values
data = data.dropna()
# Check for duplicate rows
print(data.duplicated().sum())
# Drop duplicate rows
data = data.drop_duplicates()
# Check for outliers
Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
data = data[
~((data < (Q1 - 1.5 * IQR)) | (data > (Q3 + 1.5 * IQR))).any(axis=1)
]
# Scale the data
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data)
# Split the data into training and testing sets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
data_scaled, data["quality"], test_size=0.2, random_state=42
)
在这个示例中,我们首先使用 Pandas 的 read_csv 函数加载数据,然后使用 isnull 函数检查缺失值。接着,我们使用 dropna 函数删除含有缺失值的行。
接下来,我们使用 duplicated 函数检查重复的行,并使用 drop_duplicates 函数将其删除。
我们然后使用四分位距 (IQR) 方法检查异常值,该方法计算第一四分位数和第三四分位数之间的差异。任何超出 1.5 倍 IQR 的数据点都被认为是异常值,并从数据集中移除。
在处理了缺失值、重复行和异常值之后,我们使用来自 sklearn.preprocessing 库的 StandardScaler 函数对数据进行缩放。缩放数据很重要,因为它有助于确保所有变量都在相同的尺度上,这对于大多数机器学习算法正常运行是必要的。
最后,我们使用来自 sklearn.model_selection 库的 train_test_split 函数将数据分成训练集和测试集。这个步骤对于评估模型在未见数据上的表现是必要的。
如果我忽略了这一步会怎样?
在将数据应用于机器学习算法之前不进行预处理可能会带来几个负面后果。一些主要问题包括:
-
模型性能差:如果数据没有被正确清理和格式化,算法可能无法正确理解数据,这可能导致模型性能差。这可能是由于数据集中存在缺失值、异常值或未被移除的无关数据造成的。
-
过拟合:如果数据集没有经过清理和预处理,可能会包含无关或冗余的信息,从而导致过拟合。过拟合发生在模型在一个过于特定的数据集上进行训练时,因此它在训练数据上表现良好,但在新的、未见的数据上表现较差。
-
更长的训练时间:不进行数据预处理可能导致训练时间延长,因为算法可能需要处理比必要更多的数据,这可能非常耗时。
-
理解模型的难度:如果数据没有经过预处理,可能会很难理解不同变量之间的关系以及它们如何影响模型的预测。这会使识别模型中的错误或改进领域变得更加困难。
-
偏倚的结果:如果数据没有经过预处理,它可能包含错误或偏差,这可能导致不公平或不准确的结果。例如,如果数据中包含缺失值,算法可能在处理一个偏差的数据样本,这可能导致错误的结论。
一般来说,不进行数据预处理可能导致模型的准确性降低、可解释性差以及操作困难。数据预处理是机器学习工作流中的一个重要步骤,不应被忽略。
结论
总之,在将数据应用于机器学习算法之前进行预处理是机器学习工作流中的一个关键步骤。它有助于提高准确性,减少训练模型所需的时间和资源,防止过拟合,并提高模型的可解释性。
上述代码示例演示了如何使用流行的 Python 库 Pandas 进行数据预处理,但还有许多其他库可用于数据预处理,例如 NumPy 和 Scikit-learn,可以根据项目的具体需求进行使用。
Sumit Singh 是一位致力于数据中心人工智能的连续创业者。他共同创立了下一代训练数据平台Labellerr。Labellerr 的平台使 AI-ML 团队能够轻松自动化他们的数据准备流程。
更多相关主题
概率在数据科学中的重要性
原文:
www.kdnuggets.com/2023/02/importance-probability-data-science.html
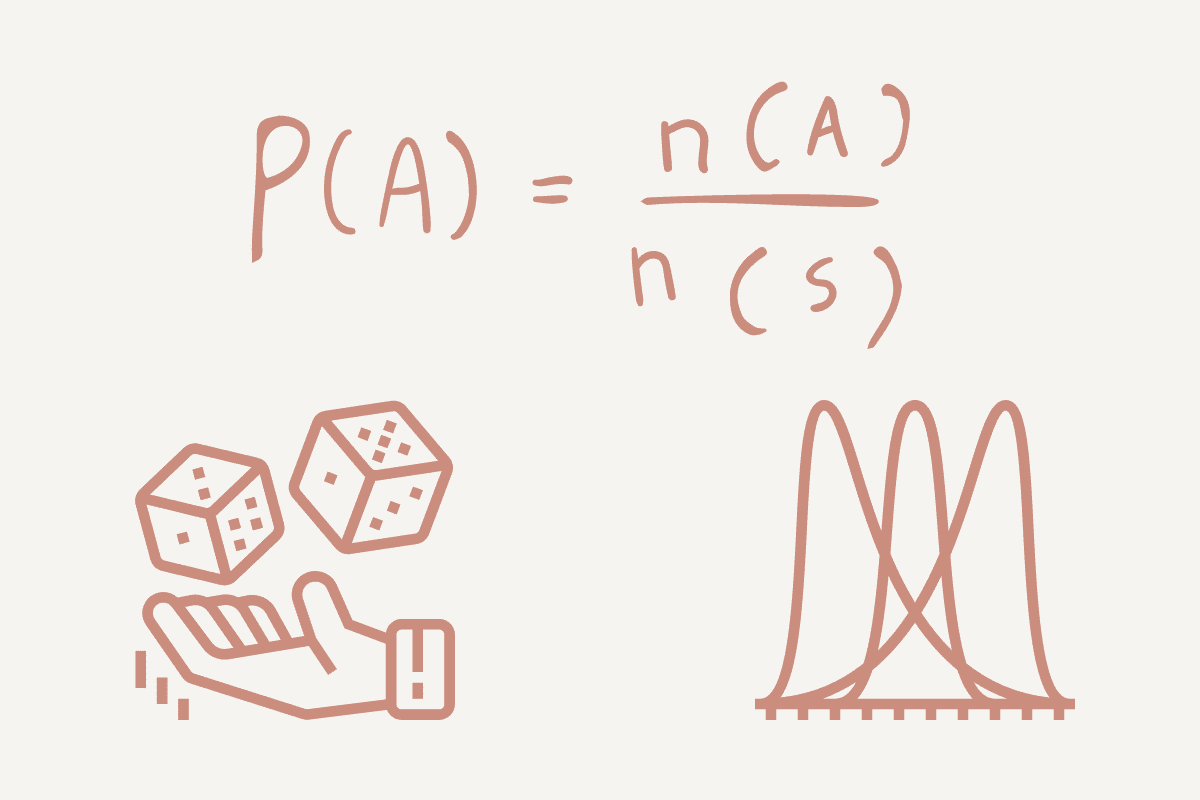
图片作者
作为一名数据科学家,你需要知道结果的准确性以确保有效性。数据科学工作流程是一个有计划的项目,具有控制条件。允许你评估每个阶段以及它如何影响你的输出。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
什么是概率?
概率是事件/事情发生的可能性的度量。它是预测分析中的一个重要元素,允许你探索结果背后的计算数学。
使用一个简单的例子,让我们看看抛硬币:要么是正面(H),要么是反面(T)。你的概率将是事件发生的方式数除以所有可能结果的总数。
-
如果我们想要找出正面的概率,那么它将是 1(正面)/ 2(正面和反面)= 0.5。
-
如果我们想要找出反面的概率,那么它将是 1(反面)/ 2(正面和反面)= 0.5。
但我们不希望混淆可能性和概率——它们是不同的。概率是指特定事件或结果发生的度量。可能性则用于当你想要增加特定事件或结果发生的机会时。
简而言之——概率是关于可能结果的,而可能性则是关于假设的。
另一个需要了解的术语是“互斥事件”。这些事件不会同时发生。例如,你不能同时向右和向左走。或者如果我们抛硬币,我们只能得到正面或反面,而不是两者。
概率的类型
-
理论概率:这关注于事件发生的可能性,并基于推理的基础。使用理论,结果是预期值。以抛硬币为例,理论概率为正面朝上的概率是 0.5 或 50%。
-
实验概率:这关注于在实验期间事件发生的频率。以抛硬币为例——如果我们抛硬币 10 次,正面朝上的次数为 6 次,则硬币正面朝上的实验概率为 6/10 或 60%。
条件概率
条件概率是基于已有事件/结果的事件/结果发生的可能性。例如,如果你在一家保险公司工作,你可能会想要根据一个人是否已办理房贷来计算他们能否支付保险的概率。
条件概率通过使用数据集中的其他变量,帮助数据科学家生成更准确的模型和输出。
分布
概率分布是一个统计函数,用来描述在给定范围内随机变量的可能值和概率。该范围将具有可能的最小值和最大值,这些值在分布图上的位置取决于统计测试。
根据项目中使用的数据类型,你可以确定使用了哪种类型的分布。我将它们分为两类:离散分布和连续分布。
离散分布
离散分布是指数据只能取特定值或具有有限数量的结果。例如,如果你掷一个骰子,有限值为 1、2、3、4、5 和 6。
离散分布有不同的类型。例如:
-
离散均匀分布是指所有结果的可能性相等。例如,在掷一个六面骰子的情况下,骰子落在 1、2、3、4、5 或 6 的概率是相等的——1/6。然而,离散均匀分布的问题在于它没有提供数据科学家可以使用和应用的相关信息。
-
伯努利分布是另一种离散分布,其中实验只有两个可能的结果,即“是”或“否”、1 或 2、真或假。这可以在掷硬币时使用,结果可能是正面或反面。使用伯努利分布时,我们有一个结果的概率(p),并可以从总概率(1)中扣除,表示为(1-p)。
-
二项分布是一系列伯努利事件的离散概率分布,它只能在实验中产生两种可能的结果,即成功或失败。例如,掷硬币时,每次实验中硬币正面朝上的概率总是 1/2。
-
泊松分布是描述一个事件在特定时间段或距离内发生次数的分布。它不是关注事件发生的具体情况,而是关注在特定区间内事件发生的频率。例如,如果每天上午 11 点有 12 辆车经过某条特定道路,我们可以使用泊松分布来计算每个月上午 11 点有多少辆车经过那条道路。
连续分布
与有限结果的离散分布不同,连续分布具有连续的结果。这些分布通常在图表上呈现为曲线或直线,因为数据是连续的。
-
正态分布 是你可能听说过的,因为它是使用最频繁的分布类型。它是围绕均值对称的分布,没有偏斜。绘制时,数据呈钟形分布,中间范围为均值。例如,身高和智商得分等特征遵循正态分布。
-
T 分布 是一种连续分布类型,用于当总体标准差(σ)未知且样本量较小时(n<30)。它的形状与正态分布相同,即钟形曲线。例如,如果我们查看一天内售出的巧克力棒数量,我们会使用正态分布。然而,如果我们想查看某一特定小时内售出的数量,我们会使用 t 分布。
-
指数分布 是一种连续概率分布,关注事件发生的时间。例如,我们可能想研究地震并使用指数分布。时间是从此时开始到地震发生的时间。指数分布绘制为一条曲线,表示概率的指数变化。
结论
从上述内容可以看出,数据科学家如何利用概率来更好地理解数据并回答问题。了解事件发生的概率对数据科学家来说非常有用,并且在决策过程中可以非常有效。
你将不断处理数据,在进行任何形式的分析之前,你需要更多地了解数据。查看数据分布可以为你提供大量信息,并可以利用这些信息来调整你的任务、过程和模型,以适应数据分布。
这减少了你花在理解数据上的时间,提供了更有效的工作流程,并产生了更准确的结果。
许多数据科学的概念基于概率学的基础。
Nisha Arya 是一名数据科学家和自由技术作家。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能在延长人类生命方面的不同方式。她是一个热衷于学习的人,寻求拓宽技术知识和写作技能,同时帮助指导他人。
更多相关主题
机器学习中可重复性的重要性
原文:
www.kdnuggets.com/2023/06/importance-reproducibility-machine-learning.html

作者提供的图片
当我自学机器学习时,我经常尝试跟随项目教程进行编码。我会按照作者列出的步骤操作。但有时,我的模型表现会比教程作者的模型更差。也许你也遇到过类似的情况。或者你刚刚从 GitHub 上拉取了同事的代码。你的模型的性能指标与同事报告的指标不同。所以做相同的事情并不能保证相同的结果,对吧? 这是机器学习中一个普遍存在的问题:可重复性的挑战。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
毫无疑问:机器学习模型只有在其他人能够重复实验并重现结果时才有用。从典型的“它在我的机器上有效”问题到机器学习模型训练方式的细微变化,可重复性面临许多挑战。
在这篇文章中,我们将深入探讨机器学习中可重复性的挑战和重要性,以及数据管理、版本控制和实验跟踪在解决机器学习可重复性挑战中的作用。
在机器学习的背景下什么是可重复性?
让我们看看如何在机器学习的背景下最好地定义可重复性。
假设有一个现有项目使用特定的机器学习算法和给定的数据集。给定数据集和算法,我们应该能够运行算法(任意次数),并在每次运行中重现(或复制)结果。
但机器学习中的可重复性并非没有挑战。我们已经讨论了其中的一些问题,让我们在下一节中更详细地讨论这些问题。
机器学习中的可重复性挑战
对于任何应用程序,都存在可靠性和可维护性等挑战。然而,在机器学习应用程序中,还存在额外的挑战。
当我们谈论机器学习应用时,我们通常指的是通常包括以下步骤的端到端机器学习管道:
作者提供的图像
因此,可重复性挑战可能由于这些步骤中的一个或多个变化而出现。大多数变化可以通过以下方式之一来捕捉:
-
环境变化
-
代码更改
-
数据更改
我们来看看这些变化如何阻碍可重复性。
环境变化
Python 和基于 Python 的机器学习框架使得开发 ML 应用变得轻而易举。然而,Python 中的依赖管理——管理一个项目所需的不同库和版本——是一项非平凡的挑战。即使是使用不同版本的库或调用使用已弃用参数的函数,也足以破坏代码。
这也包括操作系统的选择。还有一些与硬件相关的挑战,例如 GPU 浮点精度的差异等。
代码更改
从输入数据集的洗牌以确定哪些样本进入训练数据集,到训练神经网络时的权重随机初始化——随机性在机器学习中扮演着重要角色。
设置不同的随机种子可能会导致完全不同的结果。对于我们训练的每一个模型,都有一组超参数。因此,调整一个或多个超参数也可能导致不同的结果。
数据更改

作者提供的图像
即使在相同的数据集下,我们也看到超参数值和随机性的不一致会使得复制结果变得困难。因此,当数据发生变化——数据分布的变化、记录子集的修改或某些样本的丢失——会使得结果的复制变得困难。
总结:当我们尝试复制机器学习模型的结果时,即使是代码、使用的数据集以及机器学习模型运行的环境中最小的变化,也可能阻止我们得到与原始模型相同的结果。
如何解决可重复性挑战
现在我们将看看如何解决这些挑战。
作者提供的图像
数据管理
我们看到,可重复性面临的最明显挑战之一是数据。某些数据管理方法如数据集版本控制可以帮助我们跟踪数据集的变化,并存储有用的元数据。
版本控制
代码的任何更改都应使用版本控制系统(如 Git)进行跟踪。
在现代软件开发中,你可能遇到过 CI/CD 管道,这使得跟踪更改、测试新更改和推送到生产变得更简单高效。
在其他软件应用中,跟踪代码的变化是简单的。然而,在机器学习中,代码的变化也可能涉及到所使用算法和超参数值的变化。即使是简单的模型,我们可以尝试的可能性也是组合性巨大的。这就是实验跟踪变得相关的地方。
实验跟踪
构建机器学习应用程序等同于广泛的实验。从算法到超参数,我们尝试不同的算法和超参数值。因此,跟踪这些实验非常重要。
跟踪机器学习实验包括:
-
记录超参数调整
-
记录模型的性能指标、模型检查点
-
存储关于数据集和模型的有用元数据
机器学习实验跟踪、数据管理及其他工具
如所见,数据集版本控制、代码变更跟踪和机器学习实验跟踪复现了机器学习应用程序。以下是一些可以帮助你构建可复现机器学习流程的工具:
总结
总结一下,我们回顾了机器学习中可复现性的意义和挑战。我们讨论了数据和模型版本控制以及实验跟踪等方法。此外,我们还列出了一些你可以用来进行实验跟踪和更好地管理数据的工具。
DataTalks.Club 的 MLOps Zoomcamp 是一个出色的资源,可以让你获得这些工具的一些经验。如果你喜欢构建和维护端到端的机器学习管道,你可能会对了解 MLOps 工程师的角色感兴趣。
Bala Priya C 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交集上工作。她的兴趣和专长包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正在通过撰写教程、使用指南、观点文章等与开发者社区分享她的知识。
更多相关内容
数据科学家需要了解的重要统计知识
原文:
www.kdnuggets.com/2021/09/important-statistics-data-scientists.html
评论
由 Lekshmi S. Sunil, IIT Indore '23 | GHC '21 学者。

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析水平
3. Google IT 支持专业证书 - 支持您的组织进行 IT 工作
统计分析使我们能够从手头的数据中获得有价值的见解。掌握重要的统计概念和技术对于使用各种工具分析数据至关重要。
在深入细节之前,让我们看看本文涵盖的主题:
-
描述性统计与推断统计
-
数据类型
-
概率与贝叶斯定理
-
集中趋势的度量
-
偏度
-
峰度
-
离散度的度量
-
协方差
-
相关性
-
概率分布
-
假设检验
-
回归分析
描述性统计与推断统计
统计学整体涉及数据的收集、组织、分析、解释和展示。在统计学中,有两个主要分支:
-
描述性统计:这涉及描述数据的特征,通过图表/图形或使用集中趋势、变异性和分布等数值计算来组织和展示数据。一个值得注意的点是,结论是基于已知的数据得出的。
-
推断统计:这涉及从样本中得出推论和做出关于更大人群的一般化。因此,需要更复杂的计算。最终结果使用假设检验、相关性和回归分析等技术得出。预测的未来结果和得出的结论超出了现有数据的层面。
数据类型
为了使用最合适的统计技术进行适当的探索性数据分析(EDA),我们需要了解我们正在处理的数据类型。
- 分类数据
分类数据表示定性变量,如个人的性别、血型、母语等。分类数据也可以是没有数学意义的数值形式。例如,如果性别是变量,女性可以用 1 表示,男性用 0 表示。
-
名义数据:值用于标记变量,各类别之间没有定义的等级关系,即没有顺序或方向——例如,宗教、性别等。仅有两个类别的名义尺度称为“二分法”。
-
有序数据:类别之间存在顺序或等级关系——例如,质量评级、教育水平、学生成绩等级等。
- 数值数据
数值数据表示用数字表达的定量变量。例如,个人的身高、体重等。
-
离散数据:值是可计数的,通常是整数(大多数情况下是整数)。例如,停车场的汽车数量、国家数量等。
-
连续数据:观察值可以被测量但不能被计数。数据在一个范围内可以取任何值——例如,体重、身高等。连续数据可以进一步分为区间数据(有序值之间具有相同的差异,但没有真实零点)和比率数据(有序值之间具有相同的差异,并且存在真实零点)。
概率与贝叶斯定理
概率是衡量事件发生可能性的指标。
-
P(A) + P(A’) = 1
-
P(A∪B) = P(A) + P(B) − P(A∩B)
-
独立事件:如果一个事件的发生不会影响另一个事件发生的概率,则两个事件是独立的。P(A∩B) = P(A)P(B),其中 P(A) != 0 且 P(B) != 0。
-
互斥事件:如果两个事件不能同时发生,则它们是互斥的或不相交的。P(A∩B) = 0,且 P(A∪B) = P(A) + P(B)。
-
条件概率:事件 A 在另一事件 B 已经发生的情况下发生的概率。这由 P(A|B)表示。P(A|B) = P(A∩B)/P(B),当 P(B)>0 时。
-
贝叶斯定理
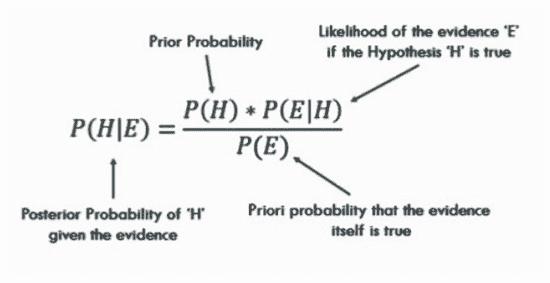
集中趋势的测量

导入统计模块。
- 均值:数据集的平均值。
numpy.mean( ) 也可以使用。
- 中位数:数据集的中间值。

numpy.median( ) 也可以使用。
- 众数:数据集中最频繁出现的值。

何时使用均值、中位数和众数?

均值、中位数和众数之间的关系:众数 = 3 中位数 — 2 均值
偏度
对称性的衡量,或更准确地说,缺乏对称性(偏斜)。
-
正态/对称分布:众数 = 中位数 = 均值
-
正偏(右偏)分布:众数 < 中位数 < 均值
-
负(左)偏态分布:均值 < 中位数 < 众数
峰度
衡量数据相对于正态分布是否为重尾或轻尾,即衡量分布的“尾部性”或“峰度”。
-
Leptokurtic - 正峰度
-
Mesokurtic - 正态分布
-
Platykurtic - 负峰度
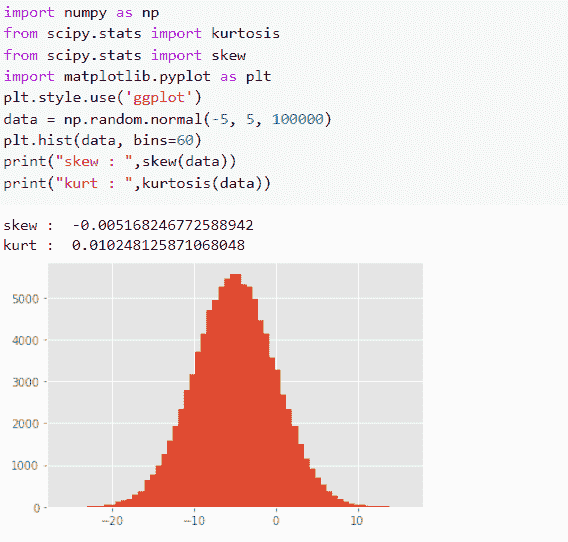
使用 Python 进行偏度和峰度计算。
离散程度的度量
描述数据围绕中心值的分布/散布情况。
范围: 数据集中最大值与最小值之间的差异。
四分位偏差:数据集的四分位数将数据分为四个相等的部分——第一个四分位数(Q1)是最小值和数据中位数之间的中间值。第二个四分位数(Q2)是数据集的中位数。第三个四分位数(Q3)是中位数和最大值之间的中间值。四分位偏差是Q = ½ × (Q3 — Q1)
四分位差: IQR = Q3 — Q1
方差: 每个数据点与均值之间的平均平方差。衡量数据集相对于均值的分散程度。
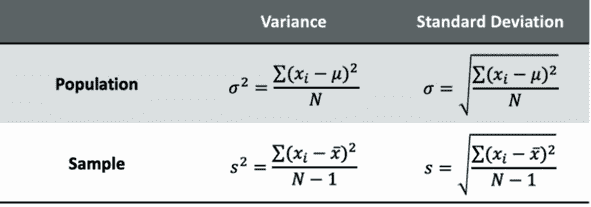
标准差: 方差的平方根。
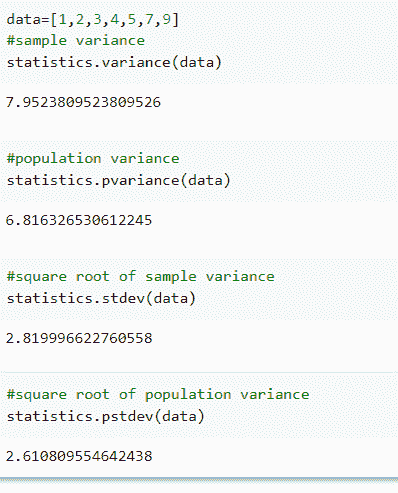
使用 Python 进行方差和标准差计算。
协方差
这是一对随机变量之间的关系,其中一个变量的变化导致另一个变量的变化。
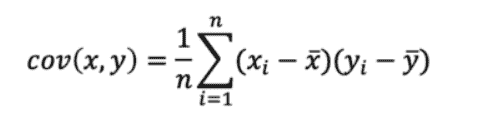
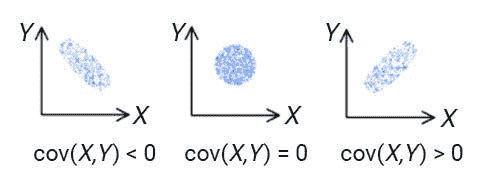
负、零和正协方差。
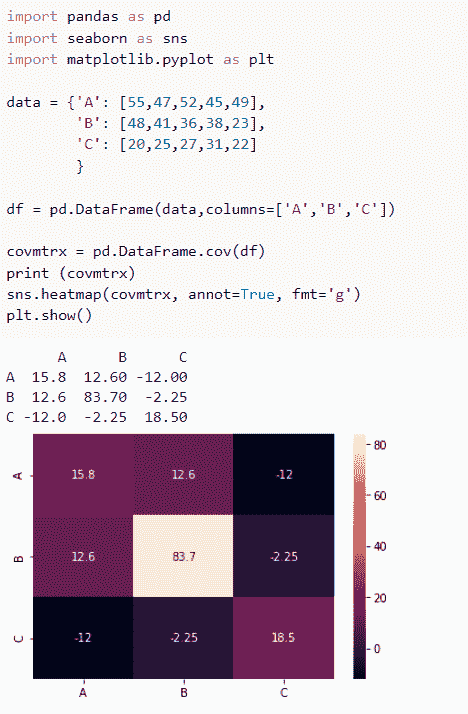
使用 Python 进行协方差矩阵及其热图表示。
相关性
它显示了一对变量是否以及在多大程度上彼此相关。
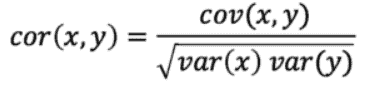
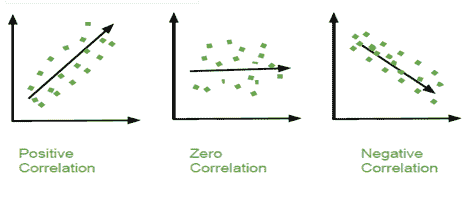
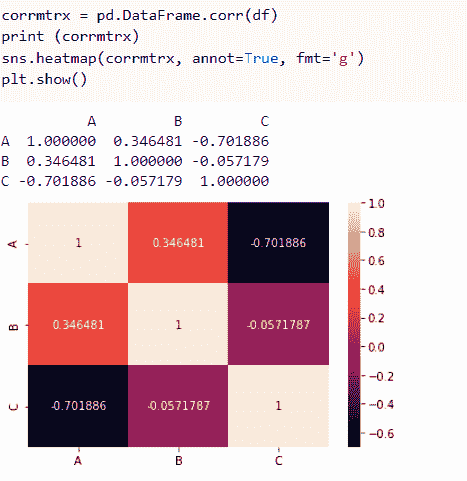
使用相同数据计算相关性矩阵。
协方差与相关性。
概率分布
概率分布主要分为两类——离散概率分布和连续概率分布。
离散概率分布:
- 伯努利分布
一个随机变量进行单次试验,只有两个可能的结果:1(成功),其概率为 p,和 0(失败),其概率为 1-p。
- 二项分布
每次试验都是独立的。每次试验只有两个可能的结果——成功或失败。进行总共 n 次相同的试验。所有试验的成功和失败概率是相同的。(试验是相同的。)
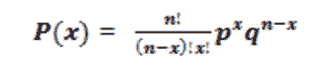
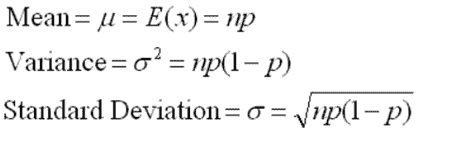
- 泊松分布
测量在特定时间段内发生给定数量事件的概率。
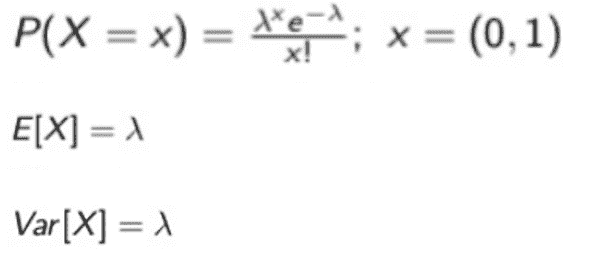
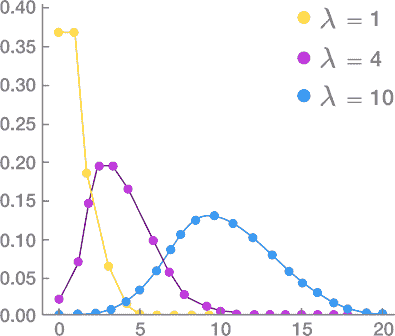
连续概率分布:
- 均匀分布
也称为矩形分布。所有结果的可能性相等。
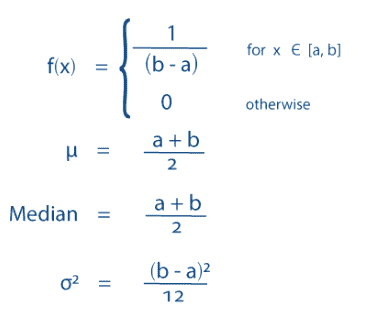
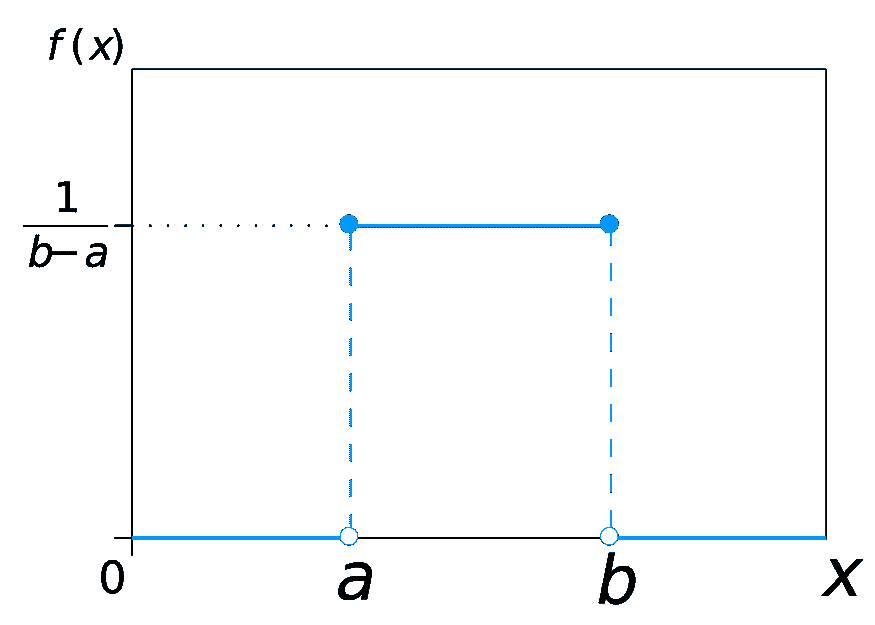
- 正态/高斯分布
分布的均值、中位数和众数重合。分布的曲线呈钟形,并关于 x = μ 对称。曲线下的总面积为 1. 精确一半的值在中心左侧,另一半在右侧。
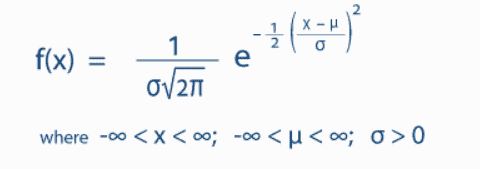
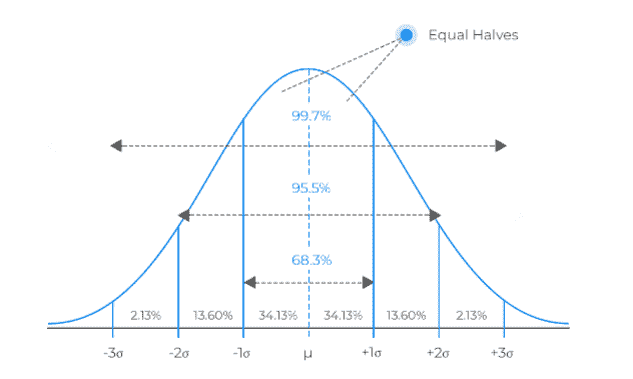
正态分布与二项分布大相径庭。然而,如果试验次数趋近于无穷大,则这两者的形状将非常相似。
- 指数分布
泊松点过程中的事件间隔时间的概率分布,即事件在一个恒定的平均速率下连续且独立地发生的过程。
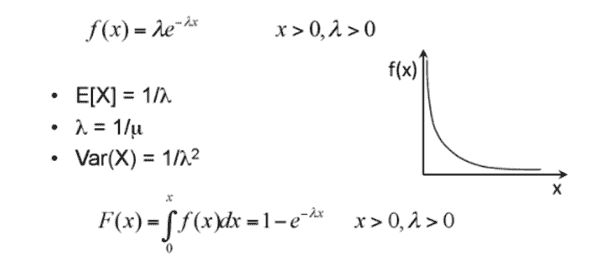
假设检验
首先,让我们来看一下零假设和备择假设之间的区别。
零假设: 关于总体参数的声明,要么被认为是真实的,要么用于提出一个论点,除非通过假设检验证明它是错误的。
备择假设: 关于总体的声明,它与零假设相矛盾,并且如果我们拒绝零假设,我们将得出什么结论。

第一类错误:拒绝一个真实的零假设
第二类错误: 未拒绝一个错误的零假设
显著性水平 (α): 在零假设真实的情况下,拒绝零假设的概率。
p 值: 在零假设真实的情况下,测试统计量至少与观察到的极端值一样极端的概率。
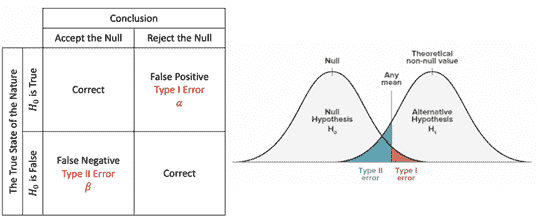
-
当 p 值 > α 时,我们未能拒绝零假设。
-
当 p 值 ≤ α 时,我们拒绝零假设,可以得出我们有一个显著的结果。
在统计假设检验中,当一个结果在给定零假设的情况下非常不可能发生时,该结果具有统计显著性。
临界值: 测试统计量尺度上的一个点,超出该点我们将拒绝零假设。它依赖于测试统计量,该统计量特定于测试类型,以及显著性水平 α,定义了测试的敏感度。
线性回归
线性回归通常是我们遇到的第一个机器学习算法。它简单,理解它为其他更高级的机器学习算法奠定了基础。
简单线性回归
对一个因变量和一个自变量之间关系的线性建模方法。
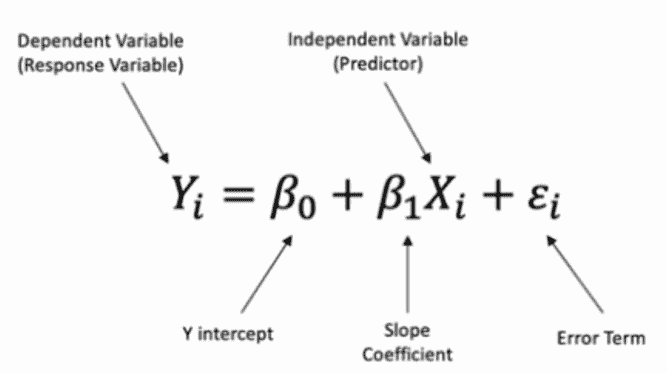
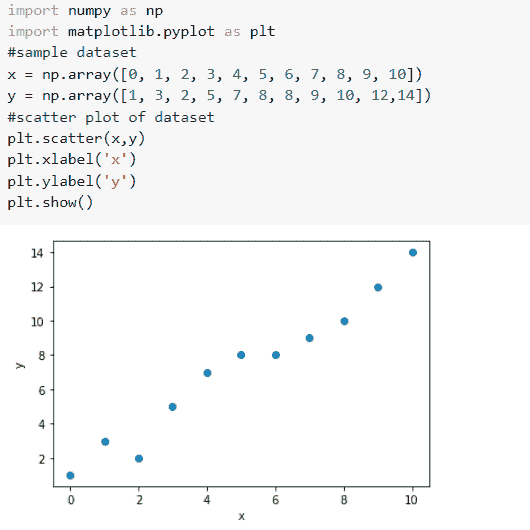
我们必须找到使模型最佳拟合数据的参数。回归线(即最佳拟合线)是预测值与观察值之间误差最小的那条线。
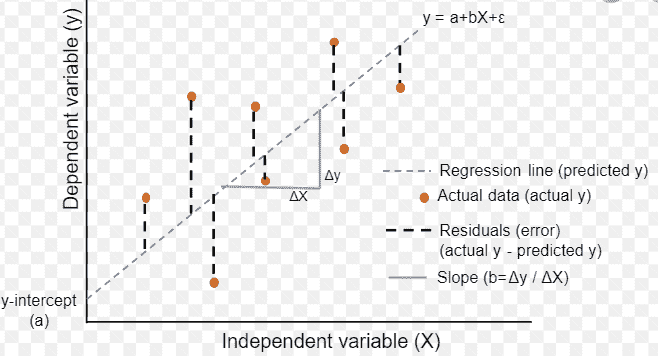
回归线。
现在,让我们尝试实现这个。
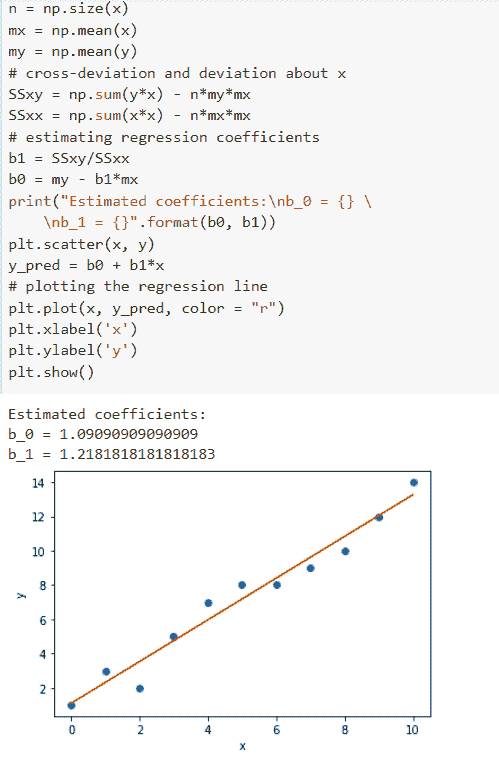
多元线性回归
对一个因变量和两个或更多自变量之间关系的线性建模方法。
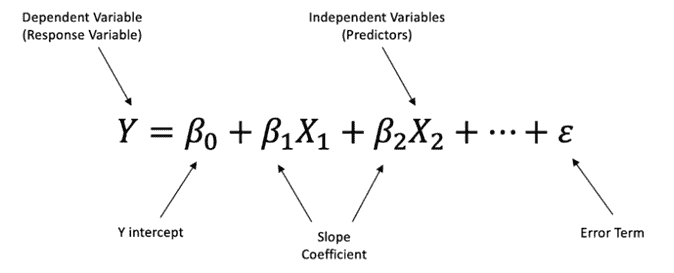
原文。已获授权转载。
相关内容:
更多相关主题
如何改进机器学习算法?吴恩达的课程,第二部分
原文:
www.kdnuggets.com/2017/12/improve-machine-learning-algorithm-lessons-andrew-ng-part2.html
评论
欢迎来到第二章,来自吴恩达的机器学习课程的经验。这一章会比较简短,我们将讨论人类水平的表现与可避免的偏差。如果你还没读第一章,这里是链接。我们开始吧!哦,还有一件事,这个系列完全基于吴恩达在 Coursera 上的最新课程。
与人类水平表现的比较
在过去几年中,越来越多的机器学习团队开始讨论将机器学习系统与人类水平表现进行比较。这是为什么呢?
-
由于深度学习的进步,这些算法突然变得更好,并且在很多机器学习应用领域变得更加可行。
-
此外,当你尝试做一些人类也能做到的事情时,设计和构建机器学习系统的工作流程会更加高效。
随着时间的推移,当你不断训练你的算法时,它会迅速改进,直到超过人类水平的表现。之后,它的进步会变得缓慢。虽然在任何情况下它都不能超过某个理论极限,称为贝叶斯最优误差,这是最好的可能误差。换句话说,任何函数从 x 到 y 的映射不能超过某个准确度水平。
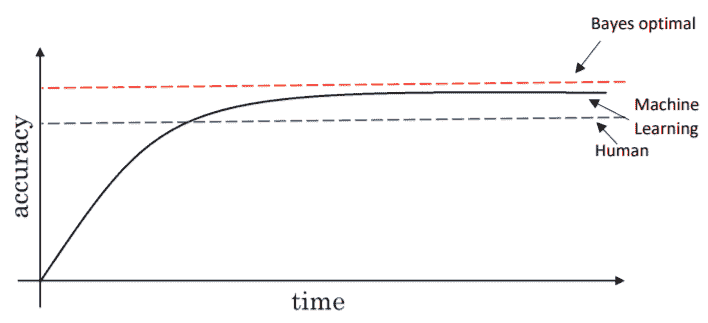
通常,人类错误和贝叶斯错误非常接近,尤其是对于自然感知问题,超越人类水平表现后改进的空间很小,因此学习速度显著减缓。
只要你的算法表现不如人类,可以使用以下方法来提高性能:
-
从人类那里获取标记数据
-
从手动错误分析中获得洞见,例如,了解人类为什么做对了这个问题。
-
更好地分析偏差/方差

可避免的偏差
我们希望我们的算法在训练集上表现良好,但不能过于良好(导致过拟合)。通过了解人类水平的表现,可以判断训练集的表现是否良好、过于良好或不够好。
示例:分类。
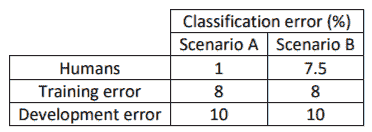
通过将人类水平表现作为贝叶斯误差的代理(例如在图像识别中),我们可以知道是否需要关注偏差或方差的回避策略,以改善系统的性能。
差异(训练误差,人类水平表现) = 可避免的偏差
差异(开发误差,训练误差) = 方差**
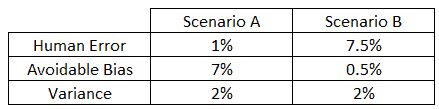
场景 A:
算法在训练集上的拟合不佳,因为目标约为 1%,而偏差为 7%。使用减少偏差的技术,例如训练更大的神经网络,延长训练集时间,或训练更好的优化算法(例如 Adam),或更改神经网络架构(使用 CNN、RNN 等)。
场景 B:
此处的重点应是减少方差,因为方差为 2%,而可避免的偏差仅为 0.5%。使用方差减少技术,例如正则化,或拥有更大的训练集,相应地调整超参数等。
注 1: 人类水平误差的定义取决于分析的目的。例如,在医学图像分类中,输入是放射学图像,输出是诊断分类决策。典型的人的误差为 x%,医生的误差为 (x-y)%,一组医生的误差为 (x-y-z)%。在代理贝叶斯误差时,你必须将 (x-y-z) 作为误差百分比。
注 2: 还有其他问题,其中机器学习显著超越了人类水平表现,特别是在结构化数据方面。例如,在线广告、推荐系统、预测系统等。
这次就到这里。感谢阅读!我们在下一篇中讨论错误分析、数据不匹配、多任务处理等。
如果你有任何问题/建议,请随时通过你的评论与我联系,或通过 LinkedIn / Twitter 与我联系。
原文。已获得许可重新发布。
相关
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关话题
如何将我的机器学习模型准确率从 80%持续提高到 90%以上
原文:
www.kdnuggets.com/2020/09/improve-machine-learning-models-accuracy.html
评论

照片由 Ricardo Arce 提供,发布在 Unsplash上。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
如果你完成了一些数据科学项目,那么你可能已经意识到,80%的准确率还算不错!但在现实世界中,80%是不够的。实际上,我工作过的大多数公司都期望最低准确率(或他们关注的其他指标)达到 90%以上。
因此,我将讨论 5 个可以显著提高准确性的做法。我强烈建议你仔细阅读这五点,因为我包含了许多初学者不知道的细节。
到了这一步,你应该明白影响机器学习模型表现的变量远比你想象的要多。
话虽如此,下面是 5 件你可以做的事情来改善你的机器学习模型!
1. 处理缺失值
我看到的一个最大错误是人们如何处理缺失值,这不一定是他们的错。很多网上的资料说,你通常通过均值填补来处理缺失值,即用给定特征的均值替换空值,但这通常不是最佳方法。
例如,假设我们有一个显示年龄和健身分数的表格,并且假设一个 80 岁的人缺少健身分数。如果我们从 15 岁到 80 岁的年龄范围中计算平均健身分数,那么 80 岁的人看起来会有比实际更高的健身分数。
因此,你首先要问自己的是为什么数据最初会缺失。
接下来,考虑处理缺失数据的其他方法,而不仅仅是均值/中位数填补:
-
特征预测建模:回到我关于年龄和健身评分的例子,我们可以建模年龄和健身评分之间的关系,然后使用该模型找到给定年龄的预期健身评分。这可以通过回归、ANOVA 等多种技术实现。
-
K 最近邻插补:使用 KNN 插补,缺失的数据会用另一个类似样本的值来填补,对于那些不知道的人,KNN 中的相似性是通过距离函数(即欧几里得距离)来确定的。
-
删除行:最后,你可以删除行。通常不推荐这样做,但当你开始时有大量数据时,这是可以接受的。
2. 特征工程
你可以显著提升机器学习模型的第二种方式是通过特征工程。特征工程是将原始数据转化为更好地表示所要解决的潜在问题的特征的过程。对于这一步骤没有特定的方法,这使得数据科学既是一门艺术,也是一门科学。话虽如此,以下是一些你可以考虑的事项:
-
将日期时间变量转换以提取仅仅是星期几、月份等信息……
-
为变量创建分箱或桶。(例如,对于身高变量,可以有 100–149 cm、150–199 cm、200–249 cm 等)
-
结合多个特征和/或值以创建一个新的特征。例如,在泰坦尼克挑战赛中,最准确的模型之一工程了一个名为“Is_women_or_child”的新变量,如果该人是女性或儿童则为 True,否则为 False。
3. 特征选择
你可以大幅提高模型准确性的第三个领域是特征选择,即选择数据集中最相关/有价值的特征。特征过多可能导致算法过拟合,而特征过少则可能导致算法欠拟合。
我喜欢使用的两种主要方法可以帮助你选择特征:
-
特征重要性:一些算法,如随机森林或 XGBoost,允许你确定哪些特征在预测目标变量的值时最为“重要”。通过快速创建这些模型并进行特征重要性分析,你将理解哪些变量比其他变量更有用。
-
降维:其中一种最常见的降维技术,主成分分析(PCA),将大量特征通过线性代数方法减少到更少的特征。
4. 集成学习算法
改善机器学习模型的最简单方法之一是选择更好的机器学习算法。如果你还不知道什么是集成学习算法,现在是学习它的时候了!
集成学习是一种将多个学习算法结合使用的方法。这样做的目的是使你能够实现比单独使用某个算法更高的预测性能。
常见的集成学习算法包括随机森林、XGBoost、梯度提升和 AdaBoost。为了说明为什么集成学习算法如此强大,我将以随机森林为例:
随机森林涉及使用原始数据的自助采样数据集创建多个决策树。然后,模型选择每棵决策树所有预测的众数(多数)。这样做的意义是什么?通过依赖“多数获胜”模型,它减少了来自单个树的错误风险。

例如,如果我们创建了一个决策树,即第三棵,它会预测 0。但是如果我们依赖所有 4 棵决策树的众数,预测值将是 1。这就是集成学习的力量!
5. 调整超参数
最后,还有一个不常被提及但仍然非常重要的方面,那就是调整模型的超参数。在这方面,你必须清楚理解你所使用的机器学习模型。否则,很难理解每个超参数的作用。
查看随机森林的所有超参数:
class sklearn.ensemble.RandomForestClassifier(n_estimators=100, *, criterion='gini', max_depth=None,
min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto',
max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True,
oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False,
class_weight=None, ccp_alpha=0.0, max_samples=None
例如,了解min_impurity_decrease是什么,可能会是个好主意,这样当你希望你的机器学习模型更加宽容时,你可以调整这个参数! 😉
原文。已获得许可重新发布。
相关内容:
更多相关话题
如何提高机器学习性能?安德鲁·吴的经验
原文:
www.kdnuggets.com/2017/12/improve-machine-learning-performance-lessons-andrew-ng.html
评论
你已经花了几周时间来构建你的机器学习系统,但性能不如你所满意。你考虑了多种方法来提高算法性能,如收集更多数据、增加隐藏单元、增加层数、改变网络架构、改变基本算法等等。但是,这些方法中哪一个能带来最佳改进呢?你可以尝试所有方法,投入大量时间,找出对你有效的。或者,你可以利用吴的经验提供的以下建议。

正交化
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
构建机器学习系统的挑战之一是你可以尝试的东西太多了,能改变的东西也很多。例如,你可以调整的超参数也有很多。知道调整哪个参数以获得什么效果的艺术,称为正交化。
在监督学习中,需要在以下四个任务上表现良好,对于每个任务,都应该有一组可以调整的参数,以使任务表现良好。
-
使训练集拟合良好
-
使开发集拟合良好
-
使测试集拟合良好
-
在实际应用中表现良好
假设你的算法在训练集上的表现不佳,你需要一个或一组特定的调整参数,以确保可以调整算法使其在训练集上拟合良好。你可以用来调整的参数包括:训练一个更大的网络或切换到更好的优化算法,如Adam 优化算法,等等。相对而言,如果你的算法在开发集上的表现不好,那么你可以使用一组关于正则化的调整参数,试图使其满足第二个标准。因此,了解你的调整参数将有助于更快地提高系统性能。
单一数字评估指标
为你的项目设置一个单一的真实数值指标作为评估指标,以便你知道调整某个参数是否对算法有帮助。在测试多个场景时,这个指标可以帮助你快速选择最有效的算法。有时候,你可能需要两个指标来评估算法,比如精度和召回率。但有了两个评估指标后,很难标记哪个算法表现更好。
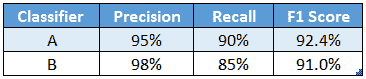
因此,与其使用两个指标——精度和召回率来选择分类器,你只需找到一个新的评估指标来结合精度和召回率。在机器学习文献中,结合精度和召回率的标准方法称为F1 分数。你通常不需要自己设计新的性能衡量标准,因为你可以根据系统的要求在机器学习文献中找到现有的标准。
满足和优化指标
可能会有一些情况,你不仅有一个(或两个),而是有 n 个你关心的指标。假设你被要求创建一个具有最大准确率的分类器,同时具有最小的时间和空间复杂度。你构建了以下 4 个分类器,你会交付哪一个?
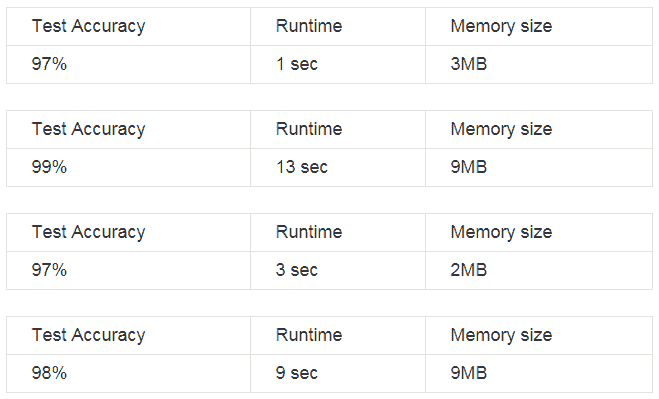
在这种情况下,选择一个指标作为优化指标,(n-1)个指标作为满足指标。在这里,最大化测试准确率(优化指标),运行时间少于 10 秒和内存需求少于 10MB(满足阈值)。通过这样做,你为团队设定了目标,使他们知道需要达成什么。
在机器学习领域,大家都知道 Andrew Ng,如果他们知道他,他们也会知道他的深度学习专业化课程在 Coursera 上。如果你想进入 AI 领域,这个专业化课程将帮助你实现。这个专业化课程中的一个课程讲述了结构化机器学习项目,你可以了解如何诊断机器学习系统中的错误,并优先考虑减少这些错误的最有前景的方向。本文基于* 这个 课程。
训练/开发/测试分布
始终确保你的开发集和测试集来自相同的分布,并且必须从所有数据中随机抽取。例如,如果你正在构建一个猫分类器,并且你的数据来自美国、英国、南美、印度、中国和澳大利亚。那么将前三个地区的数据用作开发集,而将后三个地区的数据用作测试集是不正确的。要将所有数据混合后,随机选择开发集和测试集。
选择一个开发/测试集来反映你期望将来获得的数据,并且认为在这些数据上表现良好很重要。
更改开发/测试集和评估指标
如果在项目进行到一半时你发现选择了错误的开发集或评估指标,请更改它们。毕竟,你的机器学习成功取决于—
-
知道要瞄准什么(选择正确的开发集和评估指标)
-
精确目标(在这些指标上表现良好)
如果在你的指标+开发/测试集上表现良好却与实际应用不符,那就该更改它们了。你没有设定好目标。
结论
了解你的机器学习算法的应用,按需收集数据,并随机拆分训练/开发/测试集。提出一个优化评估指标,并调整参数以在该指标上提升表现。
希望这篇文章帮助你学习如何构建一个成功的机器学习项目。接下来将有更多文章讨论人类级别的表现、可避免的偏见、错误分析、数据不匹配、多任务等。
如果你有任何问题或建议,欢迎通过评论联系我,或在LinkedIn和Twitter上与我联系。
原文。经许可转载。
相关
更多相关主题
通过人类参与提高模型性能
原文:
www.kdnuggets.com/2021/04/improving-model-performance-through-human-participation.html
评论
由 Preetam Joshi,Netflix 的高级软件工程师和 Mudit Jain,Google 的软件工程师。

人类 + 人工智能(图片来源:Pixabay)。
某些领域对假阳性非常敏感。一个例子是信用卡欺诈检测,在这种情况下,错误地将活动分类为欺诈可能会对发卡金融机构的声誉产生重大负面影响 [1]。另一个例子是使用语言模型(如 GPT-3)生成文本响应的自动聊天机器人 [2]。审核生成的文本很重要,以确保至少不会生成不当语言(如仇恨言论、脏话等)。
另一个高度敏感的领域是医疗领域,在这里,像癌症诊断这样的内容对假阳性非常敏感 [3]。在下面的部分中,我们将首先描述一个使用 ML 模型进行推断的系统,然后详细说明需要哪些修改以将人类代理纳入推断循环。
基于模型的推断
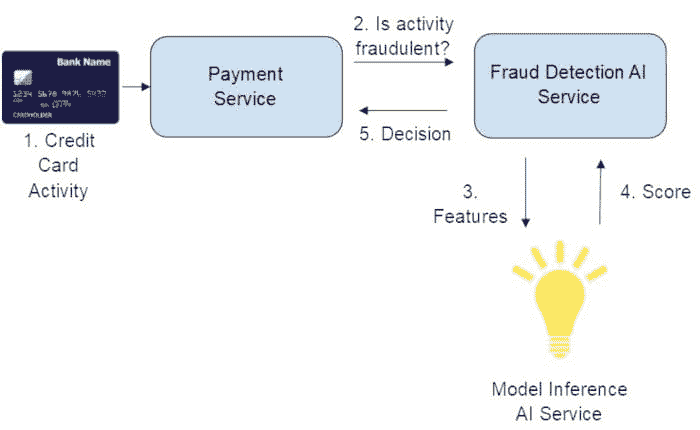
图 1. 经典模型推断系统。
让我们从一个典型的系统开始,该系统用于处理信用卡欺诈用例的机器学习模型。图 1 显示了一个简化的系统视图和模型单独负责决定给定活动是否欺诈的事件序列。
如何选择阈值?
阈值的选择是基于对精确度和召回率的要求 [5]。在图 1 中所示的示例中,精确度定义为正确预测的欺诈活动数量(真正例)除以预测为欺诈的总活动数(真正例 + 假阳性)。召回率定义为正确预测的欺诈活动数量(真正例)除以正确预测为欺诈的活动数量与实际欺诈活动数之和(真正例 + 假阴性)。在大多数情况下,需要在精确度和召回率之间做出权衡以实现系统的目标。一个有用的工具是精确度-召回率曲线。图 2 说明了精确度-召回率曲线。
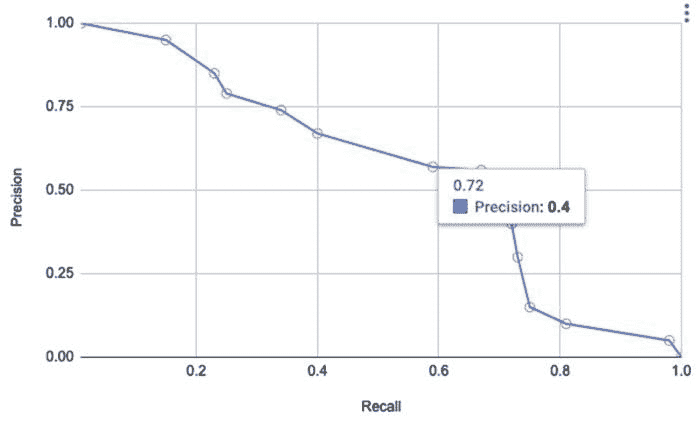
图 2. 精确度-召回率曲线。
注意到在更高的召回率下精确度会下降。在召回率为 0.72 时,精确度降到大约 0.4。为了捕捉 70% 的欺诈案件,我们将遭遇较高数量的假阳性,精确度为 40%。在我们的情况下,假阳性数量不可接受,因为这会导致非常糟糕的客户体验。我们需要在合理的召回率下获得更高的精确度。请注意,什么算作合理的假阳性数量是主观的。对于我们的用例,从图 1 中,我们需要精确度大于 0.99。
尽管我们做出了提高精确度的权衡,但在 0.99 的精确度下,召回率为 0.15,这还不够。为了实现更高的召回率,我们将获得较低的精确度,这对业务来说是不可接受的。在下一节中,我们将讨论如何利用人工输入来实现更高的总体精确度和更高的召回率。
人工参与
图 3 显示了一个包含人工互动的修改系统。
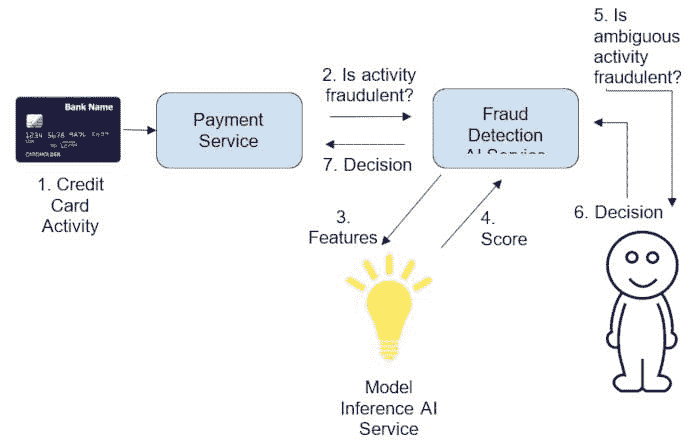
图 3. 通过人工互动提升模型性能。
提高召回率的一种方法是将人工代理纳入推理循环。在这种设置中,模型置信度低的活动子集将被发送给人工代理进行手动检查。在选择确定低置信度/模糊预测子集的阈值时,重要的是要考虑将发送给人工代理的模糊活动的数量,因为后者是稀缺资源。为了帮助选择阈值,可以使用精确度-召回率-阈值图(图 4)。
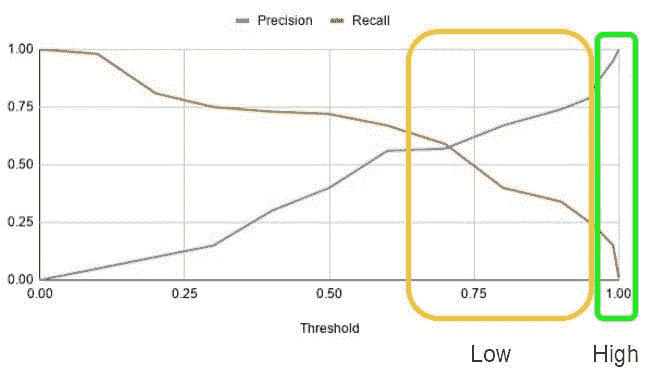
图 4. 精确度-召回率-阈值 曲线。
在我们的案例中,假设接近 1.0 的分数表示正标签(欺诈),接近 0.0 的分数表示负标签(非欺诈)。图 4 中高亮了两个区域:
-
绿色区域表示高置信度的正标签区域,即允许自动化模型决策,模型精确度令人满意(假阳性率低通常被最终用户接受)。
-
黄色区域表示低置信度的正标签区域,其中自动化模型决策的精确度水平不可接受(高假阳性率对业务产生了显著的负面影响)。
黄色区域是一个很好的候选区域,可以通过人工检查来提高精度。相同的过程也可以用于分析负标签——接近 0.0 的区域是高置信度区域,而超过某个阈值,结果变得模糊。可以将黄色区域的所有项目或部分项目发送进行人工检查。在人工检查期间,人工审查员利用他们通过严格培训过程获得的判断力和经验来决定活动的最终结果——在我们的案例中是欺诈与否。这里的关键假设是,人工审查员在处理模糊案例时比机器学习模型更出色。
如前所述,人力资源稀缺。因此,发送给人工审查员的请求量在选择阈值时是一个重要的考虑因素。图 5 显示了阈值与体积和召回率的关系示例。体积定义为每小时发送给人工审查员的项目数量。从图 5 中可以看出,阈值为 0.7 时,体积为 16K 项目(每小时)。
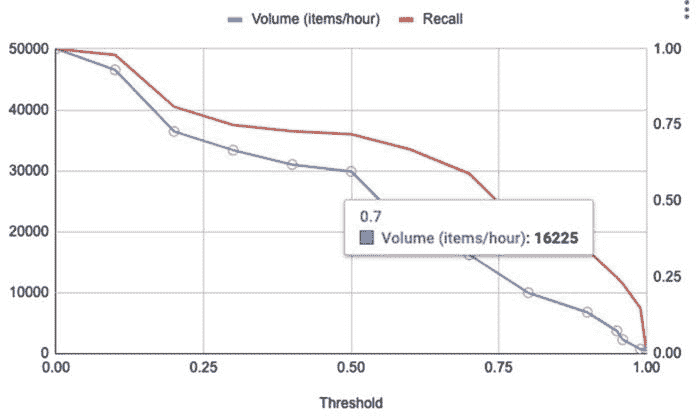
图 5. 召回率与阈值的体积(每小时请求数量)图示。
图 4 和图 5 中的图表都可以用来选择合适的阈值,以在可接受的人力审查量下获得期望的召回率。我们来做一个快速的练习,通过这两个图来确定阈值。在召回率为 0.59(阈值为 0.7)时,审查量(见图 5)大约为 16K 项目/小时。在相同的召回率下,模型精度大约为 0.6(见图 4)。假设人工审查员池能够处理 16K 项目/小时的审查量,并且假设人工审查员的精度和召回率为 95%,那么在人力审查后的精度将介于 0.95 和 0.99 之间。在这种设置下,我们能够将召回率从 0.15 提升到 0.56(0.59 [模型] * 0.95 [人工]),同时保持精度水平高于 0.95。
使用人工审查员的最佳实践
为了实现高质量的人工审查,重要的是为负责手动审查项目的人工审查员建立一个明确的培训流程。精心设计的培训计划和定期的反馈循环将帮助维持手动审查项目的高质量标准。这种严格的培训和反馈循环不仅有助于减少人为错误,还能帮助保持每项决策的服务水平协议(SLA)要求。
另一种稍微昂贵的策略是对每个手动审查的项目采用三人投票的方法,即使用 3 名审查员审查同一项目,并根据 3 名审查员的多数票决定最终结果。此外,记录审查员之间的分歧,以便团队可以回顾这些分歧,完善其判断政策。
适用于微服务的最佳实践同样适用于此。这包括对以下内容的适当监控:
-
从系统接收项目到做出决策的端到端延迟
-
代理池的整体健康状况
-
发送给人工审核的项目数量
-
对项目分类的每小时统计数据
最后,由于各种原因,模型的精确度和召回率可能会随时间变化 [4]。重要的是要通过跟踪精确度/召回率来重新审视所选择的阈值。
结论
我们回顾了一个涉及人类代理的 ML 推理系统如何在保持高精确度的同时提高召回率。这种方法在对假阳性敏感的用例中特别有用。精确度-召回率-阈值曲线是选择人工审核和自动模型决策阈值的一个很好的工具。然而,涉及人类代理会增加成本,并可能导致在经历快速增长的系统中的瓶颈。在考虑这样的系统时,仔细权衡这些方面是很重要的。
参考文献
-
假阳性癌症筛查可能会影响患者接受未来筛查的意愿
www.ncbi.nlm.nih.gov/pmc/articles/PMC5992010/ -
“你能相信你模型的不确定性吗?在数据集偏移下评估预测不确定性”,Yaniv Ovadia 等
arxiv.org/abs/1906.02530
个人简介: Preetam Joshi 是 Netflix 的高级软件工程师,专注于应用机器学习和机器学习基础设施。他曾在 Thumbtack 和 Yahoo 工作过。他获得了乔治亚理工学院计算学院的硕士学位。
Mudit Jain 是谷歌的自动化机器学习 NLP 工程师,专注于 Google Cloud 平台。他曾在微软工作过。他获得了印度理工学院坎普尔分校计算机科学与工程学士学位。
相关:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关内容
数据仓库中的机器学习与现代数据科学堆栈
原文:
www.kdnuggets.com/2021/06/in-warehouse-machine-learning-modern-data-science-stack.html
评论
作者 Nick Acosta,开发者倡导者,Fivetran 联盟。

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织的 IT
数据堆栈的融合
尽管数据分析和数据科学是相当独特的学科,但在有效实现这些学科的过程中,数据处理步骤有相当大的重叠。两者都受益于访问存储在集中位置的大量高质量数据,以及高效可靠的过程来将数据从源头带到这些中心存储库。直到最近,工作一直是用不同的技术在数据仓库(用于分析和商业智能)和数据湖(用于数据科学和机器学习)之间重复进行的。一些新服务正在努力将这些数据堆栈合并到一个环境中,这篇文章将概述这些服务及其能为数据组织带来的价值。
现代数据科学堆栈的好处
现代数据堆栈是一系列技术,能够将多个数据源集中到一个在分析中变得流行的云数据仓库中。它可以扩展以适应机器学习工作负载,形成所谓的现代数据科学堆栈。现代数据科学堆栈消除了数据分析和数据科学团队的孤岛和重复工作的服务,并将模型靠近它们正在训练和用于预测的数据,简化了从模型中心 AI 开发到数据中心 AI 开发的过渡。许多组织在数据仓储技术上投入了大量资金,以保持环境的安全、治理、运营、组织和性能,但一旦数据从数据仓库抽样到数据湖中,它就失去了所有这些特性。
还有三个不那么明显的好处我也想强调一下,这些是在我转向现代数据科学栈后发现的。将模型存储在数据仓库中意味着它们的预测也可以被存储并通过 SQL 查询获取。执行表查找而不是需要嵌入模型或框架来使用机器学习,可以大大推动组织中机器学习的普及。此外,因为机器学习过程中的每一步都在同一个地方、同一数据上发生,所以在训练时和服务时传递给模型的数据之间差异的可能性较小,这意味着可以大大避免训练-服务偏差及其检测工具。最后,由于机器学习过程的每一步都可以用 SQL 执行,因此可以使用像 Apache Airflow 这样的工具将不同的步骤组合成数据管道。
数据仓库内机器学习服务概述
BigQuery ML 和 Redshift ML

AWS 和 Google Cloud 最近都为其数据仓库 Redshift(左)和 BigQuery(右)新增了机器学习功能。
BigQuery ML 和 Redshift ML 将机器学习功能添加到 BigQuery 和 Redshift,即 Google Cloud Platform 和 AWS 各自的数据仓库。AWS 最近刚刚宣布了Redshift ML 的普遍可用性,而BigQuery ML 已经提供了一段时间。
两者都扩展了 SQL 语法,新增了一个 CREATE MODEL 命令,允许创建机器学习模型并指定诸如模型类型、用于训练的数据表和生成预测的目标特征等参数。这些新的 SQL 命令利用自动化机器学习过程来提供数据转换和模型调整,以识别候选模型中的最佳性能。自定义模型也可以与每种工具一起使用,提供了相当大的灵活性,但每种工具在开发上都有一些限制。自定义模型必须保存为 TensorFlow 模型才能在 BigQuery 中使用,而 Redshift ML 必须使用在 AWS 数据科学开发平台 SageMaker 上部署的模型。一旦模型被训练或导入到仓库中,SELECT 语句可以用 FROM 指定一个训练好的模型来代替表进行推断,这些推断可以很容易地插入到仓库中的预测表中以供使用、审核和错误分析。
Snowflake 和其他选项
Snowflake 表示他们的“整个 AI 和 ML 计划旨在将可扩展性构建到[他们的数据仓库]中,以便你可以使用你选择的工具。”之前提到的 AWS Sagemaker 平台就是一个 Snowflake 可以集成的 ML 工具,Databricks 也是如此。Databricks 正在进行更令人印象深刻的开发,他们刚刚发布了Delta Lake 1.0.0 版本,该版本从相反的方向融合了数据分析和数据科学技术栈。Delta Lake 并不是将机器学习能力引入数据仓库,而是将传统的分析和商业智能能力,如 ACID 事务,添加到数据湖中,形成一个新的数据湖屋架构,为现代数据科学栈提供类似的好处。
评审
如果你的组织有兴趣同时进行数据分析和数据科学,有多种选项可以促进这两个学科,但它们的数据管道之间有太多的共性,因此不能为数据摄取、存储和转化单独设置工具。在仓库内的机器学习工具可以用来构建现代数据科学栈,这样可以通过将所有数据和处理这些数据的从业人员移至一个集中位置,消除数据工程和模型服务组件中出现的数据孤岛。
简介: Nick Acosta 是 Fivetran 的开发者倡导者和数据科学家,他在普渡大学和南加州大学学习计算机科学。Fivetran 自动化数据摄取,并很高兴成为包括亚马逊、Databricks、谷歌和 Snowflake 在内的多家组织的技术合作伙伴。
相关:
更多相关主题
提高你的回调率与 LinkedIn 个人资料
原文:
www.kdnuggets.com/increase-your-callback-rate-with-a-linkedin-profile

图片来源:rawpixel on Freepik
如果你刚从大学毕业或决定重返职场,LinkedIn 等平台应该是你的好帮手。LinkedIn 是全球最大的职业网络,它将帮助你找到新工作,连接志同道合的人,并发现新的机会。
我过去与许多应届毕业生交谈过,他们总是不愿意创建 LinkedIn 个人资料,我一直感到困惑。但谁不对自己不熟悉的事物感到紧张呢?
了解 LinkedIn 是你的个人品牌。当你创建 LinkedIn 个人资料时,你希望它真正与你的身份、你的职业背景以及你能提供的服务相一致。
在这篇博客中,我将介绍如何设置你的 LinkedIn 个人资料,以及你需要做什么来提高你获得潜在工作和机会的回调率。那么让我们开始吧……
如果你还没有 LinkedIn 个人资料,你需要注册一个 LinkedIn 账户。完成注册后,你将拥有一个空白的 LinkedIn 个人资料,你可以对其进行自定义。
头像
首先,你需要上传一张头像,因为这是其他 LinkedIn 用户首先看到的内容。记住,LinkedIn 是一个专业网络,因此你的头像应该准确地体现这一点。
需要考虑的一些要点:
-
一张你直接看向镜头的照片
-
最多展示你身体的一半
-
简单的背景
你可以使用诸如remove.bg这样的工具来去除图像背景。LinkedIn 头像的推荐尺寸是 400x400 像素。准备好图像后,接下来就是将其上传为你的 LinkedIn 头像。
横幅
如前所述,LinkedIn 是你的个人品牌。LinkedIn 横幅可以让你通过它来展示你自己。例如,如果你有一家公司并且有一个口号,你可以将你的口号上传到横幅上。另一个例子是,软件工程师通过编程展示个人资料的分解,如下所示。
图片来源:Aaron Cordova
vvvvvv
你可以使用自己的图像作为 LinkedIn 横幅,但如果你在选择内容时遇到困难,你可以访问Canva,它提供了不同风格的横幅模板。
介绍部分
一旦你为你的 LinkedIn 个人资料添加了美学吸引力,下一步就是添加一些内容。在这里,我们将从“简介”部分开始,你可以通过点击个人资料右上角的铅笔图标进入该部分,图标旁边是你的个人资料照片。
你需要填写你的名字和姓氏,然后进入你的标题部分。你的标题非常重要,因为它告知其他成员你的专业领域,如软件工程。
这是我在 LinkedIn 上遇到的一些示例标题:
-
Google 云人工智能服务负责人
-
人工智能 | Web3 | 营销
-
在 OpenAI 担任开发者关系负责人
-
人工智能与数据科学 | 预测分析 | 数据策略 | 公共部门 | 女性在人工智能领域
如果你是应届毕业生,自信地陈述你的期望,因为你的标题是别人关注的重点。
教育部分
你可以通过两种方式填写你的 LinkedIn 教育部分。
-
第一个方法是点击相同的铅笔图标,向下滚动到教育部分并填写。
-
另一个方法是向下滚动到 LinkedIn 个人资料中的教育部分,并填写更详细的概述。
填写你的教育部分,包括大学、训练营、课程和其他成就。不要包括如幼儿园和小学等教育阶段。
完成后,你可以选择在 LinkedIn 个人资料的简介部分显示你的教育经历。你可以通过点击铅笔图标并勾选“在我的简介中显示教育经历”框来实现这一点。
位置设置
你的位置设置非常重要,也是很多用户常犯的错误。例如,你可能一生都在纽约生活和学习,但现在想要开始在旧金山的新生活和职业生涯。
你可以做的最好的事情是将“简介”部分中的位置更改为美国,并指定旧金山的具体邮政编码。这样,你的个人资料在这些特定区域内会更容易被招聘经理看到。
自定义网址
在你 LinkedIn 个人资料页面顶部,你会看到一个名为“联系信息”的链接。在这一部分,你会看到你的 LinkedIn 个人资料网址。你可以通过点击个人资料页面右侧的铅笔图标来编辑这个网址。创建一个独特的个人资料网址非常重要,以提高你的排名。
摘要部分
在你个人资料的顶部,你会看到一个“添加部分”按钮。点击这个按钮,然后选择“关于”,再选择“摘要”。我认为这一部分需要是非常简短的自我介绍,当我说简短时,我指的是 2 到 3 个短段落。
在这一部分,你可以提供更多关于你的专业和技能的详细信息,以及提及职业变化。在这里,人们可以更多地了解你,你基本上是在推销你的能力和技能。你还可以包括你的个人博客、网站等。
技能
现在让我们继续技能部分。在同一个‘添加部分’按钮中,你会看到一个‘技能’部分,点击它。在这里,你需要添加一些与你的专业相关的技能。如果你正在找工作,最好的做法是添加那些通常出现在你想要的职位描述中的技能。
查找常用词汇的最简单方法是将职位描述复制粘贴到 WordCloud,它将生成词汇的可视化表示。你可以用这个来帮助你添加需要列出的技能。
如果你列出了 5 个或更多技能,你将有更高的机会与招聘人员建立联系,并获得更多个人资料浏览。
成就
现在为你的个人资料增添一些内容。将你的成就写上!在‘添加部分’按钮中,有一个‘成就’按钮,你可以在这里添加:
-
发表的作品
-
专利
-
课程
-
项目
-
语言等。
记得填写这些内容,这将增加招聘人员访问你的 LinkedIn 页面。
发布
就像其他平台一样,例如 Instagram,发布增加参与度。发布相关的 LinkedIn 帖子将提高你的帖子在更广泛社区中的覆盖面,吸引招聘人员的关注。
你可以创建一个常规帖子、撰写文章、添加链接和上传媒体。例如,你的 YouTube 视频或博客文章。
LinkedIn 群组
如果你想扩大你的网络,一个好方法是加入 LinkedIn 群组。在 LinkedIn 页面右上角,你会看到一个名为‘工作’的网格图标。点击它,你可以查看更多 LinkedIn 产品,其中之一是‘群组’。
发现与你的兴趣领域相关的新群组。例如,一位数据科学家可能想加入 KDnuggets 数据科学与机器学习。
找工作?
如果你在积极寻找工作,一个重要的考虑点是将你的 LinkedIn 个人资料显示为‘开放求职’。在你的个人资料图片下,有一个名为‘开放求职’的按钮,你可以从下拉菜单中选择:
-
寻找新工作
-
提供服务
-
招聘
点击‘寻找新工作’,并添加你所寻找的工作类型的要求。
总结
通过上述所有步骤,你将提高招聘人员发现你个人资料的可能性。这篇逐步博客将帮助你迅速找到梦想工作!如果你有更多建议,请在评论中告诉我们。
尼莎·阿利亚 是一名数据科学家、自由技术写作人以及 KDnuggets 的社区经理。她特别关注于提供数据科学职业建议或教程,以及基于理论的数据科学知识。她还希望探索人工智能如何能促进人类生命的延续。作为一名热衷于学习的人,她寻求拓宽技术知识和写作技能,同时帮助指导他人。
更多相关内容
数据库内分析:利用 SQL 的分析功能
原文:
www.kdnuggets.com/2023/07/indatabase-analytics-leveraging-sql-analytic-functions.html

作者提供的图片
我们都知道数据分析在当今数据驱动的世界中的重要性,以及它如何从现有数据中为我们提供宝贵的见解。但有时,数据分析对于数据分析师来说非常具有挑战性和耗时。它变得繁琐的主要原因是生成的数据量激增以及需要外部工具来执行复杂的分析技术。
我们的前三大课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业生涯
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你的组织的 IT 需求
但如果我们在数据库内部分析数据,并使用显著简化的查询呢?这可以通过 SQL 分析功能实现。本文将讨论可以在 SQL 服务器中执行的各种 SQL 分析功能,并为我们提供有价值的结果。
这些功能基于一组行计算汇总值,并超越了基本的行操作。它们为我们提供了排名、时间序列计算、窗口处理和趋势分析的工具。所以在不浪费更多时间的情况下,我们开始逐一讨论这些功能,并附上详细的说明和实际示例。本教程的前提是对 SQL 查询的基本实践知识。
创建演示表
我们将创建一个演示表,并在该表上应用所有分析功能,以便你能轻松跟随教程。
注意: 本教程中讨论的一些功能在 SQLite 中不存在。因此,最好使用 MySQL 或 PostgreSQL 服务器。
这个表格包含了几位大学生的数据,包括学生 ID、学生姓名、科目和满分 100 的最终分数四列。
创建一个包含 4 列的学生表:
CREATE TABLE students
(
id INT NOT NULL PRIMARY KEY,
NAME VARCHAR(255),
subject VARCHAR(30),
final_marks INT
);
现在,我们将向该表中插入一些虚拟数据。
INSERT INTO Students (id, name, subject, final_marks)
VALUES (1, 'John', 'Maths', 89),
(2, 'Kelvin', 'Physics', 67),
(3, 'Peter', 'Chemistry', 78),
(4, 'Saina', 'Maths', 44),
(5, 'Pollard', 'Chemistry', 91),
(6, 'Steve', 'Biology', 88),
(7, 'Jos', 'Physics', 89),
(8, 'Afridi', 'Maths', 97),
(9, 'Ricky', 'Biology', 78),
(10, 'David', 'Chemistry', 93),
(11, 'Jofra', 'Chemistry', 93),
(12, 'James', 'Biology', 65),
(13, 'Adam', 'Maths', 90),
(14, 'Warner', 'Biology', 45),
(15, 'Virat', 'Physics', 56);
现在我们将可视化我们的表格。
SELECT *
FROM students
输出:
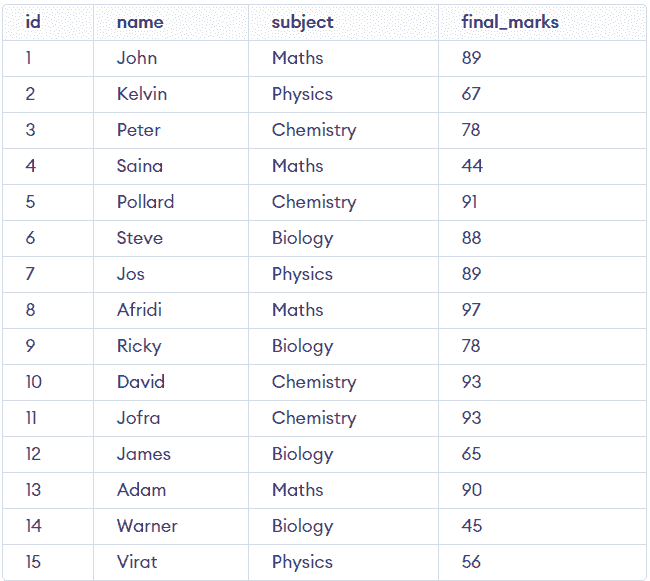
我们准备执行分析功能。
RANK() 和 DENSE_RANK()
RANK() 函数将在一个分区内根据指定的顺序为每一行分配一个特定的排名。如果行在同一个分区内具有相同的值,它们会被分配相同的排名。
让我们通过下面的示例更清楚地理解这一点。
SELECT *,
Rank()
OVER (
ORDER BY final_marks DESC) AS 'ranks'
FROM students;
输出:
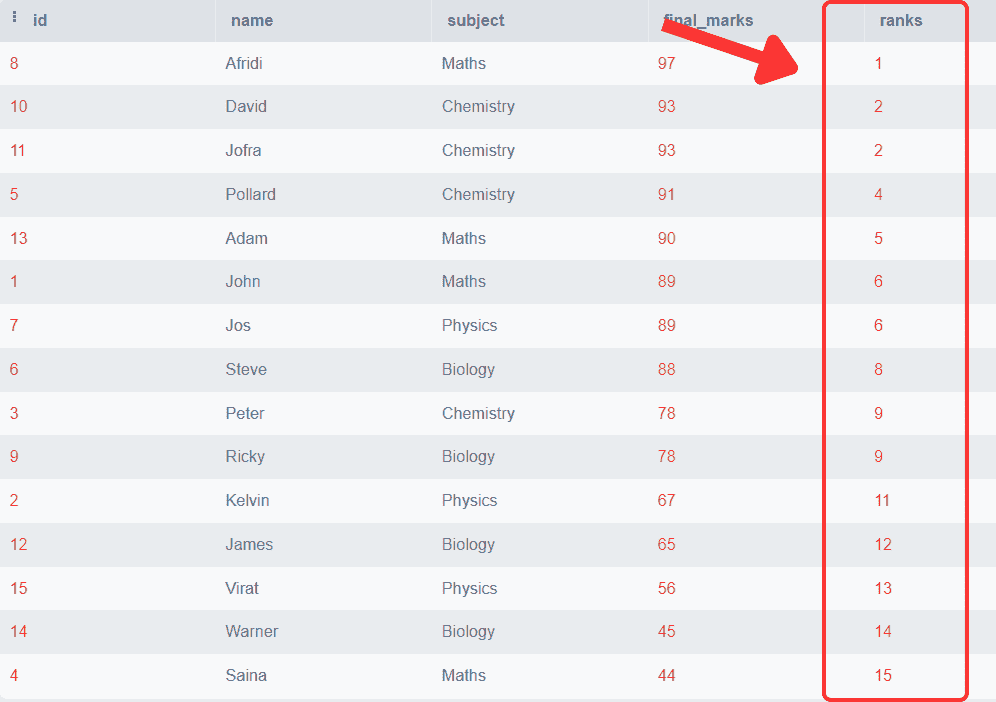
你可以观察到最终的分数是按降序排列的,每一行都与一个特定的排名相关联。你还可以观察到得分相同的学生会获得相同的排名,并且重复行后的排名会被跳过。
我们还可以找到每个科目的前几名,即可以根据科目划分排名。让我们看看如何实现。
SELECT *,
Rank()
OVER (
PARTITION BY subject
ORDER BY final_marks DESC) AS 'ranks'
FROM students;
输出:
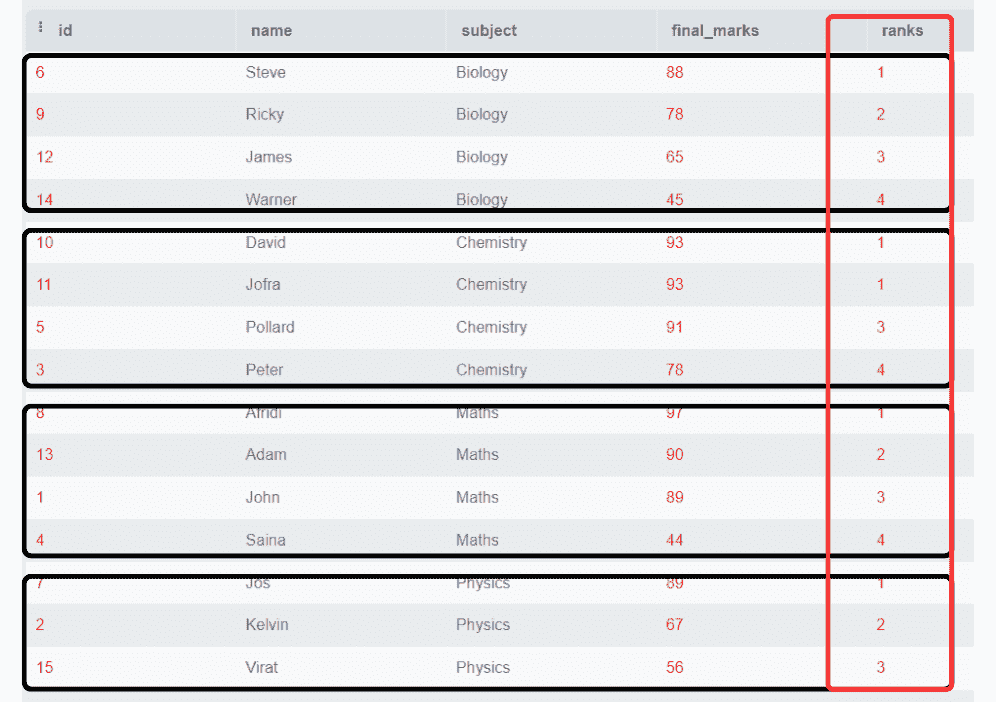
在这个示例中,我们根据科目划分了排名,排名是为每个科目单独分配的。
注意: 请注意,两名学生在化学科目中的得分相同,排名为 1,接下来的排名直接从 3 开始,跳过了 2 的排名。
RANK() 函数的特点是它不总是需要连续生成排名。下一个排名将是前一个排名与重复数量的总和。
为了克服这个问题,DENSE_RANK() 被引入以类似于 RANK() 函数的方式工作,但它始终连续分配排名。请参见下面的示例:
SELECT *,
DENSE_RANK()
OVER (
PARTITION BY subject
ORDER BY final_marks DESC) AS 'ranks'
FROM students;
输出:
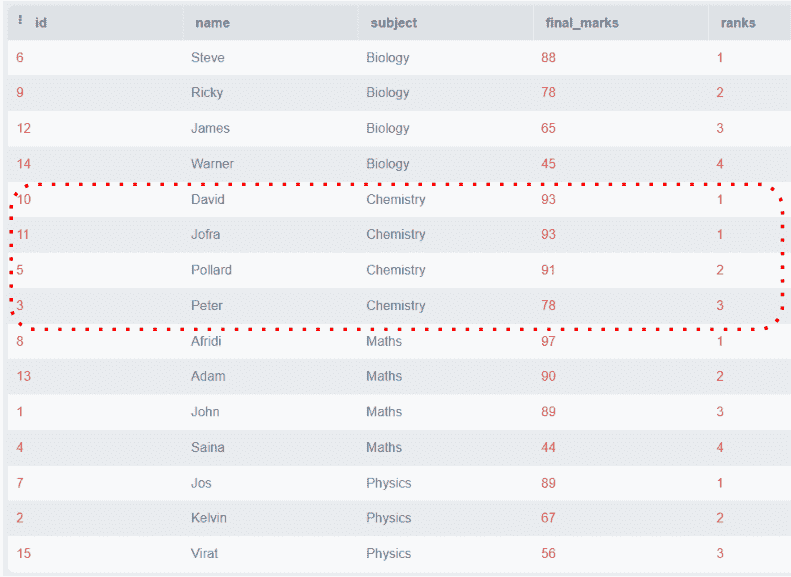
上图显示了即使在同一个分区内有重复分数,所有的排名仍然是连续的。
NTILE()
NTILE() 函数用于将行分成指定数量(N)的大致相等大小的桶。每一行都被分配一个从 1 到 N 的桶号(桶的总数)。
我们还可以在特定的分区或排序上应用 NTILE() 函数,这些分区和排序在 PARTITION BY 和 ORDER BY 子句中指定。
假设 N 不能被行数整除。那么函数将创建大小不同、相差一个的桶。
语法:
NTILE(n) OVER (PARTITION BY c1, c2 ORDER BY c3)
NTILE() 函数需要一个必需的参数 N,即桶的数量,以及一些可选的参数,如 PARTITION BY 和 ORDER BY 子句。NTILE() 将根据这些子句指定的顺序对行进行划分。
让我们以“学生”表为例。假设我们想根据最终得分将学生分组。我们将创建三个组。组 1 将包含分数最高的学生。组 2 将包括所有中等分数的学生,而组 3 将包含低分的学生。
SELECT *,
NTILE(3)
OVER (
ORDER BY final_marks DESC) AS bucket
FROM students;
输出:
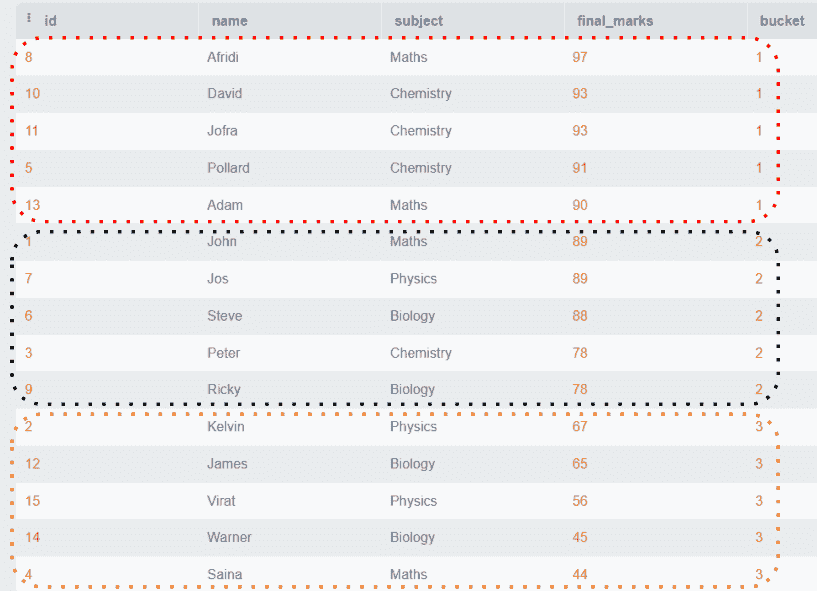
上述示例显示所有行按 final_marks 排序,并分成三组,每组包含五行。
NTILE() 在我们想要根据某些指定的标准将数据分成相等的组时非常有用。它可以用于如根据购买的商品进行客户分割或对员工表现进行分类等应用。
CUME_DIST()
CUME_DIST() 函数计算每行在指定分区或排序中的特定值的累积分布。累积分布函数(CDF)表示随机变量 X 小于或等于 x 的概率。它用 F(x) 表示,其数学公式如下:
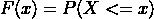
P(x) 是概率分布函数。
简单来说,CUME_DIST() 函数返回值小于或等于当前行值的行的百分比。这将有助于分析数据的分布及其在数据集中的相对位置。
SELECT *,
CUME_DIST()
OVER (
ORDER BY final_marks) AS cum_dis
FROM students;
输出:
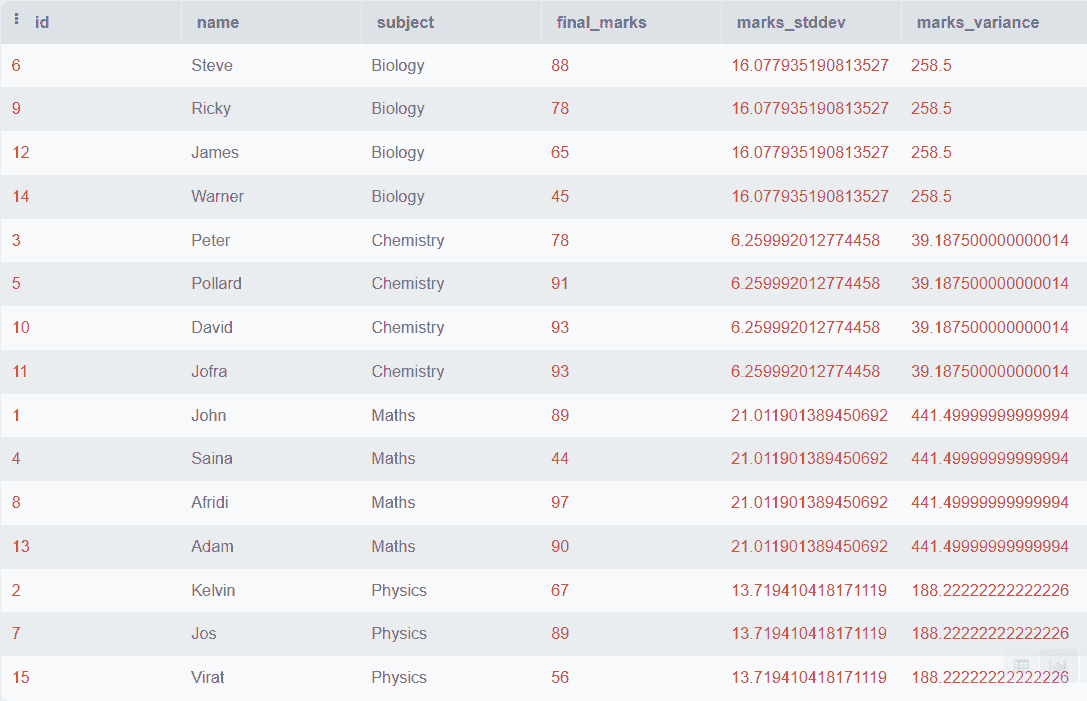
上述代码将根据 final_marks 对所有行进行排序并计算累积分布,但如果你想根据科目对数据进行分区,你可以使用 PARTITION BY 子句。以下是如何操作的示例。
SELECT *,
CUME_DIST()
OVER (
PARTITION BY subject
ORDER BY final_marks) AS cum_dis
FROM students;
输出:
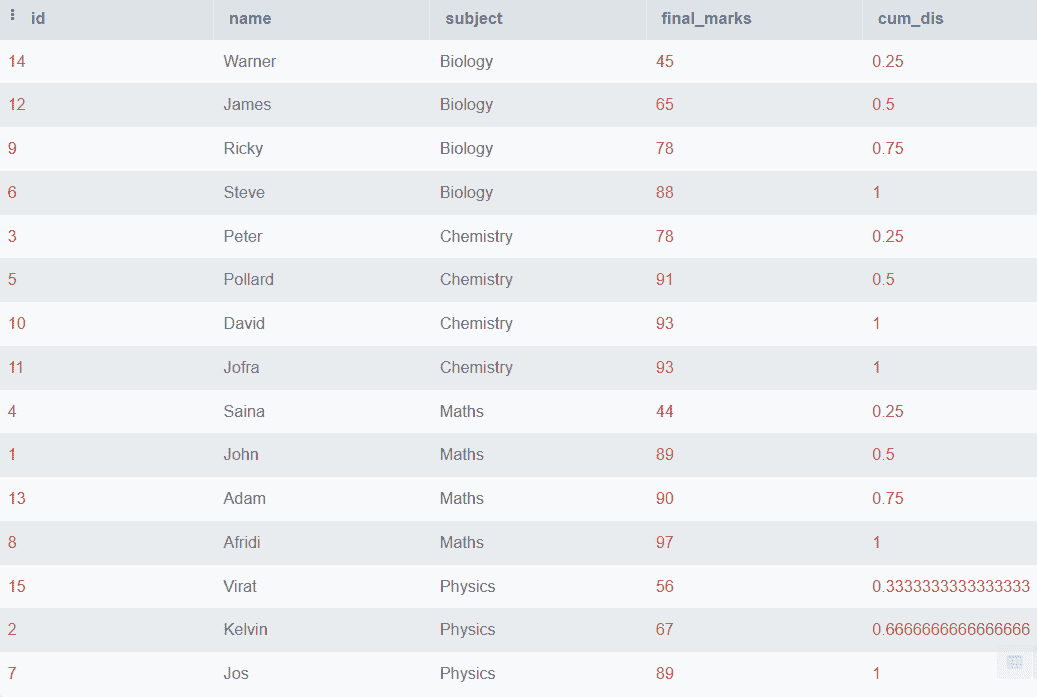
在上述输出中,我们已经看到 final_marks 按科目名称分区的累积分布。
STDDEV() 和 VARIANCE()
VARIANCE() 函数用于计算分区内给定值的方差。在统计学中,方差表示一个数值距离其均值的远近,或表示数字之间的离散程度。它的符号是 ?²。
STDDEV() 函数用于计算分区内给定值的标准偏差。标准偏差还衡量数据的变异程度,它等于方差的平方根。它的符号是 ?。
这些参数可以帮助我们找出数据的离散性和变异性。让我们看看如何实际操作。
SELECT *,
STDDEV(final_marks)
OVER (
PARTITION BY subject) AS marks_stddev,
VARIANCE(final_marks)
OVER (
PARTITION BY subject) AS marks_variance
FROM students;
输出:
上述输出显示了每个科目的最终成绩的标准差和方差。
FIRST_VALUE() 和 LAST_VALUE()
FIRST_VALUE() 函数将根据特定排序输出分区中的第一个值。类似地,LAST_VALUE() 函数将输出该分区中的最后一个值。当我们想要识别指定分区的第一个和最后一个出现的值时,可以使用这些函数。
语法:
SELECT *,
FIRST_VALUE(col1)
OVER (
PARTITION BY col2, col3
ORDER BY col4) AS first_value
FROM table_name
结论
SQL 分析函数为我们提供了在 SQL 服务器中执行数据分析的功能。使用这些函数,我们可以释放数据的真正潜力,从中获取有价值的洞察以提升我们的业务。除了上述讨论的函数,还有许多其他优秀的函数可以非常快速地解决复杂问题。你可以从这篇微软的文章中深入了解这些分析函数。
Aryan Garg 是一名电气工程本科生,目前处于最后一年。他对网页开发和机器学习领域充满兴趣。他已追求这一兴趣,并渴望在这些方向上继续发展。
更多相关主题
2022 年最需求的人工智能技能
原文:
www.kdnuggets.com/2022/08/indemand-artificial-intelligence-skills-learn-2022.html

关于人工智能(AI)的热度多年来持续增长。然而,近年来,随着科技巨头和初创公司竞相开发新的 AI 应用和能力,这一热度激增。
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您在 IT 领域的发展
在人工智能领域,机器被赋予了自主学习和工作的能力,根据提供的数据做出决策。尽管 AI 有许多不同的定义,但一般来说,可以将其总结为让计算机系统“智能化”的过程——能够理解困难任务并执行复杂命令。
AI 迅猛增长的一个主要原因是它能自动化那些耗时或让人感到疲惫的任务。例如,在零售业,AI 可以跟踪库存水平并预测客户需求,这些信息可以用于优化供应链和改善库存管理。在医疗保健中,AI 可以处理和解读医学图像,有助于诊断疾病和制定治疗计划。
因此,各个企业和行业对 AI 技能的需求非常大。根据Gartner的预测,2020 年至 2021 年,全球 AI 收入增长了 14.1%,达到了 515 亿美元。根据Fortune Business Insights的预测,在 2021-2028 年预测期内,全球 AI 产业预计将以 33.6%的年均增长率增长,到 2028 年达到 3600 亿美元。
毋庸置疑,AI 正在迅速发展,每天都变得更加复杂。在 AI 能力的快速扩展中,各行各业的企业都在寻找将 AI 融入其运营的方法。随着企业争取领先地位,具备正确技能的人将会非常抢手。
事不宜迟,让我们深入探讨雇主在员工和组织中寻找的最受欢迎的人工智能技能。
顶级人工智能技能

学生、在职人员和商业领袖对于掌握 AI 技能的热情非常高。那么,成为成功的 AI 工程师需要哪些关键能力呢?它们如下所述:
编程技能
无论你身处哪个领域,计算机编程语言都是必不可少的,因为它们是我们每天执行的计算机程序的基础。它们使我们能够与计算机沟通并创建使计算机运行的程序。很难想象没有计算机编程语言的世界。
AI aspirants 需要熟悉一些最广泛使用的编程语言,包括 Python、R、Java 和 C++等。每种编程语言都有其自身的规范,这些规范可以在人工智能和机器学习中应用。
Python
由于其简洁性、代码可靠性和执行速度,Python 在 AI 和机器学习中被广泛使用。它需要很少的代码,能帮助你编写复杂的算法,并且包括多种先进的库用于复杂和科学计算。
R
对于数值分析、统计计算、机器学习、神经网络和其他任务,R 是必需的。R 提供了收集和整理数据集、应用机器学习和统计函数以及使用矩阵变换和线性代数处理数据的能力。
Java
在 AI 中,Java 用于实现映射器、归约器、智能编程、搜索算法、遗传编程、机器学习方法、神经网络等。
C++
AI 利用 C++语言来促进过程编程和硬件资源操作。它可以用来创建浏览器、视频游戏和操作系统。由于其适应性和面向对象的特性,它在 AI 中非常有用。
库和框架
在创建 AI 应用程序时,开发人员可以访问各种库和框架。流行的框架和库包括 Seaborn、Matplotlib、TensorFlow、NumPy、Keras、Apache Spark 等。它们用于数字操作、科学计算和研究大数据集等。这些库还可以用于快速准确地编写代码。
数学和统计学
我们必须用理解和逻辑来编程机器,以使它们能够从经验中学习。这时,数学和统计学就发挥作用了。统计学是研究如何收集、分析和解释统计数据的学科,而数学是研究数字中的模式和关联的学科。得益于数学和统计学,我们拥有了评估和理解数据所需的工具。
数学和统计概念包括线性代数、统计学、概率、图论、优化方法等。这些能力可以用于解决问题和基于规范开发算法。
机器学习和深度学习
计算机科学中两个迅速发展的领域是机器学习和深度学习。它们都涉及训练计算机从数据中获取知识,而不需要明确的编程。机器学习可以用于提高软件预测的准确性。同时,深度学习可以通过为系统提供更多的数据来改进机器学习系统的性能。
总体而言,随着我们迈向一个更加数据驱动的社会,机器学习和深度学习变得越来越重要。得益于机器学习,计算机能够从经验中学习并适应新情况。深度学习作为机器学习的一个子领域,使用神经网络进行更深层次的学习。神经网络是一种由相互连接的处理节点组成的网络,能够学习识别输入数据的模式。
自然语言处理和计算机视觉
研究计算机如何解释和处理人类语言的学科称为自然语言处理(NLP)。它包括理解词义、将短语解析为其组成部分以及理解词汇关系等活动。NLP 可以用于广泛的活动,包括机器理解、文本摘要和自动翻译。
计算机视觉(CV)专注于计算机对数字图像的解释和理解。它涵盖了如识别面孔、识别照片中的物品和对象,以及预测图像中物体的三维几何形状等活动。
NLP 对人工智能至关重要,因为它使计算机能够理解人类语言,这对于创建聊天机器人或语音助手等任务至关重要。计算机视觉(CV)对人工智能同样至关重要,因为它使计算机能够解释和理解图像,这对于物体识别或面部识别等任务至关重要。
数据科学和数据分析
在我们这个日益数据驱动的世界中,理解和分析数据变得比以往任何时候都重要。数据科学和数据分析是至关重要的技能,使我们能够理解围绕我们的不断增长的数据山。
数据科学是从数据中获取意义的过程,它包括从清理和组织数据到进行复杂分析和创建预测模型的所有内容。数据科学家擅长发现数据中的模式和见解,这些可以用来开发人工智能算法和做出更好的决策。
数据分析是数据科学的重要组成部分。它涉及从大型数据集中提取可操作的见解。数据分析师擅长识别趋势、发现异常,并确定变量之间的关系,这些都可以提高人工智能应用的准确性。
软技能
你是否在想为什么软技能对于像人工智能这样的技术领域至关重要?答案很简单!是的,软技能在以技术驱动的世界中也同样重要。
在人工智能时代,软技能的价值已经开始被雇主认识到。员工需要能够利用这些技能与其他员工合作,以便在人工智能时代取得成功。
一些关键的软技能包括合作、沟通、批判性思维和解决问题。
合作
员工与其他实体之间的合作至关重要,因为它可以导致对问题更好的理解、更快的解决方案、更好的决策以及更好的最终产品。
沟通
拥有强大的沟通技能将帮助人们建立信任和融洽关系,预防和解决冲突,并使他们成为更有效的团队成员。这些技能还使人们更好地理解和执行上级的指示。
批判性思维和解决问题
批判性思维使员工能够全面了解问题的各个方面,从而做出对公司最有利的决策。解决问题的能力至关重要,因为它使员工能够找到复杂问题的创造性解决方案。这些技能使员工在工作中更加高效和有效。
下一步:你如何提升技能?
所以,如果你考虑从事人工智能职业,现在是时候采取行动了。随着企业大量投资于这一技术以及对人才的需求超过供应,现在是提升人工智能技能的最佳时机。
“提升技能”这一术语已经存在一段时间,但它最近才被广泛讨论。最简单来说,提升技能就是学习新技能或改进现有技能。我们生活在一个不断发展的世界,新技术和趋势不断涌现。为了保持领先,我们需要不断学习和适应。
那么,有哪些提升技能的选项呢?
学习新技能有多种方式,其中一些最受欢迎的包括传统学习、在线课程、研讨会、讲座和自学。
传统学习:大学和学院
传统学习通常是基于课堂的学习,这种方式已经存在了几个世纪。如果你正在寻找一个传统的课堂程序来学习人工智能,那么你可以选择多个选项,包括世界顶尖的大学,例如麻省理工学院 (MIT)和斯坦福大学。最后,你将从相关的机构或大学获得一份完成证书。
在线课程:电子学习平台
最近几年,在线课程以惊人的速度蓬勃发展。目前有多个不同的平台提供在线课程,这些课程涵盖了广泛的主题。
工作坊和研讨会
工作坊和研讨会是学习新技能或获得新知识的绝佳方式,这些活动可以是教育性的或信息性的,通常持续几小时到几天不等。许多人参加工作坊和研讨会以提升他们的商业技能或了解新领域或行业。
参加工作坊和研讨会的好处包括获得新见解、与其他专业人士建立联系,并有机会向领域专家学习和获取知识。此外,工作坊和研讨会也可以是提升简历和推动职业发展的绝佳方式。
自学:YouTube 和书籍
如果你对自学感兴趣,最好的开始方法就是直接开始学习!选择一个你感兴趣的主题,并寻找帮助你入门的资源;最好的资源包括 YouTube 和书籍。
YouTube 是全球领先的视频平台,由谷歌拥有,包含了许多关于人工智能的有用视频,如人工智能简介、如何编程人工智能以及如何应用人工智能。一些顶级资源包括Springboard、Arxiv Insights、freeCodeCamp.org和Edureka,以及其他几个资源。
一些人喜欢阅读书籍,因为它们具有触感——纸张的感觉以及在阅读时能够实际高亮和注释。这里有两本我遇到的书籍,既引人入胜又令人兴奋:
总结
随着企业越来越认识到人工智能技术如何提升他们的工作流程,对人工智能技能的需求也在不断增加。高效的人工智能专业人员将受到高度需求,并可能在广泛的行业中找到工作。此外,掌握人工智能的人将能够为自己和公司开启新的机会。
Kanchanapally Swapnil Raju 是Great Learning的技术内容策略师,他规划并持续撰写关于前沿技术的内容,如数据科学、人工智能、软件工程和云计算。他掌握了 MEAN Stack 开发技能以及 C、C++和 Java 等编程语言。他是一个不断学习的人,渴望探索新技术、提升写作技能,并指导他人。
更多相关内容
不可避免的结论:机器学习与大脑不同
原文:
www.kdnuggets.com/2022/11/inescapable-conclusion-machine-learning-like-brain.html

图片来自 rawpixel.com on Freepik
本系列九篇文章中的最后一篇总结了机器学习与大脑之间的许多不同之处——以及一些相似之处。希望这些文章能够帮助解释生物神经元的能力和局限性,这些如何与机器学习相关,以及最终需要什么来复制人脑的背景知识,使得人工智能能够获得真正的智能和理解。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
在研究机器学习和生物大脑时,不可避免的结论是机器学习与大脑并不相似。事实上,唯一的相似之处是神经网络由称为神经元的东西和称为突触的连接组成。否则,信号不同、时间尺度不同,并且由于各种原因,机器学习的算法在生物神经元中是不可行的。
神经元相对于计算机来说非常缓慢,因此它们的工作方式在根本上是不同的。确实,神经元很多,并且它们以一般并行的方式运行。但有些过程显然是串行的,比如视觉和听觉,而且神经元的缓慢速度对处理阶段的数量设置了相当严格的限制。如果你能在一秒钟的一小部分时间内看到或听到某物并做出反应,那么大脑中处理的“层数”就受限于每层处理的速度。处理速度的缓慢也意味着在生物环境中,机器学习中常见的大规模训练集是不切实际的。
人工神经网络的有序层结构对于其运作是必需的。如果允许下游层的信号回流到早期层,基本的反向传播算法将崩溃,因为其梯度下降表面不再是恒定的。这种类型的回路连接赋予了神经网络一定程度的内部记忆,使其能够基于内部状态对相同输入产生不同的结果。这对于更类似人类思维过程的想法非常好,但对于人工神经网络却不太好,因为反向传播没有办法“知道”内部状态是什么。
感知器的算法不同且与我们对生物神经元的了解不兼容。感知器执行的最基本的加法对于神经元不起作用,除非在极少数情况下。神经元具有诸如“恢复期”等特征,这使它们错过传入的脉冲,从而导致错误的加法。这个系列之前显示,0.6 + 0.1 的加法通常得到 0.6(而不是加法所建议的 0.7)。实际上,唯一可靠的加法情况是那些太慢而无用的网络。一般来说,感知器中的值表示生物神经元的脉冲频率的想法根本行不通。
机器学习依赖于相当精确的神经元值和突触权重,而这些在生物环境中都是不切实际的。这个系列演示了,神经元值需要越精确表示,每个网络层的运行速度就必须越慢。一个合理的估计是,神经元中表示的不同值数量大约为 10——而不是人工神经网络典型的精确浮点数。
设置精确的突触权重更糟。虽然一些理论方法在设置突触权重上可能有用,但观察到的生物数据表明,突触权重具有很高的随机性。事实上,它们如此之高,以至于逻辑上可以得出结论,突触本质上是数字的,代表 0 或 1,任何中间值仅表示该值正确的信心和/或该数据项被保留或遗忘的难易程度。
机器学习类似于你大脑的最大问题在于反向传播需要将特定的突触设置为特定的权重。据我们所知,目前没有任何机制可以实现这一点。突触权重会响应它们连接的神经元的近同步脉冲而变化,设置任何特定突触所需的基础设施将需要多个神经元——这完全排除了在突触权重中存储信息的价值。
当然,尽管最近的神经形态学领域在正确方向上取得了一些进展,但大部分仍然依赖于反向传播和设置特定的突触权重,而这两者都不切实际。
总的来说,尽管机器学习取得了一些显著的进展,但它与大脑的工作方式关系不大。这就是为什么我们在追求开发一种自适应图结构的原因,这种系统在神经元中被证明是可能的,并且可能代表了人工通用智能的实现方式。
查尔斯·西蒙 是一位全国知名的企业家和软件开发者,同时也是 FutureAI 的首席执行官。西蒙是《计算机会反叛吗?:为人工智能的未来做好准备》的作者,也是 Brain Simulator II 的开发者,这是一种 AGI 研究软件平台。有关更多信息,请访问这里。
主题更多
数据科学的无限宝石
原文:
www.kdnuggets.com/2019/06/infinity-stones-data-science.html
评论
目前正有一个全球范围内的流行文化现象席卷整个世界,你当然知道我在说什么:数据科学!
实际上,这是《复仇者联盟:终局之战》,是漫威电影宇宙(MCU)十多年讲述的高潮。但你可能已经知道了。
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 需求
虽然《终局之战》的故事或多或少围绕无限宝石展开——整个 MCU 也有一段时间围绕它们展开——以及它们在拯救整个宇宙(或者说一半宇宙)中的作用,但数据科学的实践实际上也可以从它们的力量中学习一些东西。我知道你可能不相信我,但让我们来看一看。

别忘了,灭霸自己其实也有一点数据科学家的性质。他识别了一个问题及其解决方案,尽管你可能会对他的结论有异议,更不用提他的思维方式完全缺乏科学过程。但那不是重点。
这里是无限宝石如何映射到数据科学实践中,以及它们可以教给我们关于自己实践的教训。
现实宝石
现实宝石赋予使用者操控物质的力量。
首先从比喻角度看。可以推测,为了操控现实,我们必须理解它。这似乎是对领域知识重要性的一个很好(足够)类比。
在没有理解项目领域的情况下开始数据科学项目不仅仅是个坏主意,最终结果很可能也不会立足于现实。我们不会允许那些从未学习过棒球规则的运动员参加职业棒球比赛;同样,我们也不应该期望在一个我们不理解的领域内能够进行称职的数据科学,无论我们的统计、分析、技术以及相关技能如何。
到底什么构成了足够的领域知识?这是相对的。你是在做一些普通约会应用的浅层描述性分析吗?还是在为一家专注于某种晦涩证券投资策略的金融机构进行深入预测分析项目?进行第一次分析所需的“约会”领域知识可能微不足道,但对于第二个分析的有用见解肯定需要扎实的金融理解。
空间宝石
空间宝石赋予用户对空间的掌控能力。
对空间的掌控,嗯?那么对数据空间的掌控呢?如何才能掌握自己的数据空间?通过探索性数据探索获得深入知识。
但是我们说的数据探索到底需要多少,具体是什么样的探索?这可能会让你感到惊讶,但……这是相对的。如果我们对描述性分析感兴趣——即没有预测的简单数据分析——我们对数据的熟悉程度越深入越好。在这种情况下,目标就是手段,因此描述、可视化和共享数据的质量,如同数据分析师一样,与探索的亲密度高度相关。
在预测分析和机器学习工作中,对于探索性数据探索的帮助程度存在不同的意见。对于那些未用于训练的数据集(即验证集和测试集)的探索性分析水平也存在不同的意见。除此之外,为了确保最大程度地掌控你的数据空间,请确保防范探索性数据分析或可视化质量差的潜在陷阱,例如相关性谬误、辛普森悖论和生态谬误。
当正确执行时,探索性数据分析将提供对数据的理解,使得成功的数据科学工作随之而来。
时间宝石
时间宝石赋予其拥有者倒退或快进时间的能力。
如果你研究过算法复杂性,你会知道算法的选择会严重影响完成特定计算任务的时间,即使数据相同,这也是算法和方法选择相当于能够快进时间的原因。
这适用于算法的直接选择,也适用于对超参数的设置,这些设置也会影响运行时间。神经网络架构可能非常复杂,但一对相同简单的神经网络在使用不同的学习率时可能有截然不同的收敛时间。
你知道关于偏差-方差权衡,但也有时空权衡,以及复杂性-速度权衡可以做出。一个逻辑回归模型可能不如一千棵树的随机森林表现得那么好,但为了速度,这种性能上的牺牲可能对你来说是值得的,更不用说逻辑回归模型可能比随机森林提供的解释性提升(如果这是你所关注的)。
这并不是说你必须选择一个更快(或更简单,或计算密集度更低,或更具解释性)的算法,但你需要记住这是你在做出的一种权衡,同时也是我们控制时间流动的最佳方式之一。
至少,这是我们控制时间流动的最佳方式之一,即使没有真正的时间宝石。
力量宝石
力量宝石赋予持有者大量的能量——这种能量足以摧毁整个星球。
听起来需要很多能量。我们在数据科学领域如何找到这种能量呢?计算能力!
计算能力(或“计算”)是我们投入到特定问题上的集体计算资源。曾经认为无限计算是计算的终极目标,这有其充分的理由。考虑一下与今天相比,一两三十年前的计算能力有多么有限。想象一下科学家们坐在一起,思考如果拥有更多的计算能力,能解决哪些问题。那时的天花板似乎无限高!
当然,事情并不完全如预期发展。确实,我们现在拥有比以往任何时候更多的计算资源,如超级计算机、云计算、由大量计算支持的公开 API,甚至是我们的笔记本电脑和智能手机。我们曾经无法想象的各种问题,现在都能得到解决,这是一项巨大的进步。然而,我们需要记住,“聪明”是对计算能力的极佳补充,数据科学及其支持技术的许多进展都得益于智慧而非单纯的计算能力。
理想情况下,可以用智慧和力量的完美平衡来解决每一个问题,用聪明的方法来设定完美的算法,并且有足够的计算能力来支持它。也许这是数据科学将来会证明自身的一个领域。
在此之前,请放心,即使对于不完美的问题解决方法,也有足够的计算资源可用。
灵魂宝石
在电影宇宙中,灵魂宝石的力量尚不清楚。在漫画中,这颗宝石允许持有者捕捉和控制他人的灵魂。
“捕捉和控制他人的灵魂”听起来很阴森,并且有些狡黠。但如果我们从更积极的角度看待灵魂宝石的概念,我们可以将其与预测的力量等同起来。我们正在训练模型以控制未标记数据的最内在本质——其灵魂——通过做出信息充分的预测,揭示其真实内容。
这根本不牵强,对吧?
灵魂宝石可以看作是预测的力量,也就是说,它位于数据科学的绝对核心。数据科学家试图达成什么?他们试图利用现有数据回答有趣的问题,以便做出尽可能与现实一致的预测。预测这一部分显得尤为重要。
鉴于其如此关键,数据科学的成果应当以最高的谨慎对待。不夸大其词,但我们工作的灵魂在于它所能创造的价值(无论是对商业、慈善机构、政府还是社会整体),轻视这一点或将预测结果视为数据科学过程中的另一步骤是不明智的。
数据科学是一场对灵魂的争夺战,加上即将到来的对思想的战斗。
心灵宝石
心灵宝石允许用户控制他人的思想。
哪一块无限宝石允许控制他人的思想?当然是心灵宝石,在数据科学的世界里,没有什么比精心制作的数据展示更能帮助控制他人的思想了,其中包括引人入胜的故事和有效的可视化。
模型已经完成,预测也已经做出,洞察力... 很有见地。现在是时候将结果告知项目相关方了。但在我们当中,非数据科学家对数据及数据科学过程的兴趣和理解不同,因此我们需要以他们能够欣赏的方式有效地展示我们的发现。
这不是某种形式的自以为是或“他们就是不懂”;这是对现实的承认,每个人都有不同的技能、兴趣和角色,而那些最能从我们工作中受益的个人不一定具备数据科学家的特点。因此,要根据受众的需要调整你的展示方式。
记住,如果你的洞察力无法转化为有用的结果,那么你的工作就不算完成。你需要说服别人你工作的价值。一旦他们被说服,他们就可以采取行动,而
通过行动实现的变化是任何数据科学项目的真正回报。
无限宝石的描述来自这篇文章。
文中提到的所有漫画人物及使用的图像均为漫威漫画公司的唯一和专有财产。
相关:
-
数据复仇者… 集合!
-
数据科学过程,再发现
-
数据科学过程
更多相关内容
Inflection-1: 个人 AI 的下一前沿
原文:
www.kdnuggets.com/2023/08/inflection1-next-frontier-personal-ai.html

图片来自作者
人工智能(AI)对当今世界产生了如此巨大的影响,而且看起来它没有减缓的迹象。AI 技术的革命正在改变未来以及我们生活的世界。
2023 年我们收到了很多新闻,AI 系统在各个方面纷纷推出。围绕 GPT-3.5 和 LLaMa 有着极大的炒作,大家普遍期望没有其他东西能够超越它们的表现。为了在生成 AI 中获得更好的表现,涉及大量的预训练和微调。
Inflection.AI是一家 AI 初创公司,致力于为每个人的独特需求创建个人 AI。2023 年 5 月,他们发布了他们的个人 AI 助手——Pi.ai,设计旨在体现同理心和安全性。大型语言模型(LLM)的主要挑战之一是安全性、数据隐私和输出准确性的问题。Inflection.AI 的目标是实现高质量、安全且有用的 AI LLM。
Inflection.AI 是一个集成的 AI 工作室,所有 AI 训练和推理均在内部进行,并建立了 Inflection-1——他们的内部 LLM,使用 Pi.ai。
Inflection-1 是什么?
当你使用像 ChatGPT 这样的 LLM 时,回应通常不会特别针对你个人。想象一下拥有一个了解你思维方式、充满同理心并且对你日常需求有用的 AI 助手或伴侣。
这就是 Inflection-1。
Inflection.AI 到底是如何实现这一点的呢?使用 Pi.ai。一种将你与技术更紧密结合的个人 AI。Pi 由 AI 模型 Inflection-1 驱动。Inflection-1 旨在创建一个可以像人类一样与你交谈的个人助手。
Inflection-1 在规模和能力上类似于 GPT-3.5,有些人甚至认为它比 GPT-3.5、Chinchilla 和 LLaMA 更优秀。它使用数千个 NVIDIA H100 GPU 在大型数据集上进行训练。
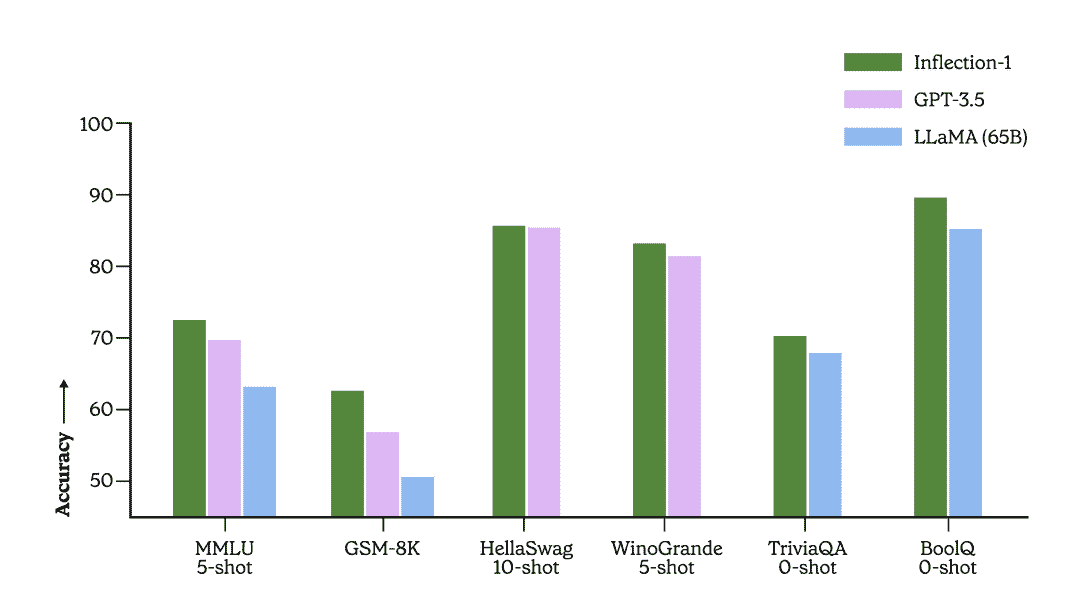
Inflection-1 有一份技术备忘录,总结了公司的评估并比较了 Inflection-1 与其他 LLM 的性能。该技术备忘录指出,Inflection-1 在其计算类别中排名第一,表明它超越了 GPT-3.5、LLaMA、Chinchilla 和 PaLM-540B。公司还将发布一份技术备忘录,展示其模型与 PaLM-2 和 GPT-4 的比较。
为了使 Inflection-1 达到这一点,它必须经历许多不同的任务,以满足独特的需求。例如,从解决日常问题到高中考试题目——都带有个人化的触感。
听起来很棒,对吧?为什么更多的人没有讨论这个?
是的,Inflection-1 在处理广泛任务方面表现非常出色——然而,它在所有任务上都不完美,例如编码。
在编程任务方面,Inflection-1 落后于 GPT-3.5。然而,这并没有阻止 Inflection.AI 的员工继续改进他们当前的大型语言模型,以便能够处理所有任务,从常识到复杂的编程脚本。
Inflection-1 功能
现在我们已经理解了 Inflection-1 的不足之处。让我们来了解它的关键功能。
对话能力
第一个特点是 Inflection-1 的对话能力。正如我们之前提到的,公司旨在创建一个与用户具有独特联系的 AI 助手。Inflection-1 具有惊人的对话能力,因为它可以以类似人类的方式理解和与用户互动。Inflection-1 可以理解广泛的话题,使其能够进行更有意义的对话。
个性化体验
Inflection-1 的设计旨在提供个性化体验,针对每位用户量身定制。通过利用大量数据和学习用户互动的结合,Inflection-1 能够适应特定的需求和要求,例如对话风格。这增加了用户与个人人工智能之间的互动和联系。
人类情感
Inflection-1 希望不仅仅是一个个人 AI。它希望成为每个用户独特的 AI。它的目标是根据用户的情感状态进行理解和回应。了解用户的情感状态,Inflection-1 能够提供支持、鼓励和陪伴——这是其他 AI 系统所不具备的。
总结
Inflection-1 正在推动当前人工智能的边界,并向更广泛的社区和其他竞争者展示人工智能的成就。他们旨在通过 API 将这项服务提供给每个人,你可以 在这里 加入候补名单。将这项技术向更广泛的社区开放,使人工智能的潜力得到普及——让每个人都能受益于人工智能的潜力。
Nisha Arya 是一名数据科学家、自由技术作家以及 KDnuggets 的社区经理。她特别感兴趣于提供数据科学职业建议或教程以及数据科学理论知识。她还希望探索人工智能如何有益于人类寿命的不同方式。作为一个热衷于学习的人,她寻求扩展她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
探索黑箱:如何欺骗神经网络
原文:
www.kdnuggets.com/2020/09/inside-blackbox-trick-neural-network.html
评论
作者:William Falcon,PyTorch Lightning 创始人
使用梯度上升来确定如何改变输入,使其被分类为 5。(所有图像均为作者自有,版权所有)。
神经网络因被视为黑箱而声名不佳。虽然理解它们的决策过程确实需要创造力,但它们并不像人们所认为的那样不透明。
在本教程中,我将展示如何使用反向传播来调整输入,使其分类为你希望的任何类别。
使用这个colab进行跟随。
(这项工作与Alfredo Canziani共同撰写,预告视频即将发布)
人类作为黑箱
让我们考虑人类的情况。如果我给你展示以下输入:
你很可能不知道这是不是 5 还是 6。实际上,我相信我甚至可以说服你认为这也可能是 8。
现在,如果你问一个人如何使某物更接近于 5,你可能会这样做:
如果我想让你把这个调整得更像 8,你可能会这样做:
现在,这个问题的答案并不容易通过几个 if 语句或查看几个系数来解释(是的,我在看你,回归)。不幸的是,对于某些类型的输入(图像、声音、视频等),可解释性确实变得更困难但并非不可能。
询问神经网络
神经网络如何回答我上面提出的相同问题?要回答这个问题,我们可以使用梯度上升来实现。
这是神经网络认为我们需要如何修改输入,使其更接近于 5 的方式。
这有两个有趣的结果。首先,黑色区域是网络认为我们需要去除像素密度的地方。第二,黄色区域是它认为我们需要增加像素密度的地方。
我们可以通过将梯度添加到原始图像中,朝着那个梯度方向迈出一步。我们当然可以重复这个过程,最终将输入形态调整为我们期望的预测。
你可以看到图像左下角的黑色斑块与人类可能认为的非常相似。
人类在左下角添加了黑色。网络也建议这样做
那么,如何让输入看起来更像一个 8 呢?以下是网络认为你需要如何改变输入的方式。
在这里,再次值得注意的是,左下角有一个黑色的区域,而中间有一个明亮的区域。如果我们将这些与输入相加,我们会得到以下结果:
在这种情况下,我不是特别相信我们已经把这个 5 转换成了 8。不过,我们已经减少了一个 5,用右侧的图像来说服你这是一个 8 的论点肯定会更容易。
梯度是你的指南
在回归分析中,我们查看系数来了解我们学到了什么。在随机森林中,我们可以查看决策节点。
在神经网络中,这归结为我们在使用梯度时有多么创造性。为了对这个数字进行分类,我们生成了一个可能预测的分布。
这就是我们所称的前向传播。

在前向传播过程中,我们计算输出的概率分布
代码中它看起来是这样的(可以使用这个 colab 跟随操作):

现在,想象一下我们想要欺骗网络,使其对输入 x 预测“5”。那么实现这一目标的方法是给它一个图像(x),计算图像的预测,然后最大化预测标签“5”的概率。
为了做到这一点,我们可以使用梯度上升来计算第 6 个索引(即:标签 = 5)(p)的预测梯度相对于输入x。
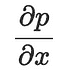
要在代码中做到这一点,我们将输入 x 作为参数传递给神经网络,选择第 6 个预测(因为我们有标签:0、1、2、3、4、5、……)第 6 个索引意味着标签“5”。
从视觉上看,这样:
预测“5”的梯度相对于输入的变化。
在代码中:

当我们调用 .backward() 时,发生的过程可以通过前面的动画进行可视化。
现在我们已经计算了梯度,我们可以对它们进行可视化和绘图:

上述梯度看起来像随机噪声,因为网络尚未训练……然而,一旦我们对网络进行训练,梯度将会更具信息量:
通过回调自动化这一过程
这是一个极其有用的工具,有助于揭示你的网络在训练过程中发生了什么。在这种情况下,我们希望自动化这个过程,使其在训练中自动发生。
为此,我们将使用 PyTorch Lightning 来实现我们的神经网络:
为了自动绘制我们在这里描述的内容,复杂的代码可以被抽象为 Lightning 中的一个回调。回调是一个在你可能关心的训练部分被调用的小程序。
在这种情况下,当一个训练批次被处理时,我们希望生成这些图像,以防一些输入出现混淆。
但... 我们通过 pytorch-lightning-bolts 使其变得更加简单,你只需安装它即可。
pip install pytorch-lightning-bolts
并将回调导入你的训练代码中。
将所有内容汇总
最终,我们可以训练我们的模型,并在 logits 出现“混淆”时自动生成图像。
Tensorboard 将自动生成类似这样的图像:
摘要
总结一下:你学会了如何使用 PyTorch 查看黑箱内部,了解了直觉,编写了一个 PyTorch Lightning 中的回调,并自动使你的 Tensorboard 实例绘制出可疑的预测。
亲自尝试一下 PyTorch Lightning 和 PyTorch Lightning Bolts。
(这篇文章是为了即将发布的视频而写的,在视频中我(威廉)和 阿尔弗雷多·坎齐安 将向你展示如何从零开始编写这些代码。)
简介: 威廉·法尔肯 是一名 AI 研究员,且是 PyTorch Lightning 的创始人。他致力于理解大脑,构建 AI 并在大规模应用中使用它。
原文。经许可转载。
相关:
-
PyTorch 多 GPU 指标库及 PyTorch Lightning 新版本中的更多内容
-
Pytorch Lightning 与 PyTorch Ignite 与 Fast.ai 比较
-
Lit BERT: NLP 转移学习的 3 个步骤
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT
更多相关主题
了解谷歌用于构建 Meena 的机器学习:一个可以讨论任何话题的聊天机器人
原文:
www.kdnuggets.com/2020/02/inside-machine-learning-google-build-meena-chatbot.html
评论

看起来每年谷歌都会计划通过在自然语言理解(NLU)系统方面取得新的惊人进展来震撼人工智能(AI)界。去年,BERT 模型无疑成为了 NLU 研究领域的头条新闻。2020 年刚开始几周,谷歌研究 发布了一篇新论文介绍了 Meena,这是一种新的深度学习模型,可以支持与任何领域的对话的聊天机器人。
NLU 是过去几年中最活跃的研究领域之一,迄今为止产生了一些最广泛采用的 AI 系统。然而,尽管取得了所有进展,大多数对话系统仍然高度限制于特定领域,这与我们作为人类能够自然地讨论不同话题的能力形成对比。在 NLU 理论中,这些专业化的对话代理被称为封闭域聊天机器人。另一种选择是一个新兴的研究领域,称为开放域聊天机器人,专注于构建可以讨论用户想聊的几乎任何话题的对话代理。如果有效,开放域聊天机器人可能是人性化计算机交互旅程中的一个关键部分。
尽管对开放域聊天机器人的兴奋不已,目前的实施尝试仍存在一些缺陷,这些缺陷阻碍了它们的普遍实用性:它们往往对开放式输入的回应不切实际,或给出模糊且通用的回答。通过 Meena,谷歌尝试解决这些挑战,构建一个可以讨论几乎任何话题的开放域聊天机器人。
在构建 Meena 之前,谷歌必须解决一个在开放域聊天机器人系统中经常被忽视的非平凡挑战。评估开放域聊天机器人质量的一个关键标准是其对话是否对人类感觉自然。这个想法似乎直观但也极其主观。我们如何测量对话的人类相似性?为了解决这个挑战,谷歌首先引入了一个新的指标,作为 Meena 聊天机器人的基石。
Sensibleness and Specificity Average
Sensibleness and Specificity Average(SSA)是一种用于开放域聊天机器人的新指标,它捕捉了人类对话的一些基本但重要的属性。具体来说,SSA 试图量化人类对话的两个关键方面:
-
讲得通。
-
讲得具体。
合理性可以说涵盖了对话中类似人类的一些最基本的方面,如常识和逻辑连贯性。合理性还捕捉了聊天机器人的其他重要方面,如一致性。然而,仅仅合理是不够的。一个通用的回答(例如:“我不知道”)可能是合理的,但它也很无聊且不具体。这样的回答经常由仅依据合理性等度量标准进行评估的机器人生成。特异性是第二个有助于量化对话互动类似人类能力的度量标准。例如,A 说:“我喜欢网球”,而 B 回答:“那很好”,那么这个回答应该被标记为“不具体”。这个回答可以在几十种不同的上下文中使用。然而,如果 B 回答:“我也是,我对罗杰·费德勒爱不释手!”那么它被标记为“具体”,因为它与讨论的内容紧密相关。
SSA →f(合理性,特异性)
SSA 度量的实际数学公式相当复杂,但 Google 进行的初步实验显示了与聊天机器人类似度的强相关性。下图展示了不同聊天机器人(蓝点)的相关性。
在制定了一个可量化的度量标准来评估类似人类的能力之后,下一步是构建一个针对该度量标准优化的开放领域聊天机器人。
Meena
Meena 是一个端到端的神经对话模型,能够学习对给定的对话上下文做出合理回应。令人惊讶的是,Meena 并不依赖全新的架构,而是利用了 Google 去年首创的进化 Transformer 架构(ET)。
ET
正如其名称所示,ET 是对传统的Transformer 架构的一种优化,这些架构在 NLU 任务中很常见。这些优化是通过对一系列在 NLU 场景中使用的 Transformer 模型应用神经架构搜索(NAS)得到的。
乍一看,ET 看起来与大多数 Transformer 神经网络架构相似。它有一个编码器,将输入序列编码为嵌入向量,还有一个解码器,使用这些嵌入向量来构建输出序列;在翻译的情况下,输入序列是待翻译的句子,输出序列是翻译结果。然而,ET 对 Transformer 模型做了一些有趣的改进。其中最有趣的是在编码器和解码器模块底部添加的卷积层,这些卷积层在两个地方以类似的分支模式添加。这种优化特别有趣,因为编码器和解码器架构在 NAS 过程中并不共享,因此这种架构被独立发现对编码器和解码器都有用,显示了这种设计的强大。原始 Transformer 完全依赖自注意力机制,而进化 Transformer 是一种混合架构,利用了自注意力和宽卷积的优点。
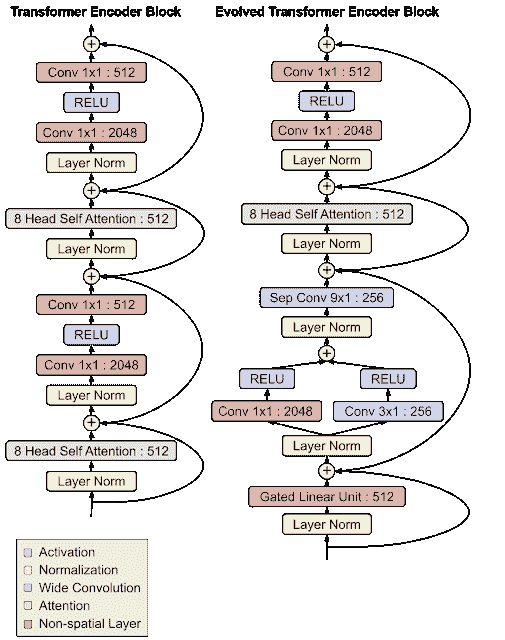
Meena 和 ET
可以将 Meena 看作一个大规模的 ET 架构。Meena 具有一个 ET 编码器块和 13 个演化变换器解码器块,如下图所示。编码器负责处理对话上下文,以帮助 Meena 理解对话中已经说过的内容。然后,解码器利用这些信息来生成实际的回应。通过调整超参数,我们发现更强大的解码器是提高对话质量的关键。
Meena 展示的一个重要方面是,对于开放域聊天机器人而言,规模确实重要。几十年来,AI 研究界一直在争论,为了使模型能够与人类进行高质量的多轮对话,我们是否可以简单地将端到端模型扩大——通过增加更多的训练数据和提高参数数量——还是需要将这种模型与其他组件结合起来?Meena 显示,大规模的端到端模型可以在对话互动中实现类人的表现。
Meena 有多大?据报道,Meena 的第一个版本有 26 亿个参数,训练数据为 341 GB 的文本,这些文本来自公共领域的社交媒体对话。为了提供一个背景,与现有的最先进生成模型 OpenAI GPT-2 相比,Meena 的模型容量大 1.7 倍,并且训练数据量是其 8.5 倍。
初步测试显示,Meena 能够在各种话题中进行对话,并达到了高水平的 SSA。
在 Meena 研究中最令人惊讶的发现之一是 SSA 量度与知名的 困惑度 在 NLU 模型中的性能指标之间存在的相关性。概念上,困惑度衡量语言模型的不确定性。困惑度越低,模型生成下一个令牌(字符、子词或单词)的信心就越高。在测试中,SSA 量度及其各个因素(特异性和合理性)与开放域聊天机器人的困惑度表现出强相关性。
鉴于其性能要求,Meena 对大多数组织来说都难以企及。然而,毫无疑问,Meena 代表了对话界面的一个重大里程碑。除了模型本身,Meena 还贡献了 SSA 量度,推动我们更接近评估聊天机器人互动的类人性。未来,我们应期待 SSA 量度中加入幽默或同理心等人类对话属性。同时,我们也应期待看到基于 Meena 一些原则的新开放域聊天机器人,推动下一代对话界面的发展。
原文。转载经许可。
相关:
-
让我们构建一个智能聊天机器人
-
NLP 与 NLU:从语言理解到处理
-
亚马逊利用自我学习教 Alexa 自我纠错
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 为你的组织提供 IT 支持
更多相关话题
神经网络内部与 Tensorflow 中的交互式代码
原文:
www.kdnuggets.com/2018/06/inside-mind-neural-network-interactive-code-tensorflow.html/2
评论
内部梯度 / 正面和负面属性

alpha 值为 1.0
现在让我们使用 内部梯度,alpha 值为 ….
0.01, 0.01, 0.03, 0.04, 0.1, 0.5, 0.6, 0.7, 0.8 和 1.0(与原始输入相同),以可视化网络的内部工作。

上述所有图像表示了不同 alpha 值下相对于输入的梯度。我们可以观察到,随着 alpha 值的增加,梯度变得越来越接近 0(黑色),这是由于网络的饱和。我们可以清楚地看到,当我们将所有图像以 gif 格式查看时,梯度变化的差异。

然而,我能够做出一个有趣的观察,随着 alpha 值变小,我的网络无法做出正确的预测。如下面所示,当 alpha 值较小时(0.01),网络预测大多为 3 或 4(猫/鹿)


红色框 → 模型预测
但随着 alpha 值的增加,最终达到 1.0,我们可以观察到模型的准确性增加。最后,让我们查看每个 alpha 值下梯度的正面和负面属性。

蓝色像素 → 与原始图像叠加的正面属性
红色像素 → 与原始图像叠加的负面属性

再次,如果我们将这些图像制作成 gif,就更容易查看变化。
积分梯度 / 正面和负面属性

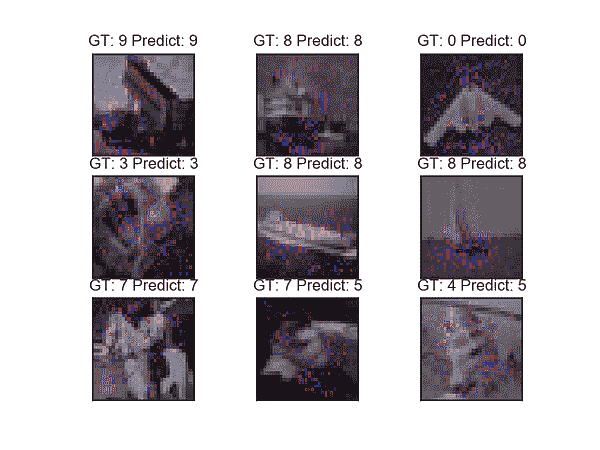
左侧图像 → 积分梯度,步长为 3000,用于 黎曼近似
右侧图像 → 正面属性用蓝色标记,负面属性用红色标记
最后,当我们使用积分梯度来可视化梯度时,我们可以观察到如上所示的结果。我发现的一个非常有趣的事实是网络如何预测马(7)、狗(5)和鹿(4)。

首先,让我们看一下原始图像,如上所示,左侧和中间的图像是马,右侧的图像是绵羊。

当我们可视化积分梯度时,可以看到一些有趣的现象。正如中间图像所示,网络认为马的头部最重要。然而,当仅仅考虑头部时,网络认为这是一张狗的图片。(而且它确实有点像狗)。右侧图像也有类似的故事,当网络仅考虑绵羊的头部时,它预测为狗。
然而,正如最左侧的图像所示,当网络接收马的整体形状(包括一些人类的部分)时,它正确地识别了这张图像为马。真是惊人!
交互式代码

对于 Google Colab,你需要一个谷歌账户来查看代码,另外你不能在 Google Colab 中运行只读脚本,所以请在你的沙盒中复制一份。最后,我永远不会请求访问你 Google Drive 上的文件,仅供参考。祝编程愉快!为了透明度,我已将所有训练日志上传到我的 GitHub。
要访问此帖子的代码,请 点击这里,要查看训练 日志请点击这里。
最后的话
由于这一领域仍在发展中,将会有新的方法和发现。(我希望我也能为这些发现做出贡献。)最后,如果你想访问原始论文“Axiomatic Attribution for Deep Networks”的代码, 请点击这里。
如果发现任何错误,请发邮件到 jae.duk.seo@gmail.com。如果你希望查看我所有写作的列表,请 点击这里查看我的网站。
同时在我的 Twitter 关注我,访问 我的网站,或者我的 YouTube 频道 以获取更多内容。我还实现了 Wide Residual Networks,请点击这里查看博客文章。
参考资料
-
Axiom/definition/theorem/proof。 (2018)。YouTube。检索于 2018 年 6 月 14 日,来自www.youtube.com/watch?v=OeC5WuZbNMI -
axiom — 词典定义。(2018)。Vocabulary.com。检索于 2018 年 6 月 14 日,来自
www.vocabulary.com/dictionary/axiom -
Axiomatic Attribution for Deep Networks — — Mukund Sundararajan, Ankur Taly, Qiqi Yan. (2017). Vimeo. 取自
vimeo.com/238242575 -
STL-10 数据集。 (2018). Cs.stanford.edu. 取自
cs.stanford.edu/~acoates/stl10/ -
Benenson, R. (2018). 分类数据集结果。 Rodrigob.github.io. 取自
rodrigob.github.io/are_we_there_yet/build/classification_datasets_results.html#53544c2d3130 -
[duplicate], H. (2018). 如何在 Matplotlib (python) 中隐藏坐标轴和网格线。 Stack Overflow. 取自
stackoverflow.com/questions/45148704/how-to-hide-axes-and-gridlines-in-matplotlib-python -
VanderPlas, J. (2018). 多个子图 | Python 数据科学手册。 Jakevdp.github.io. 取自
jakevdp.github.io/PythonDataScienceHandbook/04.08-multiple-subplots.html -
matplotlib.pyplot.subplot — Matplotlib 2.2.2 文档。 (2018). Matplotlib.org. 取自
matplotlib.org/api/_as_gen/matplotlib.pyplot.subplot.html -
matplotlib, m. (2018). matplotlib 中超过 9 个子图。 Stack Overflow. 取自
stackoverflow.com/questions/4158367/more-than-9-subplots-in-matplotlib -
pylab_examples 示例代码:subplots_demo.py — Matplotlib 2.0.0 文档。 (2018). Matplotlib.org. 取自
matplotlib.org/2.0.0/examples/pylab_examples/subplots_demo.html -
matplotlib.pyplot.hist — Matplotlib 2.2.2 文档。 (2018). Matplotlib.org. 取自
matplotlib.org/api/_as_gen/matplotlib.pyplot.hist.html -
Python?, I. (2018). 是否有一种干净的方法在 Python 中生成折线直方图? Stack Overflow. 取自
stackoverflow.com/questions/27872723/is-there-a-clean-way-to-generate-a-line-histogram-chart-in-python -
Pyplot Text — Matplotlib 2.2.2 文档。 (2018). Matplotlib.org. 取自
matplotlib.org/gallery/pyplots/pyplot_text.html#sphx-glr-gallery-pyplots-pyplot-text-py -
[ Google / ICLR 2017 / 论文总结 ] 反事实的梯度。 (2018). Towards Data Science. 于 2018 年 6 月 16 日访问,来自
towardsdatascience.com/google-iclr-2017-paper-summary-gradients-of-counterfactuals-6306510935f2 -
numpy.transpose — NumPy v1.14 手册。 (2018). Docs.scipy.org. 于 2018 年 6 月 16 日访问,来自
docs.scipy.org/doc/numpy-1.14.0/reference/generated/numpy.transpose.html -
命令,G。 (2018). 在一个命令中执行 git add 和 commit。 Stack Overflow. 于 2018 年 6 月 16 日访问,来自
stackoverflow.com/questions/4298960/git-add-and-commit-in-one-command -
如何将图像切分为红色、绿色和蓝色通道。 (2018). 如何使用 misc.imread 将图像切分为红色、绿色和蓝色通道。 Stack Overflow. 于 2018 年 6 月 16 日访问,来自
stackoverflow.com/questions/37431599/how-to-slice-an-image-into-red-green-and-blue-channels-with-misc-imread -
如何在 Windows 10 上安装 Bash shell 命令行工具。 (2016). Windows Central. 于 2018 年 6 月 16 日访问,来自
www.windowscentral.com/how-install-bash-shell-command-line-windows-10 -
Google Colab 免费 GPU 教程 — Deep Learning Turkey — Medium. (2018). Medium. 于 2018 年 6 月 16 日访问,来自
medium.com/deep-learning-turkey/google-colab-free-gpu-tutorial-e113627b9f5d -
安装 — imgaug 0.2.5 文档。 (2018). Imgaug.readthedocs.io. 于 2018 年 6 月 16 日访问,来自
imgaug.readthedocs.io/en/latest/source/installation.html -
numpy.absolute — NumPy v1.14 手册。 (2018). Docs.scipy.org. 于 2018 年 6 月 16 日访问,来自
docs.scipy.org/doc/numpy-1.14.0/reference/generated/numpy.absolute.html -
numpy.clip — NumPy v1.10 手册。 (2018). Docs.scipy.org. 于 2018 年 6 月 16 日访问,来自
docs.scipy.org/doc/numpy-1.10.0/reference/generated/numpy.clip.html -
numpy.percentile — NumPy v1.14 手册。 (2018). Docs.scipy.org. 于 2018 年 6 月 16 日访问,来自
docs.scipy.org/doc/numpy/reference/generated/numpy.percentile.html -
CIFAR-10 和 CIFAR-100 数据集。 (2018). Cs.toronto.edu. 于 2018 年 6 月 16 日访问,来自
www.cs.toronto.edu/~kriz/cifar.html -
[ICLR 2015] 追求简单性:具有交互式代码的全卷积网络 [手册…. (2018). Towards Data Science. 取自
towardsdatascience.com/iclr-2015-striving-for-simplicity-the-all-convolutional-net-with-interactive-code-manual-b4976e206760于 2018 年 6 月 16 日 -
EN10/CIFAR. (2018). GitHub. 取自
github.com/EN10/CIFAR于 2018 年 6 月 16 日 -
深度网络的公理归因 — — Mukund Sundararajan, Ankur Taly, Qiqi Yan. (2017). Vimeo. 取自
vimeo.com/238242575于 2018 年 6 月 16 日 -
(2018). Arxiv.org. 取自
arxiv.org/pdf/1506.06579.pdf于 2018 年 6 月 16 日 -
Riemann 和. (2018). En.wikipedia.org. 取自
en.wikipedia.org/wiki/Riemann_sum于 2018 年 6 月 16 日
简介: Jae Duk Seo 是瑞尔森大学的四年级计算机科学学生。
原文。经授权转载。
相关:
-
用 NumPy 从头开始构建卷积神经网络
-
我如何使用 CNN 和 TensorFlow 并在 Kaggle 挑战中失去了银牌
-
使用 TensorFlow 对象检测进行像素级分类
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关话题
数据科学手册的见解
原文:
www.kdnuggets.com/2015/05/insights-from-data-science-handbook.html
作者:瓦桑斯·戈帕尔。
过去几年,我一直试图掌握包括分析、大数据、建模、预测、机器学习、算法、数据挖掘技术、规则、计算复杂性、延迟、数据产品、数据工程、统计推断、R 编程、数据整理、数据黑客、统计建模、监督学习/无监督学习、数据可视化、非结构化数据以及其他众多使数据科学世界丰富多彩的主题。有人说这个术语本身就是一个伞式术语。市面上有许多书籍详细讨论了上述某些主题,由各自的专家撰写。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT
当我拿起这本书……”数据科学手册”时,我感觉这会有所不同,并深刻地影响我。我必须承认,我对从数据中提取见解这一美丽艺术/科学的理解已经上升到了一个全新的水平。

定义
这本书对数据科学的定义有许多版本,例如乔什·威尔斯的定义,并且讨论从这里开始,他们如何从丰富的学术背景过渡到现实世界,在那里磨练技能,实践从复杂、顽固和嘈杂的数据集中提取信息、见解和信号的技艺,并创建能够吸引受众的数据产品,从而为进一步分析建立丰富的数据来源。
正是通过这些对话,我对这门科学的理解加深了,对继续追求这门技艺的渴望也得到增强。书中的每位艺术家对数据科学的定义都有自己的见解,但总体来看,他们似乎都同意数学/统计学、计算机科学和领域专业知识的交汇点。
目标读者
这本书的目标读者理想上可以是以下几类人
-
一位有志成为数据科学家的
-
一名实践型数据科学家
-
一名数据科学家团队的领导者
-
一位企业家或商业所有者
-
一名对数据感兴趣的公民
正如我之前所说的,这 25 位艺术家来自不同领域,无法有比这份名单更好的背景代表。话虽如此,你会享受到一些深入的探讨,令人惊叹的是这些艺术家无缝地表演。无论是有志成为数据科学家的,还是精英,或者只是好奇者和鉴赏家,每个人都能找到适合自己的内容。
过渡和升级
这本书还涵盖了学习和升级实践数据科学所需技能的一个重要话题。从纯学术背景过渡到现实商业世界。像由杰克·克拉姆卡创立的 Insight Data Science这样的组织专门帮助博士后过渡到行业。另一方面,充满领域专业知识且热衷于追求这门艺术的有志数据科学家可以从克莱尔·科瑟尔的例子中获得启发,她通过在线学习 MOOCs 自主制定了数据科学的学习之旅。事实上,她还推出了一个数据科学课程——开放源代码数据科学硕士(OSDSM)计划。这些课程可以帮助你弥补学习和实践的差距。
OSDSM 是一个开源资源集合,将帮助你获得成为称职入门级数据科学家所需的技能。你可以在这里访问课程。
你必须擅长在工作中和临时升级。
Khan Academy 的数据科学家杰斯·科尔迈尔在听完 Salman 的 TED 演讲后加入了公司,他在高频交易领域有金融背景,这为讨论学习新技能和在工作中了解数据科学的学习曲线提供了贡献……
学习新技术并应用它们的速度并不稳定;这确实是波动的。当我过渡到这个新的教育和互联网生成数据领域时,我经历了一段需要学习新建模技术的时期。我对概率图模型并不熟悉;这不是我在高频交易中使用的东西。一旦我克服了初始学习曲线,学习就很大程度上是波动的。会有一个非常具体和激励的需求或目标。
最终,哈佛大学教授乔·布利兹坦在观察到……时一针见血。
你必须充满活力,努力工作,但不要因为不知道一切而感到灰心。
指标
数据科学的指标取决于你的客户希望你解决的问题。正如Palantir 的数据科学家黛安·吴所说……
有些人可能需要流媒体解决方案,而另一些人则可能希望基于数据库中的信息建立静态模型。这些可以从一个到几个十几个不等。
她说,在她的角色中,成功是非常可衡量的——它是模型性能的准确性或精确度/召回率。这也取决于你提出的问题,或是尝试找到正确的问题并用答案产生影响。
勤奋
这本书还触及了行业价值、辛勤工作和纪律的重要性。你必须准备好投入长时间的辛勤工作,不仅仅是在弥补数据科学理解上的空白,或是补充你工具箱中的某些缺失链接,也包括你正尝试解读的具体问题。DJ Patil,曾在 LinkedIn 领导数据科学团队,后来成为美国首任首席数据科学家——他在谈到这些问题时非常雄辩,他说……
当新数据科学家进入组织时,我首先告诉他们的是,他们最好是最早到达办公室的人,也是最后离开的人……你并不是因为某种神话般的“一万小时”理论而投入时间(我完全不认同这个观点,我认为这是错误的,因为它假设了线性序列学习,而不是加速的并行学习)。你投入时间是因为你可以了解很多拼凑在一起的不同事物。这就像炖菜,只有炖得久了才会变得美味。
找到相关问题和讲故事的艺术
书中还强调了问题叙述的能力以及以故事形式传达解决方案的能力,同时保持激情和好奇心。这与通常的技能同样重要。Hilary Mason,纽约的科学家和Fast Forward Labs的创始人说……
对于你正在进行的每个数据项目,你需要问自己这些问题:你在做什么?我怎么知道什么时候完成?这会产生什么影响?
她对有志成为数据科学家的人员提供了非常宝贵的建议……
尝试做一个能够发挥你优势的项目。一般来说,我将数据科学家的工作分为三类:统计、编码和讲故事/可视化。不论你最擅长哪一类,做一个能够突出这一优势的项目。然后,再做一个你最不擅长的项目。这能帮助你成长,学习新知识,并弄清楚你接下来需要学习的内容。从那里继续前进。
Mail Chimp 的数据科学家 John Foreman在谈论……时提出了一个重要的观点。
对我来说,任何数据科学家应该具备的核心技能之一是与业务沟通的能力。依赖业务中的其他人积极识别问题并将其抛给数据科学家,而他或她被动等待接受工作是非常危险的。
摇滚明星
*这些明星们…正如我在本文中已经提到的,你会发现这个名单是领域内谁是何人的激动人心的混合。
*DJ Patil, Hilary Mason, Pete Skomoroch, Riley Newman, Jonathan Goldman, Michael Hochster, **George Roumeliotis, Kevin Novak, Jace Kohlmeier, Chris Moody, Erich Owens, Luis Sanchez, **Eithon Cadag, Sean Gourley, Clare Corthell, Diane Wu, Joe Blitzstein, Josh Wills, Bradley Voytek, *Michelangelo D’Agostino, Mike Dewar, Kunal Punera, William Chen, John Foreman, Drew Conway
结论
这些艺术家的背景多样性使得这一领域非常有趣——无论是学术、职业还是领域方面,但将他们联系在一起的还是对满足饥饿状态的好奇心。这些艺术家让你思考和沉思。
为什么数据科学在今天的世界和经济中如此重要?
-
如何掌握编程、统计和领域专业知识这三大领域,成为一名有效的数据科学家?
-
如何从学术界或其他领域过渡到数据科学领域?
-
数据科学家的工作与统计学家和软件工程师有什么不同?他们如何协同工作?
-
评估公司数据科学职位时,你应该关注哪些方面?
-
建立一个有效的数据科学团队需要什么?
-
什么心态、技巧和能力将一位优秀的数据科学家与普通的区分开来?
-
数据科学的未来是什么样的?
除了上述的明星,你还可以关注那些在书中未被提及但同样为这个行业的发展辛勤工作的大师们。你可以通过谷歌搜索并通过推特或他们的网站跟随他们。
Vincent Granville, Gregory Piatetsky, Kirk Borne, Eric Colson, Marck Vaisman, Milind Bhandarkar, Monica Rogati, Simon Zhang, Dean Abbot, Nate Silver
你将永远不会错过他们的洞见和对你的点缀星光。
如果你的渴望还没有得到满足,你可以关注行业中前 50/100 名影响者和品牌的list。
最后,我给你留下一颗来自书籍的宝石…这次来自Sean Gourley,QUID 的联合创始人兼首席技术官…**
我认为数据科学将真正成为一种产品设计过程;实际上是一种算法设计过程。算法获取信息并引导我们;无论是我们阅读的信息、听的音乐、喝咖啡的地方、遇见的朋友,还是我们生活中的更新。
个人简介:Vasanth Gopal 是一位有志的数据科学家,拥有 25 年的制药行业销售经验以及 5 年的商业智能和高级分析经验。他目前正在通过 Coursera 攻读数据科学专业。
本文是经过修订的版本
这篇文章。
相关
-
数据科学中最常用、最令人困惑和最滥用的行话
-
真正的数据科学家请站出来
-
数据分析手册——与数据科学家和技术领袖的访谈,免费下载
更多相关主题
18 位令人鼓舞的 AI、大数据、数据科学、机器学习领域的女性
原文:
www.kdnuggets.com/2018/03/inspiring-women-ai-big-data-science.html
评论
女性在 STEM(科学、技术、工程和数学)领域中的代表性不足。例如,1960 年女性在计算机和数学职业中的比例为 27%。然而,尽管更多女性进入劳动力市场,经过几十年,这一比例在 2013 年下降到了 26%,根据2015 年美国人口普查数据分析。
然而,我们希望 STEM 领域的女性数量能够增加,为了庆祝国际妇女节,以下是 18 位在 AI、分析、大数据、数据科学、机器学习和机器人技术领域的令人鼓舞的女性的简介。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT 需求

-
Carrie Grimes Bostock,谷歌的杰出工程师。Grimes 的职业生涯一直在谷歌,她目前在技术研究所小组中从事数据驱动的资源规划、成本分析和分布式集群管理软件的工作。Grimes 拥有斯坦福大学统计学博士学位和哈佛大学人类学学士学位。
-
Meta S. Brown、@metabrown312 是一位顾问、演讲者和作家,致力于推广商业分析的使用。作为一名实操分析师,她曾处理过高达 9 亿美元的项目,是前沿商业分析领域的公认专家。
-
詹妮弗·查耶斯 @jenniferchayes 是微软研究院的杰出科学家和执行董事。查耶斯在女性大数据活动的职业面板讨论中表示:“你不应该让对自己能力的恐惧或担心自己可能是冒名顶替者的恐惧影响你所做的决策。你应该把大脑中的那部分放在一边,对它说谢谢你分享。我们都有这部分大脑,如果我听从了那部分大脑的声音,我的人生会非常无聊。”查耶斯拥有普林斯顿大学的数学物理学博士学位。
-
西尔维亚·基亚帕 @csilviavr 是 DeepMind 的高级研究科学家,工作领域包括概率建模和深度学习。在加入 DeepMind 之前,她曾在微软研究院剑桥分院、剑桥大学统计实验室和马克斯·普朗克生物控制理论研究所工作。
-
吉尔·戴奇 @jilldyche 是 SAS 研究所最佳实践副总裁。她是几本书的作者,包括最近的一本《新 IT:技术领导者如何在数字时代推动商业战略》。戴奇目前正在进行一个副项目,撰写一本电子书,倡导简单改进动物收容所的做法,以提高宠物领养率。
-
贾娜·埃格斯 @jeggers 是 Nara Logics 的首席执行官,这是一家受神经科学启发的人工智能公司,提供推荐和决策支持平台。她的职业生涯从三人企业起步,发展到 50,000 人的大企业。她曾在美国航空公司开设欧洲物流软件办公室,1996 年在 Lycos 涉足互联网,创办了 Intuit 的企业创新实验室,帮助 Spreadshirt 定义了大规模定制,并在洛斯阿拉莫斯国家实验室研究导电聚合物。
-
卡拉·金特里 @data_nerd 是社交媒体上顶尖的数据科学影响者之一。她目前是 Samtec 的数字营销经理。她曾与许多财富 500 强公司合作。她能够处理庞大复杂的数据库,解读业务需求,并提供量化支出、利润和趋势的情报。被称为数据狂人是这位好奇的数学家/经济学家的勇气象征,因为知识就是力量,而公司现在也开始认识到这一点。
-
Nikita Johnson,@nikitaljohnson,是 RE•WORK 的创始人,该公司组织活动,将跨学科的行业、初创公司和学术界结合在一起,探讨新兴技术(特别是人工智能)的最新进展及其对解决社会挑战的影响。
-
李飞飞,@drfeifei,是斯坦福大学计算机科学系副教授,斯坦福人工智能实验室和斯坦福视觉实验室的主任。在这些实验室中,她与来自世界各地的最杰出的学生和同事们一起工作,构建能够使计算机和机器人具备视觉和思维能力的智能算法,并开展认知和神经影像实验,以揭示大脑如何看待和思考问题。她获得了加州理工学院的博士学位。
-
Hilary Mason,@hmason,是 Cloudera 的研究副总裁。她还是 Fast Forward Labs 的创始人,这是一家机器智能研究公司,并曾担任 Accel 的数据科学家驻场专家和 bitly 的首席科学家。她热爱数据和芝士汉堡。
-
Karen Matthys,计算与数学工程研究所 (ICME) 的执行主任。她正在推进 30by30 活动,旨在到 2030 年,将计算机科学和工程领域各级组织中的女性比例提高到 30%。
-
Neha Narkhede, @nehanarkhede,是 Confluent 的联合创始人兼首席技术官,该公司推动了一款流行的大数据工具——Apache Kafka,该技术是在所有联合创始人都在 LinkedIn 工作时开发的,支持实时流处理功能。
-
Amy O'Connor,@ImAmyO,是 Cloudera 的大数据布道者。她于 2013 年加入了 Hadoop 分销商 Cloudera,此前她在诺基亚担任大数据高级总监。在 Cloudera 的职位中,她为客户引入和采用大数据解决方案提供咨询。她拥有康涅狄格大学电气工程学士学位和东北大学 MBA 学位。
-
Megan Price,人权数据分析集团的执行主任 @hrdag。她的组织利用统计分析揭示证据,以推动行动和变革。该组织曾在包括危地马拉、哥伦比亚和叙利亚在内的多个项目中工作。在叙利亚项目中,Price 担任首席统计师,并撰写了联合国人权事务高级专员办公室委托的两份关于该国记录在案死亡的近期报告。她是卡内基梅隆大学人权科学中心的研究员,获得了生物统计学博士学位。
-
莫妮卡·罗加蒂,@mrogati,Data Collective 的股权合伙人,Insight Data Science 的顾问。莫妮卡曾是可穿戴设备公司 Jawbone 的数据副总裁,也曾是 LinkedIn 的数据科学家。如今,她专注于向 Data Collective 风险投资集团提供技术尽职调查和建议,并担任 Insight Data Science Fellows Program 的顾问,该项目是一个旨在弥合学术界与数据科学职业之间差距的博士后培训奖学金项目。
-
凯特琳·斯莫尔伍德,Netflix 的科学与算法副总裁。她领导着一个由数学家、数据科学家和统计学家组成的高级团队,该团队专注于预测建模、算法研究和原型设计以及公司内的其他深度分析。她的职业生涯包括在 Yahoo 担任数据解决方案总监以及在普华永道担任定量咨询高级经理的工作。
-
凯利·汤普森,沃尔玛电子商务全球品类发展与商品解决方案高级副总裁。汤普森负责指导沃尔玛的战略、结构和运营模式,将商品销售与数据和分析结合起来。尽管沃尔玛是世界上最大的公司之一,人们通常认为大公司行动缓慢,但汤普森表示,她的组织实际上正在这个大公司内部建立更具敏捷性的东西。
-
马努埃拉·玛利亚·维洛索 是卡内基梅隆大学计算机科学学院的赫伯特·A·西蒙大学教授。她曾是 AAAI 的主席,直到 2014 年,并且是 RoboCup 联合会的共同创始人和前主席。她是 AAAI、IEEE、AAAS 和 ACM 的院士。她是人工智能和机器人技术领域的国际专家。
本文部分内容曾 在 KDnuggets 上发表。
相关:
-
停止招聘数据科学家,直到你为数据科学做好准备
-
我们为什么需要更多女性参与大数据的 4 个理由
-
女性分析师书籍作者 – 元数据列表
相关主题
Python 数据分析的 Instagram 使用指南
原文:
www.kdnuggets.com/2017/08/instagram-python-data-analysis.html/2
保存/加载数据到磁盘
因为这个请求可能需要很长时间,我们不希望在不必要的时候运行它,所以保存结果并在继续工作时加载它是一个好习惯。为此,我们将使用 Pickle。Pickle 可以序列化任何变量,保存到文件,然后加载。以下是它的工作示例。
保存:
import pickle
filename=username+"_posts"
pickle.dump(myposts,open(filename,"wb"))
加载:
import pickle
filename="nourgalaby_posts"
myposts=pickle.load(file=open(filename))
按点赞数量排序
现在我们有一个名为‘myposts’的字典列表。由于我们想按字典中的某个键进行排序,我们可以这样使用 lambda 表达式:
myposts_sorted = sorted(myposts, key=lambda k:
k['like_count'],reverse=True)
top_posts=myposts_sorted[:10]
bottom_posts=myposts_sorted[-10:]
然后我们可以像上面一样展示它们:
image_urls=get_images_from_list(top_posts)
display_images_from_url(image_urls)
过滤照片
我们可能希望对帖子列表应用一些过滤器。例如,如果帖子中有视频但我只想要图片,我可以这样过滤:
myposts_photos= filter(lambda k: k['media_type']==1, myposts)
myposts_vids= filter(lambda k: k['media_type']==2, myposts)
print len(myposts)
print len(myposts_photos)
print len(myposts_vids)
当然,你可以对结果中的任何变量应用过滤器,所以发挥你的创造力吧 😉
通知
InstagramAPI.getRecentActivity()
get_recent_activity_response= InstagramAPI.LastJson
for notifcation in get_recent_activity_response['old_stories']:
print notifcation['args']['text']
你应该看到如下内容:
userohamed3 liked your post.
userhacker32 liked your post.
user22 liked your post.
userz77 liked your post.
userwww77 started following you.
user2222 liked your post.
user23553 liked your post.
仅来自一个用户的通知
此时,我们可以随意操作和玩弄通知。例如,我可以仅获取特定用户的通知列表:
username="diana"
for notifcation in get_recent_activity_response['old_stories']:
text = notifcation['args']['text']
if username in text:
print text
让我们尝试一些更有趣的事情:查看你什么时候获得最多的点赞,即一天中的哪个时间段人们最常点赞。为此,我们将绘制一天中的时间与收到的点赞数量之间的关系。
绘制通知的日期时间:
import pandas as pd
df = pd.DataFrame({"date":dates})
df.groupby(df["date"].dt.hour).count().plot(kind="bar",title="Hour" )
正如我们在我的案例中所见,我在下午 6:00 到 10:00 之间获得最多的点赞。如果你对社交媒体感兴趣,你会知道这是高峰使用时间,也是大多数公司选择发布以获得最多互动的时间。
获取粉丝和关注者列表
在这里我将获取粉丝和关注者列表,并对其进行一些操作。
为了使用两个函数getUserFollowings和getUserFollowers,你需要先获取user_id。你可以通过以下方式获取user_id:
现在你可以简单地按如下方式使用这些函数。请注意,如果粉丝数量很多,你需要进行多次请求(稍后会详细说明)。在这里,我们进行了一个请求以获取粉丝/关注者。JSON 结果包含一个“用户”列表,其中包含每个粉丝/关注者的所有信息。
InstagramAPI.getUserFollowings(user_id)
print len(InstagramAPI.LastJson['users'])
following_list=InstagramAPI.LastJson['users']
InstagramAPI.getUserFollowers(user_id)
print len(InstagramAPI.LastJson['users'])
followers_list=InstagramAPI.LastJson['users']
如果数量很大,这个结果可能不包含完整的数据集。
获取所有粉丝
获取粉丝列表类似于获取所有帖子。我们将进行一次请求,然后使用next_max_id键进行迭代:
感谢 Francesc Garcia 的支持
import time
followers = []
next_max_id = True
while next_max_id:
print next_max_id
#first iteration hack
if next_max_id == True: next_max_id=''
_ = InstagramAPI.getUserFollowers(user_id,maxid=next_max_id)
followers.extend ( InstagramAPI.LastJson.get('users',[]))
next_max_id = InstagramAPI.LastJson.get('next_max_id','')
time.sleep(1)
followers_list=followers
你应该对关注者做同样的操作,但在这种情况下,我不会这样做,因为一个请求就足以获取到我的所有关注者。
现在我们有了所有关注者和被关注者数据的 JSON 格式列表,我将它们转换为更友好的数据类型——一个集合——以便对其执行一些集合操作。
我将只取'username'并将其转换为一个set()。
user_list = map(lambda x: x['username'] , following_list)
following_set= set(user_list)
print len(following_set)
user_list = map(lambda x: x['username'] , followers_list)
followers_set= set(user_list)
print len(followers_set)
在这里,我选择将每个用户的用户名集合在一起。'full_name'也可以用——而且更友好——但它不是唯一的,有些用户可能没有'full_name'的值。
现在我们有了两个集合,我们可以进行以下操作:
这里我们有一些关于粉丝的统计数据。你可以从这一点做很多事情,例如保存粉丝列表,然后在稍后的时间比较,以获得取消关注者的列表。
这些是你可以用 Instagram 数据做的一些事情。我希望你了解到如何使用 Instagram API,并对它的基本用途有了一个初步了解。请关注原文,因为它仍在开发中,未来将会有更多你可以做的事情。如有任何问题或建议,请随时联系我。
简介: Nour Galaby 是一位对数据科学和机器学习充满热情的数据科学爱好者。
相关内容:
-
6 件你可以用 Python 处理 Facebook 数据的有趣事情
-
情感和抑郁的分析
-
Python 为何突然变得如此受欢迎的 6 个原因
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业之路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
更多相关话题
启动 Python:在 Windows 上安装 Anaconda
原文:
www.kdnuggets.com/2020/02/install-python-anaconda-windows.html
评论
由 Michael Galarnyk,数据科学家
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
Anaconda 是一个包管理器、环境管理器和 Python 发行版,包含了许多开源包(如 numpy、scikit-learn、scipy、pandas 等)。如果你在安装 Anaconda 后需要额外的包,可以使用 Anaconda 的包管理器 conda 或 pip 来安装这些包。这非常有利,因为你无需自己管理多个包之间的依赖关系。Conda 甚至可以轻松切换 Python 2 和 3(你可以在 这里 了解更多)。事实上,安装 Anaconda 也是安装 Jupyter Notebooks 的一种常见方式。
本教程包括:
-
如何在 Windows 上下载和安装 Anaconda
-
如何测试你的安装
-
如何修复常见的安装问题
-
安装 Anaconda 后该做的事情。
如往常一样,欢迎在此处或在 YouTube 视频页面 上提问。好了,我们开始吧!
下载并安装 Anaconda
1. 访问 Anaconda 网站 并选择 Python 3.x 图形安装程序 (A) 或 Python 2.x 图形安装程序 (B)。如果你不确定要安装哪个 Python 版本,选择 Python 3. 不要选择两个版本。
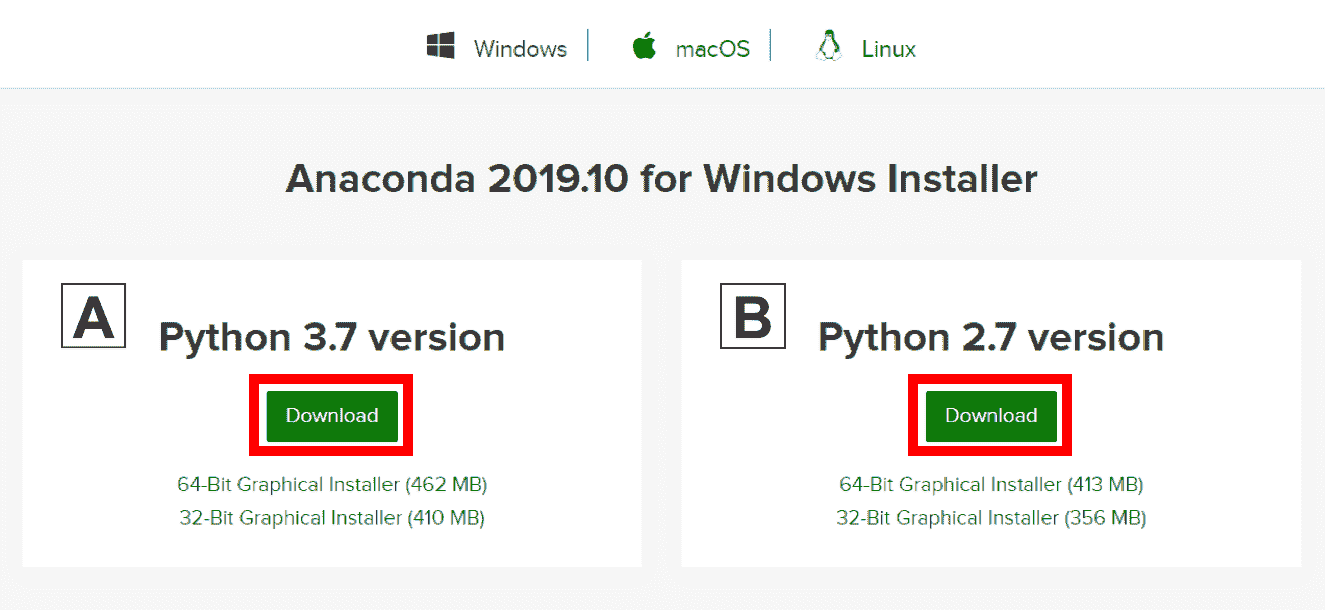
2. 查找你的下载文件。
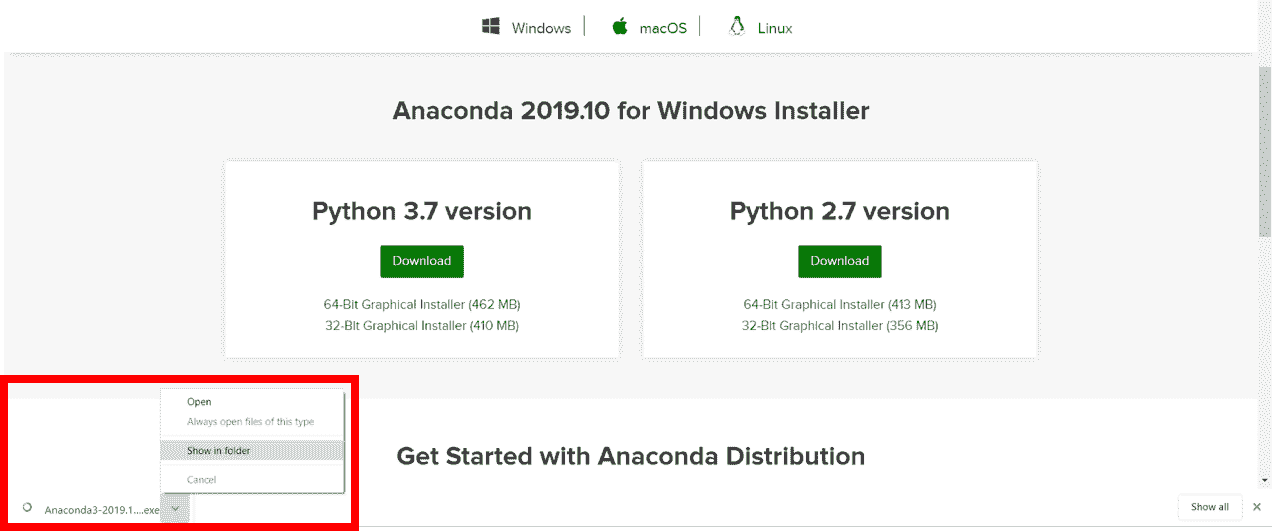
理想情况下,你应该以管理员身份打开/运行文件。
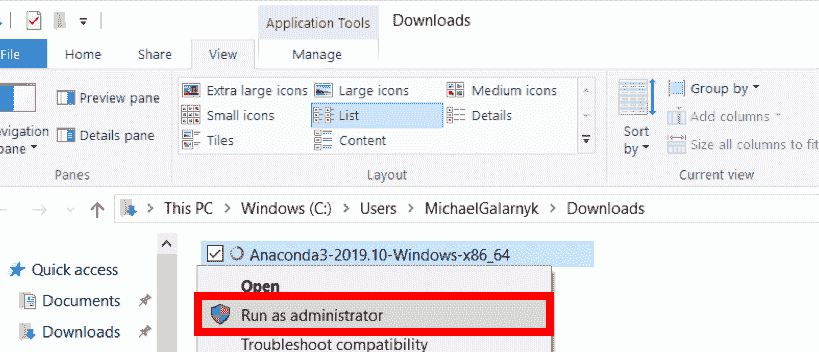
以管理员身份安装是为了在你没有权限在希望的位置安装 Anaconda 或将 Anaconda 添加到你的路径时使用。
当屏幕出现如下内容时,点击“下一步”。
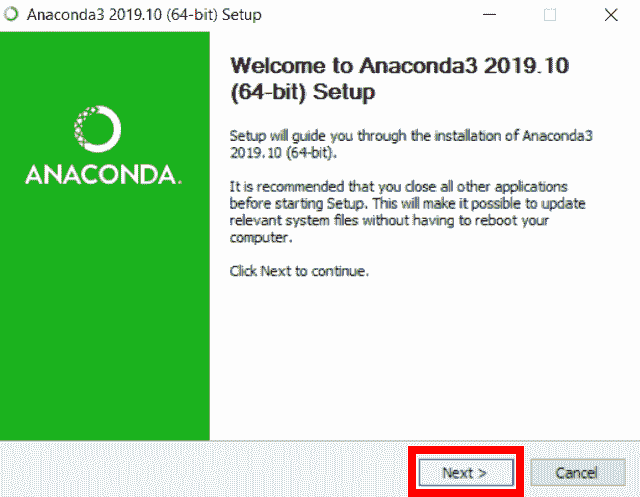
阅读许可协议并点击“我同意”。
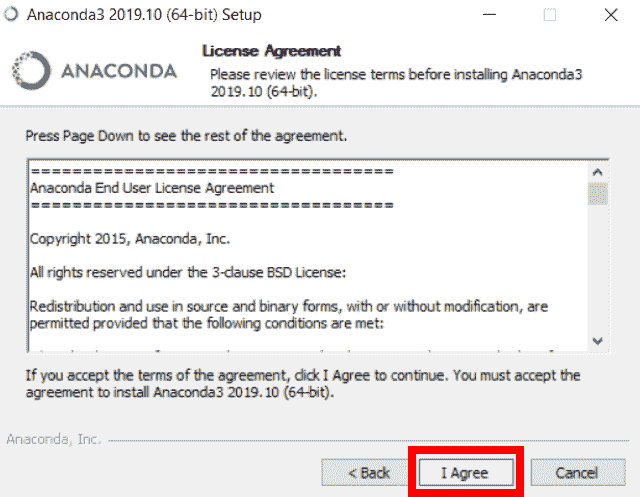
4. 选择 Just Me(推荐)或 All Users。
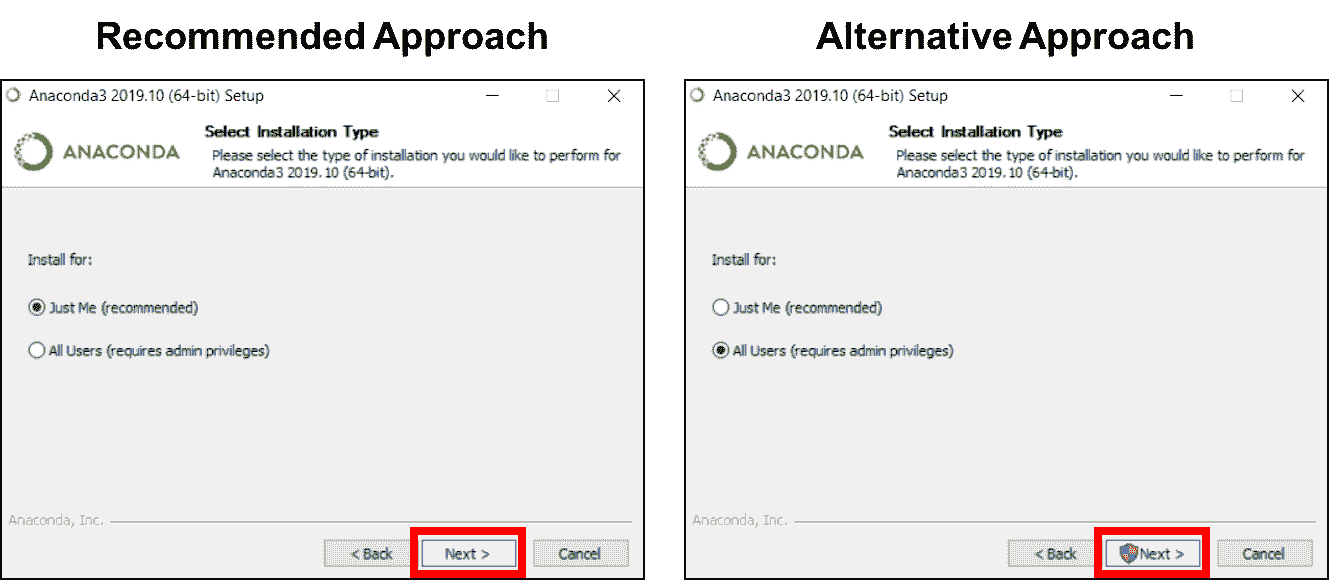
如果你不确定选择哪个,选择 Just Me,因为这样可以减轻没有管理员权限时可能出现的问题。
5. 请记下你的安装位置(1),然后点击 Next(2)。
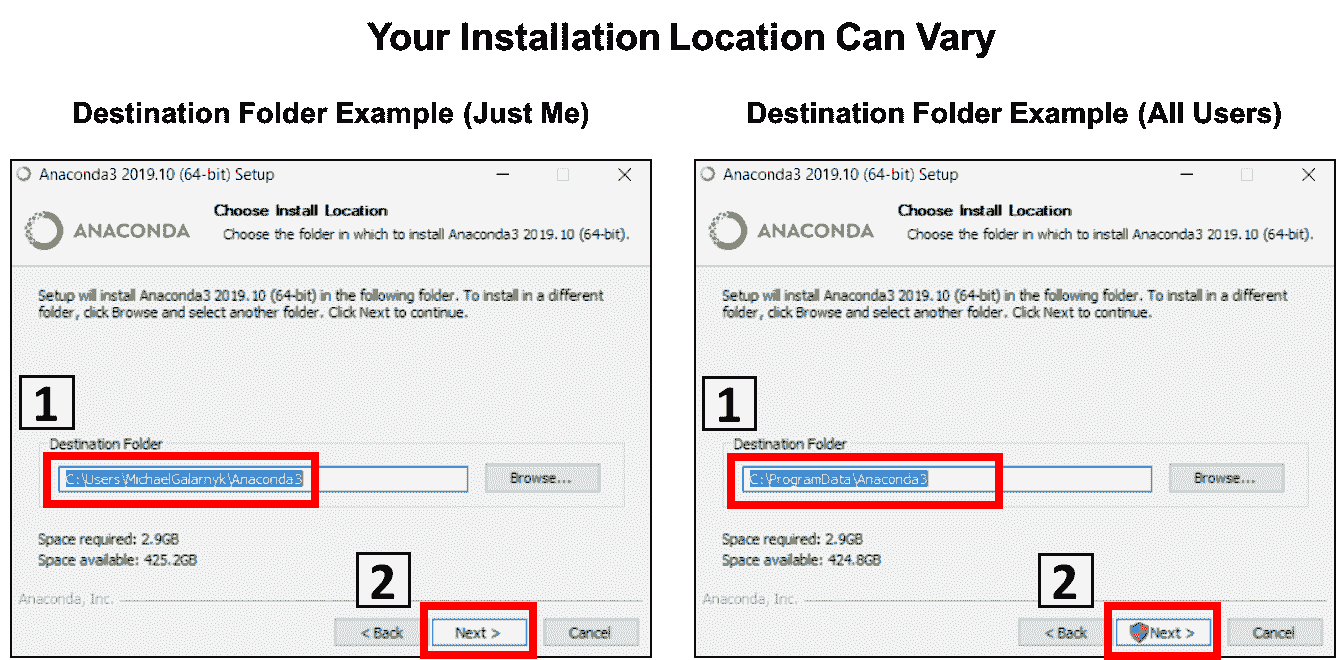
你的安装位置可能有所不同,因此请记住你安装了 Anaconda 的位置。在左侧示例图片中,路径类似于你在第 4 步中选择“Just Me”时的路径。在右侧示例图片中,路径类似于你在第 4 步中选择“All Users”时的路径。
6. 这是安装过程中的一个重要部分。推荐的方法是不要勾选(1)将 Anaconda 添加到你的路径。这意味着你需要在需要使用 Anaconda 时使用 Anaconda Navigator 或 Anaconda Command Prompt(在“开始菜单”下的“Anaconda”中)。如果你想在命令提示符中使用 Anaconda,请使用另一种方法并勾选此框。点击 Install(2)。
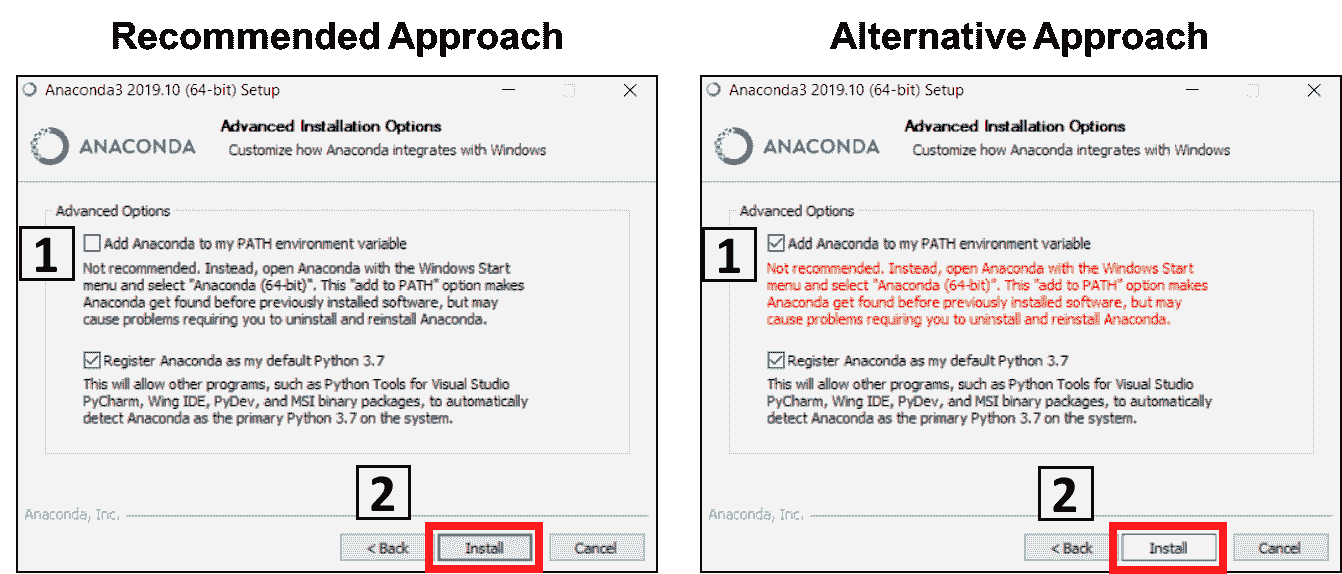
这很重要。考虑你在这一步中所做的事情。
7. 点击 Next。
8. 如果你愿意,可以安装 PyCharm,但这是可选的。点击 Next。

如果你想了解如何在 Anaconda 中使用 PyCharm,可以查看我在这里的旧教程。
9. 点击 Finish。
如何测试你的安装
测试安装的一个好方法是打开 Jupyter Notebook。你可以通过 Anaconda Prompt 或 Anaconda Navigator 完成。如果迷路了,我建议在另一个标签页中打开下面的视频。
Anaconda Navigator
1. 定位到 Anaconda Navigator 并点击 Anaconda Navigator。
图片来源:www.linkedin.com/learning/python-for-data-visualization
2. 在 Jupyter Notebook 下,点击 Launch。
图片来源:www.linkedin.com/learning/python-for-data-visualization
Anaconda Prompt
1. 定位到 Anaconda Prompt。
2. 输入以下命令以查看你是否可以启动 Jupyter(IPython)Notebook。
jupyter notebook
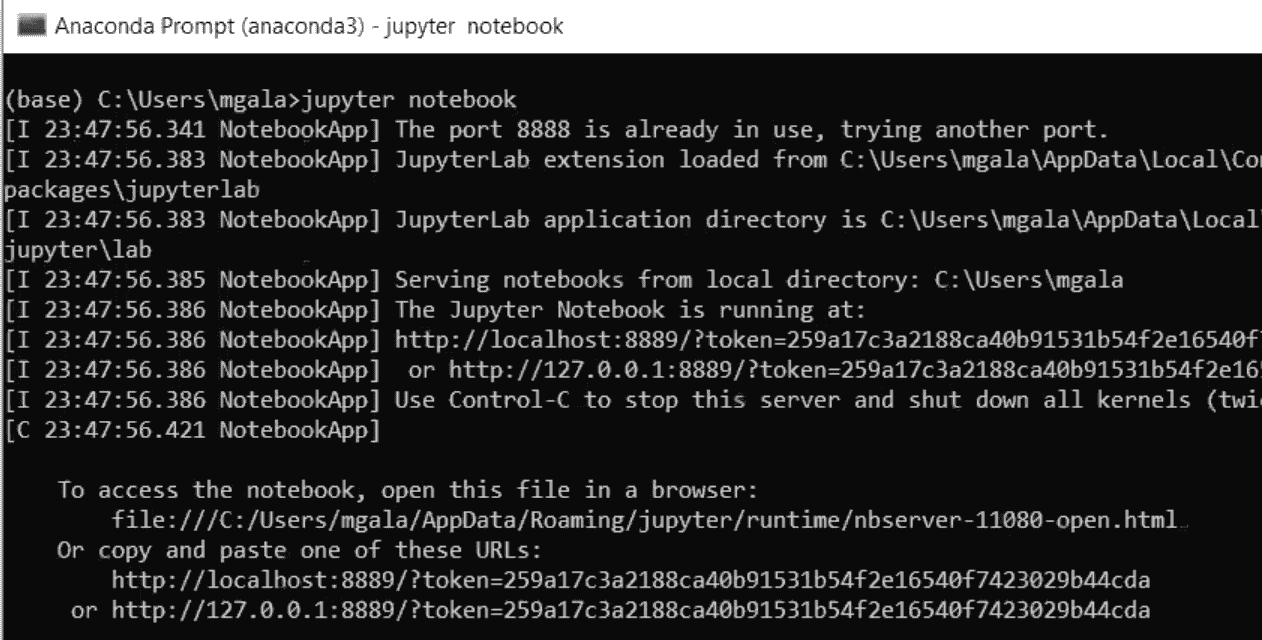
将 Anaconda 添加到 Path(可选)
这是一个 可选 步骤。这适用于你没有勾选第 6 步中的框,现在想要将 Anaconda 添加到你的 PATH 中的情况。这样做的好处是你可以在命令提示符中使用 Anaconda。
- 打开命令提示符。
- 检查你是否已经将 Anaconda 添加到你的路径中。将以下命令输入到你的 命令提示符 中。这是检查你是否已经将 Anaconda 添加到路径中的方法。如果你收到类似下图左侧的 未识别的命令 错误,请继续进行第 3 步。如果你得到类似下图右侧的输出,则表示你已经将 Anaconda 添加到路径中了。
jupyter notebook
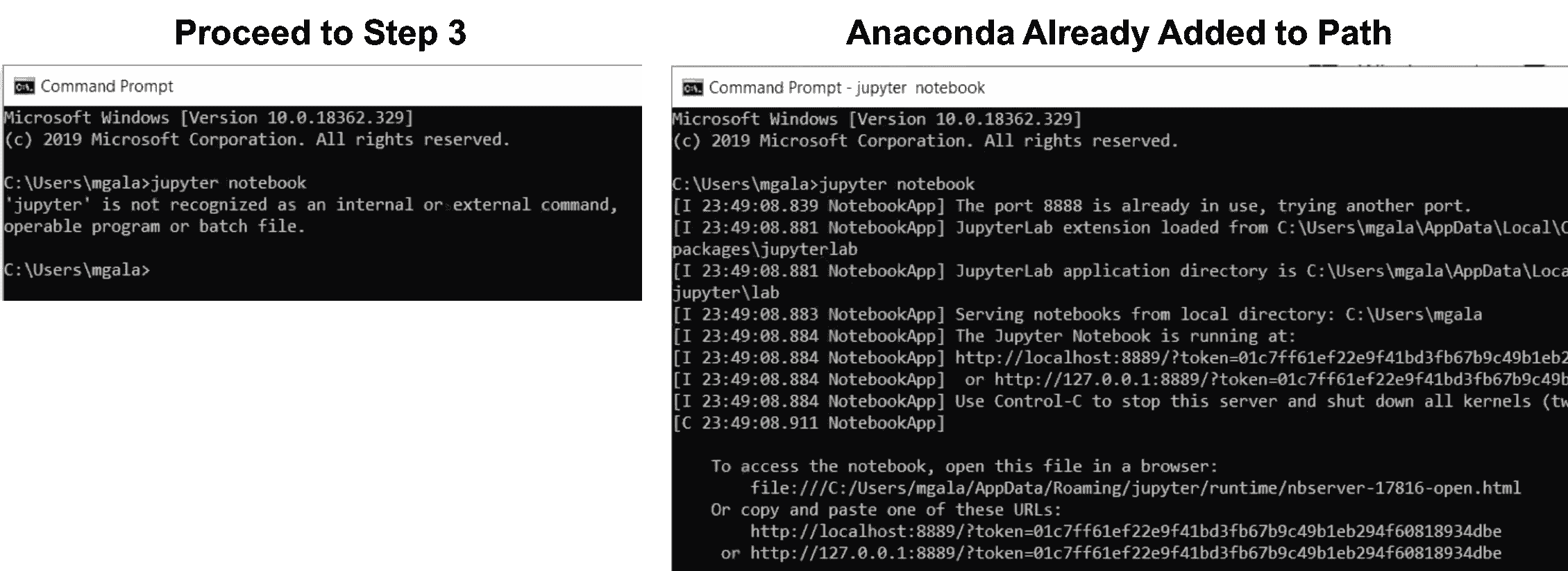
- 如果你不知道你的 conda 和/或 python 的位置,打开一个 Anaconda Prompt 并输入以下命令。这可以告诉你 conda 和 python 在你计算机上的位置。
where condawhere python
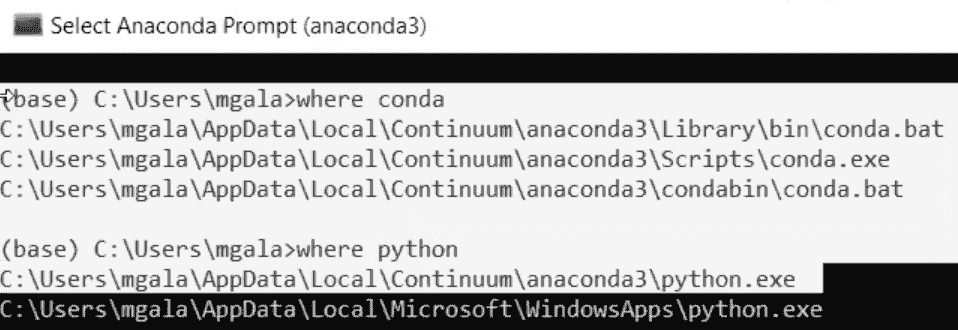
- 将 conda 和 python 添加到你的 PATH 中。你可以通过进入系统或环境变量,将步骤 3 的输出添加到你的 PATH 中来完成这一操作。在操作过程中请参考视频(请注意,这可能会根据你的 Windows 版本有所不同)。
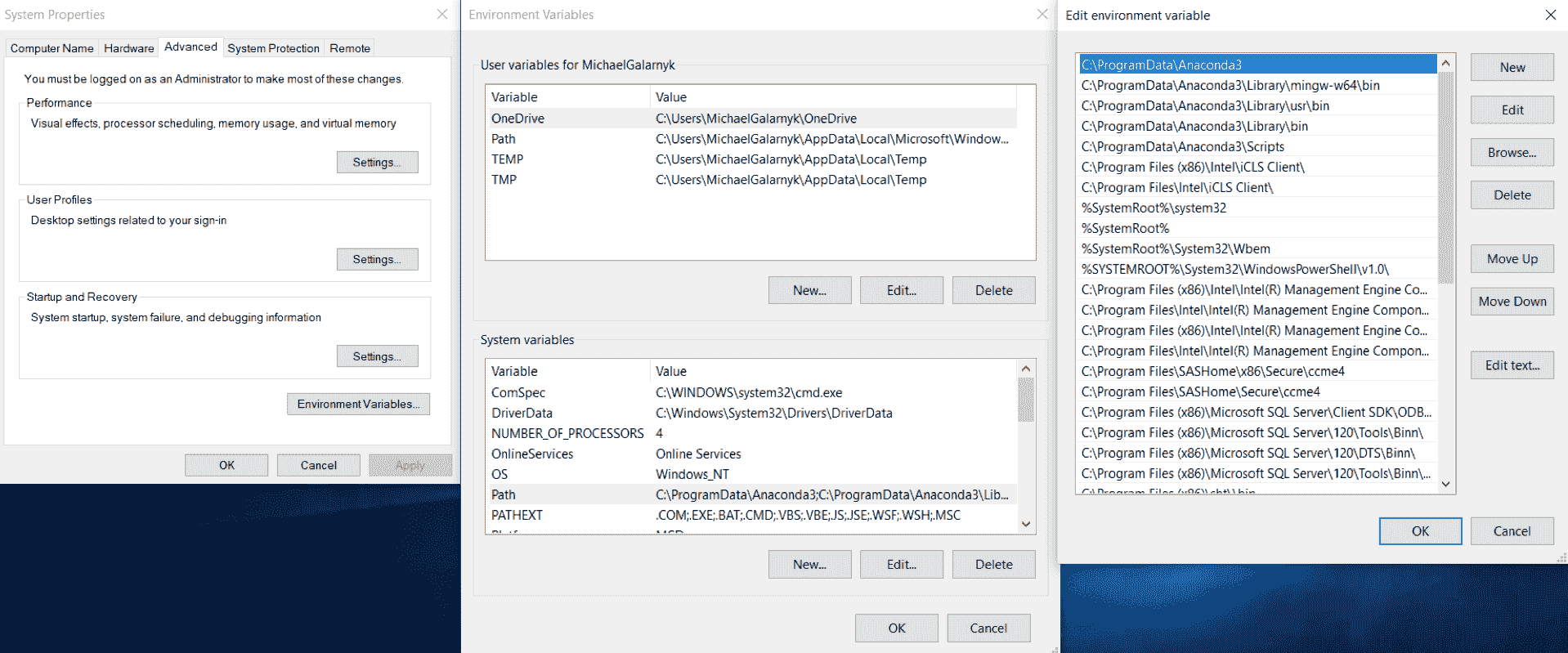
根据你使用的 Windows 版本,你的屏幕可能会有所不同。
- 打开一个 新的命令提示符。尝试在 命令提示符 中输入
conda --version和python --version以检查是否一切正常。你还可以尝试打开一个 Jupyter Notebook 进行检查。
其他常见问题
我已经尽力复制、解决了一些常见问题。以下是一些问题和我找到的一些解决方案。
Jupyter 未被识别
如果你收到 jupyter 未被识别、python 未被识别或类似错误,则很可能是路径问题。请参见“添加 Anaconda 到路径(可选)”部分。
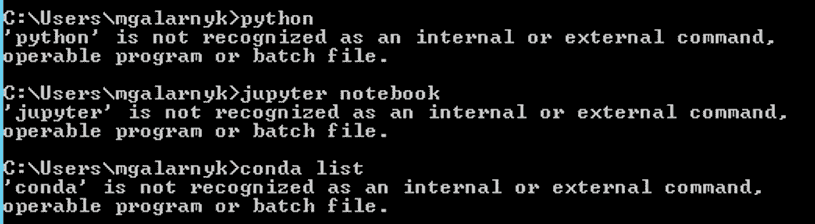
EnvironmentNotWritableError:当前用户没有对目标环境的写权限。环境位置:C:\ProgramData\Anaconda3
虽然在安装 Anaconda 后安装库时出现了图像中的错误,但请记住,在安装 Anaconda 时(特别是如果你在下载和安装 Anaconda 的第 4 步中点击了“所有用户”),也有可能出现这种错误。如果你遇到了这个错误并且想要安装库,请以管理员身份打开你的命令提示符/Anaconda Prompt 或 Anaconda Navigator 来安装你的包。
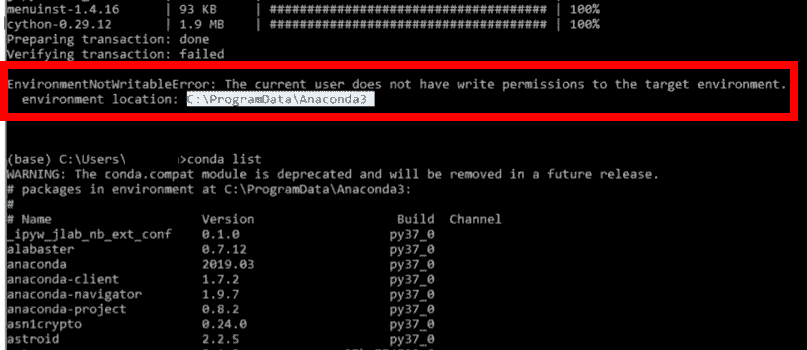
DLL 加载失败:找不到指定的模块
这是因为没有将所有内容添加到路径环境变量中。我猜测你可能没有将 condabin 或 bin 添加到你的路径中。
结论
本教程提供了一个关于如何在 Windows 上安装 Anaconda 以及如何处理常见安装问题的快速指南。如果你想了解更多关于 Anaconda 的信息,可以在 这里 学习。如果你不确定如何开始在计算机上编程,这里有几个资源:
如果你对教程有任何问题或想法,欢迎在下面的评论中或通过 Twitter 联系我。
个人简介:Michael Galarnyk 是一名数据科学家和企业培训师。他目前在斯克里普斯转化研究所工作。你可以在 Twitter (https://twitter.com/GalarnykMichael)、Medium (https://medium.com/@GalarnykMichael) 和 GitHub (https://github.com/mGalarnyk) 上找到他。
原文。经许可转载。
相关:
-
Python 元组及其方法
-
Python 列表及其操作
-
理解 Python 中的决策树分类
更多相关话题
将 ChatGPT 集成到数据科学工作流程中:技巧和最佳实践
原文:
www.kdnuggets.com/2023/05/integrating-chatgpt-data-science-workflows-tips-best-practices.html

作者提供的图片
ChatGPT、其继任者 GPT-4 以及它们的开源替代品都取得了极大的成功。开发者和数据科学家都希望提高生产力,并利用 ChatGPT 简化日常任务。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
在这里,我们将通过与 ChatGPT 的配对编程会话来探讨如何使用 ChatGPT 进行数据科学。我们将建立一个文本分类模型,视觉化数据集,确定模型的最佳超参数,尝试不同的机器学习算法等——一切都使用 ChatGPT。
在过程中,我们还将查看一些结构化提示以获得有用结果的技巧。要跟随这个过程,你需要一个免费的 OpenAI 账户。如果你是 GPT-4 用户,你也可以使用相同的提示进行跟随。
更快地建立一个可用模型
让我们尝试使用 ChatGPT 为scikit-learn 中的 20 个新闻组数据集建立一个新闻分类模型。
这是我使用的提示:“我想用 sklearn 的 20 个新闻组数据集建立一个新闻分类模型。你知道这个吗?”
尽管我的提示目前还不够具体,但我已经说明了目标和数据集:
-
目标:建立一个新的分类模型
-
使用的数据集:来自 scikit-learn 的 20 个新闻组数据集
ChatGPT 的回应告诉我们要从加载数据集开始。
# Load the dataset
newsgroups_train = fetch_20newsgroups(subset='train', shuffle=True)
newsgroups_test = fetch_20newsgroups(subset='test', shuffle=True)
既然我们已经明确了目标(建立一个文本分类模型),ChatGPT 告诉我们如何去做。
我们看到它给出了以下步骤:
-
使用
TfidfVectorizer进行文本预处理并生成数值表示。这种使用 TF-IDF 分数的方法优于使用CountVectorizer的计数方式。 -
在数据集的数字表示上创建分类模型,使用朴素贝叶斯或支持向量机(SVM)分类器。
它还提供了一个多项式朴素贝叶斯分类器的代码,所以让我们使用它,看看是否能得到一个有效的模型。
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
# Preprocess the text data
vectorizer = TfidfVectorizer(stop_words='english')
X_train = vectorizer.fit_transform(newsgroups_train.data)
X_test = vectorizer.transform(newsgroups_test.data)
# Train a Naive Bayes classifier
clf = MultinomialNB()
clf.fit(X_train, newsgroups_train.target)
# Evaluate the performance of the classifier
y_pred = clf.predict(X_test)
print(classification_report(newsgroups_test.target, y_pred))
我继续运行了上述代码。它按预期工作——没有错误。我们从一个空白屏幕到一个文本分类模型——在几分钟内——只用了一个提示。
Output >>
precision recall f1-score support
0 0.80 0.69 0.74 319
1 0.78 0.72 0.75 389
2 0.79 0.72 0.75 394
3 0.68 0.81 0.74 392
4 0.86 0.81 0.84 385
5 0.87 0.78 0.82 395
6 0.87 0.80 0.83 390
7 0.88 0.91 0.90 396
8 0.93 0.96 0.95 398
9 0.91 0.92 0.92 397
10 0.88 0.98 0.93 399
11 0.75 0.96 0.84 396
12 0.84 0.65 0.74 393
13 0.92 0.79 0.85 396
14 0.82 0.94 0.88 394
15 0.62 0.96 0.76 398
16 0.66 0.95 0.78 364
17 0.95 0.94 0.94 376
18 0.94 0.52 0.67 310
19 0.95 0.24 0.38 251
accuracy 0.82 7532
macro avg 0.84 0.80 0.80 7532
weighted avg 0.83 0.82 0.81 7532
尽管我们已经得到了一个能够解决当前问题的有效模型,但这里有一些提示可以帮助你进行提示优化。提示可以更好一些,并且分解为更小的步骤,例如:
-
请告诉我更多关于 scikit-learn 20 新组数据集的信息。
-
我可以对这个数据集执行哪些可能的任务?我可以构建一个文本分类模型吗?
-
你能告诉我哪种机器学习算法最适合这个应用吗?
可视化数据集
好的,我们已经建立了一个文本分类模型。但这个过程发生得非常快,所以让我们慢下来,尝试简单地可视化数据集。
尤其是,让我们尝试理解训练样本在 20 个新闻类别中的分布,并确定是否存在类别不平衡的情况。
这是我使用的提示:“我想可视化数据集,以理解类别分布并识别类别不平衡。你能帮我做可视化吗?”
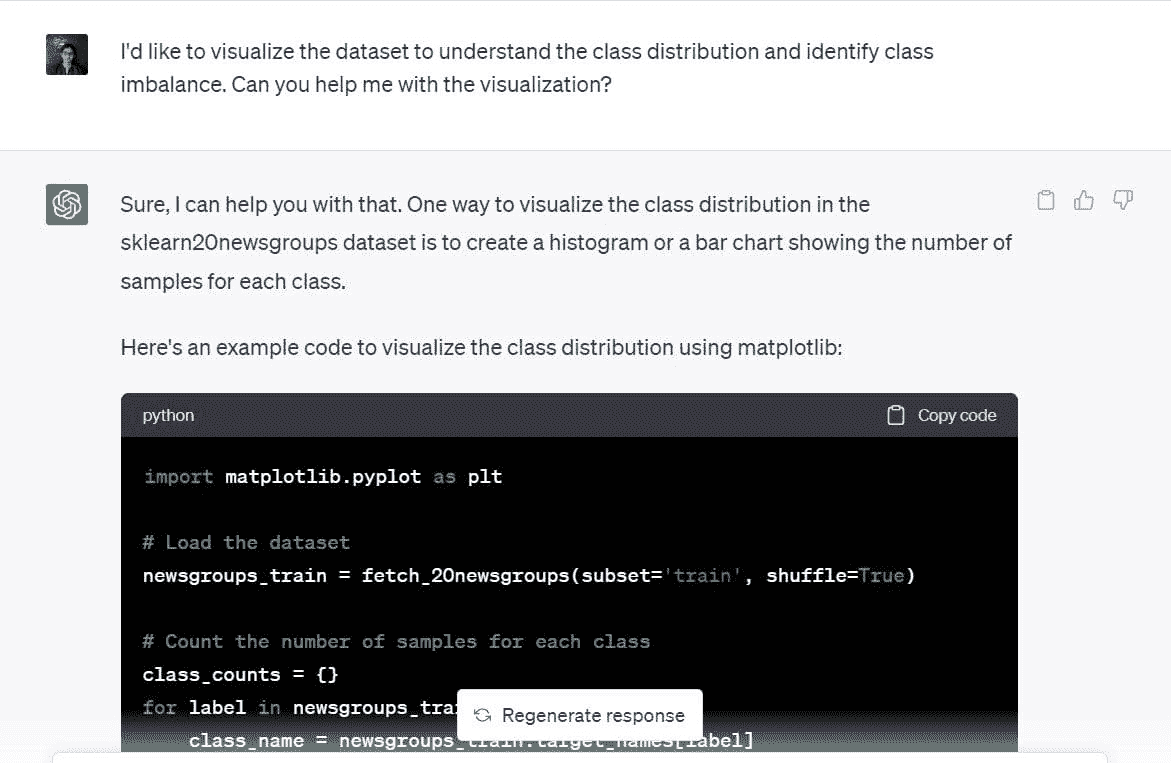
ChatGPT 建议用每个类别的样本数量的条形图或直方图作为良好的可视化方式。这听起来很合理。
这是 ChatGPT 生成的用 matplotlib 创建简单条形图的代码:
import matplotlib.pyplot as plt
# Load the dataset
newsgroups_train = fetch_20newsgroups(subset='train', shuffle=True)
# Count the number of samples for each class
class_counts = {}
for label in newsgroups_train.target:
class_name = newsgroups_train.target_names[label]
if class_name in class_counts:
class_counts[class_name] += 1
else:
class_counts[class_name] = 1
# Plot the class distribution
plt.bar(class_counts.keys(), class_counts.values())
plt.xticks(rotation=90)
plt.xlabel('Class')
plt.ylabel('Number of Samples')
plt.title('Class Distribution')
plt.show()
这是绘图结果。很整洁,标签可读。我们还可以看到 20 个类别中的每一个样本数量。
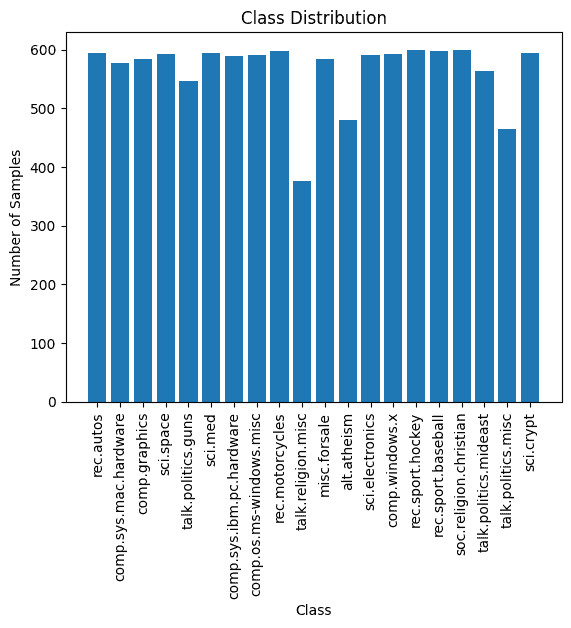
训练样本在 20 个类别中的分布大致均匀,没有明显的类别不平衡。因此,我们在前一步获得的模型是有用的。我们不需要使用任何新颖的重新采样技术来解决类别不平衡问题。
超参数调优
接下来,我想调整模型的超参数。首先,我想了解可以调整的不同超参数。然后,如果超参数不多,我们可以进行简单的网格搜索。
这是提示:“有没有我可以调整的超参数来使分类器模型更好?”
在我们得到的代码中,TfidfVectorizer 的 max_df 也是可调的。我们知道 TF-IDF 评分通过为频繁出现的术语分配更高的权重,同时为在所有文档中频繁出现的术语分配大大更低的权重来工作。max_df 使用出现的百分比来忽略某个特定术语。
例如,max_df 为 0.5 表示在至少 50% 的文档中出现的所有术语将被忽略。如果你愿意,可以去掉这个设置。但我将保留它,只是为了看看可以使用什么 max_df。
代码使用了一个简单的网格搜索,并根据交叉验证得分选择了最佳值。
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import Pipeline
# Define the pipeline with TF-IDF and Multinomial Naive Bayes
pipeline = Pipeline([
('tfidf', TfidfVectorizer(stop_words='english')),
('clf', MultinomialNB())
])
# Define the hyperparameter grid
param_grid = {
'tfidf__max_df': [0.5, 0.75, 1.0],
'clf__alpha': [0.1, 0.5, 1.0],
'clf__fit_prior': [True, False],
}
# Perform grid search with cross-validation
grid_search = GridSearchCV(pipeline, param_grid, cv=5)
grid_search.fit(newsgroups_train.data, newsgroups_train.target)
# Print the best hyperparameters and cross-validation score
print("Best hyperparameters: ", grid_search.best_params_)
print("Cross-validation score: ", grid_search.best_score_)
Output >>
Best hyperparameters: {'clf__alpha': 0.1, 'clf__fit_prior': False, 'tfidf__max_df': 0.5}
Cross-validation score: 0.9088736147919108
插入这些超参数的值后,我在分类准确率上得到了大约 2% 的提升。
在这里,我们没有很多超参数需要调整。如果你有很多超参数,每个超参数都有一组可能的值,运行网格搜索可能会很昂贵。此时,运行随机搜索可能更合适。
更快地迭代不同模型
我们在第一步中看到,SVM 对这种分类问题也能很好地工作。
现在我想为同一数据集构建一个支持向量分类器。
我使用的提示是:“你能告诉我是否可以使用 SVM 解决相同的问题吗?你能生成解决此问题的代码吗?”
下面开始:
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# Load the dataset
newsgroups_train = fetch_20newsgroups(subset='train', shuffle=True)
# Convert the text data to a matrix of TF-IDF features
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(newsgroups_train.data)
y = newsgroups_train.target
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Define the SVM classifier
clf = SVC(kernel='linear')
# Train the SVM classifier
clf.fit(X_train, y_train)
# Predict the class labels for the test set
y_pred = clf.predict(X_test)
# Calculate the accuracy of the SVM classifier
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy:', accuracy)
鉴于我们有超过 90% 的准确率,SVM 似乎是这个数据集的一个不错的选择。
Output >> Accuracy: 0.9019001325673884
如上所示,你可以使用 ChatGPT 快速尝试不同的模型来解决相同的问题。
探索降维
一旦你决定了构建一个有效的模型,你也可以探索其他可用的方向。以降维为例。
此时,我对运行降维算法不感兴趣,因为我已经有了一个有效的模型。而且特征空间的维度并不是很高。因此,在模型构建之前,我们不需要减少维度。
不过,让我们看一下针对这个特定数据集的降维方法。
我使用的提示是:“你能告诉我可以为这个数据集使用哪些降维技术吗?”

ChatGPT 提出了以下技术建议:
-
潜在语义分析或 SVD
-
主成分分析(PCA)
-
非负矩阵分解(NMF)
让我们通过列举使用 ChatGPT 的最佳实践来结束我们的讨论。
使用 ChatGPT 进行数据科学的最佳实践
使用 ChatGPT 进行数据科学时需要记住的一些最佳实践如下:
-
不要输入敏感数据和源代码:不要将任何敏感数据输入到 ChatGPT 中。当你在组织的数据团队中工作时,你通常会在客户数据上构建模型——这些数据应该保密。你可以尝试为类似的公开数据集构建原型,并将其转移到你的数据集或问题上。同样,请避免输入敏感的源代码或任何不应公开的信息。
-
对你的提示要具体:没有具体的提示,从 ChatGPT 获得有用答案是相当困难的。因此,结构化你的提示,使其足够具体。提示至少应该清晰地传达目标,一次一步。
-
将较长的提示分解为较小的提示:如果你有一个完成特定任务的思路链,尝试将其分解为更简单的步骤,并提示 ChatGPT 执行每个步骤。
-
使用 ChatGPT 进行有效调试:在这个例子中,我们得到的所有代码都没有错误;但这可能并不总是如此。你可能会遇到由于弃用特性、无效 API 引用等原因导致的错误。当你遇到错误时,可以将错误信息和相关的 traceback 传入你的提示中。然后查看提供的解决方案,再继续调试你的代码。
-
跟踪提示:如果你在日常的数据科学工作流程中经常使用(或计划使用)ChatGPT,保持对提示的跟踪可能是个好主意。这可以帮助随着时间的推移改进提示,并识别提示工程技术,从而获得更好的 ChatGPT 结果。
结论
在使用 ChatGPT 进行数据科学应用时,理解业务问题是第一步,也是最重要的一步。因此,ChatGPT 只是一个简化和自动化某些任务的工具,并且不是开发者技术专长的替代品。
然而,它仍然是一个宝贵的工具,通过帮助快速构建和测试不同的模型和算法来提高生产力。所以,让我们利用 ChatGPT 来磨练我们的技能,成为更好的开发者吧!
Bala Priya C 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交集上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过撰写教程、使用指南、观点文章等来学习和分享她的知识,服务于开发者社区。
更多相关内容
将生成性人工智能融入内容创作
原文:
www.kdnuggets.com/integrating-generative-ai-in-content-creation

图像由 Ideogram.ai 生成
我知道创作内容有多么困难,尤其是要吸引观众的注意力。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
无论我们使用什么媒介,书面、声音还是视觉,每一种都需要深思熟虑和策略来为内容提供价值。
然而,只有一些人有足够的时间来生成优质内容,尤其是像我这样兼任内容创作者的上班族。工作和个人生活可能会成为障碍。
近年来,随着生成性人工智能变得越来越主流,情况发生了变化。这是因为如果有效使用生成性人工智能,它有很大的潜力来提高我们的内容质量和效率。
生成性人工智能,如 ChatGPT,能够让内容创作变得更加轻松。你可能会想,“为什么不让工具完全生成我们的内容呢?” 实际上,我的个人经验告诉我这是一个不好的主意。未经筛选的、完全生成的人工智能内容质量实际上很差,需要重新加工。这就是为什么我建议我们使用工具来帮助我们创建内容,而不是替代这些工作。
本文将讨论我们如何将内容创作与生成性人工智能结合。让我们一起学习吧。
生成性人工智能在内容创作中的应用
当我们谈论生成性人工智能时,它指的是能够生成类似于人类生成内容的新内容的工具。
许多工具都属于生成性人工智能类别。例如,ChatGPT 是一个可以生成文本内容的生成性人工智能工具,或 Midjourney,它可以生成图像内容。随着时间的推移,这些工具已经进化到能够生成比以往更接近人类的内容。
我们将学习如何将生成性人工智能工具融入我们的内容生成流程中。我们会将其分为两个部分:文本和图像。
文本内容
文本生成的生成性人工智能是一种可以从我们提供的输入中生成类似人类的文本的工具。人工智能模型可以非常接近我们输入提示的意图。例如,生成电子邮件、创建内容草稿、规划社交媒体日程等。
在内容创作中,文本生成模型可以在很多方面帮助我们。以下是该模型如何帮助你创建内容的一些方式。
内容构思与头脑风暴
假设你是一位特定领域的内容创作者,例如数据科学、数据工程、机器学习等,并且需要新的创意来吸引观众。你可以使用生成式 AI 模型,如 ChatGPT,来生成新想法。
例如,我使用 ChatGPT 生成内容创意,使用的提示是:
“我是一名数据科学内容创作者,我想发布关于数据科学对业务重要性的内容。”
给我生成 3 个可以发布的内容创意。
结果是一个内容创意列表,解释如何处理这些内容。列表示例如下:
-
数据驱动决策的案例研究
-
数据科学在提升客户体验中的作用
-
数据科学和商业智能中的新兴趋势
实际结果包含了更长的说明,关于如何创建内容以及我们应该包含哪些内容。
ChatGPT 在这里促进创造性思维,因为我们并没有直接要求 ChatGPT 创建内容。它作为一个伙伴来激发想法和验证我们的思路。
内容大纲草稿
生成式 AI 工具不仅能够生成创意,还能帮助我们创建更详细的大纲。
虽然需要更多验证,但拥有一个大纲可以节省一些创建内容的时间。
例如,我请 ChatGPT 使用以下提示创建一个博客大纲:
“写一个关于为什么数据科学家应该学习数据工程的 300 字博客草稿大纲。”
结果是一个草拟大纲,供我们填充。以下是我用上述提示得到的结果:
标题:弥合差距:数据工程对数据科学家的重要性
介绍(50 字)
正文
-
数据科学基础(60 字)
-
增强合作与沟通(60 字)
-
增加自主性和创新性(60 字)
-
职业发展与多样性(60 字)
结果还包含了我们应该写些什么以及如何写的更详细说明。
内容增强
作为内容创作者,我们获得的最佳建议之一就是重新利用我们的内容。
有时,我们的内容已经足够好,但新的发展使我们之前的内容过时。
或者我们现有的内容没有足够的参与度,因为缺少了一些东西。
无论你以前有什么,它仍然是足够好的内容,我们可以在下一个内容中再次使用它。然而,我们仍然需要更改一些东西以提高其质量。
这就是生成式 AI 介入以帮助增强我们之前内容的地方。通过使用该工具,它们可以通过阅读和理解我们的内容,带来之前内容中缺失的新视角和结构。
例如,这里有一个可以使用的提示模板,假设的结果来自 ChatGPT。
我的内容在下面的文本中:
##插入内容##
你能分析一下它们的问题,并提供详细的改进建议,以提高观众的互动吗?
结果如下:
-
增强标题:使标题更具吸引力和引发好奇心。
-
改进引言:包含一个引人注目的事实、问题或轶事。
-
融入现实世界的例子:在机会部分使用案例研究或示例。
-
提供挑战的解决方案:讨论正在进行的努力和应对挑战的解决方案。
-
添加视觉效果和信息图:使用图表、视觉效果和信息图来说明关键点。
-
加强结论:以强有力的号召性用语结束,让读者采取行动。
正如你所见,ChatGPT 可以提供有关为什么我们的内容未按预期工作以及如何改进的详细信息。
图片内容
与文本内容不同,图片内容依赖于视觉效果来吸引观众。
使用生成式 AI 工具来生成内容对一些人来说可能有争议,但它仍然是帮助我们与观众互动的有效工具。然而,图片内容通常成为与文本内容配合的辅助内容。这就是为什么我们通常会在图片内容之前准备好文本内容。
让我们看看生成式 AI 在图片内容中的几个使用案例。
图片与文本内容的配合
你可以使用生成式 AI 做的最简单的用例是开发一张适合文本内容的图片。
在社交媒体上,包含图片的内容通常会有更多的互动,并提供观众可能忽略的额外细节。通过无尽的社交媒体滚动,图片可能会让观众停留在你的内容上。
使用生成式 AI,你可以用提示生成适合你内容的图片。
在下面的示例中,我使用 ChatGPT 和一个提示,执行 DALL·E 进行图片生成。
“我想发布关于数据科学家的内容。你能生成一张适合我将要发布内容的简单图片吗?”

使用 DALL·E 3 生成的图片
结果是一张数据科学家在多个屏幕前工作的图片。这是一张简单的图片,但我们总是可以进行调整以满足你的需求。
说到调整,我们将讨论生成式 AI 如何帮助个性化图片内容。
个性化内容创作
个性化的内容比标准图片生成能够创造更多的互动。这是因为你为每个内容都针对个体的某些方面进行定制。你甚至可以为电子邮件营销或客户礼品提供更个性化的图片内容。
例如,你想发送内容以庆祝你最有价值的观众,Charlie。你可以生成一张反映他个性的惊人图片,以显示你对观众的重视。这里是一个使用 Ideogram.ai 生成的示例提示和图片。
“排版 ‘生日快乐,Charlie’ 的背景是图书馆书籍和猫咪玩耍。”

图片生成自 Ideogram.ai
当然,个性化程度因内容创作者而异。你希望每个人都获得个人化的还是稍微更通用的图像?选择权在于你。
结论
作为内容创作者,有时内容创作可能会变得单调,并且花费大量时间。通过生成性 AI,我们可以通过将任务委托给模型来提高工作效率。
在本文中,我们了解了生成性 AI 如何通过帮助我们改进文本和图像内容来融入我们的内容创作。生成模型可以帮助我们提升或使用现有内容作为头脑风暴的平台。
Cornellius Yudha Wijaya** 是数据科学助理经理和数据撰稿人。在 Allianz Indonesia 全职工作的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 撰写各种 AI 和机器学习话题的文章。**
更多相关内容
将 Python 和 R 集成到数据分析管道中,第一部分
原文:
www.kdnuggets.com/2015/10/integrating-python-r-data-analysis-part1.html/2
命令行脚本
从命令行通过类似 Windows/Linux 的终端环境运行脚本在 R 和 Python 中是类似的。要运行的命令被分解为以下部分,
<command_to_run> <path_to_script> <any_additional_arguments>
其中:
-
<command>是要运行的可执行文件(对于 R 代码是Rscript,对于 Python 代码是Python), -
<path_to_script>是执行脚本的完整或相对文件路径。请注意,如果路径名称中有空格,则整个文件路径必须用双引号括起来。 -
<any_additional_arguments>这是传递给脚本本身的空格分隔参数的列表。请注意,这些参数将作为字符串传递。
例如,通过打开终端环境并运行以下命令来执行 R 脚本:
Rscript path/to/myscript.R arg1 arg2 arg3
一些注意事项
-
要找到
Rscript和Python命令,这些可执行文件必须已经在你的路径中。否则,必须提供其在文件系统中的完整路径。 -
路径名称包含空格会造成问题,特别是在 Windows 上,因此必须用双引号括起来,以便被识别为单个文件路径。
访问 R 中的命令行参数
在上面的例子中,arg1、arg2 和 arg3 是传递给正在执行的 R 脚本的参数,可以使用 commandArgs 函数来访问。
## myscript.R
# 获取命令行参数 myArgs <- commandArgs(trailingOnly = TRUE)
# myArgs 是包含所有参数的字符向量 print(myArgs) print(class(myArgs))
通过设置 trailingOnly = TRUE,向量 myArgs 只包含你在命令行上添加的参数。如果保持 FALSE(默认值),向量中将包含其他参数,例如刚刚执行的脚本的路径。
访问 Python 中的命令行参数
对于通过在命令行运行以下命令执行的 Python 脚本
python path/to/myscript.py arg1 arg2 arg3
参数arg1、arg2 和 arg3 可以通过先导入 sys 模块来在 Python 脚本中访问。这个模块包含了系统特定的参数和函数,但我们这里只关注 argv 属性。这个 argv 属性是一个包含当前执行脚本的所有参数的列表。列表中的第一个元素始终是正在执行脚本的完整文件路径。
# myscript.py import sys
# 获取命令行参数 my_args = sys.argv
# my_args 是一个列表,其中第一个元素是被执行的文件。 print(type(my_args)) print(my_args)
如果你只希望保留解析到脚本中的参数,可以使用列表切片来选择除第一个元素外的所有元素。
# 使用切片,选择除第一个元素之外的所有元素 my_args = sys.argv[1:]
与上述 R 的例子类似,记住所有参数都作为字符串解析,因此需要根据需要转换为预期的类型。
将输出写入文件
在通过中间文件在 R 和 Python 之间共享数据时,你有几种选择。通常,对于平面文件,CSV 是一种适合表格数据的好格式,而 JSON 或 YAML 则更适合处理结构化较少的数据(或元数据),这些数据可能包含可变数量的字段或更多嵌套的数据结构。
所有这些都是非常常见的 数据序列化格式,并且两种语言中都已有解析器。在 R 中,推荐使用以下包来处理每种格式:
而在 Python 中:
csv 和 json 模块是 Python 标准库的一部分,随 Python 本身分发,而 PyYAML 需要单独安装。所有 R 包也需要以通常的方式安装。
总结
在 R 和 Python 之间(以及反向)传递数据可以通过以下单一管道完成:
-
使用命令行传递参数,以及
-
通过结构化一致的平面文件传输数据。
然而,在某些情况下,使用平面文件作为中间数据存储既麻烦又对性能有害。在下一篇文章中,我们将探讨如何让 R 和 Python 直接调用对方并在内存中返回输出。
原文。
相关:
-
R 与 Python:面对面的数据分析
-
数据科学编程:Python 与 R 的对比
-
R 与 Python 的数据科学:赢家是……
-
R,Python 用户表现出令人惊讶的稳定性,但存在显著的区域差异
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关主题
集成 Python 和 R,第二部分:从 Python 执行 R 及反之亦然
原文:
www.kdnuggets.com/2015/10/integrating-python-r-executing-part2.html
作者:Chris Musselle (Mango Solutions)。
在上一篇文章中,我们讨论了为什么你可能想将 R 和 Python 集成到一个管道中,以及如何通过使用平面文件隔离来实现这一点。在此过程中,我们介绍了如何从命令行运行 Python 或 R 脚本,以及如何访问传入的任何附加参数。在这篇文章中,我们通过展示如何将两个脚本链接在一起,完成集成过程,方法是让 R 调用 Python,反之亦然。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
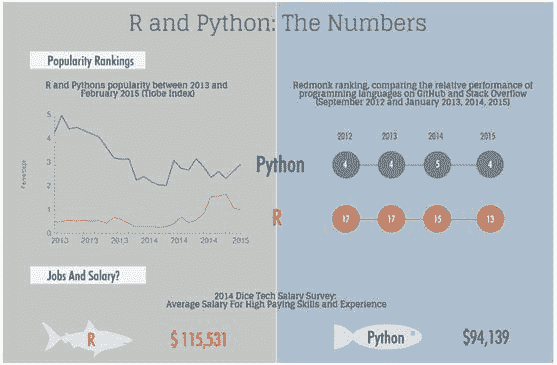
命令行执行和执行子进程
为了更好地理解子进程执行时发生的情况,值得详细回顾在命令行上执行 Python 或 R 进程时发生的事情。当运行以下命令时,会启动一个新的 Python 进程来执行脚本。
python path/to/myscript.py arg1 arg2 arg3
在执行过程中,任何输出打印到标准输出和标准错误流的内容都会显示在控制台上。实现这一点最常见的方法是通过内置函数(Python 中的print()和 R 中的cat()或print()),这些函数将给定的字符串写入stdout流。Python 进程将在脚本执行完成后关闭。
以这种方式运行命令行脚本是有用的,但如果有多个顺序但独立的脚本需要以这种方式执行,则可能变得繁琐且容易出错。然而,Python 或 R 进程可以以类似于上述命令行方法的方式直接执行另一个进程。这是有益的,因为它允许,例如,父 Python 进程启动子 R 进程来运行特定的分析脚本。一旦 R 脚本完成,这个子 R 进程的输出可以传递回父 Python 进程,而不是打印到控制台。使用这种方法可以消除在命令行上手动逐步执行的需要。
示例
为了说明一个进程如何执行另一个进程,我们将使用两个简单的示例:一个是 Python 调用 R,另一个是 R 调用 Python。每个案例中执行的分析故意简化,以便集中于实现这种调用机制的过程。
示例 R 脚本
我们的简单示例 R 脚本将从命令行接收一系列数字并返回最大值。
# max.R
# 获取命令行参数 myArgs <- commandArgs(trailingOnly = TRUE)
# 转换为数字 nums = as.numeric(myArgs)
# cat 将结果写入 stdout 流 cat(max(nums))
从 Python 执行 R 脚本
要从 Python 执行此操作,我们使用 subprocess 模块,这是标准库的一部分。我们将使用 check_output 函数来调用 R 脚本,该函数执行一个命令并存储 stdout 的输出。
要从 Python 执行 max.R 脚本,你首先需要构建要执行的命令。这的格式类似于我们在 第一部分 的博文系列中看到的命令行语句,在 Python 中表示为一个字符串列表,其中的元素对应于以下内容:
['<command_to_run>', '<path_to_script>', 'arg1' , 'arg2', 'arg3', 'arg4']
从 Python 执行 R 脚本的一个示例见以下代码。
# run_max.py 导入 subprocess
# 定义命令和参数 command ='Rscript' path2script ='path/to your script/max.R'
# 列表中的变量数量 args = ['11','3','9','42']
# 构建 subprocess 命令 cmd = [command, path2script] + args
check_output 将运行命令并将结果存储到变量中
x = subprocess.check_output(cmd, universal_newlines=True)
print('这些数字的最大值是:', x)
参数 universal_newlines=True 告诉 Python 将返回的输出解释为文本字符串,并处理 Windows 和 Linux 的换行符。如果省略该参数,输出将以字节字符串形式返回,并且必须通过调用 x.decode() 将其解码为文本,才能进行进一步的字符串操作。
示例 Python 脚本
对于我们的简单 Python 脚本,我们将根据提供的子字符串模式(第二个参数)将给定字符串(第一个参数)分割成多个子字符串。结果将逐行打印到控制台。
# splitstr.py import sys
# 获取传递的参数 string = sys.argv[1] pattern = sys.argv[2]
# 执行分割 ans = string.split(pattern)
# 将结果元素列表连接成一个以换行符分隔的字符串并打印 print('\n'.join(ans))
从 R 执行 Python 脚本
执行 R 的子进程时,建议使用 R 的system2函数来执行和捕获输出。这是因为内置的system函数使用起来更复杂,且不具备跨平台兼容性。
构建要执行的命令类似于上述 Python 示例,但system2期望命令与其参数分开解析。此外,这些参数的第一个必须始终是要执行的脚本的路径。
处理 R 脚本路径中的空格可能会带来一个最终的复杂问题。解决这个问题的最简单方法是将整个路径名用双引号括起来,然后用单引号将这个字符串包裹起来,以便 R 保留参数中的双引号。
执行 Python 脚本的 R 示例见以下代码。
# run_splitstr.R
command ="python
# 注意字符串中的单引号 + 双引号(如果路径中有空格需要) path2script='"path/to your script/splitstr.py"'
# 在向量中构建参数 string ="3523462---12413415---4577678---7967956---5456439" pattern ="---" args = c(string, pattern)
# 将脚本路径作为第一个参数添加 allArgs = c(path2script, args)
output = system2(command, args=allArgs, stdout=TRUE)
print(paste("子字符串为:\n", output))
要将标准输出捕获到字符向量中(每个元素一行),必须在system2中指定stdout=TRUE,否则仅返回退出状态。当stdout=TRUE时,退出状态会存储在一个名为“status”的属性中。
总结
可以通过使用子进程调用将 Python 和 R 集成到一个应用程序中。这些调用允许一个父进程调用另一个子进程,并捕获打印到 stdout 的任何输出。在这篇文章中,我们展示了如何使用这种方法让 R 脚本调用 Python 及反之亦然。
在未来的文章中将基于这篇文章的内容以及第一部分,展示一个实际的示例,说明如何在应用程序中将 Python 和 R 结合使用。
原文。
相关:
-
R 与 Python:正面交锋的数据分析
-
数据科学编程:Python 与 R
-
数据科学中的 R 与 Python:赢家是…
-
R 和 Python 用户表现出惊人的稳定性,但地区差异显著
更多相关话题
使用 Keras 和 TensorFlow 2 的 BERT 意图识别
原文:
www.kdnuggets.com/2020/02/intent-recognition-bert-keras-tensorflow.html
评论
由 Venelin Valkov,机器学习工程师
从文本中识别意图(IR)现在非常有用。通常,你会得到一段简短的文本(一个或两个句子),并需要将其分类到一个(或多个)类别中。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 工作
多个产品支持系统(帮助中心)使用 IR 来减少大量员工重复回答常见问题的需要。聊天机器人、自动电子邮件回复者、答案推荐系统(来自含有问答的知识库)都力求不让你占用真正人员的时间。
本指南将展示如何使用预训练的 NLP 模型,这可能解决许多企业主的(技术)支持问题。我的意思是,BERT 实在是太强大了!而且使用起来也非常简单!
数据
数据包含各种用户查询,分类为七个意图。它托管在 GitHub 上,并首次在 这篇论文 中展示。
下面是意图:
-
SearchCreativeWork(例如:找到 I, Robot 电视节目)
-
GetWeather(例如:现在波士顿,MA 风很大吗?)
-
BookRestaurant(例如:我想为我和我的男朋友预定一家高评分的餐厅,明晚去)
-
PlayMusic(例如:播放 Spotify 上的 Beyoncé 最新曲目)
-
AddToPlaylist(例如:将 Diamonds 添加到我的公路旅行播放列表中)
-
RateBook(例如:给《鼠与人》打 6 星)
-
SearchScreeningEvent(例如:查看 Wonder Woman 在巴黎的放映时间)
我做了一些预处理,并将 JSON 文件转换为易于使用/加载的 CSV 文件。我们来下载它们:
!gdown --id 1OlcvGWReJMuyYQuOZm149vHWwPtlboR6 --output train.csv
!gdown --id 1Oi5cRlTybuIF2Fl5Bfsr-KkqrXrdt77w --output valid.csv
!gdown --id 1ep9H6-HvhB4utJRLVcLzieWNUSG3P_uF --output test.csv
我们将数据加载到数据框中,并通过合并训练和验证意图来扩展训练数据:
train = pd.read_csv("train.csv")
valid = pd.read_csv("valid.csv")
test = pd.read_csv("test.csv")
train = train.append(valid).reset_index(drop=True)
我们有13,784个训练样本和两列 - text和intent。我们来看看每个意图下的文本数量:

每个意图的文本量相当平衡,因此我们不需要任何不平衡建模技术。
BERT
BERT(Bidirectional Encoder Representations from Transformers)模型,介绍于 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 论文中,使得普通机器学习从业者能够在各种 NLP 任务中取得最先进的成果。你可以在没有大量数据集的情况下实现这一点!但这如何可能呢?
BERT 是一个预训练的 Transformer 编码器堆栈。它在维基百科和Book Corpus数据集上进行训练。它有两个版本 - Base(12 个编码器)和 Large(24 个编码器)。
BERT 建立在 NLP 社区多个巧妙想法的基础上。一些例子包括 ELMo、 The Transformer和 OpenAI Transformer。
ELMo 引入了上下文词嵌入(一个词根据周围的词可以有不同的含义)。Transformer 使用注意力机制来理解词语的使用上下文。然后,这个上下文被编码成一个向量表示。实际上,它在处理长期依赖性方面表现更好。
BERT 是一个双向模型(同时向前和向后查看)。最棒的是,BERT 可以轻松用作特征提取器或在少量数据上进行微调。它在从文本中识别意图方面有多强?
使用 BERT 进行意图识别
幸运的是,BERT 论文的作者 开源了他们的工作 以及多个预训练模型。原始实现是用 TensorFlow 编写的,但也有非常好的 PyTorch 实现!
让我们从下载其中一个较简单的预训练模型开始,并解压它:
!wget https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-12_H-768_A-12.zip
!unzip uncased_L-12_H-768_A-12.zip
这将解压检查点、配置和词汇表,以及其他文件。
不幸的是,原始实现与 TensorFlow 2 不兼容。 bert-for-tf2 包解决了这个问题。
预处理
我们需要将原始文本转换为可以输入模型的向量。我们将经过三个步骤:
-
对文本进行分词
-
将令牌序列转换为数字
-
对序列进行填充,使每个序列具有相同的长度
让我们开始创建 BERT 分词器:
tokenizer = FullTokenizer(
vocab_file=os.path.join(bert_ckpt_dir, "vocab.txt")
)
让我们试试看:
tokenizer.tokenize("I can't wait to visit Bulgaria again!")
['i', 'can', "'", 't', 'wait', 'to', 'visit', 'bulgaria', 'again', '!']
令牌是小写的,并且标点符号是可用的。接下来,我们将把令牌转换为数字。分词器也可以做到这一点:
tokens = tokenizer.tokenize("I can't wait to visit Bulgaria again!")
tokenizer.convert_tokens_to_ids(tokens)
[1045, 2064, 1005, 1056, 3524, 2000, 3942, 8063, 2153, 999]
我们将自己处理填充部分。你也可以使用 Keras 填充工具来完成这部分。
我们将预处理打包成一个类,这个类主要基于这个笔记本:
class IntentDetectionData:
DATA_COLUMN = "text"
LABEL_COLUMN = "intent"
def __init__(
self,
train,
test,
tokenizer: FullTokenizer,
classes,
max_seq_len=192
):
self.tokenizer = tokenizer
self.max_seq_len = 0
self.classes = classes
((self.train_x, self.train_y), (self.test_x, self.test_y)) =\
map(self._prepare, [train, test])
print("max seq_len", self.max_seq_len)
self.max_seq_len = min(self.max_seq_len, max_seq_len)
self.train_x, self.test_x = map(
self._pad,
[self.train_x, self.test_x]
)
def _prepare(self, df):
x, y = [], []
for _, row in tqdm(df.iterrows()):
text, label =\
row[IntentDetectionData.DATA_COLUMN], \
row[IntentDetectionData.LABEL_COLUMN]
tokens = self.tokenizer.tokenize(text)
tokens = ["[CLS]"] + tokens + ["[SEP]"]
token_ids = self.tokenizer.convert_tokens_to_ids(tokens)
self.max_seq_len = max(self.max_seq_len, len(token_ids))
x.append(token_ids)
y.append(self.classes.index(label))
return np.array(x), np.array(y)
def _pad(self, ids):
x = []
for input_ids in ids:
input_ids = input_ids[:min(len(input_ids), self.max_seq_len - 2)]
input_ids = input_ids + [0] * (self.max_seq_len - len(input_ids))
x.append(np.array(input_ids))
return np.array(x)
我们通过取最长文本和最大序列长度参数之间的最小值来确定填充长度。我们还将每个文本的标记用两个特殊标记包围:以[CLS]开头,以[SEP]结尾。
微调
让我们让 BERT 用于文本分类吧!我们将加载模型并在其上附加几个层:
def create_model(max_seq_len, bert_ckpt_file):
with tf.io.gfile.GFile(bert_config_file, "r") as reader:
bc = StockBertConfig.from_json_string(reader.read())
bert_params = map_stock_config_to_params(bc)
bert_params.adapter_size = None
bert = BertModelLayer.from_params(bert_params, name="bert")
input_ids = keras.layers.Input(
shape=(max_seq_len, ),
dtype='int32',
name="input_ids"
)
bert_output = bert(input_ids)
print("bert shape", bert_output.shape)
cls_out = keras.layers.Lambda(lambda seq: seq[:, 0, :])(bert_output)
cls_out = keras.layers.Dropout(0.5)(cls_out)
logits = keras.layers.Dense(units=768, activation="tanh")(cls_out)
logits = keras.layers.Dropout(0.5)(logits)
logits = keras.layers.Dense(
units=len(classes),
activation="softmax"
)(logits)
model = keras.Model(inputs=input_ids, outputs=logits)
model.build(input_shape=(None, max_seq_len))
load_stock_weights(bert, bert_ckpt_file)
return model
我们使用我们的输入(文本和意图)微调预训练的 BERT 模型。我们还将输出展平,并添加两个全连接层和 Dropout。最后一层具有 softmax 激活函数。输出数量等于我们拥有的意图数量——七个。
现在你可以使用 BERT 来识别意图了!
训练
现在是将一切整合在一起的时候了。我们将从创建数据对象开始:
classes = train.intent.unique().tolist()
data = IntentDetectionData(
train,
test,
tokenizer,
classes,
max_seq_len=128
)
我们现在可以使用最大序列长度来创建模型:
model = create_model(data.max_seq_len, bert_ckpt_file)
查看模型摘要:
model.summar()
你会注意到,即使是这个“精简版”的 BERT 也有近 1.1 亿个参数。确实,你的模型非常庞大(她是这么说的)。
微调像 BERT 这样的模型既是一门艺术,也涉及大量的失败实验。幸运的是,作者提出了一些建议:
-
批量大小:16,32
-
学习率(Adam):5e-5,3e-5,2e-5
-
轮次数量:2,3,4
model.compile(
optimizer=keras.optimizers.Adam(1e-5),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[keras.metrics.SparseCategoricalAccuracy(name="acc")]
)
我们将使用 Adam,并使用略微不同的学习率(因为我们很牛逼),并使用稀疏分类交叉熵,因此我们不必对标签进行独热编码。
让我们拟合模型:
log_dir = "log/intent_detection/" +\
datetime.datetime.now().strftime("%Y%m%d-%H%M%s")
tensorboard_callback = keras.callbacks.TensorBoard(log_dir=log_dir)
model.fit(
x=data.train_x,
y=data.train_y,
validation_split=0.1,
batch_size=16,
shuffle=True,
epochs=5,
callbacks=[tensorboard_callback]
)
我们存储训练日志,以便你可以在Tensorboard中查看训练过程。让我们来看一下:


评估
我必须对你诚实。我对结果感到惊讶。仅使用 12.5k 样本进行训练,我们得到了:
_, train_acc = model.evaluate(data.train_x, data.train_y)
_, test_acc = model.evaluate(data.test_x, data.test_y)
print("train acc", train_acc)
print("test acc", test_acc)
train acc 0.9915119
test acc 0.9771429
很了不起,对吧?让我们看看混淆矩阵:

最后,让我们使用模型从一些自定义句子中检测意图:
sentences = [
"Play our song now",
"Rate this book as awful"
]
pred_tokens = map(tokenizer.tokenize, sentences)
pred_tokens = map(lambda tok: ["[CLS]"] + tok + ["[SEP]"], pred_tokens)
pred_token_ids = list(map(tokenizer.convert_tokens_to_ids, pred_tokens))
pred_token_ids = map(
lambda tids: tids +[0]*(data.max_seq_len-len(tids)),
pred_token_ids
)
pred_token_ids = np.array(list(pred_token_ids))
predictions = model.predict(pred_token_ids).argmax(axis=-1)
for text, label in zip(sentences, predictions):
print("text:", text, "\nintent:", classes[label])
print()
text: Play our song now
intent: PlayMusic
text: Rate this book as awful
intent: RateBook
哇,那真是(显然)很酷!好吧,虽然这些示例可能没有实际查询那么多样化,但嘿,赶紧自己试试吧!
结论
现在你知道如何对 BERT 模型进行微调以进行文本分类。你可能已经知道,它还可以用于各种其他任务!你只需要调整层即可。简单!
做 AI/ML 感觉就像拥有超能力,对吧?感谢美妙的 NLP 社区,你也可以拥有超能力!你会用它们做什么呢?
参考资料
继续你的机器学习之旅:
Python 黑客机器学习指南
通过使用 Scikit-Learn、TensorFlow 2 和 Keras 解决实际机器学习问题的实践指南
从零开始的实用机器学习
通过从头开始使用 Python 构建机器学习模型、工具和概念,深入理解它们
JavaScript 黑客深度学习
初学者在浏览器中使用 TensorFlow.js 理解机器学习的指南
简介:Venelin Valkov (GitHub) 是一名机器学习工程师,专注于使用深度学习进行文档数据提取。在空闲时间,他喜欢写作、做副项目、骑自行车和做硬拉!
原文。经允许转载。
相关:
-
BERT 正在改变 NLP 领域
-
Lit BERT:3 步完成 NLP 迁移学习
-
BERT、RoBERTa、DistilBERT、XLNet:选择哪个?
更多相关内容
交互式机器学习实验
原文:
www.kdnuggets.com/2020/05/interactive-machine-learning-experiments.html
评论
由 Oleksii Trekhleb,Uber 的软件工程师。

我在 GitHub 上开源了一个新的 交互式机器学习实验 项目。每个实验包括Jupyter/Colab 笔记本(查看模型如何训练)和演示页面(直接在浏览器中查看模型的实际效果)。
尽管模型可能有些笨拙(记住,这些只是实验,并不是生产就绪的代码),它们会尽力做到以下几点:
-
识别你在浏览器中绘制的数字或草图
-
检测和识别你展示给相机的物体
-
对上传的图像进行分类
-
和你一起写一首莎士比亚的诗
-
和你一起玩石头剪子布游戏
我已经在Python上使用TensorFlow 2 和 Keras 支持训练了这些模型,然后用React和JavaScript版本的TensorFlow在浏览器中进行演示。
模型性能
首先,让我们设定期望值。️ 这个仓库包含了机器学习的实验,而不是生产就绪、可重用、优化和微调的代码和模型。这更像是一个沙箱或游乐场,用于学习和尝试不同的机器学习方法、算法和数据集。模型可能表现不佳,并且存在过拟合/欠拟合的可能。
因此,有时你可能会看到如下内容:
但请耐心等待,有时模型可能会变得更聪明,并给出如下结果:
背景
我是一名 软件工程师,在过去的几年里,我主要从事前端和后端编程。在闲暇时间,作为一种爱好,我决定深入了解机器学习主题,以使其对我来说不再像魔法,而更像数学。
-
由于Python可能是开始尝试机器学习的一个好选择,我决定先学习其基本语法。结果,诞生了一个 Python 学习游乐场和备忘单 项目。这只是为了练习 Python,同时在需要时能有一个基本语法的备忘单(例如 dict_via_comprehension = {x: x**2 for x in (2, 4, 6)},等等)。
-
在学习了一点 Python 之后,我想深入了解机器学习背后的基本数学。所以,在通过了 Coursera 上由 Andrew Ng 教授讲授的精彩机器学习课程之后,出现了自制机器学习项目。这次是创建一个针对基本机器学习数学算法(如线性回归、逻辑回归、k 均值、多层感知机等)的备忘单。
-
下一步尝试玩转基本的机器学习数学是关于NanoNeuron的。这是关于 7 个简单的 JavaScript 函数,旨在让你感受机器如何实际“学习”。
-
在完成了 Coursera 上 Andrew Ng 教授讲授的另一个精彩深度学习专项课程之后,我决定进一步练习多层感知机、卷积和递归神经网络(CNNs 和 RNNs)。这一次,我决定不再从头开始实现所有内容,而是开始使用一些机器学习框架。我最终选择了TensorFlow 2和Keras。我也不想过多关注数学(让框架为我处理),而是希望做一些更实际、适用的事情,并且可以在浏览器中直接尝试。结果,新的互动机器学习实验出现了,我想在这里详细描述一下。
技术栈
模型训练
-
我在 TensorFlow 2 中使用了 Keras 进行建模和训练。由于我对机器学习框架没有任何经验,我需要从某些东西开始。TensorFlow 的一个卖点是它同时提供了 Python 和JavaScript 版本的库,API 类似。因此,我最终使用了 Python 版本进行训练,用 JavaScript 版本进行演示。
-
我在本地的Jupyter笔记本中使用 Python 训练了 TensorFlow 模型,有时使用Colab来加快 GPU 上的训练速度。
-
大多数模型是在老款 MacBook Pro 的 CPU(2.9 GHz 双核 Intel Core i5)上训练的。
-
当然,你不可能逃避NumPy用于矩阵/张量操作。
模型演示
-
我使用了 TensorFlow.js 来用之前训练的模型进行预测。
-
为了将 Keras HDF5 模型转换为 TensorFlow.js Layers 格式,我使用了 TensorFlow.js 转换器。将整个模型(数兆字节的数据)传输到浏览器可能效率低下,不如通过 HTTP 请求进行预测,但请记住,这些只是实验,而不是生产就绪的代码和架构。我希望避免拥有专门的后台服务以简化架构。
-
演示应用 是在 React 上使用 create-react-app 启动程序创建的,默认使用 Flow 类型检查。
-
对于样式,我使用了 Material UI。正如他们所说的,“一箭双雕”,同时尝试一个新的样式框架(对不起,Bootstrap)。
实验
简而言之,你可以通过以下链接访问演示页面和 Jupyter 笔记本:
多层感知器(MLP)实验
多层感知器(MLP) 是一种前馈人工神经网络(ANN)。多层感知器有时被称为“普通”神经网络(由多个感知器层组成),尤其是当它们只有一个隐藏层时。
手写数字识别
你绘制一个数字,模型尝试识别它。

手写草图识别
你绘制一个草图,模型尝试识别它。
卷积神经网络(CNN)实验
卷积神经网络(CNN 或 ConvNet)是一类深度神经网络,最常用于分析视觉图像(照片、视频)。它们用于检测和分类照片和视频中的物体,风格迁移,人脸识别,姿态估计等。
手写数字识别(CNN)
你画一个数字,模型尝试识别它。这个实验类似于 MLP 部分的实验,但它使用了底层的 CNN。
手写草图识别(CNN)
你画一幅草图,模型尝试识别它。这个实验类似于 MLP 部分的实验,但它使用了底层的 CNN。
猜拳游戏(CNN)
你与模型玩一个猜拳游戏。这个实验使用从零开始训练的 CNN。
猜拳游戏(MobilenetV2)
你与模型玩一个猜拳游戏。这个模型使用了迁移学习,基于MobilenetV2。

对象检测(MobileNetV2)
你通过相机向模型展示你的环境,它会尝试检测和识别物体。该模型使用迁移学习,基于 MobilenetV2。

图像分类(MobileNetV2)
你上传一张图片,模型尝试根据它“看到”的内容对图片进行分类。该模型使用迁移学习,基于 MobilenetV2。
循环神经网络(RNN)实验
一个循环神经网络(RNN)是深度神经网络的一类,最常应用于序列数据,如语音、文本或音乐。它们用于机器翻译、语音识别、语音合成等。
数字求和
你输入一个求和表达式(即17+38),模型预测结果(即55)。有趣的是,模型将输入视作一个序列,意味着它学会了当你输入一个序列1 → 17 → 17+ → 17+3 → 17+38时,它会将其“翻译”为另一个序列55。你可以将其理解为将西班牙语的 Hola 序列翻译成英语的 Hello。

莎士比亚文本生成
你开始输入一首像莎士比亚那样的诗歌,模型将继续像莎士比亚一样创作。至少它会尝试这样做。
维基百科文本生成
你开始输入一篇 Wiki 文章,模型尝试继续创作。
未来计划
正如我上面提到的,这个代码库的主要目的是作为一个学习的游乐场,而不是用于生产就绪的模型。因此,主要计划是继续学习和实验深度学习挑战和方法。接下来可能会有趣的挑战包括:
-
情感检测
-
风格迁移
-
语言翻译
-
生成图像(即手写数字)
另一个有趣的机会是调整现有模型以提高性能。我相信这可以更好地理解如何克服过拟合和欠拟合,以及当模型在训练和验证集上的准确率停留在 60%并且不再提升时应该怎么做。
希望你能从这个代码库中找到一些有用的模型训练见解,或者至少在尝试演示时玩得开心!
原文。经许可转载。
相关:
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
了解更多相关话题
直接使用 Pandas 获取交互式图表
原文:
www.kdnuggets.com/2021/06/interactive-plots-directly-pandas.html
评论
由 Parul Pandey 撰写,H2O.ai 数据科学家 | @wicds 编辑。

我们的前三名课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
信息图矢量图由 macrovector 创建 — www.freepik.com。
数据探索是任何数据分析任务中最重要的方面之一。我们进行的初步探查和检查,通过各种可视化工具的广泛目录,给予我们对数据性质的可操作性见解。然而,有时选择可视化工具比任务本身更为复杂。一方面,我们有一些易于使用的库,但在展示数据中的复杂关系时并不太有用。另一方面,还有一些提供交互性的库,但学习曲线相当陡峭。幸运的是,一些开源库已经被创建出来,试图有效地解决这个痛点。
在这篇文章中,我们将讨论两个这样的库,即 pandas_bokeh 和 cufflinks。我们将学习如何使用基本的 pandas 绘图语法创建 plotly 和 bokeh 图表,这种语法我们都很熟悉。由于文章的重点是语法而非图表类型,我们将限制在五种基本图表,即折线图、柱状图、直方图、散点图和饼图。我们将首先使用 pandas 绘图库创建这些图表,然后再在 plotly 和 bokeh 中重建这些图表,但会有一些变化。
导入数据集
我们将使用NIFTY-50 数据集。NIFTY 50 指数是 印度国家证券交易所 对印度股票市场的基准。该数据集在 Kaggle 上公开提供,但我们将使用包含四个行业股票价值的子集,即银行、制药、IT 和快速消费品(FMCG)。
你可以从这里下载示例数据集。
让我们导入所需的库和数据集以进行可视化:
# Importing required modules
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# Reading in the data
nifty_data = pd.read_csv('NIFTY_data_2020.csv',parse_dates=["Date"],index_col='Date')
nifty_data.head()
包含银行、制药、IT 和快速消费品部门的 NIFTY 指数的合并数据框。
我们还可以按月末重新采样/聚合数据。pandas 库具有一个 * resample()* 函数,用于重新采样时间序列数据。
nifty_data_resample = nifty_data.resample(rule = 'M').mean()
nifty_data_resample
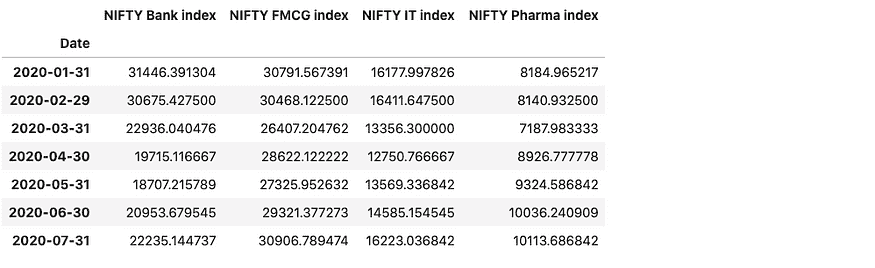
现在我们已经准备好了数据框,是时候通过不同的图表来可视化它们了。
直接使用 Pandas 绘图
让我们从最简单的绘图技术开始 — pandas 的 绘图函数。要使用 pandas 绘制图表,我们将调用 * .plot() * 方法。
语法:dataframe.plot()
plot 方法只是 matplotlib 的一个简单封装,* plt.plot() *。我们还可以指定一些额外的参数,如下所述:
Some of the important Parameters
--------------------------------
x : label or position, default None
Only used if data is a DataFrame.
y : label, position or list of label, positions, default None
title: title to be used for the plot
X and y label: Name to use for the label on the x-axis and y-axis.
figsize : specifies the size of the figure object.
kind : str
The kind of plot to produce:
- 'line' : line plot (default)
- 'bar' : vertical bar plot
- 'barh' : horizontal bar plot
- 'hist' : histogram
- 'box' : boxplot
- 'kde' : Kernel Density Estimation plot
- 'density' : same as 'kde'
- 'area' : area plot
- 'pie' : pie plot
- 'scatter' : scatter plot
- 'hexbin' : hexbin plot.
有关参数及其用法的完整列表,请参考 文档。现在我们来看一下创建不同图表的方法。在本文中,我们不会详细解释每种图表。我们只关注语法,如果你有一些 pandas 经验,这些语法是自解释的。要详细了解 pandas 图表,这篇文章 将很有帮助。
- 折线图
nifty_data.plot(title='Nifty Index values in 2020',
xlabel = 'Values',
figsize=(10,6);
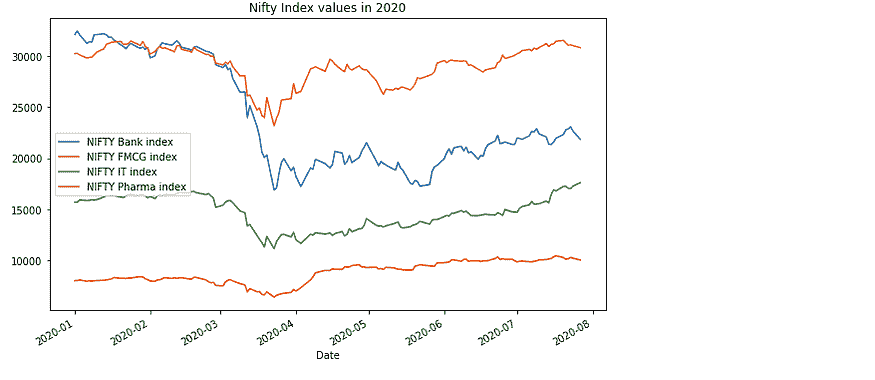
使用 pandas 绘制的折线图。
- 散点图
nifty_data.plot(kind='scatter',
x='NIFTY FMCG index',
y='NIFTY Bank index',
title = 'Scatter Plot for NIFTY Index values in 2020',
figsize=(10,6));
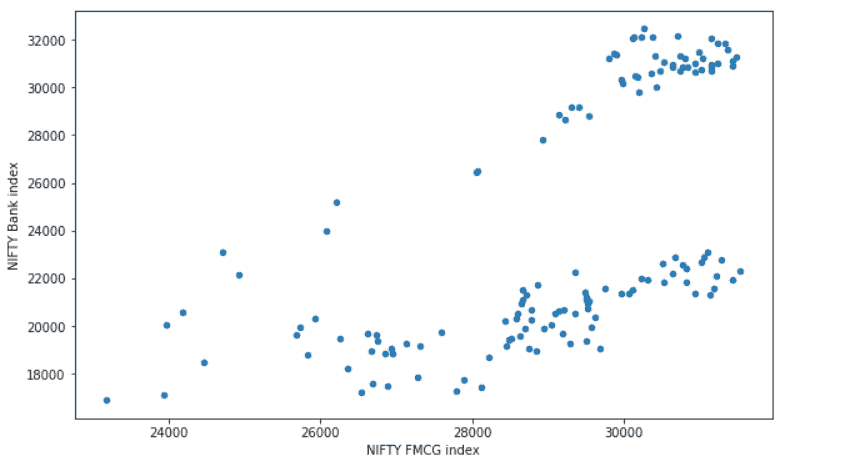
使用 pandas 绘制的散点图。
- 直方图
nifty_data[['NIFTY FMCG index','NIFTY Bank index']].plot(kind='hist',figsize=(9,6), bins=30);
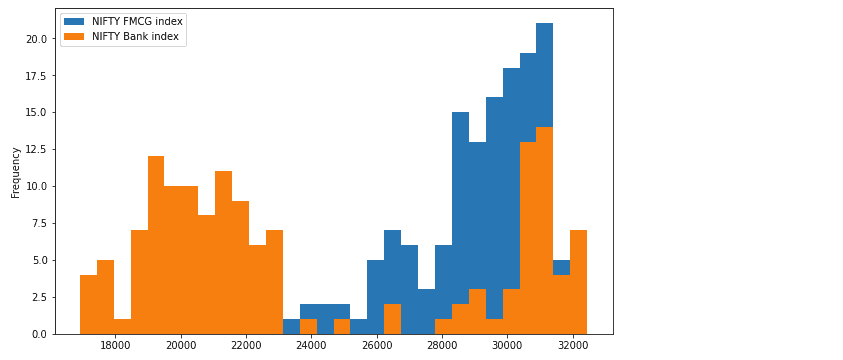
使用 pandas 绘制的直方图。
- 柱状图
nifty_data_resample.plot(kind='bar',figsize=(10,6));
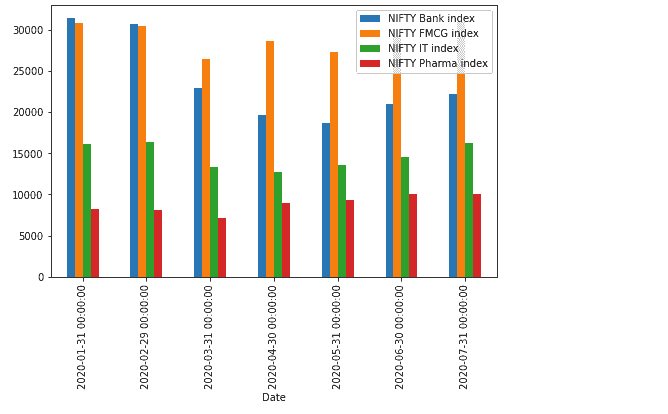
使用 pandas 绘制的柱状图。
- 堆叠柱状图
nifty_data_resample.plot(kind='barh',figsize=(10,6));
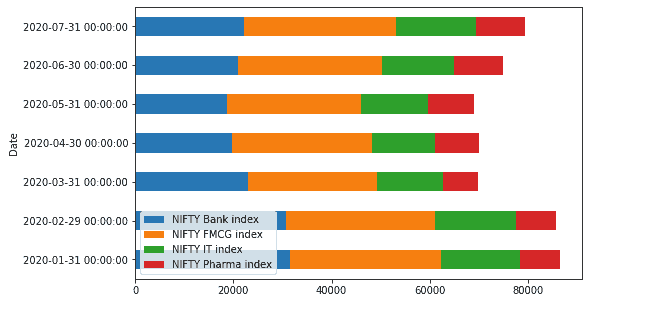
使用 pandas 绘制的堆叠柱状图。
- 饼图
nifty_data_resample.index=['Jan','Feb','March','Apr','May','June','July']
nifty_data_resample['NIFTY Bank index'].plot.pie(legend=False, figsize=(10,6),autopct='%.1f');
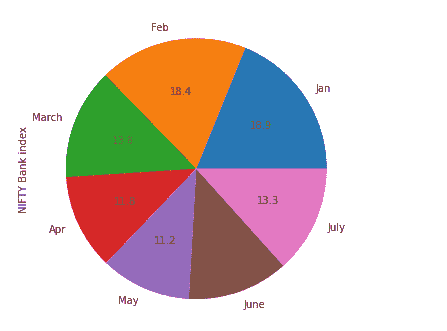
使用 pandas 绘制的饼图。
这些是可以直接使用 pandas 数据框创建的一些图表。然而,这些图表缺乏交互性和缩放、平移等功能。现在,让我们将这些现有图表的语法稍微修改一下,使其变成完全互动的图表。
Pandas 的 Bokeh 后端 — 使用 Pandas-Bokeh 绘图。
作者提供的图片。
bokeh 库在数据可视化方面明显突出。Pandas-Bokeh 为 Pandas、GeoPandas 和 Pyspark DataFrames 提供了 bokeh 绘图后端。该后端向 DataFrames 和 Series 添加了 plot_bokeh() 方法。
安装
Pandas-Bokeh 可以通过 PyPI 使用 pip 或 conda 安装:
pip install pandas-bokeh
or
conda install -c patrikhlobil pandas-bokeh
用法
Pandas-Bokeh 库应在 Pandas、GeoPandas 或 Pyspark 之后导入。
import pandas as pd
import pandas_bokeh
然后需要定义绘图输出,这可以是以下两者之一:
pandas_bokeh.output_notebook() # for embedding plots in Jupyter Notebooks.
pandas_bokeh.output_file(filename) # for exporting plots as HTML.
语法
现在,绘图 API 通过 dataframe.plot_bokeh() 可用于 Pandas DataFrame。
有关绘图输出的更多详细信息,请参见此处的参考资料或 Bokeh 文档。现在,我们将绘制上节中绘制的五种图表。我们将使用与上面相同的数据集。
import pandas as pd
import pandas_bokeh
pandas_bokeh.output_notebook()

- 折线图
nifty_data.plot_bokeh(kind='line') #equivalent to nifty_data.plot_bokeh.line()
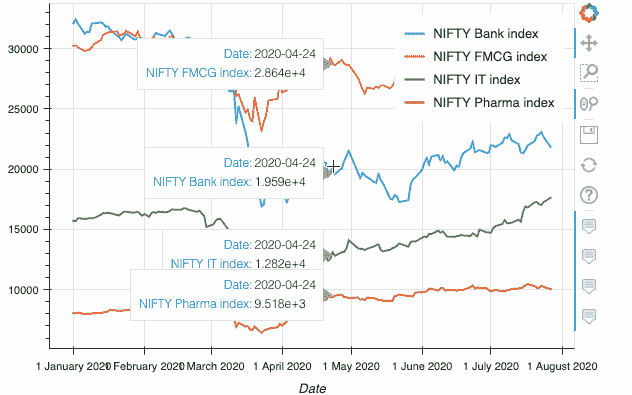
使用 pandas_bokeh 绘制的折线图。
- 散点图
nifty_data.plot_bokeh.scatter(x='NIFTY FMCG index', y='NIFTY Bank index');
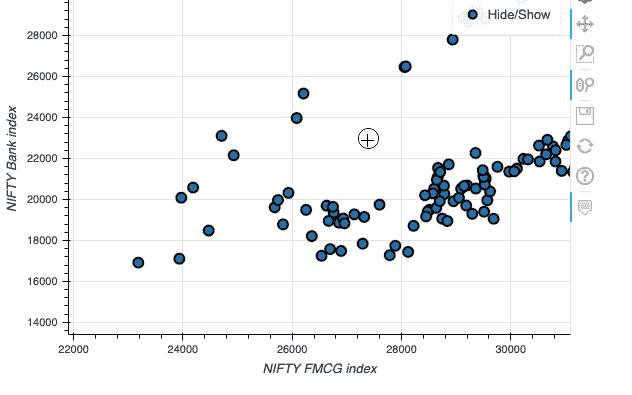
使用 pandas_bokeh 绘制的散点图。
- 直方图
nifty_data[['NIFTY FMCG index','NIFTY Bank index']].plot_bokeh(kind='hist', bins=30);
使用 pandas_bokeh 绘制的直方图。
- 条形图
nifty_data_resample.plot_bokeh(kind='bar',figsize=(10,6));
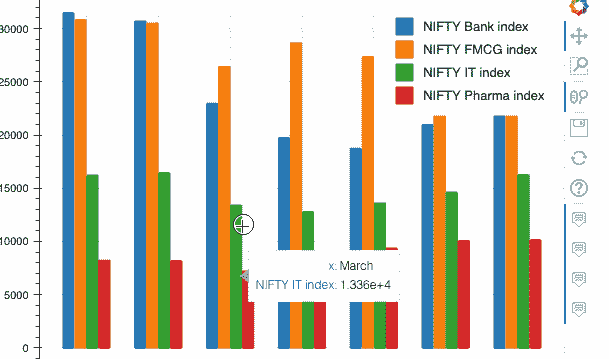
使用 pandas_bokeh 绘制的条形图。
- 堆叠条形图
nifty_data_resample.plot_bokeh(kind='barh',stacked=True);
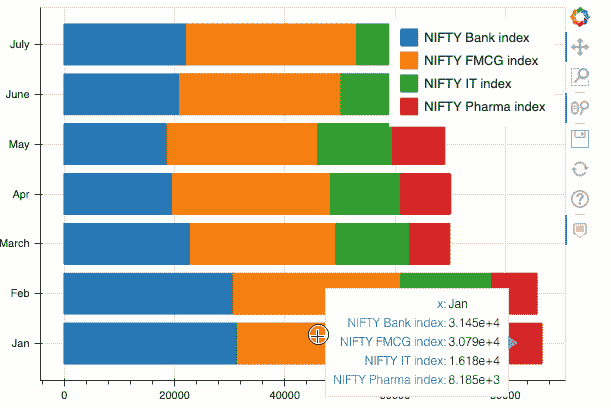
使用 pandas_bokeh 绘制的堆叠条形图。
- 饼图
nifty_data_resample.index=['Jan','Feb','March','Apr','May','June','July']
nifty_data_resample.plot_bokeh.pie(y ='NIFTY Bank index')
使用 pandas_bokeh 绘制的饼图。
此外,你还可以在同一图表中创建多个嵌套的饼图:
nifty_data_resample.plot_bokeh.pie()
使用 pandas_bokeh 绘制的嵌套饼图。
本节展示了如何在不显著改变 pandas 绘图语法的情况下无缝创建 bokeh 图表。现在,我们可以在不需要学习任何新格式的情况下享受两者的最佳结合。
Plotly 后端用于 Pandas — 使用 Cufflinks 绘图。
作者提供的图片。
另一个常用的数据可视化库是 Plotly。使用 Plotly,你可以在 Python、R 和 JavaScript 中创建交互式图表。从 4.8 版本开始,Plotly 推出了一个 Plotly Express 驱动的 Pandas 绘图后端,这意味着即使不导入 plotly,也可以创建类似 plotly 的可视化。
然而,我在这里要提到的库不是 plotly express,而是围绕 Plotly 的一个独立第三方包装库 Cufflinks。 Cufflinks 的优势在于它更加灵活,功能更多,并且 API 类似于 pandas 绘图。这意味着你只需向 Pandas 数据框添加一个 .iplot() 方法即可绘制图表。
安装
确保在安装 cufflinks 之前已安装 plotly。阅读 这篇 指南以获取说明。
pip install cufflinks
使用
代码库 提供了许多有用的示例和笔记本以供入门。
import pandas as pd
import cufflinks as cf
from IPython.display import display,HTML
#making all charts public and setting a global theme
cf.set_config_file(sharing='public',theme='white',offline=True)
就这些了。我们现在可以利用 plotly 的强大功能,但使用 pandas 的简便性。唯一的语法变化是dataframe.iplot()。
- 折线图
nifty_data.iplot(kind='line')
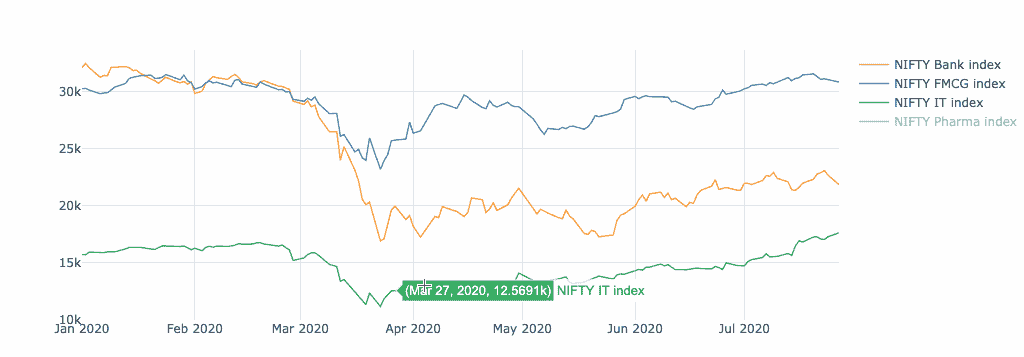
带有 cufflinks 的折线图。
- 散点图
创建散点图时,你需要提及散点轨迹的 模式。模式可以是线条、标记、文本或它们的组合。
nifty_data.iplot(kind='scatter',x='NIFTY FMCG index', y='NIFTY Bank index',mode='markers');
带有 cufflinks 的散点图。
- 直方图
nifty_data[['NIFTY FMCG index','NIFTY Bank index']].iplot(kind='hist', bins=30);
带有 cufflinks 的直方图。
- 条形图
nifty_data_resample.iplot(kind='bar');
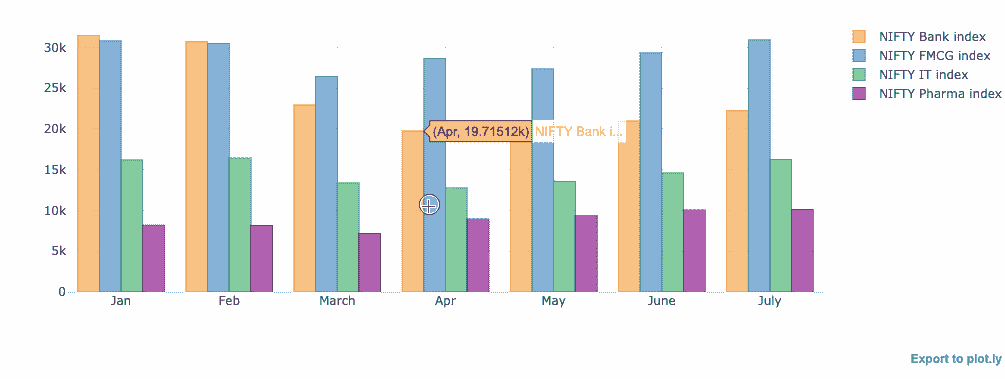
带有 cufflinks 的条形图。
- 堆叠条形图
nifty_data_resample.iplot(kind='barh',barmode = 'stack');
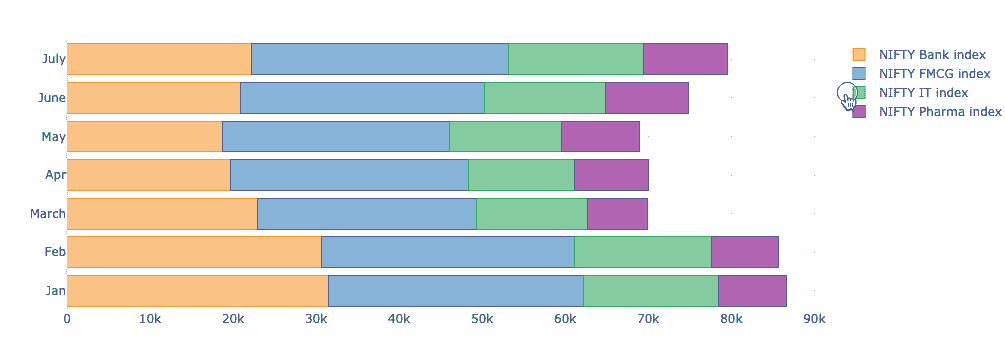
带有 cufflinks 的堆叠条形图。
- 饼图
nifty_data_resample.index=['Jan','Feb','March','Apr','May','June','July']
nifty_data_resample.reset_index().iplot(kind='pie',labels='index',values='NIFTY Bank index')
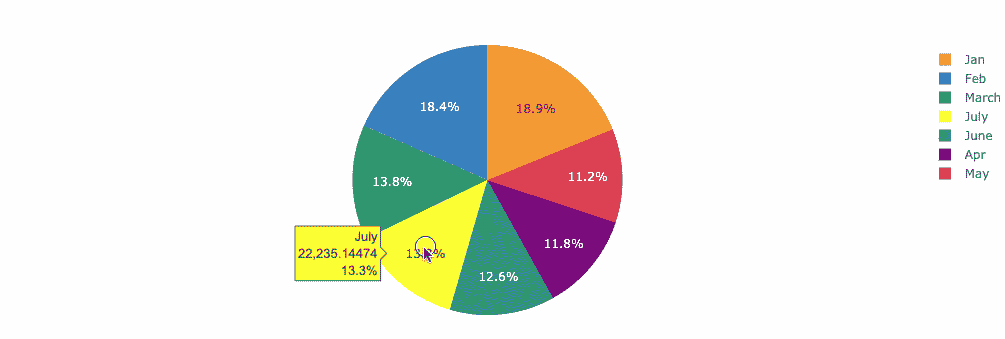
带有 cufflinks 的饼图。
Cufflinks 库提供了一种在 Plotly 内部获得 Plotly 强大功能的简单方法。语法的相似性是另一个优势。
结论
Bokeh 或 Plotly 图表可以独立传达所有信息。根据你的选择和偏好,你可以选择其中一个或两个,同时关注使可视化更直观和互动的主要目的。
原文。经许可转载。
相关:
更多相关内容
Kaggle 的数据科学/机器学习竞赛的国际替代方案
原文:
www.kdnuggets.com/2020/09/international-alternatives-kaggle-data-science-competitions.html
comments
由 Frederik Bussler,Apteo 增长部门。
我们的前三课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业。
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你的组织的 IT 需求
由作者提供。
我们都听说过 Kaggle,这也意味着竞争更多——最近,Kaggle 达到了 500 万用户。此外,并非所有竞赛对全球所有人开放。例如,以下是一个竞赛的政策:
“Kaggle 社区的成员在参赛时不是美国公民或合法永久居民,虽然可以参与竞赛,但 不具备赢得奖品的资格。如果一个团队有一名或多名成员不具备奖品资格,那么整个团队都不具备奖品资格。”
尝试其他竞赛平台,你可以成为“小池塘中的大鱼”,因为竞争者少得多。
请记住,如果你想进入这个行业,AI 竞赛并不是全部,因为你还需要统计学、计算机、沟通等知识,而不仅仅是知道如何构建模型。
除了在竞赛中排名外,你还可以从事实际项目,与世界分享。理想情况下,你的项目也可以引起非技术观众的共鸣,例如经常不了解该领域复杂性的招聘经理。为此,你可以使用像 Apteo 这样的无代码分析工具,这些工具可以让你分享非常简单易懂的分析。
话虽如此,让我们深入了解。
1. DrivenData
DrivenData 对全球所有人开放(除 OFAC 制裁国家如古巴、伊朗、伊拉克、朝鲜、苏丹和叙利亚外)。

DrivenData 资格规则。作者拍摄。
当前的竞赛包括阿尔茨海默症研究、仇恨表情检测、预测流感疫苗等。
2. CROWDANALYTIX
CROWDANALYTIX 提供像水泥质量预测这样的竞赛,参与者来自世界各地。目前竞赛数量有所减少,但同时也有很棒的 博客 可以了解更多数据科学话题。
查看 Damian Boh在 CrowdANALYTIX 竞赛中的经历:我如何在深度学习竞赛中获得前五名
3. Signate

照片由 Louie Martinez 提供,来源于 Unsplash。
Signate 基本上是日本的 Kaggle,目前的竞赛包括车辆驾驶图像识别、平滑曲线等。
4. Zindi
Zindi 是一个泛非的数据科学竞赛平台,挑战包括非洲语言自然语言处理、保险推荐、心理健康聊天机器人等。
5. Alibaba Cloud Tianchi
阿里巴巴的天池平台拥有 40 万名数据科学家,致力于图像基础的 3D 形状检索、3D 对象重建和实例分割等挑战。
6. Analytics Vidhya
Analytics Vidhya 除了是一个优秀的数据科学资源外,还是印度首选的数据科学竞赛平台,当前挑战包括贷款预测、销售预测、时间序列预测、推荐引擎等。
7. CodaLab
CodaLab 是一个总部位于法国的数据科学竞赛平台,在欧洲颇受欢迎,由微软和斯坦福大学于 2013 年联合创建。
今天,CodaLab 拥有 4 万名用户和 1,000 个竞赛,包括正在进行的 机器人视觉挑战。
结论
你不能作为非美国人赢得 Kaggle 奖品,但幸运的是,有许多区域性替代平台可供选择。
尽管我们没有涵盖南美洲或中美洲这些没有本地平台的地区,但你可以使用像 DrivenData 这样的开放访问平台,无论你身处何地。
原文。经许可转载。
相关:
更多相关话题
通过对抗正则化器进行自编码器插值
原文:
www.kdnuggets.com/2019/03/interpolation-autoencoders-adversarial-regularizer.html
评论
作者:Taraneh Khazaei(编辑:Mahsa Rahimi & Serena McDonnell)
对抗约束自编码器插值(ACAI; Berthelot et al., 2018)是一种正则化程序,使用对抗策略来创建自编码器学习表示的高质量插值。本文做出了三项主要贡献:
-
提出了 ACAI 以生成语义上有意义的自编码器插值。
-
开发了一个合成基准来量化插值的质量。
-
检查了 ACAI 学习表示在下游任务中的表现。
AISC 最近介绍并讨论了由 Mahsa Rahimi 主导的这篇论文。事件的详细信息可以在 AISC 网站上找到,完整的演讲可以在 YouTube上观看。这里,我们提供了对论文的概述,以及在 AISC 会议上提出的讨论要点。
自编码器中的插值
自编码器是一类神经网络,试图输出一个输入 xx 的近似重建,尽量减少信息损失。随着自编码器的训练,它学习将输入数据编码到一个潜在空间中,捕捉重建输出所需的所有信息。自编码器由两个部分组成,编码器和解码器,描述如下:
-
编码器接收输入数据
![Equation]() 并生成一个潜在代码
并生成一个潜在代码 ![Equation]() 。
。 -
解码器接收潜在代码
![Equation]() 并尝试重建输入数据为
并尝试重建输入数据为 ![Equation]() 。潜在空间通常维度低于数据(m < n)。
。潜在空间通常维度低于数据(m < n)。
 并生成一个潜在代码
并生成一个潜在代码 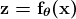 。
。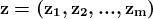 并尝试重建输入数据为
并尝试重建输入数据为  。潜在空间通常维度低于数据(m < n)。
。潜在空间通常维度低于数据(m < n)。 标准自编码器的架构
标准自编码器的架构
标准自编码器关注于输入 x 的重建,并且几乎没有学习潜在数据集的概率特征。因此,它们的生成能力非常有限。一个允许标准自编码器生成合成数据的方法是通过混合潜在编码来促进插值。然而,常规自编码器学到的潜在空间可能不连续,并且潜在编码的簇之间可能存在较大的间隙。简单地混合先前学到的潜在编码可能会导致插值落入解码器从未见过的区域,从而产生不现实的数据点。为了解决这个问题,需要将插值过程集成到自编码器架构及其训练中,使自编码器能够学习潜在的数据流形并创建有意义的插值。通过借鉴生成对抗网络的理念(Goodfellow et al., 2014),ACAI 有效地将插值过程集成到自编码器架构中。 Berthelot et al. (2018) 提出了一种方法,能够创建高质量的插值,这些插值不仅与真实数据无差异,而且是输入的语义上有意义的组合。我们将在下面详细解释 ACAI 方法。
 潜在编码在MNIST数据集上的可视化,展示了潜在空间的不连续性。
潜在编码在MNIST数据集上的可视化,展示了潜在空间的不连续性。
要了解更多关于潜在空间连续性的内容,你可以阅读这篇博客文章。
对抗约束自编码器插值(ACAI)
要插值两个输入  和
和  ,ACAI 执行以下步骤:
,ACAI 执行以下步骤:
-
使用两个编码器,
![Equation]() 和
和 ![Equation]() 首先被编码为相应的潜在编码
首先被编码为相应的潜在编码 ![Equation]() 和
和 ![Equation]() ,其中
,其中 ![Equation]() 和
和 ![Equation]() 。
。 -
然后通过凸组合
![Equation]() 对两个潜在编码进行插值,某些
对两个潜在编码进行插值,某些 ![Equation]() 。
。 -
凸组合
![Equation]() 然后通过解码器生成插值数据点,其中
然后通过解码器生成插值数据点,其中 ![Equation]() 。
。 -
最后,为了确保插值的真实性,解码后的插值
![方程]() 会通过一个判别器网络。判别器网络的目标是从插值数据点
会通过一个判别器网络。判别器网络的目标是从插值数据点 ![方程]() 中预测混合系数 α。然后,自动编码器被训练以欺骗判别器网络,使其认为
中预测混合系数 α。然后,自动编码器被训练以欺骗判别器网络,使其认为 ![方程]() 始终为 0,即尝试欺骗判别器网络,使其认为插值数据实际上是非插值的。
始终为 0,即尝试欺骗判别器网络,使其认为插值数据实际上是非插值的。
 和
和  ,其中
,其中 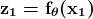 和
和 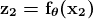 。
。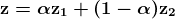 对两个潜在编码进行插值,某些
对两个潜在编码进行插值,某些 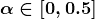 。
。 然后通过解码器生成插值数据点,其中
然后通过解码器生成插值数据点,其中 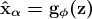 。
。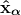 会通过一个判别器网络。判别器网络的目标是从插值数据点
会通过一个判别器网络。判别器网络的目标是从插值数据点 通过向自动编码器的损失函数添加一项来实现欺骗判别器网络。在 ACAI 中,编码器和解码器被训练以最小化以下损失函数:
其中 λ 是一个标量超参数,可以用来控制右侧正则化项的权重,而  是由
是由 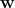 参数化的判别器网络。损失函数的第一个项试图重建输入,第二项则试图使判别器网络始终输出 0。判别器网络被训练以优化以下损失函数:
参数化的判别器网络。损失函数的第一个项试图重建输入,第二项则试图使判别器网络始终输出 0。判别器网络被训练以优化以下损失函数:
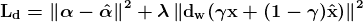
其中  是一个标量超参数。损失函数的第一个项试图恢复
是一个标量超参数。损失函数的第一个项试图恢复  。第二项是正则化项,对于创建高质量插值并非至关重要,但在对抗学习过程中有两方面的帮助。首先,它强制判别器对非插值数据始终输出 0;其次,即使自动编码器的重建质量较差,它也确保判别器接触到真实的数据。
。第二项是正则化项,对于创建高质量插值并非至关重要,但在对抗学习过程中有两方面的帮助。首先,它强制判别器对非插值数据始终输出 0;其次,即使自动编码器的重建质量较差,它也确保判别器接触到真实的数据。
当算法收敛时,期望插值点与真实数据难以区分。经验上,作者展示了学到的插值是两个输入 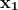 和
和 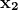 的语义平滑插值。在一组聚类和分类任务上的评估结果表明,ACAI 学到的表示在下游任务上比非-ACAI 学到的表示更有效。鉴于下游任务的性能提升,作者指出插值和表示学习之间可能存在联系。
的语义平滑插值。在一组聚类和分类任务上的评估结果表明,ACAI 学到的表示在下游任务上比非-ACAI 学到的表示更有效。鉴于下游任务的性能提升,作者指出插值和表示学习之间可能存在联系。
 ACAI 架构
ACAI 架构
基准开发
语义相似性的概念模糊、不明确且难以量化。本文的另一项贡献是定义一个基准来定量评估插值的质量。他们的基准集中在自编码 灰度图像的任务上。这些线条长为 1616 像素,从图像中心开始,向外延伸,角度为
灰度图像的任务上。这些线条长为 1616 像素,从图像中心开始,向外延伸,角度为 ,每张图像上有一条线。利用这些数据,一个有效的插值应是从到的图像,平滑且线性地调整
,每张图像上有一条线。利用这些数据,一个有效的插值应是从到的图像,平滑且线性地调整 从中的线条角度到中的线条角度,同时沿最短路径遍历。使用这些图像,可以轻松计算以下两个标准,并用于评估不同自编码器的插值能力:
从中的线条角度到中的线条角度,同时沿最短路径遍历。使用这些图像,可以轻松计算以下两个标准,并用于评估不同自编码器的插值能力:
-
平均距离:衡量插值点与真实数据点之间的平均距离。
-
平滑度:衡量插值线的角度是否在起点和终点之间遵循线性轨迹。
理想的插值应使两项评分都达到 0。以下是\piπ与 00 之间理想插值的示例。
 从
从 到 0 的完美插值
到 0 的完美插值
使用这个基准,结果显示 ACAI 在生成现实且具有语义意义的插值任务中显著优于常见的自编码器模型(如去噪自编码器和变分自编码器)。
AISC 讨论
在 AISC 会议中,提出了一系列讨论点,可以作为未来工作和自编码器插值实验的参考。
首先,对三种不同数据集上的 ACAI 表示进行了分类和聚类评估:MNIST、SVHN和CIFAR-10。虽然对于两个较简单的数据集(即 MNIST 和 SVHN),分类和聚类任务的结果都比较合理,但在 CIFAR 上的分类改进并不显著,而且所有自编码器(包括 ACAI)在 CIFAR 上的聚类结果都很差。AISC 提出了将 ACAI 扩展以在复杂数据集上更有效的想法。
其次,ACAI 论文主要关注计算机视觉任务,甚至根据图像的视觉属性定义了高质量的插值。探索 ACAI 和基准如何扩展以惠及非视觉任务如文本插值,将极具价值。最后,本文将正则化过程应用于普通自编码器。值得探索使用类似正则化机制对其他类型自编码器的影响。特别是,使用相同思想改进变分自编码器的生成能力在 AISC 会议中进行了讨论。
附加资源:
原文。经许可转载。
相关:
-
GAN 也需要一些关注
-
变分自编码器详解
-
用对抗攻击突破神经网络
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的信息技术工作
更多相关主题
解释性、可解释性和机器学习——数据科学家需要知道的
原文:
www.kdnuggets.com/2020/11/interpretability-explainability-machine-learning.html
评论
由 Susan Sivek,Alteryx。
我使用其中一个信用监控服务,它会定期通过邮件告知我我的信用评分:“恭喜,你的评分上升了!” “哎呀,你的评分下降了!”
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
几个点的波动并不意味着什么。我耸耸肩,删除这些邮件。但是,是什么导致了这些波动?
信用评分只是基于复杂模型对我们作为个体做出的许多自动决策中的一个例子。我不知道是什么导致了我评分中的那些小变化。
一些机器学习模型被称为“黑箱”,这个术语常用来描述那些其内部工作——即不同变量如何通过算法相互关联——即使是设计者也可能无法完全解释和说明的模型。

照片由 Christian Fregnan* 提供,来源于* Unsplash。
这种奇怪的情况引发了有关优先级的问题:我们如何在模型开发中优先考虑准确性、解释性和可解释性?这些价值之间是否必须存在权衡?
但首先,免责声明:有很多不同的方式来定义你将在此看到的一些术语。这篇文章只是对这个复杂问题的一个看法!
解释和说明模型
让我们深入探讨与机器学习模型相关的解释性和可解释性。假设我创建了一个基于症状、家族史等因素的高度准确的疾病诊断模型。
如果我为这个目的创建了一个逻辑回归模型,你将能够准确看到模型中每个变量分配了多少权重来预测诊断(即每个变量对我预测的贡献程度)。
但如果我使用相同的变量构建了一个复杂的神经网络模型会怎样?我们可以查看模型的层次和它们的权重,但可能会很难理解这种配置在“现实世界”中实际上意味着什么,换句话说,就是这些层次和它们的权重如何以可识别的方式与我们的变量对应。即使是专家,神经网络模型的可解释性也可能较低。
此外,我们可以考虑全局可解释性(模型如何对所有观测值有效?)和局部可解释性(给定这些特定数据点,模型如何生成特定预测?)。这两种理解层次都有其价值。
如你所想,对于疾病预测这样的情况,患者希望知道模型是如何预测他们是否患病的。同样,我的信用评分计算可能对我的生活产生重大影响。因此,我们理想中希望拥有的不仅仅是专家能够解释的模型,而是能够解释给受其影响的人。

这种可解释性非常重要,以至于在某些地方已经立法规定。欧盟的一般数据保护条例(GDPR)包含了一个“解释权”,这被证明在解释上有些挑战,但它要求对做出影响个人的数据驱动决策的机构有更大的“算法责任”。美国《平等信用机会法》要求金融机构向被拒绝信贷或给予较差贷款条件的人提供明确的决策解释。如果决策中使用了算法,它应该是可以解释的。正如Federal Trade Commission所说,“... AI 工具的使用应该是透明的、可解释的、公正的,并且具有实证基础,同时促进问责制。”
即使在特定情况下解释性并不是法律要求,能够与受模型影响的利益相关者沟通模型的工作原理仍然很重要。有些模型天生更容易转化为不太技术化的受众。例如,有些模型可以方便地进行可视化并共享。决策树模型通常可以绘制成熟悉的流程图形式,在许多情况下是可以解释的。(如果你想看看一个超级酷的动画可视化,可以浏览一下这个教程关于决策树的内容。)一些自然语言处理方法,如主题建模使用 LDA,可能提供可视化来帮助观众理解其结果的原理。

照片由Morning Brew拍摄,来源于Unsplash。
在其他情况下,你可能需要依赖于定量度量来展示模型的构建方式,但它们的含义对于非技术观众来说不那么明显。例如,许多统计模型展示了每个变量如何与模型的输出相关(例如,线性回归中的预测变量系数)。即使是random forest model也可以提供每个变量在生成模型预测中的相对重要性度量。然而,你不会确切知道所有树是如何构建的,以及它们如何共同贡献于模型提供的最终预测。
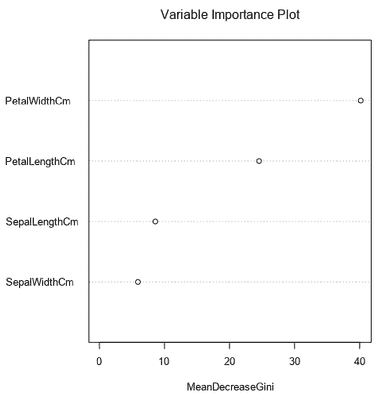
由Forest Model Tool生成的变量(特征)重要性图的示例。*
无论使用何种方法来洞察模型的操作,能够与利益相关者讨论模型如何做出预测是很重要的,这有助于通过他们的知情输入来改进模型,确保模型的公平性,并增加对其输出的信任。这种对模型洞察的需求可能会让你怀疑黑箱是否值得克服它们所带来的挑战。
黑箱是否应该避免?那准确性呢?
目前有一些任务依赖于黑箱模型。例如,图像分类任务通常由卷积神经网络处理,其详细操作人类难以理解——即使人类是其构建者!正如我将在下一部分讨论的那样,幸运的是,人类也构建了一些工具可以稍微窥探这些黑箱。不过,现在我们日常生活中有许多工具依赖于难以解释的模型,例如使用面部识别的设备。
然而,一个“黑箱”模型并不一定因为其不透明性就承诺更高的预测准确性。正如一位研究人员所言:“在考虑具有结构化数据和有意义特征的问题时,经过预处理后,更复杂的分类器(深度神经网络、提升决策树、随机森林)和更简单的分类器(逻辑回归、决策列表)之间的性能差异通常不显著。”
显然,在准确性和可解释性之间并不总是需要权衡,特别是考虑到新开发的工具和策略可以提供对复杂模型操作的洞察。一些研究人员还提出了将“白箱”(可解释的)模型与黑箱模型“叠加”或以其他方式结合,以最大化准确性和可解释性。这些有时被称为“灰箱”模型。

黑箱模型窥探工具
如上所述,人类正在构建工具以更好地理解他们已经创建的工具!除了上述的视觉和定量方法,还有一些其他技术可以用来窥探这些不透明模型的工作原理。
Python 和 R 的模型可解释性包可以提供对模型功能的洞察。例如,LIME(局部可解释模型无关解释)创建一个围绕特定观察的局部线性可解释模型,以理解全球模型如何利用该数据点生成预测。(查看Python包、R端口和vignette、介绍概述或原始研究论文。)
这个视频提供了 LIME 的快速概述,由其创建者制作。
另一种工具包叫做SHAP,它基于博弈论中的 Shapley 值概念,计算每个特征对模型预测的贡献。这种方法提供了对任何模型的全局和局部解释性。(这里你可以选择在Python或R中使用,并可以阅读原始论文,了解 SHAP 的工作原理。)
部分依赖图可以与许多模型一起使用,允许你查看模型的预测如何“依赖”于不同变量的大小。然而,这些图仅限于两个特征,这可能使它们在复杂的高维模型中不那么有用。部分依赖图可以在 Python 中使用scikit-learn或在 R 中使用pdp构建。
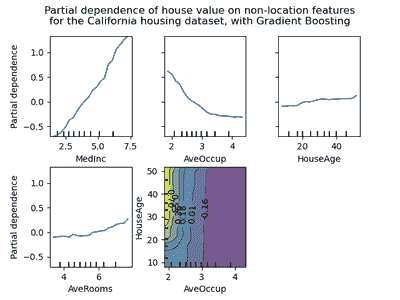
图片来自scikit-learn 文档,展示了每个特征如何影响房屋价值的结果变量。
这篇论文展示了一个有趣的示例,说明了一个交互式界面的构建,该界面用于向利益相关者解释用于糖尿病诊断的随机森林模型。该界面以用户友好的格式使用了部分依赖的概念。通过这种解释,利益相关者不仅更好地理解了模型的操作方式,还对支持进一步开发额外的预测工具感到更加自信。
即使是复杂的图像识别算法的操作也可以部分窥探。“对抗性补丁”或图像修改可以用来操控神经网络预测的分类,从而 提供洞察 算法用于生成预测的特征。这些修改有时可能非常微小,但仍可能导致对算法之前准确分类的图像产生错误预测。查看 这里的一些例子。 (酷/令人担忧的附注:这种方法也可以用来欺骗计算机视觉系统,比如 欺骗监控系统,有时仅需改变图像的一个像素。)
无论你采取何种方法来窥探模型内部,能够解释和说明其操作可以增加对模型的信任,满足监管要求,并帮助你向他人传达你的分析过程和结果。
推荐阅读:
-
模型可解释性的神话,由 Zachary C. Lipton 撰写,深入探讨定义及其有用性
-
可解释的机器学习:使黑箱模型可解释的指南,由 Christoph Molnar 提供的免费在线书籍
-
“停止为高风险决策解释黑箱机器学习模型,改用可解释的模型,” 文章 由 Cynthia Rudin 发表在 Nature Machine Intelligence 上
原始。经许可转载。
简历: 苏珊·库里·西维克,博士,是一位作家和数据迷,喜欢用日常语言解释复杂的概念。在学术界担任了 15 年的新闻学教授和研究员后,苏珊将重点转向数据科学和分析,但仍然喜欢以创意的方式分享知识。她喜欢美食、科幻小说和狗。
相关:
更多此主题内容
“请解释一下。” 机器学习模型的可解释性
原文:
www.kdnuggets.com/2019/05/interpretability-machine-learning-models.html
评论
作者:Olga Mierzwa-Sulima,Appsilon。
原文。经许可转载。
2019 年 2 月,波兰政府在银行法中新增了一项修正案,赋予客户在遭遇负面信用决策时获得解释的权利。这是实施 GDPR 在欧盟的直接后果之一。这意味着,如果决策过程是自动化的,银行需要能够解释为什么贷款没有被批准。
2018 年 10 月,全球头条报道了一个亚马逊 AI 招聘工具偏爱男性。亚马逊的模型在有偏的数据上进行训练,这些数据倾向于男性候选人。它建立了惩罚包含“女性”一词的简历的规则。
不了解模型预测的后果
上述两个例子的共同点是,银行业的模型和亚马逊构建的模型都是非常复杂的工具,所谓的黑箱分类器,这些工具没有提供直接且易于人类理解的决策规则。
如果金融机构希望继续使用基于机器学习的解决方案,它们将不得不投资于模型可解释性研究。而且它们很可能会这样做,因为这种算法在预测信用风险方面更为准确。另一方面,亚马逊如果对模型进行适当的验证和理解,可能会节省大量金钱和负面新闻。
为什么现在?数据建模的趋势。
自 2014 年以来,机器学习一直保持在 Gartner 的炒作周期榜单上,2018 年被深度学习(机器学习的一种形式)取代,这表明机器学习的采用尚未达到顶峰。

预测机器学习的增长将进一步加速。根据Univa 的报告,预计在接下来的两年内,96%的公司将会在生产中使用机器学习。
造成这种情况的原因有:数据收集的广泛性、庞大的计算资源的可用性和活跃的开源社区。机器学习的采用增长伴随着机器学习可解释性研究的增加,这种研究受到如 GDPR、欧盟的“解释权”、安全(医学、自动驾驶车辆)、可重复性、偏见或最终用户期望(调试模型以改进或了解有关研究主题的新信息)等法规的推动。

黑盒算法的可解释性可能性
作为数据科学家,我们应该能够向最终用户解释模型的工作原理。然而,这并不一定意味着要理解模型的每一个部分或生成一套决策规则。
也有可能存在这种情况:这不是必需的:
-
问题已经被很好地研究,
-
模型结果没有后果,
-
终端用户对模型的理解可能会带来系统被操控的风险。
如果我们查看 2018 年Kaggle 的机器学习和数据科学调查的结果,大约 60%的受访者认为他们能够解释大多数机器学习模型(虽然一些模型仍然难以解释)。最常用的机器学习理解方法是通过查看特征重要性和特征相关性来分析模型特征。
特征重要性分析提供了对模型学习内容和可能重要因素的初步良好见解。然而,如果特征之间存在相关性,这种技术可能不可靠。只有当模型变量是可解释的时,它才会提供良好的见解。对于许多GBM库,生成特征重要性图相对容易。
在深度学习的情况下,情况要复杂得多。当使用神经网络时,你可以查看权重,因为它们包含关于输入的信息,但这些信息是压缩的。而且,你只能分析第一层的连接,因为在更深层次上太复杂了。
难怪在 2016 年,LIME(局部可解释模型-可解释性解释)论文在 NIPS 会议上发布时产生了巨大影响。LIME 的理念是通过在可解释的输入数据上构建一个更易理解的白盒模型,来局部逼近一个黑盒模型。它在图像分类的解释和文本方面取得了良好的结果。然而,对于表格数据来说,找到可解释的特征非常困难,而且它们的局部解释可能会产生误导。
LIME 在 Python 中实现(lime和Skater)以及 R 中(lime 包和iml 包,live 包),使用起来非常方便。
另一个有前景的想法是 SHAP (Shapley Additive Explanations)。它基于博弈论。它假设特征是参与者,模型是联盟,而 Shapley 值则告诉我们如何公平地分配“收益”。这种技术公平地分配影响,使用简单,并提供了视觉上令人信服的实现。
DALEX 包(描述性机器学习解释)在 R 中提供了一套工具,帮助理解复杂模型的工作原理。使用 DALEX,你可以创建模型解释器并进行视觉检查,例如分解图。你可能还会对 DrWhy.Ai 感兴趣,它是由与 DALEX 相同的研究团队开发的。
实际应用案例
检测图片中的对象
图像识别 已经被广泛使用,例如在自动驾驶汽车中检测图片中的汽车、交通灯等,在野生动物保护中检测图片中的特定动物,或在保险中检测作物的洪水情况。
我们将使用原始 LIME 论文中的“哈士奇与狼的例子”来说明模型解释的重要性。分类任务是识别图片中是否有狼。它错误地将西伯利亚哈士奇误判为狼。多亏了 LIME,研究人员能够确定图片中哪些区域对模型的重要性。结果发现,如果图片中有雪,它会被分类为狼。

该算法使用了图片的背景,完全忽略了动物的特征。模型应该关注动物的眼睛。得益于这一发现,模型得以修正,并扩展了训练样本,以防止推理中的雪=狼问题。
分类作为决策支持系统
阿姆斯特丹 UMC 的重症监护病房 希望预测患者出院时的再入院和/或死亡概率。目标是帮助医生选择合适的时机将患者从 ICU 转移。如果医生理解模型的工作原理,他们更可能在做出最终判断时使用其建议。
为了演示如何使用 LIME 解释模型,我们可以查看 另一项研究 的例子,该研究旨在进行 ICU 中的早期死亡预测。使用随机森林模型(黑箱模型)来预测死亡状态,并使用 lime 包来局部解释每位患者的预测分数。

选定示例中的一位患者死亡概率很高(78%)。模型特征中对死亡率有贡献的因素是较高的心房颤动次数和较高的乳酸水平,这与当前医学理解一致。
人类与机器——完美的匹配
为了成功构建可解释的 AI,我们需要结合数据科学知识、算法和终端用户的专业知识。数据科学的工作并不会在创建模型后结束。这是一个迭代的、通常较长的过程,需要专家提供反馈,以确保结果是稳健的并且易于人类理解。
我们坚信,通过结合人类的专业知识和机器的性能,我们可以得出最佳结论:提升机器结果,克服人类直觉偏差。
简历: Olga Mierzwa-Sulima 是 Appsilon 的高级数据科学家和项目负责人。
资源:
相关:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
可解释性对于信任 AI 和机器学习至关重要
原文:
www.kdnuggets.com/2018/11/interpretability-trust-ai-machine-learning.html
评论
作者:Ilknur Kaynar Kabul,SAS。
随着machine learning在科学和技术领域的许多最新进展中占据了重要地位,机器学习模型的可解释性变得越来越重要。
我们周围充斥着由机器学习驱动的应用程序,机器做出的决定每天都越来越多地影响着我们个人。从平凡到挽救生命,我们向机器学习模型提出诸如:
-
我会喜欢哪首歌?
-
我能获得贷款吗?
-
我应该雇用谁?
-
我得癌症的概率是多少?
这些以及许多其他问题由大多数用户了解甚少的预测模型来回答。数据科学家通常强调模型的预测准确性——而不是理解如何这些预测实际上是如何做出的。使用机器学习,模型只是这样做的。
复杂模型更难以理解
一些机器学习模型简单且易于理解。我们知道改变输入将如何影响预测结果,并且可以对每个预测做出解释。然而,随着机器学习和人工智能的最新进展,模型变得非常复杂,包括复杂的深度神经网络和不同模型的集成。我们将这些复杂模型称为黑箱模型。
不幸的是,使黑箱模型具备卓越预测能力的复杂性也使它们非常难以理解和信任。黑箱模型内部的算法不会透露其秘密。它们通常不会提供明确的解释说明为何做出某个预测。它们只是给出一个概率,而且这些模型不透明且难以解释。有时模型参数多达数千(甚至数百万),输入特征与参数之间没有一一对应的关系,多个模型的组合以及许多参数常常影响预测结果。有些模型也对数据需求量大,需要大量数据才能达到高准确度。很难弄清楚它们从这些数据集中学到了什么,以及哪些数据点对结果的影响大于其他数据点。
由于这些原因,很难理解这些技术的过程和结果。弄清楚我们是否可以信任这些模型以及在使用它们时是否能够做出公平的决策也很困难。
如果他们学到错误的东西会发生什么?如果他们还没有准备好部署会发生什么?存在错误表述、过度简化或过拟合的风险。因此,我们在使用这些模型时需要小心,我们最好了解这些模型如何工作。
为什么准确性不够
在机器学习中,准确性是通过将机器学习模型的输出与输入数据集中的已知实际值进行比较来衡量的。
一个模型可以通过记住数据集中的不重要特征或模式来实现高准确性。如果输入数据集存在偏差,也会影响模型。此外,训练环境中的数据可能无法很好地代表模型部署后生产环境中的数据。即使最初足够具有代表性,如果考虑到生产环境中的数据不是静态的,它也可能很快变得过时。
因此,我们不能仅仅依赖于特定数据集的预测准确性。我们需要了解更多。我们需要揭开黑箱机器学习模型的神秘面纱,提高透明度和解释性,使其更加可信赖和可靠。
什么是解释性?
解释性意味着为最终用户提供特定决策或过程的解释。更具体来说,它包括:
-
理解影响结果的主要任务。
-
解释算法做出的决策。
-
发现算法学习到的模式/规则/特征。
-
对结果进行批判性分析。
-
探索算法的未知未知。
这不是关于理解模型如何处理训练数据中每一个数据点的每一个细节。
我们为什么需要解释性?
解释性对不同的人有不同的重要性:
 数据科学家希望建立具有高准确性的模型。他们希望了解细节,以找出如何选择最佳模型并改进该模型。他们还希望从模型中获得见解,以便将他们的发现传达给目标受众。
数据科学家希望建立具有高准确性的模型。他们希望了解细节,以找出如何选择最佳模型并改进该模型。他们还希望从模型中获得见解,以便将他们的发现传达给目标受众。
最终用户想知道模型为什么给出某个预测。他们想了解这些决策将如何影响他们。他们想知道自己是否被公平对待,以及是否需要对任何决策提出异议。他们希望在网上购物或点击网页广告时有一定程度的信任。
监管者和立法者希望使系统公平和透明。他们希望保护消费者。随着机器学习算法的不可避免的崛起,他们对模型做出的决策越来越感到担忧。
所有这些用户对黑箱模型有类似的期望。他们希望模型是透明的、可信赖的并且可以解释的。
-
透明:系统可以解释它是如何工作的和/或为什么给出某些预测。
-
可信赖性:系统能够在现实世界的不同场景中处理问题,而无需持续控制。
-
可解释性:系统能够传达有关其内部工作原理的有用信息,包括其学习的模式和给出的结果。
在典型的机器学习流程中,我们对用于训练模型的数据集有控制权,对我们使用的模型有控制权,并且对如何评估和部署这些模型有控制权。
何时需要可解释性?
如果你需要可解释性,首先需要问自己为什么需要它。在这个过程中,你在哪个阶段需要可解释性?并不是每种应用都需要理解模型如何做出预测。然而,如果这些预测用于高风险决策,你可能需要了解。如果你定义了目的,你应该关注在过程的哪个阶段需要哪些技术:
-
建模前的可解释性(模型输入的可解释性):在开始构建模型之前,理解数据集非常重要。你可以使用不同的探索性数据分析和可视化技术,以更好地理解数据集。这可能包括总结数据集的主要特征、找到数据集中的代表性或关键点,以及从数据集中找出相关特征。在对数据集有了整体理解后,你需要考虑在建模时将使用哪些特征。如果你想在建模后解释输入输出关系,你需要从有意义的特征开始。虽然高度工程化的特征(例如,从 t-sne、随机投影等获得的特征)可以提高模型的准确性,但在模型实际应用时,它们可能不可解释。
-
建模中的可解释性:我们可以根据模型的简单性、透明度和解释性将模型分为白箱(透明)模型和黑箱(不透明)模型。
-
白箱(透明)模型:决策树、规则列表和回归算法通常被认为属于这一类别。这些模型在使用少量预测变量时易于理解。它们使用可解释的转换,并能提供关于如何工作的更多直观感受,这有助于你理解模型中的情况。你可以向技术观众解释它们。但当然,如果你有数百个特征并构建了一个非常深且大的决策树,事情仍然可能变得复杂和难以解释。
-
黑箱(不透明)模型: 深度神经网络、随机森林和梯度提升机可以被视为这一类别的模型。它们通常使用许多预测变量和复杂的转换,有些模型有很多参数。通常很难可视化和理解这些模型内部的工作情况,也更难以向目标受众进行沟通。然而,它们的预测准确性通常比其他模型要好。近期在这一领域的研究希望使这些模型更加透明。一些研究包括作为训练过程一部分的技术。在这些模型中生成解释是提高透明度的一种方式。另一种改进是包含训练过程后的特征可视化。
-
-
后建模可解释性(post hoc interpretability): 模型预测中的可解释性帮助我们检查输入特征与输出预测之间的动态关系。某些后建模活动是特定于模型的,而其他则是模型无关的。在这个阶段添加可解释性可以帮助我们理解模型中最重要的特征,这些特征如何影响预测,每个特征对预测的贡献,以及模型对某些特征的敏感性。除了模型特定的技术,如随机森林的变量重要性输出,还有模型无关的技术,例如部分依赖(PD)图、个体条件期望(ICE)图和局部可解释模型无关解释(LIME)。
敬请关注关于这个话题的更多帖子。在这系列博客中,我们将详细介绍一些可解释性技术。我们将解释如何使用模型无关的可解释性技术来理解黑箱模型。我们还会涵盖一些最新的可解释性进展。
简介:Ilknur Kaynar Kabul 是 SAS 高级分析部门的高级经理,她领导着 SAS 研发团队,专注于机器学习算法和应用。
原文。经许可转载。
资源:
相关:
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
更多相关内容
使用 PyTorch 的可解释神经网络
原文:
www.kdnuggets.com/2022/01/interpretable-neural-networks-pytorch.html

图片由 Jan Schulz # Webdesigner Stuttgart 提供,来源于 Unsplash
有几种方法来评估机器学习模型,其中两种是 准确性 和 可解释性。一个具有高准确性的模型通常被称为 优秀 模型,它很好地学习了输入 X 和输出 y 之间的关系。
如果一个模型具有高可解释性或解释性,我们可以理解模型如何做出预测,以及如何通过改变输入特征来 影响 这种预测。虽然很难说当我们增加或减少输入的某个特征时深度神经网络的输出会如何变化,但对于线性模型来说非常简单:如果你增加特征值,输出会按该特征的系数增加。很简单。
现在,你可能经常听到这样的说法:
“有可解释的模型,也有表现良好的模型。” — 不了解情况的人
然而,如果你读过我关于 可解释增强型机器(EBM)的文章,那么你已经知道这并不准确。EBM 是一个在保持可解释性的同时具有出色性能的模型示例。
在我的旧文章中,我创建了以下图表,展示了我们如何将一些模型放置在 可解释性-准确性空间 中。
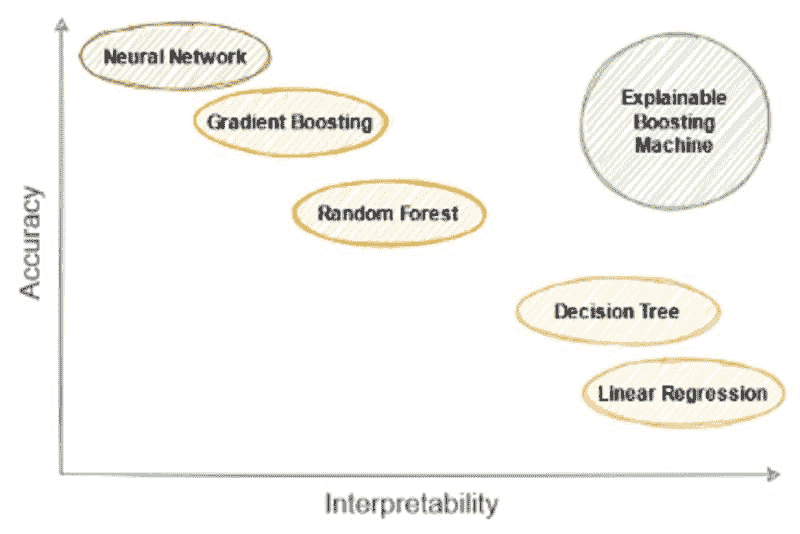
作者提供的图片。
特别是,我将深度神经网络(省略 深度)更多地放在 非常准确但难以解释 的区域。当然,你可以通过使用像 shap 或 lime 这样的库在一定程度上缓解解释性问题,但这些方法也有其自身的假设和问题。因此,让我们在本文中采用另一条路径,创建一种设计上具有可解释性的神经网络架构。
免责声明: 我即将呈现的架构只是我脑海中的构想。我不知道是否已有相关文献,至少我没有找到相关资料。但如果你知道任何做过类似工作的论文,请告知我!我会将其添加到参考文献中。
可解释架构理念
请注意,我期望你了解前馈神经网络的工作原理。我不会在这里进行详细介绍,因为已有许多很好的资源。
考虑以下玩具神经网络,它具有三个输入节点 x₁、x₂、x₃,一个输出节点 ŷ,以及三个具有六个节点的隐藏层。我在这里省略了偏置项。
图片由作者提供。
这种架构在可解释性上的问题在于,由于全连接层,输入完全混合在一起。每个单独的输入节点影响所有隐藏层节点,这种影响随着我们深入网络而变得更加复杂。
源自树的灵感
对于基于树的模型来说,通常是相同的,因为如果我们不加限制,决策树可以使用每个特征来创建一个划分。例如,标准的梯度提升及其衍生版本如 XGBoost、LightGBM 和 CatBoost 本身并不是很具备可解释性。
然而,通过使用仅依赖于单一特征的决策树,如 EBM 所做的那样,你可以使梯度提升模型具有可解释性(阅读我的文章了解更多!????)。
将树限制为这样的形式在许多情况下不会对性能产生太大影响,但使我们能够像这样可视化特征的影响:
interpretml 的 show 函数输出。图片由作者提供。
只需看看图形顶部的蓝线部分。它显示了 feature_4 对某些回归问题输出的影响。在 x 轴上,你可以看到 feature_4 的范围。y 轴显示了 分数,即输出的变化值。下面的直方图显示了 feature_4 的分布。
从图形中,我们可以看到以下内容:
-
如果 feature_4 约为 0.62,则输出比 feature_4 为 0.6 或 0.65 时增加约 10。
-
如果 feature_4 大于 0.66,则对输出的影响为负。
-
改变 feature_4 在 0.4 到 0.56 范围内的值会显著改变输出。
模型的最终预测只是不同特征分数的总和。这种行为类似于 Shapley 值,但无需计算它们。很棒,对吧?现在,让我展示如何对神经网络进行相同的操作。
删除边缘
因此,如果问题在于神经网络的输入由于边缘过多而散布在隐藏层中,我们可以考虑删除一些边缘。特别是,我们需要删除那些允许一个特征的信息流向另一个特征的边缘。仅删除这些溢出边缘,上面的玩具神经网络变为:
图片由作者提供。
我们为三个输入变量创建了三个单独的块,每个块都是一个具有单个部分输出的完全连接网络ŷᵢ。作为最后一步,这些ŷᵢ被加和,并且加上一个偏置(在图示中省略)以产生最终输出ŷ。
我们引入部分输出是为了能够创建与 EBM 允许的相同类型的图。上图中的一个块允许一个图:xᵢ 输入,ŷᵢ* 输出。稍后我们将看到如何做到这一点。
现在我们已经有了完整的架构!我认为理论上理解它是相当简单的,但让我们也来实现一下。这样,你会很高兴,因为你可以使用神经网络,而业务也会很高兴,因为神经网络是可解释的。
在 PyTorch 中的实现
我不期望你完全熟悉PyTorch,所以我会在过程中解释一些基础知识,这将帮助你理解我们自定义的实现。如果你了解 PyTorch 的基础知识,可以跳过完全连接层部分。如果你还没有安装 PyTorch,选择你的版本。
完全连接层
这些层在 PyTorch 中也被称为线性,在Keras中称为密集。它们将n个输入节点连接到m个输出节点,使用nm条带有乘法权重的边。这基本上是矩阵乘法加上一个偏置项,如以下两个代码片段所示:
import torchtorch.manual_seed(0) **# keep things reproducible**x = torch.tensor([1., 2.]) **# create an input array**
linear_layer = torch.nn.Linear(2, 3) **# define a linear layer**
print(linear_layer(x)) **# putting the input array into the layer****# Output:
# tensor([ 0.7393, -1.0621, 0.0441], grad_fn=<AddBackward0>)**
这就是你如何创建完全连接层并将它们应用于 PyTorch 张量。你可以通过linear_layer.weight获取用于乘法的矩阵,通过linear_layer.bias获取偏置。然后你可以这样做
print(linear_layer.weight @ x + linear_layer.bias) **# @ = matrix mult****# Output:
# tensor([ 0.7393, -1.0621, 0.0441], grad_fn=<AddBackward0>)**
很好,它是一样的!现在,PyTorch、Keras 等的一个好处是你可以将许多这样的层堆叠在一起以创建神经网络。在 PyTorch 中,你可以通过torch.nn.Sequential来实现这种堆叠。为了重建上面的密集网络,你可以做一个简单的
model = torch.nn.Sequential(
torch.nn.Linear(3, 6),
torch.nn.ReLU(),
torch.nn.Linear(6, 6),
torch.nn.ReLU(),
torch.nn.Linear(6, 6),
torch.nn.ReLU(),
torch.nn.Linear(6, 1),
)print(model(torch.randn(4, 3))) **# feed it 4 random 3-dim. vectors**
注意: 我尚未向你展示如何训练这个网络,这只是架构的定义,包括参数的初始化。但你可以输入三维输入并接收一维输出。
既然我们想要创建自己的层,让我们先从简单的开始:重建 PyTorch 的Linear层。以下是如何做到这一点:
import torch
import mathclass MyLinearLayer(torch.nn.Module):
def __init__(self, in_features, out_features):
super().__init__()
self.in_features = in_features
self.out_features = out_features
**# multiplicative weights
weights = torch.Tensor(out_features, in_features)
self.weights = torch.nn.Parameter(weights)
torch.nn.init.kaiming_uniform_(self.weights)**
# bias
bias = torch.Tensor(out_features)
self.bias = torch.nn.Parameter(bias)
bound = 1 / math.sqrt(in_features)
torch.nn.init.uniform_(self.bias, -bound, bound) ** def forward(self, x):
return x @ self.weights.t() + self.bias**
这段代码需要一些解释。在第一个粗体块中,我们通过
-
创建一个 PyTorch 张量(包含所有零,但这并不重要)
-
将其注册为可学习的参数到该层,这意味着梯度下降可以在训练过程中更新它,然后
-
初始化参数。
神经网络的参数初始化是一个完整的话题,所以我们不会深入探讨。如果这让你感到困扰,你也可以通过使用标准正态分布torch.randn(out_features, in_features)来初始化,但这可能会导致训练变慢。不管怎样,我们对偏置做同样的处理。
然后,层需要知道它在forward方法中应该执行的数学操作。这只是线性操作,即矩阵乘法和偏置的加法。
好的,现在我们准备为我们的可解释神经网络实现这一层了!
Block Linear Layers
现在我们设计一个BlockLinear层,我们将以以下方式使用它:首先,我们从n特征开始。BlockLinear层应该创建n个块,每个块由h个隐藏神经元组成。为了简化问题,h在每个块中是相同的,但你当然可以对其进行泛化。总的来说,第一个隐藏层将由nh个神经元组成,但只有nh条边连接到它们(而不是n²h 用于完全连接的层)。要更好地理解,请再次查看上面的图片。在这里,n = 3,h = 2。
作者提供的图片。
然后——在使用一些非线性操作如 ReLU 之后——我们将在这层后面再加一个BlockLinear层,因为不同的块不应该再次合并。我们重复这个过程,直到最后使用Linear层将一切重新绑定起来。
实现 Block Linear Layer
让我们开始编写代码。它与我们定制的线性层非常相似,因此代码应该不会太令人畏惧。
class BlockLinear(torch.nn.Module):
def __init__(self, n_blocks, in_features, out_features):
super().__init__()
self.n_blocks = n_blocks
self.in_features = in_features
self.out_features = out_features
self.block_weights = []
self.block_biases = [] **for i in range(n_blocks):
block_weight = torch.Tensor(out_features, in_features)
block_weight = torch.nn.Parameter(block_weight)
torch.nn.init.kaiming_uniform_(block_weight)
self.register_parameter(
f'block_weight_{i}',
block_weight
)
self.block_weights.append(block_weight)** **block_bias = torch.Tensor(out_features)
block_bias = torch.nn.Parameter(block_bias)
bound = 1 / math.sqrt(in_features)
torch.nn.init.uniform_(block_bias, -bound, bound)
self.register_parameter(
f'block_bias_{i}',
block_bias
)
self.block_biases.append(block_bias)** def forward(self, x):
block_size = x.size(1) // self.n_blocks
**x_blocks = torch.split(
x,
split_size_or_sections=block_size,
dim=1
)** **block_outputs = []
for block_id in range(self.n_blocks):
block_outputs.append(
x_blocks[block_id] @ self.block_weights[block_id].t() + self.block_biases[block_id]
)** return torch.cat(block_outputs, dim=1)
我再次强调了几行。第一组粗体行类似于我们在自制线性层中看到的,只是重复了n_blocks次。这为每个块创建了一个独立的线性层。
在前向方法中,我们得到一个x作为单个张量,我们首先需要使用torch.split将其拆分成块。举例来说,块大小为 2 时,结果如下:[1, 2, 3, 4, 5, 6] -> [1, 2], [3, 4], [5, 6]。然后,我们对不同的块应用独立的线性变换,并使用torch.cat将结果粘合在一起。完成了!
训练可解释神经网络
现在,我们拥有了定义我们可解释神经网络所需的所有要素。我们只需要先创建一个数据集:
X = torch.randn(1000, 3)
y = 3*X[:, 0] + 2*X[:, 1]**2 + X[:, 2]**3 + torch.randn(1000)
y = y.reshape(-1, 1)
我们可以看到这里处理的是一个包含一千个样本的三维数据集。真实关系是线性的,如果你对特征 1 进行平方,对特征 2 进行立方——这就是我们想要用模型恢复的!所以,让我们定义一个小模型,应该能够捕捉到这种关系。
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
**self.features** = torch.nn.Sequential(
BlockLinear(3, 1, 20),
torch.nn.ReLU(),
BlockLinear(3, 20, 20),
torch.nn.ReLU(),
BlockLinear(3, 20, 20),
torch.nn.ReLU(),
BlockLinear(3, 20, 1),
)
**self.lr** = torch.nn.Linear(3, 1)
def forward(self, x):
x_pre = self.features(x)
return self.lr(x_pre)
model = Model()
我将模型分为两个步骤:
-
使用
self.features计算部分输出ŷᵢ,然后 -
计算最终预测ŷ作为ŷᵢ的加权和,使用
self.lr。
这使得提取特征解释变得更容易。在self.features的定义中,你可以看到我们创建了一个包含三个块的神经网络,因为数据集中有三个特征。对于每个块,我们创建了许多隐藏层,每个块有 20 个神经元。
现在,我们可以创建一个简单的训练循环:
optimizer = torch.optim.Adam(model.parameters())
criterion = torch.nn.MSELoss()for i in range(2000):
optimizer.zero_grad()
y_pred = model(X)
loss = criterion(y, y_pred)
loss.backward()
optimizer.step()
if i % 100 == 0:
print(loss)
基本上,我们选择 Adam 作为优化器,MSE 作为损失函数,然后进行标准梯度下降,即用optimizer.zero_grad()擦除旧梯度,计算预测值,计算损失,通过loss.backward()计算损失的梯度,并通过optimizer.step()更新模型参数。你可以看到训练损失随着时间的推移而下降。我们在这里不关注验证集或测试集。训练 r² 在最后应该大于 0.95。
我们现在可以通过以下方式打印模型解释:
import matplotlib.pyplot as pltx = torch.linspace(-5, 5, 100).reshape(-1, 1)
x = torch.hstack(3*[x])for i in range(3):
plt.plot(
x[:, 0].detach().numpy(),
model.get_submodule('lr').weight[0][i].item() * model.get_submodule('features')(x)[:, i].detach().numpy())
plt.title(f'Feature {i+1}')
plt.show()
并获得
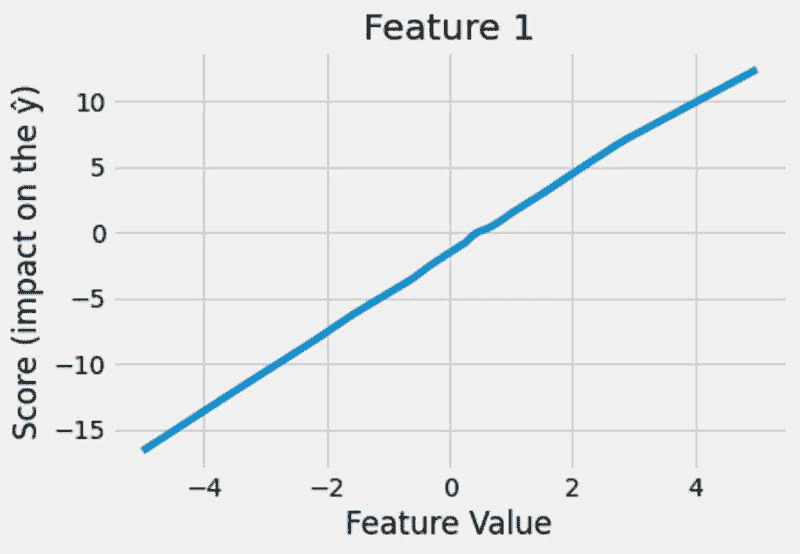
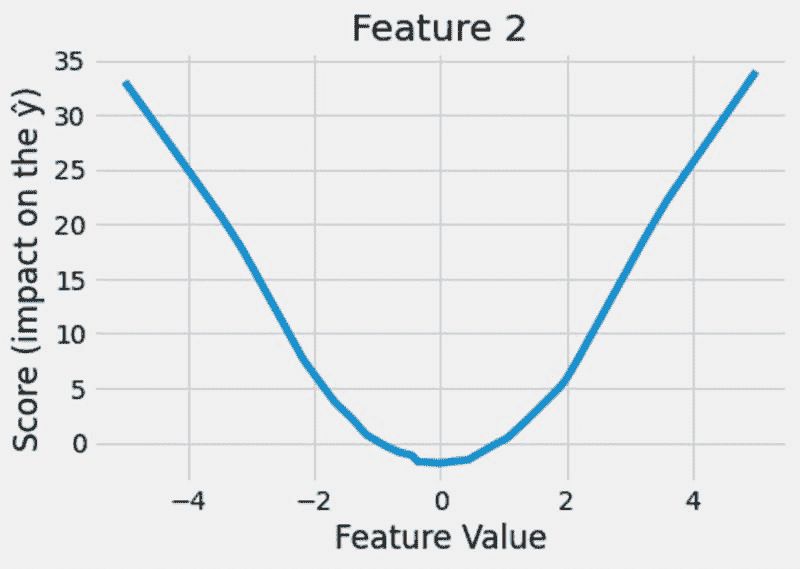
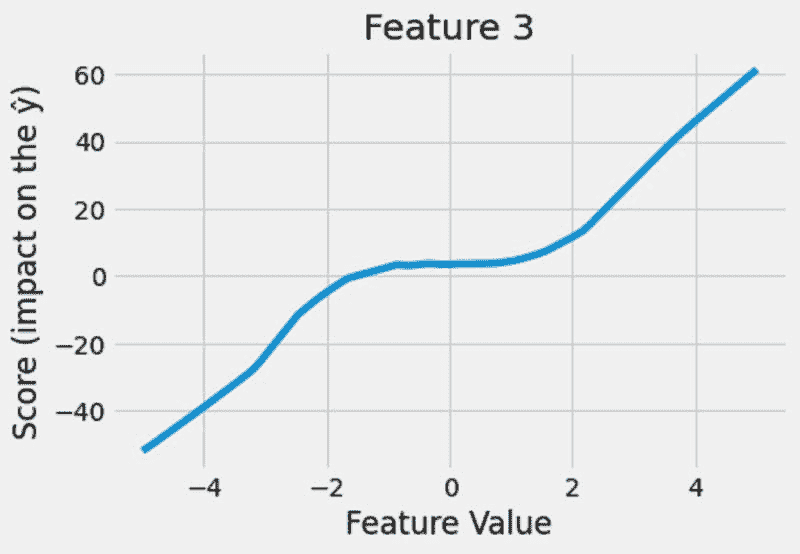
图片由作者提供。
这看起来非常不错!模型发现特征 1 的影响是线性的,特征 2 的影响是二次的,特征 3 的影响是立方的。不仅如此,模型能够向我们展示这一点,这是整个构建过程的伟大之处!
你甚至可以丢掉网络,仅仅基于这些图表进行预测!
举个例子,让我们估计网络对于x = (2, -2, 0)的输出。
-
x₁ = 2 根据第一幅图表转换为+5的预测结果。
-
x₂ = -2 根据第二幅图表转换为+9的预测结果。
-
x₃ = 0 根据第三幅图表转换为+0的预测结果。
-
从最后一层线性层仍然存在一个偏差,你可以通过
model.get_submodule('lr').bias访问这个偏差,这也需要添加,但应该很小。
总的来说,你的预测结果应该在ŷ *≈ 5 + 9 + 0 + bias ≈ 14,这相当准确。
你还可以看到你需要做什么才能最小化输出:为特征 1 选择小值,为特征 2 选择接近零的值,为特征 3 选择小值。这是你通常不能仅通过查看神经网络看到的,但通过得分函数,我们可以。这是可解释性的一个巨大好处。
请注意,上述学习到的得分函数只能对实际有训练数据的区域有信心。在我们的数据集中,我们实际上只观察到每个特征在 -3 到 3 之间的值。因此,我们可以看到,在边缘没有得到完美的x²和x³多项式。但我认为即便如此,图形的方向也大致正确,这还是很令人印象深刻的。为了充分欣赏这一点,可以将其与 EBM 的结果进行比较:
-
![使用 PyTorch 的可解释神经网络]()
-
作者提供的图片。
-
这些曲线是块状的,外推只是两边的直线,这是基于树的方法的主要缺点之一。
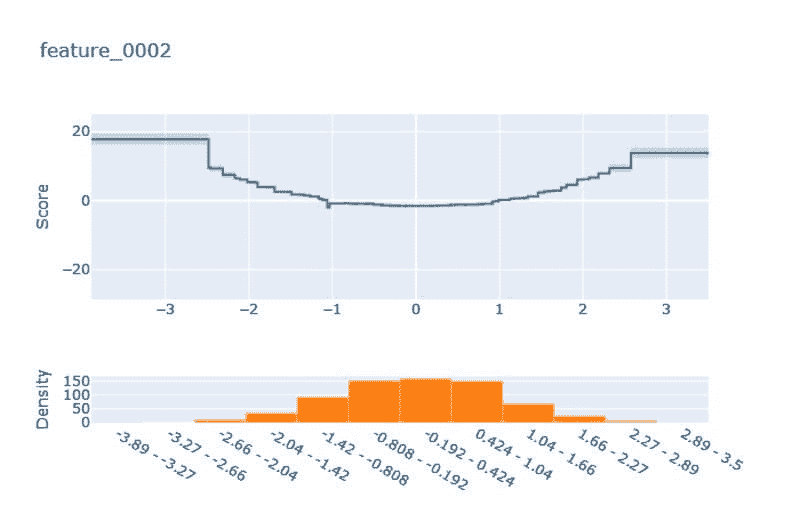
- 结论
-
在这篇文章中,我们讨论了模型的可解释性,以及神经网络和梯度提升如何未能提供它。虽然 interpretml 包的作者创建了 EBM,一个可解释的梯度提升算法,但我向你介绍了一种创建可解释神经网络的方法。
-
我们已经在 PyTorch 中实现了它,虽然代码量有点多,但也没什么太疯狂的。至于 EBM,我们可以提取每个特征的学习得分函数,甚至可以用它们来进行预测。
-
实际训练的模型甚至不再必要,这使得在低配置硬件上部署和使用成为可能。 这是因为我们只需存储每个特征的一个查找表,这在内存上很轻量。使用每个查找表的网格大小为g会导致只存储O(n_features * g)个元素,而不是可能的数百万甚至数十亿个模型参数。进行预测也很便宜:只需从查找表中加一些数字。由于这有仅为O(n_features)**的时间复杂度,查找和加法速度远快于网络的前向传播。
- 再次声明:* 我不确定这是否是一个新想法,但反正就是这样!如果你知道有解释相同想法的论文,请给我留言,我会引用它。*
-
我希望你今天学到了一些新的、有趣的、有用的东西。感谢阅读!
-
作为最后一点,如果你
-
- 想要支持我继续撰写更多关于机器学习的内容
-
- 计划无论如何获取 Medium 订阅,
-
为什么不通过这个链接来支持我呢?这对我帮助很大!????
-
为了透明起见,您的价格不会变化,但大约一半的订阅费用会直接到我这里。
-
非常感谢,如果你考虑支持我!
- 如果你有任何问题,可以在LinkedIn上联系我!
-
Dr. Robert Kübler 是 Publicis Media 的数据科学家和 Towards Data Science 的作者。
-
原文。转载许可。
- 我们的前三个课程推荐
-
![]() 1. Google 网络安全证书 - 快速进入网络安全职业。
1. Google 网络安全证书 - 快速进入网络安全职业。 -
![]() 2. Google 数据分析专业证书 - 提升你的数据分析技能
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
更多相关主题
一种简单且可解释的二分类器性能测量方法
原文:
www.kdnuggets.com/2020/03/interpretable-performance-measure-binary-classifier.html
评论
由 Mehmet Suzen 提供,理论物理学家和研究科学家。
机器学习模型的核心应用是 二分类任务。这出现在医学中的 诊断测试 以及针对消费者的 信用风险 决策等多个领域。构建分类器的技术从简单的决策树到逻辑回归,最近还有利用多层神经网络的超级酷的深度学习模型。然而,尽管这些模型在构建和训练方法上有数学上的不同,但在性能测量方面,事情变得复杂。在这篇文章中,我们提出了一种简单且可解释的二分类器性能测量方法。假设读者对分类有一定的背景知识。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT
为什么 ROC-AUC 不具有可解释性?
不同阈值产生不同的混淆矩阵(维基百科)。
报告分类器性能的事实标准是使用接收器操作特性 (ROC) - 曲线下面积 (AUC) 测量。它起源于 1940 年代美国海军在雷达的开发过程中,用于测量探测性能。 至少有 5 种不同的 ROC-AUC 定义,即使你拥有机器学习博士学位,人们也很难解释 AUC 作为性能度量的意义。由于几乎所有库中都有 AUC 功能,它几乎成为机器学习论文中分类性能的宗教仪式。然而,除了其荒谬的比较问题外,解释起来并不容易,请参见hmeasure。AUC 衡量的是从混淆矩阵提取的真实正率 (TPR) 曲线下的面积,作为假阳性率 (FPR) 的函数,不同阈值下的结果。
f(x) = y
∫ 10 f(x)dx = AUC
其中 y 是 TPR,x 是 FPR。除了有多种解释且容易产生混淆外,没有明确的目的来对 FPR 进行积分。显然,我们希望通过将 FPR 设为零来实现完美分类,但这个面积在数学上并不明确,这意味着作为一个数学对象 的具体意义并不清楚。
正确分类概率 (PCC)
对于二分类器来说,一个简单且易于解释的性能度量对技术数据科学家和非技术利益相关者都非常有用。这个方向的基本原则是分类器技术的目的是能够区分两个类别。这归结为一个概率值,即正确分类概率 (PCC)。显而易见的选择是所谓的平衡准确率 (BA)。即使由SAS推荐用于不平衡问题,他们使用了概率的乘法。这里我们将 BA 称为 PCC,并改用加法,原因是统计依赖性:
PCC = (TPR + TNR) / 2
TPR = TP / (ConditionPositive) = TP / (TP + FN)
TNR = TN / (ConditionNegative) = TN / (TN + FP).
PCC 告诉我们分类器在检测任一类别时的效果,它是一个概率值,[0,1]。请注意,即使我们的训练数据在生产中是平衡的,使用正负案例的总体准确率也是误导性的,因为我们测量性能的批次可能不平衡,因此仅用准确率作为衡量标准并不理想。
生产问题
直接的问题是如何选择生成混淆矩阵的阈值?一种选择是选择一个能够最大化 PCC 的阈值,用于在测试集上进行生产。为了提高 PCC 的估计,可以在测试集上进行重采样,以获得良好的不确定性。
结论
我们尝试通过引入 PCC,或平衡准确率,作为二分类器的简单而可解释的性能指标,来规避报告 AUC 的问题。这对于非技术观众来说很容易解释。可以引入一种改进的 PCC,考虑更好的估计特性,但主要的解释仍然是正确分类的概率。
原文。经许可转载。
相关内容:
更多相关主题
从头到尾解释数据集
评论
机器学习可能会救你于一些灾难,但有时它不会提供帮助。在某些时候,模型的准确性必须提高。这时,理解和探索数据集变得至关重要。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
要建立一个强大的 机器学习 系统,熟悉数据集、了解特征分布、识别重要和不重要的特征、发现特征之间的趋势和关系等至关重要。在深入挖掘数据之前,不要急于建模。记住,输出的质量取决于输入的质量。垃圾进,垃圾出。
数据科学家在建模之前花费大量时间进行数据准备,因为理解、生成和选择有用的特征会影响模型性能。这有助于数据科学家检查拟合模型所需的假设。除了理解输入数据集,理解模型构建过程中生成的数据也很重要——例如,可以在深度 Q 网络(DQN)的激活数据上使用不同的探索和可视化技术。
根据数据的大小和类型,理解和解释数据集可能会很有挑战性。仅凭查看从数百万个观测值中随机选择的前 100 个观测值,无法理解数据集并得出结论。如果数据有成千上万的变量,别指望为每个特征绘制统计图。最好选择少量特征或有方法总结它们。而且请记住,如果数据有异质变量,每个变量不能以相同的方式对待。
可以做什么?使用不同的探索性数据分析和可视化技术以获得更好的理解。这包括总结主要数据集特征,寻找代表性或关键点以及发现相关特征。在获得对数据集的整体理解后,你可以考虑在建模中使用哪些观察值和特征。
带有可视化的总结统计
总结统计有助于分析样本数据的信息。它指示有关连续(区间)和离散(名义)数据集变量的某些信息。可以单独或一起分析这些变量,因为它们可以帮助发现:意外值;缺失值占整个数据集的比例;偏斜度和其他问题。可以比较不同特征 across 不同特征的分布,也可以比较训练和测试数据集的特征统计信息。这有助于揭示它们之间的差异。
小心总结统计。过度信任总结统计可能会掩盖数据集中的问题。考虑使用额外的技术以全面理解数据。
基于示例的解释
假设数据集有数百万个观察值和数千个变量。在没有任何抽象的情况下理解这些数据是具有挑战性的。解决此问题的一种方法是使用基于示例的解释;这些技术可以帮助挑选重要的观察值和维度。它们可以帮助解释具有不同分布的高度复杂的大数据集。
解决此问题的技术包括寻找观察值和维度以进行特征描述、批评和区分数据集组。
-
特征描述: 作为人类,我们通常使用来自数据的代表性示例进行分类和决策。这些示例,通常称为原型,是最能描述数据集类别的观察值。它们可以用于解释类别,因为使用某个类别中的所有观察值进行解释是困难的。
-
批评: 仅仅找到原型不足以理解数据,因为它过于泛化。在某个组中,共享特征之间可能存在无法通过原型捕捉的变化。我们需要展示规则的例外(批评)。这些观察可以被视为与原型非常不同的少数观察,但仍然属于同一类别。
在下面的插图中,每个类别中的机器人图片包括具有不同头部和身体形状的机器人。穿着服装的机器人也可以属于这些类别之一,尽管它们可能与典型的机器人图片非常不同。这些图片对于理解数据是必要的,因为它们是重要的少数。
Been Kim 在这一领域的工作专注于在使用一种称为最大均值差异(MMD)评价者的无监督技术时找到那些少数群体并发现原型。
- 区分:找到代表可能不总是足够的。如果特征数量很高,仍然很难理解所选择的观察值。这是因为人类无法理解长而复杂的解释。解释需要简单。
对于那些被选择的观察值,必须考虑最重要的特征。子空间表示是解决这一问题的一种方法。使用原型和子空间表示有助于解释性。可以使用的一种方法是贝叶斯案例模型(BCM),这是一种无监督学习方法,其中底层数据使用混合模型和每个簇的重要特征集合进行建模。
除了理解重要特征,还需要了解不同簇之间的差异,以用于许多应用,例如差异诊断。为此,需要在数据中找到区分维度。思维缺口模型(MGM)结合了提取和选择方法,并报告了一组全球可区分的维度,以帮助进一步探索。
在上述示例中,通过查看从不同机器人图片中提取的特征,我们可以说头部的形状是一个区分维度。然而,眼睛的形状由于相似性,我们无法这样说。
嵌入技术
嵌入是将离散值(如单词或观察值)映射到向量的过程。不同的嵌入技术有助于可视化低维表示。嵌入可以有数百个维度。理解它们的常见方法是将它们投影到二维或三维空间中。它们在许多方面都很有用:
-
使用它们来探索局部邻域。这有助于探索与给定点最近的点,以确保它们彼此相关。选择这些点并进行进一步分析。使用它们来理解模型的行为。
-
使用它们来分析全球结构,寻找点的组。这有助于找到簇和离群点。
获取嵌入的方法有很多,包括:
- 主成分分析:这是一种线性确定性算法,旨在以尽可能少的维度捕捉数据的变异性。这是一种有效的降维算法,特别是在变量之间存在强线性关系时。
它可以用来突出变化并消除维度。如果需要解释数据,可以保留考虑了大量变化的前几个主成分。其余主成分仅占有微不足道的方差。为了可解释性和分析,这些主成分不应被保留。
- t-SNE(T-distributed Stochastic Neighbor Embedding): 一种维度减少算法,试图保留数据中的局部邻域。它是非线性和非确定性的;并允许创建 2D 或 3D 投影。t-SNE 找到其他方法可能遗漏的结构。
它对于可视化和解释数据集非常有用,但有很多需要谨慎的地方。在保留局部结构的同时,它可能会扭曲全局结构。如果需要更多关于 t-SNE 的信息,可以查看 distill.pub 上的优秀文章 “如何有效使用 t-SNE”。
使用 t-SNE 嵌入可以帮助减少数据的维度并找到结构。然而,如果数据集非常大,理解投影仍然可能很困难。检查数据的几何形状以获得更好的理解是有用的。
拓扑数据分析(TDA)
拓扑学研究的是在不撕裂对象的情况下变形时保留的几何特征。拓扑数据分析提供了使用拓扑学研究数据几何特征的工具。这包括检测和可视化特征,以及与这些特征相关的统计测量。几何特征可以是数据中的明显簇、环和触须。如果网络中存在一个环,则结论是模式会周期性地出现。
TDA 中的映射算法对于数据可视化和聚类非常有用。可以创建数据集的拓扑网络,其中节点是相似观察值的组,而边在它们有共同观察值时连接这些节点。
结论
在理解和解释数据时,没有一种适合所有情况的解决方案。选择最符合需求的解决方案。当有大量原始数据时,使用代表性示例来解释基础分布。如果是宽数据集,找出重要的维度来理解代表性样本,因为列出所有特征将难以理解。
最终,数据科学家的工作是利用现有工具来解决谜题并以易于理解的方式解释。
个人简介:Ilknur Kaynar Kabul 是 SAS 的科学家和经理,工作领域涵盖计算机科学、统计学和优化。她的工作涉及构建可扩展的机器学习算法,以帮助解决大数据问题。Kabul 是北卡罗来纳州 Women in Machine Learning and Data Science 分会的共同创始人。她拥有北卡罗来纳大学计算机科学博士学位。
相关:
更多相关话题
解释机器学习模型:概述
原文:
www.kdnuggets.com/2017/11/interpreting-machine-learning-models-overview.html
一篇文章关于机器学习解释出现在 O'Reilly 的博客上,由 Patrick Hall、Wen Phan 和 SriSatish Ambati 撰写,概述了超越常用措施的多种方法。偶然间我在周末再次读到了这篇文章,决定分享其中的一些观点。这篇文章非常棒(虽然很长),推荐给有时间的人阅读。
文章的组织结构如下:
-
概述(机器学习)函数解释的不同复杂性
-
可解释性的范围概述,包括局部(条件分布的小区域)与全局(整个条件分布)的比较
-
讨论理解和信任,以及传统的理解措施——如交叉验证和评估图——如何常常不足以激发对模型的信任
-
解释技术的三部分拆解(文章的核心内容)
第一部分包括在训练和解释机器学习算法的背景下查看和理解数据的方法,第二部分介绍了将线性模型和机器学习算法结合起来的技术,以应对可解释性至关重要的情况,第三部分描述了理解和验证最复杂的预测模型的方法。
文章的重点是对每种技术及其技术组的可解释性进行分解,而这篇文章则总结了这些技术。
第一部分:查看你的数据
本节以缓慢的节奏开始文章,并指出一些在传统方法之外执行视觉数据探索的方法。
[T]有许多种方法来可视化数据集。下面突出显示的大多数技术帮助在仅两个维度中展示整个数据集,而不仅仅是单变量或双变量的数据切片(即一次一个或两个变量)。这在机器学习中很重要,因为大多数机器学习算法会自动建模变量之间的高阶交互作用(即,结合多个变量的影响,即超过两个或三个变量)。
本节展示的可视化技术包括:
-
符号图
-
相关性图
-
2D 投影,例如 PCA、MDS 和 t-SNE
-
部分依赖图
-
残差分析
表示由大型金融公司发放贷款的相关性图。图片由 Patrick Hall 和 H2O.ai 团队提供。
推荐的一些问题可以帮助确定这些可视化技术的价值(类似的问题也会在后续部分的技术中提出),包括:
-
可视化可以帮助解释什么复杂度的函数?
-
可视化如何增强理解?
-
可视化如何增强信任?
第二部分:在受监管行业中使用机器学习
这里变得更加有趣了。
本节介绍的技术是更新的线性模型类型或使用机器学习来增强传统线性建模方法的模型。这些技术适用于那些由于可解释性问题而无法使用机器学习算法构建预测模型的从业人员。
本节概述的技术包括:
-
广义加性模型(GAMs)
-
分位回归
-
构建机器学习模型基准——也就是说,在从传统线性模型转向机器学习算法时,采用有意识的过程,逐步推进,并在过程中比较性能和结果,而不是直接从简单的回归模型跳到深度黑箱模型
-
在传统分析过程中使用机器学习——这是建议使用机器学习算法来增强分析生命周期过程,以获得更准确的预测,例如预测线性模型的退化
-
小型可解释的集成——目前已基本确定,集成方法总体上具有巨大价值,但使用简单的这种方法可能有助于提高准确性和可解释性。
-
单调性 约束——这种约束可能将复杂模型转换为可解释的非线性单调模型
单调性至少有两个非常重要的原因:
- 单调性通常是监管机构所期望的
- 单调性支持一致的理由代码生成
一张小型堆叠集成模型的示意图。图例由 Vinod Iyengar 和 H2O.ai 团队提供。
第三部分:理解复杂的机器学习模型
在我看来,这里尤其有趣。我将复杂的机器学习模型可解释性视为自动化机器学习的支持者,因为我认为这两种技术是同一事物的两个方面:如果我们要使用自动化技术在前端生成模型,那么在后端设计和使用适当的方法来简化和理解这些模型就变得极为重要。
下面是本文中概述的帮助理解复杂机器学习模型的方法。
替代模型 -- 简单地说,替代模型是一个可以用来解释更复杂模型的简单模型。如果替代模型是通过使用原始输入数据和更复杂模型的预测训练一个简单的线性回归或决策树来创建的,则简单模型的特征可以被认为是对复杂模型的准确描述。它可能根本不准确。
那么,为什么使用替代模型?
替代模型在其系数、变量重要性、趋势和交互作用与人类领域知识和合理期望一致时,能够增强信任。当与敏感性分析结合使用以测试解释是否保持稳定并与人类领域知识以及在数据轻微且有目的地扰动时、模拟有趣场景时或数据随时间变化时的合理期望一致时,替代模型可以增加信任。
局部可解释模型无关解释(LIME) -- LIME 用于基于单个观察构建替代模型。
LIME 的实现可以按如下方式进行。首先,使用复杂模型对解释性记录进行评分。然后,为了解释关于另一条记录的决策,解释记录按其与该记录的接近程度加权,并在这个加权的解释性数据集上训练一个 L1 正则化的线性模型。线性模型的参数然后帮助解释对所选记录的预测。
最大激活分析 -- 一种技术,旨在隔离出能够引发某个模型超参数最大响应的特定实例。
在最大激活分析中,寻找或模拟出能够最大限度激活神经网络中的某些神经元、层或滤波器,或决策树集合中的某些树的示例。对于最大激活分析而言,某个树的低残差类似于神经网络中高幅度的神经元输出。
那么... LIME,还是最大激活分析,还是两者结合?
如上所述,LIME 有助于解释模型在条件分布的局部区域内的预测。最大激活分析有助于增强对模型局部、内部机制的信任。这两者结合可以为复杂响应函数创建详细的局部解释。
敏感性分析 -- 该技术有助于确定有意扰动的数据或类似数据变化是否会改变模型行为并使输出不稳定;它还用于研究特定场景或极端情况的模型行为。
全局变量重要性度量 -- 通常是树模型的领域;变量重要性的启发式方法与给定变量的分裂点的深度和频率有关;较高和更频繁的变量显然更重要。
例如:
对于单个决策树,变量的重要性通过在每个选择该变量作为最佳分割候选的节点中,分割准则的累计变化来定量确定。
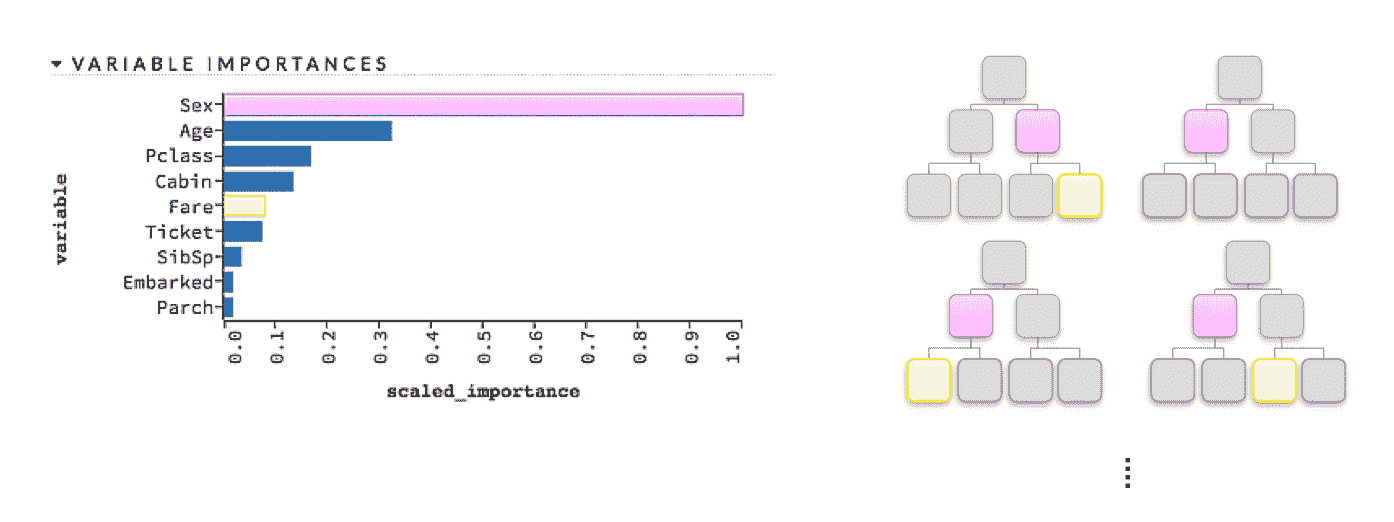
决策树集成模型中变量重要性的示意图。图由 Patrick Hall 和 H2O.ai 团队提供。
Leave-One-Covariate-Out (LOCO) -- “模型无关的均值准确度下降变量重要性度量”;最初为回归模型开发,但更广泛适用;该技术的目标是通过迭代地将变量值置为零来确定对给定行具有最大绝对影响的变量--即被确定为该行预测中最重要的变量。
变量重要性度量如何增强理解?
变量重要性度量增加了理解,因为它们告诉我们模型中最具影响力的变量及其相对排名。
Treeinterpreter -- 严格来说是基于树的模型(决策树、随机森林等)解释方法
Treeinterpreter 仅仅输出一个给定模型中某变量的偏差和个别贡献的列表,或者输入变量在单个记录中对单个预测的贡献。
我目前正在试验 Treeinterpreter,并希望很快分享我的经验。
重申一下,这篇 O'Reilly 文章我已经进行了简单总结,如果你有时间,值得全面阅读,其中详细阐述了我只是触及皮毛的技术,比我更好地将每项技术的有用性以及使用这些技术所应期待的结果结合起来。
感谢 Patrick Hall、Wen Phan 和 SriSatish Ambati,这篇信息丰富的文章的作者。
相关:
-
用 Python 和 Scikit-learn 简化决策树解释
-
模型可解释性的神话
-
局部可解释模型无关解释 (LIME)
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关主题
采访:阿尔诺·坎德,H2O.ai 谈深度学习基础
原文:
www.kdnuggets.com/2015/01/interview-arno-candel-0xdata-deep-learning.html
是H2O.ai的物理学家和黑客。在此之前,他是 Skytree 的创始高级 MTS,负责设计和实施高性能机器学习算法。他拥有十多年高性能计算的经验,并曾作为 SLAC 国家加速器实验室的工作人员科学家,访问世界上最大的超级计算机,参与了美国能源部的科学计算计划,并与 CERN 合作。阿尔诺撰写了几十篇科学论文,是备受追捧的会议演讲者。
他在苏黎世联邦理工学院获得了物理学博士和硕士学位,并以优异成绩毕业。阿尔诺被《财富》杂志评选为2014 年大数据全明星。
这是我与他的采访:
安莫尔·拉吉普罗希特: Q1. 你如何定义深度学习?它与其他机器学习技术有何不同?
 阿尔诺·坎德博士: 深度学习方法使用多个非线性变换的组合来建模数据中的高级抽象。多层前馈 人工神经网络 是一些最古老且最有用的技术。我们现在正在享受深度学习60 年的发展成果,这一过程始于 1950 年代末,当时首次提出了机器学习这个术语。深度学习在过去十年的成功很大程度上归因于摩尔定律和计算机的指数加速,但也有许多算法突破使得深度学习者的训练更加稳健。
阿尔诺·坎德博士: 深度学习方法使用多个非线性变换的组合来建模数据中的高级抽象。多层前馈 人工神经网络 是一些最古老且最有用的技术。我们现在正在享受深度学习60 年的发展成果,这一过程始于 1950 年代末,当时首次提出了机器学习这个术语。深度学习在过去十年的成功很大程度上归因于摩尔定律和计算机的指数加速,但也有许多算法突破使得深度学习者的训练更加稳健。
与诸如基于树的方法等更易解释的机器学习技术相比,传统的深度学习(使用随机梯度下降和反向传播)是一种相当“蛮力”的方法,它通过不断查看训练数据中的示例,从随机噪声开始优化大量的系数(这是一种参数化方法)。它遵循“(好的)实践使完美”的基本理念(类似于真实的大脑),但对模型质量没有强有力的保证。
现代典型的深度学习模型有数千个神经元,并学习数百万个自由参数(神经元之间的连接),但在神经元数量上(~100,000)甚至尚未能与果蝇的大脑相媲美。最先进的专用深度学习系统正在学习数十亿个参数,这仍然比人脑中的神经连接数量少约 10,000 倍。
然而,即使一些显著较小的深度学习模型已经在许多任务上超越了人类,因此人工智能的领域无疑变得更加有趣。
AR: Q2. 什么特征使得深度学习能够在标准机器学习问题上提供如此优越的结果?是否有特定的问题子集,其中深度学习比其他选项更有效?
AC: 深度学习在从原始输入特征中学习非线性派生特征方面非常有效,这与线性或基于树的方法等标准机器学习方法不同。例如,如果年龄和收入是预测支出的两个特征,那么线性模型将极大受益于手动分割年龄和收入范围为不同的组;而基于树的方法则会自动学习如何划分二维空间。
深度学习模型建立了(隐藏的)非线性特征的层次结构,这些特征组合起来可以以比其他方法少得多的努力来逼近任意函数,如 sqrt((age-40)²+0.3log(income+1)*-4)。传统上,数据科学家根据领域知识和经验明确地执行这些转换,但深度学习已被证明 在 这些转换 上极其 有效,通常比标准机器学习模型表现出更大的优势。
深度学习在预测高基数类别成员方面也表现出色,例如图像或语音识别问题,或预测推荐给用户的最佳项目。深度学习的另一个优势是它还可以用于无监督学习,其中它仅仅学习数据的内在结构而不做预测(还记得Google 猫吗?)。这在没有训练标签的情况下,或用于各种其他用例,如异常检测时很有用。

AR: Q3. H2O 架构的关键组件是什么?使用 H2O 进行深度学习有什么独特优势?
 AC: H2O 的独特之处在于它是GitHub 上排名第一的基于 Java 的开源机器学习项目(我们正在进行一个更开发者友好的重写的最后阶段)。它建立在一个分布式键值存储之上,该存储基于全球最快的非阻塞哈希表,由我们的首席技术官兼联合创始人Cliff Click编写,他因对快速 Java HotSpot 编译器的贡献而闻名。
AC: H2O 的独特之处在于它是GitHub 上排名第一的基于 Java 的开源机器学习项目(我们正在进行一个更开发者友好的重写的最后阶段)。它建立在一个分布式键值存储之上,该存储基于全球最快的非阻塞哈希表,由我们的首席技术官兼联合创始人Cliff Click编写,他因对快速 Java HotSpot 编译器的贡献而闻名。
H2O 的设计旨在以 FORTRAN 速度处理大型数据集(例如,来自 HDFS、S3 或 NFS),使用高效的(细粒度)内存中实现的著名 Mapreduce 范式,带有内置的无损列压缩(通常优于磁盘上的 gzip)。H2O 不需要 Hadoop,但可以通过 MRv1、YARN 或 Mesos 在 Hadoop 集群上启动,以实现与 HDFS 的无缝数据摄取。
 Sparkling Water紧密集成了 Apache Spark 中的数据管道与 H2O。除了原生Java和Scala API 外,H2O 还提供了一个强大的 REST API,可以通过R、Python或Tableau客户端进行连接。它还支持我们易于使用的 Web API,用于互动探索 H2O 的功能。此外,还自动生成了 Java 代码,用于将模型直接投入生产(例如,与 Storm 一起使用),这对于许多企业客户非常有用。
Sparkling Water紧密集成了 Apache Spark 中的数据管道与 H2O。除了原生Java和Scala API 外,H2O 还提供了一个强大的 REST API,可以通过R、Python或Tableau客户端进行连接。它还支持我们易于使用的 Web API,用于互动探索 H2O 的功能。此外,还自动生成了 Java 代码,用于将模型直接投入生产(例如,与 Storm 一起使用),这对于许多企业客户非常有用。
H2O 及其方法也得到了风险投资的支持,并且有一些机器学习领域最为知识渊博的专家:斯坦福大学教授特雷弗·哈斯提、罗布·提布希拉尼和斯蒂文·博伊德。其他独立的导师包括 Java API 专家乔什·布洛赫以及 S 和 R-core 成员创始人约翰·钱伯斯。我们实际上花了好几天时间讨论算法、API 和代码,这是极大的荣誉和特权。当然,来自开源社区的客户和用户也在不断验证我们的算法。
对于 H2O 深度学习,我们将许多小技巧结合起来,使其成为一种开箱即用的非常强大的方法。例如,它具备自动自适应权重初始化、自动数据标准化、分类数据扩展、自动处理缺失值、自动自适应学习率、各种正则化技术、自动性能调优、负载均衡、网格搜索、N 折交叉验证、检查点和不同的分布式训练模式等功能。最棒的是,用户无需了解任何神经网络,没有复杂的配置文件。训练过程与随机森林一样简单,并且可以对监督回归或分类问题进行预测。对于高级用户,还有许多(文档齐全的)选项可以实现对学习过程的精细控制。默认情况下,H2O 深度学习将充分利用整个集群的每一个 CPU 核心,并且经过高度优化以获得最佳性能。
我分享了我们首席执行官兼联合创始人SriSatish Ambati的愿景,即这些最近的机器智能进展可以催生出一个智能应用的整体生态系统,并从根本上丰富我们的生活。
访谈的第二部分
相关:
-
阿尔诺·坎德尔谈如何快速启动 H2O 深度学习
-
阿尔诺·坎德尔谈从物理学到机器学习的旅程
-
研究领导者谈数据挖掘、数据科学和大数据的关键趋势、顶级论文
更多相关主题
自动化数据科学与机器学习:对 Auto-sklearn 团队的采访
原文:
www.kdnuggets.com/2016/10/interview-auto-sklearn-automated-data-science-machine-learning-team.html
KDnuggets 最近举办了一场 自动化数据科学和机器学习博客比赛,收到了众多参赛作品,并对获奖文章及一对荣誉提名表示了高度赞赏。
获奖文章题为 比赛获胜者:用 Auto-sklearn 赢得 AutoML 挑战,由 Matthias Feurer、Aaron Klein 和 Frank Hutter 共同撰写,均来自弗赖堡大学,概述了 Auto-sklearn,这是一个开源 Python 工具,能够自动确定适用于分类和回归数据集的有效机器学习管道。该项目围绕成功的 scikit-learn 库构建,并赢得了最近的 AutoML 挑战。
鉴于这篇文章的受欢迎程度,我们询问了作者们是否有兴趣回答一些关于他们自己、他们的项目以及自动化数据科学的一般性后续问题。以下是这次对话的结果。
Matthew Mayo:首先,恭喜你们赢得了 KDnuggets 自动化数据科学和机器学习博客比赛,展示了你们的项目 Auto-sklearn。如果我们从介绍一下团队成员开始,并提供每个人的一些背景信息怎么样?
Matthias Feurer:我是 Frank 组的二年级博士生,主要从事超参数优化和自动化机器学习工作。我主要关注于优化预定义的机器学习管道。在攻读硕士学位期间,我开始为 Frank 工作,因为在那时的大多数研究项目中,我都对超参数调整感到厌烦。
Aaron Klein:我也是一名二年级博士生,专注于自动化深度学习。像 Matthias 一样,在加入 Frank 组之前,我曾是弗赖堡大学的硕士生。
Frank Hutter:我是弗赖堡大学计算机科学的助理教授,主要兴趣领域包括人工智能、机器学习和自动化算法设计。在搬到弗赖堡之前,我在加拿大温哥华的英属哥伦比亚大学工作了九年。
All:除了我们三个人(为 KDnuggets 博客比赛撰写了博客文章),我们获奖提交的团队还包括来自弗赖堡大学的几位博士生和博士后:Katharina Eggensperger、Jost Tobias Springenberg、Hector Mendoza、Manuel Blum、Stefan Falkner 和 Marius Lindauer。
这篇文章信息丰富,对 Auto-sklearn 的描述非常到位。是否有任何额外的信息您希望我们的读者了解 Auto-sklearn,或者自这篇文章以来发生了什么进展?您能否分享一下未来的发展计划?
短期目标是回归分析,我们可以在这方面做得更多。从长远来看,我们希望 Auto-sklearn 成为 scikit-learn 的一个灵活扩展,帮助用户优化他们的机器学习流程。我们还希望在 Auto-Net 的方向上做更多的工作,并希望通过对数据集、数据子集以及时间(针对任何时间算法)的更多推理来大幅加快优化过程。
您认为机器学习和数据科学能在多大程度上实现自动化?所谓的完全自动化系统需要多少人类互动?
尽管有几种方法可以调整机器学习流程的超参数,但迄今为止,发现新的流程构建块的工作还很少。Auto-sklearn 使用预定义的一组预处理器和分类器,按照固定的顺序进行。一个有效的方法是提出新的流程,这将非常有帮助。当然可以继续这个思路,尝试像最近几篇论文中那样自动发现新算法,例如通过梯度下降学习梯度下降。当机器学习模型的训练非常昂贵时,例如用于大数据集的最先进的深度神经网络,人类仍然能比自动化方法更好地调整超参数。我们正在研究将人类专家启发式方法转化为完全形式化算法的方法;例如,我们的 Fabolas 方法优化神经网络在数据小子集上的超参数,以加速学习整个数据集的最佳超参数。
考虑到之前的问题,数据科学家是否会很快失业?或者,如果这个想法过于激进,当前对数据科学家的热潮是否会在不久的将来被自动化所缓和?如果是的话,会到什么程度?
当然不会。所有的自动化机器学习方法都是为了支持数据科学家,而不是替代他们。这些方法可以解放数据科学家,让他们从那些机器更擅长解决的繁琐、复杂任务(如超参数优化)中解脱出来。但分析和得出结论仍然需要由人类专家来完成——特别是了解应用领域的数据科学家将仍然极其重要。不过,我们确实相信,自动化会使个体数据科学家的生产力大大提高,因此这可能会影响所需的数据科学家数量。
数据科学家能做些什么来避免被淘汰?当然,这个问题是为了增加价值,而不是捣乱。
数据科学家始终需要分析和解释统计分析的结果,因此对于刚开始从事数据科学工作的年轻毕业生,这些技能可能比其他一些技能更具未来保障(例如,手动超参数调优以最大化神经网络的效果)。
由于你过去积极参与机器学习竞赛,你有什么有趣的技巧、窍门或见解可以分享吗?
自动化和精心的重采样策略。自动化允许运行大量实验,而诸如精心交叉验证等重采样策略则有助于防止过拟合。通常,带着开放的心态进入也是很重要的,让数据说明哪种方法在不同的数据集上效果最好。
最后,你认为机器学习技术在 5 年内会处于什么位置?
很难预测未来会发生什么,尤其是在机器学习这样的快速变化领域。例如,五年前并没有多少人预见到深度学习的崛起。但我们相当确信,机器学习将会被越来越多地使用,并嵌入到每个人使用的商业工具中。
感谢你的时间。我知道你的时间非常宝贵,我们感谢你抽出几分钟来为我们的读者提供这些信息。
相关:
-
竞赛获胜者:使用 Auto-sklearn 赢得 AutoML 挑战
-
竞赛第二名:数字广告中的自动化数据科学和机器学习
-
竞赛第二名:自动化数据科学
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关主题
采访:Florian Douetteau,Dataiku 创始人,谈数据科学家赋能
原文:
www.kdnuggets.com/2016/07/interview-florian-douetteau-dataiku-empowering-data-scientists.html
评论
作者:Ajay Ohri。
Dataiku 开发了一款名为 Data Science Studio (DSS) 的协作式端到端软件平台,企业可以利用它加速内部业务和预测解决方案的开发。它承诺大幅提高公司数据科学家、业务分析师和产品经理的效率和生产力。
Florian Douetteau 是 Dataiku 的首席执行官。Florian 在 Exalead 开始了他的职业生涯,这是一家创新的搜索引擎技术公司。在那里,他领导了一个由 50 位杰出数据专家组成的研发团队,直到该公司在 2010 年被 Dassault Systemes 以 1.5 亿美元收购。随后,Florian 在 IsCool 担任首席技术官,这是一个欧洲社交游戏领域的领军企业,他管理了游戏分析和其中一个最大的欧洲云设置。Florian 还曾担任多家公司(如欧洲广告领导者 Criteo)的自由职业首席数据科学家。

这是我与他的采访:
Ajay Ohri: 描述一下你作为数据科学创业公司的历程。是什么原因让你决定制作 DSS?
Florian Douetteau: 在 2012 年,我和我的合作伙伴看到了一次机会:数据科学市场极其碎片化。我们生活在一个非常有趣的技术宇宙中,有很多工具和选项可供使用和处理数据。今天的挑战更多在于应用合适的工具和位置,然后解决多个存储系统和语言的复杂性。例如,你可能会选择使用 Pig 进行一些数据处理,使用 Hive 进行计算,使用 Python 或 R 进行高级建模,使用 ElasticSearch 进行搜索,使用 Hadoop 进行大规模处理,等等。
因此,我们退后一步,审视整体情况:我们试图解决什么问题,为什么?现有的是什么,其他人又在尝试解决什么问题。接着,我们专注于用户。我们如何比其他解决方案更好地解决数据科学生态系统的碎片化问题(包括专有和开源解决方案)?这些用户从现有解决方案中得到了什么,如何智能地将其带给他们?对我们而言,这意味着使我们的用户,无论他们的技能水平如何,都能在保持使用自己熟悉的工具和语言的自由的同时进行协作。
Ajay Ohri: 描述一下你的产品——它如何帮助经验丰富的和有志于成为数据科学家的人员?
弗洛里安·杜埃托:Dataiku 坚信要在快速发展的数据生态系统中取得成功,不论公司行业或规模如何,都必须不断地自我革新并提供创新的数据产品。考虑到这一点,我们的使命是为所有组织提供技术环境,使其团队能够有效地提供未来的数据创新。Dataiku 的协作数据科学和机器学习方法使这些组织能够与过去十年中崛起的数字巨头竞争。
借助为数据科学家和初学者分析师设计的协作和团队化用户界面、统一的数据项目开发和部署框架,以及对设计数据产品所需的所有功能和工具的即时访问,用户可以轻松地将机器学习和数据科学技术应用于各种类型、规模和格式的原始数据,以构建和部署预测数据流。
最后,用户无需处理连接和敲打工具的麻烦,所有经验水平的用户都可以快速学习和精通 R 或 Python 等语言,并了解机器学习真正的含义。
阿贾伊·奥赫里:您的客户的用户反馈是什么?您能描述一些使用 DSS 的案例研究,这些案例研究显示 DSS 比其他数据科学编辑器带来了更好的结果吗?
弗洛里安·杜埃托:由于 Dataiku DSS 的协作功能和高级分析能力,像 AXA、欧莱雅、贝克特、Webbmason、Urban Insights 等客户能够轻松地将机器学习和数据科学技术应用于各种类型、规模和格式的原始数据,以构建和部署预测数据流。应用场景包括流失预测、欺诈检测、动态客户细分、成本和物流优化、预测性维护、趋势预测等。到目前为止,反馈非常好:团队生产力提高(“在几个月内,我们的生产力提高了 30%”),新的业务机会(“有了 DSS,我们已经内部化了数据解决方案的设计和部署”),开发出能带来额外收入和节省的解决方案(“DSS 已经回本”),快速上手(“我甚至让我们的营销和业务团队尝试了”),轻松安全的部署(“我们不再需要重新编写所有代码”)等等。我们计划保持这种状态!
阿贾伊·奥赫里:您如何看待在数据科学工作流中同时使用 Python 和 R?这种方法相比于单一语言的方法有什么优势?
弗洛里安·杜埃托:在一个项目中使用不同语言(从 SQL、R 或 Python 到 Hive、Pig,或所有 Spark 相关的内容)有两个主要优点:
-
不同语言更适合数据科学工作流的不同部分——例如,R 可能更适合统计计算,而 Python 更适合算法,Hive 则适合所有与 Hadoop 相关的内容。
-
人们对所有不同的语言和技术的适应程度差异不大。如果团队经理允许他们使用最熟悉的工具,就能确保优化生产力和个人自由。

Ajay Ohri: 许多数据输入越来越通过 API 或通过网页解析文本进行。DSS 如何处理构建 API 请求并将其解析为数据框架结构这一通常耗时的任务?
Florian Douetteau: 我们通过 DSS 提供了一套插件,帮助与不同的文本分析或 API 集成。例如,我们提供了一个免费的插件,供流行的 import.io 服务使用,一个 IMDB API 的插件,一个用于各种丰富开放数据源的插件,如美国专利数据库、OpenStreetMap 或古腾堡计划。
Ajay Ohri: 我们有 Jupyter 和 RStudio 作为成熟的数据科学界面。DSS 相对于它们有什么优势?DSS 在哪些方面不会是更好的选择?
Florian Douetteau: 我们已经将 Jupyter 集成到我们的产品中。我们产品的核心功能包括:可视化数据准备、可视化机器学习、可视化、工作流、SQL 笔记本、代码笔记本。代码笔记本实际上是用 Jupyter 框架实现的。
Ajay Ohri: 你未来的计划和想法是什么?我们可以通过使用更易于使用的工具来扩展数据科学家的池吗?
Florian Douetteau: 我喜欢关注两个新的有趣趋势。一个是“实时数据”:很快,所有关于构建处理来自动态、活跃系统的数据的产品都将成为重点。这意味着实时处理。这意味着深度学习技术。这意味着拥有能够处理实时数据结构复杂性的工具和技术。
另一个趋势是“思考型应用”。今天的大型企业有两大类应用程序:
-
强制执行业务流程的事务性应用程序,
-
提供数据洞察的报告应用程序。
对于需要遵循相对简单业务流程但涉及大量数据的应用程序的需求正在增加,这些数据通过算法减少和分析,并由人工进行最终交互。现代欺诈检测应用程序就是这种情况,其中算法减少了数据中的所有微弱信号,而人工分析结果警报。这也适用于现代营销活动管理应用程序,其中算法分析过去的活动,进行归因,预测当前活动的表现,而人工做出可能的新资源分配决策。在过程质量控制、预测性维护、运营支持、人力资源等领域也有对类似“思考型应用”的需求。
新鲜事是,如今对商业应用的需求不仅仅是被动显示信息或控制过程。人们期望应用程序能够与他们“思考”;在 Dataiku,我们可以帮助人们真正实现这些应用程序。这令人兴奋!
简介: Ajay Ohri 是两本 R 书籍的作者(《R 商业分析》 和 《R 云计算》),以及即将出版的关于 Python 的书籍 《Python for R 用户》。
相关:
-
Dataiku 数据科学工作室,现在也支持 Apache Spark
-
Python 和 R 结合使用:3 种主要方法
-
数据科学的碎片化是否会导致一个帝国还是多个共和国?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在的组织进行 IT 支持
更多相关内容
采访:Joseph Babcock,Netflix 谈及 Genie、Lipstick 及其他内部开发工具
原文:
www.kdnuggets.com/2015/06/interview-joseph-babcock-netflix-in-house-developed-tools.html
Twitter 账号: @hey_anmol
目前是一名高级数据科学家,负责Netflix的 Discovery & Personalization 算法和数据处理。
在 Netflix 之前,他在约翰霍普金斯大学医学院学习计算生物学,他的博士研究集中在神经科学系,利用机器学习模型预测药物的不良副作用。
他之前还在位于芝加哥的 Accretive Health 担任数据科学家,专注于与患者账单和转诊相关的数据。
采访的第一部分
这是我与他的采访的第二部分:
Anmol Rajpurohit: Q5. 数据科学如何帮助 Netflix 识别库存差距?Discovery & Personalization 团队是否向内容获取团队提供任何建议?
Joseph Babcock: 从某种意义上说,内容获取既是一门科学,也是一门艺术。虽然很难准确确定什么使得一个节目成为热门,但我们广泛使用分析来检查用户正在观看的内容,从而确定未来我们可能要优先考虑的授权内容。例如,构建预测即将推出的标题的受欢迎程度的模型,使用专家标记为内容分配元数据标签,以及我们的消费者科学部门进行的定性访谈会,将这些实证发现与客户反馈联系起来。
我们还广泛跟踪我们原创节目的现场表现,并结合我们的市场营销工作不断优化 Netflix 制作内容的投放。
AR: Q6. Netflix 中管理大数据最常用的工具和技术是什么?
 JB: 我们的大数据基础设施主要建立在亚马逊网络服务(AWS)上,特别是支撑我们 Hadoop 集群的 Simple Storage Service(S3)文件系统。生产 ETL 任务主要用 Pig 编写,Hive 用于临时分析,Presto 用于互动分析。我们还维护一个 Teradata 云实例,这是许多报告工具(如 Microstrategy 和 Tableau)的后台。
JB: 我们的大数据基础设施主要建立在亚马逊网络服务(AWS)上,特别是支撑我们 Hadoop 集群的 Simple Storage Service(S3)文件系统。生产 ETL 任务主要用 Pig 编写,Hive 用于临时分析,Presto 用于互动分析。我们还维护一个 Teradata 云实例,这是许多报告工具(如 Microstrategy 和 Tableau)的后台。
Hadoop 作业提交是通过一个内部开发的服务 Genie 来管理的,该服务在用户提交作业时抽象了集群配置的细节(它类似于向 Web 服务器提交 POST 命令)。除了 Genie,你还可以在 Github 上找到许多我们其他的大数据工具,如 Inviso(用于可视化集群负载和调试作业性能的中央仪表板)、S3mper(S3 一致性监视器)、Lipstick(一个我们广泛使用的 Pig 的可视化界面,用于共享和分析这些作业的数据)、PigPen(Pig 的 Clojure 封装)以及 Surus(用于数据科学任务(如模型评分和异常检测)开发的用户定义函数(UDFs)集合)。
AR: Q7. 在 Netflix,数据科学家垂直对齐到业务的不同方面,而不是集中式模型(如分析卓越中心)。您认为这种组织结构有什么优缺点?
 JB: 我认为这种方法的优点在于能够在特定的数据类型上开发深厚的专业知识,无论是外部营销数据、服务器端印象数据、搜索点击还是播放日志。每种数据都有其自身的细微差别,理解这些细微差别在我们的算法中开发信号时往往变得很重要。
JB: 我认为这种方法的优点在于能够在特定的数据类型上开发深厚的专业知识,无论是外部营销数据、服务器端印象数据、搜索点击还是播放日志。每种数据都有其自身的细微差别,理解这些细微差别在我们的算法中开发信号时往往变得很重要。
与任何形式的专业化一样,潜在的缺点是缺乏接触可能提供意外灵感的其他领域,但我认为我们定期的公司内部研讨会、全体员工会议和跨团队举措是有效的手段,可以在垂直领域之间传播这种学习。
AR: Q8. Netflix 现在有很多内部开发的软件已开源。您能描述一下开发 Genie、Lipstick 和 Quinto 的动机吗?
JB: 动机在于通过自动化实现规模化和自我赋能。在 Genie 的情况下,将作业提交的细节从特定集群配置中抽象出来,使我们能够灵活地扩展资源,以在计算资源需求变化时在后台处理作业提交,同时也帮助将我们运行的越来越异质的任务(Hive、Pig、Spark、Presto 等)与通用架构结合起来。
在 Lipstick 和 Quinto 的案例中,这些工具使审计和调试 ETL 作业变得更加‘自助’,而在过去我们可能需要挖掘 Pig 日志文件或编写临时的数据质量检查。像这些工具这样的自动化和用户友好的界面提高了我们的生产力,以应对处理和理解数据中越来越困难的问题。
采访的第三部分将很快发布。
相关:
-
前 20 名 Python 机器学习开源项目
-
与 IBM 大数据产品副总裁 Anjul Bhambhri 的采访
-
最佳大数据、数据科学、数据挖掘和机器学习播客
更多相关话题
采访:Pedro Domingos:大师算法,新型深度学习,对年轻研究者的宝贵建议
原文:
www.kdnuggets.com/2014/08/interview-pedro-domingos-master-algorithm-new-deep-learning.html
作者:Gregory Piatetsky,@kdnuggets,2014 年 8 月 19 日。
 这是我与 Pedro Domingos 教授的第二部分采访,他是机器学习和数据挖掘领域的领先研究者,获得了ACM SIGKDD 2014 创新奖,被广泛认为是数据挖掘/数据科学的“诺贝尔奖”。
这是我与 Pedro Domingos 教授的第二部分采访,他是机器学习和数据挖掘领域的领先研究者,获得了ACM SIGKDD 2014 创新奖,被广泛认为是数据挖掘/数据科学的“诺贝尔奖”。
这是第一部分:采访:Pedro Domingos,KDD 2014 数据挖掘/数据科学创新奖获奖者。
许多 Domingos 教授获奖的研究理念已经实现于可自由获取的软件中,包括
-
Alchemy: 统计关系 AI 的算法 alchemy.cs.washington.edu
-
VFML: 一个用于挖掘大数据源的工具包 www.cs.washington.edu/dm/vfml/
-
NBE: 一个具有非常快推理速度的贝叶斯学习器 www.cs.washington.edu/ai/nbe
-
BVD: 用于零一损失的偏差-方差分解 www.cs.washington.edu/homes/pedrod/bvd.c
-
RISE: 一个统一的规则和实例学习器 www.cs.washington.edu/homes/pedrod/rise.c
-
SPN: 用于可处理深度学习的和-积网络 spn.cs.washington.edu
要了解更多关于他研究的内容,可以查看他的一些被引用最多的论文,链接在Google Scholar和Citeseerx。
Gregory Piatetsky: 问题 7。你发表了一篇非常好的文章 "机器学习中值得了解的几件事",列出了 12 个关键观察点。你会为数据挖掘/数据科学添加几个额外的观察点吗?
Pedro Domingos: 是的!
-
数据要么是经过整理的,要么是衰退的;关注数据的管理和挖掘同样重要。
-
每一个数字都有其故事,如果你不知道这个故事,就不能信任这个数字。
-
模型应覆盖整体,而不仅仅是部分,否则你可能会错失重点。
-
通过层次分解来驯服复杂性。
-
你的学习器的时间和空间需求应该取决于模型的大小,而不是数据的大小。
-
你应该首先自动化的工作是你自己的;然后你可以在你挖掘一个任务的时间里挖掘一千个任务。
还有许多内容,我将在我的 KDD-2014 奖项演讲中进一步讨论其中的一些。
GP: Q8. 当你在 2013 年访问 MIT CSAIL 实验室时,你正在撰写一本新书。你能告诉我们这本书的情况吗?你作为访问科学家还做了其他哪些工作?
PD:这是一本关于机器学习和大数据的科普书籍,书名是《大师算法:机器学习与大数据革命》。
这本书几乎完成了,将在 2015 年出版。目标是为数据科学做一些类似于《混沌》对复杂性理论所做的事情,或者《自私的基因》对进化博弈理论所做的事情:以一种有趣和易于理解的方式向更广泛的受众介绍基本思想,并概述该领域丰富的历史、与其他领域的联系以及其影响。
现在大家都在使用机器学习和大数据,这些话题每天都出现在媒体上,我认为像这样的书籍是非常必要的。数据科学太重要了,不应只留给我们这些专家!每个人——市民、消费者、管理者、政策制定者——都应该对把数据转化为预测的神奇黑匣子内部运作有一个基本的了解。
 在 MIT,我与Josh Tenenbaum合作进行了一项联合研究项目。目标是能够从原始传感器数据出发,逐步获得对所处情况的高层次理解,马尔可夫逻辑作为将所有部分连接起来的粘合剂。Josh 是认知科学家,他在项目中的角色是带来心理学方面的想法。事实上,我休假的一个最有趣的部分是与计算机科学家、心理学家和神经科学家交流——从他们身上可以学到很多东西。
在 MIT,我与Josh Tenenbaum合作进行了一项联合研究项目。目标是能够从原始传感器数据出发,逐步获得对所处情况的高层次理解,马尔可夫逻辑作为将所有部分连接起来的粘合剂。Josh 是认知科学家,他在项目中的角色是带来心理学方面的想法。事实上,我休假的一个最有趣的部分是与计算机科学家、心理学家和神经科学家交流——从他们身上可以学到很多东西。
GP: Q9. 你目前正在研究哪些主要方向?
PD:我正在研究一种新型的深度学习,称为求和-积网络。SPN 具有多个隐藏变量层,因此具有与深度架构(如 DBM 和 DBN)相同的能力,但有一个重大区别:在 SPN 中,概率推断始终是可处理的; 这只需通过网络进行一次传递,避免了像马尔可夫链蒙特卡罗和循环信念传播等近似方法的所有困难和不可预测性。因此,学习本身(在这些深度模型中,推断作为一个子例程使用)也变得更容易、更具可扩展性。
SPN 中的“秘密调料”是网络的结构与条件概率计算的结构同构,其中有一个求和节点用于求和,和一个乘积节点用于乘积。
在其他深度模型中,推断是一个代价高昂的循环,你必须将其包裹在模型周围,这就是麻烦的开始。有趣的是,SPN 中的求和和乘积也对应于现实世界中的实际概念,这使得它们比传统的深度模型更具可解释性:求和节点表示类别的子类,乘积节点表示部分的子部分。因此,你可以查看一个用于识别人脸的 SPN,看看某个节点模型的是什么类型的鼻子,例如。
我还在继续研究马尔可夫逻辑网络,重点是将其扩展到大数据。我们的方法是使用可处理的马尔可夫逻辑子集,就像 SQL 是第一阶逻辑的可处理子集一样。
我们当前的一个项目是基于 Freebase、DBpedia 等数据,构建一个类似于 Google 知识图谱的东西,但更加丰富。我们称之为 TPKB - 可处理的概率知识库 - 它可以回答关于维基百科等中的实体和关系的问题。我们计划在网上发布一个演示版本,然后从用户的互动中学习。
GP: Q10. 大数据和机器学习是最热门的技术领域之一,许多数据挖掘和机器学习的研究者都参与了创业。你是否考虑过创业,为什么还没有创办公司?
 PD:这正是我妻子不断问我的问题。说真的,我确实认为我的未来有一个创业机会。我还没有行动的原因有两个。首先,我想做一个基于我研究的创业项目,而在过去十年里,我的研究相当长期。这意味着直到它准备好部署还有较长的过程,但希望当它准备好时,其影响也会更大。
PD:这正是我妻子不断问我的问题。说真的,我确实认为我的未来有一个创业机会。我还没有行动的原因有两个。首先,我想做一个基于我研究的创业项目,而在过去十年里,我的研究相当长期。这意味着直到它准备好部署还有较长的过程,但希望当它准备好时,其影响也会更大。
第二个相关原因,我想做一个至少有潜力改变世界的创业项目,而实现这一点需要许多条件的配合。我经常看到同事们创业时没有考虑到所有的非技术问题,这些问题比技术问题更为重要,这不是成功的秘诀。在数据科学领域,创业公司很少完全失败,因为公司被收购的价值很高,但如果最终仅仅如此,那么也许这并不是最好的时间利用方式。
GP: Q11. 对于“大数据”热潮,你的观点是什么?有多少是炒作,有多少是现实?现在是否存在机器学习的“热潮”?(注:Gartner 最新的“Hype Cycle”报告将“大数据”列在失望的低谷)。
PD:虽然有相当多的炒作,但从根本上说,大数据的热潮是非常真实的。我喜欢“蚂蚁军队”的比喻:并不是任何单一的大数据项目会极大地改变你的底线——尽管偶尔会发生——而是当你将所有数据分析能够带来改变的地方加起来时,它确实是具有变革性的。而且我们仍然只是触及了可以做的事情的表面。瓶颈确实是数据科学家的匮乏。
机器学习随着大数据的兴起而蓬勃发展,因为如果数据是燃料,计算是引擎,那么机器学习就是火花塞。
到目前为止,机器学习在行业或公众意识中还不如数据挖掘、数据科学、分析或大数据那样成为一种热门话题,但即便如此,这种情况也在改变。
我认为“机器学习”这个术语的生命周期比“数据科学”或“大数据”要长,这很好,因为在短期和长期都有进步的空间。
GP:Q12. 你会给对机器学习、数据挖掘、数据科学感兴趣的年轻研究者什么建议?
 PD:
PD:
在你做的每一件事中都要尽全力;逐步的研究不值得你的时间。
学习你能学到的一切,但不必完全相信其中的任何内容;你的工作是让这些东西变得过时。
不要被教科书中的所有数学吓倒;在这个领域,数学是数据的仆人,而不是相反。
听取数据——进行实验、分析结果、深入挖掘、跟进惊喜——是成功的途径。
如果你大多数时间都不感到困惑和挣扎,那么你正在解决的问题可能太简单了。
与来自多个公司或行业的人不断交谈,并尝试找出他们共同的问题。这样你就知道,如果你解决了其中一个问题,你会有很大的影响。
广泛阅读,但要关注你关心的研究问题;最大的洞察力往往来自将之前分开的事物结合起来。
以明天的计算能力为目标,而不是今天的。
警惕黑客攻击;一个黑客的方案看起来聪明,但它正好是通用解决方案的对立面。
复杂性是你最大的敌人。一旦你觉得自己解决了一个问题,就抛弃这个解决方案,想出一个更简单的方案,然后再试一次。
当然,要玩得开心——没有哪个领域比这个更具乐趣。
GP:Q13. 在离开电脑的时候你喜欢做什么?最近读过什么书并喜欢它吗?
PD:我喜欢读书和听音乐。我是一个电影迷,喜欢旅行。我的所有这些爱好都很杂乱无章。我还是一个游泳者和长跑运动员。最重要的是,我会花时间和家人在一起。
我最近读过的一本引人入胜的书是 
在虚构类书籍中,我最近读过的最好的书可能是 《路》,作者是科马克·麦卡锡。这本书讲述了一位父亲和他的儿子在后末日世界中挣扎求生的故事,书中充满了力量和难以忘怀的情感。
简历: 佩德罗·多明戈斯 是华盛顿大学计算机科学与工程系的教授。他的研究兴趣包括机器学习、人工智能和数据挖掘。他在加州大学欧文分校获得信息与计算机科学博士学位,并且是 200 多篇技术论文的作者或合著者。
他是《机器学习》期刊的编辑委员会成员,国际机器学习学会的共同创始人,以及 JAIR 的前副主编。他曾担任 KDD-2003 和 SRL-2009 的程序联合主席,并在多个程序委员会中任职。他是 SIGKDD 创新奖的获得者,这一奖项是数据挖掘领域的最高荣誉。他还是 AAAI 会士,获得过斯隆奖学金、NSF CAREER 奖、富布赖特奖学金、IBM 教员奖,并在几个领先会议上获得了最佳论文奖。
相关:
-
采访:佩德罗·多明戈斯,KDD 2014 数据挖掘/数据科学创新奖得主
-
数据挖掘/数据科学“诺贝尔奖”:ACM SIGKDD 2014 创新奖颁给佩德罗·多明戈斯
-
佩德罗·多明戈斯:关于机器学习你需要知道的一些有用知识
-
在哪里学习深度学习 - 课程、教程、软件
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关话题
数据科学面试问题 – 三个案例面试示例
原文:
www.kdnuggets.com/2019/04/interview-questions-data-science.html
评论
凯瑟·丰,创始人,首席分析准备
在第一部分中,我描述了“批判性思维”的两个方面,许多数据科学招聘经理认为这是他们最期望的技能。为了测试批判性思维,招聘经理使用案例面试。案例面试在管理咨询公司中长期受到欢迎;它们涉及求职者与招聘经理之间关于商业问题的自由对话——在数据科学面试的情况下,商业问题预计将通过数据驱动的见解来解决。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域

案例面试让许多从未见过没有答案的测试的毕业生感到害怕。在行业中,任何值得解决的问题都没有答案。批判性思维是公式化思维的对立面。掌握案例面试的最佳方法是练习、练习、再练习。
我为你设置了三个示例案例面试进行练习。找一些朋友,协作完成答案。五个人的情况下,你的答案应该涵盖大多数可能性。然后找一个愿意给你反馈的招聘经理。记住:你不仅被评判内容,还被评判展示方式。
-
大学招生丑闻
-
想象你是一名数据科学家,被招募来帮助检测大学招生过程中的欺诈行为。在本次对话中,我们将重点讨论大学申请表中提交的虚假信息,无论是夸大的 GPA、虚构的体育成就、伪造的社区服务成就,还是其他类型的伪造。
-
你将建立一套欺诈检测模型。告诉我你的第一个模型将做什么,以及你为什么选择它作为第一个模型。
-
想象一下我是一名招生主任。告诉我为什么我应该为你的模型买单。
-
你需要什么训练数据来运行该模型?你将从哪里以及如何获得这些数据?
-
-
Lyft IPO
- 你正在建议一个朋友,他正在考虑 (a) 为 Lyft 开车还是 (b) 开黄色出租车。解释一下你如何比较这两种选择的盈利性。
-
Blue Apron IPO 后
- 在 2018 年第二季度,餐食包送货公司 Blue Apron 报告称,约有 70 万名客户,同比下降 24%,而每位客户的收入为 250 美元,同比略降 1 美元。 https://investors.blueapron.com/press-releases/2018/08-02-2018-120246005
高级管理层急于遏制客户流失。你的任务是找出客户流失的原因。
-
提出 5 个假设,解释为什么客户数量急剧下降。
-
选择其中一个假设,并描述你如何验证它。
-
假设你能够验证这个假设,解释一下你会推荐什么来扭转客户流失。
让我回答三个不可避免的问题。
答案钥匙在哪里?
如果你在寻求答案钥匙,你就错过了案例面试的要点。案例面试的设计是开放式的。如果这些问题有答案钥匙,那么它们对评估批判性思维就没有用处。招聘经理关注的是你如何解决问题和结构分析。
我怎么知道我有一个好的答案?
在一些朋友,或者更好的,一个招聘经理那里尝试你的答案。然后,再试一次。如果你做得对,这些不同的尝试应该会走不同的路径,因为面试问题是开放式的。
没有足够的信息来得出结论。
这正是每个现实世界的数据问题的情况。你永远没有足够的数据或所有正确的数据,这意味着你需要做出合理的假设,并继续前进。一个好的案例面试是一个对话——你通过向面试官提问来收集更多信息。
简介: Kaiser Fung 是 Principal Analytics Prep 的创始人,该公司是领先的数据分析训练营;《Numbers Rule Your World》的畅销书作者;以及 Junk Charts (www.junkcharts.com) 的作者,该博客专注于数据可视化。
Twitter: @junkcharts
Youtube: bitly.com/fungwithdata-1
资源:
相关:
更多相关话题
独家:对强化学习之父 Rich Sutton 的采访
原文:
www.kdnuggets.com/2017/12/interview-rich-sutton-reinforcement-learning.html
评论 我在 1980 年代遇见了 Rich Sutton,那时他和我都是刚获得博士学位的新人,我们一起加入了位于波士顿地区的 GTE 实验室。我在研究智能数据库,而他则在强化学习部门工作,但我们的 GTE 实验室项目离实际应用还很远。我们经常下棋,我们大致平手,但在机器学习方面,Rich 远远领先于我。Rich 既是一个杰出的研究人员,也是一个非常友好和谦逊的人。他在下面的采访中提到,“强化学习”的想法很明显,但从有想法到发展成一个具有数学基础的实际理论之间还有很大的距离,而这正是 Rich 和 Andrew Barto(他的博士生导师)为强化学习所做的工作。强化学习在 AlphaGo Zero 的成功中扮演了重要角色,如果人工通用智能(AGI)在某个时点被开发出来,强化学习可能会在其中发挥重要作用。
目前是 计算机科学教授,担任艾伯塔大学的 iCORE 主席,并且是 DeepMind 的杰出研究科学家。他是 强化学习(RL)的创始人之一,强化学习在机器学习和人工智能中越来越重要。他在 RL 领域的重要贡献包括 时间差分学习 和策略梯度方法。他是一本广受好评的书籍(与 Andrew Barto 合著) 《强化学习导论》 的作者,该书被引用超过 25,000 次,第二版即将发布。
他在斯坦福大学获得心理学学士学位(1978 年),并在马萨诸塞大学阿默斯特分校获得计算机科学硕士(1980 年)和博士学位(1984 年)。他的博士论文题为“强化学习中的时间信用分配”,在论文中他引入了演员-评论家架构和“时间信用分配”。
从 1985 年到 1994 年,萨顿在 GTE 实验室担任技术员工首席成员。随后,他在 UMass Amherst 担任高级研究科学家 3 年,之后在 AT&T 香农实验室担任首席技术员工 5 年。自 2003 年起,他在阿尔伯塔大学计算科学系担任教授和 iCORE 主席,领导强化学习与人工智能实验室(RLAI)。自 2017 年 6 月起,萨顿还共同领导了DeepMind 在阿尔伯塔的新办公室。
Rich 还在incompleteideas.net上维护一个博客/个人页面。
Gregory Piatetsky: 1. 强化学习(RL)的主要思想是什么?它与监督学习有何不同?
典型的 RL 场景是:一个代理在环境中采取行动,环境将这些行动解释为奖励和状态表示,这些奖励和状态表示反馈给代理。
来源:维基百科Rich Sutton: 强化学习是通过试错学习从奖励中获得知识,这与自然学习过程非常相似,而与监督学习不同,后者只在有监督或教学信号的特殊训练阶段进行学习,而这种信号在正常使用过程中是不可用的。
例如,语音识别目前通过监督学习完成,使用大量的语音样本及其正确的文字转录。这些转录是监督信号,在新的语音样本到来时无法获得。另一方面,游戏通常通过强化学习完成,使用游戏结果作为奖励。即使你玩一个新游戏,你也能看到自己是赢还是输,并可以利用强化学习算法来改进你的游戏表现。监督学习的方法则需要“正确”动作的示例,比如来自人类专家的示例。这当然是有用的,但在正常游戏中无法获得,并且会将学习系统的技能限制在专家的水平。强化学习则使用较少的信息性训练数据,这些数据更为丰富且不受监督者技能的限制。
GP: 2. 与安德鲁·巴托合著的经典书籍《强化学习:导论》的第二版即将出版(何时?)。第二版中涉及了哪些主要的进展?能否告诉我们关于强化学习与心理学(第十四章)和神经科学(第十五章)之间有趣联系的新章节?
RS: 第二版的完整草稿目前已经完成。
在网络上可以找到。Andy Barto 和我正在做一些最后的修订:验证所有参考文献,等等。它将在明年初以纸质形式印刷。
自从第一版发布以来,强化学习在过去二十年中发生了很多变化。其中最重要的可能是强化学习思想对神经科学的巨大影响,现在标准的脑奖励系统理论认为它们是时间差学习的一个实例(强化学习的基本学习方法之一)。
目前的理论认为,多巴胺这种神经递质的主要作用是传递时间差错,也称为奖励预测误差。这是一个巨大的发展,有很多来源、影响和测试,我们在书中的处理只能做简要总结。这些和其他发展在第十五章中进行了介绍,第十四章总结了它们在心理学中的重要前身。
总的来说,第二版比第一版大约大了三分之二。现在有五章关于函数近似的内容,而不是一章。新增了两章关于心理学和神经科学的内容。还有一章关于强化学习的前沿,包括社会影响的一部分。书中的所有内容都得到了更新和扩展。例如,新应用章节涵盖了 Atari 游戏玩法和 AlphaGo Zero。
GP: 3. 什么是深度强化学习——它与强化学习有何不同?
RS: 深度强化学习是深度学习和强化学习的结合。这两种学习方法解决了大相径庭的问题,并且结合得很好。简而言之,强化学习需要从数据中近似函数的方法来实现其所有组件——价值函数、策略、世界模型、状态更新器——而深度学习是最近开发的、最成功的函数近似器。我们的教科书主要介绍线性函数近似器,并给出了一般情况的方程。我们在应用章节和一个部分中介绍了神经网络,但要完全了解深度强化学习,还需补充如深度学习书籍 by Goodfellow, Bengio, and Courville 的内容。
GP: 4. RL 在游戏中取得了巨大成功,例如 AlphaGo Zero。你期待 RL 在其他哪些领域表现良好?
RS: 嗯,当然我相信在某种意义上强化学习是人工智能的未来。强化学习最能代表一个智能系统必须能够自主学习,没有持续监督的想法。人工智能必须能够自己判断对错。只有这样,它才能扩展到真正大量的知识和通用技能。
GP: 5. Yann LeCun 评论称 AlphaGo Zero 的成功很难推广到其他领域,因为它每天玩数百万场游戏,但你无法让现实世界的速度快于实时。当前强化学习不成功的地方(例如当反馈稀疏时)以及如何解决这个问题?
RS: 正如 Yann 会立刻同意的那样,关键是从普通的无监督数据中学习。我和 Yann 也会同意,我认为,近期的重点将是关注"预测学习"。预测学习可能很快会成为一个热门词汇。它的意思正如你所想,即预测将发生什么,然后基于实际发生的事情进行学习。因为你从发生的事情中学习,所以不需要监督者告诉你应该预测什么。但因为你只是等待事情发生,你实际上有一个监督信号。预测学习就是无监督的监督学习。预测学习可能会在应用方面取得重大进展。
唯一的问题是你是否希望将预测学习更多地看作是监督学习或强化学习的衍生物。强化学习的学生知道强化学习有一个主要的子问题,称为“预测问题”,解决这个问题的效率是算法工作的重点。实际上,第一篇讨论时序差分学习的论文题为《通过时序差分方法学习预测》。
GP: 6. 当你在 1980 年代研究强化学习时,你是否认为它会取得如此成功?
RS: 在 1980 年代,强化学习确实过时了。它基本上不存在作为一个科学或工程思想。但它仍然是一个显而易见的思想。对心理学家来说显而易见,对普通人来说也显而易见。因此,我认为它是值得研究的,并且最终会被认可。
GP: 7. 强化学习的下一步研究方向是什么?你现在在做什么?
RS:除了预测学习,我认为下一步重大进展将是当我们拥有能够以学习到的世界模型进行规划的系统时。目前,我们有出色的规划算法,但仅在模型被提供时,如所有游戏系统中所见,模型由游戏规则(以及自我对弈)提供。然而,我们没有现实世界的游戏规则的类似物。我们需要物理定律,但我们还需要知道无数其他的事情,从如何走路和看东西到其他人如何回应我们的行为。我们教科书第八章中的 Dyna 系统描述了一个集成的规划和学习系统,但它在几个方面有限。第十七章概述了可能克服这些限制的方法。我将从那里开始。
GP: 8. 强化学习可能是发展人工通用智能(AGI)的核心。你怎么看?研究人员会在可预见的未来开发出 AGI 吗?如果会,它会对人类带来巨大好处,还是像埃隆·马斯克警告的那样,对人类构成生存威胁?
RS: 我认为人工智能是通过创造类似人类的事物来理解人类思维的尝试。正如费曼所说,“我不能创造的,我无法理解”。在我看来,主要事件是我们即将第一次真正理解思维。这种理解本身将产生巨大影响。这将是我们时代,实际上是任何时代最大的科学成就。它也将是所有时代人文学科的最大成就——在深层次上理解我们自己。从这个角度来看,将其视为坏事是不可能的。确实具有挑战性,但不是坏事。我们将揭示真相。那些不希望这成为现实的人将把我们的工作视为坏事,就像科学摒弃了灵魂和精神的观念时,那些持有这些观念的人将其视为坏事一样。毫无疑问,我们今天所珍视的一些观念将在我们更深刻理解思维如何运作时面临类似的挑战。
我认为人工智能是通过创造类似人类的事物来理解人类思维的尝试。正如费曼所说,“我不能创造的,我无法理解”。在我看来,主要事件是我们即将第一次真正理解思维。这种理解本身将产生巨大影响。这将是我们时代,实际上是任何时代最大的科学成就。它也将是所有时代人文学科的最大成就——在深层次上理解我们自己。从这个角度来看,将其视为坏事是不可能的。确实具有挑战性,但不是坏事。我们将揭示真相。那些不希望这成为现实的人将把我们的工作视为坏事,就像科学摒弃了灵魂和精神的观念时,那些持有这些观念的人将其视为坏事一样。毫无疑问,我们今天所珍视的一些观念将在我们更深刻理解思维如何运作时面临类似的挑战。
关于人工智能对社会影响的更多信息,我建议读者查看我们教科书的最后一部分以及我在这个视频中的评论(https://www.youtube.com/watch?v=QqLcniN2VAk)
GP: 9. 当你远离电脑和智能手机时喜欢做什么?最近读过并喜欢的书是什么?
RS:我热爱自然,并且是哲学、经济学和科学中的思辨性思想的学生。我最近阅读并喜欢了尼尔·斯蒂芬森的《七个世界》、尤瓦尔·赫拉利的《人类简史》以及 G·爱德华·格里芬的《杰基尔岛的生物》。
相关:
更多相关话题
采访:文斯·达利,King.com 谈休闲游戏背后的严肃分析
原文:
www.kdnuggets.com/2015/03/interview-vince-darley-king-analytics-gaming.html
 文斯·达利是King的副总裁数据分析与商业智能部门,King 是一家领先的互动娱乐公司,专注于移动世界,创造了如《糖果传奇》等游戏。King 于 2014 年 3 月在纽约证券交易所上市(NYSE: KING)。
文斯·达利是King的副总裁数据分析与商业智能部门,King 是一家领先的互动娱乐公司,专注于移动世界,创造了如《糖果传奇》等游戏。King 于 2014 年 3 月在纽约证券交易所上市(NYSE: KING)。
在数据科学领域拥有超过 17 年的经验,文斯在 King 公司监督一个团队,处理所有与分析和商业智能相关的方面,包括下游和上游数据管道、数据仓库、实时和批量报告、细分和实时分析——这些信息在整个业务中用于改善玩家体验。
文斯拥有哈佛大学复杂系统的硕士学位和博士学位,以及剑桥大学数学学士学位。他还是一位出版作者,曾共同撰写《NASDAQ 市场模拟:从复杂适应系统科学中获得的主要市场洞见》。
这是我与他的采访:
安莫尔·拉杰普罗希特: Q1. 您处理的游戏和玩家数据的主要特征是什么?从这些数据中获取可操作见解的主要挑战是什么?
 文斯·达利:我们的大多数数据关注玩家在游戏关卡中的尝试——例如分数、星级、时间戳、玩家是否成功或失败,以及导致玩家失败的因素。我们还跟踪玩家对朋友的帮助——例如发送生命或移动——最后,还包括任何财务交易。
文斯·达利:我们的大多数数据关注玩家在游戏关卡中的尝试——例如分数、星级、时间戳、玩家是否成功或失败,以及导致玩家失败的因素。我们还跟踪玩家对朋友的帮助——例如发送生命或移动——最后,还包括任何财务交易。
我们游戏的一个重要特点是你可以随时随地在任何设备上玩。从数据角度来看,这可能会带来挑战,因为我们需要仔细整合非常多样的数据和标识符,以创建一个清晰的个体玩家画像。这可能很困难,因为数据量(每天 10-20 亿事件)很大,而且数据(正如所有大数据一样!)是嘈杂的。
但正确处理这些数据非常重要——购买新设备来玩游戏(因此旧设备上玩得不多)和对游戏失去兴趣且几乎不在唯一设备上玩的玩家之间有很大区别。其次,我们当然只是观察行为,但为了使见解具有实际操作性,我们需要推测关于玩家的动机/心理状态,以便采取正确的行动。这是很困难的!
AR: Q2. 在 King 公司,机器学习和预测分析的最常见用例是什么?
VD: King 真的很关心长期视角,因此最常见的情况是预测或建模游戏/网络功能变更对特定玩家群体的长期客户生命周期价值影响。
另一个常见但非常困难的情况是预测玩家将会停止游戏。这很困难,因为只有在我们能够非常早期地预测到这一点时才有用,例如当玩家仍在玩游戏时。
AR: Q3. 在基础设施方面,你们是如何调整数据架构以应对数据的快速增长的?从中有什么重要的经验教训?
VD: 在过去 3-4 年里,我们不得不进行多次调整。 第一次重大变化发生在我们的游戏在 Facebook 平台上取得成功时,我们启用了 Hadoop 以便能够扩展到数百万玩家。Hadoop 在我们经历了 Saga 游戏的爆炸性增长,以及在移动端成功地服务于数亿玩家的过程中表现良好,作为一种相对便宜、有效的“超级油轮”处理今天 2 PB 的压缩数据。我称之为“超级油轮”,因为 Hadoop 是庞大的、坚固的,但不是非常灵活。
第一次重大变化发生在我们的游戏在 Facebook 平台上取得成功时,我们启用了 Hadoop 以便能够扩展到数百万玩家。Hadoop 在我们经历了 Saga 游戏的爆炸性增长,以及在移动端成功地服务于数亿玩家的过程中表现良好,作为一种相对便宜、有效的“超级油轮”处理今天 2 PB 的压缩数据。我称之为“超级油轮”,因为 Hadoop 是庞大的、坚固的,但不是非常灵活。
因此,一年多前我们在 Hadoop 旁边添加了 Exasol 系统——这是一种非常快速的内存分析数据库——并且使我们的核心处理(例如 ETL)可以更快地完成——将夜间处理时间从 8-12 小时减少到 1-2 小时。这些经验教训很重要。
 首先,在我们的规模下(截至 2014 年第 4 季度的 1.49 亿日活跃用户),没有一种解决方案适合所有情况——需要像我们 Hadoop/Exasol 组合这样的混合解决方案。其次,我们最近让我们的 Hadoop 集群填满得有些过头了,这让它变得意外脆弱。最好留出足够的余量。
首先,在我们的规模下(截至 2014 年第 4 季度的 1.49 亿日活跃用户),没有一种解决方案适合所有情况——需要像我们 Hadoop/Exasol 组合这样的混合解决方案。其次,我们最近让我们的 Hadoop 集群填满得有些过头了,这让它变得意外脆弱。最好留出足够的余量。
在 BI 方面,我们已经使用 QlikView 进行标准化报告多年,这通常效果良好。在我们拥有数百万的历史玩家(其中约有 3.56 亿月活跃用户)的大规模环境下,构建报告以便我们能够快速按 cohort、国家、游戏、细分、获取渠道、平台进行切片和切块可能会遇到问题。QlikView 有时会感觉有点迟缓,并且它的自我感知能力不强(即,它令人惊讶地不提供很多关于监控业务用户报告延迟、加载时间、响应时间等的支持)。但总体而言,我们对它的优缺点与市场上其他东西的比较感到满意。
我们所有的数据基础设施都是内部建设的,尽管我们保持对云服务动态的关注。
AR: Q4. A-B 测试常见的问题是什么?你们有什么建议来避免/减轻这些问题?
VD: 好吧,我可以讲上几个小时关于 A-B 测试的内容,所以我们来关注几个核心难点。首先,在我们这个行业(免费游戏),几乎所有的指标都是非常偏斜/长尾的——这意味着少量的玩家很容易扭曲分析结果。其次,我们希望玩家在多个设备上有一致的体验,这使得测试变得复杂。第三,有时效果/影响是微妙的,因此我们可能需要运行实验相当长的时间才能得到确凿的结果。第四,我们希望从一个游戏中学到的东西能够足够有洞察力,以便对其他游戏的决策提供信息,但设计能够告诉你有关特定游戏的 AB 测试比设计能够告诉你关于玩家的测试要容易得多。
建议?雇佣一些优秀的数据科学家来处理统计学的微妙之处!决定你是否需要了解并准确量化“答案”,还是只需足够自信地做出合理决策——这将帮助你决定何时进行短期或长期实验。最后,在实验设计阶段专注于玩家及其体验,而不是仅仅考虑“特性 A 或特性 B 是否能给我更好的指标?”。
访谈第二部分
相关:
-
文斯·达利谈如何成为顶级收入游戏
-
机器学习元素表解码
-
做机器学习时的 7 个常见错误
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
数据科学管理者入门
原文:
www.kdnuggets.com/2018/11/intro-data-science-managers.html
评论
由 ActiveWizards 提供

我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
数据科学已经成为许多现代项目和业务的不可或缺的一部分,越来越多的决策现在依赖于数据分析。数据科学行业正经历严重的 人才短缺,不仅是数据科学家,还有一些了解分析和数据科学的管理者。作为一名经理,你最终可以成为公司数据使用的专家,为组织的发展创造机会。无论你是与数据科学团队合作,作为数据驱动业务的一部分,还是对实施数据科学解决方案感兴趣,你都应具备一定的数据知识,并理解其在组织中的能力。
数据科学是一个极其广泛且复杂的学科,涵盖了计算机科学、数学和统计学,并且是一个需要理解数据来源的知识领域:医疗、金融、网络及其他领域。
以下思维导图包含了对关键数据科学概念和技术的简明介绍,这些概念和技术已经彻底改变了商业格局,并且成为了做出有益数据驱动决策的必要条件。我们相信,这将对数据科学管理者以及面临这一快速发展领域的客户或用户都非常有用且信息丰富。
原始思维导图可以在 这里 找到。
让我们更详细地了解一下。我们思维导图的分支按照特定方式分组。在中心,有两个基础知识部分,任何数据科学项目都是基于这两个部分建立的,即数学和统计学以及编程语言。
既然我们谈论的是基于数据的科学,很明显这里的基本知识之一是数学。机器学习中的每一个算法都是基于数学原理的,理解线性代数、概率论和经典统计学的基础是必要的。
向前看,所有那些巨大的计算和不同算法的实现以及数据科学任务的解决,都是通过各种编程语言实现的。作为经理,你不需要知道如何编写算法或理解每种语言的所有细节,但你必须理解哪些语言可以实现特定任务,它们的适用性,以及它们的优缺点。
思维导图的整个右侧直接与数据科学领域相关。这是一个广泛的概念,结合了三个非常大的领域:机器人技术、机器学习和强化学习,并进一步细分这些领域。此时经理的主要任务是了解机器学习的一般算法,它们可以应用于哪些行业,以及它们可以解决哪些用例。
思维导图的左侧涵盖了数据科学的支持领域:数据存储、数据工程、大数据、数据分析、可视化和商业智能(BI)。它们有助于清理、处理、转换和表示数据,并从不同角度分析数据,从而补充不同的机器学习任务。
数据科学依赖于创建和使用数据,这些数据必须在需要时随时可用。这正是数据存储的目的。数据存储是一种以方便的形式归档数据的技术。你应该了解 SQL 和 NoSQL 数据库之间的基本区别,为什么需要云服务,哪些服务提供了更方便和易于理解的界面,你为特定任务需要什么以及其他细节。
数据工程的主要目的是将数据转换为易于分析的格式。任何数据操作都需要对数据进行一些预处理,而数据的质量转换和处理在项目的成功中往往扮演着关键角色。大致来说,数据工程的主要操作包括数据抓取、数据摄取和数据清洗。
此外,在处理数据科学任务时,您经常需要处理传统数据处理工具和仪器无法处理的大量数据集。这时,大数据解决方案就显得尤为重要。除了处理大量数据外,大数据还有一些其他特定特征,即能够处理快速到达并不断增加的数据量,以及能够并行处理结构化和非结构化数据的能力。
数据分析是获取数据集信息并发现特定见解的过程。它旨在寻找输入参数之间的各种依赖关系。数据分析是公司营销、财务、业务管理等领域的一个不可或缺的部分。
最后,数据需要理解、解释和说明。每个与数据打交道的人都认识到BI和可视化工具在展示代码隐藏信息和使其可见方面的重要性。每个人对视觉信息的感知更好且更快,因此它是每个分析和数据科学项目的一个重要组成部分。对客户和开发者都有好处,它绝对应该在数据经理的工具箱中。
结论
当然,每个分支可以进一步扩展和细分,这不是终极真理,而是我们尝试展示的视角,反映了数据科学发展的现状。
数据科学是一个复杂而广泛的领域,因此无法突出单一最重要的分支。但现在,您应该对现代数据科学领域的主要组成部分及其相互关系有了大致的了解,这将是扩展您在该领域知识的一个良好开端。
如果您对这个话题有额外的想法和意见,请在下面的评论区分享。
另外,如果您有一些特定领域希望更详细地覆盖,请告知我们。
ActiveWizards 是一个专注于数据项目(大数据、数据科学、机器学习、数据可视化)的数据科学家和工程师团队。核心专业领域包括数据科学(研究、机器学习算法、可视化和工程)、数据可视化(d3.js、Tableau 等)、大数据工程(Hadoop、Spark、Kafka、Cassandra、HBase、MongoDB 等)以及数据密集型 Web 应用开发(RESTful APIs、Flask、Django、Meteor)。
原文。经许可转载。
相关内容:
-
2018 年数据科学的前 20 个 Python 库
-
2018 年数据科学的前 20 个 R 库
-
顶级 6 种 Python NLP 库的比较
相关话题
基于高中知识的机器学习和 AI 简介
评论
介绍
今天,人工智能(AI)无处不在。
然而,这是一个复杂的主题,无论是教学还是学习。
在本文中,我概述了一种方法,通过仅凭高中知识,你可以了解人工智能、机器学习(ML)和深度学习(DL)。本文后半部分基于简单的高中数学——这应该在 GCSE 水平(15 岁左右)时比较熟悉。即使数学对你不熟悉,你仍然可以通过本文的前半部分了解机器学习和人工智能。
背景
任何关于 AI 的讨论通常会引发‘终结者’类型的讨论(机器人是否会接管人类?)。虽然媒体对 AI 感到兴奋,但现实却更加平淡。所以,在继续之前,让我们考虑一下本文将采用的一些定义。
-
人工智能: 指能够以某种程度的自主性进行推理的机器。
-
广义人工智能: 涉及那些几乎具有完全自主性的机器。广义人工智能确实是科幻小说中的内容(因此不是本文的重点)
-
狭义人工智能: 指的是能够在特定背景下学习任务的机器或系统——例如——一个能够自主(无需明确训练)拾取和排序物品的机器人手臂。
-
机器学习: 具有正式定义。汤姆·米切尔 将机器学习定义为:“机器学习领域关心的问题是如何构造能够随着经验自动改进的计算机程序。” 这个定义可以表达为:“一个计算机程序被认为是从经验(E)中学习的,涉及某一任务类别(T)和性能测量(P),如果其在任务 T 中的表现(通过 P 测量)随着经验(E)的增加而提高。”。机器学习被应用于多种场景,如垃圾邮件检测、信用卡欺诈检测、客户细分等。
-
深度学习: 我们将深度学习定义为“具有自动特征检测的机器学习应用程序。” 我们将在下文中更详细地解释这个定义。
什么是学习?
让我们从问题开始:“什么是学习?(在机器学习的背景下)”
在米切尔的定义中,我们将‘学习’一词解释为获得执行任务的能力。例如,如果我们想让系统识别一个对象,那么识别对象的能力就是任务。为了获得这种能力,我们可以采取两种对立的方法:
-
我们可以显式地编写规则来识别特定对象,或者
-
我们可以编程系统,使其通过训练过程学习识别对象的能力。
前者(基于规则的方法)在实际中不可行,因为我们必须手动编写所有可能场景的规则。因此,另一种极端的方法更具可行性。我们可以从数据中发现规则,而不是手动创建规则,然后将这些规则应用于未见过的问题。这种从训练数据集中学习的想法是大多数机器学习方法的基础(监督学习)。训练过程包括向系统提供一组示例,这些示例代表了感兴趣的特征集合。从这些示例中,系统创建一个模型——这个模型随后用于识别未见过的对象。在这种情况下,模型的简化定义是一个在数据集上训练的算法(例如:分类算法)。
以预测房价为例。房价可能受到许多因素(特征)的影响,例如卧室数量、靠近学校、靠近公共交通等。基于这些特征预测房价就是结果。这些特征是监督学习模型的输入,它可以预测房价(结果变量)。机器学习解决的问题类型包括:
-
分类:数据被分配到一个类别——例如垃圾邮件/非垃圾邮件或欺诈/非欺诈等。
-
回归:预测数据的值——例如预测股票价格、房价等。
最后,我们如何知道系统是否能执行给定任务?要测试模型的性能,我们必须使用特定于任务的定量度量来评估其输出。对于分类任务,模型的性能可以通过分类的准确率来衡量。
深度学习
那么,这与人工智能和深度学习有什么关系?记住,我们将深度学习描述为“自动特征检测”。让我们重新考虑预测房价的例子。为了确定算法的特征(例如:卧室数量、靠近优质学校等),你需要了解应用领域(领域知识)。对于复杂的应用——例如在医疗保健、基因组学等领域,领域知识可能难以获得且成本高昂。此外,使用图像、视频、序列或音频数据的应用使用层次特征。人类检测这些特征是不切实际的。
如果我们能够理解数据的结构和特征(即:在没有人工干预的情况下跟踪数据的基本表示),会怎样?
这种能力是通过一组称为表示学习的机器学习技术实现的。表示学习是一组方法,允许机器处理原始数据,并自动发现分类等算法所需的表示。
深度学习方法可以被归类为表示学习方法,这些方法具有多个表示层。这些层从原始输入开始,每一层将数据转换为更高级别的表示——作为下一层的输入。例如,最低层可能检测像素;下一层可能从像素中检测图像的边缘;再下一层可能基于边缘检测轮廓,等等。因此,神经网络中的每一层都基于前一层的表示。通过许多这样的简单变换,机器可以学习复杂的层次性概念。神经网络模型的高级表示可以区分概念的微小变化,即相似但不完全相同的概念。例如,网络可以区分狼和“看起来像狼的狗”(哈士奇、萨摩耶和德国牧羊犬)。同样的技术可以应用于实际问题,如肿瘤检测和其他数据类型——例如——面部检测或基因组数据。
更一般来说,深度学习技术用于处理非有限域的问题。例如,国际象棋是一个有限域的问题,因为国际象棋有 64 个格子,每个棋子都有一个定义好的动作。相比之下,从一张图片中识别狗对一个孩子来说很容易。但计算机不能轻易地从一张狗的图片中识别狗。识别狗的图片不是有限域的问题,因为在图片中有许多类型的狗,配置各异(例如:有项圈、尾巴被剪短等)。
为了总结这个观点,人工智能主要基于深度学习技术。
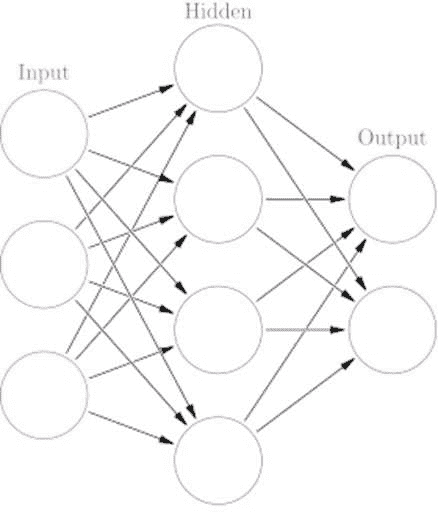
建模作为函数估计
我们现在可以基于基础数学来解决这个问题。
我们在上一节介绍的建模过程包括找到一个表示数据的函数(例如,预测房价的函数)。该函数可以表示为一个方程,并用于对未知数据进行预测。拟合模型的过程包括让算法学习预测变量(特征)与结果之间的关系。一旦算法确定了特征与结果变量之间的功能关系,它就可以预测未知特征的结果变量值。因此,最佳拟合的算法具有参数,这些参数能够最好地描述当前问题,并且能够对未见的数据点进行预测。当然,模型的强大之处在于对未见数据进行预测。
建模是一个迭代过程。最初涉及使用像散点图这样的机制找到变量之间的趋势和关系。有些关系是可以预测的;例如,年龄和经验是相关的。
线性回归
在最简单的情况下,该函数是线性的,如线性关系所示。
什么是线性关系?
线性关系意味着你可以用一条直线表示两个变量集之间的关系。线性关系可以表示许多现象。例如,拉伸橡皮筋所涉及的力是线性关系,因为更大的力会导致橡皮筋的拉伸量成比例增加。我们可以用线性方程来表示这种关系:
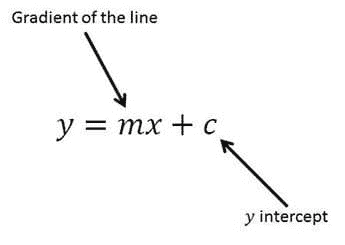
其中“m”是直线的斜率,“x”是直线上的任何点(输入或 x 值),而“c”是直线与 y 轴的交点。在线性关系中,自变量的任何变化都会导致因变量的相应变化。线性回归用于预测许多问题,如销售预测和分析客户行为。
该关系可以表示如下:
为什么从线性回归开始?
因为这是一个许多人甚至在高中水平上都熟悉的概念,并且它也允许我们将思维扩展到更复杂的想法。拟合模型的过程旨在找到参数 m 和 c 的最佳值。我们识别出一条最符合现有数据点的直线。一旦我们拟合了模型,我们可以根据输入(x 轴)来预测结果(y 轴)。模型训练涉及寻找参数,以便模型最符合数据。预测值和观察值之间的总误差最小的直线称为最佳拟合线或回归线。
在如上所述的普通最小二乘(OLS)线性回归中,我们的目标是找到最小化垂直偏移的直线(或超平面)。换句话说,我们将最佳拟合线定义为最小化平方误差总和(SSE)的线。
图:普通最小二乘回归。图片来源。
在这种情况下,需要最小化的总误差是
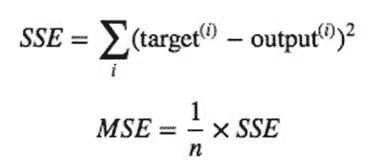
图:平方误差总和。
相同的概念可以扩展到多个特征。实际上,对于房价示例,我们已经在使用多个特征(x 值)来预测结果(y 值),即房价。因此,方程由 y = mx + c 变为如下形式:
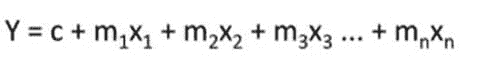
因此,可以使用基础的 GCSE 数学来理解构建和训练模型的基本原理。
结论
在这篇文章中,我们探讨了如何使用基础的高中知识开始机器学习和深度学习。本文基于即将出版的书籍,我们计划与有限数量的英国教师分享免费副本。我是牛津大学人工智能:云和边缘实现课程的课程主任,如果您是教师并对这些理念感兴趣,请在 LinkedIn 上与我联系,提到这篇文章。文中表达的观点仅代表个人,不代表我所属的任何组织。
相关:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT
更多相关主题
开发人员的机器学习简介
原文:
www.kdnuggets.com/2016/11/intro-machine-learning-developers.html/2
朴素贝叶斯分类是一种基于以前标记的数据使用概率模型进行预测的算法。特征之间相互独立,即一个特征不会影响另一个特征的值,并且一组标签会提前考虑并分配。
在分类器中使用的一些标签示例包括情感分数(可以是字符串、整数或浮点数的缩放分数),或者在目标检测中,你可以使用诸如椅子、桌子或书桌这样的标签来描述图像中的物体。特征检测是在提前决定的,比如垃圾邮件检测中的关键词出现或邮件长度。

这个示例展示了从 NLTK 书籍中修改的代码,章节 学习文本分类,并展示了如何用名字的最后一个字母作为特征在已知数据上训练模型的步骤。

使用具有大数据集的分类模型所需的基本步骤:
-
训练集:根据已知数据拟合模型
-
验证集:用于参数调整——选择模型复杂度
-
超参数:可以通过设置不同的值并选择测试效果更好的值或通过统计方法来完成
-
K-means 中的聚类数量:在我们的 K-means 示例中,我们使用了肘部法则。
-
决策树中的叶子节点数量
-
-
-
测试集:在模型运行在训练集上后评估模型——运行混淆矩阵以查找错误并比较模型

交叉验证方法有助于理解模型如何对未见数据进行泛化,且用于较小的数据集。例如,K 折交叉验证遵循以下步骤:
-
训练数据集被划分为数据子集——一个作为测试集,其余数据集用于训练。——因此你在用于训练数据的每个子集上使用相同的测试集。
-
计算每个测试/训练集的标准差。
-
平均误差率通过多个回合来估计模型性能。

R 非常适合统计/数据分析和机器学习,但由于性能和安全问题,不适合用于生产系统或实用功能。
回归诊断:异常值测试(p 值)、影响观察、评估非线性、相关性、描述性统计。
所有的统计内容:ANOVA、重采样技术、聚类、用于无监督机器学习的 PCA、决策树等。

Pandas 是一个使用数据框的 Python 库,类似于 R。虽然在生产中使用时较慢(Numpy 数组更快),但 Pandas 在 Python 环境中进行数据分析和机器学习时非常受欢迎。
使用 Pandas 的好处在于它可以将你的代码减少至少三分之二,并且你可以使用非常酷的 SQL 风格的功能,如连接、合并、透视和聚合函数。
还提供了许多 I/O 方法,使得数据的输入和导出变得简单,如:DataFrame.to_excel、.to_json、.to_csv 等。

Scikit-learn 是另一个受欢迎的 Python 库,是寻找机器学习模型的绝佳选择,提供了经过众多 Python 开发者验证的教程和文档。它涵盖了从图像分类算法到自然语言处理算法的各种内容。

以下是上面幻灯片中列出的工具、教程和视频的可点击链接:
-
R KDnuggets 机器学习包
-
Python KDnuggets 机器学习教程
查看博客的其他部分,获取有关natural language processing和机器学习算法的更多资源,例如LDA 文本分类或提高Nudity Detection算法准确度,以及使用Scikit-learn 解决 FizzBuzz的入门教程。
简介:Stephanie Kim 是 Algorithmia 的开发者推广专员。
原始文章。经许可转载。
相关:
-
掌握 Python 机器学习的 7 个步骤
-
机器学习关键术语解释
-
理解深度学习的 7 个步骤
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT
更多相关话题
使用 OpenAI Gym、RLlib 和 Google Colab 进行强化学习简介
原文:
www.kdnuggets.com/2021/09/intro-reinforcement-learning-openai-gym-rllib-colab.html
评论
由 Michael Galarnyk 和 Sven Mika
本教程将使用强化学习(RL)来帮助平衡一个虚拟的 CartPole。上面的 视频 来自 PilcoLearner,展示了在真实 CartPole 环境中使用 RL 的结果。
强化学习(RL)的一个可能定义是,一种计算方法,用于学习如何在与环境交互时最大化奖励的总和。虽然定义是有用的,但本教程旨在通过图像、代码和视频示例来展示强化学习是什么,并在此过程中介绍像代理和环境这样的强化学习术语。
特别是,本教程探讨:
-
什么是强化学习
-
OpenAI Gym CartPole 环境
-
代理在强化学习中的作用
-
如何使用 Python 库 RLlib 训练代理
-
如何使用 GPU 加速训练
-
使用 Ray Tune 进行超参数调优
什么是强化学习
正如 之前的帖子提到的,机器学习(ML),作为 AI 的一个子领域,利用神经网络或其他类型的数学模型来学习如何解释复杂的模式。由于其成熟度高,最近非常流行的两个 ML 领域是监督学习(SL),在这个领域中,神经网络学习基于大量数据进行预测,以及强化学习(RL),在该领域中,网络通过模拟器以试错的方式学习做出良好的行动决策。
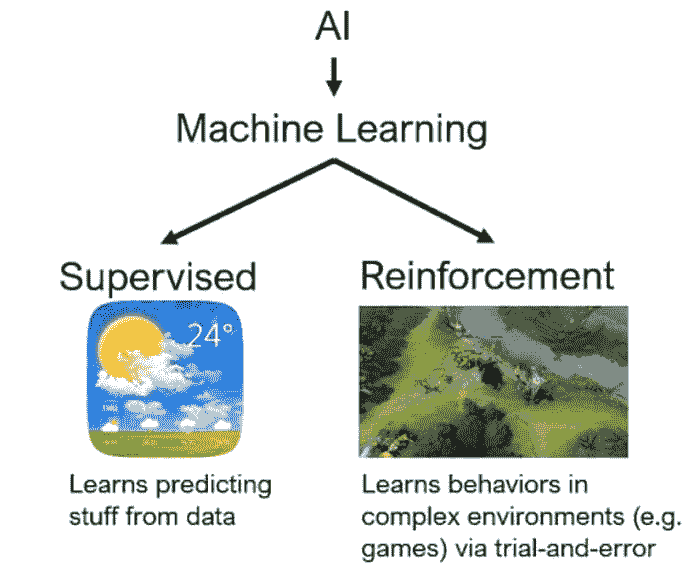
RL 是 DeepMind 的 AlphaGo Zero 和 StarCraft II AI(AlphaStar)或 OpenAI 的 DOTA 2 AI(“OpenAI Five”)等令人惊叹的成功背后的技术。请注意,强化学习的许多令人印象深刻的应用 以及它在现实决策问题中如此强大和有前景的原因是,RL 能够不断学习——有时甚至在不断变化的环境中——从完全没有做出决策的知识(随机行为)开始。
代理和环境
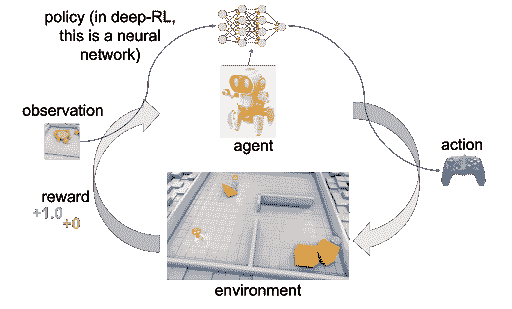
上图展示了代理与环境之间的交互和通信。在强化学习中,一个或多个代理在一个环境中进行交互,这个环境可能是像本教程中的 CartPole 这样的模拟,也可能是连接到现实世界传感器和执行器的环境。在每一步,代理接收一个观察(即环境的状态),采取一个动作,并通常接收一个奖励(代理接收奖励的频率取决于给定任务或问题)。代理通过重复试验进行学习,这些试验的序列称为一个 episode——从初始观察到“成功”或“失败”的一系列动作,使环境达到“完成”状态。强化学习框架的学习部分训练一个策略,以确定哪些动作(即顺序决策)可以使代理最大化其长期的累积奖励。
OpenAI Gym Cartpole 环境
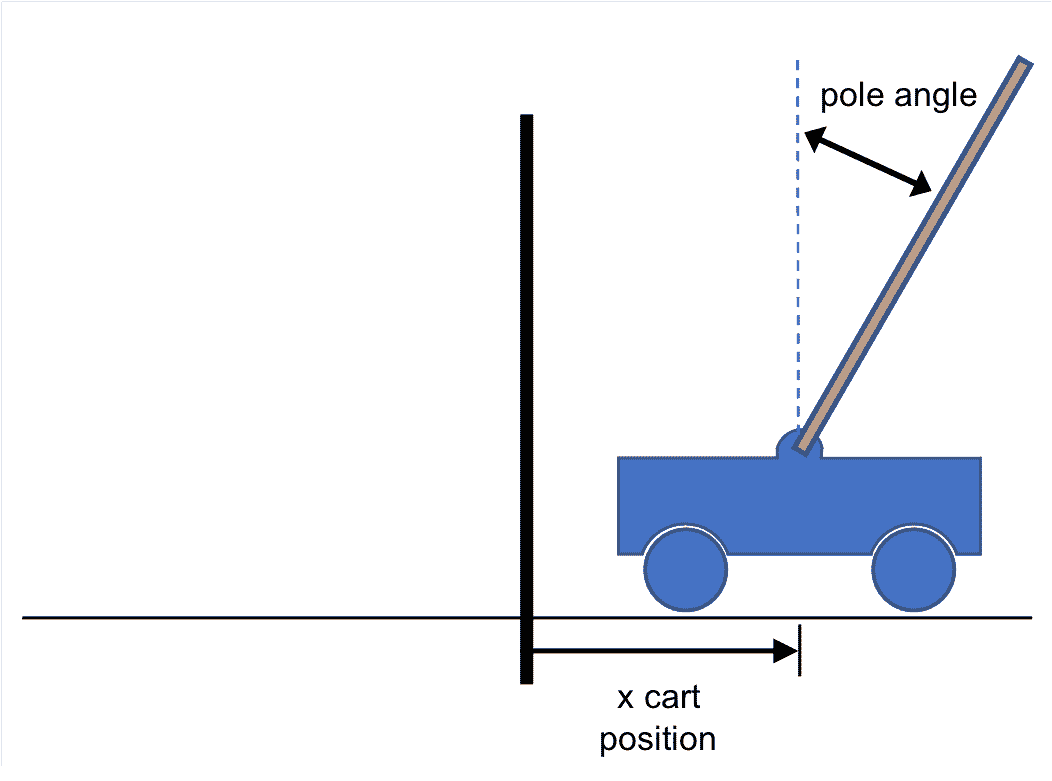
CartPole
我们要解决的问题是保持杆子直立。具体来说,杆子通过一个未驱动的关节连接到一个沿着无摩擦轨道移动的小车上。摆锤从直立位置开始,目标是通过增加或减少小车的速度来防止它倒下。
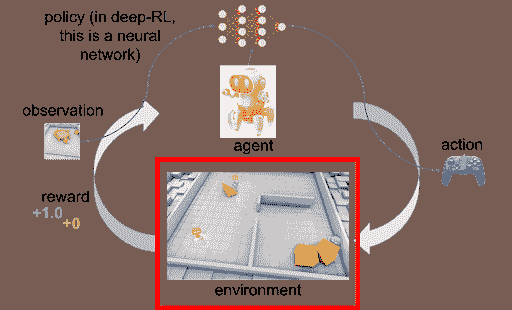
与其从头编写这个环境的代码,不如使用 OpenAI Gym,这是一个提供各种模拟环境的工具包(例如 Atari 游戏、棋盘游戏、2D 和 3D 物理模拟等)。Gym 不对代理的结构做任何假设(在这个 cartpole 示例中是什么推动小车向左或向右),并且与任何数值计算库(如 numpy)兼容。
以下代码加载了 cartpole 环境。
import gym
env = gym.make("CartPole-v0")
现在让我们通过查看动作空间来理解这个环境。
env.action_space

输出 Discrete(2) 表示有两个动作。在 cartpole 中,0 对应于“将小车推向左侧”,而 1 对应于“将小车推向右侧”。注意,在这个特定的示例中,静止不动不是一个选项。在强化学习中,代理产生一个动作输出,这个动作被发送到环境中,环境随后作出反应。环境生成一个观察(以及一个奖励信号,此处未显示),我们可以看到下面的内容:
env.reset()

观察是一个维度为 4 的向量,包括小车的 x 位置、小车的 x 速度、杆子的角度(以弧度表示,1 弧度 = 57.295 度)以及杆子的角速度。上面显示的数字是开始新一集后的初始观察(env.reset())。每个时间步(和动作)后,观察值将会变化,具体取决于小车和杆子的状态。
训练代理
在强化学习中,代理的目标是随着时间的推移产生越来越聪明的动作。它通过策略来实现这一点。在深度强化学习中,这一策略通过神经网络来表示。我们首先与 gym 环境进行互动,不使用神经网络或任何机器学习算法。相反,我们从随机运动(左或右)开始。这只是为了理解机制。
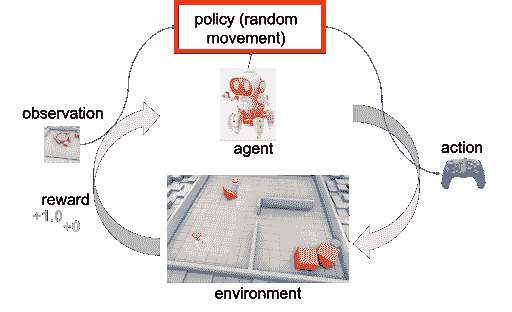
以下代码重置环境并执行 20 步(20 个周期),每次都采取随机动作并打印结果。
# returns an initial observation
env.reset()
for i in range(20):
# env.action_space.sample() produces either 0 (left) or 1 (right).
observation, reward, done, info = env.step(env.action_space.sample())
print("step", i, observation, reward, done, info)
env.close()
示例输出。cartpole 中有多个回合终止条件。在图像中,回合因超过 12 度(0.20944 弧度)而终止。其他回合终止条件包括小车位置超过 2.4(即小车中心到达显示屏边缘)、回合长度超过 200,或解决要求,即平均回报在 100 次连续试验中大于或等于 195.0。
上面打印的输出显示了以下内容:
-
步骤(环境已经循环了多少次)。在每个时间步中,代理选择一个动作,环境返回一个观察结果和一个奖励。
-
环境的观察 [x 小车位置, x 小车速度, 杆角度(弧度),杆角速度]
-
奖励是通过先前的动作获得的。这个尺度在不同环境中有所不同,但目标始终是增加你的总奖励。对于 cartpole,每一步的奖励是 1,包括终止步骤。之后奖励为 0(图中的第 18 和 19 步)。
-
done 是一个布尔值。它指示是否需要重新设置环境。大多数任务被划分为定义明确的回合,done 为 True 表示回合已经结束。在 cart pole 中,这可能是由于杆子倾斜得太远(超过 12 度/0.20944 弧度)、位置超过 2.4(即小车中心到达显示屏边缘)、回合长度超过 200,或解决要求,即平均回报在 100 次连续试验中大于或等于 195.0。
-
info 是有用的诊断信息,用于调试。对于这个 cartpole 环境,它是空的。
尽管这些数字是有用的输出,但视频可能更清晰。如果你在 Google Colab 中运行此代码,请注意,生成视频时没有可用的显示驱动程序。然而,可以安装虚拟显示驱动程序以使其正常工作。
# install dependencies needed for recording videos
!apt-get install -y xvfb x11-utils
!pip install pyvirtualdisplay==0.2.*
下一步是启动虚拟显示实例。
from pyvirtualdisplay import Display
display = Display(visible=False, size=(1400, 900))
_ = display.start()
OpenAI gym 有一个 VideoRecorder 包装器,可以将运行环境录制为 MP4 格式的视频。以下代码与之前相同,只是它录制了 200 步。
from gym.wrappers.monitoring.video_recorder import VideoRecorder
before_training = "before_training.mp4"
video = VideoRecorder(env, before_training)
# returns an initial observation
env.reset()
for i in range(200):
env.render()
video.capture_frame()
# env.action_space.sample() produces either 0 (left) or 1 (right).
observation, reward, done, info = env.step(env.action_space.sample())
# Not printing this time
#print("step", i, observation, reward, done, info)
video.close()
env.close()
通常,当 done 为 1(True)时,你会结束仿真。上面的代码让环境在达到终止条件后继续运行。例如,在 CartPole 中,这可能是当杆子倾斜、杆子消失在屏幕外,或达到其他终止条件时。
上面的代码将视频文件保存到了 Colab 磁盘中。为了在笔记本中显示它,你需要一个辅助函数。
from base64 import b64encode
def render_mp4(videopath: str) -> str:
"""
Gets a string containing a b4-encoded version of the MP4 video
at the specified path.
"""
mp4 = open(videopath, 'rb').read()
base64_encoded_mp4 = b64encode(mp4).decode()
return f'<video width=400 controls><source src="data:video/mp4;' \
f'base64,{base64_encoded_mp4}" type="video/mp4"></video>'
下面的代码渲染了结果。你应该能获得一个类似于下面的视频。
from IPython.display import HTML
html = render_mp4(before_training)
HTML(html)
播放视频显示,随机选择动作并不是保持 CartPole 直立的好策略。
如何使用 Ray 的 RLlib 训练智能体
本教程的前一部分让我们的智能体随机执行动作,忽略了来自环境的观察和奖励。智能体的目标是随着时间的推移产生越来越智能的动作,而随机动作无法实现这一目标。为了让智能体随着时间的推移产生更智能的动作,它需要一个更好的策略。在深度强化学习中,策略是通过神经网络来表示的。
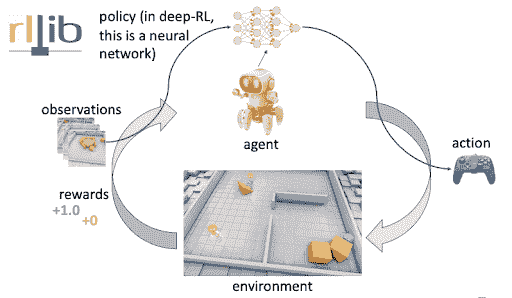
本教程将使用 RLlib 库 来训练一个更智能的智能体。RLlib 具有许多优势,比如:
-
极大的灵活性。它允许你定制 RL 周期的每一个方面。例如,本教程的这一部分将使用 PyTorch 制作一个自定义神经网络策略(RLlib 也原生支持 TensorFlow)。
-
可扩展性。强化学习应用程序可能会非常消耗计算资源,并且通常需要扩展到集群以加速训练。RLlib 不仅对 GPU 提供一流的支持,还建立在 Ray 之上,这使得从笔记本电脑到集群的 Python 程序扩展变得简单。
-
统一的 API 以及对离线、基于模型、无模型、多智能体算法等的支持(这些算法在本教程中不会被探讨)。
-
作为 Ray Project 生态系统的一部分。这有一个好处,即 RLlib 可以与生态系统中的其他库一起运行,如 Ray Tune,这是一个用于实验执行和超参数调整的库,支持任何规模(稍后会详细介绍)。
虽然这些功能中的一些在本帖中不会被完全利用,但它们对于当你想做一些更复杂的事情和解决实际问题时非常有用。你可以在 这里 了解一些 RLlib 的令人印象深刻的用例。
要开始使用 RLlib,你需要首先安装它。
!pip install 'ray[rllib]'==1.6
现在你可以使用 Proximal Policy Optimization (PPO) 算法训练一个 PyTorch 模型。这是一种非常全面的、适合所有场景的算法,你可以在这里了解更多。下面的代码使用了一个包含 32 个神经元和线性激活函数的单隐层神经网络。
import ray
from ray.rllib.agents.ppo import PPOTrainer
config = {
"env": "CartPole-v0",
# Change the following line to `“framework”: “tf”` to use tensorflow
"framework": "torch",
"model": {
"fcnet_hiddens": [32],
"fcnet_activation": "linear",
},
}
stop = {"episode_reward_mean": 195}
ray.shutdown()
ray.init(
num_cpus=3,
include_dashboard=False,
ignore_reinit_error=True,
log_to_driver=False,
)
# execute training
analysis = ray.tune.run(
"PPO",
config=config,
stop=stop,
checkpoint_at_end=True,
)
这段代码应该会产生相当多的输出。最终条目应该类似于:
该条目显示解决环境需要 35 次迭代,运行了 258 秒。每次可能会有所不同,但每次迭代大约需要 7 秒(258 / 35 = 7.3)。如果你希望了解 Ray API 并查看类似 ray.shutdown 和 ray.init 的命令,你可以查看这个教程。
如何使用 GPU 加速训练
尽管教程的其余部分使用了 CPU,但值得注意的是,你可以通过在 Google Colab 中使用 GPU 来加速模型训练。可以通过选择运行时 > 更改运行时类型并将硬件加速器设置为GPU来完成。然后选择运行时 > 重启并运行所有。

注意到,尽管训练迭代的次数可能差不多,但每次迭代的时间显著减少(从 7 秒减少到 5.5 秒)。
创建训练模型运行的视频
RLlib 提供了一个 Trainer 类,用于持有环境交互的策略。通过训练器接口,可以训练策略、计算动作和保存检查点。虽然之前从ray.tune.run返回的分析对象没有包含任何训练器实例,但它拥有从保存的检查点重建一个所需的所有信息,因为传递了checkpoint_at_end=True作为参数。下面的代码展示了这一点。
# restore a trainer from the last checkpoint
trial = analysis.get_best_logdir("episode_reward_mean", "max")
checkpoint = analysis.get_best_checkpoint(
trial,
"training_iteration",
"max",
)
trainer = PPOTrainer(config=config)
trainer.restore(checkpoint)
现在我们再创建一个视频,但这次选择训练模型推荐的动作,而不是随机行动。
after_training = "after_training.mp4"
after_video = VideoRecorder(env, after_training)
observation = env.reset()
done = False
while not done:
env.render()
after_video.capture_frame()
action = trainer.compute_action(observation)
observation, reward, done, info = env.step(action)
after_video.close()
env.close()
# You should get a video similar to the one below.
html = render_mp4(after_training)
HTML(html)
这次,杆子平衡得很好,这意味着代理已经解决了 cartpole 环境!
使用 Ray Tune 进行超参数调整
Ray 生态系统
RLlib 是一个强化学习库,是 Ray 生态系统的一部分。Ray 是一个高度可扩展的通用框架,用于并行和分布式 Python。它非常通用,这种通用性对于支持其库生态系统至关重要。生态系统涵盖了从训练、到生产服务、到数据处理等各方面。你可以将多个库一起使用,构建执行这些操作的应用程序。
本部分教程使用了Ray Tune,这是 Ray 生态系统中的另一个库。它是一个用于实验执行和超参数调优的库,支持任何规模。虽然本教程只使用网格搜索,但请注意 Ray Tune 还提供了更高效的超参数调优算法,如基于种群的训练、BayesOptSearch 和 HyperBand/ASHA。
现在让我们尝试找出能够在最少时间步数内解决 CartPole 环境的超参数。
输入以下代码,准备好可能需要一段时间来运行:
parameter_search_config = {
"env": "CartPole-v0",
"framework": "torch",
# Hyperparameter tuning
"model": {
"fcnet_hiddens": ray.tune.grid_search([[32], [64]]),
"fcnet_activation": ray.tune.grid_search(["linear", "relu"]),
},
"lr": ray.tune.uniform(1e-7, 1e-2)
}
# To explicitly stop or restart Ray, use the shutdown API.
ray.shutdown()
ray.init(
num_cpus=12,
include_dashboard=False,
ignore_reinit_error=True,
log_to_driver=False,
)
parameter_search_analysis = ray.tune.run(
"PPO",
config=parameter_search_config,
stop=stop,
num_samples=5,
metric="timesteps_total",
mode="min",
)
print(
"Best hyperparameters found:",
parameter_search_analysis.best_config,
)
通过传递 num_cpus=12 到 ray.init 请求 12 个 CPU 核心时,四个试验将在三个 CPU 上并行运行。如果这不起作用,可能是 Google 更改了 Colab 上可用的虚拟机。任何三个或更多的值都应该有效。如果 Colab 由于内存不足而出错,你可能需要执行Runtime > Factory reset runtime,然后Runtime > Run all。注意 Colab 笔记本右上角有显示 RAM 和磁盘使用情况的区域。
指定 num_samples=5 意味着你将获得五个随机样本用于学习率。对于每一个样本,有两个隐藏层大小的值和两个激活函数的值。因此,将会有 5 * 2 * 2 = 20 个试验,试验状态将在单元格的输出中显示。
注意 Ray 在运行过程中会打印当前的最佳配置。这包括所有已设置的默认值,这是找到可以调整的其他参数的好地方。
运行后,最终输出可能类似于以下输出:
INFO tune.py:549 -- 总运行时间:3658.24 秒(调优循环的时间为 3657.45 秒)。
找到的最佳超参数:{'env': 'CartPole-v0', 'framework': 'torch', 'model': {'fcnet_hiddens': [64], 'fcnet_activation': 'relu'}, 'lr': 0.006733929096170726};'''
因此,在二十组超参数中,具有 64 个神经元、ReLU 激活函数和大约 6.7e-3 学习率的组合表现最好。
结论
Neural MMO 是一个从大规模多人在线游戏建模的环境——这种游戏类型支持数百到数千名同时在线玩家。你可以通过点击这里了解 Ray 和 RLlib 如何帮助实现这些和其他项目的关键功能。
本教程通过介绍强化学习术语、展示代理与环境的互动,并通过代码和视频示例演示这些概念,从而阐明了强化学习的内容。如果你想深入了解强化学习,建议查看 Sven Mika 的 RLlib 教程。这是学习 RLlib 最佳实践、多代理算法及更多内容的绝佳方式。如果你希望随时了解 RLlib 和 Ray 的所有最新动态,考虑 关注 @raydistributed 的 Twitter 并 注册 Ray 新闻通讯。
原文 已获授权转载。
相关:
-
强化学习入门
-
Facebook 推出历史上最具挑战性的强化学习挑战之一
-
强化学习的 10 个实际应用
我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关内容
介绍 AI Explainability 360:帮助您理解机器学习模型正在做什么的新工具包
评论
可解释性是现代机器学习解决方案中最困难的挑战之一。虽然构建复杂的机器学习模型变得越来越容易,但理解模型如何发展知识并得出结论仍然是一个非常困难的挑战。通常,模型越准确,解释起来就越困难。最近,IBM 的 AI 研究人员开源了AI Explainability 360,这是一个支持机器学习模型可解释性和说明性的最先进算法工具包。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
AI Explainability 360 的发布是近年来在几十篇研究论文中概述的想法的首次实际实施。传统的软件应用程序通过引入监控代码来帮助运行时监控,机器学习模型也需要添加可解释性技术以便于调试、故障排除和版本控制。然而,解释机器学习模型的复杂性远高于传统软件应用程序。首先,我们对什么使机器学习模型具有可解释性了解非常有限。
可解释性的构建模块
几个月前,谷歌的研究人员发布了一篇非常全面的论文,概述了可解释性的核心组成部分。该论文提出了使模型可解释的四个基本挑战:
-
理解隐层的功能: 深度学习模型中的大部分知识是在隐层中形成的。了解不同隐层在宏观层面的功能对于解释深度学习模型至关重要。
-
理解隐藏层的作用: 深度学习模型中的大部分知识是在隐藏层中形成的。宏观上理解不同隐藏层的功能对于解释深度学习模型至关重要。
-
理解节点如何被激活: 解释能力的关键在于不是理解网络中单个神经元的功能,而是理解在相同空间位置上共同激活的相互连接的神经元组。通过按互联神经元组对网络进行分段,将提供一个更简单的抽象层次来理解其功能。
-
理解概念是如何形成的: 理解深度神经网络如何形成单个概念,然后将这些概念组装成最终输出,是解释性另一个关键组成部分。
另一个需要认识到的方面是,AI 模型的可解释性随着其复杂性的增加而减少。你关心的是获得最佳结果,还是关心如何获得这些结果?这就是解释性与准确性之间的矛盾的本质,它是每个机器学习场景的核心。许多深度学习技术本质上是复杂的,尽管它们在许多场景中结果非常准确,但它们可能变得难以解释。
为了应对解释性的挑战,机器学习模型需要将可解释的构建块作为一个重要组成部分。这就是 IBM 新工具包的目标。
AI Explainability 360
AI Explainability 360 是一个开源工具包,用于简化可解释机器学习模型的实现。该工具包包括一系列可解释性算法,反映了该领域的最新研究成果,并具有直观的用户界面,有助于从不同角度理解机器学习模型。AI Explainability 360 的主要贡献之一是它不依赖于机器学习模型的单一解释形式。正如人类依赖丰富且富有表现力的解释来解读特定结果一样,机器学习模型的解释性也会因涉及的角色和上下文而有所不同。AI Explainability 360 为数据科学家或业务相关人员等不同角色生成不同的解释。
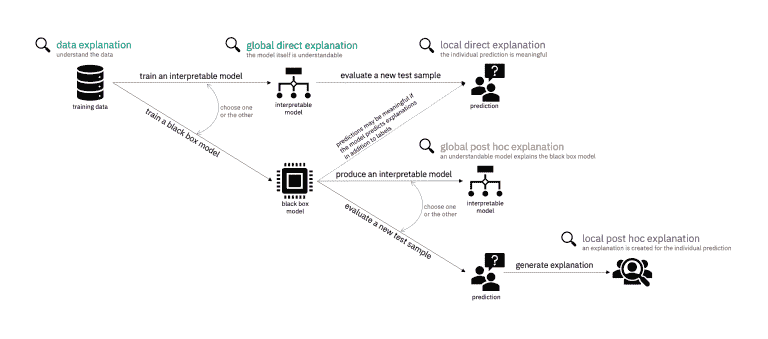
AI Explainability 360 生成的解释可以分为两大类,取决于它们是否基于数据或模型。
-
数据: 理解数据集的特征往往是可解释性的最短路径。这在依赖数据集构建相关知识的监督学习算法中尤其如此。有时,给定数据集中的特征对消费者有意义,但其他时候它们是纠缠在一起的,即多个有意义的属性组合在一个特征中。AI 可解释性 360 包含了几个专注于数据可解释性的算法。
-
模型: 模型的解释是任何机器学习可解释性的关键构建块。有几种方法可以使机器学习模型对消费者易于理解。第一种区分是直接可解释性与事后解释。直接可解释的模型是诸如决策树、布尔规则集和广义加性模型等模型格式,这些模型比较容易被人理解,并且可以直接从训练数据中学习。事后解释方法首先训练一个黑箱模型,然后在黑箱模型上构建另一个解释模型。第二种区分是全局解释与局部解释。全局解释针对整个模型,而局部解释则针对单个样本点。
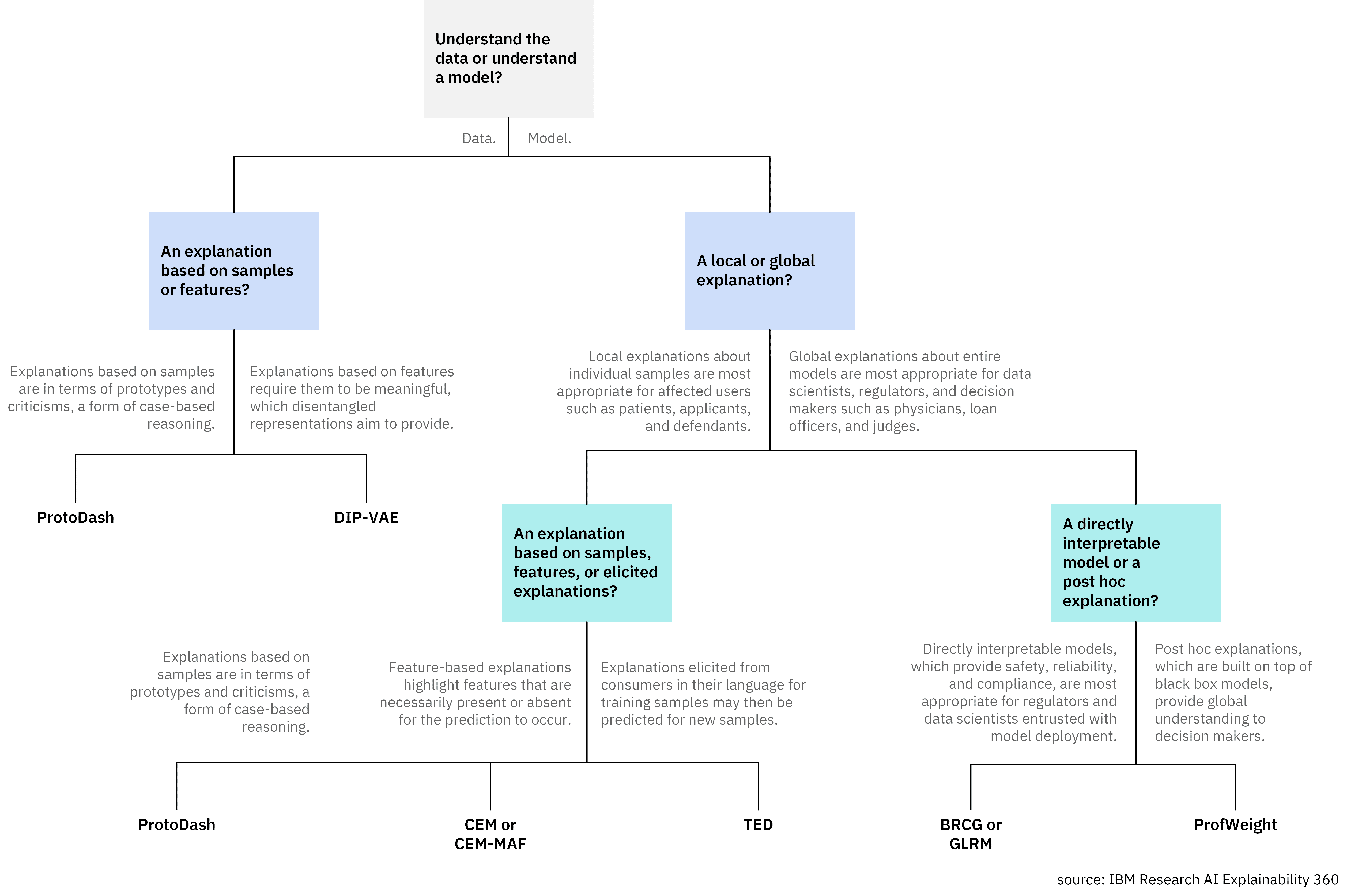
全局可解释模型、全局和局部事后解释的区分是 AI 可解释性 360 的关键贡献之一。通常,全局可解释模型更适合需要完整且离散的模型解释路径的场景。这些场景包括安全性、可靠性或合规性等领域。全局事后解释对由机器学习模型支持的决策者角色非常有用。医生、法官和贷款官员可以对模型的整体工作方式有一个全面的了解,但黑箱模型和解释之间必然存在差距。局部事后解释与受模型结果影响的个人角色相关,例如患者、被告或申请人,他们需要从特定的视角理解解释。
开发人员可以通过使用工具包中包含的 API 来开始使用 AI 可解释性 360。此外,AI 可解释性 360 包含了一系列演示和教程,可以帮助开发人员相对快速地入门。最后,该工具包提供了一个非常简单的用户界面,可用于入门机器学习可解释性的概念。
解释性是现代机器学习应用中最重要的构建块之一。AI 解释性 360 提供了最完整的堆栈之一,以简化机器学习程序的解释性,而无需成为该领域的专家。我们很可能会看到 AI 解释性 360 背后的某些理念被纳入主流深度学习框架和平台中。
原文。已获许可转载。
相关:
-
人工智能中的两个主要难点及一种应用解决方案
-
安德鲁·吴《机器学习的渴望》中 6 个关键概念
-
如何通过创建 AI 学习小组提升我的技能并获得工作
更多相关主题
介绍 Dask 的并行编程:与项目首席开发人员的访谈
原文:
www.kdnuggets.com/2016/09/introducing-dask-parallel-programming.html
在接下来的几周内,KDnuggets 计划分享一些关于 Dask 的信息和教程。
你问 Dask 是什么?根据它的 文档:
Dask 是一个用于分析的灵活并行计算库。
你的兴趣被激发了吗?如果你有兴趣了解一个为计算和互动数据科学而构建的软件项目,这可能会彻底改变你进行数据处理和并行化自己项目的方式,请阅读我与 Dask 首席开发人员马修·洛克林的讨论。

马修·梅约:首先,你能给我们一个 Dask 的一句话概述吗?
马修·洛克林: 哈,这很棘手。Dask 的使用方式非常不同,所以我们在这里需要比较笼统。
Dask 是一个用于并行编程的 Python 库,它利用任务调度来解决计算问题。
很容易与其他表面上类似的项目进行比较。你认为 Dask 还与哪些开源项目竞争?
Dask 跨越了两个不同的“竞争”项目组:
-
动态任务调度器,如 AirFlow/Luigi/Celery
-
“大数据”分析框架,如 Hadoop/Spark。
从本质上讲,Dask 看起来很像经过调整的 Airflow/Luigi/Celery。它有一个中央任务调度器,将作业(Python 函数)发送到同一台机器或集群中的许多工作进程:
Worker A,请计算 x = f(1),Worker B 请计算 y = g(2)。
Worker A,当 g(2) 完成后,请从 Worker B 获取 y 并计算 z = h(x, y)。
Dask 的不同之处在于,虽然 Airflow/Luigi/Celery 主要用于较长时间的数据工程作业,但 Dask 是为了计算和互动数据科学而设计的。我们更关注于毫秒级的响应时间、工作进程间的数据共享、Jupyter notebook 集成等,而不是定期运行作业(如 Airflow)或与大量数据工程服务集成(如 Luigi)。我不会用 Dask 来进行每日数据的摄取,但我会用它来设计和运行算法以分析这些数据。
在这个任务调度器之上,我们构建了更高级的数组、数据框和列表接口,这些接口模仿了 NumPy、Pandas 和 Python 迭代器。这将 Dask 推向了流行的“大数据”框架空间,如 Hadoop 和 Spark。尤其是如今 Spark 的主导地位相当巨大,特别是在商业分析用例中(数据摄取、SQL 相关、一些轻量级机器学习)。大多数在这些用例中使用 Dask 的人要么是因为他们想留在 Python 中,要么是因为他们喜欢 Pandas,或者是因为他们在处理一些对 Spark 过于复杂的东西,如 N 维数组或一些更高级的 Pandas 时间序列功能。如果你已经在使用 Python,Dask 通常会感觉轻量一些。不过,Spark 的成熟度要高得多,确实做得非常好。
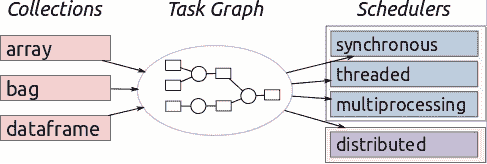
Dask 比其他潜在解决方案更擅长什么?
首先,Dask 做的很多事情比其他潜在解决方案要差。它不是要实现 SQL 或成为一个并行数据库。它不会在超级计算机上超越 MPI,也不会超越你手工优化的 C 代码。
其次,Dask 最常被使用的方式是怎样的。大多数用户使用 Dask.dataframe 或 Dask.bag 来分析 CSV 或 JSON 文件的目录。然而,如果 Dask 今天消失,这些用户也会没事,因为有很多软件项目在试图解决这个问题。
那么,剩下的是什么呢?实际上,有相当多的未被服务的领域。Dask 对于那些需要并行计算的自定义或不规则计算问题的用户来说,确实是个救星。这些用户包括科学家、量化分析师、算法开发者和不断增长的企业研究团队。这些人面临新颖的问题,需要构建自己的并行计算解决方案。Dask 的核心部分(看起来像 Airflow/Luigi/Celery)似乎很适合他们的需求。他们希望别人处理套接字/线程/弹性/数据局部性,但他们希望对其他所有事情保持相当细粒度的控制(比 map/reduce/groupby 更细)。
Dask 的接口(例如,Dask DataFrame、Dask Array、Dask Bag)似乎非常直观。你认为 Dask 还有什么其他特点,使其对潜在用户具有吸引力?
是的,正如你所建议的,复制 NumPy 和 Pandas 的接口确实降低了入门门槛。许多人都知道和喜爱 NumPy 和 Pandas。这听起来很傻,但这种选择也减少了 Dask 开发者在 API 上的焦虑和争论时间。
安装的简便性和可以立即在笔记本电脑上开始使用是一个很大的优势。Dask 作为一个纯 Python 库,可以通过标准 Python 包管理工具安装,且无需设置或配置文件,这对于广泛的用户群体都有帮助。
在人们的脑海中,从“仅仅是一个库”到“一个框架”存在一个大的飞跃。你可以像使用 Python 中的 multiprocessing 模块、Joblib 或 concurrent.futures 模块一样使用 Dask,感觉像是“仅仅是一个库”。Dask 设计成尽可能小的库,以补充现有的 PyData 生态系统中的并行处理。它从未设计成取代任何东西。许多其他库的核心开发人员似乎正是因为这个原因而接受了它。
最初,Dask 将其生命的第一年专注于单机并行处理。它满足了那些拥有“适中大数据”且希望充分利用笔记本电脑或重型工作站所有计算能力的人的需求。这个庞大的用户群体大多来自科学和金融领域,他们拥有“适中大数据”,并且不愿意处理将代码运行在集群上的复杂性。Dask 在这些用户中一开始就受到了极大的欢迎。此外,除了最大规模的问题外,单台重型工作站的性能和生产力几乎没有可比性。我们现在已经转向分布式系统,但单机并行处理今天仍然占据了大约 80%的使用比例。
你能描述一个简单的 Dask 使用案例吗,以便给读者提供一些可视化的概念?
我会给出两个例子,一个是任务调度(类似 Airflow),另一个是大数据集合(类似 Spark)。
一家汽车公司的假设质量保证团队正在使用收集的遥测数据(他们从每辆车的数百个传感器中收集数据)和关于他们认为汽车组件如何运作的工程模型来寻找故障。团队中的几个不同研究人员负责汽车的不同组件,并构建自定义的 Python 函数来建模这些组件在不同情况下的响应。其他负责集成这些组件的研究人员将前一层组件专注的研究人员创建的模型结合起来,形成一个复杂的关系树(汽车很复杂)。他们在来自数据的数百万种情况中运行这些模型。他们的聚合模型具有大量的并行性,但却非常混乱。他们将所有功能交给 Dask 处理,Dask 管理这些并行性,在原型设计期间运行在团队的笔记本电脑上,在需要处理完整数据集时运行在集群上。之后,他们生成视觉报告,并聚在一起查看结果。根据结果,各个部分的研究人员会离开并调整模型的各个部分,修改 Dask 图的某些小部分,只重新运行受影响的计算部分。
对于大数据集合(数组/数据框/列表),让我们来看一下气候科学。气候科学家拥有的数据类似于“地球每平方公里的温度、气压和风速,覆盖各种高度,追溯五十年。”他们希望筛选这些五维的密集数据立方体,对其进行分组、与其他数据集联接,并将其减少到有助于回答研究问题的汇总数据。他们使用流行的XArray 项目来管理他们的数据。XArray 在数据集较小且适合内存时(比如 1GB)使用 NumPy,但当数据集大于内存但仍适合存储(比如 10GB-100GB)时则切换到 Dask.array。在这些较大的数据集上,完整的计算可能需要一两分钟(磁盘有时较慢),但气候科学家很高兴,因为他们可以继续在笔记本电脑上工作,而无需切换到集群。他们现在可以查看分辨率更高、时间跨度更长的数据,而不必过于担心规模,一切都在他们的个人计算机上,并且使用之前在内存数据上使用的相同接口。

你是怎么参与 Dask 开发的,Matthew?
这实际上是我的全职工作。我在Continuum Analytics工作,这是一个嵌入在开源数值 Python 生态系统中的营利性公司。它们有点像数值 Python 的 RedHat。公司有强烈的激励来保持开源 Python 生态系统的强大,因此他们构建填补感知空白的开源项目。Dask 就是这些项目之一,还有其他项目如Conda、Numba和Bokeh。
如果有读者感兴趣,参与 Dask 开发的最佳方式是什么?
文档是一个不错的开始:
dask.<wbr>readthedocs.io/en/latest/
有一个带有初学者问题标签的问题跟踪器:
github.com/<wbr>dask/dask/issues
我还建议尝试分布式调度器的快速入门,它更专注于 Airflow/Luigi 工作负载:
distributed.<wbr>readthedocs.io/en/latest/<wbr>quickstart.html
不过,目前 Dask 的核心部分感觉相当稳固。我认为现在最好的做法是将 Dask 应用于新问题,并看看它们如何突破。每次发生这种情况,我们都会学习如何更好地执行任务调度。
我们还需要了解 Dask 的其他事项吗?
是的,人们现在为这些东西付费,这真是疯狂。Dask 主要靠资助(感谢 DARPA 和 Moore!),但我现在开始经常收到公司发来的电子邮件,询问是否可以为某些开源功能的开发付费。他们 立刻就提出这个问题。不再需要说服他们开源工作对每个人都更好。如果你对开源软件感兴趣,你应该感到非常高兴。如果你是一家对 Python 中灵活的分布式计算系统感兴趣的公司,你知道如何联系我 😃
感谢你抽出时间,Matthew。你的名字似乎与 Dask 开发在互联网上密不可分,我相信这让你忙碌。我们感谢你抽出时间与我们交谈。
哈哈,那只是因为我声音最大 😃
还有其他几个人,如果没有他们,Dask 绝对不会发展到今天的水平。核心开发者包括 Jim Crist、Martin Durant、Erik Welch、Masakai Horikoshi、Blake Griffith 和大约 70 位其他人。还有其他 PyData 库的开发者,如 MinRK(Jupyter)、Stephan Hoyer(XArray、Pandas)、Jeff Reback(Pandas)、Stefan van der Walt(NumPy、SKImage)、Olivier Grisel(SKLearn、Joblib),他们紧密合作,确保 Dask 能够很好地与 Python 生态系统的其他部分集成。Continuum 内部的 Ben Zaitlen、Kris Overholt、Daniel Rodriguez 和 Christine Doig 确保系统运行顺畅,使开发能够快速进行。还有资助 Dask 开发的组织,如 DARPA XData 项目、Moore 基金会和私人公司。这些组织确保像我这样的开发者可以全职工作于 Dask 项目,这真的很棒!
我肯定在那个名单中忘记了几个很棒的人。
相关:
-
科学 Python 介绍(以及一些数学原理)— Matplotlib
-
白皮书:使用 Datashader 的大数据可视化
-
关于分析准备的思考
更多相关话题
介绍 Falcon2:TII 的下一代语言模型
原文:
www.kdnuggets.com/introducing-falcon2-next-gen-language-model-by-tii

图片来源于作者
阿布扎比的技术创新研究所(TII)于 5 月 14 日发布了其下一系列 Falcon 语言模型。新模型符合 TII 作为技术推动者的使命,并作为开源模型在 HuggingFace 上提供。他们发布了两种 Falcon 2 模型变体:Falcon-2-11B 和 Falcon-2-11B-VLM。新的 VLM 模型承诺具有卓越的多模型兼容性,性能与其他开源和闭源模型相当。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
模型特性与性能
最近的 Falcon-2 语言模型拥有 110 亿个参数,并在来自 falcon-refinedweb 数据集的 5.5 万亿个标记上进行了训练。更新的、更高效的模型与 Meta 最近的 Llama3 模型(拥有 80 亿个参数)竞争良好。结果汇总在下面由 TII 分享的表格中:
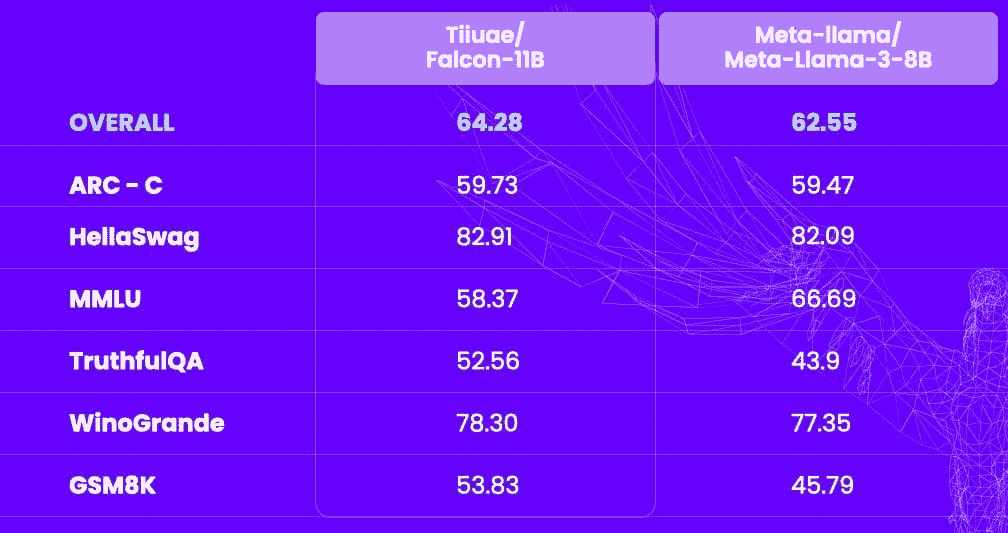
图片来源于 TII
此外,Falcon-2 模型在与谷歌的 Gemma(拥有 70 亿个参数)的比较中表现良好。Gemma-7B 仅比 Falcon-2 平均性能高出 0.01。该模型还是多语言的,训练了包括英语、法语、西班牙语和德语等常用语言。
然而,突破性的成就是 Falcon-2-11B 视觉语言模型的发布,该模型在同一语言模型中增加了图像理解和多模态功能。与 Llama3 和 Gemma 等近期模型具有相当能力的图像到文本对话能力是一项重要进展。
如何使用模型进行推断
让我们进入编码部分,这样我们就可以在本地系统上运行模型并生成响应。首先,像处理其他项目一样,让我们设置一个新的环境以避免依赖冲突。由于模型刚刚发布,我们将需要所有库的最新版本,以避免缺少支持和管道。
创建一个新的 Python 虚拟环境,并使用以下命令激活它:
python -m venv venv
source venv/bin/activate
现在我们有一个干净的环境,我们可以使用 Python 包管理器安装所需的库和依赖项。对于这个项目,我们将使用互联网上可用的图像并在 Python 中加载它们。requests 和 Pillow 库适用于此目的。此外,为了加载模型,我们将使用 transformers 库,该库内置支持 HuggingFace 模型加载和推理。我们将使用 bitsandbytes、PyTorch 和 accelerate 作为模型加载实用工具和量化工具。
为了简化设置过程,我们可以创建一个简单的需求文本文件,如下所示:
# requirements.txt
accelerate # For distributed loading
bitsandbytes # For Quantization
torch # Used by HuggingFace
transformers # To load pipelines and models
Pillow # Basic Loading and Image Processing
requests # Downloading image from URL
现在我们可以使用以下命令在一行中安装所有依赖项:
pip install -r requirements.txt
我们现在可以开始编写代码以使用模型进行推理。让我们从在本地系统中加载模型开始。模型可以在 HuggingFace 找到,总大小超过 20GB。我们无法在通常具有 8-16GB 内存的消费级 GPU 上加载模型。因此,我们需要对模型进行量化,即将模型加载为 4 位浮点数,而不是通常的 32 位精度,以减少内存需求。
bitsandbytes 库提供了一个简单的接口,用于量化 HuggingFace 中的大型语言模型。我们可以初始化一个量化配置并将其传递给模型。HuggingFace 内部处理所有必要的操作,并为我们设置正确的精度和调整。配置可以设置如下:
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
# Original model support BFloat16
bnb_4bit_compute_dtype=torch.bfloat16,
)
这使得模型可以适应 16GB GPU 内存,从而更容易加载模型而无需卸载和分发。我们现在可以加载 Falcon-2B-VLM。作为一个多模态模型,我们将同时处理图像和文本提示。LLava 模型和管道专为此目的而设计,它们允许基于 CLIP 的图像嵌入投影到语言模型输入中。transformers 库具有内置的 Llava 模型处理器和管道。我们可以按如下方式加载模型:
from transformers import LlavaNextForConditionalGeneration, LlavaNextProcessor
processor = LlavaNextProcessor.from_pretrained(
"tiiuae/falcon-11B-vlm",
tokenizer_class='PreTrainedTokenizerFast'
)
model = LlavaNextForConditionalGeneration.from_pretrained(
"tiiuae/falcon-11B-vlm",
quantization_config=quantization_config,
device_map="auto"
)
我们将 HuggingFace 模型卡上的模型 URL 传递给处理器和生成器。我们还将 bitsandbytes 量化配置传递给生成模型,这样它将自动以 4 位精度加载。
我们现在可以开始使用模型生成响应!为了探索 Falcon-11B 的多模态特性,我们需要在 Python 中加载一张图像。作为测试样本,我们加载这个标准图像 这里。要从网络 URL 加载图像,我们可以使用 Pillow 和 requests 库,如下所示:
from Pillow import Image
import requests
url = "https://static.theprint.in/wp-content/uploads/2020/07/football.jpg"
img = Image.open(requests.get(url, stream=True).raw)
requests 库从 URL 下载图像,Pillow 库可以将字节读取为标准图像格式。现在我们有了测试图像,我们可以从模型生成示例响应。
让我们设置一个示例提示模板,模型对其很敏感。
instruction = "Write a long paragraph about this picture."
prompt = f"""User:<image>\n{instruction} Falcon:"""
提示模板本身是自解释的,我们需要按照它来获得 VLM 的最佳响应。我们将提示和图像传递给 Llava 图像处理器。它内部使用 CLIP 创建图像和提示的组合嵌入。
inputs = processor(
prompt,
images=img,
return_tensors="pt",
padding=True
).to('cuda:0')
返回的张量嵌入作为生成模型的输入。我们传递这些嵌入,基于原始提供的图像和指令,使用基于变换器的 Falcon-11B 模型生成文本响应。
我们可以使用以下代码生成响应:
output = model.generate(**inputs, max_new_tokens=256)
generated_captions = processor.decode(output[0], skip_special_tokens=True).strip()
就这样!generated_captions变量是一个字符串,包含了模型生成的响应。
结果
我们使用上述代码测试了各种图像,对其中一些图像的响应进行了总结,见下图。我们看到,Falcon-2 模型对图像有很强的理解能力,并生成了清晰的答案,显示出其对图像场景的理解。它可以读取文本,还突出显示了整体信息。总之,模型在视觉任务上表现出色,可用于基于图像的对话。

图片来源:作者 | 图片来自互联网。来源:猫咪图片、卡片图片、足球图片
许可与合规
除了开源外,这些模型还以 Apache2.0 许可证发布,使其可供公开访问。这允许对模型进行修改和分发,用于个人和商业用途。这意味着你现在可以使用 Falcon-2 模型来提升基于 LLM 的应用程序,并利用开源模型为用户提供多模态能力。
总结
总体来说,新版 Falcon-2 模型显示了令人鼓舞的结果。但这还不是全部!TII 已经在着手下一次迭代,以进一步提升性能。他们计划将专家混合(MoE)和其他机器学习能力整合到模型中,以提高准确性和智能性。如果 Falcon-2 看起来像是一个改进,请准备好迎接他们的下一个公告。
Kanwal Mehreen** Kanwal 是一位机器学习工程师和技术作家,对数据科学及 AI 与医学的交集充满深厚的热情。她共同撰写了电子书《使用 ChatGPT 最大化生产力》。作为 2022 年亚太地区的 Google Generation 学者,她倡导多样性和学术卓越。她还被认定为 Teradata 多样性技术学者、Mitacs Globalink 研究学者和哈佛 WeCode 学者。Kanwal 是变革的坚定倡导者,她创立了 FEMCodes,旨在赋能女性在 STEM 领域中的发展。
更多相关主题
介绍 MPT-7B:一款全新的开源 LLM
原文:
www.kdnuggets.com/2023/05/introducing-mpt7b-new-opensource-llm.html

图片由作者提供
大型语言模型(LLM)目前正变得疯狂。然而,作为一个组织,如果没有合适的资源,可能很难跟上大型语言模型的潮流。训练和部署大型语言模型可能会很困难,你会突然感到被甩在了后面。开源 LLM,如 Meta 的 LLaMA 系列,使 LLM 资源变得可用。
另外,作为开源系列的最新补充是 MosaicML Foundations' 最新款 MPT-7B。
什么是 MPT-7B?
MPT 代表 MosaicML 预训练变换器。MPT 模型是仅解码的 GPT 风格变换器,具有许多改进:
-
性能优化层实现
-
由于架构更改,训练稳定性更高
-
无上下文长度限制
MPT-7B 是一种转换器模型,使用 1T tokens 的文本和代码从头开始训练。是的,1 万亿!它在 MosaicML 平台上训练,耗时 9.5 天,完全没有人工干预。费用大约为 $200k。
它是开源的,可用于商业用途,这个工具将彻底改变企业和组织在预测分析和决策过程中的工作方式。
MPT-7B 的主要特点包括:
-
许可用于商业用途
-
训练数据量巨大(1T tokens)
-
可以处理极长的输入
-
针对快速训练和推理进行优化
-
高效的开源训练代码。
MPT-7B 是基础模型,已被证明优于其他开源 7B - 20B 模型。MPT-7B 的质量与 LLaMA-7B 相匹配。为了评估 MPT-7B 的质量,MosaicML Foundation 组织了 11 个开源基准,并以行业标准方式进行评估。
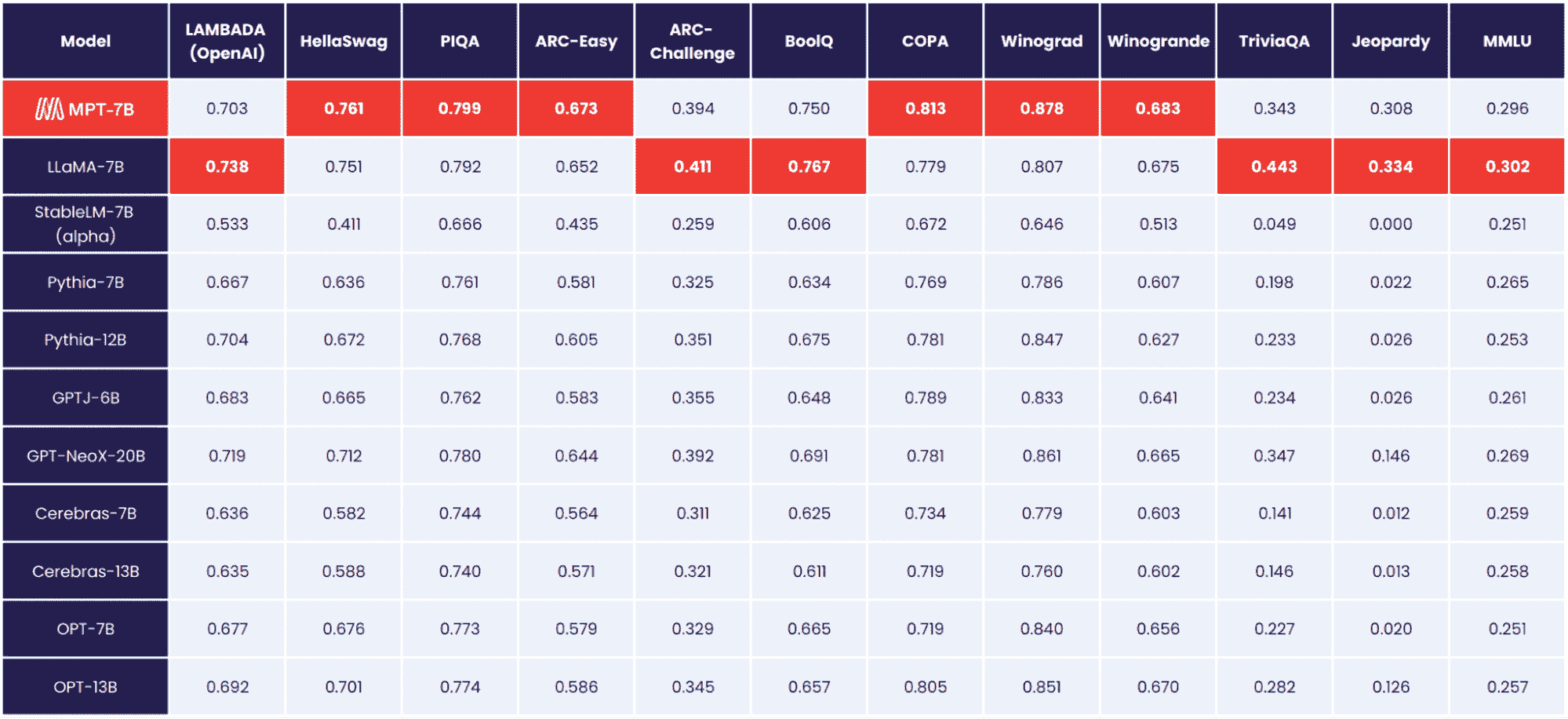
图片由 MosaicML Foundation 提供
MosaicML 基础模型也发布了三个额外微调的模型:
-
MPT-7B-Instruct
-
MPT-7B-Chat
-
MPT-7B-StoryWriter-65k+
MPT-7B-Instruct
MPT-7B-Instruct 模型用于短形式指令跟随。自 5 月 14 日以来,MPT-7B-Instruct 允许你提出快速简短的问题并立即获得回应。如果你有问题,想要一个简单的答案 - 使用 MPT-7B-Instruct。
为什么这如此出色?通常 LLMs 会根据提供的输入继续生成文本。然而,有些人希望 LLMs 将输入视为指令。指令微调使 LLMs 能够执行指令跟随输出。
MPT-7B-Chat
是的,我们还有另一个聊天机器人。MPT-7B-Chat生成对话。例如,如果您希望聊天机器人生成演讲稿,提供上下文,它将以对话的方式生成文本。或者,您可能想写一条推文,改写文章中的一段内容,它也可以为您生成对话!
为什么这如此出色?MPT-7B Chat 已经准备好并具备了进行各种对话任务的能力,能够为用户提供更无缝、更吸引人的多轮互动。
MPT-7B-StoryWriter-65k+
这是给故事创作者的!对于那些想要编写长篇背景故事的人,MPT-7B-StoryWriter-65k+是专门为此设计的模型。该模型通过对 MPT-7B 进行微调,拥有65k tokens 的上下文长度,并且可以超越 65k tokens 进行推断。MosaicML Foundation 在单节点 A100-80GB GPU 上成功生成了 84k tokens。
为什么这如此出色?因为大多数开源 LLMs 只能处理最多几千个 tokens 的序列。但只需在 MosaicML 平台上使用单节点 8xA100-80GB,您就可以微调 MPT-7B 以处理上下文长度高达 65k!
关于 MPT-7B 的更多构建细节
MosaicML 团队在仅仅几周内完成了这些模型的构建。他们在几周内处理了数据准备、训练、微调和部署。
数据来自各种来源,每个来源都有十亿个 tokens 可用。有效的 tokens 数量在每个来源中仍然保持在十亿!团队使用了EleutherAI、GPT-NeoX和20B tokenizer,使他们能够在多样化的数据上进行训练,应用一致的空格分隔符等。
所有 MPT-7B 模型都在MosaicML 平台上训练,使用了来自 Oracle Cloud 的 A100-40GB 和 A100-80GB GPU。
如果您想了解更多关于 MPT-7B 的工具和成本,请阅读:MPT-7B 博客。
总结
MosaicML 平台可以被视为组织建立自定义 LLMs 的最佳起点,无论是私有的、商业的还是社区相关的。拥有这一开源资源将使组织在使用这些工具以改善当前组织挑战时感到更加自由。
客户能够在任何计算提供商或数据源上训练 LLMs,同时保持效率、隐私和成本透明度。
你认为你将如何使用 MPT-7B?在下面的评论中告诉我们
Nisha Arya 是一名数据科学家、自由技术作家和 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何有助于延长人类寿命。作为一名热衷于学习的人员,她寻求拓宽技术知识和写作技能,同时帮助指导他人。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关主题
介绍 OpenChat:一个快速且简单的自定义聊天机器人构建平台

作者提供的图片
什么是 OpenChat
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
OpenChat 是一个开源聊天机器人控制台,使用户能够轻松运行和创建类似于 ChatGPT 的自定义聊天机器人。它简化了利用大型语言模型(LLMs)的过程,使日常用户也能轻松使用。随着 AI 技术的快速发展,这些模型的安装和使用可能会让人感到望而生畏。然而,OpenChat 通过提供一个简单的两步设置过程,简化了创建全面聊天机器人控制台的过程。
演示可以在 OpenChat 网站上查看
OpenChat 作为一个中央枢纽,用于管理多个定制的聊天机器人,使用户能够在任何地方嵌入和分享他们的机器人。目前,该平台支持 GPT 模型,但团队正在积极工作以集成各种开源 LLM,这些模型可以通过单击激活。
无论您是开发者、研究员,还是没有编程经验的个人,OpenChat 提供了一个用户友好的界面,使您能够创建可以执行各种任务的聊天机器人。
目前,您可以通过两种方式使用 OpenChat:
-
通过运行一个完全免费的本地服务器,提供安全性和对聊天机器人控制台的更大控制。
-
OpenChat 的在线版本提供了互动的用户体验,使您能够在几分钟内构建聊天机器人应用程序。
OpenChat 功能和使用案例
特性
OpenChat 提供了一个强大的平台,用于基于 GPT-3.5 和 GPT-4 创建无限制的本地聊天机器人。借助 OpenChat,你可以通过提供 PDF 文件、网站以及即将与 Notion、Confluence 和 Office 365 等平台的集成来定制你的聊天机器人。OpenChat 的一大亮点是每个聊天机器人都拥有无限的内存容量,能够无缝处理大文件,例如 400 页的 PDF。
OpenChat 还允许你将聊天机器人作为小部件嵌入到你的网站或内部公司工具中,轻松触达和与观众互动。此外,通过配对编程模式,你可以将整个代码库作为聊天机器人的数据源,实现更个性化和高级的互动。
使用案例
-
定制客户支持: 使用 OpenChat,你可以创建能够提供个性化客户支持的聊天机器人,实时回答问题并解决问题。
-
学校作业: OpenChat 可用于教育环境,帮助学生完成作业。聊天机器人可以提供作业指导、回答问题和提供学习建议。
-
公司内部知识: OpenChat 可用于构建聊天机器人,提供员工便捷访问公司内部知识的服务,例如政策、程序和培训资料。
-
构建私有聊天机器人: 你可以使用 OpenChat 构建私有聊天机器人,与客户分享,提供独特且个性化的服务。
-
个人图书馆: 你可以使用 OpenChat 创建个人书籍、文本和 PDF 图书馆,从而更容易组织和访问你的资料。
-
医疗保健: OpenChat 可用于医疗保健环境,帮助患者处理琐碎问题,例如安排预约或回答常见问题。这可以解放医疗专业人员,专注于更复杂的病例。
-
还有更多…
图片来自 OpenChat
在 2 分钟内创建一个 KDnuggets 机器人
要使用 OpenChat 的在线版本创建聊天机器人,过程非常简单:
-
使用你的 Google 凭证创建一个账户。
-
选择你想要的数据源,包括网站链接、PDF、代码库、Notion 等。
-
添加网站 URL,然后等待几秒钟,让 OpenChat 扫描你的网站以获取相关内容。
-
你的聊天机器人现在可以使用并嵌入到你的网站中。
需要注意的是,对于 OpenChat 的在线版本,扫描过程仅限于你网站的前 15 页。如果你希望扫描更多页面或对扫描过程有更大控制,可以使用自托管版本的 OpenChat。
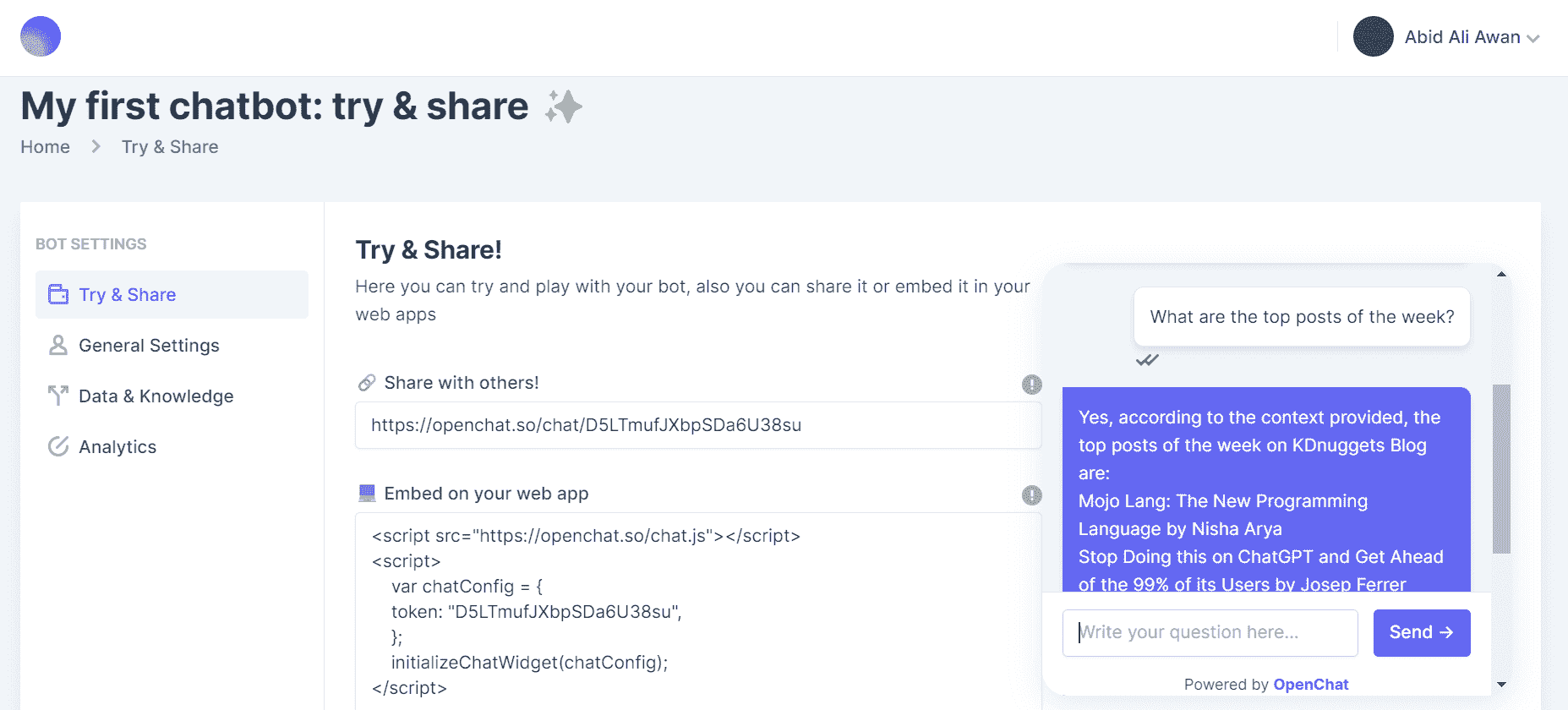
图片来自 OpenChat - 仪表板
本地安装
你可以按照 openchatai/OpenChat 中提到的几个步骤安装 OpenChat 的自托管版本。
- 首先克隆
openchatai/OpenChatGitHub 仓库:
git clone git@github.com:openchatai/OpenChat.git
- 使用你的密钥编辑
common.env文件:
OPENAI_API_KEY=
PINECONE_API_KEY=
PINECONE_ENVIRONMENT=
PINECONE_INDEX_NAME=
注意: 使用 Pinecone 作为数据库时,确保维度设置为 1536 是非常重要的。
-
OpenAI API 密钥: 只需登录到 openai.com 上的账户。一旦登录,你可以在账户设置中找到你的 API 密钥。
-
Pinecone API 密钥: 前往 Pinecone 仪表盘中的“API 密钥”标签。在这里,你可以生成新的 API 密钥或查看现有的密钥。
-
Pinecone 环境与索引名称: 在创建索引后,你可以在 Pinecone 仪表盘中找到你的环境密钥。同样,你的索引名称也可以在 Pinecone 仪表盘中找到。
- 将目录更改为仓库文件夹,然后运行:
make install
- 完成安装过程后,你可以通过在网页浏览器中导航到
http://localhost:8000来访问 OpenChat 控制台。
结论
总之,OpenChat 授权使用 MIT 许可证,可以用于任何商业用途。它是一个强大的平台,简化了构建和管理聊天机器人的过程。凭借其用户友好的界面和多功能性,OpenChat 使创建能够执行各种任务的定制聊天机器人变得轻而易举。
无论你是希望提升客户服务、简化业务流程,还是仅仅提供更具吸引力的用户体验,OpenChat 都具备你所需的一切来创建有效且高效的聊天机器人。
在这篇文章中,我们了解了 OpenChat 以及如何使用它创建由 GPT-3.5 或 GPT-4 驱动的定制聊天机器人。快去创建一个免费账户,建立一个聊天机器人,并与朋友和同事分享吧。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些挣扎于心理疾病的学生构建 AI 产品。
更多相关内容
介绍 OpenLLM:LLM 的开源库
原文:
www.kdnuggets.com/2023/07/introducing-openllm-open-source-library-llms.html

图片来源于作者
此时,我们都在思考同一个问题。LLM 的世界真的在主导吗?一些人可能预计热度会平稳,但它仍在持续上升。更多资源投入到 LLM 中,因为它显示出巨大的需求。
LLM 的性能不仅成功,而且它们在适应各种 NLP 任务(如翻译和情感分析)方面的多功能性也非常强。微调预训练的 LLM 使得针对特定任务变得更加容易,减少了从头构建模型的计算成本。LLM 已迅速被应用于各种现实世界应用,推动了研究和开发的数量。
开源模型也是 LLM 的一个重要优势,因为开源模型的可用性使研究人员和组织能够持续改进现有模型,并探索它们如何安全地融入社会。
什么是 OpenLLM?
OpenLLM 是一个用于生产环境中操作 LLM 的开放平台。使用 OpenLLM,您可以对任何开源 LLM 进行推理、微调、部署,并轻松构建强大的 AI 应用程序。
OpenLLM 包含最先进的 LLM,如 StableLM、Dolly、ChatGLM、StarCoder 等,所有这些都由内置支持。您还可以自由构建自己的 AI 应用程序,因为 OpenLLM 不仅仅是一个独立产品,还支持 LangChain、BentoML 和 Hugging Face。
这些功能,还开源?听起来有点疯狂,对吧?
更棒的是,它易于安装和使用。
如何使用 OpenLLM?
要使用 LLM,您需要系统中至少安装 Python 3.8 以及 pip。为了防止包冲突,建议使用虚拟环境。
- 一旦准备好这些,您可以通过使用以下命令轻松安装 OpenLLM:
pip install open-llm
- 为确保正确安装,可以运行以下命令:
$ openllm -h
Usage: openllm [OPTIONS] COMMAND [ARGS]...
██████╗ ██████╗ ███████╗███╗ ██╗██╗ ██╗ ███╗ ███╗
██╔═══██╗██╔══██╗██╔════╝████╗ ██║██║ ██║ ████╗ ████║
██║ ██║██████╔╝█████╗ ██╔██╗ ██║██║ ██║ ██╔████╔██║
██║ ██║██╔═══╝ ██╔══╝ ██║╚██╗██║██║ ██║ ██║╚██╔╝██║
╚██████╔╝██║ ███████╗██║ ╚████║███████╗███████╗██║ ╚═╝ ██║
╚═════╝ ╚═╝ ╚══════╝╚═╝ ╚═══╝╚══════╝╚══════╝╚═╝ ╚═╝
An open platform for operating large language models in production.
Fine-tune, serve, deploy, and monitor any LLMs with ease.
- 为了启动一个 LLM 服务器,请使用以下命令,并包括您选择的模型:
openllm start
例如,如果您想启动一个 OPT 服务器,请执行以下操作:
openllm start opt
支持的模型
OpenLLM 支持 10 种模型。您还可以在下方找到安装命令:
pip install "openllm[chatglm]"
该模型需要 GPU。
pip install openllm
该模型可以在 CPU 和 GPU 上使用。
pip install "openllm[falcon]"
该模型需要 GPU。
pip install "openllm[flan-t5]"
该模型可以在 CPU 和 GPU 上使用。
pip install openllm
这个模型需要一个 GPU。
pip install "openllm[mpt]"
这个模型可以在 CPU 和 GPU 上使用。
pip install "openllm[opt]"
这个模型可以在 CPU 和 GPU 上使用。
pip install openllm
这个模型可以在 CPU 和 GPU 上使用。
pip install "openllm[starcoder]"
这个模型需要一个 GPU。
pip install "openllm[baichuan]"
这个模型需要一个 GPU。
要了解有关运行时实现、微调支持、集成新模型和生产部署的更多信息,请查看 这里,找到适合你需求的方案。
总结一下
如果你想使用 OpenLLM 或需要帮助,你可以加入他们的 Discord 和 Slack 社区。你也可以通过他们的 开发者指南 为 OpenLLM 的代码库做贡献。
有没有人试过这个?如果试过,请在评论中告诉我们你的想法!
Nisha Arya 是一名数据科学家、自由技术写作者以及 KDnuggets 的社区经理。她特别感兴趣于提供数据科学职业建议或教程以及有关数据科学的理论知识。她还希望探索人工智能如何/能如何有利于人类寿命的不同方式。她是一位渴望学习者,寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关信息
OpenAI 介绍 Superalignment
原文:
www.kdnuggets.com/2023/08/introducing-superalignment-openai.html

图片由作者提供
OpenAI 频繁出现在媒体上,不仅因为发布了 ChatGPT、GPT-3 和 GPT-4,还因为围绕 ChatGPT 等 AI 系统的伦理问题以及当今世界的社会经济问题。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
首席执行官 Sam Altman 在 AI 安全性方面已多次发表讲话,例如在美国参议院委员会上,他表示:
“我认为如果这项技术出现问题,它可能会变得非常严重……我们希望对此保持警觉。我们希望与政府合作,防止这种情况发生。”
话虽如此,OpenAI 团队已经开始采取行动。许多人担心超智能,即一个智能超越人类思维的 AI 系统。有些人相信技术能够解决世界上许多当前的问题,然而,由于对其知之甚少或理解有限,很难权衡其利弊。
也许谈论超智能还为时尚早,但这无疑是一个需要进行的对话。最佳的做法是尽早管理这些潜在的风险,以免它们变成无法处理的大问题。
OpenAI 的做法
OpenAI 表示他们目前没有针对超智能 AI 的解决方案,不过他们正在与新团队 Superalignment 合作进行研究。他们目前使用的技术包括来自人类反馈的强化学习,这在很大程度上依赖于人类对 AI 进行监督。然而,关于未来人类无法可靠监督 AI 的问题以及处理这一问题所需的新科学突破存在担忧。
话虽如此,OpenAI 正在考虑建立一个能够从人类反馈中学习并协助人类评估 AI 的人类级别自动对齐研究人员,同时能够解决其他对齐问题。OpenAI 已将其迄今为止获得的 20% 的计算资源用于这一努力,以迭代对齐超级智能。
为了让超级对齐团队在这方面取得成功,他们需要:
1. 开发可扩展的训练方法
他们的目标是利用其他 AI 系统来帮助评估其他 AI 系统,同时更好地理解模型如何推广监督,这是人类无法监督的。
2. 验证结果模型
为了验证系统对齐的结果,OpenAI 计划自动搜索问题行为,以改进模型的稳健性,以及自动解释性。
3. 压力测试整个对齐流程
测试,测试,再测试!OpenAI 计划通过故意训练不对齐的模型来测试其整个对齐过程。这将确保所使用的技术能够检测任何形式的不对齐,特别是最恶劣的对抗测试。
OpenAI 已经进行了初步实验,结果显示良好。他们旨在利用有用的指标和持续的模型研究来推进这些工作。
总结
OpenAI 的目标是创造一个 AI 系统和人类能够和谐共处的未来,让任何一方都不会感到受到威胁。超级对齐团队的开发是一个雄心勃勃的目标,但它将向更广泛的社区提供有关机器学习使用的证据,并能够创建一个安全的环境。
Nisha Arya 是一名数据科学家、自由技术写作人以及 KDnuggets 的社区经理。她特别关注于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何能够促进人类寿命的不同方式。作为一名热衷的学习者,她寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多信息
介绍自然语言处理的测试库
原文:
www.kdnuggets.com/2023/04/introducing-testing-library-natural-language-processing.html
负责任的 AI:目标与现实
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT
虽然有很多关于训练安全、稳健和公平的 AI 模型的讨论——但很少有工具提供给数据科学家以实现这些目标。因此,生产系统中的自然语言处理(NLP)模型的前线反映了一个令人遗憾的现状。
目前的自然语言处理系统经常失败且失败得非常惨烈。[Ribeiro 2020] 显示了在替换中性词时,顶级三大云服务提供商的情感分析服务失败率为 9-16%,在更改中性命名实体时为 7-20%,在时间测试中为 36-42%,在一些否定测试中几乎为 100%。[Song & Raghunathan 2020] 显示了 50-70%的个人信息泄露到流行的词汇和句子嵌入中。[Parrish et. al. 2021] 显示了种族、性别、外貌、残疾和宗教的偏见如何根深蒂固地存在于最先进的问答模型中——有时会使可能的答案发生超过 80%的变化。[van Aken et. al. 2022] 显示了在病人记录中添加任何关于族裔的提及都会降低其预测的死亡风险——最准确的模型产生了最大的误差。
简而言之,这些系统就是不管用。我们绝不会接受一个只在某些数字上正确加法的计算器,或一个根据你放入的食物类型或时间随机改变强度的微波炉。一个经过良好工程设计的生产系统应该能在常见输入上可靠地工作。它在处理不常见输入时也应该是安全和稳健的。软件工程包括三个基本原则,以帮助我们实现这些目标。
应用软件工程基础
首先,测试你的软件。关于为什么 NLP 模型今天会失败,唯一令人惊讶的事是答案的平凡性:因为没有人测试它们。上述论文之所以新颖,是因为它们是其中的首批。如果你想交付有效的软件系统,你需要定义什么是有效,并在部署到生产环境之前测试它是否有效。每次更改软件时也应如此,因为 NLP 模型也会出现回退问题 [Xie et. al. 2021]。
其次,不要将学术模型作为生产就绪模型重复使用。NLP 科学进步的一个美妙方面是,大多数学者将他们的模型公开并易于重用。这加速了研究,并启用了像 SuperGLUE、LM-Harness 和 BIG-bench 这样的基准。然而,旨在复制研究结果的工具并不适合用于生产。可重复性要求模型保持不变——而不是保持其最新或随时间变得更稳健。一个常见的例子是 BioBERT,也许是最广泛使用的生物医学嵌入模型,发布于 2019 年初,因此将 COVID-19 视为一个词汇表外的词。
其三,测试超越准确性。由于你的 NLP 系统的业务需求包括稳健性、可靠性、公平性、毒性、效率、无偏见、无数据泄露和安全性——因此你的测试套件需要反映这些要求。语言模型的整体评估 [Liang et. al 2022] 是对这些术语在不同上下文中的定义和度量的全面回顾,非常值得一读。但你需要编写自己的测试:例如,对于你的应用程序来说,包容性实际意味着什么?
良好的测试需要具体、独立且易于维护。它们还需要有版本控制和可执行性,以便将其纳入自动构建或 MLOps 工作流。nlptest 库是一个简单的框架,可以简化这一过程。
介绍 nlptest 库
nlptest 库 是围绕五个原则设计的。
开源。这是一个基于 Apache 2.0 许可证的社区项目。它可以永久免费使用,包括商业用途,没有任何限制。背后有一个活跃的开发团队,你可以参与贡献或分叉代码。
轻量级。这个库可以在你的笔记本电脑上运行——不需要集群、高内存服务器或 GPU。只需运行 pip install nlptest 就能安装,并且可以离线运行(即在 VPN 或高合规企业环境中)。然后,生成和运行测试可以在三行代码内完成:
from nlptest import Harness
h = Harness(task="ner", model="ner.dl", hub=”johnsnowlabs”)
h.generate().run().report()
这段代码导入库,为指定模型从 John Snow Labs 的 NLP 模型中心创建一个新的命名实体识别(NER)任务的测试工具,自动生成测试用例(基于默认配置),运行这些测试,并打印出报告。
测试本身存储在 pandas 数据框中,这使得它们易于编辑、过滤、导入或导出。整个测试工具可以被保存和加载,因此要运行之前配置的测试套件的回归测试,只需调用 h.load("filename").run()。
跨库。库支持 transformers、Spark NLP 和 spacy。扩展框架以支持额外的库非常容易。作为 AI 社区,我们没有必要重复构建测试生成和执行引擎。这些库中的任何预训练或自定义 NLP 流水线都可以进行测试:
# a string parameter to Harness asks to download a pre-trained pipeline or model
h1 = Harness(task="ner", model="dslim/bert-base-NER", hub=”huggingface”)
h2 = Harness(task="ner", model="ner.dl", hub=”johnsnowlabs”)
h3 = Harness(task="ner", model="en_core_web_md", hub=”spacy”)
# alternatively, configure and pass an initialized pipeline object
pipe = spacy.load("en_core_web_sm", disable=["tok2vec", "tagger", "parser"])
h4 = Harness(task=“ner”, model=pipe, hub=”spacy”)
可扩展。由于有数百种潜在的测试类型和度量需要支持,许多项目对 NLP 任务的额外兴趣,以及自定义需求,已经付出了大量的思考,以便于实现和重用新的测试类型。
例如,对于美国英语的内置偏见测试类型之一,将名字替换为白人、黑人、亚洲人或西班牙裔常见的名字。但是,如果你的应用程序面向印度或巴西呢?那基于年龄或残疾的偏见测试呢?如果你想到了一种不同的测试通过标准怎么办?
nlptest 库是一个框架,它使你能够轻松编写并组合不同类型的测试。TestFactory 类定义了一个标准 API,用于配置、生成和执行不同的测试。我们已经尽力让你能够轻松地贡献或定制这个库以满足你的需求。
测试模型和数据。当模型还没有准备好进行生产时,问题通常出在用于训练或评估模型的数据集上——而不是模型架构本身。一个常见的问题是标记错误的训练示例,这在广泛使用的数据集中被证明是普遍存在的 [Northcutt et. al. 2021]。另一个问题是表示偏差:一个常见的挑战是,找出模型在不同种族之间的表现如何,因为没有足够的测试标签来计算一个可用的度量。因此,库可能会使测试失败,并告诉你需要更改训练和测试集以代表其他群体,修复可能的错误,或训练边缘情况。
因此,测试场景由一个任务、一个模型和一个数据集定义,即:
h = Harness(task = "text-classification",
model = "distilbert_base_sequence_classifier_toxicity",
data = “german hatespeech refugees.csv”,
hub = “johnsnowlabs”)
除了使库能够为模型和数据提供全面的测试策略外,这种设置还使你能够使用生成的测试来增强你的训练和测试数据集,这可以大大缩短修复模型并使其准备生产的时间。
接下来的章节描述了nlptest库帮助你自动化的三个任务:生成测试、运行测试和数据增强。
1. 自动生成测试
nlptest与过去的测试库之间的一个巨大区别是,现在可以在一定程度上自动生成测试。每个 TestFactory 可以定义多种测试类型,并为每种类型实现测试用例生成器和测试用例运行器。
生成的测试作为一个表格返回,包含“测试用例”和“预期结果”列,这些列取决于特定的测试。这两列旨在可读,以便业务分析师可以在需要时手动审查、编辑、添加或删除测试用例。例如,以下是由 RobustnessTestFactory 为文本“I live in Berlin.”生成的一些 NER 任务测试用例:
| 测试类型 | 测试用例 | 预期结果 |
|---|---|---|
| remove_punctuation | 我住在柏林 | 柏林:地点 |
| lowercase | i live in berlin. | berlin: Location |
| add_typos | I liive in Berlin. | 柏林:地点 |
| add_context | 我住在柏林。 #citylife | 柏林:地点 |
这里是由 BiasTestFactory 生成的文本分类任务的测试用例,使用基于美国种族的姓名替换,从文本“John Smith is responsible”开始:
| 测试类型 | 测试用例 | 预期结果 |
|---|---|---|
| replace_to_asian_name | Wang Li is responsible | 积极情感 |
| replace_to_black_name | Darnell Johnson is responsible | 负面情感 |
| replace_to_native_american_name | Dakota Begay is responsible | 中性情感 |
| replace_to_hispanic_name | Juan Moreno is responsible | 负面情感 |
这里是由 FairnessTestFactory 和 RepresentationTestFactory 类生成的测试用例。表示测试可能需要测试数据集中包含至少 30 名男性、女性和未指定性别的患者。公平性测试可能要求在对这些性别类别中的数据切片进行测试时,测试模型的 F1 得分至少为 0.85:
| 测试类型 | 测试用例 | 预期结果 |
|---|---|---|
| min_gender_representation | 男性 | 30 |
| min_gender_representation | 女性 | 30 |
| min_gender_representation | 未知 | 30 |
| min_gender_f1_score | 男性 | 0.85 |
| min_gender_f1_score | 女性 | 0.85 |
| min_gender_f1_score | 未知 | 0.85 |
关于测试用例需要注意的重要事项:
-
“测试用例”和“预期结果”的含义取决于测试类型,但在每种情况下都应该是人类可读的。这是为了在你调用
h.generate()后,可以手动审查生成的测试用例列表,并决定保留或编辑哪些用例。 -
由于测试表格是一个 pandas 数据框,你也可以在笔记本内直接编辑(使用 Qgrid),或将其导出为 CSV 文件,并让业务分析师在 Excel 中编辑。
-
虽然自动化完成了 80% 的工作,你通常仍需手动检查测试。例如,如果你在测试一个假新闻检测器,那么将“巴黎是法国的首都”替换为“巴黎是苏丹的首都”的 replace_to_lower_income_country 测试将不可避免地导致预期预测和实际预测之间的不匹配。
-
你还需要验证你的测试是否捕捉了你解决方案的业务需求。例如,上述的 FairnessTestFactory 示例没有测试非二元或其他性别身份,也没有要求性别之间的准确性几乎相等。然而,它确实使这些决策明确、易读,并且易于更改。
-
一些测试类型将只生成一个测试用例,而其他类型可能生成数百个。这是可配置的——每个 TestFactory 定义了一组参数。
-
TestFactory 类通常特定于任务、语言、地区和领域。这是有意为之,因为这允许编写更简单且更模块化的测试工厂。
2. 运行测试
在生成测试用例并随心所欲地编辑后,以下是如何使用它们的方法:
-
调用
h.run()以运行所有测试。对于测试框架表中的每个测试用例,相关的 TestFactory 将被调用以运行测试,并返回一个通过/失败标志以及一个解释性消息。 -
调用
h.report()在调用h.run()之后。这将按测试类型分组通过比例,打印一个总结结果的表格,并返回一个标志,说明模型是否通过了测试套件。 -
调用
h.save()将测试框架(包括测试表)保存为一组文件。这使你能够在以后加载并运行完全相同的测试套件,例如在进行回归测试时。
这是一个为命名实体识别(NER)模型生成的报告示例,应用了来自五个测试工厂的测试:
| 类别 | 测试类型 | 失败次数 | 通过次数 | 通过率 | 最低通过率 | 是否通过? |
|---|---|---|---|---|---|---|
| robustness | remove_punctuation | 45 | 252 | 85% | 75% | TRUE |
| bias | replace_to_asian_name | 110 | 169 | 65% | 80% | FALSE |
| representation | min_gender_representation | 0 | 3 | 100% | 100% | TRUE |
| fairness | min_gender_f1_score | 1 | 2 | 67% | 100% | FALSE |
| accuracy | min_macro_f1_score | 0 | 1 | 100% | 100% | TRUE |
虽然 nlptest 做的部分工作是计算指标——模型的 F1 分数是多少?偏差分数是多少?鲁棒性分数是多少?——但一切都被框定为一个二元结果的测试:通过或失败。正如好的测试应该做的那样,这要求你明确你的应用程序所做的和未做的事情。然后,它使你能够更快且更有信心地部署模型。它还使你能够将测试列表共享给监管者——他们可以阅读它,或自行运行以重现你的结果。
3. 数据增强
当你发现模型在鲁棒性或偏差方面存在不足时,改进的一种常见方法是添加专门针对这些不足的新训练数据。例如,如果你的原始数据集主要包含干净的文本(如维基百科文本——没有错别字、俚语或语法错误),或者缺乏穆斯林或印地语名字的代表性——那么将这些示例添加到训练数据集中应该能帮助模型更好地处理这些情况。
幸运的是,我们已经在某些情况下有一种方法可以自动生成这些示例——这与我们用于生成测试的方法相同。以下是数据增强的工作流程:
-
在生成并运行测试后,调用 h.augment() 以根据测试结果自动生成增强训练数据。请注意,这必须是新生成的数据集——测试套件不能用于重新训练模型,因为下一个版本的模型将无法再次对其进行测试。在模型训练数据上进行测试是数据泄露的一个例子,这会导致测试分数被人为地抬高。
-
新生成的增强数据集以 pandas dataframe 形式提供,你可以查看、编辑(如果需要),然后用它来重新训练或微调你的原始模型。
-
然后,你可以在之前失败的相同测试套件上重新评估新训练的模型,通过创建新的测试工具,并调用 h.load(),接着是 h.run() 和 h.report()。
这个迭代过程使 NLP 数据科学家能够不断提升他们的模型,同时遵守他们自己道德规范、公司政策和监管机构规定的规则。
入门
nlptest 库现在已上线并免费提供给你。可以通过 pip install nlptest 开始使用,或访问 nlptest.org 阅读文档和入门示例。
nlptest 也是一个早期的开源社区项目,欢迎你加入。John Snow Labs 已为该项目配备了完整的开发团队,并致力于多年改进该库,就像我们对待其他开源库一样。预计将会有频繁的更新,定期添加新的测试类型、任务、语言和平台。然而,如果你参与贡献、分享示例和文档,或者向我们反馈你最需要的内容,你将更快地获得所需的东西。访问 nlptest on GitHub 参与讨论。
我们期待共同努力,使安全、可靠和负责任的 NLP 成为日常现实。
更多相关话题
介绍 TPU v4: 谷歌前沿超级计算机用于大型语言模型
图片来源:编辑
机器学习和人工智能似乎在以非常快的速度增长,以至于有些人甚至跟不上。随着这些机器学习模型的不断进步,它们将需要更好的基础设施和硬件支持来维持运行。机器学习的进步直接推动了计算性能的扩展。让我们进一步了解 TPU v4。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
什么是 TPU v4?
TPU 代表张量处理单元,它们被设计用于机器学习和深度学习应用。TPU 是谷歌发明的,构造方式使其能够处理机器学习和人工智能的高计算需求。
当谷歌设计 TPU 时,他们将其设计为特定领域架构,这意味着它被设计为矩阵处理器,而不是通用处理器,从而专注于神经网络工作负载。这解决了谷歌的内存访问问题,这一问题使得 GPU 和 CPU 的速度减慢,导致它们使用更多的处理能力。
那么,TPU v2、v3,现在是 v4。v2 到底是什么?
TPU v2 芯片包含两个 TensorCores、四个 MXUs、一个矢量单元和一个标量单元。见下图:
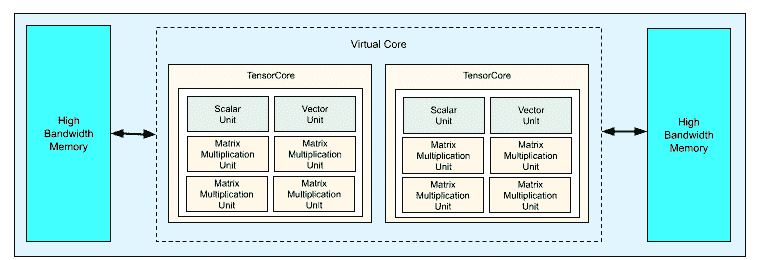
图片来源:Google
光学电路交换机(OCSes)
TPU v4 是首个部署可重构光学电路交换机的超级计算机。光学电路交换机(OCS)被认为更有效。它们减少了以前网络中的拥堵,因为它们在发生时进行传输。OCS 提高了可扩展性、可用性、模块化、部署、安全性、功率、性能等。
TPU v4 中的 OCS 和其他光学组件占 TPU v4 系统成本的不到 5%,系统功耗的不到 5%。
SparseCores
TPU v4 也是首个具有硬件支持嵌入的超级计算机。神经网络在密集向量上训练效果良好,而嵌入是将类别特征值转换为密集向量的最有效方式。TPU v4 包含第三代 SparseCores,这些数据流处理器加速了依赖于嵌入的机器学习模型。
例如,嵌入函数可以将英文单词翻译为较小的密集空间,每个单词表示为 100 维向量。嵌入是深度学习推荐模型(DLRMs)的关键元素,它们存在于我们日常生活中,用于广告、搜索排名、YouTube 等。
下图展示了在 CPU、TPU v3、TPU v4(使用 SparseCore)和 TPU v4(在 CPU 内存中使用嵌入,不使用 SparseCore)上的推荐模型性能。可以看到,TPU v4 SparseCore 在推荐模型上比 TPU v3 快 3 倍,比使用 CPU 的系统快 5 到 30 倍。
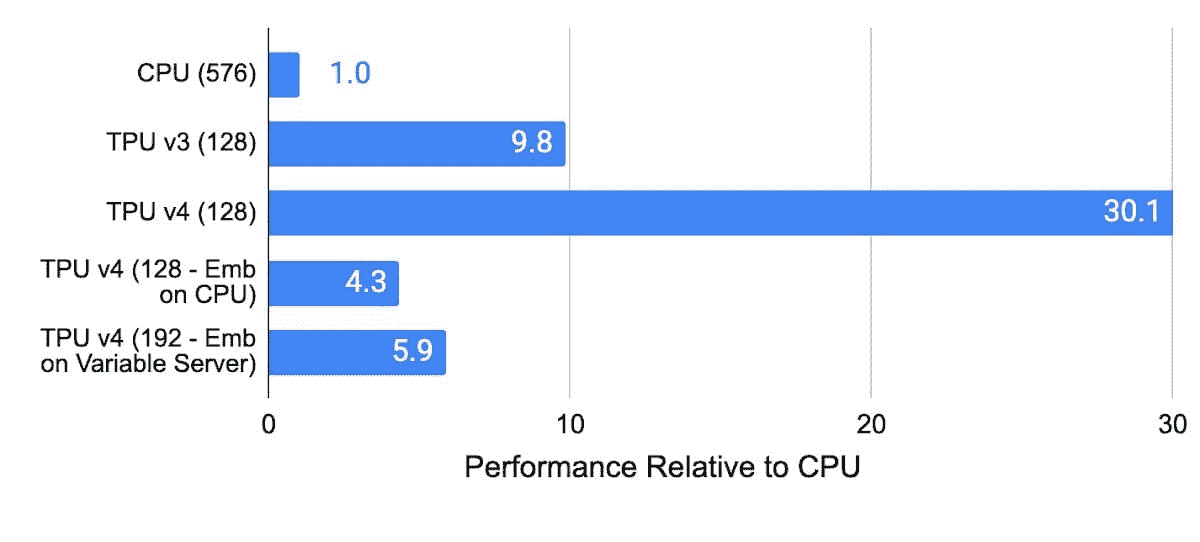
图片由 Google 提供
性能
TPU v4 的性能比 TPU v3 高 2.1 倍,性能/瓦特比提高了 2.7 倍。TPU v4 体积增大了 4 倍,达到 4096 个芯片,使其速度提高了 10 倍。OCS 的实现和灵活性也大大助力于大型语言模型。
TPU v4 超级计算机的性能和可用性正被广泛考虑用于改进大型语言模型,如 LaMDA、MUM 和 PaLM。540B 参数的 PaLM 模型在 TPU v4 上训练了超过 50 天,硬件浮点性能达到了令人惊叹的 57.8%。
TPU v4 还具有多维模型分区技术,使大型语言模型的低延迟、高吞吐量推理成为可能。
能效
随着全球公司为提升整体能效而制定更多法律法规,TPU v4 表现不俗。Google Cloud 中的 TPU v4 使用的能量比当代 DSA 少 ~2-6 倍,CO2e 排放量比典型的本地数据中心少 ~20 倍。
机器学习工作负载的变化
既然你对 TPU v4 了解更多了,你可能想知道机器学习工作负载在 TPU v4 上实际变化有多快。
下表展示了按深度神经网络模型类型的工作负载和使用的 TPU 百分比。Google 90%以上的训练在 TPU 上进行,这张表显示了 Google 生产工作负载的快速变化。
递归神经网络(RNN)的应用有所下降,因为 RNN 是一次性处理输入,而与之相比,变换模型在自然语言翻译和文本摘要方面更为出色。
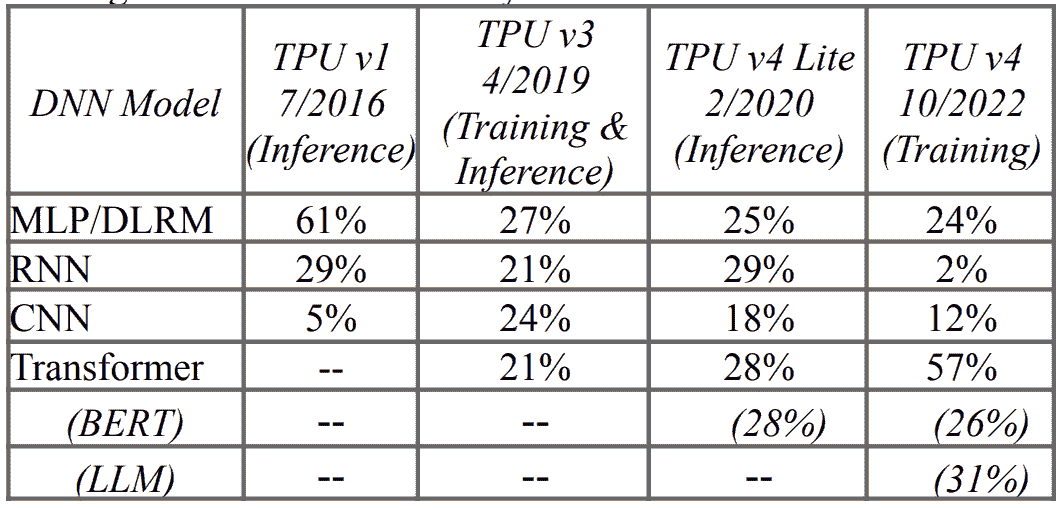
要了解更多关于 TPU v4 能力的信息,请阅读研究论文 TPU v4: 一种用于机器学习的光学可重构超级计算机,支持嵌入的硬件。
总结
去年,TPU v4 超级计算机在谷歌云的机器学习集群中向 AI 研究人员和开发者开放。该论文的作者声称 TPU v4 比 Nvidia A100 更快且功耗更低。然而,由于 Nvidia H100 GPU 的有限供应和其 4nm 架构,他们尚未能将 TPU v4 与更新的 Nvidia H100 GPU 进行比较,而 TPU v4 采用的是 7nm 架构。
你认为 TPU v4 的能力是什么,它的局限性如何,它是否比 Nvidia A100 GPU 更好?
尼莎·阿亚 是一名数据科学家、自由职业技术写作者及 KDnuggets 的社区经理。她特别关注于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何在延长人类寿命方面发挥作用。作为一个热衷学习者,她寻求拓宽技术知识和写作技能,同时帮助指导他人。
了解更多相关话题
介绍 VisualData:一个计算机视觉数据集的搜索引擎
原文:
www.kdnuggets.com/2018/09/introducing-visualdata-search-engine-computer-vision-datasets.html
评论
作者:Jie Feng,人性化 AI
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 为你的组织提供 IT 支持
计算机视觉无疑将在不久的将来改变机器与我们及环境互动的几乎所有方面。虽然这一领域仍然年轻(起源于 1960 年代),但得益于机器学习的最新进展,技术首次在历史上开始发挥作用。自动驾驶汽车、机器人技术、虚拟现实/增强现实等应用激励了人们进入这一领域,并将技术应用于更广泛的领域。它已经成为人工智能最活跃的子领域之一。
关于计算机视觉的疯狂想法每天都在发生,涉及新的研究、边项目或业务用例。要从事计算机视觉工作,你需要三样东西:数据、算法和计算。像谷歌和亚马逊这样的巨头公司通过其云平台提供了强大的计算能力。研究界(例如 arXiv)和开源社区(例如 Github)为我们带来了更好的算法和易于使用的代码。现在学习这一复杂的主题是最佳时机,而这一主题曾经需要博士级别的经验。但仍然存在一个问题——数据。更具体地说,就是具有高质量注释的视觉数据。构建一个良好的数据集需要在规模、内容平衡、视觉变化等方面进行大量思考,以帮助训练的模型在未见过的案例中表现良好。标注大规模数据集可能非常昂贵且缓慢,这使得预算有限的个人或小公司仍然面临实验新想法的障碍。
解决这个问题的答案是开源数据集。与其自己构建数据集,不如利用已经由学术研究者、爱好者和公司贡献的丰富计算机视觉数据集。这些数据集涵盖了从识别对象到重建 3D 房间,从在视频中找人到识别照片中的衬衫等多种主题。它们通常附带人工标注的高质量标签。近年来,新的数据集甚至包括了预训练的深度学习模型,你可以直接尝试,而无需自己训练。然而,发现这些数据集并不容易。它们通常分散在创作者的网站上,很难比较不同的数据集以选择适合特定任务的最佳数据集。对于新手来说,也很难找出合适的关键字来进行 Google 搜索。
这就是为什么我们构建了VisualData,这是一个计算机视觉数据集的搜索引擎。目前,每个数据集都是人工筛选的,并标记了相关主题以便过滤,你可以在搜索栏中输入关键字,这些关键字将与数据集的标题和描述匹配,以便轻松找到最佳的使用数据集。它们按照发布时间排序,因此最新添加的数据集会被优先显示。详细视图显示了数据集的完整描述,并链接到开源代码/模型。将来还会逐步添加其他有用的信息,例如关于数据集的文章/教程、使用难度等。下面展示了一些网站的示例截图。

从左到右:按(多个)主题过滤,按关键字搜索,数据集详细信息。
这是我希望在攻读博士学位时能存在的网站。现在,我希望它能帮助对计算机视觉感兴趣的人轻松探索现有数据,从而更快地进行实验。它仍处于早期阶段,未来版本中还有一些很酷的想法。我们希望了解它如何对你更有用。
附言:喜欢这个 Facebook 页面 或关注我们的 Twitter 以获取新数据集或代码发布的更新,并提供反馈和功能建议。
简介:Jie Feng 拥有哥伦比亚大学计算机科学博士学位,并且是 VisualData 的创始人。
原文。已获许可转载。
相关:
-
宣布微软研究开源数据,云托管平台用于共享数据集
-
DIY 深度学习项目
-
使用 Numpy 和 OpenCV 进行基本图像数据分析 – 第一部分
相关话题
活跃学习简介
原文:
www.kdnuggets.com/2018/10/introduction-active-learning.html
评论
由 Jennifer Prendki, Figure Eight 的机器学习副总裁
随着数据收集和存储变得越来越便宜,数据科学家面临的数据量超过了他们能够分析的能力。而且这一趋势没有减缓的迹象:物联网设备的爆炸性增长以及新的内存密集型数据格式的出现,使得数据专业人员在原始数据的海洋中挣扎。
鉴于机器学习中最激动人心的进展需要大量数据,这确实是一个令人兴奋的时代。但这也给机器学习社区带来了全新的挑战:除非数据被标注,否则它对所有依赖监督学习方法的机器学习应用基本上是无用的。
数据标注:机器学习中的新瓶颈
过去十年中,人工智能最有前景的进展之一来自于深度学习模型的使用。虽然神经网络几十年前就被发现了,但它们的实际使用直到最近才得以实现,这要归功于数据量和计算能力的增加,而旧硬件根本无法提供这些。由于大多数深度学习算法使用监督学习方法且对数据需求量大,因此现在机器学习中的新瓶颈不再是数据的收集,而是标注过程的速度和准确性。毕竟,我们大多数人都熟悉“垃圾进,垃圾出”的格言。除非你拥有高质量的数据来训练模型,否则模型的性能最终会受到影响。
由于获取未标记实例现在基本上是免费的,赢得人工智能竞赛现在取决于拥有最快、最具扩展性、灵活和可靠的方式来获取数据集的质量标签。标注大量数据已经成为一个关键问题,因为待标注的数据量变得如此庞大,甚至全球所有的人工劳动都无法满足需求。例如,即使每个边界框标注几秒钟,单靠一个人对一个 10 秒钟的视频进行行人标注也可能需要几个小时,这就是为什么越来越多的公司现在专注于构建机器学习算法以自动化标注过程。单纯的人力方法根本无法扩展。
但数据的数量并不是唯一的问题。获取标签也往往耗时(例如,当注释员被要求对较长文档的主题进行标注时),经常容易出错(有时也具有主观性),费用昂贵(例如,“标注”患者记录为癌症阳性可能需要 MRI 扫描或其他昂贵的医学检查,或验证石油存在可能需要钻探),甚至可能很危险(例如,在地雷探测的情况下)。
更快标注与更聪明标注
为应对对高质量注释的急剧需求,一种人机协作的 AI 方法,其中人类注释员验证机器学习算法的输出,看起来是一种有前途的方法。它不仅可以加快处理速度,还能提高质量,因为人类干预有助于弥补算法的不准确性。
尽管这种蛮力方法有时是最佳途径,但另一个方法在 ML 社区中正在慢慢获得更多关注:即仅标注最重要的数据实例。作为数据科学家,我们习惯于认为更多的数据等于更高的模型准确率,但虽然这绝对正确,但也要承认并非所有数据都同等重要,因为并非所有例子都包含相同数量的信息。
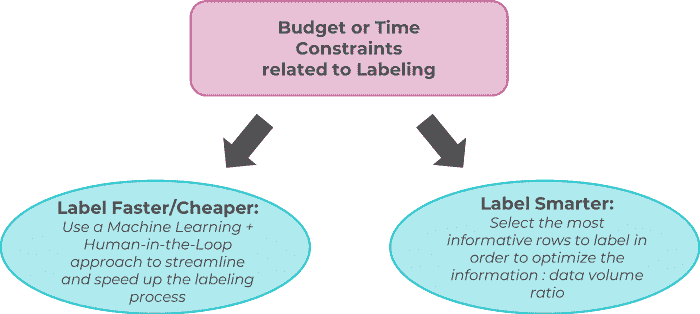
图 1:应对新兴的大标签危机的两种方法
确定模型学习的最佳实例可以发生在两个不同的时间:要么在模型构建之前,要么在模型训练期间。前者通常称为优先级排序,而后者称为主动学习。
什么是主动学习?
尽管在流行的 ML 博客中覆盖率较低,但主动学习实际上在许多现代 ML 问题中得到了令人惊讶的充分激励,特别是当标签难以获得、耗时或昂贵时。
在主动学习中,学习算法被允许从尚未标注的实例池中主动选择下一步要标注的样本。该概念背后的基本信念是,如果机器学习算法能够选择它想学习的数据,它可能在使用较少的训练标签的情况下实现更好的准确性。这种算法被称为主动学习者。主动学习者可以在训练过程中动态提出查询,通常以未标注的数据实例的形式,由被称为oracle的人类注释员进行标注。因此,主动学习是人机协作范式成功的最有力示例之一。
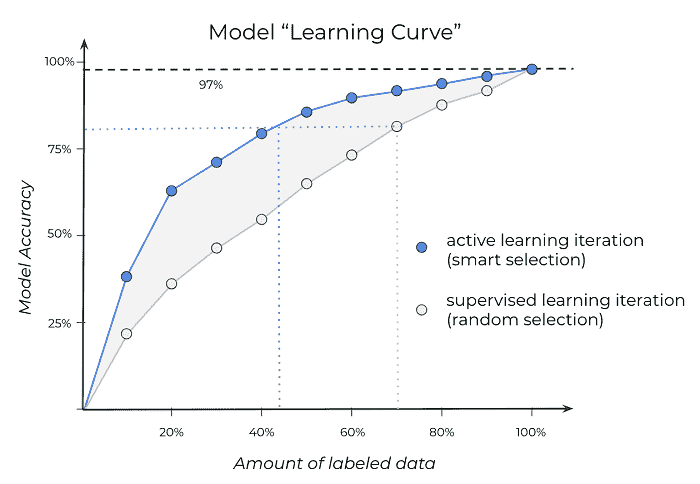
图 2:正如预期的那样,训练模型所需的数据越多,准确度越高,无论是否使用主动学习方法。然而,使用主动学习时,可以用显著更少的数据达到特定的准确度;在这个例子中,仅使用 45%的可用数据总量就可以实现 80%的准确度,而在常规监督学习的情况下则需要 70%。
主动学习是如何工作的?
主动学习可以通过不同的场景来实现。本质上,决定是否查询特定标签归结为判断获取标签的收益是否抵消了收集该信息的成本。实际上,这个决策可以根据科学家是否有有限的预算或只是试图最小化标记费用的不同而采取几种形式。总体而言,主动学习可以分为三种不同的类别:
基于流的选择性采样场景涉及确定询问数据集中某个特定未标记条目的标签是否足够有益。随着模型的训练和数据实例的呈现,它会立即决定是否需要查看标签。这种方法的缺点自然在于没有保证数据科学家会保持在其预算范围内。
基于池的采样场景也是最为人知的一个。它尝试在选择最佳查询或一组最佳查询之前评估整个数据集。主动学习者通常最初在一个完全标记的数据子集上进行训练,从而生成模型的第一个版本,该模型随后用于识别哪些实例对下一次迭代(或主动学习循环)注入训练集最有益。其最大的缺点之一在于其内存需求非常高。
成员查询合成场景可能并不适用于所有情况,因为它涉及生成合成数据。在这种场景下,学习者可以构造自己的例子进行标记。这种方法在生成数据实例较为容易时,对于解决冷启动问题(如搜索引擎中的问题)是非常有前途的。
主动学习与强化学习有何不同?
尽管强化学习和主动学习都可以减少模型所需的标签数量,但它们是非常不同的概念。
一方面,我们有强化学习。强化学习是一种目标导向的学习方法,受到行为心理学的启发,它允许你从环境中获得输入。因此,强化学习意味着代理在使用过程中会变得更好:它在使用中学习。当我们人类从错误中学习时,我们实际上是在进行一种强化学习方法。没有实际的训练阶段;而是代理通过试错过程使用预定的奖励函数来学习,该函数反馈关于特定动作的效果如何。技术上讲,强化学习不需要提供数据,而是随着进程生成自己的数据。
主动学习,另一方面,更接近于传统的监督学习。实际上,它是一种半监督学习(同时使用标注数据和未标注数据)。这一概念的核心思想是,并非所有数据的价值相同,标注一个小样本的数据可能会达到相同的准确性(如果不是更高),唯一的挑战是确定这个样本是什么。主动学习是指在训练阶段逐步动态地标注数据,以便让算法识别哪个标签对其学习更有信息量,从而更快地学习。
如何决定标注哪一行?
用于确定下一个需要标注的数据实例的方法称为查询策略。下面列出的是那些最常用和研究的策略:
不确定性采样
对于那些查询策略,首先在一个相对较小的标注数据样本上训练一个模型;然后将这个模型应用于数据集的(未标注的)其余部分。该算法基于通过推理步骤获得的信息选择下一个主动学习循环中需要标注的实例。
在这些策略中,最受欢迎的是最小置信度策略,其中模型选择那些置信度最低的实例进行标注。另一种常见策略叫做边际采样:在这种情况下,算法选择那些两个最可能的标签之间的边际较小的实例,这意味着分类器在区分这两个最可能的类别时遇到了困难。这两种策略旨在帮助模型在特定类别之间进行区分,并且在减少特定分类错误方面表现出色。然而,如果目标函数是减少对数损失,则通常基于熵的方法更为合适,在这种方法中,学习者简单地查询模型在预测中具有最高输出方差的未标注实例。
查询委员会(即,QBC)
使用这些策略,对相同标记训练集的不同模型进行训练,并用于推断其余(尚未标记)数据。对于观察到最大分歧的实例,被认为是最具信息性的。这一框架的核心思想是最小化版本空间,即与当前标记训练数据一致的假设集合。
预期影响
这些查询策略考察新标签的增加对模型整体性能的影响。期望模型变化策略旨在识别那些如果已知标签将对当前模型产生最大变化的实例。期望误差减少策略衡量的不是模型可能发生的变化量,而是模型的泛化误差可能减少的量。这种策略面临的挑战之一是,它也是最计算上昂贵的查询框架。由于最小化期望损失函数通常没有封闭形式的解,因此使用方差减少方法作为代理。
总的来说,这些方法学将输入空间整体考虑,而不是像不确定性采样或 QBC 那样关注个别实例,这使得它们在选择离群点时具有明显的优势。
密度加权方法
之前的框架描述了那些识别最具信息性的实例的策略,这些实例被认为是不确定性最高的。然而,另一种看待问题的方法是,数据集中最有价值的实例不一定是那些不确定性最大的,而是那些最能代表数据底层分布的实例:这就是信息密度框架的核心思想。
性能与限制
超过 90%的进行过主动学习工作的研究者声称他们的期望得到或完全或部分满足。这非常令人鼓舞,但人们不禁想知道其他情况下发生了什么。
现实情况是,主动学习仍未被很好地理解。例如,有一些关于 NER 的深度主动学习的有前景的工作,但许多重大问题仍然存在。例如,几乎没有研究预测特定任务或数据集是否特别容易从主动学习方法中受益。
最终,主动学习是一种特定的半监督学习情况,这类算法已被证明对偏见非常敏感,特别是因为它们容易自我满足于从基于相对较小数据集训练的模型中识别出的模式中得到的初始信念。随着高效标注成为机器学习中越来越关键的组成部分,可以预期未来几年将会有更多关于这个主题的研究成果发表。
简介: 詹妮弗·普伦基是一位数据科学领袖和数据策略师,她非常享受设想数据科学的未来并推广它。詹妮弗特别擅长培养和管理早期阶段的数据团队,并且非常擅长管理混合团队,包括产品经理、数据科学家、数据分析师和各类工程师(前端、后端、系统等)。
相关:
我们的前三推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持您的组织在 IT 领域
相关主题
AI 简介,更新版
评论
由 Imtiaz Adam,AI 和战略执行官。

我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
什么是人工智能(AI)
AI 涉及开发能够执行人类擅长的任务的计算系统,例如识别物体、理解和分析语言,以及在受限环境中做出决策。
窄域 AI: AI 的一个领域,机器被设计用来执行单一任务,并且机器在执行该任务时非常出色。然而,一旦机器训练完成,它不会推广到未见领域。这是我们今天拥有的 AI 形式,例如 Google 翻译。
人工通用智能(AGI): 一种可以完成任何人类能够做的智力任务的 AI 形式。它更具意识,并做出类似于人类决策的决定。AGI 目前仍然是一个理想,关于它的到来,各种预测从 2029 年到 2049 年甚至可能永远无法实现。它可能在未来 20 年左右到来,但面临与硬件、今日强大机器的能耗需求以及解决影响即使是最先进深度学习算法的灾难性记忆丧失等挑战。
超级智能: 是一种在所有领域的表现超越人类的智能(根据 Nick Bostrom 的定义)。这涉及到一般智慧、问题解决和创造力等方面。

经典人工智能:包括基于规则的系统、搜索算法(如无信息搜索(广度优先、深度优先、普遍成本搜索)和有信息搜索如 A 和 A*算法)。这些奠定了今天更先进的方法的坚实基础,这些方法更适合大规模搜索空间和大数据集。它还包括逻辑方法,如命题和谓词演算。虽然这些方法适用于确定性场景,但现实世界中的问题往往更适合概率方法。
该领域近年来在各个行业中产生了重大影响,包括医疗保健、金融服务、零售、营销、交通、安全、制造和旅行行业。
大数据的出现,由互联网、智能移动设备和社交媒体的到来推动,使得 AI 算法,特别是机器学习和深度学习,能够利用大数据并更优化地执行任务。加上更便宜、更强大的硬件,如图形处理单元(GPU),使 AI 发展成更复杂的架构。
机器学习
机器学习被定义为应用统计方法使计算机系统从数据中学习以实现最终目标的 AI 领域。这个术语由 Arthur Samuel 在 1959 年引入。
需要理解的关键术语
特征/属性:用于将数据表示为算法可以理解和处理的形式。例如,图像中的特征可能表示边缘和角落。
熵:随机变量中的不确定性量。
信息增益:由一些先前知识带来的信息量。
监督学习:一种处理已标记(注释)数据的学习算法。例如,通过带有标记的水果图像学习将水果分类为苹果、橙子、柠檬等。
无监督学习:一种发现数据中隐藏模式的学习算法,数据未被标记(注释)。一个例子是将客户分成不同的群体。
半监督学习:当只有一小部分数据被标记时的学习算法。
主动学习涉及一种算法可以主动询问教师标签的情况。Jennifer Prendki定义为“……一种半监督学习(其中使用了标记和未标记的数据)……主动学习是指在训练阶段逐步和动态地标记数据,以使算法识别最有信息量的标签,从而更快地学习。”
损失函数:是实际情况与算法学习到的内容之间的差异。在机器学习中,目标是最小化损失函数,以便算法能够继续在未见过的场景中进行泛化和表现。
机器学习方法(非详尽列表)
分类、回归和聚类是机器学习的三个主要领域。
分类被 Jason Brownlee 总结为“关于预测标签,而回归则是关于预测量。分类是预测离散类标签的任务。分类预测可以使用准确率进行评估,而回归预测则不能。”
回归预测建模被 Jason Brownlee 总结为“任务是从输入变量(X)到连续输出变量(y)近似一个映射函数(f)。回归是预测一个连续量的任务。回归预测可以使用均方根误差进行评估,而分类预测则不能。”
聚类被 Surya Priy 总结为“将总体或数据点划分为若干组的任务,使得同一组中的数据点彼此之间更为相似,而与其他组中的数据点则不相似。它基本上是根据相似性和差异性对对象进行的集合。”
强化学习: 是一个处理在环境中建模代理的领域,该环境不断奖励代理做出正确决策。举例来说,代理在与人类对弈的国际象棋中获胜。当代理走出正确的棋步时会获得奖励,走错则会受到惩罚。经过训练后,该代理可以在真实比赛中与人类竞争。
线性回归: 是机器学习的一个领域,它建模两个或多个具有连续值的变量之间的关系。
逻辑回归: 是一种分类技术,它将 logit 函数建模为特征的线性组合。二元逻辑回归处理变量只有两个结果(‘0’或‘1’)的情况。多项逻辑回归处理预测变量可能有多个不同值的情况。
k-均值: 是一种无监督的方法,用于根据数据实例之间的相似性对其进行分组(或聚类)。一个例子是根据相似性对人口进行分组。
K-最近邻(KNN): 是一种监督机器学习算法,可用于解决分类和回归问题。它基于这样一个假设:相似的项彼此靠近。
支持向量机(SVM): 是一种分类算法,通过在两个数据类别之间绘制分隔超平面来进行分类。一旦训练完成,SVM 模型可以用作对未见数据的分类器。
决策树: 是一种从数据中学习决策规则的算法。这些规则随后用于决策制定。
提升和集成: 是将多个表现不佳的弱学习者组合成一个强分类器的方法。自适应提升(AdaBoost)可以应用于分类和回归问题,通过结合多个弱分类器来创建一个强分类器。最近的一些关键示例包括 XG Boost,它在 Kaggle 竞赛中对表格或结构化数据表现出色(参见 Tianqi Chen 和 Carlos Guestrin 2016), 微软在 2017 年推出的 Light Gradient Boosting Machine(Light GBM),以及 Yandex 在 2017 年推出的 CatBoost。有关集成学习的更多信息,请参见 Jason Brownlee 的集成学习文章 和 KDnuggets 发表的文章 标题为 CatBoost 与 Light GBM 与 XGBoost。
随机森林: 属于集成学习技术的范畴,通过在训练期间创建多个决策树来引入随机性。输出将是各个树的平均预测值或表示类别模式的类别。这可以防止算法过拟合或记忆训练数据。
主成分分析(PCA): 是一种减少数据维度的方法,同时保持数据的可解释性。这有助于去除数据中冗余的信息,同时保留解释大部分数据的特征。
同步定位与地图构建 (SLAM): 处理机器人在未知环境中定位自己的方法。
进化遗传算法: 这些算法受到生物学的启发,灵感来源于进化理论。它们通常用于解决优化和搜索问题,通过应用包括选择、交叉和变异在内的生物启发概念。
神经网络: 是受生物启发的网络,通过层级化方式从数据中提取抽象特征。神经网络在 1980 年代和 1990 年代曾遭到抑制。是Geoff Hinton继续推动了神经网络的发展,尽管当时许多经典人工智能社区对他嗤之以鼻。深度神经网络(参见下文定义)发展的关键时刻是在 2012 年,当时来自多伦多的一个团队在 ImageNet 竞赛中用 AlexNet 网络向世界展示了自己。他们的神经网络与之前使用手工提取特征的方法相比,大大减少了错误率。
深度学习
深度学习指的是具有多个隐藏层的神经网络领域。这样的神经网络通常被称为深度神经网络。
目前使用的几种主要深度神经网络类型包括:
卷积神经网络(CNN): 卷积神经网络是一种通过卷积操作从输入数据中以层次化方式提取模式的神经网络。它主要用于具有空间关系的数据,例如图像。卷积操作通过在图像上滑动内核来提取与任务相关的特征。
递归神经网络(RNN): 递归神经网络,特别是 LSTM,用于处理序列数据。例如,时间序列数据、股票市场数据、语音、传感器信号和能源数据具有时间依赖性。LSTM 是一种更高效的 RNN,缓解了梯度消失问题,使其能够记住短期和远期的信息。
限制玻尔兹曼机(RBM): 基本上是一种具有随机属性的神经网络。限制玻尔兹曼机使用名为对比散度的方法进行训练。训练完成后,隐藏层是输入的潜在表示。RBM 学习输入的概率表示。
深度置信网络: 是由限制玻尔兹曼机组成的,每一层作为下一层的可见层。在向网络中添加额外层之前,每一层都经过训练,这有助于概率性地重建输入。该网络使用逐层无监督的方法进行训练。
变分自编码器(VAE): 是一种改进版的自编码器,用于学习输入的最优潜在表示。它由一个编码器和一个解码器以及一个损失函数组成。VAE 使用概率方法,并涉及潜在高斯模型中的近似推断。
生成对抗网络(GANs):生成对抗网络是一种使用生成器和判别器的卷积神经网络(CNN)。生成器不断生成数据,而判别器则学习区分虚假数据与真实数据。随着训练的进行,生成器不断提高生成看起来真实的虚假数据的能力,而判别器则更好地学习区分虚假和真实的数据,从而帮助生成器自我改进。训练完成后,我们可以使用生成器生成看起来很真实的虚假数据。例如,一个训练过脸部图像的 GAN 可以用来生成不存在的、非常真实的脸部图像。
变换器:用于处理序列数据,特别是在自然语言处理(NLP)领域中,处理文本数据的任务,如语言翻译。该模型于 2017 年在一篇名为"Attention is All you Need"的论文中首次提出。变换器模型的架构包括编码器和解码器的应用,以及自注意力机制,涉及到对输入序列中不同位置的关注能力,并生成序列的表示。与 RNN 相比,它们的优势在于不需要按序处理数据,这意味着在处理句子时,不需要先处理句子的开头再处理结尾。著名的变换器模型包括双向编码器表示(BERT)和 GPT 变体(来自 OpenAI)。
深度强化学习:深度强化学习算法涉及建模一个智能体,该智能体学习以尽可能最优的方式与环境互动。智能体不断采取行动,始终牢记目标,而环境则根据智能体的行动给予奖励或惩罚。通过这种方式,智能体学习以最优的方式行为,以实现目标。DeepMind 的 AlphaGo 是智能体学习下围棋并能够与人类竞争的最佳例子之一。
胶囊网络:仍然是一个活跃的研究领域。卷积神经网络(CNN)通常学习到的数据表示往往难以解释。另一方面,胶囊网络能够从输入中提取特定类型的表示,例如,它保留了物体部件之间的层次姿态关系。胶囊网络的另一个优势是它能够用比 CNN 所需的更少的数据学习表示。有关胶囊网络的更多信息,请参见胶囊之间的动态路由,堆叠胶囊自编码器和DA-CapsNet:双重注意力机制胶囊网络。
神经进化:由Kenneth O. Stanley定义为:“旨在触发一种与产生我们大脑的进化过程类似的进化过程,只不过是在计算机内部。换句话说,神经进化旨在通过进化算法来发展演化神经网络的方法。” Uber Labs 的研究人员认为,神经进化方法在一定程度上由于降低了陷入局部最小值的可能性,与基于梯度下降的深度学习算法具有竞争力。Stanley 等人表示:“我们的希望是激发对该领域的新兴趣,因为它满足了今天日益增加的计算能力的潜力,突显其许多想法如何为深度学习、深度强化学习和机器学习社区提供令人兴奋的灵感和混合资源,并解释神经进化如何在长期追求人工通用智能中证明是一个关键工具。”
神经符号人工智能:由MIT-IBM Watson AILab定义为一种将神经网络(从原始数据文件中提取统计结构——例如图像和声音文件的背景)与问题和逻辑的符号表示结合起来的 AI 方法的融合。“通过融合这两种方法,我们正在构建一种新型的 AI,其能力远超其部分之和。这些神经符号混合系统需要较少的训练数据,并跟踪进行推理和得出结论所需的步骤。它们在跨领域转移知识时也更为轻松。我们相信,这些系统将引领 AI 的新纪元,让机器更像人类一样学习,通过将词语与图像连接起来,掌握抽象概念。”
联邦学习:也称为协作学习,在维基百科中定义为一种机器学习技术,使得算法可以在多个去中心化的服务器(或设备)上进行训练,而无需交换本地数据。差分隐私旨在通过衡量联邦学习元素间通信的隐私损失来增强数据隐私保护。这项技术可能解决数据隐私和安全的关键挑战,涉及异构数据,并影响物联网(IoT)、医疗保健、银行、保险等领域,在这些领域数据隐私和协作学习至关重要,并且随着 AI IoT 的扩展,可能会成为 5G 和边缘计算时代的关键技术。
原文。经许可转载。
简介: Imtiaz Adam,计算机科学硕士(人工智能与机器学习工程师)和斯隆战略研究员,MBA,专注于人工智能和机器学习技术的开发,特别是深度学习方面。
相关:
更多相关主题
自编码器和变分自编码器(VAE)介绍
原文:
www.kdnuggets.com/2021/10/introduction-autoencoder-variational-autoencoder-vae.html
评论

我们的三大推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
近年来,基于深度学习的生成模型因在人工智能(AI)领域取得的惊人进展而越来越受到关注。依靠大量的数据、精心设计的网络架构和智能训练技术,深度生成模型展示了生成各种高度逼真内容的惊人能力,例如图像、文本和声音。
在本文中,我们将深入探讨这些生成网络,特别是自编码器、变分自编码器(VAE)及其使用 Keras 的实现。
什么是自编码器?
自编码器(AE)是旨在将其输入复制到输出的神经网络。它们通过将输入压缩成潜在空间表示,然后从该表示重建输出。
自编码器由两个主要组件组成:
-
编码器: 学习将输入数据压缩(减少)成编码表示。
-
解码器: 学习从编码表示中重建原始数据,使其尽可能接近原始输入。
-
瓶颈/潜在空间: 包含输入数据压缩表示的层。
-
重建损失: 该方法测量解码器的表现,即衡量编码和解码向量之间的差异。差异越小越好。
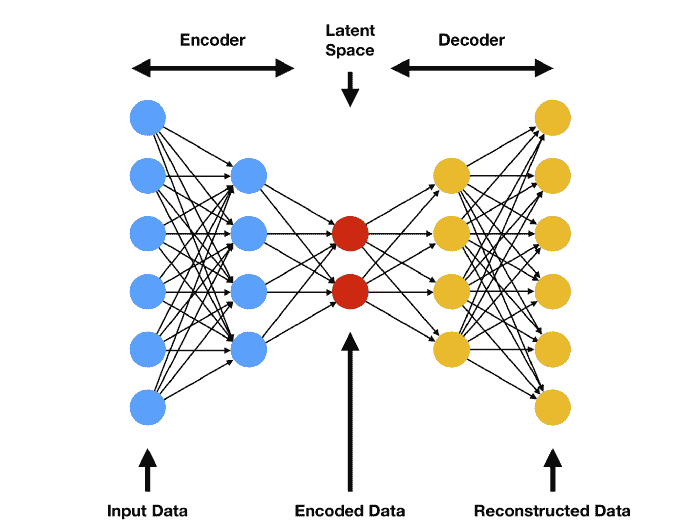
自编码器。
该模型涉及由ϕ参数化的编码函数g和由θ参数化的解码函数f。瓶颈层是:
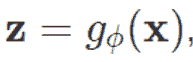
重建的输入:
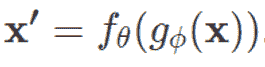
为了测量重建损失,我们可以使用交叉熵(当激活函数是 sigmoid 时)或基本的均方误差(MSE):
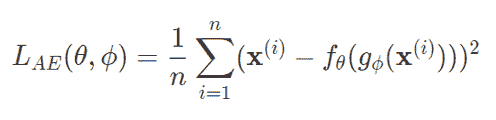
香草自编码器的类型
-
欠完备自编码器: 一个潜在空间小于输入维度的自编码器称为欠完备。学习一个欠完备的表示会迫使自编码器捕捉训练数据中最显著的特征。
-
正则化自编码器: 它们使用一个损失函数,鼓励模型除了具备将输入复制到输出的能力之外,还有其他属性。在实践中,我们通常会发现两种类型的正则化自编码器:稀疏自编码器和去噪自编码器。
-
稀疏自编码器: 稀疏自编码器通常用于学习另一任务的特征,比如分类。一个被正则化为稀疏的自编码器必须响应它训练过的数据集的独特统计特征,而不仅仅是作为一个恒等函数。这样,通过带有稀疏性惩罚的复制任务训练可以产生一个作为副产品学习到有用特征的模型。
-
去噪自编码器: 目标不再是重建输入数据。我们可以通过改变损失函数的重建误差项来获得一个学习有用东西的自编码器。这可以通过向输入图像添加一些噪声并让自编码器学习去除它来实现。这样,编码器将提取最重要的特征并学习数据的稳健表示。
不同类型的自编码器。
自编码器的应用
传统自编码器主要有两个应用:
- 噪声去除: 如上所述,噪声去除是从图像中去除噪声的过程。音频和图像都有噪声减少技术。
去噪图像。
-
降维: 由于编码器部分学习输入数据的低维表示,当你希望进行降维时,自编码器的编码器部分很有用。这在例如主成分分析(PCA)不起作用时尤其有用,但你怀疑非线性降维(即,使用具有非线性激活函数的神经网络)有效。
-
异常检测: 通过学习在某些约束条件下复制训练数据中最显著的特征,模型被鼓励准确重现最频繁观察到的特征。当遇到异常时,模型的重构性能应会变差。在大多数情况下,仅使用正常实例的数据来训练自编码器。训练后,自编码器将准确重构“正常”数据,而无法处理不熟悉的异常数据。重构误差(原始数据与其低维重构之间的误差)被用作异常分数来检测异常。
-
机器翻译: 自编码器已被应用于机器翻译,这通常被称为神经机器翻译(NMT)。与传统自编码器不同,输出不与输入匹配——它是另一种语言。在 NMT 中,文本被视为要编码到学习过程中的序列,而在解码器一侧,则生成目标语言中的序列。

降维操作。
Keras 自编码器实现
让我们使用著名的 MNIST 数据集并应用自编码器来重建它。MNIST 数据集由 70000 张 28 像素乘 28 像素的手写数字图像和 70000 个包含每个数字信息的向量组成。
# We create a simple AE with a single fully-connected neural layer as encoder and as decoder:
import numpy as np
import keras
from keras import layers
from keras.datasets import mnist
import matplotlib.pyplot as plt
# This is the size of our encoded representations
encoding_dim = 32 # 32 floats -> compression of factor 24.5, assuming the input is 784 floats
# This is our input image
input_img = keras.Input(shape=(784,))
# "encoded" is the encoded representation of the input
encoded = layers.Dense(encoding_dim, activation='relu')(input_img)
# "decoded" is the lossy reconstruction of the input
decoded = layers.Dense(784, activation='sigmoid')(encoded)
# This model maps an input to its reconstruction
autoencoder = keras.Model(input_img, decoded)
# Let's also create a separate encoder model:
# This model maps an input to its encoded representation
encoder = keras.Model(input_img, encoded)
# As well as the decoder model:
# This is our encoded (32-dimensional) input
encoded_input = keras.Input(shape=(encoding_dim,))
# Retrieve the last layer of the autoencoder model
decoder_layer = autoencoder.layers[-1]
# Create the decoder model
decoder = keras.Model(encoded_input, decoder_layer(encoded_input))
# Now let's train our autoencoder to reconstruct MNIST digits.
# First, we'll configure our model to use a per-pixel binary crossentropy loss, and the Adam optimizer:
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
#Let's prepare our input data. We're using MNIST digits, and we're discarding the labels (since we're only interested in encoding/decoding the input images).
(x_train, _), (x_test, _) = mnist.load_data()
# We will normalize all values between 0 and 1 and we will flatten the 28x28 images into vectors of size 784.
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
# Now let's train our autoencoder for 50 epochs:
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
# After 50 epochs, the autoencoder seems to reach a stable train/validation loss value of about 0.09\. We can try to visualize the reconstructed inputs and the encoded representations. We will use Matplotlib.
# Encode and decode some digits
# Note that we take them from the *test* set
encoded_imgs = encoder.predict(x_test)
decoded_imgs = decoder.predict(encoded_imgs)
n = 10 # Number of digits to display
plt.figure(figsize=(20, 4))
for i in range(n):
# Display original
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# Display reconstruction
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
这是我们得到的结果。顶部一排是原始数字,底部一排是重建的数字。使用这种基本方法,我们失去了相当多的细节。
自编码器在内容生成中的局限性
训练自编码器之后,我们可能会考虑是否可以利用该模型生成新内容。特别地,我们可能会问,是否可以从那个潜在空间中随机生成一个点并解码以获得新内容?
答案是“是的”,但生成数据的质量和相关性取决于潜在空间的规则性。潜在空间规则性取决于初始数据的分布、潜在空间的维度以及编码器的架构。很难事先确保编码器会以与我提到的生成过程兼容的聪明方式组织潜在空间。没有正则化意味着过拟合,这会导致解码后某些点的内容无意义。
我们如何确保潜在空间的正则化程度足够?我们可以在训练过程中明确引入正则化。因此,我们引入了变分自编码器。
什么是变分自编码器(VAE)?
变分自编码器(VAE)是对自编码的一个稍微现代化且有趣的变体。
VAE 假设源数据具有某种潜在概率分布(例如高斯分布),然后尝试找到该分布的参数。实现变分自编码器比实现自编码器要复杂得多。变分自编码器的主要用途之一是生成与原始源数据相关的新数据。现在,确切地说这些额外数据有什么用处很难说明。变分自编码器是一个生成系统,类似于生成对抗网络(尽管 GAN 的工作方式大相径庭)。
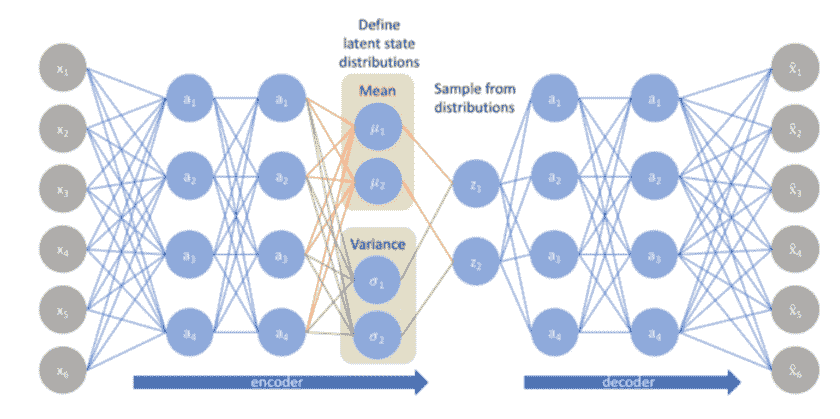
变分自编码器(VAE)背后的数学
VAE 使用 KL 散度 作为其损失函数。其目标是最小化假设分布与数据集原始分布之间的差异。
假设我们有一个分布 z,我们想从中生成观察值 x。换句话说,我们想计算:
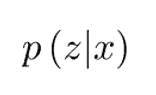
我们可以通过以下方式实现:
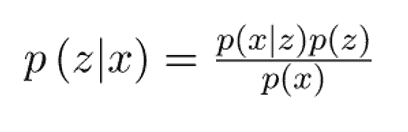
但是,p(x) 的计算可以通过积分完成,如下所示:
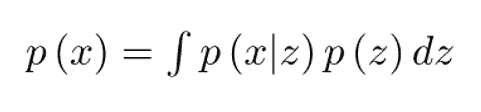
这通常使得它成为一个难以处理的分布(需要等于或更多的指数时间)。因此,我们需要将 p(z|x) 近似为 q(z|x) 以使其成为一个可处理的分布。为了更好地将 p(z|x) 近似为 q(z|x),我们将最小化 KL 散度 损失,这样可以计算两个分布之间的相似性:
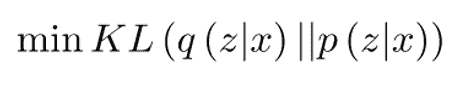
通过简化,上述最小化问题等同于以下最大化问题:
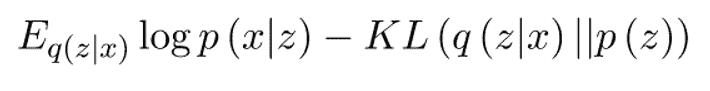
第一项表示重建似然性,另一项确保我们学习到的分布 q 与真实的先验分布 p 相似。
因此,我们的总损失由两个部分组成,一个是重建误差,另一个是 KL 散度损失:
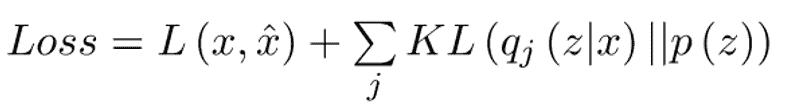
变分自编码器(VAE)的 Keras 实现
为了实现 VAE,首先,编码器网络将输入样本 x 转换为潜在空间中的两个参数,我们将其标记为 z_mean 和 z_log_sigma。然后,我们通过 z = z_mean + exp(z_log_sigma) * epsilon 从假设生成数据的潜在正态分布中随机采样相似点 z,其中 epsilon 是一个随机正态张量。
最终,解码器网络将这些潜在空间点映射回原始输入数据。
模型的参数通过两个损失函数进行训练:一个是重建损失,强制解码样本与初始输入匹配(就像在我们之前的自编码器中一样),另一个是KL 散度,用于表示学习到的潜在分布与先验分布之间的差异,作为正则化项。你实际上可以完全去掉这个后者的项,尽管它有助于学习良好的潜在空间并减少对训练数据的过拟合。
# First, here's our encoder network, mapping inputs to our latent distribution parameters:
original_dim = 28 * 28
intermediate_dim = 64
latent_dim = 2
inputs = keras.Input(shape=(original_dim,))
h = layers.Dense(intermediate_dim, activation='relu')(inputs)
z_mean = layers.Dense(latent_dim)(h)
z_log_sigma = layers.Dense(latent_dim)(h)
# We can use these parameters to sample new similar points from the latent space:
from keras import backend as K
def sampling(args):
z_mean, z_log_sigma = args
epsilon = K.random_normal(shape=(K.shape(z_mean)[0], latent_dim), mean=0., stddev=0.1)
return z_mean + K.exp(z_log_sigma) * epsilon
z = layers.Lambda(sampling)([z_mean, z_log_sigma])
# Finally, we can map these sampled latent points back to reconstructed inputs:
# Create encoder
encoder = keras.Model(inputs, [z_mean, z_log_sigma, z], name='encoder')
# Create decoder
latent_inputs = keras.Input(shape=(latent_dim,), name='z_sampling')
x = layers.Dense(intermediate_dim, activation='relu')(latent_inputs)
outputs = layers.Dense(original_dim, activation='sigmoid')(x)
decoder = keras.Model(latent_inputs, outputs, name='decoder')
# Instantiate VAE model
outputs = decoder(encoder(inputs)[2])
vae = keras.Model(inputs, outputs, name='vae_mlp')
# We train the model using the end-to-end model, with a custom loss function: the sum of a reconstruction term, and the KL divergence regularization term.
reconstruction_loss = keras.losses.binary_crossentropy(inputs, outputs)
reconstruction_loss *= original_dim
kl_loss = 1 + z_log_sigma - K.square(z_mean) - K.exp(z_log_sigma)
kl_loss = K.sum(kl_loss, axis=-1)
kl_loss *= -0.5
vae_loss = K.mean(reconstruction_loss + kl_loss)
vae.add_loss(vae_loss)
vae.compile(optimizer='adam')
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
# We train our VAE on MNIST digits:
vae.fit(x_train, x_train,
epochs=100,
batch_size=32,
validation_data=(x_test, x_test))
现在,由于我们的潜在空间是二维的,可以做一些很棒的可视化。例如,可以观察潜在二维平面上不同类别的邻域:
x_test_encoded = encoder.predict(x_test, batch_size=batch_size)
plt.figure(figsize=(6, 6))
plt.scatter(x_test_encoded[:, 0], x_test_encoded[:, 1], c=y_test)
plt.colorbar()
plt.show()
潜在二维平面上的不同数字。
每个这些彩色集群代表一种数字。在上面的图中,接近的集群是结构上相似的数字(即,在潜在空间中共享信息的数字)。
由于 VAE 是生成模型,我们还可以使用它生成新的数字!在这里,我们将扫描潜在平面,以规则的间隔采样潜在点,并为这些点生成相应的数字。这为我们提供了一个可视化的潜在流形,该流形“生成”MNIST 数字。
# Display a 2D manifold of the digits
n = 15 # figure with 15x15 digits
digit_size = 28
figure = np.zeros((digit_size * n, digit_size * n))
# We will sample n points within [-15, 15] standard deviations
grid_x = np.linspace(-15, 15, n)
grid_y = np.linspace(-15, 15, n)
for i, yi in enumerate(grid_x):
for j, xi in enumerate(grid_y):
z_sample = np.array([[xi, yi]])
x_decoded = decoder.predict(z_sample)
digit = x_decoded[0].reshape(digit_size, digit_size)
figure[i * digit_size: (i + 1) * digit_size,
j * digit_size: (j + 1) * digit_size] = digit
plt.figure(figsize=(10, 10))
plt.imshow(figure)
plt.show()

使用 VAE 生成数字。
变分自编码器(VAE)与生成对抗网络(GAN)
VAE 和 GAN 都是使用无监督学习来学习基础数据分布的非常激动人心的方法。与 VAE 相比,GAN 通常能获得更好的结果。
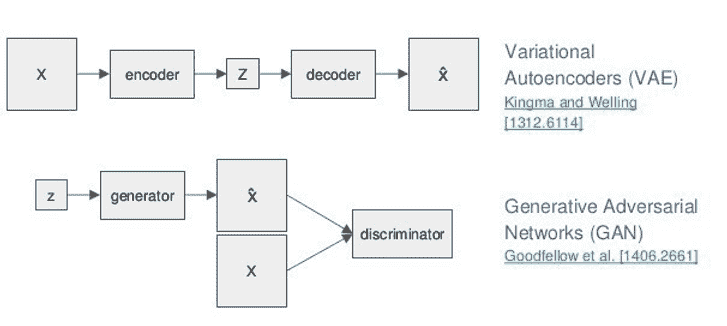
GAN 的生成器从一个相对低维的随机变量中采样并生成图像。然后,判别器对该图像进行处理,预测该图像是否属于目标分布。一旦训练完成,我只需通过采样初始随机变量并将其传递通过生成器,就能生成各种图像。
VAE 的编码器从目标分布中获取一张图像,并将其压缩到低维潜在空间中。然后,解码器的任务是将该潜在空间表示转换回原始图像。一旦网络训练完成,我可以生成各种图像的潜在空间表示,并在这些表示之间进行插值,然后通过解码器生成新图像。
这两种技术不同,因为它们优化不同的目标函数。这并不是说其中一个会在所有情况下都获胜。它们在不同情况下会很有用。学习方法优化的目标函数应该理想地匹配我们希望应用它们的任务。从这个意义上说,理论表明:
-
GANs 应该在生成漂亮的样本方面表现最好——避免生成看起来不真实的样本,但可能会低估数据的熵。
-
VAEs 应该在压缩数据方面表现最佳,因为它们最大化(一个下界)似然性。也就是说,评估 VAE 模型中的似然性是不可处理的,因此不能非常直接地用于直接熵编码。
-
目前有许多模型可以计算似然性,如 pixel-RNNs、空间 LSTMs、RIDE、NADE、NICE 等。这些模型在压缩性能方面(无损熵编码下的最短平均码长)也应该表现最佳。
我推荐一篇比较 GANs 和 VAEs 模型的论文:A Probe Towards Understanding GAN and VAE Models
结论
正如我们在本文中所见,自动编码器是一种神经网络架构,能够在数据中开创结构,以开发输入数据/图像的压缩表示。存在许多不同的自动编码器架构变体,其目标是确保压缩表示能够表示原始输入数据的显著特征;通常,使用自动编码器时最大的挑战是使模型真正学习到有意义和可泛化的潜在空间表示。
我们还研究了变分自动编码器在生成有意义表示方面的表现如何更好,并且它们也可以用作生成模型。此外,我们看到了 VAEs 与生成对抗网络(GANs)之间的不同。
致谢:
-
www.countbayesie.com/blog/2017/5/9/kullback-leibler-divergence-explained -
towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73
原文. 经许可转载。
相关:
更多相关主题
自动化机器学习简介
原文:
www.kdnuggets.com/2021/09/introduction-automated-machine-learning.html
评论
什么是 AutoML 系统?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT
机器学习(ML)作为更广泛的人工智能(AI)领域的一个子领域,正在接管各种行业和业务领域。这包括零售、医疗、汽车、金融、娱乐等。随着在各类操作中的更广泛应用以及来自具有多样技能的劳动力,学习如何使用机器学习变得越来越重要。
由于组织中不断增加的员工交叉层面对 ML 使用的扩展,开发可供各种背景的业务专业人士使用的系统变得至关重要。这意味着这些系统不能仅限于编码或编程导向,像软件工程师或数据科学家使用的那些。
这就是 AutoML 系统登场的地方。
简而言之,AutoML 使拥有有限 ML 专业知识(以及编码经验)的开发人员能够训练出特定于他们业务需求的高质量模型。虽然从学术研究角度看,AutoML 还有其他方面(即搜索适用于给定数据类型的最佳 ML 算法并证明这些系统的理论属性);但本文将重点讨论适用于日常业务和技术应用的 AutoML 系统。
为什么 AutoML 系统越来越受欢迎?
如前所述,各种背景和技能的专业人士正在进入数据科学和机器学习领域,以满足各自的业务或研发活动。并不是所有人都有严谨的背景或正式的统计科学或机器学习理论培训。
他们只需能够获取或摄取数据集,遵循完整的数据探索和模型训练工作流程,并为下游的 ML 应用生成训练好的模型。
如果他们不得不自己完成所有这些工作,将会更加耗时:
-
搜索所有可能的 ML 算法,
-
在训练数据集上评估它们,
-
以严格的方式检查验证集性能,
-
应用额外的判断(内存和 CPU 占用)以选择适合最终应用的最佳模型。
在很大程度上,AutoML 系统为数据科学家或分析师完成了所有这些繁重的工作,并自动化或简化了生产就绪使用的高度优化训练机器学习模型的生成。
因此,这些系统在广泛使用数据科学的组织中越来越受欢迎,因为它们:
-
节省组织的人力成本和人数,因为一个相对精简的员工队伍可以利用这些系统来训练和优化大量的机器学习模型。
-
通过自动化模型训练和优化,以及所谓的数据科学中的枯燥方面(即数据摄取、解析、清洗和特征探索等)来减少错误的机会。
-
减少相对高性能标准下的机器学习驱动应用程序的市场推出时间。
就市场推出时间而言,有人可能会争辩说,AutoML 系统生成的最终结果可能不如由专家 ML 工程师(使用手工特征工程或深度学习调优)设计的结果表现优异或优化得好。
然而,这种手动调整通常是一个耗时的过程,在大多数情况下,与其浪费时间去生产绝对最佳表现的模型,不如在较短时间内使模型达到生产准备状态对组织更为关键。AutoML 系统帮助组织实现这一关键业务目标,因此越来越受欢迎并广泛采用。
现在组织可以简单地为其员工购买定制化机器学习工作站,安装像 AutoML 这样的工具,以快速启动一个基于机器学习的系统,并继续进行 AI 准备生产的下一步,从而比以往更快地将成果推向市场。
AutoML 系统类型及一些著名示例
有许多不同类型的 AutoML 系统,因为它们满足数据科学或机器学习工作流程中不同任务的需求。
一些类型的 AutoML 系统包括:
-
用于自动化参数调优的 AutoML(一个相对基础的类型)
-
非深度学习的 AutoML,例如Auto-Sklearn。这类系统主要应用于数据预处理、自动特征分析、自动特征检测、自动特征选择和自动模型选择。
-
深度学习/神经网络的 AutoML,包括专门为神经网络架构搜索(NAS)设计的系统,以及像AutoKeras这样构建在流行的深度学习框架之上的实用工具包。
Auto-Sklearn
正如其名,Auto-Sklearn 是一个基于 scikit-learn 的自动化机器学习软件包。Auto-Sklearn 使数据科学家免于算法选择和超参数调整的任务。本质上,它自动搜索适合新机器学习数据集的学习算法,并优化其超参数。
它扩展了通过有效的全局优化配置通用机器学习框架的思想,这一思想在 Auto-WEKA 中被引入。为了提高泛化能力,Auto-Sklearn 在全局优化过程中构建了一个所有模型的集成。为了加速优化过程,Auto-Sklearn 使用元学习来识别相似的数据集,并利用过去积累的知识。
它包括特征工程方法,如 独热编码、数字特征标准化和主成分分析(PCA)。该库核心使用 scikit-learn 估计器来处理分类和回归问题。
Auto-Sklearn 工作流程和图示
文档:你可以在 这里找到详细文档。
代码示例:这里展示了一个使用 Auto-Sklearn 的基本分类任务代码示例。我们使用 scikit-learn 包中的内置数据集构建一个用于分类数字的 ML 模型。
import autosklearn.classification
import sklearn.model_selection
import sklearn.datasets
import sklearn.metrics
if __name__ == "__main__":
X, y = sklearn.datasets.load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = \
sklearn.model_selection.train_test_split(X, y, random_state=1)
automl = autosklearn.classification.AutoSklearnClassifier()
automl.fit(X_train, y_train)
y_hat = automl.predict(X_test)
print("Accuracy score", sklearn.metrics.accuracy_score(y_test, y_hat))
关于操作系统的说明:Auto-Sklearn 强烈依赖于 Python 模块资源。此模块是 Python 的 Unix 特定服务的一部分,Windows 机器上不可用。因此,截至今天,无法在 Windows 机器上运行 auto-sklearn。
可能的解决方案:
-
Windows 10 bash shell(见 431 和 860 获取建议)
-
虚拟机
-
Docker 镜像
MLBox

MLBox 是一个强大的自动化机器学习 Python 库。根据官方文档,它提供以下功能:
-
快速阅读和分布式数据预处理/清理/格式化
-
高度可靠的特征选择和泄漏检测,以及准确的超参数优化
-
最先进的分类和回归预测模型(深度学习、堆叠、LightGBM)
-
带有模型解释的预测
-
MLBox 已在 Kaggle 上测试,并显示出良好的性能
-
流水线构建
TPOT

TPOT 是一个 Python 自动化机器学习工具,通过遗传编程优化机器学习流水线。它也构建在 scikit-learn 之上。
示例 TPOT 流水线(来自 epistasislab.github.io/tpot/)
文档:这是 文档链接。
代码示例:
from tpot import TPOTClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data.astype(np.float64),
iris.target.astype(np.float64), train_size=0.75, test_size=0.25, random_state=42)
tpot = TPOTClassifier(generations=5, population_size=50, verbosity=2, random_state=42)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_iris_pipeline.py')
AutoKeras
AutoKeras 是由德州 A&M 大学数据实验室开发的自动化机器学习开源软件库。基于深度学习框架Keras,AutoKeras 提供了自动搜索深度学习模型架构和超参数的功能。
AutoKeras 遵循经典的 scikit-learn API 设计,因此易于使用。该框架的目标是通过使用自动化的神经网络架构搜索(NAS)算法来简化机器学习实践和研究。
文档:这里是详细的文档链接。
代码示例: 这里是一个用于 MNIST 图像分类任务的示例代码。
import numpy as np
import tensorflow as tf
from tensorflow.keras.datasets import mnist
import autokeras as ak
# Data loading
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Initialize the image classifier.
clf = ak.ImageClassifier(overwrite=True, max_trials=1)
# Feed the image classifier with training data.
clf.fit(x_train, y_train, epochs=10)
# Predict with the best model.
predicted_y = clf.predict(x_test)
print(predicted_y)
# Evaluate the best model with testing data.
print(clf.evaluate(x_test, y_test))
AutoML 系统及其重要性的总结
在本文中,我们首先解释了自动化机器学习框架或所谓的 AutoML 系统背后的核心思想。我们描述了它们的实用性以及为何它们在各种商业和技术组织中越来越受欢迎。我们还展示了一些突出的 AutoML 库和框架,并提供了相关的代码示例和架构图解。
了解这些强大的框架将对任何即将成为数据科学家的人员有益,因为它们将继续在能力和广泛应用方面发展。
请通过在下方留言告知我们您感兴趣的任何话题,或者随时通过联系我们提出您的问题。
简历:Kevin Vu 管理 Exxact Corp 博客,并与许多才华横溢的作者合作,这些作者撰写有关深度学习不同方面的文章。
原文。已获许可转载。
相关:
-
如何创建 AutoML 管道优化沙箱
-
使用 FLAML + Ray Tune 进行快速 AutoML
-
前 18 名低代码和无代码机器学习平台
更多相关话题
-
[使用 Streamlit 构建 DIY 自动化机器学习](https://www.kdnuggets.com/2021/11/diy-automated-machine-learning-app.html)
-
[入门自动化文本摘要](https://www.kdnuggets.com/2019/11/getting-started-automated-text-summarization.html)
使用 PyCaret 的二分类介绍
原文:
www.kdnuggets.com/2021/12/introduction-binary-classification-pycaret.html
评论
作者 Moez Ali,PyCaret 创始人及作者

我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT
1.0 介绍
PyCaret 是一个开源的低代码机器学习库,旨在自动化机器学习工作流。它是一个端到端的机器学习和模型管理工具,能显著加快实验周期,提高生产力。
相较于其他开源机器学习库,PyCaret 是一个替代的低代码库,可以用少量代码替代数百行代码。这使得实验变得极快且高效。PyCaret 实质上是围绕多个机器学习库和框架(如 scikit-learn、XGBoost、LightGBM、CatBoost、spaCy、Optuna、Hyperopt、Ray 等)构建的 Python 封装库。
PyCaret 的设计和简洁性受到了公民数据科学家新兴角色的启发,这一术语最初由 Gartner 提出。公民数据科学家是那些可以执行简单和中等复杂度分析任务的高级用户,这些任务以前需要更多的技术专长。
要了解更多关于 PyCaret 的信息,可以查看官方 网站 或 GitHub。
2.0 教程目标
在本教程中,我们将学习:
-
获取数据: 如何从 PyCaret 库中导入数据
-
环境设置: 如何在 PyCaret 中设置实验并开始构建分类模型
-
创建模型: 如何创建模型,进行分层交叉验证并评估分类指标
-
调整模型: 如何自动调整分类模型的超参数
-
绘图模型: 如何使用各种图表分析模型性能
-
确定模型: 如何在实验结束时确定最佳模型
-
预测模型: 如何对未见数据进行预测
-
保存/加载模型: 如何保存/加载模型以备将来使用
3.0 安装 PyCaret
安装很简单,只需几分钟。PyCaret 从 pip 的默认安装仅安装requirements.txt文件中列出的硬依赖项。
pip install pycaret
要安装完整版本:
pip install pycaret[full]
4.0 什么是二分类?
二分类是一种监督式机器学习技术,其目标是预测离散且无序的类别标签,如通过/失败、正面/负面、违约/未违约等。以下是一些分类的实际应用场景:
-
医疗测试以确定患者是否患有某种疾病——分类属性是疾病的存在。
-
一种“通过或不通过”的测试方法或工厂质量控制,即决定一个规范是否满足——一种“通过/不通过”分类。
-
信息检索,即决定某个页面或文章是否应该出现在搜索结果集中——分类属性是文章的相关性或对用户的有用性。
5.0 PyCaret 分类模块概述
PyCaret 的 分类模块(pycaret.classification)是一个监督式机器学习模块,用于基于各种技术和算法将元素分类到二进制组中。一些常见的分类问题使用场景包括预测客户违约(是或否)、客户流失(客户会离开还是留下)、疾病发现(阳性或阴性)。
PyCaret 的分类模块可以用于二分类或多分类问题。它包含超过 18 种算法和 14 种图表,用于分析模型的性能。不论是超参数调整、集成,还是像堆叠这样的高级技术,PyCaret 的分类模块应有尽有。
6.0 教程数据集
本教程将使用来自 UCI 的数据集,称为 信用卡客户违约数据集。该数据集包含有关违约支付、人口统计因素、信用数据、支付历史和信用卡客户账单的信 息,数据时间范围从 2005 年 4 月到 2005 年 9 月,共有 24,000 个样本和 25 个特征。每一列的简短描述如下:
-
ID: 每个客户的 ID
-
信用额度: 以新台币为单位的信用额度(包括个人和家庭/附加信用)
-
性别: 性别(1=男性,2=女性)
-
教育背景: (1=研究生院,2=大学,3=高中,4=其他,5=未知,6=未知)
-
婚姻状况: 婚姻状况(1=已婚,2=单身,3=其他)
-
年龄: 年龄(以年为单位)
-
PAY_0 到 PAY_6: 过去 n 个月的偿还状态(PAY_0 = 上个月 … PAY_6 = 6 个月前)(标签:-1=按时支付,1=延迟一个月付款,2=延迟两个月付款,… 8=延迟八个月付款,9=延迟九个月及以上)
-
BILL_AMT1 到 BILL_AMT6: 过去 n 个月的账单金额(BILL_AMT1 = 上个月 .. BILL_AMT6 = 6 个月前)
-
PAY_AMT1 到 PAY_AMT6: 过去 n 个月的支付金额(BILL_AMT1 = 上个月 .. BILL_AMT6 = 6 个月前)
-
默认值: 默认支付(1=是,0=否)
Target Column
数据集致谢:
Lichman, M. (2013). UCI 机器学习库。加利福尼亚州欧文:加州大学信息与计算机科学学院。
7.0 获取数据
你可以从原始来源 找到这里 下载数据,并使用 pandas (了解如何) 加载,或者你可以使用 PyCaret 的数据库,通过 get_data() 函数加载数据(这需要互联网连接)。
**# loading the dataset** from pycaret.datasets import get_data
dataset = get_data('credit')

**# check the shape of data** dataset.shape>>> (24000, 24)
为了演示 predict_model 函数在未见数据上的使用,从原始数据集中保留了 1200 条记录(约 5%)以便在最后进行预测。这不应与训练-测试-分割混淆,因为这种特定的分割是为了模拟实际场景。另一种理解方式是,这 1200 位客户在机器学习模型训练时并不可用。
**# sample 5% of data to be used as unseen data**
data = dataset.sample(frac=0.95, random_state=786)
data_unseen = dataset.drop(data.index)
data.reset_index(inplace=True, drop=True)
data_unseen.reset_index(inplace=True, drop=True)**# print the revised shape** print('Data for Modeling: ' + str(data.shape))
print('Unseen Data For Predictions: ' + str(data_unseen.shape))>>> Data for Modeling: (22800, 24)
>>> Unseen Data For Predictions: (1200, 24)
8.0 在 PyCaret 中设置环境
PyCaret 中的 setup 函数初始化环境并创建用于建模和部署的转换管道。setup 必须在执行任何其他 pycaret 函数之前调用。它需要两个强制参数:一个 pandas 数据框和目标列的名称。所有其他参数都是可选的,可以用来定制预处理管道。
当 setup 执行时,PyCaret 的推断算法将根据某些属性自动推断所有特征的数据类型。数据类型应该被正确推断,但这并非总是如此。为了解决这个问题,PyCaret 会在执行 setup 后显示一个提示,要求确认数据类型。如果所有数据类型正确,你可以按 Enter 键,或输入 quit 退出设置。
确保数据类型正确在 PyCaret 中非常重要,因为它会自动执行多种特定类型的预处理任务,这对于机器学习模型至关重要。
另外,你还可以在 setup 中使用 numeric_features 和 categorical_features 参数来预定义数据类型。
**# init setup** from pycaret.classification import *
s = setup(data = data, target = 'default', session_id=123)
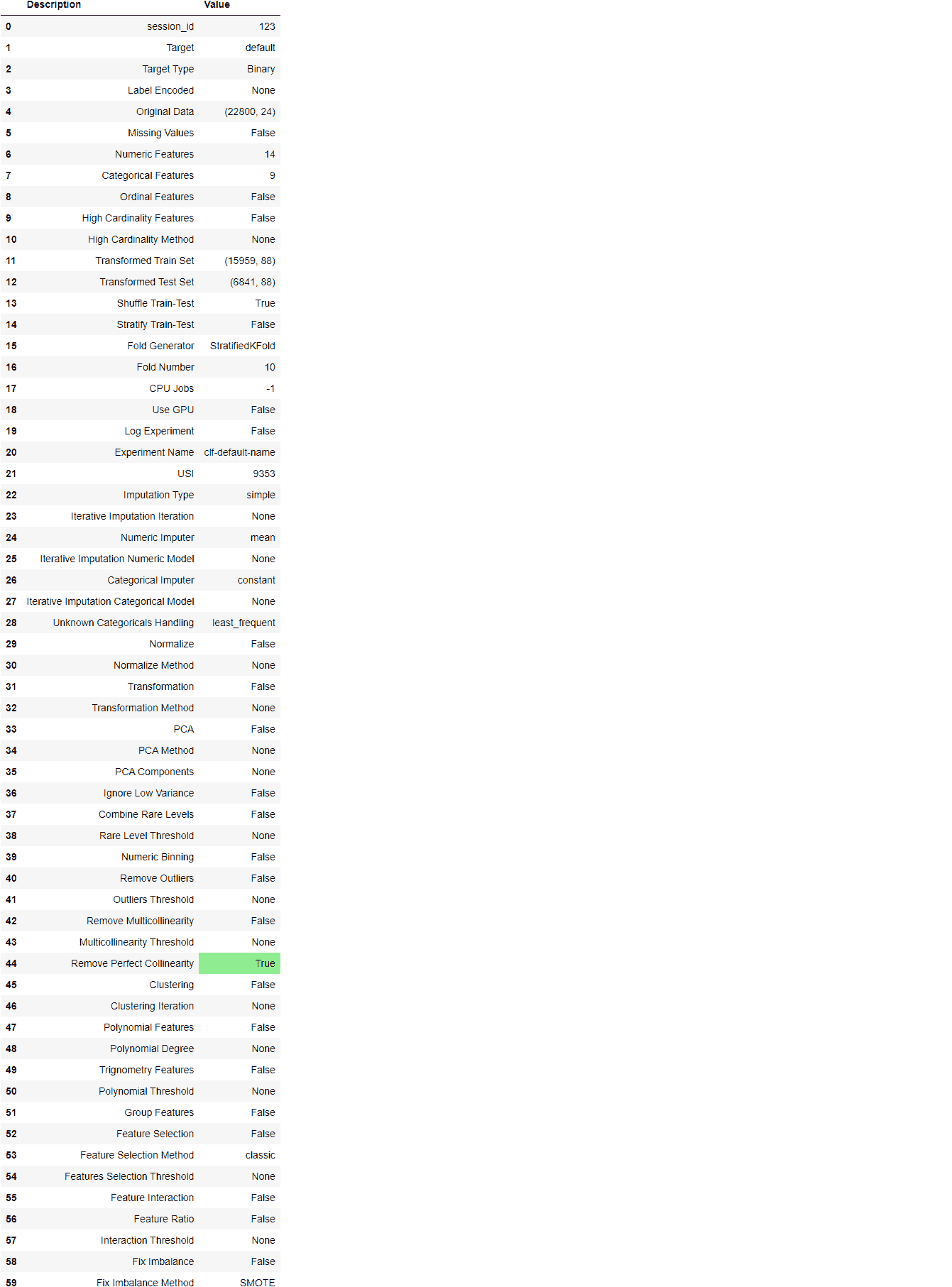
一旦设置成功执行,它会显示包含实验重要信息的信息网格。大部分信息与在执行setup时构建的预处理管道相关。大多数功能超出了本教程的范围,但需要注意一些重要的事项:
-
session_id: 作为种子分配到所有函数中的伪随机数,以便后续可重复性。如果未传递
session_id,会自动生成一个随机数分配给所有函数。在本实验中,session_id被设置为123以便后续可重复性。 -
目标类型: 二分类或多分类。目标类型会自动检测并显示。对于二分类或多分类问题,实验的执行没有区别。所有功能是相同的。
-
标签编码: 当目标变量是字符串类型(即 ‘Yes’ 或 ‘No’)时,而不是 1 或 0,它会自动将标签编码为 1 和 0,并显示映射(0: No, 1: Yes)以供参考。在这个实验中,由于目标变量是数字类型,因此不需要标签编码。
-
原始数据: 显示数据集的原始形状。在这个实验中,(22800, 24) 意味着 22,800 个样本和 24 个特征,包括目标列。
-
缺失值: 当原始数据中存在缺失值时,这将显示为 True。在本实验中,数据集中没有缺失值。
-
数值特征: 推断为数值的特征数量。在这个数据集中,24 个特征中有 14 个被推断为数值特征。
-
分类特征: 推断为分类的特征数量。在这个数据集中,24 个特征中有 9 个被推断为分类特征。
-
变换后的训练集: 显示了变换后的训练集的形状。注意到原始形状 (22800, 24) 被变换为 (15959, 91),由于独热编码,特征数量从 24 增加到 91。
-
变换后的测试集: 显示了变换后的测试/保留集的形状。测试/保留集中有 6841 个样本。这个拆分是基于默认值 70/30,可以通过
train_size参数在设置中更改。
注意,一些对建模至关重要的任务会被自动处理,如缺失值插补(在这种情况下训练数据中没有缺失值,但我们仍然需要插补器用于未见数据)、分类编码等。setup中的大部分参数是可选的,用于自定义预处理管道。这些参数超出了本教程的范围,但我们将在未来的教程中进行讲解。
9.0 比较所有模型
比较所有模型以评估性能是设置完成后建模的推荐起点(除非你确切知道需要什么类型的模型,这种情况往往不多)。此函数训练模型库中的所有模型,并使用分层交叉验证对指标进行评估。输出打印了一个得分网格,显示了折叠(默认 10 折)中的平均准确度、AUC、召回率、精度、F1、Kappa 和 MCC,以及训练时间。
best_model = compare_models()
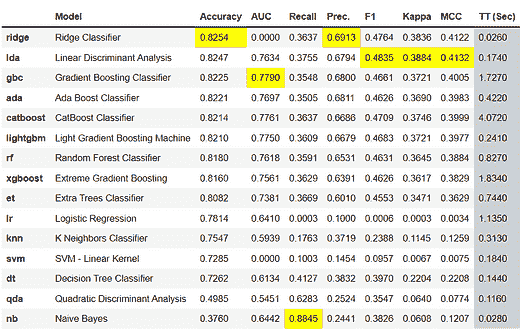
上面打印的得分网格仅用于比较目的,突出显示了表现最好的指标。网格默认按Accuracy(从高到低)排序,可以通过传递sort参数进行更改。例如,compare_models(sort = 'Recall')将按召回率而不是准确度对网格进行排序。
如果你想将折叠参数从默认值10更改为其他值,可以使用fold参数。例如,compare_models(fold = 5)将比较所有模型在 5 折交叉验证中的表现。减少折叠数将提高训练时间。默认情况下,compare_models根据默认排序顺序返回表现最佳的模型,但也可以通过使用n_select参数返回前 N 个模型的列表。
print(best_model)**>>> OUTPUT**RidgeClassifier(alpha=1.0, class_weight=None, copy_X=True, fit_intercept=True,
max_iter=None, normalize=False, random_state=123, solver='auto',
tol=0.001)
10.0 创建模型
create_model是 PyCaret 中最基本的函数,通常是大多数 PyCaret 功能的基础。顾名思义,这个函数使用可以通过fold参数设置的交叉验证来训练和评估模型。输出打印了一个得分网格,显示了按折叠计算的准确度、AUC、召回率、精度、F1、Kappa 和 MCC。
在本教程的剩余部分,我们将使用下面的模型作为候选模型。选择仅为示例目的,并不一定意味着它们是最优或适合这种数据的模型。
-
决策树分类器(‘dt’)
-
K 近邻分类器(‘knn’)
-
随机森林分类器(‘rf’)
PyCaret 的模型库中提供了 18 种分类器。要查看所有分类器的列表,可以查看文档或使用models函数查看库。
**# check available models** models()
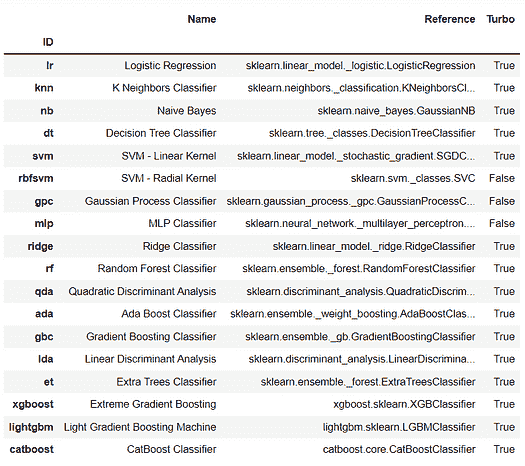
10.1 决策树分类器
dt = create_model('dt')
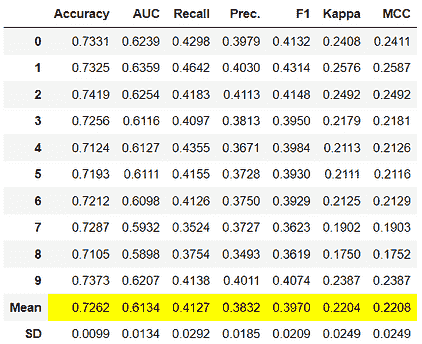
**# trained model object is stored in the variable 'dt'.**
print(dt)**>>> OUTPUT**DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=123, splitter='best')
10.2 K 近邻分类器
knn = create_model('knn')
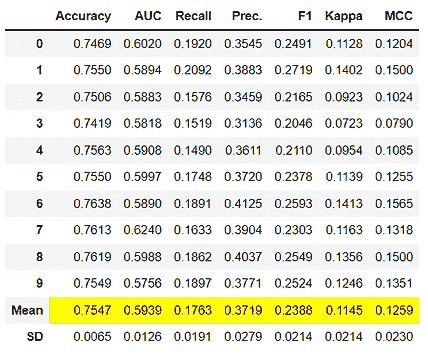
10.3 随机森林分类器
rf = create_model('rf')
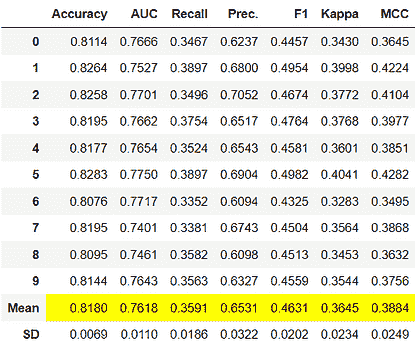
请注意,所有模型的平均得分与compare_models中打印的得分一致。这是因为在compare_models得分网格中打印的指标是所有 CV 折叠的平均得分。类似于compare_models,如果你想将折叠参数从默认值 10 更改为其他值,可以使用fold参数。例如:create_model('dt', fold = 5)将使用 5 折分层交叉验证创建一个决策树分类器。
11.0 调优模型
当使用create_model函数创建模型时,它使用默认的超参数来训练模型。为了调整超参数,使用tune_model函数。该函数使用预定义的搜索空间上的随机网格搜索自动调整模型的超参数。输出打印一个评分网格,显示了最佳模型的准确性、AUC、召回率、精确度、F1、Kappa 和 MCC。要使用自定义搜索网格,可以在tune_model函数中传递custom_grid参数(请参见下面的 11.2 KNN 调优)。
11.1 决策树分类器
tuned_dt = tune_model(dt)
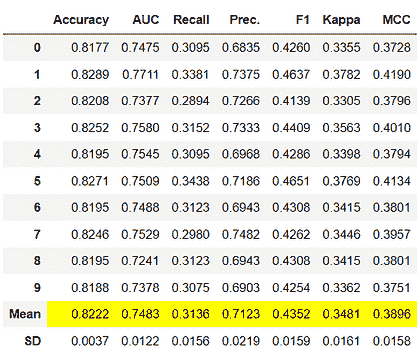
**# tuned model object is stored in the variable 'tuned_dt'.** print(tuned_dt)**>>> OUTPUT**DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='entropy',
max_depth=6, max_features=1.0, max_leaf_nodes=None,
min_impurity_decrease=0.002, min_impurity_split=None,
min_samples_leaf=5, min_samples_split=5,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=123, splitter='best')
11.2 K 最近邻分类器
import numpy as np
tuned_knn = tune_model(knn, custom_grid = {'n_neighbors' : np.arange(0,50,1)})
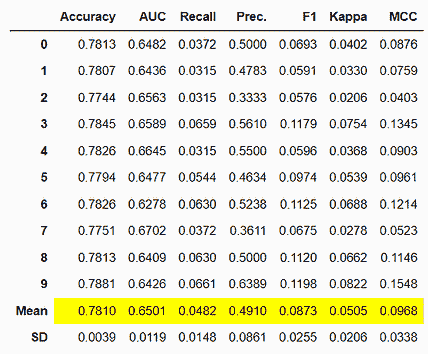
print(tuned_knn)**>>> OUTPUT**KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=-1, n_neighbors=42, p=2,
weights='uniform')
11.3 随机森林分类器
tuned_rf = tune_model(rf)
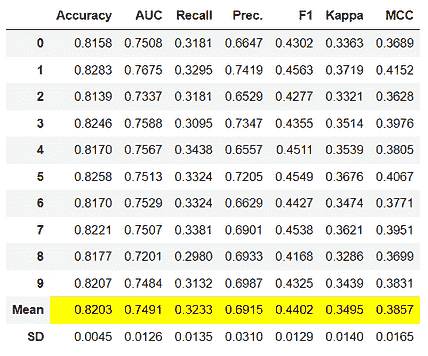
默认情况下,tune_model优化Accuracy,但这可以通过optimize参数进行更改。例如:tune_model(dt, optimize = 'AUC')将寻找使AUC最高的决策树分类器的超参数,而不是Accuracy。为了简化示例,我们仅使用了默认的Accuracy指标。通常,当数据集不平衡(如我们正在使用的信用数据集)时,Accuracy不是一个好的评估指标。选择正确的评估指标来评估分类器的方法超出了本教程的范围,但如果你想了解更多,可以点击这里阅读关于如何选择正确评估指标的文章。
仅依靠指标并不是确定生产中最佳模型的唯一标准。其他需要考虑的因素包括训练时间、k 折的标准偏差等。随着你在教程系列中的进展,我们将在中级和高级阶段详细讨论这些因素。现在,让我们继续考虑将调优后的随机森林分类器tuned_rf作为本教程剩余部分的最佳模型。
12.0 绘制模型
在模型最终确定之前,可以使用plot_model函数来分析不同方面的性能,例如 AUC、混淆矩阵、决策边界等。此函数接受一个训练好的模型对象,并基于测试集返回一个图表。
提供了 15 种不同的图表,请参见plot_model文档以获取可用图表的列表。
12.1 AUC 图
plot_model(tuned_rf, plot = 'auc')
12.2 精确度-召回率曲线
plot_model(tuned_rf, plot = 'pr')
12.3 特征重要性图
plot_model(tuned_rf, plot='feature')
12.4 混淆矩阵
plot_model(tuned_rf, plot = 'confusion_matrix')
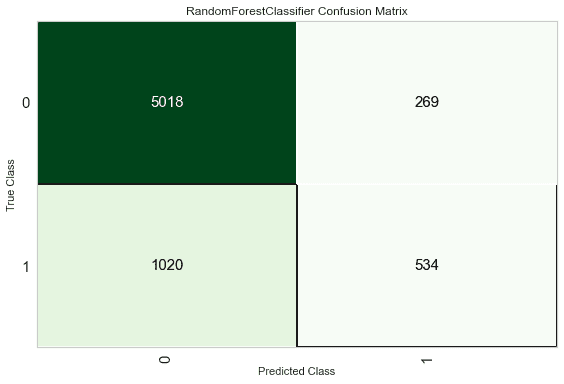
另一种 分析模型性能的方法是使用evaluate_model()函数,该函数显示了给定模型所有可用绘图的用户界面。它内部使用了plot_model()函数。
evaluate_model(tuned_rf)
13.0 在测试/保留样本上预测
在最终化模型之前,建议通过预测测试/保留集并查看评估指标来进行最后的检查。如果你查看第八部分的信息网格,你会看到 30%(6,841 个样本)的数据已经被分离出来作为测试/保留样本。我们在上面看到的所有评估指标都是基于训练集(70%)的交叉验证结果。现在,使用我们存储在tuned_rf中的最终训练模型,我们将预测测试/保留样本并评估指标,以查看它们是否与 CV 结果有实质性差异。
predict_model(tuned_rf);

在测试/保留集上的准确率是**0.8116**,相比于在tuned_rf CV 结果中达到的**0.8203**(在第 11.3 节上)。这并不是一个显著的差异。如果测试/保留集和 CV 结果之间存在较大差异,这通常表明过拟合,但也可能由于其他几个因素,需要进一步调查。在这种情况下,我们将继续完成模型并对未见数据进行预测(即我们在开始时分离出的 5%,并且从未暴露于 PyCaret)。
(提示:使用create_model时,查看 CV 结果的标准差总是好的)
14.0 部署前的模型最终化
模型最终化是实验中的最后一步。PyCaret 中的正常机器学习工作流从setup开始,随后使用compare_models比较所有模型,并根据感兴趣的指标筛选出一些候选模型,以执行多个建模技术,如超参数调优、集成、堆叠等。这一工作流将最终引导你找到最佳模型,以用于对新数据和未见数据进行预测。finalize_model函数将模型拟合到包括测试/保留样本在内的完整数据集上(在这种情况下为 30%)。该函数的目的是在模型投入生产前在完整数据集上训练最终模型。(这是可选的,你可以选择是否使用 finalize_model)。
**# finalize rf model**
final_rf = finalize_model(tuned_rf)**# print final model parameters**
print(final_rf)**>>> OUTPUT**RandomForestClassifier(bootstrap=False, ccp_alpha=0.0, class_weight={},
criterion='entropy', max_depth=5, max_features=1.0,
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0002, min_impurity_split=None,
min_samples_leaf=5, min_samples_split=10,
min_weight_fraction_leaf=0.0, n_estimators=150,
n_jobs=-1, oob_score=False, random_state=123, verbose=0,
warm_start=False)
警告: 最后的警告。一旦模型完成,整个数据集,包括测试/保留集,都将用于训练。因此,如果在finalize_model之后使用模型对保留集进行预测,打印的信息网格将会误导,因为你尝试在用于建模的相同数据上进行预测。为了仅演示这一点,我们将在predict_model下使用final_rf来比较信息网格与第十三部分上面的网格。
predict_model(final_rf);

注意,即使模型相同,final_rf中的 AUC 也从**0.7407**提高到了**0.7526**。这是因为final_rf变量在包含测试/持出集的完整数据集上进行了训练。
15.0 对未见数据进行预测
predict_model函数也用于对未见数据集进行预测。与第十三部分的唯一区别在于这次我们将传递data_unseen。这是在本教程开始时创建的变量,包含了原始数据集中从未暴露给 PyCaret 的 5%(1200 个样本)。(见第七部分以获取解释)
unseen_predictions = predict_model(final_rf, data=data_unseen)
unseen_predictions.head()

Label和Score列已添加到data_unseen数据集中。标签是预测结果,分数是预测的概率。请注意,预测结果已附加到原始数据集中,而所有转换都会在后台自动执行。你还可以检查这些指标,因为你有实际的目标列default可用。为此,我们将使用pycaret.utils模块。请看下面的示例:
**# check metric on unseen data** from pycaret.utils import check_metric
check_metric(unseen_predictions['default'], unseen_predictions['Label'], metric = 'Accuracy')**>>> OUTPUT** 0.8167
16.0 保存模型
我们现在通过将 tuned_rf模型最终化并存储在final_rf变量中来完成实验。我们还使用存储在final_rf中的模型对data_unseen进行了预测。这标志着我们的实验结束,但仍有一个问题需要询问:如果你有更多新数据需要预测怎么办?是否需要重新进行整个实验?答案是否定的,PyCaret 的内置函数save_model()允许你保存模型以及整个转换管道以供以后使用。
**# saving the final model** save_model(final_rf,'Final RF Model 11Nov2020')>>> Transformation Pipeline and Model Successfully Saved
17.0 加载已保存的模型
要在将来某个日期在相同或其他环境中加载已保存的模型,我们将使用 PyCaret 的load_model()函数,然后轻松地将已保存的模型应用于新未见数据进行预测。
**# loading the saved model**
saved_final_rf = load_model('Final RF Model 11Nov2020')>>> Transformation Pipeline and Model Successfully Loaded
一旦模型加载到环境中,你可以简单地使用相同的predict_model()函数对任何新数据进行预测。下面我们应用加载的模型来预测与第十三部分中相同的data_unseen。
**# predict on new data** new_prediction = predict_model(saved_final_rf, data=data_unseen)
new_prediction.head()
请注意,unseen_predictions和new_prediction的结果是相同的。
from pycaret.utils import check_metric
check_metric(new_prediction['default'], new_prediction['Label'], metric = 'Accuracy')>>> 0.8167
18.0 总结 / 下一步?
本教程涵盖了整个机器学习流程,从数据摄取、预处理、训练模型、超参数调优、预测到保存模型以供后续使用。我们在不到 10 个命令中完成了所有这些步骤,这些命令自然构建且非常直观,易于记忆,例如create_model()、tune_model()、compare_models()。如果没有 PyCaret,重新创建整个实验在大多数库中将需要超过 100 行代码。
我们只介绍了pycaret.classification的基础知识。在未来的教程中,我们将深入探讨高级预处理、集成方法、广义堆叠以及其他技术,这些技术能够让你完全自定义你的机器学习管道,是任何数据科学家必须掌握的。
感谢阅读 ????
重要链接
⭐ 教程 刚接触 PyCaret?查看我们的官方笔记本!
???? 示例笔记本 由社区创建。
???? 博客 贡献者的教程和文章。
???? 文档 PyCaret 的详细 API 文档
???? 视频教程 我们在各种活动中的视频教程。
???? 讨论 有问题?与社区和贡献者互动。
????️ 更新日志 变更和版本历史。
???? 路线图 PyCaret 的软件和社区发展计划。
简介: Moez Ali 撰写关于 PyCaret 及其在现实世界中的应用。如果你想自动获取通知,可以关注 Moez 在 Medium、LinkedIn 和 Twitter。
原文. 经许可转载。
相关:
-
新手指南:端到端的机器学习
-
PyCaret 2.3.5 已发布!了解新特性
-
使用 PyCaret 的新时间序列模块
更多相关主题


 浙公网安备 33010602011771号
浙公网安备 33010602011771号