KDNuggets-博客中文翻译-二十三-
KDNuggets 博客中文翻译(二十三)
原文:KDNuggets
LangChain 101: 构建你自己的 GPT 驱动应用程序
原文:
www.kdnuggets.com/2023/04/langchain-101-build-gptpowered-applications.html

图片来源:作者
ChatGPT 和 GPT-4 的成功展示了经过强化训练的大型语言模型如何产生可扩展且强大的 NLP 应用程序。
我们的前三大课程推荐
 1. Google 网络安全证书 - 快速通道进入网络安全职业。
1. Google 网络安全证书 - 快速通道进入网络安全职业。
 2. Google 数据分析专业证书 - 提升你的数据分析技能
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
然而,响应的有用性依赖于提示,这导致用户探索提示工程领域。此外,大多数实际的 NLP 用例需要比单次 ChatGPT 会话更复杂的解决方案。而这正是像 LangChain 这样的库可以提供帮助的地方!
LangChain 是一个 Python 库,帮助你利用大型语言模型构建自定义的 NLP 应用程序。
在本指南中,我们将探讨 LangChain 是什么以及你可以用它构建什么。我们还将通过构建一个简单的问答应用程序来入门 LangChain。
让我们开始吧!
LangChain 是什么?
LangChain 由 Harrison Chase 创建,是一个 Python 库,提供开箱即用的支持,用于使用 LLM 构建 NLP 应用程序。你可以连接各种数据和计算源,构建在特定领域数据源、私人库等上执行 NLP 任务的应用程序。
截至本文撰写时(2023 年 3 月),LangChain GitHub 仓库已有超过 14,000 个星标,来自世界各地的 270 多位贡献者。
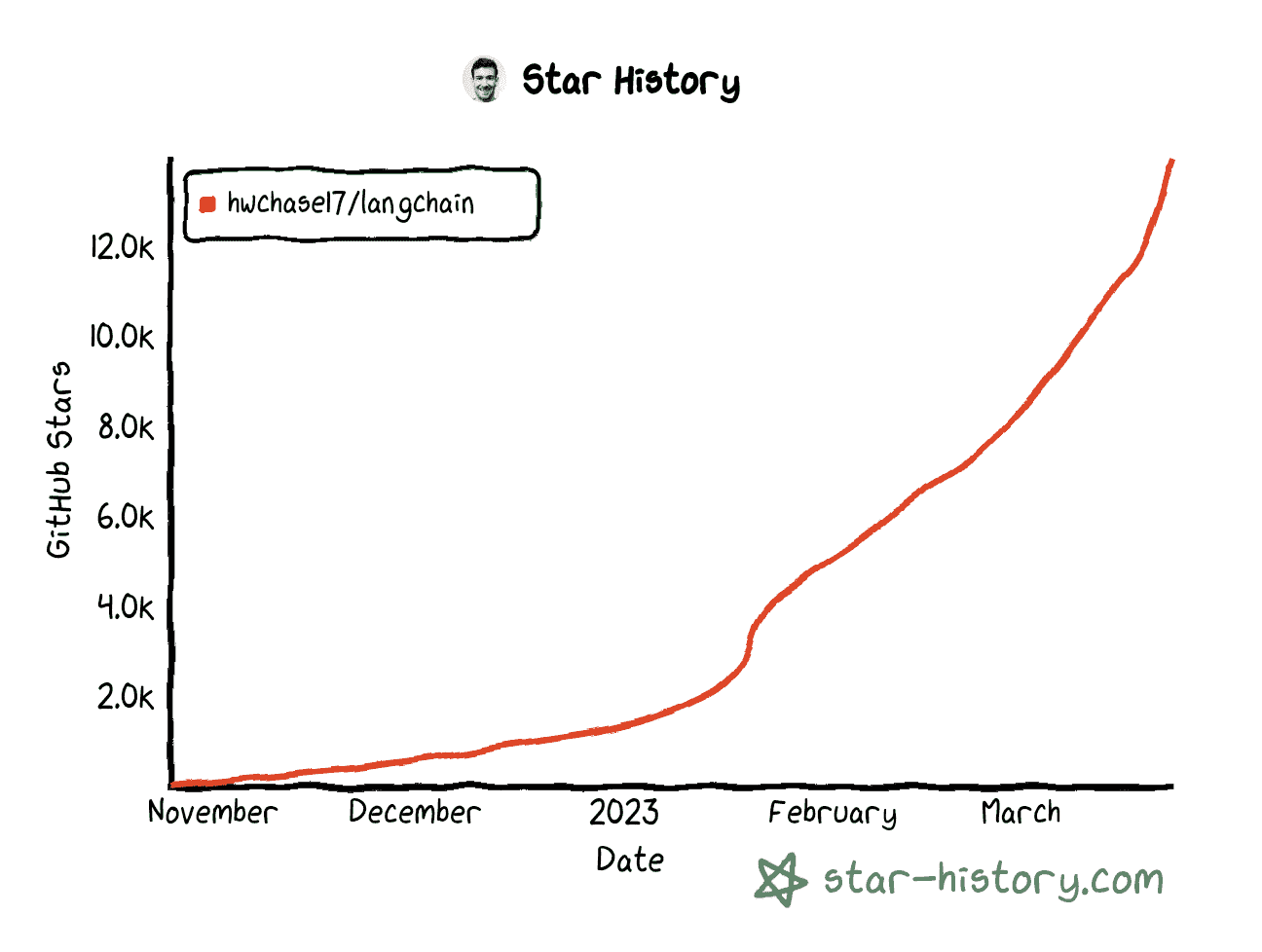
LangChain Github 星标历史 | 生成于 star-history.com
使用 LangChain 可以构建的有趣应用程序包括(但不限于):
-
聊天机器人
-
针对特定领域的总结和问答
-
查询数据库以获取信息然后处理的应用程序
-
解决特定问题的代理,例如数学和推理难题
LangChain 模块概览
接下来让我们看看 LangChain 的一些模块:
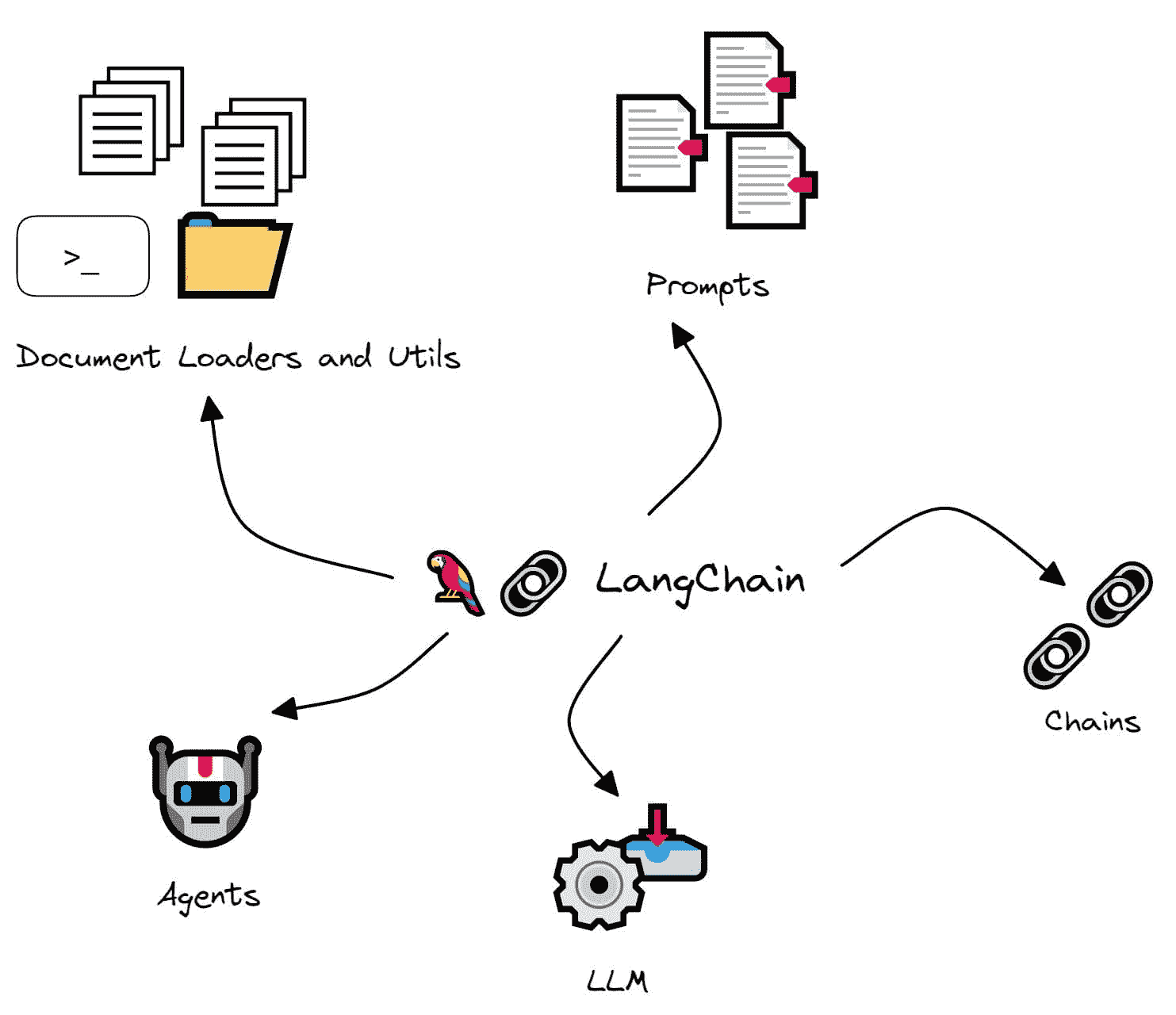
图片来源:作者
LLM
LLM 是 LangChain 的基本组件。它本质上是一个围绕大型语言模型的封装器,帮助使用特定大型语言模型的功能和能力。
链条
如前所述,LLM 是 LangChain 中的基本单元。然而,正如 LangChain 这个名字所暗示的,你可以根据特定任务将 LLM 调用链接在一起。
例如,你可能需要从特定的 URL 获取数据,汇总返回的文本,并使用生成的摘要回答问题。
链条也可以很简单。你可能需要读取用户输入,然后用这些输入构造提示。提示可以用于生成响应。
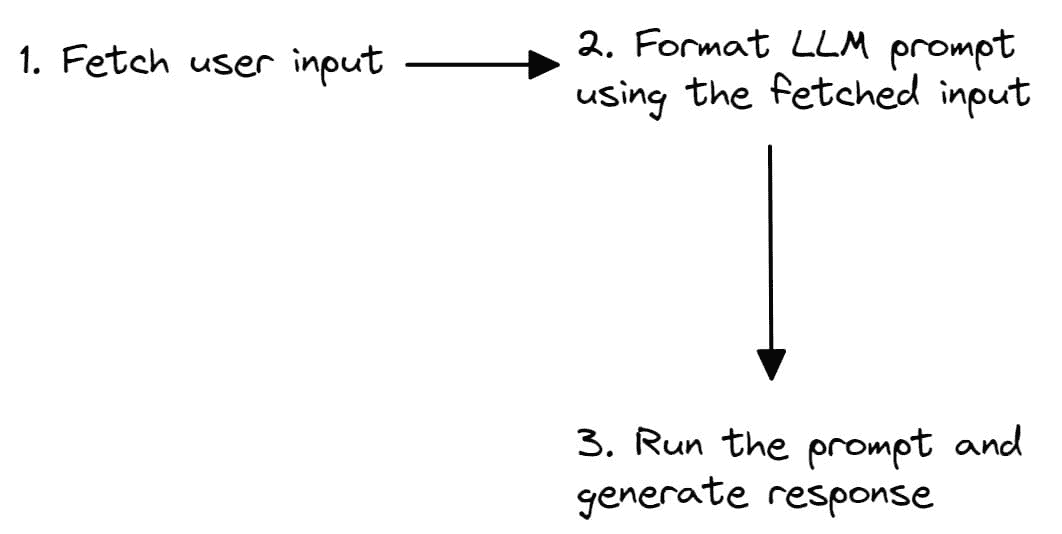
图片由作者提供
提示
提示是任何 NLP 应用程序的核心。即使在 ChatGPT 会话中,答案也只是与提示相关的。为此,LangChain 提供了可以用于格式化输入的提示模板以及许多其他实用工具。
文档加载器和工具
LangChain 的 文档加载器 和 工具 模块分别有助于连接数据源和计算。
假设你有一大批关于经济学的文本,你希望在此基础上构建一个 NLP 应用程序。你的文本库可能是文本文件、PDF 文档、HTML 网页、图像等的混合。目前,文档加载器利用 Python 库 Unstructured 将这些原始数据源转换为可以处理的文本。
工具模块提供了 Bash 和 Python 解释器会话等。这些适用于需要直接与底层系统交互的应用程序,或当我们需要代码片段来计算特定的数学量或解决问题时,而不是一次性计算答案。
代理
我们提到过,“链条”可以帮助将一系列 LLM 调用连接在一起。然而,在某些任务中,这些调用的顺序往往不是确定的。下一步可能依赖于用户输入和前一步的响应。
对于这类应用程序,LangChain 库提供了可以根据输入在过程中采取行动的“代理”,而不是一个硬编码的确定性序列。
除了上述功能,LangChain 还提供了与向量数据库的集成,并具备在 LLM 调用之间维护状态的内存功能,以及更多功能。
使用 LangChain 构建问答应用程序
现在我们已经对 LangChain 有了了解,让我们按照五个简单的步骤使用 LangChain 构建一个问答应用程序:
第一步 – 设置开发环境
在我们开始编码之前,让我们设置开发环境。我假设你已经在工作环境中安装了 Python。
你现在可以使用 pip 安装 LangChain 库:
pip install langchain
由于我们将使用 OpenAI 的语言模型,我们还需要安装 OpenAI SDK:
pip install openai
第二步 – 将 OPENAI_API_KEY 设置为环境变量
接下来,登录你的 OpenAI 账户。导航到账户设置 > 查看 API 密钥。生成一个密钥并复制它。
在你的 Python 脚本中,使用os模块并访问环境变量字典os.environ。将“OPENAI_API_KEY”设置为你刚刚复制的秘密 API 密钥:
import os
os.environ["OPENAI_API_KEY"] = "your-api-key-here"
步骤 3 – 使用 LangChain 进行简单的 LLM 调用
现在我们已经安装了所需的库,让我们看看如何使用 LangChain 进行一个简单的 LLM 调用。
为此,让我们导入 OpenAI 包装器。在这个示例中,我们将使用 text-davinci-003 模型:
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-davinci-003")
“text-davinci-003: 相比于 curie、babbage 或 ada 模型,可以更好地完成任何语言任务,提供更长的输出和一致的指令跟随。还支持在文本中插入补全。” – OpenAI 文档
让我们定义一个问题字符串并生成一个响应:
question = "Which is the best programming language to learn in 2023?"
print(llm(question))
Output >>
It is difficult to predict which programming language will be the most popular in 2023\. However, the most popular programming languages today are JavaScript, Python, Java, C++, and C#, so these are likely to remain popular for the foreseeable future. Additionally, newer languages such as Rust, Go, and TypeScript are gaining traction and could become popular choices in the future.
步骤 4 – 创建一个提示模板
让我们问另一个问题,关于学习一种新的编程语言,比如 Golang:
question = "What are the top 4 resources to learn Golang in 2023?"
print(llm(question))
Output >>
1\. The Go Programming Language by Alan A. A. Donovan and Brian W. Kernighan
2\. Go in Action by William Kennedy, Brian Ketelsen and Erik St. Martin
3\. Learn Go Programming by John Hoover
4\. Introducing Go: Build Reliable, Scalable Programs by Caleb Doxsey
虽然这对初学者来说效果不错,但当我们试图整理一份学习编程语言和技术栈的资源列表时,它很快变得重复。
这就是提示模板的用武之地。你可以创建一个可以使用一个或多个输入变量格式化的模板。
我们可以创建一个简单的模板,以获取学习任何技术栈的前 k 个资源。在这里,我们使用k和this作为input_variables:
from langchain import PromptTemplate
template = "What are the top {k} resources to learn {this} in 2023?"
prompt = PromptTemplate(template=template,input_variables=['k','this'])
步骤 5 – 运行我们的第一个 LLM 链
我们现在有了一个 LLM 和一个可以在多个 LLM 调用中重用的提示模板。
llm = OpenAI(model_name="text-davinci-003")
prompt = PromptTemplate(template=template,input_variables=['k','this'])
让我们继续创建一个 LLMChain:
from langchain import LLMChain
chain = LLMChain(llm=llm,prompt=prompt)
你现在可以将输入作为字典传入,并按如下所示运行 LLM 链:
input = {'k':3,'this':'Rust'}
print(chain.run(input))
Output >>
1\. Rust By Example - Rust By Example is a great resource for learning Rust as it provides a series of interactive exercises that teach you how to use the language and its features.
2\. Rust Book - The official Rust Book is a comprehensive guide to the language, from the basics to the more advanced topics.
3\. Rustlings - Rustlings is a great way to learn Rust quickly, as it provides a series of small exercises that help you learn the language step-by-step.
总结
就这样!你知道如何使用 LangChain 构建一个简单的问答应用程序。我希望你对 LangChain 的功能有了初步的了解。作为下一步,尝试探索 LangChain 来构建更有趣的应用程序。编程愉快!
参考资料及进一步学习
-
Chase, H. (2022). LangChain [计算机软件]. https://github.com/hwchase17/langchain
Bala Priya C 是一位技术作家,喜欢创建长篇内容。她的兴趣领域包括数学、编程和数据科学。她通过撰写教程、操作指南等向开发者社区分享她的学习成果。
更多相关话题
LangChain 备忘单
不要成为弱链
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
人工智能领域持续快速发展,不断出现新的框架和工具,使 AI 更加易于获取。最近 LLM 爆炸性发展的一个特别令人兴奋的进展是 LangChain,这是一个开源 Python 库,简化了使用大型语言模型构建 AI 应用程序的过程。
LangChain 提供了一个直观的接口,用于连接最先进的模型,如 GPT-4,并优化它们以适应定制应用程序。它支持结合多个模型的链条和模块化提示工程,实现更有影响力的互动。该库还包括通过文档加载器、相似性搜索的向量存储等工具,为你的应用程序提供外部知识。
使用 LangChain,开发者可以构建强大的基于语言的 AI 应用程序,无需重新发明轮子。其可组合结构使得轻松混合和匹配组件,如 LLMs、提示模板、外部工具和记忆。这加快了原型制作,并允许随着时间的推移无缝集成新功能。无论你是想创建聊天机器人、问答机器人还是多步骤推理代理,LangChain 都提供了快速组装先进 AI 的构建模块。
欲了解更多关于开始使用 LangChain 的信息,请查看我们的最新备忘单。

LangChain 通过可重用组件和预构建的链条简化了与语言模型的应用构建。它使模型具备数据感知和智能代理功能,从而实现更动态的互动。其模块化架构支持快速开发和定制。
对于那些刚接触对话式人工智能和大语言模型(LLMs)的人,LangChain 提供了易于理解的抽象层,简化了大型模型的使用。文档和社区支持帮助新手快速上手。更有经验的用户将欣赏到自定义和扩展提供的模块的灵活性。LangChain 使所有级别的用户都能释放大语言模型的潜力。
我们最新的备忘单 提供了 LangChain 关键功能的有用概述以及简单的代码片段以便快速入门。对于任何有兴趣使用大语言模型的人来说,LangChain 是一个必备工具,这份资源是立即上手的关键。
立即查看,并请稍后回来查看更多内容。
更多相关内容
LangChain + Streamlit + Llama:将对话 AI 带到你的本地机器
原文:
www.kdnuggets.com/2023/08/langchain-streamlit-llama-bringing-conversational-ai-local-machine.html

图片来源:作者
在过去几个月里,大型语言模型(LLMs)受到了广泛关注,吸引了全球开发者的兴趣。这些模型创造了令人兴奋的前景,特别是对于从事聊天机器人、个人助手和内容创作的开发者。LLMs 带来的可能性在开发者 | AI | NLP 社区中引发了一波热情。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT
什么是 LLM?
大型语言模型(LLMs)是指能够生成类似人类语言的文本并以自然方式理解提示的机器学习模型。这些模型通过使用包含书籍、文章、网站和其他来源的大型数据集进行训练。通过分析数据中的统计模式,LLMs 预测最可能跟随给定输入的词或短语。
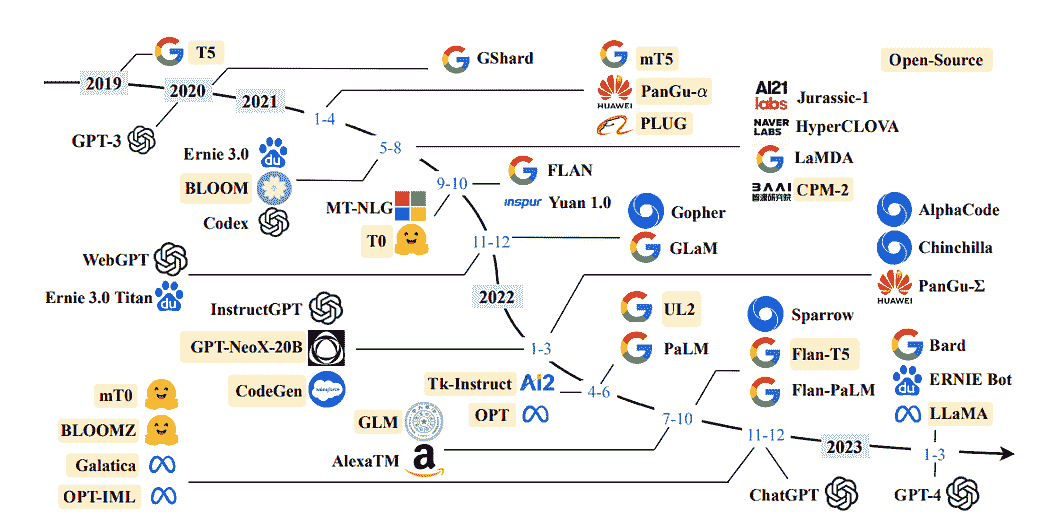
近几年 LLM 的时间轴:大型语言模型的调研
通过利用大型语言模型(LLMs),我们可以整合特定领域的数据以有效回答查询。这在处理模型初次训练时未能访问的信息时尤为有利,例如公司的内部文档或知识库。
为此目的采用的架构被称为 检索增强生成,或较少见的 生成性问答。
什么是 LangChain
LangChain 是一个令人印象深刻且免费提供的框架,精心设计用于帮助开发者创建以语言模型,特别是大型语言模型(LLMs)的强大功能为基础的应用程序。
LangChain 彻底改变了各种应用程序的开发过程,包括聊天机器人、生成式问答(GQA)和总结。通过无缝地串联来自多个模块的组件,LangChain 实现了围绕 LLMs 的强大功能创建出色的应用程序。
了解更多:官方文档
动机?
作者提供的图片
在这篇文章中,我将演示从头开始创建自己的文档助手的过程,利用 LLaMA 7b 和 Langchain,这是一个专为与 LLMs 无缝集成而开发的开源库。
下面是博客结构的概述,概述了将详细说明过程的特定部分:
-
**设置虚拟环境和创建文件结构** -
**将 LLM 安装到本地机器上** -
**将 LLM 与 LangChain 集成并自定义 PromptTemplate** -
**文档检索和回答生成** -
**使用 Streamlit 构建应用程序**
第一部分:设置虚拟环境和创建文件结构
设置虚拟环境提供了一个受控且隔离的环境来运行应用程序,确保其依赖项与其他系统范围的包分开。这种方法简化了依赖项的管理,并有助于在不同环境中保持一致性。
为了设置这个应用程序的虚拟环境,我将在我的 GitHub 仓库中提供 pip 文件。首先,让我们创建图中所示的必要文件结构。或者,你也可以直接克隆仓库以获取所需文件。
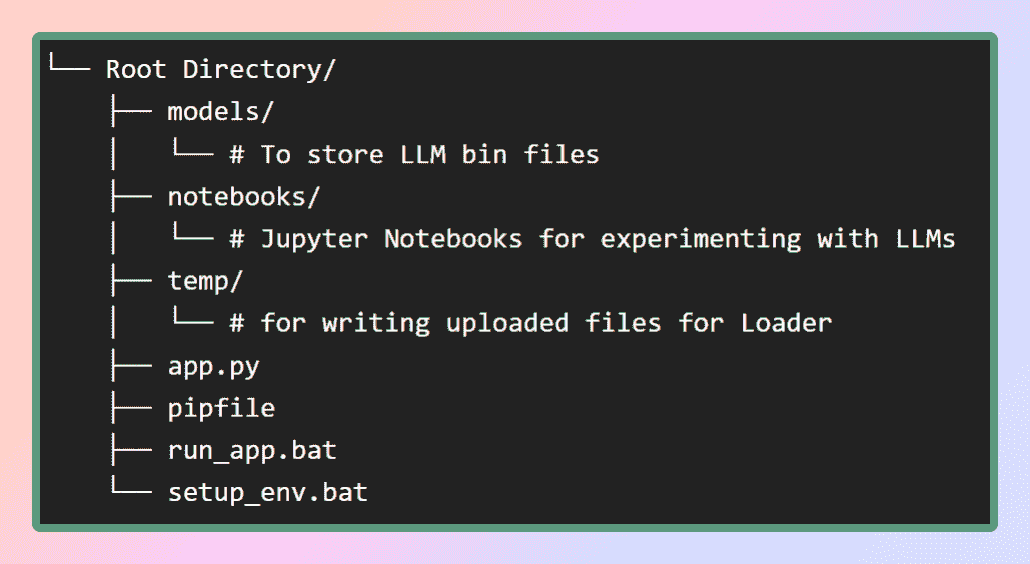
作者提供的图片:文件结构
在模型文件夹中,我们将存储下载的 LLMs,而 pip 文件将位于根目录中。
为了创建虚拟环境并安装其中的所有依赖项,我们可以使用 **pipenv install**命令,或者直接运行**setup_env.bat**批处理文件,它将从 **pipfile**中安装所有依赖项。这将确保在虚拟环境中安装所有必要的软件包和库。一旦依赖项成功安装,我们可以继续进行下一步,即下载所需的模型。这里是仓库。
第二部分:在本地机器上获取 LLaMA
什么是 LLaMA?
LLaMA 是 Meta AI 设计的新型大型语言模型,Meta 是 Facebook 的母公司。LLaMA 拥有从 70 亿到 650 亿参数的多种模型,是现有的最全面的语言模型之一。2023 年 2 月 24 日,Meta 将 LLaMA 模型公开发布,展示了其对开放科学的承诺。
图片来源: LLaMA
考虑到 LLaMA 的卓越能力,我们选择使用这个强大的语言模型来满足我们的需求。具体来说,我们将使用 LLaMA 的最小版本,即 LLaMA 7B。即便在这个较小的规模下,LLaMA 7B 仍提供显著的语言处理能力,使我们能够高效且有效地实现所需的结果。
**官方研究论文 : **
[**LLaMA: 开放且高效的基础语言模型**](https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/)
要在本地 CPU 上运行 LLM,我们需要一个 GGML 格式的本地模型。有几种方法可以实现这一点,但最简单的方法是直接从Hugging Face 模型库下载 bin 文件。在我们的案例中,我们将下载 Llama 7B 模型。这些模型是开源的,可以自由下载。
如果你想节省时间和精力,不用担心——我已经为你准备好了。这里是直接下载模型的链接?。只需下载任何一个版本,然后将文件移动到我们根目录中的 models 目录下。这样,你就能方便地使用这个模型。
什么是 GGML?为什么选择 GGML?如何使用 GGML?LLaMA CPP
GGML 是一个用于机器学习的 Tensor 库,它只是一个 C++库,允许你在 CPU 或 CPU+GPU 上运行 LLMs。它定义了一种用于分发大型语言模型(LLMs)的二进制格式。GGML 利用了一种叫做量化的技术,使大型语言模型可以在消费者硬件上运行。
那么,什么是量化?
LLM 的权重是浮点(十进制)数字。就像表示一个大整数(例如 1000)比表示一个小整数(例如 1)需要更多空间一样,表示一个高精度浮点数(例如 0.0001)也比表示一个低精度浮点数(例如 0.1)需要更多空间。对大型语言模型进行量化的过程涉及减少权重表示的精度,以减少使用模型所需的资源。GGML 支持多种量化策略(例如 4-bit、5-bit 和 8-bit 量化),每种策略在效率和性能之间提供了不同的权衡。
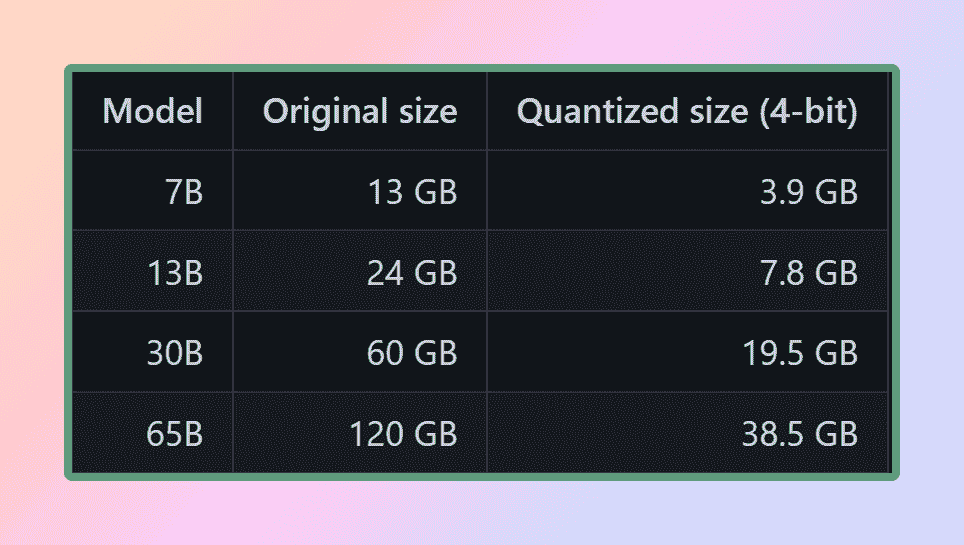
Llama 的量化大小
为了有效使用模型,考虑内存和磁盘需求是至关重要的。由于模型当前完全加载到内存中,你需要足够的磁盘空间来存储它们,以及足够的 RAM 在执行期间加载它们。对于 65B 模型,即使经过量化,建议至少拥有 40 GB 的 RAM。值得注意的是,目前的内存和磁盘要求是相等的。
量化在管理这些资源需求中起着关键作用。除非你有非常强大的计算资源
通过减少模型参数的精度和优化内存使用,量化使得模型可以在更低配置的硬件上使用。这确保了在更广泛的设置中运行模型仍然可行和高效。
如果这是一个 C++ 库,我们如何在 Python 中使用它?
这时 Python 绑定就派上用场了。绑定指的是为我们 Python 和 C++ 之间创建桥梁或接口的过程。我们将使用 **llama-cpp-python**,这是 **llama.cpp** 的 Python 绑定,充当 LLaMA 模型在纯 C/C++ 中的推理。**llama.cpp** 的主要目标是使用 4 位整数量化运行 LLaMA 模型。这种集成允许我们有效地利用 LLaMA 模型,结合 C/C++ 实现的优势和 4 位整数量化的好处。

llama.cpp 支持的模型: 来源
准备好 GGML 模型并且所有依赖项到位(感谢 pipfile)之后,是时候开始我们的 LangChain 之旅了。但在深入 LangChain 的精彩世界之前,让我们先从惯例 “Hello World” 仪式开始 — 这是我们每次探索新语言或框架时遵循的传统,毕竟 LLM 也是一种语言模型。

作者提供的图片:在 CPU 上与 LLM 互动
瞧!!!我们已经成功在 CPU 上执行了第一个 LLM,完全离线并以完全随机的方式(你可以调整超参数 temperature)。
随着这个激动人心的里程碑的完成,我们现在准备开始我们的主要目标:使用 LangChain 框架对自定义文本进行问答。
第三部分:开始使用 LLM — LangChain 集成
在上一节中,我们使用 llama cpp 初始化了 LLM。现在,让我们利用 LangChain 框架来开发基于 LLM 的应用程序。你与它们互动的主要接口是通过文本。简而言之,许多模型是文本输入,文本输出。因此,LangChain 中的许多接口都是围绕文本展开的。
提示工程的兴起
在不断发展的编程领域中,一个引人入胜的范式已经出现:提示。提示涉及向语言模型提供特定输入以引出期望的回应。这种创新的方法允许我们根据提供的输入来塑造模型的输出。
我们措辞方式中的细微差别对模型回应的性质和内容产生显著影响,这一点非常值得注意。结果可能会根据措辞的不同而发生根本性的变化,这突显了在制定提示时需要仔细考虑的的重要性。
为了与 LLM 提供无缝互动,LangChain 提供了多个类和函数,通过使用提示模板,使构造和处理提示变得简单。这是一种可重复的生成提示的方式。它包含一个文本字符串模板,可以接收来自最终用户的一组参数并生成提示。让我们看几个例子。
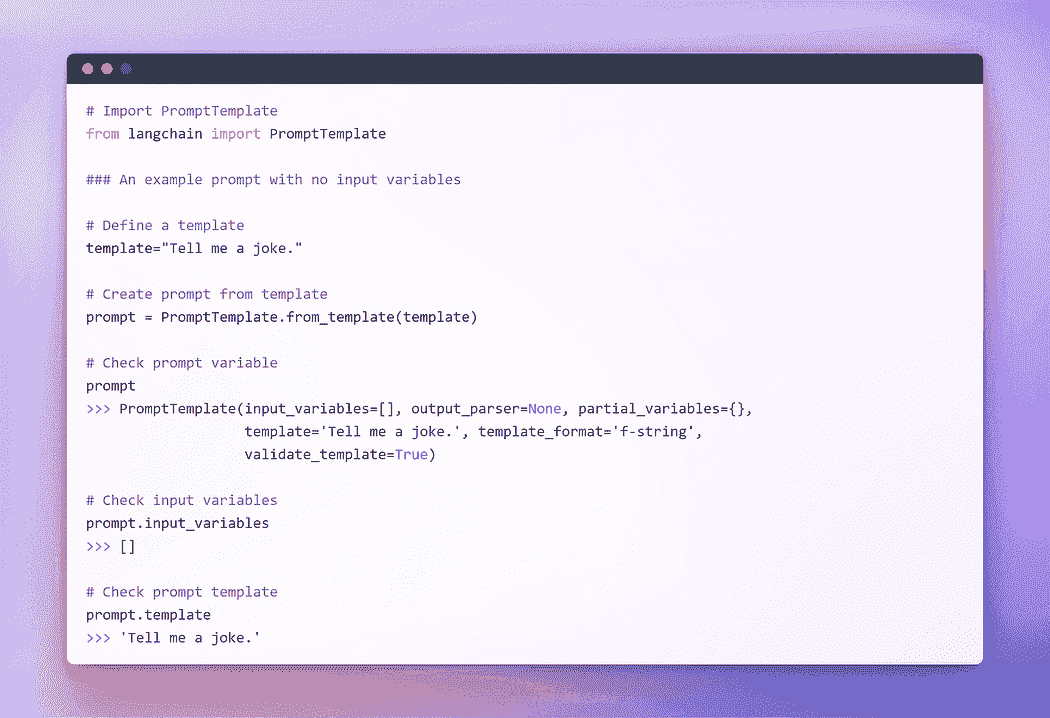
作者提供的图片:没有输入变量的提示
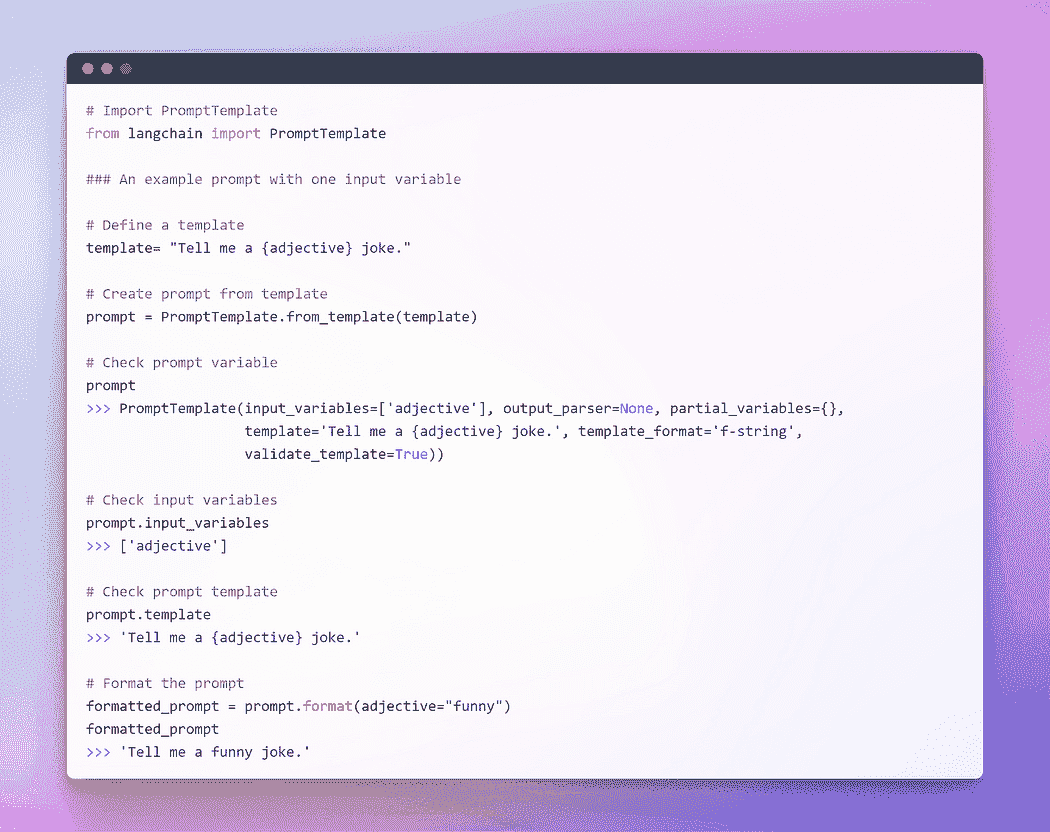
作者提供的图片:使用单一输入变量的提示
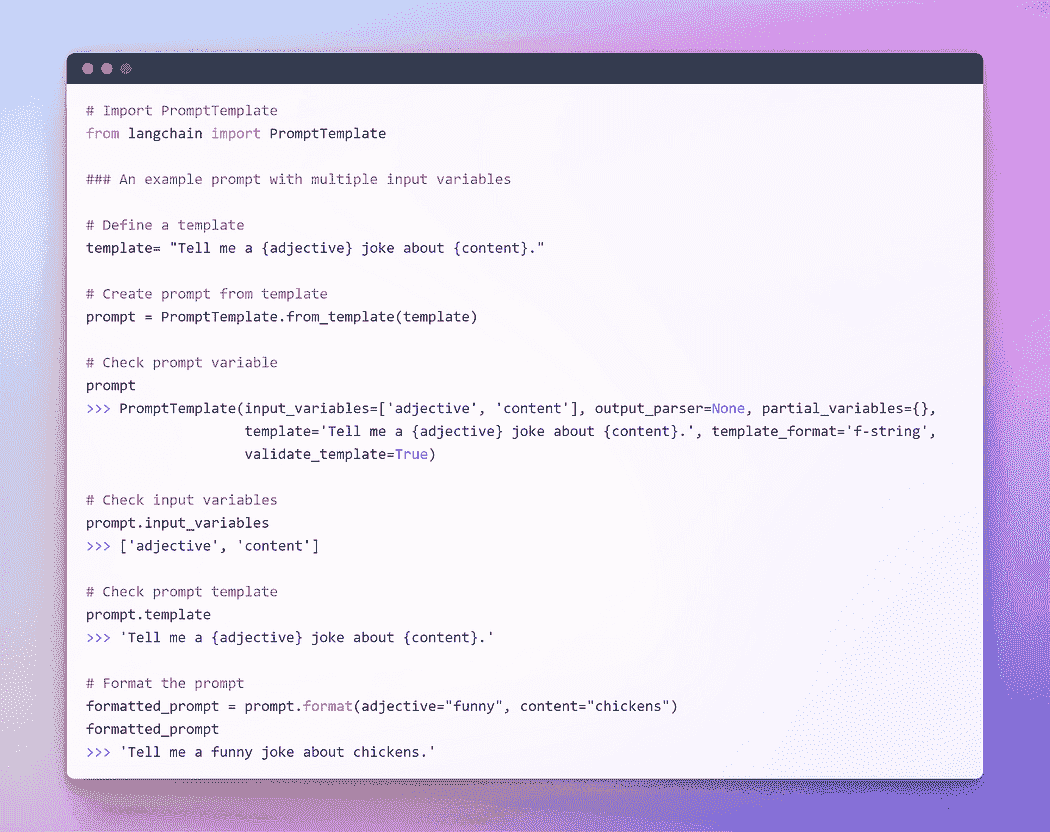
作者提供的图片:使用多个输入变量的提示
我希望之前的解释已经让你对提示的概念有了更清晰的理解。现在,让我们继续对 LLM 进行提示。
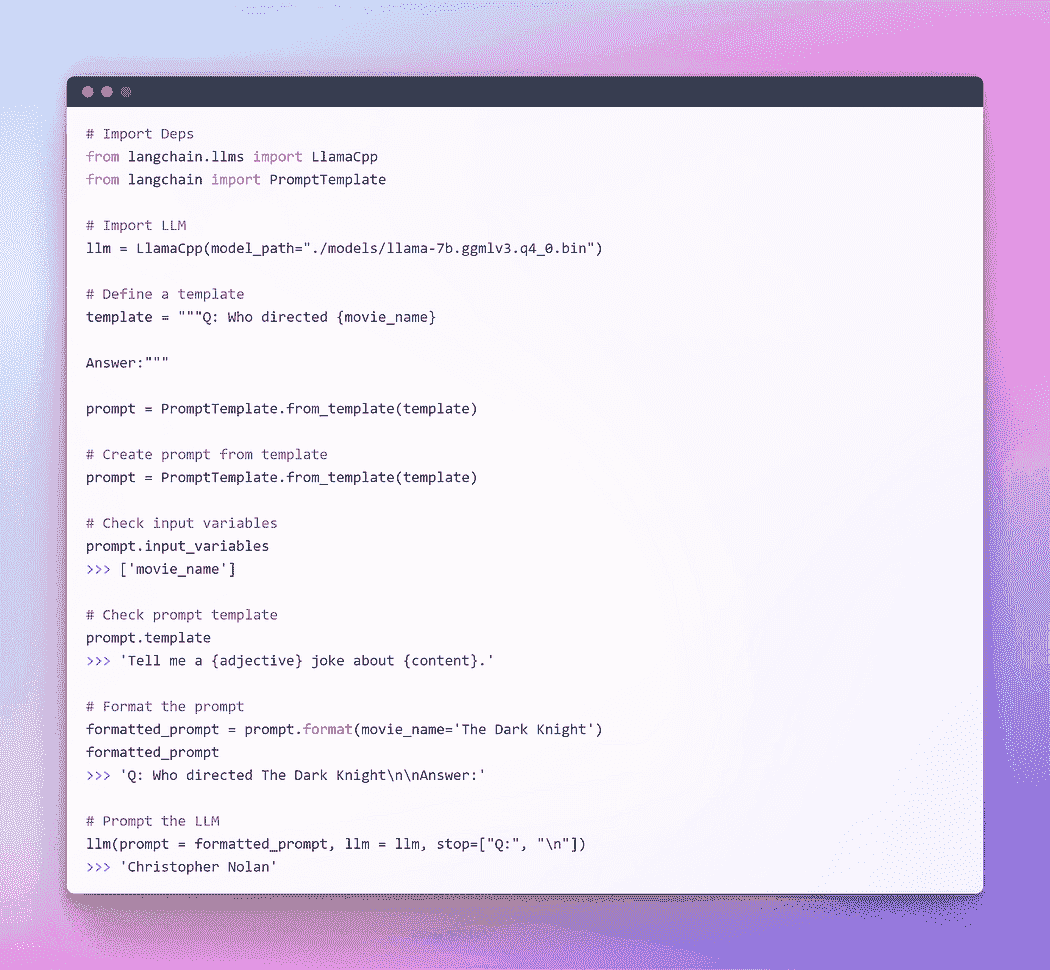
作者提供的图片:通过 Langchain LLM 进行提示
这种方法运行得很好,但这不是 LangChain 的最佳利用方式。到目前为止,我们使用了单独的组件。我们取了提示模板,格式化它,然后取了 llm,然后将这些参数传递给 llm 以生成答案。单独使用 LLM 对于简单应用程序来说是可以的,但更复杂的应用程序需要将 LLM 链接起来——无论是彼此之间,还是与其他组件之间。
LangChain 提供了 Chain 接口用于此类链式应用。我们非常泛泛地定义 Chain 为一系列对组件的调用,这些组件可以包括其他链。链允许我们将多个组件组合在一起以创建一个单一的、连贯的应用。例如,我们可以创建一个链,它接受用户输入,用提示模板格式化输入,然后将格式化后的响应传递给 LLM。我们可以通过将多个链组合在一起,或将链与其他组件组合来构建更复杂的链。
为了理解其中一个,让我们创建一个非常简单的链,它将接受用户输入,用它格式化提示,然后使用我们已经创建的上述单独组件将其发送给 LLM。
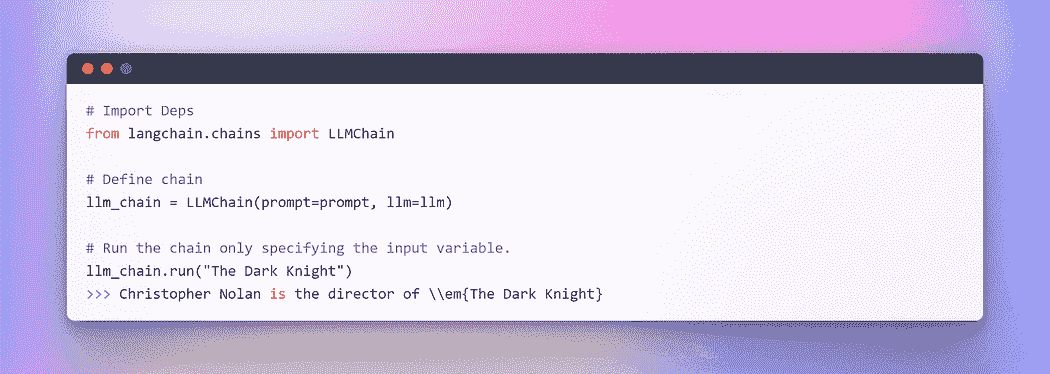
作者提供的图像:LangChain 中的链式操作
在处理多个变量时,你可以选择通过使用字典来集体输入它们。到此为止,这一部分结束了。现在,让我们深入到主要部分,我们将结合外部文本作为检索器来进行问答。
第四节:为问答生成嵌入和向量存储
在众多 LLM 应用中,需要用户特定的数据,这些数据未包含在模型的训练集中。LangChain 为你提供了加载、转换、存储和查询数据的基本组件。
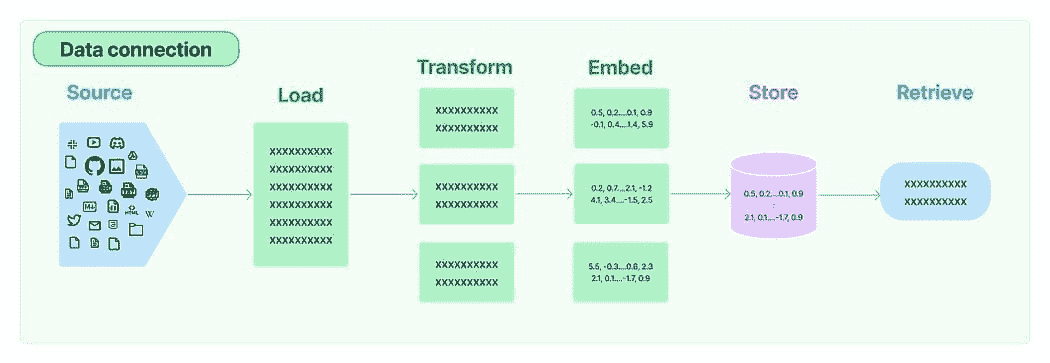
LangChain 中的数据连接:来源
五个阶段是:
-
文档加载器: 用于将数据加载为文档。
-
文档转换器: 它将文档拆分为较小的块。
-
嵌入: 它将块转换为向量表示,即嵌入。
-
向量存储: 用于在向量数据库中存储上述块向量。
-
检索器: 它用于检索与查询最相似的一组/组向量,这些向量以与查询嵌入在同一潜在空间中的向量形式存在。
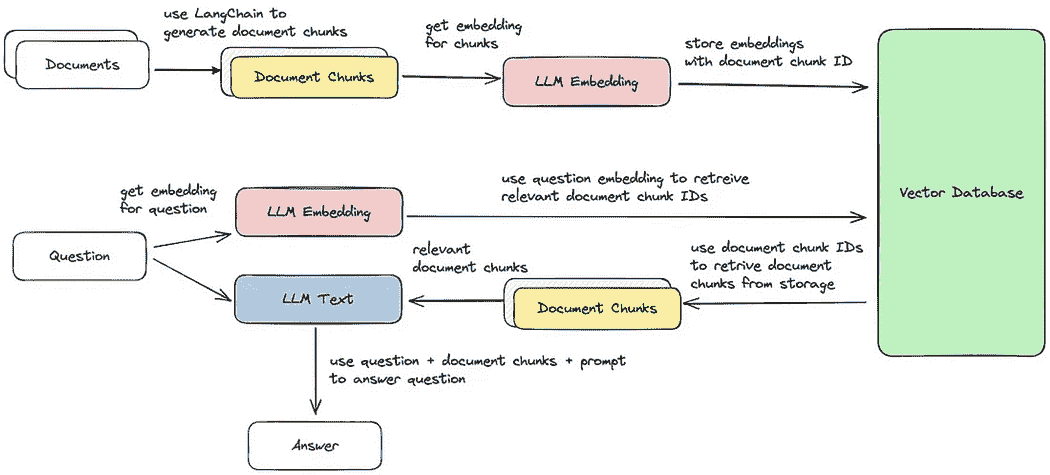
文档检索/问答循环
现在,我们将逐步进行五个步骤,以检索与查询最相似的文档块。随后,我们可以基于检索到的向量块生成答案,如所提供的图像所示。
然而,在进一步进行之前,我们需要准备一个文本以执行上述任务。为了这个虚构的测试,我从维基百科复制了一段关于一些受欢迎的 DC 超级英雄的文本。以下是文本:

作者提供的图像:用于测试的原始文本
加载与转换文档
首先,让我们创建一个文档对象。在这个示例中,我们将使用文本加载器。然而,LangChain 支持多种文档,因此根据你的具体文档,你可以使用不同的加载器。接下来,我们将使用**load**方法从预配置的源中检索数据并将其加载为文档。
一旦文档被加载,我们可以通过将其分成较小的块来继续转换过程。为此,我们将使用 TextSplitter。默认情况下,分割器在‘\n\n’分隔符处分隔文档。然而,如果你将分隔符设置为 null 并定义特定的块大小,每个块将具有指定的长度。因此,结果列表的长度将等于文档的长度除以块大小。总之,它将类似于**list length = length of doc / chunk size**。让我们实践一下。

作者提供的图像:加载和转换文档
旅程的一部分就是嵌入 !!!
这是最重要的一步。嵌入生成了文本内容的向量化表现。这具有实际意义,因为它允许我们在向量空间中概念化文本。
词嵌入只是单词的向量表示,向量包含实数。由于语言通常包含至少数万词汇,简单的二进制词向量由于维度过高可能变得不切实际。词嵌入通过在低维向量空间中提供密集的词表示来解决这个问题。
当我们谈论检索时,我们指的是检索与查询最相似的一组向量,这些向量以嵌入在相同潜在空间中的形式存在。
LangChain 中的基础嵌入类暴露了两个方法:一个用于嵌入文档,另一个用于嵌入查询。前者接受多个文本作为输入,而后者接受单个文本。

作者提供的图像:嵌入
为了全面理解嵌入,我强烈建议深入了解基础知识,因为它们构成了神经网络处理文本数据的核心。我在我的一篇博客中广泛讨论了这个主题,使用了 TensorFlow。这里是链接。
词嵌入——神经网络的文本表示
创建向量存储和检索文档
向量存储高效地管理嵌入数据的存储,并代表你执行向量搜索操作。嵌入和存储生成的嵌入向量是一种存储和搜索非结构化数据的常见方法。在查询时,非结构化查询也会被嵌入,并检索出与嵌入查询具有最高相似度的嵌入向量。这种方法能够有效地从向量存储中检索相关信息。
在这里,我们将使用 Chroma,一个专门为简化 AI 应用程序开发而设计的嵌入数据库和向量存储。它提供了一整套内置工具和功能来简化你的初始设置,所有这些都可以通过执行简单的**pip install chromadb**命令方便地安装在本地机器上。

图片由作者提供:创建向量存储
到目前为止,我们已经见证了嵌入和向量存储在从大量文档集合中检索相关片段方面的显著能力。现在,时机已到,我们将把这个检索到的片段与查询一起作为上下文呈现给 LLM。挥动它的魔法棒,我们将请求 LLM 基于我们提供的信息生成答案。关键在于提示结构。
然而,必须强调结构良好的提示的重要性。通过制定精心设计的提示,我们可以减轻 LLM 在面对不确定性时可能出现的幻觉——即它可能发明事实。
在不再拖延的情况下,让我们进入最后阶段,看看我们的 LLM 是否能够生成引人注目的答案。时刻来临,见证我们的努力成果并揭示结果吧。我们出发了?
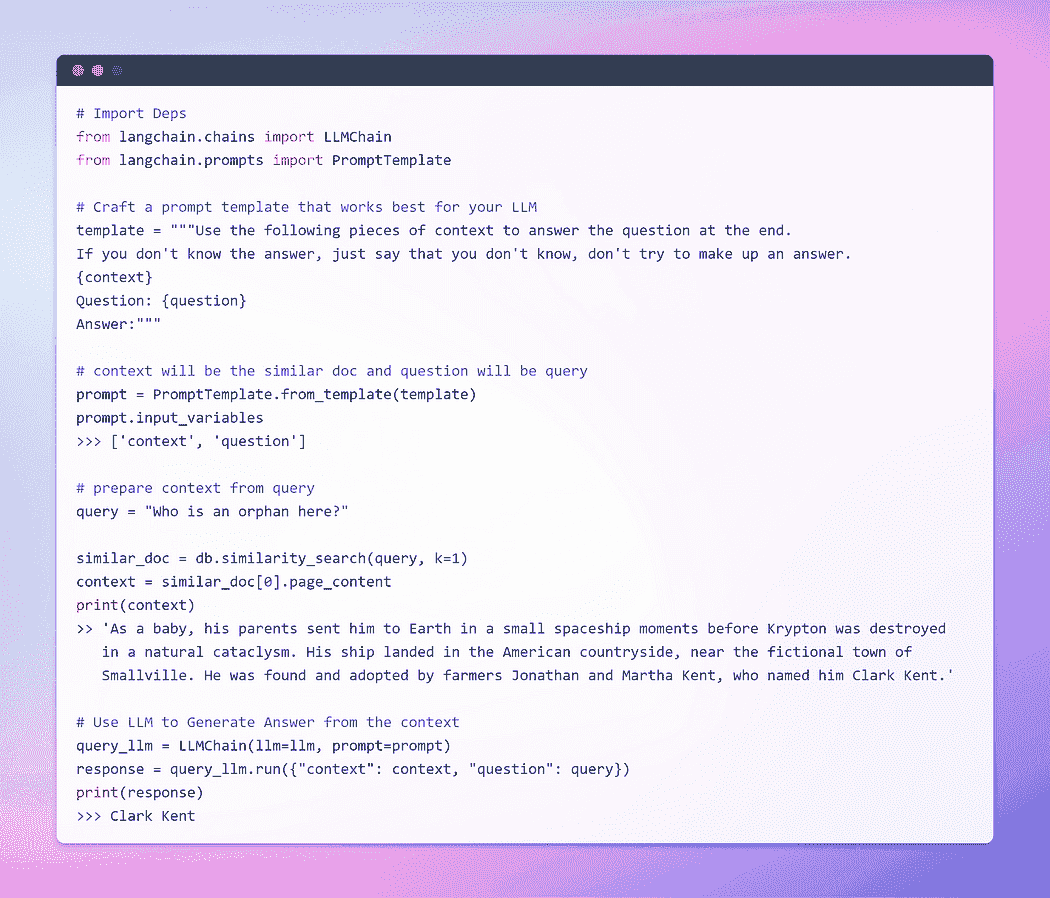
图片由作者提供:与文档的问答
这是我们一直期待的时刻!我们成功了!我们刚刚构建了我们自己的问答机器人,利用本地运行的 LLM。
第五部分:使用 Streamlit 链式操作
这一部分完全是可选的,因为它并不是 Streamlit 的全面指南。我不会深入探讨这一部分;相反,我会展示一个基本应用,允许用户上传任何文本文件。然后,他们可以通过文本输入提问。幕后功能将与我们在上一部分中讨论的保持一致。
然而,在 Streamlit 中处理文件上传时有一个警告。为了防止潜在的内存不足错误,特别是考虑到 LLM 的内存密集型特性,我将简单地读取文档并将其写入我们文件结构中的临时文件夹,命名为**raw.txt.**。这样,无论文档的原始名称是什么,Textloader 将在未来无缝处理它。
目前,该应用程序设计用于文本文件,但你可以将其适应于 PDF、CSV 或其他格式。基本概念保持不变,因为 LLM 主要用于文本输入和输出。此外,你可以尝试不同的由 Llama C++ 绑定支持的 LLM。
不再深入复杂的细节,我提供了应用程序的代码。随意自定义以适应你的特定用例。
这是 streamlit 应用程序的外观。

这次我提供了从 Wiki 复制的《黑暗骑士》的情节,并仅仅问了“谁的脸被严重烧伤?”,LLM 回复了——哈维·丹特。
好了,好了,好了!至此,我们博客的内容就结束了。
希望你喜欢这篇文章!并觉得它既有信息量又有趣。你可以关注我Afaque Umer以获得更多此类文章。
我将尝试引入更多机器学习/数据科学概念,并尝试将复杂的术语和概念拆解成更简单的形式。
Afaque Umer 是一位充满激情的机器学习工程师。他喜欢利用最新技术解决新挑战,寻找高效的解决方案。让我们一起推动 AI 的边界!
原文。已获授权转载。
更多相关话题
大型语言模型在三个难度级别中的解释
原文:
www.kdnuggets.com/large-language-models-explained-in-3-levels-of-difficulty
我们生活在一个机器学习模型处于巅峰的时代。与几十年前相比,大多数人可能从未听说过 ChatGPT 或人工智能。然而,这些正是人们不断讨论的话题。为什么?因为它们所带来的价值与投入的努力相比是如此显著。
近年来,人工智能的突破可以归因于许多因素,但其中之一就是大型语言模型(LLM)。许多文本生成 AI 都依赖于 LLM 模型;例如,ChatGPT 使用的是他们的 GPT 模型。由于 LLM 是一个重要的话题,我们应该了解它。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
本文将讨论大型语言模型(LLM)的三个难度级别,但我们只会触及 LLM 的一些方面。我们将以一种使每位读者都能理解 LLM 是什么的方式进行讨论。考虑到这一点,我们开始吧。
第 1 级:LLM 初学者级别
在第一个级别,我们假设读者对 LLM 不了解,并可能对数据科学/机器学习领域有所了解。因此,我将简要介绍人工智能和机器学习,然后再转到 LLM。
人工智能是开发智能计算机程序的科学。它旨在使程序能够执行人类可以做的智能任务,但不受人类生物需求的限制。机器学习是人工智能的一个领域,专注于利用统计算法进行数据泛化研究。从某种意义上说,机器学习通过数据研究来实现人工智能,使程序能够在没有指令的情况下执行智能任务。
历史上,计算机科学和语言学交叉的领域称为自然语言处理领域。该领域主要涉及机器对人类文本(如文本文件)的处理活动。之前,该领域仅限于基于规则的系统,但随着先进的半监督和无监督算法的引入,该领域得到了扩展,使模型能够在没有任何指导的情况下学习。其中一个先进模型是语言模型。
语言模型是一个概率性 NLP 模型,用于执行许多类似翻译、语法纠正和文本生成的人类任务。旧形式的语言模型使用纯统计方法,如 n-gram 方法,其中假设下一个词的概率仅依赖于前一个词的固定大小数据。
然而,神经网络的引入已经取代了以前的方法。人工神经网络,或称 NN,是一种模拟人脑神经结构的计算机程序。神经网络方法之所以好用,是因为它可以处理复杂的模式识别和文本数据的序列数据。这就是为什么当前的语言模型通常基于 NN。
大型语言模型,或 LLMs,是通过从大量数据文档中学习来执行通用语言生成的机器学习模型。它们仍然是语言模型,但 NN 学到的大量参数使它们被认为是大型的。通俗来说,该模型通过从给定的输入词预测下一个词来非常好地模拟人类的写作方式。
LLM 任务的例子包括语言翻译、机器聊天机器人、问答等。从任何数据输入序列中,模型可以识别单词之间的关系,并生成符合指令的输出。
几乎所有声称使用文本生成的生成式 AI 产品都由 LLMs 驱动。像 ChatGPT、Google 的 Bard 等大型产品都以 LLMs 为基础。
第二级:LLM 中级水平
读者具有数据科学知识,但需要在此级别上进一步了解 LLM。至少,读者能够理解数据领域中使用的术语。在这个层面上,我们将更深入地探讨基础架构。
如前所述,LLM 是一个在大量文本数据上训练的神经网络模型。要进一步理解这一概念,了解神经网络和深度学习的工作原理将是有益的。
在前一层中,我们解释了神经元是模仿人脑神经结构的模型。神经网络的主要元素是神经元,通常称为节点。为了更好地解释这一概念,请参见下面图像中的典型神经网络架构。
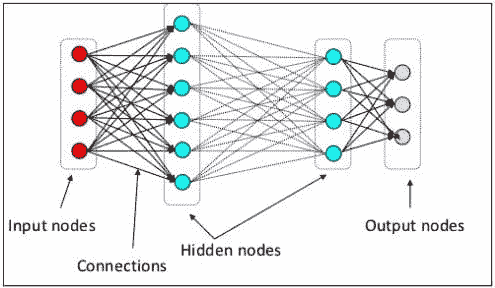
神经网络架构(图片来源:KDnuggets)
如上图所示,神经网络由三层组成:
-
输入层接收信息并将其传输到下一层的其他节点。
-
隐藏节点层是所有计算发生的地方。
-
输出节点层是计算结果所在的地方。
当我们用两个或更多隐藏层训练神经网络模型时,这称为深度学习。之所以叫深度,是因为它使用了许多层。深度学习模型的优势在于它们能够自动学习和提取数据中的特征,而传统的机器学习模型则无法做到这一点。
在大语言模型中,深度学习非常重要,因为该模型建立在深度神经网络架构之上。那么,为什么它叫 LLM 呢?因为数十亿层在大量文本数据上进行训练。这些层会产生模型参数,帮助模型学习语言中的复杂模式,包括语法、写作风格等等。
模型训练的简化过程如下面的图像所示。
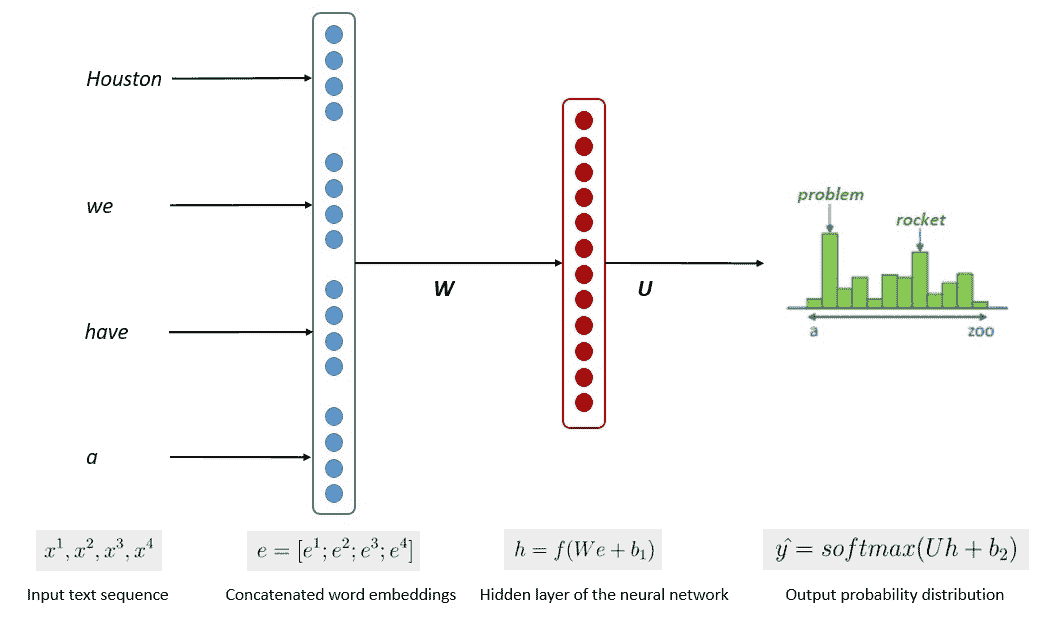
图片来源:Kumar Chandrakant(来源:Baeldung.com)
过程显示模型可以根据输入数据中每个单词或句子的可能性生成相关文本。在 LLM 中,先进的方法使用 自监督学习 和 半监督学习 来实现通用能力。
自监督学习是一种技术,其中我们没有标签,而是训练数据提供了训练反馈。它在 LLM 训练过程中被使用,因为数据通常缺乏标签。在 LLM 中,可以利用周围的上下文作为线索来预测下一个单词。相比之下,半监督学习将监督学习和无监督学习概念结合起来,使用少量标记数据为大量未标记数据生成新标签。半监督学习通常用于具有特定上下文或领域需求的 LLM。
第 3 层:LLM 高级
在第三层,我们将更深入地讨论 LLM,特别是探讨 LLM 结构以及它如何实现类似人类的生成能力。
我们已经讨论了 LLM 基于深度学习技术的神经网络模型。近年来,LLM 通常基于 变压器 架构构建。变压器基于 Vaswani et al. (2017) 引入的多头注意力机制,并已被许多 LLM 使用。
变压器是一种模型架构,旨在解决 RNN 和 LSTM 之前遇到的序列任务。语言模型的旧方法是使用 RNN 和 LSTM 顺序处理数据,模型会使用每个词输出并将其回环,以免遗忘。然而,一旦引入变压器,这些方法在长序列数据上会出现问题。
在深入了解变压器之前,我想介绍一下以前在 RNN 中使用的编码器-解码器概念。编码器-解码器结构允许输入和输出文本长度不同。一个示例用例是语言翻译,它通常具有不同的序列大小。
该结构可以分为两部分。第一部分称为编码器,它接收数据序列并基于它创建新的表示。该表示将在模型的第二部分,即解码器中使用。
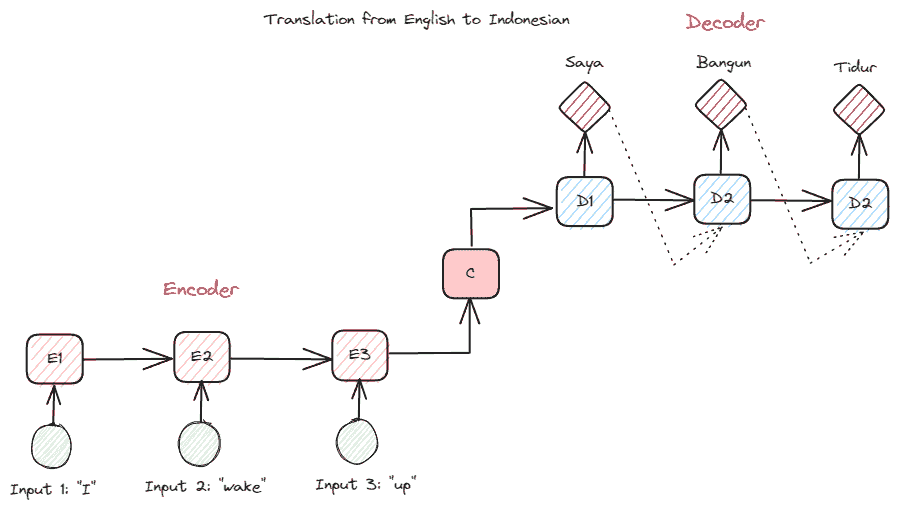
图片由作者提供
RNN 的问题在于,即使在上述编码器-解码器结构下,模型可能仍难以记住较长的序列。这时,注意力机制可以帮助解决这个问题,它是一种能够解决长输入问题的层。注意力机制在 Bahdanau et al. (2014) 的论文中被引入,用于通过关注模型输入的重要部分来解决编码器-解码器类型的 RNN 问题,同时进行输出预测。
变压器的结构受编码器-解码器类型的启发,并采用注意力机制技术构建,因此无需按顺序处理数据。整体变压器模型的结构如下面的图像所示。
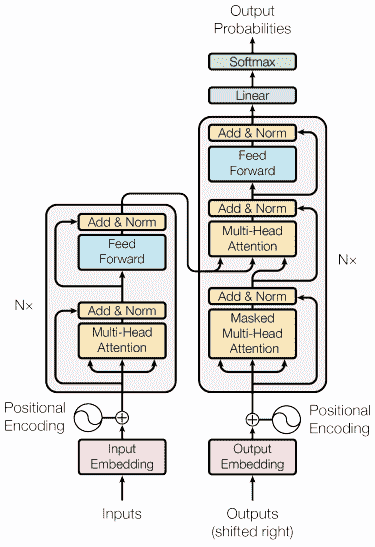
变压器架构(Vaswani et al. (2017))
在上述结构中,变压器将数据向量序列编码为词嵌入,同时使用解码将数据转换为原始形式。编码可以利用注意力机制为输入分配一定的重要性。
我们稍微谈了一下变换器如何编码数据向量,但什么是数据向量呢?让我们来讨论一下。在机器学习模型中,我们不能将原始自然语言数据输入模型,因此我们需要将其转化为数字形式。这一转换过程称为词嵌入,其中每个输入单词都通过词嵌入模型处理以获取数据向量。我们可以使用许多初始词嵌入,如 Word2vec 或 GloVe,但许多高级用户尝试使用他们自己的词汇来精细调整它们。在基本形式下,词嵌入过程可以在下图中展示。
作者提供的图片
变换器可以接受输入,并通过以数字形式呈现单词来提供更相关的上下文,如上面的数据向量。在大语言模型(LLMs)中,词嵌入通常是依赖上下文的,通常会根据使用案例和预期输出进行精细调整。
结论
我们以三个难度级别讨论了大型语言模型,从初学者到高级用户。从 LLM 的一般使用到其结构,你可以找到更详细解释这个概念的说明。
Cornellius Yudha Wijaya**** 是一名数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 撰写了各种人工智能和机器学习主题的文章。
更多相关话题
大型语言模型是什么,它们是如何工作的?
原文:
www.kdnuggets.com/2023/05/large-language-models-work.html

编辑提供的图像
大型语言模型是什么?
我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业之路。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织的 IT
大型语言模型是一种人工智能(AI)模型,旨在理解、生成和处理自然语言。这些模型在大量文本数据上进行训练,以学习人类语言的模式、语法和语义。它们利用深度学习技术,如神经网络,来处理和分析文本信息。
大型语言模型的主要目的是执行各种自然语言处理(NLP)任务,如文本分类、情感分析、机器翻译、摘要生成、问答和内容生成。一些知名的大型语言模型包括 OpenAI 的 GPT(生成预训练变换器)系列,其中 GPT-4 是最著名的之一,Google 的 BERT(双向编码器表示变换器),以及 Transformer 架构的一般应用。
大型语言模型的工作原理
大型语言模型通过使用深度学习技术分析和学习大量文本数据,使其能够理解、生成和处理人类语言,以执行各种自然语言处理任务。
A. 预训练、微调和基于提示的学习
在大规模文本语料库上进行预训练:大型语言模型(LLMs)在庞大的文本数据集上进行预训练,这些数据集通常涵盖了互联网的显著部分。通过从各种来源学习,LLMs 捕捉语言中的结构、模式和关系,使其能够理解上下文并生成连贯的文本。这一预训练阶段帮助 LLMs 建立一个强大的知识基础,作为各种自然语言处理任务的基础。
在任务特定的标记数据上进行微调:在预训练之后,LLM 会使用针对特定任务和领域(如情感分析、机器翻译或问答)的较小标记数据集进行微调。这一微调过程使模型能够将其一般语言理解适应目标任务的细微差别,从而提高性能和准确性。
基于提示的学习与传统的 LLM 训练方法有所不同,例如 GPT-3 和 BERT 的训练方法,这些方法需要在未标记的数据上进行预训练,然后用标记数据进行任务特定的微调。而基于提示的学习模型则可以通过使用提示整合领域知识,自主调整以适应各种任务。
基于提示的模型生成的输出的成功严重依赖于提示的质量。精心设计的提示可以引导模型生成精确且相关的输出。相反,设计不当的提示可能会产生不合逻辑或无关的输出。设计有效提示的技巧被称为提示工程。
B. Transformer 架构
自注意力机制:支撑许多大型语言模型(LLM)的 Transformer 架构引入了一种自注意力机制,这一机制彻底改变了语言模型处理和生成文本的方式。自注意力机制使模型能够在给定的上下文中权衡不同单词的重要性,从而在生成文本或进行预测时选择性地关注相关信息。该机制计算效率高,并提供了一种灵活的方式来建模复杂的语言模式和长距离依赖。
位置编码和嵌入:在 Transformer 架构中,输入文本首先被转换为嵌入,这些嵌入是连续的向量表示,用于捕捉单词的语义含义。然后,将位置编码添加到这些嵌入中,以提供有关句子中单词相对位置的信息。这种嵌入和位置编码的结合使 Transformer 能够以上下文感知的方式处理和生成文本,从而理解和生成连贯的语言。
C. 分词方法和技术
分词是将原始文本转换为一系列较小单位(称为标记)的过程,这些单位可以是单词、子词或字符。分词是 LLM 管道中的一个重要步骤,因为它使模型能够以结构化格式处理和分析文本。LLM 中使用了几种分词方法和技术:
基于单词的分词:这种方法将文本拆分成单独的单词,将每个单词视为一个独立的标记。虽然简单直观,但基于单词的分词在处理词汇表外的词时可能会遇到困难,并且可能无法有效处理具有复杂形态的语言。
基于子词的分词:子词方法,如字节对编码(BPE)和 WordPiece,将文本拆分为可以组合成完整单词的较小单元。这种方法使 LLMs 能够处理词汇表外的单词,并更好地捕捉不同语言的结构。例如,BPE 通过合并最常出现的字符对来创建子词单元,而 WordPiece 则采用数据驱动的方法将单词分割成子词标记。
基于字符的分词:这种方法将单个字符视为标记。虽然它可以处理任何输入文本,但基于字符的分词通常需要更大的模型和更多的计算资源,因为它需要处理更长的标记序列。
大型语言模型的应用
A. 文本生成与完成
LLMs 可以生成连贯流畅的文本,紧密模拟人类语言,使其成为创意写作、聊天机器人和虚拟助手等应用的理想选择。它们还可以根据给定的提示完成句子或段落,展示了出色的语言理解和上下文意识。
B. 情感分析
LLMs 在sentiment analysis任务中表现出色,在这些任务中,它们根据情感将文本分类为正面、负面或中性。这种能力广泛应用于客户反馈分析、社交媒体监测和市场研究等领域。
C. 机器翻译
LLMs 还可以用于机器翻译,允许用户在不同语言之间翻译文本。像 Google Translate 和 DeepL 这样的 LLMs 已经展示了令人印象深刻的准确性和流畅性,使其成为跨语言障碍沟通的宝贵工具。
D. 问答系统
LLMs 可以通过处理自然语言输入并根据其知识库提供相关答案来回答问题。这一能力已被应用于各种场景,从客户支持到教育和研究辅助。
E. 文本摘要
LLMs 可以生成长文档或文章的简明摘要,使用户能够更快地掌握主要观点。文本摘要在新闻聚合、内容策划和研究辅助等方面具有广泛的应用。
结论
大型语言模型代表了自然语言处理领域的重大进展,改变了我们与语言技术互动的方式。它们在大量数据上进行预训练,并在特定任务数据集上进行微调,从而提高了在各种语言任务上的准确性和性能。从文本生成与完成到情感分析、机器翻译、问答系统和文本摘要,LLMs 展示了非凡的能力,并已在众多领域得到应用。
然而,这些模型也面临挑战和限制。计算资源、偏见与公平性、模型可解释性以及控制生成内容是需要进一步研究和关注的领域。尽管如此,大语言模型对 NLP 研究和应用的潜在影响巨大,它们的持续发展可能会塑造 AI 和基于语言的技术的未来。
如果你想构建自己的大语言模型,可以在 Saturn Cloud 注册,开始使用免费的云计算和资源。
Saturn Cloud 是一个数据科学和机器学习平台,灵活支持 Python、R 等多种语言。可以扩展、协作并利用内置管理功能来帮助你运行代码。可以创建一个具有 4TB RAM 的笔记本,添加 GPU,连接到分布式工作节点等。Saturn 还自动化了 DevOps 和 ML 基础设施工程,使你的团队可以专注于分析。
原始文章。经许可转载。
相关主题
你所需的最后一本 SQL 数据分析指南
原文:
www.kdnuggets.com/2019/10/last-sql-guide-data-analysis-ever-need.html
评论
由 Muhsin Warfa,系统开发员/技术写作人

照片由 Tobias Fischer 提供,来自 Unsplash
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
到 2020 年,预计每秒将为地球上的每个人创造 1.7 MB 的数据。真是荒谬!数据将成为我们数字时代的新石油。数据的增长带来了从中提取意义的需求。这催生了许多职业,这些职业管理和分析数据以做出更明智的商业决策。许多这些职业要求你熟练管理数据库中的数据。
介绍
管理数据的一种常见方式是使用关系型数据库管理系统。关系型数据库以表格形式存储数据,由行和列组成。这些数据库通常包括数据和元数据。数据是存储在表中的信息,而元数据是描述数据库中数据结构或数据类型的数据。
为了能直接与这些数据库沟通,我们使用 SQL,它是结构化查询语言(Structured Query Language)的缩写。SQL 用于执行如创建、读取、更新和删除数据库中的表等任务。
SQL 是一种声明式且特定领域的语言,主要由商业分析师、软件工程师、数据分析师以及许多其他利用数据的职业使用。你不需要成为程序员或了解如 Python 等编程语言才能掌握 SQL。SQL 的语法类似于英语。只需记住一些简单的语法,你就能舒适地使用数据库系统。
“声明式编程是你说出你想要的结果,而无需说明如何做到这一点。与过程式编程相比,你必须指定获得结果的确切步骤。” — Stack Overflow
我在这篇文章中的目标是让你熟悉 SQL,并逐一介绍 SQL 概念,同时提出处理数据库的查询。
数据库设置
在本教程中,我们不会使用关系数据库管理系统(RDBMS),而是使用测试数据库来编写我们自己的查询。我们将使用 W3school 的 SQL 编辑器编辑测试数据库,链接见这里。它无需安装,因此我们可以专注于编写查询。
备忘单
由于 SQL 是一种声明性语言,记住 SQL 语句将大有帮助。随时保持一份参考指南,将有助于快速掌握查询表格时使用的关键字。这里是我创建的关键字电子表格,供参考。记住,掌握这只 SQL 猛兽的一半战斗就是记住/了解关键字。
数据定义语言(DDL)
我们的大多数查询将涉及对表格执行某种形式的操作。操作分为四类:创建、插入、更新和删除表格。
创建表格
当我们想在数据库中创建表格时,使用CREATE TABLE语句。将以下代码输入编辑器:
CREATE TABLE Countries(
Country_id int,
Country_name varchar(255),
Continent varchar(255),
Population int
);
这将创建一个名为countries的表格,其中包含四列。创建 SQL 表格的最低要求是指定列名、数据类型和长度。当然,你还可以拥有更多特性,如Not Null,意味着表格中不会输入空值,但这些是可选属性。
与表格一起工作
插入表格
创建表格后,我们可以使用INSERT INTO方法语句插入行。输入以下代码:
INSERT INTO countries(Country_id,Country_name, Continent,Population)
VALUES (1,'Somalia','Africa',14000000);
该语句将Somali作为新国家添加到countries表格中。在插入行时,指定列名和值是一个好习惯。
读取表格
当我们想查找存储在数据库中的数据时,使用Select语句。
Select * from Countries;
该语句返回一个表格,显示我们刚刚使用插入语句插入的行。*通配符表示“显示表格中的所有行”。如果你只想显示Population列,可以去掉星号,替换为其列名。
Select Population from Countries;
更新表格
如果我们想修改表格中的现有记录,可以使用UPDATE语句来做到这一点。
UPDATE Countries
SET Country_name ='Kenya'
WHERE Country_id=1;
该语句将country_id为1的行中的country_name列更新为Kenya。我们必须指定国家 ID,因为我们只想更改那一行。如果我们去掉WHERE语句,SQL 会认为我们想更新表格中的所有行。
删除表格中的记录
如果我们想删除表格中的所有行,则使用DELETE FROM语句。
DELETE FROM Countries;
如果你想删除表格而不是所有记录,可以使用DROP TABLE语句。
DROP TABLE Countries;
注意: 这会从数据库中删除整个表格,可能导致数据丢失!
过滤器
如果我们只对表格中的部分数据感兴趣,我们可以筛选表格。我们有多个语句可以用来筛选表格。过滤器基本上选择符合某些标准的行,并将结果作为过滤后的数据集返回。筛选表格不会更改原始表格。
WHERE
WHERE 子句用于筛选记录。在我们的编辑器中有一个名为 Customers 的表。如果我们想筛选来自 “USA” 的客户,我们使用 WHERE 语句。
SELECT * from Customers WHERE country = "USA";
AND, OR 和 NOT
在我们之前的例子中,只有一个条件,即“国家是美国”。我们还可以使用 AND、OR 和 NOT 组合多个条件。例如,如果你想要来自美国或巴西的客户,你可以使用 OR 语句。
SELECT * from Customers WHERE country = "USA" OR country = "Brazil";
ORDER BY
大多数时候,当我们筛选表格时,返回的数据集是未排序的。我们可以使用 ORDER BY 语句对这个筛选后的未排序数据集进行排序。
SELECT * from Customers WHERE country = "USA" OR country = "Brazil"
ORDER BY CustomerName ASC;
这将按字母顺序对筛选结果进行排序。如果我们想要降序排序,可以将 ASC 替换为 DESC。
BETWEEN
有时我们希望选择值满足特定范围的行。我们使用 BETWEEN 语句来选择并定义范围。
SELECT * from Products
WHERE Price BETWEEN 10 AND 20;
上述语句筛选了价格在 10 到 20 之间的产品。
注意: 在 BETWEEN 操作中,下限和上限都是包含在内的。
LIKE
有时我们想根据特定模式筛选表格。为此,我们使用 LIKE 语句。
SELECT * from Customers
WHERE CustomerName LIKE 'A%';
上述 SQL 语句筛选了表格,只显示名字以字母 A 开头的客户。如果你将百分号向前移动,它会筛选名字以字母 A 结尾的客户。
GROUP BY
GROUP BY 将筛选后的结果集分组。可以将其视为每列数据集的汇总组。
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country;
该语句统计了每个国家的客户数量,然后按国家分组。GROUP BY 通常与聚合函数一起使用,后者我们将在文章的后面详细讨论。
HAVING
HAVING 的引入是因为 WHERE 语句不能与聚合函数一起使用,它只处理数据库中的直接值。
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country
HAVING COUNT(CustomerID) > 3;
这个语句与上一个例子做的事情一样。唯一的区别是我们只包括客户数量超过三人的国家。
连接
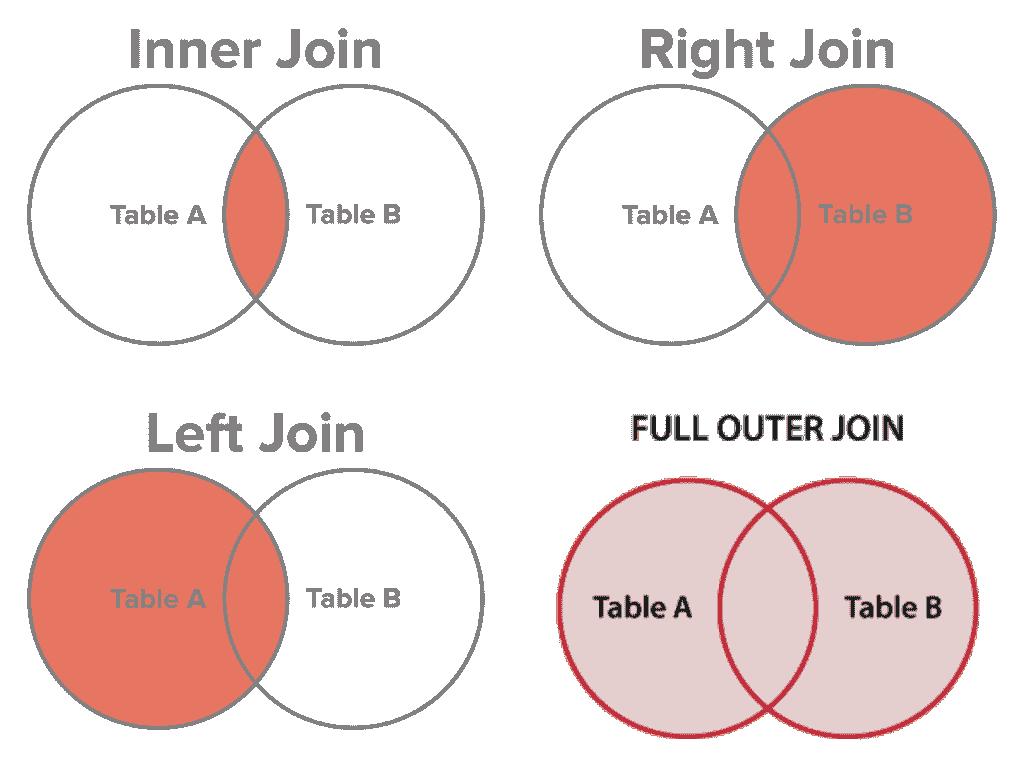
想象一下你想知道哪个客户订购了哪些产品。如果数据库遵循正确的数据库规范化技术,那么产品、客户和订单将被存储在不同的表中。如果我们想查看哪个客户订购了哪些产品,我们需要在订单表中查找客户 ID,然后去客户表查看产品购买情况,再使用产品 ID 查找产品表。正如你所看到的,如果需要重复多次,这将是一个巨大的麻烦。为了更轻松地完成这个操作,SQL 提供了一个名为 JOIN 的语句。这个子句用于基于共享的相关列将两个或更多的表行合并。
内连接
INNER JOIN,通常简称为 "JOIN",用于在共享列上将相关表合并成一个表。
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID;
上述语句返回列的订单 ID 和客户姓名。我们将订单表(左)和客户表(右)连接,但仅包括那些具有匹配客户 ID 的行。在查看内连接的维恩图时重新阅读这句话,希望这样更容易理解。
左连接
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
LEFT JOIN Orders ON Customers.CustomerID = Orders.CustomerID
ORDER BY Customers.CustomerName;
LEFT JOIN 语句用于将左表(客户表)和右表(订单表)连接,返回左表中的所有行以及右表中匹配的记录。
右连接
SELECT Orders.OrderID, Employees.LastName, Employees.FirstName
FROM Orders
RIGHT JOIN Employees ON Orders.EmployeeID = Employees.EmployeeID
ORDER BY Orders.OrderID;
RIGHT JOIN 返回右表中的所有行以及左表中匹配的记录。这将返回所有员工及他们可能下的任何订单。
外连接
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
FULL OUTER JOIN Orders ON Customers.CustomerID=Orders.CustomerID
ORDER BY Customers.CustomerName;
也被称为 FULL OUTER JOIN,用于将一个或多个表中的所有行合并。没有行会被遗漏,所有行都将包含在连接后的表中。
SQL 聚合函数
函数是一组接受输入并输出结果的过程。SQL 函数基本上是一组 SQL 语句,它接受输入,对输入执行 SQL 操作,然后将结果作为输出返回。
SQL 中有两种类型的函数:集合函数 和 值函数。任何操作表中数据行并返回单个值的函数称为集合函数。程序员通常称它们为聚合函数,因为它们将表中的行汇总成一个信息聚合。
最小值
SELECT MIN(Price) AS LeastPricy
FROM Products;
这个 SQL 函数返回产品表中所有产品的最低价格。
最大值
SELECT MAX(Price) AS MostExpensive
FROM Products;
这个 SQL 函数返回产品表中所有产品的最高价格。
平均值
SELECT AVG(Price) AS AveragePrice
FROM Products;
这个 SQL 函数返回产品表中所有产品的平均价格。
计数
SELECT COUNT(ProductID)
FROM Products;
这返回产品表中产品的数量。
总和
SELECT SUM(Quantity)
FROM OrderDetails;
这返回订单详情表中所有订单的总和。
索引
到目前为止,我们所看过的查询都是基本查询。实际上,我们在日常生活中执行的查询通常由多个 SQL 语句或函数的组合构成。当操作复杂时,这将减少查询的执行时间。
幸运的是,SQL 有一种叫做 索引 的功能,可以加快查找速度。索引是一种数据结构,它指向表中的数据。如果没有索引,搜索表中的数据将是 线性的,意味着会逐行扫描。索引非常适合表格数据。
创建索引
CREATE INDEX idx_lastname
ON Persons (LastName);
这将创建一个索引以便快速查找列中的数据。需要注意的是,索引不存储在表中,对肉眼不可见。我们通常在有大量数据检索时使用索引。
数据库事务
事务 是一系列必须执行的 SQL 语句,以确保操作成功。事务是“全有或全无”的操作。如果所有操作中只有一个失败,我们认为整个事务失败了。
事务的一个常见示例是将资金从一个账户转到另一个账户。为了使转账成功,必须从账户 A 中扣除资金并添加到账户 B 中。否则,我们将回滚事务以重新开始。当事务完成时,我们称之为 提交。这确保了数据库维护数据的完整性和一致性。
如果你想深入了解数据库事务,我建议你查看 this 这段关于数据库事务的优秀视频讲解。
数据库触发器
并非所有 SQL 查询都是单独的和孤立的。有时我们希望在另一表 B 上发生不同事件时,对表 A 执行某个操作。这就是我们使用 数据库触发器 的地方。
数据库触发器是一组在数据库内发生特定操作时执行的 SQL 语句。触发器被定义为在对表数据进行更改时运行,主要是在 DELETE、UPDATE 和 CREATE 等操作之前或之后。数据库触发器的最常见用例是验证输入数据。
提示
-
所有 SQL 保留字均为大写。其他所有内容(表、列等)均为小写。
-
将查询分成多行,而不是在单行中编写一个长语句。
-
你不能在表中添加特定位置的列,所以在设计表时要小心。
-
使用
AS别名语句时请注意;列名并没有在表中被重命名。别名仅在数据集结果中出现。 -
SQL 按以下顺序评估这些子句:
FROM、WHERE、GROUP BY、HAVING,最后是SELECT。因此,每个子句都接收前一个筛选器的过滤结果。它的样子是这样的:
SELECT(HAVING(GROUP BY(WHERE(FROM...))))
结论
你可以从我们在本文中看到的 SQL 语句的无尽排列中生成强大的查询。记住,巩固概念并提高 SQL 水平的最佳方式是通过练习和解决 SQL 问题。上面的部分示例灵感来源于W3School。你可以在像hackerrank和LeetCode这样的互动网站上找到更多练习,它们有吸引人的用户界面,帮助你更长时间地学习。
你练习得越多,你会变得越好,你训练越严格,他们就会看到你更大的潜力。* — Alcurtis Turner*
祝愿你平安和繁荣!
简介:穆欣·沃尔法 为您的组织需求构建和设计全栈网络软件应用程序。作为软件产品开发者,他参与了多个项目,从商业应用到学生课程应用,涵盖了从概念化和构思到测试和部署的所有开发生命周期。如果你喜欢这篇文章,请随时在 LinkedIn 上联系和保持联系,并关注更多文章/帖子。
原文。已获许可转载。
相关:
-
数据科学家的顶级实用 SQL 功能
-
2019 版掌握数据科学 SQL 的 7 个步骤
-
数据科学家需要 SQL 吗?
更多相关主题
数据科学的外行指南。第三部分:数据科学工作流程
原文:
www.kdnuggets.com/2020/07/laymans-guide-data-science-workflow.html
评论
由 Sciforce。
注意:这是第一部分:如何成为一名(优秀的)数据科学家 – 初学者指南 和
第二部分:数据科学的外行指南。如何构建数据项目
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
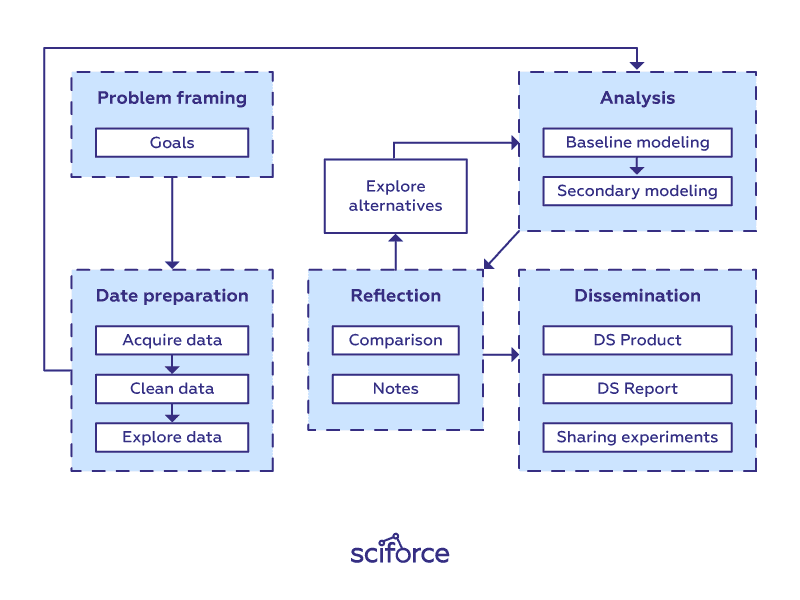
数据科学工作流程。
到目前为止,你已经获得了足够的数据科学知识和技能和完成了你的第一个(或甚至是第二个和第三个)项目。此时,是时候改进你的工作流程,以便进一步发展过程。
解决任何数据科学问题没有特定的模板(否则你会在你遇到的第一本教科书中看到它)。每个新的数据集和每个新的问题都会导致不同的路线图。然而,许多不同项目中有类似的高层步骤。
在这篇文章中,我们提供了一个可以作为数据科学项目基础的清晰工作流程。它的每个阶段和步骤当然可以单独处理,甚至可以由更大规模项目中的不同专家实施。
确定问题和目标
正如你已经知道的,在起始点,你会提出问题并尝试掌握你需要什么数据。因此,考虑你想解决的问题。你想了解更多什么?现在,忘记建模、评估指标和数据科学相关的事物。明确陈述问题和定义目标是提供良好解决方案的第一步。没有这些,你可能会在数据科学的森林中迷失方向。
数据准备阶段
在任何数据科学项目中,获取正确的数据是关键。在进行任何分析之前,你必须获取相关数据,将其重新格式化为适合计算的形式,并进行清理。

获取数据
任何数据科学工作流的第一步是获取要分析的数据。数据可以来自各种来源:
-
从本地计算机的 CSV 文件中导入;
-
从 SQL 服务器中查询;
-
从在线存储库中剥离,如公共网站;
-
通过 API 从在线源按需流式传输;
-
由物理设备自动生成,如连接到计算机的科学实验室设备;
-
由计算机软件生成,如来自网络服务器的日志。
在许多情况下,收集数据可能会变得混乱,特别是当数据不是以有组织的方式收集时。你需要处理不同的来源,并应用各种工具和方法来收集数据集。
收集数据时有几个关键点需要记住:
数据来源:准确追踪数据来源,即每一条数据来自何处以及是否仍然是最新的非常重要,因为数据常常需要重新获取以进行新的实验。重新获取数据是有帮助的,特别是当原始数据源更新时,或者研究人员想要测试替代假设时。此外,我们可以利用数据来源追溯下游分析错误到原始数据源。
数据管理:为了避免数据重复和不同版本之间的混淆,必须为创建或下载的数据文件分配适当的名称,然后将这些文件组织到目录中。当创建这些文件的新版本时,所有版本应分配相应的名称,以便能够跟踪它们之间的差异。例如,科学实验室设备可以生成数百或数千个数据文件,科学家们必须在对其进行计算分析之前对这些文件进行命名和组织。
数据存储:随着现代数据访问几乎没有限制,常常出现数据量如此庞大的情况,以至于无法放入硬盘中,因此必须存储在远程服务器上。尽管云服务越来越受欢迎,但大量的数据分析仍然是在桌面计算机上进行的,数据集可以适应现代硬盘(即少于一太字节)。

重新格式化和清理数据
原始数据通常不以便于分析的格式出现,因为这些数据是由其他人格式化的,而没有考虑到分析的需求。此外,原始数据通常包含语义错误、缺失条目或格式不一致,因此在分析之前需要“清理”。
数据整理(munging)是清理数据的过程,将所有内容放入一个工作空间,并确保数据没有缺陷。可以通过手动或编写脚本来重新格式化和清理数据。将所有值转换为正确的格式可能涉及从字符串中剥离字符、将整数转换为浮点数等许多操作。之后,需要处理缺失值和稀疏矩阵中常见的空值。处理这些数据的过程称为缺失数据插补,即用替代数据替换缺失的数据。
数据集成是一个相关的挑战,因为所有来源的数据需要整合到一个中心 MySQL 关系数据库中,该数据库作为分析的主数据源。
通常,这需要大量时间,无法完全自动化,但同时它可以提供有关数据结构和质量以及可能应用的模型和分析的洞察。

探索数据
在这里,你将开始获取关于你所查看内容的概要级洞察,并提取大的趋势。在这一步,有三个维度需要探索:数据是否暗示监督学习还是无监督学习?这是分类问题,还是回归问题?这是预测问题还是推断问题?这三组问题在解决数据科学问题时可以提供很多指导。
有许多工具可以帮助你快速理解数据。你可以从检查数据框的前几行开始,获得数据组织的初步印象。集成在多个库中的自动工具,如 Pandas 的.describe(),可以快速提供均值、计数、标准差,你可能已经会发现值得深入研究的内容。有了这些信息,你将能够确定哪个变量是目标,哪些特征是重要的。
分析阶段
分析是数据科学的核心阶段,包括编写、执行和完善计算机程序,以从前一阶段准备的数据中分析并获取洞察。尽管有许多编程语言用于数据科学项目,从解释型的“脚本”语言如 Python、Perl、R 和 MATLAB 到编译型的语言如 Java、C、C++或甚至 Fortran,但编写分析软件的工作流程在不同语言中是类似的。
如你所见,分析是一个重复的迭代循环,涉及编辑脚本或程序、执行以生成输出文件、检查输出文件以获取洞察和发现错误、调试以及重新编辑。

基线建模
作为数据科学家,你将构建许多使用不同算法的模型来执行不同任务。在处理任务的初期,值得避免使用复杂的高级模型,而是坚持使用更简单、更传统的线性回归用于回归问题,逻辑回归用于分类问题作为基线,从而进行改进。
在模型预处理阶段,你可以将特征与依赖变量分开,缩放数据,并使用训练-测试拆分或交叉验证来防止模型过拟合——过拟合是指模型过于紧密地跟踪训练数据,并且在新数据上表现不佳的问题。
模型准备好后,可以在训练数据上进行拟合,并通过预测X_test数据的y值来进行测试。最后,使用适合任务的评估指标来评估模型,如回归问题的R 平方和分类任务的准确率或ROC-AUC分数。
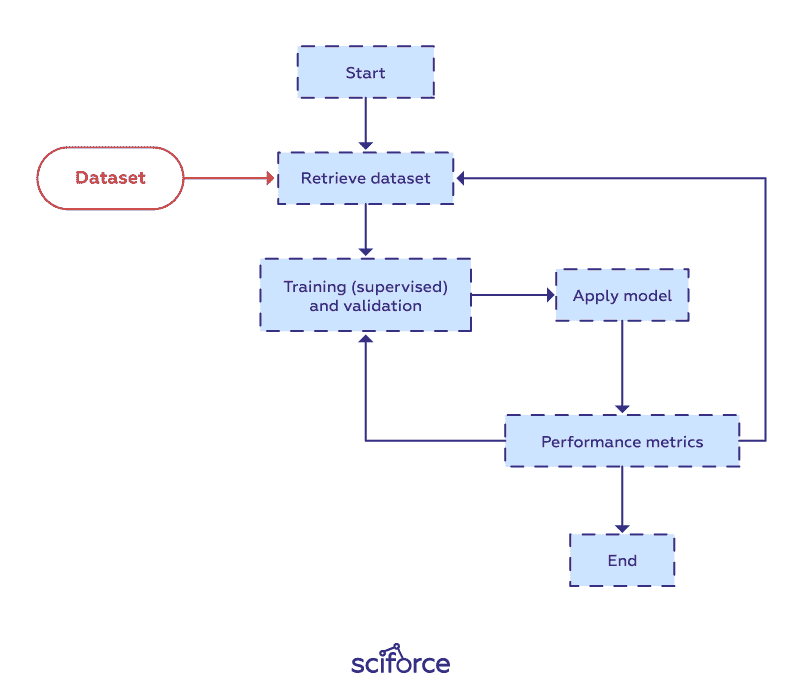

次级建模
现在是进行更深入分析的时候,如果需要,可以使用更高级的模型,如神经网络、XGBoost或随机森林。重要的是要记住,这些模型可能因为数据集较小无法提供足够的数据或特征之间存在共线性问题而最初表现得比简单易懂的模型差。
因此,次级建模步骤的关键任务是参数调优。每种算法都有一组可以优化的参数。参数是机器学习技术用于调整数据的变量。超参数是管理训练过程本身的变量,如神经网络中的节点数或隐藏层数,通过运行整个训练过程、查看整体准确性并进行调整来进行调优。
反思阶段
数据科学家经常在分析和反思阶段之间交替进行:分析阶段专注于编程,而反思阶段涉及对分析结果的思考和沟通。在检查一组输出文件后,数据科学家或数据科学家团队可以比较输出变体,通过调整脚本代码和/或执行参数来探索替代路径。数据分析过程中的许多部分是试错的:科学家运行测试,绘制输出图形,然后重新运行测试,重新绘制图形,依此类推。因此,图形是主要的比较工具,可以并排显示在显示器上以便直观地比较和对比它们的特征。补充工具包括记笔记,既有纸质的也有数字的,以跟踪思路和实验过程。
交流阶段
数据科学的最终阶段是传播结果,这些结果可以是数据科学产品的形式,也可以是书面报告,例如内部备忘录、幻灯片演示、业务/政策白皮书或学术研究出版物。
数据科学产品意味着将你的模型投入生产。在大多数公司中,数据科学家将与软件工程团队合作编写生产代码。该软件既可以用于重现实验或测试原型系统,也可以作为独立解决方案来应对市场上的已知问题,例如评估金融欺诈的风险。
另外,你还可以创建数据科学报告。你可以通过演示展示你的结果,并提供过程的技术概述。记住要考虑你的观众:如果是向数据科学同行展示,可以详细说明;如果是向销售团队或高管汇报,则应关注发现。如果公司允许发布结果,这也是获得其他专家反馈的好机会。此外,你还可以写博客文章,并将代码推送到 GitHub,以便数据科学社区可以从你的成功中学习。沟通结果是科学过程的重要部分,因此这一阶段不应被忽视。
原文。已获授权转载。
简介: SciForce 是一家总部位于乌克兰的 IT 公司,专注于基于科学驱动的信息技术的软件解决方案开发。我们在许多关键 AI 技术方面拥有广泛的专业知识,包括数据挖掘、数字信号处理、自然语言处理、机器学习、图像处理和计算机视觉。
相关:
更多相关话题
精益六西格玛如何帮助机器学习?
原文:
www.kdnuggets.com/2016/11/lean-sigma-six-help-machine-learning.html
 评论
评论
作者:Joseph Chen,高级管理人员及 BI、数据仓库、六西格玛和运筹学领域的架构师。
引言
在过去 10 多年中,我一直在使用精益六西格玛(LSS)来改进业务流程,对其效果非常满意。最近,我与一家咨询公司和一位软件供应商合作,实施了一个机器学习(ML)模型,以预测服务部件的剩余使用寿命(RUL)。让我感到最沮丧的是模型的准确性较低。如下面所示,如果人们将偏差测量为实际部件寿命与预测寿命之间的绝对差异,所得到的模型对选定的 3 个部件的平均偏差分别为 127 天、60 天和 36 天。我无法理解为什么机器学习的偏差如此之大。

在与顾问和数据科学家合作后,他们似乎只能通过数据清理将偏差改善 10%。这让我感到非常困惑。对我来说,即便在 10%的改善之后,这种偏差仍然使得预测对业务负责人来说毫无用处。这迫使我问自己以下问题:
-
机器学习真的适合作为预测工具吗?
-
人们对机器学习了解不足的是什么?
-
机器学习中缺少了什么?精益六西格玛能填补这个空缺吗?
精益六西格玛
精益六西格玛(LSS)的目标是通过减少过程的方差来提高过程性能。方差定义为 LSS 实际值与预测值之间的平方差和。LSS 的结果本质上是一个统计函数(模型),它在一组输入/自变量和输出/因变量之间建立关系,如下图所示。

通过识别输入变量与输出变量之间的相关性,LSS 模型告诉我们如何控制输入变量,以使输出变量达到我们的目标值。最重要的是,LSS 还要求被监控的过程是“稳定”的,即通过减少输入变量的方差来最小化输出变量的方差,从而达到所谓的“突破”状态。

如下图所示,如果你在没有方差控制的情况下(左图中目标周围的分布)独自达到目标(中心),就无法保证你达到了目标;如果在没有达到目标的情况下减少方差(右图),则会错过目标。只有通过保持方差小且集中,LSS 才能确保过程目标以精确的精度和可持续的最佳过程性能达成。这是 LSS 的主要贡献。

机器学习(ML)
对于有监督机器学习,它关注输入变量集与输出变量之间的函数,以得出“近似”理想函数,如下图中的绿色曲线所示。

同样,对于无监督机器学习,它寻找能够最好地区分一组簇的函数。

LSS 与 ML 的比较
众所周知,由于偏差和正常随机性,过程本质上是随机的;即,过程具有方差。因此,经典统计学和 LSS 都表明,如果输入变量具有较大方差,我们会预期输出变量也会有较大的方差。
如果 Y=a[1]x[1]+a[2]x[2]+...+a[n]x[n],则 Var(Y)=a[1]²Var(x[1])+a[2]²Var(x[2])+...+a[n]²Var(x[n])。
这强烈暗示了当输入变量具有较大方差时,机器学习模型的不准确性。这就是为什么我认为我最近的机器学习项目在预测中有如此大的不准确性,以及数据清洗只能提高准确性最多 10%的原因。
人们可能会争论数据清洗是否能提高预测质量。问题在于,机器学习(ML)中的数据清洗与最小二乘法(LSS)的方差减少不同。在 LSS 中,人们会回顾业务过程以寻找输入变量的方差源,以消除偏差或减少这些输入变量(因素)的方差;而在 ML 中,人们不会回顾业务过程;相反,ML 中的人们只是尝试纠正数据错误或消除无意义的数据。因此,这种数据清洗方法实际上并不会减少方差;实际上,它可能不会改变输入方差。因此,如果人们不了解方差的作用,ML 模型可能不会很好地工作。
例如,如果下图左侧的图表代表数据清洗后的数据点,我们会得到红色曲线作为最优 ML。但是,如果下图右侧的图表代表方差减少后的数据点,得到的 ML 模型会更加准确。


总结来说,我认为当前机器学习模型的数据清洗需要包含 LSS 的方差减少技术,以便为监督学习和无监督学习提供准确、可靠和有效的模型。人们需要花费精力审查潜在的业务流程,以减少输入方差,使其更好地解决现实世界的问题。
软件供应商和数据科学咨询公司应在机器学习的数据清洗阶段采用方差减少技术,以提供机器学习的实际价值。
简历:Joseph Chen 是一名六西格玛黑带,以及数据科学、商业智能和数据仓库的首席架构师。他拥有运筹学、信息科学和工业工程的学位,具有超过 18 年的高级分析、商业智能、数据仓库、精益六西格玛、流程优化、运营分析等领域的工作经验。
相关:
-
伟大的算法教程汇总
-
数据科学基础:数据挖掘与统计学
-
数据准备技巧、窍门和工具:与业内专家的访谈
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关话题
免费学习普林斯顿大学的计算机科学!
原文:
www.kdnuggets.com/learn-computer-science-with-princeton-university-for-free

图片来源:作者
当你考虑转行时,首先想到的就是选择哪个课程,是否回到大学,如何开始?不妨从免费的课程开始!!
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
技术世界不断发展,越来越多的组织正在寻找快速实现数字化的新方法!因此,他们需要计算机科学家、数据科学家、软件工程师等的帮助。这些不同类型的技术专业人员的共同点是他们的计算机科学知识。
计算机科学是他们技能的核心,不容错过!
在这篇博客中,我将介绍 6 个课程,这些课程将为你提供发展计算机科学职业所需的知识和技能。
计算机科学:有目的的编程
链接:计算机科学:有目的的编程
级别:初级
经验要求:无需先前经验
时长:88 小时完成或每周 29 小时,共 3 周
进度:灵活的时间安排
模块数:10
在这个课程中,你将学习基本的编程元素,如变量、条件语句、循环、数组和输入/输出,然后学习函数,介绍关键概念,如递归、模块化编程和代码重用。你还将接触到面向对象的编程。
该课程使用 Java 编程语言,教授解决计算问题的基本技能,这些技能适用于许多现代计算环境。目标是掌握 Java 的基础概念,重点不是 Java 本身。
计算机科学:算法、理论与机器
级别:中级
经验要求:计算机科学:推荐《有目的的编程》(见上文)
时长:20 小时完成或每周 6 小时,共 3 周
进度:灵活的时间安排
模块数:11
在本课程中,你将学习经典算法以及评估性能的科学技术,结合现代应用进行介绍。接下来,你将进入经典理论模型的学习,这些模型帮助我们解决关于计算的基本问题,如可计算性、普遍性和难解性。
你将学习机器体系结构(包括机器语言编程及其与 Java 编码的关系)和逻辑设计(包括从零开始构建的完整 CPU 设计)。
本课程强调应用编程、计算理论、真实计算机以及该领域的历史和发展之间的关系,包括布尔、香农、图灵、冯·诺依曼等人的贡献性质。
算法,第 I 部分
链接:算法,第 I 部分
级别:中级
经验:推荐具备计算机科学:算法、理论和机器(见上文)
时长:54 小时完成或 3 周,每周 18 小时
进度:灵活安排
模块:13
在本课程中,你将深入探讨算法和数据结构,重点是应用和 Java 实现的科学性能分析。第 I 部分涵盖了基本数据结构、排序和搜索算法。你对算法的理解必须清晰透明。随着你在计算机科学领域的发展,你将频繁参考算法,因此对算法的知识至关重要。
算法,第 II 部分
链接:算法,第 II 部分
级别:中级
经验:推荐完成算法第 I 部分(见上文)
时长:62 小时完成或 3 周,每周 20 小时
进度:灵活安排
模块:14
本课程是算法部分的第 II 部分,重点关注图和字符串处理算法。例如,你将学习无向图/有向图、最小生成树、正则表达式、数据压缩等。
算法分析
链接:算法分析
级别:高级
经验:推荐完成算法第 I 部分和第 II 部分(见上文)
时长:20 小时完成或 3 周,每周 6 小时
进度:灵活安排
模块:9
本课程将涵盖生成函数和实际渐进分析。你还将学习符号方法在算法分析中的应用,并涵盖基本结构,如排列、树、字符串、词语和映射。
计算机体系结构
链接:计算机体系结构
级别:高级
时长:49 小时完成或 3 周,每周 16 小时
进度:灵活安排
模块:21
如果你想超越基础,全面了解计算机科学的各个方面,我推荐这门计算机体系结构课程。在这门课程中,你将学习设计复杂现代微处理器的计算机体系结构。你将学习到流水线审核、缓存、超标量、内存保护、并行编程等内容。
总结
在开始新的过渡时,充分利用免费资源应该是你的首选!在这篇文章中,我为你提供了一条启动计算机科学学习之旅的路线图,而无需花费一分钱。
尼莎·阿雅 是一名数据科学家、自由技术写作人员,同时也是 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及基于理论的数据科学知识。尼莎涵盖了广泛的主题,并希望探索人工智能如何有利于人类寿命的不同方式。作为一名热衷学习者,尼莎致力于拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关内容
学习 Julia 数据分析

图片作者
Julia 是另一种编程语言,类似于 Python 和 R。它结合了 C 语言的速度和 Python 的简洁性。Julia 在数据科学领域越来越受欢迎,所以如果你想扩展你的技能并学习一种新语言,你来对地方了。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
在本教程中,我们将学习如何为数据科学设置 Julia,加载数据,进行数据分析,然后进行可视化。这个教程非常简单,以至于任何人,包括学生,都可以在 5 分钟内开始使用 Julia 进行数据分析。
1. 设置你的环境
-
下载 Julia 并通过访问 (julialang.org) 安装包。
-
现在我们需要为 Jupyter Notebook 设置 Julia。启动一个终端(PowerShell),输入
julia启动 Julia REPL,然后输入以下命令。
using Pkg
Pkg.add("IJulia")
-
启动 Jupyter Notebook,并以 Julia 作为内核开始新的笔记本。
-
创建新的代码单元,并输入以下命令以安装必要的数据科学包。
using Pkg
Pkg.add("DataFrames")
Pkg.add("CSV")
Pkg.add("Plots")
Pkg.add("Chain")
2. 加载数据
对于这个示例,我们使用来自 Kaggle 的 在线销售数据集。它包含了不同产品类别的在线销售交易数据。
我们将加载 CSV 文件并将其转换为 DataFrames,这类似于 Pandas DataFrames。
using CSV
using DataFrames
# Load the CSV file into a DataFrame
data = CSV.read("Online Sales Data.csv", DataFrame)
3. 探索数据
我们将使用 'first' 函数,而不是 head 来查看 DataFrame 的前 5 行。
first(data, 5)
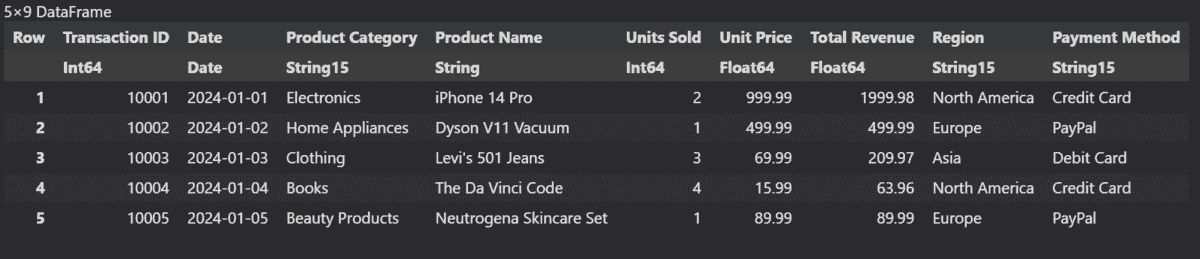
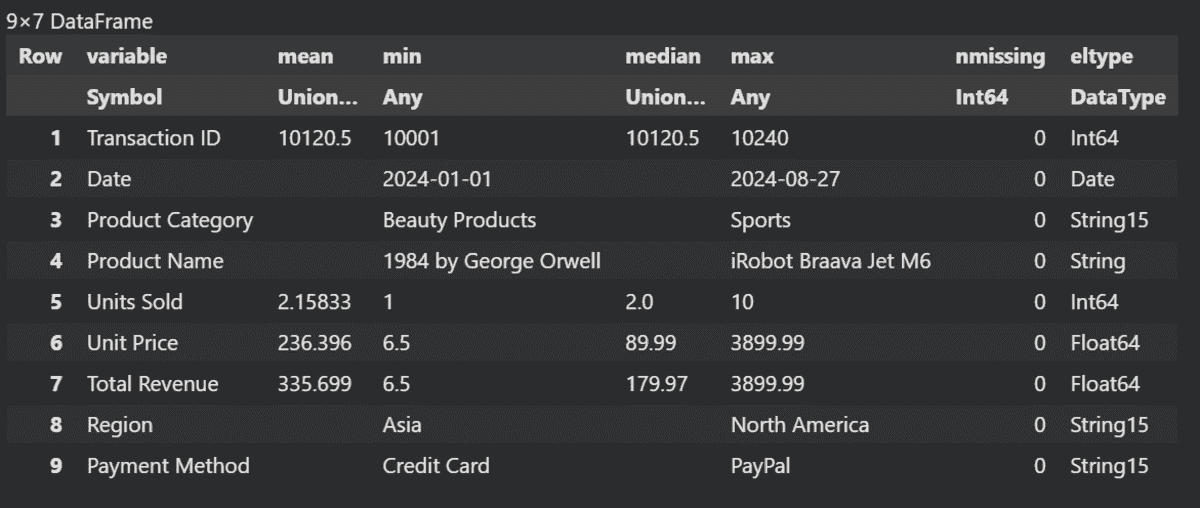
要生成数据摘要,我们将使用 describe 函数。
describe(data)
类似于 Pandas DataFrame,我们可以通过提供行号和列名来查看特定值。
data[3,"Product Name"]
输出:
"Levi's 501 Jeans"
4. 数据操作
我们将使用 filter 函数根据特定值过滤数据。它需要列名、条件、值和 DataFrame。
filtered_data = filter(row -> row[:"Unit Price"] > 230, data)
last(filtered_data, 5)

我们也可以创建一个类似于 Pandas 的新列。这么简单。
data[!, :"Total Revenue After Tax"] = data[!, :"Total Revenue"] .* 0.9
last(data, 5)
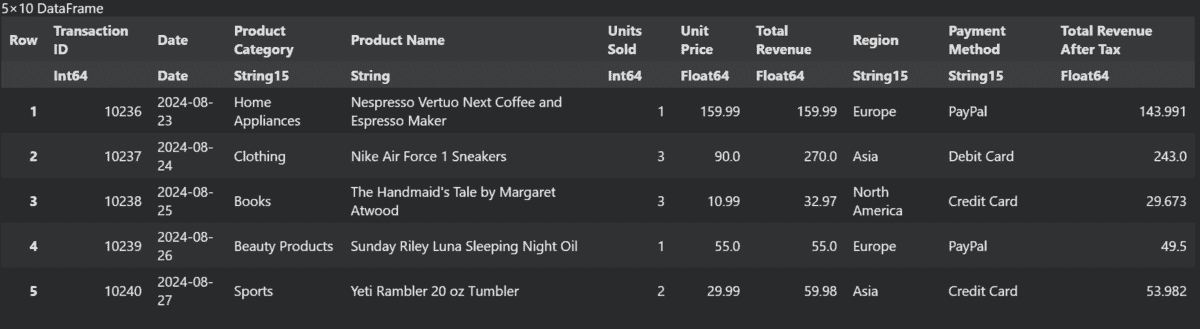
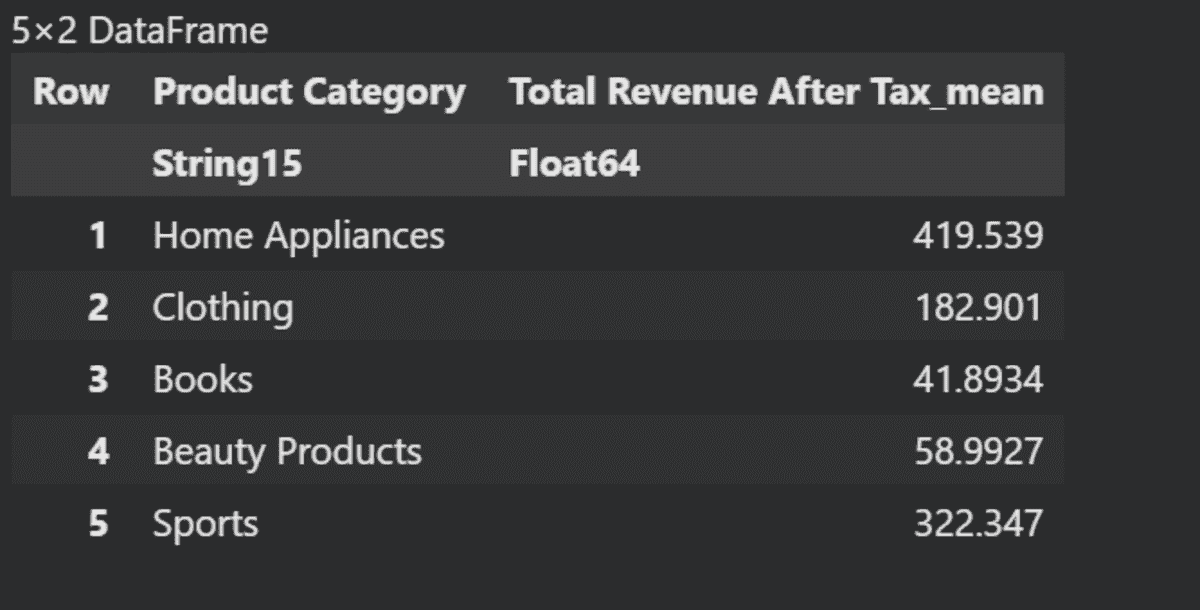
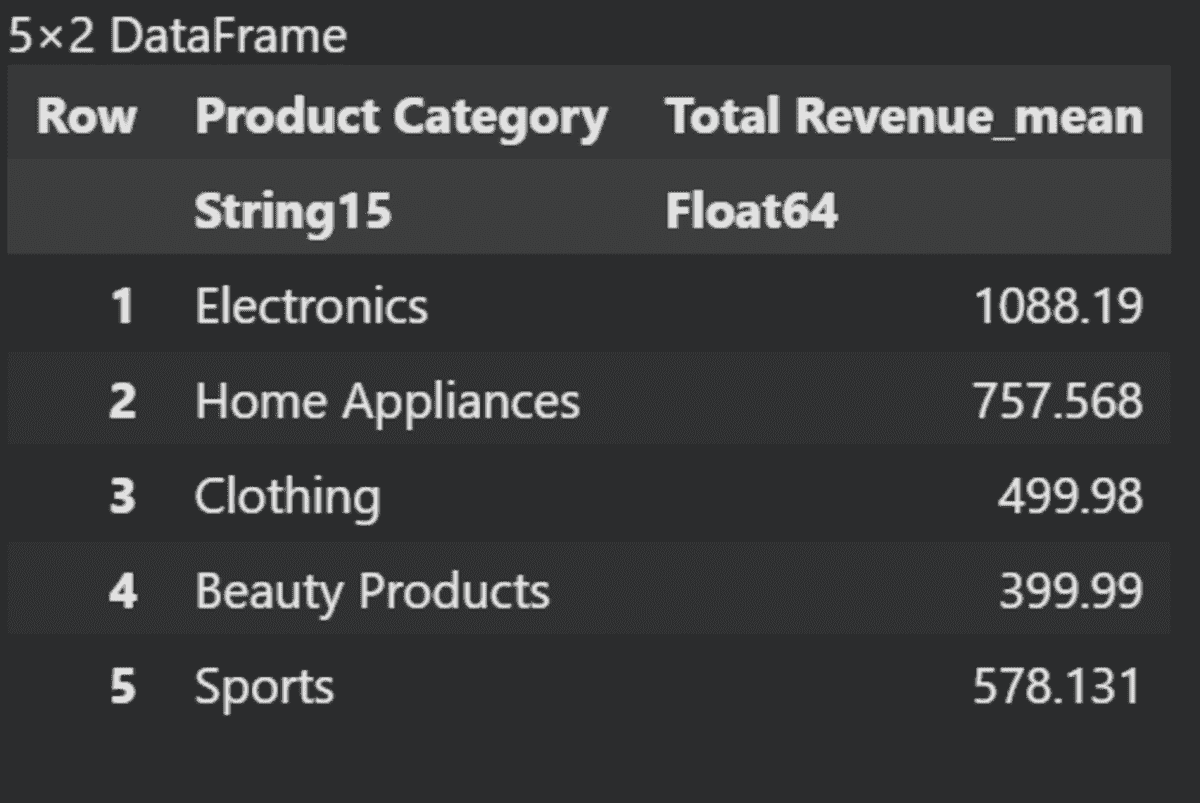
现在,我们将基于不同的“产品类别”计算“税后总收入”的均值。
using Statistics
grouped_data = groupby(data, :"Product Category")
aggregated_data = combine(grouped_data, :"Total Revenue After Tax" .=> mean)
last(aggregated_data, 5)
5. 可视化
可视化类似于 Seaborn。在我们的案例中,我们正在可视化最近创建的汇总数据的条形图。我们将提供 X 和 Y 列,然后是标题和标签。
using Plots
# Basic plot
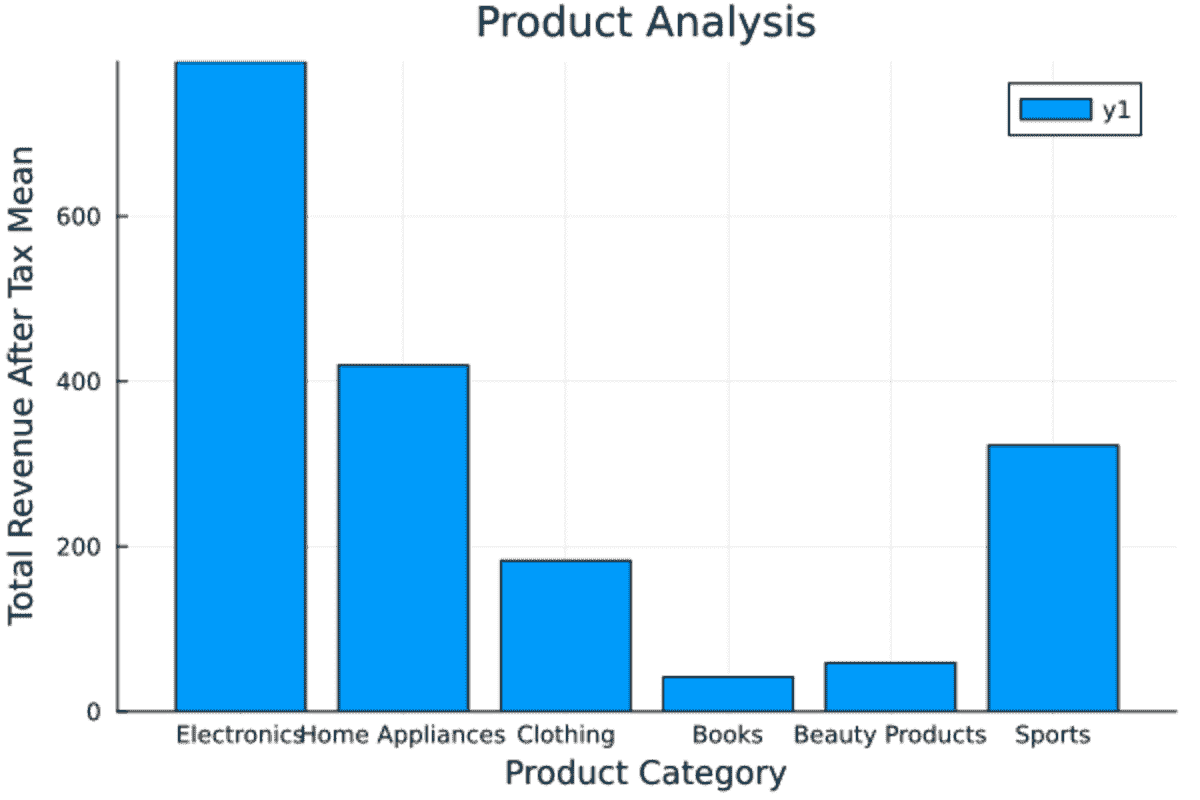
bar(aggregated_data[!, :"Product Category"], aggregated_data[!, :"Total Revenue After Tax_mean"], title="Product Analysis", xlabel="Product Category", ylabel="Total Revenue After Tax Mean")
总均收入的大部分是通过电子产品产生的。可视化效果完美且清晰。
要生成直方图,我们只需提供 X 列和标签数据。我们希望可视化销售商品的频率。
histogram(data[!, :"Units Sold"], title="Units Sold Analysis", xlabel="Units Sold", ylabel="Frequency")
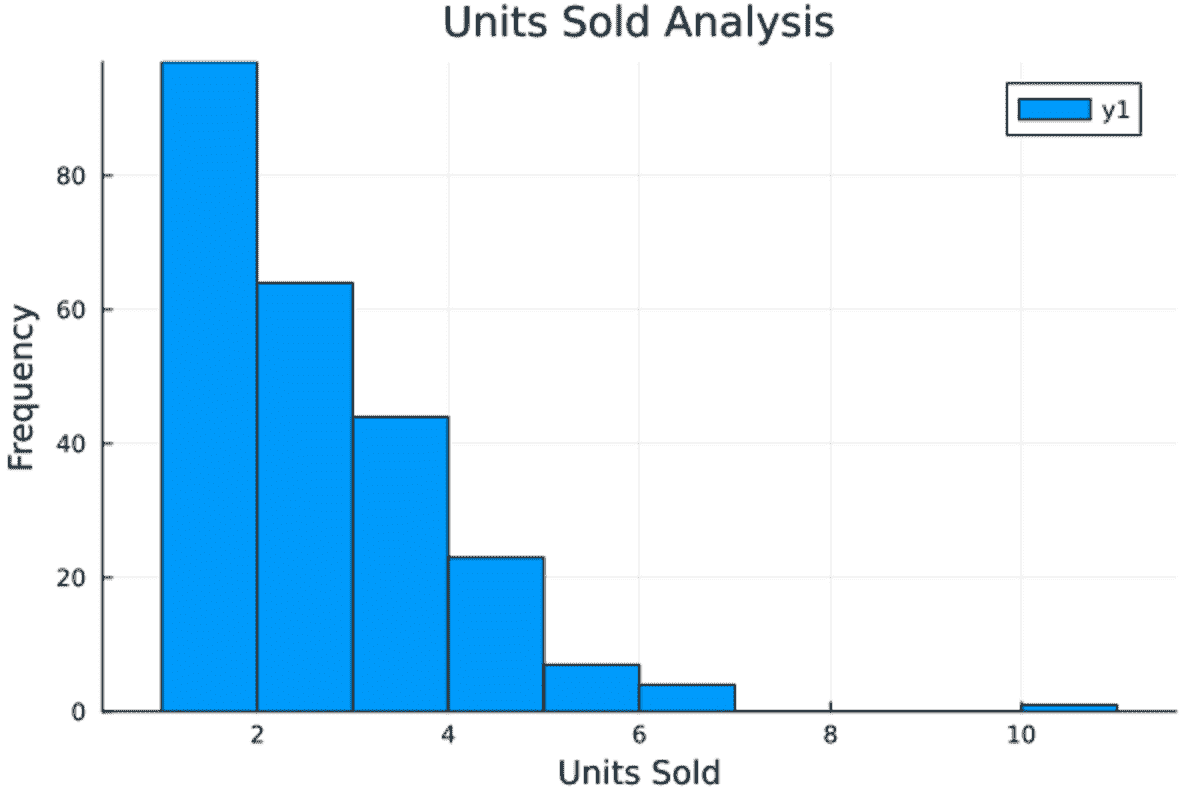
看起来大多数人购买了一到两件商品。
为了保存可视化效果,我们将使用savefig函数。
savefig("hist.png")
6. 创建数据处理管道
创建一个合适的数据管道是自动化数据处理工作流程、确保数据一致性,以及实现可扩展和高效的数据分析的必要条件。
我们将使用Chain库来创建之前用来基于不同产品类别计算总均收入的各种函数链。
using Chain
# Example of a simple data processing pipeline
processed_data = @chain data begin
filter(row -> row[:"Unit Price"] > 230, _)
groupby(_, :"Product Category")
combine(_, :"Total Revenue" => mean)
end
first(processed_data, 5)
为了将处理后的 DataFrame 保存为 CSV 文件,我们将使用CSV.write函数。
CSV.write("output.csv", processed_data)
结论
在我看来,Julia 比 Python 更简单、更快。我习惯的许多语法和函数在 Julia 中也可用,如 Pandas、Seaborn 和 Scikit-Learn。那么,为什么不学习一门新语言,并开始做得比你的同事更好呢?此外,这也将帮助你获得与研究相关的工作,因为大多数临床研究人员更倾向于使用 Julia 而不是 Python。
在本教程中,我们学习了如何设置 Julia 环境、加载数据集、进行强大的数据分析和可视化,并构建用于可重复性和可靠性的数据管道。如果你有兴趣了解更多关于 Julia 的数据科学知识,请告诉我,这样我可以为你们编写更多简单的教程。
Abid Ali Awan (@1abidaliawan)是一位认证的数据科学专业人士,他喜欢构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一款 AI 产品,帮助那些遭遇心理健康问题的学生。
更多信息
通过这本免费电子书学习数据清理和预处理
原文:
www.kdnuggets.com/2023/08/learn-data-cleaning-preprocessing-data-science-free-ebook.html

Data Science Horizons 最近发布了一本有见地的新电子书,标题为数据科学初学者的数据清理和预处理,为数据科学流程的关键早期阶段提供了全面的介绍。在本指南中,读者将了解为什么正确清理和预处理数据对于构建有效的预测模型和从分析中得出可靠结论如此重要。电子书涵盖了数据收集、清理、集成、转换和减少以准备分析的一般工作流程。它还探讨了数据清理和预处理的迭代特性,使这一过程既是一门艺术,也是一门科学。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
为什么需要这样的书?
本质上,数据是杂乱的。现实世界中的数据,即公司和组织每天收集的数据,充满了不准确、不一致和缺失的条目。正如谚语所说,“垃圾进,垃圾出。”如果我们用肮脏、不准确的数据来喂养我们的预测模型,我们的模型性能和准确性将会受到影响。
这本电子书的一个主要亮点是对用于数据处理、可视化、机器学习和处理缺失值的关键 Python 库的实际演示。读者将熟悉 Pandas、NumPy、Matplotlib、Seaborn、Scikit-learn 和 Missingno 等必备工具。本指南最后通过一个案例研究,使读者能够应用前面章节中涵盖的所有概念和技能。
数据清洗与预处理提供了处理常见数据质量问题的全面指南。它探讨了处理缺失值、检测异常值、数据标准化与缩放、特征选择、变量编码和均衡不平衡数据集的技术。读者将学习评估数据完整性的最佳实践、合并数据集、处理偏斜分布和非线性关系。通过 Python 代码示例,读者将获得实际经验,识别数据异常、填补缺失数据、提取特征,并将混乱的数据集预处理成可分析的形式。案例研究将所有主要概念结合成一个端到端的数据清洗与预处理工作流。
数据科学家工具包的核心是识别常见数据质量问题的能力。
数据清洗与预处理入门指南是任何渴望进入数据科学领域但仍需要掌握处理现实世界数据的人的绝佳起点。此指南真正带你深入了解如何将原始数据处理到最佳状态,以便你能实际使用它。到达最后,你将掌握清洗和预处理数据的所有技巧,使之变得得心应手。不再因数据中的错误而陷入困境!凭借这本电子书赋予你的技能,你将能将最棘手的数据集驯服并像专家一样提取有意义的见解。
无论你是新手还是想提升技能,数据清洗与预处理入门指南都是你数据科学书单中不可或缺的一部分。
Matthew Mayo (@mattmayo13) 是数据科学家和 KDnuggets 的主编,KDnuggets 是数据科学和机器学习的开创性在线资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。你可以通过 editor1 at kdnuggets[dot]com 与他联系。
更多相关内容
从这些 GitHub 仓库中学习数据工程
原文:
www.kdnuggets.com/2023/02/learn-data-engineering-github-repositories.html
作者提供的图片
如果你希望进入数据领域,特别是数据工程 - 那么这个博客可以为你的学习提供有价值的资源。首先,让我们简要区分数据科学家和数据工程师之间的区别。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
数据科学家的主要工作是探索数据、构建模型以及实施机器学习算法。数据工程师的主要工作是确保构建的算法在生产环境中有效运行,并创建数据管道。
数据工程师负责组织数据基础设施的所有相关工作。这些基础设施将存储业务的关键信息,从小型数据库到大规模系统。目标是确保数据的基础稳固且安全,以便进行关键分析和生成报告。
如果你仍然渴望学习数据工程,这里有一些有价值的 GitHub 仓库可以帮助你。
DataTalks.Club - data-engineering-zoomcamp
仓库链接:data-engineering-zoomcamp
正如名字所示,DataTalksClub 是一个全球数据爱好者的在线社区,讨论关于数据的所有话题。他们有一个 9 周的课程表来帮助你学习数据工程。每周的内容如下:
你可以加入下一个班次,但你也可以在自己的时间内完成。所有课程材料都是免费的,DataTalks.Club 提供了一个逐周的建议大纲来帮助你。
食谱
仓库链接: 食谱
《数据工程食谱》的作者安德雷亚斯·克雷茨在 GitHub 上发布了这本书。他的目标是为数据工程领域的新手提供一个起点,帮助你识别成为成功的数据工程师所需学习的重要主题。
这本书重点介绍了五种不同类型的内容,帮助你了解数据工程:作者发布的文章、他们播客节目的链接(视频和音频)、他推荐的 200 多个有用网站链接、数据工程面试问题和案例研究。
数据工程指南
仓库链接: 数据工程指南
如果你需要关于成为数据工程师所需学习的不同主题的指导,数据工程指南为你提供了一份不同资源的清单,让你可以获得有用的数据工程知识。
该仓库从数据工程的基本概念开始,例如需求层次、初学者指南等。还有关于讲座、算法与数据结构、SQL、编程、数据库、分布式系统、书籍、课程、博客、工具、云平台等的资源。
优秀的数据工程
仓库链接: 优秀的数据工程
如果你对数据工程的基础知识有良好的基础,或者需要更好地关注工具,这个 GitHub 仓库为你提供了一个精心策划的数据工程工具清单,涵盖了你可能遇到的工具类型。
要成为一名成功的数据工程师,你需要对工具有信心。这个仓库涵盖了所有类型的工具,包括:
数据工程师路线图
仓库链接: data-engineer-roadmap
如果你是一个视觉型学习者,需要帮助来确定成为成功数据工程师的路线——这个库适合你。它提供了现代数据工程领域的完整可视化,并作为学习指南。
仓库的作者表示:
“初学者不必对这里列出的众多工具和框架感到不知所措。一个典型的数据工程师会在几年的时间内掌握这些工具的一个子集,这取决于他的公司和职业选择。”
总体而言,这个路线图可视化是一个有效的学习大纲,适用于有志于成为数据工程师的人。
开始数据工程
仓库链接: Start Data Engineering
如果你对自己的数据工程技能感到自信并希望开始测试它们。Joseph Machado 讲述了有关数据工程、数据建模、软件工程和系统设计的内容。
他为你提供了一步步的指南,帮助你开始项目,这对于你的数据工程学习以及作为你申请工作的作品集都是有用的。
数据工程项目
仓库链接: Data-Engineering-Projects
如果你在寻找更多应用于数据工程原则的项目,这个 GitHub 库提供了以下 7 种不同类型的项目:
-
Postgres ETL
-
Cassandra ETL
-
使用 Scrapy 进行网页抓取,MongoDB ETL
-
使用 AWS Redshift 进行数据仓库处理
-
使用 Spark 和 AWS S3 的数据湖
-
使用 Airflow 进行数据管道处理
-
关键项目
数据工程面试问题
仓库链接: data-engineering-interview-questions
假设你对自己的数据工程技能感到自信,已经进行过实践,现在准备申请你一直努力争取的工作。你需要为可能在面试中出现的问题做好准备。
这个 GitHub 库包含了 2000 多个问题,帮助你准备数据工程师面试。它们还提供了答案,让你了解你在数据工程中的强项和弱项。
结论
上述 GitHub 资源将帮助你迅速成为成功的数据工程师。如果你需要学习路线图,可以阅读 完整的数据工程学习路线图。它为你提供了一个主题、领域和资源的清单,帮助你在数据工程的旅程中前进。
Nisha Arya 是一名数据科学家和自由撰稿人。她特别关注提供数据科学职业建议或教程以及数据科学理论知识。她还希望探索人工智能如何有助于延长人类寿命。作为一个渴望学习的者,她希望拓宽技术知识和写作技能,同时帮助指导他人。
更多相关话题
以 8 个(简单的)步骤学习数据科学
原文:
www.kdnuggets.com/2016/10/learn-data-science-8-steps.html/2
第 3 步. 理解数据库
当你开始学习数据科学时,你会发现很多教程专注于从平面文件中提取数据。然而,当你开始工作或接触到行业本身时,你会发现大部分工作是通过与一个或多个数据库的连接来完成的。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
而且,市场上有很多数据库。公司可能会使用像 Oracle 这样的商业数据库,也可能会选择开源替代品。这里的关键是理解数据库的工作原理。了解数据库的原理和方法,之后你会掌握相关的内容。你应该掌握的概念包括关系数据库管理系统(RDBMS)和数据仓库。这意味着关系建模与维度建模应该不会对你造成困扰,SQL 或抽取-转换-加载过程(ETL)也不应让你感到意外。
如果你想学习如何理解数据库的工作原理,你应该查看 Mongo DB 大学、斯坦福在线 的 “数据库简介” 课程以及 DataStax 和 TutorialsPoint 的教程。
第 4 步. 探索数据科学工作流程
学习过程的下一阶段是探索数据科学工作流程。许多教程或课程仅关注其中的一两个方面,但失去了作为数据科学家或数据科学团队成员时需要经历的整体流程。至关重要的是不要忽视数据科学的迭代过程。
对于那些会编程的数据科学初学者来说,了解数据科学工作流程的最简单方法是通过练习你的编程技能:可以从 R 或 Python 开始你的学习之旅。这里有几个包和库,旨在让你的编码生活更轻松。请查看下面的信息图片段:
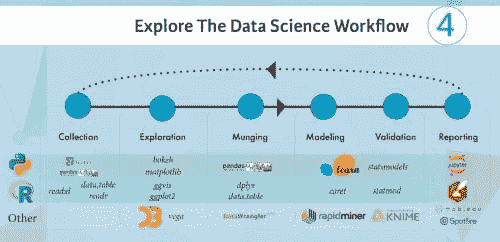
对于那些仍然觉得自己黑客技能不足的初学者来说,值得查看一些不需要你编写所有代码的开源替代方案。这些工具将允许你在数据科学工作流程中同时完成多个步骤。例如,RapidMiner允许你导入或收集数据,对其进行一些操作以清理数据,建模和评估。请注意,了解如何使用这些工具很重要,但你仍然应该继续提高你的编码技能!
步骤 5. 利用大数据提升水平
许多学习者过于关注他们所谓的数据科学“基础”,以至于忽略了更大的图景。字面上讲。你在之前的章节中得到了一些关于这一点的提示,但存在差异。就像你在许多教程中使用的平面文件与行业中使用的数据库之间的差异一样,数据的速度、多样性和规模也是如此。这是一个你不能也不应错过的现实。
大数据可能曾经是一个炒作的话题,但它确实存在,理解其涵盖的内容是非常重要的。了解大数据的三件事是:
-
了解为什么大数据需要不同的数据处理方法。最好的方法可能是查看大数据的实际应用案例。你可以在这里阅读一些。
-
熟悉一下Hadoop框架:它广泛用于分布式数据存储和处理。
-
不要忘记Spark。掌握结合 Python 或 Scala 使用 Spark 的方法是关键。而且,更好的是,你一举两得:你既能练习编码技能,又能拓宽对数据科学的视野。
步骤 6. 成长、连接和学习
成长。一旦你掌握了基础知识,就该开始成长了:通过参与数据科学挑战(比如在Kaggle或DrivenData上找到的那些)尽可能多地进行实践。它们将挑战你将理论付诸实践。此外,你还应该让你的直觉成长。
连接。作为数据科学学习者,你可能会陷入只关注自己的学习和其他学习者的学习的陷阱,但与那些在这个领域已有更多经验的人建立联系同样重要。这样,你可以建立一个可以在有问题、需要建议或提示时依靠的网络。这些人将激励你保持良好的学习状态,并挑战你更进一步。
学习。持续学习和数据科学几乎可以算是同义词。上述提到的Kaggle和DrivenData挑战将教会你一些关于数据科学实践的知识。除了这些相对较小的练习外,你还可以考虑启动一个个人项目,并更深入地探索一些内容。
第 7 步:彻底沉浸自己
就像语言沉浸一样,你需要一个数据科学的沉浸。根据你已经拥有的技能和知识,你可以考虑参加训练营、实习或找一份工作。训练营是启动或提升你数据科学学习的绝佳方式。作为额外的好处,你将遇到很多人,并有机会建立或扩展你的网络。如果你在寻找训练营时遇到困难,可以查看Galvanize和Metis,但也不要忘记你的Meetup小组可能也会为社区组织训练营和研讨会!
其次,当你已经掌握了数据科学的基础知识后,你应该考虑寻找一个实习机会。许多大公司如Facebook、Quora和Amazon之前都曾招募实习生,所以这是一个很好的开始寻找的地方。此外,你可以利用你的社交渠道或人脉网络来获取有关实习职位的第一手信息。最后,也可以关注初创公司:这些较小的公司愿意让你在工作中学习,只要你能快速学习。AngelList值得查看以获取初创公司职位的信息。
最后的沉浸选项是大多数学习者经历瓶颈的地方,正如最近在“数据科学面试”中的搜索趋势所证实的那样。即使你可能对数据科学家的职位非常热情,但在寻找工作时必须牢记几点:
-
职位发布并不总是准确的。他们可能会发布一个“数据科学家”职位,但实际上他们可能在寻找数据工程师或业务分析师。查看 DataCamp 的数据行业:谁做什么信息图,了解公司在发布职位时的要求。
-
调整你的期望:如果你没有真实的数据科学工作流程、数据库或端到端开发经验,那么直接从数据科学家或分析师职位入手是不现实的。确保在申请时你有相关的经验可供展示。
如果你不能立即找到工作,不要灰心。相反,尽量确保你保持忙碌,积累经验,并关注那些之前发布过数据科学职位的公司,比如Google、Microsoft和Twitter。
第 8 步:与社区互动
最后一步有时会被忽视。即使你在数据科学领域或者作为数据科学家有了工作,你仍然需要记住,数据科学等同于持续学习。时刻有新的进展,保持对周围发生的事情的关注和好奇是关键。因此,不要犹豫参与社交媒体讨论,订阅新闻通讯,关注数据科学行业的关键人物,收听播客……任何可以让你与社区互动的方式!
为了跟上最新的动态,你可以注册以下新闻通讯:双月刊 KD Nuggets 新闻通讯和Data Elixir或Data Science Weekly新闻通讯。接着,在Twitter上关注一些数据科学行业的关键人物。这也会帮助你跟上最新动态。一些可能会引起你兴趣的人物包括DJ Patil、Andrew Ng和Ben Lorica。
加入一些在线社区。LinkedIn、Facebook、Reddit……这些平台都提供了与同行联系的机会。你应该抓住机会成为这些小组中的一员:
-
在LinkedIn上,务必查看“Big Data, Analytics, Business Intelligence”、“Big Data Analytics”、“Data Scientists”或“Data Mining, Statistics, Big Data, Data Visualization, and Data Science”这些小组。
-
在Facebook上,"Beginning Data Science, Analytics, Machine Learning, Data Mining, R, Python"和"Learn Python"这些小组可能会引起你的兴趣。
-
你可以关注的Subreddits包括“/r/datascience”、“/r/rstats”和“/r/python”,还有很多其他的!
这个列表只是一个指引,并不是详尽无遗的!如果你想查看更多资源的概述,可以点击这里。
最后,别忘了为你加入的社区做出贡献!
在 DataCamp 上
DataCamp 是一个在线互动教育平台,专注于为数据科学提供最佳学习体验。我们的课程涉及R、Python 和 数据科学等主题,结合视频讲解和浏览器内编程挑战,使你能够通过实践学习。你可以随时随地免费开始每门课程。
简介:Karlijn Willems 是一名数据科学记者,专注于数据科学教育、最新新闻和热门趋势,并为DataCamp 社区撰写文章。她拥有文学与语言学及信息管理方面的学位。
相关:
-
团队的 4 个在线数据科学培训选项
-
数据分析与数据科学 Python 学习综合指南
-
最佳数据科学在线课程
相关主题
如何在破产时学习数据科学
评论

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
在过去的一年里,我自学了数据科学。我从数百个在线资源中学习,每天学习 6 到 8 小时。同时,我还在一家日托中心以最低工资工作。
我的目标是开始一份我热爱的职业,尽管资金不足。
正因为这个选择,我在过去几个月里取得了很多成就。我发布了自己的 网站,被一家主要的在线数据科学 出版物 刊登,并获得了竞争激烈的计算机科学研究生 项目的奖学金。
在以下文章中,我提供了指南和建议,以便你可以制定自己的数据科学课程。我希望能为他人提供工具,以开始他们自己的教育旅程,从而开始朝着更具激情的数据科学职业发展。
快速说明
当我说“数据科学”时,我指的是将数据转化为实际行动的工具集合。这些包括机器学习、数据库技术、统计学、编程和领域特定的技术。
一些资源来开始你的旅程。
互联网是一个混乱的局面。从中学习往往感觉像是从消防水龙头的喷射端喝水。

有一些更简单的替代方案可以为你整理混乱的局面。
像 Dataquest、 DataCamp 和 Udacity 这样的站点都提供数据科学技能的学习机会。每个网站都创建了一个教育程序,引导你从一个主题到另一个主题。每个都需要你花费很少的课程规划时间。
问题是什么?它们成本太高,它们不教你如何在工作环境中应用概念,而且它们阻止你探索自己的兴趣和激情。
有一些免费的替代方案,比如edX和coursera,它们提供深入特定主题的一次性课程。如果你从视频或课堂环境中学得比较好,这些都是学习数据科学的极佳途径。

免费在线教育平台,查看这个网站以获取可用的数据科学课程列表。你还可以使用一些免费的课程大纲。看看David Venturi的文章,或者开放源代码数据科学硕士(一个更传统的教育计划)。
如果你通过阅读学习得比较好,可以看看从零开始的数据科学这本书。这本教科书是一个完整的学习计划,可以通过在线资源进行补充。你可以在pdf格式(免费)找到整本书,或者从亚马逊($27)获得一本实体书。
这些只是提供详细数据科学学习路径的一些免费资源,还有很多其他的。
为了更好地理解你在教育旅程中需要获得的技能,在下一部分我将详细介绍一个更广泛的课程指南。这旨在提供高层次的指导,而不仅仅是课程或书籍的列表。
课程指南
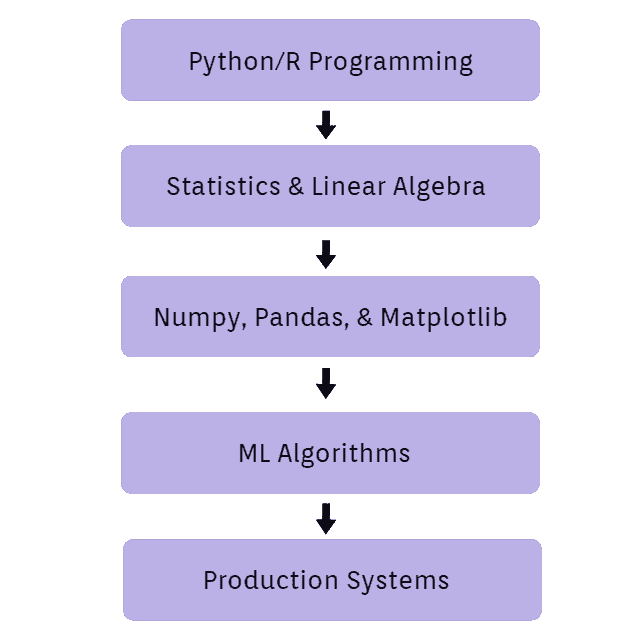
数据科学课程指南
Python 编程
编程是数据科学家的基本技能。熟练掌握 Python 的语法。了解如何以多种不同方式运行 Python 程序。(Jupyter notebook vs. 命令行 vs IDE)
我花了大约一个月的时间复习Python 文档、Python 指南以及在CodeSignal上的编码挑战。
提示:留意程序员使用的常见问题解决技巧。(发音为“算法”)
统计学和线性代数
机器学习和数据分析的前提条件。如果你已经对这些有扎实的理解,花一两周时间复习关键概念。
特别关注描述性统计。能够理解数据集是一项非常宝贵的技能。
Numpy, Pandas, 和 Matplotlib
学习如何加载、操作和可视化数据。掌握这些库对你的个人项目至关重要。

小提示:不要觉得你必须记住每个方法或函数名,这需要实践。如果忘记了,可以用 Google 搜索。
查看Pandas 文档、Numpy 文档和Matplotlib 教程。虽然还有更好的资源,但这些是我使用过的。
记住,你唯一能够学习这些库的方法就是使用它们!
机器学习
学习机器学习算法的理论和应用。然后将你学到的概念应用到你关心的真实数据上。
大多数初学者从使用UCI ML 数据库中的玩具数据集开始。玩弄这些数据,并通过指导性机器学习教程进行学习。
Scikit-learn文档提供了关于常用算法应用的优秀教程。我还发现这个podcast是一个很棒(且免费的)机器学习理论教育资源。你可以在通勤或锻炼时收听它。
生产系统
找到工作意味着能够将真实数据转化为行动。
为了做到这一点,你需要学习如何使用商业计算资源来获取、转换和处理数据。

亚马逊 Web 服务、谷歌云、微软 Azure 这是数据科学课程中最少教授的部分。主要是因为你使用的具体工具取决于你进入的行业。
然而,数据库操作是一个必要的技能。 你可以在ModeAnalytics或Codecademy上学习如何使用代码操作数据库。你也可以在DigitalOcean上便宜地实现自己的数据库。
另一个(通常)需要的技能是版本控制。 你可以通过创建一个GitHub账户并使用命令行每天提交代码,轻松掌握这个技能。
在考虑学习其他技术时,重要的是要考虑你的兴趣和热情。例如,如果你对网页开发感兴趣,那么了解一下该行业公司使用的工具。
执行课程的建议。

1. 概念会比你学习的速度更快地出现。
事实上,有成千上万的网页和论坛解释常用数据科学工具的使用。因此,在网上学习时很容易被分散注意力。
当你开始研究一个主题时,你需要牢记你的目标。如果不这样做,你可能会被吸引到任何引起你注意的有趣链接上。
解决方案是获取一个好的存储系统来保存有趣的网络资源。这样你可以将资料保存以备后用,专注于当前对你有用的主题。

我当前的 Chrome 书签栏 如果你做对了,你可以创建一个有序的学习路径,展示你应该专注的内容。你还会学得更快,避免被分心。
警告,你的阅读列表会很快增长到数百项,因为你会探索新的感兴趣的主题。别担心,这引出了我的第二条建议。
2. 不要焦虑。这是一场马拉松,而不是短跑。
自我驱动的教育常常感觉像是在阅读一个永无止境的知识库。

如果你想在数据科学领域获得成功,你需要把你的教育视为一个终身的过程。
只要记住,学习的过程本身就是一种回报。
在你的教育旅程中,你将探索自己的兴趣,并发现更多驱动你的东西。你对自己的了解越多,你从学习中获得的乐趣也会越多。
3. 学习 -> 应用 -> 重复
不要满足于仅仅学习一个概念然后转到下一个东西。学习的过程不会停止,直到你能够将一个概念应用到现实世界中。

by Allef Vinicius on Unsplash 不是每个概念都需要在你的作品集中有一个专门的项目。但重要的是要保持脚踏实地,记住你在学习是为了在世界上产生影响。
4. 建立一个作品集,它向他人展示他们可以信任你。
归根结底,怀疑是你在学习数据科学时将面临的最大困境之一。
这可能来自他人,也可能来自你自己。
你的作品集是你向世界展示你自己能力和自信的方式。
因此,建立一个作品集是你在学习数据科学期间最重要的事情。一个好的作品集可以帮你找到工作,并让你成为一个更自信的数据科学家。
把你引以为傲的项目填充到你的作品集中。
你是否从零开始构建了自己的网页应用程序?你是否创建了自己的 IMDB 数据库?你是否写过一篇有趣的医疗数据分析?
把它放入你的作品集中。
只需确保撰写的内容易于阅读,代码有良好的文档,并且作品集本身看起来不错。
harrisonjansma.com/archive 这是我的作品集。一个更简单的发布作品集的方法是创建一个包含出色的 ReadMe(摘要页面)以及相关项目文件的 GitHub 仓库。
这是一个美观却简单的GitHub 作品集。对于更高级的作品集,可以考虑使用 GitHub-IO 来托管你自己的免费网站。(示例)
5. 数据科学 + _______ = 激情事业
填空。
数据科学是一套旨在改变世界的工具。一些数据科学家建立计算机视觉系统来诊断医学影像,另一些则遍历数十亿的数据条目以找出网站用户偏好的模式。
数据科学的应用是无限的,这也是为什么找到让你兴奋的应用是很重要的。
如果你发现你热衷的主题,你会更愿意投入工作以做出一个出色的项目。这引出了我在这篇文章中最喜欢的建议。
在学习时,要时刻留意那些让你兴奋的项目或创意。

Stefan Steinbauer在Unsplash上。花时间学习后,尝试连接点滴。找到让你着迷的项目之间的相似性。然后花一些时间研究那些类型项目的行业。
一旦你找到一个你充满热情的行业,将其作为你的目标,获取该行业所需的技能和技术专长。
如果你能做到这一点,你将有能力将你的努力和对学习的热情转化为一份充满激情和成功的事业。
结论
如果你喜欢发现世界的奥秘。如果你对人工智能着迷。那么,无论你的情况如何,你都可以进入数据科学行业。
这不会很容易。
要激励你自己的教育,你需要毅力和纪律。但是如果你是那种能自我推动以提高自己的人,你完全有能力独立掌握这些技能。
毕竟,这就是数据科学家的全部意义。好奇心、自我驱动,以及对寻找答案的热情。
如果你想要更多高质量的数据科学文章,请关注我。 ????
原文。经许可转载。
个人简介:Harrison Jansma 是一位自学成才的数据科学家。在过去的 9 个月里,Harrison 离开了他的工作,开始全职学习机器学习,并报名攻读计算机科学硕士课程。Harrison 之所以这样做,是因为他的热情和目标是将机器学习应用于现实世界。这意味着对预测建模和生产环境有深入的理解。
相关:
更多相关主题
学习数据科学和商业分析以推动创新和增长
原文:
www.kdnuggets.com/2023/08/learn-data-science-business-analytics-drive-innovation-growth.html

你想知道任何企业如何能够长期生存吗?答案很简单——那就是增长。公司的增长对业务表现和利润至关重要。它还促进资产获取、投资融资和人才吸引。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
商业分析和数据科学对推动创新和业务增长至关重要。数据科学可以被企业利用来缓解不利趋势。例如,零售和金融服务公司可以利用数据科学来应对如破产、裁员或即将关闭等挑战。通过应用数据驱动的洞察和分析,这些公司可以做出明智的决策,并采取主动措施来解决这些问题。
此外,数据可以引导你的公司走向成功,你只需正确使用它。换句话说,数据是你业务分析的基础,以及你可以用它做的事情。为了启动你的业务并装备自己,以在竞争激烈的环境中脱颖而出,探索像 Great Learning 提供的最佳数据科学课程可能会带来终极变化。这些课程提供了全面和实践的数据分析、机器学习和人工智能培训,使你具备利用数据驱动洞察力的专业知识。
此外,在今天快速发展的商业环境中,投资于持续学习和技能提升变得至关重要。其他一些在线平台和教育机构也提供有价值的课程和资源,旨在提升业务增长和数据驱动决策。例如,Coursera提供了来自知名大学和行业专家的各种数据科学和商业分析课程,使学习者能够跟上前沿的方法论。
此外,对于寻求更专业技能的从业人员,像Udacity这样的平台提供数据科学、人工智能和高级分析的纳米学位项目。这些纳米学位项目提供基于项目的学习、指导和行业聚焦的课程,帮助个人获得实践经验并将其知识应用于现实世界的业务挑战。
什么是数据科学和商业分析?
使用机器学习算法,数据科学为你的业务增长创建预测模型。这些用于分析的信息对于你的业务非常关键。而且,这些信息来自广泛的来源。
商业界非常喜欢数据科学。他们将其与分析结合使用,以理解消费者行为并支持即时决策。
在商业分析中,数据分析、统计模型和其他定量技术被用于推动业务增长。
用于分析的信息用于决策制定。成功的商业分析依赖于高质量数据、对行业和相关技术有深入了解的能力强的分析师,以及坚定的承诺利用数据揭示有价值的洞察,以指导战略业务决策。
数据科学和商业分析的用途
数据科学允许从看似无序或无关的数据中提取有意义的洞察和预测。另一方面,商业分析使得分析所有可用的数据成为可能。通过利用商业分析,公司可以全面审视和解读他们的数据,获得宝贵的洞察,以推动明智的决策制定并优化业务流程。
科技公司收集的数据可以通过采用方法转化为有价值或盈利的信息。
数据科学也帮助了运输行业。使用自动驾驶车辆简化了减少碰撞次数的任务。
利用商业分析,你可以使用现代分析和统计方法揭示数据集中的隐藏模式。通过交互式仪表板和数据驱动的报告向利益相关者传达信息。根据新事实调整和维护决策。监控关键绩效指标(KPI),并迅速应对变化的模式。
如果你的公司希望实现一个或多个目标,分析就是一个好的选择。下一步是选择适合你公司需求的最佳商业分析解决方案。
让我们了解数据科学和商业分析在业务增长中的好处。

图片来源:blog.athenagt.com/wp-content/uploads/2018/09/Blog-info_1074698057-1.png
考虑两个具有说服力的案例研究,这些研究反映了数据科学和商业分析对业务增长的影响。
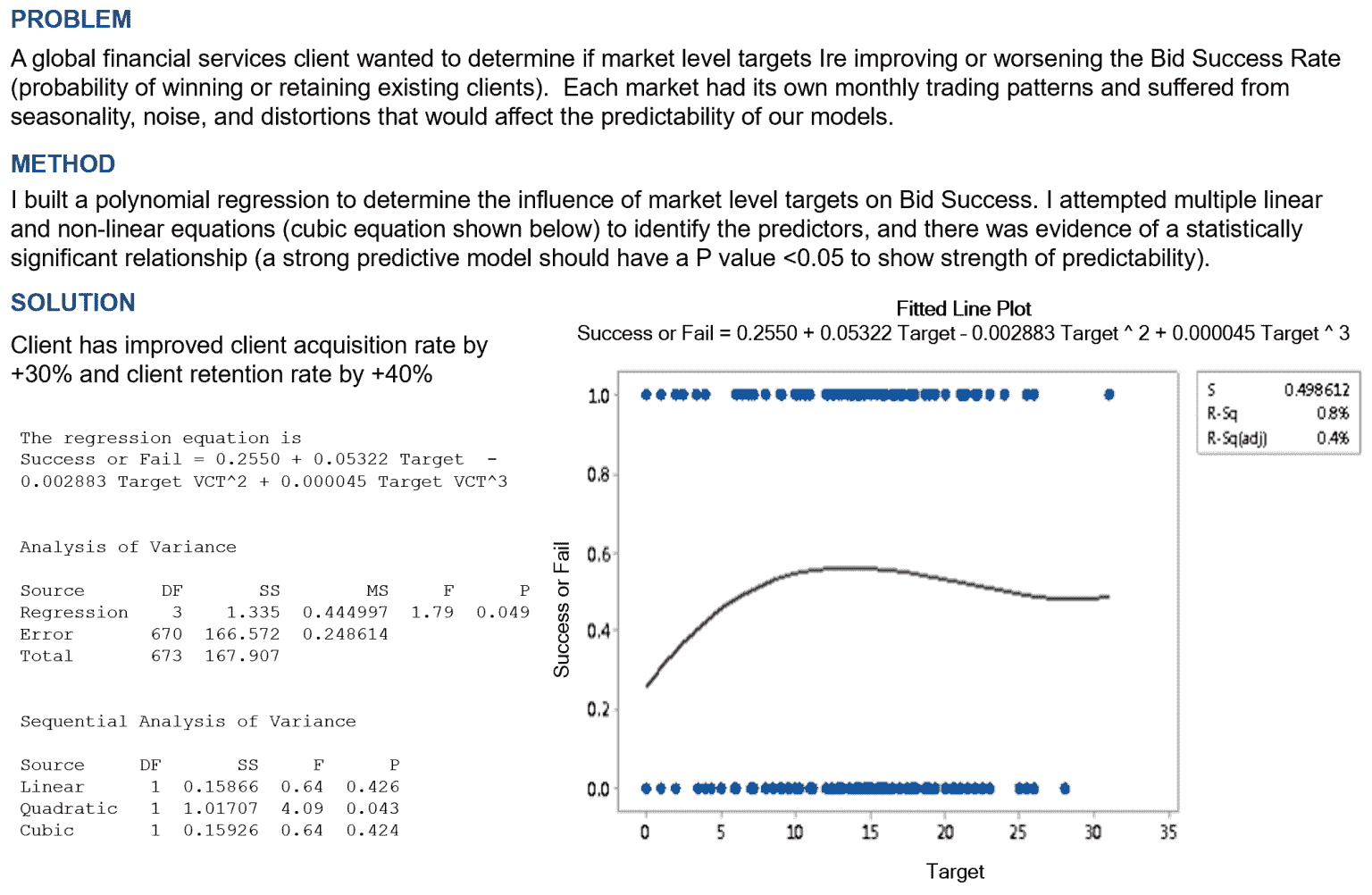
- 在案例研究 1中,采用的策略是构建一个多项式回归模型,以确定市场水平目标对竞标成功的影响。通过使用线性和非线性方程,识别出显著影响赢得或保留现有客户概率的预测变量。这个模型证明了成功,因为它使客户获取率提高了 30%,客户保留率提高了 40%。
这种方法可以应用于各种行业或企业,调整因素和变量以满足具体需求。这意味着通过识别和正确利用关键市场指标或预测因素,企业可以显著提高其客户获取和保留率。
- 在案例研究 2中,创建了一个销售激励模型以提高销售业绩。这个模型是通过多变量模型构建的,输入包括市场因素和前几年对应的政策数据。研究发现,设定的销售团队目标与其盈利完成交易的能力之间存在正相关。这一模型使销售业绩实现了 45%的年增长。
该策略强调了适当地激励销售团队和设定具有竞争力的市场特定目标以提升销售业绩的重要性。通过正确理解激励结构与销售业绩之间的关系,公司可以更好地激励销售团队并优化销售结果。
为什么选择数据科学和商业分析来服务业务?
数据科学在当前商业环境中的重要性已广为人知。这是因为企业必须基于数据做出决策,如果想要保持竞争力并继续扩展。由于它为公司提供了更有效使用数据的方法,近年来数据科学在商业领域越来越受到欢迎。今天,包括医院、银行和学院在内的企业都在利用数据科学来支持各种活动。
商业组织在不久的将来才会真正关注数据科学在商业中的重要性,因为数据几乎被应用于我们生活的每一个方面。如果他们成功了,他们有很大的机会在不失手的情况下击败竞争对手。因此,小型企业通过数据科学能够超越需要更多数据知识和经验的大型企业或更大规模的公司。
商业分析的好处
商业分析提供可操作的洞察。企业通过数据可视化对未来进行预测,这些见解支持未来的规划和决策。商业分析促进了增长并衡量了表现。了解了这些之后,现在是了解商业分析的时间,让我们看看它与商业智能的区别。
数据科学证书
要成为数据科学家,通常需要数据科学或计算机相关领域的学士学位,对于某些职位,可能还需要硕士学位。因此,在追求这一职业之前,验证所有的教育要求至关重要。
此外,各种认证,如项目模型认证、实习认证和资格证书等,对于提升你的资格和市场竞争力也很重要。如果你拥有其他学科的学位,你还可以在线攻读学位。你可以立即开始参加各种快速的在线数据科学课程。
商业分析证书
商业分析证书使你能够让雇主相信你具备使业务成功的技能。你可以说服他们你拥有推动战略决策以及收集和分析数据的必要技能。它赋予你作为商业分析师所需的能力,这些分析师利用数据来提升、扩展和优化企业流程。
数据科学能给你的业务带来什么?
智能策略始终是商业改善所需的。你可以通过以下方式在业务中使用数据科学:
-
数据挖掘与分析: 数据挖掘通过对大型数据集进行排序,揭示可以在数据分析中使用的模式和关系,以帮助解决商业问题。利用数据挖掘技术和方法,企业可以预测未来趋势,并做出更好的商业决策。
-
最终决策选择: 应从分析选项中挑选最佳和最有效的决策。企业的成功将取决于这一终极决策。
-
信息管理: 数据科学家通过实际选择有用数据,保持公司的数据银行准确和最新。公司在需要时使用这些数据银行。
商业分析和数据科学的范围
商业分析有许多不同的应用。对于那些希望在职业生涯中取得进步并获得良好薪水的人来说,商业分析在过去十年中已成为顶尖的就业选择之一。
对于拥有适当技能的人来说,印度广阔的数据科学领域提供了多个机会。通过正确的培训,企业可以从数据科学家的服务中受益,做出更好的决策,更好地了解消费者,并自动化任务。
结论
商业分析通过深入洞察帮助了许多企业实现增长。企业可以通过使用商业分析技术来个性化与客户的互动,这些技术可以通过商业分析课程学习。它们甚至可以将客户反馈纳入开发更有利可图的产品中。在可预见的未来,数据将继续是任何公司运营不可或缺的部分。数据代表了可操作的知识,能显著影响公司成功与失败的差异。正如俗话所说,知识就是力量。
通过整合数据科学工具,企业现在可以利用数据的力量来预测未来增长,主动识别潜在问题,并制定有效的成功计划。拥抱数据驱动的方法使企业能够做出明智的决策,并在当今竞争激烈的环境中保持领先。
在可预见的未来,数据将继续是任何公司运营不可或缺的部分。数据代表了可操作的知识,能显著影响公司成功与失败的差异。正如俗话所说,知识就是力量。
Erika Balla 是一位来自罗马尼亚的匈牙利内容写作专家,专注于 AI 和数据科学主题。她的目标是帮助企业简化复杂信息,让数据科学更广泛地为受众所用,凭借她在写作和先进技术知识方面的专长。
更多相关话题
通过实际操作来学习数据科学的绝佳方式
原文:
www.kdnuggets.com/2015/09/learn-data-science-by-doing.html
由 Sumendar Karupakala 提供。
“对于我们必须在做之前学习的事情,我们通过实际操作来学习它们” ~ 亚里士多德
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT

由于数据科学的综合性质,它融合了数学、统计学、经济学、计算机科学以及领域经验、黑客思维和业务影响技能,我们找不到一个地方可以一次性学习所有内容,但有很多出色的在线资源可以单独选择并学习,以成为数据科学领域的专家。如果我们想在这一领域精通,就从各种在线资源中获得这些课程吧。
挑战在于我们如何聪明地选择和使用这些教程,注册这些课程并观看视频不仅是做的一个方法,我们还应该在不同的练习中持续实践这些技巧,这些技巧由平台上的贡献者提供。大多数互动平台提供在线练习内容,如测验、问题集和可免费下载的免费数据集。
不仅要集中于技术方面,我们还必须持续关注与不同工业视角相关的大数据分析方法,因为大多数公司都在寻找对行业知识掌握得很好的商业精英。此外,如今的大数据正在推进和革新每个领域。
我列出了一些最佳的在线平台和相关课程,你可以在这些平台上学习和实践这些主题,成为数据科学专家。这些课程的独特之处在于免费注册,且大多数提供者与合作伙伴关联,提供完成证书。
Edx:
-
分析优势
-
使用 R 进行生命科学统计
-
使用 Transact-SQL 查询
-
线性代数 – 基础到前沿
-
知识管理与商业中的大数据
-
使用 Python 进行计算机科学和编程入门
-
使用 R 探索统计学
-
矩阵代数和线性模型
-
商业统计
-
我爱统计学:学习热爱统计
-
计算思维和数据科学简介
链接: www.edx.org/course/subject/data-analysis-statistics
www.edx.org/course/subject/computer-science
Coursera:
Udacity:
-
推断统计学
-
Hadoop 和 MapReduce 入门
-
使用 R 的数据分析
-
描述性统计入门
-
数据科学入门
-
数据可视化和 D3.js
链接: www.udacity.com/courses/data-science
**DataCamp: **
**Dataquest: **
**BigDataUniversity: **
-
使用 R 的数据分析简介
-
Hadoop 基础
-
SQL 对 Hadoop 的访问
链接: bigdatauniversity.com/wpcourses/?cat=334
bigdatauniversity.com/wpcourses/?cat=19
bigdatauniversity.com/wpcourses/?cat=132
bigdatauniversity.com/wpcourses/?cat=108\
bigdatauniversity.com/wpcourses/?cat=133
CodeSchool:
-
尝试 SQL
-
尝试 R
-
SQL 的续集
链接: www.codeschool.com/courses/try-sql
www.codeschool.com/courses/try-r
www.codeschool.com/courses/the-sequel-to-sql
KhanAcademy:
-
SQL 入门:查询和管理数据库
-
线性代数、概率与统计
链接: www.khanacademy.org/computing/computer-programming/sql
www.khanacademy.org/math/probability
**Stanford online lagunita: **
-
StatLearning 统计学习
-
CS101 计算机科学 101
链接: lagunita.stanford.edu/courses/HumanitiesandScience/StatLearning/
lagunita.stanford.edu/courses/Engineering/CS101/Summer2014/about
**Futurelearn: **
-
大数据:测量和预测人类行为
-
从数据到洞察: 数据分析简介
-
学习数据分析编程
链接: www.futurelearn.com/courses/big-data
www.futurelearn.com/courses/data-to-insight
www.futurelearn.com/courses/learn-to-code
Educast.Emc :
- 大数据湖
链接: educast.emc.com/learn/data-lakes-for-big-data-may-june
Udemy:
-
从零基础学习 Python 编程
-
R 编程语言
-
大数据与 Hadoop 基础
-
数据抓取和挖掘
-
数据分析师的 T-SQL
-
使用 Hadoop 生态系统进行数据分析
链接: www.udemy.com/courses/Business/Data-and-Analytics/
www.udemy.com/courses/Development/Databases/
www.udemy.com/courses/Development/Programming-Languages/
Alison:
Open2study:
Pluralsight:

简介: Sumendar Karupakala 是一位认证的大数据分析师,拥有多个分析领域的经验。他热爱使用分析工具、大数据和数据科学中的算法与技术,以便做出更聪明的决策。
相关:
-
前 20 大数据科学 MOOC 课程
-
在线教育:分析、大数据、数据挖掘和数据科学
-
商业分析与商业智能在线证书及学位
-
如何免费成为数据科学家
更多相关话题
从这些 GitHub 仓库学习数据科学
原文:
www.kdnuggets.com/2022/12/learn-data-science-github-repositories.html

图片由编辑提供
如果你想开始数据科学的职业生涯,你可能会想知道应该选择哪条学习路径。你可能看到过数据科学的训练营、Udemy 课程、学位等。面对如此众多的选择,确实很难决定走哪条路。
我们的前三推荐课程
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
哪里学习比 GitHub 仓库更好呢?如果你不知道,GitHub 是一个用于版本控制和协作的代码托管平台。谁使用 GitHub?你会看到个体专业人士、公司、大学和训练营学生、教师等使用这个平台进行协作和代码跟踪。
虽然 GitHub 不是唯一的平台,但由于以下原因,它非常受欢迎:易于使用,支持公共和私人仓库,并且对于小规模项目是免费的。GitHub 还有一个社区,帮助支持所有在 GitHub 上的用户解答问题、解决问题以及他们的整体学习之旅。多年来,人们对 GitHub 的看法各异,有些人主要将其视为协作工具,而其他人则将其视为学习门户或获取灵感的地方。
现在我们对 GitHub 有了一些了解,接下来看看你如何通过 GitHub 仓库学习数据科学。
freeCodeCamp
仓库链接:freeCodeCamp
如果你对学习数据科学的资源做过一些研究,你可能会遇到 freeCodeCamp。他们的资源非常受欢迎,最大吸引力是它们是免费的。凭借有358k人关注这个仓库,你肯定需要成为这群人中的一员。
你还可以在以下课程中获得认证:
数据科学入门
资源库链接: 数据科学入门
这是我遇到的最好的 GitHub 仓库之一!这个由微软 Azure 云倡导者提供的仓库提供了一个为期 10 周、20 节课的课程,帮助你进入数据科学领域。课程包括一个前导课程,之后是一个课后测验,写有完成课程的说明、解决方案和作业。
这个课程涵盖了数据科学的基础,旨在帮助初学者。你将学习数据科学伦理、统计与概率介绍、关系可视化等方面的内容。
开源数据科学硕士课程
资源库链接: 开源数据科学硕士课程
这个 GitHub 仓库为你提供了一个课程大纲以及相关资源。大多数资源来自大学和在职数据科学家,专注于数据科学的理论以及实际应用技能。
许多资源是免费的,唯一的费用是如果你选择购买推荐的书籍。当你完成课程后,你将被鼓励选择一个项目或数据集来展示你所学到的知识。他们还提供了一份课外学习材料清单,可以提高你的知识基础和技能。
免费数据科学书籍
资源库链接: 免费数据科学书籍
如果你是一个书迷,学习的最佳方式是翻阅书页——这个 GitHub 仓库将拯救你。它不仅提供了一个按照课程安排的书单,而且是免费的!
这些书籍将标注其难度级别,包括初学者、中级或高级。涵盖的主题包括数据科学介绍、数据处理、数据分析、数据科学应用、数据可视化、未分类和关于数据科学的 MOOCs。
数据科学课程
资源库链接: 数据科学课程
当你开始你的数据科学之路时,可能很难知道从哪里开始。这是我曾经面临的问题,也是很多我认识的人所遇到的问题。遵循课程可以帮助你有效管理时间,确保涵盖所有数据科学方面,并识别你的弱点,以便加以改进。
这个由开源社会大学提供的数据科学课程清单,列出了成为数据科学家所需的课程。虽然它们可能没有免费的材料,但拥有一个学习计划会让你的生活变得更加轻松。
超棒的数据科学
资源链接: 超棒的数据科学
类似于课程,这个超棒的数据科学 GitHub 涵盖了数据科学的各个方面。如果你需要了解成为数据科学家所需的主题,但又希望自己进行研究,那么这个 GitHub 仓库就是为你准备的。它是数据科学的工具箱。
它为你提供了有关数据科学的所有必要书籍、博客文章、网页等信息。它们还提供了关于免费课程、密集课程和可以启动你数据科学职业生涯的学院的更多信息。
数据科学全能备忘单
资源链接: 数据科学全能备忘单
备忘单是学习新知识的好方法。它们提供了基本信息,并允许你进一步研究。拥有者将这些备忘单汇集在一起,旨在帮助学生获得提供清晰内容的全面资料。
你可以找到广泛的领域提供备忘单,如统计学、Matlab、机器学习、数据仓库、深度学习等。
最佳的 ML 与 Python
资源链接: 最佳的 ML 与 Python
成为成功的数据科学家的关键方面是确保你能应用你的技能,而唯一的方式就是通过做项目。招聘者希望看到你的代码、你的思路过程以及你如何得出最终结果。
这个最佳的 ML 与 Python GitHub 仓库提供了 910 个开源项目,分为 34 个类别。这些项目根据项目质量评分进行排名,因此你可以看到哪些项目受欢迎,并了解项目的描述。你可以找到数据加载与提取、模型解释性、医学数据等类别。
数据科学面试资源 - 面试问题
资源链接: 数据科学面试资源
一旦你掌握了作为数据科学家所需的所有知识并将其应用于项目中,下一步就是申请工作并为面试做好准备。这是最棘手的部分——但这就是你一直等待的时刻。
在数据科学面试中你将被问到的硬技能问题通常会分为两个类别:理论和技术。这些 GitHub 仓库涵盖了这两方面内容,并帮助你测试自己的知识,以便为面试做好准备。它们还提供了有关如何构建简历/CV 的技巧,这是赢得招聘官青睐的重要方面。
总结
学习数据科学不会容易,但在当今这个资源丰富的时代,它绝对是可以实现的。如果你知道其他能帮助他人的优秀 GitHub 仓库,请在下方评论中分享。
Nisha Arya 是一名数据科学家和自由撰稿人。她特别关注提供数据科学职业建议或教程以及数据科学的理论知识。她还希望探索人工智能如何能够/将如何促进人类生命的长久。作为一个热衷的学习者,她寻求拓宽技术知识和写作技能,同时帮助指导他人。
更多相关主题
数据科学和机器学习的学习:路线图后的第一步
原文:
www.kdnuggets.com/2021/08/learn-data-science-machine-learning.html
评论
来源: www.wiplane.com/p/foundations-for-data-science-ml
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
在今年年初,我发布了一份关于数据科学学习路线图(见下文)的思维导图。这份路线图得到了广泛认可,文章被翻译成了多种语言,许多人感谢我发布了这份图谱。
一切都很好,直到一些有抱负的学员指出,资源太多且许多资源很贵。Python 编程是唯一一个有许多非常好的课程的领域,但对于初学者来说,它仅止步于此。
一些关于基础数据科学的重要问题让我深思:
-
学会编程后应该做什么?是否有帮助你巩固数据科学基础的主题?
-
我讨厌数学,但有些教程要么非常基础,要么对我来说过于深入。你能推荐一个紧凑而全面的数学和统计学课程吗?
-
学习机器学习算法需要多少数学基础才够?
-
开始数据分析或数据科学时,有哪些关键的统计学主题?
很多这些问题的答案可以在《深度学习》一书中找到,作者是 Ian Goodfellow 和 Yoshua Bengio。然而,对于许多人来说,这本书有点过于技术化和数学化。
这篇文章的精髓就是,学习数据科学或机器学习的第一步。
数据科学与机器学习的三大支柱

来源: wiplane.com
如果你查看任何机器学习/数据科学课程的前提条件或预习内容,你会发现它们通常结合了编程、数学和统计学。
先暂时不谈其他内容,这里是谷歌推荐的你在学习机器学习课程之前应该做的事:


developers.google.com/machine-learning/crash-course/prereqs-and-prework (CC BY 4.0)
1. 基本编程
大多数数据职位都是以编程为基础的,除了像商业智能、市场分析、产品分析师等少数职位。
我将专注于那些需要至少掌握一种编程语言的技术数据工作。我个人更喜欢 Python,因为它的多功能性和易学性——无疑是开发端到端项目的好选择。
必须掌握的数据科学主题/库的一瞥:
-
常见的数据结构(数据类型、列表、字典、集合、元组)、编写函数、逻辑、控制流、搜索和排序算法、面向对象编程以及使用外部库。
-
编写 Python 脚本以提取、格式化和存储数据到文件或回到数据库。
-
使用 NumPy 处理多维数组、索引、切片、转置、广播和伪随机数生成。
-
使用科学计算库如 NumPy 执行矢量化操作。
-
使用 Pandas 操作数据——系列、数据框、数据框中的索引、比较操作符、合并数据框、映射和应用函数。
-
使用 Pandas 处理数据——检查空值、填补空值、分组数据、描述数据、进行探索性分析等。
-
使用 Matplotlib 进行数据可视化——API 层次结构、向图形添加样式、颜色和标记、了解各种图形及其使用时机、折线图、条形图、散点图、直方图、箱线图,以及 seaborn 进行更高级的绘图。
2. 基本数学
有实际原因说明数学为何重要 对于那些想要从事机器学习实践者、数据科学家或深度学习工程师职业的人来说。
#1 线性代数用于表示数据
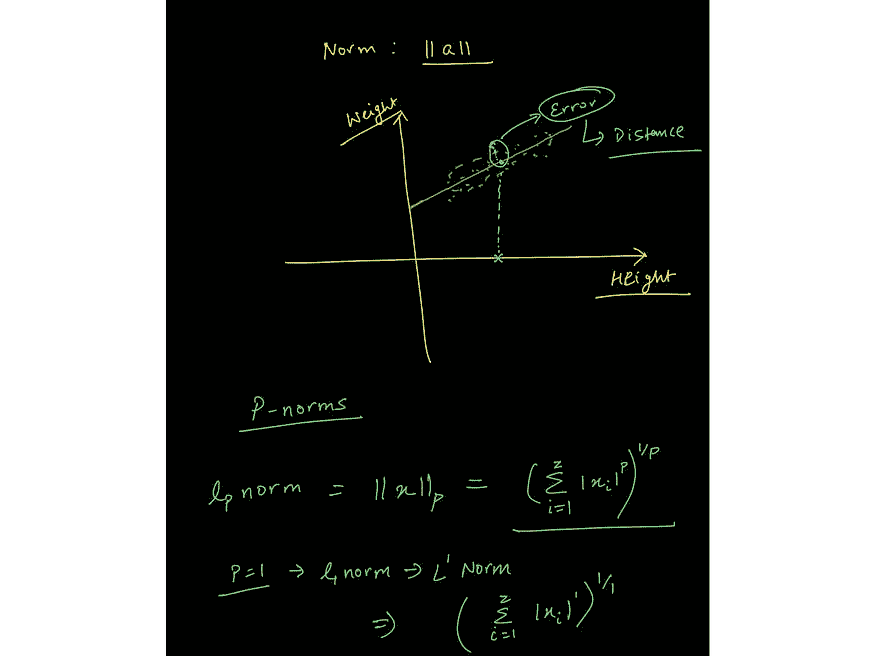
来自课程中关于向量范数的讲座的图像: www.wiplane.com/p/foundations-for-data-science-ml
机器学习本质上是数据驱动的,因为数据是机器学习的核心。我们可以将数据视为向量——一个遵循算术规则的对象。这使我们能够理解线性代数的规则如何作用于数据数组。
#2 微积分用于训练机器学习模型
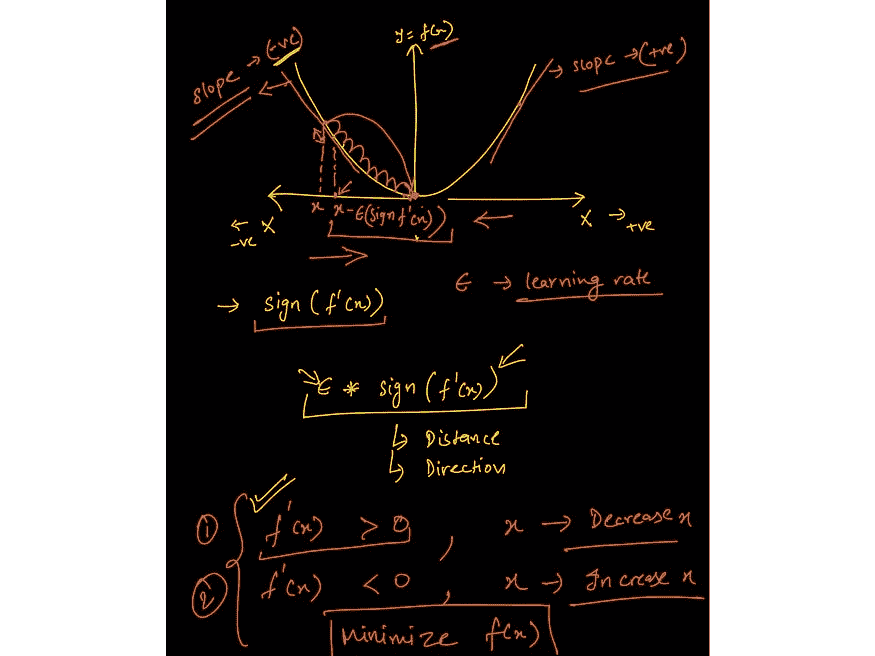
来自课程中关于梯度下降的讲座的图像: www.wiplane.com/p/foundations-for-data-science-ml
如果你以为模型训练是“自动进行”的,那么你就错了。微积分是推动大多数机器学习(ML)和深度学习(DL)算法学习的核心。
最常用的优化算法之一——梯度下降法——是偏导数的应用。
模型是某些信念和假设的数学表示。它被认为是学习(近似)数据提供过程(线性、多项式等)的过程,然后基于这个学习到的过程进行预测。
重要主题包括:
-
基础代数 — 变量、系数、方程式以及线性、指数、对数函数等。
-
线性代数 — 标量、向量、张量、范数(L1 和 L2)、点积、矩阵类型、线性变换、矩阵表示线性方程、利用向量和矩阵解决线性回归问题。
-
微积分 — 导数和极限、导数规则、链式法则(用于反向传播算法)、偏导数(计算梯度)、函数的凸性、局部/全局极小值、回归模型背后的数学、从头开始训练模型的应用数学。
#3 基本统计学
现在的每个组织都在努力实现数据驱动。为了实现这一目标,分析师和科学家需要以不同的方式利用数据,以推动决策制定。
描述数据 — 从数据到洞察
数据总是原始且难看。初步探索告诉你缺少什么,数据如何分布,以及清理数据以实现最终目标的最佳方式是什么。
为了回答定义的问题,描述统计使你能够将数据中的每一个观察转化为有意义的洞察。
量化不确定性
此外,量化不确定性的能力是任何数据公司高度重视的最有价值的技能。了解任何实验/决策的成功几率对所有业务至关重要。
这里是一些统计学的主要基础,构成了最低要求:
来自关于泊松分布讲座的图像 — www.wiplane.com/p/foundations-for-data-science-ml
-
位置的估计 — 均值、中位数以及这些的其他变体。
-
变异性的估计
-
相关性和协方差
-
随机变量 — 离散和连续
-
数据分布 — PMF、PDF、CDF
-
条件概率 — 贝叶斯统计
-
常用的统计分布 — 高斯分布、二项分布、泊松分布、指数分布
-
重要定理 — 大数法则和中心极限定理。
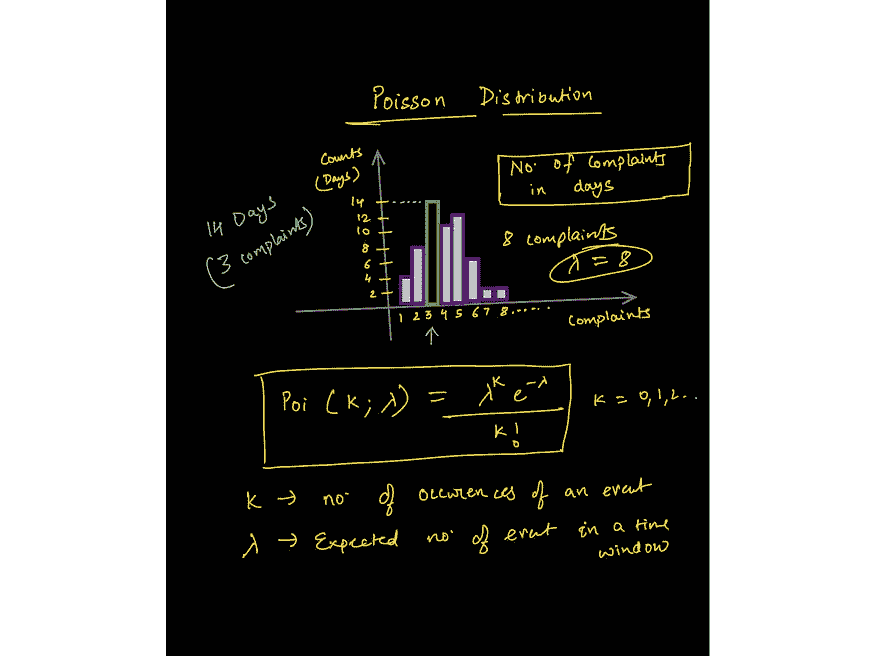
来自关于泊松分布讲座的图像 — www.wiplane.com/p/foundations-for-data-science-ml
-
推断统计 — 一种更实际和高级的统计学分支,有助于设计假设检验实验,推动我们深入理解指标的含义,同时帮助我们量化结果的显著性。
-
重要的测试 — 学生 t 检验、卡方检验、ANOVA 检验等。
每个初学者级别的数据科学爱好者在深入任何核心数据科学或核心机器学习课程之前都应关注这三个支柱
学习上述内容的资源 — 寻找一个紧凑、全面且价格实惠的课程
www.freecodecamp.org/news/data-science-learning-roadmap/
我的学习路线图也告诉你该学习什么,并且也充满了可以注册的资源、课程和项目。
但推荐的资源和我制定的路线图中存在一些不一致之处。
数据科学或机器学习课程的问题
-
我在这里列出的每个数据科学课程都要求学生对编程、数学或统计学有一定的理解。例如,Andrew Ng 最著名的机器学习课程也严重依赖于对向量代数和微积分的理解。
-
大多数涵盖数据科学的数学和统计学的课程,只是列出所需的概念清单,却没有解释这些概念如何应用及如何在机器中编程。
-
有很多优秀的资源可以深入学习数学,但大多数人并不适合,而且学习数据科学并不需要成为金牌得主。
底线: 缺乏一种只涵盖足够应用数学、统计学或编程基础以便入门数据科学或机器学习的资源。
Wiplane Academy — wiplane.com
所以,我决定自己动手做所有的事情。我花了过去 3 个月的时间开发一个课程,以为你的职业生涯奠定坚实的基础……
-
数据分析师
-
数据科学家
-
或者一位机器学习从业者/工程师
在这里,我向你展示 数据科学或机器学习的基础** — **学习数据科学和机器学习的第一步

这就是我决定启动时的样子!
一个全面但紧凑且价格实惠的课程,不仅涵盖所有的基本要素、前提条件和预备工作,还解释了每个概念如何在计算和编程中(Python)使用。
而且这还不是全部。我会根据你的反馈每月更新课程内容。了解更多 这里。
早鸟优惠!
我很兴奋地宣布这门课程的预售,因为我目前正在录制和编辑 2-3 个模块的最终部分,这些模块也将在九月的第一周上线。
抓住早鸟优惠,优惠仅有效至 2021 年 8 月 30 日。
原文。经许可转载。
简介: Harshit Tyagi 是一位具有融合经验的工程师,擅长网页技术和数据科学(即全栈数据科学),曾指导过 1000 多名 AI/Web/数据科学志愿者,同时设计数据科学和机器学习工程学习路径。此前,Harshit 与耶鲁大学、麻省理工学院和加州大学洛杉矶分校的研究科学家一起开发数据处理算法。
相关:
更多相关主题
预算内学习数据科学

图片由 DALLE 提供
找到合适的平台或课程从来不是一件容易的事。这需要很多试错,最糟糕的是当你为这些课程付费时。你会觉得自己一直在寻找最佳课程来提升职业生涯,但最后却回到起点 - 你的钱包也受到了伤害(有时一点,有时很多)。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
这就是为什么我决定撰写这篇文章,让你可以从我的错误中学习,并以预算内的方式获得所有的数据科学知识!
理解数据科学
链接:理解数据科学
让我们从 DataCamp 开始 - 这是一个提供各种课程的在线学习平台。他们的《理解数据科学》课程专为希望涉足数据科学世界的初学者设计。而且你也不用担心是否有编程经验 - 因为不需要!
这是一个 2 小时的课程,包括 15 个学习视频和 48 个练习题!分为 4 个部分,第一部分“数据科学简介”是免费的,其余 3 个部分需要你获取会员资格。会员价格合理,通过它你可以访问 DataCamp 的完整内容库,方便你在学习额外课程时使用。
从零开始的数据科学
链接:从零开始的数据科学
这是针对那些喜欢用书本作为学习方法的书虫们。在《从零开始的数据科学》这本书中,你将学习数据科学的学科内容,例如库、框架、模块和工具包。还会了解算法的工作原理以及如何从头开始实现它们。
如果你正在寻找 Python 的速成课程,想要学习数据科学的基础,深入了解机器学习的基本原理,并进一步探索 - 这本书就是为你准备的。
概率论简介
链接:概率论简介
一门为期 10 周的免费课程来自哈佛!虽然有很多在线训练营课程,但概率有时会被忽略。然而,它对于理解数据科学基础至关重要。学习概率可以让你从‘良好的’数据科学家成长为‘专家’数据科学家。
在这门课程中,你将学习不确定性和随机性、做出准确预测、常见概率分布等内容。课程是免费的,但你可以为 209 美元添加一个认证证书。
Python in a Nutshell
Python 已经被评为最受欢迎的编程语言之一——这有其原因。它简单的语法使得人们能够轻松过渡到数据科学的世界。对数据专业人士的需求很大,Python 语言无疑开辟了道路。
这本第四版《Python in a Nutshell》书包含了 26 章内容,可以带你从 Python 完全新手成为绝对专家!从在 Python 中表示数据到调试——这本书应有尽有!
数据分析与 Python
链接:数据分析与 Python
Freecodecamp.org 最初是一个希望让学习对每个人都可及的组织——这就是它名字的由来。如果你在寻找一门全面的课程,那么这门数据分析与 Python 课程强烈推荐。数据科学世界发生了很多变化,尤其是 Python、SQL 等等。
在这门课程中,你将学习成为数据科学家的绝对基础,从读取自己的数据到使用库分析数据和创建数据可视化。
总结
通过这 5 门课程/平台,你将能够从对数据科学一无所知到完善简历,申请你的第一份数据科学职位。数据科学仍然是一个非常受欢迎的角色,现在开始再好不过了!
Nisha Arya 是一名数据科学家、自由撰稿人、编辑及 KDnuggets 的社区经理。她特别关注提供数据科学职业建议、教程以及基于理论的数据科学知识。Nisha 涵盖了广泛的话题,并希望探索人工智能如何能促进人类寿命的不同方式。作为一个热衷学习者,Nisha 旨在拓宽自己的技术知识和写作技能,同时帮助他人。
更多相关主题
学习深度学习的地方 – 课程、教程、软件
原文:
www.kdnuggets.com/2014/05/learn-deep-learning-courses-tutorials-overviews.html
评论 Gregory Piatetsky,@kdnuggets,2014 年 5 月 26 日。
深度学习是机器学习研究的一个热门领域,取得了许多显著的成功,例如在面部识别中达到 97.5%的准确率、几乎完美的德国交通标志识别,甚至在狗与猫图像识别中达到 98.9%的准确率。最近许多 Kaggle 数据科学竞赛的获胜作品都使用了深度学习。
“深度学习”一词指的是训练多层神经网络的方法,并在 Geoffrey Hinton 及其合作者发表的论文之后变得流行,这些论文展示了一种快速训练这些网络的方法。
Yann LeCun,Geoff Hinton 的学生,还开发了一种非常有效的深度学习算法,称为,该算法在 80 年代末和 90 年代初成功用于自动读取支票上的金额。
在我的独家与 Yann LeCun 的采访中,了解更多关于卷积网络和推动深度学习成功的因素。
2014 年 5 月,中国搜索巨头百度聘请了 Andrew Ng,一位领先的机器学习和深度学习专家(也是 Coursera 的联合创始人),来领导他们在硅谷的新 AI 实验室,与谷歌(聘请了 Geoff Hinton)和 Facebook(聘请了 Yann LeCun 来领导 Facebook AI 实验室)展开 AI 和深度学习的竞赛。
这里有一些有用且免费的 (!) 深度学习资源:
-
DeepLearning.net,专注于深度学习的网站
-
深度学习维基百科 页面
-
NYU 深度学习课程材料 由 Yann LeCun 提供
-
Yann LeCun 关于深度学习的概述 与 Marc'Aurelio Ranzato
-
Geoff Hinton Coursera 课程 关于神经网络
-
深度学习:方法与应用书籍(134 页)来自微软语音组
-
CMU 阅读列表,包括学生笔记
-
观看:John Kaufhold 的深度学习教程,2014 年华盛顿特区数据科学聚会
-
深度学习课程在哪里?,由数据科学家兼深度学习分析的管理合伙人 John Kaufhold 撰写的博客。
-
深度学习将如何改变我们的世界,Jeremy Howard 在墨尔本数据科学会议上的总结。
支持深度学习的包包括
-
Torch7,是 LuaJIT 语言的扩展,包括一个面向深度学习和计算机视觉的面向对象包。Torch7 的主要优势是 LuaJIT 非常快且灵活。
-
Theano + Pylearn2,具有使用 Python(广泛使用)的优势,但也有使用 Python(处理大数据时较慢)的劣势。
-
cuda-convnet,基于 Yann LeCun 工作的高性能 C++/CUDA 卷积神经网络实现。
相关内容:
-
KDnuggets 独家:对深度学习专家 Yann LeCun 的采访,Facebook AI Lab 的主任
-
KDnuggets 独家:对 Yann LeCun 的采访第二部分
-
深度学习如何模拟人脑
-
深度学习在 Kaggle 的“狗与猫”竞赛中获胜
更多相关内容
使用R学习广义线性模型(GLM)
原文:https://www.kdnuggets.com/2017/10/learn-generalized-linear-models-glm-r.html/2
解释对数变换
对依赖数据和独立数据进行对数变换是一种处理非线性关系的简单方法。这种变换有助于使用线性模型分析非线性关系。我们已经讨论了对数线性回归。还有两个变体 – a) 线性–对数回归 –独立变量进行对数变换,b) 对数–对数回归 –依赖变量和独立变量都进行变换。下表显示了每个模型的方程和解释。
我们的前3个课程推荐
 1. Google 网络安全证书 - 快速进入网络安全职业生涯
1. Google 网络安全证书 - 快速进入网络安全职业生涯
 2. Google 数据分析专业证书 - 提升你的数据分析能力
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的IT需求
表2 二项逻辑回归的样本数据

二项逻辑回归
当依赖变量是类别型且取值为0和1时,使用二项逻辑回归。与简单线性回归中依赖变量的条件分布为正态分布不同,逻辑回归中的条件分布为伯努利分布。在伯努利分布中,变量只能取两个值 – 0和1,具有一定的概率。
让我们通过一个例子来理解。假设在足球中,将罚球转换为进球的能力取决于射门者的练习小时数。我们可以用1表示成功罚球,用0表示未成功罚球。数据如下:
表2 二项逻辑回归的样本数据

二项逻辑回归模型将根据练习小时数输出成功罚球的概率。逻辑回归使用逻辑函数来建模关系。逻辑函数允许将关系建模为概率,因为它的值在0和1之间。其表示如下:
 [4]
[4]
β1 的正值(负值)表示当 X 增加时 Y=1 的概率增加(减少)。逻辑回归是广泛使用的类别预测模型之一。多项式逻辑回归将二分类模型扩展到处理涉及多个类别的问题。例如,一个人是否会兑换优惠券 A、优惠券 B 或优惠券 C。现在我们将在 R 中实现逻辑回归模型。样本数据包括两个变量——点球成功/失败表示为 1/0 和练习小时。请点击这里下载。R 代码如下:
## Prepare scatter plot
#Read data from .csv file
data1 = read.csv("Penalty.csv", header = T)
head(data1)
#Scatter Plot
plot(data1, main = "Scatter Plot")
图 4 类别数据的散点图

我们可以观察到,因变量仅能取两个值——1和0。当练习时间增加时,玩家的效率也提高。现在我们将使用逻辑回归准备一个模型来预测基于练习时间的成功或失败的概率。R 代码如下:
## Fitting Logistic regression model
fit = glm(Outcome ~ Practice, family = binomial(link = "logit"), data = data1)
#Plot probabilities
plot(data1, main ="Scatter Plot")
curve(predict(fit,data.frame(Practice = x), type = "resp"), add = TRUE)
points(data1$Practice,fitted(fit),pch=20)
图 5 显示了从逻辑回归中获得的概率值。我们可以看到模型表现良好。随着练习时间的增加,成功的概率也增加。该模型在方程 [5] 中表示。可以通过插入练习小时数来获得概率值。
 [5]
[5]
图 5 使用逻辑回归的概率图

结论
在这篇文章中,我们学习了广义线性模型(GLM)。简单线性回归是 GLM 的最基本形式。GLM 的高级形式有助于以简单的方式处理非正态分布和非线性关系。我们重点介绍了对数线性回归和二元逻辑回归。当因变量与自变量之间的关系是非线性时,对数线性回归非常有用。当因变量遵循对数正态分布或泊松分布时,它也提供了快速的解决方案。
此外,我们讨论了二元逻辑回归的基本概念。当因变量遵循伯努利分布,即只能取 0 和 1 的值时,二元逻辑回归非常有用。我们还提供了各种对数变换的方程和解释,这些变换与回归模型一起使用。
除了理论解释,我们还分享了 R 代码,以便你可以在 R 中实现该模型。为了更好地理解,我们展示了结果和代码。
我们希望你觉得这篇文章有用。
个人简介: Chaitanya Sagar 是 Perceptive Analytics 的创始人兼首席执行官。Perceptive Analytics 被《Analytics India Magazine》评选为值得关注的十大分析公司之一。该公司致力于为电子商务、零售和制药公司提供市场分析服务。
相关内容:
相关主题
-
线性回归与逻辑回归:简明解释
在我们将探讨对数线性模型的解释。log(a) 是常数项,log(b) 是 Y 随 X 单位变化而增长的增长率。log(b) 的负值表明 Y 会因为 X 的单位增加而以一定百分比减少。接下来,我们将使用可口可乐销售数据在 R 中实现该模型。R 代码如下。
## Fitting Log-linear model
# Transform the dependent variable
data$LCola = log(data$Cola, base = exp(1))
#Scatter Plot
plot(LCola ~ Temperature, data = data , main = "Scatter Plot")
#Fit the best line in log-linear model
model1 = lm(LCola ~ Temperature, data)
abline(model1)
#Calculate RMSE
PredCola1 = predict(model1, data)
RMSE = rmse(PredCola1, data$LCola)
图 3 对数线性回归给出的最佳拟合线

图 3 显示了使用对数线性回归的最佳拟合线。我们可以将其视为一个两步过程,即对数据进行变换(对两边取对数),然后对变换后的数据进行简单线性回归。计算出的模型如下:
 [3]
[3]
可乐销售量可以通过将温度值代入方程[3]来预测。我们观察到与简单线性回归相比,拟合效果有了很大改善。变换后的模型的RMSE仅为0.24。请注意,日志线性回归也解决了可乐销售量出现荒谬负值的问题。对于任何温度值,我们都不会得到负的可乐销售量。简单的对数变换帮助我们处理了这种荒谬情况。在下一部分,我们将讨论其他在各种情况下非常有用的对数变换。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力。
3. 谷歌IT支持专业证书 - 支持你的组织IT需求。
更多相关话题
学习如何免费使用 ChatGPT Next Web (NextChat)
原文:
www.kdnuggets.com/learn-how-to-use-chatgpt-next-web-nextchat-for-free
作者提供的图片
ChatGPT Next Web,现在称为 NextChat,是一个聊天机器人应用,允许用户访问来自 OpenAI 和 Google AI 的先进 AI 模型。该应用程序轻量且功能丰富,提升了用户体验。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT 工作
在本教程中,我们将学习如何免费获取 Google AI API,并使用 ChatGPT Next Web 生成响应。此外,我们还将学习如何在 Windows 11 上本地使用它。最后,我们将在不到一分钟的时间内将自己的网页应用部署到 Vercel。
1. 获取免费的 Google AI API
要获取 Google AI API 密钥,我们需要访问 ai.google.dev/ 然后点击蓝色按钮“获取 API 密钥 Google AI Studio”。
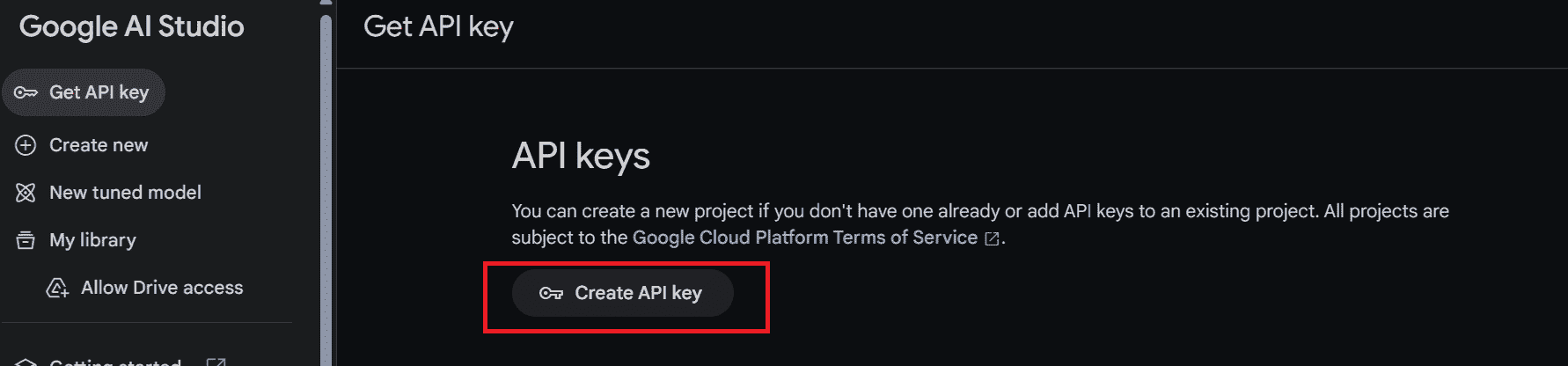
如果您已登录 Google 帐户,将会被引导至 Google AI Studio。在那里,点击左侧面板上的“获取 API 密钥”按钮,然后选择“创建 API 密钥”以生成 API 密钥。
此密钥将用于在官方网页应用、本地以及我们部署的应用中生成响应。
2. 官方网页应用
要访问官方 ChatGPT Next Web,请访问 app.nextchat.dev/。它会要求我们提供 API 密钥,通过访问身份验证页面完成。
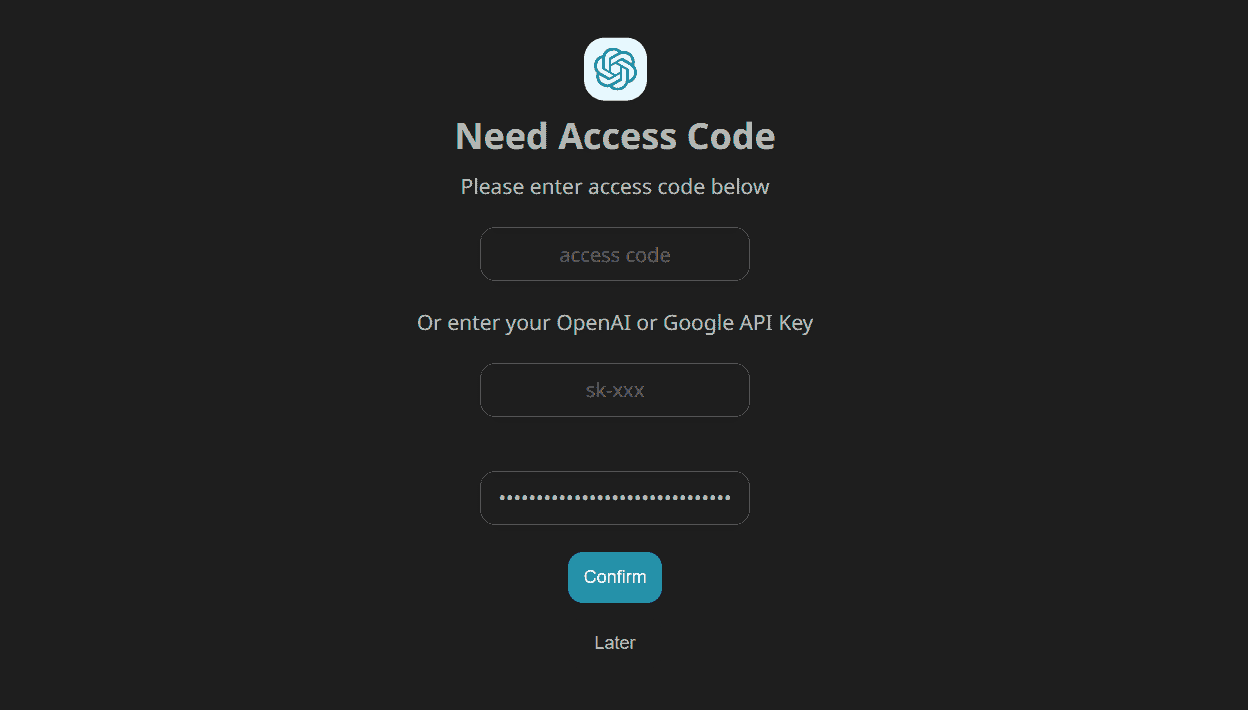
访问身份验证页面,地址为 app.nextchat.dev/#/auth,在第三个文本框中输入新创建的 Google AI API 密钥,然后点击“确认”按钮。
点击消息框上方的机器人(🤖),选择“gemini-pro”模型。
在消息框中输入提示,几秒钟内它将开始生成响应。使用起来既快速又有趣。
3. 本地 Windows 应用程序
让我们继续在你的笔记本电脑上安装 ChatGPT Next Web。这款应用程序兼容 Linux、Windows 和 MacOS。
在我们的例子中,我们将访问以下链接:github.com/ChatGPTNextWeb/ChatGPT-Next-Web/releases,点击 .exe 文件。这将下载应用程序安装文件。下载完成后,使用默认设置安装应用程序并启动它。
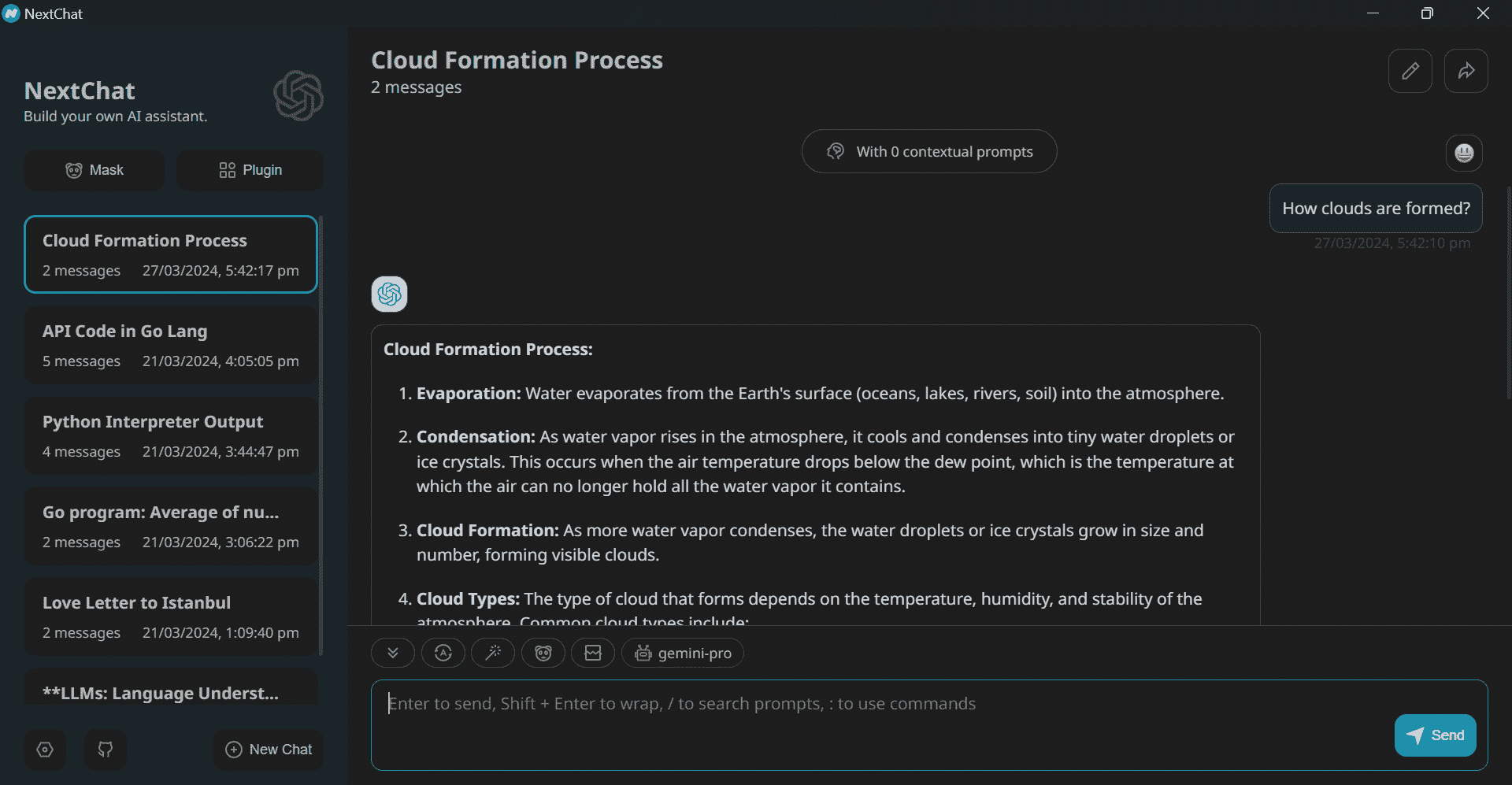
Windows 应用程序没有身份验证页面。因此,要设置 Google AI API,我们需要进入设置并向下滚动找到“模型提供者”部分。从那里,我们应该选择正确的模型提供者并提供 API 密钥,如下所示。
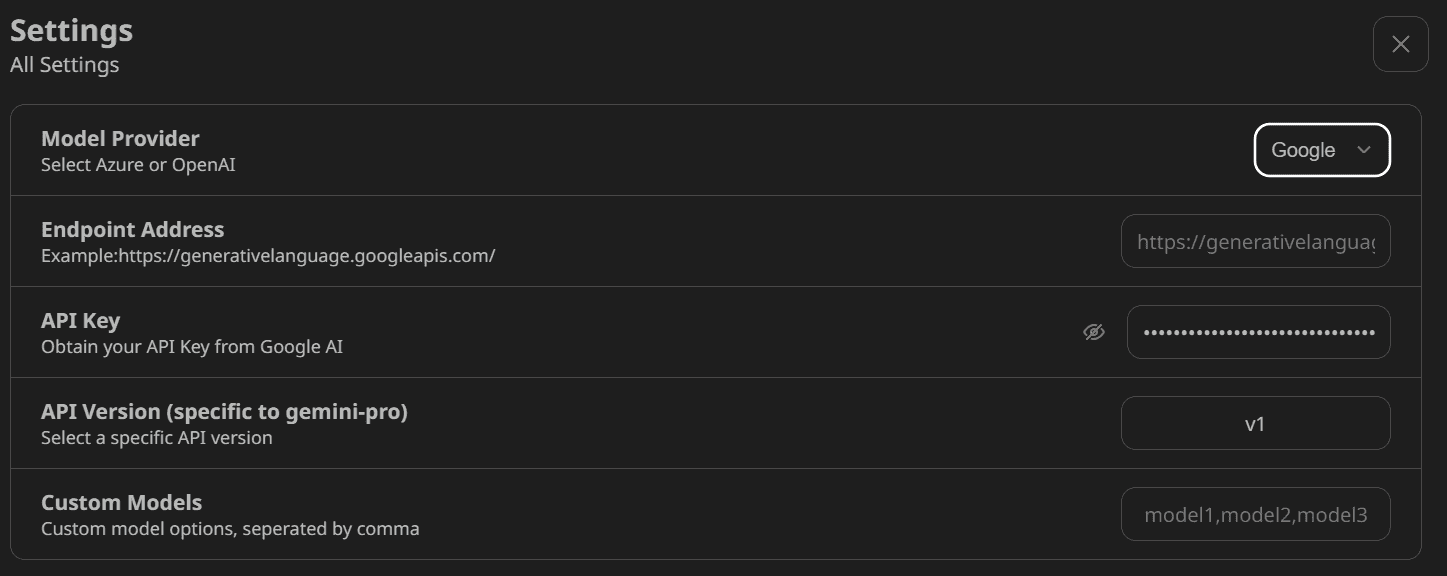
之后,选择“gemini-pro”模型并开始使用应用程序。
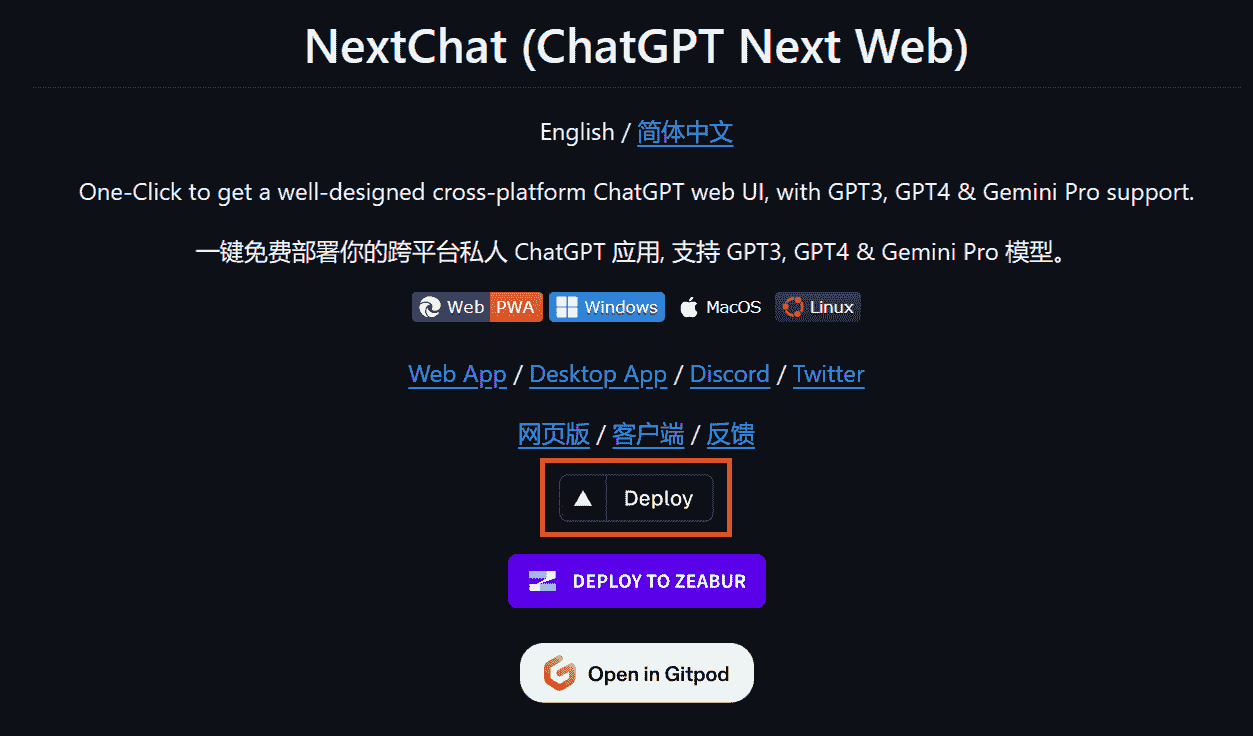
4. 一键部署你的网页应用程序
在最后一部分,我们将学习如何在 Vercel 上部署我们自己的网页应用程序。为此,我们需要访问官方 GitHub 仓库,ChatGPTNextWeb/ChatGPT-Next-Web,并点击“部署”按钮。
点击链接后,你将被导向一个新标签页。在这里,你需要注册 Vercel 并登录你的 GitHub 账户以创建一个新的仓库。按照简单的指示操作,点击部署按钮,然后等待过程完成。
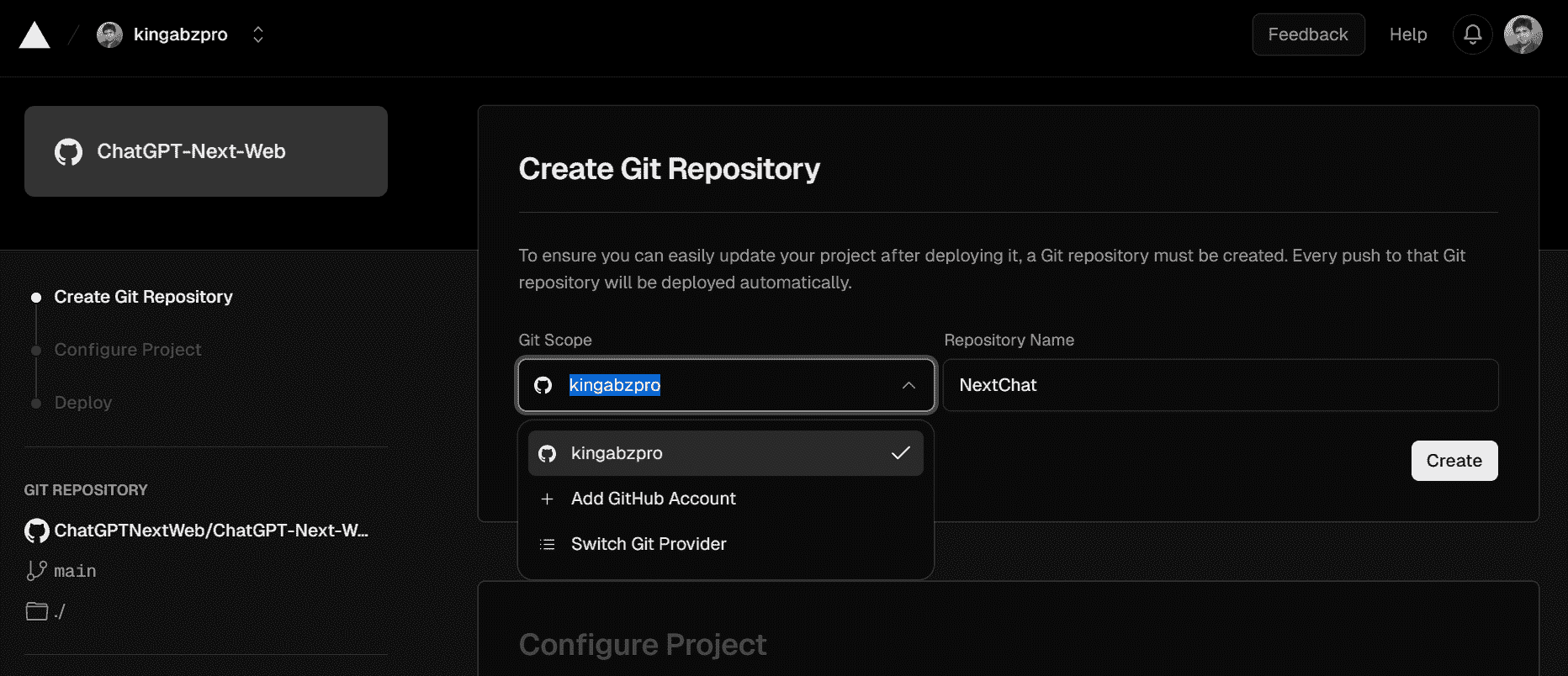
几分钟后,部署将完成,你将收到你网页应用程序的 URL。
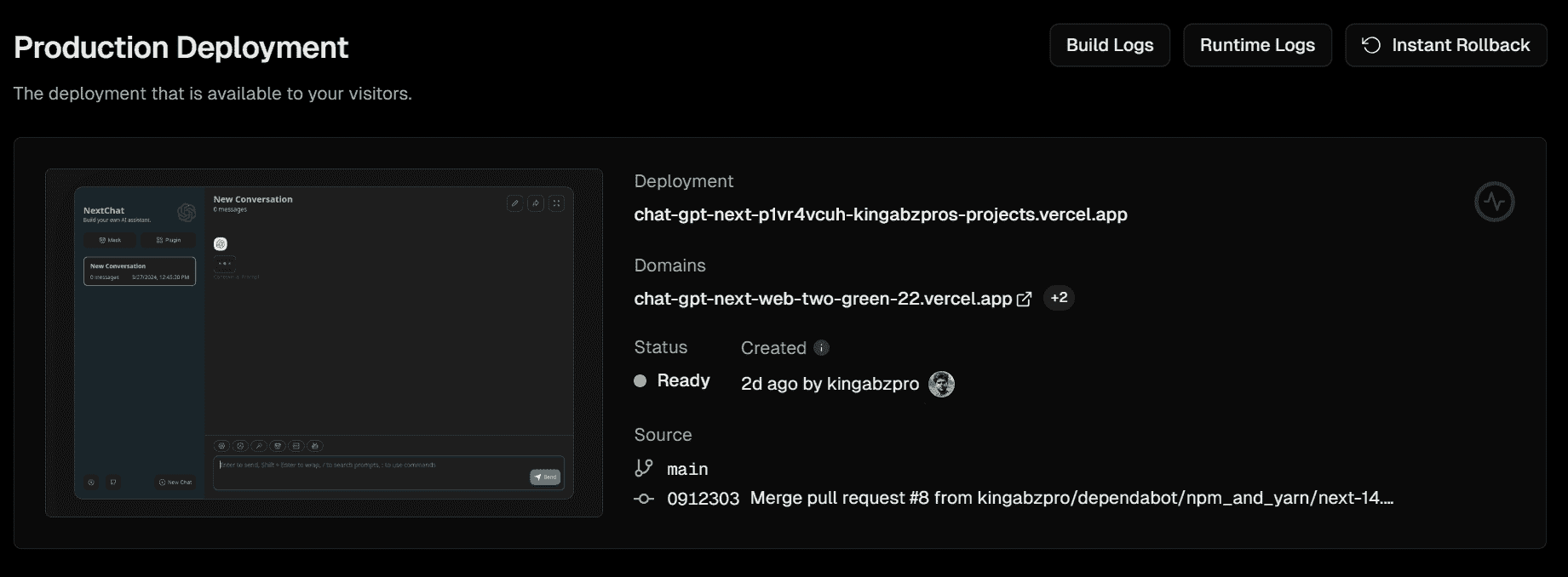
要访问 Vercel 部署的网络应用程序,请访问 chat-gpt-next-web-two-green-22.vercel.app/。我发现 NextChat 比 Bard 或 ChatGPT 更加流畅。
最终想法
我已经使用 ChatGPT Next Web 一段时间了,配有 OpenAI API 密钥。虽然这是一个付费 API,但我的月使用费用仅为约 $0.3。与其花 $20 购买 ChatGPT Pro,我可以以更低的成本访问顶级模型,并且用户界面更好。如果你使用 Gemini Pro,效果更佳,因为它对所有人都是免费的。
如果你仍然对使用这个应用程序感到不确定,跟随我的指南,使用一周时间探索其各种功能。我相信你会像我一样改变看法。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理问题的学生构建一款 AI 产品。
主题更多内容
了解大型语言模型
原文:
www.kdnuggets.com/2023/03/learn-large-language-models.html
作者提供的图片
随着 ChatGPT 和 Google Bard 的发布,越来越多的人开始谈论大型语言模型。这是新的趋势,大家都想了解更多。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
语言是我们日常生活中的重要元素。它是我们学习世界、成功职业、塑造未来的方式。它存在于新闻、网页、法律、消息服务等各个方面。它是我们与人连接和沟通的方式。
现在,随着技术的快速发展,越来越多的公司正在寻找新的方法来提升计算机学习和处理语言的能力。这得益于人工智能(AI)在语言处理技术方面的最新突破。
这些语言处理技术使公司能够构建对语言有更好理解的智能系统。这些技术基于大型预训练的 Transformer 语言模型或大型语言模型——它们具有更广泛的能力和对语言的理解,以及这些模型处理文本的需求。
什么是大型语言模型?
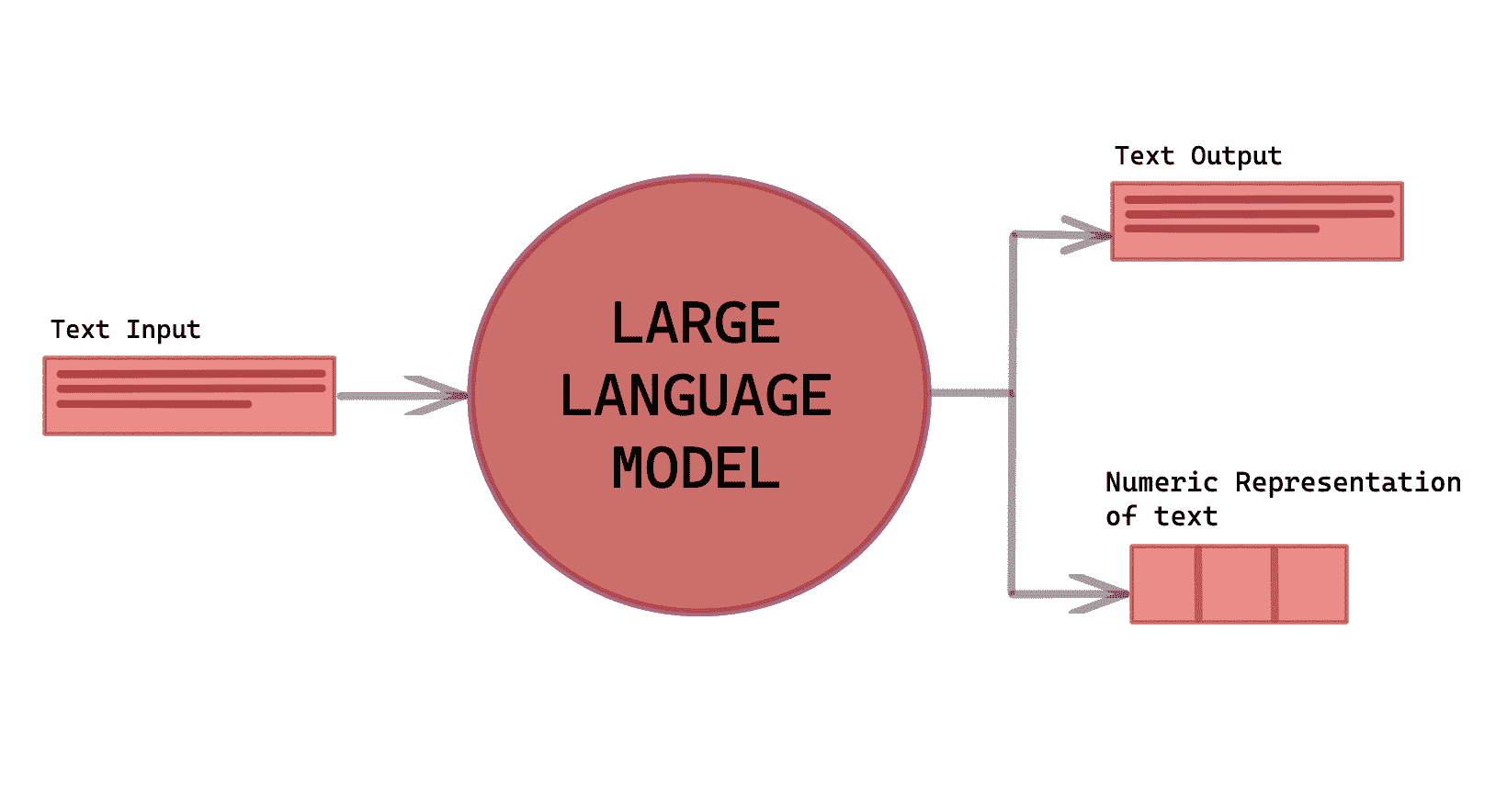
查看 AI 应用程序,如 ChatGPT 和 Google Bard——它们能够总结文章、帮助你写故事/漫画,并进行长时间类似人类的对话。它们能够做很多事情,这都归功于内嵌的大型语言模型。
大型语言模型(LLM)是一种深度学习算法,能够读取、识别、总结、翻译、预测以及生成文本。它们的预测未来单词和构造句子的能力使它们能够学习人类的说话和写作方式,并进行对话——就像人类一样!
大型语言模型是 Transformer 模型的一种,它们是目前 Transformer 模型最成功的应用之一。
Transformer 模型
Transformer 模型是神经网络,能够学习上下文并追踪序列数据中的关系,例如句子中的单词。Transformer 模型使用称为注意力或自注意力的数学技术。这些技术用于检测
Transformer 模型使用称为注意力或自注意力的数学技术。注意力是当 Transformer 模型关注另一序列的不同部分,而自注意力是当 Transformer 模型关注同一输入序列的不同部分。
Transformer 模型能够实时翻译文本和语音,并适应由不同群体组成的会议,包括听障参与者。
大型语言模型如何工作?
要创建一个表现良好的 LLM,你需要大量的数据。从其名称中的“Large”可以看出这一点。
以 ChatGPT 为例,该模型需要足够的数据来理解你所询问的一切。它会收集互联网上的所有数据和文本,经过长时间的积累,使其能够为用户生成准确和有效的输出。
该算法使用无监督学习,模型在未标记的数据上学习,通过推断隐藏结构来生成准确可靠的输出。通过这种机器学习技术,LLM 学习词汇、句子的构造以及词与词之间的关系。这有助于 LLM 更好地了解语言、上下文、语法和语言的语调。
通过这种方式,LLM 可以利用这些知识来预测和生成内容。
其他技术可以应用于 LLM,以用于特定任务。例如,模型可以针对英国历史进行微调,将重点放在英国历史的少量数据上,并为特定应用进行训练。
大型语言模型被应用在哪些领域?
我们最近见证了 LLM 在 AI 应用中的成功,如 GPT。越来越多的人将寻求发掘新机会,并在代码生成、医疗保健、机器人技术等领域与 LLM 创新。
当前 LLM 的一些应用包括:
-
客户服务:例如韩国最受欢迎的 AI 语音助手 GiGA Genie
-
金融:例如 Applica 使用虚拟助手
-
搜索引擎:例如 Google AI Bard
-
生命科学研究:例如 NVIDIA BioNeMo
总结
我知道你们中的许多人已经听说、看到,甚至使用过 ChatGPT 或 Google Bard。了解这些 AI 应用如何执行这些任务是很有意义的。我希望这能为你提供一个关于大型语言模型(LLMs)的良好介绍。
如果你想了解更多关于 ChatGPT 的信息,可以阅读这些:
-
ChatGPT: 你需要知道的一切
-
ChatGPT 入门
-
ChatGPT 作为 Python 编程助手
-
ChatGPT 快速参考表
-
学习 ChatGPT 的顶级免费资源
Nisha Arya 是一位数据科学家、自由技术作家以及 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程,以及有关数据科学的理论知识。她还希望探索人工智能如何或能够促进人类寿命的不同方式。她是一个热衷学习者,寻求扩展自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
如何在 10 天内学习机器学习
原文:
www.kdnuggets.com/2017/05/learn-machine-learning-10-days.html编辑注: 这个突出的回答来自于作者 Sebastian Raschka 在 2016 年 10 月的 Quora 会话 中提出的问题。如果你还没有完整查看这个会话,我建议你考虑去看看。

10 天?嗯,这确实是一个具有挑战性的任务 😃。不过,我认为 10 天也是一个可以对机器学习领域有一个相当不错的概览的时间框架,也许可以开始将一些技术应用到你的问题中。
在阅读了 3 个不同子领域的介绍(监督学习、无监督学习和强化学习)后,我可能会花时间研究这些领域中具有代表性的简单(但有用的)算法(也许将强化学习留到后面)。例如,用于回归分析的简单线性回归和岭回归,用于分类的逻辑回归和 k 最近邻,以及用于聚类任务的 k-means 和层次聚类。一旦你理解了每种算法的目标及其解决特定问题的方法,增加更多算法和方法到你的技能库中是相对容易的。
然而,除了算法之外,了解如何准备数据(特征选择、转换和压缩)以及如何评估模型也很重要。作为入门者,你可以查看我们在 SciPy 2016 上的《scikit-learn 机器学习教程》。它大约需要 6 小时,并总结了大部分基础知识,同时介绍了 scikit-learn 库,这对于实现和进一步学习非常有用:
如果你有兴趣了解算法背后的数学原理,Andrew Ng 的 Coursera 课程 机器学习 - 斯坦福大学 | Coursera(以及 我的书)提供了温和的介绍,但我意识到这可能超出了 10 天的范围 😃.
原始来源。经许可转载。
相关内容:
-
应对初学者机器学习/数据科学家压力的技巧
-
掌握 Python 机器学习的 7 个步骤
-
掌握 Python 机器学习的 7 个步骤
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织的 IT
更多相关内容
通过参与比赛,使机器学习速度提高 4 倍
原文:
www.kdnuggets.com/2022/01/learn-machine-learning-4x-faster-participating-competitions.html

图片由作者提供
介绍
你陷入了学习新工具、新编程语言和数学的循环中。简而言之,你的职业进展停滞不前。这是学习机器学习(ML)最慢的方式,我们需要参加多个课程,学习数学,做样本项目,最终申请工作。这将花费你超过一年时间,最终你会失去兴趣。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
有一种更好的学习机器学习(ML)的方法,就是理解基础知识后立即投入解决机器学习挑战。在这篇博客中,我将向你展示如何通过参与比赛来学习机器学习中的多个领域(NLP、计算机视觉、ASR、RL、GAN)。
图片由作者提供 | Kaggle
竞争平台
在学习了基础知识之后,我参与了 DrivenData 的 Reboot: Box-Plots for Education 挑战,这让我学会了数据处理、使用逻辑回归以及如何创建 SKlearn 管道。提交我的第一个解决方案花了我 12 天时间,此后我将所有精力投入到提高模型性能指标中,这帮助我在全球排名第 7。我的第二个比赛是在 Natural Language Processing with Disaster Tweets | Kaggle 上,信任我,我在文本分类方面做得很差,但我投入了时间和精力学习不同的技术。在第二次比赛之后,我为能够学习多个领域而欣喜若狂,因此我开始参与 Zindi 和其他竞争平台。
高度声誉的平台
即将推出的平台
如果你还不确定从哪里开始,可以看看 ML Contests。
协作学习
所有的竞争平台都有讨论区,参与者可以在这里分享问题并一起寻找解决方案。这也意味着有 3000+个团队参与解决同一个问题。协作学习还帮助你理解哪些方法对特定问题有效。你还能够跟上新趋势,并且最终,这将为你未来作为机器学习工程师的工作做好准备。
图片来源:Kaggle
你也可以作为一个四人团队参与并分担工作量。团队合作还为你准备了真实场景中的工作,其中任务将在数据团队成员之间分配。大多数人会问为什么不能通过谷歌解决方案,但在我看来,与队友讨论并找到解决方案是一种有效的解决问题的方法。
作为团队参与也有助于你培养良好的沟通技巧,这在远程项目工作中至关重要。如果你对机器学习不熟悉,你的队友也可以帮助你学习新工具和技能。
排行榜和奖品
排行榜、排名、奖牌和奖金是你参与的完美激励因素。这种竞争环境也帮助你突破界限,激励你努力工作以进入前十。当我开始在AI4D Baamtu Datamation — WOLOF 语音识别 — Zindi上工作时,我完全不知道如何处理音频或如何在 GPU 上训练模型,但经过 2 个月通过博客、YouTube 和 GitHub 项目学习,我成功达到了第一名。这让我意识到我可以学习任何东西。在此之后,我获得了足够的自信去尝试新事物并学习更多工具。如果我跟随ASR的在线课程,可能需要四个月的时间来学习,再加上四个月才能熟练掌握。
说实话,你只需多一点努力就能赢得几千美元,那么为什么不在学习新的机器学习领域时赚些钱呢?为了激励你,我分享了 Kaggle 竞赛的奖金池。
我的建议是从小做起,持续努力以达到顶级。达到顶级将教会你课程或教程中学不到的重要经验。
图片来自 Zindi
多个领域
从在线课程学习或获得大学学位不会教你有关各种机器学习问题的知识,有时你甚至没有处理非结构化数据(如音频、视频或文本)的技能。你可以通过参加多个专业化课程来学习,这可能需要一年以上的时间,或者你可以参与不同领域的各种竞赛。
参与挑战帮助我理解了之前从未知道的问题以及如何避免模型偏差。这也激励我追求在生产环境中从事机器学习的职业,这与基于研究的项目有所不同。
机器学习包括:
图片来源 magora-systems
这些领域有许多子领域,想要了解关于 AI 和各种技术的所有知识是很困难的,所以最好参与那些解决组织或公司当前问题的竞赛。你将有机会处理生产级数据,并学习各种数据处理技术。
如果你想要更聪明的学习子领域的方法,那么可以同时参与多个竞赛,不要仅限于 Kaggle,探索你最喜欢的其他平台上的竞赛。
结论
通过参与竞赛,我们将学会如何在机器学习项目中进行合作,掌握解决未知问题的最先进技术,并了解 ML 领域中的各种领域。除了学习,你还可以获得认可、荣誉和奖金。
参与竞赛不需要计算能力、数据集、IDE(环境)或知识。Kaggle 提供了一切,我们可以通过查看其他人的解决方案或在论坛上提问来学习未知领域。唯一阻止你更快学习的因素是你的舒适区和缺乏意识。我见过许多初学者在 Kaggle 上开始,现在他们在 NVIDIA、阿里巴巴、H2O 和亚马逊等大公司工作。
在这篇博客中,我们讨论了通过竞赛学习的重要性以及它如何为你准备职业生涯。希望你喜欢这篇文章。
“曾经有一段时间,我在多个平台上参与了 10 个竞赛,那段时间是我一生中最快乐的日子,因为我是一名终身学习者。”
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为挣扎于心理疾病的学生构建一个 AI 产品。
更多相关话题
有效学习机器学习算法的诀窍
原文:
www.kdnuggets.com/2020/11/learn-machine-learning-algorithms-effectively.html
评论
Shareef Shaik,有志数据科学家
 照片由 Doran Erickson 提供,来源于 Unsplash
照片由 Doran Erickson 提供,来源于 Unsplash
背景:
几天前,我的一个朋友笑着对我说:“你学习机器学习怎么这么慢?不过是几个模型,我一周就学会了。”这就是他的话。我只是对他微笑,询问他学到了什么。他告诉我了一些机器学习算法的名字。我问他具体学到了什么,他给出的明显回答是使用 Sklearn 的拟合和预测方法,以及对算法如何工作的简要概述。
带着邪魅的笑容,我问他,他会怎么做才能得到最佳参数?模型如何学习最佳权重?当我们有低延迟要求时,我们该怎么办?虽然这些问题并不复杂,但他只是静静地坐在那里看着我的脸,我笑到了最后。
从这个故事中得到的启示是,机器学习远远超出了简单的拟合和预测方法。
我们中的大多数人只是看了几个 YouTube 视频,就声称自己懂机器学习,却很快意识到自己的错误。对于所有自学的人,记住,有成千上万像你我一样学习机器学习/数据科学的人。要记住,我们将与那些拥有数据科学相关领域硕士/博士学位的人竞争。为了与他们竞争,我们需要在基础知识上真正扎实。
随着机器学习的热潮,新的课程每天不断涌现,目前的课程数量多于实际的工作岗位。面对如此庞大的资源,选择合适的课程成为了一个难题。
说实话,大多数这些课程都是平庸的,没有深入涵盖。虽然有一些好的课程,但每个课程提供的课程内容都不同。一些课程深入讲解数学部分,一些则在编码部分表现出色等等。因此,今天我不会特别提到任何课程。我将分享我遵循的方法,并建议给故事中的那位朋友。我相信这也会对你的数据科学之旅有所帮助。
介绍:
在我们深入了解算法部分之前,让我告诉你我们在机器学习项目中具体使用算法的位置。完成一个机器学习项目涉及多个阶段,每个阶段都同样重要。
 机器学习项目的关键阶段
机器学习项目的关键阶段
建模是机器学习算法发挥作用的阶段,它只是 ML 生命周期中的一个重要阶段。
好的,我们来深入探讨机器学习算法的主题。
对于每种算法,我们需要了解一些重要的事项。
 学习 ML 算法的流程
学习 ML 算法的流程
1. 算法背后的直观理解
起初,我学习一种算法后,过一段时间就会忘记,每次复习时都会觉得难以理解。我逐渐意识到,人们如果仅通过理论学习东西是很难记住的,而通过可视化学习则更容易长期记住。这就是几何帮助我们以最简单的方式可视化算法核心的地方。如果我们能找到一些有趣的现实生活中的例子,我们对算法的理解会更深入。
一旦你从任何你选择的课程中学习完一种算法,打开一个新标签页,开始搜索该算法的直观解释。相信我,互联网上有很多很酷的解释。初学者可以从 Quora 和 Medium 开始。
2. 算法是如何工作的?
一旦你对算法有了直观认识,就可以动手尝试,观察算法是如何实际工作的。你还需要检查算法在不同类型数据(如文本、分类数据、数值)上的表现。
在这一阶段,尝试多个因素,观察算法的表现,你可以参考 Scikit-Learn 中现成的算法。检查算法的参数,尝试调整它们,看看这些调整对模型性能的影响。
3. 算法的应用场景 / 不适用的场景
这是大多数人常常忽视的最重要因素,他们通常更多关注算法的“什么”和“怎么做”。理解算法的“为什么有效”或“为什么无效”对于深入了解算法至关重要。
尝试在大数据集、高维数据上实验并理解算法的表现。如果算法容易受到异常值或不平衡数据集的影响。
在面试中,最难回答的问题不是“什么”和“怎么做”,而是为什么。假设明天你在学习算法后做了一个个人项目,并且使用了某个特定的 X 算法来解决它,面试官很可能会问为什么选择 X 算法而不是 Y 算法? 假如你以准确度作为理由,那么接下来最难的问题就是你为什么认为它比其他算法更有效。
哦,天哪!这就是为什么你应该了解它在哪里有效,在哪里无效。
例如,你需要给出这样的回答:由于我们的数据是高维的且具有非线性特征,算法 X 在处理非线性数据时往往比算法 Y 表现更好,原因如下。
4. 为什么算法的可解释性很重要
这是一个关键步骤,之所以重要,是因为作为数据科学家,你可能需要向完全没有技术知识的客户展示模型。在此过程中,你可能需要说服他们相信你的模型能够预测正确的结果,并提供一些充分的理由说明他们应该采用它。你不能仅仅抛出准确率。如果你的算法是可解释的,那么你可以向他们展示模型预测结果的原因。可解释性意味着算法的特征重要性。
例如:如果你正在做一个医疗保健项目,其中你的模型预测一个人的疾病是阳性还是阴性。这是一个非常敏感的问题,他们无法承受错误,这时可解释性就显得非常重要。如果你的模型展示了预测结果的原因(例如某个特征(身体中的某些水平)大于 x 值),这将使得解释变得更容易,更有意义。
5. 为什么要了解算法的时间/空间复杂度?
当我们在实时工作时,可能需要处理大量数据,如果有低延迟的需求,这时时间和空间复杂度可以帮助你选择合适的算法。
如果你的模型占用更多内存,那么实时运行它可能会非常昂贵,特别是如果你使用的是云基础设施来运行模型。有时候,一些业务问题需要低延迟,而一些算法虽然提供了良好的准确性,但由于时间/空间复杂度的限制,无法满足这一需求。
维基百科是获取每个算法相关信息的绝佳资源。
6. 为什么我们需要理解算法背后的数学原理?
数学?是的,我明白。我们可以通过从 Scikit Learn 中导入算法而无需理解数学原理,但我告诉你,这在长期来看并不推荐。无论我们是否接受这一点,我们确实需要数学来更好地理解背后的实际情况。这可能会让一些人失望,但好消息是,我们无法避免数学,但可以简化它,避免复杂的数学。
简单来说,大多数机器学习算法的工作是最小化实际输出和预测输出之间的差异(损失)。
algorithm=最小化(损失)+ 正则化项
例如,我们应该为逻辑回归最小化对数损失,为 SVM 最小化铰链损失等。
注意:这并非适用于每一个机器学习算法,这只对一些算法有效。
为了最小化这种损失,这些算法内部使用了优化技术,如梯度下降及其其他变种,这涉及一些数学知识。所以如果你对数学不太擅长,可以尝试理解每个算法的损失函数及其梯度下降,这样你可以避免其他复杂的数学问题,保持目标不变。一旦你对这些内容感到舒适,就可以深入学习更多的数学知识。
7. 为什么从零实现它(可选):
如果你在学习吉他,你会先从基础开始,然后慢慢尝试复制他人已经创作的音乐。在这个过程中,如果你理解了他们如何创作音乐和调音,那么下一步就是创作自己的音乐,对吧?
同样地,我们可以通过从头实现现有算法来更清楚地理解它们。你将学到一些重要的要点,这可以帮助你将来构建更好的模型。只要记住,由于一些问题,我们可能无法在项目中始终使用 Scikit-learn 的算法版本。在这种情况下,你需要准备好优化或修改算法以满足你的需求。
这比说起来容易,达到这一点需要花费大量时间,这也是我将其标记为可选的原因。至少尝试实现一个算法以了解它是如何工作的。如果你发现编码困难,将算法分解成几个部分,先写伪代码,然后再尝试转换成实际代码。
《Python 机器学习》由塞巴斯蒂安·拉施卡编写,是一本非常好的书,可以指导你从零开始开发算法。
结论:
不要急于求成,花时间以最好的方式学习,而不是半途而废,每次都回来参考。记住,目标不是完美,而是扎实的基础,相信我,我们永远无法做到完美,目标始终是每天进步。如果你能理解算法的要点,并了解算法如何运作,那么从长远来看你一定会感谢自己。
在这个过程中,如果你不理解某些内容或遇到困难,把它搁置一旁,继续学习其他主题。不要只是固守不放,浪费宝贵的时间。稍后带着清新的思维再回来检查,相信我,你会感到惊讶。如果你仍然无法理解某些内容,可以寻找其他解释得更简单的资源。
最后一部,应用你所有的学习到多个不同数据类型和大小的数据集上,以获得真正的学习,实践是关键。你将通过实践学到比单纯阅读更多的东西,所以要准备好动手操作。
如果你读到这里,你肯定有学习机器学习的热情,这是学习任何技能最重要的因素。继续学习,不要放弃。
如果你有任何建议或疑问,可以在评论中告诉我,或者通过我的 Linkedin 联系我。
快乐编码!下次见!!
简介: Shareef Shaik (Medium) 是一名有志的数据科学家,热衷于利用 AI 解决实际问题。
原始。经许可转载。
相关内容:
-
如何在面试中解释关键的机器学习算法
-
了解雇主对 2020 年数据科学家角色的期望
-
如何获得最受欢迎的数据科学技能
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织的 IT
更多相关话题
从这些 GitHub 仓库中学习机器学习
原文:
www.kdnuggets.com/2023/01/learn-machine-learning-github-repositories.html

作者提供的图片
如果你还没有机会查看从这些 GitHub 仓库中学习数据科学,请查阅一下。你可能会发现一些提到的 GitHub 仓库对你的机器学习之旅很有用。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
深入了解数据科学将有助于你的机器学习职业发展。当你在新的一年中努力实现机器学习目标时,可能会被不断出现的在线课程和训练营所吸引。选择正确的课程可能很困难,而且当你不断选择错误的课程时,成本也会很高。
另一个选择是使用 GitHub 仓库,它提供有价值的资源,且几乎没有成本。GitHub 使用简单,支持公开和私人仓库,主要优点是小规模项目可以免费使用。
以下是可以帮助你在机器学习之旅中的 GitHub 仓库列表。
GitHub 社区
仓库链接:GitHub 社区
我将从 GitHub 社区开始。它旨在支持 GitHub 用户的教育旅程。我们都知道,学习新技能时,你会遇到需要解决的问题和难题。
数据科学家和机器学习工程师经常使用 GitHub,因此了解它的操作是很有价值的。这个 GitHub 社区将为你提供有价值的资源,向其他用户学习,提出问题,并成为一个鼓舞人心的社区的一部分。
超棒的机器学习
仓库链接:超棒的机器学习
一份精心策划的机器学习框架、库和软件的列表,帮助你启动机器学习职业。这个仓库的好处是按语言划分,使得更容易找到所需的编程语言资源。
这是最受欢迎的学习资源之一,因为它深入探讨了机器学习的技术细节。
Machine Learning Tutorials
仓库链接:Machine Learning Tutorials
如果你是那种需要教程来帮助你有效学习的人——这个 GitHub 仓库适合你。这个仓库提供了按主题划分的教程列表。主题包括面试资源、人工智能、统计学、分类、深度学习、计算机视觉、随机森林等。
如果你需要复习一些数据科学的主题,他们还提供了使用 R 和 Python 的数据科学教程合集。
Best of ML with Python
我在 Learn Data Science From These GitHub Repositories 中提到过这个仓库,因为它对数据科学学习非常有价值。
Best of ML with Python GitHub 仓库包含 910 个开源项目,这些项目被分为 34 个类别。项目按照项目质量评分进行排名,方便你轻松找到受欢迎的项目。你可以选择各种项目进行实践,检验你的技能,了解你的优势,并关注你的弱点。
TensorFlow Examples
仓库链接:TensorFlow Examples
如果你打算进入机器学习领域,你会听到很多关于 TensorFlow 的信息,并且你将会使用它。TensorFlow 是最受欢迎的机器学习框架之一,并且对你作为机器学习工程师的技能至关重要。
有一个前提条件部分,以帮助你入门,然后有 6 个部分:介绍、基础模型、神经网络、工具、数据管理和硬件。
Projects
将你的技能应用于项目将测试你在机器学习旅程中的进展。项目对你的个人学习成长至关重要,同时在求职/面试阶段也非常关键。招聘人员和雇主希望看到你在实际项目中应用技能,以评估你是否适合他们的公司。
这里有两个 GitHub 仓库提供了与机器学习相关的项目列表:
Machine Learning Interview
仓库链接:Machine Learning Interview
当你对自己的机器学习技能感到自信,并且已经将其应用于各种项目时,下一步就是准备面试。这个 GitHub 仓库是机器学习面试的学习计划。
了解面试中可能出现的主题是一种更好的准备方式,而不是反复重复面试问题直到记住它们。这有助于你理解背景,并为围绕该主题的任何问题做好准备。
结论
这些提到的 GitHub 仓库将为你提供成为机器学习工程师所需的资源。
如果你需要一些指导和结构来规划你的学习路线,可以阅读这个:
完整的机器学习学习路线图。
如果你是一个书虫,并且喜欢以这种方式学习,可以阅读这个:15 本免费机器学习和深度学习书籍
尼莎·阿里亚 是一名数据科学家和自由职业技术作家。她特别关注提供数据科学职业建议或教程以及有关数据科学的理论知识。她还希望探索人工智能在促进人类寿命方面的不同方式。作为一名热心学习者,她寻求扩展自己的技术知识和写作技能,同时帮助指导他人。
更多相关主题
如何为机器学习学习数学
原文:
www.kdnuggets.com/2022/02/learn-math-machine-learning.html
图片由 geralt 在 Pixabay 提供
数据科学求职者最常见的问题之一是“我需要了解多少数学才能进行机器学习?”希望进入机器学习领域的学生常常认为数学是一个巨大的障碍。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT
行业中的把关者对此问题并不提供帮助,通常将学生标记为不合格,除非他们拥有硕士学位或博士学位。
那么,进入数据科学行业你需要了解多少数学呢?
答案是:没有你想的那么多。
大多数公司通过数据解决非常相似的用例。他们要求数据科学家构建可以预测客户流失、进行细分和预测销售的机器学习模型。
解决这些问题的方法类似,任务变得相当重复。没有必要重新发明轮子,它们使用现成的机器学习算法。
即使出现需要构建自定义机器学习模型的情况,对特定主题的直观理解就足够了。你不需要深入了解,也不需要成为数学专家才能成为数据科学家。
例如,我们知道梯度下降用于在线性回归中找到最佳拟合线。你无需学习如何解微分方程,只需理解微积分的原理,就能对这一过程有所了解。
类似地,如果你要用 Tensorflow 构建神经网络,你需要进行大量的矩阵操作,但这会在计算机程序的帮助下完成。因此,你无需返回去练习代数方程的解法,只需理解它们的工作原理即可。
在这篇文章中,我将向你推荐一些资源,帮助你开始学习数据科学所需的数学。我将重点介绍三个领域——线性代数、微积分和统计学。
线性代数
线性代数 — 基础到前沿:这门 edX 上的课程将教你本科水平的线性代数。它从较慢的速度开始,只要你具备高中水平的数学知识,就可以参加这门课程。
这门课程的最佳部分是,它通过 Matlab 中的实际例子教授线性代数,这让你通过算法和编程的视角来看待这个学科。如果你的目标是为机器学习学习线性代数,这种学习方法尤其有用。
这个课程可以免费旁听。如果你想获得结业证书,可以申请经济援助。
3Blue1Brown — 线性代数精髓:我以前没有参加过这个课程,但在我寻找数学学习资源的过程中多次遇到过它。
许多机器学习爱好者都推荐这门课程,因为它为学习者提供了线性代数的概念性理解。你将获得线性代数如何运作的直观认识,而不是学习任意的公式或机械推导它们。如果你的终极目标是将这些概念应用于机器学习模型,这将非常有帮助。
微积分
我推荐两个学习机器学习所需微积分的课程。微积分精髓是 3Blue1Brown 提供的很棒的微积分入门课程。这也将为你提供微积分概念的直观理解,并深入解释公式背后的意义,而不仅仅是让你记住它们。
接下来,你可以参加 3Blue1Brown 的神经网络系列。如果你知道如何使用 Keras 等库实现神经网络,但不太了解这些模型的工作原理,你应该参加这个课程。它提供了梯度下降算法的全面解释,以及其背后的微积分概念。

《简易微积分》(第二版,1914 年,第一章)(由文章作者编辑以删除非包容性语言)。
统计学
这是我曾经参加过的最好的入门统计学课程之一,由伦敦大学提供。该课程针对的是主修非数学学科的学生,如商业和金融。
因此,统计概念的解释简单易懂,并有许多现实世界的例子。
通过学习此课程,你将了解描述性统计和推断性统计、不同的抽样分布、抽样技术、置信区间,以及如何计算 p 值。
所有这些概念在实际数据分析中都有直接应用。
这是另一个优秀的课程,帮助你学习机器学习模型背后的直觉。
和这份清单中的其他资源一样,这个课程较少关注数学公式,而是以概念性的方式解释机器学习模型。
然而,为了参加这个课程,建议你具备一定的微积分知识,因为讲师们使用的符号可能会让你感到困惑。
你将学习诸如线性回归和逻辑回归等概念,及其正则化技术,如岭回归和套索回归以及使用时机。还有一整节讲座专门讲解了用于减轻过拟合的技术,并解释了这些技术背后的数学直觉。
这是我上过的最有帮助的课程之一,因为它帮助我不再把机器学习模型视为黑箱。我理解了不同类型的模型应该在何时使用,何时应应用降维技术,以及何时进行不同种类的特征选择技术。
我花了很多时间去回顾和学习本科阶段的微积分和线性代数。然而,尽管花费了大量时间学习公式和解决微分方程,我的知识仍然存在断层,因为我从未真正理解这些概念如何与机器学习算法相关联。
上述资源是突破障碍的绝佳方式,因为它们提供了机器学习背后的数学概念理解,而不是让你陷入复杂的公式和定理之中。
Natassha Selvaraj 是一位自学成才的数据科学家,热爱写作。你可以在 LinkedIn 上与她联系。
更多相关内容
使用这本免费的电子书学习 MLOps 基础知识
原文:
www.kdnuggets.com/2023/08/learn-mlops-basics-free-ebook.html

MLOps,即机器学习运营,是一个关键学科,适用于那些希望有效构建、部署和管理机器学习模型的组织。通过将 DevOps 原则应用于机器学习工作流程,MLOps 旨在促进数据科学家与工程师之间的无缝协作,并优化端到端的机器学习生命周期。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织进行 IT 管理
MLOps 将 DevOps 的原则和最佳实践应用于数据科学和机器学习的特定需求,促进数据科学家、工程师和运营团队之间的无缝协作。
这本免费的电子书,Essential MLOps: 你需要知道的成功实施要点,来自 Data Science Horizons,提供了 MLOps 的全面介绍。您将学习帮助组织简化在生产环境中构建、部署和管理机器学习模型的基本知识。
Essential MLOps 涵盖了该主题的重要性、关键组件、必要的 MLOps 技能、工具和技术,以及真实世界的案例研究。它旨在为读者提供对 MLOps 概念、技术和工具的深入理解,以便在其组织中实施 MLOps。正如电子书所述:
通过采用 MLOps 实践并利用合适的工具和技术,组织可以简化其机器学习工作流程,优化模型性能,并推动有意义的结果。
涵盖的关键主题包括数据管理和版本控制、模型训练和评估、持续集成和持续部署(CI/CD)、监控和性能管理,以及来自电子商务、金融、医疗保健和制造业等行业的案例研究。电子书强调了 MLOps 的好处,如改善协作、加快部署、更好的模型性能,以及提高机器学习系统的可扩展性和可维护性。
图片来自 Essential MLOps: What You Need to Know for Successful Implementation
总体而言,Essential MLOps: What You Need to Know for Successful Implementation 来自 Data Science Horizons 为任何希望在组织内成功实施 MLOps 的人提供了宝贵的见解。这些实用的指导使其成为数据科学家、工程师、团队领导以及其他希望优化机器学习工作流程的专业人士的有用资源。
Matthew Mayo (@mattmayo13) 是 KDnuggets 的数据科学家和主编,该网站是开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络和自动化机器学习方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
更多相关主题
通过这个免费课程学习 MLOps

作者提供的图片 | Canva Pro
目录
-
什么是 MLOps?
-
我们为什么需要 MLOps?
-
MLOps Zoomcamp
-
最后的想法
-
常见问题解答
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
什么是 MLOps?
MLOps 代表机器学习运维。MLOps 这个术语源于 DevOps(开发运维)。它用于简化从开发到部署的机器学习过程。MLOps 包括训练机器学习模型、实验跟踪、模型优化、创建 ML 流水线、保存和服务模型以及监控和维护生产中的模型。
简而言之,你正在自动化从开发到部署的所有过程,并且你会不断监控日志、指标和性能。
我们为什么需要 MLOps?
部署机器学习模型到生产环境是复杂且具有挑战性的。典型的机器学习生命周期包括数据摄取、数据增强、建模、训练、优化、实验跟踪和结果解释。这需要整个数据团队的协作,从数据工程师到数据科学家。MLOps 使这些过程自动化,以便你可以持续监控和改进生产中的模型。
MLOps 允许你减少模型部署时间并交付更高质量的机器学习模型。它提供了巨大的扩展性和管理成千上万的机器学习模型。你可以控制、管理和监控持续集成、持续交付和持续部署 - Databricks。
MLOps Zoomcamp
MLOps Zoomcamp 教授你模型部署和监控的实际方面。这个课程不适合初学者,需要你掌握 Python、Docker、命令行、对机器学习模型有深入理解,以及至少 1 年的编程经验。如果你是完全的初学者,我建议你在学习 MLOps 之前,先参加免费的 机器学习 Zoomcamp。
课程包括七个模块和一个项目。你可以在这里注册课程。
模块 1: 介绍
我们将学习 MLOps 的基础知识、课程概述和模型成熟度。我们还将学习加载纽约出租车旅行数据集的 parquet 文件并训练一个行程时长模型。
模块 2: 实验跟踪
我们将学习 MLflow 和实验跟踪的最佳实践。我们还将学习使用 MLflow 保存和加载模型,并了解模型注册表。
模块 3: 编排和机器学习流水线
我们将了解机器学习流水线,并使用 Prefect 来编排机器学习项目。我们将把 Jupyter notebooks 转换为 ML 流水线,并学习流行的工具 KubeFlow pipelines。
模块 4: 模型部署
我们将学习批处理与在线部署以及网络服务与流媒体。我们将以批处理模式提供模型,学习网络服务,并使用 Kinesis/SQS + AWS Lambda 创建流媒体。
模块 5: 模型监控
我们将学习 ML 监控与软件监控、数据质量监控、数据漂移与概念漂移、批处理与实时监控的区别。我们将学习使用 Evidently、Prometheus 和 Grafana 监控生产中的模型。
模块 6: 最佳实践
我们将采纳 DevOps 中的最佳实践应用于机器学习工作流程:
-
虚拟环境和 Docker
-
Python 日志记录和代码检查
-
单元测试、集成测试和回归测试
-
CI/CD(GitHub Actions)
-
基础设施即代码(Terraform,CloudFormation)
-
Cookiecutter
-
Makefiles
模块 7: 流程
我们将学习 MLOps 过程和规划,使用 CRISP-DM、CRISP-ML、ML Canvas、数据景观画布和 ML 项目的文档实践(模型卡工具包)。
项目
最后,我们将把学到的工具和实践整合到一个端到端的项目中。我们将使用纽约出租车旅行数据集构建一个 MLOps 系统,以预测行程时长或司机是否会收到小费。
每周你将参加 DataTalksClub YouTube 频道上的直播课程,了解每个模块。你也可以在 这里 查看完整的播放列表。在每个模块结束时,你将获得作业,以便你能在下一周的模块中保留知识。
最终思考
我是 DataTalks.Club 免费课程的忠实粉丝,因为它们提供了关于机器学习、数据工程和 MLOps 的实用知识。如果你在寻找最好的免费数据工程或 MLOps 课程,你会发现没有。DataTalks.Club 正在使机器学习民主化,让每个人都可以免费学习机器学习操作。
如果你是一个机器学习爱好者,尝试学习 MLOps 以在职业生涯中出类拔萃,并理解数据生态系统。从数据摄取到生产。
你还可以查看 DataTalks.Club 的课程:
常见问题
什么是 MLOps 工具?
-
对于追踪 ML 实验,有MLflow和Comet。
-
对于数据和模型版本管理,有DVC、DAGsHub和Pachyderm。
-
对于优化实验,有Optuna和Sigopt。
-
对于工作流管道和编排,有Kubeflow和Apache Airflow。
-
对于模型保存和服务,有BentoML和Cortex。
-
对于生产中的模型监控,有Evidently和NewRelic。
MLOps 与 DevOps 有什么不同?
-
DevOps 是一套通过持续集成和交付高质量开发产品来改进软件开发过程的实践。
-
MLOps 是自动化机器学习应用程序的部署和监控生产性能的过程。
为什么 MLOps 很重要?
部署机器学习模型是昂贵的,而且它们并不会产生持续支持业务的价值。MLOps 使公司能够轻松地部署、监控和更新生产中的模型。
最好的免费 MLOps 课程是什么?
MLOps Zoomcamp 是最好的且对所有人免费。除此之外,你在网上找不到免费的完整 MLOps 课程。
如何获得 MLOps 认证?
目前没有 MLOps 认证。大多数组织会接受 AWS 认证 DevOps 工程师 - 专业认证 作为 MLOps 工程职位的认证。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个人工智能产品,帮助那些面临心理健康问题的学生。
相关话题
从这些 GitHub 仓库学习 MLOps
原文:
www.kdnuggets.com/2023/02/learn-mlops-github-repositories.html
图片由作者提供
机器学习操作(MLOps)是机器学习、DevOps 和数据工程的结合。MLOps 的作用是可靠且高效地部署和维护机器学习系统。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
MLOps 过程包括这三个广泛的阶段:
-
设计 ML 驱动的应用程序
-
ML 实验和开发
-
ML 操作
由于机器学习算法在我们日常生活中的使用增加,MLOps 正在成为一个非常受欢迎的职业。随着需求的增加,MLOps 工程师及相关职业的需求也将增加。如果你正在阅读这篇文章,你可能会发现自己正身处其中。
你可能正在考虑从事 MLOps 职业,或者已经决定采取这一步。在这篇文章中,我将为你提供来自 GitHub 的宝贵学习资源,帮助你在 MLOps 职业中取得成功。
MLOps 基础
仓库链接:MLOps-Basics
如果你是 MLOps 新手,最好从基础知识开始。学习基础知识将帮助你理解更深层的内容,并将你的技能应用于实践。这个 GitHub 仓库是一个系列,分为 9 周,旨在帮助你理解 MLOps 的基础知识,如模型构建、监控、配置等。
MLOps 指南
仓库链接:mlops-guide
如果你需要全面了解 MLOps,本指南适合你。本指南的总体目标是帮助项目和公司建立一个更可靠的 MLOps 环境。
它从 MLOps 的基础知识开始,例如原理、架构等。你可以深入了解 MLOps 背后的理论,然后转向实施指南,这将帮助你在教程的指导下启动自己的项目。
超棒的 MLOps
仓库链接:awesome-mlops
选项多永远没坏处。这个 GitHub 仓库为你提供了一份精心挑选的 MLOps 参考资料列表。不论你的学习方法是通过 YouTube 视频还是文章——这个仓库都有。
你将获得一份资源清单,帮助你理解 MLOps 的核心内容,并可以加入相关社区。其他主题领域包括工作流管理、特征存储、数据工程、机器学习/人工智能的经济学等。
超棒的 MLOps 工具
仓库链接:awesome-mlops
另一个与上述相同名称的 MLOps GitHub 仓库,但这个仓库涉及你需要了解的 MLOps 工具。这将帮助你掌握各种技能,并为面试阶段或获得 MLOps 工作时的相关问题做好准备。
它涵盖了如下工具主题:
DTU MLOps
仓库链接:dtu_mlops
这个 GitHub 仓库是由丹麦技术大学提供的机器学习运维课程。为了成功完成这个仓库,你需要具备以下先决条件:
-
机器学习的总体理解
-
深度学习的基础知识
-
使用 PyTorch 编程
你将获得不同类型的练习和有价值的材料,以提高你对机器学习运维的理解
MLOps 课程
仓库链接:mlops-course
如果你对自己的 MLOps 知识和技能感到自信,那么下一步是进行实战测试。最好的方法是通过项目工作来完成。这份 GitHub 仓库为你提供了一个基于项目的 MLOps 基础课程,以便你负责任地开发、部署和维护机器学习模型。
它是将机器学习与软件工程相结合,讲述如何构建生产级应用程序。这将帮助你建立一个坚实的作品集,并能够在面试阶段证明自己。
结论
网上有很多现成的资源可以帮助你在 MLOps 领域取得成功。关键在于你愿意投入多少努力,但这绝对是可能的。
如果你需要一些指导和结构来规划学习路线,可以查看以下内容:
-
完整的 MLOps 学习路线图
-
MLOps 的绝对基础
尼莎·阿雅 是一名数据科学家和自由技术写作人。她特别感兴趣于提供数据科学职业建议或教程,并围绕数据科学提供理论知识。她还希望探索人工智能在延长人类寿命方面的不同方式。作为一个热衷于学习的人,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
相关主题
你为什么以及如何学习“高效的数据科学”?
原文:
www.kdnuggets.com/2021/07/learn-productive-data-science.html
评论

图片来源:Pixabay(免费图片)
数据科学工作流的效率
数据科学和机器学习可以以不同的效率和生产力进行实践。不论应用领域或专业如何,一名数据科学家——无论是初学者还是资深专家——都应努力提升其效率,在所有典型的数据科学任务中,
-
统计分析,
-
可视化,
-
模型选择,特征工程,
-
代码质量测试,模块化,
-
并行处理,
-
轻松的 web 应用部署

图片来源:Pixabay(免费图片)
这意味着执行所有这些任务,
-
以更高的速度
-
更快的调试
-
以同步的方式
-
通过充分利用所有可用的硬件资源
在这个过程中,你应该期待学习到什么?
让我们假设有人在教授一个“高效的数据科学”课程或编写一本相关书籍——使用 Python 作为语言框架。那么,针对这样一个课程或书籍,通常应该有什么期望?

图片来源:Pixabay(免费图片)
课程/书籍应该面向那些希望超越标准方式进行数据科学和机器学习任务,并利用 Python 数据科学生态系统的全貌以提高生产力的人。
读者应该学习如何发现标准过程中的低效和瓶颈,以及如何跳出框框思考。
自动化重复的数据科学任务是读者将从阅读本书中培养的一种关键思维方式。在许多情况下,他们还将学习如何扩展现有的编码实践,以便在 Python 生态系统中使用已有的高级软件工具,处理更大数据集并提高效率,但这些工具在标准数据科学中并未教授。
这不应该是一本普通的 Python 食谱书,教授标准库如 Numpy 或 Pandas。
相反,它应该专注于有用的技术,比如如何测量 ML 模型的内存占用和执行速度,质量测试数据科学流程,模块化数据科学流程以进行应用开发等。它还应涵盖一些在自动化和加速数据科学家日常任务中非常有用的 Python 库。
此外,还应涉及帮助数据科学家处理大型和复杂数据集的工具和包,以比遵循标准 Python 数据科学技术智慧更优的方式
一些需要掌握的具体技能

图片来源: Pixabay (免费图片)
具体来说,让我们总结一些学习和实践高效数据科学的具体技能。我还尝试提供一些代表性文章的链接作为参考
-
如何构建模块化且富有表现力的数据科学管道以提高生产力(请参见这篇文章)
-
如何为数据科学和机器学习模型编写测试模块(请参见这篇文章)
-
如何高效处理大型和复杂的数据集(这在传统数据科学工具下会很困难)
-
如何充分利用 GPU 和多核处理器进行各种数据科学和分析任务,而不仅仅是专门的深度学习建模(请参见这篇文章)
-
如何快速制作 GUI 应用程序以演示数据科学/机器学习想法或模型调优(请参见这篇文章),或如何轻松(且快速)地在应用级别部署机器学习模型和数据分析代码(请参见这篇文章)
关于这一主题的理想书籍将会……

图片来源: Pixabay (免费图片)
-
教授如何识别标准数据科学代码中的低效和瓶颈,以及如何跳出思维框架解决这些问题
-
教授如何编写模块化、高效的数据分析和机器学习代码,以提高在各种情况下的生产力——探索性数据分析、可视化、深度学习等
-
涵盖了广泛的附加主题,如软件测试、模块开发、GUI 编程、ML 模型部署作为网络应用程序,这些都是新兴数据科学家必须掌握的宝贵技能,而这些技能在任何一本标准的数据科学书籍中都很难找到。
-
涵盖并行计算(例如,Dask, Ray)、可扩展性(例如,Vaex, Modin)以及 GPU 驱动的数据科学栈(RAPIDS)的实际示例。
-
向读者展示并指导一个更大且不断扩展的 Python 数据科学工具生态系统,这些工具与软件工程和生产级部署的更广泛方面相连接。
一个具体的例子:GPU 驱动和分布式数据科学
尽管学术界和商业圈广泛讨论了 GPU 和分布式计算在核心 AI/ML 任务中的应用,但它们在常规数据科学和数据工程任务中的实用性则覆盖较少。然而,使用 GPU 进行日常的统计分析或其他数据科学任务,能够大大提升成为高效数据科学家的能力。
例如,RAPIDS 软件库和 API 套件为你——一位普通的数据科学家(而不一定是深度学习从业者)——提供了完全在 GPU 上执行端到端数据科学和分析管道的选项和灵活性。
图片来源:作者创建的拼贴
即使使用中等规格的 GPU,这些库在速度上也显示出相对于其常规 Python 对应物的显著提升。自然地,我们应该在可能的情况下采纳这些,以实现高效数据科学工作流。
同样,也有出色的开源机会可以超越 Python 语言的单核限制,并采用并行计算范式,而无需改变数据科学家的核心身份。
图片来源:作者创建的拼贴
摘要
我们讨论了高效数据科学工作流的实用性和核心组件。我们设想了一个理想的课程或书籍应提供给读者的内容。我们触及了一些具体的例子,并说明了其好处。还提供了一些与掌握技能相关的资源。
你可以查看作者的GitHub库,获取机器学习和数据科学中的代码、想法和资源。如果你和我一样,对 AI/机器学习/数据科学充满热情,请随时在 LinkedIn 上添加我或在 Twitter 上关注我。
原始内容。经许可转载。
相关内容:
-
如何让自己从数百名其他数据科学候选人中脱颖而出?
-
你的机器学习代码消耗了多少内存?
-
一个错误如何浪费了我 3 年的数据科学之旅
更多相关主题
学习如何在 5 分钟内使用 PySpark(安装 + 教程)
原文:
www.kdnuggets.com/2019/08/learn-pyspark-installation-tutorial.html
评论
由乔治奥斯·德拉科斯,TUI 的数据显示科学家
我发现对于大多数人来说,开始使用 Apache Spark(本教程将集中在 PySpark 上)并在本地计算机上安装它有点困难。通过这个简单的教程,你将能非常快速地完成这项工作!
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
Apache Spark是大数据爱好者必备的工具,它是一个快速、易于使用的通用大数据处理引擎,内置流处理、SQL、机器学习和图形处理模块。这项技术是数据工程师的热门技能,但数据科学家在进行探索性数据分析(EDA)、特征提取以及当然的机器学习时也能从学习 Spark 中受益。但请记住,Spark 只有在大量节点的集群上运行时才能真正发挥作用。
目录
-
介绍
-
Spark 定义
-
Spark 应用程序
-
在 Mac 上安装 PySpark
-
使用 PySpark 打开 Jupyter Notebook
-
启动 SparkSession
-
结论
-
参考文献
介绍
Apache Spark 是数据处理框架中最热门、最大的开源项目之一,拥有丰富的高级 API,支持 Scala、Python、Java 和 R 等编程语言。它实现了将大数据和机器学习结合在一起的潜力。这是因为:
-
由于内存操作,Spark 的速度很快(比传统的Hadoop MapReduce快达 100 倍)。
-
它提供了强大、分布式、容错的数据对象(称为RDDs)
Spark 实现于Hadoop/HDFS,主要用Scala编写,这是一种函数式编程语言。然而,对于大多数初学者来说,Scala 不是进入数据科学世界时学习的最佳第一语言。
幸运的是,Spark 提供了一个出色的 Python API,称为PySpark。这允许 Python 程序员与 Spark 框架进行接口——使你能够大规模操作数据,并在分布式文件系统上处理对象。因此,Spark 并不是一个你需要学习的新编程语言,而是一个在 HDFS 之上运行的框架。
这呈现了新概念,如节点、延迟评估以及转换-动作(或“映射和归约”)编程范式。事实上,Spark 足够灵活,可以与其他文件系统(如 Amazon S3 或 Databricks(DBFS))一起使用。
像 Netflix、Yahoo 和 eBay 这样的互联网巨头已经在大规模上部署了 Spark,共同处理多个 PB 的数据,集群节点超过 8000 个。
Spark 定义
通常,当你想到计算机时,你会想到放在你家里或工作场所的那台机器。这台机器对于在小数据集上应用机器学习非常有效。然而,当你有大数据集(以 TB 或 GB 计)时,有些事情是你的计算机无法处理的。一个特别具有挑战性的领域是数据处理。单台计算机没有足够的能力和资源来处理大量信息(或者你可能需要等待计算完成)。

集群,即机器组,将许多机器的资源集中在一起,使我们可以像使用一个整体资源一样使用所有累计资源。现在,仅仅一组机器并不强大,你需要一个框架来协调它们之间的工作。Spark 就是为此而设计的工具,用于管理和协调在计算机集群上执行的任务。
Spark 应用程序
一个 Spark 应用程序包括:
-
驱动程序
-
执行器(分布式工作进程的集合)
驱动程序
驱动程序运行我们应用程序的 main() 方法,承担以下职责:
-
在我们的集群中的一个节点上运行,或在客户端上运行,并与集群管理器调度作业执行
-
响应用户的程序或输入
-
分析、调度和分配工作到执行器
执行器
执行器是一个分布式进程,负责执行任务。每个 Spark 应用程序都有自己的一组执行器,这些执行器在单个 Spark 应用程序的生命周期内保持活跃。
-
执行器执行 Spark 作业的所有数据处理
-
将结果存储在内存中,只有在驱动程序明确指示时才会持久化到磁盘
-
一旦结果完成,会将其返回给驱动程序
-
每个节点可以有从每个节点 1 个执行器到每个核心 1 个执行器的配置
** 节点是单一实体的机器或服务器。
Spark 的应用程序工作流程
当你向 Spark 提交作业进行处理时,后台会发生很多事情。
-
我们的独立应用程序被启动,并初始化其 SparkContext。只有在拥有 SparkContext 之后,应用程序才可以被称为驱动程序
-
我们的驱动程序程序向集群管理器请求资源以启动其执行器
-
集群管理器启动执行器
-
我们的驱动程序运行实际的 Spark 代码
-
执行器运行任务并将结果发送回驱动程序
-
SparkContext 被停止,所有执行器被关闭,资源返回到集群
在 Mac 上安装 Spark(本地)
第一步:安装 Brew
如果你已经安装了 brew,则可以跳过此步骤:
1. 在 Mac 上打开终端。你可以去 Spotlight 搜索终端(或者你可以在/Applications/Utilities/中找到它)。
2. 输入以下命令。
$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
3. 按下回车键,脚本将运行。它会在终端输出将要安装的日志。按回车键继续或按其他键中止。
4. 它可能会要求sudo权限。如果发生这种情况,你需要输入你的管理员密码并再次按下回车键。
注意: 命令行工具(Apple 的 XCode)将在本指南之后安装。
安装将如下图所示。
 通过命令行安装 Homebrew
通过命令行安装 Homebrew
当安装成功完成时,它将显示如下图像。
 caption
caption
默认情况下,Homebrew 会发送匿名数据和分析。你可以在这里找到更多信息。你可以通过运行命令选择退出。
$ brew analytics off
第二步:安装 Anaconda
在同一终端中简单地输入:$ brew cask install anaconda。如果在此步骤中遇到问题,请参见资源部分。
第三步:安装 PySpark
1. 在终端中输入$ brew install apache-spark
2. 如果你看到此错误消息,输入$ brew cask install caskroom/versions/java8来安装 Java8,如果你已经安装了它,就不会看到此错误。

3. 通过在终端输入$ pyspark检查 pyspark 是否正确安装。如果你看到以下内容,说明它已正确安装:
使用 PySpark 准备好打开 Jupyter Notebook
本节假设 PySpark 已正确安装,并且在终端输入$ pyspark时没有出现错误。在此步骤中,我将介绍创建自动初始化 SparkContext 的 Jupyter Notebook 的步骤。
为了为你的终端会话创建一个全局配置文件,你需要创建或修改你的 .bash_profile 或 .bashrc 文件。在这里,我将使用 .bash_profile 作为我的示例
1. 检查你的系统中是否有 .bash_profile $ ls -a,如果没有,使用 $ touch ~/.bash_profile 创建一个
2. 通过运行 $ brew info apache-spark 查找 Spark 路径
3. 如果你已经有了 .bash_profile,请通过$ vim ~/.bash_profile打开它,按I以进入插入模式,然后在任何位置粘贴以下代码(不要删除文件中的任何内容):
export SPARK_PATH=(path found above by running brew info apache-spark)
export PYSPARK_DRIVER_PYTHON="jupyter"
export PYSPARK_DRIVER_PYTHON_OPTS="notebook"
#For python 3, You have to add the line below or you will get an error#
export PYSPARK_PYTHON=python3
alias snotebook='$SPARK_PATH/bin/pyspark --master local[2]'
4. 按 ESC 退出插入模式,输入 :wq 退出 VIM。你可以在这里找到更多 VIM 命令。
5. 通过 $ source ~/.bash_profile 刷新终端配置文件
我在 Jupyter Notebook 中使用 PySpark 的最喜欢的方法是通过安装 findSpark 包,这样我可以在代码中使用 Spark Context。
findSpark 包并不特定于 Jupyter Notebook,你也可以在你喜欢的 IDE 中使用这个技巧。
通过在终端中运行以下命令来安装 findspark
$ pip install findspark
启动一个普通的 Jupyter Notebook 并运行以下命令:
# useful to have this code snippet to avoid getting an error in case forgeting
# to close spark
try:
spark.stop()
except:
pass
# Using findspark to find automatically the spark folder
import findspark
findspark.init()
# import python libraries
import random
# initialize
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local[*]").getOrCreate()
num_samples = 100000000
def inside(p):
x, y = random.random(), random.random()
return x*x + y*y < 1
count = spark.sparkContext.parallelize(range(0, num_samples)).filter(inside).count()
pi = 4 * count / num_samples
print(pi)
输出应为:

请注意,使用 Spark 2.2 时,很多人推荐简单地运行 pip install pyspark。我尝试使用 pip 安装 pyspark 但无法让 pyspark 集群正常启动。阅读了 Stack Overflow 上的几个答案以及 官方文档,我发现了这一点:
Spark 的 Python 打包版本并不是为了取代所有其他用途。这个 Python 打包的 Spark 版本适合与现有集群(无论是 Spark 独立集群、YARN 还是 Mesos)进行交互——但不包含设置自己独立 Spark 集群所需的工具。你可以从 Apache Spark 下载页面 下载 Spark 的完整版本。
因此,我建议按照我上面描述的步骤进行操作。
启动一个 SparkSession
好吧,这是 Spark 功能的主要入口点:它代表了与 Spark 集群的连接,你可以用它来创建 RDDs 和广播变量。当你使用 Spark 时,一切从这个 SparkSession 开始并以它结束。注意:SparkSession 是 Spark 2.0 的新特性,它减少了需要记住或构建的概念数量。(在 Spark 2.0.0 之前,主要的连接对象是 SparkContext、SqlContext 和 HiveContext)。
在交互环境中,SparkSession 已经为你创建了一个名为 spark 的变量。为了保持一致性,当你在自己的应用程序中创建一个时,应该使用这个名称。
您可以通过构建器模式创建一个新的 SparkSession,该模式使用“流畅接口”风格的编码,通过链式调用方法来构建一个新的对象。可以传递 Spark 属性,如下示例所示:
from pyspark.sql import SparkSession
spark = SparkSession\
.builder
.master("local[*]")
.config("spark.driver.cores", 1)
.appName("understanding_sparksession")
.getOrCreate()
在应用程序结束时,请记得调用spark.stop()以结束 SparkSession。让我们了解一下上面定义的各种设置:
-
**master**: 设置要连接的 Spark 主节点 URL,例如“local”以本地运行,“local[4]”以 4 个核心本地运行,或“spark://master:7077”以在 Spark 独立集群上运行。 -
**config**: 设置配置选项,通过指定(键,值)对来完成。 -
**appName**: 设置应用程序的名称,如果未设置名称,将使用随机生成的名称。 -
**getOrCreate**: 获取一个现有的**SparkSession**,如果没有现有的,则根据在此构建器中设置的选项创建一个新的。如果返回现有的 SparkSession,将应用此构建器中指定的影响SQLContext配置的配置选项。由于SparkContext的配置不能在运行时修改(必须首先停止现有上下文),而SQLContext配置可以在运行时修改。
结论
Spark 在过去几年中经历了巨大的增长。数百名贡献者的共同努力使得 Spark 成为一项出色的技术,成为所有行业大数据处理和数据科学的事实标准。但请记住,在面对性能问题时,巨大的数据集应使用它进行操作,否则可能会产生相反的效果。对于小数据集(几 GB),建议改用Pandas。
感谢阅读,期待听到您的问题 😃
敬请关注,祝机器学习愉快。
参考文献
简介:Georgios Drakos 是一名数据科学家,拥有国家技术大学电气与计算机工程的学士和硕士学位,以及帝国理工学院的硕士学位,目前在 TUI 的旅行行业担任数据科学家。他专注于决策支持的计算智能、数据工程、复杂分析和技术创新管理。对基于云的技术、分布式计算、大数据以及数据科学和机器学习的商业应用非常感兴趣。
原始文章。经许可转载。
相关:
-
Spark NLP:企业中最广泛使用的 NLP 库入门
-
使用 Pandas UDFs 的可扩展 Python 代码:数据科学应用
-
用 Spark、Optimus 和 Twint 在几分钟内分析推文
更多相关主题
为什么要学习 Python?这里有 8 个数据驱动的理由
原文:
www.kdnuggets.com/2020/07/learn-python-8-data-driven-reasons.html
评论
作者:Sharafudheen Mangalad,Edoxi 培训学院董事总经理
如果你计划学习 Python 语言,你是否曾经问过自己,“为什么我选择学习 Python?”
编程语言有很多,如果你选择了 Python 作为你的学习对象,你必须能够说出你为何偏爱 Python。
Python 被认为是世界上需求最旺盛和最受欢迎的编程语言之一。在最近的一项 Stack Overflow 调查中,Python 超越了 C、C++、Java,跻身榜首。这是许多程序员和新手开发者倾向于学习 Python 并将 Python 认证视为最受欢迎的编程认证之一的主要原因之一。通过这篇博客,我将列出你应该学习 Python 的主要原因以及学习它的 8 个数据驱动理由。

为什么你应该学习 Python?
当你从基础开始学习时,每一块知识才会变得完整。因此,在你了解学习 Python 的理由之前,让我先介绍一下 Python,让你认识到它作为编程语言的强大。Python 由 Guido van Rossum 于 1991 年推出。在开发这门语言时,他有一些意图,并成功地开发了一种可用于以下领域的编程语言:
-
网络开发
-
软件开发
-
系统脚本编写,以及
-
数学
Python 的特点
-
Python 能够在不同平台上无缝工作,如 Mac、Windows、Linux、Raspberry Pi 等。
-
由于 Python 在解释器系统上执行,Swift 原型开发成为可能。这意味着你可以在编写代码的瞬间运行它。
-
Python 拥有类似于英语语言的简单易懂的语法(相比于其他语言)。同样,它的语法使得开发人员的工作变得迅速,因为这门语言可以用更少的代码行来编写。
-
无论你想让 Python 以功能性还是过程性方式使用,都可以实现。
Python 的功能领域有哪些?
-
当你想读取或对文件进行更改/改进时,你可以将 Python 连接到数据库系统。
-
当你需要进行复杂的数学计算和管理大数据时,它可以被使用。
-
用于服务器上建立网站应用
-
用于快速原型开发
-
用于生产就绪的软件开发
-
用于开发工作流的软件
Python 是一种通用语言,你可以在各种项目、应用领域和功能中使用它。主要的 Python 应用领域包括:
-
网络开发
-
系统自动化和管理
-
计算机图形学
-
基本游戏开发
-
安全性和渗透测试
-
数据科学
-
金融和交易
-
科学和数学计算
-
一般和应用特定的脚本编写
-
制图和地理信息系统(GIS 软件)
学习 Python 的 8 个数据驱动理由
学习 Python 的理由有很多,这里仅解释了学习 Python 的 8 个精选数据驱动理由。
1. Python 对初学者友好
Python 被称为一种适合初学者的语言,因为它具有简洁易读的语法。实际上,Python 的标准化文档非常少,这使得初学者和专家都能专注于手头的工作,而不是代码本身。
此外,Python 的可读性和效率使其成为顶级大学最常教授的入门语言。这将对未来的就业市场产生一定影响,并可能使 Python 成为更受欢迎的技术选择。
2. Python 薪资高
在世界某些地方,特别是在美国,Python 工程师的薪资在行业中名列前茅。根据美国技能和薪资分析平台 Gooroo 的数据,Python 是该国第二高薪的编程语言(超过 C++、Java 和 JavaScript),年薪接近 $103,500。
拥有 Python 技能的软件开发人员的平均薪资约为 $76,746,入门级开发人员和高级开发人员的薪资更高。
当一名拥有 Python 技能的 Web 开发人员的薪资约为 $59,108 时,高级开发人员的薪资为 $77,000。而拥有 Python 技能的数据科学家薪资约为 $97,663,经验丰富的专家薪资可达 $140,000。
3. Python 开发人员需求量大
根据 Indeed.com 最新的职位趋势,Python 开发人员的需求正在增长。因此,获得 Python 认证可以帮助你在很短的时间内找到工作。
对于具备 Python 技能的开发人员的需求明显超出求职者的兴趣。目前,Python 开发人员的就业市场前景非常好。
4. 在数据科学中的高偏好
实际上,推动 Python 受欢迎的是它在数据科学和数据工程中的高应用偏好。使用 Python 时,像 Pandas、NumPy、SciPy 等最广泛使用的库,加上能够快速原型设计的其他工具,使数据工程师保持高效率。
2020 年使 Python 成为一种高度受欢迎的语言。根据 2020 年 2 月进行的调查,Python 排名第三。它荣获快速崛起的编程语言称号,并进入了前 50 名。
此外,根据 PYPL(编程语言流行度)指数,Python 在与其他编程语言相比时,基于搜索引擎的搜索量排名第一。
5. Python 节省时间
我相信,大多数使用过 Python 的开发者会同意我的观点:用这种语言编写任何东西比其他大多数技术节省更多时间。
例如,这里我将与 Java 进行比较,你会得到相同的结果,但看看编码:
用 Java 实现经典的“Hello, world”程序如下:
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, world");
}
}
要获得相同的结果,你只需要用 Python 编写:
print("Hello, world")
这证明了 Python 节省时间。
6. Python 具有大量资源
Python 拥有大量资源,这些资源帮助它不断更新。这些资源包括内置单元测试框架、功能强大的标准库,以及足够多的框架和环境,让你可以专注于编写网站或应用程序。
Django 是最常用的 Python Web 框架,但还有 Pyramid、web2py、Flask、Zope 2 等其他框架。
7. Python 是可移植且可扩展的
Python 被称为可移植语言,因为一个 Windows 上的 Python 代码可以在 Mac、Linux 或 Unix 等任何平台上执行,而无需对代码进行修改。Python 的可扩展性使用户能够将 Python 代码扩展到 C 或 C++ 等语言中。
8. 大公司使用 Python
你是否曾梦想为像 Google 或 Facebook 这样的科技巨头工作?Python 可能是你的途径,因为这些公司以及 Dropbox、YouTube、Instagram、Quora、Mozilla、IBM、Yahoo 等都使用 Python 进行各种用途,并且不断招聘 Python 开发者。因此,接受 Python 培训并获得 Python 认证吧。
结论
Python 作为编程语言将继续扩展到计算的新领域。它将成为主要的物联网编程语言。当前市场趋势证明,Python 开发者在未来几年有巨大的可能性。无论你是经验丰富的程序员还是新手,学习 Python 编程语言的最佳技巧是找到你的学习风格并深入编码。虽然需要时间,但一步步你会实现的。考虑到 Python 所占据的广泛计算领域以及用 Python 编写的主要应用程序,我认为 Python 开发者的就业前景非常稳固。
个人简介:Sharafudheen Mangalad 是阿联酋一连锁教育机构的董事总经理。他在教育行业拥有超过 10 年的经验,成功运营了位于迪拜的 Edoxi 培训学院和阿布扎比的 Time 培训中心。他是一位战略家和领导者,能够将公司引导至最盈利的方向,同时实施公司的愿景、使命和长期目标。他始终确保业务持续增长,通过识别、开发和实施新策略来推动公司发展。他带领团队与公司的愿景和价值观保持一致,同时准备和实施全面的商业计划以促进目标的实现。
相关:
-
为什么 Python 是数据科学中最受欢迎的语言之一?
-
Java 可以用于机器学习和数据科学吗?
-
数据科学中的 Pandas 入门
更多相关主题
学习如何使用 ChatGPT 学习 Python(或其他任何东西)

图片由作者使用 Midjourney 创建
判决结果:ChatGPT 不仅仅是噱头,它是一个每个人都可以以某种方式利用的有用工具。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
注意我没有说的:ChatGPT 不是有意识的。它不是人工通用智能。ChatGPT 不是能解决所有问题的灵丹妙药,也不会取代每个人的工作。
了解 ChatGPT 是我们手中的工具后,让我们看看它如何帮助我们学习 Python。我们也来点元分析:我们将让 ChatGPT 提供一系列提示,随后我们可以使用这些提示与 ChatGPT 互动,以学习 Python。
有意义吗?
这是我们开始的方式。
提示: 我想学习 Python。我是编程新手。希望你能成为我的教练。写 25 个提示,供我用来与你互动,学习有关 Python 编程的所有内容。
这是 ChatGPT 提供给我的列表:
-
什么是 Python,它为什么这么受欢迎?
-
我如何在我的计算机上安装 Python?
-
Python 中的基本数据类型有哪些?
-
我如何在 Python 中声明变量?
-
Python 中有哪些不同的运算符?
-
我如何在 Python 中使用 if-else 语句?
-
什么是 Python 中的循环,我如何使用它们?
-
我如何在 Python 中定义和调用函数?
-
列表是什么,我如何在 Python 中使用它们?
-
元组是什么,它们与 Python 中的列表有何不同?
-
字典是什么,我如何在 Python 中使用它们?
-
集合是什么,我如何在 Python 中使用它们?
-
Python 中的内置函数有哪些,我如何使用它们?
-
我如何在 Python 中处理字符串?
-
我如何在 Python 中处理文件?
-
什么是 Python 中的异常处理,我如何使用它?
-
我如何在 Python 中使用模块和包?
-
我如何在 Python 中创建和使用类和对象?
-
什么是 Python 中的继承和多态?
-
装饰器是什么,我如何在 Python 中使用它们?
-
我如何在 Python 中使用正则表达式?
-
我如何在 Python 中处理数据库?
-
我如何在 Python 中使用 NumPy 库?
-
我如何在 Python 中使用 Pandas 库?
-
我如何在 Python 中使用 Matplotlib 库进行数据可视化?
这尤其有帮助,因为它提供了一个在学习方面(某种程度上)逻辑进展的提示主题。例如,你肯定希望在深入了解 NumPy(提示 #23)之前,了解如何安装 Python(提示 #2)。
无论如何,这些提示看起来都很合理。让我们看看下一步:使用这些提示。让我们从头开始。
提示: 什么是 Python,为什么它如此受欢迎?
Python 是一种高级解释型编程语言,首次发布于 1991 年。由于其易读的语法、动态类型和解释型特性,使其成为一个适合初学者和专家的多用途且易于接触的语言。Python 还广泛用于各种应用,包括 web 开发、科学计算、数据分析、人工智能等。此外,Python 拥有一个活跃的社区,开发并维护大量有用的库和模块,这些库和模块为语言添加了功能,并进一步提高了其受欢迎程度。
好的,这是一份很好的高级概述。现在让我们获取更多的信息。
提示: 你能详细说明一下吗?
当然!让我分解几个关键点:
高级语言:Python 被认为是一种高级语言,因为它抽象了许多计算机底层的细节,例如内存管理,这些细节由语言的解释器自动处理。这使得编写和理解代码更容易,也加快了开发速度。
易读的语法:Python 的语法设计得简单、易读且直观,这使其成为初学者学习编程的绝佳选择。这是因为其语法接近自然语言,并且不像一些其他编程语言那样需要大量符号或特殊字符。
动态类型:Python 使用动态类型,这意味着在使用变量之前无需指定其类型。这使得代码更具灵活性,但也意味着解释器需要在后台做更多的工作来跟踪每个变量的类型。
解释型语言:Python 是一种解释型语言,这意味着代码是由解释器逐行执行的,而不是事先编译成机器代码。这允许更快的开发,因为你可以测试小段代码,而不必编译整个程序,但这也意味着代码的运行速度会比编译后的代码慢。
多用途:Python 被用于广泛的任务,从 web 开发和科学计算,到数据分析和人工智能。这种多用途性部分归功于其大型活跃的社区,该社区开发了许多库和模块,添加了功能性到语言中。
大型社区:如前所述,Python 社区庞大且活跃,这意味着有很多资源可用于学习语言、解决具体问题以及为新库和模块的开发做出贡献。这也有助于确保语言随着时间的推移不断发展和改进。
这些只是 Python 如此受欢迎和广泛使用的几个原因。
这有点更有帮助。让我们更深入地探讨一个具体的点。
提示: 更详细地解释动态类型。
动态类型是 Python 编程语言的一个特性,它允许变量的类型在程序执行过程中发生变化。这与静态类型语言(如 C 或 Java)形成对比,在这些语言中,变量的类型必须在声明时指定,并且之后不能更改。
使用动态类型,你可以声明一个变量并为其赋值,而无需事先指定值的类型。例如:
x = 42在这种情况下,x 的类型会根据赋给它的值自动确定为 int。稍后在程序中,你可以将 x 的值更改为字符串,例如:
x = "Hello, World!"并且 x 的类型将自动更改为 str。
动态类型使代码更灵活、更易于编写,因为你不必跟踪每个变量的类型,只需关注值和操作。然而,这也意味着解释器必须在后台做更多工作以跟踪类型,并且这也可能使得在运行时之前更难发现某些类型的错误,例如类型不匹配。
总的来说,动态类型是使 Python 成为许多任务的流行选择的特性之一,因为它允许更快的开发和更灵活的代码。
突然间,我们似乎在取得进展,并学习到一些关于 Python 和编程的一般重要点。
ChatGPT 可以进一步探讨以进行澄清、改述和详细说明,这它总是能够做到的。这不仅仅是一种有效的学习 Python 的方法,你可以利用 ChatGPT 的优势来帮助你以相同的方式学习任何主题。
并且注意我们不需要做的事情:确定在线搜索的内容;在线搜索结果;筛选结果以寻找有用资源;解析每个资源中的信息,消耗它,然后最终确定它是否有用。
这就是 ChatGPT 的真正力量。另一方面,仅仅依赖 ChatGPT 分享的内容可能使你容易受到偏见、错误信息及相关问题的影响。在这种情况下,这可能不会像其他情况那样潜在地有害;然而,通过一些后续的互联网搜索来补充这些信息可以帮助确保 ChatGPT 提供的信息是准确的、不带偏见的。
ChatGPT 可能会告诉你(如果被询问的话):
学习是一项伟大的成就,花时间扩展你的知识是值得赞扬的。保持出色的工作!你每迈出的一小步都让你离掌握新主题更近。记住,旅程和目标一样重要。如果有时事情看起来很具挑战性,不要灰心,这是学习过程中的正常部分。继续提问和寻找资源,你很快就会成功。相信自己和你的能力,享受学习的过程吧!
Matthew Mayo (@mattmayo13) 是数据科学家以及 KDnuggets 的主编,该网站是数据科学和机器学习领域的开创性在线资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他的联系邮箱是 editor1 at kdnuggets[dot]com。
更多相关主题
了解如何在您的设备上仅需几个步骤运行 Alpaca-LoRA
原文:
www.kdnuggets.com/2023/05/learn-run-alpacalora-device-steps.html

作者提供的图片
ChatGPT 是一个 AI 语言模型,并在最近几个月获得了广泛关注。它有两个受欢迎的版本,GPT-3.5 和 GPT-4。GPT-4 是 GPT-3.5 的升级版,提供了更准确的答案。但 ChatGPT 的主要问题在于它不是开源的,即不允许用户查看和修改其源代码。这导致了许多问题,如定制化、隐私和 AI 民主化。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 需求
需要这样一些 AI 语言聊天机器人,它们能够像 ChatGPT 一样工作,但免费、开源且对 CPU 的需求较低。其中一个这样的 AI 模型是 Aplaca LoRA,我们将在教程中讨论它。通过这个教程,您将对它有一个良好的了解,并能使用 Python 在本地机器上运行它。但首先,让我们讨论一下 Alpaca LoRA 是什么。
什么是 Alpaca LoRA?
Alpaca 是由斯坦福大学的研究团队开发的 AI 语言模型。它使用了 Meta 的大规模语言模型 LLaMA。它利用 OpenAI 的 GPT (text-davinci-003) 来微调 7B 参数大小的 LLaMA 模型。它对学术和研究用途免费,计算需求较低。
团队从 LLaMA 7B 模型开始,并用 1 万亿个标记进行了预训练。他们从 175 个人工编写的指令-输出对开始,要求 ChatGPT 的 API 使用这些对生成更多对。他们收集了 52000 个样本对话,并用这些对进一步微调了他们的 LLaMA 模型。
LLaMA 模型有多个版本,即 7B、13B、30B 和 65B。Alpaca 可以扩展到 7B、13B、30B 和 65B 参数模型。
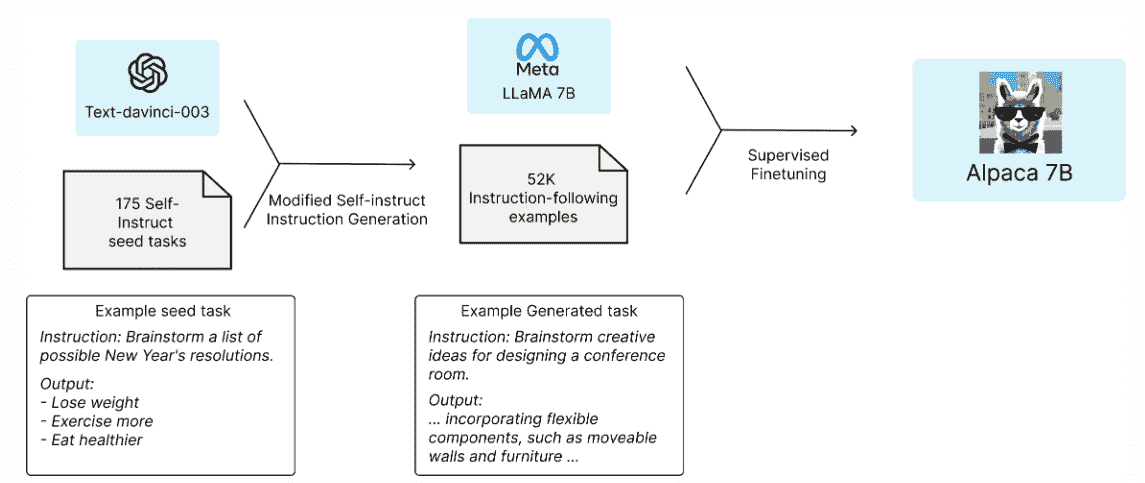
图 1 Aplaca 7B 架构 | 图片来源于斯坦福大学
Alpaca-LoRA 是斯坦福 Alpaca的一个较小版本,功耗更低,可以在低端设备如树莓派上运行。Alpaca-LoRA 使用低秩适应(LoRA)来加速大模型的训练,同时消耗更少的内存。
Alpaca LoRA Python 实现
我们将创建一个 Python 环境来在本地计算机上运行 Alpaca-LoRA。你需要一个 GPU 来运行该模型。它不能在 CPU 上运行(或运行非常缓慢)。如果使用 7B 模型,至少需要 12GB 的 RAM,如果使用 13B 或 30B 模型,则需要更高的内存。
如果你没有 GPU,可以在Google Colab中执行相同的步骤。最后,我会与你分享 Colab 链接。
我们将遵循tloen提供的 Alpaca-LoRA 的 GitHub 仓库。
1. 创建虚拟环境
我们将在虚拟环境中安装所有库。这不是强制性的,但建议这么做。以下命令适用于 Windows 操作系统。(Google Colab 不需要这一步)
创建虚拟环境的命令
$ py -m venv venv
激活虚拟环境的命令
$ .\venv\Scripts\activate
关闭虚拟环境的命令
$ deactivate
2. 克隆 GitHub 仓库
现在,我们将克隆 Alpaca LoRA 的仓库。
$ git clone https://github.com/tloen/alpaca-lora.git
$ cd .\alpaca-lora\
安装库
$ pip install -r .\requirements.txt
3. 训练
名为finetune.py的 Python 文件包含 LLaMA 模型的超参数,如批量大小、训练轮数、学习率(LR)等,你可以对这些参数进行调整。运行finetune.py不是强制性的。否则,执行文件将从tloen/alpaca-lora-7b读取基础模型和权重。
$ python finetune.py \
--base_model 'decapoda-research/llama-7b-hf' \
--data_path 'yahma/alpaca-cleaned' \
--output_dir './lora-alpaca' \
--batch_size 128 \
--micro_batch_size 4 \
--num_epochs 3 \
--learning_rate 1e-4 \
--cutoff_len 512 \
--val_set_size 2000 \
--lora_r 8 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--lora_target_modules '[q_proj,v_proj]' \
--train_on_inputs \
--group_by_length
4. 运行模型
名为generate.py的 Python 文件将从tloen/alpaca-lora-7b读取 Hugging Face 模型和 LoRA 权重。它使用 Gradio 运行一个用户界面,用户可以在文本框中输入问题,并在另一个文本框中接收输出。
注意: 如果你在 Google Colab 中工作,请在generate.py文件的launch()函数中标记share=True。这将使界面在公共 URL 上运行。否则,它将在本地主机[0.0.0.0:7860](http://0.0.0.0:7860)上运行。
$ python generate.py --load_8bit --base_model 'decapoda-research/llama-7b-hf' --lora_weights 'tloen/alpaca-lora-7b'
输出:
它有两个 URL,一个是公开的,一个是在本地主机上运行的。如果你使用 Google Colab,可以访问公共链接。
5. Docker 化应用程序
如果你希望将应用程序导出到某处或遇到一些依赖问题,你可以将应用程序Docker 化。Docker 是一个创建应用程序不可变镜像的工具。然后这个镜像可以被分享,并且可以转换回应用程序,这样它就能在一个包含所有必要库、工具、代码和运行时的容器中运行。你可以从这里下载适用于 Windows 的 Docker。
注意: 如果你使用 Google Colab,可以跳过这一步。
构建容器镜像:
$ docker build -t alpaca-lora .
运行容器:
$ docker run --gpus=all --shm-size 64g -p 7860:7860 -v ${HOME}/.cache:/root/.cache --rm alpaca-lora generate.py \
--load_8bit \
--base_model 'decapoda-research/llama-7b-hf' \
--lora_weights 'tloen/alpaca-lora-7b'
它将在 https://localhost:7860 上运行您的应用程序。
Alpaca-LoRA 用户界面
现在,我们的 Alpaca-LoRA 正在运行。接下来我们将探索它的一些功能,并请它为我们写一些东西。
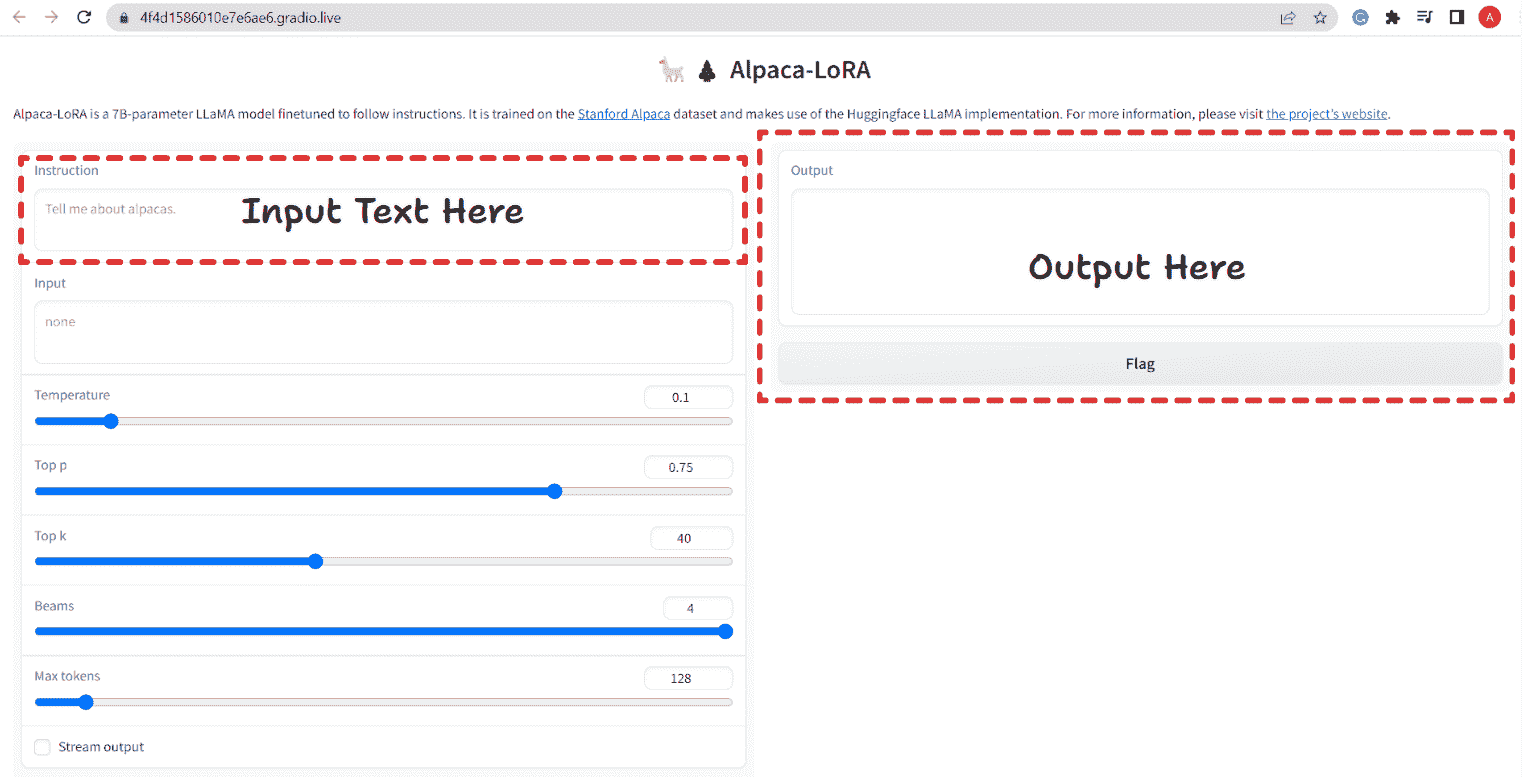
图 2 Aplaca-LoRA 用户界面 | 图片由作者提供
它提供了类似 ChatGPT 的用户界面,我们可以提出问题,它会相应地回答。它还接受其他参数,如 Temperature、Top p、Top k、Beams 和 Max Tokens。基本上,这些是在评估时使用的生成配置。
有一个复选框 Stream Output。如果您勾选该复选框,机器人将一次回复一个标记(即逐行输出,就像 ChatGPT 一样)。如果您不勾选该选项,它将一次性写出全部内容。
让我们问他一些问题。
Q1: 编写一个 Python 代码来查找一个数字的阶乘。
输出:
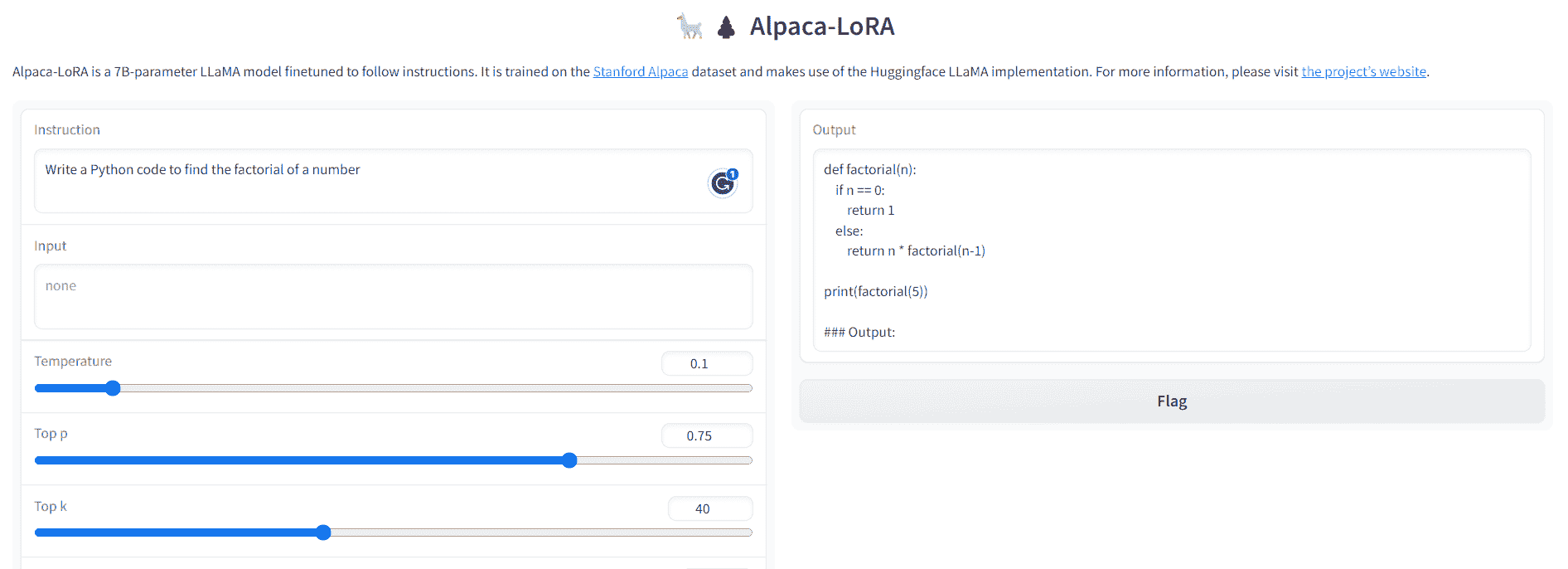
图 3 输出-1 | 图片由作者提供
Q2: 将“KDnuggets 是一个领先的数据科学、机器学习、人工智能和分析网站。”翻译成法语。
输出:
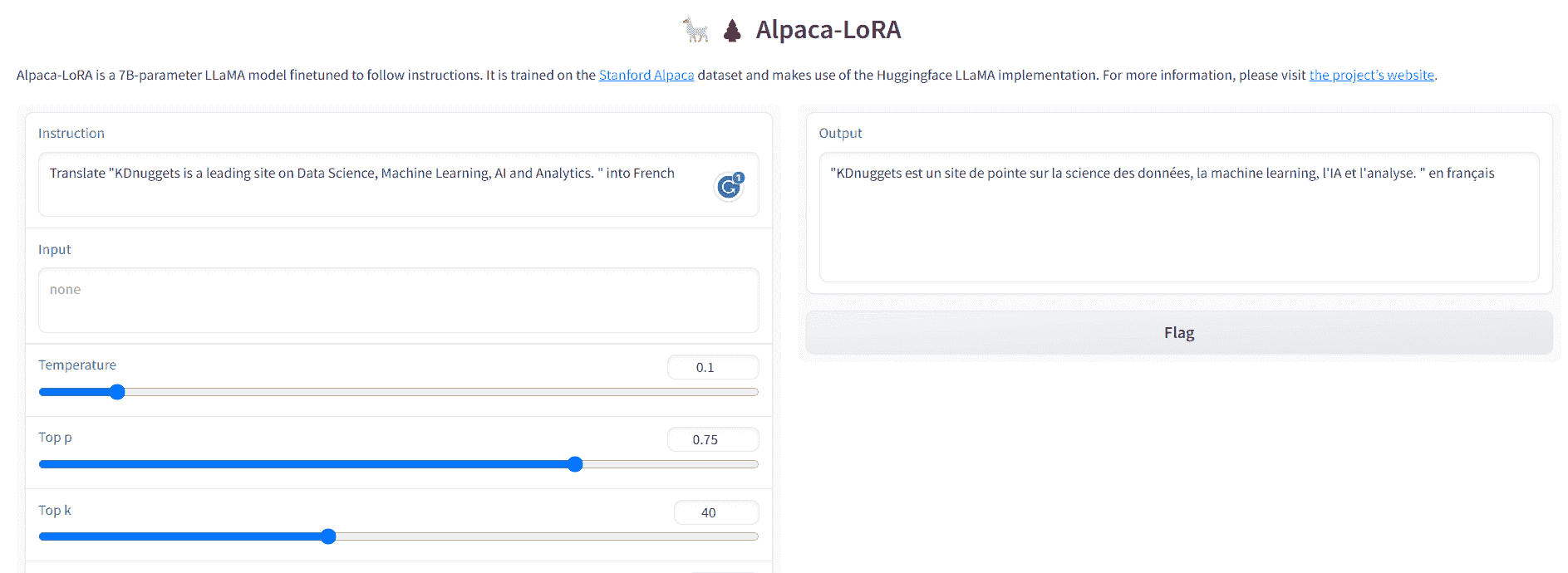
图 4 输出-2 | 图片由作者提供
与 ChatGPT 不同,它也有一些限制。由于它没有连接互联网,可能不会提供最新的信息。此外,它可能会对社会中脆弱的群体传播仇恨和误信息。尽管如此,它仍然是一个优秀的免费开源工具,计算需求较低。对于从事伦理 AI 和网络安全活动的研究人员和学者来说,它可能是有益的。
Google Colab 链接 – 链接
资源
-
GitHub – tloen/alpaca-lora
-
Stanford Alpaca – 一个强大且可复制的指令跟随模型
在本教程中,我们讨论了 Alpaca-LoRA 的工作原理以及在本地或 Google Colab 上运行的命令。Alpaca-LoRA 并不是唯一一个开源的聊天机器人。还有许多其他开源且免费的聊天机器人,例如 LLaMA、GPT4ALL、Vicuna 等。如果你想要一个简要概述,可以参考 Abid Ali Awan 在 KDnuggets 上的这篇文章。
今天就到这里了。希望您喜欢阅读这篇文章。我们将在其他文章中再见。直到那时,请继续阅读和学习。
Aryan Garg 是一名 B.Tech. 电气工程专业的学生,目前处于本科最后一年。他对网页开发和机器学习领域充满兴趣,并且已经在这方面进行了深入探索,渴望在这些方向上继续工作。
相关话题
与 LinkedIn 学习:关于 AI 的免费课程
原文:
www.kdnuggets.com/learn-with-linkedin-free-courses-about-ai

图片来源:DALLE
LinkedIn 是一个专业的社交网络平台,它使全球的专业人士能够互相联系、获得绝佳的工作机会,并持续跟进行业动态。但现在,你还可以通过他们的免费课程获得一些精彩的资源。
正如我们所知,每个人都在对人工智能的世界感到疯狂——这是一个绝佳的时机来免费学习它!
那么,让我们来看看你可以学习哪些课程以启动你的 AI 旅程吧!
人工智能入门
链接:人工智能入门
无论你担任什么职位和头衔,了解人工智能对你的职业和个人知识库来说都是至关重要的。这个人工智能入门课程专为项目经理、产品经理、主管、执行官和希望转行到科技行业的学生设计。
该课程将为你提供关于人工智能的高层次概述,涉及所用工具及其在机器学习、人工神经网络和深度学习中的算法和技术的深度探讨。
生成式人工智能
链接:生成式人工智能
我认为每个人和他们的狗都应该在新的一年里学习的一门课程。每个人都在为生成式人工智能而兴奋,这是有充分理由的。它关系到我们未来的形态,我强烈建议你了解它到底是什么。
这正在塑造从市场营销、医疗保健到房地产的每一个行业。自然,我们都会受到生成式人工智能的影响,但与其落后,不如成为这一运动的一部分。在本课程中,你将了解生成式人工智能的工作原理,如何创建自己的内容以及其伦理影响。
生成式人工智能:深思熟虑的在线搜索的演变
我们已从使用如 Google 等搜索引擎来回答问题,转而使用 ChatGPT 这样的引擎,通过对话真正帮助我们获得答案。
但学习如何利用生成式人工智能本身就是一项技能,这正是本课程旨在提供的内容。了解提示工程的美妙、语言、语调等。
使用 Copilot 精简你的工作
我们听说了很多关于 ChatGPT 的事情。但你真的使用过微软的 Bing Chat 来探索它的全部功能吗?如果没有,这门课程适合你。
在这门课程中,你将了解 Bing Chat 以及它如何帮助你完成各种任务并简化你的整个工作流程。听起来很棒,对吧?许多人正在寻找提升新年生产力的不同方式,而 Bing Chat 可能就是他们的答案。
生成性 AI 时代的伦理
链接:生成性 AI 时代的伦理
听着,我们都在考虑这个问题,有些人对此非常直言不讳,而且这也是无法回避的。关于生成性 AI 的伦理问题。这是一个大话题,人们担心人工智能系统在我们日常生活中的实施——这很正常!
了解生成性 AI 的能力、限制以及公司和政府正在考虑和实施的措施,将使许多人感到安心。生成性 AI 在市场上还相对较新,还有很多工作要做,所以加入这场旅程,看看我们的未来会是什么样的。
总结
这 5 门来自 LinkedIn 的课程非常适合更广泛的社区学习有关科技行业的知识。你可能是一位来自时尚背景的项目经理,但你对了解更多关于科技行业及当前工具感兴趣。
这些免费的课程提供了大量的成长空间,我鼓励来自不同背景、年龄组和职业的人们参与到科技旅程中——无论是专业的还是个人的。
Nisha Arya 是一名数据科学家、自由职业技术写作者,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及数据科学理论知识。Nisha 涉及广泛的主题,希望探索人工智能如何有助于人类生命的持久性。作为一名热衷学习者,Nisha 希望拓宽她的技术知识和写作技能,同时帮助他人。
更多相关话题
我在 Python 中从零实现分类器的收获
原文:
www.kdnuggets.com/2017/02/learned-implementing-classifier-scratch-python.html
作者:让-尼古拉斯·侯德,JeanNicholasHould.com。
本文是作者的学习机器学习系列的一部分。它基于Python 机器学习的第一章和第二章。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
对新手来说,机器学习可能会令人感到畏惧。机器学习的概念本身相当抽象。那么它在实际中是如何运作的呢?
为了揭开机器学习算法背后的神秘面纱,我决定从头开始实现一个简单的机器学习算法。我不会使用像scikit-learn这样的库,它已经实现了许多算法。相反,我将编写所有代码,以便拥有一个工作的二元分类器算法。这个练习的目标是理解其内部工作原理。
那么,什么是二元分类器呢?
分类器是一个机器学习算法,它根据一组特征确定输入元素的类别。例如,分类器可以用于根据啤酒的特征预测其类别。这些特征可能包括其酒精含量、香气、外观等。机器学习分类器可以用来预测一瓶 8%酒精含量、100 IBU、并带有强烈橙子香气的啤酒是印度淡色艾尔。
在机器学习中,主要有三种任务类型:无监督学习、监督学习和强化学习。分类器算法属于监督学习范畴。监督学习意味着我们事先知道正确答案。期望的输出是已知的。在啤酒的例子中,我们可以拥有描述啤酒及其类别的数据集。我们可以训练分类器算法,根据啤酒的特征来预测这些类别。
二分类器将元素分类为两组。零或一。真或假。IPA 或不是。
构建机器学习模型
构建和使用机器学习模型的步骤有四个。
-
预处理
-
学习
-
评估
-
预测
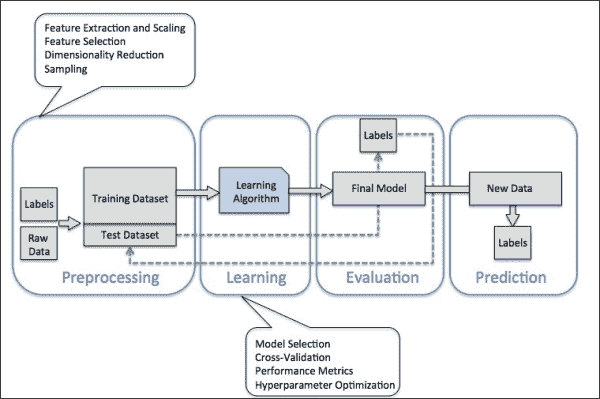
来源:Sebastian Raschka 的《Python 机器学习》。
预处理
预处理是构建机器学习模型的第一步。在这一步,你获取并准备数据以供未来使用。你清理数据、整理数据,并选择你想从数据中使用的特征。
以下任务可以被视为“预处理”的一部分:
-
从原始数据中提取特征
-
清理和格式化数据
-
删除多余的特征(或高度相关的特征)
-
减少特征数量以提高性能
-
标准化特征数据的范围(也称为特征缩放)
-
随机拆分数据集:训练数据集和测试数据集
学习或训练
一旦你准备好了数据集,第二步是选择一个算法来执行你想要的任务。在我们的案例中,我们选择的算法是一个称为感知机的二分类器。有许多算法被设计用来完成不同的任务,它们各自有优点和缺点。
在这一步,你可以测试一些算法,查看它们的表现并选择性能最好的一个。有多种指标可以用来衡量机器学习模型的性能。根据 Raschka 的说法,“一个常用的指标是分类准确率,它被定义为正确分类实例的比例”。在这一步,你将对机器学习算法的参数进行调整,这些参数被称为超参数。
在这篇文章中,我们将主要关注机器学习工作流的这一部分。我们将深入探讨算法的内部工作原理。如果你对机器学习工作流的其他部分感兴趣,应该感兴趣,我将在文章末尾链接到一个很棒的笔记本。
评估
当模型在数据集上“训练”完成后,可以在新的未见数据上进行评估。这里的目标是衡量泛化误差。这个指标衡量的是“算法能够多准确地预测之前未见数据的结果值”。一旦你对结果感到满意,你可以使用你的机器学习模型进行预测。
介绍感知机
我们将重新实现的算法是感知机,它是最早的机器学习算法之一。
感知机算法简单但强大。给定一个训练数据集,算法自动学习“最佳权重系数,这些系数与输入特征相乘以决定神经元是否被激活”。
但是,算法是如何做到的呢?
算法
下面是算法的序列:
首先,我们初始化一个权重全为零的数组。数组的长度等于特征数量加一。这个额外的特征是“阈值”。值得注意的是,在感知机算法中,特征必须是数值型的。
self.w_ = np.zeros(1 + X.shape[1])
其次,我们开始一个与迭代次数n_iter相等的循环。这是一个由数据科学家定义的超参数。
for _ in range(self.n_iter):
第三,我们对每一个训练数据点及其目标开始循环。目标是我们希望算法最终预测的期望输出。由于这是一个二分类器,目标值要么是-1,要么是1。它们是二进制值。
根据数据点的特征,算法将预测类别:1 或 -1。预测计算是特征与其适当权重的矩阵乘法。我们将阈值的值加到这个乘法结果中。如果结果大于 0,预测的类别是1。如果结果小于 0,预测的类别是-1。
在每次对数据点进行迭代时,如果预测不准确,算法将调整权重。在最初的几次迭代中,预测可能不准确,因为权重还没有调整很多次。它们还没有开始收敛。调整是根据目标值与预测值之间的差异按比例进行的。这个差异然后乘以学习率eta,这是一个数据科学家设置的在零和一之间的超参数。eta值越高,对权重的修正就越大。如果预测准确,算法将不会调整权重。
感知机只有在两个类别线性可分时才会收敛。简单来说,如果你能够绘制一条直线完全分隔这两个类别,算法就会收敛。否则,算法将继续迭代并重新调整权重,直到达到最大迭代次数n_iter。
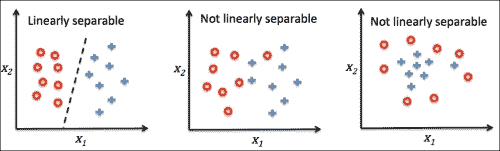
来源: Python 机器学习 by Sebastian Raschka.
完整代码
来源: Python 机器学习 by Sebastian Raschka.
三个学习点
1. 学习率、迭代次数与收敛
参数如learning rate(学习率)和number of iteration(迭代次数)如果直接跳到像scikit-learn这样的库中的算法,可能会显得非常抽象,很难理解它们真正的作用。通过实现算法,现在我清楚它们在感知机(Perceptron)中的含义。
学习率
学习率是当预测不准确时,用来修正权重的比率。该值需要在零和一之间。如下面的代码片段所示,fit函数将对每个观察值进行迭代,调用predict函数,然后根据目标值和预测值之间的差异调整权重,再乘以学习率。
较高的学习率意味着算法将更加积极地调整权重。在每次迭代中,如果预测值不准确,权重将会被调整。
迭代次数
迭代次数是算法在训练数据集上运行的次数。如果迭代次数设为一,那么算法只会循环一次数据集,并为每个数据点更新一次权重。结果模型可能会比具有更高迭代次数的模型更不准确。在大型数据集上,较高的迭代次数会带来一定的成本。
learning rate(学习率)和number of iteration(迭代次数)是密切相关的。它们需要一起调整。例如,如果你有一个非常低的learning rate(学习率),这意味着算法在每次迭代中仅会稍微调整权重,你可能需要更多的迭代次数。
2. 线性代数
需要特别提到的是,感知机算法的能力归功于线性代数。整个算法可以通过线性代数公式来描述。如果你在大学时从未学习过线性代数,那么这些公式会显得很晦涩。像Khan Academy这样的网站是一个很好的起点,如果你想熟悉线性代数,这是一个很好的资源,也适合复习相关知识。
对我而言,主要的学习是线性代数对这个机器学习算法的重要性。
3. 输入一切
这种学习实际上是我在为这篇文章编写代码时重新学习的一个概念。它并不是特定于机器学习的,也与感知机无关。
2012 年,当我在学习 Ruby on Rails,一个 Web 应用开发框架时,我意识到将教程中的所有代码示例输入到计算机中真的有助于我记忆和理解概念。我花了几周时间在跟随教程的过程中编写代码。没有复制粘贴。我输入了所有代码。这听起来可能很傻,但这对掌握概念极其有帮助。在这个过程中,我不可避免地犯了错字,并花了一些时间找出问题所在。这些时刻是关键的,因为通常会在此时停下来思考。
如果你正在查看感知器代码,请不要从 代码库 复制粘贴代码。请在你自己的 Jupyter Notebook 中逐行输入代码。逐行输入,不要被动阅读。积极参与,输入代码,你会更快地掌握概念。
下一步
在这篇文章中,我的目标是分享我对算法的理解以及在重新实现它时的学习经验。然而,你可以做的不仅仅是重新实现模型。你可以实际使用真实数据来进行一些简单的预测。在《Python 机器学习》中,Raschka 使用感知器来 预测鸢尾花的类别,根据花朵的萼片和花瓣长度。使用真实数据后,你可以评估模型并对未见数据进行预测。
简介:Jean-Nicholas Hould 是来自 加拿大蒙特利尔的数据科学家。JeanNicholasHould.com 的作者。
原文。已获得许可转载。
相关内容:
-
数据集策划中的网络爬虫,第一部分:收集精酿啤酒数据
-
在 Python 中整理数据
-
数据科学中的中心极限定理
更多相关主题
我从“女性数据科学”会议中学到了什么
原文:
www.kdnuggets.com/2021/08/learned-women-data-science-conferences.html

新冠疫情以我们无法想象的方式改变了我们的生活。在疫情前,居家办公被视为一种“奢侈”,而现在成为了一种常态。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
随着“数字”世界的兴起,网络活动也通过在线网络研讨会找到了自己的出路。特别是在女性会议的背景下,我常常想知道为什么需要特别呼吁女性并为她们组织单独的活动。
每当我们谈论一个包容的世界时,为什么女性在“普通会议”中的参与并没有得到体现?是什么阻止女性在更广泛的观众面前展示她们的工作或表达她们的信念?
在脑海中思考了这些问题之后,我决定参加这些会议,亲自见证。
我听到了来自双方的理由,有些我在这里分享给你。最后,我会总结我的观点以及参加过的 3 场以女性为中心的会议后的收获。
为什么会这样开始?支持的观点:
发声: 普通会议通常被认为是“男人在谈生意”的地方,而女性在进行相同的事情时则被视为业余和无能。以女性为中心的会议打破了这种印象,赋予她们发言和自由分享各种话题的机会,例如如何保持工作与生活的平衡、在疫情期间如何照顾孩子、从同事那里获得支持、新的商业创意或当前项目的合作。
前沿技能: 如果会议涉及来自需要颠覆性技术技能的行业的与会者,这些行业通常由男性主导,那么会议中的讨论也往往涉及到许多女性尚未掌握的技能,使得这些会议对于时间(充满家庭责任)的女性来说成为一个困难的选择。
女性会议的问题:
为什么要试图成为自然之母: 性别差异应该仅限于自然界所区分的那一点,然后就应该止步于此。之后的一切都应该基于才能、奉献和努力。为什么要把女性聚集在一个会议上,教她们如何开放自己、寻求帮助、变得果断和自信?
为什么要宣扬这些? 我的问题是,为什么我们需要教会所有成年人他们已经知道的东西?为什么我们不能对性别保持中立?没有人能教会整个社会,并改变我们用来观察世界的根深蒂固的偏见视角。这需要一种自下而上的方法,每个人都应感到有责任去推动和支持平等,抵抗社会上普遍存在的偏见。
边缘化: 这更像是一个恶性循环,在这种活动中,边缘化群体本应得到支持,但结果却是进一步边缘化。让女性和男性平等,让另一方理解、讨论、相互支持,并共同成长。
有时候,我会想这是否只限于特定领域或行业,但不幸的是,这种现象无处不在。最近,我看到一个帖子,讲述了一位高级管理人员不得不指出一个全是男性面板讨论的财经会议。
这个现象有个 Fancy 的词叫做 manel,即男性面板。

来源于作者的 LinkedIn 网络
男性倡导者: 男性在推动女性权利和机会方面发挥着至关重要的作用。改善女性在社会和职场中的状况,不能只靠另一半(俗称),即男性。
LinkedIn 推出了帮助女性提升职业发展的课程。其中有一门课程尤为突出,名为“成为职场中的男性盟友”。该课程帮助“性别多数群体”更好地理解阻碍女性发展的刻板印象。
参加了 3 个女性会议后我发现了什么?
虽然我可以继续谈论我们社会如何团结一致并将其推向正轨,但这对你来说可能听起来过于理论化。
那么,让我们看看女性相互支持的力量能创造奇迹的真实例子。
今年,我参加了 3 个这样的会议,其中女性在数据科学领域展示了卓越的工作。我发现这些网络中有一个一致的特点——来自行业的领导者分享他们的故事和处理困难局面的技巧。一些令我深有感触的建议:
做个“是人”:界限仅仅存在于我们的思维中。一旦你超越这些自我设限的界限,机会的世界将为你打开。做一个“是人”的无畏态度在个人和职业两个方面都对我产生了奇迹般的效果。我变得更加自信,能够尽我所能去应对遇到的任何挑战。
通过网络拓展人脉: 建立一个女性数据科学的生态系统,与志同道合的人建立联系,可以让你了解如何处理类似情况。它还帮助你做出更明智的决策,避免犯同样的错误。
共享相同的词汇: 了解业务需求、利益相关者的关注点,将其与自己能做出的贡献进行映射,并大声表达出来。我相信,组织会欣赏那些增加价值的员工,不会让性别、种族或宗教阻碍成功的商业贡献者。
停止对抗潜意识: 重要的是承认周围人的潜意识中可能存在微妙的偏见。但我们必须停止让它干扰我们的愿景。我是一名职场妈妈,深知每小时的价值。我更愿意通过提升自我来高效利用时间。别人可以带走任何东西,但知识永远无法被夺走。继续增加你的知识储备,它将为你铺平正确的道路。
提高生产力的方法: 女性擅长多任务处理(我们都知道这点 😃)。因此,利用这一点对我们有利是很重要的。听播客或技术课程时做饭或散步,可以让我保持警觉,并明智地利用时间。另一个重要的方面是社交媒体的正确使用,我尝试与数据科学领域的领导者建立联系,以使自己保持在最新技术和算法的前沿。
没有金律: 最后,我要说的是,没有成功的秘方。坚持“快速尝试,快速失败”的公式有时会取得好效果。因此,不要成为自我怀疑的受害者,勇敢追求你所梦想的一切。当有人试图打击你时,不要让它影响你。‘在逆境中勇敢面对’。
因此,凭借从这些会议中获得的信心,我实施了我学到的东西,即现身。是的,这帮助我克服了自我怀疑的恐惧。
尽管参加女性数据科学会议对我有所帮助,我的心愿是有一天这些会议不再贴上特定群体的标签。那将是一个这样的会议举办目的实现于一个包容和多样化的世界的日子。
直到那时,让我们践行“每人帮助一人”。
Vidhi Chugh 是一位屡获殊荣的 AI/ML 创新领袖和 AI 伦理学家。她在数据科学、产品和研究交叉点上工作,以提供商业价值和洞察力。她倡导以数据为中心的科学,是数据治理领域的领先专家,旨在构建可信赖的 AI 解决方案。
更多相关话题
机器学习的学习曲线
原文:
www.kdnuggets.com/2018/01/learning-curves-machine-learning.html/2
评论
scikit-learn中的learning_curve()函数
我们将使用learning_curve() 函数 从scikit-learn库生成回归模型的学习曲线。我们不需要单独划分验证集,因为learning_curve()会处理这一点。
在下面的代码单元格中,我们:
-
从
sklearn中进行必要的导入。 -
声明特征和目标。
-
使用
learning_curve()生成绘制学习曲线所需的数据。该函数返回一个包含三个元素的元组:训练集大小,以及验证集和训练集上的错误评分。在函数内部,我们使用以下参数:-
estimator— 指示我们用来估计真实模型的学习算法; -
X— 包含特征的数据; -
y— 包含目标的数据; -
train_sizes— 指定要使用的训练集大小; -
cv— 确定交叉验证拆分策略(我们将立即讨论这一点); -
scoring— 指定使用的错误度量;目标是使用均方误差(MSE)度量,但scoring中没有这个参数;我们将使用最接近的代理,即负 MSE,稍后需要翻转符号。
-
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import learning_curve
features = ['AT', 'V', 'AP', 'RH']
target = 'PE'
train_sizes, train_scores, validation_scores = learning_curve(
estimator = LinearRegression(), X = electricity[features],
y = electricity[target], train_sizes = train_sizes, cv = 5,
scoring = 'neg_mean_squared_error')
我们已经知道了train_sizes中的内容。现在让我们检查另外两个变量,看看learning_curve()返回了什么:
print('Training scores:\n\n', train_scores)
print('\n', '-' * 70) # separator to make the output easy to read
print('\nValidation scores:\n\n', validation_scores)
Training scores:
[[ -0\. -0\. -0\. -0\. -0\. ]
[-19.71230701 -18.31492642 -18.31492642 -18.31492642 -18.31492642]
[-18.14420459 -19.63885072 -19.63885072 -19.63885072 -19.63885072]
[-21.53603444 -20.18568787 -19.98317419 -19.98317419 -19.98317419]
[-20.47708899 -19.93364211 -20.56091569 -20.4150839 -20.4150839 ]
[-20.98565335 -20.63006094 -21.04384703 -20.63526811 -20.52955609]]
----------------------------------------------------------------------
Validation scores:
[[-619.30514723 -379.81090366 -374.4107861 -370.03037109 -373.30597982]
[ -21.80224219 -23.01103419 -20.81350389 -22.88459236 -23.44955492]
[ -19.96005238 -21.2771561 -19.75136596 -21.4325615 -21.89067652]
[ -19.92863783 -21.35440062 -19.62974239 -21.38631648 -21.811031 ]
[ -19.88806264 -21.3183303 -19.68228562 -21.35019525 -21.75949097]
[ -19.9046791 -21.33448781 -19.67831137 -21.31935146 -21.73778949]]
由于我们指定了六个训练集大小,你可能期望每种评分都有六个值。相反,我们得到了六行数据,每行有五个错误评分。
之所以会发生这种情况,是因为learning_curve()在后台执行了k-折交叉验证,其中k的值由我们为cv参数指定的值决定。
在我们的例子中,cv = 5,所以会有五次切分。对于每个切分,都会为每个指定的训练集大小训练一个估计器。上面两个数组中的每列表示一个切分,每行对应一个测试大小。下面是一个用于训练误差评分的表格,以帮助你更好地理解过程:
| 训练集大小(索引) | 切分 1 | 切分 2 | 切分 3 | 切分 4 | 切分 5 |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 0 |
| 100 | -19.71230701 | -18.31492642 | -18.31492642 | -18.31492642 | -18.31492642 |
| 500 | -18.14420459 | -19.63885072 | -19.63885072 | -19.63885072 | -19.63885072 |
| 2000 | -21.53603444 | -20.18568787 | -19.98317419 | -19.98317419 | -19.98317419 |
| 5000 | -20.47708899 | -19.93364211 | -20.56091569 | -20.4150839 | -20.4150839 |
| 7654 | -20.98565335 | -20.63006094 | -21.04384703 | -20.63526811 | -20.52955609 |
要绘制学习曲线,我们只需要每个训练集大小的一个误差评分,而不是 5 个。因此,在下一个代码单元格中,我们取每一行的平均值,并翻转误差评分的符号(如上所述)。
train_scores_mean = -train_scores.mean(axis = 1)
validation_scores_mean = -validation_scores.mean(axis = 1)
print('Mean training scores\n\n', pd.Series(train_scores_mean, index = train_sizes))
print('\n', '-' * 20) # separator
print('\nMean validation scores\n\n',pd.Series(validation_scores_mean, index = train_sizes))
Mean training scores
1 -0.000000
100 18.594403
500 19.339921
2000 20.334249
5000 20.360363
7654 20.764877
dtype: float64
--------------------
Mean validation scores
1 423.372638
100 22.392186
500 20.862362
2000 20.822026
5000 20.799673
7654 20.794924
dtype: float64
现在我们拥有绘制学习曲线所需的所有数据。
然而,在进行绘图之前,我们需要暂停并做一个重要的观察。你可能注意到一些训练集上的误差评分是相同的。对于训练集大小为 1 的行,这是预期的,但其他行呢?除了最后一行,我们有很多相同的值。例如,取第二行,从第二次拆分开始的值是相同的。为什么会这样?
这是由于没有为每次拆分随机化训练数据。我们通过下面的图示来逐步了解一个示例。当训练集的大小为 500 时,前 500 个实例被选中。对于第一次拆分,这 500 个实例将从第二个数据块中选取。从第二次拆分开始,这 500 个实例将从第一个数据块中选取。因为我们没有随机化训练集,所以第二次拆分之后用于训练的 500 个实例是相同的。这解释了 500 个训练实例的情况下,从第二次拆分开始相同的值。
相同的推理适用于 100 个实例的情况,类似的推理适用于其他情况。

要停止这种行为,我们需要将shuffle参数设置为True,以便在learning_curve()函数中对训练数据的每次拆分进行随机化。我们之前没有进行随机化有两个原因:
-
数据已经预先洗牌了五次(如文档中提到的),所以不需要再随机化了。
-
我想让你知道这个怪癖,以防你在实践中遇到它。
最后,让我们进行绘图。
学习曲线 - 高偏差和低方差
我们使用常规的 matplotlib 工作流绘制学习曲线:
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('seaborn')
plt.plot(train_sizes, train_scores_mean, label = 'Training error')
plt.plot(train_sizes, validation_scores_mean, label = 'Validation error')
plt.ylabel('MSE', fontsize = 14)
plt.xlabel('Training set size', fontsize = 14)
plt.title('Learning curves for a linear regression model', fontsize = 18, y = 1.03)
plt.legend()
plt.ylim(0,40)
(0, 40)

从这个图中我们可以提取很多信息。让我们详细地进行分析。
当训练集大小为 1 时,我们可以看到训练集的 MSE 为 0。这是正常行为,因为模型对一个数据点的拟合没有问题。因此,当在同一个数据点上进行测试时,预测是完美的。
但在验证集(包含 1914 个实例)上测试时,均方误差(MSE)飙升至大约 423.4。这一相对较高的值是我们将 y 轴范围限制在 0 到 40 之间的原因。这使我们能够更精确地读取大多数 MSE 值。如此高的值是可以预期的,因为模型在单一数据点上训练,不太可能对 1914 个在训练中未见过的新实例做出准确的泛化。
当训练集大小增加到 100 时,训练 MSE 急剧上升,而验证 MSE 也同样下降。线性回归模型没有完美预测所有 100 个训练点,因此训练 MSE 大于 0。然而,模型在验证集上的表现现在好多了,因为它使用了更多的数据进行估计。
从 500 个训练数据点开始,验证 MSE 大致保持不变。这告诉我们一个极其重要的事情:添加更多的训练数据点不会显著改善模型。因此,我们需要尝试其他方法,比如切换到可以构建更复杂模型的算法,而不是浪费时间(可能还会浪费金钱)去收集更多数据。

为了避免误解,重要的是注意到真正没有帮助的是在训练数据中添加更多的实例(行)。然而,添加更多的特征是另一回事,很可能会有所帮助,因为这会增加我们当前模型的复杂性。
现在让我们来诊断偏差和方差。偏差问题的主要指标是高验证错误。在我们的案例中,验证 MSE 停滞在大约 20 的值。但这有多好呢?我们需要一些领域知识(在这个情况下可能是物理学或工程学)来回答这个问题,但我们还是尝试一下。
从技术上讲,20 的值单位是 MW²(兆瓦平方)(单位也会平方当我们计算 MSE 时)。但我们目标列中的值是以 MW 为单位(根据文档)。取 20 MW²的平方根约为 4.5 MW。每个目标值代表净小时电力输出。因此,每小时我们的模型平均偏差为 4.5 MW。根据这个 Quora 回答,4.5 MW 相当于 4500 个手持吹风机所产生的热功率。如果我们尝试预测一天或更长时间的总能量输出,这个值将会累积。
我们可以得出结论,20 MW²的 MSE 相当大。因此,我们的模型存在偏差问题。但是这是一个低偏差问题还是一个高偏差问题?
要找到答案,我们需要查看训练误差。如果训练误差非常低,这意味着估计模型对训练数据的拟合非常好。如果模型对训练数据的拟合非常好,这意味着它对该数据集的偏差很低。
如果训练误差很高,这意味着估计模型对训练数据的拟合不够好。如果模型无法很好地拟合训练数据,这意味着它对该数据集的偏差很高。

在我们特定的案例中,训练 MSE 平稳在大约 20 MW22 的值。正如我们已经确定的,这是一个高误差分数。由于验证 MSE 很高,而训练 MSE 也很高,我们的模型存在高偏差问题。
现在让我们继续诊断最终的方差问题。估计方差至少有两种方法:
-
通过检查验证学习曲线和训练学习曲线之间的差距。
-
通过检查训练误差:其值及随着训练集大小增加的演变。

窄的差距表示低方差。一般来说,差距越窄,方差越低。反之亦然:差距越宽,方差越大。现在让我们解释为什么会这样。
正如我们之前讨论的,如果方差很高,则模型对训练数据拟合得过好。当训练数据拟合得过好时,模型将难以对未在训练中见过的数据进行泛化。当这样的模型在其训练集上进行测试,然后在验证集上进行测试时,训练误差将很低,而验证误差通常会很高。随着训练集大小的变化,这种模式会持续下去,训练误差和验证误差之间的差异将决定两条学习曲线之间的差距。
训练误差和验证误差之间的关系可以总结如下:
gap=验证误差−训练误差 gap=验证误差−训练误差
因此,两种误差之间的差异越大,差距也越大。差距越大,方差也越大。
在我们的案例中,差距非常小,因此我们可以放心地得出方差很低的结论。
高训练 MSE 分数也是检测低方差的快捷方式。如果学习算法的方差很低,那么随着训练集的变化,算法会产生简化且类似的模型。由于模型过于简化,它们甚至无法很好地拟合训练数据(它们欠拟合了数据)。因此,我们应该预期高训练 MSE。因此,高训练 MSE 可以用作低方差的指示器。

在我们的案例中,训练的均方误差(MSE)在大约 20 处趋于平稳,我们已经得出结论这是一个较高的值。因此,除了狭窄的差距,我们现在还有另一个确认表明我们有一个低方差问题。
到目前为止,我们可以得出结论:
-
我们的学习算法存在高偏差和低方差的问题,对训练数据进行欠拟合。
-
在当前学习算法下,向训练数据中添加更多实例(行)极不可能导致更好的模型。
此时的一个解决方案是更改为更复杂的学习算法。这应该能减少偏差并增加方差。错误的做法是尝试增加训练实例的数量。
通常,这另外两种修复方法也适用于处理高偏差和低方差问题:
-
在更多特征上训练当前学习算法(为了避免收集新数据,你可以轻松生成多项式特征)。这应该通过增加模型的复杂性来降低偏差。
-
减少当前学习算法的正则化,如果是这种情况。简而言之,正则化防止算法对训练数据过于拟合。如果我们减少正则化,模型将更好地拟合训练数据,因此方差将增加,偏差将减少。
学习曲线 - 低偏差和高方差
让我们看看一个未正则化的随机森林回归器在这里的表现。我们将使用与上述相同的工作流程生成学习曲线。这次我们将所有内容打包成一个函数,以便以后使用。为了进行比较,我们还将展示线性回归模型的学习曲线。
### Bundling our previous work into a function ###
def learning_curves(estimator, data, features, target, train_sizes, cv):
train_sizes, train_scores, validation_scores = learning_curve(
estimator, data[features], data[target], train_sizes = train_sizes,
cv = cv, scoring = 'neg_mean_squared_error')
train_scores_mean = -train_scores.mean(axis = 1)
validation_scores_mean = -validation_scores.mean(axis = 1)
plt.plot(train_sizes, train_scores_mean, label = 'Training error')
plt.plot(train_sizes, validation_scores_mean, label = 'Validation error')
plt.ylabel('MSE', fontsize = 14)
plt.xlabel('Training set size', fontsize = 14)
title = 'Learning curves for a ' + str(estimator).split('(')[0] + ' model'
plt.title(title, fontsize = 18, y = 1.03)
plt.legend()
plt.ylim(0,40)
### Plotting the two learning curves ###
from sklearn.ensemble import RandomForestRegressor
plt.figure(figsize = (16,5))
for model, i in [(RandomForestRegressor(), 1), (LinearRegression(),2)]:
plt.subplot(1,2,i)
learning_curves(model, electricity, features, target, train_sizes, 5)

现在让我们尝试应用我们刚刚学到的知识。此时暂停阅读并尝试自己解释新的学习曲线会是个好主意。
通过查看验证曲线,我们可以看到我们已经设法减少了偏差。虽然仍然存在一些显著的偏差,但比之前少了很多。通过查看训练曲线,我们可以推测这次存在一个低偏差问题。
两条学习曲线之间的新差距表明方差显著增加。低的训练均方误差(MSE)证实了这一高方差的诊断。
大的差距和低的训练误差也表明存在过拟合问题。过拟合发生在模型在训练集上表现良好,但在测试(或验证)集上表现较差时。
我们可以在这里做出一个更重要的观察,即添加新的训练实例很可能会导致更好的模型。验证曲线没有在使用的最大训练集大小处趋于平稳。它仍然有潜力降低并趋近于训练曲线,类似于我们在线性回归情况下看到的收敛情况。
到目前为止,我们可以得出结论:
-
我们的学习算法(随机森林)在训练数据上过拟合,表现出较高的方差和较低的偏差。
-
在当前学习算法下,增加更多的训练实例很可能会导致更好的模型。
到目前为止,我们可以做几件事情来改进我们的模型:
-
增加更多的训练实例。
-
增加我们当前学习算法的正则化。这应该会减少方差并增加偏差。
-
减少我们当前使用的训练数据中的特征数量。算法仍然会很好地拟合训练数据,但由于特征数量的减少,它会构建较简单的模型。这应该会增加偏差并减少方差。
在我们的案例中,我们没有其他现成的数据。我们可以去电厂进行一些测量,但我们将留到另一个帖子中(开个玩笑)。
不如尝试对我们的随机森林算法进行正则化。实现这一点的一种方法是调整每棵决策树中的最大叶节点数。可以通过使用 RandomForestRegressor() 的 max_leaf_nodes 参数来完成。你不必理解这种正则化技术。对于我们目前的目的,你需要关注的是这种正则化对学习曲线的影响。
learning_curves(RandomForestRegressor(max_leaf_nodes = 350), electricity, features, target, train_sizes, 5)

不错!现在差距缩小了,因此方差减少了。偏差似乎稍微增加了一点,这正是我们想要的。
但我们的工作还远未结束!验证 MSE 仍显示出很大的下降潜力。你可以采取的一些步骤包括:
-
增加更多的训练实例。
-
增加更多的特征。
-
特征选择。
-
超参数优化。
理想的学习曲线和不可减少的误差
学习曲线是一个很好的工具,可以在机器学习工作流中的每一个点上快速检查我们的模型。但是我们如何知道何时停止?我们如何识别完美的学习曲线?
对于我们之前的回归案例,你可能会认为完美的情境是当两条曲线都收敛到 MSE 为 0. 这确实是一个完美的情境,但不幸的是,这在实践中和理论上都不可能。原因是所谓的不可减少的误差。
当我们构建一个模型来映射特征X和目标Y之间的关系时,我们首先假设存在这样的关系。如果假设是正确的,那么确实存在一个完美描述X和Y之间关系的真实模型 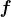 ,如下面所示:
,如下面所示:
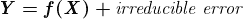 (1)
(1)
那么为什么会有错误呢?!我们不是刚刚说过 完美地描述了 X 和 Y 之间的关系吗?!
这里有一个错误,因为Y不仅是我们有限特征X的函数。可能还有许多其他特征影响Y的值。我们没有这些特征。也可能X包含测量误差。因此,除了X之外,Y也是不可约误差的函数。
现在让我们解释为什么这种误差是不可约的。当我们用模型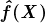 估计f(X)时,我们引入了另一种误差,称为可约误差:
估计f(X)时,我们引入了另一种误差,称为可约误差:
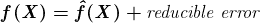 (2)
(2)
在(1)中替换f(X),我们得到:
 (3)
(3)
可约误差可以通过构建更好的模型来减少。从方程(2)中我们可以看到,如果可约误差为 0,我们估计的模型等于真实模型f(X)。然而,从(3)中我们可以看到,即使可约误差为 0,不可约误差仍然存在于方程中。因此,我们推断无论我们的模型估计有多好,通常仍然存在一些我们无法减少的误差。这就是为什么这种误差被认为是不可约的原因。
这告诉我们,在实际操作中,我们看到的最佳学习曲线是那些收敛到某种不可约误差值的曲线,而不是收敛到某种理想误差值(对于均方误差,理想的误差值是 0;我们会立即看到其他误差度量有不同的理想误差值)。

在实践中,无法准确知道不可约误差的值。我们还假设不可约误差与X无关。这意味着我们不能使用X来找到不可约误差的真实值。用更精确的数学语言表达,就是没有函数g可以将X映射到不可约误差的真实值:
不可约误差 ≠ g(X)
因此,根据我们拥有的数据无法知道不可约误差的真实值。在实践中,一个好的方法是尽可能降低误差分数,同时牢记限制由某种不可约误差决定。
那么分类呢?
到目前为止,我们了解了回归设置中的学习曲线。对于分类任务,工作流程几乎相同。主要的区别在于我们需要选择另一种误差度量——一种适合评估分类器性能的度量。我们来看一个例子:

与我们迄今为止看到的不同,注意训练误差的学习曲线高于验证误差的曲线。这是因为使用的分数,准确性,描述了模型的好坏。准确性越高,模型越好。而均方误差(MSE)则描述了模型的差劲程度。均方误差越低,模型越好。
这也对不可减少的错误有影响。对于描述模型有多差的误差度量,不可减少的错误提供了一个下界:你不能低于这个值。对于描述模型有多好的误差度量,不可减少的错误提供了一个上界:你不能高于这个值。
这里补充一点,在更技术性的写作中,通常使用贝叶斯误差率来指代分类器的最佳可能错误分数。这个概念类似于不可减少的错误。
下一步
学习曲线是诊断任何监督学习算法中的偏差和方差的绝佳工具。我们已经学习了如何使用 scikit-learn 和 matplotlib 生成它们,并如何利用它们来诊断我们模型中的偏差和方差。
为了巩固你所学到的内容,以下是一些值得考虑的下一步:
-
使用不同的数据集生成回归任务的学习曲线。
-
生成分类任务的学习曲线。
-
通过从头开始编写代码(不要使用
learning_curve()来自 scikit-learn),生成监督学习任务的学习曲线。使用交叉验证是可选的。 -
比较没有进行交叉验证和使用交叉验证获得的学习曲线。这两种曲线应针对相同的学习算法。
简介: 亚历克斯·奥尔特亚努 是 Dataquest.io 的学生成功专家。他喜欢学习和分享知识,并为新的 AI 革命做好准备。
原文。经授权转载。
相关内容:
-
机器学习中的正则化
-
如何在 Python 中生成 FiveThirtyEight 图表
-
训练集、测试集和 10 折交叉验证
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关话题
通过社交媒体学习数据科学
原文:
www.kdnuggets.com/2021/07/learning-data-science-through-social-media.html
comments
由 Susan Sivek 提供,她是 Alteryx 的数据科学记者。

我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 支持
我的社交媒体动态主要由新闻头条、小狗、烘焙食品和朋友的假期照片组成。然而,我的动态中也撒了点数据科学的内容,恰到好处地刺激我的大脑,让我在无意识地滚动时偶尔清醒过来。
如果你想把社交媒体时间专注于娱乐,我尊重这一点——但如果你希望这些社交算法向你展示真正的算法,请继续阅读。我会分享一些账户和社区,供你轻松一瞥好主意和你可以实现的技巧。
在 Twitter 上,我关注了很多数据科学新闻来源,但我也欣赏那些经常在仅有 280 个字符内分享简单信息的账户,而不链接到更长的资源。
- Data Science Fact (@DataSciFact) 发布关于各种数据科学概念的快速事实。
- Daily Python Tip (@python_tip) 每天提供一个简洁总结的想法或工具建议。

- One R Tip a Day (@RLang Tip) 由微软的 R 社区团队运营,提供你猜的,每天一个 R 小贴士。
- Probability Fact (@ProbFact) 每天提供一个概率概念或见解。
除了从你网络中的人们分享的信息中学习外,还有其他方式可以从 LinkedIn 获取有用的数据科学信息。
- 关注话题标签。通过关注 LinkedIn 上的特定话题标签(类似于在 Instagram 上关注话题标签),您可以获取更广泛的感兴趣话题的信息。例如, #datascience 在许多文章、视频和其他帖子中都有使用。LinkedIn 会将一些带有话题标签的内容插入您的主要动态中。

- 加入小组。LinkedIn 上有许多与数据科学相关的小组,分享资源、提供网络联系,并主持讨论。查看 Data Literacy Advocates、 Women in Data Science 和 Big Data and Analytics,或者寻找更多适合您兴趣的特定小组,例如 Supply Chain Data Science。
每个与数据相关的子版块都有其自己的重点和氛围。这里列出了一些,当然还有许多其他值得探索的。
-
r/datascience: 这是一个充满活力的社区,拥有超过五十万成员。每周都有讨论学习数据科学和进入该领域的线程。对内容要求较严格,并且有积极的管理。
-
r/MachineLearning: 这个子版块非常庞大(190 万成员),可以更具技术性,许多帖子专注于分享和讨论前沿的学术出版物。
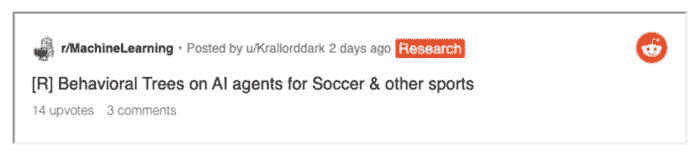
-
r/learnmachinelearning: 这个小组对刚刚开始接触机器学习的人更为友好,尽管讨论仍然可以深入。对初学者的问题比上面的两个小组更为包容。
-
r/statistics: 这个社区是“涉及统计理论、软件和应用的所有事物”的空间。您可以安全地探索统计学的最隐秘角落。
是的,在网红和#赞助帖之间,也有一些教育性的数据科学内容!
- @bigdataqueen 提供了数据科学和机器学习的新视角,您的动态中会出现精美设计的图形和详尽的、有益的说明文字。
- @pycoders 发布备忘单和快速技巧,还有大量的幽默素材,让您可以从严肃的内容中休息一下(并找到分享给同事的有趣内容)。
- @data_science_learn 分享了一些关于统计学主题和各种数据科学工具的信息帖 —— 同时,也有大量的搞笑图片。
- Women Who Code 在 Instagram 上有与数据科学和 Python 相关的专业账户。 Python 账户 每周会进行“Trivia Tuesday”活动,帮助你复习 Python 基础知识,而 数据科学账户 则提供视频片段和统计回顾帖。
原创。经许可转载。
个人简介: 苏珊·库里·西维克(Susan Currie Sivek),博士,是 Alteryx 社区的高级数据科学记者,她与全球观众探讨数据科学概念。她还是 数据科学混音秀 播客的主持人。她在学术界和社会科学方面的背景为她调查数据和传达复杂思想的方式提供了丰富的经验,同时她在新闻学中的创意训练也为她的工作增添了独特的视角。
相关内容:
更多相关内容
从机器学习错误中学习
原文:
www.kdnuggets.com/2021/03/learning-from-machine-learning-mistakes.html
评论
由Emeli Dral,Evidently AI 的 CTO 和联合创始人
图片由作者提供
当我们分析机器学习模型性能时,我们通常关注单一质量指标。对于回归问题,这可能是 MAE、MAPE、RMSE,或者其他最适合问题领域的指标。
在训练实验中优化单一指标绝对是有意义的。这样,我们可以比较不同的模型运行,并选择最佳的那个。
但当涉及到解决实际业务问题并将模型投入生产时,我们可能需要了解更多信息。模型在不同用户组中的表现如何?它会产生哪些类型的错误?
在这篇文章中,我将更详细地介绍评估回归模型性能的方法。
回归误差:过多还是过少?
当我们预测一个连续变量(如价格、需求等)时,常识定义的错误很简单:我们希望模型预测尽可能接近实际值。
在实际操作中,我们可能不仅关心绝对误差值,还会关注其他标准。例如,我们对趋势的捕捉程度如何,预测值与实际值之间是否有相关性——最后我们的错误符号是什么。
低估和高估目标值可能会有不同的业务影响。特别是当模型输出上有一些业务逻辑时。
想象一下你在为一家超市连锁进行需求预测。一些产品是易腐品,根据错误的预测交付过多会导致浪费。高估有明显的成本需要考虑。

除了经典的误差分析外,我们可能还需要追踪这种误差偏斜(高估或低估的倾向)及其随时间的变化。这在分析模型验证和生产监控时都很有意义。
为了说明分析误差偏差的概念,让我们通过一个例子来讲解。
评估模型性能
假设我们有一个模型来预测城市自行车租赁的需求。(如果你想尝试这个用例,这个Bike Demand Prediction dataset是公开的)。
我们训练了一个模型,模拟了部署,并将其在“生产”环境中的表现与训练集上的表现进行了比较。
实际中,我们需要知道实际情况。一旦我们了解实际需求,就可以计算我们模型的质量,并估计预测的偏差程度。
在训练中的参考性能和当前生产性能之间,我们可以看到误差的显著增加。

截图来自 明显 报告。
为了更好地理解质量,我们可以查看误差分布。 这确认了我们已经知道的:误差增加了。也有一些偏向过度估计的偏差。
截图来自 明显 报告。
情况并不理想,我们希望深入了解发生了什么。 我们的业务利益相关者也有相同的期望。这些误差为何发生?具体在哪里?重新训练能否提高质量?我们是否需要工程化新特征或进行进一步的后处理?
这里有一个探索它的想法。
观察边缘
聚合质量指标向我们展示了均值性能。然而,这些极端情况往往能提供有用的信息。让我们直接看这些!
我们可以将误差较高的预测进行分组,并从中学习一些有用的信息。
我们如何实现这种方法?
我们来计算每个单独预测的误差。然后,我们根据误差的类型创建两个组:
-
过度估计。 模型预测的值高于实际值的情况。
-
低估。 模型预测的值低于实际值的情况。
我们限制每组的大小,只选择 5%误差最大的极端例子。这样,我们得到了模型过度估计的前 5%预测和模型低估的前 5%预测。
剩余的 90%预测是“多数”。这一组的误差应该接近均值。
这就是我们如何可视化建议的细分。我们希望看到的情况是:大多数预测接近实际值。分析离群值可以带来有意义的洞见。
作者提供的图像。
这如何有用?
让我们以时间序列为例。 如果我们建立了一个优秀的模型,并“学习”了数据中的所有信号,误差应该是随机的。应该没有模式。除了少数可能的离群值外,所有组的误差应该接近平均值。有时稍大,有时稍小。但平均而言,差不多相同。
如果数据中有一些有用的信号可以解释误差,情况可能会有所不同。 某些特定组可能会有较大的误差。也可能会有明显的低估或高估的偏差。
在这些情况下,错误可能依赖于特定的特征值。如果我们能够找到并描述错误高于正常水平的实例,那正是我们想要调查的内容!
识别缺陷
在我们的案例中,我们可以看到,过高估计和低估组的错误都显著高于“主要”组的错误。
来自Evidently报告的截图。
然后我们可以尝试调查和探索新的模式。
为了做到这一点,我们查看 5%-组中的对象,并查看对应的特征值。逐个特征,如果可能的话。
我们的目标是确定特定特征值与高错误之间是否存在关系。为了深入了解,我们还需要区分过高估计或低估。
想象一下,我们预测医疗成本,并且始终高估某些人口统计特征的患者的价格?或者,错误是无偏的但很大,我们的模型在特定段上失败了?这就是我们想要找到的洞察。
作者提供的图片。
我们可以制作一个复杂(且计算量大的)算法来执行这一搜索,以查找表现不佳的段落。作为合理的替代方案,我们可以逐个特征进行此分析。
我们如何做到这一点?让我们绘制特征分布和目标需求,并用颜色标记我们犯高错误的示例。
在我们的自行车需求预测用例中,我们已经可以得到一些见解。如果我们绘制“湿度”特征,我们可以注意到,当湿度值在 60 到 80 之间时,我们的模型现在显著高估需求(右侧绘制)。
我们在训练数据集中看到了这些值(左侧绘制),但错误在整个范围内都是无偏的和相似的。
来自Evidently报告的截图。
我们也可以注意到其他模式。例如,在温度方面。当温度高于 30°C 时,模型也会高估需求。
来自Evidently报告的截图。
我们现在可以怀疑天气发生了变化,新的相关模式出现了。实际上,我们使用的是仅来自一年寒冷月份的数据来训练模型。当模型进入“生产”阶段时,夏天刚刚开始。随着新天气的到来,出现了新的季节性模式,而模型之前未能掌握这些模式。
好消息是,通过查看这些图表,我们可以看到数据中似乎存在一些有用的信号。用新数据重新训练我们的模型可能会有所帮助。
如何对我的模型做同样的事情?
我们在Evidently开源库中实现了这种方法。要使用它,你应该将模型应用数据准备为 pandas DataFrame,包括模型特征、预测和实际(目标)值。
该库可以与单个 DataFrame 或两个 DataFrame 一起使用——如果你想比较模型在生产环境中的表现与训练数据或其他过去的时间段。
图片来源:作者。
回归性能报告将生成一组关于模型性能的图表和一个误差偏差表。该表有助于探索特征值与误差类型和大小之间的关系。
你还可以快速排序特征,以找到那些“极端”组与“多数”组表现不同的特征。这有助于在不需要逐一查看每个特征的情况下,识别最有趣的细分。
你可以在Github上阅读完整文档。
什么时候会有用?
我们相信这种分析在你的模型生命周期中多次使用会很有帮助。你可以用它:
-
分析模型测试结果。例如,一旦你对模型进行了离线测试,或者进行了 A/B 测试或影子部署后。
-
进行生产环境中模型的持续监控。你可以在每次运行批量模型时执行此操作,也可以将其安排为定期任务。
-
决定模型是否需要重新训练。通过查看报告,你可以判断是否需要更新模型,或者重新训练是否会有所帮助。
-
调试生产环境中的模型。如果模型质量出现问题,你可以发现模型表现不佳的细分,并决定如何解决。例如,你可能会为低性能的细分提供更多数据,重建模型或在模型上添加业务规则。
如果你需要一个实际示例,这里有一个tutorial关于如何在生产环境中调试机器学习模型性能的教程:“如何在 20 天内破坏一个模型”。
简介:Emeli Dral 是 Evidently AI 的联合创始人兼首席技术官,她创建了分析和监控机器学习模型的工具。她曾共同创办一家工业 AI 初创公司,并担任 Yandex Data Factory 的首席数据科学家。她是 Coursera 上机器学习和数据分析课程的共同作者,该课程有超过 100,000 名学生。
原文。经许可转载。
相关:
-
机器学习模型监控清单:需要跟踪的 7 个事项
-
MLOps:模型监控 101
-
使用平均精度评估目标检测模型
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
更多相关话题
通过梯度下降学习学习
原文:
www.kdnuggets.com/2017/02/learning-learn-gradient-descent.html
通过梯度下降学习学习,Andrychowicz 等,NIPS 2016
阅读这些 NIPS 论文时,让我印象深刻的一点是有些论文的长度是如此之短——在介绍和评估部分之间你可能只会找到一两页!一种通用形式是从问题领域的基本数学模型开始,用函数表示。然后,选择的函数被学习,通过进入机器学习工具箱并以潜在的新方式组合现有的构建块。从这个角度看,我们可以真正称机器学习为‘函数学习’。
用这种函数的方式思考对我来说是一种回到熟悉领域的桥梁。我们有函数组合。例如,给定一个将图像映射到特征表示的函数f,以及一个作为分类器的函数g,将图像特征表示映射到对象,我们可以构建一个用g ○ f分类图像中的对象的系统。
系统模型中的每个函数可以是学习得来的,也可以直接用某些算法实现。例如,特征映射(或编码)传统上是手动实现的,但越来越多的是通过学习实现的...
从手动设计的特征到学习得来的特征的转变在机器学习中取得了巨大成功。
艺术的一部分似乎在于以一种方式定义整体模型,使得单个函数不需要做太多工作(避免输入和目标输出之间差距过大),从而使学习变得更高效/可处理,并且我们可以根据需要为每个函数采用不同的技术。在上述示例中,我们组合了一个用于创建良好表示的学习函数和另一个用于从这些表示中识别对象的函数。
我们可以拥有将现有(学习过的或其他)函数结合起来的高阶函数,当然这也意味着我们可以使用组合子。
当我们查看“函数学习器”(机器学习系统)的组件时,我们发现了什么?更多的函数!
机器学习中的任务通常可以表达为优化一个在某些领域θ ∈ Θ上定义的目标函数f(θ)的问题。
优化器函数从f θ映射到argmin[θ ∈ Θ] f θ。标准方法是使用某种形式的梯度下降(例如,SGD——随机梯度下降)。优化领域的一篇经典论文是《优化的无免费午餐定理》,它告诉我们没有通用的优化算法可以主导所有其他算法。因此,为了获得最佳性能,我们需要将优化技术与手头问题的特点匹配:
... 针对特定问题子类的专业化实际上是实现普遍性能提升的唯一方式。
因此,在为不同类别的问题定义更新规则方面,已经进行了大量研究——在深度学习中,这些包括例如momentum、Rprop、Adagrad、RMSprop和ADAM。
但如果我们不是手动设计一个优化算法(函数),而是学习它呢?通过在我们感兴趣的问题类别上进行训练,我们可以为这一类别学习一个最佳优化器!
这项工作的目标是开发一个构建学习算法的程序,使其在特定类别的优化问题上表现良好。将算法设计视为学习问题使我们能够通过示例问题实例来指定我们感兴趣的问题类别。这与通过分析有趣问题的性质并利用这些分析洞察手动设计学习算法的传统方法形成对比。
如果学习的表示最终比手动设计的表示表现更好,那么学习型优化器是否也能比手动设计的优化器表现更好呢?答案确实是肯定的!
我们的实验已确认,学习型神经网络优化器与深度学习中使用的最先进优化方法相比表现优越。
实际上,这些学习型优化器不仅表现非常好,还提供了一种有趣的跨问题集迁移学习方式。传统上,迁移学习是一个作为独立问题研究的困难领域。但在这种情况下,由于我们正在学习如何学习,直接的泛化(机器学习的关键特性,使我们能够在训练集上学习,然后在以前未见过的例子上表现良好)提供了迁移学习!
我们见证了显著的迁移能力,例如,在 12,288 参数神经艺术任务上训练的 LSTM 优化器能够在具有 49,512 参数、不同风格和不同内容图像的任务上进行泛化。我们在将其迁移到 MNIST 任务的不同架构时也观察到了类似的令人印象深刻的结果。
学习如何学习
从功能性思维来看,这是我对发生情况的心理模型……起初,你可能手动编码了一个分类器函数c,它将某些Input映射到一个Class:
c :: Input -> Class
通过机器学习,我们发现对于某些类型的函数,学习一个实现比手动编码更为有效。一个优化函数f接受一些TrainingData和一个现有的分类器函数,然后返回一个更新后的分类器函数:
type Classifier = (Input -> Class)
f :: TrainingData -> Classifier -> Classifier
我们现在的做法是,既然我们可以学习一个函数,为什么不直接学习f本身呢?
type Optimiser = (TrainingData -> Classifier -> Classifier)
g :: TrainingData -> Optimiser -> Optimiser
设ϕ为我们(优化器)的(待学习的)更新规则。我们需要评估在多次迭代中g的效果,因此g使用递归神经网络(LSTM)进行建模。该网络在时间t的状态由h[t]表示。
假设我们正在训练g以优化一个优化函数f。设g(ϕ)导致一个学习到的f θ参数集,训练g(ϕ)的损失函数使用f经过g(ϕ)训练后的预期损失作为其预期损失。
我们可以通过对ϕ进行梯度下降来最小化L(ϕ)的值。
为了扩展到数万或更多的参数,优化器网络m在目标函数的参数上逐坐标操作,类似于 RMSProp 和 ADAM 等更新规则。每个坐标的更新规则是使用一个具有遗忘门架构的 2 层 LSTM 网络实现的。
网络输入单个坐标的优化梯度以及之前的隐藏状态,并输出对应优化参数的更新。我们称这种架构为 LSTM 优化器。
运行中的学习型学习者
我们将训练好的优化器与深度学习中使用的标准优化器进行比较:SGD、RMSprop、ADAM 以及 Nesterov 加速梯度(NAG)。对于每个优化器和每个问题,我们调整了学习率,并报告了在每个问题上给出最佳最终误差的学习率结果。
优化器被训练用于 10 维二次函数、优化 MNIST 上的小型神经网络、CIFAR-10 数据集,以及学习用于神经艺术的优化器(例如,参见纹理网络)。
这里是训练的 LSTM 优化器在 Neural Art 任务上的性能与标准优化器的对比:
而且因为它们非常漂亮……这里有一些由 LSTM 优化器风格化的图像!

系统模型及学习到的组件
所以就是这样。看起来在不久的将来,最先进的技术将涉及使用学习到的优化器,就像今天使用学习到的特征表示一样。这似乎是机器可以设计出比最优秀的人类设计师更优算法的另一个交叉点。当然,学习学习算法有特别强大的潜力,因为更好的学习算法可以加速学习……
在这篇论文中,作者探讨了如何构建一个函数g来优化函数f,使得我们可以写出:
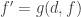
其中d是一些训练数据。
以这种方式表达时,显然会引发一个问题,如果我写:
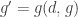
或者更进一步使用 Y 组合子找到一个固定点:
发人深省...
简介: Adrian Colyer 曾任 SpringSource 的 CTO,随后是 VMware 和 Pivotal 的应用 CTO。他现在是伦敦 Accel Partners 的风险合伙人,与欧洲的早期阶段和初创公司合作。如果你正在从事有趣的技术相关业务,他很乐意听到你的消息:你可以通过 acolyer at accel dot com 联系他。
原文。转载许可。
相关:
-
标准模型拟合方法的简明概述
-
神经网络中的深度学习:概述
-
人工智能与 2030 年的生活
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关主题
学习机器学习 vs 学习数据科学
原文:
www.kdnuggets.com/2018/12/learning-machine-learning-data-science.html
评论
作者 Terran Melconian,企业家和顾问,以及 Trevor Bass,edX

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 部门
图片由 Intersection Consulting 提供
当你想到“数据科学”和“机器学习”时,这两个术语是否混淆在一起,如同 Currier 和 Ives 或 Sturm 和 Drang?如果是这样,你来对地方了。本文将澄清两者之间的一些重要且常被忽视的区别,帮助你更好地专注于学习和招聘。
机器学习与数据科学的比较
机器学习受到了媒体的大量炒作,而这些媒体有时对术语并不十分准确。在大众话语中,它已经超出了从业者的范围,涵盖了广泛的含义和影响。机器学习指的是一种特定形式的数学优化:通过训练数据或经验,使计算机在某个任务上表现更好,而无需明确编程。这通常表现为基于已知结果的过去案例建立一个模型,并将该模型应用于预测未来案例,寻找最小化数值“误差”或“成本”函数的方式,以表示预测与现实的偏差。
注意到一些重要的商业活动在机器学习的定义中没有出现:
-
评估数据是否适合某个目的
-
制定适当的目标
-
实施系统和流程
-
与不同利益相关者沟通
这些职能的需求促成了数据科学作为一个领域的认知。哈佛商业评论告诉我们,“数据科学家的关键技能不是构建和使用深度学习基础设施的能力。而是学习能力和良好的沟通能力,以回答商业问题,将复杂的结果向非技术相关者解释清楚。” 其他作者同意:“我们认为数据科学家的一个定义特征是其技能的广度——他们能够单独完成所有需要的步骤,至少是原型级别的,以获取新见解或构建数据产品。” 另一篇 HBR 文章确认,“从机器学习中获得价值并不是关于更复杂的算法——而是让它更易于使用……大多数公司面临的差距不是机器学习不起作用,而是他们难以实际使用它。”
机器学习是数据科学家的一项重要技能,但它只是其中之一。将机器学习视为数据科学的全部,就如同将会计视为运营一个盈利公司的全部。此外,数据科学中的技能差距主要体现在与机器学习互补的领域——商业敏感性、统计学、问题框架和沟通能力。
如果你想成为一名数据科学家,寻求跨学科的教育。
数据科学家需求高且不断增长已是不争的事实。尽管如此,许多最受炒作的数据科学教育编程往往集中在机器 学习 教学 中 的。
我们认为这是一个严重的问题。许多学生过于集中于机器学习教育,而忽视了更为均衡的课程。这不幸导致了大量准备不足的初级职业人士寻求数据科学职位。两位作者,以及他们在准备这篇文章时交谈过的几位数据科学招聘经理,都面试了许多宣称具备机器学习知识的候选人,但这些候选人对于基本统计学、偏差与方差或数据质量知之甚少,更不用说提出一个连贯的项目方案以实现商业目标了。
根据作者的经验,软件工程师似乎特别容易受到过于丰富的机器学习教育的诱惑。我们推测这是因为机器学习使用了与软件开发人员已经熟悉的思维方式相同的思维方式:算法化、收敛性思维与明确的目标。过于专业化的机器学习教育提供了更有趣工作的虚假承诺,而不需要任何基本的认知转变。遗憾的是,职场市场很少能兑现这一承诺,许多遵循这条道路的人发现他们无法从工程师转变为科学家。
数据科学要求学习一种不同的思维方式:通常是发散的,定义模糊的,并且需要在技术领域内外不断地转换。数据科学家本质上是通才,受益于广泛的教育而非深入的教育。跨学科研究比狭窄的专注更有前途。
可扩展性与非可扩展性工作的区别
大多数组织通过雇佣通才数据科学家而非机器学习专家将创造显著更多的价值。要理解为什么会这样,了解 可扩展 与 非可扩展 工作之间的区别是有帮助的。
创建通用机器学习算法是一项可扩展的工作——一旦有人设计并实现了一个算法,大家几乎无需复制成本即可使用它。当然,每个人都希望使用由最佳研究人员创造的最佳算法。大多数组织负担不起顶级算法设计师的薪资,其中许多人获得七位数的年薪。幸运的是,他们的许多工作通过研究论文、开源库和云 API 向公众开放。因此,世界上最优秀的机器学习算法设计师具有巨大的影响力,他们的工作使得使用这些算法的通才数据科学家也能产生相应的重大影响。
相反,数据科学是一项可扩展性较差的活动。它涉及了解特定公司的业务、需求和资产。大多数规模较大的组织需要他们自己的数据科学家。即使其他公司的数据科学家详细发布了他们的方法,也几乎可以肯定,问题和情况的某些方面会有所不同,因此方法不能完全照搬。
当然,除了数据科学之外,还有许多非常值得且有趣的职业道路。如果你更具体地考虑从事机器学习领域的职业,这里有一个行业的“黑暗秘密”:在大型公司中,机器学习工程师实际上自己做的机器学习工作非常少。相反,他们大部分时间都花在构建数据处理管道和模型部署基础设施上。如果你想要这些(通常非常优秀的)职位,我们仍然建议将你的教育重点放在机器学习算法的少部分内容上,而更多地关注通用工程、DevOps 实践和数据管道基础设施。
虽然世界上最好的机器学习专家可能在贡献人类知识的总和方面比世界上最好的数据科学家更有价值,但一位熟练的数据科学家可以在更广泛的情况中产生巨大的影响。就业市场反映了这一点。如果你在寻找工作,最好将机器学习教育作为均衡饮食的一部分来学习。如果你希望使你的公司更加数据驱动,你可能会发现雇佣一个通才效果最好。
与炒作相反,除了基础知识之外积累机器学习教育而不在互补领域提升技能,在就业市场上的回报会递减。
简介:Terran Melconian 曾领导过软件工程、数据仓储和数据科学团队,涵盖了从初创公司到行业巨头,包括 Google 和 TripAdvisor。他目前指导那些刚刚开始数据科学工作的新公司,并向软件工程师和业务分析师教授数据科学(不仅仅是机器学习!)。
Trevor Bass 是一位拥有十多年经验的数据科学家,曾构建出高度成功和创新的产品和团队。他目前是 edX 的首席数据科学家,edX 是一个在线学习平台和 MOOC 提供商,为全球各地的学习者提供世界顶级大学和机构的高质量课程。
资源:
相关:
更多相关主题
Quora 上关于‘如何学习机器学习’的最佳建议
原文:
www.kdnuggets.com/2015/10/learning-machine-learning-quora.html/2
有趣的建议
这里是一些来自我们顾问的有趣且不常听到的建议的合集。
Xavier 的建议:
我推荐的下一步是这样的。找一本好的机器学习书籍(我的列表如下),阅读前几章的介绍,然后跳到包含你感兴趣的算法的章节。一旦找到那个算法,深入了解所有细节,尤其是实施它。在之前的在线课程中,你可能已经在 Octave 中实现了一些算法。但这里我说的是在“真实”编程语言中从头实现一个算法。你可以从一个简单的算法开始,比如 L2 正则化的逻辑回归或 k-means,但你也应该推动自己实现更有趣的算法,比如 LDA(潜在狄利克雷分配)或 SVM。
Raviteja 的建议:
获取 scikit-learn 或你选择的编程语言中的相应框架。运行上述书中的每一章的算法。Scikit 的优势在于它也提供了一些示例数据供测试。
掌握统计学(学术学科)和概率。Quora 或 Kaggle 练习等社区将帮助你跟上进度。你还可以参考这本书《统计学习的要素》。我没见过有人对这本书感到失望。虽然有点数学,但大部分是自我解释的。
Sean 的建议:
在众多语言和技术中,容易迷失方向,它们使我们能够在真实世界数据上进行机器学习实践。它们允许我们执行想法并构建模型。当它们集成到实际应用中时,它们生成具有学习能力的软件,将高维问题浓缩为聚焦的结果。但语言和技术是不断更替的。对 R 或 Python 非常精通可能会让你更快地构建模型或更好地将其集成到软件中,但这并不能说明你选择正确模型的能力,或构建一个真正应对挑战的模型的能力。做得好的机器学习艺术来自于洞察算法中的核心概念及其与尝试解决的痛点的重叠。优秀的从业者在触碰键盘之前就开始看到有趣的重叠点。
额外金句(TM)
在他的回答中,Sean 提到 www.datascienceontology.com,这是一个名副其实的网站。网站有顶级分类,如学习算法、数据库、数据清理和语言,提供了广泛且深入的数据科学术语本体,并解释了这些术语,并附有相关资源的链接。
Xavier 指出,机器学习涉及广度和深度,平衡两者的学习很重要。他建议了解最重要算法的基础,但也要尽可能学习尽可能多的低级细节。Xavier 还链接到他的回答‘最重要的 10 种数据挖掘或机器学习算法是什么?’以帮助强调学习最重要算法的观点,这个问题线程本身也是一个有用的资源。
Sean 还提到要“像研究者一样思考”,因为攻读博士学位训练学生在高级研究领域的学科能力。博士学位持有者能够自信地声明他们解决了一个原创问题,并向领域内的其他人辩护这一解决方案。根据 Sean 的说法,非博士可以通过体现这种“研究思维”的心态来模仿博士的机器学习方法。
为了平衡 Sean 对研究重要性的观点,Raviteja 强调实践。他正当地指出,如果在实现模型时不能做出明智的算法选择,那么世界上所有的理论都是无用的。他建议使用 scikit-learn(虽然 R 也可以)并获得解决问题、选择合适算法以及构建有目的模型的实际经验。
个人简介: Matthew Mayo 是一名计算机科学研究生,目前正在撰写关于并行化机器学习算法的论文。他还是一名数据挖掘学生、数据爱好者以及一名有抱负的机器学习科学家。
相关内容:
-
5 步实际学习数据科学
-
60+本大数据、数据科学、数据挖掘、机器学习、Python、R 等领域的免费书籍
-
前 20 个 Python 机器学习开源项目
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
更多相关主题
成为数据科学家后我的学习路径如何改变
原文:
www.kdnuggets.com/2021/08/learning-path-changed-becoming-data-scientist.html
评论

图片来源:Karsten Würth 在 Unsplash
我对数据科学的热情开始于两年半前。我当时的工作与数据科学毫无关系。由于我有很多东西需要学习,因此职业转型对我来说是一个巨大的挑战。
经过两年充满学习和奉献的时间,我终于找到了我的第一份数据科学家的工作。我的学习旅程当然没有停止。在作为数据科学家的工作中,我学到了大量的新知识。
学习的部分没有变化。然而,我学习的内容和方式发生了巨大的变化。在本文中,我将详细阐述这些变化。如果你正在成为数据科学家的过程中,你可能会经历类似的情况。
需要强调的是,成为数据科学家需要不断学习。数据科学仍在发展,你需要时刻保持新鲜感。我认为数据科学还不是一个成熟的领域,因此新技术和概念不断被引入。
数据的规模
对于实际问题来说,1000 万行数据并不算多。
对我来说,最显著的变化是数据的规模。当我自学时,我使用的数据集最多只有 10 万行。我现在把它视为一个小数据集。数据的规模取决于你所工作的领域和问题。一般来说,对于实际问题来说,1000 万行数据并不算多。
使用大型数据集有其自身的挑战。首先,我需要学习可以处理这种数据集的新工具。在开始作为数据科学家工作之前,Pandas 对我来说已经足够。然而,它在大规模数据处理方面并不高效。
允许分布式计算的工具更受欢迎。Spark 是其中最受欢迎的工具之一。它是一个用于大规模数据处理的分析引擎。Spark 让你可以将数据和计算分布在集群上,以实现显著的性能提升。
幸运的是,可以使用 Python 代码运行 Spark。PySpark 是 Spark 的 Python API。它结合了 Python 的简单性和 Spark 的高效性。
云计算
另一个重大变化是从本地环境转到云端。当我在学习时,我在我的电脑上完成所有工作(即本地工作)。这对练习和学习已经足够了。
然而,公司本地操作的可能性极低。大多数公司在云端工作。数据存储在云端,计算也在云端进行,等等。
为了高效地完成工作,全面了解云工具和服务非常重要。虽然有很多云服务提供商,但主要的玩家是 AWS、Azure 和 Google Cloud Platform。我不得不学习如何使用他们的服务和管理存储在云中的数据。

Git
作为数据科学家,我还经常使用的另一个工具是 git。我在学习时学会了基本的 git 命令。然而,在生产环境中工作则有所不同。Git 是一个版本控制系统。它维护了所有代码更改的历史记录。
Git 允许进行协作工作。你可能会作为团队的一员参与项目。因此,即使你在一个小型初创公司工作,git 也是必备技能。项目的开发和维护都使用 git。
Git 比看起来要复杂一些。然而,经过几个项目的实践,你会习惯它的。
不仅仅是工具!
工具并不是我学习过程中唯一的变化。我处理数据的方法也发生了变化。当你处理一个现成的数据集时,你在清理和处理数据方面能做的事情不多。例如,在机器学习任务中,你可以在几个简单的步骤后应用一个模型。
在你的工作中情况会有所不同。项目的很大一部分时间花在准备数据上。我所说的不仅仅是清理原始数据。清理原始数据也是一个重要的步骤。然而,探索数据中的潜在结构和理解特征之间的关系至关重要。
如果你在处理一个新问题,你还需要定义数据需求。这是另一个挑战,需要一套特殊的技能。领域知识是其中的一个重要部分。
特征工程比机器学习模型的超参数调优更为重要。超参数调优能够实现的提升是有限的,因此你只能在一定程度上提高性能。另一方面,一个信息丰富的特征有潜力显著改善模型。
在我开始做数据科学家之前,我专注于理解机器学习算法以及如何调整模型。现在我大部分时间都花在准备数据上。
我所说的“准备好”包括很多步骤,例如
-
清理和处理数据
-
数据重新格式化
-
探索和理解数据
统计知识对这些步骤非常重要。因此,我强烈建议你提升这方面的知识。这将对你的数据科学职业生涯大有帮助。
结论
学习数据科学有大量资源。你可以利用它们来提高你在数据科学任何基础领域的技能。然而,这些资源无法提供真实的工作经验。这没有错。只需在获得第一份工作时准备好学习不同的材料即可。
感谢阅读。如果您有任何反馈,请告知我。
简介: Soner Yildrim 是一位数据科学爱好者。查看他的作品集。
原文。已获许可转载。
相关内容:
-
是什么让我花了那么久才找到数据科学家的工作
-
你投资组合中最好的数据科学项目
-
数据科学家必须了解的 10 个统计概念
更多相关内容
四周学会 Python:学习路线图
原文:
www.kdnuggets.com/2023/02/learning-python-four-weeks-roadmap.html

图片来源:作者
现在是时候学习 Python 了。这不仅仅是我的建议:Python 目前位居TIobe 指数(2023 年 2 月)的编程语言流行度榜首。Python 的流行有很多原因,你可能有自己学习它的理由,但就我们的目的而言,Python 是数据科学领域的主流通用语言。这就是为什么你现在需要学习它。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 事务
学习编程可能是耗时、混乱且令人沮丧的。编程主题广泛多样,在线上关于学习 Python 的资源非常多,信息过载很容易让人放弃这个想法。学习一种新的编程语言(或编程本身)所需的时间也可能让人却步。
考虑到以上因素,我们制定了以下四周学习 Python 的路线图。该程序包含经过筛选的免费资源,按天和周进行组织,因此你可以明确知道每一天应该学习什么内容。为了提供额外的指导,我们还请 ChatGPT 每天提供几个相关的提示,以便你可以使用这些提示向 ChatGPT 提问,从而深入学习当天的主题。
所以,这就是:四周学会 Python 的路线图。请注意,每一天的要点是用于 ChatGPT 的提示,以便进一步学习当天的主题。希望这种略具创新的方法对你的编程学习之旅有所帮助。
第 1 周:Python 入门
第 1 天:Python 简介、安装 Python 和 IDLE、基本数据类型(int、float、str 等)和变量
-
Python 中的基本数据类型有哪些?它们是如何使用的?
-
如何在 Python 中声明和赋值变量?
-
如何在 Python 中将一种数据类型转换为另一种数据类型?
第 2 天:运算符(算术、比较、逻辑等),控制语句(if-else、for 循环等)
-
Python 中有哪些不同类型的运算符?如何使用它们?
-
如何在 Python 中使用条件语句,如 if-else?能否提供一些示例?
-
如何在 Python 中使用循环,如 for 和 while?能否提供一些示例?
-
什么是 Python 中的函数?如何定义和调用它们?
-
什么是 Python 中的库和模块?如何导入和使用它们?
-
如何在 Python 中读写文件?能否提供一些示例?
-
什么是面向对象编程,它与其他编程范式有何不同?
-
如何在 Python 中定义类和对象?能否提供一些示例?
-
如何在 Python 中使用继承和多态?能否提供一些示例?
第 5 天:回顾本周学习的内容,练习编程挑战 和 完成一个迷你项目
你可以从这些资源和提示开始,以便对第 1 周涵盖的主题有一个良好的理解。请记住,在线上还有许多其他资源,所以可以随意探索,找到最适合你的资源。
第 2 周:中级与科学 Python
第 1 天:继承与多态,以及 使用 try-except 进行错误处理
-
什么是 Python 中的继承?它如何用于代码重用?
-
多态在 Python 中如何工作?有哪些实际应用场景?
-
如何在 Python 中使用 try-except 语句处理错误?有哪些最佳实践?
第 2 天:文件处理与异常,处理 CSV 文件 和 JSON 文件
-
如何在 Python 中打开和读取文件?有哪些常见的文件模式?
-
在 Python 中处理文件时,处理异常有哪些最佳实践?
-
如何在 Python 中处理 CSV 文件和 JSON 文件?你可以使用哪些库来简化这个过程?
第 3 天:NumPy 和 Pandas 简介,涵盖数组、矩阵和数据框
-
NumPy 在 Python 中是什么,它如何用于数值计算?
-
如何在 NumPy 中处理数组和矩阵,有哪些常见的操作?
-
Pandas 在 Python 中是什么,它如何用于数据操作和分析?
第 4 天:使用 Matplotlib 和 Seaborn 进行数据分析和可视化
-
Matplotlib 在 Python 中是什么,它如何用于数据可视化?
-
使用 Matplotlib 可以创建哪些类型的图表和图形,如何自定义它们?
-
Seaborn 与 Matplotlib 有何不同,你可能在什么情况下选择其中一个?
第 5 天:复习本周涉及的主题,练习编码挑战,并完成一个迷你项目
这些资源和提示将帮助你对第 2 周涵盖的主题有一个坚实的理解。你也可以探索其他在线资源来补充学习。
第 3 周:数据存储、网络应用程序和部署
第 1 天:数据库操作,第一部分:SQL 和数据库管理简介,使用 Python 连接数据库,使用 SQL 查询和操作数据
-
SQL 是什么,如何使用它与数据库互动?
-
如何使用 Python 连接到数据库,有哪些流行的库可以使用?
-
如何在 Python 中执行 SQL 查询,以及一些基本的 SQL 操作用于查询和操作数据?
第 2 天:数据库操作,第二部分:高级 SQL 操作,存储过程 和 事务,以及 NoSQL 数据库 和 Python
-
一些高级 SQL 操作,如连接和子查询,如何使用 Python 执行这些操作?
-
存储过程和事务是什么,如何使用它们简化和优化数据库操作?
-
什么是 NoSQL,它与传统关系数据库有何不同?有哪些 NoSQL 数据库可以与 Python 一起使用?
第 3 天:Flask 网络开发简介,Flask 中的表单和验证,Flask 中的数据库操作
-
Flask 是什么?你如何使用它在 Python 中构建 Web 应用程序?
-
你如何在 Flask 中创建和验证表单?有哪些最佳实践?
-
你如何将数据库集成到 Flask 应用程序中?在 Flask 中处理数据库有哪些常见模式?
第 4 天: 将 Web 应用程序部署到云端(例如,Heroku、AWS)
-
部署 Web 应用程序的一些热门云平台有哪些,比如 Heroku 和 AWS?
-
你如何将 Flask 应用程序部署到云平台上?有哪些最佳实践?
-
你如何配置和管理云数据库?在扩展和性能方面有哪些考虑?
第 5 天:复习本周学习的主题,练习编码挑战,并完成一个 迷你项目
这些资源和提示将帮助你学习在 Python 中使用数据库的基础知识。你还可以探索其他在线资源来补充你的学习。
第四周:综合运用并展望未来
第 1 天:复习所有已学的主题,解决 编码挑战
第 2 天:练习解决实际问题并实施 迷你项目
第 3 天: 完善你的作品集,记录项目并 与社区分享
第 4 天:通过 阅读博客、观看教程 和参与 在线论坛 来提升你的知识
第 5 天:继续练习和探索新主题,开始一个新项目,并继续你的学习之旅
这些资源将帮助你展望未来的 Python 学习,并在前几周学到的基础上进一步发展。务必关注实际项目,讨论在线论坛中的问题,并且不要忘记 ChatGPT 是一个很有用的资源。你还可以探索其他在线资源来补充你的学习。
总结
这是一个全面的计划,将为你提供坚实的 Python 基础。然而,学习是一个持续的过程,需要奉献和努力,所以请确保每天练习编程,并花时间理解你正在学习的概念。祝好运!
马修·梅约 (@mattmayo13)是一名数据科学家以及 KDnuggets 的主编,这是一个开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及自动化机器学习方法。马修拥有计算机科学硕士学位和数据挖掘研究生文凭。可以通过 editor1 at kdnuggets[dot]com 联系他。
更多相关主题
学习率在人工神经网络中有用吗?
原文:
www.kdnuggets.com/2018/01/learning-rate-useful-neural-network.html
评论
这篇文章将帮助你理解我们为什么需要学习率以及它是否对训练人工神经网络有用。通过使用一个非常简单的单层感知器 Python 代码,我们将改变学习率值以理解其概念。
介绍
人工神经网络的初学者面临的一个障碍是学习率。我被问过很多次关于学习率在训练人工神经网络(ANNs)中的作用。我们为什么要使用学习率?学习率的最佳值是什么?在这篇文章中,我将通过提供一个示例来简化问题,展示学习率在训练 ANN 时的作用。我将从解释我们的 Python 代码示例开始,然后再讨论学习率。
示例
一个非常简单的示例被用来摆脱复杂性,让我们专注于学习率。一个数值输入将应用于一个单层感知器。如果输入为 250 或更小,则其值将作为网络的输出返回。如果输入大于 250,则将被裁剪为 250。下表展示了用于训练的 6 个样本。

ANN 架构
使用的 ANN 架构如下一图所示。该架构仅包含输入层和输出层。输入层只有一个神经元用于我们的单一输入。输出层也只有一个神经元用于生成输出。输出层的神经元负责将输入映射到正确的输出。同时,输出层的神经元上还应用了一个偏置,其权重为b,值为+1。输入层还有一个权重W。

激活函数
本示例中使用的激活函数的方程和图形如下图所示。当输入小于或等于 250 时,输出将与输入相同。否则,输出将被裁剪为 250。

使用 Python 的实现
实现整个网络的 Python 代码如下所示。我们将讨论代码的所有部分,尽量将其简化,然后专注于改变学习率以了解其对网络训练的影响。
1. import numpy
2.
3. def activation_function(inpt):
4. if(inpt > 250):
5. return 250 # clip the result to 250
6. else:
7. return inpt # just return the input
8.
9. def prediction_error(desired, expected):
10\. return numpy.abs(numpy.mean(desired-expected)) # absolute error
11\.
12\. def update_weights(weights, predicted, idx):
13\. weights = weights + .00001*(desired_output[idx] - predicted)*inputs[idx] # updating weights
14\. return weights # new updated weights
15\.
16\. weights = numpy.array([0.05, .1]) #bias & weight of input
17\. inputs = numpy.array([60, 40, 100, 300, -50, 310]) # training inputs
18\. desired_output = numpy.array([60, 40, 150, 250, -50, 250]) # training outputs
19\.
20\. def training_loop(inpt, weights):
21\. error = 1
22\. idx = 0 # start by the first training sample
23\. iteration = 0 #loop iteration variable
24\. while(iteration < 2000 or error >= 0.01): #while(error >= 0.1):
25\. predicted = activation_function(weights[0]*1+weights[1]*inputs[idx])
26\. error = prediction_error(desired_output[idx], predicted)
27\. weights = update_weights(weights, predicted, idx)
28\. idx = idx + 1 # go to the next sample
29\. idx = idx % inputs.shape[0] # restricts the index to the range of our samples
30\. iteration = iteration + 1 # next iteration
31\. return error, weights
32\.
33\. error, new_weights = training_loop(inputs, weights)
34\. print('--------------Final Results----------------')
35\. print('Learned Weights : ', new_weights)
36\. new_inputs = numpy.array([10, 240, 550, -160])
37\. new_outputs = numpy.array([10, 240, 250, -160])
38\. for i in range(new_inputs.shape[0]):
39\. print('Sample ', i+1, '. Expected = ', new_outputs[i], ' ,
Predicted = ', activation_function(new_weights[0]*1+new_weights[1]*new_inputs[i]))
第 17 行和第 18 行负责创建两个数组(inputs 和 desired_output),用于存储前面表格中展示的训练输入和输出数据。每个输入将根据所使用的激活函数产生相应的输出。
第 16 行创建了一个网络权重的数组。只有两个权重:一个用于输入,另一个用于偏置。它们被随机初始化为偏置 0.05 和输入 0.1。
激活函数本身是通过第 3 到 7 行定义的 activation_function(inpt) 方法实现的。它接受一个参数,即输入,并返回一个值,即期望输出。
由于预测中可能存在误差,我们需要测量该误差以了解我们离正确预测的距离。因此,有一个从第 9 到 10 行实现的方法,称为 prediction_error(desired, expected),它接受两个输入:期望输出和实际输出。这个方法只是计算每个期望输出和实际输出之间的绝对差异。任何误差的最佳值当然是 0。这是最终值。
如果出现预测误差怎么办?在这种情况下,我们必须对网络进行更改。但是具体要更改什么呢?是网络权重。为了更新网络权重,有一个方法叫做 update_weights(weights, predicted, idx),定义在第 13 到 14 行。它接受三个输入:旧权重、预测输出和具有错误预测的输入的索引。这个方法应用以下方程来更新权重:

这个方程使用当前步骤(n)的权重生成下一步骤(n+1)的权重。这个方程是我们用来了解学习率如何影响学习过程的。
最后,我们需要将所有这些拼接在一起以使网络学习。这是通过从第 20 行到 31 行定义的 training_loop(inpt, weights) 方法完成的。它进入一个训练循环。这个循环用于将输入映射到其输出,同时使预测误差最小化。
循环执行三个操作:
1. 输出预测。
2. 误差计算。
3. 更新权重。
在了解了示例及其 Python 代码后,让我们开始展示学习率在获得最佳结果方面的作用。
学习率
在前面讨论的示例中,第 13 行有学习率被使用的权重更新方程。首先,让我们假设我们没有完全使用学习率。方程将如下:
weights = weights + (desired_output[idx] - predicted)*inputs[idx]
让我们看看去除学习率的效果。在训练循环的迭代中,网络有以下输入(b=0.05 和 W=0.1,输入 = 60,期望输出=60)。
期望输出,即第 25 行激活函数的结果,将是 activation_function(0.05(+1) + 0.1(60))。预测输出将是 6.05。
在第 26 行,预测误差将通过计算期望输出和预测输出之间的差异来计算。误差将是 abs(60-6.05)=53.95。
然后在第 27 行,权重将根据上述方程进行更新。新的权重将是[0.05, 0.1] + (53.95)*60 = [0.05, 0.1] + 3237 = [3237.05, 3237.1]。
看起来新的权重与之前的权重差异太大。每个权重增加了 3,237,这实在太大了。但让我们继续进行下一次预测。
在下一次迭代中,网络将应用以下输入:(b=3237.05 和 W=3237.1,输入=40,期望输出=40)。预期输出将是 activation_function((3237.05 + 3237.1(40)) = 250。预测误差将是 abs(40 - 250) = 210。误差非常大,比之前的误差还要大。因此,我们必须再次更新权重。根据上述方程,新的权重将是[3237.05, 3237.1] + (-210)*40 = [3237.05, 3237.1] + -8400 = [-5162.95, -5162.9]。
下一张表总结了前三次迭代的结果:

随着迭代次数的增加,结果变得更差。权重的大小迅速变化,有时甚至改变了符号。它们从非常大的正值变为非常大的负值。我们如何停止权重的这种大幅度和突变?如何缩小更新权重的值?
如果我们查看上一张表中权重变化的值,似乎这个值非常大。这意味着网络以较大的速度更改其权重。这就像一个人在短时间内做出大幅度的移动。某个时刻,这个人在远东,而在很短的时间内,这个人会在远西。我们只需要让它变得更慢。
如果我们能够将这个值缩小到更小的程度,那么一切都会变得顺利。但是怎么做呢?
回到生成这个值的代码部分,看来更新方程就是生成它的原因。具体来说,就是这一部分:
(desired_output[idx] - predicted)*inputs[idx]
我们可以通过将这部分乘以一个小值(例如 0.1)来缩放它。因此,第一次迭代中生成的 3237.0 的更新值将减少到 323.7。我们甚至可以将这个值缩小到更小的值,例如 0.001。使用 0.001 时,值将仅为 3.327。
我们现在可以理解了。这一缩放值就是学习率。选择较小的学习率使权重更新的速度较小,并避免突变。随着值变大,变化速度加快,从而导致不良结果。
但学习率的最佳值是什么?
我们不能说哪个值是学习率的最佳值。学习率是一个超参数。超参数的值通过实验来确定。我们尝试不同的值,并使用那些给出最佳结果的值。有一些方法可以帮助你选择超参数的值。
测试网络
对于我们的问题,我推测值为 .00001 是合适的。在使用这个学习率训练网络后,我们可以进行测试。下表显示了对 4 个新测试样本的预测结果。似乎在使用学习率后结果有了很大改善。

简介: 艾哈迈德·贾德 于 2015 年 7 月从埃及梅努费亚大学计算机与信息学院获得信息技术学士学位,成绩优异并获得荣誉。由于在学院中排名第一,他被推荐在 2015 年于埃及的一所学院担任助教,随后在 2016 年继续担任助教和研究员。他当前的研究兴趣包括深度学习、机器学习、人工智能、数字信号处理和计算机视觉。
原文。经许可转载。
相关:
-
TensorFlow:一步一步构建前馈神经网络
-
3 个受欢迎的深度学习课程概述
-
5 个免费资源帮助你进一步理解深度学习
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关内容
学习 SQL 的艰难方式
comments 
一个不懂 SQL 的数据科学家是不值得的。
在我看来,这在任何意义上都是正确的。虽然我们在创建模型和提出不同假设时感到更有成就,但数据处理的作用不可低估。
由于 SQL 在 ETL 和数据准备任务中的普遍性,每个人都应该了解一点,以便至少能有所帮助。
我仍然记得第一次接触 SQL 的情景。这是我学习的第一个语言(如果可以这么称呼的话)。它给我留下了深刻的影响。我能够自动化很多事情,这是我之前没有想到的。
在使用 SQL 之前,我曾经使用 Excel —— VLOOKUP 和数据透视表。我在创建报告系统,一遍又一遍地做着相同的工作。SQL 使这一切都消失了。现在我可以写一个大脚本,一切都自动化了——所有的交叉表和分析都能即时生成。
这就是 SQL 的威力。尽管你可以使用 Pandas 做 SQL 能做的任何事情,但你仍然需要学习 SQL,以处理 HIVE、Teradata 和有时 Spark 等系统。
这篇文章是关于安装 SQL、解释 SQL 和运行 SQL 的。
设置 SQL 环境
学习 SQL 的最佳方式是亲自动手实践(我对任何其他你想学的东西也这么说)。
我建议不要使用像 w3schools/tutorialspoint 这样的基于网络的 SQL 资源,因为你无法使用自己的数据。
此外,我建议你学习 MySQL 版本的 SQL,因为它是开源的,易于在你的笔记本电脑上设置,并且有一个名为 MySQL Workbench 的优秀客户端,可以让你的生活更轻松。
既然这些问题都解决了,这里是逐步设置 MySQL 的步骤:
- 你可以从 Download MySQL Community Server 下载适用于你系统的 MySQL(MACOSX、Linux、Windows)。在我的情况下,我下载了 DMG 压缩包。之后,双击并安装文件。你可能需要设置一个密码。记住这个密码,因为稍后连接到 MySQL 实例时会用到。
- 创建一个名为
my.cnf的文件,并在其中放入以下内容。这是为了给你的 SQL 数据库提供本地文件读取权限。
[client]
port= 3306
[mysqld]
port= 3306
secure_file_priv=''
local-infile=1
- 打开
System Preferences>MySQL。前往Configuration并使用选择按钮浏览到my.cnf文件。
- 从
Instances选项卡重新启动服务器,点击停止然后启动。
- 一旦你让服务器运行起来,下载并安装 MySQL Workbench:下载 MySQL Workbench。Workbench 提供了一个编辑器,用于编写 SQL 查询并以结构化的方式获取结果。
- 现在打开 MySQL Workbench 并连接到 SQL。你将看到如下界面。
- 你可以看到本地实例连接已经为你设置好了。现在,只需点击该连接,使用我们之前为 MySQL 服务器设置的密码开始使用(如果你有地址、端口号、用户名和密码,你也可以创建连接到其他可能不在你机器上的现有 SQL 服务器)。
- 这样你就可以在特定数据库上编写查询。
-
检查左上角的
Schemas选项卡,查看现有的表。这里只有一个sys模式,包含表sys_config。这不是一个有趣的数据源来学习 SQL。所以,让我们安装一些数据进行练习。 -
如果你有自己的数据进行操作,那很好。你可以创建一个新的模式(数据库)并使用以下命令将其上传到表中。(你可以通过使用
Cmd+Enter或点击 ⚡️闪电按钮运行命令)
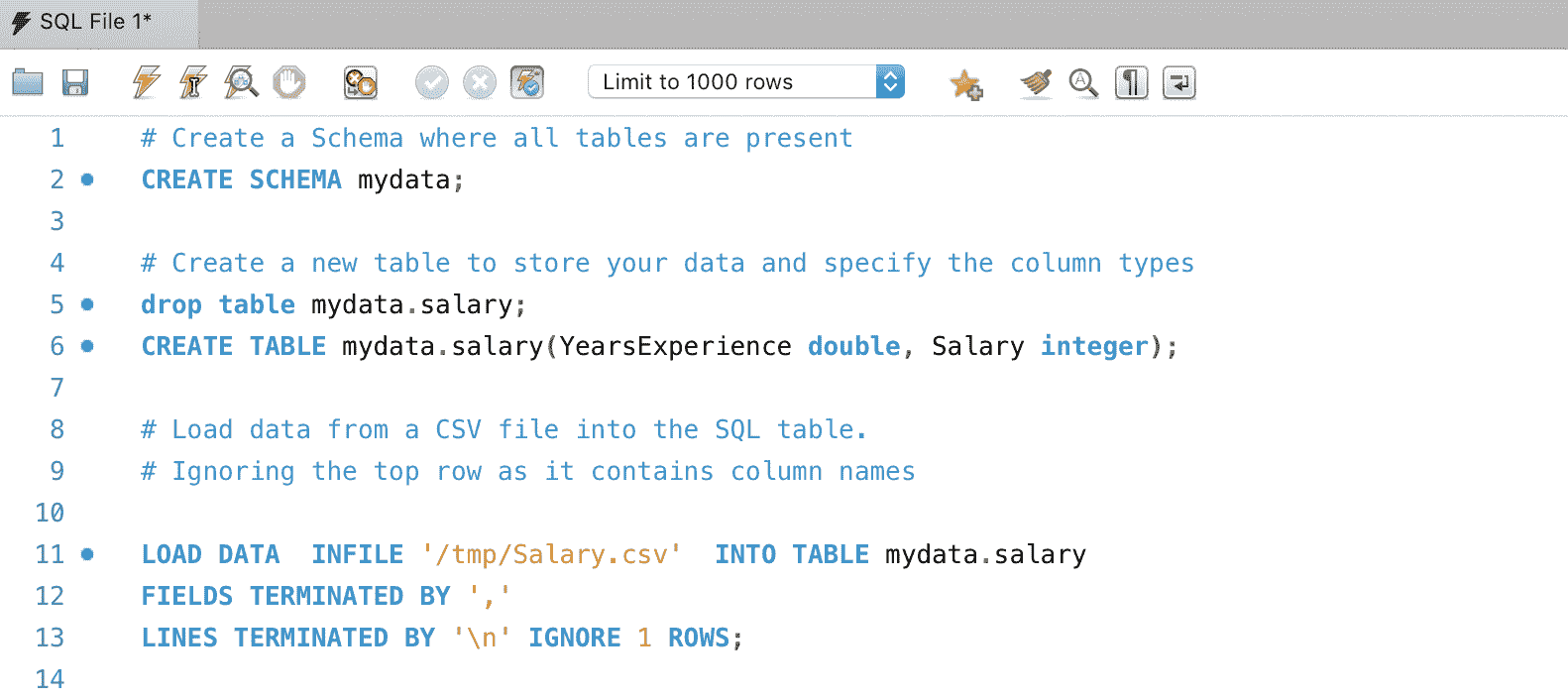
在本教程中,我将使用 Sakila 电影数据库,你可以通过以下步骤进行安装:
-
转到 MySQL 文档 下载 Sakila ZIP 文件。
-
解压缩文件。
-
现在打开 MySQL Workbench,选择 文件 > 运行 SQL 脚本 > 选择位置
sakila-db/sakila-schema.sql -
打开 MySQL Workbench,选择 文件 > 运行 SQL 脚本 > 选择位置
sakila-db/sakila-data.sql
一旦完成,你会看到 SCHEMA 列表中添加了一个新数据库。

数据操作
现在我们终于有了一些数据。
让我们开始编写一些查询。
你可以尝试通过 Sakila 示例数据库 文档详细了解 Sakila 数据库的模式。
模式图
现在,任何 SQL 查询的基本语法是:
SELECT col1, SUM(col2) as col2sum, AVG(col3) as col3avg FROM table_name WHERE col4 = 'some_value' GROUP BY col1 ORDER BY col2sum DESC;
这个查询包含四个元素:
-
SELECT:选择哪些列?在这里我们选择
col1并对col2执行 SUM 聚合,对col3执行 AVG 聚合。我们还使用as关键字为SUM(col2)起一个新名称。这称为别名。 -
FROM:我们应该从哪个表中 SELECT?
-
WHERE:我们可以使用 WHERE 语句过滤数据。
-
GROUP BY:所有未进行聚合的选择列应在 GROUP BY 中。
-
ORDER BY:按
col2sum排序
上述查询将帮助你完成大多数简单的数据库查询。
例如,我们可以使用以下方式找出不同审查等级的电影在时间上的差异:
SELECT rating, avg(length) as length_avg FROM sakila.film group by rating order by length_avg desc;
练习:提出一个问题
你现在应该自己提出一些问题。
例如,你可以尝试找出所有在 2006 年发布的电影。或者尝试找出所有评级为 PG 且长度大于 50 分钟的电影。
你可以通过在 MySQL Workbench 中运行以下操作来完成:
select * from sakila.film where release_year = 2006;
select * from sakila.film where length>50 and rating="PG";
SQL 中的连接
到目前为止,我们已经学习了如何处理单个表。但在实际应用中,我们需要处理多个表。
所以,我们接下来要学习的是如何进行连接。
现在,连接是 MySQL 数据库中不可或缺且至关重要的部分,理解它们是必要的。下面的视觉图展示了 SQL 中存在的大多数连接。我通常只使用 LEFT JOIN 和 INNER JOIN,因此我将从 LEFT JOIN 开始。
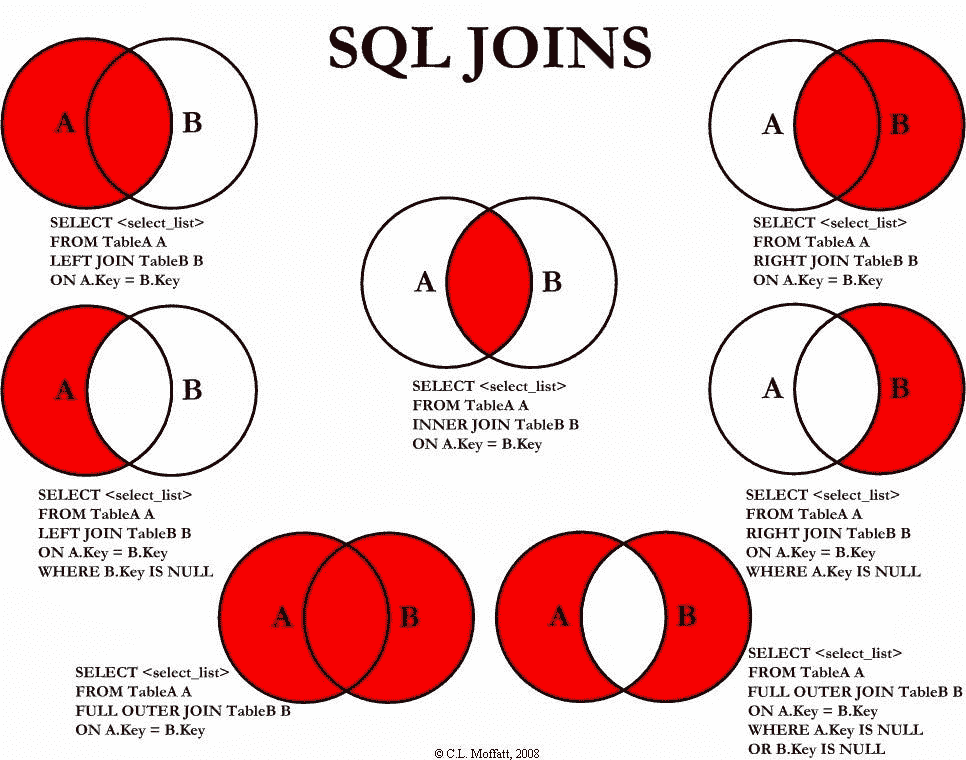
当你想保留左侧表(A)中的所有记录,并在匹配的记录上合并表 B 时,使用 LEFT JOIN。表 A 中未合并表 B 的记录在结果表中将显示为 NULL。MySQL 语法为:
SELECT A.col1, A.col2, B.col3, B.col4 from A LEFT JOIN B on A.col2=B.col3
在这里,我们从表 A 中选择 col1 和 col2,从表 B 中选择 col3 和 col4。我们还使用 ON 语句指定连接的共同列。
INNER JOIN 用于当你想合并 A 和 B,并且仅保留 A 和 B 中的共同记录时。
示例:
为了给你一个用例,让我们回到我们的 Sakila 数据库。假设我们想找出每部电影在我们的库存中有多少份。你可以通过以下方式获得:
SELECT film_id,count(film_id) as num_copies FROM sakila.inventory group by film_id order by num_copies desc;
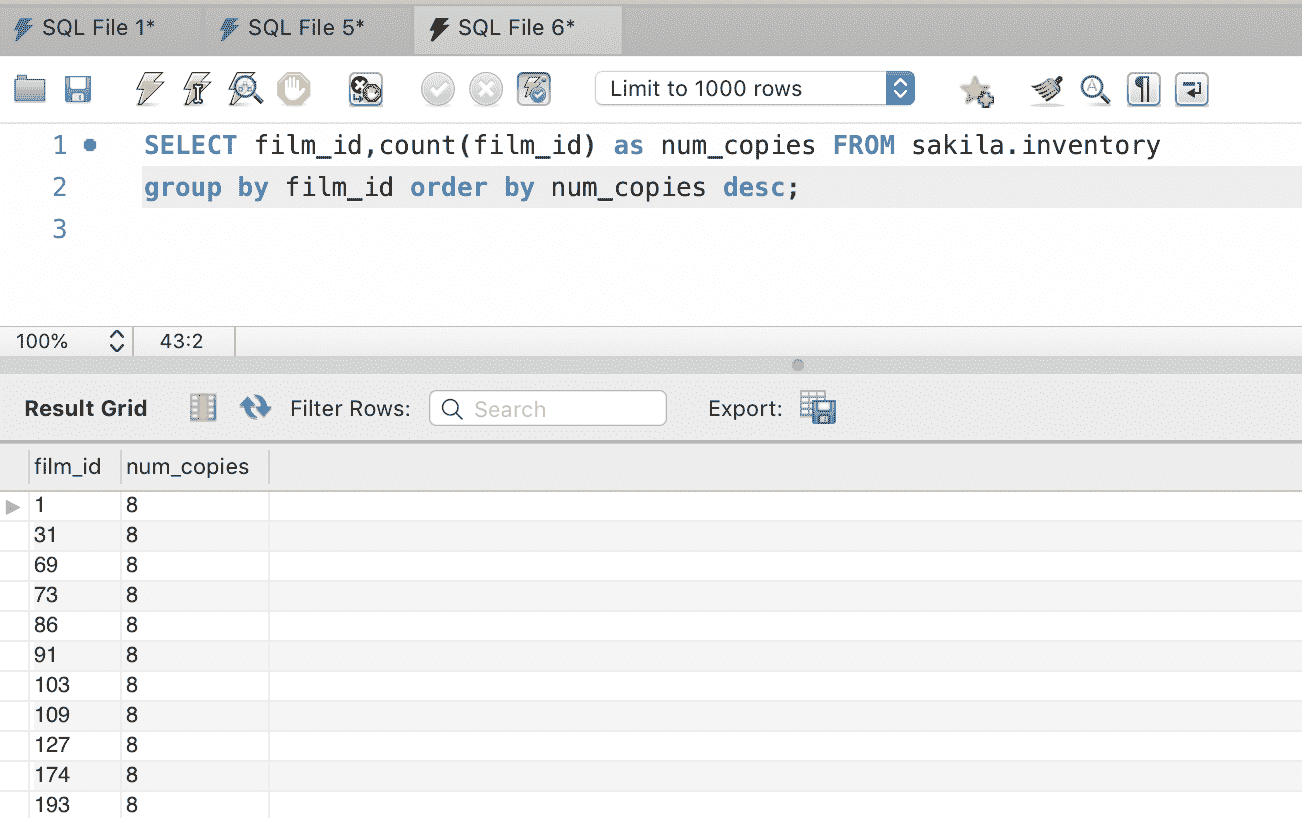
这个结果看起来有趣吗?不太有趣。ID 对我们人类来说没有意义,如果我们能得到电影的名称,我们将能更好地处理这些信息。所以我们查看 film 表,发现它有 film_id 以及电影的 title。
我们拥有所有的数据,但我们如何将其汇总到一个视图中?
使用连接来拯救我们。我们需要将 title 添加到我们的库存表信息中。我们可以通过以下方式做到这一点——
SELECT A.*, B.title from sakila.inventory A left join sakila.film B on A.film_id = B.film_id
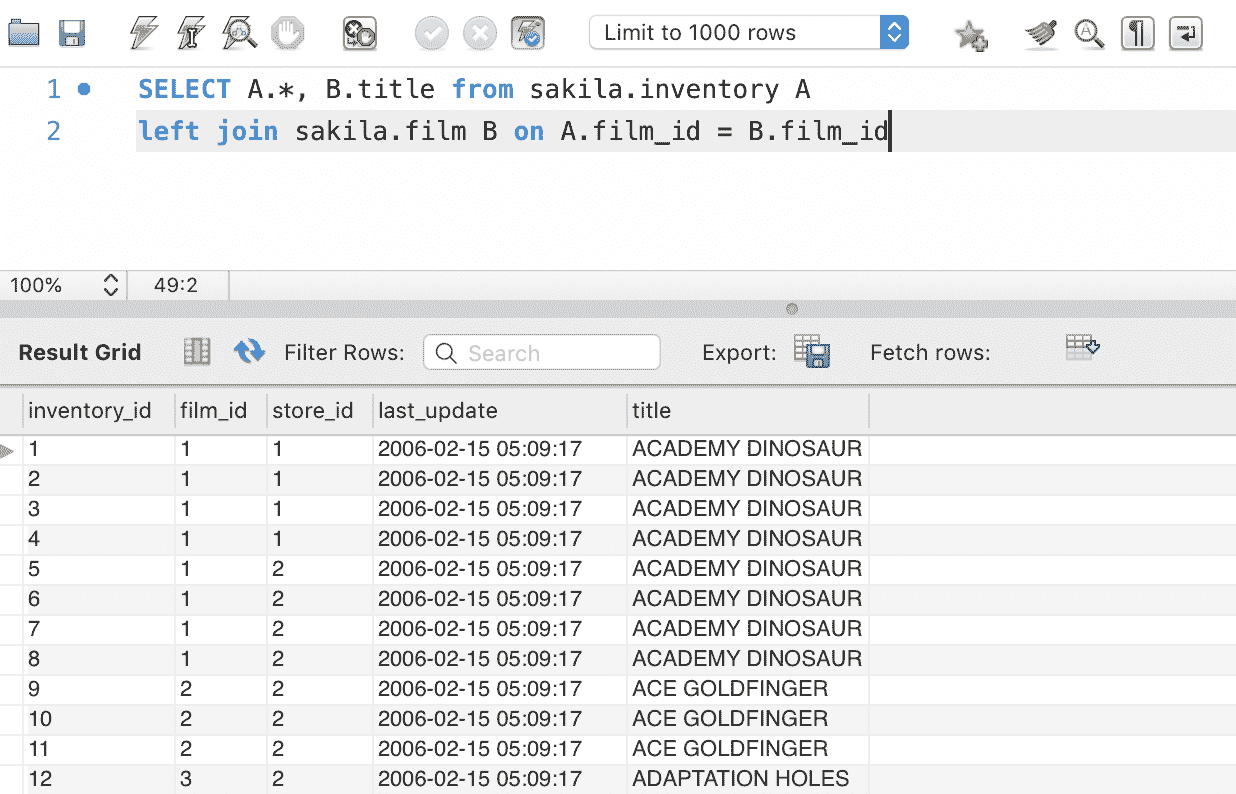
这将为你的库存表信息添加另一列。正如你可能注意到的那样,一些电影存在于 film 表中,而我们在 inventory 表中没有。我们使用左连接,因为我们想保留库存表中的所有内容,并将其与 film 表中的相应内容连接,而不是 film 表中的所有内容。
现在,我们在数据中获得了 title 作为另一个字段。这正是我们想要的,但我们还没有解决整个难题。我们想要的是库存中 title 和 num_copies 的信息。
但在我们进一步之前,我们应该首先理解内查询的概念。
内查询:
现在你有一个可以给出上述结果的查询。你可以做的一件事是使用
create table sakila.temp_table as SELECT A.*, B.title from sakila.inventory A left join sakila.film B on A.film_id = B.film_id;
然后使用简单的 GROUP BY 操作:
select title, count(title) as num_copies from sakila.temp_table group by title order by num_copies desc;
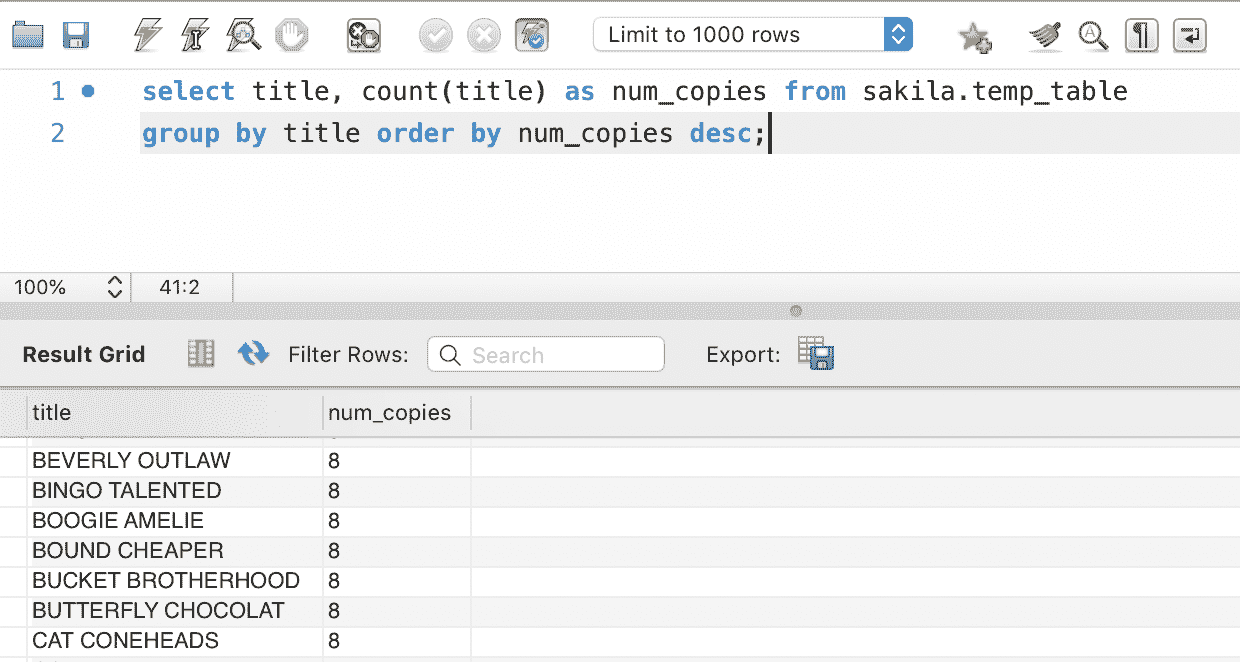
但这多了一步。我们必须创建一个临时表,这会占用系统空间。
SQL 为这些问题提供了内查询的概念。你可以用以下方式将所有内容写成一个查询:
select temp.title, count(temp.title) as num_copies from (SELECT A.*, B.title from sakila.inventory A left join sakila.film B on A.film_id = B.film_id) temp group by title order by num_copies desc;
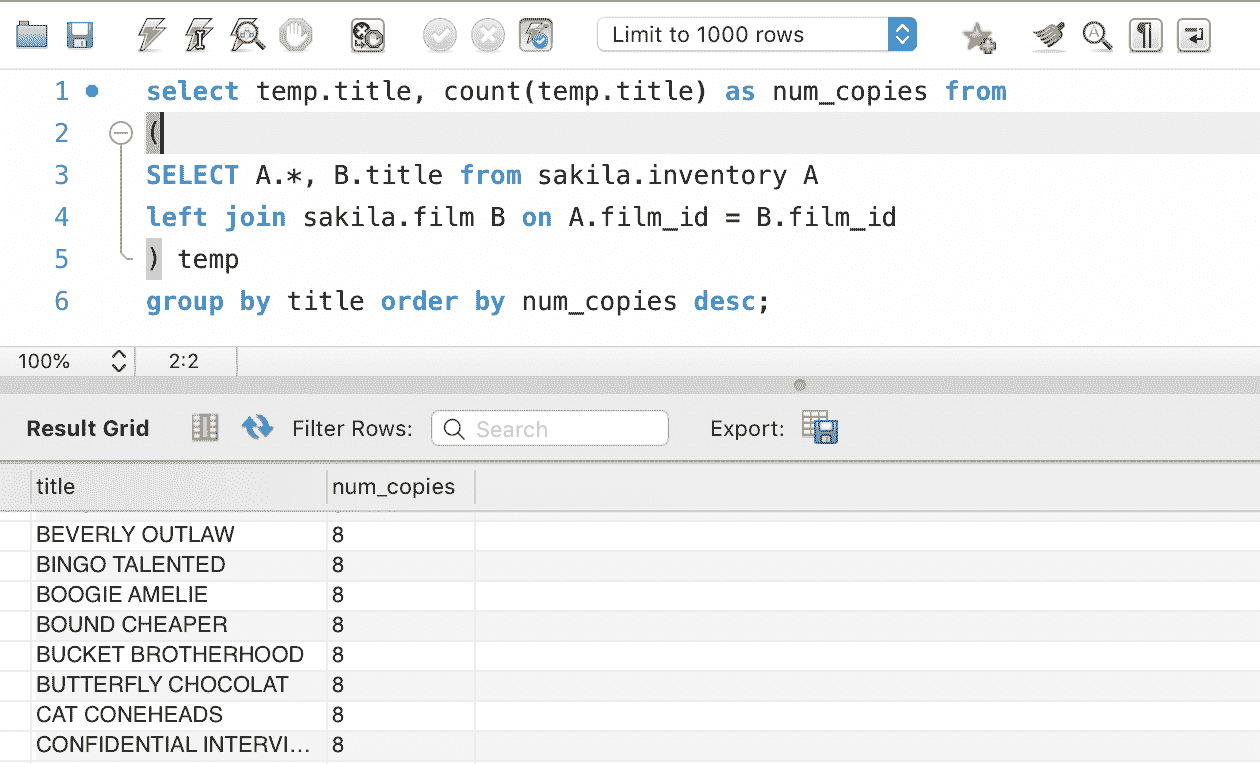
我们在这里做的是将第一个查询用括号括起来,并给这个表一个别名 temp。然后我们对 temp 执行了 GROUP BY 操作,就像对待任何表一样。正因为内查询的概念,我们才能编写有时跨越多页的 SQL 查询。
HAVING 子句
HAVING 是另一个有用的 SQL 结构。因此,我们已经得到了结果,现在我们想要获取那些副本数量少于或等于 2 的电影。
我们可以通过使用内查询概念和 WHERE 子句来实现这一点。在这里,我们将一个内查询嵌套在另一个内查询中。相当不错。
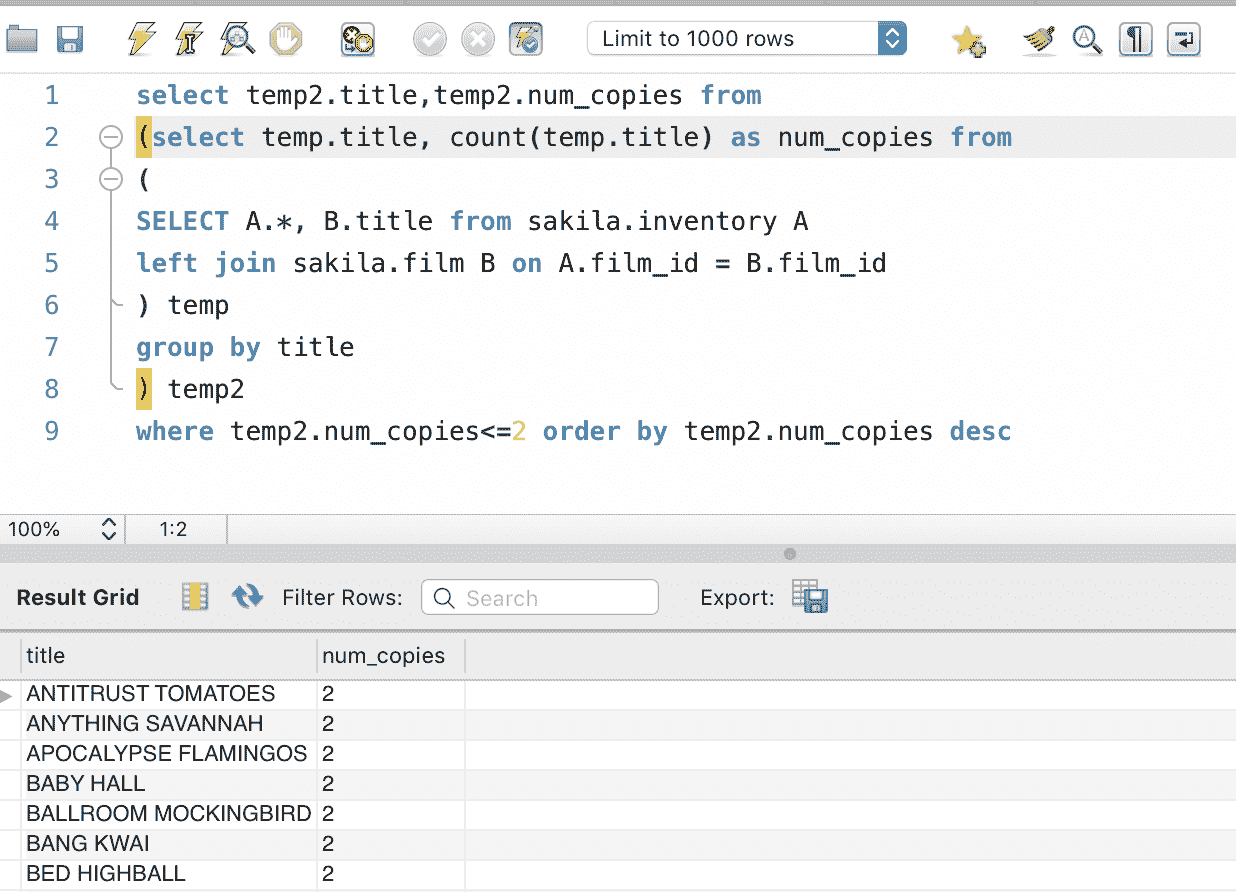
或者,我们可以使用 HAVING 子句。
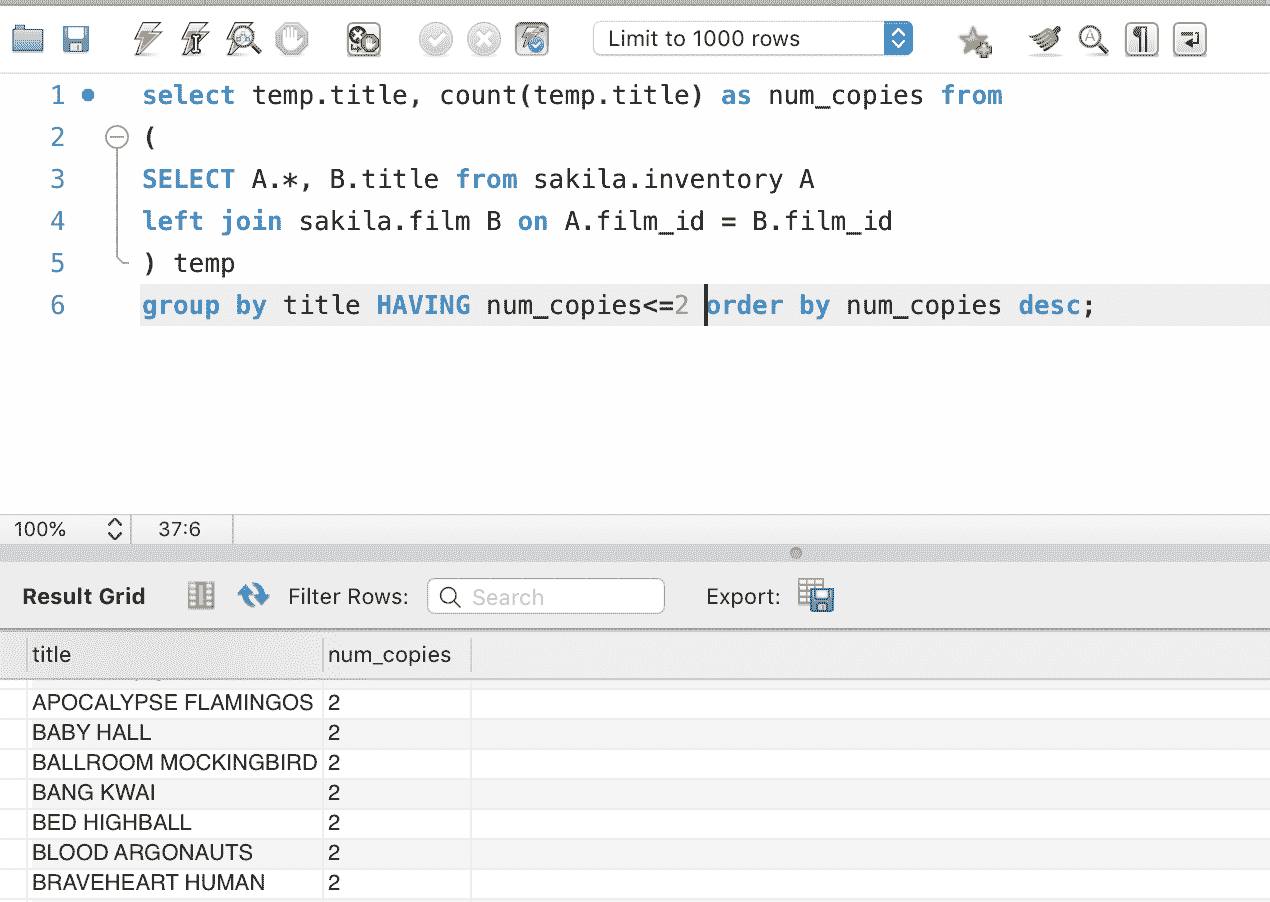
HAVING 子句用于过滤最终的聚合结果。它与 WHERE 不同,因为 WHERE 用于过滤 FROM 语句中使用的表。HAVING 在 GROUP BY 之后过滤最终结果。
如你在上述示例中已经看到的,SQL 有很多种方法可以完成同一件事。我们需要尝试提出最简洁的方法,因此在许多情况下使用 HAVING 是有意义的。
如果你能跟到这里,你已经比大多数人掌握了更多的 SQL 知识。
接下来要做的事:练习。
尝试对你的数据集提出问题,并尝试用 SQL 找出答案。
一些可以开始的问题:
-
哪位演员在我们的库存中拥有最多的独特电影?
-
在我们的库存中,哪种类型的电影租借最多?
继续学习
这只是一个简单的 SQL 使用教程。如果你想学习更多 SQL,我推荐加州大学提供的优秀课程 SQL for Data Science。请查看它,它讲解了 UNION、字符串操作、函数、日期处理等其他 SQL 概念。
我将来还会写更多适合初学者的文章。可以关注我的 Medium 或订阅我的 博客 以获取最新动态。始终欢迎反馈和建设性批评,可以通过 Twitter @mlwhiz 联系我。
另外,附上一点小免责声明——这篇文章中可能包含一些相关资源的推荐链接,分享知识从来不是坏事。
简介:Rahul Agarwal 是 WalmartLabs 的高级统计分析师。关注他的 Twitter @mlwhiz。
原文。经许可转载。
相关内容:
-
数据科学 SQL 精通的 7 个步骤 — 2019 年版
-
你将再也不需要的最后 SQL 数据分析指南
-
数据科学家的 6 条建议
我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
更多相关话题
学习系统设计:5 本必读书籍
原文:
www.kdnuggets.com/learning-system-design-top-5-essential-reads

作者提供的图像 | DALLE-3 & Canva
系统设计可能让人感到望而生畏。至少,我在想要作为初学者学习系统设计时有这种感觉。最新的趋势和流行词使得知道学习什么以及从哪里开始变得更加困难。但不用担心!在这篇文章中,我将建议一个适合初学者的良好起点,并解释为什么学习系统设计至关重要。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业领域。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT 工作
系统设计是设计大规模应用程序的一个重要组成部分,构成了 Twitter、Facebook、Instagram 等应用程序的基础。设计应用程序时,确保可靠操作、有效扩展以应对不断增长的需求,并保持程序员在系统上工作的可维护性是至关重要的。
要掌握基础系统设计概念并编写高质量代码,我推荐探索这些书籍。它们也作为准备全球顶级公司技术面试的有用资源。这个列表结合了个人推荐和程序员普遍认可的书籍。那我们就开始吧!
1. 《Head First 设计模式》
作者: Eric Freeman, Elisabeth Robson, Bert Bates, Kathy Sierra
链接: Head First 设计模式

个人推荐!这是一本对系统设计模式和架构模式初学者友好的指南。本指南使用视觉辅助工具、流程图和 UML 图,从零开始构建简单的例子。通过 Java 的面向对象原则,这本书让学习常见的设计模式变得简单,如迭代器、观察者、策略和单例,这些模式在生产级代码中常被使用。
涵盖的主题:
-
创建模式(单例、工厂方法和抽象工厂方法)
-
结构模式(适配器、外观、代理、装饰器)
-
行为模式(策略、观察者、迭代器、状态、模板方法)
-
组合模式
-
应用架构和 MVC 模式
2. 《企业应用架构模式》
作者: 马丁·福勒
链接: 企业应用架构模式

对于那些希望深入了解设计模式的人,本书是一个极好的资源。它以理论的方式探讨复杂的设计模式概念,使其成为你在面临设计选择时的宝贵参考指南。它涵盖了类似于《Head First》书中的主题,但更深入(详细的解释和 UML 图),是寻求对设计模式有全面了解的软件工程师的绝佳资源。
涵盖主题:
-
分层架构
-
并发
-
领域逻辑与关系数据库
-
Web 展示
-
分布式系统
-
设计模式
3. 清洁架构
作者: 罗伯特·C·马丁
链接: 清洁架构

本书由著名的“叔本”编写,是他备受好评的清洁代码系列的一部分。他从软件架构师的角度出发,分享了在设计可靠且可扩展系统时做出的决策。他强调了独立性的重要性,将编程选择与特定数据库、工具和语言解耦,使其成为任何希望提升技能的软件开发者必读的书籍。
涵盖主题:
-
编程范式(结构化、面向对象、函数式)
-
SOLID 设计原则
-
组件原则(内聚性、耦合性、重用性、封闭性)
-
架构原则
4. 设计数据密集型应用
作者: 马丁·克莱普曼
链接: 设计数据密集型应用

另一个个人推荐的,关于系统设计最详细的书籍之一。它全面覆盖了系统设计的主要原则,并解释了为什么事情会按这种方式工作。该书分为三个主要部分:数据系统基础、分布式数据和派生数据。第一部分探讨了数据存储系统、查询语言和大规模系统的检索方法的基本基础。第二部分重点关注分布式系统的开发,强调一致系统的重要性。最后一部分专注于大规模数据系统的批处理和流处理。
涵盖主题:
-
数据模型与查询语言
-
存储与检索
-
复制与事务系统
-
分布式系统
-
一致性
-
批处理
-
流处理
5. 系统设计面试
作者: 亚历克斯·徐
链接: 系统设计面试

最后,系统设计是顶级科技公司(包括 MAANG)面试中的一个重要部分。这本书由谷歌工程师 Alex Xu 编写,是一本受欢迎的面试准备材料,涵盖了广泛的主题。它提供了一个解决系统设计面试问题的 4 步框架,并针对 16 个实际应用提供了详细的解决方案,并配有图表。此外,它还解释了 Twitter、Google 和 YouTube 等主要系统的设计决策。
涵盖的主题:
-
面试过程概述
-
面试过程框架
-
系统设计基础(缓存、数据库、分区、负载均衡)
-
架构技术(单体架构、微服务、无服务器)
-
案例研究(设计网页爬虫、聊天系统、YouTube、Google Drive 等)
总结
如果你是一个初学者,对从何处开始感到困惑,这些书籍是你准备下一次系统设计面试的最佳资源。从涵盖数据系统的基本概念到详细的热门软件系统设计决策,这些书籍应有尽有。如果你对系统设计的炒作感到不知所措,从这里开始将使它变得不那么令人畏惧。
Kanwal Mehreen**** Kanwal 是一名机器学习工程师和技术作家,对数据科学以及 AI 与医学的交叉领域充满热情。她共同编写了电子书《利用 ChatGPT 最大化生产力》。作为 2022 年 APAC 地区的 Google Generation 学者,她倡导多样性和学术卓越。她还被认定为 Teradata 技术多样性学者、Mitacs Globalink 研究学者和哈佛 WeCode 学者。Kanwal 是变革的热心倡导者,她创办了 FEMCodes,旨在赋能女性在 STEM 领域中的发展。
更多相关话题
从快速机器学习算法基准测试中学到的经验
原文:
www.kdnuggets.com/2017/08/lessons-benchmarking-fast-machine-learning-algorithms.html
评论
由微软的 Miguel Fierro、Mathew Salvaris、Guolin Ke 和 Tao Wu 撰写。
根据 KDnuggets,提升决策树在 Kaggle 主办的机器学习挑战中占据了超过一半的获胜解决方案。除了卓越的性能,这些算法在实际应用中也具有吸引力,因为它们只需最少的调整。在这篇文章中,我们评估了两个流行的树提升软件包: XGBoost 和 LightGBM,包括它们的 GPU 实现。我们基于六个数据集的测试结果总结如下:
-
XGBoost 和 LightGBM 实现了类似的准确率指标。
-
在所有测试数据集上,无论是 CPU 还是 GPU 实现,LightGBM 的训练时间都低于 XGBoost 及其基于直方图的变体 XGBoost hist。两个库之间的训练时间差异取决于数据集,可能大到 25 倍。
-
XGBoost GPU 实现对大数据集的扩展性较差,在一半的测试中内存不足。
-
当特征维度较高时,XGBoost hist 可能显著慢于原始的 XGBoost。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
我们的所有代码都是开源的,可以在this repo中找到。我们将解释这些库背后的算法,并在不同的数据集上进行评估。你喜欢你的机器学习快速吗?那就继续阅读吧。
提升决策树的基础
梯度提升是一种机器学习技术,它生成一个以弱分类器的集合形式存在的预测模型,优化可微分的损失函数。最受欢迎的梯度提升类型之一是提升决策树,它内部由一组弱决策树组成。计算树的方法有两种不同策略:按层次和按叶节点。按层次策略逐层生长树。在这种策略中,每个节点优先分裂接近树根的节点。按叶节点策略通过在具有最高损失变化的节点处分裂数据来生长树。按层次生长通常适用于较小的数据集,而按叶节点生长则容易过拟合。按叶节点生长在大数据集上往往表现优异,其速度远快于按层次生长。

训练提升决策树的一个关键挑战是每个叶节点的寻找最佳分裂的计算成本。传统技术找到每个叶节点的准确分裂,并需要在每次迭代中扫描所有数据。另一种方法通过构建特征的直方图来近似分裂。这样,算法无需评估每个特征的所有值来计算分裂,而只需评估直方图的区间,这些区间是有限的。这种方法对大数据集效率更高,同时不影响准确性。
XGBoost 于 2014 年开始,由于在许多获胜的 Kaggle 竞赛中的应用而变得流行。最初,XGBoost 基于按层次生长算法,但最近增加了一个叶节点生长选项,利用直方图实现分裂近似。我们称这一版本为 XGBoost hist。LightGBM 是一个较新的工具,始于 2016 年 3 月,并在 2016 年 8 月开源。它基于叶节点算法和直方图近似,由于其速度引起了广泛关注(免责声明:这篇博客文章的合著者 Guolin Ke 是 LightGBM 的主要贡献者)。除了多线程 CPU 实现外,GPU 加速现在也在XGBoost和LightGBM上可用。
评估 XGBoost 和 LightGBM
我们在六个不同的数据集上进行了machine learning experiments。这些实验的代码在我们的github repo中的 python notebooks 里。我们还展示了我们使用的具体XGBoost 和 LightGBM 的编译版本,并提供了安装它们和设置实验的步骤。我们尝试了使用 CPU 和 GPU 的分类和回归问题。所有实验都在 Azure NV24 虚拟机上运行,该虚拟机配备了 24 个核心、224 GB 内存和 NVIDIA M60 GPU。操作系统为 Ubuntu 16.04。在所有实验中,我们发现 XGBoost 和 LightGBM 的准确率指标相似(此处显示 F1 分数),因此我们在这篇博客中重点关注了训练时间。下表显示了两种库在 CPU 和 GPU 实现中的训练时间以及训练时间比率。

从基准测试中的学习
正如常说的,没有任何基准是绝对真实的,但有些基准是有用的。从我们的实验中,我们发现叶节点实现通常比层级实现更快。然而,BCI 和 Planet Kaggle 数据集的 CPU 结果以及 BCI 的 GPU 结果显示,XGBoost hist 的时间比标准 XGBoost 长得多。这是由于数据集的巨大规模以及大量的特征,这给 XGBoost hist 带来了相当大的内存开销。
我们还发现 XGBoost 的 GPU 实现扩展性不好,对于三个较大的数据集出现了内存溢出错误。此外,我们不得不在航空公司数据集的 XGBoost 训练运行了 5 小时后终止。
最后,在 LightGBM 和 XGBoost 之间,我们发现 LightGBM 在所有 XGBoost 和 XGBoost hist 完成的测试中都更快,其中 XGBoost 的最大差异为 25 倍,XGBoost hist 为 15 倍。
我们想要研究不同数据大小和轮数对 CPU 与 GPU 性能的影响。在下表中,我们展示了使用航空公司数据集子样本的结果。比较 CPU 和 GPU 训练时间时,我们发现当数据集较大且轮数较多时,LightGBM 的 GPU 版本优于 CPU 版本。正如预期的那样,对于小数据集,将数据在 RAM 和 GPU 内存之间复制的额外 IO 开销掩盖了在 GPU 上运行计算的速度优势。在这里,我们没有观察到使用 XGBoost hist 在 GPU 上有任何性能提升。值得一提的是,XGBoost 的标准实现(基于精确分裂而非直方图)与多核 CPU 相比也未能从 GPU 中获益,参见这篇最近的论文。

总的来说,我们发现 LightGBM 在 CPU 和 GPU 实现中都比 XGBoost 更快。此外,如果使用 XGBoost,我们建议密切关注特征维度和内存消耗。LightGBM 显著的速度优势意味着可以进行更多迭代和/或更快的超参数搜索,如果你在优化模型时有时间限制,或希望尝试不同的特征工程思路,这将非常有用。
编程愉快!
米格尔、马修、郭林和陶。
致谢:我们感谢微软的斯蒂夫·邓、戴维·史密斯和胡塞因·伊尔迪兹对本文的帮助和反馈。
原文。经授权转载。
简介: 米格尔·费罗,数据科学家;马修·萨尔瓦里斯,数据科学家;郭林·科,副研究员;陶吴,首席数据科学经理,均在微软工作。
相关内容:
-
使用鸢尾花数据集的简单 XGBoost 教程
-
Dask 和 Pandas 与 XGBoost:在分布式系统中良好协作
-
决策树分类器:简明技术概述
更多相关内容
从我的第一次 Kaggle 比赛中学到的经验
原文:
www.kdnuggets.com/2020/09/lessons-first-kaggle-competition.html
评论
作者 Shruti Turner,帝国理工学院假肢博士研究员
图片来源:Johnson Martin 来自 Pixabay
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
一点背景
我发现开始进入一个新的编程领域是一种令人畏惧的经历。我已经编程了 8 年,但最近才对数据科学产生了浓厚的兴趣。我想分享我的经验,鼓励你们也勇敢尝试!
我最初通过参加几个 Kaggle 小课程来探索这个广阔主题的海洋。我不需要学习如何编写 Python,但我需要装备自己以进行我想要的编程。第一个是 机器学习入门 —— 这似乎是一个很好的起点。在这个课程中,你会参与一个课程内的比赛,但即使完成了它,我仍然感觉自己没有准备好参加公开比赛。接着是 中级机器学习,在这个课程中我学会了使用新模型,并深入思考数据问题。
选择比赛
我花了一些时间选择合适的比赛。我不想仅仅是用数据集做点什么,因为我希望看到自己的进步和评估自己的成功,但我也不想因为无法取得任何成就而感到沮丧。有明确的目标感觉就像一个很好的安全保障。
有一个使用与课程比赛相同数据的竞赛,但我想要一些稍微不同的东西,同时利用我学到的技能,这些技能主要集中在通过数值数据预测结果上。那个 泰坦尼克号:灾难中的机器学习 看起来不错,它标记为“入门”。我在其中表现良好并不会获得任何奖励,这可能会让人感到失望。但你必须评估:你为什么参加竞赛?在我数据科学的旅程中,我希望提升我的知识并应用我所学到的东西。
我学到了什么?
简短的回答: 颇有收获。不仅对我自己,还有如何思考数据科学问题。
详细回答:
-
我可以应用我所学到的东西——这可能是显而易见的,但能够证明自己可以在没有逐步指导的情况下完成任务,还是很令人满意的。
-
我可以发现错误并利用我的技能解决它们——我第一次提交的成绩是 0.0000,即没有正确预测任何结果。我的初步反应是泄气和沮丧。我真的以为我能够取得一些成果。结果发现,我的输出是浮点型而不是整数型。只需一个小的更改,我的成功率就突然达到了约 70%。
-
Kaggle 社区充满了知识——起初我不想查看其他共享的笔记本,我想先自己尝试一下。我仍然认为这是一个不错的做法,但在我提交了几个解决方案后查看这些笔记本,让我学到了我还不知道的内容,包括对数据的处理方法和新算法。我甚至公开分享了 我的笔记本 ,以便其他人可以使用或者我能收到反馈/建议来改进。
-
下一次开始之前进行一些规划可能会有帮助——我太急于动手了,查看了提供的数据,做了一些快速观察,然后直接开始编写代码。在查看了其他解决方案/教程笔记本后,我更加理解了在数据中寻找什么和解决问题的不同方法(以及原因!)我发现的东西与我做的不是很不同,但它们是更深入的解决方案;是在我所做的基础上的下一步。
-
我喜欢解决这些类型的问题,并且想要做更多的这类问题——如果这是我考虑追求的职业方向,这是一个重要的因素。我原本只打算花一个小时,结果下次抬头时已经过去了 4 小时。
下一步
未来,我希望提高我的数据技能,我认为 Kaggle 是一个很好的起点。我还远未完善我对泰坦尼克号竞赛的解决方案,但我从中学到了很多。
我想尝试在 Kaggle 上参加另一个比赛,但步伐要更稳妥。我会先拿出纸和笔,决定每一列数据的相关性,以及如何有效且高效地处理数据中的空白。
我也希望拓展我的知识,不仅在数值数据和预测的方法上更深入,还包括文本分析和图像识别。这将为我打开更多的机会,无论是探索新事物还是尝试更多的比赛。
如果你正在考虑进入数据科学领域,或者已经涉足此领域并想要更多练习,我非常推荐尝试 Kaggle 比赛。
简介:Shruti Turner 是伦敦帝国学院的假肢博士研究员。她热衷于利用自己的工程和编程技能来提高生活质量。
原文。经许可转载。
相关:
-
Kaggle Kernels 初学者指南:逐步教程
-
如果我必须重新开始学习数据科学,我会怎么做?
-
Kaggle Learn 是“更快的数据科学教育”吗?
更多相关内容
高级数据科学家的经验教训
原文:
www.kdnuggets.com/2022/09/lessons-senior-data-scientist.html

图片由 Kindel Media 提供
随着数据科学行业的持续增长,我认为进入该行业的人需要对他们所进入的领域有充分的了解。本文的目的是为了深入了解高级数据科学家的生活,以及他们的经验如何为未来的数据科学家提供借鉴。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
我想介绍一下 Robin Cole……
简介
Robin Cole 是 Satellite Vu 的高级数据科学家。他拥有物理学背景,曾在南安普顿大学学习,然后在帝国学院伦敦攻读光学与光子学硕士学位。一年后,他前往剑桥大学获得物理学博士学位。

来源:采访对象 LinkedIn,已获许可
从那时起,他担任了各种职位,包括研究科学家、NHS 科学家培训计划、光学系统工程师、研究工程师、数据工程师,现在是一名高级数据科学家。他具备数据分析、深度学习、数据工程和亚马逊网络服务(AWS)的技能。
由于他扎实的教育背景和多样的角色,我相信 Robin Cole 能为我们提供更深入的科技和数据领域见解。
这将是一篇访谈风格的文章。那么,让我们开始吧……
问题与答案
你是如何进入数据科学领域的?
我获得了物理学本科学位,随后获得了光学物理学博士学位。然后我进入了研究与开发领域,这其中包括编程。这时我转向编程,从实验室工作和实验转向数据分析。
我特别使用了机器学习来解决我在卫星领域工作时遇到的许多问题,并且使用了计算机视觉模型。我在研究中使用了深度学习与图像。
数据科学对你来说意味着什么?
数据科学领域有各种各样的角色,并且可以有多种用途。例如,在电子商务领域,你可以使用 SQL 和其他传统解决方案,如随机森林,来帮助创建产品推荐引擎。
在我的角色中,我特别关注深度学习,并通过计算机视觉在飞机上捕捉图像。这种深度学习方法使我能够处理这些图像,以识别和定位感兴趣的物品和类别。
我的建议是数据科学对不同的人意味着不同的东西,因此你需要探索数据科学的不同领域和途径,以找到自己感兴趣的方向。
你每天的工作是什么?
我的工作流程模仿了软件工程的方法,其中包括两周的冲刺和每日站会。
我在 9 点开始一天的工作,同时处理邮件并查看对我的研究有帮助的论文和博客。我的每日站会在上午 9 点 30 分,我们的中型团队会相互更新任务进展。剩下的时间主要用于执行独立任务。
我们有一个每两周的汇报时间,我们利用这段时间深入了解我们正在做的事情。我们还利用这段时间来管理进度。每个月,团队都会有一次汇报会议,重点关注数据科学培训需求和基础设施,如 AWS。
你未来有什么计划?
高级数据科学家通常有两条道路可以选择:要么他们在自己的领域变得更专业,要么转向管理角色。对我来说,如果我的团队中聘用了更多的数据科学家,我可能会转变为首席数据科学家。我不太考虑太远的未来——随着业务的发展,我的职责将自然发生变化。
我目前在早期阶段从事遥感数据工作,因此仍需要大量的基础研究。所以我会暂时专注于这个领域,因为这是我的兴趣所在。
有什么帮助你达到现在位置的东西吗?
在成为数据科学家之前,我花了一年时间从事数据工程工作,这帮助我提高了编程技能,特别是 Python。数据科学角色竞争激烈,我意识到我作为数据工程师的那一年在我的数据科学职业生涯中给我带来了帮助。
我还是我现在工作的初创公司里第一个被聘用的人,这意味着我承担了多个技术角色,从而让我能够提升技能,变得更加熟练和有经验。
你认为新数据科学家需要具备什么?
真实的项目!作为高级数据科学家,我经常被问到一些关于项目的基本问题,而我认为这些是数据科学家应该了解的。当谈到项目时,很多在线课程让你遵循他们的指南,但这不一定能帮助你在现实世界中。我相信初级数据科学家需要有信心独立处理项目。
你能看出大学和训练营数据科学家的区别吗?
缺乏传统教育的数据科学家显然存在一些短板,例如真实世界的项目管理、他们如何处理工作以及选择展示的方式。再一次,区别在于训练营学生缺乏真实世界的项目经验,这一点非常重要。
你会给新晋数据科学家提供什么其他建议?
当你看到机会时——就抓住它!我第一次做机器学习项目时,甚至还没有成为数据科学家。我看到一个小机会,可以测试、改进并展示我的数据科学技能。
所以我对新晋数据科学家的建议是,如果你看到一个小机会或者领域可以展示你的编程技能——就去做!这会给你带来真实的经验,并让你从书本上聪明的学生中脱颖而出。
另一条建议是找到一个导师。与经验丰富的人合作可以让你从他们那里获得反馈并交流想法。你也可以利用开源平台,参与 kaggle 竞赛,或者作为志愿者参与项目,这将是一个很好的经历。
我自己通过兼职的激情项目学习并提高了技能,我利用这些真实的项目来建立我的作品集。这些项目也可以在面试中讨论,帮助你脱颖而出!
总结
如果你想了解更多关于 Robin Cole 及其工作的内容,你可以在这里找到并了解更多信息:
我要对 Robin Cole 表示衷心的感谢,感谢他抽出时间与我坐下来,深入了解成为高级数据科学家是什么样的体验,以及新晋数据科学家应该做些什么来提升他们的职业生涯。
谢谢!
Nisha Arya 是一名数据科学家和自由技术写作人员。她特别感兴趣于提供数据科学职业建议或教程以及数据科学的理论知识。她还希望探索人工智能如何及能否有助于人类寿命的不同方式。她是一个热衷学习的人,寻求拓宽技术知识和写作技能,同时帮助指导他人。
更多相关内容
Level 50 数据科学家:需要了解的 Python 库
原文:
www.kdnuggets.com/level-50-data-scientist-python-libraries-to-know

图片来源:作者
数据科学仍然是 21 世纪最热门的职位之一。因此,对于数据科学的好奇心也就不足为奇了。但首先,什么是数据科学?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
数据科学是一个跨学科领域,包括来自不同领域的各种元素,如数据可视化、模型构建和数据处理。
在本文中,我们将深入探讨这些元素,并通过使用 Python 探索可以应用这些元素的库。无论你是专业人士还是自认为是初学者,本文一定会拓展你的知识。让我们开始吧!
图片来源:作者
第一步:数据收集
数据收集意味着从网络上整合信息的过程。
你可能会看到不同的数据项目,这些项目包括合成数据集或来自 Kaggle 的数据集。
即使这对初学者来说很好,但如果你想获得一份有竞争力的工作,你应该做更多的准备。
在 Python 中,有很多选择来实现这一点,让我们深入了解其中的三个。
Scrapy
这是一个用于 Python 的网页爬取框架,适用于大规模数据提取。
它比 BeautifulSoup 更复杂,允许进行更复杂的数据收集。
Scrapy 的一个独特功能是其高效处理异步请求的能力,使其在大规模抓取任务中更快。如果你是新手,接下来的内容更适合你。
BeautifulSoup
BeautifulSoup 用于解析 HTML 和 XML 文档。它比 Scrapy 更简单、更友好,因此非常适合初学者或简单的抓取任务。
BeautifulSoup 的一个显著特点是它在解析即使是格式不良的 HTML 时的灵活性。
Selenium
Selenium 主要用于自动化 Web 浏览器。它非常适合从需要互动的网站抓取数据,例如填写表单或包含 JavaScript 驱动的内容。
它的新颖功能是能够自动化和与网页交互,仿佛一个人正在浏览,从而允许从动态网页中收集数据。
第 2 步:数据探索
现在你有数据,但你应该探索它以查看其特性。
Scipy
Scipy 用于科学和技术计算。
与 numpy 相比,它更侧重于高级计算,提供了如优化、积分和插值等附加功能。
Scipy 的一个独特特点是其针对不同科学计算任务的广泛子模块集合。
Numpy
它是 Python 中与数据科学相关的最重要的库之一。
它声名显赫的最大原因在于其数组对象。虽然 Scipy 基于 Numpy,但 Numpy 本身也能单独工作。
一个显著特点是其执行高效数组计算的能力,这实际上是它在数据科学中如此重要的原因,不过下一个也同样重要。
Pandas
Pandas 提供了易于使用的数据结构,如数据帧,以及适合通过数据帧操作数据的数据分析工具。
Pandas 的一个新颖之处在于 DataFrames,这使其与其他数据处理工具有所不同,提供了广泛的数据处理和分析能力。
第 3 步:数据处理

作者提供的图片
数据处理是你在准备数据以便进行下一阶段的过程。
Pandas
Pandas 提供了如 DataFrame 这样的数据结构,使一切操作变得更简单。因为 Pandas 定义了太多的内置函数,它将你的 100 行代码变成了 2 个内置函数。
它还具有数据可视化能力和数据探索功能,使其比其他 Python 库更具通用性。
第 4 步:数据可视化
数据可视化使你能够在一页上讲述完整的故事。为了做到这一点,本节将涵盖其中的 3 种。
Matplotlib
如果你使用 Python 可视化数据,你就知道 matplotlib 是什么了。它是一个 Python 库,用于创建各种类型的图形,如静态的、交互式的甚至是动画的。
它是一个比其他库更具可定制性的数据显示库。你几乎可以控制图表的任何元素。
Seaborn
Seaborn 基于 Matplotlib 构建,并提供了相同图表的不同视角,如条形图。
与 Matplotlib 相比,它用于创建复杂可视化更简单,并且与 Pandas DataFrames 完全集成。
Plotly
Plotly 比其他库更具交互性。你甚至可以用它创建仪表板,还可以将你的代码与 Plotly 集成,在 Plotly 网站上查看你的图表。
如果你想了解更多,这里是 Python 数据可视化库。
步骤 5:模型构建
模型构建是你最终可以看到你的行动结果的步骤,以进行预测。为此,我们仍有太多的库可用。
Sci-kit Learn
最著名的 Python 机器学习库是 Sci-kit Learn。它提供了简单而高效的功能,可以在几秒钟内构建模型。当然,你可以自己开发许多这些功能,但你愿意写 100 行代码而不是 1 行吗?
它的新颖特点是将算法的综合集合打包在一个包中。
TensorFlow
TensorFlow 由 Google 创建,更适合高阶模型,如深度学习,并提供构建大规模神经网络的高阶功能,相比之下,Scikit-learn 主要提供基础功能。此外,还有许多免费的工具,也是由 Google 创建,使学习 TensorFlow 更加轻松。
Keras
Keras 提供了一个高级神经网络 API,并且能够在 TensorFlow 之上运行。它比 TensorFlow 更注重快速实验深度神经网络。
步骤 6:生产环境中的模型
现在你已经有了模型,但这只是脚本。为了使其更有意义,你应该将模型转化为 Web 应用程序或 API,使其准备好用于生产。
Django
最著名的 Web 框架允许你以结构化的方式开发模型。它比 Flask 和 FastAPI 更复杂,但其原因在于它具有许多内置功能,如管理面板。
以 Flask 为例,你需要从零开始开发许多东西,但如果你对 Web 框架了解不多,这里是一个很好的起点。
Flask
Flask 是一个用于 Python 的微型 Web 框架,借助它你可以更容易地开发自己的 Web 应用程序或 API。它比 Django 更灵活,更适合较小的应用程序。
FastAPI
FastAPI 速度快且易于使用,这使其变得更受欢迎。
FastAPI 的一个独特特点是其自动生成文档和使用 Python 类型提示进行内置验证。
如果你想了解更多,这里是 18 大 Python 库。
奖励步骤:云系统
在这个阶段,你已经拥有了一切,但在自己的环境中。为了将模型分享给世界并进一步测试,你应该与他人分享它们。为此,你的 Web 应用程序或 API 应该在服务器上运行。
Heroku
一个支持多种编程语言的云平台即服务 (PaaS)。
相比 AWS,它对初学者更友好,也提供更简单的网页应用部署过程。如果你是一个完全的初学者,它可能更适合你,比如 PythonAnywhere。
PythonAnywhere
PythonAnywhere 是一个基于 Python 编程语言的在线开发环境,同时提供网页托管服务,从其名称就可以理解。
相比其他工具,它更专注于特定于 Python 的项目。如果你在第 6 步选择了 Flask,你可以将你的模型上传到pythonanywhere,它也提供了一个免费的功能。
AWS(亚马逊网络服务)
AWS 有太多不同的选项,每个功能都有不同的选择。如果你打算选择一个数据库,即使是它,也有太多的选择。
它比其他工具更复杂和全面,适合大规模操作。
比如如果你在前一部分选择了 django,并花时间创建一个大规模的网页应用程序,你的下一个选择可能会是 AWS。
结束语
在这篇文章中,我们探讨了数据科学中使用的主要 Python 库。在进行数据科学项目时,请记住,没有一种终极的方法。我希望这篇文章能向你介绍不同的工具。
Nate Rosidi 是一名数据科学家,专注于产品策略。他还是一位兼任教授,教授分析学,并且是 StrataScratch 的创始人,这是一个帮助数据科学家准备面试的在线平台,提供来自顶级公司的真实面试问题。Nate 撰写有关职业市场的最新趋势,提供面试建议,分享数据科学项目,并涵盖所有 SQL 相关内容。
更多相关话题
层级系统如何帮助预测 AI 成本
原文:
www.kdnuggets.com/2022/03/level-system-help-forecast-ai-costs.html

由 Hitesh Choudhary 提供的照片,来自 Unsplash
设计和构建 AI 系统非常困难。与传统软件不同,传统软件的大部分成本发生在系统部署之前的开发过程中,而 AI 系统的大部分成本发生在之后。AI 系统的行为是通过学习得来的,可能会在初始部署后发生变化。机器学习模型会随着时间的推移而退化,如果没有持续的数据和超参数调整投资。设计决策直接影响 AI 系统的扩展能力。设计难度的核心部分在于理解这些系统如何随时间变化(或不变化!)。
在构建 AI 系统时,讨论它们的“层级”可能会很有用,就像SAE 为自动驾驶汽车定义的层级一样。采用层级系统可以帮助组织规划和准备随时间扩展复杂性的 AI 系统。层级可以提供不同 AI 系统行为的核心断点。采用层级,并在层级之间进行权衡,可以提供部署后差异的简要描述。
了解系统可能经历的哪种类型的行为变化至关重要,并将其纳入系统设计中。以下的层级框架概述了系统随着时间变化的核心差异:我们可以在设计和操作系统时使用这些差异。不同的组件可以处于不同的层级;对这些差异有直观了解可以帮助指导规划和执行。
系统复杂性由其 (a) 输入、(b) 输出 和 (c) 目标的范围定义。
AI 层级
一般而言,随着层级的提升,价值会逐渐增加。例如,一个目标可能是将一个在 Level 1 上运行的系统提升到 Level 2,但系统构建的复杂性(以及成本)也会随着层级的提升而增加。在“低”层级上开始设计一个新功能通常更有意义,因为在这个层级系统的行为比较明确,而逐步提高层级可以帮助理解系统失败的情况,因为随着层级的提高,这些情况会变得更难以理解。
重点应放在学习问题及其解决空间上。较低级别的系统更为一致,并且可以比更高级别的系统更好地探索可能的解决方案,因为后者的成本和性能变异性可能是巨大的障碍。
AI 系统的级别提供了会显著影响系统成本的断点,从传统软件(级别 0)到完全智能的软件(级别 4)。级别 4 的系统基本上可以自我维护和改进 - 它们几乎不需要内部开发团队的工作。
升级有其权衡。例如,从级别 1 升级到级别 2 可以减少持续的数据需求和定制工作,但会引入自我增强的偏见问题。选择升级需要认识到新的挑战,以及在设计 AI 系统时需要采取的行动。
升级到更高的级别可以在可扩展性(以及通常的性能/鲁棒性/等)方面带来显著的好处。我们应该认识到这些好处和成本;当我们在级别 N 上工作时,我们应该考虑到达 N+1 的工作。我们应该针对我们想要实现的目标选择适当的级别,并识别出现有 AI 系统何时需要重建以改变级别。
级别 0:确定性
不需要训练数据,不需要测试数据
不涉及学习(例如,调整参数以适应数据)的算法处于零级。
级别 0(计算机科学中的传统算法)的一个巨大好处是它们非常可靠,并且如果你解决了问题,可以证明它们是最优解。如果你能在级别 0 解决一个问题,那几乎没有办法超越它。从某种程度上说,所有算法 - 即使是排序算法(如二分查找) - 都是“适应性”的。我们通常不会认为排序算法是“学习”。学习涉及记忆 - 系统根据过去的经验改变其未来的行为。
然而,有些问题无法用预定义的算法解决。缺点是,对于那些超出人类理解范围的问题(无论是一次性还是数量上的),可能很难表现良好(例如,语音转文本、翻译、图像识别、发音建议等)。
示例:
-
Luhn 算法用于信用卡验证
-
基于正则表达式的系统(例如,信用卡号码的简单脱敏系统)。
-
信息检索算法,如 TFIDF 检索或 BM25。
-
基于词典的拼写纠正。
注意:在某些情况下,可能需要调整少量参数。例如, ElasticSearch 提供修改 BM25 参数的能力。我们可以将这些视为调整参数,即设置并忘记。这是一个模糊的界限。
级别 1:学习型
静态训练数据,静态测试数据
在离线环境中训练模型并用“冻结”权重部署到生产环境的系统。模型可能会有更新的节奏(例如添加更多标注数据),但模型所操作的环境不会影响模型。
第一级的好处在于你可以以一些训练数据的适度成本学习和部署任何功能。这是一个很好的地方来尝试不同类型的解决方案。而且,对于具有共同元素的难题(例如语音识别),你可以从递减的边际成本中获益。
缺点是对单一用例的定制在数量上是线性的:你需要为每个用例策划训练数据。这可能会随着时间的推移而变化,因此你需要不断添加注释以保持性能。这种成本可能很难承受。
示例:
-
自定义文本分类模型
-
语音转文本(声学模型)
第二级:自学习
动态+静态训练数据,静态测试数据
使用来自系统生成的训练数据来改善模型的系统。在某些情况下,数据生成独立于模型(因此我们预期随着更多数据的加入,模型性能会提高);在其他情况下,模型的干预可能会加剧模型的偏差,性能可能会随着时间的推移变差。为了消除加剧偏差的可能性,我们需要在静态(可能经过标注的)数据集上评估新模型。
第二级很棒,因为性能似乎会随着时间的推移而免费改善。缺点是,如果不加以监控,系统可能会变得更糟——它可能不会随着数据的增加而始终一致地变得更好。另一个限制是,某些第二级系统可能具有有限的改进能力,因为它们实际上是依靠自身(生成自己的训练数据);解决这种偏差可能具有挑战性。
示例:
-
朴素垃圾邮件过滤器
-
常见的语音转文本模型(语言模型)
第三级:自主(或自我纠正)
动态训练数据,动态测试数据
同时改变人类行为(例如推荐一个行动并让用户选择加入)和直接从这种行为中学习的系统,包括系统选择如何改变用户行为。从第二级到第三级的转变可能代表了系统可靠性和可实现性能的大幅提升。
第三级很棒,因为它可以持续随着时间的推移变得更好。然而,它更复杂:它可能需要真正惊人的数据量,或者一个非常精心设计的设置,才能比简单系统表现更好;它适应环境的能力也使得调试非常困难。也可能出现真正灾难性的反馈循环。例如,人类纠正一个电子邮件垃圾邮件过滤器——然而,由于人类只能纠正系统做出的错误分类,它学会了所有预测都是错误的,从而颠倒了自己的预测。
第四级:智能(或全球优化)
动态训练数据,动态测试数据,动态目标
既与环境动态互动又进行全局优化(例如,朝向一些下游目标),例如,在优化 AHT 和 CST 的同时辅助代理,或直接优化利润。例如,一个不优化下一个点击(当前方法)而是优化对话的最佳点击序列的 AutoSuggest 模型。
第 4 级有着极大的潜力——如何达到这一点并不总是显而易见的,除非经过精心设计,这些系统可能会优化到退化的解决方案。将其对准正确的问题、塑造奖励机制以及审计其行为都是庞大且非平凡的任务。
附录:矩阵布局
我们也可以将这些级别可视化为一个矩阵。
| 级别 | 叙述定义 | 输入 | 输出 | 目标 |
|---|---|---|---|---|
| 0: 确定性 | 不涉及学习(例如,不调整参数以适应数据)的算法处于第零级别。 | 无训练数据。 | 一般输出。 | 无目标。性能指标。 |
| 1: 已学习 | 模型训练在离线环境中进行,并以“冻结”权重部署到生产中。模型可能有更新的频率(例如,添加更多的标注数据),但用于训练模型的数据并非直接由系统生成。 | 静态数据,通常是标注过的。 | 简单输出(简单函数逼近) | 单一目标,从输入数据映射到输出。 |
| 2: 自我提升 | 使用从系统生成的训练数据来改进模型的系统,理想情况下数据是静态的(所以我们期望随着数据的增加模型性能会不断提升)。 | 使用从系统生成的新模型输入进行重新训练。 | 简单输出,接近输入数据。 | 单一目标,从输入数据映射到输出。 |
| 3: 自主 | 同时改变人类行为和直接从这种行为中学习的系统。这一类别的问题通常涉及如探索与开发的赌博学习范式。 | 系统使用新的模型输入和对系统先前输出的明确反馈进行重新训练。 | 政策以随时间更新模型输出。 | 累积目标,捕捉模型如何引入偏差以及人们如何与系统互动。 |
| 4: 智能 | 与环境动态互动并朝向下游目标自我优化的系统,例如,在优化 AHT 和 CST 的同时辅助代理。这一类别的问题有时涉及强化学习范式。 | 系统查看模型决策的下游影响,并优化整个系统的性能。 | 政策以优化整个系统。 | 系统目标,从局部决策到下游。 |
迈克尔·格里菲斯 是 ASAPP 的数据科学总监。他致力于识别提升客户和代理体验的机会。在 ASAPP 之前,迈克尔曾在广告、电商和管理咨询领域工作。
更多相关话题
通过 DataCamp 的新 Azure 认证提升自我
原文:
www.kdnuggets.com/level-up-with-datacamps-new-azure-certification

作者提供的图片
当你决定成为一名数据专业人士时,你知道一件事:学习永无止境。跟上市场上的新知识或提升技能以保持竞争力可能会很困难。
KDnuggets 将帮助你完成这段旅程。
我们想介绍 DataCamp 的新 Azure 学习课程,在这里你可以获得认证并开启你的新旅程。
我应该学习 Azure 吗?
在今天的市场上,Azure 认证和知识是科技行业中最受追捧的。如果你希望在云计算、大型企业基础设施和可扩展性方面发展事业——你需要学习 Azure。
但为什么呢?
如果你看看当前市场,更多初创公司正在进入,它们需要按需的 IT 资源。这就是云计算成为每个初创公司必需的资产的原因!话虽如此——它们需要合适的专业人士来处理这些任务。
获得 Azure 证书不仅会增加你的知识和技能,还会使你在对这类专业人士需求高但供应少的市场中具有很强的竞争力。
你明白我想表达的意思,对吧?
工作保障和高薪酬!
DataCamp 的 Azure 认证
认证链接:DataCamp 的 Azure 认证
这项 认证 与微软共同创建,让你从基础开始。你将掌握云计算的基本概念、模型、公共/私有和混合云,同时深入了解基础设施即服务(IaaS)、平台即服务(PaaS)和软件即服务(SaaS)。
一旦你对 Azure 及其架构组件和服务(如计算、网络和存储)有了良好的基础理解,你将继续学习用于保护、管理和管理 Azure 的工具。
你将无需编写任何代码即可学习所有这些内容。
一旦你对 Azure 的所有内容有了良好的理解并掌握了相关知识,你的下一步将是完成 AZ-900 认证——通过 DataCamp 你可以享受 50% 的折扣!
就这样——你已 认证!
总结
作为一名数据专业人士,你应该始终寻找新的方法来提升技能和拓宽知识。你希望在今天的市场上保持竞争力,尤其是在我们当前面临许多裁员的情况下。
了解你渴望成为的职业目标并开始学习吧!
Nisha Arya 是一名数据科学家、自由技术写作人,以及 KDnuggets 的编辑和社区经理。她特别感兴趣于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。Nisha 涉及广泛的话题,并希望探索人工智能如何有益于人类寿命的不同方式。作为一个热衷学习者,Nisha 旨在拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关内容
利用人工智能设计公平和公正的电动汽车充电网络
原文:
www.kdnuggets.com/leveraging-ai-to-design-fair-and-equitable-ev-charging-grids
作者:Ankur Gupta & Swagata Ashwani
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域

图片由编辑提供
人工智能在彻底改变电动汽车充电的可及性和可用性方面具有巨大潜力。随着交通行业大规模转向电动汽车,电动汽车充电需求急剧增长。2021 年,全球售出超过 650 万辆电动汽车,占乘用车销售的 9%。到 2030 年,这一数字应超过 25%。最近的分析估计,到 2040 年,满足充电需求所需的充电站数量需要增长 10 倍[1]。
图 1:按类型预测的电动汽车充电站需求
人工智能算法可以帮助创建更智能、更响应迅速的充电基础设施。然而,尽管我们欢迎这些好处,我们还必须应对快速部署的挑战,同时确保其符合公平、透明和问责等价值观。
供给人工智能模型的数据集将基于这些地区当前的电动汽车采纳情况、电动汽车需求和预期的充电器利用率来制定建议。然而,我们需要控制基于社会经济因素的偏差,以确保新建的充电站能够提供公平和公正的访问。
人工智能在电动汽车充电网络设计中的力量
还有许多科学研究[2,3]探讨了如何利用 AI 和机器学习帮助规划者决定电动汽车充电器的位置和安装的充电器类型。设计电动汽车充电网是一个复杂的问题,涉及多个因素,包括
充电器位置、定价、充电标准类型、充电速度、能源网平衡以及需求预测。让我们深入探讨 AI 如何帮助我们做出更好的决策。
1. 最佳充电站位置
AI 擅长处理庞大的数据集并提取有意义的见解。当确定最佳充电站位置时,这一能力尤为宝贵。通过分析交通模式、人口密度和地理数据等因素,AI 算法可以战略性地布置充电站,以最大限度地提高可达性和用户便利。
例如,电动汽车充电站可能需要设置在繁忙的通勤路线、主要高速公路附近或电动汽车集中区域。高密度的住宅和商业区对电动汽车充电站的需求可能更高。AI 可以分析人口数据和人口密度图来精准确定这些区域。在分析时,数据集需要结合未来电动汽车销售、人口增长和城市发展的趋势。
充电站的最佳位置:
AI 算法在分析大数据方面表现卓越。它们可以帮助确定最佳的电动汽车充电站区域。在这一评估中考虑了各种因素,包括:
-
交通模式:AI 查看交通流量和拥堵程度,以识别高使用率区域。
-
人口密度:优先考虑人口密度高的地方,以确保最大限度的可达性。
-
地理数据:这包括检查物理地形和城市规划限制,以判断其适宜性。
-
现有充电站位置:为了避免某一区域的饱和,保持均匀分布。
-
未来扩展的预测分析:AI 利用电动汽车销售趋势、人口变化和城市发展来预测未来需求,从而指导长期规划。
图 2:展示美国电动汽车充电站分布的热图
2. 需求预测
有效的需求预测策略对优化充电站的位置和运营至关重要,并且具有多个关键原因。首先,准确的需求预测可以战略性地规划充电站的位置。通过预测充电需求最高的时间和地点,AI 驱动的系统可以优化充电基础设施的地理分布。这确保了充电站在预计需求高的区域方便地设置,从而促进城市和乡村区域不同用户的可及性。
其次,需求预测有助于有效的容量规划。通过分析历史数据并结合季节性变化、时间段模式和用户行为等因素,AI 可以帮助确定每个充电站的最佳容量。这确保了基础设施设计能够满足需求而不造成电网过载或低效。以下是影响需求预测的因素。
-
电动汽车充电交易数据:
-
每次充电会话的详细信息(时间、持续时间、位置)
-
每次充电会话的能量消耗
-
充电类型(快充、慢充)
-
交通和流动数据:
-
车辆的 GPS 数据以了解旅行模式
-
不同地区和不同时间段的交通流量数据
-
用户人口统计:
-
电动汽车用户的年龄、性别和居住地点
-
天气:
-
天气条件可能影响驾驶模式
-
社会经济数据:
-
收入水平
-
城市与乡村地区
预测需求对用户满意度至关重要。用户从与其需求相匹配的充电基础设施中获益,这减少了等待时间并提供了无缝的体验。AI 分析多样的数据集,包括用户行为和偏好,能够进行个性化和以用户为中心的需求预测,从而提升电动汽车车主的整体满意度。
3. 动态充电定价模型
传统的固定定价模型可能无法发挥动态响应充电网络的全部潜力。AI 可以分析实时数据,包括能源需求、网络负荷和用户行为,以实施动态定价模型。这不仅优化了充电基础设施的利用,还鼓励用户在非高峰时段充电,促进了更均衡和可持续的能源分配。一项关于基于 Stackelberg 博弈的电动汽车充电站动态定价方案的研究[4]得出的结论是,一个精心设计的定价方案可以降低充电站的销售价格,同时提高站点的利润,实现消费者和提供商的双赢。
影响定价模型的组成部分:
-
能源需求和电网负荷: 人工智能算法可以利用实时电力需求和电网负荷数据。在高需求期间,价格可以上涨,反之亦然。
-
用户行为和模式: 分析历史充电数据,包括充电频率、时长和偏好的充电时间,有助于预测未来行为并相应调整价格。
-
时间/周和季节性: 根据一天中的时间、一周中的天数或季节来变化价格,考虑这些时期的典型使用模式。
-
充电类型(快速充电与慢速充电): 不同类型的充电可以设定不同的收费标准。
图 4:美国电动汽车充电站的定价
动态定价模型在经济实惠性和可达性中发挥作用。通过在非高峰时段或可再生能源资源丰富时提供较低的价格,人工智能驱动的系统使电动充电对各种用户更加经济实惠。这种方法符合公平原则,确保电动出行的好处对不同收入阶层的人们都能获得。
确保人工智能驱动充电中的算法公平性
电动汽车(EV)充电中人工智能驱动的解决方案正在快速发展,提供了在效率、用户体验和电网管理方面的潜在好处。
然而,这一技术进步也引发了关于算法公平性的重要考量。确保电动汽车充电中的人工智能系统公平且无偏见对于促进充电基础设施的公平访问至关重要。
多样且具有代表性的数据
为了减少偏见,确保训练数据多样且具有代表性至关重要。这包括从广泛的地理位置、人口统计群体和充电场景中收集数据。在每个数据集中,需要识别和纠正训练数据中的偏见。选择数据集时需要考虑以下各个方面:
-
地理多样性:
-
城市与乡村区域:结合来自城市和乡村环境的数据,确保充电网络设计的包容性,并满足多样化社区的需求。
-
不同气候:气候变化影响充电行为和能源消耗。反映不同气候条件的数据集有助于构建强大的人工智能模型。
-
人口统计多样性:
-
社会经济因素:包括来自不同社会经济背景的数据有助于避免偏见,并确保充电基础设施对各个收入水平的用户都能接触到。
-
文化考量:文化偏好和生活方式差异影响充电习惯。涵盖文化细微差异的多样化数据集有助于设计更具包容性的充电网络。
-
车辆多样性:
-
各种电动车型号:不同的电动车型号有不同的充电要求。纳入各种电动车的数据确保充电基础设施能够满足不同车辆的规格。
-
充电技术:数据集应考虑不同的充电技术,包括快速充电、标准充电和新兴技术,以便相应地优化电网设计。
-
时间多样性:
-
季节性变化:充电行为可能会随季节变化。涵盖不同季节的数据集使人工智能系统能够根据天气条件变化调整充电网设计。
-
一天中的时间模式:理解一天中充电需求的变化有助于优化不同时间段的充电基础设施。
在构建用于需求预测的人工智能模型时——例如预测下一电动车充电站的放置位置,确保数据集中包含上述所有特征是至关重要的。
一旦特征被整理出来,重要的是评估数据集的平衡性。数据集的不平衡可能导致结果的偏差和偏见。图表显示了一些关键特征如年龄和车辆类型偏好的平衡数据。
图 5:按年龄平衡的电动车充电站位置模型特征
图 6:按车辆类型平衡的电动车充电站位置模型特征
算法透明性
透明性是解决人工智能偏见的基石。充电算法应设计得透明,向用户提供关于充电费率、最佳时间和其他关键因素的决策过程的见解。理解算法的决策过程有助于建立信任,并使用户能够追究充电服务提供商的责任。
LIME(局部可解释模型无关解释)在提高人工智能预测的可解释性方面发挥了关键作用。通过创建可解释的模型来近似复杂机器学习模型的预测,LIME 提供了不同特征如何影响这些预测的见解。例如,在电动车充电站位置选择的背景下,LIME 可以帮助揭示模型推荐在某位置放置充电站的原因——在下面的解释图中,积极影响预测(在位置 x 放置电动车充电站)的特征受社会经济状态的影响较大。交通和人口密度对预测产生负面影响。这只是一个假设的数据集和分析,实际的预测可能会有很大的不同。这个图的目的是展示 LIME 在解释特定预测时的强大作用——哪些特征比其他特征更重要。
图 7:使用 LIME 的电动车充电站预测可解释 AI
NREL 开发的 EVI-Equity: Electric Vehicle Infrastructure for Equity Model [5] 是一个出色的工具,用于通过全面的高分辨率分析衡量全国电动车(EV)充电基础设施的公平性。它提供了一张可视化地图,允许利益相关者检查电动车充电基础设施的公平性特征,使结果的检查和理解变得简单。例如,当应用于大芝加哥地区时,下面的图表展示了基于收入和种族的充电访问差异及相关电动车采纳情况。
图 8:大芝加哥地区的 EVI-Equity 模型结果
保护用户隐私
随着联网车辆的快速兴起,车辆到云端的数据流量越来越大。这不仅包括电池容量、剩余续航等车辆指标,用户设置如气候控制,还有驾驶行为指标如加速/刹车频率、视频和音频流、反刹车/车道偏离传感器激活等。如果这些指标被不公平地使用,可能会为驾驶员创建行为档案,从而在决策中引入偏见。
当人工智能处理大量用户数据以优化充电网布局时,隐私成为至关重要的关注点。实施隐私设计原则可以确保 AI 驱动的充电基础设施尊重用户隐私,并遵守数据保护法规。
负责任数据处理的隐私技术:
-
匿名化: 匿名化涉及从数据流中去除或加密个人身份信息。通过将数据与特定个人脱钩,追踪指标回到某个特定驾驶员变得极其困难。
-
聚合: 聚合涉及将多个数据点组合成概括性的摘要。AI 可以分析更大数据集中的聚合模式,而不是处理单个驾驶员的行为指标。这不仅保护了个别驾驶员的隐私,还确保充电网决策基于整体趋势,而不是特定用户档案。
-
差分隐私: 差分隐私在单个数据点上添加噪声或随机性,使得难以确定单个用户对数据集的贡献。这种技术在数据实用性和隐私保护之间取得平衡,使 AI 能够生成准确的充电网优化,而不妨碍驾驶员的个人隐私。
-
同态加密: 同态加密允许对加密数据进行计算而无需解密。这项技术使得人工智能能够分析加密的驾驶行为数据,确保在优化过程中个人用户的隐私得以保持。这是平衡数据驱动洞察与隐私保护的强大工具。
结论
随着全球电动车(EV)采用的加速,融入人工智能的充电网络面临着既有前景又有重大责任的挑战。它们的使命是为驾驶员提供便利和可靠性,同时确保本地电网的弹性,并优先考虑公平性和问责制。尽管挑战复杂,但未来潜在的好处是巨大的,包括空气质量改善、气候变化缓解、能源独立以及促进下一代技能的发展。
人工智能和机器学习在实现这一愿景中的关键作用不容低估。这些技术有望在大规模上组织个性化的充电,服务于数百万用户。然而,为了赢得公众信任,驱动这些系统的算法必须以公平和透明的原则为核心,同时提高可及性和可靠性。
参考文献
[1] 美国电动车充电市场增长:PwC
[3] 基于数据驱动的异构电动车队智能充电 - ScienceDirect
[4] 基于 Stackelberg 博弈的光伏充电站电动车动态定价方案,考虑用户满意度 - ScienceDirect
[5] EVI-Equity:电动车基础设施公平模型 | 交通和流动性研究 | NREL
Swagata Ashwani 是一位经验丰富的数据科学家,拥有丰富的分析和大数据背景。目前担任 Boomi 的首席数据科学家,Swagata 在利用数据推动创新和效率方面发挥着关键作用。她在公司中主导生成性 AI 项目,并且是 SF Women in Data 的章节负责人,致力于建立一个丰富的社区,以庆祝数据领域的女性。
Ankur Gupta 是一位工程领导者,拥有十年的经验,涉及可持续发展、交通、通信和基础设施领域;目前担任 Uber 的工程经理。在这个角色中,他在推动 Uber 车辆平台的进步方面发挥了关键作用,通过整合前沿的电动和联网车辆,领导迈向零排放的未来。
更多相关主题
利用 GeoPandas 在 Python 中处理地理空间数据
原文:
www.kdnuggets.com/leveraging-geospatial-data-in-python-with-geopandas
空间数据由与位置相关的记录组成。这些数据可以来自 GPS 跟踪、地球观测影像和地图。每个空间数据点可以使用坐标参考系统(如经度/纬度对)在地图上精确定位,这使我们能够调查它们之间的关系。
空间数据的真正潜力在于其将数据点及其对应位置连接起来的能力,创造了无限的高级分析可能性。地理空间数据科学是数据科学中的一个新兴领域,旨在利用地理空间信息,通过空间算法和高级技术(如机器学习或深度学习)提取有价值的见解,以得出有关事件发生及其原因的有意义结论。地理空间数据科学让我们洞察事件发生的地点以及发生的原因。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 为你的组织提供 IT 支持
GeoPandas 是一个开源的 Python 包,专门用于处理信息。它在 pandas 提供的各种数据类型的基础上扩展,提供了对几何对象的空间操作——这使得使用 pandas 数据处理工具 pandas 在 Python 中进行空间分析变得更加便利。由于 GeoPandas 是建立在 Pandas 之上,因此对于熟悉 Python 语法的专业人士来说,可以迅速掌握 GeoPandas 语法。

1. 安装 GeoPandas
我们必须安装 GeoPandas 包才能使用它。然而,需要特别注意的是,GeoPandas 依赖于其他必须安装的库才能正常使用。这些依赖项包括 shapely,Fiona,pyproj 和 rtree**。 **
你可以通过两种方式下载 GeoPandas 包。首先,你可以使用 conda 安装 GeoPandas conda 包。这种方法推荐使用,因为它将提供 GeoPandas 的依赖项,而无需你自己安装。你可以运行以下命令来安装 GeoPandas:
conda install geopandas
第二种方法是使用 pip,这是 Python 中的标准包安装程序。然而,使用此方法将需要安装其余提到的依赖项。
pip install geopandas
一旦安装了 GeoPandas 包,你可以使用以下命令将其导入到你的 Python 代码中:
import geopandas as gpd
2. 读取与写入空间数据
GeoPandas 用于读取空间数据并将其转换为 GeoDataFrame。然而,重要的是要注意有两种主要的空间数据类型:
-
矢量数据: 矢量数据使用离散几何(点、线和多边形)描述地球位置的地理特征。
-
栅格数据: 栅格数据将世界编码为由网格表示的表面。网格的每个像素由一个连续值或分类类表示。
GeoPandas 主要处理矢量数据。然而,它可以与其他 Python 包结合使用来处理栅格数据,例如 rasterio. 你可以使用强大的 geopandas.read_file() 函数来读取大多数基于矢量的空间数据。矢量数据主要有两种类型:
-
Shapefile: Shapefile 是最常见的数据格式,被认为是行业级的数据类型。它由三个压缩文件组成,通常作为 zip 文件提供:
.shp 文件:此文件包含形状几何体。
.dbf 文件:此文件保存每个几何体的属性,
.shx 文件:这是形状索引文件,帮助将属性链接到形状。
-
GeoJSON: 这是一种新的地理空间数据文件格式,于 2016 年发布。由于它只包含一个文件,相比于 Shapefile,它更易于使用。
在本文中,我们将使用 geopandas.read_file() 函数读取托管在 GitHub 上的包含关于巴塞罗那市区不同区域地理空间数据的 GeoJSON 文件。
首先通过加载数据并使用下面的代码打印前五列来开始:
url = 'https://raw.githubusercontent.com/jcanalesluna/bcn-geodata/master/districtes/districtes.geojson'
districts = gpd.read_file(url)
districts.head()
接下来,为了将数据写入文件,我们可以使用 GeoDataFrame.to_file() 函数将数据写入 Shapefile,但你可以通过 driver 参数将其转换为 GeoJSON。
districts.to_file("districts.geojson", driver="GeoJSON")
3. GeoDataFrames 属性
由于GeoDataFrames是 pandas DataFrame 的子类,它继承了很多属性。然而,也存在一些区别,主要的区别是它可以存储几何列(也称为 GeoSeries)并执行空间操作。GeoDataFrame 中的几何列可以包含各种类型的矢量数据,包括点、线和多边形。然而,只有一列被认为是活动几何列,所有空间操作都将基于该列。
另一个关键特性是每列都有其相关的 CRS 信息,告诉我们候选者在地球上的位置。这个特性之所以关键,是因为如果需要合并两个空间数据集,需要确保它们表达在相同的 CRS 中,否则会得到错误的结果。CRS 信息存储在 GeoPandas 的 crs 属性中:
districts.crs
现在我们已设置正确的投影 CRS,我们准备好探索 GeoDataFrames 的属性了。
4. 探索 GeoDataFrames
GeoPandas 具有四个有用的方法和属性,可用于探索数据。我们将探讨这四个方法:
-
面积
-
质心
-
边界
-
距离
4.1. 面积
area 属性返回几何体的计算面积。在下面的示例中,我们将计算每个区的面积(单位为 km2)。
districts['area'] = districts.area / 1000000
districts['area']
4.2. 质心
第二个属性是质心,它返回几何体的中心点。在下面的代码片段中,我们将添加一个新列并保存每个区的质心:
districts['centroid']=districts.centroid
districts['centroid']

4.3. 边界
第三个方法是边界属性,它计算每个区的多边形边界。下面的代码返回它并将其保存到一个单独的列中:
districts['boundary']=districts.boundary

4.4. 距离
distance 方法计算某一几何体到特定位置的最小距离。例如,在下面的代码中,我们将计算从圣家族教堂到巴塞罗那每个区质心的距离。之后,我们将添加距离(单位为 km2)并保存到新列中。
from shapely.geometry import Point
sagrada_fam = Point(2.1743680500855005, 41.403656946781304)
sagrada_fam = gpd.GeoSeries(sagrada_fam, crs=4326)
sagrada_fam= sagrada_fam.to_crs(epsg=2062)
districts['sagrada_fam_dist'] = [float(sagrada_fam.distance(centroid)) / 1000 for centroid in districts.centroid]
5. 使用 GeoPandas 绘制数据
绘制和可视化数据是更好地理解数据的关键步骤。使用 GeoPandas 绘图与使用 Pandas 绘图一样简单且直观。这是通过建立在 matplotlib Python 包上的 GeoDataFrame.plot() 函数完成的。
我们先通过绘制巴塞罗那区的基础图来开始探索:
ax= districts.plot(figsize=(10,6))
这是一个非常基础的图表,未能提供太多信息。然而,我们可以通过为每个区域着色来使其更具信息性。
ax= districts.plot(column='DISTRICTE', figsize=(10,6), edgecolor='black', legend=True)
最后,我们可以通过添加区域的质心来向我们的图表中添加更多信息。
import contextily
import matplotlib.pyplot as plt
ax= districts.plot(column='DISTRICTE', figsize=(12,6), alpha=0.5, legend=True)
districts["centroid"].plot(ax=ax, color="green")
contextily.add_basemap(ax, crs=districts.crs.to_string())
plt.title('A Colored Map with the centroid of Barcelona')
plt.axis('off')
plt.show()
接下来,我们将探索 GeoPandas 的一个非常重要的特性,即空间关系及其如何相互关联。
6. 定义空间关系
地理空间数据在空间上相互关联。GeoPandas 使用 pandas 和 shapely 包来处理空间关系。本节涵盖常见操作。有两种主要方式来合并 GeoPandas DataFrames,即属性连接和空间连接。在本节中,我们将探讨这两者。
6.1. 属性连接
属性连接允许你使用非几何变量连接两个 GeoPandas DataFrame,这使得它类似于 Pandas 中的常规连接操作。连接操作使用 pandas.merge()方法,如下面的示例所示。在这个例子中,我们将把巴塞罗那人口数据连接到我们的地理空间数据中,以添加更多信息。
import pandas as pd
pop =pd.read_csv('2022_padro_sexe.csv', usecols=['Nom_Districte','Nombre'])
pop = pd.DataFrame(pop.groupby('Nom_Districte')['Nombre'].sum()).reset_index()
pop.columns=['NOM','population_22']
districts = districts.merge(pop)
districts
6.2. 空间连接
另一方面,空间连接是基于空间关系来合并数据帧的。在下面的示例中,我们将识别具有自行车车道的区域。 我们将首先加载数据,如下面的代码所示:
url = 'https://opendata-ajuntament.barcelona.cat/resources/bcn/CarrilsBici/CARRIL_BICI.geojson'
bike_lane = gpd.read_file(url)
bike_lane = bike_lane.loc[:,['ID','geometry']]
bike_lane.to_crs(epsg=2062, inplace=True)
要在空间上连接两个数据帧,我们可以使用 sjoin()函数。 sjoin()函数有四个主要参数:第一个是 GeoDataFrame,第二个参数是我们将添加到第一个 GeoDataFrame 的 GeoDataFrame,第三个参数是连接类型,最后一个参数是谓词,它定义了我们希望用来匹配两个 GeoDataFrame 的空间关系。最常见的部分关系有交叉、包含和在内。在这个例子中,我们将使用交叉参数。
lanes_districts = gpd.sjoin(districts, bike_lane, how='inner', predicate='intersects')
lanes_districts
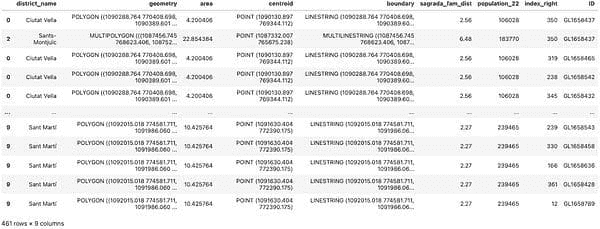
在这篇文章中,我向你介绍了如何使用开源的 GeoPandas 库进行地理空间数据分析。我们从下载 GeoPandas 包开始,然后讨论了不同类型的地理空间数据以及如何加载它们。最后,我们将探索一些基本操作,以便你能亲自接触到地理空间数据集。尽管地理空间数据分析还有很多需要探索的内容,但这篇博客作为你学习之旅的起点。
Youssef Rafaat 是一名计算机视觉研究员和数据科学家。他的研究重点是开发用于医疗保健应用的实时计算机视觉算法。他还在营销、金融和医疗保健领域担任数据科学家超过 3 年。
更多相关内容
利用 GPT 模型将自然语言转化为 SQL 查询
原文:
www.kdnuggets.com/leveraging-gpt-models-to-transform-natural-language-to-sql-queries

图片来源:作者。基础图片来自 pch-vector。
自然语言处理——或称 NLP——已经发生了巨大的发展,而 GPT 模型正处于这场变革的最前沿。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
目前,大型语言模型可以用于各种应用场景。
为了避免不必要的任务并提高我的工作效率,我开始探索训练 GPT 为我生成 SQL 查询的可能性。
就在这时,一个绝妙的主意出现了:
利用 GPT 模型的力量来解读自然语言并将其转化为结构化的 SQL 查询。
这可能吗?
让我们一起发现吧!
所以让我们从头开始……
“少量示例提示”的概念
你们中的一些人可能已经对少量示例提示的概念有所了解,而其他人可能从未听说过这个概念。
那么……这是什么?
这里的基本思想是使用一些明确的示例——或称为“示例”——来指导大型语言模型以特定的方式响应。
这就是为什么它被称为少量示例提示。
简单来说,通过展示一些用户输入的示例提示和期望的大型语言模型输出,我们可以教会模型生成一些更符合我们偏好的增强输出。
这样做,我们在某些特定领域扩展了模型的知识,以生成与我们期望的任务更为契合的输出。
那我们就来举个例子吧!
在本教程中,我将使用一个名为 chatgpt_call()的预定义函数来提示 GPT 模型。如果你想进一步了解,可以查看 以下文章。
想象一下,我希望 ChatGPT 描述一下“乐观主义”这个术语。
如果我只是简单地让 GPT 描述它,我会得到一个严肃而枯燥的描述。
## Code Block
response = chatgpt_call("Teach me about optimism. Keep it short.")
print(response)
附带相应的输出:

我的 Jupyter Notebook 截图。提示 GPT。
不过,假设我希望得到一些更具诗意的东西。我可以在提示中添加更多细节,说明我想要一个诗意的定义。
## Code Block
response = chatgpt_call("Teach me about optimism. Keep it short. Try to create a poetic definition.")
print(response)
但第二个输出看起来像一首诗,与我期望的输出无关。
我的 Jupyter Notebook 截图。提示 GPT。
我该怎么办?
我可以进一步详细描述提示,并继续迭代,直到获得一些好的输出。不过,这会花费很多时间。
相反,我可以通过设计一个示例并向模型展示,向模型展示我偏好的诗意描述类型。
## Code Block
prompt = """
Your task is to answer in a consistent style aligned with the following style.
<user>: Teach me about resilience.
<system>: Resilience is like a tree that bends with the wind but never breaks.
It is the ability to bounce back from adversity and keep moving forward.
<user>: Teach me about optimism.
"""
response = chatgpt_call(prompt)
print(response)</user></system></user>
而输出正是我所寻找的。

我的 Jupyter Notebook 截图。提示 GPT。
那么……我们如何将这一点转化为我们特定的 SQL 查询案例呢?
使用 NLP 进行 SQL 生成
ChatGPT 已经能够从自然语言提示中生成 SQL 查询。我们甚至不需要向模型展示任何表格,只需制定一个假设的计算,它就能为我们完成。
## Code Block
user_input = """
Assuming I have both product and order tables, could you generate a single table that contained all the info
of every product together with how many times has it been sold?
"""
prompt = f"""
Given the following natural language prompt, generate a hypothetical query that fulfills the required task in SQL.
{user_input}
"""
response = chatgpt_call(prompt)
print(response)
不过,正如你已经知道的,我们给模型提供的上下文越多,它生成的输出就会越好。

我的 Jupyter Notebook 截图。提示 GPT。
在本教程中,我将输入提示分为用户的具体需求和模型所期望的高层次行为。这是改善我们与 LLM 交互并使提示更加简洁的好方法。 你可以在以下文章中了解更多。
所以让我们假设我正在处理两个主要表格:PRODUCTS 和 ORDERS
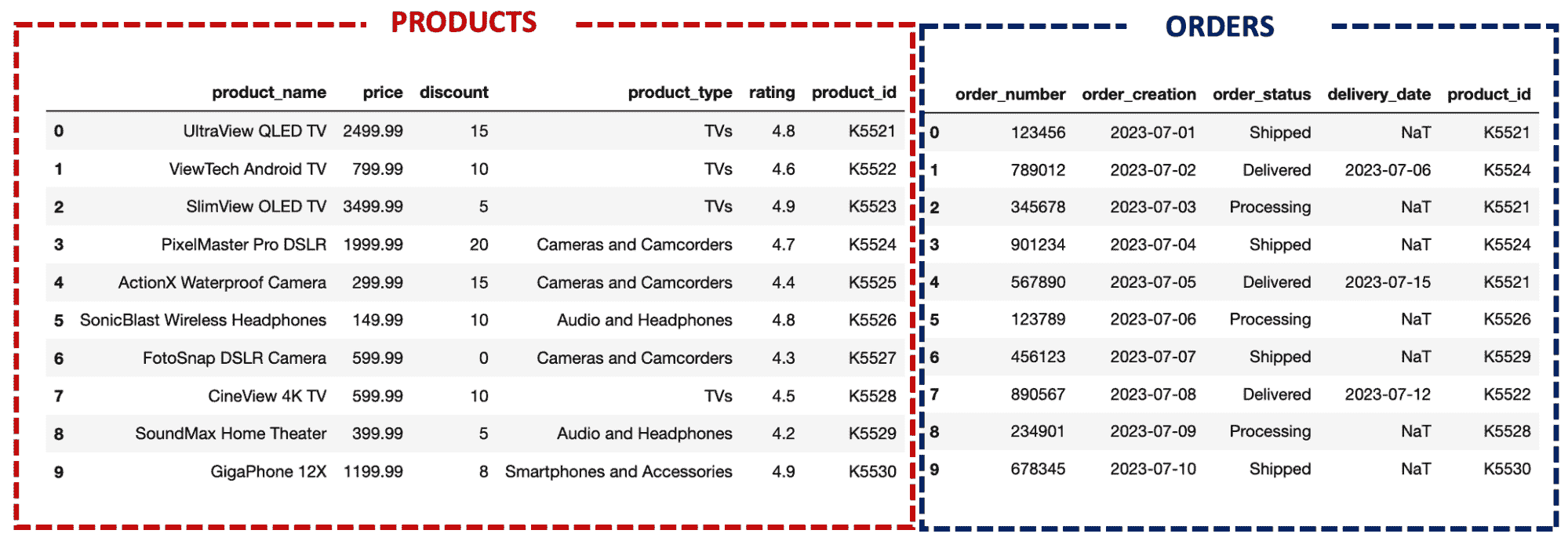
作者提供的图像。教程中将使用的表格。
如果我要求 GPT 提供一个简单的查询,模型会立刻给出解决方案,就像一开始那样,但会针对我的具体情况提供特定的表格。
## Code Block
user_input = """
What model of TV has been sold the most in the store?
"""
prompt = f"""
Given the following SQL tables, your job is to provide the required SQL queries to fulfil any user request.
Tables: <{sql_tables}>
User request: ```{user_input}```py
"""
response = chatgpt_call(prompt)
print(response)
你可以在本文末尾找到 sql_tables!
输出看起来如下!
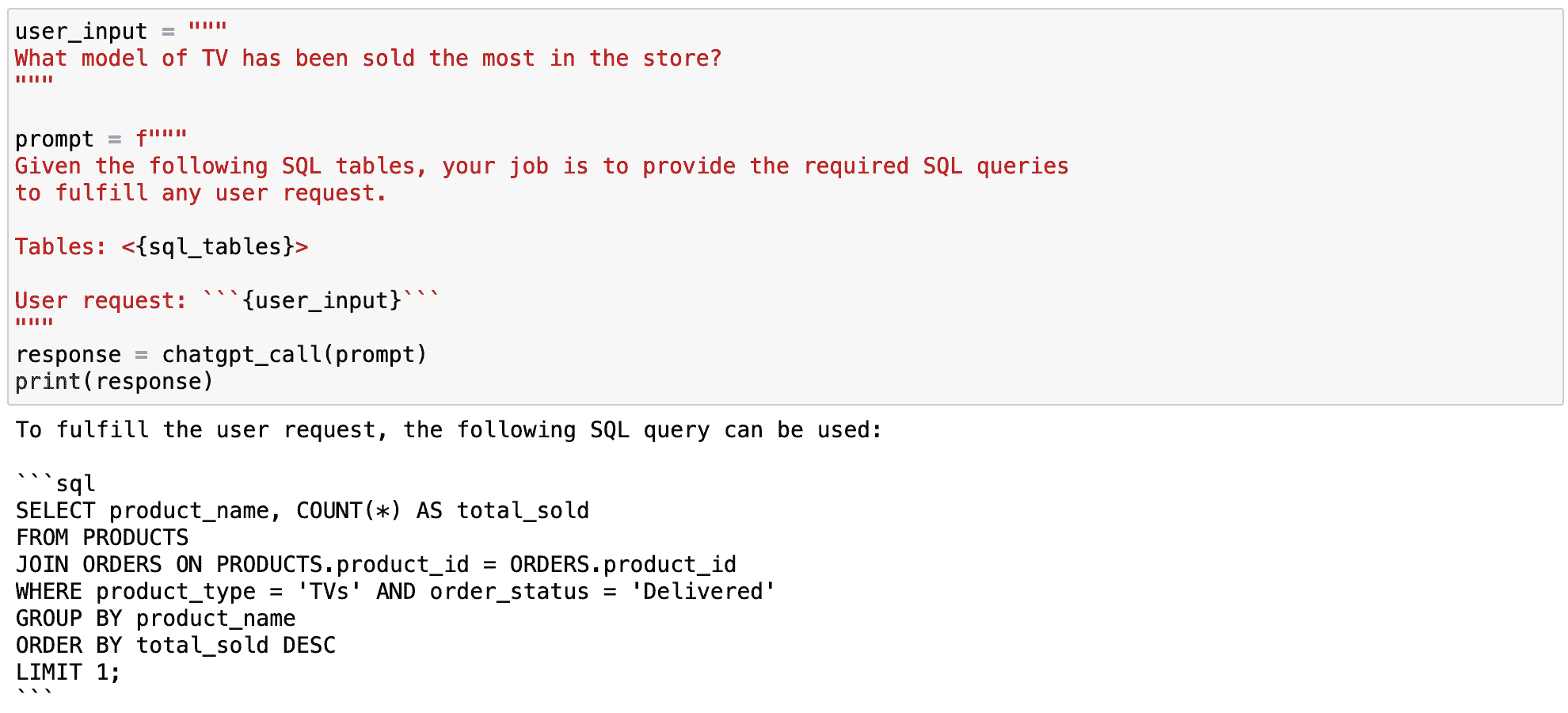
我的 Jupyter Notebook 截图。提示 GPT。
不过,我们可以观察到之前输出中的一些问题。
-
计算部分是错误的,因为它只考虑了那些已经交付的电视。任何发出的订单——无论是否已交付——都应该被视为销售。
-
查询的格式不是我希望的那样。
所以首先让我们专注于向模型展示如何计算所需的查询。
#1. 解决模型的一些误解
在这种情况下,模型只考虑那些已经作为已售出的产品,但这并不正确。我们可以通过显示两个不同的示例来解决这种误解,其中我计算了类似的查询。
## Few_shot examples
fewshot_examples = """
-------------- FIRST EXAMPLE
User: What model of TV has been sold the most in the store when considering all issued orders.
System: You first need to join both orders and products tables, filter only those orders that correspond to TVs
and count the number of orders that have been issued:
SELECT P.product_name AS model_of_tv, COUNT(*) AS total_sold
FROM products AS P
JOIN orders AS O ON P.product_id = O.product_id
WHERE P.product_type = 'TVs'
GROUP BY P.product_name
ORDER BY total_sold DESC
LIMIT 1;
-------------- SECOND EXAMPLE
User: What's the sold product that has been already delivered the most?
System: You first need to join both orders and products tables, count the number of orders that have
been already delivered and just keep the first one:
SELECT P.product_name AS model_of_tv, COUNT(*) AS total_sold
FROM products AS P
JOIN orders AS O ON P.product_id = O.product_id
WHERE P.order_status = 'Delivered'
GROUP BY P.product_name
ORDER BY total_sold DESC
LIMIT 1;
"""
现在,如果我们再次提示模型并包含之前的示例,我们可以看到,相应的查询不仅会正确——之前的查询已经有效——而且还会考虑我们想要的销售!
## Code Block
user_input = """
What model of TV has been sold the most in the store?
"""
prompt = f"""
Given the following SQL tables, your job is to provide the required SQL tables
to fulfill any user request.
Tables: <{sql_tables}>. Follow those examples the generate the answer, paying attention to both
the way of structuring queries and its format:
<{fewshot_examples}>
User request: ```{user_input}```py
"""
response = chatgpt_call(prompt)
print(response)
以下是输出:
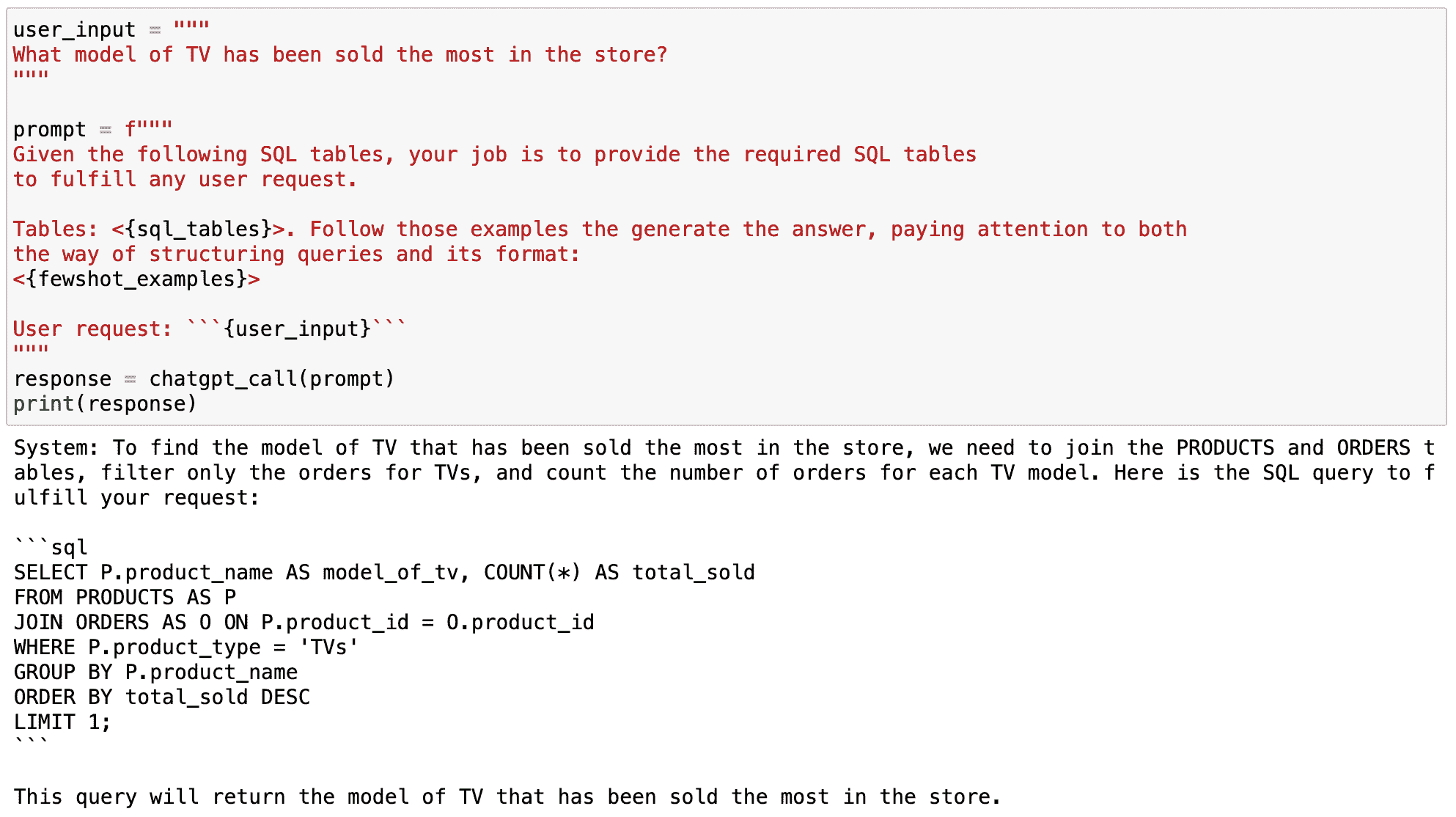
我在 Jupyter Notebook 的截图。提示 GPT。
现在如果我们检查相应的查询…
## Code Block
pysqldf("""
SELECT P.product_name AS model_of_tv, COUNT(*) AS total_sold
FROM PRODUCTS AS P
JOIN ORDERS AS O ON P.product_id = O.product_id
WHERE P.product_type = 'TVs'
GROUP BY P.product_name
ORDER BY total_sold DESC
LIMIT 1;
""")
它工作得非常好!

我在 Jupyter Notebook 的截图。提示 GPT。
#2. 格式化 SQL 查询
少量示例提示也可以是一种定制模型以符合我们自己的目的或风格的方法。
如果我们回顾之前的示例,查询完全没有格式。我们都知道,有一些良好的实践——加上一些个人的怪癖——可以帮助我们更好地阅读 SQL 查询。
这就是为什么我们可以使用少量示例提示来向模型展示我们喜欢的查询方式——包括我们的良好实践或只是我们的怪癖——并训练模型给我们我们所期望的格式化 SQL 查询。
现在,我将按照我的格式偏好准备之前相同的示例。
## Code Block
fewshot_examples = """
---- EXAMPLE 1
User: What model of TV has been sold the most in the store when considering all issued orders.
System: You first need to join both orders and products tables, filter only those orders that correspond to TVs
and count the number of orders that have been issued:
SELECT
P.product_name AS model_of_tv,
COUNT(*) AS total_sold
FROM products AS P
JOIN orders AS O
ON P.product_id = O.product_id
WHERE P.product_type = 'TVs'
GROUP BY P.product_name
ORDER BY total_sold DESC
LIMIT 1;
---- EXAMPLE 2
User: What is the latest order that has been issued?
System: You first need to join both orders and products tables and filter by the latest order_creation datetime:
SELECT
P.product_name AS model_of_tv
FROM products AS P
JOIN orders AS O
ON P.product_id = O.product_id
WHERE O.order_creation = (SELECT MAX(order_creation) FROM orders)
GROUP BY p.product_name
LIMIT 1;
"""
一旦定义了示例,我们可以将它们输入到模型中,以便模型可以模仿展示的风格。
正如你在下面的代码框中观察到的那样,在向 GPT 展示我们期望的内容后,它会模仿给定示例的风格,以相应地生成任何新输出。
## Code Block
user_input = """
What is the most popular product model of the store?
"""
prompt = f"""
Given the following SQL tables, your job is to provide the required SQL tables
to fulfill any user request.
Tables: <{sql_tables}>. Follow those examples the generate the answer, paying attention to both
the way of structuring queries and its format:
<{fewshot_examples}>
User request: ```{user_input}```py
"""
response = chatgpt_call(prompt)
print(response)
正如你在下面的输出中观察到的那样,它有效!
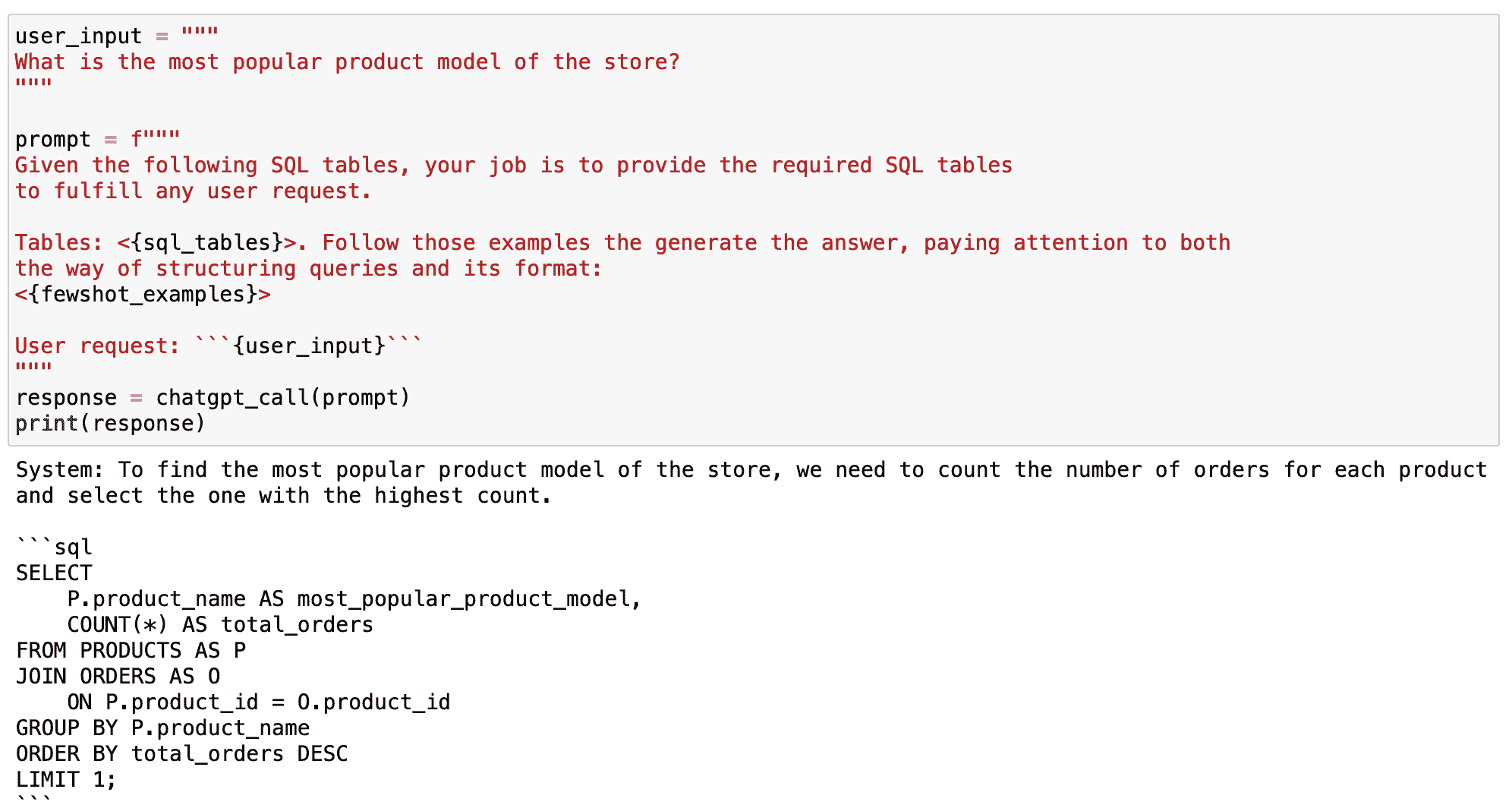
我在 Jupyter Notebook 的截图。提示 GPT。
#3. 训练模型以计算某个特定变量。
让我们深入一个说明性的场景。假设我们旨在计算哪个产品的交付时间最长。我们用自然语言向模型提出这个问题,期待一个正确的 SQL 查询。
## Code Block
user_input = """
What product is the one that takes longer to deliver?
"""
prompt = f"""
Given the following SQL tables, your job is to provide the required SQL tables
to fulfill any user request.
Tables: <{sql_tables}>. Follow those examples the generate the answer, paying attention to both
the way of structuring queries and its format:
<{fewshot_examples}>
User request: ```{user_input}```py
"""
response = chatgpt_call(prompt)
print(response)
然而,我们收到的回答远非正确。
我在 Jupyter Notebook 的截图。提示 GPT。
出了什么问题?
GPT 模型尝试直接计算两个 datetime SQL 变量之间的差异。这种计算与大多数 SQL 版本不兼容,特别是对于 SQLite 用户,创建了一个问题。
我们如何纠正这个问题?
解决方案就在我们眼前——我们回到少量示例提示的做法。
通过向模型展示我们通常如何计算时间变量——在这种情况下是交货时间——我们训练它在遇到类似变量类型时能够复制这一过程。
例如,SQLite 用户可以使用 julianday() 函数。该函数将任何日期转换为自公历初始纪元以来经过的天数。
这可以帮助 GPT 模型更好地处理 SQLite 数据库中的日期差异。
## Adding one more example
fewshot_examples += """
------ EXAMPLE 4
User: Compute the time that it takes to delivery every product?
System: You first need to join both orders and products tables, filter only those orders that have
been delivered and compute the difference between both order_creation and delivery_date.:
SELECT
P.product_name AS product_with_longest_delivery,
julianday(O.delivery_date) - julianday(O.order_creation) AS TIME_DIFF
FROM
products AS P
JOIN
orders AS O ON P.product_id = O.product_id
WHERE
O.order_status = 'Delivered';
"""
当我们使用这种方法作为模型的示例时,它会学习我们计算交货时间的偏好方式。这使得模型更适合生成适用于我们特定环境的功能性 SQL 查询。
如果我们使用之前的示例作为输入,模型将复制我们计算交货时间的方式,并将为我们具体的环境提供功能性查询。
## Code Block
user_input = """
What product is the one that takes longer to deliver?
"""
prompt = f"""
Given the following SQL tables, your job is to provide the required SQL tables
to fulfill any user request.
Tables: <{sql_tables}>. Follow those examples the generate the answer, paying attention to both
the way of structuring queries and its format:
<{fewshot_examples}>
User request: ```{user_input}```py
"""
response = chatgpt_call(prompt)
print(response)
我的 Jupyter Notebook 截图。提示 GPT。
总结
总之,GPT 模型是将自然语言转换为 SQL 查询的绝佳工具。
不过,它还不完美。
如果没有适当的训练,模型可能无法理解上下文相关的查询或特定操作。
通过使用少量示例提示,我们可以引导模型理解我们的查询风格和计算偏好。
这使我们能够充分发挥 GPT 模型在数据科学工作流中的作用,将模型转变为一个强大的工具,以适应我们独特的需求。
从未格式化的查询到完美定制的 SQL 查询,GPT 模型将个性化的魔力带到我们的指尖!
## SQL TABLES
sql_tables = """
CREATE TABLE PRODUCTS (
product_name VARCHAR(100),
price DECIMAL(10, 2),
discount DECIMAL(5, 2),
product_type VARCHAR(50),
rating DECIMAL(3, 1),
product_id VARCHAR(100)
);
INSERT INTO PRODUCTS (product_name, price, discount, product_type, rating, product_id)
VALUES
('UltraView QLED TV', 2499.99, 15, 'TVs', 4.8, 'K5521'),
('ViewTech Android TV', 799.99, 10, 'TVs', 4.6, 'K5522'),
('SlimView OLED TV', 3499.99, 5, 'TVs', 4.9, 'K5523'),
('PixelMaster Pro DSLR', 1999.99, 20, 'Cameras and Camcorders', 4.7, 'K5524'),
('ActionX Waterproof Camera', 299.99, 15, 'Cameras and Camcorders', 4.4, 'K5525'),
('SonicBlast Wireless Headphones', 149.99, 10, 'Audio and Headphones', 4.8, 'K5526'),
('FotoSnap DSLR Camera', 599.99, 0, 'Cameras and Camcorders', 4.3, 'K5527'),
('CineView 4K TV', 599.99, 10, 'TVs', 4.5, 'K5528'),
('SoundMax Home Theater', 399.99, 5, 'Audio and Headphones', 4.2, 'K5529'),
('GigaPhone 12X', 1199.99, 8, 'Smartphones and Accessories', 4.9, 'K5530');
CREATE TABLE ORDERS (
order_number INT PRIMARY KEY,
order_creation DATE,
order_status VARCHAR(50),
product_id VARCHAR(100)
);
INSERT INTO ORDERS (order_number, order_creation, order_status, delivery_date, product_id)
VALUES
(123456, '2023-07-01', 'Shipped','', 'K5521'),
(789012, '2023-07-02', 'Delivered','2023-07-06', 'K5524'),
(345678, '2023-07-03', 'Processing','', 'K5521'),
(901234, '2023-07-04', 'Shipped','', 'K5524'),
(567890, '2023-07-05', 'Delivered','2023-07-15', 'K5521'),
(123789, '2023-07-06', 'Processing','', 'K5526'),
(456123, '2023-07-07', 'Shipped','', 'K5529'),
(890567, '2023-07-08', 'Delivered','2023-07-12', 'K5522'),
(234901, '2023-07-09', 'Processing','', 'K5528'),
(678345, '2023-07-10', 'Shipped','', 'K5530');
"""
Josep Ferrer 是一位来自巴塞罗那的分析工程师。他毕业于物理工程专业,目前在应用于人类流动性的 数据科学 领域工作。他还是一名兼职内容创作者,专注于数据科学和技术。你可以通过 LinkedIn、Twitter 或 Medium 联系他。
更多相关内容
利用 CuPy 在 Python 中发挥 GPU 的威力
原文:
www.kdnuggets.com/leveraging-the-power-of-gpus-with-cupy-in-python

图片由作者提供
什么是 CuPy?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
CuPy 是一个与 NumPy 和 SciPy 数组兼容的 Python 库,旨在用于 GPU 加速计算。通过将 NumPy 替换为 CuPy 语法,你可以在 NVIDIA CUDA 或 AMD ROCm 平台上运行代码。这使你能够利用 GPU 加速执行数组相关的任务,从而更快地处理更大的数组。
通过仅替换几行代码,你可以利用 GPU 的大规模并行处理能力,显著加速数组操作,如索引、归一化和矩阵乘法。
CuPy 还使得访问低级 CUDA 功能成为可能。它允许使用 RawKernels 将 ndarrays 传递到现有的 CUDA C/C++ 程序,利用 Streams 简化性能,并直接调用 CUDA Runtime API。
安装 CuPy
你可以使用 pip 安装 CuPy,但在此之前,你需要使用下面的命令找出正确的 CUDA 版本。
!nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Wed_Sep_21_10:33:58_PDT_2022
Cuda compilation tools, release 11.8, V11.8.89
Build cuda_11.8.r11.8/compiler.31833905_0
目前 Google Colab 的版本似乎使用的是 CUDA 11.8。因此,我们将继续安装 cupy-cuda11x 版本。
如果你使用的是较旧的 CUDA 版本,我提供了一个表格来帮助你确定要安装的适当 CuPy 包。
图片来自 CuPy 12.2.0
选择正确版本后,我们将使用 pip 安装 Python 包。
pip install cupy-cuda11x
如果你安装了 Anaconda,你也可以使用conda命令自动检测并安装正确版本的 CuPy 包。
conda install -c conda-forge cupy
CuPy 基础知识
在这一部分,我们将比较 CuPy 和 Numpy 的语法,它们的相似度高达 95%。使用 np 的地方,你将用 cp 替代。
我们将首先使用 Python 列表创建一个 NumPy 和 CuPy 数组。之后,我们将计算向量的范数。
import cupy as cp
import numpy as np
x = [3, 4, 5]
x_np = np.array(x)
x_cp = cp.array(x)
l2_np = np.linalg.norm(x_np)
l2_cp = cp.linalg.norm(x_cp)
print("Numpy: ", l2_np)
print("Cupy: ", l2_cp)
正如我们所见,我们得到了类似的结果。
Numpy: 7.0710678118654755
Cupy: 7.0710678118654755
要将 NumPy 数组转换为 CuPy 数组,你可以简单地使用 cp.asarray(X)。
x_array = np.array([10, 22, 30])
x_cp_array = cp.asarray(x_array)
type(x_cp_array)
cupy.ndarray
或者,使用 .get() 将 CuPy 转换为 NumPy 数组。
x_np_array = x_cp_array.get()
type(x_np_array)
numpy.ndarray
性能比较
在这一部分,我们将比较 NumPy 和 CuPy 的性能。
我们将使用 time.time() 来计时代码执行时间。然后,我们将创建一个 3D NumPy 数组并执行一些数学函数。
import time
# NumPy and CPU Runtime
s = time.time()
x_cpu = np.ones((1000, 100, 1000))
np_result = np.sqrt(np.sum(x_cpu**2, axis=-1))
e = time.time()
np_time = e - s
print("Time consumed by NumPy: ", np_time)
Time consumed by NumPy: 0.5474584102630615
同样,我们将创建一个 3D CuPy 数组,执行数学运算,并对其性能进行计时。
# CuPy and GPU Runtime
s = time.time()
x_gpu = cp.ones((1000, 100, 1000))
cp_result = cp.sqrt(cp.sum(x_gpu**2, axis=-1))
e = time.time()
cp_time = e - s
print("\nTime consumed by CuPy: ", cp_time)
Time consumed by CuPy: 0.001028299331665039
为了计算差异,我们将 NumPy 时间与 CuPy 时间进行比较,使用 CuPy 时我们似乎得到了超过 500 倍的性能提升。
diff = np_time/cp_time
print(f'\nCuPy is {diff: .2f} X time faster than NumPy')
CuPy is 532.39 X time faster than NumPy
注意: 为了取得更好的效果,建议进行几次热身测试,以减少时间波动。
除了速度优势外,CuPy 还提供了优越的多 GPU 支持,使得可以利用多个 GPU 的集体力量。
如果你想对比结果,也可以查看我的 Colab 笔记本。
结论
总之,CuPy 提供了一种简单的方法来加速 NVIDIA GPU 上的 NumPy 代码。通过仅做少量修改将 NumPy 替换为 CuPy,你可以在数组计算中体验数量级的加速。这种性能提升使你能够处理更大规模的数据集和模型,从而实现更高级的机器学习和科学计算。
资源
-
GitHub: cupy/cupy
-
示例: cupy/examples
-
API: API 参考
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一款 AI 产品,帮助那些面临心理健康问题的学生。
更多相关主题
利用 XGBoost 进行时间序列预测
原文:
www.kdnuggets.com/2023/08/leveraging-xgboost-timeseries-forecasting.html
XGBoost(极端梯度提升)是一种开源算法,实施了 梯度提升 树,并进行了额外改进以提高性能和速度。该算法快速准确的预测能力使其成为许多竞赛的首选模型,如 Kaggle 竞赛。
XGBoost 应用的常见案例包括分类预测,如欺诈检测,或回归预测,如房价预测。然而,将 XGBoost 算法扩展到预测时间序列数据也是可能的。它是如何工作的?让我们进一步探讨。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
时间序列预测
数据科学和机器学习中的预测是一种基于随时间收集的历史数据来预测未来数值的方法,可以是规则的或不规则的间隔。
与常见的机器学习训练数据中每个观察值相互独立不同,时间序列预测的数据必须按连续顺序排列,并与每个数据点相关。例如,时间序列数据可以包括每月的股票、每周的天气、每日销售等。
让我们看看示例时间序列数据 Kaggle 的每日气候数据。
import pandas as pd
train = pd.read_csv('DailyDelhiClimateTrain.csv')
test = pd.read_csv('DailyDelhiClimateTest.csv')
train.head()
如果我们查看上述数据框,每个特征都被记录为每日数据。日期列表示数据被观察的时间,每个观察值之间是相关的。
时间序列预测通常结合数据中的趋势、季节性和其他模式进行预测。查看这些模式的一种简单方法是通过可视化。例如,我会可视化我们示例数据集中的平均温度数据。
train["date"] = pd.to_datetime(train["date"])
test["date"] = pd.to_datetime(test["date"])
train = train.set_index("date")
test = test.set_index("date")
train["meantemp"].plot(style="k", figsize=(10, 5), label="train")
test["meantemp"].plot(style="b", figsize=(10, 5), label="test")
plt.title("Mean Temperature Dehli Data")
plt.legend()
我们可以在上面的图表中很容易地看到每年都有一个共同的季节性模式。通过结合这些信息,我们可以理解数据如何工作,并决定哪个模型可能适合我们的预测模型。
典型的预测模型包括 ARIMA、向量自回归、指数平滑和 Prophet。然而,我们也可以利用 XGBoost 来提供预测。
XGBoost 预测
在准备使用 XGBoost 进行预测之前,我们必须首先安装该软件包。
pip install xgboost
安装完成后,我们将准备数据以进行模型训练。理论上,XGBoost 预测将基于单一或多个特征实现回归模型,以预测未来的数值。这就是为什么数据训练也必须是数值的原因。此外,为了将时间的变化融入我们的 XGBoost 模型,我们将把时间数据转化为多个数值特征。
让我们从创建一个函数开始,将日期转换为数值特征。
def create_time_feature(df):
df['dayofmonth'] = df['date'].dt.day
df['dayofweek'] = df['date'].dt.dayofweek
df['quarter'] = df['date'].dt.quarter
df['month'] = df['date'].dt.month
df['year'] = df['date'].dt.year
df['dayofyear'] = df['date'].dt.dayofyear
df['weekofyear'] = df['date'].dt.weekofyear
return df
接下来,我们将把这个函数应用于训练数据和测试数据。
train = create_time_feature(train)
test = create_time_feature(test)
train.head()
所需的信息现在都已经准备好。接下来,我们将定义我们想要预测的内容。在这个例子中,我们将预测平均温度,并基于上述数据制作训练数据。
X_train = train.drop('meantemp', axis =1)
y_train = train['meantemp']
X_test = test.drop('meantemp', axis =1)
y_test = test['meantemp']
我仍然会使用其他信息,如湿度,以展示 XGBoost 也可以通过多变量方法进行预测。然而,在实际应用中,我们只会纳入我们知道存在的数据来进行预测。
让我们通过将数据拟合到模型中开始训练过程。对于当前的示例,我们不会做太多超参数优化,除了树的数量。
import xgboost as xgb
reg = xgb.XGBRegressor(n_estimators=1000)
reg.fit(X_train, y_train, verbose = False)
训练过程结束后,让我们查看模型的特征重要性。
xgb.plot_importance(reg)
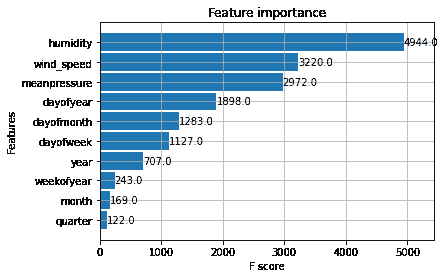
三个初始特征在预测中非常有用,但时间特征也有助于预测。让我们尝试在测试数据上进行预测并进行可视化。
test['meantemp_Prediction'] = reg.predict(X_test)
train['meantemp'].plot(style='k', figsize=(10,5), label = 'train')
test['meantemp'].plot(style='b', figsize=(10,5), label = 'test')
test['meantemp_Prediction'].plot(style='r', figsize=(10,5), label = 'prediction')
plt.title('Mean Temperature Dehli Data')
plt.legend()
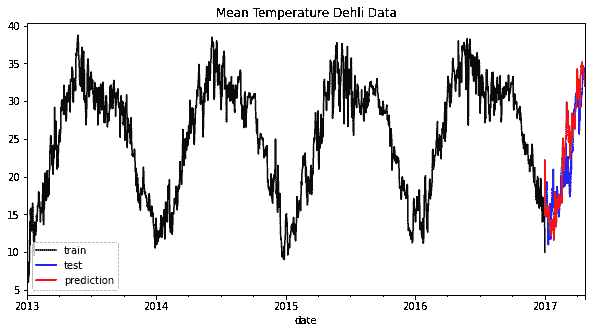
从上面的图表中,我们可以看到,预测可能看起来稍有偏差,但仍然遵循总体趋势。让我们尝试根据误差指标来评估模型。
from sklearn.metrics import mean_squared_error, mean_absolute_error, mean_absolute_percentage_error
print('RMSE: ', round(mean_squared_error(y_true=test['meantemp'],y_pred=test['meantemp_Prediction']),3))
print('MAE: ', round(mean_absolute_error(y_true=test['meantemp'],y_pred=test['meantemp_Prediction']),3))
print('MAPE: ', round(mean_absolute_percentage_error(y_true=test['meantemp'],y_pred=test['meantemp_Prediction']),3))
RMSE: 11.514
MAE: 2.655
MAPE: 0.133
结果表明,我们的预测可能有约 13%的误差,而 RMSE 也显示预测有轻微误差。模型可以通过超参数优化来改进,但我们已经了解了 XGBoost 如何用于预测。
结论
XGBoost 是一种开源算法,通常用于许多数据科学案例以及 Kaggle 竞赛中。使用案例通常包括常见的分类任务,如欺诈检测,或回归任务,如房价预测,但 XGBoost 也可以扩展到时间序列预测中。通过使用 XGBoost 回归器,我们可以创建一个能够预测未来数值的模型。
Cornellius Yudha Wijaya 是一位数据科学助理经理和数据撰稿人。他在全职工作于 Allianz Indonesia 的同时,喜欢通过社交媒体和撰写媒体分享 Python 和数据技巧。
更多相关主题
LGBMClassifier: 入门指南
原文:
www.kdnuggets.com/2023/07/lgbmclassifier-gettingstarted-guide.html

编辑者提供的图片
机器学习算法种类繁多,适合于建模特定现象。一些模型利用一组属性来优于其他模型,而另一些模型则包括弱学习者,以利用剩余属性为模型提供额外信息,这就是集成模型。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 工作
集成模型的前提是通过结合不同模型的预测以减少其误差来提高模型性能。有两种流行的集成技术:bagging 和 boosting。
Bagging,又称为自助聚合,在不同的随机子集上训练多个单独的模型,然后平均它们的预测结果以生成最终预测。而提升(Boosting)则涉及顺序训练单独的模型,每个模型试图纠正前一个模型的错误。
既然我们了解了集成模型的背景,让我们深入探讨一下提升集成模型,特别是微软开发的 Light GBM(LGBM)算法。
什么是 LGBMClassifier?
LGBMClassifier 代表 Light Gradient Boosting Machine Classifier。它使用决策树算法进行排序、分类和其他机器学习任务。LGBMClassifier 使用一种新颖的基于梯度的单边采样(GOSS)和独占特征捆绑(EFB)技术,能够准确地处理大规模数据,从而提高速度并减少内存使用。
什么是基于梯度的单边采样(GOSS)?
传统的梯度提升算法使用所有数据进行训练,这在处理大型数据集时可能非常耗时。而 LightGBM 的 GOSS 则保留了所有大梯度的实例,并对小梯度的实例进行随机采样。其背后的直觉是,大梯度的实例更难拟合,因此包含更多信息。GOSS 为小梯度的数据实例引入了一个常数乘数,以弥补采样过程中信息的丧失。
什么是独占特征捆绑(EFB)?
在稀疏数据集中,大多数特征为零。EFB 是一种近乎无损的算法,它将相互排斥的特征(即不同时为非零的特征)进行捆绑/组合,以减少维度,从而加速训练过程。由于这些特征是“排斥”的,因此保留了原始特征空间,没有显著的信息损失。
安装
可以直接使用 pip——Python 的包管理器来安装 LightGBM。在终端或命令提示符中输入以下命令,以下载和安装 LightGBM 库到你的机器上:
pip install lightgbm
Anaconda 用户可以使用以下列出的“conda install”命令来安装它。
conda install -c conda-forge lightgbm
根据你的操作系统,你可以使用本指南选择安装方法。
实践操作!
现在,让我们导入 LightGBM 和其他必要的库:
import numpy as np
import pandas as pd
import seaborn as sns
import lightgbm as lgb
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
准备数据集
我们使用流行的泰坦尼克号数据集,其中包含关于泰坦尼克号乘客的信息,目标变量表示他们是否幸存。你可以从Kaggle下载数据集,或者使用以下代码直接从 Seaborn 加载,如下所示:
titanic = sns.load_dataset('titanic')
删除不必要的列,如“deck”、“embark_town”和“alive”,因为它们冗余或不影响船上人员的生存。接下来,我们观察到“age”、“fare”和“embarked”特征有缺失值——注意不同属性用适当的统计措施进行填补。
# Drop unnecessary columns
titanic = titanic.drop(['deck', 'embark_town', 'alive'], axis=1)
# Replace missing values with the median or mode
titanic['age'] = titanic['age'].fillna(titanic['age'].median())
titanic['fare'] = titanic['fare'].fillna(titanic['fare'].mode()[0])
titanic['embarked'] = titanic['embarked'].fillna(titanic['embarked'].mode()[0])
最后,我们使用 pandas 的分类代码将分类变量转换为数字变量。现在,数据已准备好开始模型训练过程。
# Convert categorical variables to numerical variables
titanic['sex'] = pd.Categorical(titanic['sex']).codes
titanic['embarked'] = pd.Categorical(titanic['embarked']).codes
# Split the dataset into input features and the target variable
X = titanic.drop('survived', axis=1)
y = titanic['survived']
训练 LGBMClassifier 模型
要开始训练 LGBMClassifier 模型,我们需要使用 scikit-learn 中的 train_test_split 函数将数据集拆分为输入特征和目标变量,以及训练集和测试集。
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
让我们对分类数据(“who”)和序数数据(“class”)进行标签编码,以确保模型接收数字数据,因为 LGBM 不处理非数字数据。
class_dict = {
"Third": 3,
"First": 1,
"Second": 2
}
who_dict = {
"child": 0,
"woman": 1,
"man": 2
}
X_train['class'] = X_train['class'].apply(lambda x: class_dict[x])
X_train['who'] = X_train['who'].apply(lambda x: who_dict[x])
X_test['class'] = X_test['class'].apply(lambda x: class_dict[x])
X_test['who'] = X_test['who'].apply(lambda x: who_dict[x])
接下来,我们将模型超参数指定为构造函数的参数,或者可以将它们作为字典传递给 set_params 方法。
启动模型训练的最后一步是通过创建 LGBMClassifier 类的实例并将其拟合到训练数据上来加载数据集。
params = {
'objective': 'binary',
'boosting_type': 'gbdt',
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9
}
clf = lgb.LGBMClassifier(**params)
clf.fit(X_train, y_train)
接下来,让我们评估训练好的分类器在未见或测试数据集上的表现。
predictions = clf.predict(X_test)
print(classification_report(y_test, predictions))
precision recall f1-score support
0 0.84 0.89 0.86 105
1 0.82 0.76 0.79 74
accuracy 0.83 179
macro avg 0.83 0.82 0.82 179
weighted avg 0.83 0.83 0.83 179
超参数调整
LGBMClassifier 通过超参数提供了很大的灵活性,你可以调整这些超参数以获得最佳性能。这里,我们将简要讨论一些关键的超参数:
-
num_leaves:这是控制树模型复杂度的主要参数。理想情况下,num_leaves 的值应该小于或等于 2^(max_depth)。
-
min_data_in_leaf:这是防止叶子节点树过拟合的重要参数。其最佳值取决于训练样本的数量和 num_leaves。
-
max_depth:你可以使用这个参数来明确限制树的深度。如果出现过拟合,最好调整这个参数。
让我们调整这些超参数并训练一个新模型:
model = lgb.LGBMClassifier(num_leaves=31, min_data_in_leaf=20, max_depth=5)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
print(classification_report(y_test, predictions))
precision recall f1-score support
0 0.85 0.89 0.87 105
1 0.83 0.77 0.80 74
accuracy 0.84 179
macro avg 0.84 0.83 0.83 179
weighted avg 0.84 0.84 0.84 179
请注意,超参数的实际调整是一个涉及试验和错误的过程,也可能受到经验以及对提升算法和业务问题(领域知识)的深入理解的指导。
在这篇文章中,你了解了 LightGBM 算法及其 Python 实现。这是一种灵活的技术,适用于各种类型的分类问题,应该成为你机器学习工具包的一部分。
Vidhi Chugh 是一位人工智能战略家和数字化转型领导者,她在产品、科学和工程交汇处工作,致力于构建可扩展的机器学习系统。她是一位屡获殊荣的创新领导者、作者和国际演讲者。她的使命是使机器学习民主化,并打破术语,使每个人都能参与这场转型。
相关主题
提升分析 - 数据科学家的秘密武器
原文:
www.kdnuggets.com/2016/03/lift-analysis-data-scientist-secret-weapon.html
安迪·戈德施密特, Akanoo。
每当我阅读关于数据科学的文章时,我觉得总有一个重要的方面缺失:评估机器学习模型的性能和质量。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业之路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
总是有一个解决的干净问题,讨论数据获取、处理和模型创建的过程,但评估方面通常非常简略。但我确实相信,在构建新模型时,这才是最重要的。因此,本博客的第一篇文章将讨论一个非常有用的评估技术:提升分析。
机器学习涵盖了各种问题,如回归和聚类。然而,提升分析用于分类任务。因此,本文其余部分将集中在这些模型上。
提升图表背后的原因
在评估机器学习模型时,有大量可能的指标来评估性能。比如准确率、精确度-召回率、ROC 曲线等等。所有这些指标都可能有用,但它们也可能具有误导性,或者不能很好地回答当前的问题。
例如,准确率[1]对于平衡类(即每个标签大致有相同数量的出现)可能是一个有用的指标,但对于不平衡类则完全误导。问题是:数据科学家必须经常处理不平衡的类别,例如,当预测一个用户是否会在网上商店购买某样东西时。如果在 100 个客户中只有 2 个购买,那么模型很容易预测所有人都不会购买,并且仍然会达到 98%的准确率!在评估模型质量时,这完全没有用。
当然,像精确度和召回率这样的其他指标也能提供关于你模型的重要信息。但我想深入探讨另一种有价值的评估技术,通常称为提升分析。
为了说明这个概念,我们将考虑一个简单的流失模型:我们想要预测一个在线服务的客户是否会取消订阅。这是一个二分类问题:用户要么取消订阅(churn=1),要么保留订阅(churn=0)。
提升分析的基本概念如下:
-
根据预测的流失概率(0.0 到 1.0 之间的值)对数据进行分组。通常,你会查看十分位数,这样你就会有 10 组:0.0 - 0.1,0.1 - 0.2,…,0.9 - 1.0
-
计算每组的真实流失率。也就是说,你需要统计每组中流失的人数,并将其除以每组的总客户数。
这有什么用呢?
我们模型的目的是估计客户取消订阅的可能性。这意味着我们预测的(流失)概率应该与实际的流失概率直接成正比,即高预测分数应与高实际流失率相关联。反之,如果模型预测客户不会流失,我们希望确保这位客户真的不太可能流失。
但正如常言所说,一图胜千言。让我们看看理想的提升图表应如何呈现:
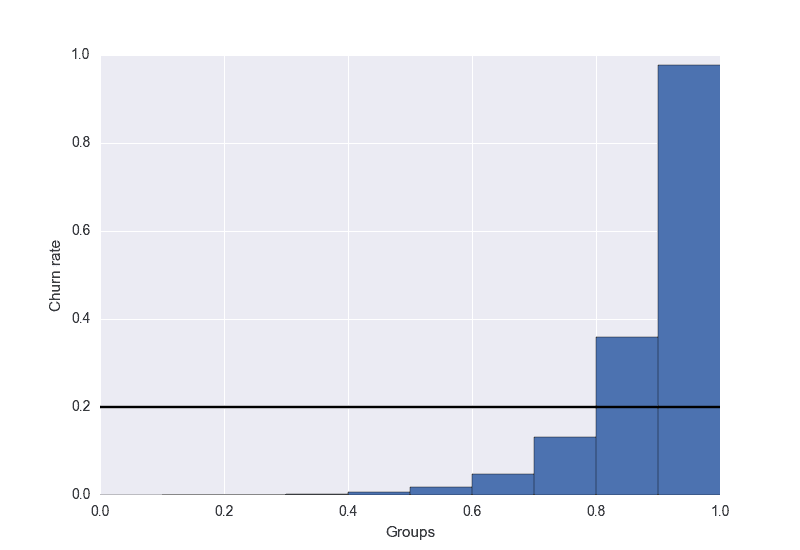
在这里你可以看到,最右边桶中的流失率最高,这正如预期的那样。对于低于 0.5 的分数,桶中的实际流失率几乎为零。你可以使用这个提升图表来验证你的模型是否如你所期望的那样运行。
假设低分组出现了峰值;那么你可以立即知道你的模型存在一些缺陷,它没有正确反映现实。因为如果它反映了现实,那么真实的流失率只能随着分数的下降而降低。当然,提升分析只能帮助到此。识别问题原因并在必要时加以修正还是要靠你自己[2]。改进模型后,你可以返回提升图表,看看质量是否有所提高。
另外,我为假设的平均流失率(20%)画了一条黑线。这对于定义目标阈值非常有用:低于阈值的分数将设置为 0,高于阈值的分数将设置为 1。在我们的例子中,你可能希望通过提供折扣来阻止客户取消订阅。然后你可以针对得分在 0.8 到 1.0 之间的所有用户,因为这是流失率高于平均流失率的范围。你不想把钱浪费在流失概率低于平均水平的客户身上。
那么,提升到底是什么呢?
到目前为止,我们只看了漂亮的图表。但通常你也会对提升分数感兴趣。定义相当简单:
lift = ( predicted rate / average rate )
在我们的情况中,rate 指的是流失率,但也可能是转化率、响应率等。
回顾我们的示例图表,最高组的提升为 0.97 / 0.2 = 4.85,第二高组为 1.8。这意味着,如果你仅针对得分高于 0.9 的用户,你可以预期比随机选择相同数量的人多捕获将近五倍的流失用户。
结论
就像其他评估指标一样,提升图并不是一劳永逸的解决方案。但它们帮助你更好地了解模型的整体性能。如果提升图的斜率不是单调的,你可以快速发现缺陷。此外,它帮助你设置一个阈值,以决定哪些用户值得定位。最后但同样重要的是,你可以估计与随机定位相比,你能更好地定位用户。
我希望这篇第一篇博客文章能给你一些新的见解,或者作为一个温故知新的回顾。如果你有任何问题或反馈,只需留下评论或 发我一条推文。
[1] 正确标记的观察值与总观察值的比率。
[2] 在某些情况下,这可能不重要,例如当你的主要目标是针对所有流失者,但如果你也针对一些不会流失的人,这并不重要。*
简介: 安迪·戈德施密特 是来自德国汉堡的数据科学家。他目前在 Akanoo 一家现场定位初创公司工作,之前在一家 DIY 网站建设者的数据团队工作过。
原文。经许可转载。
相关:
-
哪些大数据、数据挖掘和数据科学工具可以结合使用?
-
统计学否定神话:重新包装统计数据与模糊术语
-
前 10 大数据挖掘算法解析
更多相关内容
LightGBM:一种高效的梯度提升决策树
原文:
www.kdnuggets.com/2020/06/lightgbm-gradient-boosting-decision-tree.html
评论
LightGBM 算法的威力不可小觑(有意双关)。LightGBM 是一个分布式且高效的梯度提升框架,它使用基于树的学习。它是基于直方图的,将连续值放入离散的箱子中,这导致更快的训练和更高效的内存使用。在这篇文章中,我们将深入探讨 LightGBM。
LightGBM 优势
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
根据官方文档,LightGBM 框架的优势如下:
-
更快的训练速度和更高的效率
-
更低的内存使用
-
更高的准确性
-
支持并行和 GPU 学习
-
能够处理大规模数据
参数调整
该框架使用了叶子优先的树生长算法,这不同于许多其他基于树的算法使用的深度优先生长。叶子优先树生长算法通常比深度优先算法收敛更快,但更容易过拟合。
以下是我们需要调整的参数,以在叶子优先树算法上获得良好的结果:
-
num_leaves:设置叶子数为num_leaves = 2^(max_depth)将给你与深度优先树相同数量的叶子。然而,这并不是一个好的做法。理想情况下,叶子数应小于2^(max_depth) -
min_data_in_leaf防止过拟合。它的设置取决于num_leaves和训练样本的数量。对于大型数据集,可以设置为数百或数千。 -
max_depth用于限制树的深度。
通过使用以下方式可以获得更快的算法速度:
-
一个较小的
max_bin -
save_binary以加速未来学习中的数据加载 -
并行学习
-
通过设置
bagging_freq和bagging_fraction进行袋装 -
feature_fraction用于特征子抽样
为了获得更好的准确性,可以使用较大的 max_bin、使用较小的学习率与较大的 num_iterations、以及更多的训练数据。也可以使用更多的 num_leaves,但这可能导致过拟合。说到过拟合,你可以通过以下方法处理:
-
增加
path_smooth -
使用更大的训练集
-
尝试
lambda_l1、lambda_l2和min_gain_to_split进行正则化 -
避免生成非常深的树
机器学习正在迅速向数据收集地点——边缘设备靠近。订阅 Fritz AI 新闻通讯以了解更多关于这一过渡以及如何帮助扩大业务的信息。
分类特征
机器学习中处理分类特征的一种常见方法是独热编码。该方法对树模型并不理想,特别是对于高基数分类特征。基于独热编码特征构建的树是不平衡的,并且为了获得良好的准确度,必须生长得过深。
使用 categorical_feature 属性,我们可以为模型指定分类特征(无需独热编码)。分类特征应编码为小于 Int32.MaxValue 的非负整数。它们应从零开始。
LightGBM 应用
LightGBM 最适用于以下问题:
-
使用
logloss目标函数的二分类 -
使用
L2损失进行回归 -
多分类
-
使用
logloss目标函数的交叉熵 -
LambdaRank 使用
lambdarank以 NDCG 作为目标函数
指标
LightGBM 支持的指标有:
-
L1 损失
-
L2 损失
-
对数损失
-
分类错误率
-
AUC
-
NDCG
-
MAP
-
多类对数损失
-
多类错误率
-
Fair
-
Huber
-
Poisson
-
分位数
-
MAPE
-
Kullback-Leibler
-
Gamma
-
Tweedie
处理缺失值
默认情况下,LightGBM 能够处理缺失值。你可以通过设置 use_missing=false 来禁用此功能。它使用 NA 表示缺失值,但要使用零,你可以将其设置为 zero_as_missing=true。
核心参数
这是 LightGBM 的一些核心参数:
-
task默认为train。其他选项包括predict、convert_model和refit。该参数的别名是task_type。convert_model将模型转换为 if-else 格式。 -
objective默认为回归。其他选项包括regression_l1、huber、fair、poisson、quantile、mape、gamma、tweedie、binary、multiclass、multiclassova、cross_entropy、cross_entropy_lambda、lambdarank和rank_xendcg。该参数的别名有objective_type、app和application。 -
boosting默认值为gbdt— 传统的梯度提升决策树。其他选项包括rf— 随机森林,dart— Dropouts meet Multiple Additive Regression Trees,goss— 基于梯度的单侧采样。此参数的别名为boosting_type和boost。 -
num_leaves:基学习器的最大树叶数量 — 默认值为 31 -
max_depth:基学习器的最大树深度 -
learning_rate:提升学习率 -
n_estimators:要拟合的提升树的数量 — 默认值为 200000 -
importance_type:要填入feature_importances_的重要性类型。使用split表示模型中使用特征的次数将包含在结果中。 -
device_type:树学习的设备 — CPU 或 GPU。可以与device作为别名一起使用。
学习控制参数
我们来看看几个学习控制参数:
-
force_col_wise:当设置为 true 时,它强制进行按列直方图构建。建议当列数较多或总的 bins 数量较大时将其设置为 true。你也可以在内存成本需要减少时将其设置为 true,特别是当num_threads较大,例如大于 20 时。此参数仅在使用 CPU 时适用。 -
force_row_wise:当设置为 true 时,它强制进行按行直方图构建。此参数仅在使用 CPU 时适用。当数据点数量较大、总的 bins 数量较少,并且num_threads较少(例如小于或等于 16)时可以启用此选项。当你希望使用较小的bagging_fraction或goss提升训练速度时,也可以设置为 true。 -
neg_bagging_fraction:用于不平衡的二分类问题。 -
bagging_freq:Bagging 的频率。零表示禁用 bagging。 -
feature_fraction:可以用来处理过拟合。例如,设置为 0.5 意味着 LightGBM 在每棵树节点上将选择 50% 的特征。 -
extra_trees:当你想使用极端随机树时设置为 true。 -
early_stopping_round:当设置为 true 时,一旦某个参数未能改善,训练将停止。 -
max_drop:默认为 50。表示每次迭代中要丢弃的树的数量。 -
cat_l2:分类分裂中的 L2 正则化 -
cat_smooth:减少分类特征中的噪声影响,特别是对数据有限的类别。 -
path_smooth:帮助防止叶节点样本过少时的过拟合。
目标参数
这里有几个需要注意的目标参数:
-
is_unbalance:如果训练数据在分类问题中不平衡,可以设置为 true。 -
num_class:用于指示多分类问题中的类别数量。 -
scale_pos_weight:正类标签的权重。不能与is_unbalance一起使用。此参数提高了模型的总体性能指标,但可能导致对各个类别概率的估计不准确。
实际应用
现在我们将快速实现该算法。我们将使用 scikit-learn 对分类器的包装器。
一如既往,我们首先导入模型:
from lightgbm import LGBMClassifier
下一步是创建模型实例并设置目标。目标选项为回归用于 LGBMRegressor,二分类或多分类用于 LGBMClassifier,LambdaRank 用于 LGBMRanker。
model = LGBMClassifier(objective=’multiclass’)
在拟合模型时,我们可以设置分类特征:
model.fit(X_train,y_train,categorical_feature=[0,3])
一旦你对模型进行预测,你还可以获得重要特征:
predictions = model.predict(X_test)importances = model.feature_importances_
结论
我希望这能为你提供足够的 LightGBM 背景,以便你开始自主实验。我们已经看到它可以用于回归和分类问题。有关框架的更多信息,你可以查看官方文档:
欢迎访问 LightGBM 文档!- LightGBM 2.3.2 文档
LightGBM 是一个使用基于树的学习算法的梯度提升框架。它设计为可以分布式...
简介:Derrick Mwiti 是一名数据分析师、作家和导师。他致力于在每一个任务中取得出色的成果,并且是 Lapid Leaders Africa 的导师。
原文。经许可转载。
相关:
-
研究指南:机器学习模型的高级损失函数
-
Python 中的自动化机器学习
-
联邦学习:简介
更多相关主题
如何在 Python 中进行“无限制”数学运算
评论

图片来源: Pixabay(免费使用)
无限数学?
听起来像个吸引人的标题?好吧,我们真正指的是 任意精度计算,即突破我们通常熟悉的 32 位或 64 位算术的限制。
这是一个快速的例子。

如果你直接从 Python 的标准 math 模块中导入,你将获得平方根 2 的值。
你可以使用 Numpy 来选择结果是 32 位还是 64 位浮点数。

但如果你想要精确到 25 位小数的结果呢…
1.414213562373095048801689
还是 50 位小数?
1.4142135623730950488016887242096980785696718753769
我们是如何得到这些结果的?
仅使用一个名为 **mpmath** 的整洁小包。让我们详细检查一下它。
使用 mpmath 进行任意精度计算
Mpmath 是一个用于任意精度浮点算术的 Python 库。有关 mpmath 的一般信息,请参见 项目网站。
从其 网站 上看,除了任意精度算术,“*mpmath** 提供了广泛的超越函数、求和、积分、极限、根等的支持”。它还执行许多标准数学任务,例如,
-
多项式
-
根求解和优化
-
求和、乘积、极限和外推
-
微分
-
数值积分(求积)
-
求解常微分方程
-
函数逼近
-
数值逆拉普拉斯变换
简而言之,它是一个功能强大的数学库,具有无限的可能性!我们将在本文中探讨一些功能。
任意精度计算是 从我们通常熟悉的 32 位或 64 位算术的限制中突破出来…
安装和选择一个快速的后端引擎
只需使用 pip。
pip install mpmath
默认情况下,mpmath 在内部使用 Python 整数。如果系统中安装了 *[gmpy](https://code.google.com/p/gmpy/)* 1.03 版或更高版本,mpmath 会自动检测并使用 gmpy 整数,而不会改变高级用户体验。使用这个后端使得其操作速度更快,特别是在高精度下。
gmpy2 是一个 用 C 编写的 Python 扩展模块,支持多精度算术。这是安装它的方法。
代码
这是本文中展示的 包含所有代码的 Notebook。
选择精度
关于如何选择和控制 mpmath 的精度有大量的资料。鼓励读者直接查阅 这个参考资料。
我将向你展示在工作中设置精度的快捷方法。

你可以随时打印 mp 上下文以查看当前的全局精度设置。mp.prec 显示的是位精度,mp.dps 显示的是小数精度。
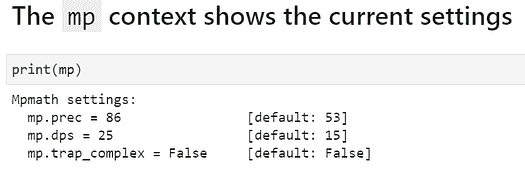
使用 mpf 实例代替普通浮点数
在上面的代码片段中,你可能注意到了一个函数 mpf。一个 mpf 实例保存了一个实值浮点数。它们与 Python 浮点数类似,但支持任意精度的算术运算。
你应该使用字符串(而不是 Python 浮点数)来定义 mpf ,以获得真正的准确性。你也可以将 mp.pretty 设置为 True 来进行舍入而不失去内部准确性。
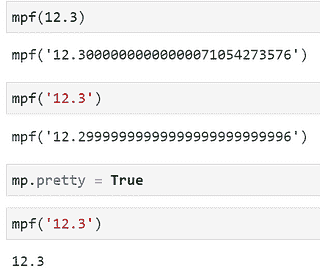

现在有些魔法!阶乘计算速度提升 11,000 倍
mpmath 可以利用智能技巧进行大规模计算。一个例子是阶乘。对于大数,它可以适当地使用近似值,而无需指导,给出比默认 Python 数学模块更快的结果。
当我们尝试计算 100,000 的阶乘时,发生了什么。mpmath 的速度是11,333 倍。

有理数和复数是原生支持的
我们可以像处理浮点数一样轻松地将有理数或复数混入计算中。为此,我们需要使用一个神奇的函数 **mpmathify** ,它与 **sympy** 内部配合工作来解释这些量。

我们不必导入像 [**fraction**](https://docs.python.org/3/library/fractions.html) 或 [**cmath**](https://docs.python.org/3/library/cmath.html) 这样的 Python 模块来处理这些量,以选择我们需要的精度。
了解所有其他的 通用工具函数[mpmath](https://mpmath.org/doc/current/general.html) 提供的信息。
快速绘图
如果系统上可用 Matplotlib,mpmath 提供了一种快速且简单的绘图选择,只需传递函数列表及其对应范围。
这是一个单行代码示例,
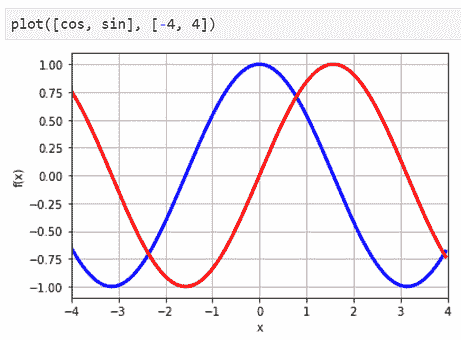
图片来源:由作者生成
另一个例子是 Fresnel 函数,
图片来源:由作者生成
复数量可以通过 cplot 轻松绘制。默认情况下,复数参数(相位)显示为颜色(色调),而幅度显示为亮度。
 图片来源:作者生成
图片来源:作者生成
表面图也是一个好选择,
图片来源:作者生成
特殊函数
mpmath 支持数百种特殊函数。以下是该列表的部分截图。有关详细信息,请参阅此文档。



图片来源:作者生成
二项式系数
使用 binomial 函数快速而轻松地计算统计学和组合数学中的二项式系数,
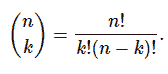
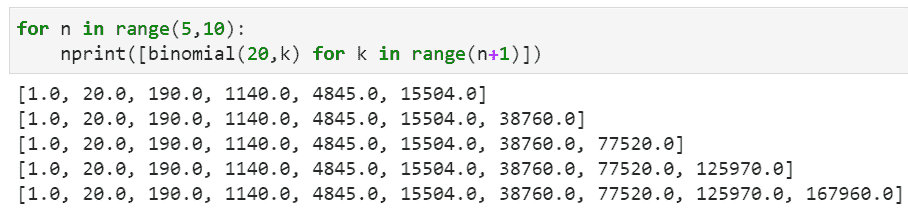
这个函数支持 巨大的参数,这正是它真正出色的地方。Scipy 的计算速度更快,但对于大数字,Scipy 甚至无法运行!
而且,扩展到非整数和负参数是自然的(使用 Gamma 函数),
超阶乘
对于整数,超阶乘定义为,
它们非常大。你能想到一种简单的方法来计算这种数字吗?
这个数字是 1.1425…后面跟着 41908 个零!为了理解这一点,可以考虑这个事实——宇宙中大约有 10⁸⁰ 个原子,即 1 后面跟着 80 个零。
无限的数学(以快速的方式),不是吗?
斐波那契数
计算斐波那契数列的朴素 Python(递归函数)是一个流行的面试问题,因为它可以通过几种不同的方法完成,而这些方法在效率上差异巨大。
然而,使用大参数或非整数(甚至复数)参数计算近似解对于 mpmath 来说是自然且简单的。这在使用原生 Python 编码时并不那么简单。

多项式评估和根
使用 polyeval 和 polyroots 函数快速且轻松地评估任意阶数的多项式并求解根。当然,polyroots 可以一次性评估所有实数和复数根。

任意函数的根求解
我们可以使用 rootfind 函数来搜索任何任意函数的根。这里是一个例子,
图片来源:作者生成
然后,我们在 -2 到 5 之间寻找所有整数附近的解,发现多个解对应于函数过零的所有 x 值。

数值微积分
计算任何阶数和任何函数的导数,

偏导数很简单,
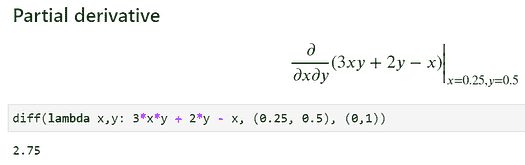
查看这个参考资料以了解其他与导数相关的高级示例和函数。
1-D 积分
简单快速的任意精度评估,

2-D 或 3-D 积分
二维或三维积分也可以处理!

阅读更多详细信息。
常微分方程
我们可以使用odefun来求解已知边界条件的常微分方程。

或者,更困难一些,

矩阵和线性代数
mpmath 包还提供了所有涉及矩阵和线性代数的标准操作。为了简洁起见,我们在这里参考文档而不是展示示例。
总结
在这篇文章中,我们展示了一个强大的 Python 库及其执行任意精度数值计算的能力,涉及各种数字和函数。基本上,这个库的主要优点是它涵盖了非常广泛的数学领域(代数、数论、微积分、特殊函数等),而且一切都在一个屋檐下,不需要加载多个库。
这个库的许多应用领域涉及复杂的科学/技术领域,如有限元模拟或密码学,但作为一个数字爱好者,你总能从这个包中挑选出对你的数据科学或机器学习工作有用的函数。
再次,这里是本文中展示的所有代码的 Notebook。
祝你数据处理愉快!
你可以查看作者的GitHub库,以获取机器学习和数据科学方面的代码、创意和资源。如果你和我一样,对 AI/机器学习/数据科学充满热情,请随时在 LinkedIn 上添加我或在 Twitter 上关注我。
简介: Tirthajyoti Sarkar 是 Adapdix Corp 的数据科学/机器学习经理。他定期为 KDnuggets 和 TDS 等出版物撰写有关数据科学和机器学习的多样化话题。他编著了数据科学书籍,并参与开源软件开发。Tirthajyoti 拥有电气工程博士学位,并正在攻读计算数据分析硕士学位。可以通过 tirthajyoti at gmail[dot]com 联系他。
相关:
-
数据科学中的基础数学:‘为什么’和‘如何’
-
为什么以及如何学习“高效的数据科学”?
-
教 AI 分类时间序列模式的合成数据
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
更多相关话题
数据科学的线性代数
原文:
www.kdnuggets.com/2022/07/linear-algebra-data-science.html
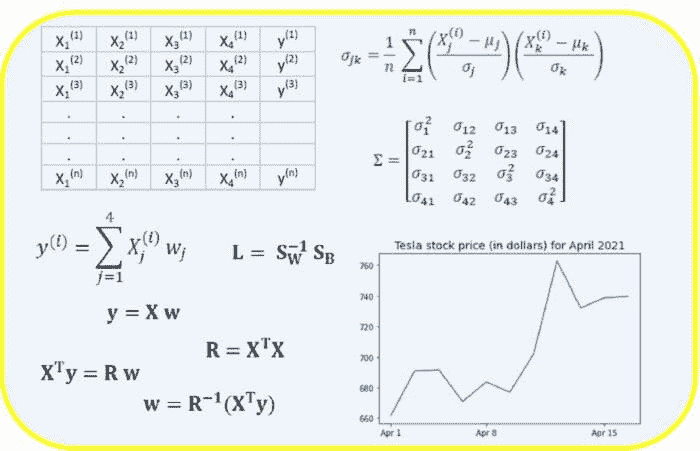
作者提供的图片。
关键要点
-
大多数有兴趣进入数据科学领域的初学者总是对数学要求感到担忧。
-
数据科学是一个非常定量的领域,需要高级数学。
-
但要开始,你只需掌握几个数学主题。
-
在本文中,我们讨论了线性代数在数据科学和机器学习中的重要性。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
线性代数
线性代数是数学的一个分支,在数据科学和机器学习中极为有用。线性代数是机器学习中最重要的数学技能。大多数机器学习模型可以用矩阵形式表示。数据集本身通常也表示为矩阵。线性代数用于数据预处理、数据转换和模型评估。以下是你需要熟悉的主题:
-
向量
-
矩阵
-
矩阵的转置
-
矩阵的逆
-
矩阵的行列式
-
矩阵的迹
-
点积
-
特征值
-
特征向量
线性代数在机器学习中的应用:使用主成分分析进行降维
主成分分析(PCA)是一种用于特征提取的统计方法。PCA 用于高维和高度相关的数据。PCA 的基本思想是将原始特征空间转换为主成分空间,如下图 1 所示:
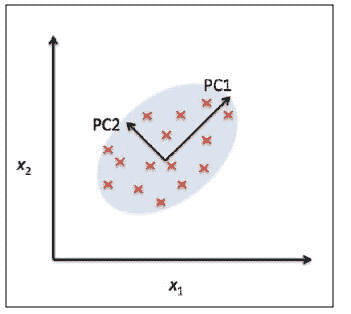
图 1:PCA 算法将旧特征空间转换为新特征空间,从而去除特征相关性。图片由 Benjamin O. Tayo 提供
PCA 变换实现了以下目标:
-
a) 通过仅关注数据集中方差大部分的组件,减少最终模型中使用的特征数量。
-
b) 去除特征之间的相关性。
PCA 的数学基础
假设我们有一个高度相关的特征矩阵,其中有4个特征和n个观察值,如下表 1 所示:

表 1. 具有 4 个变量和 n 个观测值的特征矩阵。
为了可视化特征之间的相关性,我们可以生成一个散点图,如图 1 所示。为了量化特征之间的相关程度,我们可以使用以下方程计算协方差矩阵:
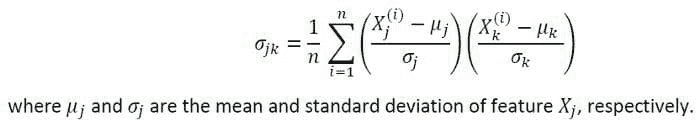
在矩阵形式中,协方差矩阵可以表示为 4 x 4 的对称矩阵:
通过进行单位 ary 变换(PCA 变换),可以对该矩阵进行对角化,得到如下结果:
由于矩阵的迹在单位 ary 变换下保持不变,我们观察到对角矩阵的特征值之和等于特征 X1、X2、X3 和 X4 中包含的总方差。因此,我们可以定义以下量:

注意,当p = 4时,累计方差如预期变为 1。
案例研究:使用鸢尾花数据集实现 PCA
为了说明 PCA 的工作原理,我们通过检查鸢尾花数据集来展示一个例子。R 代码可以从这里下载:https://github.com/bot13956/principal_component_analysis_iris_dataset/blob/master/PCA_irisdataset.R
摘要
线性代数是数据科学和机器学习中的一个重要工具。因此,初学者如果对数据科学感兴趣,必须熟悉线性代数中的基本概念。
本杰明·O·塔约 是物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的所有者。此前,本杰明曾在中欧大学、大峡谷大学和匹兹堡州立大学教授工程学和物理学。
更多相关主题
自然语言处理的线性代数
原文:
www.kdnuggets.com/2021/08/linear-algebra-natural-language-processing.html
评论
由 Taaniya Arora,数据科学家
图片由Michael Dziedzic拍摄,来源于Unsplash
自然语言处理领域涉及构建技术,以处理自然语言中的文本,并从中提取见解,以执行各种任务,从解释搜索引擎上的用户查询并返回网页,到作为聊天机器人助手解决客户查询。当依赖于从大规模文本中提取的见解做出重要决策时,例如通过社交媒体预测股票价格变化, 将每个单词表示为捕捉单词意义和整体上下文的形式变得至关重要。
在本文中,我们将从线性代数的基础开始,以了解向量及其在表示特定类型信息中的重要性、在向量空间中表示文本的不同方式,以及这一概念如何发展到我们现在拥有的最先进模型。
我们将逐步介绍以下内容 -
-
我们坐标系统中的单位向量
-
向量的线性组合
-
向量坐标系统中的跨度
-
共线性与多重共线性
-
向量的线性依赖性和独立性
-
基础向量
-
自然语言处理的向量空间模型
-
密集向量
我们坐标系统中的单位向量
i-> 表示一个单位向量(长度为 1 单位),指向 x 方向
j-> 表示 y 方向上的单位向量
它们共同构成了我们坐标向量空间的基础。
我们将在下面的后续部分中进一步讨论基础这一术语。
标准单位向量 — 作者图片
-
假设我们有一个向量 3i+ 5j
-
这个向量的 x,y 坐标分别是:3 和 5
-
这些坐标是将单位向量在 x 和 y 方向上分别缩放 3 和 5 单位的标量
二维 X-Y 空间中的一个向量 — 作者图片
两个向量的线性组合
如果u和v是二维空间中的两个向量,则它们的线性组合生成一个向量l,表示为 -
l = x1. u + x2. v
-
数字x1,x2是向量 x 的分量
-
这本质上是在给定向量上进行的缩放和加法操作。
上述线性组合的表达式等同于以下线性系统 -
Bx = l
其中B表示一个矩阵,其列为u和v。
通过下面的示例来理解,在二维空间中的向量u和v —
# Vectors u & v
# The vectors are 3D, we'll only use 2 dimensions
u_vec = np.array([1, -1, 0])
v_vec = np.array([0, 1, -1])# Vector x
x_vec = np.array([1.5, 2])# Plotting them
# fetch coords from first 2 dimensions
data = np.vstack((u_vec, v_vec))[:,:2]
origin = np.array([[0, 0, 0], [0, 0, 0]])[:,:2]
plt.ylim(-2,3)
plt.xlim(-2,3)
QV = plt.quiver(origin[:,0],origin[:,1], data[:, 0], data[:, 1], color=['black', 'green'], angles='xy', scale_units='xy', scale=1.)
plt.grid()
plt.xlabel("x-axis")
plt.ylabel("y-axis")
plt.show()
向量的线性组合 — 作者提供的图像
我们也可以从教授在他的笔记中给出的类似 3 维示例中理解这一点 -

线性代数,第一章- 向量简介,MIT
从示例中的 3 个向量绘制它们在 3D 空间中的图像(轴的单位与图中的向量不同)
u_vec = np.array([1, -1, 0])
v_vec = np.array([0, 1, -1])
w_vec = np.array([0, 0, 1])data = np.vstack((u_vec, v_vec, w_vec))
origin = np.array([[0, 0, 0], [0, 0, 0], [0, 0, 0]])
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.quiver(origin[:,0],origin[:,1], origin[:,2], data[:, 0], data[:, 1], data[:,2])ax.set_xlim([-1, 2])
ax.set_ylim([-1, 2])
ax.set_zlim([-1, 2])
plt.grid()
plt.show()
3D 空间中的向量 — 作者提供的图像
跨度
-
跨度是通过给定一对向量的线性组合可以达到的所有可能的向量组合的集合。
-
大多数二维向量对的跨度是二维空间中的所有向量。除非它们沿相同方向排列(即共线),在这种情况下,它们的跨度是一条直线。
即 span(a, b) = R²(二维空间中的所有向量),前提是它们不是共线的。
共线性
共线性是指当我们有 p 个不同的预测变量,但其中一些是其他变量的线性组合,因此它们不提供额外的信息时。两个共线向量/变量将具有接近+/-1 的相关性,并且可以通过它们的相关矩阵检测到。
当超过两个向量共线且任何一对向量可能没有高相关性时,就存在多重共线性。
线性独立性
我们说v1、v2、...、vn是线性独立的,如果它们之间没有
其他向量的线性组合。这等同于说
公式 x1.v1 + x2.v2 + ... + xn.vn = 0 表示 x1 = x2 = ... = xn = 0
由于共线向量可以表示为彼此的线性组合,因此它们是线性相关的。
基础
基础是能够表示该空间的线性独立向量集合。
我们称这些向量为基向量
自然语言处理中的向量空间模型
向量空间是一个向量集合 V,其中定义了两个操作——向量加法和标量乘法。例如,如果两个向量u和v在空间V中,则它们的和w = u + v也将位于向量空间V中。
一个二维向量空间是一组具有 2 个轴的线性独立的基向量。
每个轴表示向量空间中的一个维度。
再次回顾之前的向量a = (3,5) = 3 i + 5 j。这个向量在二维空间中用两个线性独立的基向量 — X 和 Y 表示,它们不仅代表 2 个轴,也代表空间的 2 个维度。
这里的 3 和 5 是表示在 X-Y 二维空间中的该向量的 x,y 分量。
二维 X-Y 平面中的向量 — 作者提供的图像
自然语言处理中的向量空间模型
向量空间模型是文本在向量空间中的表示。
在这里,语料库中的每个词是线性独立的基向量,每个基向量表示向量空间中的一个轴。
-
这意味着每个词与其他词/轴是正交的。
-
对于一个词汇语料库|V|,R 将包含|V| 轴。
-
术语的组合将文档表示为该空间中的点或向量。
对于 3 个词,我们将有一个 3D 向量模型,如下所示 -
3 个词的向量空间模型——作者提供的图像
上面的表格表示 TF-IDF 事件矩阵。
D1 = (0.91, 0, 0.0011) 表示在三个轴——好、房子、车子——上的文档向量。同样,我们还有D2和D3文档向量。
那么,在向量空间中的表示如何帮助我们呢?
-
使用这种表示的一个常见应用是信息检索,用于搜索引擎、问答系统等。
-
通过将文本表示为向量,我们旨在利用向量代数从文本中提取语义,并将其用于不同的应用,如搜索包含与给定搜索查询中包含的相似语义的文档。
例如,对于搜索令牌‘buy’,我们希望获取包含该词不同形式——buying、bought,甚至‘buy’的同义词的所有文档。其他初级方法,如将文档表示为二进制事件矩阵,无法捕捉到这些文档。
这是通过如余弦相似度这样的距离度量实现的,通过文档和查询的向量之间的距离,距离查询更近的文档被排在更高的位置。
- 词汇量/词汇大小可以大到几百万,例如,Google 新闻语料库有 300 万条,这意味着有那么多独立的轴/维度来表示向量。因此,我们希望在向量空间中使用操作来减少维度数量,并将相似的词放在同一个轴上。
密集向量
-
上述操作可以在文档向量上进行,这些向量通过将文档的上述向量表示扩展到分布式或密集向量表示的文档来表示。这些表示捕捉了文本的语义,并且也捕捉了词向量的线性组合。
-
以前的向量空间模型中,每个词表示一个单独的维度,导致了稀疏向量。
-
密集向量捕捉了向量表示中的上下文。密集词向量的特点是,在类似上下文中出现的词将具有类似的表示。
-
这些密集向量也称为词嵌入或分布式表示。
-
word2vec 是一个用于学习 从大规模语料库中获得词密集向量的框架。它有两个变体——skip-gram 和 CBOW(连续词袋模型)。
-
其他获取稠密向量的框架和技术包括全球向量(GloVe)、fastText、ELMo(语言模型中的嵌入)和最近的最先进 Bert 基于方法,用于在推理过程中获取上下文化的词嵌入。
结论
本文介绍了基于线性代数的向量空间概念,并强调了相关概念在自然语言处理中的应用,如文本语义表示和抽取任务。
词嵌入的应用已经扩展到更多先进的广泛应用,其性能比以前有了显著提升。
你还可以通过访问我的 Git 仓库 来参考源代码并在 colab 上运行。
希望你喜欢阅读这篇文章。 😃
参考资料
-
Gareth James, Daniela Witten, Trevor Hastie 和 Robert Tibshirani 的统计学习介绍,电子书
个人简介: Taaniya Arora 是一位数据科学家和问题解决者,尤其对 NLP 和强化学习感兴趣。
原文。转载授权。
相关:
-
最佳 SOTA NLP 课程是免费的!
-
数据科学与机器学习中的基本线性代数
-
如何克服数学恐惧并学习数据科学中的数学
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
更多相关话题
线性回归与逻辑回归:简明解释
原文:
www.kdnuggets.com/2022/03/linear-logistic-regression-succinct-explanation.html
它们都以字母‘L’开头并以回归结尾,因此人们可能会混淆它们是可以理解的。线性回归和逻辑回归是两种常用的机器学习算法,都源自于监督学习。
总结:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
监督学习是指算法在标记的数据集上进行学习,并分析训练数据。这些标记的数据集具有输入和预期的输出。
无监督学习是在未标记的数据上进行学习,推断更多关于隐藏结构的信息,以产生准确和可靠的输出。
线性回归与逻辑回归之间的关系在于它们使用标记的数据集进行预测。然而,它们之间的主要区别在于它们的使用方式。线性回归用于解决回归问题,而逻辑回归用于解决分类问题。
分类是关于通过识别对象所属的类别来预测标签,基于不同的参数。
回归是关于通过寻找因变量和自变量之间的相关性来预测连续的输出。
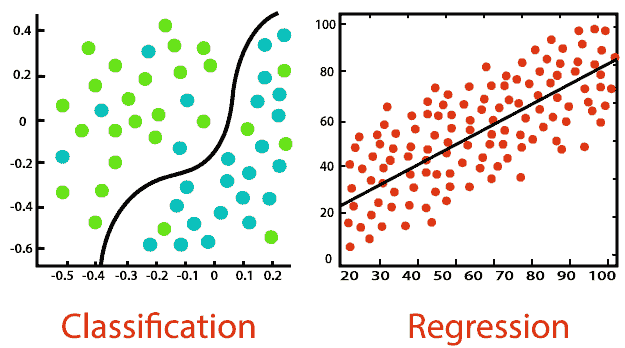
来源: Javatpoint
线性回归
线性回归被认为是从监督学习中派生出的最简单的机器学习算法之一,主要用于解决回归问题。
线性回归的用途是对连续的因变量进行预测,并利用自变量的辅助和知识。线性回归的总体目标是找到最佳拟合线,能够准确预测连续因变量的输出。连续值的例子包括房价、年龄和薪水。
简单线性回归是一种回归模型,用直线估计单个自变量和一个因变量之间的关系。如果有两个以上的自变量,我们称之为多重线性回归。
使用最佳拟合线的策略有助于我们理解因变量和自变量之间的关系;这种关系应为线性关系。
线性回归的公式
如果你还记得高中数学,你会记得公式:y = mx + b,它表示直线的斜率截距。‘y’和‘x’表示变量,‘m’描述直线的斜率,‘b’描述 y 轴截距,即直线穿过 y 轴的位置。
对于线性回归,‘y’表示因变量,‘x’表示自变量,????0 表示 y 轴截距,????1 表示斜率,描述了自变量与因变量之间的关系。
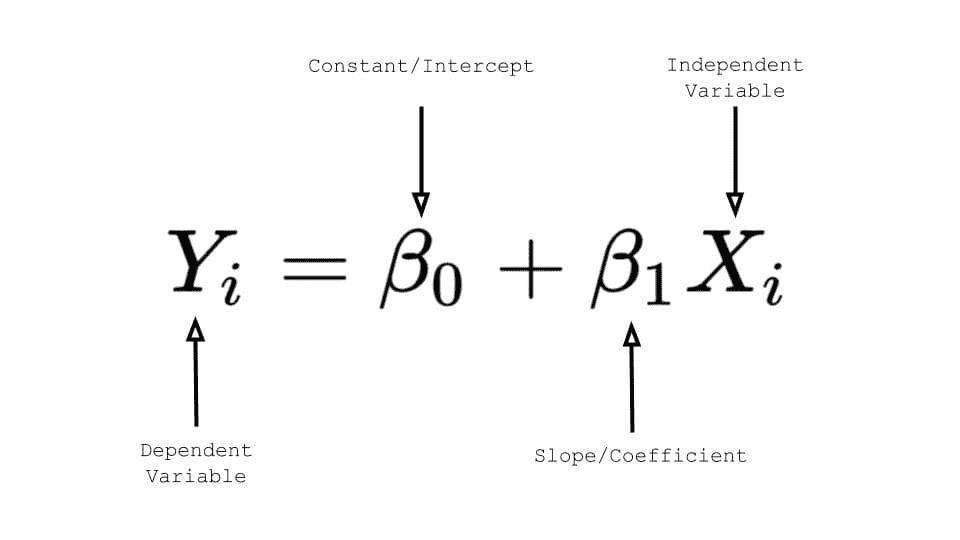
逻辑回归
逻辑回归也是一种非常流行的机器学习算法,属于监督学习的分支。逻辑回归可用于回归和分类任务,但主要用于分类。如果你想了解更多关于用于分类任务的逻辑回归,请点击此链接。
逻辑回归的一个例子是预测今天是否会下雨,使用 0 或 1,是或否,或真和假。
逻辑回归的用途是通过自变量的辅助和知识来预测分类因变量。逻辑回归的总体目标是对输出进行分类,输出只能在 0 和 1 之间。
在逻辑回归中,加权输入的总和会通过一个称为 Sigmoid 函数的激活函数,该函数将值映射到 0 和 1 之间。
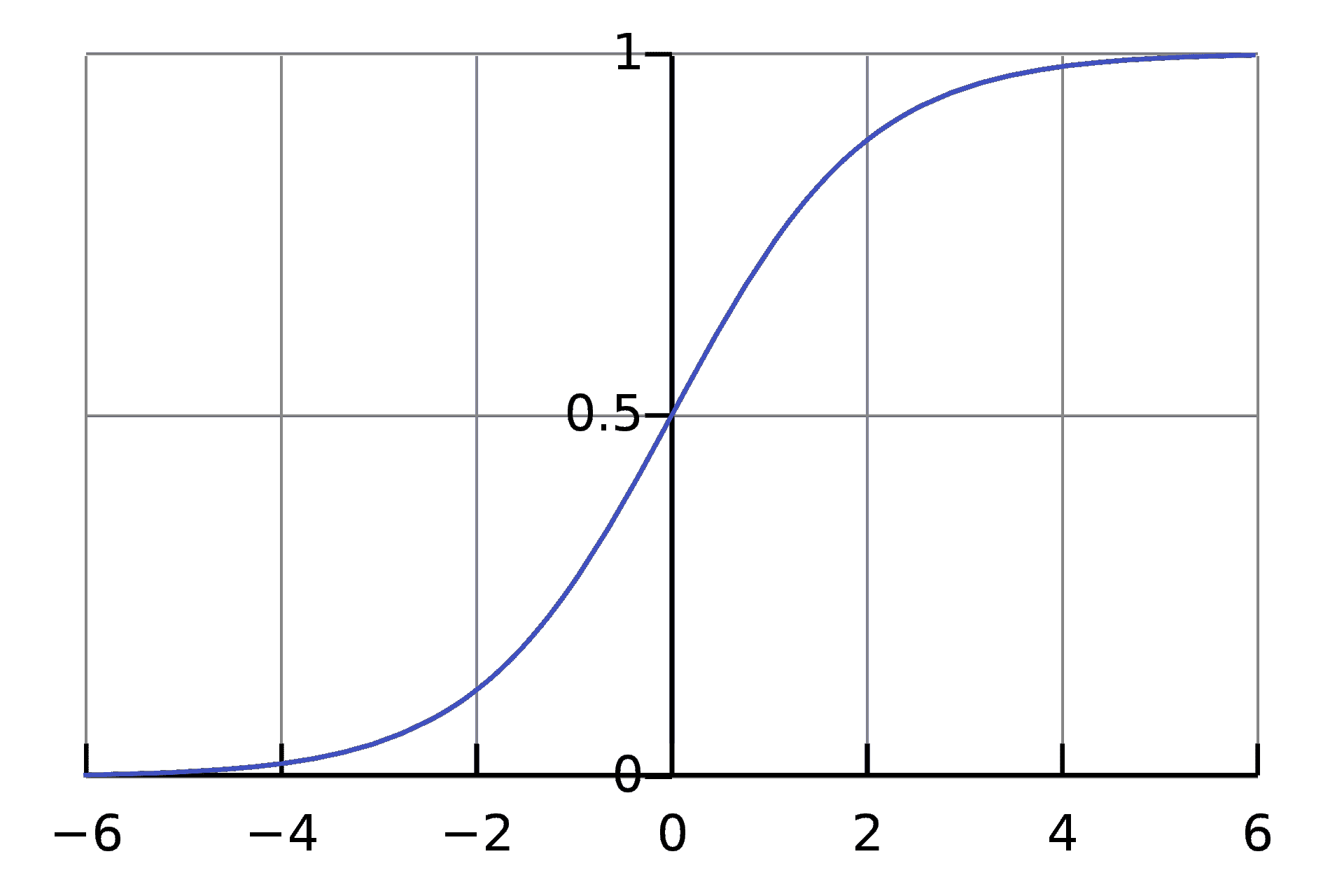
来源:维基百科
Sigmoid 函数的公式
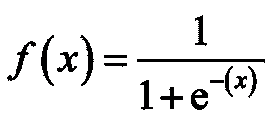
逻辑回归基于最大似然估计,这是一种在给定一些观测数据的情况下估计假设概率分布参数的方法。
成本函数
成本函数是一个用于计算误差的数学公式,它是预测值与实际值之间的差异。它简单地衡量了模型在估计 x 和 y 之间关系的能力上的错误程度。
要了解更多关于成本函数的信息,请点击此链接。
线性回归
线性回归的成本函数是均方根误差,也称为均方误差(MSE)。
MSE 衡量观察值的实际值和预测值之间的平均平方差。成本将以一个单一的数字输出,这与我们当前的权重集相关。我们使用成本函数的原因是为了提高模型的准确性;最小化 MSE 就能实现这一点。
MSE 的公式:
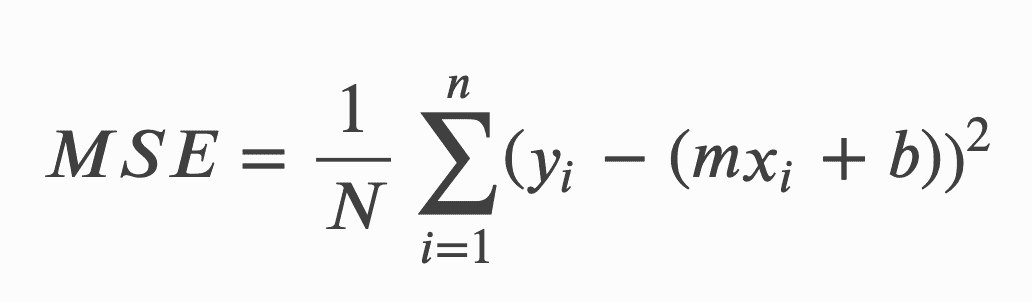
逻辑回归
逻辑回归的成本函数不能使用 MSE,因为我们的预测函数是非线性的(由于 sigmoid 变换)。因此,我们使用一种称为交叉熵的成本函数,也称为对数损失。
交叉熵衡量了给定随机变量或事件集的两个概率分布之间的差异。
交叉熵的公式:
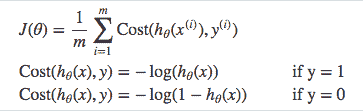
线性回归与逻辑回归比较
| 线性回归 | 逻辑回归 |
|---|---|
| 用于预测连续因变量,使用一组给定的自变量。 | 用于预测分类因变量,使用一组给定的自变量。 |
| 产生的输出必须是连续值,如价格和年龄。 | 产生的输出必须是分类值,如 0 或 1,是或否。 |
| 因变量和自变量之间的关系必须是线性的。 | 因变量和自变量之间的关系不需要是线性的。 |
| 用于解决回归问题。 | 用于解决分类问题。 |
| 我们找到并使用最佳拟合线来帮助我们轻松预测输出。 | 我们使用 S 曲线(Sigmoid)来帮助我们对预测输出进行分类。 |
| 最小二乘估计方法用于估计准确性。 | 最大似然估计方法用于估计准确性。 |
| 自变量之间可能存在多重共线性。 | 自变量之间不应存在多重共线性。 |
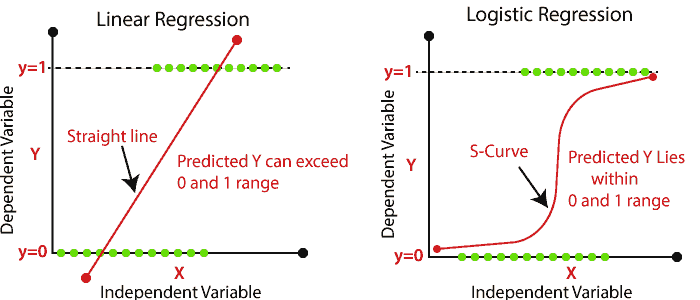
来源: javatpoint
Nisha Arya 是一名数据科学家和自由技术写作人。她特别关注提供数据科学职业建议或教程,并且对数据科学的理论知识充满兴趣。她还希望探索人工智能如何有助于人类寿命的延续。她是一个热衷学习者,寻求拓宽技术知识和写作技能,同时帮助指导他人。
更多相关话题
线性机器学习算法概述
原文:
www.kdnuggets.com/2022/07/linear-machine-learning-algorithms-overview.html
图片来源:作者
线性机器学习算法假设特征与目标变量之间存在线性关系。在本文中,我们将讨论几种线性算法及其概念。以下是你可以期待学习的内容:
-
线性机器学习算法的类型。
-
线性算法的假设。
-
各种线性机器学习算法之间的差异。
-
如何解读线性算法的结果。
-
何时使用不同的线性算法。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
让我们直接深入探讨吧。
线性机器学习算法的类型
你可以将线性算法用于分类和回归问题。让我们开始了解不同的算法以及它们解决的问题。
线性回归
线性回归可以说是最古老也是最流行的算法之一。该算法源于统计学领域,用于解决回归问题。这意味着模型的最终输出是一个数值。该算法映射了输入特征(X)与输出(y)之间的线性关系。
普通最小二乘线性回归是线性回归中最广泛使用的实现之一。它拟合一个具有系数w = (w1, …, wp)的线性模型,以最小化数据集中观察到的目标与线性近似预测的目标之间的残差平方和。[来源](https://scikit-
learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html)。
在这种方法中,拟合了多条直线,并选择返回误差最小的直线作为最佳拟合。误差是估计值与实际值之间的差异。
由于线性回归拟合的是一条直线,它可以对未来的数据进行外推,这不同于如随机森林等其他算法。基于树的算法无法预测给定数据之外的值,因为它们的预测基于不同决策树预测值的均值。
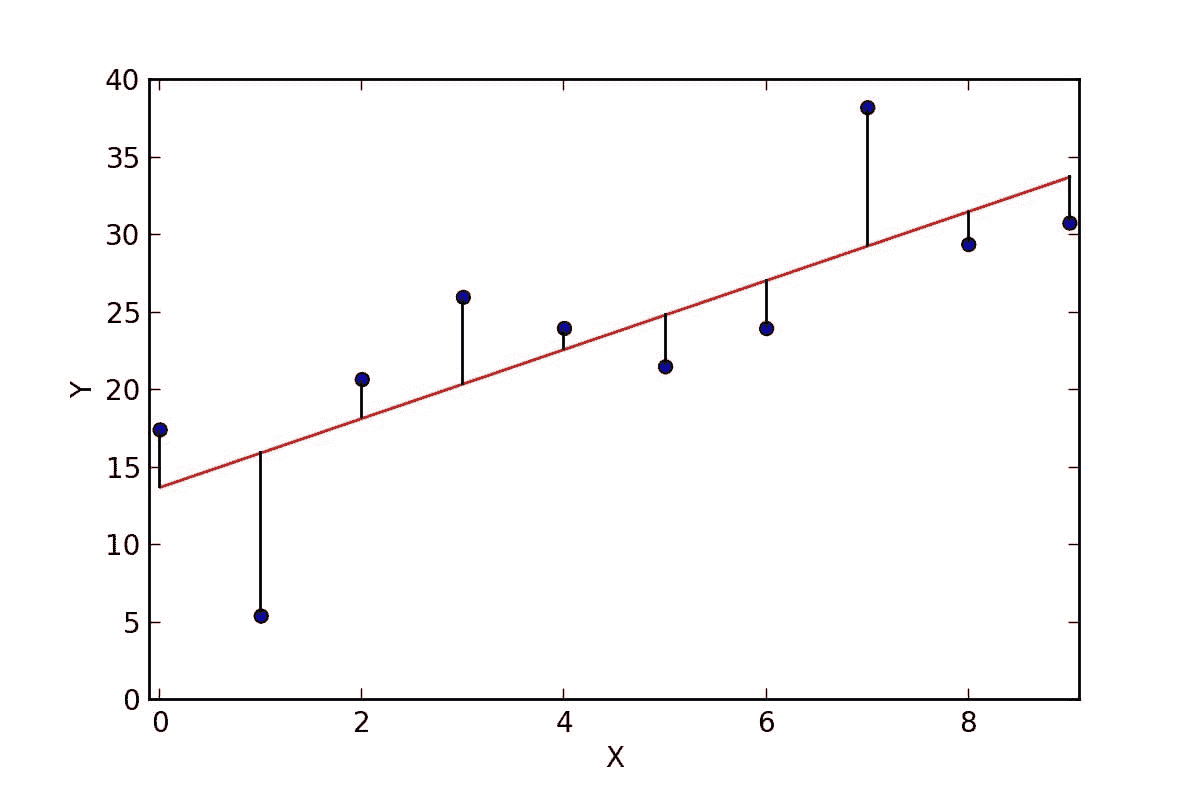
例如,当预测商品价格时,会在自变量和因变量之间拟合一条直线。线性回归线的一般方程如下:
其中:
-
c 是截距,即当 x 为零时 y 的值。
-
m 是直线的斜率。
-
x 是自变量。
-
y 是因变量。
其他线性回归算法包括:
-
套索回归 是一种引入了L1 正则化的线性模型,其目标是最小化系数的绝对和。在此算法中,不重要特征的权重被驱动到零。因此,不重要的特征会从线性方程中去除,使最终方程更简单。
-
岭回归 的系数最小化了一个带惩罚的残差平方和。此正则化被称为L2 正则化。在此算法中,不重要特征的权重被减少到接近零的小数值,但不会完全为零。这对于修剪系数同时保留所有特征并相应调整权重非常有用。
线性回归的假设
线性回归对数据中的异常值非常敏感。其他需要注意的事项包括:
-
数据呈正态分布。
-
输入变量和输出之间的关系是线性的。
-
变量之间的相关性不高。如果出现这种情况,请去除高度相关的变量。
-
标准化或归一化数据也不会对算法造成伤害!
逻辑回归
逻辑回归是一种用于分类问题的线性模型。它生成一个介于 0 和 1 之间的概率。这是通过拟合一个 逻辑函数,也称为 sigmoid 函数 实现的。该函数负责将预测值映射到介于 0 和 1 之间的数字。
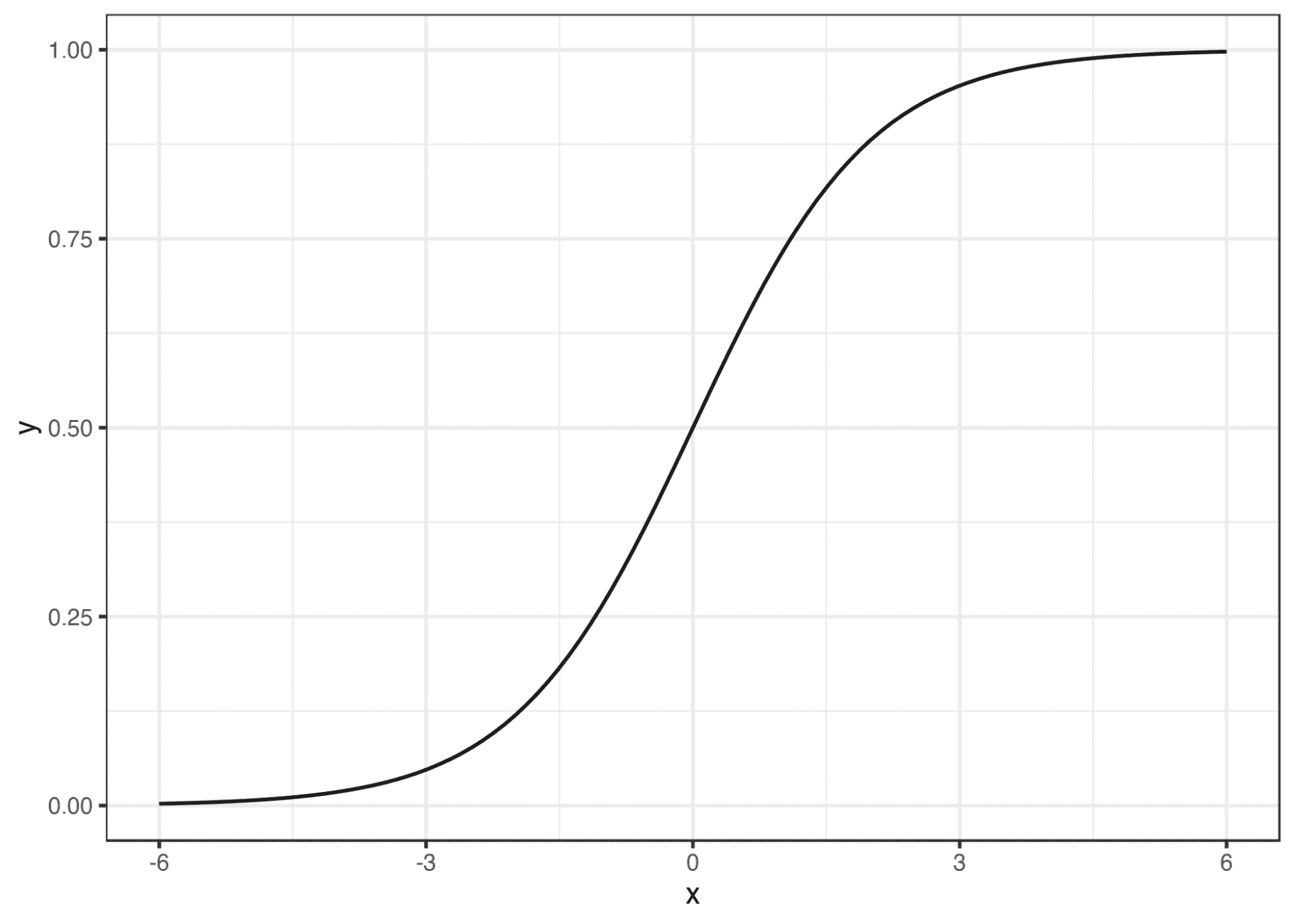
Logistic 函数 | 图像来源
当用于多类别分类时,称为多项式回归。这是通过调整逻辑回归算法来预测一个多项分布来实现的。通过将训练模型所用的损失函数从对数损失更改为交叉熵损失来实现。同时,算法也被修改为为每个类别输出一个概率,而不是单一的概率。
逻辑回归最受欢迎的实现之一是在Scikit-learn中完成的。该实现通过将class_weight参数设置为balanced来处理不平衡数据集。在这种情况下,算法将调整权重以给予样本较少的类别更多的权重,从而使算法能从该类别中学到更多。
逻辑回归假设
逻辑回归算法的假设类似于线性回归的假设。这里的独特之处在于,该算法期望目标变量是分类的。
支持向量机
支持向量机(SVM)是一种监督式机器学习算法,可用于回归和分类问题。它主要用于分类。
当数据线性可分时使用线性 SVM。在这种情况下,数据可以通过一条直线轻松分隔。
分类是通过找到最佳分隔两个类别的超平面来完成的。SVM 使用极端数据点来创建决策边界。这些极端数据点被称为支持向量,因此得名支持向量机。
向量之间的距离称为间隔。该算法通过最大化两个类别之间的间隙——即间隔来工作。最优超平面是具有最大间隔的超平面。
SVM 还可以通过一种称为核技巧的技术计算非线性分类的边界。它通过添加第三维度并在 3D 空间中分隔数据点来工作。
SVM、线性回归和逻辑回归之间的区别
线性回归算法与逻辑回归的不同在于逻辑回归输出概率。因此,逻辑回归算法可用于分类,而线性回归算法则不能。逻辑回归算法输出 0 到 1 之间的值,而线性回归算法则会外推并输出零以上或以下的值。
SVM 更具内存效率,因为它在决策函数中使用了训练数据的一个子集。与逻辑回归算法不同,SVM 不提供概率估计。SVM 也不像逻辑回归那样容易受到异常值的影响,因为它主要关注的是最接近超平面的数据点。
线性算法结果解释:汇总统计
线性回归输出每个自变量的系数。以一个用来预测商品价格的自变量 X1 为例。如果 X1 的系数是 6.2,可以这样解释:在所有因素保持不变的情况下,X1 每增加一个单位,商品价格将增加 6.2。
逻辑回归算法输出一个项目属于某个类别的概率。因此,通过设置 0.5 的阈值来解释结果,从而分隔这两个类别。
给定一个包含两个类别的数据集,SVM 算法将通过计算最佳超平面来预测项目属于哪个类别。它不计算任何概率,而是使用数据点与最优超平面的距离来分隔类别。
何时使用逻辑回归与支持向量机
逻辑回归和支持向量机是分类中两种流行的算法。然而,在某些情况下,你可能会偏好其中一个。例如,当存在异常值时,使用 SVM 更好,因为它们不会影响算法如何分离两个类别。SVM 在数据维度较高时也是更好的选择。
当类别没有很好地分离时,逻辑回归是更好的选择。否则,使用支持向量机(SVM)。不过,通常会先使用逻辑回归模型来创建基线模型。
最终思考
线性算法在机器学习中非常流行。在这篇文章中,我们探讨了几种线性模型及其内部工作原理。我们还讨论了何时偏好使用其中一种算法。一般来说,算法的选择将依赖于问题和数据集。
资源
德里克·穆伊提 在数据科学、机器学习和深度学习方面经验丰富,并且在构建机器学习社区方面具有敏锐的眼光。
更多相关话题
线性规划 101 数据科学家
原文:
www.kdnuggets.com/2023/02/linear-programming-101-data-scientists.html
图片来自维基百科
1. 线性规划的起源
对于那些对这一主题较为熟悉的人,你们可能知道线性规划的起源大致是在 1950 年代中期,一位名叫乔治·丹茨格的数学家参与了其中。如果这是你的猜测,你大致是对的,但我们都知道,归功于许多(如果不是全部)科学和数学发现的过程并非那么简单——通常有多个个体为一个研究领域的发展做出贡献,线性规划就是这种情况。初步进展由两位独立工作的数学家在 20 世纪中期同时取得,因此确实有多个贡献者。
在不深入历史的情况下,我们先对线性规划的关键进展时间线有一个大致的了解。线性规划的最初概念源于列昂尼德·坎托罗维奇试图降低自己军队的成本同时增加敌军的成本。他的努力发生在 1939 年的第二次世界大战期间,但当时被苏联忽视。与此同时,T.C. 库普曼斯有一个类似的想法,但他独立工作,且针对他自己的经济应用。几年后,1941 年,弗兰克·劳伦·希区柯克开始研究类似的想法,这些想法同样针对他自己的运输问题,但他发展出了类似于现在著名的单纯形法的解决方案。简而言之,这三个人都在正确的轨道上,但当发现获得诺贝尔经济学奖时,希区柯克已经去世,因此坎托罗维奇和库普曼斯获得了荣誉。
在 1946 年至 1947 年间,乔治·B·丹茨格开发了一种单纯形法算法,这种算法高效地解决了大多数情况下的线性规划问题——这是一项令人惊叹的成就。随后,丹茨格向约翰·冯·诺依曼介绍了线性规划中的对偶理论,冯·诺依曼当时正在发展博弈论,并惊讶地发现丹茨格在未解决的线性规划问题上取得了进展。这非常令人兴奋。(《心灵捕手》,有人看过吗?丹茨格的成就实际上是该电影情节的灵感来源!)

这些领域现在已经得到充分研究,并在重要的实际应用中被广泛使用。二战后,丹兹格的工作被应用于许多行业的日常规划应用中,数学家们很快在将线性规划问题的求解时间缩短为多项式时间方面取得了进展。这些是关于其起源的一些背景(例如,你可以在这里阅读详细信息),但现在,让我们简要了解一下最近的进展。
2. 线性规划的最新进展
最近,线性规划的研究集中在开发能够改善计算复杂性的算法上。例如,这篇论文讨论了用于加速 LP 的快速动态矩阵求逆。(不过,它内容偏向计算机科学,我们无需深入了解)。总体而言,今天有大量的研究集中在数学优化领域,无论是为了加速计算、减少低效,还是引入新的机器学习应用。
3. 应用线性规划的软件
目前有无数的软件包支持行业中的应用线性规划。你可以使用 IBM 的CPLEX、GUROBI 专有优化软件,开源 Python 包(如SciPy、Pyomo、PuLP、GEKKO),还有可能更多。一个有趣的事实是,所有这些包都使用了我们称之为代数建模语言(AML)的关键范式,这一范式在 1970 年代末期开发出来。所有这些包都在各自的领域表现出色,有许多博客文章可以阅读,以获得它们之间的良好比较——例如,可以查看这篇文章。
4. 线性规划中的主题
我们不会详细讨论,但让我们谈谈作为线性规划理论和方法的用户你应该知道的东西。线性规划的理论本身很美,但当你能够将线性规划与线性代数联系起来时,它会更美。无论你是读了一本教科书,还是参加了一个在线入门课程,还是在学校正式学习了这门课程,毫无疑问,你会得出线性规划是线性代数的一个特例,并且可能是基础线性代数最重要和相关的扩展之一的结论。
无论你选择了哪种学习线性规划的途径,你可能都遇到了以下(或类似的)主题:
-
线性程序的组成部分
-
线性程序的形式
-
常见的线性规划问题
-
对偶理论和敏感性分析
-
专门类型的线性程序
-
应用线性规划
(这听起来对吗?如果我遗漏了什么,请在下面留言。)如果是这样,并且你认为自己对所有这些话题都很熟悉,那么我建议你可以在这里停下,结束这篇文章(并祝贺自己,因为你刚刚了解了线性规划的简短历史!)。然而,如果以上话题中至少有一个对你来说是新的,那么我认为你应该继续阅读这篇文章,因为我觉得这将值得你的时间。
5. 常见线性规划问题
为了简洁和易于消化,我们将跳过序列中的前两个主题,但这里是一个好资源,你可以在这里了解线性程序的组成部分和线性程序的形式。同样,我们将省略对偶理论和敏感性分析的讨论,但一些很好的资源在这里和这里。
现在,如果你正在尝试应用线性规划原理来解决一个问题,你可能已经考虑了各种其他模型,并且(希望合理地)得出结论认为线性规划模型能够解决你的问题。如果是这样,可能你也考虑过一些经典的使用线性规划的问题:混合问题,分配问题,运输问题,旅行商问题,还有许多其他问题。
如果你的问题大致类似于这些问题中的任何一个,那么我们已经知道如何解决你的问题,你可以继续进行。如果不是,你需要更深入地思考你的问题,并找出一种巧妙的方法将其转化为线性规划问题。考虑一些类似的问题:
-
你需要一个线性规划来解决这个问题吗,还是这个问题可能是一个简单的问题?
-
你的主要目标是什么?
-
你只有一个目标,还是有多个目标?
-
这是一个最大化问题还是一个最小化问题?
-
你能想到的所有可能的约束条件是什么?
-
你的决策变量都是非负的吗,还是需要一些特殊的规格?
6. Python 中的应用线性规划:基于多伦多收容所数据的案例研究
我已经做了大量的解释,所以与其再多说些,不如直接展示一个“非标准”的应用线性规划问题,代码如下。如果你还记得,我们提到过有许多开源的 Python 包使用 AML 范式。PuLP 就是其中之一,所以我们这次使用 PuLP。
这是一个半假设性的例子,涉及 12 个真实存在的无家可归者收容所,位于多伦多市——真实的地址、真实的建筑物、虚假的房间/床位数量(即供应/容量)、虚假的新床位请求数量(即需求)、虚假的‘集群’收容所所属。话题有些沉重,我知道。这些数据来源于该市的开放数据目录。
作者编写的代码
假设我们在查看多伦多的无家可归者避难所的任意一天的床位供应和需求快照。我们选择的无家可归者避难所是战略性地分布在整个城市的——有些避难所彼此较近,而有些则相隔较远。请记住,这一点对于我们将要指定的优化问题是相关的。请注意,需求是按集群级别而不是避难所级别计算的。
此外,每增加一个床位,无论是在避难所还是在集群中,都会产生(货币和时间)成本,这些成本有所不同——有时按避难所计算,有时按集群计算。我们将集群定义为相对接近的避难所组——下方是位置相对彼此的粗略“地图”示意图。
除了货币成本之外,假设开设每个额外床位也会有时间成本——有时按避难所计算,有时按集群计算。这些时间成本的原因是,可能在邻近/集群内对床位有需求,但请求是在满员的位置提出的,需要重新安置服务用户。
我们将把这个设置为一个 多目标优化问题,因此我们的规范(代码中)需要能够适应这个问题。首先,我们最小化货币成本,然后最小化时间成本。第二个目标函数中的系数对应于特定避难所组内的相对时间增加(即,将新用户从避难所 X 转移到避难所 Y 的时间成本)。请注意,优化问题的规范不是唯一的,可能有多个规范导致相同的结果。
这是所有代码的一个长脚本。模型规范代码可以压缩/简化,但我们保持这种形式,以便你能更清楚地看到所有细节。我们注释掉了初始目标函数,因为我们在第 5 步中将其作为货币成本约束添加了。
作者代码
如果你在本地运行了这段代码,你会看到如下输出:
A:2671Islington: 1 additional bed(s).
B1:26Vaughan: 0 additional bed(s).
B2:14Vaughan: 5 additional bed(s).
C:850Bloor: 1 additional bed(s).
D1:38Bathurst: 2 additional bed(s).
D2:38Bathurst: 1 additional bed(s).
E1:135Sherbourne: 6 additional bed(s).
E2:339George: 5 additional bed(s).
E3:339George: 4 additional bed(s).
E4:339George: 0 additional bed(s).
E5:339George: 0 additional bed(s).
E6:339George: 4 additional bed(s).
Optimal Value of Objective Function: 36.9
你可能会问:这不是一个微不足道的问题吗?如果不是,那是为什么?这是一个重要的问题,这可能证明不需要指定线性规划问题!然而,在这种情况下,这是一个非平凡的问题,我们确实需要线性规划规范,考虑一下原因。
提示: 首先,我们最小化货币成本,然后最小化时间成本。你能想到用手动方式解决这个问题的方法吗?
参考文献
[1] B. Kolman 和 R.E. Beck, 《基础线性规划及应用》 (1995), ScienceDirect
[2] G.B. 丹齐格,线性规划起源的回忆(1982 年),运筹学系 — 斯坦福大学
[3] R. 福尔尔,D.M. 盖伊,B.W. 肯尼汉,数学编程建模语言(1990 年)
玛丽亚姆·瓦拉 是一名数学专业背景的数据科学家,拥有超过 3 年的工程、零售和学术领域的数据科学经验,涉及自然语言处理、推荐系统、线性规划和优化等多种问题。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关主题
使用 PuLP 进行线性规划和离散优化
原文:
www.kdnuggets.com/2019/05/linear-programming-discrete-optimization-python-pulp.html/2
评论
解决问题并打印解决方案
PuLP 提供了多种求解器算法(例如 COIN_MP、Gurobi、CPLEX 等)。对于这个问题,我们不指定任何选择,而是让程序根据问题结构默认选择。
prob.solve()
我们可以打印解决方案状态。注意,虽然在这种情况下状态是最优的,但不一定如此。如果问题表述不清或信息不足,解决方案可能是不可行或无界的。
# The status of the solution is printed to the screen
print("Status:", LpStatus[prob.status])
>> Status: Optimal
完整的解决方案包含所有变量,包括权重为零的变量。但对我们来说,只有那些具有非零系数的变量才是有趣的,即应该包含在最优饮食计划中的变量。因此,我们可以扫描问题变量,并仅在变量数量为正时打印出来。
for v in prob.variables():
if v.varValue>0:
print(v.name, "=", v.varValue)
>> Food_Frozen_Broccoli = 6.9242113
Food_Scrambled_Eggs = 6.060891
Food__Baked_Potatoes = 1.0806324
所以,最优解决方案是吃 6.923 份冷冻西兰花、6.06 份炒鸡蛋和 1.08 份烤土豆!

欢迎下载整个笔记本、数据文件,并尝试各种约束来更改您的饮食计划。代码在我的 GitHub 仓库中。
最后,我们可以打印目标函数即饮食成本,
obj = value(prob.objective)
print("The total cost of this balanced diet is: ${}".format(round(obj,2)))
>> The total cost of this balanced diet is: $5.52
如果我们希望得到一个整数解怎么办?
正如我们所看到的,最优结果返回了一组食物项的分数。这个结果可能不够实际,我们可能希望解决方案强制只有整数份量。
这引出了整数规划技术。之前优化中使用的算法是简单的线性规划,其中变量可以取任何实数值。整数规划强制某些或所有变量只能取整数值。
实际上,整数规划是一个比线性规划更难解的计算问题。整数变量使优化问题变得非凸,因此更难以解决。随着整数变量的增加,内存和解决时间可能会呈指数级增长。
幸运的是,PuLP 也可以解决具有这种限制的优化问题。
代码几乎与之前相同,因此这里没有重复。唯一的区别是变量被定义为属于**Integer**类别,而不是**Continuous**。
food_integer = LpVariable.dicts("Food",food_items,0,cat='Integer')
对于这个问题,它稍微改变了最优解,添加了冰山生菜到饮食中,并将成本增加了$0.06。你还会注意到计算时间的显著增加。
Therefore, the optimal balanced diet with whole servings consists of
--------------------------------------------------------------------
Food_Frozen_Broccoli = 7.0
Food_Raw_Lettuce_Iceberg = 1.0
Food_Scrambled_Eggs = 6.0
Food__Baked_Potatoes = 1.0
整数规划的一个酷应用是解决司机调度问题,这可能是一个NP 难题问题。请参阅这篇文章(也注意文章中他们如何计算各种操作的成本并将其用于优化问题),
[工程师的整数规划入门:简化的公交调度
这篇文章是 Remix 关于我们面临的软件工程问题系列的一部分。在这一篇中,Remix…blog.remix.com](https://blog.remix.com/an-intro-to-integer-programming-for-engineers-simplified-bus-scheduling-bd3d64895e92)
如何在一个线性规划问题中纳入二进制决策?
通常,我们希望在优化问题中包含某种“如果-那么-否则”的决策逻辑。
如果我们不想在饮食中同时包含西兰花和冰山生菜(但只包含其中之一是可以的),该怎么办?
我们如何在这个框架中表示这样的决策逻辑?

结果是,对于这种逻辑,你需要引入另一种类型的变量,称为指示变量。它们是二进制的,可以指示最优解中变量的存在或缺失。
[在 LP 问题中将指示函数作为约束
感谢你为 Mathematics Stack Exchange 贡献了答案!请务必回答这个问题。提供详细信息…math.stackexchange.com](https://math.stackexchange.com/questions/2220355/involving-indicator-function-as-a-constraint-in-a-lp-problem)
但对于这个特定的问题,使用指示变量存在一个明显的问题。理想情况下,如果指示变量为 1,你希望将食物项的成本/营养价值包含在约束方程中;如果为 0,则忽略它。从数学上讲,将其写为原始项(涉及食物项)与指示变量的乘积是直观的。但一旦你这样做,你就是在乘以两个变量,使问题变得非线性!在这种情况下,它属于二次规划(QP)的范畴(二次因为项现在是两个线性项的乘积)。
流行的机器学习技术支持向量机本质上解决了一个二次规划问题。
[什么是二次规划的直观解释?在 SVM 中如何定义它?
答案:二次规划涉及最小化一个在未知向量组件中是二次形式的目标函数…… www.quora.com
然而,使用指示变量在线性规划问题中表达二进制逻辑的这一一般概念也极为有用。我们在下一部分给出了一个使用这一技巧解决数独谜题的问题链接。
结果发现,有一个巧妙的技巧可以将这种二进制逻辑融入到这个线性规划中,而不会使其变成一个二次规划问题。
我们可以将二进制变量表示为 food_chosen 并将其实例化为 Integer,下限和上限为 0 和 1。
food_chosen = LpVariable.dicts("Chosen",food_items,0,1,cat='Integer')
然后我们编写了一段特殊代码,将通常的 food_vars 和二进制 food_chosen 关联起来,并将此约束添加到问题中。
for f in food_items:
prob += food_vars[f]>= food_chosen[f]*0.1
prob += food_vars[f]<= food_chosen[f]*1e5
如果你长时间盯着代码看,你会意识到这实际上意味着只有在相应的 food_chosen 指示变量为 1 时,我们才会给予 food_vars 重要性。但这样我们避免了直接乘法,保持了问题结构的线性。
为了包含西兰花和冰山生菜的“或”条件,我们只需写一段简单的代码,
prob += food_chosen['Frozen Broccoli']+food_chosen['Raw Iceberg Lettuce']<=1
这确保了这两个二进制变量的和至多为 1,这意味着在最优解中只能包含其中一个,但不能同时包含两个。
线性/整数规划的更多应用
在这篇文章中,我们展示了用 Python 设置和解决一个简单线性规划问题的基本流程。然而,如果你四处查看,你会发现无数的工程和商业问题可以转化为某种形式的线性规划,然后使用高效的求解器解决。以下是一些经典的示例,帮助你开始思考,
许多机器学习算法也使用优化的一般类别,其中线性规划是一个子集——凸优化。有关更多信息,请参阅以下文章,
我们展示了最受欢迎的机器学习/统计建模技术背后的核心优化框架。 towardsdatascience.com
总结与结论
在这篇文章中,我们展示了使用 Python 包 PuLP 解决简单的饮食优化问题的线性和整数编程技术。值得注意的是,即使是广泛使用的 SciPy 也内置了线性优化方法。鼓励读者尝试各种 Python 库,选择适合自己的方法。
如果你有任何问题或想法,请通过 tirthajyoti[AT]gmail.com 联系作者。你还可以查看作者的 GitHub 代码库,寻找其他有趣的 Python、R 或 MATLAB 代码片段和机器学习资源。如果你和我一样,对机器学习/数据科学充满热情,欢迎 在 LinkedIn 上添加我 或 在 Twitter 上关注我。
Tirthajyoti Sarkar - 高级首席工程师 - 半导体、人工智能、机器学习 - ON…
乔治亚理工学院科学硕士 - MS,分析学 该 MS 课程传授理论和实践… www.linkedin.com
简介:Tirthajyoti Sarkar 是 ON Semiconductor 的高级首席工程师,专注于基于深度学习/机器学习的设计自动化项目。
原文。经许可转载。
相关:
-
优化如何运作
-
使用 R 进行优化
-
机器学习中的优化:鲁棒性还是全局最小值?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 维护
更多相关内容
数据科学的线性回归
原文:
www.kdnuggets.com/2022/07/linear-regression-data-science.html
作者提供的图片
关键要点
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 需求
-
大多数有兴趣进入数据科学领域的初学者总是担心数学要求。
-
数据科学是一个非常量化的领域,需要高级数学知识。
-
但要开始,您只需掌握几个数学主题。
-
在这篇文章中,我们讨论了线性回归在数据科学和机器学习中的重要性。
线性回归(连续目标变量)
回归模型是最受欢迎的机器学习模型。回归模型用于预测连续尺度上的目标变量。回归模型几乎在每个学科领域都有应用,因此,它是最广泛使用的机器学习模型之一。本文将讨论线性回归的基础知识,并面向数据科学领域的初学者。
1. 简单线性回归
在简单线性回归中,只有一个预测变量。由于我们的目标是预测船员变量,我们从图 1中看到,舱位变量与船员变量的相关性最高。因此,我们的简单回归模型可以表示为:
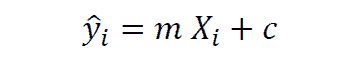
其中 m 是斜率或回归系数,c 是截距
2. 多重线性回归
假设目标变量现在依赖于几个预测变量(例如四个预测变量),那么可以使用多重回归分析来建模系统:
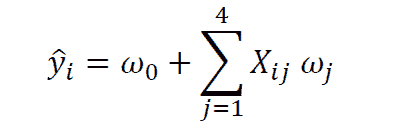
其中 X 是特征矩阵,w_0 是截距,w_1、w_2、w_3 和 w_4 是回归系数。
评估线性回归模型
用于评估线性回归模型性能的最受欢迎的指标是 R2 分数指标,其计算方法如下:
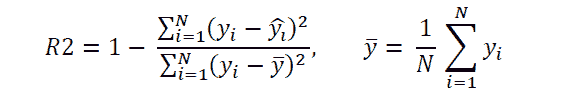
R2 评分的取值范围在 0 和 1 之间。当 R2 接近 1 时,表示预测值与实际值非常接近。如果 R2 接近零,则表示模型的预测能力非常差。
还可以使用以下其他指标来评估线性回归模型:
MSE(均方误差):使用欧几里得距离计算误差。MSE 仅给出误差的大小。
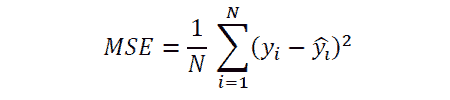
MAE(均值绝对误差):使用曼哈顿距离计算误差。MAE(如同 MSE)仅给出误差的大小。
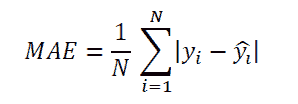
ME(均值误差):跟踪误差的符号,模型是过度预测(ME > 0)还是低估预测(ME < 0)?
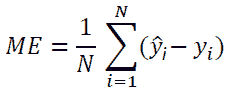
-
R2 评分 是评估线性回归模型性能的非常流行的指标。
-
在比较两个或更多模型时,使用 MSE 或 MAE,MSE 或 MAE 的值越低,模型越好。
-
当你想了解你的模型是否在平均上过度预测(ME > 0)或低估预测(ME < 0)时,请使用 ME。也可以使用 R2 评分 来比较不同的模型。
案例研究:预测船员数量的机器学习模型
在本案例研究中,我们使用 cruise_ship_info.csv 数据集构建了一个多元线性回归模型来预测船员数量。可以从这个 GitHub 仓库下载数据集和代码:github.com/bot13956/ML_Model_for_Predicting_Ships_Crew_Size
总结
-
线性回归(用于连续目标变量预测)是最流行的机器学习模型。回归模型几乎在每个学科领域都有应用,因此它是最广泛使用的机器学习模型之一。
-
线性回归模型可以分为简单回归(单一特征)和多重回归(多个目标变量)模型。
-
线性回归模型可以使用如 Pylab、Numpy 或 scikit-learn 等软件库来实现。
-
评估回归模型时可以使用多种指标,如 MSE、ME、MAE 和 R2 评分。R2 评分仍然是最受欢迎的指标。
本杰明·O·泰约 是一位物理学家、数据科学教育者和作家,也是 DataScienceHub 的所有者。此前,本杰明曾在中央俄克拉荷马大学、大峡谷大学和匹兹堡州立大学教授工程和物理学。
更多内容
使用 NumPy 从头开始线性回归
原文:
www.kdnuggets.com/linear-regression-from-scratch-with-numpy

作者提供的图像
动机
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域。
2. Google 数据分析专业证书 - 提升您的数据分析技能。
3. Google IT 支持专业证书 - 支持您的组织的信息技术。
线性回归是机器学习中最基础的工具之一。它用于找到一条适合我们数据的直线。尽管它仅适用于简单的直线模式,但理解其背后的数学帮助我们理解梯度下降和损失最小化方法。这些对于所有机器学习和深度学习任务中的更复杂模型都是重要的。
在本文中,我们将动手使用 NumPy 从头开始构建线性回归。我们将从基础开始,而不是使用 Scikit-Learn 提供的抽象实现。
数据集
我们使用 Scikit-Learn 方法生成一个虚拟数据集。目前我们只使用一个变量,但该实现将是通用的,可以在任意数量的特征上进行训练。
Scikit-Learn 提供的 make_regression 方法生成随机的线性回归数据集,并加入了高斯噪声以增加一些随机性。
X, y = datasets.make_regression(
n_samples=500, n_features=1, noise=15, random_state=4)
我们生成 500 个随机值,每个值具有 1 个特征。因此,X 的形状是 (500, 1),每个 500 个独立的 X 值都有一个对应的 y 值。因此,y 的形状也是 (500, )。
可视化的数据集如下所示:
作者提供的图像
我们的目标是找到一条最适合的直线,使其通过数据中心,最小化预测值与原始 y 值之间的平均差异。
直观
线性直线的一般方程是:
y = m*X + b
X 是数值型的,单一值。这里 m 和 b 代表梯度和 y 截距(或偏置)。这些是未知的,改变这些值可以生成不同的直线。在机器学习中,X 依赖于数据,y 值也是如此。我们只控制 m 和 b,它们作为我们的模型参数。 我们的目标是找到这两个参数的最佳值,以生成一条最小化预测值与实际 y 值之间差异的直线。
这扩展到 X 是多维的情况。在这种情况下,m 值的数量将等于数据中的维度数量。例如,如果我们的数据有三个不同的特征,我们将有三个不同的 m 值,称为权重。
方程现在变为:
y = w1X1 + w2X2 + w3*X3 + b
这可以扩展到任意数量的特征。
但我们如何知道偏置和权重的最优值?嗯,我们不知道。但是我们可以使用梯度下降方法逐步找出。我们从随机值开始,并在多个步骤中稍微调整它们,直到接近最优值。
首先,让我们初始化线性回归,稍后我们会更详细地讲解优化过程。
初始化线性回归类
import numpy as np
class LinearRegression:
def __init__(self, lr: int = 0.01, n_iters: int = 1000) -> None:
self.lr = lr
self.n_iters = n_iters
self.weights = None
self.bias = None
我们使用学习率和迭代次数这两个超参数,稍后会详细解释。权重和偏置被设置为 None,因为权重参数的数量取决于数据中的输入特征。由于我们还没有数据,因此目前将它们初始化为 None。
拟合方法
在 fit 方法中,我们提供了数据及其相关值。现在我们可以利用这些数据来初始化权重,然后训练模型以找到最优权重。
def fit(self, X, y):
num_samples, num_features = X.shape # X shape [N, f]
self.weights = np.random.rand(num_features) # W shape [f, 1]
self.bias = 0
自变量 X 将是一个形状为 (num_samples, num_features) 的 NumPy 数组。在我们的例子中,X 的形状是 (500, 1)。我们数据中的每一行都有一个相关的目标值,因此 y 的形状也是 (500,) 或 (num_samples)。
我们提取这些,并根据输入特征的数量随机初始化权重。因此,现在我们的权重也是一个大小为 (num_features, ) 的 NumPy 数组。偏置是初始化为零的单个值。
预测 Y 值
我们使用上述讨论的直线方程来计算预测的 y 值。然而,我们可以采用向量化的方法进行更快的计算,而不是通过迭代方法来求和所有值。由于权重和 X 值都是 NumPy 数组,我们可以使用矩阵乘法来获得预测值。
X 的形状是 (num_samples, num_features),而权重的形状是 (num_features, )。我们希望预测值的形状是 (num_samples, ),以匹配原始 y 值。因此,我们可以将 X 与权重相乘,即 (num_samples, num_features) x (num_features, ) 来获得形状为 (num_samples, ) 的预测值。
偏置值在每个预测的末尾添加。这可以简单地在一行中实现。
# y_pred shape should be N, 1
y_pred = np.dot(X, self.weights) + self.bias
然而,这些预测正确吗?显然不是。我们使用随机初始化的权重和偏置值,因此预测也会是随机的。
我们如何获得最优值?梯度下降。
损失函数和梯度下降
现在我们有了预测的 y 值和目标 y 值,我们可以找到这两者之间的差异。均方误差(MSE)用于比较实际值。方程如下:
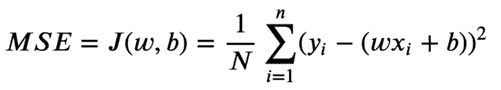
我们只关心值之间的绝对差异。预测值高于原始值和低于原始值同样糟糕。因此,我们对目标值和预测值之间的差异进行平方处理,以将负差异转换为正值。此外,这也惩罚了目标和预测之间的较大差异,因为较大的差异平方后会对最终损失贡献更多。
为了使我们的预测尽可能接近原始目标,我们现在尝试最小化这个函数。损失函数在梯度为零时达到最小值。由于我们只能优化权重和偏置值,我们对 MSE 函数关于权重和偏置值的偏导数进行计算。
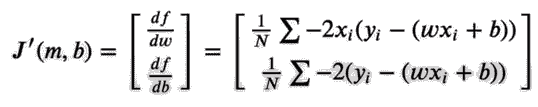
然后,我们使用梯度下降法根据梯度值优化我们的权重。
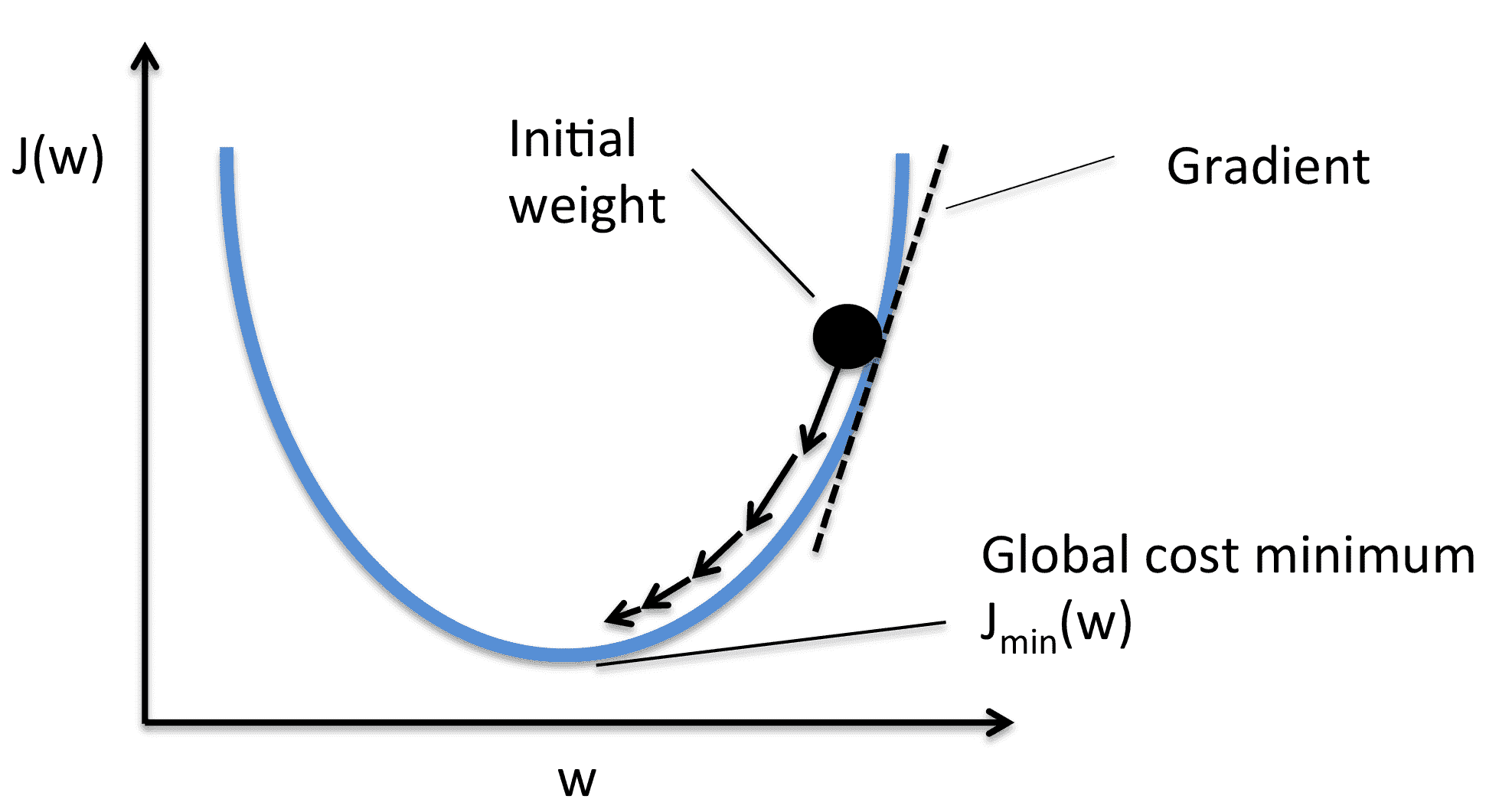
图片来自 Sebasitan Raschka
我们对每个权重值取梯度,然后将其移动到梯度的相反方向。这将使损失值趋向最小值。根据图片,梯度为正,因此我们减少权重。这将使 J(W) 或损失值趋向最小值。因此,优化方程如下:
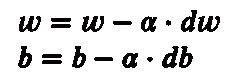
学习率(或 alpha)控制图片中显示的增量步长。我们只对值进行小幅度的调整,以稳定地向最小值移动。
实现
如果我们使用基本的代数运算简化导数方程,这将变得非常简单。
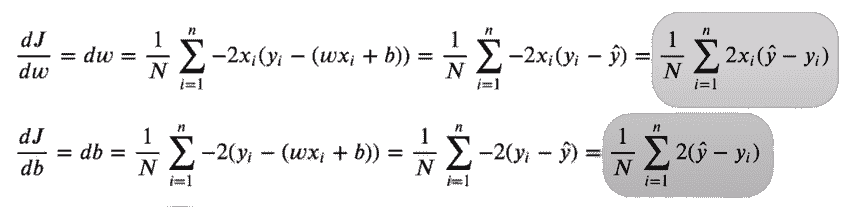
对于导数,我们使用两行代码来实现:
# X -> [ N, f ]
# y_pred -> [ N ]
# dw -> [ f ]
dw = (1 / num_samples) * np.dot(X.T, y_pred - y)
db = (1 / num_samples) * np.sum(y_pred - y)
dw 的形状仍为 (num_features, ),因此我们为每个权重有一个单独的导数值。我们分别优化这些权重。db 只有一个值。
现在,为了优化这些值,我们使用基本的减法将值移动到梯度的相反方向。
self.weights = self.weights - self.lr * dw
self.bias = self.bias - self.lr * db
同样,这只是一个单一的步骤。我们仅对随机初始化的值进行小幅度调整。现在我们重复相同的步骤,以趋近于最小值。
完整的循环如下:
for i in range(self.n_iters):
# y_pred shape should be N, 1
y_pred = np.dot(X, self.weights) + self.bias
# X -> [N,f]
# y_pred -> [N]
# dw -> [f]
dw = (1 / num_samples) * np.dot(X.T, y_pred - y)
db = (1 / num_samples) * np.sum(y_pred - y)
self.weights = self.weights - self.lr * dw
self.bias = self.bias - self.lr * db
预测
我们以与训练时相同的方式进行预测。然而,现在我们拥有了最佳的权重和偏置集合。预测值现在应该接近原始值。
def predict(self, X):
return np.dot(X, self.weights) + self.bias
结果
使用随机初始化的权重和偏置,我们的预测结果如下:
作者提供的图片
权重和偏差初始化非常接近 0,因此我们得到了一条水平线。经过 1000 次迭代训练后,我们得到了这个:
图片来源:作者
预测的线正好穿过我们数据的中心,似乎是可能的最佳拟合线。
结论
你现在已经从零开始实现了线性回归。完整代码也可以在GitHub上找到。
import numpy as np
class LinearRegression:
def __init__(self, lr: int = 0.01, n_iters: int = 1000) -> None:
self.lr = lr
self.n_iters = n_iters
self.weights = None
self.bias = None
def fit(self, X, y):
num_samples, num_features = X.shape # X shape [N, f]
self.weights = np.random.rand(num_features) # W shape [f, 1]
self.bias = 0
for i in range(self.n_iters):
# y_pred shape should be N, 1
y_pred = np.dot(X, self.weights) + self.bias
# X -> [N,f]
# y_pred -> [N]
# dw -> [f]
dw = (1 / num_samples) * np.dot(X.T, y_pred - y)
db = (1 / num_samples) * np.sum(y_pred - y)
self.weights = self.weights - self.lr * dw
self.bias = self.bias - self.lr * db
return self
def predict(self, X):
return np.dot(X, self.weights) + self.bias
穆罕默德·阿赫曼 是一名深度学习工程师,专注于计算机视觉和自然语言处理。他曾在 Vyro.AI 上工作,负责多个生成型 AI 应用的部署和优化,这些应用在全球排行榜上名列前茅。他对构建和优化智能系统的机器学习模型充满兴趣,并相信持续改进。
更多相关话题
线性回归模型选择:平衡简洁性和复杂性
原文:
www.kdnuggets.com/2023/02/linear-regression-model-selection-balancing-simplicity-complexity.html

图片来源:freepik
简单线性回归是最古老的预测建模类型之一。在简单线性回归中,我们有一个特征 ( ) 和一个连续目标变量 (
) 和一个连续目标变量 (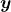 )。目标是找到一个数学函数来描述 X 和 y 之间的关系。最简单的形式是尝试一个线性(度数 = 1)关系,形式为
)。目标是找到一个数学函数来描述 X 和 y 之间的关系。最简单的形式是尝试一个线性(度数 = 1)关系,形式为 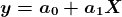 ,其中
,其中 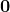 和 a**1 是需要确定的系数。一个二次模型(度数 = 2)的形式为
和 a**1 是需要确定的系数。一个二次模型(度数 = 2)的形式为  ,其中
,其中  ,
, 和
和  是需要确定的回归系数。
是需要确定的回归系数。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业之路。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持组织的 IT 需求
假设我们有一个下图所示的数据集。
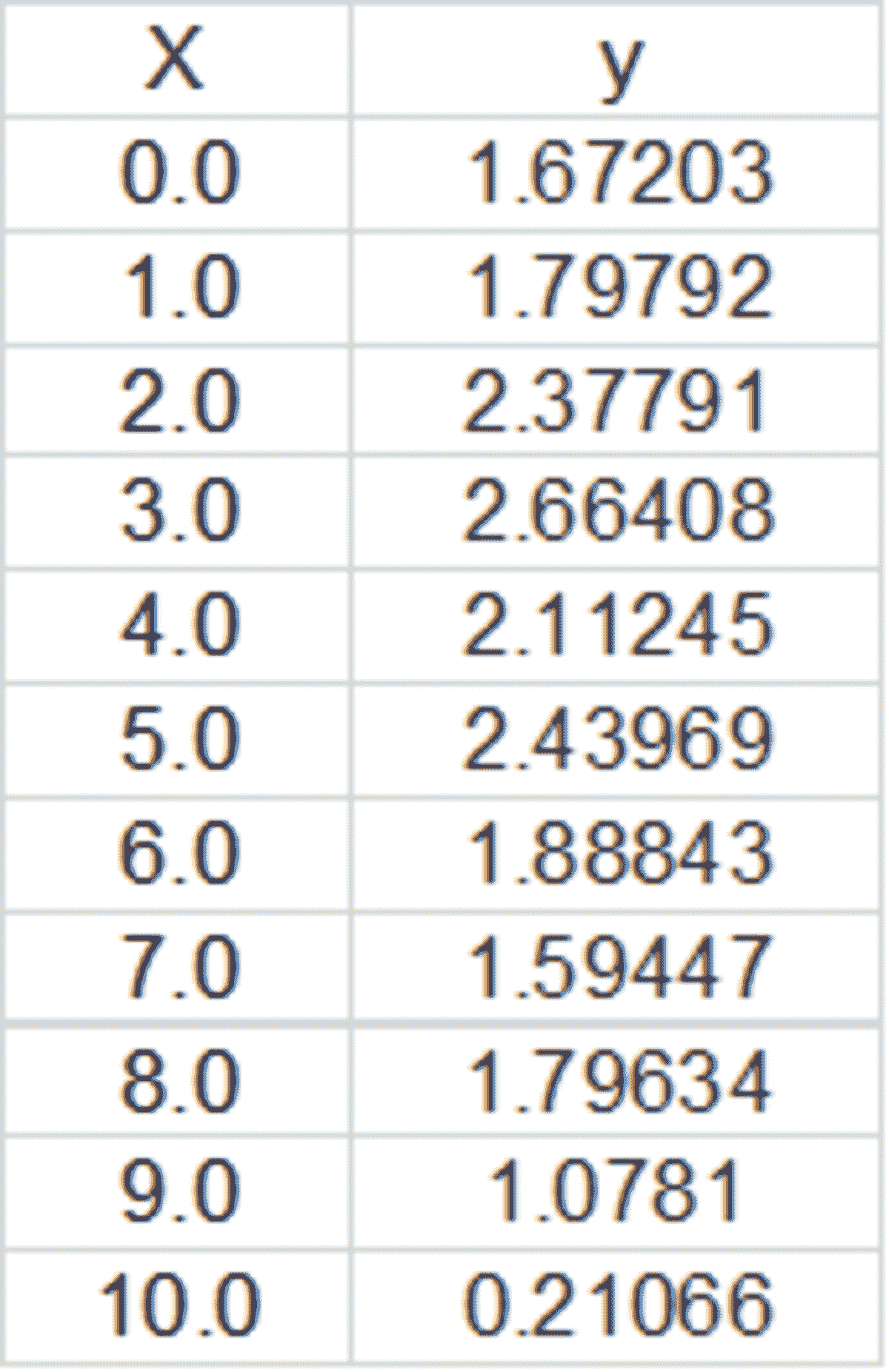
图片作者
我们的目标是执行回归分析,以量化X和y之间的关系,即y = f(X)。一旦获得这一关系,我们就可以为任何给定的X值预测新的y值。
首先,我们生成一个散点图来显示X和y之间的关系。
import pandas as pd
import pylab
import matplotlib.pyplot as plt
import numpy as np
data = pd.read_csv("file.csv")
X = data.X.values
y = data.y.values
plt.scatter(X, y)
plt.xlabel('X')
plt.ylabel('y')
plt.show()
要对数据执行一次多项式拟合(度数 = 1),我们可以使用以下代码:
degree = 1
model=pylab.polyfit(X,y,degree)
y_pred=pylab.polyval(model,X)
#calculating R-squared value
R2 = 1 - ((y-y_pred)**2).sum()/((y-y.mean())**2).sum()
通过将度数值更改为度数 = 2 和度数 = 10,我们可以对数据执行更高阶的多项式拟合。
下图展示了针对不同多项式拟合的数据所获得的原始值和预测值的图示。
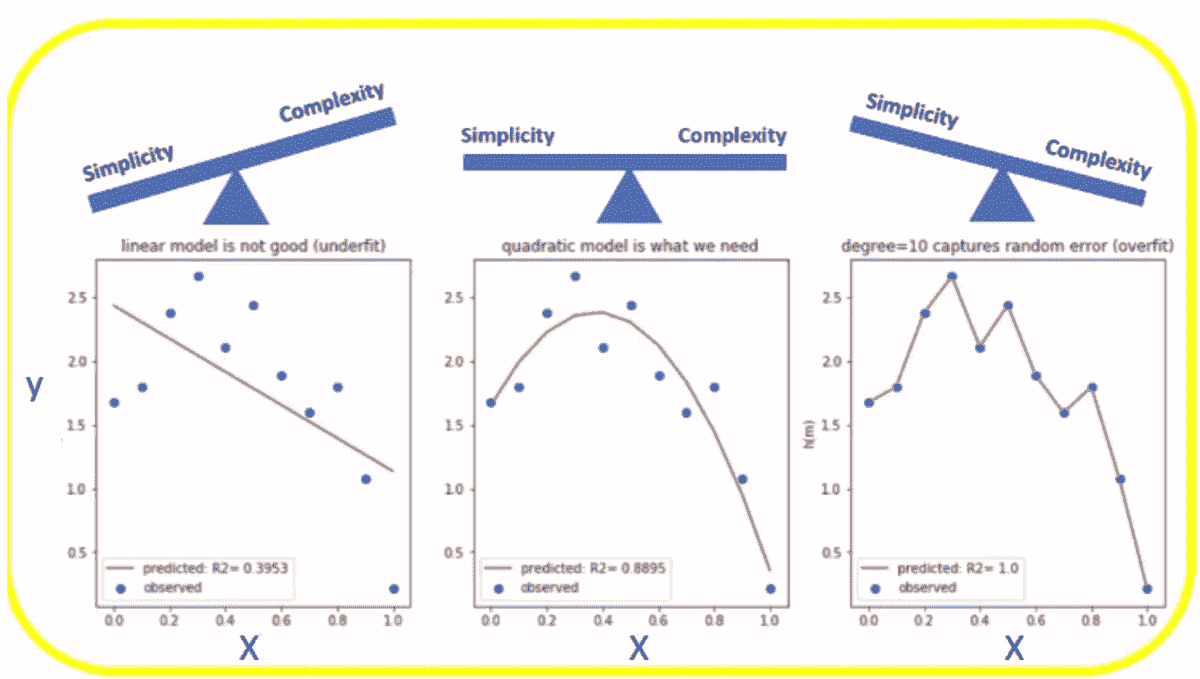
图片由作者提供
下表总结了不同模型的拟合优度得分(R2 分数):
从上图中,我们观察到以下几点:
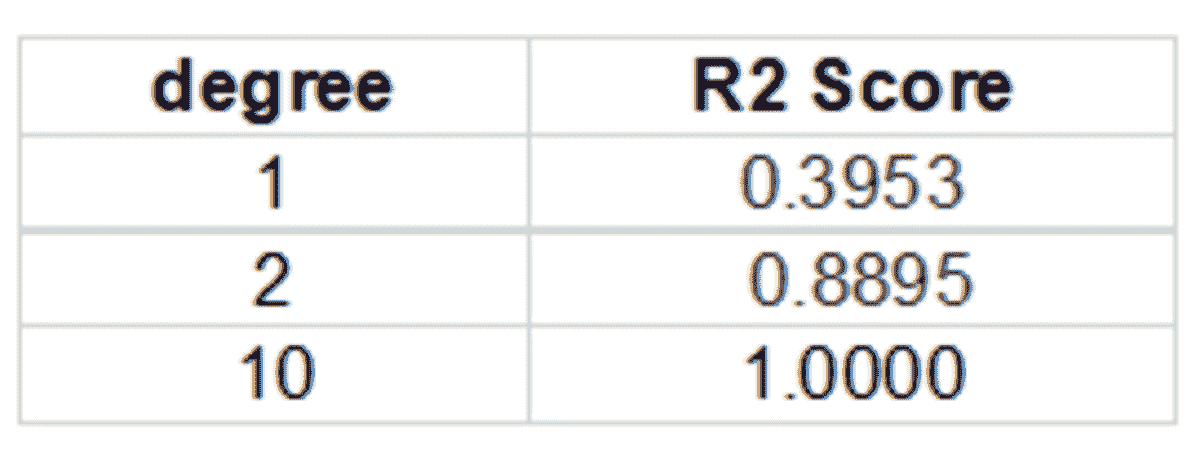
-
线性模型(度数 = 1)过于简单,因此对数据的拟合不足,导致高偏差误差。
-
更高的多项式模型(度数 = 10)过于复杂,因此对数据的拟合过度,导致高方差误差。
-
二次模型(度数 = 2)似乎在简洁性和复杂性之间提供了正确的平衡。
结论
总之,我们展示了如何使用 Python 进行简单的线性回归。通常,任何度数的多项式都可以用来拟合数据。然而,在选择最终模型时,重要的是要找到简洁性和复杂性之间的正确平衡。一个过于简单的模型对数据拟合不足,导致高偏差误差。类似地,一个过于复杂的模型则过度拟合数据,导致高方差误差。应选择一个在简洁性和复杂性之间达到适当平衡的模型,因为这种模型在应用于新数据时会产生更低的误差。
本杰明·O·泰约 是物理学家、数据科学教育者和作家,也是 DataScienceHub 的所有者。此前,本杰明曾在中欧大学、 grand canyon 大学和匹兹堡州立大学教授工程学和物理学。
更多相关主题
野外的线性回归
评论
在我一次数据科学职位的面试中,我收到了一项家庭作业,我想和你分享。
面试官给了我一个包含测量量 x 和 y 的 CSV 文件,其中 y 是一个响应变量,可以写成 x 的显式函数。已知用于测量 x 的技术在标准差意义上是测量 y 的技术的两倍好。
任务:将 y 建模为 x 的函数。
这是我需要的所有导入:
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from scipy.stats import probplot
import matplotlib.pyplot as plt
%matplotlib inline
data = pd.read_csv('data.csv', names=['x', 'y'])
data.head()
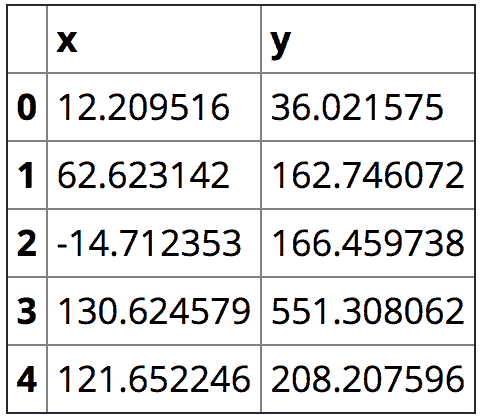 让我们可视化数据,看看是否容易通过目测捕捉到模式:
让我们可视化数据,看看是否容易通过目测捕捉到模式:
data.plot.scatter('x', 'y', title='data')
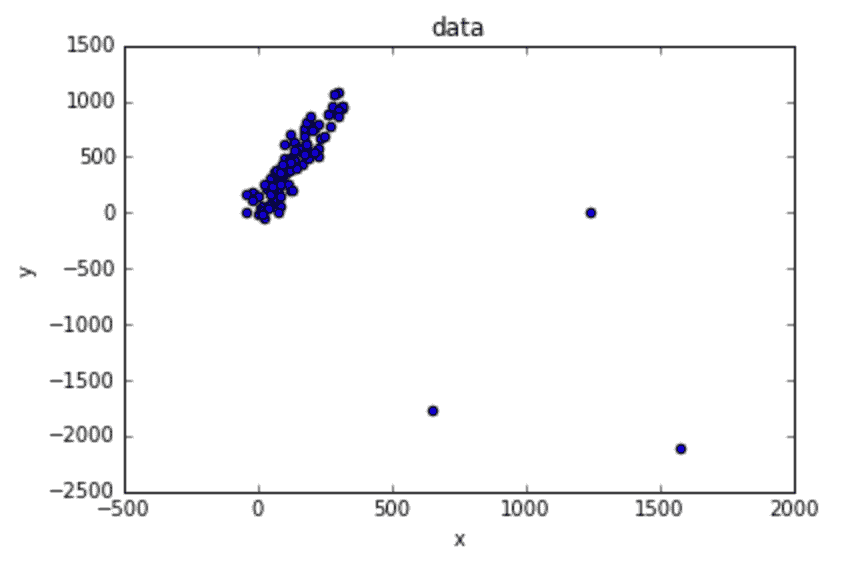
这明显看起来是线性回归的情况。我首先会手动去除异常值:
data = data[data['x'] < 600]
data.plot.scatter('x', 'y', title='data without outliers')
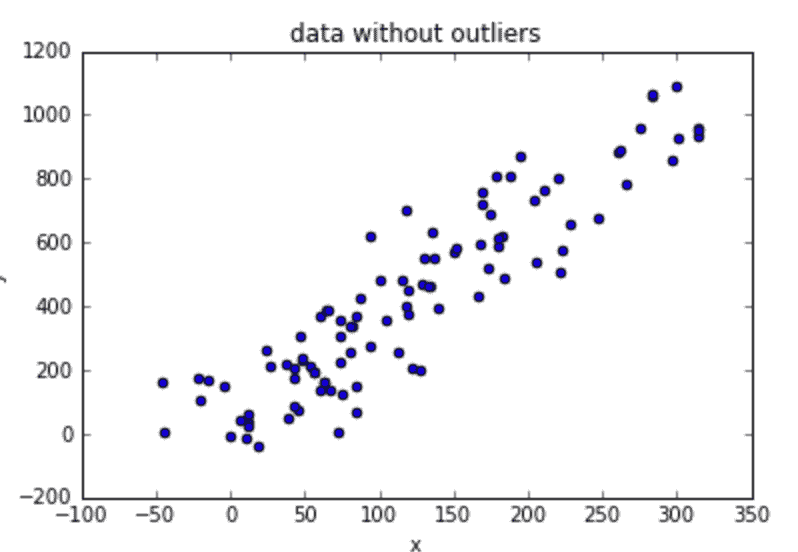
我将使用LinearRegression来拟合最佳直线:
lr = LinearRegression().fit(data[['x']], data['y'])
data.plot.scatter('x', 'y', title='linear regression')
lr_predicted_y = lr.predict(data[['x']])
plt.plot(data['x'], lr_predicted_y)
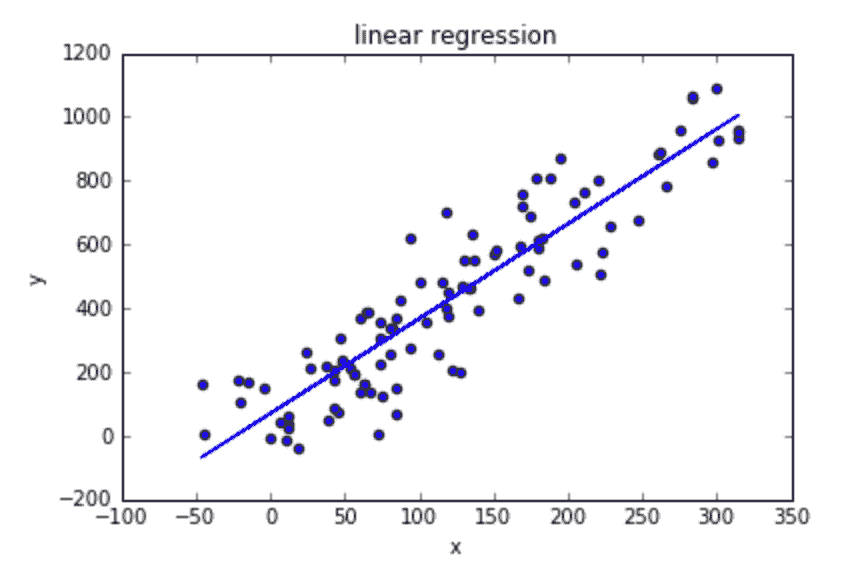
在数据上拟合一条直线视觉上看起来很有说服力,但我将验证线性回归的假设,以确保我使用了正确的模型。
如果你对线性回归假设不熟悉,你可以阅读文章深入回归分析:假设、图示与解决方案。
首先,我们将绘制残差误差:
residuals = lr_predicted_y - data['y']
plt.scatter(x=lr_predicted_y, y=residuals)
plt.title('residuals')
-
残差中似乎没有自相关。
-
异方差性似乎不是问题,因为方差看起来几乎是恒定的(除了图的左边部分,但数据不多,所以我会忽略它)。
-
多重共线性在这里不相关,因为只有一个因变量。
-
残差应当是正态分布的:我将通过 QQ 图验证这一点:
probplot(residuals, plot=plt)
看起来相当正常…
我将得出结论,假设 x 和 y 之间的线性关系最好的模型为:
print 'y = %f + %f*x' % (lr.intercept_, lr.coef_)
>>> y = 70.023655 + 2.973585*x
我们得到了一致的估计量来计算给定x的y(两者都有测量误差)的参数,换句话说,就是直线的系数。
到目前为止,我做的只是普通的线性回归。这项任务有趣的地方在于x有测量误差(这在实际应用中很常见)。
如果我们想估计计算 y 所需的参数(给定准确的 x 值,没有测量误差),我们需要使用不同的方法。使用简单线性回归而不考虑 x 随机噪声会导致直线斜率稍微小于 真实 直线斜率(描述 x 没有测量误差的直线)。你可以阅读 这篇维基百科页面 来了解原因。
我将使用 Deming 回归,这是一种可以用于假设两个变量 x 和 y 的误差是独立且正态分布的,并且它们的方差比率(记作 δ)已知的方法。这种方法非常适合我们的设置,其中我们有
用于测量 x 的技术在标准差的意义上是测量 y 的技术的两倍。
因此,在我们的设置中,δ 是 2 的平方。
使用 维基百科页面 中找到的公式,我们得到
cov = data.cov()
mean_x = data['x'].mean()
mean_y = data['y'].mean()
s_xx = cov['x']['x']
s_yy = cov['y']['y']
s_xy = cov['x']['y']
delta = 2 ** 2
slope = (s_yy - delta * s_xx + np.sqrt((s_yy - delta * s_xx) ** 2 + 4 * delta * s_xy ** 2)) / (2 * s_xy)
intercept = mean_y - slope * mean_x
使用 Deming 回归,x 和 y 之间的关系被建模为
print 'y = %f + %f*x' % (intercept, slope)
>>> y = 19.575797 + 3.391855*x
让我们绘制这两个模型:
data.plot.scatter('x', 'y', title='linear regression with & without accounting for $x$ error measurements')
plt.plot(data['x'], lr_predicted_y, label='ignoring errors in $x$')
X = [data['x'].min(), data['x'].max()]
plt.plot(X, map(lambda x: intercept + slope * x, X), label='accounting for errors in $x$')
plt.legend(loc='best')
我们拟合了两个模型:一个是简单的线性回归模型,另一个是考虑了 x 测量误差的线性回归模型。
如果我们的目的是计算给定新 x 的 y (具有测量误差,来自与训练模型时使用的测量误差相同的分布),那么较简单的模型可能就足够了。
如果我们想在没有测量误差的世界中准确表述 y 作为 x 的函数的真实关系,我们应该选择第二个模型。
这是一个很好的面试问题,因为我学到了一个新的模型,这非常棒 😃
尽管这并不完全是标题所建议的 野外线性回归 示例(好吧,我撒谎了),但这篇文章确实展示了许多人没有注意到的一个重要概念:在许多情况下,因变量的测量是不准确的,这可能需要考虑(具体取决于应用)。
小心回归!
原始。经许可转载。
简介: Yoel Zeldes 是 Taboola 的算法工程师。Yoel 是一位机器学习爱好者,尤其喜欢深度学习的见解。
相关内容:
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
LinkedIn 如何在其招聘推荐系统中使用机器学习
原文:
www.kdnuggets.com/2020/10/linkedin-machine-learning-recruiter-recommendation-systems.html
评论
来源:solutionsreview.com/business-intelligence/machine-learning-linkedin-groups/
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
我最近开始了一份新的新闻通讯,专注于人工智能教育。TheSequence 是一份无废话(即无炒作、无新闻等)的人工智能专注型新闻通讯,阅读时间为 5 分钟。目标是让你跟上机器学习项目、研究论文和概念的最新动态。请通过下面的订阅尝试一下:

LinkedIn 是市场上最受欢迎的招聘平台之一。每天,来自世界各地的招聘人员依靠 LinkedIn 来寻找和筛选适合特定职业机会的候选人。特别是,LinkedIn Recruiter 是帮助招聘人员建立和管理人才库的产品,优化成功招聘的机会。LinkedIn Recruiter 的有效性由一系列极其复杂的搜索和推荐算法驱动,这些算法结合了先进的机器学习架构与现实世界系统的实用性。
LinkedIn 一直是推动机器学习研究和发展的软件巨头之一,这并不是什么秘密。除了培养世界上最丰富的数据集之一外,LinkedIn 还不断尝试尖端的机器学习技术,以使人工智能(AI)成为 LinkedIn 体验的核心组成部分。其招聘产品中的推荐体验需要 LinkedIn 的全部机器学习专业知识,因为它成为了一个非常独特的挑战。除了处理一个极其庞大且不断增长的数据集外,LinkedIn 招聘需要处理任意复杂的查询和过滤,并提供符合特定标准的相关结果。搜索环境变化如此动态,以至于很难将结果建模为机器学习问题。在 Recruiter 的情况下,LinkedIn 使用了一个三因素标准来框定搜索和推荐模型的目标。
-
相关性: 搜索结果不仅需要返回相关的候选人,还要找出可能对目标职位感兴趣的候选人。
-
查询智能: 搜索结果不仅需要返回符合特定标准的候选人,还要返回符合类似标准的候选人。例如,搜索“机器学习”时,应该返回在其技能列表中包含数据科学的候选人。
-
个性化: 很多时候,为公司找到理想的候选人是基于匹配搜索标准之外的属性。有时,招聘人员不确定使用什么标准。个性化搜索结果是任何成功的搜索和推荐体验的关键要素。
LinkedIn 招聘和推荐体验中的一个关键标准是简单的度量标准,这一点不如之前提到的三个标准那么明显。为了简化推荐体验,LinkedIn 建立了一系列关键指标,这些指标是成功招聘的有形标志。例如,接受的 InMail 数量似乎是评估搜索和推荐过程有效性的一个明确指标。从这个角度来看,LinkedIn 将这些关键指标作为其机器学习算法的目标来最大化。
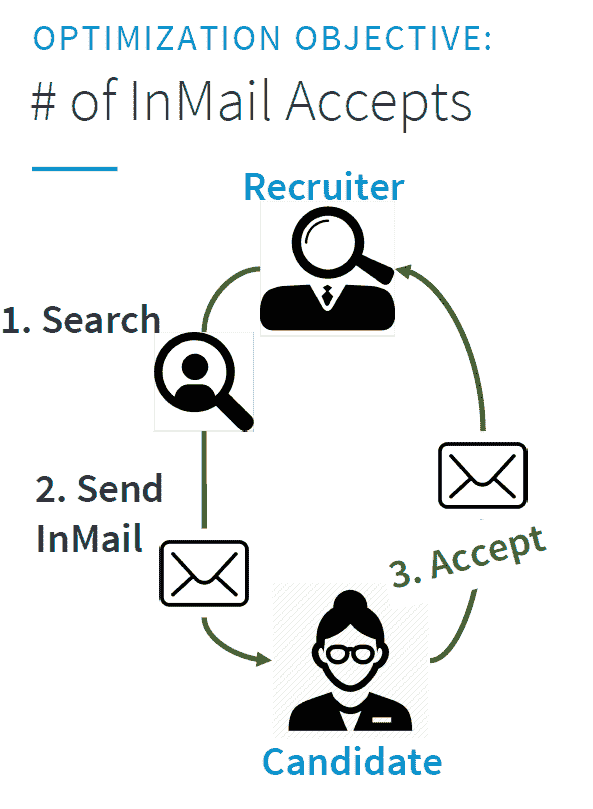
来源:engineering.linkedin.com/blog/2019/04/ai-behind-linkedin-recruiter-search-and-recommendation-systems
科学:从线性回归到梯度提升决策树
LinkedIn Recruiter 中的初始搜索和推荐体验基于线性回归模型。虽然线性回归算法易于解释和调试,但它们在像 LinkedIn 这样的庞大数据集中难以发现非线性关联。为改进这一体验,LinkedIn 决定尝试 梯度提升决策树 (GBDT),将不同的模型结合在一个更复杂的树结构中。除了更大的假设空间外,GBDT 还有一些其他优势,比如对特征共线性处理良好、能够处理具有不同范围和缺失特征值的特征等。
GBDT 本身对比线性回归提供了一些实际的改进,但也未能解决搜索体验中的一些关键挑战。在一个著名的例子中,搜索牙医的结果却返回了具有软件工程职位的候选人,因为搜索模型优先考虑了求职候选人。为改进这一点,LinkedIn 添加了一系列基于称为对偶优化的技术的上下文感知特性。基本上,这种方法通过对偶排序目标扩展了 GBDT,以比较同一上下文中的候选人,并评估哪个候选人更适合当前的搜索上下文。
来源: engineering.linkedin.com/blog/2019/04/ai-behind-linkedin-recruiter-search-and-recommendation-systems
LinkedIn Recruiter 体验中的另一个挑战是匹配具有相关职位的候选人,例如“数据科学家”和“机器学习工程师”。仅使用 GBDT 很难实现这种关联。为了解决这个问题,LinkedIn 引入了基于网络嵌入语义相似性特征的表示学习技术。在此模型中,搜索结果将补充具有类似标题的候选人,基于查询的相关性。
来源: engineering.linkedin.com/blog/2019/04/ai-behind-linkedin-recruiter-search-and-recommendation-systems
可以说,LinkedIn 招聘体验中最困难的挑战是个性化。从概念上讲,个性化可以分为两个主要类别。实体级个性化关注于在招聘过程中融入不同实体的偏好,例如招聘人员、合同、公司和候选人。为了解决这个挑战,LinkedIn 依赖于一种知名的统计方法——广义线性混合模型 (GLMix),该方法利用推断来提高预测问题的结果。具体来说,LinkedIn 招聘人员使用了一种结合了学习排名特征、树交互特征和 GBDT 模型分数的架构。学习排名特征作为预训练的 GBDT 模型的输入,该模型生成的树集成被编码成树交互特征和每个数据点的 GBDT 模型分数。然后,利用原始的学习排名特征及其非线性变换形式的树交互特征和 GBDT 模型分数,GLMix 模型可以提供招聘人员级别和合同级别的个性化服务。
来源:engineering.linkedin.com/blog/2019/04/ai-behind-linkedin-recruiter-search-and-recommendation-systems
另一种 LinkedIn 招聘体验所需的个性化模型则更注重会话中的体验。使用离线学习模型的一个缺点是,当招聘人员审查推荐的候选人并提供反馈时,这些反馈在当前搜索会话中未被考虑。为了解决这个问题,LinkedIn 招聘人员依赖于一种被称为多臂强盗模型的技术,以改善在不同候选人群体中的推荐。该架构首先将潜在的候选人空间按技能分组。然后,使用多臂强盗模型来了解哪个组更符合招聘人员的当前意图,并根据反馈更新每个技能组内候选人的排名。
来源:engineering.linkedin.com/blog/2019/04/ai-behind-linkedin-recruiter-search-and-recommendation-systems
架构
LinkedIn 招聘者的搜索和推荐体验基于一个名为Galene的专有项目,该项目构建在 Lucene 搜索栈之上。上一节描述的机器学习模型有助于为搜索过程中的不同实体构建索引。
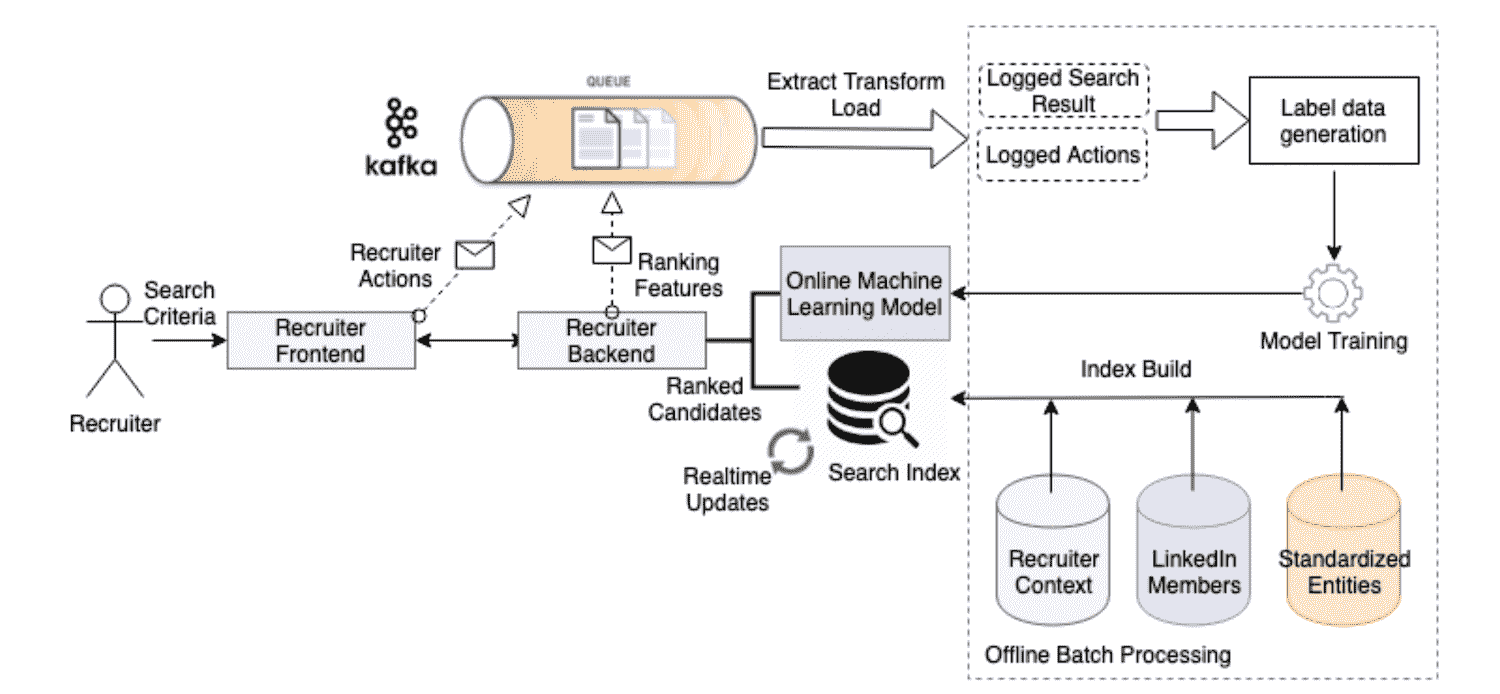
来源:engineering.linkedin.com/blog/2019/04/ai-behind-linkedin-recruiter-search-and-recommendation-systems
招聘者搜索体验的排名模型基于两个基本层的架构。
-
L1: 深入挖掘人才池并对候选人进行评分/排名。在这一层,候选人检索和排名是以分布式方式进行的。
-
L2: 通过使用外部缓存来提炼短名单人才,以应用更多动态特征。
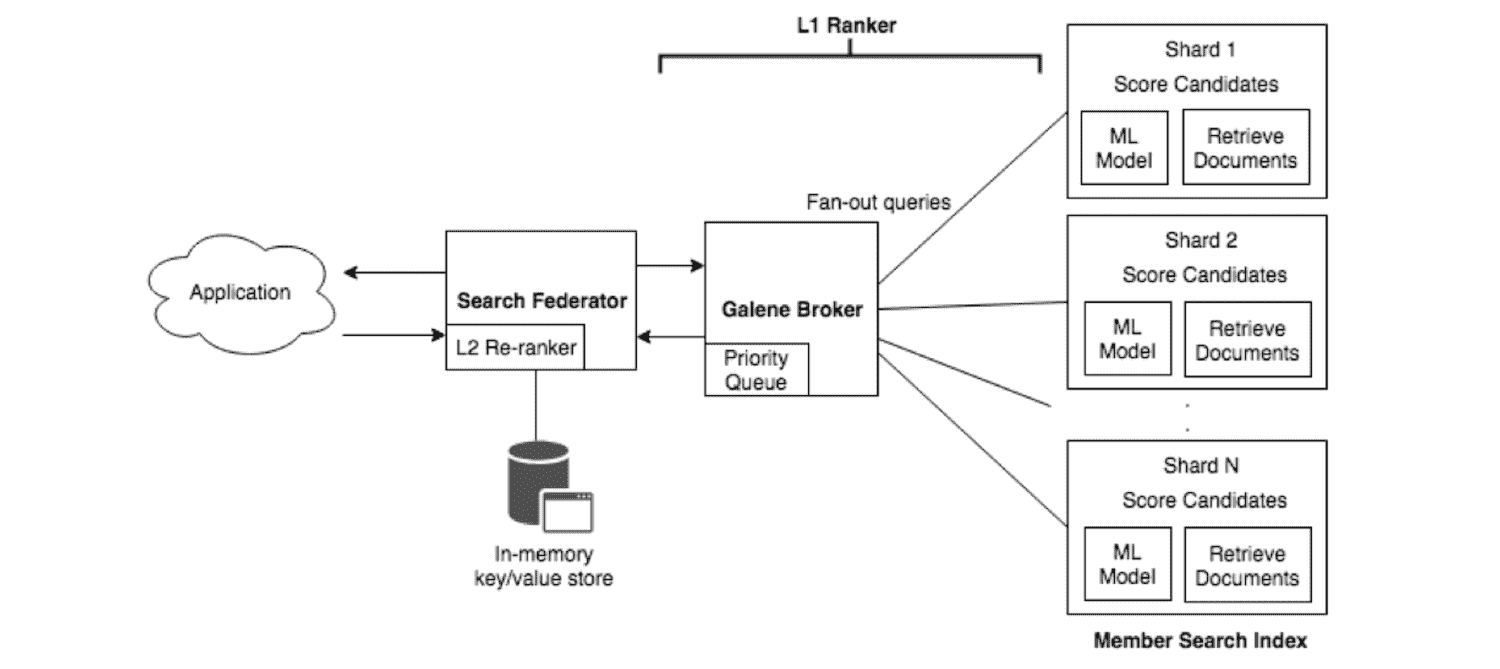
来源:engineering.linkedin.com/blog/2019/04/ai-behind-linkedin-recruiter-search-and-recommendation-systems
在这种架构中,Galene 代理系统将搜索查询请求分发到多个搜索索引分区。每个分区检索匹配的文档,并对检索到的候选人应用机器学习模型。每个分区对候选人子集进行排名,然后代理将排名候选人收集起来,并将其返回给联邦器。联邦器使用额外的排名特征对检索到的候选人进行进一步排名,结果被交付给应用程序。
LinkedIn 是构建大规模机器学习系统的公司之一。LinkedIn 招聘者所使用的推荐和搜索技术的理念对于许多不同领域的类似系统具有极大的相关性。LinkedIn 工程团队发布了一份详细的幻灯片演示文稿,提供了更多关于他们构建世界级推荐系统的见解。
原文。经许可转载。
相关:
-
LinkedIn 开源一个小组件以简化 TensorFlow-Spark 互操作性
-
LinkedIn 新闻推送排名的多目标优化自动调优
-
LinkedIn 的 Pro-ML 架构总结了构建大规模机器学习的最佳实践
更多相关话题
如何通过 Photon-ML 机器学习工具在 LinkedIn 上生成个性化推荐
原文:
www.kdnuggets.com/2017/10/linkedin-personalized-recommendations-photon-ml.html
作者:马一鸣、陈碧中与迪帕克·阿加瓦尔,LinkedIn 公司
介绍
推荐系统是自动化计算机程序,用于在不同的上下文中将项目匹配到用户。这些系统无处不在,已成为我们日常生活的不可或缺的一部分。例如,像亚马逊这样的网站向用户推荐产品,像 Yahoo! 这样的网站向用户推荐内容,像 Netflix 这样的网站向用户推荐电影,LinkedIn 上向用户推荐工作等等。鉴于用户偏好的显著异质性,提供个性化推荐是这些系统成功的关键。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
为了在大规模上实现这一目标,使用机器学习模型从反馈数据中估计用户偏好是至关重要的。这些模型是通过大量从过去用户与项目互动中获得的高频数据构建的。它们本质上是统计性的,涉及诸如序列决策过程、高维分类数据交互建模以及开发可扩展统计方法等挑战。该领域的新方法需要计算机科学家、机器学习专家、统计学家、优化专家、系统专家以及领域专家之间的紧密合作。这是大数据应用中最令人兴奋的领域之一。
LinkedIn 上的许多产品都由推荐系统驱动。这些系统的核心组件是一个易于使用和灵活的机器学习库,名为 Photon-ML,它对我们的生产力、敏捷性和开发者满意度至关重要。我们已经开源了 Photon-ML 使用的大部分算法。在本文中,我们关注模型构建的个性化方面,并解释建模原理以及如何实现 Photon-ML 以便能够扩展到数亿用户。
Photon-ML 中的个性化模型
在 LinkedIn,我们通过 Photon-ML 在许多产品领域观察到了用户参与度和其他业务指标的显著提升。以一个具体的例子来说,我们使用广义加性混合效应(GAME)模型进行个性化职位推荐,在我们的在线 A/B 实验中,为求职者产生了 20% 到 40% 更多的职位申请。

图 1. LinkedIn 职位首页的快照
作为全球最大的职业社交网络,LinkedIn 为其超过 5 亿会员提供了独特的价值主张,以便他们能够与各种职业成长机会连接。我们提供的最重要的产品之一是职位首页,它作为一个中心位置,帮助有求职意向的会员找到适合申请的职位。图 1 是 LinkedIn 职位首页的快照。页面上的主要模块之一是“您可能感兴趣的职位”,根据会员的公开资料数据和在网站上的过往活动,向会员推荐相关的职位缩略图。如果会员对推荐的职位感兴趣,可以点击该职位进入职位详细信息页面,页面上显示了原始职位发布信息,包括职位名称、描述、职责、所需技能和资格。职位详细信息页面上还有一个“申请”按钮,允许会员一键申请该职位,无论是在 LinkedIn 上还是在发布职位的公司网站上。LinkedIn 职位业务的一个关键成功指标是职位申请点击总数(即点击“申请”按钮的次数)。
我们模型的目标是准确预测会员点击推荐职位的“申请”按钮的概率。直观地说,模型由三个组件(子模型)组成:
-
捕捉会员申请职位的一般行为的全局模型,
-
针对特定会员的模型,具有特定于给定会员的参数(从数据中学习),以捕捉会员的个人行为,这些行为偏离了通用行为,以及
-
针对特定职位的模型,具有特定于给定职位的参数(从数据中学习),以捕捉职位的独特行为,这些行为偏离了通用行为。
像许多推荐系统应用一样,我们观察到每个会员或职位的数据量存在很大的异质性。网站上有新会员(因此几乎没有数据),以及有强烈求职意图且过去申请过许多职位的会员。类似地,职位也有流行和不流行之分。对于过去对不同职位有许多响应的会员,我们希望依赖于特定会员的模型。另一方面,如果会员没有很多过去的响应数据,我们希望该会员可以退回到捕捉一般行为的全局模型。
现在让我们深入探讨一下 GAME 模型如何实现如此高水平的个性化。令 y[mjt] 表示成员 m 在上下文 t 中是否申请职位 j 的二元响应,其中上下文通常包括职位展示的时间和地点。我们用 q[m] 表示成员 m 的特征向量,包含从成员的公开资料中提取的特征,例如成员的头衔、职位职能、教育历史、行业等。我们用 s[j] 表示职位 j 的特征向量,包含从职位发布中提取的特征,例如职位头衔、所需技能和经验等。令 x[mjt] 表示(m, j, t)三元组的整体特征向量,这可以包括 q[m] 和 s[j] 的特征级主效应,q[m] 和 s[j] 的外积用于捕捉成员和职位特征之间的交互作用,以及上下文的特征。我们假设 x[mjt] 不包含成员 ID 或项目 ID 作为特征,因为 ID 会与常规特征不同对待。用于预测成员 m 申请职位 j 的概率的 GAME 模型采用逻辑回归形式:
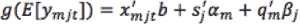 (1)
(1)
其中
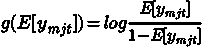
是连接函数,b 是全局系数向量(在统计学文献中也称为 固定效应 系数),α[m] 和 β[j] 分别是成员 m 和职位 j 特有的系数向量。α[m] 和 β[j] 称为 随机效应系数,它们捕捉成员 m 对不同项目特征的个人偏好以及职位 j 对不同成员特征的吸引力。对于过去对不同项目有许多响应的成员 m,我们能够准确估计她的个人系数向量 α[m] 并提供个性化预测。另一方面,如果成员 m 过去没有多少响应数据,α[m] 的后验均值将接近于零,成员 m 的模型将回退到全局固定效应组件 x'[mjt]b。相同的行为适用于每个职位的系数向量 β[j]。
Photon-ML: 可扩展的平台用于构建个性化模型
为了在 Hadoop 集群上使用大量数据训练模型,我们在 Apache Spark 的基础上开发了 Photon-ML。设计可扩展算法的一个主要挑战是需要从数据中学习的模型参数数量巨大(例如,数十亿)。如果我们天真地使用标准机器学习方法(例如 Spark 提供的 MLlib)训练模型,则更新大量参数的网络通信成本过高,计算上不可行。大量的参数主要来自用户特定和工作特定模型。因此,使算法可扩展的关键是避免将用户特定和工作特定模型中的大量参数传递或广播到集群。
我们通过应用并行块坐标下降(PBCD)解决了大规模模型训练问题,该方法交替训练全球模型、用户特定模型和工作特定模型,直到收敛。全球模型使用标准的分布式梯度下降方法进行训练。对于用户特定模型和工作特定模型,我们设计了一种模型参数更新方案,使得用户特定和工作特定模型中的参数无需在集群中的机器之间传递。相反,每个训练样本的部分得分在机器之间传递。这显著降低了通信成本。PBCD 可以轻松应用于具有不同子模型类型的模型。
结论与未来工作
在本文中,我们简要说明了如何使用 Photon-ML 实现个性化推荐。由于文章长度限制,许多有趣的优化和实现细节被省略了。我们强烈建议读者查看开源的 Photon-ML 库。在 LinkedIn,我们致力于构建最先进的推荐系统。我们对 Photon-ML 制定了令人兴奋的计划。在不久的将来,我们计划向 Photon-ML 添加更多建模能力,包括树模型和不同的深度学习算法,以捕捉非线性和更深层次的表示结构。
相关:
-
推荐系统算法概述
-
调查推荐系统的 9 个必备数据集
-
LinkedIn 上的前 10 位活跃大数据、数据科学、机器学习影响者(更新)
更多相关内容
LinkedIn 的 Pro-ML 架构总结了大规模构建机器学习的最佳实践
评论
来源: solutionsreview.com/business-intelligence/machine-learning-linkedin-groups/
我最近开始了一份专注于 AI 教育的新通讯。TheSequence 是一份不含虚假信息(即没有炒作,没有新闻等)的 AI 专注通讯,阅读时间为 5 分钟。目标是让您及时了解机器学习项目、研究论文和概念。请通过以下方式订阅试试看:
在规模化构建机器学习解决方案仍然是大多数组织的一个活跃实验领域。虽然许多公司开始了初步的机器学习试点,但很少有公司拥有强大的战略来扩展机器学习工作流程。如果考虑到目前市场上,机器学习研究和开发框架的进展速度远远快于扩展机器学习程序所需的基础设施运行时,这个问题就尤为具有挑战性。由于关于如何在规模化下构建机器学习解决方案的指导非常有限,互联网巨头如 Uber、LinkedIn、Google、Netflix 或 Microsoft 的经验就显得尤为宝贵,因为它们的可扩展性要求远远复杂于大多数公司所面临的挑战。在 LinkedIn,提供大规模机器学习解决方案的障碍变得如此关键,以至于公司决定创建一个名为 Productive Machine Learning (Pro-ML) 的独立倡议来解决这一挑战。
一个机器学习解决方案通常经历从模型训练到部署的一系列阶段。虽然在具有少量模型和小团队的机器学习解决方案中,结构化这些生命周期相对简单,但在跨越数十个数据科学团队和数千个机器学习模型时,规模化却是一场噩梦。在像 LinkedIn 这样的组织中,机器学习面临着许多著名的扩展挑战:
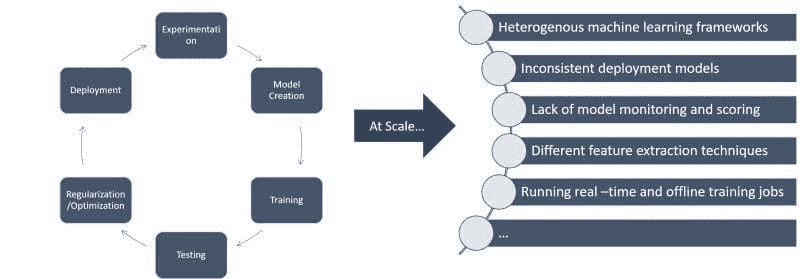
介绍 Pro-ML
LinkedIn 的 Pro-ML 倡议的目标是将机器学习工程师的工作效率提高一倍,同时提供一个开放的基础设施,以促进公司内部机器学习技术的采用。为了实现这一目标,Pro-ML 专注于提供一个强大的基础设施,能够支持机器学习解决方案生命周期中的一系列关键阶段:
-
探索与创作
-
培训
-
部署
-
运行
-
健康保障
-
特征市场

来源:engineering.linkedin.com/blog/2019/01/scaling-machine-learning-productivity-at-linkedin
探索与创作
数据探索和模型创作是机器学习解决方案生命周期中至关重要的方面。随着数据科学组织的成长,它们面临不同团队采用不同数据探索方法和依赖不同框架来创建模型的挑战。这不会成为问题,除非数据探索基础设施往往是机器学习工作流中最耗费计算资源的组件之一。
为了实现一致的数据探索和模型创作体验,Pro-ML 依赖于一个领域特定语言(DSL),该语言抽象了机器学习模型的关键表示,如输入特征、转换、算法、输出等。此外,Pro-ML 提供了 Jupyter Notebook,允许逐步探索数据、选择特征和编写 DSL。Pro-ML 团队还提供了与流行 IDE(如 IntelliJ)集成的绑定。
提供一个互操作的机制来表示机器学习模型是确保不同数据科学栈之间一致性的聪明机制。查看 Pro-ML DSL,我不禁想是否像 开放神经网络交换格式(ONNX) 这样的格式更为自然,但这种方法无论如何是有意义的。
特征市场
补充前一点,数据探索过程在机器学习工作流中的一个关键作用是识别目标数据集的关键特征。在像 LinkedIn 这样的组织规模下,机器学习解决方案需要处理成千上万的特征,这些特征需要被生成、发现、使用和监控。为应对这一挑战,Pro-ML 建立了一个名为 Frame 的模型特征中央目录。
Pro-ML 的 Frame 的目标是捕捉与数据集特征相关的元数据,包括在线和离线的。Frame 将数据捕捉到一个集中式数据库中,该数据库与 Pro-ML 的模型库连接。此外,Frame 提供了一个 UI,允许数据科学家根据各种方面(包括特征类型(数值型、类别型)、统计总结和当前在整体生态系统中的使用情况)搜索特征。
训练
在像 LinkedIn 这样的巨大组织中,机器学习训练工作流可以分为两个主要组:实时(在线)和批量(离线)。时间敏感的机器学习模型需要定期使用接近实时的数据集进行训练。其他模型则适合在较长时间周期内如每日或每周进行批量训练。
Pro-ML 提供了一个支持在线和离线模型的培训基础设施。该基础设施包括一个支持不同模型类型的培训服务,以及用于超参数调整等功能的工具。Pro-ML 的培训运行时依赖于 Hadoop 进行离线培训,同时利用如 Azkaban 和 Spark 等技术来执行培训工作流。
模型部署
模型部署是大规模机器学习解决方案中最具挑战性的方面之一。有效的模型部署通常需要将不同的模型工件结构化和打包成可移植的格式,以便在基础设施中执行。
Pro-ML 包括一个部署服务,该服务识别机器学习模型的不同工件,如特征、库或代码依赖,并将它们存储在集中式仓库中以进行自动验证。部署服务支持诸如编排、监控和通知等功能,以确保所需的代码和数据工件正确部署并正常工作。
运行
模型服务和执行是机器学习工作流中的另一个挑战性方面。与传统软件应用不同,机器学习模型的性能可能需要在其生命周期内进行不同的基础设施配置,并且其性能可能会因多个因素而有显著变化。
当前版本的 Pro-ML 包括一个名为 Quasar 的模型执行引擎,该引擎负责执行之前讨论的专有 DSL 中定义的机器学习模型。Quasar 与特征市场集成,以定期评估模型的性能,并利用主流服务框架,如 TensorFlow Serving 或 XGBoost 来启用联邦执行模型。
健康保障
机器学习模型的测试和监控特别困难。Pro-ML 包括一个健康保障层,可以测试和监控机器学习工作流。健康保障层定期验证部署模型的性能是否与培训期间展示的行为一致,并在检测到异常情况时,提供诊断问题源头的工具。Pro-ML 的健康保障层包括数据重播、错误诊断或模型重训等工具,有助于确保机器学习模型的正确行为。
Pro-ML 当前正在为不同的 LinkedIn 产品提供数百个机器学习模型。虽然 LinkedIn 尚未开源 Pro-ML 背后的许多组件,但这些模式和经验教训对于那些开始机器学习之旅的组织来说,代表了宝贵的资源。
原文. 经许可转载。
相关:
-
深度学习梦想:在单一模型中实现准确性和可解释性
-
阿根廷作家与匈牙利数学家如何教会我们机器学习的过拟合
-
神经网络能否展现想象力?DeepMind 认为它们可以
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
更多相关内容
LinkedIn、Uber、Lyft、Airbnb 和 Netflix 如何解决数据管理和发现以实现机器学习解决方案
评论
在机器学习领域,数据无疑是新的石油。管理数据集生命周期的过程是大规模机器学习解决方案中最具挑战性的部分之一。数据摄取、索引、搜索、标注和发现是维护高质量数据集所需的一些方面。这些挑战的复杂性随着目标数据集的大小和数量呈线性增加。虽然管理单一机器学习模型的训练数据集相对简单,但在数千个数据集和数百个模型之间扩展这一过程可能会变得极为困难。像 LinkedIn、Uber、Netflix、Airbnb 或 Lyft 这样的机器学习创新前沿公司,肯定体会到了这一挑战的巨大规模,并且他们已经构建了具体的解决方案来应对它。今天,我想带你了解其中的一些解决方案,希望它们能为你的机器学习之旅提供灵感。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
高质量的机器学习需要高质量的数据集,而这些数据集并不容易生产。随着机器学习的发展,对自动化训练和测试数据集生命周期管理工具和平台的需求变得越来越重要。有些矛盾的是,机器学习框架的发展速度比相应的数据管理工具集快了几个数量级。虽然如今我们拥有数十种高质量的开发框架,融入了深度学习学科的最新研究,但用于管理机器学习模型数据集生命周期的平台仍处于初期阶段。为了解决这个挑战,像 Uber 或 LinkedIn 这样的快速成长的科技公司被迫构建自己的内部数据生命周期管理解决方案,以支持不同组的机器学习模型。让我们来看看他们是如何做到的。
LinkedIn 的数据中心
数据中心是 LinkedIn 数据分析堆栈中的最新补充。LinkedIn 数据中心的核心重点是自动化与数据集相关的元数据的收集、搜索和发现,以及其他实体,如机器学习模型、微服务、人员、群体等。具体来说,数据中心旨在实现四个特定目标:
-
建模: 以开发者友好的方式建模所有类型的元数据和关系。
-
摄取: 大规模摄取大量元数据更改,既通过 API 也通过流。
-
服务: 提供收集的原始和派生元数据,以及对元数据的大规模复杂查询。
-
索引: 大规模索引元数据,并在元数据更改时自动更新索引。
为了实现上述能力,数据中心使用了包括多个 LinkedIn 内部开发的框架在内的先进技术堆栈。例如,数据中心中存储的所有元数据构造都使用Pegasus数据模式语言进行建模,该语言由 LinkedIn 数年前孵化。类似地,驱动数据中心的 API 基于 LinkedIn 的Rest.li架构,旨在提供高可扩展性的 RESTful 服务。LinkedIn 的数据存储技术,如Expresso或Galene,也被用于以支持多种用例的方式存储元数据表示,如搜索或复杂关系导航。为了抽象这些不同类型的存储,数据中心使用了一组通用的数据访问对象(DAO),如键值 DAO、查询 DAO 和搜索 DAO。这使得可以使用不同的基础存储技术来操作数据中心。
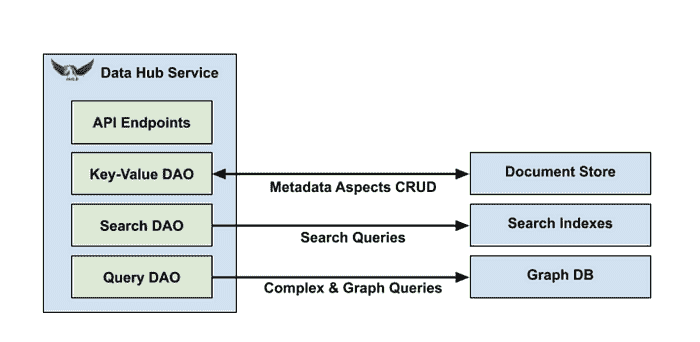
LinkedIn 的 Data Hub 的强大后台架构得到了一个简单用户界面的补充,后者支持元数据元素的搜索和发现。

Uber 的 Databook
Databook 是驱动 Uber 数据科学工作流程中数据发现和生命周期管理的主要平台。Databook 平台管理并展示关于 Uber 数据集的丰富元数据,使 Uber 员工能够在 Uber 内探索、发现和有效利用数据。从概念上讲,Databook 旨在实现四个关键功能:
-
扩展性: 新的元数据、存储和实体易于添加。
-
可访问性: 服务可以以编程方式访问所有元数据。
-
可扩展性: 支持高吞吐量读取。
-
能力: 跨数据中心读取和写入。
目前的 Databook 架构可以处理来自各种数据存储系统的元数据,包括 Vertica、PostgreSQL、MySQL 等。元数据最终在基于 ElasticSearch 的存储库中进行索引,并通过由Dropwizard提供支持的 RESTful API 展现,Dropwizard 是一个用于高性能 RESTful Web 服务的 Java 框架。
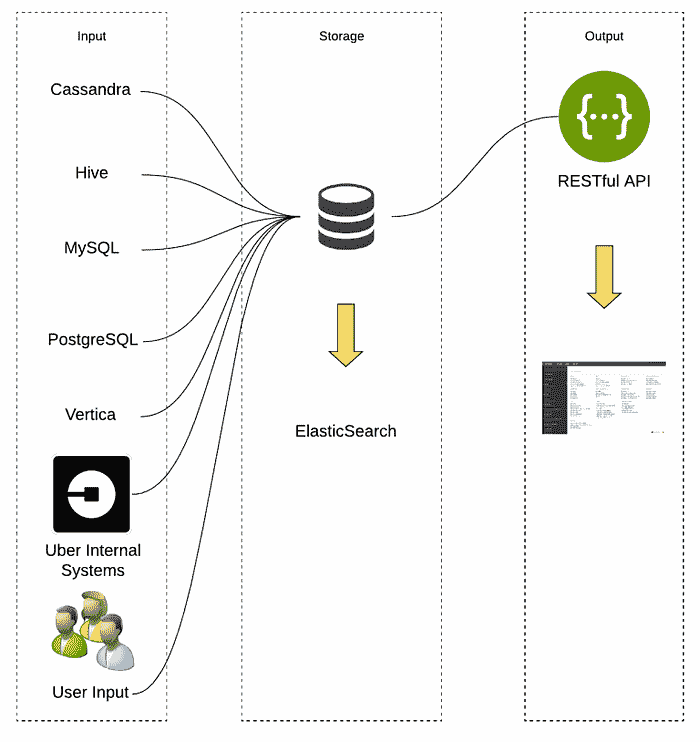
Databook 允许用户通过基于 React、Redux 和 D3.js 的简单 Web 界面搜索和浏览与特定资产相关的元数据。
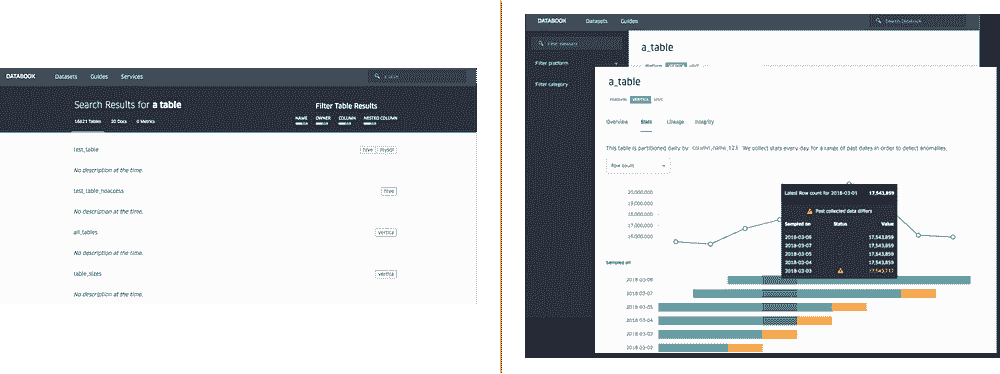
Airbnb 的 Dataportal
与许多其他快速增长的科技公司一样,Airbnb 也面临了为这些数据资产启用生命周期管理和发现层的挑战。Dataportal 是解决这些需求的方案。Dataportal 以连接图的形式捕获关于不同数据资产的元数据信息。图中的节点是各种资源:数据表、仪表板、报告、用户、团队、业务结果等。它们的连接反映了它们的关系:消费、生产、关联等。
Dataportal 技术栈以 Neo4J 和 ElasticSearch 作为主要的数据存储组件。平台上的 API 由Flask 框架提供支持,UI 基于 React 和 Redux。
Airbnb 的 Dataportal 的终极体现是一个时尚的用户界面,使得与企业数据集相关的元数据的搜索、协作和发现变得更加便捷。

Lyft 的 Amundsen
Amundsen 是 Lyft 的元数据摄取、搜索和发现平台。该平台以挪威探险家 罗纳德·阿蒙森 的名字命名,最初旨在提高数据分析师、数据科学家和工程师与数据交互的生产力。从架构的角度来看,Amundsen 提供了一个数据收集层,该层与一系列数据库以及用于元数据管理和搜索的微服务集成。
Amundsen 微服务抽象了平台的核心功能。当前版本的 Amundsen 包括以下微服务:
-
amundsenfrontendlibrary:前端服务,是一个带有 React 前端的 Flask 应用程序。
-
amundsensearchlibrary:搜索服务,利用 Elasticsearch 提供搜索功能,用于支持前端元数据搜索。
-
amundsenmetadatalibrary:元数据服务,利用 Neo4j 或 Apache Atlas 作为持久层,提供各种元数据。
-
amundsendatabuilder:用于构建元数据图谱和搜索索引的数据摄取库。用户可以使用该库的 python 脚本 或使用 Airflow DAG 来加载数据。
Amundsen 将其后台架构与简单的用户体验相结合,能够进行数据集的搜索和探索。

Netflix Metacat
Netflix 一直积极参与大数据领域的开源技术,数据发现和管理也不例外。Metacat 是 Netflix 用于自动化元数据资产生命周期的解决方案。从功能上讲,Metacat 是一个联邦服务,提供统一的 REST/Thrift 接口来访问各种数据存储的元数据。在高级层面上,Metacat 提供以下功能:
-
数据抽象和互操作性
-
业务和用户定义的元数据存储
-
数据发现
-
数据变更审计和通知
-
Hive metastore 优化
Metacat 架构结合了一个连接层,集成了不同的数据存储,一个存储层,捕获与数据资产相关的元数据,以及一个 API 层,使得元数据元素的搜索和查询成为可能。
与该领域的其他解决方案不同,Metacat 主要关注启用元数据搜索和发现所需的后台基础设施。API 的简洁性促进了基于特定需求实施不同数据目录前端的工作。
正如你所见,元数据发现和管理是一些技术快速增长公司的一个活跃发展领域。机器学习的快速发展将继续增加数据发现和管理的相关性,我们很快会看到一些这些解决方案被纳入主流机器学习堆栈中。
原文。经许可转载。
相关:
-
手动编码还是自动化数据集成——哪种方式最适合集成企业数据?
-
Andrew Ng《机器学习的渴望》中 6 个关键概念
-
统计建模与机器学习
更多相关主题
LinkedIn 如何使用机器学习来排名你的动态
原文:
www.kdnuggets.com/2022/11/linkedin-uses-machine-learning-rank-feed.html
LinkedIn 动态是该网站上数百万用户的起点,它为用户建立了第一印象,这种印象,正如你所知,将会持久。为每个用户提供一个有趣的个性化动态,将传达 LinkedIn 最重要的核心价值,即让用户与他们的网络和活动保持联系,并建立专业身份和网络。
LinkedIn 的个性化动态为用户提供了能够快速、有效且准确地查看连接更新的便利。除此之外,它还过滤掉垃圾、非专业和无关的内容,以保持用户的参与。为此,LinkedIn 通过实时应用一系列规则来确定哪些内容符合要求,这些规则基于一系列可操作的指标和预测信号。这一解决方案由机器学习和深度学习算法驱动。
在这篇文章中,我们将讨论 LinkedIn 如何使用机器学习来排序用户的动态。我们将遵循在之前两篇文章中介绍的传统机器学习项目的工作流程。
机器学习项目的工作流程从业务问题陈述和定义约束开始。接着是数据收集和数据准备,然后是建模部分,最后是部署和将模型投入生产。这些步骤将以排名 LinkedIn 动态的背景进行讨论。

LinkedIn / 照片由Alexander Shatov拍摄,来源于Unsplash
1. 明确业务问题与约束
1.1. 问题陈述
设计个性化的 LinkedIn 动态,以最大化用户的长期参与度。由于 LinkedIn 动态应该为每个用户提供有益的专业内容,以增加他们的长期参与。因此,开发能够剔除低质量内容并保留高质量专业内容的模型至关重要。然而,重要的是不要过度过滤动态内容,否则会产生大量的假阳性。因此,我们应该针对分类模型追求高精度和高召回率。
我们可以通过测量点击概率,也就是点击率(CTR),来衡量用户的参与度。在 LinkedIn 动态中,有不同的活动,每种活动的 CTR 不同;在收集数据和训练模型时应考虑这些因素。主要有五种活动类型:
-
建立连接:成员与其他成员或公司、页面进行连接或关注。
-
信息共享:分享帖子、文章或图片
-
基于个人资料的活动:与个人资料相关的活动,例如更改个人资料照片、添加新经历、更改个人资料头部等。
-
意见特定活动:与成员意见相关的活动,例如点赞、评论或转发某个帖子、文章或图片。
-
特定网站活动:LinkedIn 特有的活动,例如推荐和申请职位。
1.2. 评估指标设计
指标主要有两种类型:离线评估指标和在线评估指标。我们使用离线指标在训练和建模阶段评估我们的模型。下一步是将模型迁移到一个阶段/沙箱环境中,测试少量真实流量。在此步骤中,使用在线指标评估模型对业务指标的影响。如果与收入相关的业务指标显示持续改善,则可以安全地将模型暴露于更大比例的真实流量中。
离线指标
最大化 CTR 可以形式化为训练一个有监督的二分类模型。因此,对于离线指标,可以使用归一化交叉熵,因为它有助于模型对背景 CTR 的敏感度降低:
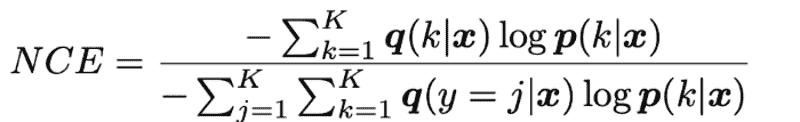
在线指标
由于在线指标应反映模型部署时用户的参与程度,我们可以使用转换率,即每个动态的点击率。
1.3. 技术要求
技术要求将分为两个主要类别:训练阶段和推理阶段。训练阶段的技术要求包括:
-
大规模训练集:训练过程中的主要要求之一是能够处理大规模的训练数据集。这需要分布式训练设置。
-
数据偏移:在社交网络中,从离线训练数据到在线数据的数据分布偏移非常常见。解决此问题的一个可能方法是每天多次增量重新训练模型。
推理阶段的技术要求包括:
-
可扩展性:能够为超过 3 亿用户提供定制化的用户动态。
-
延迟: 确保延迟时间短,以便在 250 毫秒内为用户提供排名的动态内容是很重要的。由于多个管道需要从多个来源提取数据,然后将活动输入到排名模型中,因此所有这些步骤需要在 200 毫秒内完成。因此,
-
数据新鲜度:模型必须知道用户已经看到什么,否则动态内容将显示重复内容,这会减少用户参与度。因此,数据需要运行得非常快。
1.4. 技术挑战
主要有四个技术挑战:
-
可扩展性: 主要的技术挑战之一是系统的可扩展性。由于需要服务的 LinkedIn 用户数量极大,大约 3 亿用户。每个用户平均每次访问时看到 40 个活动,每月平均访问 10 次。因此,我们有大约 1200 亿次观察或样本。
-
存储: 另一个技术挑战是数据量巨大。假设点击率每月为 1%。因此,收集到的正面数据将约为 10 亿条数据点,负面标签将为 1100 亿个。我们可以假设每个数据点有 500 个特征,为了简化计算,我们可以假设每行特征需要 500 字节来存储。因此,一个月的数据将为 1200 亿行,每行 500 字节,总大小将为 60TB。因此,我们只需在数据湖中保留最近六个月或一年的数据,其余的存档到冷存储中。
-
个性化: 另一个技术挑战是个性化,因为你需要为不同兴趣的用户提供服务,因此需要确保模型针对每个用户进行个性化。
-
内容质量评估:由于没有完美的分类器,因此某些内容将陷入灰色地带,即使是两个人也可能难以达成一致,是否适合展示给用户。因此,结合人工和机器的解决方案对于内容质量评估变得重要。
2. 数据收集
在训练机器学习分类器之前,我们首先需要收集标记数据,以便对模型进行训练和评估。数据收集是数据科学项目中的关键步骤,因为我们需要收集代表我们要解决的问题的样本数据,并且与模型投入生产后预期看到的情况相似。在本案例研究中,目标是收集大量不同类型的帖子和内容数据,如第 1.1 节所述。
我们希望收集的标记数据是用户动态中的点击或未点击标记数据。收集点击和未点击数据有三种主要方法:
-
按时间顺序对用户的信息流进行排名:数据将从用户的信息流中收集,并按时间顺序进行排名。这种方法可以用于数据收集。然而,它会基于用户的注意力吸引到前几个信息流。此外,这种方法会引发数据稀疏问题,因为某些活动(例如工作变动)相较于其他活动发生得很少,因此在数据中会被低估。
-
随机服务:第二种方法是随机提供信息流并收集点击和未点击的数据。这种方法不被推荐,因为它会导致糟糕的用户体验和非代表性的数据,而且也无法解决数据稀疏问题。
-
使用算法对信息流进行排序:我们可以使用的最后一种方法是使用算法对用户的信息流进行排序,然后使用排列来随机打乱顶级信息流。这将为信息流提供一些随机性,并有助于收集来自不同活动的数据。
3. 数据预处理与特征工程
第三步将是为建模步骤准备数据。这一步包括数据清理、数据预处理和特征工程。数据清理将处理缺失数据、异常值和噪声文本数据。数据预处理将包括标准化或归一化、处理文本数据、处理不平衡数据以及其他根据数据情况的预处理技术。特征工程将包括特征选择和降维。这一步主要依赖于数据探索步骤,因为你将获得更多理解,并对数据及其后续处理有更好的直觉。
可以从数据中提取的特征包括:
-
用户个人资料特征:这些特征包括职位、用户行业、人口统计信息、教育背景、工作经验等。这些特征是分类特征,因此必须转换为数值,因为大多数模型不能处理分类特征。对于高基数,可以使用特征嵌入,对于低基数,可以使用独热编码。
-
连接强度特征:这些特征代表用户之间的相似性。我们可以使用用户的嵌入表示,并测量它们之间的距离来计算相似性。
-
活动年龄特征:这些特征代表每个活动的年龄。可以将其处理为连续特征,也可以根据点击目标的敏感性进行分箱处理。
-
活动特征:这些特征代表活动的类型,比如标签、媒体、帖子等。这些特征也将是分类特征,并且如前所述,它们必须通过特征嵌入或独热编码转换为数值,具体取决于基数的水平。
-
亲和力特征:这些特征代表用户与活动之间的相似性。
-
意见特征:这些特征代表用户对帖子、文章、图片、工作变动和其他活动的喜欢/评论。
由于 CTR 通常很小(少于 1%),这会导致数据集不平衡。因此,数据预处理阶段的一个关键步骤是确保数据平衡。因此,我们需要对数据进行重新采样,以增加欠代表的类别。
然而,这只应在训练集上进行,而不应在验证集和测试集上进行,因为它们应代表生产环境中预期看到的数据。
4. 建模
现在数据已准备好进行建模部分,是时候选择和训练模型了。如前所述,这是一个分类问题,在这个分类问题中的目标值是点击。我们可以使用逻辑回归模型来完成这个分类任务。由于数据量非常大,因此我们可以在 Spark 中使用分布式训练的逻辑回归或使用乘法器方法。
我们还可以在分布式设置中使用深度学习模型。在这种情况下,将使用全连接层,并在最终层应用 sigmoid 激活函数。
对于评估,我们可以采用两种方法,第一种是将数据传统地拆分为训练集和验证集。另一种避免离线评估偏差的方法是使用重放评估,如下所示:
-
假设我们有截止时间点 T 的训练数据。验证数据将从 T+1 开始,我们将使用训练好的模型对其进行排序。
-
然后将模型的输出与实际点击进行比较,并计算匹配的预测点击数量。
有很多超参数需要优化,其中之一是训练数据的大小和模型保持频率。为了保持模型的更新,我们可以使用最近六个月的训练数据对现有深度学习模型进行微调,例如。
5. 高级设计
我们可以用图 1 中所示的高级设计来总结整个提要排序过程。
我们来看看下面图示中排序流程是如何进行的:
-
当用户访问 LinkedIn 主页时,请求将被发送到应用服务器以获取提要。
-
应用服务器将提要请求发送到Feed 服务。
-
Feed 服务随后从模型存储中获取最新的模型,并从特征存储中获取正确的特征。
-
特征存储:特征存储保存特征值。在推断过程中,应具有低延迟以在评分前访问特征。
-
Feed 服务接收来自ItemStore的所有提要。
-
项目存储:项目存储保存所有由用户生成的活动。除此之外,它还保存不同用户的模型。由于提供相同的排序方法对每个用户而言是重要的,因此ItemStore为正确的用户提供正确的模型。
-
信息流服务将为模型提供特征以获取预测。这里的信息流服务代表了检索和排名服务,以便于可视化。
-
该模型将返回按 CTR 可能性排序的信息流,然后返回给应用服务器。
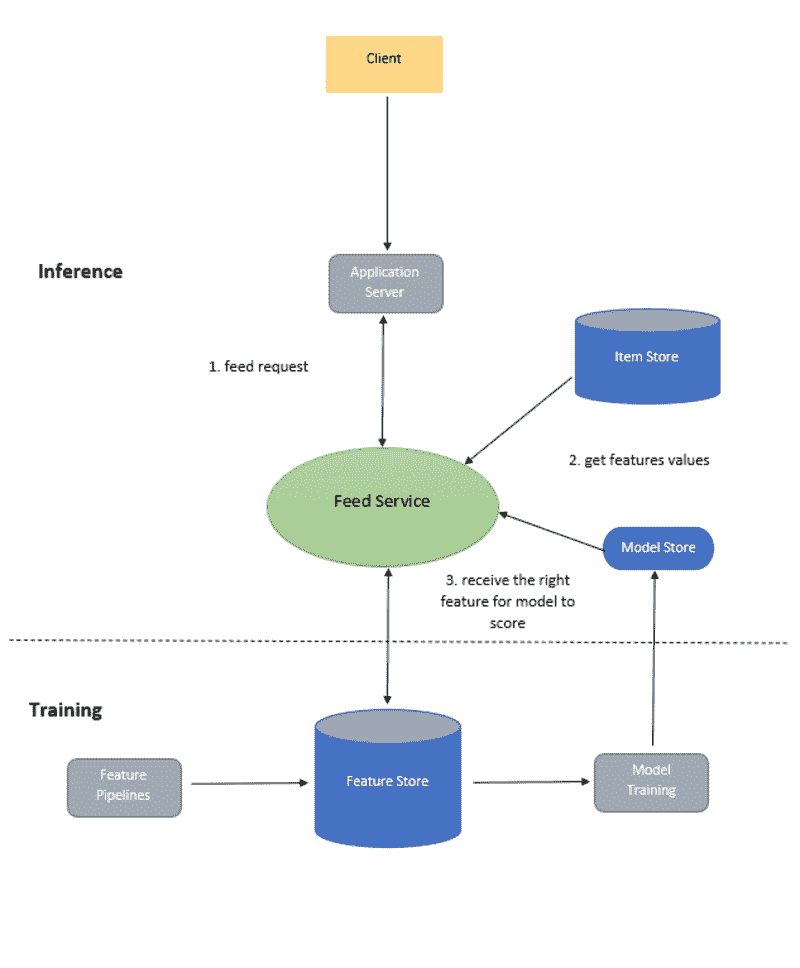
图 1. LinkedIn 信息流排名的高层设计。
为了扩展信息流排名系统,我们可以在负载均衡器前放置应用服务器。这将平衡和分配系统中多个应用服务器的负载。
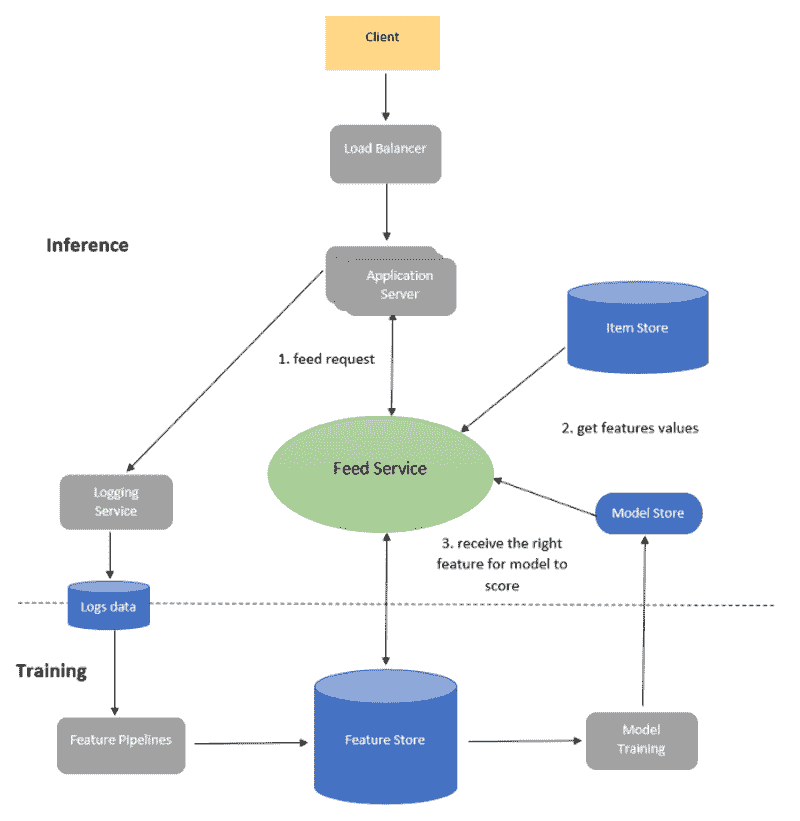
图 2. 扩展后的 LinkedIn 信息流排名高层设计。
6. 参考文献
-
机器学习设计面试
Youssef Hosni 是 Elfehres 的联合创始人,计算机视觉博士研究员,数据科学家
原文。经许可转载。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 为你的组织提供 IT 支持
更多相关话题
数据科学的 Linux 备忘单
原文:
www.kdnuggets.com/2022/11/linux-data-science-cheatsheet.html
为什么要学习 Linux?
你是数据科学家吗?你熟悉 Linux 命令行吗?如果不, 你应该了解。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
Linux 及其各种版本是一个非常 模块化的操作系统。这可能很快会引发争论,因此我不会试图说服你使用 Linux(虽然你应该使用),而是专注于帮助那些 想 使用它或已经在使用它的人。将其与命令行的强大功能结合起来,再加上大量开源的 Linux 版本,你就拥有了理想的、量身定制的工作站,满足你所需的所有操作系统性能。
命令行可能会让人望而却步,但其实不必如此。如果你把它当作是构建短小的编程命令组合的一种方式,就像 REPL 一样。你会编程,对吧?那你就可以使用命令行。
数据科学的 Linux 备忘单
成为 Linux 命令行高手的真正诀窍,不仅在于学习可用的命令,还在于保持方便的参考资料。这就是最新的 KDnuggets 备忘单的用武之地。
这份备忘单涵盖了 16 个最有用的 Linux 终端命令,足以让你从命令行处理大部分日常操作。经过一些练习,你可能会发现这使你的日常活动更加迅速、轻松,比起点击操作更为灵活。
你可以 在这里下载备忘单。
在这份备忘单中,你将学习(并参考)诸如以下的命令:
-
ls -
cd -
wc -
grep -
cp -
diff
不确定那些命令的用途?那么这个备忘单适合你!
现在查看一下,稍后再回来查看更多内容。
更多相关内容
2023 年 7 款最佳数据建模工具
原文:
www.kdnuggets.com/2023/03/list-7-best-data-modeling-tools-2023.html

图片来自 macrovectoron Freepik
数据科学和数据建模技术是相互关联的。数据建模工具使数据科学家能够更快速地访问和使用数据。通过构建数据模型,数据科学家可以获得对数据及其潜在关系的更好理解,这些模型随后可以用于构建预测模型和其他数据驱动的解决方案。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在的组织的 IT
数据建模是软件 开发过程 中的重要环节,因为它有助于确保数据库能够高效存储和检索数据,并能够处理预期的数据量和复杂性。数据建模工具是用于创建、设计和管理数据模型的计算机程序。数据模型是数据库结构的图形表示,描述了不同类型数据之间的关系。用户可以使用数据建模工具来设计、可视化和编辑数据模型。数据库管理员、数据分析师以及其他 IT 专业人士使用这些工具来构建和描述数据库系统。
在这篇文章中,我将解释几个数据建模工具,以便在分配稀缺资源用于数据科学工作时加以考虑。
大多数这些数据建模工具提供可视化数据建模、逆向工程、正向工程、协作功能、易于集成和数据映射。我特别提到的只是使它们彼此不同的独特功能。
1. Erwin 数据建模工具

ED Modeler 是一个用于设计和分析数据结构的工具,具有标准化设计,支持图示数据的部署,无论其位置和结构如何,提供自动化功能生成模式和混合架构。
关键特性:
-
可视化数据建模:使用可视化界面创建数据模型,轻松查看不同实体和数据元素之间的关系。
-
逆向工程:对现有数据库进行逆向工程,创建数据结构的可视化表示。
-
向前工程:根据数据模型生成 SQL 脚本或 DDL 语句,直接从数据模型创建或修改数据库。
-
协作:多个用户可以同时在一个数据模型上工作,使团队能够轻松地在数据建模项目上协作。
-
文档生成:生成数据模型的详细文档,包括实体、属性和关系的列表。
-
数据治理:允许组织执行数据治理政策,并确保遵守行业标准和法规。
-
集成:与数据库管理系统、数据仓储解决方案和商业智能工具的轻松集成。
2. ER/Studio

Idera 的 ER/Studio 是一个数据建模工具,能够识别多个数据库系统中的数据资产和来源,支持数据模型的创建与共享,并从开始到结束跟踪它们。
关键特性:
-
数据建模:创建可视化数据模型,包括实体-关系图(ERDs)和数据流图(DFDs)。
-
数据治理:允许组织执行数据治理政策,并确保遵守行业标准和法规。
-
数据血统:允许用户追踪数据在不同系统和流程中的流动。
-
数据掩码:允许用户在非生产环境中隐藏敏感数据,以保护数据免受泄露。
3. SQL 数据库建模工具
SQL 数据库建模工具 使开发者可以在线创建 SQL 数据库,而无需编写任何代码,因此可以轻松创建和导入脚本,并且兼容 MS SQL Server 和 MySQL。SQL 数据库建模工具的另一个优点是它允许多种视图模式。
关键特性:
-
文档生成:生成数据模型的详细文档,包括实体、属性和关系的列表。
-
SQL 代码生成:生成用于创建和修改数据库对象的 SQL 代码,包括表、视图、存储过程和函数。
-
数据建模标准:支持行业标准的数据建模符号和技术,例如 Chen ERD 符号和 UML 类图符号。
4. Oracle SQL Developer 数据建模工具
Oracle SQL Developer Data Modeler 是另一款出色的免费数据库建模工具,帮助企业获取、组织数据并从中获取洞察,同时提高生产力。它提供了广泛的数据模型,包括逻辑模型、关系模型、物理模型和多维数据类型模型。
关键特性:
-
文档:生成数据模型的详细文档,包括实体、属性和关系的列表。
-
数据治理:允许组织执行数据治理政策,并确保符合行业标准和法规。
-
集成:与各种其他工具和平台集成,如 Oracle 数据库管理系统和 Oracle 云服务。
5. IBM Infosphere Data Architect

IBM Infosphere 以其处理各种数据模式的能力而闻名,并有助于标准化应用程序、数据库和服务器之间的接口。除此之外,Infosphere 还帮助跨生命周期工作,并协助组织缩短上市时间。
关键特性:
-
建模与设计:支持多种建模技术,包括实体-关系建模、维度建模和面向对象建模。
-
数据治理:允许组织执行数据治理政策,并确保符合行业标准和法规。
-
数据库支持:该工具支持广泛的关系数据库,包括 DB2、Oracle、SQL Server 和 MySQL,以及对数据仓储平台如 Netezza 和 Informix 的支持。
-
集成:与其他 IBM 数据管理和数据仓储产品如 IBM InfoSphere DataStage 和 IBM InfoSphere Data Quality 集成。
6. MySQL Workbench

在处理复杂的 ER 模型时,Workbench 是一个合适的模型。它专门为MySQL DB创建,有助于生成、执行和优化 SQL 查询,支持包括 Mac、Linux 和 Windows 在内的所有主要操作系统。
关键特性:
-
SQL 开发:MySQL Workbench 包含一个 SQL 编辑器,用于编写、执行和优化 SQL 语句。
-
数据建模:MySQL Workbench 包含设计和反向工程数据库的功能,包括支持创建实体-关系图(ERD)和前向工程 SQL 脚本。
-
服务器管理:管理 MySQL 服务器,包括配置服务器参数的支持、监控服务器性能以及备份和恢复数据库。
-
安全管理:管理用户帐户和权限,包括创建和管理用户、角色和模式的支持。
-
可视化查询构建器:允许用户创建复杂的 SQL 查询而无需编写 SQL 代码。
7. Archi

Archi 在需要小团队内进行数据处理的小型和中型组织中得到广泛使用。它提供了一种优雅的视觉数据表示解决方案,同时成本低廉。
主要特性:
-
ArchiMate 建模:Archi 支持 ArchiMate 建模语言,这是一种企业架构建模的标准语言。
-
导入/导出:Archi 可以以多种格式导入和导出数据模型,包括 ArchiMate、BPMN 和 XMI。
-
可定制:Archi 高度可定制,允许用户创建自己的自定义元素和模板,使得建模特定架构框架变得简单。
-
轻量级:Archi 是轻量级的,不需要安装,可以作为独立应用程序在 Windows、Mac 和 Linux 上运行。
-
BPMN:Archi 能够导入和导出 BPMN 模型,并且内置支持创建 BPMN 图。
-
脚本:Archi 具有内置脚本功能,允许你编写 JavaScript 脚本来自动化重复任务并扩展其功能。
结论
使用数据建模工具可以帮助你组织和结构化数据,使其对业务更具可访问性和可用性。通过使用上述工具,你将能够提高数据质量、数据治理、改进可视化、提升集成性、加快数据分析速度,并降低成本。通过创建适当的数据模型,可以优化数据库设计,从而提高数据存储和检索操作的性能。
Nirav Oza 通过分析业务问题、制定持续改进措施以提高效率、简化运营/生产流程,并通过最优技术利用降低综合费用,帮助客户实现增长和数字化转型。
更多相关主题
Lit BERT:NLP 迁移学习的 3 个步骤
原文:
www.kdnuggets.com/2019/11/lit-bert-nlp-transfer-learning-3-steps.html
comments
作者:William Falcon,AI 研究员

BERT(Devlin 等,2018)也许是最流行的迁移学习 NLP 方法。由Huggingface提供的实现提供了许多良好的功能,并通过一个美丽的 API 抽象化了细节。
PyTorch Lightning是一个轻量级框架(实际上更像是重构你的 PyTorch 代码),允许使用PyTorch的学生、研究人员和生产团队等,轻松扩展深度学习代码并确保其可重复性。它还通过训练器标志提供 42+个高级研究功能。
Lightning 不会在 PyTorch 之上添加抽象,这意味着它与其他优秀的软件包,如 Huggingface,兼容良好!在本教程中,我们将使用他们的 BERT 实现来完成 Lightning 中的微调任务。
在本教程中,我们将通过 3 个步骤进行 NLP 的迁移学习:
-
我们将从huggingface库中导入 BERT。
-
我们将创建一个LightningModule,该模块使用 BERT 提取的特征进行微调。
-
我们将使用Lighting Trainer训练 BertMNLIFinetuner。
实时演示
如果你希望看到实际代码,复制此 colab 笔记本!
微调(即迁移学习)

如果你是一位研究人员试图改进NYU GLUE基准,或是一位数据科学家试图理解产品评论以推荐新内容,你可能在寻找一种方法来提取文本表示,从而解决不同的任务。
对于迁移学习,通常有两个步骤。你使用数据集 X 来预训练模型。然后,你使用该预训练模型将知识应用于解决数据集 B。在这种情况下,BERT 已经在 BookCorpus 和英文维基百科上进行了预训练[1]。下游任务是你关心的,即解决 GLUE 任务或分类产品评论。
预训练的好处在于我们不需要在下游任务中使用大量数据即可获得出色的结果。
使用 PyTorch Lightning 进行微调

一般来说,我们可以使用以下抽象方法通过 PyTorch Lightning 进行微调:
对于迁移学习,我们在 LightningModule 中定义了两个核心部分。
-
预训练模型(即:特征提取器)
-
微调模型。
你可以将预训练模型视为特征提取器。这可以让你以比布尔值或某些表格映射更好的方式表示对象或输入。
例如,如果你有一组文档,你可以将每个文档输入到预训练模型中,并使用输出向量将文档彼此比较。
微调模型可以任意复杂。它可以是一个深度网络,或者是一个简单的线性模型或 SVM。
使用 BERT 进行微调

Huggingface
在这里,我们将使用一个预训练的 BERT 对 MNLI 任务进行微调。这实际上是试图将文本分类为三种类别。以下是 LightningModule:
在这种情况下,我们使用来自 huggingface 库的预训练 BERT,并添加了我们自己的简单线性分类器,将给定的文本输入分类为三种类别之一。
然而,我们仍然需要定义计算验证准确性的验证循环
以及计算我们测试准确性的测试循环
最后,我们定义了优化器和我们将操作的数据集。这个数据集应该是你试图解决的下游数据集。
完整的 LightningModule 如下所示。
总结
在这里,我们学会了在 LightningModule 中使用 Huggingface BERT 作为特征提取器。这种方法意味着你可以利用非常强大的文本表示来完成以下任务:
-
情感分析
-
建议的聊天机器人回复
-
使用 NLP 构建推荐引擎
-
…
-
为文档创建嵌入进行相似性搜索
-
任何你能富有创意地想到的事情!
你还看到了PyTorch Lightning与其他库,包括Huggingface,的良好配合!
简历:William Falcon 是一位 AI 研究员、初创公司创始人、首席技术官、Google Deepmind 研究员,并且目前是 Facebook AI 的博士 AI 研究实习生。
原文。已获得许可转载。
相关:
-
Pytorch Lightning 与 PyTorch Ignite 与 Fast.ai
-
渴望注意的 RNNS:逐步构建 Transformer 网络
-
在 Pytorch 中训练快速神经网络的 9 个技巧
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
更多相关话题
LLaMA 3: Meta 迄今最强大的开源模型
原文:
www.kdnuggets.com/llama-3-metas-most-powerful-open-source-model-yet

图片由作者提供
介绍 Llama 3
Meta 最近发布了 Llama 3,这是迄今为止最强大的“开源”AI 模型之一。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
Llama 3 提供 2 种规格:Llama 3 8B,具有 80 亿个参数,以及 Llama 3 70 B,具有 700 亿个参数。
这些模型相对较小,仅稍大于其前身 Llama 2。 然而,Llama 3 似乎更注重质量而非规模,因为该模型在超过 15 万亿个数据标记上进行了训练。
由于训练数据量的增加和训练技术的进步,尽管 Llama 3 和 Llama 2 的规模相同,Llama 3 的表现显著优于 Llama 2。
这将使在本地计算机上运行 Llama 3 更加容易。
Llama 3 在其他开源模型中的表现如何?
这里是一张展示 Llama 3 在各种基准测试中与其他语言模型表现对比的表格:
来源:Meta
以下是这些基准测试的含义:
-
MMLU(大规模多任务语言理解):一个基准测试,旨在理解语言模型的多任务处理能力。该模型在数学、计算机科学和法律等多个学科中的表现被评估。
-
GPQA(研究生水平谷歌验证问答):评估模型回答搜索引擎难以直接解决的问题的能力。该基准测试评估 AI 是否能处理通常需要人类级别研究技能的问题。
-
HumanEval:评估模型通过执行编程任务来编写代码的能力。
-
GSM-8K:评估模型解决数学文字问题的能力。
-
数学:测试模型解决中学和高中数学问题的能力。
在左侧,我们看到较小模型 Llama 3 8B 与 Gemma 7B It 和 Mistral 7B Instruct 两个类似规模的开源模型的性能对比。
Llama 3 8B 在列表上的每个基准测试中均优于同等规模的语言模型。
Llama 3 70B 已与 Gemini Pro 1.5 和 Claude 3 Sonnet 进行了基准测试。这些是谷歌和 Anthropic 发布的两个最先进的 AI 模型,并且不开放源代码。
有趣的是,Gemini Pro 1.5 是谷歌的旗舰模型。据说它的表现优于目前最强大的模型 Gemini Ultra。
作为列表中唯一公开可用的模型,Llama 3 70B 在 5 个性能基准测试中击败了 Gemini Pro 1.5 和 Claude 3 Sonnet 的 3 项,这一点令人印象深刻。
认识 MetaAI:最智能、免费可用的 AI 助手
Llama 3 也为 Meta AI 提供支持,这是一个能够进行复杂推理、遵循指令和可视化想法的 AI 助手。
它具有聊天界面,允许你与 Llama 3 进行互动。你可以向它提问、进行研究,甚至让它生成图像。
与现有的 LLM 聊天机器人如 ChatGPT、Gemini 和 Claude 不同,Meta AI 完全免费使用。其最先进的模型并未隐藏在付费墙后面,使其成为现有 AI 助手的强大免费替代品。
Meta AI 已整合到 Meta 的应用套件中,如 Facebook、Instagram、WhatsApp 和 Messenger。你可以使用它在这些平台上执行高级搜索。
根据马克·扎克伯格的说法,Meta AI 现在是最智能的、免费可用的 AI 助手。
不幸的是,Meta AI 目前仅在部分国家提供,将在不久的将来向全球用户推出。
如果在你的国家尚不可用,不必担心!我将向你展示另外两种免费访问 Llama 3 的方法。
入门指南:如何访问 Llama 3
这里有另外两种免费访问 Llama 3 的方法:
使用 Hugging Face 访问 Llama 3
Hugging Face 是一个帮助开发者构建和训练机器学习模型的社区。该组织致力于使 AI 访问民主化,并允许你免费访问前沿的机器学习模型。
要在 Hugging Face 中访问 Llama 3,你首先需要通过注册创建一个 Hugging Face 帐户。
然后,导航到 HuggingChat;Hugging Face 的平台使社区中的最佳 AI 模型对公众开放。
你应该会看到如下的界面:
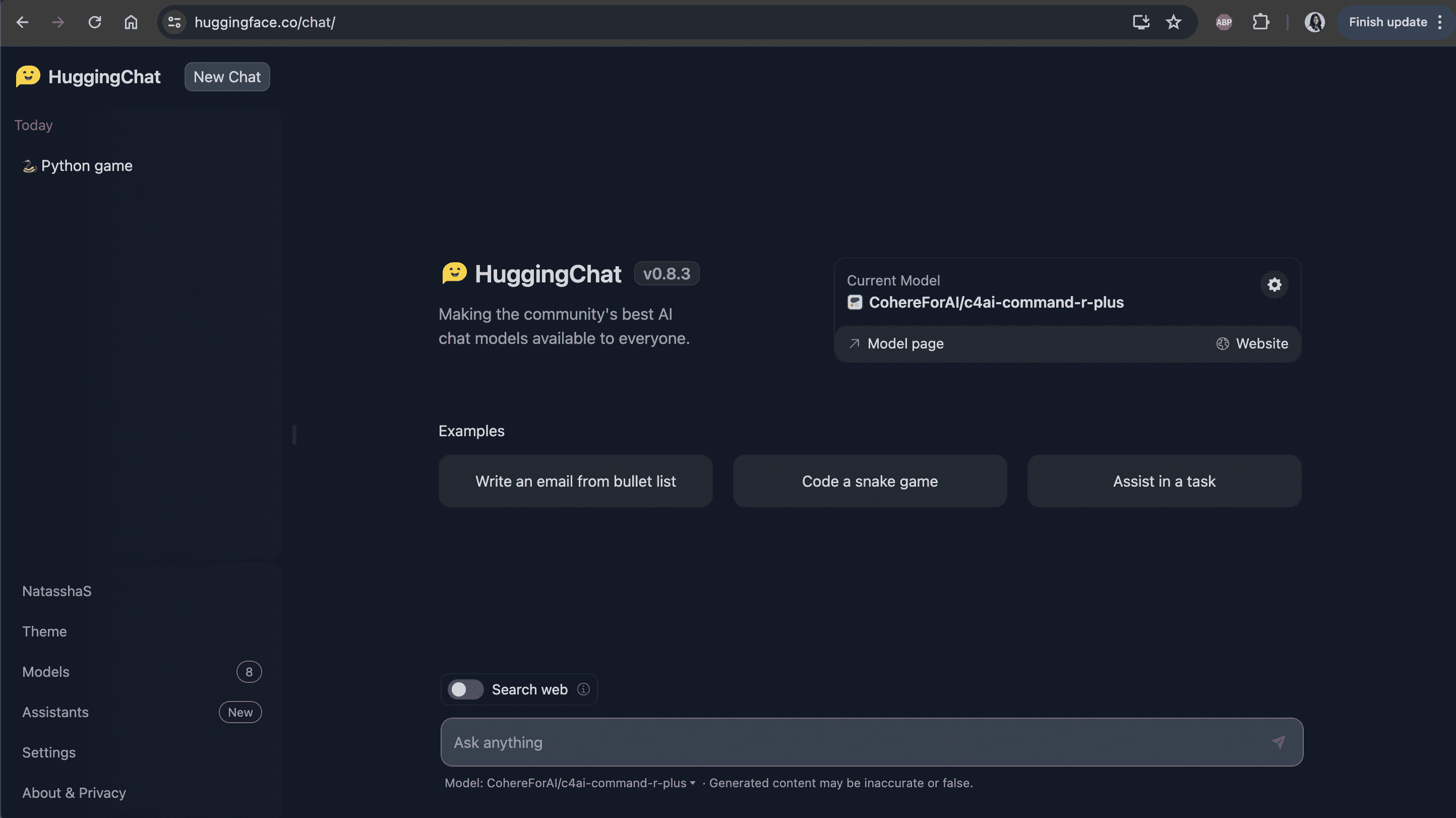
来源:HuggingChat
只需选择齿轮图标并将当前模型更改为 Meta Llama 3,如下所示:
来源:HuggingChat
然后,选择“激活”,你就可以开始与模型互动!
使用 Ollama 访问 Llama 3
Ollama 是一个允许你在本地计算机上运行语言模型的工具。使用 Ollama,你可以轻松地与开源模型如 Llama、Mistral 和 Gemma 进行交互,只需几个步骤。
要使用 Ollama 访问 Llama 3,只需导航到 Ollama 网站 并下载该工具。按照屏幕上的安装说明进行操作。
然后,导航到你的命令行界面并输入以下命令:ollama run llama3:70b。
模型下载应该需要几分钟时间。完成后,你可以在终端中输入你的提示,与 Llama 3 进行互动,如下图所示:
作者提供的图片
总结
Llama 3 是 Meta 最新公开的模型。这个 LLM 超越了 Google 和 Anthropic 发布的同类模型,目前为 Meta AI 提供支持,这是一款内置于 Meta 产品套件中的 AI 助手。
要访问 Llama 3,你可以使用 Meta AI 聊天界面,通过 HuggingChat 与模型互动,或使用 Ollama 在本地运行。
Natassha Selvaraj 是一位自学成才的数据科学家,对写作充满热情。Natassha 涉猎所有与数据科学相关的领域,是所有数据话题的真正大师。你可以通过 LinkedIn 与她联系,或查看她的 YouTube 频道。
更多相关信息
LLM 世界末日:开源克隆的复仇
原文:
www.kdnuggets.com/2023/05/llm-apocalypse-revenge-open-source-clones.html

图片来自 Adobe Firefly
“我们中的人太多了。我们拥有太多的钱、太多的设备,渐渐地,我们失去了理智。”
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 部门
弗朗西斯·福特·科波拉并不是在为那些花费过多而迷失方向的 AI 公司做隐喻,但他本可以这样做。现代启示录 是一部史诗般的作品,但制作过程漫长、困难且昂贵,就像 GPT-4 一样。我建议 LLM 的发展过于依赖金钱和设备。而且一些“我们刚刚发明了通用智能”的炒作有些疯狂。但现在是开源社区发挥其最佳优势的时候了:用更少的钱和设备提供免费的竞争软件。
OpenAI 已获得超过 110 亿美元的资金,估计 GPT-3.5 每次训练的成本为 500 万到 600 万美元。我们对 GPT-4 知之甚少,因为 OpenAI 没有透露,但我认为可以安全地假设它不会比 GPT-3.5 小。目前全球范围内的 GPU 短缺——而且这次不是因为最新的加密货币。生成式 AI 初创公司在巨大的估值下获得了超过 1 亿美元的 A 轮融资,而他们并不拥有用于支持其产品的 LLM 的任何知识产权。LLM 的风潮正处于高档次,资金正源源不断地流入。
看起来一切都已定局:只有像微软/OpenAI、亚马逊和谷歌这样的财大气粗的公司才能负担得起训练百亿参数的模型。更大的模型被认为是更好的模型。GPT-3 出了问题?只要等到有一个更大的版本,一切都会好起来!希望竞争的小公司不得不筹集更多资金,否则只能在 ChatGPT 市场上建立商品集成。由于预算更加有限,学术界被排除在外。
幸运的是,一群聪明的人和开源项目将其视为挑战而非限制。斯坦福大学的研究人员发布了 Alpaca,这是一种 70 亿参数的模型,其性能接近 GPT-3.5 的 1750 亿参数模型。由于缺乏构建 OpenAI 所用训练集的资源,他们聪明地选择了使用经过训练的开源 LLM LLaMA,并对其进行了一系列 GPT-3.5 提示和输出的微调。实质上,该模型学习了 GPT-3.5 的工作方式,事实证明这是一种非常有效的复制其行为的策略。
Alpaca 仅限于在代码和数据上进行非商业使用,因为它使用了开源的非商业 LLaMA 模型,OpenAI 明确禁止使用其 API 创建竞争产品。这确实创造了一个诱人的前景,即对 Alpaca 的提示和输出进行不同开源 LLM 的微调……创造一个具有不同许可证可能性的第三个类似 GPT-3.5 的模型。
这里还有另一层讽刺,所有主要的 LLM 都是在互联网上可获得的版权文本和图像上进行训练的,而且它们没有支付一分钱给权利持有者。这些公司以“公平使用”作为美国版权法下的豁免理由,主张其使用是“变革性的”。然而,当涉及到他们用免费数据构建的模型的输出时,他们实际上不希望任何人对他们做同样的事情。我预计随着权利持有者的觉醒,这种情况将发生变化,并可能最终进入法庭。
这是一个与限制性许可证开源作者提出的观点完全不同的点,他们对于像 CoPilot 这样的代码生成 AI 产品,反对他们的代码被用于训练,理由是许可证没有得到遵守。对于个人开源作者来说,问题在于他们需要证明立场——实质性的复制——以及他们已经遭受了损害。而且,由于模型很难将输出代码与输入(作者的源代码行)关联起来,并且没有经济损失(这本应是免费的),因此更难提出案件。这不同于以盈利为目的的创作者(例如,摄影师),他们的整个商业模式是许可证/销售他们的作品,他们由像 Getty Images 这样的聚合商代表,后者可以展示实质性的复制。
关于 LLaMA 的另一个有趣之处在于它来自 Meta。它最初仅向研究人员发布,然后通过 BitTorrent 泄露给了全世界。Meta 与 OpenAI、Microsoft、Google 和 Amazon 的业务模式根本不同,它不试图向你销售云服务或软件,因此激励措施也非常不同。它过去开源了其计算设计(OpenCompute)并见证了社区的改进——它理解开源的价值。
Meta 可能会成为最重要的开源 AI 贡献者之一。它不仅拥有巨大的资源,而且如果有大量出色的生成 AI 技术出现,它也会受益:社交媒体上会有更多内容可以变现。Meta 已发布了另外三个开源 AI 模型:ImageBind(多维数据索引)、DINOv2(计算机视觉)和 Segment Anything。后者识别图像中的独特对象,并在高度宽松的 Apache 许可证下发布。
最后,我们还发现了所谓的内部谷歌文件“我们没有护城河,OpenAI 也没有”,该文件对封闭模型与社区生产的远小于或接近于封闭源模型的创新持悲观态度。我之所以说“所谓”是因为无法验证该文章的来源是否为谷歌内部。然而,它确实包含了这张引人注目的图表:
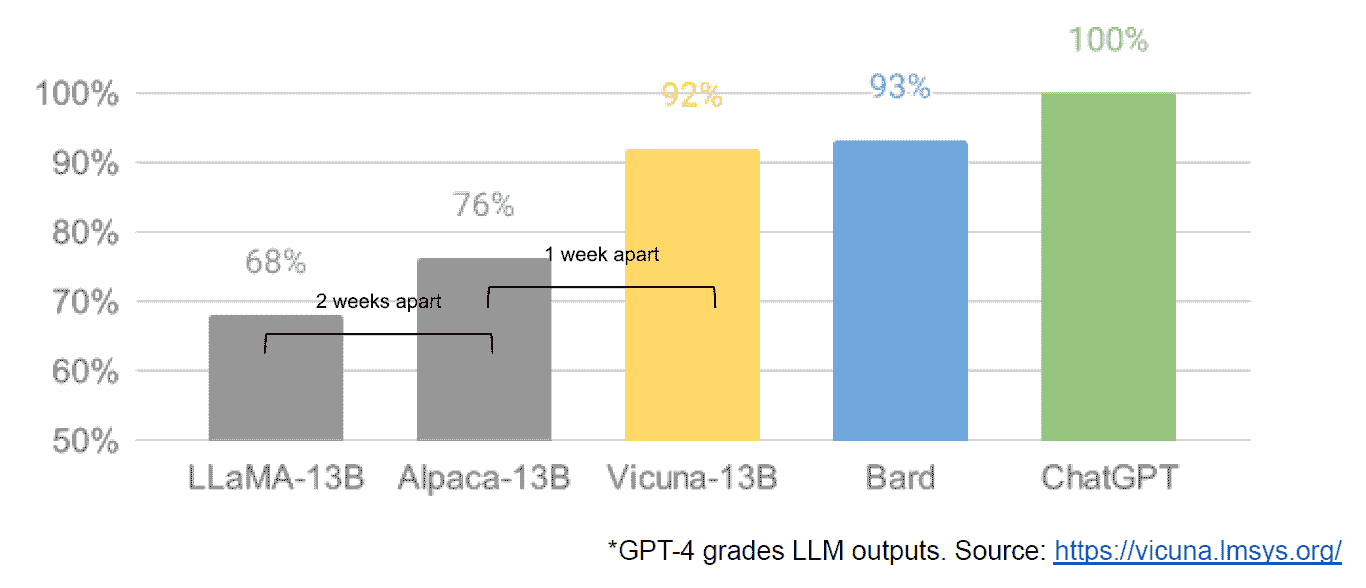
垂直轴是 GPT-4 对 LLM 输出的评分,需明确说明。
稳定扩散(Stable Diffusion),从文本合成图像,是开源生成 AI 能够比专有模型更快发展的另一个例子。该项目的最新迭代(ControlNet)已将其改进,使其超越了 Dall-E2 的能力。这是通过全球范围的大量调试实现的,导致的进展速度是任何单一机构都难以匹敌的。部分调试者发现了如何使 Stable Diffusion 在更便宜的硬件上更快地训练和运行,从而使更多人能够缩短迭代周期。
因此我们回到了起点。没有过多的资金和设备激发了整个普通人社区的巧妙创新。成为 AI 开发者的时代真是太棒了。
Mathew Lodge 是 Diffblue 的首席执行官,该公司是一家 AI For Code 初创公司。他在 Anaconda 和 VMware 等公司拥有超过 25 年的多元化产品领导经验。Lodge 目前担任 Good Law Project 董事会成员,并是皇家摄影学会理事会副主席。
相关话题
LLM 手册:从业者的策略和技巧
原文:
www.kdnuggets.com/llm-handbook-strategies-and-techniques-for-practitioners

图片由作者提供
大型语言模型(LLMs)彻底改变了机器与人类的互动方式。它们是生成性 AI 的一个子类别,专注于基于文本的应用,而生成性 AI 则更广泛,包括文本、音频、视频、图像,甚至代码!
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
AWS 很好地总结了 – “生成性人工智能(生成性 AI)是一种能够创建新内容和想法的 AI,包括对话、故事、图像、视频和音乐。它重用训练数据来解决新问题。”
生成性 AI 开辟了 AI 领域的新前沿!
大型语言模型(LLMs)具有人类般的响应生成能力,但 AI 从业者应该如何使用它们呢?是否有指南或方法来帮助行业建立对这项前沿技术的信心?
这正是我们将在本文中讨论的内容。那么,让我们开始吧。
一种开始的助手!!!
LLMs 本质上是生成器,因此建议将它们用于生成摘要、提供解释以及回答广泛的问题。通常,AI 用于辅助人类专家。同样,LLMs 可以增强你对复杂主题的理解。
行业专家认为 LLMs 是很好的讨论平台 – 是的,它们适合用来验证问题、头脑风暴、创建草稿,甚至检查是否有更好的方式来表达现有内容。这些建议为开发者和 AI 爱好者提供了测试这项强大技术的舞台。
不仅仅是文本,LLMs 还帮助生成和调试代码,以及以易于理解的方式解释复杂算法,突显了它们在解密术语方面的作用,为不同角色提供量身定制的概念理解。
好处!!
现在,让我们讨论一些突显 LLMs 在提高效率方面作用的案例。以下示例关注于生成报告和洞察,以及简化业务流程。
协作工具: 创建跨应用程序如 Slack 共享数据的总结报告是一种非常有效的方式,以便了解项目的进展。这些报告可以包括主题、当前状态、迄今为止的发展、参与者、行动项目、截止日期、瓶颈、下一步等详细信息。

图片由作者提供
供应链: 供应链规划师通常处于应急状态以满足需求订单。虽然供应链规划帮助很大,但最后一公里的交付需要专家们在战情室内齐心协力,以保持供应链计划的完整。大量的信息,通常以文本形式交换,包括对未来有用的见解。此外,这些对话的总结让所有利益相关者了解实时状态。
采用 LLMs
在技术迅速发展的背景下,重要的是不要因为担心错过而产生焦虑,而应以业务优先的心态来应对。
除了上述建议外,用户还必须保持更新,定期检查新技术和最佳实践,以确保有效使用这些模型。
分清事实与虚构
在讨论了 LLMs 的好处后,现在是时候了解另一面了。我们都知道没有免费的午餐。那么,负责任地使用 LLMs 需要什么?有许多关注点,比如模型偏见、深度伪造等潜在误用及其影响,需要对 LLMs 的伦理影响有更多的认识。

图片由作者提供
情况已经恶化到越来越难以区分人工生成的回应和机器生成的回应。
因此,建议不要仅仅凭表面考虑这些工具提供的信息,而应考虑以下提示:
-
将模型视为提高效率的工具,而不是唯一的真理源。
-
从多个来源收集信息并在采取行动之前进行交叉检查——集体智慧通过汇聚不同观点而表现出色。
-
当你考虑来自多个来源的信息的重要性和可信度时,始终检查信息来源和引用,最好选择信誉较高的来源。
-
不要假设给出的信息是真实的。寻找反对的观点,即如果这不对呢?收集有助于你反驳信息不正确的证据,而不是试图支持其有效性。
-
模型回应常常在推理上存在漏洞,要仔细阅读,质疑其相关性,并引导其得到适当的回应。
设计 LLMs 时需考虑的提示
让我们直接了解 LLMs 的实际应用,以了解它们的能力和局限性。首先,要做好多个实验和迭代周期的准备。始终保持对最新行业发展的了解,以充分利用模型的最大效益。
黄金法则是从业务目标出发,设定明确的目标和指标。通常,性能指标不仅包括准确性,还包括速度、计算资源和成本效益。这些都是必须事先决定的不可谈判的因素。
接下来的重要步骤是选择适合业务需求的 LLM 工具或平台,这也包括考虑闭源或开源模型。

图片来源:作者
LLM 的规模是另一个关键决定因素。你的用例是否需要大型模型,还是较小的近似模型,它们对计算需求的要求较低,能够在提供的准确性上做出良好的折中?请注意,较大的模型提供更好的性能,但需要消耗更多的计算资源,从而增加预算。
鉴于大型模型带来的安全和隐私风险,企业需要强大的保护措施来确保最终用户的数据安全。同样,了解提示技术以传达查询并从模型中获取信息也很重要。
这些提示技术随着重复实验而不断改进,例如通过指定响应的长度、语调或风格,以确保响应准确、相关和完整。
摘要
LLM 确实是一个强大的工具,适用于多种任务,包括信息总结、复杂概念和数据解释。然而,成功的实施需要以业务为先的思维方式,以避免陷入人工智能的炒作中,并找到真正有效的最终用途。此外,了解伦理影响,例如验证信息、质疑响应的有效性,以及注意 LLM 生成内容可能存在的偏见和风险,有助于负责任地使用这些模型。
Vidhi Chugh**是人工智能战略家和数字化转型领导者,致力于在产品、科学和工程的交叉点上构建可扩展的机器学习系统。她是一位获奖的创新领导者、作者和国际演讲者。她的使命是使机器学习大众化,并打破术语,让每个人都能参与到这场变革中。
更多相关内容
LLM 投资组合项目创意,令雇主惊叹
原文:
www.kdnuggets.com/llm-portfolio-projects-ideas-to-wow-employers

作者提供的图像
大多数缺乏技术知识的人可能会认为,与 AI 或 LLM(大语言模型)打交道是具有挑战性的,并且仅限于专家和工程师。然而,如果我告诉你,只需精通 Python,你就可以构建各种 LLM 项目,从问答系统到 YouTube 总结器,你会怎么看?你甚至可以使用多个开源模型和组件创建你自己的 GPT-4o 应用程序。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
在这个项目中,我们将探索有趣且容易实现的 LLM 项目创意,你可以使用免费或负担得起的资源进行构建。此外,每个项目创意都有一个示例项目链接,你可以查看以更好地理解它的工作原理。
1. 微调 Llama 3 及其本地使用
微调 Llama 3 及其本地使用是一个包含多个步骤和文件的完整项目。目标是使用 Kaggle 提供的免费资源在患者-医生对话的数据集上微调模型。一旦模型成功微调,它可以以高度专业的方式回答医学相关的问题。
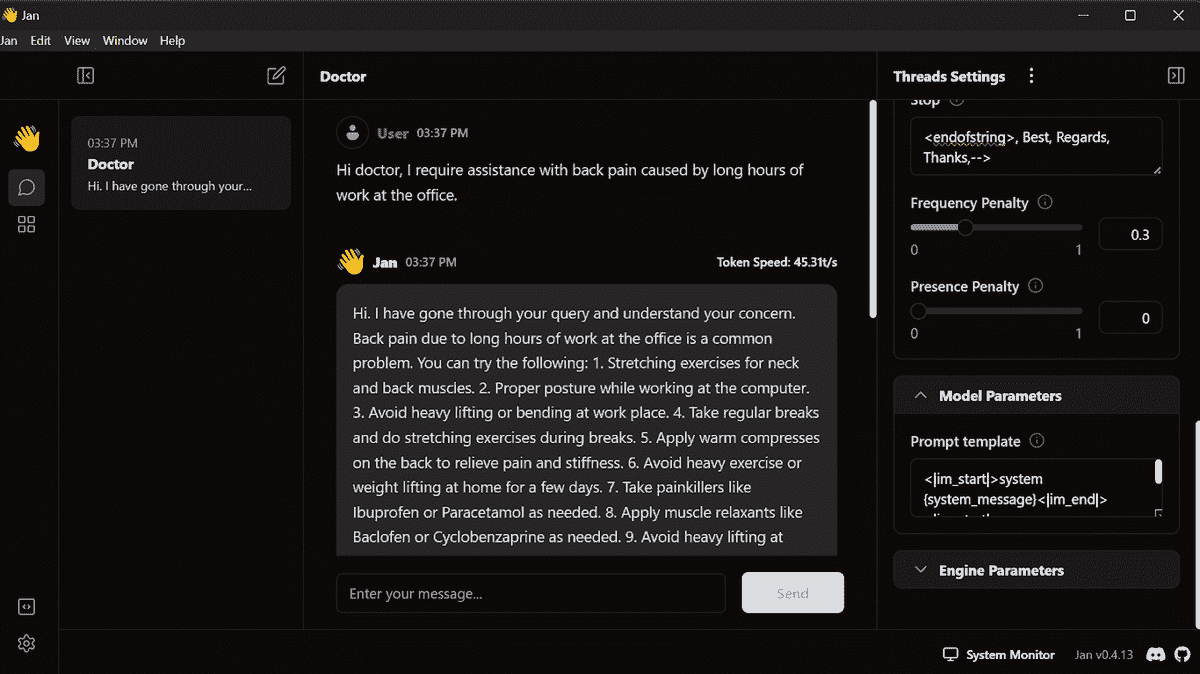
项目图像
为了在你的笔记本电脑上离线使用模型,你可以按照以下步骤进行:
-
将适配层合并到基础模型中。
-
将模型转换为 Llama.cpp 格式,这被称为 GGUF。
-
使用量化方法减小模型的大小。
-
最后,使用 Windows Jan 应用程序在你的笔记本电脑上使用模型。
保持医学对话在医生和患者之间的隐私非常重要,因此有必要在本地使用并确保隐私。
2. 问答检索系统
如果你不想微调模型,你仍然可以使用 LangChain、Chroma DB 和 Ollama 等工具在本地创建上下文感知的 AI 应用程序。这个应用程序将利用你的数据集作为上下文,然后生成响应。
要构建 RAG(检索增强生成)应用程序,你可以按照以下步骤进行:
-
加载 PDF 文件: 首先从指定文件夹中加载所有 PDF 文件。
-
拆分文本: 将文本拆分成较小的块,以便高效处理。
-
转换为嵌入: 将文本转换为嵌入并将其存储在向量数据库中。
-
构建检索链: 使用 LangChain 构建检索链。
-
开发 Python 应用程序: 创建一个合适的 Python 应用程序,以确保流畅的聊天体验。
项目图片
LangChain 通过提供高级 API 和易于使用的命令简化了这一过程。通过遵循 "如何在本地运行 Llama 3" 的教程,你可以构建一个具有上下文感知的智能 LLM 应用程序。
3. 使用 FastAPI 在 Python 中将 LLM 应用程序作为 API 端点服务
在此项目中,你将使用 OpenAI API 和 FastAPI 构建一个英语到法语的翻译器 API。该项目将分为两个主要部分:了解如何使用 OpenAI API 确保生成的输出始终为法语,以及使用 FastAPI 构建一个 REST API 来接收文本并通过简单的 CURL 命令生成输出。
如果你熟悉 FastAPI,你可以在 30 分钟内构建一个更好的 LLM 应用程序,作为 API 端点服务。
项目图片
作为参考,按照指南 "在 Python 中使用 FastAPI 将 LLM 应用程序作为 API 端点服务",并尝试服务你的 LLM。它也可以是你在本地运行的模型。
4. 假期规划助手
没有旅行代理的假期规划可能会很困难。有很多变数,有时人们甚至不知道该怎么做。那么,为什么不创建你自己的旅行行程应用程序,让它在地图上显示你的行程并提供详细的计划和各种景点呢?
在此项目中,你将构建一个 Web 应用程序,该应用程序接受用户关于旅行计划的指示,并提供行程建议,并在地图上显示这些建议。
项目图片
该项目要求你在深入项目之前学习一些关于 Gradio、启动和 Google Maps API 的基础知识。你可以通过以下教程 "使用 LangChain、Google Maps API 和 Gradio 构建智能旅行行程建议器(第一部分)" 开始,但如果你想构建假期规划助手,可能需要向你的应用程序中添加更多组件,使其更加强大。
5. YouTube 摘要器
YouTube 摘要器是一个适合初学者的项目,非常适合学生和新手学习 API 和自然语言处理。该项目涉及使用 YouTube API 从视频中提取字幕,并使用 OpenAI API 对这些字幕进行总结。鉴于一些视频可能很长,而像 ChatGPT 这样的模型的上下文窗口可能有限,该项目需要将字幕拆分成可管理的部分。每部分单独总结,然后将总结后的部分组合成整个视频的连贯摘要。
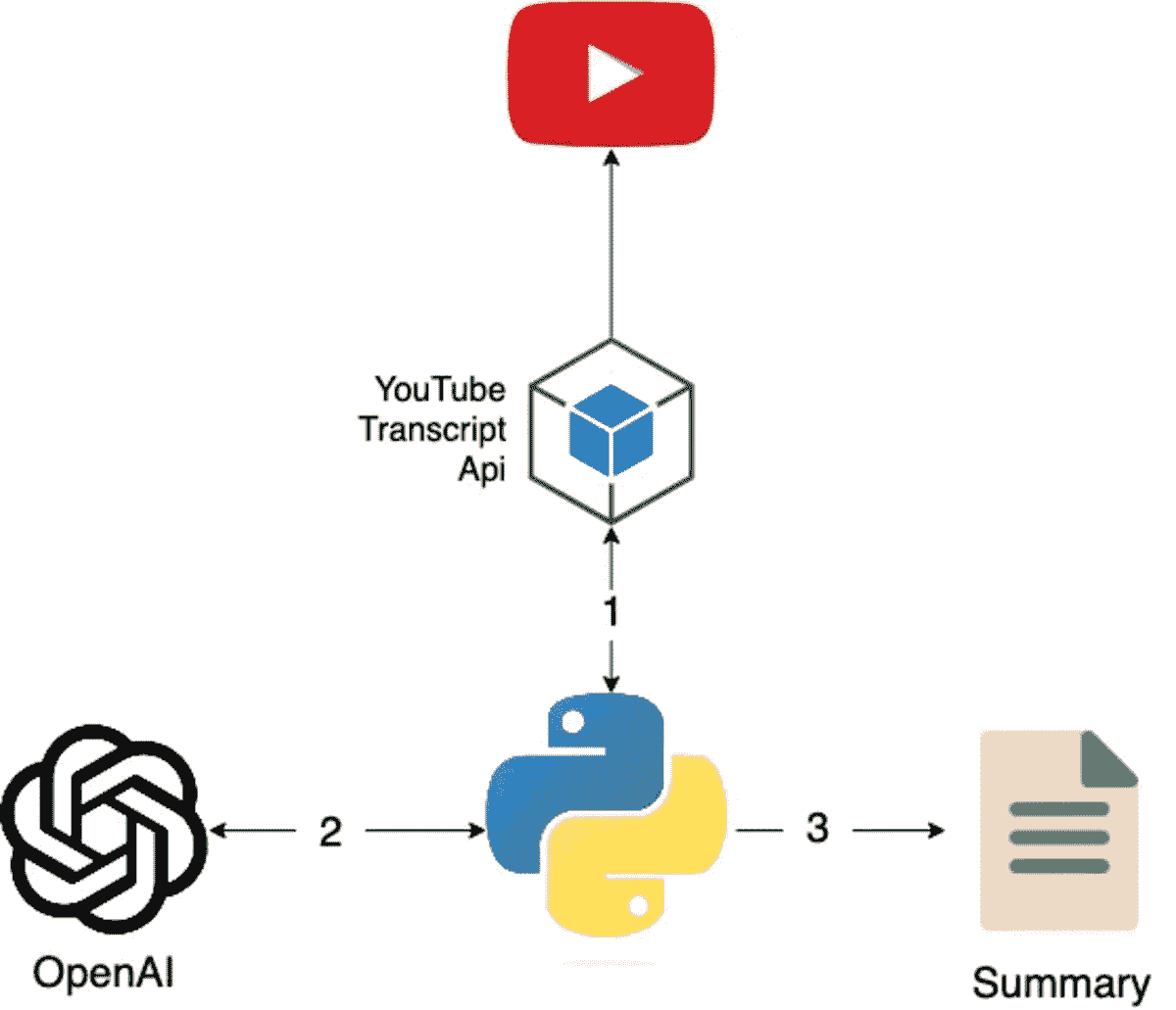
图片来自项目
你可以参考 "仅需 3 个简单步骤创建自己的 YouTube 视频摘要应用" 教程,亲自体验其精彩之处。
注意: 该项目使用的是旧版 API。你可以随时查看 OpenAI API 文档以更新到新的结构。
6. 使用 LLM 的网络爬虫
网络爬虫可能是一个有利可图的业务,通过运行一个简单的脚本,个人每天可以赚取高达 $200。它被认为有利可图,因为绕过某些网站结构可能会具有挑战性。在这种情况下,使用 Scrapy 和 Ollama 构建一个 LLM 驱动的网络爬虫可以帮助自动化或增强网页解析。
图片来自 books.toscrape.com
通过参考 "使用 LLM 进行网络爬虫" 指南,你可以学习如何在每个网页上使用 LLM 提取特定属性,如产品名称和价格。LLM 消除了手动编码以提取这些属性的需求;你需要做的只是更改提示。
7. 使用开源模型构建 GPT4o
构建一个全功能的 AI 应用通常需要数百万美元和多年的研究。如果我告诉你,你可以使用开源模型在一天之内免费构建自己的 GPT-4o 模型,你会怎么想?
在这个项目中,我们将创建一个全面的 Open GPT-4o 应用,它可以理解音频、图像和文本数据。它将包括一个实时语音聊天功能和视频聊天功能。此外,你还可以用它生成图像和视频。简而言之,它将是你的 AGI(人工通用智能)应用。
请注意,该项目没有指南或教程,因此你需要通过理解源代码来学习一切:app.py · KingNish/OpenGPT-4o at main (huggingface.co)
图片来自 OpenGPT 4o
在你构建 LLM 应用程序之前,我强烈推荐你测试一下 OpenGPT 4o。了解它的各种功能和所使用的模型类型,了解它的高效性和速度。
结语
构建 LLM 作品集项目可以显著提升你的职业前景。如果你是寻求就业的学生,这 7 个项目将帮助你比其他人更快找到工作。招聘人员和人力资源经理特别欣赏那些融入最新技术(如 AI)的项目。
首先,收藏此页面并开始构建简单的项目。随着你逐步转向更复杂的项目,确保在 LinkedIn 上持续展示你的作品。这样,你很快就会引起招聘人员的注意。
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一款帮助面临心理健康问题的学生的 AI 产品。
更多相关话题
逻辑回归用于分类
原文:
www.kdnuggets.com/2022/04/logistic-regression-classification.html
在我们更深入了解逻辑回归之前,让我们先回顾一些重要的定义,这将帮助我们更好地理解这个主题。
逻辑回归属于监督学习。监督学习是指算法在带标签的数据集上进行学习,并分析训练数据。这些带标签的数据集有输入和预期输出。
监督学习可以进一步分为分类和回归。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
分类是关于预测标签,通过识别一个对象基于不同参数属于哪个类别。
回归是关于预测连续输出,通过找出因变量和自变量之间的相关性。
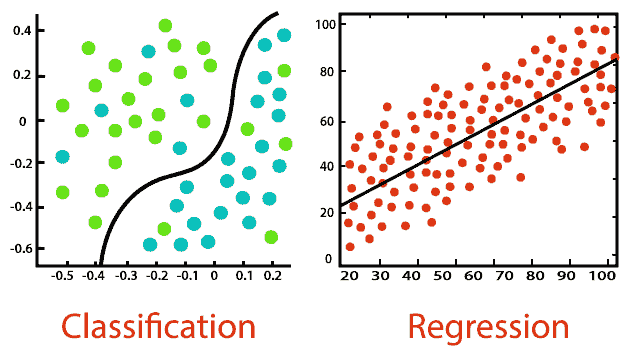
来源:Javatpoint
什么是逻辑回归?
逻辑回归是一种统计方法和机器学习算法,用于分类问题,基于概率的概念。它用于当因变量(目标)是分类变量时。
当分类问题是二元的,例如是或否、对或错时,它被广泛使用。例如,它可以用于预测一封邮件是否是垃圾邮件(1)或不是(0)。
逻辑回归使用 Sigmoid 函数来返回标签的概率。
Sigmoid 函数
Sigmoid 函数是一个数学函数,用于将预测值映射到概率值。该函数具有将任何实数值映射到 0 和 1 之间的另一个值的能力。
代码:
def sigmoid(z):
return 1.0 / (1 + np.exp(-z))
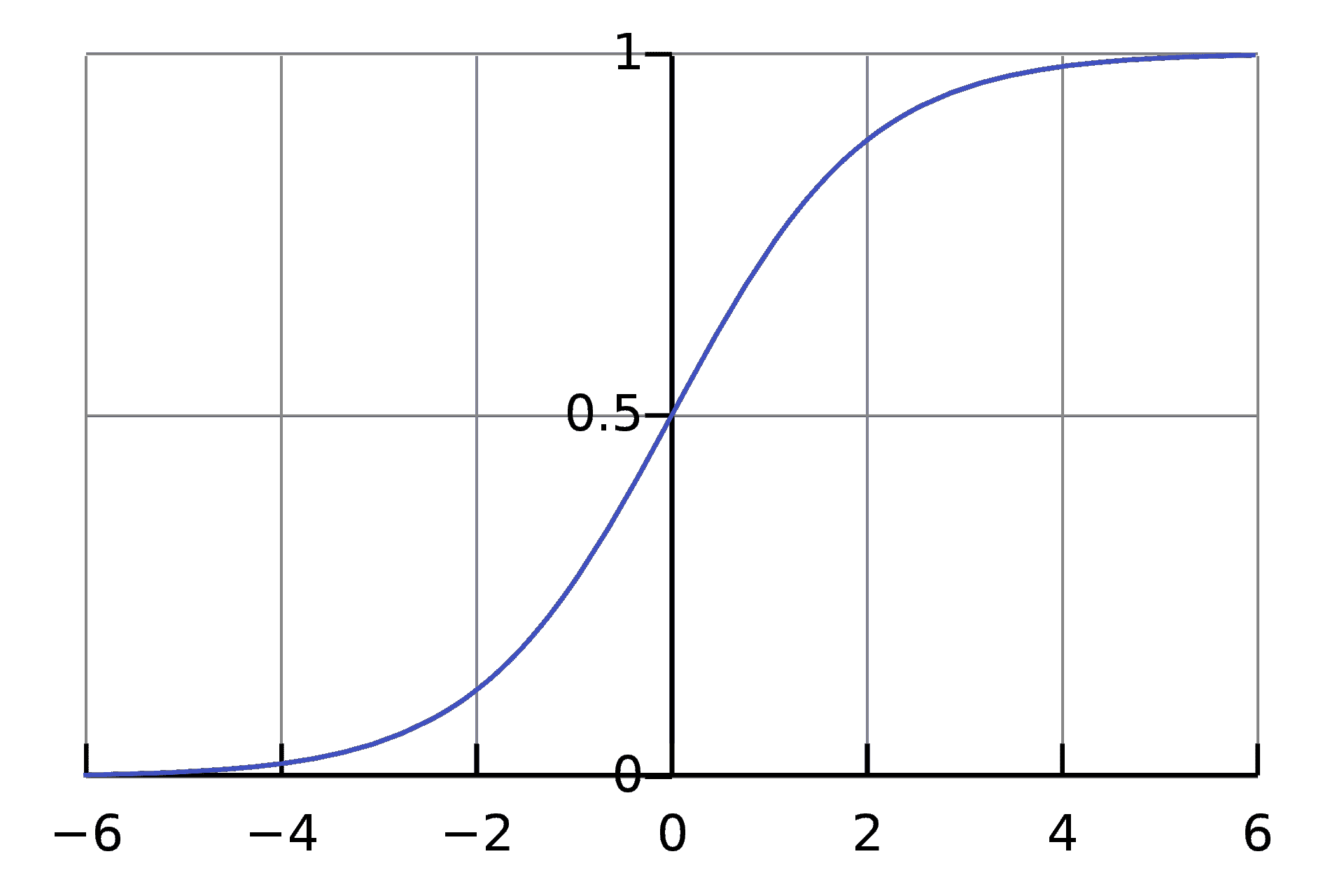
来源:维基百科
规则是逻辑回归的值必须在 0 和 1 之间。由于不能超过值 1 的限制,图形上形成一个“S”形的曲线。这是识别 Sigmoid 函数或逻辑函数的简单方法。
关于逻辑回归,使用的概念是阈值。阈值有助于定义 0 或 1 的概率。例如,阈值以上的值倾向于 1,而阈值以下的值倾向于 0。
逻辑回归的类型
-
二项型: 这意味着因变量只能有两种可能的类型,如 0 或 1,或者是“是”或“否”等。
-
多项型: 这意味着因变量可以有 3 种或更多种可能的无序类型,例如“猫”,“狗”或“羊”。
-
有序型: 这意味着因变量可以有 3 种或更多种可能的有序类型,例如“低”,“中”等。
线性回归和逻辑回归
线性回归与逻辑回归相似但有所不同。
线性回归假设因变量和自变量之间存在线性关系。它使用描述两个或多个变量的最佳拟合线。线性回归的目标是准确预测连续因变量的输出。
然而,逻辑回归预测的是依赖于其他因素的事件或类别的概率,因此逻辑回归的输出总是介于 0 和 1 之间。
要了解更多关于线性回归和逻辑回归之间的差异,可以在这个链接中阅读更多信息。
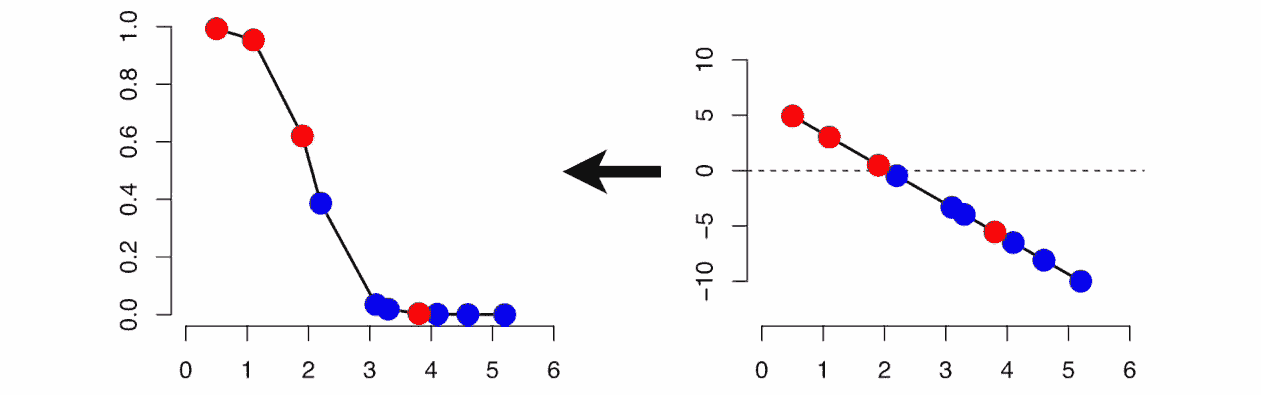
来源:gfycat
成本函数
成本函数是用于计算误差的数学公式,它是预测值和实际值之间的差异。它简单地衡量模型在估计 x 和 y 之间关系的能力方面有多么错误。
成本函数的值也可以称为成本、损失或误差。在逻辑回归中,我们使用的成本函数称为 交叉熵,也称为对数损失。其公式为:
如果你想了解更多不同类型的成本函数,请点击这个链接。
梯度下降法
为了最小化我们的成本,我们使用梯度下降法来估计模型的参数或权重。
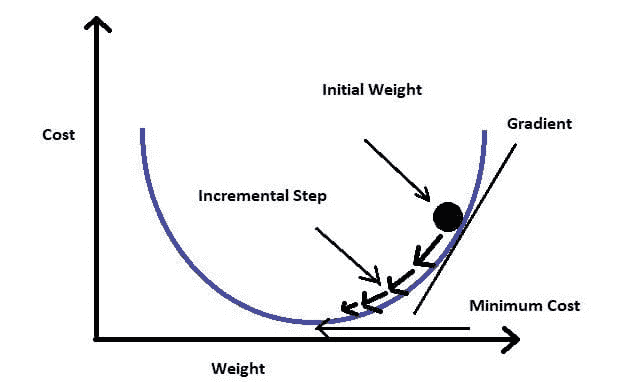 来源:
来源:逻辑回归的实现
为了举一个实现逻辑回归的简单例子,我将使用一个来自 kaggle 的数据集,该数据集探讨了通过社交媒体广告购买产品的信息。
数据集来源 - www.kaggle.com/rakeshrau/social-network-ads
1. 加载数据集和库
# Import Libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from math import exp
plt.rcParams["figure.figsize"] = (10, 6)# Download your chosen dataset
# Source of dataset - https://www.kaggle.com/rakeshrau/social-network-ads
# !wget "https://drive.google.com/uc?id=15WAD9_4CpUK6EWmgWVXU8YMnyYLKQvW8&export=download" -O data.csv -q# Load the dataset
data = pd.read_csv("data.csv")
data.head(10)
2. 训练/测试数据
# Visualizing the dataset by Age and Purchased
plt.scatter(data['Age'], data['Purchased'])
plt.show()# Divide the Data into training set and test set
X_train, X_test, y_train, y_test = train_test_split(data['Age'], data['Purchased'], test_size=0.20)
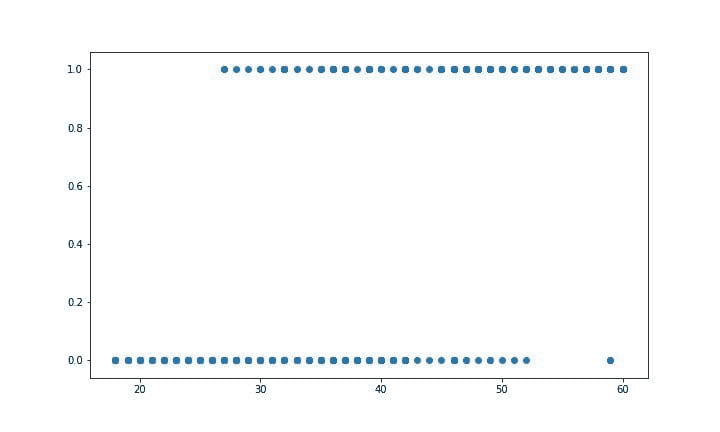
3. 构建模型
我们需要对数据进行归一化,并将均值移至原点。这是由于逻辑方程的性质,我们希望获得准确的结果。
然后我们创建一个方法来帮助我们进行预测,该方法将返回一个概率。接下来我们可以开始训练模型。模型训练了 300 个周期,在这 300 个周期中计算了偏导数,并更新了权重。
# Building the Logistic Regression model
# Normalising the data
def normalize(X):
return X - X.mean()
# Make predictions
def predict(X, b0, b1):
return np.array([1 / (1 + exp(-1*b0 + -1*b1*x)) for x in X])
# The model
def logistic_regression(X, Y):
X = normalize(X)
# Initializing variables
b0 = 0
b1 = 0
L = 0.001
epochs = 300
for epoch in range(epochs):
y_pred = predict(X, b0, b1)
D_b0 = -2 * sum((Y - y_pred) * y_pred * (1 - y_pred)) # Loss wrt b0
D_b1 = -2 * sum(X * (Y - y_pred) * y_pred * (1 - y_pred)) # Loss wrt b1
# Update b0 and b1
b0 = b0 - L * D_b0
b1 = b1 - L * D_b1
return b0, b1
4. 训练模型
如上所述,预测方程将返回一个概率。由于这是一个分类任务,我们需要将其转换为二进制值。为此,我们需要选择一个阈值。在这个例子中,我们选择阈值 0.5,这意味着所有预测值大于 0.5 的将被视为 1,而小于 0.5 的将被视为 0。
你还可以通过检查我们做了多少正确预测并将其除以测试案例的总数来计算准确率。
# Training the Model
b0, b1 = logistic_regression(X_train, y_train)# Making predictions and setting a thresholdX_test_norm = normalize(X_test)
y_pred = predict(X_test_norm, b0, b1)
y_pred = [1 if p >= 0.5 else 0 for p in y_pred]
# Plotting the data
plt.scatter(X_test, y_test)
plt.scatter(X_test, y_pred, c="red")
plt.show()# Calculating the accuracy
accuracy = 0
for i in range(len(y_pred)):
if y_pred[i] == y_test.iloc[i]:
accuracy += 1
print(f"Accuracy = {accuracy / len(y_pred)}")
绘图和准确率:
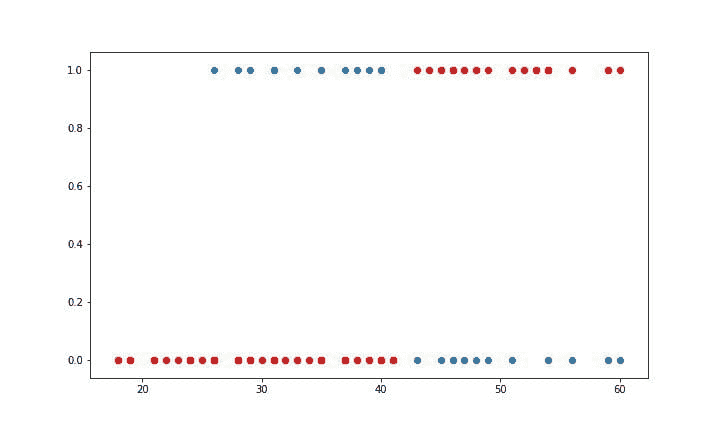
Accuracy = 0.85
使用下面的 gify 可以帮助我们直观地看到每次迭代中权重 b0 和 b1 的更新情况。
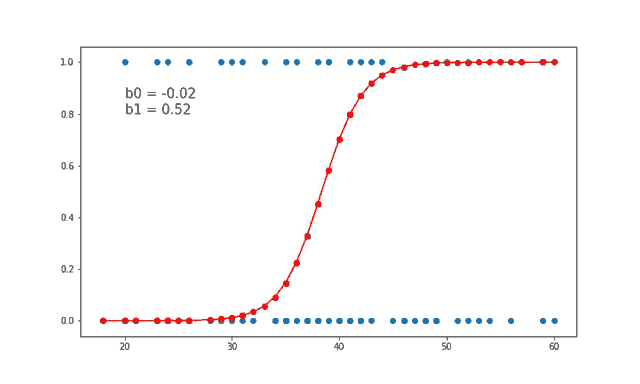
来源:gfycat
结论
逻辑回归是一种广泛使用的技术,因为它非常高效且不需要大量计算资源。当你移除与输出变量无关或关系很小的变量时,逻辑回归的效果会更好。因此,特征工程在逻辑回归的性能中是一个重要因素。
逻辑回归非常适合分类任务,但它并不是最强大的算法之一。它很容易被其他更复杂的算法超越,不过它使用起来简单且方便。然而,由于其简单性,它可以作为一个良好的基准,与其他更复杂算法的性能进行比较。
尼莎·阿亚是一名数据科学家和自由技术写作人员。她特别关注提供数据科学职业建议或教程以及数据科学相关的理论知识。她还希望探索人工智能在促进人类寿命方面的不同方式。作为一个热衷学习者,她希望拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关内容
Logistic 回归:简明技术概述
原文:
www.kdnuggets.com/2018/02/logistic-regression-concise-technical-overview.html
评论
I. 介绍:
预测二项结果(y = 0 或 1)的流行统计技术是 Logistic 回归。Logistic 回归预测分类结果(二项/多项 y 值),而线性回归适用于预测连续值结果(例如体重以 kg 为单位,降雨量以 cm 为单位)。
Logistic 回归(以下简称 LogR)的预测形式为事件发生的概率,即在给定某些输入变量 x 的情况下,y=1 的概率。因此,LogR 的结果范围在 0-1 之间。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
LogR 使用标准 Logistic 函数对数据点建模,该函数是由方程给出的 S 形曲线:
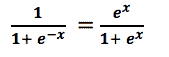
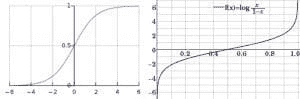
图 1:(左):标准 Logistic 函数 :Source | (右):Logit 函数 :Source
如图 1 所示,右侧的 logit 函数(范围从- ∞到+∞)是左侧 logistic 函数(范围从 0 到 1)的逆函数。
II. 概念:
LogR 中需要解的方程是:
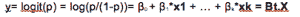
其中:
-
p = 在给定输入特征 x 的情况下,y=1 的概率。
-
x1, x2, …, xk = 输入特征集合 x。
-
B0、B1、…、Bk = 通过最大似然法估计的参数值。B0、B1、…、Bk 被估计为与其相关联的输入特征单位变化的‘对数赔率’。
-
Bt = 系数向量
-
X = 输入特征向量
估计 B0、B1、…、Bk 的值涉及概率、赔率和对数赔率的概念。让我们首先注意它们的范围:
-
概率范围从 0 到 1
-
概率范围从 0 到∞
-
对数赔率范围从-∞到+∞
示例:
示例数据集来源于UCLA 网站。
任务是预测 200 名学生是否获得荣誉(y=1 或 0),字段包括female, read, write, math, hon, femalexmath。这些字段描述了性别(female=1表示女性)、阅读成绩、写作成绩、数学成绩、荣誉状态(hon=1表示获得荣誉)以及femalexmath显示如果female=1时的数学成绩。
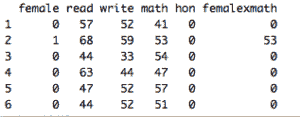
变量 hon 与女性的交叉表显示有 109 位男性和 91 位女性;这些 109 位女性中有 32 位获得了荣誉。

概率:
事件的概率是事件发生的实例数除以总实例数。
因此,女性获得荣誉的概率:

= 32/109
= 0.29
几率:
事件的几率是该事件发生的概率(y=1 的概率),除以它不发生的概率。
因此,女性获得荣誉的几率:


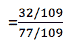
= 32/77
= 0.4155
≈ 0.42
这被解释为:
-
32/77 => 每 32 位获得荣誉的女性,相应地有 77 位女性没有获得荣誉。
-
32/77 => 每 109 位女性中(即 32+77)有 32 位获得荣誉。
对数几率:
事件的 Logit 或对数几率是几率的对数。这指的是自然对数(以‘e’为底)。因此,
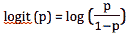
因此,女性获得荣誉的对数几率:
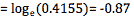
几率比:
这是 2 个几率的比率;这 2 个几率是在 x 的 2 个不同值下获得的,这 2 个 x 值相差 1 单位。
例如:当 x=0 和 x=1 时获得的几率(即当 x 值变化 1 单位时,其中 x=0 表示男性,x=1 表示女性)。
问:找出女性和男性获得荣誉的几率比。

=> 由于 OR=1.82,女性获得荣誉的几率比男性获得荣誉的几率高约 82%。
III. 概率计算:
假设我们想计算性别对获得荣誉概率的影响。
其中:
-
B0,B1,..Bk 被估计为与输入特征相关的‘对数几率’的单位变化。
-
由于 B0 是与任何输入特征无关的系数,B0=参考变量 x=0(即 x=男性)的对数几率。即这里,B0= log[(男性获得荣誉的几率)]
-
由于 B1 是输入特征‘female’的系数,
-
B1= x=女性时单位变化获得的对数几率。
-
B1=当 x=女性和 x=男性时获得的对数几率。
-
![]()
-
计算:

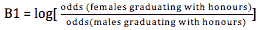
从“赔率比(OR)”部分的计算中,
B1= log (1.82)
B1= 0.593
因此,LogR 方程变为
y= -1.47 + 0.593* female
其中 female 的值分别代入 0 或 1 以表示男性和女性。
现在,让我们尝试找出当只有一个输入特征-‘女性’存在时,女性获得荣誉的概率。
在 y= -1.47 + 0.593* female 中代入 female=1
因此,y=log[odds(female)]= -1.47 + 0.593*1 = -0.877
-
因为对数赔率 = -0.877。
-
因此,赔率= e^ (Bt.X)= e^ (-0.877)= 0.416
-
而且,概率计算如下:
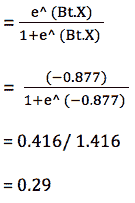
因此,当只有一个输入特征-‘女性’存在时,女性获得荣誉的概率为 0.29\。
因此,LogR 的方法论:
- 为了找到系数 B0、B1、B2、…Bk 的值,并将其代入方程: y= log(p/(1-p))= β0 + β1x1 + … + βkxk = Bt.X ,对于特定的 x 值。
- 将 B0、B1、B2、..Bk 的值和 x 的值代入此方程,得到事件的对数赔率(即给定 x 的这些值时 y=1 的对数赔率)。因此,系数是在对数尺度下获得的。
- 现在,将系数转换为赔率尺度,然后再转换为概率。使用事件的对数赔率值(Bt.X),通过 e^ (Bt.X) 得到赔率。然后,事件的概率由 {e^ (Bt.X)/[1+e^ (Bt.X)] } 推导出来。
IV. 一个重要的问题:
问:为什么不直接建模概率,为什么需要转换为对数赔率?
1) 范围受限的问题:
-
概率的范围从 0 到 1
-
赔率的范围从 0 到 ∞
-
对数赔率的范围从 - ∞ 到 +∞
尽管概率、赔率和对数赔率都传达了事件的可能性,但由于以下原因,概率和赔率并未被使用:数据集中的输入变量可能是连续值。因此,概率和赔率不应作为输出使用,因为它们的范围有限。
因此,将赔率转换为对数赔率-以扩展输出范围。
2) 对数赔率的简洁性:
概率和对数赔率都传达了事件的可能性,尽管概率对外行来说稍微更易于理解。然而,通过赔率及其对数形式更好地传达了 x 的变化(保持其他变量不变)对事件可能性的影响。这是因为事件的概率随着 x 的变化而变化,但事件的对数赔率在 x 值变化时保持不变。
这类似于两个处于相同税档两端的人——他们缴纳的税额不同,但适用相同的税率。假设$40000-$80000 的税档税率为 30%——收入$40000 的人缴纳$12000 税,收入$80000 的人缴纳$24000 税,但这两个税额的税率都是固定的(30%)。x 值(自变量——收入)发生了变化,因此 y 值(因变量——缴税金额)也发生了变化。但是在考虑一个收入$75000 的人时,如果单纯从“收入”角度来看,需要提及“收入”的最大值、平均值、最小值才能正确描述$75000 的 y 值。然而,如果单纯从固定税率的角度来看,只需考虑一个数字——30%,即可准确预测他的 y 值。
因此,如果要表达变量 x 值变化对事件概率的影响,需要在 x 的最大值、平均值和最小值处陈述 3 个不同的概率值,以描绘整体情况。但对数赔率是一个能够传达整个图景的单一数字,因为它在 x 变化时保持不变。因此,为了简洁并避免受限范围的问题,使用对数赔率来建模事件的可能性;它随后使用公式(e^ (Bt.X) )/(1+e^ (Bt.X) )转换为概率。
V. Python 和 R 实现代码:
此链接提供了一个很好的开始来使用 R 实现逻辑回归。
以下 Python 中的 LogR 代码适用于Pima 印度糖尿病数据集。它预测 Pima 印度血统患者是否会发生糖尿病。该代码灵感来自此网站。
相关内容:
-
机器学习算法:简明技术概述 - 第一部分
-
逻辑回归入门 - 第一部分
-
回归分析:入门
更多相关话题
逻辑回归是如何工作的?

编辑提供的图片
在本文中,我们将重点介绍逻辑回归算法。这是一种用于分类或预测的机器学习技术,适用于具有许多特征的数据集,但其中大多数特征价值较小,应被忽略。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
例如,假设你有几个算法用于分析你的照片。有些擅长将图像转换为文本,有些擅长检测照片中的物体,但不太擅长识别人脸,另一些则专注于寻找颜色模式。现在假设你有一张包含两个人的照片:一个在微笑,一个在皱眉——他们之中哪个更快乐?假设这不是一个需要保密的事情(其实应该不会),那么你需要的不仅仅是通过外表来判断。你想了解是什么让人们感到快乐或悲伤,因此,你需要创建一个既能识别两种情感又能做到同样好的单一算法。在这种情况下,使用像逻辑回归这样的机器学习算法可以帮助你更有效地实现目标。 了解更多。
分类
你可以使用多类分类算法来预测新数据点的类别。例如,一封电子邮件可能会被标记为垃圾邮件或正常邮件(非垃圾邮件)。为了创建一个适用于多类和多标签问题的逻辑回归算法,你可以添加这个特性。在本讲座中,我们将演示如何在 Scikit Learn 中实现逻辑回归,以处理实时问题。这是一个二分类问题的示例。要创建一个适用于多类和多标签问题的逻辑回归算法,你可以添加这个特性。
什么是逻辑回归?
逻辑回归是一种机器学习分类算法,用于预测基于某些依赖变量的特定类别的概率。简而言之,逻辑回归模型计算输入特征的总和(在大多数情况下,有一个偏置项),并计算结果的逻辑值。
逻辑回归的输出始终介于 (0 和 1) 之间,这适用于二分类任务。值越高,当前样本被分类为 class=1 的概率越高,反之亦然。
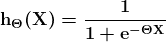
如上公式所示,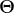 是我们要学习、训练或优化的参数,
是我们要学习、训练或优化的参数, 是输入数据。输出是当值接近 1 时的预测值,这意味着该实例更有可能是正样本(y=1)。如果值接近 0,则意味着该实例更有可能是负样本(y=0)。
是输入数据。输出是当值接近 1 时的预测值,这意味着该实例更有可能是正样本(y=1)。如果值接近 0,则意味着该实例更有可能是负样本(y=0)。
为了优化我们的任务,我们需要为此任务定义一个损失函数(成本函数或目标函数)。在逻辑回归中,我们使用对数似然损失函数。
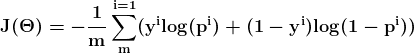
m 是训练数据中的样本数量。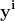 是第 i 个样本的标签,
是第 i 个样本的标签,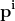 i 是第 i 个样本的预测值。当当前样本的标签为 1 时,公式的第二项为 0。我们希望第一项越大越好,反之亦然。最后,我们将所有样本的损失相加,取平均,然后添加负号。我们希望最小化二次成本函数
i 是第 i 个样本的预测值。当当前样本的标签为 1 时,公式的第二项为 0。我们希望第一项越大越好,反之亦然。最后,我们将所有样本的损失相加,取平均,然后添加负号。我们希望最小化二次成本函数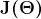 。当越小时,意味着模型对数据集的拟合越好。没有闭式解法来找出。为实现这一目标,我们需要使用一些优化算法,如梯度下降。由于是一个凸函数,梯度下降可以保证找到全局最小值。更多详情。
。当越小时,意味着模型对数据集的拟合越好。没有闭式解法来找出。为实现这一目标,我们需要使用一些优化算法,如梯度下降。由于是一个凸函数,梯度下降可以保证找到全局最小值。更多详情。
逻辑回归是如何工作的?
机器学习通常涉及预测一个定量结果或一个定性类别。前者通常被称为回归问题。在线性回归的情况下,输入是一个连续变量,预测值是一个数值。当预测一个定性结果(类别)时,任务被视为分类问题。分类问题的示例包括预测用户会购买哪些产品或目标用户是否会点击在线广告。
并非所有算法都能简洁地归入这种简单的二分法,逻辑回归就是一个显著的例子。逻辑回归属于回归家族,因为它涉及根据变量之间的定量关系预测结果。然而,与线性回归不同的是,它接受连续和离散变量作为输入,其输出是定性的。此外,它预测的是离散类别,如“是/否”或“客户/非客户”。
在实践中,逻辑回归算法分析变量之间的关系。它通过使用 Sigmoid 函数将离散结果的概率分配到 0 和 1.0 之间,从而将数值结果转换为概率表达式。概率要么是 0,要么是 1,取决于事件是否发生。对于二元预测,你可以将总体分为两个组,阈值为 0.5。高于 0.5 的被视为属于 A 组,低于 0.5 的被视为属于 B 组。
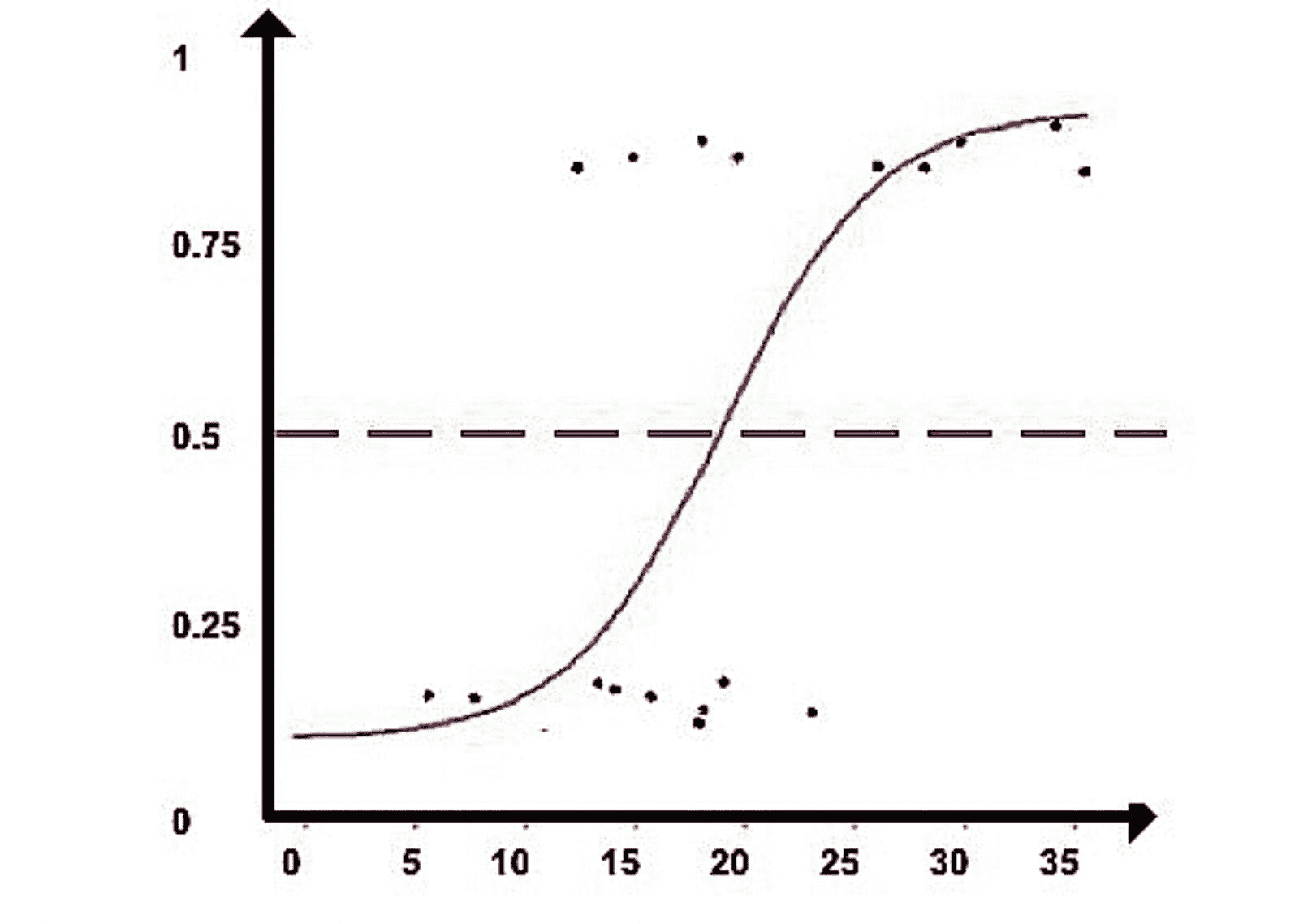
超平面用作决策线,以在数据点使用 Sigmoid 函数被分配到一个类别后,尽可能地将两个类别分开。未来数据点的类别可以通过决策边界进行预测。

结论
逻辑回归模型是一种分析技术,有助于预测未来事件发生的概率。本文将解释什么是逻辑回归,它是如何工作的,以及如何用于预测。逻辑回归是一种监督学习方法,帮助预测具有二元结果的事件,例如一个人是否能成功通过驾驶测试。为了在这种情况下做出预测,你需要过去测试结果的数据。该模型利用这些数据预测同一个人未来通过测试的可能性。逻辑回归的核心思想是基于事件发生的概率使用模型。
索尼娅·杰西卡是一个热情的学习者和狂热的科技博主。
更多相关内容
学习数据科学基础需要多长时间?
原文:
www.kdnuggets.com/2022/03/long-take-learn-data-science-fundamentals.html

作者提供的图片
学习数据科学基础所需的时间可以分为 3 个主要类别。我们在此指出,这些只是大致的值。达到一定水平的能力所需的时间取决于你的背景以及你愿意投入多少时间来学习数据科学。通常,具有物理学、数学、科学、工程、会计或计算机科学等分析学科背景的人,比那些背景与数据科学不互补的人需要的时间更少。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
基础级别 (6 – 12 个月)
在第一级,数据科学志向者应能够处理通常以逗号分隔值 (CSV) 文件格式呈现的数据集。他们应具备数据基础、数据可视化和线性回归方面的能力。
1.1 数据基础
能够操作、清理、结构化、缩放和工程化数据。应掌握使用 pandas 和 NumPy 库的技能。应具备以下能力:
-
了解如何导入和导出存储在 CSV 文件格式中的数据
-
能够清理、整理和组织数据,以便进行进一步分析或模型构建
-
能够处理数据集中缺失值
-
理解并能够应用数据插补技术,如均值插补或中位数插补
-
能够处理分类数据
-
了解如何将数据集划分为训练集和测试集
-
能够使用如 归一化 和标准化等缩放技术对数据进行缩放
-
能够通过主成分分析 (PC) 等降维技术压缩数据
1.2. 数据可视化
能够理解良好数据可视化的基本组成部分。能够使用数据可视化工具,包括 Python 的 matplotlib 和 seaborn 包;以及 R 的 ggplot2 包。应了解良好数据可视化的基本组成部分:
-
数据组件: 决定如何可视化数据的一个重要第一步是知道数据的类型,例如分类数据、离散数据、连续数据、时间序列数据等。
-
几何组件: 在这里你决定哪种可视化适合你的数据,例如散点图、折线图、条形图、直方图、Q-Q 图、平滑密度图、箱线图、成对图、热图等。
-
映射组件: 在这里,你需要决定使用哪个变量作为你的 x 变量 和使用哪个变量作为你的 y 变量。这在数据集具有多个特征时尤其重要。
-
尺度组件: 在这里,你需要决定使用什么样的尺度,例如线性尺度、对数尺度等。
-
标签组件: 这包括坐标轴标签、标题、图例、字体大小等。
-
伦理组件: 在这里,你要确保你的可视化能够讲述真实的故事。你需要注意在清洗、总结、操作和制作数据可视化时的行为,确保你不会利用可视化来误导或操控观众。
1.3 监督学习(预测连续目标变量)
熟悉线性回归及其他高级回归方法。熟练使用 scikit-learn 和 caret 等包进行线性回归模型构建。具备以下能力:
-
能够使用 NumPy 或 Pylab 执行简单的回归分析。
-
能够使用 scikit-learn 执行多重回归分析。
-
理解正则化回归方法,如 Lasso、Ridge 和 Elastic Net。
-
理解其他非参数回归方法,如 KNeighbors 回归(KNR)和支持向量回归(SVR)。
-
理解评估回归模型的各种指标,如 MSE(均方误差)、MAE(均值绝对误差)和 R2 分数。
-
能够比较不同的回归模型。
2. 中级(7-18 个月)
除了一级技能和能力外,还应具备以下能力:
2.1 监督学习(预测离散目标变量)
熟悉二分类算法,如:
-
感知机分类器
-
逻辑回归分类器
-
支持向量机(SVM)
-
能够使用核 SVM 解决非线性分类问题。
-
决策树分类器
-
K 最近邻分类器
-
朴素贝叶斯分类器
-
理解评估分类算法质量的多种指标,如准确率、精确度、敏感性、特异性、召回率、F1 分数、混淆矩阵、ROC 曲线。
-
能够使用 scikit-learn 进行模型构建。
2.2 模型评估与超参数调整
-
能够在管道中组合变换器和估算器。
-
能够使用 k 折交叉验证来评估模型性能。
-
知道如何通过学习曲线和验证曲线调试分类算法。
-
能够通过学习曲线诊断偏差和方差问题。
-
能够通过验证曲线解决过拟合和欠拟合问题
-
知道如何通过网格搜索来微调机器学习模型
-
理解如何通过网格搜索调优超参数
-
能够读取和解释混淆矩阵
-
能够绘制和解释接收者操作特征(ROC)曲线
2.3 结合不同模型进行集成学习
-
能够使用集成方法与不同的分类器
-
能够结合不同的算法进行分类
-
知道如何评估和调整集成分类器
3. 高级水平(18 – 48 个月)
能够处理高级数据集,例如文本、图像、语音和视频。除了基础和中级技能外,还应具备以下能力:
-
聚类算法(无监督学习)
-
K-means
-
深度学习
-
神经网络
-
Keras
-
TensorFlow
-
PyTorch
-
Theano
-
云系统(AWS, Azure)
总结一下,我们讨论了数据科学的 3 个水平。一级 能力可以在 6 到 12 个月内达到。二级 能力可以在 7 到 18 个月内达到。三级 能力可以在 18 到 48 个月内达到。这一切都取决于投入的努力和每个人的背景。
Benjamin O. Tayo 是物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的所有者。之前,Benjamin 曾在中 Oklahoma 大学、大峡谷大学和 Pittsburgh State 大学教授工程学和物理学。
更多相关话题
损失函数:解释
损失函数是一种评估算法学习数据并产生正确输出的方法。它使用数学公式计算预测值与实际值之间的距离。
通俗来说,损失函数衡量模型在估计 x 和 y 之间关系的能力上有多么错误。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
损失函数可以分为两类:
-
分类 - 预测标签,通过根据不同的参数识别对象属于哪个类别。
-
回归 - 预测连续输出,通过找出依赖变量和自变量之间的相关性。
以下是分类和回归任务中损失函数的类型列表。
交叉熵
交叉熵和对数损失测量的是相同的内容,但它们并不相同,用于分类任务。交叉熵衡量给定随机变量或事件集的两个概率分布之间的差异。
交叉熵的类型:
二分类交叉熵 - 用于二分类任务
-
分类交叉熵 - 用于二分类和多分类任务。这种交叉熵要求标签被编码为分类。例如;3 个类别的独热编码将使用以下表示:[0, 1, 0], [1,0,0]…)
-
稀疏交叉熵 - 用于二分类和多分类任务。这种交叉熵要求标签为整数;0 或 1 或 n
交叉熵的代码:
def CrossEntropy(yHat, y):
if y == 1:
return -log(yHat)
else:
return -log(1 - yHat)
对数损失
对数损失,即交叉熵的二分类形式,用于分类任务。它衡量分类模型的性能,其中输出是一个介于 0 和 1 之间的概率值。
随着预测概率与实际标签的偏差增大,对数损失增加。在理想情况下,完美的模型对数损失为 0。
在上图中,你可以看到当预测概率达到 1 时,Log Loss 减少。另一方面,你可以看到当预测概率减少时,Log Loss 快速增加。
使用 Scikit-learn 计算 Log Loss
from sklearn.metrics import log_loss:
LogLoss = log_loss(y_true, y_pred, eps = 1e-15,
normalize = True, sample_weight = None, labels = None)
Hinge
Hinge 是一种用于分类任务的损失函数。这种类型的损失函数在分类边界上引入了一个边际,并对损失进行惩罚。Hinge 函数对错误分类的样本进行惩罚,同时对那些在决策边界定义的边际内正确分类的样本进行惩罚。
来源: StackOverflow
-
x 轴表示距离边界的距离
-
y 轴表示损失的大小,或者函数将会承受的惩罚。
轴上的虚线表示 1,这意味着当实例与边界的距离大于 1 时,损失大小为 0。如果与边界的距离为 0,损失大小为 1。
正确分类的数据点将具有低或 0 的损失大小;低 Hinge 损失。而错误分类的数据点将具有高或 1 的损失大小;高 Hinge 损失。
Hinge 损失代码
def Hinge(y_pred, y_true):
return np.max([0., 1\. - y_pred * y_true])
均方误差损失
Mean Square Error Loss 也被称为 L2 正则化,用于回归任务。它告诉你回归线与一组数据点的接近程度。
它计算当前输出与预期输出之间的平方差,再除以输出的数量。然而,由于使用平方差,均方误差损失对异常值更敏感。
来源: freecodecamp
均方误差损失代码
def mean_square_error(y_true, y_pred):
return K.mean(K.square(y_true-y_pred), axis=-1)
均绝对误差损失
Mean Absolute Error 也被称为 L1 正则化,用于回归任务。它计算标签数据和预测数据之间的误差平方的平均值。
它计算当前输出与预期输出之间的绝对差,再除以输出的数量。其目的是最小化这些绝对差异。均绝对误差对异常值不敏感,因为它基于绝对值,而不是像均方误差那样。
为了计算均绝对误差,你需要计算模型预测与实际标签输出之间的差异。然后对差异应用绝对值,并在整个数据集上取平均值。
均绝对误差代码
def mean_abc_error(y_true, y_pred):
return K.mean(K.abs(y_true-y_pred), axis=-1)
Huber 损失
Huber 损失 是均方误差和平均绝对误差的结合。然而,区别在于它受到一个额外参数 delta (δ) 的影响。
这是一种结合了两者的方法,它告诉我们对于小于 delta 的损失值,使用均方误差;对于大于 delta 的损失值,使用平均绝对误差。
在下面的图像中,均方误差用红色表示,平均绝对误差用蓝色表示,Huber 损失用绿色表示。
Huber 损失代码
def Huber(yHat, y, delta=1.):
return np.where(np.abs(y-yHat) < delta,.5*(y-yHat)**2 , delta*(np.abs(y-yHat)-0.5*delta))
结论
我简要介绍了分类和回归的 3 种损失函数。然而,还有许多其他损失函数可以探索。
以下是一个图像,展示了分类和回归任务的不同损失函数列表。
来源: Heartbeat
尼莎·阿雅 是一名数据科学家和自由撰稿人。她特别感兴趣于提供数据科学职业建议或教程及理论知识。她还希望探索人工智能如何能够促进人类寿命的延续。作为一个热心学习者,她寻求拓宽技术知识和写作技能,同时帮助指导他人。
相关主题
彩票票假设如何挑战我们对神经网络训练的所有认知
原文:
www.kdnuggets.com/2019/05/lottery-ticket-hypothesis-neural-networks.html
评论 
来源:Pixabay
训练机器学习模型是现实世界数据科学解决方案中最具挑战性和计算开销的方面之一。几十年来,人工智能(AI)社区已经开发了数百种技术来改进机器学习模型的训练,基于一个单一的公理假设,即训练应该覆盖整个模型。最近,来自麻省理工学院(MIT)的 AI 研究人员发表了一篇挑战这一假设的论文,提出了一种更聪明、更简单的方法,通过关注模型的子集来训练神经网络。在 AI 社区中,MIT 的论文以引人注目的名字彩票票假设而闻名。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
训练机器学习模型的过程是数据科学家在理论和现实世界解决方案的约束之间常常面临妥协的领域之一。往往,一个看起来非常适合特定问题的神经网络结构无法完全实现,因为训练成本可能过高。通常,神经网络的初始训练需要大量的数据集和几天的昂贵计算使用。结果是非常大的神经网络结构,神经元和隐藏层之间有大量连接。这种结构通常需要经过优化技术来删除一些连接并调整模型的大小。
多年来困扰人工智能研究人员的一个问题是,我们是否真的需要那些大型神经网络结构。显然,如果我们连接几乎每一个神经元,可能会实现一个能够完成初始任务的模型,但成本可能会很高。我们不能从更小、更简洁的神经网络结构开始吗?这就是彩票票假设的核心。
彩票票假设
使用赌博世界的类比,机器学习模型的训练常常被比作通过购买每一张可能的彩票来赢得彩票。但如果我们知道中奖的彩票是什么样的,我们难道不能更聪明地选择票据吗?
在机器学习模型中,训练过程会产生大型神经网络结构,这些结构相当于一大包彩票。经过初步训练后,模型需要经过优化技术,如剪枝,以去除网络中不必要的权重,从而减少模型的大小而不牺牲性能。这相当于在袋子中寻找中奖票据并丢弃其余部分。很常见的是,剪枝技术最终会产生比原始网络小 90%的神经网络结构。显然的问题是:如果一个网络可以缩小尺寸,为什么我们不直接训练这个更小的结构,以便提高训练效率呢?矛盾的是,实际机器学习解决方案中的经验表明,剪枝所揭示的架构从一开始就更难训练,准确性低于原始网络。所以你可以买一大包彩票并逐步找到中奖号码,但相反的过程却太难了。或者我们曾经这样认为????
麻省理工学院的彩票票据假设的主要思想是,一致地,大型神经网络将包含一个较小的子网络,如果从一开始进行训练,将会实现与较大结构相似的准确度。具体而言,研究论文将假设概述如下:
- 彩票票据假设:一个随机初始化的密集神经网络包含一个子网络,该子网络在隔离训练时可以匹配原始网络的测试准确率,经过最多相同数量的迭代训练。*
在论文的背景下,小型子网络通常被称为中奖票据。
考虑一个形式为 f(t, a, p) 的神经网络,其中 t=训练时间,a=准确率和 p=参数。现在考虑 s 为从原始结构中生成的所有可训练神经网络的子集,经过剪枝过程。彩票票据假设告诉我们,存在 a f’(t’, a’, p’) ∈ s,使得 t’ <= t, a’ >= a 和 p’ <= p。简单来说,传统的剪枝技术揭示的神经网络结构比原始结构更小且更容易训练。

如果彩票票据假设成立,那么下一个显而易见的问题是找到识别中奖票据的策略。这个过程涉及到一个智能训练和剪枝的迭代过程,可以总结为以下五个步骤:
-
随机初始化一个神经网络。
-
训练网络直到其收敛。
-
剪枝网络的一部分。
-
为了提取“中奖票”,请将网络剩余部分的权重重置为(1)中的值——即训练开始之前它们接收到的初始化值。
-
为了评估步骤(4)中得到的网络是否确实是一个“中奖票”,请训练剪枝后的未训练网络,并检查其收敛行为和准确性。
这个过程可以运行一次或多次。在一次剪枝方法中,网络训练一次,剪枝 p% 的权重,并重置剩余的权重。尽管一次剪枝肯定有效,但彩票票假设论文显示,当该过程在 n 轮中迭代应用时,效果最佳;每轮剪枝 p1/n%的权重,而这些权重在前一轮中幸存下来。然而,一次剪枝通常产生非常稳健的结果,而无需计算上昂贵的训练。

麻省理工学院团队在一组神经网络架构中测试了彩票票假设,结果显示剪枝方法不仅能够优化架构,还能找到“中奖票”。查看下图:
在这些结果中观察两个主要方面。“中奖票”在没有宽网络的剩余冗余的情况下,比宽网络训练得更快。实际上,它们越瘦,训练得越快(在合理范围内)。然而,如果你随机重新初始化网络的权重(控制),结果网络的训练速度现在比完整网络更慢。因此,剪枝不仅仅是找到正确的架构,还包括识别“中奖票”,这是网络中特别幸运初始化的子组件。
根据实验结果,麻省理工学院团队扩展了他们最初的假设,提出了所谓的彩票系统猜想,表达了以下内容:
- 彩票票猜想:回到我们的动机问题,我们将假设扩展到一个未经测试的猜想,即 SGD 寻找并训练一个子集的良好初始化权重。密集的、随机初始化的网络比剪枝后的稀疏网络更容易训练,因为可能的子网络更多,从中训练可能恢复一个“中奖票”。
这个猜想在概念上似乎是有意义的。剪枝子网络的池子越大,找到“中奖票”的机会就越大。
彩票票假设可能成为近年来最重要的机器学习研究论文之一,因为它挑战了神经网络训练中的传统智慧。尽管剪枝通常通过训练原始网络、移除连接并进一步微调来进行,但彩票票假设告诉我们,最佳的神经网络结构可以从一开始就学习到。
原文。经许可转载。
简介:耶稣·罗德里格斯是 Invector Labs 的管理合伙人、加密货币和天使投资人、演讲者、作家、CIO.com 专栏作家以及人工智能爱好者。
资源:
相关内容:
更多相关内容
低代码:开发人员仍然需要吗?
原文:
www.kdnuggets.com/2022/04/low-code-developers-still-needed.html

建筑插图矢量图由 storyset 创建 - www.freepik.com
传统上,组织会订阅并购买大型复杂的软件来解决重大业务问题。这种情况并没有改变。人工智能和机器学习的进步使得强大的数据科学和业务分析软件成为可能。然而,组织仍然被迫在供应商规定的方法论的框架内工作。通常,几乎没有余地。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 在 IT 领域支持你的组织
替代方案是委托开发昂贵的定制软件。这通常涉及与软件开发公司签订合同或聘请经验丰富的软件开发人员来构建所需的业务应用程序。不幸的是,这并不总是经济上可行的,特别是对于那些对美国 GDP 贡献高达 44%的中小企业来说。
无代码和低代码解决方案使得以前无法获取的定制软件开发工具变得可用且更具成本效益,适用于几乎没有编码经验的中小企业和个人。然而,这是否颠覆了对开发者的需求?经验丰富的软件开发人员是否会像渡渡鸟一样消失?本指南将探讨这些问题,并证明为什么软件开发人员仍然是必需的。
什么是低代码?
低代码和无代码解决方案描述了可视化的软件开发平台,使用户能够设计和构建应用程序。它通常需要很少甚至不需要编码。因此,它们对于那些编码经验非常有限的专业人士(如业务分析师、办公室管理员、小企业主等)非常有用。
最近,我们看到初创公司战略性地选择了低代码软件开发方法,以减少开发开销并加快创新步伐。低代码和无代码平台会在后台自动生成所有所需的代码,同时为用户提供图形界面,以帮助他们设计应用程序。
一些低代码元素可以在复杂的集成开发环境中找到。例如,GUI 构建器。即使存在低代码和无代码平台,软件开发者仍然需要编写应用程序中更复杂的部分。
但随着低代码和无代码解决方案的发展,未来这可能变得不那么必要。我们已经看到无代码和低代码的机器学习解决方案和 AI。所以,软件开发者是否应该担心他们的工作安全?简短的回答是不用担心。
开发者仍然必要的原因
无代码和低代码不会完全消除对开发者的需求。然而,它将要求软件开发者重新调整和重新思考他们在技术中的角色。这个过程将涉及引入现成的解决方案来支持应用开发中的非独特方面。
未来的开发者将专注于尝试连接工具、解决方案和端点,而不是构建全新的复杂解决方案来支持业务需求或应用程序的想法。当然,仍会有新代码是你知识产权的一部分,但我们必须重新审视实现这些目标所需的步骤。
连接 API
大多数低代码和无代码平台仍然需要包括外部 API 和库来扩展应用程序的功能。例如,如果你需要你的应用程序获取当前的本地时间,你可以选择使用一个像WorldTimeAPI这样的网络服务。
如果你想构建一个具有网站监控功能的内部应用程序,你将需要访问一个可以实现此功能的 API。虽然许多低代码工具提供了建议或简便的 API 集成,但也存在局限性。API 通常需要配置,这需要经验和专业知识。
此外,你的低代码平台可能没有最适合你需求的解决方案。因此,如果开发者无法找到符合应用程序用例要求的外部解决方案,开发者有时必须自己编写 API 或插件。
无论如何,开发者将需要连接这些不同的部分并使其正常工作。这项技能对于具有多个移动组件的复杂业务环境至关重要。
配置和维护
即使是使用低/无代码构建的机器学习和数据处理引擎也需要配置和大量的数据。这将需要专家来寻找和管理正确的数据源和数据馈送。
即使是构建具有某些持久性的简单应用程序也需要使用计算机数据存储。本质上,你需要决定应用程序将如何存储其状态。这可能意味着配置应用程序以将数据存储在文件或数据库中(或两者的组合)。如果你将应用程序的持久性和一般数据存储在网上或云存储上,这会变得更加棘手。
此外,随着应用需求的变化或业务的增长,你可能会决定更改数据源。如果你之前构建了一个数据库,你可能希望将新的低代码创建的应用程序接入其中。在大多数情况下,所有这些条件都需要技术熟练的人来处理。
团队合作使梦想成真
软件开发方法论如 DevOps 和CI/CD旨在推动更快的软件部署和更新。然而,如果没有各种 IT 和软件开发资源的协作来确保软件的顺利发布和分发,它们的效果会大打折扣。
我们简要讨论了如何将工具和工作流连接将成为开发者未来的主要关注点。这仍然需要所有软件创作者之间的协作努力。你仍然需要不同的专家来尽可能优化地构建业务软件。大型关系数据库需要经验丰富的管理员来维护。
前端和网页需要 GUI 和 UX 设计师。你还需要后台开发人员来构建和连接后台逻辑。低代码开发平台声称提供集成所有这些元素的一体化解决方案。不幸的是,它们往往会产生一些非常粗糙的结果,无法与经验丰富的软件公司开发的软件相比。这可能在未来有所改变,但目前低代码平台最适合自动化和细节解决方案。
监控和管理规模
这与我们最后一点有关。业务需求随着时间的推移而发展变化,你的业务软件需求自然也会随之变化。让你的非 IT 员工去进行必要的软件更改效率并不高。这会让他们偏离主要职责,并给他们的工作负担增加不必要的压力。
扩展和特许经营应是每个中小企业的梦想。这将需要使用正确的工具和人员。使用无代码或低代码的方法在你处于建设阶段或连接各个点时可能很棒。然而,如果你计划尽可能高效地扩大业务,你将需要一些量身定制的选项,这些选项只能由经验丰富的软件开发人员提供,他们知道自己在做什么。
此外,这些软件开发人员将能够通过添加必要的更新来为你管理业务应用程序。你仍然可以保留一些低代码组件。然而,如果你希望进步,你将需要更强大的选项。
安全性
网络安全是使用低代码/无代码平台时最大的关注点。首先,许多低代码开发环境不给你访问生成的代码。这使你几乎没有可见性。
因此,你无法知道你的应用程序或低代码平台本身存在什么漏洞。在大多数情况下,你不知道它是如何安全地访问重要资产的,也没有很多方法可以改变这一点。
然后就是使用低代码创建安全应用程序的问题。低代码平台可能非常不灵活。在许多情况下,你必须使用低代码解决方案提供的加密。如果恶意行为者能够破解你的低代码平台用于创建应用程序安全元素的加密类型,这就会使每个人和公司都面临风险。
你最好的选择是请求一个软件材料清单,这将让你查看创建低代码平台所用的“成分”。你也可以选择那些以提供安全软件而闻名的供应商。
然而,在这方面,使用注重安全的软件开发人员会给你提供更多控制权。他们可以在构建你的软件时实施最新的网络安全标准和实践。大多数组织需要动态定制的安全解决方案。完全定制的软件开发可以确保更多的控制和更严格的测试。你可以全面了解软件中存在的所有组件。
结论
尽管 DIY 和公民开发者的普及尚未完全威胁到专业软件开发人员的职位安全。当然,随着低代码工具变得更加复杂,未来这一情况可能会发生变化。然而,即使如此,它们也不会完全取代软件开发人员的需求。它们只会迫使工作要求随着所有创新而变化和发展。然而,至少目前,低代码工具可以作为定制软件开发经验的补充,但它们还没有准备好完全取代它。
Nahla Davies 是一位软件开发者和技术作家。在全职从事技术写作之前,她还曾担任过多种令人兴奋的职位,其中包括在一家 Inc. 5000 级的体验品牌公司担任首席程序员,该公司客户包括三星、时代华纳、Netflix 和索尼。
更多相关主题
LSTMs 再次崛起:扩展 LSTM 模型挑战变换器的优势
原文:
www.kdnuggets.com/lstms-rise-again-extended-lstm-models-challenge-the-transformer-superiority

作者提供的图片
LSTM 最初由Sepp Hochreiter和Jurgen Schmidhuber于 1990 年代初期引入。最初的模型计算成本极高,直到 2010 年代中期,RNN 和 LSTM 才受到关注。随着数据量的增加和更好的 GPU 的出现,LSTM 网络成为语言建模的标准方法,并成为第一个大型语言模型的基础。这种情况一直持续到 2017 年基于注意力的变换器架构的发布。LSTM 逐渐被变换器架构取代,后者现在是所有最近的大型语言模型,包括 ChatGPT、Mistral 和 Llama 的标准。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能。
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作。
然而,由原始 LSTM 作者Sepp Hochreiter 最近发布的 xLSTM 论文在研究界引起了巨大轰动。结果显示其预训练结果与最新的 LLMs 进行了比较,并且提出了一个问题:LSTM 是否可以再次在自然语言处理领域取得突破。
高级架构概述
原始的 LSTM 网络有一些主要的局限性,这些局限性限制了它在更大上下文和更深层模型中的可用性。具体来说:
-
LSTM 是顺序模型,这使得训练和推理难以并行化。
-
他们的存储能力有限,所有信息必须压缩到一个单独的单元状态中。
最近发布的 xLSTM 网络引入了新的 sLSTM 和 mLSTM 模块,以解决这些不足之处。让我们从整体上了解一下模型架构,并看看作者采用了什么方法。
原始 LSTM 的简短评述
LSTM 网络使用了隐藏状态和单元状态来解决普通 RNN 网络中的梯度消失问题。他们还添加了忘记、输入和输出的 sigmoid 门来控制信息流动。方程如下:
图片来源于 论文
细胞状态(ct)经过 LSTM 单元时经过了微小的线性变换,帮助在较长的输入序列中保持梯度。
xLSTM 模型在新模块中修改了这些方程,以补救模型已知的局限性。
sLSTM 模块
该模块修改了 sigmoid 门,并对输入门和遗忘门使用了指数函数。正如作者所引述的,这可以改善 LSTM 中的存储问题,并且仍然允许多个记忆单元在每个头内混合记忆,但不跨头。修改后的 sLSTM 模块方程如下:
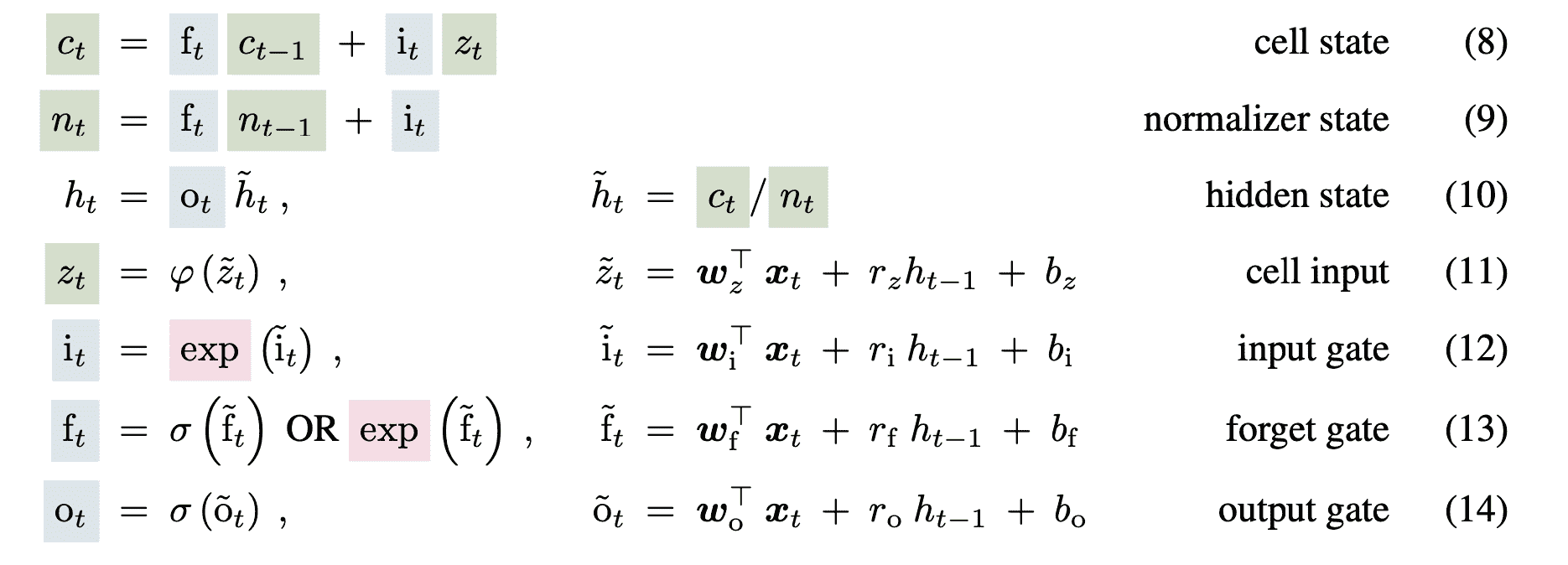
图片来源于 论文
此外,由于指数函数可能导致大值,门值使用对数函数进行归一化和稳定。
mLSTM 模块
为了解决 LSTM 网络中的并行性和存储问题,xLSTM 将细胞状态从 1 维向量修改为 2 维方阵。他们存储了作为键和值向量的分解版本,并使用与 sLSTM 模块相同的指数门控。方程如下:
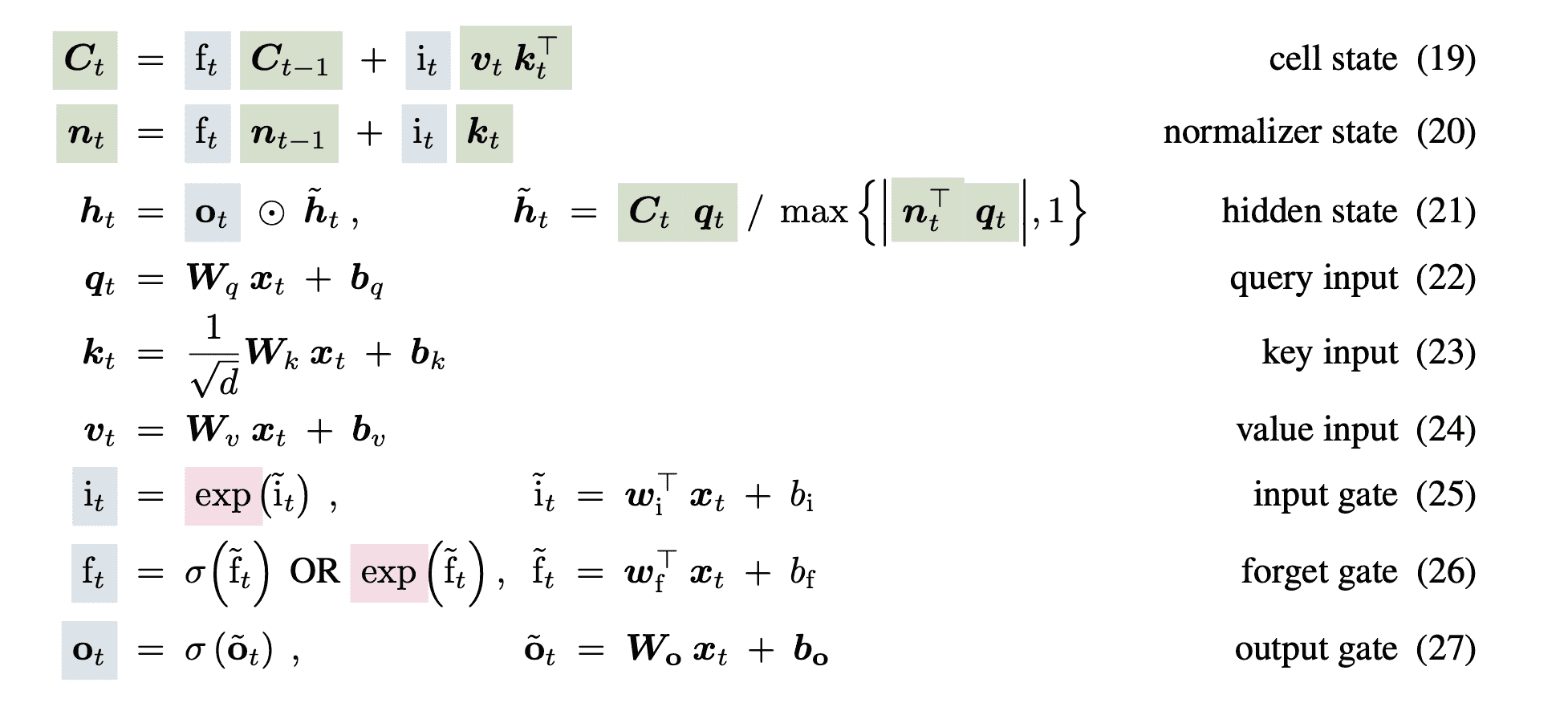
图片来源于 论文
架构图
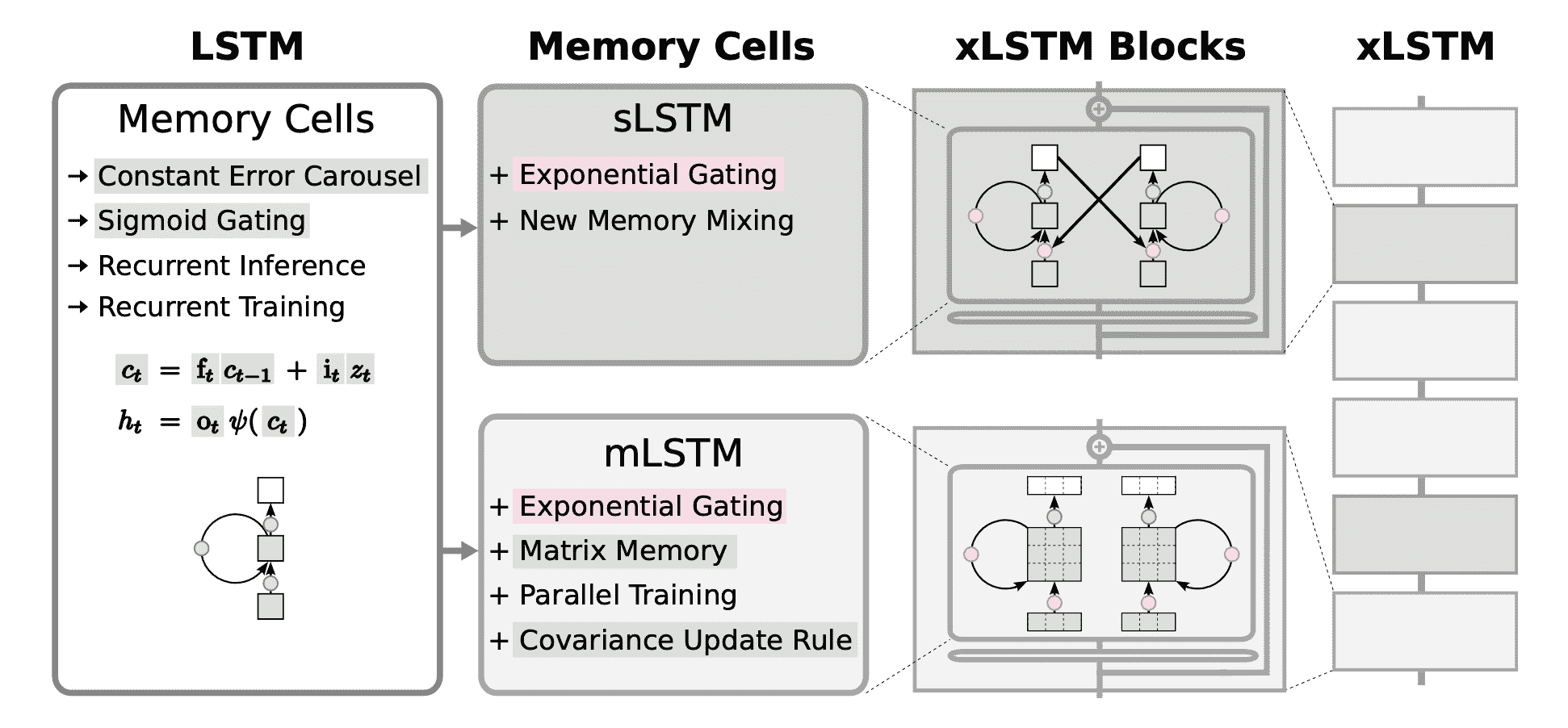
图片来源于 论文
整体 xLSTM 架构是 mLSTM 和 sLSTM 模块按不同比例顺序组合而成。如图所示,xLSTM 模块可以具有任意记忆单元。不同的模块通过层归一化堆叠在一起,形成深度残差网络。
评估结果与比较
作者在语言模型任务上训练 xLSTM 网络,并将训练模型的困惑度 (越低越好) 与当前的基于 Transformer 的 LLMs 进行比较。
作者首先在 SlimPajama 的 15B 令牌上训练模型。结果表明,xLSTM 在验证集上的困惑度得分最低,优于所有其他模型。
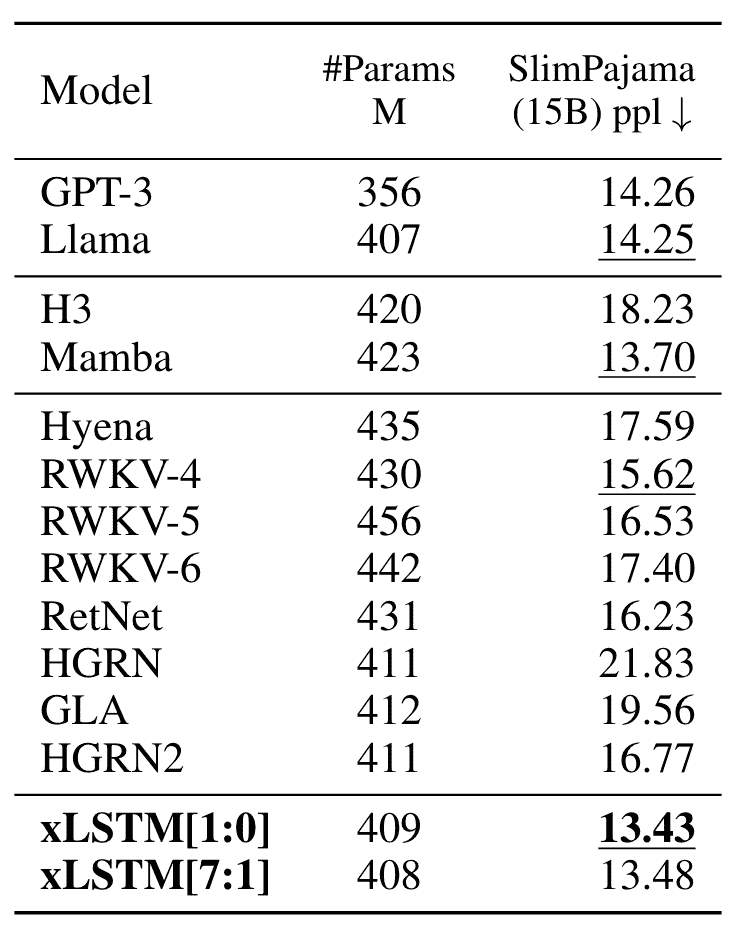
图片来源于 论文
序列长度外推
作者还分析了测试时序列长度超过模型训练时上下文长度的表现。他们在 2048 的序列长度上训练了所有模型,下面的图展示了随着令牌位置变化的验证困惑度:
图片来源于 论文
图表显示,即使对于更长的序列,xLSTM 网络仍能保持稳定的困惑度得分,并在更长的上下文长度中表现优于其他任何模型。
扩展 xLSTM 到更大模型尺寸
作者进一步在 300B 个来自 SlimPajama 数据集的标记上训练模型。结果表明,即使对于更大的模型,xLSTM 的扩展性也优于当前的 Transformer 和 Mamba 架构。
图片来源于论文
总结
这可能很难理解,不过没关系!尽管如此,你现在应该明白为什么这篇研究论文最近受到了如此关注。它的表现至少与近期的大型语言模型一样好,甚至更优。已证明它可以扩展到更大的模型,并且可以成为所有近期基于 Transformers 构建的 LLMs 的严肃竞争者。只有时间会证明 LSTMs 是否会重新获得辉煌,但现在我们知道 xLSTM 架构在挑战著名的 Transformers 架构的优势。
Kanwal Mehreen** Kanwal 是一位机器学习工程师和技术作家,对数据科学以及人工智能与医学的交叉领域充满深厚的热情。她共同撰写了电子书《利用 ChatGPT 最大化生产力》。作为 2022 年亚太地区 Google 一代学者,她倡导多样性和学术卓越。她还被誉为 Teradata 技术多样性学者、Mitacs 全球研究学者和哈佛 WeCode 学者。Kanwal 是变革的热心倡导者,创办了 FEMCodes 以赋能 STEM 领域的女性。
更多相关话题
令人惊叹的低代码机器学习功能与新的 Ludwig 更新
原文:
www.kdnuggets.com/2021/06/ludwig-update-includes-low-code-machine-learning-capabilities.html
评论

图片来源:Ludwig
我最近启动了一个新的新闻通讯,专注于 AI 教育,已经有超过 50,000 名订阅者。TheSequence 是一个不含废话(即没有炒作,没有新闻等)的 AI 专注型新闻通讯,阅读时间为 5 分钟。目标是让你了解最新的机器学习项目、研究论文和概念。请通过下面的订阅试试看:
如果你关注这个博客,你会知道我非常喜欢 Ludwig 开源项目。最初由 Uber 孵化,现在成为 Linux AI Foundation 的一部分,Ludwig 提供了当前市场上最好的低代码机器学习(ML)堆栈之一。上周,Ludwig 的 0.4 版本已开源,并包含一组酷炫的功能,这些功能可能使其在实际机器学习解决方案中更具优势。
什么是 Uber Ludwig?
从功能上讲,Ludwig 是一个框架,用于简化选择、训练和评估给定场景的机器学习模型的过程。考虑配置而不是编码机器学习模型。Ludwig 提供了一组可以组合在一起创建针对特定需求优化的端到端模型的模型架构。概念上,Ludwig 是基于一系列原则设计的:
-
无需编码: 不需要编码技能即可训练模型并使用其进行预测。
-
通用性: 一种基于数据类型的深度学习模型设计的新方法,使工具可以用于许多不同的用例。
-
灵活性: 经验丰富的用户对模型构建和训练有广泛的控制,而新手会发现它易于使用。
-
可扩展性: 易于添加新的模型架构和新的特征数据类型。
-
可理解性: 深度学习模型的内部结构通常被认为是黑箱,但我们提供标准可视化来理解其性能并比较其预测。
一种适用于一切机器学习的声明性体验
Ludwig 的发展轨迹专注于使基于配置的声明性模型能够与当前市场上的顶级机器学习堆栈互动。从这个角度来看,Ludwig 为希望在解决方案中利用最佳机器学习框架的数据科学团队提供了一个简单且一致的体验。
图片来源:Ludwig
Ludwig 0.4
Ludwig 新版的重点是简化 MLOps 实践中的声明式模型。从这一角度来看,Ludwig 0.4 包含了一系列功能,可能会简化在实际解决方案中实现 MLOps 管道的过程。让我们来回顾几个:
1) Ludwig 与 Ray
到目前为止,我最喜欢的功能是与 Ray 平台的集成。Ray 是一个高度可扩展的机器学习训练和优化过程的完整堆栈之一。在 Ludwig 0.4 中,数据科学家可以通过几行配置代码,将训练工作负载从单个笔记本电脑扩展到大型 Ray 集群。
2) 使用 Ray Tune 进行超参数搜索
Ray Tune 是 Ray 平台的一个组件,它允许在大型节点集群中进行分布式超参数搜索。Ludwig 0.4 集成了 Ray Tune,支持如 基于种群的训练、贝叶斯优化 和 HyperBand 等分布式超参数搜索算法。
3) 使用 TabNet 进行声明式表格模型
TabNet 是用于表格数据的顶级深度学习框架之一,具有前沿的注意力架构。Ludwig 的新版本通过添加新的 TabNet 组合器,支持表格特征转换和注意力机制,提供了一种声明式的表格模型体验,以实现最先进的性能。
4) 使用 MLflow 进行实验跟踪和模型服务
MLflow 正迅速成为最受欢迎的机器学习实验跟踪和模型服务平台之一。Ludwig 0.4 通过单一命令行实现基于 MLflow 的实验跟踪。此外,新版本的 Ludwig 可以通过简单的命令行语句将 ML 模型部署到 MLflow 注册表中。
原文。经许可转载。
相关内容:
-
DeepMind 想要重新构想机器学习中最重要的算法之一
-
用于解释和比较机器学习模型的仪表板
-
机器学习数据集选择的九大致命错误
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
相关话题
机器与深度学习汇编开源书
原文:
www.kdnuggets.com/2021/09/machine-deep-learning-open-book.html
评论
作者:Ori Cohen,AI/ML/DL 专家、研究员、数据科学家。

机器与深度学习汇编的部分主题列表。
将近一年前,我宣布了机器与深度学习汇编,这是一个我过去四年一直在编写的Google 文档。ML Compendium 包含了超过 500 个主题,总共有 400 多页。
今天,我宣布汇编完全开放。现在它是一个GitBook 和GitHub(请给它加星标!)上的项目。我相信知识共享,这个汇编将始终对所有人免费。
我将这个汇编视为一个门户,它是各种熟练程度人士、行业数据科学家和学术界的一个常访问资源。这个汇编将为你节省无数的搜索时间,并筛选出可能无用的文章。
汇编包括约 500 个主题,其中包含我阅读的各种总结、链接和文章,这些文章涉及我认为有趣或需要学习的主题。它包括了现代机器学习算法、大多数统计学、特征选择和工程技术、深度学习、自然语言处理、音频、深度和经典视觉、时间序列、异常检测、图形、实验管理等。此外,战略主题,如数据科学管理和团队建设,以及其他关键主题,如产品管理、产品设计和从数据科学角度看的技术栈,也被突显出来。
请记住,这是一项持续进行中的工作,涉及各种主题。如果你觉得有些内容需要更改,你现在可以通过 GitBook、GitHub 或联系我来轻松贡献。
GitBook
ML Compendium 是一个 GitBook 上的项目,这意味着你可以作为 GitBook 作者进行贡献。使用内部编辑器来编写和编辑内容既简单又直观,尤其是与通过 GitHub 拉取请求的高级选项相比。
你可以访问mlcompendium.com 网站或直接访问汇编“书”。如图 1 所示,左侧是主要主题,右侧是每个主要主题中的子主题,更不用说搜索功能比以前使用 CTRL-F 在原始文档中的方法更为先进。
图 1:机器与深度学习汇编与 GitBook 界面。
以下是两个可能引起你兴趣的话题,图 2 所示的自然语言处理(NLP)页面,以及 图 3 所示的深度神经网络(DNN)页面。
图 2:自然语言处理。
图 3:深度神经网络。
GitHub
如果你想贡献内容,你也可以使用 GitHub(图 4),请将内容放置在适当的主题下,然后创建一个新的分支并发起拉取请求。最后,如果你喜欢这个项目,别忘了给它‘Star’。
以下是使用 GitHub 贡献的简单说明:
-
git branch mybranch
-
git switch mybranch
-
添加你的内容
-
git add the-edited-file
-
git commit -m “my content”
-
git push
-
通过访问此链接创建拉取请求:
github.com/orico/stateofmlops/pull/new/***mybranch***
图 4: mlcompendium.com GitHub 项目。
.
原文. 经许可转载。
简介: Ori Cohen 博士 拥有计算机科学博士学位,专注于机器学习。他是 ML & DL 汇编以及 StateOfMLOps.com 的作者。他是 New Relic TLV 的首席数据科学家,从事 AIOps & MLOps 领域的机器学习和深度学习研究。
相关:
我们推荐的三大课程
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关主题
机器学习的 7 张图片
原文:
www.kdnuggets.com/2014/03/machine-learning-7-pictures.html
评论由 Deniz Yuret, 2014 年 2 月。
我发现自己在解释基础机器学习概念时,总是回到几个相同的图片。下面是我认为最具启发性的列表。
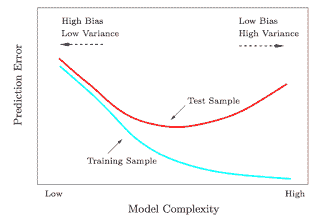 1. 偏差与方差权衡 - 测试和训练误差: 为什么较低的训练误差并不总是好事:ESL 图 2.11。测试和训练误差作为模型复杂度的函数。
1. 偏差与方差权衡 - 测试和训练误差: 为什么较低的训练误差并不总是好事:ESL 图 2.11。测试和训练误差作为模型复杂度的函数。
2. 欠拟合与过拟合: PRML 图 1.4。具有不同阶数 M 的多项式图,如红色曲线,拟合到由绿色曲线生成的数据集。
3. 奥卡姆剃刀 ITILA 图 28.3。这个图给出了为什么复杂模型可能更不可能的基本直觉。横轴表示可能数据集 D 的空间。贝叶斯定理根据模型预测发生的数据的程度来奖励模型。这些预测通过 D 上的归一化概率分布来量化。给定模型 Hi 的数据概率 P(D | Hi)称为 Hi 的证据。简单模型 H1 仅做有限范围的预测,通过 P(D|H1)表示;而更强大的模型 H2,例如拥有比 H1 更多的自由参数,可以预测更多种类的数据集。然而,这意味着 H2 对区域 C1 中的数据集的预测不如 H1 强。如果两个模型分配了相等的先验概率,那么如果数据集落在区域 C1 中,较弱的模型 H1 将是更可能的模型。
4. 特征组合 (1) 为什么集体相关的特征可能看起来个别无关,以及 (2) 为什么线性方法可能会失败。来自 Isabelle Guyon 的[特征提取幻灯片](http://clopinet.com/isabelle/Projects/ETH/)。
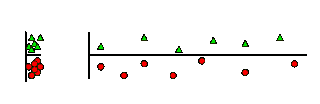 5. 无关特征: 为什么无关特征会影响 kNN、聚类和其他基于相似度的方法?左侧的图显示了在纵轴上分隔良好的两个类别。右侧的图添加了一个无关的横轴,这破坏了分组,使许多点成为对立类别的最近邻。
5. 无关特征: 为什么无关特征会影响 kNN、聚类和其他基于相似度的方法?左侧的图显示了在纵轴上分隔良好的两个类别。右侧的图添加了一个无关的横轴,这破坏了分组,使许多点成为对立类别的最近邻。
 6. 非线性基函数 非线性基函数如何将一个没有线性边界的低维分类问题转化为具有线性边界的高维问题。
6. 非线性基函数 非线性基函数如何将一个没有线性边界的低维分类问题转化为具有线性边界的高维问题。
 7. 判别式与生成式
7. 判别式与生成式
来自支持向量机教程幻灯片 by Andrew Moore:一个一维非线性分类问题,通过输入 x 转化为一个 2 维问题 z=(x, x²),可以线性分隔。
查看更多机器学习图片:www.denizyuret.com/2014/02/machine-learning-in-5-pictures.html
Deniz Yuret是土耳其伊斯坦布尔科克大学的计算机工程副教授,在人工智能实验室工作。他曾在 MIT AI 实验室工作,并共同创办了Inquira。
更多相关主题
机器学习概述:分类
原文:
www.kdnuggets.com/2017/07/machine-learning-abstracts-classification.html
由纳伦德拉·纳思·乔希撰写,卡内基梅隆大学。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
是否曾申请过信用卡并在几秒钟内获得批准?
是否读过关于银行欺诈检测的文章?
是否曾想过你的电子邮件如何过滤垃圾邮件?
是否曾好奇过相机是如何检测面部的?
一切都是分类
分类是将一些项目归类到预定义的类别或“类”中的过程。
即使机器这样做也是完全一样的。
让我们深入了解一下。
怎么做?
人类是如何执行分类任务的?假设你想处理掉家里的一些旧物品。你查看每个物品并决定是否要丢弃它。
你正在将每个项目“分类”到两个“类别”中:“丢弃”和“保留”。
让我们尝试理解一下你会考虑哪些因素来决定是否丢弃某个项目。可能的例子有:
-
你将来是否需要它?
-
它是否很贵?
-
是否可以作为二手物品转送给别人?
-
它是否具有 sentimental value?
你考虑的这些东西就是“特征”。
计算机怎么样?
计算机也以相同的方式运作。一个典型的分类算法会使用这些特征来确定如何对特定项目进行分类。
正式定义中,每个项目被称为“输入向量”。决定保留或丢弃每个项目的过程被称为该项目的“标签”。你需要提供一些示例给分类算法,让它“学习”哪些项目应该丢弃,哪些项目应该保留。这种学习方式称为“监督学习”,因为我们通过提供标签来监督算法的学习。在未来的文章中,我将详细讲解各种机器学习算法(监督学习、无监督学习、半监督学习和强化学习)。
给我一个例子,怎么样!
让我们考虑这个春季清理的例子。假设你有 10 个项目需要决定是保留还是丢弃。
你使用 7 项物品来“训练”你的分类算法。训练是使算法“学习”的过程。
我的“训练集”
经过仔细检查,我们可以推断并确认,我们保留物品只有在其具有 sentimental value 或者既在未来需要又昂贵时。
保留 = SENTIMENTAL_VALUE | (NEED_FUTURE & EXPENSIVE)
训练后,分类算法将学习到相同的内容,并尝试将其学到的应用于尚未见过的下一个物品,例如,物品 8。

物品 8
根据算法的学习,它将把物品 8 分类为保留。
我希望这能给你一个关于分类背后直觉的大致了解。在下一篇文章中,我将讨论不同类型的分类算法。
剧透提醒:
-
决策树
-
神经网络
-
支持向量机
简介:纳伦德拉·纳斯·乔希 是卡内基梅隆大学人工智能和机器学习的研究生,目前在迪士尼匹兹堡研究所进行研究实习。对自然语言、计算机视觉和深度学习有浓厚兴趣。
原文。经许可转载。
相关内容:
-
我应该使用哪种机器学习算法?
-
为什么选择人工智能和机器学习?
-
机器学习速成课程:第一部分
更多相关话题
机器学习摘要:决策树
原文:
www.kdnuggets.com/2017/08/machine-learning-abstracts-decision-trees.html
由纳伦德拉·纳斯·乔希,卡内基梅隆大学。

是存在还是不存在,这是个问题?但真的是吗?或者真的不是吗?天啊,这真是令人上瘾,不是吗?但再说一次,是吗?
决策树学习是用于分类和回归目的的经典机器学习算法。
回归是预测连续值的过程,与分类中预测离散类标签相对。
决策树的基本直觉是将所有可能的决策路径映射成一棵树。
一棵显示乘客在Titanic上生存情况的树(“sibsp”是船上配偶或兄弟姐妹的数量)。树叶下的数字显示了结果的概率和叶子中的观察百分比。来源:维基百科
从根到树叶的每条路径表示一个决策过程。让我们尝试使用我们在前一部分分类中讨论的春季清理示例来深入分析和理解决策树。
我们的训练数据。
我们推测分类算法学习到的规则是
KEEP = SENTIMENTAL_VALUE | (NEED_FUTURE & EXPENSIVE)
因此,当前问题的决策树可能是这样的:
我们春季清理问题的决策树
解释一下,没人有时间去做这个吧?
让我们看看我们是如何进行决策树构建的过程。
决策树的构建涉及分裂。在我们的例子中,每个特征只有两个可能的值(“yes”和“no”)。因此,每个特征可以有两种分裂方式。
我们可以尝试将每个特征分割成两个,但那样会得到一个非常大且效率极低的树。
我们如何确保有一棵合理且好的树?
在每个层次分裂之前,我们会根据特征的分布评估所有特征,并决定哪个特征最适合分裂。更正式地说,哪个特征在分裂时提供了最高的信息增益。
信息增益定义为确定新输入实例是否应该被分类为“yes”或“no”所需的信息量,前提是该示例从根节点到达该节点。
你所说的“到达那个节点”是什么意思?
并非所有训练示例都到达树的所有部分。例如,考虑我们春季清理示例中的第 3 项。
它在我们的决策树根部被排除并分类为“KEEP”,并没有到达树的下层。

构建决策树有许多算法。我刚才提到的是 ID3 算法,这是一个基础算法。
还有一些高级算法,如 C4.5 算法、CART(分类与回归树)和 CHAID(卡方自动交互检测器)
谢谢大家,下次我将稍微讲讲无监督学习等相关内容。
个人简介: Narendra Nath Joshi 是卡内基梅隆大学人工智能和机器学习的研究生,目前在迪士尼研究匹兹堡实习。对自然语言、计算机视觉和深度学习有浓厚兴趣。
原文。转载已获许可。
相关:
-
机器学习摘要:分类
-
我应该使用哪种机器学习算法?
-
为什么选择人工智能和机器学习?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
为什么机器学习容易受到对抗性攻击以及如何解决这个问题
原文:
www.kdnuggets.com/2019/06/machine-learning-adversarial-attacks.html
评论
AI 安全辩论跟随领域内顶尖研究者及许多当今技术愿景者的脚步进行,例如支持生命未来研究所和机器智能研究所的人士。通过媒体,这一对话可能看起来像是在担忧那些将消灭人类的未来机器人。
然而,我们在实际问题中观察到有关如何轻易失去对我们 AI 创作的掌控的真实迹象,这些问题与设计不良的机器学习系统的不良行为相关。潜在的“AI 事故”之一就是对抗性技术的案例。这种方法以一个训练好的分类模型为例,该模型在识别输入时表现良好,与人类的分类方式相比。但随后出现一个新输入,其中包含微妙但恶意伪造的数据,这导致模型表现非常糟糕。令人担忧的是,这种糟糕的行为不是模型的统计性能下降。使用这样的操控输入,模型可能仍以非常高的信心分类对象,但分类结果不再是人类所预期的。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 加速进入网络安全职业的快车道
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
表现优异并赢得比赛的图像分类器已经被对抗性攻击所欺骗。如果你仔细查看这些场景,可能会发现一个有趣的发现。令人困扰的噪声基于模型的成本函数,这表明恶意攻击者需要手中掌握模型以弄清楚如何构建对抗输入。简单地保护模型免受攻击者的攻击可能是解决问题的直接方法。
不要急于行动。
2017 年,宾州州立大学的研究人员,包括 Nicolas Papernot 和 Goodfellow,展示了远程对抗攻击可以对被视为“黑箱”的机器学习算法进行——换句话说,无需访问模型的训练数据或代码。这种方法使用了可转移性的概念,即训练来误导一个模型的样本可能会误导另一个模型(即被攻击的目标模型)。
Papernot 的团队创建了局部图像分类器模型,并训练它们以查看修改样本如何导致错误分类。然后,他们将这些对抗样本(以人眼不可察觉的方式修改的停车标志图像)发送给通过亚马逊和谷歌的 API 访问的远程深度神经网络。这些棘手的图像也欺骗了远程模型。他们甚至报告了包括对抗性防御策略的误导性远程托管模型。
(想尝试用对抗样本破坏你的模型吗?试试由 Papernot 等人开发的cleverhans库。)
这一切都非常重要,我们该如何应对?如果攻击者能够控制(或混淆)例如,驾驶你自动驾驶车辆的计算机视觉模型的分类结果,而不需要直接访问代码,那么停车标志可能会被轻易地分类为让行标志。这样一来,准时到达工作地点或者安全到达就变得不那么可能。虽然这是一个 AI 开发者必须认识到的明确问题,但它仍然代表着一个明确的挑战,应该是可以处理和解决的。这只是人类巧妙地入侵其他人类系统以造成人类问题的一种方式,对抗这些问题依然需要人类的防御。
如果这种对抗样本的情况只是冰山一角呢?是否存在某种机器处理信息的内在机制?是否有超出人类感知的因素?
最近,麻省理工学院的一组研究人员发布了一项研究,假设先前对机器学习易受对抗性技术影响的观察是标准数据集中固有模式的直接结果。虽然这些模式对人类来说难以理解,但它们作为自然特征存在,主要被监督学习算法使用。
在这篇论文中,Andrew Ilyas 等人描述了数据集中存在的稳健特征和非稳健特征的概念,这些特征都为分类提供了有用的信号。回顾起来,当我们记得分类器通常只被训练以最大化准确性时,这可能并不令人惊讶。模型使用哪些特征来获得最高准确性——由人类监督标记确定——留给模型用蛮力来处理。对我们来说像人鼻的输入图像,在算法的角度下,只是与下巴的另一个 0 和 1 的组合。
为了展示这些人类可感知和不可感知的特征如何支持准确分类,麻省理工学院团队构建了一个框架,将特征分离到不同的训练数据集中。两者都经过训练,并能按预期进行分类。如图 1 所示,模型被发现以有意义的方式使用非稳健特征,就像使用稳健特征一样,尽管这些特征对我们来说看起来像是乱码信息。

图 1. 一只青蛙的图像被分解为“稳健”的特征,用于训练分类器准确识别为青蛙,以及“非稳健”的特征,这些特征也用于训练分类器准确识别青蛙,但当输入中包含对抗性扰动时则不适用。模型使用的这些非稳健特征是固有的图像特征,并非攻击者操控或插入的 [来自 Ilyas et al. 的许可]。
让我们再次明确这一点。
合法数据由对人类不可感知的特征组成,这些特征影响训练。这些看似与适当的人类分类无关的奇怪特征不是伪影或过拟合,而是自然发生的模式,单独就足以导致分类器的学习。
换句话说,算法可能会发现那些我们作为人类期望看到的有用分类模式。然而,其他模式也在被识别,它们对我们来说毫无意义——但它们仍然是支持算法进行良好分类的模式。
麻省理工学院的 Dimitris Tsipras 对他们的结果感到兴奋,称“它有力地证明了模型确实可以学习不可感知的良好泛化特征。”
虽然这些模式对我们看起来毫无意义,但机器学习分类器正在发现并利用它们。
面对对抗性输入(例如,新数据中的小扰动),这一套无意义的特征会崩溃,从而导致错误分类。现在,不仅仅是某个第三方攻击者将误导数据插入样本中,而是非稳健特征在真实数据中存在,使得分类器容易受到对手的挑衅。
回忆一下 Papernot 等人提到的可转移性概念,这些跨数据集存在的非鲁棒特性使得它们对其他模型训练出的对抗样本敏感。一个训练来攻破某个模型的对手很可能也会攻破另一个模型,因为它正干扰着两个模型中固有的非鲁棒特性。
因此,监督学习对抗对抗样本的脆弱性是算法如何看待数据的固有属性的直接结果。算法在处理任何特征模式时表现得很好,导向最佳准确率。如果一个对手干扰了它的分类结果,那么模型仍然认为它表现得相当好。结果与我们作为人类所感知的不一致,是我们的问题。
为了增加一点人性,Tsipras 说,“模型可能依赖于数据的各种特征,我们需要明确地对模型学习的内容施加先验。”
换句话说,如果我们希望创建在我们看来是可解释的模型,那么我们需要将我们期望的感知编码到训练过程中,而不是让算法依赖于其自身的非人类装置。
那么,如果算法看到的事物与我们人类不同,这有什么问题?这有什么意外之处吗?这令人害怕吗?这是我们不想看到的事情吗?
我们知道,机器学习处理世界的方式与我们不同。只需对比 NLP 中的基础概念,即单词的意义可以通过探索人类编写的文本中的邻近词汇(如 Word2vec)来提取,而不是通过记忆词典(如我们人类所做的)。我们应该已经意识到,运行在硅片上的算法以不同于大脑中突触的方式看待信息。
然而,正是这种替代性、尽管同样有效的观点,可能使得 AI 在意图上走上与人类不同的道路。这可能让我们失去控制。
根据 Ilyas 等人的研究,一个关键的关注点应该是将人类偏见嵌入到机器学习算法中,以便始终将其引导到我们期望的视角中。Tsipras 说,他们正在积极利用鲁棒性作为工具,以将模型偏向学习对人类更有意义的特征。
在开发和训练过程中通过包括先验来使我们的模型更符合人类的期望,可能是确保我们不失去对未来 AI 控制的关键起点。
因此,在你的下一个机器学习项目中,考虑保留一点“人性”。
…
本文引用的资源:
-
Amodei, D. 等. “AI 安全中的具体问题。” arXiv.org, 2016 年 6 月。
-
Tanay, T. “对抗样本的解释。” KDnuggets,2018 年 10 月。
-
Jain, A. “用对抗攻击破解神经网络。” KDnuggets,2019 年 3 月。
-
Papernot, N. 等. “针对机器学习的实际黑箱攻击。” arXiv.org,2016 年 2 月。
-
Papernot, N. 等. “机器学习中的可迁移性:从现象到使用对抗样本的黑箱攻击。” arXiv.org,2016 年 5 月。
-
Jost, Z. “机器学习安全性。” KDnuggets,2019 年 1 月。
-
Ilyas, A. 等. “对抗样本不是错误,它们是特性。” arXiv.org,2019 年 5 月。
相关:
更多相关话题
农业中的机器学习:应用与技术
原文:
www.kdnuggets.com/2019/05/machine-learning-agriculture-applications-techniques.html
评论
由 Sciforce 提供

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的 IT 组织
最近,我们讨论了智能农业的新兴概念,该概念通过高精度算法使农业变得更加高效和有效。驱动这一机制的是机器学习——这一科学领域赋予机器在没有严格编程的情况下进行学习的能力。它与大数据技术和高性能计算一起出现,为揭示、量化和理解农业操作环境中的数据密集型过程创造了新的机会。
机器学习贯穿整个种植和收获周期。它从种子被植入土壤开始——包括土壤准备、种子育种和水分测量——最终在机器人采摘时通过计算机视觉来确定成熟度。
让我们深入探讨农业如何在每个阶段受益于机器学习:
物种管理
物种育种
我们最喜欢的应用程序是如此合乎逻辑而又如此出乎意料,因为通常你会在后期阅读有关收成预测或环境条件管理的内容。
物种选择是一个繁琐的过程,需要搜索确定水和养分使用效果、适应气候变化、抗病性、以及营养成分或更好味道的特定基因。机器学习,特别是深度学习算法,利用数十年的田间数据来分析作物在不同气候中的表现以及在过程中发展出的新特性。基于这些数据,它们可以建立一个概率模型,预测哪些基因最有可能为植物提供有益的特性。
物种识别
虽然传统的人为植物分类方法是比较叶子的颜色和形状,但机器学习可以通过分析叶脉形态提供更准确、更快速的结果,因为叶脉携带了更多有关叶片属性的信息。

田间条件管理
土壤管理
对于从事农业的专家来说,土壤是一个异质的自然资源,具有复杂的过程和模糊的机制。仅土壤温度就可以提供有关气候变化对区域产量影响的见解。机器学习算法研究蒸发过程、土壤湿度和温度,以了解生态系统的动态以及对农业的影响。
水管理
农业中的水管理影响水文、气候和农业平衡。目前,最成熟的基于机器学习的应用与估算每日、每周或每月的蒸散发量相关,从而更有效地利用灌溉系统,并预测每日露点温度,这有助于识别预期的天气现象并估算蒸散发量和蒸发量。
作物管理
产量预测
产量预测是精准农业中最重要且最受欢迎的话题之一,因为它涉及产量绘图和估算、作物供应与需求的匹配以及作物管理。最先进的方法已远远超出了基于历史数据的简单预测,而是结合了计算机视觉技术,提供实时数据和对作物、天气及经济条件的全面多维分析,以最大限度地提升农民和人口的产量。
作物质量
准确检测和分类作物质量特征可以提高产品价格并减少浪费。与人类专家相比,机器可以利用看似无意义的数据和相互关系,揭示对作物整体质量起作用的新特性并加以检测。

疾病检测
无论在露天还是温室条件下,最常用的病虫害控制方法是均匀喷洒杀虫剂。为了有效,这种方法需要大量的杀虫剂,这导致了高昂的经济成本和显著的环境成本。机器学习作为精确农业管理的一部分,针对时间、地点和受影响的植物进行农业化学品的输入。
杂草检测
除了疾病,杂草是作物生产最重要的威胁。杂草防治最大的问题在于它们难以被发现和与作物区分。计算机视觉和机器学习算法可以以低成本且无环境问题和副作用地提高杂草的检测和区分能力。在未来,这些技术将驱动机器人来销毁杂草,从而减少对除草剂的需求。
牲畜管理
牲畜生产
与作物管理类似,机器学习提供了准确的预测和估计农业参数,以优化牲畜生产系统的经济效益,如牛肉和鸡蛋生产。例如,体重预测系统可以在屠宰日的 150 天前估计未来的体重,从而允许农民相应地调整饮食和环境条件。
动物福利
在现代环境下,牲畜越来越被视为不仅仅是食物容器,而是可以在农场中感到不快乐和疲惫的动物。动物行为分类器可以将它们的咀嚼信号与饮食变化的需求联系起来,并通过它们的运动模式,包括站立、移动、进食和饮水,来判断动物所承受的压力程度,并预测其对疾病的易感性、体重增加和生产能力。

农民的小助手
这是一种可以称为额外福利的应用:想象一个农民在深夜坐着,试图弄清楚下一步的作物管理措施。他是否现在可以卖更多的作物给当地生产者,还是去参加区域博览会?他需要有人来讨论各种选择,以便做出最终决定。为了帮助他,公司们正在开发专业的聊天机器人,这些聊天机器人能够与农民进行对话,并提供有价值的事实和分析。农民用的聊天机器人预计将比面向消费者的 Alexa 和类似助手更智能,因为它们不仅能够提供数据,还能够分析这些数据并就棘手的问题咨询农民。
模型背后
虽然阅读关于未来的内容总是令人着迷,但最重要的部分是铺平道路的技术。例如,农业机器学习并不是一种神秘的技巧或魔法,而是一套定义明确的模型,这些模型收集特定数据并应用特定算法以实现预期结果。
到目前为止,机器学习在农业中的分布并不均匀。主要,机器学习技术用于作物管理过程,其次是农业条件管理和牲畜管理。
文献综述显示,农业中最受欢迎的模型是人工神经网络(ANNs 和 DL)和支持向量机(SVMs)。
ANNs(人工神经网络)受到人脑功能的启发,代表了生物神经网络结构的简化模型,模拟复杂的功能,如模式生成、认知、学习和决策。这些模型通常用于回归和分类任务,在作物管理和杂草、疾病或特定特征的检测中证明了它们的有效性。ANNs 最近发展为深度学习,扩展了 ANN 在所有领域的应用,包括农业。
SVM(支持向量机)是构建线性分隔超平面的二分类器,用于对数据实例进行分类。SVM 可以用于分类、回归和聚类。在农业中,它们被用于预测作物的产量和质量以及畜牧业的生产。
更复杂的任务,如动物福利测量,需要不同的方法,例如在集成学习中的多分类器系统或贝叶斯模型——在贝叶斯推断的背景下进行分析的概率图模型。
尽管仍处于起步阶段,基于机器学习的农场已经在向人工智能系统演变。目前,机器学习解决方案解决个别问题,但随着自动数据记录、数据分析、机器学习和决策制定进一步整合成一个互联的系统,农业实践将变成所谓的知识驱动农业,这将有能力提高生产水平和产品质量。

简介:Sciforce 是一家总部位于乌克兰的 IT 公司,专注于基于科学驱动的信息技术开发软件解决方案。
原文。经许可转载。
相关:
-
2018 年最重要的机器学习/人工智能进展是什么?
-
值得密切关注的 6 个 AI 和机器学习领域
-
2018 年最有用的 6 个机器学习项目
更多相关话题
机器学习和人工智能行业现状
原文:
www.kdnuggets.com/2020/04/machine-learning-ai-industry.html
评论
由Ed Fernandez,董事会成员、顾问、早期阶段及初创公司风险投资。
从 2012 年到 2018 年,蓝筹技术公司为内部使用实施了定制构建的机器学习平台(即 Facebook 的 FBLearning、Uber 的 Michelangelo、Twitter 的 Cortex、AirBnB 的 BigHead),这些平台大多基于开源包,并且针对各自公司的特定用例进行了深度定制。
自那时以来,行业已经看到企业级机器学习平台解决方案的强劲演变,包括来自现有供应商(如 Amazon Sagemaker、Microsoft Azure ML、Google Cloud ML 等)和领域挑战者(如 DataRobot、H2O、BigML、Dataiku)的解决方案。现有供应商采用增量策略,其机器学习服务建立在现有云服务之上,作为另一应用层,而挑战者则采取了机器学习的本土方法。
随着机器学习的普及,许多企业正迅速转向现成的数据科学和机器学习平台,以加速上市时间、降低运营成本,并提高成功率(部署和运营的机器学习模型数量)。
鉴于当前只有一小部分机器学习项目、概念验证(PoC)和模型能够投入生产并实现有意义的投资回报率(ROI),机器学习平台和自动机器学习(Automated Machine Learning)正作为首选工具出现,以加快机器学习模型的快速原型制作和用例验证(ROI 验证)。
结论:
-
尽管过去几年包括公司对机器学习项目和倡议的显著和不断增长的投入,只有一小部分机器学习模型达到了生产阶段并且产生了实际成果。那些成功的模型在很多情况下已经证明是有利可图的。在大规模应用中,帕累托原则适用,20%的机器学习项目带来了 80%的收益,而许多概念验证(PoC)项目则被弃置或冻结以便后续改进。
-
证据表明,市场正接近一个转折点,越来越多的公司倾向于购买(而非自建)与机器学习平台和工具相关的解决方案,考虑现成供应商解决方案或混合方法与开源方案。
-
自动机器学习(AutoML)以及 API是机器学习平台的重要组成部分,用于提高模型快速原型制作、机器学习用例验证和部署能力。其基本原理是通过增加机器学习候选用例的数量和成功率(生产中的机器学习模型)来实现更好的投资回报率(ROI)。
-
数据(数量和质量 — 机器学习准备就绪)、机器学习技术债务、MLOps 与 DevOps 以及企业机器学习流程和技能仍然是采纳的主要障碍。尽管如此,传统的机器学习很快就会超越炒作周期的顶峰,预计在企业中的主流采用只有 2-3 年的时间。
-
未来演变:在未来十年,除了深度学习,预计机器学习平台将逐步融入知识表示、推理、规划和优化功能,为强大的人工智能铺平道路。
免责声明:在本帖的背景下,人工智能(Artificial Intelligence)一词特指构建机器学习驱动应用的能力,这最终自动化和/或优化业务流程,不应与正式意义上的强大人工智能混淆,(作者强调,‘这至少在本十年和/或下一个十年内不太可能发生’)。
总结
[1] 定义与背景(本帖)
机器学习平台定义 • 企业中的机器学习模型与应用作为一级资产 • 机器学习应用的工作流 • 机器学习算法概述 • 机器学习平台的架构 • 机器学习炒作周期更新
[2] 大规模采用机器学习
机器学习的问题 • 机器学习系统中的技术债务 • 多少模型算是太多模型 • 对机器学习平台的需求
[3] 机器学习平台市场
机器学习平台市场参考 • 早期采用者 • 自定义构建与购买:ROI 与技术债务 • 机器学习平台 • 供应商格局
[4] 自定义构建的机器学习平台
机器学习平台市场参考 — 更深入的了解 • Facebook — FBlearner • Uber — Michelangelo • AirBnB — BigHead • 机器学习平台化进入主流
[5] 从 DevOps 到 MLOps
DevOps <> ModelOps • 机器学习平台驱动的组织 • 领导力与问责制
[6] 自动化机器学习 — AutoML
扩展机器学习 — 快速原型与 AutoML • 供应商比较 • AutoML:OptiML
[7] 机器学习平台的未来演变
超越深度学习:知识表示、推理、规划与优化
1. 定义与背景
不存在单一的机器学习平台、产品或服务。该行业仍然非常分散,“机器学习平台”、“数据科学平台”或“人工智能平台”等术语经常被互换使用。
然而,从市场上不同的产品和服务中,确实出现了共同点,总结如下:

机器学习平台提供了构建机器学习解决方案(主要是预测和处方模型)所需的高级功能。
机器学习平台支持将这些解决方案融入到业务流程、周边基础设施、产品和应用程序中。
它支持多技能的数据科学家(以及其他相关人员,如机器学习工程师、数据分析师和业务分析师/专家)在数据和分析管道中的多个任务,包括以下所有领域:
机器学习工作流 — 资源分配百分比
-
数据摄取 • 数据准备与转换 • 数据探索与可视化
-
特征工程
-
模型选择、评估与测试(及 AutoML)
-
部署
-
监控与解释性
-
维护与 • 协作

机器学习平台作为工具、系统和服务的组合,能够进行实验和快速原型开发,但它们的投资回报率在企业运营和业务流程中体现,远超实验阶段。
参考资料:
Poul Petersen,端到端机器学习应用的解剖
www.slideshare.net/bigml/mlsev-anatomy-of-an-ml-application机器学习平台研究报告 Papis.io
企业机器学习与人工智能采纳框架*
机器学习平台及工具,以及它们的产品、机器学习模型和数据驱动应用程序,可以被视为一流的企业资产,鉴于它们在企业中的影响力和投资回报率。
麦肯锡全球人工智能调查 提供了关于企业自我报告的人工智能影响及其好处的最新概述。
然而,这不仅仅是技术问题。流程、优先级和人员(领导力与问责)在引入和成功部署机器学习驱动的应用程序和服务中也发挥着重要作用。
机器学习应用程序不仅在软件开发上有所不同,部署和集成它们与现有系统也证明是一个主要挑战。考虑到机器学习软件开发的众多差异,DevOps 无法充分处理 MLOps(机器学习操作)(更多细节见第五部分)。
机器学习算法
管理机器学习算法以及支持它们的计算和数据转换需求可以说是机器学习平台为数据科学家和领域专家解决的关键任务。能够快速实验和将不同算法应用于给定数据集对于验证任何用例(假设验证)至关重要。
精确地说,AutoML(自动化机器学习)为这一过程提供了进一步的自动化,创建许多具有不同算法的模型候选者,并评估其性能以建议给定预测目标的最佳模型选项。
机器学习算法 — 监督学习与非监督学习 (#MLSEV 感谢 BigML Inc)。
实际上,大多数企业中的机器学习用例(如营销、金融、人力资源、制造业等)不需要深度学习或神经网络算法,除非有特别的性能需求,或者在需要处理非结构化数据(如视频、图像或声音)的特定用例中。
几乎 80-90% 的用例利用了传统的机器学习算法,如线性回归、逻辑回归、随机森林或集成方法,这些方法提供了可靠的结果并进一步解释了相对于更不透明的神经网络方法的可解释性。
Kaggle 的调查涵盖了近 20K 名受访者(数据科学家占据了重要部分),是监控算法使用情况的良好代理:
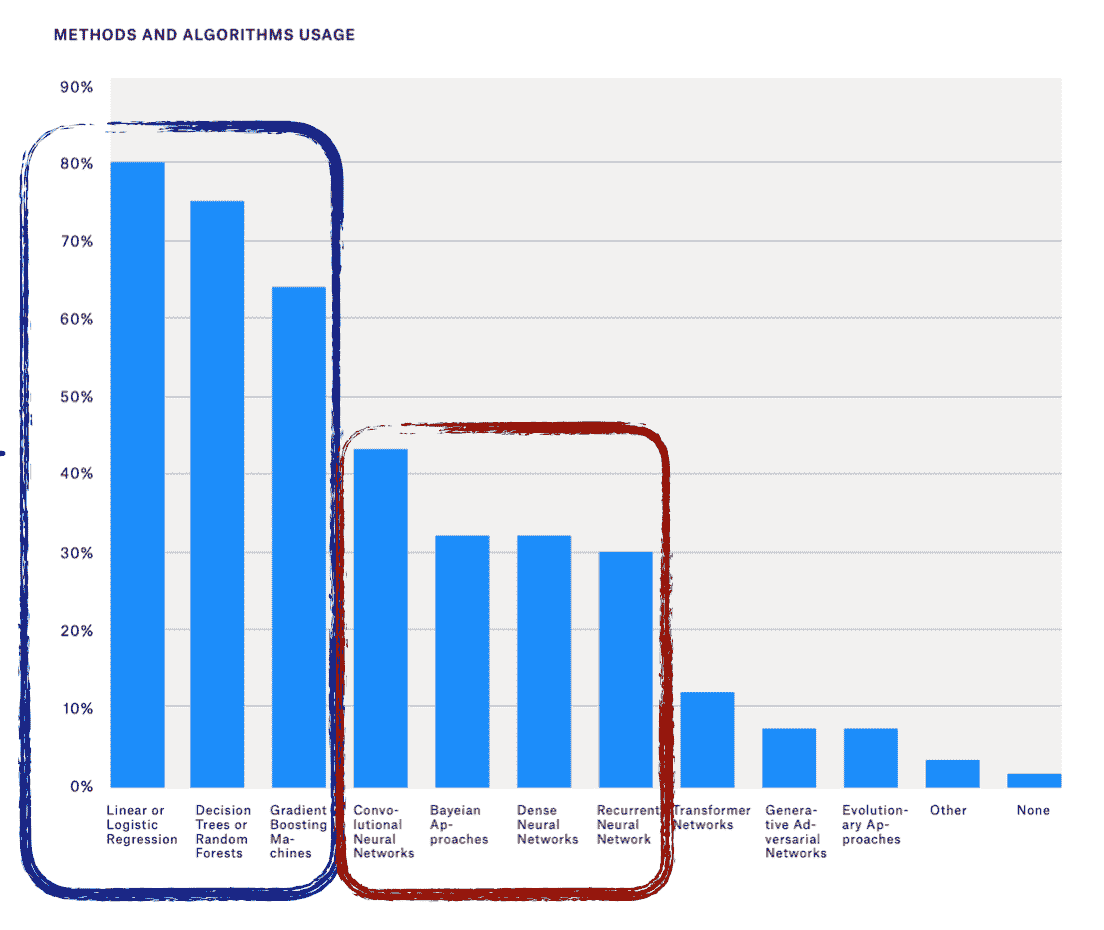
蓝色框:传统机器学习算法 — 红色框:CNN、RNN、DNN 和贝叶斯 — 来源:Kaggle · 数据科学与机器学习现状 2019。
参考资料:
Kaggle 的数据科学与机器学习现状调查
www.kaggle.com/kaggle-survey-2019麦肯锡 — 分析时代
机器学习平台架构
对于定制构建的机器学习平台,开源软件包和技术一直是首选(例如,Uber 的案例:HDFS、Spark、Samza、Cassandra、MLLib、XGBoost 和 TensorFlow),决定了大部分底层架构。
需要解决的用例和实时与静态数据建模的需求是影响平台架构的其他因素。Uber 服务的实时需求(例如,预测乘车时间)与 AirBnB(例如,推荐系统)和 FICO(例如,信用评分)在访问、处理数据需求和预测时间上有很大不同,因此具有非常独特的架构需求。
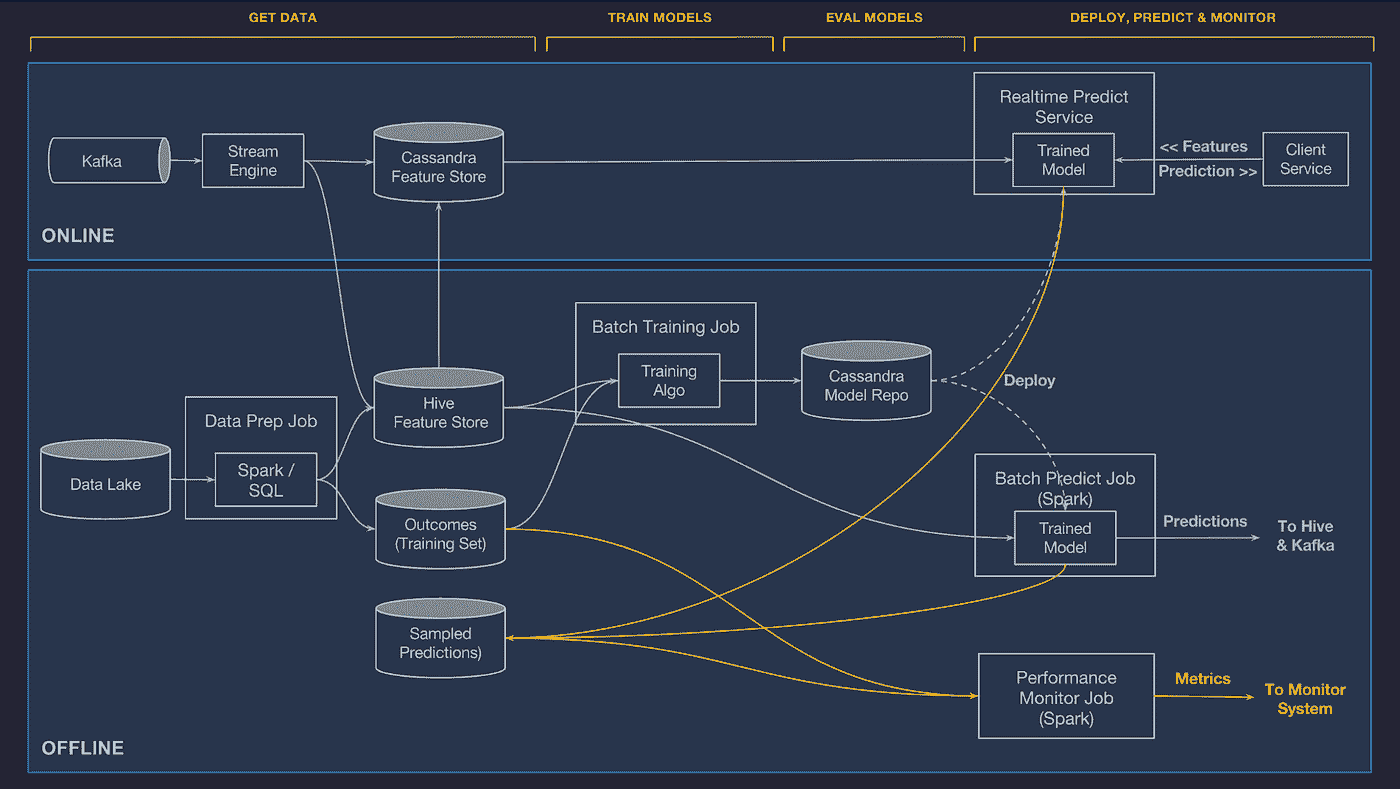
Uber 的机器学习平台 — Michelangelo,来源:Uber 工程 eng.uber.com/michelangelo-machine-learning-platform/。
例如,在 Uber 的案例中,在线部署的模型无法访问存储在 HDFS 中的数据,这使得从生产在线数据库中检索关键特征变得困难(例如,查询 UberEATS 订单服务以计算某餐厅在特定时间段内的平均餐前准备时间)。
Uber 的解决方案是预计算并在 Cassandra 中存储所需的特征,以便在预测时能够满足延迟要求(来源:Uber 工程 — Michelangelo eng.uber.com/michelangelo-machine-learning-platform/)。
商业 ML 平台,与定制构建的开源平台不同,旨在对大量多样化的 ML 问题和用例进行概括。它们的架构需要支持关键功能,同时通过抽象层允许足够的定制:
-
基础设施的自动部署和自动扩展(云端、混合和本地)——分布式
-
API——RESTful ML 服务——程序化 API 化和集成
-
高级特征工程 ——DSL
-
算法和模型的程序化使用
-
通过程序化自动化定制 ML 工作流 ——DSL
-
前端:可视化和界面
-
开发工具:绑定(Python、R、Java、C)、库、CLI 工具
DSL 领域特定语言
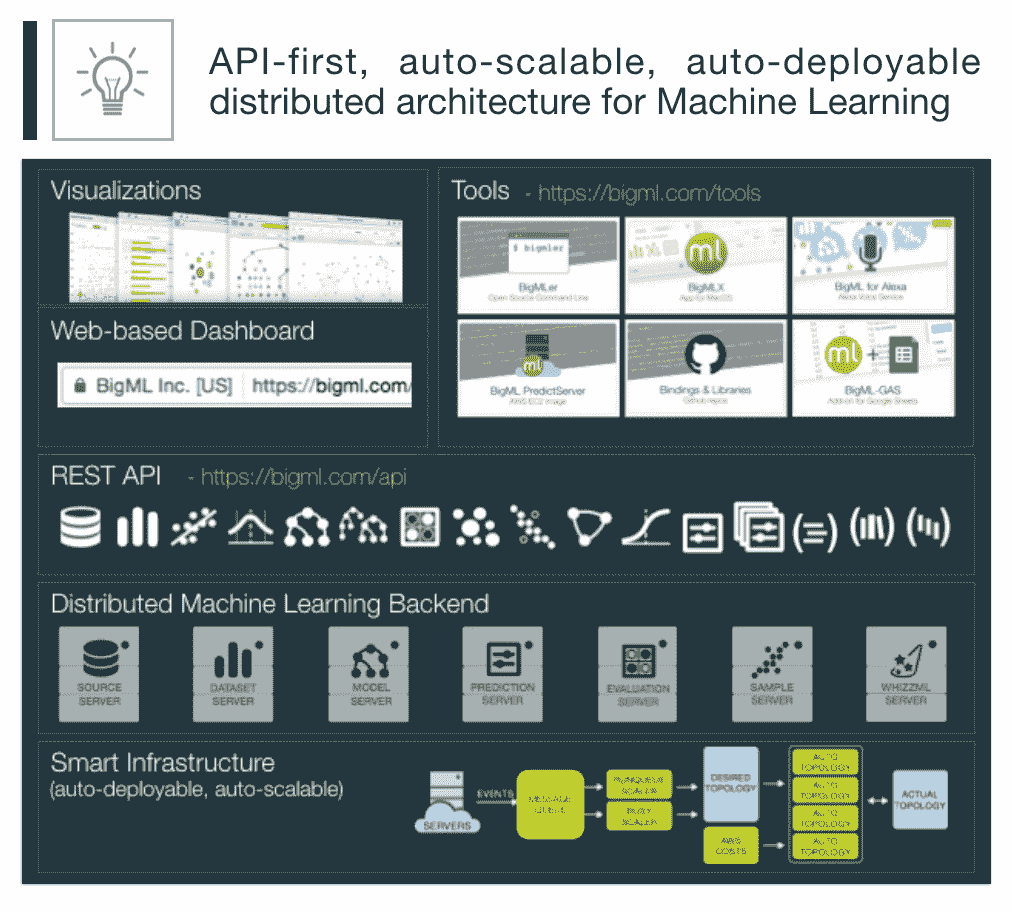
ML 平台架构概述(感谢 BigML Inc)。
APIs 和程序化自动化与 DSLs ——领域特定语言——值得另写一篇文章。特别是 AutoML,将在本系列文章的第七部分中进行讲解。
DSLs 在 APIs 和计算基础设施之上提供了必要的抽象层,以应对复杂性、自动化和定制化。DSL 方法的例子包括 Uber 的特征选择和转换 DSL (Uber’s ML Platform — Michelangelo) 和 BigML 的 ML 工作流自动化 DSL (WhizzML)。
参考资料:
Uber 工程 — Michelangelo
eng.uber.com/michelangelo-machine-learning-platform/Arxiv: 关于 DSLs 用于机器学习和大数据的调查
arxiv.org/pdf/1602.07637PAPIS.io 会议记录:机器学习 API 的过去、现在和未来
proceedings.mlr.press/v50/cetinsoy15.pdfWhizzML,一个用于 ML 工作流自动化的 DSL
bigml.com/whizzml
机器学习炒作周期的更新
随着企业和从业者超越 ML 实践的学习曲线,机器学习和深度学习技术已经经历并超越了炒作周期的高峰,迅速穿越“失望谷”(调整期望)。Gartner 最新的炒作周期报告对此进行了反映,并预测主流采用将在接下来的 2-3 年内发生。
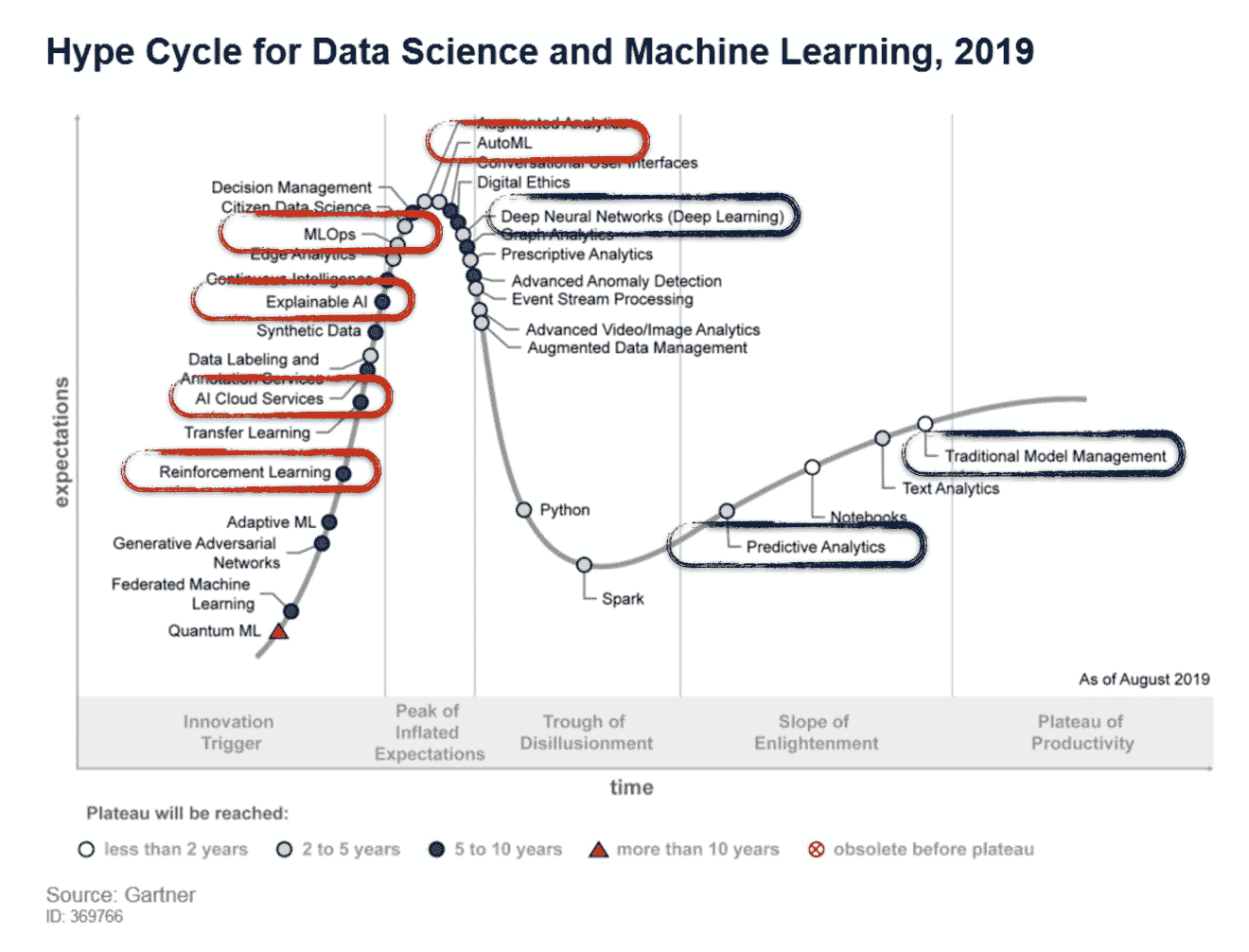
来源:Gartner 数据科学与机器学习 2019 年炒作周期。
随着趋势,新机器学习平台的功能,如 AutoML、MLOps、可解释人工智能或强化学习,正在进入炒作曲线,迅速变得过度炒作。这些新兴的机器学习技术仍然不成熟,还没有准备好进行主流或大规模采用。
自建与购买
近年来,市场已被划分为开源解决方案和行业解决方案。
从 2012 年到 2018 年,蓝筹科技公司实施了用于内部使用的定制机器学习平台(例如,Facebook 的 FBLearning、Uber 的 Michelangelo、Twitter 的 Cortex、AirBnB 的 BigHead,更多详细分析见第四部分)。
这些平台中的许多主要基于开源包,并且已被深度定制以适应这些公司的具体使用场景。
尽管开源包具有固有的免费特性(获取的成本效益)和几乎无限的定制能力,但开源的一个问题在于其相关的隐性技术债务,尤其是 Glue Code(更多细节见第二部分,请参阅 机器学习系统中的隐性技术债务。D. Sculley 等人,Google,NIPS 2015)。

正是配置、编排和整合不同开源包的成本(Glue Code)在长期中增加了成本,使得自建与购买的商业案例更倾向于行业解决方案。
行业内已经出现了企业级机器学习平台解决方案和机器学习即服务(MLaaS)的强劲发展,目前的提供者分为行业现有公司(如 Amazon Sagemaker、Microsoft Azure ML、Google Cloud ML 等)和挑战者(DataRobot、H2O、BigML、Dataiku 等)。
对于许多企业来说,一个重要的关键驱动因素是市场时间和竞争力。由于他们在传统的研发方法中难以扩大规模并成功将足够的机器学习模型投入生产,许多企业正在迅速转向现成的数据科学与机器学习平台,以加速市场进入,降低运营成本,并提高成功率(部署和运营的机器学习模型数量)。
参考资料:
机器学习系统中的隐性技术债务。D. Sculley 等人,Google,NIPS 2015
papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdfGartner 的 AI 热点周期
www.gartner.com/smarterwithgartner/top-trends-on-the-gartner-hype-cycle-for-artificial-intelligence-2019/
该帖子对应的配套幻灯片可通过以下链接获取 [在机器学习学校 #MLSEV 的演示文稿 - 3 月 26 日]
原文。经允许转载。
简介: Ed Fernandez (@efernandez) 是董事会董事、顾问、早期阶段及初创公司风投/私募股权 - 企业家,并在帕洛阿尔托的东北大学担任教职。
相关内容:
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 工作
相关话题
机器学习与人工智能:2017 年主要发展与 2018 年关键趋势
原文:
www.kdnuggets.com/2017/12/machine-learning-ai-main-developments-2017-key-trends-2018.html
评论
在 KDnuggets,我们努力跟踪行业、学术界和技术领域的主要事件和发展。我们还尽力展望未来的关键趋势。
为了总结 2017 年,我们最近向一些大数据、数据科学、人工智能和机器学习领域的领先专家征询了他们对 2017 年最重要发展的看法以及他们对 2018 年的关键趋势的预测。本文考虑了今年机器学习与人工智能的发展情况,并展望了 2018 年的可能趋势。

具体来说,我们向该领域的专家提出了以下问题:
“2017 年主要的机器学习与人工智能相关发展是什么?你认为 2018 年有哪些关键趋势?”
我们征求了众多个人的回应,并要求他们将回答控制在大约 200 字以内,尽管我们没有过于严格,允许有趣的回答稍长一些。
快速回顾一下,去年的趋势和预测 主要集中在以下主题:
-
AlphaGo 的成功
-
深度学习热潮
-
自动驾驶汽车
-
TensorFlow 对神经网络技术商品化的影响
要了解哪些发展被认为是今年最重要的,以及我们的专家认为机器学习与人工智能在 2018 年将走向何方,请阅读下面的贡献。
最后说明:没有这些专家的慷慨参与,我们无法呈现这些帖子。虽然并非我们请求的每个人都能够参与,但我们对能够参与的人表示感激。希望你们喜欢他们的见解。
Xavier Amatriain 是 Curai 的联合创始人兼首席技术官,曾担任 Quora 的工程副总裁和 Netflix 的研究/工程总监。
如果我要挑选今年的主要亮点,那一定是AlphaGo Zero (论文)。这种新方法不仅在一些最有前景的方向(如深度强化学习)中有所改进,而且还代表了一种范式转变,即这些模型可以在没有数据的情况下进行学习。我们最近还了解到,AlphaGo Zero 可以泛化到其他游戏如国际象棋。你可以在我的Quora 回答中了解更多关于我对这一进展的解读。
如果我们从人工智能的工程角度来看,今年开始时,Pytorch 获得了越来越大的关注,成为了 Tensorflow 的真正挑战者,特别是在研究领域。Tensorflow 迅速作出反应,发布了动态网络功能,即Tensorflow Fold。然而,大公司之间的“人工智能战争”还有许多其他战役,其中最激烈的一场发生在云计算领域。所有主要的服务提供商都大幅提升了他们在云端的人工智能支持。亚马逊在他们的 AWS 中展示了大量创新,例如最近推出的Sagemaker用于构建和部署机器学习模型。值得一提的是,较小的公司也开始参与其中。Nvidia 最近推出了他们的GPU 云,这有望成为训练深度学习模型的另一个有趣选择。尽管这些战斗不断,但看到行业在必要时能够团结起来也是值得欣慰的。新的ONNX神经网络表示标准化是实现互操作性的重要且必要的一步。
2017 年还见证了围绕人工智能的社会问题的持续(升级?)。埃隆·马斯克继续煽动我们离杀手机器人越来越近的想法,引起了许多人的不安。关于人工智能将在未来几年如何影响就业的问题也有了很多讨论。最后,我们还看到越来越多的关注集中在人工智能算法的透明度和偏见上。
有关 Xavier 对今年主要趋势的看法以及他对明年的期待,请查看他的年终总结。
乔治娜·科斯马 是诺丁汉特伦特大学科学与技术学院的高级讲师。
机器学习模型,特别是深度学习模型,对健康护理、法律系统、工程和金融行业等关键领域产生了重大影响。然而,大多数机器学习模型不易解释。理解一个模型如何得出预测结果在分析和诊断模型中尤为重要,在这些模型中,人类必须对模型提供的预测结果有足够的信任。重要的是,一些机器学习模型的决策必须符合法律和规定。现在是时候创建足够透明以解释其预测结果的深度学习模型了,特别是当这些模型的结果被用于影响或告知人类决策时。
佩德罗·多明戈斯是华盛顿大学计算机科学与工程系的教授。
- Libratus 在扑克中的胜利,扩展了 AI 在不完全信息游戏中的主导地位 (www.cmu.edu/news/stories/archives/2017/january/AI-beats-poker-pros.html)
- 自驾车和虚拟助手的竞争日益激烈,其中 Alexa 在虚拟助手领域表现突出。
- 谷歌、亚马逊、微软和 IBM 之间的云 AI 发展竞争。
- AlphaGo Zero 很出色,但并非突破性进展。自我对弈是机器学习中最古老的想法之一,人类在掌握围棋时需要的游戏数远远少于 500 万局。
阿吉特·贾奥卡是首席数据科学家,也是牛津大学物联网数据科学课程的创始人。
2017 年是 AI 的年头。2018 年将是 AI 成熟的年份。我们已经可以看到,AI 正在以更具“系统工程/云原生”的视角展现复杂性——如 h2o.ai 这样的公司简化了 AI 部署的复杂性。
我看到 AI 在工业物联网、零售和医疗保健领域越来越多地被用于竞争优势,这将带来更大的颠覆。我还看到 AI 在企业各级别迅速部署(这同样带来了新机会,但也导致了更多岗位的流失)。因此,我们已经超越了讨论 Python 与 R 以及猫咪的阶段!
我认为 AI 正在通过嵌入式 AI(即跨越企业和物联网的数据科学模型)融合传统企业和更广泛的供应链。
最后,懂得 AI/深度学习技术的数据科学家短缺的问题将继续存在,尤其是在工业物联网等传统行业之外。
尼基塔·约翰逊是 RE.WORK 的创始人。
2017 年在机器学习和 AI 方面取得了巨大进展,尤其是 DeepMind 最近的通用强化学习算法,在不到四小时的自我学习后击败了世界上最强的国际象棋程序。
我预计在 2018 年,我们将看到智能自动化渗透到从传统制造组织到零售、再到公用事业的各种公司。随着数据收集和分析的持续增加,企业范围的自动化系统策略将变得至关重要。这将使公司能够投资于人工智能的长期计划,并确保它成为未来增长和效率的优先事项。
我们还将看到自动化机器学习帮助让技术对非人工智能研究人员更加可及,并使更多公司能够将机器学习方法应用到他们的工作场所。
雨果·拉罗谢尔 是谷歌的研究科学家,并且是加拿大高级研究院机器与大脑学习计划的副主任。
我最兴奋和关注的机器学习趋势之一是元学习。元学习是一个特别广泛的总称。但今年,对我而言,最令人兴奋的是在少样本学习问题上的进展,它解决了从极少的样本中发现能很好泛化的学习算法的问题。Chelsea Finn 在今年初通过这篇博客文章很出色地总结了这个主题的早期进展:bair.berkeley.edu/blog/2017/07/18/learning-to-learn/。值得注意的是,在目前许多令人惊叹的机器学习博士生中,Chelsea Finn 无疑是今年最有成效和令人印象深刻的之一。
年底时,更多关于少样本学习的元学习研究成果被发布,涉及深度时间卷积网络(arxiv.org/abs/1707.03141)、图神经网络(arxiv.org/abs/1711.04043)等。我们还看到元学习方法应用于主动学习(arxiv.org/abs/1708.00088)、冷启动项目推荐(papers.nips.cc/paper/7266-a-meta-learning-perspective-on-cold-start-recommendations-for-items)、少样本分布估计(arxiv.org/abs/1710.10304)、强化学习(arxiv.org/abs/1611.05763)、层级强化学习(arxiv.org/abs/1710.09767)、模仿学习(arxiv.org/abs/1709.04905)等等。
这是一个激动人心的领域,我在 2018 年肯定会密切关注。
查尔斯·马丁 是一名数据科学家和机器学习人工智能顾问。
2017 年深度学习 AI 平台和应用出现了巨大的增长。年初,Facebook 发布了他们的 TensorFlow 竞争对手 PyTorch。Gluon、Alex、AlphaGo……进展不断。机器学习从特征工程和逻辑回归发展到阅读论文、实施神经网络和优化训练性能。在我的咨询实践中,客户寻求定制的物体检测、高级自然语言处理和强化学习。虽然市场和比特币上涨,人工智能却是一场静默的革命,零售末日引发了对人工智能将摧毁行业的真实担忧。公司希望转型。我们看到对人工智能指导的极大兴趣,包括技术和战略方面的指导。
2018 年肯定会成为全球人工智能优先经济的突破年。我们从欧洲、亚洲、印度,甚至沙特阿拉伯都有需求。全球需求将继续增长,中国和加拿大的人工智能进步,以及印度等国家从 IT 转向 AI 的情况也将推动这种增长。美国及海外的企业培训需求也很大。人工智能将带来巨大的效率提升,传统行业如制造业、医疗保健和金融业都将受益。人工智能初创公司将推出新产品并全面提高投资回报率。新技术,从机器人到自动驾驶汽车,将以更令人惊叹的进步令人惊艳。
这将是创新的伟大一年。如果你参与其中。
塞巴斯蒂安·拉施卡 是密歇根州立大学的应用机器学习和深度学习研究员、计算生物学家,同时也是 《Python 机器学习》 的作者。
在过去几年中,开源社区对新兴的深度学习框架进行了大量讨论。现在,这些工具已经有所成熟,我希望并期待看到一种不那么以工具为中心的方法,并且更多的精力会投入到开发和实施新颖的想法和应用上,特别是利用深度学习的应用。我期待看到更多令人兴奋的问题通过生成对抗神经网络和辛顿的胶囊网络来解决,这些都是今年的热门话题。
此外,正如你可能从我们最近关于给面部图像添加隐私的半对抗神经网络论文中猜到的那样,用户隐私在深度学习应用中是我非常关心的问题,我希望并期待这个话题在 2018 年得到更多关注。
布兰登·罗赫尔 是 Facebook 的数据科学家。
2017 年还因更多机器击败人类的成就而引人注目。去年,AlphaGo 通过击败世界顶尖的围棋选手,达到了智能发展的一个重要里程碑。今年,AlphaGo Zero 通过从零开始自我学习,超越了其前身。 (deepmind.com/blog/alphago-zero-learning-scratch) 它不仅击败了一个人类,还击败了全人类的围棋经验。在更实际的方面,现在一台机器在 Switchboard 基准测试中能够像人类一样转录电话对话。 (arxiv.org/abs/1708.06073)
然而,AI 的成就仍然狭窄而脆弱。即使在图像中改变一个像素也可能击败最先进的分类器。 (arxiv.org/pdf/1710.08864.pdf) 我预测 2018 年将会带来更具普遍性和鲁棒性的 AI 解决方案。几乎每个主要科技公司已经开始了人工通用智能的研究。这些团队及其早期成果将成为头条新闻。至少,“AGI”将取代“AI”成为年度流行词。
埃琳娜·沙罗娃是某投资银行的数据科学家。
2017 年主要的机器学习/人工智能相关发展是什么?
我看到越来越多的公司和个人将他们的数据和分析转移到基于云的解决方案中,同时对数据安全重要性的认识也急剧增加。
最大和最成功的科技公司一直在竞争,争取成为你的数据存储和分析平台。对数据科学家来说,这意味着他们开发的工具箱和解决方案正受到这些平台的交付能力和表现的影响。
2017 年全球出现了大量引人注目的数据安全漏洞。这是一个不容忽视的发展趋势。随着越来越多的数据迁移到第三方存储,对能够适应新威胁的更强大安全措施的需求将持续增长。
你在 2018 年看到哪些关键趋势?
确保遵守《全球数据保护条例》(GDPR)以及越来越多地需要应对机器学习系统的“隐藏”技术债务是我对 2018 年关键趋势的预测。GDPR 作为欧盟法规,具有全球影响力,所有数据科学家应该充分了解它如何影响他们的工作。根据谷歌的《NIPS’16 论文》,数据依赖性是昂贵的,随着公司创建复杂的数据驱动模型,他们将不得不仔细考虑如何解决这一成本。
塔玛拉·西佩斯是 Optum/UnitedHealth Group 的商业数据科学总监。
2017 年的主要发展和 2018 年的关键趋势:
- 深度学习和集成建模方法的力量继续展示其价值和优越性,相比其他机器学习工具,2017 年表现尤为突出。特别是深度学习,在各种领域和行业中的应用越来越广泛。
- 至于 2018 年的趋势,深度学习可能会用于从原始输入中生成新特征和新概念,取代手动创建或工程化新变量的需求。深度网络在检测数据中的特征和结构方面非常强大,数据科学家们也意识到无监督深度学习在这一方面可以释放的价值。
- 有效的异常检测也可能是未来的重点。异常和其他类型的稀有事件在许多行业的数据科学工作中都受到关注:入侵检测、金融欺诈检测、欺诈、浪费、滥用、医疗保健中的错误以及设备故障只是一些例子。检测这些稀有事件使得在这些领域中获得竞争优势成为可能。跟上这些稀有事件不断变化的性质,将是这一领域一个引人入胜且艰难的挑战。
瑞秋·托马斯 是 fast.ai 的创始人,也是 USF 的助理教授。
尽管没有像 Alpha Go 或翻转机器人那样引人注目,但我对 2017 年最兴奋的 AI 趋势是深度学习框架变得更加用户友好和易于使用。PyTorch(今年发布)对任何懂 Python 的人都很友好(主要由于其动态计算和面向对象设计)。即使是 TensorFlow 也朝着这个方向发展,通过将 Keras 集成到其核心代码库中,并宣布支持急切(动态)执行。使用深度学习的编码门槛在不断降低。我预计这种开发者可用性提高的趋势将在 2018 年继续。
第二个趋势是媒体对专制政府利用 AI 进行监控能力的关注增加。这种隐私威胁在 2017 年之前就存在,但最近才开始获得广泛关注。有关使用深度学习识别佩戴围巾和帽子的抗议者,或通过照片识别某人的性取向的研究,今年引起了更多媒体对 AI 隐私风险的关注。希望在 2018 年,我们能继续扩展关于 AI 伦理的讨论,不仅仅是埃隆·马斯克对邪恶超智能的担忧,还包括对监控、隐私以及性别和种族偏见编码的讨论。
丹尼尔·图克朗 是高级顾问。
2017 年是自动驾驶汽车和对话型数字助手的重要一年。这两种应用体现了深度学习如何将科幻变成现实。
但今年对机器学习和人工智能最重要的发展是对伦理、问责和可解释性的关注。埃隆·马斯克用他关于人工智能引发世界大战的末日预言引起了媒体的关注,而奥伦·艾齐奥尼和罗德尼·布鲁克斯等人对此进行了深思熟虑的反驳。尽管如此,我们仍面临来自机器学习模型中的偏见的明显威胁,例如 word2vec 中的性别歧视、算法刑事判决中的种族歧视,以及社交媒体评分模型的故意操控。这些问题并不新鲜,但机器学习的加速采用——特别是深度学习——使这些问题浮出水面,暴露给了公众。
我们终于看到可解释人工智能作为一个学科的出现,它将学术界、行业从业者和政策制定者聚集在一起。未来一年将加大对我们深度学习模型黑箱的揭示压力。
相关:
-
大数据:2017 年的主要进展及 2018 年的关键趋势
-
机器学习与人工智能:2016 年的主要进展及 2017 年的关键趋势
-
数据科学、机器学习:2017 年的主要进展及 2018 年的关键趋势
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
更多相关话题
哪种机器学习算法会在 2118 年使用?
原文:
www.kdnuggets.com/2018/02/machine-learning-algorithm-2118.html
comments
那么你脑海中闪现的答案是什么?随机森林、支持向量机、K 均值、K 最近邻,还是深度学习及其变体?

现在你们中的一些人可能会笑,说你怎么可能预测得这么远,预测 100 年后的事情简直疯狂。

是什么让你说回归将继续在 2118 年使用?
那么答案是林迪效应。是的,我用来预测的启发式方法就是林迪效应。
好的,下一个逻辑问题是什么是林迪效应?
林迪效应
维基百科将林迪效应定义为
林迪效应是一个概念,指的是一些非易腐物品(如技术或想法)的未来预期寿命与其当前年龄成正比,因此每一个额外的存活期都意味着更长的剩余寿命。
我最喜欢的作者之一纳西姆·尼古拉斯·塔勒布在他著名的书《反脆弱:从混乱中受益的事物》中定义了林迪效应如下。
如果一本书已经出版了四十年,我可以期望它再出版四十年。但是,主要的不同在于,如果它再存活一个十年,那么它将被期望再出版五十年。简而言之,这个规则告诉你为什么那些存在了很长时间的东西不像人一样“衰老”,而是“逆向衰老”。每经过一年没有灭绝,额外的寿命就会翻倍。这是一些坚韧性的指标。一个物品的坚韧性与其寿命成正比!
他关于林迪效应的文章‘一个叫林迪的专家’是一个极力推荐的阅读。
那么回归为什么会存活这么久?
好吧,因为它已经存活了这么久。 回归(最小二乘法)作为一个概念最早由卡尔·弗里德里希·高斯和阿德里安-玛丽·勒让德在 19 世纪发明。他们用它来确定行星及其他天体绕太阳的轨道。
“回归”一词由弗朗西斯·高尔顿创造,用来描述一个观察结果:较高的父亲往往有相对较矮的儿子,而较矮的父亲则往往有相对较高的儿子!!
好吧,很明显,回归分析已经存在超过 200 年了!!因此,根据 Lindy 效应启发式,它将再持续 200 年。因此,我可能有点保守地说,回归分析将在 2118 年继续使用。

回归分析长寿的秘密是什么?
一个相关的例子是 2016 年的Kdnuggets 调查报告

实际上,在 2011 年 kdnuggets 进行的另一项调查中,回归分析紧随其后。因此,根据 Lindy 效应,它在过去 5 年中变得‘更加永恒’了!!
(更新:在撰写本文时,我不知道还有2017 年调查。2017 年的调查中,回归分析仍然位居榜首)
回归分析仍然是广泛使用的机器学习算法。人们使用回归分析或继续使用回归分析是因为
它很简单
高度可解释(即使是Dilbert的老板也能理解 😛)
它有效
‘它有效’部分
各个领域的人们继续使用回归分析,因为它对他们有效。使用回归分析带来的投资回报率是明确的。例如,在市场营销中,市场混合建模的驱动力是回归分析。它仍然是一种流行的技术,许多快消品公司相信 MMM 的输出。其他领域也是如此。如果回归分析在提供结果方面无用,它早已消失。它仍然被工业界和学术界使用,因为‘它有效’。
神经网络及其变体怎么样?它们会在 2118 年被使用吗?
目前,Lindy 效应对神经网络或称为 AI 并不友好。它已经经历了AI 冬天。20 世纪的‘AI 冬天’阻碍了神经网络及其变体的长寿。这种中断对技术或算法的长寿而言并不是一个好兆头。
但另一方面,过去十年中 AI 相关的进展不断增强。作为一个永远的学生,我仍然对最新的 AI 突破感到着迷。因此,一个安全的预测是,我们可能会看到神经网络及其变体再持续 10-20 年,希望‘奇点’的恐惧不会造成另一个 AI 冬天。
什么可以减轻机器学习算法的 Lindy 效应?
机器学习的过度使用:是的,Lindy 效应将因为机器学习算法的错误应用和过度使用而减弱。我遇到过一些情况,人们使用了机器学习算法,而一个简单的常识性基线方法本可以奏效。拉玛·拉姆克里希南在他的文章中很好地捕捉了这一精髓。
最近数据科学被称为最性感工作的潮流也没有帮助。机器学习算法已经变成了数据科学家手中的锤子。一切看起来都像是需要敲打的钉子。在这个过程中,机器学习的错误应用或过度使用将会导致人们失望,因为它没有带来预期的价值。这将是自我造成的“AI 冬季”。
但就目前而言,回归分析将会有最后的笑声,也许在 2118 年依然如此。
你可以通过以下方式联系我
原文。经许可转载。
相关
我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业之路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的信息技术
更多相关话题
一种顶级机器学习算法解析:支持向量机(SVM)
原文:
www.kdnuggets.com/2020/03/machine-learning-algorithm-svm-explained.html
评论

支持向量机(SVM)是最流行且令人兴奋的监督学习模型之一,其关联的学习算法分析数据并识别模式。它用于解决回归和分类问题。然而,它主要用于解决分类问题。SVMs 首次由 B.E. Boser 等人于 1992 年引入,并因 1994 年手写数字识别的成功而变得流行。在 Boosting 算法(如 XGBoost 和 AdaBoost)出现之前,SVMs 曾被广泛使用。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
如果你想要一个全面的机器学习算法基础,你应该把它纳入你的工具箱。SVMs 的算法非常强大,但其背后的概念并不像你想象的那么复杂。
逻辑回归的问题
在我之前的文章中,我已经清楚地解释了逻辑回归是什么(链接)。它帮助解决分类问题,将实例分为两类。然而,存在无数个决策边界,而逻辑回归只选择了一个任意的边界。
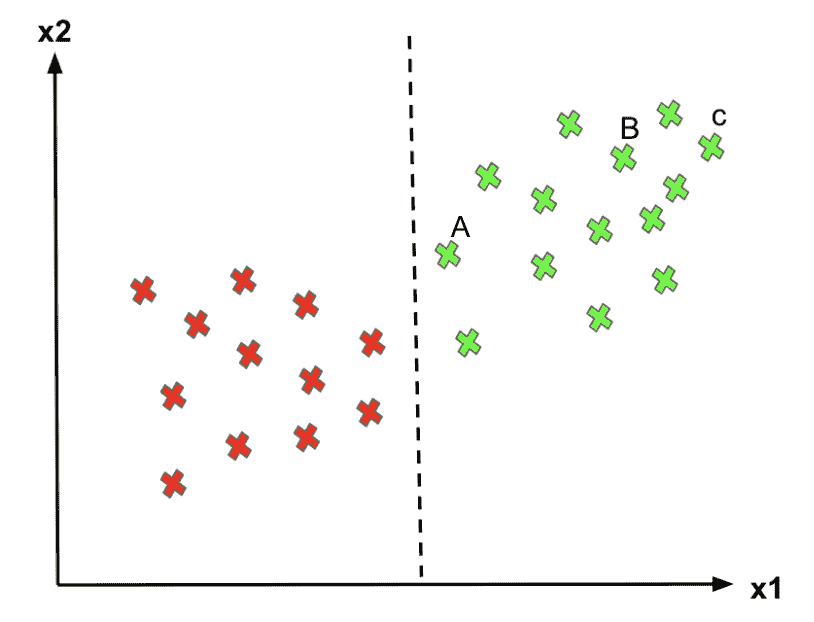
-
对于点 C,由于它远离决策边界,我们可以相当确定地将其分类为 1(绿色)。
-
对于点 A,尽管我们现在将其分类为 1,由于它非常接近决策边界,如果边界稍微向右移动,我们将把点 A 标记为“0”。因此,我们对点 C 的预测信心远高于对点 A 的预测。
逻辑回归不关心实例是否接近决策边界。因此,它选择的决策边界可能不是最优的。从上面的图可以看出,如果一个点远离决策边界,我们对预测可能更有信心。因此,最优的决策边界应该能够最大化决策边界与所有实例之间的距离,即最大化边距。这就是为什么 SVM 算法很重要!
什么是支持向量机(SVM)?
给定一组标记为属于两个类别之一的训练样本,SVM 训练算法构建一个模型,将新的样本分配到一个类别或另一个类别,从而使其成为一个非概率性的二元线性分类器。
应用支持向量机(SVM)的目标是找到二维中的最佳直线或多维中的最佳超平面,以帮助我们将空间划分为不同的类别。这个超平面(直线)是通过最大边距来确定的,即两个类别的数据点之间的最大距离。
你不觉得支持向量机(SVM)的定义和概念有些抽象吗?别担心,让我详细解释一下。
支持向量机
想象标记的训练集是两类数据点(二维):爱丽丝和灰姑娘。为了分隔这两类,有很多可能的超平面可以正确地进行分隔。如下面的图所示,我们可以使用不同的超平面(L1、L2、L3)来获得完全相同的结果。然而,如果我们添加新的数据点,使用不同超平面的结果在将新数据点分类到正确类别时会有很大差异。
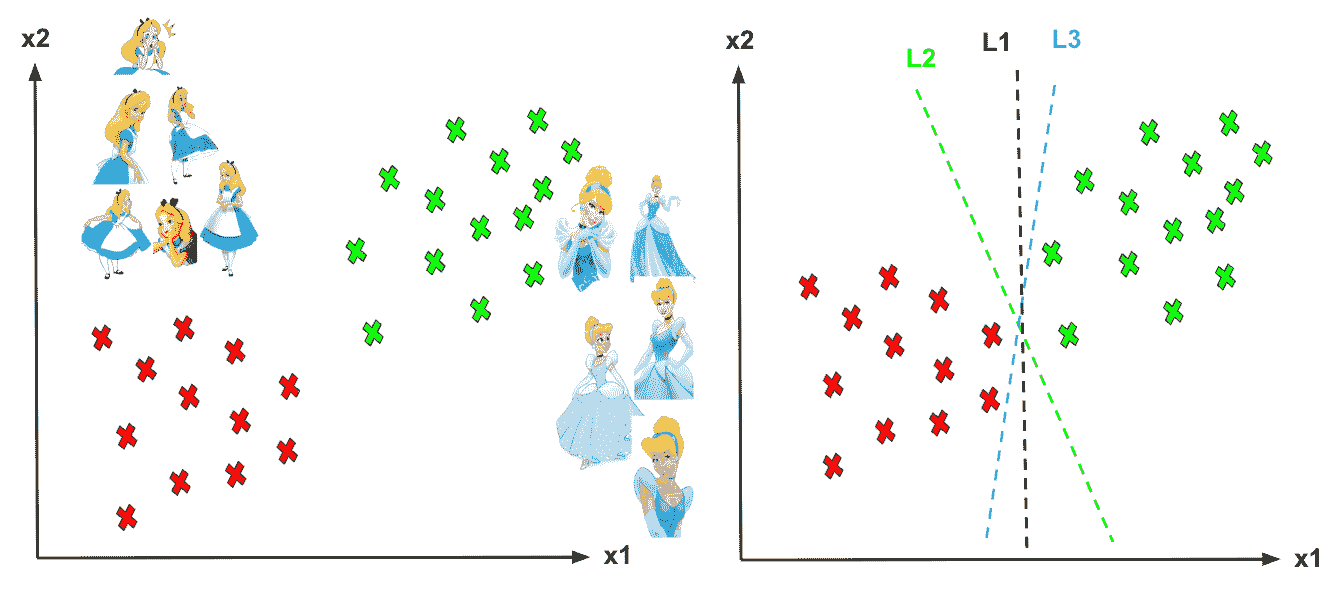
不同的超平面(L1、L2、L3)。
我们如何为类别决定一个分隔直线?我们应该使用哪个超平面?
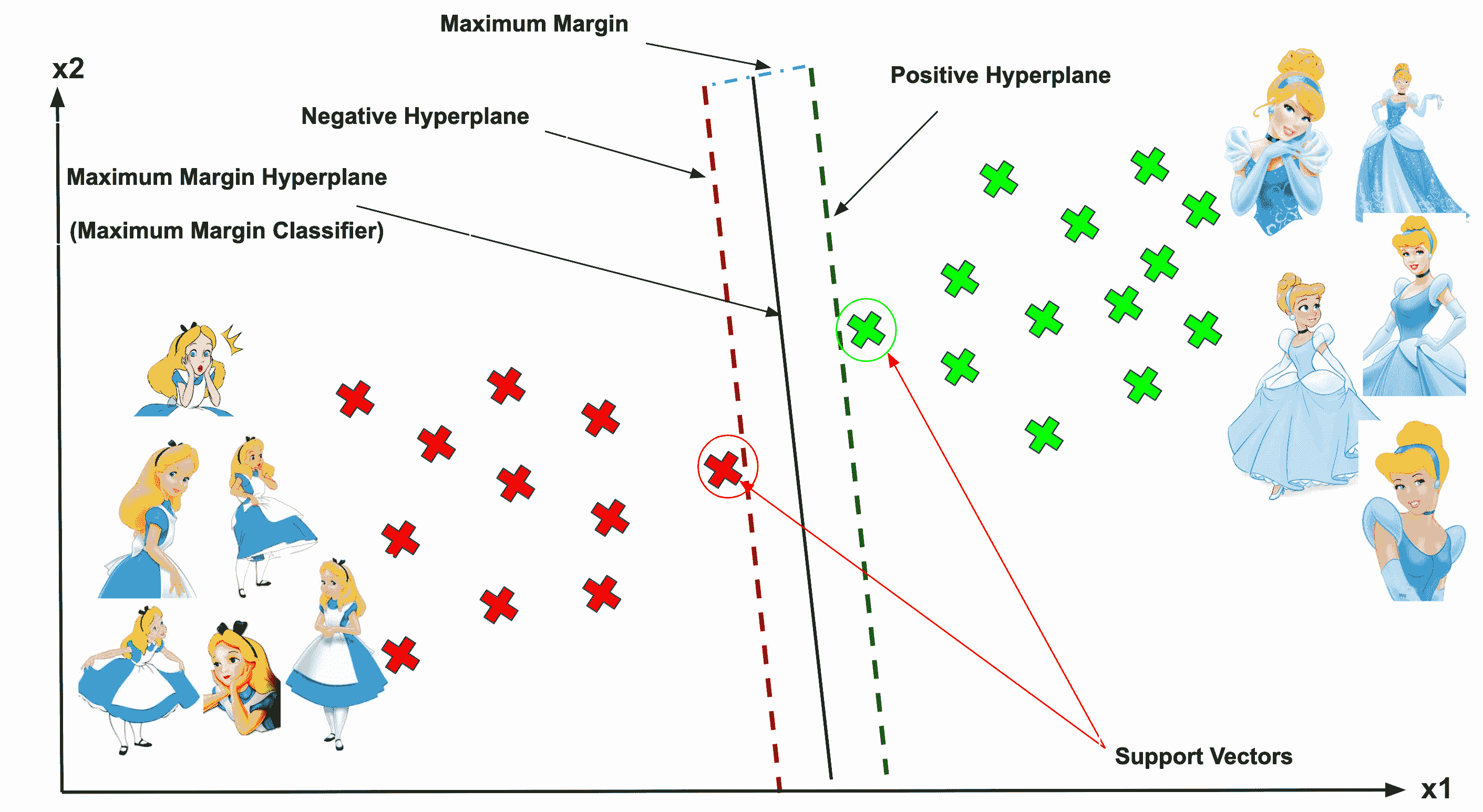
支持向量、超平面和边距
与超平面最接近的向量点被称为支持向量点,因为只有这两个点对算法的结果有贡献,其他点没有。如果一个数据点不是支持向量,那么删除它对模型没有影响。另一方面,删除支持向量会改变超平面的位置。
超平面的维度取决于特征的数量。如果输入特征的数量为 2,则超平面只是一个直线。如果输入特征的数量为 3,则超平面变为二维平面。当特征数量超过 3 时,就很难想象了。
向量与超平面的距离称为边距,它是直线与最近类别点的分隔。我们希望选择一个能最大化类别间边距的超平面。下面的图展示了什么是好的边距和坏的边距。
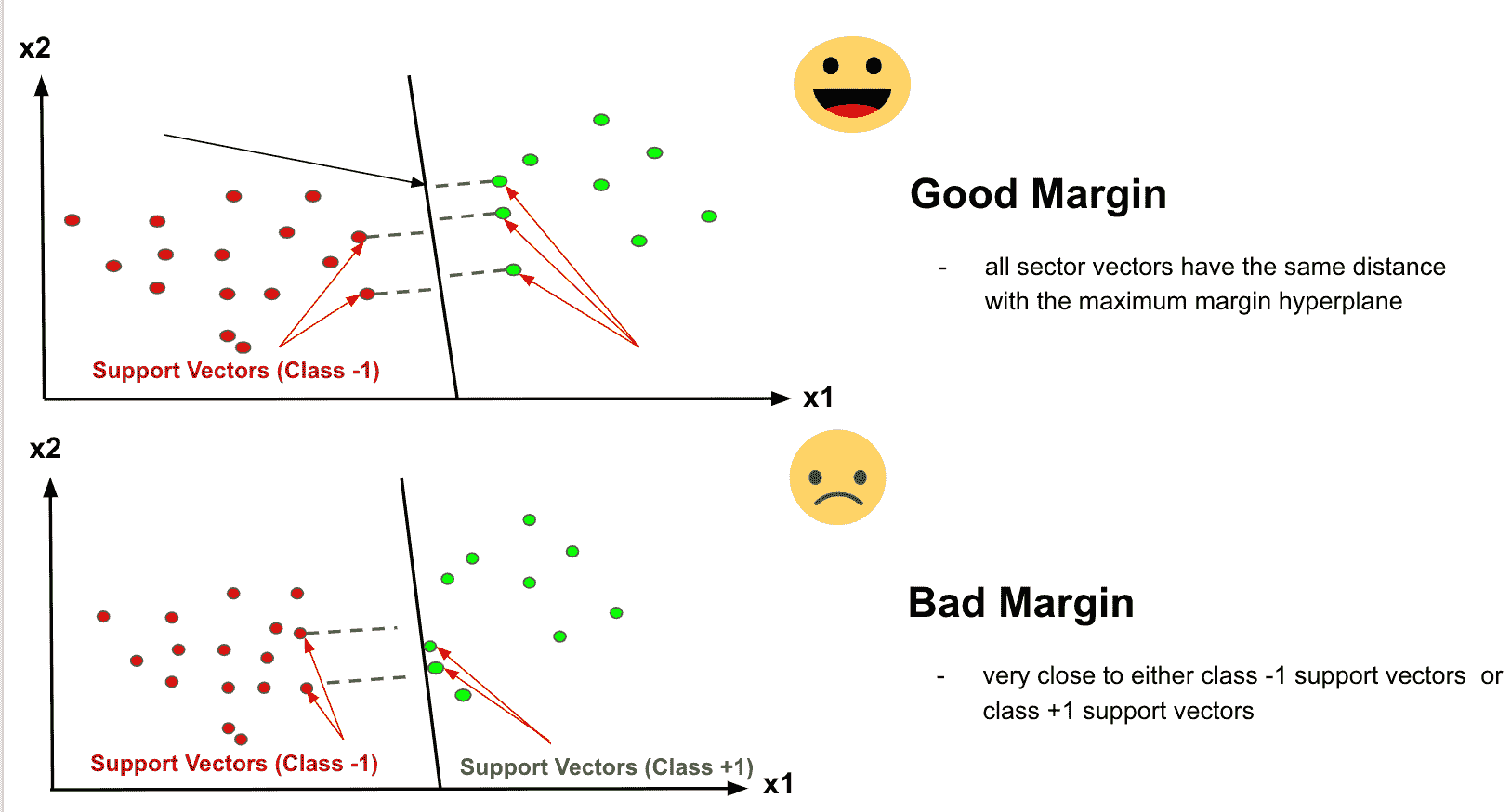
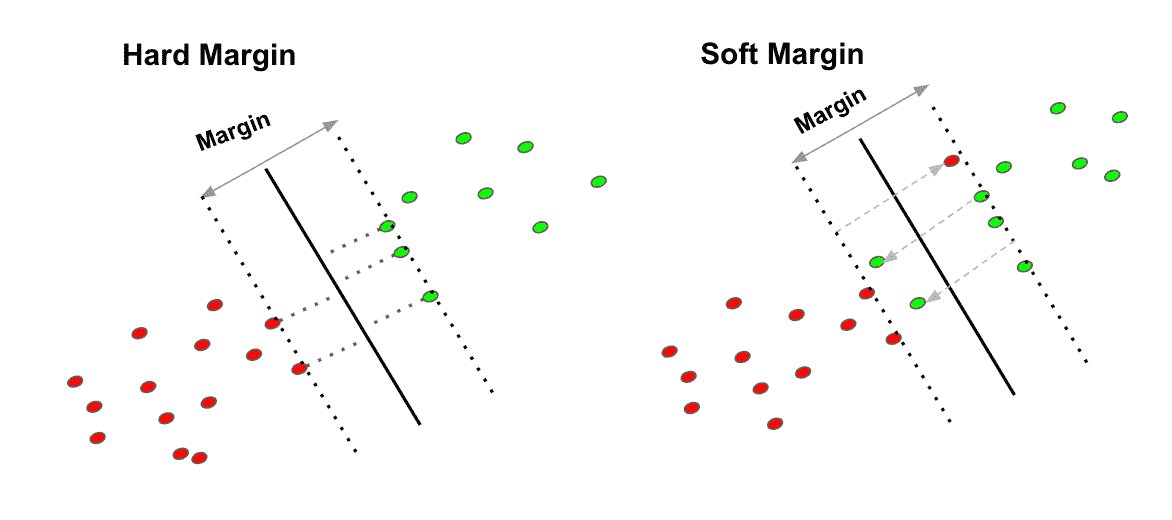
硬边际
如果训练数据是线性可分的,我们可以选择两个平行的超平面来分开两个类别的数据,从而使它们之间的距离尽可能大。
软边际
由于大多数现实世界的数据并不是完全线性可分的,我们将允许一些边际违规发生,这称为软边际分类。即便一些约束被违反,拥有一个较大的边际更为优越。边际违规意味着选择一个超平面,这可以允许一些数据点位于超平面错误的一侧或在边际与超平面的正确侧之间。
为了找到最大边际,我们需要最大化数据点与超平面之间的边际。在接下来的环节中,我将分享这个算法背后的数学概念。
线性代数回顾
在我们继续之前,让我们复习一下线性代数中的一些概念。

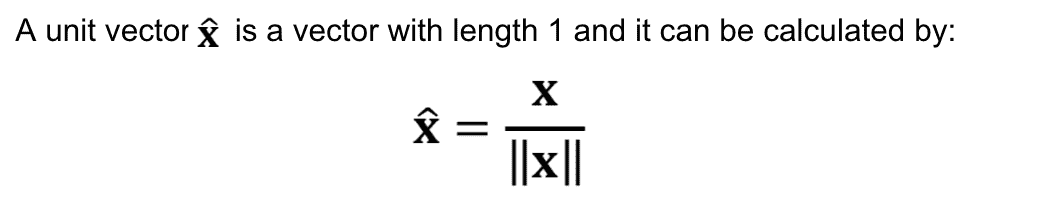
最大化边际
你可能学过直线的方程是y=ax+b。然而,你会发现超平面的方程通常被定义为:
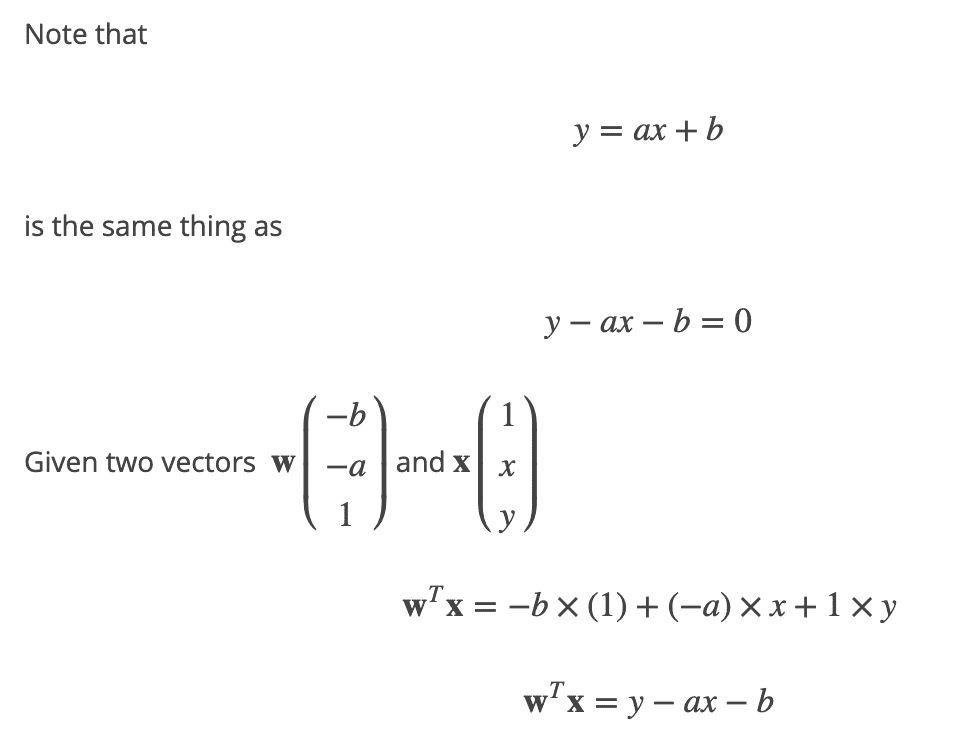
这两个方程只是用不同的方式表达相同的内容。
对于支持向量分类器(SVC),我们使用 ????T????+???? 其中 ???? 是权重向量,???? 是偏置。
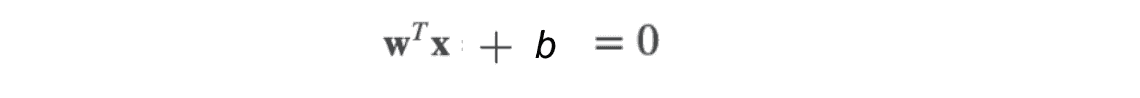
你可以看到超平面方程中的变量名称是w和x,这意味着它们是向量!向量具有大小(尺寸)和方向,这在三维或更多维度中表现得非常好。因此,“向量”的应用被用于 SVM 算法中。
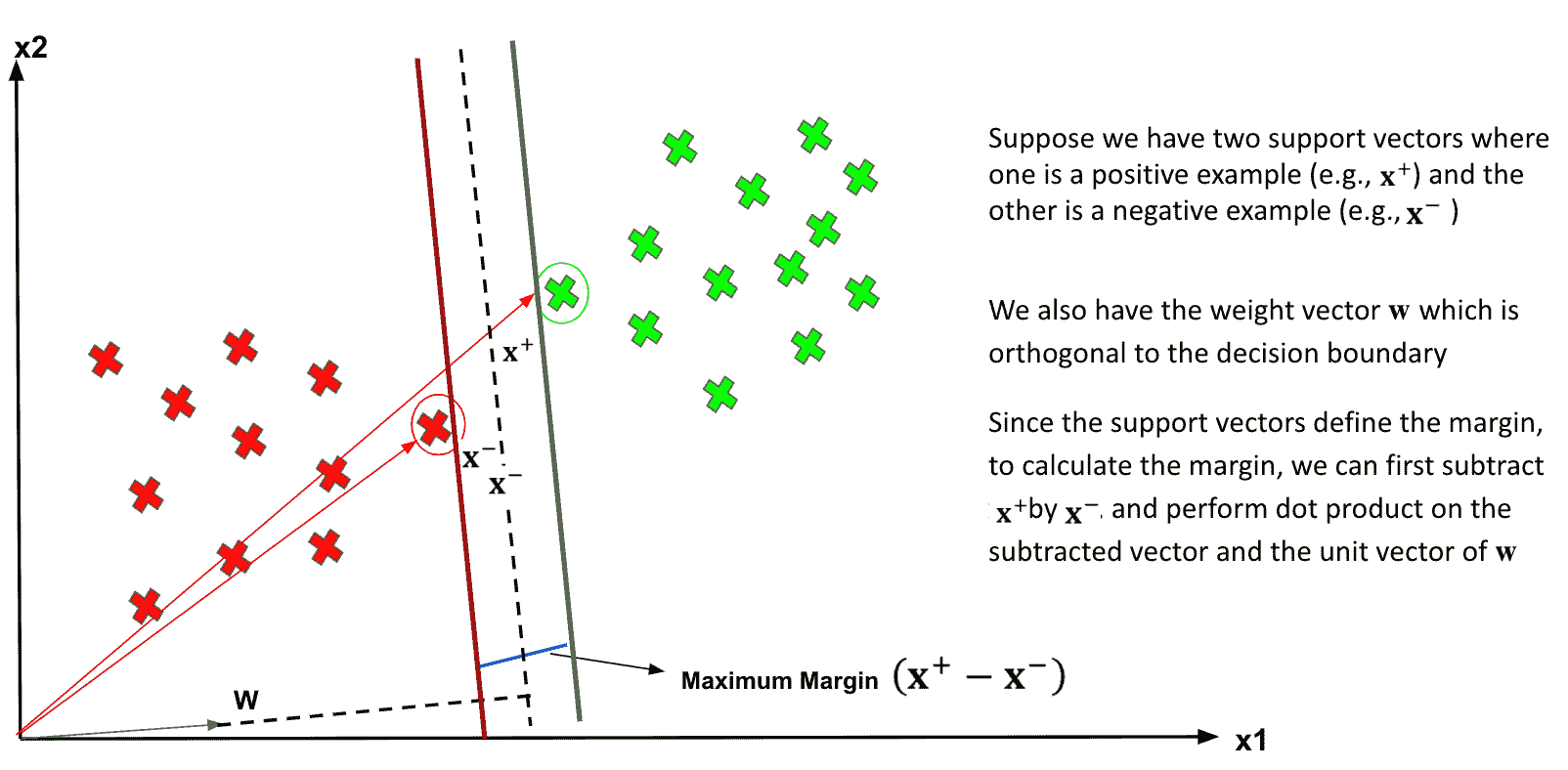
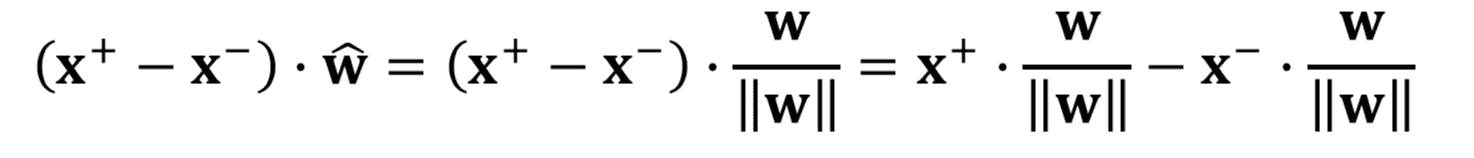
计算边际的方程。
代价函数和梯度更新
最大化边际等同于最小化损失。
在 SVM 算法中,我们寻求最大化边际,即数据点与超平面之间的边际。帮助最大化边际的损失函数是铰接损失。
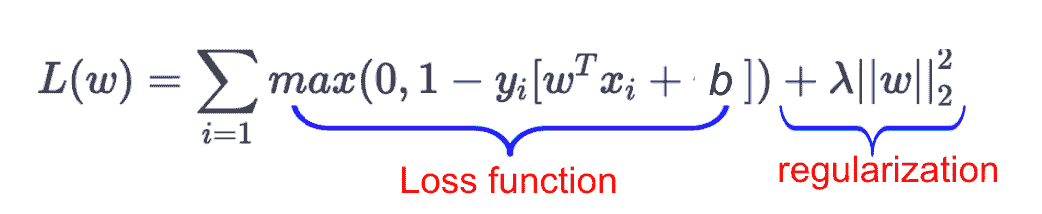
λ=1/C(C 始终用于正则化系数)。
第一个术语铰接损失的函数是用来惩罚错误分类的。它衡量由于错误分类(或数据点离分类边界比边际更近)导致的错误。第二个术语是正则化项,它是一种通过惩罚解向量中的大系数来避免过拟合的技术。λ(lambda)是正则化系数,它的主要作用是确定增加边际大小和确保 xi 位于边际正确侧之间的权衡。
“铰链”描述了错误为 0 的情况,如果数据点被正确分类(且不太靠近决策边界)。
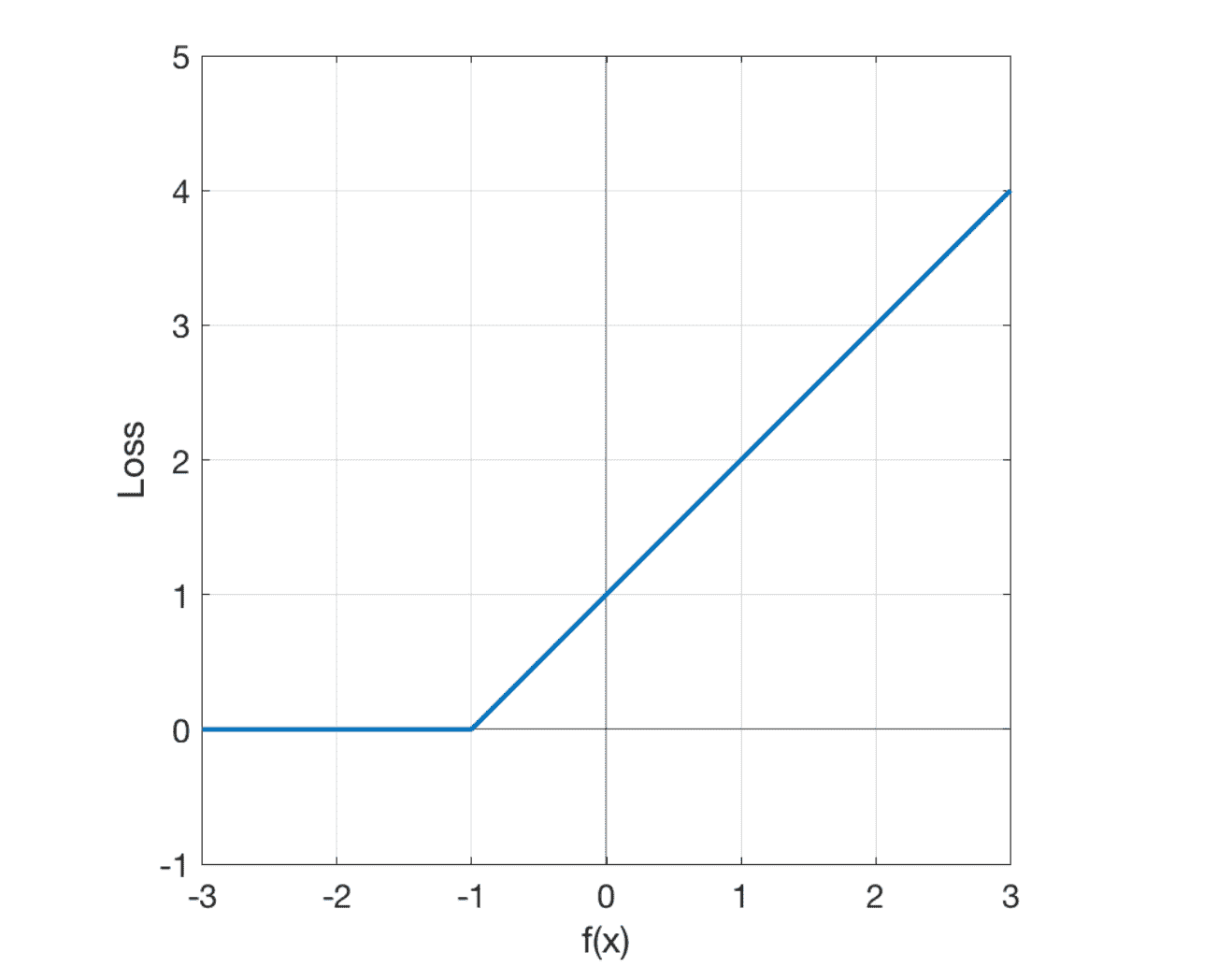
当真实类别为 -1(如你的示例中)时,铰链损失在图中看起来是这样的。
我们需要最小化上述损失函数,以找到最大间隔分类器。
我们可以从 铰链损失 中推导出间隔的公式。如果一个数据点在分类器的间隔上,铰链损失为零。因此,在间隔上,我们有:
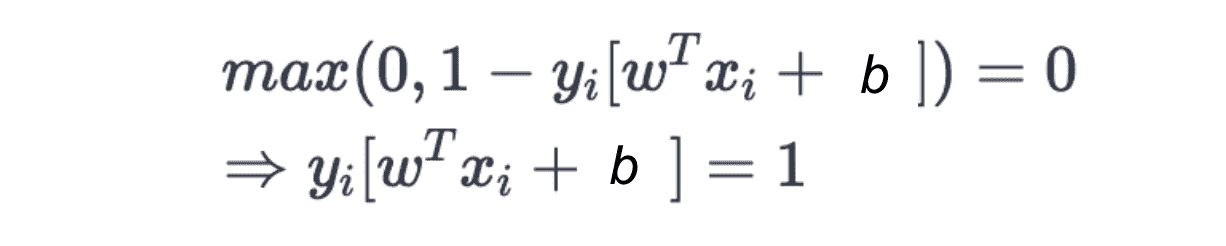
注意到 ????i 是 +1 或 -1。
因此,我们有:
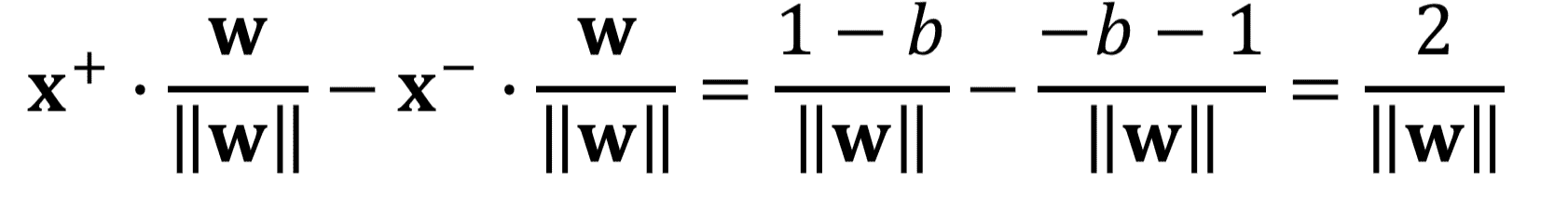
我们的目标函数是:
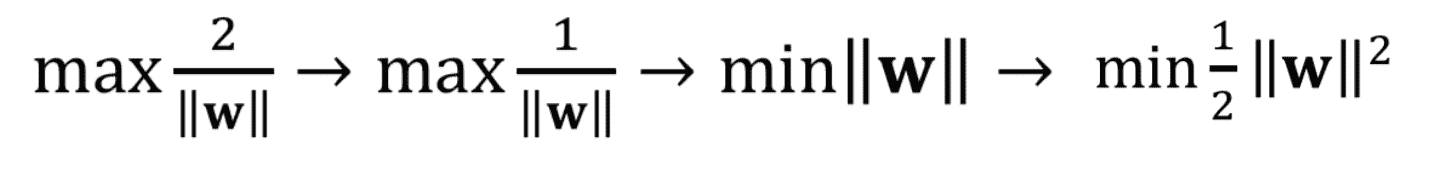
为了最小化这种目标函数,我们应该使用拉格朗日乘子。
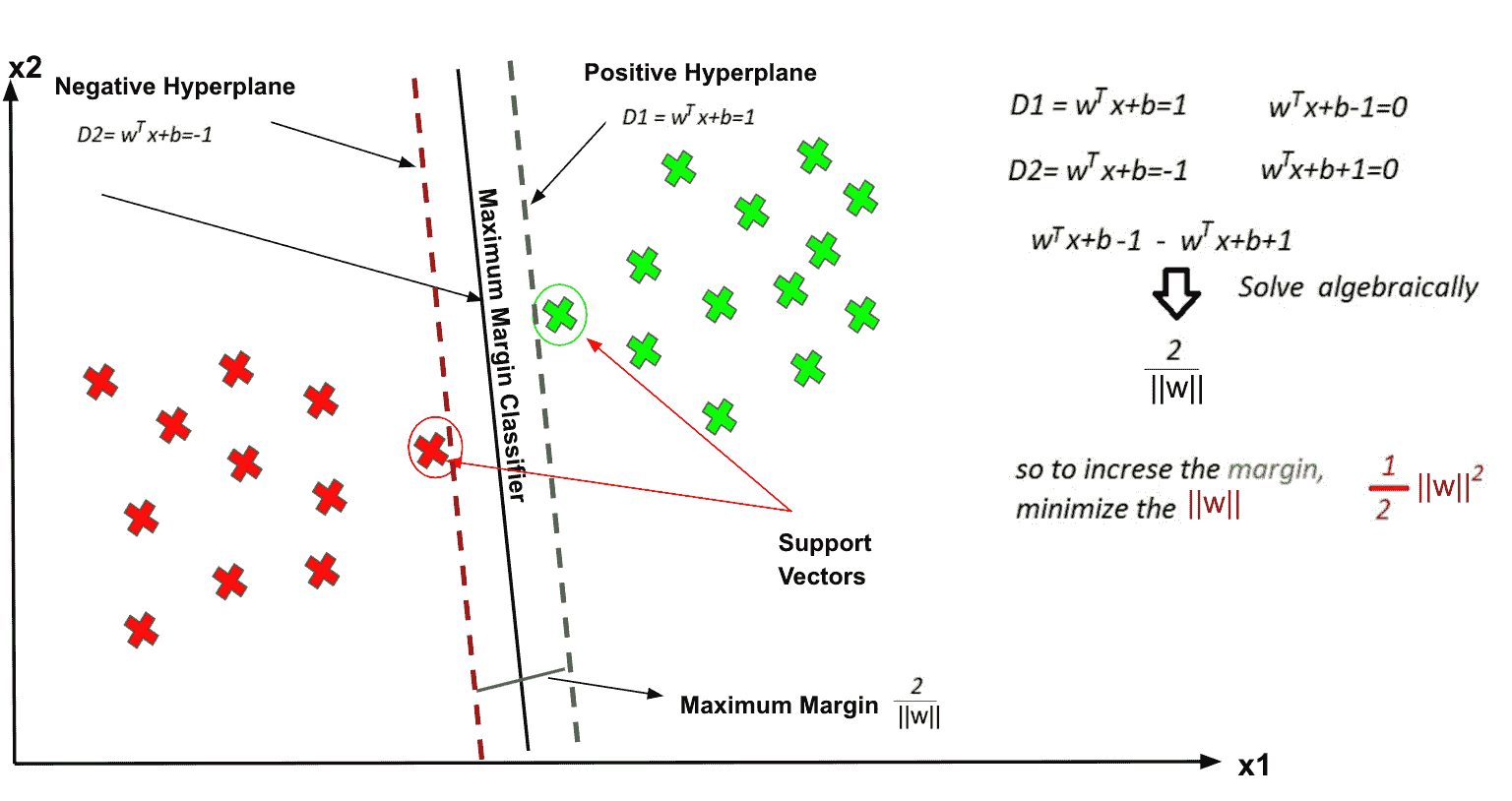
分类非线性数据
那么,对于数据点不是线性可分的情况呢?
非线性分离。
SVM 有一个称为 核函数** 技巧**。这些函数将低维输入空间转换为高维空间,即将不可分问题转换为可分问题。它主要用于非线性分离问题。如下所示:
映射到更高维度
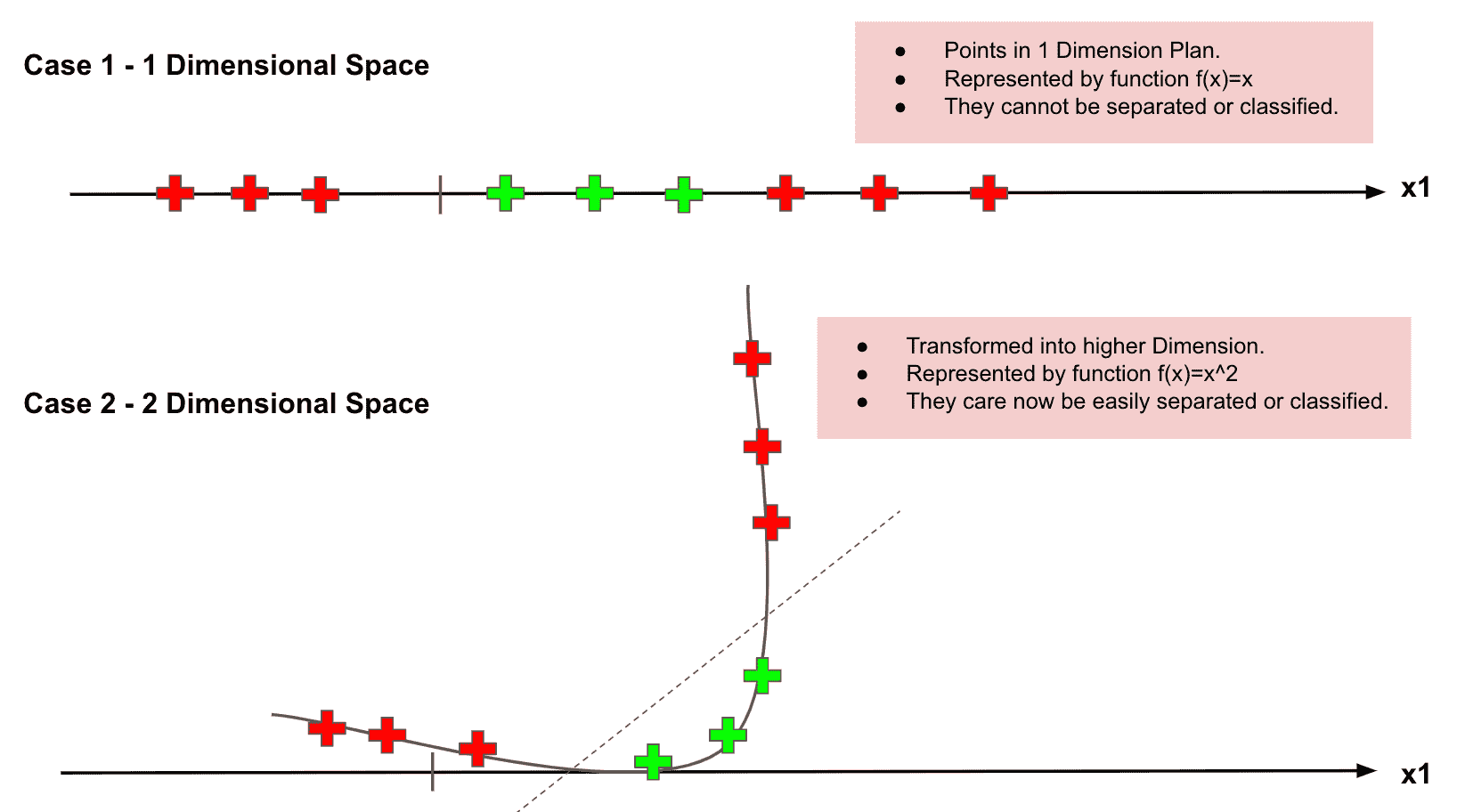
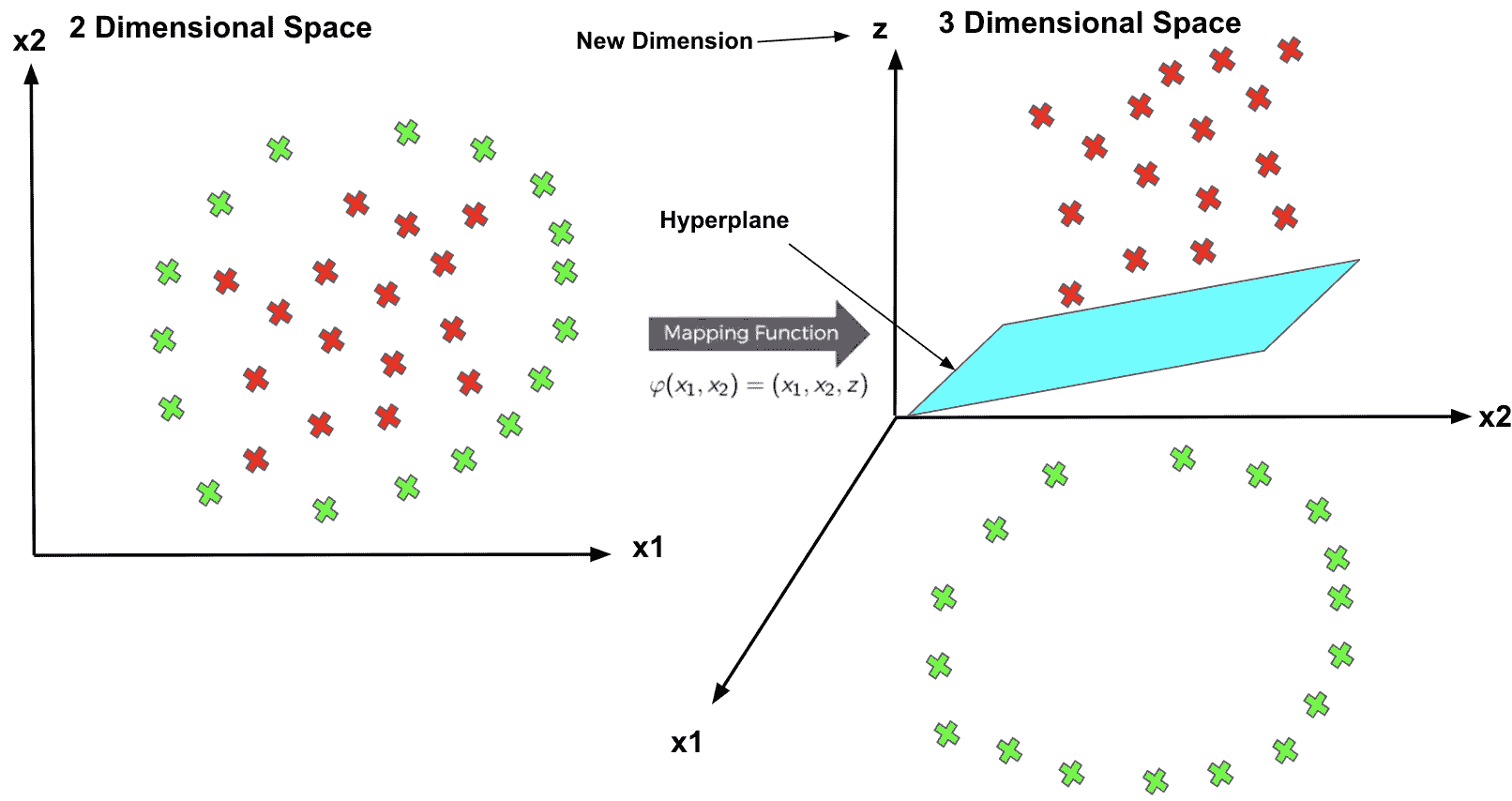
一些常用的核函数

为什么使用 SVM
-
解决数据点不是线性可分的情况
-
在更高维度下有效。
-
适用于小数据集:当特征数量多于训练样本时有效。
-
过拟合问题:超平面仅受支持向量的影响,因此 SVM 对异常值不具鲁棒性。
总结:现在你应该知道
-
逻辑回归的问题
-
什么是支持向量、超平面和间隔
-
如何使用铰链损失找到最大化的间隔
-
如何使用不同的核函数处理非线性可分的数据
原文。转载已获许可。
相关内容:
更多相关主题
你应该了解的所有机器学习算法(2021)
原文:
www.kdnuggets.com/2021/01/machine-learning-algorithms-2021.html
评论

照片由 Markus Winkler 提供,来自 Unsplash。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
随着我在机器学习领域知识的增长,机器学习算法的数量也在增加!本文将介绍数据科学社区中常用的机器学习算法。
请记住,我将会对某些算法进行更多的详细阐述,因为如果我详细解释每个算法,这篇文章将会和一本书一样长!我也会尽量减少文章中的数学内容,因为我知道对于那些不擅长数学的人来说,这可能会相当吓人。相反,我会尽量给出每个算法的简明总结,并指出一些关键特征。
有鉴于此,我将从一些基本的算法开始,然后深入探讨一些较新的算法,如 CatBoost、Gradient Boost 和 XGBoost。
线性回归
线性回归是用于建模因变量与一个或多个自变量之间关系的最基本算法之一。简单来说,它涉及找到代表两个或更多变量的“最佳拟合线”。
通过最小化点与最佳拟合线之间的平方距离来找到最佳拟合线——这被称为最小化平方残差之和。残差等于预测值减去实际值。
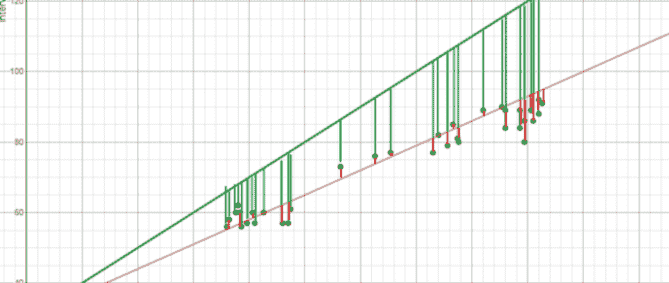
图片由作者创建。
如果现在还不明白,可以考虑上面的图片。比较绿色的最佳拟合线和红色的线,注意垂直线(残差)对于绿色线来说明显大于红色线。这是因为绿色线离数据点太远,根本不能很好地代表数据!
如果你想了解更多关于线性回归背后的数学知识,我建议你从Brilliant 的解释开始。
逻辑回归
逻辑回归类似于线性回归,但用于建模离散数量结果的概率,通常是两个。乍看之下,逻辑回归听起来比线性回归复杂得多,但实际上只多了一个步骤。
首先,你使用一个类似于线性回归最佳拟合线方程的方程来计算得分。
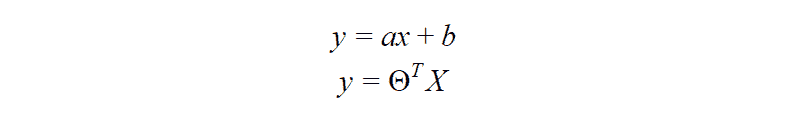
额外的步骤是将你之前计算的得分输入到下面的 Sigmoid 函数中,以便获得一个概率。这个概率然后可以转化为二进制输出,0 或 1。
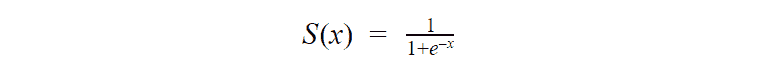
要找到初始方程的权重并计算得分,可以使用梯度下降法或最大似然法等方法。由于这超出了本文的范围,我不会详细讨论,但现在你知道它是如何工作的了!
K-最近邻
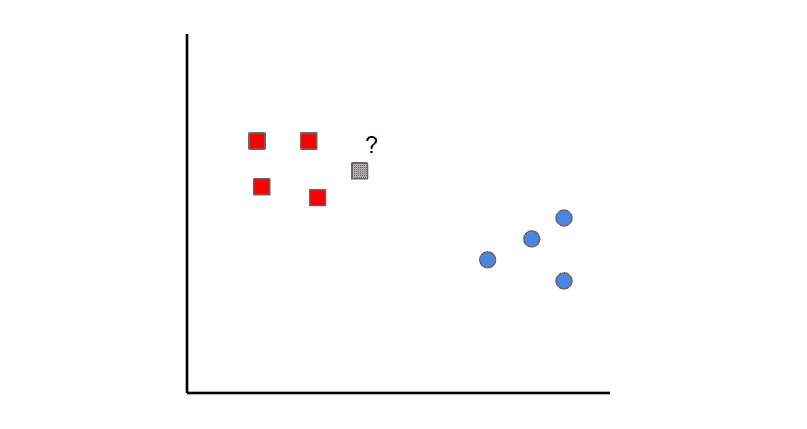
图像由作者创建。
K-最近邻是一个简单的概念。首先,你从已经分类的数据(即红色和蓝色的数据点)开始。然后,当你添加一个新的数据点时,你通过查看 k 个最近的已分类点来对其进行分类。得到最多投票的类别决定了新点的分类。
在这种情况下,如果我们设置k=1,我们可以看到灰色样本的第一个最近点是一个红色数据点。因此,这个点会被分类为红色。
需要注意的是,如果k的值设置得太低,它可能会受到离群值的影响。另一方面,如果k的值设置得太高,那么它可能会忽略只有少数样本的类别。
朴素贝叶斯
朴素贝叶斯是一种分类算法。这意味着,当输出变量是离散的时,使用朴素贝叶斯算法。
朴素贝叶斯算法可能看起来很复杂,因为它需要条件概率和贝叶斯定理的初步数学知识,但它是一个非常简单和“朴素”的概念,我会尽力通过一个例子来解释:
图像由作者创建。
假设我们有关于天气特征(如展望、温度、湿度、风力)的输入数据,以及你是否打过高尔夫的数据(即最后一列)。
朴素贝叶斯算法基本上是比较每个输入变量与输出变量类别之间的比例。这可以在下面的表格中显示。

图片由作者创建。
为了帮助你理解这一点,在温度部分,你在你打高尔夫的九天中有两天是炎热的(即,打高尔夫)。
从数学角度来看,你可以将其写为在你打高尔夫的情况下天气炎热的概率。 数学符号是 P(hot|yes)。这是条件概率的定义,对理解接下来要讲的内容至关重要。
一旦你有了这些数据,你就可以预测在任何天气特征组合下你是否会打高尔夫。
想象一下我们有一个新的一天,其特征如下:
-
天气:晴朗
-
温度:适中
-
湿度:正常
-
有风:假
首先,我们将计算在给定 X 的情况下你打高尔夫的概率 P(yes|X),然后是你不打高尔夫的概率 P(no|X)。
使用上面的图表,我们可以得到以下信息:

现在我们可以将这些信息简单地输入到以下公式中:
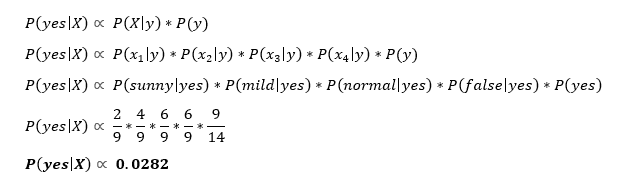
同样,你需要对 P(no|X)执行相同的步骤。

因为 P(yes|X) > P(no|X),所以你可以预测在天气晴朗、温度适中、湿度正常且无风的情况下,这个人会打高尔夫。
这就是朴素贝叶斯的本质!
支持向量机
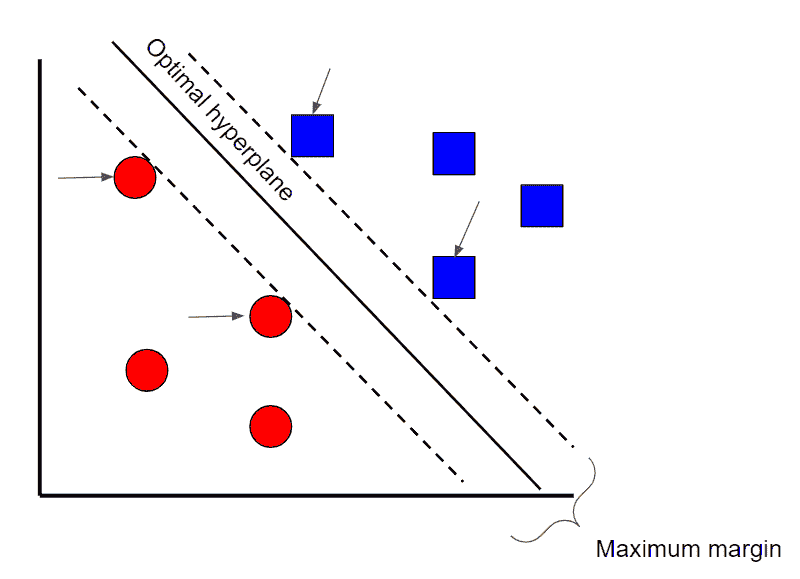
图片由作者创建。
支持向量机是一种监督分类技术,从本质上来看非常直观,但实际上可能会变得相当复杂。为了本文的目的,我们将保持在较高层次的讨论。
假设数据有两个类别。支持向量机将找到一个超平面或两个数据类别之间的边界,该边界最大化两个类别之间的间隔(见上图)。虽然有许多平面可以分隔这两个类别,但只有一个平面可以最大化两个类别之间的间隔或距离。
如果你想深入了解支持向量机的数学背景,请查看这个系列文章。
决策树
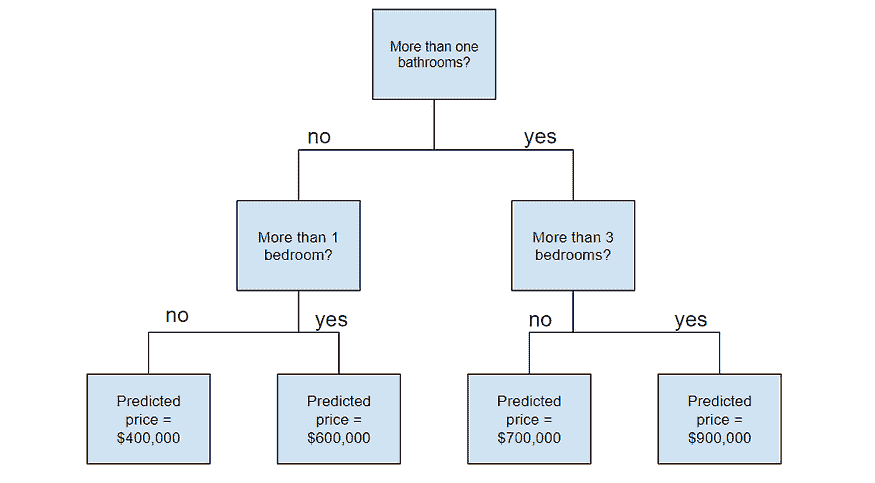
图片由作者创建。
随机森林
在理解随机森林之前,你需要了解几个术语:
-
集成学习是一种将多个学习算法结合使用的方法。这样做的目的是使你能够实现比单独使用任何一个算法更高的预测性能。
-
自助法采样是一种使用带替换的随机采样的重采样方法。这听起来很复杂,但相信我,当我说它真的很简单时——在这里阅读更多。
-
袋装当你使用自助法数据集的聚合来做决策时——我专门写了一篇关于这个主题的文章,所以如果这让你感到困惑,可以在这里查看一下。
现在你已经理解了这些术语,让我们深入探讨一下。
随机森林是一种集成学习技术,建立在决策树的基础上。随机森林涉及使用原始数据的自助法数据集创建多个决策树,并在每一步决策树中随机选择一个变量子集。然后模型选择每棵决策树预测的众数(袋装)。这样做的意义是什么?通过依赖于“多数决胜”的模型,降低了单棵树的错误风险。

图像由作者创作。
例如,如果我们创建了一棵决策树,即第三棵树,它的预测结果将是 0。如果我们依赖于所有 4 棵决策树的众数,那么预测值将是 1。这就是随机森林的强大之处!
AdaBoost
AdaBoost,即自适应增强,也是一个集成算法,利用袋装和提升方法来开发一个增强型预测器。
AdaBoost 与随机森林类似,都是通过多个决策树来进行预测。然而,有三个主要的区别使得 AdaBoost 独特:
弱分类器的示例。
-
首先,AdaBoost 创建的是弱分类器的森林,而不是树。弱分类器是一棵仅由一个节点和两个叶子组成的树(如上图所示)。
-
其次,创建的弱分类器在最终决策(最终预测)中并不是等权重的。产生更多错误的弱分类器在最终决策中的影响力会更小。
-
最后,弱分类器的创建顺序很重要,因为每个弱分类器旨在减少前一个弱分类器所犯的错误。
从本质上讲,AdaBoost 采取了一种更迭代的方法,旨在通过不断改进先前弱分类器所犯的错误来逐步提升模型。
如果你想了解更多关于 AdaBoost 背后的数学原理,请查看我的文章《5 分钟数学解释 AdaBoost》。
梯度提升
梯度提升也是一个集成算法,使用提升方法来开发增强型预测器,这一点也不奇怪。在许多方面,梯度提升与 AdaBoost 相似,但也有几个关键区别:
-
与构建桩的 AdaBoost 不同,梯度提升构建通常具有 8–32 个叶子的树。
-
梯度提升将提升问题视为优化问题,其中使用损失函数并尝试最小化误差。这就是为什么它被称为 梯度提升,因为它受到梯度下降的启发。
-
最后,树用于预测样本的残差(预测值减去实际值)。
尽管最后一点可能令人困惑,但你只需要知道的是,梯度提升开始时通过构建一棵树来拟合数据,随后构建的树旨在减少残差(误差)。它通过集中关注现有学习器表现不佳的区域来实现这一点,类似于 AdaBoost。
XGBoost
XGBoost 是目前最流行和广泛使用的算法之一,因为它非常强大。它类似于梯度提升,但具有一些额外的特性,使其更强大,包括:
-
叶节点的比例收缩(修剪) — 用于提高模型的泛化能力
-
牛顿提升 — 提供比梯度下降更直接的最小值路径,使其更快
-
额外的随机化参数 — 减少树之间的相关性,最终增强集成的强度
-
独特的树惩罚机制
我强烈推荐你观看 StatQuest 的视频,以更详细地了解算法的工作原理。
LightGBM
如果你认为 XGBoost 是最好的算法,那么请再考虑一下。LightGBM 是另一种提升算法,它在某些情况下比 XGBoost 更快且更准确。
LightGBM 的独特之处在于它使用一种叫做基于梯度的单边采样(GOSS)的独特技术来筛选数据实例,以找到分裂值。这与 XGBoost 不同,XGBoost 使用预排序和基于直方图的算法来找到最佳分裂。
了解更多关于 Light GBM 和 XGBoost 的信息请点击这里!
CatBoost
CatBoost 是另一种基于梯度下降的算法,具有一些微妙的差异,使其独特:
-
CatBoost 实现了对称树,这有助于减少预测时间,同时默认的树深度较浅(六)
-
CatBoost 利用随机排列,类似于 XGBoost 的随机化参数
-
然而,与 XGBoost 不同,CatBoost 更优雅地处理分类特征,使用如有序提升和响应编码等概念
总体而言,使 CatBoost 如此强大的原因是其低延迟要求,这使得其速度约为 XGBoost 的 八倍。
如果你想更详细地了解 CatBoost,请查看这篇 文章。
感谢阅读!
如果你坚持到了最后,恭喜你!你现在应该对所有不同的机器学习算法有了更好的了解。
如果你在理解最后几个算法时遇到困难,不要气馁——这些算法不仅更复杂,而且相对较新!因此,敬请关注更多将深入探讨这些算法的资源。
原文。经授权转载。
相关:
更多相关话题
机器学习算法:如何为您的问题选择合适的算法
原文:
www.kdnuggets.com/2017/11/machine-learning-algorithms-choose-your-problem.html
作者:丹尼尔·科尔布特,Statsbot。
当我刚开始从事数据科学时,我经常面临选择最适合我特定问题的算法的难题。如果您和我一样,当您打开关于机器学习算法的文章时,您会看到大量详细的描述。悖论在于,这些描述并没有简化选择。
在这篇针对 Statsbot的文章中,我将尝试解释基本概念,并提供在不同任务中使用各种机器学习算法的直观理解。在文章的末尾,您会发现对描述算法的主要特征的结构化概述。

首先,您应该区分 4 种机器学习任务:
-
监督学习
-
无监督学习
-
半监督学习
-
强化学习
监督学习
监督学习是从标记的训练数据中推断函数的任务。通过拟合标记的训练集,我们希望找到最优模型参数,以预测其他对象(测试集)上的未知标签。如果标签是一个实数,我们称该任务为回归。如果标签来自有限数量的值,并且这些值是无序的,那么它是分类。
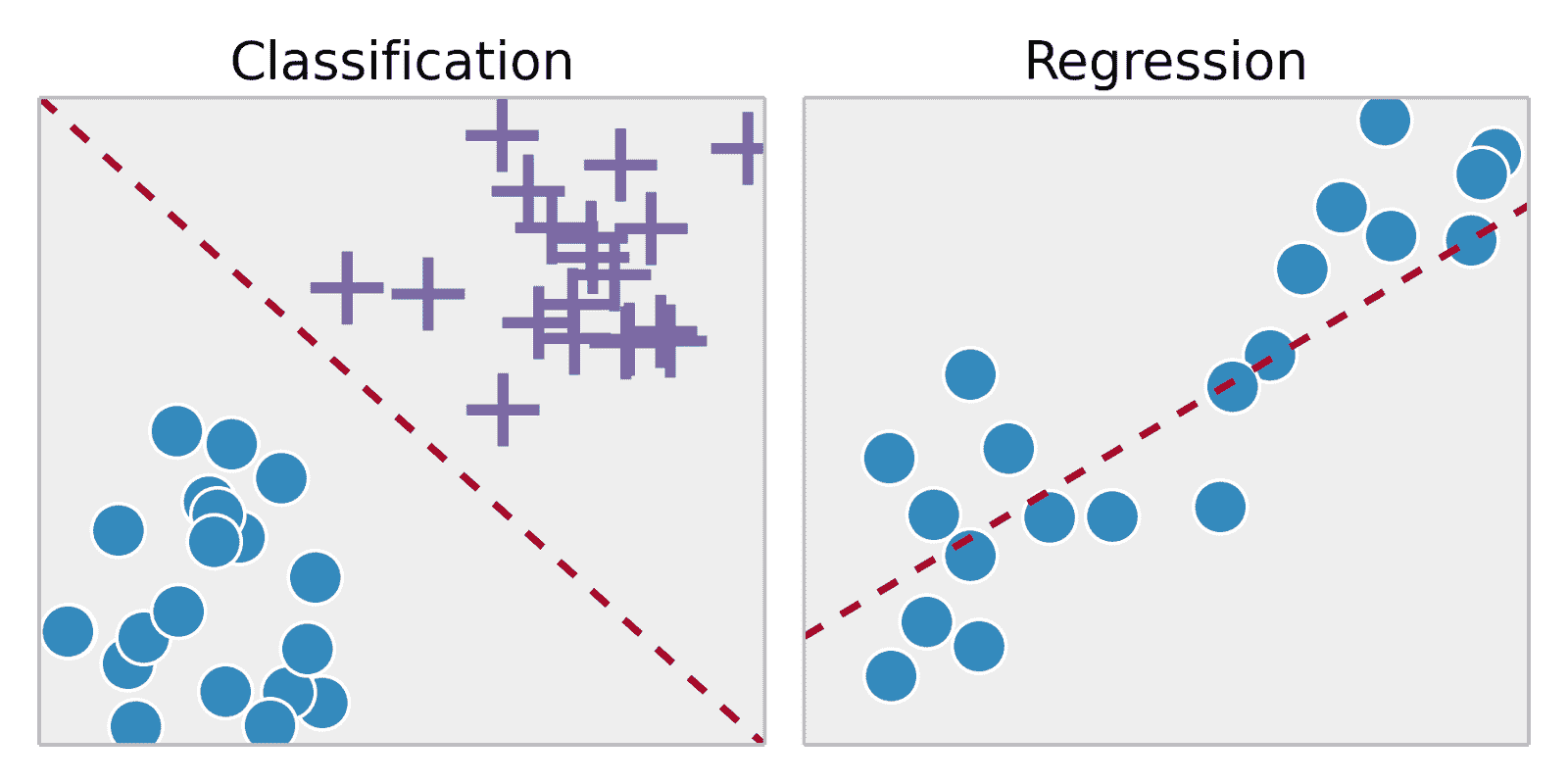
插图来源无监督学习
在无监督学习中,我们对对象的信息较少,特别是训练集是未标记的。我们的目标是什么呢?我们可以观察到对象组之间的一些相似性,并将它们纳入适当的簇中。一些对象可能与所有簇差异很大,我们将这些对象视为异常。
插图来源半监督学习
半监督学习任务包括我们之前描述的两种问题:它们使用标记和未标记的数据。这对于那些无法标记其数据的人来说是一个很好的机会。该方法使我们能够显著提高准确性,因为我们可以在少量标记数据的训练集中使用未标记数据。
插图来源强化学习
强化学习不同于我们之前讨论的任务,因为这里没有标记或未标记的数据集。RL 是一个关注软件代理如何在某种环境中采取行动以最大化累积奖励概念的机器学习领域。
插图来源想象一下,你是一个在某个陌生地方的机器人,你可以执行活动并从环境中获得奖励。每次行动后,你的行为变得越来越复杂和聪明,因此你正在训练自己在每一步上以最有效的方式行为。在生物学中,这被称为对自然环境的适应。
常用的机器学习算法
现在我们对机器学习任务的类型有了一些直观了解,让我们探讨一些最受欢迎的算法及其在现实生活中的应用。
线性回归和线性分类器
这些可能是机器学习中最简单的算法。你有对象的特征 x1,...xn(矩阵 A)和标签(向量 b)。你的目标是根据某些损失函数(例如,均方误差或平均绝对误差)找到这些特征的最优权重 w1,…wn 和偏差。在 MSE 的情况下,有一个来自最小二乘法的数学方程:
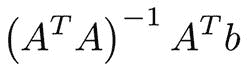
在实践中,利用梯度下降法优化它更为容易,这种方法计算效率更高。尽管这个算法很简单,但当你有成千上万个特征时(例如,词袋模型或 文本分析 中的 n-gram),它表现得相当好。更复杂的算法在处理许多特征和不是很大的数据集时容易过拟合,而线性回归则提供了不错的质量。

插图来源为了防止过拟合,我们通常使用正则化技术,如 lasso 和 ridge。其思想是将权重的绝对值之和和权重的平方和分别添加到我们的损失函数中。请阅读文章末尾的这些算法的精彩教程。
逻辑回归
不要将这些分类算法与使用“回归”作为标题的回归方法混淆。逻辑回归执行二分类,因此标签输出是二进制的。我们定义 P(y=1|x) 为在给定输入特征向量 x 的条件下,输出 y 为 1 的条件概率。系数 w 是模型希望学习的权重。
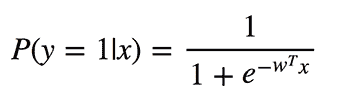
由于该算法计算每个类别的归属概率,因此你应该考虑概率与 0 或 1 的差异,并将其在所有对象上平均,就像我们在进行线性回归时所做的那样。这样的损失函数是交叉熵的平均值:
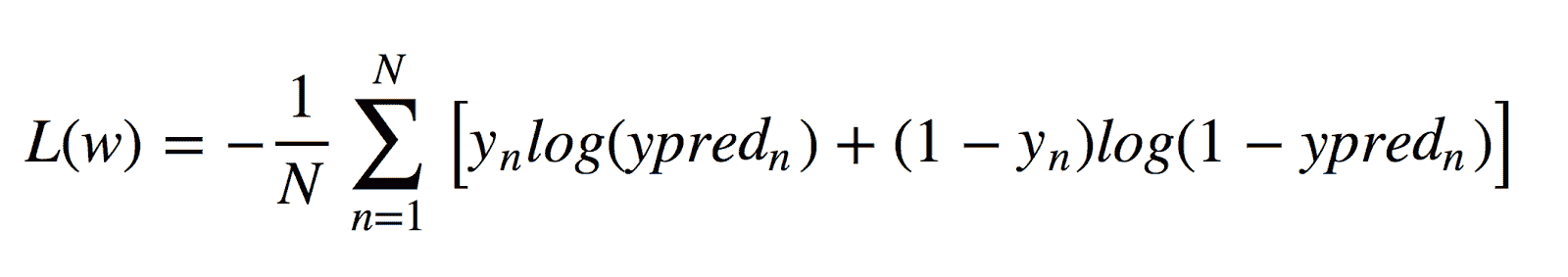
不要慌,我会让这变得简单。让y表示正确答案:0 或 1,y_pred — 预测答案。如果y等于 0,那么加法和的第一个加数为 0,第二个加数是根据对数的性质,预测的y_pred与 0 之间的距离越小。类似地,当y等于 1 时也是如此。
逻辑回归的优点是什么?它对特征进行线性组合,并应用非线性函数(sigmoid),所以它是神经网络的一个非常小的实例!
决策树
另一种流行且易于理解的算法是决策树。它们的图形帮助你看到你的思路,并且它们的引擎需要系统化、记录下来的思考过程。
这个算法的思想非常简单。在每个节点,我们在所有特征和所有可能的分裂点中选择最佳的分裂。每个分裂的选择方式是为了最大化某个函数。在分类树中,我们使用交叉熵和基尼指数。在回归树中,我们最小化在该区域内落入的点的目标值与我们分配给它的预测变量之间的平方误差之和。
插图来源我们对每个节点递归地执行此过程,直到遇到停止标准为止。停止标准可以从节点中的最小叶子数到树的高度。单棵树很少被单独使用,但与许多其他树组合在一起时,它们构建了非常高效的算法,如随机森林或梯度树提升。
K-均值
有时你不知道任何标签,你的目标是根据对象的特征分配标签。这称为聚类任务。
假设你想将所有数据对象分成 k 个簇。你需要从数据中选择 k 个随机点,并将它们命名为簇的中心。其他对象的簇由最近的簇中心定义。然后,簇的中心会被转换,直到收敛。

这是最清晰的聚类技术,但仍然存在一些缺点。首先,你应该知道簇的数量,这个数量是我们无法预知的。其次,结果依赖于开始时随机选择的点,算法也不保证我们能达到函数的全局最小值。
存在一系列具有不同优缺点的聚类方法,你可以在推荐阅读中了解它们。
主成分分析 (PCA)
你是否曾在最后一夜或最后几小时为一次困难的考试做准备?你没有机会记住所有信息,但你想在有限的时间内最大化记住的信息,例如,首先学习那些出现在许多考卷中的定理等等。
主成分分析基于相同的思想。该算法提供了降维功能。有时你有一个广泛的特征范围,这些特征可能彼此高度相关,而模型可能会在大量数据上过拟合。然后,你可以应用 PCA。
你应该计算某些向量上的投影,以最大化数据的方差,并尽可能少地丢失信息。令人惊讶的是,这些向量是数据集特征的相关矩阵的特征向量。
插图来源算法现在已经很清楚:
-
我们计算特征列的相关矩阵,并找到该矩阵的特征向量。
-
我们将这些多维向量进行投影计算,来计算所有特征在这些向量上的投影。
新特征是投影的坐标,其数量取决于计算投影的特征向量的数量。
神经网络
当我们谈论逻辑回归时,我已经提到过神经网络。存在许多在非常具体任务中有价值的不同架构。更常见的是,它是一系列层或组件,它们之间有线性连接,并且遵循非线性特性。
如果你在处理图像,卷积深度神经网络会显示出很好的效果。非线性由卷积和池化层表示,这些层能够捕捉图像的特征。

插图来源对于处理文本和序列,你最好选择递归神经网络。RNN 包含 LSTM 或 GRU 模块,能够处理我们事先知道维度的数据。也许,RNN 最著名的应用之一是机器翻译。
结论
我希望能向你解释最常用的机器学习算法的常见认知,并提供如何为你的特定问题选择一种算法的直观理解。为了让事情对你更简单,我准备了它们主要特征的结构化概述。
线性回归和线性分类器。 尽管看似简单,但在特征非常多的情况下,它们非常有用,而更好的算法往往会过拟合。
逻辑回归是最简单的非线性分类器,通过参数的线性组合和非线性函数(sigmoid)进行二分类。
决策树常类似于人们的决策过程,易于解释。但它们通常用于随机森林或梯度提升等组合中。
K 均值更为原始,但这是一个非常易于理解的算法,可以作为各种问题的基准。
主成分分析(PCA)是减少特征空间维度并尽量减少信息损失的绝佳选择。
神经网络是新一代机器学习算法,可以应用于许多任务,但其训练需要巨大的计算复杂性。
推荐来源
个人简介: 丹尼尔·科尔布特 是 Statsbot 的初级数据科学家。
原文。经许可转载。
相关内容:
-
初学者的十大机器学习算法
-
理解机器学习算法
-
机器学习算法:简明技术概述 - 第一部分
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
更多相关话题
机器学习分类算法
原文:
www.kdnuggets.com/2022/03/machine-learning-algorithms-classification.html

Kevin Ku 通过 Unsplash
你可以使用许多类型的算法,因此选择哪个算法以及哪个算法最适合你的任务可能会感到非常困惑。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 服务
区分不同类型的算法的一个好方法是通过它们的学习类型和任务。我将会介绍不同类型的分类算法。但首先,让我们理解机器学习中的不同学习类型。
机器学习的类型
机器学习有 3 种不同的类型:
-
监督学习
-
无监督学习
-
强化学习
监督学习是指算法在标记数据集上进行学习,并分析训练数据。这些标记数据集包含输入和预期输出。
一个监督学习算法的例子是逻辑回归。
无监督学习在无标记数据上进行学习,推断隐藏结构以产生准确和可靠的输出。
一个无监督学习算法的例子是 K-Means。
强化学习是训练机器学习模型以做出一系列决策。它关注于智能体如何在环境中采取行动以最大化累计奖励的概念。
分类与回归:
监督学习可以进一步分为两个类别:分类和回归。
分类是预测标签,通过识别一个对象属于哪个类别,基于不同的参数。
回归是预测连续输出,通过寻找因变量和自变量之间的相关性。
许多算法可以用于分类和回归问题。在本文中,我们将讨论可以用于分类任务的算法。
逻辑回归
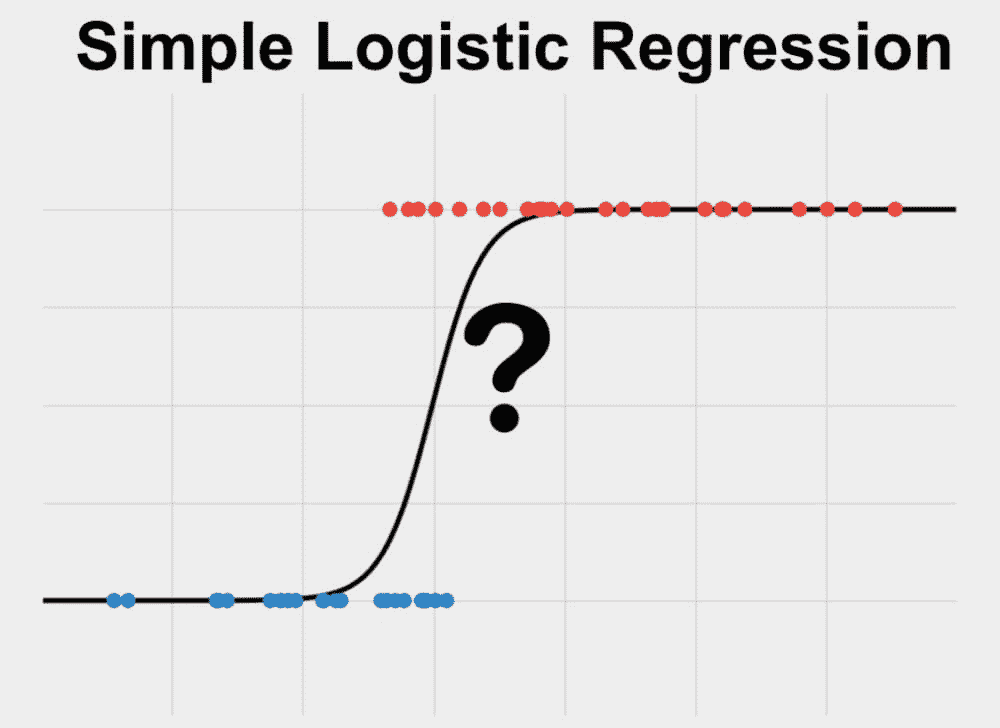
逻辑回归是一种用于分类问题的机器学习算法,基于概率的概念。它用于当因变量(目标)是分类变量时。它广泛应用于当分类问题是二元的:真或假,是或否等。逻辑回归使用 sigmoid 函数来返回标签的概率。
例如,它可以用来预测一封电子邮件是否为垃圾邮件(1)或不是(0)。
决策树
决策树是一种非参数监督学习方法,用于分类和回归。总体目标是通过从数据特征中推断出简单的决策规则来构建一个模型,以预测目标变量的值。
决策树的概念体现在它的名称中。它通过层次化的方法建立树枝,每个树枝可以被视为一个 if-else 语句。构建分类决策树的过程是通过将数据分割成多个分区,并在每个节点上再次进行分割的迭代过程。数据集的最终分类位于决策树的叶节点。
例如,将追求篮球的青少年不同的属性和特征进行分类。你的身高、体重、族裔群体变量会被划分成多个分区,然后再进行划分。
随机森林®
随机森林® 是一种监督学习算法,由许多决策树组成。一个好的记忆方法是把它当作许多树组成的森林。
随机森林算法基于决策树生成的预测结果来产生其结果。该预测是通过取各个决策树输出的平均值或均值来完成的。树木数量的增加提高了结果的精度。因此,森林中的决策树数量越多,准确性越高,过拟合被防止或至少减少。
与决策树相比,随机森林算法模型难以解释并快速做出决策,同时所需时间较长。
K-最近邻(KNN)
K-最近邻(KNN)算法是一种监督机器学习算法,可以用于解决分类和回归问题。KNN 算法假设相似的事物存在于接近的位置。
KNN 使用相似性概念,或其他词汇如距离、邻近或接近。它使用数学方法计算图上点之间的距离。通过这样做,它根据最接近的标记数据点来标记未观察到的数据。
这句话:“物以类聚,人以群分” 与 KNN 相关。
支持向量机(SVM)
支持向量机是一种监督学习模型,使用线性模型,可以用于分类和回归问题。
支持向量机算法的概念是创建一条线或一个超平面,将数据分为不同的类别。它使用那些接近超平面的数据点,这些点影响超平面的定位和方向,从而最大化分类器的边界。
随机森林 和 RANDOMFORESTS 是 Minitab, LLC 的注册商标。
Nisha Arya 是一名数据科学家和自由职业技术作家。她特别感兴趣于提供数据科学职业建议或教程以及数据科学相关的理论知识。她还希望探索人工智能如何有助于人类寿命的延续。作为一个热衷学习的人,她寻求拓宽技术知识和写作技能,同时帮助指导他人。
相关主题
机器学习算法:简明技术概述 - 第一部分
原文:
www.kdnuggets.com/2017/08/machine-learning-algorithms-concise-technical-overview-part-1.html

无论你是机器学习的新手、对特定算法或概念的初学者,还是寻求对久未使用的算法进行快速回顾的经验丰富的机器学习专家,这些简短而直截了当的教程可能会提供你所需要的帮助。每篇文章简洁地覆盖一个特定的机器学习概念。
支持向量机:简明技术概述
支持向量机(SVMs)是一种特定的分类策略。SVM 通过将训练数据集转换为更高维度,然后在这些维度中寻找最优的类别分隔边界来工作。在 SVM 中,这些边界被称为超平面,通过定位支持向量(即最能定义类别的实例)及其边距(即与支持向量之间的最短距离所定义的超平面平行的线)来确定。因此,SVM 能够对线性和非线性数据进行分类。
比较聚类技术:简明技术概述
聚类用于分析不包含预标记类别的数据。数据实例通过最大化类内相似度和最小化不同类别之间的相似度来进行分组。这意味着聚类算法识别和分组非常相似的实例,而不是那些彼此相似度较低的未分组实例。由于聚类不需要预先标记类别,它是一种无监督学习方法。
频繁模式挖掘与 Apriori 算法:简明技术概述
频繁模式挖掘最容易通过引入市场篮分析(或亲和分析)来解释,这是其广为人知的典型用途。市场篮分析试图识别由特定购物者选择并放入市场篮中的各种商品之间的关联或模式,并为比较分配支持度和置信度度量。其价值在于交叉营销和客户行为分析。
决策树分类器:简明技术概述
我相信你一定已经知道,决策树是一种辅助决策过程的流程图。内部节点代表对特定属性的测试,而离开节点的分支代表单个测试结果,叶节点代表类别标签。
在机器学习中,决策树已被使用了几十年,作为有效且易于理解的数据分类器(与许多黑箱分类器相比)。
线性回归、最小二乘法与矩阵乘法:简明技术概述
线性回归是一个简单的代数工具,试图找到最“优”(通常是直线)地拟合两个或更多属性的线,其中一个属性(简单线性回归),或几个属性的组合(多重线性回归),用于预测另一个属性,即类别属性。训练实例用于计算线性模型,其中一个属性或一组属性被绘制与另一个属性对比。然后,模型尝试识别给定特定类别属性的新实例将位于回归线上的位置。
相关:
-
机器学习关键术语解析
-
极简且干净的机器学习算法实现集合
-
机器学习摘要:分类
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关主题
机器学习算法解释,少于 1 分钟
原文:
www.kdnuggets.com/2022/07/machine-learning-algorithms-explained-less-1-minute.html

图片由 pch.vector 在 Freepik 提供
这篇文章将在不到一分钟的时间里解释一些最著名的机器学习算法——帮助每个人理解它们!
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
线性回归
线性回归是最简单的机器学习算法之一,用于对连续的因变量进行预测,基于对自变量的知识。因变量是效果,其值取决于自变量的变化。
你可能还记得学校中的最佳拟合线——这就是线性回归所产生的。一个简单的例子是根据身高预测体重。
逻辑回归
逻辑回归与线性回归类似,用于对分类因变量进行预测,基于自变量的知识。分类变量有两个或更多类别。逻辑回归将输出分类为只能在 0 和 1 之间的值。
例如,你可以使用逻辑回归来确定学生是否会被某个特定大学录取,取决于他们的成绩——结果可以是“是”或“否”,或者是 0 或 1。
决策树
决策树(DTs)是一种树状结构的概率模型,它不断分裂数据,以根据先前回答的问题进行分类或预测。该模型学习数据的特征并回答问题,以帮助你做出更好的决策。
例如,你可以使用决策树,通过“是”或“否”来确定某种特定鸟类,使用的特征数据包括羽毛、飞行或游泳能力、喙的类型等。
随机森林
类似于决策树,随机森林也是一种基于树的算法。决策树由一棵树组成,而随机森林使用多棵决策树进行决策——即一片树木的森林。
它结合了多个模型来进行预测,可用于分类和回归任务。
K-最近邻
K-最近邻利用数据点之间的距离来决定这些数据点是否可以分组。数据点之间的接近度反映了它们之间的相似性。
例如,如果我们有一个图表,其中有一组彼此靠近的数据点称为组 A,另一组彼此靠近的数据点称为组 B。当输入一个新的数据点时,根据新数据点更接近哪个组——这将是它的新分类组。
支持向量机
类似于最近邻,支持向量机执行分类、回归和异常值检测任务。它通过绘制一个超平面(直线)来分隔类别。位于直线一侧的数据点将被标记为组 A,而另一侧的数据点将被标记为组 B。
例如,当输入一个新的数据点时,依据该数据点位于超平面哪一侧及其在边界内的位置——这将决定数据点属于哪个类别。
朴素贝叶斯
朴素贝叶斯基于贝叶斯定理,这是一种用于计算条件概率的数学公式。条件概率是指在另一个事件发生的情况下,某一结果发生的机会。
它预测每个类别的概率,归属于某个特定类别,概率最高的类别被认为是最可能的类别。
k 均值聚类
K 均值聚类,类似于最近邻,但使用聚类的方法将相似的项/数据点分组在簇中。簇的数量被称为 K。你通过选择 k 值、初始化质心,然后选择组并计算平均值来完成这一过程。
例如,如果存在 3 个簇,且输入一个新的数据点,根据它属于哪个簇——这就是它所属的簇。
袋装
袋装也被称为自助聚合(Bootstrap aggregating),是一种集成学习技术。袋装用于回归和分类模型,旨在避免数据的过拟合,并减少预测中的方差。
过拟合是指模型对训练数据的拟合过于精确——基本上没有提供新的信息,这可能由各种原因造成。随机森林是袋装(Bagging)的一个例子。
提升
Boosting 的总体目标是将弱学习者转化为强学习者。弱学习者是通过应用基本学习算法找到的,这些算法生成新的弱预测规则。数据的随机样本被输入到模型中,然后进行顺序训练,旨在训练弱学习者并尝试纠正其前身。
XGBoost,代表极端梯度提升,被用于 Boosting。
降维
降维用于减少训练数据中输入变量的数量,通过降低特征集的维度。当模型具有大量特征时,模型自然更复杂,这导致过拟合的机会增加和准确性的下降。
例如,如果你有一个包含一百列的数据集,降维将把列数减少到二十。然而,你还需要特征选择来选择相关特征,并需要特征工程从现有特征中生成新的特征。
主成分分析(PCA)技术是一种降维方法。
结论
本文的目的是帮助你以最简单的术语理解机器学习算法。如果你想更深入地了解每一个算法,可以阅读这个流行的机器学习算法。
Nisha Arya 是一名数据科学家和自由技术撰稿人。她特别感兴趣于提供数据科学职业建议或教程以及数据科学的理论知识。她还希望探索人工智能如何能促进人类寿命的不同方式。作为一个热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关内容
新时代的机器学习算法在零售贷款中的应用
原文:
www.kdnuggets.com/2017/09/machine-learning-algorithms-lending.html
由 Jayesh Ametha 撰写
十多年前,当我加入一家大型美国信用卡公司时,发现预测分析仅限于多元回归和逻辑回归模型,这让我感到惊讶。这与之前在 NASA/NIST 资助的初创公司工作的经历形成了对比,在那些公司中,经常应用包括 SVM、神经网络、随机森林或梯度提升树等更广泛的机器学习(ML)方法。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 工作

在零售贷款中使用更简单模型的原因有很多。首先,决策框架已经到位,使得输入特征选择相对简单。例如,对于信用决策,可以从 5Cs of Credit(信用的 5 个要素:Character、Capacity、Capital、Collateral、Conditions)的角度考虑,并寻找满足这些要素的数据变量。这不像使用深度学习从原始图像中创建特征那么困难。其次,目标变量与输入的关系并不复杂,例如,信用风险与收入之间有一个平滑的反向关系。实际上并不需要径向基函数将收入转换到更高维空间,就像 SVM 基于图像分类所需的那样。第三,与今天不同的是,训练和部署平台当时并不适合复杂方法。最后,一个常被提到的原因是模型可解释性(尽管经验丰富的高级机器学习模型用户可能会对此提出质疑)。
随着时间的推移,前述的机器学习方法开始被探索,因为开源软件包变得普遍,数据也以不同的形式出现。然而,业务的主要价值来自于识别新的强大数据,这些数据可以显著改善客户级别的决策。虽然替代数据源始终是一个重点领域,但有些特定的业务问题可以通过近年来普及的新机器学习算法更好地解决。在这里,我们讨论三种这样的算法,重点介绍它们在零售贷款中的应用。
RNNs / LSTMs:
来自银行存款、贷款或信用卡交易的序列数据可以用来生成强大的洞察和行动。一些示例用例:
-
信用风险:理解消费者的信用历史和交易量/档案随时间的变化可以帮助做出更好的信用决策,无论是对于新申请者还是现有客户。
-
欺诈检测:识别特定的交易序列可能会提示欺诈或洗钱行为,并可作为触发器来阻止信用访问并进行调查。
-
流失预测:理解交易量和客户档案随时间的变化可以帮助识别可能流失的客户,并采取保留措施。
-
产品交叉销售/上销售:通过查看交易序列来评估客户是否经历了生活事件或“升级”以潜在改变产品或条款。
-
客户服务:通过记住和学习过去的互动,模型可以改善客户互动(无论是人工还是机器人驱动的)。
常见的统计和机器学习算法并不适合处理这类数据。虽然统计学家传统上创建了诸如不同时间窗口的平均值等特征来捕捉一些趋势信息,但LSTM(长短期记忆)网络是一类专门构建来学习序列数据的递归神经网络。
矩阵分解:
推荐系统因其在零售(亚马逊)、网络流媒体(Netflix)和知识共享(Quora)中的应用而变得流行。许多实现使用了矩阵分解,这是一种通过更快的计算能力实现的传统线性代数公式。以下是一些适用于零售贷款的用例:
-
下一步最佳推荐:这是为了确定对现有客户的下一步推荐。传统上,这通过为每个客户细分构建大量响应倾向模型来解决。“矩阵分解”可以帮助用一个优雅的模型替代,特别是当需要选择的产品众多时。
-
缺失数据:建模前的一个关键预处理步骤是处理数据集中缺失值(尽管基于树的算法本身也会处理)。矩阵分解可以用于从整体数据集中学习“相似”模式,并在应用非树型机器学习算法之前填补缺失值。
深度学习:
不言而喻,深度学习 是过去 5 年里最为显著的新兴机器学习算法,其在从大规模非结构化数据集中生成洞察方面取得了显著成功。一些零售贷款的使用案例包括:
-
语音转文本: 现成的深度学习软件可以将客户的音频转换为文本,然后可以与其他机器学习方法结合用于自动智能客服。
-
社交倾听: 将深度学习应用于来自社交媒体和客户日志的非结构化文本数据,可以帮助理解公司的 4C(品牌评估、产品反馈)、竞争对手(基准测试、战略变化)、客户(情感分析)和气候(市场趋势)。
-
客户细分: 无监督聚类通常用于细分和描述客户基础,以更好地理解并制定针对每个细分市场的战略。其训练过程受到“维度灾难”的困扰。虽然像 PCA 这样的方法被应用于解决这一问题,但深度学习可以作为创建更先进的低维特征的替代方案。
现代的端到端大数据平台提供了训练新型机器学习算法并简化其部署的计算能力。像部分依赖和决策边界距离这样的变量重要性度量可以帮助模型的可解释性。对于特定的分析问题,使用合适的技术并避免复杂性仍然很重要。模型的稳健性、增量业务价值、客户体验、实施和治理应被视为至关重要。机器学习和大量的替代数据源无疑为零售贷款领域带来了更令人兴奋的“建模”时代。
简介: Jayesh Ametha 是一位拥有超过 15 年业务战略、信用风险和高级分析经验的零售银行专业人士。
相关:
-
什么是优化及其如何使业务受益?
-
深度学习如何改变金融和零售行业
-
数据科学如何推动金融科技革命的 7 种方式
更多相关内容
《Python 和 R 中机器学习算法的比较》
原文:
www.kdnuggets.com/2023/06/machine-learning-algorithms-python-r.html

编辑器提供的图像
Python 和 R 是机器学习中最常用的两种编程语言。它们都是开源且高度可访问的,但 Python 是通用编程语言,而 R 是统计编程语言。这使得 R 非常适合各种数据角色和应用,如数据挖掘。
这两种编程语言也鼓励代码的重用,这意味着新手机器学习工程师和爱好者不必从头编写代码。使用它们构建项目的关键在于集成合适的模块和算法——你只需要知道在哪里寻找。为了帮助你,我们整理了一些 Python 和 R 中最常用的机器学习算法列表。确保收藏此指南,并在遇到困难时参考它。
1. K-Means 聚类算法
顾名思义,机器学习的最终目的是教会计算机系统使其能够自主运行。这可以通过监督学习或无监督学习来实现。
执行后者的一种方法是使用k-means 聚类算法,该算法通过对相似数据点进行分组(聚类)来寻找数据集中的模式。
在 R 编程语言中,k-means 聚类通常使用 k-means 函数来执行。不幸的是,Python 似乎没有提供一个像样的现成解决方案。Python 中的 K-means 聚类通常使用 sci-kit-learn 库的 sklearn.cluster.KMeans 类,并结合 matplotlib.pyplot 库来进行。
K-means 聚类算法是最广泛使用的无监督机器学习算法之一,你可能迟早会遇到它或需要使用它。因此,它是你应该首先学习和掌握的算法之一。
2. 决策树
决策树算法因其易用性和实用性而受到青睐。它是一种监督学习的机器学习算法,主要用于分类。例如,公司可以利用它通过聊天机器人来处理难缠的客户。
决策树教会机器如何根据之前的经验做出选择。它之所以在新手机器学习工程师中如此受欢迎,是因为它可以被建模并以图表或图解的形式可视化。这一特点使它对具有传统编程技能的人具有吸引力。
决策树主要有两种类型:
-
连续变量决策树:指的是具有无限目标变量的 决策树。
-
分类变量决策树:指的是具有分组有限目标变量的决策树。
在 R 编程中,最关注决策树的包和类包括:
-
数据集
-
caTools
-
party
-
dplyr
-
magrittr
再次,你将不得不寻找 Python 模块来实现这个算法。与 k-means 聚类算法一样,sci-kit-learn 包含了许多决策树的模块,其中 sklearn.tree 最为相关。你还可以使用 Graphviz 模块 以编程方式呈现决策树的图形表示。
3. 线性回归分析
线性回归是另一种广泛使用的监督机器学习算法。线性回归分析的目标是基于一个或一组变量推断结果或值。
与大多数算法一样,最佳的可视化方式是使用具有两个坐标轴的图形。Y 轴表示因变量,而 X 轴表示自变量。线性回归分析的目标是 形成或找到一个关系。
如果自变量的增加导致因变量的增加(类似于指数增长),这被称为正关系。另一方面,如果因变量的值在自变量的值增加时减少(类似于指数衰减),这被称为负关系。
我们使用 最佳拟合线 来确定关系,这可以通过斜率-截距线性方程 y=mx+b 表示。
那么我们如何在 R 和 Python 中实现线性回归呢?R 编程语言中最关注线性回归分析的包包括:
-
ggplot2
-
dplyr
-
broom
-
ggpubr
gg 包用于创建和绘制图形,而 dplyr 和 broom 用于操控和展示数据。sklearn.linear_model 可用于 在 Python 中构建线性回归模型。你还可以添加 NumPY 来处理大矩阵和数组。
图片由 Pexels 提供
4. 逻辑回归
与线性回归类似,逻辑回归允许我们基于其他(集合的)变量来预测一个变量的值。然而,线性回归使用度量值,而逻辑回归使用离散变量。这些是只能具有两个值之一(是或否,0 或 1,真或假等)的二分变量。
在现实世界中,这可以用于确定一个人购买产品(零售)或携带疾病(医疗保健)的可能性。例如,我们可以使用年龄、身高和体重作为自变量(x)。二元结果将是因变量(y)。因此,x 是实数域,而 y 包含离散值。
逻辑回归的目标是估计(预测)一个结果或事件的概率。由于 y 值是二元的,我们不能使用线性方程,而必须使用激活函数。
Sigmoid 函数用于表示逻辑回归:
f(x) = L / 1+e^(-x)
或
y = 1/(1+e^-(a+b1x1+b2x2+b3x3+...))
与逻辑回归最相关的 Python 包和模块有:
-
matplotlib.pyplot
-
sklearn.linear_model
-
sklearn.metrics
使用 R 生成逻辑回归的过程要简单得多,可以使用 glm() 函数来完成。
5. 支持向量机
支持向量机 (SVM) 算法 主要用于分类,但也可以用于基于回归的任务。SVM 是分类问题中最简单的方法之一。
在 SVM 中,必须分类的对象被表示为 n 维空间中的一个点。该点的每个坐标称为其特征。SVM 通过首先绘制一个超平面,使得每个类别的所有点都位于超平面的两侧,来尝试对对象进行分类。
虽然可能存在多个超平面,但 SVM 尝试找到一个最能分离两个类别的超平面。它主要通过找到两个类别之间的最大距离,即边距,来实现。触及或直接落在边距上的点称为支持向量。
由于 SVM 是一种监督机器学习方法,它需要训练数据。你可以使用 sklearn 的专用 SVM 模块在 Python 中实现这个机器学习算法。在 R 中,SVM 通常通过轮廓和绘图函数来处理。
结论
这些算法中的许多都是机器学习在概率和统计上高度依赖的见证。尽管 R 在现代机器学习工程之前就存在,但它与机器学习相关,因为它是一种统计编程语言。因此,许多算法可以很容易地从头开始构建或实现。
Python 是一种多范式通用编程语言,因此它具有更广泛的应用场景。Sci-kit-learn 是最受信赖的 Python 机器学习模块库。如果你想要了解更多关于上述算法及其他内容,请访问该库的官方网站。
Nahla Davies 是一名软件开发人员和技术作家。在将她的工作全职转向技术写作之前,她曾担任 Inc. 5,000 创意品牌组织的首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持组织的 IT 需求
更多相关话题
自驾车中使用的机器学习算法
原文:
www.kdnuggets.com/2017/06/machine-learning-algorithms-used-self-driving-cars.html
作者:Savaram Ravindra,Tekslate.com。
今天,机器学习算法被广泛用于解决制造自驾车过程中出现的各种挑战。随着传感器数据处理的整合到汽车的 ECU(电子控制单元)中,提升机器学习的利用率以完成新任务变得至关重要。潜在应用包括通过来自不同外部和内部传感器的数据融合——如激光雷达、雷达、摄像头或物联网(IoT)——评估驾驶员状态或驾驶场景分类。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
运行汽车信息娱乐系统的应用程序可以接收来自传感器数据融合系统的信息,例如,如果它发现驾驶员有问题,可以将汽车引导到医院。这种基于机器学习的应用还包括驾驶员的语音和手势识别以及语言翻译。这些算法被分类为无监督算法和监督算法。它们之间的区别在于它们如何学习。
监督算法利用训练数据集进行学习,并不断学习,直到达到他们期望的信心水平(即错误概率最小化)。监督算法可以细分为回归、分类和异常检测或维度缩减。
无监督算法试图从现有数据中提取价值。这意味着,在现有数据中,算法建立关系以检测模式,或根据数据之间的相似度将数据集划分为子组。无监督算法可以大致细分为关联规则学习和聚类。
强化学习算法是另一类机器学习算法,介于无监督学习和监督学习之间。在监督学习中,每个训练样本都有一个目标标签;在无监督学习中则完全没有标签;强化学习则包含时间延迟和稀疏标签——未来奖励。
代理根据这些奖励学习在环境中的行为。理解算法的局限性和优点,并开发高效的学习算法是强化学习的目标。强化学习有可能解决大量实际应用问题,从人工智能问题到控制工程或运筹学——这些都与自驾车的发展相关。这可以分为间接学习和直接学习。
在自动驾驶汽车中,机器学习算法的主要任务之一是持续渲染周围环境并预测这些环境可能发生的变化。这些任务被分类为 4 个子任务:
-
物体检测
-
物体识别或分类
-
物体定位和运动预测
机器学习算法大致分为 4 类:决策矩阵算法、聚类算法、模式识别算法和回归算法。某一类机器学习算法可以用于完成 2 个或更多的子任务。例如,回归算法可以用于物体定位、物体检测或运动预测。
决策矩阵算法
决策矩阵算法系统地分析、识别和评估信息集和价值之间关系的性能。这些算法主要用于决策制定。汽车是否需要刹车或左转取决于这些算法对物体识别、分类和下一个动作预测的信心水平。决策矩阵算法是由各种独立训练的决策模型组成的,这些预测在某种程度上被组合以做出总体预测,同时减少决策错误的可能性。AdaBoosting 是最常用的算法。
AdaBoosting
自适应提升(AdaBoost)是一种结合多种学习算法的方法,可用于回归或分类。与其他机器学习算法相比,它克服了过拟合问题,且通常对异常值和噪声数据较为敏感。为了创建一个复合强大的学习者,AdaBoost 使用多次迭代。因此,它被称为自适应的。通过迭代地添加弱学习者,AdaBoost 创建了一个强大的学习者。一个新的弱学习者被添加到实体中,并调整加权向量,以关注在之前轮次中被错误分类的样本。结果是一个比弱学习者的分类器具有更高准确性的分类器。
AdaBoost 帮助将弱阈值分类器提升为强分类器。上图展示了在一个单一文件中实现 AdaBoost 的代码,代码易于理解。该函数包含一个弱分类器和提升组件。弱分类器试图在数据的一个维度中找到理想的阈值,将数据分为两个类。提升部分会迭代地调用分类器,每次分类步骤后,它会改变被错误分类样本的权重。因此,创建了一系列弱分类器,它们表现得像一个强分类器。
聚类算法
有时,系统获取的图像不够清晰,导致定位和检测对象变得困难。有时,分类算法可能会遗漏对象,在这种情况下,它们无法将对象分类并报告给系统。可能的原因包括数据不连续、数据点太少或图像分辨率低。聚类算法专注于从数据点中发现结构。它描述了方法类别和回归等问题类别。聚类方法通常通过建模方法组织,如层次化和基于中心点的方法。所有方法都关注利用数据中固有的结构,将数据完美地组织成最大共同性的组。K-means、多类别神经网络是最常用的算法。
K-means
K-means 是一种著名的聚类算法。K-means 存储 k 个中心点,用于定义聚类。如果一个点比其他中心点更接近某个中心点,则该点被认为在该中心点定义的特定聚类中。通过在根据当前数据点的聚类分配选择中心点和根据当前中心点分配数据点到聚类之间交替进行。
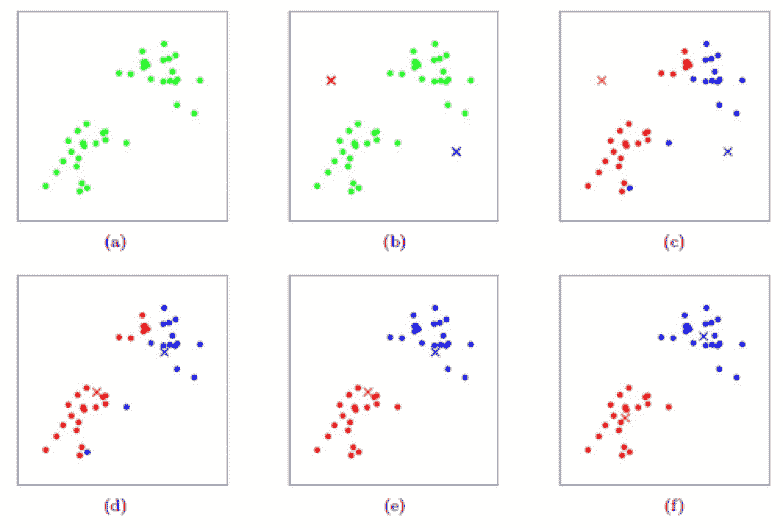
K 均值算法 – 聚类质心用十字表示,训练样本用点表示。(a) 原始数据集。(b) 随机初始聚类质心。(c-f) 演示了运行 2 次 K 均值算法的过程。在每次迭代中,每个训练样本被分配到离其最近的聚类质心,然后每个聚类质心移动到分配给它的点的均值。
模式识别算法(分类)
通过传感器获得的高级驾驶辅助系统(ADAS)的图像包含各种环境数据;需要对图像进行过滤,以确定对象类别的实例,排除无关的数据点。在对对象进行分类之前,识别数据集中的模式是一个重要步骤。这类算法被称为数据减少算法。
数据减少算法有助于减少对象的数据集边缘和多边形线段(拟合线段)以及将圆弧转换为边缘。直到一个角落,线段与边缘对齐,之后将开始一个新的线段。圆弧与类似弧形的线段序列对齐。以多种方式,将图像的特征(圆弧和线段)结合起来,形成用于确定对象的特征。
使用 PCA(主成分分析)和 HOG(方向梯度直方图),SVM(支持向量机)是 ADAS 中常用的识别算法。K 近邻算法(KNN)和贝叶斯决策规则也被使用。
支持向量机(SVM)
支持向量机(SVM)依赖于定义决策边界的决策平面概念。决策平面将包含不同类别成员的对象集合分开。下图展示了一个示意图。在这个示意图中,对象属于 RED 或 GREEN 类别。分隔线将 RED 和 GREEN 对象分开。任何落在左侧的新对象被标记为 RED,而如果落在右侧则标记为 GREEN。
回归算法
这种算法擅长预测事件。回归分析评估两个或更多变量之间的关系,并整合变量在不同尺度上的影响,主要由 3 个指标驱动。
-
回归线的形状。
-
依赖变量的类型。
-
自变量的数量。
图像(相机或雷达)在 ADAS 的激活和定位中起着重要作用,而对于任何算法来说,最大的挑战是开发一个基于图像的特征选择和预测模型。
回归算法利用环境的重复性来创建一个统计模型,该模型描述给定物体在图像中的位置与图像之间的关系。统计模型通过允许图像采样,提供了快速的在线检测,并可以离线学习。它还可以扩展到其他物体,而不需要大量的人为建模。一个物体的位置由算法返回作为在线阶段的输出,并对物体的存在做出信任。
回归算法也可以用于短期预测和长期学习。这类回归算法,包括决策森林回归、神经网络回归和贝叶斯回归等,可以用于自动驾驶汽车。
神经网络回归
神经网络被用于回归、分类或无监督学习。它们对未标记的数据进行分组、分类或在监督训练后预测连续值。神经网络通常在网络的最后一层使用一种形式的逻辑回归,将连续数据转换为类似 1 或 0 的变量。
在上图中,‘x’是输入,表示从网络的前一层传递到当前层的特征。每个最后隐藏层的节点都会接收多个 x,每个 x 会乘以一个相应的权重 w。偏差的和会被加到产品中,并传递到激活函数。激活函数是 ReLU(修正线性单元),因其不会像 sigmoid 激活函数那样在浅梯度上饱和而被广泛使用。ReLU 为每个隐藏节点提供一个输出激活 a,这些激活被加到输出节点中,输出节点传递激活的总和。这意味着执行回归的神经网络包含单一的输出节点,这个节点将前一层激活的总和乘以 1。网络的估计值‘y hat’将是结果。‘Y hat’是所有 x 映射到的因变量。你可以用这种方式利用神经网络来获得 x(自变量的数量)与 y(你试图预测的因变量)之间的关系。
原始帖子。经许可转载。
简介: Savaram Ravindra 是 Tekslate.com 的内容贡献者,曾是 Cognizant Technology Solutions 的程序分析师。他拥有 VIT 大学的纳米技术硕士学位。可以通过 savaramravindra4@gmail.com 联系他。
相关:
-
我应该使用哪个机器学习算法?
-
近期车辆技术进展简要概述
-
自动驾驶车辆成功需要超人般的感知能力
更多相关话题
机器学习算法 – 什么、为什么以及如何?
原文:
www.kdnuggets.com/2022/09/machine-learning-algorithms.html
图片由编辑提供
识别机器学习可解决的问题
机器学习是一个通过数据学习模式的领域,无需明确编程或手写规则。它是人工智能(AI)和计算机科学的一个子领域。
在机器学习成为主流之前,程序员编写的规则来源于他们的领域知识、观察到的一些精选实例以及业务需求来执行特定任务。但这种传统的交付业务结果的方式存在一些明显的限制。
-
手写规则受限于程序员能够覆盖的边缘情况的知识。这一概念在心理学领域中一篇被广泛引用的论文中有很好的解释,“魔法数字七,加或减二:我们处理信息的能力的某些限制。”
-
通常被称为米勒定律,论文描述了一个普通大脑能够容纳的有限信息量,以及随着变量和维度数量的增加,信息处理变得如何难以管理。
-
数据本质上是动态的,并且在过去十年中随着技术的普及变得更加动态。静态的预编写规则对业务采取有意义的行动帮助甚微。这就是机器学习算法的模式挖掘能力发挥最大作用的地方。
以一个欺诈检测案例为例。程序员会编写规则,例如如果交易金额超过$10K,交易地点是 X,且是某种类型,即电汇,那么它将被标记为潜在的欺诈交易。
来源:作者
这可能会有效一段时间,直到不法分子找到一种智能化的欺诈手段。传统的硬编码规则在检测欺诈方面已不再有效。随着他们操作方式的演变,我们的欺诈检测系统也需要随之发展。
此外,所有的软件开发过程都是高度协作的?—?如果编写初始规则的开发人员不再参与欺诈检测项目,新开发人员负责升级逻辑,但对之前的系统没有了解,并对最近的更改是否具有向后兼容性持怀疑态度。总而言之,更新基于规则的系统不仅是一个繁琐的过程,而且也不可扩展。
这就是机器学习算法为我们提供帮助的地方。如果指标定义明确且与业务目标一致,它会继续从新的训练数据中学习,并演变成一个复杂的机器学习系统。
如何选择合适的算法
到现在为止,我们了解了机器学习算法最适合解决什么类型的业务问题以及在给定用例的统计公式方面的广泛类别。
所以,下一步是确定哪种特定算法最适合解决机器学习问题。没有规则书或指南可以给你一个即时的答案,但我们将讨论经验丰富的数据科学家在选择候选算法集时考虑的因素。
Sci-kit learn 发布了一个流程图,这是一个很好的起点,用于了解哪些算法适用于什么类型的数据和给定问题。
来源:scikit-learn.org/stable/tutorial/machine_learning_map/index.html
很容易被大量高级算法压倒,开始通过试错方法实施它们以找到合适的模型。但时间至关重要,你需要将算法选择缩小到少量候选集,例如 2 到 3 个。
我们已经将算法搜索空间缩小到一个小集,现在将列出优缺点、限制和约束。
许多因素决定了合适的冠军模型:
-
准确性:它是否符合在阈值之上表现的资格标准?
-
数据可用性:你有多少数据?
-
资源:模型训练需要多长时间?是否计算开销大?
-
延迟:实时推断的时间
-
可解释性:预测结果是否可以解释?
-
对异常值的鲁棒性:对异常行为是否敏感?
-
非线性关联:如果数据遵循非线性模式,则排除线性模型
-
缺失值:你的算法是否能够处理缺失值?
上述列出的因素为你的选择提供了快速而简单的基础。进一步,我将通过引用“没有免费的午餐”定理,来总结这一部分,该定理指出:
“没有一个模型适用于所有问题。一种情况的优秀模型的假设可能在另一种情况下不成立,因此在机器学习中尝试多个模型并找到最适合特定情况的模型是很常见的”
要理解这个定理,我们首先必须确定模型的作用。模型试图通过在一些假设下将真实世界现象进行归纳。这些假设有助于简化建模环境,并仅关注相关细节。因此,一个适用于某个问题的模型可能不适用于另一个问题。
现在我们了解了选择机器学习算法的关键因素,你可以参考这个优秀的备忘单来了解算法的全貌。
摘要
文章的关键亮点在于理解机器学习算法的重要性。此外,它解释了不同的模型选择标准,以帮助你找到适合你业务问题的机器学习算法。值得注意的是,没有一个通用的算法能够适用于多个使用案例。文章最后分享了备忘单,以帮助理解数据类型和业务问题与算法之间的映射。
Vidhi Chugh 是一位获奖的 AI/ML 创新领袖和 AI 伦理学家。她在数据科学、产品和研究的交汇处工作,以提供业务价值和洞察。她是数据中心科学的倡导者,并在数据治理方面是领先专家,致力于构建可信的 AI 解决方案。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
更多相关主题
如何使用机器学习进行异常检测和条件监控
原文:
www.kdnuggets.com/2020/12/machine-learning-anomaly-detection-conditional-monitoring.html
评论
由 Michael Garbade,教育生态系统首席执行官兼创始人
主要收获
-
异常检测分析的主要目标是识别那些不符合正常行为的一般模式的观察值。
-
异常检测在理解数据问题时可能会很有用。
-
有些领域的异常检测方法非常有效。
-
现代机器学习工具包括隔离森林和其他类似方法,但要成功实施,你需要了解基本概念。
-
隔离森林方法是一种无监督异常值检测方法,结果具有可解释性。
介绍
在进行任何数据分析之前,需要找出数据集中是否存在异常值。这些异常值被称为异常。
本文解释了异常检测的目标,并概述了解决特定异常检测和条件监控用例所采用的方法。
什么是异常检测?实际应用案例。
异常检测分析的主要目标是识别那些不符合正常行为的一般模式的观察值。例如,图 1 显示了分类和回归问题中的异常。我们可以看到一些值偏离了大多数例子。
图 1. 分类(a,左)和回归(b,右)问题中的异常值
数据分析中有两个方向用于搜索异常:异常值检测和新颖性检测。因此,异常值是与训练数据集中其他数据点不同的观察值。新颖性数据点也与数据集中的其他观察值不同,但与异常值不同,新颖性点出现在测试数据集中,而通常在训练数据集中不存在。因此,图 1 中显示了异常值。
异常值最常见的原因是;
-
数据错误(测量不准确、舍入、书写错误等);
-
噪声数据点;
-
数据集中的隐藏模式(如欺诈或攻击请求)。
因此,异常值处理取决于数据的性质和领域。噪声数据点应进行过滤(噪声去除);数据错误应进行纠正。一些应用专注于异常选择,我们将进一步讨论一些应用。
在各种商业应用中,异常检测都很有用。例如,入侵检测系统(IDS)基于异常检测。图 2 展示了 NSL-KDD 数据集的观察分布,这是一种用于 IDS 的先进数据集。我们可以看到,大多数观察都是正常请求,而 Probe 或 U2R 是一些异常点。自然,计算机系统中的大多数请求是正常的,只有一部分是攻击尝试。
图 2. IDS 观察分布
信用卡欺诈检测系统(CCFDS)是另一个异常检测的应用案例。例如,来自 kaggle.com 的开放数据集(https://www.kaggle.com/mlg-ulb/creditcardfraud)包含了 2013 年 9 月欧洲持卡人使用信用卡的交易记录。该数据集展示了发生在两天内的交易,共有 284,807 笔交易,其中 492 笔为欺诈交易。数据集高度不平衡。正类(欺诈交易)占所有交易的 0.172%。
异常检测有两种方法:
-
监督方法;
-
无监督方法。
在监督异常检测方法中,数据集具有正常和异常观察或数据点的标签。IDS 和 CCFDS 数据集适合用于监督方法。这些用例中使用了标准的机器学习方法。监督异常检测是一种二分类问题。需要注意的是,异常检测问题的数据集往往高度不平衡。因此,在使用监督分类方法之前,使用一些数据增强程序(如 k-最近邻算法、ADASYN、SMOTE、随机抽样等)是很重要的。Jordan Sweeney 展示了如何在 Education Ecosystem 的一个项目中使用 k-最近邻算法,旅行推销员 - 最近邻。
无监督异常检测在没有关于异常和相关模式的信息时非常有用。此时使用孤立森林、OneClassSVM 或 k-means 方法。这里的主要思想是将所有观察划分为若干个簇,并分析这些簇的结构和大小。
有不同的开放数据集用于异常检测方法的测试,例如,异常检测数据集 (odds.cs.stonybrook.edu/)。
基于孤立森林的无监督异常检测
Isolation Forests 方法基于决策树的随机实现和其他结果的集成。每棵决策树都会构建到训练数据集耗尽为止。为构建决策树的新分支而选择一个随机特征和随机分裂。该算法通过决策树叶子的深度均值来区分正常点和离群点。此方法已在 scikit-learn 库中实现 (scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html)。
为了说明异常检测方法,让我们考虑一些带有离群点的玩具数据集,这些数据集已经在图 3 中展示。类 1 的点是离群点。‘class’ 列在分析中未使用,仅用于说明。
图 3. 数据集样本和散点图
让我们对这个玩具例子应用 Isolation Forests 方法,并在一些玩具测试数据集上进一步测试。结果如 图 4 所示。完整代码请见: https://www.kaggle.com/avk256/anomaly-detection。
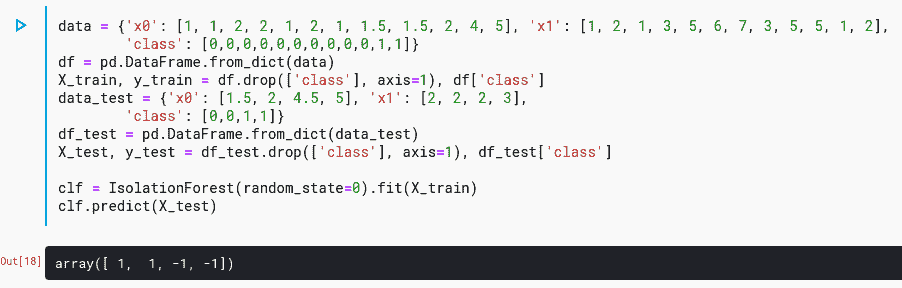
图 4. 数据集和 Isolation Forests 方法的实现
应该注意到,‘y_train’ 和 ‘y_test’ 列没有用于方法拟合。因此,Isolation Forests 方法仅使用数据点并确定离群点。因此,‘X_test’ 数据集包含两个正常点和两个离群点,经过预测方法后,我们得到两个簇的完全相等的分布。
结论
简而言之,异常检测方法可以用于分支应用,例如,清理噪声数据点和观察错误。另一方面,异常检测方法在商业应用中也很有帮助,例如入侵检测或信用卡欺诈检测系统。Andrey 在他的项目 机器学习模型:Python Sklearn & Keras 中展示了 Isolation Forests 方法是最简单有效的无监督异常检测方法之一。此外,该方法已经在先进的库 Scikit-learn 中实现。
简介: 迈克尔·加尔巴德 是 Education Ecosystem 的首席执行官兼创始人。迈克尔是一位具有前瞻性思维的全球性连环创业者,专注于软件开发、后端架构、数据科学、人工智能、金融科技、区块链和风险投资。他将技术、数据、金融和业务开发的经验与令人印象深刻的教育背景相结合,并具有识别新商业模式的天赋。作为 Education Ecosystem 的联合创始人和首席执行官,他的使命是建立全球最大的去中心化学习生态系统,服务于职业开发者和大学生。他在 Opensource.com、Dzone.com、Cybrary、Businessinsider、Entrepreneur.com、TechinAsia、Coindesk 和 Cointelegraph 等领先博客上撰写主题专家技术和商业文章。
相关:
-
异常检测,AI 和机器学习的关键任务,解释
-
介绍 MIDAS:图形异常检测的新基准
-
异常检测简介
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
数据科学的 5 个最佳机器学习 API
原文:
www.kdnuggets.com/2015/11/machine-learning-apis-data-science.html/2
3) Google Prediction API
Google Prediction API 让开发者可以利用 Google 的机器学习算法来处理数据并提供可能的结果,从而使应用程序更智能。Google Prediction API 是一种基于云的机器学习和模式匹配工具,用于机会分析、客户情感分析、流失分析、垃圾邮件检测、文档分类、购买预测、推荐、智能路由等。
Google Prediction API 使用分类器来编程 API 服务以进行预测,因此用户只需具备一些基本的编程背景,而无需掌握 AI 的工作知识即可。它从 BigQuery 和 Google Cloud Storage 读取数据。
Google Prediction API 应用
-
福特在其研究实验室中使用 Google 的 Prediction API 来提高驾驶效率。它跟踪驾驶员以创建一个驾驶员每天访问的地点和路线列表。这帮助福特智能地检测出,如果一个人在工作日的特定时间开车,那么可能是去办公室的行程。福特使用 Google Prediction API 来预测基于从其汽车中捕获的传感器数据的驾驶员行为。
-
总部位于加州的初创公司 Pondera Solutions 提供作为服务的欺诈检测,其基础是 Google 的 Prediction API。

4) 亚马逊机器学习 API
亚马逊机器学习 API 简化了需要大量模型构建、数据清洗和统计分析的预测过程。亚马逊机器学习模型只处理预测问题,通过将数据流经模型并根据预测误差缓慢调整来运作。亚马逊机器学习 API 还提供基于学习模型预测性能的可视化,以便用户获得更好的洞察。
尽管亚马逊机器学习 API 强加了一些 UI 限制或算法限制,但它用户友好且向导驱动,使其成为开发者的一个不错选择。
亚马逊机器学习 API 用例
-
使用 AWS API,数据科学家或分析师可以通过分析信号级特征来对歌曲的类型进行分类。
-
它可以用于基于加速度计、智能手机上捕获的传感器数据或陀螺仪信号的人类活动识别,以确定移动设备是否在走楼梯、走下楼梯、垂直或水平躺下、静坐或站立。
-
通过分析用户在第一周或第一个月的活动,预测用户是否会成为付费客户。
-
分析网站活动记录,以检测系统中的虚假用户、机器人或垃圾邮件发送者。
所有上述用例都假设需要预测一些在运行时未知的内容,但有足够的数据和计算能力让 Amazon 机器学习 API 解决当前的问题。
5) BigML
BigML 是一个对用户友好和开发者友好的机器学习 API,主要集中在决策树上。BigML 的目标是使预测分析对用户而言既简单易懂又美观。它专注于理解业务流程和最终用户分析师制作报告。BigML API 提供 3 种重要模式——命令行界面、Web 界面和 RESTful API。BigML 的 Web 界面非常酷,具有一键操作和画廊等功能。
BigML 使用案例-
-
BigML 帮助创建描述性模型,以理解复杂数据中各种属性与预测属性之间的关系,使业务分析师可以进行假设情景分析。
-
如果分析师希望基于过去的示例创建预测模型,BigML 是有用的。分析师可以使用 BigML 构建预测模型进行批量预测,这些预测可以下载为 CSV 文件以进行分析。
-
BigML 还在需要进行周期性预测时表现出色。模型可以在 BigML 平台上维护,然后可以根据需要通过 BigMLer 命令行界面远程使用。
选择众多且数据丰富的情况下,比赛就在于哪个机器学习 API 最佳——学习最快的人赢得胜利。机器学习算法可能不完美。这不应该成为问题,因为最终决定仍然掌握在人类手中。然而,这些机器学习算法将众多选择缩减为人类能够管理的范围。未来,机器学习将带来新颖的创新,提升人类能力,帮助人们做出良好的选择,并以强大的方式导航世界。
相关:
-
预测和机器学习的 API:投票结果和分析
-
标准化机器学习 Web 服务 API 的世界
-
云机器学习之争:Amazon vs IBM Watson vs Microsoft Azure
-
马萨诸塞州的文本挖掘与选举分析
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关内容
机器学习与人工智能:2016 年的主要发展与 2017 年的关键趋势
在 KDnuggets,我们尽力保持对行业、学术界和技术领域主要事件和发展的关注。我们也尽力展望未来的关键趋势。
我们最近询问了一些大数据、数据科学、人工智能和机器学习领域的领先专家,他们对 2016 年的重要发展和 2017 年的关键趋势发表了意见。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 需求
要了解我们发布的前两篇帖子中概述的专家意见,请参见以下内容:
-
大数据:2016 年的主要发展与 2017 年的关键趋势
-
数据科学与预测分析:2016 年的主要发展与 2017 年的关键趋势
在系列文章的最后一篇中,我们带来对以下问题的汇总回应:
“2016 年主要的人工智能/机器学习相关事件是什么?您认为 2017 年的关键趋势是什么?”
常见的主题包括深度神经网络的成功、强化学习的成就、AlphaGo 作为这两种现象联合力量的典范、机器学习在物联网、自驾车辆和自动化等方面的应用。
我们通常要求参与者将回答控制在 100 字左右,但如果情况需要,也乐于接受较长的回答。现在,来看看我们的发现吧。

Yaser Abu-Mostafa, 加州理工学院(与 Hsuan-Tien Lin 教授和 Malik Magdon-Ismail 教授协商)
2016 年和 2017 年是机器学习的激动人心的时期。有两个趋势在加速发展。首先,展示了机器学习作为一种极其强大的技术的案例。最近,AlphaGo 和不人性化加密的成功就是很有说服力的例子。其次,机器学习应用的扩展范围。更多复杂的任务,更多领域,以及对机器学习作为数据利用方式的更多接受。Google/Microsoft/Facebook/IBM 的人工智能合作伙伴关系是有原因的。
Xavier Amatriain,Quora 的工程副总裁
2016 年可能会被载入历史,成为“机器学习炒作”之年。现在似乎每个人都在做机器学习,如果他们没有在做,他们也在考虑收购一家初创公司来声称自己在做。
现在,公平地说,这些“炒作”有其原因。你能相信吗,Google 宣布开源Tensor Flow才过去了一年?Tensor Flow 已经是一个非常活跃的项目,用于从药物发现到生成音乐的各种应用。然而,Google 并不是唯一一个开源其机器学习软件的公司,许多公司跟随了这个趋势。Microsoft 开源了 CNTK,百度宣布了 PaddlePaddle 的发布,而 Amazon 最近宣布他们将支持 MXNet在其新的 AWS 机器学习平台中。另一方面,Facebook 实际上支持了两个深度学习框架的开发:Torch和Caffe。另一方面,Google 也支持了高度成功的Keras,所以在这一方面,Facebook 和 Google 的情况至少是相当的。
除了对机器学习开源项目的“炒作”和公司们的支持外,2016 年也见证了许多几个月前几乎无法想象的机器学习应用。我特别对Wavenet的音频生成质量感到印象深刻。由于我曾处理过类似的问题,因此我能够欣赏这些结果。我还想强调一些近期的唇读结果,这是一项很好的视频识别应用,未来可能会非常有用(也许有些吓人)。我还应提及谷歌在机器翻译方面的惊人进展。看到这一领域在一年内取得如此巨大的进步,令人惊叹。
实际上,机器翻译并不是我们在过去一年里在语言技术领域见到的唯一有趣的进展。我认为,看到一些将深度序列网络与侧信息结合以生成更丰富语言模型的最新方法非常有趣。在“A Neural Knowledge Language Model”中,Bengio 的团队将知识图谱与 RNNs 结合,而在“Contextual LSTM models for Large scale NLP Tasks”中,DeepMind 团队将话题融入 LSTM 模型。我们还看到许多关于语言模型中的注意力和记忆建模的有趣工作。例如,我推荐“Ask Me Anything: Dynamic Memory Networks for NLP”,这是今年 ICML 会议上展示的内容。
我不能结束这篇 2016 年的回顾而不提到我主要专业领域的进展:推荐系统。当然,深度学习也对这一领域产生了影响。虽然我仍然不建议将深度学习作为推荐系统的默认方法,但有趣的是,它已经在实践中被广泛使用,例如在Youtube中。话虽如此,在与深度学习无关的领域也有一些有趣的研究。今年 ACM Recsys 的最佳论文奖颁给了“Local Item-Item Models For Top-N Recommendation”,这是对稀疏线性方法(即SLIM)的一个有趣扩展,使用了初步的无监督聚类步骤。此外,“Field-aware Factorization Machines for CTR Prediction”,描述了在Criteo CTR Prediction Kaggle Challenge中获胜的方法,也很好地提醒我们因子分解机仍然是你机器学习工具箱中一个很好的工具。
我可能可以列出几页内容,列举过去 12 个月中机器学习的重大进展。请注意,我甚至没有列出与图像识别或深度强化学习相关的突破,或诸如自动驾驶汽车或游戏玩法等明显的应用,所有这些在 2016 年都有巨大的进展。更不用说关于机器学习对社会产生或可能产生负面影响的争议,以及围绕算法偏见和公平性的讨论。
那么,我们应该对 2017 年抱有怎样的期待呢?鉴于这个领域变化如此之快,很难做出预测。我相信我们将难以消化在几天后的NIPS 会议上看到的内容。我肯定会期待在我最关注的领域——个性化/推荐系统和自然语言处理——中看到许多机器学习的进展。例如,我相信在接下来的几个月里,我们将看到机器学习如何应对假新闻问题。但当然,我也希望看到更多的自动驾驶汽车上路,以及机器学习在健康相关应用中或用于创建更好信息和更公正社会中的良好应用。
约书亚·本吉奥,蒙特利尔大学计算机科学与运筹学系教授,加拿大统计学习算法研究主席等。
从我的角度来看,2016 年的主要事件集中在深度强化学习、生成模型和神经机器翻译领域。首先是 AlphaGo(DeepMind 的网络通过深度强化学习击败了围棋世界冠军)。整年我们看到了一系列论文展示生成对抗网络(用于生成模型的无监督学习)的成功。在无监督学习领域,我们也见证了自相关神经网络(如 DeepMind 的 WaveNet 论文)的意外成功。最后,就在一个月前,我们见证了神经机器翻译的巅峰(该技术部分由我的实验室自 2014 年起启动),Google 将这项技术扩展到 Google Translate 的规模,并取得了非常惊人的结果(接近人类水平的表现)。
我相信以下这些是对 2017 年期望进展的良好指标:在无监督学习方面取得更多进展(这仍然是一个主要挑战,我们在这方面离人类能力还很远),以及计算机理解和生成自然语言的能力,可能首先体现在聊天机器人和其他对话系统上。另一个可能的趋势是深度学习在医疗领域应用的研究和成果增加,涵盖各种类型的数据,包括医学图像、临床数据、基因组数据等。计算机视觉的进展将继续,我们将看到更多应用,包括自动驾驶汽车,但我有一种感觉,整体社区对实现真正自主性面临的挑战估计不足。

佩德罗·多明戈斯,华盛顿大学计算机科学教授,《大师算法》的作者。
2016 年的主要事件是 AlphaGo 的胜利。我们可能在 2017 年看到显著进展的两个领域是聊天机器人和自动驾驶汽车,仅仅因为许多主要公司在这些领域进行了大量投资。在更基础的方面,我们可能会看到深度学习与其他机器学习/人工智能技术的混合化增加,这对于成熟的技术来说是典型的。
奥伦·艾齐奥尼,艾伦人工智能研究所的首席执行官。他曾是华盛顿大学的教授,也是包括 Farecast 和 Decide 在内的几家公司的创始人/联合创始人,并且发表了超过 100 篇技术论文。
AlphaGo 的巨大成功是 2016 年的辉煌成就。2017 年,我们将看到更多的强化学习在神经网络中的应用,更多关于神经网络在自然语言处理和计算机视觉中的研究。然而,神经网络在有限标注数据下面临的挑战,例如Semantic Scholar这样的系统,仍然是巨大的,并且将会占据我们多年的时间。这些对深度学习以及更广泛的机器学习领域来说仍然是早期阶段。
Ajit Jaokar,#数据科学,#物联网,#机器学习,#大数据,移动,#智能城市,#教育科技(@feynlabs + @countdowncode)教学(@forumoxford + @citysciences)
2017 年将是物联网和人工智能的关键一年。根据我最近的 KDnuggets 文章,人工智能将成为企业的核心能力。对于物联网来说,这意味着能够在各种平台(云端、边缘、流媒体)上构建和部署模型。这将持续学习与通过人工智能实现持续改进的愿景联系起来。它还需要在人工智能和 DevOps 融合时获得新的能力。
Neil Lawrence,谢菲尔德大学机器学习教授
我认为目前的进展与我们预期的情况差不多。深度学习方法正被智能地应用于非常大的数据集上。对于较小的数据集,我认为我们会看到一些有趣的模型再利用方向,即重用预训练的深度学习模型。关于如何最好地进行这些操作,还有一些有趣的未解问题。另一个趋势是对该领域的媒体关注度不断增加,包括关于尚未审阅的Arxiv论文的主流文章。这种对前沿的兴趣去年也存在,但我认为今年这种趋势有所加速。对此,我认为学术界可能需要更加谨慎地选择如何推广他们的工作(例如在社交媒体上),尤其是当它尚未经过审阅时。
Randal Olson,宾夕法尼亚大学生物医学信息学研究所高级数据科学家
自动化机器学习(AutoML)系统在 2016 年开始与人类机器学习专家竞争。今年早些时候,麻省理工学院的一个团队创建了一个数据科学机器,在流行的 KDD Cup 和 IJCAI 机器学习比赛中击败了数百个团队。就在这个月,我们的内部 AutoML 系统,TPOT,开始在几个Kaggle比赛中排名 90 百分位。毫无疑问,我相信 AutoML 系统将在 2017 年开始取代人类专家进行标准机器学习分析。

Charles Martin,数据科学家和机器学习专家
2016 年是深度学习的分水岭年。我们经历了Google Tensorflow的一年,应用不断涌现。结合如 Keras、Jupyter Notebooks 和启用 GPU 的 AWS 节点,数据科学团队拥有按需的基础设施,可以开始构建真正创新的学习应用,并迅速产生收入。但他们可能没有足够的人才?这不仅仅是编码问题,也不是基础设施问题。它与传统分析大相径庭,没有人真正理解为什么深度学习有效。不过,面对现实吧,这正是谷歌和 Facebook 谈论的所有内容!而高层管理人员正在关注。2017 年,公司将寻求引入最优秀的深度学习技术,以改善财务状况。
Matthew Mayo,数据科学家,KDnuggets 副主编
2016 年的大事件必须是我们看到的深度学习的加速回报。基于(不仅仅是)神经网络的“征服”围棋可能是最突出的例子,但还有其他例子。展望 2017 年,我预计神经网络的持续进步将仍然是大新闻。然而,自动化机器学习将悄然成为一个重要事件。虽然对外界来说不如深度神经网络那样引人注目,但自动化机器学习将开始在机器学习、人工智能和数据科学领域产生深远的影响,2017 年可能会显现这一点。
Brandon Rohrer,Facebook 数据科学家
在 2016 年,机器在读唇的准确度超过了人类(arxiv.org/pdf/1611.05358.pdf),从听写中打字的速度超过了人类(arxiv.org/abs/1608.07323),并创造了逼真的人类语音(arxiv.org/pdf/1609.03499.pdf)。这些都是探索新型架构和算法的结果。卷积神经网络正在被修改得面目全非,并与强化学习者和时间感知方法结合,以开辟新的应用领域。预计 2017 年会有更多人类水平的基准被打破,特别是那些基于视觉的,因此适合 CNN。我还期待(并希望!)我们社区在决策制定、非视觉特征创建和时间感知方法等相关领域的探索会变得更加频繁和有成效。这些共同使得智能机器人成为可能。如果我们真的很幸运,2017 年将会带来一种能在制作咖啡方面击败人类的机器。
丹尼尔·腾克兰,数据科学、工程与领导力
2016 年的最大新闻是AlphaGo战胜了围棋人类世界冠军李世石。这对 AI 社区来说也是个惊喜,它将被铭记为深度学习崛起的分水岭。2016 年是深度学习和 AI 的年份。聊天机器人、自动驾驶汽车和计算机辅助诊断揭示了通过投入足够的 GPU 到合适的训练数据中,我们可以做什么。2017 年将带来成功与失望。像 TensorFlow 这样的技术将使深度学习商品化,AI 将在消费品中成为理所当然的存在。但我们将会遇到建模和优化的极限。我们必须面对数据中的偏见。我们会成长起来,意识到我们离通用 AI 或奇点还远得很。
相关:
-
大数据:2016 年的主要发展和 2017 年的关键趋势
-
数据科学与预测分析:2016 年的主要发展和 2017 年的关键趋势
-
2017 年深度学习的预测
更多相关主题
艺术家机器学习 – 视频讲座和笔记
原文:
www.kdnuggets.com/2016/04/machine-learning-artists-video-lectures-notes.html
毫无疑问,机器学习——更具体地说,深度学习——最近在艺术领域中扮演了越来越显著的角色。从Deep Dream到 Deep Forger,再到 Beyond the Fence,各种形式的艺术都受到了神经网络的创造力的影响,似乎这些变化也引起了那些不直接从事机器学习工作的人们的关注。
Gene Kogan,来自纽约大学的Tisch 艺术学院,最近启动了他的首个“艺术家机器学习”课程,这是该学院互动电信程序(ITP)中的一门选修课程。ITP 的使命是探索“通信技术的富有想象力的使用”,以及如何利用这些技术为个人的生活带来艺术和欢乐。他们自称为“最近可能的中心”,这个术语我认为非常棒。
课程不偏重技术,专注于可转移的机器学习和深度学习理解,这些理解将既可转移又可重复使用。直接来自该项目的课程描述网站:
本课程不会涵盖或假设对机器学习技术或数学细节的知识,而是专注于如何将现有工具集成到现有的交互式应用程序中,尽管会提供学习技术方面的资源。我们使用的工具将是平台无关的,这使得将机器学习添加到现有应用程序中变得更容易。编程能力将有助于定制提供的工具,但不是必需的。
对于那些无法搬到纽约市并注册为期两年的研究生课程的人来说,这门课程的最佳部分是课程材料可以在这里免费获得。在撰写时,以下讲座已经发布(直接链接):
该课程似乎非常注重机器学习在艺术创作和改进中的应用。最近新增的递归神经网络讲座表明,本课程不会仅仅专注于视觉艺术,还会涉及文本生成和字符级模型。
Kogan 还在撰写有关此主题的书籍。你可以在这里查看《艺术家的机器学习》的草稿章节,图示和互动演示也可以在这里查看。
我们祝贺像 NYU 这样的优秀机构,它们认识到将优质课程材料免费公开的重要性;我们也对 Gene Kogan 表示敬意,他对这一做法的认识和兴趣同样值得称赞。
你可以在这里了解更多关于 Tisch 艺术学院 ITP 计划的信息。
相关:
-
深度学习与艺术风格 – 艺术能否被量化?
-
Top /r/MachineLearning 帖子,8 月:深度学习模仿多位著名画家的风格
-
2024 年 1 月最佳深度学习资源
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持组织的 IT 需求
更多相关内容
机器学习——一切都关于假设
原文:
www.kdnuggets.com/2021/02/machine-learning-assumptions.html
评论
由 Vishal Mendekar 编写,精通 Python、机器学习和深度学习。
本博客讨论了流行机器学习算法的假设及其优缺点。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作

开始这个博客之前,让我先讲讲创建这个博客的原因。
有大量的数据科学爱好者正在寻找数据科学的工作,或为了更好的机会而换工作。每一个这些人都必须经历一些严格的招聘过程,包括几轮面试。
招聘人员/面试官通常会期待回答几个基本问题。了解流行的 机器学习算法 的假设及其优缺点就是其中之一。
在博客的后续部分,我将首先介绍特定算法的假设,然后是其优缺点。这将只占用你大约 5 分钟的时间,到博客结束时,你一定会学到一些东西。
我将按照以下顺序介绍假设、优缺点。
-
K-NN(K 最近邻)
-
逻辑回归
-
线性回归
-
支持向量机
-
决策树
-
朴素贝叶斯
-
随机森林(集成算法)
-
XGBoost(提升算法)
1. K-NN
假设:
-
数据在特征空间中,这意味着特征空间中的数据可以通过距离度量来测量,如曼哈顿距离、欧氏距离等。
-
每个训练数据点由一组向量和与每个向量相关联的类别标签组成。
-
对于二分类问题,‘K’ 应该是一个奇数。
优点:
-
易于理解、实现和解释。
-
是一种非参数算法,因此没有严格的假设。
-
不需要训练步骤。它在运行时使用训练数据进行预测,使其比所有需要训练的算法更快。
-
由于不需要对训练数据进行训练,数据点可以很容易地添加。
缺点:
-
当数据集很大时效率低且慢。由于计算成本,新点与训练点之间的距离很高。
-
在高维数据中表现不好,因为在更高维度中找到距离变得更加困难。
-
对离群点敏感,因为它容易受到离群点的影响。
-
当数据缺失时无法工作,因此需要手动填补数据才能使其正常工作。
-
需要特征缩放/标准化。
2. 逻辑回归
假设:
-
它假设自变量之间几乎没有或没有多重共线性。
-
通常需要大量样本才能正确预测。
-
假设观测值彼此独立。
优点:
-
易于解释、实现和训练。不需要过多的计算能力。
-
对类别分布没有假设。
-
在分类未知记录时速度快。
-
可以轻松容纳新的数据点。
-
当特征线性可分时,非常高效。
缺点:
-
试图预测精确的概率结果,这会在高维度中导致过拟合。
-
由于它具有线性决策面,因此不能解决非线性问题。
-
很难获得除了线性关系以外的复杂关系。
-
需要很少或没有多重共线性。
-
需要大规模的数据集和所有类别的足够训练样本以做出正确预测。
3. 线性回归
假设:
-
应该存在线性关系。
-
应该没有或只有很少的多重共线性。
-
同方差性:残差的方差对于任何 X 值应该是相同的。
优点:
-
当自变量和因变量之间存在线性关系时,表现非常好。
-
如果发生过拟合,可以通过 L1 或 L2 范数轻松减少过拟合。
缺点:
-
假设数据独立性。
-
线性可分性的假设。
-
对离群点敏感。
4. 支持向量机
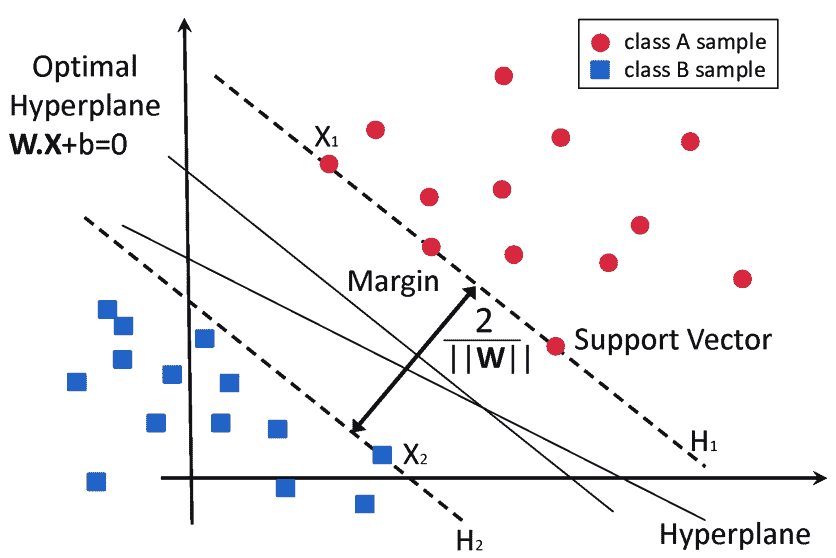
假设:
- 假设数据是独立且同分布的。
优点:
-
在高维数据上表现非常好。
-
内存高效。
-
在维度数大于样本数的情况下效果显著。
缺点:
-
不适合大型数据集。
-
当数据集有噪声时效果不好,即目标类重叠。
-
训练较慢。
-
对分类没有概率解释。
5. 决策树
假设:
-
初始时,整个训练数据被视为根。
-
记录在属性值的基础上递归分布。
优点:
-
与其他算法相比,数据准备所需时间较少。
-
不需要对数据进行归一化。
-
缺失值在一定程度上不会严重影响其性能。
-
非常直观,可以解释为 if-else 条件。
缺点:
-
训练模型需要大量时间。
-
数据的小变化可能导致决策树结构发生较大变化。
-
相对较贵的训练成本。
-
不适用于回归任务。
6. 朴素贝叶斯
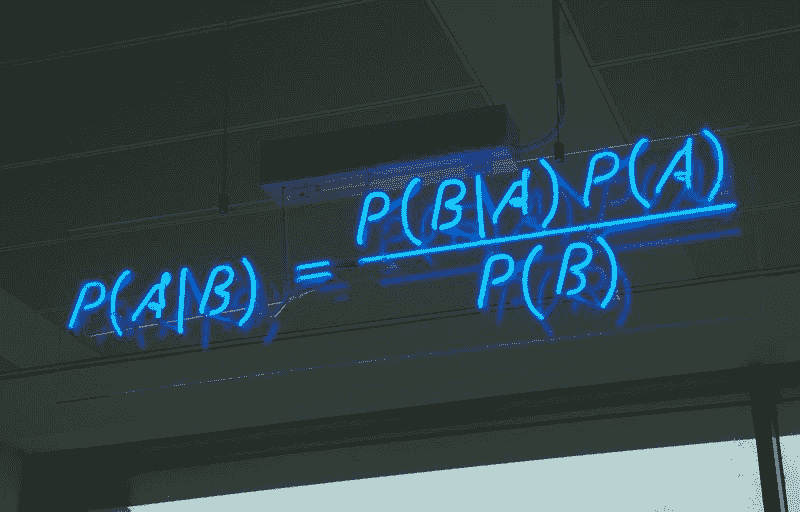
假设:
- 最大也是唯一的假设是条件独立性假设。
优点:
-
当条件独立性假设成立时,表现优异。
-
易于实现,因为只需计算概率。
-
适用于高维数据,如文本。
-
实时预测速度快。
缺点:
-
如果条件独立性不成立,则表现不佳。
-
由于多个小数字的乘法,存在数值稳定性或数值下溢的问题。
7. 随机森林
假设:
- 假设没有正式的分布。作为非参数模型,它可以处理偏斜和多模态数据。
优点:
-
对异常值具有鲁棒性。
-
对非线性数据效果良好。
-
过拟合风险低。
-
在大型数据集上运行高效。
缺点:
-
训练缓慢。
-
在处理分类变量时有偏差。
8. XGBoost
假设:
- 可能假设每个变量编码的整数值具有序数关系。
优点:
-
可以并行工作。
-
可以处理缺失值。
-
无需对数据进行缩放或归一化。
-
解释速度快。
-
执行速度快。
缺点:
-
如果参数没有正确调整,可能会出现过拟合。
-
调优困难。
原文. 经许可转载。
相关:
更多相关内容
如何利用机器学习自动标注数据
原文:
www.kdnuggets.com/2022/02/machine-learning-automatically-label-data.html

照片由 Matt Briney 在 Unsplash 提供
到 2025 年,全球创建、复制和消费的数据量预计将达到 181 兹字节。然而,由于远程工作的普及(由 Covid-19 大流行引起),我们生成、使用和 保护数据 的方式发生了变化。因此,我们可以预期会超出最初的预测。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
大多数原始数据需要分类和标注。传统的手动注释数据的方法已经变得过于耗时和低效。这主要是因为公司需要处理的数据量非常庞大。如今,我们需要更可靠和有效的技术。人工智能和机器学习可以为我们提供这些工具。本指南将深入探讨如何利用机器学习标注数据。
什么是数据标注?
数据标注描述了对数据进行标记和注释的过程。这些数据可以是媒体文件,如图像、视频或音频。或者,它可以是文本或文本文件。数据标签通常提供数据的相关信息和背景描述。例如,数据的目的、内容、创建时间和创建者。
这些标注数据通常用于训练 机器学习 模型。在数据科学中,例如,标记的音频数据文件可以用于深度学习中的自动语音识别。在商业环境中,标注的营销数据可以与机器和深度学习模型一起使用,以产生更有效的 销售生产力工具 和软件。
数据目前是如何标注的?
传统上,数据标签首先由人工输入提供。例如,可能会要求人工标注者描述图像文件的内容。根据相关机器学习模型的复杂性和目的,标签的响应可以从非常详细到二进制——包括开/关或是/否答案。
然后,这些数据会被送入机器学习模型来训练它识别模式。教会机器和深度学习模型的过程称为模型训练。即使是已建立的机器学习模型也可以使用新的标注数据进行再训练。
使用标注数据的三种最常见的数据模型和领域是:
-
计算机视觉 (CV): 机器学习的一个领域,教会计算机识别和解释图像。计算机视觉模型使用标注的视觉数据来帮助识别图像或识别模式。例如,一个训练用来区分鸟类的计算机视觉模型应首先接收标注的图像数据和有用的描述词。
-
自然语言处理(NLP): 研究教会计算机如何识别和理解书面及口语的领域。目前,NLP 的最主流应用是在写作助手中的预测文本。一些 NLP 公司会获取用户应用数据作为其最终数据集(记录用户与写作助手和其他应用互动时的数据)。然而,这些数据仍然需要在某些情况下进行注释和排序。通常,这一过程最初由人工操作员完成。
-
音频处理: 机器学习的一个领域,涉及教会机器识别和辨别声音。这些音频可以从音乐到野生动物的声音。一个使用音频处理算法的商业应用的好例子是 Shazam——一个通过录音识别歌曲的手机应用。一开始,人类标注者将负责标记和分类某些声音和噪音。如果音频涉及到语言,可能需要标注者进行转录。
使用人工标注者的缺点
正如我们之前提到的,数据标注需要人工操作员(至少在传统上)。然而,这也有一些缺点。
这既昂贵又耗时
为了有效地训练和测试你的机器学习模型,你需要一个大的数据仓库,尤其是对于大型项目。在开始时,并非所有的数据都是高质量的。
因此,其中一些数据需要在最终标记和用于训练之前进行排序。这个过程非常耗时且昂贵——尤其是手动操作时。数据准备好后,它最终可以由人工标注者进行标记和注释。这个过程也可能很昂贵和繁琐,增加了最终的开销。
容易出错
在数据科学中,上下文、一致性、协作 和准确性是关键。数据标注可能是乏味和重复的。这一不幸的事实可能使数据标注员失去兴趣并出现错误。大型和多样化的数据集可能需要不断切换上下文,这可能对标注员的专注力有害。
尽管有方法和策略可以尽量减少认知负荷和最终的倦怠,但这些无法保证标注数据的零错误。你仍然需要应对人为的偏见和错误。此外,应用审计等策略可能有助于确保数据标签的有效性,但这也同样耗时。
如何利用机器学习
这似乎有点递归,因为数据标注的整个目的就是创建数据集以训练机器学习模型。然而,数据标注员不一定必须是人工的。你可以用五种方式来标注数据:
-
内部人工标注: 涉及使用内部数据标注员。
-
合成标注: 涉及通过使用旧的、已建立的数据集来标注数据。
-
程序化标注: 涉及使用脚本和编码算法来自动化数据标注过程。
-
外包: 使用自由职业者或专门从事数据标注的公司。这些公司可能会使用他们自己的标注工具。
-
众包: 涉及使用调查和平台从普通用户(非数据科学家和专业人士)处收集和标注数据。尽管如此,众包在数据聚类方面更为有效。
上述每种方法都有其优缺点。然而,我们可以利用机器学习来规避其中的一些缺点和劣势。例如,我们不必完全用机器学习或人工智能解决方案取代内部人工标注。我们可以实现一个机器学习模型来帮助排序和准备数据。我们可以训练一个机器学习模型来区分高质量数据和多余数据。此外,我们可以实施另一个机器学习模型,在数据准备后验证和审计数据标签。
我们可以使用主动学习模型来帮助去除任何多余或非必要的描述符。实质上,机器学习可以减少人为错误和人工标注员处理数据集所需的时间。
合成标注需要一个已建立的标签数据库来注释新的数据。这种方法可以通过静态编码算法或机器学习模型完成。然而,后者是最有效的——尤其是对于较大的项目。它涉及首先用已经建立的数据集和人工标签来训练机器学习模型。一旦测试并达到能力水平,它可以标注新的原始数据。使用机器学习进行合成标注消除了对人工标注员的需求。
因为有成千上万的机器学习模型和项目,你的公司不必在内部构建机器学习模型。你可以修改和使用一个开源机器学习库或项目。许多已建立的模型可能已经能够满足你的数据标注需求。一些众包平台已经使用机器学习来帮助识别项目的最佳候选者。或者,你可以使用像 Datasaur 这样的软件来自动化标注过程。
关键要点
随着公司追求更准确的数据和数据标注,显然它们不再能仅仅依赖人工互动来实现这一目标。这并不意味着人工标注者已经过时,但随着数据及其处理方式的不断变化,我们排序和标注数据的方式也必须随之改变。
我们可以逐步实施新的基于机器学习的协议和功能,以确保数据及其标签的准确性。数据科学是一个不断发展的领域,持续不断地取得进展和突破。然而,这对你来说是好消息(至少部分是好消息),因为你不会被抛在荒野之外。已经有成熟的机器学习数据标注平台可以帮助你的公司从对经典人工标注的依赖中迁移出来。
Nahla Davies 是一位软件开发者和技术作家。在全职从事技术写作之前,她曾管理——以及其他有趣的事情——担任过一家 Inc. 5000 体验品牌组织的首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼。
更多相关话题
机器学习在移动应用开发中有哪些好处?
原文:
www.kdnuggets.com/2021/09/machine-learning-beneficial-mobile-app-development.html
评论
作者 Ria Katiyar,技术写作人

我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
你是否曾经想过为什么 YouTube 会播放你想听的音乐?或者,当你在 Amazon 上购物时,为什么会有“为你推荐”部分?机器学习就是答案。通过实施人工智能和机器学习,公司现在可以提供定制的内容,并吸引越来越多的用户。
机器学习应用正在迅速融入我们的日常生活,因为技术正在向提供智能移动中心解决方案的方向发展。
由于人工智能和机器学习技术,将会创造出更具吸引力的移动应用程序。到 2021 年,机器学习投资将总计达 580 亿美元。到 2024 年,行业的价值将达到 208.3 亿美元,年均增长率为 44.06%。专家预测,到 2024 年,神经网络市场将达到 230 亿美元。机器学习应用将为许多行业注入活力,使安全、金融、照片和视频应用获得飞跃式增长。
机器学习算法的发展显著推动了应用程序开发。不论是 Android 还是 iOS,这些平台的 SDK 都包含了许多 API,允许开发者访问设备的机器学习功能。苹果的 iPhone CPU 包括一个专用的神经引擎,可以加速特定的工作负载。Google 的 Pixel 手机同样具备设备端机器学习。
移动应用开发人员通过实施人工智能和机器学习,可以从这些颠覆性技术所带来的革命性变化中受益。这是因为人工智能和机器学习有潜力增强移动应用程序,提供更流畅的用户体验,并利用强大的功能。
移动应用开发人员如何使用机器学习来生成创新应用?
机器学习可以弥合分析用户行为和利用它生成个性化服务之间的差距。移动应用开发者将机器学习集成到应用程序中以为每个用户生成个性化体验。持续学习对机器学习至关重要。机器学习程序根据用户的日常活动学习和重新学习,以开发个性化解决方案。这一进步使得移动应用开发者能够创建一个具有理想客户体验的互动应用。
-
机器学习有助于预测分析。这项技术使应用程序能够处理大量数据,并生成根据用户需求可配置的定量预测。
-
移动应用开发者可以训练机器学习模块,以过滤垃圾邮件和潜在的不安全网站或电子邮件。这项技术提供了主动的安全措施。
-
字符识别和自然语言处理,以及预测分析,将有助于开发能够读取和解释语言的应用程序。这是机器学习程序的一个标志性时刻,为各个领域的大量新应用铺平了道路。
看一下移动应用开发者如何在不同领域实现人工智能和机器学习技术。
数据挖掘
大数据集挖掘有助于发现模式和关系。这个过程需要收集、存储、维护和分析相关数据。算法收集客户数据,并根据性别、年龄、社交媒体档案等标准进行分类,以创建个性化的应用程序和服务。
追踪
追踪金融和银行数据使得更智能的企业成为可能。该模块根据用户的信用和交易数据提供优惠。这一功能有助于为各种产品和服务创建以客户为中心的营销和目标定位。
分析
数据分析对电子商务和移动商务至关重要。大数据分析帮助像亚马逊这样的零售巨头满足客户需求。
搜索
机器学习方法有助于改善产品和服务的搜索结果。根据搜索查询、屏幕滚动、点击等因素,它们学习展示最相关的结果。可以根据搜索者的偏好定制可用信息。为了提供个性化的排名搜索结果,计算机分析搜索者的过去行为、历史和其他活动。
监控
安全和防病毒应用程序受益于数据监控和机器学习驱动的保护机制。用户可以追踪互联网活动,并设置预设的报警系统,以便检测到任何欺诈行为时触发警报。
安全
应用内认证可以受益于语音识别、生物识别和视听数据。显然,在一个允许实时更改输入的平台上,安全性是可以想象的。该程序可以用作安全的数据传输应用程序,也可以用于文件存储等。
机器学习在移动应用开发中的好处
这里有一些,可以更好、更快、更智能地部署移动应用。
-
改善整体逻辑开发路径
机器学习通过简化整个逻辑开发路径来帮助掌握代码的各个方面。机器学习帮助移动应用开发者在移动应用开发中创建各种模式和趋势,从而改善整体逻辑和编码体验。
-
增强“搜索”选项和结果
机器学习有助于提高移动应用中的搜索和结果,且消耗的时间和精力极少。此外,机器学习在移动应用中的优势如此强大,以至于它甚至使用图形和行为数据来提升用户的个性化体验。
-
识别欺诈
用户会在移动应用中保存个人信息以及其他任何信息,因此数据安全至关重要。例如,如果发生未知交易,移动应用会通过机器学习通知你,你可以随后报告以尽快解决问题。
-
与客户的积极互动
机器学习研究和对可用数据的分类也可以帮助你根据客户的偏好进行管理。通过提供最相关和易于接触的内容,你可以传达应用程序的真实印象。
-
支持视觉和自动识别的应用程序
在开始翻译时,会使用神经网络、集成了机器学习的应用程序、识别不同的面孔以及识别不同的单词。最终用户将从中受益匪浅,因为体验将更加流畅且节省时间。
-
帮助应用程序进行高级数据挖掘
大数据带来了不可控和多方面的权衡。然而,为了处理大量原始数据,需要花费大量时间和精力来评估和分类数据。机器学习可以被设置为同时评估多个档案,帮助开发出与数据紧密对齐的应用程序策略。
具有这些优良特性后,是时候适应各行各业的世界级应用程序了。
总结来说,下一代移动应用将更加智能和强大。移动应用开发者将采用最先进的技术,包括人工智能和机器学习。他们使用神经网络和强化学习算法,以及预测分析、数据挖掘和面部识别技术。健康、金融、移动商务、银行、教育和娱乐都从有效的机器学习程序中受益,这些程序包括挖掘、跟踪、分析、监控、搜索和预测。下一代移动应用的安全性、搜索、预测和定制功能将得到提升。它们的用户界面和用户体验将更加精致、直观、信息丰富、真实和引人入胜。你是否打算为你的公司开发一个新应用?试着使用机器学习技术构建一个有利可图且自学习的应用。
个人简介:Ria Katiyar 是一位内容贡献者,喜欢以简洁而引人入胜的方式撰写她的理解和知识。她是早期采用者,喜欢跟进最新的趋势和技术。
相关:
-
基础机器学习算法:初学者指南
-
学习和实践数据科学的 9 大移动应用
-
数据科学能否灵活?将最佳敏捷实践应用于数据科学过程
更多相关内容
机器学习如何使在线学习受益
原文:
www.kdnuggets.com/2022/12/machine-learning-benefit-online-learning.html
从手机到手表再到电视,我们周围的一切都变得越来越‘智能’。教育也不落后。
‘智能’的教育方法通常是将机器学习(ML)融入学习和发展中。机器学习利用人工智能方法来教系统如何在没有任何人工干预的情况下做出明智的决策。这是通过向机器学习算法提供数据来实现的,算法能够处理数据并对未来事件做出推断。
这与教育有什么关系?电子学习涉及使用我们周围的数字设备来提供引人入胜的学习体验。如果我们利用这些设备的数据来创建一种人工智能学习方法,会发生什么呢?我们无需过多寻找答案,因为这已经在进行中!
继续阅读以了解我们如何充分利用机器学习为在线学习带来的好处。
创建个性化学习体验
个人在学习模式、学习节奏甚至兴趣领域方面可以非常独特。机器学习可以以一种物理上无法实现的方式来满足每个学习者的个性化需求。
机器学习算法可以考虑学生的兴趣领域、过去的课程和评分报告,以提供公正、数据驱动的建议,告诉他们可能感兴趣的学习学科和可以追求的学习路径。为每个学习者创建这样的流畅学习旅程在传统学习方法中是无法做到的。
另一个让学习个性化的重要方式是根据每个学习者的能力调整课程内容。如果学生发现自己在评估中得分很高,人工智能算法可以呈现逐渐更难的问题。同样,有些学习者选择比其他人慢一点的节奏,这也是机器学习可以满足的需求。
帮助评估技能和知识差距
想象一下你能够客观地查看你所知道的每一个事实和你所拥有的每项技能,包括能力水平、专业知识和改进领域。这就是机器学习算法对每个学习者的观察方式。
基于所有过去的评分数据、课程历史和能力水平,机器学习可以帮助为每位学习者制定个性化报告。这些报告概述了每位学生的能力所在领域,以及他们需要改进的领域。通过这种方式,算法以公平和无偏见的方式评估学习者的知识差距。一旦识别出这些差距,学生就可以着手弥补它们。
利用机器学习理解技能差距和识别风险学习者,可以帮助机构以及其学生。一份Mckinsey 报告研究了一所在线大学在疫情期间应用机器学习模型来降低流失率的结果。这涉及分析十年的数据,以了解决定学生继续学习可能性的关键特征。
一旦验证初始模型在预测流失率方面比基准模型更成功,该模型被修改并应用于当前学生。结果模型提供了五种特征类别的学生详细见解,这些学生可能会中断学习。这五种类型中只有两种可以通过线性规则识别。这项研究证明了在高等教育中利用机器学习的价值,结果可以在下面的图像中看到:
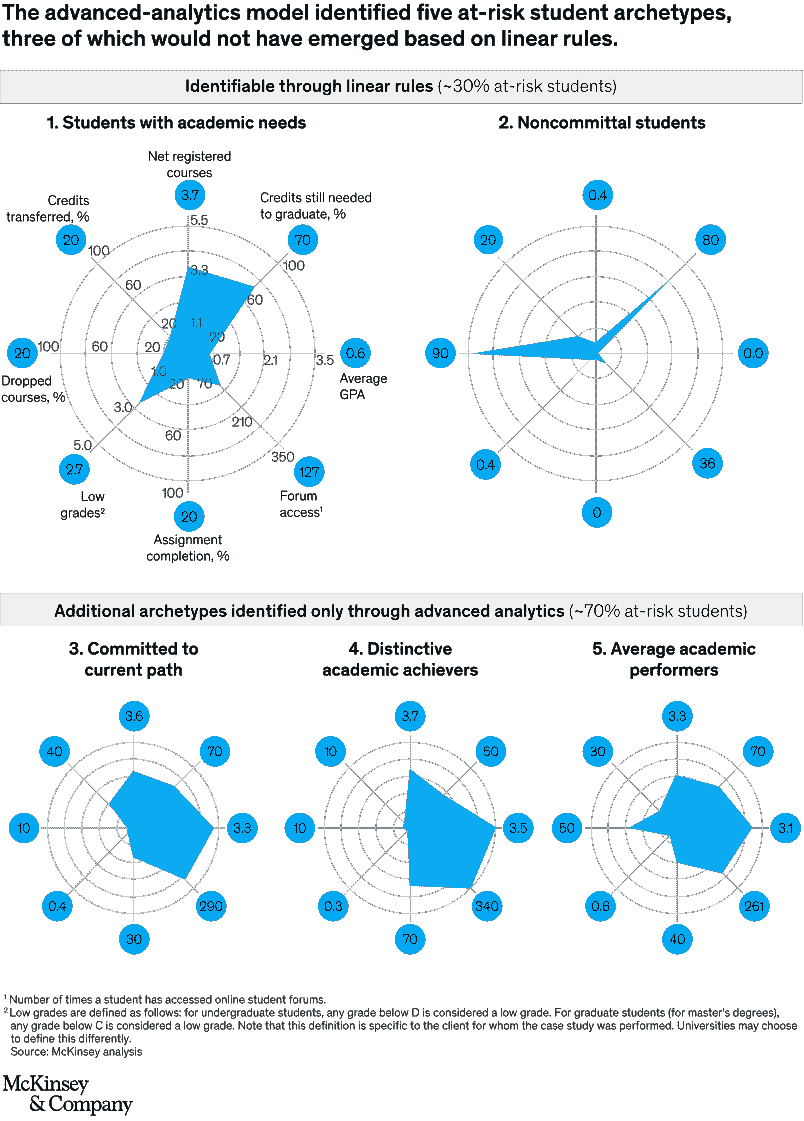
处于流失风险中的学生:麦肯锡
自动化评分与反馈
机器学习技术不仅为学习者提供各种评估格式,还可以智能地对其进行评分。这不涉及将每位学生的答案逐字匹配到一个预设的正确答案。
相反,机器学习算法可以解析陈述,以极高的准确度确定某个答案所写的上下文,并在一个尺度上进行评分,而不是简单的正确或错误。对于每个回答,算法还可以检测可能的改进方法,并向学习者提供个性化的反馈。
这对那些时间紧迫、无法逐一照顾每位学生的教师来说,可能是一个巨大的解脱。就像自动评分通过答题卡和电子学习简化了多项选择题的评估一样,机器学习技术可以评估各种回答类型的细微差别。
聊天机器人实现不间断学习
学生通过提问学到最多的东西。在在线学习的场景中,讲师并不总是能回答问题,讲座材料也不可能预见到所有学习者可能提出的问题。解决这个问题的一个好方法是使用聊天机器人来帮助学习者。
聊天机器人是智能软件,可以对学生提出的问题给出即时答案。在某些情况下,这些聊天机器人被编程为回答讲师已预见的问题,或者可以用来向学生推荐与他们问题相关的有用链接。
聊天机器人作为随时可用的个人导师,是融入互动学习的一个非常有用的工具。在线学习有时可能会令人感到孤立,而拥有一个 AI 聊天机器人可以带来显著的变化。
聊天机器人还在指导潜在学生和引导他们寻找相关资源方面发挥了重要作用。许多新生对直接联系教职员工犹豫不决,或者不知道联系哪个部门。在许多情况下,这些是没有正确指导的第一代大学生。
虚拟聊天助手可以帮助打破困惑和不确定性,正如 Pounce,乔治亚州立大学的聊天机器人所证明的那样,它于 2016 年首次部署。该大学以前在夏季期间会失去多达 20%的新生,这种现象被称为“夏季融化”。这主要是由于对财政援助的缺乏了解。Pounce 帮助减少了 20%的夏季融化 。

Pounce: 乔治亚州立大学的聊天机器人
提升你的在线学习投资回报率
将当前的在线学习系统完全改造以融入机器学习原则,最开始可能看起来是一种资源浪费。然而,如果你花时间考虑机器学习如何简化、自动化和个性化在线学习,它将最终成为一个具有成本效益的解决方案。
首先,所有电子学习平台都在朝着人工智能、高度个性化的学习方法发展,如果你选择不在学习方法中融入创新和灵活性,将会错过良机。毕竟,学习者倾向于选择提供最多资源的学习平台。
除此之外,尽管这可能看起来是一项昂贵的投资,但结合机器学习的学习解决方案所带来的回报远远超过以前采用的在线学习方法。这是因为有了虚拟助手可以随时指导、评分、反馈,甚至只是与学习者聊天时,可以做的事情要多得多。
接下来我们该如何前进?
正如你所见,机器学习具有改善学习体验的潜力。现代教育方法理解学习者,把他们置于学习体验的中心,并且赋予他们塑造自己学习旅程的权力。机器学习提供了这一切及更多。
尽管这仍处于早期阶段,但在学习与发展(L&D)中实施机器学习是值得探索的,无论你是 K12 教育机构、高等教育机构,还是寻求简化员工培训过程的公司。机器学习不仅对学习者、讲师和管理员都有好处,而且也是一种出色的投资,未来还可能证明其具有成本效益。
Maira Afzal 是 [Edly](https://edly.io?utm_source=utm-link-generator&utm_medium=kd nuggets&utm_campaign=) 的内容写作专家,该公司是一家教育技术解决方案提供商及 Open edX 合作伙伴。如需联系,请发送邮件至 hello@edly.io。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
应用于大数据的机器学习解析
原文:
www.kdnuggets.com/2017/07/machine-learning-big-data-explained.html
大数据不再是流行词汇或前沿概念;它只是存在。大数据不易或不精确地定义,但通常一旦看到它就容易识别。
虽然成功的机器学习应用不能仅仅依赖于将不断增加的大量数据“塞入”算法中并寄希望于最好,但利用大量数据进行机器学习任务的能力如今已成为从业者必须具备的技能。
尽管机器学习的大部分内容无论数据量多少都适用,但有些方面则是大数据建模的专属领域,或者比小数据量时更为适用。数据科学家Rubens Zimbres在下面的原始图形中概述了将机器学习应用于大数据的过程。
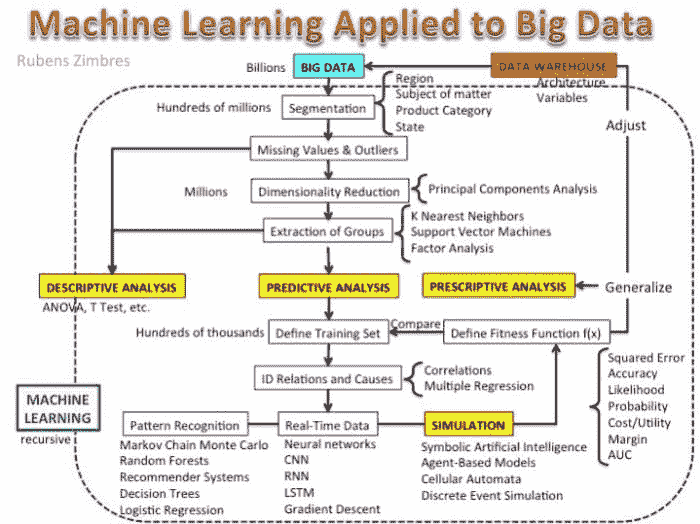
以下是 Zimbres 本人对图像的简短描述:
最重要的是,当数据科学家的需求导致数据架构需要更改时,因为这是大数据项目失败的部分,即橙色方块。当算法计算成本高昂或基础设施尚未为机器学习算法做好准备时。例如,最近巴西的大型银行正在招聘大型机专家来处理这个问题。
这张图片实际上是我为了理解整个数据科学过程而制作的思维导图。
Zimbres 的流程包括描述性、预测性和规定性分析以及模拟。重要的是,机器学习过程明确标记为递归的,这一点对于建模大量数据尤为真实。Zimbres 还详细说明了机器学习任务各个阶段的记录数量。对于数据科学的新手来说,机器学习过程的子任务以及相关算法的展示尤为重要。
尽管 Zimbres 本人表示该过程图有一些小错误(特别是“组提取”部分中应将支持向量机替换为 k 均值聚类),总体上它代表了一个相关的高层次路线图。特别是,对于数据科学的新手来说,这将非常有用。
相关:
-
特征选择的实际重要性
-
回归分析真的属于机器学习吗?
-
大数据、圣经密码与本费罗尼
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 部门
更多相关话题
2022 年你需要阅读的机器学习书籍
原文:
www.kdnuggets.com/2022/04/machine-learning-books-need-read-2022.html

Susan Q Yin via Unsplash
越来越多的企业正在采用机器学习,从预测分析到改善组织的整体工作流程。近年来,机器学习已经成为商业功能中的一个关键元素。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你在 IT 领域的组织
企业对如何实施技术以获得好处感到好奇,而机器学习专业人士则渴望了解机器学习能将我们带到何处。
为了让这项工作成功,幕后操作需要熟练理解机器学习的概念,能够分析数据、调整算法、解决问题等。
这看起来是一项庞大的工作,但都集中在一个主题下。如果你有兴趣学习机器学习或想要提升现有技能;我有一份 2022 年需要阅读的机器学习书单;包括初学者、中级、专家及所有人。
1. 机器学习入门
作者: 奥利弗·西奥博德
难度等级: 初级

如标题所述,如果你是数据科学和机器学习的绝对初学者,这本书非常适合你。尤其适合那些几乎没有编程经验的人,能够迅速引导你理解机器学习的概念。
你将接触到核心算法,配有清晰的解释和可视化示例。如果你没有数学知识或经验,也没关系,因为书的后半部分深入讲解了统计概念和应用于机器学习的具体算法。
2. 动手实践机器学习与 Scikit-Learn、Keras 和 TensorFlow
作者: 奥雷利安·热龙
难度等级: 初级

本书要求您具有先前的 Python 知识,深入探讨了流行的库,如 Scikit-Learn、Keras 和 TensorFlow 2。此书使用具体示例、最小理论和生产就绪的 Python 框架,以帮助您最大限度地学习和应用机器学习。
本书深入探讨了支持向量机、决策树、随机森林和集成方法等其他方面。您将能够应用实际的代码示例,而不需要先前过多的机器学习理论或算法知识。
3. 可解释的机器学习
作者: 克里斯托夫·莫尔纳
难度级别: 初级

这本由克里斯托夫·莫尔纳编写的书最初是一个副项目,因缺乏与机器学习成功和可解释性重要性相关的资源。
对于一些机器学习模型来说,模型可解释性可能是一个困难的任务。有些模型非常复杂,生成的输出不可读,这使得决策过程变得困难。
本书探讨了模型可解释性的重要性,人们认为一个好的解释是什么,深入探讨了如回归和决策树等可解释的模型,以及对模型无关的可解释性方法的重点关注。模型无关意味着这些方法可以应用于任何机器学习模型。
4. 机器学习设计模式:数据准备、模型构建和 MLOps 中的常见挑战解决方案
作者: 瓦利亚帕·拉克什曼南、萨拉·罗宾逊和迈克尔·芒
难度级别: 中级

理解如何解决问题和数据中的常见挑战可能会很困难。这本书由三位谷歌工程师编写,进一步探讨了用于解决机器学习中重复问题的最佳实践和解决方案。
本书包括了 30 种数据和问题表示模式,其中包括问题的描述、解决问题的各种潜在解决方案,以及为您的情况选择最佳技术的建议。
我强烈推荐这本书给任何机器学习从业者,尤其是那些专注于开发生产就绪的机器学习系统的人。 - 亚马逊评论
5. 工程化 MLOps
作者: 埃曼纽尔·拉杰
难度级别: 中级

本书为你提供了 MLOps 生命周期的全面概述。它从熟悉 MLOps 工作流程开始,探索模型打包选项,直到部署模型。帮助你更好地了解如何促进机器学习推理、模型互操作性以及端到端的模型可追溯性。
你将学习如何构建 ML 管道、持续集成和持续交付(CI/CD)管道,以及如何监控这些管道以管理企业和工业的 ML 解决方案。
在本书结束时,你将知道如何将所学知识应用于构建现实世界的项目,并对 MLOps 有 360 度的全面了解。
6. Python 机器学习
作者: 塞巴斯蒂安·拉施卡和瓦希德·米尔贾利
难度等级: 专家

本书假设你已经熟练掌握 Python 和机器学习的应用。它将直接进入概念的实际应用,包括 NumPy、Scikit-learn、TensorFlow2 等。
直接进入实际案例可以帮助你准备和理解如何应对机器学习中的现实挑战,这些挑战你在行业中会遇到。
你将掌握不同的框架、模型和技术,这些技术使机器能够从数据中“学习”。你将把机器学习知识应用于图像分类、情感分析等任务,并发现评估和调整模型的最佳实践。
主题包括降维、集成学习、聚类分析、神经网络等。
7. 人工智能超级大国:中国、硅谷与新世界秩序
作者: 李开复
难度等级: 所有人

尽管这本书几乎没有理论性的机器学习知识,但我认为这是一本每一个从事数据科学领域或对该领域感兴趣的人都应该阅读的好书。
与其不断关注如何更多地了解机器学习、MLOps 等,不如理解这一切将把我们带到哪里。未来会发生什么,人工智能将如何改变世界。
李开复通过他在中国和硅谷的生活经验,讲解了人工智能将如何显著影响劳动力,并提出了一些应对这些变化的实际解决方案。
尼莎·阿亚 是一位数据科学家和自由职业技术作家。她特别关注提供数据科学职业建议或教程以及基于理论的知识。她还希望探索人工智能在提升人类寿命方面的不同方式。作为一个热衷学习的人,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
在隔离期间开始你的机器学习职业生涯
原文:
www.kdnuggets.com/2020/05/machine-learning-career-quarantine.html
评论

照片由 Alex Knight 提供,来源于 Unsplash。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
在这篇文章中,我概述了一个完整的机器学习课程计划,考虑到这次隔离至少会持续 2 个月。
Python(第 0 天 — 第 10 天)

照片由 Hitesh Choudhary 提供,来源于 Unsplash。
从 Python 开始。它是机器学习/数据科学中最常用的语言。你可以在 3 天内轻松学习其基础知识。跟随这个 Youtube 系列 由 Sentdex 提供。你将学习 Python 中的所有函数式编程。
现在学习 面向对象编程、 列表推导式和 Lambda 函数 ,以便你可以轻松开始机器学习。
现在我假设你已经掌握了 Python 编程的基础,因此你可以阅读、编写和理解 Python 代码。
重要库(第 10 天 — 第 15 天)
照片由 Clay Banks 提供,来源于 Unsplash。
对于数据科学家/机器学习工程师而言,最重要的 3 个库是
-
Numpy
-
Pandas
-
Matplotlib
现在,我不建议只从一个地方学习,因此这 2 个教程足以让你入门了解 Numpy、Pandas 和 Matplotlib。
-
用 Python 进行数据分析 — FreeCodeCamp
现在,我相信你可以在 2 天内完成这两个教程,因此接下来的 3 天,下载一个数据集来自Kaggle,将你学到的所有知识应用到这个数据集上。即使在这个数据集上失败也是可以的,但你会有更好的理解。
数学(第 15 天 — 第 22 天)
照片由Antoine Dautry提供,来源于Unsplash。
现在,这是一个重要的部分。我希望你至少对线性代数、微积分和概率论有一个良好的掌握。给线性代数 2 天,微积分 2 天,概率论 3 天来学习这些基础知识。
机器学习算法基础(第 22 天 — 第 30 天)

照片由Clarisse Croset提供,来源于Unsplash。
在这 8 天里,你需要学习机器学习算法的基础知识,一些数学知识,以及它们的直观理解。现在没有比斯坦福大学在Coursera上的Andrew NG 机器学习课程更好的课程了。
你不需要尝试完成整个课程,只需观看视频并做一些笔记,跳过 Matlab 和数学部分,以及所有编程作业。只需在这 13 天里观看视频,了解一些基础知识,以便理解机器学习在幕后是如何工作的。
我知道这个课程很长,在 8 天内完成很困难,但如果你每天花 3–4 小时,你可以轻松地在 8 天内完成它。
应用这些算法(第 30 天 — 第 40 天)

照片由Tommy Lisbin提供,来源于Unsplash。
由行业大咖、Udacity 创始人兼总裁 Sebastian Thrun 主讲的这门免费课程非常适合应用机器学习算法。你将学习一些新算法,如朴素贝叶斯和决策树。你将学习如何使用 Sci-kit Learn,一个用于应用机器学习算法的 Python 框架,这将使你的生活更轻松。
深度学习基础(第 40 天 — 第 45 天)
完成 Deep Learning Specialization 课程中的第 1 门课程,由 deeplearning.ai 提供,通过 Coursera。你将学习神经网络的所有基本原理,并能够使用 Numpy 创建一个神经网络。你将学习前向传播和反向传播等基本概念。
TensorFlow 实践(第 45 天 — 第 60 天)

照片由 Mitchell Luo 提供,来源于 Unsplash。
Tensorflow 是由 Google 开发的深度学习框架,在市场上享有很高的声誉和职业价值。
完成 Tensorflow 由 deeplearning.ai 提供的 Coursera 专项课程,深入学习 TensorFlow 这一现代深度学习框架。完成这项专项课程的平均时间为 1 个月,每周 16 小时,但如果你每天投入 4 小时,你可以轻松在 15 天内完成。你将对计算机视觉问题、自然语言处理问题以及时间序列和序列问题有很好的掌握。简而言之,你将学到很多。
如果你在第 60 天之前完成了这些课程,这里有一些其他建议供你参考。
现在你已经了解了很多机器学习和深度学习的知识,尝试与人建立联系并争取实习机会,也可以去 kaggle.com 在他们的数据集上练习,以提高技能。
相关:
更多相关内容
使用 ChatGPT 的机器学习备忘单
原文:
www.kdnuggets.com/2023/05/machine-learning-chatgpt-cheat-sheet.html
利用 ChatGPT 进行整个 ML 流程
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
ChatGPT 被用于教育、餐饮和健身规划、编程等方方面面。
你是否考虑过使用 ChatGPT 来增强你的机器学习任务?
欲了解更多关于使用 ChatGPT 进行机器学习的信息,查看我们最新的备忘单。
使用 ChatGPT,构建机器学习项目从未如此简单。只需编写后续提示并分析结果,你就能快速轻松地训练模型,以响应用户查询并提供有用的见解。
在这个备忘单中,了解如何使用 ChatGPT 来辅助以下机器学习任务:
-
项目规划
-
特征工程
-
数据预处理
-
模型选择
-
超参数调优
-
实验跟踪
-
MLOps
查看提示和方法的示例,使得利用 ChatGPT 的力量进行机器学习变得轻而易举。随时保持备忘单以供频繁参考。
立即查看,并请及时回来获取更多信息。
更多相关内容
机器学习备忘单
原文:
www.kdnuggets.com/2018/09/machine-learning-cheat-sheets.html
评论
机器学习的备忘单很多。然而,优质、简洁的技术备忘单却不多。一套涵盖理论机器学习概念的好资源将非常宝贵。
Shervine Amidi,斯坦福大学的研究生,以及 Afshine Amidi,来自 MIT 和 Uber,创建了这样一套 资源。这些备忘单被 Shervine 和 Afshine 称为 VIP 备忘单(Github 仓库中的 PDF 在此可用),它们围绕覆盖斯坦福 CS 229 机器学习课程中的主要顶层主题进行结构化,包括:
-
符号和一般概念
-
线性模型
-
分类
-
聚类
-
神经网络
-
...以及更多
各个备忘单的链接如下:
*** 监督学习
你可以访问 Shervine 的 CS 229 资源页面 或 Github 仓库 以获取更多信息,或从上述直接下载链接下载备忘单。
你还可以找到所有备忘单合并在一个 "超级 VIP 备忘单" 中。
感谢 Shervine 和 Afshine 汇集这些精彩的资源。
相关:
-
数据科学备忘单
-
数据可视化备忘单
-
SQL 备忘单
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
更多相关内容
机器学习分类:基于数据集的图解
原文:
www.kdnuggets.com/2018/11/machine-learning-classification-dataset-based-pictorial.html
评论
机器学习中的分类概念涉及构建一个将数据分为不同类别的模型。通过输入一组预标记类别的训练数据来构建该模型,以便算法从中学习。然后,通过输入一个类别未标记的不同数据集来使用该模型,让模型基于从训练集中学到的知识来预测其类别。著名的分类方案包括决策树和支持向量机等。由于这种类型的算法需要明确的类别标记,因此分类是一种有监督学习形式。
从概念上讲,这非常直观且易于理解。但初学者可能会问这在实际生活中是如何运作的。为了将机器学习分类与实际情况联系起来,让我们一步步地看一下这个概念如何展开,具体涉及一个数据集,从一个常见的以逗号分隔值(CSV)文件——一个常用的存储和输入数据到机器学习系统的方式——到一个可以用来进行预测的模型。
在我们的练习中,我们将做以下假设:
-
我们将使用经过时间考验的成人数据集作为我们的示例。
-
我们将省略讨论数据集的任何预处理细节。
-
因此,我们将忽略数据集中类别特征的存在,这些特征在实际中需要转换为数值表示。
-
我们还将忽略空值的存在,这在实际中也需要处理。
-
最后,我们假设我们对数据集的常规训练/测试拆分感兴趣(而不是某些保留方法如交叉验证)。
我们先来看一下原始数据集,你可以在图 1 中找到。这包括完成机器学习任务所需的所有数据。我们只取了 CSV 文件的前 25 行作为示例。
请注意,你可以点击所有图片以放大查看。

图 1:原始成人数据集。
我们有一组特征变量,或称为特征,用于描述某个观察实例。行是观察实例,而列是特征。这适用于所有列,除了最右侧的列,这就是我们的目标,一个类别集合,我们将尝试通过其相关特征值进行预测——这就是分类的本质。监督学习的“其他”类别,回归,在概念上几乎相同;唯一的区别是,尽管预测旨在学习如何预测有限的分类值集合,但回归旨在预测连续的数值。
图 2 显示了我们的数据集被分为特征在红线的左侧,目标在右侧。

图 2:特征在红线的左侧,目标在右侧。
特定实例的特征被组合成一个特征向量,其示例在图 3中展示。

图 3:在完整数据集背景下显示的特征向量。
一个实例由特征向量和对应的目标组成,如图 4所示。

图 4:一个实例(或观察)包括一个特征向量和一个对应的目标。
现在我们已经定义了完整数据集的构成,我们需要做一些决定。由于我们最终希望将数据用于建模,并利用学到的知识对其他数据进行分类(而不是用于构建模型的相同数据),我们需要将数据集分为训练数据集和测试数据集。这通常通过在某个点拆分数据集来完成,拆分点由希望用于训练的数据集的百分比表示。在这个例子中,我们将使用 20 个数据实例进行训练(80%,这种拆分通常是合理的范围),剩余的 5 个数据实例用于测试我们所学到的知识。这个拆分可以在图 5中看到。

图 5:将我们的数据集拆分为训练集(黄线以上)和测试集(黄线以下)。
此时,我们对单一实体数据集的了解足够多,可以将其切分为对我们的机器学习算法有用的部分。我们需要在训练和测试集中分离特征和目标(我们将忽略确保实例随机分割的细节)。
假设我们使用的是 Python 生态系统(我对此很熟悉),这样的分割可以通过如Scikit-learn 的train_test_split函数等工具轻松实现,下面展示了一个示例:
X_train, X_test, y_train, y_test = train_test_split(
full_data[:,:-1],
full_data[:,-1:],
test_size=0.2,
random_state=42)
调用后,我们得到:
-
训练特征矩阵 (X_train),左上角(如图 6 所示)
-
训练目标向量 (y_train),右上角
-
测试特征矩阵 (X_test),左下角
-
测试目标向量 (y_test),右下角

图 6:我们的训练和测试分割,以及特征和目标的分离。
现在我们需要学习训练集中特征到目标的映射,以便将这个映射应用于我们的测试数据,以查看我们的模型的准确性。这一学习过程的结果,如图 7 所示,是一个可以随后使用的函数。这就是监督机器学习的本质:输入标记数据实例,学习这样一个函数,然后将该函数应用于未标记的数据(或故意隐瞒标签的数据)。

图 7:从原始数据到有用的预测函数,建模过程中。
训练后,函数可以应用于我们的测试集,并且可以根据测试实例中的特征做出预测(如图 8 所示)。

图 8:使用学习到的函数对测试集进行预测。
最后一个主要步骤是通过准确性等指标来衡量我们模型的有效性(请注意,我们没有讨论测试集与验证集的区别)。在测试阶段,我们的预测目标将与测试集的真实(实际)目标进行比较,并记录下来。实际操作中,这将把新向量的元素(例如,y_pred)与现有y_test向量的元素进行比较。这显示了我们的模型的有效性,并为我们提供了一个基准,我们可以用它来比较未来使用其他算法学习的分类模型(函数),甚至使用相同算法但不同超参数设置的模型。
相关:
-
使用 Mitchell 范式的学习算法简明解释
-
数据科学难题,重温
-
机器学习算法:简明技术概述
我们的前三个课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 需求
更多相关主题
什么是代码上的机器学习?
原文:
www.kdnuggets.com/2019/11/machine-learning-code-mloncode.html
评论
作者 Vadim Markovtsev,source{d} 的首席机器学习工程师
随着 IT 组织的发展,它们的代码库和不断变化的开发工具链的复杂性也在增加。工程领导者对他们的代码库、软件开发过程和团队的状态几乎没有可见性。通过将现代数据科学和机器学习技术应用于软件开发,大型企业有机会显著提高软件交付性能和工程效能。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT
在过去几年中,包括谷歌、微软、Facebook 等大型公司以及 Jetbrains 和 source{d} 等小型公司,已经与学术研究人员合作,为代码上的机器学习奠定基础。
什么是代码上的机器学习?
代码上的机器学习(MLonCode)是一个新的跨学科研究领域,涉及自然语言处理、编程语言结构以及社会和历史分析,如贡献图和提交时间序列。MLonCode 旨在从大规模源代码数据集中学习,以自动执行软件工程任务,如辅助代码审查、代码去重、软件专业评估等。
什么是源代码上的机器学习?
为什么 MLonCode 很难?
一些 MLonCode 问题需要零错误率,例如与代码生成相关的问题;自动程序修复就是一个特定的例子。一个微小的单次预测错误可能导致整个程序的编译失败。
在其他情况下,错误率必须足够低。理想的模型应尽可能少出错,以确保用户——软件开发人员——的信号与噪声比保持可接受和可靠。因此,该模型可以像传统静态代码分析工具一样使用。最佳实践挖掘就是一个很好的例子。
最后,大多数 MLonCode 问题都是无监督的,或者最多是弱监督的。手动标注数据集可能非常昂贵,因此研究人员通常需要开发相关的启发式方法。例如,有许多相似性分组任务,比如展示相似的开发者或根据专业领域帮助组建团队。我们在这个主题上的经验在于挖掘代码格式化规则并应用于修复故障,类似于 linters 的工作,但完全无监督。还有一个相关的学术竞赛用于预测格式化问题,称为 CodRep。
MLonCode 问题包括各种数据挖掘任务,这些任务从理论上看可能是简单的,但由于规模或对细节的关注仍具有技术挑战性。例子包括代码克隆检测和相似开发者聚类。这些问题的解决方案会在年度学术会议软件仓库挖掘上展示。

软件仓库挖掘会议的标志。
在解决 MLonCode 问题时,通常有以下几种源代码表示方式:
频率词典(加权的词袋模型,BOW)。例如:函数内的标识符;文件中的图形片段;一个仓库的依赖项。频率可以通过 TF-IDF 加权。这种表示方式是最简单且最可扩展的。
一个序列化的标记流(TS),对应于源代码解析序列。该流通常会与相应的抽象语法树节点链接一起增强。这种表示对传统的自然语言处理算法友好,包括序列到序列的深度学习模型。
一棵树,源自抽象语法树。我们在之后进行各种变换,例如不可逆简化或标识符海报化。这是最强大的表示方式,同时也是最难处理的。相关的 ML 模型包括各种图嵌入和门控图神经网络。
许多处理 MLonCode 问题的方法基于所谓的自然性假设(Hindle 等人):
“理论上,编程语言是复杂、灵活和强大的,但实际编写的程序大多简单且相当重复,因此它们具有有用的可预测统计特性,这些特性可以在统计语言模型中捕捉并用于软件工程任务。”
这一声明证明了大代码的有效性:源代码分析得越多,统计特性越强,训练后的机器学习模型的指标也越好。其基本关系与当前最先进的自然语言处理模型(例如 XLNet、ULMFiT 等)相同。同样,通用的 MLonCode 模型可以进行训练,并在下游任务中得到应用。
存在这样的大代码数据集。目前的终极来源是 GitHub 上的开源库。克隆数十万 Git 仓库可能会遇到技术问题,因此还有下游数据集,如 Public Git Archive、GHTorrent 和 Software Heritage Graph。
结论
随着软件继续主宰世界,我们积累了数十亿行代码,数百万个由各种编程语言、框架和基础设施构建的应用程序。MLonCode 不仅能帮助公司简化代码库和软件交付流程,还能帮助组织更好地理解和管理工程人才。通过将软件制品视为数据,并将现代数据科学和机器学习技术应用于软件工程,组织有机会获得竞争优势。
简历:Vadim Markovtsev (@vadimlearning) 是一位谷歌机器学习领域的专家,同时也是source{d}的首席机器学习工程师,他处理“庞大”和“自然”的代码。他的学术背景是编译技术和系统编程。他是一个开源爱好者和开放数据的骑士。Vadim 是历史上分布式深度学习平台 Veles (https://velesnet.ml) 的创造者之一,曾在三星工作。之后,Vadim 负责 Mail.Ru(俄罗斯最大的电子邮件服务)中的机器学习项目,以对抗电子邮件垃圾。在此之前,Vadim 还曾担任莫斯科物理技术学院的访问副教授,教授新技术并进行 ACM 类的内部编码竞赛。
相关内容:
-
面向数据科学家的面向对象编程:构建你的 ML 估计器
-
10 个优秀的 Python 资源,助力有志的数据科学家
-
为什么机器学习部署如此困难?
更多相关内容
机器学习:完整且详细的概述
原文:
www.kdnuggets.com/2016/10/machine-learning-complete-detailed-overview.html
机器学习因多种关键原因而成为一个非常热门的话题,它能够自动获取深入的见解、识别未知模式,并从数据中创建高性能的预测模型,而无需明确的编程指令。
这是一个包含链接的总结,指向一系列文章,旨在成为机器学习的全面、深入指南,对从商业高管到机器学习从业者的每个人都应该有用。它涵盖了机器学习(以及许多相关领域)的几乎所有方面,并且应该能作为该领域术语、概念、工具、注意事项和技术的充分介绍或参考。

系列的第一章首先给出了机器学习的正式和非正式定义。接着讨论了机器学习过程的端到端、不同类型的机器学习、潜在的目标和输出,以及最常用的机器学习算法的分类概述。
第二章以模型性能的概念介绍开始。讨论随后转向数据选择、预处理、拆分,以及非常有趣且关键的特征选择和特征工程话题。接着讨论了模型选择及其相关的权衡,这是一个关键步骤,因为不同的模型可以用来解决相同的问题,尽管有些模型表现更好。
第三章介绍了模型方差、偏差和过拟合的关键概念。接着讨论了模型复杂性及其控制方法,这对过拟合或缺乏过拟合有很大的影响。随后,你会看到对降维的简要介绍,最后讨论了模型评估、性能、调优、验证、集成学习和重采样方法。
第四章着重于对模型性能和错误分析的深入探讨。能够确定你使用的模型的性能和错误至关重要,因为这有助于判断你是否找到了具有可接受权衡的可行解决方案,或者是否需要进行一些更改。可能的更改包括选择不同的特征和/或模型、收集更多数据、特征工程、复杂性降低、利用集成方法等等。
第五章是系列的最后一章,深入概述了无监督学习。它接着讨论了与机器学习高度相关的其他领域,如预测分析、人工智能、统计学习和数据挖掘。文章最后简要概述了机器学习在实际应用中的使用情况。
阅读完系列中的五篇文章后,你将全面了解机器学习的大部分关键概念和方面。此外,你应该能够确定哪些领域最感兴趣,从而指导进一步的研究。
干杯,希望你享受你的机器学习之旅!
亚历克斯·卡斯特鲁尼斯是Why of AI的创始人兼 CEO,以及《AI for People and Business》的作者。他还是西北大学凯洛格/麦考密克 MBAi 项目的兼职讲师。
相关:
-
进入机器学习职业前要阅读的 5 本电子书
-
掌握 Python 机器学习的 7 个步骤
-
机器学习工程师需要了解的 10 种算法
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
更多相关话题
机器学习速成课程:第一部分
原文:
www.kdnuggets.com/2017/05/machine-learning-crash-course-part-1.html
由丹尼尔·耿和香农·史密斯,UC 伯克利。
介绍、回归/分类、成本函数和梯度下降
机器学习(ML)最近受到了很多关注,这绝非没有理由。它已经彻底改变了从图像识别到医疗保健再到交通运输等多个领域。然而,典型的机器学习解释通常是这样的:
“一个计算机程序被称为从经验E中学习,涉及某些任务类别T和性能测量P,如果它在T中的任务表现,如P所测量的那样,随着经验E的增加而改善。”
不太清楚,对吧?这篇文章是机器学习教程系列中的第一篇,旨在使机器学习对任何愿意学习的人都变得可及。我们设计它是为了让你对机器学习算法如何工作有一个扎实的理解,并提供你在项目中利用它的知识。
那么,什么是机器学习?
从本质上讲,机器学习并不是一个难以理解的概念。事实上,绝大多数的机器学习算法都关注一个简单的任务:绘制线条。特别是,机器学习的核心就是在数据中绘制线条。这是什么意思呢?我们来看看一个简单的例子。
分类
假设你是一台计算机,拥有一组苹果和橙子的图像。从每张图像中,你可以推断出水果的颜色和大小,并且你想将这些图像分类为苹果或橙子。许多机器学习算法的第一步是获取标记的训练数据。在我们的例子中,这意味着获得大量的水果图像,每张图像都标记为苹果或橙子。从这些图像中,我们可以提取颜色和大小信息,然后观察它们与苹果或橙子的关系。例如,我们标记的训练数据可能会绘制成如下图样:

红色的 x 标记的是苹果,橙色的 x 标记的是橙子。你可能会注意到数据中存在一个模式。苹果似乎集中在图表的左侧,因为它们大多是红色的,而橙子则集中在右侧,因为它们大多是橙色的。我们希望我们的算法能够学习这些类型的模式。
对于这个特定问题,我们的目标是创建一个算法,在两个标记的组之间绘制一条线,这条线称为决策边界。我们数据的最简单决策边界可能看起来像这样:

只是一条在苹果和橙子之间的直线。然而,更复杂的机器学习算法可能最终会绘制出更复杂的决策边界,如下所示:

我们的假设是,我们在上面的标记训练数据中绘制的用于区分苹果图像和橙子图像的线条,将能够在任何图像中区分苹果和橙子。换句话说,通过给我们的算法提供苹果和橙子的示例,它可以将经验推广到它以前从未遇到过的苹果和橙子的图像上。 例如,如果我们给出一个水果的图像,如下面的蓝色 X,我们可以根据我们绘制的决策边界将其分类为橙子:

这就是机器学习的威力。我们获取一些训练数据,运行一个机器学习算法,绘制出数据上的决策边界,然后将我们学到的知识推广到全新的数据上。
当然,区分苹果和橙子是一个相当平凡的任务。然而,我们可以将这种策略应用于更令人兴奋的问题,例如将肿瘤分类为恶性或良性,将电子邮件标记为垃圾邮件或非垃圾邮件,或分析指纹以用于安全系统。这种类型的机器学习——绘制线条以分隔数据——只是机器学习的一个子领域,称为分类。另一个子领域,称为回归,则专注于绘制能描述数据的线条。
回归
假设我们有一些标记好的训练数据。特别是,假设我们有各种房子的价格与其平方面积的关系。如果我们将这些信息可视化成图表,它看起来是这样的:

每一个 X 代表了一个不同的房子,每个房子都有不同的价格和平方面积。注意到虽然数据中有一些变化(换句话说,每个数据点有些散乱),但也存在一个模式:房子越大,价格也越高。我们希望我们的算法能找到并利用这一模式,根据房屋大小预测房价。
仅通过直观地观察训练数据,我们可以看到图表中大多数房子似乎落在一个对角线区域上。我们可以概括这个想法,认为所有的房子都有很高的概率出现在对角线的数据点簇上。例如,在下面的图表中,房子处于绿色 X 位置的可能性很高,而处于红色 X 位置的可能性则很低。

现在我们可以进一步概括,问一下,对于任意给定的平方英尺,房子的价值是多少?当然,得到一个精确的答案是非常困难的。然而,得到一个近似答案要容易得多。为此,我们绘制一条线穿过数据簇,尽可能靠近每个数据点。这条线称为预测器,根据房子的平方英尺预测房价。对于预测器上的任何点,高概率的情况下,该平方英尺的房子会有那个价格。从某种意义上说,我们可以说预测器代表了给定平方英尺房子的“平均”价格。

预测器不一定非得是线性的。它可以是你能想象到的任何类型的函数或模型——二次函数、正弦函数,甚至是任意函数都可以使用。然而,使用最复杂的模型作为预测器并不总是有效;不同的函数对不同的问题更为有效,程序员需要找出合适的模型。
回顾我们关于房价的模型,我们可以问:为什么要限制自己只使用一个输入变量?实际上,我们可以考虑任意多种信息,例如城市的生活成本、房屋的状况、建筑材料等等。例如,我们可以将价格与房屋所在位置的生活成本和平方英尺在一个图表上绘制,其中纵轴表示价格,两个横轴分别表示平方英尺和生活成本:
https://i.imgur.com/9C5ZeYa.mp4?_=1
在这种情况下,我们可以再次将预测器拟合到数据中。但不是绘制一条线通过数据,我们需要绘制一个平面,因为最能预测房价的函数是一个二变量函数。
https://i.imgur.com/m2cTv6d.mp4?_=2
我们已经看到了一些关于一个和两个输入变量的示例,但许多机器学习应用需要考虑数百甚至数千个变量。虽然人类遗憾地无法可视化超过三维的情况,但我们刚刚学到的相同原则也适用于这些系统。
预测器
如我们之前提到的,有许多不同类型的预测器。在我们关于房价的例子中,我们使用了线性模型来逼近我们的数据。线性预测器的数学形式大致如下:

每个x代表一个不同的输入特征,如平方英尺或生活成本,每个c被称为参数或权重。某个特定权重越大,模型对其对应特征的考虑就越多。例如,平方英尺是预测房价的一个很好的指标,因此我们的算法应通过增加与平方英尺相关的系数来给予平方英尺更多考虑。相比之下,如果我们的数据包括房间的电源插座数量,我们的算法可能会给予它相对较低的权重,因为插座数量与房价的关系不大。
在我们基于平方英尺预测房价的例子中,由于我们只考虑一个变量,我们的模型只需要一个输入特征,即一个 x:
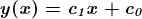
这个方程式可能在这个形式下更容易识别:
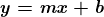
y(x)是我们的输出,在这种情况下是房价,而x是我们的特征,在这种情况下是房子的大小。c[0]是 y 截距,用于考虑房子的基础价格。
现在的问题是:机器学习算法如何选择c[2]和c[1]以使直线能够最好地预测房价?
- 值得注意的是,系数实际上可以通过一种叫做正规方程的矩阵关系直接且非常高效地找到。然而,由于这种方法在处理数百或数千个变量时变得不切实际,我们将使用机器学习算法常用的方法。
成本函数
确定选择哪些参数以最佳近似数据的关键在于找到一种方法来描述我们预测器的“错误”程度。我们通过使用成本函数(或损失函数)来实现这一点。成本函数接受一条直线和一组数据,并返回一个称为成本的值。如果直线对数据的近似较好,成本会很低;如果直线对数据的近似较差,成本会很高。
最佳预测器将最小化成本函数的输出,换句话说,它将最小化成本。为了可视化这一点,让我们看看下面的三个预测函数:

预测器a和c与数据的拟合程度并不好,我们的成本函数应该给这两条直线一个高成本。另一方面,预测器b似乎与数据拟合得非常好,因此我们的成本函数应该给它一个非常低的成本。
要查看线性回归的交互式可视化,请查看原始帖子。
那么,成本函数到底是什么?实际上,我们可以使用许多不同类型的成本函数,但在这个例子中,我们将使用一个非常常用的叫做均方误差的函数。
让我们拆解一下“均方误差”这个名字。在这里,误差指的是数据点与预测值之间的垂直距离,或者只是差值 ( x[i] - y[i] )。我们可以使用下面的图来可视化误差,其中每一个条形图代表不同的 ( x[i] - y[i] )。

对于单个数据点 ( x[i] , y[i] ),其中 x[i] 是房屋的面积,而 y[i] 是房屋的价格,预测器 y(x) 的平方误差是:
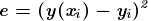
误差的平方值的好处在于一切都是正值。这样我们可以实际最小化平方误差。现在我们对所有数据点取均值,即得到均方误差:
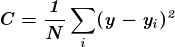
在这里,我们总结了所有的平方误差,并除以 N,即我们拥有的数据点的数量,这只是平方误差的平均值。因此,就是均方误差。
梯度下降
当我们绘制成本函数(只有两个变量)时,它会看起来像这样:

现在,很明显这个成本函数的最小值在哪里。我们可以用肉眼估算。然而,请记住我们只有一个特征——面积。在现实中,几乎所有现代机器学习算法的应用都涉及多个特征。在某些情况下,使用的参数多达tens of millions——试图想象一个千万维的空间真是太有趣了!
所以,为了找到高维成本函数的最小值,我们将使用一种叫做梯度下降的算法。正如我们很快将看到的那样,梯度下降在二维空间中有一个非常直观的解释,但该算法也可以很容易地推广到任意维数。
首先,想象一下在成本函数图上滚动一个球。当球滚动时,它总是会沿着最陡的路线前进,最终停在底部。简而言之,这就是梯度下降。我们选择图上的任何一点,找出最陡的方向,朝着那个方向移动一点,然后重复这个过程。最终,我们必然会达到成本函数的最小值。因为那个点是成本函数的最小值,所以它也是我们用来绘制直线的参数。
那么,我刚刚学到了什么?
所以在阅读了这些内容之后,希望机器学习现在开始对你变得更有意义。也希望,它不像你曾经认为的那样复杂。只要记住,机器学习实际上只是通过训练数据绘制线条。我们决定线条服务的目的,比如在分类算法中的决策边界,或者模拟现实世界行为的预测器。这些线条则来源于使用梯度下降找到成本函数的最小值。
换句话说,实际上机器学习只是模式识别。机器学习算法通过在训练数据中绘制线条来学习模式,然后将其看到的模式推广到新数据。但这引出了一个问题,机器学习是否真的在“学习”?谁能说学习不是模式识别呢?
编辑注: 如果你喜欢这篇文章,可能会想查看Machine Learning @ Berkeley blog的第二部分和第三部分:
Daniel Geng 是来自密歇根州安娜堡的 UC Berkeley 新生。你可以在某个有风景的地方看到他编程、做数学、物理或玩梗。
Shannon Shih 是一位艺术家和程序员,也是 UC Berkeley 的网络工程助理。
原文。经许可转载。
相关:
-
保持简单!如何理解梯度下降算法
-
机器学习关键术语解释
-
掌握 Python 机器学习的 7 个步骤
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关内容


 浙公网安备 33010602011771号
浙公网安备 33010602011771号