KDNuggets-博客中文翻译-二十六-
KDNuggets 博客中文翻译(二十六)
原文:KDNuggets
朴素贝叶斯算法:您需要了解的一切
原文:
www.kdnuggets.com/2020/06/naive-bayes-algorithm-everything.html
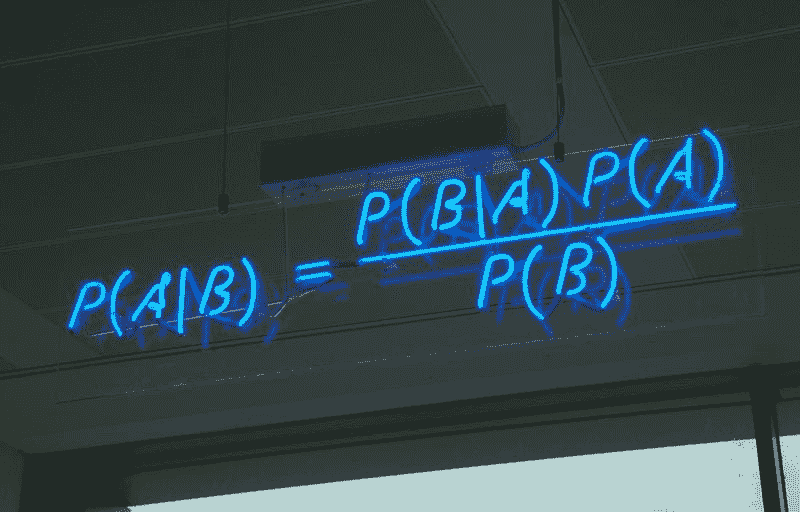
朴素贝叶斯算法简介
最简单的解决方案通常是最有效的,朴素贝叶斯就是一个很好的例子。尽管*年来机器学习取得了进展,但它不仅简单,而且快速、准确和可靠。
我们的前三个课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
 2. 谷歌数据分析专业证书 - 提升您的数据分析水*
2. 谷歌数据分析专业证书 - 提升您的数据分析水*
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
它已经成功用于许多目的,但在自然语言处理(NLP)问题上特别有效。
朴素贝叶斯是一种基于贝叶斯定理的概率机器学习算法,广泛应用于各种分类任务。在本文中,我们将深入理解朴素贝叶斯算法及其所有基本概念,以便彻底理解。
贝叶斯定理
贝叶斯定理是用于计算条件概率的简单数学公式。
条件概率是指在另一个事件(通过假设、推测、断言或证据)发生的情况下,事件发生的概率的度量。
公式是:—

这告诉我们:P(A|B),即在B 发生的情况下,A 发生的概率,也称为后验概率。当我们知道A 发生的情况下B 发生的概率,写作P(B|A),以及A单独发生的概率P(A)和B单独发生的概率P(B)。
简单来说,贝叶斯定理是一种在知道某些其他概率的情况下找出概率的方法。
朴素贝叶斯所做的假设
朴素贝叶斯的基本假设是每个特征都做出一个:
-
独立
-
相等
对结果的贡献。
让我们通过一个例子来获得更好的直观理解。考虑一个具有属性颜色、类型、来源的汽车盗窃问题,目标“被盗”可以是“是”或“否”。
朴素贝叶斯示例
数据集表示如下。
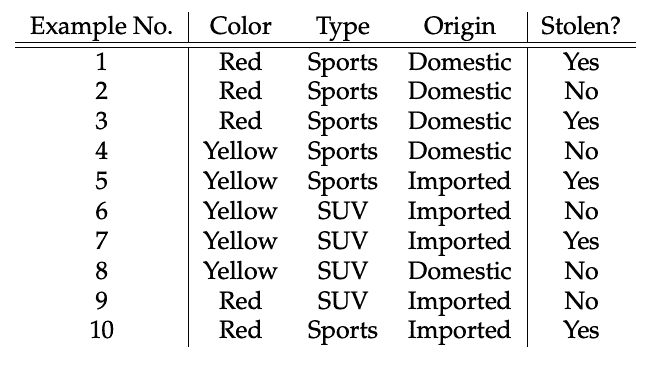
关于我们的数据集,算法所做的假设的概念可以理解为:
-
我们假设没有一对特征是相关的。例如,颜色为‘红色’与汽车的类型或来源无关。因此,特征被假设为独立的。
-
其次,每个特征被赋予相同的影响(或重要性)。例如,仅知道颜色和类型无法完美预测结果。因此,没有任何属性是不相关的,假设它们对结果的贡献是相等的。
注意: Naïve Bayes 进行的假设在实际情况中通常不正确。独立假设从未正确,但在实践中往往有效。因此称为‘Naïve’。
在我们的数据集中,我们需要根据汽车的特征来分类汽车是否被盗。列表示这些特征,而行表示单独的条目。如果我们取数据集的第一行,可以观察到,如果颜色是红色,类型是运动型,来源是国内的,则汽车被盗。因此,我们要分类一个红色的国内 SUV 是否被盗。请注意,我们的数据集中没有红色国内 SUV 的示例。
根据此示例,贝叶斯定理可以重写为:
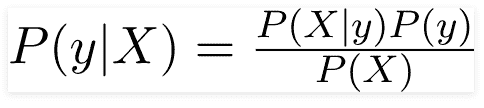
变量 y 是类变量(被盗?),表示在给定条件下汽车是否被盗。变量 X 表示参数/特征。
X 给出如下,
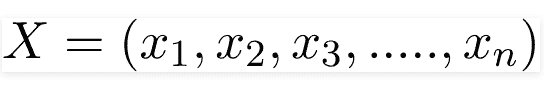
这里 x1, x2…, xn 表示特征,即它们可以映射到颜色、类型和来源。通过替代 X 并使用链式法则展开,我们得到,
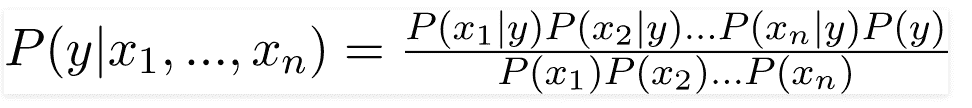
现在,你可以通过查看数据集来获得每个值并将其代入方程中。对于数据集中的所有条目,分母不变,它保持静态。因此,可以去掉分母,并引入比例。
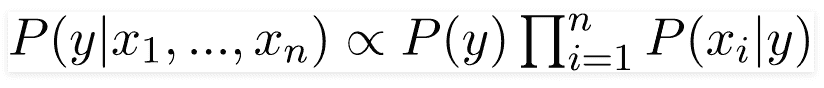
在我们的案例中,类变量(y)只有两个结果,即是或否。可能有多变量分类的情况。因此,我们需要找到具有最大概率的类变量(y)。
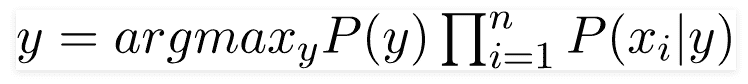
使用上述函数,我们可以在给定预测变量/特征的情况下获得类别。
后验概率 P(y|X) 可以通过首先为每个属性创建一个频率表来计算。然后,将频率表转换为可能性表,最后使用 Naïve Bayesian 方程计算每个类别的后验概率。具有最高后验概率的类别是预测的结果。以下是所有三个预测变量的频率和可能性表。
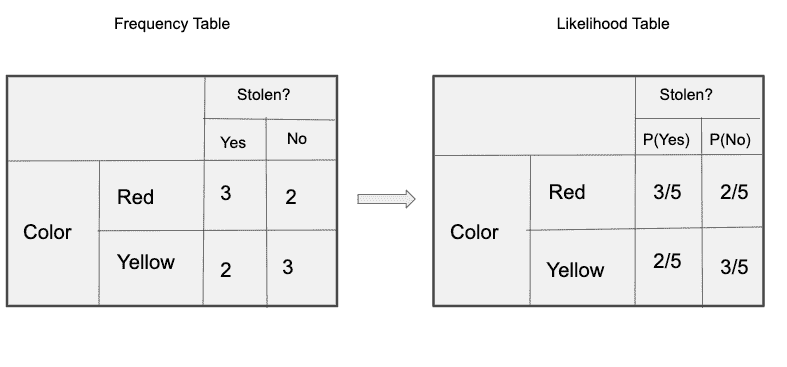
“颜色”的频率和可能性表
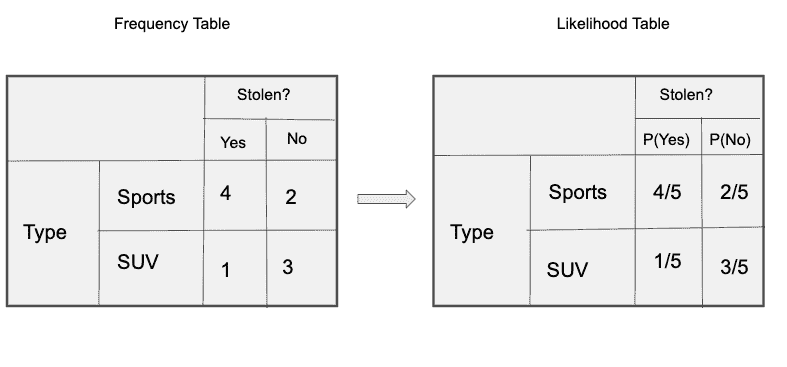
‘类型’的频率和可能性表
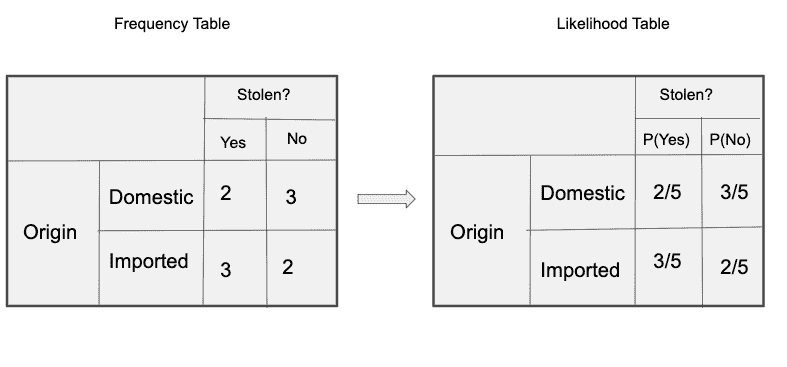
‘来源’的频率和可能性表
所以在我们的例子中,我们有 3 个预测变量X。

根据上述讨论的方程,我们可以计算后验概率 P(Yes | X)为:
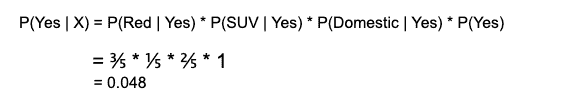
和,P( No | X ):
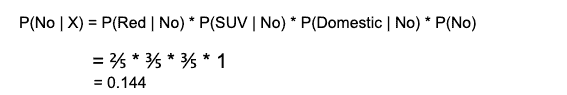
由于 0.144 > 0.048,这意味着给定特征 RED SUV 和 Domestic,我们的例子被分类为“NO”,即车辆未被盗。
零频率问题
朴素贝叶斯的一个缺点是,如果一个类别标签和某个属性值一起没有出现,那么基于频率的概率估计将为零。当所有概率相乘时,这将得到零。
在贝叶斯环境中克服‘零频率问题’的一种方法是,当一个属性值未与每个类别值一起出现时,将每个属性值-类别组合的计数加一。
例如,假设你的训练数据如下:
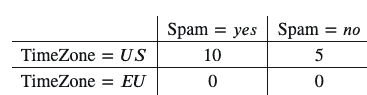
????(TimeZone=????????|Spam=????????????)=10/10=1
????(TimeZone=????????|Spam=????????????)=0/10=0
然后,在使用这个表计算概率时,你应该对每个值加一:

????(TimeZone=????????|Spam=????????????)=11/12
????(TimeZone=????????|Spam=????????????)=1/12
这就是我们如何避免得到零概率的方法。

朴素贝叶斯分类器的类型
1. 多项式朴素贝叶斯分类器
特征向量表示某些事件由多项分布生成的频率。这是通常用于文档分类的事件模型。
2. 伯努利朴素贝叶斯分类器:
在多变量伯努利事件模型中,特征是独立的布尔值(离散变量)描述输入。与多项式模型类似,这个模型在文档分类任务中很受欢迎,其中使用的是二元术语出现(即一个词是否出现在文档中)特征,而不是术语频率(即词在文档中的频率)。
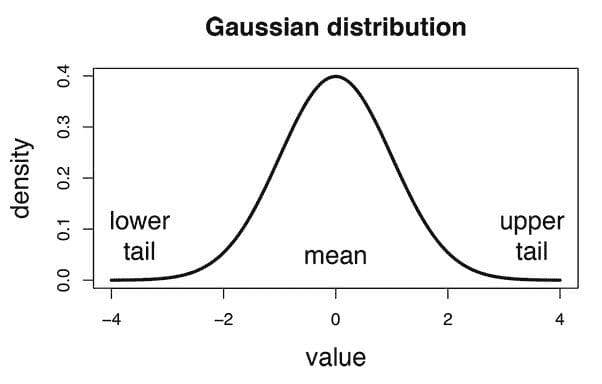
3. 高斯朴素贝叶斯分类器:
在高斯朴素贝叶斯中,与每个特征相关的连续值假设符合高斯分布 (正态分布)。当绘制时,它给出一个钟形曲线,该曲线关于特征值的均值对称,如下所示:
特征的可能性假设为高斯分布,因此,条件概率由下式给出:
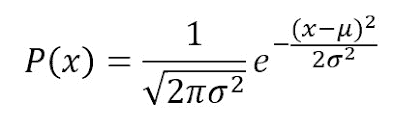
现在,如果某些特征包含数值而不是类别,即高斯分布,会怎样呢?
一种选择是在创建频率表之前将数值转换为其分类对应项。另一种选择,如上所示,可以使用数值变量的分布来很好地估计频率。例如,一种常见的方法是假设数值变量服从正态或高斯分布。
正态分布的概率密度函数由两个参数(均值和标准差)定义。
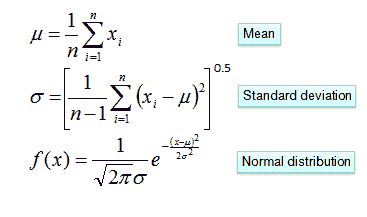
考虑高尔夫球的问题,这里唯一的预测变量是湿度,是否打高尔夫?是目标。使用上述公式,如果我们知道均值和标准差,就可以计算后验概率。

案例研究:从头开始使用 Python 构建朴素贝叶斯分类器
当前任何主要网站面临的一个问题是如何处理恶意和分裂性内容。Quora 希望解决这个问题,使其*台成为用户可以安全分享知识的地方。
Quora 是一个使人们可以相互学习的*台。在 Quora 上,人们可以提问,并与其他提供独特见解和高质量回答的人联系。一个关键挑战是筛除虚伪的问题——那些建立在虚假前提上的问题,或者那些意图陈述观点而不是寻求有用回答的问题。
目标是开发一个朴素贝叶斯分类模型,以识别和标记虚伪的问题。
数据集可以从这里下载。下载训练和测试数据后,加载并检查它。
**import** numpy **as** np
**import** pandas **as** pd
**import** os
train **=** pd.read_csv('./drive/My Drive/train.csv')
print(train.head())test **=** pd.read_csv('./drive/My Drive/test.csv')
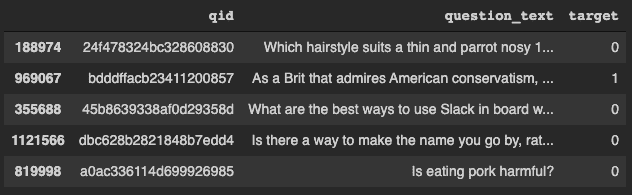
训练数据集
让我们看看真实的问题是什么样的。

真实问题
我们来看看虚伪的问题是什么样的。

虚伪问题
文本预处理
下一步是对文本进行预处理,然后将数据集拆分为训练集和测试集。预处理步骤包括:移除数字、移除字符串中的标点符号、移除停用词、词干提取和词形还原。
构建朴素贝叶斯分类器
结合所有预处理技术,并创建一个包含训练数据中每个词及其计数的字典。
-
计算文本中每个词的概率,并过滤掉概率低于阈值概率的词。概率低于阈值的词是不相关的。
-
然后对字典中的每个词,计算该词出现在不诚实问题中的概率以及它在不诚实问题中的概率。接着计算条件概率以用于朴素贝叶斯分类器。
-
使用条件概率进行预测。
结论
朴素贝叶斯算法通常用于情感分析、垃圾邮件过滤、推荐系统等。它们实现起来快速简便,但最大缺点是要求预测变量必须独立。
感谢阅读!
Nagesh Singh Chauhan 是 CirrusLabs 的一名大数据开发工程师。他在电信、分析、销售、数据科学等多个领域有超过 4 年的工作经验,专注于多个大数据组件。
原文。经授权转载。
更多相关主题
朴素贝叶斯:机器学习分类性能的基准模型
多项式朴素贝叶斯
首先,需要对分类变量进行编码。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水*
3. Google IT 支持专业证书 - 支持组织的 IT 需求
o = {'sunny': 1, 'overcast': 2, 'rainy': 3}
data.outlook = [o[item] for item in data.outlook.astype(str)]
t = {'hot': 1, 'mild': 2, 'cool': 3}
data.temp = [t[item] for item in data.temp.astype(str)]
h = {'high': 1, 'normal': 2}
data.humidity = [h[item] for item in data.humidity.astype(str)]
w = {'True': 1, 'False': 2}
data.windy = [w[item] for item in data.windy.astype(str)]
然后我们可以创建训练集和测试集
x = tennis.iloc[:,0:-1] # X is the features in our dataset
y = tennis.iloc[:,-1] # y is the Labels in our dataset
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.33, random_state=42)
接下来,我们可以继续拟合模型并进行预测
modelM = MultinomialNB().fit(X_train, y_train)
predM = model.predict(X_test)
predM
array(['yes', 'yes', 'yes', 'yes', 'yes'], dtype='<U3')
似乎所有的预测结果都返回了‘是’。这在评估模型时会有影响,如你所见。
让我们用 pandas 制作混淆矩阵,因为我个人不喜欢 Scikit-learn 的混淆矩阵。
pd.crosstab(y_test, predy, rownames=['Actual'], colnames=['Predicted'], margins=True)
Predicted yes All
Actual
no 2 2
yes 3 3
All 5 5
accuracy_score = accuracy_score(y_test, predy)
print('The accuracy of the Multinomial model is ', accuracy_score)
The accuracy of the Multinomial model is 0.6
多项式模型给出了 60% 的准确率
由于没有 false negatives,因为没有预测出‘0’类,因此模型的召回率(真正率)为 100%。召回率通过 [真正例/(真正例+假负例)] 计算。 不幸的是,这在现实情况下是不接受的,因为 100% 的召回率在实际中难以实现。这只是数学计算,需要人为解释以评估其适用性。
高斯朴素贝叶斯
由于高斯朴素贝叶斯更偏好连续数据,我们将使用Pima 印第安人糖尿病数据集
diabetes = pd.read_csv('diabetes.csv')
diabetes.dtypes
Pregnancies int64
Glucose int64
BloodPressure int64
SkinThickness int64
Insulin int64
BMI float64
DiabetesPedigreeFunction float64
Age int64
Outcome int64
dtype: object
我们可以看到所有特征都是连续的。
现在让我们测试特征是否符合高斯分布(正态分布),因为这是高斯朴素贝叶斯模型的一个必要假设(尽管如果数据不符合正态分布,模型仍然可以使用)
循环将告诉我们数据是否符合正态分布,使用著名的 Shapiro-Wilkes 检验。
for i in range(0,9):
stat,p = shapiro(diabetes[diabetes.columns[i]])
print(diabetes.columns[i], 'Test-Statistic=%.3f, p-value=%.3f' % (stat, p));
alpha = 0.05
if p > alpha:
print(diabetes.columns[i], 'looks Gaussian (fail to reject H0)')
print('---------------------------------------')
else:
print(diabetes.columns[i],'does not look Gaussian (reject H0)')
print('---------------------------------------')
Pregnancies Test-Statistic=0.904, p-value=0.000
Pregnancies does not look Gaussian (reject H0)
---------------------------------------
Glucose Test-Statistic=0.970, p-value=0.000
Glucose does not look Gaussian (reject H0)
---------------------------------------
BloodPressure Test-Statistic=0.819, p-value=0.000
BloodPressure does not look Gaussian (reject H0)
---------------------------------------
SkinThickness Test-Statistic=0.905, p-value=0.000
SkinThickness does not look Gaussian (reject H0)
---------------------------------------
Insulin Test-Statistic=0.722, p-value=0.000
Insulin does not look Gaussian (reject H0)
---------------------------------------
BMI Test-Statistic=0.950, p-value=0.000
BMI does not look Gaussian (reject H0)
---------------------------------------
DiabetesPedigreeFunction Test-Statistic=0.837, p-value=0.000
DiabetesPedigreeFunction does not look Gaussian (reject H0)
---------------------------------------
Age Test-Statistic=0.875, p-value=0.000
Age does not look Gaussian (reject H0)
---------------------------------------
Outcome Test-Statistic=0.603, p-value=0.000
Outcome does not look Gaussian (reject H0)
---------------------------------------
所有特征似乎都不符合正态分布。
让我们更进一步,来可视化它们的分布情况
diabetes.hist(figsize=(20, 10));
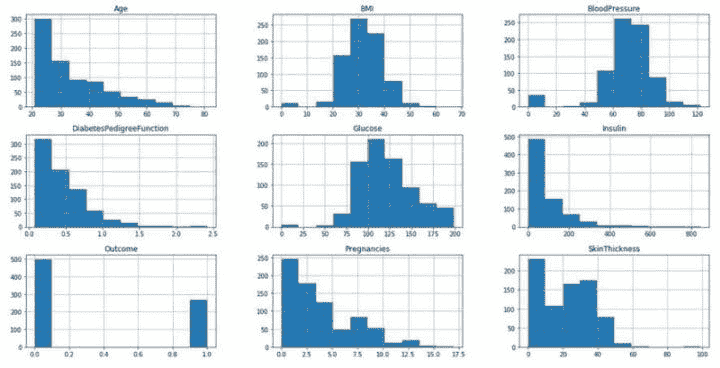
Pima 糖尿病特征的直方图
通过视觉检查,BMI 和血压似乎符合正态分布,但两侧的离群值和假设检验会让我们认为情况并非如此。尽管假设
如果不符合,我们仍然可以继续前进以适应模型。
xG = diabetes.iloc[:,0:-1] # X is the features in our dataset
yG = diabetes.iloc[:,-1] # y is the Labels in our dataset
X_trainG, X_testG, y_trainG, y_testG = train_test_split(xG, yG, test_size=0.33, random_state=42)
modelG = GaussianNB().fit(X_trainG, y_trainG)
predG = modelG.predict(X_testG)
pd.crosstab(y_testG, predG, rownames=['Actual'], colnames=['Predicted'], margins=True)
Predicted 0 1 All
Actual
0 136 32 168
1 33 53 86
All 169 85 254
这次我们可以计算召回率(真正率),因为现在两个类别都已被预测。
recall = recall_score(y_testG, predG, average='binary')
print('The Recall of the Gaussian model is', recall)
The Recall of the Gaussian model is 0.6162790697674418
我使用average='binary'因为我们的目标变量是二元目标(0 和 1)。
模型给出了 62%的真正率(召回率)。
我在获取模型的准确率时遇到困难,所以我们可以手动计算:
tn, fn, fp, tp = confusion_matrix(y_testG, predG).ravel()
accuracy = (tp + tn) /(tp+fp+tn+fn)
print('The accuracy of the Gaussian model is', accuracy)
The accuracy of the Gaussian model is 0.7440944881889764
高斯模型给出了 74%的准确率。
朴素贝叶斯的优点
-
可以处理缺失值。
- 在准备模型时会忽略缺失值,并在计算类别值的概率时也会被忽略。
-
可以处理小样本量。
- 朴素贝叶斯不需要大量的训练数据。它只需要足够的数据来理解每个特征与目标变量之间的概率关系。如果仅有少量训练数据,朴素贝叶斯通常会比其他模型表现更好。
-
尽管违反了独立性假设,模型仍然表现良好。
- 尽管独立性在现实世界数据中很少成立,但模型仍会像往常一样表现。
-
易于解释,相较而言预测速度较快。
- 朴素贝叶斯不是一种黑箱算法,最终结果可以很容易地向观众解释。
-
可以处理数值型和分类数据。
- 朴素贝叶斯是分类器,因此在处理分类数据时表现更好。尽管数值数据也可以使用,但它假设所有数值数据都是正态分布的,而现实数据中这一点不太可能成立。
朴素贝叶斯的缺点
-
朴素假设
- 朴素贝叶斯假设所有特征彼此独立。在现实生活中,几乎不可能获得一组完全独立的预测变量。
-
无法结合特征之间的交互作用。
-
模型的性能将对数据偏斜高度敏感。
- 当训练集不能代表总体人口的类别分布时,先验估计将会不准确。
-
零频率问题
-
在测试数据中存在但在训练数据中没有的类别的分类变量将被分配为零(0)概率,从而无法进行预测。
-
作为解决方案,必须对类别应用*滑技术。其中一种最简单且最著名的技术是拉普拉斯*滑技术。Python 的 Sklearn 默认实现了拉普拉斯*滑。
-
-
数据集中的相关特征必须被移除,否则在模型中会被投票两次,从而过度夸大该特征的重要性。
为什么使用朴素贝叶斯作为性能基准分类器?
我认为朴素贝叶斯应该作为第一个模型进行创建和比较,原因是:
-
它在预测中高度依赖先验目标类概率。不准确或不现实的先验可能导致误导性结果。由于朴素贝叶斯是基于概率的机器学习技术,目标的概率将极大地影响最终预测。
-
由于无需去除缺失值,你无需冒着丢失原始数据的风险。
-
独立性假设实际上几乎从未得到满足,因此由于其最基本的假设存在缺陷,结果不太可靠。
-
模型中未考虑特征之间的交互作用。然而,现实世界中的特征几乎总是存在交互作用的。
-
没有错误或方差需要最小化,而只是要在给定预测因子的情况下寻求更高的类概率。
以上所有都可以作为其他分类器应当超越朴素贝叶斯模型的有效点。虽然朴素贝叶斯在垃圾邮件过滤和推荐系统方面表现优异,但在大多数其他应用中可能并不理想。
结论
总体而言,朴素贝叶斯模型快速、强大且易于解释。然而,对目标变量的先验概率的过度依赖可能会产生非常误导和不准确的结果。分类器如决策树、逻辑回归、随机森林和集成方法应当能够超越朴素贝叶斯,成为真正有用的工具。这并不意味着朴素贝叶斯不再是一个强大的分类器。独立性假设、无法处理交互作用以及高斯分布假设使其成为一个非常难以完全信赖的算法,因为这些模型必须不断更新。
相关内容:
-
仅使用 Python 实现的朴素贝叶斯 – 无需复杂框架
-
机器学习以 88% 的准确率发现“假新闻”
-
从零开始展开朴素贝叶斯
更多相关话题
仅使用Python从零开始的朴素贝叶斯 – 无需华丽的框架
原文:https://www.kdnuggets.com/2018/10/naive-bayes-from-scratch-python.html

作者 Aisha Javed。

**从零开始展开朴素贝叶斯! 第2部分 **????
我们的前三个课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌IT支持专业证书 - 支持你的组织的IT
所以在我之前的博客文章从零开始展开朴素贝叶斯! 第1部分????中,我试图解码朴素贝叶斯(NB)机器学习算法的工作原理,通过它的算法洞察,你也一定会发现这个算法相当简单。在这篇博客中,我们将详细讲解其完整的逐步Python实现(仅使用基础Python),并且会非常明显从零开始编码NB有多么简单,而且NB在分类上并不那么天真!
目标受众是谁? ???? ???? ???? 机器学习初学者 ???? ????????
由于我一直想为绝对初学者解读机器学习,而且有人说如果你不能解释清楚,那你可能没真正理解它,所以这篇博客也特别针对寻找深入但没有那些可怕的希腊数学公式的机器学习初学者(老实说,那些吓人的数学对我来说也没什么意义!)
本教程的成果 — 朴素贝叶斯的实用Python实现
如我刚刚提到的,完整的朴素贝叶斯Python实现讲解
一旦你阅读完这篇博客文章,你将完全掌握90%的朴素贝叶斯理解和实现,剩下的10%则是从应用角度掌握它!

机器学习小鸟从零到英雄!!!
定义路线图….. ????
**里程碑 # 1: **数据预处理函数
里程碑 # 2:实现 NaiveBayes 类——定义训练和测试函数
里程碑 # 3:在训练数据集上训练 NB 模型
里程碑 # 4:使用训练好的 NB 模型进行测试
里程碑 # 5:证明 NaiveBayes 类的代码绝对通用!
在我们开始编写 Naive Bayes 的 Python 代码之前,我假设你已经熟悉:
-
Python 列表
-
Numpy 以及一点向量化代码
-
字典
-
正则表达式
让我们开始 Pythonic 的实现吧!
定义数据预处理函数
让我们从几个在实现 Naive Bayes 时需要的导入开始
里程碑 # 1 达成 🤩
实现 NaiveBayes 类——定义训练和测试函数
附加部分:我们将为 NB 分类器编写一个完全通用的代码!无论训练数据集中有多少类,以及给定什么文本数据集——它仍然能够训练一个完全有效的模型 🤔 🤔 🤔
NaiveBayes 的代码只是 稍微复杂——但我们只需要花费最多 10-15 分钟就能掌握它!之后,你绝对可以自称为“NB 大师” 🤓
这段代码在做什么?🤔
NaiveBayes 类中总共定义了四个函数:
1\. def addToBow(self,example,dict_index)
2\. def train(self,dataset,labels)
3\. def getExampleProb(self,test_example)
4\. def test(self,test_set)
代码被分为两个主要函数,即训练和测试函数。一旦你理解了这两个函数内部定义的语句,你将确切了解代码的实际作用以及其他两个函数的调用顺序。
1\. Training function that trains NB Model :
def train(self,dataset,labels)
2\. Testing function that is used to predict class labels
for the given test examples :
def test(self,test_set)
另外两个函数是为了补充这两个主要函数而定义的
1\. BoW function that supplements training function
It is called by the train function.
It simply splits the given example using space as a tokenizer
and adds every tokenized word to its corresponding BoW :
def addToBow(self,example,dict_index)
2\. Probability function that supplements test function.
It is called by the test function.
It estimates probability of the given test example so that
it can be classified for a class label :
def getExampleProb(self,test_example)
你也可以在这个 Jupyter Notebook 中查看上述代码
如果我们定义一个 NB 类,而不是使用传统的结构化编程方法,组织和重用代码会容易得多。这就是定义一个 NB 类及其相关函数的原因。
我们不仅仅想编写代码,更希望编写美观、整洁、实用且可重用的代码。没错,我们希望拥有一个优秀数据科学家可能具备的所有特质!
你知道吗?每当我们处理一个文本分类问题并打算使用NB解决时,我们只需实例化其对象,通过相同的编程接口,就可以训练一个NB分类器。而且,根据面向对象编程的一般原则,我们只在类内部定义与该类相关的函数,因此所有与NB类无关的函数将会被单独定义。
里程碑 # 2 达成 🎉 🎉
相关话题
-
Chip Huyen 分享实施ML系统的框架和案例研究
了实施 ML 系统的框架和案例研究](https://www.kdnuggets.com/2023/02/sphere-chip-huyen-shares-frameworks-case-studies-implementing-ml-systems.html)
自然语言界面到数据表
原文:
www.kdnuggets.com/2019/06/natural-language-interface-datatable.html
 评论
评论
由 Yogesh Kulkarni, Yati.io
大量结构化数据以关系数据库中的表格形式存储。以一个表格作为简化的例子,即使要访问各个单元格中的值,也需要编写逻辑或在电子表格软件中打开并手动查找。如果可以仅通过自然语言(如英语)查询字段,岂不是更好吗?
例如,如果你有一个像图 1中那样的表格,那么在聊天机器人中发送一个“2008 年哪个城市举办了奥运会?”的查询会更好,你会得到“北京”这样的答案。这比编写程序或手动搜索一个庞大的表格要用户友好得多。
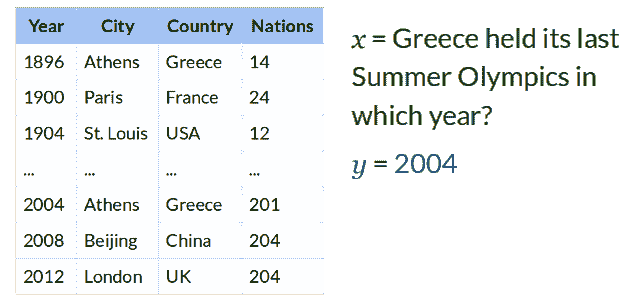
图 1:维基表格问题(来源:斯坦福 NLP 组研究博客)
上述例子确实是为数据集或数据库提供自然语言界面的巨大可能性的非常简单版本。自然语言理解(NLU)是关键技术,它会解析自然语言查询(如英语),‘理解’它,然后发出数据格式特定的查询以获取所需的答案。本文演示了如何使用 Rasa NLU 框架实现这一点。
Rasa 是一个开源聊天机器人框架。它分为两个部分,‘NLU’用于理解用户文本中的意图和实体,而‘Core’则用于对话管理。Rasa 框架的一个显著特点是其功能基于机器/深度学习,并且是在本地训练的。无需将你的数据(即用户文本)发送到某些托管服务进行 NLU 或对话管理。
示例聊天机器人
比如,你希望构建一个通用知识聊天机器人,用于查询世界各国的信息。查询如“中华人民共和国的总人口是多少?”,“印度的面积是多少?”等。
世界概况手册 是一个关于各国数据的极好来源。信息以国家网页的形式排列,包含“地理”、“经济”等部分。要查找中国的人口,首先需要在下拉列表中滚动到中国,找到“人民与社会”部分,然后你会看到中国的人口为“1,384,688,986(2018 年 7 月估计)”。在这种情况下,聊天机器人会更有效。
数据收集
首要步骤是将分散在各种网页上的数据整合到一个表格中。这个文章很好地解释了网络抓取的过程。输出是一个以国家为行、以各个字段为列的表格。
现在我们需要构建一个自然语言接口来访问这个表的字段或单元格。对于像“China 的总人口是多少?”这样的查询,我们需要获取位于“Country==China”行和名为“Population”的列交叉处的单元格中的值。简单来说,从自然语言查询中,我们需要提取两个实体,“Population 作为列”和“China 作为行”(在“Country”列中)。这里使用 Rasa NLU 进行实体提取。
实体提取
实体提取是一个在句子中找到映射到预定义实体类型的单词/标记的过程。命名实体识别(NER)是提取实体的监督方法,使用如条件随机场(CRF)等算法。
要训练 RASA NLU 的 NER,我们需要提供带有注释实体的样本句子的训练数据。图 2中展示了样本训练文件。
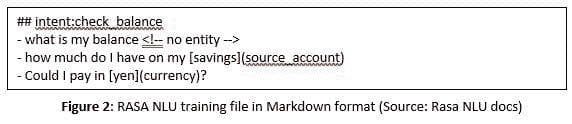
这里“savings”和“yen”分别是“source account”和“currency”实体类型的实际值。
为给定的表构建这种训练数据,将再次是一个手动的、繁琐的过程。通过对表的行和列进行迭代,注释过程可以自动化。不需要提供所有列或行的示例,因为学到的是抽象模式,而不是单元格中的硬编码实际值。
生成训练文件的代码示例如下:
n_sample_countries = 5
n_sample_columns = 5
self.all_columns = [col for col in list(self.df.columns) if col != self.primarycolumnname]
sample_sentences = []
for c in self.primary_key_values_list[:n_sample_countries]:
for col in self.all_columns[:n_sample_columns]:
sentenceformat1 = "What is " + col + " for " + c + " ?"
sentenceformat2 = "For " + c + ", what is the " + col + " ?"
sample_sentences.append(sentenceformat1)
sample_sentences.append(sentenceformat2)
尽管上述仅显示了两种句子格式,但可以添加更多变体。自动生成的 NLU 训练文件如下:
## intent:query
- What is Area for Afghanistan ?
- For Afghanistan, what is the Area ?
- What is Background for Akrotiri ?
- For Akrotiri, what is the Background ?
- What is Location for Akrotiri ?
- For Akrotiri, what is the Location ?
- What is Map references for Akrotiri ?
- For Akrotiri, what is the Map references ?
:
:
使用训练数据训练 NER 模型。当用户查询出现时,模型能够提取“行”和“列”名称。有了这两个信息,就可以在给定的表中定位值。值返回给用户。
以下是样本对话工作流:
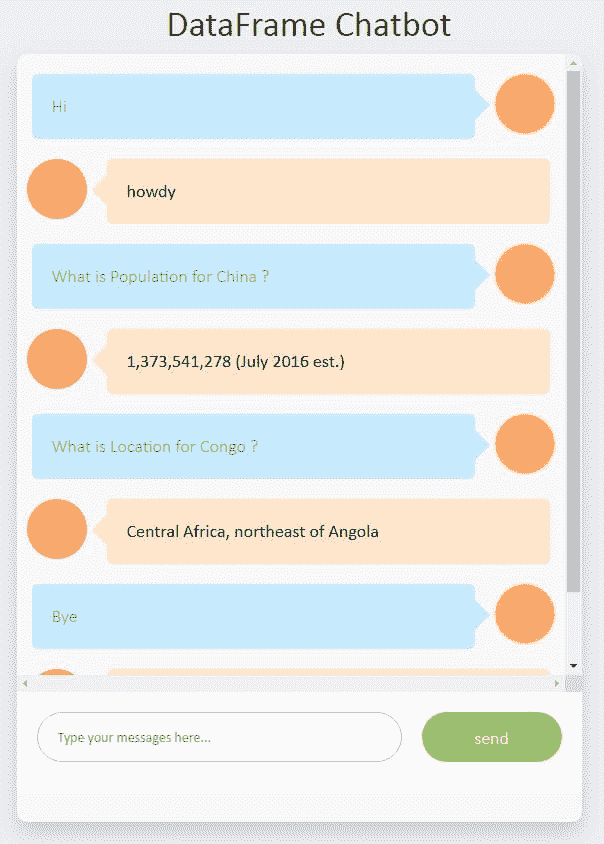 聊天机器人的源代码可以在“DataFrame Chatbot”找到。
聊天机器人的源代码可以在“DataFrame Chatbot”找到。
限制与未来展望
展示的聊天机器人示例非常简化。它可以通过以下功能进一步增强:
-
跨多个表的查询。
-
查询带有聚合和关系的,例如“哪些国家人口超过 1 亿且人均 GDP 低于$1000?”。
-
部分/完整 SQL 支持,即将自然语言查询转换为等效的 SQL 查询。
结论
本文演示了如何构建一个聊天机器人,以用户友好的方式与数据表进行交互。它在那些提供这种表格数据的领域有多种应用。
简介:Yogesh Kulkarni 是 Yati.io 的数据科学讲师兼研究员。
相关内容:
-
使用 Python 和 NLTK 构建你的第一个聊天机器人
-
TNLP – 构建一个问答模型
-
使用深度学习从职位描述中提取知识
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
更多相关话题
自然语言处理:将人类沟通与人工智能连接起来
原文:
www.kdnuggets.com/natural-language-processing-bridging-human-communication-with-ai

摄影作品由 ROMAN ODINTSOV 提供
想象一个机器能够理解你所说的话和你的感受的世界;你可以和计算机交谈,它会做出回应;科技能够筛选文本并为你总结。等一下。你不需要想象任何东西——这已经成为现实,得益于 NLP 的应用。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
作为人工智能的一个子领域,自然语言处理(NLP)已成为技术突破,使计算机能够使用人类语言进行沟通。其 市场规模 在 2023 年被评估为 189 亿美元,并预计到 2028 年将增长到 680 亿美元。考虑到 NLP 在现代世界的多种应用,从聊天机器人到机器翻译再到文档分析,这并不令人惊讶。
在这篇文章中,我们讨论了自然语言处理对商业的变革性影响,它的应用案例以及各行业的实际例子。我们还简要介绍了自然语言处理的好处、挑战以及它带来的未来机会。
理解自然语言处理的本质
自然语言处理(NLP)是一种结合了语言学、统计学和机器学习(ML)技术的方法,能够处理海量数据。这使计算机能够理解人类语言中的细微差别,理解上下文,并以有意义的方式做出回应。换句话说,NLP 算法旨在将人类沟通与人工智能连接起来。
但情况并非一直如此。下面的图表展示了 NLP 随时间演变的过程,直到达到今天的潜力。NLP 采用的关键驱动因素包括计算能力的提升、AI 和机器学习的进步以及数据的可用性。后者主要是因为云计算提供了更好的可扩展性和更低的存储及处理成本。

NLP 的演变
自然语言处理(NLP)的演变也经历了从基于规则的系统到机器学习算法的过渡,后者可以“理解”语言。在基于规则的方法中,专家手动编码每个规则在 NLP 中。这也是为什么这些系统相比机器学习更静态且不可适应。
NLP 的基本目标
深入探索 NLP 的本质时,我们应该提到其基本目标是理解和与人类语言互动。因此,我们区分以下内容:
-
自然语言理解(NLU),关注于意义的提取。它帮助理解书面和口头语言的复杂性和细微差别,处理歧义和上下文变化。例如,NLU 对区分口音或理解俚语非常有用。
-
自然语言生成(NLG),涉及从数据中生成类似人类的回应。利用统计方法和语言模型分析大量数据,NLG 帮助以对话的方式“回应”用户查询。它还处理文本摘要、机器翻译和内容创作。
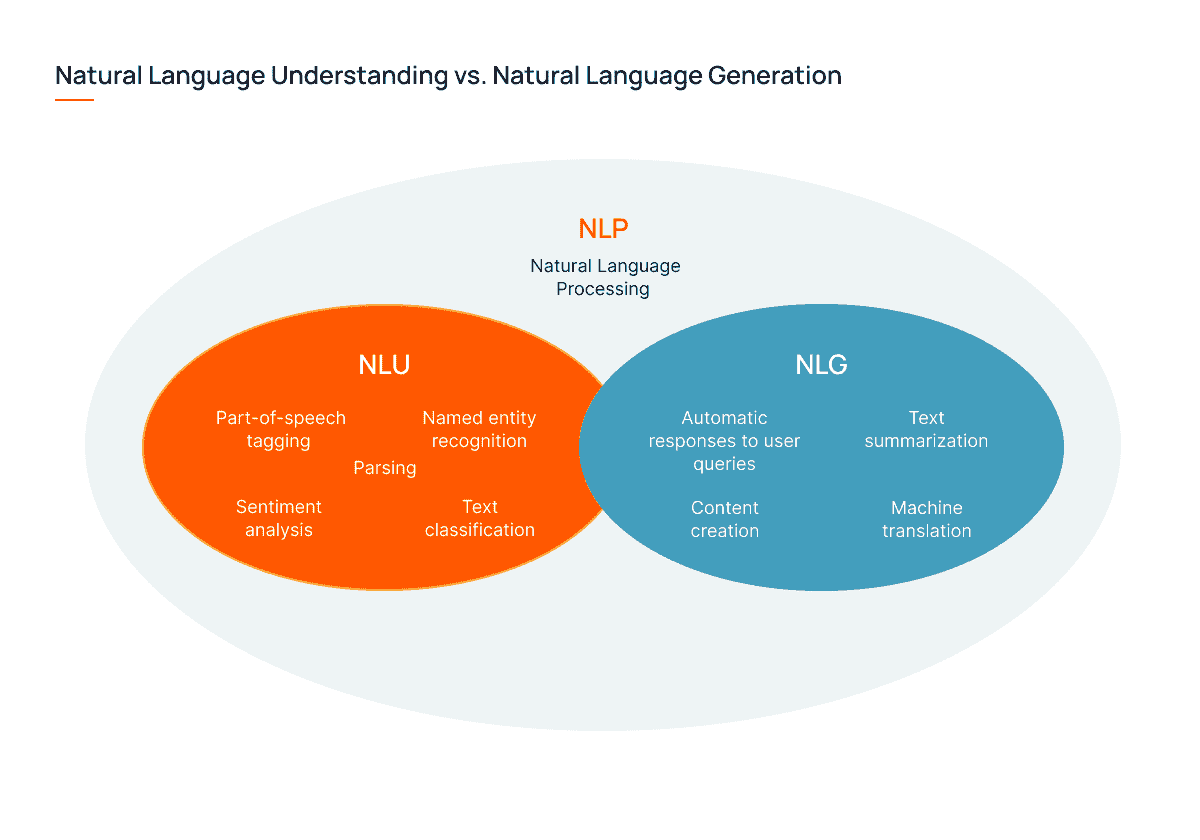
自然语言理解与自然语言生成
现在我们可以概述 NLP 的工作原理。基本上,有 2 个步骤:
-
将文本转换成机器可以理解的形式。
-
分析文本以实际理解上下文和语言,并提取意义。
与此同时,自然语言处理系统的内部发生了许多工作,以使机器能够执行这两项操作。让我们快速了解一下关键的 NLP 组件,以便更好地理解其工作原理:
-
分词:将文本分解为较小的单元,如单词或短语(标记),以便在更小、可管理的块中处理它们。
-
句法分析:解析语法结构,以正确理解句子的句法关系。
-
词性标注:为句子中的单词分配语法标签(例如,名词、动词等),以增加句法分析的深度。
-
语义分析:捕捉单词、短语和句子的含义和上下文。
-
情感分析:确定文本中表达的情感或情绪,如积极、消极或中性。
-
命名实体识别(NER):识别和分类实体,即名称、组织、地点等。
-
统计和机器学习模型:处理和分析大量数据。监督学习算法最适用于文本分类和情感分析等任务,而无监督算法则适用于聚类和主题建模。
-
语言模型:用于预测上下文中词序列的概率。这种技术广泛用于自动补全和语言生成任务。
-
语言翻译模型:用于将文本从一种语言转换为另一种语言。先进的模型,如神经机器翻译,能显著提高翻译的准确性。
-
语言生成技术:基于数据或给定上下文生成类似人类的回应。这种方法用于聊天机器人、文本摘要等。
这些组件的结合与整合使数据科学家能够构建强大的 NLP 系统,并有助于改善 AI 沟通结果。
通过 NLP 转变人类沟通
自然语言处理在各行各业中正获得越来越多的关注,每年都有新的应用出现。以下是我们对 NLP 最常见用例的回顾,以发现 NLP 在业务沟通转型中的潜力。

NLP 的主要应用
对话 AI 和聊天机器人
当想到 NLP 时,智能虚拟助手和聊天机器人是最先想到的。今天的 NLP 对话 AI 系统足够复杂,可以与用户进行真实且上下文适当的对话。
像 Siri 或 Alexa 这样的虚拟助手已经成为我们日常生活的一部分,处理像设置提醒、拨打和接听电话、寻找停车位等小任务。基于 NLP 的聊天机器人通过扩展支持服务和提高个性化来为企业做出贡献。
看一下下面由 Tidio 开发的 Lyro 聊天机器人。与普通聊天机器人不同,Lyro 不需要支持人员的训练——公司激活它后,它便开始立即响应用户的查询。
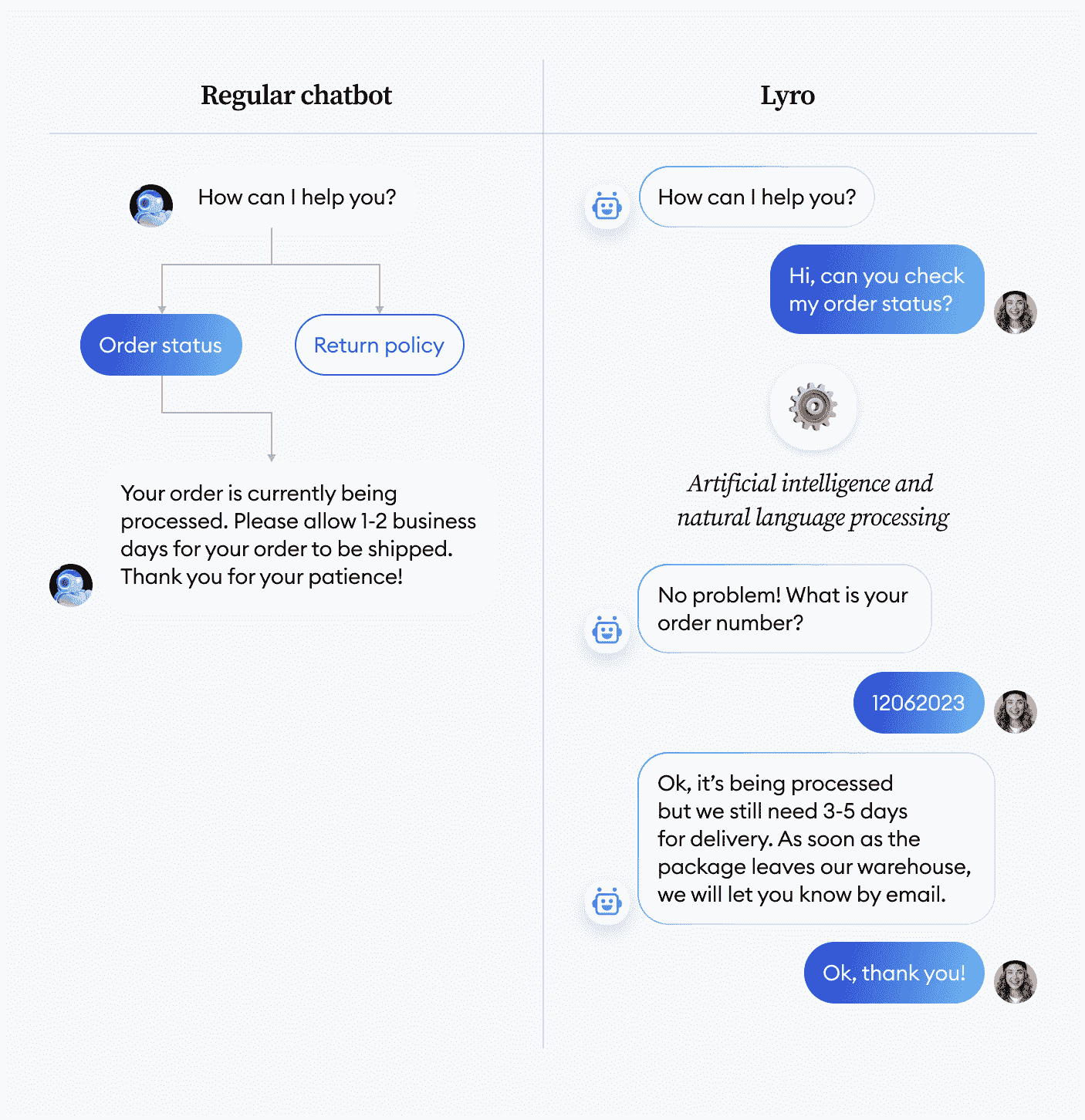
图片来自 Tidio
机器翻译
机器翻译是 NLP 的第二大突出应用。学生、语言翻译者、游客以及许多人今天都离不开 Google Translate。尽管机器翻译早在 NLP 之前就存在,但它通过以下方式将其提升到了一个新水*:
-
利用变换器增加准确性和流畅性
-
促进和简化实时语言翻译
-
实现上下文感知翻译,告别传统的逐字翻译方法
-
帮助内容本地化,以考虑文化偏好和地方方言
为了更具说明性,这里有 DeepL,一个不如 Google Translate 知名的竞争者。该工具支持 26 种语言翻译,帮助用户打破语言障碍。它还具备应用集成和网站翻译插件。
图片来源于 Deepl
文档管理
NLP 还有独特的语音转文本功能,有助于提高文档的准确性和效率。除了像口述文本这样的简单应用,NLP 还可以实现以下功能:
-
文本摘要:AI 提供的自动摘要在需要快速消化大量信息时非常有用。NLP 不仅仅是总结冗长的文本——关键词提取和句子排名使 NLP 能够以连贯的方式总结文本,捕捉关键点。
-
信息提取:在 NLP 的其他方法中,NER 在自动信息检索和知识发现方面特别高效。这极大地节省了研究人员在大量信息中筛选的时间和精力。
-
文本分类:当面对大量文本数据时,NLP 可以帮助对其进行分类。这样,公司的数据会更有条理,同时也能提高信息的可访问性。
内容生成
由于其捕捉事件和数据本质的能力,NLP 可以根据给定的信息生成内容。也许大家都听说过 ChatGPT 以及它如何通过正确的提示创建独特、有意义的内容。这些模型可以通过帮助内容创作者撰写产品说明、社交媒体帖子、文章、电子邮件等,来让他们的生活变得更轻松。
考虑一个比 GPT 更冷门的 AI 内容创作工具。OwlyWriter AI 可以节省营销人员大量时间。该工具帮助社交媒体专业人员克服写作障碍,提高工作效率,从创建帖子的标题到生成内容创意再到撰写帖子。
图片来源于 Hootsuite
语音识别
NLP 的另一个伟大应用是语音识别,它允许机器将口语转换为书面文本。同样,像 Siri 或 Google Assistant 这样的语音助手在这方面是最具代表性的例子。
语音识别还有许多其他应用场景,比如转录服务或语音控制设备。记得那种允许驾驶员安全免提控制汽车的功能。此外,智能家居设备都是基于 NLP 开发的。
情感分析
情感分析作为 NLP 技术之一,最适合分析客户评论和社交媒体情感,以获取对产品或服务的公众意见或跟踪趋势。
例如,NLP 可以帮助企业分析关于*期产品发布的客户反馈,以便做出更明智的客户满意度决策。它还支持社交媒体监控应用程序,如 Brandwatch。这些应用程序监控公司在社交网络上的内容,以了解公众对品牌的看法和感受,追踪趋势,管理在线声誉。
图片来源: Brandwatch
搜索引擎优化
像 Google 这样的搜索引擎使用 NLP 来提高搜索结果的准确性。这种方法有助于更好地理解用户查询背后的意图,并将其与最相关的搜索结果匹配。
垃圾邮件过滤
自然语言处理(NLP)革命化的另一个领域包括垃圾邮件过滤。在这里,我们不仅谈论电子邮件,还包括其他应用。例如, YouTube 使用 NLP 来过滤其视频评论区的垃圾数据。它使用一个名为 TubeSpam 的工具,该工具通过朴素贝叶斯分类器进行训练,以过滤垃圾邮件。
NLP 的应用列表要长得多。我们讨论了最大的用例,但遗漏了像自动更正和自动完成、欺诈检测等较小的用例。为了使我们的研究更全面,让我们谈谈 NLP 如何在现实生活中转变各个行业的例子。
NLP 在实际中的应用实例
尽管 NLP 在各个行业中得到了成功应用,但其最大的市场份额集中在科技、医疗保健、零售、金融服务、保险和市场营销领域。请详细了解这些领域的情况。
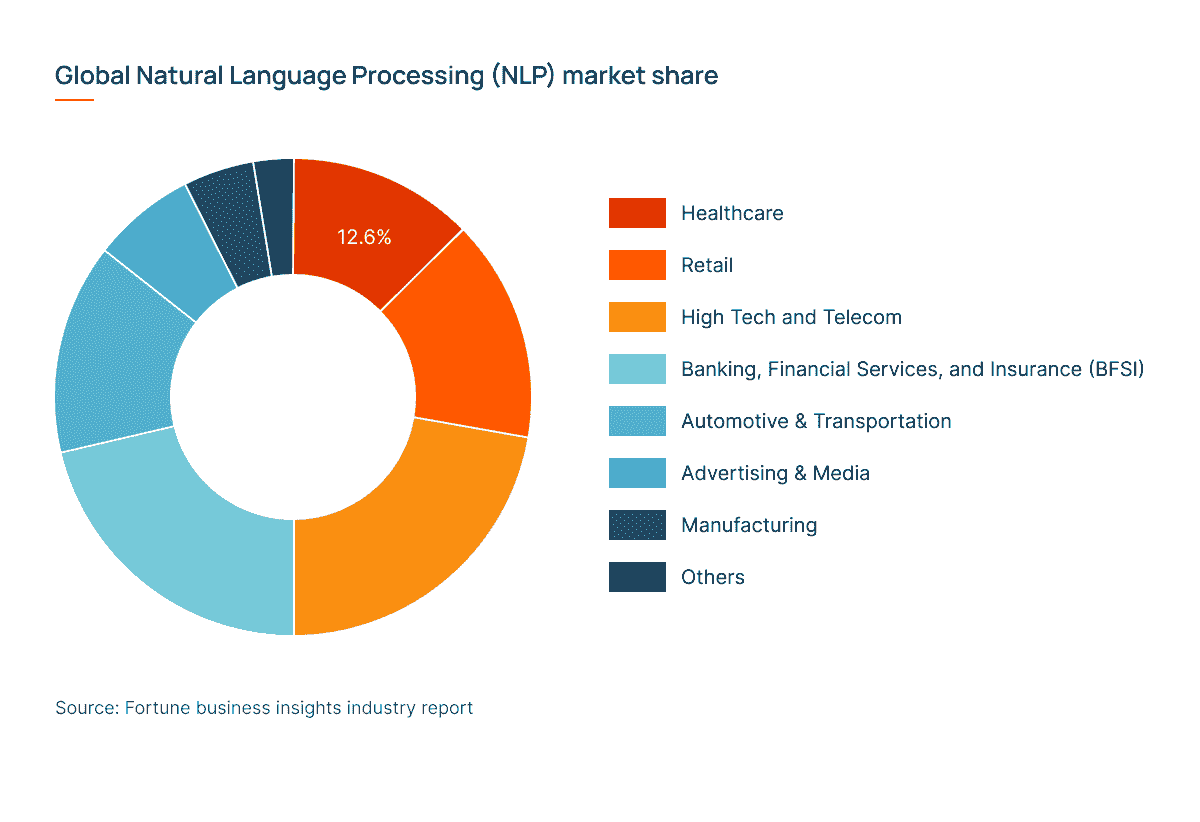
全球 NLP 市场份额按行业划分
客户服务
基于 NLP 的聊天机器人和虚拟助手彻底改变了客户服务。现在,客户可以获得全天候支持,而代理则从减少的工作负担中受益。由美国银行创建的聊天机器人 Erica 提供财务支持和指导,并帮助用户进行在线银行操作。NLP 使 Erica 能够学习用户的偏好和需求,并提供个性化建议。
让我们看看 NLP 在客户服务中的具体应用例子:
-
基于 NLP 的语音助手可以理解用户的请求并将其转发给合适的人工客服
-
用于简单任务的自动化聊天机器人,如回答问题、检查信息、安排预约等
-
使用虚拟助手进行免提设备和服务交互
-
客户反馈分析和情感分析——例如,聊天机器人可以在处理沮丧的客户时先进行道歉
电商和零售
目前,大多数知名电商网站如 Amazon、eBay 或 Walmart 使用 NLP 驱动的语义搜索,这提高了产品的可见性和搜索体验。与匹配关键字相比,语义搜索更具直观性,旨在理解用户查询背后的意图。
除了语义搜索,NLP 在零售领域还有其他应用:
-
客户情感分析,以更好地了解品牌忠诚度,并最终增强品牌实力
-
与语音助手的对话式商务
-
个性化产品推荐
教育
在教育领域,NLP 有着最具创意的应用。一个很好的例子是 Coursera 的课程推荐系统,它帮助用户根据兴趣找到最佳课程。也想想大家都喜欢的 Grammarly,这是一种基于 NLP 的解决方案,可以使你的写作清晰无误。
NLP 在教育中的其他例子包括但不限于:
-
智能辅导系统
-
基于教科书或其他培训材料生成考试题目
-
自动评分和反馈分析
-
抄袭检测软件
-
适应性学习和个性化指导及反馈
金融和银行业务
你是否曾接到过银行打来的电话,询问账户上的可疑活动?这些电话通常是由 NLP 触发的。欺诈检测是 NLP 在金融领域中的最大应用之一。曾经,Mastercard 决策智能系统专门用于指示欺诈活动,帮助公司减少了 50%的欺诈行为。亲自检查解决方案的潜力:
mastercard-a.akamaihd.net/global-risk/videos/DecisionIntelligenceExternalVideoGLOBALJul19.mp4
曝光标签:Mastercard 决策智能
自然语言处理在金融领域的其他两种应用包括:
-
对各种文本数据进行情感分析,如财务报告、社交媒体帖子和新闻文章,以预测股票价格和市场波动,从而帮助交易者和投资者做出更明智的决策
-
从财务报告和文件中提取数据,以及总结财务新闻以便快速更新
医疗保健
NLP 技术对医疗服务提供者非常有帮助,可以总结和分类临床记录和患者信息。通过这种方式,他们可以更快地访问数据并保持文档的组织性。电子健康记录的实现主要得益于自然语言处理。
此外,自然语言处理还可以协助转录,允许医生进行口述记录,减少手动数据输入。临床 NLP 系统可以帮助诊断、制定治疗计划和个性化的治疗建议。例如,Merative L.P.使用 NLP 算法为其患者开发癌症治疗计划。
保险
如同在金融领域中,保险领域也利用自然语言处理(NLP)来识别欺诈性索赔。通过分析不同类型的数据,如客户档案、沟通记录和社交网络,NLP 可以检测到欺诈的指标,并将这些索赔发送进行进一步检查。 土耳其保险公司 在切换到基于机器学习的欺诈检测系统后,投资回报率提高了 210%。
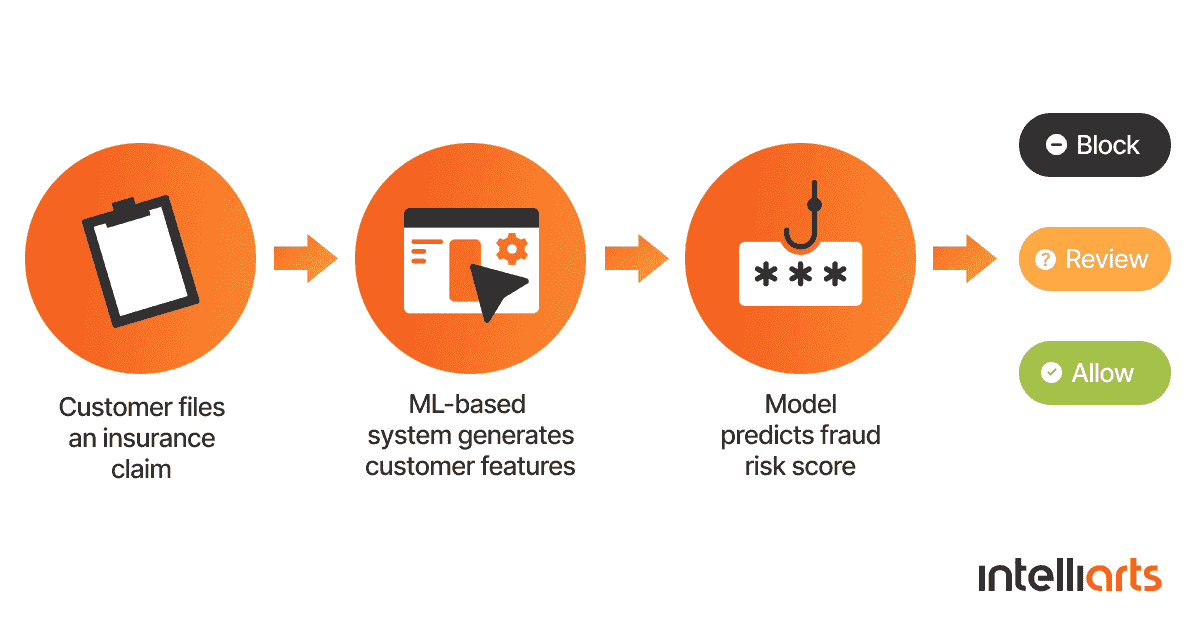
机器学习欺诈检测系统的工作原理
保险公司也可以通过文本挖掘和市场情报来监测行业趋势,从而受益于 NLP。通过这种方式,公司可以了解竞争对手的表现,并做出更多数据驱动的决策。
法律
在法律领域,自然语言处理在处理文档时最为有用。法律专业人士可以在合同审查与分析、文本总结、案件结果分析等方面使用该技术。NLP 算法帮助律师扫描大量法律文本,以找到特定的日期、术语或条款。
Luminance 利用自然语言处理(NLP)提高尽职调查和合同审查的效率。与更通用的 GPT 模型相比,该模型在 1.5 亿份法律文件上进行了训练,并由行业专家验证。公司承诺通过自动化合同处理为用户节省高达 90%的时间。
此外,法律专业人士在监管合规监控、审讯记录分析和法律研究中应用自然语言处理(NLP)。
制造业和供应链
在制造业和供应链中,自然语言处理(NLP)同样有效地保持数据组织和简化沟通。例如,它可以帮助分析和筛选大量的货运文件,解决物流挑战。
聊天机器人可以用于更快速地响应客户或供应商的查询。特斯拉早在很久之前就引入了聊天机器人,以提供卓越的客户体验。这些机器人安排试驾并回答有关特斯拉汽车的简单问题。
通过将聊天机器人与制造商的 ERP 或其他遗留系统集成,聊天机器人还可以帮助将信息集中在一个地方,改善部门间的协作。
市场营销
如前所述,情感分析在市场营销中广泛应用,以了解客户对品牌的看法。这有助于向客户推荐个性化的产品或服务,并增强决策能力。例如,麦当劳利用自然语言处理(NLP)来监控社交媒体上的客户投诉,并培训员工正确回应这些投诉。
在命名实体识别(NER)的帮助下,自然语言处理(NLP)还被用来识别热门话题和客户洞察,以便进一步在销售材料或产品设计改进中使用。
招聘
在招聘中,自然语言处理(NLP)被用于求职候选人筛选,以提高准确性和速度。例如,Intelliarts 开发的 B2B 招聘*台可以将求职者的个人资料与职位描述进行匹配,并涉及 LinkedIn 等社交媒体网站。此外,该解决方案遵循多样性、公*性和包容性(DEI)原则。客户得到的是简化的候选人筛选,同时满足 DEI 要求。
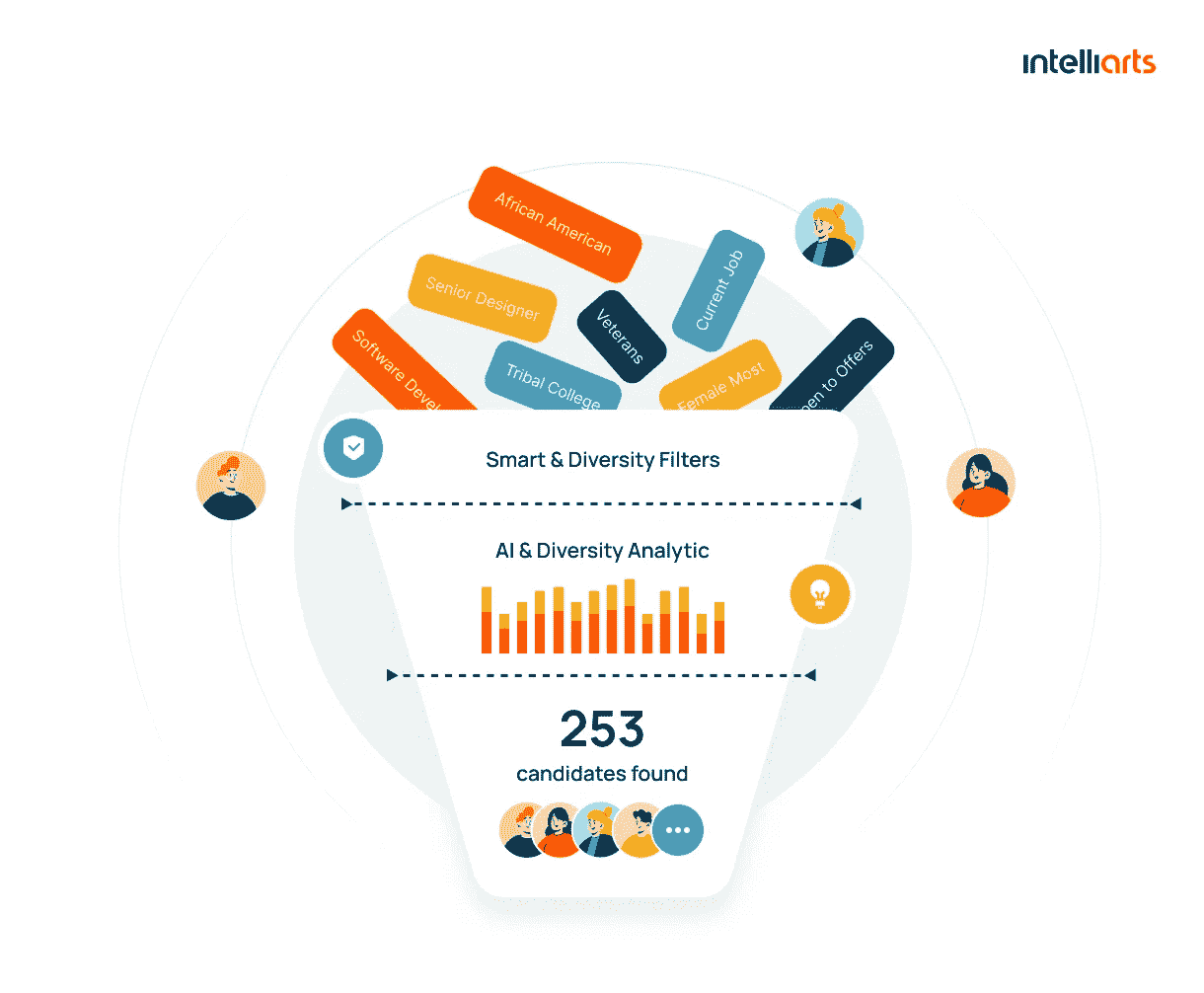
B2B 招聘*台
自然语言处理的核心挑战:*衡问题
尽管自然语言处理(NLP)在各个行业中的受欢迎程度和技术进步不断提高,但在融入现有系统的过程中仍存在一些挑战。以下是这些挑战及其潜在解决方案:
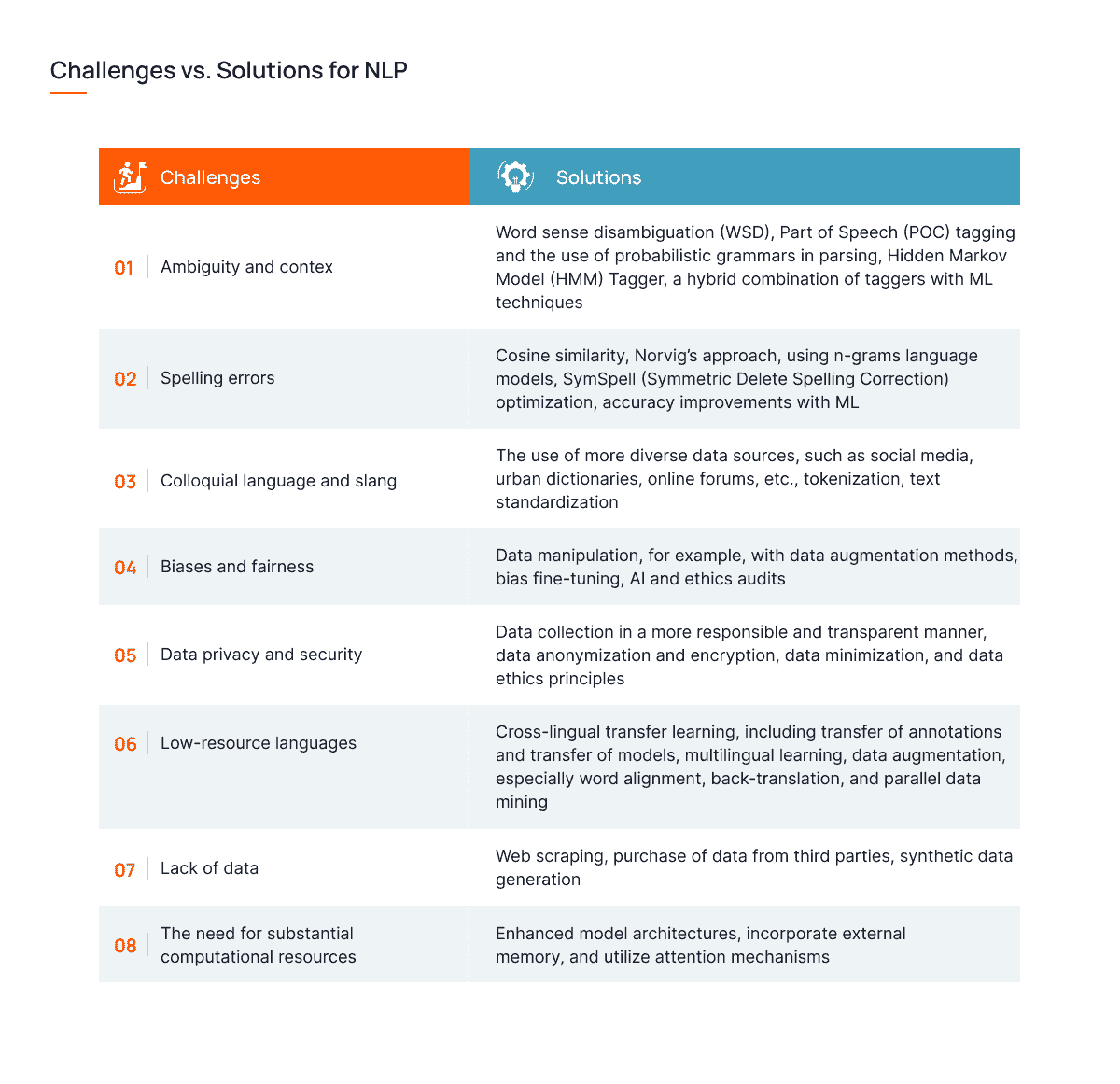
挑战与解决方案:自然语言处理
人工智能下的人类沟通未来
NLP 继续发展,新的解决方案不断涌现,以应对上述挑战。同时,NLP 研究中出现了新的应用和趋势。让我们来看看 NLP 的最新进展,以及这些进展如何进一步革新人机交互:
-
预训练和迁移学习:像 GPT-3 或 T5 这样的预训练模型是当今 NLP 领域最重要的进展之一。这一趋势肯定会持续,因为它不仅能带来高效的结果,还提供了迁移学习的机会,可以将从一个任务中学到的知识应用到其他任务和领域中。
-
多模态 NLP:NLP 终于超越了文本,研究人员尝试其在语音、视频和图像中的能力。多模态性在各个领域中找到了应用,从视频字幕生成到自动驾驶汽车,再到更准确的情感分析。
-
对话式 AI:NLP 的多模态性还体现在对话式 AI 的进步上,该技术旨在使人机互动更加自然和直观。智能家居的语音助手现在可能是研究人员最感兴趣的领域。
-
多语言 NLP:多语言和跨语言 NLP 引起了研究人员的兴趣,因为它能够提升全球沟通、增加信息获取和文化多样性。
-
可解释和可信赖的 AI:对可解释和可信赖的 AI 的需求涉及到在 NLP 中增强用户信任、问责和责任感。这在医疗、教育和法律等敏感领域尤为重要。
-
伦理和负责任的 AI:研究人员还旨在解决 NLP 中的偏见、公*性和伦理问题,以创造更负责任的 AI 应用。一个很好的例子是深度伪造检测,用于识别和标记 AI 操控的视频和音频信息。
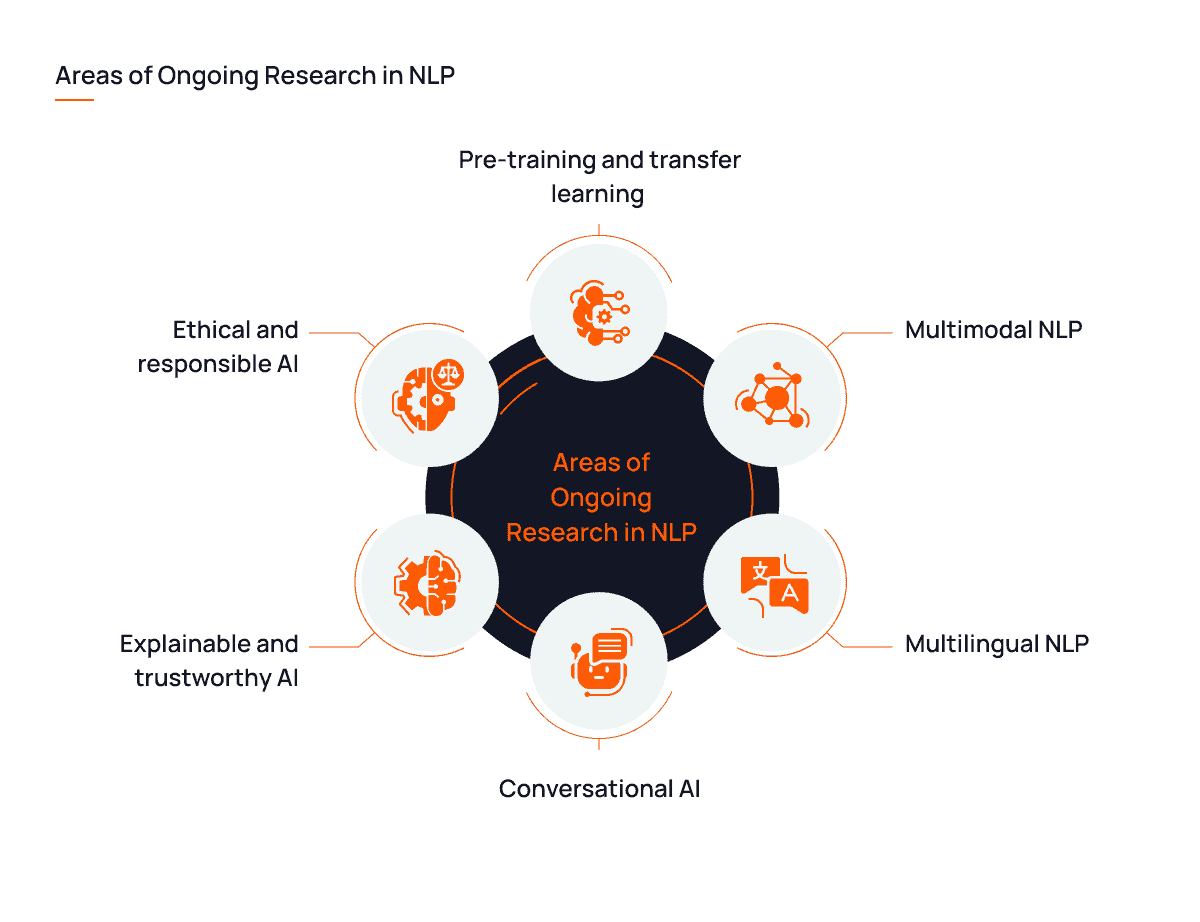
NLP 领域的持续研究
总结
NLP 的概念彻底改变了人机交互,重塑了信息获取和沟通的方式。通过将 AI 与深度学习相结合,计算机获得了阅读文本、解读语音、分析对话、判断情感等能力,证明了 NLP 在从数据中提取有价值见解方面的力量。
我们现在看到 NLP 的无限可能性,从聊天机器人和虚拟助手到情感分析和语言翻译。这些已经改变了许多行业,提高了用户体验。但 NLP 的持续研究和发展预示着更加光明的未来,标志着更多的进步和趋势。这有可能使沟通变得比以往更加无缝和包容。
Olena Zherebetska** 是 Intelliarts 的内容作者,撰写关于数据科学和机器学习的最新新闻和创新。她拥有 7 年的写作经验,喜欢在研究技术主题时深入探讨。
主题更多内容
自然语言处理如何改变数据分析
原文:
www.kdnuggets.com/2020/08/natural-language-processing-changing-data-analytics.html
评论
作者:Malcom Ridgers,BairesDev
来源:2017 年值得关注的前 5 大语义技术趋势(ontotext)。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 需求
自然语言处理(NLP)是计算机理解和处理自然人类语言的过程。如果你使用 Google 搜索、Alex、Siri 或 Google 助手,你已经见证了它的应用。NLP 的优势在于它允许用户在不必将查询内容转换成“计算机语言”的情况下进行提问。
NLP 有潜力使商业和消费者应用程序更易于使用。软件开发者已经在更多应用程序中融入了它,包括机器翻译、语音识别、情感分析、聊天机器人、市场情报、文本分类和拼写检查。
这一技术在数据分析中尤其有用,数据分析帮助商业领袖、研究人员和其他人获得洞察,从而做出有效的决策。正如我们下面将看到的,NLP 可以通过多种方式支持数据分析工作,例如解决重大全球问题,并帮助更多人,甚至那些没有数据处理训练的人,使用这些系统。
管理大数据
借助 NLP,用户可以分析比以往更多的数据,包括关键过程如医学研究。这项技术现在尤其重要,因为研究人员试图找到 COVID-19 的疫苗。
在一篇最*的文章中,世界经济论坛(WEF)指出,NLP 可以帮助研究人员应对 COVID-19,通过处理大量人类无法分析的数据。“机器可以查找、评估和总结数以万计的新冠病毒研究论文,每周都有成千上万的论文新增……。”此外,这项技术还可以通过检测新爆发来帮助追踪病毒传播。
根据 WEF 的文章,NLP 可以在数据分析师 “[训练] 机器分析完整句子的用户问题,然后阅读数据库中的数万篇学术文章,对其进行排名,并生成答案片段和摘要。”例如,研究人员可能会使用问题:“COVID-19 是季节性的吗?”系统会审核数据并返回相关响应。
解决问题
除了紧迫的健康问题外,NLP 与人工智能(AI)结合使用,可以帮助专业人士解决其他全球挑战,如清洁能源、全球饥饿、改善教育和自然灾害。例如,根据 福布斯 上的 Council Post,“像谷歌这样的巨大公司正致力于洪水预防,利用 AI 预测风险区域并通知受影响区域的人员。”
使更多专业人士能够发挥作用
根据 InformationWeek 的一篇文章,“有了自然语言搜索功能,用户不必了解 SQL 或布尔搜索,因此搜索操作变得更容易。”由于洞察的质量取决于知道如何“提出正确的问题”,这种技能可能很快成为商业运营商、经理和行政人员的必备技能。
例如,公司内的任何人都可以使用 NLP 查询 BI 系统,提问如:“与去年相比,本财年的库存周转率是多少?”系统会将每个短语转换为数字信息,搜索所需的数据,并以自然语言格式返回结果。这种查询使得任何部门的员工都能够获得关键洞察,帮助他们做出明智的决策。
创建数据驱动的文化
过去,依赖数据分析的商业智能(BI)需要经过培训的数据专业人员来正确输入查询并理解结果。但自然语言处理(NLP)正在改变这种动态,导致一些专家称之为“数据民主化”:使更多人能够访问以前仅限于具有高级技能的人员的数据集。
公司内掌握如何基于数据获取洞察的人越多,该公司就能从数据驱动的文化中受益越多,这种文化依赖于确凿的证据而非猜测、观察或理论来做决策。这种文化可以在任何行业中培养,包括医疗保健、制造业、金融、零售或物流。
例如,一位零售市场经理可能希望确定每次购买消费最多的客户的 demographics,并针对这些客户提供特别优惠或忠诚奖励。一位制造业班组长可能希望在其操作中测试不同的方法,以确定哪种方法能提供最大的效率。通过 NLP,获取这些信息所需的命令可以由业务中的任何人执行。
总结
NLP 尚未普及。根据 InformationWeek 的文章,“一些 BI 和分析供应商提供 NLP 功能,但目前它们仍属少数。更多供应商可能很快会进入市场以保持竞争力。”
随着自然语言处理的普及,人类将能够以之前无法实现的方式与计算机互动。这种新的合作模式将允许在各种人类活动中,包括商业、慈善、健康和沟通方面,取得进展。
随着计算机学习识别上下文甚至非语言的人类线索如肢体语言和面部表情,这些进展将变得更加有用。换句话说,与计算机的对话可能会变得越来越像人类对话。
马尔科姆·瑞德杰斯是一位技术专家,专注于软件外包行业。他获取最新市场新闻,并对创新及技术业务的未来有敏锐的洞察力。
相关:
-
5 本极好的自然语言处理书籍
-
数据分析中的 5 大趋势
-
数据科学家自然语言处理入门指南及 7 种常用技术
更多相关信息
自然语言处理关键术语,解释如下
原文:
www.kdnuggets.com/2017/02/natural-language-processing-key-terms-explained.html
照片由 Towfiqu barbhuiya 提供,来自 Unsplash
在计算语言学和人工智能的交汇处,我们找到了自然语言处理。广义上,自然语言处理(NLP)是一个研究人类语言以及说这些语言的人如何与技术互动的学科。NLP 是一个跨学科的话题,历史上一直是人工智能研究人员和语言学家*等的领域;显然,那些从语言学方面接*这个学科的人必须了解技术,而那些从技术领域进入这个学科的人需要学习语言学概念。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 需求
本文旨在为第二组术语提供入门级的介绍,我们将以不含废话的方式来定义一些关键的 NLP 术语。虽然阅读完本文后你不会成为语言学专家,但我们希望你能够更好地理解一些 NLP 相关的讨论,并对如何进一步学习这些话题获得一些视角。
下面是 18 个精选的自然语言处理术语,简明定义。
1. 自然语言处理(NLP)
自然语言处理(NLP)关注自然人类语言与计算设备之间的互动。NLP 是计算语言学的一个主要方面,也涉及计算机科学和人工智能的领域。
2. 分词
分词,通常是 NLP 过程中的早期步骤,这一步骤将较长的文本字符串拆分成更小的部分或标记。较大的文本块可以被分词成句子,句子可以被分词成单词,等等。文本在适当分词后,通常会进行进一步处理。
3. 标准化
在进一步处理之前,文本需要规范化。规范化通常指一系列相关任务,旨在使所有文本处于相同的水*:将所有文本转换为相同的大小写(大写或小写),删除标点符号,扩展缩写,将数字转换为其单词等。规范化使所有单词处于*等基础上,并允许处理过程均匀进行。
4. 词干提取
词干提取是去除单词中词缀(后缀、前缀、插入词缀、环绕词缀)的过程,以获取单词词干。
running → run
5. 词形还原
词形还原与词干提取相关,但不同之处在于词形还原能够基于单词的词元捕捉规范形式。
例如,将单词“better”进行词干提取会失败,无法返回其引文形式(词元的另一种说法);然而,词形还原则会得到如下结果:
better → good
应该很容易理解,为什么实现词干提取器的难度会比实现词形还原要小。
6. 语料库
在语言学和自然语言处理(NLP)中,语料库(字面上是拉丁语中的身体)指的是文本集合。这些集合可以由单一语言的文本组成,也可以跨越多种语言——多语言语料库(语料库的复数形式)可能有多种用途。语料库也可以由主题文本(历史的、圣经的等)组成。语料库通常仅用于统计语言分析和假设检验。
7. 停用词
停用词是那些在进一步处理文本之前被过滤掉的单词,因为这些单词对整体意义贡献很小,通常它们是语言中最常见的单词。例如,“the”、“and”和“a”虽然在特定段落中都是必需的单词,但通常对理解内容的贡献不大。作为一个简单的例子,如果去掉停用词,以下全字母句依然容易辨识:
The 快速的棕色狐狸跳过了the 懒狗。
8. 词性标注(POS)
词性标注包括为句子的分词部分分配类别标签。最常见的词性标注是识别单词作为名词、动词、形容词等。
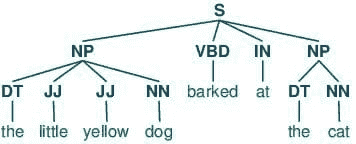
9. 统计语言建模
统计语言建模是构建统计语言模型的过程,旨在提供自然语言的估计。对于一系列输入单词,模型会为整个序列分配一个概率,这有助于估计各种可能序列的可能性。这对于生成文本的 NLP 应用特别有用。
10. 词袋模型
词袋模型是一种特定的表示模型,用于简化文本选择的内容。词袋模型省略了语法和词序,但关注于文本中词的出现次数。文本选择的最终表示为词袋 (bag 指的是多重集的集合论概念,与简单集合不同)。
词袋表示的实际存储机制可以有所不同,但以下是使用字典的简单示例以便直观理解。示例文本:
“哦,好,好,”约翰说。
“那里,那里,”詹姆斯说。“那里,那里。”
生成的词袋表示为字典:
{
'well': 3,
'said': 2,
'john': 1,
'there': 4,
'james': 1
}
11. n-grams
n-grams 是另一种用于简化文本选择内容的表示模型。与无序的词袋模型不同,n-grams 模型关注于保留文本选择中的连续 N 项序列。
上述示例的第二句话(“那里,那里,”詹姆斯说。“那里,那里。”)的三元组(3-gram)模型示例如下所示:
[
"there there said",
"there said james",
"said james there",
"james there there",
]
12. 正则表达式
正则表达式,通常缩写为 regexp 或 regex,是一种简洁描述文本模式的可靠方法。正则表达式本身表示为一个特殊的文本字符串,用于在文本选择上开发搜索模式。正则表达式可以看作是扩展的规则集合,超出了 ? 和 ***** 的通配符字符。尽管经常被认为学习起来令人沮丧,正则表达式却是非常强大的文本搜索工具。
13. Zipf 定律
Zipf 定律用于描述文档集合中词频之间的关系。如果按频率排序文档集合中的词,并且用 y 描述第 x 个词出现的次数,Zipf 的观察可以简洁地表示为 y = cx^(-1/2)(项频率与项排名成反比)。更一般地,维基百科说:
Zipf 定律表明,给定一些自然语言的语料库,任何词的频率与其在频率表中的排名成反比。因此,最频繁的词出现的频率大约是第二频繁词的两倍,第三频繁词的三倍,等等。
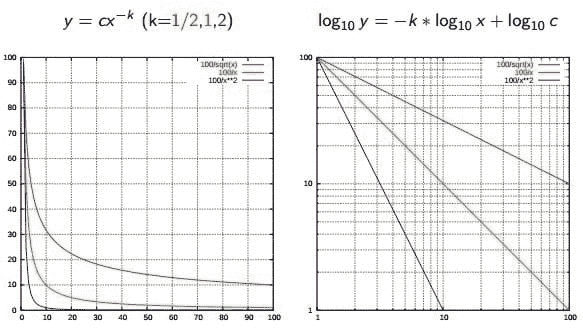
来源:维基百科
14. 相似性度量
有许多相似性度量可以应用于 NLP。我们在测量什么的相似性?通常是字符串。
-
莱文斯坦 - 使一对字符串相等所需删除、插入或替换的字符数
-
贾卡德 - 2 个集合之间重叠的度量;在 NLP 的情况下,通常文档是词的集合
-
史密斯-沃特曼 - 类似于 Levenshtein,但对替换、插入和删除分配了成本。
15. 语法分析
也被称为语法分析,语法分析的任务是将字符串视为符号,并确保它们符合既定的语法规则。这一步必须在任何进一步尝试从文本中提取洞见的分析之前进行——无论是语义分析、情感分析等——将其视为超越符号的东西。
16. 语义分析
也称为意义生成,语义分析关注于确定文本选择的含义(无论是字符还是词序列)。在读取和解析(语法分析)输入的文本选择后,可以对该文本选择进行意义解释。简单来说,语法分析关注的是文本选择由哪些词组成,而语义分析想知道这些词集合实际意味着什么。语义分析的主题既广泛又深奥,研究人员可以使用各种工具和技术。
17. 情感分析
情感分析是评估和确定文本选择中捕捉到的情感的过程,其中情感定义为感觉或情绪。这种情感可以是简单的积极(快乐)、消极(悲伤或愤怒)或中立,或者可以是沿着某个尺度的更精确的测量,其中中立在中间,积极和消极在两个方向上递增。
18. 信息检索
信息检索是基于特定查询,从文本中访问和检索最相关信息的过程,使用基于上下文的索引或元数据。最著名的信息检索实例之一是 Google 搜索。
Matthew Mayo (@mattmayo13) 是一名数据科学家和 KDnuggets 的主编,这是一个开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。你可以通过 editor1 at kdnuggets[dot]com 联系他。
了解更多相关内容
Apache Spark 的自然语言处理库 – 免费使用
原文:
www.kdnuggets.com/2017/11/natural-language-processing-library-apache-spark.html
评论
由 David Talby,Usermind 首席技术官。
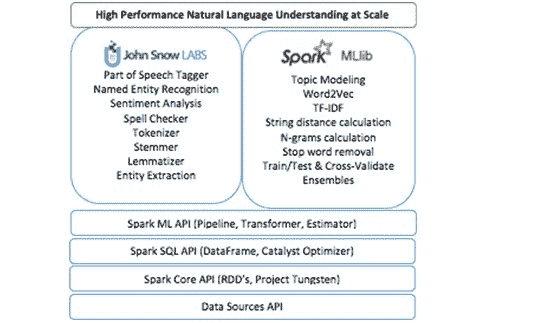
Apache Spark 是一个通用集群计算框架,原生支持分布式 SQL、流处理、图处理和机器学习。现在,Spark 生态系统还拥有一个 Spark 自然语言处理库。
John Snow Labs NLP 库遵循 Apache 2.0 许可,使用 Scala 编写,不依赖其他 NLP 或 ML 库。它本地扩展了 Spark ML Pipeline API。你将受益于:
-
无与伦比的运行时性能,因为处理直接在 Spark DataFrames 上完成,无需任何复制,并充分利用 Spark 的缓存、执行计划和优化的二进制数据格式。
-
无摩擦地重用现有的 Spark 库,包括分布式主题建模、词嵌入、n-gram 计算、字符串距离计算等。
-
通过在数据科学管道的自然语言理解、机器学习和深度学习部分使用统一的 API 提高生产力。
“通过 John Snow Labs NLP,我们兑现了使客户能够利用最新开源技术和数据科学中的学术突破的承诺,所有这些都在高性能的企业级代码库中。”,创始团队表示。此外,“John Snow Labs NLP 包含了一系列高效的自然语言理解工具,用于文本挖掘、问答、聊天机器人、事实提取、主题建模或搜索,运行规模和性能在现有技术中尚未出现。”
框架提供了标注器的概念,并且开箱即用:
-
分词器
-
归一化器
-
词干提取器
-
词形还原器
-
实体提取器
-
日期提取器
-
词性标注器
-
命名实体识别
-
句子边界检测
-
情感分析
-
拼写检查器
此外,考虑到与 Spark ML 的紧密集成,在构建 NLP 管道时你可以立即使用更多功能。这包括词嵌入、主题建模、停用词移除、各种特征工程函数(tf-idf、n-grams、相似度度量等)以及将 NLP 注释作为机器学习工作流中的特征。如果你不熟悉这些术语,这个 理解 NLP 任务的指南 是一个好的起点。
我们的虚拟团队已经在构建严重依赖自然语言理解的商业软件多年。因此,我们对 spaCy、 CoreNLP、 OpenNLP、 Mallet、 GATE、 Weka、 UIMA、 nltk、 gensim、 Negex、 word2vec、 GloVe 和一些其他工具有实际的经验。
我们是这些库的大粉丝,我们模仿它们的许多地方旨在表达我们诚挚的赞美之情。然而,当我们需要交付可扩展、高性能、高准确度的实际生产软件时,我们也多次撞上了它们的限制。
性能
我们解决的三个顶级需求中的第一个是运行时性能。你会认为随着 spaCy 及其公共基准 的出现,这个问题已经基本解决,它们反映了一个经过深思熟虑和精心实现的权衡集合。然而,在其基础上构建 Spark 应用程序时,你仍会遇到不合理的低吞吐量。
要理解原因,可以考虑 NLP 管道总是数据处理管道的一部分:例如,问题回答涉及加载训练数据、转换数据、应用 NLP 注释器、构建特征、训练价值提取模型、评估结果(训练/测试拆分或交叉验证)和超参数估计。
将数据处理框架(Spark)与 NLP 框架分开意味着你大部分的处理时间都会花在序列化和复制字符串上。
一个很好的类比是 TensorFrames——它显著提高了在 Spark 数据框上运行 TensorFlow 工作流的性能。此图像归功于 Tim Hunter 的优秀 TensorFrames 概述:
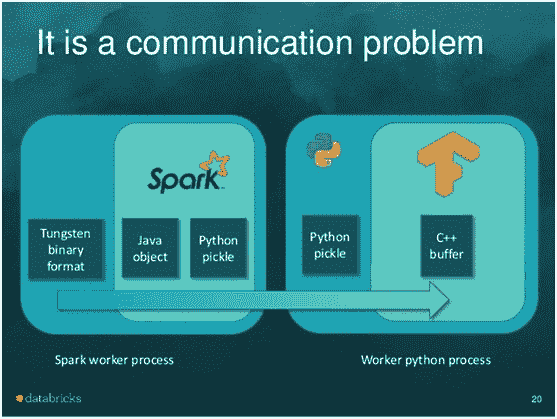
Spark 和 TensorFlow 都在性能和规模上进行了极致优化。然而,由于 DataFrames 存在于 JVM 中,而 TensorFlow 运行在 Python 进程中,因此两个框架之间的任何集成都意味着每个对象都必须序列化,经过双向的进程间通信 (!) 并在内存中至少复制两次。TensorFrames 的公开基准报告显示,仅通过在 JVM 进程中复制数据就能获得 4 倍的加速(使用 GPU 时效果更显著)。
当将 spaCy 与 Spark 一起使用时,我们遇到相同的问题:Spark 在加载和转换数据方面高度优化,但运行 NLP 管道需要将所有数据从 Tungsten 优化格式外部复制,序列化,推送到 Python 进程中,运行 NLP 管道(这一部分非常快速),然后将结果重新序列化回 JVM 进程。这自然会消耗你从 Spark 的缓存或执行计划中获得的任何性能收益,需要至少两倍的内存,并且在扩展时没有改善。使用 CoreNLP 消除了复制到另一个进程的需求,但仍然需要将所有文本从数据框中复制并将结果重新复制回来。
所以我们首先的任务是直接对优化后的数据框进行分析,就像 Spark ML 已经做的那样(来源:Databricks 的 ML Pipelines 介绍文章):
生态系统
我们的第二个核心要求是无摩擦地重用现有的 Spark 库。其中一部分是我们自己的痛点——为什么所有的 NLP 库都必须构建自己的主题建模和词嵌入实现?另一部分是务实的——我们是一个小团队,时间紧迫,需要充分利用现有资源。
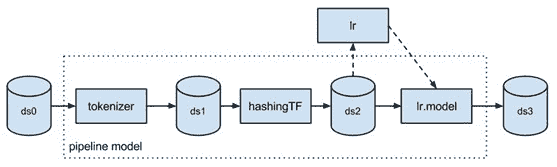
当我们开始考虑一个 Spark NLP 库时,我们首先询问了 Databricks,指引我们找出已经在构建这个库的人。当得到的回答是没有这样一个库时,我们的下一个要求是帮助我们确保这个库的设计和 API 完全符合 Spark ML 的 API 指南。这次合作的结果是这个库无缝扩展了 Spark ML,例如你可以构建这种管道:
val pipeline = new mllib.Pipeline().setStages(
Array(docAssembler,tokenizer,stemmer,stopWordRemover,hasher,idf,dtree,labelDeIndex))
在这段代码中,文档汇编器、分词器和词干提取器来自 Spark NLP 库——com.jsl.nlp.* 包。TF 哈希器、IDF 和 labelDeIndex 都来自 MLlib 的 org.apache.spark.ml.feature.* 包。dtree 阶段是 spark.ml.classification.DecisionTreeClassifier。
所有这些阶段都在一个管道内运行,该管道是可配置的、可序列化的和可测试的,并且以完全相同的方式进行。它们还在数据框上运行,而无需复制数据(与 spark-corenlp 不同),享受 Spark 的标志性内存优化、并行性和分布式扩展。
这意味着 John Snow Labs NLP 库附带了完全分布式、经过严格测试和优化的 主题建模、词嵌入、n-gram 生成和余弦相似度功能。我们不需要自己构建这些功能——它们是与 Spark 一起提供的。
最重要的是,这意味着你的 NLP 和 ML 管道现在是统一的。上述代码示例是典型的,因为它不仅仅是一个 NLP 管道——NLP 用于生成特征,然后用这些特征训练决策树。这在问答任务中很常见。一个更复杂的例子还会应用命名实体识别,按 POS 标签和共指解析过滤;训练随机森林,考虑 NLP 基于的特征和其他来源的结构化特征;并使用网格搜索进行超参数优化。能够使用统一的 API 在需要测试、重现、序列化或发布这样的管道时非常有利——甚至超出了性能和重用的好处。
企业级
我们的第三个核心要求是提供一个任务关键型、企业级的 NLP 库。我们的工作是构建生产软件。许多当前最受欢迎的 NLP 包具有学术背景——这在设计权衡中表现出来,例如优先考虑原型设计的简便性而非运行时性能,选项的广度而非简单的简约 API,以及对可扩展性、错误处理、节省内存和代码重用的轻视。
John Snow Labs NLP 库是用 Scala 编写的。它包括用于 Spark 的 Scala 和 Python API。它不依赖于任何其他 NLP 或 ML 库。对于每种类型的注释器,我们会进行学术文献综述以找出最先进的技术,进行团队讨论并决定要实现哪些算法。实现根据三个标准进行评估:
-
准确性 – 如果框架有低于标准的算法或模型,那么再好的框架也没有意义。
-
性能 – 运行时应该与任何公共基准相当或更好。没有人应该因为注释器的速度不够快以处理流式用例,或在集群设置中扩展性不好而牺牲准确性。
-
可训练性或可配置性 – NLP 是一个固有的领域特定问题。社交媒体帖子、学术论文、SEC 文件、电子病历和报纸文章使用了不同的语法和词汇。
该库已经在企业项目中使用,这意味着第一层次的错误、重构、意外瓶颈和序列化问题已得到解决。单元测试覆盖率和 参考文档 已经达到让我们放心将代码开源的水*。
John Snow Labs 是领导和资助 Spark NLP 库开发的公司。该公司为该库提供商业支持、赔偿和咨询服务。这为库提供了长期的财务支持、资助的活跃开发团队以及不断增长的现实世界项目流,推动了库的稳定性和路线图优先级。
参与方式
如果你需要 NLP 用于当前项目,请访问 John Snow Labs NLP for Apache Spark 主页 或快速入门指南进行尝试。提供预构建的 maven central (Scala) 和 pip 安装 (Python) 版本。通过 nlp@johnsnowlabs.com 或 Twitter、LinkedIn 或 Facebook 发送问题或反馈。
告诉我们 你下一步需要什么功能。
以下是我们收到的一些请求,我们期待更多反馈以设计和优先考虑:
-
提供一个 SparkR 客户端
-
提供“无 Spark”版本的 Java 和 Scala
-
添加最先进的共指消解标注器
-
添加最先进的极性检测标注器
-
添加最先进的时间推理标注器
-
发布适用于常见用例的示例应用程序,如问答、文本摘要或信息检索
-
为新领域或语言训练和发布模型
-
发布可重复、同行评审的准确性和性能基准
如果你想扩展或贡献于该库,可以从克隆 John Snow Labs NLP for Spark GitHub 仓库开始。我们使用拉取请求和 GitHub 的问题跟踪器来管理代码更改、错误和功能。该库仍处于初期阶段,我们非常欢迎各种形式的贡献和反馈。
简历: David Talby 是 Usermind 的首席技术顾问,专注于在医疗保健领域应用大数据和数据科学。
相关
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 支持
相关话题
自然语言处理管道,详细解释
原文:
www.kdnuggets.com/2021/03/natural-language-processing-pipelines-explained.html
评论
由 Ram Tavva,高级数据科学家,ExcelR Solutions 董事

介绍
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
计算机最擅长处理结构化数据集,如电子表格和数据库表格。但我们人类几乎不会以这种方式进行沟通,我们的大多数沟通都是以未结构化的格式——句子、单词、语音等,这些对计算机来说是无关的。
这很不幸,数据库中存在大量未结构化的数据。但你是否曾考虑过计算机如何处理这些未结构化数据?
是的,虽然有许多解决方案,但 NLP 始终是改变游戏规则的技术。
让我们详细了解 NLP…
什么是 NLP?
NLP 代表自然语言处理,它自动操作自然语言,例如应用程序和软件中的语音和文本。
语音可以是算法接收的任何文本,算法测量准确性,运行自我和半监督模型,然后在输入数据后以语音或文本的形式给我们期望的输出。
NLP 是最受欢迎的技术之一,它使人与计算机之间的沟通变得更加容易。如果你使用 Windows 系统,可以使用微软 Cortana;如果你使用 macOS 系统,Siri 就是你的虚拟助手。
最棒的是,即使是搜索引擎也配备了虚拟助手。例如:谷歌搜索引擎。
使用 NLP,你可以输入任何你想搜索的内容,或者点击麦克风选项说出来,你就能获得想要的结果。看看 NLP 如何使人与计算机之间的沟通变得更容易。当你看到这一点时,难道不是很惊奇吗?
无论你是想了解天气情况还是互联网的最新消息,或是周末目的地的路线,NLP 都能满足你的所有需求。
自然语言处理管道(NLP 管道)
当你在文本或语音上调用 NLP 时,它将整个数据转换成字符串,然后主字符串经过多个步骤(称为处理管道的过程)。它使用训练好的管道来监督你的输入数据,并根据语音语调或句子长度重构整个字符串。
对于每个管道,组件返回到主字符串,然后传递给下一个组件。功能和效率依赖于组件、它们的模型和训练。
NLP 如何使人与计算机之间的沟通变得简单
NLP 使用语言处理管道来读取、解码和理解人类语言。这些管道由六个主要过程组成。这些过程将整个语音或文本拆分成小块,重构、分析并处理,以从搜索引擎结果页面中获取最相关的数据。
这是帮助计算机理解人类语言的 6 个 NLP 管道内部步骤
句子分割
当你有段落需要处理时,最佳的方式是逐句进行。这降低了复杂性,简化了过程,甚至能获得最准确的结果。计算机不会像人类那样理解语言,但如果你以正确的方式对待它们,它们总能做很多事情。
例如,考虑上面的段落。然后,你的下一步是将段落拆分成单个句子。
-
当你有段落需要处理时,最佳的方式是逐句进行。
-
这降低了复杂性,简化了过程,甚至能获得最准确的结果。
-
计算机不会像人类那样理解语言,但如果你以正确的方式对待它们,它们总能做很多事情。
# Import the nltk library for NLP processes
import nltk
# Variable that stores the whole paragraph
text = "..."
# Tokenize paragraph into sentences
sentences = nltk.sent_tokenize(text)
# Print out sentences
for sentence in sentences:
print(sentence)
当你有段落需要处理时,最佳的方式是逐句进行。
这降低了复杂性,简化了过程,甚至能获得最准确的结果。
计算机不会像人类那样理解语言,但如果你以正确的方式对待它们,它们总能做很多事情。
单词标记化
标记化是将短语、句子、段落或整个文档拆分成最小单元(如单独的单词或术语)的过程。每个小单元称为标记。
这些标记可以是单词、数字或标点符号。基于单词的边界——单词的结束点,或下一个单词的开始。这也是词干提取和词形还原的第一步。
这个过程至关重要,因为通过分析文本中的单词,词义容易被解释。
让我们来看一个例子:
那只狗是一只哈士奇犬。
当你标记化整个句子时,你得到的答案是[‘That’, ‘dog’, ‘is’, ‘a’, ‘husky’, ‘breed’]。
你可以用多种方式做到这一点,但我们可以使用这种标记化的形式来:
-
计算句子中的单词数。
-
你还可以测量重复单词的频率。
自然语言工具包(NLTK)是一个用于符号和统计 NLP 的 Python 库。
import nltk
sentence_data = "That dog is a husky breed. They are intelligent and independent."
nltk_tokens = nltk.sent_tokenize(sentence_data)
print (nltk_tokens)
输出:
[‘那只狗是哈士奇品种。’, ‘它们既聪明又独立。’]
每个标记的词性预测
在词性分析中,我们必须考虑每个标记。然后,尝试弄清楚不同的词性——标记是否属于名词、代词、动词、形容词等等。
所有这些都有助于了解我们在谈论哪个句子。
让我们快速了解一些词汇:
语料库: 单数形式的文本主体。其复数形式为 corpora。
词汇表: 词汇及其含义。
标记: 基于规则分割后的每个“实体”。
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize, sent_tokenize
stop_words = set(stopwords.words('english'))
// Dummy text
txt = Everything is all about money.\
# sent_tokenize is one of the instances of
# PunktSentenceTokenizer from the nltk.tokenize.punkt module
tokenized = sent_tokenize(txt)
for i in tokenized:
# Word tokenizers is used to find the words
# and punctuation in a string
wordsList = nltk.word_tokenize(i)
# removing stop words from wordList
wordsList = [w for w in wordsList if not w in stop_words]
# Using a Tagger. Which is part-of-speech
# tagger or POS-tagger.
tagged = nltk.pos_tag(wordsList)
print(tagged)
输出:
[('一切', 'NN'), ('是', 'VBZ'), ('所有', 'DT'),('关于', 'IN'), ('钱', 'NN'), ('.', '.')]
文本词形还原
英语也是一种可以使用各种基本词形式的语言。当在计算机上工作时,它能够理解这些词用于相同概念,即使句子中存在多个具有相同基本词的词汇。这一过程就是我们在 NLP 中称之为词形还原。
这一步骤会进入词汇的根本层面,找出所有可用词汇的基本形式。它们有普通的规则来处理这些词汇,而大多数人对此并不知晓。

识别停用词
当你完成词形还原后,下一步是识别句子中的每个词。英语中有很多填充词,它们没有实际意义,但会削弱句子的效果。通常最好省略这些词,因为它们在句子中出现的频率较高。
大多数数据科学家在进行进一步分析之前会删除这些词汇。基本算法通过检查已知的停用词列表来识别停用词,因为没有标准的停用词规则。
一个有助于你更好地理解识别停用词的例子是:
# importing NLTK library stopwords
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')
nltk.download('punkt')
from nltk.tokenize import word_tokenize
## print(stopwords.words('english'))
# random sentence with lot of stop words
sample_text = "Oh man, this is pretty cool. We will do more such things."
text_tokens = word_tokenize(sample_text)
tokens_without_sw = [word for word in text_tokens if not word in stopwords.words('english')]
print(text_tokens)
print(tokens_without_sw)
输出:
带停用词的文本分词:
[‘哦’, ‘人’, ’,’ ‘这’, ‘是’, ‘挺’, ‘酷’, ‘.’, ‘我们’, ‘将’, ‘做’, ‘更多’, ‘这样的’, ’事情’, ‘.’]
不带停用词的文本分词:
[‘哦’, ‘人’, ’,’ ‘挺’, ‘酷’, ‘.’, ‘我们’, ’事情’, ‘.’]
依存句法分析
解析进一步分为三个主要类别。每一类都不同于其他类别。它们是词性标注、依存句法分析和构成短语。
词性标注(POS)主要用于分配不同的标签。这就是我们所说的 POS 标签。这些标签指示了句子中词汇的词性。而在依存短语的情况下:分析句子的语法结构。基于句子中词汇的依赖关系。
而在构成分析中:句子被拆分为子短语。这些子短语属于特定的类别,如名词短语(NP)和动词短语(VP)。
结论
在这个博客中,你简要了解了 NLP 流水线如何通过各种 NLP 过程帮助计算机理解人类语言。
从自然语言处理开始,语言处理流程是什么?自然语言处理如何使人类之间的沟通更轻松?以及 NLP 流程中的六个内幕。
自然语言处理流程涉及的六个步骤是 - 句子分割、词汇标记、每个标记的词性。文本词形还原、识别停用词和依赖解析。
简介: Ram Tavva 是 ExcelR Solutions 的高级数据科学家和总监。
相关:
-
每个数据科学家都应该知道的 6 种 NLP 技术
-
使用 NLP 改进你的简历
-
Hugging Face Transformers 包 – 这是什么以及如何使用它
相关主题
使用 Python 的自然语言处理:免费电子书
原文:
www.kdnuggets.com/2020/06/natural-language-processing-python-free-ebook.html
评论
说到自然语言处理领域,实际上涉及了很多相关的概念、技术和方法。词向量、依存解析、文本分类、正则表达式、语言模型、语音翻译;这些都可以归入 NLP 的范畴,尽管它们是非常不同的任务和技术。
鉴于这一领域的广泛性和迅速发展,建立扎实的基础概念,并以实用的方式进行学习,应被视为高度重要。本周推荐的免费电子书,使用 Python 的自然语言处理,是帮助建立这种扎实基础的绝佳方式。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析水*
3. Google IT 支持专业证书 - 支持你的组织 IT
自然语言工具包 (NLTK) 是一个通用的 NLP 库,虽然通常不被视为生产系统的选择,但非常适合用于教学和学习如何实现一些 NLP 的基本概念。这本配套书专门设计用于指导读者完成这一学习过程。
从书籍的前言:
本书提供了一个高度易于理解的自然语言处理领域介绍。它可以用于个人学习,也可以作为自然语言处理或计算语言学课程的教材,或作为人工智能、文本挖掘或语料库语言学课程的补充。书中内容非常实用,包含了数百个完整的例子和分级练习。
[...]
本书面向各种希望学习如何编写分析书面语言的程序的人群,无论其之前是否有编程经验。
如上所述,本书确实具有实用性质。尽管你在阅读过程中会遇到解释概念,但毫无疑问,这本书是为那些希望立即开始使用 Python 实施自然语言处理解决方案的人量身打造的,并且要做到现在。
值得注意的是,这版免费的在线书籍已经更新了 Python 3 的代码,因为原版书籍已*十年,使用的是 Python 2。同时,本书不提供 PDF 下载,而是以 HTML 格式在其网站上免费提供。
本书的章节如下:
-
语言处理与 Python
-
访问文本语料库和词汇资源
-
处理原始文本
-
编写结构化程序
-
词汇的分类和标记
-
学习文本分类
-
从文本中提取信息
-
分析句子结构
-
构建基于特征的语法
-
分析句子的含义
-
管理语言数据
-
后记:面对语言挑战
本书的前言还指出了这些具体的学习成果:
- 如何利用简单程序来操作和分析语言数据,以及如何编写这些程序
- 如何将 NLP 和语言学中的关键概念用于描述和分析语言
- 数据结构和算法如何在 NLP 中使用
- 语言数据如何以标准格式存储,以及如何利用这些数据来评估 NLP 技术的表现
样本块解析器输出可视化。来自《Python 自然语言处理》第七章。
本书开始时内容较慢——描述 NLP、如何使用 Python 执行一些 NLP 编程任务、如何访问自然语言内容进行处理——然后转向更大的概念,既包括概念上的(NLP),也包括编程上的(Python)。不久后,它将涉及分类、文本分类、信息提取以及其他更多被认为是经典 NLP 的话题。在掌握了这本书中的 NLP 基础后,你可以通过一些斯坦福大学的免费 课程继续学习更现代和前沿的技术。
祝所有踏入自然语言处理领域的朋友好运。这是一本很好的入门书籍,因其篇幅较短,可以相对快速地吸收,从而能够迅速进入更高级的主题。
相关:
-
深度学习与 fastai 和 PyTorch:免费电子书
-
Python 面向所有人:免费电子书
-
自动化机器学习:免费电子书
相关主题
自然语言处理配方:最佳实践和示例
原文:
www.kdnuggets.com/2020/05/natural-language-processing-recipes-best-practices-examples.html
评论
我们 KDnuggets 最*尽力突显一些优质的自然语言处理(NLP)资源,最显著的包括 The Big Bad NLP Database 和 The Super Duper NLP Repo,这是 Quantum Stat 管理的两个项目。其中第一个是围绕任务精心组织的 NLP 数据集的策划仓库,而第二个是演示这些任务实现的 Google Colab notebooks 集合。
在这种背景下,我们发现微软的Natural Language Processing Best Practices & Examples仓库是这一集合中另一个值得添加的资源。该仓库描述了其用处如下:
该仓库包含构建 NLP 系统的示例和最佳实践,以 Jupyter notebooks 和实用功能的形式提供。该仓库的重点是最先进的方法和在处理文本和语言问题的研究人员和从业者中流行的常见场景。
这些笔记本和它描述的实用功能更像是对 NLP 任务的指导,而非端到端解决方案,以确保你在实现系统时考虑到最佳实践。
这个仓库的目标是构建一整套全面的工具和示例,利用最*在 NLP 算法、神经网络架构和分布式机器学习系统方面的进展。[...] 我们希望这些工具能够显著缩短“上市时间”,通过从定义业务问题到解决方案开发的过程大幅简化体验。此外,示例笔记本将作为指导,并展示工具在各种语言中的最佳实践和使用方法。
强调Emily Bender的多语言原则,该仓库还阐明 NLP“并不等同于英语”,并确保项目的目标是“提供尽可能多语言的端到端示例”,鼓励社区贡献以促进实现。
该仓库包含一系列的Jupyter notebooks,这些笔记本实现了表格中额外描述的以下 NLP 场景。
而且这些指南并不是单一维度的;例如,文本分类笔记本中有几种不同的笔记本,使用了不同的数据集、自然语言、环境(本地或 Azure 云端)、语言模型和任务焦点的组合。
这些笔记本还依赖于utils_nlp模块中的脚本,以帮助减轻一些“从数据加载、数据集理解、模型开发、模型评估到将训练好的 NLP 模型投入生产”的繁琐任务。务必查看微软研究开发的这些工具,旨在节省时间并加速一些与自然语言处理相关的繁重任务。
我对几乎所有 NLP 的内容情有独钟,从学习资源到示例笔记本,再到框架和库、语言模型、数据集集合等等。如果你也是如此,我建议你查看微软的这个最佳实践导向的仓库。
相关内容:
-
超级 NLP 仓库:100 个即用的 Colab 笔记本
-
大型 NLP 数据库:访问* 300 个数据集
-
使用 TensorFlow 和 Keras 进行分词和文本数据准备
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析水*
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
更多相关话题
使用 spaCy 进行自然语言处理
原文:
www.kdnuggets.com/2023/01/natural-language-processing-spacy.html

图片由编辑提供
数据科学是许多子领域的总称;自然语言处理(NLP)是最著名和最重要的领域之一。自然语言处理是使计算机能够理解人类自然语言的领域。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
NLP 是一个非常有价值的领域,它连接了人类和计算机,并使我们能够利用技术改善生活。由于 NLP 的普及,你可以通过多种方式来构建 NLP 项目。其中一种方式是使用 Python 和 spaCy 库。
spaCy 是一个用于高级 NLP 的开源库,用 Python 和 Cython 编写。spaCy 使你能够轻松构建现实世界中的 NLP 应用程序。如果你是 NLP 的新手,这篇 Analytics Vidhya 上的优秀文章以非常直接的方式讲解了 NLP 的基础知识。他们还提供了一个很棒的指南,帮助你在 NLP 领域中找到方向。
一旦掌握了基础知识,你可以使用 spaCy 创建高级 NLP 应用程序。每当我遇到新的软件包库时,我都会先访问官方网站获取材料,然后再扩展到其他资源。spaCy 的官方网站提供了一门简短且实用的4 章课程,帮助你从入门到精通使用这个包。

图片来源:course.spacy
这门课程是开始学习 spaCy 和自然语言处理(NLP)的绝佳方式。另一个很棒的资源是由freeCodeCamp提供的 3 小时课程,它将带你了解 NLP 和 spaCy 的基础知识。课程涵盖了不同的主题:
-
如何安装 spaCy。
-
spaCy 容器。
-
语言学注释。
-
词向量。
-
正则表达式(基础和多词令牌)。
以及更多内容。
课程链接: www.youtube.com/watch?v=dIUTsFT2MeQ
尽管这些资源足以让你踏上成为 NLP 大师的道路,但我总是喜欢总结和备忘单,以备不时之需。幸运的是,DataCamp 提供了一个很棒的 spaCy 备忘单,你可以将其保存为最常用函数的指南。

图片来源: DataCamp
自然语言处理使计算机能够理解和使用我们的语言。今天,我们可以在日常生活中利用自然语言处理的力量。
由于自然语言处理是今天的热门话题,你可以采用不同的方法来设计、构建和开发自然语言处理应用程序。构建高级自然语言处理项目的最强大工具之一是 spaCy。今天我们向你展示了免费的资源,帮助你开始使用 spaCy,然后利用这些知识构建更大、更真实的应用程序。
Sara Metwalli 是庆应大学的博士候选人,研究如何测试和调试量子电路。我是 IBM 的研究实习生和 Qiskit 倡导者,致力于构建更量子的未来。我还是 Medium、Built-in、She Can Code 和 KDN 的作者,撰写有关编程、数据科学和技术主题的文章。我也是“Woman Who Code Python”国际分会的负责人,一个火车爱好者、旅行者和摄影爱好者。
更多相关主题
使用 spaCy 的 Python 自然语言:简介
原文:
www.kdnuggets.com/2019/09/natural-language-python-using-spacy-introduction.html
评论
作者:Paco Nathan
本文提供了使用 spaCy 和 Python 相关库的自然语言简要介绍。补充的 Domino 项目也可以查看。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT
简介
本文和配套的 Domino 项目 提供了使用 自然语言(有时称为“文本分析”)的 Python 简要介绍,使用的工具包括 spaCy 和相关库。工业界的数据科学团队必须处理大量文本,这是机器学习中使用的四大数据类别之一。通常是人类生成的文本,但并非总是如此。
想一想:商业的“操作系统”是如何工作的?通常,包括合同(销售合同、工作协议、合作伙伴关系)、发票、保险单、规章制度及其他法律等。所有这些都以文本形式存在。
你可能会遇到一些缩略语:自然语言处理(NLP)、自然语言理解(NLU)、自然语言生成(NLG)——它们分别大致表示“读取文本”、“理解意义”、“编写文本”。这些任务的重叠越来越多,因此很难对任何特定功能进行分类。
spaCy 框架——以及越来越多的插件和其他集成——提供了广泛的自然语言任务功能。它已成为 Python 中工业应用最广泛使用的自然语言库之一,并拥有相当大的社区——因此,对研究进展的商业化支持也较多,随着该领域的快速发展,支持也在不断增加。
入门
我们已经在 Domino 中配置了默认计算环境,以包含本教程所需的所有软件包、库、模型和数据。查看 Domino 项目以运行代码。


如果你对 Domino’s 计算环境如何工作感兴趣,可以查看 支持页面。
现在让我们加载 spaCy 并运行一些代码:
import spacy
nlp = spacy.load("en_core_web_sm")
现在,nlp 变量是你接触所有 spaCy 相关内容的入口,并加载了用于英语的 en_core_web_sm 小型模型。接下来,让我们通过自然语言解析器运行一个小的“文档”:
text = "The rain in Spain falls mainly on the plain."
doc = nlp(text)
for token in doc:
print(token.text, token.lemma_, token.pos_, token.is_stop)
The the DET True
rain rain NOUN False
in in ADP True
Spain Spain PROPN False
falls fall VERB False
mainly mainly ADV False
on on ADP True
the the DET True
plain plain NOUN False
. . PUNCT False
首先,我们从文本中创建了一个 doc,它是一个容器,包含了文档及其所有注释。然后我们遍历了文档,以查看 spaCy 解析了什么。
很好,但信息量很大,阅读起来有点困难。让我们将 spaCy 解析的句子重新格式化为一个 pandas 数据框:
import pandas as pd
cols = ("text", "lemma", "POS", "explain", "stopword")
rows = []
for t in doc:
row = [t.text, t.lemma_, t.pos_, spacy.explain(t.pos_), t.is_stop]
rows.append(row)
df = pd.DataFrame(rows, columns=cols)
df

可读性提高了!在这个简单的例子中,整个文档只是一个简短的句子。在那个句子中的每个词,spaCy 都创建了一个标记,我们访问了每个标记中的字段来显示:
-
原始文本
-
[词元](https://en.wikipedia.org/wiki/Lemma_(morphology) - 词的根形式
-
一个标记是否是 停用词 的标志——即,可能被过滤掉的常见词
接下来,让我们使用 displaCy 库来可视化该句子的解析树:
from spacy import displacy
displacy.render(doc, style="dep")

这是否让你想起了小学的回忆?坦白说,对于那些来自计算语言学背景的人来说,这个图示确实带来快乐。
但我们稍微退一步。你如何处理多个句子?
有用于 句子边界检测(SBD)—也称为 句子分割—的功能,基于内置/默认的 sentencizer:
text = "We were all out at the zoo one day, I was doing some acting, walking on the railing of the gorilla exhibit. I fell in. Everyone screamed and Tommy jumped in after me, forgetting that he had blueberries in his front pocket. The gorillas just went wild."
doc = nlp(text)
for sent in doc.sents:
print(">", sent)
> We were all out at the zoo one day, I was doing some acting, walking on the railing of the gorilla exhibit.
> I fell in.
> Everyone screamed and Tommy jumped in after me, forgetting that he had blueberries in his front pocket.
> The gorillas just went wild.
当 spaCy 创建文档时,它使用了一种 非破坏性分词 原则,意味着标记、句子等只是长数组中的索引。换句话说,它们不会将文本流切割成小块。因此,每个句子都是一个 span,具有 start 和 end 索引到文档数组:
for sent in doc.sents:
print(">", sent.start, sent.end)
> 0 25
> 25 29
> 29 48
> 48 54
我们可以在文档数组中索引,以提取一个句子的标记:
doc[48:54]
The gorillas just went wild.
或简单地索引到一个特定的标记,例如最后一个句子中的动词 went:
token = doc[51]
print(token.text, token.lemma_, token.pos_)
went go VERB
到目前为止,我们可以解析文档,将文档分割成句子,然后查看每个句子中标记的注释。这是一个良好的开端。
获取文本
现在我们可以解析文本了,那我们从哪里获取文本呢?一个快速的来源是利用网络。当然,当我们下载网页时,我们会得到 HTML,然后需要从中提取文本。Beautiful Soup 是一个流行的包来实现这一点。
首先,进行一些基础操作:
import sys
import warnings
warnings.filterwarnings("ignore")
在以下函数get_text()中,我们将解析 HTML 以查找所有的<p/>标签,然后提取这些标签的文本:
from bs4 import BeautifulSoup
import requests
import traceback
def get_text (url):
buf = []
try:
soup = BeautifulSoup(requests.get(url).text, "html.parser")
for p in soup.find_all("p"):
buf.append(p.get_text())
return "\n".join(buf)
except:
print(traceback.format_exc())
sys.exit(-1)
现在让我们从在线来源抓取一些文本。我们可以比较Open Source Initiative网站上托管的开源许可证:
lic = {}
lic["mit"] = nlp(get_text("https://opensource.org/licenses/MIT"))
lic["asl"] = nlp(get_text("https://opensource.org/licenses/Apache-2.0"))
lic["bsd"] = nlp(get_text("https://opensource.org/licenses/BSD-3-Clause"))
for sent in lic["bsd"].sents:
print(">", sent)
> SPDX short identifier: BSD-3-Clause
> Note: This license has also been called the "New BSD License" or "Modified BSD License"
> See also the 2-clause BSD License.
…
自然语言工作中的一个常见用例是比较文本。例如,通过这些开源许可证,我们可以下载它们的文本,解析,然后比较similarity度量:
pairs = [
["mit", "asl"],
["asl", "bsd"],
["bsd", "mit"]
]
for a, b in pairs:
print(a, b, lic[a].similarity(lic[b]))
mit asl 0.9482039305669306
asl bsd 0.9391555350757145
bsd mit 0.9895838089575453
这很有趣,因为BSD和MIT许可证似乎是最相似的文档。事实上,它们密切相关。
坦率地说,由于 OSI 免责声明在页脚中包含了一些额外的文本——但这为比较许可证提供了一个合理的*似。
自然语言理解
现在让我们深入探讨一些spaCy的自然语言理解(NLU)功能。鉴于我们有一个文档的解析,从纯语法的角度来看,我们可以提取noun chunks,即每个名词短语:
text = "Steve Jobs and Steve Wozniak incorporated Apple Computer on January 3, 1977, in Cupertino, California."
doc = nlp(text)
for chunk in doc.noun_chunks:
print(chunk.text)
Steve Jobs
Steve Wozniak
Apple Computer
January
Cupertino
California
不错。句子中的名词短语通常提供更多的信息内容——作为一种简单的过滤器,用于将长文档减少到更“精炼”的表示形式。
我们可以进一步采用这种方法,并识别文本中的named entities,即专有名词:
for ent in doc.ents:
print(ent.text, ent.label_)
Steve Jobs PERSON
Steve Wozniak PERSON
Apple Computer ORG
January 3, 1977 DATE
Cupertino GPE
California GPE
displaCy库提供了一种出色的可视化命名实体的方式:
displacy.render(doc, style="ent")

如果你正在处理knowledge graph应用程序和其他linked data,你的挑战是构建文档中的命名实体与其他相关信息之间的链接,这称为entity linking。识别文档中的命名实体是这种特定类型的 AI 工作中的第一步。例如,给定上述文本,可以将Steve Wozniak命名实体链接到lookup in DBpedia。
更一般来说,还可以将lemmas链接到描述其含义的资源。例如,在早期部分,我们解析了句子The gorillas just went wild,并能够显示单词went的词元是动词go。此时我们可以使用一个叫做WordNet的古老项目,它提供了一个英语的词汇数据库——换句话说,它是一个可计算的词典。
有一个名为spacy-wordnet的spaCy与 WordNet 的集成,由自然语言和知识图谱工作的专家Daniel Vila Suero提供。
然后我们将通过 NLTK 加载 WordNet 数据(这些事情会发生):
import nltk
nltk.download("wordnet")
[nltk_data] Downloading package wordnet to /home/ceteri/nltk_data...
[nltk_data] Package wordnet is already up-to-date!
True
注意到spaCy作为一个“管道”运行,并允许自定义管道中的部分内容。这对于支持数据科学工作中的非常有趣的工作流集成非常有用。在这里,我们将从spacy-wordnet项目中添加WordnetAnnotator:
from spacy_wordnet.wordnet_annotator import WordnetAnnotator
print("before", nlp.pipe_names)
if "WordnetAnnotator" not in nlp.pipe_names:
nlp.add_pipe(WordnetAnnotator(nlp.lang), after="tagger")
print("after", nlp.pipe_names)
before ['tagger', 'parser', 'ner']
after ['tagger', 'WordnetAnnotator', 'parser', 'ner']
在英语中,一些词因具有多种可能的含义而臭名昭著。例如,通过WordNet搜索结果来查找与withdraw一词相关的含义。
现在让我们使用spaCy来自动执行该查找:
token = nlp("withdraw")[0]
token._.wordnet.synsets()
[Synset('withdraw.v.01'),
Synset('retire.v.02'),
Synset('disengage.v.01'),
Synset('recall.v.07'),
Synset('swallow.v.05'),
Synset('seclude.v.01'),
Synset('adjourn.v.02'),
Synset('bow_out.v.02'),
Synset('withdraw.v.09'),
Synset('retire.v.08'),
Synset('retreat.v.04'),
Synset('remove.v.01')]
token._.wordnet.lemmas()
[Lemma('withdraw.v.01.withdraw'),
Lemma('withdraw.v.01.retreat'),
Lemma('withdraw.v.01.pull_away'),
Lemma('withdraw.v.01.draw_back'),
Lemma('withdraw.v.01.recede'),
Lemma('withdraw.v.01.pull_back'),
Lemma('withdraw.v.01.retire'),
…
token._.wordnet.wordnet_domains()
['astronomy',
'school',
'telegraphy',
'industry',
'psychology',
'ethnology',
'ethnology',
'administration',
'school',
'finance',
'economy',
'exchange',
'banking',
'commerce',
'medicine',
'ethnology',
'university',
…
同样,如果你正在处理知识图谱,那些来自WordNet的“词义”链接可以与图算法一起使用,以帮助识别特定词的含义。这也可以用于通过一种叫做总结的技术开发较大文本部分的摘要。这超出了本教程的范围,但在自然语言处理领域中这是一个有趣的应用。
反过来,如果你知道a priori一份文档是关于特定领域或主题集合的,那么你可以限制从WordNet返回的含义。在以下示例中,我们希望考虑金融和银行领域的 NLU 结果:
domains = ["finance", "banking"]
sentence = nlp("I want to withdraw 5,000 euros.")
enriched_sent = []
for token in sentence:
# get synsets within the desired domains
synsets = token._.wordnet.wordnet_synsets_for_domain(domains)
if synsets:
lemmas_for_synset = []
for s in synsets:
# get synset variants and add to the enriched sentence
lemmas_for_synset.extend(s.lemma_names())
enriched_sent.append("({})".format("|".join(set(lemmas_for_synset))))
else:
enriched_sent.append(token.text)
print(" ".join(enriched_sent))
I (require|want|need) to (draw_off|withdraw|draw|take_out) 5,000 euros .
这个示例看起来很简单,但如果你玩一下domains列表,你会发现结果在没有合理约束的情况下会出现一种组合爆炸的情况。想象一下拥有一个包含数百万个元素的知识图谱:你会想尽可能地限制搜索,以避免每个查询都需要数天/周/月/年来计算。
有时,试图理解文本——或者更好地说,理解一个corpus(一个包含许多相关文本的数据集)——时遇到的问题变得如此复杂,以至于你需要先可视化它。这是一个用于理解文本的交互式可视化工具:scattertext,这是Jason Kessler的天才作品。
让我们分析 2012 年美国总统选举期间的党派大会的文本数据。注意:这个单元可能需要几分钟才能运行,但经过所有这些数字运算后,结果是值得等待的。
import scattertext as st
if "merge_entities" not in nlp.pipe_names:
nlp.add_pipe(nlp.create_pipe("merge_entities"))
if "merge_noun_chunks" not in nlp.pipe_names:
nlp.add_pipe(nlp.create_pipe("merge_noun_chunks"))
convention_df = st.SampleCorpora.ConventionData2012.get_data()
corpus = st.CorpusFromPandas(convention_df,
category_col="party",
text_col="text",
nlp=nlp).build()
一旦你准备好了corpus,生成一个 HTML 中的交互式可视化:
html = st.produce_scattertext_explorer(
corpus,
category="democrat",
category_name="Democratic",
not_category_name="Republican",
width_in_pixels=1000,
metadata=convention_df["speaker"]
)
from IPython.display import IFrame
file_name = "foo.html"
with open(file_name, "wb") as f:
f.write(html.encode("utf-8"))
IFrame(src=file_name, width = 1200, height=700)
现在我们将渲染 HTML——请稍等一两分钟,它值得等待:

想象一下,如果你有过去三年中针对特定产品的客户支持文本。假设你的团队需要了解客户如何谈论该产品?这个scattertext库可能会非常有用!你可以对NPS 评分(一个客户评估指标)进行聚类(k=2),然后用聚类中的前两个组件替换民主党/共和党的维度。
概要
五年前,如果你询问有关 Python 中自然语言的开源工具,许多数据科学工作者的默认答案可能是NLTK。该项目包括几乎所有内容,但组件相对学术。另一个受欢迎的自然语言项目是斯坦福大学的CoreNLP,虽然也相当学术,但功能强大,不过 CoreNLP 在生产环境中与其他软件集成可能会有挑战。
几年前,这个自然语言领域的一切开始发生变化。spaCy的两位主要作者,Matthew Honnibal和Ines Montani,于 2015 年推出了该项目,行业采纳迅速。他们专注于一种主观性的方法(做必要的事,做到最好,不多也不少),这使得在 Python 中的数据科学工作流程中能够简单、快速地集成,并且执行速度更快、准确性更高。基于这些优先级,spaCy变成了NLTK的反面。自 2015 年以来,spaCy始终专注于作为一个开源项目(即依赖其社区进行方向指导、集成等)以及商业级软件(而非学术研究)。尽管如此,spaCy迅速纳入了机器学习的 SOTA 进展,实际上成为了将研究成果转化为行业应用的桥梁。
值得注意的是,自 2000 年代中期谷歌开始赢得国际语言翻译竞赛后,自然语言的机器学习得到了极大的提升。另一个重大变化发生在 2017-2018 年,当时,随着深度学习的诸多成功,这些方法开始超越之前的机器学习模型。例如,请参见ELMo对语言嵌入的工作,由 Allen AI 主导,接着是Google 的 BERT,以及最*的百度的 ERNIE——换句话说,全球的搜索引擎巨头们为我们提供了基于深度学习的开源嵌入语言模型的《芝麻街》剧目,这些模型现在是最先进的(SOTA)。说到这一点,为了跟踪自然语言的 SOTA,可以关注NLP-Progress和Papers with Code。
过去两年自然语言的应用场景发生了剧烈变化,深度学习技术的出现使得这些变化加速。大约在 2014 年,一个 Python 自然语言教程可能会展示词频统计、关键词搜索或情感检测,当时的目标用例相对较为*淡。而到了 2019 年,我们谈论的则是分析成千上万的文档以优化工业supply chain…或分析数亿份文档用于保险公司保单持有人,或无数份关于财务披露的文档。更现代的自然语言处理工作倾向于自然语言理解(NLU),通常用于支持知识图谱的构建,并且越来越多地应用于自然语言生成(NLG),在这里,大量类似文档可以在人工规模下进行总结。
spaCy Universe 是检查特定用例深度探讨以及了解这一领域如何发展的好地方。从这个“宇宙”中选择的一些项目包括:
-
Blackstone – 解析非结构化法律文本
-
Kindred – 从生物医学文本(例如,制药领域)中提取实体
-
mordecai – 解析地理信息
-
Prodigy – 人工干预标注数据集
-
spacy-raspberry – Raspberry PI 镜像,用于在边缘设备上运行 spaCy 和深度学习
-
Rasa NLU – Rasa 集成用于聊天应用
另外,还有几个超级新的项目值得一提:
-
spacy-pytorch-transformers 用于微调(即,使用迁移学习)Sesame Street 的角色和朋友:BERT、GPT-2、XLNet 等。
-
spaCy IRL 2019 会议 – 查看演讲视频!
我们可以用spaCy做更多的事情——希望这个教程能够提供一个入门介绍。祝你在自然语言处理工作中一切顺利。
原始。经许可转载。
相关:
-
自然语言处理中的迁移学习现状
-
Reddit 帖子分类
-
2018 年数据科学和 AI 的顶级 7 个 Python 库
相关话题
导航数据科学职位标题:数据分析师 vs. 数据科学家 vs. 数据工程师
原文:
www.kdnuggets.com/navigating-data-science-job-titles-data-analyst-vs-data-scientist-vs-data-engineer

“导航”似乎是合适的词汇。数据科学有时可能像一片狂野的海洋,每隔几分钟就会出现一个新的职位名称或专业化方向。谢谢你,数据科学。我们感激你充满活力和狂野,但我们该如何应对呢?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业之路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
首先,让我们先搞清楚基础。当我说数据科学职位时,我指的是更广泛的数据科学,包括所有的数据相关职位。对我来说,所有这些都是数据科学职位标题。
其次,数据分析师、数据科学家和数据工程师不再是新兴职位了。但它们仍然会引起一些关于谁做什么的困惑。这些职位之间有一些轻微的重叠,这并没有帮助。
许多公司在只有一个数据团队成员时甚至会让情况更糟。是的,初创公司,我在看着你们呢!
不,数据分析师、数据科学家和数据工程师并不是相同的工作!谁会想到呢?
虽然这些职位有不同的专业领域和重点,但它们都朝着同一个目标努力,作为公司内部数据团队的一部分。
为什么数据角色至关重要
每家公司都看到数据的价值,并利用数据团队来提取这些价值。通常,大多数公司都尝试实现五个常见的目标。
1. 明智决策
数据使公司不再盲目决策,依赖决策者的商业直觉(即:运气)。随着技术的进步,数据的多样性和使用可能性增加了。
数据科学利用数据提供洞见,以指导战略和决策。
2. 改善客户体验
公司必须以客户为导向,因为这就是它们的资金来源。数据科学使公司能够分析客户行为和反馈。这使企业能够根据客户的需求量身定制其产品和服务,并预测客户的需求。
3. 操作效率
虽然他们希望从客户那里赚取尽可能多的钱,但企业也希望以最有效的方式做到这一点。阅读:以最低成本完成。数据科学可以帮助实现这一目标。它可以自动化和加速任务,优化它们,并发现瓶颈。简而言之,就是处理业务的成本问题。
4. 创新与竞争力
数据科学通过识别和预测客户需求、行业趋势、经济变化等来推动创新。这里的创新可以指现有或新产品、市场营销和销售策略以及制造过程,但不限于此。
5. 风险管理
商业是一项有风险的,呃,业务。数据科学帮助识别、评估和管理公司的潜在风险。
数据科学职位名称
除非我们对每个职位有清晰的定义,否则无法分析职位名称之间的差异。让我们从这里开始,然后再讨论它们的职责、技能、使用的工具和职业发展路径。
数据分析师
角色总结: 数据分析师显而易见地分析数据。他们这样做是为了识别模式并提出可行的洞察。这些模式和洞察会以报告和仪表盘的形式呈现,使决策者能够做出明智的决策。
数据分析师主要负责描述性(发生了什么?)和诊断性(为什么发生?)的数据分析。
主要职责:
-
数据清洗: 通过标准化数据、改变数据格式以及处理重复项、缺失值和数据不一致性,使数据准备好进行分析。
-
数据分析: 使用统计方法来理解数据中的趋势、模式和洞察。
-
数据可视化和报告: 通过报告、数据可视化和仪表盘传达数据分析结果。
关键技能和工具: 主要技能和工具可以从角色描述中得出。
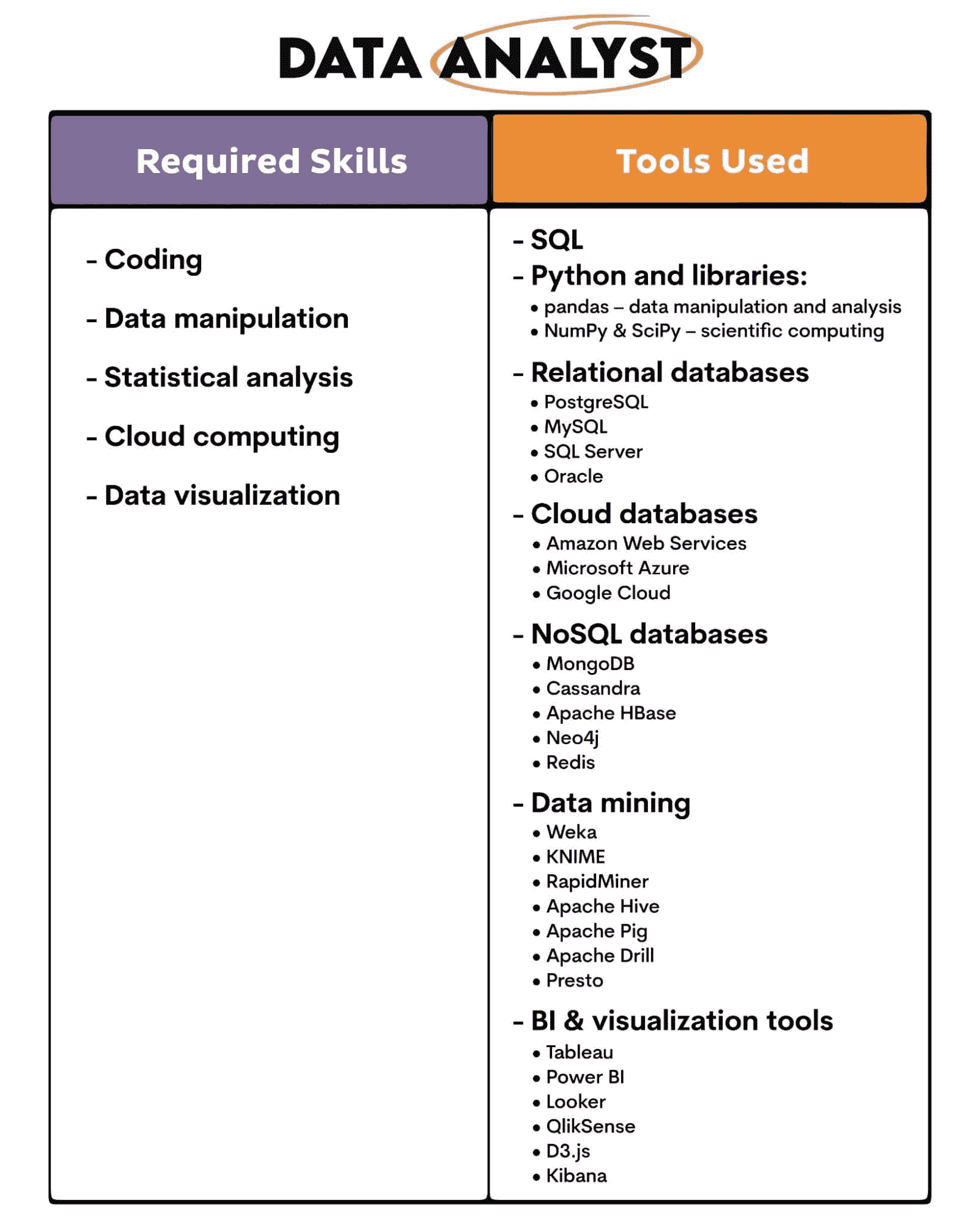
职业发展路径: 数据分析师可以晋升到更高级的分析师角色。随着经验的增加和额外教育的完成,他们可以转型为专业角色,如统计师、业务分析师,甚至数据科学家。
数据科学家
角色总结: 数据科学家也分析数据,但在更高级的层面。他们使用统计模型和机器学习算法来确定未来事件的可能性。这告诉我们,他们与数据分析师不同,关注预测性(会发生什么?)和规范性(应该做什么?)数据分析。
主要职责:
-
高级分析: 使用先进的统计技术从数据中提取洞见。
-
机器学习: 实施机器学习算法,从现有数据中学习。
-
预测建模: 构建和部署模型以预测实际和新数据中的未来事件。
这些主要职责建立在数据分析师所做的相同工作基础上。数据科学家也不能离开数据清理和数据可视化。
关键技能和工具: 以下是成为数据科学家所需的技能和工具。你会看到它们与数据分析师有一些重叠。

职业发展路径: 数据科学家从初级数据科学家开始,可以晋升为高级数据科学家、首席数据科学家和数据科学总监。他们还可以朝其他方向发展,如成为人工智能专家、机器学习工程师或计算机与信息研究科学家。
数据工程师
角色概述: 数据工程师构建数据系统,以便收集、存储和传输数据。他们确保数据的可用性、质量和可分析性(这是个词吗?)对所有数据用户而言。
主要职责:
-
数据架构: 根据数据架构师设想的设计构建数据系统。
-
数据管道: 构建系统,使数据能够从多个数据源流向数据库、数据仓库和数据湖,并为其他数据用户使用做好准备。
-
确保数据质量: 识别数据中的错误和不一致,删除它们,并提高数据的准确性和可靠性。
是的,数据工程师专注于这些任务。但他们也无法避免数据清理和数据可视化。
关键技能和工具: 这是数据工程师所使用的技能和工具。

职业发展路径: 数据工程师的职业可以晋升为高级数据工程师或数据架构师。他们也可以专注于大数据、机器学习或商业智能等领域。
数据分析师、数据科学家和数据工程师的维恩图
我们已经看到了这三个职位之间的区别。在这个过程中,我们还注意到这些职位之间在所需技能方面有一些重叠。
为了快速了解,这些可以通过维恩图进行展示。
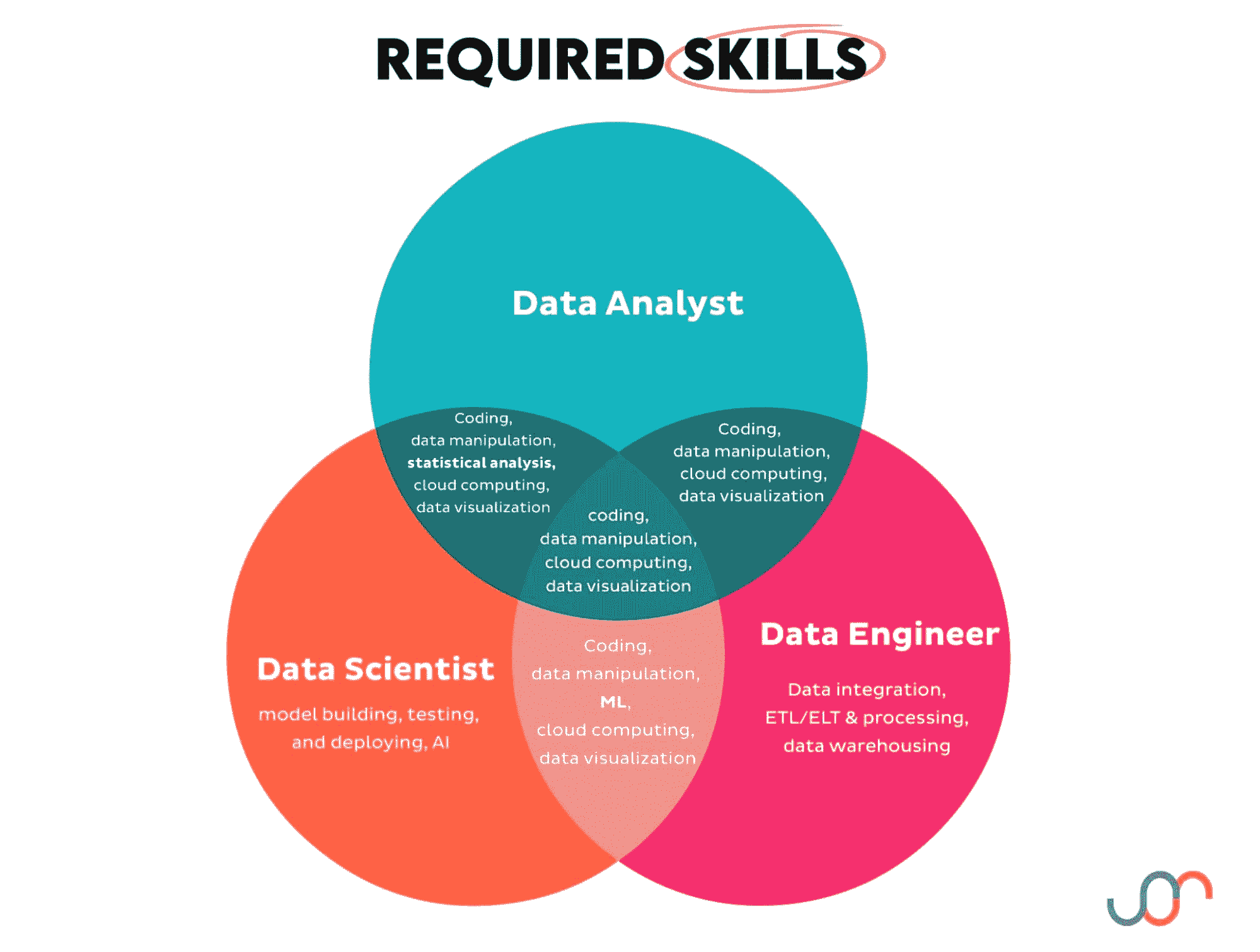
你可以看到这三个职位共享的技能有:
-
编程
-
数据处理
-
云计算
-
数据可视化
额外的技能在两个职位之间共享,并加以突出显示。
数据分析师没有任何独特的技能;其他职位在某种程度上也需要这些技能。
数据科学家独有的技能有:
-
模型构建、测试和部署
-
AI
数据工程师特有的技能有:
-
数据集成、ETL/ELT 和处理
-
数据仓储
现在让我们使用相同的可视化工具展示这些职位使用的工具。
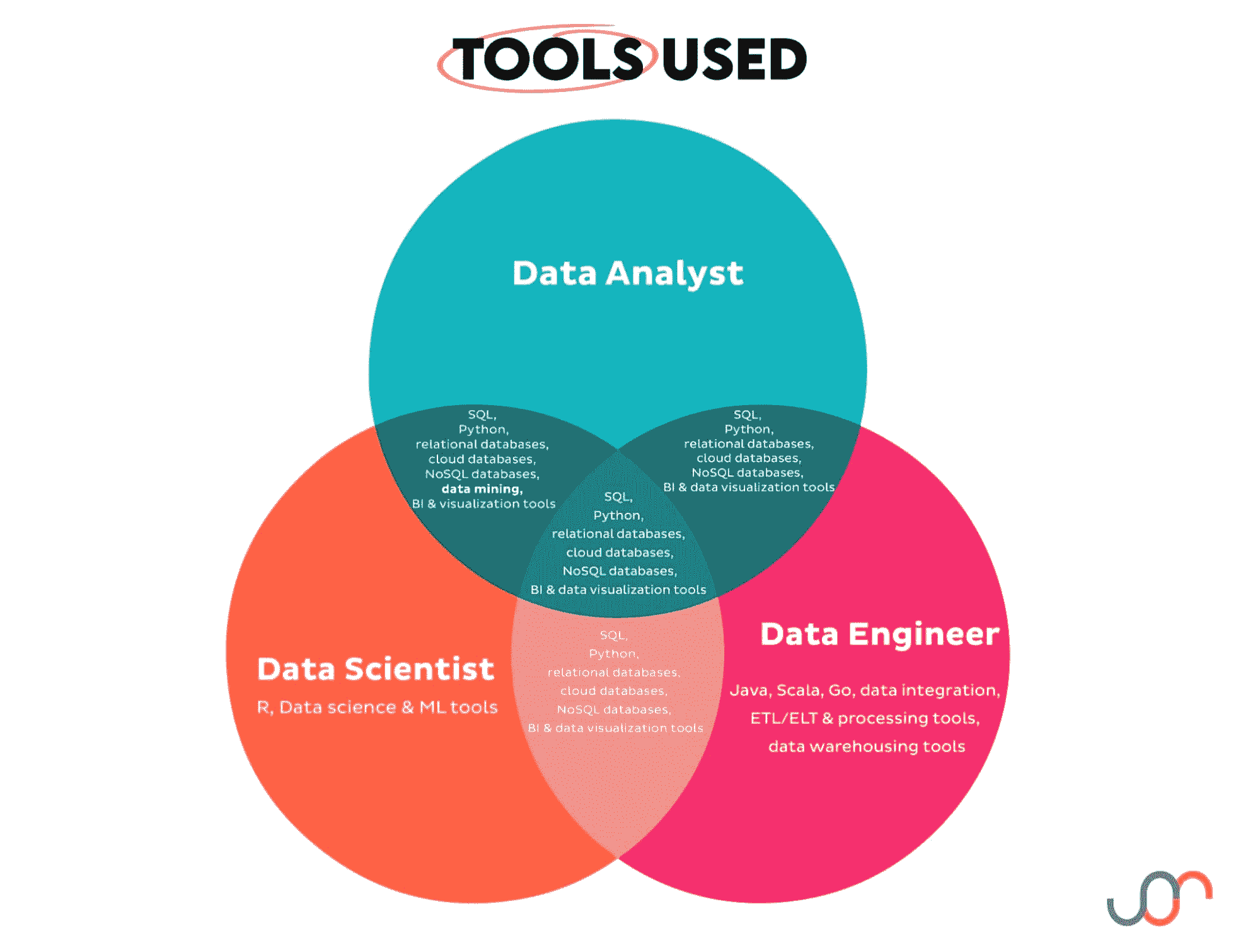
图像显示所有三个职位共享这些工具:
-
SQL
-
Python
-
关系数据库
-
云数据库
-
NoSQL 数据库
-
BI 和数据可视化工具
除此之外,两个职位之间共享的附加工具已被突出显示。
数据分析师使用的工具类型至少被另一个职位使用。虽然职位可能共享相同的工具类型,但工具的使用程度可能不同,或者同一类别中的具体工具可能有所不同。
数据科学家特有的工具有:
-
R
-
数据科学和机器学习工具
数据工程师特有的工具有:
-
Java
-
Scala
-
Go
-
数据集成、ETL/ELT 和处理工具
-
数据仓储工具
弥合差距:合作是关键
我们看到每个角色都有其独特的职责和使用的工具。三者之间也有一些重叠。这表明这些职位并不是完全不同的世界,数据分析师、数据科学家和数据工程师在数据团队中的合作至关重要。
数据分析师和数据科学家都依赖于基础设施和高质量的干净、组织良好的数据。另一方面,数据工程师在构建数据架构和提供数据时必须与数据分析师和数据科学家合作——因为他们是数据用户。
数据科学家通常需要与数据分析师合作,以更好地理解业务背景。
结论:选择你的路径
数据分析师、数据科学家和数据工程师之间的差异和相似性现在应该更加清晰。
总结:
-
如果你喜欢从数据中获取见解并传达它们,数据分析可能是你的路径。
-
如果构建预测模型和使用机器学习算法让你兴奋,考虑数据科学。
-
如果你觉得构建数据架构和确保数据流的规律性会让你感到愉悦,那么数据工程可能是正确的选择。
如果你想了解更多,请参考有关数据工程师和数据科学家以及数据分析师和数据科学家的更多细节。
内特·罗西迪是一名数据科学家,专注于产品战略。他还是一名兼职教授,教授分析课程,并且是 StrataScratch 的创始人,这是一个帮助数据科学家通过真实的面试问题准备面试的*台。内特撰写有关职业市场的最新趋势,提供面试建议,分享数据科学项目,并覆盖所有 SQL 相关内容。
更多相关内容
数据革命的导航:探索数据科学和机器学习中的蓬勃趋势

图片由 DALLE-3 生成
在不断发展的技术领域,数据革命作为一种强大的力量,重新塑造了行业、经济和社会规范。数据科学和机器学习是这一变革浪潮的核心,作为创新的关键催化剂。它们推动我们进入一个问题解决超越单纯人类认知的时代,成为人类智慧与智能机器之间的协作舞蹈。本文将进行全面的探索,深入挖掘数据科学和机器学习中的新兴趋势,揭示那些引领我们走向数据驱动未来的关键发展。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
AI 驱动的自动化:用智能系统改造行业
数据科学和机器学习中的一个重要趋势是将人工智能(AI)融入自动化。各行各业都在利用机器学习算法来简化日常任务、优化流程并提高效率。无论是在制造业、医疗保健、金融还是物流行业,AI 驱动的自动化浪潮正在根本改变企业的运营格局。这一转变降低了成本,提高了整体生产力,标志着企业在日常运作中迈出了革命性的一步。
使用案例
- 金融:
在金融领域,自动交易系统已成为中心,利用机器学习的力量来分析市场趋势并实时执行交易。这是将技术深度融合到动态的金融市场中,开启了一个效率和数据驱动决策的新纪元。
图片来自 AISmartz
- 医疗保健:
在医疗保健领域,机器学习算法的惊人能力正逐步进入关键角色。这些算法在诊断中提供帮助,提供关于患者结果的预测分析见解,甚至有助于机器人手术的精准度。这是技术与医学的卓越融合,正在重新塑造患者护理的格局。
自然语言处理(NLP)的指数增长
自然语言处理(NLP)在机器学习的广阔领域中占据了中心位置。得益于深度学习模型如 GPT-3 的进步,机器正在快速进化,展现出解码和生成模仿人类表达的语言的非凡能力。这一变革趋势正在重新塑造我们与技术的互动方式,从聊天机器人和虚拟助手的直观回应,到语言翻译和内容创作的无缝复杂性。机器理解和响应自然语言的新能力不仅重新定义了我们的沟通格局,还开辟了各种领域的全新通道,以提升可及性。
用例
- 内容生成:
像 GPT-3 这样的模型通过生成类似人类语言的文本,改变了内容创作和写作行业的格局。他们的影响力显著,引领了人工智能与作者合作,共同创作引人入胜且连贯的内容的新时代。
图片来自 AnalyticsVidhya
- 聊天机器人和虚拟助手:
自然语言处理(NLP)在 Siri 和虚拟助手如 Alexa 的功能中扮演了关键角色。这是它们理解和响应我们日常语言查询的神奇之处,使互动更加人性化和直观。
- 语言翻译:
在语言翻译中,Google 翻译依赖于自然语言处理(NLP)的精妙之处,以提供准确无误的多语言翻译。这种高超的技术应用使跨语言沟通成为可能。
伦理 AI 和负责任的数据科学实践
在不断发展的决策制定领域中,数据的关键作用不容低估。越来越受到关注的是人工智能和数据科学中的伦理考量需求。在机器学习模型的开发和部署阶段,伦理原则作为核心要素的认识显著上升。诸如偏见、公*、透明度和问责制等问题已成为讨论的重点,塑造了负责任的数据科学实践的叙述。组织正在积极拥抱这一伦理转变,采纳寻求在创新与伦理考量之间取得微妙*衡的框架和指南,引导数据世界迈向一个更具良知的时代。
使用案例
- 面部识别:
与面部识别技术相关的伦理环境十分复杂,主要因为系统中潜在的偏见。这促使了对负责任和谨慎部署的迫切需求,因为偏见面部识别的后果可能对隐私、安全和社会公正产生深远影响。
- 信用评分:
在信用评分中运用机器学习需要细致考虑,因为所涉及的模型必须精心构建,以减少任何潜在的歧视性做法。这种审慎的做法对于确保贷款实践中的公*和公正至关重要,认识到这些模型对个人财务机会的重大影响。
边缘计算和去中心化机器学习
物联网(IoT)设备的广泛采用引发了网络边缘数据生成的显著增长。一种获得显著关注的趋势是将边缘计算与去中心化机器学习相结合,旨在处理靠*数据源的数据。这一战略举措有望减少延迟并优化带宽使用。其相关性在自动驾驶汽车、智慧城市和工业物联网等领域尤为突出,这些领域中瞬间决策至关重要。将机器学习模型集成到边缘设备中对于推动智能且高度响应实时需求的系统具有重要意义。
使用案例
- 自动驾驶汽车:
在自动驾驶汽车领域,边缘计算已被证明具有变革性。通过直接处理来自传感器的数据,使这些车辆能够快速做出决策,增强了它们在道路上灵活导航的能力,并确保了对其安全和高效操作至关重要的响应水*。
- 智慧城市:
将去中心化的机器学习融入智慧城市应用标志着一个重要的进步。这一创新通过来自各种传感器的实时数据分析,提供及时的洞察,帮助城市提高整体效率,优化决策和资源分配。这展示了技术无缝集成以创建更智能、更响应的城市环境。
图片来源于TowardsDataScience
跨学科合作与混合技能组合
数据科学和机器学习的领域正在超越传统界限,发展成为一个跨学科的领域。专家们来自不同背景,能够无缝合作,解决复杂问题的趋势越来越明显。对混合技能组合的需求不断增加,这些技能组合融合了数据科学的能力、领域特定知识和有效沟通。在这个互联的数据生态系统中,能够弥合技术复杂性与非技术利益相关者之间差距的专业人士正变得越来越宝贵。
用例
- 医疗分析:
在复杂的医疗领域,数据科学家与医疗专业人士之间展开了动态合作。他们共同筛选大量的患者数据,运用综合专业知识获得宝贵的洞察,提升治疗效果,迎来个性化和有效医疗解决方案的新纪元。
- 金融和数据分析:
在金融与数据科学的交汇点,具有双重专业知识的专业人士联合合作。他们将自己的知识应用于构建预测模型,深入分析市场趋势的复杂图景,体现了金融敏锐性与数据驱动洞察的和谐融合。
总结
在数据科学和机器学习的推动下,正在进行的数据革命从根本上重塑我们的日常生活和职业领域。无论是人工智能驱动的自动化的出现,还是对伦理考量的日益重视,或是跨学科方法的协作,这些趋势都为这些领域动态而不断发展的本质提供了细致的视角。成功应对这场革命需要坚守不变的承诺,跟上发展步伐,拥抱负责任的实践,并培养持续学习的文化。展望未来,数据科学与机器学习的融合有望揭示新的可能性,持续推动各行各业的创新。
Aryan Garg 是一名 B.Tech.电气工程学生,目前处于本科最后一年。他的兴趣在于网页开发和机器学习。他已经追随这一兴趣,并渴望在这些方向上进一步发展。
相关阅读
探索你的数据科学职业生涯:从学习到收入
原文:
www.kdnuggets.com/navigating-your-data-science-career-from-learning-to-earning

图片来源于作者
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织进行 IT 工作
随着 281 家科技公司裁员 80,628 人,你为什么会对开始一个数据科学职业感兴趣呢?
现在可能看起来不是一个好时机,尤其是在公司裁员的情况下。是的,有裁员,但下图显示最*的裁员与 2022 年底和 2023 年初相比并不算严重。所以,情况并没有那么糟糕!
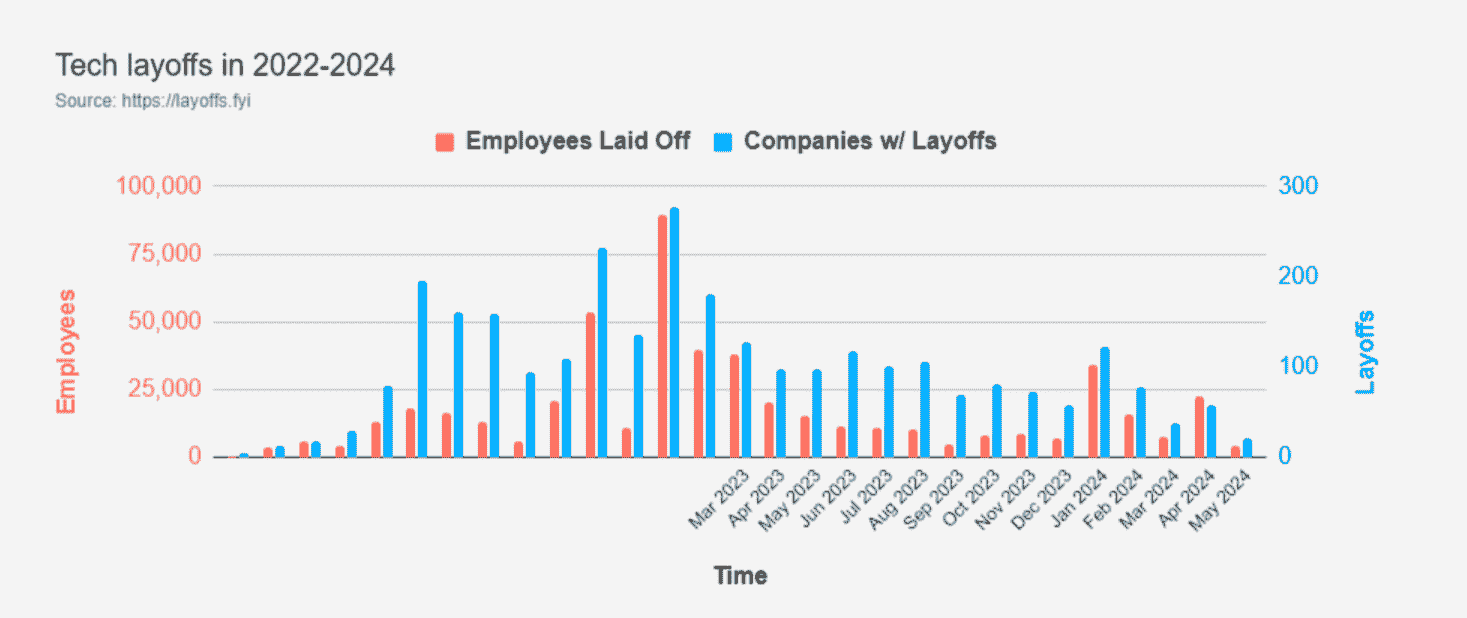
来源: layoffs.fyi
从另一个角度来看情况更为积极:公司仍在招聘数据科学家。实际上,在过去一个月内,美国在 Glassdoor 上几乎有5,500 个招聘广告。
数据科学家有一个相当活跃的就业市场。只是现在公司要求更高。他们更倾向于寻找数据科学专家而不是通才。此外,现在数据科学家需要掌握 AI 工具。以下是你如何应对这些挑战并在就业市场上脱颖而出的方式。
1. 教育路径
学习数据科学时总有两种不同的方法:
-
学术教育
-
自学
理想情况下,你应该结合这两者。
学术教育
成为数据科学家并不一定需要学术教育,但它确实提供了广泛而结构化的知识。比起从零开始成为数据科学家,后续在此基础上构建知识要容易得多。
数据科学家通常拥有计算机科学、统计学、数学甚至经济学等定量领域的学士学位。
拥有硕士学位是提升就业机会的一个好主意。通过它,你可以专注于某些领域。一些专业化的例子包括机器学习、数据分析、商业智能等。
追求博士学位通常是不必要的,除非你对公司或学术界的研究导向角色感兴趣。
自学
你可以通过为自己制定课程来成为数据科学家。这可以包括以下(非详尽)列表中的任何内容:
-
认证
-
在线课程
-
训练营
-
YT 视频
-
书籍
-
博客文章
-
社区论坛
如果时间和财务条件允许,我建议你专注于认证、在线课程和训练营。然后,辅以其他资源。
我建议的一些认证、课程和训练营包括:
-
认证分析师专业证书 (CAP) – 一个中立于供应商和技术的数据科学技能认证
-
Google 专业数据工程师认证 – 使用 Google Cloud 认证你的数据工程知识
-
IBM 机器学习专业证书 – 显然是 IBM 的机器学习认证
-
Microsoft Azure 数据工程师助理 (DP-203) 专业证书 – 微软 Azure 数据工程的证书
-
助理大数据分析师 – 大数据分析的中立认证
-
Coursera 上的数据科学专业化 – 约翰斯·霍普金斯大学的 10 门课程数据科学专业化
-
edX 上的统计学与数据科学微硕士项目 – 麻省理工学院的数据科学教育
-
Coursera 上的机器学习专业化 – 斯坦福大学和 DeepLearning.AI 提供的机器学习专业化,由 Andrew Ng 授课
-
数据科学训练营 – Springboard 提供的训练营,配有一对一辅导和就业保障(怎么样!)
-
Python 中的机器学习与深度学习训练营 – 学习 Keras 和 TensorFlow 中的机器学习和深度学习
2. 技能
数据科学家的技能可以分为技术技能和软技能。
技术技能
这些任务来源于首席数据科学家的工作:提取和处理数据,构建、测试和部署机器学习模型。
数据科学家必须使用各种编程语言和工具将所有这些知识付诸实践。
下面是一个概述。
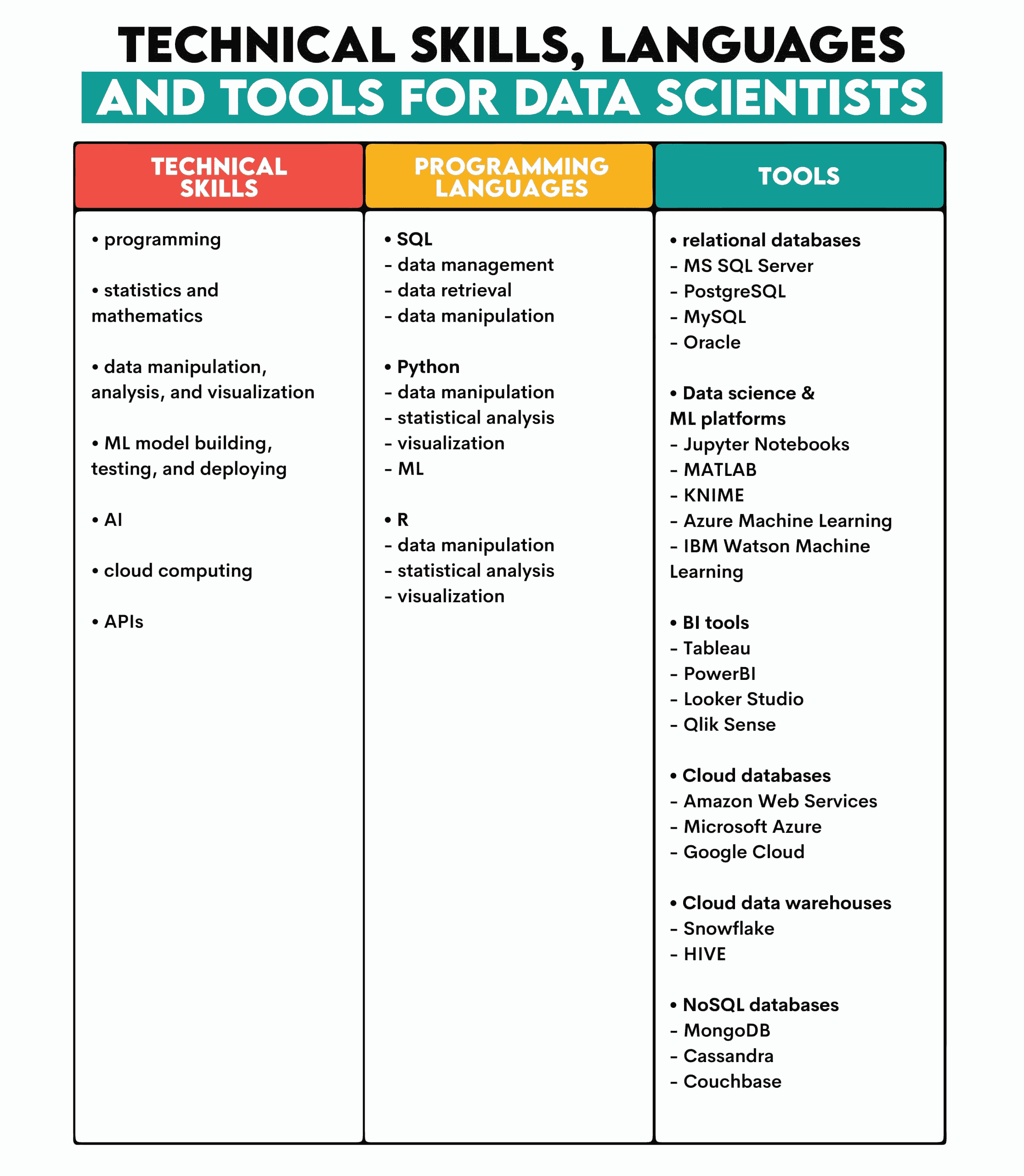
这应该是你进一步专业化的起点。例如,你可以专注于 BI 工具或数据工程工具,如Apache Kafka、Apache Spark、Talend、Airflow等。
软技能
技术技能需要以下软技能的补充。

沟通技能
这些技能包括既倾听他人的想法也传达自己的想法。
作为数据科学家的工作始于倾听他人的问题。你是那种通过数据帮助他人解决问题的心理治疗师。数据治疗师?通过理解商业问题,你可以将你的技术解决方案塑造成用户的需求。
数据科学家还必须能够将其工作的技术复杂性转化为非技术受众能够理解的内容。他们借助于可视化工具,即有效地可视化和展示你的工作是强制性的。
分析思维
你需要解决的商业问题通常会以非常非技术性的方式向你解释:“天啊,我们的客户留存率直线下降!救命啊!你,数据科学家,想办法解决这个问题。”
这需要将问题分解成逻辑块并系统性地解决。同时,需要创意,因为许多问题需要找到新颖的解决方案。
协作技能
数据科学家的理想工作日是被独自留在一旁,专注于自己的模型,并低声对其讲话(用咕噜的声音): 这是我的,我告诉你。我的。我的珍宝。是的,我的珍宝。
不幸的是,数据科学家常常需要与数据团队的其他同事合作。项目还包括跨部门团队。
适应性和灵活性,创造良好的工作氛围,有效且尊重地解决冲突?是的,我的珍宝!
项目管理
从事数据科学项目需要项目管理能力,包括任务优先级排序、协调项目团队以及跟踪项目进度和截止日期。
加上指导初级员工和在多个项目之间转换,这项技能变得至关重要。
商业敏锐性
所有数据项目的设计都是为了解决商业问题。要做到这一点,你需要对公司业务和行业有扎实的理解。这使得理解商业问题并设计考虑到可能未明确提及的依赖关系的解决方案变得更容易。
3. 职业路径和薪资
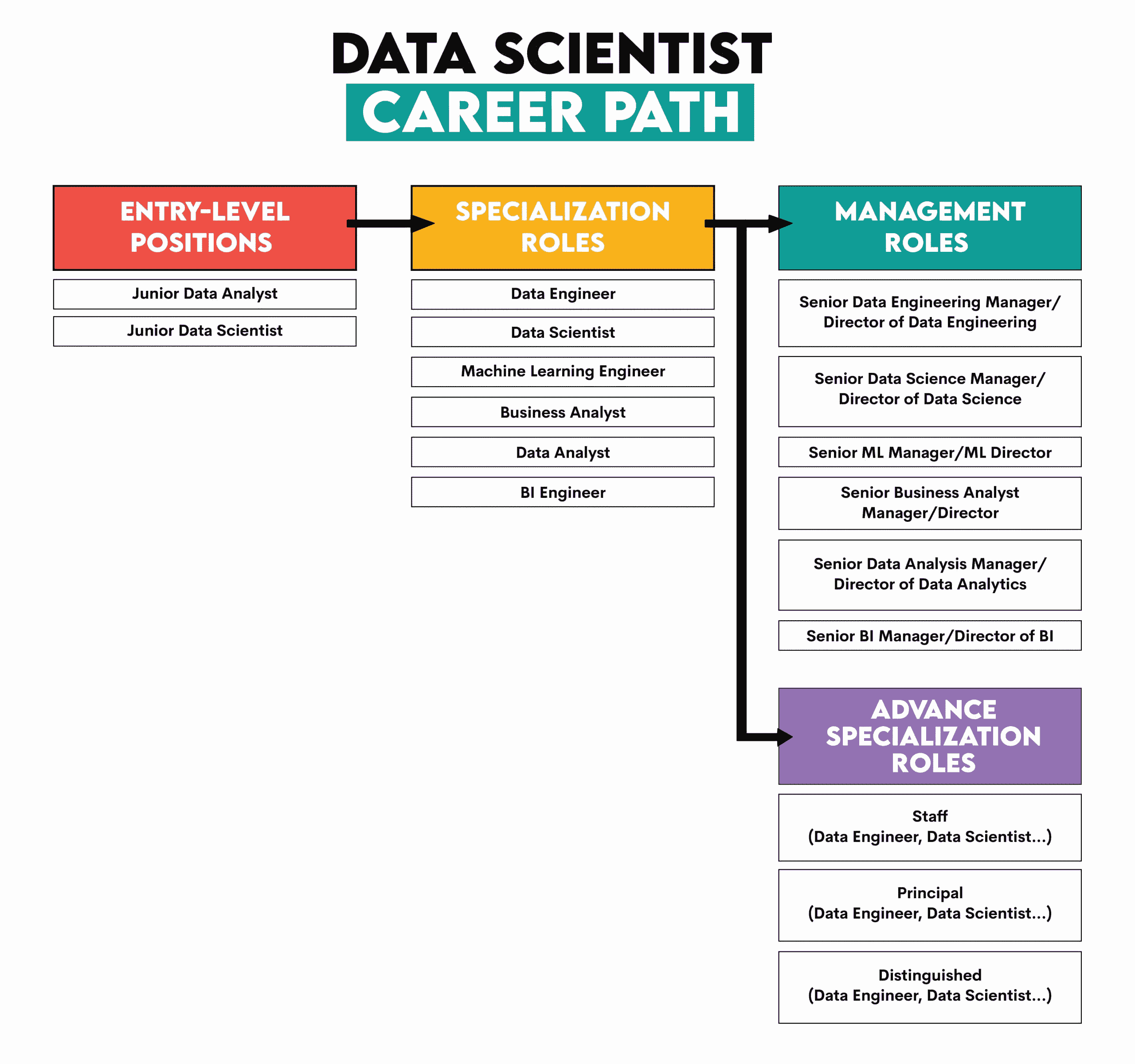
数据科学职业通常以获得初级数据分析师或初级数据科学家职位开始。
从这里,我建议你进入专业角色之一。一些例子包括数据工程师、机器学习工程师、业务分析师、数据分析师或 BI 工程师。如今的数据科学家职位也越来越成为一个专业角色——更多关注于数据探索和初步模型开发中的统计应用,而不是做端到端的项目。
根据你在特定专业职位上的年限和兴趣,你可以走两个不同的方向:管理角色或高级专业角色。
例如,管理角色可能包括之前提到的任何领域的高级经理或总监。这条路径会让你远离技术工作,管理人员和部门将成为你的核心工作。
另一种选择是继续作为个人贡献者,进一步深入你的专业领域。这些是高级专业角色。对于提到的任何专业领域,职位通常是员工、首席、杰出和研究员。
4. 薪资
数据科学仍然是一个薪资非常高的职业。在选择职业道路时,不应忽视这一点。以下是之前提到的角色的薪资概览。
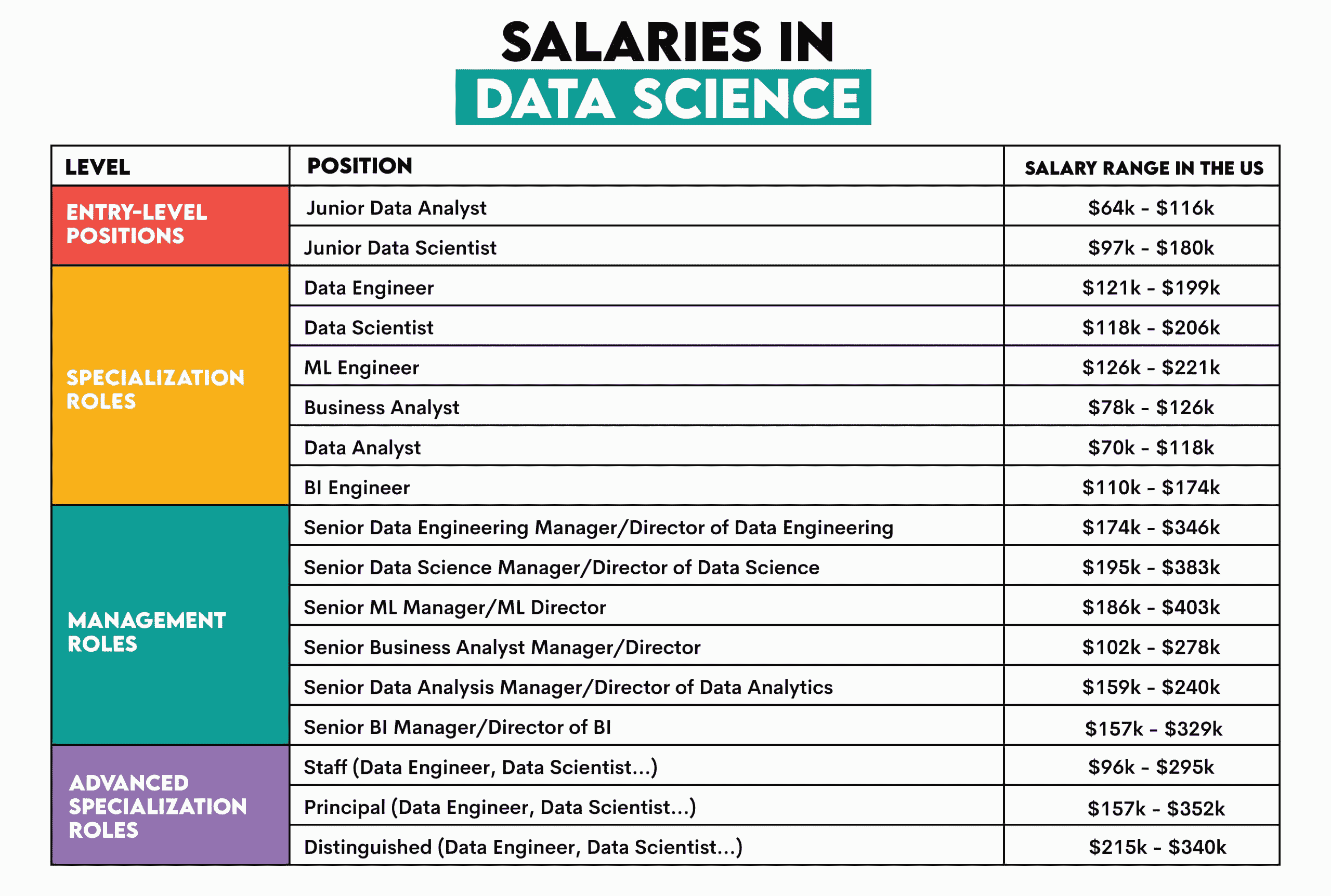
作者提供的图像,薪资数据来源: Glassdoor
5. 找工作
现在的问题是如何从学习数据科学过渡到赚取这些钱,也就是找工作。
我如果说:“找到你喜欢的职位广告,申请,面试表现出色,找到工作。”这并不会说什么新话。就这样,别客气!
然而,有两件事可以让你与其他申请者区别开来:
-
一个出色的作品集
-
面试经验
一个出色的作品集意味着拥有大量与工作相关的数据项目。数据项目是全面构建和展示你数据科学技能的最佳方式,因为完成这些项目需要高度的各项技能。当然,你也可以做一些专注于特定技能的专业项目,例如机器学习、数据工程等。
面试经验可以通过两种方式获得。第一种是面试失败很多次之后才找到工作。这是我们很多人经历过的正当方式。我不是开玩笑;获得经验让你更习惯面试过程、方法、测试主题,尤其是在时间压力下的编码。
然而,还有一种不那么痛苦的方式可以实现同样的目标:在提供实际编码和其他技术面试问题的*台上解决这些问题。
结论
虽然现在看起来可能不太明显,但现在正是进入数据科学领域的最佳时机。有两个原因。首先,如果你正在考虑开始数据科学教育,那么就去做吧。这需要一些时间。等你完成时,数据科学可能会再次蓬勃发展。
其次,如果你已经具备所有要求,尽管裁员频繁,也要申请那些职位,因为有很多这样的职位。
尽管经历了许多动荡,让我们记住数据科学仍然是最有吸引力的工作之一。
内特·罗西迪是一位数据科学家和产品策略专家。他还是一位兼职教授,教授分析学,并且是 StrataScratch 的创始人,该*台帮助数据科学家通过来自顶尖公司的真实面试题准备面试。内特撰写有关职业市场最新趋势的文章,提供面试建议,分享数据科学项目,并涵盖所有关于 SQL 的内容。
更多相关主题
分类的最*邻
原文:
www.kdnuggets.com/2022/04/nearest-neighbors-classification.html
K-最*邻
K-最*邻(KNN)是一种监督学习机器学习算法,用于回归和分类任务。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
KNN 用于基于当前训练数据点的特征对测试数据集进行预测。这是通过计算测试数据与训练数据之间的距离来完成的,假设相似的事物在较*的距离内存在。
该算法将存储学习到的数据,使其在预测和分类新数据点时更为有效。当输入一个新数据点时,KNN 算法将学习其特征。然后,它会将新数据点放置在与具有相同特征或特征的当前训练数据点更接*的位置。
KNN 中的 ‘k’ 是什么?
KNN 中的 ‘K’ 是一个参数,表示最*邻居的数量。K 是一个正整数,通常值较小,建议为奇数。
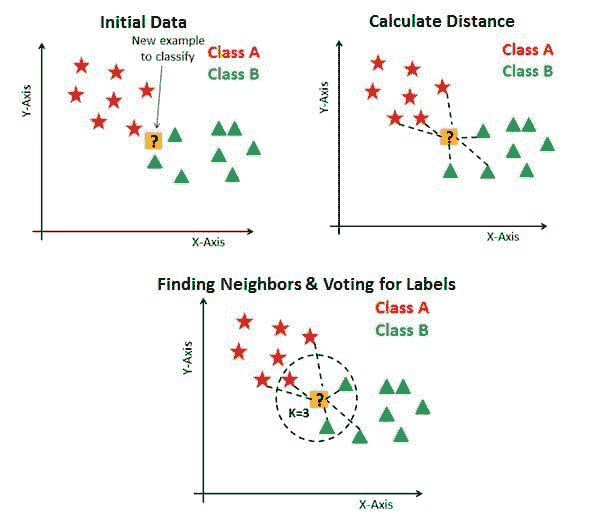
通俗地说,K 值为数据点创建了一个环境。这使得分配数据点所属的类别变得更加容易。
以下示例显示了 3 个图表。第一个图表,“初始数据”是一个将数据点绘制并分类到各个类别中的图表,并且有一个新的示例需要分类。在“计算距离”图表中,计算了新示例数据点到最*训练数据点的距离。然而,这仍然不能对新示例数据点进行分类。因此,使用 k 值,本质上创建了一个邻域,我们可以在其中对新示例数据点进行分类。
我们会说 k=3,新数据点将属于 B 类,因为与 A 类相比,更多的训练过的 B 类数据点具有与新数据点相似的特征。
来源:datacamp.com
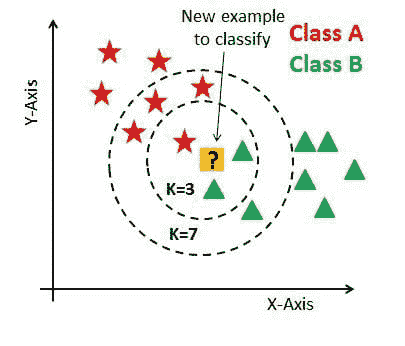
如果我们将 k 值增加到 7,我们将看到新数据点将属于 A 类,因为与 B 类相比,更多的训练过的 A 类数据点具有与新数据点相似的特征。
来源: datacamp.com
k 值通常是一个较小的数字,因为随着 k 值的增加,误差率也会增加。下图展示了这一点:
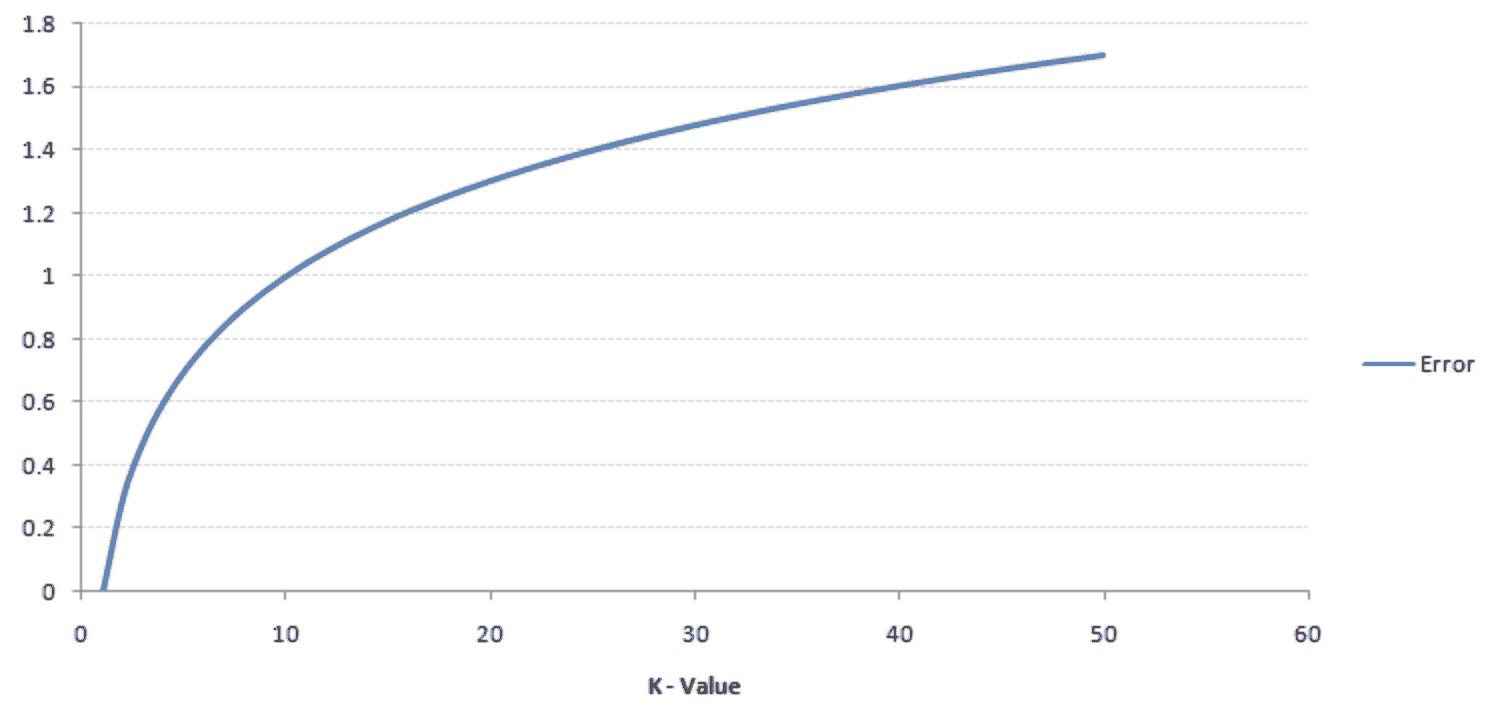
来源: analyticsvidhya
然而,如果 k 值较小,则会导致低偏差但高方差,导致模型过拟合。
还建议 k 值是奇数。这是因为如果我们尝试对一个新数据点进行分类,而类别/类的数量只有偶数(例如,A 类和 B 类),可能会产生不准确的结果。因此,强烈建议选择一个奇数的 K 值以避免*局。
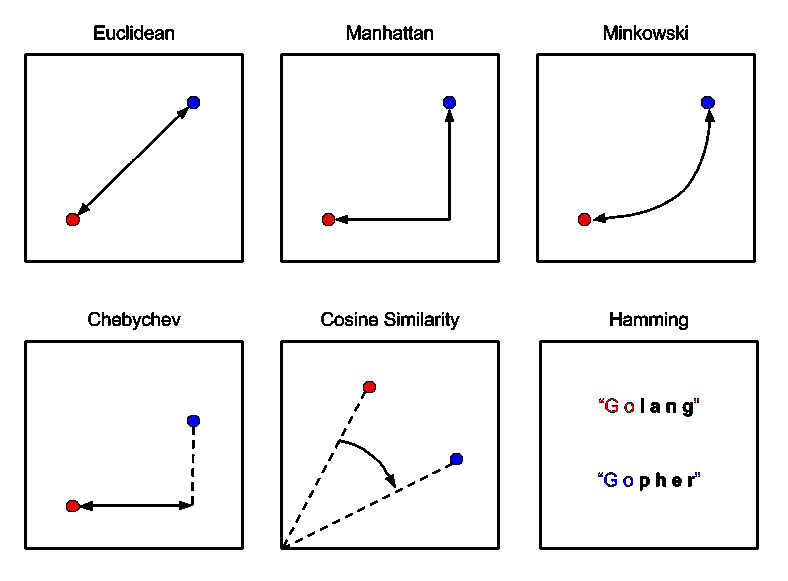
计算距离
KNN 通过计算数据点之间的距离来对新数据点进行分类。在 KNN 中,计算这种距离的最常见方法是欧几里得距离、曼哈顿距离和闵可夫斯基距离。
欧几里得距离是使用两点之间的线段长度来表示的距离。欧几里得距离的公式是新数据点(x)与现有已训练数据点(y)之间差异*方和的*方根。
曼哈顿距离是两点之间的距离,是它们的笛卡尔坐标的绝对差值的总和。曼哈顿距离的公式是新数据点(x)与现有已训练数据点(y)之间的长度总和,使用坐标轴上的线段。
闵可夫斯基距离是规范化向量空间中两点之间的距离,是欧几里得距离和曼哈顿距离的一般化。在闵可夫斯基距离的公式中,当 p=2 时,我们得到欧几里得距离,也称为 L2 距离。当 p=1 时,我们得到曼哈顿距离,也称为 L1 距离、城市街区距离和 LASSO。
下图是公式:

下图解释了三者之间的区别:
来源: Packt 订阅
KNN 算法如何工作?
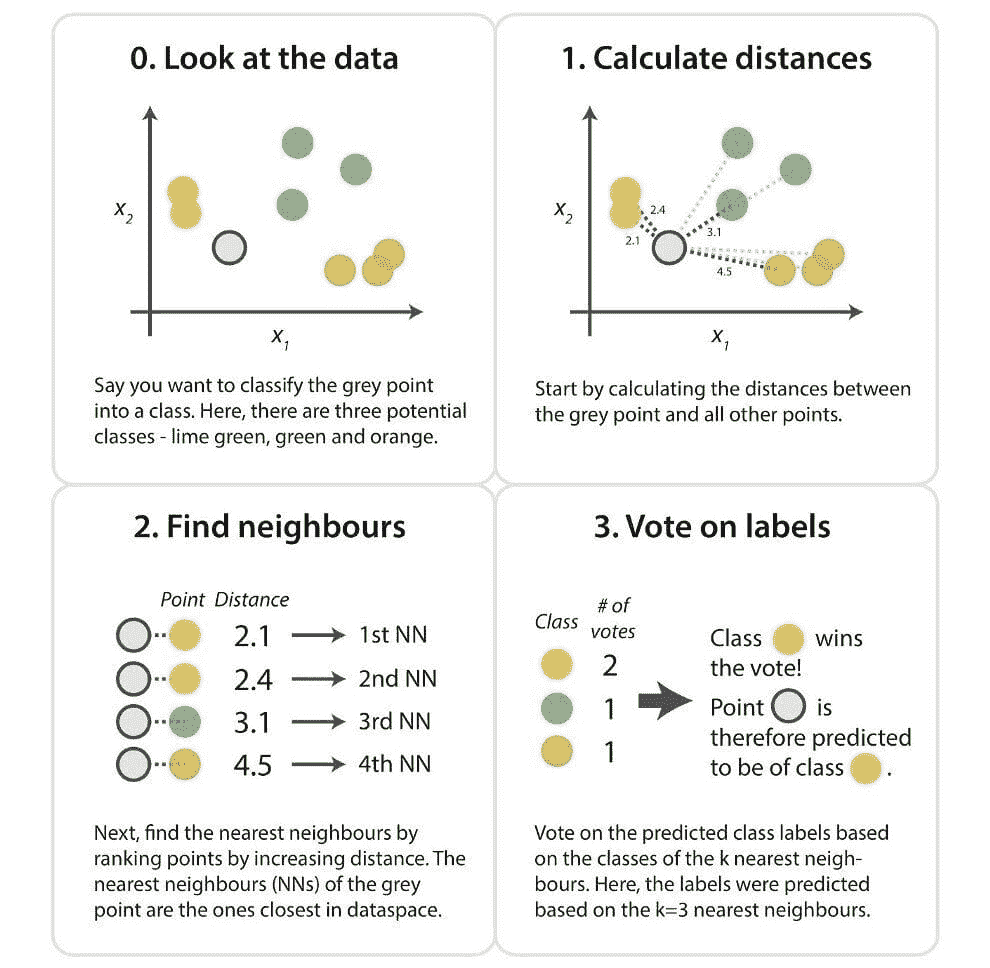
以下是 KNN 算法工作的步骤:
-
加载你的数据集
-
选择一个 k 值。建议选择奇数以避免*局。
-
计算新数据点与邻*的已训练数据点之间的距离。
-
找到与新数据点最*的 K 个邻居
以下是一个概述这些步骤的图像:
来源: kdnuggets.com
KNN 算法分类实现
我将通过一个使用鸢尾花数据集进行分类任务的 KNN 算法示例来演示。
导入库
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
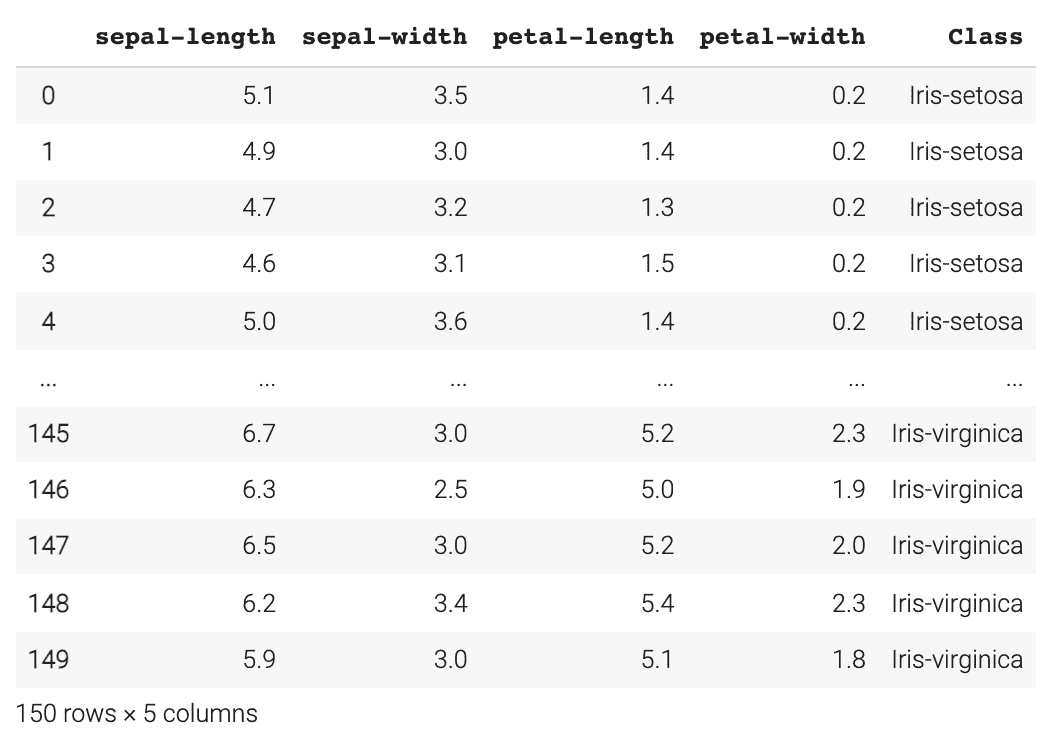
载入鸢尾花数据集
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
# Assign the column namesnames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']
# Read the dataset in
dataset = pd.read_csv(url, names=names)
dataset
数据预处理
我们需要将数据集分成属性和标签。变量 X 将包含数据集的前四列,我们称之为属性;变量 y 将包含最后一列,我们称之为标签。
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 4].values
训练测试分离
在这一步中,我们将数据集分为训练集和测试集。这让我们了解算法在训练数据上的学习效果以及在测试数据上的表现。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
特征缩放
特征缩放是在进行预测之前对数据进行预处理的重要步骤。这种方法用于归一化数据的特征范围。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
使用 KNN 进行预测
首先,我们需要从 sklearn.neighbors 库中导入 KNeighborsClassifier 类。然后选择我们的 k 值,在这个例子中,我选择了 7。请记住,强烈建议选择一个奇数值以避免出现*局。
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors=7)
classifier.fit(X_train, y_train)
然后我们开始对测试数据集进行预测。
y_pred = classifier.predict(X_test)
算法的准确率
使用 sklearn.metrics,我们可以使用 classification_report 评估算法的准确性,查看精确率、召回率和 F1 分数。
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))
这是输出的样子:
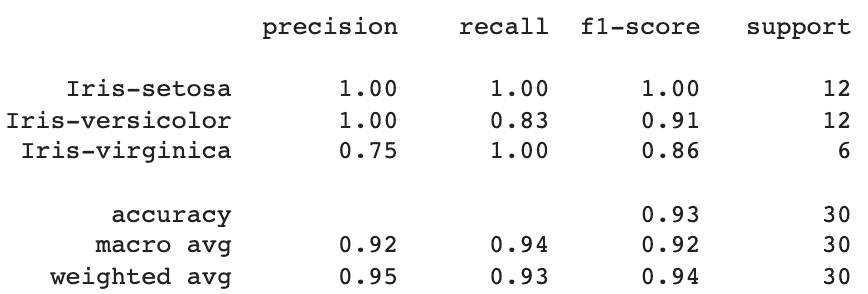
从这里我们可以看到 KNN 算法对 30 个数据点进行了分类,精确率*均达到了 95%,召回率为 93%,F1 分数为 94%。
寻找合适的 k 值
在这个例子中,我选择了 k 值为 7。然而,如果我们想要检查最佳的 k 值是多少,我们可以生成一个显示不同 k 值和其产生的误差率的图表。
我将查看 k 值在 1 到 30 之间的情况。在每次迭代中,计算*均误差并将其添加到误差列表中。
error = []
# Calculating the error rate for K-values between 1 and 30
for i in range(1, 30):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train, y_train)
pred_i = knn.predict(X_test)
error.append(np.mean(pred_i != y_test))
绘制 k 值与错误率图:
plt.figure(figsize=(12, 5))
plt.plot(range(1, 30), error, color='red', marker='o',
markerfacecolor='yellow', markersize=10)
plt.title('Error Rate K Value')
plt.xlabel('K Value')
plt.ylabel('Mean Error')
图的输出:
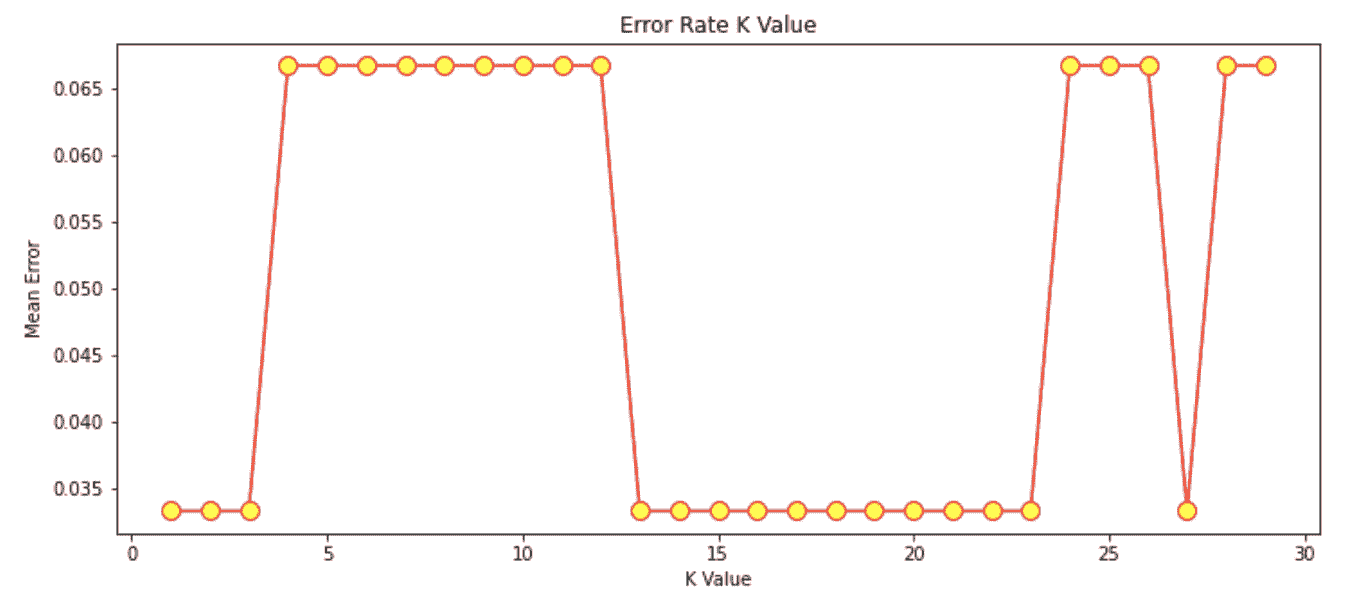
来源:作者图片
从这个图表中,我们可以看到产生*均误差为 0 的 k 值主要在 k 值为 13 到 23 之间。
摘要
KNN 是一个简单易用的算法,可用于回归和分类任务。K 值是一个参数,表示最*邻的数量。建议选择一个奇数作为 k 值。有不同的距离度量标准可用,但最常见的是欧氏距离、曼哈顿距离和闵可夫斯基距离。
尼莎·阿利亚 是一位数据科学家和自由职业技术作家。她特别感兴趣于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能在延长人类寿命方面的不同方式。作为一个热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助引导他人。
相关话题
我们是否需要*衡采样?
作者:朱炳(四川大学)、巴特·贝森斯(鲁汶大学)& 塞佩·范登·布鲁克(鲁汶大学)。
在许多实际分类任务中,如流失预测和欺诈检测,我们经常遇到类别不*衡问题,即一个类别的样本显著少于另一个类别。类别不*衡问题给标准分类学习算法带来了很大的挑战。大多数算法在不*衡数据集上往往更容易将少数类样本误分类为多数类样本。例如,当模型在一个少数类样本占比 1%的数据集上训练时,通过将所有样本都分类为多数类,可以简单地实现 99%的准确率。确实,学习不*衡数据集的问题被认为是数据挖掘研究中的十大挑战性问题之一。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能。
3. Google IT 支持专业证书 - 为你的组织提供 IT 支持。
为了解决从不*衡数据集中学习的问题,*年来提出了许多解决方案。重采样方法试图通过重采样数据来解决问题,并作为预处理阶段。它们的使用假设与分类器无关,并且可以应用于任何学习算法。因此,重采样解决方案在实际应用中非常受欢迎。使用重采样时,一个重要的问题是我们是否真的需要一个完全*衡的数据集。我们的流失预测研究表明,*衡采样并非必要。
我们在实验中使用了来自电信行业的 11 个真实数据集。考虑了七种采样方法,包括随机过采样、随机欠采样、SMOTE 采样等。我们考虑了三种不同的类别比例设置:1:3、2:3 和 1:1(少数类与多数类)。实验中使用了四种基准分类器:逻辑回归、C4.5 决策树、支持向量机(SVM)和随机森林(RF),这些在流失预测中被广泛使用。下表显示了部分结果,使用了 5 × 2 交叉验证实验设置,其中每个条目表示不同分类器和采样方法下每个采样比例的*均性能。除了 AUC 衡量标准外,我们还考虑了最大利润衡量标准,它测量了保留活动产生的利润(Verbraken et al., 2013)。
表 1:来自电信行业的不*衡数据集的实验结果
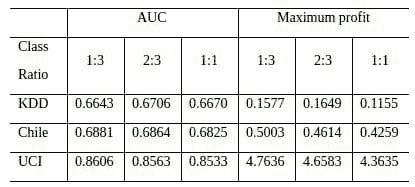
正如表格所示,在两个数据集上,1:3 的比例效果最好,而 2:3 的比例在两个数据集上排名第一。*衡类别比例从未达到最佳位置。结果明确显示,采样后没有必要生成*衡的数据集,推荐使用不太*衡的策略(1:3),因为它的表现相对较好。完整的结果和更多讨论可以在我们最*发表的论文《不*衡学习中采样技术的基准测试》中找到,该论文发表于 JORS。
参考文献:
-
H. He, E. Garcia, “从不*衡数据中学习”,《IEEE 知识与数据工程学报》,2009,21(9):1263-1284。
-
W. Verbeke, K. Dejaeger, D. Martens, J. Hur, B. Baesens, “电信行业流失预测的新见解:一种以利润驱动的数据挖掘方法”,《欧洲运筹学杂志》,2012,218(1):211-229。
-
T. Verbraken, W. Verbeke, B. Baesens, “一种新颖的利润最大化度量用于衡量客户流失预测模型的分类性能”,《IEEE 知识与数据工程学报》,2013,25(5),961-973,2013。
-
B. Zhu, B. Baesens, A. Backiel, S. vanden Broucke,“流失预测中不*衡学习的采样技术基准测试”,《运筹学学会杂志》,2017。
朱冰 是中国四川大学商学院的副教授。他的主要研究兴趣包括流失预测和欺诈检测。
巴特·贝森斯 是比利时鲁汶大学(KU Leuven)的大数据与分析学教授。他在大数据和分析方面进行了广泛的研究。他的研究成果已发表在知名国际期刊上,并在国际顶级会议上进行过展示。
塞佩·范登·布鲁克 现任比利时鲁汶大学(KU Leuven)决策科学与信息管理系助理教授。塞佩的研究兴趣包括商业数据挖掘与分析、机器学习、过程管理和过程挖掘。
相关文章:
-
构建预测流失模型的挑战
-
初学者指南:客户分群
-
在 CRISP-DM 中修复部署和迭代问题
更多关于此主题的内容
为什么你需要了解自主 AI 代理
原文:
www.kdnuggets.com/2023/06/need-know-autonomous-ai-agents.html

图片由 Bing 图像生成器提供
让我们从显而易见的开始——AI。人工智能是计算机使用数据、机器学习等来执行通常由人类完成的任务的能力。你可以使用 AI 创建内容、回答问题和生成逼真的艺术作品。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
但对于很多这些 AI 系统,你需要指示它们该做什么。但是,如果你不想提出指示,而希望你的 AI 系统能够基本上自行思考呢?
好吧,你可以使用自主 AI 代理。
什么是自主 AI 代理?
自主代理由 AI 驱动,当给出一个目标时,它们可以自行创建、优先排序和完成任务。这是通过自我指导的指令在每次迭代中循环运行来实现的。
你可以使用自主 AI 代理来管理你的社交媒体账户,创建工作待办事项列表,甚至写书。它们现在是最热门的话题,人们想了解更多。它们正在迅速发展,我们应该期待更多的新发布。
听起来很疯狂,对吧?但只要给出一个目标,自主 AI 代理就能为你做剩下的事情。它是另一个员工、队友甚至朋友。
我们已经见过一些自主 AI 代理,如 AutoGPT 和 BabyAGI。
这是否是人工通用智能(AGI)的开始,即计算机程序可以以与人类相同的能力执行任何智力任务?
自主 AI 代理能做些什么?
只要给出一个目标,自主 AI 代理就可以完成任何数字任务,例如:
-
内容创作
-
个人助理
-
个人财务管理
-
研究和数据分析
-
访问大型语言模型(LLM)工具,如 GPT
-
访问网络,
-
以及更多。
自主 AI 代理如何工作?
自主 AI 代理正在变得越来越受欢迎,越来越多的人对理解这些 AI 代理是如何构建的框架产生兴趣。那么,成功的自主 AI 代理需要哪些主要元素?
知识
AI 系统的知识库非常重要。它们不仅需要对训练数据有黄金标准般的知识,还必须能够从各种来源收集和解释数据。
记忆
像我们人类一样,拥有资源并了解它们是很好的——但你能记住吗?一个自主 AI 代理不仅需要学习新数据的能力,还需要能够回忆过去的经历。
学习
所以你有知识和记忆,但你真的在学习你需要学习的东西吗?
自主 AI 代理使用强化学习等技术——这是一种涉及模型训练及其产生决策序列以最大化累积奖励概念的机器学习类型。使用强化学习使模型能够通过反馈来改进,优化策略,并通过试错法产生成功的输出。
改善自主 AI 代理学习的另一种方法是与其他系统和用户进行沟通,以提供信息交流和协作。浏览外部来源,如数据库,也通过提供知识资源来增强学习过程,以帮助自主 AI 代理在决策过程中。
决策制定
当你拥有良好的知识库和记忆时,这有助于你的决策过程。对于自主 AI 代理来说,决策需要系统分析数据,回顾记忆,权衡不同选项,并选择最适合用户目标的行动。
另一个需要考虑的因素是,自主 AI 代理可能会被促使制定详细的行动计划,这需要大量的规划——这是在执行决策过程之前至关重要的。
为了更好地理解自主 AI 代理的框架,让我们分解下面的图像:
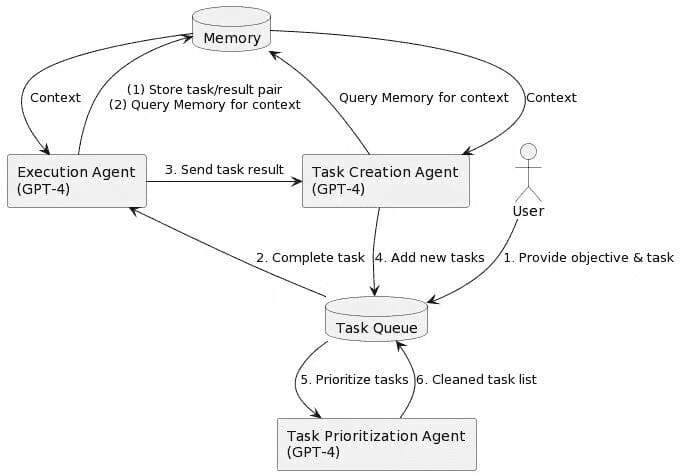
图片由Yohei提供(Baby AGI 的创建者)
上面的系统图分为 6 个步骤,这些步骤在一个无限循环中运行:
-
用户提供目标/任务。
-
这接着进入任务队列,然后传递到‘执行代理’中储存于‘内存’中。目标/任务现在已储存在内存中。
-
目标/任务接着添加上下文(回忆过去的经验和知识库),然后发送到‘执行代理’,该代理将任务结果发送到‘任务创建代理’。
-
任务现在已创建并添加到‘任务队列’中。
-
任务将必须通过‘任务优先级代理’来在其他任务中获得优先级。
-
最后一步是在‘任务优先级代理’阶段,代理清理任务列表。
为什么自主代理很重要?
几个月前,ChatGPT 发布了,我们看到很多人开始使用它。企业正在采纳它,并寻找将其整合到操作中的新方法。开发者们对插件着迷。这表明 AI 系统正在成为生态系统的重要组成部分。
对一些人来说,这可能看起来像是一个短暂的事情。然而,科技界正在获得大量投资,并以快速的速度增长以保持势头。人工智能在我们日常生活中的进步和应用比我们想象的要*得多。
我们生活在一个快节奏的数字环境中,自主 AI 代理有潜力提高不同产业的生产力和运营。这将使企业能够更高效地运作,同时仍能保持竞争力。
自主 AI 代理不像人类。它们不需要睡眠、午休等。它们可以全天候编程,以确保有效的生产、更快的结果,并减少当前员工的繁重任务工作量。
企业将开始看到劳动力成本的削减、员工生产力的提升以及效率策略的增强。然而,我们理解,自主 AI 代理的增加将导致涉及繁重重复任务的行业,如制造业的工作流失。
你会自然地看到涉及创造力、先进问题解决和创新思维的工作需求增加。还有数据分析、数据伦理和 AI 系统监控等角色,这些角色将被要求监控基于 AI 的系统。
总结
现在不再是自主 AI 代理是否会被组织采纳的问题,它正在发生。这是一个了解何时全面生效的问题。
那么你将要做什么?
-
想要创建其他人可以雇用的自主代理吗?
-
或者雇佣自主代理来提升生产力和个人生活?
我希望这篇文章已经教会你一些关于你对自主 AI 代理的期望以及它们将如何塑造我们未来的知识。如果你发现了任何关于自主 AI 代理的有趣新闻,请在下面留下评论!
尼莎·阿雅 是一名数据科学家、自由技术作家和 KDnuggets 的社区经理。她特别感兴趣于提供数据科学职业建议或教程以及数据科学的理论知识。她还希望探索人工智能如何/可以有利于人类生命的长寿。作为一个热衷学习者,她寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多关于这个话题
为什么你需要学习多于一种编程语言!
原文:
www.kdnuggets.com/2022/06/need-learn-one-programming-language.html

图片来源:ThisisEngineering RAEng 在 Unsplash
在 IT、数据科学、机器学习的领域,最大的技能需求是多样化。仅凭一种编程语言,你的能力将受到局限。不论你遇到什么工作,了解另一种语言总会对你的任务或职业有帮助。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在的组织的 IT 需求
根据Deloitte 调查,有三分之一的当前员工技能在未来三年内将不再相关。
我不仅仅是从个人经验出发,你也可以亲自验证。当你寻找技术职位时,通常会提到如果你在一种或多种编程语言方面熟练,他们会更倾向于你。这不是强制要求,而是一个偏好。这是有原因的;如果你的职业生涯中只依赖一种编程语言,你的技能会被超越。
以下是你需要学习多于一种编程语言的原因:
你最终会被淘汰...
大多数成功的公司,特别是科技公司,都是建立在不止一种编程语言之上的。你的公司可能包括 Node.js、Ruby、Java、Python 等多种编程语言。如果你只掌握一种编程语言,你的技能会开始受到限制。这些语言在不同项目或业务方面之间不可互换,这可能导致你感到被淘汰。
学习编程语言的概念与学习外语相同。一旦你掌握了一种,其他的学习起来也会变得更容易。各种编程语言之间有很多相似之处,你应该利用这一点。与其因为技能不够多样化而被淘汰,不如成为一个多才多艺的开发者。
越来越多的组织变得以数据为中心或与数据相关;因此,对技术专家的需求将持续增长。成为这一趋势的一部分总比被抛在后头要好。
将你的职业生涯提升到新水*
掌握多种编程语言并熟练运用将使你的技能具备可转移性。你可以处理更多不同类型的任务,这将得到你的上司的高度认可。这为你带来了新的机会,因为你的技能证明了对公司有益。公司喜欢能利用内部团队的技能完成任务而不必寻求外部帮助的情况。
你知道的越多,你的生活就会越轻松。你不想坐在那里感到困惑或有冒名顶替综合症;学习更多,成就更多!
灵活性
很多人面临的一个主要问题是,不仅开发者感到自己的技能无法应用或无法完成任务。这个不知道更多的因素完全取决于你自己,是否愿意学习。你也可能会厌倦一遍又一遍地做同样的事情,变得乏味。
当你掌握多种编程语言时,你的技能就会更加多样化和灵活,能够处理各种任务。你会被视为全才,并且更愿意接受新的挑战。
更多技能 = 更多的钱
掌握多种编程语言等于更多的钱。如果由于你掌握了多种编程语言而被要求处理更多的项目或任务,你通常会获得更高的薪水。如果没有,你可以主动提出要求。你的技能显然为公司带来了价值,因此你应该得到相应的经济补偿。
谁不想要更多的钱呢?而且,如果是因为你为了掌握多种编程语言而投入的时间,那也是公*的。
结论
所以如果有人问,你是否需要学习多种编程语言?答案是肯定的,肯定的,肯定的!在编程越来越流行的情况下,只掌握一种编程语言是没有用的。你应该致力于成为编程领域的专家。
Nisha Arya 是一名数据科学家和自由职业技术写作者。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何/可以如何有利于人类寿命的不同方式。她是一位渴望学习的人,希望拓宽自己的技术知识和写作技能,同时帮助引导他人。
更多相关话题
为什么你需要在 2022 年学习 Python

Hitesh Choudhary 来自 Unsplash
我与其他开发者的对话越多,Python 的受欢迎程度就越高。当我刚开始编码时,当被问到使用什么编程语言时,我会回答“Python”。我会得到各种回答,比如‘哦,太酷了,我需要学习 Python’或‘我用 R,Python 怎么样?’
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
现在,当我被问及使用什么编程语言时,回答有些不同。我会得到‘哦,是的,我从使用 R 开始学习 Python’或‘是的,Python 目前是最好的语言之一’。
在短短几年内,我关于 Python 的对话发生了积极的变化!我与没有 Python 经验的同事合作,他们对当前的编程语言感到厌倦,觉得太耗时。
这就是我写这篇文章的原因,给你一些理由说明为什么你需要在 2022 年学习 Python。如果你还不懂编程语言,或者你在考虑选择另一种语言,读读这篇文章,看看 Python 是否适合你。
Python 的历史
Python 首次出现于 1991 年 2 月 20 日。它由荷兰程序员 Guido van Rossum 创建。Python 的设计重点是通过使用显著的缩进来提高代码的易读性。该语言的构建和面向对象的方法帮助新的和现有的程序员编写清晰且易于理解的代码,从小型项目到大型项目,从小数据到大数据。
31 年后,Python 被认为是今天最好的编程语言之一。
为什么在 2022 年选择 Python?
1. 易于学习
多年来,人们被学习编程语言的复杂性所阻碍。然而,这正是 Guido van Rossum 在创建 Python 时的目标,使其成为一种通用语言。
Python 的语法简单,非常适合初学者和新手学习,同时也方便业余开发者阅读和理解。
Python 学习速度远快于几乎任何其他编程语言,越来越受欢迎。
2. 多才多艺且灵活
当你想到某件事物多功能时,你会想到它能够适应或适应许多不同的功能。
Python 几乎可以应用于任何环境,例如应用程序、网页开发、软件开发等。这使得它非常受欢迎,因为会 Python 的人可以一举多得。或者可以一举三得、四得、五得,以及更多……
精通 Python 的开发者分布在各个领域,从机器学习、人工智能、数据科学、游戏开发、网页开发等。
3. 社区和资源
没有哪个程序员知道所有的知识。开发者的世界每天都有变化;无论是新的软件、新的工具、库的更新,等等。
随着 Python 的日益普及,对基本文档和支持的需求也显著增长,以帮助 Python 开发者解决意外问题等。
Python 语言周围有大量的文档、教程、指南和课程。目前在 StackOverflow 上有 1,926,748 个与 Python 相关的问题。
你可以查看其他*台,如 Github、Youtube、Medium 等。
4. 库和框架
编程和作为开发者的美妙之处在于,有许多库和框架可以使用,这样你就不必从零开始做所有事情。这些预构建的组件包含有用且易读的代码,你可以将其集成到你的程序中。
Python 中流行的框架和库包括:
-
NumPy 用于科学计算
-
Matplotlib 用于绘制图表和图形
-
SciPy 用于工程应用
-
BeautifulSoup 用于 HTML 解析和 XML
-
,以及更多。
如果你想了解更多关于 Python 库的信息,可以阅读我的文章:2022 年数据科学家应该知道的 Python 库。
5. 高效、快速且可靠
你可能会听到专注于其他编程语言的人问“为什么 Python 这么慢?”。虽然这篇文章讲的是为什么你需要学习 Python,但事实是,与其他编程语言相比,Python 的确较慢。然而,无论花费多长时间,今天的重点是开发时间的重要性。
Python 之所以变得如此受欢迎,绝非偶然。它高效、快速且可靠;允许开发者以最小的努力创建应用程序、进行分析并生成可视化输出。
6. 物联网技术
物联网是一个互联网连接设备的系统,例如计算机设备、数字机器、物品等。它能够在不需要人与人或人与计算机交互的情况下,通过网络传输数据。
这些小型互联网连接设备支持 Python 或 Micropython,允许我们对代码进行小幅调整,并根据特定需求进行定制。
随着我们每天与互联设备互动,用户开始意识到了解 Python 的重要性,因为它是学习和理解物联网的有用语言。
7. 学术界的应用
由于其不断增长的受欢迎程度,Python 已成为学校、学院和公司在培训毕业生及其他学习形式时首选的编程语言。
大多数大学课程都使用 Python 或高度采用 Python。绝大多数认证的编程训练营和课程使用 Python。你会看到越来越多的公司采纳 Python,超过任何其他编程语言。
在学习更多关于人工智能、机器学习、深度学习、数据科学等方面的内容时,你会看到 Python 的身影。
8. 大公司正在挥舞绿色旗帜
Google 自 2006 年起就使用 Python,从那时起他们就为有志于成为开发者的人策划了许多 Python 课程。其他大公司包括 Facebook 和 Amazon Web Services。
当受人信赖的大型科技公司开始使用某种编程语言时,它就会变得更受欢迎和高度可信。这就是 C# 被微软使用、PHP 被 Facebook 使用等情况发生的原因。
9. 自动化
Python 的一个美妙之处在于它的自动化任务能力。借助各种工具和模块,Python 可以将最复杂的任务变得简单,帮助自动化这些重复且耗时的任务。这使得开发者可以将时间和精力集中在其他需要更多人工干预的任务上。
Python 已成为自动化的行业金标准。即使是使用其他编程语言的开发者,也会在自动化脚本时回到 Python。
结论
Python 编程语言几乎为每个领域提供了解决方案,从机器学习、人工智能、Web 开发到游戏开发。这些都可以应用于不同的领域,从金融、时尚到美容。在许多任务中,Python 被认为是最合适的编程语言。
大公司已经完全转向了 Python,包括 YouTube、Instagram、Google 等等。
Nisha Arya 是一位数据科学家和自由技术写作人。她特别感兴趣于提供数据科学职业建议或教程和数据科学理论知识。她还希望探索人工智能如何或将如何有利于人类寿命的不同方式。她是一个热衷学习者,寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多内容
了解你的邻居:图上的机器学习
原文:
www.kdnuggets.com/2019/08/neighbours-machine-learning-graphs.html
评论
作者:Pantelis Elinas,高级机器学习研究工程师。
我们生活在一个互联的世界中,生成大量的连接数据。社交网络、金融交易系统、生物网络、交通系统和电信网络都是例子。图 1 所示的论文引用网络是连接数据的另一个例子。
图 1:论文引用网络的可视化。节点代表研究论文,而边表示论文之间的引用,各种颜色表示报告的主题,七种颜色编码七个主题。
表示连接数据可以使用计算机科学中常用的图数据结构。
在本文中,我们将介绍各种类型的连接数据,它们表示什么,以及我们可以解决的挑战。我们还介绍图卷积网络(GCNs)。以 GCN 为例,本文还将解释现代机器学习方法如何构建连接数据的预测模型。
网络的定义和类型
图数据结构有两个基本元素:节点和边(见下图 2)。节点表示数据中的实体,例如在线社交网络的成员,而边表示这些实体之间的关系,例如社交网络成员之间的友谊。节点和边的网络构成了一个图——数据网络结构的数学表示。
图 2:图的基本组件(在此情况下为无向图)是节点和边。
图中的节点和边可以选择性地具有类型。具有单一类型的节点和单一类型的边的图称为同质图。一个同质图的例子是一个在线社交网络,其中节点代表人,边代表友谊,节点和边的类型始终相同。另一方面,具有两种或更多类型的节点和/或两种或更多类型的边的图称为异质图。一个例子是在线社交网络,其中的边有不同的类型,比如‘友谊’和‘同事’,节点的类型是‘人’(见下图 3)。
图 3:两种类型图的图示表示,同质图(左)和异质图(右)。异质图(黑白图)具有两种不同类型的节点,人和城市,通过四种不同类型的边连接。
图的节点和边还可以包含称为属性或特征的属性。以在线社交网络为例,表示一个人的节点,即人节点,可能具有年龄、薪水、爱好和位置等属性。类似地,两个人人节点之间的边缘可能具有一个日期属性,用于确定在线关系开始的时间,或一个权重属性,反映关系的强度。
我们还可以根据图是静态还是动态来对图进行分类。顾名思义,静态图不会随着时间变化,而动态图会随时间改变其结构,添加和删除节点和边,或改变属性和特征(例如,节点属性可以是时间序列),或两者兼有。
我们可以从图中学到什么?
给定一个连通数据集,我们可以解决什么类型的问题,或者换句话说,我们可以回答什么类型的查询?我们可以将连通数据可以解决的问题大致分为四类:
-
节点分类
-
链接预测
-
社区检测
-
图分类
还有其他图问题不一定适合这四类,例如旅行推销员问题。然而,对于本文,我们将专注于上述四类,因为图机器学习是解决这些问题的绝佳工具。
节点分类,也称为节点属性推断,是根据网络中其他节点的属性值来推断某些节点的缺失或不完整属性值的问题。与其他机器学习方法相比,其优势在于节点属性推断使你能够将上下文和邻域信息纳入你的预测。例如,在在线社交网络中,我们可能会对预测用户朋友网络的音乐偏好感兴趣(见下图 4)。*
图 4:一个节点分类问题的示例,推断在线社交网络成员的音乐偏好。
链接预测,另一个对网络结构数据集非常重要的问题,是推断缺失或寻找实体之间隐藏关系的问题。我们可能会对预测缺失的关系感兴趣,因为在数据收集期间某些关系对我们是隐藏的。或者,我们可能会对预测网络结构在未来如何通过插入或删除链接而演变感兴趣,给定其当前时刻的快照。链接预测是我们每天使用的算法,因为它通常是推荐系统背后的算法。例如,在在线社交网络中,我们可以使用链接预测向成员推荐新朋友。另一个例子是为内容提供商或电子商务网站进行产品推荐。
社区检测 推断基于图结构、节点属性的相似性或两者的节点社区或簇。社区检测有许多应用,[1]。一个例子是将社交网络的用户根据他们的爱好划分为社区,而无需明确询问每个用户是否对该主题感兴趣。相反,算法使用来自个人频繁互动的人的数据来回答例如“你喜欢虚构还是非虚构?”这样的话题问题。这种分段可以用来根据社区成员的共同特征提供定向广告。
图分类 是区分不同类别图的问题。举例来说,考虑将化学化合物表示为图;在这种情况下,节点是原子,边是原子之间的键。给定一组每个都表示为图的化学化合物,我们想预测一个化合物是否具有抗癌性。这是一个图分类问题,[2]。
使用图卷积网络的节点分类示例
在本文的其余部分,我们将演示如何将图机器学习应用于解决同质图中的节点分类问题。在后续的文章中,我们将考虑最先进的链接预测和社区检测方法。
我们的数据集是被称为 Cora 的论文引文网络,其中图节点代表研究论文,边代表论文之间的引文关系。如果一篇论文引用了另一篇论文,那么这两篇论文之间就有一条边。尽管引文是有向的,但为了本教程的目的,我们将对应的边视为无向。
每篇论文都有一个相关的特征向量,用于编码论文中使用的词汇信息。每篇论文的特征向量包含 1433 个二进制元素,编码了从整个语料库中提取的 1433 个关键词的存在(编码为 1)或不存在(编码为 0)。
图 5 演示了用于 Cora 中两篇论文的 词袋模型 (BoW)。每篇论文还有一个表示论文主题的属性。每篇论文有七种主题之一,如神经网络、概率论、理论等。数据集包含 2708 篇论文(节点)和 5429 个引文(边)。
图 5: 词袋模型 (BoW) 与 Cora 引文数据集中一个节点相关的特征。
我们的目标是训练一个预测模型,以推断在训练过程中对机器学习算法隐藏的论文主题。由于主题是七个类别的分类问题,因此这是一个多类别节点分类问题。
作为基线方法,我们可以使用传统的机器学习方法来解决这个问题,忽略论文之间的关系。我们可以将节点的特征向量堆叠成一个二维数组F,即设计矩阵,其维度为 2708x1433,然后在数据的子集上训练分类器,如逻辑回归、神经网络或随机森林。我们可以使用剩余的数据来评估分类器作为验证集和测试集。
这种方法,通过捕捉论文中使用的词汇与其主题之间的关系,效果相当不错。训练仅 140 个样本(每类 20 个训练样本)的 2 层多层感知器(MLP)据报道在测试中达到了约 55%的准确率,[3]。
然而,上述方法忽略了论文之间的引用关系。我们可能会认为这些关系提供了有关论文主题的额外信息,因为我们可以预期一篇论文会引用其他具有相同主题的论文。我们如何利用这些信息?
一种方法是使用手动特征工程,通过图相关的节点特征来增强基于词汇的特征向量。例如,有大量文献讨论如何计算图中节点结构位置的定量值。一个直接的结构性节点特征是节点在图中的邻居数量(节点的度)。其他有用的结构性节点特征包括 PageRank,[4]和各种中心性度量。有关中心性度量的示例,请参见图 6。
图 6:可以用于图机器学习中的手动特征工程的常见中心性度量示例。
手动特征工程被认为是成功的,并且多年来被广泛应用。然而,从深度学习和卷积神经网络的成功经验中,我们了解到,这些算法擅长自动学习能够最大化下游任务性能的基本特征。不幸的是,“传统”的神经网络和卷积神经网络算法不能直接利用关系数据。
尽管如此,研究人员最*提出了图神经网络算法,这些算法可以在训练图上的神经网络模型时利用关系信息。在这些图神经网络算法中,图卷积网络(GCN)[3]是最成功且易于理解的之一。在这篇文章中,我们将应用 GCN 模型到我们预测引用网络中论文主题的工作示例中。我们从简要描述 GCN 架构开始。
GCN 作者引入了一种新的神经网络层类型,称为图卷积层。GCN 层的结构如图 7 所示。该层具有可训练参数:权重矩阵W和偏置向量b;其输入是节点特征矩阵F和归一化的图邻接矩阵A'。
图 7:图卷积神经网络(GCN)层的基本定义。
归一化的邻接矩阵编码了图结构,通过与设计矩阵相乘,有效地*滑了节点的特征向量,基于其在图中的直接邻居。A'被归一化,以使每个邻接节点的贡献与该节点在图中的连接程度成正比。
该层的定义通过对A'FW+b应用逐元素非线性函数(如 ReLu)来完成。该层的输出矩阵Z可以用作另一个 GCN 层或任何其他类型神经网络层的输入,从而允许创建深度神经网络架构,能够学习用于下游节点分类任务的复杂节点特征层次结构。
在 Cora 数据集上训练一个 2 层 GCN 模型(通过this script使用我们开源的 Python 库StellarGraph),每层 32 个输出单元,并且模型只见到 140 个训练节点标签,相较于基线 2 层 MLP,分类准确率显著提高。在对一组留出的论文测试集进行预测时,准确率提高至大约 81%——比仅使用 BoW 节点特征并忽略论文之间引用关系的 MLP 提高了 21%。这清楚地表明,至少对于某些数据集,利用数据中的关系信息可以显著提升预测任务的性能。
节点分类只是图机器学习的一小部分,但它是一种非常强大的方法,可以帮助处理连接的数据。如果你想了解更多关于图机器学习的信息,请通过这里联系我们,如果你想尝试节点分类或其他图机器学习算法,可以下载我们开源的 Python 库StellarGraph。你可以通过学习StellarGraph 演示来深入了解图机器学习,并在我们的论坛上提出任何问题!
此项工作得到了CSIRO 的 Data61的支持,这是澳大利亚领先的数字研究网络。

参考文献:
-
Fortunato, S. (2010). “图中的社区检测”,《物理学报告》,486(3–5),75–174。
-
Wale, I. A. Watson 和 G. Karypis,“化学化合物检索和分类的描述符空间比较”,《知识与信息系统》,第 14 卷,第 3 期,第 347–375 页,2008 年。
-
Kipf, T. N., & Welling, M. (2016). “图卷积网络的半监督分类”,arXiv 预印本 arXiv:1609.02907。
-
Brin, S., & Page, L. (1998). “大规模超文本 Web 搜索引擎的构造”,《计算机网络与 ISDN 系统》,30(1–7),107–117。
个人简介:Pantelis Elinas 是高级机器学习研究工程师。他喜欢解决有趣的问题、分享知识以及开发有用的软件工具。
原文。已获授权转载。
相关:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织在 IT 领域
更多相关主题
关键机器学习技术:嵌套交叉验证,为什么以及如何使用 Python 代码
原文:
www.kdnuggets.com/2020/10/nested-cross-validation-python.html
评论
由 奥马尔·马丁内斯,Arcalea。
在这篇文章中,我们将简要讨论并实施一种技术,从宏观角度来看,这种技术可能没有得到应有的关注。前述陈述源于观察到某些模型在生产中的表现往往低于模型构建阶段的表现。尽管这种问题有许多潜在的罪魁祸首,但一个常见的原因可能在于模型选择过程。
我们的三大推荐课程
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT。
标准模型选择过程通常包括一个超参数优化阶段,在此阶段,通过使用验证技术,如 k 折交叉验证(CV),将根据验证测试结果选择一个“最佳”模型。然而,这一过程容易受到一种选择偏差的影响,使其在许多应用中不可靠。Gavin Cawley 和 Nicola Talbot 的论文中详细讨论了这一点,其中包含以下重要信息:
“在机器学习研究中,偶尔会观察到一种偏差的评估协议,即使用所有可用数据进行初步模型选择步骤,这通常作为“初步研究”的一部分进行互动操作。然后,这些数据被反复重新划分,形成一个或多个随机、互不重叠的设计和测试集。这些集随后用于使用相同的固定超参数值进行性能评估。这个做法乍看似乎无害,但测试数据不再是统计上的纯净数据,因为它们已经被模型在调整超参数时“看到过”。”
- 关于模型选择中的过拟合及其在性能评估中的后续选择偏差,2010 年。
为了说明为什么会发生这种情况,让我们用一个例子。假设我们正在进行一个机器学习任务,在其中我们基于n轮超参数优化选择一个模型,我们通过使用网格搜索和交叉验证来完成这项工作。现在,如果我们在每次n次迭代中使用相同的训练和测试数据,这意味着测试集上的性能信息通过超参数的选择被纳入训练数据。在每次迭代中,这些信息可以被过程利用以找到性能最佳的超参数,这会导致测试数据集不再纯净,无法用于性能评估。如果n很大,那么我们可能会将测试集视为一个次级训练集(宽泛地说)。
好消息是,有一些技巧可以帮助我们解决这个问题。其中一种方法是拥有一个训练集、一个测试集,以及一个验证集,然后根据验证集上的表现调整超参数。
另一种策略,也是本文的重点,是嵌套交叉验证,它与上文所提论文中的一种解决方案相吻合,通过将超参数优化视为模型拟合的一部分,并用不同的验证集来评估它,这个验证集是外层交叉验证的一部分。
简而言之,拟合,包括超参数的拟合,这本身包括一个内部交叉验证过程,就像模型过程中的其他部分一样,并不是用于评估特定拟合方法的模型性能的工具。要评估性能,你需要使用外部交叉验证过程。实际上,你可以让网格搜索(或任何其他优化工具)处理内部交叉验证,然后使用 cross_val_score 来估计外部循环中的泛化误差。因此,最终分数将通过对多个拆分的测试集分数进行*均,作为常规的交叉验证过程。
这是该方法的简化概述。这个示例在技术上并不严格,但旨在提供整个过程的直观理解。
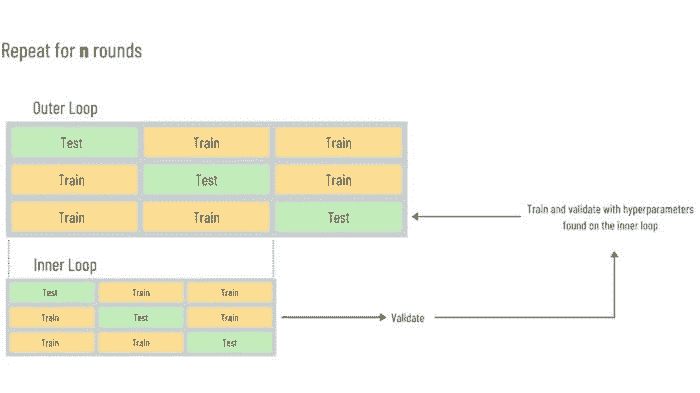
嵌套交叉验证过程的简化示意图。
Python 中的嵌套交叉验证
在 python 中实现嵌套交叉验证,多亏了scikit-learn,相对来说比较简单。
让我们来看一个例子。我们将从加载葡萄酒数据集开始,使用来自 sklearn.datasets 的所有必要模块。
现在,我们开始实例化分类器,然后指定我们希望运行的轮数/试验次数,换句话说,就是我们将进行多少次完整的内外循环过程。由于这是计算上昂贵的,我们仅仅为了演示目的,所以选择 20 轮。请记住,轮数表示你将如何在每个交叉验证过程中以不同的方式拆分数据集。
下一步是创建一个字典,以建立我们在每轮中将要探索的超参数空间,同时创建两个空数组以存储来自嵌套和非嵌套过程的结果。
下一步非常重要,我们将创建一个循环,该循环将迭代我们指定的轮数,并且包含两个不同的交叉验证对象。
对于这个例子,我们将对外部和内部循环都使用 5 折交叉验证,并且使用每轮(i)的值作为两个交叉验证对象的random_state。
然后,我们开始创建和配置对象以进行超参数优化。在这个例子中,我们将使用网格搜索。请注意,我们将'inner_cv'对象作为交叉验证方法传递给网格搜索。
随后,请注意,对于“嵌套”交叉验证过程的最终得分,我们使用cross_val_score函数,并将分类器对象'clf'(包括其自己的交叉验证过程)传递给它,这个对象就是我们用于进行超参数优化的对象,同时也传递'outer_cv'交叉验证对象。在此过程中,我们还会拟合数据,然后将每个过程的结果存储在我们之前创建的空数组中。
我们现在可以计算“简单”交叉验证和嵌套交叉验证过程中的准确率得分差异,以查看它们之间的*均不一致程度。
在这种情况下,嵌套交叉验证得分指的是嵌套过程的得分(不要与内部交叉验证过程混淆),我们将其与常规过程(非嵌套)的得分进行比较。
输出:
Avg. difference of 0.001698 with std. dev. of 0.003162.
如我们所见,非嵌套得分的*均值更为乐观。因此,单纯依赖该过程的信息可能会导致模型选择的偏差。
我们还可以绘制每次迭代的得分,并创建一个图表以获取两种过程表现的可视化比较。
输出:
最后,我们还可以绘制每一轮两个交叉验证过程的差异。
输出:
最后的思考
虽然交叉验证是评估泛化能力的行业标准,但重要的是要考虑手头的问题,并可能实施更严格的过程,以避免在选择最终模型时出现选择偏差。从个人经验来看,当处理小数据集且系统用于支持非*凡决策时,这一点尤为重要。
嵌套交叉验证并不是一个完美的过程,它是计算上昂贵的,并且绝对不是生产中模型表现差的灵丹妙药。然而,在大多数情况下,这个过程将使你对每个模型的泛化能力有一个更现实的了解。
你可以在GitHub上找到包含本文所有代码的笔记本。
简介: 爱德华多·马丁内斯是一个拥有商业分析学研究生学位的市场营销人员。目前在Arcalea工作,爱德华多将数据科学框架与营销流程整合在一起。
相关:
相关阅读
神经代码搜索:Facebook 如何利用神经网络帮助开发者搜索代码片段
原文:
www.kdnuggets.com/2019/07/neural-code-facebook-uses-neural-networks.html
comments

现如今,Google 和 StackOverflow 是每位开发者的好帮手。在进行特定项目时,开发者经常依赖外部信息来源来寻找解决方案或代码片段。然而,搜索结果通常基于元数据,而不是代码本身提供的信息。例如,如果开发者在 StackOverflow 上发布一个代码片段,它通常会包括描述和标签,以帮助将其索引以便未来搜索。该方法依赖于元数据的准确性来提供准确的搜索结果,但也忽略了可以直接从代码中推断出的信息。为了应对这一限制,Facebook AI Research(FAIR)团队一直在研究一种方法,利用自然语言处理(NLP)和信息检索(IR)直接从源代码文本中推断搜索相关信息。
FAIR 团队努力的首次成果是一个名为 Neural Code Search (NCS) 的工具,它接受自然语言查询,并从代码语料库中直接推断结果。NCS 背后的技术总结在最*发布的两篇研究论文中:
NCS 和 UNIF 两种技术背后的原理相对相似。这两种方法都依赖于代码片段的向量表示,这些向量可以用于训练模型,使语义相似的代码片段和查询在向量空间中彼此接*。这种技术能够直接使用代码片段语料库回答自然语言查询,而不依赖外部元数据。尽管 NCS 和 UNIF 两种技术相对相似,但 UNIF 通过监督模型扩展了 NCS,从而能为 NLP 查询提供更准确的答案。
NCS
其核心原理是使用嵌入生成来自代码语料库的向量表示,使得相似的代码片段在向量空间中彼此靠*。以下示例中,有两个不同的方法体,它们都涉及关闭或隐藏 Android 软件键盘(上面的第一个问题)。由于它们具有相似的语义含义,即使它们的代码行不完全相同,它们在向量空间中的表示点也彼此接*。NCS 使用方法级别的粒度在向量空间中嵌入每个代码片段。
创建向量表示的过程包括三个主要步骤:
-
提取词汇
-
构建词嵌入
-
构建文档嵌入
-
自然语言搜索检索
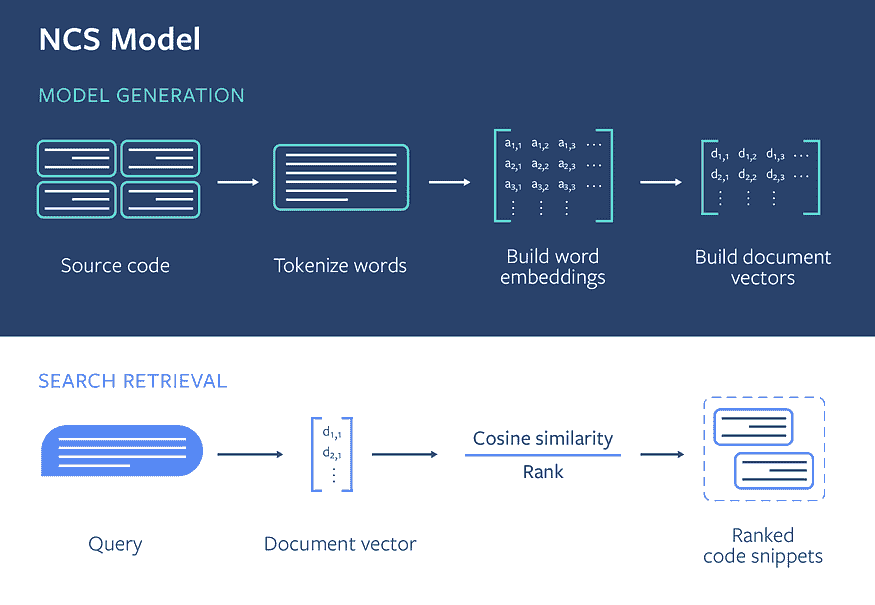
给定一个特定的代码片段,NCS 提取不同的语法部分,如方法名、方法调用、枚举、字符串文字和注释。这些工件随后使用标准的英语约定进行分词。对于输入语料库中的每个文档,NCS 以一种能够学习每个词的嵌入的方式对源代码进行分词。在这个步骤之后,我们为每个方法体提取的词列表类似于自然语言文档。
在词汇提取之后,NCS 继续使用 FastText 框架 构建词嵌入。在此过程中,FastText 使用一个可以在大语料库上无监督训练的两层密集神经网络计算向量表示。更具体地说,NCS 使用跳字模型,其中目标词的嵌入用于预测固定窗口大小内上下文词的嵌入。
这一阶段的最终步骤是通过提取的词嵌入表示方法体的一般意图。NCS 通过计算方法体中一组词的词嵌入向量的加权*均值来实现这一点。这个公式的结果被称为文档嵌入,用于创建每个方法体的索引,以便进行有效的搜索检索。
使用向量表示作为起点,NCS 现在可以尝试回答与代码片段相关的自然语言查询。给定自然语言查询,NCS 使用 FastText 框架遵循类似的分词过程。利用相同的 FastText 嵌入矩阵,NCS *均词的向量表示以创建查询句子的文档嵌入;不在词汇表中的词会被丢弃。NCS 然后使用标准相似度搜索算法,FAISS 来找到与查询最接*的文档向量。
UNIF
作为一种无监督技术,NCS 的优势在于可以快速简便地直接从代码语料中构建知识。然而,NCS 的主要限制之一是模型隐含地假设查询中的词汇来自与源代码中提取的词汇相同的领域,因为查询和代码片段都映射到同一向量空间。然而,许多代码语料并不传达任何相关的语义信息。例如,下面的代码片段获取内存空间中的可用块。仅通过无监督方式生成词嵌入,NCS 将无法匹配诸如“获取内部存储器上的空闲空间”这样的相关查询。
File path = Environment.getDataDirectory();
StatFs stat = new StatFs(path.getPath());
long blockSize = stat.getBlockSize();
long availableBlocks = stat.getAvailableBlocks();
return Formatter.formatFileSize(this, availableBlocks * blockSize);
UNIF 是对 NCS 的一种监督扩展,旨在弥合自然语言词汇与源代码词汇之间的差距。UNIF 实质上使用监督学习来修改初始的词嵌入矩阵 T,并分别为代码和查询词生成两个嵌入矩阵 Tc 和 Tq。我们还用基于学习的注意力加权方案替代了代码词嵌入的 TF-IDF 加权。这种变化实际上考虑了一些代码语料中的语义不匹配。
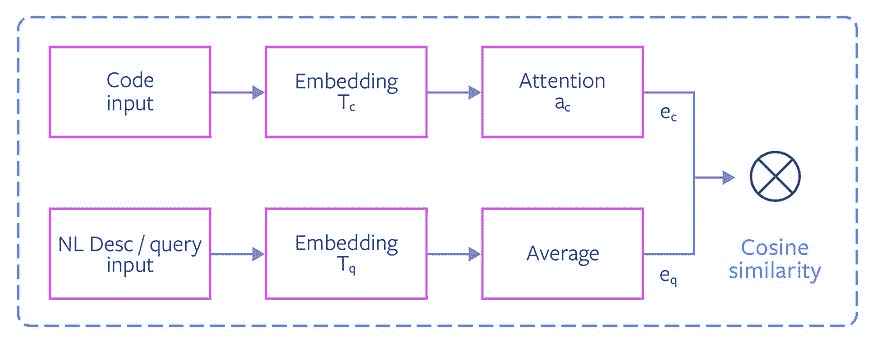
NCS 和 UNIF 实践
FAIR 团队将 NCS 和 UNIF 与最先进的信息检索模型进行了比较。使用 StackOverflow 问题的起始数据集,NCS 在各种任务中超越了流行的 BM25 模型。

同样,添加 UNIF 扩展显示了 NCS 性能的逐步提升。

NCS 和 UNIF 都提供了一种巧妙而简单的实现方法用于信息检索。以代码搜索开始是提供即时价值的一种简单方式,但 NCS 和 UNIF 背后的理念适用于许多神经搜索和信息检索场景。
原文。经许可转载。
相关:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关话题
如何知道神经网络是否适合您的机器学习计划
原文:
www.kdnuggets.com/2020/11/neural-network-right-machine-learning-initiative.html
评论
作者:Frank Fineis,Avatria 的首席数据科学家 Avatria

我们的前三名课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您组织的 IT
深度学习模型(即神经网络)现在驱动着从自动驾驶汽车到 YouTube 推荐视频的所有事物,在过去几年中变得非常流行。尽管它们很受欢迎,但该技术也有一些缺点,例如深度学习的“可重复性危机”,因为一个研究人员很常无法重现另一研究人员发布的一组结果,即使在相同的数据集上。此外,深度学习的高昂成本会让任何公司感到迟疑,因为FAANG公司已花费超过 $30,000来训练一个(非常)深的网络。即使是全球最大的科技公司也在神经网络的规模、深度和复杂性上遇到困难,而对较小的数据科学组织来说,这些问题更加明显,因为神经网络可能既费时又昂贵。此外,神经网络并不一定能超越基准模型,如逻辑回归或梯度提升模型,因为神经网络难以调优,通常需要额外的数据和工程复杂性。
鉴于这些关注点,重要的是要记住,即使考虑神经网络也必须有一个商业原因,而不是因为高管们感到害怕错过(FOMO)。
在考虑神经网络的需求时,将数据视为三种类型是有用的:
-
连续变量,由数值和小数点值组成。
-
类别变量,提供有限数量的可能值,通常具有语义。
-
文本序列,提供非结构化的语义信息。
基于决策树的算法不是处理文本序列或具有多种不同值的分类变量的最有效方法,这可能要求公司采用创造性的方式将这些值编码为模型的数值特征。这也可能意味着大量的手动特征工程工作,因为这种方法在潜在值数量超过少量时会增加模型管道的复杂性。
神经网络通常更容易学习所谓的“稀疏特征”,这也是任何考虑涉足深度学习的组织在此之前可能想要考虑的建议:
-
尽量坚持使用预构建的即插即用解决方案(至少在开始时),例如已经与TensorFlow预组装好的模型。尽管追求令人兴奋的新论文并尝试追求绝对的 SOTA 很有诱惑力,但如果模型不是来自具有一定常规用户的包(例如 GitHub/GitLab 上的用户),它可能无法直接适应你的数据集。
-
避免实现任何没有附带代码的算法。Paperswithcode.com 跟踪深度学习/AI 领域的 SOTA,并方便地链接描述神经网络架构及其在 GitHub 上的实现的论文。如果你的团队考虑基于一篇没有相应开源实现的论文(例如谷歌的seq2slate神经网络架构论文)进行建模,那就不要尝试。这将非常困难且耗时,并且可能意味着很少有人实际使用论文所提议的内容。
-
如果你没有看到立竿见影的结果,千万不要放弃!我们无法过分强调保持配置和结果精确记录的价值。可能需要调整数十个超参数,其中一些对结果的影响很小,但一些会极大地改变结果。仔细关注你选择的优化器和学习率——这组合能决定训练是否会取得零进展、少量进展或大量进展。一个好的经验法则是从非常小的学习率开始,检查训练期间的损失是否下降。
-
使用仅有的 CPU 训练神经网络可能需要很长时间,但使用 GPU(图形处理单元)可以将训练速度提高 10 倍。通过 Google Colab 获得免费的 GPU 访问权限,它方便地预装了最新版本的 TensorFlow。在评估新模型时,你的数据科学团队通常应在自己的 VPC 上进行特征提取和特征工程,然后将训练集上传到 Google Drive,以便在 Colab 笔记本中训练模型。这可以降低成本,并避免额外的基础设施维护。最后,使用 TensorFlow 的 tensorboard 工具,数据科学家可以直接从云端研究模型训练结果,并比较所有不同的实验。
-
编写可重用的代码。很容易调整神经网络的多个超参数,或者以微妙的方式操控训练集,这可能会极大地影响模型结果,并且在笔记本开发环境中可能会丢失导致这些结果的设置。但维护中心数据集创建和模型训练脚本可以让你记录最佳设置。
简介: Frank Fineis 是 Avatria 的首席数据科学家,该公司是一家数字商务公司,专注于开发电子商务解决方案。该公司构建的数据驱动产品利用机器学习为其 B2C 和 B2B 客户的电子商务需求提供可操作的见解。
相关:
-
神经网络能展现想象力吗?DeepMind 认为可以
-
黑箱内部观察:如何欺骗神经网络
-
深度学习、自然语言处理和计算机视觉的顶级 Python 库
相关话题
基于神经网络的初创公司名称生成器
原文:
www.kdnuggets.com/2018/04/neural-network-startup-name-generator.html
评论
由 Alexander Engelhardt,自由数据科学家
摘要
在这篇文章中,我展示了一个自动生成初创公司名称建议的 Python 脚本。你给它一个具有特定主题的文本语料库,例如凯尔特文本,然后它会输出类似发音的建议。一个示例调用如下:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
./generate.py -n 10 -t 1.2 -m models/gallic_500epochs.h5 wordlists/gallic.txt --suffix 软件
输出:
=======
Ercos 软件
Riuri 软件
Palia 软件
Critim 软件
Arios 软件
Veduos 软件
Eigla 软件
Isbanos 软件
Edorio 软件
Emmos 软件
我将这个脚本应用于英语、德语和法语的“普通”文本,然后尝试了凯尔特歌曲、宝可梦名字和 J.R.R. 托尔金的黑语(魔多之语)的语料库。
我已经将一些更长的样本提案列表发布在这里。
你可以在我的 GitHub 仓库中找到代码、我使用的所有文本语料库以及一些预计算模型:
github.com/AlexEngelhardt/startup-name-generator
目标
最*,我和一位同事开始创办一家软件公司,但我们想到的大多数名字都已经在用。我们想要一个具有凯尔特风格的名字,并且需要大量的候选名称来找到一个仍然可用的。
所以我开始创建一个生成新型人工词汇的神经网络。你需要输入一个你喜欢的特定风格的样本文本,例如凯尔特歌曲,它就能捕捉文本的特点(“语言”)并生成新的类似发音的词汇。著名的Andrej Karpathy 的博客文章为我提供了必要的知识和信心,这个想法是现实的。
数据预处理
我首先建立了一个原始文本的语料库。对于预处理,我剥离了所有非字母字符。然后,我将文本分割成单词并只保留唯一的单词。我认为这个步骤是合理的,因为我不希望模型学习最常见的单词,而是理解整个语料库的结构。
之后,大多数文本语料库最终成为 1000 到 2000 个单词的列表。
RNN 架构
循环神经网络可以特别好地建模语言,并且是这个词生成任务的合适类型。然而,找到‘完美’的 RNN 架构仍然有些像黑魔法。像使用多少层或多少单元这样的问题没有确定的答案,而是依赖于经验和直觉。
为了节省训练时间,我希望模型既足够复杂又尽可能简单。我选择了一个每层有 50 个单元的字符级双层 LSTM,并训练了 500 个周期。这个模型输出的单词已经听起来非常不错了。
采样温度
RNN 逐个字符生成新名称。它不仅输出下一个字符,还输出下一个字符的分布。这允许我们要么选择概率最高的字母,要么从提供的分布中采样。
我发现一个很好的方法是改变采样过程的温度。温度是一个调整采样权重的参数。“标准”温度 1 不改变权重。对于较低的温度,采样变得不那么随机,即更保守,几乎总是选择最大权重对应的字母。另一个极端,大温度,会调整权重接*均匀分布,代表完全的随机性。对于实际文本采样,温度低于 1 可能是合适的,但由于我想要新词,高温度似乎更好。
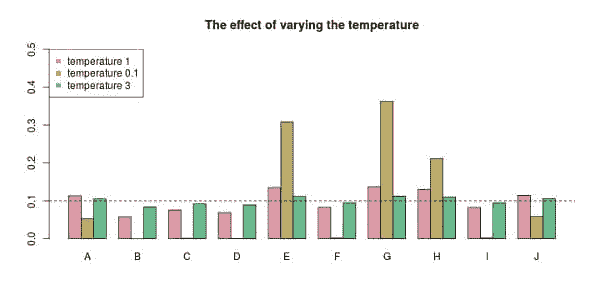
在上图中,假设我们想从 A、B、…、J 中采样一个字母。你 RNN 输出的原始权重可能是红色条。如果你降低温度,权重会变成黄色条(温度 = 0.1),如果你提高温度,它们会变成绿色条(温度 = 3)。
示例调用和输出
使用-h 参数调用脚本以打印所有可能的参数概述。以下命令在 wordlists/english.txt 语料库上训练一个 LSTM 模型 500 轮(-e 500),将模型保存(-s)到 models/english_500epochs.h5,然后用 1.2 的温度(-t 1.2)采样 10 个公司名称(-n 10),最后将“Software”添加到名称后(--suffix)(我在这里找到了一长串可能的后缀)。在训练过程中,我喜欢传递-v 参数以运行详细模式。然后,模型每 10 轮打印一些额外信息以及几个生成的示例单词:
./generate.py -v -e 500 -n 10 -t 1.2 -s models/english_500epochs.h5 wordlists/english.txt --suffix Software
我的呼叫返回了这些建议:
Officers Software
Ahips Software
Appearing Software
Introduce Software
Using Software
Alarmed Software
Interettint Software
Entwrite Software
Understood Software
Aspemardan Software
我遇到的一些其他优质名字建议,太好以至于不分享不行:
-
确实(看,它有效!)
-
Unifart(我敢你!)
-
Lyston
-
Alton
-
Rocking
-
Moor
-
Purrs
-
Ture
-
Exace
-
Overheader
在你存储模型后(使用-s 选项),加载模型比重新计算模型要快(使用-m 而不是-s 参数)。
更具异国情调的语料库
我收集了一些德语、英语和法语的文本,只为拥有一些听起来真实的单词,并评估模型对语料结构的学习效果。
然而,我的大部分时间随后花在了更有趣的语料库上。下面,我将简要描述它们,并展示一些生成单词的随机样本。
Celtic
该语料库由一个高卢词典和Eluveitie的高卢语歌曲歌词组成:
Lucia
Reuoriosi
Iacca
Helvetia
Eburo
Ectros
Uxopeilos
Etacos
Neuniamins
Nhellos
Pokemon
如果你提供一个所有宝可梦的列表,你会得到宝可梦主题的名字:
Grubbin
Agsharon
Oricorina
Erskeur
Electrode
Ervivare
Unfeon
Whinx
Onterdas
Cagbanitl
托尔金的黑语
托尔金的黑语,魔多的语言,是一个纯粹的娱乐实验:
Aratani
Arau
Ushtarak
Ishi
Kakok
Ulig
Ruga
Arau
Lakan
Udaneg
这个工具已经证明对我们很有用,提出了一些非常悦耳的名字。它也可能对其他人有帮助,我
Bio: 亚历山大·恩格尔哈特,最*获得了慕尼黑大学的统计学硕士和博士学位,随后成为了专注于机器学习的自由数据科学家。亚历山大最*对开源产生了兴趣,开始贡献于 R 包‘mlr’。这篇文章介绍了我第一个个人侧项目。
原文。转载经许可。
相关:
更多相关主题
神经网络——一种直观理解
评论
由Prateek Karkare,南洋理工大学研究助理。
人类一直对自然充满了好奇。鸟类的飞行促使我们发明了飞机;鲨鱼皮肤启发我们制作了更快的泳衣以及许多其他从自然中汲取灵感的机器。今天我们正处于构建智能机器的时代,而大脑无疑是最好的灵感来源。人类特别被进化赋予了一个能够执行最复杂任务的大脑。
自 1940 年代初以来,科学家们一直在尝试构建数学模型和算法,以模拟大脑内部的计算。尽管我们仍然离大脑所能实现的壮举有很长的距离,但我们正在逐步接*。
在追求制造智能机器的过程中,提出了几个简化的学习模型,其中最流行的是人工神经网络(ANN),或简称神经网络。神经网络是当前机器学习和人工智能领域中最强大的算法之一。顾名思义,它汲取了我们大脑中神经元及其连接方式的灵感。让我们快速窥视一下我们的脑袋。
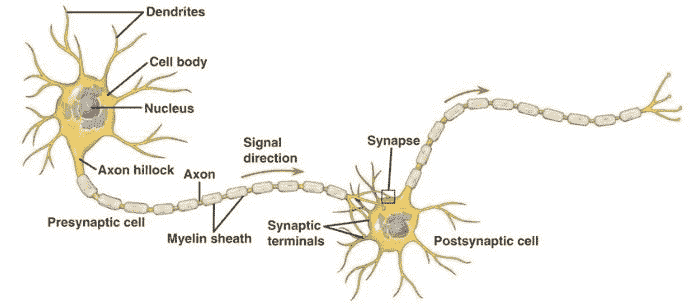
来源:biomedicalengineering.yolasite.com/neurons.php
神经元在我们大脑中连接,如上图所示。此图仅显示了两个彼此连接的神经元。实际上,成千上万的神经元通过树突与单个神经元的细胞体连接,*均而言,一个神经元连接到 10,000 个其他神经元。让我们简化这个图像,以建立一个人工神经网络模型。
多层神经网络
现在,假设细胞体仅仅存储一个数字,而连接箭头描述了数据流的方向以及每个神经元连接其他神经元的强度。不用担心这里的强度是什么意思,我们稍后会看到。我们从神经元及其连接性的生物学中获取了一些灵感。让我们看看这如何帮助我们完成大脑所做的一些任务。

感知器
好的,那就是 Megatron。
感知器是一种由 Frank Rosenblatt 于 1957 年发明的机器学习算法。感知器是一种线性分类器,你可以阅读有关线性分类器及分类算法的内容 这里。让我们看看一个非常小的分类示例。让我们尝试构建一个机器来识别一个对象是否是板球。

让我们任意选择一些这个球的属性。
-
它是红色的,我们将称这个属性为R。
-
它是球形的,我们将称这个属性为S。
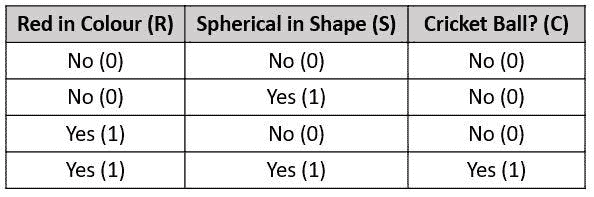
根据任意选择的属性,也称为特征,我们将对象分类为板球或非板球。上表告诉我们,如果一个球是红色的且是球形的,它就是一个板球,否则就不是。让我们看看如何用神经网络来实现这一点。
为了构建我们超级小的大脑,它可以识别板球,我们将使用一个神经元,该神经元仅加总输入并输出总和 —
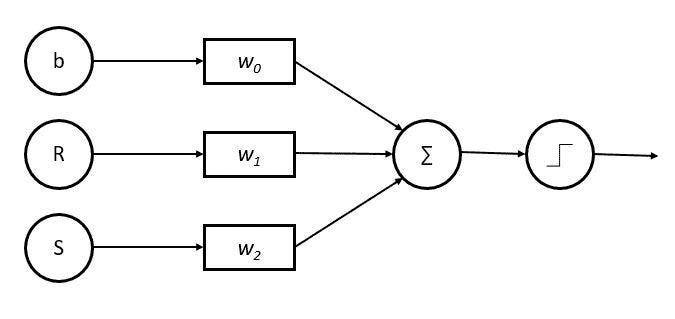
解析上述图;b, R 和 S 是输入神经元或简单来说是网络的输入,w0, w1 和 w2 是连接到中间神经元的权重,它将输入值加总。b 在这里是一个常量,称为 偏置。最后一步是最右侧的神经元,它是一个称为激活函数的函数,如果输入为正则输出 1,如果输入为负则输出 0。数学上它看起来像 —
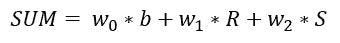
如果这个 SUM > 0,则输出 = 1 或 是;如果 SUM < 0,则输出 = 0 或 否。
让我们看看这如何帮助我们分类板球。我们为我们的连接强度 w 和常量 b 选择了一些任意的数字。如何获得这些值,即通过训练神经网络来学习这些权重,是本系列第二部分的主题。现在我们只需假设我们从某处获得了这些数字 —
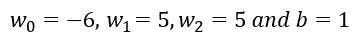
让我们拟合这些值
案例 1:当对象既不是球体 (S=0) 也不是红色 (R=0) 时

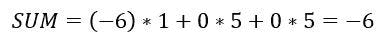
SUM < 0 这意味着输出为 0 或 否。我们的感知器表示这不是一个板球。
案例 2:当对象是球体 (S=1) 但不是红色 (R=0) 时

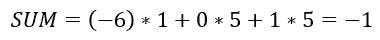
SUM < 0 这意味着输出为 0 或 否,不是一个板球。
案例 3:当对象不是球体 (S=0) 但红色 (R=1) 时

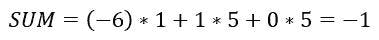
SUM < 0 这意味着输出为 0 或 否,不是一个板球。
情况 4:当对象是一个球体(S=1)并且是红色(R=1)

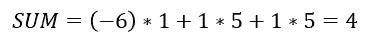
SUM>0,这意味着输出是 1。Et Voila! 我们的感知器说这是一个板球。
这是神经网络的最基本思想。我们以特定的方式连接这些感知器,最终得到一个神经网络。我已经将这个思想简化了一些,但它仍然捕捉到了感知器的本质。
多层感知器
我们将感知器的这一思想堆叠在一起,创建层的这些神经元,这就是所谓的多层感知器(MLP)或神经网络。
在我们简化的感知器模型中,我们仅使用了一个阶跃函数作为输出。在实际应用中,使用了许多不同的变换或激活函数。
我们手动且随意选择了红色和球形特征,但对于许多其他复杂任务,这种特征选择并不总是实际的。MLP 在某种程度上解决了这个问题。MLP 的输入可以直接是图像的像素值,隐藏层然后结合和转换这些像素值以在隐藏层中创建特征。本质上,单层感知器将数据转换并发送到下一层。
28 像素 x 28 像素的手写数字图像
假设我们的 MLP 试图通过查看类似上面手写数字的图像来识别一个数字。使用 MLP,我们可以直接将这个图像的像素值传递到输入层,而无需提取任何特征。然后,隐藏层会结合和转换这些像素来创建一些特征。隐藏层中的每个神经元都在训练过程中尝试学习一些特征。例如,隐藏层中的神经元 1 可能学习响应图像中的水*边缘,神经元 2 可能响应图像中的垂直边缘,以此类推。如果输入图像同时具有水*边缘和垂直边缘,隐藏层中的神经元 1 和 2 将响应,输出神经元将结合这两个特征,并可能说这是一个 7,因为 7 大致有一个垂直边缘和一个水*边缘。
当然,MLPs 并不总是学习到具有实际意义的特征,但它本质上是对输入数据的转换。例如,对于一个接收手写数字图像作为输入、隐藏层有 16 个神经元的 MLP,它会学习到类似以下的特征—

每个方块代表隐藏层中一个神经元学习到的特征
正如你可以清楚看到的,模式或多或少是随机的,没有意义。这一推断过程和 MLP 的变换在 3Blue1Brown 的精彩 YouTube 系列中得到了最佳解释——什么是神经网络。我强烈建议你去这个频道观看视频,以获得对神经网络的直观了解。一个很好的工具来可视化神经网络做的一些事情是 Tensorflow Playground,如果你有一些线性代数的背景,这个 博客中的可视化也很不错。
神经网络的今天与明天
那么,神经网络除了识别板球或手写数字之外还能完成什么任务呢?如今,神经网络被部署用于广泛的任务。图像识别、语音识别、自然语言处理、时间序列数据和许多其他应用。图像分类是神经网络成为事实上的算法的一个特定领域。神经网络在准确识别图像方面已经超越了人类。当然,构建这样高保真度的神经网络有很多复杂的技术和数学。

来源: xkcd.com
神经网络无处不在。公司利用它们来推荐你可能喜欢在 YouTube 上观看的视频,识别你对 Siri、Google Now 或 Alexa 说话时的声音和指令。神经网络现在也在生成自己的绘画和音乐作品。然而,仍然存在很多挑战。神经网络可以非常庞大,具有数百层,每层有数百个神经元,这使得在当前硬件技术下计算成为一个大挑战。训练神经网络是另一个巨大的挑战。为了训练这些神经网络,通常需要多个 GPU 一起工作,这个过程可能需要几个小时到几天。
但它们是我们在追求构建具有与人脑一样复杂智能和能力的机器过程中的现在与未来。我们离制造一个可以有一天“下载”你所有意识并创造你自身机器副本的人工大脑还有很长的路要走。但目前,这仅仅是科幻小说!

来源: xkcd.com
神经网络是一个广阔的主题,本文的目的是引发足够的好奇心,让你有一些小动力去探索这个话题。所以,去点击文章中的那些 YouTube 和 TensorFlow 链接,享受学习的乐趣吧!
注意本系列的第二部分,关于如何训练你的 D̶r̶a̶g̶o̶n NN。
简介: Prateek Karkare 是一名电气工程师学员,对物理学、计算机科学和生物学充满浓厚兴趣。
原文。经许可转载。
资源:
相关:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织进行 IT 支持
更多相关主题
使用 Numpy 进行绝对初学者的神经网络:简介
原文:
www.kdnuggets.com/2019/03/neural-networks-numpy-absolute-beginners-introduction.html
评论
由Suraj Donthi,计算机视觉顾问及 DataCamp 课程讲师
人工智能已成为当今最热门的领域之一,我们大多数希望进入这一领域的人都从神经网络开始!!
但是,当面对神经网络中的数学密集概念时,我们最终只会学习一些框架,如 Tensorflow、Pytorch 等,用于实现深度学习模型。
此外,仅仅学习这些框架而不理解其基础概念就像在玩一个黑箱。
无论你是想在行业还是学术界工作,你都将涉及到模型的工作、调整和使用,这要求你对这些概念有清晰的理解。行业和学术界都期望你对这些概念,包括数学,有充分的了解。
在这一系列教程中,我将通过逐步讲解让神经网络变得非常简单易懂。此外,你需要的数学知识将是高中水*。
让我们从人工神经网络的起源开始,并获得一些关于其演变的灵感。
关于神经网络如何发展的简要历史
必须指出的是,大多数在 1950–2000 年间开发的神经网络算法,及其现存算法,都高度受到我们大脑、神经元的工作方式、其结构以及它们如何学习和传递数据的启发。最著名的作品包括感知机(1958 年)和新认知网络(1980 年)。这些论文在解开大脑代码方面极为重要。它们试图数学化地构建我们大脑中的神经网络模型。
一切都在 1986 年由人工智能教父 Geoffrey Hinton 公式化反向传播算法之后发生了变化(没错,你学习的内容已有 30 多年历史!)。
一个生物神经元
 上图展示了一个生物神经元。它有树突接收来自其他神经元的信息。接收到的信息会传递到神经元的细胞体或细胞核。细胞核是处理信息的地方,并通过轴突将信息传递给下一个神经元层。
上图展示了一个生物神经元。它有树突接收来自其他神经元的信息。接收到的信息会传递到神经元的细胞体或细胞核。细胞核是处理信息的地方,并通过轴突将信息传递给下一个神经元层。
我们的大脑包含大约 1000 亿个这样的神经元,它们通过电化学信号进行通信。每个神经元都连接到数百甚至数千个其他神经元,这些神经元不断地传递和接收信号。
但我们的脑袋是如何仅通过发送电化学信号来处理如此多的信息的?神经元如何理解哪个信号是重要的,哪个不是?神经元如何知道要传递什么信息?
电化学信号由强信号和弱信号组成。强信号决定了哪些信息是重要的。因此,只有强信号或它们的组合通过核(神经元的 CPU)传递,并通过轴突传输到下一组神经元。
那么,为什么有些信号强而有些信号弱呢?
通过数百万年的进化,神经元已经变得对某些类型的信号敏感。当神经元遇到特定模式时,它们会被触发(激活),从而向其他神经元发送强信号,因此信息得以传递。
我们大多数人也知道,大脑的不同区域在执行诸如视觉、听觉、创造性思维等不同动作时会被激活(或接收)。这是因为大脑中特定区域的神经元被训练以更好地处理某种信息,因此只有在特定信息传递时才会被激活。下图帮助我们更好地理解大脑的不同接收区域。
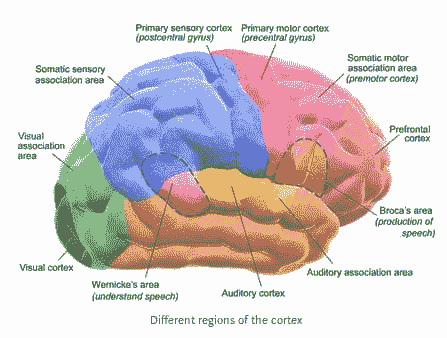 如果是这样的话… 神经元能否对不同的模式变得敏感(即,如果它们真的基于某些模式变得敏感)?
如果是这样的话… 神经元能否对不同的模式变得敏感(即,如果它们真的基于某些模式变得敏感)?
通过神经可塑性研究已显示,大脑的不同区域可以被重新连接以执行完全不同的任务。例如,负责触觉的神经元可以被重新连接以对嗅觉变得敏感。查看下面这个精彩的 TEDx 视频,以了解更多关于神经可塑性的内容。
TEDx 视频关于神经可塑性 [Source]
那么,神经元如何变得敏感呢?
不幸的是,神经科学家们仍在努力弄清楚这一点!!
但幸运的是,人工智能的奠基人 Geff 发明了反向传播,完成了对我们人工神经元的相同任务,即使它们对某些模式变得敏感。
在下一部分中,我们将探讨感知机的工作原理,并获得数学直觉。
感知机/人工神经元
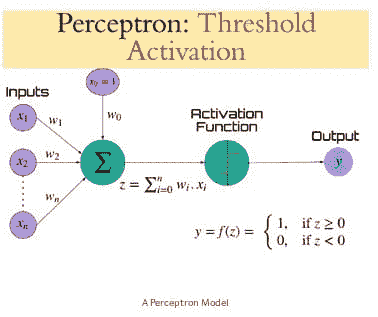
从图中可以观察到,感知机是生物神经元的反映。与权重(wᵢ)结合的输入类似于树突。这些值被求和并通过激活函数(如图中所示的阈值函数)传递。这类似于核。最后,激活值传递到下一个神经元/感知机,这类似于轴突。
潜在的权重(wᵢ)与每个输入(xᵢ)相乘,表示各自输入信号的重要性(强度)。因此,权重值越大,特征就越重要。
从这个架构中你可以推断出,权重是感知器中学习到的内容,以便得到所需的结果。一个额外的偏置(b,这里是 w₀)也是学习到的。
因此,当输入有多个(假设为 n)时,方程可以推广为:
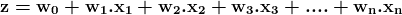
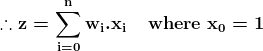
最终,求和的输出(假设为 z)被送入 阈值激活函数,该函数输出
一个例子
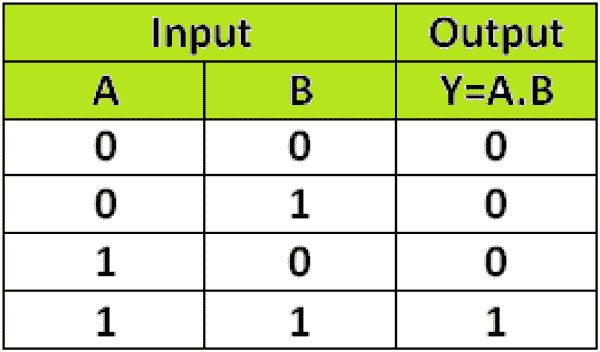
让我们考虑将感知器作为逻辑门来获得更多直观的理解。
让我们选择一个 AND Gate。该门的真值表如下所示:
AND Gate 的感知器可以如图所示。很明显,感知器有两个输入(这里是 x₁ = A 和 x₂ = B)。
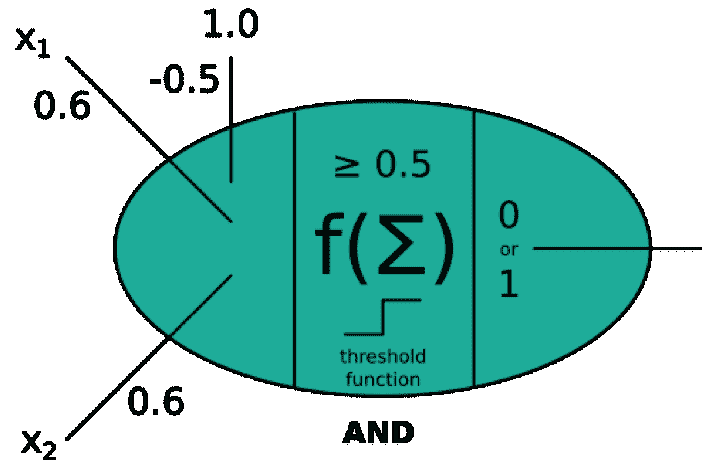
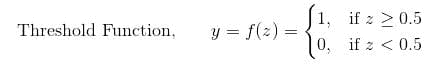
我们可以看到,对于输入 x₁, x₂ 和 x₀ = 1,将它们的权重设置为
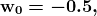
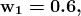
分别设置权重并保持 阈值函数 作为激活函数,我们可以得到 AND Gate。
现在,让我们动手实践,将这些内容编码并进行测试吧!
def and_perceptron(x1, x2):
w0 = -0.5
w1 = 0.6
w2 = 0.6
z = w0 + w1 * x1 + w2 * x2
thresh = lambda x: 1 if x>= 0.5 else 0
r = thresh(z)
print(r)
>>>and_perceptron(1, 1)
1
类似地,NOR Gate 的真值表是,
NOR Gate 的感知器将如下所示:
你可以将权重设置为
以便你能得到一个 NOR Gate。
你可以继续将其实现为代码,如下所示:
def nor_perceptron(x1, x2):
w0 = 0.5
w1 = -0.6
w2 = -0.6
z = w0 + w1 * x1 + w2 * x2
thresh = lambda x: 1 if x>= 0.5 else 0
r = thresh(z)
print(r)
>>>nor_perceptron(1, 1)
0
实际上你在计算的内容是…
如果你分析一下你在上述示例中所做的事情,你会发现你实际上是在调整权重值以获得所需的输出。
让我们考虑 NOR Gate 示例,并将其分解为非常细小的步骤以获得更好的理解。
通常你会首先设置一些权重值并观察结果,比如
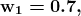
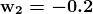
然后输出将如下面的表格所示:
那么,你如何调整权重值以获得正确的输出呢?
根据直觉,你可以很容易地观察到,w₀ 必须增加,而 w₁ 和 w₀ 必须减少或变为负值,以获得实际输出。但如果你深入分析这种直觉,你会发现你实际上是在找到实际输出和预测输出之间的差异,并最终将其反映到权重上……
这是一个非常重要的概念,你将深入挖掘,并将成为形成梯度下降和反向传播背后理念的核心。
你学到了什么?
-
神经元必须对模式变得敏感才能识别它。
-
因此,同样地,在我们的感知器/人工神经元中,需要学习的是权重。
在后续文章中,你将充分理解权重是如何被训练以识别模式的,以及存在的不同技术。
正如你稍后会看到的,神经网络与生物神经网络的结构非常相似。
虽然在本文的第一部分我们只学习了几个小概念(尽管非常重要),但它们将成为实现神经网络的坚实基础。此外,我保持这篇文章简短而精炼,以免一次性提供过多信息,有助于更好地吸收!
在下一个教程中,你将详细学习 线性回归(也可以称为具有线性激活函数的感知器),并进行实现。帮助学习权重的梯度下降算法将被详细描述和实现。最后,你将能够利用线性回归预测事件的结果。所以,前往下一篇文章进行实现吧!
你可以在这里查看文章的下一部分:
使用 Numpy 的神经网络绝对初学者 — 第二部分:线性回归
简历: Suraj Donthi 是一位计算机视觉顾问、作者、机器学习和深度学习培训师。
原文. 经许可转载。
相关:
-
神经网络 – 直观理解
-
反向传播算法揭秘
-
掌握学习率以加速深度学习
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
更多相关内容
Keras 教程:使用神经网络识别井字棋获胜者
原文:
www.kdnuggets.com/2017/09/neural-networks-tic-tac-toe-keras.html

"井字棋残局" 是我几年前用来构建神经网络的第一个数据集。当时我并不真正知道自己在做什么,因此效果并不是很好。由于最*我花了很多时间在 Keras 上,我想再次尝试这个数据集,以演示如何使用 Keras 构建一个简单的神经网络。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
数据
该数据集,可在此处获得,是一个包含 958 种可能的井字棋残局板配置的集合,其中 9 个变量代表井字棋板上的 9 个方格,第十个类别变量指明描述的棋盘配置是否是玩家 X 的胜利(positive)或非胜利(negative)结局。简而言之,某个 X 和 O 的组合是否意味着 X 获胜?顺便提一下,井字棋的可能玩法有 255,168 种。
这里是数据的更正式描述:
py` 1. 左上方格:{x,o,b} 2. 上中方格:{x,o,b} 3. 右上方格:{x,o,b} 4. 左中方格:{x,o,b} 5. 中中方格:{x,o,b} 6. 右中方格:{x,o,b} 7. 左下方格:{x,o,b} 8. 下中方格:{x,o,b} 9. 右下方格:{x,o,b} 10. 类别:{positive,negative} ```py ````
如图所示,每个方格可以被标记为 X、O 或在游戏结束时留空(b)。变量到实际方格的映射见图 1。记住,结果是基于 X 是否获胜来决定的。图 2 展示了一个示例棋盘残局布局,随后是其数据集表示。
图 1. 变量到实际井字棋板位置的映射。
图 2. 示例棋盘残局布局。
py` b,x,o,x,x,b,o,x,o,positive ```py ````
准备工作
为了使用数据集构建神经网络,需要一些数据准备和转换。以下是这些步骤的概述,以及在代码中进一步的注释。
-
将分类变量编码为数字 - 每个方格在原始数据集中表示为单一变量。然而,这对于我们的目的来说不可接受,因为神经网络需要具有连续值的变量。我们必须首先将 {x, o, b} 转换为 {0, 1, 2}。这将使用 Scikit-learn 的 LabelEncoder 类 和 预处理模块 来完成。
-
对所有独立的分类变量进行独热编码 - 一旦分类变量被编码为数字,就需要进一步处理。由于这些变量是无序的(例如,X 不大于 O),这些变量必须表示为一系列位等效值。这可以通过独热编码来实现。由于每个方格有 3 种可能性,因此编码需要 2 位。这将通过 Scikit-learn 的 OneHotEncoder 类 来完成。
-
删除每第三列以避免虚拟变量陷阱 - 由于 Scikit-learn 的独热编码过程为每个变量创建了与可能选项数量相等的列(根据数据集),因此需要删除一列以避免所谓的虚拟变量陷阱。这是为了避免冗余数据可能导致的结果偏差。在我们的情况下,每个方格有 3 个可能选项(27 列),可以用 2 列“位”来表示(我留给你确认),因此我们从新形成的数据集中删除每第三列(剩下 18 列)。
-
编码目标分类变量 - 与独立变量类似,目标分类变量也必须从 {positive, negative} 更改为 {0, 1}。
-
训练/测试集划分 - 这一点应该是可以理解的。我们将测试集设置为数据集的 20%。我们将使用 Scikit-learn 的 训练/测试集划分功能 来实现。
网络
接下来,我们需要构建神经网络,这将使用 Keras 完成。请记住,我们处理后的数据集有 18 个变量用作输入,我们进行的是二元分类预测作为输出。
-
输入神经元 - 我们有 18 个独立变量,因此我们需要 18 个输入神经元。
-
隐藏层 - 确定每个隐藏层神经元数量的一个简单(或许过于简单)——也可能完全无意义——起点是经验法则:将独立变量的数量和输出变量的数量相加,然后除以 2。如果我们决定向下取整,这将给我们 9。那么隐藏层的数量呢?最好的办法是从少量(隐藏层)开始,逐渐增加,直到网络准确率不再提高。我们将创建一个包含 2 个隐藏层的网络。
-
激活函数 - 隐藏层和输出层神经元需要激活函数。一般规则规定:隐藏层神经元默认使用 ReLU 函数,而二分类输出层神经元使用 sigmoid 函数。我们将遵循惯例。
-
优化器 - 我们将在网络中使用Adam 优化器。
-
损失函数 - 我们将在网络中使用交叉熵损失函数。
-
权重初始化 - 我们将随机设置网络层神经元的初始随机权重。
以下是我们网络的最终外观。
图 3。 网络层的可视化。
代码
这是执行上述所有操作的代码。
结果
训练网络的最大准确率达到了 98.69%。在未见过的测试集中,神经网络正确预测了 186 个实例中的 180 个类别。
通过更改训练/测试划分的随机状态(这会改变用于测试最终网络的特定 20%的数据集实例),我们能够将其提高到 186 个实例中的 184 个。然而,这不一定是一个真正的指标改进。一个独立的验证集可能会对此有所启示……如果我们有的话。
通过使用不同的优化器(与 Adam 相对),以及更改隐藏层的数量和每个隐藏层的神经元数量,训练后的网络没有在损失、准确率或正确分类的测试实例方面超出上述报告的结果。
我希望这能为你构建 Keras 神经网络提供一个有用的介绍。下一个教程将介绍卷积神经网络的构建。
相关:
-
使用 R 和 Keras 进行深度学习
-
理解深度学习的 7 个步骤
-
深度网络架构的直观指南
更多相关内容
神经科学数据科学:理解人类行为
原文:
www.kdnuggets.com/2017/03/neuroscience-data-science-human-behaviour.html
编辑注: 以下是市场营销和分析领域领先专家凯文·格雷与统计学和神经科学领域领先专家妮可·拉扎尔之间的讨论。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
凯文·格雷: 营销人员经常将“神经科学”一词使用得非常随意,并且在某些情况下可能在技术上是不正确的。例如,我曾听到在“心理学”足够的情况下使用“神经科学”。你能用普通人的话告诉我们这对你意味着什么吗?
妮可·拉扎尔: 对我来说,神经科学大致指的是对大脑的研究。这可以通过多种方式实现,从“单个神经元记录”——在简单生物的神经元中放置电极——到通过功能性磁共振成像(fMRI)、正电子发射断层扫描(PET)、脑电图(EEG)等方法对人类进行认知神经影像学。这些单个神经元记录提供了非常直接的活动测量——你实际上可以测量神经元活动随时间的变化(例如,响应某种刺激)。显然,我们通常不能在人体上进行这种记录;fMRI、PET 等提供的是间接的大脑激活和活动测量。这些也许是神经科学光谱的两个极端。“神经科学”和“心理学”之间存在重叠,但并不是所有参与神经科学的人都是心理学家——还有工程师、物理学家、应用数学家,当然,还有统计学家。
KG: 许多营销人员认为,无意识过程或情感通常主导消费者决策。因此,如果营销假设消费者是完全理性的经济行为者,那么效果将会减弱。由丹尼尔·卡尼曼、丹·艾瑞里等人普及的系统 1(“快速思维”)被营销人员广泛用于描述这种非理性的决策方面。维基百科引用的说法是:“系统 1 思维是直观的、无意识的、毫不费力的、快速的和情感驱动的。相比之下,由系统 2 驱动的决策则是深思熟虑的、有意识的、缓慢且费力的。” “隐含的”有时也用作系统 1 思维的同义词。现在神经科学家们是否就人们的决策过程达成了共识?还是说这仍然是一个有争议的问题?
NL: 我认为神经科学家们对人们如何处理信息、做决策等问题没有达成共识!“有争议”这个词可能太过强烈,但这些事情确实非常复杂。卡尼曼的框架很吸引人,它为理解世界上许多可观察现象提供了一个视角。不过,我不认为这就是全部故事。尽管我没有跟进过,但我相信最*的一些研究也打破了系统 1/系统 2 的二分法。显然,我们在更深刻的理解之前还有很长的路要走。
KG: 神经营销对不同的人来说可能意味着不同的东西,但广义上,它试图测量对营销刺激的无意识反应,即快速思维/隐含反应。 fMRI、EEG、MEG、监测心率和呼吸率的变化、面部编码、皮肤电反应、拼贴以及隐性联想测试可能是最常用的工具。基于你在神经科学方面的专业知识,这些工具中是否有不合适的,或者它们都以某种方式有效地测量隐含/快速思维?
NL: 首先,我不认为所有这些测量方法本质上都是“神经科学”的,至少不是我理解的那个定义。心跳和呼吸的变化,皮肤电反应——这些肯定是生理反应,但比 EEG 和 fMRI 更间接地反映了大脑的激活状态。这并不是说它们与个体如何对特定市场刺激做出反应完全没有关系。但我认为在基于这些不完美、不精确且间接的工具得出结论时应该谨慎。其次,至于 fMRI、EEG 和其他神经影像技术,这些显然更接*源头。然而,我对其中一些技术捕捉“快速思维”的能力持怀疑态度。例如,功能性磁共振成像的时间分辨率较低:图像获取的时间是以秒为单位的,而神经活动,包括我们对广告等刺激的反应,发生得要快得多——以毫秒为单位。EEG 的时间分辨率更好,但空间分辨率较差。要对我们的大脑如何、何时以及在哪里对市场刺激作出反应得出具体结论,需要时间分辨率和空间分辨率都很高。
KG: 一些大型市场研究公司和广告机构已经在神经营销方面投入了大量资金。特别是功能性磁共振成像(fMRI)和脑电图(EEG)*年来吸引了许多营销人员的注意。首先,从 fMRI 开始,你认为这两种方法作为神经营销技术的优缺点是什么?
NL: 我已经提到了一些:分辨率是关键。fMRI 具有良好的空间分辨率,这意味着我们可以以毫米级精度定位大脑中的哪些区域对刺激做出了反应。通过非常基本的统计分析,我们可以定位激活区域。这是 fMRI 作为影像技术受欢迎的一个优点和重要部分。从统计建模的角度来看,更难理解的是,例如,大脑区域激活的顺序,或者一个区域的激活是否引发了另一个区域的激活,这些往往是科学家(以及可能从事神经营销的人)真正关心的问题。许多统计学家、应用数学家和计算机科学家正在开发方法来回答这些更复杂的问题,但我们还没有真正解决这些问题。
fMRI 作为神经影像研究工具的主要缺点仍然是其相对较差的时间分辨率。当我们告诉人们我们可以在两到三秒内扫描整个三维大脑时,这听起来很令人印象深刻——如果你想想,其实这真的很了不起——但与大脑处理信息的速度相比,这种速度太慢了,不能允许研究人员回答他们感兴趣的许多问题。
我认为,fMRI 在神经营销中的另一个缺点是成像环境本身。我的意思是,你需要将受试者带到一个有 MRI 机器的地方,这是一台非常强大的大磁铁。它们的获取、安装和运行成本都很高,这对许多研究机构来说都是一个限制。你必须将受试者放入扫描仪中。有些人有幽闭恐惧症,无法忍受这种环境。如果你曾经做过 MR 扫描,你会知道机器非常吵,这也会令人不安和分心。这也意味着研究(在这种情况下是市场营销研究,但任何 fMRI 研究都是如此)是在高度人工的条件下进行的;我们通常不会在磁共振成像扫描仪中观看广告。
KG: 那么 EEG 呢?
NL: EEG 和 fMRI 的分辨率问题是相反的。EEG 具有非常好的时间分辨率,因此有可能更实时地记录神经活动的变化。对于那些试图精确测定微妙的时间变化的人来说,这可能是一个优势。在成像环境方面,EEG 一般比 fMRI 更友好和更容易。个人只需佩戴一个带电极的帽子,这并不太繁琐或不自然。帽子本身也不贵,这对研究人员来说也是一个好处。
另一方面,EEG 的空间分辨率较差有两个原因。一个是帽子上的电极数量通常不多——覆盖在头皮表面的电极有几百个。乍看之下可能觉得很多,但当你考虑到每个电极覆盖的区域,尤其是与 fMRI 的毫米级精度相比时,激活的定位非常模糊。此外,电极在头皮上,距离大脑产生的信号还很远。这一切意味着,通过 EEG,我们对大脑激活发生的位置了解非常不准确。
KG: 作为一名从事神经科学的统计学家,你认为神经科学面临的最大测量挑战是什么?
NL: 数据通常很嘈杂,而且在统计学家能看到之前,还会经历许多预处理阶段。这意味着一种已经间接的测量在分析之前会经过不确定数量的数据处理。这是一个巨大的挑战,许多人已经为此苦苦挣扎多年。关于噪声,来源有很多,有些来自技术,有些来自受试者。更复杂的是,受试者产生的噪声可能与实验刺激有关。例如,在眼动 fMRI 研究中,受试者可能会在看向刺激的方向时,稍微转动整个头部,这会污染数据。同样,在 EEG 研究中,有证据表明测量信号可能会与面部表情混淆。这两者都会对神经市场营销和其他热门应用的成像使用产生影响。此外,数据量很大;虽然在许多现代应用的规模中不算“巨大的”,但绝对足够大,以至于在存储和分析上会带来挑战。最后,当然,我们无法直接测量大脑活动和激活,并且可能永远无法做到这一点,这是我们面临的最大测量挑战。当测量的数据与源信号有些偏离、嘈杂且高度处理时,很难得出可靠的结论。
KG: 考虑到未来 10 到 15 年,你是否预测到那时我们会最终破解人类大脑的秘密,完全理解我们的大脑及其运作机制?还是说这将需要更长的时间?
NL: 我承认我对在 10 到 15 年内完全理解人类大脑持怀疑态度。那是一个很短的时间范围,而我们大脑的运作非常复杂。此外,“破解代码”是什么意思?在神经元及其相互连接的层面,我难以相信我们很快(如果有的话)就能达到那个程度。那是一个非常细微的尺度;人脑中有数十亿个神经元,连接太多了难以建模。即使我们能够做到这一点,我也不认为这个过程会真正揭示什么使我们成为人类,是什么让我们运转。所以,我不认为我们会建造出完全模仿人脑的人工智能或计算机——我也不确定我们为什么会想这样做,从中具体能学到什么。也许如果我们考虑神经元的集合——我们称之为“兴趣区域”(ROIs)以及这些区域之间的连接,可能会取得进展。例如,涉及语言处理的不同 ROIs 如何相互作用,使我们能够理解和生成语言?这些问题我们可能更接*回答,尽管我仍然不确定 10 到 15 年是否是合适的时间框架。不过,统计学家本来就天生怀疑!
KG: 谢谢你,Nicole!
原文. 经许可转载。
简介: 凯文·格雷 是 坎农·格雷 的总裁,这是一家市场科学与分析咨询公司。 尼科尔·拉扎 是乔治亚大学的统计学教授,并且是《功能性磁共振成像数据的统计分析》一书的作者。她是美国统计协会的选举会员,也是 美国统计学家 的主编。
相关内容:
-
你害怕问的人工智能问题(二):神经科学
-
克服追寻市场“圣杯”过程中的最后障碍
-
一种美味的数据科学方法
该主题的更多信息
来自 OpenAI 的新 ChatGPT 和 Whisper API
原文:
www.kdnuggets.com/2023/03/new-chatgpt-whisper-apis-openai.html

作者提供的图片
如果你认为你已经听到关于 ChatGPT 的所有信息,那你错了。OpenAI 已将其 ChatGPT 和 Whisper 模型开放给 API,使开发者可以访问 AI 驱动的语言和语音转文本功能。
让我们先退一步。有些人可能不知道什么是 ChatGPT 或 Whisper。所以让我给你一个简单的说明。
什么是 ChatGPT?
ChatGPT 是由 OpenAI 于 2022 年 11 月推出的基于 AI 的聊天系统。它使用生成预训练变换器 3(GPT-3)和一个自回归语言模型来生成类人文本。它是一个语言处理 AI 模型,经过训练可以预测下一个标记是什么。
ChatGPT 可以做的示例包括
-
从文章到论文,撰写长篇内容。
-
撰写短篇诗歌和打油诗
-
将复杂话题简化为通俗易懂的术语
-
帮助你规划和组织会议、假期等。
-
个性化交流
如果你想了解更多关于 ChatGPT 的信息,请查看以下文章:
-
ChatGPT:你需要知道的一切
-
ChatGPT 作为 Python 编程助手
-
ChatGPT 备忘单
ChatGPT API
ChatGPT 模型系列已经扩展,因为 OpenAI 发布了:gpt-3.5-turbo。这个新模型的价格为每 1k 标记 $0.002,比现有的 GPT-3.5 模型便宜 10 倍。
GPT 模型传统上使用非结构化文本,然后将其表示为一系列“标记”。然而,使用 ChatGPT 时,模型使用消息序列及其元数据。
什么是 Whisper?
2022 年 9 月,OpenAI 推出了 Whisper —— 一个自动语音识别(ASR)系统。这个语音转文本模型是开源的,并且获得了开发者社区的广泛赞誉。
它已经在包含多种语言的多样化音频的大型数据集上进行了 680,000 小时的训练。该模型还具有多任务处理能力,可以执行多语言语音识别、语音翻译和语言识别。这些大型数据集是从网上收集的监督数据。
上述任务作为一系列标记一起表示,以便解码器可以对其进行预测。这些任务的结合自然消除了传统语音处理管道中通常发生的几个阶段。它可以处理不同格式的文件,如 M4A、MP3、MP4、MPEG、MPGA、WAV 和 WEBM。
以下是 OpenAI 的 Whisper 方法的图片:
来自 OpenAI GitHub 的图片
Whisper API
OpenAI 听取了消费者的需求,并考虑到 Whisper 运行的难度。因此,他们现在有一个大型 v2 模型,通过 API 提供便捷的按需访问。其定价为每分钟 $0.006。
用户还将受益于 OpenAI 高度优化的服务堆栈,该堆栈提供快速的性能。
ChatGPT 和 Whisper
OpenAI 能够将 ChatGPT 的成本降低了 90%,看起来这一节省的成本现在为 API 用户开辟了更多机会。他们希望让开发者接触到尖端的语言和语音转文本能力。
开发者现在可以使用 OpenAI 的开源 Whisper 大型 v2 模型,该模型提供了更快和更具成本效益的结果。至于 ChatGPT,该模型将不断进行改进,API 用户将受益于此,同时对其模型有更深入的控制。
在收到开发者反馈后,OpenAI 做出了一些具体的改动,以帮助开发者体验:
-
开发者文档的改进
-
通过 API 提交的数据不会用于服务改进,除非你选择加入。
-
30 天的保留策略,并可根据需要选择更严格的保留选项。
开发者不必再使用 OpenAI 当前的语言方法,ChatGPT 和 Whisper API 将允许第三方开发者轻松集成到他们的*台中。
专用实例
OpenAI 还为需要更深入控制模型版本和系统性能的用户提供专用实例。开发者将按时间段付费,并分配符合他们需求的计算基础设施。这对计划每天运行 450M 个标记的开发者来说非常有经济意义。
他们将完全控制实例的负载,有启用功能和固定模型快照的选项。这不仅能减少开发者的成本,还能使他们的流程更高效。
总结
ChatGPT 和 Whisper API 的推出预计将对开发者社区产生深远的影响。它为开发者提供了新的最先进工具和能力,使他们能够构建更好、更先进的基于语言的应用程序。
尼莎·阿亚 是 KDnuggets 的数据科学家、自由技术写作人和社区经理。她特别关注提供数据科学职业建议或教程,以及数据科学的理论知识。她还希望探索人工智能如何/能够促进人类生命的延续。她是一个热衷学习的人,寻求拓宽技术知识和写作技能,同时帮助指导他人。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 部门
更多相关主题
(不那么) 新的数据科学家韦恩图
原文:
www.kdnuggets.com/2016/09/new-data-science-venn-diagram.html
评论
我认为 Drew Conway 早期尝试通过韦恩图定义数据科学是很有威望的,尽管最终由于时间的推移以及对数据科学实际意义的变化,存在一些缺陷。它曾是一个很好的方式,通过视觉手段尝试向人们解释你所做或想做的事情,尤其是在你经过深思熟虑和精心构建的口头解释后,对方却只是茫然地盯着你。或者回应类似“哦,你做大数据?”或者更加基础(且令人沮丧)的“你在用电脑工作吗?你知道吗,我的屏幕坏了。能帮我看看吗?”
出于某种原因,我从未喜欢图表中包含“黑客技能”,因为这似乎更像是数据科学家的技能(从业者),而不是数据科学本身。也许是语义问题。当然,这只是我的观点,对显然在特定时间段内发挥了作用的图表的一点小批评。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织的 IT
但是数据科学已经发生了变化,对数据科学家的期望也发生了变化。关于什么构成数据科学家没有共识 - 我们在这里不讨论这个 - 而独角兽最好还是留在我讲给女儿的睡前故事里。但是,数据科学仍然是一个(永恒的?) 未定概念并不意味着我们不应该尝试缩小范围,并对他人的尝试持开放态度。这就是 Stephan Kolassa 的新 数据科学家韦恩图 的作用所在。
好吧,虽然它不完全是新的,但对我来说(通过 Gil Press)是新的。

这是 Kolassa 在去年秋天 Data Science Stack Exchange 论坛上揭示该图表时的相关引用:
我仍然认为黑客技能、数学与统计知识以及实质性专长(为了可读性缩写为“编程”、“统计”和“商业”)很重要……但我认为沟通的角色也很重要。你通过利用你的黑客、统计和商业专长获得的所有见解,除非你能将其传达给那些可能没有这种独特知识组合的人,否则不会有任何效果。你可能需要向一个需要被说服花钱或改变流程的业务经理解释你的统计见解。或者向一个不懂统计的程序员解释。
比“原始版本”更复杂吗?绝对是。细节丰富吗?当然是。容易引发争议吗?绝对是。
实际上,Kolassa 自己也明白这一点:
我已经以保证最大程度争议的方式标记了这些领域,同时便于记忆。
作者的幽默感抛开不谈,虽然像这样的工作必然会引起一些争议并引发讨论,但特别是在将你对数据科学家的定义与他人的定义进行比较时,看看这个问题还是很有用的。这是一个必要的工作吗?绝对不是。但它很有趣。我们都这么做。
我相信你看了这个图表会立刻感到焦虑,迫不及待地想表达你的意见。立即浮现在我脑海中的几件事包括:
-
销售人员???
-
完美的数据科学家似乎距离我喜欢的 IT 主管有几步之遥 😃
但与其自己喋喋不休,不如看看别人遇到我称之为(不那么)新的数据科学家 Venn 图时的一些观点。
用户 Robert de Graaf 在原始 Stack Exchange 讨论帖上的评论提供了以下相对温和的观察:
我认为这比原始的 Conway 版本有了很大的改进,尽管我仍然无法完全摆脱这种观念——从重叠的大小暗示——即统计学教授是一个在统计和沟通方面都有相等技能的人。
El Brown 在博客Unicorn Whispering(“试图让神话般的数据科学世界变得对像我这样普通的人可及”)上对这个特定的 Venn 图有这样的间接评价:
如果你认为你确实需要数据科学家的专业技能,不要过于纠结于寻找一个拥有你认为需要或被告知拥有的每一项技能的数据科学家。创建一个具备所需技能、知识和经验的多样化团队——一种众包数据科学家——有很多好处。
Chris Moffit 在网站 Practical Business Python 上,提供了一个支持性的贡献:
我的经历进一步强化了我的信念,“完美的数据科学家”确实存在于这些多个职能的交汇处。
最后,一位未知作者,可能将其英语翻译成我认为的中文,或将其中文翻译成英语,提供了一些喜剧效果:
从科拉萨的维恩图中的完美数据科学家是一个神话般的性感独角兽忍者摇滚明星,他仅凭思考问题就能改变一个商业。
人生目标,朋友们。
谷歌搜索“神话般的性感独角兽忍者摇滚明星”没有提供任何值得(或适当)在此发布的内容。不过,有一个数据科学家Yanir Seroussi的图片确实位于前几名结果中,这让他感到荣幸。
这一切(大多)都是出于好玩的目的。对斯特凡·科拉萨表示尊敬,他通过更新我们都熟悉的经典图表,使数据科学技能更易于可视化。不管是爱还是恨,或者漠不关心,都是如此。唉。
同样对所有花时间评论他工作的人的尊敬,因为他们都知道,我确信,这有助于不断增长的数据科学职业评论数据,我们可以分析到脸色发青。这让我想知道,马拉松分析技能是否值得出现在这些图表的新版本中。我应该马上开始做一个...
相关:
-
数据科学难题,解析
-
数据科学过程,再发现
-
数据科学家是否如你所想?
了解更多主题
使用 Python 为你的照片添加新的维度
原文:
www.kdnuggets.com/2021/06/new-dimension-photos-python.html
评论
作者 Dylan Roy,工程师兼副项目爱好者

作者提供的图片
背景故事
在查看了几周前的一次露营旅行中的一些照片后,我决定拿出我以前的假期照片,用 Python 将它们制作成幻灯片。不要担心,我是在理解 Google Photos 和 Apple 等效工具已经非常擅长这方面的情况下进行的。这纯粹是为了满足我对构建副项目的瘾。
在查看可用选项时,我偶然发现了一篇带有代码的论文,该代码可以为你的照片添加一个应用 3D Ken Burns 效果的过渡。Ken Burns 效果在视频中自然地获得了 3D 效果,但在照片中则因为缺少那个维度而显得不那么吸引人。因此,在接下来的介绍中,我希望能帮你尝试并为你的照片添加这个额外的维度,就像我做到的那样。
概念
这里有一些概念是值得了解的,因为它们与我们希望实现的目标相关。尽管我们不需要了解这些,AI 模型通过估算照片中物体的深度来正确缩放物体的大小,从而为我们的 Ken Burns 效果应用了 3D 维度。随着效果在照片中的移动,模型需要通过修补来重建缺失的物体和纹理,这些在 2D 图像中并未出现。
Ken Burns 效果—对照片进行缩放和*移会产生运动的感觉。它以一位美国纪录片制作者的名字命名,他经常使用这种效果。该论文的作者为这种效果添加了通常在照片中缺失的第三维度。

CC BY-SA 3.0,通过 Wikimedia Commons
深度估计 — 描述了获取场景中物体距离测量的方法。有效地进行这项工作将导致令人信服的过渡,并且会随着视差缩放每个物体。
修补 — 这描述了由于过渡的视角变化而重建图像中不存在的部分的方法。在图像和视频中,这种技术也指修复受损、恶化或缺失的艺术品部分,以呈现完整的图像。
自己动手做
幸运的是,这篇论文的作者,Simon Niklaus、Long Mai、Jimei Yang、Feng Liu 提供了一个代码库,允许我们使用一些预训练模型将这种效果应用于我们的照片。我注意到这些模型对前景中有许多锐利边缘的照片效果不好,但对我测试过的一些照片却产生了相当令人印象深刻的结果。
我不会详细讲解如何实现这些功能,因为作者们已经在他们的论文、Github 仓库和 YouTube 视频中介绍了这些内容,这些资源都在最后的资源部分提供了。
我将引导你完成创建这些 3D 场景的方法,但如果你想在本节末尾直接尝试,我已经将我们将要讲解的所有代码添加到一个 Google Colab 中,你可以立即复制和使用。
在自己操作之前,我建议打开一个新的 Google Colab,因为在我讲解的代码示例中,我使用了一些 Colab 特定的功能以提高使用的便捷性。
设置环境和安装要求
使其正常工作的第一步是导入包含该实现和预训练模型的仓库。下面发生的操作是我们克隆了仓库,导航到它,创建输出目录,并安装所需的库。Google Colab 在启动新运行时时已经预加载了许多要求,所以只有两个是缺失的。
!git clone https://github.com/sniklaus/3d-ken-burns.git# Move into the downloaded repository
%cd 3d-ken-burns# Make a directory for the videos
!mkdir videos
video_dir = "./videos/"# Install dependencies
!pip install moviepy gevent
上传照片
在这个阶段,你只需要一个简单的方法来将照片上传到你的源/图像目录。你不必将其包含在你的笔记本中,只需通过 Colab 界面将文件拖放到相应的文件夹中即可,但这确实是一个相当不错的便利单元。
from google.colab import filesuploads = files.upload()for filename in uploads.keys():
!mv ./$filename ./images/$filename
转换你的照片
如果我们不想转换所有提供给两个目录的照片,可以使用以下简单的一行命令,这只需利用autozoom.py接口转换一张照片。
python autozoom.py --in {input_image}.jpg --out {output_video}.mp4
尽管我们希望自动化可自动化的部分,但我们可以利用 bash,遍历目录并对每张照片执行操作。
!for image in ./images/*; do python autozoom.py --in $image --out ./videos/$(basename $image | cut -f1 -d '.').mp4; done
查看你的视频
一旦你的照片转换完成,你可能想先查看输出,我们使用 IPython 的功能来构建查看视频的函数,然后提供一个选择器,供我们在目录中选择要查看的视频。
import os
from base64 import b64encodefrom IPython.display import HTML
import ipywidgets as widgetsdef video(path):
mp4 = open(path,'rb').read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
return HTML(f'<video width=600 controls loop> <source src="{data_url}" type="video/mp4"></video>')files_list = os.listdir(video_dir)
video_list = widgets.Dropdown(
options=files_list,
value="" if not files_list else files_list[0],
description='Video:',
disabled=False,
)
display(video_list)
将 Mp4 转换为动画 GIF
我添加了这一步骤是为了将应用效果的输出上传并嵌入到这篇帖子中,因此和我的所有努力一样,请利用这些知识,随意将你的 mp4 文件转换为动图。作为额外奖励,我们已经将 imageio 作为依赖项导入,所以无需安装。下面我们将使用此函数,并遍历目标目录查找要转换的 mp4 文件。
import imageio
import os, sysclass TargetFormat(object):
GIF = ".gif"
MP4 = ".mp4"
AVI = ".avi"def convertFile(inputpath, targetFormat):
"""Reference: [`gist.github.com/michaelosthege/cd3e0c3c556b70a79deba6855deb2cc8`](https://gist.github.com/michaelosthege/cd3e0c3c556b70a79deba6855deb2cc8)"""
outputpath = os.path.splitext(inputpath)[0] + targetFormat
print("converting\r\n\t{0}\r\nto\r\n\t{1}".format(inputpath, outputpath))reader = imageio.get_reader(inputpath)
fps = reader.get_meta_data()['fps']writer = imageio.get_writer(outputpath, fps=fps)
for i,im in enumerate(reader):
sys.stdout.write("\rframe {0}".format(i))
sys.stdout.flush()
writer.append_data(im)
print("\r\nFinalizing...")
writer.close()
print("Done.")for file in [x for x in os.listdir(video_dir) if x.endswith(".mp4")]:
convertFile(f"{video_dir}{file}", TargetFormat.GIF)
下载所有视频
如果你不想使用文件浏览器下载输出文件。最后一步是遍历目标文件夹,并下载每个视频。这也可以像之前使用 bash 遍历和应用效果时一样完成。
for file in os.listdir(video_dir):
files.download(f"{video_dir}{file}")
如果一切顺利,你的照片应该已经正确转换,就像我在享受博洛尼亚时拍的其中一张照片一样。

图片由作者提供
对于那些希望跳过自己制作 Colab 笔记本的人,这里是完整的实现,你可以复制并开始转换你的照片集。
关键要点
站在巨人的肩膀上,我们生活在一个可以利用前沿 AI 技术的时代,这些技术帮助我们完成通常需要特定知识的人才能做的事情。在这种情况下,我们可以使用 Simon Niklaus 和团队开发的 AI 技术,而无需学习复杂的编辑技能。
其他 Dylan 的帖子
不再花时间手动调整对齐的箭头
使用 Github Actions 部署到 Google Cloud Run
一个可扩展的 CI/CD 解决方案,使用 Actions 和 Cloud Run 实现零扩展
通过自动化你的 Readme 个人资料展示你的技能
资源
-
其他利用 Arnaldo Gabriel 的论文的 Google Colabs,一个来自 Vlad Alex,还有一个来自 Ahmed Harmouche。
个人简介: 迪伦·罗伊 是一名工程师和副项目狂热者,分享他正在进行的工作,以便像你这样的读者可以从他的经验中受益。点击此处订阅更多内容 (dylanroy.com)
原文。已获得许可转载。
相关:
-
使用 5 行代码提取图像和视频中的对象
-
用 Python 自动化的 5 项任务
-
哪个面孔是真的?应用 StyleGAN 创建虚假人物
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 需求
更多相关话题
新调查:你使用了哪些数据科学/机器学习方法和工具?
原文:
www.kdnuggets.com/2017/11/new-poll-data-science-machine-learning-methods-used.html
评论新 KDnuggets 调查正在询问:
你在过去 12 个月中为工作或实际项目使用了哪些数据科学/机器学习方法和工具?
这里是调查结果:2017 年使用的顶级数据科学和机器学习方法
这是类似的 2016 年调查结果:

另见一项非常有趣的 Kaggle 调查 2017 年数据科学与机器学习现状,其中还包括了一个关于算法的部分。
Kaggle 调查问到:工作中使用了哪些数据科学方法?顶尖的回答是
-
逻辑回归(Logistic Regression)
-
决策树(Decision Trees)
-
随机森林(Random Forests)
-
神经网络(Neural Networks)
-
贝叶斯技术(Bayesian Techniques)
-
集成方法(Ensemble Methods)
-
支持向量机(SVMs)
-
梯度提升机(Gradient Boosted Machines)
-
卷积神经网络(CNNs)
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关话题
2018 KDnuggets 调查:在过去 12 个月中,您用于分析、数据挖掘、数据科学、机器学习项目的软件是什么?
原文:
www.kdnuggets.com/2018/05/new-poll-software-analytics-data-mining-data-science-machine-learning.html
评论 KDnuggets 第 19 届年度软件调查正在进行中
在过去 12 个月中,您用于分析、数据挖掘、数据科学、机器学习项目的软件是什么?
请在下方投票。 本次调查已结束 - 以下是结果:
我们尽力包括最受欢迎的工具和*台,同时保持选择总数在 90 个以下。
工具分为 4 个部分,每部分中的工具按字母顺序排列。
-
数据科学/机器学习*台,
-
语言(包括 R 和 Python),
-
Hadoop/Spark
-
深度学习工具
 将这些不同类型的工具结合在一个调查中有些混乱,但它允许之后进行有趣的关联分析,例如 新兴生态系统:数据科学和机器学习软件分析。
将这些不同类型的工具结合在一个调查中有些混乱,但它允许之后进行有趣的关联分析,例如 新兴生态系统:数据科学和机器学习软件分析。
这是第 19 次 KDnuggets 调查,过去几次调查中有些供应商的投票过于频繁。供应商可以要求用户投票,但设置机器人投票或直接链接只为一个工具投票是不允许的。
为减少过度和机器人投票,本次调查要求进行电子邮件验证 (*)。
无论发现其他不规则投票情况,将从最终结果中删除,我们将在调查后发布匿名的投票日志,供任何人分析。
我们希望我们的分析、趋势和结果对您有所帮助,正如过去一样。
这是过去 KDnuggets 分析、数据挖掘、数据科学软件调查的结果
-
分析、数据科学、机器学习软件调查中的新领军者、趋势和惊喜,2017
-
R 和 Python 角逐顶级分析与数据科学软件 - 软件调查结果,2016
-
R 领先,RapidMiner 紧随其后,Python 赶上,大数据工具增长,Spark 引燃,2015
-
RapidMiner 继续领先,2014
-
RapidMiner 和 R 争夺第一名,2013
-
KDnuggets 2012 年调查:使用的分析、数据挖掘、大数据软件
-
KDnuggets 2011 年调查:使用的数据挖掘/分析工具
-
KDnuggets 2010 年调查:使用的数据挖掘/分析工具
-
KDnuggets 2009 年调查:使用的数据挖掘工具
-
KDnuggets 2008 年调查:使用的数据挖掘软件
-
KDnuggets 2007 年调查:数据挖掘/分析软件工具
(*) 尚未订阅 KDnuggets 新闻的投票者将自动订阅我们关于有趣观点、有用教程和其他 AI、分析、数据科学、机器学习故事的报道,但如果不喜欢,可以通过一键轻松取消订阅。
主题更多内容
2019 年 KDnuggets 投票:在过去 12 个月中,您使用了什么软件进行分析、数据挖掘、数据科学、机器学习项目?
原文:
www.kdnuggets.com/2019/05/new-poll-software-analytics-data-science-machine-learning.html
评论 KDnuggets 第 20 次年度软件投票正在进行中
在过去 12 个月中,您使用了什么软件进行分析、数据挖掘、数据科学、机器学习项目?
以下是投票结果:
我们尽量包括了最受欢迎的工具和*台,同时保持选择总数在 100 个以内。
选择项分为 4 个部分,每个部分的条目按字母顺序排列。
-
数据科学/机器学习工具、*台和框架
-
编程和数据语言(包括 R 和 Python)
-
深度学习*台/框架
-
大数据*台
 将这些不同类型的工具和*台结合在一次投票中有些混乱,但这允许进行有趣的关联分析,例如开源数据科学/机器学习生态系统的 6 个组成部分。
将这些不同类型的工具和*台结合在一次投票中有些混乱,但这允许进行有趣的关联分析,例如开源数据科学/机器学习生态系统的 6 个组成部分。
这是第 20 次 KDnuggets 投票,过去的几次投票受到了一些供应商过度投票的影响。供应商可以邀请用户投票,但不允许设置机器人投票或直接链接仅投票给一个工具。
为了减少过度和机器人投票,本次投票要求进行电子邮件验证(*)。
不规则投票将从最终结果中删除,我们将在投票后发布匿名化的投票日志,以便任何人都可以分析它们。
我们希望我们对本次投票的分析、趋势和结果对您有所帮助,就像过去一样。
以下是过去 KDnuggets 的分析、数据挖掘、数据科学软件投票结果:
-
分析、数据科学、机器学习软件投票中的新领导者、趋势和惊喜,2017
-
R,Python 争夺顶级分析、数据科学软件 - 软件投票结果,2016
-
R 领先 RapidMiner,Python 紧随其后,大数据工具增长,Spark 点燃,2015
-
RapidMiner 继续领先,2014
-
RapidMiner 和 R 争夺第一名,2013
-
KDnuggets 2012 年调查:使用的分析、数据挖掘、大数据软件
-
KDnuggets 2011 年调查:使用的数据挖掘/分析工具
-
KDnuggets 2010 年调查:使用的数据挖掘/分析工具
-
KDnuggets 2009 年调查:使用的数据挖掘工具
-
KDnuggets 2008 年调查:使用的数据挖掘软件
-
KDnuggets 2007 年调查:数据挖掘/分析软件工具
(*) 尚未订阅 KDnuggets 新闻的投票者将自动订阅我们的 AI、分析、数据科学和机器学习报道。不喜欢的话,可以轻松一键退订。
更多相关主题
谷歌、Snowflake 和微软的新专业技术证书
原文:
www.kdnuggets.com/new-professional-tech-certificates-from-google-snowflake-microsoft

作者提供的图像 | Canva
对于技术专业人士的需求根本没有减缓!如果你在考虑是否应该跳槽进入这个行业——是的,是的,再说一次是的。根据微软和 LinkedIn 的研究,*一半(确切地说是 46%)的在职专业人士正在考虑在 2024 年辞职转行。*一半是个大数字,你可能会想知道原因。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
答案很简单。人们正在与时俱进。留在一个可能不会发展的职业或行业有什么意义,为什么我不想成为一个持续增长的行业的一部分?
在生成式 AI 领域、数据和项目管理技能的需求比以往任何时候都在快速增长。日复一日,人们意识到这个领域的潜力,并希望参与其中。现在大问题是我该如何进入技术领域?
在这篇博客中,我将深入探讨 4 个刚刚推出的专业技术认证及其为何是一个良好的起点。
谷歌云数据分析
链接:谷歌云数据分析专业证书
一个面向初学者的课程,可以在灵活的时间表下完成,或在每周投入 10 小时的情况下在 2 个月内完成。它包括一个 5 课程系列和 19 个模块,你将能够启动你的云数据分析职业。
随着越来越多的组织将其运营和数据转移到云端,了解云计算及其数据访问的重要性成为了一项重要且高需求的技能。
在这个专业认证中,你将学习如何成为一个数据驱动的强者,解锁数据集中的隐藏洞察,将这些原始数字转化为塑造业务下一步的有价值的见解。你将探索数据分析在云计算中的好处,描述在 Google Cloud 中管理和存储数据的关键方面,以及应用转换策略以解决业务需求。通过专家指导和实际挑战,你将建立一个令人印象深刻的项目组合,向雇主展示你可以分析、可视化和沟通数据。
Google Cloud Cybersecurity
链接: Google Cloud Cybersecurity Professional Certificate
另一个为初学者量身定制的课程,可以灵活安排时间,或如果每周投入 10 小时,则需 2 个月完成。该课程包括 5 门课程系列和 19 个模块,你将能够启动你的 Cloud Cybersecurity 职业生涯。
数据的力量和价值将持续存在。数字世界将不断增长,世界需要能够保护它的专业人士。我们需要能够保护这些宝贵资产免受网络犯罪世界侵害的专业人士。
在这个专业认证中,你将成为数字守护者。你将学习如何在实际场景中分析和应用云安全原则,制定和实施风险管理和合规策略,以及执行有效的事件响应和恢复计划。通过专家主导的课程和通过互动实验室的沉浸式 Google Cloud 挑战,你将能够分析威胁、构建防御,并完成一个最终任务,令你的未来雇主印象深刻。
Snowflake 简介
链接: Intro to Snowflake for Devs, Data Scientists, Data Engineers
如果你不知道 Snowflake 是什么,它是一家公司,提供数据即服务,你可以更快、更轻松地启用数据存储、处理和分析解决方案。我们已经知道数据的价值,以及组织为什么想要从中获得更多。
这个专业认证旨在为那些特别希望成为开发者、数据科学家或数据工程师的初学者提供。课程需时 10 小时完成,或如果每周投入 3 小时,则需要 3 周。
你将从零基础的 Snowflake 知识成长为 Snowflake 专家。你将学习如何创建和操作 Snowflake 的核心对象,如虚拟仓库、数据库、模式、表格和阶段。你将深入了解 Snowflake 功能和对象的重要性,例如时间旅行、克隆、资源监控器、UDFs、存储过程和 Snowpark DataFrames。理解 Snowflake 基本功能将为你在数据工程、生成式 AI、机器学习和应用开发领域的职业生涯做好准备。
Microsoft UX/UI 设计
链接: Microsoft UX Design Professional Certificate
一切都在数字化,这意味着对网页开发者和数字设计师的需求非常强烈,预计在未来 6 年内将增长 23%。在微软提供的这一职业认证中,你将学习如何开启 UI/UX 设计的职业生涯。该认证特别针对初学者,由 4 门课程组成,如果每周投入 10 小时,可以在 2 个月内完成。
你将学习如何定义 UX 的核心原则、人本设计和设计思维框架,并识别 UX 团队角色和用户研究方法。然后,你将能够通过分析用户需求、使用设计构思技巧、故事板和应用信息架构,将洞察转化为解决方案。更进一步,通过使用线框图、模型和原型工具,将设计理念转化为互动原型,并利用设计系统和风格指南。最后,你将应用视觉设计原则,制作符合*台最佳实践的高保真模型,并确保所有用户的可访问性。
最好的消息是,通过这个认证,你可以获得 50%的折扣用于微软 UX 设计师 MO-300 认证考试。
总结
科技行业充满了潜力,很多人认为他们必须成为软件开发者或机器学习工程师才能获得一份蛋糕。其实还有其他路径可以选择,这些路径不需要你改变自己所爱的东西。
例如,如果你来自创意背景并希望进入科技领域,UI/UX 领域将是你创造性发挥的最佳场所。
在 2024 年,提升技能至关重要。
尼莎·阿亚 是一名数据科学家、自由职业技术作家,以及 KDnuggets 的编辑和社区经理。她特别感兴趣于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。尼莎涵盖了广泛的话题,并希望探索人工智能如何有助于人类寿命的延续。作为一个热衷学习者,尼莎寻求拓宽她的科技知识和写作技能,同时帮助指导他人。
更多相关话题
刚刚推出的新技术课程

图片来源:作者
我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
我们知道科技领域正在日新月异地发展。鉴于此,对科技专业人士的需求也在增加,为满足这种需求,越来越多的科技课程正在推出。
在科技行业中,你可以探索许多不同的方向。然而,选择哪条路可能会很困难。我应该选择课程,还是回到大学?
在这篇博客中,我将深入探讨最*推出的 3 个技术专业认证和学位。
前端网页开发
链接:前端网页开发
这是由 edX 和 Skills for Life 提供的全额资助项目,让你可以免费启动职业生涯。
在本课程中,你将学习成为前端网页开发者所需的硬技能和软技能。你将深入了解 HTML5、CSS3、Javascript、jQuery、React.js、ES6 和 Node 等编程语言。
课程有三个方面:
-
前端基础
-
使用 APIs 开发
-
现代前端框架
该课程为学生提供了应用程序编程接口(APIs)、用户体验设计以及构建和部署现代 Web 应用程序的速成课程。
除了获得以结果为导向的课程内容外,你还将获得个性化的职业资源,以支持你下一步的职业发展。
数据分析师
该课程面向希望从数据分析师角度进入科技行业的初学者。你可以在自己的时间和节奏下完成这门课程。如果每周投入 10 小时,整个课程需要 5 个月完成,但如果你能投入更多时间,完成得会更快!
认证由 5 门课程组成:
-
数据分析简介
-
使用电子表格和 SQL 进行数据分析
-
Python 数据分析
-
营销统计
-
数据管理简介
AI 产品经理
链接:AI 产品经理
你可能在其他行业担任产品经理或产品负责人,并且可能正在考虑转向科技行业。
这门由 IBM 提供的课程将教你如何:
-
应用关键的产品管理技能、工具和技术
-
了解敏捷及其他方法论的工作知识
-
学习如何将产品解决方案推向市场
-
评估有关 AI 和现有产品管理系统的真实案例研究
-
熟练掌握各种技能和工具
总结一下
当人们考虑进入科技行业时,他们总是认为自己需要成为高度熟练的软件开发人员才能取得成功。科技领域还有许多其他方面等待你去探索!
尼莎·阿利亚 是一名数据科学家,自由职业技术作家,同时也是 KDnuggets 的编辑和社区经理。她特别感兴趣于提供数据科学职业建议、教程以及数据科学的理论知识。尼莎涉及广泛的主题,并希望探索人工智能如何有利于人类生命的持久性。作为一个热衷学习者,尼莎希望拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关主题
新的 KDnuggets 教程页面:学习 R、Python、数据可视化、数据科学等
原文:
www.kdnuggets.com/2016/03/new-tutorials-section-r-python-data-visualization-data-science.html
我很高兴介绍一个新的 KDnuggets 页面教程(也在 KDnuggets 的顶级菜单项中),该页面汇集了最*的教程帖子以及学习商业分析、大数据、数据科学和数据挖掘的额外资源。
本教程页面的第一个赞助商是 DataCamp,提供多种学习数据科学的方式,包括免费的 R 数据科学入门教程和免费的 Python 数据科学入门教程。
教程页面会自动包含最* 2 个月内的所有教程帖子(教程类别中的帖子),以及过往教程帖子的索引。
最*的教程话题包括 R、Python、队列分析、时间序列数据、Apache Spark、数据科学、大数据处理、聚类、PCA、数据科学面试问题、数据湖、文本分析、亚马逊机器学习、IBM Watson、深度学习等。
这里是教程部分的一些更受欢迎的最*帖子:
-
**21 个必须了解的数据科学面试问题及答案,第一部分
**
-
21 个必须了解的数据科学面试问题及答案,第二部分
-
从开放网络中提取数据的 3 种可行方法
-
-
通过周期图从时间序列数据中获得更好的洞察
-
数据科学过程
-
顶级大数据处理框架
-
PCA 与层次聚类的比较
-
-
数据可视化入门
-
数据湖管道工:数据湖的操作化
-
亚马逊机器学习:简单易懂还是过于简单?
-
计算机科学家的贝叶斯定理讲解
-
集成方法:提高机器学习结果的优雅技巧
-
我的亲爱的华生!通过福尔摩斯介绍文本分析
-
避免这些常见的数据可视化错误
-
Apache Spark:RDD、DataFrame 还是 Dataset?
-
Scikit-learn 和 Python 堆栈教程:介绍,分类器实现
-
理解深度学习的 7 个步骤
 **
**

另见 KDnuggets 教育页面:
-
分析、数据挖掘与数据科学教育:在线和基于网页的
-
分析、数据挖掘与数据科学的证书和认证
-
分析、数据挖掘与数据科学教育:美国/加拿大
-
分析、数据挖掘与数据科学教育:欧洲
更多相关主题
管理深度学习数据集的新方式
原文:
www.kdnuggets.com/2022/03/new-way-managing-deep-learning-datasets.html

作者提供的图像
什么是 Hub?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
Hub 是 Activeloop 提供的一个开源 Python 包,它将数据组织成类似 Numpy 的数组。它与 Tensorflow 和 PyTorch 等深度学习框架无缝集成,支持更快的 GPU 处理和训练。我们可以使用 Hub API 更新数据、可视化数据,并创建机器学习管道。
Hub 允许我们以闪电般的速度访问存储的图像、音频、视频和时间序列数据。数据可以存储在 GCS/S3 桶、本地存储或 Activeloop 云中。数据可以直接用于训练 Pytorch 模型,无需设置数据管道。Hub 还配备了数据版本控制、数据集搜索查询和分布式工作负载。
我与 Hub 的体验非常棒,因为我能够在几分钟内创建和上传数据到云端。在这篇博客中,我们将探讨如何使用 Hub 创建和管理数据集。
-
在 Activeloop 云上初始化数据集
-
图像处理
-
将数据推送到云端
-
数据版本控制
-
数据可视化
Activeloop 存储
Activeloop 为开源数据集和私人数据集提供免费存储。通过推荐他人,你还可以获得最多 200 GB 的免费存储空间。Activeloop 的 Hub 与 AI 数据库接口,使我们能够可视化带有标签的数据集,并通过复杂的搜索查询有效分析数据。该*台还包含超过 100 个关于图像分割、分类和目标检测的数据集。

Activeloop 的 AI 数据库
要创建账户,你可以通过 Activeloop 网站 注册,或输入 !activeloop register。该命令会要求你添加用户名、密码和电子邮件。成功创建账户后,我们将使用 !activeloop login 登录。现在,我们可以直接从本地机器创建和管理云数据集。
如果你使用的是 Jupyter Notebook,请使用 “!” ,否则直接在 CLI 中添加命令,不需要使用它。
!activeloop register
!activeloop login -u -p <password></password>
初始化 Hub 数据集
在本教程中,我们将使用 Kaggle 数据集 Multi-class Weather,该数据集遵循 (CC BY 4.0)。该数据集包含四个基于天气分类的文件夹:Sunrise、Sunshine、Rain 和 Cloudy。
首先,我们需要安装 hub 和 kaggle 包。kaggle 包将允许我们直接下载数据集并解压。
!pip install hub kaggle
!kaggle datasets download -d pratik2901/multiclass-weather-dataset
!unzip multiclass-weather-dataset
在下一步中,我们将在 Activeloop 云上创建一个 hub 数据集。数据集函数也可以创建一个新的数据集或访问旧的数据集。你也可以提供一个 AWS 存储桶地址,在 Amazon 服务器上创建数据集。要在 Activeloop 上创建数据集,我们需要传递一个包含用户名和数据集名称的 URL。
“hub://
import hub
ds = hub.dataset('hub://kingabzpro/muticlass-weather-dataset')
数据预处理
在将数据处理成 hub 格式之前,我们需要准备数据。下面的代码将提取文件夹名称并将其存储在 class_names 变量中。在第二部分,我们将创建一个包含数据集文件夹中可用文件的列表。
from PIL import Image
import numpy as np
import os
dataset_folder = '/work/multiclass-weather-dataset/Multi-class Weather Dataset'
class_names = os.listdir(dataset_folder)
files_list = []
for dirpath, dirnames, filenames in os.walk(dataset_folder):
for filename in filenames:
files_list.append(os.path.join(dirpath, filename))
file_to_hub函数接受三个参数:文件名、数据集和类别名称。它从每张图片中提取标签并将其转换为整数。同时,它也将图像文件转换为类似 Numpy 的数组,并将其附加到张量中。对于这个项目,我们只需要两个张量,一个用于标签,一个用于图像数据。
@hub.compute
def file_to_hub(file_name, sample_out, class_names):
## First two arguments are always default arguments containing:
# 1st argument is an element of the input iterable (list, dataset, array,...)
# 2nd argument is a dataset sample
# Other arguments are optional
# Find the label number corresponding to the file
label_text = os.path.basename(os.path.dirname(file_name))
label_num = class_names.index(label_text)
# Append the label and image to the output sample
sample_out.labels.append(np.uint32(label_num))
sample_out.images.append(hub.read(file_name))
return sample_out
让我们创建一个使用‘png’压缩的图像张量和一个简单的标签张量。确保张量的名称应与我们在file_to_hub函数中提到的类似。要了解更多关于张量的知识,请参见 API Summary - Hub 2.0。
最后,我们将通过提供 files_lists、hub 数据集实例“ds”以及 class_names 来运行file_to_hub函数。这将需要几分钟,因为数据将被转换并推送到云端。
with ds:
ds.create_tensor('images', htype = 'image', sample_compression = 'png')
ds.create_tensor('labels', htype = 'class_label', class_names = class_names)
file_to_hub(class_names=class_names).eval(files_list, ds, num_workers = 2)
数据可视化
数据集现在可以在 multiclass-weather-dataset 上公开访问。我们可以查看数据集的标签或添加描述,以便其他人可以了解更多关于许可证信息和数据分布的内容。Activeloop 正在不断添加新功能,以提升查看体验。
作者提供的图像 | multiclass-weather-dataset
我们还可以使用 Python API 访问我们的数据集。我们将使用 PIL 的 Image 函数将数组转换为图像,并在 Jupyter notebook 中显示它。
Image.fromarray(ds["images"][0].numpy())

要访问标签,我们将使用包含分类信息的 class_names,并使用“labels”张量来显示标签。
class_names = ds["labels"].info.class_names
class_names[ds["labels"][0].numpy()[0]]
>>> 'Cloudy'
提交
我们还可以创建不同的分支并管理不同的版本,类似于 Git 和 DVC。在本节中,我们将更新 class_names 信息并创建一个包含消息的提交。
ds.labels.info.update(class_names = class_names)
ds.commit("Class names added")
>>> '455ec7d2b49a36c14f3d80d0879369c4d0a70143'
正如我们所见,我们的日志显示我们已成功提交了对主分支的更改。要了解更多关于版本控制的信息,请查看数据集版本控制 - Hub 2.0。
log = ds.log()
---------------
Hub Version Log
---------------
Current Branch: main
Commit : 455ec7d2b49a36c14f3d80d0879369c4d0a70143 (main)
Author : kingabzpro
Time : 2022-01-31 08:32:08
Message: Class names added
你还可以通过 Hub UI 查看所有的分支和提交。
作者提供的 Gif
结论
Hub 2.0 提供了新的数据管理工具,使机器学习工程师的工作变得轻松。Hub 可以与 AWS/GCP 存储集成,为深度学习框架如 PyTorch 提供直接的数据流。它还通过 Activeloop 云提供互动可视化和用于跟踪机器学习实验的版本控制。我认为 Hub 将成为未来数据管理的 MLOps 解决方案,因为它将解决数据科学家和工程师日常面临的许多核心问题。
在这篇博客中,我们了解了 Hub 及如何创建和推送数据到 Activeloop 云。下一步自然就是使用相同的数据集来训练模型并部署到生产环境中。因此,如果你有兴趣了解更多并想训练一个图像分类模型,可以查看在 Pytorch 中训练图像分类模型。
使用 Hub 进行深度学习项目
Abid Ali Awan (@1abidaliawan)是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,帮助那些与心理疾病斗争的学生。
更多相关主题
数据科学家的代码块分享新方式
原文:
www.kdnuggets.com/2022/03/new-ways-sharing-code-blocks.html

图片由 Starline | Freepik 提供
代码块是什么?
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
代码块是几行代码。它们可能包含提取数据集的函数、自动化任务的脚本或数据处理类。你可以分享几行代码来有效地解释事情,而不是分享整个项目。
为什么我们分享代码片段?
分享代码块可以为你的项目展示提供附加好处,如在社交媒体上吸引注意、创建互动数据报告和撰写博客。
我们怎么分享?
许多 DevOps *台提供代码共享服务,如 GitHub、Gitlab、Kaggle 和 Colab。我们还将了解新的服务,如 Deepnote、Carbon 和 Google Addon,以改善我们的工作流程。
Deepnote
Deepnote 提供了 嵌入块的分享,其中包括显示 Jupyter 单元格代码和输出的选项。嵌入块是我最喜欢的 Deepnote 功能之一;我用它来制作 Medium 博客、WordPress 网站、Google Docs 演示文稿,并在社交媒体上发布帖子。总之,这是我分享代码片段的首选工具。
要分享你的代码,你需要点击特定的 Jupyter 单元格,然后点击分享块按钮。

作者提供的图片
在分享块选项中,你可以选择包括哪些部分以及粘贴哪种类型的链接。有些网站仅支持 嵌入块 代码,而有些则支持 分享块。
“对于 Medium 博客和社交媒体帖子,我使用 分享块 链接。”

作者提供的图片
嵌入代码块显示了关于印度女性名人死亡原因的 Python 代码和爆炸甜甜圈图表。
我们还可以在博客中添加互动功能,让读者可以尝试不同的选项。下面的 Gif 来自 Towards AI 博客,展示了年度酒精饮料消费情况。我们可以播放动画并悬停以查看确切数字。
Gif 由作者提供 | Towards AI
Deepnote 嵌入单元不仅限于创建图表或互动图形。我们还可以使用 Plotly 创建整个仪表板,并在互联网上分享。
Kaggle
Kaggle 也提供嵌入单元的分享,但有一些限制。要分享你的 Jupyter 单元,你需要将你的 Kaggle Notebook 设为公开,且嵌入链接在较少的网站上有效。它不适用于 Medium 或 WordPress。你需要对你的网站进行重大修改才能使其正常工作。
转到你想分享的单元,然后点击嵌入单元选项。你也可以直接链接到你的单元,但链接会将你重定向到此笔记本。
图片由作者提供
嵌入笔记本选项包含各种选项和链接,我们可以用来分享单个单元或整个笔记本。
图片由作者提供
Colab
Google Colab 仅提供链接共享,能够将你带到一个公开共享的笔记本或特定单元。适用于处理大型笔记本并希望传达特定代码块信息的人。
图片由作者提供
GitHub Gist
GitHub Gist 是许多开发者和工程师使用的代码共享工具。你会发现包含 GitHub Gist 的机器学习教程,解释模型架构或模型训练。
GitHub Gist 加载速度更快,可以与任何博客或网站集成。缺点是你无法分享代码的输出。首先,你需要通过粘贴代码创建 gist,然后复制如下所示的嵌入链接。
图片由作者提供
代码块看起来干净,具有语法高亮和整洁的格式。
为了进行比较,我们可以看到 Deepnote 单元和 GitHub Gist。它们看起来都干净且具有互动性,带有语法高亮。
图片由作者提供
Carbon
Carbon 是一个用于创建视觉吸引力强的代码块图像的在线工具。它被社交媒体影响者、数据科学家和数据教育者使用。Carbon 是我与更广泛的受众分享代码的首选工具。Carbon 提供了各种主题选项、不同的语言和编辑选项,以创建适合你的代码块。代码块的输出格式为 PNG 或 SVG。

作者提供的图片 | Carbon
Carbon 准确地高亮语法以提供良好的可读性。它没有任何限制。你甚至可以在 Instagram 上分享它或将代码块设置为你博客的封面照片。
作者提供的图片
GitLab Snippet
GitLab Snippet 类似于 GitHub Gist,但不需要转到另一个网站。我们可以在项目内创建代码片段并与团队分享。同样,你可以在 Medium 博客、网站和社交媒体应用上使用片段。在我看来,GitLab 提供了一个完整的开发者生态系统,其中一切都在项目内可用。
作者提供的图片
Google Docs 插件
Google Docs 插件 code-blocks 提供多种颜色主题的语法高亮。它在选项方面与 Carbon 十分相似,但它会在 Google Docs 内更改你的字体,而不是创建图像。我用它来制作教程、撰写报告和创建博客草稿。你的编辑器会对代码高亮印象深刻,因为它改善了你的视觉呈现。

作者提供的图片
结论
开发者、社交媒体影响者或技术博主使用这些工具与他们的受众互动。在这篇博客中,我们了解了 Deepnote、Kaggle、Colab、GitHub Gists、Carbon、Gitlab Snippets 和 Google Docs 插件。这些工具用于通过代码分享技术信息。其中一些工具可以与其他应用轻松集成,而其他工具则提供带有代码的输出。
我最喜欢的工具是 Deepnote 嵌入代码块,它与我的工作流程集成,我在博客到社交媒体帖子中都使用它。这些工具唯一的缺点是加载时间较慢。如果你喜欢这篇博客并想继续了解更多惊人的工具,那么请在 LinkedIn 上关注我。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些面临心理健康问题的学生。
更多相关话题
自然语言处理中的 N-gram 语言建模
原文:
www.kdnuggets.com/2022/06/ngram-language-modeling-natural-language-processing.html
介绍
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 管理
语言建模用于确定单词序列的概率。这种建模有大量应用,如语音识别、垃圾邮件过滤等[1]。
自然语言处理(NLP)
自然语言处理(NLP)是人工智能(AI)与语言学的融合。它用于使计算机理解用人类语言书写的单词或陈述。NLP 的开发旨在使与计算机的工作和沟通变得更简单、更令人满意。由于所有计算机用户无法完全掌握机器的特定语言,NLP 在那些没有时间学习新机器语言的用户中表现更好。我们可以将语言定义为一组规则或符号。符号组合用于传达信息,它们受规则集合的支配。NLP 被分为两个部分:自然语言理解和自然语言生成,这涉及理解和生成文本的任务。NLP 的分类如图 1 所示[2]。
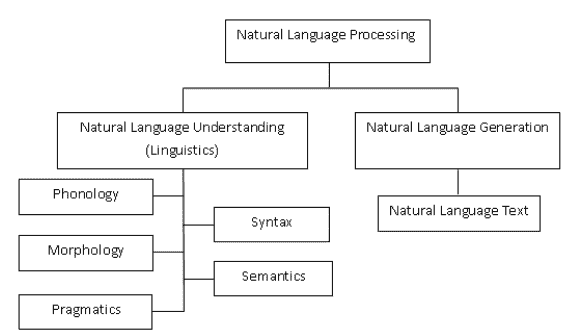
图 1 NLP 的分类
语言建模的方法
语言建模的分类如下:
统计语言建模:在这种建模中,开发了概率模型。这个概率模型预测序列中的下一个单词。例如 N-gram 语言建模。该建模可用于消歧输入。它们可以用于选择可能的解决方案。这种建模依赖于概率理论。概率是预测某事发生的可能性。
神经语言建模:神经语言建模比经典方法在独立模型以及当模型融入更大模型中,如语音识别和机器翻译等挑战性任务中,均能取得更好的结果。执行神经语言建模的一种方法是通过词嵌入[1]。
NLP 中的 N-gram 建模
N-gram 是在自然语言处理建模中用于表示 N 个词序列的模型。以建模的语句为例:“我喜欢阅读历史书籍和观看纪录片”。在一元模型(unigram)中,序列由一个词构成。对于上述语句,在一元模型中可以是“I”、“love”、“history”、“books”、“and”、“watching”、“documentaries”。在二元模型(bi-gram)中,序列由两个词构成,即“I love”、“love reading”或“history books”。在三元模型(tri-gram)中,序列由三个词构成,即“I love reading”、“history books”或“and watching documentaries”[3]。N-gram 模型的示意图(N=1,2,3)见下图 Figure 2 [5]。
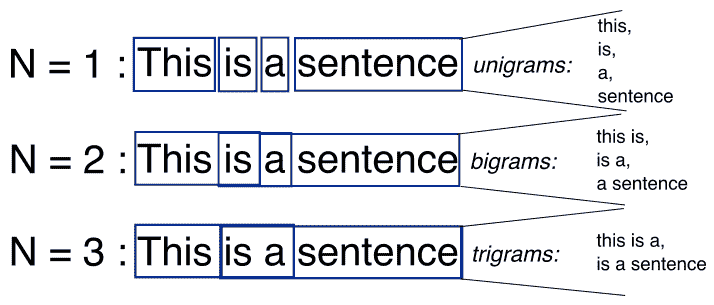
图 2 一元、二元和三元模型
对于 N-1 个词,N-gram 模型预测可以跟随序列的最常出现的词。该模型是一种概率语言模型,基于文本集合进行训练。该模型在应用中非常有用,例如语音识别和机器翻译。简单的模型有一些局限性,可以通过*滑、插值和回退进行改进。因此,N-gram 语言模型的目标是找到词序列的概率分布。考虑以下句子:“There was heavy rain”和“There was heavy flood”。通过经验可以说,第一个句子更好。N-gram 语言模型会指出“heavy rain”出现的频率高于“heavy flood”。因此,第一个句子更可能出现,并会被该模型选择。在一元模型中,模型通常依赖于词的频率,而不考虑之前的词。在二元模型中,仅考虑前一个词来预测当前词。在三元模型中,考虑两个前一个词。在 N-gram 语言模型中计算以下概率:
P (“There was heavy rain”) = P (“There”, “was”, “heavy”, “rain”) = P (“There”) P (“was” |“There”) P (“heavy”| “There was”) P (“rain” |“There was heavy”).
由于计算条件概率并不实际,但通过使用“Markov Assumptions”,可以*似为二元模型[4]:
P (“There was heavy rain”) ~ P (“There”) P (“was” |“'There”) P (“heavy” |“was”) P (“rain” |“heavy”)
N-gram 模型在自然语言处理中的应用
在语音识别中,输入可能会受到噪声的干扰。这种噪声可能导致错误的语音到文本的转换。N-gram 语言模型通过使用概率知识来纠正噪声。同样,这种模型也用于机器翻译,以生成目标语言中更自然的语句。在拼写错误纠正方面,字典有时会无用。例如,“in about fifteen minutes”中的“minuets”在字典中是一个有效的词,但在短语中是不正确的。N-gram 语言模型可以纠正这种类型的错误。
N-gram 语言模型通常应用于词级别。它也用于字符级别进行词干提取,即分离根词和后缀。通过查看 N-gram 模型,可以对语言进行分类或区分美国和英国的拼写。许多应用程序从 N-gram 模型中受益,包括词性标注、自然语言生成、词语相似性和情感提取[4]。
N-gram 模型在 NLP 中的局限性
N-gram 语言模型也存在一些局限性。存在词汇外问题。这些词在测试时出现但在训练时未出现。一种解决方案是使用固定词汇表,然后将训练中的词汇外词转换为伪词。当应用于情感分析时,二元模型优于单元模型,但特征数量翻倍。因此,将 N-gram 模型扩展到更大的数据集或提高阶数需要更好的特征选择方法。N-gram 模型对长距离上下文的捕捉较差。研究显示,每 6-gram 之后,性能提升有限。
参考文献
-
(N-Gram 语言建模与 NLTK, 2021 年 5 月 30 日)
-
(Diksha Khurana, Aditya Koli, Kiran Khatter, Sukhdev Singh, 2017 年 8 月)
-
(Mohdsanadzakirizvi, 2019 年 8 月 8 日)
-
(N-Gram 模型, 3 月 29 日)
-
(N-Gram)
Neeraj Agarwal 是 Algoscale 的创始人,这是一家涵盖数据工程、应用人工智能、数据科学和产品工程的数据咨询公司。他在该领域有超过 9 年的经验,帮助了从初创公司到财富 100 强公司的广泛组织摄取和存储大量原始数据,从而将其转化为可操作的见解,以便做出更好的决策和更快的商业价值。
相关主题
我希望在机器学习博士学位之前掌握的九种工具
原文:
www.kdnuggets.com/2021/09/nine-tools-mastered-before-phd-machine-learning.html
comments
由 Aliaksei Mikhailiuk 提供,人工智能科学家

图片由作者提供。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你在 IT 领域的组织
尽管在推动技术进步中扮演了重要角色,学术界往往忽视工业成就。到我博士学位结束时,我意识到有许多伟大的辅助工具在学术界被忽视,但在工业界被广泛采用。
从个人经验来看,我知道学习和整合新工具可能会很无聊、令人害怕,可能会拖慢进度并使人气馁,特别是当当前的设置如此熟悉且有效时。
摆脱坏习惯可能很困难。对下面列出的每个工具,我都不得不接受我做事的方式是不够理想的。然而,在这个过程中,我也学到了有时候当下看不到的结果在后期会带来十倍的回报。
在下面,我将讨论一些我在研究和构建机器学习应用时发现非常有用的工具,这些工具既适用于学术研究,也适用于人工智能工程师。我将这些工具按其目的分为四个部分:环境隔离、实验跟踪、协作和可视化。
隔离环境
机器学习是一个极其快速发展的领域,因此常用的软件包经常更新。尽管开发者们努力工作,但新版本往往与其前身不兼容。这确实会带来很多麻烦!
幸运的是,有工具可以解决这个问题!
Docker
图片由作者提供。
这些 NVIDIA 驱动程序给你带来了多少麻烦?在我的博士学位期间,我有一台由大学管理的机器,定期更新。更新在晚上进行且没有任何通知。想象一下,当我发现第二天早上大部分工作与最新驱动程序不兼容时的惊讶。
尽管这些课程并非专门针对这一点,但 docker 可以帮助你避免这些特别在截止日期前的压力情况。
Docker 允许将软件封装在称为容器的包中。容器是独立的单元,具有自己的软件、库和配置文件。从简化的角度看,容器是一个独立的虚拟操作系统,具有与外界沟通的手段。
Docker 提供了大量现成的容器供你使用,无需对如何自己配置所有内容有广泛的了解,开始使用基础知识非常简单。
对于那些想要快速入门的人,可以查看这个 教程。此外,Amazon AWS 也很好地解释了为什么以及如何在机器学习中使用 Docker,可以在 这里 查看。
Conda
现在重复使用别人的代码已经成为一种新常态。有人在 GitHub 上创建了一个有用的代码库,你可以克隆代码,安装并得到你的解决方案,而无需自己编写任何东西。
不过有一个小不便。当多个项目一起使用时,你会遇到包管理的问题,因为不同的项目需要不同版本的包。
我很高兴在我的博士研究中发现了 Conda。Conda 是一个包和环境管理系统。它允许创建多个环境,并快速安装、运行和更新包及其依赖项。你可以快速切换隔离的环境,并始终确保你的项目仅与预期的包进行交互。
Conda 提供了自己的 教程 ,介绍如何创建你的第一个环境。
运行、跟踪和记录实验
获取博士学位所需的两个关键支柱是严谨性和一致性,没有这两个条件,在应用领域获得博士学位几乎是不可能的。如果你曾经尝试过使用机器学习模型,你可能知道跟踪测试参数是多么容易丢失。以前,参数跟踪是在实验室笔记本中进行的,我相信这些在其他领域仍然非常有用,但在计算机科学领域,我们现在拥有比这更强大的工具。
Weights and biases
wandb 面板的一组简单指标的快照——训练损失、学习率和*均验证损失。注意你还可以跟踪系统参数!图片由作者提供。
experiment_res_1.csv
experiment_res_1_v2.csv
experiment_res_learning_rate_pt_5_v1.csv
...
这些名字看起来熟悉吗?如果是,那么你的模型跟踪技能应该提高了。这就是我在博士第一年的情况。作为借口,我应该说我有一个电子表格,在那里我记录每个实验的详细信息和所有相关文件。然而,这仍然非常复杂,每次参数变更的记录不可避免地会影响后处理脚本。
Weights and Biases (W&B/wandb) 是我发现得比较晚的一个宝藏工具,但现在我在每个项目中都使用它。它让你能够用几行代码跟踪、比较、可视化和优化机器学习实验。它还允许你跟踪你的数据集。尽管选项众多,我发现 W&B 易于设置,并且具有非常友好的网页界面。
对有兴趣的人来说,可以查看他们的快速设置教程 这里。
MLflow
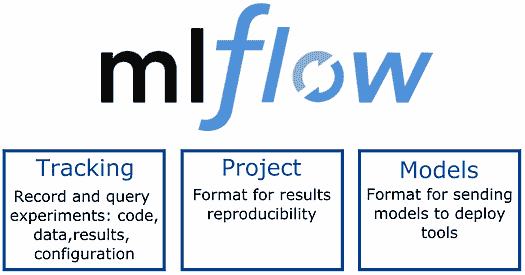
作者提供的图片。
类似于 W&B,MLFlow 提供了记录代码、模型和数据集的功能,你的模型在这些数据集上进行训练。虽然我主要用它来记录数据、模型和代码,但它提供的功能远不止这些。它允许管理整个 ML 生命周期,包括实验、可重复性和部署。
如果你想将它快速集成到你的模型中,请查看这个 教程。Databricks 还分享了关于 MLflow 的一个非常好的 解释。
Screen
在博士生涯的前半年,我常常选择将实验留到过夜,希望机器不会进入睡眠状态。当工作转到远程时,我会担心 ssh 会话中断——代码已经运行了好几个小时,几乎收敛了。
我对 screen 功能的了解较晚,因此在早晨总是不能避免半成品结果。但在这种情况下,确实是晚做总比不做好。
Screen 让你从单一的 ssh 会话中启动和使用多个 shell 会话。用 screen 启动的进程可以从会话中分离,然后在稍后的时间重新附加。因此,你的实验可以在后台运行,无需担心会话关闭或终端崩溃。
功能总结 这里。
协作
学术界以缺乏有效团队管理机制而臭名昭著。这在一定程度上是由于对个人贡献的严格要求。然而,机器学习的发展速度需要共同努力。以下是两个相当基础的工具,对于有效沟通特别是在远程工作的新领域中会非常有用。
GitHub
相当基础,对吧?在看到学术界人们如何跟踪他们的代码的种种恐怖之后,我不能更强调掌握版本控制的重要性。不再有名为 code_v1、code_v2 的文件夹。
Github 提供了一个非常有用的代码跟踪、合并和审查框架。每当一个团队构建一个深度图像质量指标时,每个成员可以有自己的代码分支并行工作。解决方案的不同部分可以合并在一起。每当有人引入一个 bug 时,可以很容易地恢复到工作版本。总体而言,我认为 git 是我在这篇文章中提到的所有工具中最重要的。
查看这个逐步指南了解如何快速启动。
Lucidchart
最*我接触到了 Lucidchart,此前我一直在使用draw.io— 一个非常简单的图表创建界面。Lucidchart 强大了千倍,功能也更为多样。它的主要优势在于协作共享空间和在图表旁边做笔记的能力。想象一下一个巨大的在线白板,配有一整套模板。
要快速入门,请查看 Lucidchart 的这个tutorial页面。
可视化
许多论文提交,特别是那些不成功的案例,教会了我演示往往和结果一样重要。如果审稿人通常没有太多时间,不理解文本,工作就会直接被拒绝。匆忙制作的图像会留下不好的印象。有人曾经告诉我:“如果你无法制作图表,我怎么能相信你的结果?”我不同意这个说法,但我确实同意印象很重要。
Inkscape
一图胜千言(实际上,纠正 84.1字)。
Inkscape 是一款免费的矢量图形软件。事实上,我在本科时的网页开发课程中学会了使用它。然而,我在攻读博士学位期间才真正学会了充分利用它——为论文制作那些漂亮的图像。
在 Inkscape 提供的所有功能中,特别有价值的是TexText扩展。使用这个软件包,你可以将你的latex公式无缝集成到图像中。
有大量的教程,然而对于基本功能,我推荐 Inkscape 团队提供的教程这里。
Streamlit
你是否曾经需要创建一个简单的网站来展示你的结果或一个简单的机器学习应用?只需几行 Python 代码,使用 Streamlit 就可以实现。
我发现它特别适用于论文补充材料,但它甚至可以在项目展示和客户演示中更加有用。
要快速入门,请查看这个教程。
总结及拓展
在攻读博士学位的同时,顺利进入行业并不容易。但这让我学到了几条重要的教训,希望我在博士学习的早期就能了解到这些。
最重要的一课是,好奇心和愿意学习和改变可以极大地影响你工作的质量。
以下是我在每个部分提到的教程的总结:
如果你喜欢这篇文章,请与朋友分享!要阅读更多机器学习和图像处理的话题,请按订阅!
我有没有遗漏什么?请随时留下注释、评论或直接给我发消息!
简介: Aliaksei Mikhailiuk 在计算机视觉、偏好聚合和自然语言处理领域拥有丰富的研究、开发、部署和维护机器学习算法的经验。
原文。经许可转载。
相关:
-
我在数据科学职业生涯三年中学到的三大重要课程
-
数据科学、数据可视化和机器学习的 38 个顶级 Python 库
-
数据科学工具的受欢迎程度,动画版
更多相关话题
NIPS 2017 重点与总结笔记
原文:
www.kdnuggets.com/2017/12/nips-2017-key-points-summary-notes.html
评论
 NIPS 2017上周在长滩举行,根据所有人的评价,它确实没有辜负期待。虽然我未能亲自到场(我希望能去),但布朗大学的三年级博士生David Abel,确实出席了,并且他辛勤地编写和整理了一份精彩的 43 页笔记,这些笔记只能用令人自愧不如来形容。他已经将这些笔记以 PDF 形式提供给所有人,并鼓励进行传播。
NIPS 2017上周在长滩举行,根据所有人的评价,它确实没有辜负期待。虽然我未能亲自到场(我希望能去),但布朗大学的三年级博士生David Abel,确实出席了,并且他辛勤地编写和整理了一份精彩的 43 页笔记,这些笔记只能用令人自愧不如来形容。他已经将这些笔记以 PDF 形式提供给所有人,并鼓励进行传播。
虽然 David 显然无法参加 NIPS 上的每一个讲座和教程,但他显然安排得非常紧凑,我们可以通过他的经历间接感受那种体验,即使是事后。
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 需求
代表所有未能在 Twitter 显示名称上临时添加"@ #NIPS2017"的我们,David,谢谢你的努力。如果你有兴趣阅读这些笔记的讨论,可以在这里找到。
另值得注意的是,David 在 NIPS 的层次化 RL 研讨会上展示了一篇题为"朝向良好的终身学习抽象"的论文(David Abel, Dilip Arumugam, Lucas Lehnert, Michael L. Littman)。
以下是 David 笔记中的几个亮点(重点突出),以及一些相关讲座的视频。
阿里·拉希米的时间测试讲座。 这引发了会议期间的大量讨论。在下半场,他提出了一些关于当前机器学习研究状态的看法,呼吁我们的方法更加严格。这在会议期间被广泛讨论,(大多数)人支持阿里的观点(至少是我交谈过的那些人),也有一些人表示他的观点没有根据,因为他似乎针对的一些方法(主要是深度学习)在实践中效果很好。我的个人看法是,他并不一定在呼吁理论来支持我们的方法,而是对严格性的呼吁。我认为对严格性的呼吁是深刻的。我认为说有效的实验对 ML 社区是有益的毫无争议。究竟这意味着什么,当然是有待辩论的(见下一个要点)。
乔厄尔·皮诺关于深度强化学习中的可重复性讲座。 一个实验表明,两种方法,假设我们称之为 A 和 B,在相同任务上取决于所选择的随机种子,相互主导。也就是说,A 在一个随机种子下实现了统计上显著优于 B 的表现,而这种主导性在不同的随机种子下则会被翻转。我非常喜欢这项工作,并且认为这正好是时候。特别是在深度强化学习中,大多数结果的形式是:“我们的算法在 X 和 Y 任务上表现更好”。
乔什·特嫩鲍姆正在讲解如何从人类行为中逆向工程智能。
Warneken 和 Tomasello 的论文[55]讨论了婴儿的 emergent helping behavior。他展示了一个视频,视频中一个婴儿主动去帮助一个成人,没有人告诉他这样做。太可爱了!
目标:逆向工程常识。
工具:概率程序。能够生成世界下一状态的模型,充当*似的“脑中的游戏引擎”,真的很强大。可能是缺失的部分。直观物理学和直观心理学的混合。
使用概率程序进行常识工程:
- 什么?建模程序(脑中的游戏引擎)。
- 如何?用于推理和模型构建的元程序,在多个时间尺度上工作,权衡速度、可靠性和灵活性。
凯特·克劳福德:偏见的问题
凯特真了不起!今天她讲述了 AI/ML 中的偏见问题。
收获:偏见是一个高度复杂的问题,渗透到机器学习的每个方面。我们必须问:我们的工作将会使谁受益,谁可能受到伤害?要把
首先考虑公*性,我们必须问这个问题。
相关内容:
-
免费观看 2017 年开放数据科学最佳演讲
-
2017 年旧金山 AI 会议的主要内容 – 第 1 天
-
2017 年开放数据科学会议(ODSC)西部大会的主要收获
更多相关主题
一种分析 Twitter、特朗普和脏话的 NLP 方法
原文:
www.kdnuggets.com/2016/11/nlp-approach-analyzing-twitter-trump-profanity.html/2
第二步:收集数据
现在是时候调用我们的脚本,并用查询‘Donald Trump OR Trump’来抓取包含‘Donald Trump’或‘Trump’的推文,然后将文件写入数据文件夹,名为‘Donald-Trump-OR-Trump.csv’。
python twitter_pull_data.py 'Donald Trump OR Trump'
尝试重新运行脚本,但这次将‘Hillary Clinton OR Hillary’作为查询传入。
在数据文件夹中有两个 CSV 文件后,我们现在可以创建一个名为 profanity_analysis.py 的脚本。
第三步:数据预处理
在接下来的脚本中,我们将首先清理数据,去除表情符号、标签、转发等。然后,我们将深入探讨英语停用词和脏话算法。
清理我们的推文就到此为止!
第四步:检查推文中的脏话
现在,我们将查看脏话检测算法,并发现推文中的脏话。这个算法基于来自noswearing.com的约 340 个单词,通过基本的字符串匹配来捕捉脏话。查看脏话算法页面以了解更多算法的细节,并了解如何通过添加自己的攻击性单词来定制单词列表,因为有趣的新攻击性俚语每天都在不断增加到英语中。不相信?看看Urban Dictionary上出现的新词汇。
脏话函数非常简单明了:
你只是传入已清除英语停用词的单词列表。我们将它们合并成一个语料库,因为我们对所有推文的总体脏话感兴趣,而不是每条推文的脏话。我们的函数 profanity()打印出算法结果以及总脏话数量。在撰写本文时,查询‘Donald Trump OR Trump’有 30 个脏话,而‘Hillary Clinton OR Clinton’返回 8 个脏话。

当我们提取 Twitter 数据时,还获取了 user_id 和转发次数。这很有用,因为你可能想通过一些轻度分析来评估推文的受欢迎程度,从而了解推文是否因脏话使用的多少而更受欢迎或不受欢迎。
如果你想查看完整代码,请查看我们的示例应用在 GitHub 上!
下一步
一定要查看我们的其他 NLP 算法,例如social sentiment analysis或LDA(标签)。像AnalyzeTweets这样的微服务将上述算法与一个检索推文的算法相结合。该算法返回每条推文的负面和正面情绪,以及每条推文的负面和正面 LDA。你可以创建无尽的组合进行快速探索性分析,或添加像脏话检测或Nudity Detection这样的算法到你的应用程序中,确保内容适合家庭观看。
享受探索*台的过程,如有任何问题,请随时联系!
简介:Stephanie Kim 是 Algorithmia 的开发者推广专家。
原文。已获得许可重新发布。
相关:
-
特朗普现象:基于推特的回顾
-
使用自然语言处理探索社交媒体多样性
-
人类向量:结合讲者嵌入让你的机器人更强大
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关主题
NLP 与计算机视觉的整合
原文:
www.kdnuggets.com/2019/06/nlp-computer-vision-integrated.html
评论
由Sciforce提供。

我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
整合与跨学科性是现代科学和工业的基石。最*尝试将一切结合在一起的一个例子是计算机视觉与自然语言处理(NLP)的整合。这两个领域都是机器学习研究中最活跃的发展领域之一。然而,直到最*,它们一直被视为独立领域,彼此之间几乎没有相互受益的方式。现在,随着多媒体的扩展,研究人员开始探索将这两种方法应用于实现单一结果的可能性。
多模态世界与符号学
人类最自然的方式是从不同来源提取和分析信息。这符合符号学理论(Greenlee 1978)——研究符号及其在不同层次上意义的关系。符号学研究符号与意义之间的关系,符号之间的形式关系(大致相当于语法)以及人类根据上下文解读符号的方式(语言学理论中的语用学)。如果我们仅考虑视觉符号,那么这会得出结论,符号学也可以通过计算机视觉来处理,从中提取有趣的符号以供自然语言处理实现相应的意义。
计算机视觉及其与 NLP 的关系
Malik 将计算机视觉任务总结为 3Rs(Malik 等,2016):重建、识别和重组。
重建 指通过结合来自多个视角、阴影、纹理或直接深度传感器的信息,估计产生特定视觉图像的 3D 场景。该过程结果是一个 3D 模型,例如点云或深度图像。
识别 涉及为图像中的对象分配标签。对于 2D 对象,识别的例子包括手写识别或人脸识别,而 3D 任务则解决从点云中识别对象等问题,这有助于机器人操作。
重组 指的是从底层到顶层的视觉过程,当原始像素被分割成表示图像结构的组时。低层次视觉任务包括边缘、轮廓和角点检测,而高层次任务涉及语义分割,这与识别任务部分重叠。
识别与语言的联系最为紧密,因为它的输出可以被解释为词语。例如,物体可以用名词表示,活动用动词表示,物体属性用形容词表示。从这个意义上说,视觉和语言通过语义表示相互连接(Gardenfors 2014;Gupta 2009)。
自然语言处理及其与计算机视觉的关系
与计算机视觉相比,NLP 任务更为多样化,包括语法(如形态学和组合性)、语义(作为意义的研究,包括词语、短语、句子和话语之间的关系)以及语用学(作为自然交流中意义的细微差别的研究)。
一些复杂的 NLP 任务包括机器翻译、对话接口、信息提取和摘要。
换句话说,从图像到词语的转换被认为是最接*机器翻译的。然而,这种在低层像素或图像轮廓与高层次词语或句子描述之间的“翻译”——即桥接语义差距(Zhao 和 Grosky 2002)——依然是一个广泛的鸿沟。
计算机视觉与 NLP 的整合范围
视觉和语言的融合并不是通过自上而下的方式顺利进行的,研究人员提出了一系列原则。集成技术主要是自下而上的发展,一些先驱者识别出一些较为具体和狭窄的问题,尝试了多种解决方案,找到了令人满意的结果。
新的轨迹开始于对当前文件大多数都是多媒体的理解,即它们包含互相关联的图像、视频和自然语言文本。例如,一篇典型的新闻文章包含记者的文字和与新闻内容相关的照片。此外,可能还会有一个包含记者的剪辑视频或事件发生现场的快照。语言和视觉数据提供了两组信息,这些信息结合成一个完整的故事,为适当且明确的沟通奠定了基础。
这种理解催生了将综合方法应用于视觉和文本内容的多个领域,不仅在处理多媒体文件时,而且在机器人技术、视觉翻译和分布式语义学领域也有应用。
多媒体文件
与多媒体相关的 NLP 和计算机视觉任务主要分为三个类别:视觉属性描述、视觉描述和视觉检索。
视觉属性描述:相比于分类,描述性方法通过分配属性来总结对象属性。这些属性可以是易于识别的二进制值,或通过学习排序框架描述的相对属性。关键在于,这些属性将提供一组上下文,作为识别特定对象属性的知识源。属性词成为一种中间表示,有助于弥合视觉空间和标签空间之间的语义差距。
视觉描述:在现实生活中,视觉描述的任务是提供图像或视频捕捉。人们认为,句子能比一堆无序的词汇提供更具信息量的图像描述。为了生成描述图像的句子,应提取一定量的低级视觉信息,这些信息提供了基本的“谁对谁做了什么,在哪里以及如何做的”的信息。从词性角度来看,“名词、动词、场景、介词”四元组可以代表从视觉检测器提取的含义。视觉模块提取的对象可以是句子中的主语或宾语。然后使用隐马尔可夫模型从有限的四元组集合中解码出最可能的句子,并结合一些语料库指导的动词和场景(介词)预测的先验信息。含义通过对象(名词)、视觉属性(形容词)和空间关系(介词)来表示。然后,通过使用网页规模的 n-grams 来确定概率,借助短语融合技术生成句子。
视觉检索:基于内容的图像检索(CBIR)是多媒体领域的另一个应用,它利用以查询字符串或概念形式的语言。通常,图像通过低级视觉特征如颜色、形状和纹理进行索引。CBIR 系统尝试用词语标注图像区域,类似于语义分割,因此关键词标签接*人类的解释。CBIR 系统使用关键词来描述图像以进行图像检索,而视觉属性则描述图像以进行图像理解。然而,视觉属性为 CBIR 提供了一个适合的中间层,并适应目标领域。
机器人技术
机器人视觉:机器人需要通过多种交互方式感知其周围环境。类似于人类通过使用关于事物的知识(如单词、短语和句子)来处理感知输入,机器人也需要将感知到的图像与语言结合,以获得有关现实世界中物体、场景、动作或事件的相关知识,对其进行理解并执行相应的动作。例如,如果一个物体很远,人类操作员可能会口头请求采取行动以获得更清晰的视角。机器人视觉任务涉及如何让机器人通过对物体执行一系列操作来操控现实世界环境,使用硬件传感器(如深度摄像头或运动摄像头),并拥有周围环境的语言化图像,以响应口头指令。
情境语言:机器人使用语言来描述物理世界并理解其环境。此外,口语和自然手势是与机器人互动的更便捷方式,前提是机器人接受了理解这种互动模式的训练。从人的角度来看,这是一种更自然的互动方式。因此,机器人应该能够感知并将其环境感知的信息转化为使用语义结构的语言。最著名的表示意义的方法是语义解析(SP),它将单词转换为逻辑谓词。SP 尝试将自然语言句子映射到对应的意义表示,这可以是类似λ-演算的逻辑形式,使用组合类别语法(CCG)作为规则来组合构建解析树。
分布式语义
早期多模态分布式语义模型:分布式语义模型(DSM)背后的思想是相似上下文中的单词应具有相似的意义。因此,单词意义可以从单词与出现的上下文之间的共现统计中恢复。这种方法被认为对计算机视觉和自然语言处理有益,例如图像嵌入和词嵌入。DSM 被应用于联合建模基于视觉特征(如颜色、形状或纹理)和文本特征(如单词)的语义。常见的流程是将视觉数据映射到单词上,并在其上应用分布式语义模型,如 LSA 或主题模型。视觉属性可以*似于分布式语义模型的语言特征。
神经 多模态分布式语义模型:神经模型通过从数据中学习更好的分布表示,已经在视觉和语言方面超越了许多传统方法。例如,多模态深度玻尔兹曼机可以比主题模型更好地建模联合视觉和文本特征。此外,神经模型可以建模一些认知上合理的现象,如注意力和记忆。对于注意力,图像可以使用 CNNs 和 RNNs 最初给出图像嵌入表示。可以在其上放置一个 LSTM 网络,像状态机一样同时生成输出,例如图像标题或一次查看图像中的相关区域。对于记忆,常识知识被集成到视觉问答中。
自然语言处理与计算机视觉的未来整合
如果结合起来,这两个任务可以解决多个领域中的许多长期存在的问题,包括:
-
设计:在设计住宅、衣物、珠宝或类似物品时,客户可以口头或书面描述需求,这些描述可以自动转换为图像以便更好地可视化。
-
描述医学图像:计算机视觉可以被训练识别更细微的问题,并比人类专家更详细地观察图像。
-
将手语转换为语音或文本,以帮助听力障碍人士,并确保他们更好地融入社会。
-
制作一个可以看到周围环境并给出口头描述的系统,可以供盲人使用。
-
制作可以将口语内容转换为图像的系统,这可能在一定程度上帮助那些不能说话和听力障碍的人。

然而,由于视觉和语言的整合是一个根本的认知问题,因此该领域的研究应考虑认知科学,这可能提供有关人类如何整体处理视觉和文本内容并基于此创建故事的见解。
参考文献:
Gärdenfors, P. 2014. 意义的几何:基于概念空间的语义学。MIT 出版社。
Greenlee, D. 1978. 符号学与符号学研究。国际哲学研究。10 (1978),251–254。
Gupta, A. 2009. 超越名词和动词。 (2009)。
Malik, J., Arbeláez, P., Carreira, J., Fragkiadaki, K., Girshick, R., Gkioxari, G., Gupta, S., Hariharan, B., Kar, A. 和 Tulsiani, S. 2016. 计算机视觉的三大 R:识别、重建和重组。模式识别。
Shukla, D., Desai A.A. 整合计算机视觉与自然语言处理:问题与挑战。VNSGU 科学与技术期刊,第 4 卷,第 1 期,第 190–196 页。
Wiriyathammabhum, P., Stay, D.S., Fermüller C., Aloimonos, Y. 计算机视觉与自然语言处理:多媒体和机器人领域的最新方法。ACM 计算机调查。49(4):1–44
原文。经许可转载。
相关:
更多相关主题
使用 NLP 来改善你的简历
评论
由David Moore,金融技术实施专家
招聘人员正在使用越来越复杂的软件和工具来扫描和匹配简历与发布的职位和职位规格。如果你的简历(CV)是通用的,或者职位规格模糊和/或通用,这些工具可能会对你不利。人工智能确实在对抗你的职位申请,我不确定你是否知道或会接受这一点!但让我展示一些可以帮助你*衡机会的技巧。自然,我们将使用 NLP(自然语言处理)、Python 和一些 Altair 可视化。你准备好反击了吗?
设想你对在网上看到的一个好职位感兴趣。还有多少其他人看到过相同的职位?有大致相同的经验和资格吗?你认为有多少申请者申请了?会少于 10 个还是少于 1,000 个?
此外,考虑到面试小组可能只有 5 名强候选人。那么你如何‘筛选’出 995 份申请,以精炼并呈现出仅 5 名强候选人?这就是为什么我说你需要*衡机会,否则就会被淘汰!
处理 1,000 份简历(CV)
我想,首先,你可以将这些简历分成 3 或 5 堆。打印出来,并分配给人工阅读者。每个阅读者从他们的堆中选择一份。5 个阅读者就是 200 份简历——挑选出最好的一两份。阅读这些将需要很长时间,最终可能只会得出一个答案。我们可以使用 Python 在几分钟内阅读所有这些简历!
在 Medium 上的文章‘如何使用 NLP(Spacy)筛选数据科学简历’中演示了只需两行代码就能收集到那 1,000 份简历的文件名。
#Function to read resumes from the folder one by one
mypath='D:/NLP_Resume/Candidate Resume'
onlyfiles = [os.path.join(mypath, f) for f in os.listdir(mypath)
if os.path.isfile(os.path.join(mypath, f))]
变量‘onlyfiles’是一个 Python 列表,包含了通过 Python os 库获取的所有简历的文件名。如果你研究这篇文章,你还会看到如何基于关键词分析几乎自动对你的简历进行排名和淘汰。由于我们试图*衡机会,我们需要关注你所期望的职位规格和你当前的简历。它们匹配吗?
匹配简历和职位描述
为了*衡机会,我们希望扫描职位描述、简历,并测量匹配度。理想情况下,我们的输出能帮助你在游戏中调整策略。
阅读文档
由于这是你的简历,你可能有 PDF 或 DOCX 格式。Python 模块可以读取大多数数据格式。图 1 演示了如何将文档内容保存到文本文件中并读取这些文档。
图 1: 从磁盘读取文本文件并创建文本对象。图片由作者从 Visual Studio Code — Jupyter Notebook 中拍摄。
第一步总是打开文件并读取行。接下来的步骤是将字符串列表转换为单一文本,并在过程中进行一些清理。图 1 创建了变量 ‘jobContent’ 和 ‘cvContent’,这些变量代表一个包含所有文本的字符串对象。下一个代码片段展示了如何直接读取 Word 文档。
import docx2txt
resume = docx2txt.process("DAVID MOORE.docx")
text_resume = str(resume)
变量 ‘text_resume’ 是一个字符串对象,保存了简历中的所有文本,就像之前一样。你也可以使用 PyPDF2。
import PyPDF2
说到这里,已经有一系列选项供从业者阅读文档并将其转换为清洁处理过的文本。这些文档可能很长,很难阅读,而且坦白说也很枯燥。你可以从总结开始。
处理文本
我喜欢 Gensim 并经常使用它。
from gensim.summarization.summarizer import summarize
from gensim.summarization import keywords
我们通过读取一个 Word 文件创建了变量 ‘resume_text’。让我们对简历和职位发布进行总结。
print(summarize(text_resume, ratio=0.2))
Gensim.summarization.summarizer.summarize 将为你创建一个简洁的总结。
summarize(jobContent, ratio=0.2)
现在你可以阅读职位角色和你现有简历的整体总结!你是否错过了总结中强调的职位角色的任何信息?小的细节可以帮助你推销自己。你的总结文档是否有意义,并突出了你的核心素质?
也许仅仅是简明的总结是不够的。接下来,让我们衡量你的简历与职位要求的相似度。图 2 提供了代码。
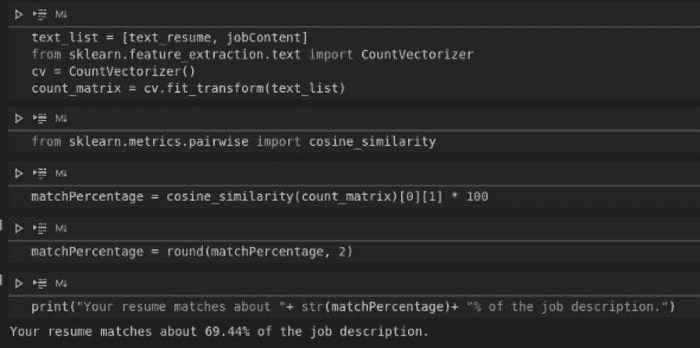
图 2 — 匹配两个文档并给出相似度评分的代码。图片由作者提供。
大致来说,我们首先列出文本对象,然后创建 sklearn CountVectorizer() 类的实例。我们还导入了 cosine_similarity 度量,它帮助我们测量两个文档的相似度。‘你的简历与职位描述匹配约 69.44%’。这听起来很棒,但我不会因此自满。现在你可以阅读文档的摘要并获取相似度测量。情况正在改善。
接下来,我们可以查看职位描述中的关键词,并查看哪些在简历中匹配到了。我们是否遗漏了一些可以提高匹配度至 100% 的关键词?现在转到 spacy。到目前为止,这是一段相当曲折的旅程。Gensim、sklearn 现在还有 spacy!希望你没有感到头晕!
from spacy.matcher import PhraseMatcher
matcher = PhraseMatcher(Spnlp.vocab)
from collections import Counter
from gensim.summarization import keywords
我们将使用 spacy 的 PhraseMatcher 功能来匹配职位描述中的关键短语与简历中的内容。Gensim 关键词可以帮助提供这些短语以供匹配。图 3 显示了如何进行匹配。
图 3: 使用关键词和短语匹配来交叉引用文档。图片由作者提供。
使用图 3 中的代码片段,可以提供匹配的关键词列表。图 4 显示了总结这些关键词匹配的方法。使用 Collections 中的 Counter 字典。

图 4 — 使用集合。计数器来计算关键字的命中次数。图片由作者提供。
“reporting” 一词包含在职位描述中,而简历中有 3 次命中。职位发布中有哪些短语或关键字在简历中没有?我们可以添加更多吗?我使用 Pandas 来回答这个问题 — 你可以在图 5 中看到输出。
图 5 — 职位描述中的关键字在简历中未提及。图片由作者提供。
如果这是真的,那也很奇怪。文档级别的匹配度为 69.44%,但看看那些在简历中未提及的长列表的关键字。图 6 显示了提及的关键字。
图 6 使用 Pandas 匹配的关键字。图片由作者提供。
实际上,与职位规范的关键字匹配非常少,这使我对 69.44% 的余弦相似度度量表示怀疑。尽管如此,情况有所改善,因为我们可以看到职位规范中的关键字在简历中未出现。关键字匹配较少意味着你更有可能被淘汰。查看缺失的关键字,你可以立即加强简历,然后重新进行分析。不过,仅仅在简历中加入关键字会产生负面后果,你必须非常谨慎。你可能通过初步的自动筛选,但由于被认为写作技巧不足而被淘汰。我们确实需要对短语进行排名,并专注于职位规范中的核心话题或单词。
接下来我们来看排名短语。对于这个练习,我将使用我自己的 NLP 类以及之前使用过的一些方法。
from nlp import nlp as nlp
LangProcessor = nlp()
keywordsJob = LangProcessor.keywords(jobContent)
keywordsCV = LangProcessor.keywords(cvContent)
使用我自己的类,我从之前创建的职位和简历对象中恢复了排名短语。下面的代码片段提供了方法定义。我们现在使用 rake 模块来提取 ranked_phrases 和 scores。
def keywords(self, text):
keyword = {}
self.rake.extract_keywords_from_text(text)
keyword['ranked phrases'] = self.rake.get_ranked_phrases_with_scores()
return keyword
图 7 提供了方法调用的输出示意图。
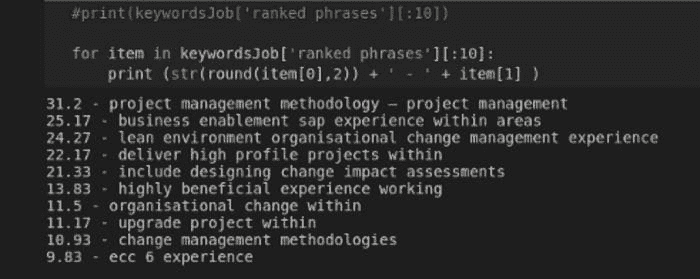
图 7 — 职位发布中的排名短语。图片由作者使用自己的代码提供。
‘project management methodology — project management’ 排名为 31.2,因此这是职位发布中的最关键话题。简历中的关键短语也可以通过小的变动来打印出来。
for item in keywordsCV['ranked phrases'][:10]:
print (str(round(item[0],2)) + ' - ' + item[1] )
从简历和职位发布中读取顶部短语,我们可以问自己是否存在匹配或相似度的程度?我们当然可以运行一个序列来找出!以下代码创建了职位发布和简历中的排名短语之间的交叉引用。
sims = []
phrases = []
for key in keywordsJob['ranked phrases']:
rec={}
rec['importance'] = key[0]
texts = key[1] sims=[]
avg_sim=0
for cvkey in keywordsCV['ranked phrases']:
cvtext = cvkey[1]
sims.append(fuzz.ratio(texts, cvtext))
#sims.append(lev.ratio(texts.lower(),cvtext.lower()))
#sims.append(jaccard_similarity(texts,cvtext)) count=0
for s in sims:
count=count+s
avg_sim = count/len(sims)
rec['similarity'] = avg_sim
rec['text'] = texts
phrases.append(rec)
请注意,我们使用 fuzzy-wuzzy 作为匹配引擎。代码中还有 Levenshtein 比率和 jaccard_similarity 函数。图 8 提供了这可能是什么样子的示意图。
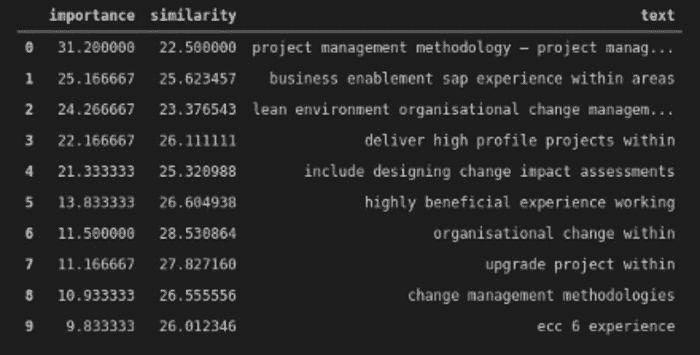
图 8 显示了职位描述与简历之间交叉引用的关键词。
“重要性”变量是来自简历的排名短语分数。“相似度”变量是模糊匹配的比率分数。术语“项目管理方法论”排名 31.2,但交叉引用评分的简历短语的*均分数仅为 22.5。尽管项目管理是职位的首要任务,但简历在不同的技术项上得分更高。你可以通过进行类似的练习来了解人工智能如何对待你的申请。
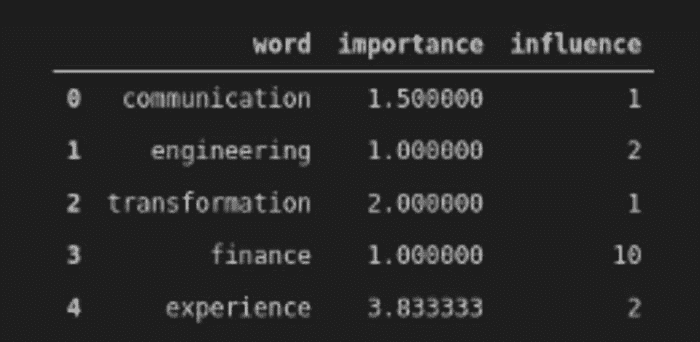
图 9 显示了简历中的术语重要性与影响力。图像由作者提供。
图 9 显示了另一种视角。通过处理词汇(单词),可以看到每个单词在职位描述中的重要性与在简历中出现的次数——特定单词在文档中的出现次数越多,影响力越大。词汇“财务”在职位描述中的重要性较低,但在简历中具有较高的影响力。这是一个财务人员在寻找 IT 工作吗?单词可能会在人工智能面前背叛你!
我相信你现在已经明白了。使用 NLP 工具和库可以帮助真正理解职位描述并衡量相对匹配度。虽然这并不完全可靠或绝对正确,但确实可以*衡竞争。你的用词很重要,但你不能在简历中随意堆砌关键词。你必须写一份强有力的简历,并申请适合你的职位。文本处理和文本挖掘是一个大话题,我们仅仅触及了可以做的表面。我发现文本挖掘和基于文本的机器学习模型非常准确。让我们看一些使用 Altair 的可视化效果,然后得出结论。
Altair 可视化
我最*一直在使用 Altair,而且比 Seaborn 或 Matplotlib 更多。Altair 的语法让我非常满意。我制作了三个可视化图表来帮助讨论——图 10 显示了简历中的关键词重要性和影响力。通过颜色比例尺,我们可以看到像“采用”这样的词在简历中出现了两次,但在职位发布中优先级较低。
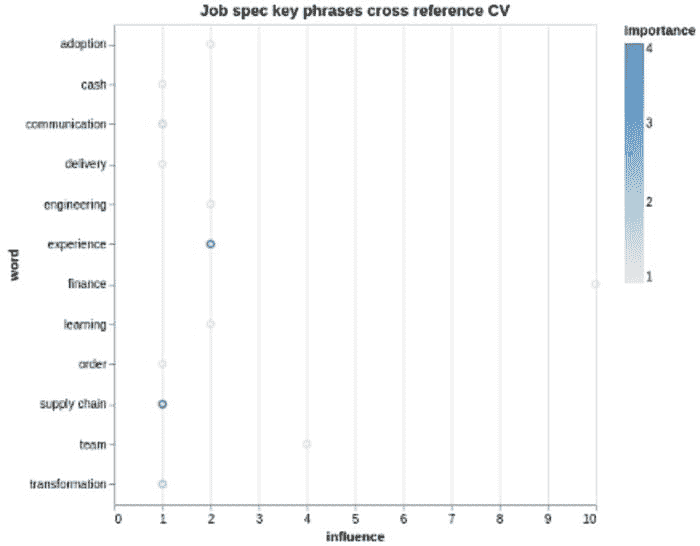
图 10 显示了 Altair 的可视化效果。图像由作者提供。图表显示了简历中按重要性和影响力排列的词汇。
图 11 显示了职位发布中发现的排名主题与简历中发现的主题的交叉引用。最重要的短语是“项目管理..”但在简历中排名的术语中得分较低。
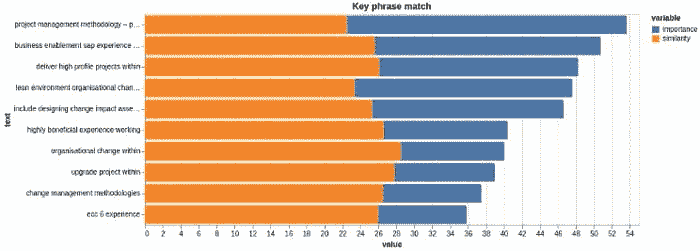
图 11. 显示了按排名短语和简历与职位发布之间的相关性的堆叠条形图。
图 12 绘制了相似词汇。财务在简历中使用了 10 次,但在职位发布中完全没有提及。词汇“项目”在简历(CV)中提到过,并且也出现在职位发布中。
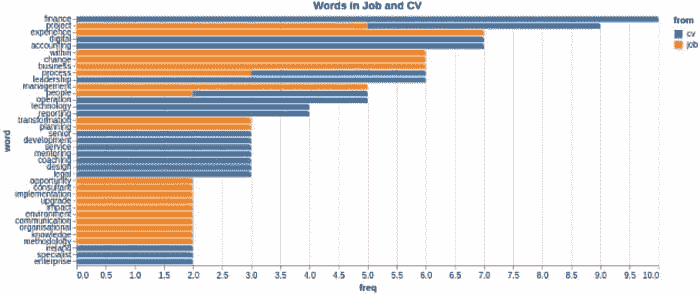
图 12:文档间关键词重叠的分析。图片由作者提供。
从图表来看,简历和职位描述似乎不匹配。共享的关键词非常少,排名的短语看起来也很不同。这就是为什么你的简历会被淹没在杂草中的原因!
结论
阅读这篇文章可能更像是一部高预算的“打得死的 CGI 好莱坞”电影。所有的大牌演员通常都会出现在这些大片中。本文中大 NLP 库扮演了主角,我们甚至还有许多其他的“客串出演”,可能是一些较老且更成熟的名字,比如 NLTK。我们使用了像 Gensim、Spacy、sklearn 等库,并演示了它们的使用。我的类也作为特别出演,封装了 NLTK、rake、textblob 以及一堆其他模块,所有这些模块都在进行文本分析并提供见解,向你展示如何避免错失实现梦想工作的机会。
实现梦想工作的关键在于对细节的明确和坚持不懈的关注,以及对求职申请、简历和求职信的精心准备。使用自然语言处理不会让你成为最佳候选人。这要靠你自己!但它可以提高你在 AI 驱动的早期筛选中的胜算。

图片由 Vidar Nordli-Mathisen 提供,来源于 Unsplash
每个渔夫都知道需要好的饵料!
简介:David Moore (@CognitiveDave) 是金融技术实施专家。David 对开发优秀的企业服务感兴趣,这些服务可以赋能用户,解放他们免于不必要的工作,并提供相关的见解。
原文。经授权转载。
相关:
-
入门指南:5 个必备的自然语言处理库
-
每个数据科学家都应该知道的 6 种 NLP 技术
相关话题
掌握 NLP 职业面试

NLP 并不是所有数据科学家都必须接触和了解的内容。是否需要了解 NLP,取决于面试你的公司。如果你对 NLP 不感兴趣,那么你至少需要知道它是什么,以便在职业生涯中避开它。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
如果你对 NLP 感兴趣并愿意了解更多,你将受益于了解可能会遇到的面试问题。
什么是 NLP?
不,这不是最*流行的那种伪科学心理学方法,他们称之为神经语言程序设计。
“我们的” NLP 也越来越受欢迎,但它指的是自然语言处理。
正如维基百科所说,自然语言或普通语言是指在人类通过使用和重复自然演变的任何语言,无需有意识的规划或预谋。
上述定义中的关键字是“人类”。在 NLP 中,还有一个额外的关键字:计算机。因此,NLP 的定义是教计算机如何理解自然语言。由于这是计算机,这种理解意味着处理和分析以不同数据格式存储的自然语言数据。
为此,NLP 结合了人工智能、计算机科学和语言学的知识。
NLP 的用途是什么?
NLP 正在成为我们日常生活的一部分。当我写下前一句话时,Google 的智能编写功能建议了“日常生活”这个短语。我接受了,因为这正是我想写的。
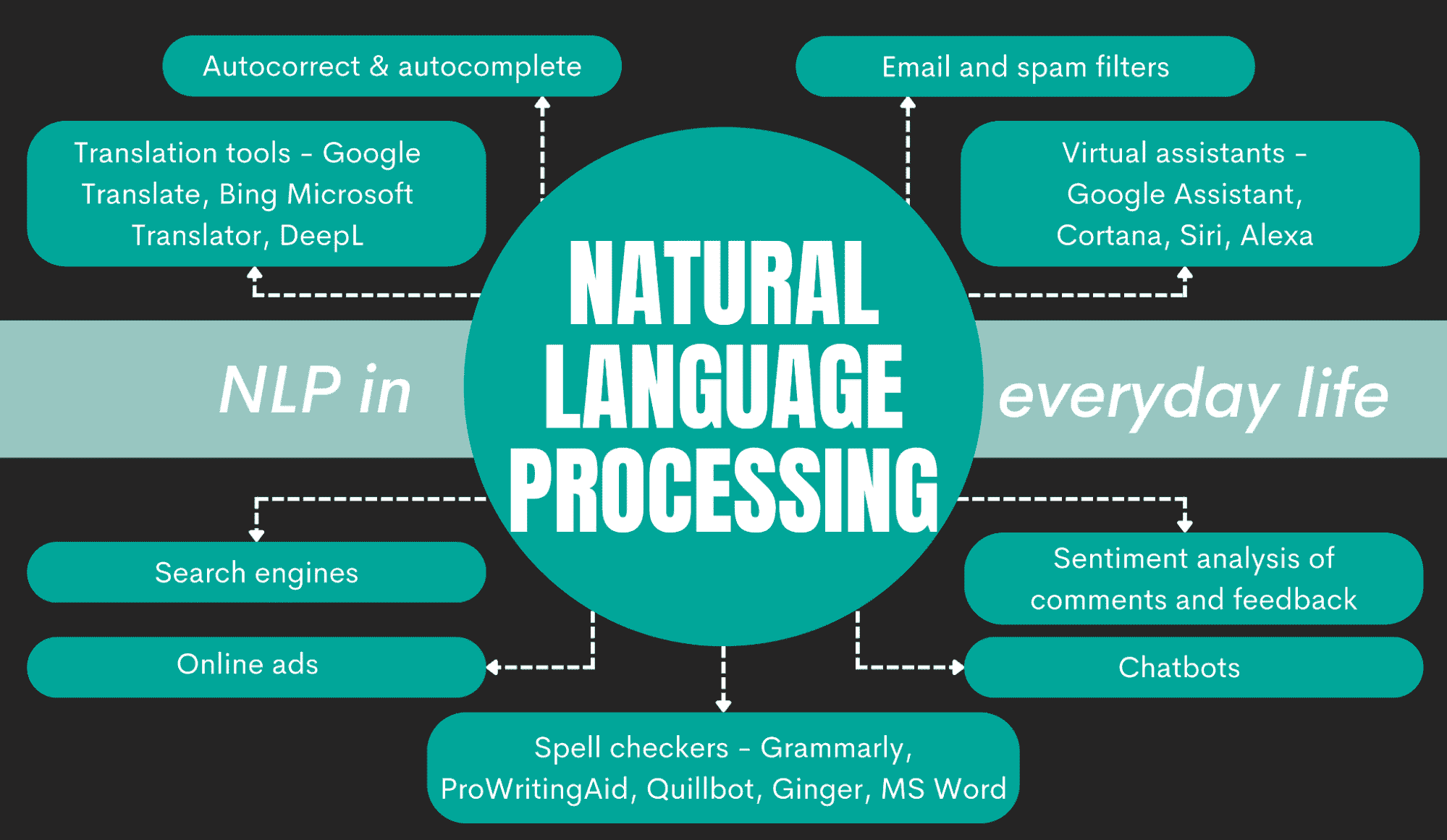
这就是其用途之一:自动纠错、自动完成和拼写检查。NLP 软件扫描文本中的语法和拼写错误,进行纠正或提供纠正建议。还有一些拼写检查器可以“理解”整个句子的语法、上下文和意义。基于这些,它们会建议纠正或更好的措辞,以符合你希望通过文本实现的目标。
语言翻译是 NLP 的另一种应用。每当你身处外国时,你可能会使用翻译工具,如 Google Translate。同时,翻译工具在社交媒体上也越来越常见,例如 Facebook、Instagram 和 YouTube。
识别和生成语音也是 NLP 的一种应用。想想 Google Assistant、Windows 语音识别、Dragon、Siri、Alexa 或 Cortana;当你说话时,它们似乎都能理解你(多多少少)。根据你告诉它们的内容,它们会执行某些操作,如浏览互联网、输入你的文字或播放你最喜欢的歌曲。其中一些工具甚至可以回应你,即生成语音。
NLP 还可以解码文本的‘情感’。换句话说,它们可以检测文本背后的情感,而不仅仅是字面意思。这意味着理解情绪(快乐、愤怒、困扰、中立……)、讽刺、双关语、隐喻和上下文中的表达。这被称为情感分析。比如理解社交媒体上的评论,移除那些违反服务条款的评论,或者通过分析客户的评论和评价来获取客户的满意度。
NLP 在在线营销中被广泛应用。你搜索的关键词会与公司的关键词、他们的产品以及广告进行匹配。因此,当你开始看到你刚刚搜索的产品的广告时,不用担心。你并没有疯;这是 NLP 和目标广告在发挥作用。
NLP 与数据科学有什么关系?
数据科学家可能对自然语言本身不感兴趣。但是,如果将计算机处理加入其中——让自然语言成为数据——那么你可能会吸引数据科学家的注意。
也许仅仅让数据科学家的眼睛一亮是不够的,但如果知道机器学习(ML)与自然语言处理(NLP)有重叠并且经常被使用,这可能会改变这一点。
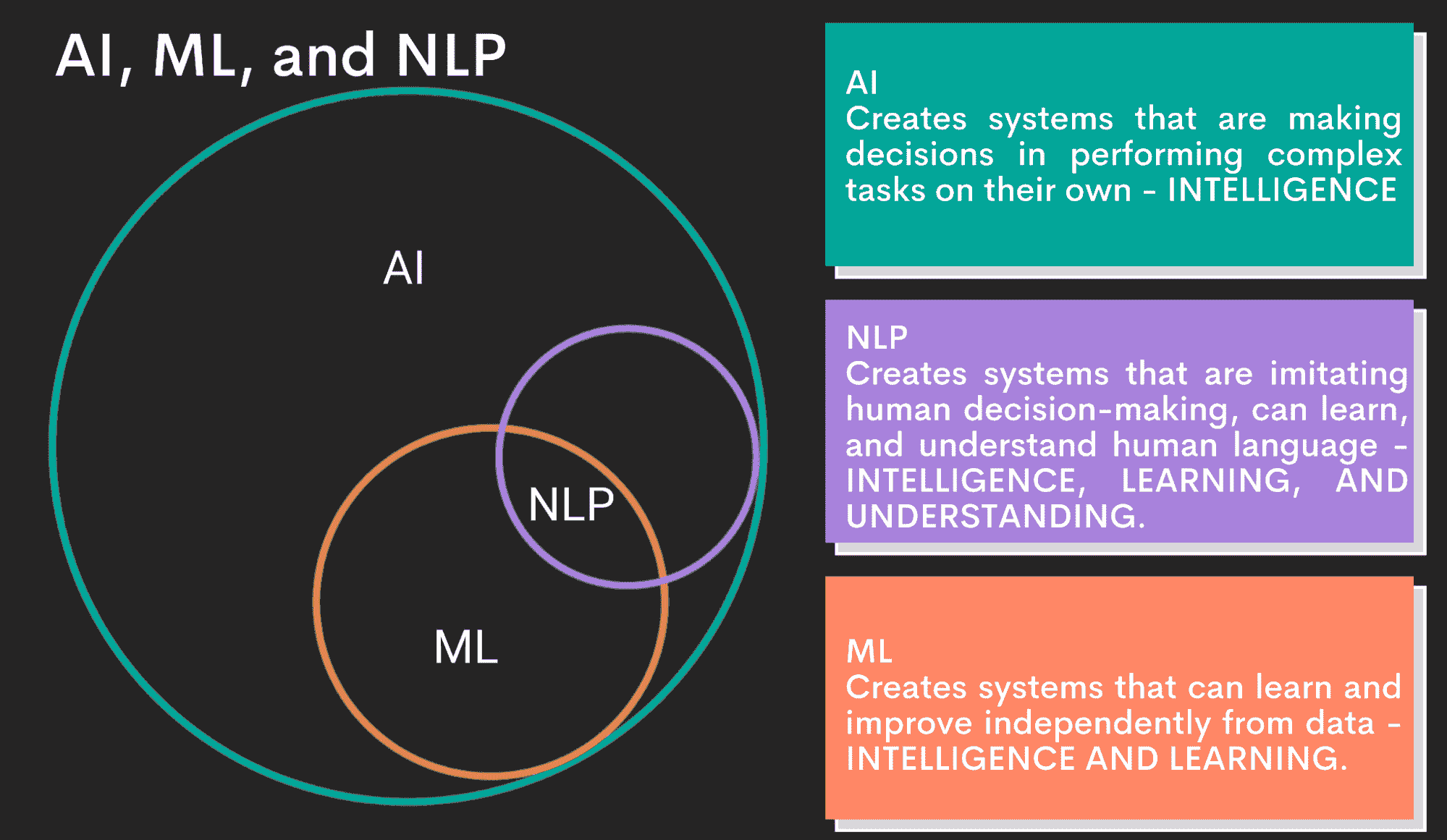
上述所有 NLP 的应用背后通常都涉及 ML。而 ML 无疑是一个深度融入数据科学的领域。
在讨论 ML 时,通常会区分监督式和无监督式 ML。
在 NLP 中最常用的监督式 ML 模型包括:
-
支持向量机(SVMs)
-
贝叶斯网络
-
最大熵
-
条件随机场
-
神经网络
无监督学习在 NLP 中并不那么常见,但仍然有一些技术被使用:
-
聚类
-
潜在语义索引(LSI)
-
矩阵分解
每个 ML 模型和算法背后都有基础的统计学概念。
这两个领域在所有寻找数据科学家的严肃公司中都受到严格考验。涉及 NLP 的公司也是如此。
NLP 中可能具有特定的术语,你需要了解这些术语。
将我在这里提到的内容结合起来,围绕三个主要主题进行面试准备。
NLP 面试问题
所有之前的讨论自然引出了 NLP 面试问题的类别:
-
一般与 NLP 术语相关的问题
-
统计问题
-
建模问题
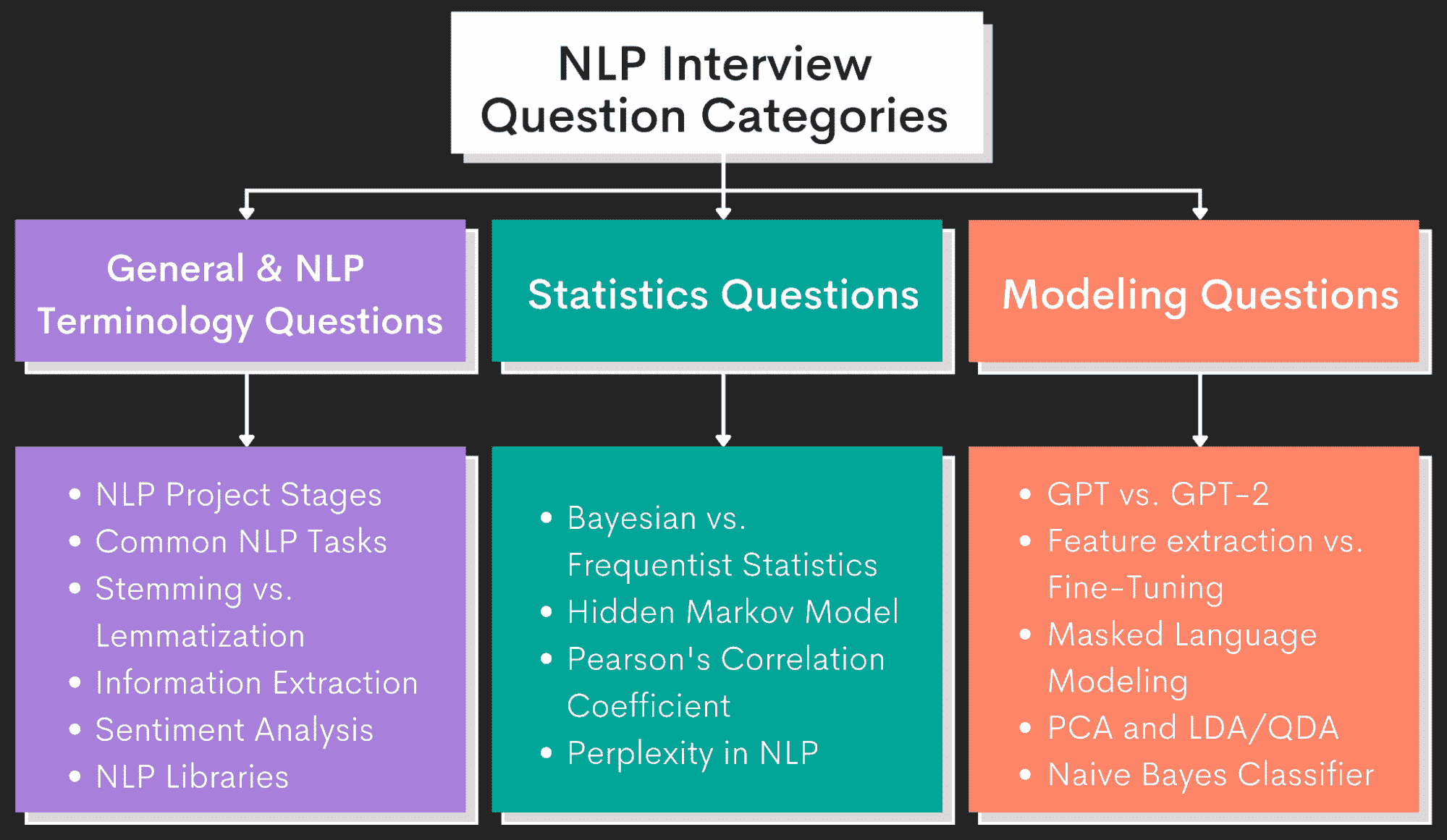
“我不会在这篇文章中涵盖编码问题。数据科学家通常需要精通编码,特别是 SQL 和 Python,这已是常识。在 NLP 领域工作的数据科学家也不例外,因此你应当为面试中的编码部分做好准备。”
1. 一般与 NLP 术语相关的面试问题
这些 NLP 面试问题涉及你对 NLP 是什么,它是如何工作的,以及特定于 NLP 的技术概念的知识。
这是最不具有‘可转移性’的数据科学知识。换句话说,如果你没有在 NLP 方面的工作经验,你之前的数据科学知识在这里不会有太大帮助。因此,如果你没有 NLP 的工作经验,请认真对待这些问题,并为面试做细致的准备。
一些问题示例是:
2. 统计面试问题
统计问题考察你对统计概念的知识,这些概念你会在作为数据科学家时经常使用,尤其是在处理 NLP 项目时。
以下是一些示例:
-
贝叶斯统计与频率统计:贝叶斯统计与频率统计的区别是什么?
-
皮尔逊相关系数:证明皮尔逊相关系数为何在-1 和 1 之间。
3. 建模面试问题
自然语言处理(NLP)面试问题的第三类涉及机器学习(ML)及模型的一般问题。这可能指的是 NLP 中最常用的 ML 算法(如上所述)以及一些在 NLP 中使用的其他特定技术和方法。
以下是一些示例:
-
PCA 和 LDA/QDA:PCA 和 LDA/QDA 之间有什么关系?
-
朴素贝叶斯分类器:朴素贝叶斯分类器的“朴素”是什么?
摘要
自然语言处理是一个在日常生活中越来越常用的领域。目前的应用包括拼写检查、自动补全工具、翻译器、语音识别和生成软件。NLP 在社交媒体监控和在线营销中也被广泛使用。
NLP 与机器学习有重叠,因此许多机器学习的知识也适用于 NLP。但不要过于自满!NLP 是一个广泛且具体的领域,需要了解非常具体的术语、技术和常用方法。
一般来说,面试问题的类型可以分为一般的 NLP 问题、统计问题和建模问题。
我给你的例子和资源只是一个开始。但即使如此,它们也足以让你在 NLP 职位面试中无所畏惧。
内特·罗西迪 是一名数据科学家和产品策略专家。他还是一名教授分析学的兼职教授,并且是StrataScratch的创始人,该*台帮助数据科学家通过来自顶级公司的真实面试问题准备面试。你可以通过Twitter: StrataScratch或LinkedIn与他联系。
更多相关内容
NLP、NLU 和 NLG:有什么区别?全面指南
原文:
www.kdnuggets.com/2022/06/nlp-nlu-nlg-difference-comprehensive-guide.html
图片由 Towfiqu barbhuiya 提供,来源于 Unsplash
你是否曾经使用过智能助手(比如 Siri 或 Alexa)来回答你的问题?答案很可能是“是”,这意味着在某种程度上,你已经对自然语言处理(NLP)有所了解。
NLP 是来自不同学科的多种方法的结合,这些方法被智能助手如 Siri 和 Alexa 用来理解我们提出的问题。它结合了人工智能和计算机科学等学科,使人类能够像与另一个人交谈一样与计算机对话。这种与机器进行类似人类对话的想法可以追溯到 艾伦·图灵 撰写的开创性论文——这篇论文奠定了我们今天使用的 NLP 技术的基础。
不同的组件支撑了 NLP 将一组非结构化数据转换为结构化数据的方式 成格式。
具体来说,这些组件被称为自然语言理解(NLU)和自然语言生成(NLG)。本文旨在快速介绍 NLP、NLU 和 NLG 之间的相似性和差异,并探讨 NLP 的未来。
NLU 和 NGL 如何融入 NLP
数据科学家和人工智能专家可以利用 NLP 将非结构化的数据转化为计算机可以转换为语音和文本的格式——他们甚至可以创建与你提问相关的上下文回复(再想想像 Siri 和 Alexa 这样的虚拟助手)。但是,NLU 和 NLG 在 NLP 中到底扮演着怎样的角色呢?
这三种学科共有的一个相似之处是它们都处理自然语言,尽管它们各自扮演着不同的角色。那么这三者之间的区别是什么呢?
这样理解:NLU 旨在理解我们作为人类所说的语言,而 NLP 则追踪数据中最重要的部分,将其结构化为数字和文本等形式;它甚至可以帮助处理恶意的 加密流量。与此同时,NLG 则将一组非结构化数据转化为我们可以理解的有意义的叙述。
定义自然语言理解(NLU)
自然语言理解依赖人工智能来理解它从语音或文本中获取的信息。它通过这种方式从书面文字中创造出我们可以找到意义的内容。一旦数据科学家使用语音识别将口语转化为书面文字,NLU 将解析出可以理解的意义,无论这些文本是否包含错误和发音问题。
自然语言理解(NLU)对数据科学家非常重要,因为没有它,他们无法从语音和聊天机器人等工具中解析出意义。毕竟,我们人类习惯于与语音启用的机器人展开对话——然而,机器却没有这种方便的奢侈。此外,NLU 可以像你一样识别语音中的情感和粗俗语。这意味着,借助 NLU 的能力,数据科学家可以对文本进行分类,并有意义地分析不同格式的内容。
自然语言理解试图解析和理解非结构化信息,以将其转化为可用的数据,而自然语言生成(NLG)则完全相反。为了此目的,接下来我们将定义 NLG,并理解数据科学家如何将其应用于实际用例。
定义自然语言生成(NLG)
当数据科学家向自然语言生成(NLG)系统提供数据时,该系统会分析这些数据集以创建通过对话可以理解的有意义的叙述。本质上,NLG 将数据集转化为你我都能理解的自然语言。
NLG 充满了现实生活中人的经验,以便生成彻底研究且准确的输出,尽可能地贴*真实。这一过程可以追溯到我们之前提到的艾伦·图灵所写的文献,关键在于让人们相信机器能够进行可信且自然的对话,不论讨论的主题是什么。
组织可以使用 NLG 来创建任何组织内部成员都可以利用的对话性叙述。例如,NLG 对于在市场营销、人力资源、销售和信息技术等部门工作的专家来说,可以带来巨大的好处——NLG 最常用于商业智能仪表板、自动内容创建和更高效的数据分析等方面。
NLP 的未来会是什么样?
尽管自然语言处理(NLP)在现代商业应用中有很多应用,但许多组织在广泛采用它方面仍然遇到困难。这在很大程度上是由于一些关键挑战:信息过载常常困扰着企业,使它们很难在看似无尽的数据海洋中判断哪些数据集是重要的。
此外,企业通常需要特定的技术和工具来从数据中提取有用的信息,如果他们希望使用 NLP 的话。最后,NLP 意味着组织需要先进的机器,如果他们希望使用 NLP 处理和维护来自不同数据源的数据集。
尽管挑战阻碍了大多数组织采用 NLP,但这些组织最终不可避免地会采纳 NLP、自然语言理解(NLU)和自然语言生成(NLG),以使机器保持可信的人类互动和对话。因此,大量投资正在进行中,涉及 NLP 子领域如语义学和句法学。
结论
总结一下我们在本文中涵盖的内容:NLU 读取并理解自然语言,而 NLG 创建并输出更多语言;NLU 为语音和文本赋予意义,而 NLG 在机器的帮助下输出语言。NLU 从语言中提取事实,而 NLG 利用 NLU 提取的见解来创建自然语言。
留意苹果和谷歌等 IT 巨头,他们将继续投资于自然语言处理(NLP),以创建类人的系统。到 2025 年,全球 NLP 市场预计将超过 220 亿美元,因此这些科技巨头改变人类与技术互动的方式只是时间问题。
Nahla Davies 是一位软件开发者和技术作家。在全职从事技术写作之前,她曾在一家《Inc. 5000》体验品牌机构担任首席程序员,该机构的客户包括三星、时代华纳、Netflix 和索尼。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织在 IT 方面
更多相关主题
我是如何使用 NLP(Spacy)筛选数据科学简历的
原文:
www.kdnuggets.com/2019/02/nlp-spacy-data-science-resumes.html
评论
由 Venkat Raman,数据科学家。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析水*
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
图片来源:pixabay
简历制作非常棘手。候选人面临许多困境,
-
是否详细描述一个项目,还是只提及最基本的信息
-
是否提及许多技能,还是仅提及他的核心能力技能
-
是否提及许多编程语言,还是仅列出几种
-
是否将简历限制为 2 页还是 1 页
这些困境对于寻找转行机会的数据科学家,甚至对于有志成为数据科学家的人员来说同样困难。
现在,在你还在想这篇文章的方向时,让我告诉你写这篇文章的原因。
背景
我有一个朋友经营自己的数据科学咨询公司。他最*获得了一个好的项目,需要他雇佣 2 名数据科学家。他在 LinkedIn 上发布了一个职位,并且令他惊讶的是,他收到了* 200 份简历。当我亲自见到他时,他感叹道,“如果有一种比逐一手动筛选所有简历更快的方式来选择最佳简历就好了”。
我过去两年一直在进行一些 NLP 项目,既作为工作的一部分,也作为爱好。我决定尝试解决我朋友的问题。我告诉我的朋友,也许我们可以解决这个问题,或者至少通过一些 NLP 技术来减少手动扫描的时间。
确切需求
我的朋友希望找一个以深度学习为核心能力的候选人,并且要具备其他机器学习算法的知识。另一位候选人需要拥有更多的大数据或数据工程技能,如 Scala、AWS、Docker、Kubernetes 等经验。
方法
一旦我理解了我的朋友理想中候选人的要求,我制定了一种解决方案。以下是我列出的解决方法
-
拥有一个字典或表格,将各种技能集分类。例如,如果有像 keras、tensorflow、CNN、RNN 这样的词语,那么将它们放在标题为“深度学习”的一栏下。
-
拥有一个 NLP 算法来解析整个简历,并基本上搜索字典或表中提到的单词
-
下一步是计算每个类别下单词的出现次数,即每个候选人类似如下的内容

上述候选人与我朋友正在寻找的“深度学习数据科学家”匹配良好。
- 以可视化方式表示上述信息,以便我们更容易选择候选人
研究
现在我已经确定了我的方法,接下来面临的重大挑战是如何实现我刚刚描述的内容。
NLP 部分 — Spacy
我一直在寻找一种可以进行“短语/单词匹配”的库。我的搜索需求由 Spacy 满足。Spacy 具有一个名为“Phrase Matcher”的功能。你可以在这里阅读更多内容。
阅读简历
有许多现成的软件包可以帮助读取简历。幸运的是,我朋友得到的所有简历都是 PDF 格式。因此,我决定探索像 PDFminer 或 PyPDF2 的 PDF 包。我选择了 PyPDF2。
语言: Python
数据可视化: Matplotlib
代码和解释
完整代码
这是完整代码的 Gist 链接。
现在我们有了完整的代码,我想强调两点。
关键词 csv
关键词 csv 在代码第 44 行被称为 ‘template_new.csv’
你可以将其替换为你选择的数据库(并在代码中进行必要的更改),但为了简单起见,我选择了传统的 Excel 表(csv)。
每个类别下的单词可以是定制的,以下是我用来进行短语匹配的单词列表。
候选人—关键词表
在代码的第 114 行,执行该行会生成一个 csv 文件,此 csv 文件显示了候选人的关键词类别计数(候选人的真实姓名已被掩盖)。它的样子如下。
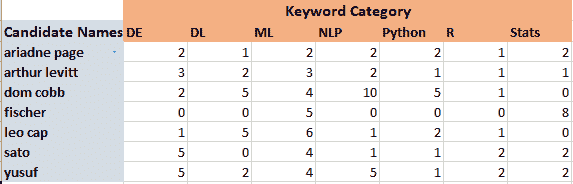
这可能不直观,因此我 resorted 到通过 matplotlib 进行数据可视化,如下所示:
这里 DE 代表数据工程,其他的都是自解释的
从图表来看,Dom Cobb 和 Fischer 更像是专家,而其他人则更像是通才!!
整个过程是否有益?
我的朋友对取得的结果感到非常惊讶,这节省了他大量的时间。更不用说,仅通过运行代码,他就从* 200 份简历中筛选出了大约 15 份。
这整个过程的用处如下
自动读取简历
代码自动打开简历并解析内容,而不是手动打开每份简历。如果手动完成这项工作,将耗费大量时间。
短语匹配和分类
如果我们手动阅读所有的简历,将很难说一个人是否在机器学习或数据工程方面有专长,因为我们在阅读时没有对短语进行计数。另一方面,这段代码只需寻找关键词,记录出现次数,并对其进行分类。
数据可视化
数据可视化在这里是一个非常重要的方面。它通过以下方式加快了决策过程
我们可以知道哪个候选人在某个特定类别下的关键词更多,从而推断他/她可能在该类别中有广泛的经验,或者他/她可能是全能型的。
我们可以对候选人进行相对比较,从而帮助我们筛选出那些不符合要求的候选人。
如何使用这段代码
求职中的数据科学家/有志成为数据科学家的:
很多公司可能已经在使用类似的代码来进行初步筛选。因此,建议根据特定的工作需求定制简历,包含必要的关键词。
一个典型的数据科学家有两个选择,要么将自己定位为全能型,要么在某一领域表现为专家,比如“自然语言处理”。根据工作需求,数据科学家可以运行这段代码来分析自己的简历,了解哪些关键词出现得更多,自己是否看起来像“全能型”或“专家”。根据结果,你可以进一步调整简历,以便更好地定位自己。
招聘人员
如果你像我的朋友一样是招聘人员并且被大量简历淹没,那么你可以运行这段代码来筛选候选人。
个人简介:Venkat Raman是一位具有商业头脑的数据科学家。希望在一生中积累知识并与他人分享。
原文。转载已获许可。
资源:
相关:
更多相关话题
AutoXGB 的简单 AutoML

作者提供的图片
自动化机器学习(AutoML)会自动运行各种机器学习过程,并优化错误指标以生成最佳模型。这些过程包括:数据预处理、编码、缩放、超参数优化、模型训练、生成工件和结果列表。自动化机器学习过程使得开发 AI 解决方案快速、用户友好,并且通常可以产生准确的低代码结果 - TechTarget。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
流行的 AutoML 库:
在本教程中,我们将使用 1994 年人口普查收入数据预测一个人是否年收入超过 50K 美元。这是一个经典的二分类问题,我们将使用 Kaggle 数据集 成人人口普查收入,该数据集采用 CC0: 公共领域 许可证。它由 Ronny Kohavi 和 Barry Becker(数据挖掘与可视化,硅谷图形公司)从 1994 年人口普查局数据库 提取。我们不会深入数据分析或模型工作原理。相反,我们将用几行代码构建一个优化的机器学习模型,并通过 FastAPI 服务器访问它。
AutoXGB
AutoXGB 是一个简单但有效的 AutoML 工具,可以直接从 CSV 文件中训练模型表格数据集。AutoXGB 使用 XGBoost 训练模型,使用 Optuna 进行超参数优化,并使用 FastAPI 提供模型推理 API 形式。
让我们开始安装 autoxgb。如果在运行服务器时遇到错误,请安装 fastapi 和 unvicorn。
pip install autoxgb
初始化中
我们将深入探讨 AutoXGB 函数的特性以及这些参数如何用于改善结果或减少训练时间。
-
train_filename: 训练数据的路径
-
output: 存储工件的输出文件夹路径
-
test_filename: 测试数据的路径。如果未指定,仅保存 OOF 预测
-
task: 如果未指定,任务将自动推断
-
task = "classification"
-
task = "regression"
-
-
idx: 如果未指定,id 列将自动生成,名称为 id
-
targets: 如果未指定,目标列将被假定为名为 target,并且问题将被视为二分类、多分类或单列回归中的一种
-
targets = ["target"]
-
targets = ["target1", "target2"]
-
-
features: 如果未指定,除了 id、targets 和 kfold 列外,将使用所有列
- features = ["col1", "col2"]
-
categorical_features: 如果未指定,将自动推断类别列
- categorical_features = ["col1", "col2"]
-
use_gpu: 如果未指定,则不使用 GPU
-
use_gpu = True
-
use_gpu = False
-
-
num_folds: 用于交叉验证的折数
-
seed: 用于可重复性的随机种子
-
num_trials: 要运行的 Optuna 尝试次数
-
默认值为 1000
-
num_trials = 1000
-
-
time_limit: Optuna 尝试的时间限制(秒)
-
如果未指定,将运行所有尝试
-
time_limit = None
-
-
fast: 如果 fast 设置为 True,则超参数调整将仅使用一个折,这样可以减少优化时间。之后它将对其余的折进行训练,并生成 OOF 和测试预测。
在我们的情况下,除了train_filename, output, target, num_folds, seed, num_trails, 和 time_limit,我们将大部分值设置为默认值。
from autoxgb import AutoXGB
train_filename = "binary_classification.csv"
output = "output"
test_filename = None
task = None
idx = None
targets = ["income"]
features = None
categorical_features = None
use_gpu = False
num_folds = 5
seed = 42
num_trials = 100
time_limit = 360
fast = False
训练与优化
是时候定义一个模型使用AutoXGB(),并将先前定义的参数添加到模型中。最后,我们将使用axgb.train()开始训练过程。它将运行 XGBoost、Optuna,并输出工件(model, predication, results, config, params, encoders)。
axgb = AutoXGB(
train_filename=train_filename,
output=output,
test_filename=test_filename,
task=task,
idx=idx,
targets=targets,
features=features,
categorical_features=categorical_features,
use_gpu=use_gpu,
num_folds=num_folds,
seed=seed,
num_trials=num_trials,
time_limit=time_limit,
fast=fast,
)
axgb.train()
训练过程花费了 10-12 分钟,我们可以在下面看到最佳结果。我认为我们可以通过增加时间限制来提高F1分数。我们还可以调整其他超参数以改善模型性能。
2022-02-09 18:11:27.163 | INFO | autoxgb.utils:predict_model:336 - Metrics: {'auc': 0.851585935958628, 'logloss': 0.3868651767621002, 'f1': 0.5351485750859325, 'accuracy': 0.8230396087432015, 'precision': 0.7282822005864846, 'recall': 0.42303153575005525}
使用 CLI 进行训练
要在终端/bash 中训练模型,我们将使用autoxgb train。我们将只设置train_filename和output 文件夹。
autoxgb train \
--train_filename binary_classification.csv \
--output output \
Web API
通过在终端运行autoxgb serve,我们可以在本地运行 FastAPI 服务器。
AutoXGB 服务参数
-
model_path -> 模型路径。在我们的案例中,这是输出文件夹。
-
port -> 服务端口 8080
-
host -> 用于服务的主机,IP 地址:0.0.0.0
-
workers -> 工作人员数量或同时请求的数量。
-
debug -> 显示错误和成功的日志
Deepnote 公共服务器
为了在云端运行服务器,Deepnote 使用 ngrok 创建公共 URL。我们只需开启该选项并使用端口 8080。如果你在本地运行,则无需遵循此步骤,直接使用 “http://0.0.0.0:8080” 访问 API 即可。
我们提供了 model path、host ip 和 port number 来运行服务器。
!autoxgb serve --model_path /work/output --host 0.0.0.0 --port 8080 --debug
我们的 API 运行顺利,你可以通过 “https://8d3ae411-c6bc-4cad-8a14-732f8e3f13b7.deepnoteproject.com” 访问它。
INFO: Will watch for changes in these directories: ['/work']
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
INFO: Started reloader process [153] using watchgod
INFO: Started server process [163]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: 172.3.161.55:40628 - "GET /docs HTTP/1.1" 200 OK
INFO: 172.3.188.123:38788 - "GET /openapi.json HTTP/1.1" 200 OK
INFO: 172.3.167.43:48326 - "GET /docs HTTP/1.1" 200 OK
INFO: 172.3.161.55:47018 - "GET /openapi.json HTTP/1.1" 200 OK
预测
我们可以添加随机输入来预测一个人的收入是否超过 $50k。在这个例子中,我们使用 FastAPI 的 /docs 选项来访问用户界面。
输入
我们将使用 FastAPI GUI 通过在链接末尾添加 /docs 来运行模型预测。例如 “172.3.167.43:39118/docs”
-
workclass: "私营"
-
education: "高中毕业"
-
marital.status: "丧偶"
-
occupation: "运输搬运"
-
relationship: "未婚"
-
race: "白人"
-
sex: "男性"
-
native.country: "美国"
-
age: 20
-
fnlwgt: 313986
-
education.num: 9
-
capital.gain: 0
-
capital.loss: 0
-
hours.per.week: 40
结果
结果为 <50k,置信度为 97.6%,>50k 的置信度为 2.3%。

使用请求进行测试
你也可以使用 Python 中的 requests 测试 API。只需将参数以字典形式推送,并以 JSON 格式获取输出。
import requests
params = {
"workclass": "Private",
"education": "HS-grad",
"marital.status": "Widowed",
"occupation": "Transport-moving",
"relationship": "Unmarried",
"race": "White",
"sex": "Male",
"native.country": "United-States",
"age": 20,
"fnlwgt": 313986,
"education.num": 9,
"capital.gain": 0,
"capital.loss": 0,
"hours.per.week": 40,
}
article = requests.post(
f"https://8d3ae411-c6bc-4cad-8a14-732f8e3f13b7.deepnoteproject.com/predict",
json=params,
)
data_dict = article.json()
print(data_dict)
## {'id': 0, '<=50K': 0.9762147068977356, '>50K': 0.023785298690199852}
项目
代码和示例可以在以下地址找到:
结论
我使用 AutoML 在 Kaggle 竞赛中获得优势,并为机器学习项目开发模型基线。你有时可以获得快速且准确的结果,但如果你想创建最先进的解决方案,你需要手动实验各种机器学习过程。
在本教程中,我们了解了 AutoXGB 的各种功能。我们可以使用 AutoXGB 进行数据预处理,训练 XGboost 模型,使用 Optuna 优化模型,并使用 FastAPI 运行 Web 服务器。总之,AutoXGB 提供了一个端到端的解决方案来处理你的日常表格数据问题。如果你对实现或使用我提到的其他 AutoML 有疑问,请在评论区留言。我很乐意回答你的所有问题。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,帮助那些在心理健康方面面临困扰的学生。
更多相关话题
-
[Nota AI 发布 NetPresso 模型搜索的测试版,...] (https://www.kdnuggets.com/2022/04/nota-ai-releases-beta-version-netpresso-model-search-hardwareaware-automl-tool.html)
数据科学中没有免费的午餐
原文:
www.kdnuggets.com/2019/09/no-free-lunch-data-science.html
评论
由 Sydney Firmin,Alteryx。
在你进行机器学习探索的过程中,你可能已经遇到过“没有免费午餐”定理。借用其名称自俗语"没有免费的午餐",数学民间定理描述了这样一种现象:没有单一算法能够适用于所有可能的场景和数据集。
没有免费午餐定理
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
一般来说,有两个没有免费午餐(NFL)定理:一个是针对机器学习的,一个是针对搜索和优化的。这两个定理是相关的,往往被归纳为一个通用的公理(民间定理)。
尽管许多不同的研究人员为关于没有免费午餐定理的集体出版物做出了贡献,但与这些研究最相关的名字是大卫·沃尔珀特。
监督学习没有免费的午餐
在他的 1996 年论文学习算法之间缺乏先验区别中,大卫·沃尔珀特探讨了是否可以在没有对目标变量做出任何假设的情况下,从训练数据集和学习算法中获得有用的理论结果。
Wolpert 在其 1996 年的论文中(通过一系列数学证明)证明了,给定一个无噪声的数据集(即没有随机变化,只有趋势)和一个以错误率为成本函数的机器学习算法时,所有机器学习算法在评估时都是等效的,使用的是泛化误差率(模型在验证数据集上的错误率)。
扩展这一逻辑(Wolpert 用数学方程进行),他展示了对于任何两个算法 A 和 B,A 比 B 表现差的情况与 A 超过 B 的情况数量相同。这甚至适用于其中一个算法是随机猜测的情况。Wolpert 证明了,对于所有可能的领域(从均匀概率分布中抽取的所有可能问题实例),算法 A 和 B 的*均性能是相同的。
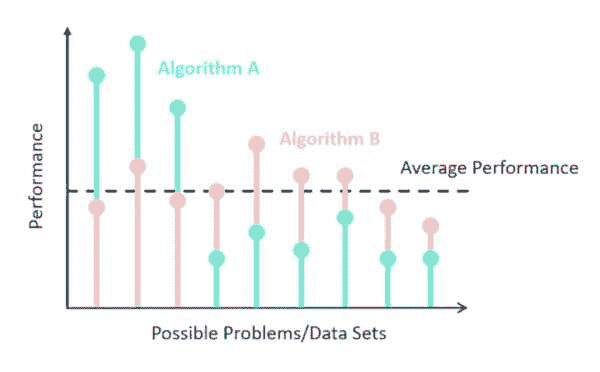
这是因为几乎所有的 (非死记硬背) 机器学习算法都对预测变量和目标变量之间的关系做出一些假设(称为 归纳或学习偏差),将 偏差 引入模型中。机器学习算法所做的假设意味着某些算法会比其他算法更好地拟合特定的数据集。这也(按定义)意味着存在许多数据集,给定的算法将无法有效建模。模型的有效性直接依赖于模型所做的假设与数据的真实性质的契合程度。
回到午餐的主题,你不能“免费”获得好的机器学习。你必须利用关于你的数据和我们生活的世界(或你的数据所在的世界)的知识来选择一个合适的机器学习模型。没有一种单一的、普遍最佳的机器学习算法,也没有独立于背景或用途的 (a priori) 理由来偏好某个算法而不是其他所有算法。
有趣的是,这篇 1996 年的论文是对哲学家 大卫·休谟 工作的数学形式化。我保证稍后会回到这个话题。
搜索和优化也没有免费午餐
Wolpert 和 Macready 在 1997 年发表的论文 优化的无免费午餐定理 展示了类似“无免费午餐”逻辑在数学领域的搜索和优化中的应用。
搜索和优化的无免费午餐定理表明,对于有限搜索空间中的搜索/优化问题,当被搜索的点没有被重新抽样时,任何两个给定搜索算法在所有可能问题上的性能都是相同的。
例如,假设你在徒步旅行,寻找地球上的最高点(极值)。为了找到它,你可能会总是选择朝着海拔升高的方向前进,像一个“爬山者”一样行动。
这在地球上是有效的,因为最高点是非常高的山脉的一部分。

现在,想象一下这样一个世界:地球上的最高点被地球上的最低点所包围。
这个家伙注定要失望。
在这种情况下,始终向下搜索的策略会表现得更好。
无论是爬山还是下坡,在两个星球上的表现都没有更好,这意味着随机搜索的效果(*均而言)也一样。在无法假设星球上的最高点会出现在其他高点附*(即*滑的表面)的情况下,我们无法知道爬山是否会比下坡表现得更好。
所有这些归结为:如果无法对优化程序做出任何先验假设,则不能期望任何优化策略比其他策略(包括随机搜索)表现得更好。通用的、万能的优化策略在理论上是不可能的,只有当一种策略专门针对特定问题时,它才能优于另一种策略。听起来很熟悉吧?没有免费的高效搜索优化。
在他 2012 年的论文《无免费午餐定理的真正含义;如何改进搜索算法》中,Wolpert 讨论了搜索与监督学习之间的紧密关系及其对“无免费午餐”定理的影响。他证明了在“无免费午餐”定理的背景下,监督学习与搜索/优化高度类似。对于这两个定理而言,“搜索算法”似乎可以与“学习算法”互换,“目标函数”也可以与“目标函数”互换。
如果你对每个“无免费午餐”定理感兴趣,可以访问www.no-free-lunch.org/获取一个很好的总结资源,其中包括 David Wolpert 关于“无免费午餐”定理概述的PowerPoint 演示文稿。有关“无免费午餐”定理的更多哲学解释,可以阅读通知:无人免费午餐,包括贝叶斯方法。
我们对“无免费午餐”确定吗?
“无免费午餐”定理引发了大量的研究和学术出版物。这些出版物并不总是支持“无免费午餐”(因为谁不想要免费的午餐呢?)。
“所有可能的问题”这一“无免费午餐”定理的组成部分是第一个难点。所有可能的问题并不反映现实世界的条件。事实上,许多人会争辩说,机器学习和优化所涉及的问题,即“现实世界”问题,与所有问题中的许多领域完全不同。现实世界往往表现出模式和结构,而“所有可能的问题”空间包括完全随机或混乱的场景。
研究人员也在哲学基础上反对取均值。如果你一只手放在开水中,另一只手冻在冰块里,那么你的手的*均温度是正常的。算法性能的*均可能会带来麻烦,因为某些算法在大多数问题上表现良好,但在一些边缘案例中表现极差。
在实证研究中,已经证明一些算法的表现始终优于其他算法。在 2014 年的论文我们是否需要数百种分类器来解决现实世界的分类问题中,研究人员发现,在UCI 机器学习库(121 个数据集)的所有数据集中,表现最好的分类器包括随机森林、支持向量机(SVM)、神经网络和提升集成。
这是一个重要的考虑因素,因为有些算法似乎在 Kaggle 排行榜上始终名列前茅,或者比其他算法更频繁地被应用于生产环境。然而,“没有免费午餐”定理提醒我们每个模型的假设,以及我们对数据和收集数据的环境(常常是潜意识中的假设)。
没有免费午餐与大卫·休谟
还记得我在(大约 800 字前)承诺会回到那位古老的死去哲学家吗?这就是那一部分。

这个家伙……
大卫·休谟是 18 世纪来自爱丁堡的哲学家,特别关注怀疑主义和经验主义。他对归纳问题进行了大量思考,这属于认识论(知识研究领域)。
为了探讨归纳问题,我们首先将世界分为两种不同的知识类型:先验和后验(这种划分可以追溯到伊曼努尔·康德的工作)。
先验知识是指独立于经验存在的知识。这种知识基于观念之间的关系,例如,2 + 2 = 4,或八边形有八个边。这种知识无论世界外部是什么样子都是真实的。
后验知识或“事实问题”是需要经验或实证证据的知识类型。这种知识构成了大部分个人和科学知识。后验知识需要观察。
归纳推理是一种用于后验知识的推理方法,我们将观察到的规律性模式应用于我们没有直接观察过的实例;例如,我观察到的所有雨都是湿的,因此,我没有观察到的所有雨也必须是湿的。
通过归纳法,我们隐含地假设了自然的一致性(有时称为一致性原则或相似性原则),并且未来将始终类似于过去。
科学完全基于归纳推理。如果没有像自然的一致性这样的假设,没有任何算法(包括像科学方法或交叉验证程序这样的高级算法)可以被证明优于随机猜测。
休谟认为,归纳推理和因果关系的信念无法被理性地证明。假设一致性没有任何理由。根据休谟的观点,归纳对人类来说是本能的,就像狗似乎本能地追逐兔子和松鼠一样。休谟并没有真正提出归纳的解决方案或证明——他只是有点耸肩地说,我们不能改变我们自身的本性,所以不必为此担忧。(我在想象他耸肩的样子。)
大卫·沃尔珀特关于有监督机器学习的无免费午餐定理的工作是对休谟的形式化。沃尔珀特甚至在他 1996 年的论文开头引用了这句休谟的话:
即使在观察到物体频繁联结后,我们也没有理由对那些我们没有经验的物体做出任何推断。
- 大卫·休谟,在《人性论》第一卷,第三部分,第十二节。
科学(以及机器学习模型)本质上相信在相同条件下,一切总是以相同的方式发生。没有理由假设因为一个模型在一个数据集上表现良好,它也会在其他数据集上表现良好。此外,科学、统计学和机器学习模型不能基于以前实验的结果对未来实验做出保证。没有任何系统可以对任何环境中的预测、控制或观察做出保证。

如果你喜欢这段哲学的绕行,想要了解更多关于休谟和归纳问题的信息,Khan Academy 上有一个很棒的视频,叫做休谟:怀疑主义与归纳,第二部分(第一部分讲的是先验知识与后验知识)。
无免费午餐定理与您
如果你已经坚持到现在,你可能在寻找这些内容对你的意义。来自“没有免费午餐”定理的两个最重要的结论是:
-
在依赖模型或搜索算法之前,始终检查你的假设。
-
没有“超级算法”能够完美适用于所有数据集。
“没有免费午餐”定理并不是为了告诉你在不同场景下该怎么做。“没有免费午餐”定理专门写来反驳类似于以下的主张:
我的机器学习算法/优化策略是最优秀的,永远如此,适用于所有场景。
模型是现实特定组件的简化(通过数据观察得出)。为了简化现实,机器学习算法或统计模型需要做出假设并引入偏差(特别称为归纳或学习偏差)。无偏学习是徒劳的,因为一个没有先验假设的学习者在面对新的、未见过的输入数据时将没有合理的基础来创建估计。算法的假设对于某些数据集有效,但对其他数据集无效。理解这些现象对理解欠拟合和偏差/方差权衡非常重要。
数据和随机选择的机器学习模型的组合不足以对未来或未知结果做出准确或有意义的预测。你,人类,需要对你的数据和我们所生活的世界的性质做出假设。积极参与假设的制定只会增强你的模型,使其更有用,即使它们是错误的。
原文。经许可转载。
简介:一名训练有素的地理学家和数据爱好者,Sydney Firmin坚信数据和知识在被清晰传达和理解时才最有价值。作为高级数据科学内容工程师,她的工作就是将技术知识和研究转化为引人入胜、富有创意和有趣的内容,服务于 Alteryx 社区。
相关:
更多相关话题
数据科学的非技术阅读清单
原文:
www.kdnuggets.com/2019/12/non-technical-reading-list-data-science.html
评论
作者:William Koehrsen,Cortex Building Intelligence 的首席数据科学家
与一些数据科学家可能喜欢相信的相反,我们永远不能将世界简化为数字和算法。当归结起来时,决策是由人类做出的,成为一个有效的数据科学家意味着要理解人和数据。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
请考虑以下真实的例子:
当 OPower,一家软件公司,希望减少能源使用,他们向客户提供了大量关于电力使用和成本的统计数据。然而,仅凭数据并不足以促使人们改变行为。此外,OPower 还需要利用行为科学,即,研究表明,当人们在账单上收到笑脸表情符号时,他们会更倾向于减少能源使用,以了解他们与邻居的比较情况!
当人们的电费账单上出现了一个????(表示他们的用电量低于邻居)和一个悲伤的表情符号(表示他们可以做得更好)时,这种简单的干预措施最终将电力消耗减少了 2–3%,在此过程中节省了数百万美元,并防止了数百万磅的二氧化碳排放。对于数据科学家来说,这可能是个震惊——你是说人们不会仅仅对数据做出反应?!——但这对OPower的首席科学官,罗伯特·西奥迪尼,一位写过关于人类行为的心理学教授来说并不奇怪。关键是你可以拥有任何数据,但你仍然需要理解人类的运作方式才能真正带来改变。
最有效的可视化不是柱状图,而是笑脸。
在我们作为数据科学家的日常工作和正式教育中,很难窥见人类的运作或退一步思考我们工作的社会影响。因此,阅读不仅仅是技术文章和教科书,还要扩展到研究人们如何做出选择以及如何利用数据来改善这些选择的作品是至关重要的。
在这篇文章中,我将重点介绍 6 本非技术性的书籍——即不涉及数学和算法的书籍——但对于数据科学家来说却是至关重要的。这些书籍对任何希望实现数据科学目标的人来说都是必要的:通过数据实现更好的现实世界决策。
这 6 本书在这里列出,并附有简要评论和要点总结:
1. 信号与噪声:为什么这么多预测会失败——但有些不会 由 Nate Silver
2. 数学毁灭武器:大数据如何增加不*等并威胁民主 由 Cathy O’Neill
3. 和 4. (并列)人类决策的计算机科学:生活中的算法** 由 Brian Christian 和 Tom Griffiths 以及 如何不犯错:数学思维的力量 由 Jordan Ellenberg
5. 思考,快与慢 由 Daniel Kahneman
6. (黑马)黑天鹅:高度不可能事件的影响** 由 纳西姆·尼古拉斯·塔勒布
重点总结与评论
1. 信号与噪声:为什么这么多预测会失败——但有些不会 由 Nate Silver

关于未来的预测——如选举、经济、国家政治和科技进步——经常是滑稽可笑的错误。这些预测在产生实际现实世界后果时不再那么幽默,在这部作品中,Silver 解释了为什么人们在做预测时往往很糟糕,并考察了在多个领域中成功打破这一趋势的少数人。事实证明,没有一个神奇的规则可以让你对未来做出准确的预测,只有一些伟大的预测者实践的基本规则。
任何人都可以从书中提供的简单建议中受益:
-
像狐狸一样思考(而不是刺猬):拥有许多小想法(狐狸),而不是一个大想法(刺猬)。如果你只有一个想法,你会倾向于寻找确认证据,并忽略任何与之矛盾的观点(这就是确认偏差)。如果你有许多小想法,你会更关注哪些是正确的,而不是支持你当前信念的东西,并且当证据不再支持这些想法时,你可以抛弃它们。这两种不同的思维方式也解释了为什么那些对自己预测更有信心的人(如电视评论员)往往更容易出错。
-
做大量预测并获得快速反馈:我们在对经常发生的事件进行估计时表现得更好,主要是因为反馈和改进的循环。每当天气预报错误时,这些信息会进入模型,使得对明天的预测更好(这也是天气预报在几十年间显著改善的一个原因)。我们在处理少见情况时最差,在这些情况下,使用尽可能多的数据是关键。
-
尽可能参考多样化的来源:每个数据提供者都有自己的偏见,但通过聚合不同的估计,你可以*均出错误——这一点在 Silver 的FiveThirtyEight中得到了很好的阐述。这种“众智”方法意味着使用与你的观点相悖的来源,而不仅仅依赖于某一领域的“专家”。
-
始终包括不确定性区间,并且不要害怕在证据发生变化时更新你的观点:人们在预测时最常犯的错误是只给出一个数字。虽然一个答案可能是公众想听的,但世界从不是严格的黑白,而是存在于不同的灰色地带,我们有责任在预测中体现这一点。表达不确定性可能显得胆怯——说希拉里获胜的概率是 70%意味着无论结果如何,你都会是对的——但这比单一的“是/否”回答更现实。此外,人们通常认为改变观点是一种弱点,但当实际情况发生变化时更新你的信念,实际上是一种重要的力量,无论是在数据科学还是形成世界观方面。
我们永远无法对世界的预测完全正确,但这不应该阻止我们通过依靠经过验证的原则来尽量减少错误。
在这个领域中,还有两本非常棒的附加书籍,分别是超级预测和专家政治判断,均由 Philip Tetlock 所著。
2. 数学毁灭性武器:大数据如何加剧不*等并威胁民主 作者:凯西·奥尼尔

《数学毁灭性武器》应当成为攻读统计学、机器学习或数据科学学位的学生,以及需要决定是否部署模型的任何人的必读书籍。所谓“数学毁灭性武器”是指任何不透明的算法——难以解释;在大规模上运作——影响到数百万甚至数十亿人,并且有可能造成严重的伤害——例如破坏民主选举或使我们社会中的一大片人群被囚禁。
核心观点是,这些数学毁灭性武器具有创建反馈循环的能力,这些反馈循环扩散了不*等,而由于我们无法看到这些算法的内部,我们将不知道如何纠正它们。只有当我们回顾并观察到巨大的损害——例如 2016 年选举或 2008 年金融危机(这两者都是由用于负面目的的算法造成的)——才会发现我们对这些模型的盲目信任可能造成的伤害。
此外,我们的模型的质量仅取决于输入的数据,而当这些数据存在偏差时,模型的预测也会存在偏差。考虑一个用于判刑的模型,它考虑到一个人首次遇到执法人员的时间。由于不公正的警务策略,如盘问和搜身,一个黑人男子可能比白人男子在更年轻时就与警方发生冲突,即使考虑到其他因素。这将导致模型推荐对黑人更长的监禁时间,而在此期间,这些个体将失去经济机会并被社会排斥。那些人更有可能再次犯罪,导致监禁的恶性循环,而这一切都源于由不公正政策生成的数据,然后被输入到黑箱中。
奥尼尔的这本书于 2016 年初发布,现在比以往任何时候都更加需要。2016 年底,俄罗斯演员利用 Facebook 的算法传播宣传,给美国民主进程造成了严重破坏。这些行动远非学术演练,它们带来了现实世界的后果,质疑了美国选举的合法性。极右派广告继续困扰 Facebook,这些广告由一种算法驱动(我们不太确定,可能是这样),该算法将参与度视为首要任务。
算法在我们日常生活中的作用只会越来越大。现在,我们上学的地方、阅读的内容、贷款是否被批准、是否找到工作以及我们购买的东西,都在很大程度上由我们无法控制且无法查询解释的算法决定。奥尼尔的书可能对机器学习模型感到悲观,但我更愿意把它看作是一种必要的批评:在机器学习围绕着如此多的盲目热情的情况下,我们需要那些愿意退一步思考的人:这些工具真的在改善人们的生活吗?我们作为一个社会应该如何采用它们?
机器学习算法只是工具,与许多工具一样,它们可以被用来做善事或坏事。幸运的是,我们仍处于早期阶段,这意味着我们可以塑造模型的使用,以确保它们致力于做出客观决策,并为最大多数人创造最佳结果。我们现在做出的选择将塑造未来几十年的数据科学,而最好是对这些辩论做好充分准备。
数据科学可能是一个年轻的领域,但已经对数百万个人的生活产生了巨大的影响,无论是好是坏。作为这一新前沿的开拓者,我们现在有责任确保我们的算法不会变成数学破坏武器。
3. & 4. (并列)生活中的算法:人类决策的计算机科学,作者布赖恩·克里斯坦和汤姆·格里菲斯,以及如何不犯错:数学思维的力量,作者乔丹·艾伦伯格


计算机科学和统计学(以及其他任何学科)在学校教学时存在一个问题:它们在抽象层面上很无聊。只有当它们应用于现实世界问题时,才会变得有趣到让我们想要去理解。这两本书都做得非常出色,将枯燥的主题转化为有趣且信息丰富的叙述,讲述了如何在日常生活中使用算法、统计和数学。
例如,在生活中的算法中,作者展示了我们如何使用探索与利用权衡和最佳停止点的概念来了解我们应该花多长时间寻找配偶(或者新的员工、晚餐的餐馆等)。同样,我们可以使用排序算法来高效地组织我们的物品,以便快速检索所需的东西。你以为你了解这些想法,甚至可能能够将它们写成代码,但你可能从未应用过它们来优化你的生活。
《如何避免犯错》的主要思想类似,艾伦伯格通过故事展示了统计概念的使用和误用,如线性回归、推断、贝叶斯推断和概率。应用概率法则显示买彩票总是一个失败的提议——除非在少数情况下回报实际为正(正如一组麻省理工学院学生发现的)。艾伦伯格并不回避展示方程式,但他将其应用于现实世界的情况。
艾伦伯格书中的核心引语是数学思维是“用其他方式扩展常识”。在许多情况下,特别是在遥远的过去,我们的直觉为我们提供了很好的服务,但在现代世界中,许多情况下我们的初步反应是完全错误的(见下一本书)。在这些情况下,我们需要依赖于概率和统计来得出最佳决定,而不是凭直觉。
这两本书都达到了恰到好处的严谨水*——结合了少量方程式和大量故事——阅读起来都很愉快。在这些书中,我发现了许多在课堂上从未完全掌握的数据科学概念,终于得以理解,且一再体验到了“啊哈”时刻的喜悦。数学、统计学和计算机科学的价值在于它们能否改善你的生活,而这两本书展示了这些学科的所有应用,您之前从未考虑过。
5. 思考,快与慢 作者:丹尼尔·卡尼曼

如果你还没有意识到这一点,那么这里有一个有用的教训:人类是不理性的,我们在生活的各个方面经常做出糟糕的决定。然而,仍然有希望的理由:一旦我们理解了为何我们无法做到最佳行动,我们就可以开始改变行为以获得更好的结果。这是卡尼曼大师之作的核心前提,记录了几十年的实验发现。
卡尼曼(2002 年诺贝尔经济学奖获得者)以及他的研究伙伴阿莫斯·特沃斯基(还有理查德·泰勒等其他人)创造了高度影响力的行为经济学领域,它将人们视为非理性的决策者,而不是理性最大化效用的人。这在经济学领域以及医学、体育、商业实践、能源节省和退休资金等各种生活领域都带来了真实的思维转变和设计选择。我们还可以将许多发现应用于数据科学,例如如何呈现研究结果。
在这部严谨而高度愉快的著作中,卡尼曼概述了我们不理性行为的各种方式,包括 锚定、可得性和替代启发式(经验法则) 或我们对 损失规避 的倾向以及陷入沉没成本谬误。他还概述了也许是最重要的结论:我们 有两种不同的思维系统。
-
系统 1 快速而直观:这种模式是由进化设计出来的,用于在没有考虑证据的情况下做出快速决策。虽然这种模式在我们狩猎采集的过去很有效,但在信息丰富的世界中,它常常让我们陷入麻烦,尤其是当我们不花时间查看数据时。
-
系统 2 慢而理性:在选项众多且证据来源不同的情况下,我们需要使用这种模式。运用系统 2 需要付出努力,但这种努力能带来更好的决策和结果,从而得到丰厚的回报。
使用系统 1 是自然的,我们必须克服数百万年的进化才能使用系统 2。尽管这很困难,但在信息丰富的世界中,我们需要花时间锻炼系统 2 的思维。虽然我们有时可能会遇到过度思考的问题,但思维不足——使用系统 1 而不是系统 2——是一个更严重的问题。
这本书对理解人们如何做决策至关重要,并且对我们作为数据科学家能做些什么来帮助人们做出更好的选择具有指导意义。
这本书还提出了在数据科学之外适用的结论,比如 两个自我的概念:体验自我和记忆自我。体验自我是我们在事件发生时的逐时感受,但比记忆自我重要得多,记忆自我是我们对事件的后续感知。记忆自我根据“峰值-结束”规则对经历进行评分,这对医学、生活满意度以及迫使自己做不愉快的任务有深远的影响。我们会记住事件的时间远比实际经历的时间要长,因此在经历过程中,我们必须尽力最大化记忆自我的未来满足感。
如果你想了解实际的人类心理学,而不是传统课堂上呈现的理想化版本,那么这本书是最好的起点。
6. (黑马):黑天鹅:高度不可能事件的影响 作者:纳西姆·尼古拉斯·塔勒布

塔勒布在名单上只能占据一个位置,那就是局外人的位置。 塔勒布 是一位前量化交易员,他在 2000 年和 2007 年的市场低迷期间赚取了可观的财富,他已经成为一位直言不讳的学者研究者,因其作品获得了全球的 赞誉与批评。主要来说,塔勒布关注一个想法:当代思维方式的失败,尤其是在极端不确定的时候。在 《黑天鹅》 中,塔勒布提出了一个概念,即我们对支配人类活动的随机性视而不见,因此当事情没有按预期发展时会感到沮丧。 《黑天鹅》 最初于 2007 年出版,自 2008 年和 2016 年的意外事件以来变得更为相关,这些事件彻底颠覆了传统模型。
当然,基于中心论点,立刻出现的问题是:那么,不可思议的事件按照定义不会经常发生,我们不应该担心它们吗?关键点在于,虽然每个不可思议的事件 本身不太可能发生,但综合来看,几乎可以肯定的是 在你的生命周期中会发生许多意外事件,甚至在一年内也是如此。任何一年发生经济崩溃的机会微乎其微,但概率会累积,直到每十年全球某处发生经济衰退成为接*可能的事实。
我们不仅应该期望改变世界的事件高频发生,而且不应该听信那些受限于过去发生过的事件的专家。正如任何投资股市的人都应该知道的那样,过去的表现无法预测未来的表现,这是一个我们在数据科学模型中(使用过去数据)应当谨慎考虑的教训。此外,我们的世界不是正态分布的,而是具有胖尾特征,少数极端事件——大萧条——或少数富有的个人——比尔·盖茨——掩盖了所有其他人。当极端事件发生时,没有人会做好准备,因为它们的规模远远超出以往任何事件的规模。
《黑天鹅》 对数据科学家来说很重要,因为它展示了任何仅基于过去表现的模型往往会出错,并带来灾难性的后果。所有机器学习模型都是仅基于过去的数据构建的,这意味着我们不应过于信任它们。模型(包括塔勒布的模型)是对现实的有缺陷的*似,我们应确保有系统来应对它们不可避免的失败。
需要注意的是,塔勒布不仅以其新颖的观点而著称,还以其极具对抗性而闻名。他愿意接受所有挑战,并定期批评像史蒂文·*克这样的学者,或像内特·西尔弗这样的公众人物。他的观点对我们在严重偏斜的时代中理解情况非常有帮助,但他的态度可能会让人感到有些不快。不过,我认为这本书值得一读,因为它提供了非主流的思维体系。
(这本书是塔勒布五部曲《Incerto》中的第二部,阐述了他的完整哲学。《黑天鹅》讨论了高度不可能事件的概念,而《Incerto》中的第四本书,《反脆弱:从混乱中获益的事物》讨论了如何不仅使自己对干扰保持强健,还可以利用这些干扰使自己处于更有利的位置。我认为《黑天鹅》对数据科学来说是最相关的。)
结论
在经过一天的电脑屏幕盯视之后,我找不到比一本书(无论是纸质书、电子书还是有声书)更好的方式来结束一天。数据科学要求不断扩展你的工具箱,即使在我们想要放松、远离工作的时刻,这也不意味着我们不能继续学习。
这些书籍都是引人入胜的阅读材料,同时也教会了我们关于data science和生活的课程。这里描述的 6 部作品将为更技术性的著作提供有益的补充,展示了什么实际上驱动着人类。了解人们实际的思维方式——而不是理想化的模型——对实现更好的数据驱动决策同样至关重要。
原文。转载经许可。
简介: 威廉·科尔森 是 Cortex Intel 的数据科学家和数据科学传播者。
相关:
更多相关话题
非营利组织如何从数据科学的力量中受益
评论
作者:Ramya Sriram,Kolabtree。

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
非营利组织是否能从数据科学中受益?Every Action的调查发现,90%的非营利组织表示他们正在收集数据,但“几乎一半的人表示他们对数据如何(以及确实)影响他们的工作并不完全了解”。鉴于大多数非营利机构没有专门的数据分析团队,这并不令人惊讶。然而,大数据的浪潮现在也开始影响非政府组织和政府机构,这些机构可以利用数据科学产生更大的影响。数据分析可以帮助这些组织确保他们将时间、精力、资金和资源投入到正确的渠道。非营利组织需要资金来实现其使命,同时也需要证明其工作的成果,以吸引捐赠者。数据科学在优化这一周期方面具有巨大的潜力,也帮助组织做出明智、合理的决策。虽然并非每个组织都能负担得起全职数据分析师,但一些组织通过在*台如Kaggle和Stack Exchange上寻求帮助,或通过Kolabtree和Experfy雇佣自由数据科学家和顾问,来填补资源缺口。以下是非营利组织和慈善组织如何利用数据科学的一些例子。
1. 市场营销和筹款
非营利组织拥有庞大的数据集,可以利用这些数据集开发统计模型,帮助它们优化筹款工作。国际特赦组织使用细分和预测建模来帮助识别和定位正确的群体,从而制定更精细的营销策略。数据洞察帮助非政府组织根据各种因素识别和分类捐赠者,这样它们可以更有效地推动营销和筹款工作。数据分析还帮助慈善组织发现关系,从而制定具体的激励措施。在研究数据并发现能够为捐赠者提供一些东西后,而不是反过来,麦克米伦癌症支持组织推出了“世界最大咖啡”计划,这使得收入从1500 万英镑跃升至 2000 万英镑。
2. 监控和实施具体活动
数据科学可以帮助非营利组织准确衡量其活动的表现,并帮助它们调整流程以获得更好的结果。数据分析和可视化在危机中的实时追踪和优化救援工作中也能发挥重要作用。总部位于美国的软件公司 Qlik 提供的数据科学工具,能够帮助组织发现洞察、模式并增强关键决策过程。在过去,他们曾与非营利组织合作,利用数据的力量推动社会公益事业:在尼泊尔地震期间支持救援工作,以及防止埃博拉病毒传播在西非。
芝加哥大学运营一个名为社会公益数据科学的项目,培训研究员从事专注于社会影响的数据科学项目。研究员们与政府部门和非营利组织合作,解决与教育、医疗保健、公共安全和环境相关的问题。他们的一个项目,与芝加哥公共卫生部门合作,使用预测分析帮助预防儿童铅中毒。在 1978 年禁用铅基涂料之前,铅基涂料被广泛使用,而住在老旧房屋中的儿童仍然可能暴露于此。模型根据各种因素识别可能使用铅基涂料的房屋,从而减轻暴露的危险。
3. 精简资金

总部位于印度的 Akshaya Patra 基金会 转向大数据以帮助他们找到一种具有成本效益的方式,将他们的午餐计划送到全国各地的政府学校。优化他们提供该计划的路线帮助他们确保有效使用资金。根据分析中的洞察分配资金帮助非政府组织充分利用资源,这是其顺利运作的关键。
数据科学对于政府组织和非营利组织,无论大小,具有巨大的潜力这一点非常明确。然而,访问专家是这些组织面临的一个常见问题。流程往往繁琐,资金可能不足以雇佣一个完整的团队。因此,许多组织看不到数据科学的力量显现。像 Datakind 这样的组织帮助将数据科学家与社会组织连接起来,但科学家们提供的服务通常是志愿的。一个解决方案是,组织可以 咨询自由职业数据科学专家来处理短期项目。这帮助他们在保持成本效益的同时,获得数据分析专家的专业知识。这绝对是第三部门可以利用数据科学的一个方式,并保持自身的赋能,从而赋能他人。
个人简介: Ramya Sriram 是 Kolabtree(kolabtree.com)的数字内容经理,该公司总部位于伦敦,帮助将企业和研究人员与全球自由职业科学家连接起来。Kolabtree 的全球专家团队包括来自 NASA、哈佛、斯坦福、牛津、麻省理工、剑桥等机构的专家。组织可以从按需*台的数据科学家、机器学习和人工智能专家的咨询中受益。
相关内容
更多相关主题
西北大学的在线数据科学硕士课程
原文:
www.kdnuggets.com/2021/02/northwestern-ms-data-science.html
| 通过西北大学推进你的数据科学职业生涯。数据科学与商业战略的整合创造了对能够理解大数据的专业人士的需求。建立必要的技术,
所需的分析、领导能力,适应当今数据驱动世界的职业生涯
西北大学的数据科学硕士课程。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业生涯! 2. 谷歌数据分析专业证书 - 提升你的数据分析技能! 3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
你将从一流的行业专家中学习。你可以
从广泛的专业方向和选修课程中选择,以适应你的目标
完全在线获得西北大学的硕士学位。 |
|
| 夏季申请截止日期:4 月 15 日 |  | 秋季申请截止日期:7 月 15 日 |
| 秋季申请截止日期:7 月 15 日 |
|
|
| |
 体育报道中充满了统计数据。西北大学已经提供了帮助
体育报道中充满了统计数据。西北大学已经提供了帮助
让我呈现复杂的概念,以便
观众不会因数学而感到困扰。在
广播的需求
传达数据至关重要。”爱德华·埃格罗斯,体育记者和主播
KDFW 达拉斯 |
|
| 相关课程信息系统硕士健康分析硕士 |
|---|
|
芝加哥东芝加哥大道 339 号
芝加哥,伊利诺伊州 60611
312-503-2579 | 与我们联系

|
了解更多相关主题
来自西北大学的在线数据科学硕士课程
原文:
www.kdnuggets.com/2021/07/northwestern-online-ms-data-science.html
赞助文章。
| 适用于数据驱动世界的关键技能,培养统计和分析专长,以及实施高层次数据驱动决策所需的管理和领导技能,来自于西北大学的
在线数据科学硕士项目。
-
学习创建强大的分析解决方案,将数据转化为可操作的洞察。
-
与经验丰富的行业专家团队互动,他们正在重新定义数据如何改善决策和提升投资回报率。
-
从广泛的专业和选修课程中进行选择,以适应你的目标。
-
完全在线获得西北大学的硕士学位。
|
|
|
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。 2. 谷歌数据分析专业证书 - 提升你的数据分析技能! 3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
冬季申请截止日期 10 月 15 日 | | 春季申请截止日期 1 月 15 日 |
|
|
| |
对我来说,该项目最大的好处是它给了我一个
更深入地理解
预测模型如何工作及其应用
同样重要的是,它
让我能够传达什么
预测分析的含义。”杰森·奥奎,产品经理,Adobe |
|
| 相关课程 信息系统硕士 健康分析硕士 |
|---|
|
339 东芝加哥大道
芝加哥,伊利诺伊州 60611
312-503-2579 | 与我们联系
|
更多相关话题
NoSQL 初学者
评论
什么是 NoSQL?
NoSQL 实际上是对 SQL 刚性结构的回应。最初创建于 1970 年代初期,NoSQL 直到 2000 年代末才真正起飞,那时亚马逊和谷歌都投入了大量的研究和开发。自那时以来,它成为现代世界的重要组成部分,许多全球的大型网站都使用某种形式的 NoSQL。
那么 NoSQL 到底是什么?本质上,它是一种创建数据库的理念,不 需要模式,也不 以关系模型存储数据。实际上,NoSQL 有多种 NoSQL 数据库 可供选择,每种都有自己的专业化和使用案例。因此,NoSQL 在填补细分市场方面极其多样,你几乎可以肯定找到适合你需求的 NoSQL 数据模型。
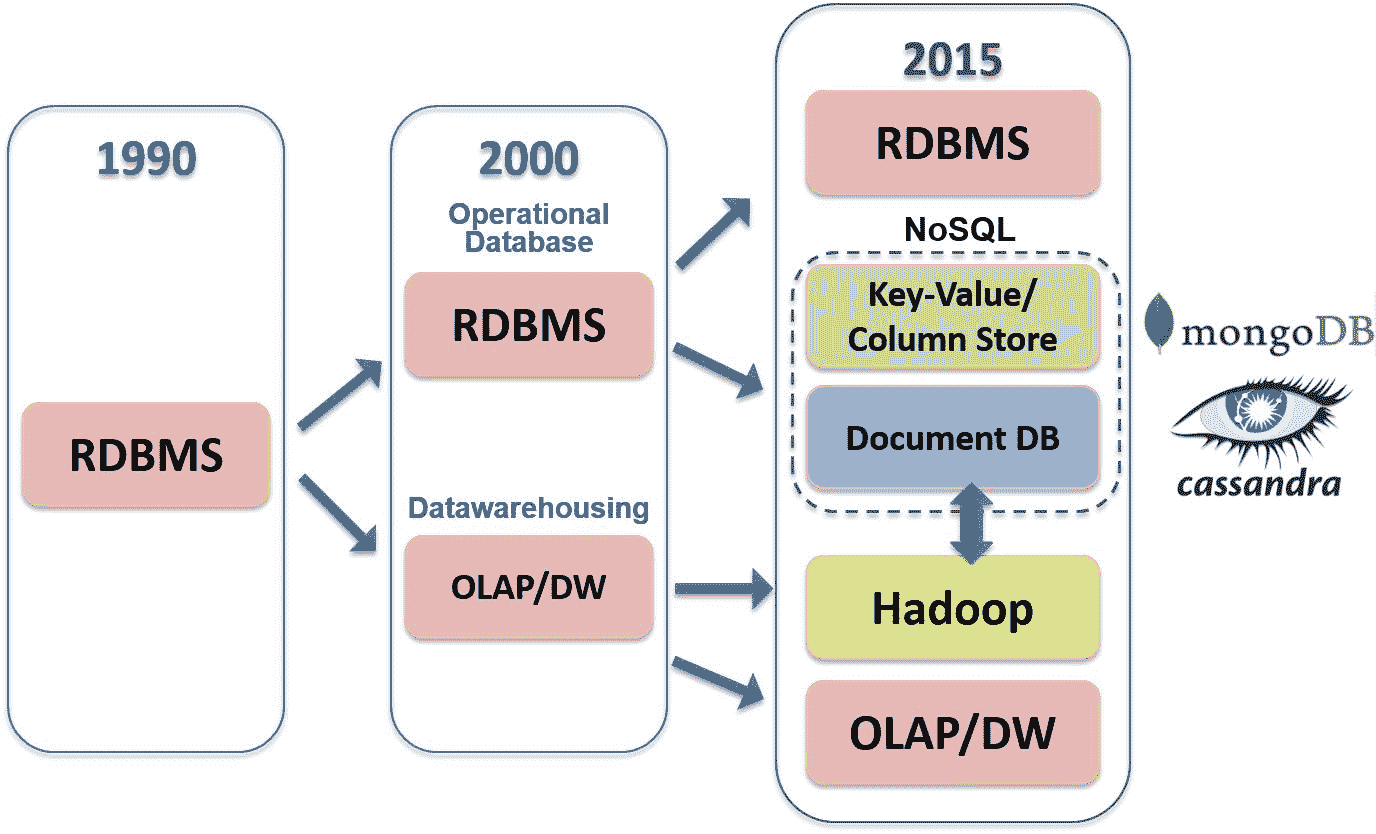
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT 需求
SQL 与 NoSQL 的区别
虽然 SQL 是 一种特定的数据库和语言,但 NoSQL 不是,但这并不意味着我们不能探讨两者之间的一般理念和区别。
可扩展性
对于 SQL,唯一真正的扩展方式是垂直升级。这意味着你需要购买比现有设备更高端、更昂贵的设备,以获得更好的性能。 使用 NoSQL 扩展 是通过水*扩展完成的,所以你只需再加入一个分片,基本就完成了。
这意味着 NoSQL 对于未来可能增长的应用程序来说绝对是很棒的,其中硬件可能成为一个重要障碍。
模式
SQL 从根本上构建,以避免 数据重复。这最终 意味着任何 SQL 项目都需要一位专家设计师在实施之前花费很长时间在模式上。这个步骤不仅在长期内对维护 数据质量 很重要,而且也可能相当昂贵。
另一方面,由于 NoSQL 不要求使用模式,你可以避免初始设计阶段的费用和时间。此外,缺乏模式意味着大多数 NoSQL 数据库具有极大的灵活性,允许你更改甚至混合数据类型和模型。这使得数据库的管理和处理变得更加容易。
性能
使用 SQL 查询数据通常需要跨多个表进行。使用 NoSQL 时,所有数据都包含在一个表中,因此查询要容易得多。这也导致了 NoSQL 更擅长 处理高性能任务。例如,Amazon DB 每秒可以处理数百万个查询,这对像 Amazon 这样的全球商店非常有用。
支持
关于 NoSQL 的唯一真正的大缺点是,它没有 SQL 那么成熟。请记住,SQL 有几十年的发展历程,这种成熟度体现在信息检索的便捷性上。同样,找到 SQL 专家要比找到 NoSQL 专家容易得多。
最后,由于 NoSQL 不是单一的数据库或语言,而是数十种数据模型,这种细粒度进一步分化了任何潜在的专业知识,使 NoSQL 成为一个专业化的领域。因此,信息和支持的依赖主要会集中在较小的社区中。
NoSQL 数据库的类型
虽然有超过半打的 NoSQL 数据模型可供选择,但我们将在这里介绍四种主要模型,这些模型对 理解 NoSQL 数据库 至关重要。
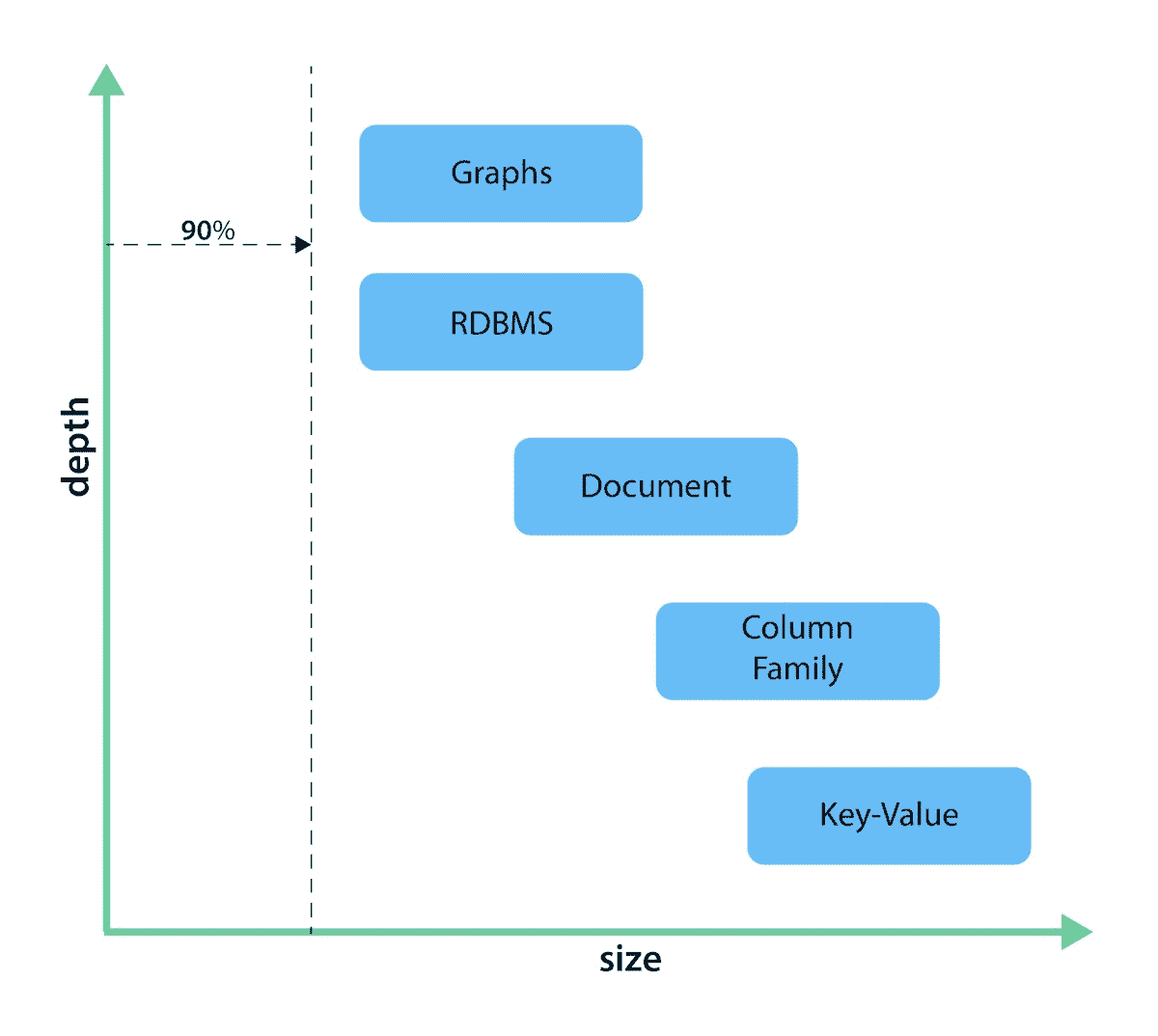
文档存储
这种数据模型允许你将信息存储为任何类型的数据。这与 SQL 相对立,后者严重依赖 XML 和 JSON,本质上将二者结合起来,这可能使任何查询变得低效(或效率较低)。由于 NoSQL 不使用模式,因此无需进行关系数据存储,也无需将二者结合起来。
事实上,如果你愿意,还可以选择一个特定于 XML 的 NoSQL 数据模型。
图形
图形或网络数据模型围绕数据之间的关系这一概念构建。在这种数据模型中,信息以关系和节点的形式存储,节点保存数据,关系描述任何一组节点之间的关系。
正如名称所示,如果你一直在关注的话,这是一种展示图表信息的优秀数据模型。从不同数据集的快速可视化能力,尤其是彼此之间的关系,能够提供大量洞察,无需翻阅几百页的数据。
键值存储
正如其名称所示,这种数据模型使用键和指针来存储信息。由于键和值都可以是你想要的任何数据,键值存储数据模型非常灵活。它的目的是为了检索、存储和管理数组,适合高容量应用。
实际上,Amazon DB 是一种键值存储数据模型,这种数据模型类型是由 Amazon 自己首创的。键值存储也是一个通用类别,其中还存在其他数据模型,一些图数据模型本质上也像键值存储。
面向列的
与 SQL 传统上按行存储数据不同,面向列的数据模型按列存储数据。这些列被分组到家庭中,每个家庭可以包含几乎无限数量的列。写入和读取也按列进行,因此整个系统非常高效,旨在实现快速搜索与访问以及数据聚合。
尽管如此,它在复杂查询方面并不是很好。
结论
需要记住的一点是,NoSQL 不是为了替代 SQL,而是为了补充 SQL。NoSQL 本身主要使用专门的数据库 来填补 SQL 的不足,虽然你完全可以选择不使用 SQL,但 NoSQL 并不排除使用 SQL。有时你可能会同时使用 SQL 和 NoSQL。
简历: 亚历克斯·威廉姆斯 是一位经验丰富的全栈开发者,也是 Hosting Data UK 的所有者。亚历克斯在伦敦大学毕业,主修信息技术,之后作为开发者领导了来自世界各地客户的各种项目,工作* 10 年。最*,亚历克斯转为独立 IT 顾问并开设了自己的博客。在博客中,他探讨了网页开发、数据管理、数字营销以及为刚起步的在线企业主提供解决方案。
相关:
-
如何获得最受欢迎的数据科学技能
-
在 Azure Databricks 上使用 Spark、Python 或 SQL
-
5 个棘手的 SQL 查询解决方案
更多相关主题
NoSQL 数据库及其应用场景

作者图片
在 1970 年代,埃德加·F·科德 提出了关系数据库模型,通常称为 SQL 数据库。这些数据库主要设计用于处理具有关系模型的结构化数据。它们可以处理事务数据,即在具有预定义模式的表中存储和操作数据。著名的 SQL 数据库例子有 MySQL、PostgreSQL 和 Oracle Server。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
在 1980 年代,它们获得了巨大的流行,但之后数据需求和数据量增加,数据类型的需求变得更加多样化,以至于 SQL 数据库感到吃力。此外,它们在横向扩展方面复杂,这使得它们不适合处理大量数据。
为了应对 SQL 数据库的这些局限性,在 2000 年代初期,NoSQL 数据库出现了。它们是面向文档的数据库,使用快速的键值对存储数据。它们能够从文档中解析数据,并将数据存储在键下,而不是像 SQL 数据库那样定义严格的信息表。
NoSQL 数据库现在已成为主流,并提供了相对于 SQL 数据库的各种优势。但这并不一定意味着 NoSQL 数据库比 SQL 更好。SQL 和 NoSQL 数据库服务于不同的目的,采用不同的数据管理方法。一个用于关系数据,另一个用于非关系数据。SQL 数据库仍在使用中,当需要运行复杂查询且数据库模式已明确定义时。著名的例子有 MongoDB、Cassandra、Neo4J 和 Redis。
但在下文讨论的某些领域,NoSQL 数据库优于 SQL 数据库。
NoSQL 数据库的优势
以下是 NoSQL 数据库在某些方面表现优于 SQL 数据库的关键特性。
- 灵活性:
这意味着数据可以动态地添加或移除,而不需要更改原始数据库的结构。与 SQL 数据库不同,它们不需要严格的模式。它们被设计用来处理任何数据格式,包括结构化、半结构化或非结构化数据。这使得开发人员可以专注于应用程序开发,而不必担心数据库模式。
- 可扩展性:
NoSQL 数据库支持水*扩展,这意味着我们可以通过添加更多服务器来扩展系统,而不是增加单个服务器的容量。这使得它在处理大量请求时更强大。
- 高可用性:
由于其将数据库复制到多个服务器的特性,它为用户提供了非常低的延迟和几乎零停机时间。此外,它们还将流量分配到各个服务器,以减少单个服务器的负担。
- 性能:
它们被设计用于优化读写性能,使其适用于实时数据处理应用程序,其中每天生成数 TB 的数据。它们具有更快的查询响应时间,并支持数据库分片,从而提升整体性能。
图片由作者提供
这些是 NoSQL 数据库在某些方面比 SQL 数据库表现更好的地方。以下部分将讨论 NoSQL 数据库的类型及其使用案例。
NoSQL 数据库类型
有多种类型的 NoSQL 数据库,每种都有其自身的优点和限制。以下是一些流行的数据库类型:
键值
这是最灵活的 NoSQL 数据库。它需要键值对来存储数据。键可以是一个唯一属性,如 id,对应特定的值。应用程序可以在值字段中存储任何类型的数据。这些数据库适合实时应用、缓存或会话管理。Redis 和 Riak 是著名的键值数据库示例。
使用案例:
这个数据库最适合电子商务*台,在这些*台上,像订单、用户档案和产品目录等大量客户相关数据每天都会生成。由于其低延迟和快速处理能力,它适合实时库存管理和处理高流量。
面向文档
这些数据库以文档形式存储数据,主要是 JSON 对象。这最适合存储半结构化或非结构化数据,无需明确指定文档的字段。MongoDB 是一个著名的面向文档的数据库示例。
使用案例:
这最适合用于内容管理系统,例如博客网站。以文章、评论、分类和标签的形式存储和快速检索数据。基于文档的数据适合存储非结构化数据,如文本、图像、链接等。此外,其灵活的模式行为允许对数据模型进行轻松更改。
图数据库
这种类型的 NoSQL 数据库最适合存储彼此紧密相关的数据。它们以节点和边的形式存储数据,用于表示对象之间的复杂关系。最适合用于社交媒体应用和创建推荐引擎。著名的例子有 Neo4J 和 InfoGrid。
使用案例:
它们最适合用于创建推荐引擎。例如,Youtube 会根据用户的观看历史推荐视频。图数据库可以存储和处理互联的数据,并快速提供相关内容。
列式数据库
在这种类型的 NoSQL 数据库中,数据存储在列族中。类似类型的数据被分组到单元格中,并存储在数据列中而不是行中。一个列甚至可以包含多个行和列,这些行和列都有自己唯一的 ID。
在传统的 SQL 数据库中,查询是逐行执行的。但在列式数据库中,查询只针对我们想要的特定列执行。这节省了时间,并使其适合处理大规模数据集。它们可能看起来像 SQL 数据库,因为它们涉及某种形式的模式管理,并且与关系表的工作方式相同。但它们比 SQL 数据库更灵活和高效,因此被归类为 NoSQL 数据库。
列式数据库的流行例子包括 Apache HBase 和 Apache Cassandra。你可以阅读这篇由 Alex Williams 撰写的文章,以获取更多关于这个主题的信息。
使用案例:
列族数据库最适合用于数据仓储应用。这些应用需要分析大量数据以获得商业智能,并且具有高写入吞吐量,而列族数据库完全可以承担这些任务。
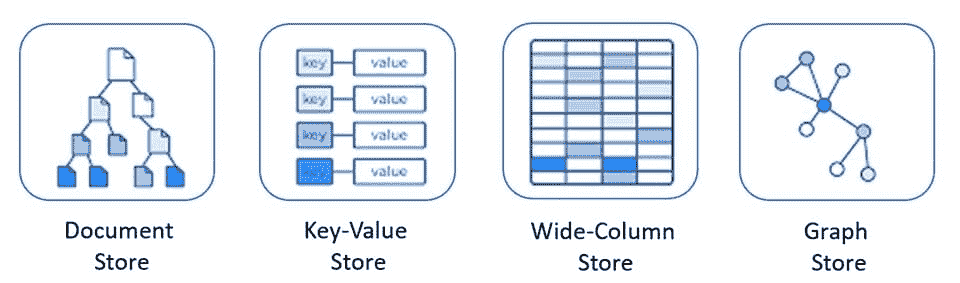
不同类型的 NoSQL 数据库 | 作者图片
结论
在本文中,我们了解了什么是 NoSQL 数据库,并初步了解了 SQL 与 NoSQL 数据库之间的根本区别。接着,我们讨论了几种流行的 NoSQL 数据库类型及其使用场景。
在 SQL 和 NoSQL 数据库之间总是存在一个选择什么? 的问题。要做出正确的选择,首先必须了解应用程序的使用案例、数据模型、可扩展性和性能,然后再决定。
希望你喜欢阅读这篇文章。如果你有任何评论或建议,请通过Linkedin与我联系。
Aryan Garg 是一名 B.Tech. 电气工程学生,目前在本科最后一年。他对 Web 开发和机器学习领域充满兴趣。他已经追求了这个兴趣,并渴望在这些方向上进一步工作。
更多相关内容
键值数据库解释
原文:
www.kdnuggets.com/2021/04/nosql-explained-understanding-key-value-databases.html
NoSQL 在我们日常生活中变得越来越重要,一些最受欢迎的*台和服务依赖它们以闪电般的速度提供内容。当然,NoSQL 涵盖了多种数据库类型,但最受欢迎的无疑是键值存储。
这种数据模型的极简设计使得它与关系数据库相比表现得极其迅速。不仅如此,由于它遵循可扩展的 NoSQL 设计理念,键值存储允许灵活性和快速启动。
我们的前三大课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业轨道。
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你的组织的 IT 需求
键值存储是如何工作的?
键值存储实际上非常简单。一个值(基本上可以是任何数据或信息)与一个标识其位置的键一起存储。事实上,这是几乎每种编程语言中存在的一种设计概念,如数组或映射对象。不同之处在于,它是持久化存储在数据库管理系统中的。
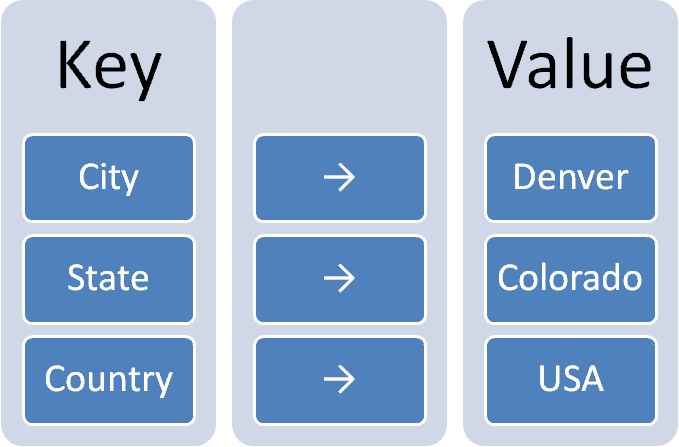
键值存储之所以如此受欢迎,是因为信息的存储方式类似于一种不透明的块,而不是离散的数据。因此,实际上不需要对数据库进行索引来提高性能。相反,它由于其结构方式而自行提高性能。类似地,它没有自己的语言,而是依赖简单的 get、put 和 delete 命令。
当然,这也带来了一个缺点,即从请求中获取的信息没有经过过滤。这种对数据的控制缺失在某些情况下可能会成为问题,但大多数情况下,这种交换是值得的。由于键值存储速度快且可靠,大多数程序员会解决可能遇到的任何过滤/控制问题。
键值存储的好处
作为 NoSQL 数据模型中更受欢迎的形式之一,键值存储在构建数据库时有很多好处:
可扩展性:与关系数据库相比,键值存储(如 NoSQL 一般)在水*扩展方面具有无限的可扩展性。与扩展是垂直和有限的关系数据库相比,这对于复杂和大型数据库来说是一个很大的优势。
更具体地说,它通过分区和复制来管理这方面的工作。它还通过绕过低开销的服务器调用来最小化 ACID 保证。
无/简化查询:一般来说,键值存储几乎无法进行查询,除了在特定情况下查询键,即便如此也不总是可能。因此,在会话、用户配置文件、购物车等情况下,键值存储使处理变得更便宜,因为只需一次读取请求和一次写入请求(由于数据存储的 blob 样式)。
同样,处理并发问题也更为容易,因为你只需解决一个键。
移动性:由于没有查询语言,键值存储在从一个系统迁移到另一个系统时非常容易,无需新的架构或更改代码。因此,从旧的操作系统迁移到新的操作系统不会像关系数据库那样造成严重中断。
何时使用键值存储
传统关系数据库并不适合处理大量读写操作,这正是键值存储的优势所在。由于其易于扩展,键值存储可以处理成千上万的用户。此外,凭借内置的冗余,它可以在存储或数据丢失的情况下正常工作。
因此,键值存储在以下几种情况中表现出色:
-
用户偏好和配置文件存储
-
大规模用户会话管理
-
产品推荐(例如在 电子商务*台 上)
-
根据用户的数据配置文件定制广告投放
-
仅更新数据的数据缓存
键值存储还在其他各种情况下表现良好。例如,由于其可扩展性,它通常用于大数据研究。同样,键值存储在会话管理中表现良好,无论是 Web 应用程序还是 MMO 游戏,以及管理单个玩家的会话。
另一个很好的用途是在*台上的临时和季节性购买激增。例如,在圣诞节、感恩节、国定假日等情况中。与其在全年的使用不多的基础设施上投入大量资金,不如利用键值存储的快速和简便的扩展性,商店可以购买一个或多个临时分片来帮助处理这些季节性的激增。
流行键值数据库的示例
有几种不同类型的键值数据库模型可以选择,例如,有些将数据存储在 SSD 上,而其他则存储在 RAM 上。事实上,一些最受欢迎和广泛使用的数据库是键值存储,我们在日常生活中每天都依赖它们。
Amazon DynamoDB: 可能是最广泛使用的键值存储数据库,实际上,正是对 DynamoDB 的研究真正使 NoSQL 变得非常流行。
Aerospike: 开源数据库,优化了内存存储。
Berkeley DB: 另一个开源数据库,是一个高性能的数据库存储库,尽管它相对基础。
Couchbase: 有趣的是,它允许进行文本搜索和类似 SQL 的查询。
Memcached: 通过将缓存数据存储在 RAM 中来加速网站,而且它是免费和开源的。
Riak: 为开发应用程序而设计,它与其他数据库和应用程序兼容良好。
Redis: 一个多用途的数据库,同时也充当内存缓存和消息代理。
结论
键值存储的真正优势在于它的简单性。虽然这可能是一把双刃剑,特别是在处理金融交易等更复杂的事务时,但它的目的就是弥补关系数据库的不足。通过结合关系型和非关系型数据库,我们可以创建一个更高效的管道,无论是用于数据分析还是处理用户。
亚历克斯·威廉姆斯 是一位经验丰富的全栈开发者,也是 Hosting Data UK 的拥有者。亚历克斯从伦敦大学毕业,主修 IT,之后在全球各地为客户领导了各种项目,工作了* 10 年。最*,亚历克斯转为独立 IT 顾问,并开设了自己的博客。在那里,他探讨了网页开发、数据管理、数字营销以及刚刚起步的在线企业主的解决方案。
更多相关话题
NoSQL 全知道大全
原文:
www.kdnuggets.com/2021/05/nosql-know-it-all-compendium.html
评论
编辑备注: 这是从 KDnuggets 文章中摘录的合集,由作者 Alex Williams 编写,涵盖了针对初学者的 NoSQL 主题和概念,附有进一步阅读的完整文章链接。

什么是 NoSQL?
NoSQL 本质上是对 SQL 刚性结构的回应。虽然 NoSQL 在 1970 年代初期首次创建,但直到 2000 年代末,亚马逊和谷歌都投入了大量的研究和开发,NoSQL 才真正起飞。从那时起,它已经成为现代世界的重要组成部分,许多全球大网站都使用某种形式的 NoSQL。
那么 NoSQL 到底是什么呢?本质上,它是一种创建数据库的理念,不需要模式,也不将数据存储在关系模型中。实际上,NoSQL 提供了各种 NoSQL 数据库,每种数据库都有自己的专业化和使用案例。因此,NoSQL 在填补特定需求时非常多样化,你几乎可以找到符合你需求的 NoSQL 数据模型。
虽然 SQL 是特定的数据库和语言,但 NoSQL 并不是,但这并不意味着我们不能看看两者之间的通用理念和差异。
继续阅读NoSQL 入门指南。
SQL 与 NoSQL
开发者们都非常清楚持续教育的必要性。无论是学习新的框架还是新的服务,创新和适应都是开发的基础。今天的一个热点话题是选择标准的 SQL 数据库还是转向 NoSQL 数据库。
NoSQL 数据库已经存在了几十年,感谢 Carlo Strozzi 的创新。然而,这些数据库直到 2000 年代初期才开始受到关注。当时,谷歌和亚马逊等公司开始更加努力地开发 NoSQL 数据库。尽管它们*年来变得非常流行,许多开发者、架构师和设计师可能仍未完全了解 NoSQL 数据库所提供的功能。
因此,了解这两种数据库之间的差异,可以参考以下每个开发者都应该知道的 7 个关键要点。
继续阅读SQL 与 NoSQL: 7 个关键要点。
NoSQL 已越来越受欢迎,作为传统 SQL 数据库和数据库管理方法的补充工具。正如我们所知,NoSQL 不遵循 SQL 的关系模型,这使得它能够做许多强大的事情。更重要的是,它非常灵活和可扩展,这对那些没有时间或预算来设计 SQL 数据库的新项目来说非常有利。
因此,我们将深入探讨不同的 数据模型 是如何工作的。
列导向数据库
从表面上看,列存储数据库确实做了它所宣传的事情:即,它不是按行组织信息,而是按列组织。这使得它们的功能与关系数据库中的表类似。当然,由于这是一个 NoSQL 数据库,这种数据模型使它们更加灵活。
更具体地说,列数据库使用密钥空间的概念,这有点像关系模型中的模式。这个密钥空间包含所有的列族,列族中包含行,行中包含列。一开始可能有点难以理解,但相对来说还是比较简单的。
通过快速查看,我们可以看到一个列族包含几行。在每一行中,可以有几列不同的列,具有不同的名称、链接,甚至大小(这意味着它们不需要遵循标准)。此外,这些列仅存在于它们自己的行中,并且可以包含值对、名称和时间戳。
继续阅读 列导向数据库解析。
图数据库
具有讽刺意味的是,尽管是一个非关系数据库,图形主要基于多关系数据“路径”的概念。
图数据库的结构一般比较直接。它们主要由两个组成部分构成:
-
节点:这实际上是数据本身。它可以是一个 YouTube 视频的观看次数,阅读推文的人数,甚至是基本信息,如人的名字、地址等。
-
边:这解释了两个节点之间的实际关系。有趣的是,边还可以包含自身的信息,例如两个节点之间关系的性质。类似地,边也可能具有描述数据流向的方向。
继续阅读 图数据库解析。
文档数据库
表面上看,文档数据库的理念是你可以在文档中存储任何类型的信息。这意味着你可以混合和匹配任何你想要的数据,而不必担心数据库无法解析它。当然,在实际操作中,大多数文档数据库仍然倾向于使用某种形式的模式、文件格式和预定结构。
与既是表格型又是关系型的 SQL 数据库相比,文档存储没有 SQL 的那些缺陷和限制。这意味着处理手头信息要容易得多,查询也可以更简单。具有讽刺意味的是,你在 SQL 数据库中可以执行的操作,如删除、添加和查询,也可以在文档存储中执行。
如前所述,每个文档需要某种键,该键通过唯一 ID 提供。当在任何过程中提供唯一 ID 时,文档中的信息会被直接读取和处理,而不是逐列提取。
继续阅读 文档数据库解析。
键值数据库
键值存储实际上相当简单。一个值,可以是任何数据或信息,存储在一个标识其位置的键下。事实上,这是一种几乎存在于每个编程中的设计概念,如数组或映射对象。不同之处在于,它是持久存储在数据库管理系统中的。
键值存储之所以如此受欢迎,是因为信息的存储方式是一种不透明的二进制大对象,而不是离散的数据。因此,实际上无需为数据库建立索引以提高其性能。相反,由于其结构的方式,数据库本身的性能更快。类似地,它实际上没有自己特定的语言,而是依赖于简单的 get、put 和 delete 命令。
当然,这也带来了一个缺点,即你从请求中获取的信息没有经过过滤。在某些情况下,这种数据控制的缺失可能会带来问题,但大多数情况下,这种交换是值得的。由于键值存储快速且可靠,大多数程序员会绕过可能出现的任何过滤/控制问题。
继续阅读 键值数据库解析。
简介:亚历克斯·威廉姆斯 是一名经验丰富的全栈开发人员,同时也是 Hosting Data UK 的拥有者。在伦敦大学 IT 专业毕业后,亚历克斯作为开发人员为来自世界各地的客户领导了各种项目* 10 年。最*,亚历克斯转为独立 IT 顾问,并开设了自己的博客。在博客中,他探索了网络开发、数据管理、数字营销和针对刚起步的在线商业主的解决方案。
相关:
-
NoSQL 入门
-
SQL 与 NoSQL:7 个关键要点
-
是否使用 SQL:这是个问题!
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
更多相关主题
让你脱颖而出的不那么炫酷的 SQL 概念
原文:
www.kdnuggets.com/2022/02/not-so-sexy-sql-concepts-stand-out.html
SQL(结构化查询语言)是管理关系型数据库数据的编程语言。大多数数据科学家将使用关系型数据,而有一个较小的误解认为数据库操作的工作落在了伟大的“数据工程师”身上。从实际角度来看,作为数据科学家,每次需要提取一条数据时,你希望去找别人吗?
实际上,很多数据科学职位要求具备 SQL 经验/技能,但我们要么在学术中没有学习,要么不愿意自己学习,以便有更多时间学习 R 和 Python。是的,确实一天、一个星期、一个月等时间有限,但数据库是我们数据的家,数据科学家必须拥有一把钥匙!
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
当然,这不会是革命性的突破,但正因为这些概念在数据科学工具包中并不主流,才阻碍了人们提升技能,将数据科学水*提升到一个新层次。

在这篇文章中,我讨论了一些数据科学家不熟悉的 SQL 决策概念。我将使用 SQL Server 作为我的 SQL 选择。请注意,如果你使用 MySQL、PostgreSQL 等,语法将会有所不同:
1. SQL 视图
现在,简单总结一下你为何需要这种技术,视图(Views)将减少你重复运行相同脚本以访问相同数据的需求。我们经常会创建一个 SQL 脚本,一旦它正确,我们就将其保存到文件夹中,然后再次运行。既然我们可以将其保存为视图(View)并像使用 SQL 表一样使用它,何必这样做呢?
以下 SQL 脚本展示了一个普通的 SELECT 和 JOIN 语句,*均水*的新 SQL 用户或初学者 SQL 学术课程将会使用。
SELECT
p.customer_name,
p.customer_address,
b.order_item
b.order_qty
FROM
customers.purchases p
INNER JOIN purchases.orders b
ON b.order_id = p.order_id;
现在,假设你需要在工作中多次引用这个表,每次都发现自己在重新运行脚本。如果这是一个大表,你知道这可能需要非常长的时间。使用视图可以节省时间,让你随时引用它,并且几乎像正常表一样操作它。
CREATE VIEW customers.orders
AS
SELECT
p.customer_name,
p.customer_address,
b.order_item
b.order_qty
FROM
customers.purchases p
INNER JOIN purchases.orders b
ON b.order_id = p.order_id;
创建视图就是这么简单。这并不是存储或创建一个新表,而是让用户能够用一个简单的命令如‘SELECT * FROM customers.orders’来创建之前的表。你只需这样做,而不必保存文件并重新运行脚本。只需打开你的 SQL 应用程序并运行相关的选择语句即可。
2. 存储过程
存储过程是一段你可以保存并在需要时执行的 SQL 代码。这是创建 SQL 数据处理工作流效率的另一种方法。
CREATE PROCEDURE spCustomerOrders
AS
BEGIN
SELECT
p.customer_name,
p.customer_address,
b.order_item
b.order_qty
FROM
customers.purchases p
INNER JOIN purchases.orders b
ON b.order_id = p.order_id;
END;
要执行上述过程,只需输入
EXEC spCustomerOrders;
再次,这是一种创建小效率的简单方法。这确实类似于视图,但执行方法不同。从本质上讲,这是正确的,但区别在于你可以为存储过程指定参数。它的工作方式类似于 SQL 中的函数或过滤器。我认为这主要用作快速过滤方法,而不是其他任何东西。当然,现在你可以添加参数,还有许多其他可能性。
CREATE PROCEDURE spCustomerOrders(@ord_qty AS Int)
AS
BEGIN
SELECT
p.customer_name,
p.customer_address,
b.order_item
b.order_qty
FROM
customers.purchases p
INNER JOIN purchases.orders b
ON b.order_id = p.order_id;
WHERE b.order_qty >= @ord_qty
END;
在上述示例中,我们将‘@ord_qty’参数添加到了spCustomerOrders过程。它在 SQL Server 中总是以‘@’开头,‘AS int’用于指定期望的数据类型。在这种情况下,我们在 WHERE 子句中使用它来根据购买数量筛选客户和订单详情。
要执行存储过程,只需简单地输入
EXEC spCustomerOrders 125;
上述命令将执行存储过程,返回订单数量超过 125 的客户和订单详情。
3. 标量函数
作为一名统计学家,我认为很多人可以拼凑出标量函数的定义。但我还是给你一个定义。在 SQL 中,标量函数是一段代码,它接收一个或多个参数来计算并返回一个单一的值。我们经常使用 SQL 来创建数据汇总。
在我个人看来,可以把它看作是 GROUP BY 2.0。可能有点夸张,但本质上允许你对 SQL 默认情况下可能无法直接获取的数据进行更复杂的计算。
CREATE FUNCTION customers.GrossProfit_per_Cust(
@ord_qty INT,
@price DEC(10,2),
@cost_of_sales DEC(10,2)
)
RETURNS DEC(10,2)
AS
BEGIN
RETURN (@ord_qty * @price)-@cost_of_sales;
END;
上述函数用于通过将订单数量乘以价格并减去销售成本来查找每位客户的毛利润(这不是会计课,所以如果不正确请见谅!)。
以最简单的方式,你可以像这样使用函数:
SELECT customers.GrossProfit_per_cust(12,50,200)
这看起来不错,但真正的价值在于在典型的 SELECT 语句中使用它,以将数据汇总提升到另一个层次。
SELECT
p.customer_name, SUM(customers.GrossProfit_per_cust(b.ord_qty, b.price, b.cost_of_sales) gross_profit
FROM customers.purchases p
INNER JOIN purchases.orders b
ON b.order_id = p.order_id;
GROUP BY p.customer_name
ORDER BY gross_profit DESC;
结论
这些是数据科学家可用但在学术层面未被充分利用的 3 个 SQL 概念,并且在许多初学者数据科学家的优先级列表中并不高。数据库现在正转向云端,全球生成的数据也在不断增加。
数据库技术需要跟上数据的步伐,以尽可能发挥其作用,而当今和未来的数据科学家需要能够以高于仅仅拥有最复杂的代码(如 GROUP BY)的水*来操作数据库。我们需要改进流程,更快、更灵活。
Asel Mendis (@aselmendis) 是一位在澳大利亚的 数据科学家。他来自斯里兰卡,自 2019 年起进入数据领域。作为数据科学家,他的目标是利用相关技术和方法创造洞察和价值。他是 KDnuggets 的贡献编辑。他对位置智能、空间分析、人口统计学、机器学习、数据可视化以及使用 R 和 Python 的统计学感兴趣。他拥有皇家墨尔本理工大学的分析硕士学位,专攻应用统计学,并于 2021 年开始攻读应用统计学博士学位,研究主题为道路黑点。他还是澳大利亚统计学会的会员,并获得了统计学研究生(GStat)称号,未来期望成为认证统计学家(AStat)。
更多相关主题
他们没有告诉你关于机器学习的事
评论
作者:Mike West,SQL Server 布道者。

我们的前三个课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
真相。
这里有一些现实世界的见解。
-
我的工作大部分是数据驱动的。大约 90%。
-
建模只是我工作的一个小部分。
-
我在日常工作中根本不使用数学。
-
没有入门级的机器学习工程职位。
-
大多数应用建模不是深度学习。
-
现实世界中的模型不是在笔记本电脑上构建的。
-
除非你是一个从事数据工作的程序员或经验丰富的数据专业人士,否则你需要 5 到 8 年才能进入实际工作。
-
没有参加训练营并获得工作的现实世界机器学习工程师。
-
机器学习工程师的顶级技能是 SQL。
-
大多数人永远无法通过电话面试。
祝你好运。
设定一些现实的期望。
成为一个对机器学习充满热情的学习者。
如果你没有相关技能,那么找一份与 SQL 和数据相关的工作。没有数据技能,就没有工作。
原文. 经许可转载。
相关:
更多相关话题
Noteable 插件:自动化数据分析的 ChatGPT 插件
原文:
www.kdnuggets.com/2023/06/noteable-plugin-chatgpt-plugin-automates-data-analysis.html

图片来源:编辑
生成式 AI 文本工具如 ChatGPT 使我们的生活变得更加轻松。从内容规划、回答问题到代码生成,这些现在都变得可能。这在几年前是无法想象的。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水*
3. Google IT 支持专业证书 - 支持您的组织的 IT
ChatGPT 的能力通过ChatGPT 插件进一步扩展。ChatGPT 可以通过插件连接到第三方应用程序,并增强工具以执行额外的操作。其中之一是进行数据分析,我们将在本文中进一步探讨。
它是如何工作的?让我们深入了解一下。
Noteable 插件
Noteable 是一家初创公司,提供用于任何数据活动的协作笔记本,例如数据准备、EDA 和机器学习开发。这意味着我们可以与多个用户共享一个笔记本。该笔记本还可以根据需要使用 Python、R 和 SQL 编程语言。
Noteable 的一个增强功能是ChatGPT Noteable 插件。使用此插件,用户可以通过将提示输入*台来加快数据处理。这款插件非常适合需要熟悉笔记本的非技术用户和需要帮助的技术用户。
如何使用 Noteable 插件
要使用 Noteable 插件,你需要访问 ChatGPT 插件。这意味着你需要成为 ChatGPT Plus 用户。目前,这是访问第三方插件到 ChatGPT *台的唯一途径。
成为 Plus 用户后,前往设置并激活插件选择。目前,插件处于 Beta 阶段,因此它会在 Beta 功能部分中。

图片来源:作者
一旦激活插件,你将在 ChatGPT *台的 GPT-4 模型下看到插件选择。
图片由作者提供
选择插件并找到插件商店。搜索 Noteable 并安装插件。
图片由作者提供
安装完成后,从所有已安装的 Noteable 插件中找到 Noteable 插件并启用它们。现在我们可以使用插件了。
图片由作者提供
首先,我会提供提示:“你能给我一个用于 Titanic 数据集的简单 EDA 吗?”
图片由作者提供
ChatGPT 会提示我们在 Noteable 中没有设置默认项目。这意味着我们需要在使用此插件之前设置 Noteable 项目。为此,我们必须登录到Noteable并创建项目。它是免费的,因此我们不需要设置信用卡或其他东西。
登录 Noteable 后,选择“创建”按钮和“项目”。之后,为你的项目命名并复制 URL 链接。
图片由作者提供
有了项目 URL,将其传递给 ChatGPT,并使用类似于下面图片的提示。

图片由作者提供
现在我们准备好让 ChatGPT 自动执行分析。一旦你输入上述提示,Noteable 插件将尝试找到数据并提供 EDA。结果会显示在你的 ChatGPT 中。
图片由作者提供
不仅限于 ChatGPT 的结果,包含数据分析代码的笔记本也将在你的 Noteable 项目中准备好。
图片由作者提供
如果你愿意,可以在 ChatGPT 中继续分析;例如,我要求 ChatGPT 提供一个试图预测幸存者的机器学习模型,
图片由作者提供
我还要求 ChatGPT 将模型保存为 pickle 对象。输出还展示了如果需要如何部署模型。
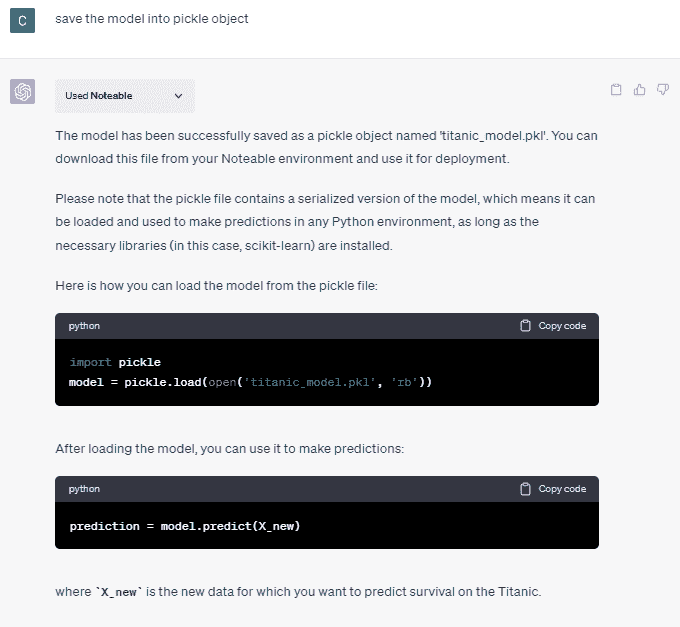
图片由作者提供
如果我们查看 Noteable 项目,其中包含了由 ChatGPT 生成的分析模型对象。
作者提供的图片
我们可以通过提供更多的提示或更改数据集(通过提供数据集链接给 ChatGPT)来进一步探索。利用这个 Noteable 插件,我们可以做很多事情。
结论
ChatGPT 插件改变了工具的使用方式,其中之一就是数据分析过程。使用 Noteable 插件,我们现在可以通过几行文本加速许多数据工作,如数据准备、探索性数据分析(EDA)和机器学习开发。
Cornellius Yudha Wijaya 是一位数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
更多相关内容
笔记本反模式
评论
作者:Kristina Young,高级数据科学家
在过去几年中,许多工具尝试解决将机器学习模型投入生产的挑战。这些工具似乎都有一个共同点,那就是将笔记本集成到生产流程中。本文旨在解释为什么这种推动将笔记本用于生产的趋势是一种反模式,并给出一些建议。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯的快车道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
什么是笔记本?
让我们首先定义一下这些是什么,特别是对于那些没有接触过笔记本的读者,或者称其为其他名称的读者。
笔记本是允许用户创建包含代码、可视化和文本的文档的 web 界面。它们如下所示:
图片来源:arogozhnikov.github.io/2016/09/10/jupyter-features.html
笔记本适合做什么?
与你从引言中得到的印象相反,笔记本并非全然不好。在某些场景中,它们可能非常有用,这将在下面的子节中描述。
数据分析
这可能是它们最常见的用途。当遇到新的数据集时,需要深入挖掘数据并进行某些可视化以便理解。笔记本适合这种情况,因为它们允许我们:
-
快速开始
-
在一个地方查看原始数据和可视化
-
可以使用许多现有的清理和可视化工具
-
记录我们的进展和发现(可以提取为 HTML)
实验
在机器学习方面,通常需要进行大量实验,才能选择最终的解决方案。笔记本在玩弄数据和各种模型时很有用,以便了解什么对给定的数据有效,什么无效。
一次性任务
笔记本也是一个很好的试验场。有时需要执行一次自动化任务,但可能不熟悉或不愿意编写 bash 脚本或使用其他类似工具。
教学或技术演示
在教授 Python 或为同事进行技术演示时,你可能希望立即展示代码及其结果。笔记本在这方面表现出色,因为它们允许你在同一文档中运行代码并显示结果。它们可以展示可视化效果,使用标题表示各个部分,并提供演示者可能需要的额外文档。
代码评估
如果你的公司向候选人提供编码挑战,笔记本可能是一个有用的工具。这也取决于你的公司需要评估的内容。笔记本允许候选人将文档、解释和他们的解决方案合并到一个页面中。只要候选人提供了包需求,它们也很容易让评估者运行。然而,它们不能提供对候选人对软件工程原则理解的广泛评估,这一点我们将在下一节中更好地理解。
笔记本的不足之处是什么?
现在许多公司都在尝试解决将模型投入生产的问题。这些公司的数据科学家可能来自各种背景,包括:统计学、纯数学、自然科学和工程学。他们共同的特点是通常能够舒适地使用笔记本进行分析和实验,因为这个工具就是为此目的而设计的。因此,大型基础设施公司一直专注于通过在笔记本生态系统中提供“一键部署”工具来弥补“生产化差距”,从而鼓励在生产中使用笔记本。不幸的是,由于笔记本最初并未设计为服务于这个目的,这可能会导致无法维护的生产系统。
一想到笔记本在生产环境中的应用,我总会想到连体漫画的实用性——看起来美观,但在某些情况下非常不实用。

图片来源:twitter.com/lorynbrantz/status/765220720595066880
现在我们知道了笔记本的优势,让我们在接下来的章节中探讨它们的不足之处。
持续集成(CI)
笔记本并不是为自动运行或通过 CI 管道处理而设计的,因为它们是为了探索而建的。它们通常涉及文档和可视化,这会给任何 CI 管道增加不必要的工作。尽管它们可以作为普通的 Python 脚本提取,然后在 CI 管道中运行,但在大多数情况下,你会想要运行脚本的测试,而不是脚本本身(除非你正在创建需要通过管道暴露的工件)。
测试
笔记本不可测试,这是我对它们的主要痛点之一。没有围绕这些笔记本创建的测试框架,因为它们的目的是作为游乐场,而不是生产系统。与普遍的看法相反,数据产品中的测试和其他软件产品中的测试一样重要且可能。为了测试一个笔记本,必须将笔记本中的代码提取到脚本中,这意味着笔记本本身无用。它需要维护以匹配提取脚本中的代码,或者分叉成更多未经测试的混乱。
如果你想了解更多关于测试 ML 管道的内容,可以查看这篇文章: 测试你的 ML 管道。
版本控制
如果你曾经把笔记本放到 git 或任何其他版本控制系统中并打开了一个拉取请求,你可能会注意到这个拉取请求完全无法阅读。这是因为笔记本需要跟踪单元格的状态,因此在运行笔记本以生成你美丽的 HTML 视图时,后台会发生很多更改。这些更改也需要被版本化,导致视图不可读。
当然,你可能在一个使用配对而不是拉取请求的团队中,所以你可能不关心拉取请求不可读。然而,你通过这种可读性的降低失去了版本控制的另一个优势:在恢复代码或查看旧版本以查找可能引入或修复问题的更改时,你需要完全依赖提交信息并手动回退以检查更改。
这是笔记本的一个众所周知的问题,但也是人们正在努力解决的问题。有一些插件可以用来至少在你的版本控制系统的网页视图中缓解这个问题。一个这样的工具示例是 Review Notebook App。
协作
在笔记本中进行协作是困难的。你唯一可行的协作选项是配对,或者像玩文明游戏一样轮流使用笔记本。这是因为:
-
笔记本在后台管理大量状态,因此在同一个笔记本上异步工作可能会导致许多不可管理的合并冲突。这对远程团队来说尤其糟糕。
-
所有的代码也都在同一个地方(除了导入的包),因此对相同的代码有持续的更改,使得跟踪更改的效果变得更加困难。这由于缺乏测试(如上所述)特别糟糕。
-
上面提到的版本控制问题
状态
状态在上述两个问题中已经提到过,但它值得单独列出以强调。笔记本具有一个全局状态。每次运行单元格时,这个状态都会发生变化,这可能会导致以下问题:
-
状态而非代码本身的不可管理的合并冲突
-
版本控制的可读性差
-
缺乏可重现性。你可能在笔记本中工作时,其状态已经无法重现,因为导致该状态的代码已经被删除,但状态没有更新。
工程标准
笔记本鼓励不良工程标准。我想强调这里的鼓励一词,因为很多这些问题是笔记本用户可以避免的。笔记本中常见的反模式有:
-
依赖状态:笔记本严重依赖状态,尤其是因为它们通常涉及在前几个单元格中对数据执行一些操作,以便将这些数据输入到某个算法中。对状态的依赖可能导致代码中的意外后果和副作用。
-
重复:不能将一个笔记本导入到另一个笔记本中,因此在不同笔记本中进行多次实验时,往往需要复制粘贴公共部分。如果其中一个笔记本发生变化,其他笔记本立即过时。通过提取公共代码部分并将其导入到不同的笔记本中,可以改善这一点。笔记本内部也经常出现重复,不过只需使用函数即可轻松避免。
-
缺乏测试:无法测试笔记本,如上述测试部分所示。
包管理
笔记本中没有包管理。笔记本使用其运行环境中安装的包。需要手动跟踪该特定笔记本使用的包,因为在同一环境中运行的不同笔记本可能需要不同的包。一个建议是始终在新的虚拟环境中运行笔记本,分别跟踪该特定笔记本的需求。或者,环境中的所有笔记本都依赖于单个要求文件。
那我们该怎么做呢?

图片来源 theverybesttop10.com/animal-imposters/
很好,现在我们知道为什么生产环境中的笔记本是个坏主意,也知道为什么我们需要停止将实验工具伪装成生产化工具。那么这使我们处于何种境地呢?这取决于你团队的技能和结构。你的团队很可能由以下两种人组成:
-
具有工程技能的数据科学家
-
或者,专注于实验的数据科学家和将模型投入生产的 ML/数据工程师
那么我们来看一下下面这两种情境。
具有工程技能的数据科学团队
在这种情境下,你的数据科学团队负责从头到尾的模型。这就是说,负责实验以及生产化。这些是需要记住的一些事项:
-
如果你仍然喜欢使用笔记本进行实验,可以继续使用,但在以下情况下需要避免使用:
-
协作
-
将模型带到你的游乐场之外
-
-
从现有的软件工程框架和原则中学习
-
查看一些可能帮助你设计基础设施或提供灵感的工具和架构(小心,有时会有笔记本选项可用——这是个陷阱!):
工程与数据科学技能的分离
一些大型组织倾向于更专业化的技能组合,其中数据科学家从事实验工作,而 ML/数据工程师则将其推向生产。上述场景中列出的点仍然适用,但我有一个针对该场景的额外建议:
请,请,请 不要把模型扔过围栏! 一起坐下来,沟通并进行配对/集体编程,将管道推向生产。模型只有为最终用户提供价值时才有效。
结论
像对待任何工具一样,笔记本有其使用场所,也有应避免使用的地方。让我们最后回顾一下这些内容。
| 好 | 差 |
|---|---|
| 数据分析 | 持续集成 |
| 实验 | 测试 |
| 一次性任务 | 版本控制 |
| 教学/技术演示 | 协作 |
| 代码评估 | 状态 |
| 工程标准 | |
| 包管理 |
总结来说,我希望你从这篇文章中得到两个信息:
-
对 ML 从业者:笔记本用于实验,而不是生产化。坚持软件工程原则和框架来将事物推向生产,它们基于过去的经验教训设计而成,我们应当加以利用。
-
对创建工具的人:我们感谢你们为大家简化工作 ♥,但请远离笔记本反模式。专注于创建更易用的工具,鼓励积极的软件工程模式。我们希望:
-
可测试性
-
版本管理
-
协作
-
可重复性
-
可扩展性
-
简历:Kristina Young 是 BCG Digital Ventures 的高级数据科学家。她曾在 SoundCloud 担任推荐团队的后端和数据工程师。她的工作经历包括咨询和研究。她曾在各种技术领域担任过后端、Web 和移动开发人员。
原始文章。已获得转载许可。
相关内容:
-
测试你的机器学习管道
-
数据科学家的自动版本控制
-
简易一键 Jupyter Notebook
更多相关话题
特征预处理的笔记:什么,为什么,怎么做
原文:
www.kdnuggets.com/2018/10/notes-feature-preprocessing-what-why-how.html
评论
原始数据与移动数据与移动&缩放数据(来源:人工智能 GitBook)
本文涵盖了一些与数值数据预处理相关的重要点,重点讨论特征值的缩放和处理异常值的广泛问题。
特征缩放的影响
特征缩放可以定义为“用来标准化独立变量或数据特征范围的方法。” 特征缩放是数据预处理的主要组成部分之一,可以应用于所有类型的数据。
一些模型受特征缩放的影响,而另一些则不受影响。非树基模型容易受特征缩放的影响:
-
线性模型
-
最*邻分类器
-
神经网络
相反,树基模型不受特征缩放的影响。这应该很明显,但树基建模算法的例子包括:
-
普通决策树
-
随机森林
-
梯度提升树
为什么会这样?
想象一下,我们将特定特征值的尺度乘以 100。如果我们考虑沿着与该特征对应的轴的数据点定位,这将对如最*邻分类器等模型产生明显影响。例如,线性模型、最*邻和神经网络都对数据点值之间的相对位置敏感;实际上,这就是 K 最*邻(kNN)的明确前提。
由于树基模型在特征数据轴上寻找最佳划分位置,这种相对位置的重要性要小得多。如果确定的划分位置在点 a 和 b 之间,那么如果这两个点都被某个常数乘或除,这一点将保持不变。
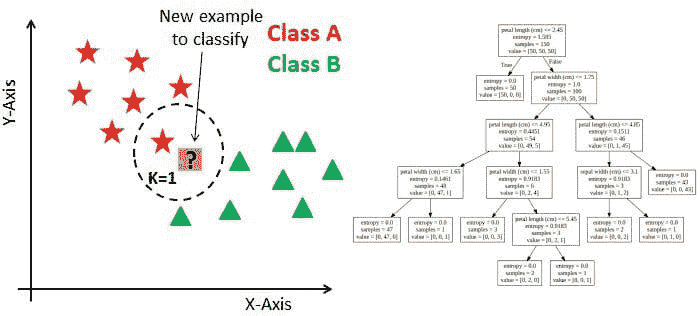
左侧的算法,如 kNN,生成的模型易受特征缩放的影响;右侧的树基模型则不受特征缩放的影响
特征缩放的一个潜在用途是测试特征的重要性。例如,对于 kNN 来说,给定特征的值越大,它对模型的影响越大。我们可以通过有意放大一个或多个我们认为更重要的特征的尺度,来利用这一事实,观察这些更大值的轻微变化是否会影响结果模型。相反,将特征的数据点值乘以零会导致沿该轴的数据点堆叠,使该特征在建模过程中无用。
这涵盖了线性模型,但神经网络呢?事实证明,神经网络也受到尺度的重大影响:正则化的影响与特征尺度成正比。如果没有适当的缩放,梯度下降方法可能会遇到问题。
最后,提供一个最简单的特征缩放重要性示例:考虑 k-means 聚类。如果你的数据有 4 列,其中 3 列的值在 0 和 1 之间缩放,而第四列的值在 0 和 1,000 之间,那么相对容易确定这些特征中的哪一个将是聚类结果的唯一决定因素。
特征缩放方法
最小/最大缩放
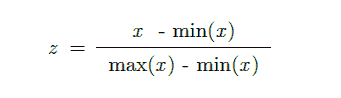
-
这种方法将值缩放在 0 和 1 之间 ???? [0, 1]
-
将最小值设置为零,最大值设置为一,所有其他值相应地缩放在两者之间
-
Scikit-learn
sklearn.preprocessing.MinMaxScaler模块就是这样一个实现
from sklearn.preprocessing import MinMaxScaler
# import some data
sc = MinMaxScaler()
data = sc.fit_transform(data))
标准缩放
-
这种方法通过将数据的均值设置为 0,将标准差设置为 1 来进行缩放
-
从特征值中减去均值,并除以标准差
-
这导致了标准化分布
-
Scikit-learn
sklearn.preprocessing.StandardScaler模块就是这样一个实现
from sklearn.preprocessing import StandardScaler
# import some data
sc = StandardScaler()
sc.fit_transform(data))
这些(及其他)缩放方法在实践中的区别是什么?这取决于应用的具体数据集,但实际上结果通常是大致相似的。
处理异常值
人们经常强烈反对“去除异常值”的讨论。现实情况是,异常值可能会不利地扭曲模型。真正的问题不是去除异常值本身,而是你需要理解异常值与数据的关系,并做出是否应去除它们以及原因的知情判断。去除异常值的替代方法是使用某种形式的缩放来管理它们。
离群值不仅对特征可能是个问题,对目标值也可能如此。例如,如果所有目标值都在 0 到 1 之间,而引入了一个目标值为 100,000 的新数据点,那么生成的回归模型会开始对模型中的其他数据点进行不真实的高预测。
请记住,离群值通常代表 NaNs,特别是当它们超出上下界且紧密聚集时(例如,所有 NaNs 可能已经转换为-999)。这种类型的离群值会人为地扭曲分布,因此绝对需要一些处理方法。领域知识和数据检查是决定如何处理离群值的最有用工具。
裁剪
修正线性模型中的离群值的一种方法是将值保持在上下界之间。我们如何选择这些界限?一种合理的方法是使用百分位数——仅保持在第一个和第 99 个百分位数之间的值。这种裁剪形式被称为温莎化。
有关温莎化的更多信息,请参考scipy.stats.mstats.winsorize。
import numpy as np
from scipy.stats.mstats import winsorize
# import some data
data = winsorize(data, limits = 0.01)
排名变换
排名变换去除特征值之间的相对距离,并用表示特征值排名的一致间隔替代(例如:第一、第二、第三...)。这将离群值移动到其他特征值附*(在一个规律的间隔内),并且可以作为线性模型、kNN 和神经网络的有效方法。
有关排名变换的更多信息,请参考scipy.stats.rankdata。
from scipy.stats import rankdata
rankdata([0, 2, 3, 2])
# Output:
# array([ 1\. , 2.5, 4\. , 2.5])
日志变换
对于非树模型,日志变换可能非常有用。它们可以将较大的特征值从极端值驱离,靠*特征均值。它还有使接*零的值更易区分的效果。
有关实施这些变换的更多信息,请参见numpy.log和numpy.sqrt。
将各种预处理方法结合到一个模型中可能会很有用,通过使用不同的方法预处理数据集实例的百分比,然后将结果合并到一个训练集中。或者,通过集成在不同预处理数据上训练的模型(与前述方法描述比较)也可能是有益的。
预处理不是“万能”的情况,你愿意根据可靠的数学原理尝试不同的方法,可能会增加模型的稳健性。
参考文献:
- 如何赢得数据科学竞赛:向顶尖 Kagglers 学习,国家研究大学高等经济学院(Coursera)
相关:
-
掌握数据准备的 7 个步骤,使用 Python
-
文本数据预处理:Python 实践指南
-
数据准备技巧、窍门和工具:与内部人士的访谈
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关内容
从初学者到高手:为什么你的 Python 技能在数据科学中至关重要
原文:
www.kdnuggets.com/novice-to-ninja-why-your-python-skills-matter-in-data-science

由作者使用 DALL•E 3 创建的图像
介绍
我们知道编程是数据科学家需要具备的有用(必要?)技能。但是需要什么程度的编程技能呢?数据科学家是否应该目标是“足够好”,还是应当期望成为高级程序员?我们是否应该追求成为编程高手?
如果我们要探讨这个话题,我们应该首先了解初学者、中级和高级程序员的情况——或者至少了解他们的 代码 看起来如何。
在下面,你将找到 2 个编程任务,每个任务包括 3 个代码片段;分别展示了初学者、中级程序员和高级程序员完成这些任务的方法,并附有一些关于差异的解释。这将为我们讨论编程能力的重要性奠定基础。
请记住,这些都是为了模仿不同级别编程而构造的方法。所有的脚本都是功能性代码并能完成任务,但它们在优雅性、效率和 Python 规范性方面各有不同。
任务:求一个数的阶乘
首先,让我们考虑一个简单但可以用多种方式解决的任务:计算给定数的阶乘。我们将为假设中的初学者、中级和高级 Python 程序员实现这个任务,并比较代码中的差异。
初学者的方法
初学者可能使用直接的方法,通过 for 循环来计算阶乘。以下是他们可能的做法。
n = int(input("Enter a number to find its factorial: "))
factorial = 1
if n < 0:
print("Factorial does not exist for negative numbers")
elif n == 0:
print("The factorial of 0 is 1")
else:
for i in range(1, n + 1):
factorial *= i
print(f"The factorial of {n} is {factorial}")
中级程序员的方法
中级程序员可能使用函数来提高代码的重用性和可读性,并且还会使用 math 库进行基本检查。
import math
def factorial(n):
if n < 0:
return "Factorial does not exist for negative numbers"
elif n == 0:
return 1
else:
return math.prod(range(1, n + 1))
n = int(input("Enter a number to find its factorial: "))
result = factorial(n)
print(f"The factorial of {n} is {result}")
高级程序员的方法
高级程序员可能会使用递归并添加类型提示以便于维护。他们还可能会利用 Python 的简洁且富有表现力的语法。
from typing import Union
def factorial(n: int) -> Union[int, str]:
return 1 if n == 0 else n * factorial(n - 1) if n > 0 else "Factorial does not exist for negative numbers"
n = int(input("Enter a number to find its factorial: "))
print(f"The factorial of {n} is {factorial(n)}")
总结
让我们看看不同级别之间的代码差异以及最突出的特点。
-
初学者:使用较长的整体代码,不使用函数或库,逻辑直接
-
中级程序员:使用函数以改善结构,使用
math.prod计算乘积 -
高级程序员:使用递归以保持优雅,添加类型提示,并使用 Python 的条件表达式以提高简洁性
任务:生成斐波那契数
作为第二个例子,我们来考虑一个任务:找到前 n 个斐波那契数列。以下是不同级别的程序员可能如何解决这个任务。
初学者的方法
初学者可能使用基本的 for 循环和列表来收集斐波那契数。
n = int(input("How many Fibonacci numbers to generate? "))
fibonacci_sequence = []
if n <= 0:
print("Please enter a positive integer.")
elif n == 1:
print([0])
else:
fibonacci_sequence = [0, 1]
for i in range(2, n):
next_number = fibonacci_sequence[-1] + fibonacci_sequence[-2]
fibonacci_sequence.append(next_number)
print(fibonacci_sequence)
中级程序员的方法
中级程序员可能会使用列表推导式和zip函数实现更具 Python 风格的处理。
n = int(input("How many Fibonacci numbers to generate? "))
if n <= 0:
print("Please enter a positive integer.")
else:
fibonacci_sequence = [0, 1]
[fibonacci_sequence.append(fibonacci_sequence[-1] + fibonacci_sequence[-2]) for _ in range(n - 2)]
print(fibonacci_sequence[:n])
专家的方法
专家可能会使用生成器实现更高效的内存管理,并利用 Python 的解包特性在一行中交换变量。
def generate_fibonacci(n: int):
a, b = 0, 1
for _ in range(n):
yield a
a, b = b, a + b
n = int(input("How many Fibonacci numbers to generate? "))
if n <= 0:
print("Please enter a positive integer.")
else:
print(list(generate_fibonacci(n)))
总结
让我们看看主要的差异是什么,以及哪些编程差异将专业水*区分开来。
-
初学者:使用基本控制结构和列表,简单但略显冗长
-
中级:利用列表推导式和
zip实现更具 Python 风格和简洁的解决方案 -
专家:使用生成器实现内存高效的解决方案,并使用解包进行优雅的变量交换
“忍者”编码的好处
如果所有示例代码都能正常工作并最终完成任务,为什么我们还要努力成为最优秀的程序员? 很好的问题!
成为熟练的程序员不仅仅是让代码工作。以下是为什么努力成为更好的程序员是有益的几个原因:
1. 效率
-
时间:编写更高效的代码意味着任务完成得更快,这对程序员和使用软件的任何人都是有益的
-
资源利用:高效的代码使用更少的 CPU 和内存,这对在有限资源或大规模运行的应用程序至关重要
2. 可读性和可维护性
-
合作:代码通常由团队编写和维护。干净、结构良好且注释充分的代码更容易让其他人理解和合作
-
长期性:随着项目的发展或演变,可维护的代码更容易扩展、调试和重构,从长远来看节省时间和精力
3. 可重用性
-
模块化:编写解决问题效果好的函数或模块意味着你可以轻松地在其他项目或上下文中重用这些代码
-
社区贡献:高质量的代码可以开源,并惠及更广泛的开发者社区
4. 稳健性和可靠性
-
错误处理:高级程序员通常编写不仅能解决问题而且能优雅地处理错误的代码,使软件更加可靠
-
测试:了解如何编写可测试的代码和实际的测试,确保代码在各种场景中按预期工作
5. 技能认可
-
职业发展:被认定为熟练的程序员可以带来晋升、工作机会和更高的薪水
-
个人满足感:知道自己能够编写高质量代码带来成就感和自豪感
6. 适应性
-
新技术:扎实的基础技能使得适应新语言、库或范式变得更加容易
-
问题解决:对编程概念的深入理解增强了你创造性和有效性地解决问题的能力
7. 成本效益
-
较少的调试:编写良好的代码通常更不容易出错,从而减少调试所花费的时间和资源
-
可扩展性:优秀的代码可以更容易地扩展或缩减,从长远来看更具成本效益
所以,尽管完成工作确实很重要,但完成工作的方式可以对个人发展、团队和组织产生广泛的影响。我们都应该努力成为最好的程序员,这同样适用于数据科学家。
Matthew Mayo (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 和 Statology 的主编,以及 Machine Learning Mastery 的特约编辑,Matthew 旨在使复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、语言模型、机器学习算法以及探索新兴的 AI。他致力于在数据科学社区中普及知识。Matthew 从 6 岁起就开始编程。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析水*
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关话题
NumPy 用于图像处理

图像来源于 freepik
NumPy 是 Python 中强大的图像处理工具。它允许你使用数组操作来处理图像。本文探讨了使用 NumPy 的几种图像处理技术。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
导入库
我们必须导入所需的库:PIL、NumPy 和 Matplotlib。PIL 用于打开图像。NumPy 允许高效的数组操作和图像处理。Matplotlib 用于可视化图像。
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
裁剪图像
我们定义坐标以标记要从图像中裁剪的区域。新图像仅包含选定部分,丢弃其余部分。
# Load the image using PIL (Python Imaging Library)
img = Image.open('cat.jpg')
# Convert the image to a NumPy array
img_array = np.array(img)
# Define the cropping coordinates
y1, x1 = 1000, 1000 # Top-left corner of ROI
y2, x2 = 2500, 2000 # Bottom-right corner of ROI
cropped_img = img_array[y1:y2, x1:x2]
# Display the original image and the cropped image
plt.figure(figsize=(10, 5))
# Display the original image
plt.subplot(1, 2, 1)
plt.imshow(img_array)
plt.title('Original Image')
plt.axis('off')
# Display the cropped image
plt.subplot(1, 2, 2)
plt.imshow(cropped_img)
plt.title('Cropped Image')
plt.axis('off')
plt.tight_layout()
plt.show()
旋转图像
我们使用 NumPy 的'rot90'函数将图像数组逆时针旋转 90 度。
# Load the image using PIL (Python Imaging Library)
img = Image.open('cat.jpg')
# Convert the image to a NumPy array
img_array = np.array(img)
# Rotate the image by 90 degrees counterclockwise
rotated_img = np.rot90(img_array)
# Display the original image and the rotated image
plt.figure(figsize=(10, 5))
# Display the original image
plt.subplot(1, 2, 1)
plt.imshow(img_array)
plt.title('Original Image')
plt.axis('off')
# Display the rotated image
plt.subplot(1, 2, 2)
plt.imshow(rotated_img)
plt.title('Rotated Image (90 degrees)')
plt.axis('off')
plt.tight_layout()
plt.show()

翻转图像
我们使用 NumPy 的'fliplr'函数水*翻转图像数组。
# Load the image using PIL (Python Imaging Library)
img = Image.open('cat.jpg')
# Convert the image to a NumPy array
img_array = np.array(img)
# Flip the image horizontally
flipped_img = np.fliplr(img_array)
# Display the original image and the flipped image
plt.figure(figsize=(10, 5))
# Display the original image
plt.subplot(1, 2, 1)
plt.imshow(img_array)
plt.title('Original Image')
plt.axis('off')
# Display the flipped image
plt.subplot(1, 2, 2)
plt.imshow(flipped_img)
plt.title('Flipped Image')
plt.axis('off')
plt.tight_layout()
plt.show()

图像的负片
图像的负片是通过反转其像素值来制作的。在灰度图像中,每个像素的值从最大值(8 位图像为 255)中减去。在彩色图像中,这是为每个颜色通道单独完成的。
# Load the image using PIL (Python Imaging Library)
img = Image.open('cat.jpg')
# Convert the image to a NumPy array
img_array = np.array(img)
# Check if the image is grayscale or RGB
is_grayscale = len(img_array.shape) < 3
# Function to create negative of an image
def create_negative(image):
if is_grayscale:
# For grayscale images
negative_image = 255 - image
else:
# For color images (RGB)
negative_image = 255 - image
return negative_image
# Create negative of the image
negative_img = create_negative(img_array)
# Display the original and negative images
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(img_array)
plt.title('Original Image')
plt.axis('off')
plt.subplot(1, 2, 2)
plt.imshow(negative_img)
plt.title('Negative Image')
plt.axis('off')
plt.tight_layout()
plt.show()

二值化图像
二值化图像将其转换为黑白图像。每个像素根据阈值标记为黑色或白色。小于阈值的像素变为 0(黑色),大于阈值的像素变为 255(白色)。
# Load the image using PIL (Python Imaging Library)
img = Image.open('cat.jpg')
# Convert the image to grayscale
img_gray = img.convert('L')
# Convert the grayscale image to a NumPy array
img_array = np.array(img_gray)
# Binarize the image using a threshold
threshold = 128
binary_img = np.where(img_array < threshold, 0, 255).astype(np.uint8)
# Display the original and binarized images
plt.figure(figsize= (10, 5))
plt.subplot(1, 2, 1)
plt.imshow(img_array, cmap='gray')
plt.title('Original Grayscale Image')
plt.axis('off')
plt.subplot(1, 2, 2)
plt.imshow(binary_img, cmap='gray')
plt.title('Binarized Image (Threshold = 128)')
plt.axis('off')
plt.tight_layout()
plt.show()
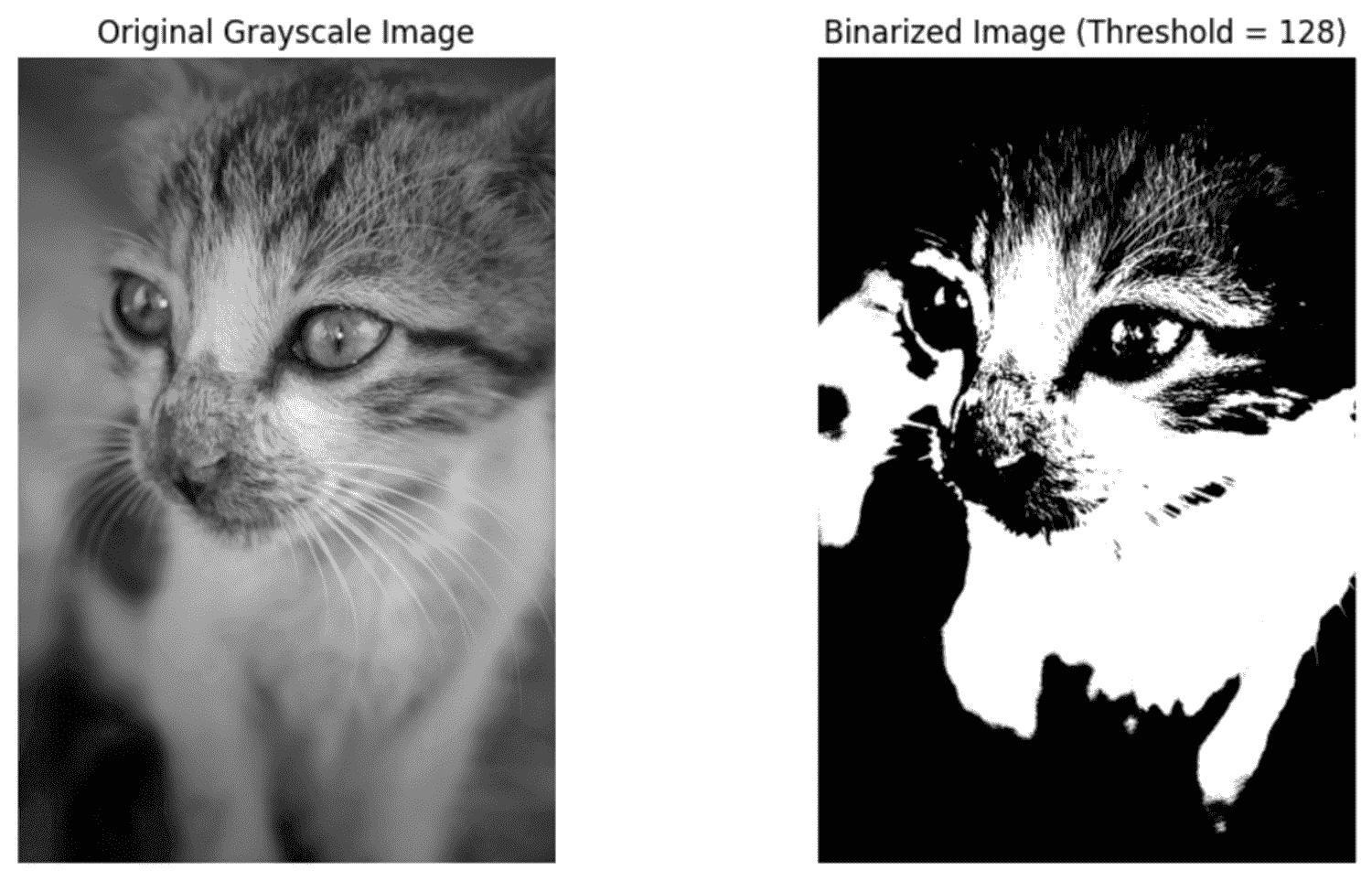
颜色空间转换
颜色空间转换将图像从一种颜色模型转换为另一种。这是通过改变像素值的数组来完成的。我们使用 RGB 通道的加权和将彩色图像转换为灰度图像。
# Load the image using PIL (Python Imaging Library)
img = Image.open('cat.jpg')
# Convert the image to a NumPy array
img_array = np.array(img)
# Grayscale conversion formula: Y = 0.299*R + 0.587*G + 0.114*B
gray_img = np.dot (img_array[..., :3], [0.299, 0.587, 0.114])
# Display the original RGB image
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(img_array)
plt.title('Original RGB Image')
plt.axis('off')
# Display the converted grayscale image
plt.subplot(1, 2, 2)
plt.imshow(gray_img, cmap='gray')
plt.title('Grayscale Image')
plt.axis('off')
plt.tight_layout()
plt.show()

像素强度直方图
直方图显示了图像中像素值的分布。图像被展*为一维数组以计算直方图。
# Load the image using PIL (Python Imaging Library)
img = Image.open('cat.jpg')
# Convert the image to a NumPy array
img_array = np.array(img)
# Compute the histogram of the image
hist, bins = np.histogram(img_array.flatten(), bins=256, range= (0, 256))
# Plot the histogram
plt.figure(figsize=(10, 5))
plt.hist(img_array.flatten(), bins=256, range= (0, 256), density=True, color='gray')
plt.xlabel('Pixel Intensity')
plt.ylabel('Normalized Frequency')
plt.title('Histogram of Grayscale Image')
plt.grid(True)
plt.show()
图像掩膜
掩膜图像意味着根据规则显示或隐藏部分内容。标记为 1 的像素被保留,而标记为 0 的像素被隐藏。
# Load the image using PIL (Python Imaging Library)
img = Image.open('cat.jpg')
# Convert the image to a NumPy array
img_array = np.array(img)
# Create a binary mask
mask = np.zeros_like(img_array[:, :, 0], dtype=np.uint8)
center = (img_array.shape[0] // 2, img_array.shape[1] // 2)
radius = min(img_array.shape[0], img_array.shape[1]) // 2 # Increase radius for a bigger circle
rr, cc = np.meshgrid(np.arange(img_array.shape[0]), np.arange(img_array.shape[1]), indexing='ij')
circle_mask = (rr - center [0]) ** 2 + (cc - center [1]) ** 2 < radius ** 2
mask[circle_mask] = 1
# Apply the mask to the image
masked_img = img_array.copy()
for i in range(img_array.shape[2]): # Apply to each color channel
masked_img[:,:,i] = img_array[:,:,i] * mask
# Displaying the original image and the masked image
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(img_array)
plt.title('Original Image')
plt.axis('off')
plt.subplot(1, 2, 2)
plt.imshow(masked_img)
plt.title('Masked Image')
plt.axis('off')
plt.tight_layout()
plt.show()

总结
本文展示了使用 NumPy 处理图像的不同方法。我们使用了 PIL、NumPy 和 Matplotlib 来裁剪、旋转、翻转和二值化图像。此外,我们了解了创建图像负片、改变色彩空间、制作直方图以及应用掩膜。
Jayita Gulati 是一位对构建机器学习模型充满热情的机器学习爱好者和技术作家。她拥有利物浦大学的计算机科学硕士学位。
更多相关内容
NumPy 在线性代数应用中的应用

图片来源:编辑
NumPy 是一个高效的线性代数工具。它有助于矩阵操作和方程求解。本文描述了用于线性代数的 NumPy 函数。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
矩阵乘法
矩阵乘法从两个矩阵创建一个新矩阵。将第一个矩阵的每一行与第二个矩阵的每一列相乘,将乘积相加得到新矩阵中的每个元素。
# Define matrices
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
# Matrix multiplication
C = np.dot(A, B)
print("Matrix Multiplication:\n", C)
# Output:
# [[19 22]
# [43 50]]
矩阵逆
将一个矩阵与其逆矩阵相乘得到单位矩阵。这有助于解决线性方程组。只有方阵和非奇异矩阵才有逆矩阵。
# Define a square matrix
A = np.array([[1, 2], [3, 4]])
# Matrix inversion
A_inv = np.linalg.inv(A)
print("Matrix Inversion:\n", A_inv)
# Output:
# [[-2\. 1.]
# [ 1.5 -0.5]]
矩阵行列式
矩阵行列式是来自矩阵的一个数字。它告诉我们矩阵是否可以被逆转。我们使用特定规则根据矩阵大小进行计算。
# Define a square matrix
A = np.array([[1, 2], [3, 4]])
# Compute the determinant
det_A = np.linalg.det(A)
print("Determinant of the Matrix:", det_A)
# Output: -2.0000000000000004
矩阵迹
迹是对角元素的总和。它仅适用于方阵。我们得到一个数字作为迹。
# Define a square matrix
A = np.array([[1, 2], [3, 4]])
# Compute the trace of the matrix
trace_A = np.trace(A)
print("Trace of the Matrix:", trace_A)
# Output: 5
矩阵转置
矩阵转置将矩阵沿其对角线翻转,它交换行和列。
# Define a matrix
A = np.array([[1, 2, 3], [4, 5, 6]])
# Compute the transpose of the matrix
A_T = np.transpose(A)
print("Transpose of the Matrix:\n", A_T)
# Output:
# [[1 4]
# [2 5]
# [3 6]]
特征值和特征向量
特征值显示了特征向量在变换过程中被缩放的程度。特征向量在此变换下方向不变。
# Define a square matrix
A = np.array([[1, 2], [3, 4]])
# Compute eigenvalues and eigenvectors
eigenvalues, eigenvectors = np.linalg.eig(A)
print("Eigenvalues:", eigenvalues)
print("Eigenvectors:\n", eigenvectors)
# Output:
# Eigenvalues: [-0.37228132 5.37228132]
# Eigenvectors:
# [[-0.82456484 -0.41597356]
# [ 0.56576746 -0.90937671]]
LU 分解
LU 分解将一个矩阵分成两部分。一部分是下三角矩阵(L)。另一部分是上三角矩阵(U)。它有助于解决线性最小二乘问题和求解特征值。
import numpy as np
from scipy.linalg import lu
# Define a matrix
A = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# LU Decomposition
P, L, U = lu(A)
# Display results
print("LU Decomposition:")
print("P matrix:\n", P)
print("L matrix:\n", L)
print("U matrix:\n", U)
# Output
# LU Decomposition:
# P matrix:
# [[0\. 1\. 0.]
# [0\. 0\. 1.]
# [1\. 0\. 0.]]
# L matrix:
# [[ 1\. 0\. 0\. ]
# [ 0.33333333 1\. 0\. ]
# [ 0.66666667 -0.5 1\. ]]
# U matrix:
# [[ 7\. 8\. 9\. ]
# [ 0\. 0.33333333 0.66666667]
# [ 0\. 0\. 0\. ]]
QR 分解
QR 分解将一个矩阵分成两部分。一部分是正交矩阵(Q)。另一部分是上三角矩阵(R)。它有助于解决线性最小二乘问题和求解特征值。
import numpy as np
from scipy.linalg import qr
# Define a matrix
A = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# QR Decomposition
Q, R = qr(A)
# Display results
print("QR Decomposition:")
print("Q matrix:\n", Q)
print("R matrix:\n", R)
# Output
# QR Decomposition:
# Q matrix:
# [[-0.26726124 -0.78583024 0.55708601]
# [-0.53452248 -0.08675134 -0.83125484]
# [-0.80178373 0.6172134 0.08122978]]
# R matrix:
# [[-7.41619849 -8.48528137 -9.55445709]
# [ 0\. -0.90453403 -1.80906806]
# [ 0\. 0\. 0\. ]]
SVD(奇异值分解)
SVD 将一个矩阵分解为三个矩阵:U、Σ 和 V。U 和 V 是正交矩阵。Σ 是对角矩阵。它在数据降维和解决线性系统等许多应用中非常有用。
import numpy as np
from scipy.linalg import svd
# Define a matrix
A = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# Singular Value Decomposition
U, s, Vh = svd(A)
# Display results
print("SVD Decomposition:")
print("U matrix:\n", U)
print("Singular values:\n", s)
print("Vh matrix:\n", Vh)
# Output
# SVD Decomposition:
# U matrix:
# [[-0.21483724 0.88723069 0.40824829]
# [-0.52058739 0.24964395 -0.61237224]
# [-0.82633755 -0.38794279 0.61237224]]
# Singular values:
# [16.84810335 1.06836951 0\. ]
# Vh matrix:
# [[-0.47967118 -0.57236779 -0.66506439]
# [ 0.77669099 0.07568647 -0.62531812]
# [-0.40824829 0.81649658 -0.40824829]]
线性方程的直接解法
找到满足系统中方程的变量值。每个方程表示一条直线。解是这些直线相交的地方。
# Define matrix A and vector B
A = np.array([[3, 1], [1, 2]])
B = np.array([9, 8])
# Solve the system of linear equations Ax = B
x = np.linalg.solve(A, B)
print("Solution to Ax = B:", x)
# Output: [2\. 3.]
最小二乘拟合
最小二乘拟合找到数据点的最佳匹配。它降低了实际值与预测值之间的*方差异。
# Define matrix A and vector B
A = np.array([[1, 1], [1, 2], [1, 3]])
B = np.array([1, 2, 2])
# Solve the linear least-squares problem
x, residuals, rank, s = np.linalg.lstsq(A, B, rcond=None)
print("Least Squares Solution:", x)
print("Residuals:", residuals)
print("Rank of the matrix:", rank)
print("Singular values:", s)
# Output:
# Least Squares Solution: [0.66666667 0.5]
# Residuals: [0.33333333]
# Rank of the matrix: 2
# Singular values: [4.07914333 0.60049122]
矩阵范数
矩阵范数衡量矩阵的大小。范数对于检查数值稳定性和分析矩阵很有用。
# Define a matrix
A = np.array([[1, 2], [3, 4]])
# Compute various norms
frobenius_norm = np.linalg.norm(A, 'fro')
one_norm = np.linalg.norm(A, 1)
infinity_norm = np.linalg.norm(A, np.inf)
print("Frobenius Norm:", frobenius_norm)
print("1-Norm:", one_norm)
print("Infinity Norm:", infinity_norm)
# Output:
# Frobenius Norm: 5.477225575051661
# 1-Norm: 6.0
# Infinity Norm: 7.0
条件数
矩阵的条件数衡量对输入变化的敏感性。高条件数意味着解决方案可能不稳定。
# Define a matrix
A = np.array([[1, 2], [3, 4]])
# Compute the condition number of the matrix
condition_number = np.linalg.cond(A)
print("Condition Number:", condition_number)
# Output: 14.933034373659268
矩阵秩
矩阵的秩是独立行或列的数量。它显示了矩阵的大小及其覆盖向量空间的能力。
# Define a matrix
A = np.array([[1, 2], [3, 4]])
# Compute the rank of the matrix
rank_A = np.linalg.matrix_rank(A)
print("Matrix Rank:", rank_A)
# Output: 2
结论
NumPy 简化了诸如矩阵运算和线性方程等任务。你可以在这个网站上了解更多关于这些 NumPy 函数的信息。
Jayita Gulati 是一位机器学习爱好者和技术写作人,她对构建机器学习模型充满激情。她拥有利物浦大学的计算机科学硕士学位。
相关话题
如何处理 NumPy 中的维度

图片来源:Garik Barseghyan,来自 Pixabay
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
np.newaxis
-
它用于增加现有数组的维度。它使用切片操作符重新创建数组。
-
维度在数组中的位置通过 np.newaxis 临时添加。‘None’ 也可以用来代替 np.newaxis。
np.reshape:
- 它用于将数组重新调整为所需的布局。
np.expand_dims:
- 它通过在扩展数组形状中的轴位置插入新轴来扩展数组的形状
让我们看看一些主要应用场景,其中上述 NumPy 维度处理操作非常有用:
应用 1:Rank 1 数组到行/列向量的转换
在这里,我们创建了一个形状为 (4,) 的 4 元素数组,这称为 Rank 1 数组。
Array of 4 elements: [0 1 2 3]
Notice the shape, this is rank 1 array: (4,)
after transpose: (4,)
然而,Rank 1 数组往往会导致模糊的结果,因为它们不一致地表现为行/列向量。如上所示,如果我们对 x1 进行转置,其形状保持不变。
因此,通常建议明确指定数组的维度。这可以通过上述三种技术实现:
- 使用 np.newaxis:
row vector: [[0 1 2 3]]
(1, 4)
column vector:
[[0]
[1]
[2]
[3]]
(4, 1)
- 使用 np.reshape
Row vector using reshape: [[0 1 2 3]]
column vector using reshape:
[[0]
[1]
[2]
[3]]
- 使用 np.expand_dims
Row vector using expand_dims: [[0 1 2 3]]
column vector using expand_dims:
[[0]
[1]
[2]
[3]]
应用 2:增加维度
创建另一个形状为 (2,4,28) 的数组 x2,并检查如何将 x2 的维度从 3D 扩展到 5D

从上述内容中需要注意的关键点是 np.reshape 也允许你拆分维度。
应用 3:广播
根据 NumPy 文档:
broadcasting 描述了 numpy 在算术操作中如何处理不同形状的数组。
例如,当我们将以下两个数组相加时,由于形状不匹配,会显示 'ValueError':
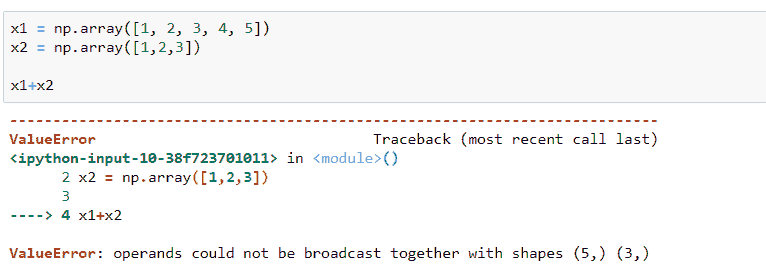
让我们看看 np.newaxis 如何增加下面一个数组的维度:
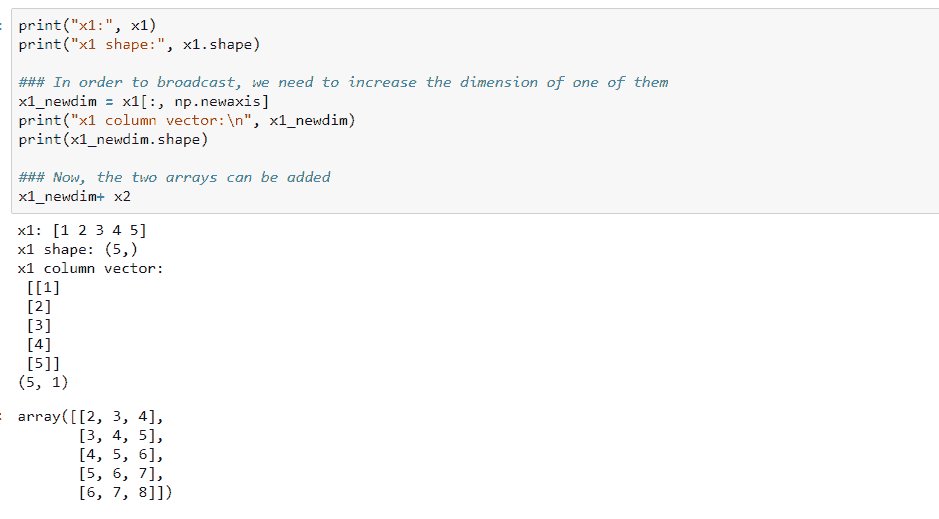
由于我们主要需要调整数组的维度以进行正确的广播操作,np.reshape 和 np.expand_dims 增加维度的方式效果相同(如前面的例子所示)。
感谢阅读 !!!
带有完整代码的 Jupyter notebook 放置在 这里。
参考资料:
-
stackoverflow.com/questions/46334014/np-reshapex-1-1-vs-x-np-newaxis?noredirect=1&lq=1 -
stackoverflow.com/questions/28385666/numpy-use-reshape-or-newaxis-to-add-dimensions
Vidhi Chugh 是一位获奖的 AI/ML 创新领袖和 AI 伦理学家。她在数据科学、产品和研究的交汇处工作,以提供商业价值和洞察力。她倡导以数据为中心的科学,并在数据治理领域拥有领先的专业知识,致力于构建可信赖的 AI 解决方案。
原文。已获许可重新发布。
更多相关内容
只有 NumPy:从头理解和创建计算图神经网络
原文:
www.kdnuggets.com/2019/08/numpy-neural-networks-computational-graphs.html
评论
作者 Rafay Khan。
理解新概念可能很困难,尤其是当现在有大量资源但仅提供了对复杂概念的粗略解释时。这篇博客是为了填补有关如何创建计算图形式的神经网络的详细讲解的空缺。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
在这篇博客文章中,我总结了我所学到的内容,以便回馈社区并帮助新手。我将创建常见形式的神经网络,完全依靠NumPy。
这篇博客文章分为两个部分,第一部分将理解神经网络的基础知识,第二部分将包含实现第一部分所学内容的代码。
第Ⅰ部分:理解神经网络
让我们深入探讨
神经网络是一种受到大脑工作方式启发的模型。类似于大脑中的神经元,我们的‘数学神经元’也直观地彼此连接;它们接收输入(树突),对其进行一些简单的计算,然后产生输出(轴突)。
学习某样东西的最佳方式是亲自构建它。让我们从一个简单的神经网络开始,并手动解决它。这将让我们了解计算是如何在神经网络中流动的。
图 1. 简单的输入输出神经网络。
如上图所示,大多数时候你会看到神经网络以类似的方式描绘。但这张简洁的图片隐藏了一些复杂性。让我们展开它。
图 2. 扩展的神经网络
现在,让我们逐一查看图中的每个节点,了解它所代表的内容。
图 3. 输入节点 x₁ 和 x₂
这些节点代表了我们用于第一个和第二个特征的输入,x₁ 和 x₂,定义了我们提供给神经网络的单个示例,因此被称为“输入层”*
图 4. 权重
w₁ 和 w₂ 表示我们的权重向量(在一些神经网络文献中,它用theta符号表示,即** θ **)。直观地说,这些决定了每个输入特征在计算下一个节点时应有多大影响。如果你对此不熟悉,可以将它们视为类似于线性方程中的‘斜率’或‘梯度’常数。
权重是我们神经网络需要“学习”的主要值。所以最初,我们将它们设置为 随机值 并让我们的“学习算法”决定最佳权重,以产生正确的输出。
为什么随机初始化?稍后会详细说明。
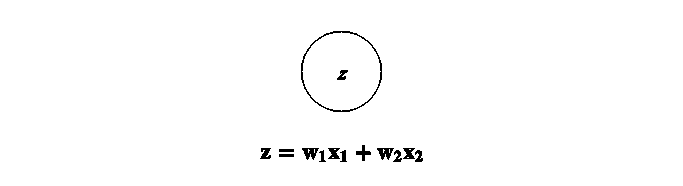
图 5. 线性操作
这个节点表示一个线性函数。简单地说,它接收所有传入的输入,并将它们创建成一个线性方程/组合。(根据惯例,理解为每个节点的线性组合包含权重和输入,除了输入层中的输入节点,因此这个节点在图中经常被省略,如图 1 所示。在这个示例中,我将它保留)
图 6. 输出节点
这个 σ 节点将输入传递给以下函数,称为 sigmoid 函数(因其 S 形曲线而得名),也称为 logistic 函数:
图 7. Sigmoid(Logistic)函数
Sigmoid 是神经网络中众多“激活函数”之一。激活函数的作用是将输入转换到不同的范围。例如,如果 z > 2,那么 σ(z) ≈ 1,类似地,如果 z < -2,则 σ(z) ≈ 0。所以,sigmoid 函数将输出范围压缩到 (0, 1)(此‘()’符号表示排他性边界;函数渐*线但不会完全输出 0 或 1,而是接*边界值)。
在我们上面的神经网络中,由于它是最后一个节点,因此它执行输出的功能。预测输出用 ŷ 表示。(注意:在一些神经网络文献中,这用‘h(θ)’* 表示,其中‘h’称为假设,即这是神经网络的假设,也就是输出预测,给定参数 θ;其中 θ 是神经网络的权重*)。
现在我们知道每个元素代表什么了,让我们通过手动计算一些虚拟数据中的每个节点来展现我们的实力吧。
图 8. 或门
上面的数据代表一个OR门(如果任何输入为 1 则输出 1)。表格的每一行代表一个‘示例’,我们希望神经网络从中学习。通过学习这些示例,我们希望神经网络能够执行 OR 门的功能;给定输入特征,x₁ 和 x₂,尝试输出相应的y(也称为‘标签’)。我还将这些点绘制在二维*面上,以便于可视化(绿色交叉点表示输出(y)为1的点,而红色点表示输出为0的点)。
这个 OR 门数据特别有趣,因为它是线性可分的,即我们可以画一条直线来将绿色交叉点与红色点分开。
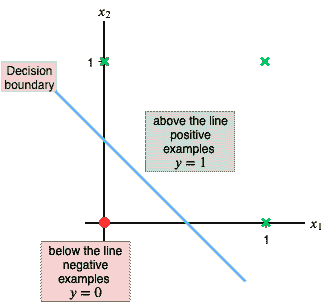
图 9. 显示 OR 门数据是线性可分的
我们将很快看到我们的简单神经网络如何执行这一任务。
数据在我们的神经网络中从左到右流动。在技术术语中,这个过程叫做‘前向传播’;每个节点的计算结果被传递到它所连接的下一个节点。
让我们详细了解一下神经网络在给定第一个示例x₁=0 和 x₂=0 时将执行的所有计算。同时,我们将初始化权重** w₁和w₂** 为w₁=0.1 和 w₂=0.6(回顾一下,这些权重是随机选择的)

图 10. 从 OR 表数据中进行的第一个示例的前向传播
以我们当前的权重,w₁= 0.1 和 w₂ = 0.6,我们的网络输出距离我们期望的位置还有点距离。预测的输出,ŷ,应该是ŷ≈0对于x₁=0 和 x₂=0,现在它的ŷ=0.5。
那么,如何告诉神经网络它距离我们期望的输出有多远呢?这时,损失函数来救援。
损失函数
损失函数是一个简单的方程,告诉我们神经网络预测的输出(ŷ)与期望输出(y)之间的距离,只针对一个示例。
损失函数的导数决定了是增加还是减少权重。正的导数意味着减少权重,而负的导数则意味着增加权重。**斜率越陡峭,预测错误越大。
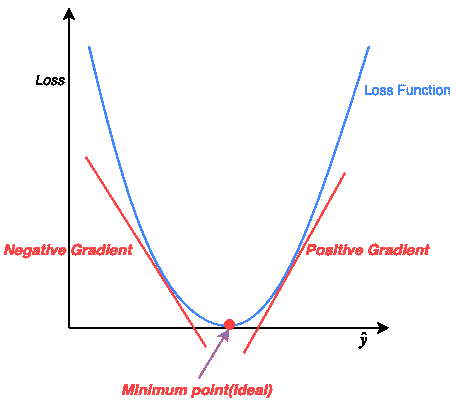
图 11. 损失函数的可视化
图 11 中描绘的损失函数曲线是一个理想化的版本。在实际情况下,损失函数可能不会如此*滑,而是沿着到达最小值的路径上有一些起伏和鞍点。
有许多不同种类的损失函数每种都计算预测输出与期望输出之间的误差。在这里,我们将使用其中一种最简单的损失函数,即*方误差损失函数。定义如下:
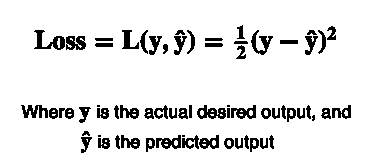
图 12. 损失函数。计算单个示例的误差
采用*方保持一切都为正,以及分数 (1/2) 是为了在对*方 项求导时可以相互抵消 (在一些机器学习从业者中,常常会省略这个分数)。
从直观上讲,*方误差损失函数帮助我们最小化预测线(蓝线)与实际数据(绿色点)之间的垂直距离。在后台,这条预测线是我们的z(线性函数)节点。
图 13. 损失函数效应的可视化
现在我们知道了损失函数的目的,让我们计算当前预测的误差ŷ=0.5,已知y=0
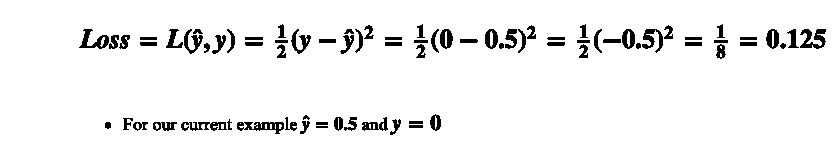
图 14. 第一个示例计算的损失
如我们所见,损失是0.125。基于此,我们现在可以使用损失函数的导数来检查是否需要增加或减少权重。
这个过程被称为反向传播,因为我们将执行与前向阶段相反的操作。我们将从输出向输入追踪,而不是从输入到输出。简单来说,反向传播使我们能够找出神经网络的每一部分对损失的责任程度。
为了执行反向传播,我们将采用以下技术:在每个节点,我们只计算局部梯度(该节点的偏导数),然后在反向传播过程中,当我们从上游接收到梯度的数值时,将这些数值与局部梯度相乘,传递给各自连接的节点。
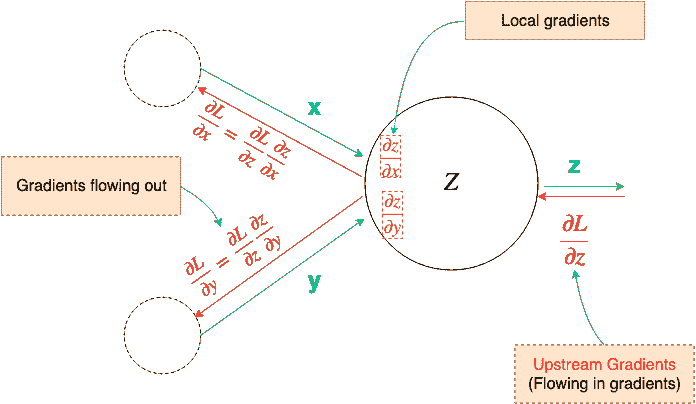
图 15. 梯度流
这是一种从微积分中链式法则的推广。
由于ŷ(预测标签)决定了我们的损失,而y(实际标签)是常数,对于单个示例,我们将对损失关于ŷ进行偏导数计算
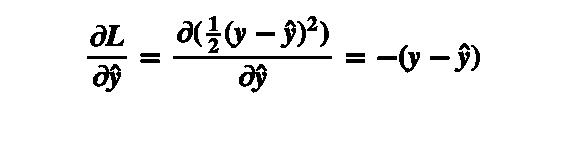
图 16. 损失对ŷ的偏导数
由于反向传播步骤可能看起来有些复杂,我将逐步讲解:
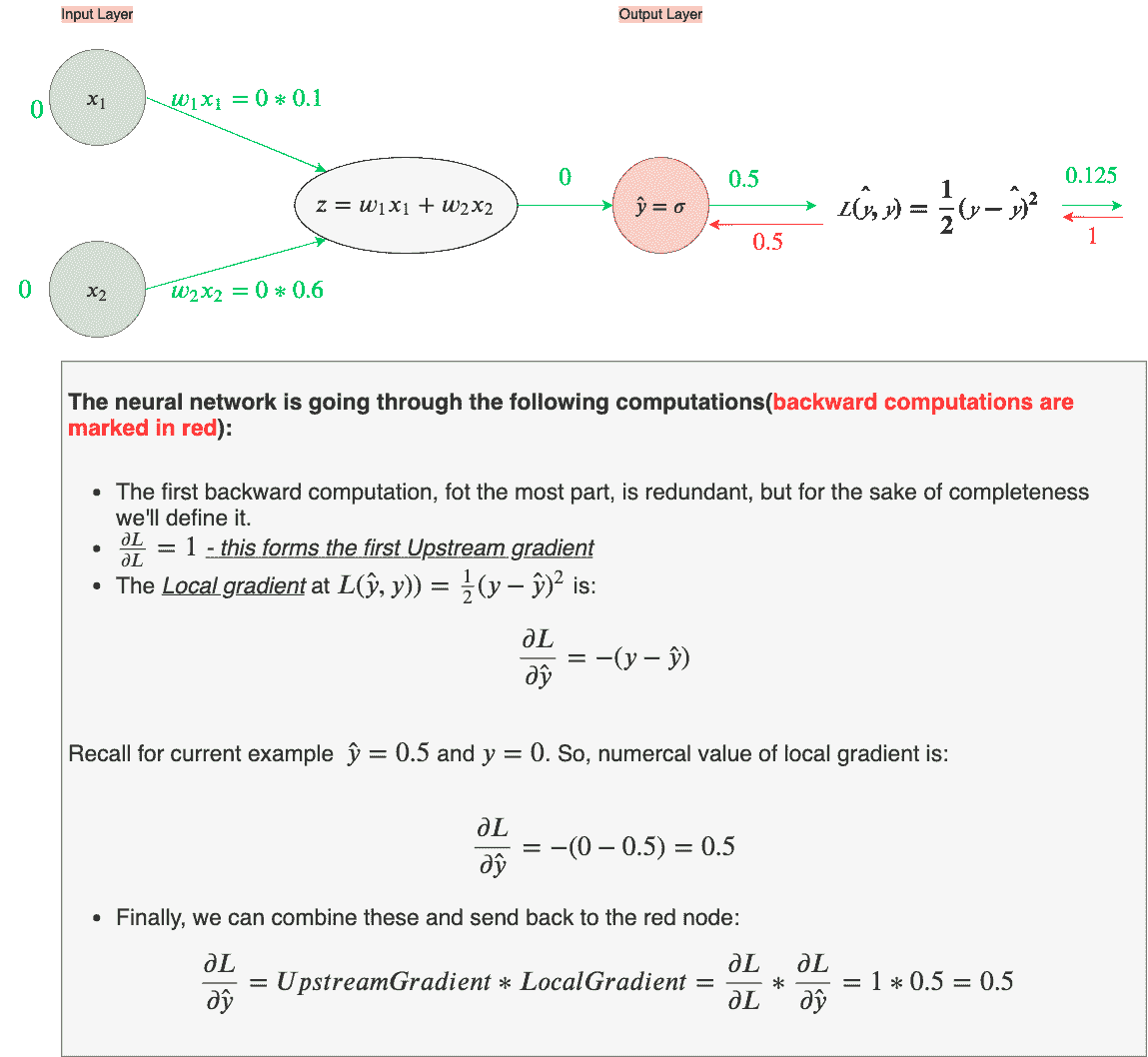
图 17.a. 反向传播
对于下一个计算,我们需要 sigmoid 函数的导数,因为它形成了红色节点的局部梯度。让我们推导一下。
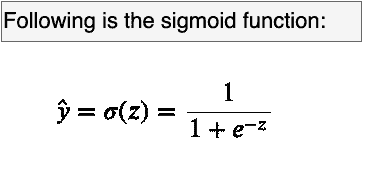
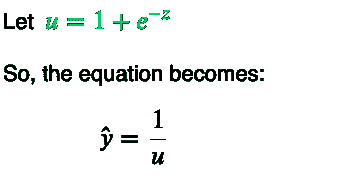
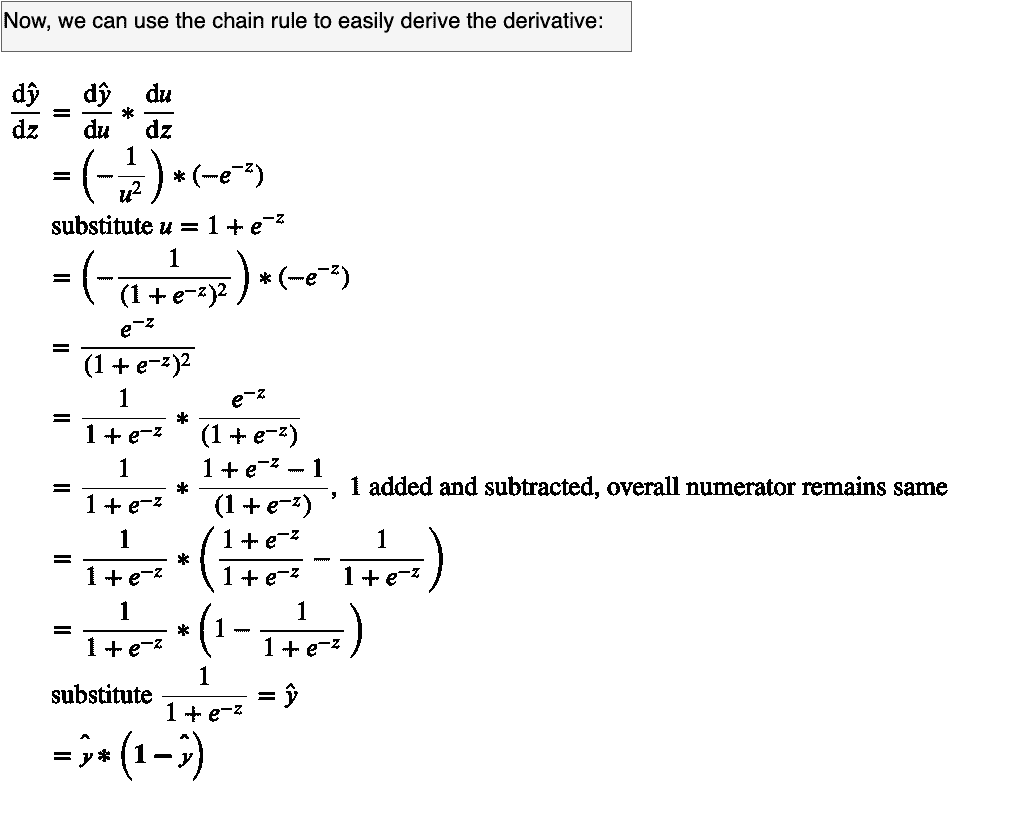
图 18. Sigmoid 函数的导数。
让我们在下一步的反向计算中使用这一点
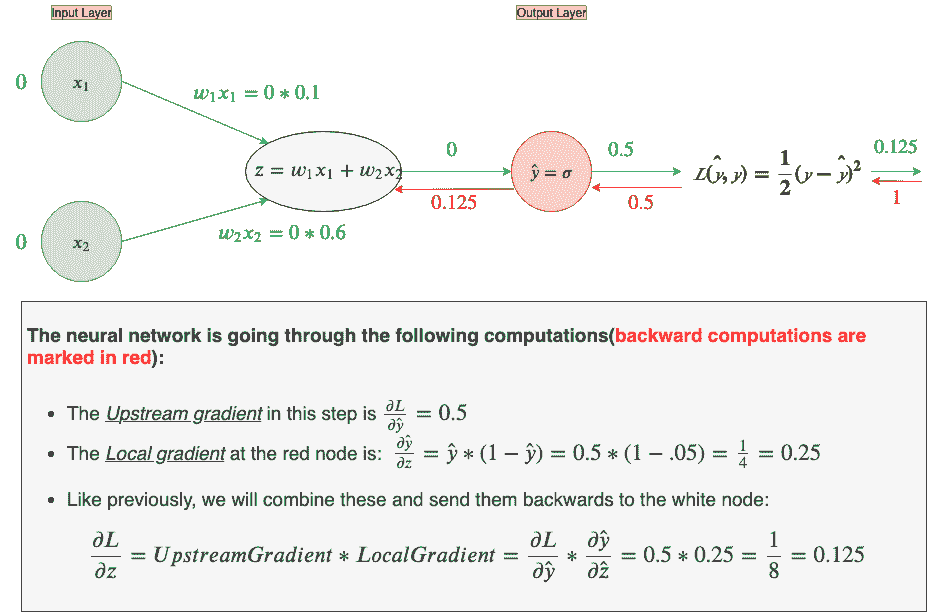
图 17.b. 反向传播
反向计算不应传播到输入,因为我们不希望更改输入数据(即红色箭头不应指向绿色节点)。我们只想更改与输入相关的权重。
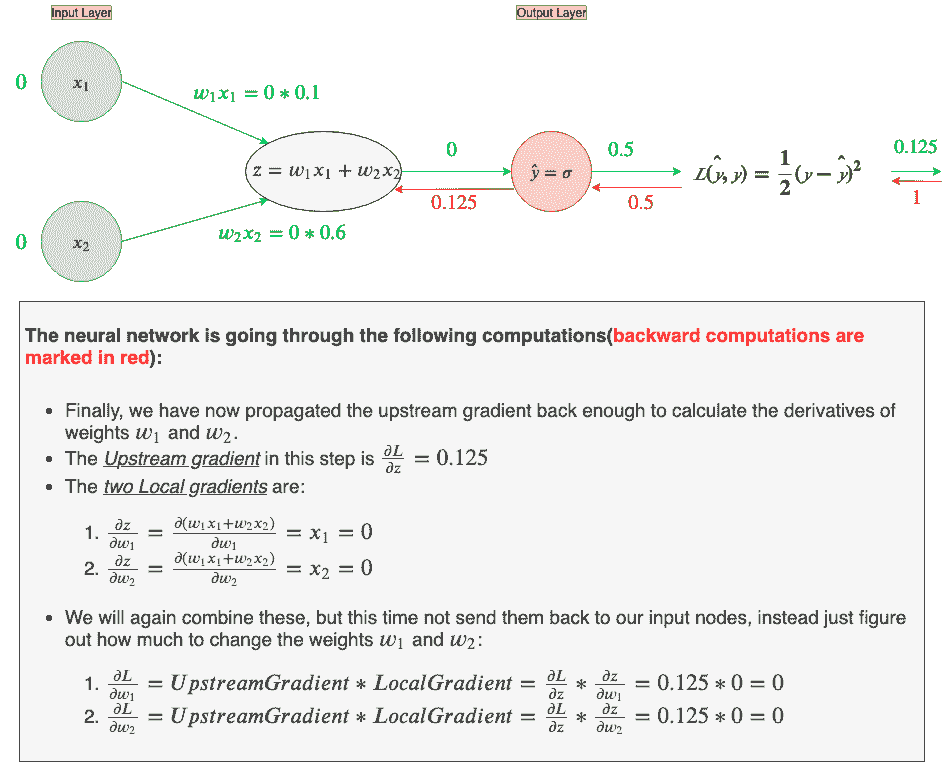
图 17.c. 反向传播
发现了什么奇怪的东西吗?权重 w₁和 w₂对损失的导数是零!如果导数为零,我们不能增加或减少权重。那么,如果我们不能调整权重,如何在这种情况下获得期望的输出呢?这里的关键点是局部梯度(∂z/∂w₁和∂z/∂w₂)是x₁和x₂,在这个例子中,都是零(即没有提供信息)。
这让我们引出了偏置的概念。
偏置
回想一下你高中时的直线方程。
图 19. 直线方程
这里 b是偏置项。从直观上讲,偏置告诉我们所有用 x(自变量)计算的输出应该有一个加性偏置为 b。所以,当x=0(没有来自自变量的信息)时,输出应该偏向于仅仅是*b。
请注意,没有偏置项的直线只能通过原点(0, 0),线与线之间唯一的区别就是梯度m。*
图 20. 从原点出发的直线
所以,利用这些新信息,让我们在神经网络中添加一个节点:偏置节点。(在神经网络文献中,除了输入层之外,每一层都假设有一个偏置节点,就像线性节点一样,因此这个节点在图中也常常被省略。)
图 21. 带偏置节点的扩展神经网络
现在我们用相同的例子进行前向传播,x₁=0, x₂=0, y=0,并设置偏置b=0(初始偏置总是设置为零,而不是随机数),让反向传播的损失来调整偏置。
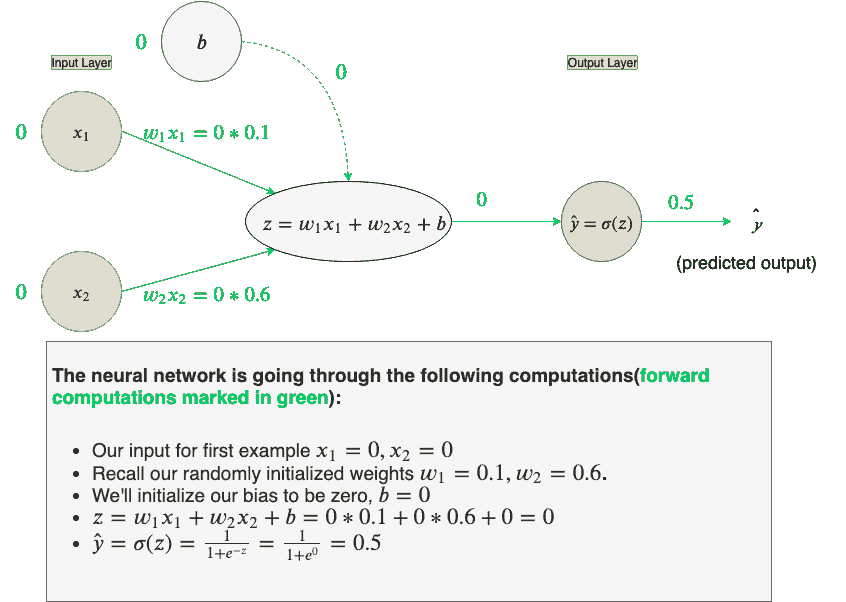
图 22. 带偏置单元的 OR 表数据的前向传播第一个例子
好吧,偏置为“b=0”的前向传播没有改变我们的输出,但在做出最终判断之前,让我们进行反向传播。
如前所述,让我们一步步地进行反向传播。
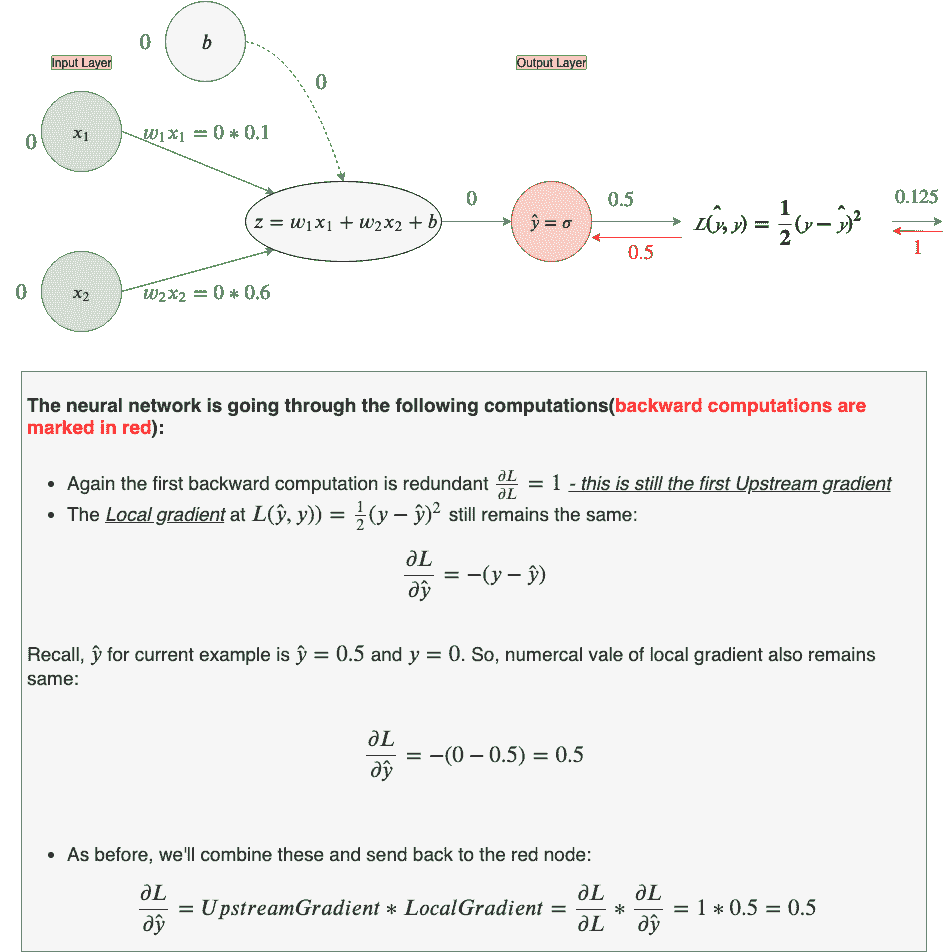
图 23.a. 带偏置的反向传播
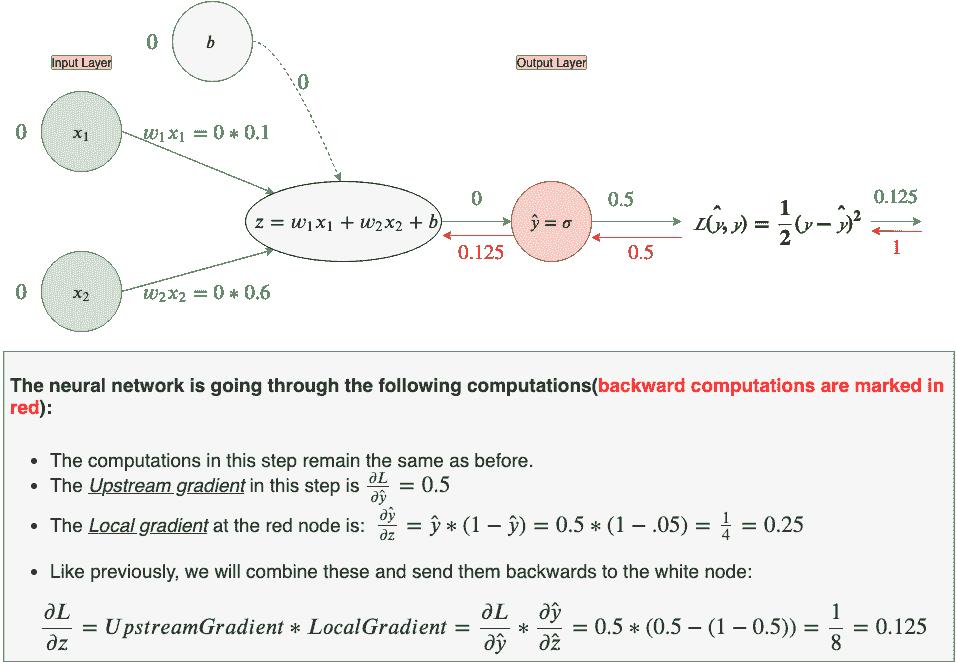
图 23.b. 带偏置的反向传播
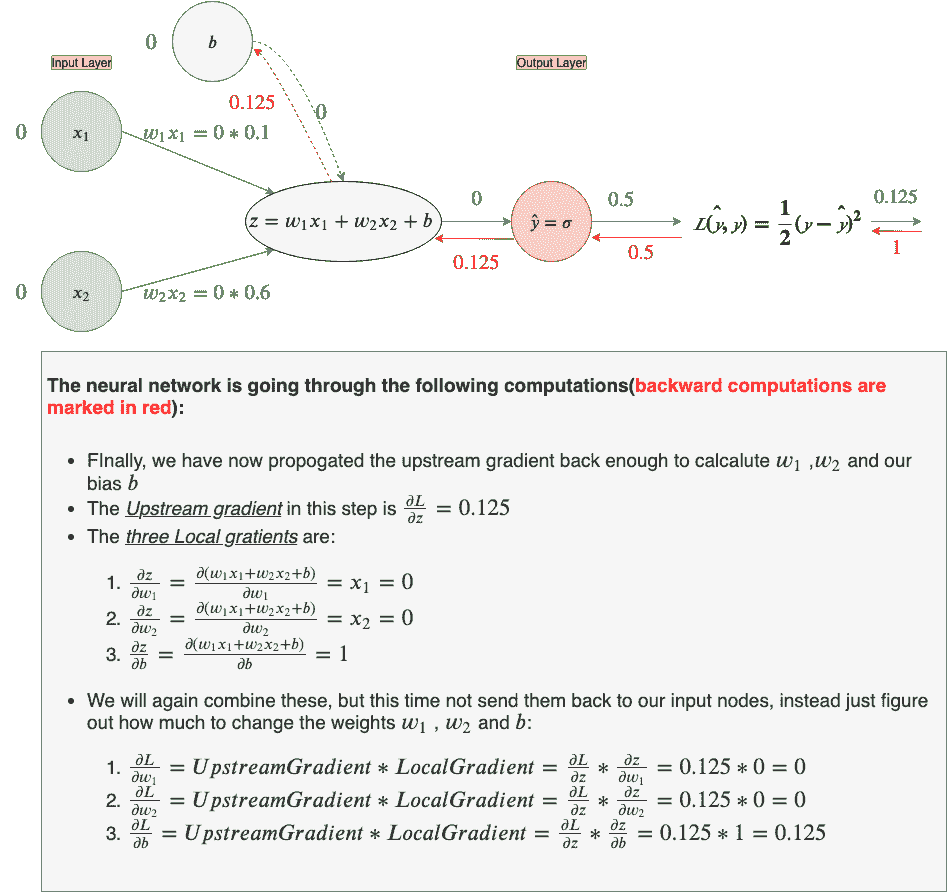
图 23.c. 带偏置的反向传播
太好了!我们刚刚找到了调整偏置的量。由于偏置的导数(∂L/∂b)为正 0.125,我们需要沿着梯度的负方向调整偏置(回忆之前的损失函数曲线)。这在技术上称为梯度下降,因为我们使用梯度的方向“下降”从斜坡区域到*坦区域。让我们开始吧。
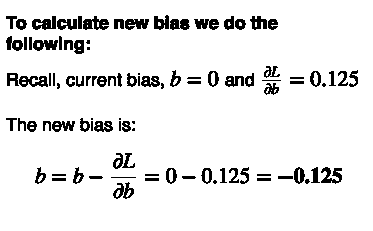
图 24. 使用梯度下降计算的新偏差
现在,我们已经将偏差略微调整为 b=-0.125,让我们通过进行 前向传播和** 检查新的损失**来测试我们是否做对了。
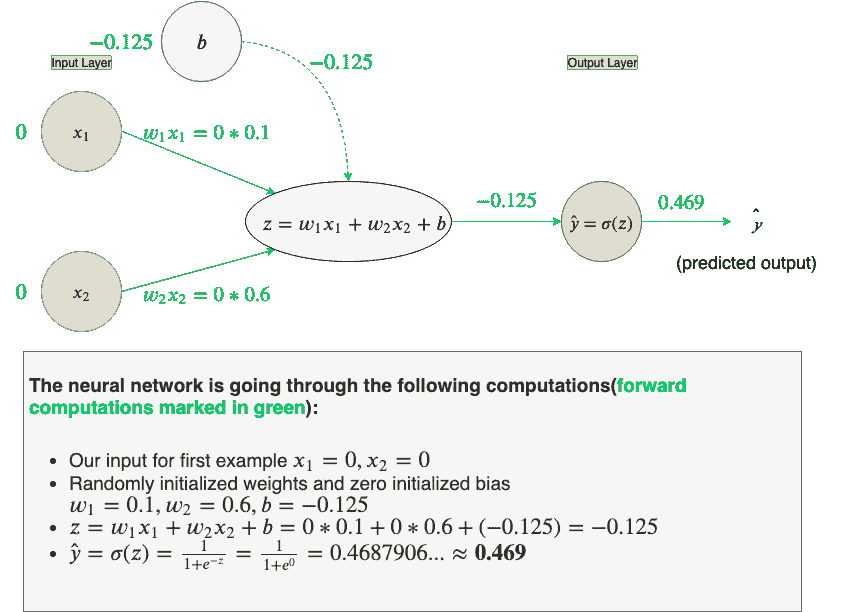
图 25. 使用新计算的偏差进行前向传播
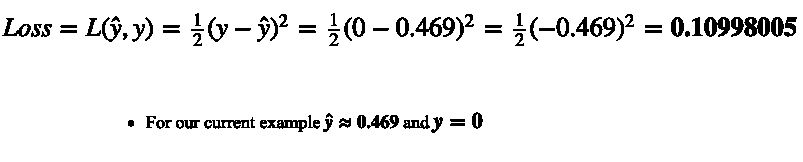
图 26. 新计算的偏差后的损失
现在我们的预测输出是*** ŷ≈0.469(四舍五入到小数点后 3 位), 比之前的 0.5 有了轻微的改进,损失从 0.125 降到大约 0.109。这种轻微的修正是神经网络通过将预测输出与期望输出 y 进行比较后‘学习’到的,然后朝梯度的相反方向移动。 ***相当酷,对吧?
现在你可能会想,这只是比之前的结果略有改进,我们如何才能达到最小损失。两个因素发挥作用: a) 我们执行了多少次‘训练’(每个训练周期包括前向传播、反向传播和通过梯度下降更新权重)。 b) 学习率。
学习率???那是什么?让我们来谈谈它。
学习率
回顾一下,我们如何通过在梯度的相反方向上移动来计算新的偏差(即梯度下降)。
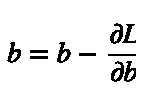
图 27. 更新偏差的方程
注意到当我们更新偏差时,我们在梯度的相反方向上移动了 1 步。
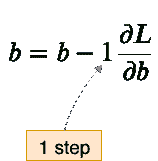
图 28. 更新偏差的方程,显示“步数”
我们可以在梯度的相反方向上移动 0.5、0.9、2、3 或任何我们想要的步数。这种‘步数’就是我们定义的学习率,通常用** α(alpha)表示。***

图 29. 梯度下降的一般方程
学习率定义了我们达到最小损失的速度。让我们在下面可视化学习率的作用:
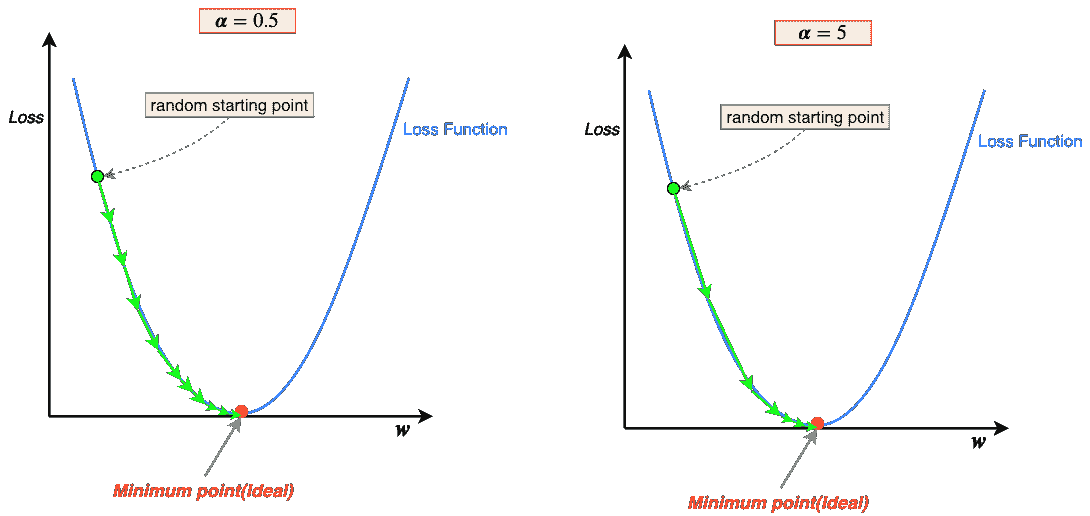
图 30. 可视化学习率的效果
如你所见,使用较低的学习率(α=0.5)时,我们沿曲线的下降较慢,需要很多步才能到达最小点。另一方面,使用较高的学习率(α=5),我们步伐更大,更快到达最小点。
眼尖的读者可能注意到,梯度下降步骤(绿色箭头)在接*最小点时越来越小,这是为什么呢?回忆一下,学习率在曲线上的那个点与梯度相乘;当我们从倾斜区域下降到 u 形曲线的*坦区域时,接*最小点,梯度不断变小,因此步伐也变小。因此,在训练过程中改变学习率是不必要的(一些梯度下降的变体开始时使用较高的学习率以快速下坡,然后逐渐降低,这被称为“退火学习率”)
那么,结论是什么呢?只需将学习率设置得尽可能高,以便快速达到最佳损失吗?不是的。学习率可能是把双刃剑。学习率过高,参数(权重/偏置)不会达到最佳值,而是开始远离最佳值。学习率过小,参数收敛到最佳值的时间过长。
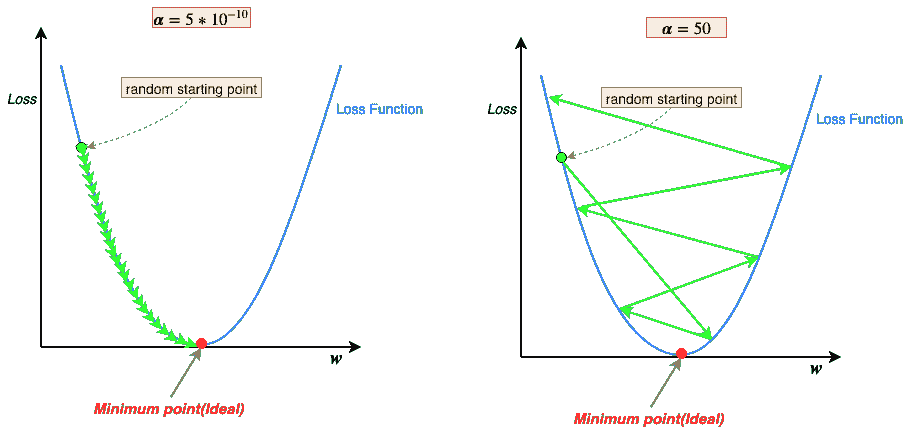
图 31. 可视化非常低与非常高学习率的效果。
小学习率(α=5*10⁻¹⁰)导致需要很多步骤才能达到最小点,这很容易理解;将梯度乘以一个小数(α)会导致步伐成比例地变小。
大学习率(α=50)导致梯度下降发散可能令人困惑,但答案很简单;注意到在每一步,梯度下降通过沿直线(图中的绿色箭头)移动来逼*其下行路径,简而言之,它估计其向下的路径。当学习率过高时,我们迫使梯度下降采取更大的步伐。更大的步伐往往过高估计了向下的路径并越过了最小点,然后为了纠正错误的估计,梯度下降试图朝着最小点移动,但由于学习率过高,再次越过最小点。这个不断过高估计的循环最终导致结果发散(每次训练周期后的损失增加,而不是减少)。
学习率被称为超参数。超参数是神经网络不能通过梯度反向传播实质上学习的参数,它们必须由神经网络模型的创建者根据问题及其数据集手动调整。(上面选择的损失函数也是超参数)
总而言之,目标不是找到“完美的学习率”,而是找到一个足够大的学习率,使神经网络能够成功有效地训练而不发散。
到目前为止,我们仅使用一个示例(x₁=0和x₂=0)来调整我们的权重和偏差(实际上,到目前为止仅调整了偏差????),这将整个数据集(或门表)中的一个示例的损失降低了。但我们有多个示例需要学习,我们希望减少所有示例的损失。理想情况下,在一次训练迭代中,我们希望减少所有训练示例的损失。这称为批量梯度下降(或完整批量梯度下降),因为我们在每次训练迭代中使用整个训练示例批量来改善我们的权重和偏差。(其他形式包括迷你批量梯度下降,我们在每次迭代中使用数据集的一个子集,以及随机梯度下降,我们在每次训练迭代中仅使用一个示例,就像我们到目前为止所做的那样。)
神经网络经过所有训练示例的训练迭代称为Epoch。如果使用迷你批量,则在神经网络遍历所有迷你批量后,epoch 就完成了,这对于随机梯度下降也是类似的,其中一个批量仅是一个示例。*
在进一步讨论之前,我们需要定义一个叫做成本函数的概念。
成本函数
当我们执行“批量梯度下降”时,我们需要稍微修改我们的损失函数,以适应不仅仅是一个示例,而是批量中的所有示例。这种调整后的损失函数称为成本函数。
另外,请注意,成本函数的曲线类似于损失函数的曲线(相同的 U 形)。
与在一个示例上计算损失不同,成本函数计算所有示例的*均损失。
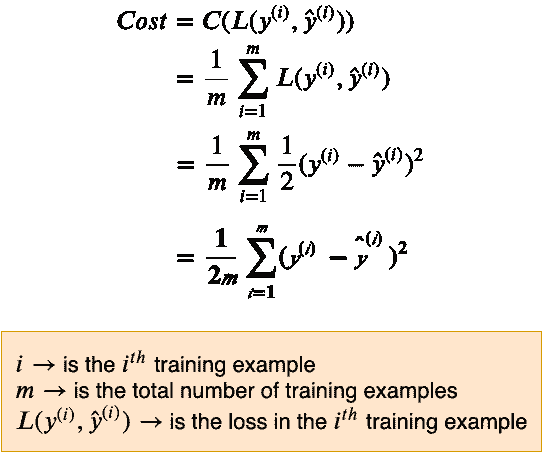
图 32. 成本函数
直观地说,成本函数是在扩展损失函数的能力。回想一下,损失函数是如何帮助最小化单个数据点和预测线(z)之间的垂直距离的。成本函数有助于同时最小化多个数据点之间的垂直距离(*方误差损失)。
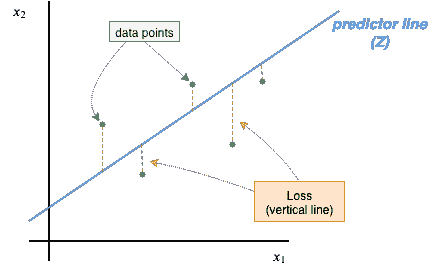
图 33. 成本函数效果的可视化
在批量梯度下降中,我们将使用成本函数的导数,而不是损失函数,来指导我们在所有示例中的最低成本路径。(在某些神经网络文献中,成本函数有时也用字母‘J’表示。)
让我们看看成本函数的导数方程如何与损失函数的普通导数不同。
成本函数的导数
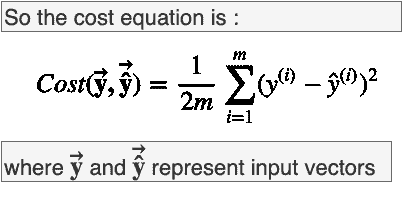
图 34. 成本函数显示它接受输入向量
对这个成本函数取导数,它以向量为输入并对其进行求和,可能有些棘手。因此,让我们从一个简单的示例开始,然后再推广导数。

图 35. 简单向量化示例中的成本计算
在成本的计算中没有新内容。正如预期的那样,成本最终是损失的*均值,但实现现在是向量化的(我们进行了向量化减法,接着是逐元素的指数运算,称为 Hadamard 指数运算)。让我们推导偏导数。

图 36. 简单示例中雅可比矩阵的计算
从中,我们可以将偏导数方程进行概括。
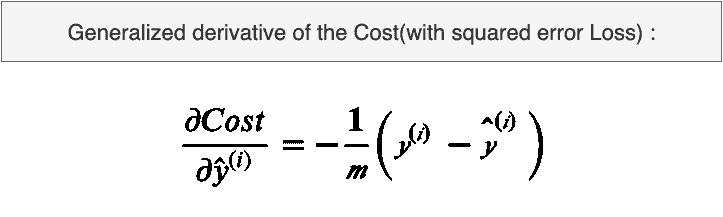
图 37. 广义偏导数方程
现在我们应该花点时间注意一下损失的导数与成本的导数之间的区别。

图 38. 损失和成本相对于(w.r.t)** ŷ⁽ⁱ⁾**的偏导数比较
稍后我们将看到这个小变化如何体现在梯度计算中。
回到批量梯度下降。
批量梯度下降有两种方法:
1. 对于每次训练迭代,创建单独的临时变量(大写的 Δ),这些变量将累积来自训练集中每个“m” 示例的权重和偏置的梯度(小写的 δ),然后在迭代结束时使用累积梯度的*均值更新权重。这是一种慢方法。(对于那些熟悉时间复杂度分析的人,你可能会注意到,随着训练数据集的增长,这将成为一个多项式时间算法 O(n²))

图 39. 批量梯度下降慢方法
2. 更快的方法与上述类似,但使用向量化计算来一次性计算所有训练样本的所有梯度,因此移除了内部循环。向量化计算在计算机上运行速度更快。这是所有流行神经网络框架使用的方法,也是我们在本博客剩下部分将遵循的方法。
对于向量化计算,我们将对神经网络计算图的“Z”节点进行调整,并使用成本函数而不是损失函数。
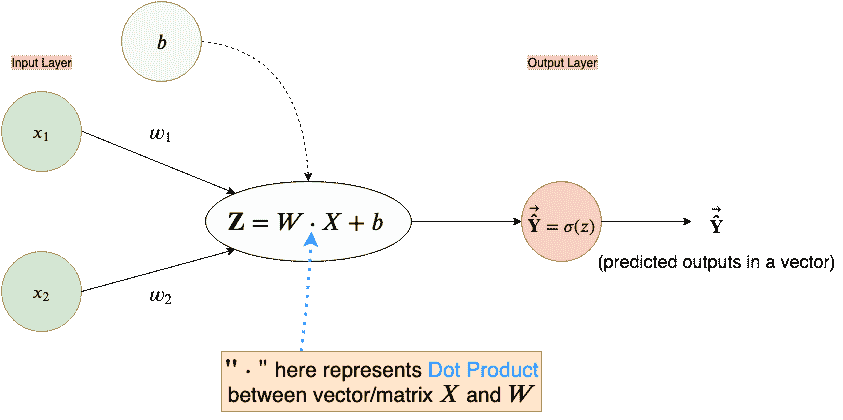
图 40. Z 节点的向量化实现
请注意,在上图中,我们对** dot-product** 进行了计算,这里的W和X可以是适当大小的矩阵或向量。偏置b在这里仍然是一个单一的数字(一个标量量),将以逐元素的方式添加到点积的输出中。预测的输出不仅是一个数字,而是一个向量Ŷ,其中每个元素是各自示例的预测输出。
在进行前向传播和反向传播之前,让我们设置数据(X, W, b & Y)。
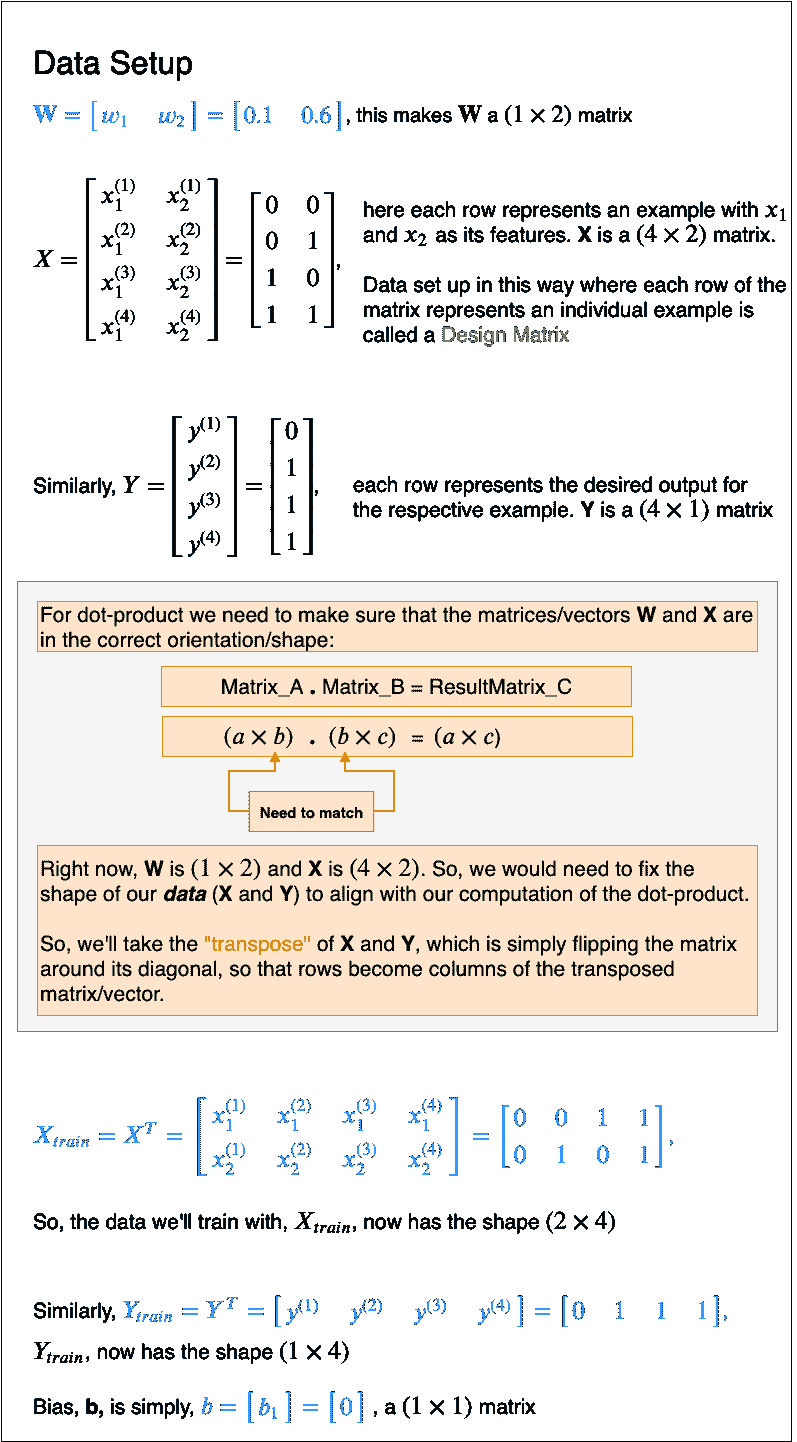
图 41. 设置向量化计算的数据。
我们现在终于准备好使用Xₜᵣₐᵢₙ、Yₜᵣₐᵢₙ、W和b进行前向传播和反向传播。
(注意:下列所有结果都四舍五入到小数点后三位,仅为简洁起见)
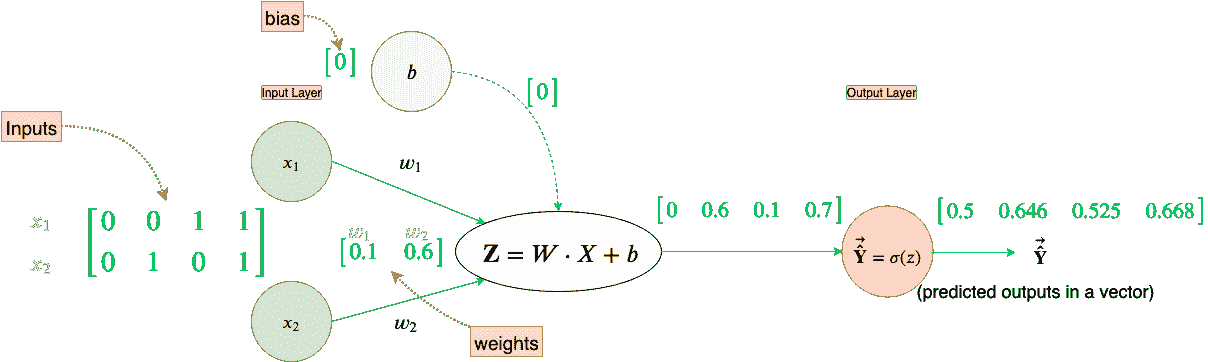

图 42. 对 OR 门数据集的向量化前向传播
通过向量化我们的计算,我们在一次操作中计算了数据集中所有示例的前向传播步骤,这真是太棒了。
我们现在可以计算这些输出预测的成本。(我们将详细讲解计算过程,以确保没有混淆)
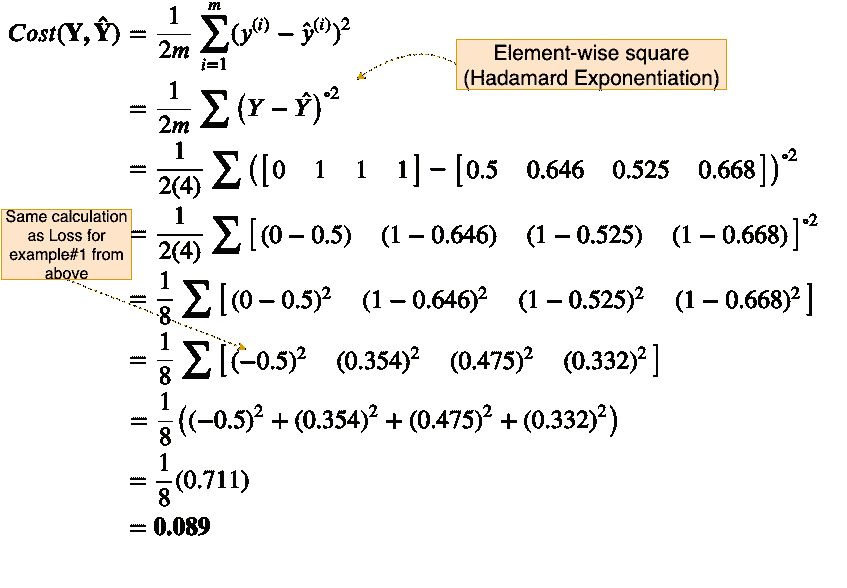
图 43. 对 OR 门数据的成本计算
我们当前权重W下的成本为0.089。我们的目标是使用反向传播和梯度下降来减少这一成本。和以前一样,我们将逐步进行反向传播。
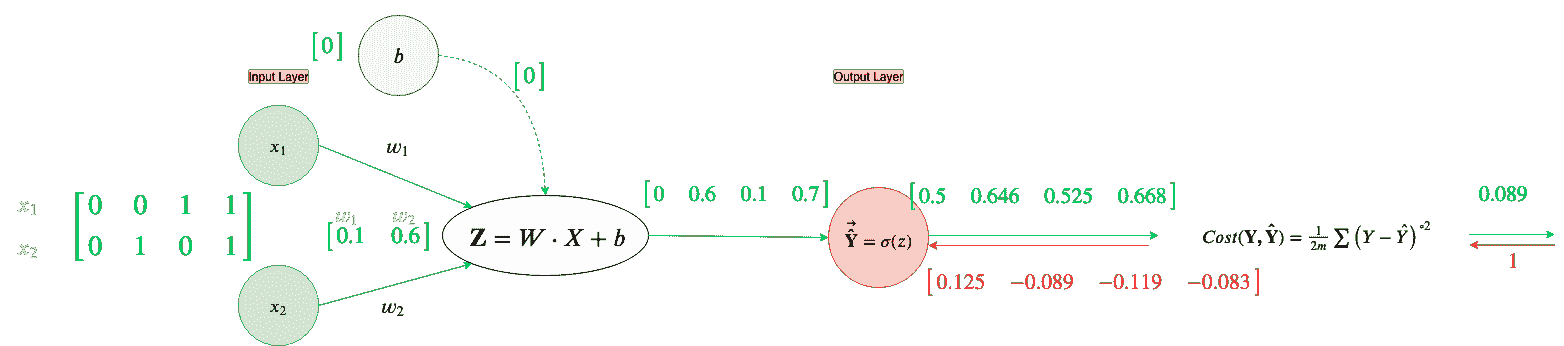

图 44.a. 对 OR 门数据的向量化反向传播
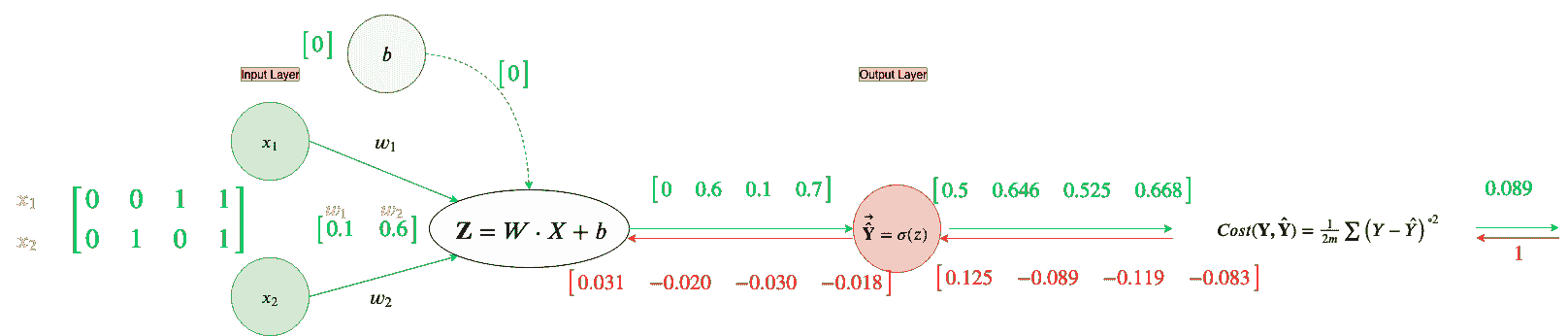

图 44.b. 对 OR 门数据的向量化反向传播
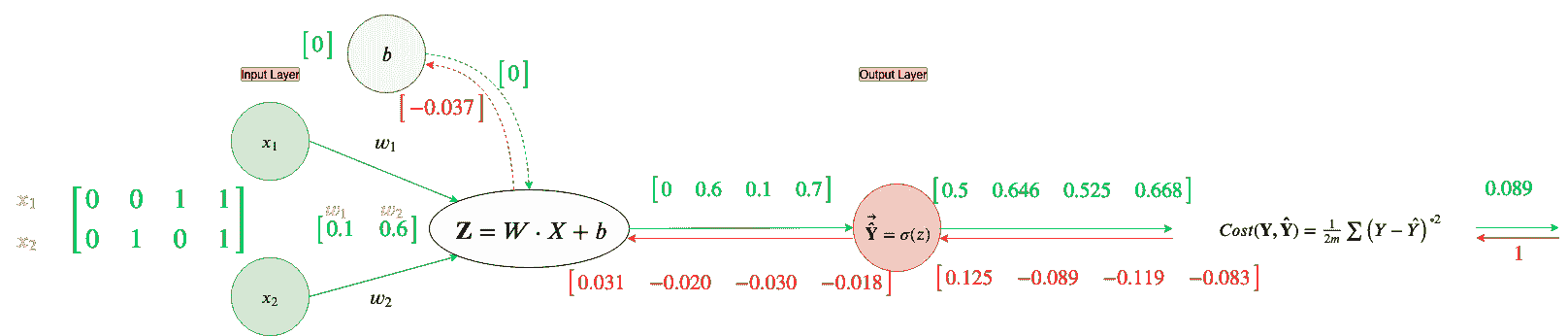

图 44.c. 对 OR 门数据的向量化反向传播
哇,我们使用了批量梯度下降的向量化实现来一次性计算所有梯度。
(细心的人可能会好奇在最后一步中如何计算局部梯度和最终梯度。别担心,我会在最后一步解释梯度的推导过程。现在只需知道最后一步中定义的梯度是对计算 ∂Cost/∂W 和 ∂Cost/∂b 的简单方法的一种优化即可)
让我们更新权重和偏置,保持学习率与之前的非向量化实现相同,即α=1。
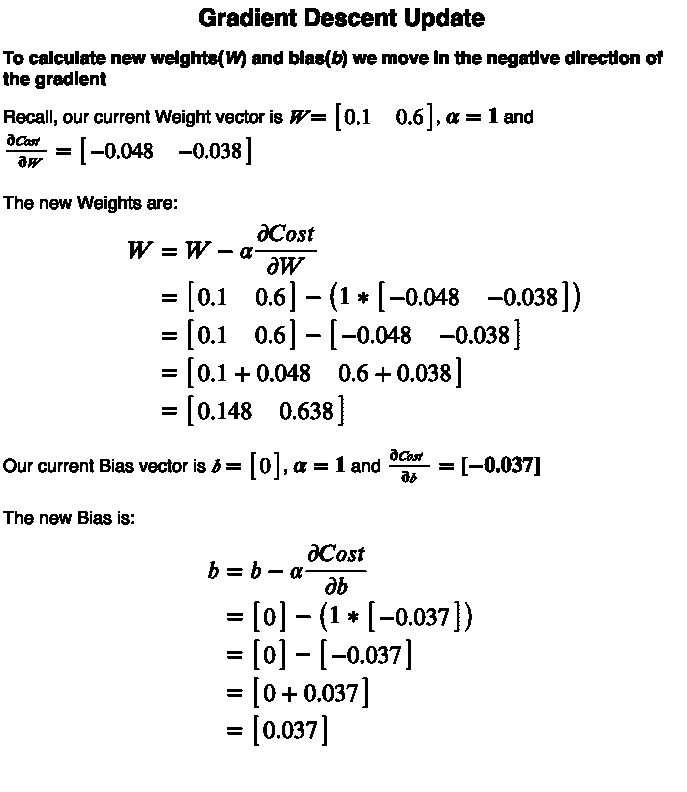
图 45. 计算的新权重和偏置
现在我们已经更新了权重和偏置,进行前向传播并计算新成本以检查我们是否做对了。
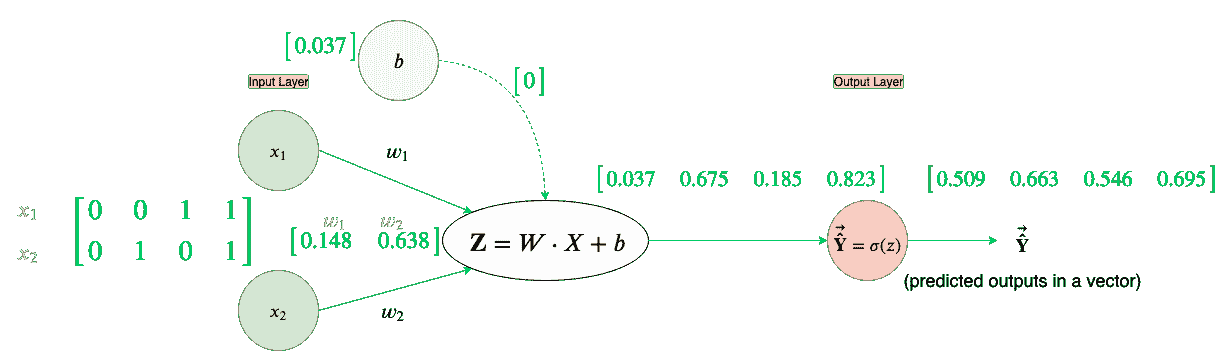

图 46. 使用更新后的权重和偏置的向量化前向传播
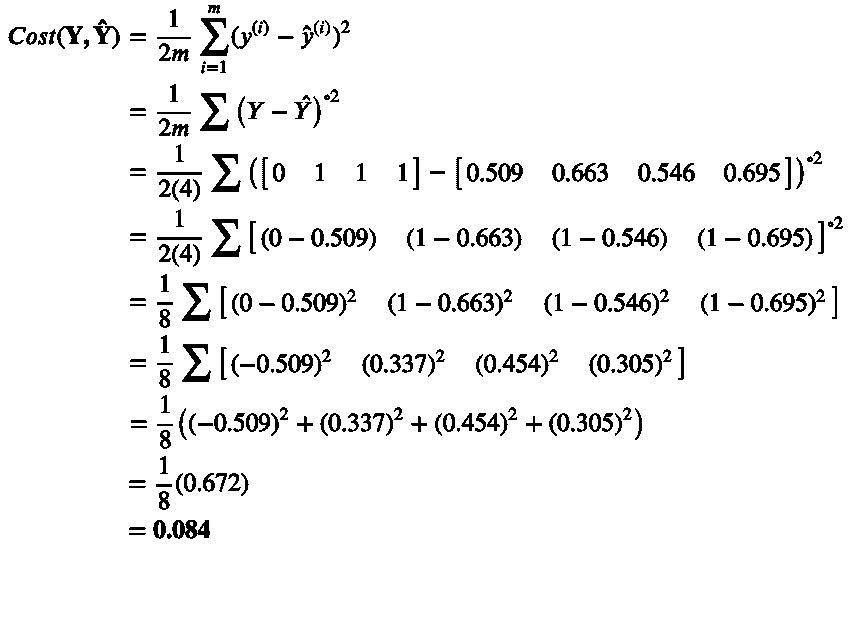
图 47. 更新参数后的新成本
所以,我们将成本(所有示例的*均损失)从最初的成本0.089减少到0.084。在我们收敛到较低成本之前,还需要进行多次训练迭代。
在这一点上,我建议你自己执行反向传播步骤。结果应该是(四舍五入到小数点后三位):∂Cost/∂W = [-0.044, -0.035] 和 ∂Cost/∂b = [-0.031]。
回想一下,在我们训练神经网络之前,我们如何预测神经网络可以分离图 9 中的两个类别,而在大约 5000 个 Epochs(全批量训练迭代)后,成本稳步下降到大约0.0005,我们得到了以下决策边界:
图 48。5000 个 Epochs 后的成本曲线和决策边界
成本曲线基本上是经过一定次数迭代(epochs)后绘制的成本值。注意,成本曲线在大约 3000 个 epochs 后趋于*坦,这意味着神经网络的权重和偏置已收敛,因此进一步训练只会稍微改善我们的权重和偏置。为什么?回想一下 u 形损失曲线,当我们越来越接*最小点(*坦区域)时,梯度变得越来越小,因此梯度下降的步长非常小。
决策边界显示了神经网络输出从一种变为另一种的线。我们可以通过为决策边界上下区域着色来更好地可视化这一点。
图 49。5000 个 Epochs 后的决策边界可视化
这使得情况更加清晰。红色阴影区域是决策边界下方的区域,决策边界下的所有区域输出(ŷ)为0。同样,决策边界上方的所有区域,阴影为绿色,输出为1。总之,我们的简单神经网络通过查看训练数据并找出如何分离两个输出类别(y=1和y=0)学会了决策边界。现在当x₁或x₂或两者都是 1 时,输出神经元就会激活(产生 1)。
现在是查看“1/m”(“m”是训练数据集中样本总数)在成本函数中如何体现在梯度的最终计算中的好时机。

图 50。比较相对于成本和损失的导数对神经网络参数的影响
由此,最重要的一点是,通过成本函数更新权重所使用的梯度是训练迭代过程中计算的所有梯度的*均值; 偏置也是如此。你可以通过自己检查向量化计算来确认这一点。
取所有梯度的*均值有一些好处。首先,它给我们一个较少噪声的梯度估计。其次,结果学习曲线*滑,帮助我们轻松判断神经网络是否在学习。这两个特性在训练神经网络时非常有用,尤其是在处理标记错误的数据集时。
这很好,但你是怎么计算梯度 ∂Cost/∂W 和 ∂Cost/∂b 的呢?
我经常从中学习的神经网络指南和博客文章往往省略了复杂的细节,或者对这些细节给出了非常模糊的解释。在这篇博客中,我们将逐一讨论所有内容,绝不遗漏任何细节。
首先,我们来处理∂Cost/∂b。我们为什么要对梯度进行求和?
为了说明这一点,我在三个非常简单的方程上应用我们的计算图技术。
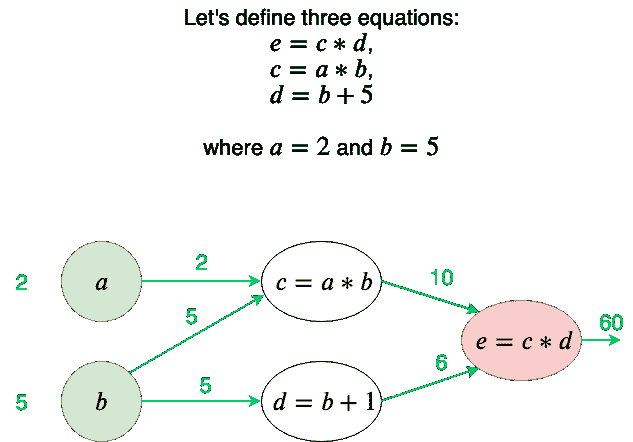
图 51. 简单方程的计算图
我特别关注b节点,所以我们来对它进行反向传播。
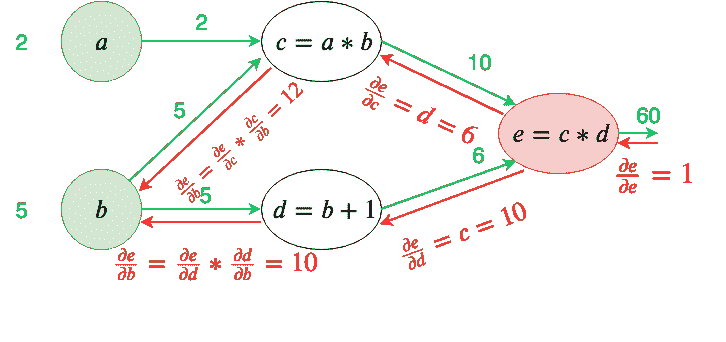
图 52. 简单方程的计算图上的反向传播
注意到** b** 节点正在从** 两个** 其他节点接收梯度。因此,流入节点***b *的梯度总和是两个流入梯度的总和。
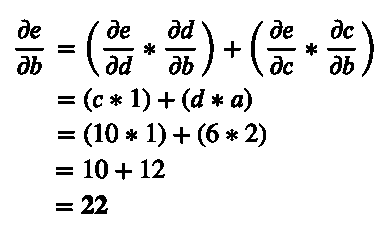
图 53. 流入节点b的梯度总和
从这个例子中,我们可以概括出以下规则:对一个节点,求和所有可能路径上的所有流入梯度。
让我们可视化一下这个规则在计算偏差时是如何应用的。我们的神经网络可以被看作是对每个示例进行独立的计算,但在训练迭代中使用共享的权重和偏差参数。下图中,偏差(b) 被可视化为我们神经网络执行的所有单独计算的共享参数。
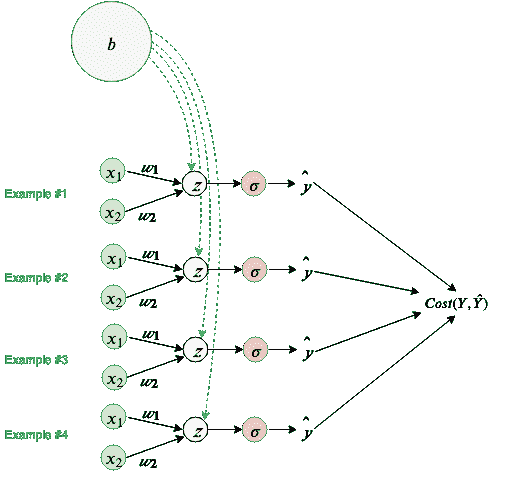
图 54. 可视化偏差参数在训练周期中的共享情况。
按照上面定义的一般规则,我们将对所有可能路径上的所有流入梯度进行求和,得到偏差节点b的总梯度。
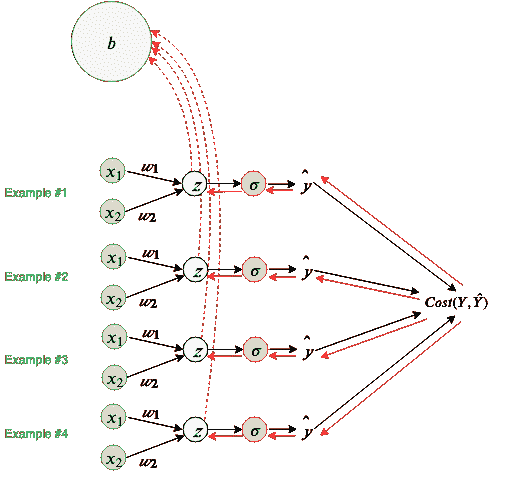
图 55. 可视化所有可能的反向传播路径到共享偏差参数
由于∂Z/∂b(Z 节点的局部梯度)等于1,所以在***b ***处的总梯度是每个示例相对于成本的梯度总和。

图 56. 证明∂Cost/∂b 是上游梯度的总和
现在我们已经搞清楚了偏差的导数,接下来我们要讨论权重的导数,更重要的是权重的局部梯度。
为什么局部梯度(∂Z/∂W)等于输入训练数据(X_train)的转置?
这可以用与上述偏差计算类似的方法来回答,但主要的复杂性在于计算权重矩阵(W)和数据矩阵(Xₜᵣₐᵢₙ)之间的点积的导数,这形成了我们的局部梯度。

图 57.a. 计算点积的导数。
点积的这个导数有点复杂,因为我们不再处理标量量,而是W和X都是矩阵,W⋅X的结果也是矩阵。让我们先通过一个简单的例子深入探讨,然后从中进行概括。
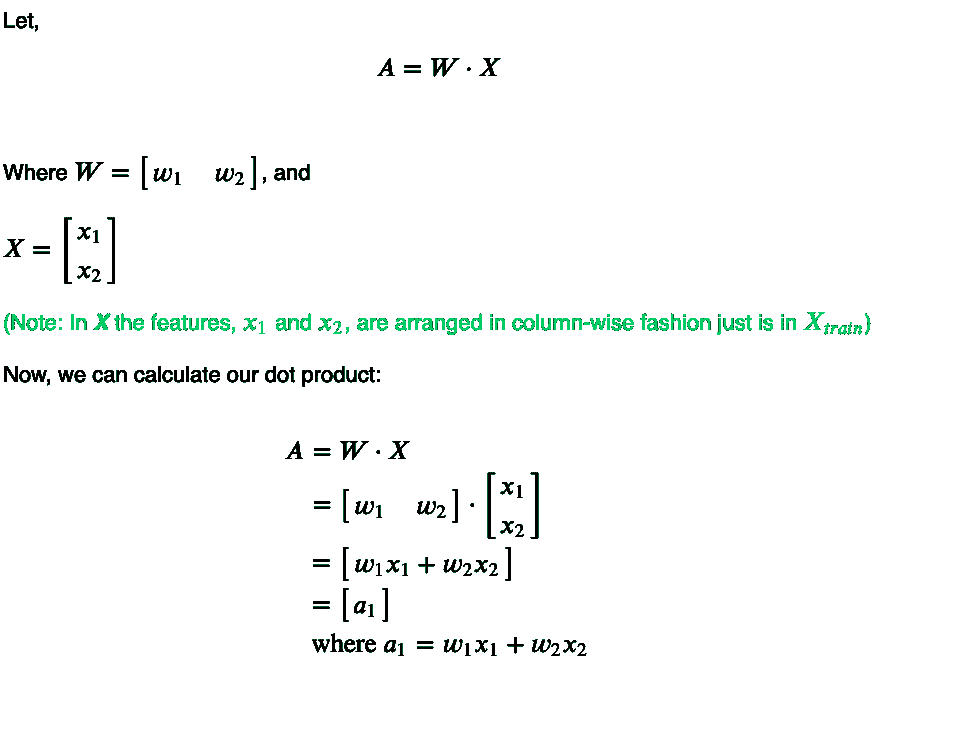
图 57.b. 点积导数的计算。
让我们计算A相对于W的导数。

图 57.c. 点积导数的计算。
让我们在一个处理多个示例的训练迭代中可视化这一点。(注意输入示例是列向量。)
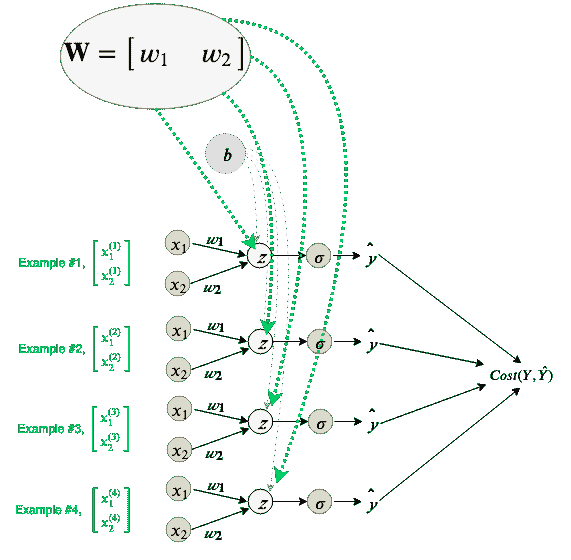
图 58. 训练周期中共享权重的可视化
就像偏置(b)在训练迭代中的每次计算中都被共享一样,权重(W)也在被共享。我们也可以可视化梯度回流到权重,如下所示(注意每个示例相对于W的局部导数结果是输入示例的行向量,即输入的转置):
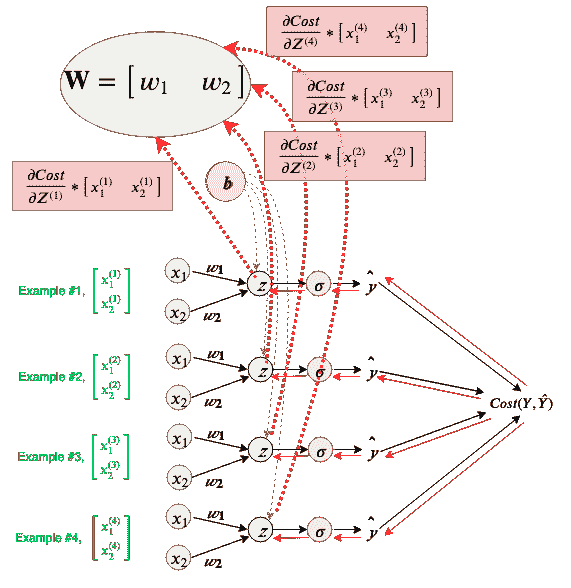
图 59. 可视化所有可能的反向传播路径到共享权重参数
再次遵循上述的一般规则,我们将汇总来自所有可能路径的梯度到权重节点W。
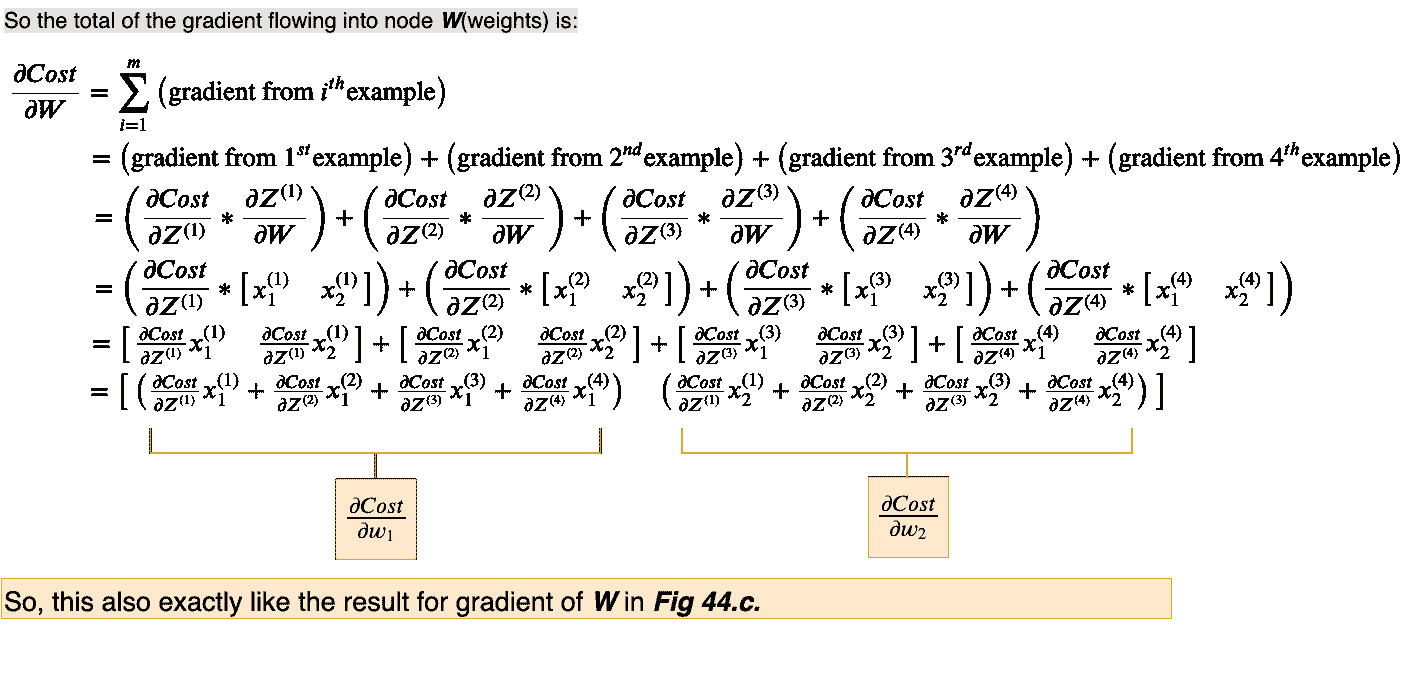
图 60. 在可视化之后∂Cost/∂W 的推导。
到目前为止,我们计算∂Cost/∂W的方法虽然正确且解释得很好,但它并不是最优的计算方法。我们也可以对这个计算进行向量化。接下来我们来做这个。

图 61. 证明∂Cost/∂W 是上游梯度与Xₜᵣₐᵢₙ的转置之间的点积
有没有更简单的方法来找出这一点,而不需要数学计算?
是的!使用维度分析。
在我们的 OR 门示例中,我们知道流入节点Z的梯度是(1 × 4)矩阵,Xₜᵣₐᵢₙ是(2 × 4)矩阵,且相对于W的 Cost 的导数需要与W大小相同,即(1 × 2)。因此,生成(1 × 2)矩阵的唯一方法是计算Z与Xₜᵣₐᵢₙ的转置的点积。

同样,知道偏置b是一个简单的(1 × 1)矩阵,流入节点 Z 的梯度是(1 × 4),通过维度分析我们可以确定相对于b的 Cost 的梯度也需要是(1 × 1)矩阵。鉴于局部梯度(∂Z/∂b)仅等于1,我们可以通过汇总上游梯度来实现这一点。
*最后,当推导导数表达式时,先在小示例上进行工作,然后再从那里推广。例如,在这里,当计算相对于 ***W 的点积的导数时,我们使用了一个单列向量作为测试案例,并从那里推广。如果我们使用整个数据矩阵,那么导数将导致一个 (4 × 1 × 2) 张量(多维矩阵),其计算可能会变得有些复杂。
在结束这一部分之前,让我们看一个稍微复杂的例子。
图 62. XOR 门数据
上面的图 62 表示 XOR 门数据。注意到,标签 y 仅在 x₁ 或 x₂ 中的一个值等于 1 时才等于 1,而不是两个值都等于 1。这使得这个数据集特别具有挑战性,因为数据不是线性可分的,即没有单一的直线决策边界能够成功地分隔数据中的两个类别(y=1 和 y=0)。XOR 曾经是早期形式的人工神经网络的祸根。
图 63. 一些错误的线性决策边界
记住,我们当前的神经网络之所以成功,是因为它能够找出能够成功分隔 OR 门数据集两个类别的直线决策边界。这里,直线无法解决问题。那么,我们如何让神经网络解决这个问题呢?
嗯,我们可以做两件事:
-
修改数据本身,使得除了特征 x₁ 和 x₂ 外,第三个特征提供一些额外的信息,帮助神经网络确定一个好的决策边界。这一过程称为 特征工程。
-
改变神经网络的架构,使其更深。
让我们比较一下两者,看看哪一个更好。
特征工程
让我们看看一个类似 XOR 数据的数据集,这将帮助我们做出一个重要的认识。
图 64. 不同象限中的 XOR 类数据
图 64 中的数据与 XOR 数据完全相同,只是每个数据点分布在不同的象限中。注意到在 第 1 象限和第 3 象限中的所有值都是正的,而在 第 2 象限和第 4 象限中的所有值都是负的。
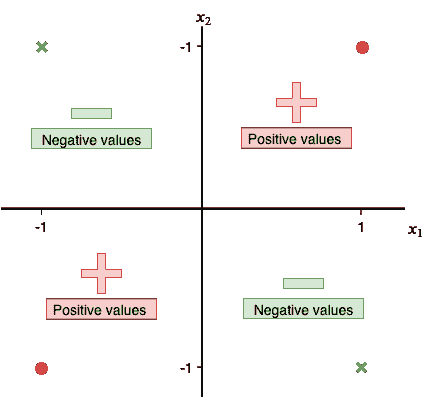
图 65. 正负象限
为什么呢?在 第 1 和 第 3 象限中,值的符号被*方,而在 第 2 和 第 4 象限中,值是负数和正数之间的简单乘积,结果是负数。
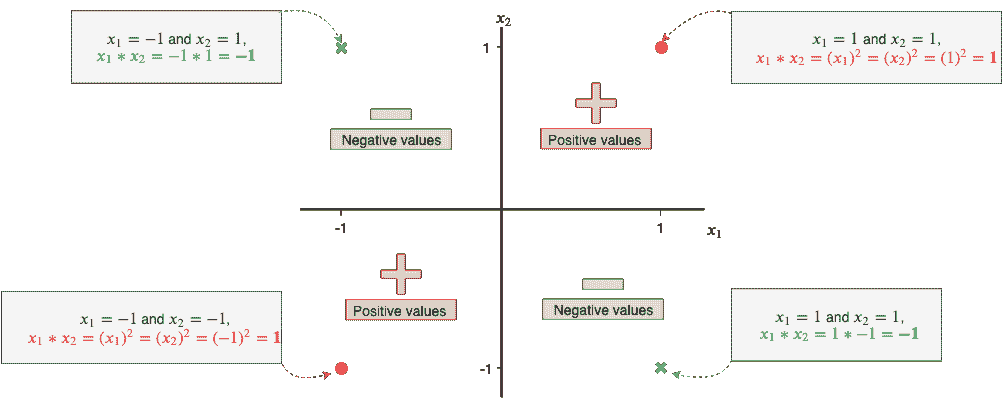
图 66. 特征乘积的结果
这为我们提供了一个使用两个特征的乘积来工作的模式。我们甚至可以在 XOR 数据中看到类似的模式,每个象限都可以以类似的方式进行识别。
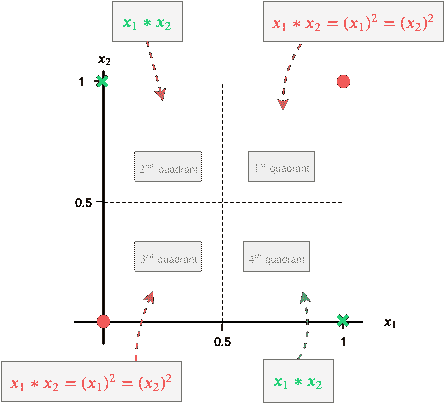
图 67. XOR 数据图中的象限模式
因此,一个好的第三个特征 x₃ 将是特征 x₁ 和 x₂ 的乘积(即 x₁x₂)。*
特征的乘积称为 特征交叉,结果是一个新的 合成特征。特征交叉可以是特征本身(例如 x₁², x₁³,…),两个或更多特征的乘积(例如 x₁x₂, x₁x₂x₃, …),甚至是两者的组合(例如 x₁²x₂)。例如,在一个房屋数据集中,其中输入特征是房屋的宽度和长度(以码为单位),标签是房屋在地图上的位置,房屋的宽度和长度之间的特征交叉可能是这个位置的更好预测器,从而给我们一个新的特征“房屋大小(*方码)”。
让我们将新的合成特征添加到我们的训练数据 Xₜᵣₐᵢₙ 中。
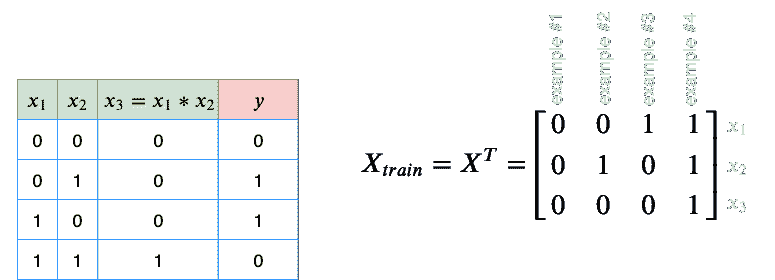
图 68. 新的训练数据
使用此特性交叉,我们现在可以成功地学习决策边界,而无需显著改变神经网络的架构。我们只需要在输入层添加一个用于 x₃ 的输入节点以及一个相应的权重(随机设置为 0.2)。
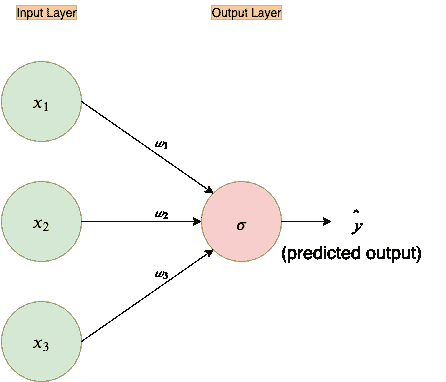
图 69. 以特征交叉(x₃)为输入的神经网络
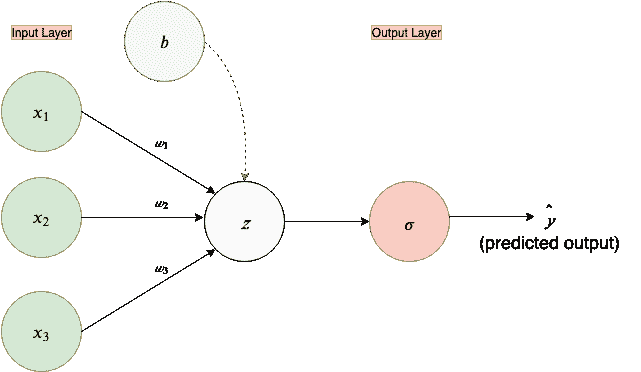
图 70. 扩展的神经网络,以特征交叉(x₃)为输入
以下是神经网络的第一次训练迭代,您可以自行进行计算并确认这些计算,因为它们是很好的练习。由于我们已经熟悉了这种神经网络架构,我将不会像以前一样逐步讲解所有计算步骤。
(下面的所有计算均四舍五入到小数点后三位)
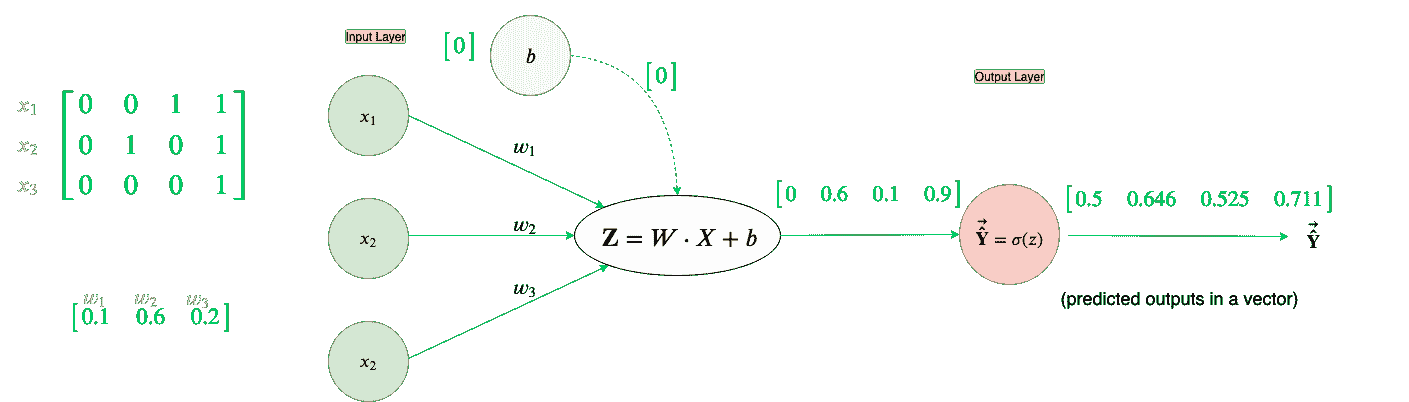
图 71. 第一次训练迭代中的前向传播

图 72. 第一次训练迭代中的反向传播
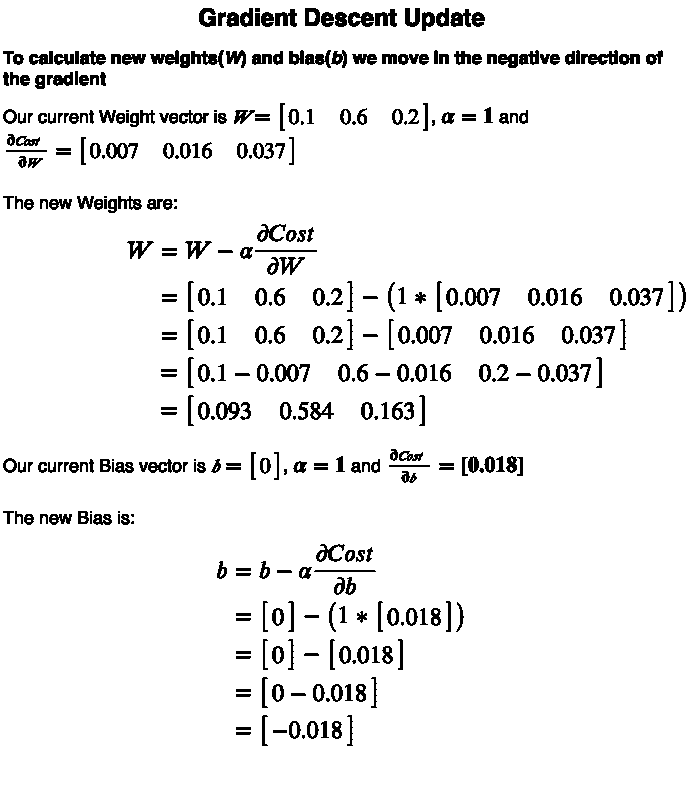
图 73. 第一次训练迭代中新权重和偏置的梯度下降更新
经过 5000 次迭代后,学习曲线和决策边界如下:
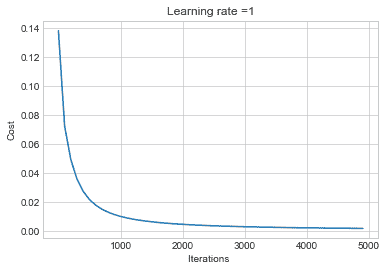
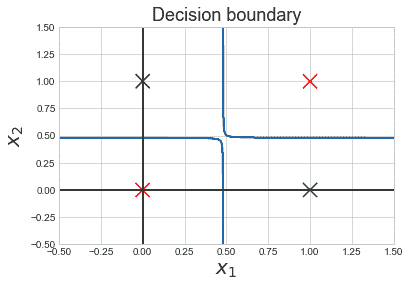
图 74. 具有特征交叉的神经网络的学习曲线和决策边界
如前所述,为了更好地可视化,我们可以对神经网络决策从一种到另一种的区域进行阴影处理。
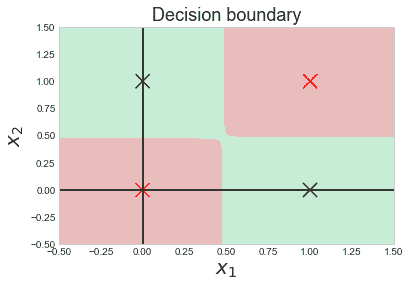
图 75. 为了更好的可视化而阴影处理的决策边界
注意,特征工程使我们能够创建一个非线性的决策边界。 它是如何做到的?我们只需查看 Z 节点正在计算的函数。
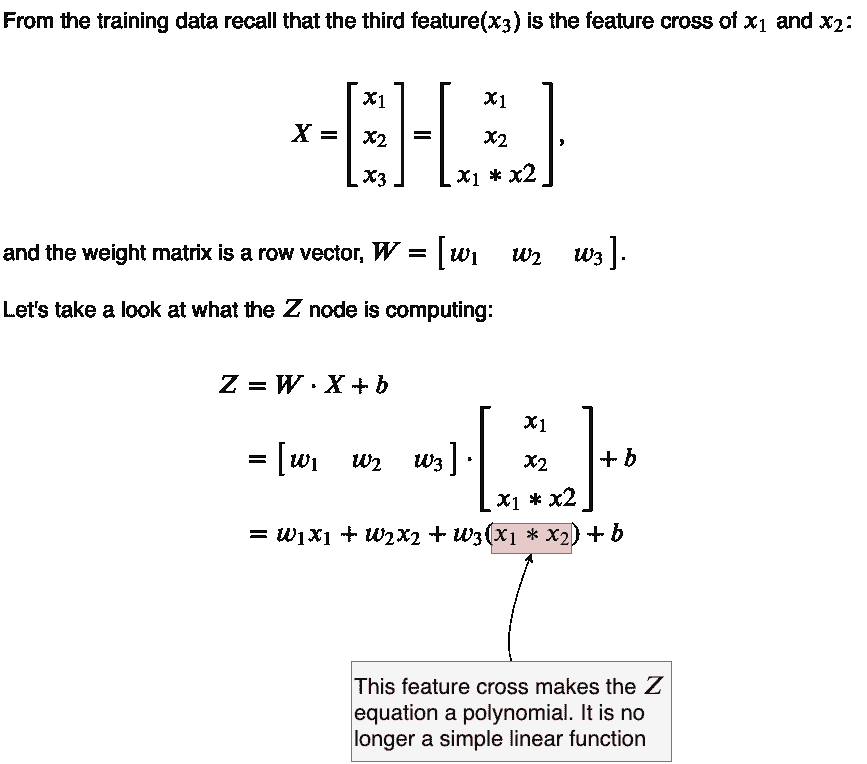
图 76. 节点Z在添加特征交叉后计算多项式
因此,特征交叉帮助我们创建了复杂的非线性决策边界。
这是一个非常强大的想法!
更改神经网络架构
这是更有趣的方法,因为它让我们绕过特征工程,让神经网络自行找出特征交叉!
让我们看看以下神经网络:
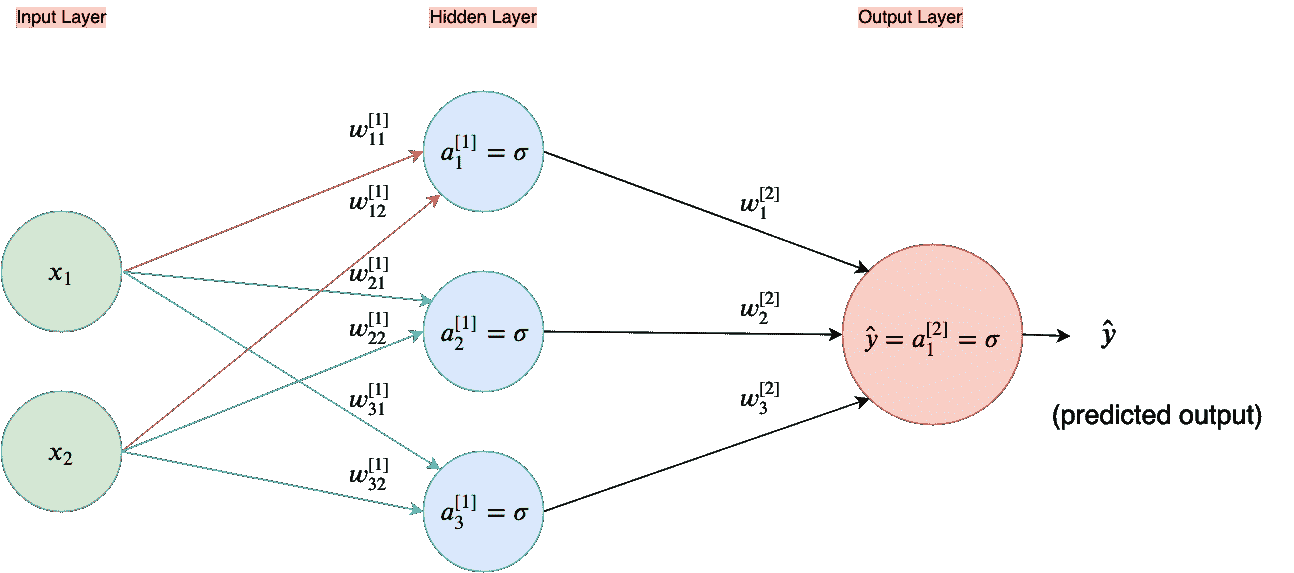
图 77. 具有一个隐藏层的神经网络。
因此,我们在神经网络架构中添加了一些新的节点,保持输入层和输出层不变。这些新增的节点列称为隐藏层。 为什么叫隐藏层?因为在定义后,我们无法直接控制隐藏层中的神经元如何学习,不像输入层和输出层,我们可以通过更改数据来改变它们;同时,由于隐藏层既不是神经网络的输出也不是输入,它们本质上对用户来说是隐藏的。
我们可以有任意数量的隐藏层,每层可以有任意数量的神经元。这个结构需要由神经网络的创建者定义。因此,隐藏层的数量和每层神经元的数量也是超参数。我们添加的隐藏层越多,神经网络架构越深;我们在隐藏层中添加的神经元越多,网络架构越宽。神经网络模型的深度就是“深度学习”这一术语的来源。
图 77 中的架构具有一个隐藏层,包含三个 sigmoid 神经元,是经过一些实验后选择的。
由于这是一个新的架构,我将逐步讲解计算过程。
首先,让我们扩展神经网络。
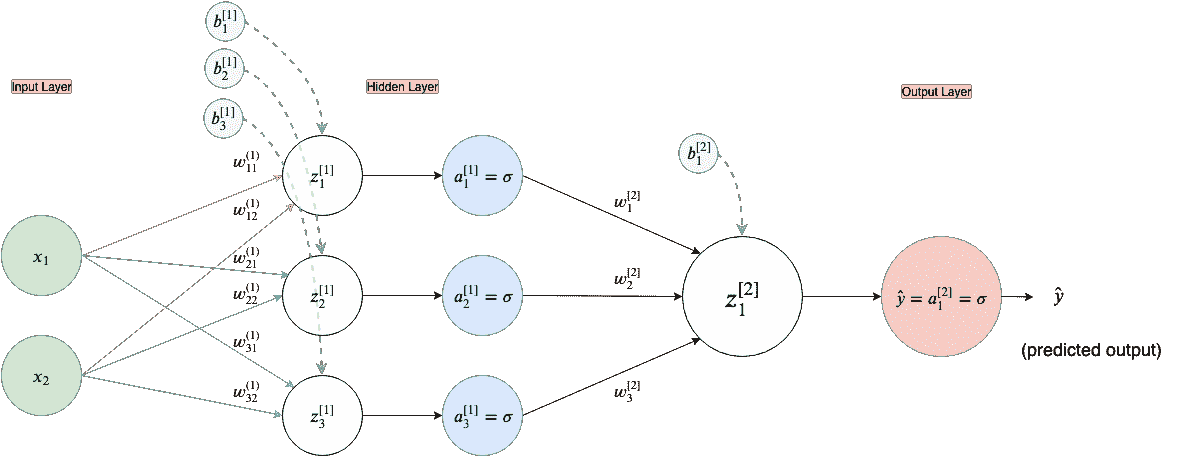
图 78. 扩展的神经网络,具有一个隐藏层
现在让我们进行前向传播:
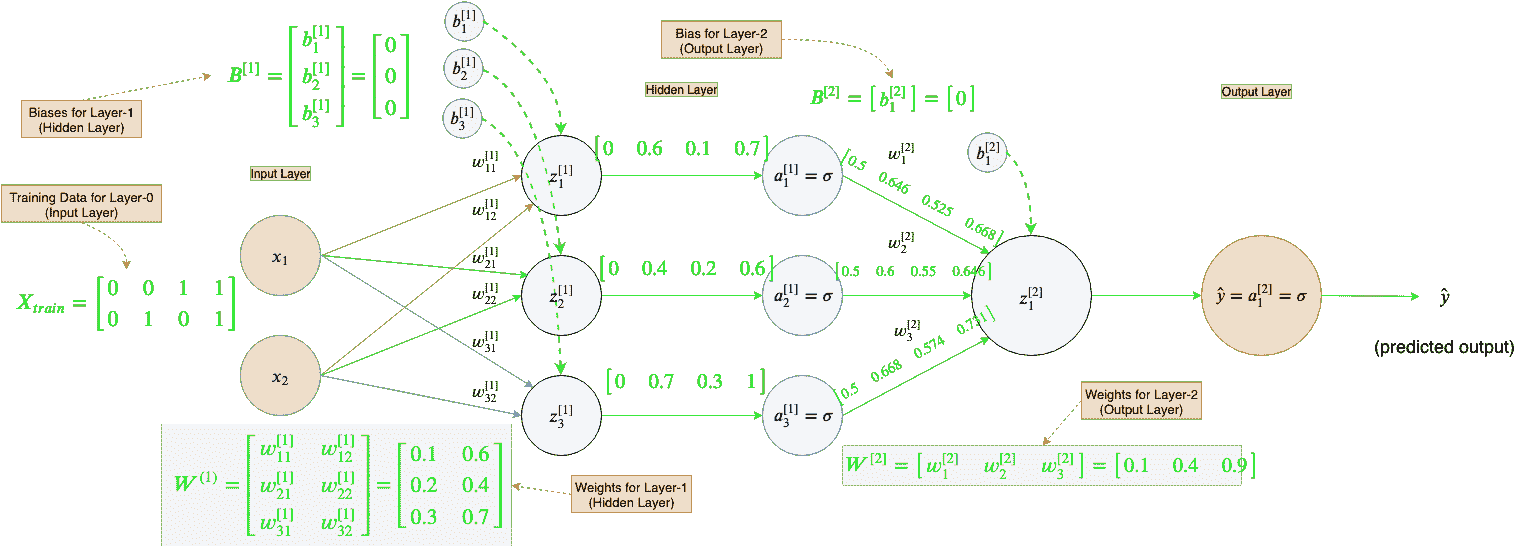

图 79.a. 在具有隐藏层的神经网络上进行前向传播
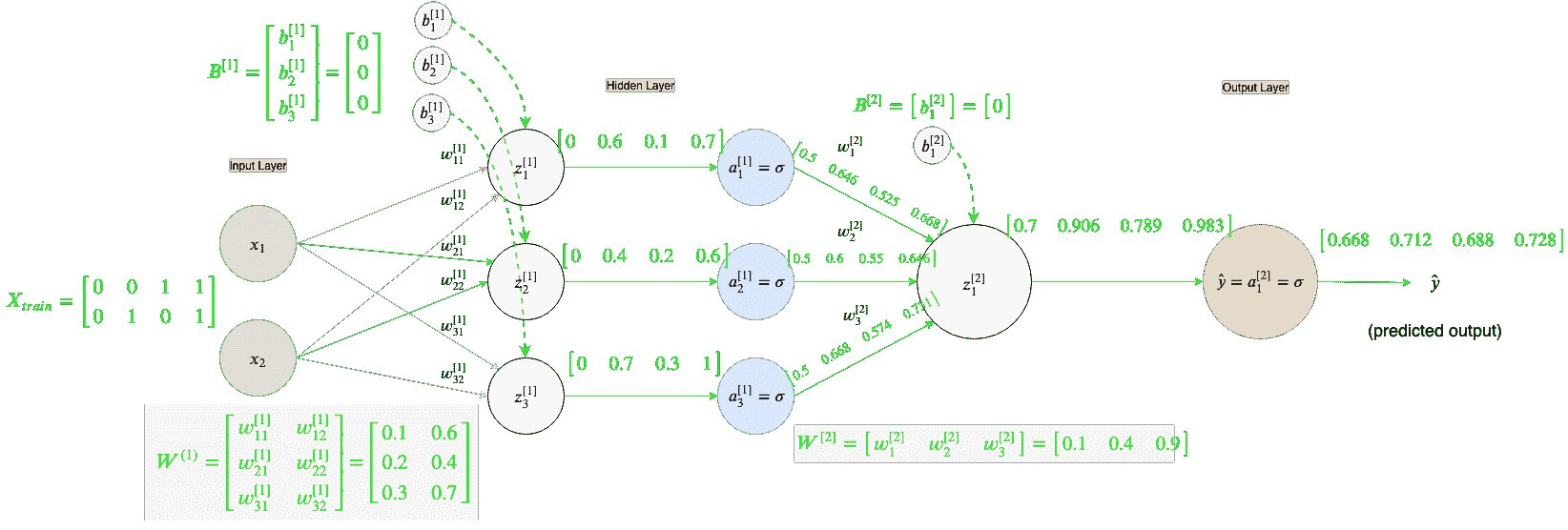

图 79.b. 在具有隐藏层的神经网络上进行前向传播
现在我们可以计算成本:
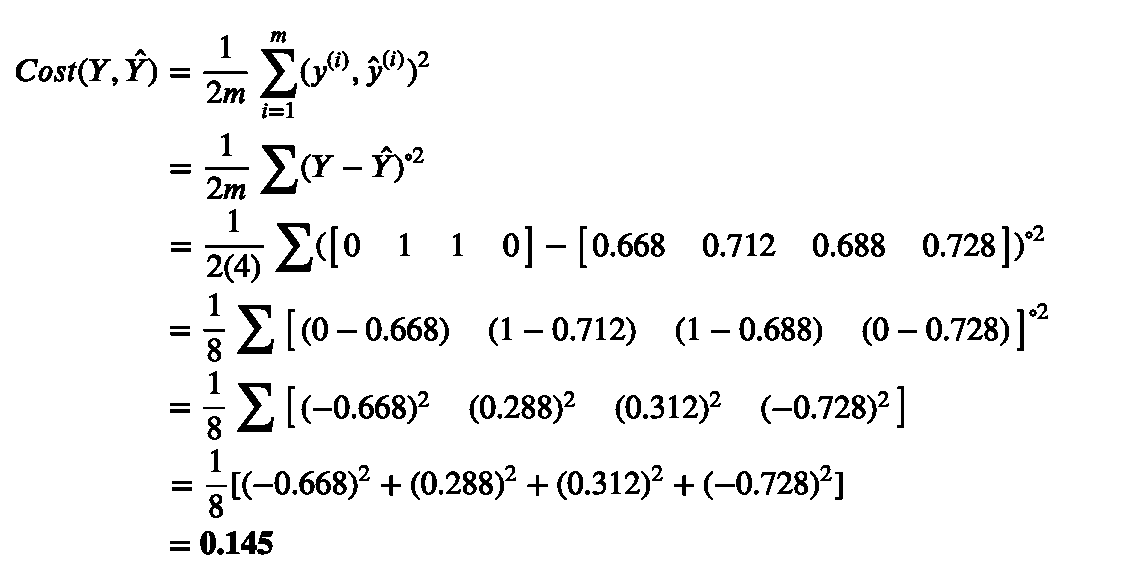
图 80. 在第一次前向传播后,具有一个隐藏层的神经网络的成本
计算成本后,我们可以进行反向传播并改进权重和偏置。
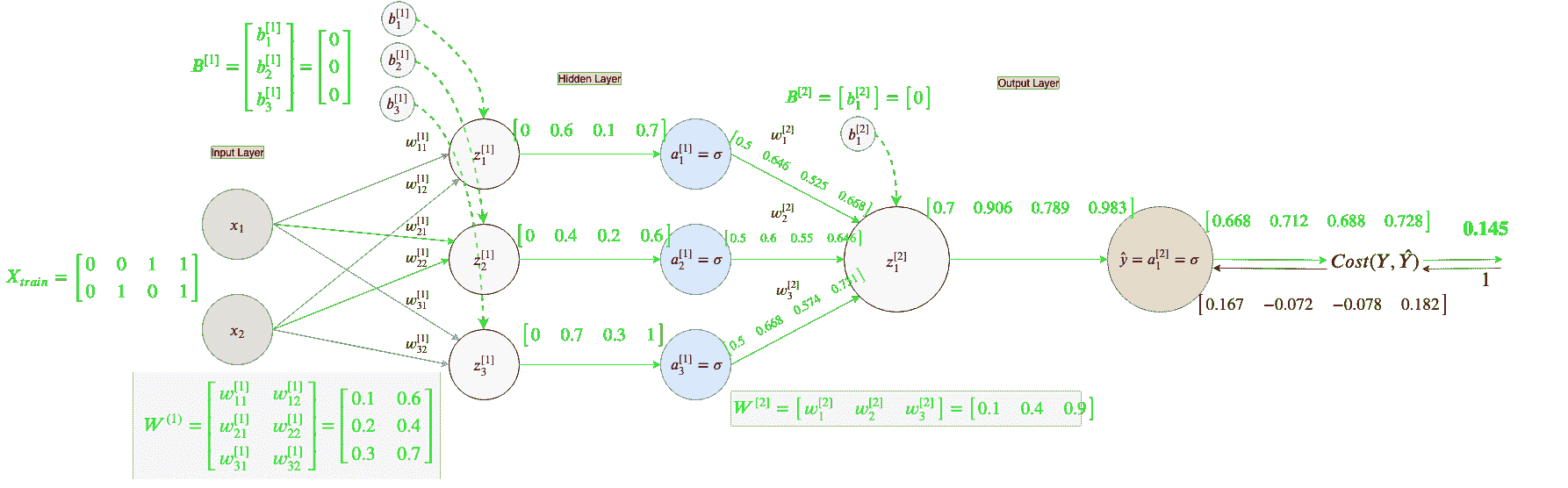

图 81.a. 在具有隐藏层的神经网络上进行反向传播
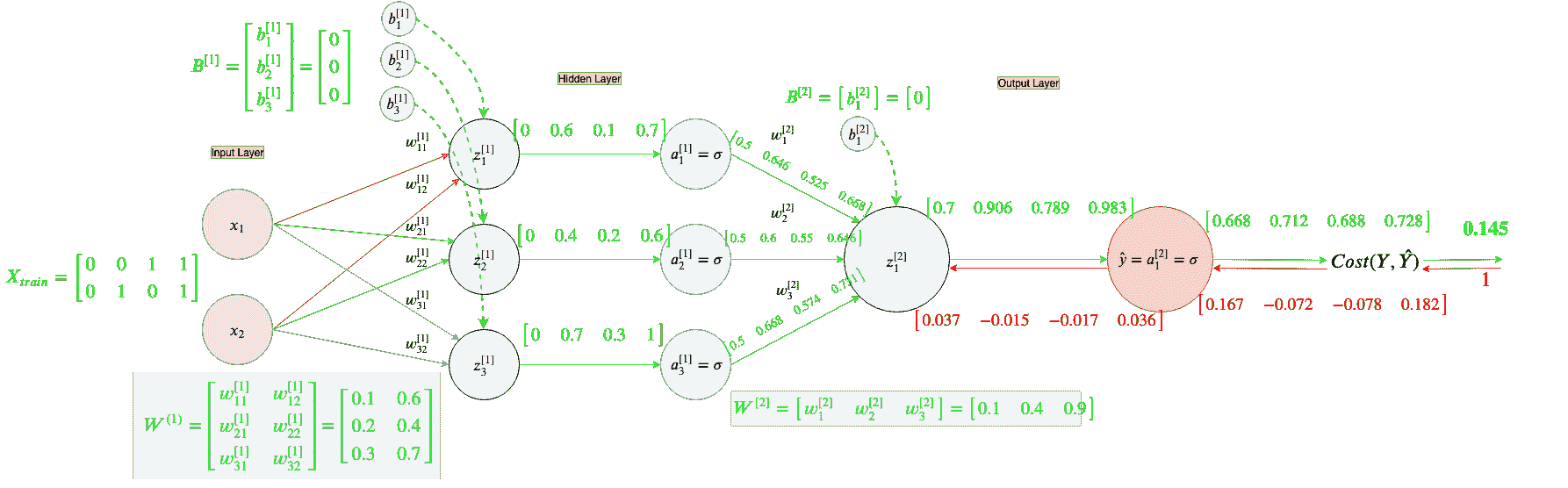

图 81.b. 带有隐藏层的神经网络的反向传播
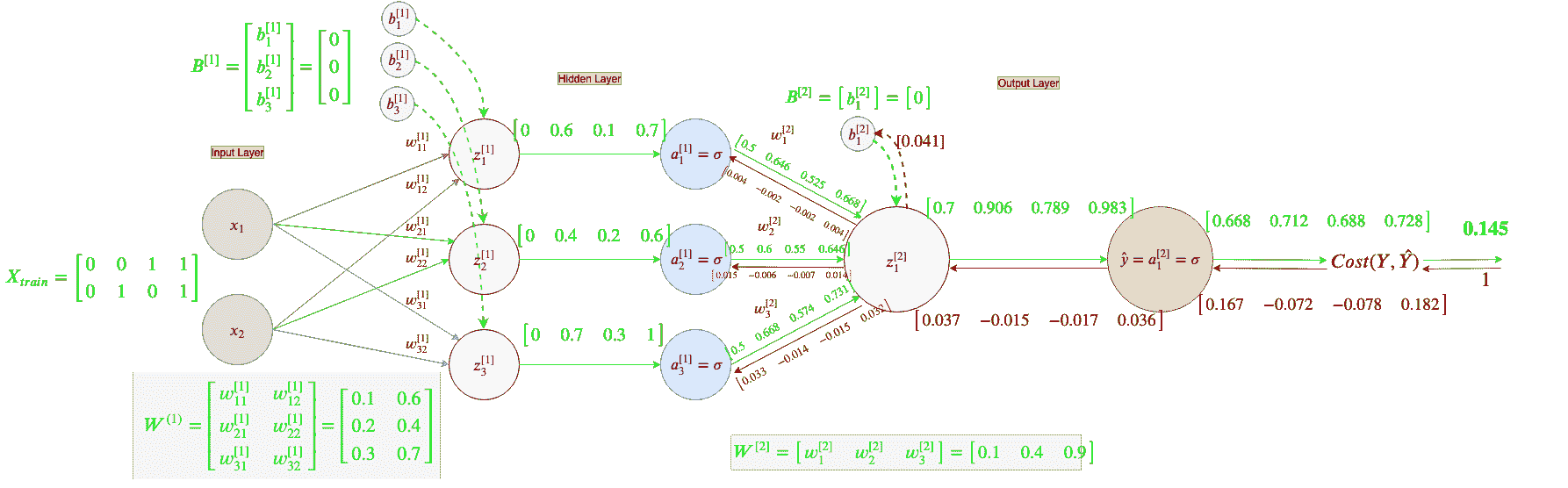

图 81.c. 带有隐藏层的神经网络的反向传播
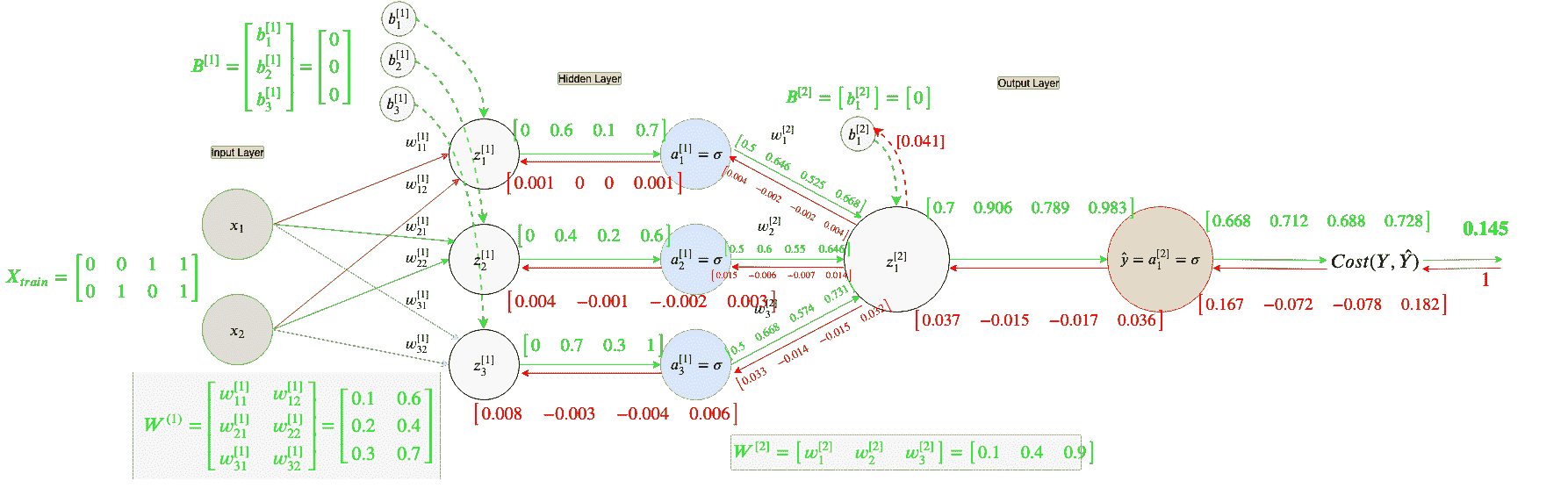

图 81.d. 带有隐藏层的神经网络的反向传播
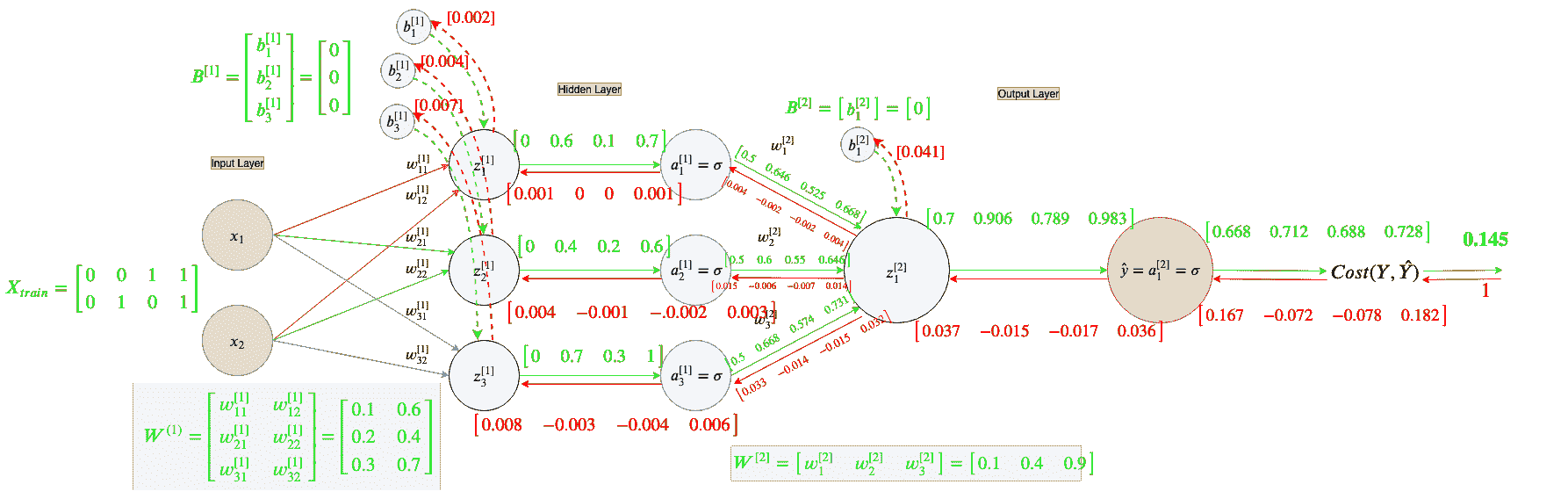

图 81.e. 带有隐藏层的神经网络的反向传播
呼!这真是很多内容,但它大大提高了我们的理解。让我们进行梯度下降更新:
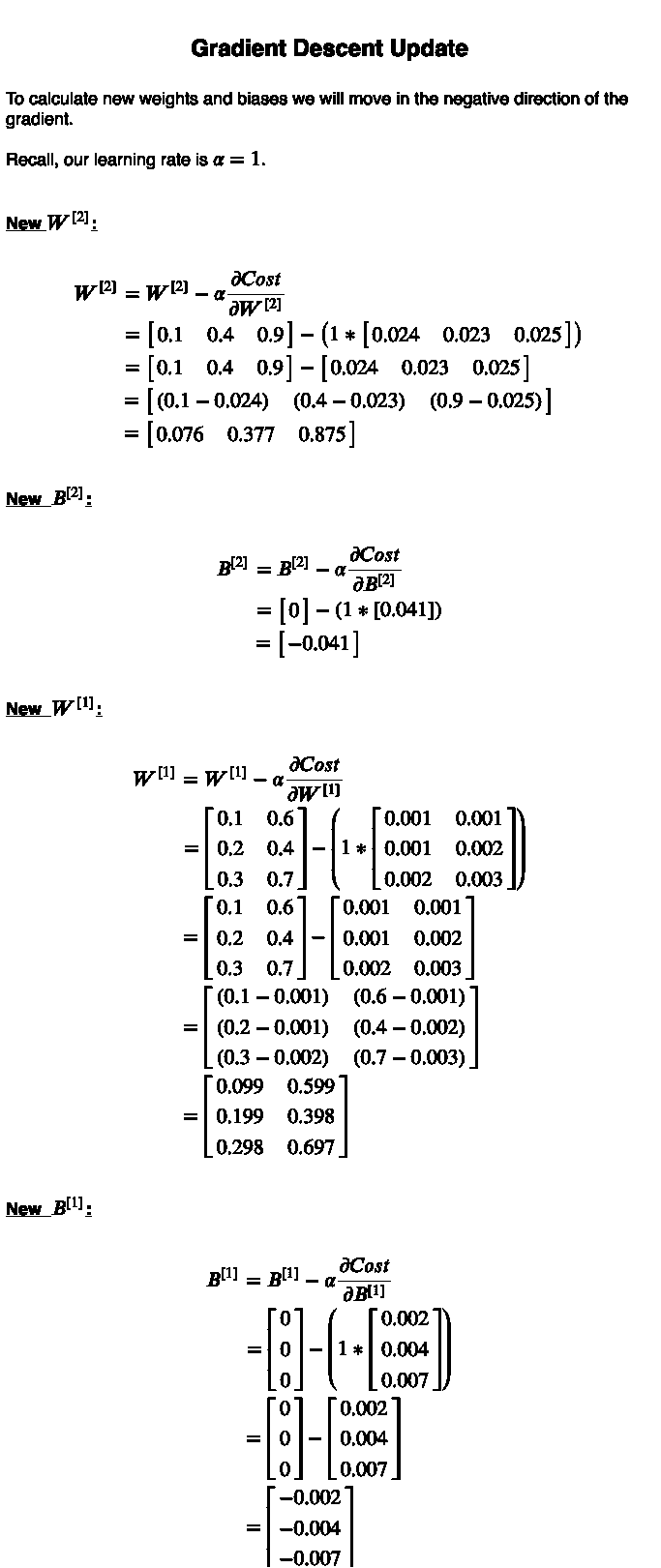
图 82. 带有隐藏层的神经网络的梯度下降更新
在这一点上,我鼓励所有读者自己进行一次训练迭代。得到的梯度应大致为(四舍五入到 3 位小数):
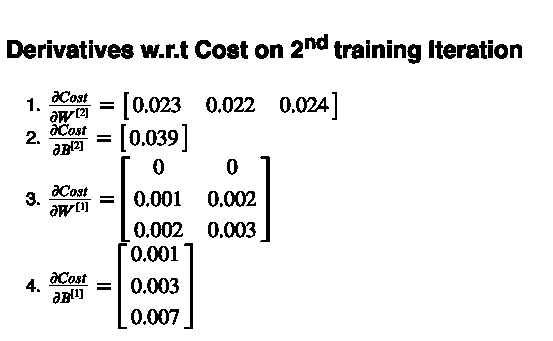
图 83. 第二次训练迭代期间计算的导数
经过 5000 次迭代后,成本稳定下降至约0.0009,我们得到如下的学习曲线和决策边界:
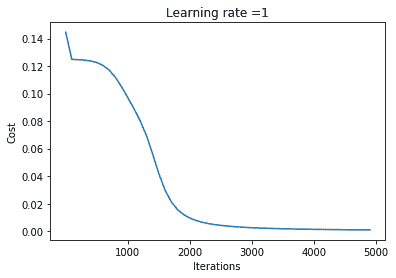
图 84. 带有一个隐藏层的神经网络的学习曲线和决策边界
让我们还可视化神经网络从 0(红色)到 1(绿色)的决策变化:
图 85. 带有一个隐藏层的神经网络的阴影决策边界
这表明神经网络实际上已经学会了在哪里激活(输出 1)和在哪里保持静默(输出 0)。
如果我们再添加另一个隐藏层,可能有 2 或 3 个 sigmoid 神经元,我们可以得到一个更复杂的决策边界,可能会更紧密地拟合我们的数据,但我们将把这个留到编码部分。
在我们结束这一部分之前,我想回答一些剩下的问题:
1- 那么,特征工程和深度神经网络哪个更好?
好吧,答案取决于许多因素。一般来说,如果我们有大量的训练数据,我们可以直接使用深度神经网络来获得令人满意的准确度,但如果数据有限,我们可能需要进行一些特征工程,以从神经网络中提取更多性能。正如你在上面的特征工程示例中看到的,为了创建良好的特征交叉,我们需要对所使用的数据集有深入的了解。
特征工程与深度神经网络的结合是一个强大的组合。
2- 如何计算神经网络中的层数?
按惯例,我们不计算没有可调权重和偏置的层。因此,虽然输入层是一个单独的“层”,但在指定神经网络的深度时我们不计算它。
所以,我们最后一个例子是“2 层神经网络”(一个隐藏层+输出层),而之前的所有例子只是“1 层神经网络”(仅输出层)。
3- 为什么使用激活函数?
激活函数是非线性函数,给神经元添加非线性。特征交叉是隐藏层中堆叠激活函数的结果。因此,一系列激活函数的组合产生了复杂的非线性决策边界。在本博客中,我们使用了 sigmoid/logistic 激活函数,但还有许多其他类型的激活函数(ReLU 是隐藏层的热门选择),每种都有一定的好处。 激活函数的选择也是创建神经网络时的一个超参数。
没有激活函数来添加非线性,无论我们堆叠多少线性函数,它们的结果仍然是线性的。 请考虑以下几点:

图 86. 显示堆叠线性层/函数结果为线性层/函数
你可以使用任何非线性函数作为激活函数。一些研究人员甚至使用了 cos 和 sin 函数。激活函数最好是连续的,即函数的定义域中没有断点。
4- 为什么随机初始化权重?
现在这个问题更容易回答了。注意,如果我们将层中的所有权重设置为相同的值,那么通过每个节点的梯度将是相同的。简而言之,层中的所有节点将学习关于数据的相同特征。将权重设置为 随机值有助于打破权重的对称性,以便层中的每个节点都有机会学习训练数据的独特方面。
神经网络中设置权重的方法有很多。对于小型神经网络,设置权重为小的随机值是可以的。对于较大的网络,我们倾向于使用“Xavier”或“He”初始化方法(将在编码部分介绍)。这两种方法都将权重设置为随机值,但控制其方差。 目前,可以说当网络似乎无法收敛且使用“纯粹”的小随机值设置权重时,成本变得静态或减小得很慢时,使用这些方法就足够了。 权重初始化是一个活跃的研究领域,将成为未来“Nothing but Numpy”博客的主题。
偏置也可以随机初始化。但是在实践中,它似乎对神经网络的性能没有太大影响。也许这是因为神经网络中的偏置项数量远少于权重。
我们在这里创建的神经网络类型称为“全连接前馈网络”或简单地称为“前馈网络”。
这部分内容结束了。
第二部分:编写模块化神经网络
这一部分的实现遵循面向对象编程原则。
让我们首先查看线性层类。构造函数接受以下参数:传入数据的形状(input_shape),层输出的神经元数量(n_out),以及需要执行的随机权重初始化类型(ini_type=”plain”,默认为“plain”,即仅小随机高斯数)。
initialize_parameters 是一个用于定义权重和偏差的辅助函数。我们稍后会单独查看它。
线性层实现以下函数:
-
forward(A_prev):此函数允许线性层接受来自前一层的激活值(输入数据可以看作是来自输入层的激活值),并对其执行线性操作。 -
backward(upstream_grad):此函数计算成本对权重、偏差和来自前一层的激活值的导数(dW、db和dA_prev)。 -
update_params(learning_rate=0.1):此函数使用在backward函数中计算的导数,对权重和偏差执行梯度下降更新。默认学习率(α)为 0.1。
import numpy as np # import numpy library
from util.paramInitializer import initialize_parameters # import function to initialize weights and biases
class LinearLayer:
"""
This Class implements all functions to be executed by a linear layer
in a computational graph
Args:
input_shape: input shape of Data/Activations
n_out: number of neurons in layer
ini_type: initialization type for weight parameters, default is "plain"
Opitons are: plain, xavier and he
Methods:
forward(A_prev)
backward(upstream_grad)
update_params(learning_rate)
"""
def __init__(self, input_shape, n_out, ini_type="plain"):
"""
The constructor of the LinearLayer takes the following parameters
Args:
input_shape: input shape of Data/Activations
n_out: number of neurons in layer
ini_type: initialization type for weight parameters, default is "plain"
"""
self.m = input_shape[1] # number of examples in training data
# `params` store weights and bias in a python dictionary
self.params = initialize_parameters(input_shape[0], n_out, ini_type) # initialize weights and bias
self.Z = np.zeros((self.params['W'].shape[0], input_shape[1])) # create space for resultant Z output
def forward(self, A_prev):
"""
This function performs the forwards propagation using activations from previous layer
Args:
A_prev: Activations/Input Data coming into the layer from previous layer
"""
self.A_prev = A_prev # store the Activations/Training Data coming in
self.Z = np.dot(self.params['W'], self.A_prev) + self.params['b'] # compute the linear function
def backward(self, upstream_grad):
"""
This function performs the back propagation using upstream gradients
Args:
upstream_grad: gradient coming in from the upper layer to couple with local gradient
"""
# derivative of Cost w.r.t W
self.dW = np.dot(upstream_grad, self.A_prev.T)
# derivative of Cost w.r.t b, sum across rows
self.db = np.sum(upstream_grad, axis=1, keepdims=True)
# derivative of Cost w.r.t A_prev
self.dA_prev = np.dot(self.params['W'].T, upstream_grad)
def update_params(self, learning_rate=0.1):
"""
This function performs the gradient descent update
Args:
learning_rate: learning rate hyper-param for gradient descent, default 0.1
"""
self.params['W'] = self.params['W'] - learning_rate * self.dW # update weights
self.params['b'] = self.params['b'] - learning_rate * self.db # update bias(es)
图 87. 线性层类
现在让我们看看Sigmoid 层类,它的构造函数接受作为参数的前一个线性层传入的数据形状(input_shape)。
Sigmoid 层实现以下函数:
-
forward(Z):此函数允许 Sigmoid 层接受来自前一层的线性计算值(Z),并对其执行 Sigmoid 激活。 -
backward(upstream_grad):此函数计算成本对Z(dZ)的导数。
import numpy as np # import numpy library
class SigmoidLayer:
"""
This file implements activation layers
inline with a computational graph model
Args:
shape: shape of input to the layer
Methods:
forward(Z)
backward(upstream_grad)
"""
def __init__(self, shape):
"""
The consturctor of the sigmoid/logistic activation layer takes in the following arguments
Args:
shape: shape of input to the layer
"""
self.A = np.zeros(shape) # create space for the resultant activations
def forward(self, Z):
"""
This function performs the forwards propagation step through the activation function
Args:
Z: input from previous (linear) layer
"""
self.A = 1 / (1 + np.exp(-Z)) # compute activations
def backward(self, upstream_grad):
"""
This function performs the back propagation step through the activation function
Local gradient => derivative of sigmoid => A*(1-A)
Args:
upstream_grad: gradient coming into this layer from the layer above
"""
# couple upstream gradient with local gradient, the result will be sent back to the Linear layer
self.dZ = upstream_grad * self.A*(1-self.A)
图 88. Sigmoid 激活层类
initialize_parameters函数仅在线性层中使用,用于设置权重和偏差。它根据输入(n_in)和输出(n_out)的大小定义权重矩阵和偏差向量的形状。然后,这个辅助函数将权重(W)和偏差(b)以 Python 字典的形式返回给相应的线性层。
def compute_cost(Y, Y_hat):
"""
This function computes and returns the Cost and its derivative.
The is function uses the Squared Error Cost function -> (1/2m)*sum(Y - Y_hat)^.2
Args:
Y: labels of data
Y_hat: Predictions(activations) from a last layer, the output layer
Returns:
cost: The Squared Error Cost result
dY_hat: gradient of Cost w.r.t the Y_hat
"""
m = Y.shape[1]
cost = (1 / (2 * m)) * np.sum(np.square(Y - Y_hat))
cost = np.squeeze(cost) # remove extraneous dimensions to give just a scalar
dY_hat = -1 / m * (Y - Y_hat) # derivative of the squared error cost function
return cost, dY_hat
图 89. 设置权重和偏差的辅助函数
最后,成本函数compute_cost(Y, Y_hat)以最后一层的激活值(Y_hat)和真实标签(Y)作为参数,计算并返回*方误差成本(cost)及其导数(dY_hat)。
def compute_cost(Y, Y_hat):
"""
This function computes and returns the Cost and its derivative.
The is function uses the Squared Error Cost function -> (1/2m)*sum(Y - Y_hat)^.2
Args:
Y: labels of data
Y_hat: Predictions(activations) from a last layer, the output layer
Returns:
cost: The Squared Error Cost result
dY_hat: gradient of Cost w.r.t the Y_hat
"""
m = Y.shape[1]
cost = (1 / (2 * m)) * np.sum(np.square(Y - Y_hat))
cost = np.squeeze(cost) # remove extraneous dimensions to give just a scalar
dY_hat = -1 / m * (Y - Y_hat) # derivative of the squared error cost function
return cost, dY_hat
图 90. 计算*方误差成本和导数的函数。
此时,你应该在另一个窗口中打开2_layer_toy_network_XOR* Jupyter 笔记本,并对照本博客和笔记本进行查看。*
现在我们准备好创建我们的神经网络了。让我们使用图 77中定义的架构来处理 XOR 数据。
# define training constants
learning_rate = 1
number_of_epochs = 5000
np.random.seed(48) # set seed value so that the results are reproduceable
# (weights will now be initailzaed to the same pseudo-random numbers, each time)
# Our network architecture has the shape:
# (input)--> [Linear->Sigmoid] -> [Linear->Sigmoid] -->(output)
#------ LAYER-1 ----- define hidden layer that takes in training data
Z1 = LinearLayer(input_shape=X_train.shape, n_out=3, ini_type='xavier')
A1 = SigmoidLayer(Z1.Z.shape)
#------ LAYER-2 ----- define output layer that take is values from hidden layer
Z2= LinearLayer(input_shape=A1.A.shape, n_out=1, ini_type='xavier')
A2= SigmoidLayer(Z2.Z.shape)
图 91. 定义层和训练参数
现在我们可以开始主要的训练循环:
costs = [] # initially empty list, this will store all the costs after a certian number of epochs
# Start training
for epoch in range(number_of_epochs):
# ------------------------- forward-prop -------------------------
Z1.forward(X_train)
A1.forward(Z1.Z)
Z2.forward(A1.A)
A2.forward(Z2.Z)
# ---------------------- Compute Cost ----------------------------
cost, dA2 = compute_cost(Y=Y_train, Y_hat=A2.A)
# print and store Costs every 100 iterations.
if (epoch % 100) == 0:
#print("Cost at epoch#" + str(epoch) + ": " + str(cost))
print("Cost at epoch#{}: {}".format(epoch, cost))
costs.append(cost)
# ------------------------- back-prop ----------------------------
A2.backward(dA2)
Z2.backward(A2.dZ)
A1.backward(Z2.dA_prev)
Z1.backward(A1.dZ)
# ----------------------- Update weights and bias ----------------
Z2.update_params(learning_rate=learning_rate)
Z1.update_params(learning_rate=learning_rate)
图 92. 训练循环
运行笔记本中的循环,我们看到成本在 4900 次迭代后下降到大约 0.0009。
...
Cost at epoch#4600: 0.001018305488651183
Cost at epoch#4700: 0.000983783942124411
Cost at epoch#4800: 0.0009514180100050973
Cost at epoch#4900: 0.0009210166430616655
学习曲线和决策边界如下所示:
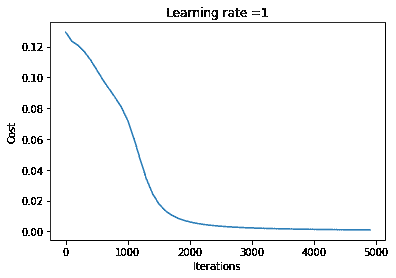
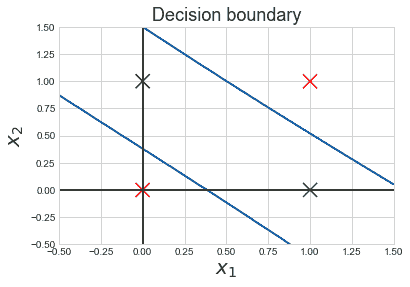
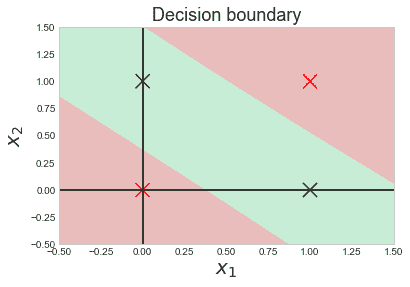
图 93. 学习曲线、决策边界及阴影决策边界。
我们训练的神经网络生成的预测是准确的。
The predicted outputs:
[[ 0\. 1\. 1\. 0.]]
The accuracy of the model is: 100.0%
确保查看 代码库 中的其他笔记本。我们将在未来的“Nothing but NumPy”博客中基于在本博客中学到的内容进行构建,因此,建议你记忆层类并尝试重建 OR 门示例,以作为练习,PartⅠ*。
本博客到此结束。希望你喜欢。
如有任何问题,请随时通过 twitter @RafayAK 联系我。
本博客的完成离不开以下资源和人士的帮助:
-
Andrew Ng (@AndrewYNg) 和他在 Coursera 上的 深度学习 和 机器学习 课程
-
特伦斯·帕尔 (@the_antlr_guy) 和 杰里米·霍华德 (@jeremyphoward) (
explained.ai/matrix-calculus/index.html) -
Ian Goodfellow (@goodfellow_ian) 和他精彩的 书籍
-
最后,感谢 Hassan-uz-Zaman (@OKidAmnesiac) 和 Hassan Tauqeer 的宝贵反馈。
原文。经许可转载。
相关:
更多相关主题
NumPy 与 Pandas 结合以更高效的数据分析
原文:
www.kdnuggets.com/numpy-with-pandas-for-more-efficient-data-analysis

作为一个数据从业者,Pandas 是任何数据操作活动的首选包,因为它直观且易于使用。这就是为什么许多数据科学教育课程在学习课程中包括 Pandas 的原因。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在的组织的 IT
Pandas 是建立在 NumPy 包上的,特别是 NumPy 数组。许多 NumPy 函数和方法仍然与它们兼容,因此我们可以使用 NumPy 有效地提升 Pandas 数据分析。
这篇文章将探讨几个示例,说明 NumPy 如何帮助我们提高 Pandas 数据分析的体验。
让我们深入了解一下。
使用 NumPy 改进 Pandas 数据分析
在继续教程之前,我们应该安装所有必要的软件包。如果尚未安装,你可以使用以下代码来安装 Pandas 和 NumPy。
pip install pandas numpy
我们可以首先解释 Pandas 和 NumPy 之间的联系。如上所述,Pandas 建立在 NumPy 包上。让我们看看它们如何相互补充,以改进我们的数据分析。
首先,让我们尝试使用相应的软件包创建一个 NumPy 数组和 Pandas DataFrame。
import numpy as np
import pandas as pd
np_array= np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
pandas_df = pd.DataFrame(np_array, columns=['A', 'B', 'C'])
print(np_array)
print(pandas_df)
Output>>
[[1 2 3]
[4 5 6]
[7 8 9]]
A B C
0 1 2 3
1 4 5 6
2 7 8 9
如上面的代码所示,我们可以使用具有相同维度结构的 NumPy 数组来创建 Pandas DataFrame。
接下来,我们可以在 Pandas 数据处理和清理步骤中使用 NumPy。例如,我们可以使用 NumPy 的 NaN 对象作为缺失数据的占位符。
df = pd.DataFrame({
'A': [1, 2, np.nan, 4, 5],
'B': [5, np.nan, np.nan, 3, 2],
'C': [1, 2, 3, np.nan, 5]
})
print(df)
Output>>
A B C
0 1.0 5.0 1.0
1 2.0 NaN 2.0
2 NaN NaN 3.0
3 4.0 3.0 NaN
4 5.0 2.0 5.0
如上面的结果所示,NumPy 的 NaN 对象在 Pandas 中成为任何缺失数据的同义词。
这段代码可以检查每个 Pandas DataFrame 列中的 NaN 对象数量。
df.isnull().sum()
Output>>
A 1
B 2
C 1
dtype: int64
数据收集者可能会将 DataFrame 列中的缺失数据值表示为字符串。如果发生这种情况,我们可以尝试用 NumPy 的 NaN 对象替换该字符串值。
df['A'] = df['A'].replace('missing data'', np.nan)
NumPy 还可以用于异常值检测。让我们看看如何做到这一点。
df = pd.DataFrame({
'A': np.random.normal(0, 1, 1000),
'B': np.random.normal(0, 1, 1000)
})
df.loc[10, 'A'] = 100
df.loc[25, 'B'] = -100
def detect_outliers(data, threshold=3):
z_scores = np.abs((data - data.mean()) / data.std())
return z_scores > threshold
outliers = detect_outliers(df)
print(df[outliers.any(axis =1)])
Output>>
A B
10 100.000000 0.355967
25 0.239933 -100.000000
在上面的代码中,我们使用 NumPy 生成随机数,然后创建一个使用 Z-score 和 sigma 规则检测离群值的函数。结果是包含离群值的 DataFrame。
我们可以使用 Pandas 进行统计分析。NumPy 可以帮助在聚合过程中实现更高效的分析。例如,这是使用 Pandas 和 NumPy 进行的统计聚合。
df = pd.DataFrame({
'Category': [np.random.choice(['A', 'B']) for i in range(100)],
'Values': np.random.rand(100)
})
print(df.groupby('Category')['Values'].agg([np.mean, np.std, np.min, np.max]))
Output>>
mean std amin amax
Category
A 0.524568 0.288471 0.025635 0.999284
B 0.525937 0.300526 0.019443 0.999090
使用 NumPy,我们可以将统计分析函数应用于 Pandas DataFrame,并获得类似上述输出的汇总统计信息。
最后,我们将讨论使用 Pandas 和 NumPy 的矢量化操作。矢量化操作是一种同时对数据执行操作的方法,而不是逐个循环执行。结果将更快且内存优化。
例如,我们可以使用 NumPy 在 DataFrame 列之间执行逐元素加法操作。
data = {'A': [15,20,25,30,35], 'B': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)
df['C'] = np.add(df['A'], df['B'])
print(df)
Output>>
A B C
0 15 10 25
1 20 20 40
2 25 30 55
3 30 40 70
4 35 50 85
我们还可以通过 NumPy 数学函数转换 DataFrame 列。
df['B_exp'] = np.exp(df['B'])
print(df)
Output>>
A B C B_exp
0 15 10 25 2.202647e+04
1 20 20 40 4.851652e+08
2 25 30 55 1.068647e+13
3 30 40 70 2.353853e+17
4 35 50 85 5.184706e+21
还可以使用 NumPy 对 Pandas DataFrame 进行条件替换。
df['A_replaced'] = np.where(df['A'] > 20, df['B'] * 2, df['B'] / 2)
print(df)
Output>>
A B C B_exp A_replaced
0 15 10 25 2.202647e+04 5.0
1 20 20 40 4.851652e+08 10.0
2 25 30 55 1.068647e+13 60.0
3 30 40 70 2.353853e+17 80.0
4 35 50 85 5.184706e+21 100.0
这些是我们探索的所有示例。这些 NumPy 函数无疑会帮助改善你的数据分析过程。
结论
本文讨论了 NumPy 如何通过 Pandas 帮助提高高效的数据分析。我们尝试了数据预处理、数据清理、统计分析和使用 Pandas 和 NumPy 的矢量化操作。
希望这对你有所帮助!
Cornellius Yudha Wijaya**** 是一位数据科学助理经理和数据撰写者。在全职工作于印尼安联时,他喜欢通过社交媒体和写作分享 Python 和数据技巧。Cornellius 撰写了各种 AI 和机器学习主题。
更多相关内容
如何使用 NVIDIA GPU 加速库
原文:
www.kdnuggets.com/2021/07/nvidia-gpu-accelerated-libraries.html
评论

如何使用 NVIDIA GPU 加速库进行 AI
如果你正在进行 AI 项目,那么是时候利用 NVIDIA GPU 加速库了,如果你还没有这样做的话。直到 2000 年代末,AI 项目才通过 GPU 训练的神经网络变得可行,从而大幅加速了这一过程。从那时起,NVIDIA 便开始制造一些最佳的深度学习 GPU,使得 GPU 加速库成为 AI 项目的热门选择。
如果你想知道如何利用 NVIDIA GPU 加速库进行 AI 项目,这个指南将帮助解答问题,并让你走上正确的道路。
为什么要使用 NVIDIA GPU 加速库进行 AI?
关于 NVIDIA CUDA-X 库的演示,图片来源
说到 AI 或更广泛的机器学习,使用 GPU 加速库是一个很好的选择。GPU 具有显著更多的核心和大量的内存带宽,这使得 GPU 能够以高速进行并行处理——这是大多数机器学习项目的必需条件。
使用 GPU 进行 AI 和深度学习已经成为解析极其复杂的数学矩阵的常规方法。NVIDIA GPU 的并行处理能力使它们能够轻松分解这些矩阵。利用 GPU 加速库进行下一次 AI 项目将最终是最快和最有效的解决方案。
最终,虽然 CPU 可以 用于操作深度学习项目中的神经网络,但它们根本无法超越 GPU 加速库。
哪款 NVIDIA GPU 最适合 AI?

计算机屏幕上的编码,图片来源
简单来说,最佳的图形渲染 GPU 通常也是 AI 项目的最佳选择。然而,GPU 需要足够强大。GPU 的处理能力越强,神经网络的解析能力也就越强。
实际上,在选择一个 NVIDIA GPU时,有几个因素需要考虑:
-
兼容性
-
热设计功耗(TDP)值
-
内存
-
CUDA
兼容性
尽管这是一个基本因素,但它可能是最重要的因素之一。如果你的 GPU 与 PC 配置不兼容,那么一切都毫无意义。务必仔细检查,确保你购买的 GPU 符合 PC 的要求。
TDP(热设计功耗)值

用于冷却计算机的风扇,图片来源
GPU 在处理大量数据时可能会变热。制造商标示的TDP 值将告诉你安全范围是什么。在许多情况下,需要一个冷却系统来降低热量并提高性能。
内存
神经网络可能包含大量需要处理和存储的数据(即使只是暂时存储)。你需要一个具有良好内存容量的 GPU,以确保尽可能*稳地运行。
CUDA
CUDA 生态系统图,图片来源
CUDA 是 NVIDIA 设计的并行计算*台。它是机器学习、深度学习和 AI 的行业标准。CUDA 核心越多,处理能力越强。
使用哪些 GPU 进行人工智能(AI)?
NVIDIA GeForce RTX 2080 Ti Founders Edition

GeForce RTX 2080 Ti Founders Edition 在盒子里,图片来源
为了给你一个选择 NVIDIA GPU 的参考,我们强烈推荐GeForce RTX 2080 Ti Founders Edition。这款 GPU 在每个基准测试中都表现超凡!尽管它不是 NVIDIA 最新的 GPU,并且只有RTX 3080 Ti的一半 CUDA 核心,但价格显著较低,使其成为一个很好的入门级 GPU。然而,如果你能负担得起更新的 GPU 并且它适合你的 PC 配置,那就毫不犹豫选择较新的型号吧!
Tom's Guide 对 RTX 2080 Ti 和 RTX 3080 Ti 进行了很好的比较。
就兼容性而言,它比一些其他 GPU 稍微宽一点、长一点,而且TDP 值为 260 W,比标准 GPU 稍高。
它拥有 11BG 的充足内存和 616 GB/s 的内存带宽,CUDA 拥有高达 4352 个核心。在RTX 2080 Ti Founders Edition GPU 中,包含了大量的并行处理能力。
NVIDIA GPU 加速库有哪些不同类型?

各种 Python 库,图片来源
NVIDIA 发布了CUDA-X,这与上面提到的CUDA相同,但性能大幅提升。通过CUDA-X访问的 GPU 加速库从高性能计算(HPC)到人工智能及其间的所有内容。
6 个 NVIDIA GPU 加速库用于人工智能与深度学习
NVIDIA 在谈论他们的 GPU 加速库时说得最好:
NVIDIA® CUDA-X,基于 NVIDIA CUDA®,是一个库、工具和技术的集合,提供比 CPU 单核替代方案显著更高的性能——跨越多个应用领域,从人工智能(AI)到高性能计算(HPC)……库提供了高度优化的算法和函数,你可以将其融入到你新的或现有的应用程序中……许多 GPU 加速库被设计为非常容易替代现有的 CPU 库,最大限度地减少对现有代码的影响。
这里有六个 NVIDIA GPU 加速库,你可以将它们融入到你的深度学习或人工智能项目中。
数学库
当你使用高性能计算进行复杂或密集的数学运算时,利用 GPU 加速库可以极为有用。这些数学库可以用于将基础、中级和复杂的算法和方程式构建到你的项目中,这对化学、医学影像、流体动力学、地震勘探以及许多其他常见应用场景都很有用。
以下是当前的数学库列表:
-
cuBLAS: GPU 加速的基础线性代数(BLAS)库
-
cuFFT: 用于快速傅里叶变换的 GPU 加速库
-
CUDA 数学库: GPU 加速的标准数学函数库
-
cuRAND: GPU 加速的随机数生成(RNG)
-
cuSOLVER: GPU 加速的稠密和稀疏直接解算器
-
cuSPARSE: GPU 加速的稀疏矩阵 BLAS
-
cuTENSOR: GPU 加速的张量线性代数库
-
AmgX: 用于模拟和隐式非结构化方法的 GPU 加速线性解算器
如何使用 NVIDIA 数学库?
这个标准数学计算和函数的集合很容易通过使用“#include math.h”添加到你的源代码中,安装也非常简单。NVIDIA 提供了一个很棒的快速入门指南来帮助你入门。
并行算法库
并行算法库 是用于生成图表和研究数据点间关系的高效算法。这些库非常适合各种可观测科学、物流以及任何需要对大量数据点得出结论的项目。
如何使用 NVIDIA 并行算法库
如果你在 C++ 操作中研究数据点间的关系,那么 NVIDIA 并行算法库 是你数据结构需求的完美、高效解决方案。
目前提供的并行算法库如下:
- Thrust:Thrust 是一个强大的并行算法库,通过高质量和灵活的 GPU 编程及编程接口,显著提高开发者的生产力。
NVIDIA 提供了一个 快速入门指南,帮助你开始使用 Thrust 提供的 并行算法 序列。
图像和视频库
如果你在进行深度学习或 AI 项目,处理视觉数据,那么 图像和视频库 将是你项目的重要组成部分。这些库用于解码图像和视频,以便进行处理、重新编码,并由各种程序(包括神经网络)使用。
目前提供的图像和视频库如下:
-
nvJPEG:高性能 GPU 加速的 JPEG 解码库。
-
NVIDIA 性能原语:提供 GPU 加速的图像、视频和信号处理功能。
-
NVIDIA 视频编解码 SDK:一整套用于 Windows 和 Linux 的硬件加速视频编码和解码的 API、示例和文档。
-
NVIDIA 光流 SDK:暴露了 NVIDIA Turing™ GPU 在计算图像之间像素相对运动方面的最新硬件能力。
如何使用 NVIDIA 图像和视频库
为了充分利用 CUDA 的 GPU 处理能力,NVIDIA 提供了众多库供选择。这些库可以满足你所有的图像和视频解码、编码及处理需求。
要深入了解 图像和视频库,你可以探索 nvJPEG 文档 开始使用。
通信库
这些库可能具有一些较为小众的用途,但通信库是 GPU 加速库所能做的一个很好的例子。它们优化了多个 GPU 之间的通信能力,大幅提升了其他 NVIDIA 库的速度、性能和效率。
下面是当前可用的通信库:
如何使用 NVIDIA 通信库
如果你正在使用多个 GPU,那么这些库将优化所有 GPU 和多节点通信的功能。
如果你想深入了解这些通信库,可以查看此NVSHMEM 文档。
深度学习库
现在,对于这篇文章来说,深度学习库是讨论的最重要的库。这些库利用CUDA实现最佳使用和性能,同时还利用 GPU 的一些专门组件。这样可以在并行处理和运行时之间实现最佳灵活性。
大多数用于 AI 项目的深度学习库将使用多个其他库来执行神经网络中所需的所有功能。
下面是当前可用的深度学习库:
-
NVIDIA cuDNN:用于深度神经网络的 GPU 加速原语库。
-
NVIDIA TensorRT™:高性能的深度学习推理优化器和生产部署运行时。
-
NVIDIA Jarvis:用于开发引人入胜且具有上下文感知的 AI 驱动对话应用的*台。
-
NVIDIA DeepStream SDK:用于 AI 视频理解和多传感器处理的实时流式分析工具包。
-
NVIDIA DALI:便携式的开源库,用于解码和增强图像及视频,以加速深度学习应用。
如何使用 NVIDIA 深度学习库
从实时流式分析到优化,这些 GPU 加速库针对深度学习的设计旨在利用CUDA和你 GPU 硬件的细节,以实现最佳的神经网络性能。
查看此NVIDIA DALI 文档以熟悉这些深度学习库的可能交付内容。
合作伙伴库
这些是 NVIDIA 纳入了CUDA和CUDA-X的开源库,以扩展 NVIDIA GPU 加速库的有用性和适应性。合作伙伴库为您提供更多选项和能力,以从深度学习或人工智能项目中获得最佳结果。
以下是当前可用的合作伙伴库:
-
OpenCV:用于计算机视觉、图像处理和机器学习的 GPU 加速开源库,现在支持实时操作。
-
FFmpeg:一个开源多媒体框架,提供用于音频和视频处理的插件库。
-
ArrayFire:用于矩阵、信号和图像处理的 GPU 加速开源库。
-
MAGMA:由 Magma 提供的针对异构架构的 GPU 加速线性代数例程。
-
IMSL Fortran 数值库:由 RogueWave 提供的 GPU 加速开源 Fortran 库,具有数学、信号和图像处理、统计功能。
-
Gunrock:专为 GPU 设计的图处理库。
-
CHOLMOD:用于稀疏直接求解器的 GPU 加速函数,包含在 SuiteSparse 线性代数包中,由教授编写。
-
Triton Ocean SDK:由 Triton 提供的海洋、游戏中的水体、模拟和训练应用的实时视觉模拟。
-
CUVIlib:用于加速医疗、工业和国防领域图像应用的原语。
如何使用 NVIDIA 合作伙伴库
这些合作伙伴库提供了开源项目的灵活性,并结合了CUDA的强大功能,为您的项目提供最佳选择。
可用的合作伙伴库列表不断扩展,请务必查看不断增长的列表这里,找到适合您特定项目和需求的最佳合作伙伴库!
在其他文章中获取更多有用的见解
哪些 GPU 加速库最适合您的深度学习、机器学习、人工智能或其他项目?是否有我们遗漏的内容您希望我们涵盖?我们希望帮助您做出最佳决策,请与我们联系!
您可以在SabrePC 博客上找到其他文章。请关注即将发布的更多有用文章。如果您有任何问题或希望建议我们关注其他主题,请随时联系我们。
原文。经许可转载。
相关:
-
通过 Saturn Cloud 使用 Pandas 在 GPU 上超充 Python
-
作为数据科学家管理你的可重用 Python 代码
-
告别大数据。你好,海量数据!
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
进一步了解此话题
NYU 数据科学项目 – 需要了解的事项
原文:
www.kdnuggets.com/2014/06/nyu-data-science-program-overview.html
作者:Ran Bi,2014 年 6 月
对于数据科学家而言,这是一个激动人心的时刻,对于像我这样希望成为数据科学家的人来说也是如此。幸运的是,我在去年这个时候被录取到了 NYU 数据科学项目。这是我在这个新数据科学项目中的经历总结。希望它能让你对 NYU 的数据科学有更清晰的了解。
这是第一部分, 第二部分,我将详细介绍人员和课程。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT

让我从基本信息开始。 这里有一些数字:31 名学生,12 门课程,2 年。Yann LeCun 教授是去年数据科学中心(CDS)的主任。但 Yann 去了 Facebook,现在他是 NYU 的兼职教授。Raghu Varadhan 教授和 David Hogg 教授继任成为我们的新主任。
这个项目有什么特别之处? 首先,这是世界上第一个名为“数据科学”的硕士项目。[查看其他许多项目]。但这只是一个名字,虽然是一个非常热门的名字。CMU 称之为计算数据科学,改名自大型信息系统;斯坦福没有更改名称,但它开始提供统计学和 ICME 部门下的数据科学硕士课程。
其次,它位于纽约。嗯,哥伦比亚的数据科学与工程研究所和康奈尔纽约科技也在纽约。就个人而言,我认为出色的 教职员工 和由于“Exabyte 时代”和“大苹果”的众多机会使其成为一个有吸引力的项目。
正如 CDS 的网站所说,
这个倡议特别专注于利用大数据的潜在力量,转变从医疗保健到商业再到政府等各个领域。
我认为对数据科学家的高需求是因为它在各个领域中的重要性。数据科学项目提供了灵活性,可以通过特定领域的课程进行定制,例如生物学、经济学、神经科学、物理学、政治学、心理学和音乐。 点击这里 查看预先批准的选修课程的完整列表。
CDS 今年收到超过六百份申请,并录取了约 90 名学生,其中 48 名已经入学。这略高于 50%,这是正常的。我收到了一些关于该项目的问题,例如“这个项目是学术型还是职业型”。这可能听起来奇怪,但六门必修课程中的五门是为博士项目设计的。该硕士项目的目标是帮助所有学生找到工作。所以你可以称之为职业型或学术型,随你喜欢。
此外,数据科学博士项目正在筹备中。目前正在等待州政府的审核。由于缺乏工作人员,州政府的进度较慢。对于提案本身没有反馈。“我们不能在提案获批之前进行宣传,”Roy 说。

Ran Bi 是纽约大学数据科学项目的硕士生。她在 NYU 期间完成了多个机器学习、深度学习和大数据分析项目。她本科期间的金融工程背景也使她对商业分析感兴趣。
相关:
-
NYU 数据科学中心:Moore-Sloan 数据科学研究员
-
KDnuggets 独家:与深度学习专家、Facebook AI 实验室主任 Yann LeCun 的访谈
-
KDnuggets 独家:与 Yann LeCun 的访谈第二部分
-
NYU、伯克利、UW 三方数百万美元合作伙伴关系,利用数据科学家和大数据的潜力
更多相关主题
oBERT: 复合稀疏化为 NLP 提供更快、更准确的模型
原文:
www.kdnuggets.com/2022/05/obert-compound-sparsification-delivers-faster-accurate-models-nlp.html
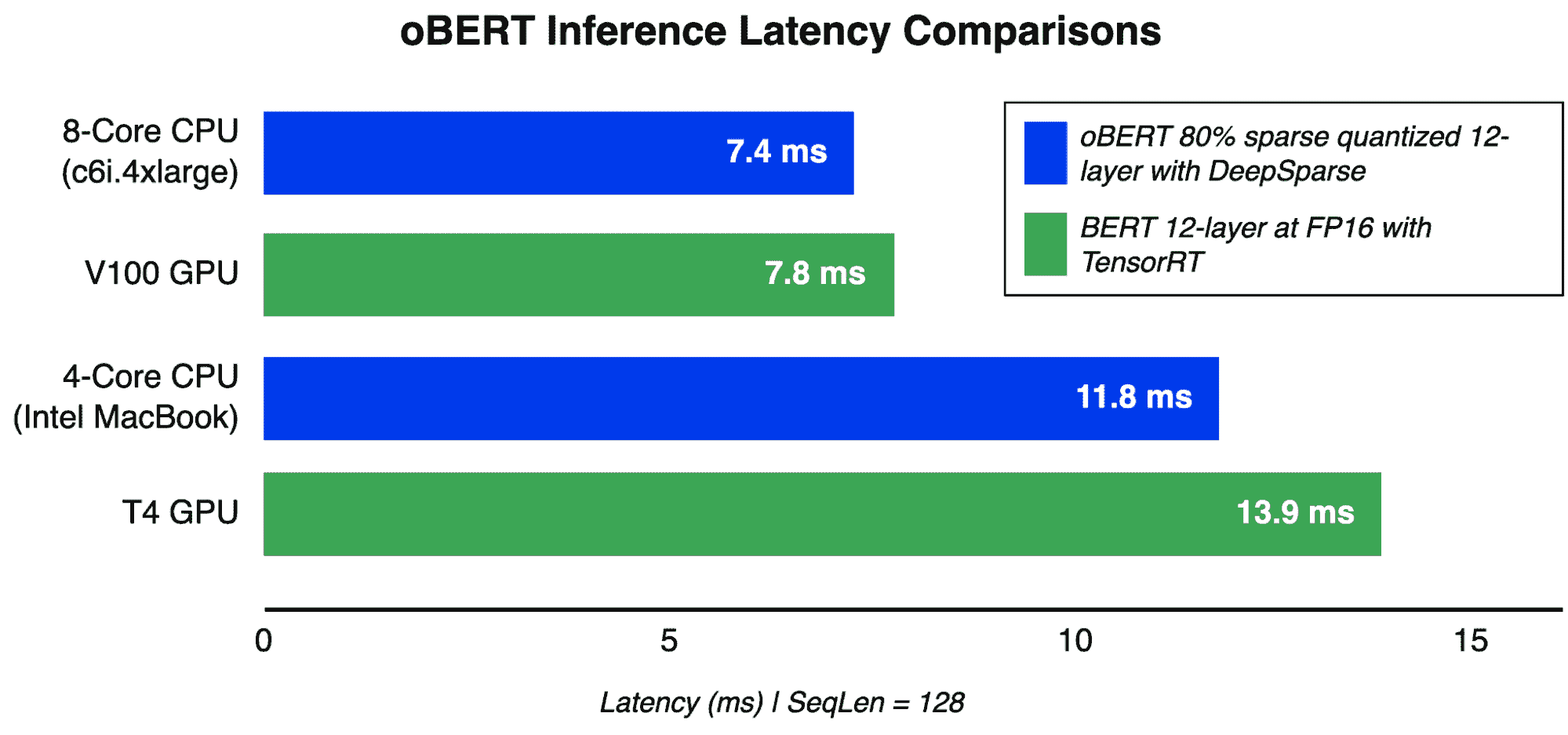
比较了在 SQuAD 数据集上,The Optimal BERT Surgeon (oBERT) 与其他方法的推理性能加速。oBERT 的性能是在 c5.12xlarge AWS 实例上使用 DeepSparse Engine 测量的。
现代世界由通过文本进行的持续沟通构成。想想消息应用、社交网络、文档和协作工具,或者书籍。这种沟通为希望利用这些数据改善用户体验的公司生成了大量可操作的数据。例如,下面这个视频展示了用户如何使用 NLP 神经网络 – BERT 在 Twitter 上跟踪加密货币的总体情感。通过许多创新贡献,BERT 显著提升了 NLP 任务的最先进水*,如文本分类、标记分类和问答。然而,它是以非常“过度参数化”的方式实现的。其 500MB 的模型大小和慢速推理限制了许多高效的部署场景,尤其是在边缘设备上。而云部署变得相当昂贵,速度也很快。
BERT 的低效特性并未被忽视。许多研究人员致力于降低其成本和规模。当前最活跃的研究之一是模型压缩技术,如更小的架构(结构化剪枝)、蒸馏、量化和非结构化剪枝。几个更具影响力的论文包括:
-
DistilBERT 使用了 知识蒸馏 将知识从 BERT 基础模型转移到一个 6 层版本。
-
TinyBERT 实现了一个更复杂的蒸馏设置,以更好地将知识从基线模型转移到一个 4 层版本。
-
运动剪枝结合了幅度和梯度信息,以在使用蒸馏进行微调时移除冗余参数。
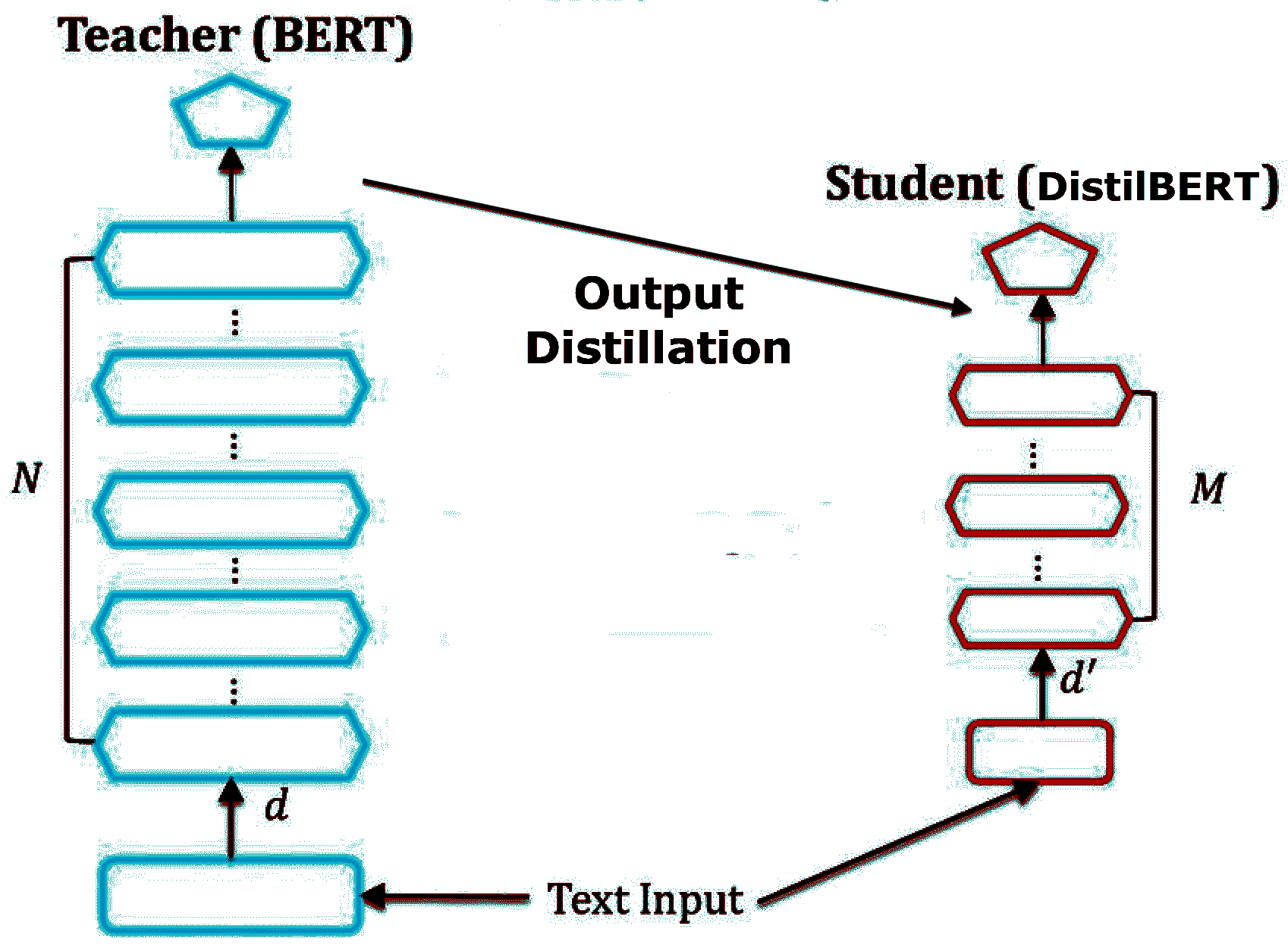
DistilBERT 训练示意图 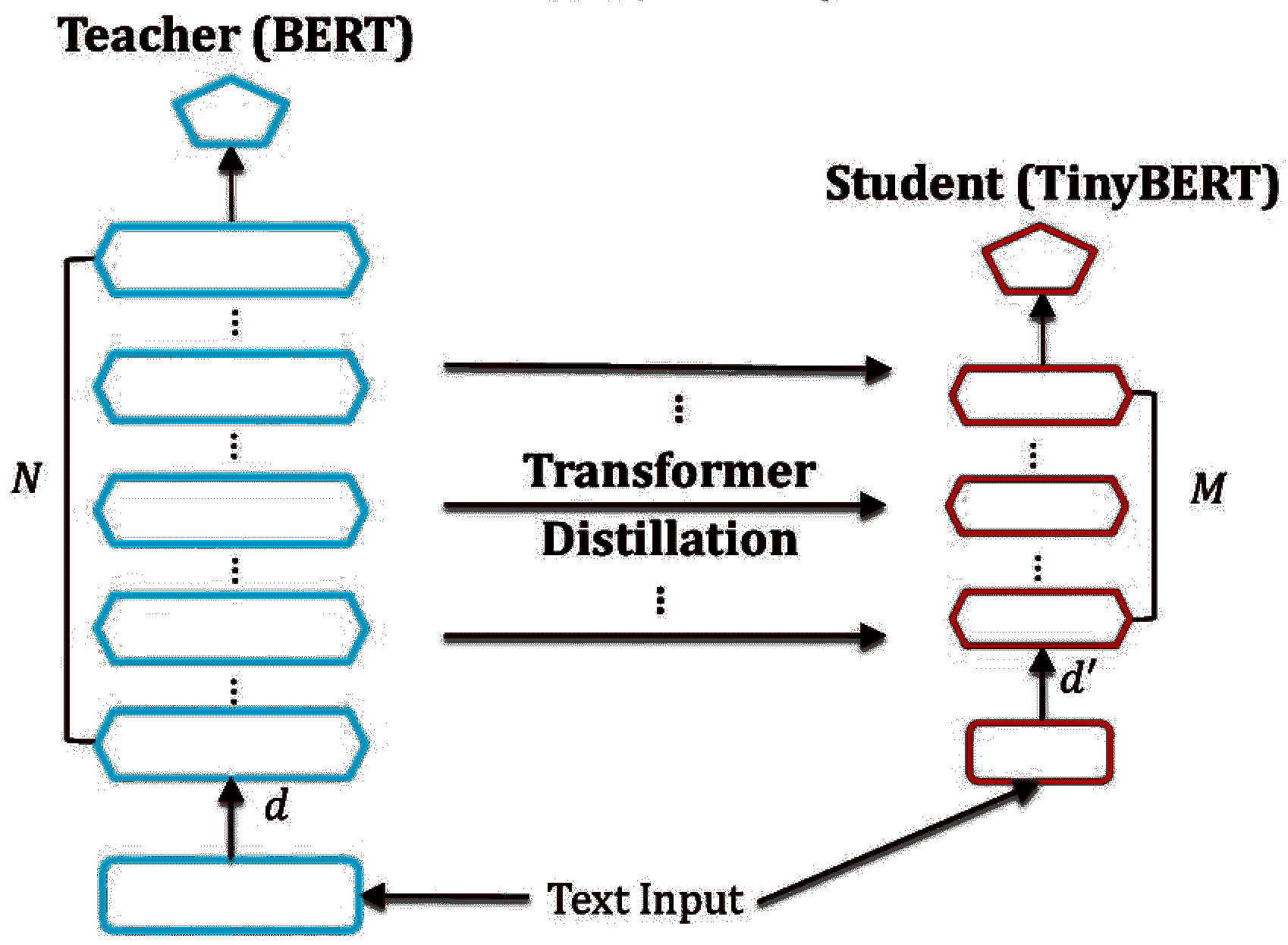
TinyBERT 训练示意图
BERT 是高度过参数化的
我们在最*的论文中展示了 BERT 的高度过度参数化,The Optimal BERT Surgeon。网络的 90%可以在对模型和其准确性影响最小的情况下移除!
真的,90%?是的!我们在 Neural Magic 的研究团队与 IST Austria 合作,通过实施二阶剪枝算法 Optimal BERT Surgeon,将之前最佳的 70%稀疏度提高到了 90%。该算法使用泰勒展开来*似每个权重对损失函数的影响——这意味着我们确切知道网络中哪些权重是多余的,可以安全移除。当将此技术与蒸馏训练结合时,我们能够实现 90%的稀疏度,同时恢复 99%的基准准确性!
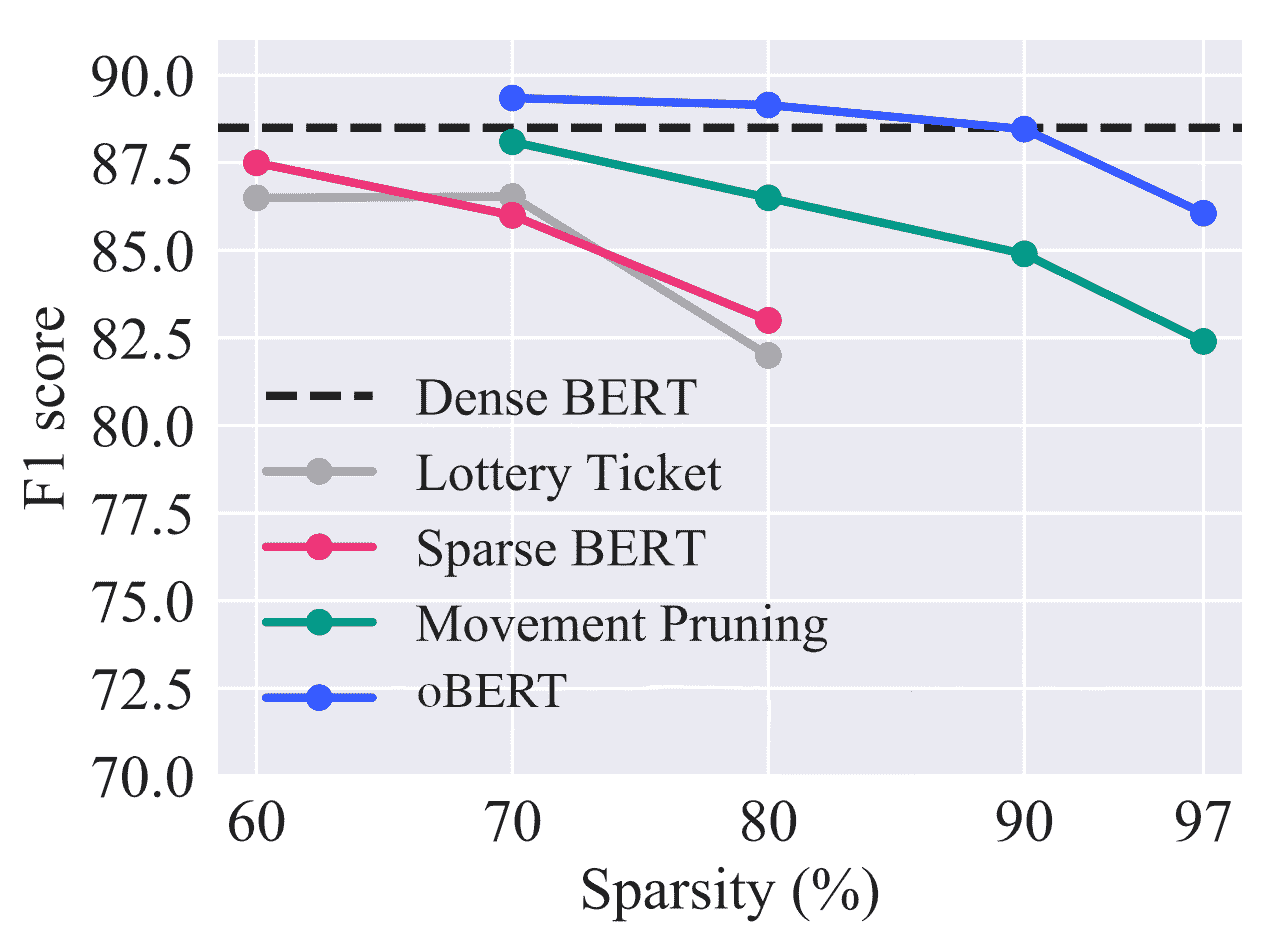
相对于当前最先进的无结构剪枝方法在 12 层 BERT-base-uncased 模型和问答 SQuAD v1.1 数据集上的性能概述。
但是,BERT 的结构化剪枝版本是否也过度参数化了呢?为了解答这个问题,我们移除了最多 3/4 的层来创建我们的 6 层和 3 层稀疏版本。我们首先用蒸馏技术重新训练了这些压缩模型,然后应用了 Optimal BERT Surgeon 剪枝。通过这样做,我们发现这些已经压缩的模型中 80%的权重可以进一步移除而不影响准确性。例如,我们的 3 层模型在保留 95%准确性的同时移除了 BERT 中的 1.1 亿个参数中的 8100 万个,从而创建了我们的Optimal BERT Surgeon 模型(oBERT)。
鉴于我们引入的 oBERT 模型的高稀疏度,我们使用了DeepSparse Engine来测量推理性能——这是一种自由提供的、稀疏感知的推理引擎,旨在提高稀疏神经网络在普通 CPU 上的性能,比如笔记本电脑中的 CPU。下图显示了经过剪枝的 12 层模型和 3 层模型的加速结果,前者优于 DistilBERT,后者优于 TinyBERT。结合 DeepSparse Engine 和 oBERT,高准确度的 NLP CPU 部署现在的时间为几毫秒(几=个位数)。
更好的算法使得深度学习在任何地方都能高效运作
在应用结构化剪枝和 Optimal BERT Surgeon 剪枝技术后,我们结合了量化感知训练,以利用 DeepSparse Engine 对 X86 CPU 的稀疏量化支持。将量化和我们的稀疏模型与4 块剪枝及 DeepSparse VNNI 支持结合,最终得到了一个量化的、80%稀疏的 12 层模型,达到了 99%的恢复目标。这些技术的结合被称为“复合稀疏化”。
oBERT 在 CPU 和 GPU 上以批处理大小 1、序列长度 128 进行的延迟推理比较。
结果是 BERT 模型在现成的 CPU 上达到了 GPU 级别的性能。使用稀疏量化的 oBERT 12 层模型时,4 核 Intel MacBook 的性能现在优于 T4 GPU,而 8 核服务器在对延迟敏感的应用中表现优于 V100。使用 3 层和 6 层模型会进一步加速,但准确率稍低。
“4 核 Intel MacBook 的性能现在比 T4 GPU 更强,而 8 核服务器在对延迟敏感的应用中表现优于 V100。”
让复合稀疏化为你服务
Twitter 自然语言处理视频对比了从 oBERT 到未经优化的基线模型的性能改进。
结合研究社区的精神并促进持续贡献,创建 oBERT 模型的源代码已通过SparseML开源,模型也可以在SparseZoo上免费获取。此外,DeepSparse Twitter 加密示例在DeepSparse 仓库中开源。试试它来高效跟踪加密趋势或其他趋势!最后,我们还推出了简单的用例演示,以突出应用这些研究到数据中所需的基本流程。
Mark Kurtz (@markurtz_) 是 Neural Magic 的机器学习总监,并且是一位经验丰富的软件和机器学习领导者。Mark 精通工程和机器学习的全栈,并对模型优化和高效推理充满热情。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水*
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关话题
使用 Luminoth 进行对象检测
评论

在这篇文章中,我们将探讨如何使用 Luminoth 库来检测图片或视频中的对象。Luminoth 是一个开源的 计算机视觉 库,使用 Python 构建,基于 TensorFlow 和 Sonnet。这个库由 Tryolabs开发。你可以在这里了解更多关于 Luminoth 及其其他项目的信息:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
Tryolabs 是一个机器学习和数据科学咨询公司,帮助公司构建和实施定制的解决方案…](https://tryolabs.com/)
Sonnet 是一个基于 TensorFlow 的神经网络库。Luminoth 是一个相对较新的库,处于 alpha 质量发布阶段。我们将展示如何使用 Luminoth 检测图像中的对象,如下图所示。
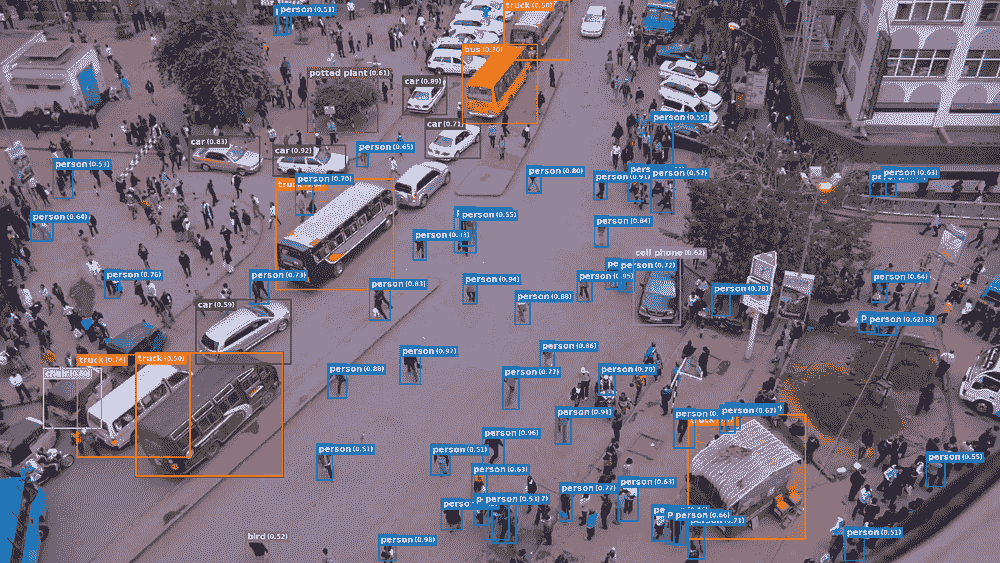
安装
我们可以通过快速的 pip 安装命令安装 Luminoth:
pip3 install luminoth
Luminoth 提供了我们可以使用的预训练检查点。然而,也可以调整我们自己的数据集并进行训练。让我们深入了解一下。
这个库的美妙之处在于它使对象检测的工作变得简单。让我们通过这个图像来进行一个简单的示例。

为了做到这一点,我们首先需要启动终端。预测图像中的对象相对简单。然而,在我们开始做预测之前,我们需要下载一个检查点,以便我们能有一致的起点。Luminoth 提供了一个lumi命令,我们将用它来完成大部分操作。
管理检查点可以通过lumi checkpoint命令完成,该命令将下载预训练模型,我们将使用这些模型进行预测。这是一个巨大的优势——训练图像识别模型需要很长时间和大量计算能力。然而,也可以使用云基础设施(Google Cloud、AWS 等)进行自己的训练。
lumi checkpoint refresh
现在我们来查看已下载的检查点。这可以通过lumi checkpoint list命令完成。
lumi checkpoint list

我们可以清楚地看到我们有两个检查点:
-
Faster R-CNN w/COCO—一个基于 Faster R-CNN 模型训练的物体检测模型。使用 COCO 数据集。
-
SSD w/Pascal VOC—一个基于单次多框检测器(SSD)模型训练的物体检测模型。使用 Pascal 数据集。
现在我们将使用 Luminoth 的命令行界面来预测上面展示的图像中的物体。
lumi predict bike.jpg
该命令以 JSON 格式输出预测结果。

你我都能同意,这个输出至少在视觉上并不令人满意。幸运的是,Luminoth 的团队提供了一种将图像中的物体作为标签输出的方式。
为此,我们首先创建一个名为predictions的目录,用于存放 JSON 输出和预测图像。记住我们仍在终端中操作。
mkdir predictions
完成后,我们可以运行将进行预测并返回带标签物体的图像的命令。
lumi predict bike.jpg -f predictions/objects.json -d predictions/
这个命令可能需要几分钟时间来运行。完成后,我们将在预测文件夹中看到下面的输出。

我们可以看到,它预测图像中的物体是摩托车,准确率高达 100%。它还能够预测到栅栏后面的汽车。很酷,对吧?
Luminoth 还允许我们使用特定的检查点运行预测。我们可以使用Fast检查点并进行测试。我们可以通过其 ID 或别名来实现。
lumicheckpoint info fast
或
lumicheckpoint info aad6912e94d9
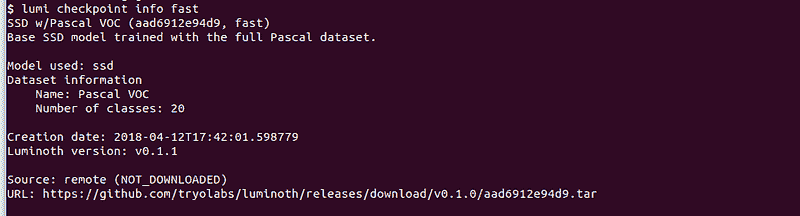
让我们使用这个检查点来预测摩托车图像中的物体。
lumi predict bike.jpg --checkpoint fast -f predictions/objects.json -d predictions/
我们将得到一个提示,下载本地检查点,当下载完成后,预测将会发生。我们看到它能够预测摩托车,但无法识别栅栏后面的汽车。

Luminoth 允许我们在网页界面上进行这些预测。要打开网页界面,请运行以下命令。
lumi server web
然后访问localhost:5000/以访问网页界面。
我们只需在计算机上浏览一张图像,然后点击提交按钮。我们可以调整概率阈值。提高阈值会减少预测的图像数量,但概率更高,降低阈值则会增加预测的图像数量,但概率较低。
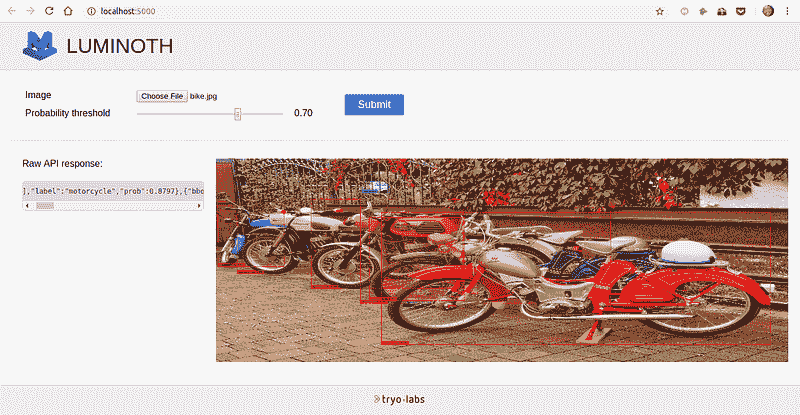
我们还可以利用这个库在视频中检测对象。这一过程将根据计算机的处理能力花费一段时间。
lumi predict traffic.mp4 -f predictions/objects.json -d predictions/
结论
市面上有很多计算机视觉工具。Luminoth 的独特之处在于其易于实现。它还提供了可以直接使用的训练模型。要了解更多关于此库的信息,请查看官方 文档。
如果你刚刚开始学习机器学习或者想要提升技能,这本书非常适合你。](https://leanpub.com/introductorytutorialsformachinelearning)
个人简介: 德里克·姆维提 是数据分析师、作家和导师。他致力于在每项任务中取得优异成绩,并且是 Lapid Leaders Africa 的导师。
原文。已获许可转载。
相关:
-
深度学习中的 PyTorch 入门
-
如何在计算机视觉中做到所有事情
-
比较 TensorFlow 中的 MobileNet 模型
更多相关内容
数据科学家的面向对象编程:构建你的 ML 估算器
原文:
www.kdnuggets.com/2019/08/object-oriented-programming-data-scientists-estimator.html
评论
更新:你可以在这里找到最新的 Python 脚本(包含线性回归类定义和方法)。利用它进一步构建或进行实验。
问题是什么?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
数据科学家往往来自于与传统计算机科学/软件工程相去甚远的背景——物理学、生物学、统计学、经济学、电气工程等。
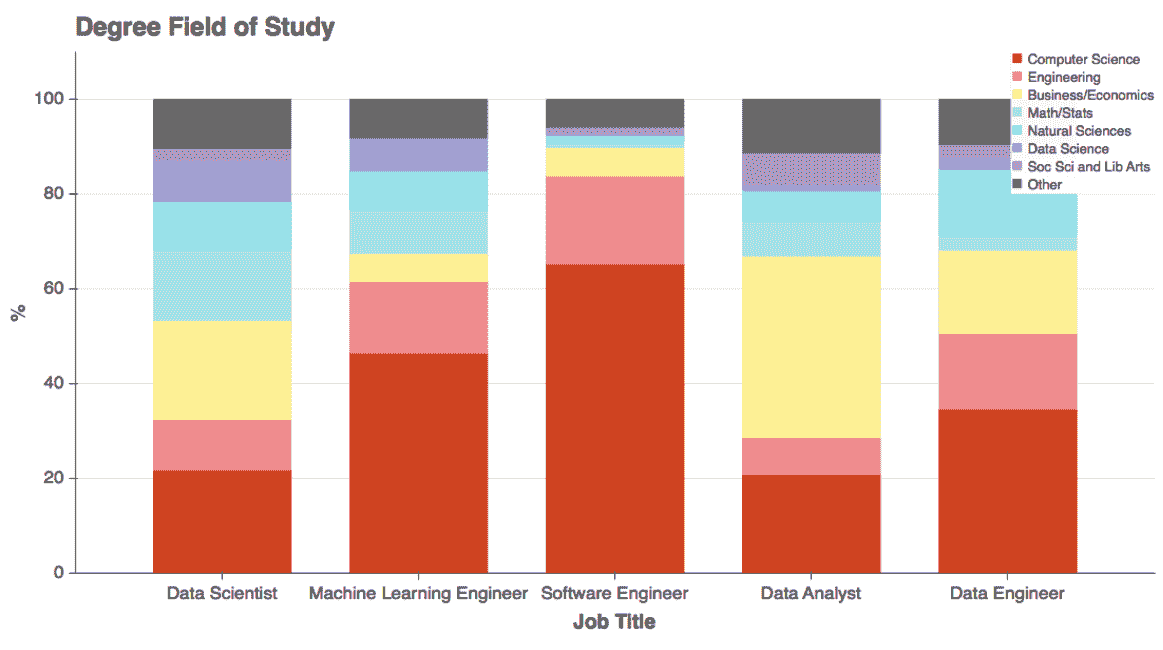
来源:“数据科学家来自哪里?”
但最终,他们预计会掌握足够的编程/软件工程知识,以对他们的组织和业务产生真正的影响。
如何构建可扩展的机器学习系统——第一部分/2 部分
那么,大多数现代编程语言和软件工程范式的核心是什么?
但面向对象编程(OOP)的原理对初学者来说可能感觉陌生或甚至令人畏惧。因此,那些背景中没有计算机编程正式培训的数据科学家可能会发现面向对象编程的概念在日常工作中有些难以接受。
受欢迎的数据科学/人工智能/机器学习的 MOOC 和训练营也无济于事。
他们尝试为新兴的数据科学家提供一种统计学、数值分析、科学编程、机器学习(ML)算法、可视化,甚至可能还有一点用于部署这些 ML 模型的网络框架的混合风味。
几乎所有这些都可以学习和实践,即使不严格遵循面向对象编程的原则。事实上,渴望学习最新神经网络架构或最酷数据可视化技术的年轻数据科学家,如果被面向对象编程范式的细节淹没,可能会感到窒息。因此,MOOCs 通常不会在数据科学课程中混合或强调它。
一个简单的例子(还有一些…)
让我用 Python 举个例子,因为它是数据科学和机器学习任务中增长最快的语言。
算术例子
如果让你编写一个程序来实现涉及几个数字 a 和 b 的加法、减法、乘法和除法,你最有可能怎么做?
你很可能会打开一个 Jupyter notebook,在一个单元格中输入以下内容,按 shift-enter 并获取结果。
a+b
a-b
a*b
a/b
如果你喜欢通过使用函数来整理事物,你可以这样做,
def add(a,b):
return a+b
...
但是你会去定义一个完整的(包括初始化方法)的 Calc 类 并将这些函数放入该类作为 方法 吗?这些都是类似性质的操作,并且处理相似的数据。为什么不封装到一个更高级的对象中呢?为什么不是下面的代码?
class Calc:
def __init__(self,a,b):
self.a = a
self.b = b
def add(self):
return self.a+self.b
def sub(self):
return self.a-self.b
def mult(self):
return self.a*self.b
def div(self):
return self.a/self.b
不,你不会这样做。对这个特定问题来说,做这样的事情可能没有意义。但这个想法是有效的——如果你有数据和函数(在面向对象编程的术语中称为方法),可以逻辑地结合起来,那么它们应该封装在一个类中。
但为了快速得到一些简单的数值计算结果,这似乎工作量太大了。那么,这有什么意义?数据科学家通常的价值在于他们是否能得到数据问题的正确答案,而不是他们在代码中使用了什么复杂的对象。
数据科学家的例子
如果数据科学家不是以这种方式编程,那么是否意味着他们实际上不需要使用这些复杂的编程结构?
错误。
在无意识的情况下,数据科学家大量利用了面向对象编程范式的好处。一直如此。
还记得plt.plot在import matplotlib.pyplot as plt之后吗?
那些.符号。你有一丝面向对象编程的痕迹。就在这里。
或者,你还记得在 Jupyter notebook 中学会了这个酷技巧——在输入一个点(.)后按下 Tab 键,从而显示所有可以与一个object关联的函数吗?像这样,
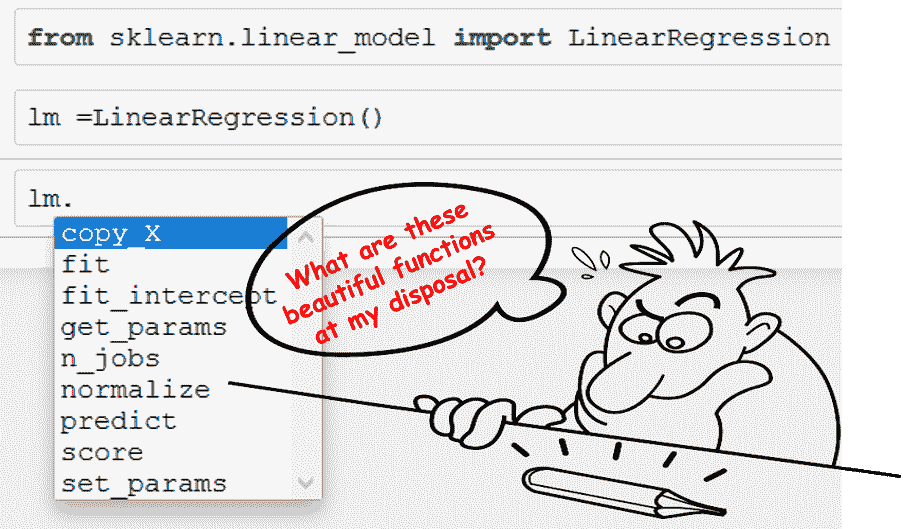
这个例子展示了什么?
这个例子展示了逻辑一致性的遵守。
如果没有面向对象编程范式,我们就不得不将这些函数命名为linear_model_linear_regression_fit、linear_model_linear_regression_predict,等等。它们不会被归入一个共同的逻辑单元下。
为什么?因为它们是不同的函数,作用于不同的数据集。fit函数需要训练特征和目标,而predict只需要测试数据集。fit函数不期望返回任何东西,而predict则期望返回一组预测结果。
那么,为什么它们会在同一个下拉菜单下显示?尽管它们不同,但它们有一个共同点,即它们都可以被想象成整体线性回归过程的重要部分——我们期望线性回归能够适应一些训练数据,然后能够对未来未见的数据进行预测。我们还期望线性回归模型能给出一些关于拟合效果的指示——通常是一个被称为回归系数或 R² 的数值量。正如预期的,我们看到一个函数score,它正好返回那个 R² 数字,也在fit和predict附*。
整洁又干净,不是吗?
数据、函数和参数共存于一个逻辑单元内。
这是怎么做到的?
这是因为我们超越了个体差异,把线性回归视为一个高级过程,并决定它应该服务于哪些基本操作以及它应该告知用户哪些关键参数。
我们创建了一个高层次的类叫做LinearRegression,在其中将所有这些看似不相关的函数归为一个组,以便于记录和提高可用性。
一旦我们从库中导入了这个类,我们只需创建一个类的实例——我们称之为lm。就这样。所有归入该类下的函数都通过新定义的实例lm对我们可用。
如果我们对函数的某些内部实现不满意,我们可以修改它们并在修改后重新附加到主类上。只有内部函数的代码发生变化,其他没有改变。
看,看起来多么合逻辑且可扩展?

创建你自己的 ML 估算器
传统的面向对象编程介绍会有很多使用类的例子,比如——动物、体育、几何形状。
对于数据科学家来说,为什么不使用他们在代码中每天使用的对象——机器学习估算器来说明这些概念呢?就像上面图片中显示的 Scikit-learn 库中的lm对象一样。
一个经典的线性回归估算器——带有一丝变化
在这个 Github 仓库中,我一步步展示了如何构建一个简单的线性回归(单变量或多变量)估算器类,遵循面向对象编程的范式。
是的,它是那种古老的线性回归类。它具有与 Scikit-learn 的 LinearRegression 类相同的fit和predict方法。但它有更多功能。这里是一个简要预览……

是的,这个估计器比 Scikit-learn 的估计器更丰富,因为它除了标准的fit、predict和 R² score函数外,还具有一系列对线性回归建模任务至关重要的其他实用工具。
特别是对于数据科学家和统计建模人员——他们不仅希望进行预测,还希望
线性回归深深扎根于统计学习中,因此必须检查模型的‘优度……
你如何开始构建这个类?
我们从一个简单的代码片段开始定义类。我们将其命名为MyLinearRegression。
在这里,self表示对象本身,而__init__是一个在创建类的实例时会调用的特殊函数。顾名思义,__init__可以用来用必要的参数(如果有的话)初始化类。

我们可以添加一个简单的描述字符串以保持诚实 😃

接下来,我们添加核心的fit方法。请注意文档字符串,它描述了方法的目的、功能以及期望的数据类型。这些都是良好面向对象编程原则的一部分。

我们可以生成一些随机数据来测试到目前为止的代码。我们创建一个两个变量的线性函数。以下是数据的散点图。
现在,我们可以创建一个名为mlr的MyLinearRegression类的实例。如果我们尝试打印回归参数,会发生什么呢?

因为self.coef_被设置为None,所以在尝试打印mlr.coef_时得到的结果是一样的。注意,自创建mlr实例后,self变成了mlr的同义词。
但是fit的定义包括在拟合完成后设置属性。因此,我们可以直接调用mlr.fit()并打印出拟合的回归参数。
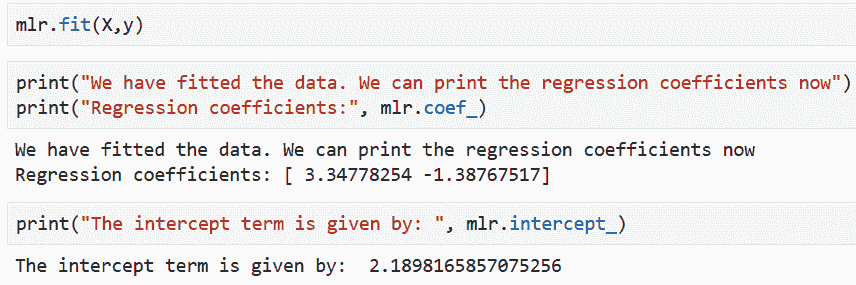
最重要的Predict方法
拟合之后就是预测。我们可以很容易地将该方法添加到我们的回归类中。

如果我们想添加一个(或几个)绘图工具函数怎么办?
到目前为止,我们开始扩展我们的回归类,并添加一些标准 scikit-learn 类中没有的东西!例如,我们总是想查看拟合值与真实值的比较。为此创建一个函数很简单。我们将其命名为plot_fitted。
请注意,方法类似于普通函数。它可以接受额外的参数。在这里,我们有一个参数reference_line(默认设置为False),它在拟合与真实图中绘制了一条 45 度参考线。另外,注意文档字符串的描述。

我们可以通过简单地做以下操作来测试方法plot_fitted,
m = MyLinearRegression()
m.fit(X,y)
m.plot_fitted()
或者,我们可以选择绘制参考线,
m.plot_fitted(reference_line=True)
我们得到以下图!
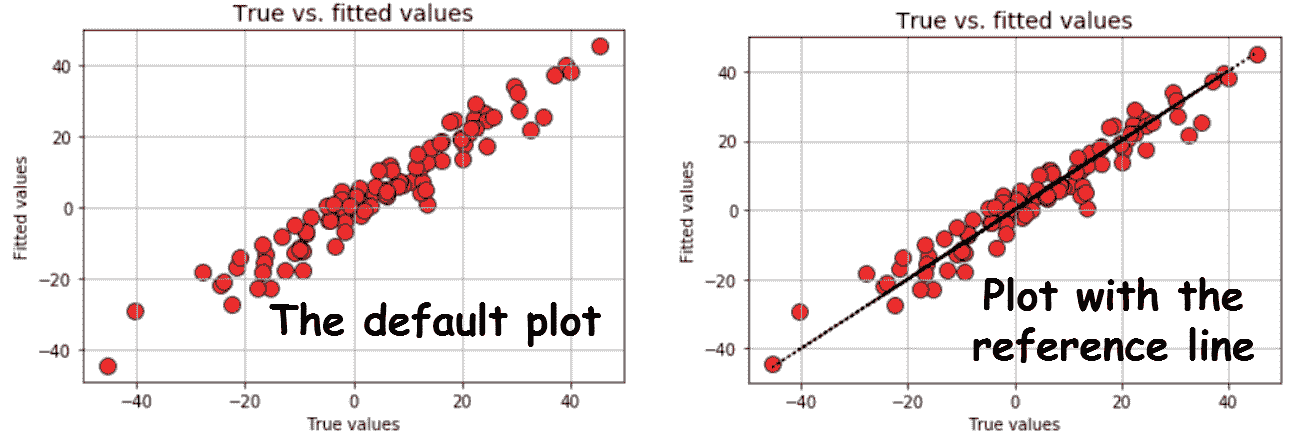
一旦我们明白可以将任何有用的方法添加到处理相同数据(训练集)且目的相同(线性回归)的类中,我们的想象力就没有界限了!如何将以下图添加到我们的类中?
-
对角图(绘制所有特征和输出之间的成对关系,类似于 R 中的
pairs函数) -
拟合与残差图(这属于线性回归的诊断图,即检查基本假设的有效性)
-
直方图和分位数-分位数(Q-Q)图(这用于检查误差分布的正态性假设)
继承 — 不要让你的主类过于繁重
当我们热情地规划要添加到类中的实用方法时,我们认识到这种方法可能会使主类的代码非常长且难以调试。为了解决这个难题,我们可以利用面向对象编程的另一个美丽原则——继承。
继承是一个类从另一个类派生或继承属性的能力。其好处…
我们进一步认识到并非所有绘图类型相同。Pairplots 和拟合与真实数据的绘图性质相似,因为它们只能从数据中推导出。其他绘图与拟合优度和残差有关。
因此,我们可以创建两个独立的类来实现这些绘图功能——Data_plots和Diagnostic_plots。
而且你猜怎么着!我们可以将我们的主MyLinearRegression类定义为这些工具类的组成部分。这就是继承的实例。
注意:这可能与标准的父类-子类继承实践有所不同,但在这里使用了相同的语言特性,以保持主类的简洁和紧凑,同时从其他类似构建的类中继承有用的方法。
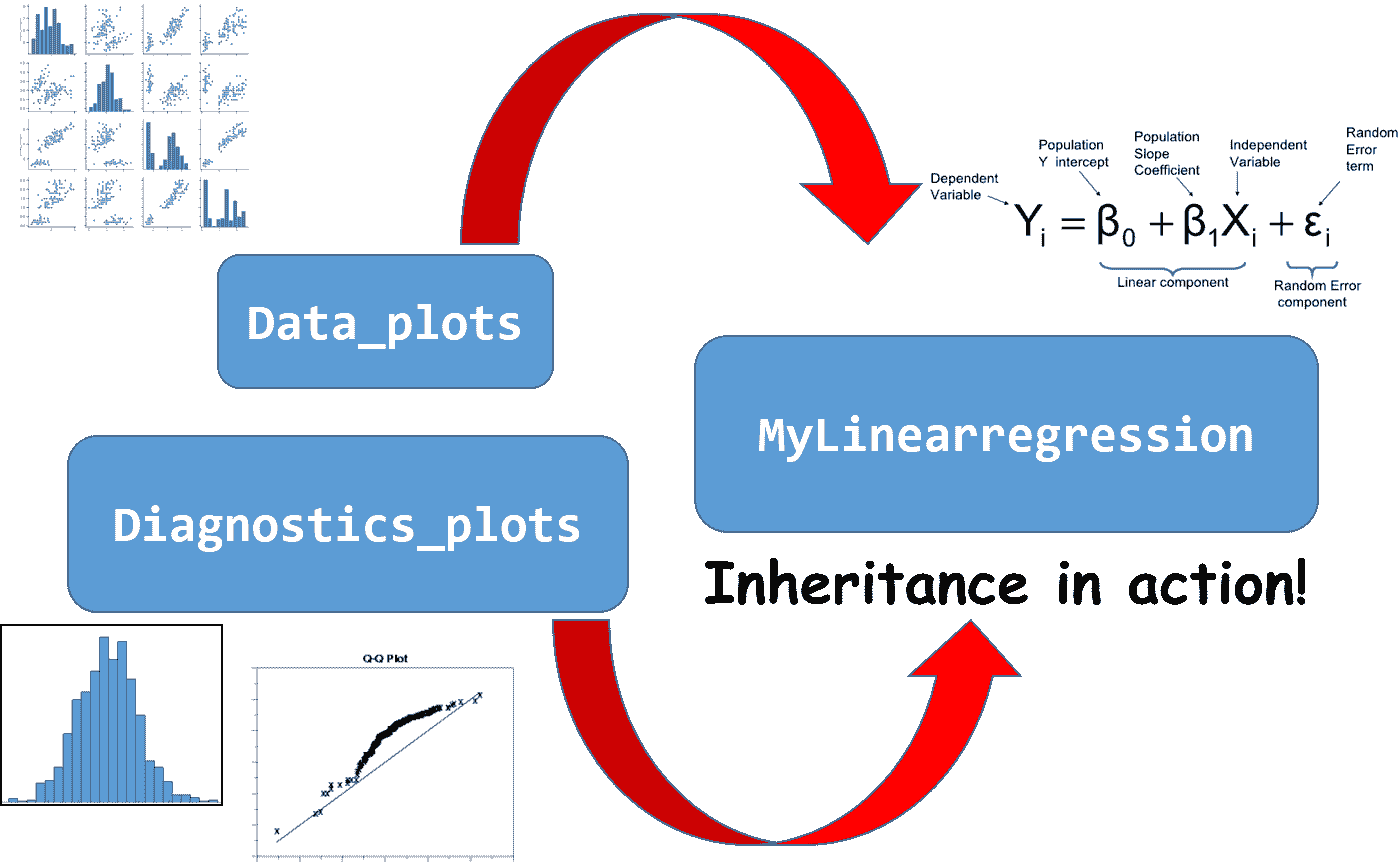
注意以下代码片段仅供说明。请使用上面的 Github 链接查看实际代码。

Data_plots类!图
Diagnostics_plots类
而且MyLinearRegression的定义仅略有改变,
class MyLinearRegression(Diagnostics_plots,Data_plots):
def __init__(self, fit_intercept=True):
self.coef_ = None
self.intercept_ = None
self._fit_intercept = fit_intercept
...
通过简单地将Data_plots和Diagnostics_plots的引用传递给MyLinearRegression类的定义,我们继承了这些类的所有方法和属性。
现在,为了检查误差项的正态性假设,我们可以简单地拟合模型并运行这些方法。
m = MyLinearRegression() # A brand new model instance
m.fit(X,y) # Fit the model with some datam.histogram_resid() # Plot histogram of the residuals
m.qqplot_resid() # Q-Q plot of the residuals
我们得到,
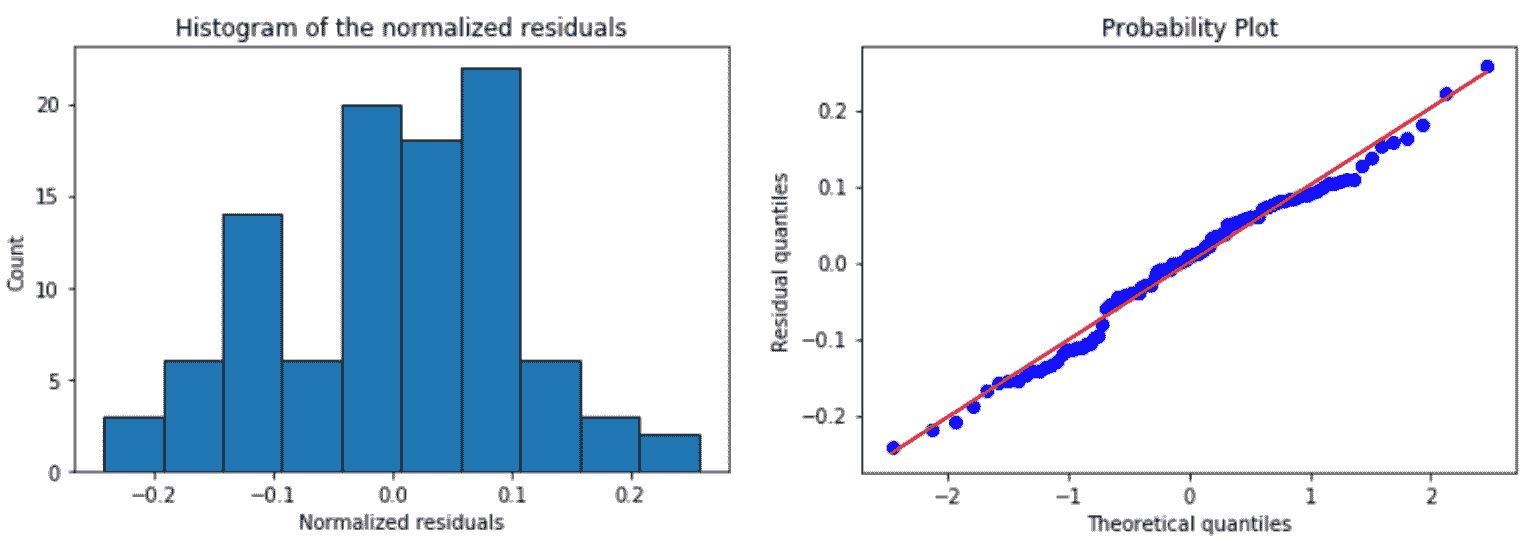
再次,代码的分离在这里发挥作用。你可以在不触及主类的情况下修改和改进核心绘图工具。高度灵活且减少错误的做法!
利用面向对象编程的强大功能做更多的事情
我们不会进一步详细说明可以添加到MyLinearRegression的各种工具类和方法。你可以查看 Github 仓库。
添加的额外类
为了完整性,我们添加了,
-
一个用于计算各种回归指标的类
Metrics— SSE、SST、MSE、R²和调整后的R²。 -
一个用于绘制 Cook 距离、杠杆和影响图的类
Outliers -
一个用于计算方差膨胀因子(VIF)的类
Multicollinearity
总的来说,宏观计划如下,
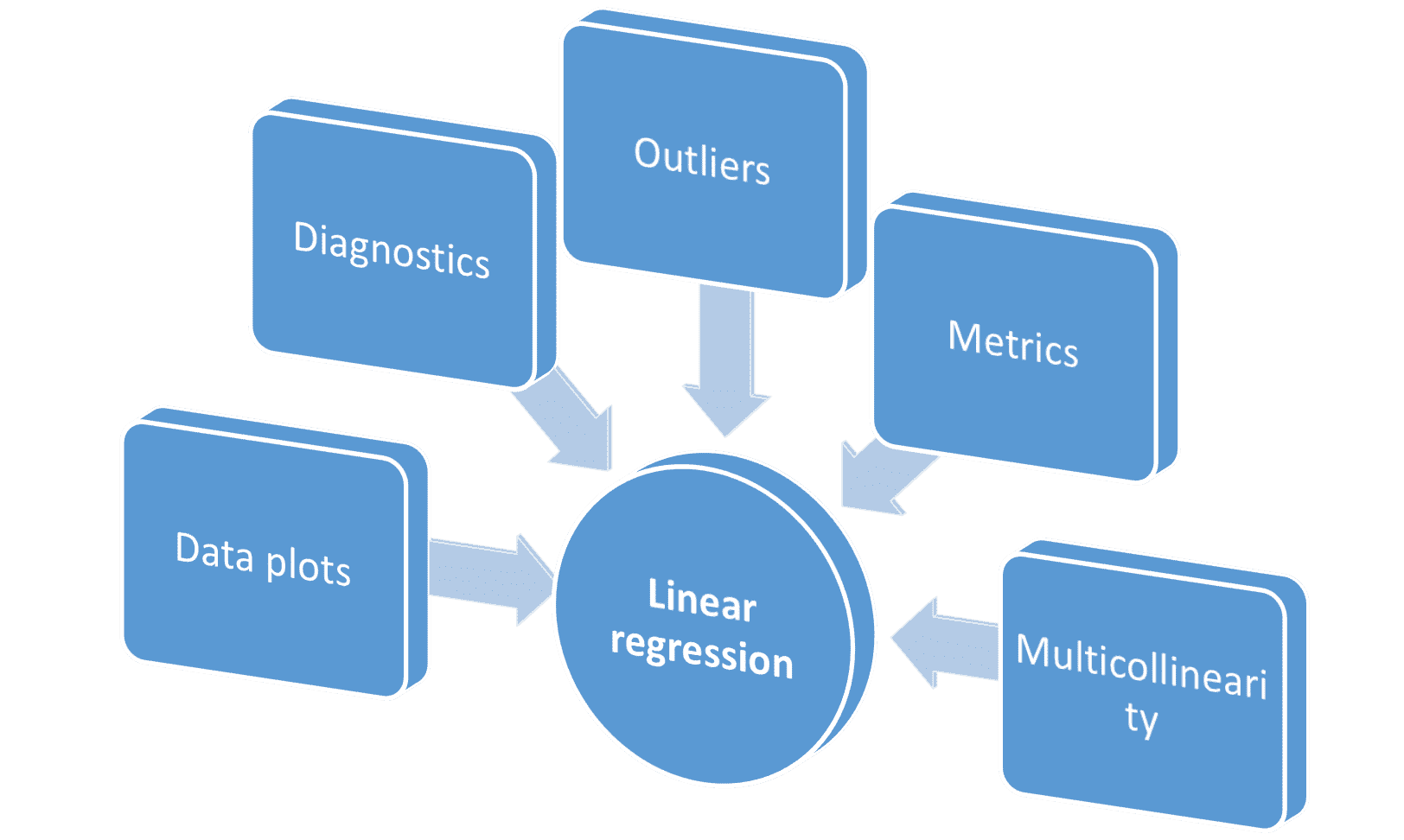
这个类是否比 Scikit-learn 的 LinearRegression 类更丰富?由你决定。
通过创建分组工具来添加语法糖
一旦你继承了其他类,它们的行为就像你熟悉的普通 Python 模块一样。因此,你可以向主类添加工具方法,以便同时执行子类中的多个方法。
例如,下面的方法一次运行所有常见的诊断检查。注意我们是如何通过放置一个简单的.DOT,即Diagnostics_plot.histogram_resid来访问绘图方法的。就像从 Pandas 或 NumPy 库中访问函数一样!

主类中的run_diagnostics方法
有了这个,我们可以在数据拟合后用一行代码运行所有的诊断。
m = MyLinearRegression() # A brand new model instance
m.fit(X,y) # Fit the model with some datam.run_diagnostics()
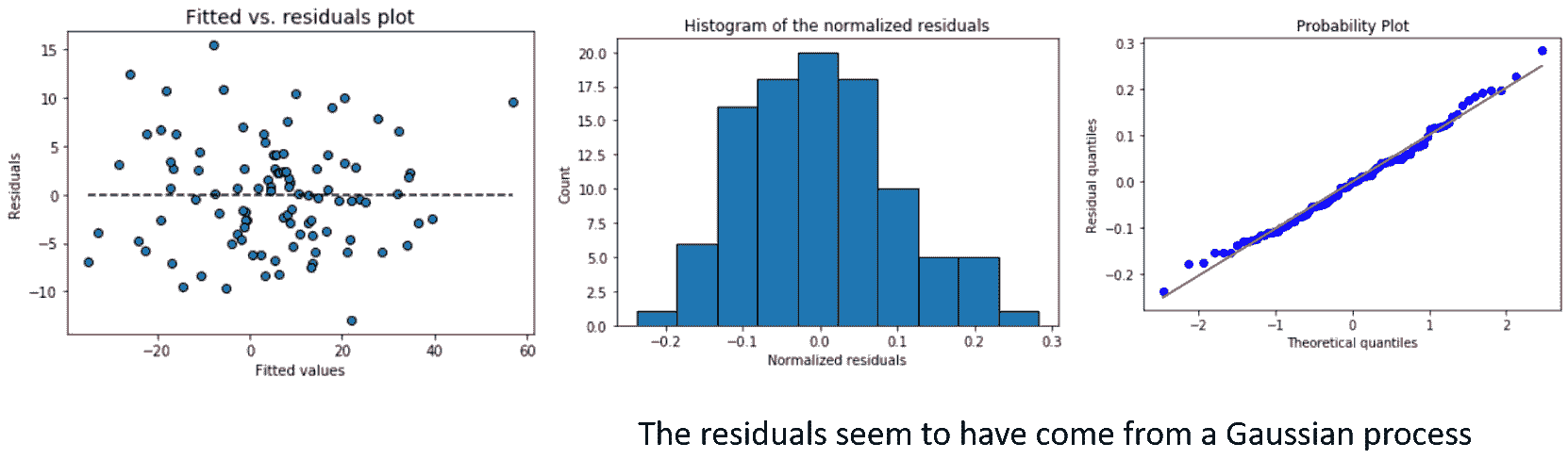
同样,你可以将所有的异常值绘图功能添加到一个实用方法中。
模块化——将类作为模块导入
虽然这不是一个经典的 OOP 原则,但遵循 OOP 范式的主要优势是能够模块化你的代码。
你可以在标准的 Jupyter 笔记本中试验和开发所有这些代码。但为了最大程度的模块化,考虑将笔记本转换为独立的可执行 Python 脚本(.py 扩展名)。作为良好的实践,删除文件中的所有不必要的注释和测试代码,仅保留类。
一旦你这样做了,你可以从完全不同的笔记本中导入MyLinearRegression类。这通常是测试你的代码的首选方式,因为这不会触及核心模型,而是仅用不同的数据样本和功能参数进行测试。

此时,你可以考虑将这个 Python 脚本放到 Github 上,创建一个 Setup.py 文件,建立适当的目录结构,并将其发布为一个独立的线性回归包,该包可以进行拟合、预测、绘图、诊断等操作。
当然,你还需要添加大量的文档字符串描述、函数使用示例、断言检查和单元测试,以使其成为一个优秀的包。
作为数据科学家,现在你已经为自己的技能库增加了一项重要技能——遵循面向对象编程(OOP)原则的软件开发。
这并不难,对吧?
后记
动机与相关文章
为撰写这篇文章,我受到这篇精彩文章的启发,这篇文章更详细地探讨了 Python 中 OOP 的概念,并结合了机器学习的背景。
面向对象编程(OOP)并不容易理解。你可以不断阅读教程,但仍可能无法完全掌握…
我写了一篇类似的文章,在深度学习的背景下涉及了更多基础方法。可以在这里查看,
通过混合简单的面向对象编程概念,如函数化和类继承,你可以添加…
课程?
我尝试寻找相关课程,但如果你使用的是 Python,发现很少有相关课程。大多数软件工程课程使用的是 Java。以下是两个可能对你有帮助的课程,
如果你有任何问题或想法,请通过tirthajyoti[AT]gmail.com联系作者。此外,你可以查看作者的 GitHub 仓库,获取其他有趣的 Python、R 或 MATLAB 代码片段和机器学习资源。如果你像我一样对机器学习/数据科学充满热情,请随时在 LinkedIn 上添加我或关注我在 Twitter 上的动态。
原文。经许可转载。
相关:
-
如何通过简单的面向对象编程提升你的深度学习原型
-
数学编程 — 促进数据科学进步的关键习惯
-
使用 Python 优化:如何在最小风险下赚取最大金额?
更多相关话题
数据科学家简明易懂的面向对象编程解释
原文:
www.kdnuggets.com/2020/12/object-oriented-programming-explained-simply-data-scientists.html
评论
图片由Jelleke Vanooteghem在Unsplash上提供
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
面向对象编程(OOP)对于初学者来说可能是一个难以理解的概念。这主要是因为很多地方并没有以正确的方式解释它。通常,很多书籍从讲解 OOP 的三个重要术语开始——封装、继承和多态。但当书本能够解释这些主题时,任何刚开始学习的人可能已经感到迷茫了。
因此,我考虑了让这个概念对其他程序员、数据科学家和 Python 爱好者更容易理解的方法。我打算通过去掉所有术语,并通过一些例子来实现。我会从解释类和对象开始。然后我会解释在各种情况下类为什么重要以及它们如何解决一些基本问题。这样,读者也能在文章结束时理解这三个重要术语。
在这个名为Python Shorts的系列帖子中,我将解释一些由 Python 提供的简单但非常有用的构造、一些必备技巧以及我在数据科学工作中经常想到的一些使用案例。
这篇文章是以通俗的方式解释面向对象编程。
什么是对象和类?
简单来说,Python 中的一切都是对象,而类是对象的蓝图。所以当我们写:
a = 2
b = "Hello!"
我们创建了一个值为 2 的int类对象a,和一个值为“Hello!”的str类对象b。在某种程度上,当我们使用数字或字符串时,这两个特定的类是默认提供给我们的。
除此之外,我们中的许多人实际上在使用类和对象时甚至没有意识到这一点。例如,当你使用任何 Scikit-Learn 模型时,你实际上是在使用一个类。
clf = RandomForestClassifier()
clf.fit(X,y)
在这里,你的分类器clf是一个对象,而 fit 是定义在类RandomForestClassifier中的一个方法。
但是为什么要使用类?
我们在使用 Python 时经常使用它们。但究竟是什么原因呢?类有什么特别之处?我可以用函数做到同样的事吗?
是的,你可以。但是,与函数相比,类确实为你提供了很多强大的功能。举个例子,str 类为对象定义了很多函数,我们可以通过按下 tab 键直接访问这些函数。虽然也可以编写所有这些函数,但那样的话,它们就不会通过按下 tab 键直接使用。

类的这一特性被称为封装。从 维基百科 —— 封装 指的是将数据与操作这些数据的方法捆绑在一起,或者限制对某些对象组件的直接访问。
在这里,str 类将数据(“Hello!”)与操作数据的所有方法捆绑在一起。我将在文章结束时解释该语句的第二部分。以同样的方式,RandomForestClassifier 类将所有分类器方法(fit、predict 等)捆绑在一起。
除此之外,类的使用还可以帮助我们使代码更加模块化和易于维护。假设我们要创建一个类似于 Scikit-Learn 的库。我们需要创建很多模型,每个模型都将具有 fit 和 predict 方法。如果我们不使用类,我们将不得不为每个不同的模型创建很多函数,如下所示:
RFCFit
RFCPredict
SVCFit
SVCPredict
LRFit
LRPredict and so on.
这种代码结构工作起来简直是一场噩梦,因此 Scikit-Learn 将每个模型定义为一个具有 fit 和 predict 方法的类。
创建一个类
现在我们理解了为什么要使用类以及它们的重要性,那么我们如何真正开始使用它们呢?创建一个类非常简单。下面是你将编写的任何类的基本代码:
class myClass:
def __init__(self, a, b):
self.a = a
self.b = b def somefunc(self, arg1, arg2):
#SOME CODE HERE
我们在这里看到很多新关键字。主要的有 class、__init__ 和 self。这些是什么?通过一些示例可以很容易地解释。
假设你在一个拥有许多账户的银行工作。我们可以创建一个名为 account 的类,用于处理任何账户。例如,下面我创建了一个基础的玩具类 Account,它存储用户的数据——即 account_name 和 balance。它还提供了两个方法来 deposit/withdraw 银行账户中的钱。请仔细阅读,它遵循与上面相同的结构。
class Account:
def __init__(self, account_name, balance=0):
self.account_name = account_name
self.balance = balance
def deposit(self, amount):
self.balance += amount
def withdraw(self,amount):
if amount <= self.balance:
self.balance -= amount
else:
print("Cannot Withdraw amounts as no funds!!!")
我们可以通过以下方式创建一个名为 Rahul 的账户,并设置金额为 100:
myAccount = Account("Rahul",100)
我们可以通过以下方式访问这个账户的数据:

但是,这些属性 balance 和 account_name 是如何已经分别设置为 100 和 “Rahul” 的?我们从未调用 __init__ 方法,那么为什么对象会获得这些属性?答案是 __init__ 是一个魔法方法(还有许多其他魔法方法,我会在下一个关于魔法方法的帖子中扩展),每当我们创建对象时它都会运行。所以当我们创建 myAccount 时,它会自动运行函数 __init__。
现在我们了解了__init__,让我们尝试向账户中存入一些钱。我们可以通过以下方式实现:

我们的余额上升到 200。但是你有没有注意到,我们的函数 deposit 需要两个参数,即 self 和 amount,但我们只提供了一个,仍然能正常工作。
那么,**self** 是什么?** 我喜欢通过以不同的方式调用相同的函数来解释 self。下面,我调用了属于 account 类的同一个函数 deposit,并为其提供了 myAccount 对象和 amount。现在,函数接受两个参数,这是它应该有的。

我们的 myAccount 余额如预期增加了 100。所以我们调用的是同一个函数。现在,这只有在 self 和 myAccount 完全相同的对象时才会发生。当我调用 myAccount.deposit(100) 时,Python 将相同的对象 myAccount 作为参数 self 提供给函数调用。这就是为什么函数定义中的 self.balance 实际上指代 myAccount.balance。
但仍然存在一些问题
图片由Volodymyr Hryshchenko拍摄,来源于Unsplash
我们知道如何创建类,但仍然有另一个重要的问题我还没有触及。
假设你在苹果 iPhone 部门工作,并且需要为每个 iPhone 型号创建一个不同的类。在这个简单的示例中,我们假设我们 iPhone 的第一个版本目前只做一件事——打电话并具有一些内存。我们可以将这个类写成:
class iPhone:
def __init__(self, memory, user_id):
self.memory = memory
self.mobile_id = user_id
def call(self, contactNum):
# Some Implementation Here
现在,苹果计划推出 iPhone1,这个 iPhone 型号引入了一项新功能——拍照功能。实现这一功能的一种方法是复制粘贴上述代码,创建一个新的类 iPhone1,如下所示:
class iPhone1:
**def __init__(self, memory, user_id):
self.memory = memory
self.mobile_id = user_id**
self.pics = [] **def call(self, contactNum):
# Some Implementation Here** def click_pic(self):
# Some Implementation Here
pic_taken = ...
self.pics.append(pic_taken)
但正如你所见,上面显示的(加粗的部分)代码重复过多,而 Python 提供了一个解决代码重复的问题的方法。编写我们 iPhone1 类的一个好方法是:
Class iPhone1(**iPhone**):
def __init__(self,**memory,user_id**):
**super().__init__(memory,user_id)**
self.pics = []
def click_pic(self):
# Some Implementation Here
pic_taken = ...
self.pics.append(pic_taken)
这就是继承的概念。根据维基百科:继承是基于另一个对象或类创建一个对象或类的机制,从而保留类似的实现。简单来说,iPhone1现在可以访问类iPhone中定义的所有变量和方法。
在这种情况下,我们不需要进行代码重复,因为我们已经从父类 iPhone 继承(获取)了所有方法。因此,我们不必再次定义call函数。此外,我们没有使用 super 在__init__函数中设置 mobile_id 和 memory。
但这**super().init(memory,user_id)**是什么?
在现实生活中,你的__init__函数不会是这样简洁的两行函数。你需要在类中定义很多变量/属性,而将它们复制到子类(这里是 iphone1)中会变得麻烦。因此存在 super()。这里**super().__init__()**实际上调用了父类iPhone的**__init__**方法。所以在这里,当iPhone1类的__init__函数运行时,它会自动使用父类的__init__函数设置memory和user_id。
我们在 ML/DS/DL 中哪里可以看到这个? 下面是我们如何创建一个PyTorch模型。该模型从nn.Module类继承了所有内容,并使用super调用了该类的__init__函数。
class myNeuralNet(nn.Module): def __init__(self):
**super().__init__()**
# Define all your Layers Here
self.lin1 = nn.Linear(784, 30)
self.lin2 = nn.Linear(30, 10) def forward(self, x):
# Connect the layer Outputs here to define the forward pass
x = self.lin1(x)
x = self.lin2(x)
return x
但什么是多态? 我们对类的理解越来越好,所以我想我现在会尝试解释多态。看下面的类。
这里我们有基础class Shape和其他派生类——Rectangle和Circle。还要注意我们在Square类中如何使用多层继承,它是从Rectangle派生的,而Rectangle又从Shape派生。每个这些类都有一个名为area的函数,根据形状定义。因此,通过多态,一个同名函数可以做多种事情。实际上,这就是多态的字面意思:“具有多种形式的东西”。因此,我们的函数area具有多种形式。
多态在 Python 中的另一种实现方式是使用isinstance方法。使用上面的类,如果我们这样做:
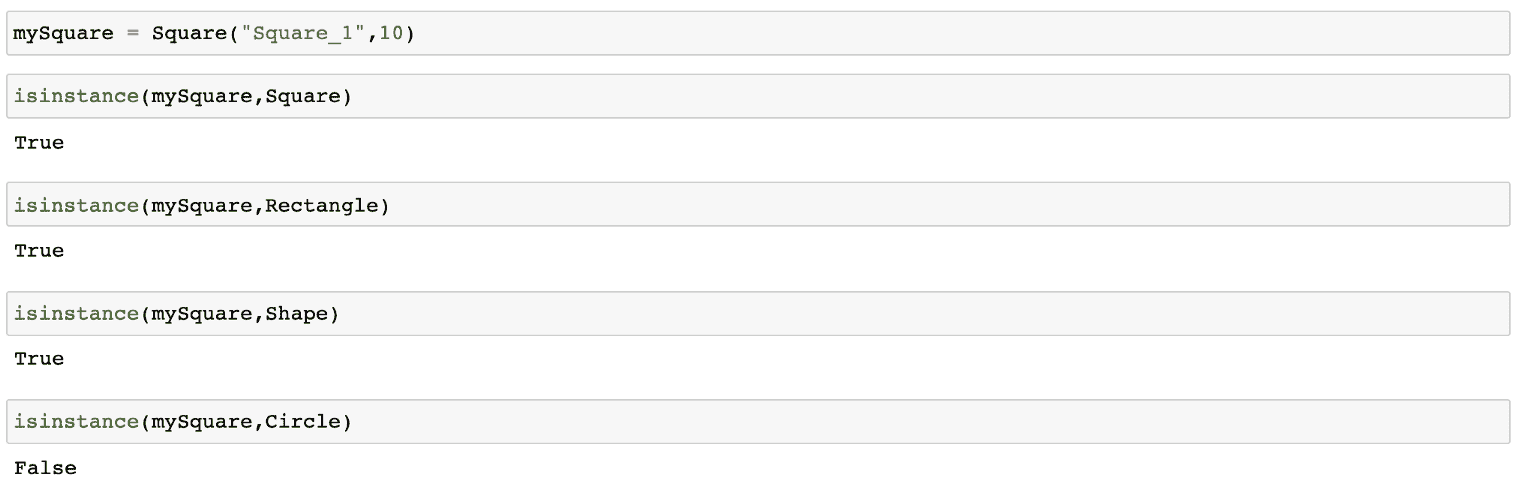
因此,对象mySquare的实例类型是Square,
Rectangle 和 Shape。因此对象是多态的。这具有许多优良的属性。例如,我们可以创建一个与Shape对象一起工作的函数,它将完全适用于任何派生类(Square、Circle、Rectangle等),通过利用多态。

更多信息:
为什么我们会看到以单下划线和双下划线开头的函数名或属性名?有时我们想让类中的属性和函数保持私有,不让用户看到它们。这是封装的一部分,我们希望“限制对对象某些组件的直接访问”。例如,假设我们不想让用户在创建后看到我们 iPhone 的内存(RAM)。在这种情况下,我们通过在变量名中使用下划线来创建属性。
所以当我们以以下方式创建iPhone类时,你将无法在你的 ipython 笔记本中使用 Tab 访问你的memory或privatefunc,因为该属性现在被用 _ 标记为私有。

但你仍然可以通过(虽然不推荐)更改变量值。

你也可以使用方法 _privatefunc,通过myphone._privatefunc()。如果你想避免这种情况,可以在变量名前使用双下划线。例如,print(myphone.__memory)的调用会引发错误。此外,你不能通过myphone.__memory = 1来更改对象的内部数据。
但如你所见,你可以在你的类定义中通过setMemory函数访问和修改这些self.__memory值。
结论

照片由Jeshoots.com拍摄,发布在Unsplash上
我希望这对你理解类有所帮助。关于类的内容还有很多,我将在下一篇关于魔术方法的帖子中讨论。敬请关注。此外,总结一下,这篇文章中我们学习了 OOP 和创建类以及 OOP 的各种基础知识:
-
封装:对象包含所有属于自己的数据。
-
继承:我们可以创建一个类层次结构,其中父类的方法传递给子类。
-
多态性:一个函数有多种形式,或者对象可能有多种类型。
为了结束这篇文章,我将给你一个练习,我认为这可能会帮助你理清一些概念。创建一个类来管理三维对象(球体和立方体),包括体积和表面积。基本的代码框架如下:
import mathclass Shape3d:
def __init__(self, name):
self.name = name def surfaceArea(self):
pass
def volume(self):
pass
def getName(self):
return self.name
class Cuboid():
passclass Cube():
pass
class Sphere():
pass
我会把答案放在这篇文章的评论中。
如果你想了解更多关于Python的知识,我推荐你查看来自密歇根大学的中级 Python 课程。千万不要错过。
我将来也会写更多这样的文章。请告诉我你对这个系列的看法。关注我在Medium上的动态,或订阅我的博客以获取相关信息。正如往常一样,我欢迎反馈和建设性的批评,可以通过 Twitter 联系我@mlwhiz。
此外,小免责声明——这篇文章中可能包含一些关联链接到相关资源,因为分享知识从来不是一件坏事。
简介:Rahul Agarwal 是 WalmartLabs 的高级统计分析师。关注他在 Twitter 上的动态@mlwhiz。
原文。经授权转载。
相关:
-
10 个被低估的 Python 技能
-
数据科学家需要注意的 6 条建议
-
每个数据科学家都必须知道的 5 种分类评估指标
更多相关主题
数据工程的 Observability
原文:
www.kdnuggets.com/2020/02/observability-data-engineering.html
评论
由 Evgeny Shulman,Databand.ai 联合创始人。
Observability 是一个在 Ops 社区快速增长的概念,*年来受到主要监控/日志公司和 Datadog、Splunk、New Relic、Sumo Logic 等思想领袖的推动。它被描述为监控 2.0,但实际上远不止于此。Observability 使工程师能够基于对系统内部状态和操作环境的深刻理解,了解系统是否按照预期工作。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域

Sumo Logic 将 Observability 描述为以下内容:
这是一种监控和分析事件日志、关键绩效指标(KPI)及其他数据的能力,从而获得可操作的见解。一个 Observability *台将数据以三种主要格式(日志、指标和跟踪)进行汇总,将其处理成事件和 KPI 测量,并利用这些数据提供有关系统安全性和性能的可操作见解。
Observability 比监控更深入,通过为系统指标提供更多上下文,提供系统操作的更深层次视图,并指出工程师是否需要介入进行修复。换句话说,虽然监控告诉你某个微服务消耗了特定量的资源,但 Observability 会告诉你其当前状态与关键故障相关,你需要进行干预。
那么数据呢?
直到现在,Observability 一直存在于 DevOps 或 DevSecOps 的领域,专注于应用程序、微服务、网络和基础设施健康。但负责管理数据管道的团队(数据工程师和 DataOps)往往被迫自己摸索。这可能适用于那些对数据能力投资不大的组织,但对于拥有严肃数据基础设施的公司来说,缺乏专业管理工具会导致重大低效和生产力差距。
为什么现有工具不够用?
当前数据工程师的典型做法是使用最初为应用程序或基础设施构建的标准监控工具来监控他们的数据流程。使用这些通用工具,数据工程团队可以获得高层次的作业(或 DAG)状态和数据库性能摘要,但会缺乏管理管道所需的详细信息。这种差距导致许多团队花费大量时间追踪问题或处于持续的焦虑状态。
标准工具无效的原因是数据管道的行为与软件应用程序和基础设施非常不同。
Zabbix 和 Airflow,我们如何将所有正确的数据集中在一个地方?
差异
这里是数据管道,特别是批处理过程与其他基础设施类型之间的一些主要区别。
周期性
大多数监控工具是为了监督系统的持续运行而构建的,24/7\运行。任何停机时间都是不好的,这意味着访问者无法访问网站或用户无法访问应用程序。另一方面,批处理数据过程设计上是按离散时间段运行的。因此,它们需要不同类型的监控,因为你提出的大多数问题没有像“开/关”,“上/下”,“绿/红”那样简单的二元答案。需要理解更多维度——计划开始时间、实际开始时间、结束时间和可接受的范围。
与其他系统不同,数据管道定期在成功之前失败是完全正常的。一个 DAG 可能在成功运行之前失败 6 或 7 次。这可能是由于某种类型的可取的作业节流,如数据库池。
要点是,DAG 的典型行为与其他基础设施服务非常不同。使用标准警报,数据团队会收到大量无意义的警报,数百封未读的通知邮件,无法从噪音中筛选出有用信息。
长期运行的过程
数据管道通常是长期运行的过程,完成需要许多小时。我们的客户反馈回来的*均时间约为 6 小时。监控长期运行的过程具有挑战性,因为错误可能在作业后期出现,你需要等待并观察很长时间才能知道是否成功或失败。这导致了更高的失败成本,因为如果下游出现问题,需要从头开始重新启动作业。团队需要能够收集早期警告的方式和更智能的历史分析方法,以预测失败。
复杂的依赖关系
DAG 本质上是复杂的。它们有内部依赖关系,如任务序列,以及外部依赖关系,如数据何时可用以及前一个作业的输出。这个相互依赖的网络创建了独特的监控需求,你需要了解过程的更广泛背景,以便了解问题如何级联或追溯。
数据流
当然,我们不能忘记数据管道依赖于数据。这是另一个需要监控和理解的复杂维度,包括模式、分布和数据完整性。例如,大多数批处理作业操作于某个数据窗口,即过去 60 天。你需要知道在这 60 天里是否存在问题,例如数据未生成。
尽管有大量的数据跟踪解决方案,今天的团队真正不同的是,专业化和开源的使用大大增加,很难找到与现代工具栈(即 Airflow、Spark、Kubernetes、Snowflake)易于集成、通用并提供适当扩展性的框架。
成本归属
最后但同样重要的是,管道监控中的成本归属更为困难,因为团队需要从多个角度查看流程以理解其投资回报率。示例包括按以下方式查看成本:
-
环境(我生产 Spark 集群上的管道成本 X)
-
数据源提供商(从 Salesforce 读取数据的管道成本 Y)
-
数据消费者(将数据传递给数据科学团队的管道成本 Z)
将这些因素结合在一起,监控数据管道与其他基础设施的差异归结为管道需要监控更多的维度,并且需要非常详细的状态报告。这些问题在使用更复杂系统如 Kubernetes 和 Spark 的团队中更加严重。如果没有可观测性,数据工程团队将盲目操作,大部分时间都在追踪问题和调试。
我们的建议
在我们之前管理数据工程团队的经历中,我们总是难以保持对项目和基础设施的良好可见性。我们建议你更多地考虑数据栈的可观测性,并考虑使其独特的因素。这将帮助你通过更容易对齐团队状态、更快识别问题和更快调试来建立更强大的数据操作。以下是我们建议的最佳实践:
(1)在你的 DAG 中逐步投资数据/元数据收集。首先跟踪管道输入和输出的基本指标,以便立即发现是否有显著的数据变化,以及这些变化是否是管道内部问题还是由外部事件引起的。示例包括报告输入/输出文件的数量和大小。
下一步是提取有关管道内部的信息——即任务之间的中间结果。这些是管道中任务之间的输入和输出。拥有内部可见性将帮助你准确地深入到 DAG 中查看问题或变化发生的地方。
对数据监控来说,下一个重要的补充将是跟踪模式、分布以及输入和输出文件的其他统计指标。
逐步进行这些改进将帮助你在不进行大规模项目的情况下更好地了解你的管道,并使你能够尝试适合每个可见性层级的正确工具和方法。
(2)定义管道回归测试并跟踪你的测试指标。 就像软件工程师在应用程序代码投入生产之前进行测试一样,数据工程师也必须测试管道代码。
对于有测试或 CI/CD 流程的团队,我们看到两个常见的问题。首先,要确保在数据回归测试中使用的数据是最新的,并且代表真实的生产数据。我们建议使用最新成功的生产管道运行的数据。其次,需要一些基本的自动化工具,这些工具可以在这些数据上运行新的 DAG 代码,并在推送到生产环境之前警报问题。
自动化测试管道将帮助你更好地理解数据流中的细微差别,并在数据消费者遇到问题之前发现问题。你可以发现管道中的错误,识别数据质量的变化,以免数据分析师和科学家感到意外,并在更新/重新训练机器学习模型时做出决策。
(3)定义并监控标准的 KPI,以便所有角色——数据工程师、分析师和科学家——都可以对齐。 对于一个从事机器学习的团队,这可能意味着数据工程师需要了解由数据科学家构建的模型性能指标(如 R2),而数据科学家需要关注数据工程师管理的数据摄取过程的指标(如过滤事件的数量)。在这些共享指标上创建团队之间的对齐是非常强大的,因为每一方都会理解问题,而不需要反复沟通。
这里有一个例子——假设一个数据工程师添加了一个额外的数据源。这个源包含了大量的噪声,因此工程师添加了过滤器,以确保只有有用的数据能够通过。数据科学家开始使用这些数据并训练一个模型。了解数据如何被准备好能让数据科学家更好地管理他们的模型。他们可以预测如果模型在没有类似过滤数据的环境中投入使用会出现的问题,并能提供建议,说明当他们的模型需要在未来重新训练时数据应该如何处理。
总结
除了入门外,随着数据工程团队的扩展,观察能力将变得更加重要,使用正确的工具来完成工作是至关重要的。
不要假设你用来运行流程的工具可以自行监控。大多数团队用来运行数据堆栈的工具在可观测性方面存在显著差距——例如,依赖 Airflow 监控 Airflow 可能会迅速演变成过度复杂和不稳定的局面。此外,也不要假设你可以仅用标准的时间序列监控工具来监控计划任务,因为数据流程的复杂性非常不同。
要真正实现可观测性,你需要将执行指标(CPU、运行时间、I/O、数据读取和写入)、管道指标(管道中的任务数量、每个任务的 SLA)、数据指标和 ML 指标(R2、MAE、RMSE)集中在一个地方,并建立一个专门的系统来确保日志的准确性和状态的一致性。
原文。经许可转载。
相关链接:
更多相关话题
我们对算法的痴迷如何破坏了计算机视觉:以及合成计算机视觉如何修复它
原文:
www.kdnuggets.com/2021/10/obsession-algorithms-broke-computer-vision.html
评论
作者:Paul Pop,Neurolabs 的联合创始人兼首席执行官
合成计算机视觉旨在将虚拟世界中的内容翻译回现实世界。(图片来自作者)
????️ 计算机视觉的现状
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
根据Crunchbase的数据,截至目前,过去 8 年里,计算机视觉领域的初创公司获得了超过 150 亿美元的投资。超过 20 家公司目前的估值已超过 10 亿美元,并且根据Forbes的报道,未来还会有更多。
为什么这些公司如此受重视?简单来说,它们在教计算机如何“看”。通过这样做,它们在自动化以前由人类视觉完成的任务。
这一繁荣是由于 2012 年计算机视觉领域的拐点,随着神经网络的出现——这些算法模仿人脑,并使用大量人工标注的数据进行训练。自 2012 年以来,算法不断改进,在许多视觉任务中已能与人类匹敌,例如物体计数,唇读或癌症筛查。
在接下来的 10 年里,每个人都尽了自己的一份力:学术界通过改进算法引领了潮流;大公司则投资了大量人力,勤勉地标注这些图像数据集。其中一些努力甚至被开源,惠及社区,比如ImageNet,一个包含 1400 万张图像的数据集。
不幸的是,现在这些系统正在投入生产时,我们遇到了瓶颈:
-
我们拥有的标记数据是不可靠的。来自 MIT 研究人员的系统研究发现,ImageNet 的*均错误率为5.93%的错误标记,其他数据集的*均错误率为 3.4%。
-
解决数据问题的努力很少。学术界的智力投入几乎完全专注于算法开发,忽视了对良好数据的基本需求——Andrew Ng 的估计比例为99%的算法关注 vs 1%的数据。
-
计算机视觉算法不能很好地泛化从一个领域到另一个领域。一个在法国南部训练检测汽车的算法在雪地中的挪威会很难检测到同样的汽车。同样,一个在特定相机上训练的系统可能在另一种相机品牌和型号上表现不佳。
♟️ 寻找灵感
早在 1946 年,艾伦·图灵就建议将棋类作为计算机能力的基准,此后这一领域经过了大量研究,吸引了广泛的媒体关注。
衡量棋类表现的一种被广泛接受的方法是通过Elo 评级系统,它提供了对玩家技能的有效比较。下图展示了世界冠军和棋类引擎。过去 50 年里,人类表现徘徊在 2800 的评级附*,然后在 2010 年被计算机所压制。
直到上个十年,我们人类设计的棋类算法基于我们能设计和理解的规则。深度学习革命让我们突破了人类理解的局限,带来了飞跃——就像它在计算机视觉领域一样。
棋类引擎与人类 ELO 评级(图片来自作者)
尽管深度学习棋类游戏引擎的进步非常显著,但现在已经被下一个级别的棋类引擎:AlphaZero(来自 DeepMind)所压制。更令人印象深刻的是,AlphaZero 并未使用任何人类来源的数据来实现这一性能。它的构建没有任何关于历史棋局的知识,也没有任何寻找最佳走法的人类指导。AlphaZero 既是老师也是学生——它通过自我对弈并在过程中学习来教会自己如何更好地玩游戏。
AlphaZero 击败了当时最强的棋类引擎Stockfish 8,且没有输掉一场比赛,即使在 AlphaZero 被给予少一个数量级的时间来计算下一步棋时,依然保持了这一优势。
考虑到 AlphaZero 的显著进展,人们不禁要问:我们能否将其在国际象棋中的成功转化为计算机视觉?
???? 新潮流:数据中心化 AI
在新的数据中心化 AI范式下,目标不是创造更好的算法,而是通过改变数据本身来提高性能。即使我们忽略获取和标记图像数据集的困难,数据质量的问题仍然存在:我们是否均匀覆盖了所有可能的使用案例?数据是否涵盖了边缘案例?
如果我们要跟随数据中心化计算机视觉的路径,就必须控制数据来源过程。数据需要*衡,我们需要充分理解影响计算机视觉模型学习的参数。
让我们以一个简单的例子来看待控制这三个参数:摄像机角度、光照和遮挡。你能想象在收集上千张相关图像的同时,还要细心控制这三个参数的值吗?使用真实数据,这个任务是艰巨的。
???? 我们今天如何管理数据?
在过去 5 年里,我们在优化数据收集过程和数据标签质量方面取得了巨大的进步。此外,我们学会了通过使用各种数据增强技术来充分利用数据集。给定我们数据集中的一张图像,我们应用数学函数来创造更多的数据多样性。
目前已有超过 400 家公司,总市场价值达到 1.3 万亿美元(稍高于 Facebook 的市场价值),专注于满足我们最新算法的数据需求。
但当前的路径是否走到死胡同了?我们是否达到了基于人类来源数据集的算法的极限?就像在国际象棋中,只要我们使用人类来源的数据作为算法的输入,我们在设计上就无法显著超越自己的能力。
在国际象棋中,深度学习突破的出现是当我们停止依赖次优的人类数据,并允许机器生成自己的数据以优化学习时。在计算机视觉领域,我们也必须如此,允许机器生成其优化学习所需的数据。
???? 计算机视觉的下一步是什么?
创建训练数据的真正可扩展方式是通过虚拟现实引擎。就真实感而言,输出已变得无法区分现实世界,给予用户完全的场景控制。这使得用户能够生成智能数据,这些数据对计算机视觉模型的学习真正有用。合成数据可以成为新数据中心 AI 框架所需的基石。
我们有充分的理由相信,视觉合成数据广泛应用的时机已经到来。
-
虚拟现实引擎拥有专门的组件用于合成数据生成(NVIDIA IsaacSim, Unity Perception),所生成的数据不仅仅是视觉上的盛宴,而且对于训练更好的算法至关重要。
-
3D 资产正迅速成为商品——最新的iPhone 配备了 LiDAR,而第一代 3D 扫描应用正在产生出色的结果。
-
元宇宙即将到来,并且意义重大。如果预测中的一部分$60B 增长变成现实,我们将生活在一个虚拟现实成为日常的世界中。数字双胞胎今天已有实际应用:例如 BMW 的未来工厂和 Google 的供应链双胞胎。
-
行业内的创新者已经开始使用虚拟现实来改进计算机视觉算法:特斯拉正在使用虚拟世界来生成边缘案例和新颖的驾驶场景视图。
????️????️ 合成计算机视觉 (SCV)
拥有构建自己数据的正确工具,我们可以设想一个计算机视觉算法在没有繁琐的手动数据标记过程下开发和训练的世界。Gartner 预测,在未来 3 年内,合成数据将比真实数据更为普遍。
为什么不再进一步呢?如果有一个世界,其中人类不需要为计算机视觉标注图像,会怎样?
???? 未来光明
使用合成计算机视觉,我们在虚拟现实中构建模型,然后在现实世界中部署。就像 AlphaZero 自己学习了什么在国际象棋中重要一样,我们让算法决定它们需要看到什么,以便最佳地学习。
在合成计算机视觉(SCV)中,我们使用虚拟现实引擎训练计算机视觉模型,并将这些模型部署到现实世界中。
????超越 RGB 图像
现实远比人眼所能看到的要复杂得多。我们构建的算法主要集中在一个人类可以理解和标注的范围内。但情况不必非如此——我们可以为超出人类感知范围的传感器构建算法。我们可以在虚拟现实中以编程方式训练这些算法,而无需对它们的有效性产生怀疑。
???? 更聪明,而非更辛苦
我们可以聪明地选择数据来源来让算法学习,而不是构建更大的模型和使用更多的计算能力来解决问题。算法不需要更多相同的数据来学习,它们需要各种各样的数据。
Deep Mind 展示了 AlphaZero 只是起点,他们将相同的原则应用于围棋、星际争霸和蛋白质折叠。如今,我们拥有所有必要的构建模块来构建一个AlphaZero 式的计算机视觉,这是一个在设计上不受人类输入限制的自学习系统。一个能够创建和操控虚拟场景,并通过这些场景自我学习如何解决视觉自动化任务的系统。
???? 合成数据生成领域的先驱
合成计算机视觉的基础是建立在合成数据上的。大约有30 家初创公司在视觉合成数据生成领域运营。其中一些专注于特定垂直领域的用例,而大多数则在多个垂直领域中横向操作。

按重点分类的合成数据公司(图像作者提供)。
到了 2021 年,我们仍处于起步阶段。请记住,合成数据只是待解决难题的一部分!
❓亲爱的读者,您有以下问题:
- 很容易想象,在 10 年内,你的智能手机在通用视觉感知方面将比你更强大,但我们将如何实现这一点呢?
-
(增强)数据标注员是会长期存在还是仅仅是一个过渡阶段?
-
标注工作会从 2D 世界转移到 3D 世界吗?还是我们可以完全不采用这种方法?
- 通过深度学习算法在计算机视觉领域取得了最先进的成果——合成计算机视觉能否推动一波此前未曾出现的改进算法?
简介: Paul Pop 是 Neurolabs 的联合创始人兼首席执行官。拥有爱丁堡大学计算机科学与人工智能背景,并在过去十年中从事计算机视觉工作。曾在 Hudl 领导团队开发了如今在大多数欧洲足球联赛中使用的计算机视觉球员跟踪系统。
相关:
-
计算机视觉的开源数据集
-
合成数据类型和生成方法概述
-
教 AI 用合成数据分类时间序列模式
更多相关话题
2021 年 ODSC West 的 7 个最酷的机器学习话题
原文:
www.kdnuggets.com/2021/11/odsc-7-coolest-machine-learning-topics.html
赞助文章。
ODSC West 2021 即将到来,议程已经公布。现在是快速了解此次活动中最新和最酷的趋势的好时机。以下是我们推荐的一些热门机器学习话题,以帮助机器学习和数据科学从业者了解领域中的热门话题。
机器学习安全性
停下来思考一下有多少机器学习模型是基于来自社交媒体和网络的众包数据进行训练的,并且意识到如何容易污染训练数据。事实上,这篇微软去年的论文将其列为主要关切(第 2 页)。由基础模型、大规模模型和自主系统驱动,机器学习安全正迅速成为涵盖 AI 和 ML 许多领域的广泛话题。对抗性攻击、后门模型脆弱性、实际部署尾部风险、风险监控和提升防御是 ML 安全领域的一些话题。预计将听到更多关于这一快速发展的主题。
基础模型
大规模训练模型如 GPT-3 和BERT在过去几年中备受关注,因其突破性的成就而获得赞誉。斯坦福 HAI 中心称这些模型为基础模型,这些模型也受到了新的审视。单一模型可以用于许多应用,这增加了机器学习系统设计的挑战和风险。理解这些模型的能力、机会和风险对于构建负责任的 AI 至关重要。ODSC West 将展示许多这些模型,剖析它们的能力和脆弱性。
机器学习可观测性
MLOPs、AIOPs、DataOps。由于重大的行业投资和大量的风险投资资金,任何缩略词都有可能成为当前的热门话题。深入挖掘,你会发现无论缩略词如何,机器学习系统工程领域仍然存在许多未解决的问题。一旦投入生产,机器学习工程师需要监控模型漂移、数据漂移、数据退化、模型改进以及错误检测。可观察性不仅仅适用于实时系统或生产环境。应用机器学习可观察性学科可以及早发现问题,并表明某些机器学习生命周期是静态的。ODSC West 将拥有迄今为止最强的数据工程和 MLOps 会议阵容之一。
深度生成学习
深度生成模型(DGMs)已经存在了一段时间,并因生成深度伪造技术而受到广泛关注,但它们也成功应用于隐马尔可夫模型、GANs、贝叶斯网络、自回归模型等。DGMs 是具有多个隐藏层的神经网络,利用大量样本训练高维概率分布。尽管早期取得了一些成功,但 DGMs 的更广泛应用仍处于初期阶段。这是许多顶尖大学中最热门的研究课题之一,研究人员寻求更好的方法来设计和训练这些模型。随着一些行业顶尖人才的持续关注,我们可以期待更多突破和更广泛的实际应用。
隐私保护的机器学习和差分隐私
允许多个组织协作构建、训练和部署机器学习模型而不危害数据隐私的重要性持续上升。负责任的人工智能是一个广泛的术语,行业内的人更愿意关注确保真正端到端、隐私保护的机器学习模型的众多挑战性问题。现在的重点是机器学习生命周期的所有阶段,包括理解与训练数据、模型输入、模型权重、模型输出和模型监控相关的隐私。此外,该领域正在超越基本的差分 隐私技术,如故意在模型输入和输出中引入统计噪声或其他类型的噪声。机器学习从业者将在 ODSC West 找到有关这一主题的最新信息。
基于深度学习的自然语言处理
得益于*年来的进展,包括迁移学习和变换器模型,自然语言处理(NLP)在行业中继续受到关注。结合监督学习和无监督学习的新技术正在获得关注,并且利用各种深度学习技术的进展仍在继续。递归神经网络和循环神经网络(RNN)处理序列信息(如文本)的特长,使它们在 NLP 模型中特别有用。如前所述,深度生成模型(DGM)已经在 NLP 领域取得了重大突破。ODSC West 将有许多关于 NLP 的精彩会议。
网络安全中的机器学习
鉴于机器学习安全性日益重要,工程师和人工智能专家必须扩大他们在网络安全方面的知识。此外,网络安全是一个快速增长的领域,这得益于机器学习工具和方法的应用。专家们正在运用机器学习来帮助预测和制定更好的威胁事件响应,监控和应对不断演变的威胁,并大大加速数字取证技术。再加上对机器学习、深度学习和自主系统的对抗攻击风险的增加,你会发现这是一个在未来十年内有望大幅增长的领域。这是一个ODSC 的新关注领域。西部会议将有一些网络 ML 领域的领先专家。
立即注册 ODSC West 2021
在我们即将于 11 月 16 日至 18 日在旧金山举行的活动中,ODSC West 2021 将展示大量关于机器学习主题、深度学习、NLP、MLOps 等的演讲、研讨会和培训课程。你可以 立即注册以享受所有票种 20% 的折扣,或 注册获取免费 AI 展会通行证 以了解一些 AI 界的大牌现在在做什么。一些 机器学习主题的亮点会议 包括:
-
迈向更节能的神经网络?动动脑筋!:Olaf de Leeuw | 数据科学家 | Dataworkz
-
实用 MLOps:自动化之旅:Evgenii Vinogradov, 博士 | DHW 开发负责人 | YooMoney
-
现代生存建模在 Python 中的应用:Brian Kent, 博士 | 数据科学家 | The Crosstab Kite 创始人
-
使用变更检测算法检测大型系统中的异常行为:Veena Mendiratta, 博士 | 网络可靠性和分析研究员 | 西北大学
MLOps 会议:
-
使用可重复实验进行超参数调优:Milecia McGregor | 高级软件工程师 | Iterative
-
MLOps…… 从模型到生产:Filipa Peleja, 博士 | 领先数据科学家 | Levi Strauss & Co
-
在异构*台上开发和部署模型的操作化:Sourav Mazumder | 数据科学家、思想领袖、AI 和 ML 操作化领袖 | IBM
-
使用 Ploomber 在 45 分钟内开发和部署机器学习管道:Eduardo Blancas | 数据科学家 | Fidelity Investments
深度学习会议:
-
GANs:理论与实践,使用 TensorFlow 进行图像合成:Ajay Baranwal | 中心主任 | 电子制造深度学习中心有限公司
-
使用图进行机器学习:超越表格数据:Dr. Clair J. Sullivan | 数据科学倡导者 | Neo4j
-
使用 TF-Agents 和 TensorFlow 2.0 深入探索 PPO 强化学习:Oliver Zeigermann | 软件开发者 | embarc 软件咨询有限公司
-
使用 Google Cloud AI *台入门时间序列预测:Karl Weinmeister | 开发者关系工程经理 | 谷歌
如何免费参加 ODSC West 2021
我们还提供了若干种免费参加活动的选项。选项包括:
-
AI 展会与演示剧场:无论你是希望将 AI 雄心提升到新水*的 CxO,还是寻求最新生产力工具的机器学习从业者,我们的 AI 展会和演示剧场都是你的理想之地。线下通行证可在 这里 免费获取,虚拟通行证可在 这里 获取。
-
Ai X 峰会:向商业和机器学习专家学习,了解第一手的实际案例,并看看你也能如何将人工智能融入你的业务。你可以使用代码 FREEAIX 这里 获得一天线下和虚拟通行证的 100%折扣。
-
全程通行证奖学金:我们正在扩展我们的奖学金通行证项目,为参会者提供对 ODSC 的无限制访问,包括实操培训课程和深度研讨会。只需在本周五之前填写 此表单 即可。
-
关心
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关内容
了解为什么 ODSC 是最推荐的应用数据科学会议
原文:
www.kdnuggets.com/2018/10/odsc-understand-most-recommended-conference-applied-data-science.html
赞助帖子。
|
|
|
| |
|
|
|
|
在超过 4,500 名与会者的情况下,开放数据科学大会(ODSC West)已经大幅增长,成为专注于数据科学实际应用的领先活动。
当我们询问新参会者如何听说 ODSC 时,大多数人选择朋友或同事推荐。参会者离开 ODSC 后,扩展了他们的网络,了解了数据科学领域最新的模型、框架和突破。 ODCS 大会为期 4 天,包含 40 场培训课程、50 场研讨会和超过 200 位讲者,提供了无与伦比的深度和广度,涵盖深度学习、机器学习和其他数据科学话题。
我们的日程安排包括一些领先的数据科学思想领袖和许多在应用数据科学领域的崭露头角的明星。与这些专家见面,连接与你的同行,共同参与极具趣味性的项目。
为什么要等待?我们的培训通行证几乎售罄,像往年一样,其他通行证也将很快售罄。
对数据科学的商业方面感兴趣?加入我们,参加加速 AI(与 ODSC West 同期举行),与来自彭博社、SalesForce、AIG、德勤、DataRobot及其他公司顶级行业 AI 专家共度两天。利用我们的四天商务通行证,结合两者的最佳优势!
期待在旧金山见到你,
ODSC 团队 |
|
|
| |
| |
|
更多相关话题
OLAP 与 OLTP:数据处理系统的比较分析
原文:
www.kdnuggets.com/2023/08/olap-oltp-comparative-analysis-data-processing-systems.html

图片来源:作者
现在,组织从各种来源生成大量数据:客户互动、销售交易、社交媒体等等。从这些数据中提取有意义的信息需要能够有效处理、存储和分析数据的系统。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 部门
OLAP(在线分析处理)和 OLTP(在线事务处理)系统在数据处理方面扮演着关键角色。OLAP 系统使企业能够进行复杂的数据分析并推动业务决策。另一方面,OLTP 系统确保日常操作的顺利进行。它们处理实时事务过程,同时保持数据一致性。
让我们进一步了解 OLAP 和 OLTP 系统,并理解它们之间的关键区别。
OLAP 和 OLTP 系统概述
我们将从 OLAP 和 OLTP 系统的概述开始:
什么是 OLAP 系统?
OLAP(在线分析处理) 是一类数据处理系统,旨在支持复杂的分析查询,并从大量的历史数据中提供有价值的见解。
OLAP 系统对于商业智能、数据仓库和决策支持系统等应用至关重要。它们使组织能够分析趋势、发现模式,并基于历史数据做出战略决策。
这些系统利用 OLAP 立方体,这是一种允许进行多维数据分析的基本组件(稍后我们将学习有关 OLAP 立方体的内容)。
什么是 OLTP 系统?
OLTP(在线事务处理) 指的是一种数据处理系统,专门用于实时事务操作和日常操作任务。
OLTP 数据库维护 ACID(原子性、一致性、隔离性、持久性)属性,确保可靠和一致的事务。OLTP 系统通常用于需要快速且并发处理小型、快速和实时事务的应用程序。
因为 OLTP 系统确保数据始终保持最新和一致,所以它们非常适合用于电子商务、银行和金融交易等应用。
OLAP 与 OLTP:它们之间的区别是什么?
现在我们已经了解了 OLAP 和 OLTP 系统,让我们继续了解它们的区别。
#1 – 系统规模和数据量
OLAP 系统通常比 OLTP 系统大得多。OLAP 系统管理大量的历史数据,通常需要显著的存储容量和计算资源。
与 OLAP 系统相比,OLTP 系统处理的数据集相对较小,重点是实时处理和快速响应时间。
#2 – 数据模型
OLAP 数据库使用非规范化的数据结构以优化查询性能。通过存储预聚合和冗余数据,这些系统可以高效地处理复杂的分析查询,无需大量连接。非规范化结构加快了数据检索,但可能会导致存储需求增加。
OLAP 系统支持多维数据分析,通常使用星型或雪花型模式实现,其中数据被组织成维度和度量。所有 OLAP 系统的核心是OLAP 立方体,它促进了多维数据分析。那么 OLAP 立方体是什么?
OLAP 立方体用于多维数据分析 | 图片来源于作者
OLAP 立方体是一种多维数据结构,将数据组织成多个维度和度量。
-
每个维度表示一个特定的类别或属性,例如时间、地理、产品或客户。
-
度量是与这些维度相关的数值或指标。这些通常包括数据如销售收入、利润、销售数量或任何其他相关的 KPI(关键绩效指标)。
立方体的多维结构允许用户从不同的角度探索数据,包括钻取、切片、切块和汇总等操作—在不同的粒度级别查看数据。
例如,考虑一个包含电子商务公司销售数据的 OLAP 立方体。立方体的维度可能包括:
-
时间(月份、季度、年份),
-
地理(国家、地区等),以及
-
产品类别(电子产品、时尚、家用电器等)。
一些度量包括销售收入、销售数量和利润。OLAP 立方体让你通过选择特定维度分析销售表现,例如查看特定时间段内某一地区的销售收入,或比较不同产品类别的销售情况。
OLTP 数据库采用规范化的数据结构,以最小化数据冗余并确保数据完整性。规范化将数据分为多个相关表,减少数据异常的风险并提高存储效率。
#3 – 查询类型与响应时间
OLAP 系统优化了处理涉及聚合、排序、分组和计算的复杂分析查询。这些查询通常涉及大量历史数据,并需要显著的计算资源。由于其分析性质,OLAP 查询可能具有较长的执行时间。
OLTP 系统设计用于处理大量小型、快速和并发的事务查询。这些查询主要涉及单条记录的插入、更新和删除。OLTP 系统专注于实时数据处理,并确保事务操作的快速响应时间。
#4 – 性能需求
OLAP 系统旨在支持复杂的分析查询和多维数据分析。
OLTP 系统应该具备快速的响应时间。它们应能够支持大量的并发事务,同时保持数据完整性——数据差异最小化。
OLAP 与 OLTP:总结区别
让我们通过列出 OLAP 和 OLTP 系统在我们讨论的不同特性上的区别来总结我们的讨论:
| 特性 | OLAP | OLTP |
|---|---|---|
| 数据量 | 大量历史数据 | 小量实时事务数据 |
| 系统规模 | 远大于 OLTP 系统 | 远小于 OLTP 系统 |
| 数据模型 | 为了性能而非规范化 | 为了完整性和最小冗余而规范化 |
| 查询类型 | 复杂分析查询 | 简单查询 |
| 响应时间 | 可能较长的执行时间 | 更快的响应时间 |
| 性能需求 | 数据的多维分析,针对涉及聚合的复杂查询优化以提高检索速度 | 实时并发事务的快速处理,具有低延迟 |
总结
总结:OLAP 系统有助于对大量历史数据进行深入分析,而 OLTP 系统则确保快速可靠的实时操作。
然而,在实际应用中,组织通常会在其数据处理生态系统中部署 OLAP 和 OLTP 的组合。这种混合方法使他们能够有效管理操作数据,同时从历史数据中获取有价值的见解。
如果你想开始学习数据工程,查看这份数据工程初学者指南。
Bala Priya C 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过编写教程、操作指南、评论文章等方式,学习并与开发者社区分享她的知识。
更多相关内容
SQL 中的 OLAP 查询:回顾
原文:
www.kdnuggets.com/2018/09/olap-queries-sql-refresher.html
评论
作者:Wilfried Lemahieu,Seppe vanden Broucke,Bart Baesens

我们的前三推荐课程
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
以下文章基于我们最*的书籍:《数据库管理原则 - 存储、管理和分析大数据与小数据的实用指南》(详见 www.pdbmbook.com)。
在这篇文章中,我们详细讲解了如何在 SQL 中实现 OLAP 查询。为了方便执行 OLAP 查询和数据聚合,SQL-99 引入了对 GROUP BY 语句的三种扩展:CUBE、ROLLUP 和 GROUPING SETS 操作符。
CUBE操作符计算指定属性类型每个子集上的 GROUP BY 的并集。其结果集表示基于源表的多维立方体。考虑以下 SALES TABLE。
| 产品 | 季度 | 地区 | 销售额 |
|---|---|---|---|
| A | Q1 | Europe | 10 |
| A | Q1 | America | 20 |
| A | Q2 | Europe | 20 |
| A | Q2 | America | 50 |
| A | Q3 | America | 20 |
| A | Q4 | Europe | 10 |
| A | Q4 | America | 30 |
| B | Q1 | Europe | 40 |
| B | Q1 | America | 60 |
| B | Q2 | Europe | 20 |
| B | Q2 | America | 10 |
| B | Q3 | America | 20 |
| B | Q4 | Europe | 10 |
| B | Q4 | America | 40 |
示例 SALESTABLE。
我们现在可以制定以下 SQL 查询:
SELECT QUARTER, REGION, SUM(SALES)
FROM SALESTABLE
GROUP BY CUBE (QUARTER, REGION)
基本上,这个查询计算了 SALESTABLE 的 2² = 4 种分组的并集,分组为:{(quarter,region), (quarter), (region), ()},其中()表示一个空的分组列表,代表整个 SALESTABLE 的总聚合。换句话说,由于 quarter 有 4 个值,region 有 2 个值,结果多重集将包含 42+41+1*2+1 或 15 个元组,如表 1 所示。维度列 Quarter 和 Region 中已添加了 NULL 值以指示发生的聚合。如果需要,可以用更有意义的‘ALL’替换这些 NULL 值。更具体地说,我们可以添加 2 个 CASE 子句,如下所示:
SELECT CASE WHEN grouping(QUARTER) = 1 THEN 'All' ELSE QUARTER END AS QUARTER, CASE WHEN grouping(REGION) = 1 THEN 'All' ELSE REGION END AS REGION, SUM(SALES)
FROM SALESTABLE
GROUP BY CUBE (QUARTER, REGION)
grouping() 函数在聚合过程中生成 NULL 值时返回 1,否则返回 0。这有助于区分生成的 NULL 和可能的真实 NULL。我们不会将其添加到后续的 OLAP 查询中,以避免不必要的复杂化。
此外,注意第五行销售额的 NULL 值。这代表了在原始 SALESTABLE 中不存在的属性组合,因为显然在欧洲的 Q3 没有销售产品。注意,除了 SUM(),SELECT 语句中还可以使用其他 SQL 聚合函数,如 MIN()、MAX()、COUNT() 和 AVG()。
| 季度 | 区域 | 销售额 |
|---|---|---|
| Q1 | Europe | 50 |
| Q1 | America | 80 |
| Q2 | Europe | 40 |
| Q2 | America | 60 |
| Q3 | Europe | NULL |
| Q3 | America | 40 |
| Q4 | Europe | 20 |
| Q4 | America | 80 |
| Q1 | NULL | 130 |
| Q2 | NULL | 100 |
| Q3 | NULL | 40 |
| Q4 | NULL | 90 |
| NULL | Europe | 110 |
| NULL | America | 250 |
| NULL | NULL | 360 |
表 1:使用 Cube 运算符的 SQL 查询结果。
ROLLUP 运算符计算指定属性类型列表的每个前缀的并集,从最详细的到总计。它特别适用于生成包含小计和总计的报告。ROLLUP 与 CUBE 运算符的主要区别在于前者生成一个显示指定属性类型值层级的聚合结果集,而后者生成一个显示所有选定属性类型值组合的聚合结果集。因此,属性类型的提及顺序对于 ROLLUP 很重要,但对于 CUBE 运算符则不然。考虑以下查询:
SELECT QUARTER, REGION, SUM(SALES)
FROM SALESTABLE
GROUP BY ROLLUP (QUARTER, REGION)
此查询生成了三个分组的并集 {(季度, 区域), (季度}, ()},其中 () 代表完全聚合。结果多重集将有 4*2+4+1 或 13 行,显示在表 2 中。可以看到,区域维度首先被汇总,然后是季度维度。注意与表 1 中 CUBE 运算符的结果相比,被省略的两行。
| 季度 | 区域 | 销售额 |
|---|---|---|
| Q1 | Europe | 50 |
| Q1 | America | 80 |
| Q2 | Europe | 40 |
| Q2 | America | 60 |
| Q3 | Europe | NULL |
| Q3 | America | 40 |
| Q4 | Europe | 20 |
| Q4 | America | 80 |
| Q1 | NULL | 130 |
| Q2 | NULL | 100 |
| Q3 | NULL | 40 |
| Q4 | NULL | 90 |
| NULL | NULL | 360 |
表 2:使用 ROLLUP 运算符的 SQL 查询结果。
前面的示例将 GROUP BY ROLLUP 构造应用于两个完全独立的维度,它也可以应用于表示同一维度上不同聚合级别(因此不同详细级别)的属性类型。例如,假设 SALESTABLE 元组表示了更详细的城市级别销售数据,并且表中包含三个与位置相关的列:City、Country 和 Region。我们可以制定以下 ROLLUP 查询,分别按城市、国家、地区和总计计算销售总额:
SELECT REGION, COUNTRY, CITY, SUM(SALES)
FROM SALESTABLE
GROUP BY ROLLUP (REGION, COUNTRY, CITY)
请注意,在这种情况下,SALESTABLE 将包括 City、Country 和 Region 属性类型在一个表中。由于这三种属性类型表示同一维度中的不同详细级别,它们在传递上相互依赖,说明这些数据仓库数据确实是非规范化的。
GROUPING SETS 操作符生成的结果集等同于多个简单 GROUP BY 子句的 UNION ALL 结果。考虑以下示例:
SELECT QUARTER, REGION, SUM(SALES)
FROM SALESTABLE
GROUP BY GROUPING SETS ((QUARTER), (REGION))
该查询等同于:
SELECT QUARTER, NULL, SUM(SALES)
FROM SALESTABLE
GROUP BY QUARTER
UNION ALL
SELECT NULL, REGION, SUM(SALES)
FROM SALESTABLE
GROUP BY REGION
结果见表 3。
| 季度 | 地区 | 销售额 |
|---|---|---|
| Q1 | NULL | 130 |
| Q2 | NULL | 100 |
| Q3 | NULL | 40 |
| Q4 | NULL | 90 |
| NULL | 欧洲 | 110 |
| NULL | 美国 | 250 |
表 3:使用 GROUPING SETS 操作符的 SQL 查询结果
可以在单个 SQL 查询中使用多个 CUBE、ROLLUP 和 GROUPING SETS 语句。不同组合的 CUBE、ROLLUP 和 GROUPING SETS 可以生成等效的结果集。考虑以下查询:
SELECT QUARTER, REGION, SUM(SALES)
FROM SALESTABLE
GROUP BY CUBE (QUARTER, REGION)
该查询等同于:
SELECT QUARTER, REGION, SUM(SALES)
FROM SALESTABLE
GROUP BY GROUPING SETS ((QUARTER, REGION), (QUARTER), (REGION), ())
同样,以下查询:
SELECT QUARTER, REGION, SUM(SALES)
FROM SALESTABLE
GROUP BY ROLLUP (QUARTER, REGION)
与以下内容相同:
SELECT QUARTER, REGION, SUM(SALES)
FROM SALESTABLE
GROUP BY GROUPING SETS ((QUARTER, REGION), (QUARTER),())
给定需要聚合和检索的数据量,OLAP SQL 查询可能会非常耗时。加快性能的一种方法是将这些 OLAP 查询转换为物化视图。例如,使用 CUBE 操作符的 SQL 查询可以用来预计算选定维度上的聚合,结果可以存储为物化视图。物化视图的一个缺点是需要额外的努力定期刷新这些物化视图,但通常公司对接*当前版本的数据是满意的,因此同步可以在夜间或固定时间间隔进行。
欲了解更多信息,我们很高兴推荐我们的最新书籍:数据库管理原理 - 大数据与小数据存储、管理和分析的实用指南。
简介:Wilfried Lemahieu 是 KU Leuven(比利时)的教授,研究领域包括大数据存储、集成与分析、数据质量以及业务流程管理和服务导向。
塞佩·范登·布鲁克 于 2014 年在比利时 KU Leuven 获得应用经济学博士学位。目前,塞佩在 KU Leuven 的决策科学与信息管理系担任助理教授。塞佩的研究兴趣包括商业数据挖掘和分析、机器学习、过程管理和过程挖掘。他的工作已发表在知名国际期刊上,并在顶级会议上展示。
巴特·贝森斯是 KU Leuven 的副教授,并且是南安普顿大学(英国)的讲师。他在分析、客户关系管理、网络分析、欺诈检测和信用风险管理方面做了广泛的研究。他的研究成果已发表在知名国际期刊上(例如《机器学习》、《管理科学》、《IEEE 神经网络汇刊》、《IEEE 知识与数据工程汇刊》、《IEEE 演化计算汇刊》、《机器学习研究杂志》等),并在国际顶级会议上进行了展示。
相关:
更多相关话题
Ollama 教程:本地运行 LLMs 变得超级简单
原文:
www.kdnuggets.com/ollama-tutorial-running-llms-locally-made-super-simple
图片由作者提供
在本地运行大型语言模型(LLMs)非常有帮助——无论你是想玩玩 LLMs 还是使用它们构建更强大的应用程序。但是,配置工作环境并让 LLMs 在你的机器上运行并不简单。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
那么,如何在没有麻烦的情况下本地运行 LLMs 呢?Ollama 就是答案,它使得使用开源大型语言模型的本地开发变得轻而易举。使用 Ollama,你运行 LLM 所需的一切——模型权重和所有配置——都被打包成一个 Modelfile。就像 Docker 对 LLMs 一样。
在本教程中,我们将深入了解如何使用 Ollama 在本地运行大型语言模型。所以让我们直接进入步骤!
第一步:下载 Ollama 以开始
首先,你应该将 Ollama 下载到你的机器上。Ollama 支持所有主要*台:MacOS、Windows 和 Linux。
要下载 Ollama,你可以访问 官方 GitHub 仓库 并从那里跟随下载链接。或者访问 官方网站 下载适用于 Mac 或 Windows 机器的安装程序。
我使用的是 Linux:Ubuntu 发行版。如果你也是像我一样的 Linux 用户,你可以运行以下命令来执行安装脚本:
$ curl -fsSL https://ollama.com/install.sh | sh
安装过程通常需要几分钟。在安装过程中,任何 NVIDIA/AMD GPU 将被自动检测。确保你已安装驱动程序。仅 CPU 模式也可以正常工作,但可能会慢很多。
第二步:获取模型
接下来,你可以访问 模型库 查看当前支持的所有模型家族列表。默认下载的模型是带有 latest 标签的。在每个模型的页面上,你可以获取更多信息,如大小和量化方式。
你可以通过标签列表搜索以找到你想要运行的模型。对于每个模型系列,通常有不同大小的基础模型和经过指令调优的变体。我对运行来自 Google DeepMind 的 Gemma 轻量级模型系列 中的 Gemma 2B 模型感兴趣。
你可以使用 ollama run 命令来运行模型,以直接与模型进行交互。不过,你也可以先将模型下载到你的机器上,然后再运行。这与使用 Docker 镜像的方式非常相似。
对于 Gemma 2B,运行以下拉取命令将模型下载到你的机器上:
$ ollama pull gemma:2b
模型的大小为 1.7B,拉取应该需要一两分钟:
步骤 3:运行模型
使用如上所示的 ollama run 命令运行模型:
$ ollama run gemma:2b
这样会启动一个 Ollama REPL,你可以在其中与 Gemma 2B 模型进行交互。以下是一个示例:

对于关于 Python 标准库的简单问题,回应似乎相当不错。并且包括了最常用的模块。
步骤 4:通过系统提示自定义模型行为
你可以通过设置系统提示自定义 LLMs,以实现特定的期望行为:
-
设置系统提示以实现期望的行为。
-
通过给模型命名来保存它。
-
退出 REPL 并运行你刚刚创建的模型。
假设你希望模型始终用尽可能简单的英语解释概念或回答问题。以下是实现方法:
>>> /set system For all questions asked answer in plain English avoiding technical jargon as much as possible
Set system message.
>>> /save ipe
Created new model 'ipe'
>>> /bye
现在运行你刚刚创建的模型:
$ ollama run ipe
以下是一个示例:
步骤 5:在 Python 中使用 Ollama
运行 Ollama 命令行客户端并在 Ollama REPL 本地与 LLMs 进行交互是一个很好的开始。但通常你会希望在应用程序中使用 LLMs。你可以在你的机器上将 Ollama 作为服务器运行,并运行 cURL 请求。
但也有更简单的方法。如果你喜欢使用 Python,你会想要构建 LLM 应用程序,以下是几种方法:
-
使用官方 Ollama Python 库
-
使用 Ollama 与 LangChain
在运行以下部分中的代码片段之前,请拉取你需要使用的模型。
使用 Ollama Python 库
要使用 Ollama Python 库,你可以像这样使用 pip 安装:
$ pip install ollama
还有一个官方的 JavaScript 库,如果你更喜欢用 JS 开发,可以使用它。
一旦你安装了 Ollama Python 库,你可以在 Python 应用程序中导入它并使用大型语言模型。以下是一个简单语言生成任务的代码片段:
import ollama
response = ollama.generate(model='gemma:2b',
prompt='what is a qubit?')
print(response['response'])
使用 LangChain
另一种在 Python 中使用 Ollama 的方法是使用 LangChain。如果你有现有的使用 LangChain 的项目,集成或切换到 Ollama 会很容易。
确保你已安装 LangChain。如果没有,请使用 pip 安装:
$ pip install langchain
这是一个示例:
from langchain_community.llms import Ollama
llm = Ollama(model="llama2")
llm.invoke("tell me about partial functions in python")
在 Python 应用程序中使用 LLM 使得根据应用程序的需要在不同的 LLM 之间切换变得更加容易。
总结
使用 Ollama,你可以在本地运行大型语言模型,并通过几行 Python 代码构建由 LLM 驱动的应用程序。在这里,我们探讨了如何在 Ollama REPL 中以及在 Python 应用程序中与 LLM 进行交互。
接下来我们将尝试使用 Ollama 和 Python 构建一个应用程序。在那之前,如果你希望深入了解 LLM,请查看 掌握大型语言模型的 7 个步骤。
Bala Priya C**** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专业领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过撰写教程、操作指南、观点文章等与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关主题
人工智能与机器学习:顶级影响者与品牌
原文:
www.kdnuggets.com/2016/03/onalytica-ai-machine-learning-top-influencers-brands.html
Onalytica是一家专注于社交网络分析和影响者关系软件的公司,最*发布了他们最新的《人工智能与机器学习领域的前 100 名影响者与品牌报告》。该报告列出了每个类别中的前 100 名,并通过图形化方式探索了它们之间的关系。
报告的网站分享了每个类别(影响者和品牌)的前 50 名名单,而可下载的完整报告则包含前 100 名。作为预览,这里是前 20 名影响者的名单:
| 排名 | Twitter 账号 | 姓名 | 公司 | 影响者评分 |
|---|---|---|---|---|
| 1 | @MikeTamir | Michael Tamir | Galvanize | 42.37 |
| 2 | @KirkDBorne | Kirk Borne | Booz Allen Hamilton | 41.5 |
| 3 | @kdnuggets | Gregory Piatetsky | KDnuggets | 36.87 |
| 4 | @craigbrownphd | Craig Brown, Ph.D. | STEM | 32.61 |
| 5 | @bobgourley | Bob Gourley | Cognitio Corp | 23.73 |
| 6 | @davidwkenny | David Kenny | IBM Watson | 23.49 |
| 7 | @genekogan | Gene Kenny | Sourcetone | 23.18 |
| 8 | @randhindi | Rand Hindi | Snips | 22.87 |
| 9 | @mappingbabel | Jack Clark | Bloomberg | 17.51 |
| 10 | @randal_olson | Randal Olson | 宾夕法尼亚大学 | 17.03 |
| 11 | @jordannovet | Jordan Novet | VentureBeat | 16.92 |
| 12 | @GaryMarcus | Gary Marcus | Geometric Intelligence | 16.53 |
| 13 | @xamat | Xavier Amatriain | Quora | 15.69 |
| 14 | @RickKing16 | Rick King | 顾问 | 14.95 |
| 15 | @EdKwedar | Ed Kwedar | 顾问 | 14.21 |
| 16 | @miha_jlo | Mihajlo Grbovic | Yahoo Labs | 13.62 |
| 17 | @ilparone | Jarno M. Koponen | Random, TechCrunch | 13.16 |
| 18 | @alexjc | Alex J. Champandard | AiGameDev, nucl.ai | 12.35 |
| 19 | @guestrin | Carlos Guestrin | Dato | 11.57 |
| 20 | @willknight | Will Knight | Technology Review | 9.73 |
以下是顶级影响者之间关系的图示(Onalytica 网站上也有类似的图示用于顶级品牌)。点击放大。
顶级影响者关系图(点击放大)。
Onalytica 联系了一些顶级影响者,了解他们对人工智能和机器学习的看法,并在他们的帖子中包含了一些见解。 Kirk Borne,Booz Allen Hamilton 的首席数据科学家以及排名第二的影响者,分享了以下观点:
我认为机器学习指的是一组基础的数学算法,这些算法学习描述数据中的模式和特征的模型,而数据挖掘则是应用这些算法从大数据集中发现知识,人工智能则是将这些算法应用于设备(如机器人)中以实现自主行动和决策。
KDnuggets 的 Gregory Piatetsky-Shapiro 表示:
过去那些声称人工智能不会击败人类棋手、或无法识别图像等“专家”们,已经被证明是错误的。人工智能和机器学习似乎没有任何成就的障碍。现在是认真对待人工智能的时候了,需要考虑其带来的巨大利益以及来自人类级别人工智能的巨大风险。
而 Randal Olson,宾夕法尼亚大学生物医学信息学研究所的博士后研究员,分享了以下内容:
随着 DeepMind 的 AlphaGO 挑战世界顶级围棋选手,Boston Dynamics 的双足机器人(Atlas)进军机器人领域,以及更多的发展,2016 年看起来将是人工智能和机器学习的突破性一年。
以下是前 20 个品牌的名单:
| 排名 | Twitter 账号 | 名称 | 影响者评分 |
|---|---|---|---|
| 1 | @xdotai | x.ai | 100 |
| 2 | @wef | 世界经济论坛 | 76.43 |
| 3 | @IBMWatson | IBM Watson | 70.41 |
| 4 | @xprize | XPRIZE | 68.77 |
| 5 | @TechCrunch | TechCrunch | 46.66 |
| 6 | @MSFTResearch | 微软研究 | 45.93 |
| 7 | @IBM | IBM | 38.03 |
| 8 | @Microsoft | @Microsoft | 37.16 |
| 9 | @techreview | 麻省理工科技评论 | 36.4 |
| 10 | @Forbes | 福布斯 | 33.16 |
| 11 | @nvidia | NVIDIA | 30.94 |
| 12 | @Techmeme | Cloudera | 27.41 |
| 13 | @analyticbridge | 大数据科学 | 26.24 |
| 14 | @sejournal | SearchEngineJournal® | 26.17 |
| 15 | @YahooLabs | Yahoo Labs | 19.13 |
| 16 | @Toyota | Toyota USA | 18.59 |
| 17 | @innovateuk | Innovate UK | 18.55 |
| 18 | @TechRepublic | TechRepublic | 15.29 |
| 19 | @singularityhub | Singularity Hub | 15.22 |
| 20 | @open_ai | OpenAI | 15.14 |
完整报告可以 从 Onalytica 的网站 下载。
相关内容:
-
2016 年大数据:顶级影响者和品牌
-
前 100 大大数据专家
-
数据科学领域的 123 位最具影响力人物
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关内容
机器学习程序的入职培训
原文:
www.kdnuggets.com/2018/04/onboarding-machine-learning.html
评论
Adam Hunt,首席数据科学家,RiskIQ

现如今,“机器学习”是你在阅读几乎任何行业时无法避免的流行词汇。
其“超越”人类的能力被誉为一种神奇的投资回报率提升器,能够在最小化资源支出的同时极大地提高生产力。安全行业也不例外。随着互联网规模的攻击活动压倒了安全团队,导致他们在海量数据中难以快速处理警报,机器学习本应成为现代网络安全问题的灵丹妙药。然而,随着巨大的宣传往往带来巨大的失望,我们现在正在经历越来越多的人的反感,他们认为机器学习根本没有达到预期。
事实是,机器学习并不是万能的灵丹妙药。然而,这并不意味着它对安全程序没有极大的帮助,也对网络安全的未来至关重要,人们只需要重新考虑使用它的方式。与其将其视为全能的机器人霸主,揭示其潜力的秘诀是将其视为一个非常初级的员工。
机器学习并不是房间里的那个唯一
机器学习模型快速、无疲倦、记忆力强但完全没有常识。就像任何一个实习生在第一天一样,你不会指望它知道你的组织如何运作,也不一定知道你希望它最终掌握的概念。当你开始使用机器学习程序时,把它当作一个入职培训过程来思考。一开始,你需要频繁检查你的模型,并花费大量时间将它们引导到正确的方向。最初,这些模型希望通过处理大量数据以惊人的速度推动你的业务达到新高,但它们甚至不理解你要求它们完成的任务。
机器学习无法进行批判性思维,这可能是大多数失望的来源,也解释了为什么在机器学习时代的网络安全中,人类需要扮演非常重要的角色。由于你的模型是低层次(但勤奋)的任务执行者,无法看到全局,你需要不断地喂给它们指令。随着时间的推移,它们会根据你的反馈逐渐识别模式,并开始理解你希望它们寻找的内容。
随着你的模型学习,你需要对它们进行的检查会越来越少,但它们不能也不应该完全自主。它们不会像你一样看待事物,也不会遵循像我们自己的思维过程。它们可能会迅速偏离当前任务,导致你的整个程序陷入混乱。
下面是如何充分利用你的机器学习程序,以确保它能够兑现其宣传的方式:
实施安全网和监控:
一旦你认为你的模型表现良好,你需要一些措施来确保它不会偏离轨道。在构建管道之前,请确保你有适当的安全网。第一个安全网就是我们所称的触发器。如果你的模型在某一段时间内分类的实例数量超出了你的预期,你的触发器会自动禁用它。这一措施对于防止你的模型失控至关重要。
模型在首次发布时出现偏离预期的情况非常常见,因为虽然你提供了一个全新的、精心挑选的数据集供模型学习,但现实世界非常复杂,复杂程度远超你的预期。就像一个刚毕业的大学生,你的模型将遇到课本中没有的情况,从而使其依赖于通过训练数据形成的偏见。
例如,如果你的训练数据仅包含猫和狗,当你提供给它一条鱼时,它会尝试将其分类为猫或狗。与具备常识的人不同,你的模型需要被纠正,从错误中学习并重新尝试。用于训练你模型的算法也存在固有的偏见。就像人一样,每个模型都会对问题形成自己的观点。起初,它会做出过于简单的假设(我们稍后会详细讲解)。
下一个安全网是白名单。这些是你希望你的模型忽略的项目列表。在理想情况下,你不需要白名单,因为你会投入时间来优化特征并重新训练你的模型,直到它正确处理特定的例子。然而,当你需要立即采取行动时,你会感激自己拥有这些白名单。虽然不是理想的解决方案,但白名单不仅能防止你当前的模型错误分类实例,还能帮助你的未来模型。
防止退化:
你的模型一开始可能工作正常,但如果没有适当的反馈,其性能会随着时间的推移而退化(第一周的精确度会比第十周更高)。模型退化到不可接受水*所需的时间取决于你的容忍度和模型对问题的泛化能力。
世界时刻在变化,你的模型也应随之变化。如果你希望你的模型跟上当前的趋势,选择一个基于实例的模型或一个可以增量学习的模型是至关重要的。就像频繁的反馈帮助员工学习和成长一样,你的模型也需要这种反馈。
主动学习:
主动学习让专家参与其中。当模型不确定如何对某个实例进行分类时,能够请求帮助是至关重要的。模型通常会提供一个概率或分数,其预测会根据你提供的某个阈值转化为二元决策(即威胁或非威胁)。
但如果没有指导,情况会很快变得棘手。想象一个初级安全研究员不知道如何评估某个威胁。他们认为某些东西可能是恶意的,但不确定。他们发了一封邮件请求帮助,但那封邮件可能一个月或更久都没有得到回应。
如果员工自由行动,他们可能会做出错误的假设。如果实例刚好低于截止点,但威胁是真实的,模型将继续忽略它,导致潜在的严重假阴性。然而,如果模型选择采取行动,它将继续标记良性实例,产生大量假阳性。开发一个反馈机制,使你的模型能够识别和展示可疑项,对模型的成功至关重要。
混合与协同训练:
每个人都知道协作和多样性有助于组织成长。当首席执行官被“唯唯诺诺”的人包围,或者孤狼决定自己可以做得更好时,想法会停滞。机器学习模型也不例外。数据科学家有他们“首选”的算法来训练他们的模型。重要的是不仅要尝试其他算法,还要将不同的算法结合起来尝试。
结论
我们生活在一个数据驱动的社会中,人类真的无法独自应对。通过一些工作,机器学习可以用来利用员工的知识和能力来填补人才库中的必要空缺。然而,机器学习模型不是你可以设置后就不管的东西。它们需要频繁的反馈和监控,以提供最佳性能。为自己着想,让反馈变得简单。你投入的时间将带来回报。
个人简介:亚当·亨特 是 RiskIQ 的首席数据科学家。他拥有普林斯顿大学的物理学博士学位(2013 年)。
相关:
我们的前三大课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关内容
让你的数据项目价值提高 10 倍的一个问题
原文:
www.kdnuggets.com/2021/02/one-question-data-project-10x-valuable.html
评论
布列塔尼·戴维斯,Narrator 数据主管。

我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织的 IT
数据人员的工作是帮助人们做出决策。无论是快速的临时查询还是高度复杂的统计模型,归根结底,我们都是在为决策提供信息。
我们有多少人在手机上访问我们的网站?
我应该给这个客户提供什么折扣?
谁可能会流失?
决策是我们工作的核心,以至于我们有时会在开始数据项目之前忘记承认它们。我们假设决策融入了我们所做的一切,因此当产品团队提出像“哪些产品常常一起购买?”这样的问题时,我们自然会直接进入数据需求、最佳方法等的探讨。虽然这是一个简单的问题,而数据工作可能会很有趣。我们应该如何可视化结果?如果模式随时间发生了变化怎么办?我们直接进入数据分析,而没有花时间真正(我指的是真正)理解我们试图提供信息的决策。
细节决定成败——而细节在这里尤为重要。如果不了解数据将如何使用,我们无法给出正确的答案。
“如果我只有一个小时来拯救世界,我会花五十五分钟来定义问题,只用五分钟来寻找解决方案。” – 阿尔伯特·爱因斯坦
神奇的问题
幸运的是,我们不需要花费所有时间来定义问题。这里有一个简单的问题,可以在几分钟内抓住任何数据请求的核心:
“你试图做出什么决定?”
附注:在获得答案后你会采取什么行动?
如果没有行动,就不会有影响。这个问题将剖析所有杂乱无章的内容,直接进入行动。
答案可能会非常有启发性!这就是它如此强大的原因。
一个好的回应是具体的! 几乎立即,你应该能够想象他们看到数据后的行动。如果没有,那就是一个信号,表明需要暂停并在考虑数据之前明确问题。
一个好的回答听起来是这样的:
-
“我需要知道哪些客户可能会流失,因为我想给他们发送 10 美元的忠诚积分以挽救他们。”
-
“我需要了解如何对我们的客户进行分段,因为我想基于我们最高价值的客户建立一个类似的受众。”
-
“我需要知道哪一天的打开率最高,因为我想知道我们应该在什么时候发送邮件以获得最多的参与。”
这些回答是具体的,并且有明确的行动计划。很明显,行动将根据数据的结果而改变。不幸的是,并非所有的回答一开始都是好的回答。
以下是一些需要注意的红旗示例:
-
听起来具体但实际上不具体的回答。 小心那些听起来很具体但实际上并非如此的回答。“我需要对我们的客户进行分段,以便我可以个性化他们的邮件。”这是什么意思?他们将如何个性化邮件?我们可能会发现邮件团队只是想更新主题行以提高打开率。这些信息可能会改变整个分析。
-
“一旦我看到数据,我就知道该怎么做。” 这通常是没有行动计划的标志。这些回答通常会导致一个分析有趣但不可操作的常见情况。如果你听到这样的回答,我建议和你的同事进行一些假设演练:“如果数据说 X,你会怎么做?如果它说 Y 呢?”我喜欢这个练习,因为它允许你们俩窥探未来,在你们有了答案但仍不知道如何处理的情况下。大多数人倾向于对数据能为他们做什么进行浪漫化幻想,这也是为什么当你得到分析结果但它无法解决任何问题时会感到失望。假设游戏有助于让每个人回到现实,并对数据能够实现的内容保持务实态度。
-
“一旦我知道答案,我将能够问。” 更多的问题是好的,只要它们最终能引导到行动。无尽的问题只是会导致更多的学习,学习固然重要,但它不是公司运作的核心——决策才是。对于这样的回答,跟踪问题的线索,看看是否最终能得到一个行动:“在你回答后续问题之后,你打算做什么?”
-
“我不知道。” 一个熟练的数据分析师通常可以识别出那些不会产生实际行动的数据问题,但帮助其他人看到这一点可能会很困难。问相关人员数据将如何改变他们的决策是一个很好的方式,帮助他们意识到他们的数据问题不会给出他们想要的结果。经常问这个魔法问题,你一定会得到一些“我不知道”的回答。当这种情况发生时,这是一个重新调整的绝佳机会。从一个决策开始并找出需要的数据要比反过来要容易得多。
下次有人向你提出数据请求时,请记住那个神奇的问题。并且记住,一个糟糕的回答并不意味着游戏结束。这应该是你达到最终、更好数据问题的起点。一个熟练的数据分析师总是会挖掘出真正的问题,并在开始任何项目之前理解真实的决策。这就是一个数据项目“有趣”和一个能产生影响的数据项目之间的区别。
原文。经授权转载。
相关内容:
更多相关内容
数据科学实用技巧:如何使用一对多和一对一进行多分类
原文:
www.kdnuggets.com/2020/08/one-vs-rest-one-multi-class-classification.html
评论
由机器学习专业人士兼作家托马斯·格雷。

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水*
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
只有少数分类模型支持多分类。特定算法,包括逻辑回归和感知机,最适合于二分类,并不支持多于两个类别的分类任务。解决多分类问题的最佳替代方法是将多分类数据集拆分为多个适合二分类模型的数据集合。
用于二分类问题的算法无法处理多分类任务。因此,启发式方法,如一对一和一对多,用于将多分类问题拆分为多个二进制数据集,并训练二分类模型。
二分类与多分类
分类问题在机器学习中很常见。在大多数情况下,开发者倾向于使用监督机器学习方法来预测给定数据集的类别表。与回归不同,分类涉及设计分类器模型并训练它来输入和分类测试数据集。为此,你可以将数据集分为二分类或多分类模块。
如其名所示,二分类涉及解决只有两个类别标签的问题。这使得过滤数据、应用分类算法和训练模型以预测结果变得简单。另一方面,多分类适用于输入训练数据中有多个类别标签的情况。该技术使开发者能够将测试数据分类为多个二进制类别标签。
话虽如此,虽然二分类只需一个分类模型,但多分类方法中使用的模型则取决于分类技术。以下是多分类算法的两种模型。
多类别分类的一对多分类模型
一对多模型,也称为一对所有,是一种定义明确的启发式方法,利用二分类算法进行多类别分类。该技术涉及将多类别数据集拆分成多个二分类问题。之后,训练一个二分类器来处理每个二分类模型,其中最有信心的一个进行预测。
例如,对于一个包含红色、绿色和蓝色数据集的多类别分类问题,二分类可以按如下方式进行分类:
-
问题一:红色 vs. 绿色/蓝色
-
问题二:蓝色 vs. 绿色/红色
-
问题三:绿色 vs. 蓝色/红色
使用此模型唯一的挑战在于你需要为每个类别创建一个模型。上述数据集中的三个类别需要三个模型,这对于具有百万行数据的大数据集、较慢的模型(如神经网络)以及具有大量类别的数据集可能会很具挑战性。
一对多方法需要单独的模型来预测类似概率的得分。然后使用得分最高的类别索引来预测类别。因此,它通常用于能够自然预测得分或数值类别成员资格的分类算法,如感知器和逻辑回归。
多类别分类的一对一分类模型
与一对多模型类似,一对一模型是另一种出色的启发式方法,它利用二分类算法来处理多类别数据集。它也将多类别数据集拆分成二分类问题。然而,与一对多模型将数据集拆分为每个类别的单一二分类数据组不同,一对一分类模型将数据集分组为每个类别与其他所有类别的对比数据文件。
例如,考虑到具有四个类别的多类别数据集问题 — 蓝色、红色、绿色和黄色 — 一对一方法将其拆分为以下六个二分类数据集:
问题一:红色 vs. 绿色
问题二:红色 vs. 蓝色
问题三:红色 vs. 黄色
问题四:绿色 vs. 黄色
问题五:蓝色 vs. 绿色
问题六:蓝色 vs. 黄色
上述内容相比之前解释的一对多方法有更多的分类数据集。因此,用于计算二分类数据集总数的公式变为:
类别数 x (类别数 - 1)/2
从上述四个多类别数据集中,该公式给出了预期的六个二分类问题,如下所示:
4 x (4 - 1)/2
(4 x 3) /2
12/2
=6
虽然每个二分类模型只能预测一个类别标签,但“一对一”策略会预测投票最多的模型。如果二分类模型能够准确预测数值类别成员,如概率,那么得分总和最多的类别将被视为类别标签。
从本质上讲,该模型最适合支持支持向量机和相关的基于核的分类算法。这可能是因为核方法的规模与训练数据集的大小不成比例。此外,使用训练数据的子集可以逆转这种效果。
Scikit-learn 中由 SVC 类 实现的支持向量学习机器支持多类分类的“一对一”分类方法。要使用此方法,你需要将“决策函数形状”设置更改为“ovo”。
此外,scikit-learn 归档还允许使用单独的“一对一”分类器多类方法,使得“一对一”选项可以与任何分类器一起使用。这使得该多类方法可以与任何其他二分类器(如感知器、逻辑回归、SVM 或本身支持多类分类的不同分类器)一起使用。
结论
如前所述,使用“一对多”多类分类选项使处理大型数据集变得困难,因为类别实例数量庞大。然而,“一对一”多类分类选项仅将主要数据集拆分为每对类别的单一二分类任务。
尽管“一对多”方法无法处理多个数据集,但它训练的分类器数量较少,使其成为更快的选择,且经常受到青睐。另一方面,“一对一”方法由于特定类别的主导性,较少产生数据集的不*衡。
话虽如此,你认为哪一种方法更好呢?请在下方评论区分享你的想法。
简介: Thomas Glare 是一位机器学习专家,教开发者如何从现代机器学习方法和实践教程中获得最佳效果。你可以在此 网站 上找到他的文章。
相关内容:
了解更多此主题
顶级大学的人工智能、数据科学、机器学习在线证书/课程
原文:
www.kdnuggets.com/2020/09/online-certificates-ai-data-science-machine-learning-top.html
评论当前的疫情没有减少对人工智能、数据科学、机器学习人才的需求,但加速了在线教育的转变。
我们最*发布了顶级大学在线人工智能、分析、数据科学、机器学习硕士学位调查。
但典型学位需要 12-18 个月才能获得,许多人可能希望通过参加课程并获得证书来更快地入门。在去年,我们介绍了在线分析、数据科学、机器学习证书,但现在在线课程的选项太多,无法进行全面调查,因此在本博客中,我们仅涵盖了QS 全球大学排名中排名前 20 的计算机科学大学的课程和证书。非常感谢Ahmad Anis收集了这些数据。
下图 1 显示了 Y 轴上的排名和 X 轴上的成本(以美元计)。
图 1:顶级 20 所大学的人工智能、数据科学、商业分析、机器学习在线证书/课程
一些大学在自己的*台上提供课程,但大多数大学也通过流行的在线教育*台 Coursera 和 edX 提供课程(用颜色表示)。我们发现,通过 Coursera / edX 获得的课程/证书比直接从大学获得的要便宜得多。
我们还研究了证书的类型(用形状表示),数据科学是最常见的。其分布为:
-
数据科学, 19
-
M: 机器学习, 10
-
人工智能, 8
-
B: 商业, 4
-
Py: Python, 4
-
R, 3
-
DL: 深度学习, 2
-
V: 数据可视化, 2
表 1:顶级在线分析、商业分析、数据科学硕士课程。
| **计算机科学排名
2020** | 大学/课程 | 描述 | 学习时长 | 学费(美元) |
| 1 | MIT 机器学习:从数据到决策 | 这不是一门编码课程,而是介绍机器学习工具和技术如何帮助在各种情况下做出更好决策的课程。 | 8 周,在线(不包括导向课程);每周 6-8 小时 | $2300 |
|---|---|---|---|---|
| 1 | MIT 商业中的机器学习 | 在课程结束时,你将获得一个可以立即应用于业务的实际行动计划。 | 6 周,每周在线 4-5 小时,额外 2-3 小时 | $3200 |
| 1 | MIT 应用商业分析 | 完成应用商业分析后,你将知道哪种分析方法最适合你的情况,更重要的是,如何处理大数据并利用其实现更好的商业成果。 | 6 周在线学习;每周 5-6 小时 | $2800 |
| 1 | edX/MIT 商业分析优化方法 | 你将被介绍到优化的理论、算法和应用。线性和整数规划将通过代数和几何两种方式教授,然后应用于数据问题。学生将发展对代数公式的理解,并使用 Julia/JuMP 进行计算。 | 6 周 每周 6-8 小时 | $49 |
| 1 | edX/MIT 统计与数据科学微硕士@reg; 计划 | 从概率和统计到数据分析和机器学习,掌握解决复杂数据挑战所需的技能。完成这个微硕士计划将为你准备如:数据科学家、数据分析师、商业智能分析师、系统分析师、数据工程师等职位 | 5 门课程 1 年 2 个月 | $1350 |
| 2 | 斯坦福 大规模数据集挖掘研究生证书 | 你将掌握从大数据集(如网页、社交网络图和大型文档库)中提取信息的高效强大技术和算法。用这些技能提升你的职业生涯,为你的公司提供获得竞争优势的力量。 | *均 1-2 年;最长 3 年完成 | $5533 |
| 2 | 斯坦福大学 数据、模型与优化研究生证书 | 该证书专注于识别和解决信息数学问题。你将使用易于可视化和理解的统一原则来解决核心分析和算法问题。随着计算机科学和系统优化的进步,这个动态的项目将让你接触到在通信、金融和电气工程中使用的各种应用和工具。 | *均 1-2 年;最长 3 年完成 | $5533 |
| 2 | 斯坦福大学 人工智能研究生证书 | 利用虚拟进入斯坦福教授(如 Andrew Ng)的课堂,体验人工智能革命的前沿。课程提供人工智能原理和技术的基础和高级技能,包括逻辑、知识表示、概率模型和机器学习。学生可以深入研究课题,课程涵盖机器人技术、视觉和自然语言处理等领域。 | *均 1-2 年;最多 3 年完成 | $5533 |
| 2 | 斯坦福大学 机器学习 CS229 | 该课程提供机器学习和统计模式识别的广泛介绍。学习监督学习和无监督学习以及学习理论、强化学习和控制。探索机器学习的最新应用,并为机器设计和开发算法。 | 3 个月 | $4732 |
| 2 | Coursera/斯坦福大学 机器学习 | 机器学习、数据挖掘和统计模式识别的广泛介绍。主题包括:(i)监督学习(参数化/非参数化算法,支持向量机,核函数,神经网络)。 (ii)无监督学习(聚类,降维,推荐系统,深度学习)。 (iii)机器学习中的最佳实践(偏差/方差理论;机器学习和人工智能的创新过程) | 54 小时 | $79 |
| 2 | 斯坦福大学 机器学习 XCS229I | 监督学习/ 无监督学习 | 12 周 | $1595 |
| 2 | 斯坦福大学 机器学习战略与强化学习导论 XCS229IMI | 强化学习/ 机器学习战略 | 每周 8-12 小时,12 周 | $1595 |
| 2 | Coursera/斯坦福大学 医疗保健中的人工智能专业 | 人工智能在医疗保健中的当前和未来应用,目标是学习如何安全且合乎伦理地将人工智能技术引入临床。 | 每周 2 小时,8 个月 | $632 |
| 2 | Coursera/斯坦福大学 概率图模型专业 | 概率图模型是各种应用(如医疗诊断、图像理解、语音识别、自然语言处理等)的最先进方法的基础。它们也是制定许多机器学习问题的基础工具。 | 每周 11 小时,4 个月 | $316 |
| 4 | edX/加州大学伯克利分校 数据科学基础专业证书 | 由 BerkeleyX 提供的专业证书将教你如何结合数据与 Python 编程技能,提出问题并探索你在未来工作中可能遇到的问题,无论在任何学科领域,甚至在日常生活中。这门课程将为你提供一个新的视角来探讨你关心的问题和难题。 | 4 个月,每周 4 - 6 小时 | $537 |
| 4 | edX/加州大学伯克利分校 数据科学与工程 XSeries 程序(Spark) | 学生将获得构建和调试 Spark 应用程序的实践经验。课程将涵盖 Spark 的内部细节和分布式机器学习算法,为学生提供处理大数据和开发分布式环境代码的直觉。 | 3 个月,每周 5 - 10 小时 | $247 |
| 4 | edX/加州大学伯克利分校 使用 Apache Spark 进行大数据分析 | 这门统计和数据分析课程将尝试阐明数据科学家的预期输出,然后教学生如何使用 PySpark(Spark 的一部分)来满足这些期望。 | 4 周,每周 5-10 小时 | $99 |
| 5 | 牛津大学 牛津人工智能项目 | 该课程针对希望理解人工智能工作原理和可能性的管理者、商业领袖及技术专业人士。它提供了一个独特的机会,让你在构建人工智能应用的商业案例的同时,反思人工智能的应用及其局限性,从而形成有见地的观点。 | 6 周 | $3391 |
| 7 | edX/哈佛大学 CS50 Python 人工智能入门 | 在这门人工智能入门课程中学习如何使用 Python 进行机器学习。 | 7 周,每周 10-30 小时 | $199 |
| 7 | edX/哈佛大学 生命科学数据分析专业证书 | 使用开源的 R 编程语言,你将获得处理复杂生命科学和基因组数据所需工具的深刻理解。你将学习需要的数学概念和数据分析技术,以推动数据驱动的研究。 | 4 个月,每周 2 - 4 小时 | $626.4 |
| 7 | edX/哈佛大学 使用 Python 进行研究 | 在本课程中,我们首先回顾 Python 3 的基础知识,然后学习在研究环境中常用的工具。此版本的课程包括一个新的统计学习模块。通过引导介绍和更独立的深入探索相结合,你将通过各种案例研究实践新的 Python 技能,这些案例研究因其科学广度和覆盖不同 Python 特性而被选中。 | 12 周,每周 2-4 小时 | $99 |
| 7 | edX/哈佛大学 数据科学专业证书 | 该项目涵盖了概率、推断、回归和机器学习等概念,并帮助你开发一套必需的技能,包括 R 编程、使用 dplyr 进行数据整理、使用 ggplot2 进行数据可视化、使用 Unix/Linux 进行文件组织、使用 git 和 GitHub 进行版本控制以及使用 Rstudio 准备可重复文档。 | 1 年 5 个月;每周 2-3 小时 | $442 |
| 7 | 哈佛大学 文本分析与自然语言处理 | 本课程向学生介绍了使用各种工具进行文本分析的工具、技术和机会。 | 4 个月 | $2900 |
| 8 | 洛桑联邦理工学院 应用数据科学:机器学习 | 这个中级课程将为你提供在数据科学热门领域的实践经验。你将学习数据获取、转换和预测分析的技术和工具,确保你在处理整个数据管道方面拥有坚实的基础。 | 450 小时 | $6468 |
| 8 | 洛桑联邦理工学院 应用数据科学:沟通与可视化 | 通过这个中级课程,你将学习数据科学流程中两个关键领域的最佳实践:沟通和可视化。你将学习需要的工具和技术,以生成更深入的探索性数据分析图形,并以更大的影响力将数据发现传达给多样化的观众。 | 450 小时 | $6468 |
| 8 | 洛桑联邦理工学院 数据科学基础 | 这个初级课程将让你深入了解各种数据类型及其用途。你将获得所有数据处理过程的实际操作经验,并掌握自动化数据、分析数据以及利用获得的洞察做出战略业务决策所需的工具和技术。 | 150 小时 | $1716 |
| 8 | edX/EPFL 生命科学家的图像处理与分析 | 本课程将教你从图像获取到图像过滤和分割的核心概念,帮助你独立处理简单的图像分析工作流程。 | 7 周,每周 2-3 小时 | $199 |
| 9 | edX/ 苏黎世联邦理工学院 自主移动机器人 | 运动、感知和智能导航的基本概念和算法。 | 15 周 | $50 |
| 10 | Coursera/ 多伦多大学 GIS、地图制作与空间分析专业 | 你将学习如何创建 GIS 数据,如何查找和评估在线数据,如何设计有效的地图,以及如何筛选数据和分析空间关系,还会学习如何处理卫星图像。 | 6 个月,每周 3 小时 | $294 |
| 10 | Coursera/ 多伦多大学 自动驾驶汽车专业 | 本专业将为你提供对自动驾驶汽车行业中最先进工程实践的全面了解。 | 7 个月,每周 5 小时 | $553 |
| 10 | edX/ 多伦多大学 量子机器学习 | 在本课程中,我们将介绍几个量子机器学习算法,并用 Python 实现它们。 | 9 周,每周 6-8 小时 | $49 |
| 10 | 多伦多大学 数据科学 | 你将涵盖预测分析专业工具箱中的基本内容,包括神经网络和深度学习;数据提取和分析中使用的编程语言和软件;以及数据安全、合规和隐私问题。 | 从开始日期起 3 年完成 | $4539 |
| 10 | 多伦多大学 人工智能 | 机器学习、深度学习和强化学习的实践技能 | 从开始日期起 3 年完成 | $2985 |
| 12 | edX/ 新加坡国立大学 建筑、工程和建筑数据科学 | 本课程介绍了数据科学技能,针对建筑设计、施工和运营中的应用。你将在此背景下学习实际编码,重点是基础 Python 编程和 Pandas 库。 | 7 周,每周 4-6 小时 | $199 |
| 14 | edX/ 帝国理工学院 数据分析基础 | 本课程将涵盖数据收集、展示、描述和从数据集中推断的基础知识。 | 6 周,每周 4-6 小时 | $79 |
| 14 | Coursera/ 伦敦帝国学院 机器学习数学专业化 | 学习数据科学和机器学习应用所需的数学基础知识。 | 4 个月,每周 4 小时 | $196 |
| 14 | Coursera/ 伦敦帝国学院 TensorFlow 2 入门 | 在本课程中,你将学习一个完整的端到端工作流程,用于开发 TensorFlow 深度学习模型,包括使用 Sequential API 构建、训练、评估和预测模型,验证模型并包括正则化,实现回调,以及保存和加载模型。 | 26 小时 | $49 |
| 14 | Coursera/ 伦敦帝国学院 使用 TensorFlow 2 自定义模型 | 在本课程中,你将深入了解 TensorFlow,以便为任何应用程序开发完全自定义的深度学习模型和工作流程。你将使用 TensorFlow 的低级 API 来开发复杂的模型架构、完全自定义的层和灵活的数据工作流程。你还将扩展对 TensorFlow API 的知识,包括序列模型。 | 27 小时 | $49 |
| 14 | Coursera/ 伦敦帝国学院 公共卫生统计分析与 R 专业化 | 掌握公共卫生统计学并学习 R。通过 R 提高你的统计思维能力,学习关键的数据分析方法。 | 4 个月 每周 3 小时 | $196 |
| 15 | 加州大学洛杉矶分校 数据科学 | 学习利用大数据的力量提取洞察力并改善决策,以解决现实世界的问题。获得数据管理和可视化、机器学习、统计模型等方面的实践经验,为数据科学职业做好准备。该证书可以在线或通过远程教学完成。 | 标准:6-24 个月,强化型 10 周 | $3980 |
| 15 | 加州大学洛杉矶分校 数据工程师的 Python | 专注于大数据分析,课程涵盖数值计算、数据分析、非结构化数据、统计建模、数据可视化以及 Python 作为数据分析编程语言。该项目可以在线或在课堂上完成。 | 约 29 周 | $3785 |
| 18 | Coursera / 华盛顿大学 大规模数据科学专业化 | 解决实际数据挑战。通过三门课程掌握计算、统计和信息数据科学。 | 5 个月,每周 3 小时 | $245 |
| 18 | Coursera / 华盛顿大学 机器学习专项课程 | 通过一系列实际案例研究,你将获得在机器学习主要领域的应用经验,包括预测、分类、聚类和信息检索。你将学习分析大型和复杂的数据集,创建随着时间的推移而自我适应和改进的系统,并构建能够从数据中做出预测的智能应用程序。 | 7 个月,每周 3 小时 | $49 |
| 18 | Coursera / 华盛顿大学 社交媒体数据分析 | 学习成果:完成本课程后,你将能够:1. 利用各种应用程序编程接口(API)服务从不同的社交媒体来源(如 YouTube、Twitter 和 Flickr)收集数据。2. 使用相关性、回归和分类等方法处理主要为结构化的数据,以获取关于数据来源和生成这些数据的人的见解。3. 分析主要为文本评论的非结构化数据,识别其中表达的情感。4. 使用不同的工具来收集、分析和探索社交媒体数据,以用于研究和开发目的。 | 13 小时 | $49 |
| 19 | edX/ 哥伦比亚大学 商业分析微硕士®项目 | 将使学习者掌握技能、洞察力和理解力,通过数据、统计和定量分析,以及解释性和预测建模,来提高商业绩效,从而帮助做出可操作的决策。 | 1 年,每周 8 - 10 小时 | $896.4 |
| 19 | edX/ 哥伦比亚大学 人工智能微硕士®项目 | 通过一个创新的在线项目,深入了解计算机科学中最迷人和增长最快的领域之一,该项目涵盖了人工智能及其应用领域中的有趣和引人入胜的主题。 | 1 年,每周 8 - 10 小时 | $896.4 |
| 19 | edX/ 哥伦比亚大学 数据科学高管专业证书 | 在数据科学与分析专业证书项目中,你将深入了解最新的数据科学工具及其在金融、医疗、产品开发、销售等领域的应用。通过实际案例,我们将展示数据科学如何改善公司决策和绩效,个性化医疗,并推进你的职业目标。 | 4 个月,每周 7 - 10 小时 | $267.3 |
| 19 | 康奈尔大学 Python 编程 | 本证书项目采用严格的以用户为中心的 Python 软件工程方法。其目标不仅仅是教你如何使用 Python,更是让你理解 Python 的核心原理,并发展成为一个熟练的 Python 程序员和软件开发人员的能力。你将设计、编码、测试、可视化、分析和调试 Python 函数和程序。同时,你还将获得一套强大的工具,以帮助你完成课程作业。 | 4.5 个月,每周 8-12 小时 | $3600 |
| 19 | 康奈尔大学 机器学习 | 通过数学和直觉的结合,你将练习构建机器学习问题的框架,并构建一个心理模型来理解数据科学家如何程序化地解决这些问题。通过研究和实现 k *邻、朴素贝叶斯、回归树等算法,你将探索各种机器学习算法,并练习选择最佳模型,考虑如何有效实施这些模型的关键原则。你还将有机会在实时数据上实现算法,同时通过集成方法和支持向量机等方法调试和改进模型。最后,课程将探讨神经网络的内部工作原理,以及如何为不同类型的数据构建和调整神经网络。 | 3.5 个月,每周 6-9 小时 | $3600 |
| 19 | 康奈尔大学 数据科学的 Python | 掌握使用 Python 以有意义的方式分析和可视化数据的能力,从而帮助解决复杂的商业问题。使用如 Jupyter Notebooks、NumPy 和 Pandas 等工具,你将有机会分析实际数据集,以识别数据中的模式和关系。你将获得使用内置和自定义数据类型的经验,以创建富有表现力和计算能力强的数据科学项目。最后,你将使用 Python 和 scikit-learn 构建预测性机器学习模型。 | 5 个月,每周 3-5 小时 | $3600 |
| 19 | 康奈尔大学 R 数据分析证书 | 你将学习数据操作和可视化的技术,通过描述性统计描述数据,以及聚类。你将通过使用传统的参数模型(回归和逻辑回归)以及机器学习技术来扩展这些基本的报告方法。此外,你还将开发线性、非线性和 Monte Carlo 决策模型,使你能够做出更明智的决策。 | 约 72 小时 | $3600 |
| 19 | 康奈尔大学 TABLEAU 中的数据可视化 | 你将通过研究不同的数据类型及其在 Tableau 中的表达方式来开始这个证书课程。随着对 Tableau 的熟悉,你将练习根据标准分析和观众评估构建基本可视化。随着课程的进展,你将超越基本分析,结合批评和反馈,介绍可视化的迭代过程。最终,你将获得自信,使用你的数据可视化技能讲述引人入胜的故事。 | 2 个月 | $3600 |
相关:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关内容
成为更好的数据科学家必须参加的在线课程
原文:
www.kdnuggets.com/2020/09/online-courses-better-data-scientist.html
评论
由David Adrián Cañones,数据科学家与机器学习工程师

我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
一些背景,曾经有一段时间…
我在 2015 年开始了数据科学的学习。这并不是一个有意的决定,而是对我雇主需求的回应。我在一家为西班牙公司提供自动化服务的公司工作,我们需要利用数据来自动化那些规则不能轻易硬编码的复杂任务。我刚刚从工程专业毕业,正值经济危机严重时期,具有一定的统计建模知识,并且熟练使用 MATLAB。
在 2015 年,还没有专门的数据科学学位或训练营来快速进入该领域(至少在西班牙是这样),你能获得的最接*的学科是:数学(在西班牙,主要是为了成为公共教育系统中的教师/教授)或软件工程(大多数人更感兴趣于应用开发或创建新的“X”的 Uber,而不是当时乏味的数据科学工作)。
在这种背景下,大多数数据科学从业者都是刚刚从定量学科(大量来自不同领域的工程师,以及经济学和类似学科的人)毕业的新人。在这个背景下,我发现了一些珍贵的在线资源,它们在当时帮助了我,并且长期来看,让我今天(2020 年)成为了更好的数据科学家。
免责声明:在线课程不会让你成为数据科学家
成为数据科学家需要具备以下几种东西:
-
一个定量学位(不是严格必要,但有帮助)。
-
实际的现实世界和相关项目经验。这是这个列表中最重要的一点,也是最难获得的。
-
被优秀的专业人士包围。正如我以前的老板常说的:如果你是房间里最聪明的人,你应该开始担心了。
-
对数据科学如何运作有一个良好的理解,包括对数据结构、系统和算法在后台如何工作的理论知识。
这一最后要点是本文的重点。我将在此介绍的在线课程专注于数据科学的理论基础。这些课程有一些共同特点:
-
这些课程不是那种你可以在通勤时一小时内完成的典型 DataCamp 纳米课程。这些是需要你投入时间的长期而艰难的课程。
-
由顶级大学的优秀教授教授。
-
在行业中被非常重视,包括公司、招聘人员等。
这些课程不会让你成为数据科学家,但在你通过真实项目练习技能、学习所需工具等的过程中,这些课程将为你长期成为数据科学家的成功奠定基础,并使你区别于那些仅仅训练机器学习模型和编写代码却对实际情况一无所知的*庸数据科学家。
本文没有任何课程的赞助
这点需要记住。与推荐数据科学课程的其他帖子和列表不同,这里有两个优势:
-
我已经完成了这里列出的每一门课程,我推荐它们的原因是基于我的个人经验,它们确实值得。我将附上每门课程的相应证书以证明我的话。
-
显然,没有任何课程作者赞助我在此列出他们的内容。
这些课程
让我们按时间顺序开始吧...
1. 使用 Python 的计算机科学与编程导论

Eric Grimson
这是 MIT 的 Eric Grimson 教授开设的真正优秀的课程。由于我有一些 MATLAB 经验,我作为数据科学家的第一个目标之一是学习 Python。当我参加这门课程时,内容是为 Python 2 准备的,但最*已更新为 Python 3。
这门课程有趣的地方在于,它介绍了计算机科学中一些重要的概念,这些概念通常被许多数据科学家忽略,例如:
-
数据结构
-
计算复杂度(Big O 符号)
-
面向对象编程
-
算法
-
递归
如果你是一名有经验的数据科学家但没有 Python 知识,应该考虑参加这门课程,因为它现在是标准课程。
2. 计算思维与数据科学导论
这是前一个课程的第二部分。它重点关注应用于统计的编程。你可以期待编写大量的模拟代码。非常有趣。
3. 分析边缘
这是教授 Dimitris Bertsimas 开设的一个好课程。它聚焦于机器学习和优化算法的混合,并结合一些使用ggplot的可视化。课程内容包括:
-
线性模型
-
决策树
-
随机森林
-
聚类(k-means)
-
线性规划
-
一些自然语言处理(如今有点过时)
所有内容都用 R 语言教授。
4. 机器学习

Andrew Ng
这个课程不需要介绍。这可能是关于机器学习最著名的课程,也是*年来机器学习热潮的重要推动者。
这门课程由著名教授兼 AI 倡导者 Andrew Ng(斯坦福大学)教授。课程优秀,重点讲解了最流行的机器学习算法,包括其数学基础。
这是该领域最受重视的课程之一。
在 2016 年,这门课程是用 MATLAB/Octave 教授的。我最*看到他们正在将 MATLAB 更新为 Python,但这个更新尚未发布。
5. 数据学习
这门由加州理工学院的教授 Yaser S. Abu-Mostafa 开设的有趣课程深入探讨了什么是统计学习,为什么它是可行的,以及如何正确进行,详细涵盖了如偏差-方差权衡、过拟合、正则化、验证、泛化理论等方面。
它以理论和严格的方式解释了机器学习的基础,不推荐没有数学背景的人学习。
其内容基于同名的书籍:

数据学习(书籍)
6. 深度学习专业化

deeplearning.ai
这是著名的深度学习专业化课程,由 Andrew Ng 教授及其新的教育项目deeplearning.ai开设,是当前该领域最受重视的证书之一。
这是一个长期的 5 门课程专门化课程,专注于神经网络,这是当今最重要的算法之一,也是处理非结构化数据(图像、声音、文本、视频等)的最佳算法。
从第一门课程中的基础和数学知识开始,讲解神经网络,接着是超参数调优、项目规划与策略、卷积架构,最后是序列模型架构。
这些课程高度结构化、严谨且基础扎实,同时也很实用,包含大量真实的应用案例。
这些是我推荐的高质量课程。
然而,这些并不是我进入这个领域以来唯一完成的课程。我一直在参加各种课程,有时甚至同时参加两门;大多数课程都是关于数据科学的,虽然我有时也会扩展到其他主题,如城市设计、能源等。如果有兴趣,也许我会在另一篇文章中涉及这些话题。
你可以查看我完成的所有课程的完整列表 在我的 LinkedIn 个人资料中。
荣誉提名
有些课程不符合上述部分的资格,但值得一提……
1. 深度学习导论
这是莫斯科高等经济学院的一门课程。未在上述列表中列出,因为它非常广泛且不够结构化,但广泛性也可能是它的一个优点。
如果你在寻找一个简短的深度学习介绍课程,覆盖了许多架构而不太关注其背后的数学,并且不想花费几个月的时间来完成 deeplearning.ai 的完整深度学习专门化课程,这就是你的课程。
最终项目是构建一个能够生成图像字幕的应用,非常有趣且有趣。
2. 如何赢得数据科学竞赛:向顶级 Kagglers 学习
这是一个不同的机器学习课程。如果我只能选一个课程来学习机器学习,并且必须选择一个,我会选择这个课程。
这门课程涵盖了你成为高效数据科学家所需了解的几乎所有内容,涉及重要主题如下:
-
探索性数据分析。
-
从实际的角度出发,讲解了许多不同的机器学习算法(何时以及为何选择某一种算法而不是另一种以完成特定任务)。
-
技术如均值/目标编码。
-
来自 Kaggle 竞赛的许多真实案例,由竞赛获胜者和 Kaggle 大师如 Μαριος Μιχαηλιδης 进行讲解。
虽然本课程专注于竞争性数据科学(Kaggle 竞赛),这与实际的工业机器学习项目不同,在实际项目中不仅需要获得最佳分数(还需要考虑推理速度、维护性、鲁棒性等),但你可以获得改进机器学习模型的灵感。
3. 医疗保健 AI 专业
Pie & AI(医学 AI 启动活动)
这个非常*期的专业由deeplearning.ai提供,讲述如何将人工智能应用于医疗保健领域。
鉴于 COVID-19 疫情的当前情况,不用说,公众和私营部门的努力正朝着寻找创新解决方案以应对这一公共卫生危机的方向发展。
目前,AI 应用于医疗保健被认为是一个全新的领域,并且在未来十年中最有前景的领域(从数据科学家的角度来看):
AI 不会取代医生,但使用 AI 的医生会取代那些不使用 AI 的医生 — Andrew Ng
在过去几年中,像市场营销、客户管理、能源等领域的 AI 解决方案取得了显著发展,但医疗保健领域由于以下原因一直滞后:
-
与数据隐私和伦理考虑相关的行政障碍。
-
对于一个相对传统的领域缺乏兴趣,在该领域医生与技术人员之间的沟通并不总是容易。
-
算法性能至关重要(涉及到人们的生命),因此 AI 的实施必须非常谨慎。
最*的疫情改变了公众对健康数据使用的看法,政府和公众都更愿意探索 AI 在医学领域的可能性。
这个专业由 3 门课程组成,涵盖:
-
医疗诊断中的 AI:学习如何基于医学图像等识别疾病。
-
医疗预后中的 AI:学习如何预测患者的未来健康。
-
医疗治疗中的 AI:了解因果推断、随机对照试验、模型解释性。这是这个专业中最不有趣的课程,而且由于它相对较新(2020 年 5 月),作业中仍然存在一些错误。
这些课程从技术角度来看并不非常困难,但如果你打算参加这个专业,最好有一些数据科学的经验,因为它专注于解释传统 AI 和医疗 AI 的关键差异。这些差异包括:
-
医疗保健的具体性能指标。
-
适用于医疗图像分割的深度学习架构。
-
强调生存分析。
如果你 希望在 10 年后仍然是一名数据科学家,在一个数据科学普遍化的竞争环境中,你应该选择这个专业。
感谢阅读这篇文章,希望这些信息能帮助你提升职业发展或学到新东西。
PS:感谢 Miriam Cañones 在撰写本文时提供的反馈。
本文 最初发布 在我的 个人网站和博客。
简介:David Adrián Cañones (LinkedIn)是一名数据科学家和机器学习工程师。David 拥有超过五年的经验,帮助公司和机构利用数据解决复杂问题。
原始文献。经许可转载。
相关:
-
超越表面:有实质内容的数据科学 MOOC
-
MIT 免费课程:Python 计算机科学与编程入门
-
超棒的机器学习和 AI 课程
相关主题
在线培训和 Nvidia 研讨会
原文:
www.kdnuggets.com/2022/07/online-training-workshops-nvidia.html

来源: Nvidia
Nvidia 由 Jensen Huang、Chris Malachowsky 和 Curtis Priem 于 1993 年 4 月创立。到 2022 年,公司已有 22,473 名员工。他们因开发集成电路而闻名,这些电路用于电子游戏主机到计算机。公司具有高度创新性,新产品快速推出。他们现在是硬件、软件、人工智能等领域的全球领导者。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
听起来很酷,对吧?更棒的是,Nvidia 在其深度学习学院下提供自定进度的在线培训。
Nvidia 自定进度在线培训有什么了不起的地方?
Nvidia 的自定进度在线培训的魅力在于它提供:
-
技术专长 - 让你接受来自技术行业专家的顶级培训
-
行业内流行的软件、工具和框架 - 没必要浪费时间在不再使用的软件或框架上。获得当前工具的实际操作经验等将提升你的技能
-
结合实际案例的不同产业 - 人工智能被应用于各种产业。通过 Nvidia 的培训,你可以学习到深度学习、加速计算、数据科学等,适用于不同的行业。
-
获得证书 - 通过特定课程,你可以获得 NVIDIA 深度学习学院的证书,这有助于你的职业发展。
对我来说,最重要的方面是我将接受来自数据科学、机器学习、人工智能、计算、GPU 等领域的领先公司之一的培训。亚马逊正在使用 Nvidia 的产品。Snapchat 也在使用 Nvidia 的产品。他们显然有一些很棒的东西可以提供,所以你为什么不通过参加他们的在线培训来了解更多呢?
Nvidia 提供什么课程?
他们在 5 个不同领域提供课程,我将提到每个领域中的热门课程。
深度学习
第一个领域是深度学习!
他们的一门热门深度学习课程是 大规模深度学习与 Horovod,费用为 $30,课程时长为 2 小时。
另一个他们最受欢迎的深度学习课程是 在 Jetson Nano 上入门 AI,这是免费的,完成时间为 8 小时。
加速计算
现在让我们深入了解加速计算,这对 Nvidia 非常重要。
他们最受欢迎的加速计算课程是 CUDA C/C++加速计算基础,费用为$90,完成时间为 8 小时。
他们第二受欢迎的加速计算课程是 CUDA Python 加速计算基础,费用与上述相同;$90,完成时间为 8 小时。
数据科学
我们来到了一个非常受欢迎且需求量大的领域:数据科学!
他们提供的第一个课程是 使用 cuDF 加速 DataFrame 操作,这是免费的,完成时间为 30 分钟。
第二个是 加速端到端数据科学工作流,费用为$90,完成时间为 6 小时。
图形与模拟
有些人实际上只知道 Nvidia 的图形与模拟。这在公司中非常重要,如果你考虑在 Nvidia 工作,你应该参加以下课程:
协作 3D 工作流中的 USD 入门是免费的,完成时间为 2 小时。
基础设施
最后但同样重要的是基础设施领域。
他们最受欢迎的课程是 数据中心 AI 简介,单独课程费用为$45,或作为白金会员的一部分费用为$450,完成时间为 4 小时。
他们最新的课程是 DOCA 介绍(针对 DPU),这是免费的,完成时间为 2 小时。
教育者计划
他们还为学生提供了在深度学习、加速计算和机器人领域的实践经验,以满足对 AI 专业人才的高需求。
这些工作坊是免费的,并且在 EMEA(欧洲、中东、非洲)、巴西、印度、拉丁美洲和北美提供。
一个即将举行的工作坊是 深度学习基础,将于 2022 年 6 月 22 日星期三,从上午 9:00 到下午 5:00 CEST/EMEA,UTC+2。
如果你想查看他们在六月的其他即将举行的工作坊,请点击这个链接:NVIDIA DLI 学生工作坊。
Nvidia 的培训合作伙伴
Nvidia 的深度学习学院还与领先的教育组织合作,提升全球范围内的知识。他们提供的课程包括:
Udacity:
MathWorks:
Microsoft Azure:
结论
如果你想了解更多关于 Nvidia 提供的不同课程,请访问他们的深度学习学院目录了解更多信息。他们有一些很棒的课程,其中包含了对下一次人工智能革命至关重要的资源。
Nisha Arya 是一位数据科学家和自由技术写作者。她特别关注提供数据科学职业建议或教程以及数据科学理论知识。她还希望探索人工智能如何在延续人类生命方面发挥作用。作为一个热衷学习者,她寻求拓宽技术知识和写作技能,同时帮助引导他人。
更多相关话题
你真正需要的唯一 Jupyter Notebook 扩展
原文:
www.kdnuggets.com/2021/06/only-jupyter-notebooks-extension-truly-need.html
评论
由 Olga Chernytska,高级机器学习工程师

我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
在 Jupyter Notebook 中工作时,将你的函数和类存储在单独的 .py 文件中并只导入它们是很方便的。这使得你的笔记本更易读,你可以在多个笔记本中轻松重用相同的函数和类。
假设你启动了你的笔记本,从 .py 文件中导入了自定义函数,加载了大数据集,并使用自定义函数进行了预处理。结果发现一个用于预处理的函数不正确,因此你修正了 .py 文件中的代码,然后再次运行带有预处理的单元格 —— 然而……没有变化,错误依然存在。Jupyter Notebook 没有看到更新后的函数版本。
不幸的是,这里唯一能做的就是重启内核,丢失已经加载到内存中的所有数据集。
除非你正在使用autoreload。
它是如何工作的
根据文档,autoreload “在执行用户代码之前自动重新加载模块” [1]。
这意味着现在你只需:在 .py 文件中修正函数,保存更改,返回笔记本并运行带有预处理的单元格。笔记本中的所有函数导入都会重新加载到最新版本,单元格中的代码会被执行 —— 你可以看到修正后的函数如何工作。

使用
为了实现这一魔法,将这段代码放入笔记本的第一个单元格中,并在启动内核后首先运行它:
%load_ext autoreload
%autoreload 2
你只需在内核启动时运行一次。autoreload 将一直工作,直到你停止内核。
安装
不需要安装,它应该已经存在。Autoreload 在你安装 Jupyter Notebook 或 Jupyter Lab 时会自动安装。
更多
Autoreload 允许你仅重新加载特定模块,或排除某些模块的重新加载。如果你需要此功能,请查看官方文档 [1]。
参考文献
[1] IPython 文档
个人简介: Olga Chernytska 是一家大型东欧外包公司的高级机器学习工程师;参与了多个美国、欧洲和亚洲顶级公司的数据科学项目;主要专业领域和兴趣是深度计算机视觉。
原文。经许可转载。
相关:
-
数据科学家在 Python 中常犯的 15 个错误(以及如何修复它们)
-
停止从命令行运行 Jupyter 笔记本
-
JupyterLab 3 到来了:立即升级的关键原因
更多相关话题
仅使用 Numpy:使用 Numpy 实现 GAN 和 Adam 优化器
原文:
www.kdnuggets.com/2018/08/only-numpy-implementing-gans-adam-optimizer.html
评论
由 Jae Duk Seo,瑞尔森大学
今天我受到这篇博客 “生成对抗网络在 TensorFlow 中的实现” 的启发,想要用 Numpy 自行实现 GAN。以下是 @goodfellow_ian 的 原始 GAN 论文。下面是从 Simple GAN 生成的所有图像的 gif。
在继续阅读之前,请注意我不会涉及太多数学内容。我会侧重于代码的实现和结果,数学部分可能会在以后讨论。我正在使用 Adam 优化器,但在这篇文章中我不会解释 Adam 的实现。
GAN 中判别器的前向传播 / 部分反向传播
再次说明,我不会深入详细讲解,但请注意红色框中的数据区域。在 GAN 的判别网络中,这些数据可以是真实图像或由生成网络生成的虚假图像。我们的图像是 (1,784) 的 MNIST 数据集向量。
还有一点需要注意的是 红色 (L2A) 和蓝色 (L2A)。红色 (L2A) 是我们判别网络在真实图像输入下的最终输出。而蓝色 (L2A) 是我们判别网络在虚假图像输入下的最终输出。

我们的实现方式是先获取真实图像和虚假数据,然后将它们输入网络中。
-
第 128 行——获取真实图像数据
-
第 147 行——获取虚假图像数据(由生成网络生成)
-
第 162 行——我们判别网络的成本函数。
同时,请注意蓝色框区域,即我们的成本函数。让我们比较一下原始论文中的成本函数,如下所示。
图片 来自原始 论文
区别在于我们在第一个术语 log(L2A) 前面加了一个 (-) 负号。

如上所述,在 TensorFlow 实现中,我们如果要最大化某个值时会翻转符号,因为 TF 的自动微分只能最小化。
我考虑了这一点,决定以类似的方式实现。因为我想最大化我们判别器对真实图像正确猜测的机会,同时最小化判别器对假图像错误猜测的机会,并且希望这些值的总和能够*衡。然而,我对此部分尚未百分之百确定,会尽快重新审视这个问题。
前向传播/生成器在 GAN 中的部分反向传播

GAN 中生成器网络的反向传播过程有点复杂。
-
蓝色框——来自生成器网络的生成假数据
-
绿色框(左下角)——判别器接收生成的(蓝色框)输入并执行前向传播过程
-
橙色框——生成器网络的成本函数(我们再次希望最大化生成真实数据的机会)
-
绿色框(右上角)——生成器网络的反向传播过程,但我们必须将梯度传递整个判别器网络。
下面是已实现代码的截图。
标准的反向传播,没什么特别的。
训练结果:失败的尝试
我很快意识到训练 GAN 是非常困难的,即使使用 Adam 优化器,网络似乎也没有很好地收敛。因此,我将首先向你展示所有失败的尝试及其网络架构。
1. 生成器,2 层:200,560 个隐藏神经元,输入向量大小 100

2. 生成器,tanh() 激活函数,2 层:245,960 个隐藏神经元,输入向量大小 100

3. 生成器,3 层:326,356,412 个隐藏神经元,输入向量大小 326

4. 生成器,2 层:420,640 个隐藏神经元,输入向量大小 350

5. 生成器,2 层:660,780 个隐藏神经元,输入向量大小 600
6. 生成器,2 层:320,480 个隐藏神经元,输入向量大小 200

如上所示,它们似乎都学到了一些东西,但实际上并没有哈哈。然而,我能够使用一个很棒的技巧生成一种看起来像数字的图像。
极端步进梯度衰减

上面是一个 gif,我知道区别很细微,但相信我 我不是在整蛊你。这个技巧非常简单且易于实现。我们首先设定一个较高的学习率进行第一次训练,然后在第一次训练后将学习率衰减因子设置为 0.01。由于某些未知原因(我想进一步调查),这似乎有效。
但代价非常高,我认为我们正趋向于一个“地方”,在这里网络只能生成某种类型的数据。也就是说,从-1 到 1 之间的均匀分布的数字来看,生成器只会生成仅仅看起来像 3 或 2 等的图像……但关键点在于,网络无法生成不同的一组数字。这一点从图像中所有的数字都看起来像 3 这一事实中可以得到证明。
然而,这些图像在某种程度上看起来像数字。所以,让我们再看看一些结果。
如上所示,随着时间的推移,数字变得更加清晰。一个好的例子是生成的 3 或 9 的图像。
互动代码
更新:我已经迁移到 Google Colab 进行交互式代码演示!因此,您需要一个 Google 账号来查看代码,并且您不能在 Google Colab 中运行只读脚本,所以请在您的工作区复制一份。最后,我绝不会请求访问您 Google Drive 上的文件,仅供参考。祝编程愉快!
请点击 这里访问在线互动代码

运行代码时,请确保您在“main.py”标签页上,如上图绿色框中所示。程序会要求您输入一个随机数作为种子,如蓝色框中所示。之后,它将生成一张图像,查看该图像请点击上方的“点击我”标签,红色框所示。
结语
训练 GAN 即使是部分有效也是一项巨大的工作,我想研究更有效的 GAN 训练方法。最后,感谢 @replit,这些家伙太棒了!
如果发现任何错误,请通过电子邮件联系我:jae.duk.seo@gmail.com。
同时,请在我的 Twitter 上关注我 这里,访问 我的网站,或我的 YouTube 频道 获取更多内容。如果您感兴趣,我还对解耦神经网络进行了比较 这里。
参考文献
-
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2014). 生成对抗网络。见 神经信息处理系统的进展 (第 2672–2680 页)。
-
免费在线 GIF 制作工具——轻松制作 GIF 图像。(无日期)。于 2018 年 1 月 31 日检索自
gifmaker.me/ -
TensorFlow 中的生成对抗网络。(无日期)。于 2018 年 1 月 31 日检索自
wiseodd.github.io/techblog/2016/09/17/gan-tensorflow/ -
J. (无日期). Jrios6/Adam-vs-SGD-Numpy。检索于 2018 年 1 月 31 日,来自
github.com/jrios6/Adam-vs-SGD-Numpy/blob/master/Adam%20vs%20SGD%20-%20On%20Kaggles%20Titanic%20Dataset.ipynb -
Ruder, S. (2018 年 1 月 19 日). 梯度下降优化算法概述。检索于 2018 年 1 月 31 日,来自
ruder.io/optimizing-gradient-descent/index.html#adam -
E. (1970 年 1 月 1 日). Eric Jang. 检索于 2018 年 1 月 31 日,来自
blog.evjang.com/2016/06/generative-adversarial-nets-in.html
个人简介: Jae Duk Seo 是赖尔森大学的四年级计算机科学学生。
原文. 经许可转载。
相关内容:
-
通过 Tensorflow 中的交互式代码洞悉神经网络的思维
-
使用 NumPy 从零开始构建卷积神经网络
-
我如何使用 CNN 和 Tensorflow,并在 Kaggle 挑战赛中失去了银牌
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 为你的组织提供 IT 支持
更多相关话题
本体论与数据科学
评论
照片来源:Valentin Antonucci,Pexels
如果你对本体论这个词感到陌生,不用担心,我会首先介绍它是什么,然后说明它对数据世界的重要性。我将明确区分哲学本体论与计算机科学中与信息和数据相关的本体论。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
本体论(哲学部分)

简单来说,本体论可以说是对存在的事物的研究。但这个定义还有另一部分,这部分将在接下来的章节中对我们有所帮助,那就是本体论通常也包括有关存在实体的最一般特征和关系的问题。
本体论为存在的事物打开了新门。让我给你一个例子。

量子力学开辟了对现实和自然中“存在”的新视角。在 20 世纪的一些物理学家看来,量子形式主义中根本没有现实。在另一极端,有许多量子物理学家持相反观点:即单一演化的量子态完全描述了实际的现实,令人震惊的是,几乎所有的量子备选态必须始终继续共存(处于叠加态)。因此,这为“存在”在自然界中的“事物”打开了全新的视角和理解。
但让我们回到定义中的实体关系部分。有时,当我们谈论实体及其关系时,本体论被称为形式本体论。这些理论试图给出某些实体属性和关系的精确数学表述。这样的理论通常提出关于这些实体的公理,这些公理用某种基于形式逻辑系统的形式语言表达。
这将使我们能够进行一个量子跳跃到文章的下一部分。

本体论(信息与计算部分)
如果我们重新回顾上述形式本体论的定义,然后考虑数据和信息,我们可以建立一个框架来研究数据及其与其他数据的关系。在这个框架中,我们以特别有用的方式表示信息。以特定形式本体论表示的信息可以更容易地被自动化信息处理访问,如何做到这一点是计算机科学(如数据科学)中的一个活跃研究领域。这里形式本体论的使用是代表性的。它是一个表示信息的框架,因此无论所使用的形式理论是否真正描述了一个实体领域,它都可以在代表性上成功。
现在是了解本体论如何在数据科学领域帮助我们的好时机。
如果你记得我上一篇关于语义技术的文章:
深度学习现在无处不在,无论是在你的手表、电视、手机,还是某种程度上你所在的*台……towardsdatascience.com](https://towardsdatascience.com/deep-learning-for-the-masses-and-the-semantic-layer-f1db5e3ab94b)
我谈到了关联数据的概念。关联数据的目标是以一种结构化的方式发布数据,使其能够被轻松消费并与其他关联数据结合起来。我还讨论了知识图谱的概念,它由集成的数据和信息集合组成,还包含大量不同数据之间的链接。
好吧,所有这些定义中缺失的概念是本体论。因为这是我们连接实体并理解其关系的方式。通过本体论可以实现这样的描述,但首先我们需要正式地指定组件,如个体(对象实例)、类、属性和关系,以及限制、规则和公理。
这里是解释上述段落的图示方式:
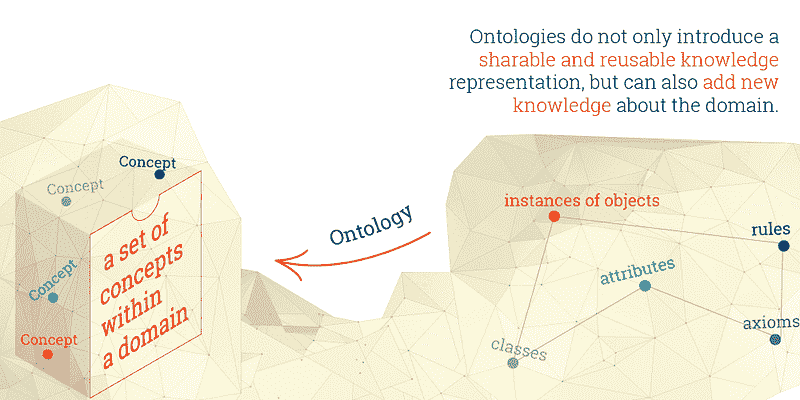
www.ontotext.com/knowledgehub/fundamentals/what-are-ontologies/
数据库建模与本体论
目前,大多数采用数据建模语言(如 SQL)的技术都是使用“构建模型,然后使用模型”的僵化思维方式设计的。
例如,假设你想在关系数据库中更改一个属性。你之前认为该属性是单值的,但现在它需要是多值的。对于几乎所有现代关系数据库,这种更改将要求你删除该属性的整个列,然后创建一个全新的表来保存所有这些属性值以及一个外键引用。
这不仅仅是很多工作,还会使处理原始表的任何索引失效。它还会使用户编写的相关查询失效。简而言之,做出这个改变可能非常困难和复杂。通常,这种变化麻烦到让人们干脆不去做。
相比之下,本体论语言中的所有数据建模语句(以及其他一切)本质上是增量的。事后增强或修改数据模型可以通过修改概念轻松实现。
从 RDBS 到知识图谱
到目前为止,我发现的将数据湖转变为智能数据湖的最简单框架是 Anzo。通过这个,你可以迈出向完全连接的企业数据结构的第一步。
数据结构是支持公司所有数据的*台。它如何管理、描述、结合和普遍访问。这个*台由企业知识图谱构成,以创建一个统一且一致的数据环境。
形成这种数据结构首先需要在现有数据之间创建本体论。这一过渡也可以被看作是从传统数据库到图数据库+语义的过程。
根据这份演示文稿由剑桥语义学公司提供,有三个原因说明图数据库是有用的:
-
图数据库的产品展示了能力和多样性的成熟
-
图谱被用来解决经典图问题之外的任务
-
复杂数据的数字化转型需要图谱
因此,如果你将这些好处与基于本体论构建的语义层结合起来,你可以将数据从这种状态:
www.slideshare.net/camsemantics/the-year-of-the-graph
转变为这种状态
www.slideshare.net/camsemantics/the-year-of-the-graph
你会有一个人类可读的数据表示,它唯一标识并用通用业务术语连接数据。这一层帮助最终用户自主、安全且自信地访问数据。
然后,你可以创建复杂的模型来发现不同数据库中的模式。
www.slideshare.net/camsemantics/the-year-of-the-graph
在其中,你有表示实体之间关系的本体论。也许这里举个本体论的例子会更好。这个例子取自
本体论和语义技术再次变得流行。它们在 2000 年代初曾是热门话题,但...enterprise-knowledge.com](https://enterprise-knowledge.com/what-is-an-ontology/)
让我们创建一个关于你的员工和顾问的本体论:
在这个例子中,Kat Thomas 是一位顾问,她正在与 Bob Jones 合作进行销售流程重设计项目。Kat 为 Consult, Inc 工作,而 Bob 向 Alice Reddy 汇报。通过这个本体论,我们可以推断出很多信息。由于销售流程重设计涉及销售,我们可以推断 Kat Thomas 和 Bob Jones 在销售方面具有专业知识。Consult, Inc 也必须在这一领域提供专业知识。我们还知道 Alice Reddy 可能负责 Widgets, Inc 的某些销售方面,因为她的直接下属正在进行销售流程重设计项目。
当然,你可以在关系数据库中使用主键,并创建多个连接来获取相同的关系,但这种方法更直观,更易于理解。
而令人惊叹的是,Anzo 将会连接到你的数据湖(意味着大量数据存储在 HDFS 或 Oracle 等中),并为你自动创建这个图表!然后你可以自行添加或更改本体论。
数据科学的未来(仅指明年 lol)
在这篇文章中:
2018 年人工智能、数据科学、分析的主要发展及 2019 年关键趋势
和过去一样,我们为您带来专家的预测和分析汇总。我们询问了主要的...www.kdnuggets.com
我讨论了未来几年(可能)的数据科学将会发生的事情。
对我而言,2019 年的关键趋势:
-
AutoX:我们将看到更多公司开发并将自动化机器学习和深度学习技术及库纳入其技术栈。这里的 X 意味着这些自动化工具将扩展到数据摄取、数据整合、数据清洗、探索和部署。自动化将继续存在。
-
语义技术:今年对我来说最有趣的发现之一是数据科学与语义之间的联系。这不是数据领域的新领域,但我看到越来越多的人对语义、本体论、知识图谱及其与数据科学和机器学习的关系产生兴趣。
-
编程减少:这是一件难以言说的事,但随着数据科学过程中的几乎每一步都被自动化,我们将每天编程越来越少。我们将拥有创建代码的工具,这些工具将通过自然语言处理理解我们的需求,然后将其转化为查询、句子和完整程序。我认为[编程]仍然是一个非常重要的技能,但它很快会变得更容易。
这就是我撰写这篇文章的原因之一,试图跟踪行业中的动态,你应该意识到这一点。我们将减少编程,并在不久的将来更多地使用语义技术。这更接*于我们思考的方式。我是说,你会在关系数据库中思考吗?我并不是说我们在图形中思考,但在我们的脑袋和知识图谱之间传递信息要比创建奇怪的数据库模型容易得多。
期待我在这个有趣话题上的更多内容。如果你有任何建议,请告诉我 😃
如果你有问题,直接在 Twitter 上关注我:
[Favio Vázquez (@FavioVaz) | Twitter]
Favio Vázquez (@FavioVaz) 的最新推文。数据科学家。物理学家和计算工程师。我有一个…twitter.com](https://twitter.com/faviovaz)
和 LinkedIn:
[Favio Vázquez — 创始人 — Ciencia y Datos | LinkedIn]
查看 Favio Vázquez 在 LinkedIn 上的个人资料,这是全球最大的职业社区。Favio 列出了 16 个职位…www.linkedin.com](https://www.linkedin.com/in/faviovazquez/)
那里见 😃
简介: Favio Vazquez 是一名物理学家和计算机工程师,专注于数据科学和计算宇宙学。他对科学、哲学、编程和音乐充满热情。他是 Ciencia y Datos 的创始人,这是一个西班牙语的数据科学出版物。他热爱新挑战,喜欢与优秀团队合作并解决有趣的问题。他是 Apache Spark 合作项目的一部分,参与 MLlib、Core 和文档工作。他喜欢将自己的科学知识、数据分析、可视化和自动学习的专业技能应用于帮助世界变得更美好。
原文。经许可转载。
相关:
-
本体是什么?你能找到的最简单定义…或退款*
-
2018 年人工智能、数据科学、分析的主要发展以及 2019 年的关键趋势
-
数据科学的核心
更多相关话题
Open Assistant: 探索开放和协作聊天机器人开发的可能性

作者提供的图片 | Bing 图像创作者
我们正在看到 ChatGPT 开源替代品的快速发展,其中一些如 Vicuna产生了令人惊叹的结果。但有一个问题。这些新模型有使用限制,我们不能将它们用于商业用途。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
另一方面,Open Assistant 正在努力改变这一点。他们的使命是让每个人都能访问像 ChatGPT 和 GPT-4 这样的优秀聊天型大型语言模型。
在这篇文章中,我们将了解 Open Assistant 项目及其特性、限制和计划。此外,我们还将为你提供所有资源,帮助你开始创建自己的聊天机器人。
什么是 Open Assistant?
Open-Assistant项目正在革新语言技术。与其将高质量的大型语言模型私有化,他们让所有人都可以使用数据集、模型、代码源和 Open Assistant *台。
Open-Assistant 模型是在来自 13,000 多名志愿者的数据集上进行训练的。收集的数据集包含超过 60 万次互动、15 万条消息和 1 万棵完全标注的对话树,涵盖多种语言的各种话题。
观看启动视频以了解这个项目有多酷。
如果你访问他们的 Hugging Face 页面,你会看到多个基于 Open Assistant 数据集训练的模型架构,例如 Stable LM、LLaMA、Pythia、Galactica 等。他们正在基于最新数据开发一款最先进的模型,并很快将推出具备安全功能的该模型。
注意:一些模型如 LLaMA 有使用限制(仅限研究),但你也会看到像 Pythia 这样的模型可用于任何用途。
如何尝试
你可以查看 Hugging Face 的 demo 与模型互动,或免费注册官方 chat 体验最先进的模型。
众所周知,该项目是由开源社区为社区创建的,你将看到一些选项来改善聊天体验并参与数据收集。
与 AI 聊天
Open Assistant 允许你与聊天机器人对话,并对其回应提供反馈。要开始,请注册并点击聊天按钮。然后,使用竖起或倒立的拇指图标对聊天机器人的消息做出反应,帮助它学习。
图片来自 Chat
贡献数据收集
数据收集的用户界面非常简单。只需点击仪表板按钮,选择任务,然后开始贡献。你可以通过提交、排名和标记模型提示和回应来提高 Open Assistant 的能力。
图片来自 Open Assistant
当你对数据集做出有效贡献时,你的得分会在公共排行榜上显示。这是一种游戏化贡献过程的方式。
图片来自 Open Assistant
限制
Open Assistant 的限制是大多数开源大型语言模型的限制。这些模型在编程和数学交互方面训练较少,导致在回答数学和编程问题时表现非常糟糕。
该模型在生成有趣的回答方面表现良好,更像人类,但有时会产生事实错误或误导性的回答。
你需要了解这些模型相对于 ChatGPT 来说较小,并且会有一些限制。
未来计划
Open Assistant 的创始人有一个愿景,即创建一个未来的助手,它可以执行各种任务,如写邮件、进行有意义的工作、使用 API 和动态研究信息。此外,他们希望他们的助手对所有使用者都可以进行自定义和扩展。
-
他们将继续收集更多高质量数据,并训练更好的模型。
-
他们的愿景是创建一个统一的*台,包括对话助手、通过搜索引擎检索、API 和第三方集成,以及为开发者提供的构建模块。
-
他们还有一些私有模型,计划在完成安全功能后公开。
-
社区正在着手推出一种方法论,这将帮助在消费级 GPU 上训练和运行大型语言模型。
入门指南
Open Assistant 项目完全透明,并且允许商业使用。只有少数模型,如 LLaMa,受到限制。其他所有内容,包括模型、数据集、代码、推理、论文、演示和文档,都是免费的和公开的。
这个*台让你能为数据集贡献并登上排行榜。你还可以使用公开数据集训练你的模型。探索无限可能。
-
GitHub: LAION-AI/Open-Assistant
-
HuggingFace 演示: Chat Llm Streaming - 由 olivierdehaene 提供的 Hugging Face 空间
-
官方聊天: 聊天 (open-assistant.io)(需要注册)
-
数据集: OpenAssistant/oasst1
别忘了给项目点赞、星标和支持。他们无私地做这些,值得我们的喜爱。
Abid Ali Awan(@1abidaliawan)是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为挣扎于心理健康问题的学生构建一款 AI 产品。
更多相关内容
打开黑箱:如何利用可解释的机器学习
原文:
www.kdnuggets.com/2019/08/open-black-boxes-explainable-machine-learning.html
评论
由Maarten Grootendorst,Emset。
随着机器学习和人工智能越来越受欢迎,越来越多的组织正在采用这一新技术。预测建模帮助过程变得更加高效,同时也让用户获得利益。人们可以根据专业技能和经验预测你可能赚多少钱。输出可能只是一个数字,但用户通常想知道为什么给出这个值!
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水*
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
在本文中,我将演示一些创建可解释预测的方法,并指导你打开这些黑箱模型。

本文使用的数据集是美国成人收入数据集,通常用于预测某人是否赚取少于 50K 或多于 50K,这是一个简单的二分类任务。你可以在这里获取数据,或者可以跟随这里的笔记本进行操作。
数据相对简单,包含个人的关系、职业、种族、性别等信息。
建模
类别变量被进行了一次性编码,目标设置为 0(≤50K)或 1(>50K)。现在,假设我们想使用一个在分类任务中表现优秀但非常复杂且输出难以解释的模型,这个模型是 LightGBM,它与 CatBoost 和 XGBoost 一起,常用于分类和回归任务。
我们从简单地拟合模型开始:
from lightgbm import LGBMClassifier
X = df[df.columns[1:]]
y = df[df.columns[0]]
clf = LGBMClassifier(random_state=0, n_estimators=100)
fitted_clf = clf.fit(X, y)
我应该注意到,最好有一个训练/测试分割,并且有额外的保留数据来防止任何过拟合。
接下来,我快速检查模型的性能,使用 10 折交叉验证:
from sklearn.model_selection import cross_val_score
scores_accuracy = cross_val_score(clf, X, y, cv=10)
scores_balanced = cross_val_score(clf, X, y, cv=10,scoring="balanced_accuracy")
有趣的是,scores_accuracy 在 10 折交叉验证中的*均准确率为 87%,而 scores_balanced 为 80%。事实证明,目标变量是不*衡的,25%的目标属于 1,75%属于 0。因此,选择正确的验证指标非常重要,因为它可能会虚假地表示一个好的模型。
现在我们已经创建了模型,接下来就是解释它具体做了什么。由于 LightGBM 使用高效的梯度提升决策树,输出的解释可能会很困难。
部分依赖图(PDP)
部分依赖图(PDP)显示了某个特征对预测模型结果的影响。它在特征分布上对模型输出进行边际化,以提取感兴趣特征的重要性。我使用的包,PDPbox,可以在这里找到。
假设
这个重要性计算基于一个重要的假设,即感兴趣的特征与所有其他特征(目标除外)不相关。原因在于,这样会显示出可能不现实的数据点。例如,体重和身高是相关的,但 PDP 可能会显示大体重和非常小的身高对目标的影响,而这种组合的可能性很小。通过在 PDP 底部显示一个小条,可以部分解决这个问题。
相关性
因此,我们检查特征之间的相关性,以确保没有问题:
import seaborn as sns
corr = raw_df.corr()
sns.heatmap(corr,
xticklabels=corr.columns,
yticklabels=corr.columns)
我们可以看到特征之间没有明显的相关性。然而,我稍后会进行一些独热编码,以准备数据进行建模,这可能会导致相关特征的产生。
连续变量
PDP 图可以用来可视化一个变量在所有数据点上的输出影响。让我们从一个明显的例子开始,连续变量capital_gain对目标的影响:
from pdpbox import pdp
pdp_fare = pdp.pdp_isolate(
model=clf, dataset=df[df.columns[1:]], model_features=df.columns[1:], feature='Capital_gain'
)
fig, axes = pdp.pdp_plot(pdp_fare, 'Capital_gain', plot_pts_dist=True)
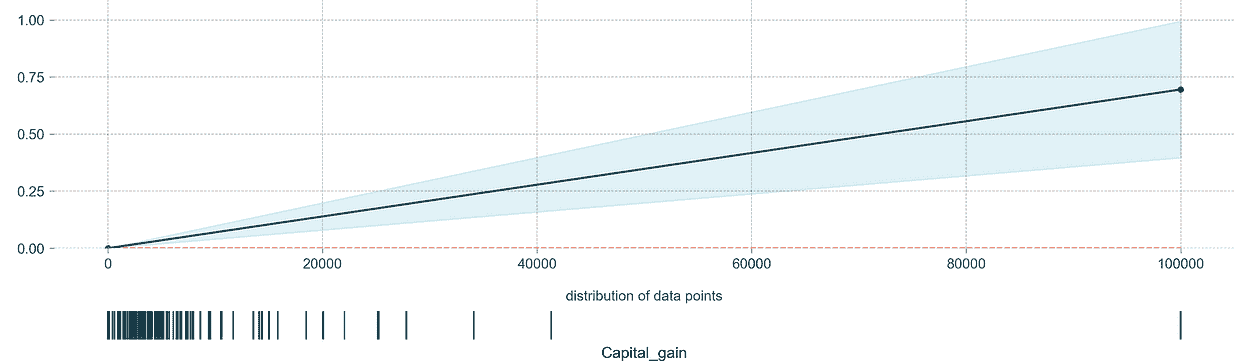
x 轴显示了 capital_gain 可能的值,y 轴则表示它对二分类概率的影响。显然,随着capital_gain的增加,其赚取<50K 的机会也会增加。注意,底部的数据点条有助于识别不常出现的数据点。
独热编码变量
现在,如果你有一个已经进行独热编码的分类变量呢?你可能想查看各类别的单独影响,而不必单独绘制它们。使用 PDPbox,你可以同时显示多个二分类变量的效果:
pdp_race = pdp.pdp_isolate(
model=clf, dataset=df[df.columns[1:]],
model_features=df.columns[1:],
feature=[i for i in df.columns if 'O_' in i if i not in
['O_ Adm-clerical',
'O_ Armed-Forces',
'O_ Armed-Forces',
'O_ Protective-serv',
'O_ Sales',
'O_ Handlers-cleaners']])
fig, axes = pdp.pdp_plot(pdp_race, 'Occupation', center=True,
plot_lines=True, frac_to_plot=100,
plot_pts_dist=True)
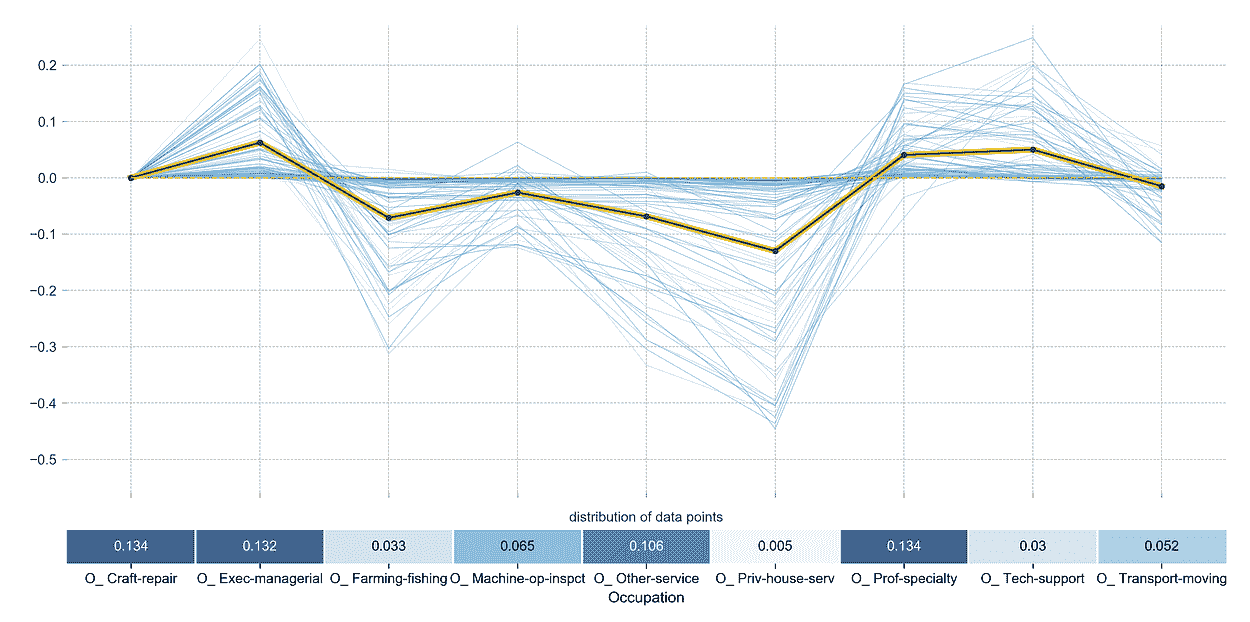
在这里,你可以清楚地看到,无论是处于管理职位还是技术职位,都对获得更多机会有正面影响。如果你在渔业工作,机会会减少。
变量之间的交互
最后,变量之间的交互可能是有问题的,因为 PDP 会为组合创建值,如果变量高度相关,这些值可能不太可能存在。
inter1 = pdp.pdp_interact(
model=clf, dataset=df[df.columns[1:]],
model_features=df.columns[1:], features=['Age', 'Hours/Week'])
fig, axes = pdp.pdp_interact_plot(
pdp_interact_out=inter1, feature_names=['Age', 'Hours/Week'],
plot_type='grid', x_quantile=True, plot_pdp=True)
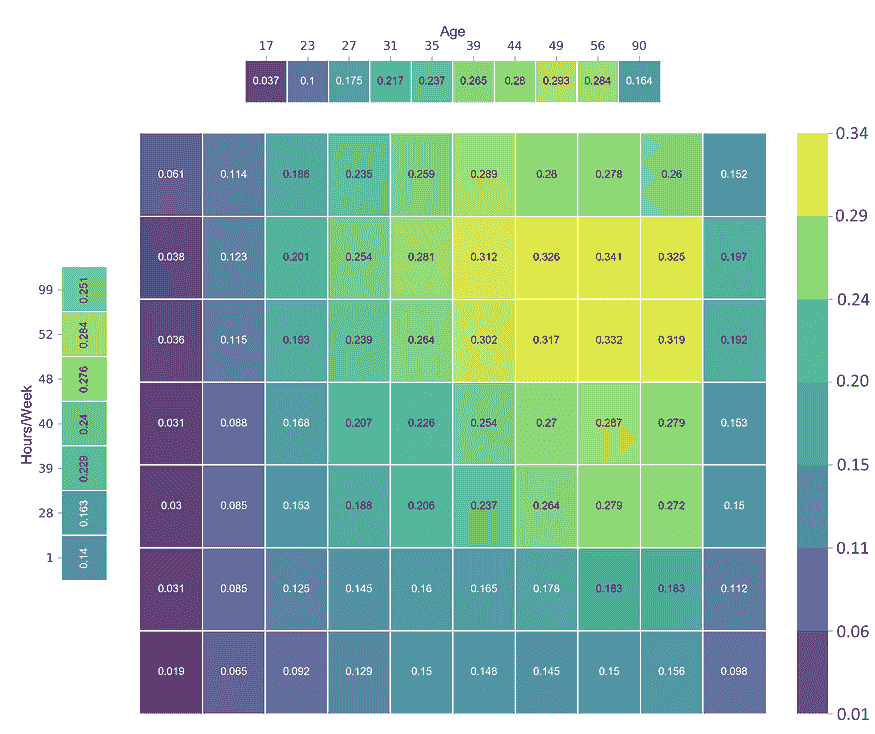
该矩阵告诉你,如果一个人约 49 岁并且每周工作大约 50 小时,他们可能赚得更多。我应该指出,重要的是要记住数据集中所有交互的实际分布。这个图可能会显示出一些有趣的交互,但这些交互很少或永远不会发生。
局部可解释模型无关解释(LIME)
LIME 基本上试图远离推导全局特征的重要性,而是*似局部预测中特征的重要性。它通过从中预测的行(或数据点集)生成假数据,然后计算假数据与真实数据之间的相似性,并根据假数据和真实数据之间的相似性来*似变化的影响。我使用的包可以在这里找到。
from lime.lime_tabular import LimeTabularExplainer
explainer = LimeTabularExplainer(X.values, feature_names=X.columns,
class_names=["<=50K", ">50K"],
discretize_continuous=True,
kernel_width=5)
i = 304
exp = explainer.explain_instance(X.values[i], clf.predict_proba,
num_features=5)
exp.show_in_notebook(show_table=True, show_all=False)

LIME 对单行数据的输出。
输出显示了前 5 个变量对预测概率的影响。这有助于确定模型为何做出特定预测,同时也为用户提供了解释。
缺点
注意 LIME 尝试为初始行寻找不同值的邻域(核宽度)在一定程度上是一个可以优化的超参数。有时你需要根据数据选择更大的邻域。找到合适的核宽度有点像试错过程,因为它可能会影响解释的可解释性。
Shapley 加法解释(SHAP)
一个(相当)新的发展是将 Shapley 值应用于机器学习。其本质上,SHAP 使用博弈论来跟踪每个变量的边际贡献。对于每个变量,它随机从数据集中抽样其他值并计算模型评分的变化。这些变化然后被*均以创建总结评分,同时也提供了有关特定数据点的某些变量的重要性的信息。
点击这里查看我在分析中使用的包。有关 SHAP 理论背景的更深入解释,请点击这里。
可解释性的三个公理
SHAP 因其满足可解释性的三个公理而受到好评:
-
任何对预测值没有影响的特征,其 Shapley 值应为 0(虚拟特征)
-
如果两个特征对预测增加相同的值,则它们的 Shapley 值应相同(可替代性)
-
如果你有两个或更多预测需要合并,你应该能够简单地将对个别预测计算的 Shapley 值相加(加性原理)
二分类
让我们看看如果计算单行的 Shapley 值结果会如何:
import shap
explainer = shap.TreeExplainer(clf)
shap_values = explainer.shap_values(X)
shap.initjs()
shap.force_plot(explainer.expected_value, shap_values[1,:],
X.iloc[1,:])

单个数据点的 Shapley 值。
该图显示了一个基准值,用于指示预测的方向。由于大多数目标是 0,因此基准值为负数并不奇怪。
红色条形图显示当教育年数为 13 时,目标为 1(>50K)的概率增加了多少。更高的教育通常会带来更多的收入。
蓝色条形图显示这些变量降低了概率,其中年龄的影响最大。这是合理的,因为年轻人通常赚得更少。
回归
Shapley 在处理回归(连续变量)时直观上表现得更好,而不是二分类。为了展示一个例子,让我们训练一个模型,从同一个数据集中预测年龄:
# Fit model with target Age
X = df[df.columns[2:]]
y = df[df.columns[1]]
clf = LGBMRegressor(random_state=0, n_estimators=100)
fitted_clf = clf.fit(X, y)
# Create Shapley plot for one row
explainer = shap.TreeExplainer(clf)
shap_values = explainer.shap_values(X)
shap.initjs()
i=200
shap.force_plot(explainer.expected_value, shap_values[i,:], X.iloc[i,:])

单个数据点的 Shapley 值。
在这里,你可以快速观察到,如果你从未结婚,预测的年龄大约降低 8 岁。这比分类任务更有助于解释预测,因为你直接谈论的是目标的值,而不是其概率。
一热编码特征
加性公理允许对所有数据点的每个特征的 Shapley 值进行求和,以创建均值绝对 Shapley 值。换句话说,它提供了全局特征重要性:
shap.summary_plot(shap_values, X, plot_type="bar", show=False)
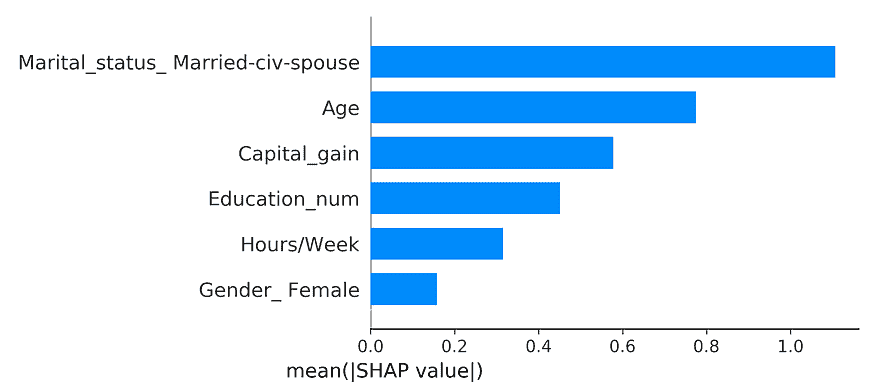
然而,你可以立即看到使用 Shapley 值处理一热编码特征的问题,它们是针对每个一热编码特征显示的,而不是它们最初所代表的。
幸运的是,加性公理允许将每个一热编码生成特征的 Shapley 值进行求和,以表示整个特征的 Shapley 值。
首先,我们需要对所有一热编码特征的 Shapley 值进行求和:
summary_df = pd.DataFrame([X.columns,
abs(shap_values).mean(axis=0)]).T
summary_df.columns = ['Feature', 'mean_SHAP']
mapping = {}
for feature in summary_df.Feature.values:
mapping[feature] = feature
for prefix, alternative in zip(['Workclass', 'Education',
'Marital_status', 'O_',
'Relationship', 'Gender',
'Native_country', 'Capital',
'Race'],
['Workclass', 'Education',
'Marital_status', 'Occupation',
'Relationship', 'Gender',
'Country', 'Capital', 'Race']):
if feature.startswith(prefix):
mapping[feature] = alternative
break
summary_df['Feature'] = summary_df.Feature.map(mapping)
shap_df = (summary_df.groupby('Feature')
.sum()
.sort_values("mean_SHAP", ascending=False)
.reset_index())
现在,所有 Shapley 值已在所有特征中取*均并对一热编码特征进行求和,我们可以绘制结果特征重要性:
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style="whitegrid")
f, ax = plt.subplots(figsize=(6, 15))
sns.barplot(x="mean_SHAP", y="Feature", data=shap_df[:5],
label="Total", color="b")
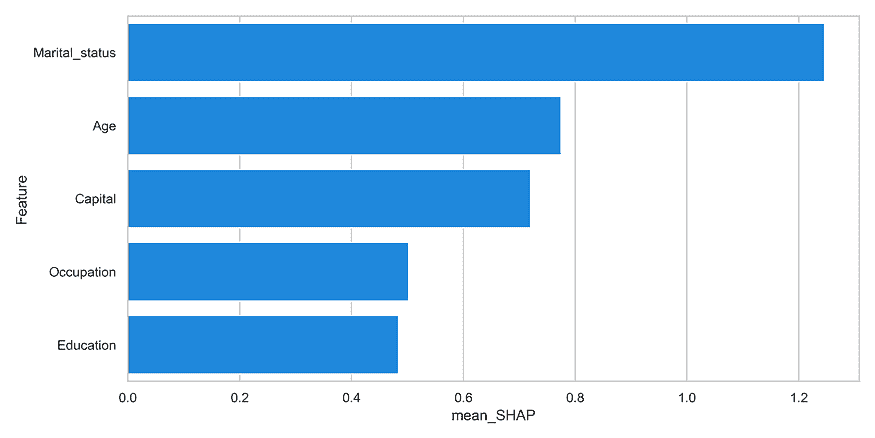
现在我们可以看到,职业比最初的 Shapley 总结图表所显示的要重要得多。因此,在向用户解释特征的重要性时,确保利用加性原理。用户可能更感兴趣于职业的重要性,而不是具体的职业。
结论
尽管这不是第一篇讨论可解释和解释性机器学习的文章,但我希望这能帮助你了解在开发模型时如何使用这些技术。
对 SHAP 的关注日益增加,我希望通过使用独热编码特征展示加法公理,能够深入理解如何使用这种方法。
带有代码的笔记本可以在此处找到。
简介: Maarten Grootendorst 是数据科学家 | I/O 心理学家 | 临床心理学家 | Emset 的联合创始人。
原文。经许可转载。
相关:
更多相关内容
开放数据的地理可视化
原文:
www.kdnuggets.com/2020/01/open-data-germany-maps-viz.html
评论
由 Dr. Juan Camilo Orduz,数学家与数据科学家
在这篇文章中,我想展示如何使用公开(开放)数据在 Python 中创建地理可视化。地图是处理地理定位数据时传达和比较信息的绝佳方式。有许多框架可以绘制地图,这里我重点介绍 matplotlib 和 geopandas(并简要介绍 mplleaflet)。
参考: 一个非常好的 matplotlib 介绍是来自 Python 数据科学手册 的 Matplotlib 可视化 章节,由 Jake VanderPlas 撰写。
备注: 当我完成写这本笔记本时,我发现 R 语言中有类似的分析 在这里。请查看一下!
准备笔记本
import geopandas as gpd
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('seaborn')
%matplotlib inline
获取德国数据
本文的主要数据来源是 www.suche-postleitzahl.org/downloads。我们在这里下载了三个数据集:
-
plz-gebiete.shp:包含德国邮政编码多边形的 shapefile。 -
zuordnung_plz_ort.csv:邮政编码到城市和联邦州的映射。 -
plz_einwohner.csv:人口分配到每个邮政编码区域。
德国地图
我们首先生成一个包含最重要城市的德国地图。
# Make sure you read postal codes as strings, otherwise
# the postal code 01110 will be parsed as the number 1110\.
plz_shape_df = gpd.read_file('../Data/plz-gebiete.shp', dtype={'plz': str})
plz_shape_df.head()
| plz | note | geometry | |
|---|---|---|---|
| 0 | 52538 | 52538 Gangelt, Selfkant | POLYGON ((5.86632 51.05110, 5.86692 51.05124, … |
| 1 | 47559 | 47559 Kranenburg | POLYGON ((5.94504 51.82354, 5.94580 51.82409, … |
| 2 | 52525 | 52525 Waldfeucht, Heinsberg | POLYGON ((5.96811 51.05556, 5.96951 51.05660, … |
| 3 | 52074 | 52074 亚琛 | POLYGON ((5.97486 50.79804, 5.97495 50.79809, … |
| 4 | 52531 | 52531 Übach-Palenberg | POLYGON ((6.01507 50.94788, 6.03854 50.93561, … |
geometry 列包含定义邮政编码形状的多边形。
我们可以使用 geopandas 映射工具 来通过 plot 方法生成地图。
plt.rcParams['figure.figsize'] = [16, 11]
# Get lat and lng of Germany's main cities.
top_cities = {
'Berlin': (13.404954, 52.520008),
'Cologne': (6.953101, 50.935173),
'Düsseldorf': (6.782048, 51.227144),
'Frankfurt am Main': (8.682127, 50.110924),
'Hamburg': (9.993682, 53.551086),
'Leipzig': (12.387772, 51.343479),
'Munich': (11.576124, 48.137154),
'Dortmund': (7.468554, 51.513400),
'Stuttgart': (9.181332, 48.777128),
'Nuremberg': (11.077438, 49.449820),
'Hannover': (9.73322, 52.37052)
}
fig, ax = plt.subplots()
plz_shape_df.plot(ax=ax, color='orange', alpha=0.8)
# Plot cities.
for c in top_cities.keys():
# Plot city name.
ax.text(
x=top_cities[c][0],
# Add small shift to avoid overlap with point.
y=top_cities[c][1] + 0.08,
s=c,
fontsize=12,
ha='center',
)
# Plot city location centroid.
ax.plot(
top_cities[c][0],
top_cities[c][1],
marker='o',
c='black',
alpha=0.5
)
ax.set(
title='Germany',
aspect=1.3,
facecolor='lightblue'
);
首位数字邮政编码区域
接下来,让我们绘制不同地区对应于每个邮政编码的第一个数字。
# Create feature.
plz_shape_df = plz_shape_df \
.assign(first_dig_plz = lambda x: x['plz'].str.slice(start=0, stop=1))
fig, ax = plt.subplots()
plz_shape_df.plot(
ax=ax,
column='first_dig_plz',
categorical=True,
legend=True,
legend_kwds={'title':'First Digit', 'loc':'lower right'},
cmap='tab20',
alpha=0.9
)
for c in top_cities.keys():
ax.text(
x=top_cities[c][0],
y=top_cities[c][1] + 0.08,
s=c,
fontsize=12,
ha='center',
)
ax.plot(
top_cities[c][0],
top_cities[c][1],
marker='o',
c='black',
alpha=0.5
)
ax.set(
title='Germany First-Digit-Postal Codes Areas',
aspect=1.3,
facecolor='white'
);
联邦州地图
现在让我们将每个邮政编码映射到相应的区域:
plz_region_df = pd.read_csv(
'../Data/zuordnung_plz_ort.csv',
sep=',',
dtype={'plz': str}
)
plz_region_df.drop('osm_id', axis=1, inplace=True)
plz_region_df.head()
| ort | plz | bundesland | |
|---|---|---|---|
| 0 | Aach | 78267 | 巴登-符腾堡 |
| 1 | Aach | 54298 | 莱茵兰-普法尔茨 |
| 2 | 亚琛 | 52062 | 北莱茵-威斯特法伦 |
| 3 | 亚琛 | 52064 | 北莱茵-威斯特法伦 |
| 4 | 亚琛 | 52066 | 北莱茵-威斯特法伦 |
# Merge data.
germany_df = pd.merge(
left=plz_shape_df,
right=plz_region_df,
on='plz',
how='inner'
)
germany_df.drop(['note'], axis=1, inplace=True)
germany_df.head()
| plz | 几何 | first_dig_plz | 城市 | 联邦州 | |
|---|---|---|---|---|---|
| 0 | 52538 | POLYGON ((5.86632 51.05110, 5.86692 51.05124, … | 5 | 甘根特 | 北莱茵-威斯特法伦 |
| 1 | 52538 | POLYGON ((5.86632 51.05110, 5.86692 51.05124, … | 5 | 塞尔夫坎特 | 北莱茵-威斯特法伦 |
| 2 | 47559 | POLYGON ((5.94504 51.82354, 5.94580 51.82409, … | 4 | 克拉能堡 | 北莱茵-威斯特法伦 |
| 3 | 52525 | POLYGON ((5.96811 51.05556, 5.96951 51.05660, … | 5 | 海因斯贝格 | 北莱茵-威斯特法伦 |
| 4 | 52525 | POLYGON ((5.96811 51.05556, 5.96951 51.05660, … | 5 | 瓦尔德费赫特 | 北莱茵-威斯特法伦 |
生成联邦州地图:
fig, ax = plt.subplots()
germany_df.plot(
ax=ax,
column='bundesland',
categorical=True,
legend=True,
legend_kwds={'title':'Bundesland', 'bbox_to_anchor': (1.35, 0.8)},
cmap='tab20',
alpha=0.9
)
for c in top_cities.keys():
ax.text(
x=top_cities[c][0],
y=top_cities[c][1] + 0.08,
s=c,
fontsize=12,
ha='center',
)
ax.plot(
top_cities[c][0],
top_cities[c][1],
marker='o',
c='black',
alpha=0.5
)
ax.set(
title='Germany - Bundesländer',
aspect=1.3,
facecolor='white'
);
居民数量
现在我们将包括每个邮政编码的居民数量:
plz_einwohner_df = pd.read_csv(
'../Data/plz_einwohner.csv',
sep=',',
dtype={'plz': str, 'einwohner': int}
)
plz_einwohner_df.head()
| plz | 居民数 | |
|---|---|---|
| 0 | 01067 | 11957 |
| 1 | 01069 | 25491 |
| 2 | 01097 | 14811 |
| 3 | 01099 | 28021 |
| 4 | 01108 | 5876 |
# Merge data.
germany_df = pd.merge(
left=germany_df,
right=plz_einwohner_df,
on='plz',
how='left'
)
germany_df.head()
| plz | 几何 | first_dig_plz | 城市 | 联邦州 | 居民数 | |
|---|---|---|---|---|---|---|
| 0 | 52538 | POLYGON ((5.86632 51.05110, 5.86692 51.05124, … | 5 | 甘根特 | 北莱茵-威斯特法伦 | 21390 |
| 1 | 52538 | POLYGON ((5.86632 51.05110, 5.86692 51.05124, … | 5 | 塞尔夫坎特 | 北莱茵-威斯特法伦 | 21390 |
| 2 | 47559 | POLYGON ((5.94504 51.82354, 5.94580 51.82409, … | 4 | 克拉能堡 | 北莱茵-威斯特法伦 | 10220 |
| 3 | 52525 | POLYGON ((5.96811 51.05556, 5.96951 51.05660, … | 5 | 海因斯贝格 | 北莱茵-威斯特法伦 | 49737 |
| 4 | 52525 | POLYGON ((5.96811 51.05556, 5.96951 51.05660, … | 5 | 瓦尔德费赫特 | 北莱茵-威斯特法伦 | 49737 |
生成地图:
fig, ax = plt.subplots()
germany_df.plot(
ax=ax,
column='einwohner',
categorical=False,
legend=True,
cmap='autumn_r',
alpha=0.8
)
for c in top_cities.keys():
ax.text(
x=top_cities[c][0],
y=top_cities[c][1] + 0.08,
s=c,
fontsize=12,
ha='center',
)
ax.plot(
top_cities[c][0],
top_cities[c][1],
marker='o',
c='black',
alpha=0.5
)
ax.set(
title='Germany: Number of Inhabitants per Postal Code',
aspect=1.3,
facecolor='lightblue'
);
城市地图
我们现在可以使用 ort 特征筛选城市。
- 慕尼黑
munich_df = germany_df.query('ort == "München"')
fig, ax = plt.subplots()
munich_df.plot(
ax=ax,
column='einwohner',
categorical=False,
legend=True,
cmap='autumn_r',
)
ax.set(
title='Munich: Number of Inhabitants per Postal Code',
aspect=1.3,
facecolor='lightblue'
);
- 柏林
berlin_df = germany_df.query('ort == "Berlin"')
fig, ax = plt.subplots()
berlin_df.plot(
ax=ax,
column='einwohner',
categorical=False,
legend=True,
cmap='autumn_r',
)
ax.set(
title='Berlin: Number of Inhabitants per Postal Code',
aspect=1.3,
facecolor='lightblue'
);
柏林
我们可以使用门户网站 www.statistik-berlin-brandenburg.de 获取柏林的官方邮政编码与区域映射信息,详见 这里。经过一些格式化处理(非结构化原始数据):
berlin_plz_area_df = pd.read_excel(
'../Data/ZuordnungderBezirkezuPostleitzahlen.xls',
sheet_name='plz_bez_tidy',
dtype={'plz': str}
)
berlin_plz_area_df.head()
| plz | 区域 | |
|---|---|---|
| 0 | 10115 | 中心 |
| 1 | 10117 | 中心 |
| 2 | 10119 | 中心 |
| 3 | 10178 | 中心 |
| 4 | 10179 | 中心 |
但请注意,这张地图不是一对一的,即一个邮政编码可以对应多个区域:
berlin_plz_area_df \
[berlin_plz_area_df['plz'].duplicated(keep=False)] \
.sort_values('plz')
| plz | 区域 | |
|---|---|---|
| 2 | 10119 | 中心 |
| 41 | 10119 | 帕克诺 |
| 4 | 10179 | 中心 |
| 26 | 10179 | 弗里德里希斯海因-克罗伊茨贝格 |
| 42 | 10247 | 帕克诺 |
| … | … | … |
| 133 | 14197 | 施特格利茨-泽尔多夫 |
| 95 | 14197 | 夏洛滕堡-威尔默斯多夫 |
| 165 | 14197 | 恩赫尔霍夫-舍讷贝格 |
| 134 | 14199 | 施特格利茨-泽尔多夫 |
| 96 | 14199 | 夏洛滕堡-威尔默斯多夫 |
99 行 × 2 列
因此,我们需要更改邮政编码分组变量。
柏林社区
幸运的是,网站insideairbnb.com/get-the-data.html,包含了许多城市的 AirBnB 数据(这绝对值得研究!),有一个方便的数据集neighbourhoods.geojson,它将柏林的区域映射到邻里:
berlin_neighbourhoods_df = gpd.read_file('../Data/neighbourhoods.geojson')
berlin_neighbourhoods_df = berlin_neighbourhoods_df \
[~ berlin_neighbourhoods_df['neighbourhood_group'].isnull()]
berlin_neighbourhoods_df.head()
| 邻里 | 邻里组 | 几何 | |
|---|---|---|---|
| 0 | Blankenfelde/Niederschönhausen | Pankow | MULTIPOLYGON (((13.41191 52.61487, 13.41183 52… |
| 1 | Helmholtzplatz | Pankow | MULTIPOLYGON (((13.41405 52.54929, 13.41422 52… |
| 2 | Wiesbadener Straße | Charlottenburg-Wilm. | MULTIPOLYGON (((13.30748 52.46788, 13.30743 52… |
| 3 | Schmöckwitz/Karolinenhof/Rauchfangswerder | Treptow - Köpenick | MULTIPOLYGON (((13.70973 52.39630, 13.70926 52… |
| 4 | Müggelheim | Treptow - Köpenick | MULTIPOLYGON (((13.73762 52.40850, 13.73773 52… |
fig, ax = plt.subplots()
berlin_df.plot(
ax=ax,
alpha=0.2
)
berlin_neighbourhoods_df.plot(
ax=ax,
column='neighbourhood_group',
categorical=True,
legend=True,
legend_kwds={'title': 'Neighbourhood', 'loc': 'upper right'},
cmap='tab20',
edgecolor='black'
)
ax.set(
title='Berlin Neighbourhoods',
aspect=1.3
);
 这里的划分对应于
这里的划分对应于Neighbourhood⊂⊂Neighbourhood Group。
柏林精选地点
有时候,将著名地点包含在地图上是很有用的,以便用户可以识别它们并理解距离和比例。实现这一点的一种方法是手动输入每个点的纬度和经度(如上所述)。当然,这可能耗时且容易出错。正如预期的那样,有一个可以自动获取这种数据的库,即geopy。
这是一个简单的例子:
from geopy import Nominatim
locator = Nominatim(user_agent='myGeocoder')
location = locator.geocode('Humboldt Universität zu Berlin')
print(location)
柏林洪堡大学,Dorotheenstraße,Spandauer Vorstadt,Mitte,柏林,10117,德国
让我们编写一个函数来获取纬度和经度坐标:
def lat_lng_from_string_loc(x):
locator = Nominatim(user_agent='myGeocoder')
location = locator.geocode(x)
if location is None:
None
else:
return location.longitude, location.latitude
# Define some well-known Berlin locations.
berlin_locations = [
'Alexander Platz',
'Zoo Berlin',
'Berlin Tegel',
'Berlin Schönefeld',
'Berlin Adlershof',
'Olympia Stadium Berlin',
'Berlin Südkreuz',
'Frei Universität Berlin',
'Mauerpark',
'Treptower Park',
]
# Get geodata.
berlin_locations_geo = {
x: lat_lng_from_string_loc(x)
for x in berlin_locations
}
# Remove None.
berlin_locations_geo = {
k: v
for k, v in berlin_locations_geo.items()
if v is not None
}
让我们查看结果地图:
berlin_df = germany_df.query('ort == "Berlin"')
fig, ax = plt.subplots()
berlin_df.plot(
ax=ax,
color='orange',
alpha=0.8
)
for c in berlin_locations_geo.keys():
ax.text(
x=berlin_locations_geo[c][0],
y=berlin_locations_geo[c][1] + 0.005,
s=c,
fontsize=12,
ha='center',
)
ax.plot(
berlin_locations_geo[c][0],
berlin_locations_geo[c][1],
marker='o',
c='black',
alpha=0.5
)
ax.set(
title='Berlin - Some Relevant Locations',
aspect=1.3,
facecolor='lightblue'
);
圣诞市场
让我们通过包含其他类型的信息来丰富地图。有关柏林公开数据的绝佳资源是柏林开放数据。在许多有趣的数据集中,我找到了一份关于城市周边圣诞市场的数据(这些市场真的很有趣!)在这里。你可以通过公共 API 访问这些数据。让我们使用requests模块来完成这项任务:
import requests
# GET request.
response = requests.get(
'https://www.berlin.de/sen/web/service/maerkte-feste/weihnachtsmaerkte/index.php/index/all.json?q='
)
response_json = response.json()
转换为 pandas 数据框。
berlin_maerkte_raw_df = pd.DataFrame(response_json['index'])
我们没有邮政编码功能,但我们可以通过从plz_ort列中提取来创建一个。
berlin_maerkte_df = berlin_maerkte_raw_df[['name', 'bezirk', 'plz_ort', 'lat', 'lng']]
berlin_maerkte_df = berlin_maerkte_df \
.query('lat != ""') \
.assign(plz = lambda x: x['plz_ort'].str.split(' ').apply(lambda x: x[0]).astype(str)) \
.drop('plz_ort', axis=1)
# Convert to float.
berlin_maerkte_df['lat'] = berlin_maerkte_df['lat'].str.replace(',', '.').astype(float)
berlin_maerkte_df['lng'] = berlin_maerkte_df['lng'].str.replace(',', '.').astype(float)
berlin_maerkte_df.head()
| 名称 | 区域 | 纬度 | 经度 | 邮政编码 | |
|---|---|---|---|---|---|
| 0 | Charlottenburg 宫前的圣诞市场 | Charlottenburg-Wilmersdorf | 52.519951 | 13.295946 | 14059 |
| 1 |
- Gedächtniskirche 圣诞市场
| Charlottenburg-Wilmersdorf | 52.504886 | 13.335511 | 10789 |
|---|---|---|---|
| 2 | Wilmersdorf 步行区的圣诞市场 | Charlottenburg-Wilmersdorf | 52.509313 |
| 3 | 圣诞市场在西区 | Charlottenburg-Wilmersdorf | 52.512538 |
| 4 | Johannisstraße 的柏林-Grunewald 圣诞市场 | Charlottenburg-Wilmersdorf | 52.488350 |
让我们绘制圣诞市场的位置:
fig, ax = plt.subplots()
berlin_df.plot(ax=ax, color= 'green', alpha=0.4)
for c in berlin_locations_geo.keys():
ax.text(
x=berlin_locations_geo[c][0],
y=berlin_locations_geo[c][1] + 0.005,
s=c,
fontsize=12,
ha='center',
)
ax.plot(
berlin_locations_geo[c][0],
berlin_locations_geo[c][1],
marker='o',
c='black',
alpha=0.5
)
berlin_maerkte_df.plot(
kind='scatter',
x='lng',
y='lat',
c='r',
marker='*',
s=50,
label='Christmas Market',
ax=ax
)
ax.set(
title='Berlin Christmas Markets (2019)',
aspect=1.3,
facecolor='white'
);
互动地图
我们可以使用 mplleaflet 库,它将 matplotlib 图表转换为包含可*移、可缩放的 Leaflet 地图的网页。
- 柏林邻里
import mplleaflet
fig, ax = plt.subplots()
berlin_df.plot(
ax=ax,
alpha=0.2
)
berlin_neighbourhoods_df.plot(
ax=ax,
column='neighbourhood_group',
categorical=True,
cmap='tab20',
)
mplleaflet.display(fig=fig)
- 圣诞市场
fig, ax = plt.subplots()
berlin_df.plot(ax=ax, color= 'green', alpha=0.4)
berlin_maerkte_df.plot(
kind='scatter',
x='lng',
y='lat',
c='r',
marker='*',
s=30,
ax=ax
)
mplleaflet.display(fig=fig)
我希望这些数据源和代码片段能作为探索使用 Python 进行地理数据分析和可视化的起点。
简介: 胡安·卡米洛·奥尔杜斯博士 (@juanitorduz) 是一位总部位于柏林的数学家和数据科学家。
原文。经许可转载。
相关:
-
每位数据科学家都应阅读的 6 本关于开放数据的书籍
-
数据可视化的八个经典例子
-
元数据丰富化对实现开放数据集的价值至关重要
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT
更多相关话题
开放数据及其必要性

图片作者
什么是开放数据?
开放数据是指任何人都可以用于任何目的的数据。它允许个人或公司使用、重用和重新分发数据而没有法律问题。数据受作者署名或相似共享许可 - opendatahandbook。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
为了更好地理解,让我们深入探讨这些功能。
-
开放访问和可用性: 数据必须是完整的,并且可以通过互联网轻松下载。数据还应该以方便和修改过的形式提供。
-
开放再利用: 数据必须在允许最终用户重新使用和重新分发的许可证下,这还包括混合多个数据集。
-
普遍参与: 每个人都可以使用、重用和重新分发数据,不受任何研究领域、个人或团体的歧视。
为了推动开放数据的使用,全球数据社区每年庆祝 国际开放数据日。在 3 月 6 日,全球各地的各种组织会举办讲座、研讨会、演示、黑客马拉松,并宣布开放数据发布。

图片来源于 it24hrs
为什么重要
如果你想知道为什么开放数据如此必要,简单的答案是,它加速了创新,减少了偏见,改善了质量,并降低了数据收集的成本。为了更好地理解,我们将详细学习开放数据的优势。
互操作性
互操作性意味着不同组织或系统能够协同工作。在我们的案例中,结合多个数据,使用类似数据处理复杂问题,并允许不同组件协同工作。互操作性对于解决复杂问题至关重要,它支持各种组织发现改进现有系统和开发新产品与服务的新方法。
经济成本
当数据被公开分享时,我们在收集新数据集上节省了大量资源。我们不仅节省了成本,还节省了收集全新数据集所需的时间和人力资源。开放数据还可以帮助公司将资源转移到新产品的研发中。
数据质量
当数据被多个方使用和重复使用时,发现并纠正错误的机会就会增加。随着时间的推移,数据的集体使用将提高对数据源的信心,这将帮助我们避免不确定性和偏见。
验证
研究出版物中提供的解决方案或方法论应当是可重复和可验证的。这只有在数据与研究解决方案一起共享时才有可能。验证将提高研究的质量并加速创新。它还帮助我们避免机器学习模型中的偏见,从而创建面向共同利益的包容性数据应用。

图片由作者提供
如何找到开放数据
世界正朝着开放数据政策迈进,许多组织和公司正在分享数据。通过简单的谷歌搜索,任何人都可以在特定领域找到多个数据集。此外,还有一些专业*台提供对数据集的公共访问。
Kaggle
Kaggle是一个社区驱动的*台,数据科学家们在这里分享数据、研究、代码,并参与数据竞赛。如果你在寻找数据集,Kaggle 应该是你的首选目的地,因为你可以通过简单的搜索找到各种开放源代码的数据集。
谷歌数据集搜索
谷歌数据集搜索使用谷歌搜索引擎,但专门用于数据。通过简单的搜索,你可以从各种来源找到任何类型的数据。例如,如果你喜欢某个数据集并想了解更多,它将提供 GitHub、Kaggle 和其他各种*台的链接以供查看和下载。
Data.Gov
美国政府在 2015 年公开了所有数据。这些数据收集包括了 200,000 个数据集,涵盖从气候变化到犯罪的各个领域。该*台用户友好,数据集以常见文件格式提供。你会惊讶于从Data.Gov获取的最详细人口统计数据集中学到的东西。
Datahub.io
Datahub包含了各种高质量数据集的集合,按不同类别组织。你可以找到有关气候变化、娱乐、教育、医疗保健等的数据。该*台关注于像股市数据、房产价格、通货膨胀和物流等数据集。
全球健康观察数据仓库
全球健康观察数据存储库 包含全球健康相关的统计数据。 该数据集涵盖了从疟疾到 HIV/AIDS、抗菌素耐药性和疫苗接种率的所有健康问题。 对于在医疗行业工作的数据科学家来说,这个存储库是一个宝贵的资源,因为这些统计数据可以帮助他们开发前沿的 AI 解决方案。
如果你在寻找一些稀有的数据集,查看 G2 提供的 50 个最佳开放数据源 。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,喜欢构建机器学习模型。 目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。 Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些面临心理健康问题的学生开发 AI 产品。
相关主题
使用 EvalML 实现简单的开源 Python AutoML
原文:
www.kdnuggets.com/2021/02/open-source-automl-python-evalml.html
评论
由 Dylan Sherry,EvalML 团队负责人

Alteryx 托管两个开源建模项目。
Featuretools 是一个用于执行自动化特征工程的框架。它擅长将时间序列和关系数据集转化为机器学习的特征矩阵。
Compose 是一个用于自动预测工程的工具。它允许你构建预测问题并生成监督学习的标签。
我们已经看到 Featuretools 和 Compose 使用户能够轻松地将多个表结合成用于机器学习的转化和聚合特征,并定义时间序列监督机器学习用例。
我们接着问了一个问题:接下来会发生什么?Featuretools 和 Compose 的用户如何以简单灵活的方式构建机器学习模型?
我们很高兴地宣布一个新的开源项目加入了 Alteryx 开源生态系统。EvalML 是一个用于自动化机器学习(AutoML)和模型理解的库,使用 Python 编写。
import evalml
# obtain features, a target and a problem type for that target
X, y = evalml.demos.load_breast_cancer()
problem_type = 'binary'
X_train, X_test, y_train, y_test = evalml.preprocessing.split_data(
X, y, problem_type=problem_type, test_size=.2)
# perform a search across multiple pipelines and hyperparameters
automl = AutoMLSearch(X=x, y=y, problem_type=problem_type)
automl.search()
# the best pipeline is already refitted on the entire training data
best_pipeline = automl.best_pipeline
best_pipeline.predict(X_test)

EvalML 的 AutoML 搜索演示
EvalML 提供了一个简单的统一界面,用于构建机器学习模型,使用这些模型生成洞察并进行准确预测。EvalML 在同一个 API 下提供对多个建模库的访问。EvalML 支持多种监督机器学习问题类型,包括回归、二元分类和多类别分类。自定义目标函数让用户可以直接根据他们重视的内容来寻找模型。最重要的是,我们旨在使 EvalML 稳定高效,并在每次发布时进行机器学习性能测试。
EvalML 的亮点
1. 简单统一的建模 API
EvalML 减少了获得准确模型所需的努力,节省了时间和复杂性。
AutoML 生成的 EvalML 流水线包括开箱即用的预处理和特征工程步骤。一旦用户确定了他们想要建模的数据的目标列,EvalML 的 AutoML 将运行搜索算法来训练和评估一组模型,允许用户从这些模型中选择一个或多个模型,然后使用这些模型进行洞察驱动的分析或生成预测。
EvalML 设计为与 Featuretools良好兼容,它可以从多个表中集成数据并生成特征以增强 ML 模型,以及与 Compose兼容,这是一个用于标签工程和时间序列汇总的工具。EvalML 用户可以轻松控制 EvalML 如何处理每个输入的特征,例如数值特征、分类特征、文本、日期时间等。

你可以在 EvalML 中使用 Compose 和 Featuretools 来构建机器学习模型。
EvalML 模型使用管道数据结构表示,由组件图组成。AutoML 对数据应用的每个操作都会记录在管道中。这使得从选择模型到部署模型变得容易。定义自定义组件、管道和目标在 EvalML 中也很简单,无论是用于 AutoML 还是作为独立元素。
2. 特定领域的目标函数
EvalML 支持定义自定义目标函数,你可以根据你的数据和领域进行定制。这使你能够阐明在你的领域中使模型有价值的因素,然后使用 AutoML 找到能够提供这些价值的模型。
自定义目标用于在 AutoML 排行榜上对模型进行排名,无论是在搜索过程中还是之后。使用自定义目标将帮助引导 AutoML 搜索到具有最高影响力的模型。自定义目标还将被 AutoML 用于调整二分类模型的分类阈值。
EvalML 文档提供了自定义目标的示例以及如何有效使用它们。
3. 模型理解
EvalML 提供了多种模型和工具用于模型理解。目前支持特征重要性和置换重要性、部分依赖、精确率-召回率、混淆矩阵、ROC 曲线、预测解释以及二分类器阈值优化。

部分依赖的示例来自于 EvalML 文档。
4. 数据检查
EvalML 的数据检查可以在建模之前捕捉数据中的常见问题,避免这些问题导致模型质量问题或神秘的错误和堆栈跟踪。当前的数据检查包括检测 target leakage(模型在训练期间接触到的在预测时不可用的信息)、无效数据类型、高类别不*衡、高空值列、常量列,以及可能是 ID 而对建模无用的列。

使用 EvalML 入门
你可以通过访问 我们的文档页面 来开始使用 EvalML,我们提供了安装说明以及tutorials,展示了如何使用 EvalML 的示例,用户指南 介绍了 EvalML 的组件和核心概念,API 参考 等更多内容。EvalML 的代码库在github.com/alteryx/evalml。要与团队联系,请查看我们的开源 Slack。我们积极参与代码库,并将回应你提出的任何问题。
下一步是什么?
EvalML 有一个活跃的功能路线图,包括时间序列建模、AutoML 期间的管道并行评估、AutoML 算法的升级、新模型类型和预处理步骤、模型调试和部署工具、异常检测支持等更多功能。
想了解更多?如果你对项目的更新感兴趣,请花一点时间关注这个博客,给我们的 GitHub 仓库加个星,并关注更多即将推出的功能和内容!
个人简介: Dylan Sherry 是一位软件工程师,领导着开发 EvalML AutoML 包的团队。Dylan 拥有十年的自动建模技术经验。
原文。经授权转载。
相关内容:
-
Uber 开源了 Ludwig 的第三版,它是无代码机器学习*台
-
高级超参数优化/调整的算法
-
使用 PyCaret 2.0 构建自己的 AutoML
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的 IT 组织
相关话题
计算机视觉的开源数据集
原文:
www.kdnuggets.com/2021/08/open-source-datasets-computer-vision.html
评论

计算机视觉(CV)是人工智能(AI)和机器学习(ML)领域中最令人兴奋的子领域之一。它是许多现代 AI/ML 管道中的重要组成部分,并且正在改变几乎所有行业,使组织能够彻底革新机器和业务系统的工作方式。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
在学术上,计算机视觉已经是计算机科学中的一个成熟领域,多年来,这一领域经过了大量的研究以不断完善。然而,深度神经网络的使用最*彻底革新了这一领域,并为其加速增长注入了新的动力。
计算机视觉有着多种应用领域,例如:
-
自动驾驶
-
医学影像分析与诊断
-
场景检测与理解
-
自动图像标题生成
-
社交媒体上的照片/面孔标记
-
家庭安全
-
制造业缺陷识别与质量控制
在这篇文章中,我们探讨了一些在深度学习(DL)领域中用于训练最先进的机器学习系统的流行且有效的数据集。
仔细选择合适的开源数据集
在图像和视频文件上训练机器是一项数据密集型操作。单一图像文件是一个多维的、多兆字节的数字实体,仅包含整个“智能图像分析”任务中的微小“洞察”部分。
相比之下,一个相似规模的零售销售数据表可以在相同的计算硬件开支下为机器学习算法提供更多的洞见。在讨论现代计算机视觉管道所需的数据规模和计算时,值得记住这一点。
因此,在几乎所有情况下,几百张(甚至几千张)图像不足以训练高质量的机器学习模型用于计算机视觉任务。几乎所有现代计算机视觉系统使用复杂的深度学习模型架构,如果没有提供足够数量的精心选择的训练样本,即标记图像,它们将会表现不足。因此,成为一种高度常见的趋势是稳健、具有泛化能力的生产级深度学习系统通常需要数百万张精心挑选的图像进行训练。
此外,对于视频分析,选择和编制训练数据集的任务可能更加复杂,因为视频文件或从多个视频流中获得的帧具有动态特性。
在这里,我们列出了一些最受欢迎的数据集(包括静态图像和视频剪辑)。
计算机视觉模型的流行开源数据集
并非所有数据集都适用于所有类型的计算机视觉任务。常见的计算机视觉任务包括:
-
图像分类
-
对象检测
-
对象分割
-
多对象注释
-
图像描述
-
人体姿态估计
-
视频帧分析
我们展示了一些涵盖大部分这些类别的流行开源数据集。
ImageNet(最著名)
ImageNet 是一个持续的研究努力,旨在为全球研究人员提供一个易于访问的图像数据库。它或许是最著名的图像数据集,被研究人员和学习者一致称为金标准。
该项目的灵感来源于图像和视觉研究领域日益增长的需求——更多的数据。它按照 WordNet 层次结构进行组织。WordNet 中每个有意义的概念,可能由多个词或词组描述,称为“同义词集”或“synset”。WordNet 中有超过 100,000 个同义词集。类似地,ImageNet 旨在提供*均 1000 张图像来说明每个同义词集。
ImageNet 大规模视觉识别挑战赛(ILSVRC)是一个全球年度比赛,评估算法(由大学或企业研究团队提交)在大规模对象检测和图像分类方面的表现。一个主要动机是允许研究人员在更广泛的对象上比较检测进展——利用相当昂贵的标注工作。另一个动机是衡量计算机视觉在大规模图像索引、检索和注释方面的进展。这是整个机器学习领域讨论最多的年度比赛之一。

CIFAR-10(适合初学者)
这是一个图像集合,常用于初学者训练机器学习和计算机视觉算法。它也是机器学习研究中最受欢迎的数据集之一,用于快速比较算法,因为它捕捉了特定架构的优缺点,而不会对训练和超参数调整过程施加不合理的计算负担。
它包含 60,000 张 32×32 的彩色图像,分为 10 个不同的类别。这些类别包括飞机、汽车、鸟类、猫、鹿、狗、青蛙、马、船和卡车。

MegaFace 和 LFW(面部识别)
Labeled Faces in the Wild (LFW) 是一个旨在研究非约束性面部识别问题的面部照片数据库。它包含 13,233 张 5,749 个人的图像,这些图像从网络上抓取和检测而来。作为额外的挑战,机器学习研究人员可以使用数据集中有两张或更多张不同照片的 1,680 个人的图片。因此,它是一个公共的面部验证基准,也称为配对匹配(需要至少两张同一人的图像)。
MegaFace 是一个大规模开源面部识别训练数据集,是商业面部识别问题的最重要基准之一。它包含 4,753,320 张面孔,涉及 672,057 个身份,非常适合大型深度学习架构的训练。所有图像均来自 Flickr(雅虎的数据集),并且获得了创作共用许可证。

IMDB-Wiki(性别和年龄识别)
IMDB-Wiki 是一个具有性别和年龄标签的最大且开源的数据集,用于训练面部图像。该数据集中共有 523,051 张面孔图像,其中 460,723 张来自 20,284 位 IMDB 名人,62,328 张来自维基百科。

MS Coco(物体检测与分割)
COCO 或 Common Objects in COntext 是一个大规模的物体检测、分割和图像说明数据集。该数据集包含 91 种易于识别的物体类型,共有 2.5 百万个标注实例,分布在 328,000 张图像中。此外,它提供了更多复杂的计算机视觉任务资源,如多物体标注、分割掩码注释、图像说明和关键点检测。它由一个直观的 API 提供支持,帮助加载、解析和可视化 COCO 中的注释。该 API 支持多种注释格式。
MPII Human Pose(姿态估计)
此数据集用于评估关节人体姿态估计。它包括约 25K 张图像,包含 40K 多人,具有标注的身体关节。每张图像都从 YouTube 视频中提取,并提供了前后未标注的帧。总体而言,数据集涵盖了 410 种人类活动,每张图像都附有活动标签。

Flickr-30k(图像字幕)
这是一个图像字幕语料库,由 158,915 条众包字幕描述 31,783 张图像组成。这是对先前Flickr 8k 数据集的扩展。新图像和字幕专注于涉及日常活动和事件的人们。

20BN-SOMETHING-SOMETHING(人类动作视频剪辑)
该数据集是一个大量密集标注的视频剪辑集合,展示了人类使用日常物品执行预定义的基本动作。它由大量众包工人创建,使机器学习模型能够对物理世界中发生的基本动作进行细致入微的理解。
这里是数据集中捕获的一些常见人类活动的子集:

Barkley DeepDrive(用于自动驾驶车辆训练)
伯克利深度驾驶数据集由加州大学伯克利分校提供,包括超过 100K 个视频序列,具有多种注释类型,包括目标边界框、可驱动区域、图像级标记、车道标记和全帧实例分割。此外,该数据集在表现各种地理、环境和天气条件方面具有广泛的多样性。
这对训练强健的自动驾驶模型非常有用,使其不容易被不断变化的道路和驾驶条件所惊讶。

这些数据集的正确硬件和基准测试
不用说,仅有这些数据集不足以建立高质量的机器学习系统或商业解决方案。需要正确选择数据集、训练硬件以及巧妙的调整和基准测试策略的混合,以获得任何学术或商业问题的最佳解决方案。
这就是为什么高性能 GPU几乎总是与这些数据集配对使用,以提供所需的性能。
GPU 的开发(主要针对视频游戏行业)是为了处理大规模的并行计算,使用数千个微小的计算核心。它们还具有大容量内存带宽,以应对神经网络训练过程中需要的快速数据流(处理单元到缓存,再到较慢的主内存及回传)。这使得它们成为处理计算机视觉任务计算负载的理想商品硬件。
然而,市场上有许多 GPU 选项,这确实可能让普通用户感到困惑。多年来发布了一些好的基准测试策略,以指导潜在买家。在基准测试中,必须考虑多种(a)深度神经网络(DNN)架构,(b)GPU,以及(c)广泛使用的数据集(如我们在前一部分讨论的)。
例如,这篇优秀的文章考虑了以下内容:
此外,良好的基准测试必须考虑多个性能维度。
性能维度考虑
主要有三个指标:
-
第二批次时间:完成第二批训练的时间。这个数字衡量的是在 GPU 尚未长时间运行至升温前的性能。有效地说,没有热降频。
-
*均批次时间:在 ImageNet 中 1 个 epoch 或在 CIFAR 中 15 个 epoch 后,*均批次时间。这个测量考虑了热降频。
-
同时*均批次时间:在 ImageNet 中 1 个 epoch 或在 CIFAR 中 15 个 epoch 后,所有 GPU 同时运行的*均批次时间。这衡量了由于所有 GPU 散发的综合热量对系统的热降频影响。
原始。经允许转载。
相关:
更多相关内容
谷歌、优步和 Facebook 的数据科学与人工智能开源项目
原文:
www.kdnuggets.com/2019/11/open-source-projects-google-uber-facebook-data-science-ai.html
comments 
开源正成为分享和改进技术的标准。一些世界上最大的组织,如谷歌、Facebook 和优步,正在将它们在工作流程中使用的技术开源给公众。这使得普通人能够利用在全球最大公司中使用的技术。可能最知名的开源项目是 PyTorch 和 Tensorflow(这两个项目恰巧都是深度学习的事实标准)。
Facebook 开源项目
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作


- PyTorch 基本上是数据科学社区中最著名的深度学习库。它拥有一个丰富的生态系统,数据科学家可以利用这些工具进行各种任务。可用的一些工具包括用于贝叶斯优化的BoTorch、用于设计和使用自然语言处理深度学习模型的AllenNLP、用于轻松构建和评估神经网络的fastai以及提供完整 scikit-learn 兼容性的高级接口skorch。

- Prophet 是一个开源时间序列预测库,提供Python 和 R的 API。它能够在具有高季节性的数据上表现良好,并能够考虑假期效应。它可以处理数据中的缺失值和异常值。时间序列中的一个大问题是缺失数据,因为数据应是顺序的,常见的做法是用均值或中位数填补缺失值(大多数情况下这不是时间序列中的最佳选择)。
Uber 的开源项目


- CausalML 是 Uber 提供的开源工具,用于提升建模和因果推断方法,采用机器学习技术。它允许用户从实验或观察数据中估计条件*均处理效应(CATE)或个体处理效应(ITE)。

- Ludwig 可能是 Uber 最著名的开源项目。Ludwig 允许用户训练和测试深度学习模型,而无需编写代码,只需指定 YAML。它构建在 Tensorflow 之上。对于有偏好的用户,还提供了 Python API。

- Pyro 由 Uber AI Labs 维护,并建立在 PyTorch 之上,用于深度概率编程。它建立在通用、可扩展、最小和灵活的原则上。正在开发一个名为 NumPyro 的 Pyro 概率编程库的测试版,具有 NumPy 后端,以实现更快的处理速度。

- Kepler.gl 是 Uber 提供的开源地理空间分析工具箱,用于大规模数据集的处理。它旨在帮助数据科学家使用交互式和数据驱动的方法在位置数据上产生影响。它构建在 Mapbox GL 和 Deck.gl 之上。
谷歌开源项目


- Google Datalab 是一个交互式可视化探索工具,具有 IPython 后端,这意味着它拥有一个熟悉的 Jupyter 环境,因此经常使用 Jupyter 的用户会感到很熟悉。Cloud Datalab 使得可以使用 Python、SQL 和 JavaScript(用于 BigQuery 用户自定义函数)在 BigQuery、Cloud Machine Learning Engine、Compute Engine 和 Cloud Storage 上分析数据。然而,如果决定使用云资源(如虚拟机和 Cloud Storage),则需要付费。

- 这个框架无需介绍。Tensorflow 与 PyTorch 一起被视为数据科学社区的事实标准深度学习框架。Tensorflow 激发了许多扩展,以更好地利用库,从可视化到直接从命令库的生产 API。
- CausalImpact 库是一个 R 库,用于估计设计干预对时间序列的因果效应。该库使用贝叶斯时间序列模型来估计事件发生时的效果,即使没有现实世界的证据。这在随机实验不可用或不可行时特别有用。
相关:
-
2018 年回顾:机器学习开源项目与框架
-
Facebook 一直在悄悄开源一些令人惊叹的 PyTorch 深度学习功能
-
LinkedIn、Uber、Lyft、Airbnb 和 Netflix 如何解决机器学习解决方案的数据管理和发现问题
更多相关话题
语音识别的开源工具包
原文:
www.kdnuggets.com/2017/03/open-source-toolkits-speech-recognition.html
作者:Cindi Thompson,硅谷数据科学。
作为 SVDS 深度学习 R&D 团队的成员,我们对比了递归神经网络(RNN)和其他语音识别方法。直到几年前,语音识别的最先进技术是基于语音学的方法,包括发音、声学和语言模型的独立组件。通常,这包括与隐马尔可夫模型(HMM)相结合的 n-gram 语言模型。我们希望从这个基线模型开始,然后探索将其与较新的方法(如百度的Deep Speech)相结合的方式。虽然存在解释这些基线语音学模型的总结,但似乎没有易于消化的博客文章或论文来比较不同免费工具的权衡。
这篇文章回顾了使用传统 HMM 和 n-gram 语言模型的主要免费语音识别工具包选项。对于操作、通用和面向客户的语音识别,购买如Dragon或Cortana等产品可能更为合适。但在研发环境中,通常需要更灵活和针对性的解决方案,这就是我们决定开发自己的语音识别管道的原因。下面列出了在免费或开源领域中的主要竞争者,并对它们进行了几个特征的评分。
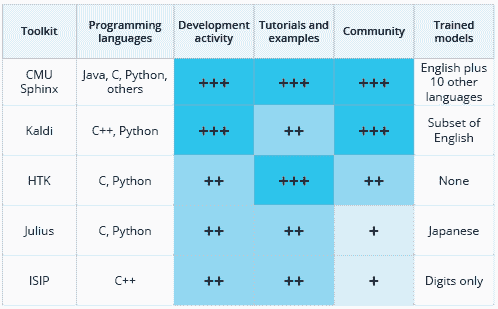
开源和免费语音识别工具包的对比。
本分析基于我们的主观经验以及从仓库和工具包网站上获取的信息。这也不是一个详尽的语音识别软件列表,其中大多数软件列在这里(包括非开源)。2014 年,Gaida 等人发表了一篇论文,评估了CMU Sphinx、Kaldi和HTK的性能。注意,HTK 在其通常的解释中并不完全是开源的,因为代码不能被重新分发或用于商业用途。
编程语言: 根据你对不同语言的熟悉程度,你可能自然会偏好某个工具包。除 ISIP 外,所有列出的选项都有 Python 包装器,通常可以在主站点找到或通过网络搜索快速找到。当然,Python 包装器可能无法暴露工具包核心代码的全部功能。CMU Sphinx 也有多个其他编程语言的包装器。
开发活动: 所列项目均源于学术研究。CMU Sphinx,如其名称所示,是卡内基梅隆大学的产物。它以某种形式存在了大约 20 年,现在可在 GitHub(包括C 和 Java 版本)和 SourceForge 上找到,并且在两个*台上都有*期活动。Java 和 C 版本在 GitHub 上似乎只有一个贡献者,但这并不能反映项目的历史现实(在 SourceForge 代码库上有 9 位管理员和十多位开发者)。Kaldi 的学术根源来自 2009 年的一个研讨会,其代码现在托管在 GitHub 上,拥有 121 位贡献者。HTK 于 1989 年在剑桥大学开始其生命历程,曾商业化一段时间,但现在许可回剑桥,并且不再作为开源软件提供。尽管其最新版本在 2015 年 12 月更新,但之前的版本是在 2009 年。Julius 自 1997 年起开发,并于 2016 年 9 月发布了最后一个重大版本,拥有一个稍微活跃的 GitHub 代码库,其中有三位贡献者,这可能仍未完全反映现实。ISIP 是第一个最先进的开源语音识别系统,源自密西西比州立大学。它主要在 1996 到 1999 年间开发,最后一次发布是在 2011 年,但在 GitHub 出现之前,该项目基本上已停滞不前。^(1)
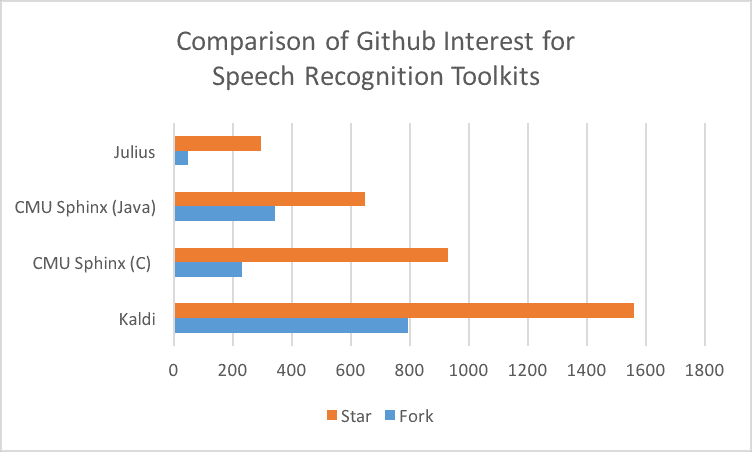
社区: 在这里,我们考察了邮件列表和讨论列表以及相关的开发者社区。CMU Sphinx 有在线讨论论坛,并且在其代码库中有活跃的关注。然而,我们怀疑 SourceForge 和 GitHub 上的代码库重复是否阻碍了更广泛的贡献。相比之下,Kaldi 拥有论坛和邮件列表以及一个活跃的 GitHub 代码库。HTK 有邮件列表但没有开放的代码库。Julius 网站上的用户论坛链接已损坏,但在日本网站上可能会有更多信息。ISIP 主要面向教育用途,其邮件列表档案已不再有效。
教程和示例: CMU Sphinx 拥有非常易读、详尽且易于跟随的文档;Kaldi 的文档也很全面,但在我看来稍显难以跟随。然而,Kaldi 确实涵盖了语音识别的音素和深度学习方法。如果你对语音识别不熟悉,HTK 的教程文档(供注册用户使用)提供了该领域的良好概述,并包括系统的实际设计和使用文档。Julius 项目专注于日语,最新的文档是日语的^(2),但他们也在积极翻译成英语,并提供这些文档;这里有一些运行语音识别的示例这里。最后,ISIP 项目有一些文档,但导航起来有些困难。
训练模型: 尽管使用这些开源或免费工具的主要原因是因为你想训练专门的识别模型,但能够开箱即用地与系统对话是一个很大的优势。CMU Sphinx 包含英语和许多其他模型可供使用,连接到这些模型的 Python 文档直接包含在GitHub readme中。Kaldi 对现有模型解码的说明深藏在文档中,但我们最终发现了一个在 egs/voxforge 子目录中训练的英文 VoxForge 数据集的模型,并且可以通过运行 online-data 子目录中的脚本进行识别。我们没有深入挖掘其他三个包,但它们都至少附带了简单的模型或似乎与VoxForge网站提供的格式兼容,该网站是一个相当活跃的众包语音识别数据和训练模型的库。
未来,我们将讨论如何开始使用 CMU Sphinx。我们还计划在之前的深度学习帖子基础上,进行一个将神经网络应用于语音的帖子,并将神经网络的识别性能与 CMU Sphinx 进行比较。与此同时,我们始终欢迎对我们博客帖子的反馈和问题,因此如果你对这些工具包或其他工具包有更多看法,请告知我们。
参考文献
-
blog.neospeech.com/2016/07/08/top-5-open-source-speech-recognition-toolkits
-
Gaida, Christian, 等。“比较开源语音识别工具包。”技术报告,DHBW 斯图加特(2014)。
个人简介:辛迪·汤普森 是一位具有自然合作精神的问题解决者,能够利用强大的沟通和协调技巧弥合技术和业务方面的关切。拥有人工智能博士学位,她带来了机器学习、自然语言理解和研发领域的独特学术与行业经验。
原文. 经许可转载。
相关:
-
人工智能与聊天机器人语音识别入门
-
在对话语音识别中实现人类*衡
-
前 20 个 Python 机器学习开源项目,已更新
我们的前 3 个课程推荐
1. Google 网络安全证书 - 加速你的网络安全职业发展
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关内容
OpenAI API 初学者指南:您的易于跟随的入门指南
原文:
www.kdnuggets.com/openai-api-for-beginners-your-easy-to-follow-starter-guide

图片来源:作者
在本教程中,我们将学习如何设置和使用 OpenAI API 以适应各种用例。教程设计为易于跟随,即使对于那些对 Python 编程知识有限的人也是如此。我们将探讨任何人如何生成响应并访问高质量的大型语言模型。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
什么是 OpenAI API?
OpenAI API 使开发者能够轻松访问由 OpenAI 开发的各种 AI 模型。它提供了一个用户友好的界面,帮助开发者将由最先进的 OpenAI 模型驱动的智能功能融入到他们的应用程序中。该 API 可以用于多种用途,包括文本生成、多轮对话、嵌入、转录、翻译、文本转语音、图像理解和图像生成。此外,API 兼容 curl、Python 和 Node.js。
入门指南
要开始使用 OpenAI API,您首先需要在 openai.com 上创建一个帐户。以前,每个用户都会获得免费的信用,但现在新用户需要购买信用。
要购买信用,请转到“Settings”,然后是“Billing”,最后点击“Add Payment Details”。输入您的借记卡或信用卡信息,并确保禁用自动充值。充值 10 美元后,您可以使用它一年。
通过导航到“API keys”并选择“Create new secret key”来创建 API 密钥。给它命名,然后点击“Create secret key”。
复制 API 并在本地机器上创建一个环境变量。
我使用 Deepnote 作为我的 IDE。创建环境变量很简单。只需转到“集成”,选择“创建环境变量”,为密钥提供名称和值,然后创建集成。
接下来,我们将使用 pip 安装 OpenAI Python 包。
%pip install --upgrade openai
我们现在将创建一个可以全球访问各种模型的客户端。
如果你已经设置了名为"OPENAI_API_KEY"的环境变量,你就不需要向 OpenAI 客户端提供 API 密钥。
from openai import OpenAI
client = OpenAI()
请注意,只有当你的环境变量名称不同于默认名称时,才应提供 API 密钥。
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get("SECRET_KEY"),
)
文本生成
我们将使用传统功能生成响应。完成函数需要模型名称、提示和其他参数来生成回复。
completion = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt="Write a short story about Elon Musk being the biggest troll.",
max_tokens=300,
temperature=0.7,
)
print(completion.choices[0].text)
GPT3.5 模型生成了关于埃隆·马斯克的惊人故事。

我们还可以通过提供额外的参数stream来流式传输我们的响应。
不同于等待完整的响应,流式特性使得输出在生成后立即进行处理。这种方法通过逐个返回语言模型的输出,帮助减少感知延迟,而不是一次性返回所有输出。
stream = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt="Write a Python code for accessing the REST API securely.",
max_tokens=300,
temperature=0.7,
stream = True
)
for chunk in stream:
print(chunk.choices[0].text, end="")

聊天
该模型使用了 API 聊天完成。在生成响应之前,让我们探索可用模型。
你可以查看所有可用模型的列表,或阅读官方文档中的模型页面。
print(client.models.list())
我们将使用最新版本的 GPT-3.5,并提供系统提示和用户消息的字典列表。确保遵循相同的消息模式。
completion = client.chat.completions.create(
model="gpt-3.5-turbo-1106",
messages=[
{
"role": "system",
"content": "You are an experienced data scientist, adept at presenting complex data concepts with creativity.",
},
{
"role": "user",
"content": "What is Feature Engineering, and what are some common methods?",
},
],
)
print(completion.choices[0].message.content)
如我们所见,我们生成了与传统 API 相似的结果。那么,为什么要使用这个 API?接下来,我们将学习为什么聊天完成 API 更灵活且更易于使用。
Feature engineering is the process of selecting, creating, or transforming features (variables) in a dataset to improve the performance of machine learning models. It involves identifying the most relevant and informative features and preparing them for model training. Effective feature engineering can significantly enhance the predictive power of a model and its ability to generalize to new data.
Some common methods of feature engineering include:
1\. Imputation: Handling missing values in features by filling them in with meaningful values such as the mean, median, or mode of the feature.
2\. One-Hot Encoding: Converting categorical variables into binary vectors to represent different categories as individual features.
3\. Normalization/Standardization: Scaling numerical features to bring t.........
我们现在将学习如何与 AI 模型进行多轮对话。为此,我们将把助手的回应添加到先前的对话中,并在相同的消息格式中包含新的提示。之后,我们将向聊天完成函数提供字典列表。
chat=[
{"role": "system", "content": "You are an experienced data scientist, adept at presenting complex data concepts with creativity."},
{"role": "user", "content": "What is Feature Engineering, and what are some common methods?"}
]
chat.append({"role": "assistant", "content": str(completion.choices[0].message.content)})
chat.append({"role": "user", "content": "Can you summarize it, please?"})
completion = client.chat.completions.create(
model="gpt-3.5-turbo-1106",
messages=chat
)
print(completion.choices[0].message.content)
模型已经理解了上下文并为我们总结了特征工程。
Feature engineering involves selecting, creating, or transforming features in a dataset to enhance the performance of machine learning models. Common methods include handling missing values, converting categorical variables, scaling numerical features, creating new features using interactions and polynomials, selecting important features, extracting time-series and textual features, aggregating information, and reducing feature dimensionality. These techniques aim to improve the model's predictive power by refining and enriching the input features.
嵌入
要开发高级应用程序,我们需要将文本转换为嵌入。这些嵌入用于相似性搜索、语义搜索和推荐引擎。我们可以通过提供 API 文本和模型名称来生成嵌入。就是这么简单。
text = "Data Engineering is a rapidly growing field that focuses on the collection, storage, processing, and analysis of large volumes of structured and unstructured data. It involves various tasks such as data extraction, transformation, loading (ETL), data modeling, database design, and optimization to ensure that data is accessible, accurate, and relevant for decision-making purposes."
DE_embeddings = client.embeddings.create(input=text, model="text-embedding-3-small")
print(chat_embeddings.data[0].embedding)
[0.0016297283582389355, 0.0013418874004855752, 0.04802832752466202, -0.041273657232522964, 0.02150309458374977, 0.004967313259840012,.......]
音频
现在,我们可以将文本转换为语音,将语音转换为文本,并通过音频 API 进行翻译。
文字转录
我们将使用Wi-Fi 7 Will Change Everything YouTube 视频,并将其转换为 mp3 格式。之后,我们将打开文件,并将其提供给音频转录 API。
audio_file= open("Data/techlinked.mp3", "rb")
transcript = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file
)
print(transcript.text)
Whisper 模型非常出色。它可以完美地转录音频内容。
The Consumer Electronics Show has officially begun in Las Vegas and we'll be bringing you all the highlights from right here in our regular studio where it's safe and clean and not a desert. I hate sand. The Wi-Fi Alliance announced that they have officially confirmed the Wi-Fi 7 standard and they've already started to certify devices to ensure they work together. Unlike me and Selena, that was never gonna last. The new standard will have twice the channel bandwidth of Wi-Fi 5, 6, and 6E, making it better for, surprise,......
翻译
我们还可以将英文音频转录成另一种语言。在我们的例子中,我们将其转换为乌尔都语。我们只需添加一个名为language的参数,并提供 ISO 语言代码“ur”。
translations = client.audio.transcriptions.create(
model="whisper-1",
response_format="text",
language="ur",
file=audio_file,
)
print(translations)
对于非拉丁语语言的翻译不完美,但对于最小可行产品来说已经足够用了。
کنسومر ایلیکٹرانک شاہی نے لاس بیگیس میں شامل شروع کیا ہے اور ہم آپ کو جمہوری بہترین چیزیں اپنے ریگلر سٹوڈیو میں یہاں جارہے ہیں جہاں یہ آمید ہے اور خوبصورت ہے اور دنیا نہیں ہے مجھے سانڈ بھولتا ہے وائ فائی آلائنٹس نے اعلان کیا کہ انہوں نے وائ فائی سیبن سٹانڈرڈ کو شامل شروع کیا اور انہوں ن........
文本转语音
为了将文本转换为自然的语音,我们将使用语音 API,并提供模型名称、配音演员名称和输入文本。接下来,我们将把音频文件保存到我们的“Data”文件夹中。
response = client.audio.speech.create(
model="tts-1",
voice="alloy",
input= '''I see skies of blue and clouds of white
The bright blessed days, the dark sacred nights
And I think to myself
What a wonderful world
'''
)
response.stream_to_file("Data/song.mp3")
要在 Deepnote Notebook 中收听音频文件,我们将使用 IPython Audio 函数。
from IPython.display import Audio
Audio("Data/song.mp3")

视觉
OpenAI API 通过聊天完成函数为用户提供了对多模态模型的访问。为了理解图像,我们可以使用最新的 GPT-4 视觉模型。
在消息参数中,我们提供了一个关于图像和图像 URL 提问的提示。图像来源于Pixabay。请确保遵循相同的消息格式,以避免任何错误。
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Could you please identify this image's contents and provide its location?",
},
{
"type": "image_url",
"image_url": {
"url": "https://images.pexels.com/photos/235731/pexels-photo-235731.jpeg?auto=compress&cs=tinysrgb&w=1260&h=750&dpr=2",
},
},
],
}
],
max_tokens=300,
)
print(response.choices[0].message.content)
输出内容完美地解释了图像。
This is an image of a person carrying a large number of rice seedlings on a carrying pole. The individual is wearing a conical hat, commonly used in many parts of Asia as protection from the sun and rain, and is walking through what appears to be a flooded field or a wet area with lush vegetation in the background. The sunlight filtering through the trees creates a serene and somewhat ethereal atmosphere.
It's difficult to determine the exact location from the image alone, but this type of scene is typically found in rural areas of Southeast Asian countries like Vietnam, Thailand, Cambodia, or the Philippines, where rice farming is a crucial part of the agricultural industry and landscape.
我们也可以加载本地图像文件,并将其提供给聊天完成 API。为此,我们首先需要从 pexels.com 下载图像,下载地址为Manjeet Singh Yadav。
!curl -o /work/Data/indian.jpg "https://images.pexels.com/photos/1162983/pexels-photo-1162983.jpeg?auto=compress&cs=tinysrgb&w=1260&h=750&dpr=2"
然后,我们将加载图像并将其编码为 base64 格式。
import base64
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
image_path = "Data/indian.jpg"
# generating the base64 string
base64_image = encode_image(image_path)
我们将提供元数据和图像的 base64 字符串,而不是提供图像 URL。
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Could you please identify this image's contents.",
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
},
},
],
}
],
max_tokens=100,
)
print(response.choices[0].message.content)
模型成功地分析了图像,并提供了详细的解释。
The image shows a woman dressed in traditional Indian attire, specifically a classical Indian saree with gold and white colors, which is commonly associated with the Indian state of Kerala, known as the Kasavu saree. She is adorned with various pieces of traditional Indian jewelry including a maang tikka (a piece of jewelry on her forehead), earrings, nose ring, a choker, and other necklaces, as well as bangles on her wrists.
The woman's hairstyle features jasmine flowers arranged in
图像生成
我们还可以使用 DALLE-3 模型生成图像。我们只需提供模型名称、提示、尺寸、质量和图像数量给图像 API。
response = client.images.generate(
model="dall-e-3",
prompt="a young woman sitting on the edge of a mountain",
size="1024x1024",
quality="standard",
n=1,
)
image_url = response.data[0].url
生成的图像保存在网上,你可以下载以便本地查看。为此,我们将使用request函数下载图像,提供图像 URL 和你想保存的本地目录。之后,我们将使用 Pillow 库的 Image 函数打开并显示图像。
import urllib.request
from PIL import Image
urllib.request.urlretrieve(image_url, '/work/Data/woman.jpg')
img = Image.open('/work/Data/woman.jpg')
img.show()
我们获得了一张高质量的生成图像。简直太惊艳了!

如果你在运行任何 OpenAI Python API 时遇到困难,欢迎查看我在 Deepnote 上的项目。
结论
我已经尝试使用 OpenAPI 一段时间了,我们最终只用了 0.22 美元的信用额度,这让我觉得非常实惠。通过我的指南,即使是初学者也可以开始构建自己的 AI 应用程序。这是一个简单的过程——你无需训练自己的模型或部署它。你可以通过 API 访问最先进的模型,且每次新版本发布时都在不断改进。
在本指南中,我们介绍了如何设置 OpenAI Python API 并生成简单的文本响应。我们还学习了多轮对话、嵌入、转录、翻译、文本转语音、视觉和图像生成 API。
如果你希望我使用这些 API 构建一个高级 AI 应用,请告知我。
感谢阅读。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专家,喜欢构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理健康问题的学生构建 AI 产品。
更多相关主题
OpenAI 的 AI 安全方法

作者图片
你可能看到过 OpenAI CEO 山姆·奥特曼在 16 日的美国参议院委员会上的视频。如果没有,山姆·奥特曼呼吁美国立法者对人工智能(AI)进行监管。CEO 就新技术的担忧和可能的陷阱进行了作证。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 工作
自从 ChatGPT 发布以来,市场上涌现了大量的大语言模型以及其他 AI 模型。在过去几个月里,政府之间关于 AI 及其对社会安全的监管有了各种讨论。欧盟正在推动他们的 AI 法案,其他大陆也在效仿。
山姆·奥特曼一直关注人工智能使用中的伦理问题和担忧,并推动更多的监管。他发表声明说:
“我认为如果这项技术出现问题,可能会变得非常严重……我们希望对此大声疾呼。我们希望与政府合作,防止这种情况发生。”
OpenAI 的安全承诺
OpenAI 一直坚持其保持 AI 安全和有益的承诺。他们理解,像 ChatGPT 这样的工具已经提升了许多人的生产力、创造力和整体工作体验。然而,安全仍然是他们的主要优先事项之一。
那么,OpenAI 是如何确保他们的 AI 模型安全的呢?
严格测试
在任何 AI 系统发布之前,OpenAI 都会进行严格的测试,借助外部专家并不断寻找改进系统的方法。他们使用如人类反馈强化学习等技术来改善模型的行为,从而建立更好的安全和监控系统。
OpenAI 在发布其最新模型 GPT-4 之前,花费了超过 6 个月的时间确保其安全。
现实世界应用
没有什么比实际应用更好的测试了。创建一个新的系统并尽力防止所有可能的风险是好的。但是你不能在实验室中控制这些风险,你必须让它真正投入公众使用。
不幸的是,对于 AI 系统,你无法限制或预测公众如何使用它——是受益还是滥用。OpenAI 发布 AI 系统时设置了多项保护措施,并且一旦扩大了能够访问其 AI 系统的人群,他们会确保持续改进。
提供给开发者的 API 也使 OpenAI 能够监控潜在的滥用行为,并利用这些信息来构建缓解措施。OpenAI 认为,社会应在 AI 继续发展的过程中发挥重要作用。
保护儿童
OpenAI 在 AI 安全方面的一个主要关注点是保护儿童。他们目前正在研究用户必须年满 18 岁,或在 13 岁以上并获得父母同意的验证选项。他们已经表示不允许其技术用于生成任何形式的仇恨、暴力或成人内容。
他们还制定了更多工具和方法来保护儿童,例如,当用户尝试将已知的儿童性虐待材料上传到我们的图像工具时,OpenAI 已经部署了 Thorn 的 Safer 来检测、审查并报告给国家失踪和被剥削儿童中心。
为了确保儿童从 ChatGPT 等工具中获益,OpenAI 与 Khan Academy 合作,建立了一个AI 驱动的助手,作为学生的虚拟导师和教师的课堂助手。
隐私
大型语言模型已在各种公开可用的来源上进行训练,有些人认为这存在隐私问题。OpenAI 已声明:
“我们不使用数据来出售我们的服务、做广告或建立个人档案——我们使用数据来使我们的模型对人们更有帮助。”
他们的目标是让像 ChatGPT 这样的工具了解世界,而不是个人隐私。为了确保这一点,在可行的情况下,OpenAI 从训练数据集中删除个人信息,并微调其模型以拒绝任何有关个人信息的请求。它还会要求个人从 OpenAI 的系统中删除其个人信息。
准确性
对 ChatGPT 等工具的用户反馈使 OpenAI 能够标记被认为不正确的输出,并将其作为主要数据来源。提高事实准确性是他们的重点之一,GPT-4 产生事实内容的可能性比 GPT-3.5 高 40%。
总结
随着 OpenAI 阐述其 AI 安全方法,并且 CEO Sam Altman 解决了 AI 系统的潜在问题,敦促政府制定相关法规,这是解决 AI 安全问题的开始。
这将需要更多的时间、资源以及从市场上最有能力的模型中学习。OpenAI 等待了超过 6 个月才部署 GPT-4,然而,他们已经表示为了确保安全,可能需要更长时间。
你认为接下来会发生什么?
如果你想观看 OpenAI 的萨姆·阿尔特曼在 16 日星期二的听证会,你可以在这里查看:ChatGPT 首席萨姆·阿尔特曼在国会就 AI 作证。
尼莎·阿雅 是一名数据科学家、自由技术写作人以及 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程及理论知识。她还希望探索人工智能如何有助于延长人类寿命的不同方式。作为一个热衷学习的人,她寻求扩展她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
OpenAI 发布了两种神奇地将语言与计算机视觉联系起来的变换器模型
原文:
www.kdnuggets.com/2021/01/openai-transformer-models-link-language-computer-vision.html
评论 
来源: www.rev.com/blog/what-is-gpt-3-the-new-openai-language-model
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
我最*开始了一份新的专注于 AI 教育的通讯,已经拥有超过 50,000 名订阅者。TheSequence 是一份无废话(即无炒作、无新闻等)的 AI 专注通讯,阅读时间为 5 分钟。其目标是让你了解机器学习项目、研究论文和概念。请通过下面的订阅链接试试:
变换器被广泛认为是过去十年机器学习的最大突破之一,而 OpenAI 一直处于这一领域的中心。OpenAI 的 GPT-3 可以说是最著名且争议最大的机器学习模型之一。GPT-3 训练有数十亿个参数,被数百家公司积极使用,以自动化各种语言任务,如问答、文本生成等。如此成功,自然 OpenAI 继续探索 GPT-3 和变换器模型的不同变种。几天前,我们看到了一种变种,当时 OpenAI 发布了两种新的变换器架构,这些架构以有趣且几乎神奇的方式将图像和语言任务结合在一起。
等等,我刚才说变换器被用在计算机视觉任务中?没错!虽然自然语言理解(NLU)仍然是变换器模型的最大战场,但将这些架构适应于计算机视觉领域已经取得了惊人的进展。OpenAI 在这一领域的首次亮相有两个模型:
-
CLIP: 使用变换器从语言监督中有效地学习视觉概念。
-
DALL·E: 使用变换器从文本说明生成图像。
CLIP
通过 CLIP,OpenAI 试图解决一些计算机视觉模型的显著挑战。首先,为计算机视觉构建训练数据集非常具有挑战性且昂贵。虽然语言模型可以在像维基百科这样的广泛可用的数据集上进行训练,但计算机视觉领域却没有类似的资源。其次,大多数计算机视觉模型高度专业化于单一任务,且很少能适应新任务。
CLIP 是一种基于图像数据集并使用语言监督的变换器架构。CLIP 使用图像编码器和文本解码器来预测哪些图像与数据集中给定的文本配对。这一行为随后用于训练一个零样本分类器,可以适应多个图像分类任务。
这是一个能够学习复杂视觉概念同时保持高效性能的模型。零样本方法使得 CLIP 能够在不进行重大调整的情况下适应不同的数据集。
DALL·E
OpenAI 的 DALL·E 是一个基于 GPT-3 的模型,能够从文本描述生成图像。其概念是结合变换器和生成模型,以适应复杂的图像生成场景。
DALL·E 接收文本和图像作为输入数据集,其中包含约 1280 个标记(256 个文本标记和 1024 个图像标记)。该模型基于简单的解码器架构,训练时使用最大似然生成所有标记,逐个生成。DALL·E 还包括一个注意力掩码,用于关联文本和图像。
变换器架构的使用产生了一个能够从高度复杂的句子生成图像的生成模型。请查看下面的一些示例。

来源: openai.com/blog/dall-e/#fn1
DALL·E 和 CLIP 都代表了多任务变换器模型的重要进展,毫无疑问是计算机视觉领域的重要里程碑。我们很可能很快会看到这些模型的重大应用。
原文. 经许可转载。
相关:
-
如何将表格数据与 HuggingFace Transformers 结合
-
计算走向极致: 回顾 Sutton 对 AI 的痛苦教训
-
数据科学家必读的 NLP 和深度学习文章
更多相关话题
OpenAI 的 Whisper API 用于转录和翻译
原文:
www.kdnuggets.com/2023/06/openai-whisper-api-transcription-translation.html
插图由作者提供 | 来源:flaticon
你积累了大量录音,但没有精力开始听和转录它们?当我还是学生时,我记得我每天都要与录制的课程斗争,听了几个小时,大部分时间都被转录占用了。而且,这不是我的母语,我不得不将每一句话拖到 Google 翻译中以转换成意大利语。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
现在,人工转录和翻译已成为过去。著名的 ChatGPT 研究公司 OpenAI 推出了用于语音转文字的 Whisper API!只需几行 Python 代码,你就可以调用这个强大的语音识别模型,将思想从脑海中释放出来,专注于其他活动,比如数据科学项目的实践和提升你的作品集。让我们开始吧!
Whisper 是什么?
Whisper 是一个基于神经网络的模型,由 OpenAI 开发,用于解决语音转文字任务。它属于 GPT-3 家族,并因其将音频高精度转录为文本的能力而变得非常受欢迎。
它不仅限于处理英语,还扩展到 50 多种语言。如果你想了解你的语言是否包括在内,请查看这里。此外,它还可以将任何语言的音频翻译成英语。
像其他 OpenAI 产品一样,有一个 API 可以访问这些语音识别服务,允许开发者和数据科学家将 Whisper 集成到他们的*台和应用中。
如何访问 Whisper API?
GIF 由作者提供
在深入之前,你需要几个步骤来获取 Whisper API 的访问权限。首先,登录到OpenAI API 网站。如果你还没有账户,你需要创建一个。登录后,点击你的用户名并选择“查看 API 密钥”选项。然后,点击“创建新 API 密钥”按钮,并将新创建的 API 密钥复制到你的 Python 代码中。
使用 Whisper API 进行转录
首先,让我们下载 Kevin Stratvert 的 YouTube 视频,他是一位非常受欢迎的 YouTuber,帮助来自世界各地的学生掌握技术并通过学习工具提升技能,如 Power BI、视频编辑和 AI 产品。例如,假设我们想转录视频“3 个令人惊叹的 AI 工具”。
我们可以直接使用 pytube 库下载这个视频。要安装它,你需要以下命令行:
pip install pytube3
pip install openai
我们还需要安装 openai 库,因为在教程后续部分会用到它。一旦所有 Python 库安装完毕,我们只需将视频的 URL 传递给 YouTube 对象。然后,我们获取最高分辨率的视频流,接着下载视频。
from pytube import YouTube
video_url = "https://www.youtube.com/watch?v=v6OB80Vt1Dk&t=1s&ab_channel=KevinStratvert"
yt = YouTube(video_url)
stream = yt.streams.get_highest_resolution()
stream.download()
文件下载完成后,是时候开始有趣的部分了!
import openai
API_KEY = 'your_api_key'
model_id = 'whisper-1'
language = "en"
audio_file_path = 'audio/5_tools_audio.mp4'
audio_file = open(audio_file_path, 'rb')
在设置好参数并打开音频文件后,我们可以转录音频并将其保存为 Txt 文件。
response = openai.Audio.transcribe(
api_key=API_KEY,
model=model_id,
file=audio_file,
language='en'
)
transcription_text = response.text
print(transcription_text)
输出:
Hi everyone, Kevin here. Today, we're going to look at five different tools that leverage artificial intelligence in some truly incredible ways. Here for instance, I can change my voice in real time. I can also highlight an area of a photo and I can make that just automatically disappear. Uh, where'd my son go? I can also give the computer instructions, like, I don't know, write a song for the Kevin cookie company....
正如预期的那样,输出非常准确。甚至连标点符号也非常精确,我非常印象深刻!
使用 Whisper API 进行翻译
这次,我们将把意大利语的音频翻译成英语。和之前一样,我们下载音频文件。在我的示例中,我使用了这个 YouTube 视频,这是意大利知名 YouTuber Piero Savastano 的视频,他以非常简单有趣的方式教授机器学习。你只需复制之前的代码,并仅更改 URL。一旦下载完成,我们像以前一样打开音频文件:
audio_file_path = 'audio/ml_in_python.mp4'
audio_file = open(audio_file_path, 'rb')
然后,我们可以从意大利语开始生成英语翻译。
response = openai.Audio.translate(
api_key=API_KEY,
model=model_id,
file=audio_file
)
translation_text = response.text
print(translation_text)
输出:
We also see some graphs in a statistical style, so we should also understand how to read them. One is the box plot, which allows to see the distribution in terms of median, first quarter and third quarter. Now I'm going to tell you what it means. We always take the data from the data frame. X is the season. On Y we put the count of the bikes that are rented. And then I want to distinguish these box plots based on whether it is a holiday day or not. This graph comes out. How do you read this? Here on the X there is the season, coded in numerical terms. In blue we have the non-holiday days, in orange the holidays. And here is the count of the bikes. What are these rectangles? Take this box here. I'm turning it around with the mouse....
最终想法
就这样!我希望这个教程能帮助你开始使用 Whisper API。在这个案例研究中,它应用于 YouTube 视频,但你也可以尝试播客、Zoom 会议和会议。我发现转录和翻译后的结果非常令人印象深刻!这个 AI 工具现在确实帮助了很多人。唯一的限制是只能翻译成英语文本,而不能反向翻译,但我相信 OpenAI 很快会提供。感谢阅读!祝你有美好的一天!
资源
尤金尼亚·安奈罗 目前是意大利帕多瓦大学信息工程系的研究员。她的研究项目集中于持续学习与异常检测的结合。
更多相关主题
OpenChatKit: 开源的 ChatGPT 替代品
原文:
www.kdnuggets.com/2023/03/openchatkit-opensource-chatgpt-alternative.html

作者提供的图片
介绍
我们的前三个课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在的组织在 IT 方面
开源与闭源之间的战争已经持续了一段时间。在 OpenAI 推出 GPT-3 作为闭源模型后,EleutherAI 推出了名为 GPT-Neo 的开源替代品,提供了对比结果。同样,当 DALL·E 2 推出时,Stability AI 发布了开源版本 DALL·E 2,称为 Stable Diffusion。
我们都知道 ChatGPT 以及人们如何渴望获得模型的开源版本,并在更多控制下安全地构建他们的应用。目前,ChatGPT 提供了 API 访问和微调能力,但你将使用他们的服务和机器来执行各种任务。
2023 年 3 月 10 日,Together Computer 发布了开源版本的 ChatGPT,称为 OpenChatKit。开源替代品允许开发者对聊天机器人的行为有更多控制,并根据其特定需求进行定制。此外,它对更广泛的用户和社区更加可及,尤其是那些可能没有资源访问专有模型的用户。
什么是 OpenChatKit
OpenChatKit 提供了一套强大的开源工具,用于创建通用和专业的聊天机器人应用。它是模型的第一个版本,开发者发布了一套工具和流程,通过社区贡献来改进模型。
Together Computer 发布了在 Apache-2.0 许可下的 OpenChatKit 0.15,包括源代码、模型权重和训练数据集。
你可以在 Hugging Face 上试用基于模型的演示:OpenChatKit。它类似于 ChatGPT,你写一个提示,模型会用答案、代码块、表格或文本来回应你。
图片来自作者 | OpenChatKit
OpenChatKit 附带基础机器人和创建自定义聊天机器人应用程序的构建块。
该工具包由 4 个组件组成:
-
针对聊天的指令调优大型语言模型,微调自 EleutherAI 的 GPT-NeoX-20B。
-
关于如何微调模型以在特定任务上实现高准确率的说明。
-
可扩展的检索系统,用于使用来自 Wikipedia、新闻源或体育比分的知识更新机器人响应。
-
从 GPT-JT-6B 微调而来,旨在进行审查以筛选出机器人回应的问题。
指令调优的大型语言模型
OpenChatKit 的基础是一个名为 GPT-NeoXT-Chat-Base-20B 的大型语言模型。它基于 EleutherAI 的 GPT-NeoX 模型,并在 4300 万条高质量对话指令上进行了微调。开发团队特别关注了多轮对话、问答、分类、提取和总结等多个任务的调优。
图片来自 TOGETHER
该模型开箱即用,提供了一个强大的基础。正如我们所见,它在 HELM 基准测试中得分高于其基础模型 GPT-NeoX。GPT-NeoXT-Chat-Base-20B 模型在问答、提取和分类任务上表现相当出色。
模型的局限性
这是该模型的第一个版本,你会看到许多错误、漏洞和合适的答案。在本次会议中,我们将审查模型难以理解的一些领域。
-
基于知识:聊天机器人可能会给出事实错误的结果。ChatGPT 也存在相同的问题。团队正在开发一个检索系统,以更新错误信息。
-
基于代码:该模型没有在足够大的源代码语料库上进行训练,因此编写准确的代码可能会遇到困难。你可能会感到沮丧。
-
上下文切换:如果在对话过程中开始谈论其他话题,聊天机器人不会自动切换主题,而是继续提供与之前话题相关的答案。
-
重复:聊天机器人有时会重复回复或卡住。你可以刷新页面来重置它。
-
创意回答:与 ChatGPT 不同,聊天机器人不会生成文章或创意故事。它仅限于短小的回复。
结论
OpenChatKit 是一个很好的倡议,借助社区的帮助,我们可以很快看到一个更好的聊天机器人版本。如果你期待 OpenChatKit 能像 ChatGPT 一样提供令人惊叹的回答,你可能会失望,因为它还处于早期阶段,并且训练数据集不够多样化。
在这篇文章中,我们了解了 ChatGPT 开源版本的宝贵见解,这对开发者和数据科学社区来说是好消息。此外,我们还探索了其工作原理,并深入研究了该工具包的四个组成部分,这些部分可以帮助创建一个完全可定制的聊天机器人,配备最新的新闻更新和管理功能。
资源
尝试演示并阅读更多关于模型的信息,以获取有关模型微调和其他重要工具的资讯。
Abid Ali Awan (@1abidaliawan) 是一位认证数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,以帮助那些遭受心理疾病困扰的学生。
更多相关内容
学习如何开发和部署梯度提升机器模型
原文:
www.kdnuggets.com/2017/01/opendatagroup-develop-deploy-gradient-boosting-machine-model.html
|
| |
|
| |
|
|
|
点击这里注册
你的组织是否准备好大规模部署分析模型?你现有的系统是否以正确的方式连接以利用最新的分析能力?加入我们的在线研讨会,详细了解如何使用 Python、Kafka 和 FastScore 创建和部署梯度提升机器模型。本次由 Open Data 的 Matthew Mahowald 主持的研讨会,将提升你对梯度提升好处的理解,以及在生产系统中部署和维护实时流梯度提升机器模型的最简单方法。我们的研讨会将重点提供 3 个关键要点:
-
学习如何使用 SciKit Learn 和 Python 创建梯度提升机器
-
了解使用 FastScore(一种语言无关的分析引擎)进行特征转换、训练和部署 GBM 所需的步骤
-
观看 GBM 分析汽车保险风险的实时演示
我们的 3 个顶级课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路! 2. Google 数据分析专业证书 - 提升你的数据分析技能! 3. Google IT 支持专业证书 - 支持你的组织进行 IT 服务
2017 年 1 月 25 日 - 上午 10 点 PST(下午 1 点 EST)
立即注册!
|  | Matthew 是 Open Data Group 的数据科学家和软件工程师。他拥有西北大学数学博士学位,研究过弦理论和拓扑场论的几何。在 ODG,Matthew 专注于使用 FastScore 开发和部署机器学习模型。 |
| Matthew 是 Open Data Group 的数据科学家和软件工程师。他拥有西北大学数学博士学位,研究过弦理论和拓扑场论的几何。在 ODG,Matthew 专注于使用 FastScore 开发和部署机器学习模型。 |
| |
|
|
| |
|
|
更多相关主题
OpenML:分享、发现和进行机器学习
原文:
www.kdnuggets.com/2014/08/openml-share-discover-do-machine-learning.html

最*,一篇有趣的论文介绍了OpenML,这可能提供了一种挖掘数据的替代方法。不要混淆。这里介绍的 OpenML 是一个开放科学*台,正如其名称所示,机器学习研究人员可以在这里分享他们的所有数据集、算法和实验。它的标志由四种颜色组成,每种颜色代表 OpenML 的一个重要部分。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织中的 IT 工作
以下是 OpenML 的四个关键数字。(截至 2014 年 8 月 11 日)
230 个数据集。这些是机器学习的输入数据——如蘑菇数据库、垃圾邮件、字母图像识别等。每个数据集提供了属性的简要描述,如默认准确度、类别数、特征数等。
1172 个任务。如果研究人员想要操作数据,则会创建任务。这些任务分为四种类型:监督分类、学习曲线、监督数据流分类和监督回归,具体取决于期望分享的结果类型。所有用户都可以下载并解决这些任务。
364 个流程。流程是解决 OpenML 任务的算法、工作流或脚本的实现,通常通过插件完成。科学家们还可以上传实际代码或通过 URL 引用它,如果代码托管在 GitHub 或其他开源*台上。在每个流程页面上,都会比较该流程运行过的所有任务的结果。
24990 次运行。尝试解决任务并获得所需输出称为一次运行。以运行 24980 为例。它在任务 36上执行Flow weka.Bagging_SMO_PolyKernel(1),这是对数据集segment的监督分类。它还提供了评估结果,如 AUC、混淆矩阵、预测准确性等。人们可以轻松比较同一任务上的所有运行结果。

值得一提的是,OpenML 可以与其他机器学习工具集成,如 Weka、R,以便人们可以自动上传数据和代码。例如,在 Weka 中,我们可以添加多个任务和 Weka 算法进行运行。插件将下载所有数据,在每个任务上运行每个算法,然后自动将结果上传到 OpenML。手动运行上传目前正在开发中。人们只能通过插件或 API(Java/R)上传运行结果。
OpenML 还是 Kaggle?
开源*台的好处随着用户的增加而增长。当人们开始熟悉 OpenML 时,上述数字肯定会增加,或者当你阅读这篇文章时可能已经在增长。OpenML 的一个明显好处是研究人员可以定义自己的任务,并构建算法来解决其他任务。所有共享的结果都在线存储和组织,方便访问、重用和讨论。
你可能会想到 Kaggle,人们也可以在上面下载数据集并评估不同的算法。然而,OpenML 的设计目的是共享和比较研究结果。它侧重于合作,而不是竞争。在 Kaggle 竞赛中展示机器学习技能是个好主意。但只要进行足够的运行,OpenML 将是一个发现新知识的地方。
Ran Bi 是纽约大学数据科学项目的硕士生。在 NYU 学习期间,她完成了多个机器学习、深度学习及大数据分析的项目。她的本科背景是金融工程,因此也对商业分析感兴趣。
相关:
-
Prediction.io 开源机器学习服务器
-
MLlib:Apache Spark 的机器学习组件
-
当 Watson 遇到机器学习
更多相关话题
OpenStreetMap 数据到 ML 训练标签用于目标检测
原文:
www.kdnuggets.com/2019/09/openstreetmap-data-ml-training-labels-object-detection.html
comments
作者 Shay Strong,EagleView 数据科学与机器学习总监
我想创建一个无缝的教程,将 OpenStreetMap (OSM) 矢量数据转换为适用于机器学习 (ML) 模型的格式。特别是,我非常感兴趣于为灾难救援应用程序创建一个紧凑、干净的流程,其中我们可以使用像 OSM 中众包的建筑多边形来训练一个监督目标检测器,以发现未映射位置中的建筑物。
构建基础深度学习目标检测器的配方包括两个组成部分:(1)训练数据(栅格图像 + 矢量标签对)和(2)模型框架。深度学习模型本身将是一个单次检测器 (SSD) 目标检测器。我们将使用 OSM 多边形作为标签数据的基础,并使用 Digital Globe 影像作为栅格数据。我们不会在这里详细讲解 SSD,因为有很多现成的资源可供参考。我们将在 AWS Sagemaker 中运行目标检测器。当前文章仅关注训练数据生成。我会在后续文章中讨论模型训练。
我应该指出,这个教程可以在这个 Github repo 中找到,所以如果你想深入了解,可以跳过这篇文章。尽管这是即将到来的 UW Geohackweek 的一部分正在进行中的工作。我预计将把这个教程与 HOT-OSM 相关任务结合使用——这些任务可能会有作为特定项目的一部分的众包矢量数据。为了建立一个演示,我们将使用一个最*的 HOT OSM 任务区域,该区域在 2019 年被气旋肯尼思影响,即科摩罗的 Nzwani。
 2019 年 4 月底的气旋肯尼思路径。
2019 年 4 月底的气旋肯尼思路径。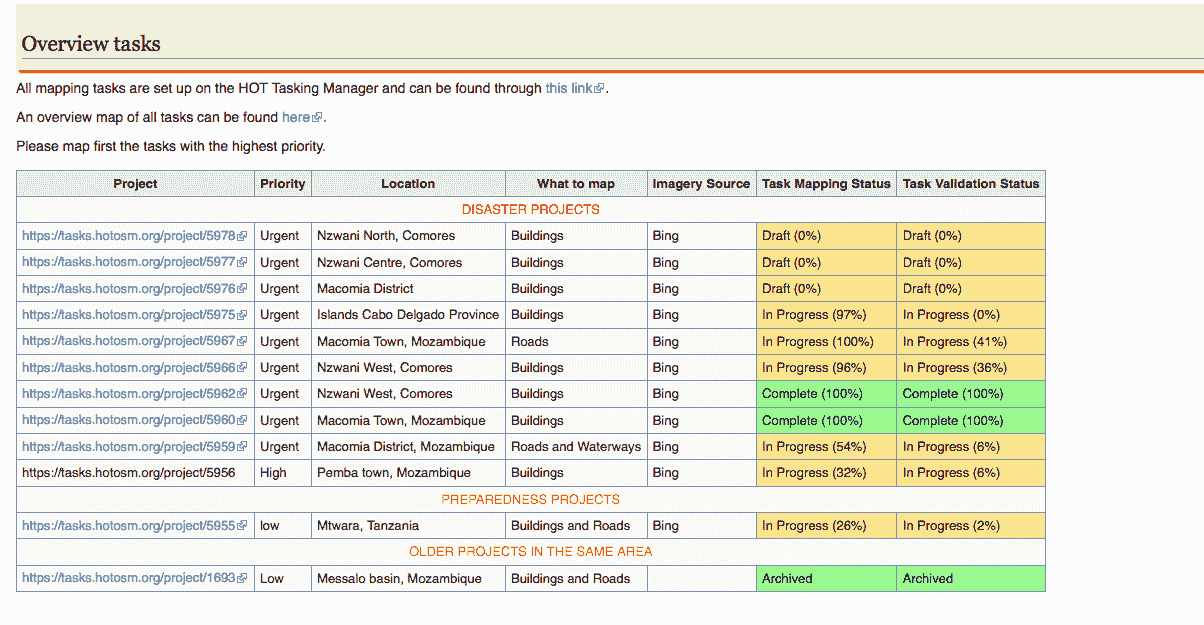 来自
来自 wiki.openstreetmap.org/wiki/2019_Cyclone_Kenneth 的 HOT-OSM 任务数据。
OSM 矢量数据是免费的。我们所需的影像通常不是。欢迎来到 GIS 的世界。不过,Digital Globe has Open Data 提供了许多这些自然灾害区域的影像。因此,我们可以获取这些数据用于这个应用(稍后再讲)。
我决定使用 OSMNX Python 库来与 OSM 进行接口(否则可能会有些令人望而却步)。根据 HOT-OSM 任务,科摩罗的恩茨瓦尼被标记为“紧急”地点(见上表)。所以我将从那里开始,因为似乎有大量的训练数据可用。
 (左) OSM 的节点与边的‘DiGraph’。(右) 恩茨瓦尼的陆地与叠加的道路和建筑物。
(左) OSM 的节点与边的‘DiGraph’。(右) 恩茨瓦尼的陆地与叠加的道路和建筑物。
如果你检查建筑物的长度(返回的一个 geopandas 数据框),你会看到大量的特征。我们将这些用作我们对象检测器的训练数据。
让我们获取一些 DG 图像。为了创建一个对象检测器,我们将模仿 VOC Pascal 训练数据格式,我们需要一对对图像(jpegs)和矢量(xml)标签。xml 文件有特定的格式。你可以在这个(导航困难的)网站上阅读相关信息。
我更倾向于直接从 Digital Globe Open Data 网站获取数据,但遗憾的是,目前似乎没有覆盖该事件后该区域的图像。我真的想将这个位置作为重点考虑,考虑到我们发现的建筑物数量和这个任务的相关性。所以,我将单独下载必要的图像,并为此演示提供一个小的子集。你可以在 GitHub 仓库中找到一个示例 GeoTIFF。
让我稍微离题谈谈 DG Open Data 网站。这个网站相当难以搜索,尽管提供了大量及时和相关的免费图像用于自然灾害影响区域,但作为个人用户,几乎不可能以地理空间的方式有效搜索。归根结底,很难确定哪个图像可能最佳地包含我感兴趣区域的大量建筑物。我的典型流程是点击网站上的一些缩略图,找到一个有显著城市化增长的区域。城市区域必须有建筑物!我在查看缩略图中的模式 20 分钟后有些放弃了(实际上是 45 分钟,因为我对模式匹配有些强迫症)。假设 DG Open Data 未来某个时刻有这张图像,随后的步骤对于你下载的任何 GeoTIFF 仍将保持一致。
如果你直接从 DG Open Data 网站获取图像,它们实际上是 Cloud Optimized GeoTIFF (COG) 格式,这样可以非常方便地创建虚拟栅格 (vrt)。这样做的好处是,我们可以创建一个轻量级的文件,该文件可以在本地 QGIS 窗口中加载,而无需下载整个 tif 文件。我们可以剪裁、子集化等,最终得到我们想要的图像,而不是多余的区域。
一旦你拥有了 GeoTIFF,我们将使用 GDAL 将其转换为 MBtile 格式,然后将其解包到 x/y/z slippymap (TMS) 目录结构中。MBtiles 对我们非常有利,因为它们是 256x256 的图像切片 (png),适合用于深度学习模型训练格式。
你可能会注意到生成的图像是以嵌套文件结构保存的。我们需要将它们“扁*化”,使所有图像都位于一个目录中。你不能只是将它们复制到一个目录中,因为 .png 文件名不是唯一的。我们还会将它们从 png 转换为 jpeg。我们将它们放入一个没有实际意义的 VOC 风格文件夹中,以区分它与合法的 VOC 数据集 VOC1900。
太棒了。图像处理完成了!
接下来,我们将对建筑物进行缓冲处理,扩展到最*的矩形。这就是目标检测器所需的。
现在我们已经将建筑物表示为轴对齐的边界框,我们将使用我新的最爱工具 Supermercado。我们将前往“超市”以识别所有与建筑边界框重叠的 TMS 瓦片。我们将 TMS 瓦片 ID 映射到建筑边界框本身,然后将建筑边界框(以地理空间纬度/经度格式表示)转换为 slippymap 瓦片参考框架。现在,我们将拥有一个与我们在同一网格上解包的图像一致的 TMS 瓦片网格上的建筑边界框。
最后,我们要清理 xml 标签和图像,以确保去除多余的矢量标签。我们只需要一对相同的图像和注释。
现在你应该有一个干净且准备好的 VOC 风格图像和标签目录,准备进行训练。
VOC1900/
│___ Annotations/*xml
|___ JPEGImages/*jpeg
接下来将是实际的训练过程。敬请关注。
个人简介: Shay Strong 是 EagleView 的数据科学与机器学习总监,对地理空间机器学习和遥感感兴趣。
原始内容。经许可转载。
相关内容:
-
2019 年目标检测指南
-
使用 Tensorflow 目标检测和 OpenCV 分析足球比赛
-
在航空图像中使用 RetinaNet 进行行人检测
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT
更多相关主题
操作化机器学习:成功 MLOps 的七个考虑因素
原文:
www.kdnuggets.com/2018/04/operational-machine-learning-successful-mlops.html
评论
作者:Nisha Talagala,ParallelM。
机器学习无处不在。从广告到物联网到医疗保健,以及其他领域,几乎所有行业都在采用或研究机器学习(ML)以提升业务。然而,为了利用 ML 获得正的投资回报率(ROI),它需要被操作化或投入生产。
将机器学习投入生产带来了一系列独特的挑战。
操作化的第一步是了解你的 ML 应用的样子、它的各个部分以及它们如何协同工作。
1: 了解你的 ML 应用
在大多数情况下,ML 用于优化(即添加洞察)业务应用。虽然这听起来很简单,但一个 ML 操作通常需要多个互补但独立的 ML 程序(训练、推理等)协同运行。什么是 ML 应用?ML 应用是一起提供 ML 功能的程序和依赖项的集合。
图 1(a)展示了将机器学习(ML)添加到业务应用中的最基本方式。业务应用请求预测,这些预测可以由 ML 推理程序提供(微服务方法在这里很受欢迎)。ML 推理程序使用一个离线训练的模型,这通常由数据科学家完成。虽然这个流程很简单,但通常不够充分。在数据变化频繁的行业(如广告技术)中,需要对模型进行频繁的重新训练,以跟上变化的环境。此时需要添加一个重新训练管道以供推理使用,最终形成图 1(b)中的模式。
重新训练引入了许多模型,可能需要人工干预以决定哪些模型部署到生产环境中(在财政、健康或其他结果与 ML 预测相关的情况下,这一点尤为重要)。添加人工审批会导致图 1(c)中的模式。如果使用先进的算法(如集成模型)来提高准确性,模式将变为图 1(d)中的模式。
最后,许多生产部署会并行使用多个预测管道(如冠军/挑战者、金丝雀等)来监控预测模式,检测意外的变化或异常。添加这样的测试基础设施生成了类似于图 1(e)的模式。
图 1: ML 应用
一旦你的机器学习(ML)应用程序定义完毕,下一步就是确保它能够安全且成功地投入生产。
投资回报率:机器学习应用程序应该改善其伴随的业务应用,同时保持在行业和组织的要求范围内。
2: 衡量成功
机器学习应用程序存在的目的是服务于业务需求。业务应用的成功指标或关键绩效指标(KPI)应当被追踪,并与机器学习应用的引入及随后的优化相关联。这种关联为所有利益相关者提供了可见性,确保机器学习投资能够产生足够的回报,并帮助从数据科学家到运营人员的每个人衡量和证明新的运营投资。
3: 管理生产机器学习风险
风险管理并不会在模型开发阶段结束。一旦投入运行,模型需要被监控并不断评估,以确保它们在预期的范围内运行。生产机器学习的健康状况受到复杂性的影响,因为实时数据没有标签(因此无法使用常见的指标如准确率、精确度、召回率等)。替代方法(如数据偏差检测、漂移检测、金丝雀管道、生产 A/B 测试)应成为机器学习应用的一部分。
4: 确保治理和合规
一些行业,比如金融服务,已经有了多年的机器学习合规要求。其他行业和地区也开始引入指导方针,比如欧盟的GDPR或纽约市算法问责法案。一个全面的生产治理机制对于确保机器学习应用程序(以及所有相关的模型、管道、代码、执行等)能够被追踪以实现可重复性、可审计性,并辅助解释性是至关重要的。
与 DevOps 的和谐:MLOps 应该与现有的 DevOps 集成,同时提供管理机器学习所需的额外独特能力。
5: 自动化
机器学习管道是代码,经典的 DevOps 工具链组件(如 Git 这样的源代码库、Jenkins 这样的自动化设施、AirFlow 这样的编排工具等)在 MLOps 中扮演着重要角色。然而,除了业务重点、风险降低和合规需求之外,生产中的机器学习还带来了额外的 CI/CD 和编排挑战,这些挑战是常见 DevOps 工具链无法解决的。例如,像图 1(e) 中的 ML 应用可能会有多个管道并行执行,并且有 ML 特定的相互依赖关系(如模型批准/传播或漂移检测)也需要进行管理。这些 ML CI/CD 和 ML 编排需要与组织中已经存在的 DevOps 实践无缝集成。
6: 规模
ML 应用可能需要不同于它们所服务的业务应用的硬件配置和扩展点。例如,训练神经网络模型可能需要强大的 GPU,而训练常规 ML 模型可能需要 CPU 集群。根据推理实现的不同,可能需要流处理器集群、REST 端点或批处理推理操作。许多强大的生产级分析引擎(如 Spark、Flink、PyTorch、scikit-learn 等)存在用于执行 ML 管道。ML 应用需要根据管道的需求,合理配置和映射到这些引擎中的一个或多个。
与组织的和谐: MLOps 应该使你所有的组织职能协同工作,以使 ML 为你的业务应用发挥作用。
7: 人员
生产中的机器学习需要组织内的多个职能(数据科学家、数据工程师、业务分析师和运营人员)进行协作。每个角色需要查看 ML 应用的不同方面。数据科学家可能关注训练准确性的指标、生产 A/B 测试的置信度或数据偏差检测,而运营人员可能想查看正常运行时间和资源利用率,业务分析师可能希望看到 KPI 的改进。MLOps 工具链需要为所有这些参与方提供可见性、管理访问控制和协作功能。
总结: 结合一切
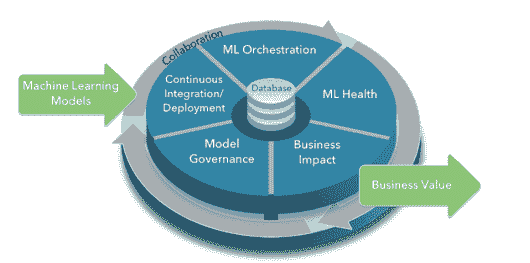
总体而言,你的 MLOps 应该包含图 2 中的所有元素,所有元素应协同工作,以形成一个成功的 ML 操作的整体。
简介: Nisha Talagala 是 ParallelM 的 CTO/VP 工程。她的背景是分布式系统的软件开发,专注于存储、I/O、文件系统、持久内存和闪存非易失性存储。之前在 PM 之前,她是 Fusion-io(被 SanDisk 收购)的首席架构师/研究员,开发持久内存、非易失性内存文件系统(NVMFS)和应用加速的新技术和软件栈。她拥有加州大学伯克利分校的博士学位,并持有 56 项专利。
相关:
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT 工作
更多相关内容
将机器学习从概念验证转化为生产
原文:
www.kdnuggets.com/2022/05/operationalizing-machine-learning-poc-production.html

机器人卡通矢量图由 vectorjuice 创建 - www.freepik.com
许多公司使用机器学习来帮助创造竞争优势和发展业务。然而,要使机器学习有效并不容易,因为它需要在研究和工程之间找到*衡。虽然可以根据当前研究提出一个好的创新解决方案,但由于工程效率、成本和复杂性,可能无法投入生产。大多数公司尚未从机器学习中获得显著的投资回报,因为只有在模型投入生产后才会实现这种收益。让我们深入探讨挑战和最佳实践,以使机器学习发挥作用。
首先,让我们框定一个典型 AI 项目的主要阶段:
-
概念验证(PoC) – 此阶段的目的是验证机器学习是否真的能解决当前的问题。同时,估算在生产中解决问题所需的成本和时间。
-
工程 – 顾名思义,这一阶段的重点是模型工程,以实现规模和可靠性,设置验证框架和数据管道。
-
维护或 AI 操作 – 这是一个重要步骤,因为数据不是静态的,会不断变化,这意味着模型需要用新数据进行训练,并频繁部署到生产中。如果不自动化模型训练、部署、验证以及最终监控,这将无法有效完成。
接下来,理解数据科学家在设计机器学习解决方案时需要解决的关键挑战,以确保业务的投资回报(ROI)是重要的。针对每一个挑战,都有成功克服这些挑战的建议。
-
数据 – 质量和数量
-
算法选择 – 准确性与成本
-
生产中的模型性能
-
部署自动化和监控(MLOps)
-
处理规模
数据 – 质量和数量
任何机器学习模型中最重要的部分是数据,训练一个模型既需要质量也需要数量。首先让我们从数量开始。
挑战 1:数据不足
许多时候,公司或团队的数据要么太少,要么太多。在 PoC 阶段,即使数据量不大,也能轻松验证方法,但该解决方案可能无法适用于所有生产场景。这是因为用于训练和验证的数据集可能不能代表全部数据,并且在某些情况下可能无法获取数据,例如在罕见的医学疾病情况下。
让我通过一个实例来详细说明这一点:我们的一位法律领域客户希望根据法规对文件进行分类,并提取每个法规的信息。初始训练数据集仅有 20 份文件,目标是对一百万份文件进行分类。小训练数据集的挑战在于确保模型不会过拟合数据。过拟合会确保在 PoC 阶段(我们不使用未见数据验证模型时)准确率很高,但在模型投入生产时却不一定。我们选择了一个简单的一类分类模型,它可以从小数据集中学习模式而不会过拟合,并在数据增多后投入生产并进行改进。
推荐
选择可以处理小数据的算法,通过将功能范围限定为仅解决已见模式并收集未见模式的数据,将其投入生产。通过迭代改进模型以涵盖其他场景。或者,使用半监督学习,它可以处理较少数据的问题。
挑战 2:数据过多
与小数据类似,大数据也是一个问题,因为机器学习模型的训练时间可能非常长,并且所需的计算能力可能很高。我们需要创建一个代表完整数据集的子集数据集。挑战不仅在于选择正确的采样技术,还在于自动化样本收集过程,以确保数据不过时。
我们遇到了类似的情况,我们为一家广告公司在实时竞价领域解决了一个投标价格预测问题,该公司每天收到* 700 亿个请求。我们不能在全部数据上训练模型,甚至捕获 PoC 所需的数据也需要一些工程工作,以确保原始数据和采样数据的分布保持一致。
推荐
通过将数据采样模块集成到数据处理管道中来自动化训练数据集的创建。为了解决数据较少的问题,使用过采样技术,如 SMOTE(合成少数类过采样技术),可以从当前数据分布中生成合成样本。
挑战 3:数据质量
数据质量也很重要,因为输入模型的数据质量决定了模型输出的 AI 质量。PoC 阶段训练数据的分布可能与生产阶段数据的分布不同,从而导致生产中的错误增加。这主要是由于使用了不正确的采样技术。
推荐
为了解决大数据问题,我们必须使用良好的采样技术来创建适合问题陈述的最佳训练数据。在实时竞价项目中,我们使用了随机采样,因为数据来自均匀分布。
算法选择
在项目的 PoC 阶段,数据科学家主要关注解决方案和结果。然而,任何组织只有在解决方案具有成本效益(相较于当前解决方案)并且在性能(响应时间等)上表现突出时,才会批准项目。在选择算法时,重要的是要关注机器学习解决方案的运行成本。
机器学习解决方案的成本取决于我们选择的算法或技术。例如,使用特定领域数据从头开始训练深度学习模型可能会得到良好的准确性,但需要多个 GPU 进行训练,而经典的机器学习解决方案可能不需要 GPU。计算成本可能会根据方法和训练数据的大小非线性增长。
我也遇到过类似的问题。在处理语音克隆问题时,我们可以选择从头开始训练卷积神经网络(CNN)基础的深度学习模型或使用迁移学习。我们选择了基于迁移学习的解决方案,因为成本降低了 60%,而且克隆的准确性足够好,不会在生产中看到差异。
推荐
在考虑机器学习解决方案时,我们也应注意基础设施成本。这些成本应作为比较不同模型时的一个指标,除了准确性指标。控制基础设施成本的一些方法包括:
-
避免在可以使用 CPU 完成的任务中使用 GPU。例如,经典的机器学习模型可以使用 CPU 进行训练。
-
尽可能使用迁移学习。
-
仅在需要时训练模型。例如,当数据分布发生变化或新增类别时。定期训练模型而数据变化不大,会增加项目的基础设施开销。
模型性能
标准指标如 MAPE、F1 分数、IOU 等可以用于衡量模型性能。这些指标在 PoC 阶段测试模型时效果很好,但在考虑业务 ROI 时可能效果不佳。如果机器学习模型实施不当,也可能对业务产生负面影响。
一个例子是我们为一家广告公司构建的评分预测模型,该模型在机器学习指标方面的准确性很好,但业务的成功衡量标准是收入最大化。我们必须提出一种集成方法来实现收入最大化。
推荐
为了最小化影响,采用 A/B 测试方法逐步推出解决方案。关键是要使部署自动化,以便在需要时能够回滚 ML 解决方案。
部署自动化与监控
这是整个项目中最重要的部分,但由于工程和 DevOps 团队对机器学习的理解不足,大多数人忽视了这一点。持续监控模型性能是非常重要的,因为如果输入数据发生变化,模型结果可能会变化。在这一阶段,你需要克服以下问题:
-
大多数数据工程师不理解采样、数据准备和模型验证技术,因此无法建立数据管道以收集训练数据和验证模型。
-
DevOps 团队在管理模型版本、回滚等方面常常缺乏机器学习经验。
-
缺乏工具来帮助监控生产中的机器学习模型。
对于前面提到的竞标价格预测问题,我们修改了数据处理管道,通过采样生成训练数据并存储在一个公共位置,如果数据分布发生变化,可以触发训练管道。DevOps 团队通过逐步部署模型到一个集群来自动化模型部署。DevOps 团队还设置了模型准确性的监控,以在准确性下降到特定阈值以下时生成警报。
推荐
数据科学家应该在开发解决方案之前定义生产环境中模型性能的指标和指标。一旦定义好,数据科学家需要与工程和 DevOps 团队紧密合作,建立数据处理管道和监控系统。
处理规模
定义 ML 模型规模的两个重要因素是:
-
模型可以处理的请求数量
-
执行时间(延迟)
我们可以通过线性扩展模型部署来扩大模型可以处理的请求数量。执行时间是规模的一个关键因素,因为它增加了处理延迟,从而影响规模。
机器学习 PoC 就像一个研究项目,包含不同类型的实验,以找出针对当前问题的最佳算法或方法。具有最佳准确度的解决方案的时间复杂度可能较高,导致延迟较高。构建解决方案时,考虑解决方案的复杂度很重要,因为如果简化解决方案,放弃准确度可能是最佳选择。
以竞标问题为例,我们使用强化学习实时预测竞标价格。预测所需的整体时间必须少于 60-70 毫秒,这意味着机器学习模型的执行时间必须更短以避免超时。为了减少整体执行时间,我们通过降低强化学习模型中环境的复杂性,改用 JAVA 而非 Python 实现模型,并进行部署来降低复杂度。
推荐
在选择算法时,执行时间是一个重要的指标。有时,如果通过简单算法可以减少总体延迟,牺牲一定的准确性也是值得的。
结论
要成功地将机器学习模型部署到生产环境中:
-
定义用于在 PoC 阶段验证模型性能的指标和指示器。
-
根据基础设施预算和延迟要求选择机器学习方法。
-
自动化数据处理管道以进行训练和执行。
阿拉赫·沙尔玛 是 Talentica Software 的数据科学家,该公司是一家全球产品开发公司,帮助初创公司开发产品。阿拉赫是印度科学学院班加罗尔的校友。他通过采用强化学习、机器学习和自然语言处理,帮助企业获得竞争优势。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
更多相关内容
机器学习初创企业的机会在哪里?
原文:
www.kdnuggets.com/2016/06/opportunites-machine-learning-startups.html
作者:Libby Kinsey,风险投资人。
机器学习和人工智能在数据驱动的业务中迅速普及,也就是说,很多企业都在使用。这里我选择了几个可能还未被大公司占领的领域。这并非全新领域——如果我能想到下一个杀手级应用,我会尝试去实现它!
‘工具和镐’玩法
这种说法源于加州淘金热,当时售卖工具的商人赚得盆满钵满(而淘金者的结果则各异),机器智能的“工具”则是硬件、数据流,以及(可以说是)算法本身。
-
令人惊讶的是,机器智能的算法开发绝大多数都是开源的。当然也有例外——去年,牛津大学申请了一项高效的替代反向传播的专利,即反馈对齐算法(第 14 页)——我想知道他们打算如何将其商业化?那些使人们能够轻松使用学习算法的高质量 SaaS 服务将会找到热切的客户,而MetaMind将尖端深度学习带到你的数据集中,就是一个拥有所有正确资质的例子。我还喜欢另一个项目,自动统计学家,它通过贝叶斯推断搜索模型,以发现最适合你数据的解释。好奇 AI 公司,一家通用人工智能公司,其首个项目是废物分类(乍一看虽不吸引人但利润丰厚),据报道计划将其 AI 软件作为工具包销售。
-
大公司可以访问大量的数据集,并可以获得更多(如,IBM 最*收购《天气频道》数据资产,价值 15 亿美元)。但迄今为止的重点还是在低挂的果实上,比如社交或电子商务数据,因此在获取和/或标注数据更困难的地方仍有机会。Affectiva的面部情感反应数据库、Pallas Ludens(端到端数据注释服务)和opensensors.io(为公共传感器数据来源增加价值)都属于这一类别。基因组和医学图像数据——由于一些棘手的隐私问题——将促进个性化治疗和护理,并改善诊断。顺便提一句,看看Genomics England 如何推进其行业合作将会很有趣。
-
在硬件方面,GPU 实现了一些非凡的进展。(也有非常普通的进展——NVIDIA GeForce GTX Titan 使我能够在音频中检测到蝙蝠叫声。)
蝙蝠叫声的频谱图(下图)和卷积神经网络预测(上图)。
但这些处理器是为图形设计的。高效学习和推理的下一个飞跃将来自专门为机器学习设计的处理器。Graphcore称它们为智能处理器单元。与此同时,Nervana Systems、Teradeep(Yann LeCun 是顾问)和Thinci正在打造自己的定制硬件。
将Udacity、Coursera和Kaggle等公司,包括在这个类别中是合理的,它们帮助教育或管理代码库和项目(例如,Atlassian,准备上市)。
利用情感
这是一个初创公司数量较少的应用领域。引用MIT 情感计算小组的话:
“情感是人类体验的基础,影响认知、感知以及日常任务,如学习、交流,甚至理性决策。然而,技术人员在很大程度上忽视了情感,给人们创造了一个常常令人沮丧的体验……”

用于训练微表情检测器的图像(感谢 JB!)
第一个任务是训练模型识别人的情感。Emotient、RealEyes和Affectiva都使用面部表情来推测情感,目前主要(看起来)用于市场营销。Cogito Corp和Beyond Verbal则集中于理解声音中的情感线索,以进行市场研究并提供更好的客户体验。
然后,建模情感行为,例如为了与人类自然互动。Jibo,这个‘友好’的机器人,是一个有趣的例子,仅用‘眼睛’来表达自己。肯定会有便宜的玩具,既适应又响应(像Paro治疗用的海豹机器人,但用于玩耍),虽然我还没找到这些玩具。这些玩具有避免像 Toy Talk 和 Mattel 的‘Hello BarbieTM’这样的对话玩具隐私问题的优势,至少在语音可以在本地处理而不是在云端之前。
其他应用包括个性化护理和教育、冲突解决与谈判培训,以及自适应游戏。这些任务似乎非常适合机器学习,因为情感体验是主观且变化多端的。
渗透专业领域
我将把是否机器智能会使我们所有人变得多余的猜测留给其他人,而是指出它当然有潜力在许多专业任务中协助人类(从而为客户提供更多选择和价值)。
这些技术可能会做什么呢?以法律行业为例。Ravn Systems自动化处理法律工作中的(重复、乏味的)文件审查;Bitproof’s Peter是一个 AI 法律助手,可以请求签名、生成合同和公证文件;而Premonition.ai利用数据搜索司法中的无意识偏见(对于看过《傲骨贤妻》第一季第十集的观众,这并不新鲜!)。
类似的招聘、保险、财务管理等工具将使专业人员能更多地关注工作中更令人满意的方面,如行使判断、决策以及……客户娱乐。
革新医疗
药物发现被认为是昂贵且风险大的,但如果可以利用数据减少风险,找到更好的开发目标呢?这正是Stratified Medical的假设,使用深度学习进行制药研发。
其他方面,Enlitic 和 Zebra Medical 试图利用深度学习进行准确的诊断/决策支持工具,而 Your.MD 与英国国家健康服务合作,通过应用程序提供个性化健康援助。
更好的搜索
“那部电影叫什么来着,那个我姐姐喜欢的德国演员出演的…跟外星人有关的…非常朋克的原声带?”
搜索需要能够处理不精确、主观和个人化的内容,就像人类一样。它需要帮助我们从所有噪音中发现和策划对我们相关的内容。这涉及到学习上下文和内容属性。实际上,这本身就是一个博客文章,但这里有几个例子:
-
Clarify 通过其 API 使音频和视频可搜索。它相当于扫描文本中的关键词以确定相关性,是一个节省时间的绝佳应用。
-
Lumi 从你的浏览历史中学习你的喜好,以提供相关的、最新的内容。一个为无尽好奇心者服务的服务。
-
Yossarian Lives 是一个可以进行横向联系的搜索引擎,类似于人类,以助力创造力。
-
EyeEm 已将机器学习融入其摄影市场,允许无标签地搜索诸如‘愉快的’和‘雨天伦敦’等属性,而 Cortexica 和 Sentient Technologies / Shoes.com 利用相似性来优化产品搜索。
搜索相关性的一个关键方面无疑是‘可信度’,以便能够验证或评分社交媒体和新闻网站中的内容和声明。有人在做这个吗?
网络安全
机器学习在网络安全领域已经吸引了大量的风险投资(例如,Lookout 收到 2.82 亿美元,Vectra Networks 收到 7800 万美元,Darktrace 收到 4000 万美元,Cybereason 收到 8900 万美元),但不断传来的坏消息(如最*的 黑客事件)显示市场还远未稳定。
就像任何‘热门’领域一样,很难区分多个表面上类似的初创公司。我确实需要在这个领域做更多的工作,并将密切关注 Cyber London,这是一个网络安全初创公司的加速器。
应用领域如此之多,很难只关注几个。我错过了一些我最喜欢的公司,因为它们不符合这些类别中的任何一个,而且我在这篇文章发布后不可避免地会改变对类别的看法。尤其是因为我下周将参加NIPS,我期待这次经历会让我大开眼界。 (编者注:NIPS 并不是下周)。
发展速度以及对新数据集的应用是机器智能如此令人兴奋的原因。尤其是在伦敦,目前确实有一种势头感,因为它靠*一系列世界级学术机构(帝国理工、UCL、牛津和剑桥),有一个成熟的初创生态系统(例如,像Entrepreneur First这样的加速器积极吸引机器学习人才),以及目标客户中心的所在地——金融、法律和政府。
那么,请告诉我,我漏掉了什么?
简介:Libby Kinsey 与英国的机器学习初创公司和风险投资公司合作。她在去年完成了 UCL 的机器学习硕士学位,此前花了约十年时间投资于高科技初创公司。
原文。转载已获许可。
相关内容:
-
微软正变成 M(ai)crosoft
-
英特尔在认知技术上的投资:影响与新机遇
-
数据科学与认知计算:HPE Haven OnDemand 的简单推理与洞察之道
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 需求
更多相关话题
最优估计算法:卡尔曼滤波器和粒子滤波器
原文:
www.kdnuggets.com/2020/02/optimal-estimation-algorithms-kalman-particle-filters.html
评论
照片由Daniel Jerez拍摄,来源于Unsplash
最优估计算法
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
最优估计算法在我们日常生活中扮演着非常重要的角色。今天,我将通过一些实际的例子向你介绍两种算法(卡尔曼滤波器和粒子滤波器)。
让我们设想一下我们正在驾驶一辆无人驾驶汽车,我们即将进入一个长隧道。在这个例子中,我们的汽车利用不同的传感器,如 GPS 估计、加速度计和摄像头,以便跟踪它在地图上的位置以及与其他车辆或行人的互动。然而,当在隧道中旅行时(特别是非常长的隧道),我们的 GPS 信号因干扰而变弱。因此,我们的汽车可能更难以估计其位置。我们可以做些什么来解决这个问题呢?
一个简单的解决方案是将我们的加速度计传感器数据与弱 GPS 信号结合使用。事实上,通过对加速度进行双重积分,我们可以计算出汽车的位置。然而,这种简单的测量会包含一些漂移,因此不完全准确,因为我们的测量误差会随时间传播(见图 1)。为了解决这个问题,我们可以使用卡尔曼滤波器或粒子滤波器。
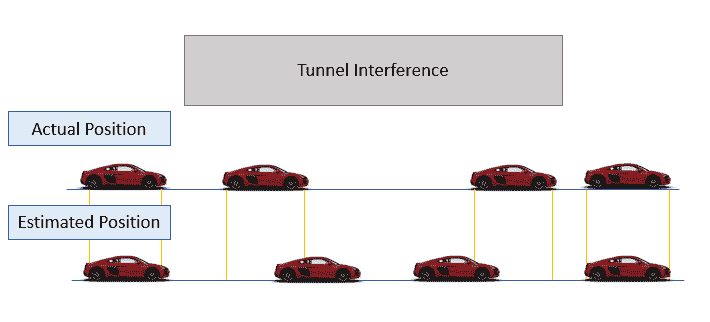
图 1:自主汽车在时间上的位置估计
卡尔曼滤波器
卡尔曼滤波器在机器人技术(例如SLAM 系统)和强化学习中有广泛应用。卡尔曼滤波器可以用于机器人技术中以追踪环境中一群机器人的运动,也可以在强化学习中用于追踪不同的软件代理。
卡尔曼滤波器是一个迭代的数学过程,使用一组方程和连续的数据输入,以估计物体的真实位置、速度等,当测量值包含不确定性或误差时。[1]
因此,卡尔曼滤波器可以简单地与机器学习模型进行比较。它们接受一些输入数据,执行一些计算以进行估计,计算其估计误差,并迭代地重复这一过程,以减少最终损失。卡尔曼滤波器执行的迭代过程可以总结为三个主要步骤:
-
卡尔曼增益计算:通过使用输入数据和估计中的误差来计算。
-
当前估计计算:通过使用原始输入数据、我们的前一估计和卡尔曼增益来计算。
-
估计误差计算:最终通过使用卡尔曼增益和我们的当前估计来计算。
这一过程在图 2 中简要总结。
图 2:卡尔曼滤波器工作流程(改编自[1])
存在不同种类的卡尔曼滤波器,示例包括:线性卡尔曼滤波器、扩展卡尔曼滤波器和无迹卡尔曼滤波器。如果你对卡尔曼滤波器的详细数学解释感兴趣,这个由 MIT 的 Tony Lacey 提供的教程是一个很好的起点[2]。
卡尔曼滤波器的主要问题之一是它们只能用于建模可以用高斯噪声描述的情况。然而,许多非高斯过程可以用高斯术语进行*似,或者通过某种变换(例如对数变换、*方根变换等)转换为高斯分布。
为了克服这种限制,可以使用一种替代方法:粒子滤波器。
粒子滤波器
粒子滤波器可以用于解决非高斯噪声问题,但通常比卡尔曼滤波器计算上更为昂贵。这是因为粒子滤波器使用模拟方法而不是解析方程来解决估计任务。
粒子滤波器通常用于:
-
金融市场分析(尤其是随机过程分析)
-
强化学习
-
机器人定位(例如直接全局策略搜索)
粒子滤波器基于蒙特卡罗方法,通过将原始数据离散化为粒子(每个粒子代表不同的状态)来处理非高斯问题。粒子数量越多,我们的粒子滤波器能够处理的分布类型就越广泛。
像卡尔曼滤波器一样,粒子滤波器也利用迭代过程来生成其估计。每次迭代可以分解为三个主要步骤 [3]:
-
从原始分布中提取多个样本(粒子)。
-
按重要性对所有采样粒子进行加权(粒子落在特定区间的数量越多,其概率密度越高)。
-
通过用更可能的粒子替换更不可能的粒子来进行重采样(类似于进化算法,只有最适合的元素才能存活)。
该过程总结在图 3 中。从下图可以看到,在这个例子中,我们的粒子滤波器在一次迭代后能够了解我们的对象更可能处于哪个范围。通过反复进行这一过程,我们的滤波器将能够进一步缩小其分散范围。
图 3:单粒子滤波器迭代
如果你有兴趣在 Python 中实现最优估计算法,FilterPy 或 Pyro 库是两个很好的解决方案。特别是,Pyro 是 Uber 开发的通用概率编程语言,可用于各种贝叶斯分析,使用 PyTorch 作为后端。
希望你喜欢这篇文章,谢谢阅读!
联系方式
如果你想获取我最新的文章和项目,请关注我在 Medium并订阅我的邮件列表。以下是我的一些联系信息:
参考书目
[1] 特殊主题 — 卡尔曼滤波器 (2 of 55) 简单示例的流程图 (单一测量值),Michel van Biezen。访问链接:www.youtube.com/watch?v=CaCcOwJPytQ
[2] 第十一章:教程:卡尔曼滤波器,Tony Lacey。访问链接:web.mit.edu/kirtley/kirtley/binlustuff/literature/control/Kalman%20filter.pdf
[3] 粒子滤波器和蒙特卡罗定位简介,Cyrill Stachniss。访问链接:ais.informatik.uni-freiburg.de/teaching/ws12/mapping/pdf/slam09-particle-filter-4.pdf
个人简介:Pier Paolo Ippolito 是数据科学家和南安普顿大学人工智能硕士毕业生。他对人工智能进展和机器学习应用(如金融和医学)有浓厚兴趣。通过 Linkedin 与他联系。
原文。经许可转载。
相关:
-
物联网的数据科学:传感器融合与卡尔曼滤波器,第一部分
-
如何优化你的 Jupyter Notebook
-
GPU 加速的数据分析与机器学习
更多相关内容
使用 Pandas fillna() 输入缺失数据的最佳方式
原文:
www.kdnuggets.com/2023/02/optimal-way-input-missing-data-pandas-fillna.html

图片由 catalyststuff 提供,来源于 Freepik
在数据探索阶段,我们经常会遇到缺失数据的变量。缺失数据可能由于各种原因存在;采样错误、故意遗漏或随机原因。无论原因是什么,我们需要分析缺失数据的原因。关于缺失数据类型的文章由 Yogita Kinha 提供,是一个很好的起点。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析技能。
3. Google IT 支持专业证书 - 支持您组织的 IT 事务。
经过适当的分析,解决缺失数据问题的一种方法是填充数据。幸运的是,Pandas 允许轻松输入缺失数据。我们怎么做呢?填补缺失数据的最佳方式是什么?让我们一起学习。
Pandas Fillna 函数
根据 Pandas 的 文档,Fillna 是一个 Pandas 函数,用于用指定的方法填充 NA/NaN 值。在 Pandas DataFrame 中,我们将缺失的数据对象指定为 NaN 对象。使用 Fillna,我们将用我们分析过的其他值替换这些 NaN 值。
让我们试用一个数据集示例来尝试这个函数。本文将使用 Kaggle 上的地方性登革热训练数据集(许可证:CC0:公共领域)。
import pandas as pd
df = pd.read_csv('dengue_features_train.csv')
df.head(10)
正如我们在上述数据集中所看到的,‘ndvi_ne’ 列中存在缺失数据。使用 Pandas 的 fillna 函数,我们可以轻松地用其他值替换缺失数据。让我给你一个例子。
df.fillna(0).head(10)
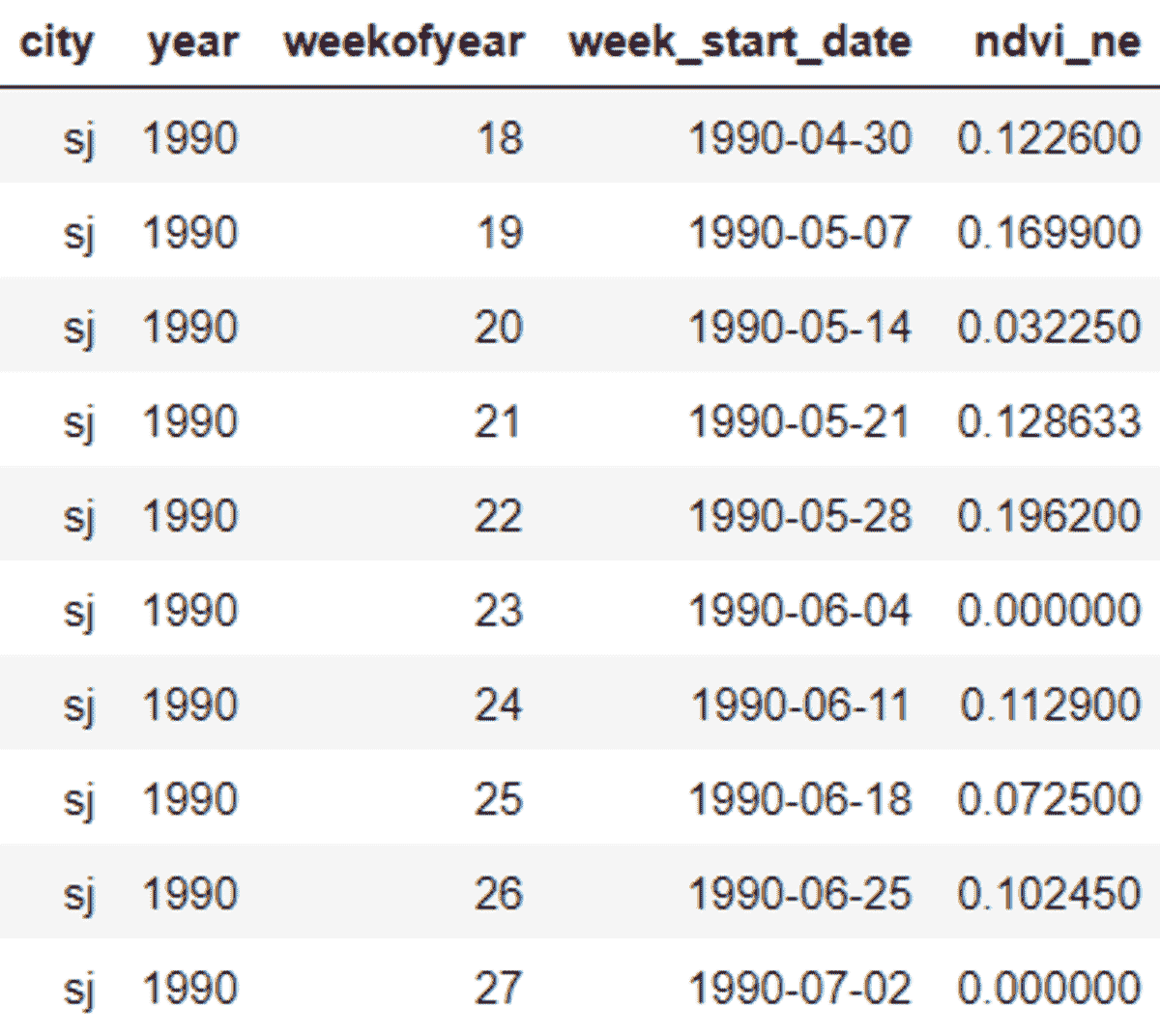
使用fillna函数,我们用值 0 替换了缺失的数据。使用fillna函数时,你可以用任何值来替换它。例如,我用字符串‘zero’替换了缺失值。
df.fillna('zero').head(10)
或者我甚至可以使用函数来替换缺失值,这虽然可以做到,但并不实用。
df.fillna(pd.isna).head(10)
另外,fillna函数在执行时不会改变实际的数据集。如果你希望 DataFrame 在执行函数时被替换,可以运行以下代码。
df.fillna(0, inplace = True)
当你运行上述代码时不会有输出,但你的 DataFrame 会受到影响。如果你还在实验数据中,请不要使用参数 inplace。
在多个列上替换缺失值
使用fillna函数时必须小心。如果我们在整个 DataFrame 上运行该函数,它会用传入的值填充所有缺失的数据,即使这不是你的意图。通过使用数据示例来看看我在说什么。
df[df['ndvi_ne'].isna()]
我尝试获取所有‘ndvi_ne’列缺失的观察值。如果我们查看上面的输出,可以看到几个列也包含缺失数据。让我们尝试使用fillna函数来填充它们。
df[df['ndvi_ne'].isna()].fillna('zero')
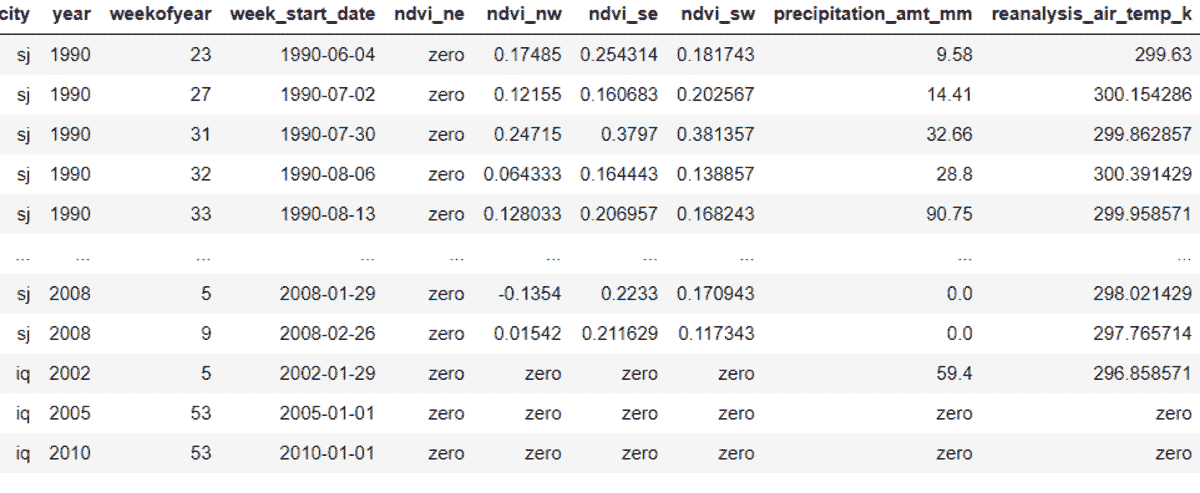
所有的缺失数据现在都被字符串‘zero’值替换了。通常,这不是我们想要的。如果我们只想替换某些列的缺失数据,我们可以在使用fillna函数之前先选择这些列。
df['ndvi_ne'].fillna(0)

还有一种优化的方法来填充缺失数据,即通过传递一个包含列名作为键和替换值的字典。让我们通过代码示例来尝试一下。
df[df['ndvi_ne'].isna()].fillna({'ndvi_ne':0,
'ndvi_nw':'zero',
'ndvi_se': df['ndvi_se'].mean()})
使用上述代码,我们将列‘ndvi_ne’替换为 0,将‘ndvi_nw’替换为‘zero’,将‘ndvi_se’替换为列均值。其余部分未被修改,因为我们没有在函数中指定它们。
填充第 n 个连续缺失的数据
Pandas fillna函数还允许用户指定要替换的缺失数据的数量。通过使用 limit 参数,我们可以连续填充到第 n 个缺失数据。让我们通过代码示例尝试一下。
df[df['ndvi_ne'].isna()].fillna(0, limit = 3).head()

从上述输出中,我们可以看到只有五行缺失数据中的三行被替换了。如果我们更改限制参数,可能会看到不同的结果。
df[df['ndvi_ne'].isna()].fillna(0 , limit = 2).head()

显示的数据中只有两行被替换。缺失数据不需要彼此相邻。它们可以在不同的行中,限制参数只会替换前两个缺失数据(如果限制参数设置为两)。
前向填充和后向填充
Pandas fillna函数的优点在于,我们可以从前一个观测值或后续观测值中填充缺失数据。让我们尝试从前一个观测值中填充数据。提醒一下,我们在以下列中有缺失数据。
df['ndvi_ne'].head(10)
然后,我们将使用fillna函数用前一行的数据替代缺失的数据。
df['ndvi_ne'].head(10).fillna(method = 'ffill')
缺失数据现在已被前一行的数据替代,或者我们可以称之为前向填充。让我们尝试反向操作:后向填充或从后续行填充缺失数据。
df['ndvi_ne'].head(10).fillna(method = 'bfill')
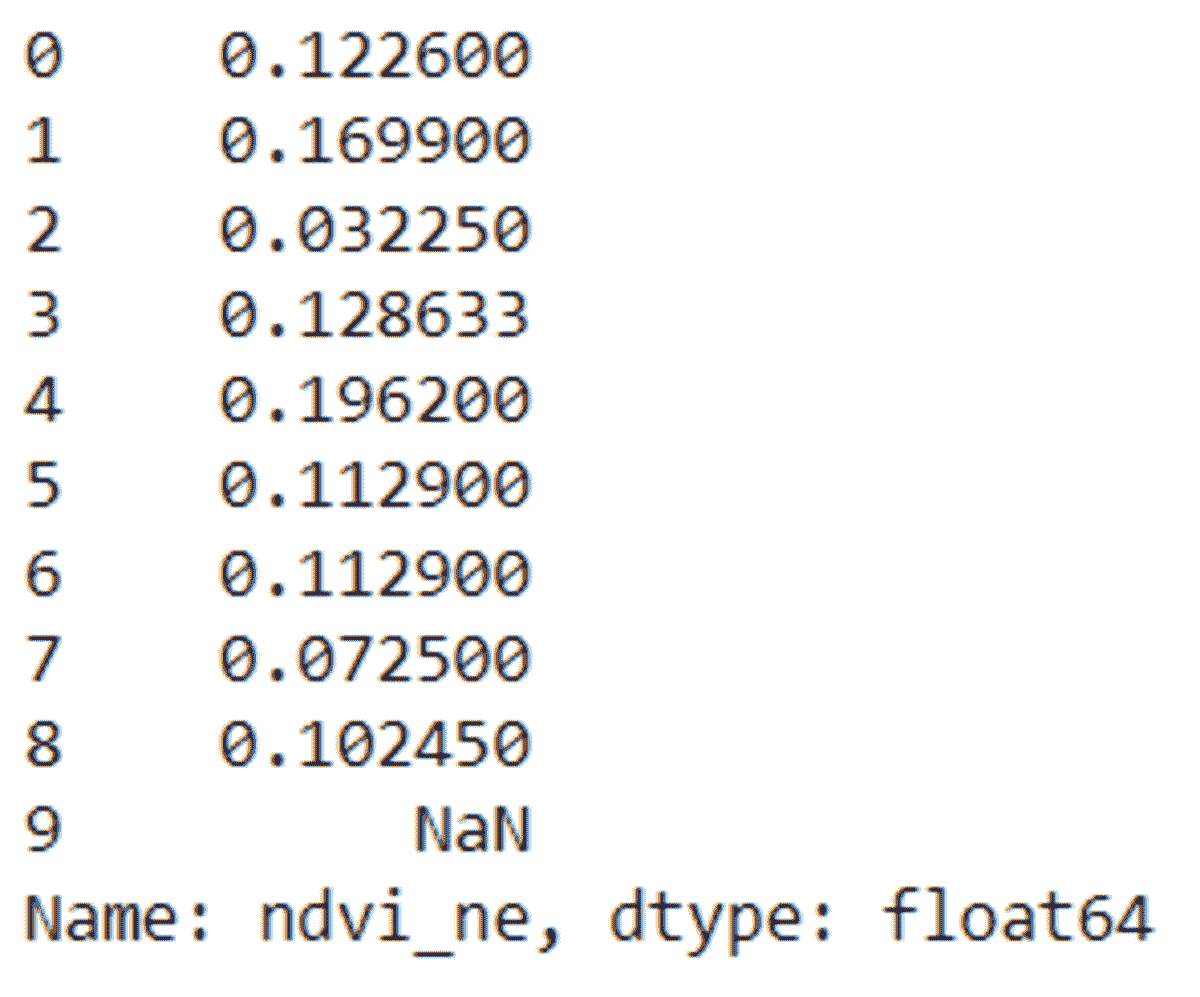
从上面的输出中,我们可以看到最后的数据仍然缺失。由于在缺失数据行之后没有任何观测值,函数将其保持原样。
前向填充和后向填充方法在知道前后数据仍然相关时非常有效,例如在时间序列数据中。假设股票数据;前一天的数据可能在第二天仍然适用。
结论
缺失数据是数据预处理和探索中的典型情况。处理缺失数据的一种方法是用另一个值替代它。为此,我们可以使用名为fillna的 Pandas 函数。使用该函数很简单,但有几种方法可以最佳地填充数据,包括在多个列中替换缺失数据、限制填充范围以及使用其他行填充数据。
Cornellius Yudha Wijaya 是一名数据科学助理经理和数据撰稿人。在全职工作于印尼安联期间,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
更多相关内容
数据科学家的优化基础
原文:
www.kdnuggets.com/2018/08/optimization-101-data-scientists.html
评论
由 Rajiv Shah,DataRobot的数据科学家
作为数据科学家,你花费大量时间来帮助做出更好的决策。你建立预测模型以提供改进的洞察力。你可能会预测图像是猫还是狗、下个月的商店销售量,或者某个部件的失败可能性。在这篇文章中,我不会帮助你做出更好的预测,而是如何做出最佳决策。
这篇文章致力于为你提供有关优化的一些背景知识。它从一个简单的玩具示例开始,展示了优化计算背后的数学原理。之后,这篇文章处理了一个更复杂的优化问题,尝试为幻想足球选择最佳团队。下面的 FanDuel 图片是一个非常常见的游戏,广泛被玩耍(问问你的亲戚吧)。文章中的优化策略被证明能够持续获胜!在此过程中,我将展示一些代码片段,并提供 R、Python 和 Julia 的工作代码链接。如果你赢得了钱,随时可以分享 😃
 一个简单的示例,我在 网上 找到的,从一个木匠制作两种尺寸的书架开始,大型和小型。制作一个大型书架需要 6 小时,制作一个小型书架需要 2 小时。大型书架的利润是 50 美元,小型书架的利润是 20 美元。木匠每周只能花 24 小时制作书架,并且每周必须制作至少 2 个每种尺寸的书架。作为数据科学家,你的工作是帮助木匠最大化她的收入。
一个简单的示例,我在 网上 找到的,从一个木匠制作两种尺寸的书架开始,大型和小型。制作一个大型书架需要 6 小时,制作一个小型书架需要 2 小时。大型书架的利润是 50 美元,小型书架的利润是 20 美元。木匠每周只能花 24 小时制作书架,并且每周必须制作至少 2 个每种尺寸的书架。作为数据科学家,你的工作是帮助木匠最大化她的收入。
你最初可能会认为,由于大型书架利润最高,为什么不专注于它们呢?在这种情况下,你的利润将是 (2$20) + (3$50),即 190 美元。这是一个相当不错的基准,但不是最佳答案。是时候拿出代数,创建定义问题的方程式了。首先,我们从约束条件开始:
x>=2 ## large bookcases
y>=2 ## small bookcases
6x + 2y <= 24 (labor constraint)
我们试图最大化的目标函数是:
P = 50x + 20y
如果我们手动做代数运算,我们可以将约束条件转换为y <= 12 - 3x。然后,我们绘制所有的约束条件,并找出制作小型和大型书架的可行区域:
 下一步是确定最佳点。使用线性规划的角点原则,目标函数的最大值和最小值都出现在可行区域的一个顶点上。在这里,最大值(2,6)是当我们制作 2 个大书柜和 6 个小书柜时,这会产生$220 的收入。
下一步是确定最佳点。使用线性规划的角点原则,目标函数的最大值和最小值都出现在可行区域的一个顶点上。在这里,最大值(2,6)是当我们制作 2 个大书柜和 6 个小书柜时,这会产生$220 的收入。
这是一个非常简单的玩具问题,通常会有更多的约束条件,并且目标函数可能会变得复杂。在优化中有许多经典问题,例如路由算法以找到最佳路径、调度算法以优化人员配置,或者寻找将一组人分配到任务集中的最佳方法。作为数据科学家,你需要拆解你试图最大化的内容,并以方程式的形式识别约束条件。一旦你能做到这一点,我们可以交给计算机来解决。那么接下来我们将通过一个更复杂的例子来进行说明。
幻想足球
在过去几年中,幻想运动的受欢迎程度不断上升。其中一种游戏是选择一组足球运动员,以组成最好的球队。每个足球运动员都有一个价格,并且有一个薪资上限。挑战在于在薪资上限内优化你的球队,以获得最高的总积分。这种类型的优化问题被称为背包问题或指派问题。
简单线性优化
让我们从加载数据集并查看原始数据开始。你需要知道薪资以及预期积分。大多数足球迷花很多时间来预测一个球员将会得多少分。如果你想建立一个预测球员预期表现的模型,可以查看本的博客文章。
 目标是为一个薪资上限(假设为 50,000 美元)构建最佳可能的队伍。一个队伍由一个四分卫、跑卫、外接手、紧端锋和一个防守组成。我们可以使用 R 中的lpSolve包来设置问题。以下是设置约束的代码片段。
目标是为一个薪资上限(假设为 50,000 美元)构建最佳可能的队伍。一个队伍由一个四分卫、跑卫、外接手、紧端锋和一个防守组成。我们可以使用 R 中的lpSolve包来设置问题。以下是设置约束的代码片段。 如果你仔细分析,你会发现我们为 QB 设置了 1 名球员的最小和最大值。然而,对于 RB,我们允许最多 3 名和最少 2 名。这在梦幻足球中并不罕见,因为有一个叫做灵活球员的角色,任何人都可以选择,而他们可以是 RB、WR 或 TE。现在让我们看看目标的代码:
如果你仔细分析,你会发现我们为 QB 设置了 1 名球员的最小和最大值。然而,对于 RB,我们允许最多 3 名和最少 2 名。这在梦幻足球中并不罕见,因为有一个叫做灵活球员的角色,任何人都可以选择,而他们可以是 RB、WR 或 TE。现在让我们看看目标的代码: 代码显示我们已经设置了一个最大化得分的目标,并包括了我们的约束条件。一旦代码运行,它将输出一个最佳队伍!我分叉了一个现有的仓库,并且 R 代码和数据集可以在这里找到。 还可以找到一个更复杂的python优化仓库。
代码显示我们已经设置了一个最大化得分的目标,并包括了我们的约束条件。一旦代码运行,它将输出一个最佳队伍!我分叉了一个现有的仓库,并且 R 代码和数据集可以在这里找到。 还可以找到一个更复杂的python优化仓库。 高级步骤
高级步骤
到目前为止,我们已经建立了一个非常简单的优化方法来解决这个问题。还有几种其他策略可以进一步改进优化器。首先,可以通过使用一种叫做堆叠的策略来增加我们团队的方差,这样可以确保你的四分卫(QB)和外接手(WR)在同一支队伍中。一个简单的优化是一个选择 QB 和 WR 来自同一支队伍的约束。另一种策略是使用重叠约束来选择多个阵容。重叠约束确保了球员的多样性,而不是每个优化后的队伍中都是相同的球员。这个策略在提交多个阵容时特别有效。你可以在这里阅读更多关于这些策略的信息,并在 Julia 中运行代码这里。以下是堆叠约束的代码片段(这是用于冰球优化的):

去年,在 Sloan 体育会议上,Haugh 和 Sighal 提出了一个包含附加优化约束的论文。他们包括了对对手队伍可能是什么样的预测。毕竟,有些球员的受欢迎程度要高得多。利用这些知识,你可以预测可能会对抗你的队伍的队伍。这里的方法使用了 Dirichlet 回归来建模球员。结果是一个大大改进的优化器,能够持续获胜!
我希望这篇文章能够向你展示优化策略如何帮助你找到最佳的解决方案。
简介:Rajiv Shah 是 DataRobot 的数据科学家,他与客户合作进行预测并实施这些预测。之前,Rajiv 曾是 Caterpillar 和 State Farm 数据科学团队的一员。他热爱数据科学,喜欢指导数据科学家、参加活动演讲和撰写博客。他拥有伊利诺伊大学香槟分校的博士学位。
相关:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
更多相关话题
使用 Python 优化:如何以最小的风险赚取最多的利润?
原文:
www.kdnuggets.com/2019/06/optimization-python-money-risk.html
评论
介绍
现代数据科学和分析企业的主要目标之一是为商业和技术公司解决复杂的优化问题以最大化他们的利润。
在我的文章“使用 Python 的线性规划和离散优化”中,我们涉及了基本的离散优化概念,并介绍了一个用于解决此类问题的Python 库 PuLP。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 部门
尽管线性规划 (LP) 问题仅由线性目标函数和约束定义,但它可以应用于从医疗保健到经济学、商业到军事等各种不同领域的惊人广泛的问题。
在这篇文章中,我们展示了一个使用 Python 编程的线性规划的惊人应用——在最小化相关风险的同时最大化股市投资组合的预期利润。
听起来有趣吗?请继续阅读。
如何在股市中最大化利润并最小化风险?
1990 年诺贝尔经济学奖颁给了哈里·马科维茨,他因其著名的现代投资组合理论 (MPT)而受到认可。该理论的原始论文早在 1952 年就已发表。

来源:AZ Quotes
这里的关键字是*衡。
一个好的*衡投资组合必须提供保护(最小化风险)和机会(最大化利润)。
当涉及到最小化和最大化等概念时,将问题用数学优化理论来表述是很自然的。
基本思想相当简单,根植于人类固有的厌恶风险的天性中。
一般来说,股市统计数据显示,较高的风险与更高回报的概率相关,而较低的风险与较低回报的概率相关。
MPT 假设投资者是厌恶风险的,即在两个投资组合提供相同预期回报的情况下,投资者将更偏好于风险较小的那个。想一想,只有在高风险股票具有较高回报概率时,你才会选择它们。
但如何量化风险?这确实是一个模糊的概念,对不同的人可能有不同的含义。然而,在普遍接受的经济理论中,股票价格的变动性(波动性)(在固定时间范围内定义)等同于风险。
因此,核心优化问题是最小化风险,同时确保一定的利润回报。或者,在保持风险低于某个阈值的情况下最大化利润。

一个示例问题
在本文中,我们将展示投资组合优化问题的一个非常简化的版本,该版本可以转化为 LP 框架,并通过简单的 Python 脚本高效解决。
目标是展示这些优化求解器在解决复杂现实问题中的能力和可能性。
我们使用了三只股票的 24 个月股价(月均值)——微软、Visa、沃尔玛。这些数据较旧,但完美展示了这个过程。
图:三家公司在某个 24 个月期间的月度股价。
如何定义回报?我们可以通过从当前月份的*均股价中减去前一个月的*均股价,并除以前一个月的价格来简单地计算滚动的月度回报。
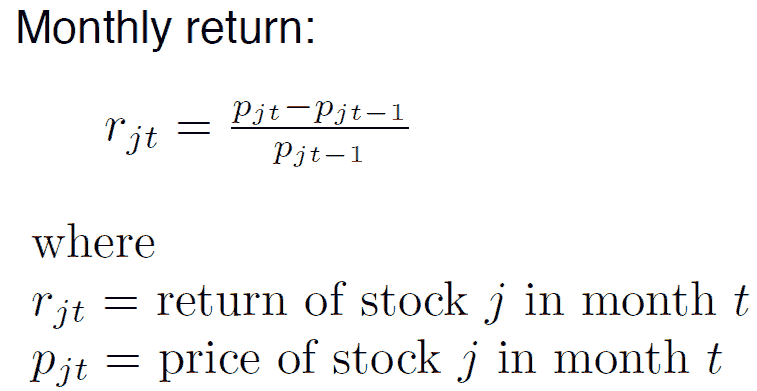
回报如图所示,
优化模型
股票的回报是一个不确定的量。我们可以将其建模为随机向量。
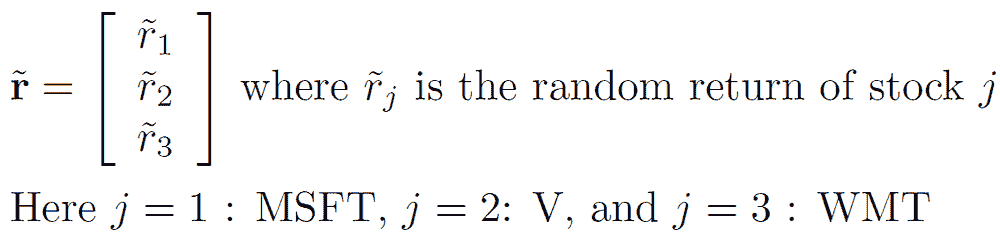
投资组合也可以建模为一个向量。
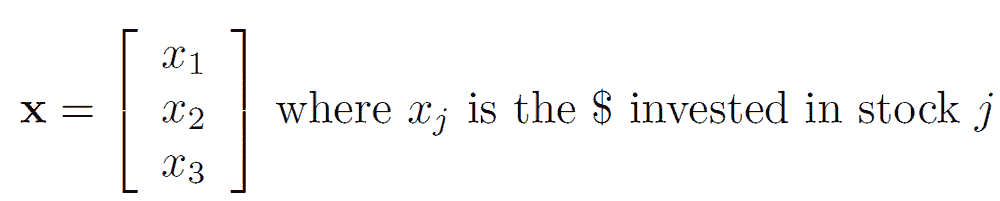
因此,某一投资组合的回报由这些向量的内积给出,它是一个随机变量。百万美元的问题是:
我们如何比较随机变量(对应不同投资组合)以选择“最佳”投资组合?
按照 Markowitz 模型,我们可以将问题表述为,
给定固定金额的钱(比如 $1000),我们应该如何在三只股票中进行投资,以便 (a) 一个月的期望回报至少达到给定的阈值,并且 (b) 最小化投资组合回报的风险(方差)。
我们不能投资负的数量。这是非负性约束,
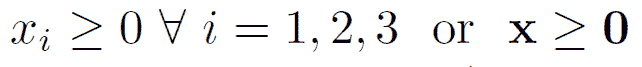
假设没有交易成本,总投资受限于现有资金,
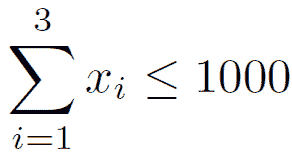
投资回报,
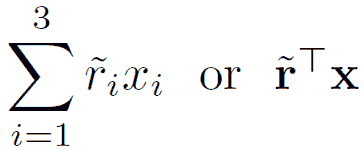
但这是一个随机变量。所以,我们必须使用期望数量,
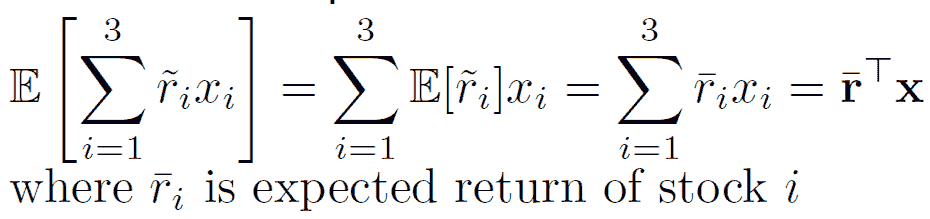
假设我们想要一个最小期望回报。因此,
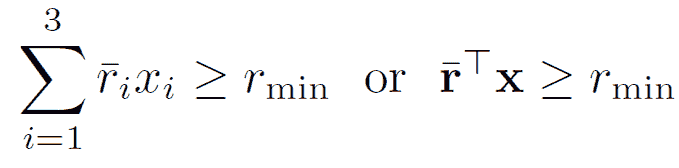
现在,为了建模风险,我们必须计算方差,
总结起来,最终的优化模型是,
接下来,我们展示使用流行的 Python 库来制定和解决这个问题是多么简单。
使用 Python 来解决优化问题:CVXPY
我们将使用的库是叫做CVXPY的。它是一个嵌入 Python 的凸优化问题建模语言。它允许你以自然的方式表达你的问题,遵循数学模型,而不是求解器要求的限制性标准形式。
完整代码见此 Jupyter notebook。这里,我只展示核心代码片段。
为了设置必要的数据,关键是从每月价格的数据表中计算回报矩阵。代码如下,
import numpy as np
import pandas as pd
from cvxpy import *
mp = pd.read_csv("monthly_prices.csv",index_col=0)
mr = pd.DataFrame()
# compute monthly returns
for s in mp.columns:
date = mp.index[0]
pr0 = mp[s][date]
for t in range(1,len(mp.index)):
date = mp.index[t]
pr1 = mp[s][date]
ret = (pr1-pr0)/pr0
mr.set_value(date,s,ret)
pr0 = pr1
现在,如果你将原始数据表和回报表并排查看,它看起来如下,
接下来,我们简单地从这个回报矩阵中计算均值(期望)回报和协方差矩阵,
# Mean return
r = np.asarray(np.mean(return_data, axis=1))
# Covariance matrix
C = np.asmatrix(np.cov(return_data))
之后,CVXPY 允许按照我们上面构建的数学模型简单地设置问题,
# Get symbols
symbols = mr.columns
# Number of variables
n = len(symbols)
# The variables vector
x = Variable(n)
# The minimum return
req_return = 0.02
# The return
ret = r.T*x
# The risk in xT.Q.x format
risk = quad_form(x, C)
# The core problem definition with the Problem class from CVXPY
prob = Problem(Minimize(risk), [sum(x)==1, ret >= req_return, x >= 0])
注意使用 CVXPY 框架中非常有用的类,如quad_form() 和 Problem()。
完成了!
我们可以编写一个简单的代码来解决问题并展示确保最小回报为 2% 的最佳投资数量,同时将风险保持在最低。
try:
prob.solve()
print ("Optimal portfolio")
print ("----------------------")
for s in range(len(symbols)):
print (" Investment in {} : {}% of the portfolio".format(symbols[s],round(100*x.value[s],2)))
print ("----------------------")
print ("Exp ret = {}%".format(round(100*ret.value,2)))
print ("Expected risk = {}%".format(round(100*risk.value**0.5,2)))
except:
print ("Error")
最终结果为,

扩展问题
不用多说,我们模型的设置和简化假设可能会让这个问题看起来比实际更简单。但一旦你理解了解决这种优化问题的基本逻辑和机制,你就可以将其扩展到多种场景中,
-
数以百计的股票,更长的时间跨度数据
-
多重风险/收益比率和阈值
-
最小化风险或最大化回报(或两者兼得)
-
一组公司的共同投资
-
二选一的场景——投资于可口可乐或百事可乐,但不能同时投资于两者
你需要构建更复杂的矩阵和更长的约束列表,使用指示变量将其转化为一个 混合整数问题 - 但所有这些问题都被像 CVXPY 这样的包本质上支持。
查看 CVXPY 包的示例页面 以了解使用该框架可以解决的优化问题的广度。
摘要
在这篇文章中,我们讨论了如何利用经典经济理论中的关键概念来制定一个简单的股票市场投资优化问题。
为了说明,我们以三家公司每月*均股价的样本数据集为例,展示了如何使用 NumPy、Pandas 等基础 Python 数据科学库以及一个叫做 CVXPY 的优化框架快速建立线性规划模型。
对这些灵活且强大的包有工作知识,对未来的数据科学家来说具有极大的价值,因为在科学、技术和商业问题的各个方面都需要解决优化问题。
鼓励读者尝试更复杂的投资问题版本,以便享受乐趣和学习。
原文。转载许可。
简介: Tirthajyoti Sarkar 是 ON Semiconductor 的高级首席工程师,负责基于深度学习/机器学习的设计自动化项目。
相关内容:
更多相关内容


 浙公网安备 33010602011771号
浙公网安备 33010602011771号