KDNuggets-博客中文翻译-二十八-
KDNuggets 博客中文翻译(二十八)
原文:KDNuggets
使用时间序列分析预测电力消耗
原文:
www.kdnuggets.com/2020/01/predict-electricity-consumption-time-series-analysis.html
评论
图片来源:gfycat.com/frailofficialdegus
介绍
“时间序列模型用于基于定期观察到的事件(以及收集的数据)预测未来事件。”
我们将处理一个小的预测问题,并尝试解决它,过程中学习时间序列预测。
什么是时间序列分析
时间序列预测是一种通过时间序列预测事件的技术。该技术在许多研究领域中使用,从地质学到行为学再到经济学。这些技术通过分析过去的趋势来预测未来事件,假设未来趋势将与历史趋势类似。
时间序列预测在各种应用中执行,包括:
-
天气预测
-
地震预测
-
天文学
-
统计学
-
数学金融
-
计量经济学
-
模式识别
-
信号处理
-
控制工程
时间序列预测有时只是专家研究某个领域并提供预测的分析。然而,在许多现代应用中,时间序列预测利用计算机技术,包括:
时间序列分析的两个主要目标是:(a)识别由观察序列表示的现象的性质,以及(b)预测(预测时间序列变量的未来值)。这两个目标都要求识别并或多或少地正式描述观察到的时间序列数据的模式。一旦模式建立,我们可以将其与其他数据解释和整合(即,在我们调查现象的理论中使用,例如,季节性商品价格)。无论我们对现象的理解深度和解释(理论)的有效性如何,我们都可以将识别出的模式外推以预测未来事件。
时间序列预测的阶段
解决时间序列问题与常规建模任务略有不同。解决时间序列问题的简单/基本过程可以通过以下步骤来演示。我们将了解每个阶段需要执行的任务。我们还将查看我们解决问题的每个阶段的 Python 实现。
步骤是—
1. 可视化时间序列
在这一步中,我们尝试可视化序列。我们尝试识别与序列相关的所有潜在模式,如趋势和季节性。现在不必担心这些术语,因为我们将在实现过程中讨论它们。可以说,这更像是一种对时间序列数据的探索性分析。
2. 时间序列平稳化
平稳时间序列是指其统计属性(如均值、方差、自相关等)随时间保持不变的序列。大多数统计预测方法基于这样的假设:时间序列可以通过数学变换大致平稳化(即“平稳化”)。平稳化的序列相对容易预测:你只需预测其统计属性在未来与过去相同!另一个尝试平稳化时间序列的原因是能够获得有意义的样本统计量,如均值、方差和与其他变量的相关性。这些统计量仅在序列平稳时才对未来行为有描述意义。例如,如果序列随着时间的推移持续增加,样本均值和方差将随着样本量的增加而增长,并且它们总是会低估未来时期的均值和方差。如果序列的均值和方差不明确,那么它与其他变量的相关性也不明确。
3. 为我们的模型寻找最佳参数
我们需要为预测模型找到最佳参数,当我们拥有一个平稳序列时。这些参数来自 ACF 和 PACF 图。因此,这个阶段更多的是关于绘制上述两个图形,并基于它们提取最佳模型参数。不要担心,我们将在下面的实现部分中介绍如何确定这些参数!
4. 拟合模型
一旦我们拥有了最佳模型参数,我们可以拟合一个 ARIMA 模型来学习序列的模式。始终记住,时间序列算法仅适用于平稳数据,因此使序列平稳是一个重要的方面。
5. 预测
在拟合模型后,我们将在此阶段进行未来预测。由于我们现在对解决时间序列问题的基本流程比较熟悉,让我们进入实现部分。
问题陈述
数据集可以从这里下载。数据集仅包含 2 列,一列是日期,另一列与消费百分比有关。
它展示了 1985 年至 2018 年的电力消耗情况。目标是预测接下来 6 年的电力消耗,即直到 2024 年。
加载数据集
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
# Above is a special style template for matplotlib, highly useful for visualizing time series data
from pylab import rcParams
rcParams['figure.figsize'] = 10, 7df = pd.read_csv('/Users/.../.../.../Electric_consumption.csv')
现在,定义列名,删除空值,将日期转换为 DateTime 格式,并将日期设置为索引列,因为没有索引就无法绘制图表。
df.columns=['Date', 'Consumption']
df=df.dropna()
df['Date'] = pd.to_datetime(df['Date'])
df.set_index('Date', inplace=True) #set date as index
df.head()
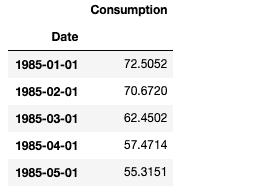
数据集
现在,让我们开始按照预定义的步骤进行:
1. 可视化时间序列。
plt.xlabel("Date")
plt.ylabel("Consumption")
plt.title("production graph")
plt.plot(df)
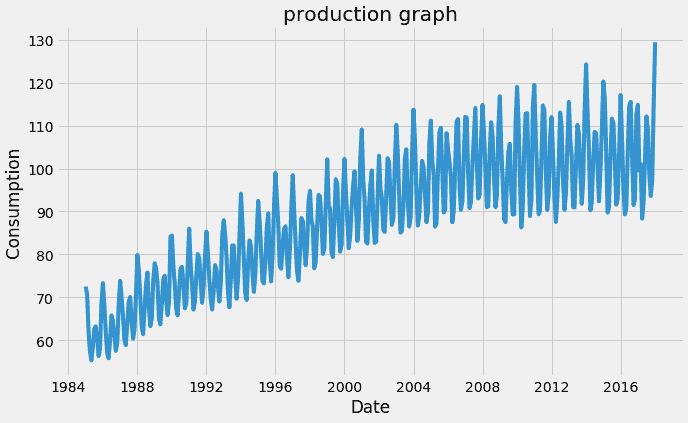
原始时间序列数据点
记住,对于时间序列预测,序列需要是平稳的。序列应具有恒定的均值、方差和协方差。
这里需要注意几个点,均值在这种情况下不是恒定的,因为我们可以清楚地看到上升趋势。
因此,我们已确定我们的序列不是平稳的。我们需要一个平稳的序列来进行时间序列预测。在下一阶段,我们将尝试将其转换为平稳序列。
让我们绘制散点图:
df.plot(style='k.')
plt.show()
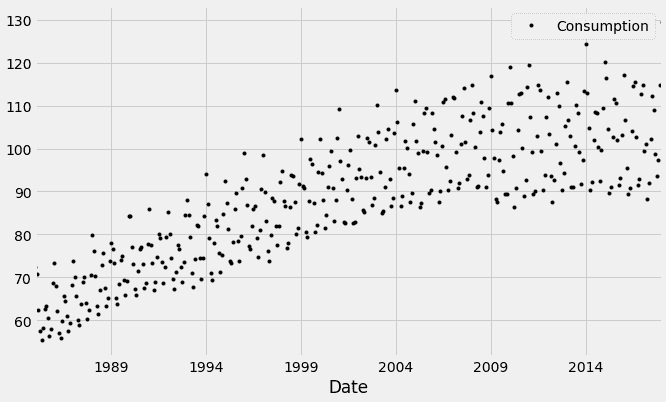
时间序列数据点的散点图
我们还可以通过分布来可视化我们序列中的数据。
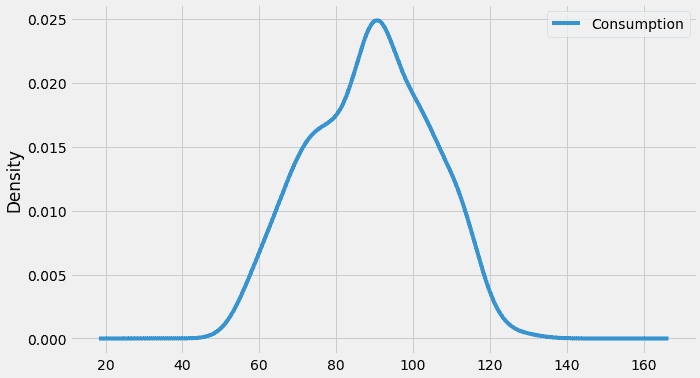
我们可以观察到消费值近似正态分布(钟形曲线)。
此外,给定的时间序列被认为包含三个系统性组件,包括水平、趋势、季节性,以及一个非系统性组件称为噪声。
这些组件定义如下:
-
水平:序列中的平均值。
-
趋势:序列中增加或减少的值。
-
季节性:序列中重复的短期周期。
-
噪声:序列中的随机变化。
为了进行时间序列分析,我们可能需要从序列中分离出季节性和趋势。通过这一过程,结果序列将变得平稳。
所以,让我们从时间序列中分离趋势和季节性。
from statsmodels.tsa.seasonal import seasonal_decompose
result = seasonal_decompose(df, model='multiplicative')
result.plot()
plt.show()
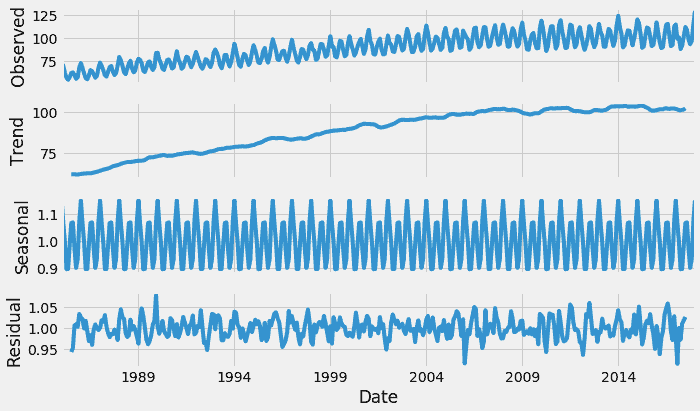
这可以让我们更深入了解数据和现实世界的行为。显然,存在上升趋势和每年电力消费达到最高的重复事件。
2. 使时间序列平稳。
首先,我们需要检查序列是否平稳。
ADF(增强型 Dickey-Fuller)检验
Dickey-Fuller 检验是最受欢迎的统计检验之一。它可以用来确定序列中是否存在单位根,从而帮助我们理解序列是否平稳。该检验的原假设和备择假设如下:
原假设: 序列具有单位根(a=1 的值)
备择假设: 序列没有单位根。
如果我们未能拒绝原假设,则可以说该序列是非平稳的。这意味着该序列可以是线性平稳或差分平稳的(我们将在下一部分了解更多关于差分平稳的内容)。
如果均值和标准差都是平坦的线(均值恒定且方差恒定),则序列变为平稳。
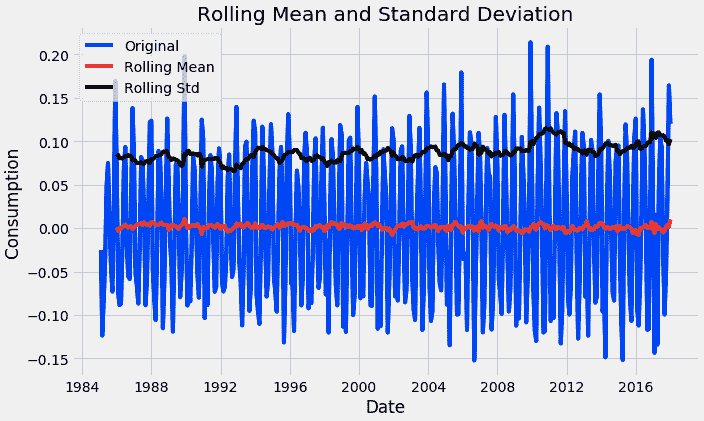
以下函数可以绘制一个序列及其滚动均值和标准差。
from statsmodels.tsa.stattools import adfuller
def test_stationarity(timeseries):
#Determing rolling statistics
rolmean = timeseries.rolling(12).mean()
rolstd = timeseries.rolling(12).std()
#Plot rolling statistics:
plt.plot(timeseries, color='blue',label='Original')
plt.plot(rolmean, color='red', label='Rolling Mean')
plt.plot(rolstd, color='black', label = 'Rolling Std')
plt.legend(loc='best')
plt.title('Rolling Mean and Standard Deviation')
plt.show(block=False)
#perform dickey fuller test
print("Results of dickey fuller test")
adft = adfuller(timeseries['Consumption'],autolag='AIC')
# output for dft will give us without defining what the values are.
#hence we manually write what values does it explains using a for loop
output = pd.Series(adft[0:4],index=['Test Statistics','p-value','No. of lags used','Number of observations used'])
for key,values in adft[4].items():
output['critical value (%s)'%key] = values
print(output)
test_stationarity(df)
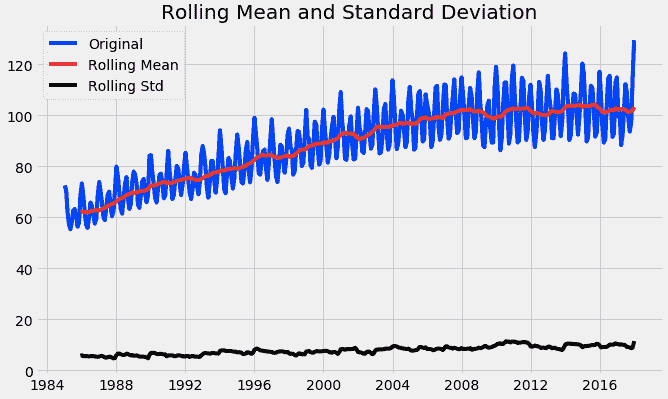
通过上述图表,我们可以看到均值和标准差的增加,因此我们的序列不是平稳的。
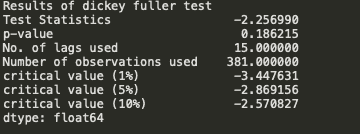
迪基-富勒检验的结果
我们看到 p 值大于 0.05,因此我们不能拒绝原假设。此外,测试统计量也大于临界值,因此数据是非平稳的。
为了获得平稳的序列,我们需要从序列中去除趋势和季节性。
我们首先对序列取对数,以减少值的大小并减少序列中的上升趋势。然后在得到序列的对数后,我们计算序列的滚动平均数。滚动平均数是通过输入过去 12 个月的数据,在序列的每个后续点上提供一个均值消耗值来计算的。
df_log = np.log(df)
moving_avg = df_log.rolling(12).mean()
std_dev = df_log.rolling(12).std()
plt.plot(df_log)
plt.plot(moving_avg, color="red")
plt.plot(std_dev, color ="black")
plt.show()
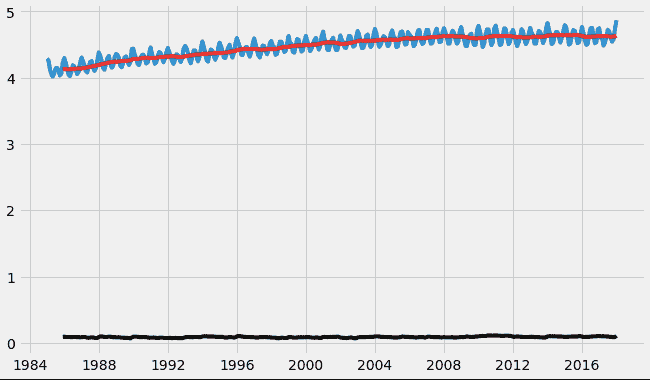
计算均值后,我们在序列中的每个点上取序列值与均值之间的差异。
通过这种方式,我们去除序列中的趋势,并获得一个更平稳的序列。
df_log_moving_avg_diff = df_log-moving_avg
df_log_moving_avg_diff.dropna(inplace=True)
再次执行迪基-富勒检验(ADFT)。每次都需要执行此函数,以检查数据是否平稳。
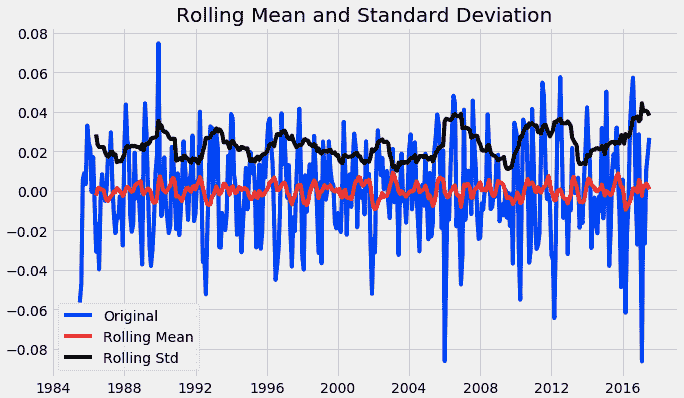
test_stationarity(df_log_moving_avg_diff)
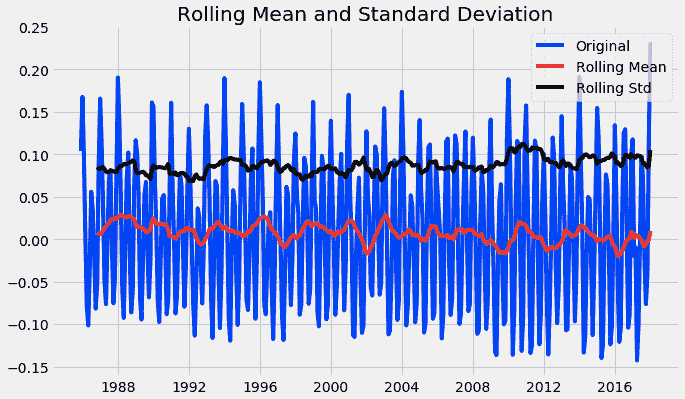
从上图中,我们观察到数据达到了平稳状态。
当我们得出结论时,一个模块已经完成。我们需要检查加权平均数,以理解时间序列数据的趋势。取之前的对数数据并执行以下操作。
weighted_average = df_log.ewm(halflife=12, min_periods=0,adjust=True).mean()
指数加权移动平均数(EMA)是最近 n 个价格的加权平均数,其中权重随着每个之前的价格/周期呈指数递减。换句话说,该公式赋予近期价格比过去价格更多的权重。
之前我们用移动平均数减去了 df_log,现在用相同的 df_log 减去加权平均数,并再次执行迪基-富勒检验(ADFT)。
logScale_weightedMean = df_log-weighted_average
from pylab import rcParams
rcParams['figure.figsize'] = 10,6
test_stationarity(logScale_weightedMean)
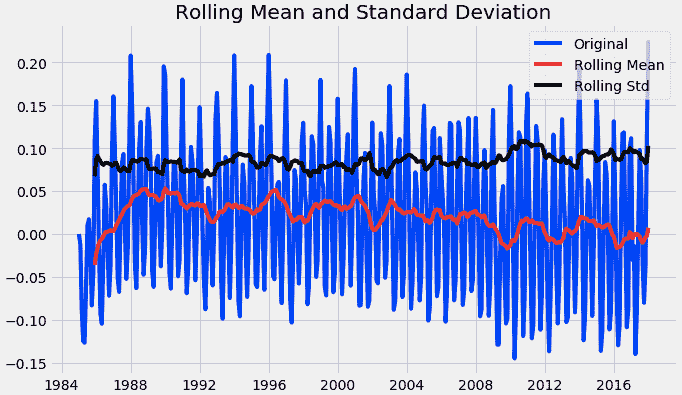
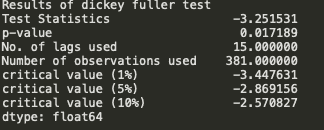
迪基-富勒检验的结果
从上图中,我们观察到数据达到了平稳状态。我们还看到测试统计量和临界值相对接近。
数据中可能会出现高季节性的情况。
在这些情况下,仅去除趋势并没有太大帮助。我们还需要处理序列中的季节性。处理这种情况的一种方法是差分。
差分是一种转换时间序列数据集的方法。
它可以用来去除序列对时间的依赖,即所谓的时间依赖性。这包括趋势和季节性等结构。差分可以通过去除时间序列水平的变化来帮助稳定时间序列的均值,从而消除(或减少)趋势和季节性。
差分是通过从当前观察值中减去前一个观察值来进行的。
再次执行 Dickey-Fuller 测试(ADFT)。
df_log_diff = df_log - df_log.shift()
plt.title("Shifted timeseries")
plt.xlabel("Date")
plt.ylabel("Consumption")
plt.plot(df_log_diff)#Let us test the stationarity of our resultant series
df_log_diff.dropna(inplace=True)test_stationarity(df_log_diff)
下一步是执行分解,这提供了一种结构化的思考时间序列预测问题的方法,既包括建模复杂性的一般性方面,也包括如何在给定模型中最好地捕捉每个组件的具体方面。最后,再次执行 Dickey-Fuller 测试(ADFT)。
from chart_studio.plotly import plot_mpl
from statsmodels.tsa.seasonal import seasonal_decompose
result = seasonal_decompose(df_log, model='additive', freq = 12)
result.plot()
plt.show()trend = result.trend
trend.dropna(inplace=True)seasonality = result.seasonal
seasonality.dropna(inplace=True)residual = result.resid
residual.dropna(inplace=True)test_stationarity(residual)
在分解之后,如果我们查看残差,那么均值和标准差都是平坦的。我们得到了我们的平稳序列,现在可以继续寻找模型的最佳参数。
3. 寻找我们模型的最佳参数
在我们构建预测模型之前,需要确定模型的最佳参数。为这些最佳参数,我们需要 ACF 和 PACF 图。
非季节性 ARIMA 模型被分类为“ARIMA(p,d,q)”模型,其中:
p → 自回归项的数量,
d → 实现平稳性所需的非季节性差分数量,以及
q → 预测方程中滞后的预测误差数量。
p 和 q 的值通过 ACF 和 PACF 图得出。所以让我们理解 ACF 和 PACF 吧!
自相关函数(ACF)
统计相关性总结了两个变量之间关系的强度。皮尔逊相关系数是一个介于-1 和 1 之间的数字,分别描述负相关或正相关。零值表示没有相关性。
我们可以计算时间序列观察值与前一个时间步的相关性,称为滞后。因为时间序列观察值的相关性是与前面时间的同一序列的值计算的,这被称为序列相关性,或自相关性。
时间序列的自相关图按滞后显示,称为自相关函数,或缩写为 ACF。该图有时也称为自相关图或自相关图。
偏自相关函数(PACF)
偏自相关是时间序列中某个观察值与前期观察值的关系的总结,剔除了中间观察值的关系。
在滞后 k 的偏自相关是去除任何因较短滞后项而产生的相关性后的相关性。
观测值和先前时间步的观测值之间的自相关包括直接相关和间接相关。部分自相关函数旨在去除这些间接相关。
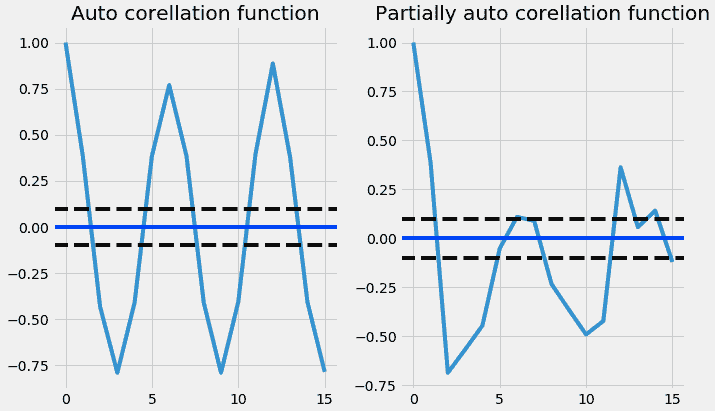
以下代码绘制了 ACF 和 PACF 图:
from statsmodels.tsa.stattools import acf,pacf
# we use d value here(data_log_shift)
acf = acf(df_log_diff, nlags=15)
pacf= pacf(df_log_diff, nlags=15,method='ols')#plot PACF
plt.subplot(121)
plt.plot(acf)
plt.axhline(y=0,linestyle='-',color='blue')
plt.axhline(y=-1.96/np.sqrt(len(df_log_diff)),linestyle='--',color='black')
plt.axhline(y=1.96/np.sqrt(len(df_log_diff)),linestyle='--',color='black')
plt.title('Auto corellation function')
plt.tight_layout()#plot ACF
plt.subplot(122)
plt.plot(pacf)
plt.axhline(y=0,linestyle='-',color='blue')
plt.axhline(y=-1.96/np.sqrt(len(df_log_diff)),linestyle='--',color='black')
plt.axhline(y=1.96/np.sqrt(len(df_log_diff)),linestyle='--',color='black')
plt.title('Partially auto corellation function')
plt.tight_layout()
4. 拟合模型
为了从上述图表中找到 p 和 q 值,我们需要检查图表第一次从原点切断或降至零的地方,从图表中 p 和 q 值接近 3,即图表从原点切断的地方(画一条线到 x 轴)。现在我们有了 p、d、q 值。接下来,我们可以代入 ARIMA 模型并查看输出结果。
from statsmodels.tsa.arima_model import ARIMA
model = ARIMA(df_log, order=(3,1,3))
result_AR = model.fit(disp = 0)
plt.plot(df_log_diff)
plt.plot(result_AR.fittedvalues, color='red')
plt.title("sum of squares of residuals")
print('RSS : %f' %sum((result_AR.fittedvalues-df_log_diff["Consumption"])**2))
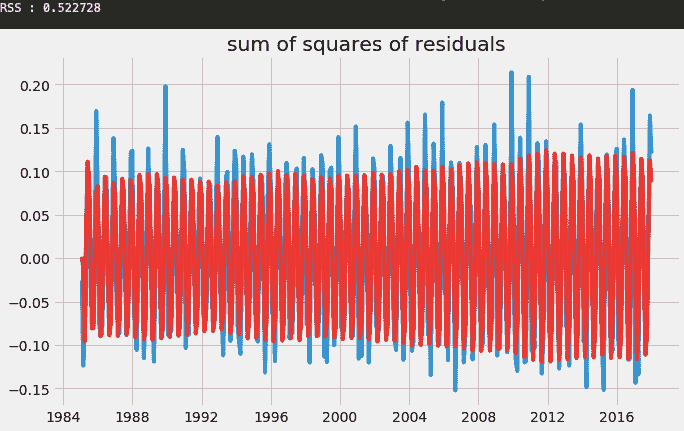
RSS 值越小,模型越有效。你可以通过 (2,1,0)、(3,1,1) 等组合来寻找最小的 RSS 值。
5. 预测
以下代码帮助我们预测未来 6 年的洗发水销售量。
result_AR.plot_predict(1,500)
x=result_AR.forecast(steps=200)
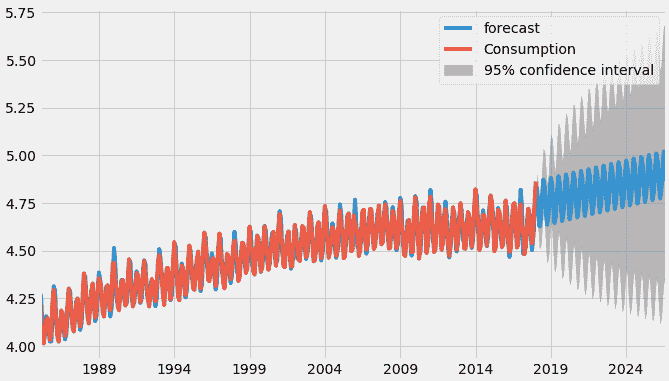
从上述图表中,我们计算了到 2024 年的未来预测,灰色区域是置信区间,这意味着预测不会越过该区域。
结论
最后,我们成功构建了一个 ARIMA 模型,并实际预测了未来的时间段。请注意,这只是一个基本实现,旨在帮助入门时间序列预测。还有很多概念如平滑等,模型如 ARIMAX、prophet 等可以用于构建时间序列模型。
好了,文章到此为止,希望大家阅读愉快,欢迎在评论区分享你的意见/想法/反馈。

图片来源: mrwgifs.com/grainy-classic-the-end-gif/
你可以在这个 GitHub 链接中找到完整代码:github.com/nageshsinghc4/Time-Series-Analysis
快乐学习 !!!
简介: 纳盖什·辛格·乔汉 是一位数据科学爱好者。对大数据、Python 和机器学习感兴趣。
原文,已获许可转载。
相关:
-
结合不同方法创建高级时间序列预测
-
AutoML 在时序关系数据中的应用:新的前沿
-
时间序列分析:使用 KNIME 和 Spark 的简单示例
我们的前三个课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业。
1. 谷歌网络安全证书 - 快速进入网络安全职业。
 2. Google 数据分析专业证书 - 提升你的数据分析水平
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你组织的 IT
更多相关主题
使用回归模型预测加密货币价格
原文:
www.kdnuggets.com/2022/05/predicting-cryptocurrency-prices-regression-models.html
来源: unsplash.com/s/photos/cryptocurrency
介绍
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织的 IT 工作
截至 2022 年 3 月,加密货币市场市值超过 2 万亿美元 [1],但仍然极其波动,曾在 2021 年 11 月达到 3 万亿美元。个别加密货币也表现出相同的波动性,仅在过去一个月内,以太坊和比特币分别下降了超过 18% 和 19%。新货币进入市场的数量也在增加,截至 2022 年 3 月,已有超过 18,000 种加密货币存在 [2]。
这种波动性使得长期加密货币预测更加困难。本文将介绍如何使用线性回归模型开始进行加密货币预测。我们将查看多个时间间隔的预测,同时使用各种模型特征,如开盘价、最高价、最低价和交易量。本文中讨论的加密货币包括更为成熟的比特币和以太坊,以及仍处于相对早期阶段的 Polkadot 和 Stellar。
方法
在本文中,我们将使用多元线性回归。回归模型用于通过拟合一条线来确定变量之间的关系。简单线性回归是用来预测一个依赖变量(例如加密货币的收盘价),使用一个自变量(如开盘价),而多元线性回归则考虑多个自变量。
我们将使用的数据来自 CoinCodex [3],提供了每日的开盘价、最高价、最低价和收盘价以及交易量和市值。我们实验了各种特征组合,以生成模型,并对每日和每周的间隔进行了预测。使用了 Python 的 sklearn 包来训练模型,并用 R2 值作为模型准确性的指标,其中 1 表示完美模型。
使用的数据和生成的模型已上传至Layer 项目,可以下载以供进一步使用和研究。所有结果和相应图表也可以在Layer 项目中找到。本文将讨论实现模型所用代码的各个部分。完整代码可在此collab notebook中访问。
为了初始化项目并访问数据和模型,您可以运行:
import layer
layer.login()
layer.init("predictingCryptoPrices")
数据被上传到 Layer 项目中,涵盖了 4 个加密货币数据集(比特币、以太坊、Polkadot 和 Stellar),通过定义用于读取数据的函数,并用数据集和资源装饰器进行了注释。
@dataset("bitcoin")
@resources(path="./data")
def getBitcoinData():
return pd.read_csv("data/bitcoin.csv")
layer.run([getBitcoinData])
您可以运行以下命令来访问数据集并将其保存到 pandas 数据框中。
layer.get_dataset("bitcoin").to_pandas()
layer.get_dataset("ethereum").to_pandas()
layer.get_dataset("polkadot").to_pandas()
layer.get_dataset("stellar").to_pandas()
预测
每日预测
第一组多元回归模型是为了预测每日间隔的价格而构建的。首先使用当天的开盘价、最低价和最高价来预测收盘价。使用了一年的每日价格数据,并进行了 75%-25%的训练-测试拆分。以下函数用于训练给定数据集的模型。
def runNoVolumePrediction(dataset):
# Defining the parameters
# test_size: proportion of data allocated to testing
# random_state: ensures the same test-train split each time for reproducibility
parameters = {
"test_size": 0.25,
"random_state": 15,
}
# Logging the parameters
# layer.log(parameters)
# Loading the dataset from Layer
df = layer.get_dataset(dataset).to_pandas()
df.dropna(inplace=True)
# Dropping columns we won't be using for the predictions of closing price
dfX = df.drop(["Close", "Date", "Volume", "Market Cap"], axis=1)
# Getting just the closing price column
dfy = df["Close"]
# Test train split (with same random state)
X_train, X_test, y_train, y_test = train_test_split(dfX, dfy, test_size=parameters["test_size"], random_state=parameters["random_state"])
# Fitting the multiple linear regression model with the training data
regressor = LinearRegression()
regressor.fit(X_train,y_train)
# Making predictions using the testing data
predict_y = regressor.predict(X_test)
# .score returns the coefficient of determination R² of the prediction
layer.log({"Prediction Score :":regressor.score(X_test,y_test)})
# Logging the coefficient corresponding to each variable
coeffs = regressor.coef_
layer.log({"Opening price coeff":coeffs[0]})
layer.log({"Low price coeff":coeffs[1]})
layer.log({"High price coeff":coeffs[2]})
# Plotting the predicted values against the actual values
plt.plot(y_test,predict_y, "*")
plt.ylabel('Predicted closing price')
plt.xlabel('Actual closing price')
plt.title("{} closing price prediction".format(dataset))
plt.show()
#Logging the plot
layer.log({"plot":plt})
return regressor
函数运行时使用了模型装饰器,以将模型保存到 Layer 项目中,如下所示。
@model(name='bitcoin_prediction')
def bitcoin_prediction():
return runNoVolumePrediction("bitcoin")
layer.run([bitcoin_prediction])
要访问此预测集中的所有模型,您可以运行以下代码。
layer.get_model("bitcoin_prediction")
layer.get_model("ethereum_prediction")
layer.get_model("polkadot_prediction")
layer.get_model("stellar_prediction")
表 1 总结了使用该模型的 4 种加密货币的 R2 统计数据。
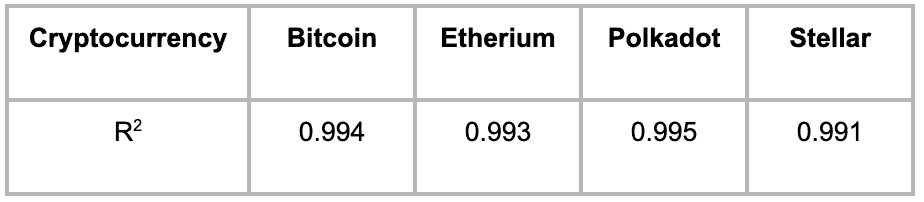
表 1:使用当天的开盘价、最低价和最高价预测加密货币收盘价的准确性
下面的图表显示了最佳和最差表现的货币 Polkadot 和 Stellar(图 1a 和 1b)的预测值与真实值的对比。
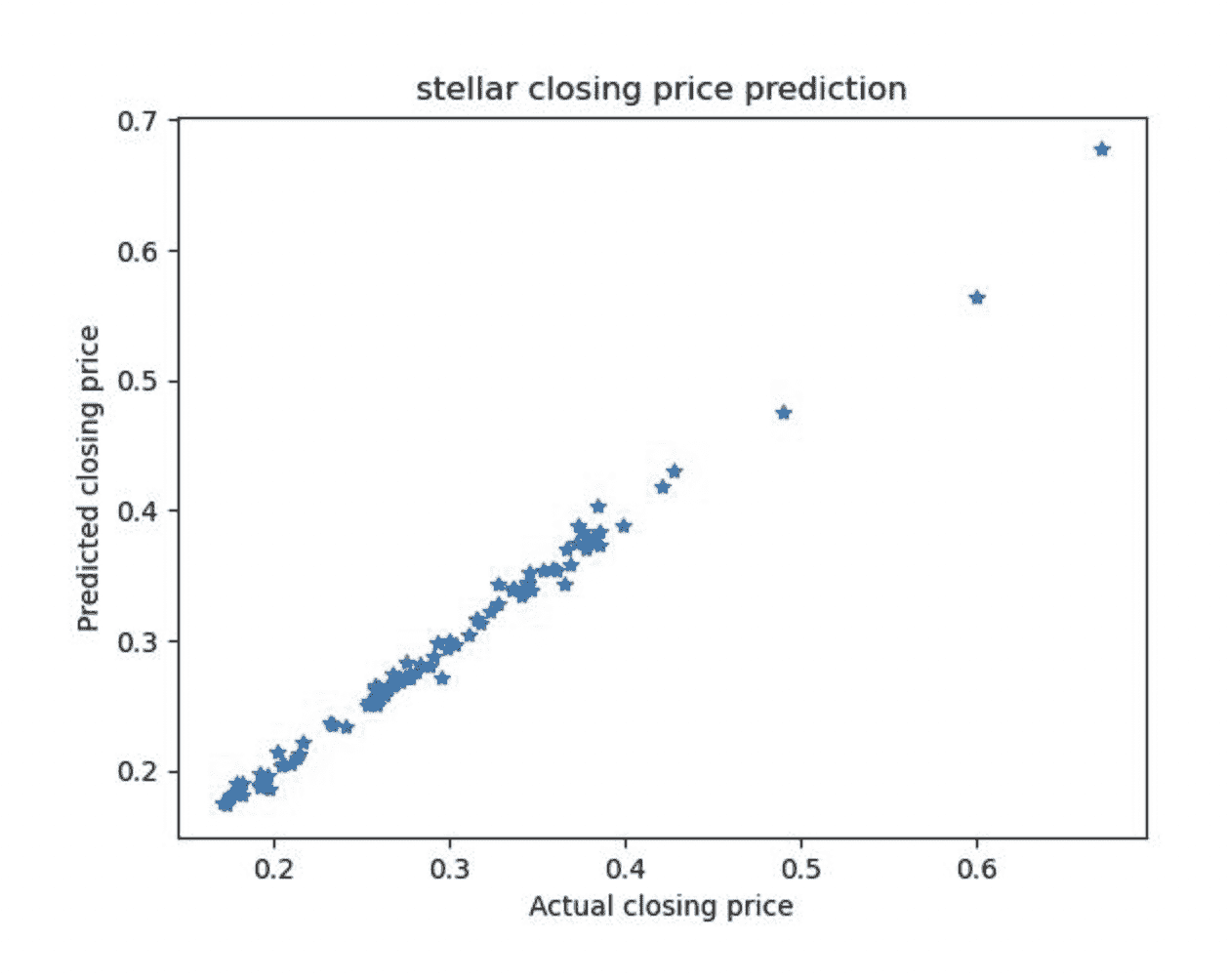
图 1a:Stellar 预测的收盘价与当天真实收盘价的对比,使用开盘价、最低价和最高价作为特征!Polkadot 预测的收盘价
图 1b:Polkadot 预测的收盘价与当天真实收盘价的对比,使用开盘价、最低价和最高价作为特征
从图表和 R2 值中,我们可以看到使用开盘价、最低价和最高价的线性回归模型对于所有 4 种货币都非常准确,无论它们的成熟程度如何。
接下来,我们研究是否添加交易量可以改进模型。交易量对应于当天的总交易笔数。有趣的是,在使用开盘价、最低价、最高价和交易量拟合回归模型后,结果基本相同。你可以在 Layer 项目中访问 bitcoin_prediction_with_volume、ethereum_prediction_with_volume、polkadot_prediction_with_volume 和 stellar_prediction_with_volume 模型。进一步的调查显示,4 种加密货币中交易量变量的系数都是 0。这表明,加密货币的交易量并不是预测当天价格的良好指标。
每周预测
在下一个模型中,我们查看了使用本周一的开盘价以及本周的最低价和最高价预测周末价格。对于这个模型,使用了过去 5 年的比特币、以太坊和 Stellar 的数据。对于 2020 年才发布的 Polkadot,则使用了所有历史数据。
下载数据后,计算了每周的最低价和最高价,并记录了本周的开盘价和收盘价。这些数据集也可以通过运行 Layer 来访问:
layer.get_dataset("bitcoin_5Years").to_pandas()
layer.get_dataset("ethereum_5Years").to_pandas()
layer.get_dataset("polkadot_5Years").to_pandas()
layer.get_dataset("stellar_5Years").to_pandas()
再次使用了 75%-25%的训练-测试拆分,并利用一周的开盘价、最高价和最低价拟合了多重线性回归模型。这些模型也可以在 Layer 项目中访问。R2 指标再次用于与下表 2 中显示的结果进行比较。
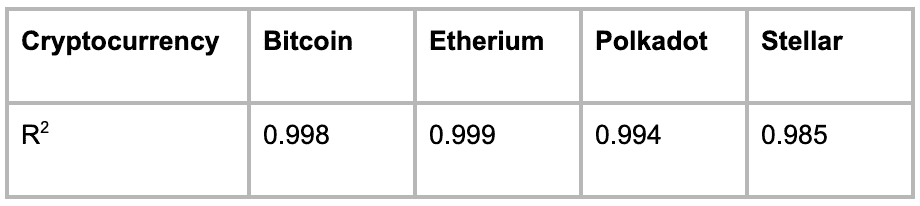
表 2:使用开盘价、最低价和最高价预测加密货币收盘价的准确性
在用一周的数据进行预测时,模型的准确性略低于用一天的数据进行预测,但准确性仍然非常高。即便是表现最差的加密货币 Stellar,其 R2 分数也达到了 0.985。
结论
总体而言,使用开盘价、最低价和最高价作为特征的线性回归模型在每日和每周间隔上表现都很好。这些模型的自然扩展是预测更远的未来,例如使用本周的数据预测下周的价格。
[3] https://coincodex.com/crypto/stellar/historical-data/
Eleonora Shantsila 是一位全栈软件工程师,目前在名为 Lounge 的活动初创公司工作,之前曾在金融服务领域担任全栈工程师。Eleonora 拥有数学(圣安德鲁斯大学本科)和计算科学(哈佛大学硕士)的背景,闲暇时喜欢从事数据科学项目。欢迎在LinkedIn 上连接。
更多相关话题
使用机器学习预测心脏病?不要!
原文:
www.kdnuggets.com/2020/11/predicting-heart-disease-machine-learning.html
评论
Venkat Raman,True Influence 的数据科学家
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
最近,我被邀请担任数据科学竞赛的评委。学生们被提供了“心脏病预测”数据集,可能是 Kaggle 上可用数据集的改进版本。我之前见过这个数据集,并且经常看到各种自称数据科学大师的人教导天真的人如何通过机器学习预测心脏病。
我相信“使用机器学习预测心脏病”是一个经典的例子,展示了如何不将机器学习应用于一个问题,特别是在需要大量领域经验的情况下。
让我拆解一下在这个数据集上应用机器学习的各种问题。
直接投入问题的综合症 – 这通常是许多人犯的第一个错误。直接投入到问题中,想着应用哪种机器学习算法。将 EDA 等作为这一过程的一部分,并不是在思考问题。相反,这表明你已经接受了问题需要数据科学解决方案的观点。相反,在开始任何分析之前需要提出的一个相关问题是,“这个问题通过应用机器学习真的可以预测吗?”。
对数据的盲目信任 – 这是第一个要点的扩展。直接投入问题意味着你对数据有盲目的信任。人们假设数据是正确的,而不去仔细审查数据。例如,数据集只提供了收缩压。如果你和任何医生或甚至急救员谈话,他们会告诉你,单靠收缩压不能给出完整的情况。舒张压的报告也很重要。很多人甚至不会问“特征是否足够预测结果,还是需要更多特征”这个问题。
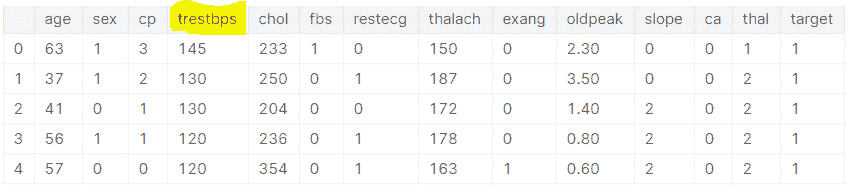
每位患者的数据不足:我们来看看上面的数据集。如果你注意到,每个特征下只有一个数据点。根本性的问题在于血压、胆固醇、心跳等特征不是静态的。它们是有范围的。一个人的血压每小时和每天都可能变化,心跳也是如此。因此,当涉及到预测问题时,无法确定 135 mm hg 的血压是否是导致心脏病的因素,还是 140 mm hg,而数据集可能报告的是 130 mm hg。理想情况下,每个特征应对每位患者进行多次测量。
现在让我们来探讨问题的核心。
在没有领域经验的情况下应用算法 - 数据科学应用在医疗保健中失败率高的原因之一是,应用算法的数据科学家缺乏足够的医学知识。
其次,在医疗保健中,因果关系被非常重视。进行许多严格的临床和统计测试以推断因果关系。
在案例研究中,任何机器学习算法只是试图将输入映射到输出,同时减少一些误差度量。此外,机器学习算法本身不是分类器,我们通过设置一些切割点或阈值将其作为分类器。再次强调,这些切割点不是为了推导因果关系,而只是为了获得“有利的指标”。
这个问题被低代码库的使用所加剧。这个案例研究恰恰展示了低代码库可能危险的原因。低代码库适合十几种或更多的算法。大多数人甚至不知道这些算法中的一些是如何工作的!他们只是根据像 F1、精准率、召回率和准确率这样的指标选择“最佳”算法。
专注于准确性指标的低代码库导致了‘古德哈特法则’——“当一个衡量标准成为目标时,它就不再是一个好的衡量标准。”

图片来源:https://sketchplanations.com/goodharts-law
如果你在进行预测,你就暗示了因果关系。在医疗保健中,单纯的预测是不够的,需要证明因果关系。机器学习分类算法无法回答‘因果关系’的问题。
认为他们解决了一个真正的医疗保健问题 – 最后但同样重要的是,许多人认为,通过将机器学习算法应用于医疗保健数据集并获得一些准确性指标,他们已经解决了一个真正的医疗保健问题。尤其是在涉及医疗保健领域时,没有什么比这更远离真相的了。
总结:
也许有成千上万的商业问题真正需要数据科学/机器学习解决方案。但与此同时,人们不应陷入“对一个拿着锤子的人来说,所有的东西都像钉子”的陷阱。把一切都看作钉子(数据科学问题),把机器学习算法看作(锤子),可能会非常适得其反。数据科学在商业问题中的 80%失败率很大程度上可以归因于此。
优秀的数据科学家就像优秀的医生。优秀的医生会在开重药或手术前首先建议保守的治疗。同样,优秀的数据科学家在盲目应用多个机器学习算法之前,应首先提出一些相关的问题。
医生:手术 :: 数据科学家 : 机器学习
欢迎您的评论和意见。
个人简介:Venkat Raman 是一位具有商业头脑的数据科学家。他通过数据科学帮助企业蓬勃发展。他在创新和将数据科学技术应用于商业问题方面有着良好的业绩记录。他是一个永恒的知识追求者,并相信对任何任务都应尽最大努力。
原文。已获得许可转载。
相关内容:
-
人工智能将如何变革医疗保健(它能解决美国医疗系统的问题吗?)
-
用于精准医学和更好医疗保健的人工智能
-
医疗保健中的人工智能:创新初创公司的回顾
相关主题
预测:2015 年分析和数据科学招聘市场
原文:
www.kdnuggets.com/2015/01/predictions-2015-analytics-data-science-hiring-market.html
当我写下2014 年的预测时,我写到由于大数据的存在,分析已变得不可避免。展望 2015 年,我比以往任何时候都更相信这一点。
这不仅仅是公众关注的分析问题——数据科学也被推到了聚光灯下,分析专业人员和数据科学家的招聘市场已经进入了过度驱动阶段。尽管薪资上涨公司仍然在努力招聘,而且有才华的专业人员几乎比你打个响指的速度还要快地进出市场。虽然保持求职技能的敏锐依然至关重要,但现在对于寻求工作的量化分析师来说,没有比现在更好的时机了。
那么这些兴奋的迹象对明年意味着什么呢?我有几个预测:
-
如果你不是数据迷,就忘了 C 级高管的位置——也许不是明年的情况,但这是商业发展的方向。有效管理任何大型组织的复杂性已经显著升级,未来的成功将取决于任何 C 级领导者对“大数据”的敏锐程度。
-
传统的财富 100 强公司加入数据科学热潮——随着数据科学趋势的不断加剧,我预测传统公司将建立他们的数据科学团队。尽管去年仍存在一些困惑和犹豫,今年将看到更多的投资和招聘计划。我收到的公司询问电话数量显著增加,我预计这种情况将持续到 2015 年。从谷歌、LinkedIn、亚马逊或 Uber 等科技公司,到 Gap、苏黎世保险、通用汽车、Clorox 和 AIG 等传统公司,各行各业的组织都在加入数据科学的热潮中。
-
加州失去光彩 – 几乎一半的数据科学家——这些大数据运动中的关键人物——都在西海岸为技术和游戏公司工作。然而,加州的城市占据了美国房价最高的前十个城市中的九个,而且租金也非常高。然而,我预测加州热潮将会减退的最大原因是,专业人士们将开始意识到,在金州之外有很多高薪工作,这些工作可能提供更多的机会来产生可衡量的影响、推动职业发展,或在公司中领导大数据计划,而不是成为大型科技公司中的“另一个量化分析师”。
-
招聘初创公司变得更加困难 – 初创公司泡沫几年的时间,热潮刚刚开始消退,但我预测明年初创公司吸引顶尖人才的能力将会减弱。专业人士将不再盲目跳槽到初创公司,希望获得一场彩票般的成功,因为他们看到许多同事失败了。
-
分析与数据科学之间的界限模糊 – 随着更多预测分析专业人士习惯于处理非结构化数据,我相信分析将会自然演变,更多的分析专业人士将掌握处理数据科学中常见的非结构化数据所需的技能。想知道成为数据科学家需要什么吗?这里是我列出的必备数据科学技能 ,这是公司都在寻找的。
-
训练营和 MOOCs 继续风靡 – 希望弥补人才缺口的公司正在寻找更快的方式来提高员工技能,而希望获得新技能的专业人士则在寻找快速的入门课程。这些项目在准备学生方面的成功如何还有待观察,但只要你有强大的定量基础,它们是更快、更便宜的过渡方式。查看这篇文章以了解更多关于这些不同学习方法的内容。
-
告别 Hadoop,迎接 Spark!SAS,那是什么? – 如果相信谷歌的话,那么 Hadoop 正逐渐退出大数据的讨论。除了 Hortonworks 最近的 IPO 外,我听到的消息全是关于 Spark 的。编程语言如 R 和 Python 无处不在,我相信未来在于开源工具;正如总是保持工具的新鲜度对成功至关重要一样,这一领域快速发展的特点也要求如此。
-
分析师薪资区间上涨 – 根据我们的薪资研究报告,预测分析薪资(非管理层)的平均为$88.4k,平均奖金 11%,管理层的薪资为$160k,奖金 19.1%。此外,这些薪资正在上涨。数据科学家的薪资更高,非管理层的平均薪资为$120k,平均奖金 14.5%,管理层的薪资为$183k,奖金 19.5%。想要招聘大数据专业人才的公司需要确保薪资竞争力,并且考虑其他吸引人才的方式,特别是考虑到他们可能面临多个竞争报价。欲了解分析师、数据科学家和市场研究专业人员的完整薪资信息,可以免费下载我们所有的薪资研究报告。
原文: www.burtchworks.com/2015/01/12/predictions-2015-analytics-data-science-hiring-market/
相关:
-
成为数据科学家需要具备的 9 项必备技能
-
招聘量化分析师,请修正您的招聘流程
-
难以捉摸的数据科学家推动高薪资
更多相关话题
人工智能、分析、机器学习、数据科学、深度学习研究 2019 年的主要发展及 2020 年的关键趋势
原文:
www.kdnuggets.com/2019/12/predictions-ai-machine-learning-data-science-research.html
评论
又到年末了,这意味着是时候进行 KDnuggets 年度年终专家分析和预测。今年我们提出了这个问题:
2019 年人工智能、数据科学、深度学习和机器学习的主要发展是什么?2020 年你期望哪些关键趋势?
我们的前三大课程推荐
1. Google 网络安全证书 - 加入网络安全领域的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
回顾我们专家一年前的预测,我们看到了一些可以被视为自然技术进步的混合,以及一些更为雄心勃勃的预测。出现了一些普遍的主题,以及几个值得注意的单独预测。
尤其是,对人工智能的持续担忧被多次提及,这一预测确实似乎已经实现。有关自动化机器学习的进展的讨论普遍存在,但关于它是否有用还是会失败的观点意见不一。我认为这在一定程度上仍未定论,但当对技术的期望得到缓解时,它更容易被视为一种有用的补充,而不是一个即将取代的存在。增加善用人工智能也被特别提到,原因充分,且有大量例子可以证明这一预测的准确性。提出实用机器学习将迎来考验的观点,标志着趣味和游戏的时代即将结束,现在是机器学习需要有所作为的时候了。这一点确实符合实际,越来越多的从业者正在寻找这些机会。最后,提到对反乌托邦人工智能发展(包括监控、恐惧和操控)的担忧,可以通过对过去一年新闻的简单检查,自信地将其归入成功预测的类别。
也有一些预测尚未实现。这在这样的活动中是不可避免的,我们将把这些留给感兴趣的读者自行探索。
今年我们的专家名单包括 Imtiaz Adam、Xavier Amatriain、Anima Anandkumar、Andriy Burkov、Georgina Cosma、Pedro Domingos、Ajit Jaokar、Charles Martin、Ines Montani、Dipanjan Sarkar、Elena Sharova、Rosaria Silipo 和 Daniel Tunkelang。我们感谢他们从繁忙的年终日程中抽出时间为我们提供见解。
这是未来一周中 3 篇类似文章的第一篇。虽然这些文章将分别涉及研究、部署和行业,但这些学科之间存在相当大的重叠,因此我们建议你在发布时查看所有 3 篇文章。

不再耽搁,以下是今年专家组对 2019 年关键趋势和 2020 年预测的分析。
Imtiaz Adam (@DeepLearn007) 是一位人工智能与战略执行官。
2019 年,各组织对数据科学中的伦理和多样性问题有了更高的意识。
《彩票票假设》论文展示了用剪枝简化深度神经网络训练的潜力。《神经符号概念学习者》论文展示了将逻辑与深度学习结合起来,提升数据和记忆效率的潜力。
GANs 的研究获得了动力,深度强化学习尤其受到了大量研究关注,包括逻辑强化学习和用于参数优化的遗传算法等领域。
TensorFlow 2 带来了集成了 Keras 的 eager execution 默认模式。
2020 年,数据科学团队和商业团队将更加整合。5G 将成为智能物联网增长的催化剂,边缘的 AI 推理意味着 AI 将越来越多地进入物理世界。深度学习与增强现实的结合将改变客户体验。
Xavier Amatriain (@xamat) 是 Curai 的联合创始人兼首席技术官。
我认为,很难争辩这一点:这一年确实是深度学习和自然语言处理的年份。更具体地说,是语言模型的年份。甚至更具体地说,是 Transformers 和 GPT-2 的年份。是的,可能很难相信,但自 OpenAI 首次发布谈论他们的GPT-2 语言模型已经不到一年。这篇博客文章引发了关于 AI 安全的大量讨论,因为 OpenAI 对发布该模型感到不安。从那时起,该模型被公开复制,并最终发布。然而,这并不是这一领域唯一的进展。我们看到 Google 发布了AlBERT或XLNET,并谈论 BERT 是近年来对 Google 搜索的最大改进。从Amazon和Microsoft到Facebook,每个人似乎都真正投身于语言模型革命中,我期待在 2020 年看到这一领域的令人印象深刻的进展,似乎我们越来越接近通过图灵测试。
Anima Anandkumar (@AnimaAnandkumar) 是 NVIDIA 的机器学习研究主任和加州理工学院的布伦教授。
研究人员旨在更好地理解深度学习及其泛化特性和失败案例。减少对标记数据的依赖是关键焦点,自我训练等方法获得了关注。模拟变得在 AI 训练中更加相关,并在如自动驾驶和机器人学习等视觉领域变得更为逼真,包括在 NVIDIA 平台如 DriveSIM 和 Isaac 上。语言模型变得越来越庞大,例如 NVIDIA 的 80 亿参数 Megatron 模型在 512 个 GPU 上训练,并开始生成连贯的段落。然而,研究人员发现这些模型中存在虚假的相关性和不良的社会偏见。AI 监管成为主流,许多知名政治家表示支持政府机构禁止面部识别。AI 会议开始执行行为规范,并增加了提高多样性和包容性的努力,从去年 NeurIPS 更名开始。在即将到来的一年里,我预测将会有新的算法发展,而不仅仅是深度学习的肤浅应用。这将特别影响“科学中的 AI”,如物理学、化学、材料科学和生物学等许多领域。
Andriy Burkov (@burkov) 是 Gartner 的机器学习团队负责人,且是《百页机器学习书》的作者。
主要的发展无疑是 BERT,这种语言建模神经网络模型提高了几乎所有任务的自然语言处理质量。谷歌甚至将其作为相关性的主要信号之一——多年来最重要的更新。
在我看来,关键趋势将是 PyTorch 在行业中的更广泛应用,对更快的神经网络训练方法和在便捷硬件上快速训练神经网络的研究增加。
乔治娜·科斯马 (@gcosma1) 是拉夫堡大学的高级讲师。
在 2019 年,我们欣赏到深度学习模型的令人印象深刻的能力,例如 YOLOv3,特别是在实时物体检测等各种复杂计算机视觉任务中。我们还看到生成对抗网络继续在深度学习社区中受到关注,尤其是在图像合成方面,如 BigGAN 模型在 ImageNet 生成中的应用,以及 StyleGAN 在人体图像合成中的应用。今年我们还意识到欺骗深度学习模型的容易程度,一些研究还表明深度神经网络容易受到对抗性示例的攻击。在 2019 年,我们还见证了偏见的 AI 决策模型被用于面部识别、招聘和法律应用中。2020 年,我预计会看到多任务 AI 模型的发展,这些模型旨在通用且多功能,同时也期待看到对伦理 AI 模型的兴趣增加,因为 AI 正在改变健康、金融服务、汽车及其他许多领域的决策。
佩德罗·多明戈斯 (@pmddomingos) 是华盛顿大学计算机科学与工程系的教授。
2019 年的主要发展:
-
上下文嵌入的迅速传播。它们虽然不到两岁,但现在已主导了自然语言处理,谷歌已经在其搜索引擎中部署了这些嵌入,据报道改善了 10%的搜索结果。从视觉到语言,先在大数据上预训练模型,然后针对特定任务进行调整,已成为标准做法。
-
双重下降的发现。我们对过度参数化模型如何在完全拟合训练数据的同时进行良好泛化的理论理解显著提高,特别是对于观察到的现象的候选解释——与经典学习理论预测相反——即随着模型容量的增加,泛化误差先下降,再上升,然后再次下降。
-
媒体和公众对 AI 进展的看法变得更加怀疑,对自动驾驶汽车和虚拟助手的期望降低,华而不实的演示也不再被轻信。
2020 年的关键趋势:
-
深度学习圈试图从低级感知任务如视觉和语音识别“爬升”到高级认知任务如语言理解和常识推理的速度将会加快。
-
依靠不断增加数据和计算能力来获得更好结果的研究模式将达到其极限,因为它处于一个比摩尔定律更陡峭的指数成本曲线上,已经超出了即使是富有公司能够承担的范围。
-
如果运气好的话,我们将进入一个黄金时代,在这个时代里,既没有关于人工智能的过度炒作,也没有另一个人工智能寒冬。
Ajit Jaokar (@AjitJaokar) 是牛津大学“人工智能:云和边缘实现”课程的课程主任。
在 2019 年,我们在牛津大学重新品牌了我们的课程,改为人工智能:云和边缘实现。这也反映了我个人的观点,即 2019 年是云计算成熟的一年。这一年,我们所谈论的各种技术(大数据、人工智能、物联网等)在云计算的框架内汇聚在一起。这一趋势将继续——特别是对于企业。公司将进行“数字化转型”——他们将利用云作为统一的范式来转型由人工智能驱动的过程(有点像重新工程化企业 2.0)。
在 2020 年,我还看到自然语言处理的成熟(BERT、Megatron)。5G 将继续部署。我们将在 5G 全面部署后看到物联网的更广泛应用(例如:自动驾驶汽车)。最后,在物联网方面,我关注一种叫做 MCU(微控制器单元)的技术——特别是机器学习模型在 MCU 上的部署。
我相信人工智能是一个颠覆性的变化,每天我们都能看到令人着迷的人工智能应用实例。艾尔文·托夫勒在《未来冲击》中预测的许多情景今天已经发生——人工智能将如何进一步放大这些变化仍待观察!遗憾的是,人工智能的变化速度将让许多人被抛在后面。
Charles Martin 是人工智能科学家、顾问及 Calculation Consulting 的创始人。
BERT、ELMO、GPT2 等等!2019 年的人工智能在自然语言处理领域取得了巨大进展。OpenAI 发布了他们的大型 GPT2 模型——即文本的深度伪造。谷歌宣布使用 BERT 进行搜索——自 Panda 以来最大的一次变化。即使是我在加州大学伯克利分校的合作者也发布了(量化的)QBERT 以适应低足迹硬件。现在每个人都在制作自己的文档嵌入。
这对 2020 年意味着什么?根据搜索专家的说法,2020 年将是相关性(嗯,他们都在做什么?)的年份。预计向量空间搜索将最终获得 traction,采用 BERT 风格的精细调优嵌入。
在 2019 年,PyTorch 超过 Tensorflow 成为 AI 研究的首选。随着 TensorFlow 2.x 的发布(以及对 pytorch 的 TPU 支持),2020 年的 AI 编程将完全围绕急切执行展开。
大公司在 AI 方面取得进展了吗?报告显示成功率为 1/10。不太理想。因此,AutoML 在 2020 年将会受到需求,尽管我个人认为,就像制作出色的搜索结果一样,成功的 AI 需要特定于业务的定制解决方案。

伊内斯·蒙塔尼(@_inesmontani)是一位从事人工智能和自然语言处理技术的程序开发人员,并且是 Explosion 的联合创始人。
每个人都选择“DIY AI”而不是云解决方案。推动这一趋势的一个因素是迁移学习的成功,这使得任何人都可以用较高的准确性训练自己的模型,且能够针对非常具体的使用案例进行微调。由于每个模型只有一个用户,因此服务提供商无法利用规模经济。迁移学习的另一个优点是数据集不再需要那么大,因此标注工作也在内部进行。内部化的趋势是一个积极的发展:商业 AI 远比许多人预期的要分散。几年前,人们担心每个人都只会从一个提供商那里获取“他们的 AI”。然而,人们并没有从任何提供商那里获取 AI——他们自己动手做。
迪潘詹·萨尔卡 是 Applied Materials 的数据科学负责人,Google 开发者专家 - 机器学习,作者、顾问和培训师。
2019 年,人工智能领域的主要进展集中在 Auto-ML、可解释 AI 和深度学习方面。数据科学的民主化在过去几年中仍然是一个关键方面,各种与 Auto-ML 相关的工具和框架正试图简化这一过程。然而,仍需注意的是,我们在使用这些工具时必须小心,以确保不会得到有偏见或过拟合的模型。公平性、问责制和透明性仍然是客户、企业和公司接受 AI 决策的关键因素。因此,可解释 AI 不再只是研究论文中的话题。许多优秀的工具和技术已经开始使机器学习模型的决策更加可解释。最后但同样重要的是,我们看到深度学习和迁移学习,特别是自然语言处理领域的许多进展。我期待在 2020 年看到更多关于自然语言处理和计算机视觉的深度迁移学习研究和模型,希望能看到结合深度学习和神经科学精华的工作,从而引领我们迈向真正的 AGI。
埃琳娜·沙罗娃 是 ITV 的高级数据科学家。
到目前为止,2019 年最重要的机器学习进展是在玩游戏时使用深度强化学习,通过 DeepMind 的DQN和AlphaGo实现的;这导致了围棋冠军李世石的退休。另一个重要进展是在自然语言处理领域,Google 开源了 BERT(深度双向语言表示),而微软领导了 GLUE 基准并通过开发和开源 MT-DNN集成体用于发音分辨任务。
重要的是要强调欧洲委员会发布的《可信 AI 伦理指南》——这是首个设定合法、道德和稳健 AI 合理指南的官方出版物。
最后,我想和 KDnuggets 的读者分享的是,PyData London 2019的所有主题演讲者都是女性——这是一个令人欢迎的发展!
我预期 2020 年的主要机器学习发展趋势将继续集中在自然语言处理(NLP)和计算机视觉(computer vision)领域。采用机器学习(ML)和数据科学(DS)的行业已经认识到,他们在定义共享的最佳实践标准方面已经滞后,包括招聘和留住数据科学家、管理涉及 DS 和 ML 的项目复杂性,以及确保社区保持开放和合作。因此,我们应该会看到未来会更多关注这些标准。
Rosaria Silipo(@DMR_Rosaria)是 KNIME 的首席数据科学家。
2019 年最令人期待的成就是主动学习、强化学习和其他半监督学习程序的采用。半监督学习可能为处理目前充斥我们数据库的未标记数据带来希望。
另一个伟大的进展是将 autoML 概念中的“auto”纠正为“guided”。对于更复杂的数据科学问题,专家干预似乎是不可或缺的。
在 2020 年,数据科学家将需要一个快速的解决方案来进行模型部署、持续模型监控和灵活的模型管理。真正的商业价值将来自数据科学生命周期的这三个最终部分。
我还相信,深度学习黑箱的更广泛应用将引发机器学习解释性(MLI)的问题。我们将在 2020 年底看到 MLI 算法是否能够应对解释深度学习模型内部运作的挑战。
Daniel Tunkelang (@dtunkelang) 是一名独立顾问,专注于搜索、发现和机器学习/人工智能。
人工智能的前沿依然专注于语言理解和生成。
OpenAI 宣布了 GPT-2 以预测和生成文本。OpenAI 当时没有发布训练模型,担心恶意应用,但最终他们 改变了主意。
谷歌发布了一款 80MB 的设备端语音识别器,使得在移动设备上进行语音识别成为可能,而无需将数据发送到云端。
与此同时,我们看到对人工智能和隐私的担忧越来越严重。今年,所有主要的数字助手公司都遭遇了员工或承包商监听用户对话的反对声。
2020 年人工智能会发生什么?我们将看到对话式人工智能的进一步发展,以及更好的图像和视频生成。这些进展将引发更多关于恶意应用的担忧,我们可能会看到一两起丑闻,尤其是在选举年。善与恶的人工智能之间的紧张关系不会消失,我们必须学习更好的应对方式。
相关:
-
2018 年机器学习与人工智能的主要发展及 2019 年的关键趋势
-
2018 年人工智能、数据科学、分析的主要发展及 2019 年的关键趋势
-
行业预测:2018 年人工智能、机器学习、分析与数据科学的主要发展及 2019 年的关键趋势
更多相关话题
AI、分析、机器学习、数据科学、深度学习技术 2019 年的主要进展和 2020 年的关键趋势
原文:
www.kdnuggets.com/2019/12/predictions-ai-machine-learning-data-science-technology.html
评论在 2019(以及之前的几年),我们询问了一些顶尖专家他们对 2020 年的预测。
去年预测的一些趋势已经显现:
-
对 AI 伦理的更多关注
-
数据科学的民主化
-
强化学习的进展
-
中国在 AI 领域的成功增长
2019 年也有一些惊喜——去年的专家们没有预测到自然语言处理的突破(如 GPT-2 以及其他版本的 BERT 和 Transformers)。
我们今年再次询问了我们的专家:
2019 年人工智能、数据科学、深度学习和机器学习的主要进展是什么?你对 2020 年有何关键趋势预期?
我们收到了大约 20 个回复,第一部分,主要关注研究,已经发布。
这是第二部分,更加关注技术、行业和部署。一些共同的主题包括:AI 炒作、AutoML、云计算、数据、可解释 AI、AI 伦理。
这里是 Meta Brown、Tom Davenport、Carla Gentry、Nikita Johnson、Doug Laney、Bill Schmarzo、Kate Strachnyi、Ronald van Loon、Favio Vazquez 和 Jen Underwood 的回答。

Meta Brown,@metabrown312,是《Data Mining for Dummies》的作者和 A4A Brown 的主席
在 2018 年,我们看到“人工智能”一词的使用剧增,这一术语被用来描述从真正复杂的应用程序和日益成功的自动驾驶汽车到在直销中使用的普通倾向评分。我预测在 2019 年,人们会意识到这全是数学。我有一半的预测是对的。
一方面,越来越多的人开始看到现在所谓的“AI”的局限性。公众意识到面部识别技术可以被 Juggalo 化妆所干扰,客户服务聊天机器人背后没有智能生命,试图让软件比医生更聪明可能花费数百万仍然可能失败。
尽管如此,“人工智能”仍然是一个热门的流行词,风险投资的钱仍在不断涌入。2019 年前 9 个月,AI 初创企业获得了超过 130 亿美元的投资。
在 2020 年,预计人工智能的两种前景之间会出现越来越明显的二分化:一种是公众对 AI 的疑虑、怀疑和对其局限性的认识不断增长;另一种是商业和投资界继续对 AI 的承诺投入希望、梦想和资金。
汤姆·达文波特、@tdav 是巴布森学院信息技术与管理的总统杰出教授,国际分析学会的联合创始人,麻省理工学院数字经济倡议的研究员,以及德勤分析的高级顾问。
2019 年的主要发展:
-
在数据科学的更结构化方面,自动化机器学习工具的广泛部署。
-
广泛认识到分析和人工智能具有需要有意识地解决的伦理维度。
-
越来越多的人认识到,大多数分析和人工智能模型没有被部署,结果对创建这些模型的组织没有价值。
2020 年的即将发展:
-
提供创建、管理和监控组织的机器学习模型套件的工具,重点是对漂移模型进行持续重新训练和模型库存管理。
-
对分析和人工智能翻译员的地位和认可有所改善,他们与业务用户和领导者合作,将业务需求转化为模型的高级规范。
-
认识到模型与数据的契合度只是决定其是否有用的一个考虑因素。
卡拉·根特里、@data_nerd 是咨询数据科学家和 Analytical-Solution 的所有者。
又一年关于人工智能、机器学习和数据科学能做什么和不能做什么的炒作,我对大量未经培训的专业人士涌入这些领域感到不安,以及那些不断颁发所谓认证和学位的学院,教师们根本没有资格教授这些课程。
数据科学和机器学习依赖于大量数据,但我们面临另一年的偏见误解,数据需要解释总是存在偏见风险。无偏数据是独立的,不需要解释,例如 - 玛丽通过增加销售投资回报率 10%与玛丽是个勤奋工作的人,这是一种意见,无法衡量。
前几天有一篇文章的标题引起了我的注意“数据科学正在衰退吗”?我在阅读之前的初步想法是“不是,但所有那些想当专家和炒作确实没有帮助我们的领域 - 数据科学不仅仅是编写代码”。对技术的误解加上缺乏数据和必要的基础设施将继续困扰我们,但至少有些人意识到 21 世纪最性感的工作其实并不那么性感,因为我们大部分时间都在清洗和准备数据,然后才能获得洞察并回答业务问题。
在 2020 年,让我们都记住,关键在于数据,并确保我们能够以诚信和透明度推动我们的领域发展。要想继续朝着积极的方向前进,AI 的“黑箱”时代必须结束。记住,你所构建的算法、模型、聊天机器人等可能会对某人的生活产生影响,数据库中的数据点对应的是一个生命,因此要消除你的偏见,让事实本身说话……像往常一样,享受数据的乐趣,并负责任地使用数据。
尼基塔·约翰逊,@teamrework,创始人,RE.WORK 深度学习与 AI
在 2019 年,我们见证了多个领域的突破,这些突破使得 AI 得到了前所未有的广泛应用。先进的软件技术,如迁移学习和强化学习,也帮助推动了 AI 突破和应用的进展,帮助分离系统改进与我们作为人类的知识限制。
明年 2020 年,我们将看到向“可解释 AI”的转变,以提供更多的透明度、问责制和 AI 模型及技术的可重复性。我们需要增加对每种工具的局限性、优缺点的了解。增强的学习将提高我们与所用产品建立信任的能力,同时也让 AI 的决策更具合理性!
道格·拉尼,@Doug_Laney,首席数据策略师,Caserta,《信息经济学》畅销书作者,伊利诺伊大学 Gies 商学院客座教授
AI 从 90 年代早期的辉煌日子复苏,以及数据科学的主流化,完全是由数据推动的。今天的大数据“只是数据”。尽管其规模不断扩大,但不再会压倒存储或计算能力。至少现在没有任何组织会因为数据庞大而受到阻碍。(提示:云计算。)确实,渐进改进的技术和方法已经出现,但来自社交媒体平台的数据泛滥、伙伴间的数据交换、从网站采集的数据以及来自连接设备的数据滴漏,带来了前所未有的洞察、自动化和优化。这也催生了新的数据驱动业务模型。
在 2020 年,我设想(没有恶意,或者说有点恶意?)扩展的信息生态系统将出现,进一步促进 AI 和数据科学驱动的商业伙伴数字协调。一些组织可能会选择自建数据交换解决方案,以货币化他们及他人的信息资产。其他组织则会通过区块链支持的数据交换平台和/或数据聚合器提供各种替代数据,来推动其高级分析能力。
Bill Schmarzo,@schmarzo,是 Hitachi Vantara 的首席技术官,负责物联网与分析。
2019 年的主要发展
-
在智能手机、网站、家居设备和车辆中集成 AI,日益增长的“消费者验证点”。
-
数据工程角色日益重要,数据操作(DataOps)类别的正式化也证明了这一点。
-
在高管层中对数据科学业务潜力的尊重日益增加。
-
首席信息官(CIO)继续在兑现数据货币化承诺方面遇到困难;数据湖的失望导致数据湖的“第二次手术”。
2020 年的关键趋势
-
更多现实世界的例子展示了工业公司如何利用传感器、边缘分析和 AI 创建随着使用变得更智能的产品;这些产品在使用过程中价值上升,而非贬值。
-
由于无法提供合理的财务或运营影响,宏大的智能空间项目仍然在初始试点阶段挣扎,难以进一步发展。
-
经济衰退将加大“拥有者”和“非拥有者”之间的差距,特别是在利用数据和分析推动有意义的业务成果的组织中。
Kate Strachnyi,@StorybyData,致力于用数据讲述故事 | 跑者 | 两个孩子的妈妈 | 数据科学与分析领域的顶级声音。
2019 年,我们看到数据可视化/商业智能软件领域的整合;Salesforce 收购了 Tableau 软件,Google 收购了 Looker。这些对商业智能工具的投资展示了公司对数据民主化和使用户更容易查看和分析数据的重视。
我们可以预期 2020 年将继续向自动化数据分析/数据科学任务转变。数据科学家和工程师需要可以扩展的工具来解决更多问题。这种需求将促使自动化工具在数据科学过程的多个阶段得到开发。例如,某些数据准备和清洗任务已经部分自动化,但由于公司的独特需求,完全自动化仍然困难。其他自动化候选任务包括特征工程、模型选择等。
Ronald van Loon,@Ronald_vanLoon,广告总监,帮助数据驱动的公司取得成功。大数据、数据科学、物联网、AI 领域的 Top10 影响者
在 2019 年,行业见证了可解释 AI 和增强分析的日益采用,这使得企业能够弥合 AI 潜力与基于无偏见 AI 结果的决策技术复杂性之间的差距。全栈 AI 方法是 2019 年的另一项发展,组织们接受了这种方法,以帮助加快创新路径并支持 AI 增长,同时改善不同团队和个人之间的集成与沟通。
在 2020 年,我们将看到一些由于对话式 AI 易用性和直观界面而出现的客户体验改进趋势。这种自动化解决方案使公司能够扩大规模并转变客户体验,同时提供 24/7 的客户通道,并提供快速问题解决和可靠的自助服务机会。此外,狭义智能将继续支持我们如何最有效地利用人类和机器的优势,同时将 AI 融入我们的现有流程,并努力改变我们向 AI 提出的问题。
Favio Vazquez、@FavioVaz,Closter 的首席执行官
在 2019 年,我们看到了人工智能最前沿领域的惊人进展,主要集中在深度学习方面。数据科学有能力利用这些进展解决更难的问题并塑造我们所生活的世界。数据科学是利用科学催化变革并将论文转化为产品的引擎。我们的领域不再仅仅是“炒作”,它正在成为一个严肃的领域。我们将看到关于数据科学及其相关领域的重要在线和离线教育的增加。希望我们能对所做的工作及其方式更有信心。语义技术、决策智能和知识数据科学将在未来几年成为我们的伙伴,因此我建议大家开始探索图数据库、本体论和知识表示系统。
Jen Underwood、@idigdata,推动组织更快发展的自然力量
在 2019 年,我们达到了一个关键点,即组织必须认真对待在算法经济中的竞争。市场领先的公司通过规划企业范围的 AI 战略,提高了数据科学的显著性,而不是仅仅赞助一次性的项目。与此同时,成熟的数据科学组织启动了伦理、治理和 ML Ops 计划。不幸的是,尽管机器学习的采用率有所提高,但大多数人仍未取得成功。
从技术角度来看,我们见证了混合分布式计算和无服务器架构的兴起。同时,算法、框架和 AutoML 解决方案迅速从创新发展到商品化。
我预计 2020 年个人数据安全、监管、算法偏见和深度伪造话题将主导头条新闻。欣慰的是,可解释 AI 的进步以及自然语言生成和优化技术将有助于弥合数据科学与商业之间的差距。随着数据素养和公民数据科学项目的进一步出现,机器学习从业者应继续蓬勃发展。
这是基于他们预测的词云

相关:
更多相关内容
行业预测:2018 年 AI、机器学习、分析与数据科学的主要进展以及 2019 年的关键趋势
 评论
评论
随着我们继续为 KDnuggets 读者带来年终总结和 2019 年的预测,我们向许多有影响力的行业公司征询了他们的看法,提出了这个问题:
2018 年 AI、机器学习、分析与数据科学的主要进展是什么?你预期 2019 年会有什么关键趋势?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
对于行业对今年发生的事件及未来发展趋势的看法,我们收集了来自 Domino Data Lab、dotData、Figure Eight、GoodData、KNIME、MapR、MathWorks、OpenText、ParallelM、Salesforce、Splice Machine、Splunk 和 Zoomdata 的见解。

这些专家指出的关键主题包括变化中的分析格局、数据科学如何继续影响业务,以及将被用来实现这一点的新兴技术。
一定要查看我们上周分享的收集意见,当时我们向一组专家提出了相关问题,“2018 年数据科学和分析的主要进展是什么?你预期 2019 年会有什么关键趋势?”
Josh Poduska 是 Domino Data Lab 的首席数据科学家。
AI:从炒作到 2019 年的业务影响。人工智能的蜜月期正式结束。2019 年将是人工智能成为组织现实的一年,而非实验、调试和疑虑。
忘记谷歌的 AI 呼叫中心代理。数据科学的最大影响将体现在你未曾想到的地方……在业务中那些较少“性感”的部分,比如更快的客户技术支持电话服务、优化库存、更智能的产品摆放、减少购买中的浪费时间等。
消费者对 AI 的理解将会发生剧烈变化。我们将不再将 AI 与未来的机器人和自动驾驶汽车联系在一起,而是与提升生产力的工具和帮助日常琐事的预测联系在一起。
藤卷亮平博士是 dotData 的首席执行官兼创始人,该公司专注于为企业提供端到端的数据科学自动化和操作化。
对从 AI 和 ML 项目中获得更大投资回报的压力将推动更多商业领袖寻求创新解决方案。 尽管许多行业正在对数据科学进行大量投资,但数据科学技能和资源的稀缺限制了组织内 AI 和 ML 项目的进展。此外,由于过程的迭代性质和数据准备及特征工程的手动工作,一支数据科学团队每年只能执行几个项目。到 2019 年,数据科学自动化平台将占据大量思维份额。数据科学自动化将涵盖比机器学习自动化更广泛的领域,包括数据准备、特征工程、机器学习和数据科学管道的生产。这些平台将加速数据科学,执行更多商业举措,同时保持当前的投资和资源。
数据科学任务将变成 5 分钟的操作,并在几天内带来业务价值。 过去需要几个月时间的数据科学项目已经不再存在。到 2019 年,我们将看到企业在实施和优化他们的 AI 和机器学习项目方面发生转变。新的数据科学自动化平台提供了一个单一的、无缝的平台,使公司能够加速、普及和操作整个数据科学过程——从原始数据到特征工程再到机器学习——消除数据科学中最耗时、最劳动力和技能密集的任务。因此,曾经需要几个月完成的工作,现在只需几天,这大大加快了 AI 和机器学习项目的价值实现时间。
戴尔·布朗是 Figure Eight 的业务发展副总裁。
-
AI 平台供应商将创建更多工具,以便非数据科学家/开发者能够更快地构建 AI - “随着公司对 AI 需求的增加,我们也看到训练有素的数据科学家持续短缺。为了提高 AI 的采用,AI 平台需要赋能传统开发者,提供工具以使他们能够更快地创建机器学习模型,并确保他们拥有一个集成平台,允许开发者注释和标记数据,以提高模型的准确性。”
-
企业级 AI 集成与整合将会发生 - “AI 的广泛采用将迫使企业级公司要么加速开发 AI 相关工具,要么收购并将其整合到他们的平台中——速度要快于他们的竞争对手。”
凯文·史密斯是 GoodData 的产品营销副总裁。
数据科学家的需求将发生急剧变化。数据科学家,曾被认为是 21 世纪最性感的职业,将与我们今天所知的非常不同。随着分析被推向最终用户,自助服务成为常态,数据准备工具变得更加强大,数据科学家将更多地转变为顾问,而不是数据来源和准备专家。他们将负责帮助企业理解数据、解释结果以及可能采取的行动方案。这对数据科学家而言是一个更高价值的角色,最终也是更好地利用他们的技能。
迈克尔·伯瑟尔德是KNIME的首席执行官。
我看到的两个持续的趋势是自动化和可解释性。前者将在 2019 年继续受到关注,但随后会面临一个问题,即只有相对明确的数据科学问题才适合完全自动化。更强大的环境是数据科学家可以将自动化与互动结合,真正允许他们将数据科学部署给他人,而不必将所有工作外包给自称的专家。对于所有需要理解(或控制)基础决策的数据类型,深度学习的可解释性将变成一个更大的问题。我们永远不会接受 AI 在安全关键决策中的“人为失败”。
杰克·诺里斯是MapR的数据和应用高级副总裁。
2019 年是容器和人工智能在主流中相遇的一年 - NVIDIA 在今年年底宣布了开源 Rapids。这预示着在操作化 AI、数据科学家之间更好的共享以及在各地分布处理的关注点如何推动容器化。另一个推动这一预测的上升技术是 Kubeflow,它将补充容器和分布式分析。
塞斯·德兰是MathWorks的数据分析产品营销经理。
机器学习将被整合到产品和服务中 - 公司将越来越多地使用机器学习算法来使产品和服务“从数据中学习”并提高性能。机器学习已经出现在一些领域:图像处理和计算机视觉用于面部识别,能源生产的价格和负荷预测,工业设备故障预测等等。预计在来年,随着更多公司受到启发,将机器学习算法集成到他们的产品和服务中,机器学习将变得越来越普遍,这些公司将使用可扩展的软件工具,包括 MATLAB。
公司将利用领域专家来弥补数据科学技能差距——许多公司难以找到数据科学专才,企业正在为现有的工程师和科学家提供可扩展的工具,如 MATLAB,以使他们能够进行数据科学。由于这些工程师和科学家具有现有的流程和业务知识,他们将能够很好地应用数据科学技术,评估结果,并确定将模型与业务系统集成的最佳方法。
Zachary Jarvinen 是OpenText的技术战略、人工智能和分析部门负责人。
2019 年,长期承诺的企业人工智能转型将开始真正展开。大多数企业已经达到了数字成熟的阶段,确保能够大规模访问高质量数据。凭借成熟的数据集,人工智能供应商可以提供更低成本、更易于使用的人工智能工具,适用于特定的业务场景。大规模的企业人工智能效应将会非常显著。Gartner 预计,到 2022 年,人工智能的商业价值将达到近 3.9 万亿美元。消费者也将在几乎每个行业中受益。他们将看到更多创新的产品和服务、更智能的家居、工厂和城市、改善的健康状况以及更高的生活质量。
人工智能将增强——而不是取代——劳动力。人工智能应用将具有变革性,提高效率和性能,产生巨大的成本节省,并催生更多创新的产品和服务。然而,未来的工作将涉及人类和人工智能。最具创新性的公司已经开始规划如何最好地实现这种共生的未来。在短期内——这意味着数据科学领域的技术工人缺口将持续存在,需求将保持非常高。教育机会将扩展以帮助解决这一需求。在长期内——随着我们发展解锁人工智能的技能和技术,社会将从人工智能增强的工人、家居、车辆、电网、工厂、城市等方面受益巨大。
Sivan Metzger 是ParallelM的首席执行官,该公司在机器学习运营(MLOps)领域迅速成长。
其他业务领域将被引入,共享机器学习的责任。随着公司面临从竞争对手中脱颖而出的压力增加以及商业领袖的挫折感加剧,其他职能将被拉入以帮助实现机器学习计划。这些职能包括运营和业务分析师,他们可以在数据科学家完成机器学习模型的构建后,接过这些责任。
Ketan Karkhanis 是Salesforce的高级副总裁兼分析总经理。
AI 增强分析将成为主流 - 2019 年将是 AI 主导的分析(被称为自动化发现)成为主流的一年。人脑并不具备在亚秒速度下评估数百万种数据组合的能力,但机器学习正是为解决这个问题而构建的完美解决方案。企业领导者和数据分析师越来越明白,AI 不会取代工作,而是增强工作能力,我预计在未来一年中,大多数数据分析师将能够在无需编写代码的情况下掌握数据科学的力量。
Monte Zweben 是 Splice Machine 的首席执行官,这是一款用于实时应用的智能数据平台。
-
Hadoop 的新客户增长将减缓,Hadoop 集群的增长将放慢。
-
基于云的 SQL 数据平台将实现大规模增长
-
机器学习将进入运营阶段,从后台实验中走出,融入实时、关键任务的企业应用程序。
-
Oracle 的客户转向扩展 SQL 平台将达到一个点,届时公司将在季度披露中透露风险因素。
Andi Mann 是 Splunk 的首席技术倡导者。
-
2019 年将是机器学习在工作场所全面实现的一年——“AI 即服务(AIaaS)”的增加将涌入市场,为企业提供更多解决方案。
-
到 2019 年,工程招聘将继续上升,因为更多的组织需要工程师来帮助管理孤立的工具集成。
-
“工具为工具”的崛起,专注于更好地支持 IT 操作。
最终的预测来自 Zoomdata 的高管。
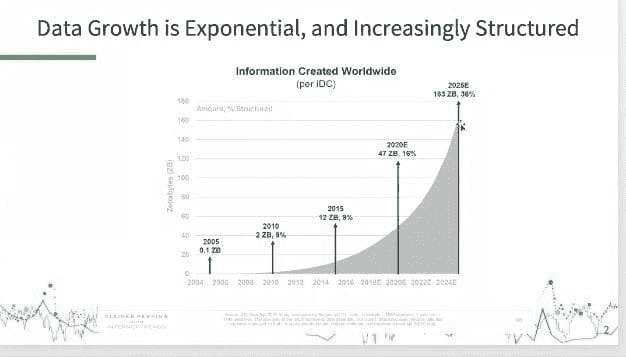
数据可视化的增长(由于数据结构化程度的提升) - 到 2019 年,企业将最终接受数据可视化,并看到其潜力。我们别无选择——数据增长是指数级的,并且由于物联网(见图表)变得越来越结构化。就像今天的消费者可以查看自己家的能耗并与邻居的能耗进行比较一样,我们将开始看到这种情况(终于!)渗透到供应链中。例如,自动化分析将发现一些有趣的内容,创建该项内容的可视化表示——然后向人类展示,以便采取行动。数据将从整个数据集中提取,使企业管理者能够以前所未有的方式看清全局。
相关信息:
-
行业预测:2017 年主要 AI、大数据、数据科学发展及 2018 年趋势
-
机器学习与 AI 在 2018 年的主要发展及 2019 年关键趋势
-
AI、数据科学、分析在 2018 年的主要发展及 2019 年的关键趋势
更多相关主题
2018 年机器学习与人工智能的主要发展及 2019 年的关键趋势
原文:
www.kdnuggets.com/2018/12/predictions-machine-learning-ai-2019.html
comments
在 KDnuggets,我们努力保持对行业、学术界和技术主要事件和发展的关注。我们还尽力展望即将出现的关键趋势。
在往年,我们曾带来过专家的预测和分析的集合。今年我们提出了以下问题:
2018 年机器学习和人工智能的主要发展是什么,您对 2019 年的关键趋势有什么预期?
以下是 Anima Anandkumar、Andriy Burkov、Pedro Domingos、Ajit Jaokar、Nikita Johnson、Zachary Chase Lipton、Matthew Mayo、Brandon Rohrer、Elena Sharova、Rachel Thomas 和 Daniel Tunkelang 的回应。

这些专家提到的关键主题包括深度学习的进展、迁移学习、机器学习的局限性、自然语言处理的变化趋势等。
请务必查看我们上周分享的意见,当时我们向一组专家询问了相关问题,"2018 年数据科学和分析的主要发展是什么,您对 2019 年的关键趋势有什么预期?"
Anima Anandkumar (@AnimaAnandkumar) 是 NVIDIA 的机器学习研究主任和加州理工学院的布伦教授。
2018 年机器学习和人工智能的主要发展是什么?
“深度学习的低垂果实已经基本被采摘完毕”
重点开始从标准的监督学习转向更具挑战性的机器学习问题,如半监督学习、领域适应、主动学习和生成模型。生成对抗网络(GANs)继续受到研究人员的热捧,他们尝试更困难的任务,如照片真实感(bigGANs)和视频到视频的合成。开发了替代生成模型(如神经渲染模型),以将生成和预测结合在一个网络中,以帮助半监督学习。研究人员将深度学习应用扩展到许多科学领域,如地震预测、材料科学、蛋白质工程、高能物理和控制系统。在这些情况下,领域知识和约束与学习相结合。例如,为了改善无人机的自主着陆,学习了地面效应模型来修正基础控制器,并且学习被保证是稳定的,这在控制系统中非常重要。
预测:
“人工智能将弥合模拟和现实之间的差距,使其更加安全和具备物理感知能力”
我们将看到新领域适应技术的发展,这些技术可以无缝地将知识从模拟环境转移到现实世界。模拟的使用将帮助我们克服数据稀缺问题,加速新领域和新问题的学习。从模拟到真实数据的适应(Sim2real)将在机器人技术、自动驾驶、医学影像、地震预测等领域产生重大影响。模拟是考虑所有可能情景的绝佳方式,尤其在安全关键应用如自动驾驶中。内置于复杂模拟器中的知识将以新的方式被利用,使 AI 更加具备物理意识,更加健壮,并能够推广到新的、未见过的情景。
安德烈·布尔科夫 (@burkov) 是 Gartner 的机器学习团队负责人。
这是我作为从业者的个人看法,并非基于研究的 Gartner 官方声明。以下是我的想法:
2018 年机器学习和人工智能的主要发展是什么?
TensorFlow 在学术界输给了 PyTorch。谷歌的巨大影响力和覆盖面有时可能会使市场走向次优方向,就像 MapReduce 和随后的 hadoop 狂热一样。
深度伪造(及其类似技术,包括声音)摧毁了最可信的信息来源:视频镜头。没有人再能够像以前那样说:我看到了那个家伙说这些话的视频。几十年前我们就不再相信印刷文字,但视频直到现在才变得不可靠。
强化学习以深度学习的形式卷土重来,这非常出乎意料且令人兴奋!
谷歌的系统可以代表你拨打餐厅电话,并成功地伪装成人类,这是一个重要的里程碑。然而,这也引发了许多关于伦理和 AI 的问题。
个人助手和聊天机器人很快达到了它们的极限。虽然它们比以往更出色,但仍未达到大家去年所期望的水平。
你期待 2019 年有哪些关键趋势?
-
我预计大家会比今年更为兴奋于 AutoML 的承诺。我也预期它会失败(除了某些非常具体和明确的用例,如图像识别、机器翻译和文本分类,在这些情况下,手工特征不是必需的,或者是标准的,原始数据接近机器所期望的输入,并且数据量充足)。
-
营销自动化:随着成熟的生成对抗网络和变分自编码器的发展,我们现在可以生成成千上万张同一人的照片或风景照片,这些图片之间仅有小的面部表情或情绪差异。根据消费者对这些图片的反应,我们可以生成最佳的广告活动。
-
在移动设备上实时生成的语音几乎无法与真人区分。
-
自动驾驶出租车将继续停留在测试/概念验证阶段。
佩德罗·多明戈斯 (@pmddomingos) 是华盛顿大学计算机科学与工程系的教授。
经过多年的炒作,2018 年是对人工智能的过度担忧的一年。听媒体和一些研究人员的话,你会认为剑桥分析公司在 2016 年选举中帮助特朗普赢得了胜利,机器学习算法充斥着偏见和歧视,机器人正来抢夺我们的工作甚至我们的生活。这不仅仅是空谈:欧洲和加利福尼亚已通过了严厉的隐私法律,联合国正在讨论禁止智能武器等。公众对人工智能的看法越来越黑暗,这既危险又不公平。希望 2019 年能是理智回归的一年。
阿吉特·贾奥卡尔 (@AjitJaokar) 是首席数据科学家以及牛津大学物联网数据科学课程的创始人。
2018 年,一些趋势开始兴起。自动化机器学习就是其中之一,强化学习则是另一个。这两种新兴趋势将在 2019 年显著扩展。作为我在牛津大学(物联网数据科学课程)教学的一部分,我看到物联网越来越多地融入到大型生态系统中,如自动驾驶汽车、机器人和智慧城市。通过与Dobot的合作,我认为协作机器人(cobots)是 2019 年的一个关键趋势。与之前的流水线机器人不同,新型机器人将具备自主性,并且能够理解情感(在我的课程中,我们还与情感研究实验室在这一领域合作)。最后,一个有些争议的观点是:在 2019 年,我们所知的数据科学家的角色将趋向于从研究转向产品开发。我认为人工智能将与下一代数据产品的创造更加紧密地联系在一起。数据科学家的角色也将随之变化。
尼基塔·约翰逊 (@nikitaljohnson) 是 RE.WORK 的创始人。
我们在 2018 年见证的一个发展是,开源工具数量的增加降低了入门门槛,使人工智能更加普及,确保了组织之间的更好合作。这些社区对确保人工智能在社会和商业所有领域的传播至关重要。
同样,在 2019 年,我们将看到更多公司专注于“善用 AI”,继承 Google 最近宣布的 AI for Social Good 项目,以及微软的 AI for Good 倡议。这种向积极影响的 AI 转变正在获得关注,因为社会要求公司具有更高的社会目的。
Zachary Chase Lipton (@zacharylipton) 是卡内基梅隆大学的机器学习助理教授及Approximately Correct Blog的创始人。
让我们从深度学习场景开始,它占据了公众对机器学习和人工智能讨论的主要份额。也许我会让一些人不悦,但这是对 2018 年的一个合理解读:最大的进展是没有进展!当然,这种看法过于简单,但请允许我详细说明。相当大一部分最大的进展更多地是“调整”而非质新想法。BigGAN是一个更大的 GAN。逐步增长的 GAN 产生了非常吸引眼球的结果,在某些方面是一个巨大的进步,但在方法上,它只是一个带有巧妙课程学习技巧的 GAN。在 NLP 领域,年度最大新闻是ELMO和BERT的上下文嵌入。这些在经验上绝对是了不起的进展。但自 2015-16 年 Andrew Dai 和 Quoc Le 在更小规模上进行这项工作以来,我们一直在预训练语言模型并微调以进行下游分类任务。所以,也许更悲观的看法是,这一年并没有被新“重大想法”主导。另一方面,积极的看法可能是现有技术的全部能力尚未发挥出来,硬件、系统和工具的快速发展可能会在挤出这些 3-4 年旧想法的所有价值方面发挥第二幕。
我认为,现在有很多新鲜的想法在深度学习的新兴理论中酝酿。包括Sanjeev Arora、Tengyu Ma、Daniel Soudry、Nati Srebro等在内的大量研究人员正在进行一些非常激动人心的工作。长久以来,我们有的是严谨的第一原理理论,但往往忽视了实践,然后是“实验性的”机器学习,这实际上关心的是科学而不是排行榜追逐。现在出现了一种新的探究模式,其中理论和实验更加紧密地结合。你开始看到受到实验启发的理论论文,以及进行实验的理论论文。最近,我有一个启发性的经历,从一篇理论论文中获得了一个点子,真正揭示了一种我没有预料到的自然现象。
对于 2019 年及以后,我认为应用机器学习将面临一场审视。我们正急于进入所有这些实际领域,声称要“解决”问题,但到目前为止,我们工具箱中唯一可靠的工具仍然是监督学习,而仅凭模式匹配我们能做的事有一定限制。监督模型找出关联,但它们并不能提供理由。它们不知道哪些信息是可靠的,哪些信息是不稳定的(即可能随时间变化)。这些模型不能告诉我们干预的效果。当我们在与人类互动的系统中部署基于监督学习的自动化系统时,我们没有预见到它们如何扭曲激励,从而改变其环境,破坏它们所依赖的模式。我认为在接下来的一年里,我们将看到更多的机器学习项目被废弃,或者因为这些限制而陷入麻烦,我们也会看到社区中更具创意的成员将更多关注从功能拟合排行榜转向解决表征学习和因果推理之间的差距的问题。
Matthew Mayo (@mattmayo13) 是 KDnuggets 的编辑。
对我来说,2018 年在机器学习领域似乎是一个精细化的年份。例如,迁移学习得到了更广泛的应用和关注,特别是在自然语言处理领域,这要归功于诸如通用语言模型微调用于文本分类(ULMFiT)和双向编码器表示(BERT)等技术。这些并不是去年自然语言处理领域唯一的进展;另一个值得注意的是来自语言模型的嵌入(ELMo),这是一个深度上下文化的词表示模型,在模型所用的每个任务上都取得了显著的改进。其他的突破似乎集中在现有技术的改进上,例如BigGANs。此外,由于许多倡导社区成员的声音,关于机器学习中的包容性和多样性的非技术性讨论也成为主流(可以参考NeurIPS作为一个例子)。
我相信在 2019 年,研究的关注将从监督学习转向如强化学习和半监督学习等领域,因为这些领域的潜在应用正变得越来越显著。现在我们已经处于图像识别和生成被“解决”(为了避免使用更具负担的术语)的阶段,例如,我们在此过程中学到的知识可以帮助研究人员追求更复杂的机器学习应用。
作为一名业余的自动化机器学习(AutoML)倡导者,我认为我们将继续看到 AutoML 的渐进式进展,以至于普通的监督学习任务将能够通过现有和开发中的方法自信地进行算法选择和超参数优化。我认为,自动化机器学习的广泛认知将从替代实践者转变为增强实践者(或者可能已经达到了这一临界点)。AutoML 将不再被视为替代机器学习工具箱的威胁,而是作为工具箱中的另一个工具。相反,我觉得实践者将定期在日常场景中使用这些工具已是板上钉钉的事情,并且被期望知道如何使用它们。
布兰登·罗赫尔 (@brohrer) 是 Facebook 的数据科学家。
2018 年的一个重要趋势是数据科学教育机会的激增和成熟。在线课程是最早的数据科学教育场所。它们在所有级别上继续受到欢迎,每年有更多的学生、变体和话题。
在学术界,新的数据科学硕士项目正在以每年大约十几个的速度启动。我们的高等教育机构正在响应公司和学生的呼声,提供专门的数据相关领域项目。(今年,18 位行业合著者和我以及 11 位学术贡献者,共同创建了一个虚拟行业顾问委员会来帮助支持这一爆炸性增长。)
在非正式的领域,教程博客帖子随处可见。它们为数据科学的集体理解做出了很大贡献,无论是对读者还是作者。
从 2019 年开始,学术数据科学项目将成为获取进入首个数据科学职位所需的基本技能的更常见方式。这是一件好事。受认证机构监管的机构将填补一个长期存在的空白。到目前为止,数据科学的资格主要是通过以往的工作经验来证明的。这造成了一个悖论:新的数据科学家无法展示他们的资格,因为他们从未有过数据科学职位,而他们无法获得数据科学职位,因为他们不能展示自己的资格。来自教育机构的凭证是打破这一循环的一种方式。
然而,在线课程不会消失。对许多人来说,大学教育的时间和经济承诺使其无法实现。既然数据科学教育已经确立,它将始终拥有实际的轨道。通过坚持不懈地展示项目工作、相关经验和在线培训,新数据科学家将能够展示他们的技能,即使没有学位。在线课程和教程将继续变得更加普遍、复杂和重要于数据科学教育。实际上,一些知名的数据科学和机器学习项目甚至将他们的课程放到线上,并提供非在校学生的注册选项。我预计数据科学大学学位与在线培训课程之间的界限将继续模糊。在我看来,这才是“数据科学民主化”的最真实形式。
埃琳娜·沙罗娃是 ITV 的高级数据科学家。
2018 年在机器学习(ML)和人工智能(AI)领域的主要发展是什么?
在我看来,2018 年将因以下三件事件而被 AI 和 ML 社区铭记。
首先,欧盟全球数据保护条例(GDPR)旨在提高个人数据使用的公平性和透明度。该条例揭示了个人对控制其个人数据的权利,并获取关于数据使用的信息,但也引起了对法律解释的一些困惑。迄今为止的结果是,大多数公司认为自己已经符合规定,仅仅对数据处理做了一些表面上的更改,而忽视了重新设计数据存储和处理基础设施的根本需要。
其次,剑桥分析丑闻在整个数据科学(DS)社区投下了阴影。如果说之前的争论主要集中在确保人工智能(AI)和机器学习(ML)产品的公平性上,那么这个丑闻引发了更深层次的伦理问题。对Facebook 涉事的最新调查意味着它不会很快平息。随着数据科学领域的成熟,这样的发展将发生在许多行业中,超越了政治。有些将更加悲剧,例如Uber 在亚利桑那州的自动驾驶汽车事件,这些事件将引发强烈的公众反应。技术是权力,权力伴随着责任。正如诺姆·乔姆斯基所说:“只有在民间故事、儿童故事和智识期刊中,权力才被明智地使用以摧毁邪恶。现实世界教给我们的教训却非常不同,只有故意和专注的无知才能未能察觉这些教训。”
最后,从积极的角度来看,亚马逊推出自家服务器处理器芯片意味着我们可能会接近一个云计算普及不再成为成本问题的日子。
你对 2019 年有哪些主要趋势的预期?
数据科学家的角色和责任正超越了建立能够准确预测的模型。2019 年,机器学习(ML)、人工智能(AI)和数据科学(DS)从业者的主要趋势将是对遵循既定软件开发实践的责任日益增加,特别是在测试和维护方面。数据科学的最终产品必须与公司技术堆栈的其他部分共存。对专有软件高效运行和维护的要求将适用于我们构建的模型和解决方案。这意味着最佳的软件开发实践将支撑我们需要遵循的机器学习规则。
Rachel Thomas (@math_rachel) 是 fast.ai 的创始人,也是 USF 的助理教授。
2018 年的两个主要人工智能发展是:
1. 转移学习在自然语言处理中的成功应用
2. 对人工智能的反乌托邦滥用(包括仇恨团体和独裁者的监控与操控)的关注不断增加
转移学习是将预训练模型应用于新数据集的实践。转移学习是计算机视觉进展爆炸性增长的关键因素,2018 年,转移学习在自然语言处理领域成功应用,包括来自fast.ai和 Sebastian Ruder 的ULMFiT、艾伦研究所的 ELMo、OpenAI 变换器和谷歌的 Bert。这些进展既令人兴奋又令人担忧,详见这篇纽约时报文章。
像 Facebook 的决定性角色在缅甸种族灭绝中的作用,YouTube 不成比例地推荐阴谋理论(其中许多推广了白人至上主义),以及政府监控和执法机构使用人工智能的情况,终于在 2018 年开始获得更多主流媒体的关注。虽然这些人工智能的误用情况严重且令人恐惧,但更多的人开始意识到这些问题,并越来越多地反对它们,这是一件好事。
我预计这些趋势会在 2019 年继续,随着自然语言处理的快速进展(正如 Sebastian Ruder今年夏天所写,“自然语言处理的 ImageNet 时刻已经到来”),以及在技术如何用于监控、煽动暴力和被危险政治运动操控方面的更多反乌托邦发展。
Daniel Tunkelang (@dtunkelang)是一位独立顾问,专注于搜索、发现和机器学习/人工智能。
2018 年在自然语言处理和理解中,词嵌入的复杂性取得了两个重大进展。
第一个是在三月。来自艾伦人工智能研究所和华盛顿大学的研究人员发布了“深度语境化词表示”,并引入了 ELMo(Embeddings from Language Models),这是一种开源的深度语境化词表示,相较于 word2vec 或 GloVe 等上下文无关的词嵌入有所改进。作者通过简单地用 ELMo 预训练模型中的向量替代,展示了对现有自然语言处理系统的改进。
第二个突破发生在 11 月。谷歌开源了 BERT(双向编码器表示从变换器),这是一个双向、无监督的语言表示,预先在维基百科上进行训练。正如作者在《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》中所展示的那样,他们在各种自然语言处理基准测试中取得了显著改进,甚至相对于 ELMo 也有显著提高。
在智能扬声器快速普及(到 2018 年底约为 1 亿台)和移动手机上数字助手的普及之间,自然语言理解的进展正迅速从实验室转向实际应用。这是自然语言处理研究和实践的激动人心的时代。
但我们仍然有很长的路要走。
今年,艾伦研究所的研究人员发布了“Swag: A Large-Scale Adversarial Dataset for Grounded Commonsense Inference”,这是一个用于句子完成任务的数据集,需要常识理解。他们的实验表明,最先进的自然语言处理技术仍远远落后于人类表现。
但希望我们能在 2019 年看到更多的自然语言处理突破。计算机科学领域的许多顶尖人才正在努力研发,行业也渴望应用他们的成果。
相关内容:
-
2018 年 AI、数据科学、分析的主要发展与 2019 年的关键趋势
-
机器学习与人工智能:2017 年的主要发展与 2018 年的关键趋势
-
数据科学、机器学习:2017 年的主要发展与 2018 年的关键趋势
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
-
[AI、分析、机器学习、数据科学、深度学习等的主要发展](https://www.kdnuggets.com/2021/12/developments-predictions-ai-machine-learning-data-science-research.html)
预测科学与数据科学
原文:
www.kdnuggets.com/2016/11/predictive-science-vs-data-science.html
评论

我们可以谈论营养科学,它关注我们吃什么。我们可以谈论运动科学,它关注我们如何利用这些卡路里。或者我们可以全面地讨论结果——我认为这涉及到一个更重要的问题,大多数人最终关心的——健康科学。鉴于结果——健康科学——通常比原料——营养学——或将原料转化为更有用的东西的过程——运动科学——更有趣,我们为何往往讨论数据科学而非预测科学?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
明确来说,数据科学不仅仅是预测或分类。它还包括其他机器学习技术,如聚类和频繁项集挖掘。它还包括数据可视化和数据讲述。它也可以涵盖传统的数据挖掘框架的各个方面,例如 KDD 过程,包括数据选择、预处理和转换。数据科学还可以包括其他算法和数据相关任务的方法,超出我在这里提到的内容。
我以前已经全面定义了数据科学:
数据科学是一门多方面的学科,包括机器学习和其他分析过程、统计学及相关的数学分支,越来越多地借用高性能科学计算,以最终从数据中提取洞察,并利用这些新发现的信息讲述故事。
在考虑“预测科学”与数据科学时,我将数据科学的细微相关部分作为对照。事实上,将数据科学拆解为组成的“科学”(例如聚类科学)无疑有助于表达我们究竟在做什么,但显然以一个吸引眼球的总括性术语为代价。
但退一步看,数据无疑是输入,是原材料。从这个意义上讲,数据科学强调的是预测过程中的“什么”。虽然数据是预测难题中的主要成分,且可能是最难获取的,“数据科学”似乎忽略了另一个主要组成部分以及有趣的见解。
算法是变革性的过程。那么 算法科学 呢?它关注的是工具,即“如何”,并且深深根植于计算机科学中。然而,这仍然无法准确描述整体预测过程;数据被抛弃,转而关注将其转化为预测的过程。任何成功的描述可能会集中在最终结果上。
整体预测过程的结果是预测。或者是假设呢?我不是以一种普通的“假设与预测”的方式来提问,而是在询问“预测还是假设是特定分类器/模型的更有价值的输出?”
无论是预测还是假设,这两者中的一个将是整体预测科学难题中最有趣的部分。预测科学——或者如果你觉得“预测科学”更合适——听起来还不错。但实际上,这不就是“科学”?这似乎非常不具体。
那么统计学呢?我们是应用统计学家吗?来源于维基百科:
“应用统计”包括描述统计和推断统计的应用。
加入处方统计,这似乎是朝着正确方向迈出的一步。然而,在这种情况下,重点放在统计过程的应用上,而... 实际上并没有牺牲多少。但我会争辩说,这实际上没有对推断统计和处方统计给予适当的重视,或许过于依赖描述统计,因此在描述预测科学时也显得不够充分。
预测分析?也许是最接近的术语,但这个词目前似乎更贴近商业世界而非科学世界。我没有在研究中看到这个术语,通常它似乎完全属于大企业的领域。这对于它本身来说是可以的,但它的性质似乎并未将科学置于前沿(尽管显然科学支撑着它的使用)。
我不知道是否有解决方案。公平地说,我甚至不知道这个问题是否存在于我的脑海之外。但我认为一切归结为以下几点,并且可以在数据科学的预测方面之外进行概括:数据科学这个术语是否真的对我们这些数据科学家,或者对其他人有实际价值?
我不打算给出建议,即使我有,恐怕也会被忽视。这没关系。但作为一个对“数据科学”这个术语并不特别感到兴奋或舒适的人,我认为值得对我们所做的工作以及如何分类这些任务进行自省。确实,将某个名称赋予广泛相关任务的职业是方便的,但我们是否因为这个森林而看不到树木?
当谈到非常复杂的预测科学时,数据可能是新石油,而算法则是特别的调味料,但它们的配对预测能力才是真正的“钱景”,无论是比喻上还是字面上。
相关:
-
数据科学与大数据的解释
-
数据科学的核心
-
数据科学的分裂会导致一个帝国还是多个共和国?
相关话题
Prefect 自动化与协调数据管道的方法
原文:
www.kdnuggets.com/2021/09/prefect-way-automate-orchestrate-data-pipelines.html
评论
由 Murallie Thuwarakesh,Stax, Inc. 的数据科学家提供。
插图来自 Undraw。
我曾经是 Apache Airflow 的大粉丝。即使今天,我对它也没有太多抱怨。但新技术 Prefect 让我惊叹不已,我忍不住将所有内容迁移到它上面。
Prefect(以及 Airflow)是一个工作流自动化工具。你可以协调各个任务以完成更复杂的工作。你可以管理任务依赖关系、在任务失败时重试任务、调度任务等。
我相信工作流管理是每个数据科学项目的支柱。即使是小项目,也可以通过像 Prefect 这样的工具获得显著的好处。它消除了大量重复任务的部分。不用说,它还消除了复杂项目中的心理负担。
本文涵盖了关于 Prefect 的一些常见问题,包括:
-
Prefect 核心概念的简短介绍;
-
为什么我决定从 Airflow 迁移。
-
Prefect 的令人惊叹的功能和与其他技术的集成,以及;
-
如何在其云部署与本地部署选项之间做出决定。
快速启动 Prefect。
Prefect 是一个既简约又完整的工作流管理工具。它的设置极其简单。然而,它能够完成 Airflow 等工具能够做的所有任务,甚至更多。
你可以使用 PyPI、Conda 或 Pipenv 安装它,它就绪待用。更多关于此的内容在 Airflow 部分中有比较。
pip install prefect
# conda install -c conda-forge prefect
# pipenv install --pre prefect
在我们深入使用 Prefect 之前,先来看一个未管理的工作流。这有助于理解 Prefect 在工作流管理中的角色。
以下脚本查询一个 API(提取 — E),从中选择相关字段(转换 — T),并将其追加到文件中(加载 — L)。它包含执行每个任务的三个函数。这是一个直接但日常使用的工作流管理工具用例 —— ETL。
代码由 作者 提供。
该脚本从 OpenWeatherMap API 下载天气数据,并将风速值存储在一个文件中。现实生活中的 ETL 应用可能很复杂。但这个示例应用很好地涵盖了基本方面。
注意:请将 API 密钥替换为真实的密钥。你可以从 openweathermap.org/api 获取一个。
你可以使用命令 python app.py 运行此脚本,其中 app.py 是你脚本文件的名称。这将创建一个名为 windspeed.txt 的新文件,包含一个值。这是你访问 API 时波士顿的风速。如果你重新运行脚本,它将向同一文件追加另一个值。
你的第一个 Prefect ETL 工作流。
上面的脚本运行良好。然而,它缺少完整 ETL 的一些关键特性,比如重试和调度。此外,如前所述,实际的 ETL 可能在一个工作流中有数百个任务。其中一些可以并行运行,而有些则依赖于一个或多个其他任务。
想象一下,如果有一个临时网络问题阻止你调用 API,脚本会立即失败而不会再做进一步尝试。在实时应用程序中,这种停机时间并不奇怪。它们发生的原因有很多——服务器停机、网络停机、服务器查询限制超出。
此外,你必须每次手动执行上述脚本以更新你的 windspeed.txt 文件。然而,将工作流调度在预定时间内运行在 ETL 工作流中是很常见的。
这时像 Prefect 和 Airflow 这样的工具就派上用场了。下面是你如何调整上面的代码使其成为 Prefect 工作流的方法。
代码来自 作者。
@task 装饰器将一个普通的 Python 函数转换为 Prefect 任务。可选参数允许你指定其重试行为。在上面的例子中,我们配置了该函数在失败之前尝试三次。我们还配置了每次重试之间延迟三分钟。
使用这种新设置,我们的 ETL 对我们之前讨论的网络问题具有弹性。
要测试其功能,请将计算机从网络断开连接,并用python app.py运行脚本。你会看到一条消息,说明第一次尝试失败,下一次将会在接下来的 3 分钟内开始。在三分钟内,将计算机重新连接到互联网。已经运行的脚本现在将无错误地完成。
使用 Prefect 调度工作流。
重试只是 ETL 故事的一部分。许多工作流应用程序的另一个挑战是按计划间隔运行它们。Prefect 的调度 API 对任何 Python 程序员来说都是直接了当的。它是如何工作的,下面是说明。
代码来自 作者。
我们创建了一个 IntervalSchedule 对象,它在脚本执行后五秒启动。我们还将其配置为以一分钟为间隔运行。
如果你用python app.py运行脚本并监控 windspeed.txt 文件,你会看到每分钟都会有新值出现。
除了这种简单的调度外,Prefect 的调度 API 提供了更多的控制。你可以用类似 cron 的方法调度工作流,使用带有时区的时钟时间,或者做一些更有趣的事情,比如仅在周末执行工作流。我在这里没有涵盖所有内容,但 Prefect 的官方 文档 非常完美。
Prefect UI。
像 Airflow(和许多其他工具)一样,Prefect 也附带一个具有美观 UI 的服务器。它允许你控制和可视化你的工作流执行。
插图来自 作者。
要运行这个,你需要在计算机上安装 docker 和 docker-compose。不过,启动它只需一个命令,令人惊讶。
**$** prefect server start

插图由 作者 提供。
这个命令将启动 prefect 服务器,你可以通过你的网页浏览器访问它:[localhost:8080/](http://localhost:8080/)。
然而,Prefect 服务器本身无法执行你的工作流。它的作用只是为所有 Prefect 活动提供一个控制面板。由于这个仪表板与应用程序的其余部分解耦,你可以使用 Prefect cloud 完成相同的任务。我们将在稍后详细讨论这个问题。
执行任务时,我们还需要一些其他东西。好消息是,它们也不复杂。
因为服务器仅作为控制面板,我们需要一个代理来执行工作流。以下命令将启动一个本地代理。如果你的项目需要,你也可以选择 docker 代理或 Kubernetes 代理。
**$** prefect agent local start
插图由 作者 提供。
一旦服务器和代理运行,你将需要创建一个项目并将工作流注册到该项目中。为此,请将执行工作流的行更改为以下内容。
代码由 作者 提供。
现在在终端中,你可以使用 prefect create project <project name> 命令创建一个项目。然后重新运行脚本将其注册到项目中,而不是立即运行。
**$** prefect create project 'Tutorial'
**$** python app.py
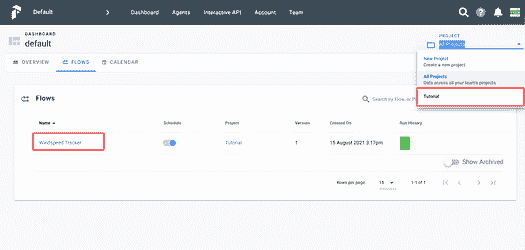
插图由 作者 提供。
在网页界面中,你可以看到新项目‘Tutorial’出现在下拉菜单中,我们的风速跟踪器在工作流列表中。该工作流已经计划并正在运行。如果你愿意,也可以手动运行它们。
插图由 作者 提供。
带参数的工作流运行。
我们在前一个练习中创建的工作流是固定的。它只查询波士顿,马萨诸塞州,我们无法更改它。这时我们可以使用参数。下面是如何调整我们的代码以在运行时接受参数。
代码由 作者 提供。
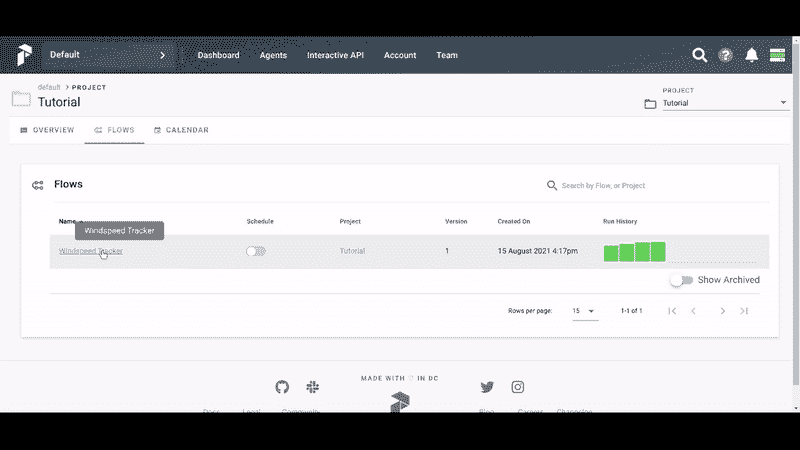
我们已经将函数更改为接受城市参数,并在 API 查询中动态设置它。在 Flow 内部,我们创建一个默认值为‘Boston’的参数对象,并将其传递给 Extract 任务。
如果你在 UI 中手动运行风速跟踪器工作流,你会看到一个名为 input 的部分。在这里,你可以为每次执行设置城市的值。
插图由 作者 提供。
这是运行工作流的一种方便方法。在许多情况下,ETL 和其他工作流都附带运行时参数。
我为什么决定从 Airflow 迁移到 Prefect?
Airflow 是一个出色的工作流管理平台。在许多项目中,它为我节省了大量时间。然而,我们需要欣赏那些取代旧技术的新技术。这就是 Airflow 和 Prefect 的情况。
Airflow 很多地方做得很好,但其核心假设从未预见到数据应用的丰富多样性。
— Prefect 文档。
我在这里描述的内容并不是说如果你偏好 Airflow 就没有解决方案。我们有大多数问题的解决办法。然而,在 Prefect 中,这些问题的解决方案是工具原生支持的。
相比于 Airflow,Prefect 的 安装 非常简单。对于训练有素的眼睛,这可能不是问题。然而,对于任何想要开始工作流编排和自动化的人来说,这是一种麻烦。
Airflow 需要在后台运行一个 服务器 来执行任何任务。然而,在 Prefect 中,服务器是可选的。这是使用 Prefect 的一个巨大优势。我有许多在计算机上作为服务运行的小项目。以前,我必须在启动时启动 Airflow 服务器。因为 Prefect 可以独立运行,所以我不再需要启动这个额外的服务器。
Airflow 不具备使用 参数 运行工作流(或 DAG)的灵活性。我使用的解决方法是让应用程序从数据库中读取这些参数。这对于如此简单的任务来说不是一个很好的编程技术。在这方面,Prefect 的参数概念非常出色。
Prefect 允许拥有相同工作流的不同 版本。每次你将工作流注册到项目中时,它会创建一个新版本。如果你需要运行以前的版本,你可以轻松地在下拉菜单中选择它。这在 Airflow 中是不可能的。
Prefect 还允许我们创建团队和基于角色的访问控制。每个团队可以管理自己的配置。授权 是每个现代应用程序的重要部分,Prefect 以最佳方式处理它。
最后,我发现 Prefect 的 UI 更加直观和吸引人。Airflow 的 UI,尤其是其任务执行可视化,刚开始时很难理解。
Prefect 的生态系统及其与其他技术的集成。
Prefect 内置了与许多其他技术的集成。它消除了大量的开销,使得与这些技术的工作变得非常简单。
现实项目经常需要处理多种技术。例如,当你的 ETL 失败时,你可能想要向维护者发送电子邮件或 Slack 通知。
在 Prefect 中,发送这样的通知是非常简单的。你可以使用 Prefect 的任务库中的 EmailTask,设置凭据,然后开始发送电子邮件。
你可以在他们的 官方文档 中了解更多关于 Prefect 丰富生态系统的内容。在本文中,我们将看到如何发送电子邮件通知。
要发送电子邮件,我们需要使凭证对 Prefect 代理可访问。你可以通过在$HOME/.prefect/config.toml中创建以下文件来实现。
代码来自作者。
你的应用程序现在已准备好发送电子邮件。以下是我们成功捕获风速测量时如何发送通知。
代码来自作者。
在上述代码中,我们创建了 EmailTask 类的一个实例。在初始化期间,我们使用了电子邮件配置的所有静态元素。然后在 Flow 中,我们使用了带有变量内容的实例。
上述配置将发送包含捕获的风速测量的电子邮件。但其主题将始终保持为‘捕获的新风速’。
Prefect Cloud 与本地服务器部署。
我们已经了解了如何启动本地服务器。因为这个服务器只是一个控制面板,你可以轻松地使用云版本代替。要做到这一点,我们需要遵循一些额外的步骤。
-
创建一个Prefect cloud账户。
-
从API 密钥页面生成一个密钥。
-
在你的终端中,将后端设置为云:
prefect backend cloud。 -
还需要使用生成的密钥登录:
prefect auth login --key YOUR_API_KEY。 -
现在,像往常一样启动代理:
prefect agent local start。
在云仪表板中,你可以管理之前在本地服务器上完成的所有操作。
在选择云版本和服务器版本时,一个重要问题是安全性。根据 Prefect 的文档,服务器仅存储与工作流执行相关的数据和用户提供的自愿信息。由于代理在你的本地计算机上执行逻辑,你可以控制数据存储的位置。
云选项在性能方面也很合适。使用一个云服务器,你可以管理多个代理。因此,你可以轻松地扩展你的应用程序。
最后的想法
Airflow 曾是我构建 ETL 和其他工作流管理应用程序的最终选择。然而,Prefect 让我改变了主意,现在我正在将所有内容从 Airflow 迁移到 Prefect。
Prefect 是一个简单的工具,具有超越 Airflow 的灵活扩展性。你甚至可以在 Jupyter notebook 中运行它。同时,你可以将其作为完整的任务管理解决方案进行托管。
除了工作流管理的核心问题外,Prefect 还解决了你可能在实时系统中经常遇到的其他问题。管理带有授权控制的团队、发送通知等就是其中的一些。
在这篇文章中,我们讨论了如何创建一个 ETL,它
-
根据配置重试一些任务;
-
按计划运行工作流;
-
接受运行时参数,并且;
-
当操作完成时,发送电子邮件通知。
我们只是触及了 Prefect 能力的表面。我建议阅读官方文档以获取更多信息。
还不是 Medium 会员?请使用此链接 成为会员。你可以享受数千篇有见地的文章,并支持我,因为我通过推荐你获得少量佣金。
个人简介:Murallie Thuwarakesh (@Thuwarakesh) 是 Stax, Inc. 的数据科学家,并且是 Medium 上的顶级分析写作者。Murallie 分享了他在数据科学中的每日探索。
原文。经授权转载。
相关内容:
-
Prefect:如何使用 Python 编写和安排你的第一个 ETL 管道
-
使用 Gretel 和 Apache Airflow 构建合成数据管道
-
本地开发和测试 AWS 的 ETL 管道
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关内容
Prefect: 如何用 Python 编写和调度您的第一个 ETL 管道
原文:
www.kdnuggets.com/2021/08/prefect-write-schedule-etl-pipeline-python.html
评论
由 Dario Radečić,NEOS 的顾问

照片由 Helena Lopes 提供,来自 Pexels
我们的三大课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业轨道
2. Google Data Analytics Professional Certificate - 提升您的数据分析技能
3. Google IT Support Professional Certificate - 支持您在 IT 领域的组织
Prefect 是一个基于 Python 的工作流管理系统,基于一个简单的前提— 您的代码可能正常工作,但有时它并不(source)。当一切按预期工作时,没有人会考虑工作流系统。但当事情出问题时,Prefect 将确保您的代码成功失败。
作为一个工作流管理系统,Prefect 使得在数据管道中添加日志记录、重试、动态映射、缓存、失败通知等变得非常容易。当您不需要它时,它是隐形的——当一切按预期运行时;而当您需要它时,它是可见的。就像保险一样。
虽然 Prefect 不是唯一的 Python 用户工作流管理系统,但它无疑是最高效的一个。像 Apache Airflow 这样的替代品通常表现良好,但在处理大型项目时会带来很多麻烦。您可以在这里阅读 Prefect 与 Airflow 的详细比较。
本文涵盖了库的基础知识,例如任务、流程、参数、失败和计划,并解释了如何在本地和云端设置环境。我们将使用 Saturn Cloud 来完成这部分,因为它使配置变得毫不费力。这是由数据科学家制作的云平台,因此大部分繁重的工作都为您完成了。
Saturn Cloud 可以轻松处理 Prefect 工作流。它也是从仪表板到分布式机器学习、深度学习和 GPU 训练的前沿解决方案。
今天您将学习如何:
-
本地安装 Prefect
-
使用 Python 编写一个简单的 ETL 管道
-
使用 Prefect 声明任务、流程、参数、调度并处理失败
-
在 Saturn Cloud 中运行 Prefect
如何在本地安装 Prefect
我们将在虚拟环境中安装 Prefect 库。以下命令将通过 Anaconda 创建并激活一个名为prefect_env的环境,基于 Python 3.8:
conda create — name prefect_env python=3.8
conda activate prefect_env
你需要输入y几次来指示 Anaconda 继续,但这在每次安装时都是这样的。在库方面,我们需要Pandas用于数据处理,Requests用于下载数据,当然,还需要Prefect用于工作流管理:
conda install requests pandas
conda install -c conda-forge prefect
我们现在拥有了开始编写 Python 代码所需的一切。接下来我们开始动手吧。
用 Python 编写 ETL 管道
今天我们将使用 Prefect 完成一个相对简单的任务——运行一个 ETL 管道。这个管道将从一个虚拟 API 下载数据,转换数据,并将其保存为 CSV 文件。JSON Placeholder 网站将作为我们的虚拟 API。除此之外,它还包含十个用户的虚假数据:
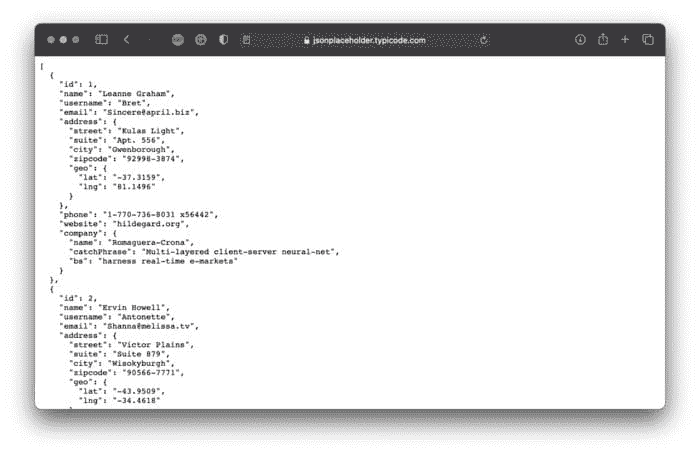
图 1 — 虚假用户数据(来源:https://jsonplaceholder.typicode.com/users))(图片由作者提供)
首先创建一个 Python 文件——我将其命名为01_etl_pipeline.py。另外,请确保有一个文件夹来保存提取和转换的数据。我称之为data,它位于 Python 脚本所在的位置。
任何 ETL 管道都需要实现三个功能——用于提取、转换和加载数据。在我们的案例中,这些功能将完成以下任务:
-
extract(url: str) -> dict— 对url参数发出一个 GET 请求。测试是否返回了一些数据——如果是的话,它将作为字典返回。否则,会抛出一个异常。 -
transform(data: dict) -> pd.DataFrame— 转换数据,仅保留特定的属性:ID、姓名、用户名、电子邮件、地址、电话号码和公司。将转换后的数据作为 Pandas DataFrame 返回。 -
load(data: pd.DataFrame, path: str) -> None— 将之前转换过的data保存到path处的 CSV 文件中。我们还会在文件名中添加时间戳,以免文件被覆盖。
在函数声明之后,所有三个函数在执行 Python 脚本时都会被调用。这是完整的代码片段:
现在你可以通过在终端中执行以下命令来运行脚本:
python 01_etl_pipeline.py
如果一切正常,你不应该看到任何输出。然而,你应该在data文件夹中看到 CSV 文件(我运行了文件两次):
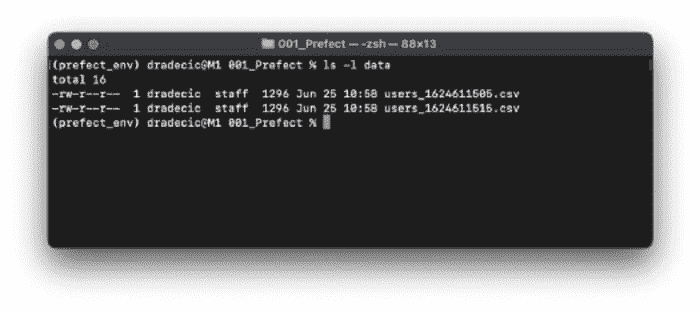
图 2 — 运行 ETL 管道两次后 data 文件夹中的 CSV 文件列表(图片由作者提供)
正如你所看到的,ETL 管道运行并完成没有任何错误。但如果你想按照计划运行管道呢?这时Prefect派上用场了。
探索 Prefect 的基础知识
在本节中,你将学习 Prefect 任务、流程、参数、调度等的基础知识。
Prefect 任务
让我们从最简单的开始 — 任务。它基本上是你工作流中的一个单独步骤。为了跟上进度,创建一个名为 02_task_conversion.py 的新 Python 文件。从 01_etl_pipeline.py 复制所有内容,然后你就可以开始了。
要将 Python 函数转换为 Prefect 任务,你首先需要进行必要的导入 — from prefect import task,然后装饰任何感兴趣的函数。以下是一个示例:
@task
def my_function():
pass
这就是你需要做的全部!这是我们 ETL 流程的更新版本:
让我们运行它,看看会发生什么:
python 02_task_conversion.py
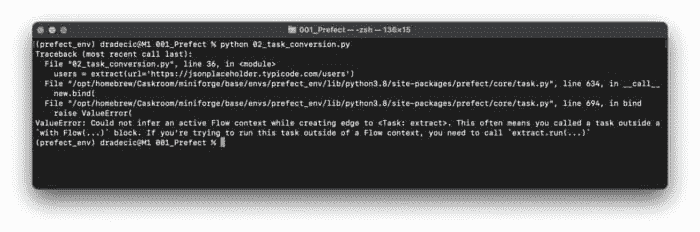
图 3 — 使用 Prefect 将函数转换为任务(图片由作者提供)
看起来似乎出了问题。这是因为 Prefect Task 不能在没有 Prefect Flow 的情况下运行。接下来我们来实现它。
Prefect 流程
将 02_task_conversion.py 中的所有内容复制到一个新文件 — 03_flow.py。在声明之前,你需要从 prefect 库中导入 Flow。
要声明一个流程,我们将编写另一个 Python 函数 — prefect_flow()。它不会接受任何参数,也不会被装饰。函数内部,我们将使用 Python 的上下文管理器来创建一个流程。该流程应包含与之前在 if __name__ == '__main__' 代码块中相同的三行代码。
在提到的代码块中,我们现在需要用相应的 run() 函数来运行流程。
这是该文件的完整代码:
让我们运行它,看看会发生什么:
python 03_flow.py
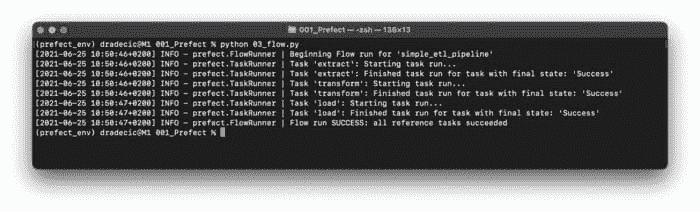
图 4 — 第一次运行 Prefect 流程(图片由作者提供)
这真是太棒了!不仅 ETL 流程被执行了,我们还获得了关于每个任务开始和结束时间的详细信息。我已经运行了文件两次,因此应该会有两个新的 CSV 文件保存到 data 文件夹中。让我们验证一下是否如此:
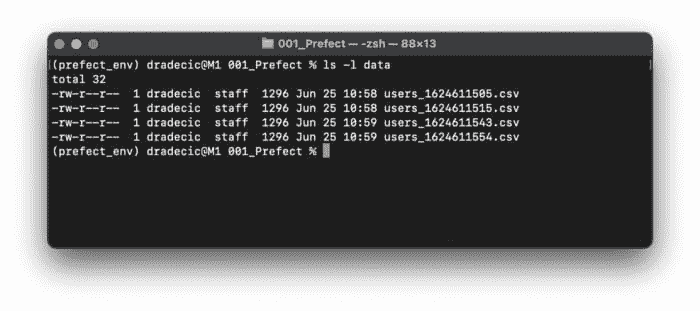
图 5 — Prefect 流程生成的 CSV 文件(图片由作者提供)
这就是如何使用 Prefect 运行一个简单的 ETL 流程。它目前还没有比纯 Python 实现带来很多好处,但我们很快会改变这一点。
Prefect 参数
硬编码参数值从来不是一个好主意。这就是 Prefect Parameters 发挥作用的地方。首先,将 03_flow.py 中的所有内容复制到一个新文件 — 04_parameters.py。你需要从 prefect 包中导入 Parameter 类。
你可以在流程上下文管理器中使用这个类。以下是你可能会觉得有用的参数:
-
name— 参数的名称,将在运行流程时使用。 -
required— 一个布尔值,指定该参数是否是执行流程所必需的。 -
default— 指定参数的默认值。
我们将声明一个用于 API URL 的参数 — param_url = Parameter(name='p_url', required=True)。
要给参数赋值,你需要将 parameters 字典指定为 run() 函数的一个参数。参数名称和值应以键值对的形式编写。
这是该文件的完整代码:
让我们运行文件,看看会发生什么:
python 04_parameters.py
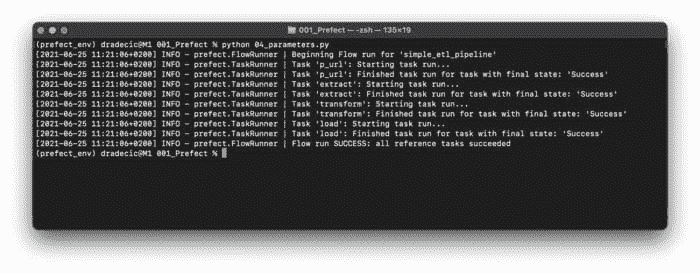
图 6 — 运行包含参数的 Prefect 流(图像作者提供)
我已经运行了两次文件,因此data文件夹中应出现两个新的 CSV 文件。让我们确认一下:
图 7 — Prefect 流生成的 CSV 文件(图像作者提供)
就这样——在一个地方指定参数值。这使得将来进行更改变得容易,也方便管理更复杂的工作流。
接下来,我们将探讨 Prefect 的一个特别有用的功能——调度。
Prefect 调度
今天我们将探讨两种调度任务的方法——间隔调度和Cron 调度。第二种可能听起来很熟悉,因为 Cron 是在 Unix 上调度任务的著名方法。
我们将从 间隔调度器 开始。首先,将04_intervals.py中的所有内容复制到05_interval_scheduler.py。你需要从prefect.schedules中导入IntervalScheduler。
然后,我们将在 prefect_flow() 函数声明之前创建导入类的实例,并指示其每十秒运行一次。这可以通过设置 interval 参数的值来实现。
要将调度器连接到工作流,你需要在使用上下文管理器初始化Flow类时为schedule参数指定值。
整个脚本文件应如下所示:
让我们运行文件,看看会发生什么:
python 05_interval_scheduler.py
图 8 — 使用间隔调度(图像作者提供)
如你所见,整个 ETL 管道运行了两次。Prefect 将向终端报告下一次执行的时间。
现在,让我们探讨 Cron 调度器。将05_interval_scheduler.py中的所有内容复制到06_cron_scheduler.py。这一次,你将导入CronSchedule而不是IntervalSchedule。
在类初始化时,你需要为cron参数指定一个 cron 模式。五个星号符号将确保工作流每分钟运行一次。这是 Cron 的最低可能间隔。
其余部分保持不变。以下是代码:
让我们运行文件:
python 06_cron_scheduler.py
图 9 — 使用 Cron 调度(图像作者提供)
如你所见,ETL 管道每分钟运行两次,正如 Cron 模式所指定的。接下来的部分,我们将探讨如何处理失败——并解释为什么你应该总是做好准备。
完美失败
迟早,你的工作流中会发生意外错误。Prefect 提供了一种极其简单的方法来重试任务的执行。首先,将04_parameters.py中的所有内容复制到一个新文件中 — 07_failures.py。
extract()函数可能因为各种网络原因而失败。例如,API 可能暂时不可用,但几秒钟后会恢复。这些情况在生产环境中时有发生,不应该完全崩溃你的应用程序。
为了避免不必要的崩溃,我们可以稍微扩展一下task装饰器。它可以接受不同的参数,今天我们将使用max_retries和retry_delay。这两个参数不言自明,所以我不会进一步解释。
唯一的问题是 — 我们的工作流现在不会失败。但如果我们在flow.run()内部放置一个不存在的 URL 作为参数值,它会失败。以下是代码:
让我们运行文件:
python 07_failures.py

图 10 — 使用 Prefect 防止失败(作者提供的图像)
任务失败了,但工作流并没有崩溃。当然,在经过十次重试后,它会崩溃,不过你始终可以更改参数规格。
这就是在本地使用 Prefect 的所有内容。接下来,让我们将代码移到云端,并探讨一下变化。
在 Saturn Cloud 中运行 Prefect
让我们立即开始动手吧。首先,注册一个免费的Prefect Cloud账户。注册过程简单明了,不需要进一步解释。注册完成后,创建一个项目。我将其命名为SaturnCloudDemo。
在转到Saturn Cloud之前,你需要在 Prefect 中创建一个 API 密钥来连接这两个服务。你可以在设置中找到API Key选项。如你所见,我将其命名为SaturnDemoKey:
图 11 — 创建 Prefect Cloud API 密钥(作者提供的图像)
现在你已经具备了所需的一切,前往Saturn Cloud创建一个免费账户。一旦进入仪表板,你会看到多个项目创建选项。选择Prefect选项,如下所示:

图 12 — 在 Saturn Cloud 中创建 Prefect 项目(作者提供的图像)
Saturn Cloud 现在会自动为你完成所有繁重的工作,几分钟后,你可以通过点击按钮打开 JupyterLab 实例:
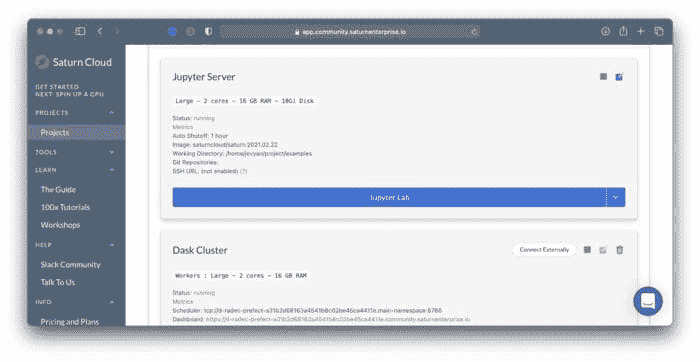
图 13 — 在 Saturn Cloud 中打开 JupyterLab(作者提供的图像)
你将可以访问两个笔记本 — 第二个笔记本展示了在 Saturn Cloud 中使用 Prefect 的快速演示。如下所示:

图 14 — Saturn Cloud 中的 Prefect Cloud 笔记本(作者提供的图像)
你只需要更改两个设置来使笔记本正常工作。首先,将项目名称更改为 Prefect Cloud 中你的项目名称。其次,将 <your_api_key_here> 替换为几分钟前生成的 API 密钥。如果你做对了,你应该会看到以下消息:
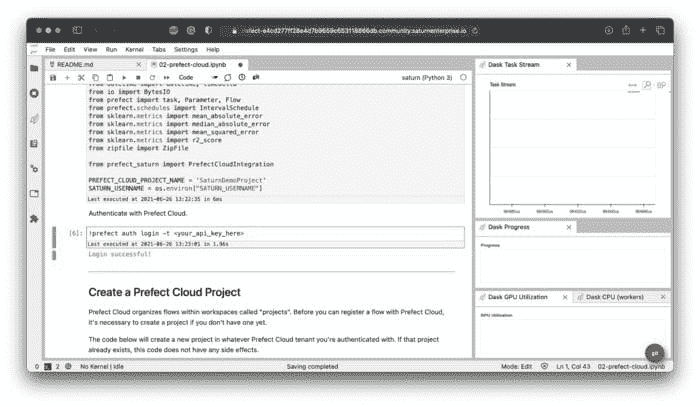
图 15 — Saturn Cloud 中的登录成功消息(图片由作者提供)
为了进行测试,请运行接下来的每个单元格。然后转到 Prefect Cloud 仪表板并打开你的项目。它不会像几分钟前那样空着:
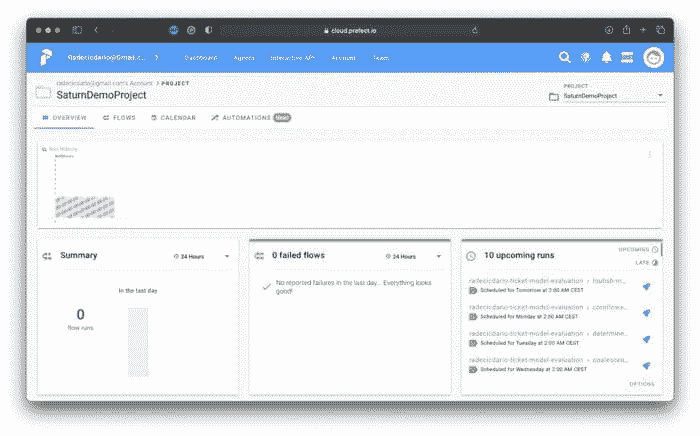
图 16 — 成功的 Prefect 任务调度(图片由作者提供)
这就是你需要做的全部!随意复制/粘贴我们的 ETL 管道并验证其是否有效。这就是 Saturn Cloud 的亮点——你可以从本地机器上复制/粘贴代码,几乎无需更改,因为所有繁琐的配置都自动完成。
让我们在下一部分总结一下。
最后的思考
那么,这就是 Prefect 的基础知识介绍,包括本地和云端的内容。我希望即使在阅读这篇文章之前你对这个话题一无所知,也能看到工作流管理系统在生产应用中的价值。
要获取更高级的指南,即配置日志记录和 Slack 通知,请参考 官方文档。提供的示例足以帮助你入门。
保持联系
简介: Dario Radečić 是 NEOS 的顾问。
原文。经许可转载。
相关内容:
-
AWS 本地 ETL 管道的开发与测试
-
什么是 ETL?
-
dbt 数据转换 – 实用教程
更多相关主题
准备数据科学面试中的行为问题
原文:
www.kdnuggets.com/2021/07/prepare-behavioral-questions-data-science-interviews.html
评论
作者 Zijing Zhu,经济学博士,数据科学认证专家

照片由Clem Onojeghuo拍摄,来源于Unsplash
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
在我之前关于数据科学面试准备的文章中,我列出了用于练习的技术问题,包括machine learning、statistics和probability theory。我还讨论了在数据科学面试前后准备案例分析问题的策略。这篇文章是数据科学面试准备系列的第五篇,主要关注行为问题。我将首先讨论如何准备行为环节,然后列出一些常见问题,供你练习这些技巧。
我在面试过程中最喜欢行为面试,因为与其他技术面试相比,它相对轻松。在我了解回答行为面试问题的策略之前,我总感觉在这个环节中我是在和人聊我经历过的有趣事情。尽管在面试过程中保持较少的压力心态是件好事,但过于放松可能会让你无法给面试官留下深刻的印象。我最终讲述了过多的细节,错过了证明自己符合面试官要求的机会。请记住,即使你主要是在与面试官聊天,你仍然会通过这轮对话被评估。你应该把这轮面试视为展示你基于经验和个性为何是最佳候选人的机会。没有扎实的例子和明确的结构,你无法有效地展示自己,这将在本文中讨论。
第一部分:收集有力的例子
行为面试问题的回答内容是基础。在面试过程中,为了保持对话流畅,你很少有时间思考完美的例子来回答问题。因此,在准备面试时,我们应从收集所有“有用”的经历开始,并按问题类型进行分类。这样,你就会知道你总会有话题可谈,并且有合适的例子来支持你的论点。在这一部分,我将讨论收集有力例子的过程。
制作你的清单
你应该使用哪些例子来回答行为面试问题?考虑一下你过去的工作和学习经历,并将其分类到不同的类别中。
当我准备行为面试问题时,我使用了以下表格来头脑风暴我所经历的经验。尽管问题可以用无数种方式提出,我们可以将它们概括为以下八类。你遇到过哪些挑战?你如何优先安排工作?你有哪些成就想要分享?有哪些例子能展示你的领导能力?你什么时候遇到过冲突,如何处理的?你犯过哪些错误?你如何适应新环境,融入其中?
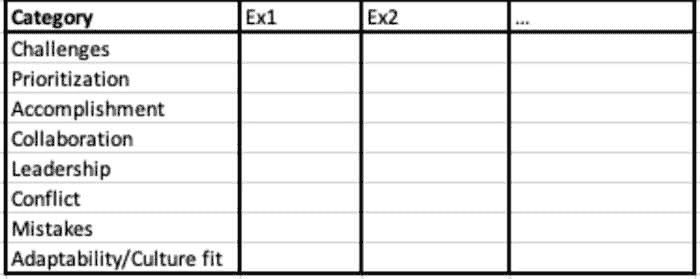
类别清单
对于每个类别,搜索你的记忆并准备至少一个例子分享。如果每个类别有多个例子,那就更好!将它们全部写下来,并从不同方面加以强调。例如,在展示你的成就的同一类别中,你可能会找到一个例子强调你的自学能力,另一个则显示你是一个团队合作者。这些都是面试官可能会寻找的优秀特质。收集所有这些例子,并学习如何根据面试中的问题背景优先选择分享的例子。
优先考虑例子
如果你有多个挑战已经克服,那么在回答特定问题时,你应该选择哪个挑战?我建议你遵循以下原则来优先考虑例子:
-
优先考虑影响力较大的例子:影响力是关键。它展示了你工作的成果,并证明你符合申请的要求。当你说你为项目构建了一个新模型时,人们可能会质疑,直到你提到这个模型增加了 x%的客户留存率。
-
优先考虑相关的例子:相关性有几个方面。首先,根据问题的背景和提问方式,答案可能会有所不同。因此,在面试过程中,积极倾听非常重要。尽管你可能已经准备好了很好的演讲,但如果与问题无关,你应该根据问题调整你的回答。此外,如果你申请的是工作岗位,那么工作相关的例子比学校项目更为相关。
-
优先考虑近期的例子:讨论最近发生的例子比讨论很久以前发生的事情更好。例如,你可以讨论你在最近职位上的经历。如果你有工作经验,当被问及领导力技能时,你仍然使用学校的例子,面试官可能会对你在职场中实践技能的能力产生疑虑。这会发出不好的信号。
研究公司的核心价值观和职位描述
面试官希望从你讲述的经历中发现一些关键特征。一般来说,这些特征包括:
-
良好的沟通者
-
自信与谦逊
-
主动进取者
-
遵守规则和协议的能力
-
独立自主
-
与他人合作良好
-
问题解决者
-
对角色和公司的承诺
-
领导力特质
-
公司的积极代表
你使用的例子应向面试官展示你具备他们所寻找的关键特征。此外,每家公司都有其核心价值观,可能会优先考虑某些品质。你应该在线上轻松找到这些核心价值观或从职位描述中总结出来。在准备例子时,记住所有核心价值观,并在回答中尽量融入并优先考虑它们。
充分利用每个例子
在回答有关解决冲突的问题时,除了展示你解决问题的技能外,你还可以展示你出色的沟通能力和领导力。 因此,我建议你也为你所有的代表性例子制作下表:

首先总结这个例子的量化影响。然后尝试挖掘这个例子并勾选这个例子有助于展示的类别。你可以写一个关于你在这个例子中完成的任务的单句总结,展示你在这一类别中的质量。
如果你有工作经验,你可以很容易找到许多例子,无论是全职、兼职还是实习。对于新毕业生,学术经验也可以作为工作经验来处理。你可以谈谈你参与的一个个人研究项目;你如何与顾问合作,他们类似于职场中的主管;你如何与其他研究生合作,他们类似于职场中的同事。如果你曾经担任过助教,即使这份工作本身可能与你现在申请的职位无关,你仍然可以谈谈一些展现你沟通和领导技能的经历。
诚实
不要编造任何例子! 不要假装成你不是的人。 找到工作不是故事的终点,而是开始的篇章。你不希望给未来的同事或老板留下错误的印象,让他们觉得你以后每天都要假装成别人的样子。与其编造例子,不如回顾你已有的经验,并深入挖掘细节。当我寻找我的第一份全职工作时,我在向一些面试官证明我在职场上的能力时遇到了一些困难。我特别强调了我在初创公司实习的经历,尤其是我与来自不同团队的主管和同事合作的部分。这段经历给了我很多可以用来证明我的沟通和领导技能的例子,并向面试官展示我能够在快节奏的工作环境中表现出色。这也是为什么我们需要深入挖掘并充分利用所有例子的原因。
第二部分:建立和实践结构
你的回答应该始终有条理。否则,你会发现自己很容易在没有重点的情况下滔滔不绝或喋喋不休。你不是在跟朋友聊天,所以你不需要深入每一个细节。你也不是在写悬疑小说,所以不需要让读者绞尽脑汁并尝试给他们惊喜。在面试中,你的回答应该直接、简洁明了。
遵循 STAR 结构
STAR 代表 Situation(情境)、Task(任务)、Action(行动)、Result(结果)。这是一个可靠的方法来构建你的回答。

作者绘制
你从简要描述你所处的情况或需要完成的任务开始你的回答。然后谈谈你需要完成的任务。接着列出你为完成这些任务所采取的行动。最后,总结一下你的行动结果是什么。例如,发生了什么?事件如何结束?你达成了什么?你学到了什么?注意:
-
你可以用结果来描述情况。例如,你可以从“我想分享一下我建立了一个模型,减少了 x%的客户流失”开始你的回答。
-
你选择的任务需要是具体的,而非一般的或假设性的。
-
即使是一个团队项目,也要专注于描述你的任务和行动。如果你需要提到其他人的任务,强调沟通和协作技能。
-
如果你能量化结果,它总是会显得更令人印象深刻。
有关更多细节和示例,请参阅这篇文章和许多其他在线文章,以帮助你练习这种结构。
关注影响而非过程
我无法强调足够展示你工作的影响有多么重要。你怎么做固然重要,但不是优先考虑的,因为你不是在一个知识分享会议上。你应该专注于你做了什么,特别是结果是什么。量化对公司关键 KPI 的影响会更令人印象深刻。
将细节留到后续问题中
起初不要深入细节,尤其是技术细节。保持你的回答清晰且直截了当。首先简要介绍示例,并专注于影响和结果。如果面试官对你如何取得结果感到好奇,他们会问跟进问题,然后你可以详细说明。如前所述,诚实地讲述你知道什么和不知道什么。如果你假装自己做过某事或详细了解某事,面试官可能会问跟进问题并发现你在撒谎。这是一个很糟糕的信号。
第三部分:练习常见问题
现在你有了一些示例,并且知道了正确的结构,练习以下问题:
-
讲述一下你曾被要求做过从未做过的事情的经历?你学到了什么?
-
讲述一下你曾同时负责多个项目的经历。你是如何组织时间的?结果如何?
-
讲述一下在工作中有重要的事情未按计划进行的经历。你的角色是什么?结果如何?你从这次经历中学到了什么?
-
讲述一下你曾经需要和一个难以相处的人一起工作的经历。你是如何处理与那个人的互动的?
-
讲述一下在问题出现时你的主管不在的经历。你是如何处理这种情况的?你咨询了谁?
最后的备注
你可以在线找到很多其他问题来练习。当我说练习时,我并不是让你写下答案然后阅读,希望在面试中遇到完全一样的问题。相反,要练习用一种固定的结构来回答问题。此外,要在镜子前面或与伙伴一起练习,以便获得反馈。请记住,在面试过程中,你并不是在演讲,而是在与他人交谈。因此,积极倾听,并注意他人的反应是非常重要的。我知道在虚拟面试中可能会更具挑战性,我有一篇文章这里帮助你更好地为虚拟面试做准备。目标是进行一次良好的对话,因此你应该专注于回答问题,而不是提供“完美答案”。
这篇文章就到这里。感谢阅读。这里是我所有博客文章的列表。如果你感兴趣,可以查看一下!
我的快乐之地
个人简介:Zijing Zhu 拥有经济学博士学位,获得数据科学认证,并对生活充满热情。
原文。经授权转载。
相关内容:
-
数据科学面试中你应该知道的 10 个统计概念
-
麦肯锡教给我的 5 个课程,让你成为更优秀的数据科学家
-
数据科学家编码面试终极指南
更多相关内容
为有效的 Tableau 和 Power BI 仪表板准备数据
原文:
www.kdnuggets.com/2022/06/prepare-data-effective-tableau-power-bi-dashboards.html
商业智能(BI)技术如 Power BI 和 Tableau 用于收集、集成、分析和展示商业信息。这些工具可以帮助你分析商业数据并可视化信息,以获得有价值的见解。
创建一个提供见解的仪表板可以是一个快速的过程(特别是当你对所选择的 BI 工具有一定的专业知识后)。你可能已经是专家,但仍会发现当你尝试做以下一项(或多项)时,事情会变得非常棘手和耗时:
-
连接多个数据源
-
玩转数据类型和数据分类
-
创建将数据源混合在一起的数据模型
-
创建一个涉及多个聚合层级的可视化
-
自动化你的仪表板刷新
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
BI 工具可以在展示数据、创建用户视图,甚至有时执行行级安全方面表现出色。现在,PowerBI 和 Tableau 都提供了针对上述复杂用例的功能。这些功能可以帮助构建一次性的快速分析,但在构建有效、可扩展和稳定的可视化时,面对广泛且要求高的受众就显得不足够。大多数情况下,在完成一个临时分析后,数据分析师需要将其转化为稳定的报告,这就面临着以智能方式自动化工作的挑战。
诀窍?
将数据准备工作与分析工作解耦,并坚持使用 BI 工具进行可视化和格式化。 通过将过程简化为输入和输出,你将为自己未来的心理健康和客户满意度进行投资。解耦意味着每一步都在最合适的工具中完成,然后自动化,最终这些拼图的部分是简单且彼此独立的。
很好,但是怎么做?
我已经列出了分离数据旅程阶段所需的步骤,并使每个步骤在之后简单自动化。请注意,无论你的技术背景如何,你都应该能够遵循这些步骤(从基本的 Excel 文件到复杂的 Python 流程)。你可以随时调整你的方法,以拆解你的过程,并使你未来的自己(或你的备份/替代人员)能够重复/更新/更改它。没有人应该在每次想做小修改时都需要剖析一个变成黑箱的文件!
了解最终的仪表板需求
从仔细倾听开始。客户和最终用户(或产品负责人)会带来他们的愿望清单和必需品。他们会关注他们想看到的最终效果和格式。作为报告的负责人,你需要记住的是,报告的目的是:
-
分析数据
-
得出结论
-
做出更好的决策
因此,当他们说“我需要 A,并且应该显示 B”时,你的下一个问题不应该是:
-
什么颜色?
-
什么大小?
-
什么类型的图表?
相反,最好找出你的产品负责人为什么想要看到那个指标。问问自己:他们想要达成什么目标?当你了解他们的优先级时,你可以在开始分析他们的数据之前回答一些重要问题,例如:
-
这是一次临时分析吗?
-
我想回答什么问题?
-
我的受众是谁?
-
他们习惯于什么细节级别?
-
这个报告是否有助于促进定期讨论?
-
那次讨论的格式是什么?
-
我如何确保这些讨论围绕解决问题展开?
(而不是关注数字的来源或它们对每个参与者的意义?)
这是信任发挥作用的地方。如果你的客户知道你理解他们的需求并花时间清理和优化他们的数据,他们会相信这些数据反映了他们的现实。最终,这就是每个客户想要的。可以信任的数据。
在这个过程的这个阶段,在经过几次对话后,你应该对所需的工作范围、仪表板的目的以及他们计划如何使用它有了更清晰的了解。这样你就可以开始工作,并且要尽快完成(你可以确定,花在这个阶段的时间越多,愿望清单上会增加更多的附加需求)
访问数据
这是你多任务处理技能受到考验的阶段。确保你提出一个类似这样的清单:
| 数据源 | 所需频率 | 目的 | 访问者 | 状态 | 临时解决方案 |
|---|---|---|---|---|---|
| 数据源 A | 每日更新 | 需要用于主页 KPI:- A - B - C | 团队/人员 | 已请求/票证开放/等待批准/已批准/… | 使用提取数据 |
| 数据源 B | 每周更新 | 需要用于安全层(用户和角色) | 团队/人员 | 使用测试环境/虚拟数据 | |
| 源 C | 每月更新 | 实现实际与目标对比功能所需 | 团队/人员 | 不可用 |
这将大大有助于跟踪你想要什么和不想要什么,同时保护你免受瓶颈困扰。商业中最不愿听到的就是借口,所以提供事实吧。这是我拥有的和我没有的,以及在等待它时我正在使用的。你的产品负责人将会知道如何准确帮助你,因为他们希望你迅速推进到一个完成的解决方案。他们还会知道哪些数据已被提供给你作为替代方案(提取数据、测试/虚拟数据等……),以便你能在没有最终数据的情况下继续工作。
最重要的是,这展示了资源的机智(在最终访问待定时仍能工作)和透明度(他们准确知道为什么某个部分的解决方案尚未构建或在处理非生产数据)。保持合作伙伴的参与和建立信任要求你具备机智和透明度。这将为你在未来阶段节省许多麻烦。
数据摄取(获取)
从快速胜利开始,确保在流程早期有一个简单的演示,并专注于拥有一些数据。获取最原始的数据,而不是那些无人负责的处理过的数据。如果原始数据过大,那么就使用它的一个子集。一个典型的错误是过早地将数据聚合,直到太晚时才意识到需要更多。在演示时,摄取每个数据源的原始子集。
在这一点上(而不是更晚的时候!),记录和文档你所获取的内容,并始终告知客户你已获得足够的数据来构建第一个演示。有些仪表板可能需要二十多个不同的数据源,结合多种方式,这些方式难以记住。在这里,摄取后,你开始建立你的 ERD (如何构建实体关系图),或针对更简单的用例,构建你的数据库图以简单记录你拥有的(或计划拥有的)数据。无需花哨,你可以使用笔和纸、白板、数字白板工具(如 Excalidraw、Microsoft Whiteboard、Visio、Google Draw……)或 markdown (mermaid ERD),只要你理解你拥有的数据以及它们如何合并成最终的平面表格即可。
数据合并
这是你创造最大价值的地方。通过在数据之间建立强有力的关系,你构建了干净且完整的操作数据集,使最终用户的工作更加轻松。理想情况下,他们可以在几秒钟内连接到产品(使用 SQL、Python、Tableau、PowerBI 等),并直接开始分析。这不是一项容易的任务,它取决于你在第一步(理解最终需求)做得有多好。像处理任何棘手任务一样,先将其拆解为步骤,并使用一个 可视化示例:
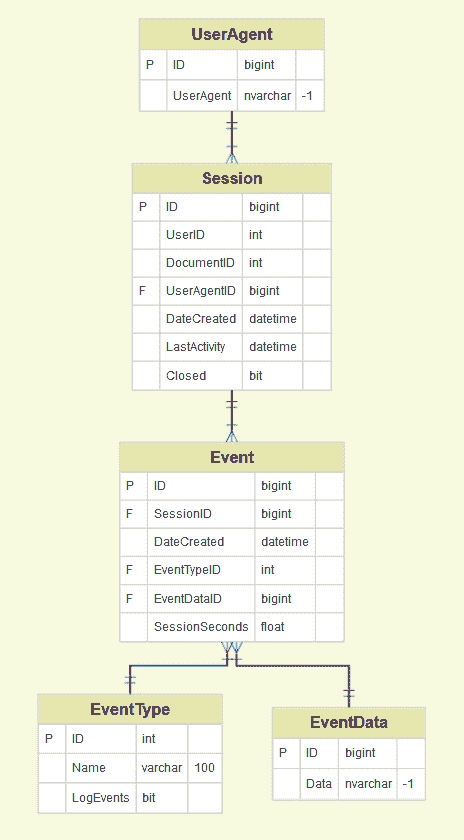
在当前示例中,我们有五个数据集(UserAgent、Session、Event、EventType、EventData)
使用你的可视化工具(基于前一步骤构建)并确保每个原始数据集都有一个唯一的键,可以用来与其他数据集建立连接(这些可以是来自数据源的自定义 ID,或自动生成的键)。你可能需要清理(注意数据类型!)某些字段,并生成你的键(例如,添加一个连接列)以确保连接正常工作。
请注意,在此示例中,每个 UserAgent 都有一个 ID,每个会话都有自己的 ID,并且还有它关联的 UserAgentID。在会话期间,会发生一个事件(新的 ID)。花一点时间识别出哪些是你的核心数据集,即那些处于你将要报告的同一级别的数据集?这将帮助你建立所有的连接并在需要时进行联接。请参见以下一些场景:
-
UserAgent 层级分析:最终用户希望拥有一个仪表盘,允许他们了解出现了多少个 UserAgent 以及它们的参与情况(每个会话的会话数和事件数……)。你需要以“UserAgent”数据集作为核心,然后将 Sessions 和 Events 作为补充信息,以帮助你回答有关用户的问题。
-
会话分析:最终用户希望拥有一个仪表盘,允许他们了解发生了多少个会话,也许还有一些用户或与这些会话相关的事件的特征。在这里,你的核心数据集将是“Session”,并与“Event”、“EventType”、“EventData”进行联接……
-
事件分析:最终用户希望拥有一个仪表盘,允许他们了解用户会话期间发生的最常见事件。在这里,核心数据集将是“Event”,并与“Event Type”、“Sessions”、“EventData”进行联接……
记住,你的仪表板可能需要以上所有内容。你可能需要关注不同的数据集,因此如果你正确完成了第一步,你会知道你需要多个操作表作为产品的一部分。执行你的连接(使用 SQL、Python、数据处理工具或甚至在最初阶段使用 Excel),并定期检查记录数,以防止在连接表时生成虚假行,并创建最简单的操作表版本。
将所有终端用户要求的计算直接添加到模型中(而不是你的可视化工具上)。每次用户需要使用这些计算数据时,他们将直接从数据集中获取,而不是从仪表板导出。这也更具扩展性,并避免了由多个用户构建的不同仪表板之间的数据差异。
现在你有了初步操作数据,回到多任务处理。你可以构建一个快速演示来让终端用户使用,以便给你提供数据准确性的反馈,同时你并行处理下一步。
清理和格式化数据。
首先,快速浏览数据,以了解你使用了什么数据。然后查看(例如,前 10 行和最后 10 行),注意细节。这包括:
-
数据类型(数值、文本、日期、布尔值、数组)。
-
数据格式(小数、整数)。
-
相同数据类型的所有列原始数据格式是否一致(例如,所有日期列是否有相同的日期格式)。
-
是否是数值(定量)和类别(定性)数据。
-
如果是文本数据 -> 它是什么?城市名称?产品代码?
这些都有助于理解数据之间的关系,确定数据需要什么样的准备/处理,并调整可视化技术。记得查找空值、数字/文本、语言之间的不同格式(对于自由文本)和 HTML 标签清理。
通过过滤或快速摘要完成这项工作。所有这些都会避免在可视化过程中繁琐的步骤,如果数据清晰且格式正确,准备可视化只需几次点击。
其次,深入了解细节。根据数据类型,数据清理的方法不同,可能存在不同种类的“异常值”。对特定数据类型要查看的内容总结:
日期
-
检查数据存储的数据类型。如果数据与日期无关,存在例如日期被处理为数值的风险,那么开头的零可能会被删除。
-
保持一致的格式(例如,'YYYY-MM-DD')。
-
日期只应在有意义的情况下使用(例如,出生日期不应是未来的)。
文本
-
如果文本很长(例如推文),使用分词方法。
-
确保名称的一致性(例如,数据可能包含 'USA'、'United States of America' 和 'U.S.A.',这些都是指同一事物)。
数值
-
保持格式一致(例如,保留两位小数,整数应表现为整数,而非小数等)
-
检测异常值(例如通过可视化、Z-score 方法、IQR 方法,异常值可能对指标有显著影响,这就是为什么重要的是要思考它们为何出现以及是否需要删除/修正它们,或者它们是否包含重要且真实的信息,这可能对业务(例如欺诈)至关重要)-> 异常值是一个庞大的话题
-
逗号或句号 -> 保持一致
同样,如果你有分类数据,确保类别有意义,并且没有两个类别适用于同一事物。记得记录你创建/调整的类别,以便数据用户能准确了解其含义
第三,提供列名。
-
在处理/建模时记得使用简单、描述性的列名,避免词间的空格和特殊符号,以免给自己带来不必要的麻烦
-
对于业务使用的最终模型,使用他们所需的列名
-
尽量遵循 命名规范(或按照指南创建自己的规范),记录下来并让你的数据用户熟悉它。在数据集之间保持一致,你将逐渐在你的组织中建立起清晰数据的文化,大家都能理解
如果你理解你的产品负责人的优先事项,像 Power BI 和 Tableau 这样的商业智能技术可以优化和准备数据用于 Tableau 和 PBI 仪表板。一旦你获得数据,你可以进行摄取、组合、清理和格式化。
此时,你可能已经准备好跳到你的 BI 工具(PowerBI、Tableau……)中,将所有这些步骤整合到一个文件中,连接到数百万个原始提取数据。抵制这个冲动,相信解耦的过程!记住,简单是这里的关键词
-
听,听,听。
-
制作作为参考的列表
-
将事情分解成更小的步骤(数据摄取、数据验证、数据清理……)
-
对于数据处理,使用为自动化数据建模而设计的工具
(Python、SQL、可视化 SQL,甚至 Excel,如果这是你熟悉的)
-
最终仪表板要坚持使用可视化工具
别忘了记录你的进展!你将转到下一个有趣的项目,很可能会忘记所有细节。虽然这篇文章没有覆盖这个内容,但可以看看 如何构建自解释的流程 并在截止日期临近时节省时间。
“你的未来自我会感谢你!”
Valeria Perluzzo 是 dyvenia 的分析主管。
更多相关话题
如何准备数据科学面试
原文:
www.kdnuggets.com/2022/12/prepare-data-science-interview.html

图片由作者提供
如果你未能准备,你就是在准备失败。这不是我的话,而是本杰明·富兰克林的话。老 Beejey 考虑到他一生中担任的多个职位,可能是面试方面的专家。他的建议对数据科学面试来说再好不过了。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
拿破仑·波拿巴采纳了 Beejey 的建议,但在滑铁卢公司面试失败后,意识到过度准备是灵感的敌人。
一如既往,真相总是在两个极端之间。你如何在准备充分与保持个性和自发性之间找到平衡?
我将讨论你需要彻底准备的内容以及你应有意少准备的内容。

图片由作者提供
如何准备(并成功)数据科学面试?
在面试之前,你需要彻底了解几件事情。这些都是需要知识、训练有素和精准的基础内容。只有在充分准备的情况下,你才能做到这一点。
-
研究公司
-
研究职位
-
了解面试过程
-
练习技术技能
-
构建项目组合
每次数据科学职位面试都围绕技术技能展开。然而,所有其他准备阶段同样重要。这些准备将使你高效地练习技术技能,并在面试中使其脱颖而出。
1. 研究公司
这一部分的准备通常被认为是必要的,因为‘它留下了好印象’。你不想留下好印象。你想在面试中表现出色。这两者通常被混淆。做一些事情以留下好印象意味着你在尝试做你认为面试官想听的内容。大家都在说同样的事:面试官喜欢看到你对公司和角色进行了研究。
是的,这是真的。但留下好印象只是结果,而不是彻底研究公司的原因。你这么做的原因是你需要知道一旦你获得工作,你和你的技能如何适应。如果你想在那里适应的话。

图片来源:作者
需要关注的事项
在研究公司时,你应关注公司的:
-
历史
-
产品
-
组织结构
-
雇主
-
财务表现
-
竞争对手
-
新闻
历史。 这包括了解公司成立的时间,它在你所在市场的历史,以及它如何在历史中发生变化(如合并、收购、所有权变更)。
你可能希望了解,因为你可能不想为一家拥有可疑所有者的公司工作。或者你特别喜欢公司如何自然成长为今天的模样?也许你想避开新成立的公司,认为那些历史更久远的公司更能给你安全感。或者初创公司正是你所寻找的。
产品。 通过了解公司销售的产品,你可以获得更多关于公司概况的信息。他们的产品是便宜且低质量的吗?还是以质量闻名?哪些产品是主要的收入来源?你是否已经使用了这些产品,或者对其中一些产品有极大的反感?公司的市场份额是多少?他们的最新产品是什么?
组织结构。 检查公司的组织结构。了解他们的组织架构是多么高层或扁平。查找他们的高管、他们的经验以及就业历史。找出员工人数。熟悉各个部门,并了解每个部门的目的。找出他们在多少个国家和地区运营。
雇主。 查看他们的现任和前任雇员对公司的评价。他们为什么离开?他们为什么留下?此外,在这个阶段,你还应该尝试了解你职位的薪资范围。
财务表现。 不需要查看过去十年的所有财务报告。但要了解最新的总体趋势,如收入、利润和股价。
竞争对手。 这与公司的产品有关。找出他们的产品与谁竞争。与竞争对手相比,他们的表现如何?公司的市场份额是在缩小还是增长?通过了解竞争对手,你还会对公司的行业有更多了解。
新闻。 通过阅读关于公司的新闻,你可以对公司的未来有所了解。他们是否推出了新产品或停产了一些产品?他们是否打算上市?谁想接管公司?公司是否在收购其竞争对手?公司的首席执行官是否采取了你喜欢或不喜欢的政治立场?
让我向你展示,了解上述内容对你来说有多重要,而不仅仅是你留下的印象。希望你能够选择你想工作的雇主。对数据科学家绝望的雇主可能会把你放在那种位置上,所以你需要了解你的谈判能力。
如果你对此有所了解,这意味着你也可以选择你的雇主。如果你被面试的是一个成立了 2 年的初创公司(历史),他们销售市场上最受欢迎的产品,你是(产品与竞争对手)的粉丝,而且你只有一个老板(层级结构),这个老板非常直言不讳并且在为种族不平等问题做些什么(新闻),你可能会非常愿意为这样的公司工作。尤其是当他们为数据科学家提供高于平均水平的薪资(员工)时。
从中,你还可以更清楚地了解公司可能如何利用你的技术专长以及他们使用什么技术。了解这些信息能为你的技术技能准备提供更多方向。
但你如何判断公司的情况是否适合你?
去哪里寻找?
你所需信息的来源是:
-
公司网站
-
公司的社交媒体账号
-
相关媒体渠道
-
LinkedIn
-
论坛和其他网站上(潜在)雇主对公司的评价
2. 研究职位
现在你对公司了解得很清楚了,进一步了解你申请的职位。

作者提供的图片
再次查看职位描述。记录下提到的技术。广告重点关注哪些技能?(你在练习技术技能时会用到。)你的日常工作是什么?你将与哪些团队/部门/分支机构合作?你向谁汇报?
为什么这很重要?例如,如果你是产品开发团队中的数据科学家,你知道你的技术技能准备将需要更具产品导向。
3. 了解面试流程
一旦你对公司的总体情况和你的位置有了感觉,下一步就是了解公司的面试流程。
在这里你会更具体地了解。你需要知道面试中会有什么期待和会见到谁。
面试的内容
数据科学面试通常包括三个阶段:
-
电话筛选/在线评估
-
面对面面试
-
HR 面试
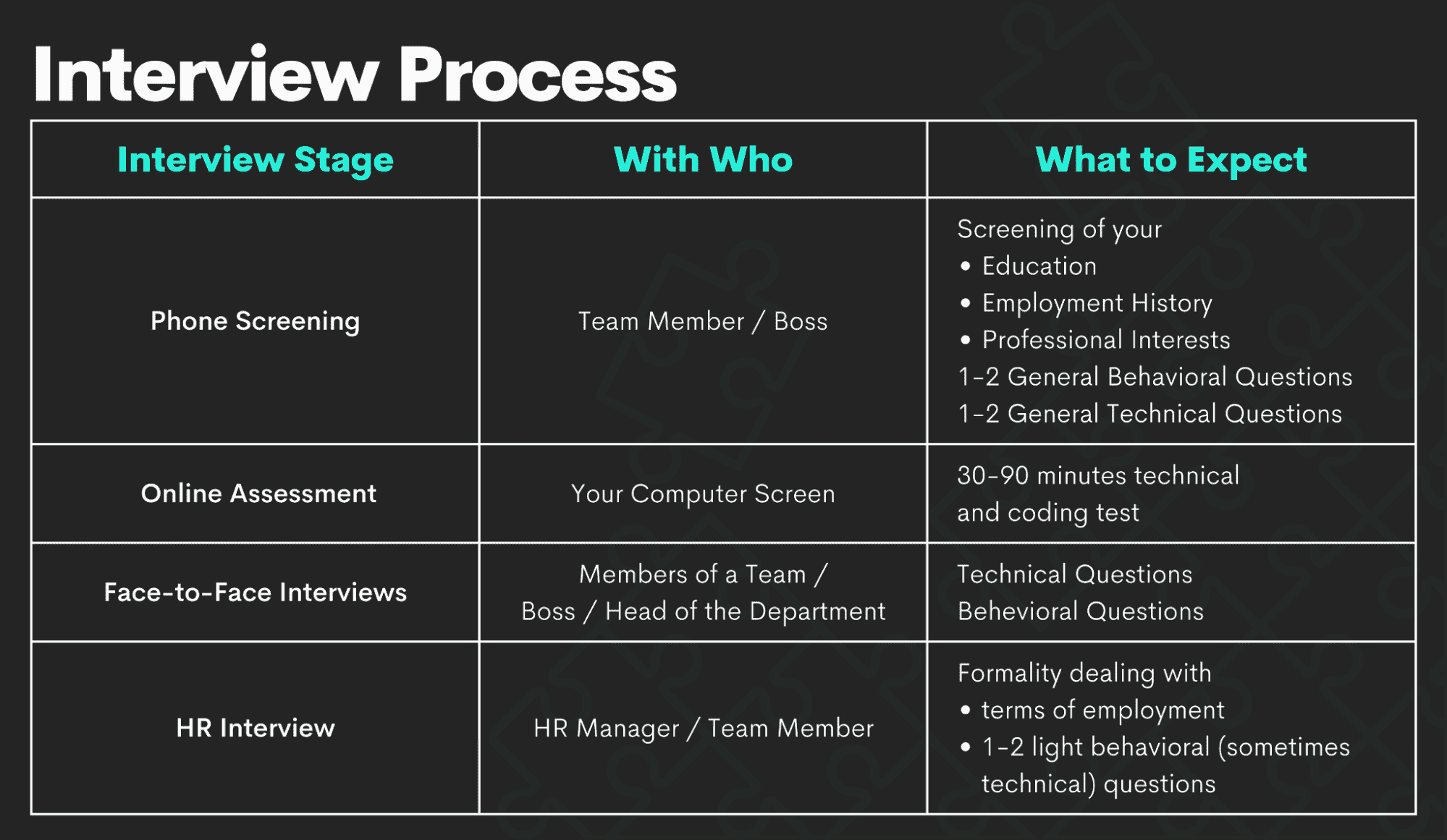
作者提供的图片
电话筛选涉及到你未来的团队成员或老板了解你。你会讲解你的简历,谈论你的教育背景、工作经历以及职业兴趣。这个阶段通常包括几个行为问题,可能还会有一两个一般性的技术问题,以确保你是这个职位的合适人选。
一些公司还喜欢通过在线评估来测试你的技术和编程知识。通常需要 30 到 90 分钟。
面对面面试的次数取决于公司。无论如何,这通常是面试过程中的最严峻环节。你将会被各种行为和技术问题轰炸,还有可能会有编程测试,甚至可能会有家庭作业。根据公司情况,这也可能包括与高管的面试。
如果你能挺过这些,最后阶段通常只是形式上的。
HR 面试只是为了对雇主在其他面试阶段了解到的关于你的信息做最后确认。预计会有一些非常简单的行为问题,偶尔也会有技术问题。这个阶段主要是讨论薪资、福利以及其他与你的雇佣相关的细节。
面试的相关人员
相关人员?不是那个乐队。在这里你要找出谁将会是面试官。如果你知道他们的名字,可以进行调研。
在 LinkedIn 上查找他们的工作经历。用谷歌搜索他们。试着找到他们的社交媒体账户。别担心,他们也会偷偷关注你。
从你了解到的情况,你可以对他们有一定的了解。这可以帮助你知道在面试中期待什么,以及如何适应面试官。例如,如果面试官没有技术背景,你可以尝试不要在回答中使用过多的技术术语。也许这正是他们想测试的:你如何向非技术人员解释技术问题?此外,你也可以通过提及你们都喜爱的足球队来建立联系。
但要保持一些尊严。不要试图讨好面试官。
4. 练习技术技能
没办法告诉你面试中会问到的具体问题。但我可以告诉你会遇到哪些类型的问题。
我和我的团队在 2021 年为我们的数据科学面试指南进行了这个分析。可以放心地说,在这期间没有发生显著变化,所学内容没有过时。
我们的研究发现,数据科学家最常见的问题类型是编码。其他经常出现的主题包括建模、算法和统计。
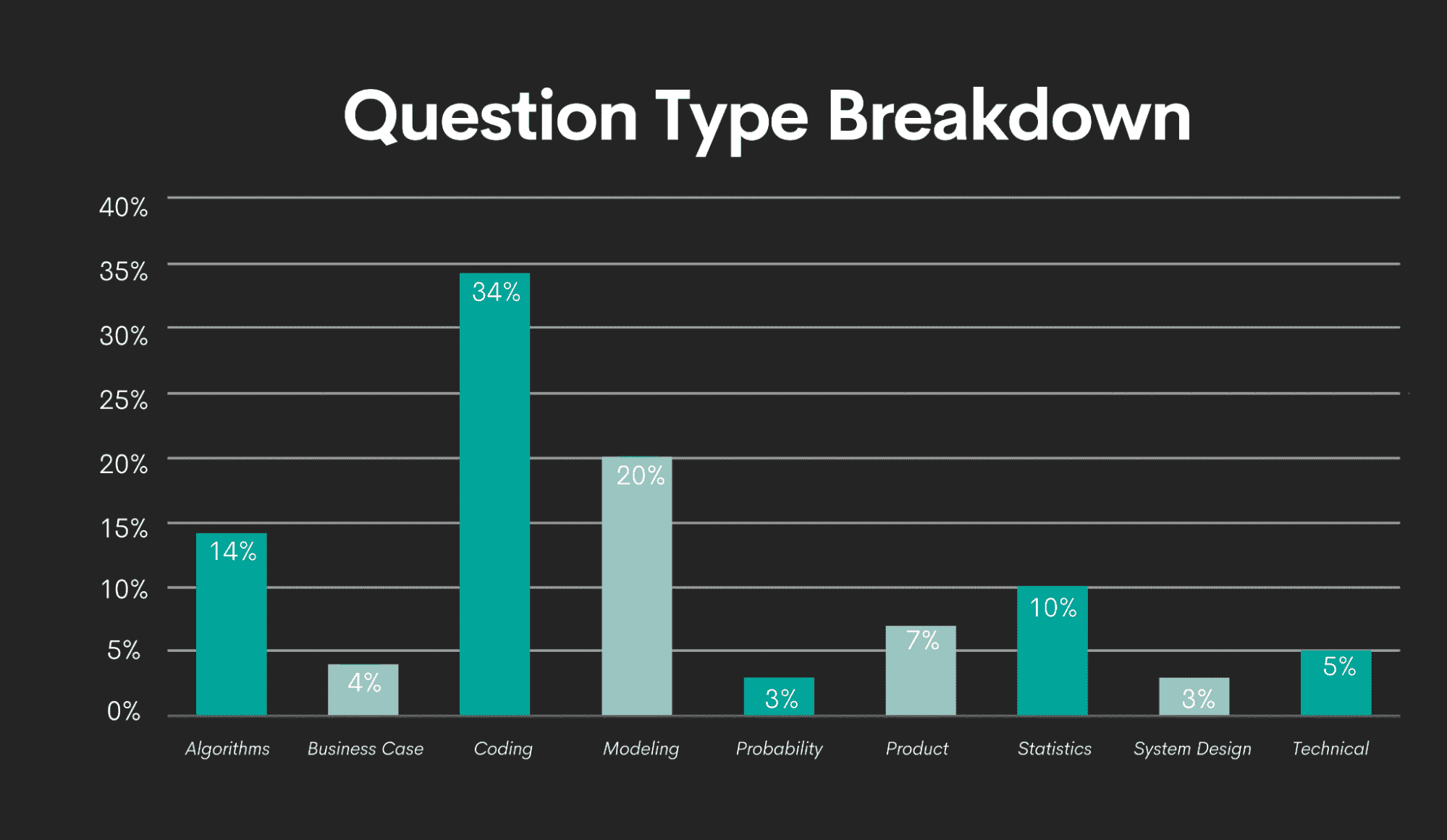
图片作者
数据科学中最常见的编程语言是
-
SQL
-
Python,
-
R
你应该将编程练习集中在这三种语言上。但这也是你通过研究公司、职位和面试过程而受益的地方。
你应该知道数据科学家在特定公司使用哪些编程语言。也许这三种语言都同等重要?也许他们只使用其中一种语言。如果你知道这一点,你可以集中精力在它上面,而不是浪费时间在他们甚至不使用的编程语言上。或者,你可以扩展你的准备,因为你知道公司会希望你使用额外的编程语言。
如果你在谷歌上搜索“数据科学面试问题”,你会找到许多资源,其中包含更多或更少的通用问题。最常见的情况下,这将是四个最流行类别中的问题。
随意阅读这些内容,理解他们的答案并解码。你还可以在如 Glassdoor、Quora 或 reddit 等网站上找到一些实际的问题。
这可能是一个好的开始,但通常不够。
这个部分的名字中有“练习”是有原因的。回答技术问题需要练习,尤其是编程方面。
由于编程是最受欢迎的主题,我建议你解决尽可能多的编程挑战。这不仅会提高你对重要编程概念的掌握,还会提升你的速度。你会习惯于问题的提问方式。通过练习,你还可以发展自己的系统化解题方法。
一些好的资源用于 数据科学面试问题 是:
5. 项目作品集
尽管面试可能会让人感到不知所措,但它们只能给出候选人的技能和整体适应性的大致估计。
再次强调,你不是为了取悦面试官而创建作品集。拥有数据科学项目的作品集是一个好主意,因为这是你将所有数据科学技能应用于实际问题的终极考验。
当你构建你的作品集时,你会将你的技术技能准备提升到一个全新的水平。
当然,并不是每个项目都值得展示在你的作品集里。当你选择做哪些项目时,最好选择那些涉及以下方面的项目:

作者提供的图片
-
使用实际数据(APIs 和其他技术)
-
使用数据库存储数据,最好是云数据库
-
构建模型
-
部署模型/使用可视化工具创建图形
-
发布你的工作以获取反馈(reddit,GitHub)
做那些需要所有这些技能的项目将意味着你掌握了所有必要的数据科学技能。
在面试前检查你的作品集。删除一些你以前的初学者项目。只保留那些你认为能充分展示你当前技能的项目。
如果你的作品集很庞大,根据你面试的职位进行调整。选择几个最适合职位描述的项目。
什么不该准备(并且成功)?
现在,让我们看看你应该有意少准备什么,以便在面试中表现得最好。
我说的少准备是什么意思?我并不是指完全不准备。我是说,你应该只准备一些一般性的指导方针。对预期的情况和该说些什么有一个大致的了解。
但不要再进一步了!面试的这一部分严重依赖于你和面试官之间的互动,取决于面试的方向,这是不可预测的。你无法预先设定这些!
所以尽量放松,注意你周围的环境,针对你听到和看到的做出反应。这是你能拥有的最佳‘准备’。
面试官提问
当然,你是‘允许’思考不同的场景以及你应该问面试官的问题。如果你在面试前发现自己有一些好的问题,可以记住它们并在面试时提问。
如果你没有准备好问题,不要慌张。首先,说没有愚蠢的问题是不对的。是的,有愚蠢的问题。(当我说愚蠢时,我指的是为了提问而提问。)所以,没有提前准备好问题总比准备一些愚蠢的问题要好。
其次,问题会在与你的面试官对话过程中自然地出现。如果面试官提到一个数据库,这时你可以问他们使用的是哪个数据库和 SQL 方言。他们说你将成为数据科学团队的一员,你可以问他们团队有多少成员,谁会是你的上司。
你能看到它是多么自然吗?问题的要点在于不要假装专注。专注会导致你有问题要问。记住,尽管它被称为面试,它实际上是一场对话。在对话中,每个参与者都在提问和回答问题之间转换。
行为问题
我之前提到过,面试中除了技术问题,还会有行为问题。
你也不应该详细准备这些问题。这些问题没有正确答案,答案应该来自于你的经验,你对情况的处理,以及你的思考。简而言之,来自于你的个性。
面试官想了解你。让他们了解你。留出一些自发性、沉默和思考的空间。不要害怕停顿,也不要害怕两周前没有准备好每一个词。
是的,提前考虑一下你如何与团队成员解决冲突,或者想到一个显示你在压力下如何反应的例子,这是好的。但只需从一般的角度考虑,以便你对故事有一个大致的了解。不要把你想说的一切都背下来。
你对这些问题的回答不应该是机械的。此外,与普遍看法相反,面试官欣赏那些在回答前花时间思考的人。当然,有些面试官不这样做。但是,你愿意为一家不允许你思考的公司工作吗?作为数据科学家?我也不愿意。
摘要
数据科学面试准备 本身并不复杂,特别是考虑到可以帮助你的资源数量。使其相对困难的是,正确完成准备工作需要时间。
这需要你在充分准备和展示个人风格之间找到平衡。
尝试在下次面试中应用这些一般性的建议,看看效果如何。
Nate Rosidi 是一名数据科学家和产品战略专家。他还是一名兼职教授,教授分析课程,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过来自顶级公司的真实面试问题为面试做准备。可以在 Twitter: StrataScratch 或 LinkedIn 上与他联系。
相关主题
Presto 为数据科学家 – SQL 适用于任何数据
原文:
www.kdnuggets.com/2018/04/presto-data-scientists-sql.html
评论
由 Kamil Bajda-Pawlikowski,Starburst Data 的 CTO 提供。
最初由 Facebook 开发,Presto 是一个开源、分布式 ANSI SQL 查询引擎,它能够快速分析各种数据源,数据规模从吉字节到拍字节不等。对于数据科学家来说,这对于在几秒钟内返回大数据查询结果非常理想,通过支持仪表板、报告和临时分析,加快数据科学发现的迭代过程。
Presto 被从零开始设计和构建,目的是成为一个快速的 SQL 查询引擎。它遵循经典的 MPP SQL 引擎设计,其中查询处理在机器集群上并行进行。因此,高度并发的查询以交互速度执行。然而,它有一个显著的偏离传统并行数据库管理系统的教科书配方——计算和存储的分离。Presto 的架构完全抽象化了它可以连接的数据源。连接器 API 允许为文件系统和对象存储、NoSQL 存储、关系数据库系统以及自定义服务构建插件。只要数据科学家能够将数据映射到表格、列和行等关系概念中,就可以创建一个 Presto 连接器。
实际上,Presto 配备了大量现有的连接器,包括 HDFS、S3、Cassandra、Accumulo、MongoDB、MySQL、PostgreSQL 和其他数据存储。此外,在 Presto 的单个安装中,用户可以注册多个目录,并运行访问多个连接器的数据的查询。此外,虽然许多数据科学项目和生产应用程序需要执行 ETL,但使用 Presto,你可以直接查询数据所在的位置。
例如,想象一下将来自 RDBMS 的客户数据与 Kafka 中的最新事件关联,并回到 Hadoop 或 S3 查看这些数据如何与过去的趋势相关。这确实是“SQL-on-Anything”。
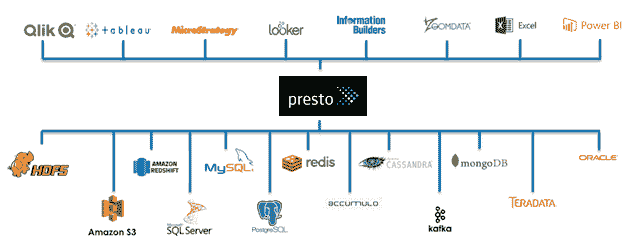
Presto 将许多最流行的大数据源与各种分析、商业智能、仪表板和可视化应用程序连接起来。
与大量 SQL-on-Hadoop 引擎不同,Presto 在大数据查询和分析中不依赖于 Hadoop。它几乎可以部署在任何地方,无论是在公共云、虚拟机集群还是本地专用集群。如果 Hadoop 在其中,数据科学家可以放心。Presto 仅通过连接到 Hive Metastore 允许用户与 Hive、Spark 和其他 Hadoop 生态系统工具共享相同的数据。一个不依赖于 Hadoop 的额外好处是供应商中立的方法,以及对包括 Avro、ORC、Parquet、RCFile、Text 等常见文件格式的原生支持。
在过去几年里,Presto 在 各种规模的企业 中经历了前所未有的增长,从快速发展的互联网公司到《财富》500 强。除了 Facebook,早期采用者还包括 Airbnb、Dropbox、Groupon 和 Netflix 等。Presto 路线图的加速以及成功的概念验证也导致了在 Bloomberg、Comcast、FINRA、LinkedIn 和 Lyft 以及 Slack、Twitter、Uber 和 Yahoo! Japan 的生产部署。
确实,上个月在 圣荷西的 Strata Data Conference 上,几位领先的 Presto 采用者 讨论了他们的部署 并展示了互动速度、卓越的查询并发性 和出色的可扩展性。
除了快速的 ANSI SQL 和对多种数据源的访问外,Presto 还为数据科学家提供了什么?考虑易用性、简单的部署和通过 Superset、Redash、Jupyter 和众多支持 JDBC 和 ODBC 的分析工具的访问。考虑到 Presto 与数据科学生态系统的良好集成,它支持包括 C、Go、Java、Python、R 和 Ruby on Rails 在内的流行编程语言。
此外,Presto 具有大量的 内置分析函数,包括 lambda 表达式和函数、窗口函数、正则表达式,甚至地理空间函数——被 Uber 公共地广泛使用。除了标准 SQL 数据类型,数据科学家还可以处理复杂类型,如映射、数组、结构体和 JSON。
如果这引起了你的兴趣,我鼓励你下载免费的开源 Presto 并分享你的故事。对许多数据科学家来说,这可以迅速成为快速查询大数据和互动分析的游戏规则改变者。
相关:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 事务
更多相关内容
机器学习中的主要监督学习算法
原文:
www.kdnuggets.com/2022/06/primary-supervised-learning-algorithms-used-machine-learning.html

什么是监督学习?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
监督学习是机器学习的一个子集,其中机器学习模型在已标记(输入)数据上进行训练。结果是,监督模型能够尽可能准确地预测进一步的结果(输出)。
监督学习背后的概念可以通过实际场景来解释,例如教师第一次辅导孩子学习新主题。
为了简化,假设教师想要教孩子成功识别猫和狗的图像。教师将通过不断展示猫或狗的图像,并告知孩子这些图像是狗还是猫,来开始辅导过程。
猫和狗的图像可以被视为已标记的数据,因为孩子/机器学习模型在训练过程中将被告知哪些数据属于哪个类别。
监督学习用于什么?监督学习可以用于回归和分类问题。分类模型允许算法确定给定数据属于哪个组。例子包括真假、狗/猫等。
虽然回归模型能够根据之前的数据预测数值,例如预测某员工的薪资或房地产的售价。
在本教程中,我们将列出一些最常见的监督学习算法,并提供这些算法的实际教程。
请注意,这些教程使用 Python 编写。所有使用的数据集都可以在 Kaggle 上找到,因此无需下载任何大型数据集。
线性回归
线性回归是一种监督学习算法,根据给定的输入值预测输出值。线性回归用于目标(输出)变量返回连续值的情况。
线性算法主要有两种类型,简单和多重线性回归。
简单线性回归仅使用一个独立(输入)变量。例如,根据一个孩子的身高预测其年龄。
另一方面,多重线性回归可以使用多个独立变量来预测最终结果。例如,根据房产的位置、大小、需求等预测房地产价格。
以下是线性回归公式
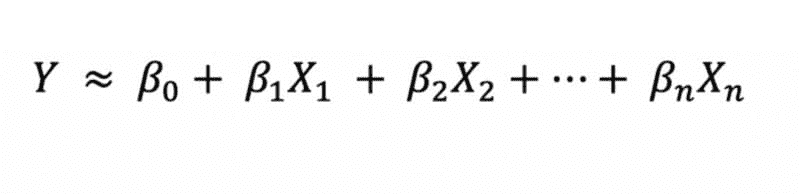
在我们的 Python 示例中,我们将使用线性回归根据给定的 x 值预测 y 值。
我们给定的数据集将仅包含两列;x 和 y。注意,y 结果将返回连续值。
要查找使用的数据集,请查看Kaggle 上的随机线性回归数据集。以下是该数据集的截图。
Python 中的线性回归模型示例
1. 导入必要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import linear_model
from sklearn.model_selection import train_test_split
import os
2. 读取和采样我们的数据集
为了简化数据集,我们取了 50 行数据的样本,并将数据值四舍五入到 2 位有效数字。
注意,在完成此步骤之前,您应导入给定的数据集。
df = pd.read_csv("../input/random-linear-regression/train.csv")
df=df.sample(50)
df=round(df,2)
3. 过滤空值和无限值
如果我们的数据集中包含空值和无限值,可能会出现不必要的错误。因此,我们将使用 clean_dataset 函数清除数据集中这些值。
def clean_dataset(df):
assert isinstance(df, pd.DataFrame), "df needs to be a pd.DataFrame"
df.dropna(inplace=True)
indices_to_keep = ~df.isin([np.nan, np.inf, -np.inf]).any(1)
return df[indices_to_keep].astype(np.float64)
df=clean_dataset(df)
4. 选择我们的依赖值和独立值
注意,我们将数据转换为 DataFrame 格式。dataframe 数据类型是一个二维结构,将数据排列成行和列。
5. 拆分数据集
我们将把数据集分为训练集和测试集。我们选择测试数据集的大小为总数据集的 20%。
注意,通过设置 random_state=1,每次模型运行时将发生相同的数据分割,从而得到完全相同的训练集和测试集。
这在你想进一步调整模型时可能会很有用。
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=1)
6. 建立线性回归模型
使用导入的线性回归模型,我们可以在模型中自由使用线性回归算法,而无需考虑获得的 x 和 y 训练变量。
lm=linear_model.LinearRegression()
lm.fit(x_train,y_train)
7. 以散点图方式绘制我们的数据
df.plot(kind="scatter", x="x", y="y")
8. 绘制我们的线性回归线
plt.plot(X,lm.predict(X), color="red")
蓝色点表示我们的数据点,而红色线是由模型绘制的最佳拟合线。线性模型算法将始终尝试绘制最佳拟合线,以尽可能准确地预测结果。
逻辑回归
类似于线性回归,逻辑回归用于根据定义的输入变量预测输出值,但这两种算法的主要区别在于逻辑回归算法的输出应为分类(离散)变量。
对于我们的 Python 示例,我们将使用逻辑回归将给定的花分类为两种不同的类别/物种。我们的数据集将包括不同花卉物种的多个特征。
我们模型的主要目的是将给定的花识别为鸢尾花-石斛(Iris-setosa)、鸢尾花-变色(Iris-versicolor)或鸢尾花-维吉尼卡(Iris-virginica)。
要查找使用的数据集,请查看 Kaggle 上的鸢尾数据集?—?逻辑回归。下面是给定数据集的截图。
使用 Python 的逻辑回归模型示例
1. 导入必要的库
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
2. 导入数据集
data = pd.read_csv('../input/iris-dataset-logistic-regression/iris.csv')
3. 选择自变量和因变量
对于我们的自变量(x),我们将包括所有可用的列,除了类型列。至于我们的因变量(y),我们只会包括类型列。
X = data[['x0','x1','x2','x3','x4']]
y = data[['type']]
4. 划分数据集
我们将把数据集分为两部分,80%用于训练数据集,20%用于测试数据集。
X_train,X_test,y_train,y_test = train_test_split(X,y, test_size=0.2, random_state=1)
5. 运行逻辑回归模型
我们将从 linear_model 库中导入整个逻辑回归算法。然后,我们可以将 X 和 y 的训练数据适配到逻辑模型中。
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(random_state = 0)
model.fit(X_train, y_train)
6. 评估模型的性能
print(lm.score(x_test, y_test))
返回的值为0.9845128775509371,这表明我们的模型表现优异。
请注意,随着测试得分的提高,模型的性能也会提高。
7. 绘制图表
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(range(len(X_test)), pred,'o',c='r')
输出图表:
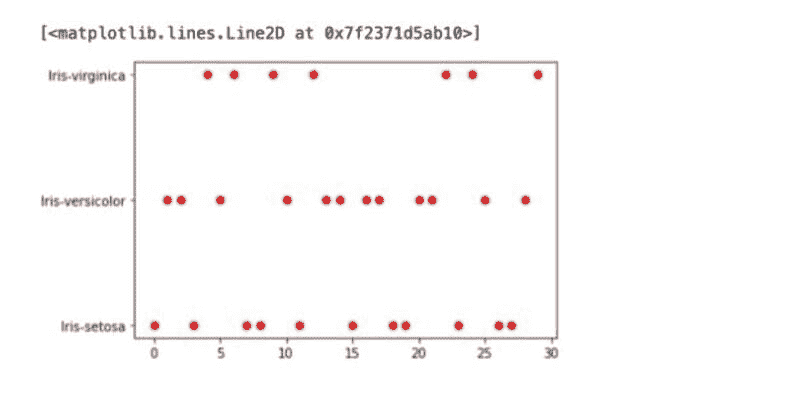
在逻辑图中,红色点表示给定的数据点。点被清晰地分为 3 个类别:维吉尼卡、变色和石斛花物种。
使用这种技术,逻辑回归模型可以根据花卉在图上的位置轻松地对花的类型进行分类。
支持向量机
支持向量机(SVM)算法是由弗拉基米尔· Vapnik 创造的另一种著名的监督机器学习模型,能够处理分类和回归问题。尽管如此,它更常用于分类问题而非回归问题。
SVM 算法能够将给定的数据点分成不同的组。这是通过让我们的算法绘制数据,然后画出最合适的线来将数据分成多个类别来完成的。
如下图所示,绘制的线将数据集完美地分成了两个不同的组,蓝色和绿色。
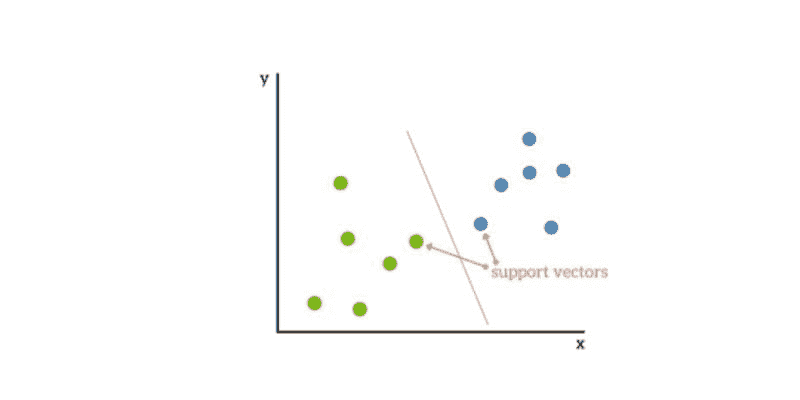
SVM 模型可以根据绘图的维度绘制线条或超平面。线条只能处理二维数据集,即只有两列的数据集。
由于可能会使用多个特征来预测给定的数据集,因此需要更高的维度。当我们的数据集结果超过 2 维时,支持向量机模型会绘制出更合适的超平面。
在我们的支持向量机 Python 示例中,我们将对 3 种不同的花卉类型进行物种分类。我们的自变量将包括某种花卉的所有给定特征,而因变量将是该花卉所属的指定物种。
我们的花卉物种包括Iris-setosa、Iris-versicolor和Iris-virginica。
要查找使用的数据集,请查看Kaggle 上的 Iris Flower Dataset。下面是给定数据集的截图。
使用 Python 的支持向量机模型示例
1. 导入必要的库
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
2. 阅读给定的数据集
注意,在进行此步骤之前,您应该导入给定的数据集。
data = pd.read_csv(‘../input/iris-flower-dataset/IRIS.csv’)
3. 将数据列拆分为因变量和自变量
我们将 X 值作为自变量,其中包含除物种列之外的所有列。
对于我们的因变量,y 变量将仅包含物种列,这是我们的模型应该预测的。
X = data.drop(‘species’, axis=1)
y = data[‘species’]
4. 将数据集拆分为训练数据集和测试数据集
我们将数据集分为两部分,其中 80%的数据用于训练数据集,20%的数据用于测试数据集。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
5. 导入 SVM 并运行模型
我们整体导入了支持向量机算法。然后我们使用从前面步骤中获得的 X 和 y 训练数据集运行了它。
from sklearn.svm import SVC
model = SVC( )
model.fit(X_train, y_train)
6. 测试我们模型的性能
model.score(X_test, y_test)
为了评估我们模型的性能,我们将使用评分函数。在其中,我们将把在第四步中创建的 X 和 y 测试值传递给评分方法。
返回的值是0.9666666666667,这表明我们的模型表现良好。
注意,测试分数的增加也意味着模型性能的提升。
其他流行的监督机器学习算法
尽管线性、逻辑回归和支持向量机算法相当可靠,我们还会提到一些值得一提的监督机器学习算法。
1. 决策树
决策树算法 是一种监督机器学习模型,利用类似树的结构进行决策。决策树通常用于分类问题,在这种问题中,模型可以决定数据集中给定项所属的类别。
请注意,使用的树形结构是倒置树。
2. 随机森林
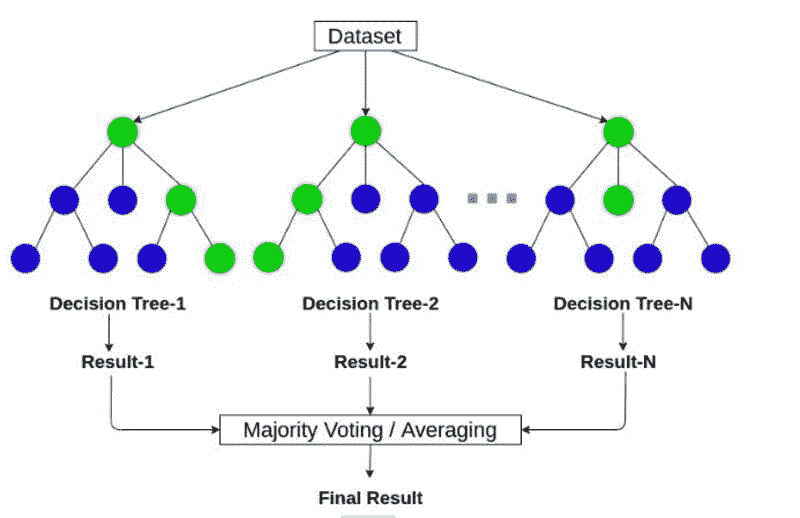
被认为是一种更复杂的算法,随机森林算法通过构建大量决策树来实现其最终目标。
意味着同时构建多个决策树,每个树返回自己的结果,然后将结果结合以获得更好的结果。
对于分类问题,随机森林模型会生成多个决策树,并根据大多数树预测的分类组来分类给定对象。
这样,模型可以修正由单棵树造成的任何过拟合。虽然随机森林算法也可以用于回归,但可能会导致较差的结果。
3. k-最近邻
k-最近邻(KNN)算法是一种监督机器学习方法,将所有给定数据分组为不同的组。
这种分组是基于不同个体之间的共同特征。KNN 算法可以用于分类和回归问题。
KNN 问题的一个例子是将动物图像分类为不同的组。
结论
回顾我们在本文中学到的内容,我们首先定义了监督机器学习以及它可以解决的两种问题类型。
接下来我们解释了分类和回归问题,并给出了每种问题类型的输出数据类型的一些示例。
然后我们解释了什么是线性回归,它是如何工作的,并提供了一个用 Python 编写的具体例子,该例子试图根据独立的 X 变量预测 Y 值。
我们还解释了一个与线性回归模型类似的模型,即逻辑回归模型。我们说明了什么是逻辑回归,并给出了一个分类模型的例子,该模型将给定的图像分类为特定的花卉品种。
对于我们的最后一个算法,我们使用了支持向量机算法,我们也用它来预测三种不同花卉的花卉品种。
在我们文章的结尾,我们简要介绍了其他知名的监督机器学习算法,如决策树、随机森林和 K 最近邻算法。
无论你是出于学校、工作还是娱乐阅读这篇文章,我们认为从这些基本算法入手可能是开始你新的机器学习热情的好方法。
如果你感兴趣并希望了解更多关于机器学习的世界,我们建议你进一步了解这些算法的工作原理以及如何调整这些模型以进一步提升其性能。别忘了,还有许多其他监督算法等着你去学习。
Kevin Vu 负责管理 Exxact Corp 博客,并与许多才华横溢的作者合作,这些作者撰写有关深度学习的不同方面的文章。
原文。经许可转载。
更多相关话题
使用 Scikit-Learn 的主成分分析(PCA)
原文:
www.kdnuggets.com/2023/05/principal-component-analysis-pca-scikitlearn.html
图片作者
如果您对无监督学习范式比较熟悉,您可能会接触到降维及用于降维的算法,例如主成分分析(PCA)。机器学习的数据集通常包含大量特征,但如此高维的特征空间并不总是有用的。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
一般来说,并非所有特征都是同等重要的,某些特征对数据集的方差占比很大。降维算法的目标是将特征空间的维度减少到原始维度的一个小部分。在这样做的过程中,具有高方差的特征仍然被保留——但位于转换后的特征空间中。而主成分分析(PCA)是最受欢迎的降维算法之一。
在本教程中,我们将学习主成分分析(PCA)的工作原理,并了解如何使用 scikit-learn 库实现它。
主成分分析(PCA)是如何工作的?
在我们继续使用 scikit-learn 实现主成分分析(PCA)之前,了解 PCA 的工作原理是有帮助的。
如前所述,主成分分析是一种降维算法。这意味着它减少了特征空间的维度。但它是如何实现这种降维的呢?
该算法背后的动机是存在某些特征能够捕捉到原始数据集中很大一部分的方差。因此,找到数据集中最大方差的方向是很重要的。这些方向被称为主成分。而 PCA 实质上是将数据集投影到主成分上。
那么我们如何找到主成分呢?
假设数据矩阵 X 的维度为num_observations x num_features,我们对 X 的协方差矩阵执行eigenvalue decomposition。
如果特征均值为零,则协方差矩阵为 X.T X。这里,X.T 是矩阵 X 的转置。如果特征最初不都是零均值,我们可以从每一列的每个条目中减去该列的均值,然后计算协方差矩阵。可以简单地看出,协方差矩阵是一个num_features阶的方阵。
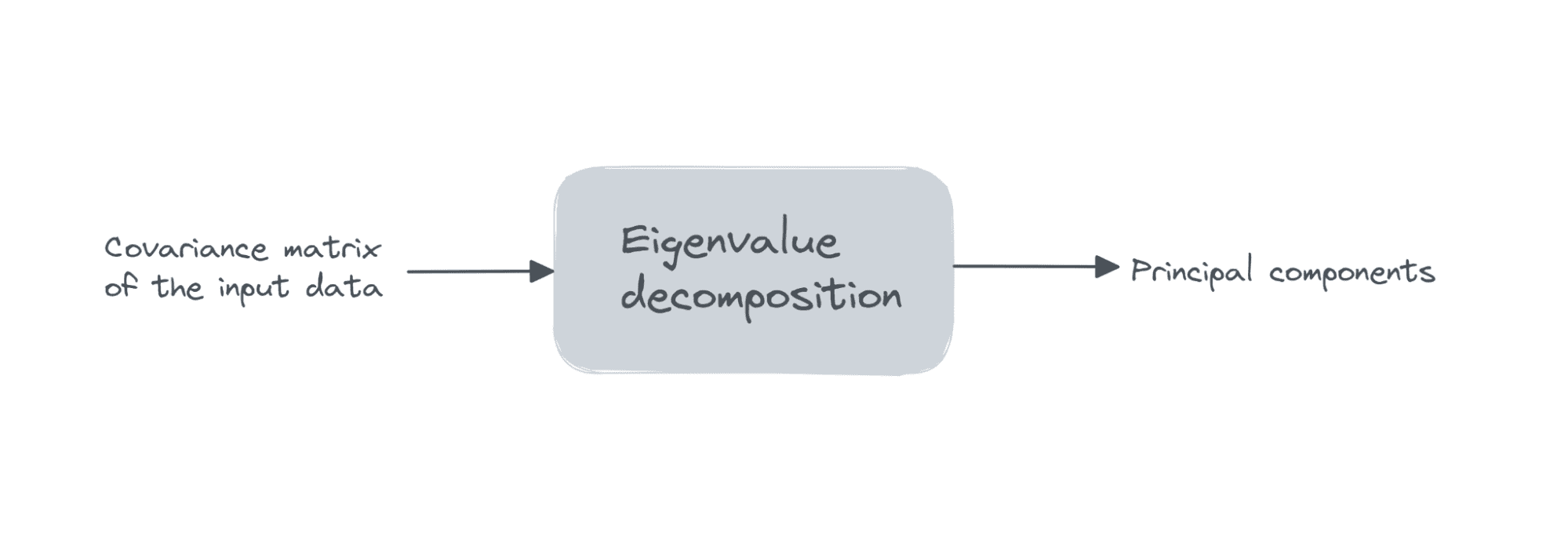
作者图片
前k个主成分是对应于k 个最大特征值的特征向量。
因此,PCA 的步骤可以总结如下:
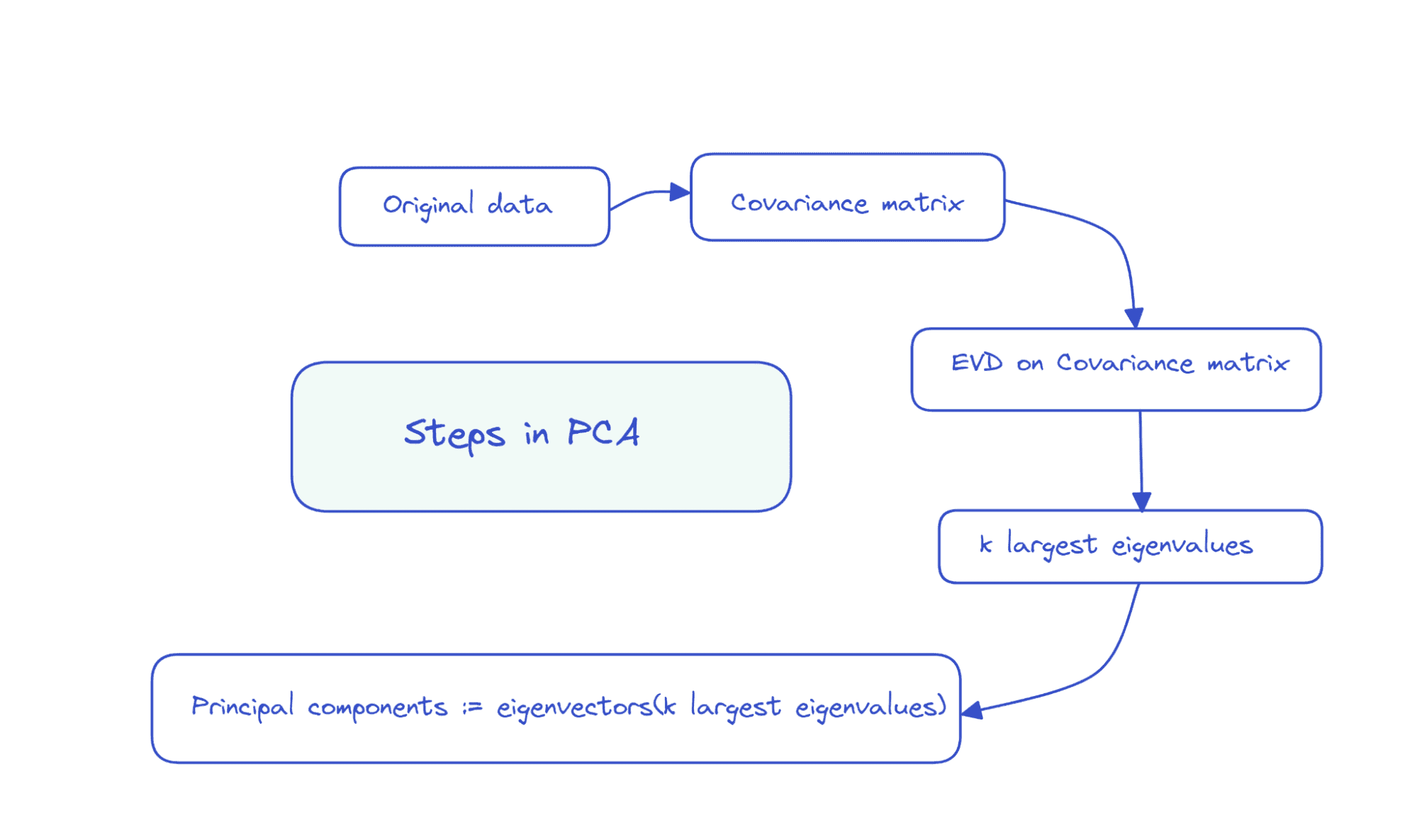
作者图片
由于协方差矩阵是对称的且半正定的,特征分解采用如下形式:
X.T X = D Λ D.T
其中,D 是特征向量矩阵,Λ 是特征值的对角矩阵。
使用 SVD 的主成分
另一种可以用来计算主成分的矩阵分解技术是奇异值分解(SVD)。
奇异值分解(SVD)定义适用于所有矩阵。给定一个矩阵 X,X 的 SVD 为:X = U Σ V.T。这里,U、Σ 和 V 分别是左奇异向量、奇异值和右奇异向量的矩阵。V.T. 是 V 的转置。
因此,X 的协方差矩阵的 SVD 表示为:
比较这两种矩阵分解的等效性:
我们有以下内容:
计算矩阵的 SVD 有计算效率高的算法。scikit-learn 实现的 PCA 在内部也使用 SVD 来计算主成分。
使用 Scikit-Learn 执行主成分分析 (PCA)
现在我们已经了解了主成分分析的基本概念,让我们继续进行 Scikit-Learn 的实现。
步骤 1 – 加载数据集
为了理解如何实现主成分分析,我们使用一个简单的数据集。在本教程中,我们将使用作为 scikit-learn 的datasets模块一部分的 wine 数据集。
我们从加载和预处理数据集开始:
from sklearn import datasets
wine_data = datasets.load_wine(as_frame=True)
df = wine_data.data
它有 13 个特征和总共 178 条记录。
print(df.shape)
Output >> (178, 13)
print(df.info())
Output >>
<class>RangeIndex: 178 entries, 0 to 177
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 alcohol 178 non-null float64
1 malic_acid 178 non-null float64
2 ash 178 non-null float64
3 alcalinity_of_ash 178 non-null float64
4 magnesium 178 non-null float64
5 total_phenols 178 non-null float64
6 flavanoids 178 non-null float64
7 nonflavanoid_phenols 178 non-null float64
8 proanthocyanins 178 non-null float64
9 color_intensity 178 non-null float64
10 hue 178 non-null float64
11 od280/od315_of_diluted_wines 178 non-null float64
12 proline 178 non-null float64
dtypes: float64(13)
memory usage: 18.2 KB
None</class>
步骤 2 – 预处理数据集
下一步,让我们对数据集进行预处理。特征都在不同的尺度上。为了将它们都转换到一个共同的尺度,我们将使用StandardScaler,它将特征转换为均值为零、方差为一的形式:
from sklearn.preprocessing import StandardScaler
std_scaler = StandardScaler()
scaled_df = std_scaler.fit_transform(df)
步骤 3 – 对预处理的数据集进行 PCA
要找到主成分,我们可以使用来自 scikit-learn 的decomposition模块中的 PCA 类。
让我们通过将主成分数量 n_components 传递给构造函数来实例化一个 PCA 对象。
主成分的数量是你希望将特征空间减少到的维度数。在这里,我们将主成分数量设置为 3。
from sklearn.decomposition import PCA
pca = PCA(n_components=3)
pca.fit_transform(scaled_df)
除了调用 fit_transform() 方法,你还可以先调用 fit(),然后再调用 transform() 方法。
请注意,当我们使用 scikit-learn 实现的 PCA 时,诸如计算协方差矩阵、对协方差矩阵进行特征分解或奇异值分解以获得主成分等步骤都被抽象化了。
第 4 步 – 检查 PCA 对象的一些有用属性
我们创建的 PCA 实例 pca 具有多个有用的属性,有助于我们理解其背后的情况。
components_ 属性存储了最大方差的方向(主成分)。
print(pca.components_)
Output >>
[[ 0.1443294 -0.24518758 -0.00205106 -0.23932041 0.14199204 0.39466085
0.4229343 -0.2985331 0.31342949 -0.0886167 0.29671456 0.37616741
0.28675223]
[-0.48365155 -0.22493093 -0.31606881 0.0105905 -0.299634 -0.06503951
0.00335981 -0.02877949 -0.03930172 -0.52999567 0.27923515 0.16449619
-0.36490283]
[-0.20738262 0.08901289 0.6262239 0.61208035 0.13075693 0.14617896
0.1506819 0.17036816 0.14945431 -0.13730621 0.08522192 0.16600459
-0.12674592]]
我们提到主成分是数据集中最大方差的方向。但我们如何衡量在我们选择的主成分数量中捕获了总方差的多少呢?
explained_variance_ratio_ 属性捕获了每个主成分所捕获的总方差比。因此,我们可以将这些比率相加以获得所选数量主成分的总方差。
print(sum(pca.explained_variance_ratio_))
Output >> 0.6652996889318527
在这里,我们看到三个主成分捕获了数据集总方差的超过 66.5%。
第 5 步 – 分析解释方差比的变化
我们可以尝试通过改变主成分数量 n_components 来运行主成分分析。
import numpy as np
nums = np.arange(14)
var_ratio = []
for num in nums:
pca = PCA(n_components=num)
pca.fit(scaled_df)
var_ratio.append(np.sum(pca.explained_variance_ratio_))
为了可视化主成分数量的 explained_variance_ratio_,我们可以绘制如下两个量:
import matplotlib.pyplot as plt
plt.figure(figsize=(4,2),dpi=150)
plt.grid()
plt.plot(nums,var_ratio,marker='o')
plt.xlabel('n_components')
plt.ylabel('Explained variance ratio')
plt.title('n_components vs. Explained Variance Ratio')
当我们使用所有 13 个主成分时,explained_variance_ratio_ 为 1.0,表示我们已经捕获了数据集中的 100% 方差。
在这个例子中,我们看到使用 6 个主成分可以捕获输入数据集中超过 80% 的方差。
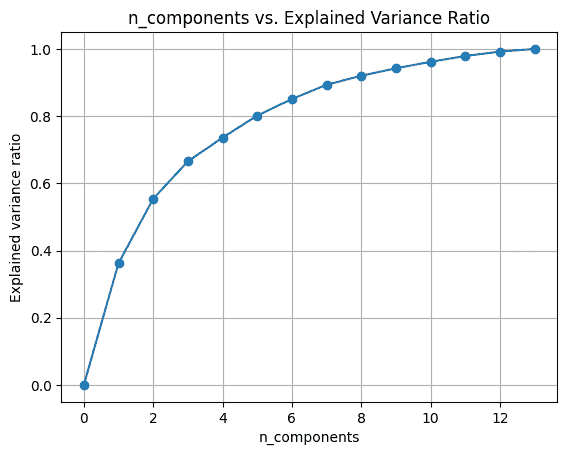
结论
希望你已经学会了如何使用 scikit-learn 库中的内置功能执行主成分分析。接下来,你可以尝试在你选择的数据集上实现 PCA。如果你在寻找好的数据集进行实验,可以查看这个数据科学项目数据集网站列表。
进一步阅读
[1] 计算线性代数,fast.ai
Bala Priya C 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专业领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正致力于通过撰写教程、操作指南、评论文章等,学习并与开发者社区分享她的知识。
更多相关主题
优先排序数据科学模型以便投入生产
原文:
www.kdnuggets.com/2022/04/prioritizing-data-science-models-production.html

图片来源于 airfocus,在 unsplash.com
很少有企业拥有不受限制的数据科学预算。用于人员、技术、分析环境和平台的资金通常远小于公司对知识的需求。在我曾经工作的公司中,新的分析模型的愿望清单需要将我们的研究人员数量翻倍,这显然是不可能的。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
Therese Gorski,多个优先级排序工作的领导者,告诉我优先级排序的需求在许多产品管理组织中很常见。它通常是评估许多市场产品创意的更大过程的一部分。她说,因此,将优先级排序过程管理得像其他产品开发投资一样是有用的。
在这篇文章中,我提出了一些标准供公司在分配稀缺资源用于数据科学工作时考虑。我的建议是与每个参与生产、营销、销售、融资、支持或维护公司产品的部门人员讨论这些标准。公司员工的见解应来自所有层级,而不仅仅是领导层。这应当辅以受每个模型影响的外部利益相关者的见解。广泛的意见反馈将有助于最大化客户效用,从而增加他们和你公司的销售额和利润。广泛的意见反馈也将提升你产品的社会价值。
十二项考虑标准
以下表格中的标准受到了 Therese 及其在几家公司工作的同事以及最近文献关于使模型有用的属性和应避免的陷阱的启发。其中一些标准可以在生产前进行权衡;其他标准则涉及已经生产出的模型。
模型属性应在生产前后进行权衡,因为直到训练过程的后期甚至之后,才可能清楚任何模型是否可能变得或保持有用。此外,新模型通常要与长期出售但需要定期且重要投资以维持或更新的旧模型竞争有限的资金。因此,考虑每个模型对业务成功的可能贡献非常重要。这要求在评估投资或继续投资数据科学模型的效用时,权衡多种标准和视角。
考虑到这些因素,以下表格列出了十二个考虑标准。这样的文件可以分发给利益相关者和员工,以便从多方收集对每个标准的评分,然后汇总讨论。
如表格所示,这些十二个标准以声明的形式出现,每个回应者的任务是记录他们对每个模型中每个声明的同意程度。为了简化,我假设同意程度的范围从 1(强烈不同意)到 5(强烈同意)。使用相同的范围通过减少回应的差异性来增加结果的可靠性;它也使每个声明更易于解释。
另一个重要任务是权衡每个标准的重要性。在这里,重点是标准而非模型,Excel 文件包括一个列来指定每个标准的权重。您的业务利益相关者是否希望对每个标准赋予相同的重要性,还是认为某些标准比其他标准更重要,需要更高的权重?这个讨论可能会很有启发性,也可能会引发争议,有三种选项值得考虑。有些人可能认为权重的讨论应该在收集到一致性数据之后进行,这样可以促进标准权重与一致性水平之间的独立性,意味着一个不会影响另一个。其他人可能会持不同意见,先评估每个标准的重要性,然后评估每个模型中每个标准的一致性水平。第三种选择,如表中所示,是在评估一致性水平的同时,询问利益相关者对每个标准应给予多少权重,然后使用所有响应者的结果来共同决定每个标准的权重。使用对您的组织效果更好的选项。如果不确定哪种方法更好,可以对不同的独立随机评估子集尝试不同的方法,或随着时间的推移尝试不同的方法,以帮助决定哪种方法更适合您。
评分模型
一旦这些活动完成并且所有受访者提供了每个模型的评分,就可以开始对每个模型进行评分。每个模型的得分可以从每个受访者那里计算,基于所有人一致同意的标准权重和受访者对每个标准的一致性水平:
受访者 A 的总得分 =  标准权重 * 一致性水平
标准权重 * 一致性水平
总和从 1 到 12,因为每个模型有十二个标准。例如,假设受访者 A 对每个标准都强烈同意,并且每个标准的权重都是 1.0\。那么他的得分将等于 60(即,12 个标准乘以 5 的值,表示对每个标准都强烈同意)。大多数受访者会将他们的分数从 1 到 5 进行变化,使得标准权重非常重要。
一旦从每个受访者那里获得了每个模型的分数,就可以通过将所有受访者的分数相加或平均来获得整体模型得分。这些数据可以在另一张表格中呈现和比较。可以生成模型标准和模型得分的均值、中位数、方差和箱形图,带有和不带有异常值。这将有助于讨论哪些标准最重要,以及采用或保留哪些模型。
标准有效性
提议的标准的有效性也很重要。我试图通过涵盖我与同事讨论的分析模型质量的几个问题,以及最近文献中描述的内容来解决内容有效性。因此,一个标准涉及到所考虑的模型是否可能测量或预测真实感兴趣结果,而不是该结果的代理。评论这个问题时,布赖恩·霍赫雷因,另一位著名的分析领导者提到,没有数据集能够完美捕捉人类行为或自然界的复杂性,所以问题是当数据不完美时,是否以及如何继续建模。Christian (2020)、Hall 等人 (2021) 和 Obermeyer 等人 (2021) 提供了一些在这种情况下如何继续的想法。
模型的复杂性和性能也在表格中被列为重要标准。根据布赖恩的说法,我们需要那些易于理解但足够复杂以准确预测或理解感兴趣结果的模型。其他人也同意这一点(例如,Christian, 2020;Hall 和 Gill (2019))。这些模型应在统计指标上表现良好,并且具有高灵敏度和低虚假发现率。它们还应提供比竞争对手模型更好或更有用的见解。
能够得出因果推断也反映在标准中,因为数据科学家和政策制定者对这一领域的兴趣日益增长。因果关系基于对真实感兴趣结果的测量,如前所述,这依赖于拥有合适的数据和其他资源。当数据、资源或建模过程未能充分捕捉人类本性时,因果推断将受到限制。
还建议考虑模型的透明度、可信度、公平性、偏见和安全性,以及在建模过程中保护数据和研究对象的努力。
在我工作过的地方,模型被开发、维护和更新,以便它们可以作为公司销售或希望销售的产品中的组件。因此,每个模型对公司和客户收入与利润的最终贡献非常重要。对公司声誉的潜在贡献也很重要。这些都很难为任何给定的分析模型估算,因为它们必须考虑到模型的有效使用期,而这很难预测。关于数据科学努力对收入、利润和声誉的大小和时机的贡献,可能会有激烈的讨论。这些讨论会揭示争议;公开和专业地处理这些争议将会建立信任,并对不同的意见有更广泛的理解和尊重。
表中提到的最后两个标准反映了每个模型对员工福祉、士气和满意度的贡献,以及对专业思想领导力的贡献。我们应该建立能够吸引和激励公司全体员工的模型。给予员工参与思想领导力的机会,并允许他们影响模型生产,将培养忠诚度并提供专业成长的机会。
除了列出评估每个标准重要性的标准和建议外,该表还提到了关于每个标准需要考虑的几个问题。我还提供了引用或链接,以便在文献中找到关于这些问题的更多信息。
图片由 Stephen Dawson 提供,来源于 unsplash.com
限制与讨论
这本简短的模型优先级指南中还有很多未涵盖的内容。我的重点是面向外部的模型,尽管类似的标准也可以用于内部工作。
你可能会认为十几个标准太多了,或者太少——找出适合你公司的标准。你可能会识别出其他重要的标准或需要解决的其他问题。虽然我在表中提供了一些关于需要考虑的问题的想法,但没有说明如何解决这些问题或如何解决有关这些问题的争议。下面列出的参考文献以及表中所列的参考文献可以帮助解决这些问题。我鼓励你查看这些资料。这些作者在他们的领域中非常著名,并提供了许多值得考虑的见解。
模型评分后会发生什么?评分过程和结果应在内部和外部贡献者之间讨论。如果有必要,可以进行调整,也许采用收集、整理和分发评论以进行后续讨论的方法。这可以根据需要重复多次,以达成一致。
但要小心最响亮的声音和最高级别的声音症候群。预期一些情感上的呼吁或观点可能会有意或无意地使标准偏向某些模型而非其他模型,或压制辩论。这些问题应该被广泛讨论。也许是在小组中,也许是个人讨论,但每个人都应该了解不同的观点,以便能够专业地解决利弊。
Hall 等人(2021)和 Obermeyer 等人(2021)提供了关于当模型表现不佳或被认为不太有用时的建议。他们还提出了如何利用人员、流程和技术来改进模型的想法。他们及其他人(例如,Christian, 2020; Melchionna 2022)强烈推荐由人类专家和非专家提供指导,特别是那些代表我们模型覆盖的群体的专家。有关模型问责制和审计流程的指导也在他们的工作中提到。
扩展与最终思考
数据科学家可能会建议其他优先级设定方法。大公司通常会追踪其产品的表现。如果是这样,可能可以收集到足够的关于其产品属性的数据,或者模型的基础数据,然后使用聚类和回归模型,或其他机器学习技术,来帮助设定每个标准的权重。
为了便于数据收集和分析,一些公司通过给每个输入贴上标签,将其产品商品化。这些输入应包括每个产品所采用的所有数据科学模型。公司随后可能会为每个模型和其他输入分配类似零件号的标识。由于模型和其他特性可以在多个产品中使用多年,这有助于识别数据科学团队和其他团队对公司产品的贡献范围。考虑到创建每个输入所需的工作量和资源,有助于在参与产品开发和管理的团队之间分配收入或利润信用。跟踪这些信用随着时间的推移也有助于员工对标准的权重和建模工作的市场价值进行推断,以优先考虑未来的工作。
理想情况下,应该就使用哪些标准、如何对每个标准加权,以及如何在公司内优先排序模型达成共识,或至少形成强大的多数意见。经验表明,这将需要一些时间,因此数据科学路线图应当预留足够的时间,以完成深思熟虑的模型优先级设定过程。第一次使用时,这可能需要三到四个月。预计后续应用会快得多。我已经多次做过这个过程,乐意提供帮助。希望你觉得这个过程有用。
致谢
我要感谢 Therese Gorski 和 Brian Hochrein 对本文的有益评论。他们的见解使文章大为改进。任何剩余的错误均由我承担。
参考文献
-
A. Christian, 对齐问题:机器学习与人类价值(2020),纽约,NY:W.W. Norton & Company
-
A. Géron, 动手实践机器学习:使用 Scikit-Learn、Keras 和 TensorFlow 构建智能系统的概念、工具和技术,第 2**版(2019),Sebostopal,CA:O’Reilly Media, Inc.
-
P. Hall 和 N. Gill, 机器学习可解释性简介:公平性、问责制、透明度和可解释 AI 的应用视角,第 2**版(2019),Sebostopal,CA:O’Reilly Media, Inc.
-
P. Hall, N. Gill 和 B. Cox, 负责任的机器学习(2021),Sebostopal,CA:O’Reilly Media, Inc.
-
D. Husereau, M. Drummond, F. Augustovski 等,《整合健康经济评估报告标准(CHEERS)2022 解释与阐述:ISPOR CHEERS II 良好实践工作组的报告》(2022),价值健康 25:1:10-31。
-
M. Maziarz,经济学中的因果关系哲学:因果推断与政策建议(2020),纽约,NY:Routledge
-
M. Melchionna,世卫组织:是时候消除人工智能中的年龄歧视了(2022 年 2 月 10 日),健康 IT 分析,
healthitanalytics.com/news/who-its-time-to-eliminate-ageism-in-artificial-intelligence -
S.L. Morgan 和 C. Winship,反事实与因果推断:社会研究的方法与原则,第 2 版(2015),英国剑桥:剑桥大学出版社
-
Z. Obermeyer, R. Nissan, M. Stern 等,算法偏见手册(2021 年 6 月),芝加哥,IL:芝加哥大学应用人工智能中心
-
R. Ozminkowski,什么原因导致什么,我们如何知道?(2021 年 9 月 14 日),迈向数据科学,
towardsdatascience.com/what-causes-what-and-how-would-we-know-b736a3d0eefb -
J. Pearl, M. Glymour 和 N.P. Jewell,统计学中的因果推断:入门(2016),英国威斯萨塞克斯,Chichester:John Wiley & Sons
-
J. Pearl 和 D. Mackenzie,为什么之书:因果关系的新科学(2018),纽约,NY:Basic Books
-
B. Schmarzo,《数据、分析与数字化转型的经济学:引导组织数字化转型的定理、法则与赋能》(2020),英国伯明翰:Packt Publishing
-
L. Wee, M.J. Sander, F.J.van Kujik 等,《预测模型的报告标准与批判性评估》,见于临床数据科学基础(2019),编辑:A. Dekker, M. Dumontier, 和 P. Kubben,通过
doi.org/10.1007/978-3-319-99713-1开放获取
Ron Ozminkowski 博士 是一位国际认可的顾问、作家和高管,专注于医疗分析和机器学习,其出版的工作已被全球 90 多个国家的读者阅读。
更多相关话题
成为 Pandas,Python 的数据处理库的专家
评论
由Julien Kervizic,GrandVision NV 高级企业数据架构师
Pandas 库是 Python 中最流行的数据处理库。它通过其数据框 API 提供了一种简便的数据处理方式,灵感来自 R 的数据框。
 照片由Damian Patkowski拍摄,Unsplash
照片由Damian Patkowski拍摄,Unsplash
了解 Pandas 库
了解 Pandas 的关键之一是理解 Pandas 主要是围绕一系列其他 Python 库的包装器。主要包括 Numpy、SQLAlchemy、Matplotlib 和 openpyxl。
数据框的核心内部模型是一系列 numpy 数组,Pandas 函数如现已弃用的“as_matrix”返回结果在该内部表示中。
Pandas 利用其他库将数据输入和输出到数据框中,例如,通过 read_sql 和 to_sql 函数使用 SQLAlchemy。而 openpyxl 和 xlsx writer 则用于 read_excel 和 to_excel 函数。
Matplotlib 和 Seaborn 用于提供一个简单的接口来绘制数据框中的信息,使用如 df.plot()这样的命令。
Numpy 的 Pandas——高效的 Pandas
经常听到的抱怨之一是 Python 运行缓慢或难以处理大量数据。大多数情况下,这是由于编写的代码效率低下。确实,本地 Python 代码往往比编译代码慢,但像 Pandas 这样的库有效地提供了 Python 代码到编译代码的接口。了解如何正确地与其接口,可以让我们充分发挥 Pandas/Python 的优势。
应用向量化操作
Pandas,像其底层库 Numpy 一样,执行向量化操作比执行循环更高效。这些效率来源于向量化操作通过 C 编译代码而非本地 Python 代码进行,同时利用了向量化操作对整个数据集进行处理的能力。
apply 接口通过使用 CPython 接口进行循环,从而提高了一些效率:
df.apply(lambda x: x['col_a'] * x['col_b'], axis=1)
但大部分性能提升将来自于使用向量化操作本身,无论是直接在 Pandas 中还是通过直接调用其内部的 Numpy 数组。

正如你从上面的图片中可以看到,性能差异可能非常巨大,通过矢量化操作处理(3.53 毫秒)和用 Apply 循环进行加法(27.8 秒)之间的差距。通过直接调用 numpy 的数组和 API,可以获得额外的效率,例如:

Swifter: Swifter 是一个 Python 库,简化了在数据框上对不同类型操作的矢量化,其 API 与 Apply 函数非常相似。
高效数据存储通过 DTYPES
在将数据框加载到内存中时,无论是通过 read_csv、read_excel 还是其他数据框读取函数,SQL 都会进行类型推断,这可能会导致效率低下。这些 API 允许你明确指定每列的类型,从而实现更高效的数据存储。
df.astype({'testColumn': str, 'testCountCol': float})
Dtypes 是 Numpy 的本地对象,它允许你定义存储某些信息所使用的确切类型和位数。
Numpy 的 dtype np.dtype('int32') 例如表示一个 32 位长的整数。Pandas 默认使用 64 位整数,通过使用 32 位可以节省一半的空间:
memory_usage() 显示了每列所使用的字节数,由于每列只有一个条目(行),因此每个 int64 列的大小为 8 字节,而 int32 为 4 字节。
Pandas 还引入了分类 dtype,允许对频繁出现的值进行高效的内存利用。在下面的例子中,我们可以看到,将字段 posting_date 转换为分类值后,内存利用率降低了 28 倍。
在我们的例子中,只需更改这种数据类型,数据框的总体大小就减少了 3 倍以上:
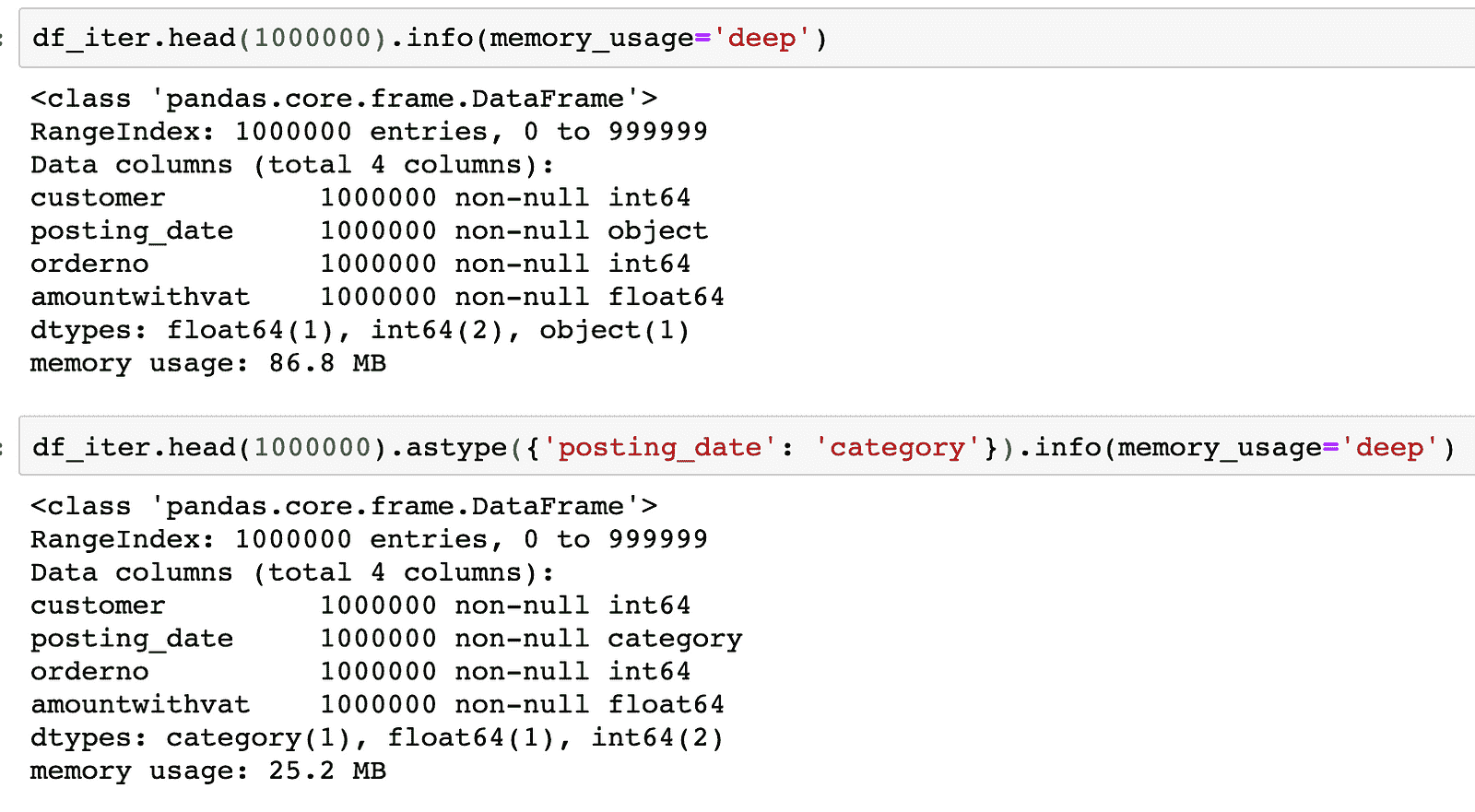
不仅使用正确的 dtypes 允许你在内存中处理更大的数据集,还使一些计算变得更有效。在下面的例子中,我们可以看到,使用分类类型为 groupby/sum 操作带来了 3 倍的速度提升。

在 Pandas 中,你可以在数据加载时(read_)或作为类型转换(astype)来定义 dtypes。
CyberPandas: CyberPandas 是一种不同的库扩展,支持更多种类的数据类型,包括 ipv4 和 ipv6 数据类型,并高效地存储它们。
处理大数据集的 CHUNKS
Pandas 允许通过块加载数据框,因此可以将数据框作为迭代器进行处理,并能够处理比可用内存更大的数据框。
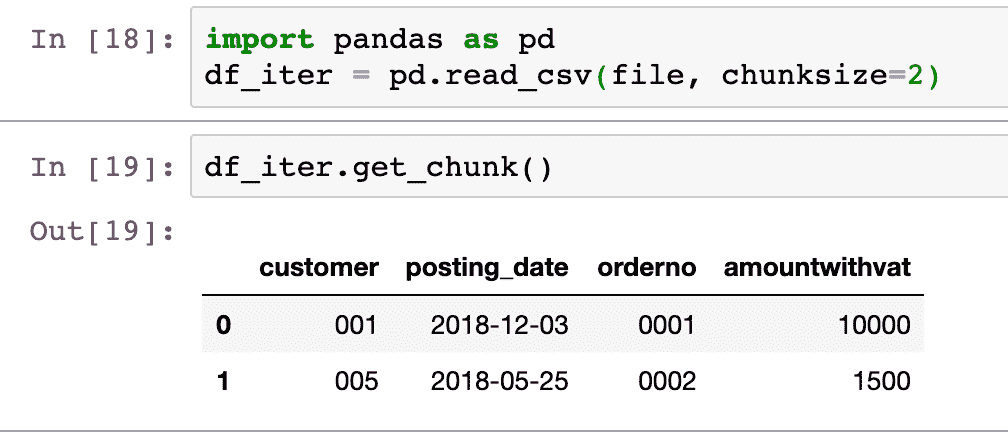
在读取数据源时定义 chunksize 和使用 get_chunk 方法的组合,使 Pandas 能够将数据作为 迭代器 进行处理。例如,在上述示例中,数据框每次读取 2 行。这些块可以被迭代:
i = 0
for a in df_iter:
# do some processing chunk = df_iter.get_chunk()
i += 1
new_chunk = chunk.apply(lambda x: do_something(x), axis=1)
new_chunk.to_csv("chunk_output_%i.csv" % i )
其输出可以被保存到 CSV 文件中、进行 pickle 操作、导出到数据库等……
通过块设置操作员也允许某些操作通过 多处理 来完成。
Dask: 这是一个建立在 Pandas 之上的框架,考虑了多处理和分布式处理。它利用了内存和磁盘上的 Pandas 数据框块集合。
SQL Alchemy 的 Pandas — 数据库 Pandas
Pandas 也建立在 SQLAlchemy 之上与数据库接口,因此能够从各种 SQL 类型的数据库中下载数据集,并将记录推送到数据库中。直接使用 SQLAlchemy 接口(而不是使用 Pandas API)可以执行 Pandas 中原生不支持的某些操作,如事务或 upserts。
SQL 事务
Pandas 也可以利用 SQL 事务,处理提交和回滚。Pedro Capelastegui 在他的 博客文章 中解释了 Pandas 如何通过 SQLAlchemy 上下文管理器利用事务。
with engine.begin() as conn:
df.to_sql(
tableName,
con=conn,
...
)
使用 SQL 事务的优点在于,如果数据加载失败,事务将会回滚。
SQL 扩展
PandaSQL
Pandas 有一些 SQL 扩展,如 pandasql 这个库允许在数据框上执行 SQL 查询。通过 pandasql,数据框对象可以像数据库表一样直接进行查询。
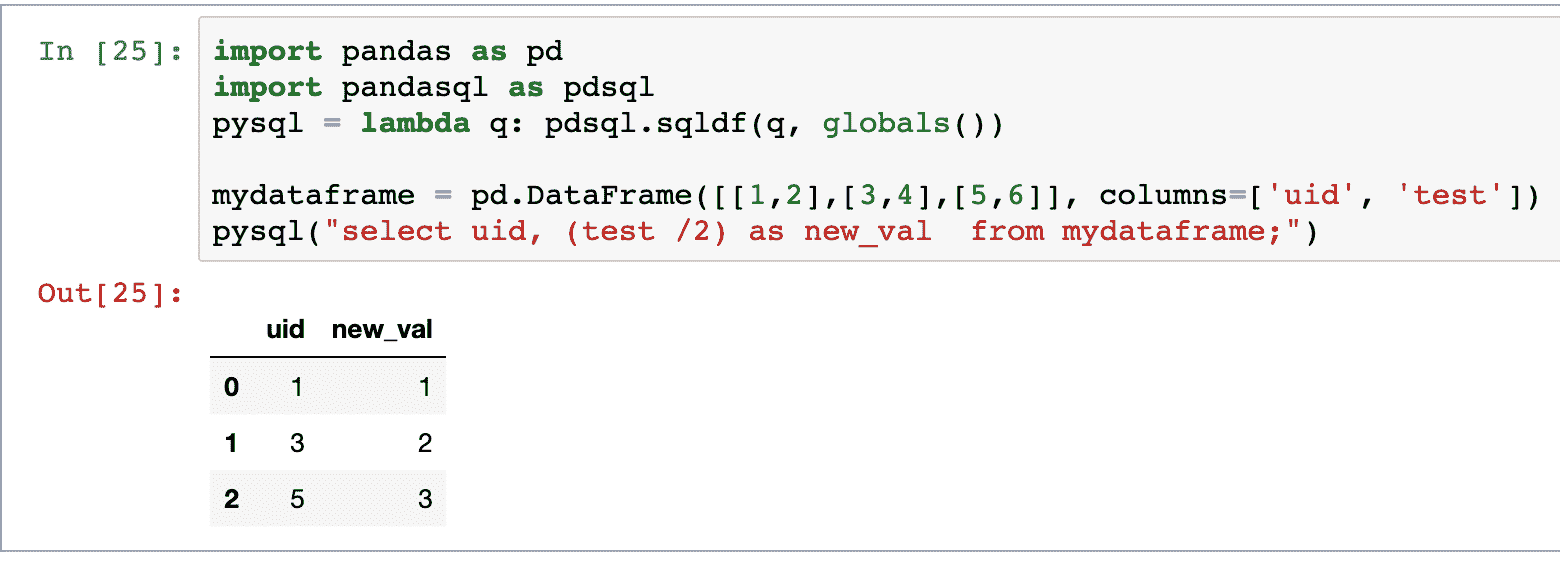
SQL UPSERTs
Pandas 本身不支持对支持此功能的数据库进行 upsert 导出。存在 Pandas 补丁 以实现此功能。
MatplotLib/Seaborn — 可视化 Pandas
Matplotlib 和 Seaborn 可视化已经集成在一些数据框 API 中,例如通过 .plot 命令。有关接口工作的相当全面的文档可以在 Pandas 网站 上找到。
扩展: 存在不同的扩展,如 Bokeh 和 plotly,以在 Jupyter notebooks 中提供交互式可视化,同时也可以扩展 matplotlib 以处理 3D 图形。
其他扩展
还有很多其他 Pandas 扩展,用于处理非核心功能。其中之一是 tqdm,它提供了进度条功能;另一个是 pretty Pandas,它允许格式化数据框并添加汇总信息。
tqdm
tqdm 是 Python 中的一个进度条扩展,它与 Pandas 互动,允许用户在使用相关函数(progress_map 和 progress_apply)时查看 Pandas 数据框的操作进度:

PrettyPandas
PrettyPandas 是一个库,提供了格式化数据框和添加表格摘要的简便方法:
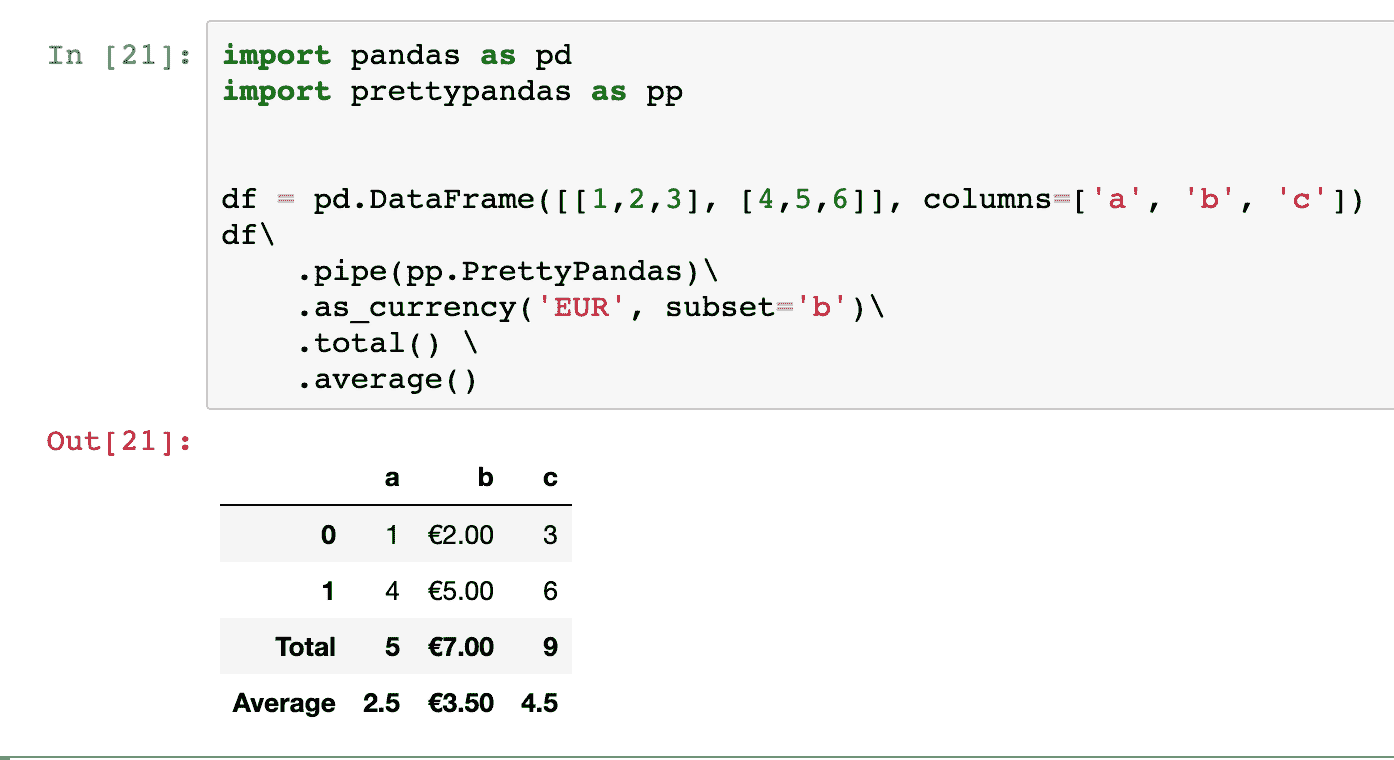
个人简介:Julien Kervizic 是 GrandVision NV 的高级企业数据架构师。
原文。经授权转载。
相关:
-
Pandas 数据框索引
-
初学者使用 Pandas 的数据可视化与探索
-
Python 数据准备案例文件:基于分组的插补
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业之路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
了解更多主题
数据科学中的概率分布
原文:
www.kdnuggets.com/2020/02/probability-distributions-data-science.html
评论
介绍
拥有扎实的统计学背景对于数据科学家的日常工作极为有益。每当我们开始探索一个新的数据集时,我们首先需要做一个探索性数据分析(EDA),以了解某些特征的主要特点。如果我们能够理解数据分布中是否存在任何模式,我们可以根据我们的案例研究量身定制机器学习模型。这样,我们可以在更短的时间内获得更好的结果(减少优化步骤)。实际上,一些机器学习模型在某些分布假设下效果最佳。因此,了解我们处理的是哪些分布,可以帮助我们识别出最适合的模型。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
数据的不同类型
每次我们处理一个数据集时,我们的数据集代表了一个样本,来自于一个总体。利用这个样本,我们可以尝试理解其主要模式,从而在没有机会检查整个总体的情况下,对整个总体进行预测。
让我们假设我们想要预测给定一组特征的房价。我们可能会在线找到一个包含旧金山所有房价的数据集(我们的样本),经过一些统计分析后,我们可能能够对美国其他城市的房价做出相当准确的预测(我们的总体)。
数据集由两种主要类型的数据组成:数值型(例如,整数、浮点数)和类别型(例如,名字、笔记本电脑品牌)。
数值数据还可以进一步分为其他两个类别:离散和连续。离散数据只能取某些特定值(例如,学校中的学生数量),而连续数据可以取任何实际或分数值(例如,身高和体重)。
从离散随机变量可以计算出概率质量函数,而从连续随机变量可以推导出概率密度函数。
概率质量函数给出一个变量等于某个值的概率,而概率密度函数的值本身不是概率,因为它们需要在给定范围内积分。
自然界中存在许多不同的概率分布(图 1),在本文中,我将介绍数据科学中最常用的分布。
图 1: 概率分布流程图 [1]
在本文中,我将提供如何创建不同分布的代码片段。如果你对额外资源感兴趣,可以在 这个我的 GitHub 仓库中找到。
首先,我们需要导入所有必要的库:
伯努利分布
伯努利分布是最容易理解的分布之一,可以作为推导更复杂分布的起点。
该分布只有两个可能的结果和一个试验。
一个简单的例子是一次掷硬币的结果。如果硬币是偏向的或不偏向的,那么结果为正面或反面的概率可以分别视为p和(1 - p)(互斥事件的概率总和需要等于一)。
在图 2 中,我提供了一个关于偏向硬币的伯努利分布的例子。
图 2: 偏向硬币的伯努利分布
均匀分布
均匀分布可以很容易地从伯努利分布中推导出来。在这种情况下,允许有可能无限多的结果,并且所有事件发生的概率是相同的。
例如,假设掷一个公平的骰子。在这种情况下,有多个可能的事件,每个事件发生的概率相同。
图 3: 公平骰子的掷骰分布
二项分布
二项分布可以被认为是遵循伯努利分布的事件结果的总和。因此,二项分布用于二元结果事件,并且所有连续试验中的成功和失败的概率是相同的。该分布接受两个参数作为输入:事件发生的次数和分配给两个类别之一的概率。
二项分布的一个简单示例是重复掷某个次数的偏向或不偏向硬币。
改变偏向的量会改变分布的外观(图 4)。
图 4: 二项分布变化的事件发生概率
二项分布的主要特征包括:
-
在多次试验中,每次试验彼此独立(一个试验的结果不会影响另一个试验)。
-
每次试验只能有两个可能的结果(例如,赢或输),其概率分别为p和(1 - p)。
如果给定成功的概率(p)和试验次数(n),我们可以使用以下公式(见图 5)计算这些 n 次试验中成功的概率(x)。
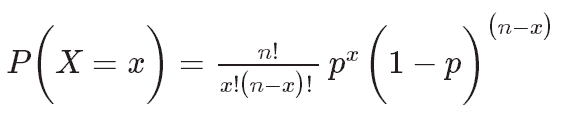
图 5:二项分布公式 [2]
正态(高斯)分布
正态分布是数据科学中最常用的分布之一。许多发生在我们日常生活中的常见现象都遵循正态分布,例如:经济中的收入分布、学生的平均成绩、人口的平均身高等。此外,小随机变量的和通常也遵循正态分布(中心极限定理)。
“在概率论中,中心极限定理(CLT)表明,在某些情况下,当独立随机变量相加时,其适当标准化的和趋向于正态分布,即使原始变量本身并不服从正态分布。”
— 维基百科
图 6:高斯分布
一些可以帮助我们识别正态分布的特征包括:
-
曲线在中心对称。因此,均值、众数和中位数都相等,使得所有值围绕均值对称分布。
-
分布曲线下的面积等于 1(所有概率的总和必须等于 1)。
可以使用以下公式推导出正态分布(见图 7)。
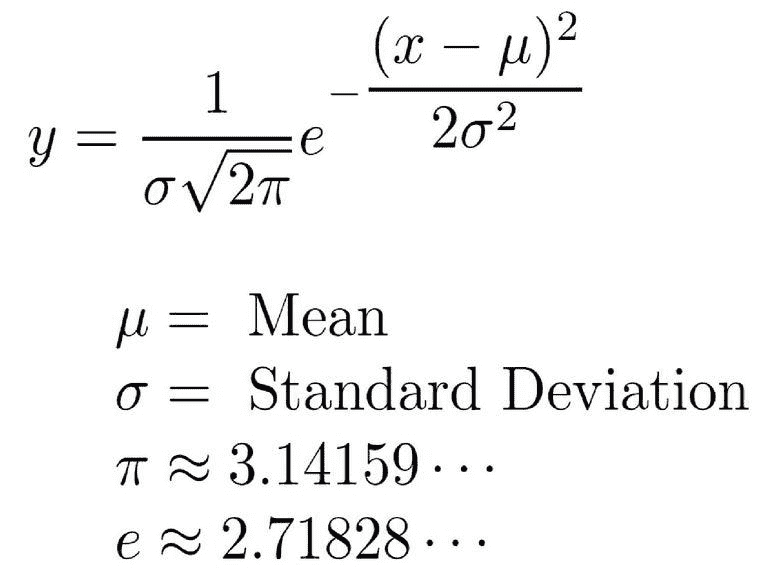
图 7:正态分布公式 [3]
在使用正态分布时,分布的均值和标准差起着非常重要的作用。如果我们知道它们的值,就可以通过检查概率分布(见图 8)轻松找出预测确切值的概率。实际上,得益于分布的特性,68%的数据位于均值的一个标准差内,95%位于均值的两个标准差内,99.7%位于均值的三个标准差内。
图 8:正态分布 68–95–99.7 规则 [4]
许多机器学习模型被设计为在使用遵循正态分布的数据时表现最佳。以下是一些例子:
-
高斯朴素贝叶斯分类器
-
线性判别分析
-
二次判别分析
-
最小二乘回归模型
此外,在某些情况下,还可以通过应用对数和平方根等变换将非正态数据转换为正态形式。
泊松分布
泊松分布常用于找到某个事件发生的概率,或者在不知道事件发生频率的情况下预测事件发生的次数。此外,泊松分布还可以用于预测在给定时间段内事件发生的次数。
泊松分布,例如,常被保险公司用于进行风险分析(例如,预测在预定时间段内发生的车祸数量)以决定车险定价。
在处理泊松分布时,我们可以对不同事件发生的平均时间有信心,但事件发生的确切时刻在时间上是随机分布的。
泊松分布可以使用以下公式进行建模(图 9),其中λ代表在一个时间段内可以发生的预期事件数量。
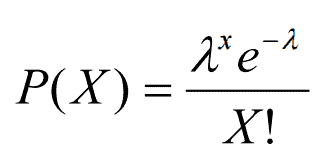
图 9:泊松分布公式 [5]
描述泊松过程的主要特征是:
-
事件彼此独立(如果一个事件发生,这不会改变另一个事件发生的概率)。
-
事件可以在定义的时间段内发生任意次数。
-
两个事件不能同时发生。
-
事件发生的平均速率是恒定的。
在图 10 中,展示了在一个时间段内预期事件数量(λ)变化如何改变泊松分布。
图 10:泊松分布变化λ
指数分布
最后,指数分布用于建模不同事件发生之间的时间。
例如,假设我们在一家餐馆工作,我们想预测不同顾客到餐馆的时间间隔。使用指数分布来解决这个问题,可能是一个完美的起点。
指数分布的另一个常见应用是生存分析(例如,设备/机器的预期寿命)。
指数分布由一个参数λ控制。λ值越大,指数曲线衰减得越快(图 11)。
图 11:指数分布
指数分布使用以下公式进行建模(图 12)。
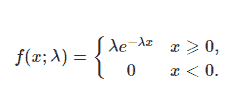
图 12:指数分布公式 [6]
如果你有兴趣调查概率分布如何用来解密随机过程,你可以在这里找到更多信息。
联系方式
如果你想随时了解我的最新文章和项目,请关注我的 Medium并订阅我的邮件列表。以下是我的一些联系方式:
参考书目
[1] 数据科学统计学简介。
Diogo Menezes Borges,《数据科学家的成长历程》。访问网址:medium.com/diogo-menezes-borges/introduction-to-statistics-for-data-science-7bf596237ac6
[2] 二项随机变量,UF 生物统计学开放学习教科书。访问网址:bolt.mph.ufl.edu/6050-6052/unit-3b/binomial-random-variables/
[3] 正态分布或钟形曲线公式。ThoughtCo,Courtney Taylor**。 **访问网址:www.thoughtco.com/normal-distribution-bell-curve-formula-3126278
[4] 解释正态分布的 68–95–99.7 规则。
Michael Galarnyk,Medium。访问网址:towardsdatascience.com/understanding-the-68-95-99-7-rule-for-a-normal-distribution-b7b7cbf760c2
[5] 正态分布、二项分布与泊松分布,Make Me Analyst。访问网址:makemeanalyst.com/wp-content/uploads/2017/05/Poisson-Distribution-Formula.png
[6] 指数函数公式,&learning。访问网址:www.andlearning.org/exponential-formula/
简介: Pier Paolo Ippolito 是一名数据科学家,拥有南安普顿大学人工智能硕士学位。他对人工智能进展和机器学习应用(如金融和医学)有浓厚的兴趣。可以在 Linkedin 上与他联系。
原文。已获得许可转载。
相关:
-
什么是泊松分布?
-
如何优化你的 Jupyter Notebook
-
入门 R 编程
更多相关主题
概率:Statology 入门
作者提供的图片 | Midjourney & Canva
KDnuggets 的姐妹网站,Statology,拥有大量由专家撰写的统计学相关内容,这些内容在短短几年内积累而成。我们决定通过组织和分享一些精彩的教程,帮助读者了解这个出色的统计、数学、数据科学和编程资源,并与 KDnuggets 社区分享。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
学习统计学可能很困难。它可能让人沮丧。最重要的是,它可能让人困惑。这就是为什么Statology在这里提供帮助。
这个系列集中于介绍概率概念。如果你对概率不熟悉,或需要复习,这些教程系列非常适合你。试试看,并浏览 Statology 上的其他内容。
理论概率:定义 + 示例
概率是统计学中的一个主题,描述了某些事件发生的可能性。当我们谈论概率时,我们通常指的是两种类型之一。
你可以通过以下技巧来记住理论概率和实验概率之间的区别:
-
事件发生的理论概率可以通过数学理论来计算。
-
事件发生的实验概率可以通过直接观察实验结果来计算。
后验概率:定义 + 示例
后验概率是考虑到新信息后某个事件发生的更新概率。
例如,我们可能对某个事件“A”在考虑到刚刚发生的事件“B”之后的概率感兴趣。我们可以使用以下公式来计算这个后验概率:
P(A|B) = P(A) * P(B|A) / P(B)
如何解读赔率比
在统计学中,概率指的是某个事件发生的机会。它的计算方式是:
概率:
P(事件) = (# 可取结果)/ (# 可能结果)
例如,假设我们在一个袋子里有四个红球和一个绿球。如果你闭上眼睛随机抽取一个球,选择到绿球的概率计算为:
P(绿球) = 1 / 5 = 0.2。
大数法则:定义 + 示例
大数法则表示,随着样本大小的增加,样本均值会更接近于期望值。
这最基本的例子涉及掷硬币。每次我们掷硬币时,它正面朝上的概率是 1/2。因此,经过无限次掷硬币,正面出现的期望比例是 1/2 或 0.5。
集合操作:并集、交集、补集和差集
集合是项的集合。
我们用大写字母表示集合,并用花括号定义集合中的项。例如,假设我们有一个叫做“A”的集合,元素为 1, 2, 3。我们可以写作:
A = {1, 2, 3}
本教程解释了概率和统计中最常用的集合操作。
一般乘法规则(解释与示例)
一般乘法规则表示,任何两个事件 A 和 B 同时发生的概率可以计算为:
P(A 和 B) = P(A) * P(B|A)
竖线 | 表示“在给定的情况下”。因此,P(B|A) 可以读作“在 A 发生的情况下 B 发生的概率”。
如果事件 A 和 B 是独立的,那么 P(B|A) 简单等于 P(B),规则可以简化为:
P(A 和 B) = P(A) * P(B)
要获取更多类似的内容,请持续关注 Statology,并订阅他们的每周通讯,以确保您不会错过任何信息。
Matthew Mayo (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 和 Statology 的主编,以及 Machine Learning Mastery 的贡献编辑,Matthew 旨在让复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、语言模型、机器学习算法和探索新兴的人工智能。他的使命是让数据科学社区中的知识民主化。Matthew 从 6 岁开始编程。
更多相关主题
如何在几秒钟内处理数百万行的 DataFrame
原文:
www.kdnuggets.com/2022/01/process-dataframe-millions-rows-seconds.html

图片由 Jason Blackeye 提供,来源于 Unsplash
数据科学正在经历其复兴时刻。很难跟上所有可能改变数据科学工作方式的新工具。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 部门
我最近在与一位同事的交谈中了解到这个新的数据处理引擎,这位同事也是一名数据科学家。我们讨论了大数据处理,这是该领域创新的前沿,这个新工具就出现了。
尽管 pandas 是 Python 中数据处理的事实标准工具,但它并不适合处理大数据。对于更大的数据集,迟早会遇到内存溢出异常。
研究人员早在很久以前就面临了这个问题,这促使了像 Dask 和 Spark这样的工具的开发,它们试图通过将处理分布到多台机器上来克服“单机”限制。
这个活跃的创新领域也为我们带来了像 Vaex这样的工具,试图通过提高单机处理的内存效率来解决这个问题。
而且问题不仅仅于此。还有另一种大数据处理工具你应该了解……
认识 Terality

图片由 Frank McKenna 提供,来源于 Unsplash
Terality 是一个无服务器数据处理引擎,在云端处理数据。无需管理基础设施,因为 Terality 负责计算资源的扩展。其目标用户是工程师和数据科学家。
我与 Terality 团队交换了几封电子邮件,因为我对他们开发的工具感兴趣。他们迅速回复了。这些是我向团队提出的问题:

我给 Terality 团队发的第 n 封邮件(作者截图)
使用 Terality 进行数据处理的主要步骤是什么?
-
Terality 附带一个 Python 客户端,你可以将其导入到 Jupyter Notebook 中。
-
然后你以“pandas 方式”编写代码,Terality 安全地上传你的数据,并处理分布式计算(以及扩展)以计算你的分析。
-
处理完成后,你可以将数据转换回常规的 pandas DataFrame,并在本地继续分析。
幕后发生了什么?
Terality 团队开发了一个专有的数据处理引擎——它不是 Spark 或 Dask 的分支。
目标是避免 Dask 的缺陷,Dask 与 pandas 的语法不同,异步操作,未包含所有 pandas 函数,并且不支持自动扩展。
Terality 的数据处理引擎解决了这些问题。
Terality 是否可以免费使用?
Terality提供一个免费计划,允许你每月处理最多 500 GB 的数据。它还为需求更大的公司和个人提供付费计划。
在本文中,我们将重点关注免费计划,因为它适用于许多数据科学家。
Terality 如何计算数据使用量? (来自 Terality 的文档)
考虑一个总大小为 15GB 的数据集,如操作 df.memory_usage(deep=True).sum() 所返回的那样。
对该数据集执行一个(1)操作,例如 .sum 或 .sort_values,将消耗 Terality 中 15GB 的处理数据。
只有在任务运行成功状态下才会记录可计费使用量。
数据隐私如何?
当用户执行读取操作时,Terality 客户端将数据集复制到 Terality 在 Amazon S3 上的安全云存储中。
Terality 对数据隐私和保护有严格的政策。他们保证不会使用数据,并安全地处理数据。
Terality 不是存储解决方案。他们将在 Terality 客户端会话关闭后的最多 3 天内删除你的数据。
Terality 处理目前发生在 AWS 的法兰克福区域。
数据需要公开吗?
不!
用户需要访问本地计算机上的数据集,Terality 将在幕后处理上传过程。
上传操作也进行了并行处理,因此更快。
Terality 能处理大数据吗?
目前,在 2021 年 11 月, Terality 仍处于测试阶段。它优化了最多 100-200 GB 的数据集。
我询问了团队是否计划增加此功能,他们计划很快开始优化到 Terabytes 级别。
让我们试驾一下

由 尤金·赫斯季亚科夫 拍摄的照片,发布在 Unsplash 上
我惊讶于你可以简单地用 Terality 的包替换 pandas 的导入语句,然后重新运行你的分析。
请注意,一旦你导入了 Terality 的 Python 客户端,数据处理将不再在本地机器上进行,而是在 Terality 的云端数据处理引擎中完成。
现在,让我们安装 Terality 并在实践中尝试一下……
设置
你可以通过运行以下命令来安装 Terality:
pip install --upgrade terality
然后你在 Terality 上创建一个免费账户,并生成一个 API 密钥:

在 Terality 上生成新的 API 密钥(截图由作者提供)
最后一步是输入你的 API 密钥(同时用你的电子邮件替换电子邮件):
terality account configure --email your@email.com
让我们从小处开始……
现在,我们已经安装了 Terality,可以运行一个小示例来熟悉它。
实践表明,使用 Terality 和 pandas 两者结合,你可以充分发挥它们各自的优势——一个用于聚合数据,另一个则在本地分析聚合后的数据
以下命令通过导入 pandas.DataFrame 创建一个 terality.DataFrame:
**import** **pandas** **as** **pd**
**import** **terality** **as** **te**df_pd = pd.DataFrame({"col1": [1, 2, 2], "col2": [4, 5, 6]})
df_te = te.DataFrame.from_pandas(df_pd)
现在,数据已经在 Terality 的云端,我们可以继续进行分析:
df_te.col1.value_counts()
运行过滤操作和其他熟悉的 pandas 操作:
df_te[(df_te["col1"] >= 2)]
一旦我们完成分析,可以使用以下命令将其转换回 pandas DataFrame:
df_pd_roundtrip = df_te.to_pandas()
我们可以验证 DataFrames 是否相等:
pd.testing.assert_frame_equal(df_pd, df_pd_roundtrip)
让我们搞大点……
我建议你查看 Terality 的快速入门 Jupyter Notebook, 其中介绍了 40 GB Reddit 评论数据集的分析。他们还有一个包含 5 GB 数据集的小型教程。
我点击了 Terality 的 Jupyter Notebook 并处理了 40 GB 的数据集。它在 45 秒内读取了数据,并花费了 35 秒进行排序。与另一个表的合并花费了 1 分钟 17 秒。感觉就像在我的笔记本电脑上处理一个更小的数据集。
然后我尝试在我的笔记本电脑(配备 16 GB 主内存)上用 pandas 加载相同的 40GB 数据集——结果返回了内存不足的异常。
官方 Terality 教程带你分析一个包含 Reddit 评论的 5GB 文件。
结论

照片由 Sven Scheuermeier 拍摄,来源于 Unsplash
我尝试了 Terality,并且我的体验没有遇到重大问题。这让我感到惊讶,因为它们官方仍在测试阶段。另一个好兆头是他们的支持团队非常响应迅速。
当你有一个大型数据集无法在本地机器上处理时,我认为 Terality 的应用场景非常出色——无论是因为内存限制还是处理速度。
使用 Dask(或 Spark)需要启动一个集群,这样的成本远高于使用 Terality 完成分析的成本。
此外,配置这样一个集群是一个繁琐的过程,而使用 Terality 你只需要更改导入语句。
我喜欢的另一点是我可以在本地 JupyterLab 中使用它,因为我有许多扩展、配置、深色模式等。
我期待着团队在接下来的几个月中取得的 Terality 进展。
Roman Orac 是一位机器学习工程师,在改进文档分类和项目推荐系统方面取得了显著成功。Roman 具有管理团队、指导初学者和向非工程师解释复杂概念的经验。
原文。经许可转载。
了解更多相关主题
使用 R 进行过程挖掘:介绍
原文:
www.kdnuggets.com/2017/11/process-mining-r-introduction.html/2
然后,我们可以从这些信息创建一个 igraph 对象,并导出它以使用 Graphviz 渲染,从而得到以下过程图(片段):
我们的前 3 个课程推荐
1. Google 网络安全证书 - 进军网络安全事业快速通道
2. Google 数据分析专业证书 - 提升数据分析能力
3. Google IT 支持专业证书 - 在 IT 方面支持您的组织
现在,我们可以进一步扩展这个基本框架,并将其与预测性和描述性分析模型合并。一些实验的想法包括:
-
筛选事件日志和流程图,只显示高频行为
-
尝试不同的着色方式,例如不基于频率或性能,而是其他有趣的数据属性
-
扩展框架以包括基本的符合性检查,例如通过突出显示偏差流程
-
将决策挖掘(或概率度量)应用于分流,以预测将遵循哪些路径
现在,我们来应用一个简单的扩展:假设我们对“分析报价请求”活动感兴趣,并希望带入一些与该活动相关的更多信息,例如资源属性,即执行该活动的人员。
因此,我们使用频率计数构建了两个新的数据框,将频率计数作为我们感兴趣的指标:
col.box.blue <- colorRampPalette(c('#DBD8E0', '#014477'))(20)
col.arc.blue <- colorRampPalette(c('#938D8D', '#292929'))(20)
activities.counts <- activities.basic %>%
select(act) %>%
group_by_all %>%
summarize(metric=n()) %>%
ungroup %>%
mutate(fillcolor=col.box.blue[floor(linMap(metric, 1,20))])
edges.counts <- edges.basic %>%
select(a.act, b.act) %>%
group_by_all %>%
summarize(metric=n()) %>%
ungroup %>%
mutate(color=col.arc.blue[floor(linMap(metric, 1,20))],
penwidth=floor(linMap(metric, 1, 5)),
metric.char=as.character(metric))
接下来,我们筛选我们感兴趣的活动的事件日志,计算持续时间,然后为每个执行此活动的资源-活动对计算频率和性能指标。
acts.res <- eventlog %>%
filter(Activity == "Analyze Request for Quotation") %>%
mutate(Duration=Complete-Start) %>%
select(Duration, Resource, Activity) %>%
group_by(Resource, Activity) %>%
summarize(metric.freq=n(), metric.perf=median(Duration)) %>%
ungroup %>%
mutate(color='#75B779',
penwidth=1,
metric.char=formatSeconds(as.numeric(metric.perf)))
在这里使用的一个有用的 igraph 函数是“graph_from_data_frame”。此函数期望一个顶点的数据框(除了第一列以外的所有列自动充当属性),并期望一个边的数据框(除了前两列以外的所有列自动充当属性)。因此,我们构造了最终的顶点(活动)数据框如下所示。填充颜色基于节点是否表示一个活动(我们使用上面设置的颜色)或一个资源(我们使用绿色):
a <- bind_rows(activities.counts %>% select(name=act, metric=metric) %>%
mutate(type='Activity'),
acts.res %>% select(name=Resource, metric=metric.freq) %>%
mutate(type='Resource')) %>%
distinct %>%
rowwise %>%
mutate(fontsize=8,
fontname='Arial',
label=paste(name, metric, sep='\n'),
shape=ifelse(type == 'Activity', 'box', 'ellipse'),
style=ifelse(type == 'Activity', 'rounded,filled', 'solid,filled'),
fillcolor=ifelse(type == 'Activity',
activities.counts[activities.counts$act==name,]$fillcolor, '#75B779'))
And construct a data frame for the edges as well:
e <- bind_rows(edges.counts,
acts.res %>% select(a.act=Resource, b.act=Activity, metric.char, color, penwidth)) %>%
rename(label=metric.char) %>%
mutate(fontsize=8, fontname='Arial')
Finally, we can construct an igraph object as follows:
gh <- graph_from_data_frame(e, vertices=a, directed=T)
导出和绘制此对象后,我们看到所有三个资源都对我们的活动的执行做出了相同的贡献,它们的中位执行时间(显示在绿色弧上)也相似:
当然,我们现在已经有一个强大的框架,可以从中开始创建更丰富的过程图,并嵌入更多注释和信息。
在这篇文章中,我们提供了一个快速的旋风之旅,介绍了如何使用 R 创建丰富的流程图。正如所见,这在典型的流程发现工具不可用的情况下可能非常有用,同时还提供了关于如何将典型的流程挖掘任务与其他与数据挖掘相关的任务进行增强或更容易组合的提示。希望您喜欢阅读这篇文章,并迫不及待地想看看您会如何处理您的事件日志。
更多阅读:
-
vanden Broucke S., Vanthienen J., Baesens B. (2013). Volvo IT 比利时 VINST. 第 3 届业务流程智能挑战赛论文集合,与第 9 届国际业务流程智能研讨会(BPI 2013)共同举办。北京(中国),2013 年 8 月 26 日(编号 3)。亚琛(德国):亚琛工业大学。
ceur-ws.org/Vol-1052/paper3.pdf
个人简介:Seppe vanden Broucke 是比利时鲁汶大学经济与商业学院的助理教授。他的研究兴趣包括商业数据挖掘和分析、机器学习、流程管理和流程挖掘。他的工作已发表在知名国际期刊上,并在顶级会议上做过报告。Seppe 的教学包括高级分析、大数据和信息管理课程。他还经常为行业和企业的听众进行教学。
相关文章:
-
流程挖掘中的隐私、安全性和伦理
-
流程挖掘:数据科学与流程科学的交叉点
-
通过统计模型改进您的流程
关于这个话题的更多内容
生产机器学习监控:异常值、漂移、解释器与统计性能
评论
由亚历杭德罗·索塞多,Seldon 的工程总监
作者提供的图像
“机器学习模型的生命周期只有在生产环境中开始”
在本文中,我们展示了一个端到端的示例,展示了生产中机器学习模型监控的最佳实践、原则、模式和技术。我们将展示如何将标准的微服务监控技术适应于已部署的机器学习模型,以及更高级的范式,包括概念漂移、异常检测和人工智能解释。
我们将从头开始训练一个图像分类机器学习模型,将其作为微服务部署在 Kubernetes 中,并引入广泛的高级监控组件。这些监控组件将包括异常检测器、漂移检测器、AI 解释器和指标服务器——我们将涵盖每个组件的底层架构模式,这些模式考虑了规模的需求,并设计为在数百或数千个异构机器学习模型中高效工作。
你还可以以视频形式查看这篇博客文章,该视频作为 PyCon 香港 2020 的主题演讲——主要的区别在于演讲使用了 Iris Sklearn 模型作为端到端示例,而不是 CIFAR10 Tensorflow 模型。
端到端机器学习监控示例
在本文中,我们展示了一个端到端的实际示例,涵盖了下面部分中概述的每个高级概念。
-
复杂机器学习系统监控介绍
-
CIFAR10 Tensorflow Renset32 模型训练
-
模型打包与部署
-
性能监控
-
事件基础设施监控
-
统计监控
-
异常检测监控
-
概念漂移监控
-
解释性监控
在本教程中,我们将使用以下开源框架:
-
Tensorflow — 广泛使用的机器学习框架。
-
Alibi Explain — 白盒和黑盒机器学习模型解释库。
-
Albi Detect — 先进的机器学习监控算法,用于概念漂移、异常检测和对抗性检测。
-
Seldon Core — 机器学习模型的部署与编排及监控组件。
你可以在 提供的 jupyter notebook 中找到本文的完整代码,这将允许你运行模型监控生命周期中的所有相关步骤。
让我们开始吧。
1. 复杂机器学习系统监控简介
生产机器学习的监控很困难,而且随着模型数量和高级监控组件的增加,复杂性呈指数级增长。这部分是因为生产机器学习系统与传统的软件微服务系统的差异——以下概述了一些关键差异。
作者提供的图像
-
专用硬件 — 优化的机器学习算法实现通常需要访问 GPU、更大的 RAM、专用的 TPU/FPGAs 以及其他动态变化的需求。这导致需要特定的配置,以确保这些专用硬件可以产生准确的使用指标,更重要的是,这些指标可以与相应的底层算法关联。
-
复杂的依赖图 — 工具和基础数据涉及复杂的依赖关系,这些关系可能跨越复杂的图结构。这意味着处理单个数据点可能需要在多个跳跃之间进行状态评估,这可能会引入额外的领域特定抽象层,需要在可靠解读监控状态时考虑。
-
合规要求 — 生产系统,特别是在高度监管的环境中,可能涉及复杂的审计政策、数据要求以及在每个执行阶段收集资源和文档的要求。有时,显示和分析的指标必须根据指定的政策限制给相关人员,这些政策的复杂性可能因用例而异。
-
可重复性 — 除了这些复杂的技术要求外,还需要组件的可重复性,确保运行的组件可以在另一个时间点以相同的结果执行。对于监控系统,重要的是系统在设计时考虑到这一点,以便能够重新运行特定的机器学习执行,以重现特定的指标,无论是用于监控还是审计目的。
生产机器学习的构造涉及多阶段模型生命周期中的广泛复杂性。这包括实验、评分、超参数调整、服务、离线批处理、流处理等。每个阶段可能涉及不同的系统和各种异质工具。因此,确保我们不仅学习如何引入特定于模型的指标进行监控,而且要识别可以用于在规模上有效监控部署模型的更高级别的架构模式,这一点至关重要。这是我们在下面每个部分中将要覆盖的内容。
2. CIFAR10 Tensorflow Resnet32 模型训练

来自开源的CIFAR10 数据集的图像
我们将使用直观的CIFAR10 数据集。这个数据集包含的图像可以被分类为 10 个类别之一。模型将以形状为 32x32x3 的数组作为输入,并以一个包含 10 个概率的数组作为输出,表示该图像属于哪个类别。
我们能够从 Tensorflow 数据集中加载数据——即:
10 个类别包括:cifar_classes = [“airplane”, “automobile”, “bird”, “cat”, “deer”, “dog”, “frog”, “horse”, “ship”, “truck”]。
为了训练和部署我们的机器学习模型,我们将遵循下图所示的传统机器学习工作流程。我们将训练一个模型,然后可以将其导出和部署。
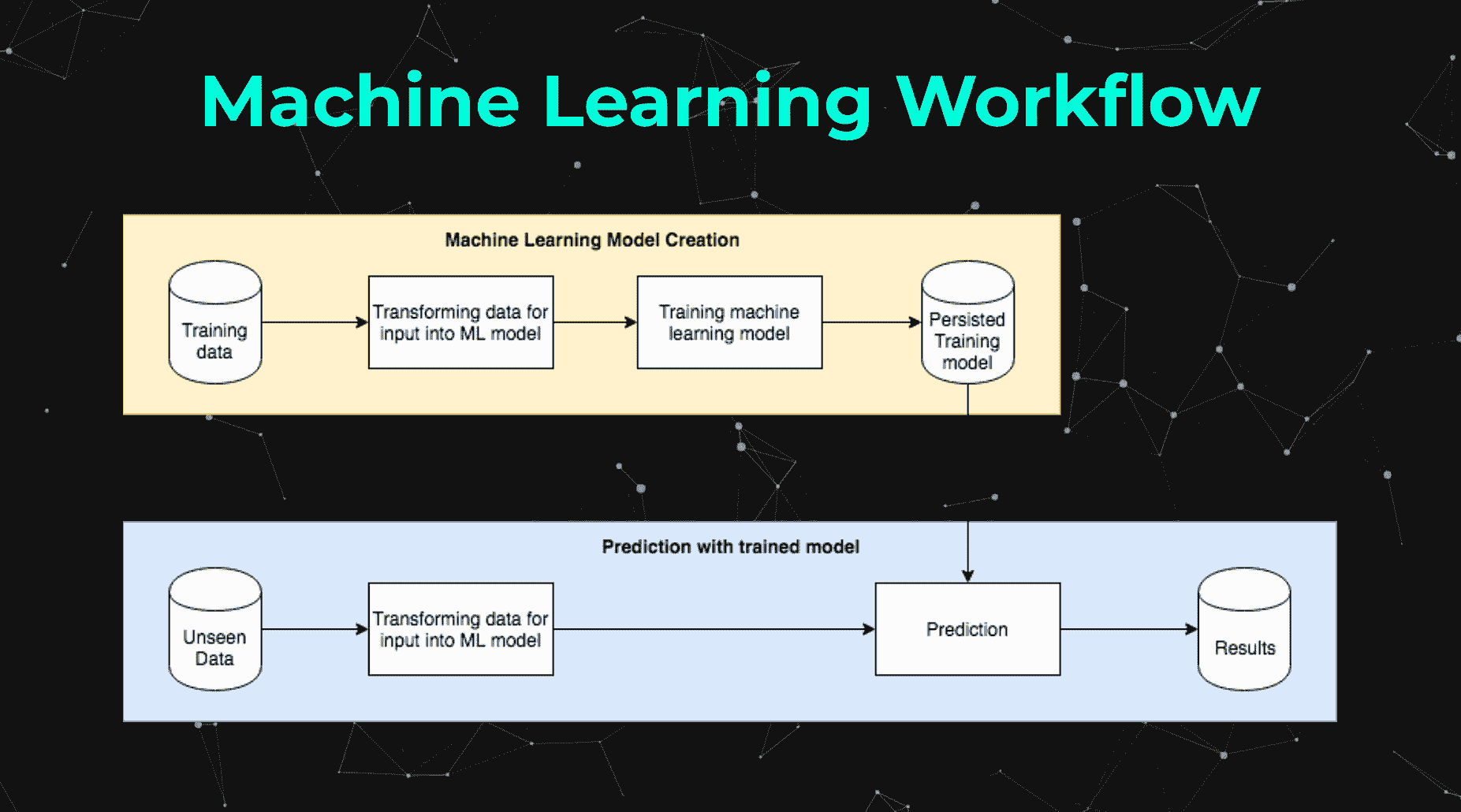
我们将使用 Tensorflow 来训练这个模型,利用Residual Network,这无疑是最具突破性的架构之一,因为它使得训练多达数百甚至上千层的网络成为可能,并且性能良好。在这个教程中,我们将使用 Resnet32 实现,幸运的是,我们可以通过 Alibi Detect 包提供的工具使用它。
使用我的 GPU,这个模型训练了大约 5 小时,幸运的是,我们可以使用通过 Alibi Detect fetch_tf_model工具检索的预训练模型。
如果你仍然想训练 CIFAR10 resnet32 tensorflow 模型,你可以使用 Alibi Detect 包提供的辅助工具,如下所述,或者直接导入原始网络并自行训练。
我们现在可以在“未见数据”上测试训练好的模型。我们可以使用一个被分类为卡车的 CIFAR10 数据点来测试它。我们可以通过 Matplotlib 绘制数据点来查看。

我们现在可以通过模型处理该数据点,你可以想象它应该被预测为“卡车”。
我们可以通过找到概率最高的索引来确定预测的类别,在这种情况下,它是index 9,概率为 99%。从类别名称(例如cifar_classes[ np.argmax( X_curr_pred )])可以看出,第 9 类是“卡车”。
3. 打包与部署模型
我们将使用 Seldon Core 将模型部署到 Kubernetes 中,它提供了多种选项将我们的模型转换为一个完全成熟的微服务,暴露 REST、GRPC 和 Kafka 接口。
我们在使用 Seldon Core 部署模型时的选项包括 1) 使用语言封装来部署我们的 Python、Java、R 等代码类,或 2) 使用预打包模型服务器直接部署模型工件。在本教程中,我们将使用Tensorflow 预打包模型服务器来部署我们之前使用的 Resnet32 模型。
这种方法将使我们能够利用 Kubernetes 的云原生架构,它通过水平可扩展的基础设施支持大规模微服务系统。在本教程中,我们将深入了解和利用应用于机器学习的云原生和微服务模式。
下面的图表总结了部署模型工件或代码本身的选项,以及我们可以选择部署单个模型或构建复杂的推理图的能力。
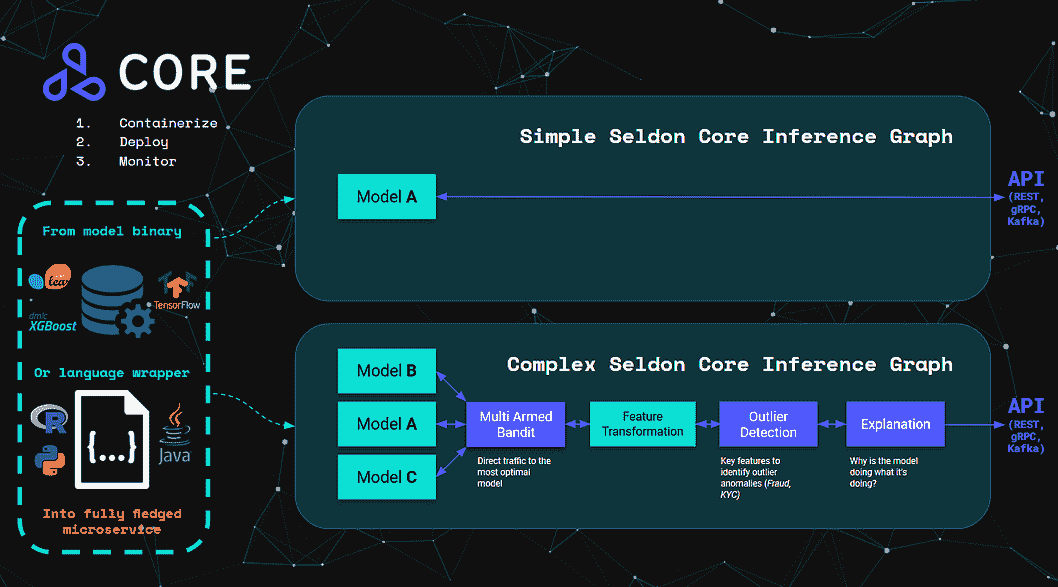
顺便提一下,您可以使用KIND(Kubernetes in Docker)或Minikube等开发环境在 Kubernetes 上进行设置,然后按照此示例的笔记本或Seldon 文档中的说明进行操作。您需要确保安装 Seldon,并配置相应的 Ingress 提供者,如 Istio 或 Ambassador,以便发送 REST 请求。
为了简化教程,我们已经上传了训练好的 Tensorflow Resnet32 模型,可以在这个公共 Google 桶中找到:gs://seldon-models/tfserving/cifar10/resnet32。如果您已经训练了自己的模型,可以将其上传到您选择的桶中,可以是 Google 桶、Azure、S3 或本地 Minio。对于 Google,您可以使用下面的gsutil命令行进行操作:
我们可以使用 Seldon 通过自定义资源定义配置文件部署模型。下面是将模型工件转换为完全成熟的微服务的脚本。
现在我们可以看到模型已经部署并正在运行。
$ kubectl get pods | grep cifarcifar10-default-0-resnet32-6dc5f5777-sq765 2/2 Running 0 4m50s
现在我们可以通过发送相同的卡车图像来测试已部署的模型,看看我们是否仍然得到相同的预测。
数据点通过plt.imshow(X_curr[0])显示
我们可以通过发送如下所述的 REST 请求来实现,然后打印结果。
上述代码的输出是对 Seldon Core 提供的 URL 的 POST 请求的 JSON 响应。我们可以看到预测正确地结果为“卡车”类别。
{'predictions': [[1.26448288e-06, 4.88144e-09, 1.51532642e-09, 8.49054249e-09, 5.51306611e-10, 1.16171261e-09, 5.77286274e-10, 2.88394716e-07, 0.00061489339, 0.999383569]]}
Prediction: truck
4. 性能监控
我们将涵盖的第一个监控支柱是传统的性能监控,这是你在微服务和基础设施领域中会找到的传统和标准监控功能。当然,在我们的案例中,我们将其应用于已部署的机器学习模型。
一些机器学习监控的高级原则包括:
-
监控运行中的 ML 服务性能
-
识别潜在瓶颈或运行时警告
-
调试和诊断 ML 服务的意外性能
为此,我们将介绍在生产系统中常用的前两个核心框架:
-
Elasticsearch 用于日志——一个文档键值存储系统,通常用于存储容器的日志,这些日志可以用于通过堆栈跟踪或信息日志诊断错误。在机器学习的情况下,我们不仅用它来存储日志,还用来存储机器学习模型的预处理输入和输出,以便进一步处理。
-
Prometheus 用于指标——一个时间序列存储系统,通常用于存储实时指标数据,然后可以利用像 Grafana 这样的工具进行可视化。
Seldon Core 为任何已部署的模型提供了开箱即用的 Prometheus 和 Elasticsearch 集成。在本教程中,我们将参考 Elasticsearch,但为了简化对几个高级监控概念的直观理解,我们将主要使用 Prometheus 进行指标和 Grafana 进行可视化。
在下图中,你可以看到导出的微服务如何使任何容器化的模型能够导出指标和日志。指标由 Prometheus 抓取,日志由模型转发到 Elasticsearch(通过我们在下一部分中介绍的事件基础设施进行)。值得明确的是,Seldon Core 还支持使用 Jaeger 的 Open Tracing 指标,显示了 Seldon Core 模型图中所有微服务跳跃的延迟。
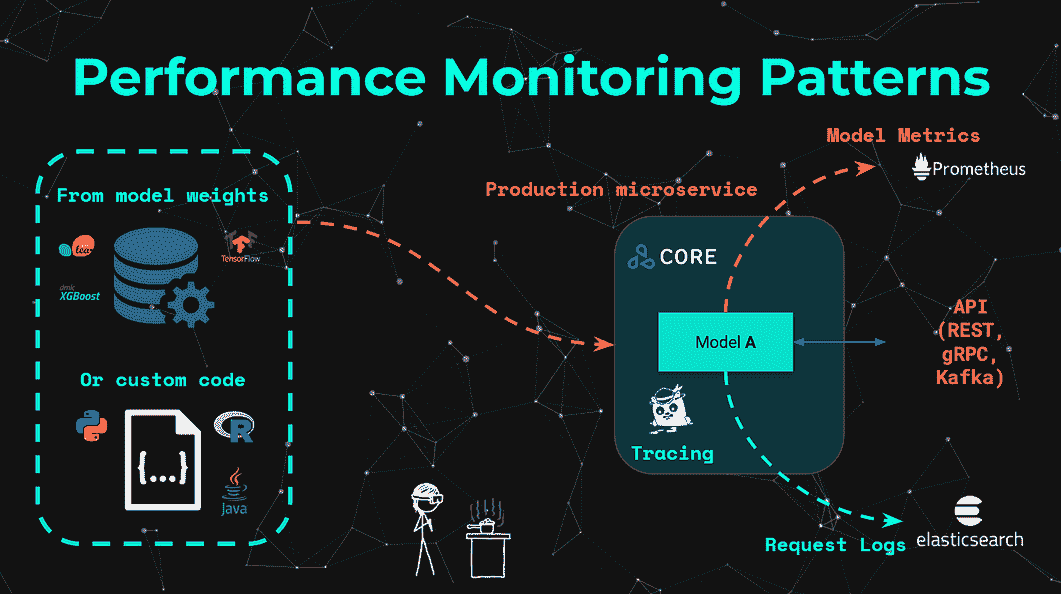
作者提供的图片
一些由 Seldon Core 模型暴露的性能监控指标示例,也可以通过进一步集成添加:
-
每秒请求数
-
每个请求的延迟
-
CPU/内存/数据利用率
-
自定义应用指标
在本教程中,你可以使用Seldon Core Analytics 包来设置 Prometheus 和 Grafana,该包会设置一切,以便实时收集指标,然后在仪表板上进行可视化。
我们现在可以可视化部署模型相对于其特定基础设施的利用率指标。使用 Seldon 部署模型时,你需要考虑多个属性,以确保模型的最佳处理。这包括分配的 CPU、内存和为应用程序保留的文件系统存储,还包括相应的配置,用于相对于分配的资源和预期请求运行进程和线程。
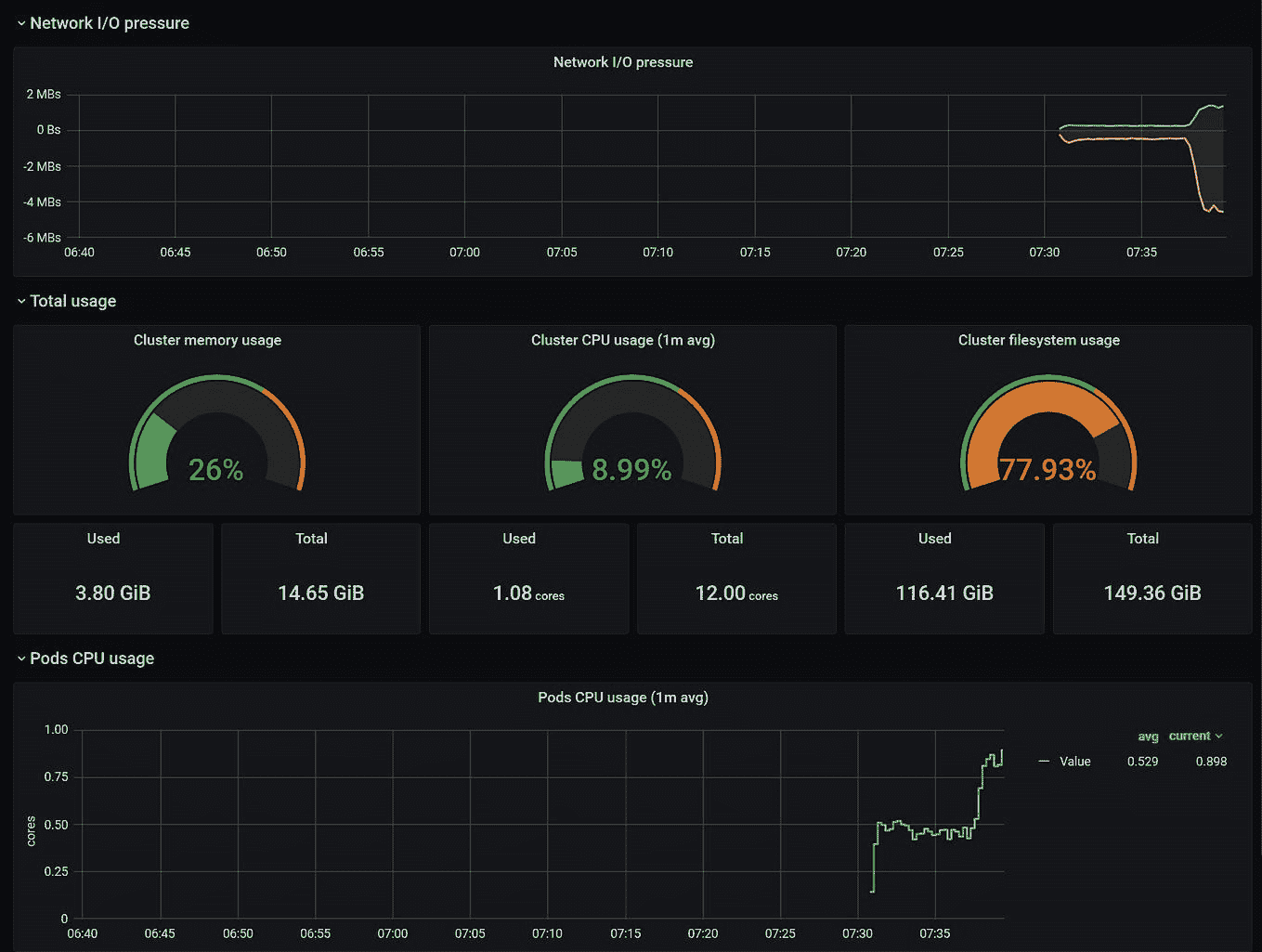
图片来源:作者
同样,我们也能够监控模型本身的使用情况——每个 Seldon 模型都暴露模型使用指标,如每秒请求数、每个请求的延迟、模型的成功/错误代码等。这些指标很重要,因为它们能够映射到底层机器学习模型的更高级/专用概念。大的延迟峰值可以根据模型的底层需求进行诊断和解释。模型显示的错误也被抽象成简单的 HTTP 错误代码,这有助于将先进的机器学习组件标准化为微服务模式,从而使 DevOps / IT 管理人员更容易大规模管理。
图片来源:作者
5. 监控的事件基础设施
为了能够利用更高级的监控技术,我们将首先简要介绍事件基础设施,这使得 Seldon 可以使用先进的机器学习算法进行异步数据监控,并在可扩展的架构中运行。
Seldon Core 利用KNative Eventing来使机器学习模型能够将模型的输入和输出转发到更高级的机器学习监控组件,如异常检测器、概念漂移检测器等。
我们不会详细介绍 KNative 引入的事件基础设施,但如果你感兴趣,Seldon Core 文档中有多个实际示例,展示了如何利用 KNative 事件基础设施将有效负载转发到进一步的组件如 Elasticsearch,以及 Seldon 模型如何连接到处理事件。
对于本教程,我们需要使模型能够将所有处理过的负载输入和输出转发到 KNative Eventing 代理,这将使所有其他高级监控组件能够订阅这些事件。
下面的代码向部署配置中添加了一个“logger”属性,用于指定代理位置。
6. 统计监控
性能指标对于微服务的常规监控是有用的,然而对于机器学习的专业领域,有一些广为人知和广泛使用的指标在模型生命周期的训练阶段之外都至关重要。更常见的指标包括准确率、精确度、召回率,但也包括像均方根误差、KL 散度等更多指标。
本文的核心主题不仅仅是指定如何计算这些指标,因为通过一些 Flask 包装魔法使单个微服务暴露这些指标并不是一项艰巨的任务。关键在于识别可以在数百或数千个模型中引入的可扩展架构模式。这意味着我们需要对接口和模式进行一定程度的标准化,以便将模型映射到相关基础设施中。
一些高级原则围绕更专业的机器学习指标,如下所示:
-
针对统计机器学习性能的监控
-
基准测试多个不同模型或不同版本
-
针对数据类型和输入/输出格式的专业化
-
有状态的异步“反馈”提供(如“注释”或“修正”)
鉴于这些需求,Seldon Core 引入了一套架构模式,允许我们引入“可扩展指标服务器”的概念。这些指标服务器包含现成的处理模型处理数据的方法,通过订阅相应的事件主题,最终暴露出如下一些指标:
-
原始指标:真正例、假负例、假正例、真正负例
-
基本指标:准确率、精确度、召回率、特异性
-
专业指标:KL 散度、均方根误差等
-
按类别、特征和其他元数据的细分
作者提供的图像
从架构的角度来看,这可以通过上面的图示更加直观地展示。这展示了如何通过模型提交单个数据点,然后由任何相应的指标服务器处理。指标服务器还可以在提供“正确/注释”标签后处理这些标签,这些标签可以与 Seldon Core 在每个请求中添加的唯一预测 ID 关联。通过从 Elasticsearch 存储中提取相关数据来计算和暴露专业指标。
目前,Seldon Core 提供了一套开箱即用的 Metrics Servers:
-
BinaryClassification — 处理以二元分类形式出现的数据(例如 0 或 1),以暴露原始指标以显示基本统计指标(准确率、精确度、召回率和特异性)。
-
MultiClassOneHot — 处理以 one hot 预测形式出现的数据用于分类任务(例如[0, 0, 1]或[0, 0.2, 0.8]),然后可以暴露原始指标以显示基本统计指标。
-
MultiClassNumeric — 处理分类任务中以数值数据点形式出现的数据(例如 1,或[1]),然后可以暴露原始指标以显示基本统计指标。
在这个示例中,我们将能够部署一个类型为“MulticlassOneHot”的 Metric Server——你可以在下面总结的代码中看到使用的参数,但完整的 YAML 文件可以在 jupyter notebook 中找到。
一旦我们部署了我们的指标服务器,现在我们只需通过相同的微服务端点向我们的 CIFAR10 模型发送请求和反馈。为了简化工作流程,我们将不发送异步反馈(这会与 elasticsearch 数据进行比较),而是发送“自包含”的反馈请求,其中包含推断“响应”和推断“真实值”。
以下函数为我们提供了一种发送大量反馈请求的方法,以获得我们用例的大致准确率(正确预测与错误预测的数量)。
现在我们可以首先发送反馈以获得 90%的准确率,然后为了确保我们的图表看起来漂亮,我们可以发送另一批请求,这将导致 40%的准确率。
这基本上赋予我们实时可视化 MetricsServer 计算的指标的能力。
作者提供的图片
从上面的仪表板中,我们可以对通过这种架构模式能够获得的指标类型有一个高层次的直觉。上述状态统计指标特别需要异步提供额外的元数据,然而,即使指标本身的计算方法可能非常不同,我们可以看到基础设施和架构要求可以被抽象和标准化,以便这些指标能够以更可扩展的方式处理。
随着我们深入研究更高级的统计监控技术,我们将继续看到这种模式。
7. 异常检测监控
对于更高级的监控技术,我们将利用 Alibi Detect 库,特别是它提供的一些高级异常检测算法。Seldon Core 为我们提供了一种将异常检测器作为架构模式进行部署的方法,还为我们提供了一个经过优化的预打包服务器,以服务 Alibi Detect 异常检测模型。
异常检测的一些关键原则包括:
-
检测数据实例中的异常
-
当出现异常值时进行标记/警报
-
识别可能有助于诊断异常值的潜在元数据
-
启用对已识别异常值的深入分析
-
启用检测器的持续/自动化再训练
对于异常值检测器,尤其重要的是允许计算在模型之外进行,因为这些计算通常比较重,并且可能需要更多专业化的组件。已部署的异常值检测器可能会带来与机器学习模型类似的复杂性,因此在这些高级组件中覆盖相同的合规性、治理和血统概念是很重要的。
下图展示了模型如何通过事件基础设施转发请求。异常值检测器随后处理数据点,以计算其是否为异常值。该组件能够将异常值数据异步存储在相应的请求条目中,或者它能够将指标暴露给 Prometheus,这也是我们在本节中将要可视化的内容。
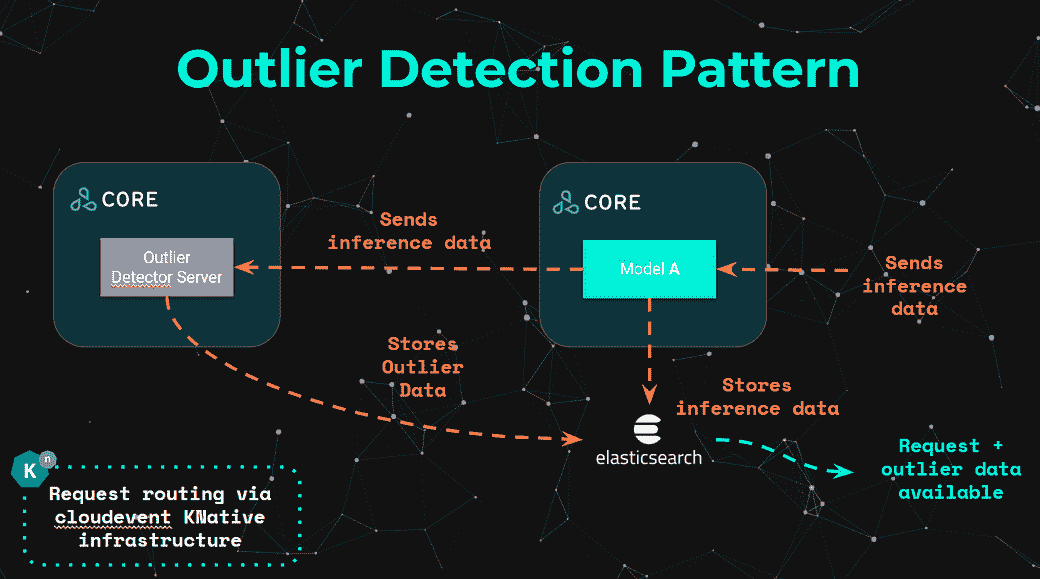
作者提供的图像
在本示例中,我们将使用Alibi Detect 变分自编码器异常值检测器技术。异常值检测器在一批未标记但正常(内点)数据上进行训练。VAE 检测器尝试重建其接收到的输入数据,如果输入数据无法被很好地重建,则会被标记为异常值。
Alibi Detect 提供了允许我们从零开始导出异常值检测器的工具。我们可以使用fetch_detector函数来获取它。
如果你想训练异常值检测器,可以通过简单地利用OutlierVAE类及其相应的编码器和解码器来实现。
为了测试异常值检测器,我们可以拍摄相同的卡车图像,并观察如果在图像中逐渐添加噪声,异常值检测器的表现如何。我们还可以使用 Alibi Detect 可视化函数plot_feature_outlier_image来绘制这些结果。
我们可以创建一组修改过的图像,并通过以下代码将其传递给异常值检测器。
我们现在在变量all_X_mask中拥有一组修改过的样本,每个样本都带有逐渐增加的噪声。我们现在可以将这 10 个样本全部通过异常值检测器进行检测。
在查看结果时,我们可以看到前 3 个数据点没有被标记为异常值,而其余的数据点被标记为异常值——我们可以通过打印值print(od_preds[“data”][“is_outlier”])来查看这一点。该命令会显示如下数组,其中 0 表示非异常值,1 表示异常值。
array([0, 0, 0, 1, 1, 1, 1, 1, 1, 1])
我们现在可以可视化异常值实例级别的评分如何与阈值映射,这反映了上述数组中的结果。
同样,我们可以深入了解异常值检测器评分通道的直观感受,以及重建的图像,这应能清晰地展示其内部操作方式。

我们现在可以将异常值检测器投入生产。我们将利用与指标服务器类似的架构模式,即 Alibi Detect Seldon Core 服务器,它将监听数据的推理输入/输出。每个通过模型的数据点,相关的异常值检测器将能够处理它。
主要步骤是首先确保我们上面训练的异常值检测器已上传到 Google 桶等对象存储中。我们已经将其上传到 gs://seldon-models/alibi-detect/od/OutlierVAE/cifar10,但如果你愿意,可以上传并使用自己的模型。
一旦我们部署了异常值检测器,我们将能够发送大量请求,其中许多将是异常值,其他的则不是。
我们现在可以在仪表盘上可视化一些异常值——每个数据点都会有一个新的入口,并包括它是否为异常值。
图片由作者提供
8. 漂移监测
随着时间的推移,实际生产环境中的数据可能会发生变化。虽然这种变化不是剧烈的,但可以通过数据分布的漂移来识别,尤其是在模型预测输出方面。
漂移检测的关键原则包括:
-
识别数据分布中的漂移,以及模型输入和输出数据之间关系的漂移。
-
标记出找到的漂移以及发现漂移时的相关数据点
-
允许深入查看用于计算漂移的数据
在漂移检测的概念中,与异常值检测用例相比,我们面临进一步的复杂性。主要是需要对每个漂移预测进行批量输入,而不是单个数据点。下图展示了与异常值检测器模式类似的工作流程,主要区别在于它保持一个滚动窗口或滑动窗口来进行处理。
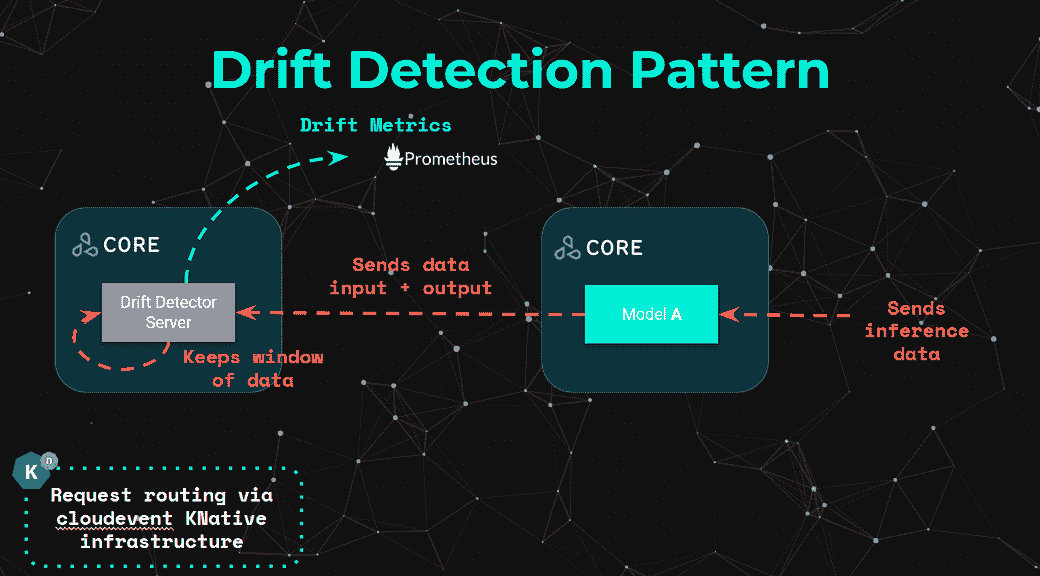
图片由作者提供
在这个例子中,我们将再次使用 Alibi Detect 库,它为我们提供了 Kolmogorov-Smirnov 数据漂移检测器用于 CIFAR-10。
对于这种技术,将能够使用 KSDrift 类来创建和训练漂移检测器,这还需要一个使用“未训练自编码器 (UAE)”的预处理步骤。
为了测试异常检测器,我们将生成一组带有损坏数据的检测器。Alibi Detect 提供了一套很好的工具,我们可以用来以逐渐增加的方式生成图像的损坏/噪声。在这种情况下,我们将使用以下噪声:[‘gaussian_noise’, ‘motion_blur’, ‘brightness’, ‘pixelate’]。这些将使用下面的代码生成。
以下是一个来自创建的损坏数据集的数据点,其中包含上述不同类型的逐渐增加的损坏图像。
我们现在可以尝试运行一些数据点以计算是否检测到漂移。初始批次将由来自原始数据集的数据点组成。
这会如预期输出:漂移?没有!
类似地,我们可以在损坏的数据集上运行它。
我们可以看到所有请求都被标记为漂移,如预期的那样:
Corruption type: gaussian_noise
Drift? Yes!
Corruption type: motion_blur
Drift? Yes!
Corruption type: brightness
Drift? Yes!
Corruption type: pixelate
Drift? Yes!
部署漂移检测器
现在我们可以按照上述架构模式部署我们的漂移检测器。与异常检测器类似,我们首先必须确保我们训练的漂移检测器可以上传到对象存储。我们目前可以使用我们准备好的 Google 存储桶 gs://seldon-models/alibi-detect/cd/ks/drift 进行部署。
这将具有类似的结构,主要区别是我们还将指定 Alibi Detect 服务器使用的所需批量大小,以便在运行模型之前作为缓冲。在这种情况下,我们选择批量大小为 1000。
现在我们已经部署了异常检测器,首先尝试从正常数据集中发送 1000 个请求。
接下来我们可以发送损坏的数据,这将在发送 10k 数据点后导致检测到漂移。
我们可以在 Grafana 仪表盘上可视化检测到的不同漂移点。
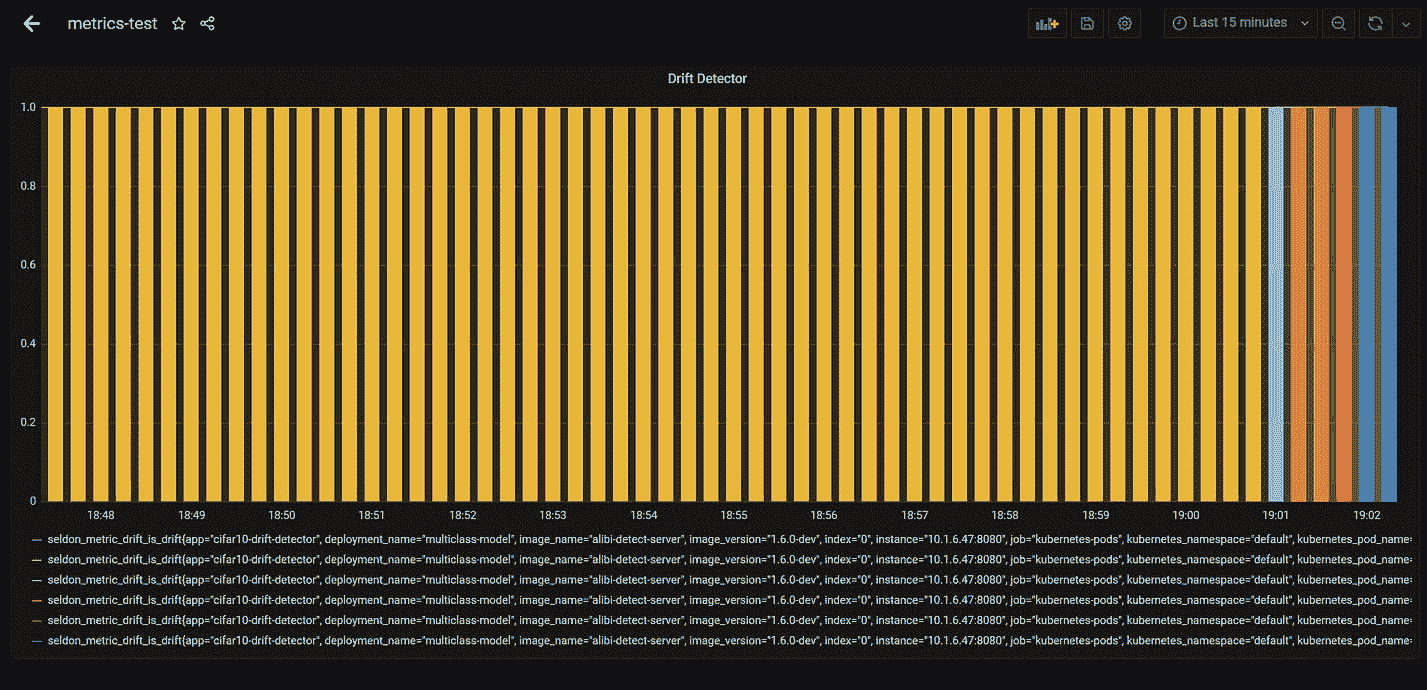
作者提供的图像
9. 可解释性监控
人工智能可解释性技术对于理解复杂的黑箱机器学习模型的行为至关重要。当前的重点是提供对可解释组件可以大规模部署的架构模式的直观理解和实际示例。模型可解释性的关键原则包括:
-
对模型行为进行人类可解释的洞察
-
引入特定用例的可解释性功能
-
识别关键指标,例如信任评分或统计性能阈值
-
启用使用一些更复杂的机器学习技术
关于可解释性有广泛的不同技术,但理解不同类型的解释器的高层主题很重要。这些包括:
-
范围(本地 vs 全局)
-
模型类型(黑箱 vs 白箱)
-
任务(分类、回归等)
-
数据类型(表格、图像、文本等)
-
洞察(特征归因、对比事实、影响训练实例等)
作为接口的解释器在数据流模式上有相似之处。即许多解释器需要与模型处理的数据进行互动,并且能够与模型本身进行互动——对于黑箱技术,这包括输入/输出,而对于白箱技术,则包括模型本身的内部。
图片由作者提供
从架构的角度来看,这主要涉及一个独立的微服务,该服务不仅接收推断请求,还能够与相关模型互动,通过发送相关数据“反向工程”模型。这在上面的图示中有所展示,但一旦我们深入到示例中,这将变得更加直观。
对于这个示例,我们将使用 Alibi Explain 框架,并使用Anchor Explanation技术。该本地解释技术告诉我们在特定数据点中具有最高预测能力的特征。
我们可以简单地通过指定数据集的结构以及一个允许解释器与模型的预测功能互动的lambda来创建我们的 Anchor 解释器。
我们能够识别模型中在此案例中预测图像的锚点。
我们可以通过显示解释本身的输出锚点来可视化锚点。
我们可以看到图像的锚点包括卡车的挡风玻璃和轮子。
在这里,您可以看到解释器与我们部署的模型互动。在部署解释器时,我们将遵循相同的原则,但与使用在本地运行模型的lambda不同,这将是一个调用远程模型微服务的函数。
我们将采用类似的方法,只需将上面的图像上传到对象存储桶。与之前的示例类似,我们提供了一个存储桶,路径为gs://seldon-models/tfserving/cifar10/explainer-py36–0.5.2。我们现在可以部署一个解释器,该解释器可以作为 Seldon 部署的 CRD 部分进行部署。
我们可以通过运行kubectl get pods | grep cifar来检查解释器是否正在运行,这应当会输出两个正在运行的 pod:
cifar10-default-0-resnet32-6dc5f5777-sq765 2/2 Running 0 18m
cifar10-default-explainer-56cd6c76cd-mwjcp 1/1 Running 0 5m3s
类似于我们向模型发送请求的方式,我们也能够向解释器路径发送请求。在这里,解释器将与模型本身互动,并打印出反向工程的解释。
我们可以看到解释的输出与我们上面看到的一样。
最后,我们还可以看到一些来自解释器本身的与指标相关的组件,这些组件可以通过仪表板进行可视化。
Coverage: 0.2475
Precision: 1.0
与其他基于微服务的机器学习组件类似,解释器也可以暴露这些和其他更专业的性能或高级监控指标。
结束语
在总结之前,需要指出的是将这些高级机器学习概念抽象为标准化架构模式的重要性。这样做的原因主要是为了使机器学习系统具备规模化的能力,同时也便于在整个技术栈中进行高级组件的集成。
上述提到的所有高级架构不仅适用于各个高级组件,而且还可以启用我们可以称之为“集成模式”的功能——即将高级组件连接到其他高级组件的输出上。
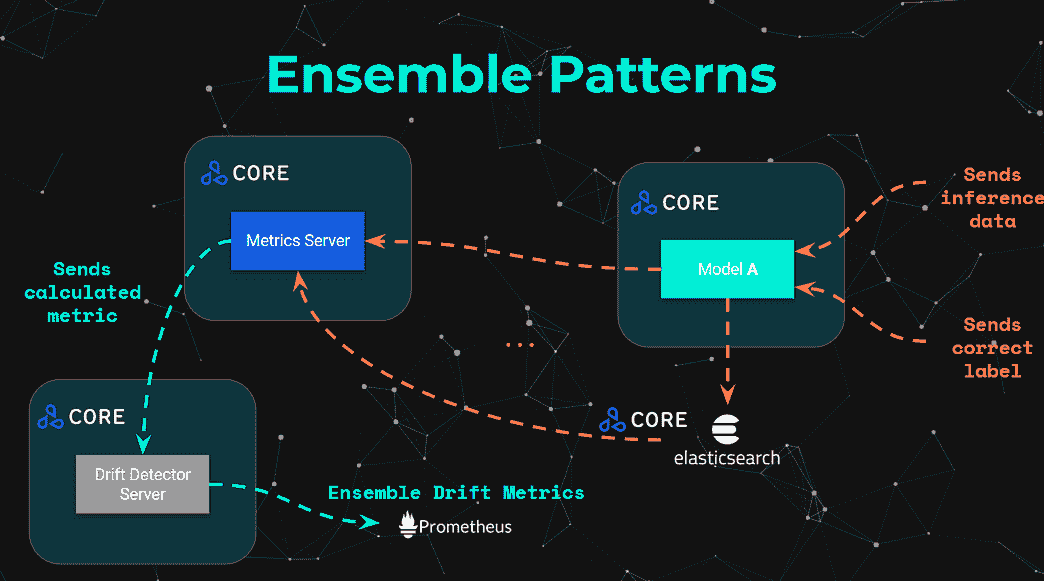
作者提供的图片
还需要确保结构化和标准化的架构模式,使开发人员能够提供监控组件,这些组件也是高级机器学习模型,具备与之管理风险所需的治理、合规性和追溯相同的水平。
这些模式通过 Seldon Core 项目不断被优化和发展,前沿的异常检测、概念漂移、可解释性等算法也在不断改进——如果你对进一步讨论感兴趣,请随时联系。此教程中的所有示例都是开源的,欢迎提出建议。
如果你对机器学习模型的可扩展部署策略的更多实际示例感兴趣,你可以查看:
个人简介:Alejandro Saucedo 是 Seldon 的工程总监、The Institute for Ethical AI 的首席科学家,以及 ACM 委员会成员。
原文。经许可转载。
相关:
-
可解释性、可说明性与机器学习——数据科学家需要了解的内容
-
使用 TensorFlow Serving 部署训练好的模型到生产环境
-
AI 不仅仅是一个模型:实现完整工作流成功的四个步骤
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
相关主题
生产就绪的机器学习 NLP API,使用 FastAPI 和 spaCy
原文:
www.kdnuggets.com/2021/04/production-ready-machine-learning-nlp-api-fastapi-spacy.html
评论
作者:Julien Salinas,全栈开发者,NLPCloud.io 的创始人兼首席技术官

FastAPI 是一个新的 Python API 框架,今天越来越多地被用于生产环境中。我们在 NLP Cloud 的底层使用 FastAPI。NLP Cloud 是一个基于 spaCy 和 HuggingFace transformers 的 API,提供命名实体识别(NER)、情感分析、文本分类、摘要等服务。FastAPI 帮助我们快速构建了一个快速且稳健的机器学习 API,服务于 NLP 模型。
让我告诉你我们为什么做出这样的选择,并展示如何基于 FastAPI 和 spaCy 实现一个用于命名实体识别(NER)的 API。
为什么选择 FastAPI?
直到最近,我一直使用 Django Rest Framework 来构建 Python API。但 FastAPI 提供了几个有趣的功能:
-
它非常快速
-
它文档齐全
-
它易于使用
-
它会自动为你生成 API 架构(如 OpenAPI)
-
它在底层使用 Pydantic 进行类型验证。对于像我这样习惯静态类型的 Go 开发者来说,能够利用这样的类型提示非常酷。它使代码更清晰,减少了错误的可能性。
FastAPI 的性能使其成为机器学习 API 的一个优秀候选者。考虑到我们在 NLP Cloud 中服务了许多基于 spaCy 和 transformers 的高要求 NLP 模型,FastAPI 是一个很好的解决方案。
设置 FastAPI
你可以选择自己安装 FastAPI 和 Uvicorn(FastAPI 前面的 ASGI 服务器):
pip install fastapi[all]
如你所见,FastAPI 在一个 ASGI 服务器后面运行,这意味着它可以原生处理使用 asyncio 的异步 Python 请求。
然后你可以用类似这样的方式运行你的应用:
uvicorn main:app
另一个选择是使用 Sebastián Ramírez(FastAPI 的创始人)慷慨提供的 Docker 镜像。这些镜像已维护,并且开箱即用。
例如,Uvicorn + Gunicorn + FastAPI 镜像将 Gunicorn 添加到堆栈中,以处理并行进程。基本上,Uvicorn 处理单个 Python 进程中的多个并行请求,而 Gunicorn 处理多个并行 Python 进程。
如果你按照镜像文档正确操作,应用程序应该会自动通过 docker run 启动。
这些图像是可定制的。例如,你可以调整 Gunicorn 创建的并行进程数量。根据你的 API 需求调整这些参数非常重要。如果你的 API 服务一个需要几个 GB 内存的机器学习模型,你可能想要减少 Gunicorn 的默认并发,否则你的应用程序将快速消耗过多内存。
简单的 FastAPI + spaCy NER API
假设你想创建一个使用spaCy进行命名实体识别(NER)的 API 端点。基本上,NER 是从句子中提取实体如名字、公司、职位等。有关 NER 的更多细节,如果需要的话。
这个端点将接受一个句子作为输入,并返回一个实体列表。每个实体由实体第一个字符的位置、实体的最后位置、实体的类型以及实体文本本身组成。
端点将以 POST 请求的方式进行查询:
curl "http://127.0.0.1/entities" \
-X POST \
-d '{"text":"John Doe is a Go Developer at Google"}'
它将返回类似这样的内容:
[
{
"end": 8,
"start": 0,
"text": "John Doe",
"type": "PERSON"
},
{
"end": 25,
"start": 13,
"text": "Go Developer",
"type": "POSITION"
},
{
"end": 35,
"start": 30,
"text": "Google",
"type": "ORG"
},
]
下面是我们如何操作:
import spacy
from fastapi import FastAPI
from pydantic import BaseModel
from typing import List
model = spacy.load("en_core_web_lg")
app = FastAPI()
class UserRequestIn(BaseModel):
text: str
class EntityOut(BaseModel):
start: int
end: int
type: str
text: str
class EntitiesOut(BaseModel):
entities: List[EntityOut]
@app.post("/entities", response_model=EntitiesOut)
def read_entities(user_request_in: UserRequestIn):
doc = model(user_request_in.text)
return {
"entities": [
{
"start": ent.start_char,
"end": ent.end_char,
"type": ent.label_,
"text": ent.text,
} for ent in doc.ents
]
}
首要的是我们正在加载 spaCy 模型。对于我们的示例,我们使用了一个大型的 spaCy 预训练英文模型。大型模型占用更多内存和磁盘空间,但由于在更大的数据集上进行训练,因此提供了更好的准确性。
model = spacy.load("en_core_web_lg")
稍后,我们将通过以下方式使用这个 spaCy 模型进行 NER:
doc = model(user_request_in.text)
# [...]
doc.ents
第二个令人惊叹的 FastAPI 特性是使用 Pydantic 强制数据验证的能力。基本上,你需要提前声明用户输入的格式和 API 响应的格式。如果你是 Go 开发者,你会发现这与使用结构体进行 JSON 解组非常相似。例如,我们这样声明返回实体的格式:
class EntityOut(BaseModel):
start: int
end: int
type: str
text: str
请注意,start和end是句子中的位置,因此它们是整数,而type和text是字符串。如果 API 尝试返回一个未实现此格式的实体(例如,如果start不是整数),FastAPI 将抛出错误。
如你所见,将一个验证类嵌套到另一个类中是可能的。这里我们返回的是一个实体列表,因此我们需要声明以下内容:
class EntitiesOut(BaseModel):
entities: List[EntityOut]
一些简单类型如int和str是内置的,但更复杂的类型如List需要显式导入。
为了简洁起见,响应验证可以在装饰器中实现:
@app.post("/entities", response_model=EntitiesOut)
更高级的数据验证
使用 FastAPI 和 Pydantic 可以做许多更高级的验证。例如,如果你需要用户输入的最小长度为 10 个字符,你可以这样做:
from pydantic import BaseModel, constr
class UserRequestIn(BaseModel):
text: constr(min_length=10)
现在,如果 Pydantic 验证通过,但你后来发现数据有问题,因此想要返回 HTTP 400 代码,该怎么办?
只需引发一个HTTPException:
from fastapi import HTTPException
raise HTTPException(
status_code=400, detail="Your request is malformed")
这只是几个例子,你可以做更多!只需查看 FastAPI 和 Pydantic 文档即可。
根路径
在反向代理后运行这样的 API 是很常见的。例如,我们在 NLPCloud.io 背后使用的是 Traefik 反向代理。
在反向代理后运行时,一个棘手的事情是你的子应用程序(这里是 API)并不一定知道整个 URL 路径。实际上,这很好,因为它表明你的 API 与应用程序的其余部分是松散耦合的。
例如,我们希望 API 认为端点 URL 是 /entities,但实际的 URL 可能是类似 /api/v1/entities 的东西。这里是如何通过设置根路径来实现:
app = FastAPI(root_path="/api/v1")
如果你手动启动 Uvicorn,你也可以通过传递额外的参数来实现:
uvicorn main:app --root-path /api/v1
结论
如你所见,使用 FastAPI 创建 API 非常简单,而 Pydantic 的验证使得代码非常表达清晰(从而减少了对文档的需求)并且更不容易出错。
FastAPI 提供了出色的性能,并且可以直接使用 asyncio 进行异步请求,这对于需求高的机器学习模型非常有利。上面的示例关于使用 spaCy 和 FastAPI 的命名实体提取几乎可以认为是生产就绪的(当然,API 代码只是完整集群应用程序的一小部分)。到目前为止,FastAPI 从未成为我们 NLPCloud.io 基础设施的瓶颈。
如果你有任何问题,请随时提问!
简历: Julien Salinas 是一位全栈工程师,精通 Python/Django、Go、Vue.js、Linux 和 Docker。他是 NLPCloud.io 的创始人和首席技术官,该 API 帮助开发人员和数据科学家轻松地在生产环境中使用 NLP。他喜欢山脉、滑雪、拳击……同时也是两个男孩的父亲。
原文。经许可转载。
相关:
-
如何将 Transformers 应用于任何长度的文本
-
如何在 Kubernetes 中部署 Flask API 并与其他微服务连接
-
机器学习项目为何会失败?
我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
主题更多内容
为什么数据科学家的专业协会是个糟糕的主意
原文:
www.kdnuggets.com/2018/07/professional-association-data-scientists-bad-idea.html
评论
由 安东尼·托卡尔,Verge Labs。
数据科学家这两个词,当它们组合在一起,并放在简历或 LinkedIn 资料下方时,显著地带来了大量的工作机会、随机的连接请求和猎头的关注。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
这并不是什么秘密,这个职业的入门门槛非常低——在 Udemy 或 Coursera 上拿到一个证书就可以了!大家也都知道数据科学很难——毕竟,扎实的统计基础和无偏的编程技能不容易获得,更不用说需要再加上一些商业头脑了。这些似乎不太匹配...
进入数据科学专业协会。由于对认证候选人信誉的保证,公司现在可以放心,知道他们的数据科学家是真正的专家。
 在大多数情况下,您在法律上不能雇佣不是专业机构成员的会计师或精算师,而且您也不愿意这样做。例如,特许会计师协会、精算师协会以及无数其他组织都有严格的资格标准,并要求会员遵守专业和道德标准。数据科学专业协会可以提供同样的保证。
在大多数情况下,您在法律上不能雇佣不是专业机构成员的会计师或精算师,而且您也不愿意这样做。例如,特许会计师协会、精算师协会以及无数其他组织都有严格的资格标准,并要求会员遵守专业和道德标准。数据科学专业协会可以提供同样的保证。
只是有 一个问题。 很少有值得信赖的数据科学家会加入这样的组织。
考虑一下成为优秀数据科学家的条件:
大多数数据科学课程的重点是最后一点。确实,有一些课程也关注沟通,但事实是数据科学是一门应用学科,最好的学习方式是实践。以上原因就是为什么有志的数据科学家被鼓励在线分享他们的工作(通过博客、GitHub、Kaggle 等)——这是比学位或认证更强的信号。
对技术的关注也有其他限制:
-
谁将管理这样的程序?即使是该领域的专家也在许多方面有过时的知识,而且,即使如此,公认的“独角兽”也很少。
-
它能跟上吗?创新的速度非常快,最好的教育项目不断被修订。
-
它会扼杀创新吗?数据科学是一个年轻的领域,由背景各异的从业者组成。遵循单一的课程可能会限制某些领域和应用达到其潜力的能力。
上述段落的假设是,技术资格是该机构的要求。当然,还有其他行业团体没有这样的要求,但很少有人能争辩说,加入这样的团体能提供太多信号。该领域过于庞大,任何运营者都不可能在没有标准化测试的情况下,客观地认证成员,因此我们倾向于将这一机制作为基础支柱。
你可以辩称,上述原因只是该职业年轻的一个特征。随着数据科学的成熟,许多今天常用的方法将被视为标准实践。某些领域的创新速度无疑会趋于平稳。但未来的“数据科学家”将拥有与今天的数据科学家截然不同的技能。我们现在称之为数据科学的领域将分裂成各种子领域,每个子领域都有其自身的标准和原型。也许其中一些可能适合于机构代表。今天——不那么适合。简介: 安东尼·托卡尔是 Verge Labs 的总监,并且是悉尼数据科学社区若干见面会的组织者。
原创。经许可转载。
相关:
更多相关主题
使用 timeit 和 cProfile 进行 Python 代码性能分析
原文:
www.kdnuggets.com/profiling-python-code-using-timeit-and-cprofile

作者提供的图片
作为一名软件开发人员,你在职业生涯中可能会多次听到 “过早优化是万恶之源” 的名言。虽然对于小项目来说,优化可能不是非常有用(或绝对必要),但性能分析通常是有帮助的。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
完成模块编码后,进行性能分析是一种良好的实践,可以测量每个部分执行所需的时间。这有助于识别代码异味并指导优化以提高代码质量。所以在优化之前一定要进行性能分析!
要迈出第一步,本指南将帮助你开始使用 Python 中的内置 timeit 和 cProfile 模块进行性能分析。你将学习如何使用命令行界面和在 Python 脚本中等效的调用方式。
如何使用 timeit 性能分析 Python 代码
timeit 模块是 Python 标准库的一部分,提供了一些方便的函数,可以用来计时短代码片段。
让我们以反转 Python 列表的简单示例为例。我们将测量使用以下方法获取列表反转副本的执行时间:
-
reversed()函数,以及 -
列表切片。
>>> nums=[6,9,2,3,7]
>>> list(reversed(nums))
[7, 3, 2, 9, 6]
>>> nums[::-1]
[7, 3, 2, 9, 6]
在命令行中运行 timeit
你可以使用以下语法在命令行中运行 timeit:
$ python -m timeit -s 'setup-code' -n 'number' -r 'repeat' 'stmt'
你需要提供要测量执行时间的语句 stmt。
你可以在需要时指定 setup 代码——使用短选项 -s 或长选项 --setup。setup 代码只会运行一次。
执行语句的次数:短选项 -n 或长选项 --number 是可选的。重复此循环的次数:短选项 -r 或长选项 --repeat 也是可选的。
让我们在示例中查看上述内容:
这里创建列表是 setup 代码,反转列表是要计时的语句:
$ python -m timeit -s 'nums=[6,9,2,3,7]' 'list(reversed(nums))'
500000 loops, best of 5: 695 nsec per loop
当你没有指定repeat的值时,使用默认值 5。当你没有指定number时,代码将运行足够多的次数,以达到至少0.2 秒的总时间。
此示例明确设置了执行语句的次数:
$ python -m timeit -s 'nums=[6,9,2,3,7]' -n 100Bu000 'list(reversed(nums))'
100000 loops, best of 5: 540 nsec per loop
repeat的默认值是 5,但我们可以将其设置为任何合适的值:
$ python3 -m timeit -s 'nums=[6,9,2,3,7]' -r 3 'list(reversed(nums))'
500000 loops, best of 3: 663 nsec per loop
让我们也来测量列表切片方法的时间:
$ python3 -m timeit -s 'nums=[6,9,2,3,7]' 'nums[::-1]'
1000000 loops, best of 5: 142 nsec per loop
列表切片方法似乎更快(所有示例均在 Ubuntu 22.04 上的 Python 3.10 中)。
在 Python 脚本中运行 timeit
这是在 Python 脚本中运行 timeit 的等效方法:
import timeit
setup = 'nums=[9,2,3,7,6]'
number = 100000
stmt1 = 'list(reversed(nums))'
stmt2 = 'nums[::-1]'
t1 = timeit.timeit(setup=setup,stmt=stmt1,number=number)
t2 = timeit.timeit(setup=setup,stmt=stmt2,number=number)
print(f"Using reversed() fn.: {t1}")
print(f"Using list slicing: {t2}")
timeit()可调用对象返回stmt执行number次的执行时间。注意,我们可以明确指定运行次数,或者让number取默认值 1000000。
Output >>
Using reversed() fn.: 0.08982690000000002
Using list slicing: 0.015550800000000004
这将执行语句——而不重复计时器函数——指定的number次,并返回执行时间。通常也可以使用time.repeat()并取最小时间,如下所示:
import timeit
setup = 'nums=[9,2,3,7,6]'
number = 100000
stmt1 = 'list(reversed(nums))'
stmt2 = 'nums[::-1]'
t1 = min(timeit.repeat(setup=setup,stmt=stmt1,number=number))
t2 = min(timeit.repeat(setup=setup,stmt=stmt2,number=number))
print(f"Using reversed() fn.: {t1}")
print(f"Using list slicing: {t2}")
这将重复运行代码number次,重复repeat次,并返回最小执行时间。这里我们有 5 次重复,每次 100000 次。
Output >>
Using reversed() fn.: 0.055375300000000016
Using list slicing: 0.015101400000000043
如何使用 cProfile 分析 Python 脚本
我们已经看到 timeit 可以用来测量短代码片段的执行时间。然而,在实际应用中,分析整个 Python 脚本更有帮助。
这将给我们所有函数和方法调用的执行时间——包括内置函数和方法。因此,我们可以更好地了解更昂贵的函数调用,并识别优化机会。例如:可能存在一个过慢的 API 调用。或者一个函数可能有一个可以用更 Pythonic 的推导式替换的循环。
让我们学习如何使用 cProfile 模块(也属于 Python 标准库)来分析 Python 脚本。
考虑以下 Python 脚本:
# main.py
import time
def func(num):
for i in range(num):
print(i)
def another_func(num):
time.sleep(num)
print(f"Slept for {num} seconds")
def useful_func(nums, target):
if target in nums:
return nums.index(target)
if __name__ == "__main__":
func(1000)
another_func(20)
useful_func([2, 8, 12, 4], 12)
这里有三个函数:
-
func()循环遍历数字范围并打印出来。 -
包含对
sleep()函数调用的another func()。 -
useful_func()返回列表中目标数字的索引(如果目标在列表中)。
上述列出的函数将在每次运行 main.py 脚本时被调用。
在命令行运行 cProfile
使用命令行运行 cProfile:
python3 -m file-name.py
这里我们将文件命名为 main.py:
python3 -m main.py
运行此代码应该会得到以下输出:
Output >>
0
...
999
Slept for 20 seconds
以及以下配置文件:
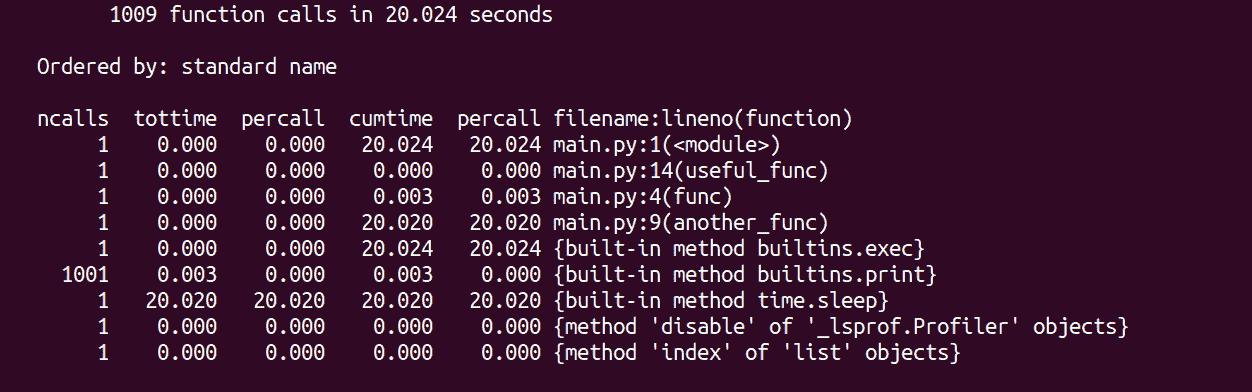
这里,ncalls指的是函数调用的次数,percall指的是每次函数调用的时间。如果ncalls的值大于 1,则percall是所有调用的平均时间。
脚本的执行时间被 another_func 所主导,该函数使用内置的 sleep 函数调用(休眠 20 秒)。我们也看到 print 函数调用的开销相当大。
在 Python 脚本中使用 cProfile
尽管在命令行运行 cProfile 工作得很好,你也可以将性能分析功能添加到 Python 脚本中。你可以使用 cProfile 结合 pstats 模块 来进行性能分析和访问统计信息。
作为处理资源设置和拆除的最佳实践,使用 with 语句并创建一个作为上下文管理器的 profile 对象:
# main.py
import pstats
import time
import cProfile
def func(num):
for i in range(num):
print(i)
def another_func(num):
time.sleep(num)
print(f"Slept for {num} seconds")
def useful_func(nums, target):
if target in nums:
return nums.index(target)
if __name__ == "__main__":
with cProfile.Profile() as profile:
func(1000)
another_func(20)
useful_func([2, 8, 12, 4], 12)
profile_result = pstats.Stats(profile)
profile_result.print_stats()
让我们更深入地查看生成的输出文件:
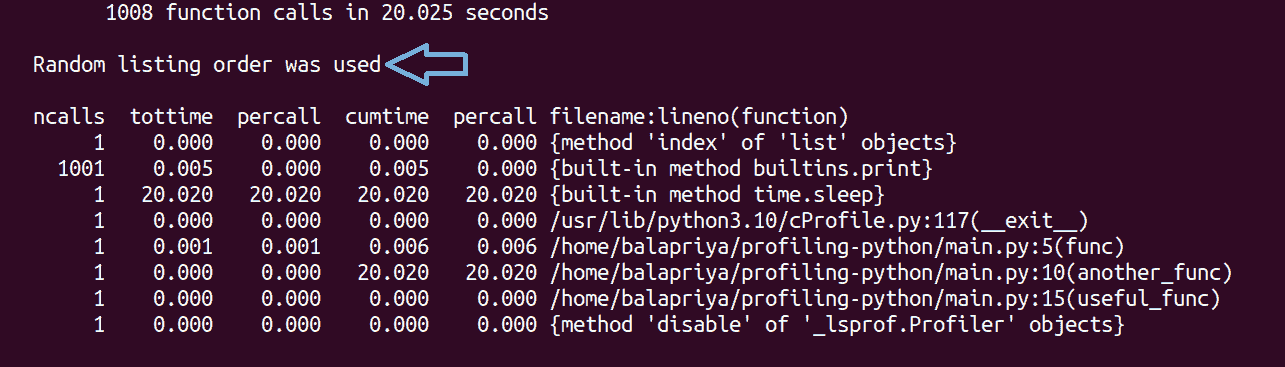
当你分析一个大型脚本时,按执行时间排序结果 会很有帮助。为此,你可以在 profile 对象上调用 sort_stats 方法,并根据执行时间进行排序:
...
if __name__ == "__main__":
with cProfile.Profile() as profile:
func(1000)
another_func(20)
useful_func([2, 8, 12, 4], 12)
profile_result = pstats.Stats(profile)
profile_result.sort_stats(pstats.SortKey.TIME)
profile_result.print_stats()
现在运行脚本时,你应该能看到按时间排序的结果:
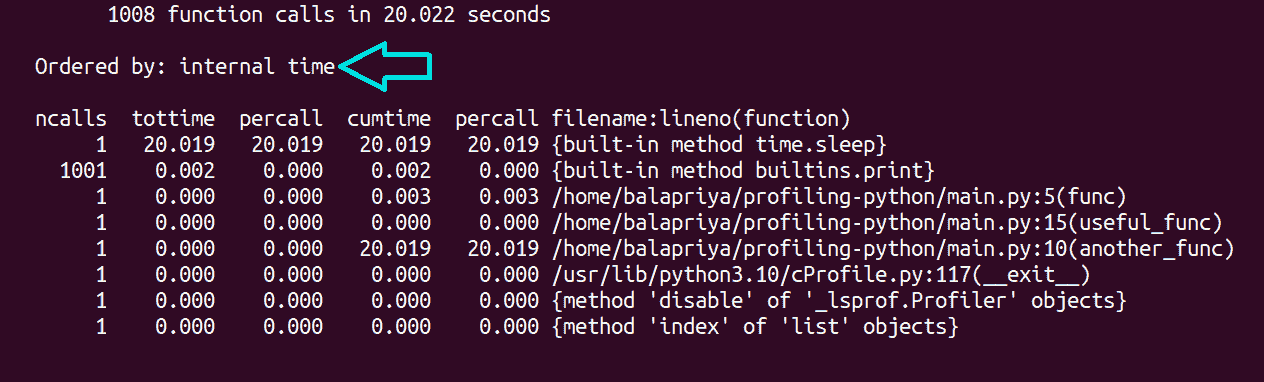
结论
我希望这份指南能帮助你开始使用 Python 进行性能分析。始终记住,优化不应以牺牲可读性为代价。如果你有兴趣了解其他性能分析工具,包括第三方 Python 包,请查看这篇关于 Python 性能分析器的文章。
Bala Priya C 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交集处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和咖啡!目前,她正在学习并通过撰写教程、操作指南、意见文章等与开发者社区分享她的知识。
更多相关主题
数据科学编程最佳实践
原文:
www.kdnuggets.com/2018/08/programming-best-practices-data-science.html
评论
作者:Srini Kadamati,Dataquest.io
数据科学生命周期通常包含以下组件:
-
数据检索
-
数据清理
-
数据探索和可视化
-
统计或预测建模
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速踏上网络安全职业生涯之路。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
虽然这些组件有助于理解不同的阶段,但它们并没有帮助我们深入编程工作流程。
通常,整个数据科学生命周期最终变成了任意的笔记本单元格混合体,这些单元格位于 Jupyter Notebook 中或是一个混乱的脚本中。此外,大多数数据科学问题要求我们在数据检索、数据清理、数据探索、数据可视化和统计/预测建模之间切换。
但还有更好的方法!在这篇文章中,我将深入探讨大多数人在进行数据科学编程工作时切换的两种思维方式:原型思维和生产思维。
| 原型思维优先考虑: | 生产思维优先考虑: |
|---|---|
| 小片段代码的迭代速度 | 整个管道的迭代速度 |
| 较少抽象(直接修改代码和数据对象) | 更多抽象(改为修改参数值) |
| 代码结构较少(模块化较少) | 代码结构更多(模块化更多) |
| 帮助你和他人理解代码和数据 | 帮助计算机自动运行代码 |
我个人使用JupyterLab来完成整个过程(原型设计和生产化)。我推荐至少在原型设计阶段使用 JupyterLab**。
Lending Club 数据
为了更具体地理解原型设计思维和生产思维之间的区别,让我们使用一些真实数据。我们将使用来自点对点借贷网站Lending Club的借贷数据。与银行不同,Lending Club 并不直接借出资金。Lending Club 实际上是一个市场,供借款人向寻求贷款的个人提供贷款(如家庭维修、婚礼费用等)。我们可以利用这些数据构建模型,预测给定的贷款申请是否会成功。我们不会在这篇文章中深入探讨构建预测机器学习管道,但在我们的机器学习项目演练课程中有涉及。
Lending Club 提供详细的历史数据,涵盖已完成的贷款(Lending Club 批准的贷款申请,并找到贷方)和被拒绝的贷款(Lending Club 拒绝的贷款申请,资金未发生变动)。请前往他们的data download page并在DOWLNOAD LOAN DATA下选择2007-2011。

原型思维
在原型思维中,我们关注的是快速迭代,尝试理解数据的一些属性和真相。创建一个新的 Jupyter notebook,并添加一个 Markdown 单元格来解释:
-
您对 Lending Club 进行的任何研究,以更好地了解该平台
-
有关您下载的数据集的任何信息
首先,让我们将 CSV 文件读入 pandas。
import pandas as pd
loans_2007 = pd.read_csv('LoanStats3a.csv')
loans_2007.head(2)
我们得到两部分输出,首先是一个警告。
/home/srinify/anaconda3/envs/dq2/lib/python3.6/site-packages/IPython/core/interactiveshell.py:2785: DtypeWarning: Columns (0,1,2,3,4,7,13,18,24,25,27,28,29,30,31,32,34,36,37,38,39,40,41,42,43,44,46,47,49,50,51,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,123,124,125,126,127,128,129,130,131,132,133,134,135,136,142,143,144) have mixed types. Specify dtype option on import or set low_memory=False.
interactivity=interactivity, compiler=compiler, result=result)
然后是数据框的前 5 行,我们在这里避免展示(因为内容较长)。
我们还得到了以下数据框输出:
| 注释由 Prospectus 提供 (链接) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| d | member_id | loan_amnt | funded_amnt | funded_amnt_inv | term | int_rate | installment | grade | sub_grade | emp_title | emp_length | home_ownership | annual_inc | verification_status | issue_d | loan_status | pymnt_plan | url | desc | purpose | title | zip_code | addr_state | dti | delinq_2yrs | earliest_cr_line | inq_last_6mths | mths_since_last_delinq | mths_since_last_record | open_acc | pub_rec | revol_bal | revol_util | total_acc | initial_list_status | out_prncp | out_prncp_inv | total_pymnt | total_pymnt_inv | total_rec_prncp | total_rec_int | total_rec_late_fee | recoveries | collection_recovery_fee | last_pymnt_d | last_pymnt_amnt | next_pymnt_d | last_credit_pull_d | collections_12_mths_ex_med | mths_since_last_major_derog | policy_code | application_type | annual_inc_joint | dti_joint | verification_status_joint | acc_now_delinq | tot_coll_amt | tot_cur_bal | open_acc_6m | open_act_il | open_il_12m | open_il_24m | mths_since_rcnt_il | total_bal_il | il_util | open_rv_12m | open_rv_24m | max_bal_bc | all_util | total_rev_hi_lim | inq_fi | total_cu_tl | inq_last_12m | acc_open_past_24mths | avg_cur_bal | bc_open_to_buy | bc_util | chargeoff_within_12_mths | delinq_amnt | mo_sin_old_il_acct | mo_sin_old_rev_tl_op | mo_sin_rcnt_rev_tl_op | mo_sin_rcnt_tl | mort_acc | mths_since_recent_bc | mths_since_recent_bc_dlq | mths_since_recent_inq | mths_since_recent_revol_delinq | num_accts_ever_120_pd | num_actv_bc_tl | num_actv_rev_tl | num_bc_sats | num_bc_tl | num_il_tl | num_op_rev_tl | num_rev_accts | num_rev_tl_bal_gt_0 | num_sats | num_tl_120dpd_2m | num_tl_30dpd | num_tl_90g_dpd_24m | num_tl_op_past_12m | pct_tl_nvr_dlq | percent_bc_gt_75 | pub_rec_bankruptcies | tax_liens | tot_hi_cred_lim | total_bal_ex_mort | total_bc_limit | total_il_high_credit_limit | revol_bal_joint | sec_app_earliest_cr_line | sec_app_inq_last_6mths | sec_app_mort_acc | sec_app_open_acc | sec_app_revol_util | sec_app_open_act_il | sec_app_num_rev_accts | sec_app_chargeoff_within_12_mths | sec_app_collections_12_mths_ex_med | sec_app_mths_since_last_major_derog | hardship_flag | hardship_type | hardship_reason | hardship_status | deferral_term | hardship_amount | hardship_start_date | hardship_end_date | payment_plan_start_date | hardship_length | hardship_dpd | hardship_loan_status | orig_projected_additional_accrued_interest | hardship_payoff_balance_amount | hardship_last_payment_amount | disbursement_method | debt_settlement_flag | debt_settlement_flag_date | settlement_status | settlement_date | settlement_amount | settlement_percentage | settlement_term |
警告提示我们,如果在调用pandas.read_csv()时将low_memory参数设置为False,pandas 对每列的类型推断将会得到改善。
第二个输出更有问题,因为 DataFrame 存储数据的方式存在问题。JupyterLab 内置了一个终端环境,我们可以打开它并使用 bash 命令 head 来观察原始文件的前两行:
head -2 LoanStats3a.csv
虽然第二行包含我们期望的 CSV 文件中的列名,但看起来第一行在 pandas 尝试解析文件时使 DataFrame 的格式出现了问题:
Notes offered by Prospectus (https://www.lendingclub.com/info/prospectus.action)
添加一个 Markdown 单元格,详细描述你的观察结果,并添加一个代码单元格,考虑这些观察结果。
import pandas as pd
loans_2007 = pd.read_csv('LoanStats3a.csv', skiprows=1, low_memory=False)
从 Lending Club 下载页面 阅读数据字典,以了解哪些列不包含对特征有用的信息。desc 和 url 列似乎立即符合这个标准。
loans_2007 = loans_2007.drop(['desc', 'url'],axis=1)
下一步是删除任何具有超过 50% 缺失行的列。使用一个单元格来探索哪些列符合该标准,另一个单元格实际删除这些列。
loans_2007.isnull().sum()/len(loans_2007)
loans_2007 = loans_2007.dropna(thresh=half_count, axis=1)
因为我们使用 Jupyter notebook 来跟踪我们的想法和代码,我们依赖于环境(通过 IPython 内核)来跟踪状态的变化。这使我们可以自由格式化,移动单元格,重复运行相同的代码等。
通常,原型思维模式下的代码应专注于:
-
可理解性
-
Markdown 单元格用以描述我们的观察和假设
-
实际逻辑的小段代码
-
许多可视化和计数
-
-
最小化抽象
- 大多数代码不应该放在函数中(应该感觉更面向对象)
假设我们花了一个小时来探索数据并编写描述数据清洗的 markdown 单元格。然后我们可以切换到生产思维模式,使代码更加健壮。
生产思维
在生产思维模式下,我们要专注于编写可以泛化到更多情况的代码。在我们的例子中,我们希望我们的数据清洗代码适用于 Lending Club 的任何数据集(来自其他时间段)。将代码泛化的最佳方法是将其转化为数据管道。数据管道是使用来自 函数式编程 的原则设计的,其中数据在函数内部被修改,然后在函数之间传递。
这是使用单个函数封装数据清洗代码的管道的第一次迭代:
import pandas as pd
def import_clean(file_list):
frames = []
for file in file_list:
loans = pd.read_csv(file, skiprows=1, low_memory=False)
loans = loans.drop(['desc', 'url'], axis=1)
half_count = len(loans)/2
loans = loans.dropna(thresh=half_count, axis=1)
loans = loans.drop_duplicates()
# Drop first group of features
loans = loans.drop(["funded_amnt", "funded_amnt_inv", "grade", "sub_grade", "emp_title", "issue_d"], axis=1)
# Drop second group of features
loans = loans.drop(["zip_code", "out_prncp", "out_prncp_inv", "total_pymnt", "total_pymnt_inv", "total_rec_prncp"], axis=1)
# Drop third group of features
loans = loans.drop(["total_rec_int", "total_rec_late_fee", "recoveries", "collection_recovery_fee", "last_pymnt_d", "last_pymnt_amnt"], axis=1)
frames.append(loans)
return frames
frames = import_clean(['LoanStats3a.csv'])
在上述代码中,我们将之前的代码抽象为一个单独的函数。该函数的输入是文件名列表,输出是 DataFrame 对象列表。
通常,生产思维模式应专注于:
-
健康的抽象
-
代码应该进行泛化,以兼容类似的数据源
-
代码不应过于泛化,以至于难以理解
-
-
管道稳定性
- 可靠性应与其运行的频率匹配(每日?每周?每月?)
思维模式切换
假设我们尝试对来自 Lending Club 的所有数据集运行函数,而 Python 返回了错误。一些潜在的错误来源包括:
-
一些文件中列名的方差
-
由于 50% 的缺失值阈值,丢弃的列的方差
-
基于 pandas 类型推断的不同列类型
在这些情况下,我们应该实际切换回我们的原型笔记本并进一步调查。当我们确定需要让我们的管道更灵活并考虑数据中的特定变化时,我们可以将其重新纳入管道逻辑中。
这是一个示例,我们调整了函数以适应不同的丢弃阈值:
import pandas as pd
def import_clean(file_list, threshold=0.5):
frames = []
for file in file_list:
loans = pd.read_csv(file, skiprows=1, low_memory=False)
loans = loans.drop(['desc', 'url'], axis=1)
threshold_count = len(loans)*threshold
loans = loans.dropna(thresh=half_count, axis=1)
loans = loans.drop_duplicates()
# Drop first group of features
loans = loans.drop(["funded_amnt", "funded_amnt_inv", "grade", "sub_grade", "emp_title", "issue_d"], axis=1)
# Drop second group of features
loans = loans.drop(["zip_code", "out_prncp", "out_prncp_inv", "total_pymnt", "total_pymnt_inv", "total_rec_prncp"], axis=1)
# Drop third group of features
loans = loans.drop(["total_rec_int", "total_rec_late_fee", "recoveries", "collection_recovery_fee", "last_pymnt_d", "last_pymnt_amnt"], axis=1)
frames.append(loans)
return frames
frames = import_clean(['LoanStats3a.csv'], threshold=0.7)
默认值仍然是0.5,但如果需要,我们可以将其覆盖为0.7。
这里有几种方式可以使管道更加灵活,按优先级递减:
-
使用可选、位置性和必需的参数
-
在函数内使用 if / then 语句以及布尔输入值
-
使用新的数据结构(字典、列表等)来表示特定数据集的自定义操作
这个管道可以扩展到数据科学工作流程的所有阶段。这里有一些示例代码,预览了它的样子。
import pandas as pd
def import_clean(file_list, threshold=0.5):
## Code
def visualize(df_list):
# Find the most important features and generate pairwise scatter plots
# Display visualizations and write to file.
plt.savefig("scatter_plots.png")
def combine(df_list):
# Combine dataframes and generate train and test sets
# Drop features all dataframes don't share
# Return both train and test dataframes
return train,test
def train(train_df):
# Train model
return model
def validate(train_df, test-df):
# K-fold cross validation
# Return metrics dictionary
return metrics_dict
frames = import_clean(['LoanStats3a.csv', 'LoanStats2012.csv'], threshold=0.7)
visualize(frames)
train_df, test_df = combine(frames)
model = train(train_df)
metrics = test(train_df, test_df)
print(metrics)
下一步
如果你有兴趣深化理解和进一步实践,我推荐以下步骤:
-
学习如何将管道转换为可以作为模块或从命令行运行的独立脚本:
docs.python.org/3/library/**main**.html -
学习如何使用 Luigi 构建可以在云中运行的更复杂的管道: 在 Python 和 Luigi 中构建数据管道
-
了解更多关于数据工程的内容: Dataquest 上的数据工程帖子
生物:Srini Kadamati 是 Dataquest.io 的内容总监。
原文。转载已获许可。
相关:
-
Swiftapply – 自动高效的 pandas apply 操作
-
与机器学习算法相关的数据结构
-
Python 函数式编程简介
更多相关主题
特定数据角色的编程语言
原文:
www.kdnuggets.com/2023/06/programming-languages-specific-data-roles.html

作者图片
当你对进入数据领域感兴趣时,可能很难知道你需要学习哪个编程语言来满足你的特定兴趣或技能。许多人因为听说某种编程语言非常流行或缺乏足够的知识而浪费了大量时间来熟练掌握一种特定的编程语言。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
很多数据科学角色被交替使用,有时也被互换宣传。你可能会看到有人把数据分析师和数据科学家视为相同的角色,或者把数据科学家和机器学习工程师视为相同角色。
这可能是因为招聘人员或员工对不同角色之间的区别了解不够,以吸引兴趣或能够雇用一个能一举两得的人。
本博客旨在让你对哪些编程语言是特定数据角色所需或必不可少的有一个快速而简单的了解。
流行的数据角色
让我们从定义流行的数据角色开始。
数据分析师 - 查阅数据并提供解释数据的报告和可视化。
数据科学家 - 收集、清理、分析数据,提供报告、可视化,并操作数据以进行高级数据分析。
数据工程师 - 负责建立和维护组织的数据基础设施,同时确保数据能够接受关键分析并生成和制作报告。
机器学习工程师 - 负责构建能够处理大量数据的人工智能系统,并能够生成和开发能够学习和进行未来预测的算法。
研究科学家 - 在数据方面,负责研究、设计和分析来自调查、实验和试验的信息。
顶级编程语言
如果你去谷歌搜索“顶级编程语言”,你会看到这些语言的混合,可能还有其他几种:
-
Javascript
-
Python
-
Go
-
Java
-
Kotlin
-
PHP
-
C#
-
Swift
-
R
-
Ruby
-
C 和 C++
-
Matlab
-
SQL
所以在网上看到这些之后,你可能会想 - 接下来我该怎么做?我真正需要什么来满足我感兴趣的角色?
特定数据角色的顶级语言
数据分析师
作为数据分析师,你将负责扫描数据,找出有价值的信息,并提供报告或可视化。因此,数据分析师最好的编程语言是 Python 和/或 SQL。
-
Python - 将允许你分析、操作、清理和可视化数据。
-
SQL - 将使你能够轻松地与数据库进行沟通。
数据科学家
作为数据科学家,你可以选择多种编程语言。数据科学家使用的最流行语言是 Python 和 SQL,其次是 R、C++ 和 Java。
R、C++ 和 Java 仍然流行,然而,Python 和 SQL 因其更简单的编码能力而广受欢迎,同时能产生相同的结果。
-
Python 拥有更大的开发者社区,丰富的库,简洁的语法和可移植性。这就是数据科学家所想要和需要的一切。
-
SQL 具有存储、检索、管理和操作数据的能力,还能提取性能指标来指导数据科学家的工作。
数据工程师
作为数据工程师,最受欢迎的编程语言是:
-
Java - 它是数据工程师使用最久且最合适的语言。数据工程师花费大量时间使用基于 Java 的开源框架 Hadoop。
-
Python - 帮助数据工程师构建高效的数据管道,编写 ETL 脚本,设置统计模型并进行分析。
-
SQL - 使他们能够建模数据,提取性能指标,并开发可重用的数据结构。
机器学习工程师
作为机器学习工程师,最受欢迎的编程语言是:
-
Python - 良好的库生态系统,更好的可读性,灵活性,创建良好的可视化,社区支持等。简单的语法和结构在机器学习工程师的工作中非常有利。
-
C++ - 这也是机器学习工程师非常宝贵的编程语言,因为它快速且可靠,这对于机器学习是必要的,同时还拥有良好的库资源。
-
Java - 如果你想从事网页开发、大数据、云开发和应用开发,Java 对你的技能组合至关重要。它的性能也优于 Python。
研究科学家
作为研究科学家,你不会处理后端问题,而是更多地了解数据和团队发现可以告诉你的信息。与数据分析师类似,能够使你受益的编程语言有:
-
Python 是一种通用编程语言,允许你写更少的代码行但执行相同的操作。
-
R 是一种统计编程语言,允许你建立统计模型并创建数据可视化。
为了简化,我制作了上述图像,以便你可以直观地了解根据你的兴趣领域应该关注什么。
根据上述图像,它显示了你在特定数据角色中需要什么类型的编程语言以及其重要性。圆圈越大,对特定数据角色越重要。
根据 Stack Overflow 2022 年开发者调查,JavaScript 是使用最广泛的编程语言,而且已经使用了十年。然而,如果谈到用于学习编程的语言,HTML/CSS、JavaScript 和 Python 排在前列,并且相互接近。
结论
随着数据角色的不断发展,跟上所有变化可能会令人不堪重负。在你转向下一个或学习新技能之前,先掌握一门编程语言的熟练程度更为明智。一步一步来,总比同时试图学习 10 项技能要好。
一旦你根据兴趣领域决定了编程语言,下一步就是使自己在该语言上达到熟练程度。
有许多现成的资源可以帮助你的学习,你只需要知道正确的资源。下面是一些你可以受益的链接
-
2022 年顶级数据分析师认证课程
-
完整的数据科学学习路线图
-
完整的机器学习学习路线图
-
完整的数据工程学习路线图
尼莎·阿利亚 是一位数据科学家、自由技术写作者和 KDnuggets 的社区经理。她特别关注于提供数据科学职业建议或教程,以及数据科学的理论知识。她还希望探索人工智能如何/能够提升人类生命的持久性。她是一个热衷学习者,寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关主题
-
2023 年数据科学的 8 种编程语言)
使用 tqdm 的 Python 进度条,带来乐趣与收益
原文:
www.kdnuggets.com/2022/09/progress-bars-python-tqdm-fun-profit.html

Gif 作者
tqdm
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
在阿拉伯语中,tqdm(taqadum)意味着进展,它用于为循环创建智能进度条。你只需要将 tqdm 包裹在任何可迭代对象上 - tqdm(iterable)。
tqdm 可以帮助你为数据处理、训练机器学习模型、多循环 Python 函数以及从互联网下载数据创建进度条。
使用 pip 安装该软件包:
pip install tqdm
复制粘贴下面的代码,并在我们的机器上运行,以亲身体验 tqdm 的魔力。
tqdm 显示了进度条、迭代次数、运行循环所用的时间以及每秒的迭代频率。
from tqdm import tqdm
for i in tqdm(range(10000)):
pass
100%|????????????????????????????????????????| 10000/10000 [00:00<00:00, 1764759.54it/s]
在本教程中,我们将学习如何自定义进度条,并将其与 pandas 数据框集成。我们还将学习额外的功能,如并发。
Python 进度条教程
tqdm 和 Python 函数
在下面的示例中,我们创建了一个 fun 函数,它接受整数 x 并在 x 秒延迟后运行。
然后,我们将 tqdm 包裹在 range 函数周围,这样它将运行一个循环,进行 0-9 的 10 次迭代。
第一次迭代将花费 零 秒。第二次迭代将花费 1 秒,以此类推。循环完成花费了 45 秒,我们体验到了动画进度条。
太棒了!
tqdm.notebook 在列表中
在这一部分,我们将使用 tqdm.notebook 模块在 Jupyter Notebook 中使用 Ipython 小部件显示进度条。
首先,创建一个简单的不同颜色的列表。然后,使用循环逐一打印名称,每次打印之间延迟一秒钟。
我们在列表周围添加了包装器,它显示了一个多色进度条。
太棒了!

多个进度条
让我们创建多循环进度条以模拟机器学习模型训练。
-
trange 是 tqdm 在 range 函数周围的一个包装。
-
外层循环将运行 10 次,延迟 0.01 秒。
-
desc 用于标记进度条。我会在进度条之前显示它。
-
内部循环将运行 10,000 次,延迟为 0.001。
正如我们所观察到的,多重进度条的动画效果非常惊艳。为了更好地理解,我希望你复制代码、修改它,并在你的机器上运行,亲身体验这份魔法。

tqdm 适用于数据科学。
在这一部分,我们将把 tqdm 集成到 pandas dataframe 中,并使用 progress_apply 将函数应用于 dataframe,同时显示进度条。
加载数据集
首先,我们将从 Kaggle 加载 酒店预订 数据集。然后,我们将显示 dataframe 的前五行。
数据集包含 2015 年 7 月 1 日至 2017 年 8 月 31 日之间的城市酒店和度假酒店预订的 119390 条观察数据,包括实际到达的预订和被取消的预订。
你可以向右滚动以查看值和列名。
使用 tqdm
在这一部分,我们将使用客户的姓名创建一个新的列“user_name”。
-
tqdm.pandas 用于为 pandas dataframe 启动进度条。我们还将添加进度条标签“Processing the name column”。
-
user_name 函数将字符串转换为小写,并用“–”替换空格。
-
使用 .progress_apply() 函数对 dataframe 应用函数。这类似于 apply() 函数。对于 map() 函数,你可以使用 .progress_map()。
-
显示前三行
如果你向右滚动,你会看到一个新的列 user_name,其中包含值。
并行处理工具
tqdm 不仅仅是循环的进度条。它还提供了如 tqdm.contrib.concurrent 的并行处理实用工具。
在这一部分,我们将从电子邮件列中提取 email provider。
-
从 tqdm.contrib.concurrent 导入 process_map。
-
provider_extraction 函数将根据“@”和“.”拆分文本。
-
使用 process_map 将函数映射到 df["email"] 上。我们将基于 CPU 数量选择 8 个 max_worker,并将 chunksize 设置为 64。
-
添加进度条标签并自定义它,以显示绿色进度条而不是黑色。
-
查看“email_provider”列的前 5 个值。
成功了!我们用绿色进度条提取了电子邮件提供者。这不是很棒吗?
结论
玩弄 tqdm 并与大家分享我的经验是一次有趣的经历。除了乐趣,它还为软件开发提供了必要的功能。
我使用了 GitHub gist、Deepnote 嵌入和 Kaggle 来添加代码块和 Gif。你可以查看这些工具,并使用 tqdm 创造你的魔法。
在这篇博客中,我们学习了 tqdm 在 Python 循环、列表、多级进度条、pandas 集成以及使用并发模块进行并行处理中的应用。
阅读 文档 以了解更多功能:
-
异步
-
回调函数(Dask,Keras)
-
迭代器的装饰器(Tkinter,Matplotlib)
-
CLI(终端,控制台)
-
精简包装器(并发,itertools)
-
日志记录
-
发送更新(slack,discord,telegram)
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为那些在心理健康上挣扎的学生构建 AI 产品。
更多关于这个主题
掌握数据工程的项目建议
原文:
www.kdnuggets.com/project-ideas-to-master-data-engineering

图片由作者提供
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
对于任何数据领域的初学者来说,真正理解某一特定数据领域往往是困难的。你可以阅读理论解释和职位描述,观看解释它们的 YouTube 视频,但你的理解总停留在“明白了,但不完全”这一层次。
数据工程也是如此。当然,你需要了解什么是数据工程,以及 数据工程师做什么。我们将从这里开始。但你应该用实践来补充这些理论知识;在它们的交汇处存在真正的知识。
实际从事数据工程工作时,掌握数据工程是相当困难的。这主要是因为数据工程不仅仅涉及数据处理,还涉及数据架构和构建数据基础设施。
然而,有一种方法可以做到,那就是进行数据工程项目。了解数据工程师的工作将帮助我们选择适合的项目来掌握数据工程。
什么是数据工程?
数据工程确保数据从多个不同的数据源流向数据存储,这些数据可以是批量的,也可以是实时的,供数据用户使用。在此过程中,数据还会被处理、分析,并转化为适合使用的格式。
这被称为数据管道,而数据工程师的工作是构建和维护它。
从这些描述中,我们可以提炼出数据工程的关键方面:
-
数据转化与处理
-
数据可视化
-
数据管道
-
数据存储
要掌握数据工程,你的项目应该专注于或包括以下一些主题。
由于数据工程的性质,想出一个只涉及其一个方面的项目几乎是不可能的;这就是数据工程师工作的全面性。真的不可能做一个仅处理数据的项目——好吧,这些数据来自哪里,又到哪里去呢?
所以,我选择的大多数项目都是端到端的数据工程项目,这些项目将教你如何构建数据管道——数据工程的核心。然而,这些项目采用了不同的方法和技术,因此你可以从一个项目中学到的方面,可能在另一个项目中学不到。
数据工程项目点子
作者提供的图像
通过做项目,你能了解数据工程在实践中的实际情况。完成一个项目,你必须展示各种技术技能,对常见数据工程工具的熟悉程度,以及对整个过程的理解。
这使得这些项目非常适合学习。
1. 数据管道开发项目
没有比构建数据管道更能体现数据工程了。确保数据从源头流向数据用户,并通过扩展来支持数据驱动的决策,这正是数据工程的核心。
通过进行数据管道开发项目,你将学习到如何整合来自各种来源的数据以及整个 ETL 过程。
项目建议
链接: CodeWith You (Yusuf Ganiyu) 的 AWS 端到端数据工程
描述:这是一个优秀的项目,目标是构建一个数据管道,该管道将从 Reddit 中提取数据,进行转换,然后将其加载到 Redshift 数据仓库中。
视频引导你完成每一步,并且项目的 源代码也可以在 GitHub 上获取。
使用的技术:
2. 数据转换项目
数据转换意味着数据被改变为与分析工具兼容的标准化格式,适合于分析。
除了使数据分析和决策成为可能之外,数据转换还在提高数据质量方面发挥着重要作用,因为它涉及数据的清理和验证。
项目建议
链接: StrataScratch 的 Chama 数据转换
描述:这里的任务是使用你选择的任何编程语言来转换位于三个 .csv 文件中的 Chama 数据,但需遵循特定的转换规则。
使用的技术:
3. 数据湖实现项目
数据湖是存储大量原始格式数据的中央存储库。它们在处理和分析大数据时至关重要。随着大数据在商业中的日益普及,数据工程师必须了解如何实施数据湖。
项目建议
链接: Kaviprakash Selvaraj 的端到端 Azure 数据工程项目
描述:这个 Azure 数据端到端的数据工程项目使用销售数据。它涵盖了数据摄取、处理和存储等主题。它的有趣之处在于,它概述了设置和管理数据湖的步骤,即 Azure 数据湖。
使用的技术:
4. 数据仓库项目
数据从数据湖中提取,经过结构化处理后存储在数据仓库中。这些数据仓库作为商业智能的中央数据存储库。
实施数据仓库使得数据检索更高效,简化了数据管理,同时确保数据质量并提供数据洞察。
在数据仓库项目中,你将学习数据建模和数据库管理。
项目建议
描述:这个端到端的项目使用 NYC 出租车数据,目标是在 AWS 中构建一个 ELT 管道。它适合学习数据仓库,因为数据被加载到数据仓库中,即 Amazon Redshift。
使用的技术:
5. 实时数据处理项目
实时处理数据变得越来越重要,以便企业能够做出及时和主动的决策。因此,数据工程师必须了解如何建立一个能够有效且高效地实时处理数据的系统。
项目建议
链接: CodeWithYu (Yusuf Ganiyu) 的实时数据流
描述:这个 CodeWithYu 视频为你提供了关于构建数据流管道的详细指导。你将学习如何设置数据管道、实时流数据、分布式同步、数据处理、数据存储和容器化。
你将使用的数据是由随机用户.me API 生成的。正如我之前链接的其中一个视频,这个视频也有一个在 GitHub 上的源码。
使用的技术:
6. 数据可视化项目
虽然数据可视化可能不是你在考虑数据工程时首先想到的事情,但它是数据工程师的一项重要技能。
在数据工程的背景下,可视化数据通常意味着创建操作仪表板,展示数据管道的当前状态,例如处理速度或摄取的数据量。
数据工程师还可能会为存储在数据仓库中的数据创建仪表板,以帮助业务用户更轻松地获取所需信息。
项目建议
链接:从原始数据到数据可视化 - Naufaldy Erianda 的数据工程项目
描述:这个项目的目标是从各种资源中提取数据,对其进行转换,并使其可用于数据可视化。最后,你将创建一个在 Looker Studio 中的仪表板。
使用的技术:
结论
数据工程是一个复杂的领域,可能对初学者来说有些令人望而生畏。真正开始理解数据工程的最简单方法是通过做数据工程项目。
我建议了六个项目来教你:
-
构建管道
-
转换数据
-
实现数据湖
-
实现数据仓库
-
为实时数据处理构建一个管道
-
可视化数据
机器学习在自动化各种数据工程任务中越来越重要。因此,为了不被落在后头,可以查看一些机器学习项目和数据科学项目,这些项目也可以用来练习数据工程技能。
内特·罗西迪是一位数据科学家,专注于产品策略。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过顶级公司提供的真实面试问题为面试做准备。内特撰写有关职业市场的最新趋势,提供面试建议,分享数据科学项目,并涵盖所有 SQL 相关内容。
相关话题
数据科学作品集中应包括的项目
原文:
www.kdnuggets.com/2019/04/projects-include-data-science-portfolio.html
评论
作者 Charlie Custer,Dataquest.io
这是最近发布的Dataquest.io 职业指南中的摘录,特别是章节如何为数据科学职位申请创建项目组合。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT

数据科学作品集应包括 3-5 个展示你与工作相关技能的项目。目标是证明你能够完成工作,因此,作品集越能体现你申请职位的日常工作,它就越具说服力。
“[不要随意选择项目来加入你的简历或作品集,” Pramp 的首席执行官兼联合创始人 Refael “Rafi” Zikavashvili 说。“解决与你感兴趣的公司相关的问题。”
这适用于你在项目中承担的任务种类,也适用于你的项目考察的主题领域以及你处理的数据集类型。让我们更深入地了解这三个因素:
任务种类:你申请的工作中需要做哪些事情?你会做很多数据清理吗?机器学习?数据可视化?自然语言处理?你会专注于分析,还是会为其他人构建仪表板和其他分析工具?无论这些问题的答案是什么,都应将它们整合到你的作品集中。
主题领域:你是在寻找市场营销职位吗?你可能需要突出那些旨在回答市场营销相关问题的项目。如果你在寻找移动应用开发的数据工作,你会想展示那些能从应用数据中提取有用产品洞察的项目。使用你的项目展示你对申请职位相关的主题和商业问题的了解或至少兴趣,可以帮助你的申请脱颖而出。
数据集类型:不同类型的数据在不同的行业中可能很常见,因此展示你有处理类似数据集的经验有助于证明你具备完成工作的能力。例如,如果你在目标职位中可能会处理大量时间序列数据,展示一些时间序列分析技能会很有帮助。
遇到疑问时,请包含以下项目:
你的作品集越是精心定制以匹配你申请的具体职位,结果可能会越好。但是,如果你申请的是入门级职位,你可能会广泛撒网,并且也很可能会看中那些无论行业如何都需要大量相同技能的职位。如果你准备一个包含这些类别中至少一个项目的作品集,你将迈出优秀的一步。
数据清洗项目:数据准备、数据处理、数据清洗——无论你怎么称呼它,这占据了大多数数据科学工作的 60-80%,所以你绝对需要一个展示你数据清洗技能的项目。至少,你需要找到一个混乱的数据集(不要选择已经清洗过的数据),提出一些有趣的分析问题进行审查,然后清洗数据并执行一些基本分析以回答这些问题。
如果你想提升难度,收集你自己的数据(通过 API、网页抓取或其他方法)可以展示一些额外的技能。处理某种非结构化数据(与混乱但仍然结构化的数据集相对)也会显得不错。
数据讲述与可视化项目:讲述故事、提供真实洞察和用数据说服他人是任何数据科学工作的关键部分。如果你不能让 CEO 理解或基于分析采取行动,即使是世界上最好的分析也没有用。这个项目应该带领读者进行分析旅程,并得出即使是对编码或统计学背景几乎没有的普通人也能理解的结论。
数据可视化和沟通技巧在这里将十分重要,以展示和解释你的代码在做什么。可以选择用 Jupyter Notebook 或 R Markdown 呈现,但你可以通过额外的修饰来增加难度,比如自定义图表设计或包含一些互动元素。
团队项目:在团队中合作展示了你具备沟通和协作技能,这些在数据科学工作中非常重要。任何类型的项目都可以是团队项目;重要的是展示你能够在团队环境中有效工作,无论是在个人互动方面(清晰沟通、公平分工、真诚合作)还是在技术方面(使用 Git 和 GitHub 管理项目)。
如果你想提升难度,可以尝试参与一个受欢迎的开源项目,比如为你选择的编程语言中的数据科学相关开源库做贡献。这可能相当困难,但如果你能成功贡献到一个受欢迎的库或包中,这将使你的申请在雇主眼中脱颖而出。
例如,Spice IT Recruitment的首席 IT 招聘官 Alina Chistyakova 表示,“对知名开源项目的成功提交”是使数据科学作品集在她眼中脱颖而出的因素之一。Kitware的人力资源总监 Jeff Hall 表示,“真正为我们特定的开源项目做出贡献的候选人,会在申请者中加分。”
其他值得考虑的项目类型
端到端系统构建项目:许多数据科学工作可能包括构建能够有效分析定期数据集的系统,而不是仅仅分析单个特定数据集。例如,你可能会被要求为销售团队构建一个仪表盘,该仪表盘可视化公司的销售数据,并随着新数据的到来而定期更新。
这个项目应该展示你能够构建一个在新数据集输入时能执行相同分析的系统,并且能够构建一个其他人可以相对轻松理解和运行的系统。最简单的版本就是有良好注释的代码,能够从公共、定期更新的数据集中获取数据并进行一些分析。其README文件应解释如何供他人使用,并且项目应相对容易让其他编码者通过命令行运行。
如果你想提升难度,完全可以尝试构建全面互动的网页仪表盘,或者构建一个处理实时/流数据的系统。关键在于展示你能构建一个可重用的分析系统,其他人,至少是其他程序员,可以理解它。
解释性博客文章、文章或讲座:能够用简单易懂的术语解释复杂的技术概念是任何数据科学家都应具备的宝贵技能,因此,如果能在博客文章、文章或会议讲座中对某些技术概念进行解释,并且解释得当,这可以成为你作品集中的一个很好的补充。只要确保选择一个适当复杂且你理解并能解释的主题。例如,解释在你目标行业中常用的机器学习算法底层发生了什么的博客文章,可能会是一个很好的作品集补充。
简介: Charlie Custer 是 Dataquest.io 的内容营销人员,是各种类型内容的创作者,尤其是:作家、编辑以及专注于 2D After Effects 工作的动画设计师。
原文。经允许转载。
相关内容:
-
在接受那份高大上的数据科学工作前请三思
-
如何辨别好数据科学工作和差数据科学工作
-
破解数据科学家面试
更多相关主题
-
[5 个数据科学作品集的 Python 项目](https://www.kdnuggets.com/2022/12/5-python-projects-data-science-portfolio.html)
-
[5 个高级数据科学作品集项目](https://www.kdnuggets.com/2023/03/5-advance-projects-data-science-portfolio.html)
-
[5 个数据科学毕业生作品集项目](https://www.kdnuggets.com/5-portfolio-projects-for-final-year-data-science-students)
-
[7 个机器学习作品集项目,提升简历](https://www.kdnuggets.com/2022/09/7-machine-learning-portfolio-projects-boost-resume.html)
-
[令人惊叹的 LLM 作品集项目创意](https://www.kdnuggets.com/llm-portfolio-projects-ideas-to-wow-employers)
-
[7 个 AI 作品集项目,提升简历](https://www.kdnuggets.com/7-ai-portfolio-projects-to-boost-the-resume)
提示工程师:技能、学习路线图和薪资
原文:
www.kdnuggets.com/prompt-engineer-skills-learning-roadmap-and-salary

作者提供的图片
我们都知道生成性 AI 是每个人都在谈论的话题。公司正在探索将其整合到业务中的新方法。一些公司正在考虑构建自己的工具。机器学习工程师正在寻找转型为提示工程师的方法。每个人都想分一杯羹。
生成性 AI 市场将继续增长并变得更加流行。许多人关注的一个主要方面是如何进入这个 450 亿美元的市场。
掌握生成性 AI 的基础是关于提示工程的。随着市场的增长,提示工程师的市场也将增长。
提示工程是为生成性 AI 工具设计输入的最佳实践,旨在产生最佳输出。公司希望获得这些最佳输出,因此需要最优秀的人来实现!
提示工程师需求旺盛,且正从中获得良好的职业发展:AI 提示工程师年薪 30 万美元
提示工程师需要哪些技能?
提示工程师需要的主要硬技能是技术熟练度:
-
人工智能
-
机器学习模型
-
自然语言处理
-
GPT(生成式预训练变换器)
除了这些硬技能,他们还需要在语言敏锐度方面的软技能:
-
语言
-
语法
-
语法
-
语义学
我如何成为一名提示工程师?
由于这是一个一般性的博客文章,你们中的一些人可能已经是机器学习工程师,而一些人可能刚刚起步。因此,我将创建一个路线图来帮助你从头到尾成为提示工程师。
机器学习
链接: 机器学习专业化
首先,你需要对机器学习有一个良好的理解。斯坦福大学提供了这门课程,而 DeepLearning.AI 专门针对那些希望通过掌握机器学习的基本概念进入人工智能领域,同时通过一个 3 课程的项目来发展实际的机器学习技能的人。
自然语言处理
链接: 自然语言处理 (NLP) 专业化
一旦你对机器学习模型有了良好的基础理解,你现在需要了解语言的美妙以及它是如何在计算机中处理的。通过你从机器学习专业化中学到的内容,你将通过四个实践课程学习如何掌握前沿的 NLP 技术。
生成性 AI 和大型语言模型
链接: 使用大型语言模型的生成性 AI
现在是时候将这两者结合起来。将你对机器学习模型和自然语言处理的知识融合在一起,以理解大型语言模型。你将获得基础知识、实践技能,并对生成式 AI 的工作原理有一个功能性理解,同时在 AWS 专家的指导下利用前沿技术创造价值。
生成式 AI 和变换器
链接: 生成式 AI 语言建模与变换器
成为提示工程师的职业生涯中至关重要的一点是学习变换器。变换器帮助机器理解、解释和生成自然语言。在本课程中,你将能够解释变换器中的注意机制概念,并能够描述基于解码器的 GPT 和基于编码器的 BERT 的语言建模。然后,你将继续实施位置编码、掩蔽、注意机制、文档分类,并创建像 GPT 和 BERT 这样的 LLM。
提示工程
当你掌握了所有这些知识后,你需要学习提示工程。你职业转型的最终目标是理解并建立对提示工程最佳实践的直觉。有很多资源可以帮助你完善它。在这种情况下,你的软技能将发挥作用,以及你理解语言的能力和理解 ChatGPT 等工具及其语言解释方式的能力。
提示工程师薪资
根据公司、地点和经验年限的不同,你的薪资会有所变化。
如果我们看看英国伦敦的提示工程师,入门级提示工程师的起薪在 30,000 英镑到 40,000 英镑之间。随着经验的积累,你可以期望赚取 40,000 英镑到 50,000 英镑。在高级职位,提示工程师的薪资范围从 50,000 英镑到 70,000 英镑。
话虽如此,在美国,一些提示工程师在一些领先公司每年的收入高达 350,000 美元。
如果你想赚大钱,并且渴望追求提示工程的职业生涯,可以看看提示工程中的更多专业技能,例如多模态提示工程、提示安全和提示测试自动化。
总结
如果你正在考虑提示工程,现在是进行职业转型的时候了。生成式 AI 市场只会继续增长,需要人们来满足这些高需求。
Nisha Arya 是一名数据科学家、自由技术作家、以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及与数据科学相关的理论知识。Nisha 涵盖了广泛的话题,并希望探索人工智能如何有助于人类寿命的延续。作为一个热衷的学习者,Nisha 旨在拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
提示工程 101:掌握有效的 LLM 沟通
原文:
www.kdnuggets.com/prompt-engineering-101-mastering-effective-llm-communication

图片由作者使用 DALL•E 3 创建
介绍
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
提示工程,像语言模型本身一样,在过去的 12 个月里取得了长足的进步。仅仅一年前,ChatGPT 的问世就将所有人对 AI 的恐惧和期望推向了一个充满压力的高压锅中,几乎在一夜之间加速了 AI 末日和拯救故事的传播。当然,提示工程在 ChatGPT 之前就已经存在,但我们用来从现在充斥我们生活的各种语言模型中引发所需回应的技术范围,随着 ChatGPT 的崛起,也真正进入了自己的发展阶段。五年前,随着最初的 GPT 问世,我们开玩笑说“提示工程师”有一天可能会成为一个职业头衔;而今天,提示工程师已经成为最热门的技术(或技术相关)职业之一。
提示工程是构建可以被生成型 AI 模型解读和理解的文本的过程。提示是描述 AI 应该执行任务的自然语言文本。
从“提示工程” 维基百科条目
抛开炒作不谈,提示工程现在已经成为那些经常与 LLM 互动的人的生活中不可或缺的一部分。如果你正在阅读这篇文章,那么你很可能就是你,或者你可能正朝着这样的职业方向发展。对于那些想了解提示工程是什么,以及——更重要的是——当前的提示策略环境是什么样的,这篇文章就是为你准备的。
入门
让我们从基础开始。这篇文章,与 ChatGPT 进行有效互动的提示工程,在机器学习大师网站上涵盖了提示工程的基础概念。具体来说,介绍的主题包括:
-
提示原则,概述了在优化提示过程中需要记住的几个基础技巧
-
基础提示工程,如提示措辞、简洁性以及正面和负面提示
-
高级提示工程策略,包括单次和多次提示、链式思维提示、自我批评和迭代提示
-
合作力量技巧,用于识别和培养与 ChatGPT 的合作氛围,以推动进一步成功
提示工程是有效利用大型语言模型(LLMs)的关键方面,是定制与 ChatGPT 交互的强大工具。它涉及制定清晰而具体的指令或查询,以引导语言模型产生所需的响应。通过精心构造提示,用户可以将 ChatGPT 的输出引导向其预期的目标,并确保更准确和有用的回应。
来自《机器学习大师》文章 "有效与 ChatGPT 互动的提示工程"
一旦你掌握了基础知识,并对提示工程及一些当前最有用的技术有了了解,你就可以继续学习掌握这些技术。
提示工程技术深度探讨
以下 KDnuggets 文章分别概述了单一的常见提示工程技术。这些技术的复杂性有一个逻辑进展,因此从顶部开始逐步阅读将是最佳方法。
每篇文章包含了首次提出该技术的学术论文概述。你可以在文章中阅读该技术的解释,了解它如何与其他技术相关联,并找到其实现的示例,如果你对阅读或浏览相关论文感兴趣,也可以在文章中找到相关链接。
本文深入探讨了链式思维(CoT)提示的概念,这是一种增强大型语言模型(LLMs)推理能力的技术。它讨论了 CoT 提示背后的原理、应用及其对 LLM 性能的影响。
新的方法将问题解决表示为对大型语言模型的推理步骤进行搜索,允许超越从左到右解码的战略探索和规划。这提高了在数学谜题和创意写作等挑战中的表现,并增强了 LLM 的可解释性和适用性。
Auto-CoT 提示方法让大语言模型自动生成自己的演示来引导复杂推理,采用基于多样性的采样和零-shot 生成,减少了人工创建提示的工作。实验表明,它在推理任务中与手动提示的性能相匹配。
提示工程中的并行处理:Skeleton-of-Thought 技术
探索 Skeleton-of-Thought 提示工程技术如何通过减少延迟、提供结构化输出和优化项目来增强生成式 AI。
解锁 GPT-4 总结的能力,利用链式密度(CoD)技术,该技术旨在平衡信息密度以获得高质量的总结。
探索链式验证提示工程方法,这是减少大语言模型中幻觉的重要一步,确保 AI 响应可靠且真实。
发现 Graph of Thoughts 如何旨在革新提示工程及大语言模型,使问题解决变得更加灵活和类人化。
Thought Propagation:大语言模型复杂推理的类比方法
Thought Propagation 是一种提示工程技术,指示大语言模型识别和解决与原始查询类似的一系列问题,然后利用这些相似问题的解决方案直接生成新答案或制定详细的行动计划,以完善原始解决方案。
额外资源
尽管上述内容应该能帮助你开始工程化有效的提示,但以下资源可能提供一些额外的深度和/或替代视角,你可能会发现有用。
掌握生成式 AI 和提示工程:数据科学家的实用指南 [电子书] 来自 数据科学视野
这本电子书提供了对生成式 AI 和提示工程的深入理解,涵盖了关键概念、最佳实践和实际应用。你将获得对流行 AI 模型的见解,学习设计有效提示的过程,并探讨这些技术的伦理考虑。此外,书中包括了展示不同行业实际应用的案例研究。
无论你是寻求灵感的作家、追求高效的内容创作者、热衷于知识分享的教育者,还是需要专业应用的从业人员,《掌握生成式 AI 文本提示》都是你的首选资源。在本指南结束时,你将能够利用生成式 AI 的力量,提升创造力,优化工作流程,并解决各种问题。
我们的电子书充满了引人入胜的见解和实用策略,涵盖了广泛的主题,如理解人类认知和 AI 模型、有效提示的心理学原理、考虑认知原理设计提示、评估和优化提示,以及将心理学原理融入你的工作流程。我们还包括了成功提示工程示例的实际案例研究,以及对提示工程、心理学和跨学科合作未来的探索。
提示工程学是一门相对新的学科,旨在开发和优化提示,以高效地使用语言模型(LMs)进行各种应用和研究主题。提示工程技巧有助于更好地理解大型语言模型(LLMs)的能力和局限性。
生成式 AI 是当今世界上最热门的流行词,我们创建了最全面(且免费的)使用指南。该课程针对非技术读者,适合那些甚至可能没有听说过 AI 的人,是你进入生成式 AI 和提示工程的绝佳起点。技术读者也会在我们的后续模块中找到有价值的见解。
结论
提示工程是 AI 工程师和 LLM 高级用户必备的技能。除此之外,提示工程已经发展成为一个独立的 AI 专业领域。目前还无法确定提示工程的确切角色——或者是否专职提示工程师职位会继续受到 AI 专业人士的青睐——但有一点是明确的:掌握提示工程的知识绝不会成为你的负担。通过本文中的步骤,你现在应该已经拥有了构建自己高性能提示的良好基础。
谁知道呢?也许你就是下一个 AI 语言大师。
Matthew Mayo (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为KDnuggets和Statology的主编,以及Machine Learning Mastery的贡献编辑,Matthew 的目标是让复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、语言模型、机器学习算法以及探索新兴的人工智能。他的使命是普及数据科学社区中的知识。Matthew 从 6 岁起就开始编程。
更多相关内容
提示工程:一场集成的梦想

图片由我使用 Microsoft Image Creator 创建
自从 OpenAI 向公众发布 ChatGPT 以来,关于一种新兴梦幻职业——提示工程师的讨论如潮水般涌现。这被誉为“AI 最火的工作”,承诺提供六位数薪资,无需编程经验。爱好者们将其描述为未来的工作,在这里,任何人都可以赚取 高达$335K的薪水,只需通过巧妙的交流让机器人给出正确的答案。毫不奇怪,Instagram 上的赚钱达人、YouTube 上的职业布道者和自称的 TikTok 预言者对此十分热衷。虽然这听起来像是一份梦幻工作,但它真的可实现吗?让我们深入了解一下背后的实际情况吧。
分析招聘广告数据可以提供关于劳动需求趋势、职责、资格要求和薪资预期的有价值见解。因此,我决定查看所谓的“AI 最火的工作”的广告数据,没有任何推测或假设。我从流行的在线招聘平台收集了 73 份最近发布的独特职位广告数据。阅读我的数据收集方法并访问数据集这里。虽然 73 个样本可能不是理想的样本量,但它为我们的分析提供了全面的起点。初步的发现令人清醒:雇主对“提示工程师”的需求稀缺。
现在,让我们看看数据。最常提到的职位名称是“提示工程师”。然而,“IT 创新分析师”、“自由职业 ML/AI 工程师”、“数据科学家”和“AI 工程师”等其他职位名称也出现了。我为职位描述中提到的资格要求和职责创建了词云。我认为词云并不意味着揭示非凡的见解,但它们可以代表文本中重要亮点的简明版本。如您所见,在职位广告中,雇主谈论计算机科学、模型开发、python、提示设计、机器学习、大型语言模型、自然语言处理和人工智能的频率高于其他内容。

1.如果将其与许多早期的轶事文章相比,这个样本量大得多,那些文章仅根据一个职位广告构建了六位数薪水的整个论点。
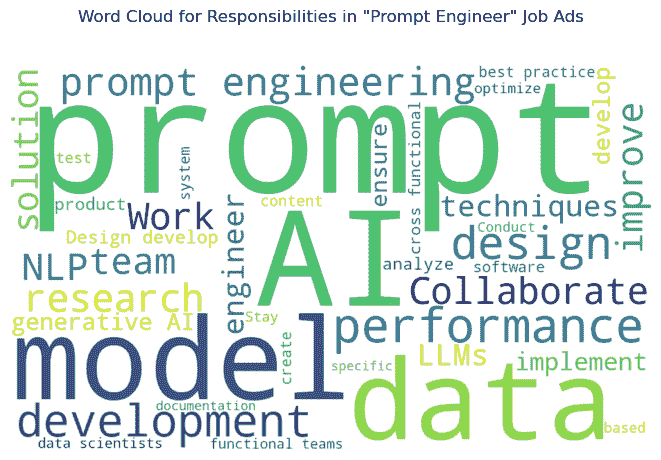
接下来,我使用 ChatGPT 和 Claude 总结了收集到的广告文本语料库,以识别顶级提示工程资格。我进行了多轮不同方法的提示,然后手动检查数据,以确保获得稳定和有效的输出。
提示工程师职位所需的基本资格:
-
Python 编程能力(2-5 年的经验),包括对 TensorFlow、PyTorch、Keras 等 AI/机器学习框架的经验。
-
NLP 和 LLM 的工作知识(2-5 年的经验),如 BERT、GPT-3/4、T5 等。了解这些模型的工作原理以及如何对其进行微调。
-
强大的分析和解决问题的能力。具备批判性思维、设计有效提示、分析模型性能和解决问题的能力是至关重要的。
-
精通提示工程原理和技术,如思维链、上下文学习、思维树等。这有助于引导模型实现期望结果。
-
出色的沟通技能,包括口头和书面沟通。这对于跨团队协作、解释技术概念和文档记录是必要的。
提示工程职位的核心职责包括:
-
提示设计与优化:设计、开发、测试和改进 AI 生成的文本提示,以最大限度地提高在各种应用中的有效性。这包括利用迁移学习技术和语言学专业知识来打造高质量和多样化的提示。
-
集成与部署:确保优化后的提示与整体产品或系统的无缝集成。与工程师协作,将提示和模型实施到生产环境中。
-
性能评估与改进:通过使用指标和用户反馈对提示性能进行严格评估。进行持续的测试和分析,以识别优化领域并迭代提示。
-
协作与需求收集:与数据科学家、内容创作者和产品经理等跨职能团队紧密合作,以理解需求并确保提示与业务目标和用户需求一致。
-
知识共享:记录提示工程的过程和结果。教育团队关于提示的最佳实践。保持对最新人工智能进展的关注,以带来创新。
可以公平地说,所谓的“AI 最热门工作”中的“无编程经验”前提与现实相差甚远,因为提示工程市场上最受需求的技能是编程熟练度和 NLP 及 LLMs 经验。而且这些并不是简单的编程技能,他们寻找的是熟悉 ML 和 AI 框架的专家。雇主不仅要求对 LLMs 和编码有“了解”,而且平均来看,他们寻求具有 2-5 年处理结构化和非结构化数据、编码、NLP、ML 和 AI 经验的专家。
阅读主要职责可以更清楚地了解为什么这个职位要求如此高的编程和 LLMs 技能。作为一种专业工作,提示工程并不是坐在电脑前玩生成 AI 模型来提供正确答案。它是关于构建业务信息系统,优化输入,与其他信息系统和产品无缝集成,并向用户和客户提供价值。换句话说,企业并不是寻找能够与 ChatGPT 聊天的人,而是希望聘请能够优化类似 GPT 的模型并将其与自己产品集成的专家。
职位广告数据分析显示,技术背景在计算机科学、数学、分析、工程、物理或语言学方面更受青睐。通常要求计算机科学或相关领域的学士学位,更高级的职位通常要求或更倾向于高级学位。薪资根据责任和资历差异很大,最低可达 30k 美元,每年最高可达 50 万美元。平均而言,包含薪资信息的职位广告年薪在 90k 到 195k 美元之间。
尽管最初充满热情,但关于提示工程作为梦想工作的可行性产生了怀疑。正如沃顿商学院教授伊桑·莫利克去年在一条twitter post中写道,“提示工程师不是未来的工作”,因为“AI 变得更容易”,在解读基本提示方面更为智能。一个月前,Coursera 发布了一份经过深思熟虑的prompt 工程职业指南(另见此处)。似乎最初的生成 AI 热潮正在缓慢消退,我们现在有更好的机会了解 AI 的现状和未来趋势。不要误解我的意思。生成 AI 输出的质量在很大程度上依赖于输入。学习如何使用和与这些复杂模型互动正成为几乎所有人都需要的重要技能。越来越多的科学研究表明,系统化的提示方法可以显著改善这些模型的结果(参见1,2,3,4,5,6,7)。然而,“提示工程”并不是(也从未是)一些人想象中的梦想工作。如果没有丰富的编程、自然语言处理、机器学习、产品开发和软件集成经验,没有人会为你仅仅通过顺利引导 ChatGPT 得到正确答案而支付六位数的薪水。
提示工程和生成 AI 应用的现状和未来似乎受到两个重要趋势的影响:首先,正如伊桑·莫利克提到的,生成 AI 模型在从简单的提示中生成良好输出方面变得越来越熟练,可能类似于互联网搜索引擎在从简单的搜索查询中返回更相关结果的能力。其次,生成 AI 模型正越来越多地集成到商业产品、服务和平台中。这种适应对 AI 经济的成功至关重要。因此,了解如何优化、微调、定制和将生成 AI 模型与当前信息系统和产品集成是并将继续是一项宝贵的技能。这就是为什么当前的提示工作广告中对程序员、系统设计师以及能够与其他产品开发团队成员协作的人的需求如此巨大。
Mahdi Ahmadi 是北德克萨斯大学信息技术与决策科学系的临床助理教授,我教授数据挖掘、商业智能和数据分析。我的主要研究领域是机器学习和数据挖掘技术在商业中的应用。我还为企业、高等教育机构和非营利组织提供数据分析问题的咨询。
更多相关内容
数据科学训练营在瑞士苏黎世,2018 年 1 月 15 日至 4 月 6 日
原文:
www.kdnuggets.com/2017/10/propulsion-data-science-bootcamp-zurich.html
总部位于瑞士苏黎世,Propulsion Academy 提供为期 12 周的完整数据科学训练营,毕业后具备工作所需的技能。由于前期项目的校友已经进入职场,课程重点包括数据科学的关键概念,如统计学、R 和 Python、数据清洗、实验设计、机器学习、数据可视化和自然语言处理。欲了解更多信息,请查看课程页面。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
多亏了谷歌以及两所知名大学——苏黎世联邦理工学院和苏黎世大学的强大存在,苏黎世的数据科学领域正蓬勃发展。公司们发现很难找到人才来满足对数据科学的新需求。
瑞士位于欧洲的心脏地带,其战略位置和高质量的生活使其对欧洲及其他地区的人们极具吸引力。该项目的世界级讲师拥有 Facebook、Airbnb、超级高铁技术和 MIT 的经验。课程重点在于实践学习,学生们将在最终项目中使用真实公司的数据。对于美国学生来说,这是一个绝佳的机会,可以暂时离开,成为一个绝妙项目的一部分。
要被接受进入该项目,候选人必须通过个人和技术面试。任何人都有潜力入选,但被接受的候选人通常拥有数学、科学和金融背景。准备好迎接挑战了吗?
。
使用代码KDNUGGETS在申请表中可以获得折扣。
更多相关信息
TensorFlow 中的机器学习模型剪枝
原文:
www.kdnuggets.com/2020/12/pruning-machine-learning-models-tensorflow.html
评论
在上一篇文章中,我们回顾了一些关于剪枝神经网络的主要文献。我们了解到剪枝是一种模型优化技术,涉及到在权重张量中消除不必要的值。这将导致更小的模型,其准确性非常接近基线模型。
在这篇文章中,我们将通过一个示例来应用剪枝,并查看对最终模型大小和预测误差的影响。
导入常见库
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
我们的第一步是处理几个导入:
-
Os和Zipfile将帮助我们评估模型的大小。 -
tensorflow_model_optimization用于模型剪枝。 -
load_model用于加载已保存的模型。 -
当然还包括
tensorflow和keras。
最后,我们初始化 TensorBoard,以便能够可视化模型:
import os
import zipfile
import tensorflow as tf
import tensorflow_model_optimization as tfmot
from tensorflow.keras.models import load_model
from tensorflow import keras
%load_ext tensorboard
数据集生成
在这个实验中,我们将使用 scikit-learn 生成一个回归数据集。然后,我们将数据集拆分为训练集和测试集:
from sklearn.datasets import make_friedman1
X, y = make_friedman1(n_samples=10000, n_features=10, random_state=0)from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
模型无剪枝
我们将创建一个简单的神经网络来预测目标变量 y。然后检查均方误差。在此之后,我们将其与整个模型剪枝后的结果进行比较,然后与仅剪枝 Dense 层后的结果进行比较。
接下来,我们设置一个回调,在模型停止改进后停止训练,经过 30 轮。
early_stop = keras.callbacks.EarlyStopping(monitor=’val_loss’, patience=30)
让我们打印出模型的摘要,以便将其与剪枝模型的摘要进行比较。
model = setup_model()model.summary()
让我们编译模型并训练它。
model.compile(optimizer=’adam’,
loss=tf.keras.losses.mean_squared_error,
metrics=[‘mae’, ‘mse’])model.fit(X_train,y_train,epochs=300,validation_split=0.2,callbacks=early_stop,verbose=0)
由于这是一个回归问题,我们监控的是平均绝对误差和均方误差。
这是绘制为图像的模型。输入是 10,因为我们生成的数据集有 10 个特征。
tf.keras.utils.plot_model(
model,
to_file=”model.png”,
show_shapes=True,
show_layer_names=True,
rankdir=”TB”,
expand_nested=True,
dpi=96,
)
现在让我们检查均方误差。我们可以继续到下一部分,看看剪枝整个模型时该误差如何变化。
from sklearn.metrics import mean_squared_errorpredictions = model.predict(X_test)print(‘Without Pruning MSE %.4f’ % mean_squared_error(y_test,predictions.reshape(3300,)))Without Pruning MSE 0.0201
使用 ConstantSparsity 剪枝计划剪枝整个模型
让我们将上述均方误差与修剪整个模型后获得的均方误差进行比较。第一步是定义修剪参数。权重修剪是基于大小的。这意味着一些权重在训练过程中被转换为零。模型变得稀疏,从而使其更容易压缩。稀疏模型还使推理更快,因为零值可以被跳过。
期望的参数是修剪计划、块大小和块池化类型。
-
在这种情况下,我们设置了 50% 的 稀疏性,意味着 50% 的权重将被置零。
-
block_size— 块的尺寸(高度、宽度)矩阵权重张量中的稀疏模式。
-
block_pooling_type— 用于池化权重的函数块。必须是
AVG或MAX。
现在我们可以通过应用我们的修剪参数来修剪整个模型。
让我们查看模型摘要。将其与未修剪模型的摘要进行比较。从下面的图像中我们可以看到整个模型已经被修剪——稍后我们将通过修剪一个密集层后获得的摘要看到不同之处。
model_to_prune.summary()

在我们可以将模型拟合到训练和测试集之前,我们必须编译模型。
model_to_prune.compile(optimizer=’adam’,
loss=tf.keras.losses.mean_squared_error,
metrics=[‘mae’, ‘mse’])
由于我们正在应用修剪,我们需要定义几个修剪回调函数,除了早期停止回调函数外。我们定义了记录模型的文件夹,然后创建了一个包含回调函数的列表。
tfmot.sparsity.keras.UpdatePruningStep() 更新修剪包装器与优化器步骤。如果不指定它,将会导致错误。
tfmot.sparsity.keras.PruningSummaries() 将修剪摘要添加到 Tensorboard。
log_dir = ‘.models’
callbacks = [
tfmot.sparsity.keras.UpdatePruningStep(),
# Log sparsity and other metrics in Tensorboard.
tfmot.sparsity.keras.PruningSummaries(log_dir=log_dir),
keras.callbacks.EarlyStopping(monitor=’val_loss’, patience=10)
]
解决了这些问题后,我们可以将模型拟合到训练集。
model_to_prune.fit(X_train,y_train,epochs=100,validation_split=0.2,callbacks=callbacks,verbose=0)
检查该模型的均方误差时,我们注意到它略高于未修剪模型的均方误差。
prune_predictions = model_to_prune.predict(X_test)print(‘Whole Model Pruned MSE %.4f’ % mean_squared_error(y_test,prune_predictions.reshape(3300,)))Whole Model Pruned MSE 0.1830
仅使用 PolynomialDecay 修剪计划修剪密集层
现在,让我们实现相同的模型——但这一次,我们只修剪密集层。注意在修剪计划中使用的 [PolynomialDecay](https://www.tensorflow.org/model_optimization/api_docs/python/tfmot/sparsity/keras/PolynomialDecay) 函数。
从摘要中,我们可以看到只有第一个密集层将被修剪。
model_layer_prunning.summary()
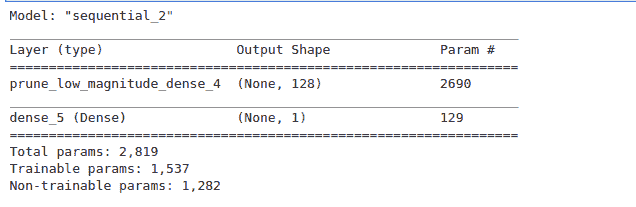
然后我们编译并拟合模型。
model_layer_prunning.compile(optimizer=’adam’,
loss=tf.keras.losses.mean_squared_error,
metrics=[‘mae’, ‘mse’])model_layer_prunning.fit(X_train,y_train,epochs=300,validation_split=0.1,callbacks=callbacks,verbose=0)
现在,让我们检查均方误差。
layer_prune_predictions = model_layer_prunning.predict(X_test)print(‘Layer Prunned MSE %.4f’ % mean_squared_error(y_test,layer_prune_predictions.reshape(3300,)))Layer Prunned MSE 0.1388
我们无法将此处获得的 MSE 与之前的进行比较,因为我们使用了不同的剪枝参数。如果你想比较它们,请确保剪枝参数相似。经过测试,layer_pruning_params 在这种特定情况下比 pruning_params 的误差更低。比较不同剪枝参数获得的 MSE 很有用,以便你可以选择不会降低模型性能的参数。
比较模型大小
现在让我们比较有剪枝和无剪枝模型的大小。我们首先训练并保存模型权重以供后续使用。
我们将设置基础模型并加载保存的权重。然后我们剪枝整个模型。我们编译、训练模型,并在 Tensorboard 上可视化结果。
这是 TensorBoard 上剪枝总结的一个快照。
其他剪枝总结也可以在 Tensorboard 上查看。
现在让我们定义一个函数来计算模型的大小。
现在我们定义导出模型并计算其大小。
对于剪枝模型, tfmot.sparsity.keras.strip_pruning() 用于恢复原始模型的稀疏权重。注意被剪枝和未剪枝模型的大小差异。
model_for_export = tfmot.sparsity.keras.strip_pruning(model_for_pruning)
Size of gzipped pruned model without stripping: 6101.00 bytes
Size of gzipped pruned model with stripping: 5140.00 bytes
对两个模型进行预测,我们发现它们具有相同的均方误差。
Model for Prunning Error 0.0264
Model for Export Error 0.0264
最终思考
你可以测试不同的剪枝计划如何影响模型的大小。显然,这里的观察结果并不普遍。你需要尝试不同的剪枝参数,了解它们如何影响你的模型大小、预测误差和/或准确性,具体取决于你的问题。
要进一步优化模型,你可以对其进行量化。如果你想深入了解这一点以及更多内容,请查看下面的资源和仓库。
资源
Keras 中的剪枝示例 | TensorFlow 模型优化
欢迎来到基于幅度的权重剪枝的端到端示例。有关剪枝是什么以及如何...
适用于移动和嵌入式设备的 TensorFlow Lite
在这篇文章中,我们通过一个示例来应用剪枝,并查看对最终模型大小的影响...
8 位量化和 TensorFlow Lite:通过低精度加速移动推理
heartbeat.fritz.ai
简介:德里克·姆维提是一位数据科学家,对知识分享充满热情。他通过 Heartbeat、Towards Data Science、Datacamp、Neptune AI、KDnuggets 等博客积极参与数据科学社区。他的内容在互联网上的浏览量超过一百万次。德里克还是一名作者和在线讲师。他还与多个机构合作,实施数据科学解决方案并提升员工技能。德里克在多媒体大学学习了数学和计算机科学,还是 Meltwater 创业技术学校的校友。如果数据科学、机器学习和深度学习的世界引起了你的兴趣,你可能会想了解他的Python 数据科学与机器学习完整课程。
原文。经许可转载。
相关:
-
使用 TensorFlow Serving 将训练好的模型部署到生产环境
-
处理机器学习中的不平衡数据
-
如何将 PyTorch Lightning 模型部署到生产环境
更多主题
使用简单的 Python 包拉取和分析金融数据
原文:
www.kdnuggets.com/2020/07/pull-analyze-financial-data-simple-python-package.html
评论
图片来源:Pixabay(商业用途免费)
介绍
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
股票市场分析和良好的投资(为了长期增长)需要仔细审查财务数据。各种指标和比率通常用于这种分析,即评估股票的固有质量。你可能在财务和投资专家的讨论中听说过其中的一些。
例如,市盈率或PE 比率。它是股价与年收益/每股的比率。
或者,每股账面价值。它是公司普通股权益与其流通股数的比率。当一只股票被低估时,它的每股账面价值相对于市场上当前的股价会更高。
利用市盈率和 PEG 评估股票的未来
市盈率(P/E)是投资者和分析师用于确定股票的最广泛使用的指标之一……
通常这些数据可以从像雅虎财经这样的网页上获得。然而,除非你使用某种付费注册服务,否则你无法以编程方式下载或抓取数据。
雅虎财经 - 股票市场实时行情、报价、商业与金融新闻
在雅虎财经,你可以获得免费的股票报价、最新新闻、投资组合管理资源、国际市场……
然而,许多微服务存在,它们通过简单的 API 调用提供这些数据。为了利用这一点,我们在本文中展示了如何编写一个简单的 Python 类脚本,以接口连接到金融数据微服务。

图像来源:作者截屏(网站)
使用这个 Python 类,你可以通过调用一系列简单的方法来提取数据并构建一个 Pandas DataFrame,其中包含几乎所有重要的财务指标和比率。
我们还提供了简单的图表方法(柱状图和散点图),用于图形化分析数据。
请注意,你需要从网站上获取自己的秘密 API 密钥(免费),并在实例化类对象后注册它。
说到这一点,让我们深入了解 Python 包/类以及附带的各种方法。
Python 类和各种内置方法
核心 Python 类可以在我的 Github 仓库中找到。欢迎给仓库加星和分叉,进行改进。你可以直接克隆该仓库,并在自己的笔记本中开始使用脚本。
**> mkdir My_project
> cd My_Project
> git clone** [**https://github.com/tirthajyoti/Finance-with-Python.git**](https://github.com/tirthajyoti/Finance-with-Python.git) **> cd financeAPI**
为了保持代码整洁,在本文中,我们展示了在测试 Jupyter 笔记本中使用该类的方法。
我们首先导入常规库和类对象。
从文件中读取秘密 API 密钥并注册
注意,你需要在与代码文件相同的目录中有一个名为 Secret_Key.txt 的文件。没有它,你无法继续。
在这里注册:https://financialmodelingprep.com/login
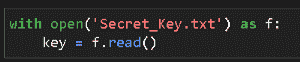
创建一个类实例

它有一个描述
没有注册密钥,我们无法访问数据
我们肯定想要开始提取数据。假设我们想为公司 Apple(股票代码为‘AAPL’)构建一个数据字典。我们可以尝试,但不会成功,因为我们还没有用类对象注册秘密密钥。

所以,我们注册了秘密密钥
让我们现在构建一个数据字典
对于该类中的所有方法,我们必须传递公司(在美国金融市场上的)股票代码。例如,Apple Inc 的代码是‘AAPL’。

如果我们检查这个字典,会发现从 API 端点拉取了大量数据。下面提供了部分截图。
用多个公司的数据构建一个 DataFrame
使用 Python 字典是可以的,但对于大规模数据分析,我们应考虑构建 Pandas DataFrame。我们提供了一个内置方法来实现这一点。构建 DataFrame 就像传递一个股票代码列表一样简单,代码会为您完成所有的数据抓取和结构化工作。
比如我们想下载以下公司的所有财务数据,
-
Twitter
-
Facebook
-
Microsoft
-
Nvidia
-
苹果
-
Salesforce

一份格式良好的 DataFrame 准备好了!
究竟有哪些数据可用?
我们可以轻松检查从 API 服务中提取的数据类型。注意,我们传递参数‘profile’,‘metrics’ 或 ‘ration’,并返回相应的数据项列表。

绘图 — 可视化分析
在这个包中,我们包含了用于数据的简单可视化分析的代码。
查看各种指标和财务比率在简单条形图中的表现通常是有帮助的。为此,只需传递您想绘制的变量名称。您还可以包括常见的 Matplotlib 关键字参数,例如颜色和透明度(alpha)。
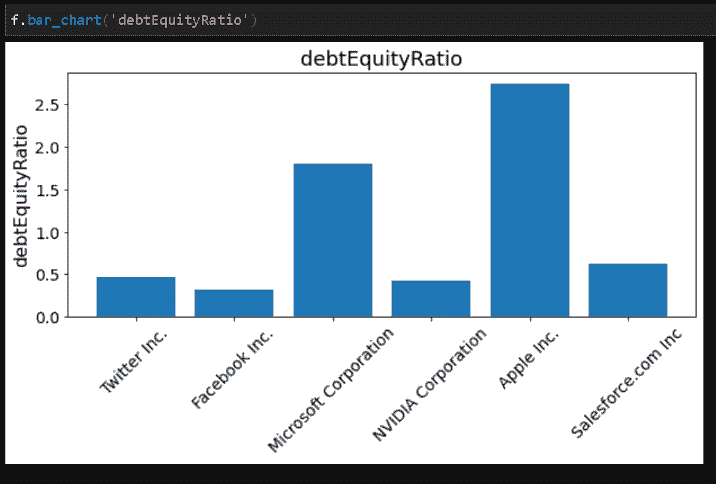
您还可以绘制简单的散点图来直观分析财务指标之间的关系。
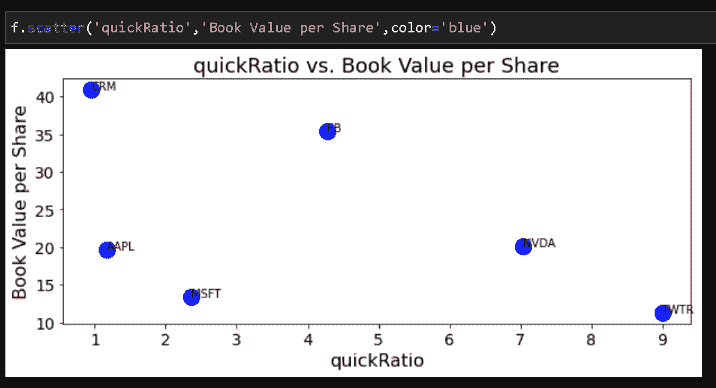
您还可以传递第三个变量用于调整散点图中标记的大小。这在间接上有助于在二维图中可视化超过两个变量。例如,我们在下面的代码中将股价参数作为第三个变量传递。
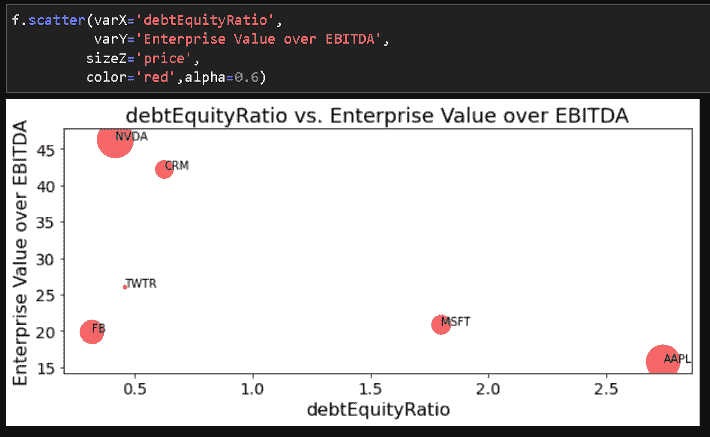
自定义分析与底层 DataFrame
投资者经常会想要根据可用数据创建自己的筛选器和投资逻辑。
例如,我们可能只考虑市值 > 2000 亿美元的公司,然后在条形图中查看企业价值与 EBITDA 比的指标。
我们可以访问底层 DataFrame,创建自定义 DataFrame,然后将此自定义 DataFrame 分配给一个新的financeAPI()对象,以利用现成的图表方法。
这样,我们就无需再次从 API 请求数据。我们应该尽量避免读取数据,因为免费 API 密钥的读取数据量有限。

然后我们根据这个自定义 DataFrame(嵌入在自定义类对象中)绘制条形图。
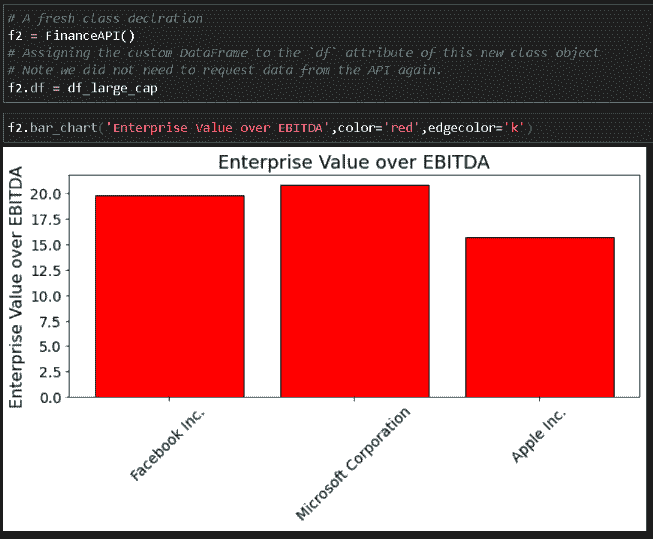
摘要
我们展示了一个简单的 Python 类/包的实现和使用,这可以用于从微服务中提取广泛的金融指标和比率。
要获取此服务的免费 API 密钥,必须进行注册。使用量当然在免费账户下是有限制的。网站还提供了无限使用的付费计划。
请注意,本工作重点关注静态金融数据,即年度财务报表中的数据,而非动态时间序列股市定价数据。它应当用于评估公司的长期财务实力,以便进行以增长为导向的投资。
作为数据科学家,你可能经常需要编写自定义的类/包以从微服务 API 中提取和分析数据,希望这篇文章(及相关代码库)能为你提供一个简单但有效的入门介绍。

图片来源:Pixabay(可商用免费)
你还可以查看作者的GitHub** 代码库**,获取机器学习和数据科学方面的代码、想法和资源。如果你像我一样,对 AI/机器学习/数据科学充满热情,请随时在 LinkedIn 上添加我或在 Twitter 上关注我。
原文。经许可转载。
相关:
-
时间序列分类:合成与真实金融时间序列
-
数据科学家免费的经济学与金融课程
-
在金融服务中应用 NLP 的四种方法
更多相关话题
将无代码机器学习推向边缘
原文:
www.kdnuggets.com/2021/07/pushing-no-code-machine-learning-edge.html
评论
图片由Markus Winkler提供,来源于Unsplash
将无代码机器学习推向边缘
无代码或低代码平台近年来获得了广泛关注,因为那些编程和开发经验有限的人对相关技术产生了兴趣。这些平台允许缺乏经验的人做一些事情,比如构建移动应用程序、在网站和工作环境中部署 Web 应用程序,甚至利用人工智能和机器学习。
传统上,一个人需要在各种开发和编程学科中拥有扎实的背景才能真正利用机器学习,但现在已经不再是这样。当然,对于那些具备适当背景的人,部署可以更加复杂,但 TinyML 和无代码机器学习解决方案正在使这些技术对所有人更具可及性。
实际上,这是一种无代码人工智能的形式,其目标不仅仅是“使人工智能普及”,还在于在商业环境中大幅扩展其能力。无代码机器学习或自动机器学习(autoML)虽然不如它们的人工智能同行那样流行,但它们确实是一个新兴领域。TinyML 虽然略有不同,但由于逻辑嵌入在设备本身中,也提供了相同的好处。
将计算推向边缘
即使在低代码形式下,这些技术也需要不断且大量的数据流,并实时摄取和处理这些数据。人工智能和机器学习解决方案可以比人脑更快地处理信息。因此,它们已经提高了效率和输出。但它们也受到当前网络的限制,这些网络可能会出现带宽和服务中断、瓶颈以及各种延迟或复杂情况。
理所当然,提供所需的主动连接来解锁这些技术可以进一步提升性能好处。这正是边缘计算发挥作用的地方。
边缘计算涉及将计算和处理解决方案移近源头,或者说移至处理需求发生的地方。这弥合了实际设备上进行的复杂计算与在外部服务器或系统上远程进行的计算之间的差距。
本地处理事件意味着为设备提供足够的能力来完成工作,但这并不总是可能、方便或具有成本效益。相比之下,远程处理提供了更多的能力,但通常以速度和性能为代价。边缘计算解决方案提供了两者的最佳结合,改善了可扩展性、可靠性和定制性。
还可以优化“边缘”的位置,以减少延迟、降低运营和服务成本、提高可见性、加速部署等等。一家物联网初创公司在顾问的帮助下利用了 AWS 计算优化器,实施了计算节省计划——将整体账单降低了 37.5%每月。这突显了云和边缘计算解决方案的潜在灵活性和动态特性。
与无代码机器学习的关系是什么?
无代码机器学习旨在使相关技术的民主化和提高可访问性。这意味着越来越多的人将能够访问机器学习、人工智能和神经网络解决方案,而依赖性和可靠性将变得更加重要。
问题是,大多数选择使用无代码或低代码解决方案的人员通常没有足够的能力或基础设施来支持宏观层面的机器学习平台。想象一下,一个小型初创公司推出了一款移动应用,该应用使用机器学习分析用户的电影和电视偏好,以提供推荐。这个主意不错,对吧?像这样的解决方案已经在探索中并且已经在使用中。
起初,处理能力不会成为问题。但一旦安装基础扩展到数十万甚至数百万的不同用户和账户,就需要大量的计算能力来支持平台。
在某个时候,开发者需要扩展其基础设施,以处理更大量的工作,而不会影响性能和可靠性。从成本和性能的角度来看,边缘计算解决方案是一种更可管理的方式。这些方案也更加容易获取,这也是云技术的主要优势之一。
无代码应用的边缘计算
另一个因素是无代码机器学习应用的支持方式。将无代码平台本身推向网络边缘具有相同的效率、性能和成本效益。
当你使用开发平台,如 IDE 时,你希望获得几乎即时的反馈。如果 Web 应用程序充分利用了边缘处理,那么这会改善整个体验,并使快速反馈成为可能。
另一方面,TinyML 不需要边缘计算 或互联网连接的硬件。一切都在设备或微控制器上本地进行。它已成为工业物联网 (IIoT) 的首选实践,其中嵌入式计算提供了无与伦比的性能和速度。
边缘计算 vs. 云计算
理解边缘计算和云计算并非可以互换,且它们不互相替代是很重要的。它们用于不同的目的。边缘计算通常是处理和传递时间敏感数据的首选解决方案,而云计算则用于没有时间限制的数据。
边缘计算最适合本地化的情况,其中开放连接可能不稳定,大部分处理能力必须迅速而靠近设备或系统完成。当技术依赖于速度和可靠性时,比如 在医疗和保健设备 中,边缘计算也是一个出色的解决方案。在所有其他情况下,云计算可能适用。
因此,将无代码 ML 平台和计算工作推到边缘并不意味着技术上推到云端。它们有相似之处,但并不相同。
未来的边缘
边缘计算是一种可行且有益的数据处理形式,极其适用于更传统的机器学习应用以及无代码或低代码 ML 部署。它将计算能力更接近最终用户或系统的输出,从而提高性能和可靠性,并提供一种更具可扩展性的解决方案,能够满足 ML 驱动应用程序的需求。
简介:Devin Partida 是一名大数据和技术作家,同时也是 ReHack.com 的主编。
相关:
-
在边缘设备上实施 MLOps
-
高性能深度学习:如何训练更小、更快、更好的模型 – 第四部分
-
MLOps 是一门工程学科:初学者概述
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 管理
更多相关内容
PyCaret 101: 初学者入门指南
原文:
www.kdnuggets.com/2021/06/pycaret-101-introduction-beginners.html
评论
由 Moez Ali,PyCaret 的创始人兼作者

PyCaret — 一个开源的低代码 Python 机器学习库
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织的 IT
PyCaret
PyCaret 是一个开源的低代码机器学习库和端到端模型管理工具,内置于 Python 中,用于自动化机器学习工作流程。它的易用性、简单性以及能够快速高效地构建和部署端到端机器学习管道的能力将令你惊叹。
PyCaret 是一个低代码库,可以用几行代码替代数百行代码。这使得实验周期变得极其快速高效。
PyCaret 是 简单易用的。PyCaret 中执行的所有操作都被顺序存储在一个 Pipeline 中,完全自动化以 部署。无论是填补缺失值、进行独热编码、转换分类数据、特征工程,还是超参数调优,PyCaret 都会自动完成。要了解更多关于 PyCaret 的信息,请观看这段 1 分钟的视频。
PyCaret — 一个开源的低代码 Python 机器学习库
PyCaret 的特点
作者提供的图像
PyCaret 的模块
PyCaret 是一个模块化库,按模块排列,每个模块代表一个机器学习用例。截止到本文撰写时,支持以下模块:
作者提供的图像 — PyCaret 支持的机器学习用例
时间序列模块正在开发中,将在下一个主要版本中推出。
安装 PyCaret
安装 PyCaret 非常简单,仅需几分钟。我们强烈建议使用虚拟环境,以避免与其他库的潜在冲突。
PyCaret 的默认安装是一个精简版的 pycaret,只安装了硬性依赖项,列在这里。
**# install slim version (default)** pip install pycaret**# install the full version**
pip install pycaret[full]
当你安装 PyCaret 的完整版时,所有的可选依赖项也会被安装,详细信息见 这里。

PyCaret 数字化 — 作者提供的图片
???? 开始吧
在我向你展示如何用 PyCaret 轻松做机器学习之前,让我们先从高层次上谈谈机器学习生命周期:
机器学习生命周期 — 作者提供的图片(从左到右阅读)
-
业务问题 — 这是机器学习工作流的第一步。根据用例和问题的复杂性,这一步可能需要几天到几周的时间才能完成。在这一阶段,数据科学家会与主题专家(SME)会面,以了解问题,采访关键利益相关者,收集信息,并设定项目的总体期望。
-
数据来源与 ETL — 一旦理解了问题,就可以利用访谈中获得的信息从企业数据库中获取数据。
-
探索性数据分析(EDA) — 模型尚未开始。EDA 是你分析原始数据的阶段。你的目标是探索数据,评估数据的质量、缺失值、特征分布、相关性等。
-
数据准备 — 现在是准备数据模型训练的时候了。这包括将数据划分为训练集和测试集、填补缺失值、独热编码、目标编码、特征工程、特征选择等。
-
模型训练与选择 — 这是大家都兴奋的步骤。这包括训练一堆模型、调整超参数、模型集成、评估性能指标、模型分析如 AUC、混淆矩阵、残差等,最后选择一个最佳模型用于生产环境中的业务应用。
-
部署与监控 — 这是最后一步,主要涉及 MLOps。这包括打包最终模型、创建 Docker 镜像、编写评分脚本,然后将所有这些整合在一起,最终将其发布为一个 API,用于对通过管道传入的新数据进行预测。
传统的方法相当繁琐、耗时,并且需要大量的技术知识,我可能无法在一个教程中涵盖所有内容。然而,在这个教程中,我将使用 PyCaret 来演示数据科学家如何变得如此高效地完成这些任务。
???? 业务问题
在本教程中,我将使用达顿商学院的一个非常流行的案例研究,该案例研究发表在哈佛商业评论上。案例涉及两个未来要结婚的人。名叫Greg的男子想买一个戒指向名叫Sarah的女孩求婚。问题是找到 Sarah 会喜欢的戒指,但在朋友的建议下,Greg 决定买一个钻石石头,以便 Sarah 可以决定她的选择。Greg 随后收集了 6000 颗钻石的数据,包括价格和切工、颜色、形状等属性。
???? 数据
在本教程中,我将使用达顿商学院的一个非常流行的案例研究的数据集,该案例研究发表在哈佛商业评论上。本教程的目标是根据钻石的属性(如克拉重量、切工、颜色等)预测钻石价格。你可以从PyCaret 的仓库下载数据集。
**# load the dataset from pycaret** from pycaret.datasets import get_data
data = get_data('diamond')
数据的样本行
???? 探索性数据分析
让我们做一些快速的可视化,以评估独立特征(重量、切工、颜色、清晰度等)与目标变量Price的关系。
**# plot scatter carat_weight and Price**
import plotly.express as px
fig = px.scatter(x=data['Carat Weight'], y=data['Price'],
facet_col = data['Cut'], opacity = 0.25, template = 'plotly_dark', trendline='ols',
trendline_color_override = 'red', title = 'SARAH GETS A DIAMOND - A CASE STUDY')
fig.show()
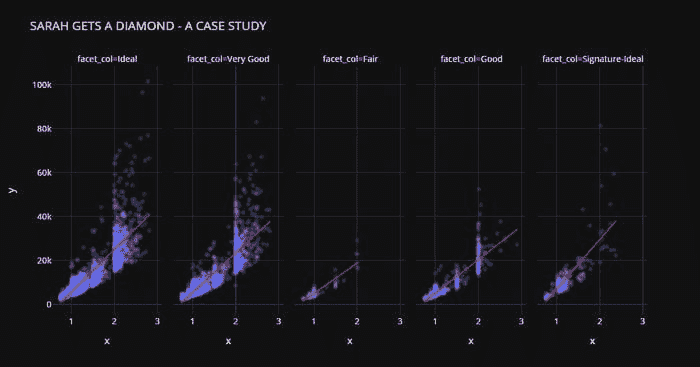
让我们检查目标变量的分布。
**# plot histogram**
fig = px.histogram(data, x=["Price"], template = 'plotly_dark', title = 'Histogram of Price')
fig.show()
注意到Price的分布是右偏的,我们可以快速检查对数变换是否能使Price大致正态分布,从而给假设正态分布的算法提供机会。
import numpy as np**# create a copy of data**
data_copy = data.copy()**# create a new feature Log_Price**
data_copy['Log_Price'] = np.log(data['Price'])**# plot histogram**
fig = px.histogram(data_copy, x=["Log_Price"], title = 'Histgram of Log Price', template = 'plotly_dark')
fig.show()
这确认了我们的假设。变换将帮助我们摆脱偏斜,使目标变量大致符合正态分布。基于此,我们将在训练模型之前对Price变量进行变换。
???? 数据准备
在 PyCaret 的所有模块中,setup是任何使用 PyCaret 的机器学习实验中的第一个也是唯一的强制步骤。该函数负责在训练模型之前所需的所有数据准备工作。除了执行一些基本的默认处理任务外,PyCaret 还提供了广泛的预处理功能。要了解 PyCaret 中所有预处理功能的更多信息,请参见这个链接。
**# initialize setup**
from pycaret.regression import *
s = setup(data, target = 'Price', transform_target = True, log_experiment = True, experiment_name = 'diamond')

pycaret.regression 模块中的 setup 函数
当你初始化 PyCaret 中的setup函数时,它会分析数据集并推断所有输入特征的数据类型。如果所有数据类型都被正确推断,你可以按回车继续。
注意:
-
我已传递
log_experiment = True和experiment_name = 'diamond',这将告诉 PyCaret 自动记录所有的指标、超参数和模型工件,在建模阶段进行时,这一切都在后台进行。这是由于与MLflow的集成实现的。 -
此外,我在
setup中使用了transform_target = True。PyCaret 将使用 box-cox 变换在后台转换Price变量。这影响了数据的分布,类似于对数变换(技术上有所不同)。如果你想了解更多关于 box-cox 变换的信息,你可以参考这个链接。
设置输出 — 为显示目的已截断
???? 模型训练与选择
现在数据已经准备好进行建模,让我们使用compare_models函数开始训练过程。它将训练模型库中的所有算法,并使用 k 折交叉验证评估多个性能指标。
**# compare all models**
best = compare_models()
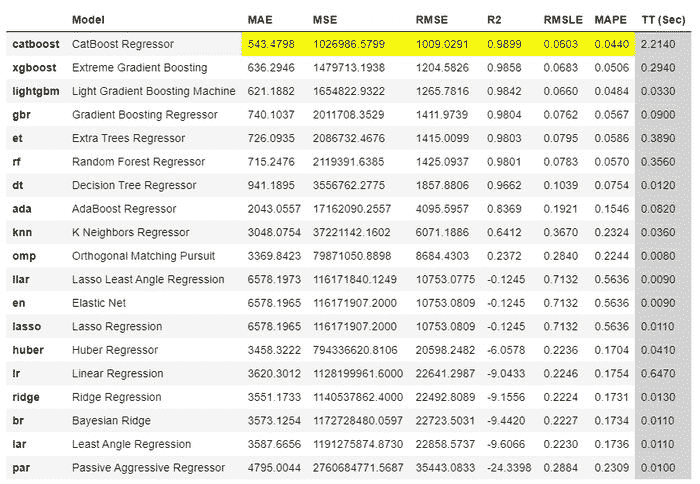
compare_models的输出
**# check the residuals of trained model**
plot_model(best, plot = 'residuals_interactive')
最佳模型的残差和 QQ 图
**# check feature importance**
plot_model(best, plot = 'feature')
完成并保存 Pipeline
现在让我们最终确定最佳模型,即在整个数据集(包括测试集)上训练最佳模型,然后将 Pipeline 保存为 pickle 文件。
**# finalize the model**
final_best = finalize_model(best)**# save model to disk** save_model(final_best, 'diamond-pipeline')
save_model函数将把整个 Pipeline(包括模型)保存为本地磁盘上的 pickle 文件。默认情况下,它将把文件保存到与 Notebook 或脚本所在的文件夹相同的位置,但如果需要,您也可以传递完整路径:
save_model(final_best, 'c:/users/moez/models/diamond-pipeline'
???? 部署
记住我们在设置函数中传递了log_experiment = True以及experiment_name = 'diamond'。让我们看看 PyCaret 在 MLflow 的帮助下在后台做了什么神奇的事情。要查看这些魔法,让我们启动 MLflow 服务器:
**# within notebook (notice ! sign infront)** !mlflow ui**# on command line in the same folder** mlflow ui
现在打开你的浏览器,输入“https://localhost:5000”。它将打开一个类似这样的用户界面:
上表中的每一项代表一个训练运行,产生一个训练好的 Pipeline 和一堆元数据,如运行的日期时间、性能指标、模型超参数、标签等。让我们点击其中一个模型:
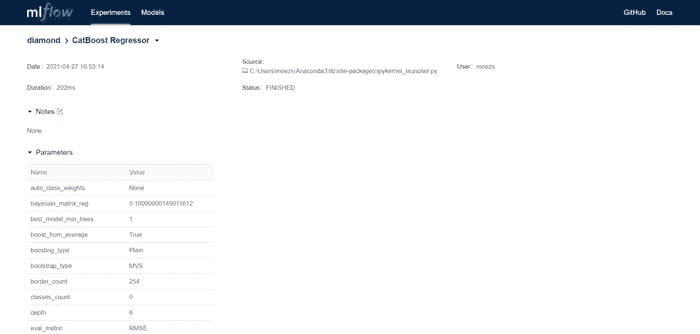
第一部分 — CatBoost 回归器
第二部分 — CatBoost 回归器(续)
第三部分 — CatBoost 回归器
注意你有一个logged_model的地址路径。这是使用 Catboost 回归器训练的 Pipeline。你可以使用load_model函数读取这个 Pipeline。
**# load model**
from pycaret.regression import load_model
pipeline = load_model('C:/Users/moezs/mlruns/1/b8c10d259b294b28a3e233a9d2c209c0/artifacts/model/model')**# print pipeline** print(pipeline)

print(pipeline)的输出
现在让我们使用这个 Pipeline 对新数据进行预测
**# create a copy of data and drop Price** data2 = data.copy()
data2.drop('Price', axis=1, inplace=True)**# generate predictions** from pycaret.regression import predict_model
predictions = predict_model(pipeline, data=data2)
predictions.head()
从管道生成的预测
哇哦!我们现在从训练好的管道中获得了推断。如果这是你的第一次,恭喜你。请注意,所有的转换,如目标转换、独热编码、缺失值填充等,都是在后台自动完成的。你将得到一个包含实际规模预测的数据框,这才是你关心的。

作者提供的图像

作者提供的图像
使用这个轻量级的工作流自动化库在 Python 中没有什么限制。如果你觉得有用,请不要忘记在我们的 GitHub 仓库中给我们 ⭐️。
想了解更多关于 PyCaret 的信息,请关注我们的 LinkedIn 和 Youtube。
加入我们的 Slack 频道。邀请链接 在这里。
你可能还会感兴趣:
在 Power BI 中使用 PyCaret 2.0 构建自己的 AutoML
在 Google Kubernetes Engine 上部署机器学习管道
使用 AWS Fargate 无服务器部署 PyCaret 和 Streamlit 应用
使用 PyCaret 和 Streamlit 构建并部署机器学习网页应用
在 GKE 上部署使用 Streamlit 和 PyCaret 构建的机器学习应用
重要链接
安装 PyCaret Notebook 教程 为 PyCaret 做贡献
想了解某个特定模块?
点击下面的链接查看文档和工作示例。
结束
简介: Moez Ali 是数据科学家,也是 PyCaret 的创始人和作者。
原文. 经许可转载。
相关内容:
-
使用 PyCaret 和 MLflow 的简单 MLOps
-
使用 PyCaret 编写和训练自定义机器学习模型
-
你不知道的 PyCaret 的 5 件事
更多相关内容
使用 PyCaret 的新时间序列模块
原文:
www.kdnuggets.com/2021/12/pycaret-new-time-series-module.html
评论
作者及创始人 Moez Ali
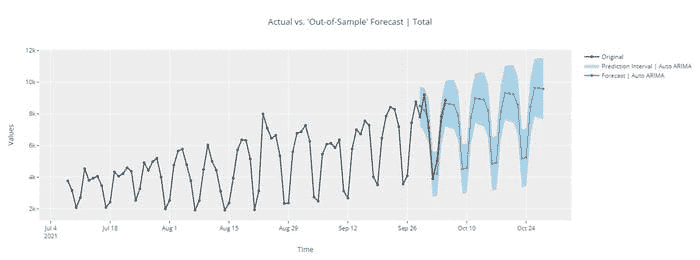
(图像来自作者) PyCaret 新时间序列模块
???? 介绍
PyCaret 是一个开源的低代码机器学习库,能够自动化机器学习工作流。它是一个端到端的机器学习和模型管理工具,能显著加快实验周期,提高你的生产力。
与其他开源机器学习库相比,PyCaret 是一个低代码替代库,它可以用几行代码替代数百行代码。这使得实验变得快速且高效。PyCaret 本质上是多个机器学习库和框架(如 scikit-learn、XGBoost、LightGBM、CatBoost、spaCy、Optuna、Hyperopt、Ray 等)的 Python 封装。
PyCaret 的设计和简洁性受到了“公民数据科学家”这一新兴角色的启发,这一术语首次由 Gartner 提出。公民数据科学家是能够执行简单和中等复杂分析任务的高级用户,这些任务以前需要更多的技术专长。
⏰ PyCaret 时间序列模块
PyCaret 的新时间序列模块现已处于 beta 阶段。保持 PyCaret 的简洁性,它与现有 API 一致,并具有许多功能。包括统计测试、模型训练与选择(30+ 算法)、模型分析、自动化超参数调优、实验记录、云部署等。所有这些功能仅需少量代码(就像 pycaret 的其他模块一样)。如果你想尝试,可以查看官方的 快速入门 笔记本。
你可以使用 pip 安装这个库。如果你在同一环境中安装了 PyCaret,你必须为 pycaret-ts-alpha 创建一个单独的环境,因为存在依赖冲突。pycaret-ts-alpha 将在下一个主要版本中与主 pycaret 包合并。
pip install pycaret-ts-alpha
➡️ 示例工作流
PyCaret 的时间序列模块工作流程非常简单。它从 setup 函数开始,在这里你定义预测范围 fh 和折叠数 folds。你还可以将 fold_strategy 定义为 expanding 或 sliding。
在设置完成后,著名的 compare_models 函数会训练和评估 30+ 种算法,从 ARIMA 到 XGboost(TBATS、FBProphet、ETS 等)。
plot_model 函数可以在训练前或训练后使用。在训练前使用时,它提供了一系列时间序列 EDA 图表,使用 plotly 接口。当与模型一起使用时,plot_model 对模型残差进行处理,并可用于评估模型拟合情况。
最后,predict_model 用于生成预测。
???? 加载数据
import pandas as pd
from pycaret.datasets import get_data
data = get_data('pycaret_downloads')
data['Date'] = pd.to_datetime(data['Date'])
data = data.groupby('Date').sum()
data = data.asfreq('D')
data.head()
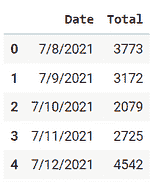
(图像来自作者)
# plot the data
data.plot()

(图像来自作者)‘pycaret_downloads’的时间序列图
这个时间序列是 PyCaret 库从 pip 每日下载次数的数据。
⚙️ 初始化设置
**# with functional API** from pycaret.time_series import *
setup(data, fh = 7, fold = 3, session_id = 123)**# with new object-oriented API** from pycaret.internal.pycaret_experiment import TimeSeriesExperiment
exp = TimeSeriesExperiment()
exp.setup(data, fh = 7, fold = 3, session_id = 123)

(图像来自作者)setup 函数的输出
???? 统计测试
check_stats()
(图像来自作者)check_stats 函数的输出
???? 探索性数据分析
**# functional API**
plot_model(plot = 'ts')**# object-oriented API** exp.plot_model(plot = 'ts')
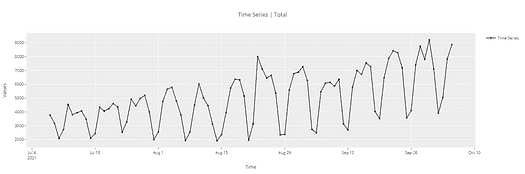
(图像来自作者)
**# cross-validation plot** plot_model(plot = 'cv')
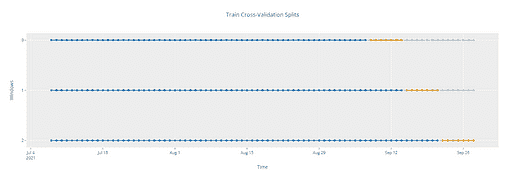
(图像来自作者)
**# ACF plot** plot_model(plot = 'acf')
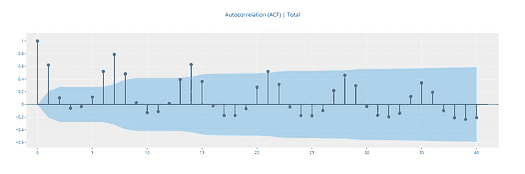
**# Diagnostics plot** plot_model(plot = 'diagnostics')
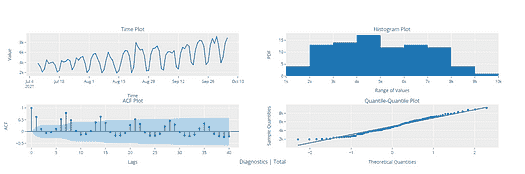
**# Decomposition plot**
plot_model(plot = 'decomp_stl')
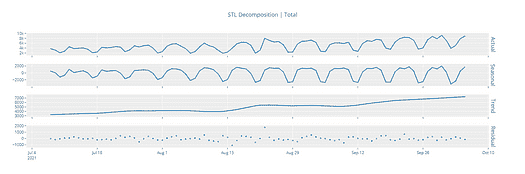
✈️ 模型训练与选择
**# functional API** best = compare_models()**# object-oriented API** best = exp.compare_models()
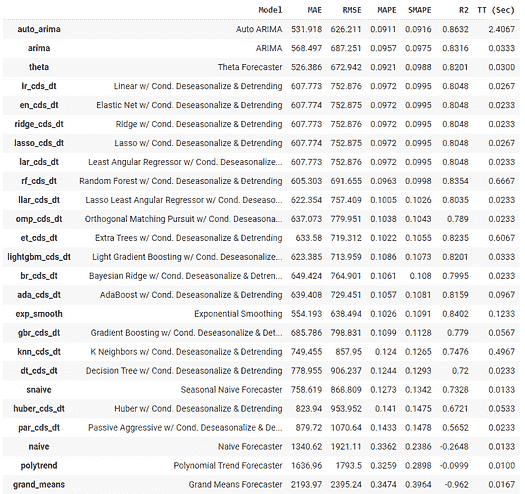
(图像来自作者)compare_models 函数的输出
create_model 在时间序列模块中的工作方式与在其他模块中的工作方式完全相同。
**# create fbprophet model** prophet = create_model('prophet')
print(prophet)
(图像来自作者)create_model 函数的输出

(图像来自作者)打印函数的输出
tune_model 也没有太大区别。
tuned_prophet = tune_model(prophet)
print(tuned_prophet)
(图像来自作者)tune_model 函数的输出

(图像来自作者)打印函数的输出
plot_model(best, plot = 'forecast')
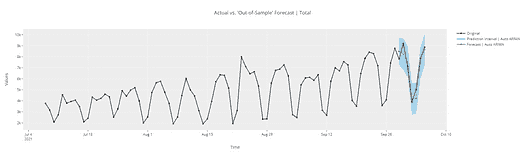
(图像来自作者)
**# forecast in unknown future** plot_model(best, plot = 'forecast', data_kwargs = {'fh' : 30})
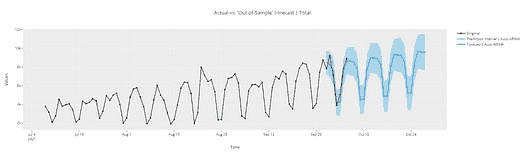
(图像来自作者)
# in-sample plot
plot_model(best, plot = 'insample')
# residuals plot
plot_model(best, plot = 'residuals')
# diagnostics plot
plot_model(best, plot = 'diagnostics')
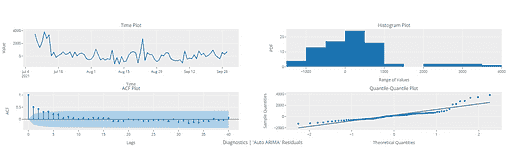
???? 部署
**# finalize model** final_best = finalize_model(best)**# generate predictions** predict_model(final_best, fh = 90)
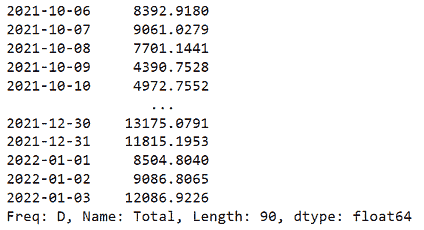
(图像来自作者)
**# save the model** save_model(final_best, 'my_best_model')

(图像来自作者)
该模块仍处于 beta 版。我们每天都在添加新功能,并进行每周的 pip 发布。请确保创建一个独立的 Python 环境,以避免与主 pycaret 的依赖冲突。该模块的最终版本将与下一次主要版本的 pycaret 合并。
???? 时间序列文档
???? 功能与路线图
开发人员:
Nikhil Gupta (主讲), Antoni Baum Satya Pattnaik Miguel Trejo Marrufo Krishnan S G
使用这个轻量级的 Python 工作流自动化库,你可以实现无限可能。如果你觉得有用,请不要忘记在我们的 GitHub 仓库上给我们 ⭐️。
想了解更多关于 PyCaret 的信息,请关注我们 LinkedIn 和 Youtube。
加入我们的 Slack 频道。邀请链接 这里。
重要链接
⭐ 教程 新手入门 PyCaret?查看我们的官方笔记本!
???? 示例笔记本 由社区创建。
???? 博客 贡献者的教程和文章。
???? 文档 PyCaret 的详细 API 文档
???? 视频教程 我们的各类活动视频教程。
???? 讨论区 有问题?与社区和贡献者互动。
????️ 更新日志 变更和版本历史。
???? 路线图 PyCaret 的软件和社区发展计划。
个人简介:Moez Ali 讨论 PyCaret 及其实际应用。如果你希望自动接收通知,可以在 Medium、LinkedIn 和 Twitter 上关注 Moez。
原文。经允许转载。
相关:
-
多变量时间序列分析与基于 LSTM 的 RNN
-
PyCaret 2.3.5 新版发布!了解新功能
-
前 5 大时间序列方法
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
更多相关主题
使用 PyCaret 预测客户流失(正确的方法)
原文:
www.kdnuggets.com/2021/07/pycaret-predict-customer-churn-right-way.html
评论
由 Moez Ali,PyCaret 的创始人和作者
使用 PyCaret 预测客户流失(正确的方法) — 图片由作者提供
介绍
客户留存是采用订阅制商业模式的公司主要的关键绩效指标之一。竞争尤其在 SaaS 市场中非常激烈,因为客户可以从众多供应商中自由选择。一旦发生糟糕的体验,客户可能会转向竞争对手,从而导致客户流失。
什么是客户流失?
客户流失是指在某个时间范围内停止使用贵公司产品或服务的客户百分比。计算流失率的一种方法是将某个时间间隔内流失的客户数量除以该时间段开始时的活跃客户数量。例如,如果你有 1000 个客户,上个月流失了 50 个,那么你的月流失率就是 5%。
预测客户流失是一个具有挑战性但极其重要的业务问题,尤其是在客户获取成本(CAC)较高的行业,如技术、电信、金融等。预测某个客户面临高流失风险的能力,同时还有时间采取措施,代表了公司一个巨大的潜在收入来源。
客户流失机器学习模型在实践中如何使用?
客户流失预测模型的主要目标是通过主动与客户互动来留住那些流失风险最高的客户。例如:提供礼品券或任何促销价格,并将他们锁定一年或两年,以延长他们对公司的终身价值。
这里有两个广泛的概念需要理解:
-
我们希望客户流失预测模型能提前预测流失(例如,提前一个月、三个月或甚至六个月——这取决于具体用例)。这意味着你必须非常小心截止日期,即你不应在机器学习模型中使用截止日期之后的信息作为特征,否则会出现数据泄露。截止日期之前的时间段称为事件。
-
通常,对于客户流失预测,你需要花一些时间创建一个目标列,它通常不会以你希望的形式存在。例如,你想预测客户是否会在下一个季度流失,因此你需要遍历事件截止日期时的所有活跃客户,并检查他们是否在下一个季度离开了公司(1 表示是,0 表示否)。在这种情况下,季度被称为绩效窗口。
如何创建客户流失数据集 — 作者提供的图片
客户流失模型工作流程
现在你已经理解了数据来源和流失目标的创建(这是问题中最具挑战性的部分之一),让我们讨论一下这个机器学习模型将在业务中如何使用。请从左到右阅读下图:
-
模型在客户流失历史上进行训练(X 特征的事件期和目标变量的性能窗口)。
-
每个月,活跃的客户基础会被传递给机器学习预测模型,以返回每个客户的流失概率(在商业术语中,这有时称为流失评分)。
-
列表将按从最高到最低的概率值(或称为评分)进行排序,客户保留团队将开始与客户互动以防止流失,通常是通过提供某种促销或礼品卡来锁定更多的年份。
-
流失概率非常低的客户(或模型预测为无流失)是满意的客户。对此不会采取任何行动。
客户流失模型工作流程 — 作者提供的图片
让我们开始一个实际的例子
在本节中,我将展示机器学习模型训练与选择、超参数调优、结果分析和解释的完整端到端工作流程。我还将讨论可以优化的指标以及为什么像 AUC、准确率、召回率等传统指标可能不适合客户流失模型。我将使用PyCaret——一个开源的低代码机器学习库来进行此实验。本教程假设你对 PyCaret 有基本了解。
PyCaret
PyCaret 是一个开源的低代码机器学习库和端到端模型管理工具,基于 Python 构建,用于自动化机器学习工作流程。PyCaret 因其易用性、简洁性和快速高效地构建和部署端到端机器学习管道的能力而闻名。要了解更多关于 PyCaret 的信息,请查看他们的 GitHub。
PyCaret 的特点 — 作者提供的图片
安装 PyCaret
**# install pycaret** pip install pycaret
????数据集
对于本教程,我使用的是来自 Kaggle 的电信客户流失数据集。数据集中已经包含了我们可以直接使用的目标列。你可以直接从这个GitHub链接读取这个数据集。(特别鸣谢 srees1988)
**# import libraries**
import pandas as pd
import numpy as np**# read csv data** data **=** pd.read_csv('[`raw.githubusercontent.com/srees1988/predict-churn-py/main/customer_churn_data.csv'`](https://raw.githubusercontent.com/srees1988/predict-churn-py/main/customer_churn_data.csv'))
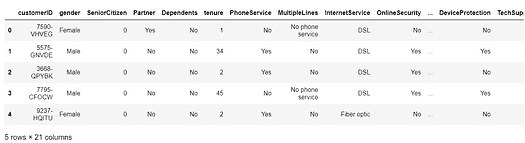
示例数据集 — 作者提供的图片
???? 探索性数据分析
**# check data types** data.dtypes
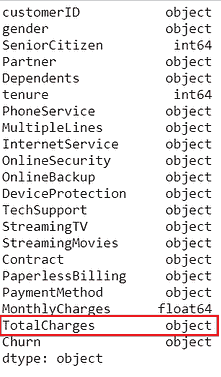
数据类型 — 作者提供的图片
注意到 TotalCharges 是 object 类型而不是 float64。经过调查,我发现这一列中有一些空格,这导致 Python 强制将数据类型设为 object。要解决这个问题,我们需要在更改数据类型之前修剪空格。
**# replace blanks with np.nan**
data['TotalCharges'] = data['TotalCharges'].replace(' ', np.nan)**# convert to float64**
data['TotalCharges'] = data['TotalCharges'].astype('float64')
直观上,合同类型、合同期限(客户的停留时间)和定价计划在客户流失或留存方面是非常重要的信息。让我们探索一下它们之间的关系:
gist.github.com/moezali1/2624c9a5eaf78d9a7ffa1b97195a4812
根据合同期限、费用和合同类型的客户流失(图片由作者提供)
注意到大部分流失现象出现在“按月合同”中。这很有道理。此外,我还发现随着合同期限的增加和总费用的增加,拥有高期限和低费用的客户的可能性相较于拥有高期限和高费用的客户要低。
缺失值
**# check missing values** data.isnull().sum()
缺失值 — 图片由作者提供
注意到由于我们用 np.nan 替换了空白值,现在 TotalCharges 中有 11 行缺失值。没问题 — 我会让 PyCaret 自动进行填补。
????数据准备
在 PyCaret 的所有模块中,setup 是任何机器学习实验中第一个也是唯一一个强制性的步骤。这个函数处理了模型训练前所需的所有数据准备工作。除了执行一些基本的默认处理任务外,PyCaret 还提供了广泛的数据预处理功能。要了解 PyCaret 中所有预处理功能的更多信息,可以查看这个链接。
**# init setup**
from pycaret.classification import *
s = setup(data, target = 'Churn', ignore_features = ['customerID'])
pycaret.classification 中的 setup 函数 — 图片由作者提供
每当你在 PyCaret 中初始化 setup 函数时,它会对数据集进行分析并推断所有输入特征的数据类型。在这种情况下,你可以看到除了 tenure、MonthlyCharges 和 TotalCharges,其他所有特征都是类别型的,这样是正确的,你现在可以按回车键继续。如果数据类型推断不正确(这有时会发生),你可以使用 numeric_feature 和 categorical_feature 来覆盖数据类型。
同样注意到,我在 setup 函数中传递了 ignore_features = ['customerID'],这样在训练模型时它将不会被考虑。这样做的好处是 PyCaret 不会从数据集中删除该列,它只是会在模型训练时在后台忽略它。因此,当你最终生成预测时,你不需要担心自己再将 ID 重新合并回来。
setup 函数的输出 — 为了显示而截断 — 图片由作者提供
???? 模型训练与选择
数据准备完成后,让我们通过使用compare_models功能开始训练过程。该功能训练模型库中所有可用的算法,并使用交叉验证评估多个性能指标。
**# compare all models**
best_model = compare_models(sort='AUC')
compare_models 的输出 — 作者提供的图片
基于AUC的最佳模型是Gradient Boosting Classifier。使用 10 折交叉验证的 AUC 为 0.8472。
**# print best_model parameters**
print(best_model)

最佳模型参数 — 作者提供的图片
超参数调优
你可以使用 PyCaret 中的tune_model函数来自动调优模型的超参数。
**# tune best model**
tuned_best_model = tune_model(best_model)
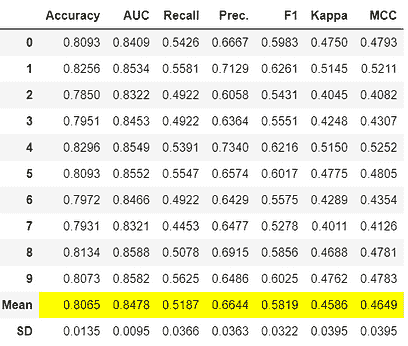
tune_model 结果 — 作者提供的图片
请注意,AUC 从0.8472略微增加到0.8478。
模型分析
**# AUC Plot**
plot_model(tuned_best_model, plot = 'auc')
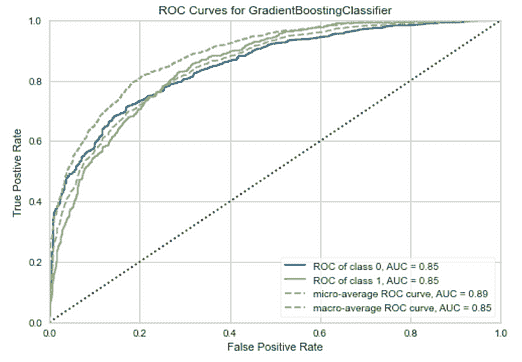
AUC 图 — 作者提供的图片
**# Feature Importance Plot**
plot_model(tuned_gbc, plot = 'feature')
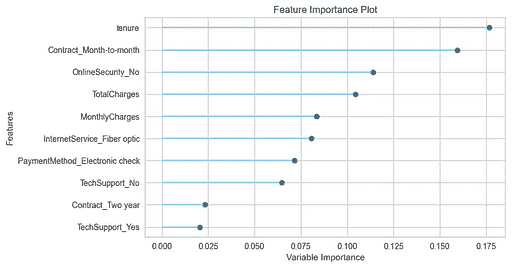
特征重要性图 — 作者提供的图片
**# Confusion Matrix**
plot_model(tuned_best_model, plot = 'confusion_matrix')
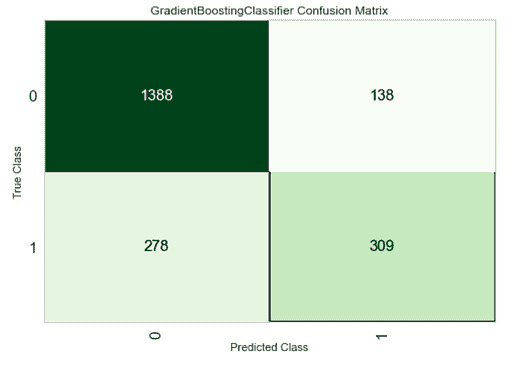
混淆矩阵梯度提升分类器 — 作者提供的图片
这个混淆矩阵是在测试集上生成的,其中包含我们数据的 30%(2,113 行)。我们有 309 个真正例(15%)——这些客户我们将能够延长生命周期价值。如果我们没有做出预测,那么就没有干预的机会。
我们还有 138 个(7%)假正例,因为向这些客户提供的促销只是额外的成本,我们将因此亏损。
1,388 个(66%)是真正负例(优质客户),278 个(13%)是假负例(这是一个错失的机会)。
到目前为止,我们已经训练了多个模型以选择 AUC 最高的最佳模型,然后调优该模型的超参数,以在 AUC 方面挤出更多的性能。然而,最佳 AUC 不一定能转化为最佳的商业模型。
在流失模型中,真正例的奖励通常与假正例的成本大相径庭。我们使用以下假设:
-
$1,000 的优惠券将提供给所有被识别为流失(真正例 + 假正例)的客户;
-
如果我们能够阻止客户流失,我们将获得$5,000 的客户生命周期价值。
使用这些假设和上述混淆矩阵,我们可以计算该模型的$影响:

$ 模型对 2,113 名客户的影响 — 作者提供的图片
这是一个不错的模型,但问题在于它不是一个商业智能模型。与没有模型相比,它的表现相当不错,但我们如何训练和选择一个能够最大化商业价值的模型呢?为了实现这一点,我们必须使用商业指标而非传统指标如 AUC 或准确率来训练、选择和优化模型。
???? 在 PyCaret 中添加自定义指标
多亏了 PyCaret,使用 add_metric 函数实现这一点变得极其简单。
**# create a custom function** def calculate_profit(y, y_pred):
tp = np.where((y_pred==1) & (y==1), (5000-1000), 0)
fp = np.where((y_pred==1) & (y==0), -1000, 0)
return np.sum([tp,fp])**# add metric to PyCaret** add_metric('profit', 'Profit', calculate_profit)
现在让我们运行 compare_models 看看魔法。
**# compare all models**
best_model = compare_models(sort='Profit')
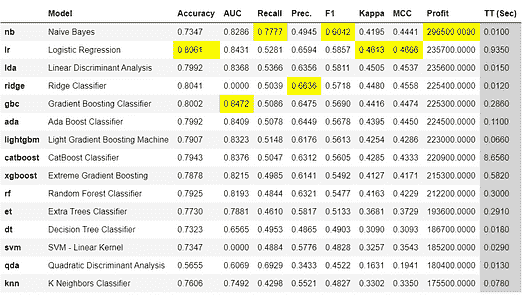
compare_models 输出 — 图片由作者提供
注意这次新增了一个列 Profit,令人惊讶的是,虽然朴素贝叶斯在 AUC 方面表现较差,但在利润方面却是最佳模型。我们来看看原因:
**# confusion matrix**
plot_model(best_model, plot = 'confusion_matrix')
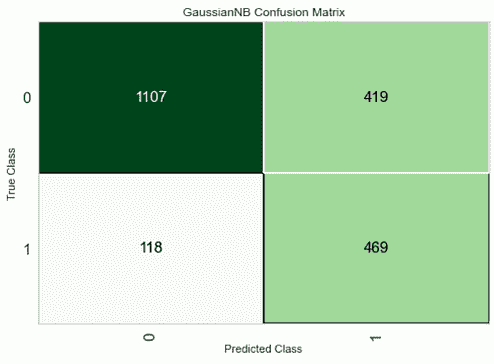
混淆矩阵 朴素贝叶斯 — 图片由作者提供
总客户数量仍然相同(测试集中的 2,113 位客户),变化的是模型在假阳性和假阴性上的错误情况。让我们使用相同的假设(如上所述)来为其添加一些 $ 价值:

$ 模型对 2,113 位客户的影响 — 图片由作者提供
哇!* 我们刚刚用一个 AUC 比最佳模型少 2% 的模型增加了大约 $400,000 的利润。这是怎么发生的?首先,AUC 或任何其他现成的分类指标(准确率、召回率、精确度、F1、Kappa 等)并不是一个商业智能指标,因此没有考虑风险和回报。添加自定义指标并将其用于模型选择或优化是一个很好的主意,也是正确的做法。*
我希望你会欣赏 PyCaret 的简洁和易用性。仅需几行代码,我们就能训练多个模型,并选择对业务最重要的模型。我是一名常规博主,主要写关于 PyCaret 及其在实际应用中的用例。如果你希望自动接收通知,可以关注我的 Medium、 LinkedIn 和 Twitter。

PyCaret — 图片由作者提供

PyCaret — 图片由作者提供
使用这个轻量级的 Python 工作流自动化库,你可以实现无限的可能。如果你觉得这有用,请不要忘记在我们的 GitHub 仓库上给我们 ⭐️。
想要了解更多关于 PyCaret 的信息,请关注我们的 LinkedIn 和 YouTube。
加入我们的 Slack 频道。邀请链接 在这里。
重要链接
更多 PyCaret 相关教程:
一个逐步教程,讲解如何在 Alteryx Designer 中使用 PyCaret 训练和部署机器学习模型
一个逐步指南,讲解如何在 KNIME 中使用 PyCaret 训练和部署端到端的机器学习管道
一个适合初学者的逐步教程,讲解如何在机器学习实验中集成 MLOps,使用 PyCaret
一个适合初学者的逐步教程,讲解如何使用 PyCaret 构建端到端的机器学习管道……
一个逐步教程,讲解如何使用 PyCaret 对时间序列数据进行无监督异常检测
一个逐步教程,快速开发和互动机器学习管道
使用 PyCaret 进行多时间序列预测的逐步教程
简介:Moez Ali 是一名数据科学家,也是 PyCaret 的创始人兼作者。
原文。经许可转载。
相关:
-
PyCaret 101:初学者介绍
-
5 个你不知道的 PyCaret 相关内容
-
客户流失预测:全球性能研究
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 部门
了解更多这个话题
使用 PyCaret 编写和训练你自己的自定义机器学习模型
原文:
www.kdnuggets.com/2021/05/pycaret-write-train-custom-machine-learning-models.html
评论
作者 Moez Ali,PyCaret 创始人兼作者

由 Rob Lambert 在 Unsplash 提供的照片
PyCaret
PyCaret 是一个开源的低代码机器学习库和端到端模型管理工具,构建于 Python 上,用于自动化机器学习工作流。它因易用性、简洁性以及能够快速高效地构建和部署端到端 ML 原型而受到极大的欢迎。
PyCaret 是一个替代性的低代码库,可以用几行代码替代数百行代码。这使得实验周期显著加快且高效。
PyCaret 简单且 易于使用。PyCaret 中执行的所有操作都依次存储在一个 Pipeline 中,该 Pipeline 完全自动化以 进行部署。无论是填补缺失值、进行独热编码、转换分类数据、特征工程,还是超参数调优,PyCaret 都会自动完成所有这些操作。
本教程假设你对 PyCaret 有一定的知识和经验。如果你以前没有使用过 PyCaret,也没关系——你可以通过这些教程快速入门:
安装 PyCaret
安装 PyCaret 非常简单,只需几分钟即可完成。我们强烈建议使用虚拟环境,以避免与其他库潜在的冲突。
PyCaret 的默认安装是 pycaret 的精简版,只安装了硬性依赖项,列在这里。
**# install slim version (default)** pip install pycaret**# install the full version**
pip install pycaret[full]
当你安装完整版本的 pycaret 时,所有的可选依赖项也会被安装,列在这里。
???? 让我们开始吧
在我们开始讨论自定义模型训练之前,让我们先快速演示一下 PyCaret 如何与开箱即用的模型一起工作。我将使用 PyCaret 的仓库 中的“insurance”数据集。该数据集的目标是根据一些属性预测患者费用。
???? 数据集
**# read data from pycaret repo** from pycaret.datasets import get_data
data = get_data('insurance')
来自保险数据集的示例行
???? 数据准备
在 PyCaret 的所有模块中,setup 是任何 PyCaret 机器学习实验中第一个也是唯一的强制步骤。此函数处理所有训练模型前所需的数据准备工作。除了执行一些基本的默认处理任务外,PyCaret 还提供了各种预处理功能。要了解 PyCaret 中所有预处理功能的更多信息,你可以查看这个 链接。
**# initialize setup** from pycaret.regression import *
s = setup(data, target = 'charges')
pycaret.regression 模块中的 setup 函数
每当你初始化 PyCaret 中的 setup 函数时,它会对数据集进行分析,并推断所有输入特征的数据类型。如果所有数据类型都被正确推断,你可以按回车键继续。
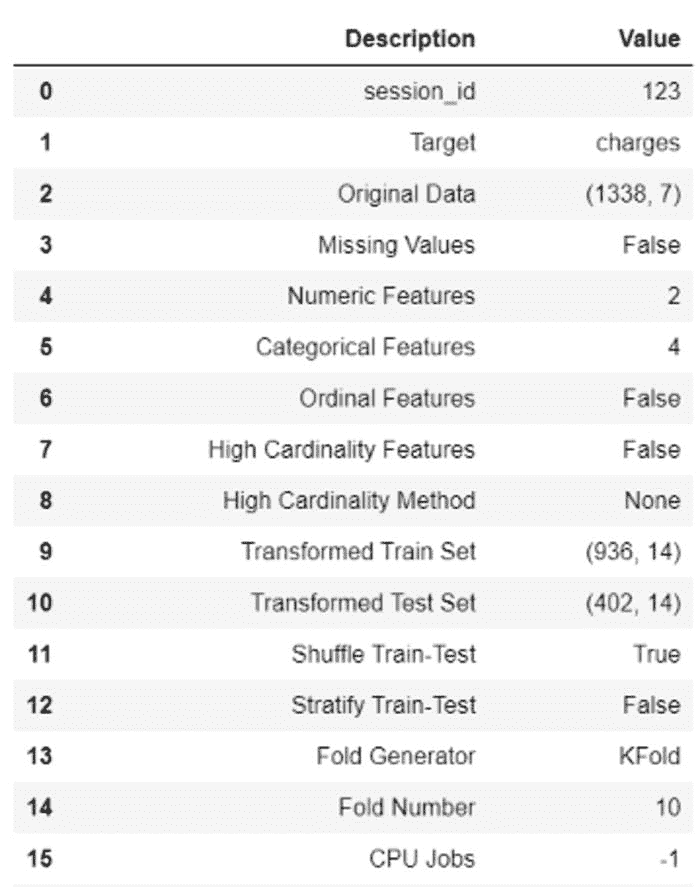
从 setup 输出 — 输出已截断以便展示
???? 可用模型
要检查所有可用训练模型的列表,你可以使用名为 models 的函数。它会显示一个包含模型 ID、名称和实际估计器参考的表格。
**# check all the available models** models()
从 models() 输出 — 输出已截断以便展示
???? 模型训练与选择
PyCaret 中用于训练任何模型的最常用函数是 create_model。它接受一个你想要训练的估计器的 ID。
**# train decision tree** dt = create_model('dt')
从 create_model('dt') 输出
输出显示了 10 折交叉验证指标的均值和标准差。此函数的输出是一个训练后的模型对象,实际上是一个 scikit-learn 对象。
print(dt)

从 print(dt) 输出
要在循环中训练多个模型,你可以编写一个简单的列表推导式:
**# train multiple models**
multiple_models = [create_model(i) for i in ['dt', 'lr', 'xgboost']]**# check multiple_models** type(multiple_models), len(multiple_models)
>>> (list, 3)print(multiple_models)
从 print(multiple_models) 输出
如果你想训练库中所有可用的模型而不是仅仅几个选择的模型,可以使用 PyCaret 的 compare_models 函数,而不是编写自己的循环(不过结果会是一样的)。
**# compare all models**
best_model = compare_models()
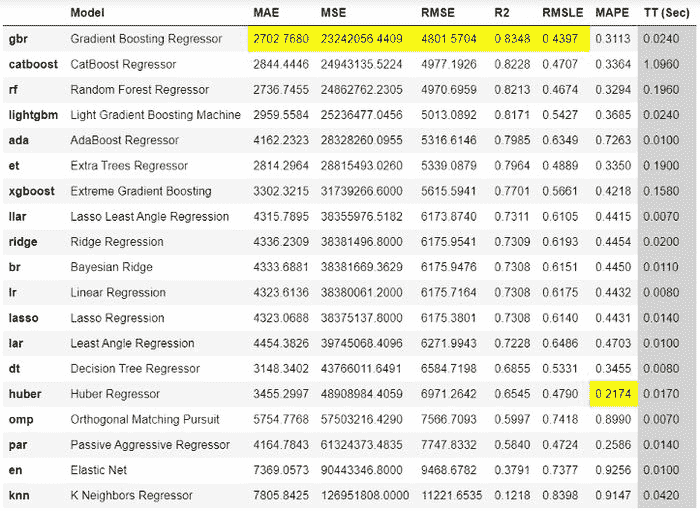
从 compare_models 函数输出
compare_models 返回的输出显示了所有模型的交叉验证指标。根据此输出,梯度提升回归器是最好的模型,使用 10 折交叉验证在训练集上的均值绝对误差(MAE)为 $2,702。
**# check the best model**
print(best_model)

从 print(best_model) 输出
上述网格中显示的指标是交叉验证得分,要查看 best_model 在保留集上的得分:
**# predict on hold-out** pred_holdout = predict_model(best_model)

从 predict_model(best_model) 函数输出
要在未见数据集上生成预测,你可以使用相同的 predict_model 函数,但只需传递额外的参数 data:
**# create copy of data drop target column**
data2 = data.copy()
data2.drop('charges', axis=1, inplace=True)**# generate predictions** predictions = predict_model(best_model, data = data2)
从 predict_model(best_model, data = data2) 输出
???? 编写和训练自定义模型
到目前为止,我们看到的是在 PyCaret 中对所有可用模型的训练和模型选择。然而,PyCaret 对自定义模型的处理方式完全相同。只要你的估计器兼容 sklearn API 风格,它将以相同的方式工作。让我们看几个例子。
在我展示如何编写自定义类之前,我将首先演示如何处理自定义非-sklearn 模型(在 sklearn 或 pycaret 的基础库中不可用的模型)。
???? GPLearn 模型
虽然遗传编程(GP)可以用于执行各种任务,gplearn 特意限制于解决符号回归问题。
符号回归是一种机器学习技术,旨在识别最能描述关系的潜在数学表达式。它首先通过构建一组天真的随机公式来表示已知自变量与其因变量目标之间的关系,以预测新数据。然后,每一代程序从前一代中进化,选择适应度最好的个体进行遗传操作。
要使用 gplearn 的模型,你必须首先安装它:
**# install gplearn** pip install gplearn
现在你可以简单地导入未训练的模型,并将其传递给 create_model 函数:
**# import untrained estimator**
from gplearn.genetic import SymbolicRegressor
sc = SymbolicRegressor()**# train using create_model** sc_trained = create_model(sc)
从 create_model(sc_trained) 的输出
print(sc_trained)

从 print(sc_trained) 的输出
你也可以检查这一点的持出评分:
**# check hold-out score** pred_holdout_sc = predict_model(sc_trained)

从 predict_model(sc_trained) 的输出
???? NGBoost 模型
ngboost 是一个 Python 库,实现了自然梯度提升,如 “NGBoost: Natural Gradient Boosting for Probabilistic Prediction” 中所述。它构建在 Scikit-Learn 之上,旨在根据适当的评分规则、分布和基础学习器的选择具有可扩展性和模块化。关于 NGBoost 基础方法的教学介绍可以在这个 幻灯片文档 中找到。
要使用 ngboost 的模型,你必须首先安装 ngboost:
**# install ngboost**
pip install ngboost
安装完成后,你可以从 ngboost 库中导入未训练的估计器,并使用 create_model 来训练和评估模型:
**# import untrained estimator**
from ngboost import NGBRegressor
ng = NGBRegressor()**# train using create_model** ng_trained = create_model(ng)
从 create_model(ng) 的输出
print(ng_trained)
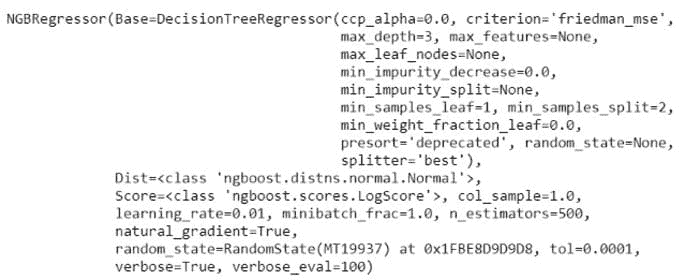
从 print(ng_trained) 的输出
???? 编写自定义类
上述两个示例 gplearn 和 ngboost 是 PyCaret 的自定义模型,因为它们在默认库中不可用,但您可以像使用任何其他现成模型一样使用它们。然而,可能会有一种使用案例涉及编写自己的算法(即算法背后的数学),在这种情况下,您可以从 sklearn 继承基类并编写自己的数学。
让我们创建一个朴素的估算器,它在 fit 阶段学习 target 变量的均值,并对所有新数据点预测相同的均值,不论 X 输入如何(这在现实生活中可能没有用,但只是为了演示功能)。
**# create custom estimator**
import numpy as npfrom sklearn.base import BaseEstimatorclass MyOwnModel(BaseEstimator):
def __init__(self):
self.mean = 0
def fit(self, X, y):
self.mean = y.mean()
return self
def predict(self, X):
return np.array(X.shape[0]*[self.mean])
现在让我们使用这个估算器进行训练:
**# import MyOwnModel class**
mom = MyOwnModel()**# train using create_model** mom_trained = create_model(mom)
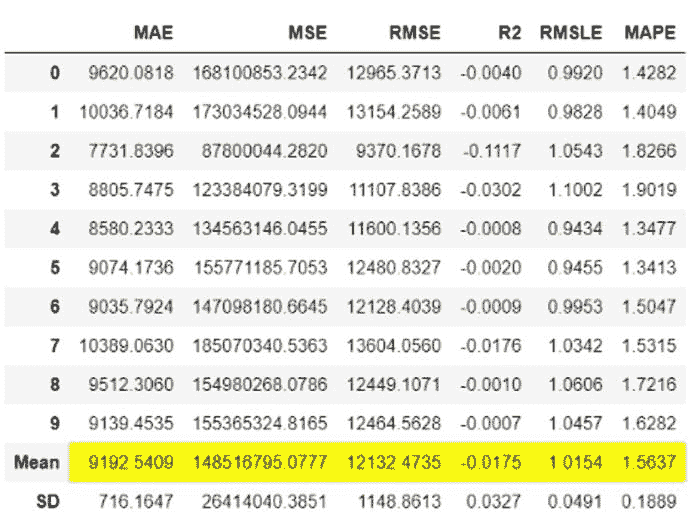
来自 create_model(mom) 的输出
**# generate predictions on data**
predictions = predict_model(mom_trained, data=data)
来自 predict_model(mom, data=data) 的输出
注意到 Label 列,即预测值,对于所有行来说都是相同的数字 $13,225,这因为我们以这样的方式创建了这个算法:它从训练集的均值中学习,并预测相同的值(只是为了简单起见)。
我希望您会欣赏 PyCaret 的易用性和简洁性。仅需几行代码,您就可以进行端到端的机器学习实验,并编写自己的算法,而无需调整任何原生代码。
敬请期待!
下周我将编写一个教程来推进这个教程。我们将编写一个更复杂的算法,而不仅仅是均值预测。我将在下一个教程中介绍一些复杂的概念。请关注我在 Medium、LinkedIn 和 Twitter 的更新。
使用这个轻量级的 Python 工作流自动化库,您可以实现无限的目标。如果您觉得有用,请不要忘记在我们的 GitHub 仓库上给我们 ⭐️。
想了解更多关于 PyCaret 的信息,请关注我们的 LinkedIn 和 Youtube。
加入我们的 Slack 频道。邀请链接 在这里。
您可能还会感兴趣:
在 Power BI 中使用 PyCaret 2.0 构建您自己的 AutoML
在 Google Kubernetes Engine 上部署机器学习管道
使用 AWS Fargate 无服务器架构部署 PyCaret 和 Streamlit 应用
使用 PyCaret 和 Streamlit 构建并部署机器学习 web 应用
在 GKE 上部署使用 Streamlit 和 PyCaret 构建的机器学习应用
重要链接
安装 PyCaret 笔记本教程 为 PyCaret 做贡献
想了解某个特定模块?
点击下面的链接查看文档和实际示例。
简介: Moez Ali 是一名数据科学家,也是 PyCaret 的创始人和作者。
原文。经授权转载。
相关:
-
使用 PyCaret + MLflow 进行简单的 MLOps
-
GitHub 是你所需的最佳 AutoML
-
使用 Docker 容器将机器学习管道部署到云端
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关内容
PyCharm 针对数据科学家的功能
评论
由迪利普·库马尔,Target 的首席工程师
我最近开始使用 PyCharm 作为 Spyder 的替代品,非常喜欢它。本文讨论了一些 PyCharm 的功能,这些功能使我完全从 Spyder 转移到 PyCharm。以下功能是与 Spyder 的比较,而非通用 IDE。
PyCharm 配备了美丽的‘Dracula’主题
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
-
终端:你可以在 IDE 中获得一个 shell 脚本,这有助于轻松访问多个功能,例如从命令行测试你的脚本、从 gs/aws 下载数据文件、git 交互。
-
Git:谈到 git,PyCharm 提供了 git 集成。从 IDE 中,你可以添加需要加入 gitignore 的文件、添加和提交。你可以随时查看你所在的分支、哪些文件处于修改、添加、提交状态(根据项目视图中的颜色)等。我提到过我们可以直接从 IDE 内部的终端进行 git push 吗?
-
版本控制:你可以在 IDE 内部查看你的 git 变更日志。你还可以将你的文件与最新的 git 提交文件进行比较,以查看你的更改。
-
插件:PyCharm 还提供了许多插件来支持非 Python 文件。因此,当你处理配置文件(如 yaml/json/ini)、shell 脚本或 sql/html/css 文件时,IDE 知道预期的格式并自动进行缩进、关键词高亮等。你甚至可以使用 iPython 笔记本,尽管坦白说,它看起来有些混乱,我会选择 Jupyter 来处理笔记本。其他一些值得注意的插件包括 git、flask、vim 等。
-
项目维护:当你在处理大型项目时,有几个最佳实践需要遵循,例如创建 readme 文件、使用虚拟环境、管理需求文件等。所有这些都可以通过 PyCharm 轻松处理。你还可以很容易地进行代码重构,检查对象的依赖关系,追踪对象的源头等。
-
调试器:Spyder 中也有这个功能,但我从未在 Spyder 中使用过它。你可以创建调试点,并检查代码在这些点的行为。
-
分段运行代码:这在 Spyder 中非常自然。你选择你想运行的代码部分,然后按下 cmd+return。这在 PyCharm 中不那么直接,但也可以实现(Mac 上为 Option + Shift + E)。这在编写独立脚本时非常方便。
尽管有这些好处,但也有一些缺点:
-
内存消耗:PyCharm 消耗了我 Mac 上大约 1.5GB 的内存。这对于一个 IDE 来说似乎有点多。
-
数据可视化:对我来说,Spyder 最大的优势在于它的变量浏览器。你 可以 在 PyCharm 中可视化数据框,但与 Spyder 相比远不及。绘图也是如此。PyCharm 中的绘图渲染时间显著长于 Spyder。
-
学习曲线:我认为 Spyder 在数据科学家中受欢迎的原因在于它非常简单。你只需安装它,打开它,你就会知道它是如何工作的。然而,PyCharm 有一定的学习曲线,比如设置解释器、搞清楚如何运行选定的代码而不是整段代码等。你需要花费几个小时来真正理解和欣赏它的工作原理。
理想情况下,如果你在一个需要多个脚本互相交互的项目中工作,你绝对应该尝试 PyCharm。如果你的所有脚本都是独立的分析,Spyder(甚至更好的 - Jupyter)应该足以满足你的需求。
简介:Dileep Kumar 是 Target 的首席工程师,他在该公司实现机器学习和深度学习技术,致力于推荐系统、图像数据、社交图分析和文本数据。
原文。经许可转载。
相关:
-
这里是最受欢迎的 Python IDE / 编辑器
-
数据科学家常犯的 10 个编码错误
-
你的机器学习代码可能很糟糕的 4 个原因
更多相关话题
Pydantic 教程:简化 Python 中的数据验证
原文:
www.kdnuggets.com/pydantic-tutorial-data-validation-in-python-made-simple

作者提供的图片
为什么使用 Pydantic?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
Python 是一种动态类型语言。因此,你可以创建变量而无需明确指定数据类型。你也可以随时将完全不同的值赋给同一个变量。虽然这使得初学者更容易上手,但也同样容易在你的 Python 应用程序中创建无效对象。
你可以创建数据类,允许定义带有类型提示的字段。但它们不直接支持数据验证。引入 Pydantic,一个流行的数据验证和序列化库。Pydantic 提供开箱即用的数据验证和序列化支持。这意味着你可以:
-
利用 Python 的类型提示来验证字段,
-
使用 Pydantic 提供的自定义字段和内置验证器,并
-
根据需要定义自定义验证器。
在本教程中,我们将建模一个简单的‘员工’类,并使用 Pydantic 的数据验证功能来验证不同字段的值。让我们开始吧!
安装 Pydantic
如果你有 Python 3.8 或更高版本,你可以使用 pip 安装 Pydantic:
$ pip install pydantic
如果你在应用程序中需要电子邮件验证,可以在安装 Pydantic 时像这样安装可选的 email-validator 依赖:
$ pip install pydantic[email]
或者,你可以运行以下命令安装 email-validator:
$ pip install email-validator
注意:在我们的示例中,我们将使用电子邮件验证。如果你希望跟随代码进行,请安装相应的依赖。
创建一个基本的 Pydantic 模型
现在让我们创建一个简单的Employee类。首先,我们创建一个继承自BaseModel类的类。各种字段和预期类型如下所示:
# main.py
from pydantic import BaseModel, EmailStr
class Employee(BaseModel):
name: str
age: int
email: EmailStr
department: str
employee_id: str
注意,我们已将电子邮件指定为 Pydantic 支持的EmailStr类型,而不是普通的 Python 字符串。这是因为所有有效的字符串可能不是有效的电子邮件。
在员工模型中验证字段
因为Employee类很简单,让我们为以下字段添加验证:
-
email:应为有效的电子邮件。指定EmailStr可以满足这个要求,我们在创建具有无效电子邮件的对象时会遇到错误。 -
employee_id:应为有效的员工 ID。我们将为该字段实现自定义验证。
实现自定义验证
在这个例子中,假设employee_id应该是一个长度为 6 的仅包含字母数字字符的字符串。
我们可以使用@validator装饰器与employee_id字段作为参数,并定义validate_employee_id方法,如下所示:
# main.py
from pydantic import BaseModel, EmailStr, validator
...
@validator("employee_id")
def validate_employee_id(cls, v):
if not v.isalnum() or len(v) != 6:
raise ValueError("Employee ID must be exactly 6 alphanumeric characters")
return v
现在,这种方法检查我们尝试创建的 Employee 对象的employee_id是否有效。
此时,你的脚本应该如下所示:
# main.py
from pydantic import BaseModel, EmailStr, validator
class Employee(BaseModel):
name: str
age: int
email: EmailStr
department: str
employee_id: str
@validator("employee_id")
def validate_employee_id(cls, v):
if not v.isalnum() or len(v) != 6:
raise ValueError("Employee ID must be exactly 6 alphanumeric characters")
return v
使用 Pydantic 模型加载和解析 JSON 数据
在实际操作中,将 API 的 JSON 响应解析为像 Python 字典这样的数据结构是非常常见的。假设我们有一个名为‘employees.json’的文件(在当前目录中),其记录如下:
# employees.json
[
{
"name": "John Doe",
"age": 30,
"email": "john.doe@example.com",
"department": "Engineering",
"employee_id": "EMP001"
},
{
"name": "Jane Smith",
"age": 25,
"email": "jane.smith@example.com",
"department": "Marketing",
"employee_id": "EMP002"
},
{
"name": "Alice Brown",
"age": 35,
"email": "invalid-email",
"department": "Finance",
"employee_id": "EMP0034"
},
{
"name": "Dave West",
"age": 40,
"email": "dave.west@example.com",
"department": "HR",
"employee_id": "EMP005"
}
]
我们可以看到,在对应于‘Alice Brown’的第三条记录中,我们有两个无效的字段:email和employee_id:
因为我们已经指定电子邮件应为EmailStr,所以电子邮件字符串将自动进行验证。我们还添加了validate_employee_id类方法来检查对象是否具有有效的员工 ID。
现在让我们添加代码来解析 JSON 文件并创建员工对象(我们将使用内置的json 模块)。我们还从 Pydantic 中导入ValidationError类。实际上,我们尝试创建对象,当数据验证失败时处理 ValidationError 异常,并打印出错误:
# main.py
import json
from pydantic import BaseModel, EmailStr, ValidationError, validator
...
# Load and parse the JSON data
with open("employees.json", "r") as f:
data = json.load(f)
# Validate each employee record
for record in data:
try:
employee = Employee(**record)
print(f"Valid employee record: {employee.name}")
except ValidationError as e:
print(f"Invalid employee record: {record['name']}")
print(f"Errors: {e.errors()}")
当你运行脚本时,你应该会看到类似的输出:
Output >>>
Valid employee record: John Doe
Valid employee record: Jane Smith
Invalid employee record: Alice Brown
Errors: [{'type': 'value_error', 'loc': ('email',), 'msg': 'value is not a valid email address: The email address is not valid. It must have exactly one @-sign.', 'input': 'invalid-email', 'ctx': {'reason': 'The email address is not valid. It must have exactly one @-sign.'}}, {'type': 'value_error', 'loc': ('employee_id',), 'msg': 'Value error, Employee ID must be exactly 6 alphanumeric characters', 'input': 'EMP0034', 'ctx': {'error': ValueError('Employee ID must be exactly 6 alphanumeric characters')}, 'url': 'https://errors.pydantic.dev/2.6/v/value_error'}]
Valid employee record: Dave West
正如预期的那样,只有对应于‘Alice Brown’的记录不是有效的员工对象。放大输出的相关部分,你可以看到关于为什么email和employee_id字段无效的详细信息。
这是完整的代码:
# main.py
import json
from pydantic import BaseModel, EmailStr, ValidationError, validator
class Employee(BaseModel):
name: str
age: int
email: EmailStr
department: str
employee_id: str
@validator("employee_id")
def validate_employee_id(cls, v):
if not v.isalnum() or len(v) != 6:
raise ValueError("Employee ID must be exactly 6 alphanumeric characters")
return v
# Load and parse the JSON data
with open("employees.json", "r") as f:
data = json.load(f)
# Validate each employee record
for record in data:
try:
employee = Employee(**record)
print(f"Valid employee record: {employee.name}")
except ValidationError as e:
print(f"Invalid employee record: {record['name']}")
print(f"Errors: {e.errors()}")
总结
本教程到此为止!这是一个 Pydantic 的入门教程。希望你了解了建模数据的基础知识,并使用了 Pydantic 提供的内置和自定义验证。本教程中使用的所有代码都在GitHub上。
接下来,你可以尝试在你的 Python 项目中使用 Pydantic,并探索序列化功能。编程愉快!
Bala Priya C** 是一位来自印度的开发者和技术作者。她喜欢在数学、编程、数据科学和内容创作的交汇点工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过撰写教程、操作指南、评论文章等与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编程教程。**
更多相关主题
Pydon’ts – 编写优雅的 Python 代码:免费书评
原文:
www.kdnuggets.com/2022/05/pydonts-write-elegant-python-code-free-book-review.html

图片由作者提供
当我开始学习 Python 时,我的全部关注点都在学习数据科学,而不是编程语言的工程方面。我错过了许多核心概念,这些概念本可以帮助我编写干净且可重复的代码。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
我在这条路上并不孤单。我的一些同事和其他数据科学家也遇到类似的问题,他们只是想用编写不良代码的方式解决数据科学问题。这些代码难以阅读、繁琐且更难以重现和维护。大多数数据专业人员使用函数式编程而不是面向对象的方法,这适合实验但不适合生产。有些人甚至不知道链式比较运算符、海象运算符、repr、序列索引、切片和模式匹配是什么。
这些糟糕的编码习惯会导致延迟和冲突,因为很难理解和优化现有代码。因此,我开始学习针对软件工程师的 Python。我参加了多个课程并阅读了有关掌握 Python 的书籍。这些资源帮助我理解了面向对象编程、编码风格、清晰且可重复的代码、重构和测试驱动开发。但这还不是全部。我想要学习更多。我想学习如何编写优雅、引人注目且富有表现力的代码。这时我发现了一本免费的书籍,叫做 Pydon'ts,它帮助我理解了在编码实践中遗漏了什么。
在这本简短的书评中,我提到了我喜欢这本书的地方,以及你如何利用这本书来给你的同事留下深刻印象,并提高编写优雅代码的能力。
书评
Pydon'ts 是完全免费的,包含超过 330 页的纯知识。这本书适合所有希望提高编写优雅且可用于生产的代码能力的专业人士和爱好者。尤其是那些仍在编写只能自己理解的代码的数据科学家。书中包括 20 章内容,讲解了 Python 内置函数及其各种用法模式。每章包括介绍、单个函数的各种用法模式、编码示例、结论和参考资料。简而言之,每章都像是一篇详细解释每个概念的短博客,并附有真实项目示例。

书的作者 Rodrigo 编写 Python 已有七年半,他有一个博客 Mathspp Blog,涵盖了数学和编程语言的有趣概念。他在 Python 社区中备受尊敬,他的愿景是免费教导人们 Python 语言的最佳实践。Python 是一门丰富的语言,本书中的每一章都详细探讨了单一特性,并附有覆盖所有角度的代码示例。
本书详细涵盖的 Python 特性:
-
代码风格很重要
-
命名很重要
-
链式比较操作符
-
赋值表达式和 walrus 操作符 :=
-
Truthy、Falsy 和 bool
-
深度解包
-
使用星号赋值进行解包
-
EAFP 和 LBYL 编码风格
-
Zip up
-
str 和 repr
-
结构化模式匹配教程
-
结构化模式匹配反模式
-
注意递归
-
序列索引
-
习惯用法的序列切片
-
掌握序列切片
-
序列切片的内部工作
-
reduce 的力量
-
下划线的用法
-
名字 dunder 属性
-
小规模重构
-
字符串的 translate 和 maketrans 方法
-
使用 REPL 提高生产力
-
set 和 frozenset
-
列表推导式基础
-
条件表达式
-
值传递、引用和赋值
-
字符串格式化比较
要下载免费书籍,您需要点击这个 链接,然后将价格设置为$0 以购买书籍。它会要求您添加姓名和电子邮件,然后带您到一个新窗口,您可以在其中下载 pdf。您还可以以$5 购买一本书以表示感谢,或者以$13 购买以表示对作者工作的更多喜爱。完全由您决定。
结束语
Python 在数据专业人士中很受欢迎。我们用它来进行统计实验、数据分析、数据管理、商业智能和机器学习。但我们并不完全了解所有可以帮助我们编写优雅有效程序的内置函数。我们只是对语言有一个基本的理解,通过试错产生解决方案。这种实践仅限于实验,并且在生产环境中会失败。
《Pydon’ts》是一本编写得很好的有趣书籍。如果你是一个非常有动力的专业人士,可以利用这本书来提升你对 Python 内置功能的知识。此外,你还可以用这本书来学习如何编写简洁和富有表现力的代码。这本书的独特之处在于它包括了来自真实项目的 Python 代码示例。

在 Twitter 上关注 Rodrigo ????????,他会发布带解释的代码片段。目前,他正在教授 Python 列表推导式。这些课程简短,学习和理解这些迷你课程只需 5 分钟。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些挣扎于心理疾病的学生。
相关主题
PySpark 数据科学

图片由作者提供
PySpark 是 Apache Spark 的 Python 接口。它是一个开源库,允许你构建 Spark 应用程序,并在分布式环境中使用 PySpark shell 分析数据。你可以使用 PySpark 进行批处理、运行 SQL 查询、数据框、实时分析、机器学习和图形处理。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
使用 Spark 的优势:
-
内存缓存支持实时计算和低延迟。
-
它可以通过多种方式部署:Spark 的集群管理器、Mesos 和通过 Yarn 的 Hadoop。
-
提供用户友好的 API 适用于所有流行的语言,隐藏了运行分布式系统的复杂性。
-
它在内存中比 Hadoop MapReduce 快 100 倍,在磁盘上快 10 倍。
在这个基于代码的教程中,我们将学习如何初始化 Spark 会话、加载数据、更改 Schema、运行 SQL 查询、可视化数据,并训练机器学习模型。
入门指南
如果你想在本地机器上使用 PySpark,需要安装 Python、Java、Apache Spark 和 PySpark。如果想避免这些步骤,你可以使用 Google Colab 或 Kaggle。这两个平台都自带预安装的库,你可以在几秒钟内开始编程。
在 Google Colab Notebook 中,我们将首先安装 pyspark 和 py4j。
%pip install pyspark py4j -qq
之后,我们需要提供会话名称以初始化 Spark 会话。
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('PySpark_for_DataScience').getOrCreate()
使用 PySpark 导入数据
在这个教程中,我们将使用来自 Kaggle 的 Global Spotify Weekly Chart。它包含有关艺术家和 Spotify 全球周榜上歌曲的信息。
就像 Pandas 一样,我们可以使用 spark.read.csv 函数从 CSV 加载数据到数据框,并使用 printSchema() 函数显示 Schema。
df = spark.read.csv(
'/content/spotify_weekly_chart.csv',
sep = ',',
header = True,
)
df.printSchema()
输出:
正如我们所观察到的,PySpark 已将所有列加载为字符串。为了进行探索性数据分析,我们需要更改 Schema。
root
|-- Pos: string (nullable = true)
|-- P+: string (nullable = true)
|-- Artist: string (nullable = true)
|-- Title: string (nullable = true)
|-- Wks: string (nullable = true)
|-- Pk: string (nullable = true)
|-- (x?): string (nullable = true)
|-- Streams: string (nullable = true)
|-- Streams+: string (nullable = true)
|-- Total: string (nullable = true)
更新 Schema
要更改模式,我们需要创建一个新的数据模式,并将其添加到StructType函数中。你需要确保每个列字段具有正确的数据类型。
from pyspark.sql.types import *
data_schema = [
StructField('Pos', IntegerType(), True),
StructField('P+', StringType(), True),
StructField('Artist', StringType(), True),
StructField('Title', StringType(), True),
StructField('Wks', IntegerType(), True),
StructField('Pk', IntegerType(), True),
StructField('(x?)', StringType(), True),
StructField('Streams', IntegerType(), True),
StructField('Streams+', DoubleType(), True),
StructField('Total', IntegerType(), True),
]
final_struc = StructType(fields = data_schema)
然后,我们将使用额外的参数schema加载 CSV 文件。之后,我们将打印模式以检查是否做了正确的更改。
df = spark.read.csv(
'/content/spotify_weekly_chart.csv',
sep = ',',
header = True,
schema = final_struc
)
df.printSchema()
输出:
如我们所见,列的数据类型各不相同。
root
|-- Pos: integer (nullable = true)
|-- P+: string (nullable = true)
|-- Artist: string (nullable = true)
|-- Title: string (nullable = true)
|-- Wks: integer (nullable = true)
|-- Pk: integer (nullable = true)
|-- (x?): string (nullable = true)
|-- Streams: integer (nullable = true)
|-- Streams+: double (nullable = true)
|-- Total: integer (nullable = true)
探索数据
你可以使用toPandas()函数将数据作为数据框进行探索。
注意: 我们使用了
limit来显示前五行。这与 SQL 命令类似。这意味着我们可以使用 PySpark Python API 执行 SQL 命令以运行查询。
df.limit(5).toPandas()
就像 pandas 一样,我们可以使用describe()函数来显示数据分布的摘要。
df.describe().show()

count()函数用于显示行数。阅读 Pandas API on Spark 以了解类似的 API。
df.count()
# 200
列操作
你可以使用withColumnRenamed函数重命名列。它需要旧名称和新名称作为字符串。
df = df.withColumnRenamed('Pos', 'Rank')
df.show(5)
要删除单个或多个列,你可以使用drop()函数。
df = df.drop('P+','Pk','(x?)','Streams+')
df.show(5)
你可以使用.na来处理缺失值。在我们的例子中,我们删除了所有缺失值的行。
df = df.na.drop()
## Or
#data.na.replace(old_value, new_vallue)
数据分析
对于数据分析,我们将使用 PySpark API 来转换 SQL 命令。在第一个示例中,我们选择了三列,并显示了前 5 行。
df.select(['Artist', 'Artist', 'Total']).show(5)
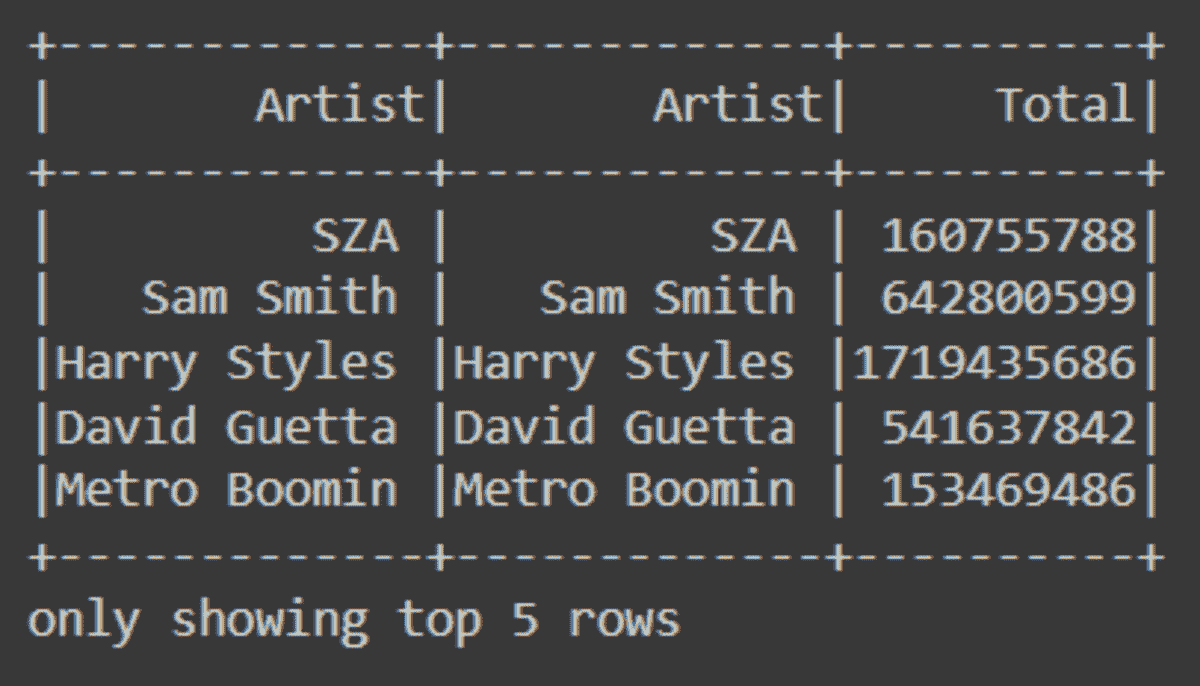
对于更复杂的查询,我们将筛选“Total”大于或等于 6 亿到 7 亿的值。
注意: 你还可以使用 df.Total.between(600000000, 700000000)来筛选记录。
from pyspark.sql.functions import col, lit, when
df.filter(
(col("Total") >= lit("600000000")) & (col("Total") <= lit("700000000"))
).show(5)
编写 if/else 语句,使用when函数创建分类列。
df.select('Artist', 'Title',
when(df.Wks >= 35, 1).otherwise(0)
).show(5)
你可以将所有 SQL 命令作为 Python API 运行完整的查询。
df.select(['Artist','Wks','Total'])\
.groupBy('Artist')\
.mean()\
.orderBy(['avg(Total)'], ascending = [False])\
.show(5)
数据可视化
让我们使用上述查询,并尝试将其显示为条形图。我们绘制了“艺术家与平均歌曲播放量”的关系,并且仅显示前七名艺术家。
如果你问我,这太棒了。
vis_df = (
df.select(["Artist", "Wks", "Total"])
.groupBy("Artist")
.mean()
.orderBy(["avg(Total)"], ascending=[False])
.toPandas()
)
vis_df.iloc[0:7].plot(
kind="bar",
x="Artist",
y="avg(Total)",
figsize=(12, 6),
ylabel="Average Average Streams",
)
保存结果
在处理数据和运行分析之后,是时候保存结果了。
你可以将结果保存为所有流行的文件类型,例如 CSV、JSON 和 Parquet。
final_data = (
df.select(["Artist", "Wks", "Total"])
.groupBy("Artist")
.mean()
.orderBy(["avg(Total)"], ascending=[False])
)
# CSV
final_data.write.csv("dataset.csv")
# JSON
final_data.write.save("dataset.json", format="json")
# Parquet
final_data.write.save("dataset.parquet", format="parquet")
数据预处理
在这一部分,我们正在为机器学习模型准备数据。
-
类别编码:使用 StringIndexer 将类别列转换为整数。
-
组装特征:将重要特征组装成一个向量列。
-
缩放:使用 StandardScaler 缩放函数对数据进行缩放。
from pyspark.ml.feature import (
VectorAssembler,
StringIndexer,
OneHotEncoder,
StandardScaler,
)
## Categorical Encoding
indexer = StringIndexer(inputCol="Artist", outputCol="Encode_Artist").fit(
final_data
)
encoded_df = indexer.transform(final_data)
## Assembling Features
assemble = VectorAssembler(
inputCols=["Encode_Artist", "avg(Wks)", "avg(Total)"],
outputCol="features",
)
assembled_data = assemble.transform(encoded_df)
## Standard Scaling
scale = StandardScaler(inputCol="features", outputCol="standardized")
data_scale = scale.fit(assembled_data)
data_scale_output = data_scale.transform(assembled_data)
data_scale_output.show(5)
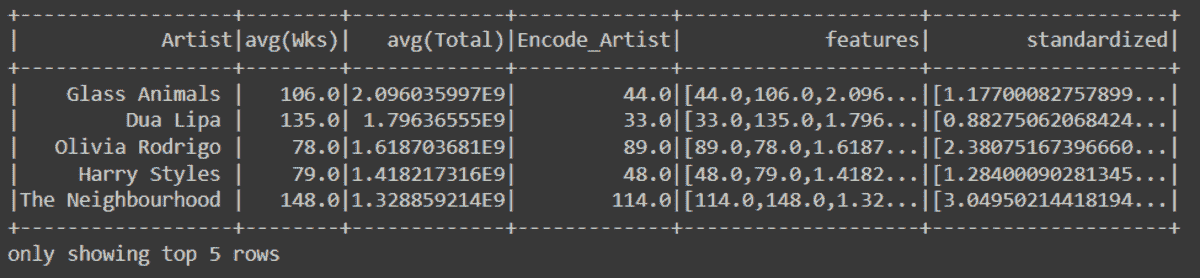
KMeans 聚类
我已经运行了 Kmean 肘部法来找出 k 值。如果你想查看所有的代码源和输出,可以查看我的 notebook。
就像 scikit-learn 一样,我们将提供多个聚类,并训练 Kmeans 聚类模型。
from pyspark.ml.clustering import KMeans
KMeans_algo=KMeans(featuresCol='standardized', k=4)
KMeans_fit=KMeans_algo.fit(data_scale_output)
preds=KMeans_fit.transform(data_scale_output)
preds.show(5)
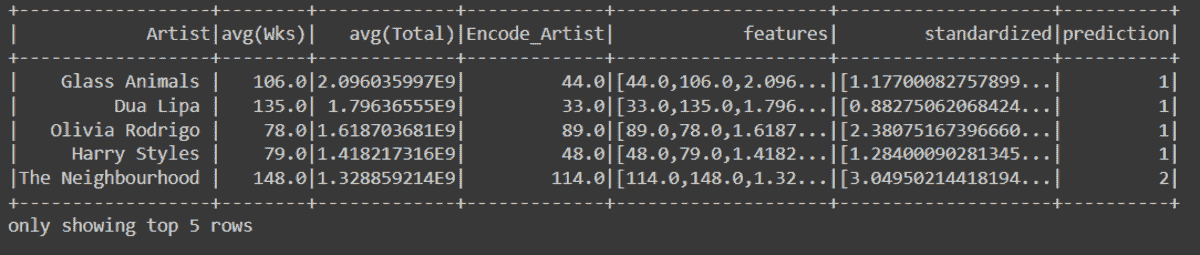
可视化预测
在这一部分,我们将使用 matplotlib.pyplot.barplot 来显示 4 个聚类的分布。
import matplotlib.pyplot as plt
import seaborn as sns
df_viz = preds.select(
"Artist", "avg(Wks)", "avg(Total)", "prediction"
).toPandas()
avg_df = df_viz.groupby(["prediction"], as_index=False).mean()
list1 = ["avg(Wks)", "avg(Total)"]
for i in list1:
sns.barplot(x="prediction", y=str(i), data=avg_df)
plt.show()
总结
在本教程中,我概述了你可以通过 PySpark API 做些什么。该 API 允许你执行类似 SQL 的查询、运行 pandas 函数,并训练类似于 scikit-learn 的模型。你可以在分布式计算中获得所有世界的最佳体验。
在处理大型数据集(>1GB)时,它比许多 Python 包表现更为出色。如果你是程序员,并且对 Python 代码感兴趣,请查看我们的 Google Colab notebook。你只需下载并添加来自 Kaggle 的数据即可开始工作。
如果你希望我继续编写其他 Python 库的基于代码的教程,请在评论中告诉我。
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专家,热衷于构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为那些与心理疾病作斗争的学生打造一个 AI 产品。
相关主题
PySpark SQL 备忘单:Python 中的大数据
原文:
www.kdnuggets.com/2017/11/pyspark-sql-cheat-sheet-big-data-python.html
由 Karlijn Willems, DataCamp。
用 Python 处理大数据
大数据无处不在,通常以三个 V 特征来描述:速度(Velocity)、多样性(Variety)和体积(Volume)。大数据是快速的、多样的,并且体积庞大。作为数据科学家、数据工程师、数据架构师等角色,无论你在数据科学行业中担任何种角色,你都将早晚接触到大数据,因为公司现在收集了大量的数据。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你所在组织的 IT
然而,数据并不总是意味着信息,这就是你,数据科学爱好者,发挥作用的地方。你可以利用 Apache Spark,这是一款“用于大规模数据处理的快速且通用的引擎”,来开始解决大数据给你和你所在公司带来的挑战。
不过,当你在使用 Spark 时,疑问可能会不断出现。遇到问题时,可以查看 DataCamp 的 Apache Spark 教程:ML with PySpark tutorial 或免费下载 备忘单!
接下来,我们将深入探讨备忘单的结构和内容。
PySpark 备忘单
PySpark 是 Spark 的 Python API,将 Spark 编程模型暴露给 Python。Spark SQL 是 PySpark 的一个模块,允许你以 DataFrames 的形式处理结构化数据。这与通常用于处理非结构化数据的 RDDs 相对。

提示: 如果你想了解更多关于 RDD 和 DataFrame 之间的差异,以及 Spark DataFrames 与 pandas DataFrames 的不同之处,你一定要查看 Apache Spark in Python: 初学者指南。
初始化 SparkSession
如果你想使用 PySpark 开始进行 Spark SQL 工作,你需要先启动一个 SparkSession:你可以用它来创建 DataFrames、将 DataFrames 注册为表、对表执行 SQL 查询以及读取 parquet 文件。即使这些对你来说听起来非常陌生,也不用担心——你会在本文后面了解更多关于这些的内容!
你通过首先从 pyspark 包附带的 sql 模块中导入 SparkSession 来启动一个 SparkSession。接下来,你可以初始化一个变量 spark,例如,不仅构建 SparkSession,还给应用程序命名,设置配置,然后使用 getOrCreate() 方法来获取已存在的 SparkSession,或者在尚不存在的情况下创建一个!最后这个方法将非常实用,特别是为了将来参考,因为它会防止你同时运行多个 SparkSessions!
很酷,不是吗?

检查数据
当你导入数据后,使用一些内置属性和方法检查 Spark DataFrame 是时候了。这样,你可以在开始操作 DataFrames 之前,更好地了解你的数据。
现在,你可能已经从使用 pandas DataFrames 或 NumPy 的经验中了解了本节中提到的大多数方法和属性,例如 dtypes、head()、describe()、count(),等等。还有一些可能对你来说是新的方法,例如 take() 或 printSchema() 方法,或 schema 属性。

尽管如此,你会发现提升过程相当温和,因为你可以最大限度地利用你在数据科学包方面的前期知识。
重复值
在检查数据时,你可能会发现一些重复值。为了解决这个问题,你可以使用 dropDuplicates() 方法,例如,在你的 Spark DataFrame 中删除重复值。
查询
你可能还记得,使用 Spark DataFrames 的主要原因之一是你有一种更结构化的数据处理方式——查询就是处理数据的一种更结构化的方式,无论你是在关系型数据库中使用 SQL、在 No-SQL 数据库中使用类似 SQL 的语言、还是在 Pandas DataFrames 中使用 query() 方法,等等。

现在我们在讨论 Pandas DataFrames 时,你会注意到 Spark DataFrames 遵循类似的原则:你使用方法来更好地了解你的数据。然而,在这种情况下,你不会使用 query()。相反,你需要利用其他方法来获取你想要的结果:在第一次使用时,select() 和 show() 将是你获取 DataFrames 信息的好帮手。
在这些方法中,你可以构建你的查询。和标准 SQL 一样,你可以在 select() 中指定你想要返回的确切列。你可以使用常规字符串来完成,也可以借助 DataFrame 本身来指定列名,如以下示例:df.lastName 或 df[“firstName”]。
请注意,后者的方法在某些情况下会给你更多的自由,特别是当你想用额外的函数如 isin() 或 startswith() 精确指定你要检索的信息时。
除了 select() 外,你还可以利用 PySpark SQL 的 functions 模块来指定查询中的 when 子句,例如,如下表所示:

总的来说,你可以看到,使用 select()、help() 和 functions 模块的功能,有很多可能性可以帮助你更大程度地处理和了解你的数据。
添加、更新和删除列
你可能还希望查看如何向 Spark DataFrame 添加、更新或删除某些列。你可以使用 withColumn()、withColumnRenamed() 和 drop() 方法轻松完成。你现在可能已经知道,当你使用 Pandas DataFrames 时,你也可以使用 drop() 方法。你可以在这里阅读更多信息。

按组
同样,就像 Pandas DataFrames 一样,你可能希望按某些值分组并聚合一些值 - 下面的示例展示了如何使用 groupBy() 方法,并结合 count() 和 show() 来检索和显示你的数据,以年龄为分组,并显示具有该年龄的人数。

相关主题
PySyft 和私人深度学习的兴起
原文:
www.kdnuggets.com/2019/06/pysyft-emergence-deep-learning.html
评论 
信任是实施深度学习应用的关键因素。从训练到优化,深度学习模型的生命周期依赖于不同方之间的可信数据交换。这种动态在实验室环境中确实有效,但结果容易受到各种安全攻击的威胁,这些攻击会操控模型中不同参与者之间的信任关系。我们以一个使用金融交易来分类特定客户信用风险的信用评分模型为例。
传统的训练或优化模型机制假设执行这些操作的实体将完全访问这些金融数据集,这就打开了各种隐私风险的大门。随着深度学习的发展,在数据集和模型生命周期中执行隐私约束的机制变得越来越重要。在尝试解决这一巨大挑战的技术中,PySyft 是一个最近在深度学习社区中稳步获得关注的框架。
深度学习应用中隐私的重要性直接与分布式、多方模型的兴起相关。传统的深度学习解决方案依赖于集中式方,这些方控制模型的整个生命周期,即使使用大型分布式计算基础设施也是如此。这就是一个组织创建预测模型的情况,该模型管理访问其网站的客户的偏好。然而,集中式深度学习拓扑在诸如移动设备或物联网(IOT)等依赖大量设备生成数据和执行模型的场景中已被证明是不切实际的。
在这些场景中,分布式方不仅常常生成敏感数据集,还执行和评估深度学习模型的性能。这种动态要求负责创建、训练和执行深度学习模型的不同方之间建立双向隐私关系。
向更分布式架构的过渡是深度学习模型中需要强大隐私机制的主要动力之一。这是PySyft 旨在解决的挑战,但如果没有机器学习和分布式编程几个研究领域的演进,这将是不可能的。
使能因素
深度学习模型中的隐私问题已经存在多年,但能够提供解决方案的技术现在才开始达到一定的可行性。以 PySyft 为例,该框架利用了过去十年中机器学习和加密领域的三种最吸引人的技术:
-
安全多方计算
-
联邦学习
-
差分隐私
安全多方计算
安全多方计算(sMPC)是一种加密技术,它允许不同的参与方在保持输入数据私密的情况下进行计算。在计算机科学理论中,sMPC 通常被视为解决著名的姚氏百万富翁问题的方案,该问题由计算机科学家姚期智于 1980 年代提出。该问题描述了一个场景,其中多个百万富翁希望知道谁更富有,但不披露他们的实际财富。百万富翁问题出现在许多现实世界的场景中,如拍卖、选举或在线游戏。
从概念上讲,sMPC 用安全计算替代了对可信中介的需求。在 sMPC 模型中,一组具有私密输入的参与方计算分布式函数,如公平性、隐私性和正确性等安全属性被保留。
 联邦学习
联邦学习
联邦学习是一种新的 AI 系统学习架构,适用于在高度分布的拓扑结构中运行的系统,如移动设备或物联网(IOT)系统。最初由 Google 研究实验室提出,联邦学习代表了一种替代集中式 AI 训练的方法,其中通过中央服务器协调,从参与设备的联盟中训练一个共享的全局模型。在该模型中,不同的设备可以在保持大部分数据在设备上的同时,贡献于模型的训练和知识。
在联邦学习模型中,一方下载深度学习模型,通过从给定设备上的数据学习来改进模型,然后将更改总结为一个小的集中更新。只有这个模型的更新被发送到云端,通过加密通信进行传输,并与其他用户的更新立即进行平均,以改进共享模型。所有训练数据仍保留在原始设备上,云端不会存储单个更新。
 差分隐私
差分隐私
差分隐私是一种用于限制统计算法对包含在更大数据集中的对象隐私影响的技术。大致上,如果一个观察者看到算法的输出无法判断是否使用了某个特定个体的信息,那么该算法就是差分隐私的。差分隐私通常在识别数据库中可能存在的个人信息的背景下讨论。尽管它并不直接涉及识别和重新识别攻击,但差分隐私算法被证明能够抵抗这种攻击。
PySyft
PySyft 是一个使深度学习模型中的安全、隐私计算成为可能的框架。PySyft 将联邦学习、安全的多方计算和差分隐私结合在一个编程模型中,集成到 PyTorch、Keras 或 TensorFlow 等不同的深度学习框架中。PySyft 的原则 最初在一篇研究论文中阐述,其 首个实现由 OpenMind 主导,OpenMind 是领先的去中心化 AI 平台之一。
PySyft 的核心组件是一个叫做 SyftTensor 的抽象。SyftTensors 旨在表示数据的状态或转换,可以将它们链式连接在一起。链结构的头部始终是 PyTorch 张量,SyftTensors 所体现的转换或状态可以通过子属性向下访问,通过父属性向上访问。
使用 PySyft 相对简单,与标准的 PyTorch 或 Keras 程序没有太大区别。下面的动画展示了一个使用 PySyft 开发的简单分类模型。
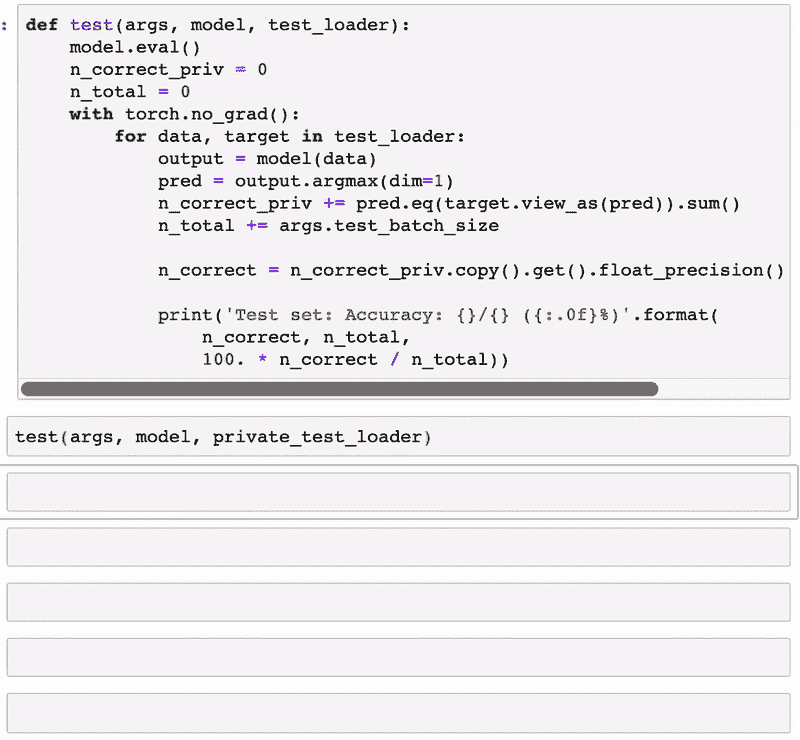
PySyft 代表了在深度学习程序中实现强大隐私模型的首次尝试之一。随着领域的发展,隐私可能会成为下一代深度学习框架的基础构件之一。
原文。经许可转载。
简介: Jesus Rodriguez 是一位技术专家、执行投资人和创业顾问。作为软件科学家,Jesus 是一位国际知名的演讲者和作者,他的贡献包括数百篇文章和在行业会议上的演讲。
相关:
-
如何在数据隐私时代构建分析产品
-
自编码器:使用 TensorFlow 的 Eager Execution 进行深度学习
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
更多相关话题
Pythia: 一套用于深入研究的 16 个 LLM
原文:
www.kdnuggets.com/2023/08/pythia-suite-16-llms-indepth-research.html

图片来源:作者
如今,大型语言模型和如 ChatGPT 和 GPT-4 这样的 LLM 驱动的聊天机器人已广泛融入我们的日常生活中。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT
然而,仅解码的自回归变换器模型在 LLM 应用成为主流之前就已经广泛用于生成 NLP 应用。了解它们在训练中的演变以及它们随着规模扩大而性能的变化是很有帮助的。
Pythia 是 Eleuther AI 的一个项目,提供了一套 16 个大型语言模型,用于研究、分析和进一步研究的可重复性。本文介绍了 Pythia。
Pythia 套件提供了什么?
如前所述,Pythia 是一套由 16 个大型语言模型组成的套件——仅解码的自回归变换器模型——在公开可用的数据集上进行训练。套件中的模型大小从 7000 万到 120 亿参数不等。
-
整个套件是在相同的数据和相同的顺序下训练的。这有助于训练过程的可重复性。因此,我们不仅可以复制训练管道,还可以深入分析语言模型并研究其行为。
-
套件还提供了下载训练数据加载器和每个 16 个语言模型的 154 个模型检查点的设施。
训练数据和训练过程
现在,让我们深入了解 Pythia LLM 套件的详细信息。
训练数据集
Pythia LLM 套件是在以下数据集上训练的:
-
Pile 数据集,包含 3000 亿个标记
-
去重的 Pile 数据集,包含 2070 亿个标记。
共有 8 种不同的模型尺寸,其中最小和最大的模型分别具有 7000 万和 120 亿个参数。其他模型尺寸包括 1600 万、4100 万、10 亿、14 亿、28 亿和 69 亿。
这些模型中的每一个都在 Pile 和去重的 Pile 数据集上进行训练,形成了总共 16 个模型。下表展示了模型的大小和部分超参数。
模型和超参数 | 图像来源
有关使用的超参数的完整细节,请参阅 Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling。
训练过程
这里是架构和训练过程的概述:
-
所有模型都有完全密集的层,并使用 flash attention。
-
为了更容易解释,使用了未绑定的嵌入矩阵。
-
使用了 1024 的批量大小和 2048 的序列长度。这个大批量大小大大减少了实际训练时间。
-
训练过程还利用了诸如数据和张量并行等优化技术
对于训练过程,使用了由 Eleuther AI 开发的 GPT-Neo-X library(包括来自 DeepSpeed library 的功能)。
模型检查点
每个模型有 154 个检查点。每 1000 次迭代设置一个检查点。此外,在训练过程的早期阶段,还有按对数间隔设置的检查点:1、2、4、8、16、32、64、128、256 和 512。
Pythia 与其他语言模型的比较
Pythia LLM 套件与现有语言建模基准进行评估,包括 OpenAI 的 LAMBADA 变体。结果发现,Pythia 的表现与 OPT 和 BLOOM 语言模型相当。
优势和局限性
Pythia LLM 套件的主要优势是可重复性。数据集是公开的,预标记的数据加载器和 154 个模型检查点也都是公开的。超参数的完整列表也已发布。这使得模型训练和分析的复制变得更简单。
在 [1] 中,作者解释了他们为何选择英文数据集而非多语言文本语料库的理由。但拥有可重复的多语言大型语言模型训练流程是有帮助的,特别是在鼓励更多的研究和多语言大型语言模型动态的研究方面。
案例研究概述
研究还展示了利用 Pythia 套件中大型语言模型训练过程的可重复性的一些有趣的案例研究。
性别偏见
所有大型语言模型都容易受到偏见和虚假信息的影响。研究集中在通过修改预训练数据来减轻性别偏见,使得固定比例的数据包含特定性别的代词。这种预训练也是可重复的。
记忆化
大型语言模型中的记忆化也是一个广泛研究的领域。序列记忆化被建模为泊松点过程。研究旨在了解特定序列在训练数据集中的位置是否会影响记忆化。观察结果表明,位置不会影响记忆化。
预训练术语频率的影响
对于参数数量为 2.8B 及以上的语言模型,在预训练语料库中出现特定任务术语的情况被发现可以提高模型在问答等任务上的表现。
模型的规模与在更复杂任务(如算术和数学推理)上的表现之间也存在相关性。
算术加法任务表现 | 图片来源
总结与下一步
让我们总结一下讨论中的关键点。
-
Pythia by Eleuther AI 是一个包含 16 个大型语言模型(LLMs)的套件,这些模型在公开可用的 Pile 数据集和去重后的 Pile 数据集上进行了训练。
-
LLMs 的规模范围从 70M 到 12B 参数不等。
-
训练数据和模型检查点是开源的,能够重建精确的训练数据加载器。因此,LLM 套件对于更好地理解大型语言模型的训练动态非常有帮助。
下一步,你可以在 Hugging Face Hub 上探索 Pythia 模型套件和模型检查点。
参考资料
[1] Pythia:分析大型语言模型的训练和扩展的套件,arXiv,2023
Bala Priya C 是来自印度的开发人员和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专业领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她致力于学习并通过编写教程、操作指南、观点文章等与开发者社区分享她的知识。
更多相关话题
Plotnine:Python 中 ggplot2 的替代品
原文:
www.kdnuggets.com/2019/12/python-alternative-ggplot2.html
comments
R 的忠实用户知道 ggplot2 可以简化处理探索性数据分析和数据可视化的过程。它使得创建优雅而强大的图形变得非常简单,帮助解读数据中的潜在关系。
Python 的绘图库,如 matplotlib 和 seaborn,确实允许用户创建优雅的图形,但相比于 R 中 ggplot2 的简单、可读和分层的方法,它们缺乏标准化的语法来实现图形语法,使得在 Python 中实现起来更加困难。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升您的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT
这个问题的答案在于 Plotnine。
我会说这种风格与 R 中的 ggplot2 99% 相似。主要区别在于你将会看到的几个简短示例中的括号用法。使用 plotnine 的最佳收获之一是输出基本上与 R 中得到的相同。视觉上没有明显差异。
我们可以使用许多plotnine 的 API 来制作我们的图表。
(
ggplot(mtcars, aes(‘wt’, ‘mpg’, color=’factor(cyl)’))
+ geom_point()
+ labs(title=’Miles per gallon vs Weight’, x=’Weight’, y=’Miles per gallon’)
+ guides(color=guide_legend(title=’Number of Cylinders’)) )
ggplot 在 R 中的主要卖点之一是能够 FACET。我们也有许多选项来用一行代码绘制数据的子集。
(ggplot(mtcars, aes(‘wt’, ‘mpg’, color=’factor(cyl)’))
+ geom_point()
+ labs(title=’Miles per gallon vs Weight’,x=’Weight’, y=’Miles per gallon’)
+ guides(color=guide_legend(title=’Cylinders’))
+ facet_wrap(‘~gear’)
)
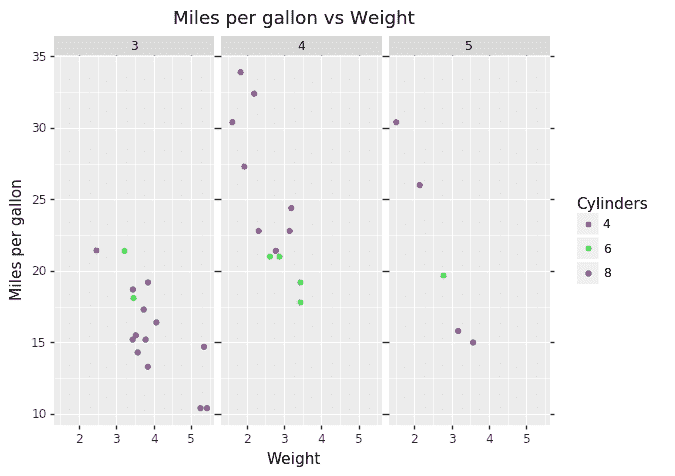
只需在前面的代码末尾添加 facet_wrap(‘~gear’) 我们现在就有了一个分面图。 这实际上比使用 Matplotlib 和 Seaborn 简单得多。Matplotlib 需要你为每一组变量创建一个单独的图表(例如,上面的图表有 3 个图表,所以你必须创建 3 个图表),而 Seaborn 比 Matplotlib 更简单,但需要使用不同的命令,这可能会让缺乏经验的用户感到困惑。
美学改进
如果没有正确格式化这些可视化图形,那么创建它们是没有意义的。
(ggplot(mtcars, aes(‘wt’, ‘mpg’, color=’factor(cyl)’, size = ‘hp’))
+ geom_point()
+ theme_bw()
+ labs(title=’Miles per gallon vs Weight’,x=’Weight’, y=’Miles per gallon’)
+ guides(color=guide_legend(title=’Cylinders’))
+ facet_wrap(‘~gear’)
)
通过添加**size = ‘hp’**,我们可以从数据中获得另一个见解(马力的数量),并使用**theme_bw()**为图形提供一个标准化的格式和一个简单的主题。theme_bw()是任何使用 ggplot2 的 R 用户都会知道的一个主题命令。它基本上是进行其他主题和格式实验之前使用的默认主题。
查看我们如何将 ipywidgets 与 Plotnine、Jupyter Notebook 和 JupyterLab 集成。
当我们深入研究时,我们会发现 Plotnine 提供了我们从 R 中的 ggplot2 获得的简单 API 和令人惊叹的视觉效果。Seaborn 能够用一行代码格式化图形,但 Matplotlib 则不能。Seaborn 在某种程度上确实与 Plotnine 和 ggplot2 有相似之处,但其易于解读的语法赋予了它独特的卖点,使得切换变得容易。
相关:
-
Vega-Lite: 交互式图形的语法
-
如何在 Python(和 R)中可视化数据
-
理解箱线图
相关话题
使用 Python API 进行数据科学项目
原文:
www.kdnuggets.com/2021/09/python-apis-data-science-project.html
评论
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
使用 API 进行数据科学是所有数据科学家必备的技能,应纳入你的数据科学项目中。在我们之前的博客 - 数据分析项目创意,我们概述了你所需的唯一数据科学项目,并讨论了使用 API 收集数据的重要性。因此,在这篇文章中,我们想展示如何使用 Python 从 YouTube API 中提取数据,并使用 Python 中的请求库。
所以让我们深入了解如何使用 API 进行数据科学。我们将提取数据并查看 JSON 响应,然后将所有这些数据保存到 Pandas DataFrame 中。

为什么要从 API 收集数据?
你可能会想,为什么我们不直接使用 CSV 或从数据库中提取数据?你应该学习 API 的原因有两个:
1. API 是一种非常常见的行业、专业数据收集方式,因此如果你将来从事数据科学工作,你需要学习如何使用它。
2. 与从数据库提取数据相比,这是一种更复杂和高级的数据收集方式。因此,这也是学习 API 的另一个理由,可以给你的同事和招聘经理留下深刻印象。
工具和平台
平台
我们将使用 Google Colabs,它基本上是 Jupyter notebooks。如果你愿意,可以使用 Jupyter notebooks,但我们将使用 Colabs,因为它容易启动并将工作保存到 Google 云端硬盘中。
导入
现在第一步是导入库。
#import libraries
import requests
import pandas as pd
import time

API 密钥
下一步是获取 API 密钥。我们将从 Youtube API 获取数据,特别是从我们的频道中获取数据。为了通过 API 访问我们的频道信息,我们需要申请一个 API 密钥。你可以通过访问这个链接 - https://www.slickremix.com/docs/get-api-key-for-youtube/ 来完成。我们不想在这篇文章中详细讲解如何使用 Youtube API,所以我们将留给你自己去获取 API 密钥。但一般来说,每当你使用 API 时,你总是需要一个密钥。获取密钥的方法因每个 API 服务而异。所以假设你完成了这个过程并获得了你的 API 密钥。
现在我们将获取我们频道中的所有视频,然后从每个视频中获取指标:
频道中的视频列表
-
视频 ID
-
视频标题
-
发布日期
视频指标
-
观看次数
-
链接数量
-
不喜欢次数
-
评论数量
现在我们需要的是我们的频道 ID。这两个参数将用于进行 API 调用。
#keys
API_KEY = "AIXXXXXXXX"
CHANNEL_ID = "UCW8Ews7tdKKkBT6GdtQaXvQ"
使用 requests 库进行测试
让我们快速测试一下 API 调用。使用 requests 库,你可以通过将 API 的 URL 放入 get() 方法中来进行调用。
#make API call
response = requests.get('https://api.github.com').json()
什么是 JSON 文件?
它是一种常见的数据文件,以 JS 对象形式发送,并通常以属性-值对或数组的形式包含你的数据。并将数据保存在一个叫做 response 的变量中。
现在让我们查看数据:
response

例如,如果你想查找用户的电子邮件,你可以在 get() 方法中使用 email_url。
emails_url': 'https://api.github.com/user/emails'
我们刚刚测试了请求库,并快速测试了其功能。现在让我们调用 Youtube API 并抓取一些数据。
与 YouTube API 的协作
所以进行 API 调用最困难的部分是弄清楚如何构建 URL,主要是要在 URL 中添加哪些参数。我们目前有一个根 URL。
url = "https://www.googleapis.com/youtube/v3/
这是我们数据的位置。我们只需要定义要收集的数据类型。为此,我们现在需要将参数添加到 URL 中,以从特定频道获取特定的视频信息。
最困难的部分是弄清楚要在 URL 中添加哪些参数和属性?你如何弄清楚这一点?最佳的方法是阅读官方文档。YouTube API 官方文档
我们将进行一次“搜索”,并包含多个参数,如“part”、“channelID”和我的 API 密钥。在“parts”参数中,我们将添加 id 和 snippet 属性,以抓取包含 videoID 和有关视频本身的信息的 ID 数据,如你在列表中看到的。

url = "https://www.googleapis.com/youtube/v3/search?key="+API_KEY+"&
channelId="+CHANNEL_ID+"&part=snippet,id&order=date&maxResults=10000"
+pageToken
我们通过 YouTube API 执行“搜索”。所有位于“?”右侧的部分是我们添加的参数,用于请求特定的信息。
-
首先,我们在这个 key 参数中添加存储在 API_KEY 变量中的 API 密钥。
-
我们指定要收集信息的频道 ID。
-
接下来是 part 参数,我们指定要获取 snippet 和 ID 数据。从文档中可以看到,当我们请求 snippet 和 ID 数据时,可以期待获得哪些数据。
-
按日期排序数据,然后我们希望 API 调用中的 maxResults 为 10000 个视频。
-
最后,pageToken 是一个令牌,即一个代码,它用于获取搜索结果的下一页。我们将在稍后尝试提取所有数据时处理它。
构建这个可能很困难,而且需要很多试错。但是一旦你玩弄它并获取到所需的数据,你就不必再担心了。所以整个 URL 被保存在我们的 URL 变量中。
API 调用的响应
我们以与 GitHub 示例相同的方式进行 API 调用。
pageToken = ""
response = requests.get(url).json()
这是 API 调用的输出。
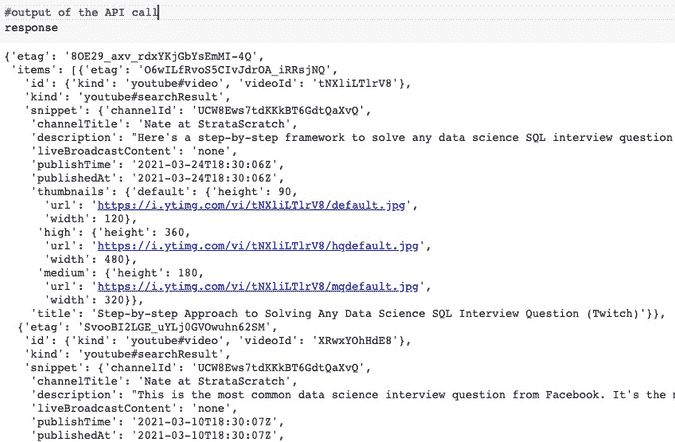
数据解析
你如何理解这些数据?首先,让我们确定我们感兴趣的内容是什么?我们看到响应顶部的 etag 键,然后是响应中的第二个键 items 键。items 键以方括号开始,然后基本上列出了我们频道中的所有视频。如果我们查看响应的末尾,我们最终会看到频道中的最后一个视频以及 items 键的结束方括号。然后我们会看到其他的键,如 kind、nextPageToken 等等。
你还可以看到我们有 95 个结果但只检索了 50 个。nextPageToken 键将帮助我们获取搜索结果的下一页视频。但我们稍后会讨论这一点。
所以我们的 API 调用给我们提供了所有视频的搜索结果以及一些关于视频的信息。所有这些信息都存储在 items 键中。所以让我们只抓取这些数据并过滤掉其他的。
你可以通过指定 items 键来轻松完成这一操作。
response['items']
response['items'][0]
解析输出并将其保存到变量中
很明显,我们需要做的是遍历 items 键中的所有视频并保存特定的信息。让我们先将信息保存到变量中,然后最后构建循环。
让我们保存视频 ID。为此,我们需要调用 response 变量、item 键和第一个位置。然后一旦我们得到这个,我们选择 id 键和 videoID 键。我们可以将该值保存在 video_id 变量中。这基本上是你如何遍历数组并保存你想要的数据。
video_id = response['items'][0]['id']['videoId']
对视频标题做相同的操作。这里我们还将任何 & 符号替换为空白
video_title = response['items'][0]['snippet']['title']
video_title = str(video_title).replace("&","")
然后让我们抓取上传日期
upload_date = response['items'][0]['snippet']['publishedAt']
我们只想抓取日期,省略时间戳。
T 上拆分,并抓取输出的左侧部分。
upload_date = str(upload_date).split("T")[0]
所以这就是你如何保存所有信息。
创建循环
让我们创建一个循环,遍历在 API 调用中收集的所有视频并保存信息。
我们将遍历 response['items'] 数组,所以我们的 for loop 从
for video in response['items']:
接下来,我们需要添加一些逻辑,确保我们只收集视频信息。因此,为了确保这一点,我们需要确保只关注视频。如果你查看响应,你会看到
'kind': 'youtube#video',
所以我们将添加一个 if 语句来确保我们保存的是视频信息。正如你所看到的,我们不是使用 response['items'] 而是使用 video 变量,因为我们在 for loop 中。
if video['id']['kind'] == "youtube#video":
最后,我们构建的所有用于收集响应信息的变量,我们将再次使用这些变量,但只需将变量名更改为 video。你的最终结果将如下所示。
for video in response['items']:
if video['id']['kind'] == "youtube#video":
video_id = video['id']['videoId']
video_title = video['snippet']['title']
video_title = str(video_title).replace("&","")
upload_date = video['snippet']['publishedAt']
upload_date = str(upload_date).split("T")[0]
进行第二次 API 调用
收集这些信息是很好的,但这还不够有趣。我们还希望收集每个视频的观看次数、点赞和点踩次数。这些不在第一次 API 调用中。我们需要做的是进行第二次 API 调用来收集这些信息,因为我们需要使用从第一次 API 调用中收集到的 video_id,然后进行第二次 API 调用以获取观看次数、点赞、点踩和评论数。
既然我们已经向你展示了如何进行 API 调用,我们建议你尝试自己完成第二次 API 调用。如果你成功完成了第二次 API 调用,它应该类似于下面的样子:
url_video_stats = "https://www.googleapis.com/youtube/v3/videos?id="
+video_id+"&part=statistics&key="+API_KEY
response_video_stats = requests.get(url_video_stats).json()
view_count = response_video_stats['items'][0]['statistics']['viewCount']
like_count = response_video_stats['items'][0]['statistics']['likeCount']
dislike_count = response_video_stats['items'][0]['statistics']
['dislikeCount']
comment_count = response_video_stats['items'][0]['statistics']
['commentCount']
现在,我们需要将其添加到 'for loop' 中。我们会得到类似这样的结果:
for video in response['items']:
if video['id']['kind'] == "youtube#video":
video_id = video['id']['videoId']
video_title = video['snippet']['title']
video_title = str(video_title).replace("&","")
upload_date = video['snippet']['publishedAt']
upload_date = str(upload_date).split("T")[0]
#colleccting view, like, dislike, comment counts
url_video_stats = "https://www.googleapis.com/youtube/v3/videos?id="
+video_id+"&part=statistics&key="+API_KEY
response_video_stats = requests.get(url_video_stats).json()
view_count = response_video_stats['items'][0]['statistics']
['viewCount']
like_count = response_video_stats['items'][0]['statistics']
['likeCount']
dislike_count = response_video_stats['items'][0]['statistics']
['dislikeCount']
comment_count = response_video_stats['items'][0]['statistics']
['commentCount']
保存到 Pandas DataFrame
现在让我们构建一个 Pandas DataFrame,以便保存所有这些信息。由于我们已经知道了所有要保存的信息,我们将创建一个空白的 Pandas DataFrame,并在 'for loop' 之前添加列标题。
df = pd.DataFrame(columns=["video_id","video_title","upload_date",
"view_count","like_count","dislike_count","comment_count"])
接下来,我们将把在 'for loop' 中保存到变量的数据追加到这个 Pandas DataFrame 中。我们将在 'for loop' 内部使用 append() 方法来实现这一点。
df = df.append({'video_id':video_id,'video_title':video_title,
'upload_date':upload_date,'view_count':view_count,
'like_count':like_count,'dislike_count':dislike_count,
'comment_count':comment_count},ignore_index=True)
整个 'for loop' 看起来是这样的:
for video in response['items']:
if video['id']['kind'] == "youtube#video":
video_id = video['id']['videoId']
video_title = video['snippet']['title']
video_title = str(video_title).replace("&","")
upload_date = video['snippet']['publishedAt']
upload_date = str(upload_date).split("T")[0]
#collecting view, like, dislike, comment counts
url_video_stats = "https://www.googleapis.com/youtube/v3/videos?id="
+video_id+"&part=statistics&key="+API_KEY
response_video_stats = requests.get(url_video_stats).json()
view_count = response_video_stats['items'][0]['statistics']
['viewCount']
like_count = response_video_stats['items'][0]['statistics']
['likeCount']
dislike_count = response_video_stats['items'][0]['statistics']
['dislikeCount']
comment_count = response_video_stats['items'][0]['statistics']
['commentCount']
df = df.append({'video_id':video_id,'video_title':video_title,
'upload_date':upload_date,'view_count':view_count,
'like_count':like_count,'dislike_count':dislike_count,
'comment_count':comment_count},ignore_index=True)
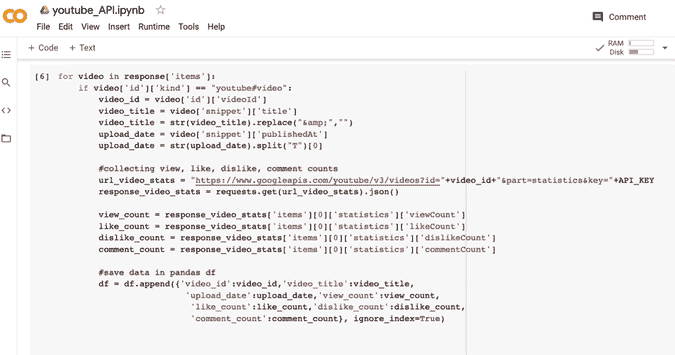

我们目前编写的代码运行得非常好,但仍有一些可以改进的地方。主要需要改进的是将抓取视频信息的 API 调用与主部分分开,因为第二次 API 调用的逻辑不需要与保存数据的逻辑混合。
因此,我们可以将第二次 API 调用分离到自己的函数中,只需传递我们从第一次 API 调用中收集到的 video_id。
def get_video_details(video_id):
url = "https://www.googleapis.com/youtube/v3/videos?id="+video_id+"&
part=statistics&key="+API_KEY
response = requests.get(url).json()
return response['items'][0]['statistics']['viewCount'],\
response['items'][0]['statistics']['likeCount'],\
response['items'][0]['statistics']['dislikeCount'],\
response['items'][0]['statistics']['commentCount']
然后我们可以将主要工作封装到一个函数中。
def get_videos(df):
pageToken = ""
while 1:
url = "https://www.googleapis.com/youtube/v3/search?key="+API_KEY+"
&channelId="+CHANNEL_ID+"&part=snippet,id&order=date&maxResults=10000&"
+pageToken
response = requests.get(url).json()
time.sleep(1) #give it a second before starting the for loop
for video in response['items']:
if video['id']['kind'] == "youtube#video":
video_id = video['id']['videoId']
video_title = video['snippet']['title']
video_title = str(video_title).replace("&","")
upload_date = video['snippet']['publishedAt']
upload_date = str(upload_date).split("T")[0]
print(upload_date)
view_count, like_count, dislike_count, comment_count = get_
video_details(video_id)
df = df.append({'Video_id':video_id,'Video_title':
video_title,
"Upload_date":upload_date,"View_count":
view_count,
"Like_count":like_count,"Dislike_count":
dislike_count,
"Comment_count":comment_count},ignore_index=
True)
try:
if response['nextPageToken'] != None: #if none, it means it
reached the last page and break out of it
pageToken = "pageToken=" + response['nextPageToken']
except:
break
return df
最后,我们可以以这种方式调用函数。
df = pd.DataFrame(columns=["Video_id","Video_title","Upload_date",
"View_count","Like_count","Dislike_count","Comment_count"]) #build our
dataframe
df = get_videos(df)
print(df)
让我们看看最终的输出,我们得到一个 Pandas DataFrame,其中包括 video_id、video_title、upload_date、view_count、like_count、dislike_count 和 comment_count。
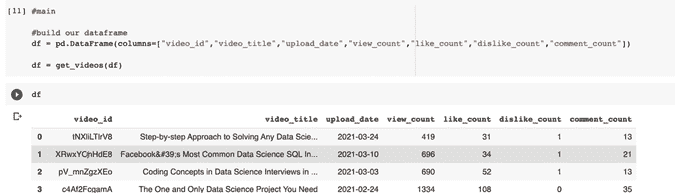
这就是你可以在数据科学项目中使用 Python API 的方法,从 API 中获取数据并将其保存到 Pandas DataFrame 中。作为数据科学家,你应该知道如何从 API 中抓取数据。让我们来分解一下我们所执行的步骤:
-
学会了使用 request 库进行 API 调用
-
向 YouTube API 发出了 API 调用:我们向 API 传递了一个 URL,指定了我们想要的数据。我们必须仔细阅读文档来构建 URL。
-
将数据收集为 JSON:我们将数据作为 JSON 对象收集,并首先将其解析为变量。
-
将数据保存为 Pandas DataFrame
-
最后,我们添加了一些错误处理逻辑并清理了代码
找到一些令人兴奋的 Python 数据科学家职位面试问题,这些问题适合初学者或寻找更具挑战性的任务的人。
个人简介:Nathan Rosidi (@StrataScratch) 是一名数据科学家和产品策略专家。他还是一名兼职教授,教授分析课程,并且是 StrataScratch 的创始人,该平台帮助数据科学家准备顶级公司的真实面试问题。
相关内容:
-
生产就绪的机器学习 NLP API 使用 FastAPI 和 spaCy
-
使用 Flask 构建 RESTful API
-
构建你的第一个数据科学应用程序
更多相关话题
Python 基础:语法、数据类型和控制结构
原文:
www.kdnuggets.com/python-basics-syntax-data-types-and-control-structures
作者提供的图片
你是一个初学者,想学习 Python 编程吗?如果是的话,这个适合初学者的教程将帮助你熟悉语言的基础知识。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
本教程将介绍 Python 的——相当于英语友好的——语法。你还将学习如何处理不同的数据类型、条件语句和循环。
如果你已经在开发环境中安装了 Python,请启动一个 Python REPL 并开始编写代码。或者如果你想跳过安装——立即开始编码——我建议你前往Google Colab并开始编写代码。
你好,Python!
在我们用 Python 编写经典的“Hello, world!”程序之前,先了解一下这门语言。Python 是解释型语言。这是什么意思?
在任何编程语言中,你编写的所有源代码都应该被翻译成机器语言。虽然像 C 和 C++这样的编译语言需要在程序运行之前获得整个机器代码,但解释器会解析源代码并即时解释。
创建一个 Python 脚本,输入以下代码并运行:
print("Hello, World!")
为了打印出Hello, World!,我们使用了print()函数,它是 Python 中的众多内置函数之一。
在这个超简单的例子中,请注意“Hello, World!”是一个序列——一串字符。Python 字符串由一对单引号或双引号界定。因此,要打印任何消息字符串,你可以使用print("<message_string>")。
读取用户输入
现在让我们更进一步,使用input()函数从用户那里读取一些输入。你应该始终提示用户,让他们知道应该输入什么。
这是一个简单的程序,它接收用户的名字作为输入,并向他们问好。
注释通过提供额外的上下文来帮助提高代码的可读性。Python 中的单行注释以#开头。
请注意,代码片段中的字符串前面有一个f。这样的字符串称为格式化字符串或 f-strings。要在 f-string 中替换变量的值,请在一对大括号中指定变量的名称,如下所示:
# Get user input
user_name = input("Please enter your name: ")
# Greet the user
print(f"Hello, {user_name}! Nice to meet you!")
当你运行程序时,系统会首先提示你输入,然后打印出问候信息:
Please enter your name: Bala
Hello, Bala! Nice to meet you!
让我们继续学习 Python 中的变量和数据类型。
Python 中的变量和数据类型
变量在任何编程语言中都像容器,用于存储信息。在我们编写的代码中,我们已经创建了一个变量user_name。当用户输入他们的名字(一个字符串)时,它会存储在user_name变量中。
Python 中的基本数据类型
让我们通过基本的数据类型在 Python 中逐一了解:int、float、str和bool,使用简单的示例逐步进行:
整数(int):整数是没有小数点的整数。你可以这样创建整数并将其分配给变量:
age = 25
discount= 10
这些是将值分配给变量的赋值语句。在像 C 这样的语言中,你需要在声明变量时指定数据类型,但 Python 是动态类型语言。它从值中推断数据类型。因此,你可以重新分配变量以保存完全不同数据类型的值:
number = 1
number = 'one'
你可以使用type函数检查 Python 中任何变量的数据类型:
number = 1
print(type(number))
number是一个整数:
Output >>> <class 'int'>
我们现在将一个字符串值分配给number:
number = 'one'
print(type(number))
Output >>> <class 'str'>
浮点数(float):浮点数表示带有小数点的实数。你可以这样创建float数据类型的变量:
height = 5.8
pi = 3.14159
你可以对数值数据类型进行各种操作——加法、减法、整数除法、指数运算等。以下是一些示例:
# Define numeric variables
x = 10
y = 5
# Addition
add_result = x + y
print("Addition:", add_result) # Output: 15
# Subtraction
sub_result = x - y
print("Subtraction:", sub_result) # Output: 5
# Multiplication
mul_result = x * y
print("Multiplication:", mul_result) # Output: 50
# Division (floating-point result)
div_result = x / y
print("Division:", div_result) # Output: 2.0
# Integer Division (floor division)
int_div_result = x // y
print("Integer Division:", int_div_result) # Output: 2
# Modulo (remainder of division)
mod_result = x % y
print("Modulo:", mod_result) # Output: 0
# Exponentiation
exp_result = x ** y
print("Exponentiation:", exp_result) # Output: 100000
字符串(str):字符串是字符的序列,封装在单引号或双引号中。
name = "Alice"
quote = 'Hello, world!'
布尔值(bool):布尔值表示True或False,指示条件的真实性。
is_student = True
has_license = False
Python 在处理不同数据类型方面的灵活性使你能够有效地存储、执行各种操作和操控数据。
这是一个将我们迄今为止学到的所有数据类型结合在一起的示例:
# Using different data types together
age = 30
score = 89.5
name = "Bob"
is_student = True
# Checking if score is above passing threshold
passing_threshold = 60.0
is_passing = score >= passing_threshold
print(f"{name=}")
print(f"{age=}")
print(f"{is_student=}")
print(f"{score=}")
print(f"{is_passing=}")
这是输出结果:
Output >>>
name='Bob'
age=30
is_student=True
score=89.5
is_passing=True
超越基本数据类型
假设你正在管理一个教室中的学生信息。创建一个集合来存储所有学生的信息会比为每个学生重复定义变量更有帮助。
列表
列表是有序的项集合——用一对方括号括起来。列表中的项可以是相同或不同的数据类型。列表是可变的,这意味着你可以在创建后更改其内容。
这里,student_names包含学生的名字:
# List
student_names = ["Alice", "Bob", "Charlie", "David"]
元组
元组是类似于列表的有序集合,但它们是不可变的,这意味着你不能在创建后更改其内容。
假设你希望student_scores成为一个不可变的集合,包含学生的考试成绩。
# Tuple
student_scores = (85, 92, 78, 88)
字典
字典是键值对的集合。字典的键应该是唯一的,它们映射到对应的值。字典是可变的,允许你将信息与特定键关联起来。
在这里,student_info包含关于每个学生的姓名和分数作为键值对:
student_info = {'Alice': 85, 'Bob': 92, 'Charlie': 78, 'David': 88}
但请稍等,还有一种更优雅的方法来创建 Python 中的字典。
我们即将学习一个新概念:字典推导式。如果一开始不清楚没关系。你可以随时学习更多并在以后继续研究。
但推导式相当直观。如果你想让student_info字典的键是学生姓名,对应的值是他们的考试分数,你可以这样创建字典:
# Using a dictionary comprehension to create the student_info dictionary
student_info = {name: score for name, score in zip(student_names, student_scores)}
print(student_info)
请注意我们如何使用zip()函数同时遍历student_names列表和student_scores元组。
Output >>>
{'Alice': 85, 'Bob': 92, 'Charlie': 78, 'David': 88}
在这个例子中,字典推导式直接将student_names列表中的每个学生姓名与student_scores元组中的对应考试分数配对,创建了student_info字典,其中姓名作为键,分数作为值。
现在你已经熟悉了基本数据类型以及一些序列/可迭代对象,让我们进入讨论的下一部分:控制结构。
Python 中的控制结构
当你运行一个 Python 脚本时,代码按脚本中的顺序依次执行。
有时,你需要实现逻辑来根据特定条件控制执行流程,或遍历可迭代对象以处理其中的项目。
我们将学习如何通过 if-else 语句实现分支和条件执行。我们还将学习如何使用循环遍历序列,以及循环控制语句 break 和 continue。
If 语句
当你需要仅在特定条件为真时执行一块代码时,你可以使用if语句。如果条件为假,这块代码将不会被执行。
图片由作者提供
考虑这个例子:
score = 75
if score >= 60:
print("Congratulations! You passed the exam.")
在这个例子中,只有当score大于或等于 60 时,if块中的代码才会被执行。由于score是 75,因此将打印出“恭喜!你通过了考试。”
Output >>> Congratulations! You passed the exam.
If-else 条件语句
if-else语句允许你在条件为真时执行一块代码,而在条件为假时执行另一块代码。
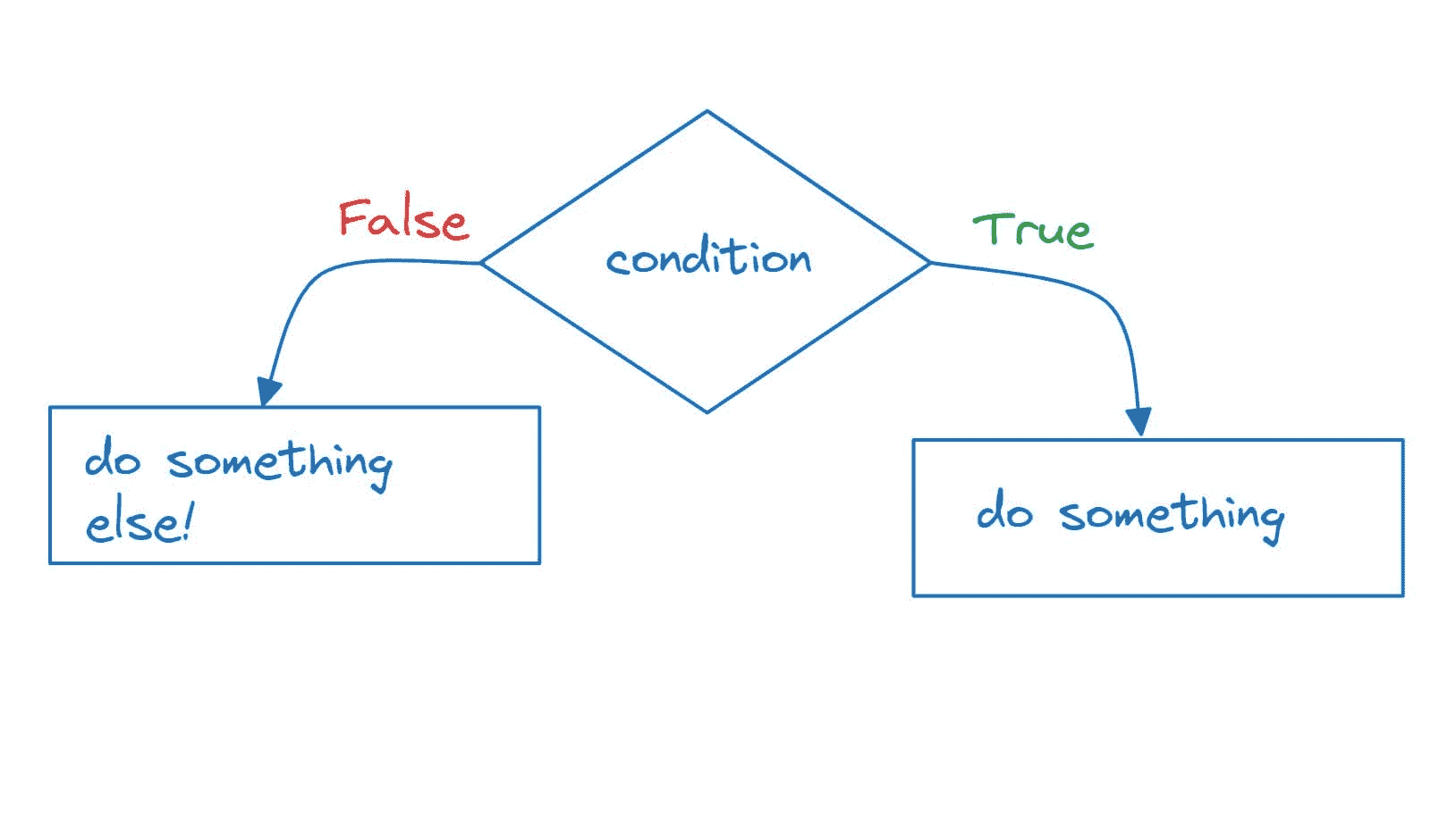
图片由作者提供
让我们基于测试分数的例子进行扩展:
score = 45
if score >= 60:
print("Congratulations! You passed the exam.")
else:
print("Sorry, you did not pass the exam.")
在这里,如果score小于 60,else块中的代码将被执行:
Output >>> Sorry, you did not pass the exam.
If-elif-else 结构
if-elif-else语句用于在有多个条件需要检查时。它允许你测试多个条件,并为第一个满足条件的情况执行相应的代码块。
如果if和所有elif语句中的条件都为假,则执行else块。
图片来源:作者
score = 82
if score >= 90:
print("Excellent! You got an A.")
elif score >= 80:
print("Good job! You got a B.")
elif score >= 70:
print("Not bad! You got a C.")
else:
print("You need to improve. You got an F.")
在这个例子中,程序检查score是否符合多个条件。第一个满足条件的代码块将被执行。由于score是 82,我们得到:
Output >>> Good job! You got a B.
嵌套if语句
嵌套的if语句用于在另一个条件内检查多个条件。
name = "Alice"
score = 78
if name == "Alice":
if score >= 80:
print("Great job, Alice! You got an A.")
else:
print("Good effort, Alice! Keep it up.")
else:
print("You're doing well, but this message is for Alice.")
在这个例子中,有一个嵌套的if语句。首先,程序检查name是否是"Alice"。如果为真,它会检查score。由于score是 78,因此执行内部的else块,打印"Good effort, Alice! Keep it up."。
Output >>> Good effort, Alice! Keep it up.
Python 提供了几种循环结构来迭代集合或执行重复任务。
for循环
在 Python 中,for循环提供了一种简洁的语法,让我们能够迭代现有的可迭代对象。我们可以这样迭代student_names列表:
student_names = ["Alice", "Bob", "Charlie", "David"]
for name in student_names:
print("Student:", name)
上述代码的输出为:
Output >>>
Student: Alice
Student: Bob
Student: Charlie
Student: David
while循环
如果你想在某个条件为真时执行一段代码,你可以使用while循环。
让我们使用相同的student_names列表:
# Using a while loop with an existing iterable
student_names = ["Alice", "Bob", "Charlie", "David"]
index = 0
while index < len(student_names):
print("Student:", student_names[index])
index += 1
在这个例子中,我们有一个包含学生姓名的student_names列表。我们使用while循环通过跟踪index变量来迭代列表。
循环会继续进行,只要index小于列表的长度。在循环内部,我们打印每个学生的姓名,并增加index以移动到下一个学生。注意使用len()函数来获取列表的长度。
这与使用for循环迭代列表得到的结果相同:
Output >>>
Student: Alice
Student: Bob
Student: Charlie
Student: David
我们使用一个while循环,从列表中弹出元素直到列表为空:
student_names = ["Alice", "Bob", "Charlie", "David"]
while student_names:
current_student = student_names.pop()
print("Current Student:", current_student)
print("All students have been processed.")
列表方法pop移除并返回列表中的最后一个元素。
在这个例子中,while循环只要student_names列表中还有元素就会继续进行。在循环内部,使用pop()方法来移除并返回列表中的最后一个元素,并打印当前学生的姓名。
循环会继续,直到所有学生都被处理完毕,并在循环外打印最终消息。
Output >>>
Current Student: David
Current Student: Charlie
Current Student: Bob
Current Student: Alice
All students have been processed.
for循环通常在迭代现有可迭代对象如列表时更为简洁且易读。但while循环在循环条件更复杂时可以提供更多控制。
循环控制语句
break会提前退出循环,而continue会跳过当前迭代的其余部分并进入下一次迭代。
这是一个示例:
student_names = ["Alice", "Bob", "Charlie", "David"]
for name in student_names:
if name == "Charlie":
break
print(name)
当name为 Charlie 时,控制从循环中跳出,输出结果为:
Output >>>
Alice
Bob
模拟 Do-While 循环行为
在 Python 中,没有像某些其他编程语言中的 do-while 循环。然而,你可以使用带有 break 语句的 while 循环来实现相同的行为。下面是如何在 Python 中模拟 do-while 循环:
while True:
user_input = input("Enter 'exit' to stop: ")
if user_input == 'exit':
break
在这个例子中,循环将无限运行,直到用户输入“exit”。循环至少运行一次,因为条件最初设置为 True,然后在循环内部检查用户的输入。如果用户输入“exit”,则会执行 break 语句,从而退出循环。
这是一个示例输出:
Output >>>
Enter 'exit' to stop: hi
Enter 'exit' to stop: hello
Enter 'exit' to stop: bye
Enter 'exit' to stop: try harder!
Enter 'exit' to stop: exit
请注意,这种方法类似于其他语言中的do-while循环,其中循环体在检查条件之前至少会执行一次。
总结与下一步
希望你能顺利跟随这个教程进行编码。现在你已经掌握了 Python 的基础知识,是时候开始编码一些超级简单的项目,以应用你所学到的所有概念了。
Bala Priya C 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和咖啡!目前,她正在通过撰写教程、使用指南、观点文章等,与开发者社区分享她的知识。
更多相关内容
Python 控制流程备忘单
原文:
www.kdnuggets.com/2022/11/python-control-flow-cheatsheet.html
顺其自然
程序不仅仅是从第一行到最后一行逐条执行的命令序列。编程需要能够循环处理数据,根据输入做出决策,并在达到特定目标之前运行命令,还有许多其他执行策略。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
我们控制程序中命令执行的方式称为流程控制。由于控制代码执行的流程可能对程序有很大影响,计算算法是命令的组合以及它们的执行顺序。不了解如何控制你的代码执行,你作为程序员将无法完成太多事情。
自从 goto 的时代以来,流程控制的状态已经取得了很大的进展。大多数现代编程语言中都有许多常见的执行模式,尽管它们的语法因语言而异。Python 有自己的一套通常比较可读的流程控制,这正是我们最新备忘单关注的内容。
准备好学习流程控制,并在你征服编程世界的过程中拥有一个便捷的参考。
你可以 在这里下载备忘单。
我们新的快速参考备忘单 将为你提供在 Python 中实现流程控制的理解。这个资源将提供一个概述和快速参考:
-
比较运算符
-
布尔运算符
-
if语句 -
三元条件运算符
-
while循环 -
for循环
流程控制是编程的一个重要方面,因此每位有志于编程的人都需要掌握它。矛盾的是,尽管程序员在职业生涯中不断进步,但对于一些常用命令和结构的确切语法,程序员往往仍需进行查阅。本备忘单提供了你快速学习这些策略所需的信息,并作为未来参考。
立即查看,并请持续关注更多内容。
更多相关内容
Python 用于数据分析……真的那么简单吗?!
原文:
www.kdnuggets.com/2020/04/python-data-analysis-really-that-simple.html
评论
由 Ferenc Bodon 博士,数据工程师,Kx 云解决方案架构师

图形设计及制作由 CineArt 完成
Python 是一种流行的编程语言,易于学习,效率高,并且得到了一个大型活跃社区的支持。它是一个通用语言,具有专门针对各种领域的库,包括网页开发、脚本编写、数据科学和 DevOps。
它的主要数据分析库 Pandas 在数据科学家和数据工程师中获得了很大人气。它遵循 Python 的原则,因此似乎易于学习、阅读并允许快速开发……至少基于教科书的示例。但如果我们离开教科书示例的安全和便利世界会发生什么?Pandas 是否仍然是一个易于使用的表格数据分析工具?它与其他专业工具如 R 和 kdb+ 相比表现如何?
在这篇文章中,我将通过执行一些基于多个列的聚合的示例,探讨超出最简单用例的情况。我的用例复杂度大约在 5 级中的第 2 级。任何分析数据表的人都会遇到这个问题,可能在第二周。为了比较,我还将介绍其他旨在数据分析的流行工具。
-
首先,这个问题可以通过 ANSI SQL 解决,因此所有传统的 RDBM 系统如 PostegreSQL、MySQL 等都可以参与。在实验中,我将使用 BigQuery,这是 Google 提供的一种无服务器、高度可扩展的数据仓库解决方案。
-
R编程语言专为统计分析设计。它通过其类data.frame本地支持表格。由于核心函数aggregate的限制,使用多重聚合非常不方便。R 社区开发了库plyr以简化 data.frame 的使用。库plyr已经停用,库dplyr被引入,承诺提供改进的 API 和更快的执行速度。库dplyr是tidyverse集合的一部分,旨在用于专业数据科学工作。它提供了一个抽象查询层,并将查询与数据存储解耦,无论数据是 data.frame 还是支持 ANSI SQL 的外部数据库。库data.table是dplyr的一个替代方案,以其速度和简洁的语法而闻名。data.table 也可以通过 dplyr 语法进行查询。
-
在Q/Kdb+编程语言中,表格也是一等公民,并且速度是语言的主要设计概念。Kdb+ 利用多核处理器,并从 2004 年诞生之初就使用了 map-reduce(如果数据在磁盘上是分区的)。从 4.0 版本(2020 年 3 月发布)开始,大多数原语(如 sum、avg、dev)使用从属线程并行执行,即使表格在内存中。生产力是另一个设计考量——任何不有助于理解的冗余编程元素(即使是一个括号)都被视为视觉噪音。Kdb+ 是任何数据分析工具的良好候选者。
我将考虑各种解决方案的优雅性、简洁性和速度。同时,我会调查如何调优性能,并通过并行计算利用多核处理器或计算机集群。
问题
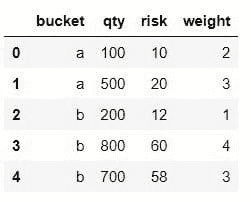
我们得到一个简单的表格,包含四列,其中一列是名义列,称为bucket,另外三列是数值列,分别是qty、risk和weight。为了简化起见,我们假设数值列包含整数。
我们希望查看每个bucket的情况。
-
元素的数量,作为列 NR
-
qty 和 risk 的总和和平均值,作为列 TOTAL_QTY/TOTAL_RISK 和 AVG_QTY/AVG_RISK
-
qty 和 risk 的加权平均值,作为列 W_AVG_QTY 和 W_AVG_RISK。权重在列 weight 中提供。
为了得到解决方案,我不会使用任何已弃用的方法,例如 通过嵌套字典重命名聚合。让我们分别解决每个任务。
每个桶中的元素数量
获取每个桶中的元素数量看起来不太吸引人,需要大量输入

字面上的 bucket 被要求三次,并且你需要使用 5 个括号/圆括号 ????。
R 中的解决方案看起来更具吸引力。

dplyr 和 data.table 库的开发人员也厌恶字词重复。他们分别引入了特殊的内置变量 n() 和 .N,用于表示当前组中的观察数量。这简化了表达式,我们可以省略一对括号。
ANSI SQL 表达式简单易懂。
你可以通过在 GROUP BY 子句中使用列索引来避免字面上的重复。依我看,这不是一个推荐的设计,因为表达式不具自我文档性且不够稳健。实际上,Apache 已弃用数字的使用 在 GROUP BY 子句中。
kdb+ 表达式更优雅。它不需要括号、引号或任何字词重复。

SQL 是数据分析的基础,因此每个人可能都理解 ANSI SQL 和 kdb+ 解决方案。R 和 kdb+ 开发人员同意“GROUP BY”过于冗长,简单的“by”字面量就足够表达。
请注意,除了 Pandas 之外,没有语言在这个简单表达式中使用任何引号。在 Pandas 中,查询需要四对引号 ???? 来包裹列名。在 R、SQL 和 kdb+ 中,你可以像引用变量一样引用列。R 中的 .() 表示 list(),允许这种方便的特性。
多列的聚合
使用 Pandas 计算单列的总和和平均值以及多个列的总和都非常简单




如果你尝试将这两种方法结合起来,代码会变得很麻烦,因为这会导致列名冲突。需要引入 多级列和函数 map。


SQL、R 和 kdb+ 的等效方式不需要引入任何新概念。新的聚合操作只需用逗号分隔即可。你可以使用关键字 sum和 avg/mean来分别获取总和和平均值。

观察 kdb+ 表达式的简洁性;它不需要括号或方括号。

加权平均
加权平均由 Numpy 库支持,而 Pandas 依赖于该库。不幸的是,它不能像 np.sum 一样使用。你需要将其包装在 lambda 表达式中,引入一个局部变量,使用 apply而不是 agg,并从系列创建数据框。


标准 SQL 以及其 Google 扩展 BigQuery 都没有提供内置的加权平均函数。你需要记住定义并手动实现它。

同样,R 和 Q/Kdb+ 的解决方案也不需要引入任何新概念。加权平均函数是原生支持的,接受两个列名作为参数。

在 kdb+ 中,你可以使用中缀表示法来获得更自然的语法——只需说“w 加权平均 x”。

一语双关
让我们将所有部分放在一起。我们创建了多个数据框,因此我们需要将它们合并。


请注意,第一个 join 表达式与其他表达式无关。它从一个字符串列表中创建一个字符串,而其他表达式则执行 left joins。
为了获得最终结果,我们需要三个表达式和一个临时变量res。如果我们花更多时间去搜索论坛,我们会发现这个复杂性部分是由于函数 agg 中嵌套字典的弃用造成的。同时,我们可能会发现使用仅函数 apply 的另一种不太被记录的方法,无需连接。不幸的是,这种解决方案返回所有类型为 float 的数值列,因此需要显式地转换整数列。
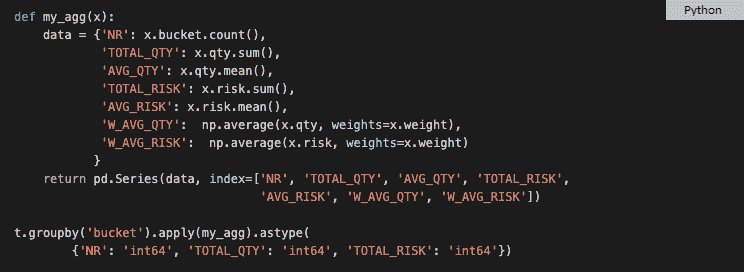
这个解决方案需要创建一个可能在源代码中永远不会再使用的临时函数。我们可以将所有语句压缩到一个无状态的解决方案中,但这样会导致代码难以阅读和维护,且会变得嵌套。而且,这第二种方法在中型表格上会更慢。
Pandas 在 2019 年 7 月 18 日的发布 中支持了通过 named aggregator 的分组聚合。它提供了一种比前面提到的基于 apply 的解决方案更优雅的语法,并且不需要类型转换。同时,开发人员可能也认识到过多使用引号带来的痛苦。不幸的是,加权平均数不受支持,因为在聚合中只能使用单列。为了完整性,我们提供了新的正确语法,忽略了加权平均数的计算。很高兴看到输出列名称不再需要引号。

相比之下,SQL 早在 30 年前就已经能够提供优雅的解决方案。
让我们看看 R 是如何使用 data.table 来解决这个任务的

以及 kdb+ 中的解决方案是如何呈现的
看起来 kdb+ 具有最直观、最简单和最可读的解决方案。它是无状态的,不需要括号/方括号和临时变量(或函数)的创建。
那性能怎么样呢?
实验在 Windows 和 Linux 上使用稳定的最新二进制文件和库进行。查询执行了一百次,测试 Jupyter 笔记本可在 Github. 找到。数据是随机生成的。桶字段是大小为二的字符串,字段qty和risk由 64 位整数表示。R 中使用库 bit64 来获取 64 位整数。下表总结了以毫秒为单位的执行时间。坐标轴为对数刻度。将两个 Python 3.6.8 版本与 Pandas 0.25.3 比较了三个 R 库(版本 3.6.0)和两个 kdb+ 版本。
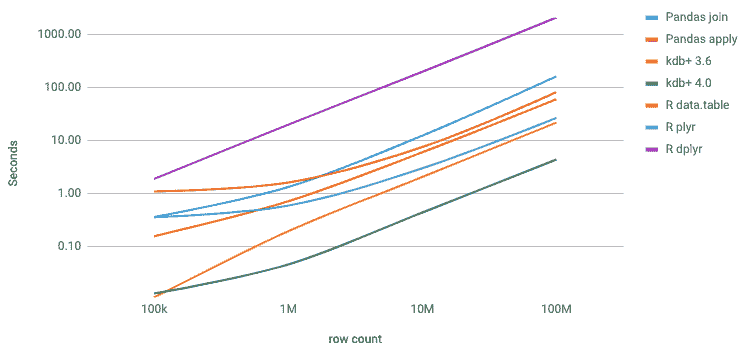
kdb+ 解决方案不仅比 Pandas 更优雅,而且速度快了一个数量级。R 的 data.table 1.12.6 版本在这个特定查询上比 kdb+ 3.6 慢三倍。kdb+ 4.0 在处理亿级行的表时比 kdb+ 3.6 快五倍。dplyr 0.8.3 版本比 plyr 1.8.5 慢两个数量级。
Pandas 在处理 10 亿行的输入表时达到了内存限制。所有其他解决方案都能处理这个数据量而不会耗尽内存。
让我们看看如何减少执行时间。
性能优化
列的桶包含字符串。如果领域大小很小且有很多重复,则建议使用分类值而不是字符串。类别类似于枚举,由整数表示,因此它们消耗的内存较少且比较速度更快。你可以通过以下方式在 Pandas 中将字符串转换为分类。

但在构建表格时创建分类列更节省内存。我们使用函数 product 通过运用 笛卡尔积生成长度为二的字符串全集。在下面的代码片段中,我们省略了创建其他列的语法。N 存储要插入的行数。

在 R 中,类别称为因素。类 data.frame 会自动将字符串转换为因素(使用 "stringAsFactors = FALSE" 以避免这种情况),但在 data.table 中,字符串被保留原样,原因很充分。

BigQuery 没有类别或因子的概念。相反,它应用了各种编码和压缩技术以实现最佳性能。要生成随机字符串,你可以使用 Unicode 码点、RAND 函数和CODE_POINTS_TO_STRING以及一些类型转换。小写字母 "a" 的码点是 97,你可以通过使用函数TO_CODE_POINTS来确定这一点。

你可以使用用户定义函数来避免代码重复。
相比之下,在 kdb+ 中,操作看起来是这样的:

构造N?M会根据 M 的类型生成 N 个随机值。如果 M 是整数、浮点数、日期或布尔值,则返回随机的整数、浮点数、日期或布尔值向量。如果 M 是列表,则会随机选择列表元素。如果 N 是负整数,则结果将不包含重复项。在 kdb+ 中,许多运算符以类似的方式被重载。
在 kdb+ 术语中,枚举被称为符号,并被开发者广泛使用。该语言强烈支持符号。你可以在不预定义可能值的情况下使用它们,kdb+ 会为你维护映射。
根据我的测量,通过类别/符号的优化在 Pandas 和 kdb+ 中将运行时间减少了两倍。R 的 data.table 显示了不同的特性。使用因子而不是字符串对性能没有影响。这是由于通过全局字符串池的内置字符串优化。尽管因子以 32 位整数存储,而字符串需要 64 位指针指向池元素,但这种差异对执行时间的影响微乎其微。
如果我们使用需要更少空间的类型,可以进一步提高性能。例如,如果列qty可以放入 2 字节,那么我们可以在 Pandas 中使用int16以及在 kdb+ 中使用short。这会导致较少的内存操作,而内存操作通常是数据分析中的瓶颈。R 不支持 2 字节整数,因此我们使用了其默认的占用 4 字节的整数类型。
默认的 32 位整数(在 R 中)会导致 5-6 倍的执行时间改进。仅在真正需要大基数时使用 64 位整数。特别是对于 dplyr 包尤其如此。
在计算聚合时,我们需要跟踪由于分组而产生的桶。如果表按组列排序,则聚合会更快,因为组已经在 RAM 中连续存储。执行时间在 Pandas 中降到约三分之一,在 R 中降到一半,在 kdb+ 中降到五分之一。下面展示了在排序表上进行类型优化后的执行时间,表大小为 10 亿。
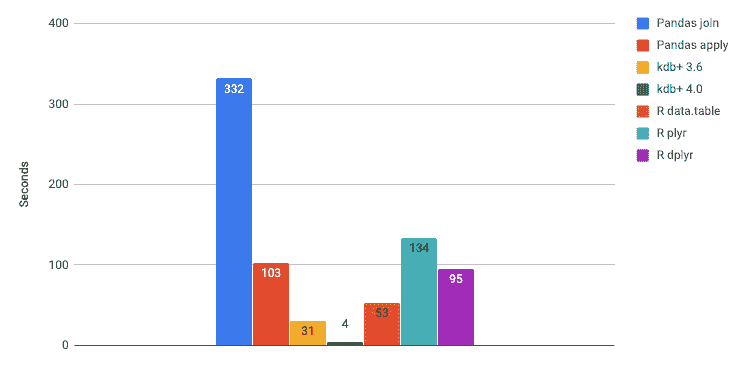
并行化
所有现代计算机都有多个 CPU 核心。Pandas 默认在单个核心上运行。我们需要做些什么才能使计算并行化并利用多个核心?
Python 库 Dask 和 Ray 是用于执行并行计算的两个最著名的库。库 Modin 是这些引擎之上的 Pandas 数据框的包装器。媒体广泛报道,通过将一行代码替换为

到

这对于少量教科书示例可能是正确的,但在实际生活中并不适用。在我的简单练习中,我遇到了 Ray 和 Dask 的多个问题。让我逐一描述这些问题,从 Ray 开始。
首先,类别类型不受支持。其次,函数 apply 和 agg 的行为与相应的 Pandas 函数不同。使用多个聚合与 agg 中的 group-by 不受支持,因此操作回退到 Pandas 操作。函数 applies 仅处理返回标量的 lambda 函数。这禁用了第二种更优雅的 Pandas 解决方案。此外,apply 返回一个 Modin 数据框,而不是一个系列。你需要转置结果并将列索引(0)重命名为有意义的列名,例如

最终,代码运行速度明显慢于 Pandas 等效版本,并且在处理 1 亿行数据时出现了故障。Pandas 和其他工具可以轻松处理 10 亿行数据。
转到 Dask 库也有一些麻烦。首先,如果桶的类型是分类的,它不处理加权平均数。我们失去了一个重要的性能提升技巧。其次,你需要提供类型提示以抑制警告。这意味着又一次列名重复。在更优雅的基于 apply 的解决方案中,你需要四次输入输出列名(如 TOTAL_QTY)☹️。因此,转到 Dask 并不像通过简单的 compute 语句扩展代码那样简单。

kdb+ 的并行化是自动的,对于版本 4.0 的磁盘上分区表和内存表都适用。你不会观察到任何类型问题 - 一切运行顺畅。你只需要通过 命令行参数 -s 启动 kdb+ 的多进程模式。 内置的 map-reduce 分解将计算扩展到多个核心,涵盖大多数操作,包括 sum、avg、count、wavg、cor,等等。你还可以通过手动分区表来获得性能提升,并使用函数 peach 并行执行函数。我们需要做的只是从

到
这种简单的代码修改使得在 16 核心的 kdb+ 版本 3.6 机器上执行速度提高了近一个数量级。由于版本 4.0 已经使用了并行计算,手动并行化没有价值。如果你追求最佳性能,那么代码在 kdb+ 4.0 中将比在 3.6 中更简单。
R data.table 默认也使用多个线程,并在后台并行执行查询。你可以通过函数 setDTthreads 检查和设置 data.table 使用的线程数量。
让我们比较所有语言中最有效版本的执行时间。对于 SQL,我们评估了 BigQuery,因为它由于大规模并行化被认为是处理大型数据集的最快 SQL 实现。
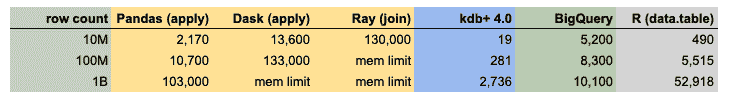
kdb+ 再次在这一类别中获胜,BigQuery 排名第二。R data.table 比 Pandas 快两倍。
超过 10 亿行
我们的经验中最大的数据表包含十亿行。超过这个数量,表格无法完全加载到内存中,因此 Pandas 不再适用。与其他竞争者相比,专为并行处理和计算机集群设计的 Dask 和 Ray 性能表现较差。对于 BigQuery,表的大小几乎无关紧要。 如果我们将行数从十亿增加到十亿或一百亿行,执行时间几乎不会增加。
在 kdb+ 中,数据可以持久化到磁盘,因此可以处理 TB 级别的数据。查询将保持不变,kdb+ 自动应用 map-reduce 并利用多核处理器。此外,如果数据被分段且分段位于具有独立 IO 通道的不同存储上,则 IO 操作将并行执行。这些低级优化使基于 kdb+ 的解决方案能够优雅地扩展。
使用 kdb+ 的分布式计算
作为一个最终的简单练习,我们来探讨如何将计算分布到多个 kdb+ 进程中,利用我们的机器集群,并水平分区我们的示例表。要实现类似 Ray/Dask/Spark 的分布式计算,kdb+ 有多困难?
函数 peach 使用外部的、从属的 kdb+ 进程,而不是从属线程,如果变量 .z.pd 存储连接到从属 kdb+ 进程的连接句柄。

我们可以通过桶值拆分表t

最后,我们可以分布式执行 select 语句并合并结果。函数 raze 类似于 Pandas 的 concat 函数。从一个表格列表中,它通过连接生成一个大表。

做得好!我们用四行代码实现了 "kdb-spark"。
代码简洁性
我收集了一些关于代码本身的统计数据。虽然短代码不一定意味着干净的代码,但对于这个特定的例子,这些指标与简洁性有很好的相关性。
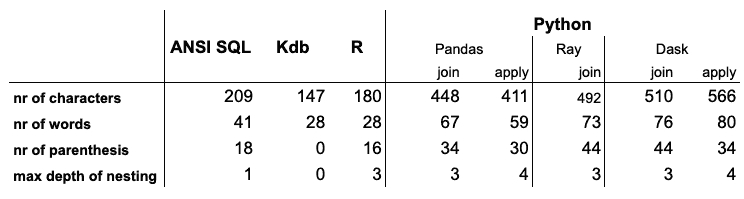
结论
我的观察结果汇总在下表中。表情符号 ???? 代表优秀,✔️ 代表良好,☹️ 代表令人失望的表现。
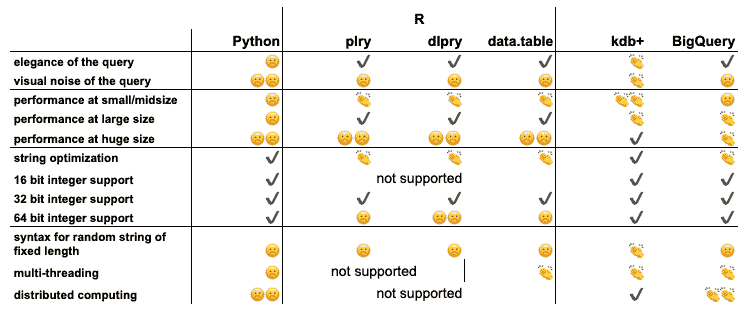
Python 通常是学生学习的第一个编程语言。它简单、性能优越,学习曲线平缓。它的库 Pandas 是将新手引入数据分析世界的自然步骤。Pandas 也常用于专业环境和更复杂的数据分析中。Pandas 在简单的教科书练习中看起来很诱人,但在我们的简单现实用例中使用起来不够方便。
目前更多的关注集中在扩展 Pandas 和通过集群计算支持大表。Ray、Dask 和 Modin 仍处于早期阶段,存在许多限制。在我们的用例中,它们只是增加了语法复杂性,并且实际上降低了性能。
R 在简洁性、优雅性和性能方面都优于 Pandas。它拥有几个内置的优化功能,例如固有的多线程。字符串表示的优化效果非常好,使得开发人员可以专注于分析而非细节问题。不足为奇的是,R data.table 正在 移植到 Python。也许未来 data.table 包会成为 Pandas 的替代品?
kdb+ 将数据分析提升到了一个新的水平。它设计用于极高的生产力。在我们的用例中,它在简洁性、优雅性和性能方面都是明显的赢家。难怪资本市场的 20 家顶尖组织中有 20 家选择了 kdb+ 作为数据分析的主要工具。在这个行业中,数据分析推动了收入,工具在极端条件下进行测试。
如果你没有手头的计算机集群,那么 BigQuery 在处理超过 100 亿行的数据时表现出色。如果你需要分析巨大的表格且对运行时间非常敏感,那么 BigQuery 能很好地满足你的需求。
相关工作
数据库操作基准测试 最初由 Matt Dowle 启动,他是 R data.table 的创建者。除了 Pandas、data.table、dask dplyr,他们还测试了 Apache Spark、ClickHouse 和 Julia 数据帧 在各种查询和不同参数下的表现。任何人都可以并排查看这些查询,甚至可以下载测试环境以进行自定义硬件的实验。
Mark Litwintschik 使用了 NYC 出租车驾驶数据库和四个查询,测试了 33 个数据库类系统。他提供了测试环境的详细描述、所用设置以及一些宝贵的个人备注。这是一项全面的工作,展示了 Mark 在大数据平台方面的杰出知识。他的观察与我们的实验一致,kdb+ 在非 GPU 基于的数据库解决方案中表现出最快的速度。
STAC-M3 基准测试最初由几家全球最大的银行和交易公司于2010 年开发。其目的是精确测量新兴硬件和软件创新如何提高时间序列分析的性能。在 STAC-M3 开发之后,kdb+迅速成为硬件供应商运行测试时的首选数据库平台,因为它设定了其他软件供应商无法超越的性能标准。此外,Google 也认可 STAC-M3 作为时间序列分析的行业标准基准。他们使用 kdb+来展示将数据和工作负载从本地迁移到 GCP 并不意味着性能的妥协。
致谢
我想感谢Péter Györök、Péter Simon Vargha和Gergely Daróczi提供的有见地的建议。
简介:Ferenc Bodon 博士 是一位经验丰富的数据工程师、软件开发人员、多语言程序员和软件架构师,拥有数据挖掘和统计学的学术背景。他具备长期思考能力,始终致力于寻找高质量、可靠且可扩展的解决方案,并允许快速开发。相信软件质量,并且在找到“卓越解决方案”之前无法放松。
原文。经许可转载。
相关:
-
10 个简单技巧加速你的 Python 数据分析
-
你所需的最后一份 SQL 数据分析指南
-
柏林租金冻结:我可以在网上找到多少非法的高价房源?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的捷径。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关话题
Python 数据准备案例文件:删除实例与基本插补
原文:
www.kdnuggets.com/2017/09/python-data-preparation-case-files-basic-imputation.html

数据准备涵盖了许多潜在的内容:数据集成、数据转换、特征选择、特征工程等等。数据准备的一个最基本、也是最重要的方面是处理缺失值。
从实际的角度来看,处理包含缺失值的数据实例有 3 种一般方法:
-
删除具有缺失值的数据实例
-
用某些派生值填充缺失值
-
如果你的算法可以处理缺失值,就保留缺失值原样
请记住,这些方法仅从技术角度来看。它们并没有解决在特定情境下哪个方法或方法组合是合适的。这些决策取决于对数据、领域和期望结果的理解,不能在这样的文章中详细讨论。
当然,删除具有缺失值的数据实例的第一种方法有多种实现方式:删除所有具有任何缺失值的实例;删除所有具有 2 个或更多缺失值的实例;删除所有仅缺少特定特征值的实例。同样,第二种方法,即填充缺失值——或称为插补——可以基于多种测量标准,包括均值、中位数、众数、回归或其他策略。第三种方法提到,一些机器学习算法,如随机森林,通常可以充分处理缺失值,而其他算法则无法处理。
由于第#1 点和第#3 点相对简单(尽管选择它们的推理可能复杂,但决定采纳后的操作相当简单),第#2 点,即插补,是我们将在本系列文章中主要讨论的内容。如你所见,插补的变种足够多,需要额外的关注。
我想再次提醒,这只是处理缺失数据值的几种方法的简要概述,并强调没有对任何特定情境下的某种方法表示认可,尤其是涉及到与领域相关的整体决策时。你应该注意在这些问题上需要寻求其他指导。
数据
对于这些练习,我们将使用一个通过Mockaroo构建的模拟银行信息数据集。该小数据集包括 10 个变量或特征(包括类别或目标变量)-- 对应于表格的列 -- 和 1000 个实例 -- 对应于表格的行(见图 1)。我们的练习目的是模拟一个使用银行客户数据来决定(并预测)是否向客户提供特别优惠的过程,假设“更好”的客户会收到优惠。
什么才是“更好”的客户?我们将如何对数据建模?我们现在还不太关心这些。我们将在数据准备过程中进行一些业余猜测,但终极目标是为建模和预测过程准备好数据集,而不是执行该过程。在现实生活中,你不想凭空揣测领域知识,但在此过程中,我们会对数据的有用性做出一些合理的假设。
我们的计划包括一些数据检查以及使用一些基本的填补方法来帮助填补数据集中的缺失值,并决定是否根据缺失的变量决定是否删除某些实例。
让我们开始导入数据集并查看它。我们还将总结缺失值。首先,在这里获取数据集。
py` import pandas as pd import numpy as np # 导入数据集 dataset_filename = 'mock_bank_data_original.csv' df = pd.read_csv(dataset_filename) # 总结缺失值 print 'Null values by variable:' print '------------------------' df.isnull().sum() py ```` py` Null values by variable: ------------------------ customer_id 18 name 0 email 158 sex 111 age 113 state 40 cheq_balance 23 savings_balance 96 credit_score 0 special_offer 0 dtype: int64py ```` 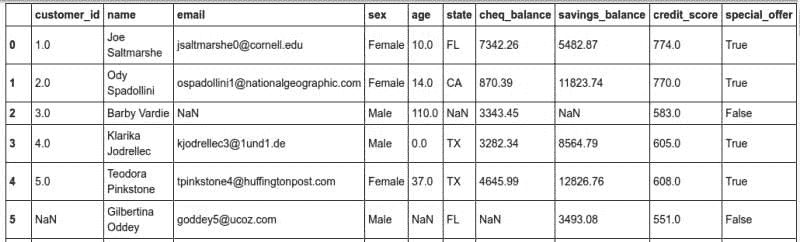
图 1: 我们练习的模拟银行数据集。
处理过程
本文将处理第一组数据预处理任务,具体包括删除某些实例和进行一些基本的填补。接下来的两篇文章将演示如何基于不同变量的类别成员身份进行填补(例如,使用华盛顿州所有人的平均薪资来确定华盛顿州居民的缺失薪资值)以及通过回归进行填补(例如,使用变量的组合进行线性回归,并基于结果线性回归模型填补不同变量的缺失值)。
删除缺失州值的实例
我们的初步假设是,我们将以客户所在的州为基础进行大部分准备,因此我们将不幸地牺牲任何缺少该变量值的实例。坏消息是我们将减少到 960 个实例;好消息是(希望)我们不会再牺牲更多。
插补缺失的信用评分
假设拥有领域知识的人已经指出,所有客户的中位信用评分可以作为有效的缺失值替代。虽然可以使用均值、最频繁值,或其他更复杂的方案,但我们的专家确保这是填补该变量缺失值的合适方法。
请注意,也可以使用类似于用同一州银行客户的平均信用评分进行替代的方法。然而,我们将把这种方法留到下一篇文章的任务中使用。
丢弃不必要的变量
由于我们不需要所有变量来预测哪个客户会收到优惠(例如,客户的名字是“Daniel”还是“Michael”不应有区别),我们将继续丢弃不必要的数据。我们可以将此任务留到所有数据预处理完成后,但由于这篇文章的步骤有点少,我们现在就利用机会完成它。
具体来说,我们绝对不需要 'customer_id'、'name' 或 'email' 变量。
保存新数据集
接下来,由于我们想将数据集保存为新形式以便在下一个教程中使用,我们将创建一个新的、最新的 CSV 文件。
代码
完整的代码及其注释如下所示。
这起步缓慢,我们进展不大,但希望这些麻烦对下一次有帮助,当我们讨论按类别成员进行插补,或基于组的插补,然后是回归插补时。很高兴的是,我们现在已经演示了基于相同变量的所有值的基本插补,以便将其与我们更具创意的方法进行比较。
嘿,至少我们已经完成了枯燥的部分。下一篇文章会很快发布;在此期间,请查看下面的相关帖子,以获取更多关于数据准备的阅读材料。
相关内容:
-
用 Python 掌握数据准备的 7 个步骤
-
从零开始的 Python 机器学习工作流 第一部分:数据准备
-
数据准备技巧、窍门和工具:内部人士的访谈
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关主题
Python 数据准备案例文件:基于分组的插补
原文:
www.kdnuggets.com/2017/09/python-data-preparation-case-files-group-based-imputation.html

这是本系列关于 Python 数据准备的第二篇文章,专注于基于分组的插补。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
复习
虽然第一篇文章展示了一种简单的插补缺失值的方法,基于相同变量的均值,但这并不是填补缺失值的最复杂方法。假设,如我们的数据集示例(见第一篇文章),我们有四个州的客户,我们希望利用这些州的居住地作为区分客户的手段,并相应地填补缺失值。这是一种更为细致的方法。
更具体地说,让我们使用给定状态下客户的平均账户余额来确定在相同状态下其他客户缺失余额值的替代值。
我不会详细介绍模拟数据或任务;可以查看第一篇文章以获取必要的背景。同时,在这里获取数据集(在第一篇文章练习后的状态)。
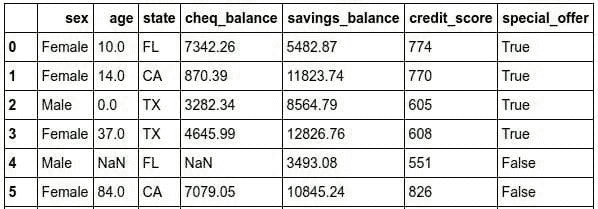
图 1: 我们练习的模拟银行数据集(练习 1 之后)。
过程
这次的过程非常简单,因为我们只有一个任务。
插补缺失账户余额
我们将假设我们的领域专家已得出结论,缺失的账户余额最好用同一状态下客户的平均账户余额来替代(这也是为什么我们必须删除缺少状态值的实例)。这将适用于支票账户和储蓄账户。
首先,让我们看看数据集中缺失值的当前状态。
import pandas as pd
import numpy as np
# Importing the dataset
dataset_filename = 'mock_bank_data_original.csv'
df = pd.read_csv(dataset_filename)
# Summarize missing values
print 'Null values by variable:'
print '------------------------'
df.isnull().sum()
Null values by variable:
------------------------
sex 108
age 107
state 0
cheq_balance 23
savings_balance 91
credit_score 0
special_offer 0
dtype: int64
我们的支票账户余额(请原谅“q”;我是加拿大人)和储蓄账户余额分别有 23 个和 91 个缺失值。
代码
首先,让我们比较按州划分的余额均值与总体均值(插补前),以满足兴趣。
print 'Overall cheq_balance mean:', df['cheq_balance'].mean().round(2)
print 'Overall savings_balance mean:', df['savings_balance'].mean().round(2)
Overall cheq_balance mean: 4938.91
Overall savings_balance mean: 9603.64
print 'cheq_balance mean by state:'
print '---------------------------'
print df.groupby(['state']).mean().groupby('state')['cheq_balance'].mean().round(2)
cheq_balance mean by state:
---------------------------
state
CA 4637.23
FL 4993.99
NY 4932.80
TX 5175.78
Name: cheq_balance, dtype: float64
print 'savings_balance mean by state:'
print '------------------------------'
print df.groupby(['state']).mean().groupby('state')['savings_balance'].mean().round(2)
savings_balance mean by state:
------------------------------
state
CA 9174.56
FL 9590.59
NY 10443.61
TX 9611.70
Name: savings_balance, dtype: float64
虽然可能没有预期的那么戏剧性,但很明显为什么这种基于分组的填补方法对于这种问题是有效的。例如,加利福尼亚州($9174.56)和纽约州($10443.61)之间的平均储蓄账户余额差异接近$1270。使用$9603.64 的整体均值来填补缺失值不会提供最准确的画面。这涉及到拟合优度。
现在我们可以使用 Pandas 的‘groupby’和‘transform’功能,以及一个 lambda 函数来填补这些缺失值。然后我们在下面的代码行中对结果进行四舍五入。
# Replace cheq_balance NaN with mean cheq_balance of same state
df['cheq_balance'] = df.groupby('state').cheq_balance.transform(lambda x: x.fillna(x.mean()))
df.cheq_balance = df.cheq_balance.round(2)
# Replace savings_balance NaN with mean savings_balance of same state
df['savings_balance'] = df.groupby('state').savings_balance.transform(lambda x: x.fillna(x.mean()))
df.savings_balance = df.savings_balance.round(2)
就这样。我们相关的缺失值现在已经用相同州的均值填补好了。
检查结果:
Null values by variable:
------------------------
sex 108
age 107
state 0
cheq_balance 0
savings_balance 0
credit_score 0
special_offer 0
dtype: int64
好了!
现在让我们保存数据集以备下次使用。
# Output modified dataset to CSV
df.to_csv('mock_bank_data_original_PART2.csv', index=False)
这就是本次练习的全部内容。我们仍然需要处理‘性别’和‘年龄’变量的缺失值。下次我们将探讨基于回归的填补方法,以帮助处理其中之一。
相关:
-
7 步掌握 Python 数据准备
-
从零开始的 Python 机器学习工作流第一部分:数据准备
-
数据准备技巧、窍门和工具:与内部人士的访谈
更多相关内容
一个 Python 数据处理脚本模板
原文:
www.kdnuggets.com/2021/08/python-data-processing-script-template.html
评论

像你们中的许多人一样,我倾向于编写许多用于执行类似任务的 Python 脚本,或至少遵循类似的功能模式。为了避免重复自己(或者从不同角度看,为了以完全相同的方式重复自己),我喜欢为这些类型的脚本设置模板代码,以保持编程生活尽可能轻松。
我最近写了关于 作为数据科学家的可重用 Python 代码管理 的文章,基于相同的思路,我整理了一个通用的 Python 数据处理脚本模板,这几乎是我现在开始大多数项目时使用的。它随着时间的推移发生了变化并进行了调整,但当前版本是我大多数非专业(即非机器学习)脚本的首选模板。
首先,这里简要介绍一下我现在通常希望通过脚本广泛实现的目标:
-
解析命令行参数
-
设置所需的路径和文件名
-
访问 Google Sheets 进行数据检索和存储
-
访问 SQL 数据库进行数据检索和存储
-
文件系统管理
-
HTML 和其他文本处理
-
使用一些我自己定制的 Python 模块
-
从互联网上检索一些资源,例如 HTML 或 CSV 文件
让我们一步步地查看代码。
库
我对导入的内容和方式很讲究。第一行导入(主要是)标准库模块;接下来的几行导入第三方库,顺序为“import”,“import ... as ...”,以及“from ... import ...”;导入一个名为 const 的自定义模块,它作为一个独立的 Python 文件包含不变的项目特定变量赋值(常量);最后,导入任何我自己定制的 Python 模块,在这种情况下是来自我自己的预处理库的“dates”模块。
import sys, re, datetime, os, glob, argparse, json, yaml, pprint, urllib.request, wget, logging
import gspread
import sqlite3
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
from oauth2client.service_account import ServiceAccountCredentials
import const
from my_preprocessing import dates
退出函数
除了错误日志记录,我还添加了一些退出函数,以便在后续代码中调用,原因各异。以下是一些示例,其中第一个是我总是包含的。
def quit():
"""Program was not initialized correctly"""
print("example: python template.py -o something_here -b")
sys.exit(1)
def custom_error(message):
"""Some other custom error"""
print("There is a problem: %s" % message)
sys.exit(2)
我喜欢 argparse,见下文,但我喜欢调用一个自定义退出函数,并给出如何初始化命令行脚本的具体示例,而不仅仅是 argparse 的默认消息。第二个函数显然会根据需要被重新用于特定的任务。
解析命令行参数
我使用 argparse 来解析命令行参数,为什么不呢?这些参数被包含在我的模板中,方便快速编辑,因此我不需要一直查阅文档。
# Parse and process command line args
parser = argparse.ArgumentParser(description='Python data processing command line template.')
parser.add_argument('required_arg', metavar='req', type=int,
help='a required arg of type int')
parser.add_argument('-o', '--optional', type=str, default='default_value',
help='optional arg of type str')
parser.add_argument('-b', '--boolean', action='store_true',
help='optional boolean arg, False if not used')
# Call custom function for additional console output when parse fails
try:
args = parser.parse_args()
except SystemExit:
quit()
# Assign command line args to variables
var_1 = args.req
var_2 = args.optional
var_3 = args.boolean
注意在 try/except 块中调用的自定义退出函数,以及将解析的参数分配给更友好的变量名。
数据文件名和路径
现在是设置项目特定数据文件名和路径的时候,因为我几乎总是在处理某种数据。将这些存储在 YAML 文件中的好处是它们被集中在一个地方,并且可以轻松更改而无需在代码中搜索。
# Process data filenames
files_yaml = '/path/to/files/config/files.yaml'
with open(files_yaml) as f:
files_dict = yaml.safe_load(f)
input_file = files_dict['input']
temp_file = files_dict['temp']
output_file = files_dict['output']
database_file = files_dict['example.db']
在这里,我从项目 YAML 文件中获取了输入、输出、临时和数据库文件,该文件位于同一目录中,如下所示:
input: '/path/to/project/specific/input/file'
output: '/path/to/project/specific/output/file'
temp: '/path/to/project/specific/temp/file'
database: '/path/to/project/specific/database/file.db'
文件名或位置有变化?只需在这里更改一次即可。
Google Sheets 设置和配置
我已经开始使用 Google Sheets 进行大部分(小规模)数据存储,因此我需要能够访问和操作这些数据。我使用 gspread 库来做到这一点,配置内容超出了本文的范围。
# Google Sheets API setup
creds_yaml = '/path/to/credentials/config/google_api.yaml'
with open(creds_yaml) as f:
creds_dict = yaml.safe_load(f)
scope = creds_dict['scope']
creds_file = creds_dict['creds_file']
creds = ServiceAccountCredentials.from_json_keyfile_name(creds_file, scope)
client = gspread.authorize(creds)
# Google Sheets workbook and sheet setup
data_workbook = 'sample-workbook'
data_sheet = client.open(data_workbook).sheet1
这段代码从一对 YAML 和 JSON 文件中获取 API 凭据数据,进行身份验证,并连接到特定的工作簿和特定的工作表,以便在后续代码中进行一些操作。
SQLite 设置和配置
我还定期使用 SQLite3 访问和操作 SQL 数据库。这里是设置和配置数据库连接的代码。
# Create database connection
con = sqlite3.connect(database_file)
# Perform some SQL tasks
cur = con.cursor()
# ...
# Save (commit) the changes
con.commit()
# Close connection
con.close()
BeautifulSoup、字符串操作和使用“常量”
抓取 HTML 是我常做的任务,我通过结合使用 BeautifulSoup 库、简单的字符串操作和正则表达式来完成。下面是设置 BeautifulSoup、删除一些 HTML 标签、使用存储在 const 模块中的一些变量进行简单字符串替换以及使用正则表达式的一些示例代码。这些都是示例代码段,可以在不查阅文档的情况下进行更改。
Using BeautifulSoup for HTML scraping """
# Make the soup
html = input_file.read()
soup = BeautifulSoup(html, 'lxml')
""" Using variables from imported const file """
# Drop invalid tags
for tag in const.INVALID_TAGS:
for match in soup.find_all(tag):
match.replaceWithChildren()
# BeautifulSoup bytes to string
soup_str = str(soup)
# String replacements and footer append
for pair in const.PAIRS:
soup_str = soup_str.replace(str(pair[0]), str(pair[1]))
soup_str += const.FOOTER_INFO
""" Using regular expressions substitution """
# Remove excess newlines
soup_str = re.sub(r'\n\s*\n\n', '\n', soup_str)
# Output resulting HTML to file, clean up
output_file.write(soup_str)
output_file.close()
input_file.close()
在这种情况下,最终结果被保存到文件中,所有打开的文件都被关闭了。
自定义库
这是一些自定义库功能的示例。有关此代码创建一些简单日期特征的功能,请查看 这里。由于我经常使用我的预处理代码片段集合,它们已被打包为 my_preprocessing 库,我会自动导入。
# Date feature engineering
my_date = dates.process_date('2021-12-31')
pprint.pprint(my_date)
整个模板
现在我们已经讨论了代码,这里是我每次创建新的数据处理脚本时复制并设置的整个 template.py 文件。
我希望有人觉得这有用。
相关:
-
作为数据科学家的可重用 Python 代码管理
-
Python 数据结构比较
-
使用 Python 自动化 Microsoft Excel 和 Word
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 方面的工作
了解更多相关话题
Python 数据科学入门
原文:
www.kdnuggets.com/2019/02/python-data-science-beginners.html
评论
作者 Saurabh Hooda,Hackr.io
为什么选择 Python?
Python 是一种流行的高级面向对象编程语言,被大量软件开发人员广泛使用。Guido van Rossum 于 1991 年设计了它,Python 软件基金会进一步发展了它。但问题是,既然已经有数十种基于面向对象概念的编程语言,为什么还需要这一个新语言?因此,开发此语言的主要目的是强调代码的可读性和科学及数学计算(如 NumPy、SymPy、Orange)。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
Python 的语法非常简洁且长度短。Python 是一种开源且可移植的语言,支持一个庞大的标准库。
从一个 Python 示例开始
# To Add Two Numbers
num1 = 1
num2 = 8
sum = num1+num2
print(sum)
输出
9
什么是数据科学?
你一定听说过数据科学,但你对这个术语了解多少?谁能成为数据科学家?
数据科学是一个包含各种工具、数据接口和应用机器学习原理的集合,用于从原始数据中发现隐藏的模式。原始数据存储在企业数据仓库中,并以创意方式使用,以从中生成商业价值。
通过这个信息图可以理解数据科学的应用。
数据分析师和数据科学家是不同的;数据分析师负责处理数据历史并解释发生了什么,而数据科学家需要各种高级机器学习算法,通过分析概念来识别特定事件的发生。
Python 数据科学简介
有多种编程语言可以用于数据科学(如 SQL、Java、Matlab、SAS、R 等),但Python 是数据科学家在所有这些编程语言中最为偏好的选择。
Python 具有一些卓越的优点,包括:
-
Python 非常强大且简单,因此易于学习。如果你是初学者,不需要担心语法问题。
-
Python 支持许多平台,如 Windows、Mac、Linux 等。
-
Python 是一种高级编程语言,因此你可以用接近英语的简单语言编写程序,这将内部转换为低级代码。
-
Python 是一种解释型语言,这意味着它一次运行一条指令。
-
Python 可以进行数据可视化、数据分析和数据处理;NumPy 和 Pandas 是一些用于处理的库。
-
Python 提供了各种强大的库用于机器学习和科学计算。使用这种语言,可以在相对简单的语法中轻松进行各种复杂的科学计算和机器学习算法。
开发人员偏爱 Python 的原因有很多。我们需要定义一些术语来解释,从数据处理开始。
数据处理用于快速而轻松地提取、过滤和转换数据,并且结果高效。有两个重要的库用于执行这些任务:NumPy 和 Pandas。
NumPy 是一个开源库,可以在 Python 中免费使用,代表着 Numerical Python。它是一个流行的 Python 库,在科学计算中非常有用,提供了数组对象以及集成 C 和 C++ 的工具。NumPy 提供了一个强大的 N 维数组,以行和列的形式呈现。这些可以从 Python 列表初始化。要使用它,首先需要通过命令提示符输入以下命令来安装库:conda install numpy。然后你可以进入 IDE 并输入 import numpy 以使用它。
示例:创建一个 NumPy 一维数组
首先,你需要导入 NumPy 库。为此,写:
import numpy as np
创建一个数组:
a = np.array([1, 2, 3])
a
输出
array([1, 2, 3])
类似地,Pandas 是一个强大的库,因其创建数据框的能力而闻名,并且可以用于数据处理和数据分析。Pandas 适用于各种数据,如矩阵、统计数据、观察数据等。要安装 Pandas,你需要按照与 NumPy 相同的步骤,在命令提示符中输入:conda install pandas。然后你可以进入 IDE 并输入 import pandas 以使用它。
示例:创建一个 Pandas 操作
首先,你需要导入 Pandas 库。为此,写:
import pandas as pd
创建 2 个列表:
lst1 = [‘a’, ’b’, ’c’]
lst2 = [1, 2, 3]
pd.Series(lst1)
输出:
0 a
1 b
2 c
dtype: object
在输出中,0、1、2 是索引。如果你想根据你的参考显示索引值,可以执行以下操作:
lst1 = [‘a’, ’b’, ’c’]
lst2 = [1, 2, 3]
pd.Series(lst1, index=lst2)
输出:
1 a
2 b
3 c
dtype: object
如何选择最佳的 Python 数据科学框架
Python 拥有许多用于数据分析、数据处理和数据可视化的框架。Python 编程是数据科学的理想选择,适用于评估大型数据集、可视化数据集等。
数据分析和 Python 编程 互为补充。Python 是数据科学的一个了不起的语言,非常适合那些希望进入数据科学领域的人。它支持大量的数组库和框架,提供了干净高效的数据科学工作选择。各种框架和库具有特定的用途,必须根据你的需求进行选择。在这里,我们列出了一些用于数据科学的 最佳 Python 框架。
初学者最佳 Python 数据科学框架
NumPy: 如我们之前总结的,NumPy 是 Numerical Python 的简称。它是 Python 编程中最受欢迎的库,并且是数据科学高级工具的基础。深入理解 NumPy 数组有助于有效使用 Pandas,特别是对数据科学家来说。NumPy 多才多艺,你可以处理多维数组和矩阵。NumPy 具有许多与统计、数值计算、线性代数、傅里叶变换等相关的内置函数。NumPy 是科学计算的标准库,提供强大的工具以与 C 和 C++ 集成。如果你想精通数据科学,那么 NumPy 是必须学习的库。
SciPy: 它是一个开源库,用于计算各种模块,如图像处理、积分、插值、特殊函数、优化、线性代数、傅里叶变换、聚类等许多任务。这个库与 NumPy 一起使用,以执行高效的数值计算。
SciKit: 这个受欢迎的库用于数据科学中的机器学习,提供各种分类、回归和聚类算法,支持支持向量机、朴素贝叶斯、梯度提升和逻辑回归。SciKit 旨在与 SciPy 和 NumPy 兼容。
Pandas: Pandas 以在 Python 中提供数据框而闻名。与其他领域特定语言如 R 相比,这是一个强大的数据分析库。使用 Pandas 更容易处理缺失数据,支持处理来自多个不同资源的不同索引数据,并支持自动数据对齐。它还提供数据分析和数据结构的工具,如合并、重塑或切片数据集,并且在处理时间序列数据时非常有效,提供强大的工具来加载来自 Excel、平面文件、数据库和快速 HDF5 格式的数据。
Matplotlib: Matplotlib 代表 Python 中的数学绘图库。这是一个主要用于数据可视化的库,包括 3D 图、直方图、图像图、散点图、条形图和带有缩放和平移功能的功率谱,以适应不同硬拷贝格式的发布。它支持几乎所有平台,如 Windows、Mac 和 Linux。该库还作为 NumPy 库的扩展。Matplotlib 具有一个 pyplot 模块,用于可视化,通常与 MATLAB 相比较。
这些库是初学者开始使用Python 编程语言进行数据科学的最佳选择。还有许多其他 Python 库,例如用于自然语言处理的 NLTK、用于网络挖掘的 Pattern、用于深度学习的 Theano、IPython、用于网页抓取的 Scrapy、Mlpy、Statsmodels 等。但是,对于刚开始学习数据科学的初学者来说,熟悉上述顶级库是必不可少的。
我们希望这篇文章能帮助你选择最佳的数据科学框架或库。如果你还有任何问题或需要指导或支持,可以联系我们。
简历: Saurabh Hooda 曾在全球电信和金融巨头公司担任多个职位。在 Infosys 和 Sapient 工作了十年后,他创办了自己的第一家公司 Leno,解决了一个超本地化的图书共享问题。他对产品营销和分析很感兴趣。他的最新项目 Hackr.io 推荐了每种编程语言的最佳数据科学教程和在线编程课程。所有教程均由编程社区提交和投票。
原创。转载需经许可。
相关:
-
冷启动问题:如何构建你的机器学习组合
-
探索 Python 基础知识
-
2018 年人工智能和数据科学的进展及 2019 年趋势
更多相关内容
Python 数据科学中的 Pandas 与 Spark DataFrame:关键区别
原文:
www.kdnuggets.com/2016/01/python-data-science-pandas-spark-dataframe-differences.html
作者:Christophe Bourguignat。
编辑者注:点击代码图片以放大。
随着 1.4 版本的改进,Spark DataFrames可能会成为新的 Pandas,使祖先 RDDs 看起来像字节码。
我在 Kaggle 竞赛中大量使用 Pandas(和 Scikit-learn)。迄今为止没有人用 Spark 赢得 Kaggle 挑战,但我相信这会发生。因此,现在是准备未来并开始使用它的时候了。Spark DataFrames 可以在pyspark.sql包中找到(名字奇怪且历史悠久:现在不仅仅是关于 SQL!)。
我并不是一个 Spark 专家,但这是我初次尝试时注意到的一些事项。在我的 GitHub 上,你可以找到这篇文章的IPython Notebook 伴侣。
读取
使用 Pandas,你可以轻松读取 CSV 文件,使用read_csv()。
默认情况下,Spark DataFrame 支持从流行的专业格式中读取数据,如 JSON 文件、Parquet 文件、Hive 表——无论是从本地文件系统、分布式文件系统(HDFS)、云存储(S3)还是外部关系数据库系统。

但CSV 在 Spark 中不被原生支持。你需要使用一个单独的库:spark-csv。
pandasDF = pd.read_csv('train.csv')
sparkDF = sqlContext.read.format('com.databricks.spark.csv').options(header='true').load('train.csv)
计数
sparkDF.count() 和 pandasDF.count() 并不完全相同。
第一个返回行数,第二个返回每列的非 NA/null观测值数量。
并不是说 Spark 还不支持.shape——在 Pandas 中经常使用。
查看
在 Pandas 中,要查看 DataFrame 的表格内容,通常使用pandasDF.head(5)或pandasDF.tail(5)。在 IPython Notebooks 中,它会显示一个带有连续边框的漂亮数组。
在 Spark 中,你可以使用sparkDF.head(5),但它有难看的输出。你应该更倾向于使用sparkDF.show(5)。注意你不能查看最后几行(.tail() 尚不存在,因为在分布式环境中难以实现)。
推断类型
在 Pandas 中,你很少需要处理类型:类型会被推断出来。
使用从 CSV 文件加载的 Spark DataFrames 时,默认假设类型为“字符串”。
编辑:在 spark-csv 中,有一个 'inferSchema' 选项(默认禁用),但我没有设法让它工作。它似乎在 1.1.0 版本中不起作用。
要在 Spark 中更改类型,你可以使用 .cast() 方法,或等效的 .astype() 方法,这是为像我这样来自 Pandas 世界的人创建的别名 😉。注意,你必须创建一个新列,并删除旧列(一些改进存在以允许类似“就地”更改,但在 Python API 中尚不可用)。

描述
在 Pandas 和 Spark 中,.describe() 生成各种摘要统计信息。由于两个原因,它们给出的结果略有不同:
-
在 Pandas 中,NaN 值会被排除。在 Spark 中,NaN 值会导致均值和标准差的计算失败。
-
标准差的计算方式不同。Pandas 默认使用无偏(或修正)标准差,而 Spark 使用未经修正的标准差。区别在于分母上使用 N-1 而不是 N。
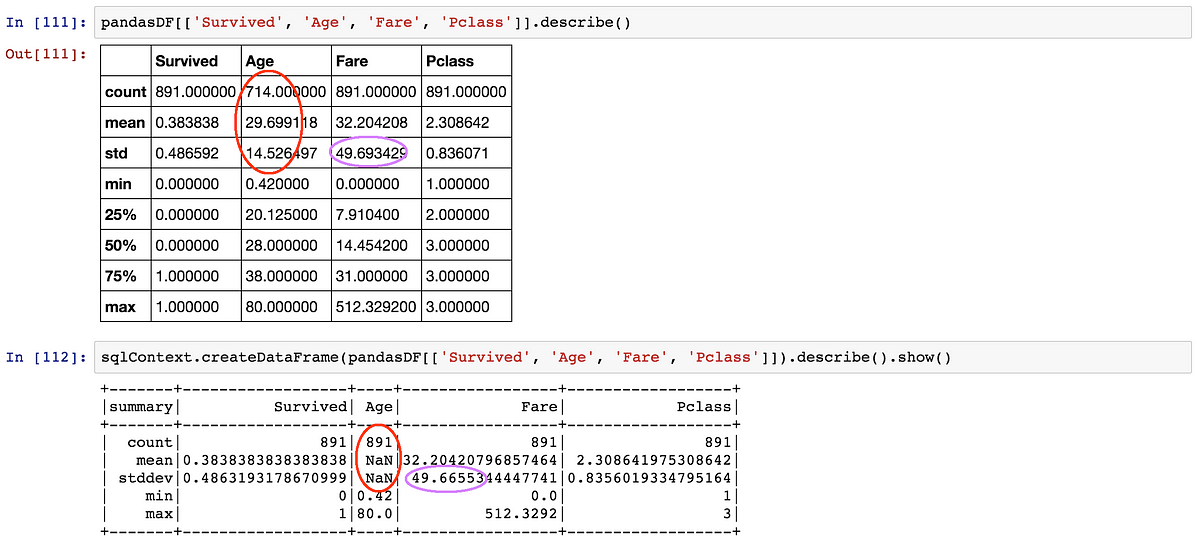
整理
在机器学习中,通常会创建新的列,这些列是基于已存在的列(特征工程)的计算结果。
在 Pandas 中,你可以使用‘[ ]’运算符。在 Spark 中则不行——DataFrames 是不可变的。你应该使用 .withColumn()。
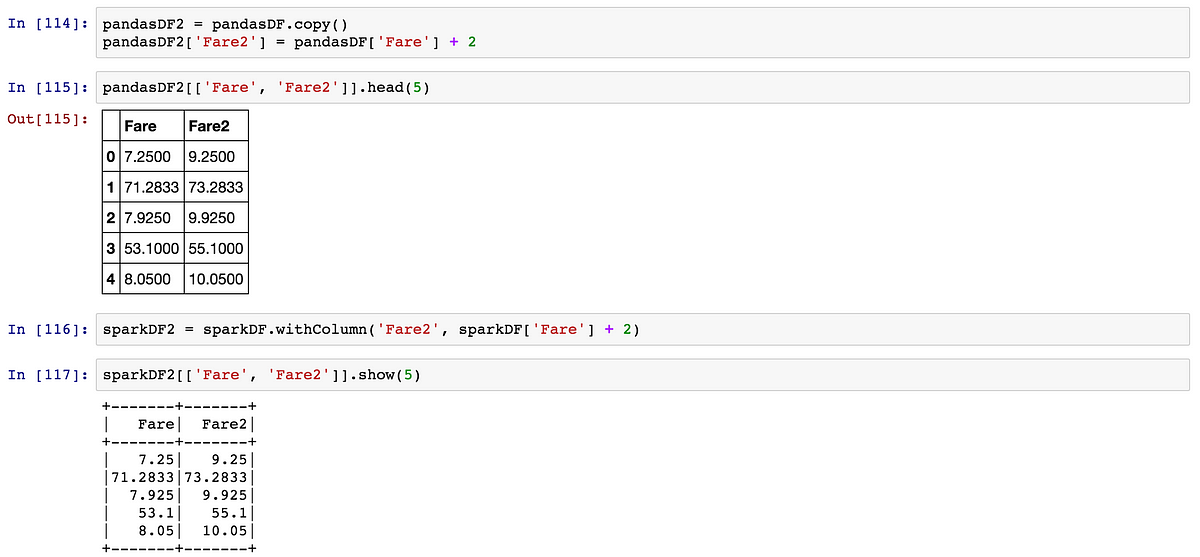
总结
Spark 和 Pandas DataFrames 非常相似。不过,Pandas API 仍然更方便和强大——但差距在迅速缩小。
尽管 Spark 有其固有的设计限制(不可变性、分布式计算、惰性求值等),Spark 仍然希望尽可能模仿 Pandas(甚至方法名也不例外)。我猜这个目标很快就会实现。
并且使用 Spark.ml,模仿 scikit-learn,Spark 可能成为工业化数据科学的完美一站式工具。
感谢Olivier Girardot帮助改进这篇文章。
编辑 1:Olivier 刚发布了一篇新文章,提供了更多见解:从 Pandas 到 Apache Spark DataFrames
编辑 2:这是另一篇相关主题的文章:Pandarize Your Spark Dataframes
简介:Christophe Bourguignat 是数据爱好者、Kaggle 大师、博主以及 AXA 数据创新实验室的校友。
原文。经许可转载。
相关:
-
Spark 2015 年度回顾
-
初学者指南:使用 Apache Spark 进行大数据机器学习
-
掌握 Python 机器学习的 7 个步骤
更多相关主题
如何以正确的方式学习 Python 数据科学
原文:
www.kdnuggets.com/2019/06/python-data-science-right-way.html
评论
大多数有志于成为数据科学家的新人通过参加为开发人员准备的编程课程开始学习 Python。他们还开始在像LeetCode这样的网站上解决 Python 编程谜题,假设在开始使用 Python 分析数据之前,他们必须掌握编程概念。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织 IT
这是一个巨大的错误,因为数据科学家使用 Python 来检索、清理、可视化和构建模型,而不是开发软件应用程序。因此,你必须把大部分时间集中在学习 Python 中的模块和库上,以执行这些任务。
遵循这些逐步的步骤来学习 Python 数据科学。
配置你的编程环境
Jupyter Notebook 是一个强大的编程环境,用于开发和展示数据科学项目。
在你的计算机上安装 Jupyter Notebook 最简单的方法是安装 Anaconda。Anaconda 是数据科学中最广泛使用的 Python 发行版,预装了所有最流行的库。
你可以阅读标题为 “使用 Anaconda 发行版安装 Jupyter Notebook 的初学者指南” 的博客文章,了解如何安装 Anaconda。在安装 Anaconda 时,选择最新的 Python 3 版本。
安装 Anaconda 后,请阅读 这篇文章 以了解如何使用 Jupyter Notebooks。
仅学习 Python 的基础知识
Code Academy 提供了一个优秀的 Python 课程,完成大约需要 20 小时。你不需要升级到 Pro 版本,因为你的目标只是熟悉 Python 编程语言的基础。
Numpy 和 Pandas - 学习它们的绝佳资源
Python 在处理大量数据和数值密集型算法时较慢。你可能会问,为什么 Python 是数据科学中最受欢迎的编程语言?
答案是,在 Python 中,很容易将数字计算任务以 C 或 Fortran 扩展的形式转移到底层。这正是 Numpy 和 Pandas 所做的。
首先,你应该学习 Numpy。它是 Python 科学计算的最基础模块。Numpy 提供了高度优化的多维数组支持,这些数组是大多数机器学习算法的基本数据结构。
接下来,你应该学习 Pandas。数据科学家大部分时间都在清理数据,这也被称为数据清洗或数据处理。
Pandas 是用于数据处理的最流行的 Python 库。Pandas 是 NumPy 的扩展。Pandas 的底层代码广泛使用了 NumPy 库。Pandas 的主要数据结构叫做数据框。
Pandas 的创建者 Wes McKinney 写了一本极好的书,叫做《Python 数据分析》。请阅读第 4、5、7、8 和 10 章以学习 Pandas 和 Numpy。这些章节涵盖了处理数据时最常用的 Numpy 和 Pandas 特性。
学习使用 Matplotlib 可视化数据
Matplotlib 是创建基本可视化的基础 Python 包。你必须学习如何使用 Matplotlib 来创建一些最常见的图表,如折线图、柱状图、散点图、直方图和箱线图。
另一个良好的绘图库是建立在 Matplotlib 之上并与 Pandas 紧密集成的 Seaborn。在这个阶段,我建议你快速学习如何在 Matplotlib 中创建基本图表,而不是专注于 Seaborn。
我写了一个四部分的教程,讲解如何使用 Matplotlib 开发基本图表。
第一部分:Matplotlib 中的基本图形
第二部分:如何控制图形的样式和颜色,例如标记、线条粗细、线条模式以及使用颜色映射。
第三部分:注释、控制坐标轴范围、纵横比和坐标系统
第四部分:处理复杂图形
你可以通过这些教程掌握 Matplotlib 的基础知识。
快速说明,你不需要花费太多时间学习 Matplotlib,因为现在公司已经开始采用像 Tableau 和 Qlik 这样的工具来创建交互式可视化。
如何使用 SQL 和 Python
在组织中,数据存储在数据库中。因此,你需要知道如何使用 SQL 检索数据,并使用 Python 在 Jupyter Notebook 中进行分析。
数据科学家使用 SQL 和 Pandas 操作数据。因为有些数据操作任务使用 SQL 更为简单,而有些任务使用 Pandas 更高效。我个人喜欢用 SQL 来检索数据,然后在 Pandas 中进行操作。
今天,公司使用像Mode Analytics和Databricks这样的分析平台来轻松处理 Python 和 SQL。
因此,你应该知道如何高效地结合使用 SQL 和 Python。要学习这一点,你可以在计算机上安装 SQLite 数据库,存储一个 CSV 文件,并使用 Python 和 SQL 进行分析。这里有一篇很棒的博客文章展示了如何做到这一点:使用 SQLite 在 Python 中编程数据库。
在阅读上述博客文章之前,你应该了解 SQL 的基础。Mode Analytics 有一个很好的 SQL 教程:SQL 简介。阅读他们的 BASIC SQL 部分,以真正掌握 SQL 的基础,因为每个数据科学家都应该知道如何高效地使用 SQL 检索数据。
用 Python 学习基础统计学
大多数有志的数据科学家直接跳到学习机器学习,而没有学习统计学的基础。
不要犯这个错误,因为统计学是数据科学的基石。另一方面,志向远大的数据科学家在学习统计学时只是学习理论概念,而不是实际应用概念。
所谓实际概念是指你应该了解统计学可以解决什么问题。理解使用统计学可以克服什么挑战。
这里是你应该了解的一些基础统计概念:
采样、频率分布、均值、中位数、众数、变异度量、概率基础、显著性检验、标准差、z 分数、置信区间和假设检验(包括 A/B 测试)。
一本很好的实用统计学书籍是《数据科学家的实用统计学:50 个基本概念》。不幸的是,对于像我这样的 Python 爱好者来说,书中的代码示例是用 R 语言编写的。我建议你阅读书中的前四章。阅读前四章以理解我之前提到的基础统计概念,忽略代码示例,仅理解概念。书中的其余章节主要集中在机器学习上。我将在下一节讨论如何学习机器学习。
大多数人推荐 Think Stats 来学习用 Python 进行统计分析,但作者教授的是他自己定制的函数,而不是使用像 Statsmodels 这样的标准 Python 库来进行统计。这就是我没有推荐这本书的原因。
完成后,你的目标是用 Python 实现你学到的基本概念。StatsModels 是一个流行的 Python 库,用于在 Python 中构建统计模型。StatsModels 网站上有 很好的教程 介绍如何使用 Python 实现统计概念。
或者,你也可以观看 Gaël Varoquaux 的视频。他展示了如何使用 Pandas 和 Stats Models 进行推论统计和探索性统计。
使用 Scikit-Learn 进行机器学习
Scikit-Learn 是 Python 中最受欢迎的机器学习库之一。你的目标是学习如何使用 Scikit-Learn 实现一些最常见的机器学习算法。
以下是如何操作的。
首先,观看 Andrew Ng 在 Coursera 上的 机器学习 课程的第 1、2、3、6、7 和 8 周的视频。我跳过了神经网络部分,因为作为起点,你需要集中精力学习最广泛使用的机器学习技术。
完成后,阅读 “动手机器学习:使用 Scikit-Learn 和 TensorFlow” 一书。只需阅读书的前一部分(大约 300 页)。这是一本非常实用的机器学习书籍。
通过完成本书中的编码练习,你将学习如何使用 Python 实现你在 Andrew Ng 课程中学到的理论概念。
结论
最后的步骤是做一个数据科学项目,涵盖以上所有步骤。你可以找到一个你喜欢的数据集,然后提出一些通过分析它来回答的有趣商业问题。但是,不要选择像 Titanic 机器学习 这样通用的数据集。你可以阅读 "寻找免费数据集的 19 个地方" 来寻找数据集。
另一种方法是将数据科学应用于你感兴趣的领域。例如,如果你想预测股票市场价格,你可以从 Yahoo Finance 抓取实时数据并存储在 SQL 数据库中,然后使用机器学习来预测股票价格。
如果你想从其他行业转行到数据科学,我建议你从一个利用你领域专业知识的项目开始。我在之前的博客文章中对这种方法进行了深入的解释,分别是 "将职业转向数据科学的分步指南 – 第一部分" 和 "将职业转向数据科学的分步指南 – 第二部分"。
如果你有任何问题,请在评论中告诉我!
相关:
-
初学者的数据科学 Python
-
全面学习 Python 数据分析和数据科学指南
-
动手实践:数据分析的 Python 入门
更多相关内容
Python 数据结构比较
原文:
www.kdnuggets.com/2021/07/python-data-structures-compared.html
评论
图片由 Hitesh Choudhary 提供,来源于 Unsplash
选择存储数据的结构是解决编程任务和实施解决方案的重要部分,但往往没有得到应有的关注。不幸的是,在 Python 中,我经常看到列表被用作万能的数据结构。列表当然有其优点,但也有其缺点。还有很多其他的数据结构选项。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
让我们来看看 5 种不同的 Python 数据结构,看看它们如何用于存储我们在日常任务中可能处理的数据,以及它们在存储时所用的相对内存和创建及访问时所需的时间。
数据结构的类型
首先,让我们列出我们将在此考虑的 5 种数据结构,并提供一些初步见解。
类
在这种情况下,我们讨论的是普通类(与下面的数据类相对),Python 文档对其进行了高层次的描述:
类提供了一种将数据和功能捆绑在一起的方法。创建一个新类会创建一种新的类型的对象,允许创建该类型的新实例。每个类实例可以附加属性以维护其状态。类实例也可以具有方法(由其类定义)以修改其状态。
使用类的优点在于它们是传统的,并且被广泛使用和理解。它们是否在相对需要的内存或时间上过于冗余,是需要考虑的问题。
数据类
在 Python 3.7 中新增的 数据类 是一种特殊的类,主要用于持有数据,提供了一些开箱即用的免费方法,用于典型功能,如实例化和打印实例内容。创建数据类是通过使用 @dataclass 装饰器来实现的。
尽管使用了非常不同的机制,数据类可以被认为是“带有默认值的可变命名元组”。因为数据类使用正常的类定义语法,你可以自由使用继承、 metaclasses、文档字符串、自定义方法、类工厂和其他 Python 类特性。这样的类被称为数据类,但实际上这个类没有什么特别之处:装饰器为类添加生成的方法,并返回与给定类相同的类。
正如你所见,自动生成的方法以及相关的时间节省是考虑数据类的主要原因。
命名元组
命名元组是优雅的实现一种有用的数据结构,本质上是带有命名字段的元组子类。
命名元组为元组中的每个位置赋予含义,使代码更具可读性和自文档性。它们可以在常规元组使用的地方使用,并且可以通过名称而不是位置索引访问字段。
初看,命名元组似乎是 Python 中最接近简单 C 风格结构体的东西,使得它们对许多人具有天然的吸引力。
字典
Python 字典是键值对的集合。
Python 字典是可变的无序集合(它们不记录元素位置或插入顺序)的键值对。字典中的键必须是唯一且可哈希的。这包括数字、字符串和元组等类型。列表和字典不能用作键,因为它们是可变的。
字典的优势在于它们简单,数据易于访问,而且使用和理解都很广泛。
列表
这就是所谓的“万用”Python 数据超结构,或者说很多代码会让你这么认为。实际上,列表是这样的:
列表是可变的有序且按索引排列的对象集合。列表的项是任意的 Python 对象。列表由放置在方括号中的逗号分隔的表达式列表组成。
为什么列表被广泛使用?它很简单易懂且易于实现,通常是学习 Python 时第一个接触的结构。是否存在与速度和内存使用相关的缺点?让我们来看看。
实现
首先,让我们看看这些结构的创建过程以及它们之间的比较。
我们可能使用这些数据结构存储数据的原因差异很大,但对于那些缺乏想象力的人,我们可以假设我们正在从 SQL 数据库中提取数据,需要将每条记录存储在这种结构中,以便在将数据进一步推进到我们的管道之前进行一些处理。
鉴于此,以下是创建每个五种结构的实例化代码。
""" class """
class CustomerClass:
def __init__(self, cust_num:str, f_name:str, l_name:str, address:str,
city:str, state:str, phone:str, age:int):
self.cust_num = cust_num
self.f_name = f_name
self.l_name = l_name
self.address = address
self.city = city
self.state = state
self.phone = phone
self.age = age
def to_string(self):
return(f'{self.cust_num}, {self.f_name}, {self.l_name}, {self.age},
{self.address}, {self.city}, {self.state}, {self.phone}'stgrcutures)
""" data class """
from dataclasses import dataclass
@dataclass
class CustomerDataClass:
cust_num: int
f_name: str
l_name: str
address: str
city: str
state: str
phone: str
age: int
""" named tuple """
from collections import namedtuple
CustomerNamedTuple = namedtuple('CustomerNamedTuple',
'cust_num f_name l_name address city state phone age')
""" dict """
def make_customer_dict(cust_num: int, f_name: str, l_name: str, address: str,
city: str, state: str, phone: str, age: int):
return {'cust_num': cust_num,
'f_name': f_name,
'l_name': l_name,
'address': address,
'city': city,
'state': state,
'phone': phone,
'age': age}
""" list """
def make_customer_list(cust_num: int, f_name: str, l_name: str, address: str,
city: str, state: str, phone: str, age: int):
return [cust_num, f_name, l_name, address,
city, state, phone, age]
注意以下几点:
-
内置类型字典和列表的实例化已放入函数中。
-
上述讨论中类和数据类实现之间的区别。
-
命名元组的(显然主观的)优雅和简单性。
让我们看看这些结构的实例化情况,并比较实现这些操作所需的资源。
测试和结果。
我们将为每种结构创建一个单独的实例,每个实例中包含一个数据记录。我们将重复这个过程,将相同的数据字段用于每种结构 1,000,000 次,以获得更好的平均时间,并在我的一台简朴的 Dell 笔记本电脑上执行此过程,使用的是基于 Ubuntu 的操作系统。

比较下面五种结构实例化的代码。
""" instantiating structures """
from sys import getsizeof
import time
# class
customer_1 = CustomerClass('EP90210', 'Edward', 'Perez', '123 Fake Street', 'Cityville', 'TX', '888-456-1234', 56)
print(f'Data: {customer_1.to_string()}')
print(f'Type: {type(customer_1)}')
print(f'Size: {getsizeof(customer_1)} bytes')
t0 = time.time()
for i in range(1000000):
customer = CustomerClass('EP90210', 'Edward', 'Perez', '123 Fake Street', 'Cityville', 'TX', '888-456-1234', 56)
t1 = time.time()
print('Time: {:.3f}s\n'.format(t1-t0))
# data class
customer_2 = CustomerDataClass('EP90210', 'Edward', 'Perez', '123 Fake Street', 'Cityville', 'TX', '888-456-1234', 56)
print(f'Data: {customer_2}')
print(f'Type: {type(customer_2)}')
print(f'Size: {getsizeof(customer_2)} bytes')
t0 = time.time()
for i in range(1000000):
customer = CustomerDataClass('EP90210', 'Edward', 'Perez', '123 Fake Street', 'Cityville', 'TX', '888-456-1234', 56)
t1 = time.time()
print('Time: {:.3f}s\n'.format(t1-t0))
# named tuple
customer_3 = CustomerNamedTuple('EP90210', 'Edward', 'Perez', '123 Fake Street', 'Cityville', 'TX', '888-456-1234', 56)
print(f'Data: {customer_3}')
print(f'Type: {type(customer_3)}')
print(f'Size: {getsizeof(customer_3)} bytes')
t0 = time.time()
for i in range(1000000):
customer = CustomerNamedTuple('EP90210', 'Edward', 'Perez', '123 Fake Street', 'Cityville', 'TX', '888-456-1234', 56)
t1 = time.time()
print('Time: {:.3f}s\n'.format(t1-t0))
# dict
customer_4 = make_customer_dict('EP90210', 'Edward', 'Perez', '123 Fake Street', 'Cityville', 'TX', '888-456-1234', 56)
print(f'Data: {customer_4}')
print(f'Type: {type(customer_4)}')
print(f'Size: {getsizeof(customer_4)} bytes')
t0 = time.time()
for i in range(1000000):
customer = make_customer_dict('EP90210', 'Edward', 'Perez', '123 Fake Street', 'Cityville', 'TX', '888-456-1234', 56)
t1 = time.time()
print('Time: {:.3f}s\n'.format(t1-t0))
# list
customer_5 = make_customer_list('EP90210', 'Edward', 'Perez', '123 Fake Street', 'Cityville', 'TX', '888-456-1234', 56)
print(f'Data: {customer_5}')
print(f'Type: {type(customer_5)}')
print(f'Size: {getsizeof(customer_5)} bytes')
t0 = time.time()
for i in range(1000000):
customer = make_customer_list('EP90210', 'Edward', 'Perez', '123 Fake Street', 'Cityville', 'TX', '888-456-1234', 56)
t1 = time.time()
print('Time: {:.3f}s\n'.format(t1-t0))
这是上述内容的输出:
Data: EP90210, Edward, Perez, 56, 123 Fake Street, Cityville, TX, 888-456-1234
Type: <class '__main__.CustomerClass'>
Size: 56 bytes
Time: 0.657s
Data: CustomerDataClass(cust_num='EP90210', f_name='Edward', l_name='Perez', address='123 Fake Street', city='Cityville', state='TX', phone='888-456-1234', age=56)
Type: <class '__main__.CustomerDataClass'>
Size: 56 bytes
Time: 0.630s
Data: CustomerNamedTuple(cust_num='EP90210', f_name='Edward', l_name='Perez', address='123 Fake Street', city='Cityville', state='TX', phone='888-456-1234', age=56)
Type: <class '__main__.CustomerNamedTuple'>
Size: 112 bytes
Time: 0.447s
Data: {'cust_num': 'EP90210', 'f_name': 'Edward', 'l_name': 'Perez', 'address': '123 Fake Street', 'city': 'Cityville', 'state': 'TX', 'phone': '888-456-1234', 'age': 56}
Type: <class 'dict'>
Size: 368 bytes
Time: 0.318s
Data: ['EP90210', 'Edward', 'Perez', '123 Fake Street', 'Cityville', 'TX', '888-456-1234', 56]
Type: <class 'list'>
Size: 128 bytes
Time: 0.184s
最后,另一个有用的数据是了解我们结构中存储的值的相对访问时间(在下面的例子中为地址)。相同的检索操作将重复 1,000,000 次,下面报告了平均时间。
""" accessing an element """
# class
t0 = time.time()
for i in range(1000000):
address = customer_1.address
t1 = time.time()
print(f'Type: {type(customer_1)}')
print('Time: {:.3f}s\n'.format(t1-t0))
# data class
t0 = time.time()
for i in range(1000000):
address = customer_2.address
t1 = time.time()
print(f'Type: {type(customer_2)}')
print('Time: {:.3f}s\n'.format(t1-t0))
# named tuple
t0 = time.time()
for i in range(1000000):
address = customer_3.address
t1 = time.time()
print(f'Type: {type(customer_3)}')
print('Time: {:.3f}s\n'.format(t1-t0))
# dictionary
t0 = time.time()
for i in range(1000000):
address = customer_4['address']
t1 = time.time()
print(f'Type: {type(customer_4)}')
print('Time: {:.3f}s\n'.format(t1-t0))
# list
t0 = time.time()
for i in range(1000000):
address = customer_5[3]
t1 = time.time()
print(f'Type: {type(customer_5)}')
print('Time: {:.3f}s\n'.format(t1-t0))
以及输出:
Type: <class '__main__.CustomerClass'>
Time: 0.098s
Type: <class '__main__.CustomerDataClass'>
Time: 0.092s
Type: <class '__main__.CustomerNamedTuple'>
Time: 0.134s
Type: <class 'dict'>
Time: 0.095s
Type: <class 'list'>
Time: 0.117s
本文的意图不是推荐使用哪种数据结构,也不是建议存在一个适用于所有情况的最佳结构。相反,我们想要了解一些不同的选项及其相对的优缺点。像所有事情一样,必须做出权衡,并且在做出这些决策时,诸如可理解性、易用性等定量考虑因素也需要纳入考虑。
也就是说,从以上分析中有一些事情显而易见:
-
在所有结构中,字典使用的存储量最大,在我们的例子中几乎是下一个最大结构的 3 倍——不过在我们查看扩展效应和内部字段数据类型之前,应该谨慎做出概括。
-
不出所料,列表的实例化速度最快,但从中检索元素的速度却不是最快(几乎是最慢的)。
-
在我们的例子中,命名元组是检索元素时速度最慢的结构,但在存储空间方面居中。
-
两个类的实例化相对较长(这是预期的),但在元素检索和空间使用方面,两者与其他结构相比都非常具有竞争力。
所以我们不仅不打算在每种情况下推荐单一结构,也没有明确的赢家可以在每种情况下推荐。即使基于我们的小实验谨慎地进行一般化,显然在选择用于特定工作的结构时需要考虑优先级。至少,这些有限的实验提供了一些对 Python 中数据结构性能的小窗口洞察。
相关:
-
作为数据科学家管理你的可重用 Python 代码
-
5 个 Python 数据处理技巧及代码片段
-
Python 中的日期处理和特征工程
更多相关内容
Python 深度学习框架概述
原文:
www.kdnuggets.com/2017/02/python-deep-learning-frameworks-overview.html
由 Madison May, indico。
我最近发现了我在 Data Science Stack Exchange 上关于 “最佳 Python 神经网络库” 的一个旧回答,这让我意识到在过去 2.5 年里 Python 深度学习生态系统的巨大变化。我在 2014 年 7 月推荐的库 pylearn2 已不再积极开发或维护,但许多深度学习库已崛起取而代之。每个库都有其自身的优缺点。我们在 indico 的生产或开发中使用了大多数列表中的技术,但对于少数未使用的,我将借鉴他人的经验,以帮助提供 2017 年 Python 深度学习生态系统的清晰全面的图景。
特别是,我们将关注:
-
Theano
-
Lasagne
-
Blocks
-
TensorFlow
-
Keras
-
MXNet
-
PyTorch
Theano
描述:
Theano 是一个 Python 库,允许你高效地定义、优化和评估涉及多维数组的数学表达式。它支持 GPU 并执行高效的符号微分。
文档:
deeplearning.net/software/theano/
总结:
Theano 是驱动我们列表中许多其他深度学习框架的数值计算工具。它由 Frédéric Bastien 和蒙特利尔大学 MILA 实验室的优秀研究团队开发。它的 API 级别较低,为了编写有效的 Theano 代码,你需要非常熟悉在其他框架中隐藏的算法。如果你拥有丰富的学术机器学习专业知识,寻找对模型进行非常细粒度控制,或希望实现新颖或不寻常的模型,Theano 是首选库。一般来说,Theano 牺牲了易用性以换取灵活性。
优点:
-
灵活
-
如果正确使用则性能良好
缺点:
-
学习曲线较陡
-
更低级别的 API
-
编译复杂的符号图可能较慢
资源:
Lasagne
描述:
一个用于在 Theano 中构建和训练神经网络的轻量级库。
文档:
总结:
由于 Theano 主要旨在成为一个符号数学库,Lasagne 在 Theano 之上提供了更适合深度学习的抽象。它主要由 DeepMind 的研究科学家 Sander Dieleman 编写和维护。Lasagne 允许用户从Layer层面进行思考,提供像“Conv2DLayer”和“DropoutLayer”等构建块来进行操作,而无需在符号变量之间指定函数关系。Lasagne 在提供丰富的常见组件以帮助层定义、层初始化、模型正则化、模型监控和模型训练的同时,几乎没有牺牲灵活性。
优点:
-
仍然非常灵活
-
比 Theano 更高层次的抽象
-
文档和代码包含各种意大利面梗
缺点:
- 社区较小
资源:
Blocks
描述:
一个用于构建和训练神经网络的 Theano 框架。
文档:
blocks.readthedocs.io/en/latest/
总结:
类似于 Lasagne,Blocks 试图在 Theano 之上添加一层抽象,以便比编写原始 Theano 代码更清晰、更简单、更标准化地定义深度学习模型。它由蒙特利尔大学的实验室 MILA 编写——这些人中有一些参与了 Theano 及其第一个高层接口 PyLearn2 的构建。它比 Lasagne 灵活一些,但有效使用的学习曲线稍微困难一些。Blocks 对递归神经网络架构有很好的支持,如果你对探索这类模型感兴趣,它值得一看。与 TensorFlow 并列,Blocks 是我们在 indico 生产环境中部署的许多 API 的首选库。
优点:
-
仍然非常灵活
-
比 Theano 更高层次的抽象
-
经过非常充分的测试
缺点:
-
学习曲线较陡
-
社区较小
资源:

TensorFlow
描述:
一个使用数据流图进行数值计算的开源软件库。
文档:
www.tensorflow.org/api_docs/python/
摘要:
TensorFlow 是低级符号计算库(如 Theano)和高级网络规范库(如 Blocks 和 Lasagne)之间的混合体。尽管它是 Python 深度学习库中的最新成员,但由于得到 Google Brain 团队的支持,它可能已经拥有了最大的活跃社区。它支持在多个 GPU 上运行机器学习模型,提供高效的数据管道工具,并具有内置的模型检查、可视化和序列化模块。最近,TensorFlow 团队决定将对 Keras 的支持纳入其中,Keras 是我们列表中的下一个深度学习库。社区似乎一致认为,尽管 TensorFlow 存在不足之处,但其社区的庞大和项目的巨大势头意味着学习 TensorFlow 是一个安全的选择。因此,TensorFlow 是我们 indico 目前选择的深度学习库。
优点:
-
由软件巨头 Google 支持
-
社区非常庞大
-
网络训练的低级和高级接口
-
比基于 Theano 的选项编译模型速度更快
-
支持多 GPU 清洁操作
缺点:
-
在许多基准测试中最初较慢于基于 Theano 的选项,尽管 TensorFlow 正在赶上。
-
RNN 支持仍被 Theano 超越
资源:
Keras
描述:
Python 的深度学习库。卷积神经网络、递归神经网络等。可以在 Theano 或 TensorFlow 上运行。
文档:
摘要:
Keras 可能是所有库中最高层次、最用户友好的库。它由 Google Brain 团队的另一成员 Francis Chollet 编写和维护。它允许用户选择构建的模型是运行在 Theano 还是 TensorFlow 的符号图上。Keras 的用户界面受到 Torch 启发,因此如果你有 Lua 机器学习的经验,Keras 绝对值得一试。部分得益于优秀的文档和相对易用性,Keras 社区非常庞大且活跃。最近,TensorFlow 团队宣布计划内置 Keras 支持,因此 Keras 很快将成为 TensorFlow 项目的一个子集。
优点:
-
你可以选择 Theano 或 TensorFlow 后端
-
直观的高层接口
-
更易于学习
缺点:
- 比其他选项更不灵活,更具规定性
资源:
MXNet
描述:
MXNet 是一个旨在兼顾效率和灵活性的深度学习框架。
文档:
mxnet.io/api/python/index.html#python-api-reference
总结:
MXNet 是亚马逊在深度学习中的首选库,可能是所有库中性能最优的。它具有类似 Theano 和 TensorFlow 的数据流图,提供对多 GPU 配置的良好支持,具有类似 Lasagne 和 Blocks 的高级模型构建模块,并且几乎可以在任何你能想到的硬件上运行(包括手机)。Python 支持只是冰山一角——MXNet 还提供了对 R、Julia、C++、Scala、Matlab 和 JavaScript 的接口。如果你在寻找无与伦比的性能,选择 MXNet,但你必须愿意处理一些 MXNet 的怪癖。
优点:
-
超快的基准测试
-
极其灵活
缺点:
-
最小的社区
-
比 Theano 的学习曲线更陡峭
资源:
PyTorch
描述:
Python 中具有强大 GPU 加速的张量和动态神经网络。
文档:
总结:
PyTorch 刚刚发布了一周多,它是我们 Python 深度学习框架列表中的新成员。它是 Lua 的 Torch 库在 Python 上的松散移植,并且值得注意的是,它由 Facebook 人工智能研究团队(FAIR)支持,并且 设计用于处理动态计算图 —— 这是 Theano、TensorFlow 和其衍生品所没有的特性。虽然 PyTorch 在 Python 深度学习生态系统中扮演什么角色尚不明朗,但所有迹象都表明,PyTorch 是我们列表中其他框架的一个非常可敬的替代品。
优点:
-
来自 Facebook 的组织支持
-
对动态图的清晰支持
-
高级和低级 API 的结合
缺点:
-
比其他选项成熟度低得多(用他们自己的话说——“我们处于早期发布的 Beta 阶段。期待一些冒险。”)
-
官方文档之外的参考/资源有限
资源:
简历:Madison May 是一位开发者、设计师和工程师,同时是 indico 数据解决方案 的首席技术官。
原文。转载已获许可。
相关:
-
深度学习、人工直觉与 AGI 的追求
-
深度学习为何与机器学习截然不同
-
深度学习是灵丹妙药吗?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的信息技术
相关话题更多
Python 字典指南:10 个 Python 字典方法及示例
评论
由 Michael Galarnyk,数据科学家
本 Python 字典教程涵盖:
-
如何定义字典
-
如何访问字典中的值
-
如何添加、更新和删除字典中的键
-
Python 字典方法
-
如何遍历字典
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
这样,让我们开始吧。
定义一个 Python 字典
字典使用花括号 {} 编写。
 定义字典。键用红色标出。值用蓝色标出。
定义字典。键用红色标出。值用蓝色标出。
*# Define a dictionary code*
webstersDict = {'person': 'a human being',
'marathon': 'a running race that is about 26 miles',
'resist': 'to remain strong against the force',
'run': 'to move with haste; act quickly'}
字典 webstersDict 使用了字符串作为字典的键,但字典的键可以是任何不可变的数据类型(数字、字符串、元组等)。字典的值几乎可以是任何东西(整数、列表、函数、字符串等)。
例如,下面的字典 genderDict 使用整数作为键,字符串作为值。
*# Define a dictionary*
genderDict = {0: 'male',
1: 'female'}
需要强调的一点是,如果你尝试将键设为可变数据类型(如列表),你将会遇到错误。
# Failure to define a dictionary
webstersDict = {(1, 2.0): 'tuples can be keys',
1: 'ints can be keys',
'run': 'strings can be keys',
['sock', 1, 2.0]: 'lists can NOT be keys'}
 使用列表作为键定义字典失败。列表不是不可变的
使用列表作为键定义字典失败。列表不是不可变的
访问 Python 字典中的值
要访问字典值,可以使用方括号 []。
例如,下面的代码使用键‘marathon’来访问值‘一场约 26 英里的长跑’。
*# Get value of the 'marathon' key*
webstersDict['marathon']
 访问键‘marathon’
访问键‘marathon’
请记住,如果尝试访问一个不存在的键的值,你会得到 KeyError 错误。
*# Try to get value for key that does not exist*
webstersDict['nonexistentKey']
 如果尝试查找一个不存在的键,将会导致 KeyError 错误。
如果尝试查找一个不存在的键,将会导致 KeyError 错误。
在 Python 字典方法部分,你将看到使用字典get 方法来避免 KeyErrors 的实用性。
添加、更新和删除 Python 字典中的键
添加或更新键
你可以添加一个新的键值对。
*# add one new key value pair to a dictionary*
webstersDict['shoe'] = 'an external covering for the human foot'
 将新键‘shoe’添加到字典中。新键‘shoe’被红色矩形框住。
将新键‘shoe’添加到字典中。新键‘shoe’被红色矩形框住。
你也可以更新键值对。
 更新字典键‘marathon’
更新字典键‘marathon’
在 Python 字典方法部分,你会看到你还可以使用字典update 方法一次添加或更新多个键值对。
从 Python 字典中删除键
可以使用del删除字典中的键及其对应的值。
# Remove the key 'resist' from the dictionary
del webstersDict['resist']
 从字典 webstersDict 中移除键‘resist’。
从字典 webstersDict 中移除键‘resist’。
在 Python 字典方法部分,你会看到你还可以使用字典pop 方法删除键。
Python 字典方法
Python 字典有不同的方法可以帮助你修改字典。本节教程只是介绍了各种 Python 字典方法。
update 方法
update 方法对于一次更新多个键值对非常有用。它接受一个字典作为参数。
*# Using update method to add two key value pairs at once*
webstersDict.update({'ran': 'past tense of run',
'shoes': 'plural of shoe'})
 将‘ran’和‘shoes’这两个键添加到字典中。
将‘ran’和‘shoes’这两个键添加到字典中。
get 方法
*# Define a dictionary*
storyCount = {'is': 100,
'the': 90,
'Michael': 12,
'runs': 5}
get 方法返回给定键的值。如果键不存在,字典默认返回 None。
# Since the key 'Michael' exists, it will return the value 12
storyCount.get('Michael')
 由于键‘Michael’存在,它返回值 12。如果‘Michael’不存在,它将返回 None。
由于键‘Michael’存在,它返回值 12。如果‘Michael’不存在,它将返回 None。
这个方法对于查找你不确定是否在字典中的键非常有用,以避免 KeyErrors。
 键‘chicken’不存在。
键‘chicken’不存在。
你还可以指定一个默认值,以在键不存在时返回。
*# Make default value for key that doesn't exist 0.*
storyCount.get('chicken', 0)
 如果你尝试一个Python 词频统计,你可以看到这个方法的实用性。
如果你尝试一个Python 词频统计,你可以看到这个方法的实用性。
pop 方法
pop 方法移除一个键并返回其值。
storyCount.pop('the')
 移除字典中的键‘the’前后的字典。
移除字典中的键‘the’前后的字典。
keys 方法
keys 方法返回字典的键。
storyCount.keys()
values 方法
values 方法返回字典中的值。
storyCount.values()
items 方法
items 方法返回一个类似于元组的列表对象,每个元组的形式为(键,值)。
webstersDict.items()

遍历字典
你可以通过使用 for 循环遍历字典的键。
for key in storyCount:
print(key)
 遍历字典的键。
遍历字典的键。
你也可以通过使用 keys 方法遍历字典的键。
for key in storyCount.keys():
print(key)
 遍历字典的键。
遍历字典的键。
下面的 for 循环使用 items 方法在每次循环迭代中访问一个(键,值)对。
for key, value in webstersDict.items():
print(key, value)
 遍历字典的键值对。
遍历字典的键值对。
如果你在理解这一部分时遇到困难,我建议观看以下 视频。
结束语
如果你有任何问题,请在此处或通过 Twitter 告诉我!下一篇文章,Python 单词计数 将回顾 Python 字典方法,列表操作,以及 字符串操作。如果你想学习如何使用 Pandas、Matplotlib 或 Seaborn 库,请考虑参加我的 Python 数据可视化 LinkedIn 学习课程。这里有一个 免费预览视频。
简介: 迈克尔·加拉尔尼克 是一名数据科学家和企业培训师。他目前在斯克里普斯转化研究所工作。你可以在 Twitter (https://twitter.com/GalarnykMichael)、Medium (https://medium.com/@GalarnykMichael) 和 GitHub (https://github.com/mGalarnyk) 上找到他。
原文。转载经许可。
相关:
-
Python 元组和元组方法
-
Python 列表和列表操作
-
如何构建数据科学投资组合
更多相关主题
Python 枚举:如何在 Python 中构建枚举
原文:
www.kdnuggets.com/python-enum-how-to-build-enumerations-in-python
图片来源:作者
如果你使用过像 C++ 或 Java 这样的编程语言,你可能已经使用了枚举来创建命名常量。当你有一个变量,它可以取一个固定数量的值时,枚举是很有用的——这些值通常是相关的,如一周中的天数、学生成绩、订单状态等。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
然而,Python 并没有一个显式的枚举数据类型。但你可以使用 Python 标准库中的 enum 模块来创建枚举。本教程将教你如何做。
让我们开始吧!
什么是枚举,为什么要使用它们?
枚举代表“枚举”,由一组预定义的命名常量组成。这些常量通常相关联。常见的例子包括一年中的月份、一周中的天数、等级、顺序和任务状态。
总结一下:枚举本质上是相关常量的集合,每个常量都有一个有意义的名称。
在 Python 中,你可以使用 enum 模块 来创建枚举(我们将很快进行演示!)。
为什么使用枚举
使用枚举有助于提高代码的清晰度和可维护性。方法如下:
-
枚举通过用有意义的标签替换神秘数字或字符串来增强代码的清晰度。它们还使代码更具自文档化,因为枚举成员的名称传达了它们的目的。
-
枚举通过提供一种简单的方式来定义和管理相关常量,从而提高代码的可维护性。
-
通过将变量赋值限制为仅有效的枚举值,枚举还确保了类型安全。
-
枚举便于对相关常量进行简单的迭代和比较。
现在让我们在 Python 中创建我们的第一个枚举。
使用 Python 的 Enum 类创建枚举
我们将创建一个 TaskStatus 枚举,它包含以下四个名称和值:
图片来源:作者
首先,我们从 enum 模块中导入 Enum 类来创建枚举。
然后我们定义一个新的类 TaskStatus,它继承自 Enum 来创建枚举。每个成员都定义了一个唯一的名称和一个可选的值,如下所示:
from enum import Enum
class TaskStatus(Enum):
TODO = 0
IN_PROGRESS = 1
DONE = 2
ABANDONED = -1
我们创建的所有枚举成员都是 Enum 类的实例。你可以通过调用isinstance()函数来验证,如下所示:
print(isinstance(TaskStatus.TODO,Enum))
Output >>> True
让我们通过将TaskStatus枚举转换成列表来打印出所有成员:
print(list(TaskStatus))
你应该看到以下输出:
Output >>>
[<TaskStatus.TODO: 0>, <TaskStatus.IN_PROGRESS: 1>, <TaskStatus.DONE: 2>, <TaskStatus.ABANDONED: -1>]
所有枚举成员都有一个名称和一个值。这意味着你可以通过它们的名称来访问枚举成员,比如TaskStatus.TODO。或者通过值来访问它们,比如TaskStatus(0)。
使用 Python 枚举
现在我们已经创建了一个简单的TaskStatus枚举,接下来让我们学习如何执行一些简单的任务,例如对枚举成员进行迭代。
迭代枚举
在 Python 中,你可以以类似于处理任何可迭代对象的方式来处理枚举。例如,你可以使用len()函数来计算枚举成员的数量:
num_statuses = len(TaskStatus)
print(num_statuses)
Output >>> 4
你也可以像迭代 Python 的可迭代对象(如列表)一样迭代枚举。在下面的 for 循环中,我们访问每个枚举成员的名称和值,并将它们打印出来:
for status in TaskStatus:
print(status.name, status.value)
这是输出结果:
Output >>>
TODO 0
IN_PROGRESS 1
DONE 2
ABANDONED -1
枚举中的排序
在示例中,状态及其对应的数字值如下:
-
TODO: 0
-
IN_PROGRESS: 1
-
DONE: 2
-
ABANDONED: -1
但你也可以使用默认的排序方式,通过使用auto()辅助函数。当你这样做时,如果枚举中有‘n’个成员,分配的值是 1 到 n。但你可以传入一个起始值,比如 k,auto(k)用于使枚举从 k 开始并递增到 k + n。
让我们按如下方式修改TaskStatus枚举:
from enum import Enum, auto
class TaskStatus(Enum):
TODO = auto()
IN_PROGRESS = auto()
DONE = auto()
ABANDONED = auto()
现在让我们打印出这些成员:
print(list(TaskStatus))
我们看到这些值是 1 到 4,正如预期的那样:
Output >>>
[<TaskStatus.TODO: 1>, <TaskStatus.IN_PROGRESS: 2>, <TaskStatus.DONE: 3>, <TaskStatus.ABANDONED: 4>]
基于 TaskStatus 枚举——一个更有用的示例
现在,让我们在已有的TaskStatus枚举基础上继续构建。在你的工作目录中创建一个 task.py 文件,并包含以下版本的枚举:
# task.py
from enum import Enum
class TaskState(Enum):
TODO = 0
IN_PROGRESS = 1
DONE = 2
ABANDONED = -1
假设我们有一个任务,包含一个名称和一个当前状态。有效的状态转换如下所示:
作者提供的图片
让我们创建一个Task类:
class Task:
def __init__(self, name, state):
self.name = name
self.state = state
def update_state(self, new_state):
# Define valid state transitions based on the current state
valid_transitions = {
TaskState.TODO: [TaskState.IN_PROGRESS, TaskState.ABANDONED],
TaskState.IN_PROGRESS: [TaskState.DONE, TaskState.ABANDONED],
TaskState.DONE: [],
TaskState.ABANDONED: []
}
# Check if the new state is a valid transition from the current state
if new_state in valid_transitions[self.state]:
self.state = new_state
else:
raise ValueError(f"Invalid state transition from {self.state.name} to {new_state.name}")
我们有一个update_status()方法,用于检查在当前状态下过渡到新状态是否有效。对于无效的过渡,会引发 ValueError 异常。
这是Task类的一个实例:状态为 TODO 的“写报告”任务:
# Create a new task with the initial state "To Do"
task = Task("Write Report", TaskState.TODO)
# Print the task details
print(f"Task Name: {task.name}")
print(f"Current State: {task.state.name}")
Output >>>
Task Name: Write Report
Current State: TODO
将任务的状态更新为 IN_PROGRESS 应该能成功,因为这是一个有效的状态转换:
# Update the task state to "In Progress"
task.update_state(TaskState.IN_PROGRESS)
print(f"Updated State: {task.state.name}")
Output >>> Updated State: IN_PROGRESS
一旦任务完成,我们可以将其状态更新为 DONE:
# Update the task state to "DONE"
task.update_state(TaskState.DONE)
print(f"Updated State: {task.state.name}")
Output >>> Updated State: DONE
但如果你尝试将状态更新为无效的状态,比如尝试将 DONE 更新为 TODO,你会遇到 ValueError 异常:
# Attempt to update the task state to an invalid state
task.update_state(TaskState.TODO)
这是因为从 DONE 到 TODO 的无效状态转换引发的 ValueError 的追溯:
Traceback (most recent call last):
File "/home/balapriya/enums/task.py", line 46, in <module>
task.update_state(TaskState.TODO)
File "/home/balapriya/enums/task.py", line 30, in update_state
raise ValueError(f"Invalid state transition from {self.state.name} to {new_state.name}")
ValueError: Invalid state transition from DONE to TODO</module>
总结
在本教程中,我们学习了如何通过编写一个简单的 TaskStatus 枚举来构建枚举。我们学习了如何访问枚举成员并对其进行迭代。
此外,我们还学习了如果你选择使用 auto() 辅助函数来设置枚举成员的值,默认排序是如何工作的。然后,我们尝试在一个更有用的示例中使用 TaskStatus 枚举。
你可以在 GitHub 上找到代码示例。我会在另一个 Python 教程中再见到你们。在那之前,祝编程愉快!
Bala Priya C**** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正在通过编写教程、操作指南、观点文章等,学习并与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关内容
《人人都能学 Python》:免费电子书
原文:
www.kdnuggets.com/2020/05/python-everybody-free-ebook.html
Openshare twitter count:
评论
这是新的一周,这也意味着是时候介绍和分享一本新的免费电子书了。本周我们回归基础,介绍人人都能学 Python,作者是 Charles R. Severance,这本书旨在帮助你开发或增强 Python 编程基础技能。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
《人人都能学 Python》是作为 Coursera 上的Python for Everybody Specialization、edX 上的Python for Everybody(2 门课程)以及 FutureLearn 上的Python for Everybody(2 门课程)的配套教材编写的,这些课程都是由书的作者创作的。
根据作者的说法,这本书特别适合那些希望在数据科学和数据分析背景下学习 Python 的个人:
本书的目标是提供一个以信息学为导向的编程入门。计算机科学方法和本书采用的信息学方法的主要区别在于,前者更注重于解决信息学领域中常见的数据分析问题。
首先,你应该知道《人人都能学 Python》使用的是 Python 3,尽管仍有一本使用 Python 2 的旧版书籍可供选择,如果你出于某种原因想学习 Python 2(不过你绝对不应该这样做),但它也以代码为中心,不花费太多时间在编程理论上,而是直接进入实现部分。
简而言之,《人人都能学 Python》教你所需的 Python 知识,使你能够立即编写实用的代码,尤其是从数据分析的角度。
这本书的目录如下:
-
为什么你应该学习编写程序?
-
变量、表达式和语句
-
条件执行
-
函数
-
迭代
-
字符串
-
文件
-
列表
-
字典
-
元组
-
正则表达式
-
网络程序
-
使用 Web 服务
-
面向对象编程
-
使用数据库和 SQL
-
数据可视化
对这本书 Kindle 版的亚马逊评论中写道:
我还没有找到比这本书更好的 Python 初学者书籍。此外,作为一名职业 Python 程序员,我发现自己经常参考这本书来澄清某些点,并加强对基本原理的理解。(我可能是专业的,但我仍然是个新手。)我买过几本厚重、昂贵的 Python 编程书籍,上面有动物的封面,但这些书往往会积灰。总之,我对这本书以及编写它所付出的努力有了新的认识。感谢你,Severance 教授!
这不是唯一的好评;这本书有 448 条评价,平均评分为 4.6(满分 5 分),这应该说明很多人也发现《人人学 Python》很有用。普遍的看法是,这本书快速覆盖了概念,以易于理解的方式进行讲解,并直接进入了相应的代码。
除了英文,这本书还提供了西班牙语、意大利语、葡萄牙语和中文版本。你可以在书籍网站上找到更多信息和这些版本的链接。
PDF 下载请点击这里。你也可以选择以一系列交互式 Jupyter 笔记本的形式阅读这本书,点击这里。如果你喜欢这本书并想支持作者,可以在亚马逊购买纸质版或电子版(Kindle 版)。
如果你是数据科学新手,并希望掌握这一领域最主要的编程语言之一,《人人学 Python》是你书单上的首选。
相关内容:
-
自动化机器学习:免费电子书
-
机器学习数学:免费电子书
-
深度学习:免费电子书
更多相关内容
Python f-Strings 魔法:每个编码人员都需要知道的 5 个改变游戏规则的技巧
原文:
www.kdnuggets.com/python-fstrings-magic-5-gamechanging-tricks-every-coder-needs-to-know

编辑器提供的图片
如果你使用 Python 已有一段时间,你可能已经停止使用传统的 format() 方法来格式化字符串,并转而使用更简洁、更易于维护的 f-Strings 自 Python 3.6 引入。但这还不是全部。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
从 Python 3.8 开始,你可以使用一些巧妙的 f-string 特性进行调试、格式化日期时间对象和浮点数等。我们将在本教程中深入探讨这些使用案例。
注意:要运行代码示例,你需要安装 Python 3.8 或更高版本。
1. 更轻松的调试
当你编写代码时,你可能会使用 print() 语句来打印变量,以验证它们的值是否如你所预期。使用 f-strings,你可以包含变量名 以及 它们的值,从而更轻松地调试。
请考虑以下示例:
length = 4.5
breadth = 7.5
height = 9.0
print(f'{length=}, {breadth=}, {height=}')
这会输出:
Output >>> length=4.5, breadth=7.5, height=9.0
当你想了解调试过程中变量的状态时,这一特性尤其有用。然而,对于生产代码,你应该设置所需的日志级别。
2. 优雅地格式化浮点数和日期
在 Python 中打印浮点数和日期时间对象时,你需要:
-
将浮点数格式化为在小数点后包含固定数量的数字
-
以特定的统一格式格式化日期
f-strings 提供了一种直接的方式来根据你的需求格式化浮点数和日期。
在这个例子中,你可以通过指定 {price:.2f} 来格式化 price 变量,以显示小数点后两位:
price = 1299.500
print(f'Price: ${price:.2f}')
Output >>> Price: $1299.50
你可能会使用 strftime() 方法来格式化 Python 中的日期时间对象。但你也可以使用 f-strings 来完成。以下是一个示例:
from datetime import datetime
current_time = datetime.now()
print(f'Current date and time: {current_time:%Y-%m-%d %H:%M:%S}')
Output >>> Current date and time: 2023-10-12 15:25:08
让我们编写一个简单的示例,包括日期和浮点数格式化:
price = 1299.500
purchase_date = datetime(2023, 10, 12, 15, 30)
print(f'Product purchased for ${price:.2f} on {purchase_date:%B %d, %Y at %H:%M}')
Output >>>
Product purchased for $1299.50 on October 12, 2023 at 15:30
3. 数值中的基数转换
F-strings 支持数值数据类型的进制转换,允许你将数字从一个进制转换到另一个进制。因此,你无需编写单独的进制转换函数或 lambda 来查看不同进制的数字。
要打印十进制数字 42 的二进制和十六进制等效值,你可以使用 f-string,如下所示:
num = 42
print(f'Decimal {num}, in binary: {num:b}, in hexadecimal: {num:x}')
Output >>>
Decimal 42, in binary: 101010, in hexadecimal: 2a
如所见,当你需要以不同进制(如二进制或十六进制)打印数字时,这非常有用。我们再来看一个从十进制到八进制转换的例子:
num = 25
print(f'Decimal {num}, in octal: {num:o}')
Output >>> Decimal 25, in octal: 31
记得 10 月 31 日 = 12 月 25 日吗?是的,这个例子灵感来源于 “为什么开发者会把万圣节和圣诞节搞混?” 的 meme。
4. 有用的 ASCII 和 repr 转换
你可以在 f-strings 中使用 !a 和 !r 转换标志,将字符串格式化为 ASCII 和 repr 字符串。
有时你可能需要将字符串转换为 ASCII 表示法。这里是如何使用 !a 标志来做到这一点:
emoji = "🙂"
print(f'ASCII representation of Emoji: {emoji!a}')
Output >>>
ASCII representation of Emoji: '\U0001f642'
要访问任何对象的 repr,你可以使用带有 !r 标志的 f-strings:
from dataclasses import dataclass
@dataclass
class Point3D:
x: float = 0.0
y: float = 0.0
z: float = 0.0
point = Point3D(0.5, 2.5, 1.5)
print(f'Repr of 3D Point: {point!r}')
Python 数据类 默认实现了 __repr__,因此我们不必显式地编写一个。
Output >>>
Repr of 3D Point: Point3D(x=0.5, y=2.5, z=1.5)
5. 格式化 LLM 提示模板
在处理大型语言模型如 Llama 和 GPT-4 时,f-strings 对于创建提示模板非常有用。
不需要硬编码提示字符串,你可以使用 f-strings 创建 可重用且可组合的提示模板。然后你可以根据需要插入变量、问题或上下文。
如果你使用像 LangChain 这样的框架,你可以使用该框架的 PromptTemplate 功能。但即使没有,你仍然可以使用基于 f-string 的提示模板。
提示可以简单到:
prompt_1 = "Give me the top 5 best selling books of Stephen King."
或者一个稍微更灵活(但仍然非常简单)的:
num = 5
author = 'Stephen King'
prompt_2 = f"Give me the top {num} best selling books of {author}."
在某些情况下,在提示中提供上下文和一些示例是很有帮助的。
考虑一下这个例子:
# context
user_context = "I'm planning to travel to Paris; I need some information."
# examples
few_shot_examples = [
{
"query": "What are some popular tourist attractions in Paris?",
"answer": "The Eiffel Tower, Louvre Museum, and Notre-Dame Cathedral are some popular attractions.",
},
{
"query": "What's the weather like in Paris in November?",
"answer": "In November, Paris experiences cool and damp weather with temperatures around 10-15°C.",
},
]
# question
user_question = "Can you recommend some good restaurants in Paris?"
这是一个使用 f-strings 的可重用提示模板。你可以在任何上下文、示例、查询用例中使用:
# Constructing the Prompt using a multiline string
prompt = f'''
Context: {user_context}
Examples:
'''
for example in few_shot_examples:
prompt += f'''
Question: {example['query']}\nAnswer: {example['answer']}\n'''
prompt += f'''
Query: {user_question}
'''
print(prompt)
这是我们这个例子的提示:
Output >>>
Context: I'm planning to travel to Paris; I need some information.
Examples:
Question: What are some popular tourist attractions in Paris?
Answer: The Eiffel Tower, Louvre Museum, and Notre-Dame Cathedral are some popular attractions.
Question: What's the weather like in Paris in November?
Answer: In November, Paris experiences cool and damp weather with temperatures around 10-15°C.
Query: Can you recommend some good restaurants in Paris?
总结
就这样。我希望你能发现一些可以添加到你的程序员工具箱中的 Python f-string 特性。如果你有兴趣学习 Python,可以查看我们编纂的 5 本免费书籍助你掌握 Python。祝学习愉快!
Bala Priya C**** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她致力于通过撰写教程、操作指南、观点文章等与开发者社区分享她的知识。Bala 还创建了有趣的资源概述和编码教程。
更多相关主题
Python 函数参数:终极指南
原文:
www.kdnuggets.com/2023/02/python-function-arguments-definitive-guide.html

图片由作者提供
像所有编程语言一样,Python 允许你定义函数。定义函数后,你可以在脚本中随处调用它,还可以从一个模块中导入函数到另一个模块。函数使你的代码变得模块化和可重用。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 工作
在 Python 中,你可以定义函数以接受不同类型的参数。本指南将教你所有关于 Python 函数参数的知识。让我们开始吧。
Python 函数的快速回顾
要定义一个 Python 函数,你可以使用def关键字后跟函数名称和括号。如果你希望函数接受参数,则应该在括号内指定参数名称。定义函数后,你可以用参数值(称为参数)调用它。
例如,考虑add()函数的定义:num1和num2是参数,函数调用中用于这些参数的值是参数。
参数与参数 | 图片由作者提供
位置参数
考虑以下函数meet()。它接受三个字符串并打印出该人的信息。
def meet(name,job_title,city):
return f"Meet {name}, a {job_title} from {city}."
你可以按如下方式用参数调用函数:
meet1 = meet('James','Writer','Nashville')
print(meet1)
Output >> Meet James, a Writer from Nashville.
使用这种方式调用函数时,参数作为位置参数传递。位置参数会按照它们在函数调用中出现的相同顺序映射到函数参数。
因此,函数调用中的第一个、第二个和第三个参数分别用作name、job_title和city的值。
这是一个例子。
meet2 = meet('Artist','John','Austin')
print(meet2)
Output >> Meet Artist, a John from Austin.
在这种情况下,输出“Meet Artist, a John from Austin.”是不合理的。这时,关键字参数可以发挥作用。
关键字参数
使用关键字参数调用函数时,你应该指定参数的名称和它接受的值。
你可以按照任何顺序指定关键字参数,只要参数的名称正确。我们可以调用相同的函数 meet(),但这次使用关键字参数。
meet3 = meet(city='Madison',name='Ashley',job_title='Developer')
print(meet3)
Output >> Meet Ashley, a Developer from Madison.
如果你想同时使用位置参数和关键字参数怎么办?这会使你的代码不够清晰,不推荐这样做。但如果你在函数调用中使用位置参数和关键字参数,位置参数应 始终 置于关键字参数之前。否则,你会遇到错误。
调用具有可变参数数量的函数
到目前为止,我们知道参数的数量,并相应地定义了函数。然而,这种情况并非总是如此。如果你希望你的函数每次被调用时都能接受可变数量的参数,该怎么办呢?

图片来自作者
在处理 Python 代码库时,你可能会遇到如下形式的函数定义:
def some_func(*args, **kwargs):
# do something on args and kwargs
使用 *args 和 **kwargs 在函数定义中,你可以让函数分别接受可变数量的位置参数和关键字参数。它们的工作方式如下:
-
args将可变数量的位置参数收集为一个元组,然后可以使用 * 解包运算符进行解包。 -
kwargs将函数调用中的所有关键字参数收集为一个字典。这些关键字参数可以通过 ** 运算符解包。
注意: 使用
*args和**kwargs并不是严格要求。你可以使用任何你选择的名称。
让我们通过示例更好地理解这一点。
可变数量的位置参数
函数 reverse_strings 接受可变数量的字符串并返回一个反转字符串的列表。
def reverse_strings(*strings):
reversed_strs = []
for string in strings:
reversed_strs.append(string[::-1])
return reversed_strs
你现在可以根据需要调用函数,传递一个或多个参数。以下是一些示例:
def reverse_strings(*strings):
reversed_strs = []
for string in strings:
reversed_strs.append(string[::-1])
return reversed_strs
Output >> ['nohtyP']
rev_strs2 = reverse_strings('Coding','Is','Fun')
print(rev_strs2)
Output >> ['gnidoC', 'sI', 'nuF']
可变数量的关键字参数
以下函数 running_sum() 接受可变数量的关键字参数:
def running_sum(**nums):
sum = 0
for key,val in nums.items():
sum+=val
return sum
由于 nums 是一个 Python 字典,你可以对字典对象调用 items() 方法以获取一个元组列表。每个元组都是一个键值对。
这里有几个例子:
sum1 = running_sum(a=1,b=5,c=10)
print(sum1)
Output >> 16
sum2 = running_sum(num1=7,num2=20)
print(sum2)
Output >> 27
注意: 当使用
*args和**kwargs时,位置参数和关键字参数不是必需的。因此,这是一种使你的函数参数 可选 的方法。
使用参数的默认值
在定义 Python 函数时,你可以为一个或多个参数提供默认值。如果你为某个特定参数提供了默认值,你就不必在函数调用中使用该参数。
-
如果在函数调用中提供了与参数对应的值,该值会被使用。
-
否则,将使用默认值。
在以下示例中,函数 greet() 具有一个参数 name,其默认值设置为 "there"。
def greet(name='there'):
print(f"Hello {name}!")
所以当你用特定字符串作为参数调用 greet() 时,它的值会被使用。
greet('Jane')
Output >> Hello Jane!
当你没有传递名称字符串时,将使用默认参数 "there"。
greet()
Output >> Hello there!
可变默认参数 - 奇特案例
使用默认参数时,你应该小心不要将默认值设置为可变对象。那为什么呢?让我们通过一个例子来理解。

图片来源 | 创建于 imgflip
以下函数append_to_list()接受一个元素和一个列表作为参数。它将元素追加到列表的末尾,并返回结果列表。
# def_args.py
def append_to_list(elt,py_list=[]):
py_list.append(elt)
return py_list
你会期待以下行为:
-
当函数同时用元素和列表调用时,它会返回包含追加元素到原始列表末尾的列表。
-
当你仅用元素作为参数调用函数时,它会返回一个仅包含该元素的列表。
但让我们看看会发生什么。
打开你的终端,运行python -i以启动 Python REPL。我已在def_args.py文件中定义了append_to_list()函数。
>>> from def_args import append_to_list
当你用数字 4 和列表 [1,2,3] 作为参数调用函数时,我们得到 [1,2,3,4],这是预期的结果。
>>> append_to_list(4,[1,2,3])
[1, 2, 3, 4]
现在,让我们进行一系列函数调用,仅将元素追加到列表中:
>>> append_to_list(7)
[7]
>>> append_to_list(9)
[7, 9]
>>> append_to_list(10)
[7, 9, 10]
>>> append_to_list(12)
[7, 9, 10, 12]
等等,这不是我们预期的结果。第一次函数用 7 作为参数(没有列表)被调用时,我们得到 [7]。然而,在随后的调用中,我们看到元素被追加到这个列表中。
这是因为默认参数只在函数定义时绑定一次。列表在函数调用append_to_list(7)期间首次被修改。列表不再为空。所有后续对函数的调用—即使没有列表—也会修改原始列表。
因此,你应该避免使用可变的默认参数。一个可能的解决方法是将默认值设置为None,并在函数调用没有包含列表时初始化一个空列表。
结论
这是你在本教程中学到的总结。你学会了如何使用位置参数和关键字参数调用 Python 函数,以及如何使用*args和**kwargs分别传递可变数量的位置参数和关键字参数。接着,你学习了如何为某些参数设置默认值,以及可变默认参数的奇特情况。希望你觉得这个教程对你有帮助。继续编码!
Bala Priya C是一位技术写作人员,喜欢创作长篇内容。她的兴趣领域包括数学、编程和数据科学。她通过撰写教程、操作指南等与开发者社区分享她的学习经验。
更多相关话题
Python 图形画廊
由 Yan Holtz,布里斯班昆士兰脑研究所
Python 目前是数据科学领域领先的编程语言,其次是 R [参考: KDnuggets]。数据可视化是这一领域的关键步骤,Python 在图形表示数据方面提供了 极大的可能性。然而,众多工具和文档的复杂性使得构建所需图表变得困难。
Python 图形画廊 是一个展示用 Python 制作的数百种图形的网站,始终提供可重复的代码片段。
400 张图形和 40 个部分
画廊目前提供大约 400 张不同的图表,组织在 40 个部分中。每个部分由设计师 Conor Healy 制作的徽标表示。颜色取决于图形的主题:分布、相关性、整体部分、地图、流程、演变……这种分类受到 图形连续体 的启发,应该可以帮助你快速找到所需的图表。

当然,大多数常见的图形类型如 条形图、散点图、箱线图 或 直方图 都在其中。但也有一些不那么常见的数据可视化类型,比如 棒棒糖 图、气泡 图、2D 密度 图或 词云。
从简单到复杂
一旦进入图表部分,会显示几个示例,从最简单到最复杂。通常,第一个示例描述输入数据集必须如何格式化,以及如何使用默认参数生成图形。提供了解释,代码被缩短到最少且逐行注释,这使得理解函数的工作原理变得容易。这里是一个关于 最简单的密度图 的概述:
示例会逐步引导你从非常基础的版本到高度自定义的图表。每个示例旨在解释一个特定的技巧,比如自定义颜色、翻转坐标轴、添加多个分组等等。在该部分的末尾,你将找到一些‘实际案例’,结合所有这些技巧,得到一个漂亮的自定义图形。
重点关注 Matplotlib 和 Seaborn
在制作 Python 图表时,存在许多库。我决定主要依赖Matplotlib和Seaborn,这两个工具目前是主要使用的工具。几乎所有类型的图表都可以用它们制作。当它们无法满足需求时,我会使用其他库,如用于地图的folium或用于网络的networkX。
请注意,Matplotlib 和 Seaborn 都有一个专门的页面,展示了适用于每种图表类型的通用技巧,如自定义坐标轴和标题、调用不同的主题、控制颜色等。这些页面可以帮助你快速找到我们容易忘记的日常代码片段。
访问此链接 here 获取代码。
结论
Python Graph Gallery展示了数百个图形,并希望能帮助你快速实现所需的图表。在这方面,它主要旨在从技术角度帮助用户。
然而,最终目标也是提高用户在数据可视化领域的知识:
-
通过访问该网站,你可能会发现适合你的数据的新型数据可视化选项。
-
每个部分都有一个简短的描述,解释何时建议使用该图表类型。
-
有时在部分底部会包括一个不良图表示例,警告你关于这种图表类型的常见错误。
该画廊是 Yan Holtz 在他的夜晚和假期期间开发的项目。因此,请对错误、不准确之处和英语语言错误宽容。任何错误或反馈都非常欢迎,通过 yan.holtz.data@gmail.com 或推特: @R_Graph_Gallery 提供。最后但同样重要的是,请注意 Python 图形画廊有一个双胞胎姐妹网站:R graph gallery。
作者简介
Yan Holtz 是一位热衷的数据分析师和生物信息学家,目前在布里斯班的昆士兰脑研究所工作。他对数据可视化情有独钟,这使他建立了R和Python图表库。他可以通过以下方式联系到他:yan.holtz.data@gmail.com。
相关内容:
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
更多相关内容
Python 在 Excel 中:这将永远改变数据科学
原文:
www.kdnuggets.com/python-in-excel-this-will-change-data-science-forever

图片由作者提供
作为一名从事行业工作的数据科学家,过去一年感觉像是一场新技术突破和 AI 创新的过山车。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
像 ChatGPT、Notable、Pandas AI 和代码解释器这样的工具为我节省了大量时间,在编写、研究、编程和数据分析等任务中表现尤为突出。
就在我以为事情已经不能再更好了的时候,微软和 Anaconda 宣布了Python 与 Excel 的集成!
你现在可以在 Excel 电子表格中编写 Python 代码来分析数据、构建机器学习模型并创建可视化效果。
那么……为什么 Python 和 Excel 的集成会引起如此轰动呢?
在 Excel 中编写 Python 代码的能力将为数据科学家和分析师开启新的大门。
当我获得第一个数据科学工作时,我以为自己会大部分时间在 Jupyter Notebook 中工作。令我惊讶的是,我在工作的第一天就不得不学习使用 Excel,因为高层管理、利益相关者和客户更喜欢从电子表格中解释结果。
实际上,我过去甚至创建过 Tableau 仪表板来向客户展示结果,但最终因为他们对 Excel 更为熟悉,所以不得不在 Excel 中重新构建图表。
这并不是我所在组织的独特之处。截至 2023 年,全球已有超过一百万家公司和 15 亿人使用 Excel。
许多数据从业者,如我自己,发现自己常常在 Python IDE 和 Excel 电子表格之间切换。我们使用前者构建机器学习模型和分析数据,使用后者来展示我们的发现。
Python 和 Excel 的集成将帮助数据科学家和分析师简化工作流程,让我们能够在一个平台上进行数据分析、建模和展示。
还不相信吗?
让我们探索一下这种组合的一些潜在使用案例。
数据科学家在 Excel 中使用 Python 的方法
以下是数据科学家可以将电子表格的功能与 Python 的广泛库结合使用的一些方法:
1. 数据预处理
如果我可以将我工作中的某一部分外包出去,那就是数据准备。这是一项繁琐的任务,当使用本机 Excel 功能时变得极其耗时。
借助新的 Python-Excel 集成功能,用户现在可以直接将像 Pandas 这样的库导入到 Excel 中,并在 Excel 电子表格中直接进行高级筛选和数据聚合。
你只需在电子表格中的一个单元格中输入“=PY”,然后高亮显示你想用 Python 分析的数据,就会为你创建一个 Pandas dataframe。然后,你可以像在 Jupyter Notebook 中一样对这些数据进行分组和处理。
这是一个展示如何在 Excel 中创建 Pandas dataframe 的示例:
来源:Microsoft
2. 机器学习
虽然 Excel 提供了诸如线性回归和图表趋势线拟合等基本工具,但大多数机器学习用例需要更复杂的建模技术,这超出了 Excel 的本机能力。
借助这种 Python-Excel 集成功能,用户现在可以在 Excel 中使用 Scikit-Learn 等库构建和训练高级统计模型。模型结果可以在 Excel 中可视化和展示,弥合建模与决策制定之间的差距。
这是一个展示如何使用 Python 在 Excel 中构建决策树分类器的图像:
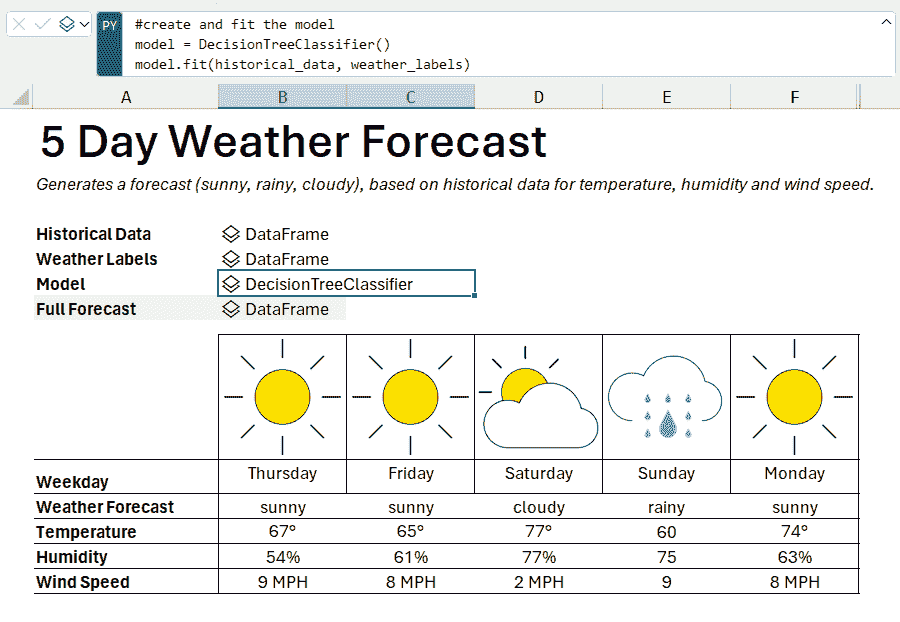
来源:Microsoft
3. 数据分析
在 Excel 中分析数据的过程可能非常繁琐——当同时处理多个文件时,用户需要手动复制和粘贴数据,拖动公式到单元格,并手动合并数据。
例如,如果我有五个这样的每月销售数据工作表:
如果我想找到一个月内销售量超过 100 个单位的产品,我首先需要手动将所有工作表的数据复制并粘贴到第一个工作表的数据下方。然后,我需要更改日期格式并创建数据透视表。
最后,我还需要添加一个筛选器来找到符合我标准的产品。
每次我在不同的文件或工作表中获得新的销售数据时,我都需要手动复制和粘贴。
随着数据量的增加,这个过程变得越来越困难且容易出错。
相反,整个分析可以通过以下代码行在 Python 中简化:
# 1\. Merge the data
df_merged = pd.concat([df_jan, df_feb], ignore_index=True)
# 2\. Convert the date format
df_merged['Date'] = pd.to_datetime(df_merged['Date']).dt.strftime('%Y-%m-%d')
# 3\. Compute the total units sold for each product
grouped_data = df_merged.groupby('Product').agg({'Units Sold': 'sum'}).reset_index()
# 4\. Identify products that sold more than 100 units
products_over_100 = grouped_data[grouped_data['Units Sold'] > 100]
products_over_100
每次有新数据进来时,我只需更改一行代码并重新运行程序,就能获得所需的结果。通过 Python 与 Excel 的集成,我可以在一个平台上监督整个数据分析流程,从而最大化效率。
4. 数据可视化
尽管 Excel 本身提供了大量的可视化选项,但该工具在构建图表类型方面仍然有些限制。像小提琴图、热图和对角图这样的图表在 Excel 中并不容易获得,这使得数据科学家难以表示复杂的统计关系。
运行 Python 代码的能力将使 Excel 用户能够使用如 Matplotlib 和 Seaborn 等库来创建更复杂、更具自定义的图表。
来源:微软
如何在 Excel 中使用 Python?
在撰写本文时,Python 与 Excel 的功能仅通过Microsoft 365 Insider 计划提供。你需要注册并选择 Beta Channel Insider 级别才能访问此功能,因为它尚未公开推出。
一旦你加入了 365 Insider 计划,你会在“公式”选项卡中找到一个 Python 部分。你只需点击“插入 Python”即可开始编写自己的 Python 代码。
另外,你可以在任意单元格中输入=PY来开始使用。
来源:Anaconda
Python 与 Excel 的集成将使数据科学民主化
随着 ChatGPT 的发布,以及诸如代码解释器和 Notable 等插件的出现,许多曾经需要强大技术专长的任务变得更容易执行。
对于数据科学家和分析师而言尤其如此——你现在可以将 CSV 文件上传到 ChatGPT,它将清理、分析并构建你的数据集模型。
在我看来,Python 与 Excel 的集成使我们离数据科学和分析的民主化更近了一步。
在市场营销和金融等领域,那些完全依赖 Excel 的行业专家现在将能够执行 Python 代码来分析他们的数据,而无需下载编程 IDE。
在一个熟悉的界面中处理数据,加上 ChatGPT 在编写代码方面的熟练,将使非程序员能够执行数据科学工作流程,并使用 Python 代码解决问题。
如果你是一个不懂编码的 Excel 用户,这对于你来说是一个在你已经熟悉的界面中学习 Python 编程的绝佳机会。
Natassha Selvaraj 是一位自学成才的数据科学家,对写作充满热情。你可以在LinkedIn上与她联系。
更多相关话题
Python 在金融中的应用:Jupyter Notebook 内的实时数据流
原文:
www.kdnuggets.com/python-in-finance-real-time-data-streaming-within-jupyter-notebook

在本博客中,你将学习如何在你最喜欢的工具 Jupyter Notebook 中实时可视化数据流。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力。
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理。
在大多数项目中,Jupyter Notebooks 中的动态图表需要手动更新;例如,可能需要你点击重新加载以获取新数据并更新图表。这对于任何快节奏的行业,包括金融,都效果不佳。想象一下,因为用户没有在那个时刻点击重新加载,错过了关键的买入信号或欺诈警报。
在这里,我们将展示如何从手动更新过渡到在 Jupyter Notebook 中使用流式或实时方法,从而使你的项目更高效、更具响应性。
涵盖内容:
-
实时可视化: 你将学习如何让数据生动起来,实时观看数据的每一秒变化。
-
Jupyter Notebook 精通: 充分利用 Jupyter Notebook 的强大功能,不仅用于静态数据分析,还用于动态流数据。
-
Python 在量化金融中的应用案例: 探索一个实际的金融应用,实施在金融领域广泛使用的解决方案,使用真实世界的数据。
-
流数据处理: 理解实时处理数据的基础和好处,这一技能在今天快节奏的数据世界中变得越来越重要。
在本博客结束时,你将学会如何在你的 Jupyter Notebook 中构建类似下面的实时可视化效果。

快速回顾实时数据处理
我们项目的核心在于流处理的概念。
简而言之,流处理就是实时处理和分析生成的数据。可以把它想象成高峰时段的 Google Maps,你可以实时看到交通更新,从而做出即时且高效的路线调整。
有趣的是,根据高盛 CIO 在这期 Forbes 播客中所说,向流数据或实时数据处理的发展是我们正在前进的重大趋势之一。
Jupyter Notebooks 作为实时数据分析工具
这就是将实时数据处理的强大功能与 Jupyter Notebooks 的互动和熟悉环境结合起来。
此外,Jupyter Notebooks 与容器化环境配合良好。因此,我们的项目不仅仅局限于本地机器;我们可以将它们带到任何地方——在从同事的笔记本电脑到云服务器的任何设备上平稳运行。
我们在 Python 中的应用案例:布林带
在金融领域,每一秒都至关重要,无论是用于欺诈检测还是交易,这也是流数据处理变得至关重要的原因。这里的重点是布林带,这是一个对金融交易有帮助的工具。该工具包括:
-
中间带: 这是一个 20 周期移动平均线,计算过去 20 个周期(例如高频分析中的 20 分钟)的平均股价,提供近期价格趋势的快照。
-
外带波段: 位于中间带上下 2 个标准差的位置,它们指示市场波动性——带子越宽表明波动性越大,带子越窄则表明波动性较小。
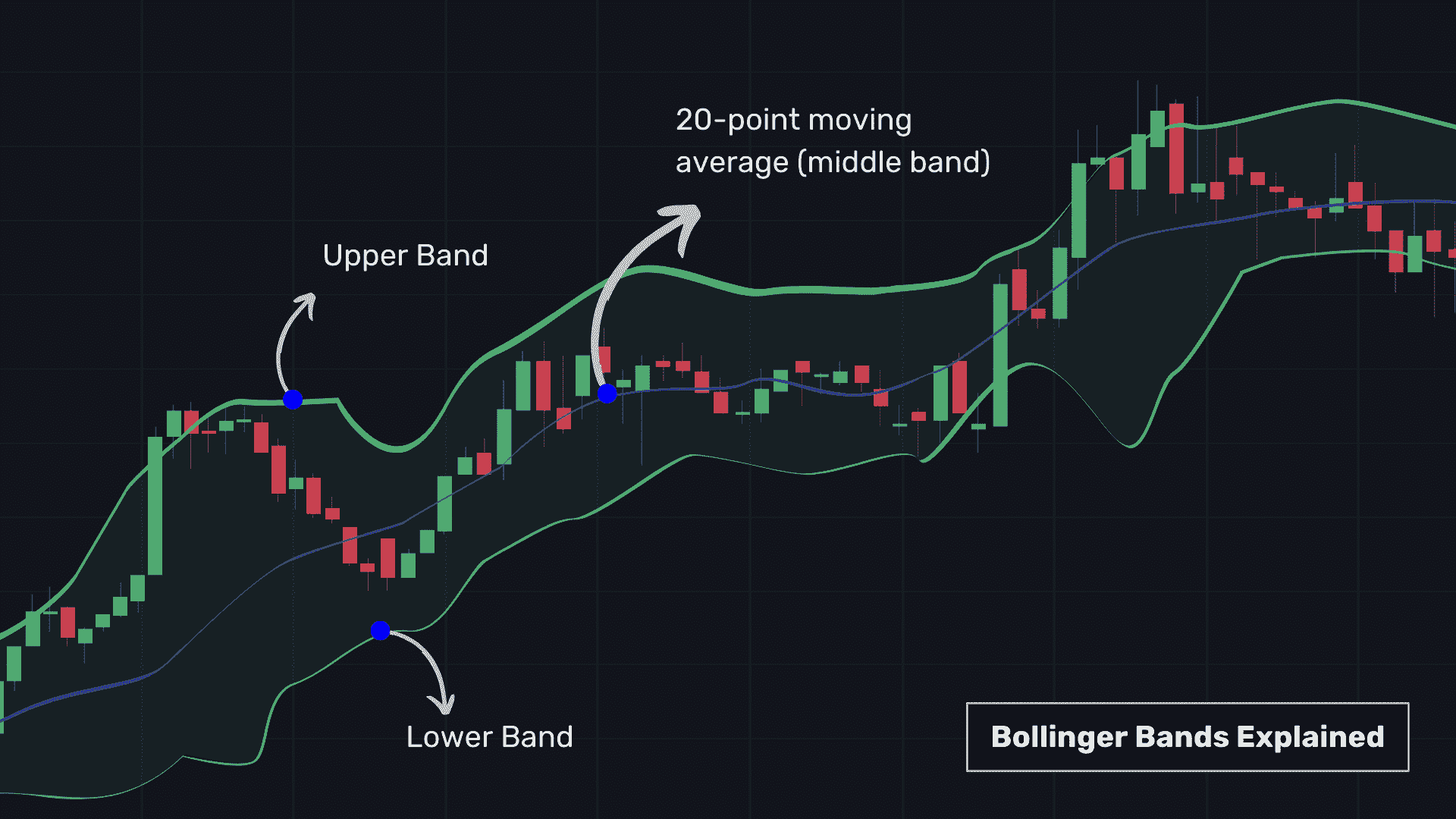
在布林带中,当移动平均价格触及或超过上带时(通常标记为红色,提示卖出),表明可能存在超买情况;当价格跌破下带时(通常标记为绿色,提示买入),则表明可能存在超卖情况。
算法交易者通常将布林带与其他技术指标配合使用。
在生成布林带时,我们通过整合交易量进行了一个重要的调整。传统上,布林带不考虑交易量,仅基于价格数据进行计算。
因此,我们在 VWAP ± 2 × VWSTD 的距离上标记了布林带,其中:
-
VWAP:一个1 分钟成交量加权平均价格,提供更具成交量敏感度的视角。
-
VWSTD:代表一个集中20 分钟标准差,即市场波动性的度量。
技术实现:
-
我们使用时间滑动窗口(‘pw.temporal.sliding’)来分析 20 分钟的时间段数据,类似于在实时数据上移动放大镜。
-
我们使用减少器(‘pw.reducers’),它们处理每个窗口中的数据,以为每个窗口产生特定的结果,例如此情况下的标准差。
查看在我们的 Jupyter Notebook 中实现实时流数据的工具
-
Polygon.io: 实时和历史市场数据提供商。虽然你可以使用它的 API 获取实时数据,但我们已经将一些数据预先保存到 CSV 文件中,以便于演示,便于跟随而无需 API 密钥。
-
Pathway: 一个开源的 Python 框架,用于快速数据处理。它处理批量(静态)和流数据(实时)。
-
Bokeh: 理想的动态可视化工具,Bokeh 通过引人入胜的交互式图表让我们的流数据生动起来。
-
Panel: 为我们的项目增强实时仪表板功能,与 Bokeh 协作,随着新数据流入更新我们的可视化。
步骤教程:在 Jupyter Notebook 中可视化实时数据。
这包括六个步骤:
-
执行 pip 安装相关框架并导入相关库。
-
获取样本数据
-
设置计算的数据源
-
计算布林带所需的统计数据
-
使用 Bokeh 和 Panel 创建仪表板
-
执行运行命令
1. 导入和设置
首先,让我们快速安装必要的组件。
%%capture --no-display
!pip install pathway
首先导入必要的库。这些库将帮助进行数据处理、可视化以及构建互动仪表板。
# Importing libraries for data processing, visualization, and dashboard creation
import datetime
import bokeh.models
import bokeh.plotting
import panel
import pathway as pw
2. 获取样本数据
接下来,从 GitHub 下载样本数据。这一步对于访问我们的可视化数据至关重要。在这里,我们获取了苹果公司(AAPL)的股票价格。
# Command to download the sample APPLE INC stock prices extracted via Polygon API and stored in a CSV for ease of review of this notebook.
%%capture --no-display
!wget -nc https://gist.githubusercontent.com/janchorowski/e351af72ecd8d206a34763a428826ab7/raw/ticker.csv
注意: 本教程利用了一个发布在 这里 的展示
3. 数据源设置
使用 CSV 文件创建一个流数据源。这模拟了一个实时数据流,为处理实时数据提供了一种实际的方法,而不需要 API 密钥,同时也简化了首次构建项目的过程。
# Creating a streaming data source from a CSV file
fname = "ticker.csv"
schema = pw.schema_from_csv(fname)
data = pw.demo.replay_csv(fname, schema=schema, input_rate=1000)
# Uncommenting the line below will override the data table defined above and switch the data source to static mode, which is helpful for initial testing
# data = pw.io.csv.read(fname, schema=schema, mode="static")
# Parsing the timestamps in the data
data = data.with_columns(t=data.t.dt.utc_from_timestamp(unit="ms"))
注意: 数据处理不会立即发生,而是在最后执行运行命令时进行。
4. 计算布林带所需的统计数据
在这里,我们将简要构建我们上述讨论的交易算法。我们有一个虚拟的苹果公司股票价格流。现在,要创建布林带,
-
我们将计算加权 20 分钟标准差(VWSTD)
-
价格的 1 分钟加权运行平均(VWAP)
-
将上述两者合并。
# Calculating the 20-minute rolling statistics for Bollinger Bands
minute_20_stats = (
data.windowby(
pw.this.t,
window=pw.temporal.sliding(
hop=datetime.timedelta(minutes=1),
duration=datetime.timedelta(minutes=20),
),
behavior=pw.temporal.exactly_once_behavior(),
instance=pw.this.ticker,
)
.reduce(
ticker=pw.this._pw_instance,
t=pw.this._pw_window_end,
volume=pw.reducers.sum(pw.this.volume),
transact_total=pw.reducers.sum(pw.this.volume * pw.this.vwap),
transact_total2=pw.reducers.sum(pw.this.volume * pw.this.vwap**2),
)
.with_columns(vwap=pw.this.transact_total / pw.this.volume)
.with_columns(
vwstd=(pw.this.transact_total2 / pw.this.volume - pw.this.vwap**2)
** 0.5
)
.with_columns(
bollinger_upper=pw.this.vwap + 2 * pw.this.vwstd,
bollinger_lower=pw.this.vwap - 2 * pw.this.vwstd,
)
)
# Computing the 1-minute rolling statistics
minute_1_stats = (
data.windowby(
pw.this.t,
window=pw.temporal.tumbling(datetime.timedelta(minutes=1)),
behavior=pw.temporal.exactly_once_behavior(),
instance=pw.this.ticker,
)
.reduce(
ticker=pw.this._pw_instance,
t=pw.this._pw_window_end,
volume=pw.reducers.sum(pw.this.volume),
transact_total=pw.reducers.sum(pw.this.volume * pw.this.vwap),
)
.with_columns(vwap=pw.this.transact_total / pw.this.volume)
)
# Joining the 1-minute and 20-minute statistics for comprehensive analysis
joint_stats = (
minute_1_stats.join(
minute_20_stats,
pw.left.t == pw.right.t,
pw.left.ticker == pw.right.ticker,
)
.select(
*pw.left,
bollinger_lower=pw.right.bollinger_lower,
bollinger_upper=pw.right.bollinger_upper
)
.with_columns(
is_alert=(pw.this.volume > 10000)
& (
(pw.this.vwap > pw.this.bollinger_upper)
| (pw.this.vwap < pw.this.bollinger_lower)
)
)
.with_columns(
action=pw.if_else(
pw.this.is_alert,
pw.if_else(
pw.this.vwap > pw.this.bollinger_upper, "sell", "buy"
),
"hold",
)
)
)
alerts = joint_stats.filter(pw.this.is_alert)
你可以查看笔记本 这里 以更深入地了解计算过程。
5. 仪表板创建
是时候通过 Bokeh 图表和 Panel 表格可视化来实现我们的分析了。
# Function to create the statistics plot
def stats_plotter(src):
actions = ["buy", "sell", "hold"]
color_map = bokeh.models.CategoricalColorMapper(
factors=actions, palette=("#00ff00", "#ff0000", "#00000000")
)
fig = bokeh.plotting.figure(
height=400,
width=600,
title="20 minutes Bollinger bands with last 1 minute average",
x_axis_type="datetime",
y_range=(188.5, 191),
)
fig.line("t", "vwap", source=src)
band = bokeh.models.Band(
base="t",
lower="bollinger_lower",
upper="bollinger_upper",
source=src,
fill_alpha=0.3,
fill_color="gray",
line_color="black",
)
fig.scatter(
"t",
"vwap",
color={"field": "action", "transform": color_map},
size=10,
marker="circle",
source=src,
)
fig.add_layout(band)
return fig
# Combining the plot and table in a Panel Row
viz = panel.Row(
joint_stats.plot(stats_plotter, sorting_col="t"),
alerts.select(
pw.this.ticker, pw.this.t, pw.this.vwap, pw.this.action
).show(include_id=False, sorters=[{"field": "t", "dir": "desc"}]),
)
viz
当你运行这个单元格时,笔记本中会为图表和表格创建占位容器。计算开始后,它们会被实时数据填充。
6. 运行计算
所有准备工作已完成,现在是时候运行数据处理引擎了。
# Command to start the Pathway data processing engine
%%capture --no-display
pw.run()
随着仪表板实时更新,你将看到布林带如何触发动作——绿色标记用于买入,红色标记用于卖出,通常是在稍高的价格。
注意: 在小部件初始化并可见后,你应该手动运行 pw.run()。你可以在这个 GitHub 问题中找到更多细节 这里。
TL;DR
在这篇博客中,我们了解了布林带,并带你通过 Jupyter Notebook 实现实时金融数据的可视化。我们展示了如何利用布林带和一系列开源 Python 工具将实时数据流转化为可操作的洞察。
本教程提供了一个实时金融数据分析的实际例子,利用开源技术从数据获取到交互式仪表板的完整解决方案。你可以通过以下方式创建类似的项目:
-
通过从 Yahoo Finance、Polygon、Kraken 等 API 获取实时股票价格,为你选择的股票进行操作。
-
对你最喜欢的一组股票、ETF 等进行操作。
-
利用除布林带以外的其他交易工具。
通过将这些工具与 Jupyter Notebook 中的实时数据集成,你不仅是在分析市场,还在体验市场的发展过程。
祝你流媒体体验愉快!
Mudit Srivastava**** 在 Pathway 工作。在此之前,他是 AI Planet 的创始成员,并且在 LLMs 和实时机器学习领域活跃地建设社区。
更多相关话题
Python Lambda 函数详解
原文:
www.kdnuggets.com/2023/01/python-lambda-functions-explained.html

编辑者提供的图像
自计算机编程出现以来,函数通过提供如重用性、可读性、模块化、错误减少和易于修改等优势,扮演了重要角色。重用性被认为是函数最有用的特性之一,但如果我告诉你有一些函数虽然不可重用但仍然有用,你会怎么想?要了解更多,请继续阅读!
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 工作
Lambda 函数及其语法
lambda 函数没有名称,是一个立即调用的函数。它可以接受任意数量的参数,但只返回一个表达式,这与普通函数不同。
它有如下语法:
lambda parameters: expression
上述 lambda 函数的语法包含三个元素:
-
关键字 “lambda” — 类似于用户定义函数中的‘def’
-
parameters — 类似于普通函数中的参数
-
expression — 这是用来计算结果的操作
与普通函数不同,lambda 函数中的参数没有括号。考虑到表达式是一行代码,它需要简洁,但同时必须对参数执行所需的操作。lambda 函数在定义时被消耗,因此不能在未明确重新定义的情况下重用。
通常,lambda 函数作为参数传递给高阶函数,如 Python 内置函数 – filter()、map() 或 reduce()。但什么是高阶函数呢?
高阶函数定义为接收其他函数作为参数的函数(将在后续章节中讨论)。
用途与示例
现在我们已经了解了语法,是时候用一个简单的例子来理解 lambda 函数了。假设你想计算一个数字的平方。你可以定义一个名为“square”的函数,或者编写一个如下所示的 lambda 函数:
def square(x):
return x**2
lambda x: x**2
上述 lambda 函数接受一个参数 x 并返回它的平方。
调用 Lambda 函数
调用 lambda 函数非常简单,首先包装 lambda 函数的构造,然后在括号中放入参数。
(lambda x: x**2)(3)
Output >> 9
使用多个参数调用
对于具有多个参数的 lambda 函数,输入参数由逗号分隔。相应的参数在执行时遵循相同的顺序。
(lambda x, y, z: x**2 + y**2 + z**2)(1, 2, 0)
Output >> 100
单一条件语句
您还可以执行条件操作,例如下面示例中的 if-else 块:
(lambda x: 100 if x > 100 else (50 if x > 50 else x))(75)
Output >> 100
嵌套条件语句
由于这些是单行函数,条件嵌套是通过圆括号而不是缩进来完成的。
(lambda x: 100 if x > 100 else (50 if x > 50 else x))(75)
Output >> 50
与上述 lambda 函数对应的用户定义函数如下所示。
def conditional_statement_demo(x):
if x > 100:
return100
elif x > 50:
return 50
else:
return x
conditional_statement_demo(75)
Output >> 50
请注意,在嵌套条件场景中,用户定义的函数是更好的选择。
赋值给变量
lambda 函数也可以赋值给变量,并像用户定义的函数一样调用。
square = lambda x: x**2
square(3)
Output >> 9
尽管可以将函数赋值给变量,但这很少使用,因为它违背了 lambda 函数的唯一目的,即立即调用。变量赋值在将 lambda 函数用于另一个函数时比较有用。
字符串连接
以下示例演示了如何连接两个字符串——在其中,您打印包含作为参数传递的人的名字的欢迎消息。
welcome_msg = lambda name : print('Hi', name + '! This is your computer.')
welcome_msg(“Vidhi”)
Output >> Hi Vidhi! This is your computer.
嵌套函数
lambda 函数在另一个函数内部使用时最为强大。
让我们考虑一个用户定义的函数示例,该函数接受一个参数,用作任何数字的指数。
def power(y):
return lambda x : x**y
square = power(2)
print(square(5))
Output >> 25
通过下划线调用
是时候来点魔法了!让我们通过另一种方式来调用 lambda 函数。
lambda x, y : x**y
_(2,3)
Output >> 8
这里发生了什么?一旦定义了 lambda 函数(本质上是匿名函数),它将使用“_”和参数进行调用。
与 map() 一起使用
lambda 函数经常作为 map() 函数的参数使用。它将序列映射到一个函数,并且不需要明确的定义(尤其是对于下面显示的这种简单操作)
print(list(map(lambda x: x**2, range(1,11))))
Output >> [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
map() 将从 1 到 10 的序列映射到 lambda 函数,并返回序列中所有元素的平方。
与 reduce() 一起使用
reduce 函数对序列中的所有元素执行 lambda 函数中定义的操作,以返回一个单一的输出值。示例中将 1 到 4 的所有元素相乘,并计算输出为 123*4 = 24。
from functools import reduce
print(reduce((lambda x, y: x * y), range(1,5)))
Output >> 24
让我们检查另一个示例,其中 reduce 与 lambda 函数一起使用,以返回两个元素中较大的一个。当将列表作为第二个参数传递时,它返回列表中的最大数字。
lst = [8, 9, 50, 6, 12]
print(reduce(lambda a, b: a if a > b else b, lst))
Output >> 50
与 filter() 一起使用
lambda 函数的另一个重要用途是与 filter() 一起使用。在以下示例中,如果数字是奇数,lambda 函数返回 True。当与 filter 一起使用时,它返回列表中的所有奇数。
lst = [12, 2, 8, 46, 3, 34, 68, 92, 49]
result = list(filter(lambda x: (x % 2 != 0), lst))
print(result)
Output >> [3, 49]
lambda 函数非常方便,可以节省大量编码工作。本文解释了 lambda 函数的语法以及它与用户定义的函数的不同之处。希望您发现它对开始学习 lambda 函数的基础知识有所帮助。
Vidhi Chugh 是一位人工智能策略师和数字化转型领导者,致力于在产品、科学和工程交汇处构建可扩展的机器学习系统。她是一位获奖的创新领袖、作者和国际演讲者。她的使命是使机器学习大众化,并打破术语,让每个人都能参与这一转型。
更多相关主题
数据科学家在 2022 年应该了解的 Python 库
原文:
www.kdnuggets.com/2022/04/python-libraries-data-scientists-know-2022.html
随着越来越多的人进入科技领域,试图从事数据科学家、数据分析师、机器学习工程师等角色,编程语言 Python 变得越来越受欢迎。由于其简化的语法,Python 语言被认为是最易于使用的编程语言之一。
随着数据科学的流行,新的库不断发布,以帮助解决数据科学中的挑战。学习库的方方面面可能会非常让人不知所措;然而,有些库对我们的学习至关重要。
以下是每个数据科学家在 2022 年应该了解的 Python 库,以保持和提升他们的编程技能。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
Pandas

来源:
Pandas 是由Wes McKinney于 2008 年创建的,是一个用于数据处理和分析的 Python 库。Wes McKinney 基于对强大且灵活分析工具的需求构建了 Pandas。
Pandas 可以处理:
-
处理缺失数据(表示为 NaN)
-
数据集的灵活重塑和透视
-
数据集的索引、操作、重命名、合并和连接
-
时间序列专用功能
-
以及更多
核心任务: 数据处理和分析
如何安装 Pandas: Pandas 安装
pip install pandas
获取书籍: Wes McKinney 的《数据分析的 Python 语言》
NumPy

来源:
NumPy 是另一个用于 Python 的库,主要用于数学函数。它在处理多维数组对象及各种派生对象(如掩码数组和矩阵)方面非常受欢迎,主要用于机器学习计算。该软件包含线性代数、傅里叶变换和矩阵计算函数。
NumPy 可以处理:
-
数组操作如加法、乘法、切割、排序、索引。
-
处理线性代数。
-
NumPy Python 中的基本切片和高级索引。
-
添加/删除/排序元素。
核心任务: 处理数组,使用数学函数。
如何安装 NumPy: NumPy 安装
pip install numpy
SciPy

来源:
SciPy 代表科学 Python。SciPy 是一个免费且开源的 Python 库,是主要建立在 NumPy 扩展上的数学算法和函数集合。
SciPy:
-
可以操作和可视化数据。
-
包含多种子包,帮助解决与科学计算相关的最常见挑战和问题。
-
可以处理线性代数、积分、常微分方程、微积分和信号处理。
-
易于使用和理解,计算速度快。
-
它可以操作 NumPy 库的数组。
核心任务: 解决科学和数学问题。
如何安装 SciPy: SciPy 安装
pip install scipy
conda install scipy
Matplotlib

来源:
Matplotlib 是 NumPy 的一个数值扩展,它是一个跨平台的数据可视化和图形绘制库,用于 Python。它与 NumPy 一起使用,提供了一个有效的环境,是一个开源的 MatLab 替代品。
Matplotlib 可以:
-
创建高质量的数据图表。
-
创建折线图、散点图、条形图和直方图、饼图、茎图、频谱图。
-
制作可以缩放、平移和更新的交互式图形。
-
自定义可视化的样式和布局。
-
导出到不同的文件格式。
核心任务: 创建静态、动画和/或交互式的 Python 可视化图。
如何安装 Matplotlib: Matplotlib 安装
pip install matplotlib
conda install matplotlib
GitHub: Matplotlib
教程: Matplotlib 教程
进一步阅读的书籍:
-
掌握 matplotlib 由 Duncan M. McGreggor 编写。
-
使用 Matplotlib 创建交互式应用程序 由 Benjamin Root 编写。
-
《Matplotlib for Python Developers》 作者:Sandro Tosi
Seaborn

Seaborn 是一个建立在 matplotlib 之上的库,并与 pandas 数据结构紧密集成。它提供了一个高层接口,通过其绘图函数绘制吸引人且信息丰富的统计图形,帮助你进一步探索和理解数据。
Seaborn 能:
-
创建散点图、直方图、条形图、箱线图等
-
显示两个或三个数据点之间的线性关系
-
比 matplotlib 更舒适地处理 Pandas 数据框
-
执行语义映射和统计聚合以生成信息图。
核心任务: 在 Python 中制作统计图形
如何安装 Seaborn: Seaborn 安装
pip install seaborn
conda install seaborn
Scikit-learn

来源:
Scikit-learn 是一个免费的机器学习库,包含有效的机器学习和统计建模工具,如分类、回归、聚类和降维。
Sci-kit Learn 的主要优点是开源、易于使用、文档完善且用途广泛。
Scikit-learn 可用于:
-
监督学习和无监督学习
-
聚类和降维
-
集成方法
-
交叉验证
-
特征提取和选择
核心任务: 机器学习和统计建模
如何安装 Sci-kit Learn: Sci-kit Learn 安装
pip install scikit-learn
进一步阅读:
- 《动手学习机器学习:使用 Scikit-Learn、Keras 和 TensorFlow》 作者:Aurelien Geron
TensorFlow

来源:
TensorFlow 由 Google Brain 团队构建,是一个开源的深度学习应用库。TensorFlow 还通过帮助开发者创建具有多个层的大规模神经网络,使构建深度学习模型变得容易。
TensorFlow 可/已用于:
-
语音和声音识别
-
情感分析、文本分类
-
文本应用程序,如 Google 翻译、Gmail 等。
-
人脸识别,如 Facebook Deep Face、照片标记等
核心任务: 使用 Python 开发和训练模型
如何安装 TensorFlow: TensorFlow 安装
pip install tensorflow
进一步阅读的书籍:
-
使用 Scikit-Learn、Keras 和 TensorFlow 进行实践机器学习 作者为 Aurelien Geron
-
学习 TensorFlow:构建深度学习系统指南 作者为 Itay Lieder、Tom Hope 和 Yehezkel S. Resheff
-
TensorFlow 深度学习:从线性回归到强化学习 作者为 Bharath Ramsundar 和 Reza Bosagh
尼莎·阿亚 是一名数据科学家和自由撰稿人。她特别感兴趣于提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探索人工智能在延长人类寿命方面的不同方式。作为一名热衷于学习的人,她寻求拓宽自己的技术知识和写作技能,同时帮助引导他人。
更多相关内容
可解释机器学习的 Python 库
原文:
www.kdnuggets.com/2019/09/python-libraries-interpretable-machine-learning.html
评论
由 Rebecca Vickery, 数据科学家
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
随着关于人工智能偏见的关注日益增加,企业能够解释其模型产生的预测以及模型本身的工作原理变得越来越重要。幸运的是,越来越多的数据科学 Python 库正在开发中,旨在解决这个问题。在以下内容中,我将简要介绍四个最成熟的解释和解释机器学习模型的包。
以下库均可通过 pip 安装,附带良好的文档,并强调视觉解释。
yellowbrick
这个库本质上是 scikit-learn 库的扩展,提供了一些非常有用且美观的机器学习模型可视化。可视化对象,即核心接口,是 scikit-learn 估计器,因此如果你习惯使用 scikit-learn,工作流程应该非常熟悉。
可以呈现的可视化内容包括模型选择、特征重要性和模型性能分析。
让我们通过几个简短的示例来说明。
这个库可以通过 pip 安装。
pip install yellowbrick
为了说明一些特性,我将使用一个名为酒识别的 scikit-learn 数据集。该数据集包含 13 个特征和 3 个目标类别,可以直接从 scikit-learn 库中加载。在下面的代码中,我导入数据集并将其转换为数据框。数据可以在分类器中使用,无需额外预处理。
import pandas as pd
from sklearn import datasets
wine_data = datasets.load_wine()
df_wine = pd.DataFrame(wine_data.data,columns=wine_data.feature_names)
df_wine['target'] = pd.Series(wine_data.target)
我还使用 scikit-learn 进一步将数据集拆分为测试集和训练集。
from sklearn.model_selection import train_test_split
X = df_wine.drop(['target'], axis=1)
y = df_wine['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
接下来,让我们使用 Yellowbricks 可视化工具查看数据集中特征之间的相关性。
from yellowbrick.features import Rank2D
import matplotlib.pyplot as plt
visualizer = Rank2D(algorithm="pearson", size=(1080, 720))
visualizer.fit_transform(X_train)
visualizer.poof()
现在让我们拟合一个 RandomForestClassifier,并使用另一个可视化工具评估性能。
from yellowbrick.classifier import ClassificationReport
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
visualizer = ClassificationReport(model, size=(1080, 720))
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.poof()
ELI5
ELI5 是另一个有用的可视化库,用于调试机器学习模型并解释它们产生的预测。它与最常用的 Python 机器学习库兼容,包括 scikit-learn、XGBoost 和 Keras。
让我们使用 ELI5 来检查我们上述训练的模型的特征重要性。
import eli5
eli5.show_weights(model, feature_names = X.columns.tolist())

默认情况下,show_weights 方法使用 gain 计算权重,但你可以通过添加 importance_type 参数来指定其他类型。
你还可以使用 show_prediction 来检查个别预测的原因。
from eli5 import show_prediction
show_prediction(model, X_train.iloc[1], feature_names = X.columns.tolist(),
show_feature_values=True)

LIME
LIME(局部可解释模型无关解释)是一个用于解释机器学习算法预测的包。LIME 支持对各种分类器的个别预测进行解释,并且内置支持 scikit-learn。
让我们使用 LIME 来解释我们之前训练的模型的一些预测。
LIME 可以通过 pip 安装。
pip install lime
首先,我们构建解释器。这需要一个训练数据集作为数组、模型中使用的特征名称以及目标变量中的类别名称。
import lime.lime_tabular
explainer = lime.lime_tabular.LimeTabularExplainer(X_train.values,
feature_names=X_train.columns.values.tolist(),
class_names=y_train.unique())
接下来,我们创建一个使用模型对数据样本进行预测的 lambda 函数。这借鉴了这个出色的、更加深入的 教程。
predict_fn = lambda x: model.predict_proba(x).astype(float)
然后我们使用解释器来解释对选定示例的预测。结果如下所示。LIME 生成一个可视化图,展示特征对这个特定预测的贡献。
exp = explainer.explain_instance(X_test.values[0], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)
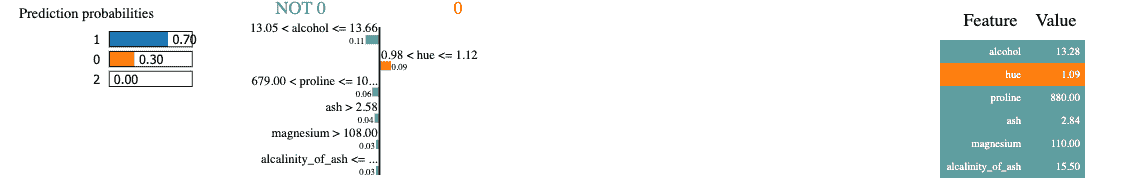
MLxtend
这个库包含大量机器学习的辅助函数。它涵盖了如堆叠和投票分类器、模型评估、特征提取和工程以及绘图等内容。除了文档之外,这篇 论文 是一个很好的资源,可以更详细地了解这个包。
让我们使用 MLxtend 来比较投票分类器与其组成分类器的决策边界。
同样,它可以通过 pip 安装。
pip install mlxtend
我正在使用的导入包如下所示。
from mlxtend.plotting import plot_decision_regions
from mlxtend.classifier import EnsembleVoteClassifier
import matplotlib.gridspec as gridspec
import itertoolsfrom sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
下面的可视化只能同时处理两个特征,因此我们将首先创建一个包含特征 proline 和 color_intensity 的数组。我选择了这两个特征,因为它们在我们之前使用 ELI5 检查的所有特征中具有最高的权重。
X_train_ml = X_train[['proline', 'color_intensity']].values
y_train_ml = y_train.values
接下来,我们创建分类器,将它们拟合到训练数据中,并使用 MLxtend 可视化决策边界。输出结果显示在代码下方。
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
eclf = EnsembleVoteClassifier(clfs=[clf1, clf2, clf3], weights=[1,1,1])
value=1.5
width=0.75
gs = gridspec.GridSpec(2,2)
fig = plt.figure(figsize=(10,8))
labels = ['Logistic Regression', 'Random Forest', 'Naive Bayes', 'Ensemble']
for clf, lab, grd in zip([clf1, clf2, clf3, eclf],
labels,
itertools.product([0, 1], repeat=2)):
clf.fit(X_train_ml, y_train_ml)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X_train_ml, y=y_train_ml, clf=clf)
plt.title(lab)
这绝不是解释、可视化和说明机器学习模型的库的详尽列表。这个优秀的帖子包含了许多其他有用的库,可以尝试一下。
感谢阅读!
个人简介:Rebecca Vickery 正在通过自学学习数据科学。Holiday Extras 的数据科学家。alGo 的联合创始人。
原文。经许可转载。
相关:
-
揭开黑箱:如何利用可解释机器学习
-
解释性机器学习/xAI 的数据科学手册
-
每个数据科学家都应该知道的命令行基础知识
更多相关话题
Python 列表与列表操作
原文:
www.kdnuggets.com/2019/11/python-lists-list-manipulation.html
评论
由 Michael Galarnyk,数据科学家
Python 列表与列表操作视频
在开始之前,我应该提到,本文博客和上述 视频 中的代码可以在我的 github 上找到。
定义列表
列表用方括号 [] 包裹
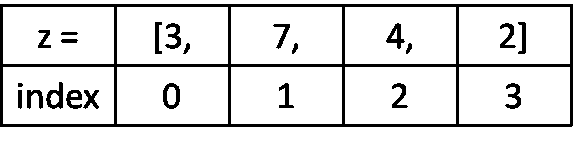
定义列表。此表中的第二行索引是访问列表项的方法。
# Define a list
z = [3, 7, 4, 2]
列表存储一个有序的项集合,这些项可以是不同类型的。上面定义的列表中的所有项都是同一类型(int),但列表中的所有项不需要是相同类型,如下所示。
# Define a list
heterogenousElements = [3, True, 'Michael', 2.0]
列表包含一个 int,一个 bool,一个字符串和一个 float。
访问列表中的值
列表中的每一项都有一个分配的索引值。需要注意的是,Python 是一个基于零索引的语言。这意味着列表中的第一个项的索引是 0。
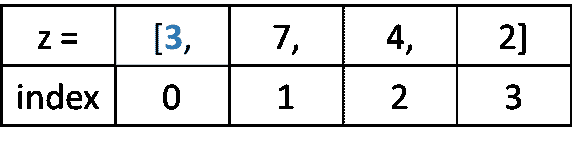
访问索引为 0 的项(用蓝色标出)
# Define a list
z = [3, 7, 4, 2]*# Access the first item of a list at index 0*
print(z[0])

访问索引为 0 的项的输出。
Python 还支持负索引。负索引从末尾开始。有时使用负索引来获取列表中的最后一项会更方便,因为你不需要知道列表的长度即可访问最后一项。
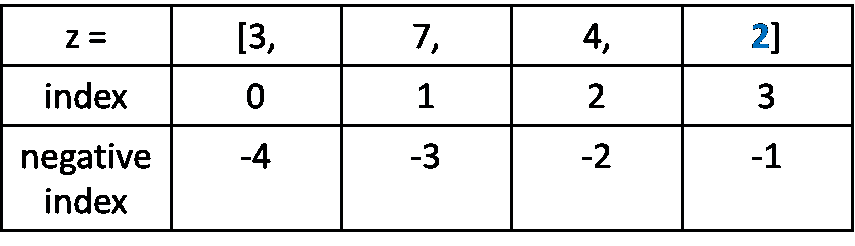
访问最后一个索引处的项。
*# print last item in the list*
print(z[-1])

访问列表中最后一项的输出
作为提醒,你也可以使用正索引访问相同的项(如下所示)。

访问列表 z 中最后一项的替代方法
列表切片
切片适用于获取列表中的子集。以下示例代码将返回一个列表,其中包含从索引 0 开始到不包括索引 2 的项。
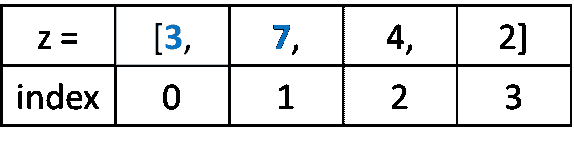
第一个索引是包含的(在 : 之前),而最后一个索引(在 : 之后)是不包含的
# Define a list
z = [3, 7, 4, 2]print(z[0:2])
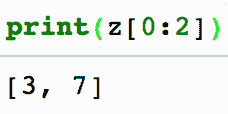
列表切片语法。
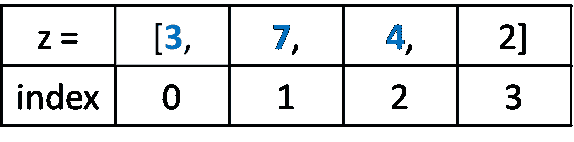
*# everything up to but not including index 3*
print(z[:3])

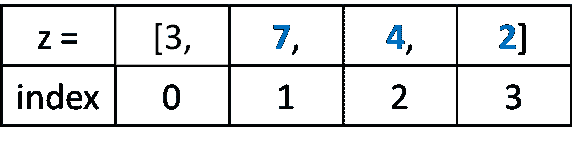
下面的代码返回一个包含从索引 1 到列表末尾的项的列表
*# index 1 to end of list*
print(z[1:])

更新列表中的项
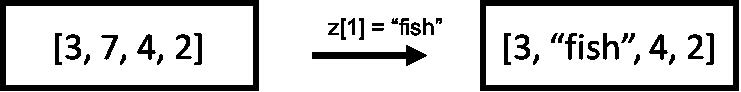
Python 中的列表是可变的。这意味着在定义列表后,可以更新列表中的单个项。
# Defining a list
z = [3, 7, 4, 2]# Update the item at index 1 with the string "fish"
z[1] = "fish"
print(z)

修改列表中项的代码
列表方法
Python 列表有不同的方法帮助你修改列表。本教程部分仅介绍各种 Python 列表方法。
索引方法

# Define a list
z = [4, 1, 5, 4, 10, 4]

索引方法返回值出现的第一个索引。在下面的代码中,它将返回 0。
print(z.index(4))

你还可以指定从哪里开始搜索。
print(z.index(4, 3))

计数方法
count 方法的作用如其名称所示。它计算一个值在列表中出现的次数
random_list = [4, 1, 5, 4, 10, 4]
random_list.count(5)
排序方法

对 Python 列表进行排序——实际代码为:z.sort()
sort 方法会原地对列表进行排序和修改。
z = [3, 7, 4, 2]
z.sort()
print(z)

上面的代码将一个列表按从低到高排序。下面的代码显示了你也可以按从高到低的顺序对列表进行排序。
将 Python 列表按从高到低排序
*# Sorting and Altering original list*
*# high to low*
z.sort(reverse = True)
print(z)

顺便提一下,你也可以将字符串列表按从 a 到 z 和从 z 到 a 进行排序,具体可以参见这里。
追加方法

将值 3 添加到列表的末尾。
append 方法将元素添加到列表的末尾。这会在原地发生。
z = [7, 4, 3, 2]
z.append(3)
print(z)

删除方法

remove 方法删除列表中第一次出现的值。
z = [7, 4, 3, 2, 3]
z.remove(2)
print(z)

代码从列表 z 中删除值 2 的第一次出现
弹出方法
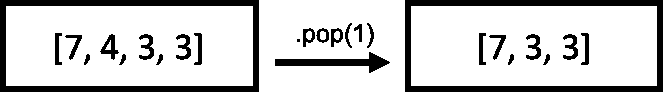
z.pop(1) 移除索引为 1 的值,并返回值 4。
pop 方法移除你提供的索引处的项。此方法还会返回你从列表中移除的项。如果你不提供索引,它将默认移除最后一个索引处的项。
z = [7, 4, 3, 3]
print(z.pop(1))
print(z)

扩展方法

该方法通过附加项来扩展列表。其好处在于你可以将列表合并在一起。
z = [7, 3, 3]
z.extend([4,5])
print(z)

将列表[4, 5]添加到列表 z 的末尾。
另外,也可以使用+运算符来完成相同的操作。
print([1,2] + [3,4])
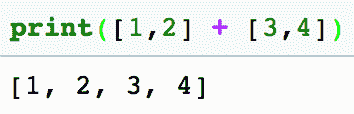
插入方法
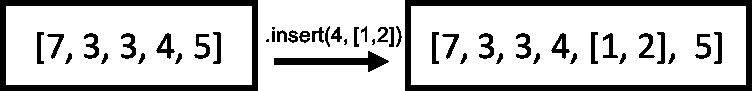
在索引 4 处插入列表 [1,2]
插入方法在你提供的索引之前插入一个项目
z = [7, 3, 3, 4, 5]
z.insert(4, [1, 2])
print(z)

结语
如果你有任何问题,请通过这里或 youtube 视频 的评论区或 Twitter 告诉我!下篇文章将回顾 python 字典。如果你想学习如何利用 Pandas、Matplotlib 或 Seaborn 库,请考虑参加我的 Python 数据可视化 LinkedIn 学习课程。这是一个 免费预览视频。
个人简介:Michael Galarnyk 是一位数据科学家和企业培训师。他目前在斯克里普斯转化研究所工作。你可以在 Twitter (https://twitter.com/GalarnykMichael)、Medium (https://medium.com/@GalarnykMichael) 和 GitHub (https://github.com/mGalarnyk) 上找到他。
原文。已获许可转载。
相关内容:
-
理解箱线图
-
应用于 Pandas DataFrames 的集合操作
-
理解 Python 中的分类决策树
我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关内容
Python 机器学习:电子书评测
原文:
www.kdnuggets.com/2022/06/python-machine-learning-ebook-review.html编辑注: 为了完全透明,机器学习精通是 KDnuggets 的姐妹网站。作者获得了该书的副本,并完全自主地进行评审。

作者提供的图片
我认识的大多数人可以构建、验证和部署机器学习模型,但他们不了解 Python 语言的基础知识。他们主要关注模型架构,而不是学习生产级编码实践。这些软件工程实践是提高生产力的必要条件。
机器学习完全是关于实验和构建更好解决方案的迭代。如果你通过学习单元测试、调试、日志记录、代码检查、文档编制和多线程处理来简化这一过程,你可以改善数据工作流。这些实践已成为数据科学解决方案的行业标准,提供更快、更可靠的开发流程。
Pytest 示例来自书籍
Python 机器学习适合那些对 Python 语言了解有限但希望深入学习的人。
这本书分为 5 个部分:
-
基础知识: 你将学习 Python 语言特性,如列表推导式、装饰器和生成器。
-
调试、性能分析和代码检查: 你将学习日志记录、调试文档和代码检查。
-
更好的代码,更好的软件: 学习编写更好代码的技巧,如测试、实验、命令行参数和序列化。
-
充实你的书库: 探索 Python 生态系统、网页抓取、数据可视化、数据增强、多进程、网页框架和部署。我们还将学习如何使用 API、SQLite、dbm、Excel 和 Google Sheets 下载和管理数据。
-
平台: 了解免费云平台(Google Colab、Kaggle),用于构建、验证和实验机器学习项目。
我喜欢这本书的地方
这本书涵盖了与机器学习相关的所有必要主题,并提供了代码示例。你可以跟随教程在本地机器上进行测试。如果你问我,这本书是进入 Python 机器学习世界的门户。你可以利用这本书赢得 Kaggle 比赛,开发和部署你的项目,参与开源项目,并在顶尖公司找到工作。
大多数公司希望机器学习工程师了解软件开发、单元测试、文档编写、多线程和日志记录。编写干净且易读的代码将帮助你和团队理解你所做的更改。你将学习为你的机器学习项目编写有效、可读且更快的代码。
例如,你将学习为你的 Keras 模型编写回调函数。这将教你函数式编程的基本原理以及如何将机器学习框架集成在一起。

来自书中的图片 | 定义 CheckpointCallback
除此之外,你将学习 Python 语法的核心概念,以及如何使用它来获取、处理、操作和管理数据集。
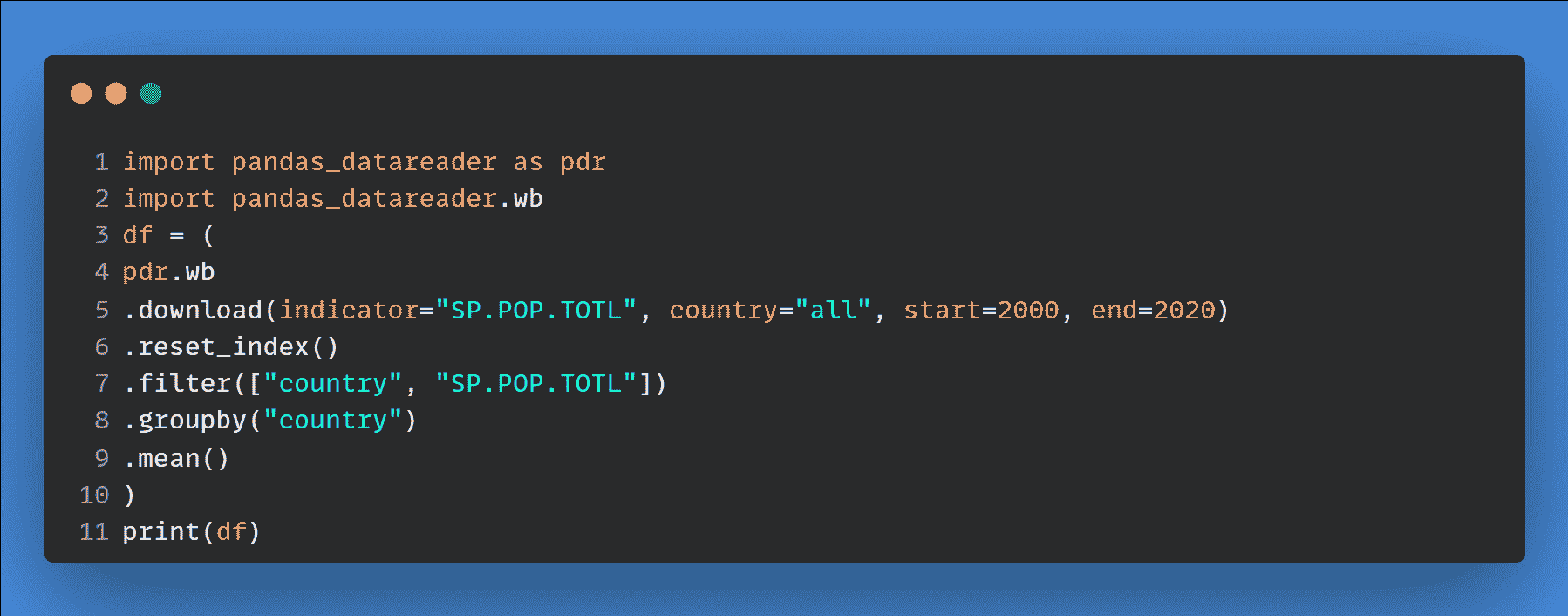
来自书中的示例 | 函数式语法
我喜欢这本书的设计方式,它从基础知识开始,然后逐步深入到高级概念。这将为你应对各种机器学习项目中的问题做好准备。你将通过逐步编码的课程学习高级概念。
机器学习初学者的重要主题
这本书不是关于机器学习的。我不会教你高级算法或深度学习的核心概念。相反,你将学习 Python 在机器学习过程中的应用。
例如,你将学习如何使用 joblib 引入多个进程,以改善数据处理和模型训练时间。
你还将学习机器学习操作,例如实验跟踪、模型训练和部署、数据管理、数据可视化、Python 网络框架、深度学习框架以及免费的云平台。
来自书中的图片 | 由 make_s_curve() 和 make_swiss_roll() 生成的数据集
尽管这本书涵盖了几乎所有与 Python 编程相关的主题,但我还是创建了一个对进入机器学习领域至关重要的主题列表。
重要主题:
-
Python 中的语言特性
-
Python 类及其在 Keras 中的应用
-
Python 中的函数式编程
-
Python 中的日志记录
-
注释、文档字符串和类型提示
-
异常处理和调试
-
在 Python 中进行实验
-
你的 Python 脚本的命令行参数
-
单元测试和编写更好的代码
-
Python 中的网页抓取
-
获取机器学习的数据集
-
机器学习项目的数据管理
-
NumPy、SciPy 和 Pandas
-
使用 matplotlib、Seaborn 和 Bokeh 进行数据可视化
-
Python 中的多进程
-
你的 Python 项目的 Web 框架
-
部署 Python 项目
-
Google Colab 和 Kaggle 用于机器学习项目
来自书中的图片 | 模型训练后的 Dash 网络应用
这些主题将帮助你了解机器学习生态系统中的开发和部署过程、实验、质量保证和优化。
结论
现在是进入数据科学和机器学习领域的最佳时机。需求很高,你可以年薪超过$120K - indeed.com。这本书将帮助你学习编写生产级代码所需的所有技能。
在这本电子书中,我涵盖了机器学习中 Python 的核心主题,并给出了我的看法。它适合那些对运行 Python 程序有一定了解,并希望进一步了解 Python 功能和工业实践的初学者。
如果你喜欢这篇评论,可以考虑购买一本Python for Machine Learning 书籍,价格为$37,或查看machinelearningmastery.com上的精彩教程。
查看我对数据科学书籍的其他评论:
-
Pydon’ts – 编写优雅的 Python 代码:免费书评
-
SQL 专业笔记:免费电子书评审
-
命令行数据科学:免费电子书
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一款 AI 产品,帮助那些在心理健康方面挣扎的学生。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
相关话题
如何使用 Python 和机器学习来预测足球比赛的赢家
原文:
www.kdnuggets.com/2023/01/python-machine-learning-predict-football-match-winners.html

图片来源:Freepik
介绍
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你在 IT 领域的组织
Python 是最具多功能性的编程语言之一。多年来,Python 编程已发展成为构建各种机器学习应用程序的最受欢迎的编程语言。
这种应用程序的一个关键元素通常是根据可处理的数据进行某种预测。预测具有不确定性这一方面,使用 Python 编程可以很容易地解决。
在本文中,我们将尝试解决这样一个问题。借助 Python 编程,我们将尝试预测足球比赛的结果。
由于这个问题涉及一定程度的不确定性,Python 编程可能是研究和解决这个问题的最佳选择。这正是我们在这里尝试实现的目标。
概述
足球是一项运动,与其他运动一样,涉及到许多本质上真正不可预测的元素。
众所周知,足球比赛的结果往往与预期不同。
在这种情况下,预测足球比赛的赢家成为一个挑战。然而,即使我们无法预知特定比赛的事件,我们也可以了解过去比赛中发生的事件。
当需要时,这些数据成为成功预测的关键元素。这是数据科学问题的基础,即研究过去的数据统计以预测可能的未来。
因此,在这个问题中,我们将基于过去比赛的数据来得出结果。我们将基于过去的数据进行统计研究,并预测足球比赛中最可能的赢家。
为此,我们将使用监督学习来构建一个用于检测的算法,使用 Python 编程。
问题陈述
本文旨在执行:
-
网络爬虫以收集过去足球比赛的数据
-
使用检测模型的监督学习来预测足球比赛的结果,基于收集的数据
-
检测模型的评估
涉及的步骤
1. 网络爬虫
网络爬虫是一种从互联网上不同网站的大量数据中提取相关数据的方法。
要提取的数据大多是非结构化的,且以 HTML 格式存在。这些数据以将其转化为结构化的列表形式的方式进行爬取,便于后续处理应用。
为了成功进行网络爬虫,我们需要将搜索范围缩小到包含特定足球比赛数据的网站。
确定后,我们将使用该 URL 主要访问网页的 HTML 脚本。
使用此 HTML 代码,爬虫将其转换为所需的输出格式(可能是电子表格、列表或 CSV/JSON 文件等)。
为了解决这个问题,我们将对网站 FBref.com 上的数据进行网络爬虫。
涉及的步骤包括:
-
导航到上述网站的“Competitions”部分。
-
选择任何提到的比赛(如 2022-23 赛季英超),以提取结果用于预测。
-
转到所选比赛部分下的“Scores & Fixtures”部分。
比分将用于进行预测,因此我们需要抓取这些信息。因此,复制页面的 URL。
在这种情况下(假设为英超联赛),链接将是:fbref.com/en/comps/9/schedule/Premier-League-Scores-and-Fixtures#sched_2022-2023_9_1
你还可以根据需要获取其他比赛的链接。
-
然而,需要注意的是,我们也可以使用任何其他网站来进行检测。
例如,我们可以通过提供比赛比分的链接,比如
en.wikipedia.org/wiki/2022_FIFA_World_Cup,直接从维基百科抓取比赛结果。 -
要执行实际的网络爬虫,需要将复制的 URL 提供给网络爬虫脚本或代码,以提取相关的比赛数据。
-
脚本将用于将一个赛季中的所有比赛合并成一个列表或.csv 文件。
-
从上面复制的 URL 将作为输入提供,同时提供包含锦标赛信息的表格的 ID。
-
汇总的包含所有比赛的列表将作为输出接收。
-
不必要的信息会被省略,如球员统计数据。
-
信息仅限于包含映射到球队数据的比赛数据,以便能够预测哪个球队会赢。
-
结果被附加以包含有关比赛和球队的数据(省略了与球员相关的信息),并借助数据框完成。
这主要是网页抓取的方式,提取的数据是基于过去的数据,用于预测未来的赢家。
让我们通过以下代码片段来理解这一点:
首先,我们将导入必要的库。
import pandas as pd
from bs4 import BeautifulSoup
import requests
接下来,我们将使用 Beautiful Soup 创建一个 soup 来提取网站的 HTML 代码。
url = 'https://en.wikipedia.org/wiki/2022_FIFA_World_Cup'
res = requests.get(url)
content = res.text
soup = BeautifulSoup(content, 'lxml')
然后,我们将提取比赛的信息,以此为基础预测,例如 FIFA 世界杯比赛的数据。
match_data = soup.find_all('div', class_='footballbox')
接下来,我们将提取主场和客场球队的数据/分数。
for match in match_data:
home_team.append(match.find('th', class_='fhome').get_text())
score.append(match.find('th', class_='fscore').get_text())
away_team.append(match.find('th', class_='faway').get_text())
最后,我们将数据存储在数据框中,以便导出到 .csv 文件。
dict_football = {'home_team': home_team, 'score': score, 'away_team': away_team}
df_football = pd.DataFrame(dict_football)
df_football.to_csv("fifa_worldcup_data.csv", index=False)
2. 数据预处理
在运行实际检测模型之前处理数据变得至关重要。因此,我们在这种情况下也将执行相同的操作。
这些步骤包括创建一个变量来存储在之前比赛中赢得的分数的平均值。
这是因为检测只能基于我们已有的数据进行,因为我们无法访问任何未来的数据。
我们将计算存储赛季比赛信息的不同变量的平均值。
此外,我们还将存储各种其他变量的移动平均值。
球队的分数通过每场胜利记为 3 分,平局记为 2 分,失败记为 1 分来汇总。这些值用于汇总球队在过去几场比赛中的所有分数。
接下来,为了确保主场和客场球队之间的区分,我们可以进行适当的计算。
然而,在这种情况下,我们可以假设需要为 FIFA 世界杯推导结果。
由于比赛在中立场地进行,我们可以在这种情况下忽略主场和客场球队的概念。
如果需要考虑这些,我们必须记住从客场球队的结果中减去主场球队的结果,以检查主场球队是否优于客场球队。
3. 实现预测模型
为了进行实际检测,我们可以使用不同类型的预测模型。在这种情况下,我们将考虑 3-4 种模型来实施实际预测。这里考虑的预测模型如下:
泊松分布
泊松分布是一种预测算法,用于通过在固定区间内定义概率并具有恒定均值速率来检测事件的可能性。
泊松分布预测某个事件在特定时间间隔内发生的次数。这意味着它帮助提供事件发生的概率度量,而不是简单的可能或不可能的结果。
这就是为什么它通常适用于多分类问题,但对二分类问题也同样有效(将两个类别视为数据集中的多类别)。
实现的代码片段如下:
定义一个“predict”函数来计算主队和客队的积分。
def predict(home_team, away_team):
# Calculate the value of lambda (λ) for both Home Team and Away Team.
if home_team in df_football.index and away_team in df_football.index:
lambda_home_team = df_football.at[home_team,'GoalsScored'] * df_football.at[away_team,'GoalsConceded']
lambda_away_team = df_football.at[away_team,'GoalsScored'] * df_football.at[home_team,'GoalsConceded']
接下来,使用泊松分布的公式来计算“p”的值,如下所示。
然后使用这个值来计算平局(pr_draw)、主队获胜(pr_home)和客队获胜(pr_away)的相应概率。
p = poisson.pmf(x, lambda_home_team) * poisson.pmf(y, lambda_away_team)
if x == y:
pr_draw += p
elif x > y:
pr_home += p
else:
pr_away += p
主队和客队的积分分别计算,然后用于进行最终预测。
points_home_team = 3 * pr_home + pr_draw
points_away_team = 3 * pr_away + pr_draw
这就是我们如何借助机器学习模型(在这个例子中是泊松分布)对足球比赛获胜者进行基本预测的方法。
这种特定的方法也可以通过简单地更改考虑中的预测模型公式扩展到其他模型。
最终结果将以比较研究的形式评估不同模型,以确保我们使用最合适的模型获得最佳结果。
让我们简要了解一下其他我们也可以用来进行类似预测的模型。
支持向量机
SVM 或支持向量机是一种基于监督学习的算法。
它主要用于分类问题。它通过在各种数据之间创建边界来进行分类。
由于它作为两个数据实体之间的分隔工作,因此它主要被认为是一个二分类解决方案。
但它也可以被修改或扩展为多分类问题。
要使用 Python 编程进行 SVM 预测,我们可以使用以下方法:
svc_predict = svm.SVC()
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.30)
svc_predict.fit(x_train, y_train)
在这里,svc_predict 是针对训练数据 x_train 和 y_train 的 SVM 计算。x_train 和 y_train 包含用于训练模型的数据,而 x_test 和 y_test 表示用于测试模型的数据。
KNN
K-最近邻或 KNN 是一种基于监督学习的算法。
它通过类标签进行数据分类。基本上,类被标记以创建分隔。
每个属于相同类型的数据实体都有相同的类别标签。
对于回归情况,预测是通过取“K”个最近邻的平均值来进行的。
邻居之间的距离通常是它们之间的欧几里得距离。
然而,也可以使用其他距离度量来完成相同的任务。
knn_predict = KNeighborsClassifier()
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.30)
knn_predict.fit(x_train, y_train)
逻辑回归
逻辑回归是用于二分类问题的线性模型。
它可以用来预测事件的发生概率,这也是我们在此场景中使用它的原因。
在逻辑回归的情况下,因变量被限制在 0 到 1 的范围内。
这就是它为何在二分类问题中表现良好的原因,例如足球比赛中的胜负情景。
logistic_predict = LogisticRegression()
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.30)
logistic_predict.fit(x_train, y_train)
4. 使用指标评估结果
为了评估通过不同模型获得的结果,我们可以使用指标来映射哪个模型的表现优于其他模型。
在这里,我们可以计算准确度来确定模型的表现质量。相关的公式如下所示:
准确度 = (真正例 + 真负例)/
(真正例 + 假负例 + 真负例 + 假正例)
真正例是指正确预测的正面结果。同样,真正负例是指正确预测的负面结果。
假负例是指错误预测的负面结果。同样,假正例是指错误预测的正面结果。
要检查准确度,我们需要将预测输出与真实输出进行比较。这是我们检查哪个模型的预测结果最接近实际结果的方法。
结论
这个特定问题非常复杂,但我们仍然通过 Python 编程轻松地达到了结果。
尽管结果不是绝对准确,但算法仍然展示了 Python 编程如何每天改变世界。
算法能够轻松地逻辑预测结果,这是一项可能没有游戏相关的先验信息, humans 可能无法完成的任务。
使用这样的预测模型,我们可以对其进行微调,并在未来获得更好的结果。
希望你已经了解了如何使用 Python 和机器学习来预测数据。你可以通过免费的资源如 KDnuggets,Scaler,或者 freecodecamp 来学习更多关于 Python 的知识。
快乐学习!
Vaishnavi Amira Yada 是一名技术内容作家。她拥有 Python、Java、DSA、C 等方面的知识。她发现自己在写作方面很有才华,并且非常喜欢它。
更多相关内容
Python Matplotlib 备忘单
原文:
www.kdnuggets.com/2023/01/python-matplotlib-cheat-sheets.html
你不可能在 Python 中完成数据科学项目而不使用 Matplotlib。实际上,如果有这样的情况:
from matplotlib import pyplot as plt
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 在 IT 方面支持你的组织
如果它不在你代码的前三行或四行之内,那么可能有些东西遗漏了。Matplotlib 是 Python 中最著名和最常用的绘图库。它允许你创建清晰且互动的可视化,使你的数据更易于理解,你的结果更具说服力。
你的可视化可以改变别人对你结果的看法,无论你是向客户还是同事展示。为了创建引人注目的可视化,你需要能够充分利用 Matplotlib 所提供的全部功能。
这篇文章的目的就是提供一些资源,帮助你入门、实践和掌握使用 Matplotlib 创建强有力的可视化以支持你的结果。
如果你是数据科学的新手或想要刷新你的知识,一个很好的起点是Freecodecamp上的 90 分钟 Matplotlib 教程。
另一个很好的起点是GeeksforGeeks的这篇文章,它将带你一步一步地从安装 Matplotlib 到在不到 5 分钟内创建美丽的可视化。
如果你想知道如何用 Matplotlib 制作互动可视化,UCLA 高级研究实验室的这个视频将展示基础知识,所有使用的材料都可以在GitHub上找到。
在你掌握了基础知识后,拥有一个常用函数的总结总是很有帮助的,这些函数你在创建数据科学项目时肯定会用到。
所以,让我和你分享我最喜欢的三个 Matplotlib 备忘单。

图片来源:Matplotlib
-
无论你是 Matplotlib 的初学者、中级用户还是高级用户,你都可以在官方 Matplotlib 网站上找到你需要的一切。这些备忘单包含创建、编辑甚至动画效果的提示和代码片段。除了备忘单外,它们还提供了基于你在使用该库的经验水平的基本功能指南。
-
接下来是由 Datacamp 创建的备忘单。Datacamp 提供了备忘单的 pdf/png 版本,你可以在同一 网页 上找到代码片段。如果你想在编辑之前试用这些代码片段或将其融入你的代码中,这非常适合。
-
最后但同样重要的是,CodeAcademy也提供了一个简单的备忘单,既有 pdf 格式,也有网页格式。这个简单的备忘单帮助你掌握使用 Matplotlib 的基础知识。

图片来源: DataCamp
这些资源将帮助你建立对 Matplotlib 的扎实理解。但如果你想进一步掌握这个库,这个由官方 Matplotlib 创作者提供的手册和这篇再生文章将教你一些技巧,将你的图表和可视化提升到一个新的层次。
知道如何创建引人注目的可视化图形是每个数据科学家在工作中取得成功的必备技能。我希望你能利用这些资源来构建和提升你的数据可视化技能,并将你的职业生涯提升到一个新的水平。
Sara Metwalli 是慶應義塾大学的博士生,研究测试和调试量子电路的方法。我是 IBM 的研究实习生和 Qiskit 的倡导者,帮助构建一个更具量子未来。我还是 Medium、Built-in、She Can Code 和 KDN 的撰稿人,撰写有关编程、数据科学和技术主题的文章。我也是国际女性编程 Python 分会的负责人,一个火车爱好者、旅行者和摄影爱好者。
相关主题
Python 超越 R,成为数据科学、机器学习平台的领导者
原文:
www.kdnuggets.com/2017/08/python-overtakes-r-leader-analytics-data-science.html
评论上一个 KDnuggets 调查 询问
你在 2016 和 2017 年是否使用了 R、Python(及其包)、两者,或其他工具用于分析、数据科学、机器学习工作?
Python 并未完全“吞并” R,但基于 954 位投票者的结果显示,2017 年 Python 生态系统 超越 R 成为分析、数据科学、机器学习的领先平台。
另请参见我的后续文章:Python 与 R – 谁在数据科学、机器学习中真正领先?
虽然在 2016 年 Python 排在第 2 位(“主要使用 Python”份额为 34%,而“主要使用 R”的份额为 42%),但在 2017 年 Python 达到了 41%,而 R 为 36%。
使用 两者 R 和 Python 的 KDnuggets 读者的份额也从 2017 年的 8.5% 增加到 12%,而主要使用 其他 工具的份额从 16% 下降到 11%。
 图 1: Python、R、两者或其他平台在 2016 年和 2017 年的使用份额
图 1: Python、R、两者或其他平台在 2016 年和 2017 年的使用份额
接下来,我们将检查不同平台之间的过渡。
 图 2: 分析、数据科学、机器学习平台
图 2: 分析、数据科学、机器学习平台
从 2016 到 2017 年的 R、Python、两者和其他的过渡**
这张图表看起来复杂,但我们看到两个关键方面,Python 在这两个方面都赢了:
-
忠诚度:Python 用户更忠诚,2016 年的 91% Python 用户继续使用 Python。而只有 74% 的 R 用户继续使用,其他平台用户中有 60% 继续使用。
-
切换:只有 5% 的 Python 用户转向 R,而转向 Python 的 R 用户则是两倍,达到了 10%。在 2016 年同时使用两者的人中,只有 49% 继续使用两者,38% 转向 Python,11% 转向 R。
净的,我们查看跨多个年的趋势。
在我们的 2015 年 R 与 Python 调查中,我们没有提供“Python 和 R 两者”选项,因此为了比较 4 年间的趋势,我们用 2016 和 2017 年 Python 和 R 的份额进行替换
Python* = (Python 分享) + 50% 的 (Python 和 R)
R* = (R 分享) + 50% 的 (Python 和 R)
我们看到 R 使用的份额在缓慢下降(从 2015 年的约 50% 下降到 2017 年的 36%),而 Python 份额则稳步增长——从 2014 年的 23% 增长到 2017 年的 47%。其他平台的份额也在稳步下降。
 图 3: Python 与 R 与其他平台在分析、数据科学和机器学习中的 2014-17 趋势
图 3: Python 与 R 与其他平台在分析、数据科学和机器学习中的 2014-17 趋势
最后,我们查看了按地区的趋势和模式。各地区的参与情况是:
-
美国/加拿大,40%
-
欧洲,35%
-
亚洲,12.5%
-
拉丁美洲,6.2%
-
非洲/中东,3.6%
-
澳大利亚/新西兰,3.1%
为了简化图表,我们将“同时”投票分配给 R 和 Python,并将亚洲、澳大利亚/新西兰、拉丁美洲和非洲/中东的 4 个参与较少的地区合并为一个“其他”地区。
 图 4: Python 与 R 与其他地区,2016 年对比 2017 年**
图 4: Python 与 R 与其他地区,2016 年对比 2017 年**
我们在所有地区观察到相同的模式:
-
Python 份额增加,8-10%
-
R 份额下降,大约 2-4%
-
其他平台的下降,5-7%
对于 Python 用户来说,未来看起来非常光明,但我们预计 R 和其他平台在可预见的未来将保持一定份额,因为它们有着庞大的用户基础。
评论
比尔·温克勒,计算速度等。
我们是一个使用 SAS 的团队,拥有大约 30 名新获得博士学位的人员和其他主要使用 R 的人员。由于我们开始转向基于云的环境,一些人开始使用 Python。对于使用基于严格理论模型的软件处理国家文件,我们使用高度优化的 C 和 FORTRAN 例程。SAS、R,甚至有时 Python 都慢了 100 多倍。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
Python Pandas 在 7 个简单步骤中的数据发现
原文:
www.kdnuggets.com/2020/03/python-pandas-data-discovery.html
评论

当我第一次开始使用 Python 分析数据时,我写的第一行代码是‘import pandas as pd’。我对pandas是什么感到非常困惑,并且在代码上挣扎了很多。我的脑海中有很多问题:为什么每个人在 Python 的第一行代码中都使用‘import pandas as pd’?pandas有什么特别的价值?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
我相信如果我能了解其背景会更好。由于我的好奇心,我通过不同的渠道进行了调查,例如:在线课程、谷歌、教师等。最终,我得到了答案。让我在这篇文章中与你分享这个答案。
背景
Pandas,即面板数据的缩写,由著名开发者 Wes McKinney 于 2008 年 1 月 11 日首次发布。Wes McKinney 厌恶研究人员浪费时间的想法。我最终通过他在采访中所说的话理解了pandas的重要性。
“科学家们不必要地处理简单数据操作任务让我感到非常糟糕,”
“我告诉人们,它使那些不是计算机科学专家的人也能分析和处理数据,”
Pandas 是现在数据分析师使用的主要工具之一,并且在推动 Python 在数据科学家社区中的使用方面发挥了重要作用。根据过去十年左右StackOverflow问答网站的流量,Python 的用户数量迅速增长。下图展示了Pandas 相对于其他一些 Python 软件库的巨大增长!
参考:编码俱乐部
现在是开始的时候了!让我们动手进行一些编码吧!这并不难,适合任何初学者。总共有 7 个步骤。
第 1 步:导入库
import pandas as pd
第 2 步:读取数据
方法 1:加载包含表格数据的文本文件
df=pd.read_csv(‘clareyan_file.csv’)
方法 2:从 Python 字典 创建一个 Pandas DataFrame
#create a Python script that converts a Python dictionary{ } into a Pandas DataFrame
df = pd.DataFrame({
'year_born': [1984, 1998, 1959, pd.np.nan, 1982, 1990, 1989, 1974, pd.np.nan, 1982],
'sex': ['M', 'W', 'M', 'W', 'W', 'M', 'W', 'W', 'M', 'W'],
'name': ['George', 'Elizabeth', 'John', 'Julie', 'Mary', 'Bob', 'Jennifer', 'Patricia', 'Albert', 'Linda']
})
#display the top 5 rows
df.head()
#display the top 10
df.head(10)
#display the bottom 5 rows
df.tail(5)
输出
这里,我使用了:df.head() 备注:python 列表是从 0 开始索引的,所以第一个元素是 0,第二个是 1,以此类推。
步骤 3:理解数据类型、行数和列数
df.shape
输出
(10,3) #(行, 列)
print('Number of variables: {}'.format(df.shape[1]))
print('Number of rows: {}'.format(df.shape[0]))
输出
变量数量:3
行数:10
数据类型是编程中的一个重要概念,它包含了数据项的分类或归类。
# Check the data type
df.dtypes
输出

如果你对数据类型不太熟悉,这个表格可能对你有用。

数据类型
# basic data information(columns, rows, data types and memory usage)
df.info()
输出

从输出中,我们知道有 3 列,占用了 153MB 的内存。
步骤 4:观察分类数据
#use the dataframe.nunique() function to find the unique values
unique_counts = pd.DataFrame.from_records([(col, df[col].nunique()) for col in df.columns],columns=['Column_Name', 'Num_Unique']).sort_values(by=['Num_Unique'])
输出
上表突出了每列的唯一值,这些值可能会帮助你确定哪些值可能是分类变量。例如,性别的唯一值为 2(这很合理 [M/F])。名称和出生年份可能不太可能是分类变量,因为唯一值的数量相当大。
#inspect the categorical column in detail
df['sex']
输出

# Counting
df.sex.value_counts()
输出

6 名女性和 4 名男性
步骤 5:探索数据
# look into the specify data
df[(df['sex']=='M') & (df['year_born']==1990)]
输出
要使用 &(AND)、~(NOT)和 |(OR),你必须在逻辑操作前后加上“(” 和 “)”。
此外,使用 loc 和 iloc 你可以对 DataFrames 执行几乎所有你能想到的数据选择操作。让我给你一些例子。
#show the *row* at position zero (1st row) df.iloc[0]
输出

#show the 1st column and 1st *row*
df.iloc[0,0]
输出
1984
接下来,我将使用 loc 进行数据选择。
#Gives you the ***row*** at position zero (2nd row)
df.loc[1]
输出

第 2 行
#give you the first row and the column of 'sex'
df.loc[0,'sex']
输出
‘M’
#select all rows where sex is male
df.loc[df.sex=='M']
输出
#only show the column of 'year born' where sex is male
df.loc[df.sex=='M','year_born']
输出

# find the mean of year_born of male
df.loc[df.sex=='M', 'year_born'].median()
输出
1984.0
其他聚合: min()、max()、sum()、mean()、std()
从上述示例中,你应该知道如何使用 iloc 和 loc 的功能。iloc 是 “integer location” 的缩写。iloc 使我们可以以 ‘矩阵’ 风格的标记方式访问 DataFrame,即 [行, 列] 标记方式。loc 是基于标签的,这意味着你必须根据行和列的标签(名称)指定行和列。
根据我的经验,人们容易混淆 loc 和 iloc 的使用。因此,我更倾向于使用其中一个——loc。
步骤 6:查找缺失值
#find null values and sort descending
df.isnull().sum().sort_values(ascending=False)
输出

‘year_born’ 列中有 2 个缺失值。
步骤 7:处理缺失值
当传递inplace=True时,数据将在原地重命名。
#method 1: fill missing value using mean
df['year_born'].fillna((df['year_born'].mean()), inplace= True)
输出
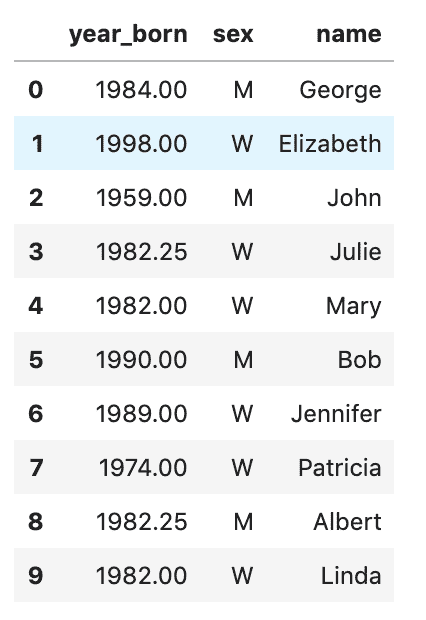
Julie 和 Albert 的出生年份是 1982.25(由均值替代)。
#method 2 drop the rows with missing value
df.dropna(inplace = True)
第 4 行和第 9 行已被删除。
步骤 8:数据可视化
Matplotlib 是一个 Python 的 2D 绘图库。你可以用几行代码轻松生成图表、直方图、功率谱、条形图、散点图等。这里的例子是绘制一个直方图。%matplotlib inline 会使你的绘图输出显示并存储在笔记本中,但与 pandas.hist() 的工作方式无关。
%matplotlib inline
df.loc[df.sex=='W', 'year_born'].hist()
输出
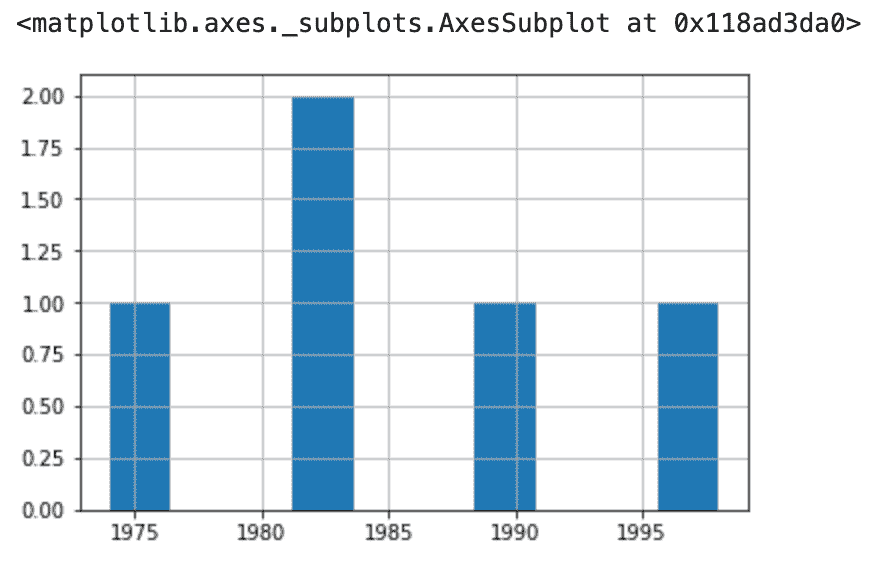
性别=’W’的出生年份。
#plot a histogram showing 'year_born'
df.hist(column='year_born')
输出
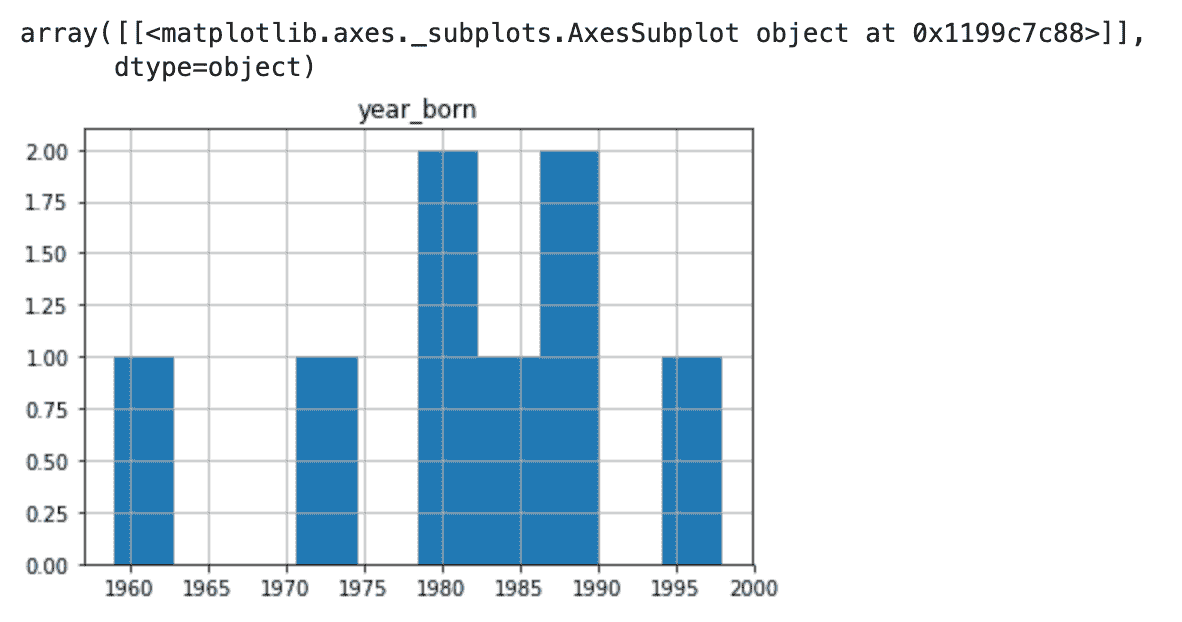
太棒了!我已经完成了使用pandas库进行数据发现的所有 7 个步骤。让我总结一下我使用过的函数:

附赠:让我介绍一下只用两行代码进行探索性数据分析(EDA)的最快方法:pandas_profiling

import pandas_profiling
df.profile_report()
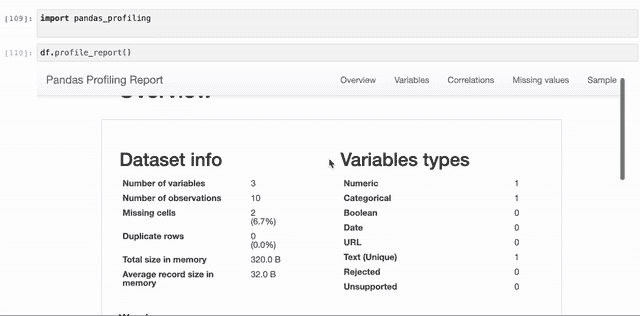
其内容包括:
- 概述:
数据集信息:变量数量、观测数量、缺失单元格、重复行 0、内存中的总大小及内存中平均记录大小
-
变量:缺失值及其百分比、不同计数、唯一值
-
相关性
-
缺失值:‘矩阵’和‘计数’
-
示例:前 10 行和最后 10 行
原文。经许可转载。
相关:
更多相关主题
Python 模式:使用 max 代替 if
原文:
www.kdnuggets.com/2019/01/python-patterns-max-instead-if.html
评论

在编写 Python 代码时,我常常需要查看一组对象,为每个对象确定一个分数,并保存最佳分数及其相关对象。例如,寻找用我目前拥有的字母在 Scrabble 中能拼出的最高分单词。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
一种方法是循环遍历所有对象,使用占位符记住到目前为止看到的最佳对象,如下所示:
# Set up placeholder variables
best_score = 0
best_word = None
# Try all possible words, saving the best one seen
for word in possible_words(my_letters):
score = score_word(word)
if score > best_score:
best_score = score
best_word = word
你可能之前在自己的代码中写过这种逻辑。代码并不复杂,但我们仍然可以通过快速调整来提高其可读性。
使用 max() 简化
if score > best_score 让你想起了什么?我们可能会实现 max() 函数的方式!使用 max() 有助于我们简化代码:
# Set up placeholder variables
best_seen = (0, None)
# Try all possible words, saving the best one seen
for word in possible_words(my_letters):
score = score_word(word)
newest_seen = (score, word)
best_seen = max(best_seen, newest_seen)
将所有数据存储在一个元组中意味着分配和比较现在可以一次性处理。这降低了我们混淆分配的可能性,并使我们所做的事情更加明确。
这里有一个潜在的陷阱:max() 选择第一个元素最大的元组(在我们的例子中是分数),这是我们想要的。但如果两个元组的第一个元素相同,max() 会继续比较其余元素,直到打破平局。因此,如果两个单词具有相同的分数,max() 将继续比较单词,它是按字典顺序进行的。
为了让 max() 仅比较第一个元素,我们可以使用 key 参数。key 参数接受一个对每个对象调用的函数,并返回另一个用于比较的对象。我们可以使用它来选择第一个条目,如下所示:
# Set up placeholder variables
best_seen = (0, None)
# Try all possible words, saving the best one seen
for word in possible_words(my_letters):
score = score_word(word)
newest_seen = (score, word)
best_seen = max(best_seen, newest_seen, key=lambda x: x[0])
更简单
在上述示例中,我们想保存分数和单词,但如果我们只关心生成最高分的单词,而不是分数本身呢?那么就有一个更简单的方法!
默认情况下,max() 使用标准比较运算符,但我们可以将其更改为使用上面相同的 key 参数中的 score_word()。这样我们就有了:
words = possible_words(my_letters)
best_word = max(words, key=score_word)
这给了我们一个非常紧凑(且相对可靠)的模式,将所有的循环和占位符都推入了max()的实现中。
个人简介:亚历山大·古德 目前是 Intuit 的数据科学家,使用机器学习进行欺诈预防。他获得了加州大学伯克利分校的物理学学士学位,以及明尼苏达大学双城分校的基础粒子物理学博士学位。
原文。转载已获许可。
相关:
-
5 个“清洁代码”技巧将显著提高你的生产力
-
传统编程与机器学习有多大不同?
-
使用 Python 加速数据预处理 2–6 倍
更多相关话题
如何获得 Python PCAP 认证:路线图、资源、成功技巧,基于我的经验
原文:
www.kdnuggets.com/2021/09/python-pcap-certification-roadmap-resources.html
评论
由Mehul Varsha Singh,诺丁汉大学 AI 本科生。
Python 是这个十年最受欢迎的编程语言。就是这样。
我们的前三推荐课程
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织进行 IT 工作
不论你学习 Python 的原因是什么,你都需要在某个时点验证你的知识是否符合国际标准。
“如果你正在学习它,那你不妨通过认证来获得一个证书。” - Mehul
证书路线图由 Python Institute OpenEDG 提供
也许最重要且被讨论的四个 Python 证书来自于Python Institute OpenEDG。
Python Institute 认证路线图由 OpenEDG 提供。
我于 2021 年 8 月 11 日取得了PCAP(Python 认证助理程序员)证书,成绩为 90%。
考试 - 关键细节
-
考试版本:PCAP-31–03
-
持续时间:65 分钟 + 10 分钟(保密协议)
-
问题数量:40
-
及格分数:70%
-
考试方式:由 Pearson Vue 在线监考
-
考试形式:选择题(单项和多项)
-
价格:295.00 美元(未折扣)
想要认证费折扣?当你完成 Open EDG 的 PCAP 课程(Python Essentials Part 1 和 Python Essentials Part 2)后,你将获得一张 50%的折扣券,将考试费用降低至 147.50 美元。
不允许使用 IDE。
我为考试制定的计划
所以,我决定了:“Mehul,你必须在 8 月之前获得 PCAP 认证。” 这就是我,在 6 月 31 号!
然后我开始在 Excel 中制定计划。
简而言之:1 个月准备和 2 周模拟测试。
我查看了PCAP 课程大纲,该大纲可以通过Open EDG 提供的免费自学培训课程获取。
该考试包含4 个模块(模块和包、字符串和异常、面向对象编程、杂项)。

模块。
我决定每周进行1 个模块的学习。
所以,从周一到周五,我会学习大纲,周六和周日则从W3 Schools做题以复习那些主题。
在 1 个月内,我完成了 PCAP 的大纲。
接下来的两周,我专注于进行练习测试/模拟考试。
一些额外的资源和笔记:
-
思科网络学院(免费且自定进度,包括额外的练习测试,完成后还可以获得考试的 50%折扣券)
-
免费样题测试 由 Open EDG 提供
-
在 PCAP 免费课程(第二部分)中,你每个模块会有 1 个小测验和 1 个测试,以及一个可以重复进行的最终总结测试(如上所述)。
-
外部来源的模拟测试(非 PCAP):这些模拟测试的难度通常高于实际考试,这将使你在参加实际考试时占有优势!在参加正式考试之前,我至少有 3 次得分达到 85%。
-
闪卡:它们非常有效,尤其是在考试前进行即时复习。
一些小贴士!
-
关注概念。
-
考试包含:当选择时你可能会感到困惑,因为每个答案之间没有明确的区别。解决时使用排除法。
-
尽可能多做题,因为这会给你在考试中带来优势。
-
使用秒表进行练习测试(我能够在 30 分钟内完成最终考试,剩下的时间用于检查)。
-
在学习过程中,如果你不理解一个程序,将其复制粘贴到调试器中并理解程序流程。这将帮助你在考试时,当他们要求你预测输出(尤其是面向对象相关问题)时。
最后,如果你不能解决一个问题,不要感到沮丧。理解解决方案,记下答案的原因,然后再试一次。我个人喜欢逐行阅读代码并解决问题。

好了,这就是我完成 PCAP 的全部经历。
希望我的经历和资源能给你信心和动力,帮助你顺利通过 PCAP 考试!
个人简介: Mehul Varsha Singh 是诺丁汉大学的 AI 本科生,同时还是一名受过训练的舞者、吉他手和 Maybank 学生大使。
相关:
相关主题
为什么 Python 是数据科学中最受欢迎的语言之一?
原文:
www.kdnuggets.com/2020/01/python-preferred-languages-data-science.html
评论
作者:Poli Dey Bhavsar,内容撰写者,来自 Helios Solutions。
根据 Indeed、Glassdoor 和 Dice 等招聘网站的数据显示,数据科学家的需求 每年持续增长,因各行各业的企业越来越依赖数据驱动的洞察力。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
事实上,通往这一热门职业的学习路径有很多,选择合适的路径取决于你在职业生涯中的位置。除了数学和统计技能外,编程专长也是一名有志数据科学家需要掌握的必备技能之一。

让我们深入挖掘数据科学社区中最受欢迎的编程语言吧!
数据科学家最常用的前三大编程语言
根据 Kaggle 进行的调查 结果,Python 是最常用的编程语言,其次是 SQL 和 R(见下图)。

这项调查覆盖了近 24,000 名数据专业人士,其中 4 分之 3 的受访者推荐有志的数据科学家从 Python 开始他们的学习之旅。 在本文中,让我们探讨是什么使 Python 成为数据专业人士中最受追捧的编程语言,以及为何选择 Python 进行数据分析。
为什么数据科学家喜欢 Python?
数据科学家需要处理复杂的问题,问题解决过程基本包括四个主要步骤——数据收集与清理、数据探索、数据建模和数据可视化。
Python 为他们提供了有效执行这一过程所需的所有工具,每个步骤都有专用库,我们将在本文后续部分讨论。这些工具包括强大的统计和数值库,如 Pandas、Numpy、Matplotlib、SciPy、scikit-learn 等,以及先进的深度学习库,如 Tensorflow、PyBrain 等。
此外,Python 已成为 AI 和 ML 的默认语言,数据科学与人工智能有交集。因此,这种多才多艺的语言成为数据科学家中使用最广泛的编程语言也就不足为奇了。
这种基于解释器的高级编程语言不仅易于使用,而且使数据科学家能够实现解决方案,同时遵循所需算法的标准。
现在,让我们来看看数据科学问题解决过程的步骤以及数据挖掘的 Python 包,这些包应该是数据科学家工具箱中不可或缺的一部分:
-
数据收集与清洗
-
数据探索
-
数据建模
-
数据可视化与解释
数据收集与清洗
使用 Python,你可以处理几乎所有格式的数据,如来自网络的 CSV(逗号分隔值)、TSV(制表符分隔值)或 JSON。
无论你是想直接将 SQL 表导入代码中,还是需要抓取任何网站,Python 都可以通过其专用库,如PyMySQL和BeautifulSoup,轻松完成这些任务。前者使你能够轻松连接到 MySQL 数据库以执行查询和提取数据,而后者则帮助你读取 XML 和 HTML 类型的数据。在提取和替换值后,你还需要在数据清洗阶段处理缺失的数据集,并相应地替换无效值。
此外,如果你在处理特定数据集时遇到困难,可以通过谷歌搜索该数据集和 Python 来找到解决方案,这要归功于强大而充满活力的 Python 社区!
数据探索
现在你的数据已经收集和整理完毕,确保所有收集的数据都进行了标准化。现在你有了干净的数据,确定需要回答的业务问题,然后将该问题转化为数据科学问题。
为此,探索数据以识别其属性,并将其分为不同类型,如数值型、序数型、名义型、分类型等,以提供所需的处理。
一旦数据根据类型进行分类,数据分析 Python 库NumPy和Pandas将帮助你从数据中发掘洞察,使你可以轻松高效地操作数据。
现在你的数据已经准备好使用了,是时候进入人工智能和机器学习领域进行数据建模了。
数据建模
这是数据科学过程中一个非常关键的阶段,你需要努力减少数据集的维度。
Python 有许多先进的库,帮助你利用机器学习的力量执行数据建模中的任务。
你想对数据进行数值建模分析吗?只需在工具包中寻找Numpy!借助SciPy,你可以轻松进行科学计算和计算。Scikit-learn 代码库为你提供了直观的接口,并帮助你将机器学习算法应用于数据中,而无需任何复杂性。
数据建模完成后,你需要可视化和解释数据,以获得可操作的洞察。
数据可视化与解释
Python 有许多数据可视化包。Matplotlib 是其中最常用的库,用于生成基本的图形和图表。如果你需要设计精美的高级图形,也可以尝试另一个 Python 库,Plotly。
另一个 Python 库,IPython,帮助你进行交互式数据可视化,并支持使用 GUI 工具包。如果你想将发现嵌入到交互式网页中,nbconvert 函数可以帮助你将 IPython 或 Jupyter 笔记本转换为丰富的 HTML 片段。
数据可视化之后,数据的呈现至关重要,必须以能够驱动你在项目开始时提出的业务问题的方式进行。
既然你已经提供了对业务问题的答案以及可操作的洞察,请记住,你的解释对组织的利益相关者而言应该是有用的。
准备好迎接 Python 以实现你的数据科学目标了吗?
有如此多的理由在你踏上数据科学之旅时考虑 Python 编程,这里还有另一个值得考虑的有力理由。顶级科技巨头也因各种原因使用 Python。以下是 Amazon 使用 Python 的原因:

那么,你对使用Python 进行数据科学有何看法?即使你更倾向于其他语言进行数据科学,也请告诉我们你的观点。请通过在下方留言与我们分享你的经验。
简介: Poli Dey Bhavsar 是 Helios Solutions 的内容作者。她通过撰写关于最新科技趋势和 IT 进展的故事来发挥对内容的热情。当她不在键盘前时,她在烹饪美食、旅行,并尝试揭示生命的意义。
相关:
更多相关主题
Python 和 R 数据科学课程
原文:
www.kdnuggets.com/2020/02/python-r-courses-data-science.html
评论 来源
来源
由于 Python 和 R 是今天数据科学家的必备技能,持续学习至关重要。在线课程无疑是职业生涯中提升技能的最佳和最灵活的方式。这个列表包含了知名课程,可以帮助任何想要开始了解每种语言及其专业应用的人。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
1. CS50 的计算机科学导论

本课程适合非计算机科学专业以及没有编程经验的人。根据课程描述,Python 是你将会熟悉的语言之一。虽然这与数据科学在统计和可视化方面并不直接相关,但基本的编程概念仍然非常重要。
2. 应用数据科学与 Python 专业化

这是密歇根大学的一门中级课程。该专业包含 5 门课程,并通过 Python 进行讲解。课程涉及的主题包括统计学、机器学习、信息可视化、文本分析和社会网络分析。
3. CS50 的 Python 人工智能导论

这个课程也适合数据科学初学者。它带我们了解 AI 的基本概念,例如 AI 的算法基础、图搜索算法、分类、优化、强化学习等。根据课程网站,这也是一个免费课程,仅需支付费用以获得可验证的证书。
4. 约翰霍普金斯大学的 R 编程课程

这是一个更适合有 R 编程经验的中级课程。它采用了更编程的方式,例如如何在 R 中构建函数和循环。课程中还使用了统计学作为示例。
5. 线性模型和矩阵代数简介
这门课程将带你通过线性代数在生命科学领域的应用。建议参加此课程的人应具备数学或统计学的基础知识。课程将使用 R 语言进行学习,涉及矩阵运算和统计推断等主题。
6. 数据科学:生产力工具
尽管 R 不是像 Java 或 Python 那样传统的编程语言,但学习这个生产力工具仍然有用,它可以帮助你组织代码,并使用 IDE 更快、更高效地编写代码。
相关:
-
R 编程入门
-
成为数据工程师的 7 个资源
-
2019 年 5 大著名深度学习课程/学校
更多相关话题
Python 正则表达式备忘单
原文:
www.kdnuggets.com/2018/04/python-regular-expressions-cheat-sheet.html
评论
由 Alex Yang 提供,Dataquest
这个备忘单基于 Python 3 的 正则表达式文档。如果你有兴趣学习 Python,我们有一个免费的 Python 编程:初学者 课程供你尝试。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
特殊字符
^ | 匹配其右侧的表达式在字符串的开头。它匹配每个字符串中每个\n之前的此类实例。
$ | 匹配其左侧的表达式在字符串的末尾。它匹配每个字符串中每个\n之前的此类实例。
. | 匹配除行结束符(如\n)之外的任何字符。
\ | 转义特殊字符或表示字符类。
A|B | 匹配表达式A或B。如果A首先匹配,则B将不会被尝试。
+ | 贪婪地匹配其左侧的表达式 1 次或多次。
* | 贪婪地匹配其左侧的表达式 0 次或多次。
? | 贪婪地匹配其左侧的表达式 0 次或 1 次。但是,如果?被添加到限定符(+、*和?本身)中,它将以非贪婪的方式进行匹配。
{m} | 匹配其左侧的表达式m次,并不少于。
{m,n} | 匹配其左侧的表达式m到n次,并不少于。
{m,n}? | 匹配其左侧的表达式m次,并忽略n。参见上面的?。
字符类(即特殊序列)
\w | 匹配字母数字字符,即a-z、A-Z和0-9。它还匹配下划线_。
\d | 匹配数字,即0-9。
\D | 匹配任何非数字字符。
\s | 匹配空白字符,包括\t、\n、\r和空格字符。
\S | 匹配非空白字符。
\b | 匹配单词的起始和结束处的边界(或空字符串),即 \w 和 \W 之间。
\B | 匹配 \b 不匹配的地方,即 \w 字符的边界。
\A | 匹配其右侧的表达式在字符串的绝对开始处,无论是单行模式还是多行模式。
\Z | 匹配其左侧的表达式在字符串的绝对结束处,无论是单行模式还是多行模式。
集合
[ ] | 包含一个字符集合以进行匹配。
[amk] | 匹配 a、m 或 k。它不匹配 amk。
[a-z] | 匹配从 a 到 z 的任何字母。
[a\-z] | 匹配 a、- 或 z。它匹配 - 因为 \ 对其进行转义。
[a-] | 匹配 a 或 -,因为 - 没有用来表示字符系列。
[-a] | 同上,匹配 a 或 -。
[a-z0-9] | 匹配从 a 到 z 和从 0 到 9 的字符。
[(+*)] | 特殊字符在集合内变为字面量,因此这匹配 (、+、* 和 )。
[^ab5] | 添加 ^ 排除集合中的任何字符。这里,它匹配不是 a、b 或 5 的字符。
组
( ) | 匹配括号内的表达式并将其分组。
(? ) | 在这样的括号内,? 作为扩展符号。其含义取决于其右侧的字符。
(?PAB) | 匹配表达式 AB,并可以通过组名访问。
(?aiLmsux) | 这里,a、i、L、m、s、u 和 x 是标志:
-
a— 仅匹配 ASCII -
i— 忽略大小写 -
L— 区域依赖 -
m— 多行 -
s— 匹配所有 -
u— 匹配 Unicode -
x— 详细
(?:A) | 匹配由 A 表示的表达式,但与 (?PAB) 不同,它无法在之后被检索。
(?#...) | 注释。内容供我们阅读,不用于匹配。
A(?=B) | 向前断言。只有在 B 之后,才匹配表达式 A。
A(?!B) | 向前否定断言。只有在不跟随 B 的情况下,才匹配表达式 A。
(?<=B)A | 正向回顾断言。只有在 B 紧接其左侧时,才匹配表达式 A。这只能匹配固定长度的表达式。
(?<!B)A | 向后否定断言。只有在 B 不紧接其左侧时,才匹配表达式 A。这只能匹配固定长度的表达式。
(?P=name) | 匹配由早期名为“name”的组匹配的表达式。
(...)\1 | 数字 1 对应第一个匹配的组。如果我们想匹配相同表达式的更多实例,只需使用其数字而不是重新书写整个表达式。我们可以使用从 1 到 99 的这些组及其对应的数字。
流行的 Python re 模块函数
re.findall(A, B) | 匹配字符串 B 中表达式 A 的所有实例,并将它们以列表形式返回。
re.search(A, B) | 匹配字符串 B 中表达式 A 的第一个实例,并返回它作为 re 匹配对象。
re.split(A, B) | 使用分隔符 A 将字符串 B 拆分成列表。
re.sub(A, B, C) | 在字符串C中将A替换为B。
Python 用户的有用正则表达式网站
简介: Alex Yang 是一位对代码能做的事情充满兴趣的作家。他还喜欢公民科学和新媒体艺术。
原文。转载经许可。
相关:
-
30 份重要的数据科学、机器学习与深度学习备忘单
-
Python 中的函数式编程介绍
-
文本数据预处理:Python 中的操作指南
更多相关主题
让 Python 使用 SQL 通过 pandasql
本文最初出现在 Yhat 博客。Yhat(官网)是一家位于布鲁克林的公司,旨在使数据科学对开发人员、数据科学家和企业都适用。Yhat 提供一个软件平台,用于部署和管理预测算法作为 REST API,同时消除了与生产环境相关的痛苦工程障碍,如测试、版本控制、扩展和安全性。
介绍
我最喜欢 Python 的一件事是,用户可以观察 R 社区,然后模仿其中的最佳部分。我坚信,语言的有用性在于它的库和工具。
本文介绍了 pandasql,这是我们(Yhat)编写的一个 Python 包,用于模拟 R 包 sqldf。它是一个小巧但强大的库,由仅仅 358 行代码 组成。pandasql 的理念是让 Python 能够使用 SQL。对于那些来自 SQL 为主背景或仍然“以 SQL 为思维方式”的用户,pandasql 是一个不错的方式,可以充分利用这两种语言的优势。
在本介绍中,我们将展示如何在我们为数据探索和分析构建的集成开发环境(IDE)Rodeo 内部快速上手 pandasql。Rodeo 是一个开源且完全免费的工具。如果你是 R 用户,它类似于 RStudio 的工具。到目前为止,Rodeo 只能运行 Python 代码,但上周 我们添加了 对其他多种语言(markdown、JSON、julia、SQL、markdown)的语法高亮支持。正如你可能读到或猜到的那样,我们对 Rodeo 有大计划,包括添加 SQL 支持,以便你可以在 Rodeo 内部直接运行 SQL 查询,即使没有我们便捷的 pandasql。更多内容将在接下来的一两周内发布!
下载 Rodeo
从 Yhat 网站上的 Rodeo 页面 下载适用于 Mac、Windows 或 Linux 的 Rodeo 开始。
ps 如果你下载 Rodeo 遇到问题或有疑问,我们全天候(好吧,差不多)监控我们的 讨论论坛。
如果你感兴趣的话,提供一点背景信息
在幕后,pandasql 使用 pandas.io.sql 模块在 DataFrame 和 SQLite 数据库之间转移数据。操作在 SQL 中执行,结果返回,然后数据库被销毁。该库大量使用 pandas 的 write_frame 和 frame_query,这两个函数让你可以读写 pandas 和(大多数)任何 SQL 数据库。
安装 pandasql
使用 Rodeo 的包管理器窗格安装 pandasql。只需搜索 pandasql 并点击安装包。

如果你喜欢这种方式,你也可以在文本编辑器中运行 ! pip install pandasql 来安装。
查看数据集
pandasql 有两个内置的数据集,我们将在下面的示例中使用它们。
-
meat:来自美国农业部的数据集,包含有关牲畜、乳制品和家禽展望及生产的指标 -
births:来自联合国统计司的数据集,包含按月的活产统计数据
运行以下代码来查看数据集。
在 Rodeo 内部,你实际上不需要使用 print.variable.head() 语句,因为你可以直接检查数据框。

奇怪的图表
注意,图表会同时出现在控制台和图表标签(右下角标签)中。
提示:你可以通过点击窗格顶部的箭头来“弹出”你的图表。如果你在使用多个显示器,并希望将其中一个专门用于数据可视化,这非常方便。

使用方法
为了使这篇文章简洁易读,我们只给出了大部分查询的代码片段和几行结果。
如果你在使用 Rodeo,这里有一些开始时的提示:
-
Run Script确实会运行你在文本编辑器中编写的所有内容。 -
你可以突出显示一段代码并通过点击
Run Line或按 Command + Enter 来运行它。 -
你可以调整窗格的大小(当我不做绘图时,我会缩小右下角的窗格)。
基础知识(Basics)
编写一些 SQL 语句并通过将 DataFrames 替换为表格来在你的 pandas DataFrame 上执行。
pandasql 创建一个数据库、架构及所有内容,加载你的数据,并运行你的 SQL。
聚合(Aggregation)
pandasql 支持聚合。你可以在 group by 子句中使用别名列名或列号。
locals() 与 globals()
pandasql 需要访问你会话/环境中的其他变量。你可以在执行 SQL 语句时将 locals() 传递给 pandasql,但如果你运行很多查询,这可能会很麻烦。为了避免每次都传递 locals,你可以在脚本中添加这个辅助函数来设置 globals(),如下所示:
连接(joins)
你可以使用普通 SQL 语法来连接数据框。
WHERE 条件
这是一个 WHERE 子句。
这只是 SQL
由于 pandasql 是由 SQLite3 驱动的,你可以做几乎所有 SQL 能做的事情。这里有一些使用常见 SQL 特性(如子查询、排序、函数和联合)的示例。
最后的思考

pandas 是一个非常出色的数据分析工具,我们认为这主要归功于它极易理解、简洁且表达力强。最终,有大量理由去学习merge、join、concatenate、melt和其他原生pandas特性,以便更好地切割和处理数据。查看一下文档获取一些示例。
我们希望pandasql能成为 Python 和pandas新手的有用学习工具。在我个人学习 R 的经历中,sqldf是一个熟悉的接口,帮助我尽快高效地使用新工具。
我们希望你能查看pandasql和 Rodeo;如果你这样做了,请告诉我们你的想法!
原文。经许可转载。
相关:
-
优秀的机器学习算法极简和干净实现合集
-
Pandas 备忘单:Python 中的数据科学和数据整理
-
Python 中的统计数据分析
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT 工作
更多相关内容
没有复杂正则表达式语法的 Python 字符串匹配
原文:
www.kdnuggets.com/2023/02/python-string-matching-without-complex-regex-syntax.html

图片由作者提供
我对正则表达式(RegEx)有一种爱恨交织的关系,尤其是在 Python 中。我喜欢你可以在不编写多个逻辑函数的情况下提取或匹配字符串。这比字符串搜索功能更好。
我不喜欢的是学习和理解 RegEx 模式的难度。我可以处理简单的字符串匹配,例如提取所有字母数字字符并清理 NLP 任务的文本。当涉及到从垃圾文本中提取 IP 地址、电子邮件和 ID 时,事情变得更困难。你必须编写复杂的 RegEx 字符串模式来提取所需的项。
为了简化复杂的 RegEx 任务,我们将学习一个名为 pregex 的简单 Python 包。此外,我们还将查看一些从长文本字符串中提取日期和电子邮件的示例。
入门 PRegEx
Pregex 是建立在 re 模块之上的高级 API。它是一种没有复杂正则表达式模式的正则表达式,使任何程序员都容易理解和记住正则表达式。此外,你不必对模式进行分组或转义元字符,它是模块化的。
你可以简单地使用 PIP 安装这个库。
pip install pregex
为了测试 PRegEx 强大的功能,我们将使用来自 文档 的修改版示例代码。
在下面的示例中,我们提取 HTTP URL 或带端口号的 IPv4 地址。我们无需为此创建复杂的逻辑。我们可以使用内置函数 HttpUrl 和 IPv4。
-
使用 AnyDigit() 创建端口号。端口的第一位数字不能为零,接下来的三位数字可以是任何数字。
-
使用 Either() 来添加多个逻辑,以提取 HTTP URL 或带端口号的 IP 地址。
from pregex.core.pre import Pregex
from pregex.core.classes import AnyDigit
from pregex.core.operators import Either
from pregex.meta.essentials import HttpUrl, IPv4
port_number = (AnyDigit() - '0') + 3 * AnyDigit()
pre = Either(
HttpUrl(capture_domain=True, is_extensible=True),
IPv4(is_extensible=True) + ':' + port_number
)
我们将使用包含字符和描述的长文本字符串。
text = """IPV4--192.168.1.1:8000--
address--https://www.abid.works--
website--https://www.kdnuggets.com--text"""
在提取匹配的字符串之前,让我们看一下 RegEx 模式。
regex_pattren = pre.get_pattern()
print(regex_pattren)
输出
如我们所见,这很难阅读,甚至难以理解发生了什么。这正是 PRegEx 发挥作用的地方。它为执行复杂的正则表达式任务提供了一个用户友好的 API。
(?:https?:\/\/)?(?:www\.)?(?:[a-z\dA-Z][a-z\-\dA-Z]{,61}[a-z\dA-Z]\.)*([a-z\dA-Z][a-z\-\dA-Z]{,61}[a-z\dA-Z])\.[a-z]{2,6}(?::\d{1,4})?(?:\/[!-.0-~]+)*\/?(?:(?<=[!-\/\[-`{-~:-@])|(?<=\w))|(?:(?:\d|[1-9]\d|1\d{2}|2(?:[0-4]\d|5[0-5]))\.){3}(?:\d|[1-9]\d|1\d{2}|2(?:[0-4]\d|5[0-5])):[1-9]\d{3}
就像 re.match 一样,我们将使用 .get_matches(text) 来提取所需的字符串。
results = pre.get_matches(text)
print(results)
输出
我们已经提取了带端口号的 IP 地址和两个网页 URL。
['192.168.1.1:8000', 'https://www.abid.works', 'https://www.kdnuggets.com']
示例 1:日期格式
让我们看几个示例,了解 PRegEx 的全部潜力。
在这个示例中,我们将从下面的文本中提取某些类型的日期模式。
text = """
04-15-2023
2023-08-15
06-20-2023
06/24/2023
"""
通过使用 Exactly() 和 AnyDigit(),我们将创建日期的日、月和年。日和月是两位数字,而年是四位数字。它们由“ - ”破折号分隔。
在创建模式后,我们将运行 get_match 以提取匹配的字符串。
from pregex.core.classes import AnyDigit
from pregex.core.quantifiers import Exactly
day_or_month = Exactly(AnyDigit(), 2)
year = Exactly(AnyDigit(), 4)
pre = (
day_or_month +
"-" +
day_or_month +
"-" +
year
)
results = pre.get_matches(text)
print(results)
输出
['04-15-2023', '06-20-2023']
让我们通过使用 get_pattern() 函数来查看 RegEx 模式。
regex_pattren = pre.get_pattern()
print(regex_pattren)
输出
如我们所见,它具有简单的 RegEx 语法。
\d{2}-\d{2}-\d{4}
示例 2: 电子邮件提取
第二个示例有点复杂,我们将从垃圾文本中提取有效的电子邮件地址。
text = """
user1@abid.works
editorial@@kdnuggets.com
lover@python.gg.
editorial1@kdnuggets.com
"""
-
使用
OneOrMore()创建一个用户模式。我们将使用AnyButFrom()从逻辑中去除“@”和空格。 -
类似于用户模式,我们通过从逻辑中去除额外的字符“.”来创建一个公司模式。
-
对于域名,我们将使用
MatchAtLineEnd()从行尾开始搜索,匹配任意两个或更多字符,除了“@”、空格和句点。 -
将三者结合以创建最终模式:user@company.domain。
from pregex.core.classes import AnyButFrom
from pregex.core.quantifiers import OneOrMore, AtLeast
from pregex.core.assertions import MatchAtLineEnd
user = OneOrMore(AnyButFrom("@", ' '))
company = OneOrMore(AnyButFrom("@", ' ', '.'))
domain = MatchAtLineEnd(AtLeast(AnyButFrom("@", ' ', '.'), 2))
pre = (
user +
"@" +
company +
'.' +
domain
)
results = pre.get_matches(text)
print(results)
输出
如我们所见,PRegEx 已经识别出两个有效的电子邮件地址。
['user1@abid.works', 'editorial1@kdnuggets.com']
注意: 两个代码示例是 The PyCoach 工作的修改版本。
结论
如果你是数据科学家、分析师或 NLP 爱好者,你应该使用 PRegEx 来清理文本并创建简单的逻辑。这将减少你对 NLP 框架的依赖,因为大部分匹配可以通过简单的 API 完成。
在这个迷你教程中,我们学习了 Python 包 PRegEx 及其用例。你可以通过阅读官方 文档 或使用可编程正则表达式解决一个 wordle 问题来了解更多。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专家,热爱构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为遭受心理疾病困扰的学生开发一个 AI 产品。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在的组织的 IT
更多相关主题
Python 字符串方法
图片由作者提供
在这篇博客中,我们将回顾 Python 的内置方法来操作字符串。你可以使用这些方法进行布尔检查以及替换或更改字符串的形式。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
代码示例
upper
upper() 方法将所有小写字母转换为大写字母。
text = 'knoWledge dIsCoverY NuggETS'
# Converting string to uppercase
new_string = text.upper()
print(f"Before: {text}\nAfter: {new_string}\n")
Before: knoWledge dIsCoverY NuggETS
After: KNOWLEDGE DISCOVERY NUGGETS
replace
replace() 方法需要两个参数,将所有子字符串的出现替换为另一个子字符串。
# Replacing the string
new_string = text.replace("knoWledge dIsCoverY ","KD")
print(f"Before: {text}\nAfter: {new_string}\n")
Before: knoWledge dIsCoverY NuggETS
After: KDNuggETS
find
find() 会搜索一个子字符串,如果找到,它将返回子字符串的最小索引。
# Find the string
new_string = text.find("dIsCoverY")
print(f"The string is at {new_string} index\n")
The string is at 10 index
isnumeric
isnumeric() 方法返回“True”,如果字符串中的所有字符都是数字。
# Is the text numerical?
new_string = text.isnumeric()
print(f"Is the text numerical? {new_string}\n")
print(f"Is·the·text·numerical?·{new_string}\n")
#·Is·the·text·numerical?
new_string·=·text.isnumeric()
Is the text numerical? False
所有 Python 字符串方法列表
大小写转换
-
lower(): 它将所有大写字母转换为小写字母。
-
capitalize(): 它将字符串的第一个字符转换为大写字母。
-
upper(): 它将所有小写字母转换为大写字母。
-
title(): 它将字符串转换为标题大小写。
-
casefold(): 它实现了不区分大小写的字符串匹配。
-
swapcase(): 它将所有大写字母转换为小写字母,将所有小写字母转换为大写字母。
检查
-
startswith(): 如果字符串以给定的子字符串开头,它返回“True”。
-
endswith(): 如果字符串以给定的子字符串结尾,它返回“True”。
-
isalnum(): 它检查字符串中的所有字符是否都是字母数字字符。
-
isalpha(): 它检查字符串中的所有字符是否都是字母。
-
isdecimal(): 它检查字符串中的所有字符是否都是十进制字符。
-
isdigit(): 它检查字符串中的所有字符是否都是数字。
-
isidentifier(): 它检查字符串是否是有效的标识符。
-
islower(): 它检查字符串中的所有字符是否都是小写字母。
-
isnumeric(): 它检查字符串中的所有字符是否都是数字。
-
isprintable(): 如果字符串中的所有字符都是可打印字符或字符串为空,它返回“True”。
-
isspace(): 它检查字符串中的所有字符是否都是空白字符。
-
istitle(): 它检查字符串中的所有字符是否都是标题大小写。
-
isupper(): 它检查字符串中的所有字符是否都是大写字母。
拆分和连接
-
join(): 它返回一个拼接后的字符串。
-
partition(): 它在分隔符的第一次出现处拆分字符串。
-
rpartition(): 它将字符串拆分为三部分。
-
rsplit(): 它使用指定的分隔符从右侧拆分字符串。
-
splitlines(): 它在行边界处拆分行。
-
split(): 它使用指定的分隔符拆分字符串。
填充和清理
-
center(): 用指定的字符填充字符串。
-
ljust(): 它使用指定的宽度将字符串左对齐。
-
rjust(): 它使用指定的宽度将字符串右对齐。
-
lstrip(): 它移除字符串开头的字符。
-
rstrip(): 它移除字符串末尾的字符。
-
strip(): 它移除字符串的前导和尾随字符。
-
zfill(): 它返回一个在字符串左侧填充‘0’字符的副本。
查找和替换
-
encode(): 它使用指定的编码方案对字符串进行编码。
-
find(): 它返回指定子字符串的最小索引。
-
rfind(): 它返回指定子字符串的最高索引。
-
index(): 它返回子字符串在字符串中首次出现的位置。
-
rindex(): 它返回子字符串在字符串中出现的最高索引。
-
replace(): 它需要两个参数来将所有出现的子字符串替换为另一个子字符串。
杂项
-
count(): 它计算子字符串在字符串中出现的次数。
-
expandtabs(): 它指定在字符串中用“\t”符号替代的空格数量。
-
maketrans(): 它返回一个翻译表。
-
translate(): 它使用翻译映射更改字符串。
-
format(): 它格式化字符串以便控制台打印。
-
format_map(): 它使用字典在字符串中格式化指定的值。
学习资源
Abid Ali Awan (@1abidaliawan) 是一位认证数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理疾病的学生开发 AI 产品。
更多相关话题
Python 字符串处理备忘单
原文:
www.kdnuggets.com/2020/01/python-string-processing-primer.html
Python 中的字符串处理
自然语言处理和文本分析目前是研究和应用的热门领域。这些领域包含了各种具体的技能和概念,需要彻底理解后才能进行有意义的实践。然而,在达到这一点之前,基本的字符串操作和处理是必须的。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
我认为需要讨论两种广泛的计算字符串处理技能。第一种是 正则表达式,一种基于模式的文本匹配方法。可以寻找许多关于正则表达式的优秀介绍,但视觉学习者可能会喜欢 fast.ai 的代码优先自然语言处理课程视频。
另一种显著的计算字符串处理技能是能够利用给定编程语言的标准库进行基本字符串操作。因此,本文是一个简短的 Python 字符串处理入门。
请注意,有意义的文本分析远远超出了字符串处理,这些更高级技术的核心可能不需要你经常手动操作文本。然而,文本数据处理是成功的文本分析项目中重要且耗时的部分,以上提到的字符串处理技能在这里将非常宝贵。基本水平上理解文本的计算处理对理解更高级的文本分析技术也是概念上非常重要的。
以下许多示例使用了 Python 标准库中的 string 模块,因此手头有它作为参考是个好主意。
这个实用的备忘单包含了所有的代码在 这个可下载的 PDF 文件 中。
去除空白
去除空白是基本的字符串处理需求。你可以使用 lstrip() 方法去除前导空白(左侧),使用 rstrip() 去除尾随空白(右侧),使用 strip() 去除前导和尾随空白。
s = ' This is a sentence with whitespace. \n'
print('Strip leading whitespace: {}'.format(s.lstrip()))
print('Strip trailing whitespace: {}'.format(s.rstrip()))
print('Strip all whitespace: {}'.format(s.strip()))
Strip leading whitespace: This is a sentence with whitespace.
Strip trailing whitespace: This is a sentence with whitespace.
Strip all whitespace: This is a sentence with whitespace.
对于去除空白之外的字符感兴趣?相同的方法也很有用,通过传递你希望去除的字符(们)来使用它们。
s = 'This is a sentence with unwanted characters.AAAAAAAA'
print('Strip unwanted characters: {}'.format(s.rstrip('A')))
Strip unwanted characters: This is a sentence with unwanted characters.
如果需要,请不要忘记查看字符串format()的文档。
拆分字符串
将字符串拆分成更小的子字符串列表在 Python 中通常是有用的,可以通过split()方法轻松完成。
s = 'KDnuggets is a fantastic resource'
print(s.split())
['KDnuggets', 'is', 'a', 'fantastic', 'resource']
默认情况下,split() 以空白字符进行拆分,但也可以传递其他字符(们)序列。
s = 'these,words,are,separated,by,comma'
print('\',\' separated split -> {}'.format(s.split(',')))
s = 'abacbdebfgbhhgbabddba'
print('\'b\' separated split -> {}'.format(s.split('b')))
',' separated split -> ['these', 'words', 'are', 'separated', 'by', 'comma']
'b' separated split -> ['a', 'ac', 'de', 'fg', 'hhg', 'a', 'dd', 'a']
将列表元素合并成一个字符串
需要以上操作的相反操作吗?你可以使用join()方法将列表元素字符串连接成一个单一字符串。
s = ['KDnuggets', 'is', 'a', 'fantastic', 'resource']
print(' '.join(s))
KDnuggets is a fantastic resource
这倒是真的!如果你想用空白之外的内容连接列表元素呢?这个可能会有点奇怪,但也很容易实现。
s = ['Eleven', 'Mike', 'Dustin', 'Lucas', 'Will']
print(' and '.join(s))
Eleven and Mike and Dustin and Lucas and Will
反转字符串
Python 并没有内置的字符串反转方法。然而,鉴于字符串可以像列表一样切片,反转一个字符串可以以与反转列表元素相同的简洁方式完成。
s = 'KDnuggets'
print('The reverse of KDnuggets is {}'.format(s[::-1]))
The reverse of KDnuggets is: steggunDK
转换大写和小写
转换大小写可以通过upper()、lower() 和 swapcase() 方法完成。
s = 'KDnuggets'
print('\'KDnuggets\' as uppercase: {}'.format(s.upper()))
print('\'KDnuggets\' as lowercase: {}'.format(s.lower()))
print('\'KDnuggets\' as swapped case: {}'.format(s.swapcase()))
'KDnuggets' as uppercase: KDNUGGETS
'KDnuggets' as lowercase: kdnuggets
'KDnuggets' as swapped case: kdNUGGETS
检查字符串成员
在 Python 中检查字符串成员的最简单方法是使用 in 运算符。语法非常自然语言化。
s1 = 'perpendicular'
s2 = 'pen'
s3 = 'pep'
print('\'pen\' in \'perpendicular\' -> {}'.format(s2 in s1))
print('\'pep\' in \'perpendicular\' -> {}'.format(s3 in s1))
'pen' in 'perpendicular' -> True
'pep' in 'perpendicular' -> False
如果你更感兴趣于在字符串中查找子字符串的位置(而不是仅仅检查子字符串是否包含在其中),find() 字符串方法可能会更有帮助。
s = 'Does this string contain a substring?'
print('\'string\' location -> {}'.format(s.find('string')))
print('\'spring\' location -> {}'.format(s.find('spring')))
'string' location -> 10
'spring' location -> -1
默认情况下,find() 返回子字符串第一次出现的第一个字符的索引,如果未找到子字符串,则返回 -1。查看文档以获取对默认行为的可用调整。
替换子字符串
如果你想要替换子字符串,而不仅仅是查找它们呢?Python 的 replace() 字符串方法可以处理这个需求。
s1 = 'The theory of data science is of the utmost importance.'
s2 = 'practice'
print('The new sentence: {}'.format(s1.replace('theory', s2)))
The new sentence: The practice of data science is of the utmost importance.
一个可选的计数参数可以指定在相同子字符串出现多次时,进行的连续替换的最大次数。
合并多个列表的输出
有多个字符串列表想要按元素组合在一起?使用zip()函数没有问题。
countries = ['USA', 'Canada', 'UK', 'Australia']
cities = ['Washington', 'Ottawa', 'London', 'Canberra']
for x, y in zip(countries, cities):
print('The capital of {} is {}.'.format(x, y))
The capital of USA is Washington.
The capital of Canada is Ottawa.
The capital of UK is London.
The capital of Australia is Canberra.
检查变位词
想要检查一对字符串是否是变位词吗?在算法上,我们只需统计每个字符串中每个字母的出现次数,并检查这些计数是否相等。使用Counter类来完成这个任务非常简单。
from collections import Counter
def is_anagram(s1, s2):
return Counter(s1) == Counter(s2)
s1 = 'listen'
s2 = 'silent'
s3 = 'runner'
s4 = 'neuron'
print('\'listen\' is an anagram of \'silent\' -> {}'.format(is_anagram(s1, s2)))
print('\'runner\' is an anagram of \'neuron\' -> {}'.format(is_anagram(s3, s4)))
'listen' an anagram of 'silent' -> True
'runner' an anagram of 'neuron' -> False
检查回文
如果你想检查一个单词是否是回文怎么办?在算法上,我们需要创建该单词的反向,然后使用==运算符检查这两个字符串(原始字符串和反向字符串)是否相等。
def is_palindrome(s):
reverse = s[::-1]
if (s == reverse):
return True
return False
s1 = 'racecar'
s2 = 'hippopotamus'
print('\'racecar\' a palindrome -> {}'.format(is_palindrome(s1)))
print('\'hippopotamus\' a palindrome -> {}'.format(is_palindrome(s2)))
'racecar' is a palindrome -> True
'hippopotamus' is a palindrome -> False
确保你下载了Python 字符串处理备忘单。
更多相关主题
5 个 Python 数据处理技巧与代码片段
原文:
www.kdnuggets.com/2021/07/python-tips-snippets-data-processing.html
评论 
图片来源:Hitesh Choudhary 在 Unsplash
本文包含 5 个有用的 Python 代码片段,初学者可能会发现这些对数据处理非常有帮助。
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 工作
Python 是一种灵活的通用编程语言,提供了多种方法来处理和完成相同的任务。这些代码片段阐明了一种针对特定情况的方法;你可能会发现它们有用,或者发现你找到了另一种更合适的方法。
1. 合并多个文本文件
让我们从合并多个文本文件开始。如果你有多个文本文件在同一个目录中需要合并为一个文件,这段 Python 代码将完成这一任务。
首先我们获取路径中所有 txt 文件的列表;然后我们读取每个文件并将其内容写入新的输出文件;最后,我们重新读取新文件并将内容打印到屏幕上以进行验证。
import glob
# Load all txt files in path
files = glob.glob('/path/to/files/*.txt')
# Concatenate files to new file
with open('2020_output.txt', 'w') as out_file:
for file_name in files:
with open(file_name) as in_file:
out_file.write(in_file.read())
# Read file and print
with open('2020_output.txt', 'r') as new_file:
lines = [line.strip() for line in new_file]
for line in lines: print(line)
file 1 line 1
file 1 line 2
file 1 line 3
file 2 line 1
file 2 line 2
file 2 line 3
file 3 line 1
file 3 line 2
file 3 line 3
2. 将多个 CSV 文件合并为一个数据框
继续探讨文件合并的主题,这次让我们处理将多个逗号分隔值文件合并为一个 Pandas 数据框。
我们首先获取路径中 CSV 文件的列表;然后,对于路径中的每个文件,我们将内容读取到各自的数据框中;之后,我们将所有数据框合并为一个数据框;最后,我们打印结果以检查。
import pandas as pd
import glob
# Load all csv files in path
files = glob.glob('/path/to/files/*.csv')
# Create a list of dataframe, one series per CSV
fruit_list = []
for file_name in files:
df = pd.read_csv(file_name, index_col=None, header=None)
fruit_list.append(df)
# Create combined frame out of list of individual frames
fruit_frame = pd.concat(fruit_list, axis=0, ignore_index=True)
print(fruit_frame)
0 1 2
0 grapes 3 5.5
1 banana 7 6.8
2 apple 2 2.3
3 orange 9 7.2
4 blackberry 12 4.3
5 starfruit 13 8.9
6 strawberry 9 8.3
7 kiwi 7 2.7
8 blueberry 2 7.6
3. 压缩与解压文件到 Pandas
假设你正在使用一个 Pandas 数据框,例如上面代码片段中的结果数据框,并希望将数据框直接压缩保存到文件中。这个代码片段将实现这一点。
首先我们将创建一个数据框以供示例使用;然后,我们将直接压缩并保存数据框到文件;最后,我们将从压缩文件中直接读取数据框并打印以进行验证。
import pandas as pd
# Create a dataframe to use
df = pd.DataFrame({'col_A': ['kiwi', 'banana', 'apple'],
'col_B': ['pineapple', 'grapes', 'grapefruit'],
'col_C': ['blueberry', 'grapefruit', 'orange']})
# Compress and save dataframe to file
df.to_csv('sample_dataframe.csv.zip', index=False, compression='zip')
print('Dataframe compressed and saved to file')
# Read compressed zip file into dataframe
df = pd.read_csv('sample_dataframe.csv.zip',)
print(df)
Dataframe compressed and saved to file
col_A col_B col_C
0 kiwi pineapple blueberry
1 banana grapes grapefruit
2 apple grapefruit orange
4. 展开列表
或许你正面临一个处理嵌套列表的情况,也就是说,一个列表的所有元素都是列表。这个代码片段将把这个嵌套列表展平为一个线性列表。
首先,我们将创建一个列表的列表用于示例;然后我们将使用列表推导式以 Pythonic 的方式展平列表;最后,我们将打印结果列表以进行验证。
# Create of list of lists (a list where all of its elements are lists)
list_of_lists = [['apple', 'pear', 'banana', 'grapes'],
['zebra', 'donkey', 'elephant', 'cow'],
['vanilla', 'chocolate'],
['princess', 'prince']]
# Flatten the list of lists into a single list
flat_list = [element for sub_list in list_of_lists for element in sub_list]
# Print both to compare
print(f'List of lists:\n{list_of_lists}')
print(f'Flattened list:\n{flat_list}')
List of lists:
[['apple', 'pear', 'banana', 'grapes'], ['zebra', 'donkey', 'elephant', 'cow'], ['vanilla', 'chocolate'], ['princess', 'prince']]
Flattened list:
['apple', 'pear', 'banana', 'grapes', 'zebra', 'donkey', 'elephant', 'cow', 'vanilla', 'chocolate', 'princess', 'prince']
5. 排序元组列表
这段代码将探讨根据指定元素对元组进行排序的想法。元组是一个常被忽视的 Python 数据结构,它是存储相关数据片段的好方法,而不需要使用更复杂的结构类型。
在这个示例中,我们将首先创建一个大小为 2 的元组列表,并用数字数据填充它们;接着我们将分别按第一个和第二个元素对这些对进行排序,打印两个排序过程的结果以检查结果;最后,我们将扩展这种排序到混合的字母数字数据元素。
# Some paired data
pairs = [(1, 10.5), (5, 7.), (2, 12.7), (3, 9.2), (7, 11.6)]
# Sort pairs by first entry
sorted_pairs = sorted(pairs, key=lambda x: x[0])
print(f'Sorted by element 0 (first element):\n{sorted_pairs}')
# Sort pairs by second entry
sorted_pairs = sorted(pairs, key=lambda x: x[1])
print(f'Sorted by element 1 (second element):\n{sorted_pairs}')
# Extend this to tuples of size n and non-numeric entries
pairs = [('banana', 3), ('apple', 11), ('pear', 1), ('watermelon', 4), ('strawberry', 2), ('kiwi', 12)]
sorted_pairs = sorted(pairs, key=lambda x: x[0])
print(f'Alphanumeric pairs sorted by element 0 (first element):\n{sorted_pairs}')
Sorted by element 0 (first element):
[(1, 10.5), (2, 12.7), (3, 9.2), (5, 7.0), (7, 11.6)]
Sorted by element 1 (second element):
[(5, 7.0), (3, 9.2), (1, 10.5), (7, 11.6), (2, 12.7)]
Alphanumeric pairs sorted by element 0 (first element):
[('apple', 11), ('banana', 3), ('kiwi', 12), ('pear', 1), ('strawberry', 2), ('watermelon', 4)]
以上就是 5 个 Python 代码片段,这些片段可能对初学者处理各种数据处理任务有所帮助。
相关:
-
SQL 中的数据准备及备忘单!
-
如何在命令行清理文本数据
-
数据科学、数据可视化和机器学习的顶级 Python 库
更多关于这个主题
Python 元组和元组方法
评论
由 Michael Galarnyk,数据科学家
元组是有序的项序列,就像列表一样。元组和列表的主要区别在于元组不可更改(不可变),而列表则可以(可变)。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
初始化元组
有两种方法可以初始化一个空元组。你可以通过使用 () 并且不包含任何值来初始化一个空元组。
# Way 1
emptyTuple = ()
你也可以通过使用 tuple 函数来初始化一个空元组。
# Way 2
emptyTuple = tuple()
含有值的元组可以通过用逗号分隔的值序列来初始化。
# way 1
z = (3, 7, 4, 2)# way 2 (tuples can also can be created without parenthesis)
z = 3, 7, 4, 2

你可以使用或不使用括号初始化元组。
重要的是要记住,如果你想创建一个只包含一个值的元组,你需要在项后面加上一个逗号。
# tuple with one value
tup1 = ('Michael',)# tuple with one value
tup2 = 'Michael',# This is a string, NOT a tuple.
notTuple = ('Michael')
访问元组中的值
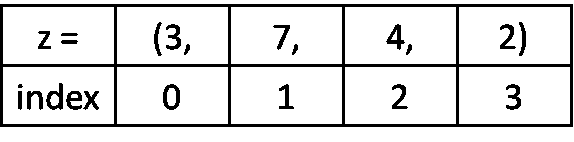
你可以使用或不使用括号初始化元组。
元组中的每个值都有一个指定的索引值。重要的是要注意 Python 是零索引的语言。这意味着元组中的第一个值在索引 0 处。
# Initialize a tuple
z = (3, 7, 4, 2)*# Access the first item of a tuple at index 0*
print(z[0])

访问索引 0 处项的输出。
Python 还支持负索引。负索引从元组的末尾开始。使用负索引获取元组中的最后一项有时更方便,因为你不需要知道元组的长度来访问最后一项。
*# print last item in the tuple*
print(z[-1])

访问元组中最后一项的输出
提醒一下,你也可以使用正索引访问相同的项(如下所示)。

另一种访问元组 z 中最后一项的方法
元组切片
切片操作返回一个包含所请求项的新元组。切片适用于获取元组中的子集。对于下面的示例代码,它将返回一个包含从索引 0 到不包括索引 2 的项的元组。
第一个索引是包含的(在 : 之前),最后一个(在 : 之后)则不包含
# Initialize a tuple
z = (3, 7, 4, 2)# first index is inclusive (before the :) and last (after the :) is not.
print(z[0:2])

元组的切片语法
*# everything up to but not including index 3*
print(z[:3])

所有到达但不包括索引 3 的项
你甚至可以使用负索引进行切片。
print(z[-4:-1])

元组是不可变的
元组是不可变的,这意味着在初始化元组后,无法更新元组中的单个项。如下面的代码所示,你不能更新或更改元组项的值(这与 Python 列表 的可变性不同)。
z = (3, 7, 4, 2)z[1] = "fish"
即使元组是不可变的,也可以取现有元组的部分来创建新的元组,如下例所示。
# Initialize tuple
tup1 = ('Python', 'SQL')# Initialize another Tuple
tup2 = ('R',)# Create new tuple based on existing tuples
new_tuple = tup1 + tup2;
print(new_tuple)

元组方法
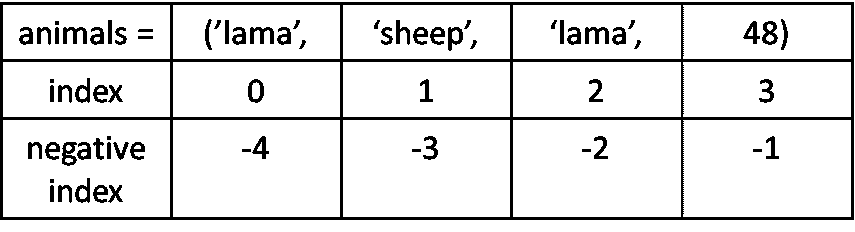
在开始本节之前,让我们先初始化一个元组。
# Initialize a tuple
animals = ('lama', 'sheep', 'lama', 48)
index 方法
index 方法返回值出现的第一个索引。
print(animals.index('lama'))
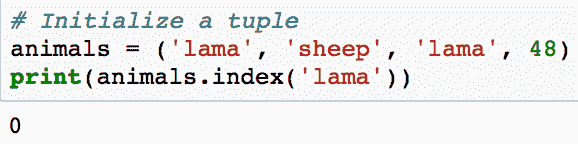
count 方法
count 方法返回元组中值出现的次数。
print(animals.count('lama'))
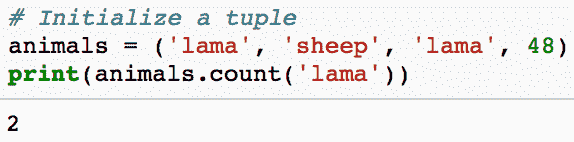
字符串‘lama’在元组 animals 中出现了两次
迭代元组
你可以通过使用 for 循环来迭代元组中的项。
for item in ('lama', 'sheep', 'lama', 48):
print(item)

元组解包
元组对于序列解包非常有用。
x, y = (7, 10);
print("Value of x is {}, the value of y is {}.".format(x, y))

枚举
enumerate 函数返回一个包含每次迭代的计数(从默认的 0 开始)和从序列中获得的值的元组:
friends = ('Steve', 'Rachel', 'Michael', 'Monica')
for index, friend in enumerate(friends):
print(index,friend)

元组相对于列表的优点
本节的快速视频
列表和元组是标准的 Python 数据类型,用于以序列形式存储值。tuple 是 不可变的,而 list 是 可变的。以下是元组相对于列表的一些其他优点(部分来自 Stack Overflow)
- 元组比列表更快。 如果你定义了一组常量值,并且你唯一要做的就是迭代它,使用元组而不是列表。性能差异可以通过
timeit库部分测量,该库允许你测量 Python 代码的执行时间。下面的代码运行每种方法 100 万次,并输出总共花费的时间(以秒为单位)。
import timeitprint(timeit.timeit('x=(1,2,3,4,5,6,7,8,9,10,11,12)', number=1000000))print(timeit.timeit('x=[1,2,3,4,5,6,7,8,9,10,11,12]', number=1000000))

- 一些元组可以作为字典的键(特别是那些包含不可变值如字符串、数字和其他元组的元组)。列表不能用作字典键,因为列表是可变的(你可以在这里了解字典)。
- 元组可以作为集合中的值,而列表不行(你可以在这里了解更多关于集合的内容)。

结论
如果你对教程有任何问题或想法,可以在下方评论区或通过Twitter联系我。下一篇文章将回顾Python 字典及字典方法。如果你想了解如何使用 Pandas、Matplotlib 或 Seaborn 库,请考虑参加我的Python 数据可视化 LinkedIn 学习课程。这里是免费预览视频。

个人简介: Michael Galarnyk 是一名数据科学家和企业培训师。他目前在 Scripps 转化研究所工作。你可以在 Twitter (https://twitter.com/GalarnykMichael)、Medium (https://medium.com/@GalarnykMichael) 和 GitHub (https://github.com/mGalarnyk) 找到他。
原文。经授权转载。
相关:
-
Python 列表和列表操作
-
理解箱线图
-
应用于 Pandas DataFrame 的集合操作
相关话题
Python 如何用于数据可视化?
原文:
www.kdnuggets.com/2022/12/python-used-data-visualization.html

图片来自 Freepik
介绍
我们的前三大课程推荐
1. Google 网络安全证书 - 加入网络安全职业的快车道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
研究如何以视觉方式表示数据称为数据可视化。它通过图形化绘制数据有效地传达数据中的发现。
我们可以通过数据可视化获得数据的视觉总结。当数据以图像、地图和图表呈现时,人类大脑更容易处理和理解这些数据。
无论是小型还是大型数据集,都能从数据可视化中获益,但大数据集尤为突出,因为人工查看、处理和理解所有数据是困难的。
数据可视化的研究涉及通过将数据放入视觉背景中来尝试理解数据,以揭示可能无法通过其他方式看到的模式、趋势和连接。
使用 Python 进行数据可视化
数据可视化可以使用任何编程语言进行,但选择 Python 更适合数据可视化,因为 Python 代码行数较少。
Python 具有简单的语法,编写代码所需时间非常少,同时 Python 提供了多种数据可视化的包或库,利用现有的功能。一些用于数据可视化的 Python 库包括 matplotlib 和 seaborn 以及许多其他数据可视化的包。
Matplotlib、Seaborn、Bokeh 和 Plotly 是 Python 中用于数据可视化的库。
-
Matplotlib 用于绘制图表,如散点图、折线图、饼图和条形图,matplotlib 处理数组和数据集字段。
-
Seaborn 用于复杂的数据可视化,例如着色和设计图表,并且 seaborn 能处理整个数据集。
-
Bokeh 用于通过使事物互动来进行数据可视化,并使用 HTML 和 JavaScript 在网页浏览器中呈现数据。
-
Plotly 也用于数据可视化,使图表更具吸引力,并允许自定义。
现在,让我们详细了解这些内容。
1. Matplotlib
Matplotlib 用于绘制图形,如散点图、线图、饼图和条形图,且 matplotlib 处理的是数据集的数组和字段。
Matplotlib 是一个低级接口,非常易于使用并提供灵活性,如前所述,matplotlib 处理使用 NumPy 创建的数组。
要安装 matplotlib,我们需要使用以下命令,
pip install matplotlib
在命令提示符中运行此命令,您会看到如下所示。
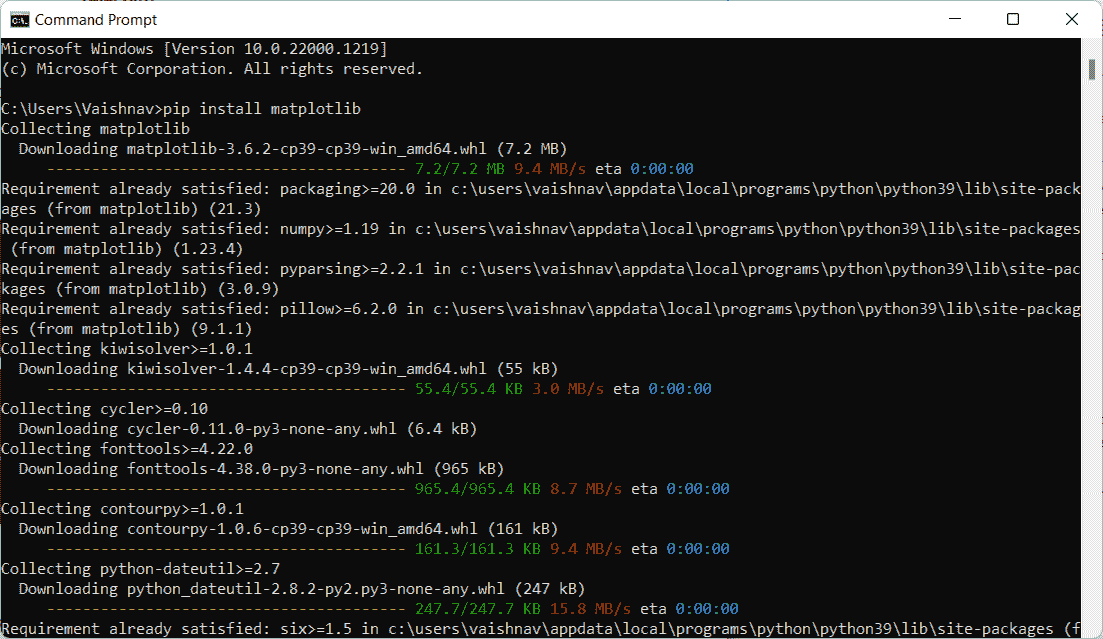
图片由作者提供
现在,我们可以使用 matplotlib 来可视化数据。
线图
线图用于表示数据集中的两个不同字段,或使用 plot() 函数显示两个字段之间的关系。
我们可以用 Python 编程,如下所示
import pandas as pd
import matplotlib. pyplot as plt
data = pd.read_csv("diabetes.csv")
plt. plot(data['Preg'])
plt. plot(data['age'])
plt. title("Line Plot")
plt. xlabel('Preg')
plt. label('age')
plt. show()
输出:
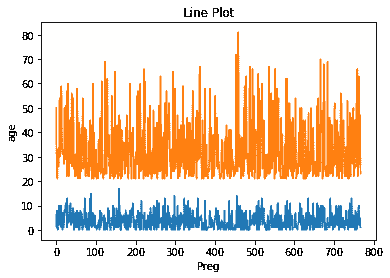
散点图
散点图 用于表示两个字段之间的关系,使用 matplotlib 库中的 scatter() 函数,该函数使用点来表示数据。
我们可以用 Python 编程,如下所示
import pandas as pd
import matplotlib. pyplot as plt
data = pd.read_csv("diabetes.csv")
plt. scatter(data['Preg'], data['age'])
plt. title("Scatter Plot")
plt. xlabel('Preg')
plt. label('age')
plt. show()
输出:
条形图
条形图用于使用 matplotlib 库中的 bar() 函数表示分类数据。
我们可以用 Python 编程,如下所示
import pandas as pd
import matplotlib. pyplot as plt
data = pd.read_csv("diabetes.csv")
plt. bar(data['Preg'], data['age'])
plt. title("Bar Plot")
plt. xlabel('Preg')
plt. ylabel('age')
plt.show()
输出:
直方图
直方图用于以组的形式表示数据,使用 matplotlib 库中的 hist() 函数来表示数据。
我们可以用 Python 编程,如下所示
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv("diabetes.csv")
plt.hist(data['age'])
plt.title("Histogram Plot")
plt.show()
输出:
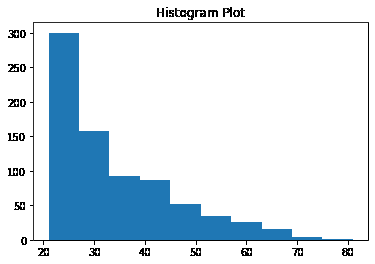
2. Seaborn
Seaborn 用于数据的复杂可视化,如着色、图形设计,且 seaborn 可以处理整个数据集。
Seaborn 具有高层接口,能够生成具有吸引力且色彩丰富的输出。
要安装 seaborn,我们需要使用以下命令,
pip install seaborn
在命令提示符中运行此命令,您会看到如下所示。
图片由作者提供
现在,我们可以使用 seaborn 来可视化数据。
线图
线图用于表示数据集中的两个不同字段,或显示两个字段之间的关系,使用 seaborn 中的 lineplot() 函数。
我们可以用 Python 编程,如下所示
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
data = pd.read_csv("diabetes.csv")
sns.lineplot(x='Preg', y='age', data=data)
plt.show()
输出:
散点图
散点图用于表示两个字段之间的关系,使用 seaborn 库中的 scatterplot() 函数,该函数使用点来表示数据。
我们可以用 Python 编程,如下所示
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
data = pd.read_csv("diabetes.csv")
sns.scatterplot(x='Preg', y='age', data=data, hue='class')
plt.show()
输出:
条形图
条形图用于表示分类数据,使用 seaborn 库中的 barplot()函数来表示数据。
我们可以用 Python 编写如下代码
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
data = pd.read_csv("diabetes.csv")
sns.barplot(x='Preg', y='age', data=data, hue='class')
plt.show()
输出:
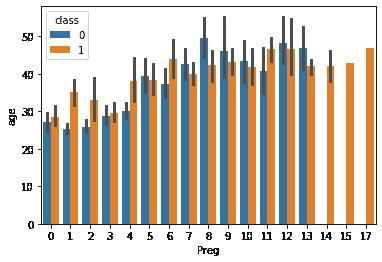
直方图
直方图用于将数据以分组的形式表示,使用 matplotlib 库中的 histplot()函数来表示数据。
我们可以用 Python 编写如下代码
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
data = pd.read_csv("diabetes.csv")
sns.histplot(x='age',kde=True, data=data, hue='class')
plt.show()
输出:
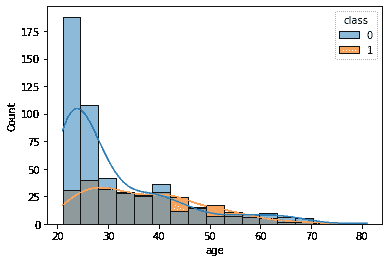
3. Bokeh
Bokeh 用于数据可视化,通过使内容互动,使用 HTML 和 JavaScript 在网页浏览器中表示数据,并具有高级互动性。
要安装 seaborn,我们需要使用以下命令
pip install bokeh
在命令提示符中运行此命令,你将看到如下效果。
作者提供的图片
现在,我们可以使用 bokeh 来可视化数据。
折线图
折线图用于表示数据集中两个不同字段之间的关系,或使用 bokeh 中的 line()函数显示两个字段之间的关系。
我们可以用 Python 编写如下代码,
from bokeh.plotting import figure, output_file, show
import pandas as pd
graph = figure(title = "Bokeh Bar Chart")
data = pd.read_csv("diabetes.csv")
df = data['age'].value_counts()
graph.line(df, data['age'])
show(graph)
输出:
散点图
散点图用于表示两个字段之间的关系,使用 bokeh 库中的 scatter()函数,通过点来表示数据。
我们可以用 Python 编写如下代码
from bokeh.plotting import figure, output_file, show
import pandas as pd
graph = figure(title = "Bokeh Bar Chart")
data = pd.read_csv("diabetes.csv")
df = data['age'].value_counts()
graph.scatter(df, data['age'])
show(graph)
输出:
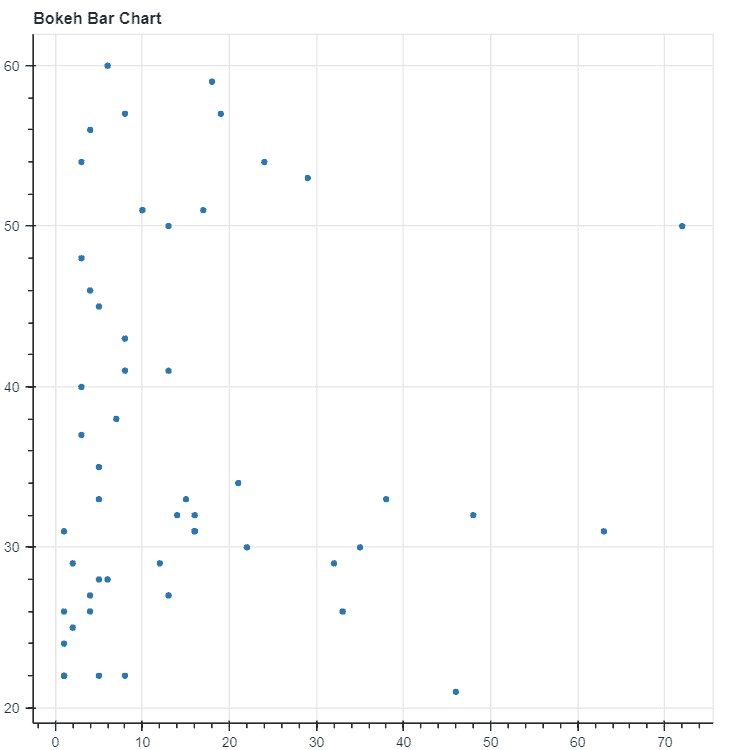
条形图
条形图用于表示分类数据,使用 bokeh 库中的 vbar()和 hbar()函数来表示数据。
我们可以用 Python 编写如下代码
from bokeh.plotting import figure, output_file, show
import pandas as pd
graph = figure(title = "Bokeh Bar Chart")
data = pd.read_csv("diabetes.csv")
graph.vbar(data['age'], top=data['Preg'])
show(graph)
输出:
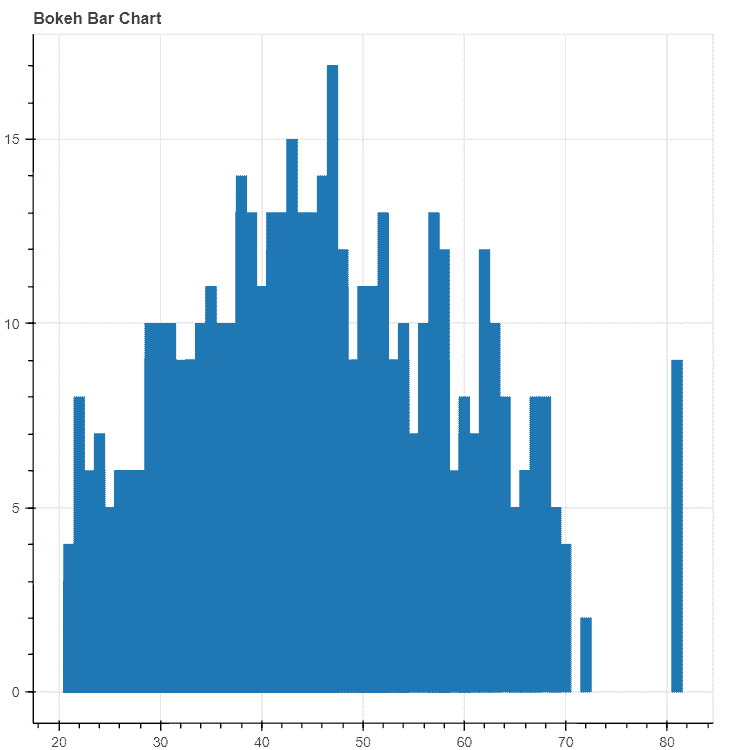
4. Plotly
Plotly 也用于数据可视化,使图表更具吸引力并允许自定义。
要安装 plotly,我们需要使用以下命令
pip install plotly
在命令提示符中运行此命令,你将看到如下效果。
作者提供的图片
现在,我们可以使用 plotly 来可视化数据。
折线图
折线图用于表示数据集中两个不同字段之间的关系,或使用 plotly 中的 line()函数显示两个字段之间的关系。
我们可以用 Python 编写如下代码
import plotly.express as px
import pandas as pd
data = pd.read_csv("diabetes.csv")
fig = px.line(data, y='age', color='class')
fig.show()
输出:
散点图
散点图用于表示两个字段之间的关系,使用 plotly 库中的 scatter()函数,通过点来表示数据。
我们可以用 Python 编写如下代码
import plotly.express as px
import pandas as pd
data = pd.read_csv("diabetes.csv")
fig = px.scatter(data, x='Preg', y='age', color='class')
fig.show()
输出:
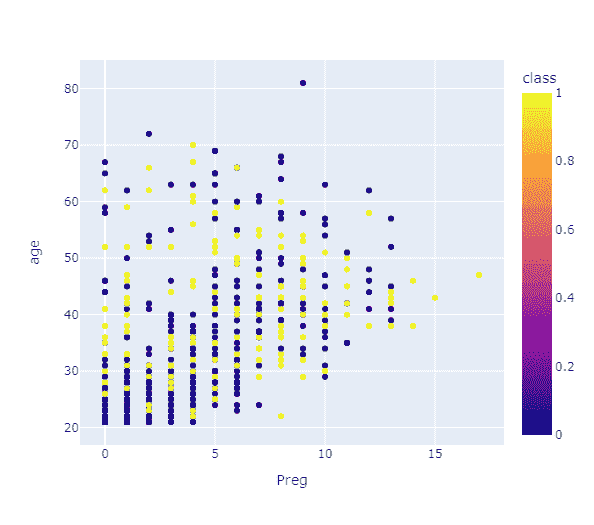
条形图
条形图用于使用 plotly 库中的 bar()函数表示分类数据。
我们可以用 Python 编写如下代码
import plotly.express as px
import pandas as pd
data = pd.read_csv("diabetes.csv")
fig = px.bar(data, x='Preg', y='age', color='class')
fig.show()
输出:
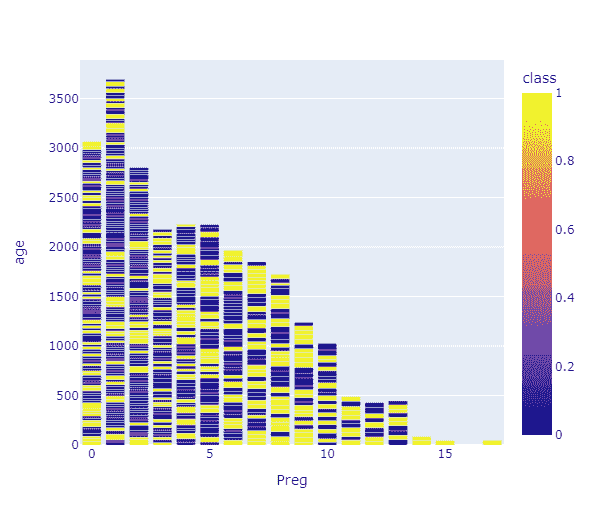
直方图
直方图用于使用 matplotlib 库中的 histogram()函数以分组形式表示数据。
我们可以用 Python 编写如下代码
import plotly.express as px
import pandas as pd
data = pd.read_csv("diabetes.csv")
fig = px.histogram(data, x='age', color='class')
fig.show()
输出:
这些是使用 Python 库进行数据可视化的不同方法。现在让我们简要总结一下讨论的内容。
结论
-
首先,我们了解了什么是数据可视化以及为什么要进行数据可视化。
-
数据可视化的研究涉及通过将数据置于可视化上下文中,以揭示可能不易察觉的模式、趋势和关联。
-
接下来,我们了解了如何使用 Python 进行数据可视化以及为什么可以选择 Python 进行数据可视化。
-
我们了解了使用 Python 进行数据可视化的不同库。
-
我们通过合适的示例和输出代码理解了每种数据可视化技术。
希望您学会了如何使用 Python 及其不同类型的库轻松地可视化数据。您可以通过免费的资源如 Kdnuggets、Scaler或Wiki了解更多关于 Python 及其各种库的知识。
Vaishnavi Amira Yada是一位技术内容作家。她具备 Python、Java、DSA、C 等方面的知识。她发现自己对写作充满热情,并且非常喜爱它。
更多相关主题


 浙公网安备 33010602011771号
浙公网安备 33010602011771号